Repository: spencermountain/compromise
Branch: master
Commit: 758eee33b8c0
Files: 1062
Total size: 5.9 MB
Directory structure:
gitextract_c9wmq0vi/
├── README.md
├── builds/
│ ├── compromise.js
│ ├── one/
│ │ ├── compromise-one.cjs
│ │ └── compromise-one.mjs
│ ├── three/
│ │ ├── compromise-three.cjs
│ │ └── compromise-three.mjs
│ └── two/
│ ├── compromise-two.cjs
│ └── compromise-two.mjs
├── changelog.md
├── data/
│ ├── README.md
│ ├── lexicon/
│ │ ├── adjectives/
│ │ │ ├── adjectives.js
│ │ │ └── comparables.js
│ │ ├── dates/
│ │ │ ├── dates.js
│ │ │ ├── durations.js
│ │ │ ├── months.js
│ │ │ └── weekdays.js
│ │ ├── index.js
│ │ ├── misc/
│ │ │ ├── adverbs.js
│ │ │ ├── conjunctions.js
│ │ │ ├── currencies.js
│ │ │ ├── determiners.js
│ │ │ ├── expressions.js
│ │ │ └── prepositions.js
│ │ ├── misc.js
│ │ ├── nouns/
│ │ │ ├── actors.js
│ │ │ ├── demonyms.js
│ │ │ ├── organizations.js
│ │ │ ├── possessives.js
│ │ │ ├── pronouns.js
│ │ │ ├── properNouns.js
│ │ │ ├── relative-prounoun.js
│ │ │ ├── singulars.js
│ │ │ ├── sportsTeams.js
│ │ │ └── uncountables.js
│ │ ├── numbers/
│ │ │ ├── cardinals.js
│ │ │ ├── multiples.js
│ │ │ ├── ordinals.js
│ │ │ └── units.js
│ │ ├── people/
│ │ │ ├── femaleNames.js
│ │ │ ├── firstnames.js
│ │ │ ├── honorifics.js
│ │ │ ├── lastnames.js
│ │ │ ├── maleNames.js
│ │ │ └── people.js
│ │ ├── places/
│ │ │ ├── cities.js
│ │ │ ├── countries.js
│ │ │ ├── places.js
│ │ │ └── regions.js
│ │ ├── switches/
│ │ │ ├── actor-verb.js
│ │ │ ├── adj-gerund.js
│ │ │ ├── adj-noun.js
│ │ │ ├── adj-past.js
│ │ │ ├── adj-present.js
│ │ │ ├── noun-gerund.js
│ │ │ ├── noun-verb.js
│ │ │ ├── person-adj.js
│ │ │ ├── person-date.js
│ │ │ ├── person-noun.js
│ │ │ ├── person-place.js
│ │ │ ├── person-verb.js
│ │ │ └── unit-noun.js
│ │ └── verbs/
│ │ ├── infinitives.js
│ │ ├── modals.js
│ │ ├── participles.js
│ │ ├── phrasals.js
│ │ └── verbs.js
│ └── pairs/
│ ├── AdjToNoun.js
│ ├── Comparative.js
│ ├── Gerund.js
│ ├── Participle.js
│ ├── PastTense.js
│ ├── PresentTense.js
│ ├── Superlative.js
│ └── index.js
├── demos/
│ ├── performance.html
│ ├── plugin.html
│ └── web-worker/
│ ├── _worker.js
│ └── index.html
├── eslint.config.js
├── one/
│ └── package.json
├── package.json
├── plugins/
│ ├── _experiments/
│ │ ├── ast/
│ │ │ ├── README.md
│ │ │ ├── package.json
│ │ │ ├── scratch.js
│ │ │ └── src/
│ │ │ ├── ast.js
│ │ │ ├── compute/
│ │ │ │ └── index.js
│ │ │ ├── lines.js
│ │ │ └── plugin.js
│ │ ├── cmd-k/
│ │ │ ├── README.md
│ │ │ ├── package.json
│ │ │ ├── scratch.js
│ │ │ └── src/
│ │ │ ├── plugin.js
│ │ │ ├── searchBang.js
│ │ │ └── slashCmd.js
│ │ ├── compress/
│ │ │ ├── README.md
│ │ │ └── src/
│ │ │ ├── index.js
│ │ │ └── lz.js
│ │ ├── markdown/
│ │ │ ├── README.md
│ │ │ ├── package.json
│ │ │ ├── scratch.js
│ │ │ └── src/
│ │ │ ├── Wrap.js
│ │ │ ├── parse/
│ │ │ │ ├── crawl.js
│ │ │ │ ├── index.js
│ │ │ │ ├── toPlaintext.js
│ │ │ │ └── uuid.js
│ │ │ └── plugin.js
│ │ └── sentiment/
│ │ ├── README.md
│ │ ├── package.json
│ │ ├── scratch.js
│ │ ├── src/
│ │ │ ├── data/
│ │ │ │ ├── _pckd.js
│ │ │ │ └── index.js
│ │ │ ├── emoji.js
│ │ │ ├── escape.js
│ │ │ ├── lib.js
│ │ │ └── plugin.js
│ │ └── test.js
│ ├── dates/
│ │ ├── README.md
│ │ ├── builds/
│ │ │ ├── compromise-dates.cjs
│ │ │ └── compromise-dates.mjs
│ │ ├── changelog.md
│ │ ├── demo/
│ │ │ └── index.html
│ │ ├── index.d.cts
│ │ ├── index.d.ts
│ │ ├── package.json
│ │ ├── scratch.js
│ │ ├── scripts/
│ │ │ ├── perf.js
│ │ │ └── version.js
│ │ ├── src/
│ │ │ ├── _version.js
│ │ │ ├── api/
│ │ │ │ ├── dates.js
│ │ │ │ ├── durations/
│ │ │ │ │ ├── index.js
│ │ │ │ │ └── parse.js
│ │ │ │ ├── find/
│ │ │ │ │ ├── index.js
│ │ │ │ │ └── split.js
│ │ │ │ ├── index.js
│ │ │ │ ├── normalize.js
│ │ │ │ ├── parse/
│ │ │ │ │ ├── index.js
│ │ │ │ │ ├── normalize.js
│ │ │ │ │ ├── one/
│ │ │ │ │ │ ├── 01-tokenize/
│ │ │ │ │ │ │ ├── 01-shift.js
│ │ │ │ │ │ │ ├── 02-counter.js
│ │ │ │ │ │ │ ├── 03-time.js
│ │ │ │ │ │ │ ├── 04-relative.js
│ │ │ │ │ │ │ ├── 05-section.js
│ │ │ │ │ │ │ ├── 06-timezone.js
│ │ │ │ │ │ │ ├── 07-weekday.js
│ │ │ │ │ │ │ ├── _timezones.js
│ │ │ │ │ │ │ └── index.js
│ │ │ │ │ │ ├── 02-parse/
│ │ │ │ │ │ │ ├── 01-today.js
│ │ │ │ │ │ │ ├── 02-holidays.js
│ │ │ │ │ │ │ ├── 03-next-last.js
│ │ │ │ │ │ │ ├── 04-yearly.js
│ │ │ │ │ │ │ ├── 05-explicit.js
│ │ │ │ │ │ │ └── index.js
│ │ │ │ │ │ ├── 03-transform/
│ │ │ │ │ │ │ ├── addCounter.js
│ │ │ │ │ │ │ └── index.js
│ │ │ │ │ │ ├── index.js
│ │ │ │ │ │ └── units/
│ │ │ │ │ │ ├── Unit.js
│ │ │ │ │ │ ├── _day.js
│ │ │ │ │ │ ├── _time.js
│ │ │ │ │ │ ├── _week.js
│ │ │ │ │ │ ├── _year.js
│ │ │ │ │ │ └── index.js
│ │ │ │ │ └── range/
│ │ │ │ │ ├── 01-two-times.js
│ │ │ │ │ ├── 02-date-range.js
│ │ │ │ │ ├── 03-one-date.js
│ │ │ │ │ ├── _reverse.js
│ │ │ │ │ ├── combos/
│ │ │ │ │ │ └── index.js
│ │ │ │ │ ├── index.js
│ │ │ │ │ └── intervals/
│ │ │ │ │ └── index.js
│ │ │ │ ├── times.js
│ │ │ │ └── toJSON.js
│ │ │ ├── compute/
│ │ │ │ ├── 00-year.js
│ │ │ │ ├── 01-time-range.js
│ │ │ │ ├── 02-timezone.js
│ │ │ │ ├── 03-fixup.js
│ │ │ │ ├── index.js
│ │ │ │ └── matches.js
│ │ │ ├── debug.js
│ │ │ ├── model/
│ │ │ │ ├── regex.js
│ │ │ │ ├── tags.js
│ │ │ │ └── words/
│ │ │ │ ├── dates.js
│ │ │ │ ├── durations.js
│ │ │ │ ├── holidays.js
│ │ │ │ ├── index.js
│ │ │ │ ├── times.js
│ │ │ │ └── timezones.js
│ │ │ └── plugin.js
│ │ └── tests/
│ │ ├── _lib.js
│ │ ├── ambig-month.test.js
│ │ ├── ambig-week.test.js
│ │ ├── ambig-weekday.test.js
│ │ ├── backlog/
│ │ │ ├── combo.ignore.js
│ │ │ ├── duckling.ignore.js
│ │ │ ├── interval.ignore.js
│ │ │ └── units.ignore.js
│ │ ├── before-after.test.js
│ │ ├── chronic.test.js
│ │ ├── day-start.test.js
│ │ ├── dmy.test.js
│ │ ├── duration-range.test.js
│ │ ├── duration.test.js
│ │ ├── durations.test.js
│ │ ├── end.test.js
│ │ ├── equals.test.js
│ │ ├── false-positive.test.js
│ │ ├── format.test.js
│ │ ├── full-iso.test.js
│ │ ├── fullDates.test.js
│ │ ├── has-date.test.js
│ │ ├── misc.test.js
│ │ ├── phrase.test.js
│ │ ├── startDates.test.js
│ │ ├── tagger/
│ │ │ ├── ambiguous.test.js
│ │ │ ├── date-chunk.test.js
│ │ │ └── date_tag.test.js
│ │ ├── times.test.js
│ │ ├── timezone.test.js
│ │ ├── to-iso.test.js
│ │ ├── today.test.js
│ │ ├── tokenizer.test.js
│ │ └── week.test.js
│ ├── paragraphs/
│ │ ├── README.md
│ │ ├── builds/
│ │ │ ├── compromise-paragraphs.cjs
│ │ │ └── compromise-paragraphs.mjs
│ │ ├── index.d.ts
│ │ ├── package.json
│ │ ├── src/
│ │ │ ├── api.js
│ │ │ └── plugin.js
│ │ └── tests/
│ │ ├── _lib.js
│ │ └── misc.test.js
│ ├── payload/
│ │ ├── README.md
│ │ ├── builds/
│ │ │ ├── compromise-payload.cjs
│ │ │ └── compromise-payload.mjs
│ │ ├── index.d.ts
│ │ ├── package.json
│ │ ├── scratch.js
│ │ ├── src/
│ │ │ ├── debug.js
│ │ │ └── plugin.js
│ │ └── tests/
│ │ ├── _lib.js
│ │ └── payload.test.js
│ ├── speech/
│ │ ├── README.md
│ │ ├── builds/
│ │ │ ├── compromise-speech.cjs
│ │ │ └── compromise-speech.mjs
│ │ ├── demo/
│ │ │ └── index.html
│ │ ├── index.d.ts
│ │ ├── package.json
│ │ ├── scratch.js
│ │ ├── src/
│ │ │ ├── api.js
│ │ │ ├── compute/
│ │ │ │ ├── index.js
│ │ │ │ ├── soundsLike/
│ │ │ │ │ ├── index.js
│ │ │ │ │ ├── metaphone.js
│ │ │ │ │ └── transformations.js
│ │ │ │ └── syllables/
│ │ │ │ ├── index.js
│ │ │ │ ├── postProcess.js
│ │ │ │ └── syllables.js
│ │ │ └── plugin.js
│ │ └── tests/
│ │ ├── _lib.js
│ │ ├── soundsLike.test.js
│ │ └── syllables.test.js
│ ├── speed/
│ │ ├── README.md
│ │ ├── builds/
│ │ │ ├── compromise-speed.cjs
│ │ │ └── compromise-speed.mjs
│ │ ├── demo/
│ │ │ └── index.html
│ │ ├── index.d.ts
│ │ ├── package.json
│ │ ├── scratch.js
│ │ ├── scripts/
│ │ │ └── version.js
│ │ ├── src/
│ │ │ ├── _version.js
│ │ │ ├── keypress/
│ │ │ │ └── index.js
│ │ │ ├── lazyParse/
│ │ │ │ ├── lazyParse.js
│ │ │ │ ├── maybeMatch.js
│ │ │ │ └── plugin.js
│ │ │ ├── plugin.js
│ │ │ ├── stream/
│ │ │ │ └── streamFile.js
│ │ │ └── workerPool/
│ │ │ ├── index.js
│ │ │ ├── plugin.js
│ │ │ ├── pool/
│ │ │ │ ├── create.js
│ │ │ │ └── worker.js
│ │ │ └── rip.js
│ │ └── tests/
│ │ ├── _lib.js
│ │ ├── files/
│ │ │ └── freshPrince.txt
│ │ └── stream.test.js
│ ├── stats/
│ │ ├── README.md
│ │ ├── builds/
│ │ │ ├── compromise-stats.cjs
│ │ │ └── compromise-stats.mjs
│ │ ├── demo/
│ │ │ └── index.html
│ │ ├── index.d.ts
│ │ ├── package.json
│ │ ├── scratch.js
│ │ ├── scripts/
│ │ │ ├── generate.js
│ │ │ └── pack.js
│ │ ├── src/
│ │ │ ├── compute.js
│ │ │ ├── ngram/
│ │ │ │ ├── endGrams.js
│ │ │ │ ├── getGrams.js
│ │ │ │ ├── index.js
│ │ │ │ ├── sort.js
│ │ │ │ ├── startGrams.js
│ │ │ │ └── tokenize.js
│ │ │ ├── plugin.js
│ │ │ └── tfidf/
│ │ │ ├── _model.js
│ │ │ ├── idf.js
│ │ │ ├── index.js
│ │ │ ├── tf.js
│ │ │ └── unpack.js
│ │ └── tests/
│ │ ├── _lib.js
│ │ ├── edgegram.test.js
│ │ ├── misc.test.js
│ │ └── ngram.test.js
│ └── wikipedia/
│ ├── README.md
│ ├── builds/
│ │ ├── compromise-wikipedia.cjs
│ │ └── compromise-wikipedia.mjs
│ ├── config.js
│ ├── demo/
│ │ └── index.html
│ ├── index.d.ts
│ ├── package.json
│ ├── scratch.js
│ ├── scripts/
│ │ ├── generate/
│ │ │ ├── 01-download.js
│ │ │ ├── 02-filter.js
│ │ │ ├── 03-compress.js
│ │ │ ├── _no-list.js
│ │ │ └── index.js
│ │ ├── perf.js
│ │ └── stat.js
│ ├── src/
│ │ ├── _model.js
│ │ └── plugin.js
│ └── tests/
│ ├── _lib.js
│ └── misc.test.js
├── scratch.js
├── scripts/
│ ├── chunks.js
│ ├── coreference/
│ │ └── index.js
│ ├── debug.js
│ ├── match-linter.js
│ ├── match.js
│ ├── pack.js
│ ├── patterns/
│ │ ├── manual.js
│ │ ├── patterns.js
│ │ └── tester.js
│ ├── perf/
│ │ ├── _fetch.js
│ │ ├── flame/
│ │ │ ├── _sotu-text.js
│ │ │ └── index.js
│ │ ├── index.js
│ │ ├── novel.js
│ │ ├── package.json
│ │ ├── pool/
│ │ │ ├── _lib.js
│ │ │ ├── lookup-worker.js
│ │ │ ├── pool.js
│ │ │ └── worker.js
│ │ └── versions.js
│ ├── plugins.js
│ ├── test/
│ │ ├── coverage.js
│ │ ├── index.js
│ │ ├── smoke.test.js
│ │ ├── stress.js
│ │ └── types.ts
│ ├── typescript/
│ │ ├── one.ts
│ │ ├── three.ts
│ │ └── two.ts
│ └── version.js
├── src/
│ ├── 1-one/
│ │ ├── cache/
│ │ │ ├── api.js
│ │ │ ├── compute.js
│ │ │ ├── methods/
│ │ │ │ ├── cacheDoc.js
│ │ │ │ └── index.js
│ │ │ └── plugin.js
│ │ ├── change/
│ │ │ ├── api/
│ │ │ │ ├── case.js
│ │ │ │ ├── concat.js
│ │ │ │ ├── harden.js
│ │ │ │ ├── index.js
│ │ │ │ ├── insert.js
│ │ │ │ ├── lib/
│ │ │ │ │ ├── _sort.js
│ │ │ │ │ ├── insert.js
│ │ │ │ │ └── remove.js
│ │ │ │ ├── remove.js
│ │ │ │ ├── replace.js
│ │ │ │ ├── sort.js
│ │ │ │ └── whitespace.js
│ │ │ ├── compute/
│ │ │ │ ├── index.js
│ │ │ │ └── uuid.js
│ │ │ └── plugin.js
│ │ ├── contraction-one/
│ │ │ ├── compute/
│ │ │ │ ├── contractions/
│ │ │ │ │ ├── _splice.js
│ │ │ │ │ ├── apostrophe-d.js
│ │ │ │ │ ├── apostrophe-t.js
│ │ │ │ │ ├── french.js
│ │ │ │ │ ├── index.js
│ │ │ │ │ ├── number-range.js
│ │ │ │ │ └── number-unit.js
│ │ │ │ └── index.js
│ │ │ ├── model/
│ │ │ │ ├── contractions.js
│ │ │ │ ├── index.js
│ │ │ │ └── number-suffix.js
│ │ │ └── plugin.js
│ │ ├── freeze/
│ │ │ ├── compute.js
│ │ │ ├── debug.js
│ │ │ └── plugin.js
│ │ ├── lexicon/
│ │ │ ├── compute/
│ │ │ │ ├── index.js
│ │ │ │ ├── multi-word.js
│ │ │ │ └── single-word.js
│ │ │ ├── lib.js
│ │ │ ├── methods/
│ │ │ │ ├── expand.js
│ │ │ │ └── index.js
│ │ │ └── plugin.js
│ │ ├── lookup/
│ │ │ ├── api/
│ │ │ │ ├── buildTrie/
│ │ │ │ │ ├── compress.js
│ │ │ │ │ └── index.js
│ │ │ │ ├── index.js
│ │ │ │ └── scan.js
│ │ │ └── plugin.js
│ │ ├── match/
│ │ │ ├── api/
│ │ │ │ ├── _lib.js
│ │ │ │ ├── index.js
│ │ │ │ ├── join.js
│ │ │ │ ├── lookaround.js
│ │ │ │ ├── match.js
│ │ │ │ └── split.js
│ │ │ ├── lib.js
│ │ │ ├── methods/
│ │ │ │ ├── index.js
│ │ │ │ ├── match/
│ │ │ │ │ ├── 01-failFast.js
│ │ │ │ │ ├── 02-from-here.js
│ │ │ │ │ ├── 03-getGroup.js
│ │ │ │ │ ├── 03-notIf.js
│ │ │ │ │ ├── _lib.js
│ │ │ │ │ ├── index.js
│ │ │ │ │ ├── steps/
│ │ │ │ │ │ ├── and-block.js
│ │ │ │ │ │ ├── astrix.js
│ │ │ │ │ │ ├── contraction-skip.js
│ │ │ │ │ │ ├── greedy-match.js
│ │ │ │ │ │ ├── logic/
│ │ │ │ │ │ │ ├── and-or.js
│ │ │ │ │ │ │ ├── greedy.js
│ │ │ │ │ │ │ └── negative-greedy.js
│ │ │ │ │ │ ├── negative.js
│ │ │ │ │ │ ├── optional-match.js
│ │ │ │ │ │ ├── or-block.js
│ │ │ │ │ │ └── simple-match.js
│ │ │ │ │ └── term/
│ │ │ │ │ ├── _fuzzy.js
│ │ │ │ │ └── doesMatch.js
│ │ │ │ ├── parseMatch/
│ │ │ │ │ ├── 01-parseBlocks.js
│ │ │ │ │ ├── 02-parseToken.js
│ │ │ │ │ ├── 03-splitHyphens.js
│ │ │ │ │ ├── 04-inflect-root.js
│ │ │ │ │ ├── 05-postProcess.js
│ │ │ │ │ └── index.js
│ │ │ │ └── termMethods.js
│ │ │ └── plugin.js
│ │ ├── output/
│ │ │ ├── api/
│ │ │ │ ├── _fmts.js
│ │ │ │ ├── _text.js
│ │ │ │ ├── debug.js
│ │ │ │ ├── html.js
│ │ │ │ ├── index.js
│ │ │ │ ├── json.js
│ │ │ │ ├── out.js
│ │ │ │ ├── text.js
│ │ │ │ └── wrap.js
│ │ │ ├── methods/
│ │ │ │ ├── debug/
│ │ │ │ │ ├── _color.js
│ │ │ │ │ ├── chunks.js
│ │ │ │ │ ├── client-side.js
│ │ │ │ │ ├── highlight.js
│ │ │ │ │ ├── index.js
│ │ │ │ │ └── tags.js
│ │ │ │ ├── hash.js
│ │ │ │ └── index.js
│ │ │ └── plugin.js
│ │ ├── pointers/
│ │ │ ├── api/
│ │ │ │ ├── index.js
│ │ │ │ └── lib/
│ │ │ │ ├── _lib.js
│ │ │ │ ├── difference.js
│ │ │ │ ├── intersection.js
│ │ │ │ ├── split.js
│ │ │ │ └── union.js
│ │ │ ├── methods/
│ │ │ │ ├── getDoc.js
│ │ │ │ └── index.js
│ │ │ └── plugin.js
│ │ ├── sweep/
│ │ │ ├── api.js
│ │ │ ├── lib.js
│ │ │ ├── methods/
│ │ │ │ ├── buildNet/
│ │ │ │ │ ├── 01-parse.js
│ │ │ │ │ └── index.js
│ │ │ │ ├── index.js
│ │ │ │ ├── sweep/
│ │ │ │ │ ├── 01-getHooks.js
│ │ │ │ │ ├── 02-trim-down.js
│ │ │ │ │ ├── 04-runMatch.js
│ │ │ │ │ └── index.js
│ │ │ │ └── tagger/
│ │ │ │ ├── canBe.js
│ │ │ │ └── index.js
│ │ │ └── plugin.js
│ │ ├── tag/
│ │ │ ├── api/
│ │ │ │ ├── index.js
│ │ │ │ └── tag.js
│ │ │ ├── compute/
│ │ │ │ └── tagRank.js
│ │ │ ├── lib.js
│ │ │ ├── methods/
│ │ │ │ ├── addTags/
│ │ │ │ │ ├── 01-validate.js
│ │ │ │ │ ├── 02-fmt.js
│ │ │ │ │ ├── _colors.js
│ │ │ │ │ └── index.js
│ │ │ │ ├── canBe.js
│ │ │ │ ├── index.js
│ │ │ │ ├── setTag.js
│ │ │ │ └── unTag.js
│ │ │ └── plugin.js
│ │ ├── tokenize/
│ │ │ ├── compute/
│ │ │ │ ├── alias.js
│ │ │ │ ├── freq.js
│ │ │ │ ├── index.js
│ │ │ │ ├── machine.js
│ │ │ │ ├── normal/
│ │ │ │ │ ├── 01-cleanup.js
│ │ │ │ │ ├── 02-acronyms.js
│ │ │ │ │ └── index.js
│ │ │ │ ├── offset.js
│ │ │ │ ├── reindex.js
│ │ │ │ └── wordCount.js
│ │ │ ├── methods/
│ │ │ │ ├── 01-sentences/
│ │ │ │ │ ├── 01-simple-split.js
│ │ │ │ │ ├── 02-simple-merge.js
│ │ │ │ │ ├── 03-smart-merge.js
│ │ │ │ │ ├── 04-quote-merge.js
│ │ │ │ │ ├── 05-parens-merge.js
│ │ │ │ │ ├── index.js
│ │ │ │ │ └── is-sentence.js
│ │ │ │ ├── 02-terms/
│ │ │ │ │ ├── 01-hyphens.js
│ │ │ │ │ ├── 02-slashes.js
│ │ │ │ │ ├── 03-ranges.js
│ │ │ │ │ └── index.js
│ │ │ │ ├── 03-whitespace/
│ │ │ │ │ ├── index.js
│ │ │ │ │ └── tokenize.js
│ │ │ │ ├── index.js
│ │ │ │ ├── parse.js
│ │ │ │ └── unicode.js
│ │ │ ├── model/
│ │ │ │ ├── abbreviations/
│ │ │ │ │ ├── honorifics.js
│ │ │ │ │ ├── misc.js
│ │ │ │ │ ├── months.js
│ │ │ │ │ ├── nouns.js
│ │ │ │ │ ├── organizations.js
│ │ │ │ │ ├── places.js
│ │ │ │ │ └── units.js
│ │ │ │ ├── aliases.js
│ │ │ │ ├── index.js
│ │ │ │ ├── lexicon.js
│ │ │ │ ├── prefixes.js
│ │ │ │ ├── punctuation.js
│ │ │ │ ├── suffixes.js
│ │ │ │ └── unicode.js
│ │ │ └── plugin.js
│ │ └── typeahead/
│ │ ├── api.js
│ │ ├── compute.js
│ │ ├── lib/
│ │ │ ├── allPrefixes.js
│ │ │ └── index.js
│ │ └── plugin.js
│ ├── 2-two/
│ │ ├── contraction-two/
│ │ │ ├── api/
│ │ │ │ ├── contract.js
│ │ │ │ └── index.js
│ │ │ ├── compute/
│ │ │ │ ├── _splice.js
│ │ │ │ ├── apostrophe-d.js
│ │ │ │ ├── apostrophe-s.js
│ │ │ │ ├── apostrophe-t.js
│ │ │ │ ├── index.js
│ │ │ │ └── isPossessive.js
│ │ │ └── plugin.js
│ │ ├── lazy/
│ │ │ ├── lazyParse.js
│ │ │ ├── maybeMatch.js
│ │ │ └── plugin.js
│ │ ├── postTagger/
│ │ │ ├── api.js
│ │ │ ├── compute/
│ │ │ │ └── index.js
│ │ │ ├── model/
│ │ │ │ ├── _misc.js
│ │ │ │ ├── adjective/
│ │ │ │ │ ├── adj-adverb.js
│ │ │ │ │ ├── adj-gerund.js
│ │ │ │ │ ├── adj-noun.js
│ │ │ │ │ ├── adj-verb.js
│ │ │ │ │ └── adjective.js
│ │ │ │ ├── adverb.js
│ │ │ │ ├── conjunctions.js
│ │ │ │ ├── dates/
│ │ │ │ │ ├── date-phrase.js
│ │ │ │ │ └── date.js
│ │ │ │ ├── expressions.js
│ │ │ │ ├── index.js
│ │ │ │ ├── nouns/
│ │ │ │ │ ├── nouns.js
│ │ │ │ │ ├── organizations.js
│ │ │ │ │ └── places.js
│ │ │ │ ├── numbers/
│ │ │ │ │ ├── fractions.js
│ │ │ │ │ ├── money.js
│ │ │ │ │ └── numbers.js
│ │ │ │ ├── person/
│ │ │ │ │ ├── ambig-name.js
│ │ │ │ │ └── person-phrase.js
│ │ │ │ └── verbs/
│ │ │ │ ├── adj-gerund.js
│ │ │ │ ├── auxiliary.js
│ │ │ │ ├── imperative.js
│ │ │ │ ├── noun-gerund.js
│ │ │ │ ├── passive.js
│ │ │ │ ├── phrasal.js
│ │ │ │ ├── verb-noun.js
│ │ │ │ └── verbs.js
│ │ │ └── plugin.js
│ │ ├── preTagger/
│ │ │ ├── compute/
│ │ │ │ ├── index.js
│ │ │ │ ├── penn.js
│ │ │ │ ├── root.js
│ │ │ │ └── tagger/
│ │ │ │ ├── 1st-pass/
│ │ │ │ │ ├── 01-colons.js
│ │ │ │ │ └── 02-hyphens.js
│ │ │ │ ├── 2nd-pass/
│ │ │ │ │ ├── 00-tagSwitch.js
│ │ │ │ │ ├── 01-case.js
│ │ │ │ │ ├── 02-suffix.js
│ │ │ │ │ ├── 03-regex.js
│ │ │ │ │ ├── 04-prefix.js
│ │ │ │ │ └── 05-year.js
│ │ │ │ ├── 3rd-pass/
│ │ │ │ │ ├── 01-acronym.js
│ │ │ │ │ ├── 02-neighbours.js
│ │ │ │ │ ├── 03-orgWords.js
│ │ │ │ │ ├── 04-placeWords.js
│ │ │ │ │ ├── 05-fallback.js
│ │ │ │ │ ├── 06-switches.js
│ │ │ │ │ ├── 07-verb-type.js
│ │ │ │ │ ├── 08-imperative.js
│ │ │ │ │ ├── _adhoc.js
│ │ │ │ │ └── _fillTags.js
│ │ │ │ ├── _fastTag.js
│ │ │ │ └── index.js
│ │ │ ├── methods/
│ │ │ │ ├── expand/
│ │ │ │ │ ├── byTag.js
│ │ │ │ │ └── index.js
│ │ │ │ ├── index.js
│ │ │ │ ├── looksPlural.js
│ │ │ │ ├── quickSplit.js
│ │ │ │ └── transform/
│ │ │ │ ├── adjectives/
│ │ │ │ │ ├── conjugate/
│ │ │ │ │ │ ├── fromAdverb.js
│ │ │ │ │ │ ├── lib.js
│ │ │ │ │ │ └── toAdverb.js
│ │ │ │ │ ├── index.js
│ │ │ │ │ └── inflect.js
│ │ │ │ ├── index.js
│ │ │ │ ├── nouns/
│ │ │ │ │ ├── index.js
│ │ │ │ │ ├── toPlural/
│ │ │ │ │ │ ├── _rules.js
│ │ │ │ │ │ └── index.js
│ │ │ │ │ └── toSingular/
│ │ │ │ │ ├── _rules.js
│ │ │ │ │ └── index.js
│ │ │ │ └── verbs/
│ │ │ │ ├── conjugate/
│ │ │ │ │ └── index.js
│ │ │ │ ├── getTense/
│ │ │ │ │ ├── _guess.js
│ │ │ │ │ └── index.js
│ │ │ │ ├── index.js
│ │ │ │ └── toInfinitive/
│ │ │ │ └── index.js
│ │ │ ├── model/
│ │ │ │ ├── _expand/
│ │ │ │ │ ├── index.js
│ │ │ │ │ └── irregulars.js
│ │ │ │ ├── clues/
│ │ │ │ │ ├── _adj.js
│ │ │ │ │ ├── _gerund.js
│ │ │ │ │ ├── _noun.js
│ │ │ │ │ ├── _person.js
│ │ │ │ │ ├── _verb.js
│ │ │ │ │ ├── actor-verb.js
│ │ │ │ │ ├── adj-gerund.js
│ │ │ │ │ ├── adj-noun.js
│ │ │ │ │ ├── adj-past.js
│ │ │ │ │ ├── adj-present.js
│ │ │ │ │ ├── index.js
│ │ │ │ │ ├── noun-gerund.js
│ │ │ │ │ ├── noun-verb.js
│ │ │ │ │ ├── person-adj.js
│ │ │ │ │ ├── person-date.js
│ │ │ │ │ ├── person-noun.js
│ │ │ │ │ ├── person-place.js
│ │ │ │ │ ├── person-verb.js
│ │ │ │ │ └── unit-noun.js
│ │ │ │ ├── index.js
│ │ │ │ ├── irregulars/
│ │ │ │ │ └── plurals.js
│ │ │ │ ├── lexicon/
│ │ │ │ │ ├── _data.js
│ │ │ │ │ ├── emoticons.js
│ │ │ │ │ ├── frozenLex.js
│ │ │ │ │ ├── index.js
│ │ │ │ │ └── misc.js
│ │ │ │ ├── models/
│ │ │ │ │ ├── _data.js
│ │ │ │ │ └── index.js
│ │ │ │ ├── orgWords.js
│ │ │ │ ├── patterns/
│ │ │ │ │ ├── endsWith.js
│ │ │ │ │ ├── neighbours.js
│ │ │ │ │ ├── prefixes.js
│ │ │ │ │ └── suffixes.js
│ │ │ │ ├── personWords.js
│ │ │ │ ├── placeWords.js
│ │ │ │ └── regex/
│ │ │ │ ├── regex-normal.js
│ │ │ │ ├── regex-numbers.js
│ │ │ │ └── regex-text.js
│ │ │ ├── plugin.js
│ │ │ └── tagSet/
│ │ │ ├── dates.js
│ │ │ ├── index.js
│ │ │ ├── misc.js
│ │ │ ├── nouns.js
│ │ │ ├── values.js
│ │ │ └── verbs.js
│ │ └── swap/
│ │ ├── api/
│ │ │ ├── swap-verb.js
│ │ │ └── swap.js
│ │ └── plugin.js
│ ├── 3-three/
│ │ ├── adjectives/
│ │ │ └── plugin.js
│ │ ├── adverbs/
│ │ │ └── plugin.js
│ │ ├── chunker/
│ │ │ ├── api/
│ │ │ │ ├── api.js
│ │ │ │ ├── chunks.js
│ │ │ │ └── clauses.js
│ │ │ ├── compute/
│ │ │ │ ├── 01-easy.js
│ │ │ │ ├── 02-neighbours.js
│ │ │ │ ├── 03-matcher.js
│ │ │ │ ├── 04-fallback.js
│ │ │ │ ├── 05-fixUp.js
│ │ │ │ └── index.js
│ │ │ └── plugin.js
│ │ ├── coreference/
│ │ │ ├── api/
│ │ │ │ └── pronouns.js
│ │ │ ├── compute/
│ │ │ │ ├── findIt.js
│ │ │ │ ├── findPerson.js
│ │ │ │ ├── findThey.js
│ │ │ │ ├── index.js
│ │ │ │ └── lib.js
│ │ │ └── plugin.js
│ │ ├── misc/
│ │ │ ├── acronyms/
│ │ │ │ └── index.js
│ │ │ ├── parentheses/
│ │ │ │ ├── fns.js
│ │ │ │ └── index.js
│ │ │ ├── plugin.js
│ │ │ ├── possessives/
│ │ │ │ └── index.js
│ │ │ ├── quotations/
│ │ │ │ ├── fns.js
│ │ │ │ └── index.js
│ │ │ ├── selections/
│ │ │ │ └── index.js
│ │ │ └── slashes/
│ │ │ └── index.js
│ │ ├── normalize/
│ │ │ ├── api.js
│ │ │ ├── methods.js
│ │ │ └── plugin.js
│ │ ├── nouns/
│ │ │ ├── api/
│ │ │ │ ├── api.js
│ │ │ │ ├── hasPlural.js
│ │ │ │ ├── isPlural.js
│ │ │ │ ├── isSubordinate.js
│ │ │ │ ├── parse.js
│ │ │ │ ├── toJSON.js
│ │ │ │ ├── toPlural.js
│ │ │ │ └── toSingular.js
│ │ │ ├── find.js
│ │ │ └── plugin.js
│ │ ├── numbers/
│ │ │ ├── fractions/
│ │ │ │ ├── api.js
│ │ │ │ ├── convert/
│ │ │ │ │ ├── toCardinal.js
│ │ │ │ │ └── toOrdinal.js
│ │ │ │ ├── find.js
│ │ │ │ └── parse.js
│ │ │ ├── numbers/
│ │ │ │ ├── _toString.js
│ │ │ │ ├── api.js
│ │ │ │ ├── find.js
│ │ │ │ ├── format/
│ │ │ │ │ ├── index.js
│ │ │ │ │ ├── suffix.js
│ │ │ │ │ ├── toOrdinal/
│ │ │ │ │ │ ├── numOrdinal.js
│ │ │ │ │ │ └── textOrdinal.js
│ │ │ │ │ └── toText/
│ │ │ │ │ ├── data.js
│ │ │ │ │ └── index.js
│ │ │ │ ├── isUnit.js
│ │ │ │ └── parse/
│ │ │ │ ├── index.js
│ │ │ │ └── toNumber/
│ │ │ │ ├── data.js
│ │ │ │ ├── findModifiers.js
│ │ │ │ ├── index.js
│ │ │ │ ├── parseDecimals.js
│ │ │ │ ├── parseNumeric.js
│ │ │ │ └── validate.js
│ │ │ └── plugin.js
│ │ ├── redact/
│ │ │ └── plugin.js
│ │ ├── sentences/
│ │ │ ├── api.js
│ │ │ ├── conjugate/
│ │ │ │ ├── toFuture.js
│ │ │ │ ├── toInfinitive.js
│ │ │ │ ├── toNegative.js
│ │ │ │ ├── toPast.js
│ │ │ │ └── toPresent.js
│ │ │ ├── parse/
│ │ │ │ ├── index.js
│ │ │ │ └── mainClause.js
│ │ │ ├── plugin.js
│ │ │ └── questions.js
│ │ ├── topics/
│ │ │ ├── orgs/
│ │ │ │ └── api.js
│ │ │ ├── people/
│ │ │ │ ├── api.js
│ │ │ │ ├── find.js
│ │ │ │ ├── gender.js
│ │ │ │ └── parse.js
│ │ │ ├── places/
│ │ │ │ ├── api.js
│ │ │ │ └── find.js
│ │ │ ├── plugin.js
│ │ │ └── topics.js
│ │ └── verbs/
│ │ ├── api/
│ │ │ ├── api.js
│ │ │ ├── conjugate/
│ │ │ │ ├── toFuture.js
│ │ │ │ ├── toGerund.js
│ │ │ │ ├── toInfinitive.js
│ │ │ │ ├── toNegative.js
│ │ │ │ ├── toParticiple.js
│ │ │ │ ├── toPast.js
│ │ │ │ └── toPresent.js
│ │ │ ├── debug.js
│ │ │ ├── lib.js
│ │ │ ├── parse/
│ │ │ │ ├── adverbs.js
│ │ │ │ ├── getSubject.js
│ │ │ │ ├── grammar/
│ │ │ │ │ ├── forms.js
│ │ │ │ │ └── index.js
│ │ │ │ ├── index.js
│ │ │ │ └── root.js
│ │ │ └── toJSON.js
│ │ ├── find.js
│ │ └── plugin.js
│ ├── 4-four/
│ │ ├── facts/
│ │ │ ├── api.js
│ │ │ ├── parse/
│ │ │ │ ├── adjective.js
│ │ │ │ ├── index.js
│ │ │ │ ├── noun.js
│ │ │ │ ├── pivot.js
│ │ │ │ ├── postProcess.js
│ │ │ │ ├── statement/
│ │ │ │ │ └── index.js
│ │ │ │ └── verb.js
│ │ │ └── plugin.js
│ │ └── sense/
│ │ ├── api/
│ │ │ └── api.js
│ │ ├── compute/
│ │ │ └── index.js
│ │ ├── model/
│ │ │ ├── _data.js
│ │ │ ├── index.js
│ │ │ ├── more.js
│ │ │ └── senses/
│ │ │ ├── adjective.js
│ │ │ ├── index.js
│ │ │ ├── noun.js
│ │ │ └── verb.js
│ │ └── plugin.js
│ ├── API/
│ │ ├── View.js
│ │ ├── _lib.js
│ │ ├── extend.js
│ │ ├── inputs.js
│ │ ├── methods/
│ │ │ ├── compute.js
│ │ │ ├── index.js
│ │ │ ├── loops.js
│ │ │ └── utils.js
│ │ └── world.js
│ ├── _version.js
│ ├── four.js
│ ├── nlp.js
│ ├── one.js
│ ├── three.js
│ └── two.js
├── tagger.scratch.js
├── tests/
│ ├── _ignore/
│ │ ├── abbreviation.ignore.js
│ │ ├── before-after.ignore.js
│ │ ├── participle.ignore.js
│ │ ├── punctuation.ignore.js
│ │ ├── quotations.ignore.js
│ │ └── toQuestion.ignore.js
│ ├── bugs.md
│ ├── four/
│ │ ├── _lib.js
│ │ ├── facts.ignore.js
│ │ ├── match.ignore.js
│ │ └── misc.ignore.js
│ ├── hmm.js
│ ├── one/
│ │ ├── _lib.js
│ │ ├── cache/
│ │ │ ├── cache.test.js
│ │ │ ├── keep-cache.test.js
│ │ │ └── offset.test.js
│ │ ├── change/
│ │ │ ├── append.test.js
│ │ │ ├── case.test.js
│ │ │ ├── concat.test.js
│ │ │ ├── fork.ignore.js
│ │ │ ├── hyphenate.test.js
│ │ │ ├── insert.test.js
│ │ │ ├── join.test.js
│ │ │ ├── loop-mutate.test.js
│ │ │ ├── prepend.test.js
│ │ │ ├── reindex.test.js
│ │ │ ├── remove.test.js
│ │ │ ├── replace-sub.test.js
│ │ │ ├── split.test.js
│ │ │ └── splitOn.test.js
│ │ ├── lexicon/
│ │ │ └── lexicon.test.js
│ │ ├── lookup/
│ │ │ ├── lookup-long.test.js
│ │ │ └── lookup.test.js
│ │ ├── match/
│ │ │ ├── doc-match.test.js
│ │ │ ├── encoding.test.js
│ │ │ ├── fuzzy.test.js
│ │ │ ├── if.test.js
│ │ │ ├── lookaround.test.js
│ │ │ ├── match-method.test.js
│ │ │ ├── named-silent.test.js
│ │ │ ├── negative.test.js
│ │ │ ├── punctuation-match.test.js
│ │ │ ├── regex.test.js
│ │ │ ├── sweep-not.test.js
│ │ │ ├── sweep.test.js
│ │ │ └── syntax.test.js
│ │ ├── match.test.js
│ │ ├── misc/
│ │ │ ├── freeze.test.js
│ │ │ ├── inputs.test.js
│ │ │ ├── isFull.test.js
│ │ │ ├── loops.test.js
│ │ │ ├── misc.test.js
│ │ │ ├── pointer.test.js
│ │ │ ├── random.test.js
│ │ │ ├── reservedwords.test.js
│ │ │ ├── safe-contractions.test.js
│ │ │ ├── slash.test.js
│ │ │ ├── sort.test.js
│ │ │ ├── typeahead.test.js
│ │ │ ├── unicode.test.js
│ │ │ └── whitespace.test.js
│ │ ├── miss.test.js
│ │ ├── output/
│ │ │ ├── hash.test.js
│ │ │ └── html.test.js
│ │ ├── pointers/
│ │ │ ├── complement.test.js
│ │ │ ├── difference.test.js
│ │ │ ├── intersection.test.js
│ │ │ └── union.test.js
│ │ └── tokenize/
│ │ ├── hyphen-matrix.test.js
│ │ ├── hyphens.test.js
│ │ ├── punctuation.test.js
│ │ ├── sentence-split.test.js
│ │ └── term-split.test.js
│ ├── three/
│ │ ├── _lib.js
│ │ ├── acronym.test.js
│ │ ├── adjectives/
│ │ │ ├── adj-adv.test.js
│ │ │ ├── adj-noun.test.js
│ │ │ ├── adjectives.test.js
│ │ │ ├── comparative.test.js
│ │ │ └── superlative.test.js
│ │ ├── api.test.js
│ │ ├── chunker/
│ │ │ ├── chunks.ignore.js
│ │ │ └── clauses.test.js
│ │ ├── clause.test.js
│ │ ├── coreference/
│ │ │ ├── base-coref.ignore.js
│ │ │ ├── more.ignore.js
│ │ │ └── tricky-coref.ignore.js
│ │ ├── full-api.test.js
│ │ ├── fuzz.test.js
│ │ ├── hashTags.test.js
│ │ ├── json-three.test.js
│ │ ├── match.test.js
│ │ ├── misc.test.js
│ │ ├── miss.test.js
│ │ ├── normalize/
│ │ │ ├── normalize-custom.test.js
│ │ │ ├── normalize-methods.test.js
│ │ │ └── normalize-preset.test.js
│ │ ├── nouns/
│ │ │ ├── adjectives.test.js
│ │ │ ├── isPlural.test.js
│ │ │ ├── noun-find.test.js
│ │ │ ├── parse.test.js
│ │ │ ├── toPlural.test.js
│ │ │ └── toSingular.test.js
│ │ ├── numbers/
│ │ │ ├── backlog/
│ │ │ │ ├── agreement.ignore.js
│ │ │ │ ├── conversion.ignore.js
│ │ │ │ ├── money.ignore.js
│ │ │ │ └── overlap.ignore.js
│ │ │ ├── bigNumber.test.js
│ │ │ ├── fractions.test.js
│ │ │ ├── misc.test.js
│ │ │ ├── number-parse.test.js
│ │ │ ├── percent.test.js
│ │ │ ├── prefix.test.js
│ │ │ ├── toCardinal.test.js
│ │ │ ├── toText.test.js
│ │ │ ├── units.test.js
│ │ │ └── value.test.js
│ │ ├── parentheses.test.js
│ │ ├── people/
│ │ │ ├── gender.test.js
│ │ │ ├── people-parse.test.js
│ │ │ └── people.test.js
│ │ ├── places.test.js
│ │ ├── plugin.test.js
│ │ ├── possessives.test.js
│ │ ├── quotations.test.js
│ │ ├── redact.test.js
│ │ ├── sentences/
│ │ │ ├── debullet.test.js
│ │ │ ├── isQuestion.test.js
│ │ │ ├── misc-conjugate.test.js
│ │ │ ├── misc.test.js
│ │ │ ├── negative.test.js
│ │ │ ├── sentence-participle.ignore.js
│ │ │ ├── sentence.test.js
│ │ │ ├── svo.test.js
│ │ │ ├── tense.test.js
│ │ │ ├── toFuture.test.js
│ │ │ ├── toGerund.ignore.js
│ │ │ ├── toPast.test.js
│ │ │ └── toPresent.test.js
│ │ ├── setTag.test.js
│ │ ├── slashes.test.js
│ │ ├── subsets.test.js
│ │ ├── sweep-tag.test.js
│ │ ├── text-three.test.js
│ │ ├── topics.test.js
│ │ └── verbs/
│ │ ├── auxiliary.test.js
│ │ ├── conjugate.test.js
│ │ ├── imperative.test.js
│ │ ├── isplural.test.js
│ │ ├── misc.test.js
│ │ ├── parse.test.js
│ │ ├── parts.test.js
│ │ ├── phrasal.test.js
│ │ ├── phrasals.test.js
│ │ ├── subject.test.js
│ │ ├── toFuture.test.js
│ │ ├── toGerund.test.js
│ │ ├── toInfinitive.test.js
│ │ ├── toNegative.test.js
│ │ ├── toPast.test.js
│ │ ├── toPastParticiple.test.js
│ │ ├── toPresent.test.js
│ │ ├── verb-find.test.js
│ │ ├── verb-forms.test.js
│ │ └── verb-root.test.js
│ └── two/
│ ├── _backlog.js
│ ├── _lib.js
│ ├── contractions/
│ │ ├── contract.test.js
│ │ ├── contraction-match.test.js
│ │ ├── contraction.test.js
│ │ ├── expand.test.js
│ │ ├── had-would.test.js
│ │ ├── is-has-possessive.test.js
│ │ └── match-contraction.test.js
│ ├── freeze/
│ │ ├── freeze.test.js
│ │ ├── internal.test.js
│ │ └── lex.test.js
│ ├── groups/
│ │ ├── named-match.test.js
│ │ └── named-multi.test.js
│ ├── match/
│ │ ├── and.test.js
│ │ ├── blocks.test.js
│ │ ├── capture.test.js
│ │ ├── fancy-match.test.js
│ │ ├── greedy-capture.test.js
│ │ ├── lookahead.test.js
│ │ ├── match-tricky.test.js
│ │ ├── match.test.js
│ │ ├── min-max.test.js
│ │ ├── multiword.test.js
│ │ ├── not.test.js
│ │ ├── or.test.js
│ │ ├── root-match.test.js
│ │ └── soft-match.test.js
│ ├── match.test.js
│ ├── misc/
│ │ ├── canBe.test.js
│ │ ├── confidence.test.js
│ │ ├── constructor.test.js
│ │ ├── emoji.test.js
│ │ ├── lazy.test.js
│ │ ├── misc.test.js
│ │ ├── multiTag.test.js
│ │ ├── remove-more.test.js
│ │ ├── root.test.js
│ │ ├── smoke.test.js
│ │ ├── tagRank.test.js
│ │ ├── term-ids.test.js
│ │ ├── unique.test.js
│ │ └── wordcount.test.js
│ ├── miss.test.js
│ ├── output/
│ │ ├── json.test.js
│ │ ├── out.test.js
│ │ └── text.test.js
│ ├── plugin/
│ │ ├── addTags.ignore.js
│ │ └── addWords.test.js
│ ├── tagger/
│ │ ├── _pennSample.js
│ │ ├── actors.test.js
│ │ ├── inline.test.js
│ │ ├── lexicon.test.js
│ │ ├── multi.test.js
│ │ ├── number-match.test.js
│ │ ├── penn.test.js
│ │ ├── swears.test.js
│ │ ├── topics.test.js
│ │ └── untag.test.js
│ ├── transform/
│ │ ├── clone.test.js
│ │ ├── replace.test.js
│ │ └── swap.test.js
│ └── variables/
│ ├── gerund.test.js
│ ├── org-match.test.js
│ ├── past-adj.test.js
│ ├── person-match.test.js
│ ├── present-noun.test.js
│ └── verb-phrase.test.js
├── three/
│ └── package.json
├── tokenize/
│ └── package.json
├── tsconfig.json
├── two/
│ └── package.json
└── types/
├── misc.d.ts
├── one.d.cts
├── one.d.ts
├── three.d.cts
├── three.d.ts
├── two.d.cts
├── two.d.ts
└── view/
├── one.d.cts
├── one.d.ts
├── three.d.cts
├── three.d.ts
├── two.d.cts
└── two.d.ts
================================================
FILE CONTENTS
================================================
================================================
FILE: README.md
================================================
compromise
modest natural language processing
npm install compromise
don't you find it strange,
how easy text is to make ,
↬ᔐᖜ ↬ parse and use ?
compromise
tries its best to turn text into data.
it makes limited and sensible decisions.
don't be fancy, at all:
```js
if (doc.has('simon says #Verb')) {
return true
}
```
grab parts of the text:
```js
let doc = nlp(entireNovel)
doc.match('the #Adjective of times').text()
// "the blurst of times?"
```
and get data:
```js
import plg from 'compromise-speech'
nlp.extend(plg)
let doc = nlp('Milwaukee has certainly had its share of visitors..')
doc.compute('syllables')
doc.places().json()
/*
[{
"text": "Milwaukee",
"terms": [{
"normal": "milwaukee",
"syllables": ["mil", "wau", "kee"]
}]
}]
*/
```
-because it actually is-
```js
let doc = nlp('the purple dinosaur')
doc.nouns().toPlural()
doc.text()
// 'the purple dinosaurs'
```
conjugating all forms of a basic word list.
The final lexicon is ~14,000 words :
you can read more about how it works, [here](https://observablehq.com/@spencermountain/compromise-internals). it's weird.
okay -
compromise/one
A tokenizer of words, sentences, and punctuation.
```js
import nlp from 'compromise/one'
let doc = nlp("Wayne's World, party time")
let data = doc.json()
/* [{
normal:"wayne's world party time",
terms:[{ text: "Wayne's", normal: "wayne" },
...
]
}]
*/
```
compromise/one splits your text up, wraps it in a handy API,
/one is quick - most sentences take a 10th of a millisecond.
It can do ~1mb of text a second - or 10 wikipedia pages.
Infinite jest takes 3s.
compromise/two
A part-of-speech tagger, and grammar-interpreter.
```js
import nlp from 'compromise/two'
let doc = nlp("Wayne's World, party time")
let str = doc.match('#Possessive #Noun').text()
// "Wayne's World"
```
compromise/two automatically calculates the very basic grammar of each word.
this is more useful than people sometimes realize.
Light grammar helps you write cleaner templates, and get closer to the information.
83 tags , arranged in a handsome graph .
#FirstName → #Person → #ProperNoun → #Noun
you can see the grammar of each word by running `doc.debug()`
you can see the reasoning for each tag with `nlp.verbose('tagger')`.
if you prefer Penn tags
compromise/three
Phrase and sentence tooling.
```js
import nlp from 'compromise/three'
let doc = nlp("Wayne's World, party time")
let str = doc.people().normalize().text()
// "wayne"
```
compromise/three is a set of tooling to zoom into and operate on parts of a text.
`.numbers()` grabs all the numbers in a document, for example - and extends it with new methods, like `.subtract()`.
When you have a phrase, or group of words, you can see additional metadata about it with `.json()`
```js
let doc = nlp('four out of five dentists')
console.log(doc.fractions().json())
/*[{
text: 'four out of five',
terms: [ [Object], [Object], [Object], [Object] ],
fraction: { numerator: 4, denominator: 5, decimal: 0.8 }
}
]*/
```
```js
let doc = nlp('$4.09CAD')
doc.money().json()
/*[{
text: '$4.09CAD',
terms: [ [Object] ],
number: { prefix: '$', num: 4.09, suffix: 'cad'}
}
]*/
```
### .extend():
This library comes with a considerate, common-sense baseline for english grammar.
You're free to change, or lay-waste to any settings - which is the fun part actually.
the easiest part is just to suggest tags for any given words:
```js
let myWords = {
kermit: 'FirstName',
fozzie: 'FirstName',
}
let doc = nlp(muppetText, myWords)
```
or make heavier changes with a [compromise-plugin](https://observablehq.com/@spencermountain/compromise-plugins).
```js
import nlp from 'compromise'
nlp.extend({
// add new tags
tags: {
Character: {
isA: 'Person',
notA: 'Adjective',
},
},
// add or change words in the lexicon
words: {
kermit: 'Character',
gonzo: 'Character',
},
// change inflections
irregulars: {
get: {
pastTense: 'gotten',
gerund: 'gettin',
},
},
// add new methods to compromise
api: View => {
View.prototype.kermitVoice = function () {
this.sentences().prepend('well,')
this.match('i [(am|was)]').prepend('um,')
return this
}
},
})
```
### Docs:
##### gentle introduction:
- **[#1) Input → output](https://docs.compromise.cool/tutorial-1)**
- **[#2) Match & transform](https://docs.compromise.cool/compromise-tutorial-2)**
- **[#3) Making a chat-bot](https://docs.compromise.cool/compromise-making-a-bot)**
##### Documentation:
| Concepts | API | Plugins |
| ------------------------------------------------------------------------------------------- | :---------------------------------------------------------------------------------------------: | -------------------------------------------------------------------------------------: |
| [Accuracy](https://observablehq.com/@spencermountain/compromise-accuracy) | [Accessors](https://observablehq.com/@spencermountain/compromise-accessors) | [Adjectives](https://observablehq.com/@spencermountain/compromise-adjectives) |
| [Caching](https://observablehq.com/@spencermountain/compromise-cache) | [Constructor-methods](https://observablehq.com/@spencermountain/compromise-constructor-methods) | [Dates](https://observablehq.com/@spencermountain/compromise-dates) |
| [Case](https://observablehq.com/@spencermountain/compromise-case) | [Contractions](https://observablehq.com/@spencermountain/compromise-contractions) | [Export](https://observablehq.com/@spencermountain/compromise-export) |
| [Filesize](https://observablehq.com/@spencermountain/compromise-filesize) | [Insert](https://observablehq.com/@spencermountain/compromise-insert) | [Hash](https://observablehq.com/@spencermountain/compromise-hash) |
| [Internals](https://observablehq.com/@spencermountain/compromise-internals) | [Json](https://observablehq.com/@spencermountain/compromise-json) | [Html](https://observablehq.com/@spencermountain/compromise-html) |
| [Justification](https://observablehq.com/@spencermountain/compromise-justification) | [Character Offsets](https://observablehq.com/@spencermountain/compromise-offsets) | [Keypress](https://observablehq.com/@spencermountain/compromise-keypress) |
| [Lexicon](https://observablehq.com/@spencermountain/compromise-lexicon) | [Loops](https://observablehq.com/@spencermountain/compromise-loops) | [Ngrams](https://observablehq.com/@spencermountain/compromise-ngram) |
| [Match-syntax](https://observablehq.com/@spencermountain/compromise-match-syntax) | [Match](https://observablehq.com/@spencermountain/compromise-match) | [Numbers](https://observablehq.com/@spencermountain/compromise-values) |
| [Performance](https://observablehq.com/@spencermountain/compromise-performance) | [Nouns](https://observablehq.com/@spencermountain/nouns) | [Paragraphs](https://observablehq.com/@spencermountain/compromise-paragraphs) |
| [Plugins](https://observablehq.com/@spencermountain/compromise-plugins) | [Output](https://observablehq.com/@spencermountain/compromise-output) | [Scan](https://observablehq.com/@spencermountain/compromise-scan) |
| [Projects](https://observablehq.com/@spencermountain/compromise-projects) | [Selections](https://observablehq.com/@spencermountain/compromise-selections) | [Sentences](https://observablehq.com/@spencermountain/compromise-sentences) |
| [Tagger](https://observablehq.com/@spencermountain/compromise-tagger) | [Sorting](https://observablehq.com/@spencermountain/compromise-sorting) | [Syllables](https://observablehq.com/@spencermountain/compromise-syllables) |
| [Tags](https://observablehq.com/@spencermountain/compromise-tags) | [Split](https://observablehq.com/@spencermountain/compromise-split) | [Pronounce](https://observablehq.com/@spencermountain/compromise-pronounce) |
| [Tokenization](https://observablehq.com/@spencermountain/compromise-tokenization) | [Text](https://observablehq.com/@spencermountain/compromise-text) | [Strict](https://observablehq.com/@spencermountain/compromise-strict) |
| [Named-Entities](https://observablehq.com/@spencermountain/topics-named-entity-recognition) | [Utils](https://observablehq.com/@spencermountain/compromise-utils) | [Penn-tags](https://observablehq.com/@spencermountain/compromise-penn-tags) |
| [Whitespace](https://observablehq.com/@spencermountain/compromise-whitespace) | [Verbs](https://observablehq.com/@spencermountain/verbs) | [Typeahead](https://observablehq.com/@spencermountain/compromise/compromise-typeahead) |
| [World data](https://observablehq.com/@spencermountain/compromise-world) | [Normalization](https://observablehq.com/@spencermountain/compromise-normalization) | [Sweep](https://observablehq.com/@spencermountain/compromise-sweep) |
| [Fuzzy-matching](https://observablehq.com/@spencermountain/compromise-fuzzy-matching) | [Typescript](https://observablehq.com/@spencermountain/compromise-typescript) | [Mutation](https://observablehq.com/@spencermountain/compromise-mutation) |
| [Root-forms](https://observablehq.com/@spencermountain/compromise-root) |
##### Talks:
- **[Language as an Interface](https://www.youtube.com/watch?v=WuPVS2tCg8s)** - by Spencer Kelly
- **[Coding Chat Bots](https://www.youtube.com/watch?v=c_hmwFwvO0U)** - by KahWee Teng
- **[On Typing and data](https://vimeo.com/496095722)** - by Spencer Kelly
##### Articles:
- **[Geocoding Social Conversations with NLP and JavaScript](http://compromise.cool)** - by Microsoft
- **[Microservice Recipe](https://eventn.com/recipes/text-parsing-with-nlp-compromise)** - by Eventn
- **[Adventure Game Sentence Parsing with Compromise](https://killalldefects.com/2020/02/20/adventure-game-sentence-parsing-with-compromise/)**
- **[Building Text-Based Games](https://killalldefects.com/2019/09/24/building-text-based-games-with-compromise-nlp/)** - by Matt Eland
- **[Fun with javascript in BigQuery](https://medium.com/@hoffa/new-in-bigquery-persistent-udfs-c9ea4100fd83#6e09)** - by Felipe Hoffa
- **[Natural Language Processing... in the Browser?](https://dev.to/charlesdlandau/natural-language-processing-in-the-browser-52hj)** - by Charles Landau
##### Some fun Applications:
- **[Automated Bechdel Test](https://github.com/guardian/bechdel-test)** - by The Guardian
- **[Story generation framework](https://perchance.org/welcome)** - by Jose Phrocca
- **[Tumbler blog of lists](https://leanstooneside.tumblr.com/)** - horse-ebooks-like lists - by Michael Paulukonis
- **[Video Editing from Transcription](https://newtheory.io/)** - by New Theory
- **[Browser extension Fact-checking](https://github.com/AlexanderKidd/FactoidL)** - by Alexander Kidd
- **[Siri shortcut](https://routinehub.co/shortcut/3260)** - by Michael Byrns
- **[Amazon skill](https://github.com/tajddin/voiceplay)** - by Tajddin Maghni
- **[Tasking Slack-bot](https://github.com/kevinsuh/toki)** - by Kevin Suh
[[see more]](https://observablehq.com/@spencermountain/compromise-projects)
##### Comparisons
- [Compromise and Spacy](https://observablehq.com/@spencermountain/compromise-and-spacy)
- [Compromise and NLTK](https://observablehq.com/@spencermountain/compromise-and-nltk)
### Plugins:
These are some helpful extensions:
##### Dates
`npm install compromise-dates`
- **[.dates()](https://observablehq.com/@spencermountain/compromise-dates)** - find dates like `June 8th` or `03/03/18`
- **[.dates().get()](https://observablehq.com/@spencermountain/compromise-dates)** - simple start/end json result
- **[.dates().json()](https://observablehq.com/@spencermountain/compromise-dates)** - overloaded output with date metadata
- **[.dates().format('')](https://observablehq.com/@spencermountain/compromise-dates)** - convert the dates to specific formats
- **[.dates().toShortForm()](https://observablehq.com/@spencermountain/compromise-dates)** - convert 'Wednesday' to 'Wed', etc
- **[.dates().toLongForm()](https://observablehq.com/@spencermountain/compromise-dates)** - convert 'Feb' to 'February', etc
- **[.durations()](https://observablehq.com/@spencermountain/compromise-dates)** - `2 weeks` or `5mins`
- **[.durations().get()](https://observablehq.com/@spencermountain/compromise-dates)** - return simple json for duration
- **[.durations().json()](https://observablehq.com/@spencermountain/compromise-dates)** - overloaded output with duration metadata
- **[.times()](https://observablehq.com/@spencermountain/compromise-dates)** - `4:30pm` or `half past five`
- **[.times().get()](https://observablehq.com/@spencermountain/compromise-dates)** - return simple json for times
- **[.times().json()](https://observablehq.com/@spencermountain/compromise-dates)** - overloaded output with time metadata
##### Stats
`npm install compromise-stats`
- **[.tfidf({})](https://observablehq.com/@spencermountain/compromise-tfidf)** - rank words by frequency and uniqueness
- **[.ngrams({})](https://observablehq.com/@spencermountain/compromise-ngram)** - list all repeating sub-phrases, by word-count
- **[.unigrams()](https://observablehq.com/@spencermountain/compromise-ngram)** - n-grams with one word
- **[.bigrams()](https://observablehq.com/@spencermountain/compromise-ngram)** - n-grams with two words
- **[.trigrams()](https://observablehq.com/@spencermountain/compromise-ngram)** - n-grams with three words
- **[.startgrams()](https://observablehq.com/@spencermountain/compromise-ngram)** - n-grams including the first term of a phrase
- **[.endgrams()](https://observablehq.com/@spencermountain/compromise-ngram)** - n-grams including the last term of a phrase
- **[.edgegrams()](https://observablehq.com/@spencermountain/compromise-ngram)** - n-grams including the first or last term of a phrase
##### Speech
`npm install compromise-syllables`
- **[.syllables()](https://observablehq.com/@spencermountain/compromise-syllables)** - split each term by its typical pronunciation
- **[.soundsLike()](https://observablehq.com/@spencermountain/compromise-soundsLike)** - produce a estimated pronunciation
##### Wikipedia
`npm install compromise-wikipedia`
- **[.wikipedia()](https://observablehq.com/@spencermountain/compromise-wikipedia)** - compressed article reconciliation
### Typescript
we're committed to typescript/deno support, both in main and in the official-plugins:
```ts
import nlp from 'compromise'
import stats from 'compromise-stats'
const nlpEx = nlp.extend(stats)
nlpEx('This is type safe!').ngrams({ min: 1 })
```
#### Limitations:
- **slash-support:**
We currently split slashes up as different words, like we do for hyphens. so things like this don't work:
nlp('the koala eats/shoots/leaves').has('koala leaves') //false
- **inter-sentence match:**
By default, sentences are the top-level abstraction.
Inter-sentence, or multi-sentence matches aren't supported without a plugin :
nlp("that's it. Back to Winnipeg!").has('it back')//false
- **nested match syntax:**
the danger beauty of regex is that you can recurse indefinitely.
Our match syntax is much weaker. Things like this are not (yet) possible:
doc.match('(modern (major|minor))? general')
complex matches must be achieved with successive **.match()** statements.
- **dependency parsing:**
Proper sentence transformation requires understanding the [syntax tree](https://en.wikipedia.org/wiki/Parse_tree) of a sentence, which we don't currently do.
We should! Help wanted with this.
##### FAQ
☂️ Isn't javascript too...
yeah it is!
here for information about speed & performance, and
here for project motivations
💃 Can it run on my arduino-watch?
Only if it's water-proof!
quick start for running compromise in workers, mobile apps, and all sorts of funny environments.
🌎 Compromise in other Languages?
✨ Partial builds?
we do offer a tokenize-only build, which has the POS-tagger pulled-out.
(spencer's cool) vs. (spencer's house) )
#### See Also:
- **[en-pos](https://github.com/finnlp/en-pos)** - very clever javascript pos-tagger _by [Alex Corvi](https://github.com/alexcorvi)_
- **[naturalNode](https://github.com/NaturalNode/natural)** - fancier statistical nlp in javascript
- **[winkJS](https://winkjs.org/)** - POS-tagger, tokenizer, machine-learning in javascript
- **[dariusk/pos-js ](https://github.com/dariusk/pos-js)** - fastTag fork in javascript
- **[compendium-js](https://github.com/Ulflander/compendium-js)** - POS and sentiment analysis in javascript
- **[nodeBox linguistics](https://www.nodebox.net/code/index.php/Linguistics)** - conjugation, inflection in javascript
- **[reText](https://github.com/wooorm/retext)** - very impressive [text utilities](https://github.com/wooorm/retext/blob/master/doc/plugins.md) in javascript
- **[superScript](https://github.com/superscriptjs/superscript)** - conversation engine in js
- **[jsPos](https://code.google.com/archive/p/jspos/)** - javascript build of the time-tested Brill-tagger
- **[spaCy](https://spacy.io/)** - speedy, multilingual tagger in C/python
- **[Prose](https://github.com/jdkato/prose/)** - quick tagger in Go by Joseph Kato
- **[TextBlob](https://github.com/sloria/TextBlob)** - python tagger
MIT
================================================
FILE: builds/compromise.js
================================================
!function(e,t){"object"==typeof exports&&"undefined"!=typeof module?module.exports=t():"function"==typeof define&&define.amd?define(t):(e="undefined"!=typeof globalThis?globalThis:e||self).nlp=t()}(this,(function(){"use strict";var e={methods:{one:{},two:{},three:{},four:{}},model:{one:{},two:{},three:{}},compute:{},hooks:[]};const t={compute:function(e){const{world:t}=this,n=t.compute;return"string"==typeof e&&n.hasOwnProperty(e)?n[e](this):(e=>"[object Array]"===Object.prototype.toString.call(e))(e)?e.forEach((r=>{t.compute.hasOwnProperty(r)?n[r](this):console.warn("no compute:",e)})):"function"==typeof e?e(this):console.warn("no compute:",e),this}};var n={forEach:function(e){return this.fullPointer.forEach(((t,n)=>{const r=this.update([t]);e(r,n)})),this},map:function(e,t){const n=this.fullPointer.map(((t,n)=>{const r=this.update([t]),o=e(r,n);return void 0===o?this.none():o}));if(0===n.length)return t||this.update([]);if(void 0!==n[0]){if("string"==typeof n[0])return n;if("object"==typeof n[0]&&(null===n[0]||!n[0].isView))return n}let r=[];return n.forEach((e=>{r=r.concat(e.fullPointer)})),this.toView(r)},filter:function(e){let t=this.fullPointer;t=t.filter(((t,n)=>{const r=this.update([t]);return e(r,n)}));return this.update(t)},find:function(e){const t=this.fullPointer.find(((t,n)=>{const r=this.update([t]);return e(r,n)}));return this.update([t])},some:function(e){return this.fullPointer.some(((t,n)=>{const r=this.update([t]);return e(r,n)}))},random:function(e=1){let t=this.fullPointer,n=Math.floor(Math.random()*t.length);return n+e>this.length&&(n=this.length-e,n=n<0?0:n),t=t.slice(n,n+e),this.update(t)}};const r={termList:function(){return this.methods.one.termList(this.docs)},terms:function(e){const t=this.match(".");return"number"==typeof e?t.eq(e):t},groups:function(e){if(e||0===e)return this.update(this._groups[e]||[]);const t={};return Object.keys(this._groups).forEach((e=>{t[e]=this.update(this._groups[e])})),t},eq:function(e){let t=this.pointer;return t||(t=this.docs.map(((e,t)=>[t]))),t[e]?this.update([t[e]]):this.none()},first:function(){return this.eq(0)},last:function(){const e=this.fullPointer.length-1;return this.eq(e)},firstTerms:function(){return this.match("^.")},lastTerms:function(){return this.match(".$")},slice:function(e,t){let n=this.pointer||this.docs.map(((e,t)=>[t]));return n=n.slice(e,t),this.update(n)},all:function(){return this.update().toView()},fullSentences:function(){const e=this.fullPointer.map((e=>[e[0]]));return this.update(e).toView()},none:function(){return this.update([])},isDoc:function(e){if(!e||!e.isView)return!1;const t=this.fullPointer,n=e.fullPointer;return!t.length!==n.length&&t.every(((e,t)=>!!n[t]&&(e[0]===n[t][0]&&e[1]===n[t][1]&&e[2]===n[t][2])))},wordCount:function(){return this.docs.reduce(((e,t)=>(e+=t.filter((e=>""!==e.text)).length,e)),0)},isFull:function(){const e=this.pointer;if(!e)return!0;if(0===e.length||0!==e[0][0])return!1;let t=0,n=0;return this.document.forEach((e=>t+=e.length)),this.docs.forEach((e=>n+=e.length)),t===n},getNth:function(e){return"number"==typeof e?this.eq(e):"string"==typeof e?this.if(e):this}};r.group=r.groups,r.fullSentence=r.fullSentences,r.sentence=r.fullSentences,r.lastTerm=r.lastTerms,r.firstTerm=r.firstTerms;const o=Object.assign({},r,t,n);o.get=o.eq;class View{constructor(t,n,r={}){[["document",t],["world",e],["_groups",r],["_cache",null],["viewType","View"]].forEach((e=>{Object.defineProperty(this,e[0],{value:e[1],writable:!0})})),this.ptrs=n}get docs(){let t=this.document;return this.ptrs&&(t=e.methods.one.getDoc(this.ptrs,this.document)),t}get pointer(){return this.ptrs}get methods(){return this.world.methods}get model(){return this.world.model}get hooks(){return this.world.hooks}get isView(){return!0}get found(){return this.docs.length>0}get length(){return this.docs.length}get fullPointer(){const{docs:e,ptrs:t,document:n}=this,r=t||e.map(((e,t)=>[t]));return r.map((e=>{let[t,r,o,a,i]=e;return r=r||0,o=o||(n[t]||[]).length,n[t]&&n[t][r]&&(a=a||n[t][r].id,n[t][o-1]&&(i=i||n[t][o-1].id)),[t,r,o,a,i]}))}update(e){const t=new View(this.document,e);if(this._cache&&e&&e.length>0){const n=[];e.forEach(((e,t)=>{const[r,o,a]=e;(1===e.length||0===o&&this.document[r].length===a)&&(n[t]=this._cache[r])})),n.length>0&&(t._cache=n)}return t.world=this.world,t}toView(e){return new View(this.document,e||this.pointer)}fromText(e){const{methods:t}=this,n=t.one.tokenize.fromString(e,this.world),r=new View(n);return r.world=this.world,r.compute(["normal","freeze","lexicon"]),this.world.compute.preTagger&&r.compute("preTagger"),r.compute("unfreeze"),r}clone(){let e=this.document.slice(0);e=e.map((e=>e.map((e=>((e=Object.assign({},e)).tags=new Set(e.tags),e)))));const t=this.update(this.pointer);return t.document=e,t._cache=this._cache,t}}Object.assign(View.prototype,o);const a=function(e){return e&&"object"==typeof e&&!Array.isArray(e)};function i(e,t){if(a(t))for(const n in t)a(t[n])?(e[n]||Object.assign(e,{[n]:{}}),i(e[n],t[n])):Object.assign(e,{[n]:t[n]});return e}const s=function(e,t,n,r){if(o=e,"[object Array]"===Object.prototype.toString.call(o))return void e.forEach((e=>s(e,t,n,r)));var o;const{methods:a,model:l,compute:u,hooks:c}=t;e.methods&&function(e,t){for(const n in t)e[n]=e[n]||{},Object.assign(e[n],t[n])}(a,e.methods),e.model&&i(l,e.model),e.irregulars&&function(e,t){const n=e.two.models||{};Object.keys(t).forEach((e=>{t[e].pastTense&&(n.toPast&&(n.toPast.ex[e]=t[e].pastTense),n.fromPast&&(n.fromPast.ex[t[e].pastTense]=e)),t[e].presentTense&&(n.toPresent&&(n.toPresent.ex[e]=t[e].presentTense),n.fromPresent&&(n.fromPresent.ex[t[e].presentTense]=e)),t[e].gerund&&(n.toGerund&&(n.toGerund.ex[e]=t[e].gerund),n.fromGerund&&(n.fromGerund.ex[t[e].gerund]=e)),t[e].comparative&&(n.toComparative&&(n.toComparative.ex[e]=t[e].comparative),n.fromComparative&&(n.fromComparative.ex[t[e].comparative]=e)),t[e].superlative&&(n.toSuperlative&&(n.toSuperlative.ex[e]=t[e].superlative),n.fromSuperlative&&(n.fromSuperlative.ex[t[e].superlative]=e))}))}(l,e.irregulars),e.compute&&Object.assign(u,e.compute),c&&(t.hooks=c.concat(e.hooks||[])),e.api&&e.api(n),e.lib&&Object.keys(e.lib).forEach((t=>r[t]=e.lib[t])),e.tags&&r.addTags(e.tags),e.words&&r.addWords(e.words),e.frozen&&r.addWords(e.frozen,!0),e.mutate&&e.mutate(t,r)},l=function(e){return"[object Array]"===Object.prototype.toString.call(e)},u=function(e,t,n){const{methods:r}=n,o=new t([]);if(o.world=n,"number"==typeof e&&(e=String(e)),!e)return o;if("string"==typeof e){return new t(r.one.tokenize.fromString(e,n))}if(a=e,"[object Object]"===Object.prototype.toString.call(a)&&e.isView)return new t(e.document,e.ptrs);var a;if(l(e)){if(l(e[0])){const n=e.map((e=>e.map((e=>({text:e,normal:e,pre:"",post:" ",tags:new Set})))));return new t(n)}const n=e.map((e=>e.terms.map((e=>(l(e.tags)&&(e.tags=new Set(e.tags)),e)))));return new t(n)}return o},c=Object.assign({},e),h=function(e,t){t&&h.addWords(t);const n=u(e,View,c);return e&&n.compute(c.hooks),n};Object.defineProperty(h,"_world",{value:c,writable:!0}),h.tokenize=function(e,t){const{compute:n}=this._world;t&&h.addWords(t);const r=u(e,View,c);return n.contractions&&r.compute(["alias","normal","machine","contractions"]),r},h.plugin=function(e){return s(e,this._world,View,this),this},h.extend=h.plugin,h.world=function(){return this._world},h.model=function(){return this._world.model},h.methods=function(){return this._world.methods},h.hooks=function(){return this._world.hooks},h.verbose=function(e){const t="undefined"!=typeof process&&process.env?process.env:self.env||{};return t.DEBUG_TAGS="tagger"===e||!0===e||"",t.DEBUG_MATCH="match"===e||!0===e||"",t.DEBUG_CHUNKS="chunker"===e||!0===e||"",this},h.version="14.15.0";var d={one:{cacheDoc:function(e){const t=e.map((e=>{const t=new Set;return e.forEach((e=>{""!==e.normal&&t.add(e.normal),e.switch&&t.add(`%${e.switch}%`),e.implicit&&t.add(e.implicit),e.machine&&t.add(e.machine),e.root&&t.add(e.root),e.alias&&e.alias.forEach((e=>t.add(e)));const n=Array.from(e.tags);for(let e=0;e/^\p{Lu}[\p{Ll}'’]/u.test(e)||/^\p{Lu}$/u.test(e),b=(e,t,n)=>{if(n.forEach((e=>e.dirty=!0)),e){const r=[t,0].concat(n);Array.prototype.splice.apply(e,r)}return e},v=function(e){const t=e[e.length-1];!t||/ $/.test(t.post)||/[-–—]/.test(t.post)||(t.post+=" ")},y=(e,t,n)=>{const r=/[-.?!,;:)–—'"]/g,o=e[t-1];if(!o)return;const a=o.post;if(r.test(a)){const e=a.match(r).join(""),t=n[n.length-1];t.post=e+t.post,o.post=o.post.replace(r,"")}},w=function(e,t,n,r){const[o,a,i]=t;0===a||i===r[o].length?v(n):(v(n),v([e[t[1]]])),function(e,t,n){const r=e[t];if(0!==t||!f(r.text))return;n[0].text=n[0].text.replace(/^\p{Ll}/u,(e=>e.toUpperCase()));const o=e[t];o.tags.has("ProperNoun")||o.tags.has("Acronym")||f(o.text)&&o.text.length>1&&(o.text=(a=o.text,a.replace(/^\p{Lu}/u,(e=>e.toLowerCase()))));var a}(e,a,n),b(e,a,n)};let k=0;const P=e=>(e=e.length<3?"0"+e:e).length<3?"0"+e:e,A=function(e){let[t,n]=e.index||[0,0];k+=1,k=k>46655?0:k,t=t>46655?0:t,n=n>1294?0:n;let r=P(k.toString(36));r+=P(t.toString(36));let o=n.toString(36);o=o.length<2?"0"+o:o,r+=o;return r+=parseInt(36*Math.random(),10).toString(36),e.normal+"|"+r.toUpperCase()},C=function(e){if(e.has("@hasContraction")&&"function"==typeof e.contractions){e.grow("@hasContraction").contractions().expand()}},N=e=>"[object Array]"===Object.prototype.toString.call(e),j=function(e,t,n){const{document:r,world:o}=t;t.uncache();const a=t.fullPointer,i=t.fullPointer;t.forEach(((s,l)=>{const u=s.fullPointer[0],[c]=u,h=r[c];let d=function(e,t){const{methods:n}=t;return"string"==typeof e?n.one.tokenize.fromString(e,t)[0]:"object"==typeof e&&e.isView?e.clone().docs[0]||[]:N(e)?N(e[0])?e[0]:e:[]}(e,o);0!==d.length&&(d=function(e){return e.map((e=>(e.id=A(e),e)))}(d),n?(C(t.update([u]).firstTerm()),w(h,u,d,r)):(C(t.update([u]).lastTerm()),function(e,t,n,r){const[o,,a]=t,i=(r[o]||[]).length;ae.replace(/^\p{Ll}/u,(e=>e.toUpperCase())),H=e=>e.replace(/^\p{Lu}/u,(e=>e.toLowerCase()));T.replaceWith=function(e,t={}){let n=this.fullPointer;const r=this;if(this.uncache(),"function"==typeof e)return function(e,t,n){return e.forEach((e=>{const r=t(e);e.replaceWith(r,n)})),e}(r,e,t);const o=r.docs[0];if(!o)return r;const a=t.possessives&&o[o.length-1].tags.has("Possessive"),i=t.case&&(s=o[0].text,/^\p{Lu}[\p{Ll}'’]/u.test(s)||/^\p{Lu}$/u.test(s));var s;e=function(e,t){if("string"!=typeof e)return e;const n=t.groups();return e=e.replace(I,(e=>{const t=e.replace(/\$/,"");return n.hasOwnProperty(t)?n[t].text():e})),e}(e,r);const l=this.update(n);n=n.map((e=>e.slice(0,3)));const u=(l.docs[0]||[]).map((e=>Array.from(e.tags))),c=l.docs[0][0].pre,h=l.docs[0][l.docs[0].length-1].post;if("string"==typeof e&&(e=this.fromText(e).compute("id")),r.insertAfter(e),l.has("@hasContraction")&&r.contractions){r.grow("@hasContraction+").contractions().expand()}if(r.delete(l),a){const e=r.docs[0],t=e[e.length-1];t.tags.has("Possessive")||(t.text+="'s",t.normal+="'s",t.tags.add("Possessive"))}if(c&&r.docs[0]&&(r.docs[0][0].pre=c),h&&r.docs[0]){const e=r.docs[0][r.docs[0].length-1];e.post.trim()||(e.post=h)}const d=r.toView(n).compute(["index","freeze","lexicon"]);if(d.world.compute.preTagger&&d.compute("preTagger"),d.compute("unfreeze"),t.tags&&d.terms().forEach(((e,t)=>{e.tagSafe(u[t])})),!d.docs[0]||!d.docs[0][0])return d;if(t.case){const e=i?D:H;d.docs[0][0].text=e(d.docs[0][0].text)}return d},T.replace=function(e,t,n){if(e&&!t)return this.replaceWith(e,n);const r=this.match(e);return r.found?(this.soften(),r.replaceWith(t,n)):this};const E={remove:function(e){const{indexN:t}=this.methods.one.pointer;this.uncache();let n=this.all(),r=this;e&&(n=this,r=this.match(e));const o=!n.ptrs;if(r.has("@hasContraction")&&r.contractions){r.grow("@hasContraction").contractions().expand()}let a=n.fullPointer;const i=r.fullPointer.reverse(),s=function(e,t){t.forEach((t=>{const[n,r,o]=t,a=o-r;e[n]&&(o===e[n].length&&o>1&&function(e,t){const n=e.length-1,r=e[n],o=e[n-t];o&&r&&(o.post+=r.post,o.post=o.post.replace(/ +([.?!,;:])/,"$1"),o.post=o.post.replace(/[,;:]+([.?!])/,"$1"))}(e[n],a),e[n].splice(r,a))}));for(let t=e.length-1;t>=0;t-=1)if(0===e[t].length&&(e.splice(t,1),t===e.length&&e[t-1])){const n=e[t-1],r=n[n.length-1];r&&(r.post=r.post.trimEnd())}return e}(this.document,i);if(a=function(e,t){return e=e.map((e=>{const[n]=e;return t[n]?(t[n].forEach((t=>{const n=t[2]-t[1];e[1]<=t[1]&&e[2]>=t[2]&&(e[2]-=n)})),e):e})),e.forEach(((t,n)=>{if(0===t[1]&&0==t[2])for(let t=n+1;te[2]-e[1]>0))).map((e=>(e[3]=null,e[4]=null,e)))}(a,t(i)),n.ptrs=a,n.document=s,n.compute("index"),o&&(n.ptrs=void 0),!e)return this.ptrs=[],n.none();return n.toView(a)}};E.delete=E.remove;const G={pre:function(e,t){return void 0===e&&this.found?this.docs[0][0].pre:(this.docs.forEach((n=>{const r=n[0];!0===t?r.pre+=e:r.pre=e})),this)},post:function(e,t){if(void 0===e){const e=this.docs[this.docs.length-1];return e[e.length-1].post}return this.docs.forEach((n=>{const r=n[n.length-1];!0===t?r.post+=e:r.post=e})),this},trim:function(){if(!this.found)return this;const e=this.docs,t=e[0][0];t.pre=t.pre.trimStart();const n=e[e.length-1],r=n[n.length-1];return r.post=r.post.trimEnd(),this},hyphenate:function(){return this.docs.forEach((e=>{e.forEach(((t,n)=>{0!==n&&(t.pre=""),e[n+1]&&(t.post="-")}))})),this},dehyphenate:function(){const e=/[-–—]/;return this.docs.forEach((t=>{t.forEach((t=>{e.test(t.post)&&(t.post=" ")}))})),this},toQuotations:function(e,t){return e=e||'"',t=t||'"',this.docs.forEach((n=>{n[0].pre=e+n[0].pre;const r=n[n.length-1];r.post=t+r.post})),this},toParentheses:function(e,t){return e=e||"(",t=t||")",this.docs.forEach((n=>{n[0].pre=e+n[0].pre;const r=n[n.length-1];r.post=t+r.post})),this}};G.deHyphenate=G.dehyphenate,G.toQuotation=G.toQuotations;var O={alpha:(e,t)=>e.normalt.normal?1:0,length:(e,t)=>{const n=e.normal.trim().length,r=t.normal.trim().length;return nr?-1:0},wordCount:(e,t)=>e.wordst.words?-1:0,sequential:(e,t)=>e[0]t[0]?-1:e[1]>t[1]?1:-1,byFreq:function(e){const t={};return e.forEach((e=>{t[e.normal]=t[e.normal]||0,t[e.normal]+=1})),e.sort(((e,n)=>{const r=t[e.normal],o=t[n.normal];return ro?-1:0})),e}};const F=new Set(["index","sequence","seq","sequential","chron","chronological"]),V=new Set(["freq","frequency","topk","repeats"]),z=new Set(["alpha","alphabetical"]);var B={unique:function(){const e=new Set,t=this.filter((t=>{const n=t.text("machine");return!e.has(n)&&(e.add(n),!0)}));return t},reverse:function(){let e=this.pointer||this.docs.map(((e,t)=>[t]));return e=[].concat(e),e=e.reverse(),this._cache&&(this._cache=this._cache.reverse()),this.update(e)},sort:function(e){const{docs:t,pointer:n}=this;if(this.uncache(),"function"==typeof e)return function(e,t){let n=e.fullPointer;return n=n.sort(((n,r)=>(n=e.update([n]),r=e.update([r]),t(n,r)))),e.ptrs=n,e}(this,e);e=e||"alpha";const r=n||t.map(((e,t)=>[t]));let o=t.map(((e,t)=>({index:t,words:e.length,normal:e.map((e=>e.machine||e.normal||"")).join(" "),pointer:r[t]})));return F.has(e)&&(e="sequential"),z.has(e)&&(e="alpha"),V.has(e)?(o=O.byFreq(o),this.update(o.map((e=>e.pointer)))):"function"==typeof O[e]?(o=o.sort(O[e]),this.update(o.map((e=>e.pointer)))):this}};const S=function(e,t){if(e.length>0){const t=e[e.length-1],n=t[t.length-1];!1===/ /.test(n.post)&&(n.post+=" ")}return e=e.concat(t)};var $={concat:function(e){if("string"==typeof e){const t=this.fromText(e);if(this.found&&this.ptrs){const e=this.fullPointer,n=e[e.length-1][0];this.document.splice(n,0,...t.document)}else this.document=this.document.concat(t.document);return this.all().compute("index")}if("object"==typeof e&&e.isView)return function(e,t){if(e.document===t.document){const n=e.fullPointer.concat(t.fullPointer);return e.toView(n).compute("index")}return t.fullPointer.forEach((t=>{t[0]+=e.document.length})),e.document=S(e.document,t.docs),e.all()}(this,e);if(t=e,"[object Array]"===Object.prototype.toString.call(t)){const t=S(this.document,e);return this.document=t,this.all()}var t;return this}};var M={harden:function(){return this.ptrs=this.fullPointer,this},soften:function(){let e=this.ptrs;return!e||e.length<1||(e=e.map((e=>e.slice(0,3))),this.ptrs=e),this}};const L=Object.assign({},{toLowerCase:function(){return this.termList().forEach((e=>{e.text=e.text.toLowerCase()})),this},toUpperCase:function(){return this.termList().forEach((e=>{e.text=e.text.toUpperCase()})),this},toTitleCase:function(){return this.termList().forEach((e=>{e.text=e.text.replace(/^ *[a-z\u00C0-\u00FF]/,(e=>e.toUpperCase()))})),this},toCamelCase:function(){return this.docs.forEach((e=>{e.forEach(((t,n)=>{0!==n&&(t.text=t.text.replace(/^ *[a-z\u00C0-\u00FF]/,(e=>e.toUpperCase()))),n!==e.length-1&&(t.post="")}))})),this}},x,T,E,G,B,$,M),K={id:function(e){const t=e.docs;for(let e=0;e(e.implicit=e.text,e.machine=e.text,e.pre="",e.post="",e.text="",e.normal="",e.index=[r,o+t],e))),n[0]&&(n[0].pre=e[r][o].pre,n[n.length-1].post=e[r][o].post,n[0].text=e[r][o].text,n[0].normal=e[r][o].normal),e[r].splice(o,1,...n))},R=/'/,Q=new Set(["what","how","when","where","why"]),Z=new Set(["be","go","start","think","need"]),_=new Set(["been","gone"]),X=/'/,Y=/(e|é|aison|sion|tion)$/,ee=/(age|isme|acle|ege|oire)$/;var te=(e,t)=>["je",e[t].normal.split(X)[1]],ne=(e,t)=>{const n=e[t].normal.split(X)[1];return n&&n.endsWith("e")?["la",n]:["le",n]},re=(e,t)=>{const n=e[t].normal.split(X)[1];return n&&Y.test(n)&&!ee.test(n)?["du",n]:n&&n.endsWith("s")?["des",n]:["de",n]};const oe=/^([0-9.]{1,4}[a-z]{0,2}) ?[-–—] ?([0-9]{1,4}[a-z]{0,2})$/i,ae=/^([0-9]{1,2}(:[0-9][0-9])?(am|pm)?) ?[-–—] ?([0-9]{1,2}(:[0-9][0-9])?(am|pm)?)$/i,ie=/^[0-9]{3}-[0-9]{4}$/,se=function(e,t){const n=e[t];let r=n.text.match(oe);return null!==r?!0===n.tags.has("PhoneNumber")||ie.test(n.text)?null:[r[1],"to",r[2]]:(r=n.text.match(ae),null!==r?[r[1],"to",r[4]]:null)},le=/^([+-]?[0-9][.,0-9]*)([a-z°²³µ/]+)$/,ue=function(e,t,n){const r=n.model.one.numberSuffixes||{},o=e[t].text.match(le);if(null!==o){const e=o[2].toLowerCase().trim();return r.hasOwnProperty(e)?null:[o[1],e]}return null},ce=/'/,he=/^[0-9][^-–—]*[-–—].*?[0-9]/,de=function(e,t,n,r){const o=t.update();o.document=[e];let a=n+r;n>0&&(n-=1),e[a]&&(a+=1),o.ptrs=[[0,n,a]]},ge={t:(e,t)=>function(e,t){return"ain't"===e[t].normal||"aint"===e[t].normal?null:[e[t].normal.replace(/n't/,""),"not"]}(e,t),d:(e,t)=>function(e,t){const n=e[t].normal.split(R)[0];if(Q.has(n))return[n,"did"];if(e[t+1]){if(_.has(e[t+1].normal))return[n,"had"];if(Z.has(e[t+1].normal))return[n,"would"]}return null}(e,t)},me={j:(e,t)=>te(e,t),l:(e,t)=>ne(e,t),d:(e,t)=>re(e,t)},pe=function(e,t,n,r){for(let o=0;o2)return a.out.concat(r)}return null},fe=function(e,t){const n=t.fromText(e.join(" "));return n.compute(["id","alias"]),n.docs[0]},be=function(e,t){for(let n=t+1;n<5&&e[n];n+=1)if("been"===e[n].normal)return["there","has"];return["there","is"]};var ve={contractions:e=>{const{world:t,document:n}=e,{model:r,methods:o}=t,a=r.one.contractions||[];n.forEach(((r,i)=>{for(let s=r.length-1;s>=0;s-=1){let l=null,u=null;if(!0===ce.test(r[s].normal)){const e=r[s].normal.split(ce);l=e[0],u=e[1]}let c=pe(a,r[s],l,u);!c&&ge.hasOwnProperty(u)&&(c=ge[u](r,s,t)),!c&&me.hasOwnProperty(l)&&(c=me[l](r,s)),"there"===l&&"s"===u&&(c=be(r,s)),c?(c=fe(c,e),U(n,[i,s],c),de(n[i],e,s,c.length)):he.test(r[s].normal)?(c=se(r,s),c&&(c=fe(c,e),U(n,[i,s],c),o.one.setTag(c,"NumberRange",t),c[2]&&c[2].tags.has("Time")&&o.one.setTag([c[0]],"Time",t,null,"time-range"),de(n[i],e,s,c.length))):(c=ue(r,s,t),c&&(c=fe(c,e),U(n,[i,s],c),o.one.setTag([c[1]],"Unit",t,null,"contraction-unit")))}}))}};const ye={model:q,compute:ve,hooks:["contractions"]},we=function(e){const t=e.world,{model:n,methods:r}=e.world,o=r.one.setTag,{frozenLex:a}=n.one,i=n.one._multiCache||{};e.docs.forEach((e=>{for(let n=0;nn;r-=1){const i=e.slice(n,r+1),s=i.map((e=>e.machine||e.normal)).join(" ");!0!==a.hasOwnProperty(s)||(o(i,a[s],t,!1,"1-frozen-multi-lexicon"),i.forEach((e=>e.frozen=!0)))}}void 0!==a[s]&&a.hasOwnProperty(s)&&(o([r],a[s],t,!1,"1-freeze-lexicon"),r.frozen=!0)}}))};const ke=e=>"�[34m"+e+"�[0m",Pe=e=>"�[3m�[2m"+e+"�[0m",Ae=function(e){e.docs.forEach((e=>{console.log(ke("\n ┌─────────")),e.forEach((e=>{let t=` ${Pe("│")} `;const n=e.implicit||e.text||"-";!0===e.frozen?t+=`${ke(n)} ❄️`:t+=Pe(n),console.log(t)}))}))};var Ce={compute:{frozen:we,freeze:we,unfreeze:function(e){return e.docs.forEach((e=>{e.forEach((e=>{delete e.frozen}))})),e}},mutate:e=>{const t=e.methods.one;t.termMethods.isFrozen=e=>!0===e.frozen,t.debug.freeze=Ae,t.debug.frozen=Ae},api:function(e){e.prototype.freeze=function(){return this.docs.forEach((e=>{e.forEach((e=>{e.frozen=!0}))})),this},e.prototype.unfreeze=function(){this.compute("unfreeze")},e.prototype.isFrozen=function(){return this.match("@isFrozen+")}},hooks:["freeze"]};const Ne=function(e,t,n){const{model:r,methods:o}=n,a=o.one.setTag,i=r.one._multiCache||{},{lexicon:s}=r.one||{},l=e[t],u=l.machine||l.normal;if(void 0!==i[u]&&e[t+1]){for(let r=t+i[u]-1;r>t;r-=1){const o=e.slice(t,r+1);if(o.length<=1)return!1;const i=o.map((e=>e.machine||e.normal)).join(" ");if(!0===s.hasOwnProperty(i)){const e=s[i];return a(o,e,n,!1,"1-multi-lexicon"),!e||2!==e.length||"PhrasalVerb"!==e[0]&&"PhrasalVerb"!==e[1]||a([o[1]],"Particle",n,!1,"1-phrasal-particle"),!0}}return!1}return null},je=/^(under|over|mis|re|un|dis|semi|pre|post)-?/,xe=new Set(["Verb","Infinitive","PastTense","Gerund","PresentTense","Adjective","Participle"]),Ie=function(e,t,n){const{model:r,methods:o}=n,a=o.one.setTag,{lexicon:i}=r.one,s=e[t],l=s.machine||s.normal;if(void 0!==i[l]&&i.hasOwnProperty(l))return a([s],i[l],n,!1,"1-lexicon"),!0;if(s.alias){const e=s.alias.find((e=>i.hasOwnProperty(e)));if(e)return a([s],i[e],n,!1,"1-lexicon-alias"),!0}if(!0===je.test(l)){const e=l.replace(je,"");if(i.hasOwnProperty(e)&&e.length>3&&xe.has(i[e]))return a([s],i[e],n,!1,"1-lexicon-prefix"),!0}return null};var Te={lexicon:function(e){const t=e.world;e.docs.forEach((e=>{for(let n=0;n{const o=e[r],a=(r=(r=r.toLowerCase().trim()).replace(/'s\b/,"")).split(/ /);a.length>1&&(void 0===n[a[0]]||a.length>n[a[0]])&&(n[a[0]]=a.length),t[r]=t[r]||o})),delete t[""],delete t.null,delete t[" "],{lex:t,_multi:n}}}};var He={addWords:function(e,t=!1){const n=this.world(),{methods:r,model:o}=n;if(!e)return;if(Object.keys(e).forEach((t=>{"string"==typeof e[t]&&e[t].startsWith("#")&&(e[t]=e[t].replace(/^#/,""))})),!0===t){const{lex:t,_multi:a}=r.one.expandLexicon(e,n);return Object.assign(o.one._multiCache,a),void Object.assign(o.one.frozenLex,t)}if(r.two.expandLexicon){const{lex:t,_multi:a}=r.two.expandLexicon(e,n);Object.assign(o.one.lexicon,t),Object.assign(o.one._multiCache,a)}const{lex:a,_multi:i}=r.one.expandLexicon(e,n);Object.assign(o.one.lexicon,a),Object.assign(o.one._multiCache,i)}};var Ee={model:{one:{lexicon:{},_multiCache:{},frozenLex:{}}},methods:De,compute:Te,lib:He,hooks:["lexicon"]};const Ge=function(e,t){const n=[{}],r=[null],o=[0],a=[];let i=0;e.forEach((function(e){let o=0;const a=function(e,t){const{methods:n,model:r}=t,o=n.one.tokenize.splitTerms(e,r).map((e=>n.one.tokenize.splitWhitespace(e,r)));return o.map((e=>e.text.toLowerCase()))}(e,t);for(let e=0;e0&&!n[i].hasOwnProperty(l);)i=o[i];if(n.hasOwnProperty(i)){const e=n[i][l];o[u]=e,r[e]&&(r[u]=r[u]||[],r[u]=r[u].concat(r[e]))}else o[u]=0}}return{goNext:n,endAs:r,failTo:o}},Oe=function(e,t,n){let r=0;const o=[];for(let a=0;a0&&(void 0===t.goNext[r]||!t.goNext[r].hasOwnProperty(i));)r=t.failTo[r]||0;if(t.goNext[r].hasOwnProperty(i)&&(r=t.goNext[r][i],t.endAs[r])){const n=t.endAs[r];for(let t=0;t{for(let n=e.length-1;n>=0;n-=1)if(e[n]!==t)return e=e.slice(0,n+1);return e},ze={buildTrie:function(e){return function(e){return e.goNext=e.goNext.map((e=>{if(0!==Object.keys(e).length)return e})),e.goNext=Ve(e.goNext,void 0),e.failTo=Ve(e.failTo,0),e.endAs=Ve(e.endAs,null),e}(Ge(e,this.world()))}};ze.compile=ze.buildTrie;var Be={api:function(e){e.prototype.lookup=function(e,t={}){if(!e)return this.none();"string"==typeof e&&(e=[e]);var n;let r=function(e,t,n){let r=[];n.form=n.form||"normal";const o=e.docs;if(!t.goNext||!t.goNext[0])return console.error("Compromise invalid lookup trie"),e.none();const a=Object.keys(t.goNext[0]);for(let i=0;i0&&(r=r.concat(l))}return e.update(r)}(this,(n=e,"[object Object]"===Object.prototype.toString.call(n)?e:Ge(e,this.world)),t);return r=r.settle(),r}},lib:ze};const Se=function(e,t){return t?(e.forEach((e=>{const n=e[0];t[n]&&(e[0]=t[n][0],e[1]+=t[n][1],e[2]+=t[n][1])})),e):e},$e=function(e,t){let{ptrs:n}=e;const{byGroup:r}=e;return n=Se(n,t),Object.keys(r).forEach((e=>{r[e]=Se(r[e],t)})),{ptrs:n,byGroup:r}},Me=function(e,t,n){const r=n.methods.one;return"number"==typeof e&&(e=String(e)),"string"==typeof e&&(e=r.killUnicode(e,n),e=r.parseMatch(e,t,n)),e},Le=e=>"[object Object]"===Object.prototype.toString.call(e),Ke=e=>e&&Le(e)&&!0===e.isView,Je=e=>e&&Le(e)&&!0===e.isNet;var We={matchOne:function(e,t,n){const r=this.methods.one;if(Ke(e))return this.intersection(e).eq(0);if(Je(e))return this.sweep(e,{tagger:!1,matchOne:!0}).view;const o={regs:e=Me(e,n,this.world),group:t,justOne:!0},a=r.match(this.docs,o,this._cache),{ptrs:i,byGroup:s}=$e(a,this.fullPointer),l=this.toView(i);return l._groups=s,l},match:function(e,t,n){const r=this.methods.one;if(Ke(e))return this.intersection(e);if(Je(e))return this.sweep(e,{tagger:!1}).view.settle();const o={regs:e=Me(e,n,this.world),group:t},a=r.match(this.docs,o,this._cache),{ptrs:i,byGroup:s}=$e(a,this.fullPointer),l=this.toView(i);return l._groups=s,l},has:function(e,t,n){const r=this.methods.one;if(Ke(e)){return this.intersection(e).fullPointer.length>0}if(Je(e))return this.sweep(e,{tagger:!1}).view.found;const o={regs:e=Me(e,n,this.world),group:t,justOne:!0};return r.match(this.docs,o,this._cache).ptrs.length>0},if:function(e,t,n){const r=this.methods.one;if(Ke(e))return this.filter((t=>t.intersection(e).found));if(Je(e)){const t=this.sweep(e,{tagger:!1}).view.settle();return this.if(t)}const o={regs:e=Me(e,n,this.world),group:t,justOne:!0};let a=this.fullPointer;const i=this._cache||[];a=a.filter(((e,t)=>{const n=this.update([e]);return r.match(n.docs,o,i[t]).ptrs.length>0}));const s=this.update(a);return this._cache&&(s._cache=a.map((e=>i[e[0]]))),s},ifNo:function(e,t,n){const{methods:r}=this,o=r.one;if(Ke(e))return this.filter((t=>!t.intersection(e).found));if(Je(e)){const t=this.sweep(e,{tagger:!1}).view.settle();return this.ifNo(t)}e=Me(e,n,this.world);const a=this._cache||[],i=this.filter(((n,r)=>{const i={regs:e,group:t,justOne:!0};return 0===o.match(n.docs,i,a[r]).ptrs.length}));return this._cache&&(i._cache=i.ptrs.map((e=>a[e[0]]))),i}};var qe={before:function(e,t,n){const{indexN:r}=this.methods.one.pointer,o=[],a=r(this.fullPointer);Object.keys(a).forEach((e=>{const t=a[e].sort(((e,t)=>e[1]>t[1]?1:-1))[0];t[1]>0&&o.push([t[0],0,t[1]])}));const i=this.toView(o);return e?i.match(e,t,n):i},after:function(e,t,n){const{indexN:r}=this.methods.one.pointer,o=[],a=r(this.fullPointer),i=this.document;Object.keys(a).forEach((e=>{const t=a[e].sort(((e,t)=>e[1]>t[1]?-1:1))[0],[n,,r]=t;r{const a=n.before(e,t);if(a.found){const e=a.terms();r[o][1]-=e.length,r[o][3]=e.docs[0][0].id}})),this.update(r)},growRight:function(e,t,n){"string"==typeof e&&(e=this.world.methods.one.parseMatch(e,n,this.world)),e[0].start=!0;const r=this.fullPointer;return this.forEach(((n,o)=>{const a=n.after(e,t);if(a.found){const e=a.terms();r[o][2]+=e.length,r[o][4]=null}})),this.update(r)},grow:function(e,t,n){return this.growRight(e,t,n).growLeft(e,t,n)}};const Ue=function(e,t){return[e[0],e[1],t[2]]},Re=(e,t,n)=>{return"string"==typeof e||(r=e,"[object Array]"===Object.prototype.toString.call(r))?t.match(e,n):e||t.none();var r},Qe=function(e,t){const[n,r,o]=e;return t.document[n]&&t.document[n][r]&&(e[3]=e[3]||t.document[n][r].id,t.document[n][o-1]&&(e[4]=e[4]||t.document[n][o-1].id)),e},Ze={splitOn:function(e,t){const{splitAll:n}=this.methods.one.pointer,r=Re(e,this,t).fullPointer,o=n(this.fullPointer,r);let a=[];return o.forEach((e=>{a.push(e.passthrough),a.push(e.before),a.push(e.match),a.push(e.after)})),a=a.filter((e=>e)),a=a.map((e=>Qe(e,this))),this.update(a)},splitBefore:function(e,t){const{splitAll:n}=this.methods.one.pointer,r=Re(e,this,t).fullPointer,o=n(this.fullPointer,r);for(let e=0;e{a.push(e.passthrough),a.push(e.before),e.match&&e.after?a.push(Ue(e.match,e.after)):a.push(e.match)})),a=a.filter((e=>e)),a=a.map((e=>Qe(e,this))),this.update(a)},splitAfter:function(e,t){const{splitAll:n}=this.methods.one.pointer,r=Re(e,this,t).fullPointer,o=n(this.fullPointer,r);let a=[];return o.forEach((e=>{a.push(e.passthrough),e.before&&e.match?a.push(Ue(e.before,e.match)):(a.push(e.before),a.push(e.match)),a.push(e.after)})),a=a.filter((e=>e)),a=a.map((e=>Qe(e,this))),this.update(a)}};Ze.split=Ze.splitAfter;const _e=function(e,t){return!(!e||!t)&&(e[0]===t[0]&&e[2]===t[1])},Xe=function(e,t,n){const r=e.world,o=r.methods.one.parseMatch;n=n||"^.";const a=o(t=t||".$",{},r),i=o(n,{},r);a[a.length-1].end=!0,i[0].start=!0;const s=e.fullPointer,l=[s[0]];for(let t=1;t)?\/.*?[^\\/]\/[?\]+*$~]*)(?:\s|$)/,nt=/([!~[^]*(?:<[^<]*>)?\([^)]+[^\\)]\)[?\]+*$~]*)(?:\s|$)/,rt=/ /g,ot=e=>/^[![^]*(<[^<]*>)?\//.test(e)&&/\/[?\]+*$~]*$/.test(e),at=function(e){return e=(e=e.map((e=>e.trim()))).filter((e=>e))},it=/\{([0-9]+)?(, *[0-9]*)?\}/,st=/&&/,lt=new RegExp(/^<\s*(\S+)\s*>/),ut=e=>e.charAt(0).toUpperCase()+e.substring(1),ct=e=>e.charAt(e.length-1),ht=e=>e.charAt(0),dt=e=>e.substring(1),gt=e=>e.substring(0,e.length-1),mt=function(e){return e=dt(e),e=gt(e)},pt=function(e,t){const n={};for(let r=0;r<2;r+=1){if("$"===ct(e)&&(n.end=!0,e=gt(e)),"^"===ht(e)&&(n.start=!0,e=dt(e)),"?"===ct(e)&&(n.optional=!0,e=gt(e)),("["===ht(e)||"]"===ct(e))&&(n.group=null,"["===ht(e)&&(n.groupStart=!0),"]"===ct(e)&&(n.groupEnd=!0),e=(e=e.replace(/^\[/,"")).replace(/\]$/,""),"<"===ht(e))){const t=lt.exec(e);t.length>=2&&(n.group=t[1],e=e.replace(t[0],""))}if("+"===ct(e)&&(n.greedy=!0,e=gt(e)),"*"!==e&&"*"===ct(e)&&"\\*"!==e&&(n.greedy=!0,e=gt(e)),"!"===ht(e)&&(n.negative=!0,e=dt(e)),"~"===ht(e)&&"~"===ct(e)&&e.length>2&&(e=mt(e),n.fuzzy=!0,n.min=t.fuzzy||.85,!1===/\(/.test(e)))return n.word=e,n;if("/"===ht(e)&&"/"===ct(e))return e=mt(e),t.caseSensitive&&(n.use="text"),n.regex=new RegExp(e),n;if(!0===it.test(e)&&(e=e.replace(it,((e,t,r)=>(void 0===r?(n.min=Number(t),n.max=Number(t)):(r=r.replace(/, */,""),void 0===t?(n.min=0,n.max=Number(r)):(n.min=Number(t),n.max=Number(r||999))),n.greedy=!0,n.min||(n.optional=!0),"")))),"("===ht(e)&&")"===ct(e)){st.test(e)?(n.choices=e.split(st),n.operator="and"):(n.choices=e.split("|"),n.operator="or"),n.choices[0]=dt(n.choices[0]);const r=n.choices.length-1;n.choices[r]=gt(n.choices[r]),n.choices=n.choices.map((e=>e.trim())),n.choices=n.choices.filter((e=>e)),n.choices=n.choices.map((e=>e.split(/ /g).map((e=>pt(e,t))))),e=""}if("{"===ht(e)&&"}"===ct(e)){if(e=mt(e),n.root=e,/\//.test(e)){const e=n.root.split(/\//);n.root=e[0],n.pos=e[1],"adj"===n.pos&&(n.pos="Adjective"),n.pos=n.pos.charAt(0).toUpperCase()+n.pos.substr(1).toLowerCase(),void 0!==e[2]&&(n.sense=e[2])}return n}if("<"===ht(e)&&">"===ct(e))return e=mt(e),n.chunk=ut(e),n.greedy=!0,n;if("%"===ht(e)&&"%"===ct(e))return e=mt(e),n.switch=e,n}return"#"===ht(e)?(n.tag=dt(e),n.tag=ut(n.tag),n):"@"===ht(e)?(n.method=dt(e),n):"."===e?(n.anything=!0,n):"*"===e?(n.anything=!0,n.greedy=!0,n.optional=!0,n):(e&&(e=(e=e.replace("\\*","*")).replace("\\.","."),t.caseSensitive?n.use="text":e=e.toLowerCase(),n.word=e),n)},ft=/[a-z0-9][-–—][a-z]/i,bt=function(e,t){const{all:n}=t.methods.two.transform.verb||{},r=e.root;return n?n(r,t.model):[]},vt=function(e,t){const{all:n}=t.methods.two.transform.noun||{};return n?n(e.root,t.model):[e.root]},yt=function(e,t){const{all:n}=t.methods.two.transform.adjective||{};return n?n(e.root,t.model):[e.root]},wt=function(e){return e=function(e){let t=0,n=null;for(let r=0;r(e.fuzzy&&e.choices&&e.choices.forEach((t=>{1===t.length&&t[0].word&&(t[0].fuzzy=!0,t[0].min=e.min)})),e)))}(e=e.map((e=>{if(void 0!==e.choices){if("or"!==e.operator)return e;if(!0===e.fuzzy)return e;!0===e.choices.every((e=>{if(1!==e.length)return!1;const t=e[0];return!0!==t.fuzzy&&!t.start&&!t.end&&void 0!==t.word&&!0!==t.negative&&!0!==t.optional&&!0!==t.method}))&&(e.fastOr=new Set,e.choices.forEach((t=>{e.fastOr.add(t[0].word)})),delete e.choices)}return e}))),e},kt=function(e,t){for(const n of t)if(e.has(n))return!0;return!1},Pt=function(e,t){for(let n=0;nn?r:n)+1;if(Math.abs(n-r)>(o||100))return o||100;const a=[];for(let e=0;e4)return n;l=t[i-1],u=s===l?0:1,c=a[o-1][i]+1,(h=a[o][i-1]+1)1&&i>1&&s===t[i-2]&&e[o-2]===l&&(h=a[o-2][i-2]+u)-1!==e.post.indexOf(t),Tt={hasQuote:e=>Ct.test(e.pre)||Nt.test(e.post),hasComma:e=>It(e,","),hasPeriod:e=>!0===It(e,".")&&!1===It(e,"..."),hasExclamation:e=>It(e,"!"),hasQuestionMark:e=>It(e,"?")||It(e,"¿"),hasEllipses:e=>It(e,"..")||It(e,"…"),hasSemicolon:e=>It(e,";"),hasColon:e=>It(e,":"),hasSlash:e=>/\//.test(e.text),hasHyphen:e=>jt.test(e.post)||jt.test(e.pre),hasDash:e=>xt.test(e.post)||xt.test(e.pre),hasContraction:e=>Boolean(e.implicit),isAcronym:e=>e.tags.has("Acronym"),isKnown:e=>e.tags.size>0,isTitleCase:e=>/^\p{Lu}[a-z'\u00C0-\u00FF]/u.test(e.text),isUpperCase:e=>/^\p{Lu}+$/u.test(e.text)};Tt.hasQuotation=Tt.hasQuote;let Dt=function(){};Dt=function(e,t,n,r){const o=function(e,t,n,r){if(!0===t.anything)return!0;if(!0===t.start&&0!==n)return!1;if(!0===t.end&&n!==r-1)return!1;if(void 0!==t.id&&t.id===e.id)return!0;if(void 0!==t.word){if(t.use)return t.word===e[t.use];if(null!==e.machine&&e.machine===t.word)return!0;if(void 0!==e.alias&&e.alias.hasOwnProperty(t.word))return!0;if(!0===t.fuzzy){if(t.word===e.root)return!0;if(At(t.word,e.normal)>=t.min)return!0}return!(!e.alias||!e.alias.some((e=>e===t.word)))||t.word===e.text||t.word===e.normal}if(void 0!==t.tag)return!0===e.tags.has(t.tag);if(void 0!==t.method)return"function"==typeof Tt[t.method]&&!0===Tt[t.method](e);if(void 0!==t.pre)return e.pre&&e.pre.includes(t.pre);if(void 0!==t.post)return e.post&&e.post.includes(t.post);if(void 0!==t.regex){let n=e.normal;return t.use&&(n=e[t.use]),t.regex.test(n)}if(void 0!==t.chunk)return e.chunk===t.chunk;if(void 0!==t.switch)return e.switch===t.switch;if(void 0!==t.machine)return e.normal===t.machine||e.machine===t.machine||e.root===t.machine;if(void 0!==t.sense)return e.sense===t.sense;if(void 0!==t.fastOr){if(t.pos&&!e.tags.has(t.pos))return null;const n=e.root||e.implicit||e.machine||e.normal;return t.fastOr.has(n)||t.fastOr.has(e.text)}return void 0!==t.choices&&("and"===t.operator?t.choices.every((t=>Dt(e,t,n,r))):t.choices.some((t=>Dt(e,t,n,r))))}(e,t,n,r);return!0===t.negative?!o:o};const Ht=function(e,t){if(!0===e.end&&!0===e.greedy&&t.start_i+t.tn.max)return e.t=e.t+n.max,!0;if(!0===e.hasGroup){Et(e,e.t).length=r-e.t}return e.t=r,!0},Ot=function(e,t=0){const n=e.regs[e.r];let r=!1;for(let a=0;a{let o=0;const a=e.t+r+t+o;if(void 0===e.terms[a])return!1;const i=Dt(e.terms[a],n,a+e.start_i,e.phrase_length);if(!0===i&&!0===n.greedy)for(let t=1;t{const r=n.every(((t,n)=>{const r=e.t+n;return void 0!==e.terms[r]&&Dt(e.terms[r],t,r,e.phrase_length)}));return!0===r&&n.length>t&&(t=n.length),r}))&&t}(e);if(r){if(!0===n.negative)return null;if(!0===e.hasGroup){Et(e,e.t).length+=r}if(!0===n.end){const t=e.phrase_length-1;if(e.t+e.start_i!==t)return null}return e.t+=r,!0}return!!n.optional||null},zt=function(e){const{regs:t}=e,n=t[e.r],r=Object.assign({},n);r.negative=!1;if(Dt(e.terms[e.t],r,e.start_i+e.t,e.phrase_length))return!1;if(n.optional){const n=t[e.r+1];if(n){if(Dt(e.terms[e.t],n,e.start_i+e.t,e.phrase_length))e.r+=1;else if(n.optional&&t[e.r+2]){Dt(e.terms[e.t],t[e.r+2],e.start_i+e.t,e.phrase_length)&&(e.r+=2)}}}return n.greedy?function(e,t,n){let r=0;for(let o=e.t;or||(e.t+=r,0))}(e,r,t[e.r+1]):(e.t+=1,!0)},Bt=function(e){const{regs:t,phrase_length:n}=e,r=t[e.r];return e.t=function(e,t){const n=Object.assign({},e.regs[e.r],{start:!1,end:!1}),r=e.t;for(;e.te.t?null:!0!==r.end||e.start_i+e.t===n||null},St=function(e){const{regs:t}=e,n=t[e.r],r=e.terms[e.t],o=e.t;if(n.optional&&t[e.r+1]&&n.negative)return!0;if(n.optional&&t[e.r+1]&&function(e){const{regs:t}=e,n=t[e.r],r=e.terms[e.t],o=Dt(r,t[e.r+1],e.start_i+e.t,e.phrase_length);if(n.negative||o){const n=e.terms[e.t+1];n&&Dt(n,t[e.r+1],e.start_i+e.t,e.phrase_length)||(e.r+=1)}}(e),r.implicit&&e.terms[e.t+1]&&function(e){const t=e.terms[e.t],n=e.regs[e.r];if(t.implicit&&e.terms[e.t+1]){if(!e.terms[e.t+1].implicit)return;n.word===t.normal&&(e.t+=1),"hasContraction"===n.method&&(e.t+=1)}}(e),e.t+=1,!0===n.end&&e.t!==e.terms.length&&!0!==n.greedy)return null;if(!0===n.greedy){if(!Bt(e))return null}return!0===e.hasGroup&&function(e,t){const n=e.regs[e.r],r=Et(e,t);e.t>1&&n.greedy?r.length+=e.t-t:r.length++}(e,o),!0},$t=function(e,t,n,r){if(0===e.length||0===t.length)return null;const o={t:0,terms:e,r:0,regs:t,groups:{},start_i:n,phrase_length:r,inGroup:null};for(;o.r!e.optional)))break;return null}if(!0===e.anything&&!0===e.greedy){if(!Gt(o))return null;continue}if(void 0!==e.choices&&"or"===e.operator){if(!Ft(o))return null;continue}if(void 0!==e.choices&&"and"===e.operator){if(!Vt(o))return null;continue}if(!0===e.anything){if(e.negative&&e.anything)return null;if(!St(o))return null;continue}if(!0===Ht(e,o)){if(!St(o))return null;continue}if(e.negative){if(!zt(o))return null;continue}if(!0!==Dt(o.terms[o.t],e,o.start_i+o.t,o.phrase_length)){if(!0!==e.optional)return null}else{if(!St(o))return null}}const a=[null,n,o.t+n];if(a[1]===a[2])return null;const i={};return Object.keys(o.groups).forEach((e=>{const t=o.groups[e],r=n+t.start;i[e]=[null,r,r+t.length]})),{pointer:a,groups:i}},Mt=function(e,t){return e.pointer[0]=t,Object.keys(e.groups).forEach((n=>{e.groups[n][0]=t})),e},Lt=function(e,t,n){let r=$t(e,t,0,e.length);return r?(r=Mt(r,n),r):null},Kt={one:{termMethods:Tt,parseMatch:function(e,t,n){if(null==e||""===e)return[];t=t||{},"number"==typeof e&&(e=String(e));let r=function(e){const t=e.split(tt);let n=[];t.forEach((e=>{ot(e)?n.push(e):n=n.concat(e.split(nt))})),n=at(n);let r=[];return n.forEach((e=>{(e=>/^[![^]*(<[^<]*>)?\(/.test(e)&&/\)[?\]+*$~]*$/.test(e))(e)||ot(e)?r.push(e):r=r.concat(e.split(rt))})),r=at(r),r}(e);return r=r.map((e=>pt(e,t))),r=function(e,t){const n=t.model.one.prefixes;for(let t=e.length-1;t>=0;t-=1){const r=e[t];if(r.word&&ft.test(r.word)){let o=r.word.split(/[-–—]/g);if(n.hasOwnProperty(o[0]))continue;o=o.filter((e=>e)).reverse(),e.splice(t,1),o.forEach((n=>{const o=Object.assign({},r);o.word=n,e.splice(t,0,o)}))}}return e}(r,n),r=function(e,t){return e.map((e=>{if(e.root)if(t.methods.two&&t.methods.two.transform){let n=[];e.pos?"Verb"===e.pos?n=n.concat(bt(e,t)):"Noun"===e.pos?n=n.concat(vt(e,t)):"Adjective"===e.pos&&(n=n.concat(yt(e,t))):(n=n.concat(bt(e,t)),n=n.concat(vt(e,t)),n=n.concat(yt(e,t))),n=n.filter((e=>e)),n.length>0&&(e.operator="or",e.fastOr=new Set(n))}else e.machine=e.root,delete e.id,delete e.root;return e}))}(r,n),r=wt(r),r},match:function(e,t,n){n=n||[];const{regs:r,group:o,justOne:a}=t;let i=[];if(!r||0===r.length)return{ptrs:[],byGroup:{}};const s=r.filter((e=>!0!==e.optional&&!0!==e.negative)).length;e:for(let t=0;te&&(e=Math.abs(n-1))}}else{const e=Lt(o,r,t);e&&i.push(e)}}return!0===r[r.length-1].end&&(i=i.filter((t=>{const n=t.pointer[0];return e[n].length===t.pointer[2]}))),t.notIf&&(i=function(e,t,n){return e=e.filter((e=>{const[r,o,a]=e.pointer,i=n[r].slice(o,a);for(let e=0;e{e.groups[t]&&n.push(e.groups[t])})):e.forEach((e=>{n.push(e.pointer),Object.keys(e.groups).forEach((t=>{r[t]=r[t]||[],r[t].push(e.groups[t])}))}))),{ptrs:n,byGroup:r}}(i,o),i.ptrs.forEach((t=>{const[n,r,o]=t;t[3]=e[n][r].id,t[4]=e[n][o-1].id})),i}}};var Jt={api:function(e){Object.assign(e.prototype,et)},methods:Kt,lib:{parseMatch:function(e,t){const n=this.world(),r=n.methods.one.killUnicode;return r&&(e=r(e,n)),n.methods.one.parseMatch(e,t,n)}}};const Wt=/^\../,qt=/^#./,Ut=function(e,t){const n={},r={};return Object.keys(t).forEach((o=>{let a=t[o];const i=function(e){let t="",n="";return e=e.replace(/&/g,"&").replace(//g,">").replace(/"/g,""").replace(/'/g,"'"),Wt.test(e)?t=``),t+=">",{start:t,end:n}}(o);"string"==typeof a&&(a=e.match(a)),a.docs.forEach((e=>{if(e.every((e=>e.implicit)))return;const t=e[0].id;n[t]=n[t]||[],n[t].push(i.start);const o=e[e.length-1].id;r[o]=r[o]||[],r[o].push(i.end)}))})),{starts:n,ends:r}};var Rt={html:function(e){const{starts:t,ends:n}=Ut(this,e);let r="";return this.docs.forEach((e=>{for(let o=0;o{let n=e.pre||"",o=e.post||"";"some"===t.punctuation&&(n=n.replace(Zt,""),Xt.test(o)&&(o=" "),o=o.replace(_t,""),o=o.replace(/\?!+/,"?"),o=o.replace(/!+/,"!"),o=o.replace(/\?+/,"?"),o=o.replace(/\.{2,}/,""),e.tags.has("Abbreviation")&&(o=o.replace(/\./,""))),"some"===t.whitespace&&(n=n.replace(/\s/,""),o=o.replace(/\s+/," ")),t.keepPunct||(n=n.replace(Zt,""),o="-"===o?" ":o.replace(Qt,""));let a=e[t.form||"text"]||e.normal||"";"implicit"===t.form&&(a=e.implicit||e.text),"root"===t.form&&e.implicit&&(a=e.root||e.implicit||e.normal),"machine"!==t.form&&"implicit"!==t.form&&"root"!==t.form||!e.implicit||o&&Yt.test(o)||(o+=" "),r+=n+a+o})),!1===n&&(r=r.trim()),!0===t.lowerCase&&(r=r.toLowerCase()),r},tn={text:{form:"text"},normal:{whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"normal"},machine:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"none",unicode:"some",form:"machine"},root:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"root"},implicit:{form:"implicit"}};tn.clean=tn.normal,tn.reduced=tn.root;const nn=[];let rn=0;for(;rn<64;)nn[rn]=0|4294967296*Math.sin(++rn%Math.PI);const on=function(e){let t,n,r,o=decodeURI(encodeURI(e))+"",a=o.length;const i=[t=1732584193,n=4023233417,~t,~n],s=[];for(e=--a/4+2|15,s[--e]=8*a;~a;)s[a>>2]|=o.charCodeAt(a)<<8*a--;for(rn=o=0;rn>4]+nn[o]+~~s[rn|15&[o,5*o+1,3*o+5,7*o][a]])<<(a=[7,12,17,22,5,9,14,20,4,11,16,23,6,10,15,21][4*a+o++%4])|r>>>-a),t,n])t=0|a[1],n=a[2];for(o=4;o;)i[--o]+=a[o]}for(e="";o<32;)e+=(i[o>>3]>>4*(1^o++)&15).toString(16);return e},an={text:!0,terms:!0},sn={case:"none",unicode:"some",form:"machine",punctuation:"some"},ln=function(e,t){return Object.assign({},e,t)},un={text:e=>en(e,{keepPunct:!0},!1),normal:e=>en(e,ln(tn.normal,{keepPunct:!0}),!1),implicit:e=>en(e,ln(tn.implicit,{keepPunct:!0}),!1),machine:e=>en(e,sn,!1),root:e=>en(e,ln(sn,{form:"root"}),!1),hash:e=>on(en(e,{keepPunct:!0},!1)),offset:e=>{const t=un.text(e).length;return{index:e[0].offset.index,start:e[0].offset.start,length:t}},terms:e=>e.map((e=>{const t=Object.assign({},e);return t.tags=Array.from(e.tags),t})),confidence:(e,t,n)=>t.eq(n).confidence(),syllables:(e,t,n)=>t.eq(n).syllables(),sentence:(e,t,n)=>t.eq(n).fullSentence().text(),dirty:e=>e.some((e=>!0===e.dirty))};un.sentences=un.sentence,un.clean=un.normal,un.reduced=un.root;const cn={json:function(e){const t=(n=this,"string"==typeof(r=(r=e)||{})&&(r={}),(r=Object.assign({},an,r)).offset&&n.compute("offset"),n.docs.map(((e,t)=>{const o={};return Object.keys(r).forEach((a=>{r[a]&&un[a]&&(o[a]=un[a](e,n,t))})),o})));var n,r;return"number"==typeof e?t[e]:t}};cn.data=cn.json;const hn=function(e){const t=e.pre||"",n=e.post||"";return t+e.text+n},dn=function(e,t){const n=function(e,t){const n={};return Object.keys(t).forEach((r=>{e.match(r).fullPointer.forEach((e=>{n[e[3]]={fn:t[r],end:e[2]}}))})),n}(e,t);let r="";return e.docs.forEach(((t,o)=>{for(let a=0;ae.reduce(((e,t)=>e+t.pre+t.text+t.post),"").trim()));return e.filter((e=>e))}if("freq"===e||"frequency"===e||"topk"===e)return function(e){const t={};e.forEach((e=>{t[e]=t[e]||0,t[e]+=1}));const n=Object.keys(t).map((e=>({normal:e,count:t[e]})));return n.sort(((e,t)=>e.count>t.count?-1:0))}(this.json({normal:!0}).map((e=>e.normal)));if("terms"===e){let e=[];return this.docs.forEach((t=>{let n=t.map((e=>e.text));n=n.filter((e=>e)),e=e.concat(n)})),e}return"tags"===e?this.docs.map((e=>e.reduce(((e,t)=>(e[t.implicit||t.normal]=Array.from(t.tags),e)),{}))):"debug"===e?this.debug():this.text()},wrap:function(e){return dn(this,e)}};var mn={text:function(e){let t={};var n;if(e&&"string"==typeof e&&tn.hasOwnProperty(e)?t=Object.assign({},tn[e]):e&&(n=e,"[object Object]"===Object.prototype.toString.call(n))&&(t=Object.assign({},e)),void 0!==t.keepSpace||this.isFull()||(t.keepSpace=!1),void 0===t.keepEndPunct&&this.pointer){const e=this.pointer[0];e&&e[1]?t.keepEndPunct=!1:t.keepEndPunct=!0}return void 0===t.keepPunct&&(t.keepPunct=!0),void 0===t.keepSpace&&(t.keepSpace=!0),function(e,t){let n="";if(!e||!e[0]||!e[0][0])return n;for(let r=0;r"�[32m"+e+fn,red:e=>"�[31m"+e+fn,blue:e=>"�[34m"+e+fn,magenta:e=>"�[35m"+e+fn,cyan:e=>"�[36m"+e+fn,yellow:e=>"�[33m"+e+fn,black:e=>"�[30m"+e+fn,dim:e=>"�[2m"+e+fn,i:e=>"�[3m"+e+fn},vn={tags:function(e){const{docs:t,model:n}=e;0===t.length&&console.log(bn.blue("\n ──────")),t.forEach((t=>{console.log(bn.blue("\n ┌─────────")),t.forEach((t=>{const r=[...t.tags||[]];let o=t.text||"-";t.sense&&(o=`{${t.normal}/${t.sense}}`),t.implicit&&(o="["+t.implicit+"]"),o=bn.yellow(o);let a="'"+o+"'";if(t.reference){const n=e.update([t.reference]).text("normal");a+=` - ${bn.dim(bn.i("["+n+"]"))}`}a=a.padEnd(18);const i=bn.blue(" │ ")+bn.i(a)+" - "+function(e,t){return t.one.tagSet&&(e=e.map((e=>{if(!t.one.tagSet.hasOwnProperty(e))return e;const n=t.one.tagSet[e].color||"blue";return bn[n](e)}))),e.join(", ")}(r,n);console.log(i)}))})),console.log("\n")},clientSide:function(e){console.log("%c -=-=- ","background-color:#6699cc;"),e.forEach((e=>{console.groupCollapsed(e.text());const t=e.docs[0].map((e=>{let t=e.text||"-";e.implicit&&(t="["+e.implicit+"]");return{text:t,tags:"["+Array.from(e.tags).join(", ")+"]"}}));console.table(t,["text","tags"]),console.groupEnd()}))},chunks:function(e){const{docs:t}=e;console.log(""),t.forEach((e=>{const t=[];e.forEach((e=>{"Noun"===e.chunk?t.push(bn.blue(e.implicit||e.normal)):"Verb"===e.chunk?t.push(bn.green(e.implicit||e.normal)):"Adjective"===e.chunk?t.push(bn.yellow(e.implicit||e.normal)):"Pivot"===e.chunk?t.push(bn.red(e.implicit||e.normal)):t.push(e.implicit||e.normal)})),console.log(t.join(" "),"\n")})),console.log("\n")},highlight:function(e){if(!e.found)return;const t={};e.fullPointer.forEach((e=>{t[e[0]]=t[e[0]]||[],t[e[0]].push(e)})),Object.keys(t).forEach((n=>{let r=e.update([[Number(n)]]).text();e.update(t[n]).json({offset:!0}).forEach(((e,t)=>{r=function(e,t,n){const r=((e,t,n)=>{const r=9*n,o=t.start+r,a=o+t.length;return[e.substring(0,o),e.substring(o,a),e.substring(a,e.length)]})(e,t,n);return`${r[0]}${bn.blue(r[1])}${r[2]}`}(r,e.offset,t)})),console.log(r)})),console.log("\n")}};var yn={api:function(e){Object.assign(e.prototype,pn)},methods:{one:{hash:on,debug:vn}}};const wn=function(e,t){if(e[0]!==t[0])return!1;const[,n,r]=e,[,o,a]=t;return n<=o&&r>o||o<=n&&a>n},kn=function(e){const t={};return e.forEach((e=>{t[e[0]]=t[e[0]]||[],t[e[0]].push(e)})),t},Pn=function(e,t){const n=kn(t),r=[];return e.forEach((e=>{const[t]=e;let o=n[t]||[];if(o=o.filter((t=>function(e,t){return e[1]<=t[1]&&t[2]<=e[2]}(e,t))),0===o.length)return void r.push({passthrough:e});o=o.sort(((e,t)=>e[1]-t[1]));let a=e;o.forEach(((e,t)=>{const n=function(e,t){const[n,r]=e,o=t[1],a=t[2],i={};if(ra&&(i.after=[n,a,e[2]]),i}(a,e);o[t+1]?(r.push({before:n.before,match:n.match}),n.after&&(a=n.after)):r.push(n)}))})),r};var An={one:{termList:function(e){const t=[];for(let n=0;n{if(!r)return;let[a,i,s,l,u]=r,c=t[a]||[];if(void 0===i&&(i=0),void 0===s&&(s=c.length),!l||c[i]&&c[i].id===l)c=c.slice(i,s);else{const n=function(e,t,n){for(let r=0;r<20;r+=1){if(t[n-r]){const o=t[n-r].findIndex((t=>t.id===e));if(-1!==o)return[n-r,o]}if(t[n+r]){const o=t[n+r].findIndex((t=>t.id===e));if(-1!==o)return[n+r,o]}}return null}(l,t,a);if(null!==n){const r=s-i;c=t[n[0]].slice(n[1],n[1]+r);const a=c[0]?c[0].id:null;e[o]=[n[0],n[1],n[1]+r,a]}}0!==c.length&&i!==s&&(u&&c[c.length-1].id!==u&&(c=function(e,t){const[n,r,,,o]=e,a=t[n],i=a.findIndex((e=>e.id===o));return-1===i?(e[2]=t[n].length,e[4]=a.length?a[a.length-1].id:null):e[2]=i,t[n].slice(r,e[2]+1)}(r,t)),n.push(c))})),n=n.filter((e=>e.length>0)),n},pointer:{indexN:kn,splitAll:Pn}}};const Cn=function(e,t){const n=e.concat(t),r=kn(n);let o=[];return n.forEach((e=>{const[t]=e;if(1===r[t].length)return void o.push(e);const n=r[t].filter((t=>wn(e,t)));n.push(e);const a=function(e){let t=e[0][1],n=e[0][2];return e.forEach((e=>{e[1]n&&(n=e[2])})),[e[0][0],t,n]}(n);o.push(a)})),o=function(e){const t={};for(let n=0;n{e.passthrough&&n.push(e.passthrough),e.before&&n.push(e.before),e.after&&n.push(e.after)})),n},jn=(e,t)=>{return"string"==typeof e||(n=e,"[object Array]"===Object.prototype.toString.call(n))?t.match(e):e||t.none();var n},xn=function(e,t){return e.map((e=>{const[n,r]=e;return t[n]&&t[n][r]&&(e[3]=t[n][r].id),e}))},In={union:function(e){e=jn(e,this);let t=Cn(this.fullPointer,e.fullPointer);return t=xn(t,this.document),this.toView(t)}};In.and=In.union,In.intersection=function(e){e=jn(e,this);let t=function(e,t){const n=kn(t),r=[];return e.forEach((e=>{let t=n[e[0]]||[];t=t.filter((t=>wn(e,t))),0!==t.length&&t.forEach((t=>{const n=function(e,t){const n=e[1]t[2]?t[2]:e[2];return n{e=Cn(e,[t])})),e=xn(e,this.document),this.update(e)};var Tn={methods:An,api:function(e){Object.assign(e.prototype,In)}};const Dn=function(e){return!0===e.optional||!0===e.negative?null:e.tag?"#"+e.tag:e.word?e.word:e.switch?`%${e.switch}%`:null},Hn=function(e,t){const n=t.methods.one.parseMatch;return e.forEach((e=>{e.regs=n(e.match,{},t),"string"==typeof e.ifNo&&(e.ifNo=[e.ifNo]),e.notIf&&(e.notIf=n(e.notIf,{},t)),e.needs=function(e){const t=[];return e.forEach((e=>{t.push(Dn(e)),"and"===e.operator&&e.choices&&e.choices.forEach((e=>{e.forEach((e=>{t.push(Dn(e))}))}))})),t.filter((e=>e))}(e.regs);const{wants:r,count:o}=function(e){const t=[];let n=0;return e.forEach((e=>{"or"!==e.operator||e.optional||e.negative||(e.fastOr&&Array.from(e.fastOr).forEach((e=>{t.push(e)})),e.choices&&e.choices.forEach((e=>{e.forEach((e=>{const n=Dn(e);n&&t.push(n)}))})),n+=1)})),{wants:t,count:n}}(e.regs);e.wants=r,e.minWant=o,e.minWords=e.regs.filter((e=>!e.optional)).length})),e};var En={buildNet:function(e,t){e=Hn(e,t);const n={};e.forEach((e=>{e.needs.forEach((t=>{n[t]=Array.isArray(n[t])?n[t]:[],n[t].push(e)})),e.wants.forEach((t=>{n[t]=Array.isArray(n[t])?n[t]:[],n[t].push(e)}))})),Object.keys(n).forEach((e=>{const t={};n[e]=n[e].filter((e=>"boolean"!=typeof t[e.match]&&(t[e.match]=!0,!0)))}));const r=e.filter((e=>0===e.needs.length&&0===e.wants.length));return{hooks:n,always:r}},bulkMatch:function(e,t,n,r={}){const o=n.one.cacheDoc(e);let a=function(e,t){return e.map(((n,r)=>{let o=[];Object.keys(t).forEach((n=>{e[r].has(n)&&(o=o.concat(t[n]))}));const a={};return o=o.filter((e=>"boolean"!=typeof a[e.match]&&(a[e.match]=!0,!0))),o}))}(o,t.hooks);a=function(e,t){return e.map(((e,n)=>{const r=t[n];return(e=(e=e.filter((e=>e.needs.every((e=>r.has(e)))))).filter((e=>void 0===e.ifNo||!0!==e.ifNo.some((e=>r.has(e)))))).filter((e=>0===e.wants.length||e.wants.filter((e=>r.has(e))).length>=e.minWant))}))}(a,o),t.always.length>0&&(a=a.map((e=>e.concat(t.always)))),a=function(e,t){return e.map(((e,n)=>{const r=t[n].length;return e=e.filter((e=>r>=e.minWords)),e}))}(a,e);const i=function(e,t,n,r,o){const a=[];for(let n=0;n0&&(l.ptrs.forEach((e=>{e[0]=n;const t=Object.assign({},s,{pointer:e});void 0!==s.unTag&&(t.unTag=s.unTag),a.push(t)})),!0===o.matchOne))return[a[0]]}return a}(a,e,0,n,r);return i},bulkTagger:function(e,t,n){const{model:r,methods:o}=n,{getDoc:a,setTag:i,unTag:s}=o.one,l=o.two.looksPlural;if(0===e.length)return e;return("undefined"!=typeof process&&process.env?process.env:self.env||{}).DEBUG_TAGS&&console.log(`\n\n �[32m→ ${e.length} post-tagger:�[0m`),e.map((e=>{if(!e.tag&&!e.chunk&&!e.unTag)return;const o=e.reason||e.match,u=a([e.pointer],t)[0];if(!0===e.safe){if(!1===function(e,t,n){const r=n.one.tagSet;if(!r.hasOwnProperty(t))return!0;const o=r[t].not||[];for(let t=0;te.frozen=!0))}void 0!==e.unTag&&s(u,e.unTag,n,e.safe,o),e.chunk&&u.forEach((t=>t.chunk=e.chunk))}))}},Gn={lib:{buildNet:function(e){const t=this.methods().one.buildNet(e,this.world());return t.isNet=!0,t}},api:function(e){e.prototype.sweep=function(e,t={}){const{world:n,docs:r}=this,{methods:o}=n;let a=o.one.bulkMatch(r,e,this.methods,t);!1!==t.tagger&&o.one.bulkTagger(a,r,this.world),a=a.map((e=>{const t=e.pointer,n=r[t[0]][t[1]],o=t[2]-t[1];return n.index&&(e.pointer=[n.index[0],n.index[1],t[1]+o]),e}));const i=a.map((e=>e.pointer));return a=a.map((e=>(e.view=this.update([e.pointer]),delete e.regs,delete e.needs,delete e.pointer,delete e._expanded,e))),{view:this.update(i),found:a}}},methods:{one:En}};const On=/ /,Fn=function(e,t){"Noun"===t&&(e.chunk=t),"Verb"===t&&(e.chunk=t)},Vn=function(e,t,n,r){if(!0===e.tags.has(t))return null;if("."===t)return null;!0===e.frozen&&(r=!0);const o=n[t];if(o){if(o.not&&o.not.length>0)for(let t=0;t0)for(let t=0;t{const r=e.map((e=>e.text||"["+e.implicit+"]")).join(" ");var o;"string"!=typeof t&&t.length>2&&(t=t.slice(0,2).join(", #")+" +"),t="string"!=typeof t?t.join(", #"):t,console.log(` ${(o=r,"�[33m�[3m"+o+"�[0m").padEnd(24)} �[32m→�[0m #${t.padEnd(22)} ${(e=>"�[3m"+e+"�[0m")(n)}`)})(e,t,o),!0!=(s=t,"[object Array]"===Object.prototype.toString.call(s)))if("string"==typeof t)if(t=t.trim(),On.test(t))!function(e,t,n,r){const o=t.split(On);e.forEach(((e,t)=>{let a=o[t];a&&(a=a.replace(/^#/,""),Vn(e,a,n,r))}))}(e,t,a,r);else{t=t.replace(/^#/,"");for(let n=0;nzn(e,t,n,r)))},Bn=function(e){return e.children=e.children||[],e._cache=e._cache||{},e.props=e.props||{},e._cache.parents=e._cache.parents||[],e._cache.children=e._cache.children||[],e},Sn=/^ *(#|\/\/)/,$n=function(e){let t=e.trim().split(/->/),n=[];t.forEach((e=>{n=n.concat(function(e){if(!(e=e.trim()))return null;if(/^\[/.test(e)&&/\]$/.test(e)){let t=(e=(e=e.replace(/^\[/,"")).replace(/\]$/,"")).split(/,/);return t=t.map((e=>e.trim())).filter((e=>e)),t=t.map((e=>Bn({id:e}))),t}return[Bn({id:e})]}(e))})),n=n.filter((e=>e));let r=n[0];for(let e=1;e{let n=[],r=[e];for(;r.length>0;){let e=r.pop();n.push(e),e.children&&e.children.forEach((n=>{t&&t(e,n),r.push(n)}))}return n},Ln=e=>"[object Array]"===Object.prototype.toString.call(e),Kn=e=>(e=e||"").trim(),Jn=function(e=[]){return"string"==typeof e?function(e){let t=e.split(/\r?\n/),n=[];t.forEach((e=>{if(!e.trim()||Sn.test(e))return;let t=(e=>{const t=/^( {2}|\t)/;let n=0;for(;t.test(e);)e=e.replace(t,""),n+=1;return n})(e);n.push({indent:t,node:$n(e)})}));let r=function(e){let t={children:[]};return e.forEach(((n,r)=>{0===n.indent?t.children=t.children.concat(n.node):e[r-1]&&function(e,t){let n=e[t].indent;for(;t>=0;t-=1)if(e[t].indent{t[e.id]=e}));let n=Bn({});return e.forEach((e=>{if((e=Bn(e)).parent)if(t.hasOwnProperty(e.parent)){let n=t[e.parent];delete e.parent,n.children.push(e)}else console.warn(`[Grad] - missing node '${e.parent}'`);else n.children.push(e)})),n}(e):(Mn(t=e).forEach(Bn),t);var t},Wn=function(e,t){let n="-> ";t&&(n=(e=>"�[2m"+e+"�[0m")("→ "));let r="";return Mn(e).forEach(((e,o)=>{let a=e.id||"";if(t&&(a=(e=>"�[31m"+e+"�[0m")(a)),0===o&&!e.id)return;let i=e._cache.parents.length;r+=" ".repeat(i)+n+a+"\n"})),r},qn=function(e){let t=Mn(e);t.forEach((e=>{delete(e=Object.assign({},e)).children}));let n=t[0];return n&&!n.id&&0===Object.keys(n.props).length&&t.shift(),t},Un={text:Wn,txt:Wn,array:qn,flat:qn},Rn=function(e,t){return"nested"===t||"json"===t?e:"debug"===t?(console.log(Wn(e,!0)),null):Un.hasOwnProperty(t)?Un[t](e):e},Qn=e=>{Mn(e,((e,t)=>{e.id&&(e._cache.parents=e._cache.parents||[],t._cache.parents=e._cache.parents.concat([e.id]))}))},Zn=/\//;let _n=class g{constructor(e={}){Object.defineProperty(this,"json",{enumerable:!1,value:e,writable:!0})}get children(){return this.json.children}get id(){return this.json.id}get found(){return this.json.id||this.json.children.length>0}props(e={}){let t=this.json.props||{};return"string"==typeof e&&(t[e]=!0),this.json.props=Object.assign(t,e),this}get(e){if(e=Kn(e),!Zn.test(e)){let t=this.json.children.find((t=>t.id===e));return new g(t)}let t=((e,t)=>{let n=(e=>"string"!=typeof e?e:(e=e.replace(/^\//,"")).split(/\//))(t=t||"");for(let t=0;te.id===n[t]));if(!r)return null;e=r}return e})(this.json,e)||Bn({});return new g(t)}add(e,t={}){if(Ln(e))return e.forEach((e=>this.add(Kn(e),t))),this;e=Kn(e);let n=Bn({id:e,props:t});return this.json.children.push(n),new g(n)}remove(e){return e=Kn(e),this.json.children=this.json.children.filter((t=>t.id!==e)),this}nodes(){return Mn(this.json).map((e=>(delete(e=Object.assign({},e)).children,e)))}cache(){return(e=>{let t=Mn(e,((e,t)=>{e.id&&(e._cache.parents=e._cache.parents||[],e._cache.children=e._cache.children||[],t._cache.parents=e._cache.parents.concat([e.id]))})),n={};t.forEach((e=>{e.id&&(n[e.id]=e)})),t.forEach((e=>{e._cache.parents.forEach((t=>{n.hasOwnProperty(t)&&n[t]._cache.children.push(e.id)}))})),e._cache.children=Object.keys(n)})(this.json),this}list(){return Mn(this.json)}fillDown(){var e;return e=this.json,Mn(e,((e,t)=>{t.props=((e,t)=>(Object.keys(t).forEach((n=>{if(t[n]instanceof Set){let r=e[n]||new Set;e[n]=new Set([...r,...t[n]])}else if((e=>e&&"object"==typeof e&&!Array.isArray(e))(t[n])){let r=e[n]||{};e[n]=Object.assign({},t[n],r)}else Ln(t[n])?e[n]=t[n].concat(e[n]||[]):void 0===e[n]&&(e[n]=t[n])})),e))(t.props,e.props)})),this}depth(){Qn(this.json);let e=Mn(this.json),t=e.length>1?1:0;return e.forEach((e=>{if(0===e._cache.parents.length)return;let n=e._cache.parents.length+1;n>t&&(t=n)})),t}out(e){return Qn(this.json),Rn(this.json,e)}debug(){return Qn(this.json),Rn(this.json,"debug"),this}};const Xn=function(e){let t=Jn(e);return new _n(t)};Xn.prototype.plugin=function(e){e(this)};const Yn={Noun:"blue",Verb:"green",Negative:"green",Date:"red",Value:"red",Adjective:"magenta",Preposition:"cyan",Conjunction:"cyan",Determiner:"cyan",Hyphenated:"cyan",Adverb:"cyan"},er=function(e){if(Yn.hasOwnProperty(e.id))return Yn[e.id];if(Yn.hasOwnProperty(e.is))return Yn[e.is];const t=e._cache.parents.find((e=>Yn[e]));return Yn[t]},tr=function(e){return e?"string"==typeof e?[e]:e:[]},nr=function(e,t){return e=function(e,t){return Object.keys(e).forEach((n=>{e[n].isA&&(e[n].is=e[n].isA),e[n].notA&&(e[n].not=e[n].notA),e[n].is&&"string"==typeof e[n].is&&(t.hasOwnProperty(e[n].is)||e.hasOwnProperty(e[n].is)||(e[e[n].is]={})),e[n].not&&"string"==typeof e[n].not&&!e.hasOwnProperty(e[n].not)&&(t.hasOwnProperty(e[n].not)||e.hasOwnProperty(e[n].not)||(e[e[n].not]={}))})),e}(e,t),Object.keys(e).forEach((t=>{e[t].children=tr(e[t].children),e[t].not=tr(e[t].not)})),Object.keys(e).forEach((t=>{(e[t].not||[]).forEach((n=>{e[n]&&e[n].not&&e[n].not.push(t)}))})),e};var rr={one:{setTag:zn,unTag:function(e,t,n){t=t.trim().replace(/^#/,"");for(let r=0;r0)for(let e=0;e0&&(e=function(e){return Object.keys(e).forEach((t=>{e[t]=Object.assign({},e[t]),e[t].novel=!0})),e}(e)),e=nr(e,t);const n=function(e){const t=Object.keys(e).map((t=>{const n=e[t],r={not:new Set(n.not),also:n.also,is:n.is,novel:n.novel};return{id:t,parent:n.is,props:r,children:[]}}));return Xn(t).cache().fillDown().out("array")}(Object.assign({},t,e)),r=function(e){const t={};return e.forEach((e=>{const{not:n,also:r,is:o,novel:a}=e.props;let i=e._cache.parents;r&&(i=i.concat(r)),t[e.id]={is:o,not:n,novel:a,also:r,parents:i,children:e._cache.children,color:er(e)}})),Object.keys(t).forEach((e=>{const n=new Set(t[e].not);t[e].not.forEach((e=>{t[e]&&t[e].children.forEach((e=>n.add(e)))})),t[e].not=Array.from(n)})),t}(n);return r},canBe:function(e,t,n){if(!n.hasOwnProperty(t))return!0;const r=n[t].not||[];for(let t=0;to.one.setTag(r,e,i,n,t))):o.one.setTag(r,e,i,n,t),this.uncache(),this},tagSafe:function(e,t=""){return this.tag(e,t,!0)},unTag:function(e,t){if(!this.found||!e)return this;const n=this.termList();if(0===n.length)return this;const{methods:r,verbose:o,model:a}=this;!0===o&&console.log(" - ",e,t||"");const i=a.one.tagSet;return or(e)?e.forEach((e=>r.one.unTag(n,e,i))):r.one.unTag(n,e,i),this.uncache(),this},canBe:function(e){e=e.replace(/^#/,"");const t=this.model.one.tagSet,n=this.methods.one.canBe,r=[];this.document.forEach(((o,a)=>{o.forEach(((o,i)=>{n(o,e,t)||r.push([a,i,i+1])}))}));const o=this.update(r);return this.difference(o)}};var ir={addTags:function(e){const{model:t,methods:n}=this.world(),r=t.one.tagSet,o=(0,n.one.addTags)(e,r);return t.one.tagSet=o,this}};const sr=new Set(["Auxiliary","Possessive"]);var lr={model:{one:{tagSet:{}}},compute:{tagRank:function(e){const{document:t,world:n}=e,r=n.model.one.tagSet;t.forEach((e=>{e.forEach((e=>{const t=Array.from(e.tags);e.tagRank=function(e,t){return e=e.sort(((e,n)=>{if(sr.has(e)||!t.hasOwnProperty(n))return 1;if(sr.has(n)||!t.hasOwnProperty(e))return-1;let r=t[e].children||[];const o=r.length;return r=t[n].children||[],o-r.length})),e}(t,r)}))}))}},methods:rr,api:function(e){Object.assign(e.prototype,ar)},lib:ir};const ur=/([.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s)/g,cr=/^[.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s$/,hr=/((?:\r?\n|\r)+)/,dr=/[a-z0-9\u00C0-\u00FF\u00a9\u00ae\u2000-\u3300\ud000-\udfff]/i,gr=/\S/,mr=function(e){return Boolean(e.match(/\n$/))},pr={'"':'"',""":""","“":"”","‟":"”","„":"”","⹂":"”","‚":"’","«":"»","‹":"›","‵":"′","‶":"″","‷":"‴","〝":"〞","〟":"〞"},fr=RegExp("["+Object.keys(pr).join("")+"]","g"),br=RegExp("["+Object.values(pr).join("")+"]","g"),vr=function(e){if(!e)return!1;const t=e.match(br);return null!==t&&1===t.length},yr=/\(/g,wr=/\)/g,kr=/\S/,Pr=/^\s+/,Ar=function(e,t){const n=e.split(/[-–—]/);if(n.length<=1)return!1;const{prefixes:r,suffixes:o}=t.one;if(1===n[0].length&&/[a-z]/i.test(n[0]))return!1;if(r.hasOwnProperty(n[0]))return!1;if(n[1]=n[1].trim().replace(/[.?!]$/,""),o.hasOwnProperty(n[1]))return!1;if(!0===/^([a-z\u00C0-\u00FF`"'/]+)[-–—]([a-z0-9\u00C0-\u00FF].*)/i.test(e))return!0;return!0===/^[('"]?([0-9]{1,4})[-–—]([a-z\u00C0-\u00FF`"'/-]+[)'"]?$)/i.test(e)},Cr=function(e){const t=[],n=e.split(/[-–—]/);let r="-";const o=e.match(/[-–—]/);o&&o[0]&&(r=o);for(let e=0;e(e[t]=!0,e)),{});const Dr=/\p{Letter}/u,Hr=/[\p{Number}\p{Currency_Symbol}]/u,Er=/^[a-z]\.([a-z]\.)+/i,Gr=/[sn]['’]$/,Or=/([A-Z]\.)+[A-Z]?,?$/,Fr=/^[A-Z]\.,?$/,Vr=/[A-Z]{2,}('s|,)?$/,zr=/([a-z]\.)+[a-z]\.?$/,Br=function(e){return function(e){return!0===Or.test(e)||!0===zr.test(e)||!0===Fr.test(e)||!0===Vr.test(e)}(e)&&(e=e.replace(/\./g,"")),e},Sr=function(e,t){const n=t.methods.one.killUnicode;let r=e.text||"";r=function(e){const t=e=(e=(e=e||"").toLowerCase()).trim();return e=(e=(e=e.replace(/[,;.!?]+$/,"")).replace(/\u2026/g,"...")).replace(/\u2013/g,"-"),!1===/^[:;]/.test(e)&&(e=(e=(e=e.replace(/\.{3,}$/g,"")).replace(/[",.!:;?)]+$/g,"")).replace(/^['"(]+/g,"")),""===(e=(e=e.replace(/[\u200B-\u200D\uFEFF]/g,"")).trim())&&(e=t),e.replace(/([0-9]),([0-9])/g,"$1$2")}(r),r=n(r,t),r=Br(r),e.normal=r},$r=/[ .][A-Z]\.? *$/i,Mr=/(?:\u2026|\.{2,}) *$/,Lr=/\p{L}/u,Kr=/\. *$/,Jr=/^[A-Z]\. $/;var Wr={one:{killUnicode:function(e,t){const n=t.model.one.unicode||{},r=(e=e||"").split("");return r.forEach(((e,t)=>{n[e]&&(r[t]=n[e])})),r.join("")},tokenize:{splitSentences:function(e,t){if(e=e||"",!(e=String(e))||"string"!=typeof e||!1===kr.test(e))return[];const n=function(e){const t=[],n=e.split(hr);for(let e=0;e0&&(o.push(a),e[t]=""):e[t+1]=a+(e[t+1]||"")}return o}(r,t),r=function(e){const t=[];for(let n=0;n0?(n[n.length-1]+=a,n.push(t)):n.push(a+t),a=""):a+=t}return a&&(0===n.length&&(n[0]=""),n[n.length-1]+=a),n=function(e){for(let t=1;te)),n},splitWhitespace:(e,t)=>{const{str:n,pre:r,post:o}=function(e,t){const{prePunctuation:n,postPunctuation:r,emoticons:o}=t.one;let a=e,i="",s="";const l=Array.from(e);if(o.hasOwnProperty(e.trim()))return{str:e.trim(),pre:i,post:" "};let u=l.length;for(let e=0;e(s=e||"",""))),e=a,i=""),{str:e,pre:i,post:s}}(e,t);return{text:n,pre:r,post:o,tags:new Set}},fromString:function(e,t){const{methods:n,model:r}=t,{splitSentences:o,splitTerms:a,splitWhitespace:i}=n.one.tokenize;return e=o(e=e||"",t).map((e=>{let n=a(e,r);return n=n.map((e=>i(e,r))),n.forEach((e=>{Sr(e,t)})),n})),e}}}};const qr={},Ur={};[[["approx","apt","bc","cyn","eg","esp","est","etc","ex","exp","prob","pron","gal","min","pseud","fig","jd","lat","lng","vol","fm","def","misc","plz","ea","ps","sec","pt","pref","pl","pp","qt","fr","sq","nee","ss","tel","temp","vet","ver","fem","masc","eng","adj","vb","rb","inf","situ","vivo","vitro","wr"]],[["dl","ml","gal","qt","pt","tbl","tsp","tbsp","km","dm","cm","mm","mi","td","hr","hrs","kg","hg","dg","cg","mg","µg","lb","oz","sq ft","hz","mps","mph","kmph","kb","mb","tb","lx","lm","fl oz","yb"],"Unit"],[["ad","al","arc","ba","bl","ca","cca","col","corp","ft","fy","ie","lit","ma","md","pd","tce"],"Noun"],[["adj","adm","adv","asst","atty","bldg","brig","capt","cmdr","comdr","cpl","det","dr","esq","gen","gov","hon","jr","llb","lt","maj","messrs","mlle","mme","mr","mrs","ms","mstr","phd","prof","pvt","rep","reps","res","rev","sen","sens","sfc","sgt","sir","sr","supt","surg"],"Honorific"],[["jan","feb","mar","apr","jun","jul","aug","sep","sept","oct","nov","dec"],"Month"],[["dept","univ","assn","bros","inc","ltd","co"],"Organization"],[["rd","st","dist","mt","ave","blvd","cl","cres","hwy","ariz","cal","calif","colo","conn","fla","fl","ga","ida","ia","kan","kans","minn","neb","nebr","okla","penna","penn","pa","dak","tenn","tex","ut","vt","va","wis","wisc","wy","wyo","usafa","alta","ont","que","sask"],"Place"]].forEach((e=>{e[0].forEach((t=>{qr[t]=!0,Ur[t]="Abbreviation",void 0!==e[1]&&(Ur[t]=[Ur[t],e[1]])}))}));var Rr=["anti","bi","co","contra","de","extra","infra","inter","intra","macro","micro","mis","mono","multi","peri","pre","pro","proto","pseudo","re","sub","supra","trans","tri","un","out","ex"].reduce(((e,t)=>(e[t]=!0,e)),{});const Qr={"!":"¡","?":"¿Ɂ",'"':'“”"❝❞',"'":"‘‛❛❜’","-":"—–",a:"ªÀÁÂÃÄÅàáâãäåĀāĂ㥹ǍǎǞǟǠǡǺǻȀȁȂȃȦȧȺΆΑΔΛάαλАаѦѧӐӑӒӓƛæ",b:"ßþƀƁƂƃƄƅɃΒβϐϦБВЪЬвъьѢѣҌҍ",c:"¢©ÇçĆćĈĉĊċČčƆƇƈȻȼͻͼϲϹϽϾСсєҀҁҪҫ",d:"ÐĎďĐđƉƊȡƋƌ",e:"ÈÉÊËèéêëĒēĔĕĖėĘęĚěƐȄȅȆȇȨȩɆɇΈΕΞΣέεξϵЀЁЕеѐёҼҽҾҿӖӗễ",f:"ƑƒϜϝӺӻҒғſ",g:"ĜĝĞğĠġĢģƓǤǥǦǧǴǵ",h:"ĤĥĦħƕǶȞȟΉΗЂЊЋНнђћҢңҤҥҺһӉӊ",I:"ÌÍÎÏ",i:"ìíîïĨĩĪīĬĭĮįİıƖƗȈȉȊȋΊΐΪίιϊІЇіїi̇",j:"ĴĵǰȷɈɉϳЈј",k:"ĶķĸƘƙǨǩΚκЌЖКжкќҚқҜҝҞҟҠҡ",l:"ĹĺĻļĽľĿŀŁłƚƪǀǏǐȴȽΙӀӏ",m:"ΜϺϻМмӍӎ",n:"ÑñŃńŅņŇňʼnŊŋƝƞǸǹȠȵΝΠήηϞЍИЙЛПийлпѝҊҋӅӆӢӣӤӥπ",o:"ÒÓÔÕÖØðòóôõöøŌōŎŏŐőƟƠơǑǒǪǫǬǭǾǿȌȍȎȏȪȫȬȭȮȯȰȱΌΘΟθοσόϕϘϙϬϴОФоѲѳӦӧӨөӪӫ",p:"ƤΡρϷϸϼРрҎҏÞ",q:"Ɋɋ",r:"ŔŕŖŗŘřƦȐȑȒȓɌɍЃГЯгяѓҐґ",s:"ŚśŜŝŞşŠšƧƨȘșȿЅѕ",t:"ŢţŤťŦŧƫƬƭƮȚțȶȾΓΤτϮТт",u:"ÙÚÛÜùúûüŨũŪūŬŭŮůŰűŲųƯưƱƲǓǔǕǖǗǘǙǚǛǜȔȕȖȗɄΰυϋύ",v:"νѴѵѶѷ",w:"ŴŵƜωώϖϢϣШЩшщѡѿ",x:"×ΧχϗϰХхҲҳӼӽӾӿ",y:"ÝýÿŶŷŸƳƴȲȳɎɏΎΥΫγψϒϓϔЎУучўѰѱҮүҰұӮӯӰӱӲӳ",z:"ŹźŻżŽžƵƶȤȥɀΖ"},Zr={};Object.keys(Qr).forEach((function(e){Qr[e].split("").forEach((function(t){Zr[t]=e}))}));const _r=/\//,Xr=/[a-z]\.[a-z]/i,Yr=/[0-9]/,eo=function(e,t){const n=e.normal||e.text||e.machine,r=t.model.one.aliases;if(r.hasOwnProperty(n)&&(e.alias=e.alias||[],e.alias.push(r[n])),_r.test(n)&&!Xr.test(n)&&!Yr.test(n)){const t=n.split(_r);t.length<=3&&t.forEach((t=>{""!==(t=t.trim())&&(e.alias=e.alias||[],e.alias.push(t))}))}return e},to=/^\p{Letter}+-\p{Letter}+$/u,no=function(e){let t=e.implicit||e.normal||e.text;t=t.replace(/['’]s$/,""),t=t.replace(/s['’]$/,"s"),t=t.replace(/([aeiou][ktrp])in'$/,"$1ing"),to.test(t)&&(t=t.replace(/-/g,"")),t=t.replace(/^[#@]/,""),t!==e.normal&&(e.machine=t)},ro=function(e,t){const n=e.docs;for(let r=0;rro(e,eo),machine:e=>ro(e,no),normal:e=>ro(e,Sr),freq:function(e){const t=e.docs,n={};for(let e=0;e{let i=(e=e.toLowerCase().trim()).length;t.max&&i>t.max&&(i=t.max);for(let s=t.min;s{delete r[e]})),r}(e,t,this.world());return Object.keys(o).forEach((e=>{n.one.typeahead.hasOwnProperty(e)?delete n.one.typeahead[e]:n.one.typeahead[e]=o[e]})),this}};var co={model:{one:{typeahead:{}}},api:function(e){e.prototype.autoFill=so},lib:uo,compute:io,hooks:["typeahead"]};h.extend(J),h.extend(yn),h.extend(Jt),h.extend(Tn),h.extend(lr),h.plugin(ye),h.extend(ao),h.extend(Ce),h.plugin(p),h.extend(Be),h.extend(co),h.extend(Ee),h.extend(Gn);var ho={addendum:"addenda",corpus:"corpora",criterion:"criteria",curriculum:"curricula",genus:"genera",memorandum:"memoranda",opus:"opera",ovum:"ova",phenomenon:"phenomena",referendum:"referenda",alga:"algae",alumna:"alumnae",antenna:"antennae",formula:"formulae",larva:"larvae",nebula:"nebulae",vertebra:"vertebrae",analysis:"analyses",axis:"axes",diagnosis:"diagnoses",parenthesis:"parentheses",prognosis:"prognoses",synopsis:"synopses",thesis:"theses",neurosis:"neuroses",appendix:"appendices",index:"indices",matrix:"matrices",ox:"oxen",sex:"sexes",alumnus:"alumni",bacillus:"bacilli",cactus:"cacti",fungus:"fungi",hippopotamus:"hippopotami",libretto:"libretti",modulus:"moduli",nucleus:"nuclei",octopus:"octopi",radius:"radii",stimulus:"stimuli",syllabus:"syllabi",cookie:"cookies",calorie:"calories",auntie:"aunties",movie:"movies",pie:"pies",rookie:"rookies",tie:"ties",zombie:"zombies",leaf:"leaves",loaf:"loaves",thief:"thieves",foot:"feet",goose:"geese",tooth:"teeth",beau:"beaux",chateau:"chateaux",tableau:"tableaux",bus:"buses",gas:"gases",circus:"circuses",crisis:"crises",virus:"viruses",database:"databases",excuse:"excuses",abuse:"abuses",avocado:"avocados",barracks:"barracks",child:"children",clothes:"clothes",echo:"echoes",embargo:"embargoes",epoch:"epochs",deer:"deer",halo:"halos",man:"men",woman:"women",mosquito:"mosquitoes",mouse:"mice",person:"people",quiz:"quizzes",rodeo:"rodeos",shoe:"shoes",sombrero:"sombreros",stomach:"stomachs",tornado:"tornados",tuxedo:"tuxedos",volcano:"volcanoes"},go={Comparative:"true¦bett1f0;arth0ew0in0;er",Superlative:"true¦earlier",PresentTense:"true¦bests,sounds",Condition:"true¦lest,unless",PastTense:"true¦began,came,d4had,kneel3l2m0sa4we1;ea0sg2;nt;eap0i0;ed;id",Participle:"true¦0:09;a06b01cZdXeat0fSgQhPoJprov0rHs7t6u4w1;ak0ithdra02o2r1;i02uY;k0v0;nd1pr04;ergoJoJ;ak0hHo3;e9h7lain,o6p5t4un3w1;o1um;rn;g,k;ol0reS;iQok0;ught,wn;ak0o1runk;ne,wn;en,wn;ewriNi1uJ;dd0s0;ut3ver1;do4se0t1;ak0h2;do2g1;roG;ne;ast0i7;iv0o1;ne,tt0;all0loBor1;bi3g2s1;ak0e0;iv0o9;dd0;ove,r1;a5eamt,iv0;hos0lu1;ng;e4i3lo2ui1;lt;wn;tt0;at0en,gun;r2w1;ak0ok0;is0;en",Gerund:"true¦accord0be0doin,go0result0stain0;ing",Expression:"true¦a0Yb0Uc0Sd0Oe0Mfarew0Lg0FhZjeez,lWmVnToOpLsJtIuFvEw7y0;a5e3i1u0;ck,p;k04p0;ee,pee;a0p,s;!h;!a,h,y;a5h2o1t0;af,f;rd up,w;atsoever,e1o0;a,ops;e,w;hoo,t;ery w06oi0L;gh,h0;! 0h,m;huh,oh;here nPsk,ut tut;h0ic;eesh,hh,it,oo;ff,h1l0ow,sst;ease,s,z;ew,ooey;h1i,mg,o0uch,w,y;h,o,ps;! 0h;hTmy go0wT;d,sh;a7evertheless,o0;!pe;eh,mm;ah,eh,m1ol0;!s;ao,fao;aCeBi9o2u0;h,mph,rra0zzC;h,y;l1o0;r6y9;la,y0;! 0;c1moCsmok0;es;ow;!p hip hoor0;ay;ck,e,llo,y;ha1i,lleluj0;ah;!ha;ah,ee4o1r0;eat scott,r;l1od0sh; grief,bye;ly;! whiz;ell;e0h,t cetera,ureka,ww,xcuse me;k,p;'oh,a0rat,uh;m0ng;mit,n0;!it;mon,o0;ngratulations,wabunga;a2oo1r0tw,ye;avo,r;!ya;h,m; 1h0ka,las,men,rgh,ye;!a,em,h,oy;la",Negative:"true¦n0;ever,o0;n,t",QuestionWord:"true¦how3wh0;at,e1ich,o0y;!m,se;n,re; come,'s",Reflexive:"true¦h4it5my5o1the0your2;ir1m1;ne3ur0;sel0;f,ves;er0im0;self",Plural:"true¦dick0gre0ones,records;ens","Unit|Noun":"true¦cEfDgChBinchAk9lb,m6newt5oz,p4qt,t1y0;ardEd;able1b0ea1sp;!l,sp;spo1;a,t,x;on9;!b,g,i1l,m,p0;h,s;!les;!b,elvin,g,m;!es;g,z;al,b;eet,oot,t;m,up0;!s",Value:"true¦a few",Imperative:"true¦bewa0come he0;re","Plural|Verb":"true¦leaves",Demonym:"true¦0:15;1:12;a0Vb0Oc0Dd0Ce08f07g04h02iYjVkTlPmLnIomHpEqatari,rCs7t5u4v3welAz2;am0Gimbabwe0;enezuel0ietnam0I;gAkrai1;aiwTex0hai,rinida0Ju2;ni0Prkmen;a5cotti4e3ingapoOlovak,oma0Spaniard,udRw2y0W;ede,iss;negal0Cr09;sh;mo0uT;o5us0Jw2;and0;a2eru0Fhilippi0Nortugu07uerto r0S;kist3lesti1na2raguay0;ma1;ani;ami00i2orweP;caragu0geri2;an,en;a3ex0Lo2;ngo0Drocc0;cedo1la2;gasy,y07;a4eb9i2;b2thua1;e0Cy0;o,t01;azakh,eny0o2uwaiI;re0;a2orda1;ma0Ap2;anO;celandic,nd4r2sraeli,ta01vo05;a2iB;ni0qi;i0oneU;aiAin2ondur0unO;di;amEe2hanai0reek,uatemal0;or2rm0;gi0;ilipino,ren8;cuadoVgyp4mira3ngli2sto1thiopi0urope0;shm0;ti;ti0;aPominUut3;a9h6o4roat3ub0ze2;ch;!i0;lom2ngol5;bi0;a6i2;le0n2;ese;lifor1m2na3;bo2eroo1;di0;angladeshi,el6o4r3ul2;gaE;azi9it;li2s1;vi0;aru2gi0;si0;fAl7merBngol0r5si0us2;sie,tr2;a2i0;li0;genti2me1;ne;ba1ge2;ri0;ni0;gh0r2;ic0;an",Organization:"true¦0:4Q;a3Tb3Bc2Od2He2Df27g1Zh1Ti1Pj1Nk1Ll1Gm12n0Po0Mp0Cqu0Br02sTtHuCv9w3xiaomi,y1;amaha,m1Bou1w1B;gov,tu3C;a4e2iki1orld trade organizati33;leaRped0O;lls fargo,st1;fie2Hinghou2R;l1rner br3U;gree3Jl street journ2Im1E;an halOeriz2Xisa,o1;dafo2Yl1;kswagMvo;b4kip,n2ps,s1;a tod3Aps;es3Mi1;lev3Fted natio3C;er,s; mobi32aco beRd bOe9gi frida3Lh3im horto3Amz,o1witt3D;shi49y1;ota,s r 05;e 1in lizzy;b3carpen3Jdaily ma3Dguess w2holli0s1w2;mashing pumpki35uprem0;ho;ea1lack eyed pe3Xyr0Q;ch bo3Dtl0;l2n3Qs1xas instrumen1U;co,la m1F;efoni0Kus;a8cientology,e5ieme2Ymirnoff,np,o3pice gir6quare0Ata1ubaru;rbuc1to34;ks;ny,undgard1;en;a2x pisto1;ls;g1Wrs;few2Minsbur31lesfor03msu2E;adiohead,b8e4o1yana3C;man empi1Xyal 1;b1dutch she4;ank;a3d 1max,vl20;bu1c2Ahot chili peppe2Ylobst2N;ll;ders dige1Ll madrid;c,s;ant3Aizn2Q;a8bs,e5fiz2Ihilip4i3r1;emier 1udenti1D;leagTo2K;nk floyd,zza hut; morrBs;psi2tro1uge0E;br33chi0Tn33;!co;lant2Un1yp16; 2ason27da2P;ld navy,pec,range juli2xf1;am;us;aAb9e6fl,h5i4o1sa,vid3wa;k2tre dame,vart1;is;ia;ke,ntendo,ss0QvZ;l,s;c,st1Otflix,w1; 1sweek;kids on the block,york0D;a,c;nd22s2t1;ional aca2Po,we0U;a,c02d0S;aDcdonalCe9i6lb,o3tv,y1;spa1;ce;b1Tnsanto,ody blu0t1;ley cr1or0T;ue;c2t1;as,subisO;helin,rosoft;dica2rcedes benz,talli1;ca;id,re;ds;cs milk,tt19z24;a3e1g,ittle caesa1P; ore09novo,x1;is,mark,us; 1bour party;pres0Dz boy;atv,fc,kk,lm,m1od1O;art;iffy lu0Roy divisi0Jpmorgan1sa;! cha09;bm,hop,k3n1tv;g,te1;l,rpol;ea;a5ewlett pack1Vi3o1sbc,yundai;me dep1n1P;ot;tac1zbollah;hi;lliburt08sbro;eneral 6hq,ithub,l5mb,o2reen d0Ou1;cci,ns n ros0;ldman sachs,o1;dye1g0H;ar;axo smith kli04encoW;electr0Nm1;oto0Z;a5bi,c barcelo4da,edex,i2leetwood m03o1rito l0G;rd,xcY;at,fa,nancial1restoZ; tim0;na;cebook,nnie mae;b0Asa,u3xxon1; m1m1;ob0J;!rosceptics;aiml0De5isney,o4u1;nkin donu2po0Zran dur1;an;ts;j,w jon0;a,f lepp12ll,peche mode,r spieg02stiny's chi1;ld;aJbc,hFiDloudflaCnn,o3r1;aigsli5eedence clearwater reviv1ossra09;al;c7inba6l4m1o0Est09;ca2p1;aq;st;dplSg1;ate;se;a c1o chanQ;ola;re;a,sco1tigroup;! systems;ev2i1;ck fil a,na daily;r1y;on;d2pital o1rls jr;ne;bury,ill1;ac;aEbc,eBf9l5mw,ni,o1p,rexiteeU;ei3mbardiIston 1;glo1pizza;be;ng;o2ue c1;roV;ckbuster video,omingda1;le; g1g1;oodriL;cht2e ge0rkshire hathaw1;ay;el;cardi,idu,nana republ3s1xt5y5;f,kin robbi1;ns;ic;bYcTdidSerosmith,iRlKmEnheuser busDol,ppleAr6s4u3v2y1;er;is,on;di,todesk;hland o1sociated E;il;b3g2m1;co;os;ys; compu1be0;te1;rs;ch;c,d,erican3t1;!r1;ak; ex1;pre1;ss; 5catel2ta1;ir;! lu1;ce1;nt;jazeera,qae1;da;g,rbnb;as;/dc,a3er,tivision1;! blizz1;ard;demy of scienc0;es;ba",Possessive:"true¦its,my,our0thy;!s","Noun|Verb":"true¦0:9W;1:AA;2:96;3:A3;4:9R;5:A2;6:9K;7:8N;8:7L;9:A8;A:93;B:8D;C:8X;a9Ob8Qc7Id6Re6Gf5Sg5Hh55i4Xj4Uk4Rl4Em40n3Vo3Sp2Squ2Rr21s0Jt02u00vVwGyFzD;ip,oD;ne,om;awn,e6Fie68;aOeMhJiHoErD;ap,e9Oink2;nd0rDuC;kDry,sh5Hth;!shop;ck,nDpe,re,sh;!d,g;e86iD;p,sD;k,p0t2;aDed,lco8W;r,th0;it,lk,rEsDt4ve,x;h,te;!ehou1ra9;aGen5FiFoD;iDmAte,w;ce,d;be,ew,sA;cuum,l4B;pDr7;da5gra6Elo6A;aReQhrPiOoMrGuEwiDy5Z;n,st;nDrn;e,n7O;aGeFiEoDu6;t,ub2;bu5ck4Jgg0m,p;at,k,nd;ck,de,in,nsDp,v7J;f0i8R;ll,ne,p,r4Yss,t94uD;ch,r;ck,de,e,le,me,p,re;e5Wow,u6;ar,e,ll,mp0st,xt;g,lDng2rg7Ps5x;k,ly;a0Sc0Ne0Kh0Fi0Dk0Cl0Am08n06o05pXquaBtKuFwD;ea88iD;ng,pe,t4;bGit,m,ppErD;fa3ge,pri1v2U;lDo6S;e6Py;!je8;aMeLiKoHrEuDy2;dy,ff,mb2;a85eEiDo5Pugg2;ke,ng;am,ss,t4;ckEop,p,rD;e,m;ing,pi2;ck,nk,t4;er,m,p;ck,ff,ge,in,ke,lEmp,nd,p2rDte,y;!e,t;k,l;aJeIiHlGoFrDur,y;ay,e56inDu3;g,k2;ns8Bt;a5Qit;ll,n,r87te;ed,ll;m,n,rk;b,uC;aDee1Tow;ke,p;a5Je4FiDo53;le,rk;eep,iDou4;ce,p,t;ateboa7Ii;de,gnDl2Vnk,p,ze;!al;aGeFiEoDuff2;ck,p,re,w;ft,p,v0;d,i3Ylt0;ck,de,pe,re,ve;aEed,nDrv1It;se,t2N;l,r4t;aGhedu2oBrD;aEeDibb2o3Z;en,w;pe,t4;le,n,r2M;cDfegua72il,mp2;k,rifi3;aZeHhy6LiGoEuD;b,in,le,n,s5X;a6ck,ll,oDpe,u5;f,t;de,ng,ot,p,s1W;aTcSdo,el,fQgPje8lOmMnLo17pJque6sFturn,vDwa6V;eDi27;al,r1;er74oFpe8tEuD;lt,me;!a55;l71rt;air,eaDly,o53;l,t;dezvo2Zt;aDedy;ke,rk;ea1i4G;a6Iist0r5N;act6Yer1Vo71uD;nd,se;a38o6F;ch,s6G;c1Dge,iEke,lly,nDp1Wt1W;ge,k,t;n,se;es6Biv0;a04e00hYiXlToNrEsy4uD;mp,n4rcha1sh;aKeIiHoDu4O;be,ceFdu3fi2grDje8mi1p,te6;amDe6W;!me;ed,ss;ce,de,nt;sDy;er6Cs;cti3i1;iHlFoEp,re,sDuCw0;e,i5Yt;l,p;iDl;ce,sh;nt,s5V;aEce,e32uD;g,mp,n7;ce,nDy;!t;ck,le,n17pe,tNvot;a1oD;ne,tograph;ak,eFnErDt;fu55mA;!c32;!l,r;ckJiInHrFsEtDu1y;ch,e9;s,te;k,tD;!y;!ic;nt,r,se;!a7;bje8ff0il,oErDutli3Qver4B;bAd0ie9;ze;a4ReFoDur1;d,tD;e,i3;ed,gle8tD;!work;aMeKiIoEuD;rd0;ck,d3Rld,nEp,uDve;nt,th;it5EkD;ey;lk,n4Brr5CsDx;s,ta2B;asuBn4UrDss;ge,it;il,nFp,rk3WsEtD;ch,t0;h,k,t0;da5n0oeuvB;aLeJiHoEuD;mp,st;aEbby,ck,g,oDve;k,t;d,n;cDe,ft,mAnIst;en1k;aDc0Pe4vK;ch,d,k,p,se;bFcEnd,p,t4uD;gh,n4;e,k;el,o2U;eEiDno4E;ck,d,ll,ss;el,y;aEo1OuD;i3mp;m,zz;mpJnEr46ssD;ue;c1Rdex,fluGha2k,se2HteDvoi3;nt,rD;e6fa3viD;ew;en3;a8le2A;aJeHiGoEuD;g,nt;l3Ano2Dok,pDr1u1;!e;ghli1Fke,nt,re,t;aDd7lp;d,t;ck,mGndFrEsh,tDu9;ch,e;bo3Xm,ne4Eve6;!le;!m0;aMear,ift,lKossJrFuD;arDe4Alp,n;antee,d;aFiEoDumb2;uCwth;ll,nd,p;de,sp;ip;aBoDue;ss,w;g,in,me,ng,s,te,ze;aZeWiRlNoJrFuD;ck,el,nDss,zz;c38d;aEoDy;st,wn;cDgme,me,nchi1;tuB;cFg,il,ld,rD;ce,e29mDwa31;!at;us;aFe0Vip,oDy;at,ck,od,wD;!er;g,ke,me,re,sh,vo1E;eGgFlEnDre,sh,t,x;an3i0Q;e,m,t0;ht,uB;ld;aEeDn3;d,l;r,tuB;ce,il,ll,rm,vo2W;cho,d7ffe8nMsKxFyeD;!baD;ll;cGerci1hFpDtra8;eriDo0W;en3me9;au6ibA;el,han7u1;caDtima5;pe;count0d,vy;a01eSiMoJrEuDye;b,el,mp,pli2X;aGeFiEoD;ne,p;ft,ll,nk,p,ve;am,ss;ft,g,in;cEd7ubt,wnloD;ad;k,u0E;ge6p,sFt4vD;e,iDor3;de;char7gui1h,liEpD;at4lay,u5;ke;al,bKcJfeIlGmaCposAsEtaD;il;e07iD;gn,re;ay,ega5iD;ght;at,ct;li04rea1;a5ut;b,ma7n3rDte;e,t;a0Eent0Dh06irc2l03oKrFuD;be,e,rDt;b,e,l,ve;aGeFoEuDy;sh;p,ss,wd;dAep;ck,ft,sh;at,de,in,lTmMnFordina5py,re,st,uDv0;gh,nDp2rt;s01t;ceHdu8fli8glomeIsFtDveN;a8rD;a6ol;e9tru8;ct;ntDrn;ra5;bHfoGmFpD;leDouCromi1;me9;aCe9it,u5;rt;at,iD;ne;lap1oD;r,ur;aEiDoud,ub;ck,p;im,w;aEeDip;at,ck,er;iGllen7nErD;ge,m,t;ge,nD;el;n,r;er,re;ke,ll,mp,noe,pGrXsFtEuDve;se,ti0I;alog,ch;h,t;!tuB;re;a03eZiXlToPrHuEyD;pa11;bb2ck2dgEff0mp,rDst,zz;den,n;et;anJeHiFoadEuD;i1sh;ca6;be,d7;ge;aDed;ch,k;ch,d;aFg,mb,nEoDrd0tt2x,ycott;k,st,t;d,e;rd,st;aFeCiDoYur;nk,tz;nd;me;as,d,ke,nd,opsy,tD;!ch,e;aFef,lt,nDt;d,efA;it;r,t;ck,il,lan3nIrFsEtt2;le;e,h;!gDk;aDe;in;!d,g,k;bu1c05dZge,iYlVnTppQrLsIttGucEwaD;rd;tiD;on;aDempt;ck;k,sD;i6ocia5;st;chFmD;!oD;ur;!iD;ve;eEroa4;ch;al;chDg0sw0;or;aEt0;er;rm;d,m,r;dreHvD;an3oD;ca5;te;ce;ss;cDe,he,t;eFoD;rd,u9;nt;nt,ss;se",Actor:"true¦0:7B;1:7G;2:6A;3:7F;4:7O;5:7K;a6Nb62c4Ud4Be41f3Sg3Bh30i2Uj2Qkin2Pl2Km26n1Zo1Sp0Vqu0Tr0JsQtJuHvEw8yo6;gi,ut6;h,ub0;aAe9i8o7r6;estl0it0;m2rk0;fe,nn0t2Bza2H;atherm2ld0;ge earn0it0nder0rri1;eter7i6oyF;ll5Qp,s3Z;an,ina2U;n6s0;c6Uder03;aoisea23e9herapi5iktok0o8r6ut1yco6S;a6endseLo43;d0mp,nscri0Bvel0;ddl0u1G;a0Qchn7en6na4st0;ag0;i3Oo0D;aiXcUeRhPiMki0mu26oJpGquaFtBu7wee6;p0theart;lt2per7r6;f0ge6Iviv1;h6inten0Ist5Ivis1;ero,um2;a8ep7r6;ang0eam0;bro2Nc2Ofa2Nmo2Nsi20;ff0tesm2;tt0;ec7ir2Do6;kesp59u0M;ia5Jt3;l7me6An,rcere6ul;r,ss;di0oi5;n7s6;sy,t0;g0n0;am2ephe1Iow6;girl,m2r2Q;cretInior cit3Fr6;gea4v6;a4it1;hol4Xi7reen6ulpt1;wr2C;e01on;l1nt;aEe9o8u6;l0nn6;er up,ingE;g40le mod3Zof0;a4Zc8fug2Ppo32searQv6;ere4Uolution6;ary;e6luYru22;ptio3T;bbi,dic5Vpp0;arter6e2Z;back;aYeWhSiRlOoKr8sycho7u6;nk,p31;logi5;aGeDiBo6;d9fess1g7ph47s6;pe2Ktitu51;en6ramm0;it1y;igy,uc0;est4Nme mini0Unce6s3E;!ss;a7si6;de4;ch0;ctiti39nk0P;dca0Oet,li6pula50rnst42;c2Itic6;al scie6i2;nti5;a6umb0;nn0y6;er,ma4Lwright;lgrim,one0;a8iloso7otogra7ra6ysi1V;se;ph0;ntom,rmaci5;r6ssi1T;form0s4O;i3El,nel3Yr8st1tr6wn;i6on;arWot;ent4Wi42tn0;ccupa4ffBp8r7ut6;ca5l0B;ac4Iganiz0ig2Fph2;er3t6;i1Jomet6;ri5;ic0spring;aBe9ie4Xo7u6;n,rser3J;b6mad,vi4V;le2Vo4D;i6mesis,phew;ce,ghb1;nny,rr3t1X;aEeDiAo7u6yst1Y;m8si16;der3gul,m7n6th0;arDk;!my;ni7s6;f02s0Jt0;on,st0;chan1Qnt1rcha4;gi9k0n8rtyr,t6y1;e,riar6;ch;ag0iac;ci2stra3I;a7e2Aieutena4o6;rd,s0v0;bor0d7ndlo6ss,urea3Fwy0ym2;rd;!y;!s28;e8o7u6;ggl0;gg0urna2U;st0;c3Hdol,llu3Ummigra4n6; l9c1Qfa4habi42nov3s7ve6;nt1stig3;pe0Nt6;a1Fig3ru0M;aw;airFeBistoAo8u6ygie1K;man6sba2H;!ita8;bo,st6usekN;age,e3P;ri2;ir,r6;m7o6;!ine;it;dress0sty2C;aLeIhostGirl26ladi3oCrand7u6;e5ru;c9daug0Jfa8m7pa6s2Y;!re4;a,o6;th0;hi1B;al7d6lf0;!de3A;ie,k6te26;eep0;!wr6;it0;isha,n6;i6tl04;us;mbl0rden0;aDella,iAo7r6;eela2Nie1P;e,re6ster pare4;be1Hm2r6st0;unn0;an2ZgZlmm17nanci0r6tt0;e6st la2H; marsh2OfigXm2;rm0th0;conoEdDlectriCm8n7x6;amin0cellency,i2A;emy,trepreneur,vironmenta1J;c8p6;er1loye6;e,r;ee;ci2;it1;mi5;aKeBi8ork,ri7u6we02;de,tche2H;ft0v0;ct3eti7plom2Hre6va;ct1;ci2ti2;aDcor3fencCi0InAput9s7tectLvel6;op0;ce1Ge6ign0;rt0;ee,y;iz6;en;em2;c1Ml0;d8nc0redev7ug6;ht0;il;!dy;a06e04fo,hXitizenWlToBr9u6;r3stomer6;! representat6;ive;e3it6;ic;lJmGnAord9rpor1Nu7w6;boy,ork0;n6ri0;ciTte1Q;in3;fidantAgressSs9t6;e0Kr6;ibut1o6;ll0;tab13ul1O;!e;edi2m6pos0rade;a0EeQissi6;on0;leag8on7um6;ni5;el;ue;e6own;an0r6;ic,k;!s;a9e7i6um;ld;erle6f;ad0;ir7nce6plFract0;ll1;m2wI;lebri6o;ty;dBptAr6shi0;e7pe6;nt0;r,t6;ak0;ain;et;aMeLiJlogg0oErBu6;dd0Fild0rgl9siness6;m2p7w6;om2;ers05;ar;i7o6;!k0th0;cklay0de,gadi0;hemi2oge8y6;!frie6;nd;ym2;an;cyc6sR;li5;atbox0ings;by,nk0r6;b0on7te6;nd0;!e07;c04dWge4nQpLrHsFtAu7yatull6;ah;nt7t6;h1oG;!ie;h8t6;e6orney;nda4;ie5le6;te;sis00tron6;aut,om0;chbis8isto7tis6;an,t;crU;hop;ost9p6;ari6rentiS;ti6;on;le;a9cest1im3nou8y6;bo6;dy;nc0;ly5rc6;hi5;mi8v6;entur0is1;er;ni7r6;al;str3;at1;or;counBquaintanArob9t6;ivi5or,re6;ss;st;at;ce;ta4;nt","Adj|Noun":"true¦0:16;a1Db17c0Ud0Re0Mf0Dg0Ah08i06ju05l02mWnUoSpNrIsBt7u4v1watershed;a1ision0Z;gabo4nilla,ria1;b0Vnt;ndergr1pstairs;adua14ou1;nd;a3e1oken,ri0;en,r1;min0rori13;boo,n;age,e5ilv0Flack,o3quat,ta2u1well;bordina0Xper5;b0Lndard;ciali0Yl1vereign;e,ve16;cret,n1ri0;ior;a4e2ou1ubbiL;nd,tiY;ar,bBl0Wnt0p1side11;resent0Vublican;ci0Qsh;a4eriodic0last0Zotenti0r1;emi2incip0o1;!fession0;er,um;rall4st,tie0U;ff1pposi0Hv0;ens0Oi0C;agg01ov1uts;el;a5e3iniatJo1;bi01der07r1;al,t0;di1tr0N;an,um;le,riG;attOi2u1;sh;ber0ght,qC;stice,veniT;de0mpressioYn1;cumbe0Edividu0no0Dsta0Eterim;alf,o1umdrum;bby,melF;en2old,ra1;ph0Bve;er0ious;a7e5i4l3u1;git03t1;ure;uid;ne;llow,m1;aFiL;ir,t,vo1;riOuriO;l3p00x1;c1ecutUpeV;ess;d1iK;er;ar2e1;mographUrivO;k,l2;hiGlassSo2rude,unn1;ing;m5n1operK;creCstitueOte2vertab1;le;mpor1nt;ary;ic,m2p1;anion,lex;er2u1;ni8;ci0;al;e5lank,o4r1;i2u1;te;ef;ttom,urgeois;st;cadem9d6l2ntarct9r1;ab,ct8;e3tern1;at1;ive;rt;oles1ult;ce1;nt;ic","Adj|Past":"true¦0:4Q;1:4C;2:4H;3:4E;a44b3Tc36d2Je29f20g1Wh1Si1Jj1Gkno1Fl1Am15n12o0Xp0Mqu0Kr08sLtEuAv9w4yellow0;a7ea6o4rinkl0;r4u3Y;n,ri0;k31th3;rp0sh0tZ;ari0e1O;n5p4s0;d1li1Rset;cov3derstood,i4;fi0t0;a8e3Rhr7i6ouTr4urn0wi4C;a4imm0ou2G;ck0in0pp0;ed,r0;eat2Qi37;m0nn0r4;get0ni2T;aOcKeIhGimFm0Hoak0pDt7u4;bsid3Ogge44s4;pe4ta2Y;ct0nd0;a8e7i2Eok0r5u4;ff0mp0nn0;ength2Hip4;ed,p0;am0reotyp0;in0t0;eci4ik0oH;al3Efi0;pRul1;a4ock0ut;d0r0;a4c1Jle2t31;l0s3Ut0;a6or5r4;at4e25;ch0;r0tt3;t4ut0;is2Mur1;aEe5o4;tt0;cAdJf2Bg9je2l8m0Knew0p7qu6s4;eTpe2t4;or0ri2;e3Dir0;e1lac0;at0e2Q;i0Rul1;eiv0o4ycl0;mme2Lrd0v3;in0lli0ti2A;a4ot0;li28;aCer30iBlAo9r5u4;mp0zzl0;e6i2Oo4;ce2Fd4lo1Anou30pos0te2v0;uc0;fe1CocCp0Iss0;i2Kli1L;ann0e2CuS;ck0erc0ss0;ck0i2Hr4st0;allLk0;bse7c6pp13rgan2Dver4;lo4whelm0;ok0;cupi0;rv0;aJe5o4;t0uri1A;ed0gle2;a6e5ix0o4ut0ys1N;di1Nt15u26;as0Clt0;n4rk0;ag0ufact0A;e6i5o4;ad0ck0st,v0;cens0m04st0;ft,v4;el0;tt0wn;a5o15u4;dg0s1B;gg0;llumSmpAn4sol1;br0cre1Ldebt0f8jZspir0t5v4;it0olv0;e4ox0Y;gr1n4re23;d0si15;e2l1o1Wuri1;li0o01r4;ov0;a6e1o4um03;ok0r4;ri0Z;mm3rm0;i6r5u4;a1Bid0;a0Ui0Rown;ft0;aAe9i8l6oc0Ir4;a4i0oz0Y;ctHg19m0;avo0Ju4;st3;ni08tt0x0;ar0;d0il0sc4;in1;dCl1mBn9quipp0s8x4;agger1c6p4te0T;a0Se4os0;ct0rie1D;it0;cap0tabliZ;cha0XgFha1As4;ur0;a0Zbarra0N;i0Buc1;aMeDi5r4;a01i0;gni08miniSre2s4;a9c6grun0Ft4;o4re0Hu17;rt0;iplWou4;nt0r4;ag0;bl0;cBdRf9l8p7ra6t5v4;elop0ot0;ail0ermQ;ng0;re07;ay0ight0;e4in0o0M;rr0;ay0enTor1;m5t0z4;ed,zl0;ag0p4;en0;aPeLhIlHo9r6u4;lt4r0stom03;iv1;a5owd0u4;sh0;ck0mp0;d0loAm7n4ok0v3;centr1f5s4troC;id3olid1;us0;b5pl4;ic1;in0;r0ur0;assi9os0utt3;ar5i4;ll0;g0m0;lebr1n6r4;ti4;fi0;tralJ;g0lcul1;aDewild3iCl9o7r5urn4;ed,t;ok4uis0;en;il0r0t4und;tl0;e5i4;nd0;ss0;as0;ffl0k0laMs0tt3;bPcNdKfIg0lFmaz0nDppBrm0ss9u5wa4;rd0;g5thor4;iz0;me4;nt0;o6u4;m0r0;li0re4;ci1;im1ticip1;at0;a5leg0t3;er0;rm0;fe2;ct0;ju5o7va4;nc0;st0;ce4knowledg0;pt0;and5so4;rb0;on0;ed",Singular:"true¦0:5J;1:5H;2:4W;3:4S;4:52;5:57;6:5L;7:56;8:5B;a52b4Lc3Nd35e2Xf2Og2Jh28in24j23k22l1Um1Ln1Ho1Bp0Rqu0Qr0FsZtMuHvCw9x r58yo yo;a9ha3Po3Q;f3i4Rt0Gy9;! arou39;arCeAideo ga2Qo9;cabu4Jl5C;gOr9t;di4Zt1Y;iety,ni4P;nBp30rAs 9;do43s5E;bani1in0;coordinat3Ader9;estima1to24we41; rex,aKeJhHiFoErBuAv9;! show;m2On2rntLto1D;agedy,ib9o4E;e,u9;n0ta46;ni1p2rq3L;c,er,m9;etF;ing9ree26;!y;am,mp3F;ct2le6x return;aNcMeKhor4QiJkHoGpin off,tDuBy9;ll9ner7st4T;ab2X;b9i1n28per bowl,rro1X;st3Ltot0;atAipe2Go1Lrate7udent9;! lo0I;i39u1;ft ser4Lmeo1I;elet5i9;ll,r3V;b38gn2Tte;ab2Jc9min3B;t,urity gua2N;e6ho2Y;bbatic0la3Jndwi0Qpi5;av5eDhetor2iAo9;de6om,w;tAv9;erb2C;e,u0;bDcBf9publ2r10spi1;er9orm3;e6r0;i9ord label;p2Ht0;a1u46;estion mark,ot2F;aPeMhoLiIlGoErAu9yram1F;ddi3HpErpo1Js3J;eBo9;bl3Zs9;pe3Jta1;dic1Rmi1Fp1Qroga8ss relea1F;p9rt0;py;a9ebisci1;q2Dte;cn2eAg9;!gy;!r;ne call,tocoK;anut,dAr9t0yo1;cen3Jsp3K;al,est0;nop4rAt9;e,hog5;adi11i2V;atme0bj3FcBpia1rde0thers,utspok5ve9wn3;n,r9;ti0Pview;cuAe9;an;pi3;arBitAot9umb3;a2Fhi2R;e,ra1;cot2ra8;aFeCiAo9ur0;nopo4p18rni2Nsq1Rti36uld;c,li11n0As9tt5;chief,si34;dAnu,t9;al,i3;al,ic;gna1mm0nd15rsupi0te9yf4;ri0;aDegCiBu9;ddi1n9;ch;me,p09; Be0M;bor14y9; 9er;up;eyno1itt5;el4ourn0;cBdices,itia8ni25sAtel0Lvert9;eb1J;e28titu1;en8i2T;aIeEighDoAu9;man right,s22;me9rmoFsp1Ftb0K;! r9;un; scho0YriY;a9i1N;d9v5; start,pho9;ne;ndful,sh brown,v5ze;aBelat0Ilaci3r9ul4yp1S;an9enadi3id;a1Cd slam,ny;df4r9;l2ni1I;aGeti1HiFlu1oCrAun9;er0;ee market,i9onti3;ga1;l4ur9;so9;me;ePref4;br2mi4;conoFffi7gg,lecto0Rmbas1EnCpidem2s1Zth2venBxAyel9;id;ampZempl0Nte6;i19t;er7terp9;ri9;se;my;eLiEoBr9ump tru0U;agonf4i9;er,ve thru;cAg7i4or,ssi3wn9;side;to0EumenE;aEgniDnn3sAvide9;nd;conte6incen8p9tri11;osi9;ti0C;ta0H;le0X;athBcAf9ni0terre6;ault 05err0;al,im0;!b9;ed;aWeThMiLlJoDr9;edit caBuc9;ib9;le;rd;efficDke,lCmmuniqLnsApi3rr0t0Xus9yo1;in;erv9uI;ato02;ic,lQ;ie6;er7i9oth;e6n2;ty,vil wM;aDeqCick5ocoBr9;istmas car9ysanthemum;ol;la1;ue;ndeli3racteri9;st2;iAllEr9;e0tifica1;liZ;hi3nFpErCt9ucus;erpi9hedr0;ll9;ar;!bohyd9ri3;ra1;it0;aAe,nib0t9;on;l,ry;aMeLiop2leJoHrDu9;nny,r9tterf4;g9i0;la9;ry;eakAi9;ck;fa9throB;st;dy,ro9wl;ugh;mi9;sh;an,l4;nkiArri3;er;ng;cSdMlInFppeti1rDsBtt2utop9;sy;ic;ce6pe9;ct;r9sen0;ay;ecAoma4tiA;ly;do1;i5l9;er7y;gy;en; hominDjAvan9;tage;ec8;ti9;ve;em;cCeAqui9;tt0;ta1;te;iAru0;al;de6;nt","Person|Noun":"true¦a0Eb07c03dWeUfQgOhLjHkiGlFmCnBolive,p7r4s3trini06v1wa0;ng,rd,tts;an,enus,iol0;a,et;ky,onPumm09;ay,e1o0uby;bin,d,se;ed,x;a2e1o0;l,tt04;aLnJ;dYge,tR;at,orm;a0eloW;t0x,ya;!s;a9eo,iH;ng,tP;a2e1o0;lGy;an,w3;de,smi4y;a0erb,iOolBuntR;ll,z0;el;ail,e0iLuy;ne;a1ern,i0lo;elds,nn;ith,n0;ny;a0dEmir,ula,ve;rl;a4e3i1j,ol0;ly;ck,x0;ie;an,ja;i0wn;sy;am,h0liff,rystal;a0in,ristian;mbers,ri0;ty;a4e3i2o,r0ud;an0ook;dy;ll;nedict,rg;k0nks;er;l0rt;fredo,ma","Actor|Verb":"true¦aCb8c5doctor,engineAfool,g3host,judge,m2nerd,p1recruit,scout,ushAvolunteAwi0;mp,tneA;arent,ilot;an,ime;eek,oof,r0uide;adu8oom;ha1o0;ach,nscript,ok;mpion,uffeur;o2u0;lly,tch0;er;ss;ddi1ffili0rchite1;ate;ct",MaleName:"true¦0:H6;1:FZ;2:DS;3:GQ;4:CZ;5:FV;6:GM;7:FP;8:GW;9:ET;A:C2;B:GD;aF8bE1cCQdBMeASfA1g8Yh88i7Uj6Sk6Bl5Mm48n3So3Ip33qu31r26s1Et0Ru0Ov0CwTxSyHzC;aCor0;cChC1karia,nAT;!hDkC;!aF6;!ar7CeF5;aJevgenBSoEuC;en,rFVsCu3FvEF;if,uf;nDs6OusC;ouf,s6N;aCg;s,tC;an,h0;hli,nCrosE1ss09;is,nC;!iBU;avi2ho5;aPeNiDoCyaEL;jcieBJlfgang,odrFutR;lFnC;f8TsC;lCt1;ow;bGey,frEhe4QlC;aE5iCy;am,e,s;ed8iC;d,ed;eAur;i,ndeD2rn2sC;!l9t1;lDyC;l1ne;lDtC;!er;aCHy;aKernDAiFladDoC;jteB0lodymyr;!iC;mFQsDB;cFha0ktBZnceDrgCOvC;a0ek;!nC;t,zo;!e4StBV;lCnC7sily;!entC;in9J;ghE2lCm70nax,ri,sm0;riCyss87;ch,k;aWeRhNiLoGrEuDyC;!l2roEDs1;n6r6E;avD0eCist0oy,um0;ntCRvBKy;bFdAWmCny;!asDmCoharu;aFFie,y;!z;iA6y;mCt4;!my,othy;adEeoDia0SomC;!as;!dor91;!de4;dFrC;enBKrC;anBJeCy;ll,nBI;!dy;dgh,ha,iCnn2req,tsu5V;cDAka;aYcotWeThPiMlobod0oKpenc2tEurDvenAEyCzym1;ed,lvest2;aj,e9V;anFeDuC;!aA;fan17phEQvCwaA;e77ie;!islaCl9;v,w;lom1rBuC;leymaDHta;dDgmu9UlCm1yabonga;as,v8B;!dhart8Yn9;aEeClo75;lCrm0;d1t1;h9Jne,qu1Jun,wn,yne;aDbastiEDk2Yl5Mpp,rgCth,ymoCU;e1Dio;m4n;!tC;!ie,y;eDPlFmEnCq67tosCMul;dCj2UtiA5;e01ro;!iATkeB6mC4u5;!ik,vato9K;aZeUheC8iRoGuDyC;an,ou;b99dDf4peAssC;!elEG;ol00y;an,bLc7MdJel,geIh0lHmGnEry,sDyC;!ce;ar7Ocoe,s;!aCnBU;ld,n;an,eo;a7Ef;l7Jr;e3Eg2n9olfo,riC;go;bBNeDH;cCl9;ar87c86h54kCo;!ey,ie,y;cFeA3gDid,ubByCza;an8Ln06;g85iC;naC6s;ep;ch8Kfa5hHin2je8HlGmFndEoHpha5sDul,wi36yC;an,mo8O;h9Im4;alDSol3O;iD0on;f,ph;ul;e9CinC;cy,t1;aOeLhilJiFrCyoG;aDeC;m,st1;ka85v2O;eDoC;tr;r8GtC;er,ro;!ipCl6H;!p6U;dCLrcy,tC;ar,e9JrC;!o7;b9Udra8So9UscAHtri62ulCv8I;!ie,o7;ctav6Ji2lImHndrBRrGsDtCum6wB;is,to;aDc6k6m0vCwaBE;al79;ma;i,vR;ar,er;aDeksandr,ivC;er,i2;f,v;aNeLguyBiFoCu3O;aDel,j4l0ma0rC;beAm0;h,m;cFels,g5i9EkDlC;es,s;!au,h96l78olaC;!i,y;hCkCol76;ol75;al,d,il,ls1vC;ilAF;hom,tC;e,hC;anCy;!a5i5;aYeViLoGuDyC;l4Nr1;hamDr84staC;fa,p6E;ed,mG;di10e,hamEis4JntDritz,sCussa;es,he;e,y;ad,ed,mC;ad,ed;cGgu5hai,kFlEnDtchC;!e8O;a9Pik;house,o7t1;ae73eC3ha8Iolaj;ah,hDkC;!ey,y;aDeC;al,l;el,l;hDlv3rC;le,ri8Ev4T;di,met;ay0c00gn4hWjd,ks2NlTmadZnSrKsXtDuric7VxC;imilBKwe8B;eHhEi69tCus,y69;!eo,hCia7;ew,i67;eDiC;as,eu,s;us,w;j,o;cHiGkFlEqu8Qsha83tCv3;iCy;!m,n;in,on;el,o7us;a6Yo7us;!elCin,o7us;!l8o;frAEi5Zny,u5;achDcoCik;lm;ai,y;amDdi,e5VmC;oud;adCm6W;ou;aulCi9P;ay;aWeOiMloyd,oJuDyC;le,nd1;cFdEiDkCth2uk;a7e;gi,s,z;ov7Cv6Hw6H;!as,iC;a6Een;g0nn52renDuCvA4we7D;!iS;!zo;am,n4oC;n5r;a9Yevi,la5KnHoFst2thaEvC;eCi;nte;bo;nCpo8V;!a82el,id;!nC;aAy;mEnd1rDsz73urenCwr6K;ce,t;ry,s;ar,beAont;aOeIhalHiFla4onr63rDu5SylC;e,s;istCzysztof;i0oph2;er0ngsl9p,rC;ilA9k,ollos;ed,id;en0iGnDrmCv4Z;it;!dDnCt1;e2Ny;ri4Z;r,th;cp2j4mEna8BrDsp6them,uC;ri;im,l;al,il;a03eXiVoFuC;an,lCst3;en,iC;an,en,o,us;aQeOhKkub4AnIrGsDzC;ef;eDhCi9Wue;!ua;!f,ph;dCge;i,on;!aCny;h,s,th6J;anDnC;!ath6Hie,n72;!nC;!es;!l,sCy;ph;o,qu3;an,mC;!i,m6V;d,ffFns,rCs4;a7JemDmai7QoCry;me,ni1H;i9Dy;!e73rC;ey,y;cKdBkImHrEsDvi2yC;dBs1;on,p2;ed,oDrCv67;e6Qod;d,s61;al,es5Wis1;a,e,oCub;b,v;ob,qu13;aTbNchiMgLke53lija,nuKonut,rIsEtCv0;ai,suC;ki;aDha0i8XmaCsac;el,il;ac,iaC;h,s;a,vinCw3;!g;k,nngu6X;nac1Xor;ka;ai,rahC;im;aReLoIuCyd6;beAgGmFsC;eyDsC;a3e3;in,n;ber5W;h,o;m2raDsse3wC;a5Pie;c49t1K;a0Qct3XiGnDrC;beAman08;dr7VrC;iCy2N;!k,q1R;n0Tt3S;bKlJmza,nIo,rEsDyC;a5KdB;an,s0;lEo67r2IuCv9;hi5Hki,tC;a,o;an,ey;k,s;!im;ib;a08e00iUlenToQrMuCyorgy;iHnFsC;!taC;f,vC;!e,o;n6tC;er,h2;do,lC;herDlC;auCerQ;me;aEegCov2;!g,orC;!io,y;dy,h7C;dfr9nza3XrDttfC;ri6C;an,d47;!n;acoGlEno,oCuseppe;rgiCvan6O;!o,s;be6Ies,lC;es;mo;oFrC;aDha4HrCt;it,y;ld,rd8;ffErgC;!e7iCy;!os;!r9;bElBrCv3;eCla1Nr4Hth,y;th;e,rC;e3YielC;!i4;aXeSiQlOorrest,rCyod2E;aHedFiC;edDtC;s,z;ri18;!d42eri11riC;ck,k;nCs2;cEkC;ie,lC;in,yn;esLisC;!co,z3M;etch2oC;ri0yd;d5lConn;ip;deriFliEng,rC;dinaCg4nan0B;nd8;pe,x;co;bCdi,hd;iEriC;ce,zC;io;an,en,o;benez2dZfrYit0lTmMnJo3rFsteb0th0ugenEvCymBzra;an,eCge4D;ns,re3K;!e;gi,iDnCrol,v3w3;est8ie,st;cCk;!h,k;o0DriCzo;co,qC;ue;aHerGiDmC;aGe3A;lCrh0;!iC;a10o,s;s1y;nu5;beAd1iEliDm2t1viCwood;n,s;ot28s;!as,j5Hot,sC;ha;a3en;!dGg6mFoDua2QwC;a2Pin;arC;do;oZuZ;ie;a04eTiOmitrNoFrag0uEwDylC;an,l0;ay3Hig4D;a3Gdl9nc0st3;minFnDri0ugCvydGy2S;!lF;!a36nCov0;e1Eie,y;go,iDykC;as;cCk;!k;i,y;armuFetDll1mitri7neCon,rk;sh;er,m6riC;ch;id;andLepak,j0lbeAmetri4nIon,rGsEvDwCxt2;ay30ey;en,in;hawn,moC;nd;ek,riC;ck;is,nC;is,y;rt;re;an,le,mKnIrEvC;e,iC;!d;en,iEne0PrCyl;eCin,yl;l45n;n,o,us;!iCny;el,lo;iCon;an,en,on;a0Fe0Ch03iar0lRoJrFuDyrC;il,us;rtC;!is;aEistC;iaCob12;no;ig;dy,lInErC;ey,neliCy;s,us;nEor,rDstaC;nt3;ad;or;by,e,in,l3t1;aHeEiCyde;fCnt,ve;fo0Xt1;menDt4;us;s,t;rFuDyC;!t1;dCs;e,io;enC;ce;aHeGrisC;!toC;phCs;!eC;!r;st2t;d,rCs;b5leC;s,y;cDdrCs6;ic;il;lHmFrC;ey,lDroCy;ll;!o7t1;er1iC;lo;!eb,v3;a09eZiVjorn,laUoSrEuCyr1;ddy,rtKst2;er;aKeFiEuDyC;an,ce,on;ce,no;an,ce;nDtC;!t;dDtC;!on;an,on;dFnC;dDisC;lav;en,on;!foOl9y;bby,gd0rCyd;is;i0Lke;bElDshC;al;al,lL;ek;nIrCshoi;at,nEtC;!raC;m,nd;aDhaCie;rd;rd8;!iDjam3nCs1;ie,y;to;kaMlazs,nHrC;n9rDtC;!holomew;eCy;tt;ey;dCeD;ar,iC;le;ar1Nb1Dd16fon15gust3hm12i0Zja0Yl0Bm07nTputsiSrGsaFugustEveDyCziz;a0kh0;ry;o,us;hi;aMchiKiJjun,mHnEon,tCy0;em,hCie,ur8;ur;aDoC;!ld;ud,v;aCin;an,nd8;!el,ki;baCe;ld;ta;aq;aMdHgel8tCw6;hoFoC;iDnC;!i8y;ne;ny;er7rCy;eDzC;ej;!as,i,j,s,w;!s;s,tolC;iCy;!y;ar,iEmaCos;nu5r;el;ne,r,t;aVbSdBeJfHiGl01onFphonsEt1vC;aPin;on;e,o;so,zo;!sR;!onZrC;ed;c,jaHksFssaHxC;!andC;er,rC;e,os,u;andCei;ar,er,r;ndC;ro;en;eDrecC;ht;rt8;dd3in,n,sC;taC;ir;ni;dDm6;ar;an,en;ad,eC;d,t;in;so;aGi,olErDvC;ik;ian8;f8ph;!o;mCn;!a;dGeFraDuC;!bakr,lfazl;hCm;am;!l;allFel,oulaye,ulC;!lDrahm0;an;ah,o;ah;av,on",Uncountable:"true¦0:2E;1:2L;2:33;a2Ub2Lc29d22e1Rf1Ng1Eh16i11j0Yk0Wl0Rm0Hn0Do0Cp03rZsLt9uran2Jv7w3you gu0E;a5his17i4oo3;d,l;ldlife,ne;rm8t1;apor,ernacul29i3;neg28ol1Otae;eDhBiAo8r4un3yranny;a,gst1B;aff2Oea1Ko4ue nor3;th;o08u3;bleshoot2Ose1Tt;night,othpas1Vwn3;foEsfoE;me off,n;er3und1;e,mod2S;a,nnis;aDcCeBhAi9ki8o7p6t4u3weepstak0;g1Unshi2Hshi;ati08e3;am,el;ace2Keci0;ap,cc1meth2C;n,ttl0;lk;eep,ingl0or1C;lf,na1Gri0;ene1Kisso1C;d0Wfe2l4nd,t3;i0Iurn;m1Ut;abi0e4ic3;e,ke15;c3i01laxa11search;ogni10rea10;a9e8hys7luto,o5re3ut2;amble,mis0s3ten20;en1Zs0L;l3rk;i28l0EyH; 16i28;a24tr0F;nt3ti0M;i0s;bstetri24vercrowd1Qxyg09;a5e4owada3utella;ys;ptu1Ows;il poliZtional securi2;aAe8o5u3;m3s1H;ps;n3o1K;ey,o3;gamy;a3cha0Elancholy,rchandi1Htallurgy;sl0t;chine3g1Aj1Hrs,thema1Q; learn1Cry;aught1e6i5ogi4u3;ck,g12;c,s1M;ce,ghtn18nguis1LteratWv1;ath1isVss;ara0EindergartPn3;icke0Aowled0Y;e3upit1;a3llyfiGwel0G;ns;ce,gnor6mp5n3;forma00ter3;net,sta07;atiSort3rov;an18;a7e6isto09o3ung1;ckey,mework,ne4o3rseradi8spitali2use arrest;ky;s2y;adquarteXre;ir,libut,ppiHs3;hi3te;sh;ene8l6o5r3um,ymnas11;a3eZ;niUss;lf,re;ut3yce0F;en; 3ti0W;edit0Hpo3;ol;aNicFlour,o4urnit3;ure;od,rgive3uri1wl;ness;arCcono0LducaBlectr9n7quip8thi0Pvery6x3;ist4per3;ti0B;en0J;body,o08th07;joy3tertain3;ment;ici2o3;ni0H;tiS;nings,th;emi02i6o4raugh3ynas2;ts;pe,wnstai3;rs;abet0ce,s3;honZrepu3;te;aDelciChAivi07l8o3urrency;al,ld w6mmenta5n3ral,ttIuscoB;fusiHt 3;ed;ry;ar;assi01oth0;es;aos,e3;eMwK;us;d,rO;a8i6lood,owlHread5u3;ntGtt1;er;!th;lliarJs3;on;g3ss;ga3;ge;cKdviJeroGirFmBn6ppeal court,r4spi3thleL;rin;ithmet3sen3;ic;i6y3;o4th3;ing;ne;se;en5n3;es2;ty;ds;craft;bi8d3nau7;yna3;mi6;ce;id,ous3;ti3;cs",Infinitive:"true¦0:9G;1:9T;2:AD;3:90;4:9Z;5:84;6:AH;7:A9;8:92;9:A0;A:AG;B:AI;C:9V;D:8R;E:8O;F:97;G:6H;H:7D;a94b8Hc7Jd68e4Zf4Mg4Gh4Ai3Qj3Nk3Kl3Bm34nou48o2Vp2Equ2Dr1Es0CtZuTvRwI;aOeNiLors5rI;eJiI;ng,te;ak,st3;d5e8TthI;draw,er;a2d,ep;i2ke,nIrn;d1t;aIie;liADniAry;nJpI;ho8Llift;cov1dJear8Hfound8DlIplug,rav82tie,ve94;eaAo3X;erIo;cut,go,staAFvalA3w2G;aSeQhNoMrIu73;aIe72;ffi3Smp3nsI;aBfo7CpI;i8oD;pp3ugh5;aJiJrIwaD;eat5i2;nk;aImA0;ch,se;ck3ilor,keImp1r8L;! paD;a0Ic0He0Fh0Bi0Al08mugg3n07o05p02qu01tUuLwI;aJeeIim;p,t5;ll7Wy;bNccMffLggeCmmKppJrI;mouFpa6Zvi2;o0re6Y;ari0on;er,i4;e7Numb;li9KmJsiIveD;de,st;er9it;aMe8MiKrI;ang3eIi2;ng27w;fIng;f5le;b,gg1rI;t3ve;a4AiA;a4UeJit,l7DoI;il,of;ak,nd;lIot7Kw;icEve;atGeak,i0O;aIi6;m,y;ft,ng,t;aKi6CoJriIun;nk,v6Q;ot,rt5;ke,rp5tt1;eIll,nd,que8Gv1w;!k,m;aven9ul8W;dd5tis1Iy;a0FeKiJoI;am,t,ut;d,p5;a0Ab08c06d05f01group,hea00iZjoi4lXmWnVpTq3MsOtMup,vI;amp,eJiIo3B;sEve;l,rI;e,t;i8rI;ie2ofE;eLiKpo8PtIurfa4;o24rI;aHiBuctu8;de,gn,st;mb3nt;el,hra0lIreseF;a4e71;d1ew,o07;aHe3Fo2;a7eFiIo6Jy;e2nq41ve;mbur0nf38;r0t;inKleBocus,rJuI;el,rbiA;aBeA;an4e;aBu4;ei2k8Bla43oIyc3;gni39nci3up,v1;oot,uI;ff;ct,d,liIp;se,ze;tt3viA;aAenGit,o7;aWerUinpoiFlumm1LoTrLuI;b47ke,niArIt;poDsuI;aFe;eMoI;cKd,fe4XhibEmo7noJpo0sp1tru6vI;e,i6o5L;un4;la3Nu8;aGclu6dJf1occupy,sup0JvI;a6BeF;etermi4TiB;aGllu7rtr5Ksse4Q;cei2fo4NiAmea7plex,sIva6;eve8iCua6;mp1rItrol,ve;a6It6E;bOccuNmEpMutLverIwe;l07sJtu6Yu0wI;helm;ee,h1F;gr5Cnu2Cpa4;era7i4Ipo0;py,r;ey,seItaH;r2ss;aMe0ViJoIultiply;leCu6Pw;micJnIspla4;ce,g3us;!k;iIke,na9;m,ntaH;aPeLiIo0u3N;ke,ng1quIv5;eIi6S;fy;aKnIss5;d,gI;th5;rn,ve;ng2Gu1N;eep,idnJnI;e4Cow;ap;oHuI;gg3xtaI;po0;gno8mVnIrk;cTdRfQgeChPitia7ju8q1CsNtKun6EvI;a6eIo11;nt,rt,st;erJimi6BoxiPrI;odu4u6;aBn,pr03ru6C;iCpi8tIu8;all,il,ruB;abEibE;eCo3Eu0;iIul9;ca7;i7lu6;b5Xmer0pI;aLer4Uin9ly,oJrI;e3Ais6Bo2;rt,se,veI;riA;le,rt;aLeKiIoiCuD;de,jaInd1;ck;ar,iT;mp1ng,pp5raIve;ng5Mss;ath1et,iMle27oLrI;aJeIow;et;b,pp3ze;!ve5A;gg3ve;aTer45i5RlSorMrJuI;lf4Cndrai0r48;eJiIolic;ght5;e0Qsh5;b3XeLfeEgJsI;a3Dee;eIi2;!t;clo0go,shIwa4Z;ad3F;att1ee,i36;lt1st5;a0OdEl0Mm0FnXquip,rWsVtGvTxI;aRcPeDhOiNpJtIu6;ing0Yol;eKi8lIo0un9;aHoI;it,re;ct,di7l;st,t;a3oDu3B;e30lI;a10u6;lt,mi28;alua7oI;ke,l2;chew,pou0tab19;a0u4U;aYcVdTfSgQhan4joy,lPqOrNsuMtKvI;e0YisI;a9i50;er,i4rI;aHenGuC;e,re;iGol0F;ui8;ar9iC;a9eIra2ulf;nd1;or4;ang1oIu8;r0w;irc3lo0ou0ErJuI;mb1;oaGy4D;b3ct;bKer9pI;hasiIow1;ze;aKody,rI;a4oiI;d1l;lm,rk;ap0eBuI;ci40de;rIt;ma0Rn;a0Re04iKo,rIwind3;aw,ed9oI;wn;agno0e,ff1g,mi2Kne,sLvI;eIul9;rIst;ge,t;aWbVcQlod9mant3pNru3TsMtI;iIoDu37;lJngI;uiA;!l;ol2ua6;eJlIo0ro2;a4ea0;n0r0;a2Xe36lKoIu0S;uIv1;ra9;aIo0;im;a3Kur0;b3rm;af5b01cVduBep5fUliTmQnOpMrLsiCtaGvI;eIol2;lop;ch;a20i2;aDiBloIoD;re,y;oIy;te,un4;eJoI;liA;an;mEv1;a4i0Ao06raud,y;ei2iMla8oKrI;ee,yI;!pt;de,mIup3;missi34po0;de,ma7ph1;aJrief,uI;g,nk;rk;mp5rk5uF;a0Dea0h0Ai09l08oKrIurta1G;a2ea7ipp3uI;mb3;ales4e04habEinci6ll03m00nIrro6;cXdUfQju8no7qu1sLtKvI;eIin4;ne,r9y;aHin2Bribu7;er2iLoli2Epi8tJuI;lt,me;itu7raH;in;d1st;eKiJoIroFu0;rm;de,gu8rm;ss;eJoI;ne;mn,n0;eIlu6ur;al,i2;buCe,men4pI;eIi3ly;l,te;eBi6u6;r4xiC;ean0iT;rcumveFte;eJirp,oI;o0p;riAw;ncIre5t1ulk;el;a02eSi6lQoPrKuI;iXrIy;st,y;aLeaKiJoad5;en;ng;stfeLtX;ke;il,l11mba0WrrMth1;eIow;ed;!coQfrie1LgPhMliLqueaKstJtrIwild1;ay;ow;th;e2tt3;a2eJoI;ld;ad;!in,ui3;me;bysEckfi8ff3tI;he;b15c0Rd0Iff0Ggree,l0Cm09n03ppZrXsQttOuMvJwaE;it;eDoI;id;rt;gIto0X;meF;aIeCraB;ch,in;pi8sJtoI;niA;aKeIi04u8;mb3rt,ss;le;il;re;g0Hi0ou0rI;an9i2;eaKly,oiFrI;ai0o2;nt;r,se;aMi0GnJtI;icipa7;eJoIul;un4y;al;ly0;aJu0;se;lga08ze;iKlI;e9oIu6;t,w;gn;ix,oI;rd;a03jNmiKoJsoI;rb;pt,rn;niIt;st1;er;ouJuC;st;rn;cLhie2knowled9quiItiva7;es4re;ce;ge;eQliOoKrJusI;e,tom;ue;mIst;moJpI;any,liA;da7;ma7;te;pt;andPduBet,i6oKsI;coKol2;ve;liArt,uI;nd;sh;de;ct;on",Person:"true¦0:1Q;a29b1Zc1Md1Ee18f15g13h0Ri0Qj0Nk0Jl0Gm09n06o05p00rPsItCusain bolt,v9w4xzibit,y1;anni,oko on2uji,v1;an,es;en,o;a3ednesday adams,i2o1;lfram,o0Q;ll ferrell,z khalifa;lt disn1Qr1;hol,r0G;a2i1oltai06;n dies0Zrginia wo17;lentino rossi,n goG;a4h3i2ripp,u1yra banks;lZpac shakur;ger woods,mba07;eresa may,or;kashi,t1ylor;um,ya1B;a5carlett johanss0h4i3lobodan milosevic,no2ocr1Lpider1uperm0Fwami; m0Em0E;op dogg,w whi1H;egfried,nbad;akespeaTerlock holm1Sia labeouf;ddam hussa16nt1;a cla11ig9;aAe6i5o3u1za;mi,n dmc,paul,sh limbau1;gh;bin hood,d stew16nald1thko;in0Mo;han0Yngo starr,valdo;ese witherspo0i1mbrandt;ll2nh1;old;ey,y;chmaninoff,ffi,iJshid,y roma1H;a4e3i2la16o1uff daddy;cahont0Ie;lar,p19;le,rZ;lm17ris hilt0;leg,prah winfr0Sra;a2e1iles cra1Bostradam0J; yo,l5tt06wmQ;pole0s;a5e4i2o1ubar03;by,lie5net,rriss0N;randa ju1tt romn0M;ly;rl0GssiaB;cklemo1rkov,s0ta hari,ya angelou;re;ady gaga,e1ibera0Pu;bron jam0Xch wale1e;sa;anye west,e3i1obe bryant;d cudi,efer suther1;la0P;ats,sha;a2effers0fk,k rowling,rr tolki1;en;ck the ripp0Mwaharlal nehru,y z;liTnez,ron m7;a7e5i3u1;lk hog5mphrey1sa01;! bog05;l1tl0H;de; m1dwig,nry 4;an;ile selassFlle ber4m3rrison1;! 1;ford;id,mo09;ry;ast0iannis,o1;odwPtye;ergus0lorence nightinga08r1;an1ederic chopN;s,z;ff5m2nya,ustaXzeki1;el;eril lagasse,i1;le zatop1nem;ek;ie;a6e4i2octor w1rake;ho;ck w1ego maradoC;olf;g1mi lovaOnzel washingt0;as;l1nHrth vadR;ai lNt0;a8h5lint0o1thulhu;n1olio;an,fuci1;us;on;aucKop2ristian baMy1;na;in;millo,ptain beefhe4r1;dinal wols2son1;! palmF;ey;art;a8e5hatt,i3oHro1;ck,n1;te;ll g1ng crosby;atB;ck,nazir bhut2rtil,yon1;ce;to;nksy,rack ob1;ama;l 6r3shton kutch2vril lavig8yn ra1;nd;er;chimed2istot1;le;es;capo2paci1;no;ne",Adjective:"true¦0:AI;1:BS;2:BI;3:BA;4:A8;5:84;6:AV;7:AN;8:AF;9:7H;A:BQ;B:AY;C:BC;D:BH;E:9Y;aA2b9Ec8Fd7We79f6Ng6Eh61i4Xj4Wk4Tl4Im41n3Po36p2Oquart7Pr2Ds1Dt14uSvOwFye29;aMeKhIiHoF;man5oFrth7G;dADzy;despreB1n w97s86;acked1UoleF;!sa6;ather1PeFll o70ste1D;!k5;nt1Ist6Ate4;aHeGiFola5T;bBUce versa,gi3Lle;ng67rsa5R;ca1gBSluAV;lt0PnLpHrGsFttermoBL;ef9Ku3;b96ge1; Hb32pGsFtiAH;ca6ide d4R;er,i85;f52to da2;a0Fbeco0Hc0Bd04e02f01gu1XheaBGiXkn4OmUnTopp06pRrNsJtHus0wF;aFiel3K;nt0rra0P;app0eXoF;ld,uS;eHi37o5ApGuF;perv06spec39;e1ok9O;en,ttl0;eFu5;cogn06gul2RlGqu84sF;erv0olv0;at0en33;aFrecede0E;id,rallel0;am0otic0;aFet;rri0tF;ch0;nFq26vers3;sur0terFv7U;eFrupt0;st0;air,inish0orese98;mploy0n7Ov97xpF;ect0lain0;eHisFocume01ue;clFput0;os0;cid0rF;!a8Scov9ha8Jlyi8nea8Gprivileg0sMwF;aFei9I;t9y;hGircumcFonvin2U;is0;aFeck0;lleng0rt0;b20ppea85ssuGttend0uthorF;iz0;mi8;i4Ara;aLeIhoHip 25oGrF;anspare1encha1i2;geth9leADp notch,rpB;rny,ugh6H;ena8DmpGrFs6U;r49tia4;eCo8P;leFst4M;nt0;a0Dc09e07h06i04ki03l01mug,nobbi4XoVpRqueami4XtKuFymb94;bHccinAi generis,pFr5;erFre7N;! dup9b,vi70;du0li7Lp6IsFurb7J;eq9Atanda9X;aKeJi16o2QrGubboFy4Q;rn;aightFin5GungS; fFfF;or7V;adfa9Pri6;lwa6Ftu82;arHeGir6NlendBot Fry;on;c3Qe1S;k5se; call0lImb9phistic16rHuFviV;ndFth1B;proof;dBry;dFub6; o2A;e60ipF;pe4shod;ll0n d7R;g2HnF;ceEg6ist9;am3Se9;co1Zem5lfFn6Are7; suf4Xi43;aGholFient3A;ar5;rlFt4A;et;cr0me,tisfac7F;aOeIheumatoBiGoF;bu8Ztt7Gy3;ghtFv3; 1Sf6X;cJdu8PlInown0pro69sGtF;ard0;is47oF;lu2na1;e1Suc45;alcit8Xe1ondi2;bBci3mpa1;aSePicayu7laOoNrGuF;bl7Tnjabi;eKiIoF;b7VfGmi49pFxi2M;er,ort81;a7uD;maFor,sti7va2;!ry;ciDexis0Ima2CpaB;in55puli8G;cBid;ac2Ynt 3IrFti2;ma40tFv7W;!i3Z;i2YrFss7R;anoBtF; 5XiF;al,s5V;bSffQkPld OnMrLth9utKverF;!aIbMdHhGni75seas,t,wF;ei74rou74;a63e7A;ue;ll;do1Ger,si6A;d3Qg2Aotu5Z; bFbFe on o7g3Uli7;oa80;fashion0school;!ay; gua7XbFha5Uli7;eat;eHligGsF;ce7er0So1C;at0;diFse;a1e1;aOeNiMoGuF;anc0de; moEnHrthFt6V;!eFwe7L;a7Krn;chaGdescri7Iprof30sF;top;la1;ght5;arby,cessa4ighbor5wlyw0xt;k0usiaFv3;ti8;aQeNiLoHuF;dIltiF;facet0p6;deHlGnFot,rbBst;ochro4Xth5;dy;rn,st;ddle ag0nF;dbloZi,or;ag9diocEga,naGrFtropolit4Q;e,ry;ci8;cIgenta,inHj0Fkeshift,mmGnFri4Oscu61ver18;da5Dy;ali4Lo4U;!stream;abEho;aOeLiIoFumberi8;ngFuti1R;stan3RtF;erm,i4H;ghtGteraF;l,ry,te;heart0wei5O;ft JgFss9th3;al,eFi0M;nda4;nguBps0te5;apGind5noF;wi8;ut;ad0itte4uniW;ce co0Hgno6Mll0Cm04nHpso 2UrF;a2releF;va1; ZaYcoWdReQfOgrNhibi4Ri05nMoLsHtFvalu5M;aAeF;nDrdepe2K;a7iGolFuboI;ub6ve1;de,gF;nifica1;rdi5N;a2er;own;eriIiLluenVrF;ar0eq5H;pt,rt;eHiGoFul1O;or;e,reA;fiFpe26termi5E;ni2;mpFnsideCrreA;le2;ccuCdeq5Ene,ppr4J;fFsitu,vitro;ro1;mJpF;arHeGl15oFrop9;li2r11;n2LrfeA;ti3;aGeFi18;d4BnD;tuE;egGiF;c0YteC;al,iF;tiF;ma2;ld;aOelNiLoFuma7;a4meInHrrGsFur5;ti6;if4E;e58o3U; ma3GsF;ick;ghfalut2HspF;an49;li00pf33;i4llow0ndGrdFtM; 05coEworki8;sy,y;aLener44iga3Blob3oKrGuF;il1Nng ho;aFea1Fizzl0;cGtF;ef2Vis;ef2U;ld3Aod;iFuc2D;nf2R;aVeSiQlOoJrF;aGeFil5ug3;q43tf2O;gFnt3S;i6ra1;lk13oHrF; keeps,eFge0Vm9tu41;g0Ei2Ds3R;liF;sh;ag4Mowe4uF;e1or45;e4nF;al,i2;d Gmini7rF;ti6ve1;up;bl0lDmIr Fst pac0ux;oGreacF;hi8;ff;ed,ili0R;aXfVlTmQnOqu3rMthere3veryday,xF;aApIquisi2traHuF;be48lF;ta1;!va2L;edRlF;icF;it;eAstF;whi6; Famor0ough,tiE;rou2sui2;erGiF;ne1;ge1;dFe2Aoq34;er5;ficF;ie1;g9sF;t,ygF;oi8;er;aWeMiHoGrFue;ea4owY;ci6mina1ne,r31ti8ubQ;dact2Jfficult,m,sGverF;ge1se;creGePjoi1paCtF;a1inA;et,te; Nadp0WceMfiLgeneCliJmuEpeIreliAsGvoF;id,ut;pFtitu2ul1L;eCoF;nde1;ca2ghF;tf13;a1ni2;as0;facto;i5ngero0I;ar0Ce09h07i06l05oOrIuF;rmudgeon5stoma4teF;sy;ly;aIeHu1EystalF; cleFli7;ar;epy;fFv17z0;ty;erUgTloSmPnGrpoCunterclVveFy;rt;cLdJgr21jIsHtrF;aFi2;dic0Yry;eq1Yta1;oi1ug3;escenFuN;di8;a1QeFiD;it0;atoDmensuCpF;ass1SulF;so4;ni3ss3;e1niza1;ci1J;ockwiD;rcumspeAvil;eFintzy;e4wy;leGrtaF;in;ba2;diac,ef00;a00ePiLliJoGrFuck nak0;and new,isk,on22;gGldface,naF; fi05fi05;us;nd,tF;he;gGpartisFzarE;an;tiF;me;autifOhiNlLnHsFyoN;iWtselF;li8;eGiFt;gn;aFfi03;th;at0oF;v0w;nd;ul;ckwards,rF;e,rT; priori,b13c0Zd0Tf0Ng0Ihe0Hl09mp6nt06pZrTsQttracti0MuLvIwF;aGkF;wa1B;ke,re;ant garGeraF;ge;de;diIsteEtF;heFoimmu7;nt07;re;to4;hGlFtu2;eep;en;bitIchiv3roHtF;ifiFsy;ci3;ga1;ra4;ry;pFt;aHetizi8rF;oprF;ia2;llFre1;ed,i8;ng;iquFsy;at0e;ed;cohKiJkaHl,oGriFterX;ght;ne,of;li7;ne;ke,ve;olF;ic;ad;ain07gressiIi6rF;eeF;ab6;le;ve;fGraB;id;ectGlF;ue1;ioF;na2; JaIeGvF;erD;pt,qF;ua2;ma1;hoc,infinitum;cuCquiGtu3u2;al;esce1;ra2;erSjeAlPoNrKsGuF;nda1;e1olu2trF;aAuD;se;te;eaGuF;pt;st;aFve;rd;aFe;ze;ct;ra1;nt",Pronoun:"true¦elle,h3i2me,she,th0us,we,you;e0ou;e,m,y;!l,t;e,im",Preposition:"true¦aPbMcLdKexcept,fIinGmid,notwithstandiWoDpXqua,sCt7u4v2w0;/o,hereSith0;! whHin,oW;ersus,i0;a,s a vis;n1p0;!on;like,til;h1ill,oward0;!s;an,ereby,r0;ough0u;!oM;ans,ince,o that,uch G;f1n0ut;!to;!f;! 0to;effect,part;or,r0;om;espite,own,u3;hez,irca;ar1e0oBy;sides,tween;ri7;bo8cross,ft7lo6m4propos,round,s1t0;!op;! 0;a whole,long 0;as;id0ong0;!st;ng;er;ut",SportsTeam:"true¦0:18;1:1E;2:1D;3:14;a1Db15c0Sd0Kfc dallas,g0Ihouston 0Hindiana0Gjacksonville jagua0k0El0Am01new UoRpKqueens parkJreal salt lake,sBt6utah jazz,vancouver whitecaps,w4yW;ashington 4h10;natio1Mredski2wizar0W;ampa bay 7e6o4;ronto 4ttenham hotspur;blue ja0Mrapto0;nnessee tita2xasD;buccanee0ra0K;a8eattle 6porting kansas0Wt4; louis 4oke0V;c1Drams;marine0s4;eah13ounH;cramento Rn 4;antonio spu0diego 4francisco gJjose earthquak1;char08paB; ran07;a9h6ittsburgh 5ortland t4;imbe0rail blaze0;pirat1steele0;il4oenix su2;adelphia 4li1;eagl1philNunE;dr1;akland 4klahoma city thunder,rlando magic;athle0Lrai4;de0;england 8orleans 7york 4;g5je3knYme3red bul0Xy4;anke1;ian3;pelica2sain3;patrio3revolut4;ion;anchEeAi4ontreal impact;ami 8lwaukee b7nnesota 4;t5vi4;kings;imberwolv1wi2;rewe0uc0J;dolphi2heat,marli2;mphis grizz4ts;li1;a6eic5os angeles 4;clippe0dodFlaB;esterV; galaxy,ke0;ansas city 4nF;chiefs,roya0D; pace0polis col3;astr05dynamo,rocke3texa2;olden state warrio0reen bay pac4;ke0;allas 8e4i04od6;nver 6troit 4;lio2pisto2ti4;ge0;broncYnugge3;cowbo5maver4;icZ;ys;arEelLhAincinnati 8leveland 6ol4;orado r4umbus crew sc;api7ocki1;brow2cavalie0guar4in4;dia2;bengaVre4;ds;arlotte horAicago 4;b5cubs,fire,wh4;iteB;ea0ulQ;diff4olina panthe0; city;altimore Alackburn rove0oston 6rooklyn 4uffalo bilN;ne3;ts;cel5red4; sox;tics;rs;oriol1rave2;rizona Ast8tlanta 4;brav1falco2h4;awA;ns;es;on villa,r4;os;c6di4;amondbac4;ks;ardi4;na4;ls",Unit:"true¦a07b04cXdWexVfTgRhePinYjoule0BkMlJmDnan08oCp9quart0Bsq ft,t7volts,w6y2ze3°1µ0;g,s;c,f,n;dVear1o0;ttR; 0s 0;old;att,b;erNon0;!ne02;ascals,e1i0;cXnt00;rcent,tJ;hms,unceY;/s,e4i0m²,²,³;/h,cro2l0;e0liK;!²;grLsR;gCtJ;it1u0;menQx;erPreP;b5elvins,ilo1m0notO;/h,ph,²;!byGgrEmCs;ct0rtzL;aJogrC;allonJb0ig3rB;ps;a0emtEl oz,t4;hrenheit,radG;aby9;eci3m1;aratDe1m0oulombD;²,³;lsius,nti0;gr2lit1m0;et0;er8;am7;b1y0;te5;l,ps;c2tt0;os0;econd1;re0;!s","Noun|Gerund":"true¦0:3O;1:3M;2:3N;3:3D;4:32;5:2V;6:3E;7:3K;8:36;9:3J;A:3B;a3Pb37c2Jd27e23f1Vg1Sh1Mi1Ij1Gk1Dl18m13n11o0Wp0Pques0Sr0EsTtNunderMvKwFyDzB;eroi0oB;ni0o3P;aw2eB;ar2l3;aEed4hispe5i5oCrB;ap8est3i1;n0ErB;ki0r31;i1r2s9tc9;isualizi0oB;lunt1Vti0;stan4ta6;aFeDhin6iCraBy8;c6di0i2vel1M;mi0p8;aBs1;c9si0;l6n2s1;aUcReQhOiMkatKl2Wmo6nowJpeItFuCwB;ea5im37;b35f0FrB;fi0vB;e2Mi2J;aAoryt1KrCuB;d2KfS;etc9ugg3;l3n4;bCi0;ebBi0;oar4;gnBnAt1;a3i0;ip8oB;p8rte2u1;a1r27t1;hCo5reBulp1;a2Qe2;edu3oo3;i3yi0;aKeEi4oCuB;li0n2;oBwi0;fi0;aFcEhear7laxi0nDpor1sB;pon4tructB;r2Iu5;de5;or4yc3;di0so2;p8ti0;aFeacek20laEoCrBublis9;a1Teten4in1oces7;iso2siB;tio2;n2yi0;ckaAin1rB;ki0t1O;fEpeDrganiCvB;erco24ula1;si0zi0;ni0ra1;fe5;avi0QeBur7;gotia1twor6;aDeCi2oB;de3nito5;a2dita1e1ssaA;int0XnBrke1;ifUufactu5;aEeaDiBodAyi0;cen7f1mi1stB;e2i0;r2si0;n4ug9;iCnB;ea4it1;c6l3;ogAuB;dAgg3stif12;ci0llust0VmDnBro2;nova1sp0NterBven1;ac1vie02;agi2plo4;aDea1iCoBun1;l4w3;ki0ri0;nd3rB;roWvB;es1;aCene0Lli4rBui4;ee1ie0N;rde2the5;aHeGiDlCorBros1un4;e0Pmat1;ir1oo4;gh1lCnBs9;anZdi0;i0li0;e3nX;r0Zscina1;a1du01nCxB;erci7plo5;chan1di0ginB;ee5;aLeHiGoub1rCum8wB;el3;aDeCiB;bb3n6vi0;a0Qs7;wi0;rTscoDvi0;ba1coZlBvelo8;eCiB;ve5;ga1;nGti0;aVelebUhSlPoDrBur3yc3;aBos7yi0;f1w3;aLdi0lJmFnBo6pi0ve5;dDsCvinB;ci0;trBul1;uc1;muniDpB;lBo7;ai2;ca1;lBo5;ec1;c9ti0;ap8eaCimToBubT;ni0t9;ni0ri0;aBee5;n1t1;ra1;m8rCs1te5;ri0;vi0;aPeNitMlLoGrDuB;dge1il4llBr8;yi0;an4eat9oadB;cas1;di0;a1mEokB;i0kB;ee8;pi0;bi0;es7oa1;c9i0;gin2lonAt1;gi0;bysit1c6ki0tt3;li0;ki0;bando2cGdverti7gi0pproac9rgDssuCtB;trac1;mi0;ui0;hi0;si0;coun1ti0;ti0;ni0;ng",PhrasalVerb:"true¦0:92;1:96;2:8H;3:8V;4:8A;5:83;6:85;7:98;8:90;9:8G;A:8X;B:8R;C:8U;D:8S;E:70;F:97;G:8Y;H:81;I:7H;J:79;a9Fb7Uc6Rd6Le6Jf5Ig50h4Biron0j47k40l3Em31n2Yo2Wp2Cquiet Hr1Xs0KtZuXvacuu6QwNyammerBzK;ero Dip LonK;e0k0;by,ov9up;aQeMhLiKor0Mrit19;mp0n3Fpe0r5s5;ackAeel Di0S;aLiKn33;gh 3Wrd0;n Dr K;do1in,oJ;it 79k5lk Lrm 69sh Kt83v60;aw3do1o7up;aw3in,oC;rgeBsK;e 2herE;a00eYhViRoQrMuKypP;ckErn K;do1in,oJup;aLiKot0y 30;ckl7Zp F;ck HdK;e 5Y;n7Wp 3Es5K;ck MdLe Kghten 6me0p o0Rre0;aw3ba4do1in,up;e Iy 2;by,oG;ink Lrow K;aw3ba4in,up;ba4ov9up;aKe 77ll62;m 2r 5M;ckBke Llk K;ov9shit,u47;aKba4do1in,leave,o4Dup;ba4ft9pa69w3;a0Vc0Te0Mh0Ii0Fl09m08n07o06p01quar5GtQuOwK;earMiK;ngLtch K;aw3ba4o8K; by;cKi6Bm 2ss0;k 64;aReQiPoNrKud35;aigh2Det75iK;ke 7Sng K;al6Yup;p Krm2F;by,in,oG;c3Ln3Lr 2tc4O;p F;c3Jmp0nd LrKveAy 2O;e Ht 2L;ba4do1up;ar3GeNiMlLrKurB;ead0ingBuc5;a49it 6H;c5ll o3Cn 2;ak Fe1Xll0;a3Bber 2rt0und like;ap 5Vow Duggl5;ash 6Noke0;eep NiKow 6;cLp K;o6Dup;e 68;in,oK;ff,v9;de19gn 4NnKt 6Gz5;gKkE; al6Ale0;aMoKu5W;ot Kut0w 7M;aw3ba4f48oC;c2WdeEk6EveA;e Pll1Nnd Orv5tK; Ktl5J;do1foLin,o7upK;!on;ot,r5Z;aw3ba4do1in,o33up;oCto;al66out0rK;ap65ew 6J;ilAv5;aXeUiSoOuK;b 5Yle0n Kstl5;aLba4do1inKo2Ith4Nu5P;!to;c2Xr8w3;ll Mot LpeAuK;g3Ind17;a2Wf3Po7;ar8in,o7up;ng 68p oKs5;ff,p18;aKelAinEnt0;c6Hd K;o4Dup;c27t0;aZeYiWlToQrOsyc35uK;ll Mn5Kt K;aKba4do1in,oJto47up;pa4Dw3;a3Jdo1in,o21to45up;attleBess KiNop 2;ah2Fon;iLp Kr4Zu1Gwer 6N;do1in,o6Nup;nt0;aLuK;gEmp 6;ce u20y 6D;ck Kg0le 4An 6p5B;oJup;el 5NncilE;c53ir 39n0ss MtLy K;ba4oG; Hc2R;aw3ba4in,oJ;pKw4Y;e4Xt D;aLerd0oK;dAt53;il Hrrow H;aTeQiPoLuK;ddl5ll I;c1FnkeyMp 6uthAve K;aKdo1in,o4Lup;l4Nw3; wi4K;ss0x 2;asur5e3SlLss K;a21up;t 6;ke Ln 6rKs2Ax0;k 6ryA;do,fun,oCsure,up;a02eViQoLuK;ck0st I;aNc4Fg MoKse0;k Kse4D;aft9ba4do1forw37in56o0Zu46;in,oJ;d 6;e NghtMnLsKve 00;ten F;e 2k 2; 2e46;ar8do1in;aMt LvelK; oC;do1go,in,o7up;nEve K;in,oK;pKut;en;c5p 2sh LtchBughAy K;do1o59;in4Po7;eMick Lnock K;do1oCup;oCup;eLy K;in,up;l Ip K;aw3ba4do1f04in,oJto,up;aMoLuK;ic5mpE;ke3St H;c43zz 2;a01eWiToPuK;nLrrKsh 6;y 2;keLt K;ar8do1;r H;lKneErse3K;d Ke 2;ba4dKfast,o0Cup;ear,o1;de Lt K;ba4on,up;aw3o7;aKlp0;d Ml Ir Kt 2;fKof;rom;f11in,o03uW;cPm 2nLsh0ve Kz2P;at,it,to;d Lg KkerP;do1in,o2Tup;do1in,oK;ut,v9;k 2;aZeTive Rloss IoMrLunK; f0S;ab hold,in43ow 2U; Kof 2I;aMb1Mit,oLr8th1IuK;nd9;ff,n,v9;bo7ft9hQw3;aw3bKdo1in,oJrise,up,w3;a4ir2H;ar 6ek0t K;aLb1Fdo1in,oKr8up;ff,n,ut,v9;cLhKl2Fr8t,w3;ead;ross;d aKng 2;bo7;a0Ee07iYlUoQrMuK;ck Ke2N;ar8up;eLighten KownBy 2;aw3oG;eKshe27; 2z5;g 2lMol Krk I;aKwi20;bo7r8;d 6low 2;aLeKip0;sh0;g 6ke0mKrKtten H;e F;gRlPnNrLsKzzle0;h F;e Km 2;aw3ba4up;d0isK;h 2;e Kl 1T;aw3fPin,o7;ht ba4ure0;ePnLsK;s 2;cMd K;fKoG;or;e D;d04l 2;cNll Krm0t1G;aLbKdo1in,o09sho0Eth08victim;a4ehi2O;pa0C;e K;do1oGup;at Kdge0nd 12y5;in,o7up;aOi1HoNrK;aLess 6op KuN;aw3b03in,oC;gBwB; Ile0ubl1B;m 2;a0Ah05l02oOrLut K;aw3ba4do1oCup;ackBeep LoKy0;ss Dwd0;by,do1in,o0Uup;me NoLuntK; o2A;k 6l K;do1oG;aRbQforOin,oNtKu0O;hLoKrue;geth9;rough;ff,ut,v9;th,wK;ard;a4y;paKr8w3;rt;eaLose K;in,oCup;n 6r F;aNeLiK;ll0pE;ck Der Kw F;on,up;t 2;lRncel0rOsMtch LveE; in;o1Nup;h Dt K;doubt,oG;ry LvK;e 08;aw3oJ;l Km H;aLba4do1oJup;ff,n,ut;r8w3;a0Ve0MiteAl0Fo04rQuK;bblNckl05il0Dlk 6ndl05rLsKtMy FzzA;t 00;n 0HsK;t D;e I;ov9;anWeaUiLush K;oGup;ghQng K;aNba4do1forMin,oLuK;nd9p;n,ut;th;bo7lKr8w3;ong;teK;n 2;k K;do1in,o7up;ch0;arTg 6iRn5oPrNssMttlLunce Kx D;aw3ba4;e 6; ar8;e H;do1;k Dt 2;e 2;l 6;do1up;d 2;aPeed0oKurt0;cMw K;aw3ba4do1o7up;ck;k K;in,oC;ck0nk0stA; oQaNef 2lt0nd K;do1ov9up;er;up;r Lt K;do1in,oCup;do1o7;ff,nK;to;ck Pil0nMrgLsK;h D;ainBe D;g DkB; on;in,o7;aw3do1in,oCup;ff,ut;ay;ct FdQir0sk MuctionA; oG;ff;ar8o7;ouK;nd; o7;d K;do1oKup;ff,n;wn;o7up;ut",ProperNoun:"true¦aIbDc8dalhousHe7f5gosford,h4iron maiden,kirby,landsdowne,m2nis,r1s0wembF;herwood,paldiB;iel,othwe1;cgi0ercedes,issy;ll;intBudsB;airview,lorence,ra0;mpt9nco;lmo,uro;a1h0;arlt6es5risti;rl0talina;et4i0;ng;arb3e0;et1nt0rke0;ley;on;ie;bid,jax","Person|Place":"true¦a8d6h4jordan,k3orlando,s1vi0;ctor9rgin9;a0ydney;lvador,mara,ntia4;ent,obe;amil0ous0;ton;arw2ie0;go;lexandr1ust0;in;ia",LastName:"true¦0:BR;1:BF;2:B5;3:BH;4:AX;5:9Y;6:B6;7:BK;8:B0;9:AV;A:AL;B:8Q;C:8G;D:7K;E:BM;F:AH;aBDb9Zc8Wd88e81f7Kg6Wh64i60j5Lk4Vl4Dm39n2Wo2Op25quispe,r1Ls0Pt0Ev03wTxSyKzG;aIhGimmerm6A;aGou,u;ng,o;khar5ytsE;aKeun9BiHoGun;koya32shiBU;!lG;diGmaz;rim,z;maGng;da,g52mo83sGzaC;aChiBV;iao,u;aLeJiHoGright,u;jcA5lff,ng;lGmm0nkl0sniewsC;kiB1liams33s3;bGiss,lt0;b,er,st0;a6Vgn0lHtG;anabe,s3;k0sh,tG;e2Non;aLeKiHoGukD;gt,lk5roby5;dHllalGnogr3Kr1Css0val3S;ba,ob1W;al,ov4;lasHsel8W;lJn dIrgBEsHzG;qu7;ilyEqu7siljE;en b6Aijk,yk;enzueAIverde;aPeix1VhKi2j8ka43oJrIsui,uG;om5UrG;c2n0un1;an,emblA7ynisC;dorAMlst3Km4rrAth;atch0i8UoG;mHrG;are84laci79;ps3sG;en,on;hirDkah9Mnaka,te,varA;a06ch01eYhUiRmOoMtIuHvGzabo;en9Jobod3N;ar7bot4lliv2zuC;aIeHoG;i7Bj4AyanAB;ele,in2FpheBvens25;l8rm0;kol5lovy5re7Tsa,to,uG;ng,sa;iGy72;rn5tG;!h;l71mHnGrbu;at9cla9Egh;moBo7M;aIeGimizu;hu,vchG;en8Luk;la,r1G;gu9infe5YmGoh,pulveA7rra5P;jGyG;on5;evi6iltz,miHneid0roed0uGwarz;be3Elz;dHtG;!t,z;!t;ar4Th8ito,ka4OlJnGr4saCto,unde19v4;ch7dHtGz;a5Le,os;b53e16;as,ihDm4Po0Y;aVeSiPoJuHyG;a6oo,u;bio,iz,sG;so,u;bKc8Fdrigue67ge10j9YmJosevelt,sItHux,wG;e,li6;a9Ch;enb4Usi;a54e4L;erts15i93;bei4JcHes,vGzzo;as,e9;ci,hards12;ag2es,iHut0yG;es,nol5N;s,t0;dImHnGsmu97v6C;tan1;ir7os;ic,u;aUeOhMiJoHrGut8;asad,if6Zochazk27;lishc2GpGrti72u10we76;e3Aov51;cHe45nG;as,to;as70hl0;aGillips;k,m,n6I;a3Hde3Wete0Bna,rJtG;ersHrovGters54;!a,ic;!en,on;eGic,kiBss3;i9ra,tz,z;h86k,padopoulIrk0tHvG;ic,l4N;el,te39;os;bMconn2Ag2TlJnei6PrHsbor6XweBzG;dem7Rturk;ella4DtGwe6N;ega,iz;iGof7Hs8I;vGyn1R;ei9;aSri1;aPeNiJoGune50ym2;rHvGwak;ak4Qik5otn66;odahl,r4S;cholsZeHkolGls4Jx3;ic,ov84;ls1miG;!n1;ils3mG;co4Xec;gy,kaGray2sh,var38;jiGmu9shiG;ma;a07c04eZiWoMuHyeG;rs;lJnIrGssoli6S;atGp03r7C;i,ov4;oz,te58;d0l0;h2lOnNo0RrHsGza1A;er,s;aKeJiIoz5risHtG;e56on;!on;!n7K;au,i9no,t5J;!lA;r1Btgome59;i3El0;cracFhhail5kkeHlG;l0os64;ls1;hmeJiIj30lHn3Krci0ssiGyer2N;!er;n0Po;er,j0;dDti;cartHlG;aughl8e2;hy;dQe7Egnu68i0jer3TkPmNnMrItHyG;er,r;ei,ic,su21thews;iHkDquAroqu8tinG;ez,s;a5Xc,nG;!o;ci5Vn;a5UmG;ad5;ar5e6Kin1;rig77s1;aVeOiLoJuHyG;!nch;k4nGo;d,gu;mbarGpe3Fvr4we;di;!nGu,yana2B;coln,dG;b21holm,strom;bedEfeKhIitn0kaHn8rGw35;oy;!j;m11tG;in1on1;bvGvG;re;iGmmy,ng,rs2Qu,voie,ws3;ne,t1F;aZeYh2iWlUnez50oNrJuHvar2woG;k,n;cerGmar68znets5;a,o34;aHem0isGyeziu;h23t3O;m0sni4Fus3KvG;ch4O;bay57ch,rh0Usk16vaIwalGzl5;czGsC;yk;cIlG;!cGen4K;huk;!ev4ic,s;e8uiveG;rt;eff0kGl4mu9nnun1;ucF;ll0nnedy;hn,llKminsCne,pIrHstra3Qto,ur,yGzl5;a,s0;j0Rls22;l2oG;or;oe;aPenOha6im14oHuG;ng,r4;e32hInHrge32u6vG;anD;es,ss3;anHnsG;en,on,t3;nesGs1R;en,s1;kiBnings,s1;cJkob4EnGrv0E;kDsG;en,sG;en0Ion;ks3obs2A;brahimDglesi5Nke5Fl0Qno07oneIshikHto,vanoG;u,v54;awa;scu;aVeOiNjaltal8oIrist50uG;!aGb0ghAynh;m2ng;a6dz4fIjgaa3Hk,lHpUrGwe,x3X;ak1Gvat;mAt;er,fm3WmG;ann;ggiBtchcock;iJmingw4BnHrGss;nand7re9;deGriks1;rs3;kkiHnG;on1;la,n1;dz4g1lvoQmOns0ZqNrMsJuIwHyG;asFes;kiB;g1ng;anHhiG;mo14;i,ov0J;di6p0r10t;ue;alaG;in1;rs1;aVeorgUheorghe,iSjonRoLrJuGw3;errGnnar3Co,staf3Ctierr7zm2;a,eG;ro;ayli6ee2Lg4iffithGub0;!s;lIme0UnHodGrbachE;e,m2;calvAzale0S;dGubE;bGs0E;erg;aj,i;bs3l,mGordaO;en7;iev3U;gnMlJmaIndFo,rGsFuthi0;cGdn0za;ia;ge;eaHlG;agh0i,o;no;e,on;aVerQiLjeldsted,lKoIrHuG;chs,entAji41ll0;eem2iedm2;ntaGrt8urni0wl0;na;emi6orA;lipIsHtzgeraG;ld;ch0h0;ovG;!ic;hatDnanIrG;arGei9;a,i;deY;ov4;b0rre1D;dKinsJriksIsGvaB;cob3GpGtra3D;inoza,osiQ;en,s3;te8;er,is3warG;ds;aXePiNjurhuMoKrisco15uHvorakG;!oT;arte,boHmitru,nn,rGt3C;and,ic;is;g2he0Omingu7nErd1ItG;to;us;aGcki2Hmitr2Ossanayake,x3;s,z; JbnaIlHmirGrvisFvi,w2;!ov4;gado,ic;th;bo0groot,jo6lHsilGvriA;va;a cruz,e3uG;ca;hl,mcevsCnIt2WviG;dGes,s;ov,s3;ielsGku22;!en;ki;a0Be06hRiobQlarkPoIrGunningh1H;awfo0RivGuz;elli;h1lKntJoIrGs2Nx;byn,reG;a,ia;ke,p0;i,rer2K;em2liB;ns;!e;anu;aOeMiu,oIristGu6we;eGiaG;ns1;i,ng,p9uHwGy;!dH;dGng;huJ;!n,onGu6;!g;kJnIpm2ttHudhGv7;ry;erjee,o14;!d,g;ma,raboG;rty;bJl0Cng4rG;eghetHnG;a,y;ti;an,ota1C;cerAlder3mpbeLrIstGvadi0B;iGro;llo;doHl0Er,t0uGvalho;so;so,zo;ll;a0Fe01hYiXlUoNrKuIyG;rLtyG;qi;chan2rG;ke,ns;ank5iem,oGyant;oks,wG;ne;gdan5nIruya,su,uchaHyKziG;c,n5;rd;darGik;enG;ko;ov;aGond15;nco,zG;ev4;ancFshw16;a08oGuiy2;umGwmG;ik;ckRethov1gu,ktPnNrG;gJisInG;ascoGds1;ni;ha;er,mG;anG;!n;gtGit7nP;ss3;asF;hi;er,hG;am;b4ch,ez,hRiley,kk0ldw8nMrIshHtAu0;es;ir;bInHtlGua;ett;es,i0;ieYosa;dGik;a9yoG;padhyG;ay;ra;k,ng;ic;bb0Acos09d07g04kht05lZnPrLsl2tJyG;aHd8;in;la;chis3kiG;ns3;aImstro6sl2;an;ng;ujo,ya;dJgelHsaG;ri;ovG;!a;ersJov,reG;aGjEws;ss1;en;en,on,s3;on;eksejEiyEmeiIvG;ar7es;ez;da;ev;arwHuilG;ar;al;ams,l0;er;ta;as",Ordinal:"true¦eBf7nin5s3t0zeroE;enDhir1we0;lfCn7;d,t3;e0ixt8;cond,vent7;et0th;e6ie7;i2o0;r0urt3;tie4;ft1rst;ight0lev1;e0h,ie1;en0;th",Cardinal:"true¦bEeBf5mEnine7one,s4t0zero;en,h2rDw0;e0o;lve,n5;irt6ousands,ree;even2ix2;i3o0;r1ur0;!t2;ty;ft0ve;e2y;ight0lev1;!e0y;en;illions",Multiple:"true¦b3hundred,m3qu2se1t0;housand,r2;pt1xt1;adr0int0;illion",City:"true¦0:74;1:61;2:6G;3:6J;4:5S;a68b53c4Id48e44f3Wg3Hh39i31j2Wk2Fl23m1Mn1Co19p0Wq0Ur0Os05tRuQvLwDxiBy9z5;a7h5i4Muri4O;a5e5ongsh0;ng3H;greb,nzib5G;ang2e5okoha3Sunfu;katerin3Hrev0;a5n0Q;m5Hn;arsBeAi6roclBu5;h0xi,zh5P;c7n5;d5nipeg,terth4;hoek,s1L;hi5Zkl3A;l63xford;aw;a8e6i5ladivost5Molgogr6L;en3lni6S;ni22r5;o3saill4N;lenc4Wncouv3Sr3ughn;lan bat1Crumqi,trecht;aFbilisi,eEheDiBo9r7u5;l21n63r5;in,ku;i5ondh62;es51poli;kyo,m2Zron1Pulo5;n,uS;an5jua3l2Tmisoa6Bra3;j4Tshui; hag62ssaloni2H;gucigal26hr0l av1U;briz,i6llinn,mpe56ng5rtu,shk2R;i3Esh0;an,chu1n0p2Eyu0;aEeDh8kopje,owe1Gt7u5;ra5zh4X;ba0Ht;aten is55ockholm,rasbou67uttga2V;an8e6i5;jiazhua1llo1m5Xy0;f50n5;ya1zh4H;gh3Kt4Q;att45o1Vv44;cramen16int ClBn5o paulo,ppo3Rrajevo; 7aa,t5;a 5o domin3E;a3fe,m1M;antonio,die3Cfrancisco,j5ped3Nsalvad0J;o5u0;se;em,t lake ci5Fz25;lou58peters24;a9e8i6o5;me,t59;ga,o5yadh;! de janei3F;cife,ims,nn3Jykjavik;b4Sip4lei2Inc2Pwalpindi;ingdao,u5;ez2i0Q;aFeEhDiCo9r7u6yong5;ya1;eb59ya1;a5etor3M;g52to;rt5zn0; 5la4Co;au prin0Melizabe24sa03;ls3Prae5Atts26;iladelph3Gnom pe1Aoenix;ki1tah tik3E;dua,lerYnaji,r4Ot5;na,r32;ak44des0Km1Mr6s5ttawa;a3Vlo;an,d06;a7ew5ing2Fovosibir1Jyc; 5cast36;del24orlea44taip14;g8iro4Wn5pl2Wshv33v0;ch6ji1t5;es,o1;a1o1;a6o5p4;ya;no,sa0W;aEeCi9o6u5;mb2Ani26sc3Y;gadishu,nt6s5;c13ul;evideo,pelli1Rre2Z;ami,l6n14s5;kolc,sissauga;an,waukee;cca,d5lbour2Mmph41ndo1Cssi3;an,ell2Xi3;cau,drAkass2Sl9n8r5shh4A;aca6ib5rakesh,se2L;or;i1Sy;a4EchFdal0Zi47;mo;id;aDeAi8o6u5vSy2;anMckn0Odhia3;n5s angel26;d2g bea1N;brev2Be3Lma5nz,sb2verpo28;!ss27; ma39i5;c5pzig;est16; p6g5ho2Wn0Cusan24;os;az,la33;aHharFiClaipeBo9rak0Du7y5;iv,o5;to;ala lump4n5;mi1sh0;hi0Hlka2Xpavog4si5wlo2;ce;da;ev,n5rkuk;gst2sha5;sa;k5toum;iv;bHdu3llakuric0Qmpa3Fn6ohsiu1ra5un1Iwaguc0Q;c0Pj;d5o,p4;ah1Ty;a7e6i5ohannesV;l1Vn0;dd36rusalem;ip4k5;ar2H;bad0mph1OnArkutUs7taXz5;mir,tapala5;pa;fah0l6tanb5;ul;am2Zi2H;che2d5;ianap2Mo20;aAe7o5yder2W; chi mi5ms,nolulu;nh;f6lsin5rakli2;ki;ei;ifa,lifax,mCn5rb1Dva3;g8nov01oi;aFdanEenDhCiPlasgBo9raz,u5;a5jr23;dal6ng5yaquil;zh1J;aja2Oupe;ld coa1Bthen5;bu2S;ow;ent;e0Uoa;sk;lw7n5za;dhi5gt1E;nag0U;ay;aisal29es,o8r6ukuya5;ma;ankfu5esno;rt;rt5sh0; wor6ale5;za;th;d5indhov0Pl paso;in5mont2;bur5;gh;aBe8ha0Xisp4o7resd0Lu5;b5esseldorf,nkirk,rb0shanbe;ai,l0I;ha,nggu0rtmu13;hradSl6nv5troit;er;hi;donghIe6k09l5masc1Zr es sala1KugavpiY;i0lU;gu,je2;aJebu,hAleve0Vo5raio02uriti1Q;lo7n6penhag0Ar5;do1Ok;akKst0V;gUm5;bo;aBen8i6ongqi1ristchur5;ch;ang m7ca5ttago1;go;g6n5;ai;du,zho1;ng5ttogr14;ch8sha,zh07;gliari,i9lga8mayenJn6pe town,r5tanO;acCdiff;ber1Ac5;un;ry;ro;aWeNhKirmingh0WoJr9u5;chareTdapeTenos air7r5s0tu0;g5sa;as;es;a9is6usse5;ls;ba6t5;ol;ne;sil8tisla7zzav5;il5;le;va;ia;goZst2;op6ubaneshw5;ar;al;iCl9ng8r5;g6l5n;in;en;aluru,hazi;fa6grade,o horizon5;te;st;ji1rut;ghd0BkFn9ot8r7s6yan n4;ur;el,r07;celo3i,ranquil09;ou;du1g6ja lu5;ka;alo6k5;ok;re;ng;ers5u;field;a05b02cc01ddis aba00gartaZhmedXizawl,lSmPnHqa00rEsBt7uck5;la5;nd;he7l5;an5;ta;ns;h5unci2;dod,gab5;at;li5;ngt2;on;a8c5kaOtwerp;hora6o3;na;ge;h7p5;ol5;is;eim;aravati,m0s5;terd5;am; 7buquerq6eppo,giers,ma5;ty;ue;basrah al qadim5mawsil al jadid5;ah;ab5;ad;la;ba;ra;idj0u dha5;bi;an;lbo6rh5;us;rg",Region:"true¦0:2O;1:2L;2:2U;3:2F;a2Sb2Fc21d1Wes1Vf1Tg1Oh1Ki1Fj1Bk16l13m0Sn09o07pYqVrSsJtEuBverAw6y4zacatec2W;akut0o0Fu4;cat1k09;a5est 4isconsin,yomi1O;bengal,virgin0;rwick3shington4;! dc;acruz,mont;dmurt0t4;ah,tar4; 2Pa12;a6e5laxca1Vripu21u4;scaEva;langa2nnessee,x2J;bas10m4smQtar29;aulip2Hil nadu;a9elang07i7o5taf16u4ylh1J;ff02rr09s1E;me1Gno1Uuth 4;cZdY;ber0c4kkim,naloa;hu1ily;n5rawak,skatchew1xo4;ny; luis potosi,ta catari2;a4hodeA;j4ngp0C;asth1shahi;ingh29u4;e4intana roo;bec,en6retaro;aAe6rince edward4unjab; i4;sl0G;i,n5r4;ak,nambu0F;a0Rnsylv4;an0;ha0Pra4;!na;axa0Zdisha,h4klaho21ntar4reg7ss0Dx0I;io;aLeEo6u4;evo le4nav0X;on;r4tt18va scot0;f9mandy,th4; 4ampton3;c6d5yo4;rk3;ako1O;aroli2;olk;bras1Nva0Dw4; 6foundland4;! and labrad4;or;brunswick,hamp3jers5mexiTyork4;! state;ey;galPyarit;aAeghala0Mi6o4;nta2r4;dov0elos;ch6dlanDn5ss4zor11;issippi,ouri;as geraPneso18;ig1oac1;dhy12harasht0Gine,lac07ni5r4ssachusetts;anhao,i el,ylG;p4toba;ur;anca3e4incoln3ouisI;e4iR;ds;a6e5h4omi;aka06ul2;dah,lant1ntucky,ra01;bardino,lmyk0ns0Qr4;achay,el0nata0X;alis6har4iangxi;kh4;and;co;daho,llino7n4owa;d5gush4;et0;ia2;is;a6ert5i4un1;dalFm0D;ford3;mp3rya2waii;ansu,eorg0lou7oa,u4;an4izhou,jarat;ajuato,gdo4;ng;cester3;lori4uji1;da;sex;ageUe7o5uran4;go;rs4;et;lawaMrby3;aFeaEh9o4rim08umbr0;ahui7l6nnectic5rsi4ventry;ca;ut;i03orado;la;e5hattisgarh,i4uvash0;apRhuahua;chn5rke4;ss0;ya;ra;lGm4;bridge3peche;a9ihar,r8u4;ck4ryat0;ingham3;shi4;re;emen,itish columb0;h0ja cal8lk7s4v7;hkorto4que;st1;an;ar0;iforn0;ia;dygHguascalientes,lBndhr9r5ss4;am;izo2kans5un4;achal 7;as;na;a 4;pradesh;a6ber5t4;ai;ta;ba5s4;ka;ma;ea",Place:"true¦0:4T;1:4V;2:44;3:4B;4:3I;a4Eb3Gc2Td2Ge26f25g1Vh1Ji1Fk1Cl14m0Vn0No0Jp08r04sTtNuLvJw7y5;a5o0Syz;kut1Bngtze;aDeChitBi9o5upatki,ycom2P;ki26o5;d5l1B;b3Ps5;i4to3Y;c0SllowbroCn5;c2Qgh2;by,chur1P;ed0ntw3Gs22;ke6r3St5;erf1f1; is0Gf3V;auxha3Mirgin is0Jost5;ok;laanbaatar,pto5xb3E;n,wn;a9eotihuac43h7ive49o6ru2Nsarskoe selo,u5;l2Dzigo47;nto,rquay,tt2J;am3e 5orn3E;bronx,hamptons;hiti,j mah0Iu1N;aEcotts bluff,eCfo,herbroQoApring9t7u5yd2F;dbu1Wn5;der03set3B;aff1ock2Nr5;atf1oud;hi37w24;ho,uth5; 1Iam1Zwo3E;a5i2O;f2Tt0;int lawrence riv3Pkhal2D;ayleigh,ed7i5oc1Z;chmo1Eo gran4ver5;be1Dfr09si4; s39cliffe,hi2Y;aCe9h8i5ompeii,utn2;c6ne5tcai2T; 2Pc0G;keri13t0;l,x;k,lh2mbr6n5r2J;n1Hzance;oke;cif38pahanaumokuak30r5;k5then0;si4w1K;ak7r6x5;f1l2X;ange county,d,f1inoco;mTw1G;e8i1Uo5;r5tt2N;th5wi0E; 0Sam19;uschwanste1Pw5; eng6a5h2market,po36;rk;la0P;a8co,e6i5uc;dt1Yll0Z;adow5ko0H;lands;chu picchu,gad2Ridsto1Ql8n7ple6r5;kh2; g1Cw11;hatt2Osf2B;ibu,t0ve1Z;a8e7gw,hr,in5owlOynd02;coln memori5dl2C;al;asi4w3;kefr7mbe1On5s,x;ca2Ig5si05;f1l27t0;ont;azan kreml14e6itchen2Gosrae,rasnoyar5ul;sk;ns0Hs1U;ax,cn,lf1n6ps5st;wiN;d5glew0Lverness;ian27ochina;aDeBi6kg,nd,ov5unti2H;d,enweep;gh6llc5;reL;bu03l5;and5;!s;r5yw0C;ef1tf1;libu24mp6r5stings;f1lem,row;stead,t0;aDodavari,r5uelph;avenAe5imsS;at 8en5; 6f1Fwi5;ch;acr3vall1H;brita0Flak3;hur5;st;ng3y villa0W;airhavHco,ra;aAgli9nf17ppi8u7ver6x5;et1Lf1;glad3t0;rope,st0;ng;nt0;rls1Ls5;t 5;e5si4;nd;aCe9fw,ig8o7ryd6u5xb;mfri3nstab00rh2tt0;en;nca18rcKv19wnt0B;by;n6r5vonpo1D;ry;!h2;nu8r5;l6t5;f1moor;ingt0;be;aLdg,eIgk,hClBo5royd0;l6m5rnwa0B;pt0;c7lingw6osse5;um;ood;he0S;earwat0St;a8el6i5uuk;chen itza,mney ro07natSricahua;m0Zt5;enh2;mor5rlottetPth2;ro;dar 5ntervilA;breaks,faZg5;rove;ld9m8r5versh2;lis6rizo pla5;in;le;bLpbellf1;weQ;aZcn,eNingl01kk,lackLolt0r5uckV;aGiAo5;ckt0ok5wns cany0;lyn,s5;i4to5;ne;de;dge6gh5;am,t0;n6t5;own;or5;th;ceb6m5;lNpt0;rid5;ge;bu5pool,wa8;rn;aconsfEdf1lBr9verly7x5;hi5;ll; hi5;lls;wi5;ck; air,l5;ingh2;am;ie5;ld;ltimore,rnsl6tters5;ea;ey;bLct0driadic,frica,ginJlGmFn9rc8s7tl6yleOzor3;es;!ant8;hcroft,ia; de triomphe,t6;adyr,ca8dov9tarct5;ic5; oce5;an;st5;er;ericas,s;be6dersh5hambra,list0;ot;rt0;cou5;rt;bot7i5;ngd0;on;sf1;ord",Country:"true¦0:38;1:2L;2:3B;a2Xb2Ec22d1Ye1Sf1Mg1Ch1Ai14j12k0Zl0Um0Gn05om2pZqat1KrXsKtCu7v5wal4yemTz3;a25imbabwe;es,lis and futu2Y;a3enezue32ietnam;nuatu,tican city;gTk6nited 4ruXs3zbeE; 2Ca,sr;arab emirat0Kkingdom,states3;! of am2Y;!raiV;a8haCimor les0Co7rinidad 5u3;nis0rk3valu;ey,me2Zs and caic1V;and t3t3;oba1L;go,kel10nga;iw2ji3nz2T;ki2V;aDcotl1eCi9lov8o6pa2Dri lanka,u5w3yr0;az3edAitzerl1;il1;d2riname;lomon1Xmal0uth 3;afr2KkMsud2;ak0en0;erra leoFn3;gapo1Yt maart3;en;negLrb0ychellZ;int 3moa,n marino,udi arab0;hele26luc0mart21;epublic of ir0Eom2Euss0w3;an27;a4eIhilippinUitcairn1Mo3uerto riN;l1rtugF;ki2Dl4nama,pua new0Vra3;gu7;au,esti3;ne;aBe9i7or3;folk1Ith4w3;ay; k3ern mariana1D;or0O;caragua,ger3ue;!ia;p3ther1Aw zeal1;al;mib0u3;ru;a7exi6icro0Bo3yanm06;ldova,n3roc5zambA;a4gol0t3;enegro,serrat;co;cAdagasc01l7r5urit4yot3;te;an0i16;shall0Xtin3;ique;a4div3i,ta;es;wi,ys0;ao,ed02;a6e5i3uxembourg;b3echtenste12thu1G;er0ya;ban0Isotho;os,tv0;azakh1Fe4iriba04o3uwait,yrgyz1F;rXsovo;eling0Knya;a3erG;ma16p2;c7nd6r4s3taly,vory coast;le of m2rael;a3el1;n,q;ia,oJ;el1;aiTon3ungary;dur0Ng kong;aBermany,ha0QibraltAre8u3;a6ern5inea3ya0P;! biss3;au;sey;deloupe,m,tema0Q;e3na0N;ce,nl1;ar;bUmb0;a7i6r3;ance,ench 3;guia0Epoly3;nes0;ji,nl1;lklandUroeU;ast tim7cu6gypt,l salv6ngl1quatorial4ritr5st3thiop0;on0; guin3;ea;ad3;or;enmark,jibou5ominica4r con3;go;!n C;ti;aBentral african Ah8o5roat0u4yprRzech3; 9ia;ba,racao;c4lo3morQngo brazzaville,okGsta r04te de ivoiL;mb0;osE;i3ristmasG;le,na;republic;m3naUpe verde,ymanA;bod0ero3;on;aGeDhut2o9r5u3;lgar0r3;kina faso,ma,undi;azil,itish 3unei;virgin3; is3;lands;liv0nai5snia and herzegoviHtswaHuvet3; isl1;and;re;l3n8rmuG;ar3gium,ize;us;h4ngladesh,rbad3;os;am4ra3;in;as;fghaGlDmBn6r4ustr3zerbaij2;al0ia;genti3men0uba;na;dorra,g5t3;arct7igua and barbu3;da;o3uil3;la;er3;ica;b3ger0;an0;ia;ni3;st2;an",FirstName:"true¦aTblair,cQdOfrancoZgabMhinaLilya,jHkClBm6ni4quinn,re3s0;h0umit,yd;ay,e0iloh;a,lby;g9ne;co,ko0;!s;a1el0ina,org6;!okuhF;ds,naia,r1tt0xiB;i,y;ion,lo;ashawn,eif,uca;a3e1ir0rM;an;lsFn0rry;dall,yat5;i,sD;a0essIie,ude;i1m0;ie,mG;me;ta;rie0y;le;arcy,ev0;an,on;as1h0;arl8eyenne;ey,sidy;drien,kira,l4nd1ubr0vi;ey;i,r0;a,e0;a,y;ex2f1o0;is;ie;ei,is",WeekDay:"true¦fri2mon2s1t0wednesd3;hurs1ues1;aturd1und1;!d0;ay0;!s",Month:"true¦dec0february,july,nov0octo1sept0;em0;ber",Date:"true¦ago,on4som4t1week0yesterd5; end,ends;mr1o0;d2morrow;!w;ed0;ay",Duration:"true¦centurAd8h7m5q4se3w1y0;ear8r8;eek0k7;!end,s;ason,c5;tr,uarter;i0onth3;llisecond2nute2;our1r1;ay0ecade0;!s;ies,y",FemaleName:"true¦0:J7;1:JB;2:IJ;3:IK;4:J1;5:IO;6:JS;7:JO;8:HB;9:JK;A:H4;B:I2;C:IT;D:JH;E:IX;F:BA;G:I4;aGTbFLcDRdD0eBMfB4gADh9Ti9Gj8Dk7Cl5Wm48n3Lo3Hp33qu32r29s15t0Eu0Cv02wVxiTyOzH;aLeIineb,oHsof3;e3Sf3la,ra;h2iKlIna,ynH;ab,ep;da,ma;da,h2iHra;nab;aKeJi0FolB7uIvH;et8onDP;i0na;le0sen3;el,gm3Hn,rGLs8W;aoHme0nyi;m5XyAD;aMendDZhiDGiH;dele9lJnH;if48niHo0;e,f47;a,helmi0lHma;a,ow;ka0nB;aNeKiHusa5;ck84kIl8oleAviH;anFenJ4;ky,toriBK;da,lA8rHs0;a,nHoniH9;a,iFR;leHnesH9;nILrH;i1y;g9rHs6xHA;su5te;aYeUhRiNoLrIuHy2;i,la;acJ3iHu0J;c3na,sH;hFta;nHr0F;iFya;aJffaEOnHs6;a,gtiH;ng;!nFSra;aIeHomasi0;a,l9Oo8Ares1;l3ndolwethu;g9Fo88rIssH;!a,ie;eHi,ri7;sa,za;bOlMmKnIrHs6tia0wa0;a60yn;iHya;a,ka,s6;arFe2iHm77ra;!ka;a,iH;a,t6;at6it6;a0Ecarlett,e0AhWiSkye,neza0oQri,tNuIyH;bIGlvi1;ha,mayIJniAsIzH;an3Net8ie,y;anHi7;!a,e,nH;aCe;aIeH;fan4l5Dphan6E;cI5r5;b3fiAAm0LnHphi1;d2ia,ja,ya;er2lJmon1nIobh8QtH;a,i;dy;lETv3;aMeIirHo0risFDy5;a,lDM;ba,e0i5lJrH;iHr6Jyl;!d8Ifa;ia,lDZ;hd,iMki2nJrIu0w0yH;la,ma,na;i,le9on,ron,yn;aIda,ia,nHon;a,on;!ya;k6mH;!aa;lJrItaye82vH;da,inj;e0ife;en1i0ma;anA9bLd5Oh1SiBkKlJmInd2rHs6vannaC;aCi0;ant6i2;lDOma,ome;ee0in8Tu2;in1ri0;a05eZhXiUoHuthDM;bScRghQl8LnPsJwIxH;anB3ie,y;an,e0;aIeHie,lD;ann7ll1marDGtA;!lHnn1;iHyn;e,nH;a,dF;da,i,na;ayy8G;hel67io;bDRerAyn;a,cIkHmas,nFta,ya;ki,o;h8Xki;ea,iannGMoH;da,n1P;an0bJemFgi0iInHta,y0;a8Bee;han86na;a,eH;cHkaC;a,ca;bi0chIe,i0mo0nHquETy0;di,ia;aERelHiB;!e,le;een4ia0;aPeOhMiLoJrHute6A;iHudenCV;scil3LyamvaB;lHrt3;i0ly;a,paluk;ilome0oebe,ylH;is,lis;ggy,nelope,r5t2;ige,m0VnKo5rvaDMtIulH;a,et8in1;ricHt4T;a,e,ia;do2i07;ctav3dIfD3is6ksa0lHphD3umC5yunbileg;a,ga,iv3;eHvAF;l3t8;aWeUiMoIurHy5;!ay,ul;a,eJor,rIuH;f,r;aCeEma;ll1mi;aNcLhariBQkKlaJna,sHta,vi;anHha;ur;!y;a,iDZki;hoGk9YolH;a,e4P;!mh;hir,lHna,risDEsreE;!a,iDDlBV;asuMdLh3i6Dl5nKomi7rgEVtH;aHhal4;lHs6;i1ya;cy,et8;e9iF0ya;nngu2X;a0Ackenz4e02iMoJrignayani,uriDJyH;a,rH;a,iOlNna,tG;bi0i2llBJnH;a,iH;ca,ka,qD9;a,cUdo4ZkaTlOmi,nMrItzi,yH;ar;aJiIlH;anET;am;!l,nB;dy,eHh,n4;nhGrva;aKdJe0iCUlH;iHy;cent,e;red;!gros;!e5;ae5hH;ae5el3Z;ag5DgNi,lKrH;edi7AiIjem,on,yH;em,l;em,sCG;an4iHliCF;nHsCJ;a,da;!an,han;b09cASd07e,g05ha,i04ja,l02n00rLsoum5YtKuIv84xBKyHz4;bell,ra,soBB;d7rH;a,eE;h8Gild1t4;a,cUgQiKjor4l7Un4s6tJwa,yH;!aHbe6Xja9lAE;m,nBL;a,ha,in1;!aJbCGeIja,lDna,sHt63;!a,ol,sa;!l1D;!h,mInH;!a,e,n1;!awit,i;arJeIie,oHr48ueri8;!t;!ry;et46i3B;el4Xi7Cy;dHon,ue5;akranAy;ak,en,iHlo3S;a,ka,nB;a,re,s4te;daHg4;!l3E;alDd4elHge,isDJon0;ei9in1yn;el,le;a0Ne0CiXoQuLyH;d3la,nH;!a,dIe2OnHsCT;!a,e2N;a,sCR;aD4cJel0Pis1lIna,pHz;e,iA;a,u,wa;iHy;a0Se,ja,l2NnB;is,l1UrItt1LuHvel4;el5is1;aKeIi7na,rH;aADi7;lHn1tA;ei;!in1;aTbb9HdSepa,lNnKsJvIzH;!a,be5Ret8z4;!ia;a,et8;!a,dH;a,sHy;ay,ey,i,y;a,iJja,lH;iHy;aA8e;!aH;!nF;ia,ya;!nH;!a,ne;aPda,e0iNjYla,nMoKsJtHx93y5;iHt4;c3t3;e2PlCO;la,nHra;a,ie,o2;a,or1;a,gh,laH;!ni;!h,nH;a,d2e,n5V;cOdon9DiNkes6mi9Gna,rMtJurIvHxmi,y5;ern1in3;a,e5Aie,yn;as6iIoH;nya,ya;fa,s6;a,isA9;a,la;ey,ie,y;a04eZhXiOlASoNrJyH;lHra;a,ee,ie;istHy6I;a,en,iIyH;!na;!e,n5F;nul,ri,urtnB8;aOerNlB7mJrHzzy;a,stH;en,in;!berlImernH;aq;eHi,y;e,y;a,stE;!na,ra;aHei2ongordzol;dij1w5;el7UiKjsi,lJnIrH;a,i,ri;d2na,za;ey,i,lBLs4y;ra,s6;biAcARdiat7MeBAiSlQmPnyakuma1DrNss6NtKviAyH;!e,lH;a,eH;e,i8T;!a6HeIhHi4TlDri0y;ar8Her8Hie,leErBAy;!lyn8Ori0;a,en,iHl5Xoli0yn;!ma,nFs95;a5il1;ei8Mi,lH;e,ie;a,tl6O;a0AeZiWoOuH;anMdLlHst88;es,iH;a8NeHs8X;!n9tH;!a,te;e5Mi3My;a,iA;!anNcelDdMelGhan7VleLni,sIva0yH;a,ce;eHie;fHlDph7Y;a,in1;en,n1;i7y;!a,e,n45;lHng;!i1DlH;!i1C;anNle0nKrJsH;i8JsH;!e,i8I;i,ri;!a,elGif2CnH;a,et8iHy;!e,f2A;a,eJiInH;a,eIiH;e,n1;!t8;cMda,mi,nIque4YsminFvie2y9zH;min7;a7eIiH;ce,e,n1s;!lHs82t0F;e,le;inIk6HlDquelH;in1yn;da,ta;da,lRmPnOo0rNsIvaHwo0zaro;!a0lu,na;aJiIlaHob89;!n9R;do2;belHdo2;!a,e,l3B;a7Ben1i0ma;di2es,gr72ji;a9elBogH;en1;a,e9iHo0se;a0na;aSeOiJoHus7Kyacin2C;da,ll4rten24snH;a,i9U;lImaH;ri;aIdHlaI;a,egard;ry;ath1BiJlInrietArmi9sH;sa,t1A;en2Uga,mi;di;bi2Fil8MlNnMrJsItHwa,yl8M;i5Tt4;n60ti;iHmo51ri53;etH;!te;aCnaC;a,ey,l4;a02eWiRlPoNrKunJwH;enHyne1R;!dolD;ay,el;acieIetHiselB;a,chE;!la;ld1CogooH;sh;adys,enHor3yn2K;a,da,na;aKgi,lIna,ov8EselHta;a,e,le;da,liH;an;!n0;mLnJorgIrH;ald5Si,m3Etrud7;et8i4X;a,eHna;s29vieve;ma;bIle,mHrnet,yG;al5Si5;iIrielH;a,l1;!ja;aTeQiPlorOoz3rH;anJeIiH;da,eB;da,ja;!cH;esIiHoi0P;n1s66;!ca;a,enc3;en,o0;lIn0rnH;anB;ec3ic3;jr,nArKtHy7;emIiHma,oumaA;ha,ma,n;eh;ah,iBrah,za0;cr4Rd0Re0Qi0Pk0Ol07mXn54rUsOtNuMvHwa;aKelIiH;!e,ta;inFyn;!a;!ngel4V;geni1ni47;h5Yien9ta;mLperanKtH;eIhHrel5;er;l31r7;za;a,eralB;iHma,ne4Lyn;cHka,n;a,ka;aPeNiKmH;aHe21ie,y;!li9nuH;elG;lHn1;e7iHy;a,e,ja;lHrald;da,y;!nue5;aWeUiNlMma,no2oKsJvH;a,iH;na,ra;a,ie;iHuiH;se;a,en,ie,y;a0c3da,e,f,nMsJzaH;!betHveA;e,h;aHe,ka;!beH;th;!a,or;anor,nH;!a,i;!in1na;ate1Rta;leEs6;vi;eIiHna,wi0;e,th;l,n;aYeMh3iLjeneKoH;lor5Vminiq4Ln3FrHtt4;a,eEis,la,othHthy;ea,y;ba;an09naCon9ya;anQbPde,eOiMlJmetr3nHsir5M;a,iH;ce,se;a,iIla,orHphi9;es,is;a,l6F;dHrdH;re;!d5Ena;!b2ForaCraC;a,d2nH;!a,e;hl3i0l0GmNnLphn1rIvi1WyH;le,na;a,by,cIia,lH;a,en1;ey,ie;a,et8iH;!ca,el1Aka,z;arHia;is;a0Re0Nh04i02lUoJristIynH;di,th3;al,i0;lPnMrIurH;tn1D;aJd2OiHn2Ori9;!nH;a,e,n1;!l4;cepci5Cn4sH;tanHuelo;ce,za;eHleE;en,t8;aJeoIotH;il54;!pat2;ir7rJudH;et8iH;a,ne;a,e,iH;ce,sZ;a2er2ndH;i,y;aReNloe,rH;isJyH;stH;al;sy,tH;a1Sen,iHy;an1e,n1;deJlseIrH;!i7yl;a,y;li9;nMrH;isKlImH;ai9;a,eHot8;n1t8;!sa;d2elGtH;al,elG;cIlH;es8i47;el3ilH;e,ia,y;itlYlXmilWndVrMsKtHy5;aIeIhHri0;er1IleErDy;ri0;a38sH;a37ie;a,iOlLmeJolIrH;ie,ol;!e,in1yn;lHn;!a,la;a,eIie,otHy;a,ta;ne,y;na,s1X;a0Ii0I;a,e,l1;isAl4;in,yn;a0Ke02iZlXoUrH;andi7eRiJoIyH;an0nn;nwDoke;an3HdgMgiLtH;n31tH;!aInH;ey,i,y;ny;d,t8;etH;!t7;an0e,nH;da,na;bbi7glarIlo07nH;iAn4;ka;ancHythe;a,he;an1Clja0nHsm3M;iAtH;ou;aWcVlinUniArPssOtJulaCvH;!erlH;ey,y;hJsy,tH;e,iHy7;e,na;!anH;ie,y;!ie;nItHyl;ha,ie;adIiH;ce;et8i9;ay,da;ca,ky;!triH;ce,z;rbJyaH;rmH;aa;a2o2ra;a2Ub2Od25g21i1Sj5l18m0Zn0Boi,r06sWtVuPvOwa,yIzH;ra,u0;aKes6gJlIn,seH;!l;in;un;!nH;a,na;a,i2K;drLguJrIsteH;ja;el3;stH;in1;a,ey,i,y;aahua,he0;hIi2Gja,miAs2DtrH;id;aMlIraqHt21;at;eIi7yH;!n;e,iHy;gh;!nH;ti;iJleIo6piA;ta;en,n1t8;aHelG;!n1J;a01dje5eZgViTjRnKohito,toHya;inet8nH;el5ia;te;!aKeIiHmJ;e,ka;!mHtt7;ar4;!belIliHmU;sa;!l1;a,eliH;ca;ka,sHta;a,sa;elHie;a,iH;a,ca,n1qH;ue;!tH;a,te;!bImHstasiMya;ar3;el;aLberKeliJiHy;e,l3naH;!ta;a,ja;!ly;hGiIl3nB;da;a,ra;le;aWba,ePiMlKthJyH;a,c3sH;a,on,sa;ea;iHys0N;e,s0M;a,cIn1sHza;a,e,ha,on,sa;e,ia,ja;c3is6jaKksaKna,sJxH;aHia;!nd2;ia,saH;nd2;ra;ia;i0nIyH;ah,na;a,is,naCoud;la;c6da,leEmNnLsH;haClH;inHyY;g,n;!h;a,o,slH;ey;ee;en;at6g4nIusH;ti0;es;ie;aWdiTelMrH;eJiH;anMenH;a,e,ne;an0;na;!aLeKiIyH;nn;a,n1;a,e;!ne;!iH;de;e,lDsH;on;yn;!lH;i9yn;ne;aKbIiHrL;!e,gaK;ey,i7y;!e;gaH;il;dKliyJradhIs6;ha;ya;ah;a,ya",Honorific:"true¦director1field marsh2lieutenant1rear0sergeant major,vice0; admir1; gener0;al","Adj|Gerund":"true¦0:3F;1:3H;2:31;3:2X;4:35;5:33;6:3C;7:2Z;8:36;9:29;a33b2Tc2Bd1Te1If19g12h0Zi0Rl0Nm0Gnu0Fo0Ap04rYsKtEuBvAw1Ayiel3;ar6e08;nBpA;l1Rs0B;fol3n1Zsett2;aEeDhrBi4ouc7rAwis0;e0Bif2oub2us0yi1;ea1SiA;l2vi1;l2mp0rr1J;nt1Vxi1;aMcreec7enten2NhLkyrocke0lo0Vmi2oJpHtDuBweA;e0Ul2;pp2ArA;gi1pri5roun3;aBea8iAri2Hun9;mula0r4;gge4rA;t2vi1;ark2eAraw2;e3llb2F;aAot7;ki1ri1;i9oc29;dYtisf6;aEeBive0oAus7;a4l2;assu4defi9fres7ig9juve07mai9s0vAwar3;ea2italiAol1G;si1zi1;gi1ll6mb2vi1;a6eDier23lun1VrAun2C;eBoA;mi5vo1Z;ce3s5vai2;n3rpleA;xi1;ffCpWutBverAwi1;arc7lap04p0Pri3whel8;goi1l6st1J;en3sA;et0;m2Jrtu4;aEeDiCoBuAyst0L;mb2;t1Jvi1;s5tiga0;an1Rl0n3smeri26;dAtu4;de9;aCeaBiAo0U;fesa0Tvi1;di1ni1;c1Fg19s0;llumiGmFnArri0R;cDfurHsCtBviA;go23ti1;e1Oimi21oxica0rig0V;pi4ul0;orpo20r0K;po5;na0;eaBorr02umilA;ia0;li1rtwar8;lFrA;atiDipCoBuelA;i1li1;undbrea10wi1;pi1;f6ng;a4ea8;a3etc7it0lEoCrBulfA;il2;ee1FighXust1L;rAun3;ebo3thco8;aCoA;a0wA;e4i1;mi1tte4;lectrJmHnExA;aCci0hBis0pA;an3lo3;aOila1B;c0spe1A;ab2coura0CdBergi13ga0Clive9ric7s02tA;hral2i0J;ea4u4;barras5er09pA;owe4;if6;aQeIiBrA;if0;sAzz6;aEgDhearCsen0tA;rAur11;ac0es5;te9;us0;ppoin0r8;biliGcDfi9gra3ligh0mBpres5sAvasG;erE;an3ea9orA;ali0L;a6eiBli9rA;ea5;vi1;ta0;maPri1s7un0zz2;aPhMlo5oAripp2ut0;mGnArrespon3;cer9fDspi4tA;inBrA;as0ibu0ol2;ui1;lic0u5;ni1;fDmCpA;eAromi5;l2ti1;an3;or0;aAil2;llenAnAr8;gi1;l8ptAri1;iva0;aff2eGin3lFoDrBuA;d3st2;eathtaAui5;ki1;gg2i2o8ri1unA;ci1;in3;co8wiA;lAtc7;de4;bsorVcOgonMlJmHnno6ppea2rFsA;pi4su4toA;nBun3;di1;is7;hi1;res0;li1;aFu5;si1;ar8lu4;ri1;mi1;iAzi1;zi1;cAhi1;eleDomA;moBpan6;yi1;da0;ra0;ti1;bi1;ng",Comparable:"true¦0:3C;1:3Q;2:3F;a3Tb3Cc33d2Te2Mf2Ag1Wh1Li1Fj1Ek1Bl13m0Xn0So0Rp0Iqu0Gr07sHtCug0vAw4y3za0Q;el10ouN;ary,e6hi5i3ry;ck0Cde,l3n1ry,se;d,y;ny,te;a3i3R;k,ry;a3erda2ulgar;gue,in,st;a6en2Xhi5i4ouZr3;anqu2Cen1ue;dy,g36me0ny;ck,rs28;ll,me,rt,wd3I;aRcaPeOhMiLkin0BlImGoEpDt6u4w3;eet,ift;b3dd0Wperfi21rre28;sta26t21;a8e7iff,r4u3;pUr1;a4ict,o3;ng;ig2Vn0N;a1ep,rn;le,rk,te0;e1Si2Vright0;ci1Yft,l3on,re;emn,id;a3el0;ll,rt;e4i3y;g2Mm0Z;ek,nd2T;ck24l0mp1L;a3iRrill,y;dy,l01rp;ve0Jxy;n1Jr3;ce,y;d,fe,int0l1Hv0V;a8e6i5o3ude;mantic,o19sy,u3;gh;pe,t1P;a3d,mo0A;dy,l;gg4iFndom,p3re,w;id;ed;ai2i3;ck,et;hoAi1Fl9o8r5u3;ny,r3;e,p11;egna2ic4o3;fouSud;ey,k0;liXor;ain,easa2;ny;dd,i0ld,ranL;aive,e5i4o3u14;b0Sisy,rm0Ysy;bb0ce,mb0R;a3r1w;r,t;ad,e5ild,o4u3;nda12te;ist,o1;a4ek,l3;low;s0ty;a8e7i6o3ucky;f0Jn4o15u3ve0w10y0N;d,sy;e0g;ke0l,mp,tt0Eve0;e1Qwd;me,r3te;ge;e4i3;nd;en;ol0ui19;cy,ll,n3;secu6t3;e3ima4;llege2rmedia3;te;re;aAe7i6o5u3;ge,m3ng1C;bYid;me0t;gh,l0;a3fXsita2;dy,rWv3;en0y;nd13ppy,r3;d3sh;!y;aFenEhCiBlAoofy,r3;a8e6i5o3ue0Z;o3ss;vy;m,s0;at,e3y;dy,n;nd,y;ad,ib,ooD;a2d1;a3o3;st0;tDuiS;u1y;aCeebBi9l8o6r5u3;ll,n3r0N;!ny;aCesh,iend0;a3nd,rmD;my;at,ir7;erce,nan3;ci9;le;r,ul3;ty;a6erie,sse4v3xtre0B;il;nti3;al;r4s3;tern,y;ly,th0;appZe9i5ru4u3;mb;nk;r5vi4z3;zy;ne;e,ty;a3ep,n9;d3f,r;!ly;agey,h8l7o5r4u3;dd0r0te;isp,uel;ar3ld,mmon,st0ward0zy;se;evKou1;e3il0;ap,e3;sy;aHiFlCoAr5u3;ff,r0sy;ly;a6i3oad;g4llia2;nt;ht;sh,ve;ld,un3;cy;a4o3ue;nd,o1;ck,nd;g,tt3;er;d,ld,w1;dy;bsu6ng5we3;so3;me;ry;rd",Adverb:"true¦a08b05d00eYfSheQinPjustOkinda,likewiZmMnJoEpCquite,r9s5t2u0very,well;ltima01p0; to,wards5;h1iny bit,o0wiO;o,t6;en,us;eldom,o0uch;!me1rt0; of;how,times,w0C;a1e0;alS;ndomRth05;ar excellenEer0oint blank; Lhaps;f3n0utright;ce0ly;! 0;ag05moX; courGten;ewJo0; longWt 0;onHwithstand9;aybe,eanwhiNore0;!ovT;! aboX;deed,steY;lla,n0;ce;or3u0;ck1l9rther0;!moK;ing; 0evK;exampCgood,suH;n mas0vI;se;e0irect2; 2fini0;te0;ly;juAtrop;ackward,y 0;far,no0; means,w; GbroFd nauseam,gEl7ny5part,s4t 2w0;ay,hi0;le;be7l0mo7wor7;arge,ea6; soon,i4;mo0way;re;l 3mo2ongsi1ready,so,togeth0ways;er;de;st;b1t0;hat;ut;ain;ad;lot,posteriori",Conjunction:"true¦aXbTcReNhowMiEjust00noBo9p8supposing,t5wh0yet;e1il0o3;e,st;n1re0thN; if,by,vM;evL;h0il,o;erefOo0;!uU;lus,rovided th9;r0therwiM;! not; mattEr,w0;! 0;since,th4w7;f4n0; 0asmuch;as mIcaForder t0;h0o;at;! 0;only,t0w0;hen;!ev3;ith2ven0;! 0;if,tB;er;o0uz;s,z;e0ut,y the time;cau1f0;ore;se;lt3nd,s 0;far1if,m0soon1t2;uch0; as;hou0;gh",Currency:"true¦$,aud,bQcOdJeurIfHgbp,hkd,iGjpy,kElDp8r7s3usd,x2y1z0¢,£,¥,ден,лв,руб,฿,₡,₨,€,₭,﷼;lotyQł;en,uanP;af,of;h0t5;e0il5;k0q0;elK;oubleJp,upeeJ;e2ound st0;er0;lingG;n0soF;ceEnies;empi7i7;n,r0wanzaCyatC;!onaBw;ls,nr;ori7ranc9;!os;en3i2kk,o0;b0ll2;ra5;me4n0rham4;ar3;e0ny;nt1;aht,itcoin0;!s",Determiner:"true¦aBboth,d9e6few,le5mu8neiDplenty,s4th2various,wh0;at0ich0;evC;a0e4is,ose;!t;everal,ome;!ast,s;a1l0very;!se;ch;e0u;!s;!n0;!o0y;th0;er","Adj|Present":"true¦a07b04cVdQeNfJhollIidRlEmCnarrIoBp9qua8r7s3t2uttFw0;aKet,ro0;ng,u08;endChin;e2hort,l1mooth,our,pa9tray,u0;re,speU;i2ow;cu6da02leSpaN;eplica01i02;ck;aHerfePr0;eseUime,omV;bscu1pen,wn;atu0e3odeH;re;a2e1ive,ow0;er;an;st,y;ow;a2i1oul,r0;ee,inge;rm;iIke,ncy,st;l1mpty,x0;emHpress;abo4ic7;amp,e2i1oub0ry,ull;le;ffu9re6;fu8libe0;raE;alm,l5o0;mpleCn3ol,rr1unterfe0;it;e0u7;ct;juga8sum7;ea1o0;se;n,r;ankru1lu0;nt;pt;li2pproxi0rticula1;ma0;te;ght","Person|Adj":"true¦b3du2earnest,frank,mi2r0san1woo1;an0ich,u1;dy;sty;ella,rown",Modal:"true¦c5lets,m4ought3sh1w0;ill,o5;a0o4;ll,nt;! to,a;ight,ust;an,o0;uld",Verb:"true¦born,cannot,gonna,has,keep tabs,msg","Person|Verb":"true¦b8ch7dr6foster,gra5ja9lan4ma2ni9ollie,p1rob,s0wade;kip,pike,t5ue;at,eg,ier2;ck,r0;k,shal;ce;ce,nt;ew;ase,u1;iff,l1ob,u0;ck;aze,ossom","Person|Date":"true¦a2j0sep;an0une;!uary;p0ugust,v0;ril"};const mo=36,po="0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ",fo=po.split("").reduce((function(e,t,n){return e[t]=n,e}),{});var bo=function(e){if(void 0!==fo[e])return fo[e];let t=0,n=1,r=mo,o=1;for(;n=0;n--,o*=mo){let r=e.charCodeAt(n)-48;r>10&&(r-=7),t+=r*o}return t};const vo=function(e,t,n){const r=bo(t);return r{let a=e.nodes[r];"!"===a[0]&&(t.push(o),a=a.slice(1));const i=a.split(/([A-Z0-9,]+)/g);for(let a=0;a{const t=function(e){if(!e)return{};const t=e.split("|").reduce(((e,t)=>{const n=t.split("¦");return e[n[0]]=n[1],e}),{}),n={};return Object.keys(t).forEach((function(e){const r=yo(t[e]);"true"===e&&(e=!0);for(let t=0;t{if(jo[t]=e,"Noun|Verb"===e){const e=Ao(t,xo);jo[e]="Plural|Verb"}})):Object.keys(t).forEach((t=>{No[t]=e}))})),[":(",":)",":P",":p",":O",";(",";)",";P",";p",";O",":3",":|",":/",":\\",":$",":*",":@",":-(",":-)",":-P",":-p",":-O",":-3",":-|",":-/",":-\\",":-$",":-*",":-@",":^(",":^)",":^P",":^p",":^O",":^3",":^|",":^/",":^\\",":^$",":^*",":^@","):","(:","$:","*:",")-:","(-:","$-:","*-:",")^:","(^:","$^:","*^:","<3","No[e]="Emoticon")),delete No[""],delete No.null,delete No[" "];const Io="Singular";var To={beforeTags:{Determiner:Io,Possessive:Io,Acronym:Io,Noun:Io,Adjective:Io,PresentTense:Io,Gerund:Io,PastTense:Io,Infinitive:Io,Date:Io,Ordinal:Io,Demonym:Io},afterTags:{Value:Io,Modal:Io,Copula:Io,PresentTense:Io,PastTense:Io,Demonym:Io,Actor:Io},beforeWords:{the:Io,with:Io,without:Io,of:Io,for:Io,any:Io,all:Io,on:Io,cut:Io,cuts:Io,increase:Io,decrease:Io,raise:Io,drop:Io,save:Io,saved:Io,saves:Io,make:Io,makes:Io,made:Io,minus:Io,plus:Io,than:Io,another:Io,versus:Io,neither:Io,about:Io,favorite:Io,best:Io,daily:Io,weekly:Io,linear:Io,binary:Io,mobile:Io,lexical:Io,technical:Io,computer:Io,scientific:Io,security:Io,government:Io,popular:Io,formal:Io,no:Io,more:Io,one:Io,let:Io,her:Io,his:Io,their:Io,our:Io,us:Io,sheer:Io,monthly:Io,yearly:Io,current:Io,previous:Io,upcoming:Io,last:Io,next:Io,main:Io,initial:Io,final:Io,beginning:Io,end:Io,top:Io,bottom:Io,future:Io,past:Io,major:Io,minor:Io,side:Io,central:Io,peripheral:Io,public:Io,private:Io},afterWords:{of:Io,system:Io,aid:Io,method:Io,utility:Io,tool:Io,reform:Io,therapy:Io,philosophy:Io,room:Io,authority:Io,says:Io,said:Io,wants:Io,wanted:Io,is:Io,did:Io,do:Io,can:Io,wise:Io}};const Do="Infinitive";var Ho={beforeTags:{Modal:Do,Adverb:Do,Negative:Do,Plural:Do},afterTags:{Determiner:Do,Adverb:Do,Possessive:Do,Reflexive:Do,Preposition:Do,Cardinal:Do,Comparative:Do,Superlative:Do},beforeWords:{i:Do,we:Do,you:Do,they:Do,to:Do,please:Do,will:Do,have:Do,had:Do,would:Do,could:Do,should:Do,do:Do,did:Do,does:Do,can:Do,must:Do,us:Do,me:Do,let:Do,even:Do,when:Do,help:Do,he:Do,she:Do,it:Do,being:Do,bi:Do,co:Do,contra:Do,de:Do,inter:Do,intra:Do,mis:Do,pre:Do,out:Do,counter:Do,nobody:Do,somebody:Do,anybody:Do,everybody:Do},afterWords:{the:Do,me:Do,you:Do,him:Do,us:Do,her:Do,his:Do,them:Do,they:Do,it:Do,himself:Do,herself:Do,itself:Do,myself:Do,ourselves:Do,themselves:Do,something:Do,anything:Do,a:Do,an:Do,up:Do,down:Do,by:Do,out:Do,off:Do,under:Do,what:Do,all:Do,to:Do,because:Do,although:Do,how:Do,otherwise:Do,together:Do,though:Do,into:Do,yet:Do,more:Do,here:Do,there:Do,away:Do}};const Eo={beforeTags:Object.assign({},Ho.beforeTags,To.beforeTags,{}),afterTags:Object.assign({},Ho.afterTags,To.afterTags,{}),beforeWords:Object.assign({},Ho.beforeWords,To.beforeWords,{}),afterWords:Object.assign({},Ho.afterWords,To.afterWords,{})},Go="Adjective";var Oo={beforeTags:{Determiner:Go,Possessive:Go,Hyphenated:Go},afterTags:{Adjective:Go},beforeWords:{seem:Go,seemed:Go,seems:Go,feel:Go,feels:Go,felt:Go,stay:Go,appear:Go,appears:Go,appeared:Go,also:Go,over:Go,under:Go,too:Go,it:Go,but:Go,still:Go,really:Go,quite:Go,well:Go,very:Go,truly:Go,how:Go,deeply:Go,hella:Go,profoundly:Go,extremely:Go,so:Go,badly:Go,mostly:Go,totally:Go,awfully:Go,rather:Go,nothing:Go,something:Go,anything:Go,not:Go,me:Go,is:Go,face:Go,faces:Go,faced:Go,look:Go,looks:Go,looked:Go,reveal:Go,reveals:Go,revealed:Go,sound:Go,sounded:Go,sounds:Go,remains:Go,remained:Go,prove:Go,proves:Go,proved:Go,becomes:Go,stays:Go,tastes:Go,taste:Go,smells:Go,smell:Go,gets:Go,grows:Go,as:Go,rings:Go,radiates:Go,conveys:Go,convey:Go,conveyed:Go,of:Go},afterWords:{too:Go,also:Go,or:Go,enough:Go,as:Go}};const Fo="Gerund";var Vo={beforeTags:{Adverb:Fo,Preposition:Fo,Conjunction:Fo},afterTags:{Adverb:Fo,Possessive:Fo,Person:Fo,Pronoun:Fo,Determiner:Fo,Copula:Fo,Preposition:Fo,Conjunction:Fo,Comparative:Fo},beforeWords:{been:Fo,keep:Fo,continue:Fo,stop:Fo,am:Fo,be:Fo,me:Fo,began:Fo,start:Fo,starts:Fo,started:Fo,stops:Fo,stopped:Fo,help:Fo,helps:Fo,avoid:Fo,avoids:Fo,love:Fo,loves:Fo,loved:Fo,hate:Fo,hates:Fo,hated:Fo},afterWords:{you:Fo,me:Fo,her:Fo,him:Fo,his:Fo,them:Fo,their:Fo,it:Fo,this:Fo,there:Fo,on:Fo,about:Fo,for:Fo,up:Fo,down:Fo}};const zo="Gerund",Bo="Adjective",So={beforeTags:Object.assign({},Oo.beforeTags,Vo.beforeTags,{Imperative:zo,Infinitive:Bo,Plural:zo}),afterTags:Object.assign({},Oo.afterTags,Vo.afterTags,{Noun:Bo}),beforeWords:Object.assign({},Oo.beforeWords,Vo.beforeWords,{is:Bo,are:zo,was:Bo,of:Bo,suggest:zo,suggests:zo,suggested:zo,recommend:zo,recommends:zo,recommended:zo,imagine:zo,imagines:zo,imagined:zo,consider:zo,considered:zo,considering:zo,resist:zo,resists:zo,resisted:zo,avoid:zo,avoided:zo,avoiding:zo,except:Bo,accept:Bo,assess:zo,explore:zo,fear:zo,fears:zo,appreciate:zo,question:zo,help:zo,embrace:zo,with:Bo}),afterWords:Object.assign({},Oo.afterWords,Vo.afterWords,{to:zo,not:zo,the:zo})},$o={beforeTags:{Determiner:void 0,Cardinal:"Noun",PhrasalVerb:"Adjective"},afterTags:{}},Mo={beforeTags:Object.assign({},Oo.beforeTags,To.beforeTags,$o.beforeTags),afterTags:Object.assign({},Oo.afterTags,To.afterTags,$o.afterTags),beforeWords:Object.assign({},Oo.beforeWords,To.beforeWords,{are:"Adjective",is:"Adjective",was:"Adjective",be:"Adjective",off:"Adjective",out:"Adjective"}),afterWords:Object.assign({},Oo.afterWords,To.afterWords)},Lo="PastTense",Ko="Adjective",Jo={beforeTags:{Adverb:Lo,Pronoun:Lo,ProperNoun:Lo,Auxiliary:Lo,Noun:Lo},afterTags:{Possessive:Lo,Pronoun:Lo,Determiner:Lo,Adverb:Lo,Comparative:Lo,Date:Lo,Gerund:Lo},beforeWords:{be:Lo,who:Lo,get:Ko,had:Lo,has:Lo,have:Lo,been:Lo,it:Lo,as:Lo,for:Ko,more:Ko,always:Ko},afterWords:{by:Lo,back:Lo,out:Lo,in:Lo,up:Lo,down:Lo,before:Lo,after:Lo,for:Lo,the:Lo,with:Lo,as:Lo,on:Lo,at:Lo,between:Lo,to:Lo,into:Lo,us:Lo,them:Lo,his:Lo,her:Lo,their:Lo,our:Lo,me:Lo,about:Ko}};var Wo={beforeTags:Object.assign({},Oo.beforeTags,Jo.beforeTags),afterTags:Object.assign({},Oo.afterTags,Jo.afterTags),beforeWords:Object.assign({},Oo.beforeWords,Jo.beforeWords),afterWords:Object.assign({},Oo.afterWords,Jo.afterWords)};const qo={afterTags:{Noun:"Adjective",Conjunction:void 0}},Uo={beforeTags:Object.assign({},Oo.beforeTags,Ho.beforeTags,{Adverb:void 0,Negative:void 0}),afterTags:Object.assign({},Oo.afterTags,Ho.afterTags,qo.afterTags),beforeWords:Object.assign({},Oo.beforeWords,Ho.beforeWords,{have:void 0,had:void 0,not:void 0,went:"Adjective",goes:"Adjective",got:"Adjective",be:"Adjective"}),afterWords:Object.assign({},Oo.afterWords,Ho.afterWords,{to:void 0,as:"Adjective"})},Ro={Copula:"Gerund",PastTense:"Gerund",PresentTense:"Gerund",Infinitive:"Gerund"},Qo={Value:"Gerund"},Zo={are:"Gerund",were:"Gerund",be:"Gerund",no:"Gerund",without:"Gerund",you:"Gerund",we:"Gerund",they:"Gerund",he:"Gerund",she:"Gerund",us:"Gerund",them:"Gerund"},_o={the:"Gerund",this:"Gerund",that:"Gerund",me:"Gerund",us:"Gerund",them:"Gerund"},Xo={beforeTags:Object.assign({},Vo.beforeTags,To.beforeTags,Ro),afterTags:Object.assign({},Vo.afterTags,To.afterTags,Qo),beforeWords:Object.assign({},Vo.beforeWords,To.beforeWords,Zo),afterWords:Object.assign({},Vo.afterWords,To.afterWords,_o)},Yo="Singular",ea="Infinitive",ta={beforeTags:Object.assign({},Ho.beforeTags,To.beforeTags,{Adjective:Yo,Particle:Yo}),afterTags:Object.assign({},Ho.afterTags,To.afterTags,{ProperNoun:ea,Gerund:ea,Adjective:ea,Copula:Yo}),beforeWords:Object.assign({},Ho.beforeWords,To.beforeWords,{is:Yo,was:Yo,of:Yo,have:null}),afterWords:Object.assign({},Ho.afterWords,To.afterWords,{instead:ea,about:ea,his:ea,her:ea,to:null,by:null,in:null})},na="Person";var ra={beforeTags:{Honorific:na,Person:na},afterTags:{Person:na,ProperNoun:na,Verb:na},beforeWords:{hi:na,hey:na,yo:na,dear:na,hello:na},afterWords:{said:na,says:na,told:na,tells:na,feels:na,felt:na,seems:na,thinks:na,thought:na,spends:na,spendt:na,plays:na,played:na,sing:na,sang:na,learn:na,learned:na,wants:na,wanted:na}};const oa="Month",aa={beforeTags:{Date:oa,Value:oa},afterTags:{Date:oa,Value:oa},beforeWords:{by:oa,in:oa,on:oa,during:oa,after:oa,before:oa,between:oa,until:oa,til:oa,sometime:oa,of:oa,this:oa,next:oa,last:oa,previous:oa,following:oa,with:"Person"},afterWords:{sometime:oa,in:oa,of:oa,until:oa,the:oa}};var ia={beforeTags:Object.assign({},ra.beforeTags,aa.beforeTags),afterTags:Object.assign({},ra.afterTags,aa.afterTags),beforeWords:Object.assign({},ra.beforeWords,aa.beforeWords),afterWords:Object.assign({},ra.afterWords,aa.afterWords)};const sa="Place",la={beforeTags:{Place:sa},afterTags:{Place:sa,Abbreviation:sa},beforeWords:{in:sa,by:sa,near:sa,from:sa,to:sa},afterWords:{in:sa,by:sa,near:sa,from:sa,to:sa,government:sa,council:sa,region:sa,city:sa}},ua="Unit",ca={"Actor|Verb":Eo,"Adj|Gerund":So,"Adj|Noun":Mo,"Adj|Past":Wo,"Adj|Present":Uo,"Noun|Verb":ta,"Noun|Gerund":Xo,"Person|Noun":{beforeTags:Object.assign({},To.beforeTags,ra.beforeTags),afterTags:Object.assign({},To.afterTags,ra.afterTags),beforeWords:Object.assign({},To.beforeWords,ra.beforeWords,{i:"Infinitive",we:"Infinitive"}),afterWords:Object.assign({},To.afterWords,ra.afterWords)},"Person|Date":ia,"Person|Verb":{beforeTags:Object.assign({},To.beforeTags,ra.beforeTags,Ho.beforeTags),afterTags:Object.assign({},To.afterTags,ra.afterTags,Ho.afterTags),beforeWords:Object.assign({},To.beforeWords,ra.beforeWords,Ho.beforeWords),afterWords:Object.assign({},To.afterWords,ra.afterWords,Ho.afterWords)},"Person|Place":{beforeTags:Object.assign({},la.beforeTags,ra.beforeTags),afterTags:Object.assign({},la.afterTags,ra.afterTags),beforeWords:Object.assign({},la.beforeWords,ra.beforeWords),afterWords:Object.assign({},la.afterWords,ra.afterWords)},"Person|Adj":{beforeTags:Object.assign({},ra.beforeTags,Oo.beforeTags),afterTags:Object.assign({},ra.afterTags,Oo.afterTags),beforeWords:Object.assign({},ra.beforeWords,Oo.beforeWords),afterWords:Object.assign({},ra.afterWords,Oo.afterWords)},"Unit|Noun":{beforeTags:{Value:ua},afterTags:{},beforeWords:{per:ua,every:ua,each:ua,square:ua,cubic:ua,sq:ua,metric:ua},afterWords:{per:ua,squared:ua,cubed:ua,long:ua}}},ha=(e,t)=>{const n=Object.keys(e).reduce(((t,n)=>(t[n]="Infinitive"===e[n]?"PresentTense":"Plural",t)),{});return Object.assign(n,t)};ca["Plural|Verb"]={beforeWords:ha(ca["Noun|Verb"].beforeWords,{had:"Plural",have:"Plural"}),afterWords:ha(ca["Noun|Verb"].afterWords,{his:"PresentTense",her:"PresentTense",its:"PresentTense",in:null,to:null,is:"PresentTense",by:"PresentTense"}),beforeTags:ha(ca["Noun|Verb"].beforeTags,{Conjunction:"PresentTense",Noun:void 0,ProperNoun:"PresentTense"}),afterTags:ha(ca["Noun|Verb"].afterTags,{Gerund:"Plural",Noun:"PresentTense",Value:"PresentTense"})};const da="Adjective",ga="Infinitive",ma="PresentTense",pa="Singular",fa="PastTense",ba="Adverb",va="Plural",ya="Actor",wa="Verb",ka="Noun",Pa="LastName",Aa="Modal",Ca="Place",Na="Participle";var ja=[null,null,{ea:pa,ia:ka,ic:da,ly:ba,"'n":wa,"'t":wa},{oed:fa,ued:fa,xed:fa," so":ba,"'ll":Aa,"'re":"Copula",azy:da,eer:ka,end:wa,ped:fa,ffy:da,ify:ga,ing:"Gerund",ize:ga,ibe:ga,lar:da,mum:da,nes:ma,nny:da,ous:da,que:da,ger:ka,ber:ka,rol:pa,sis:pa,ogy:pa,oid:pa,ian:pa,zes:ma,eld:fa,ken:Na,ven:Na,ten:Na,ect:ga,ict:ga,ign:ga,oze:ga,ful:da,bal:da,ton:ka,pur:Ca},{amed:fa,aped:fa,ched:fa,lked:fa,rked:fa,reed:fa,nded:fa,mned:da,cted:fa,dged:fa,ield:pa,akis:Pa,cede:ga,chuk:Pa,czyk:Pa,ects:ma,iend:pa,ends:wa,enko:Pa,ette:pa,iary:pa,wner:pa,fies:ma,fore:ba,gate:ga,gone:da,ices:va,ints:va,ruct:ga,ines:va,ions:va,ners:va,pers:va,lers:va,less:da,llen:da,made:da,nsen:Pa,oses:ma,ould:Aa,some:da,sson:Pa,ians:va,tion:pa,tage:ka,ique:pa,tive:da,tors:ka,vice:pa,lier:pa,fier:pa,wned:fa,gent:pa,tist:ya,pist:ya,rist:ya,mist:ya,yist:ya,vist:ya,ists:ya,lite:pa,site:pa,rite:pa,mite:pa,bite:pa,mate:pa,date:pa,ndal:pa,vent:pa,uist:ya,gist:ya,note:pa,cide:pa,ence:pa,wide:da,vide:ga,ract:ga,duce:ga,pose:ga,eive:ga,lyze:ga,lyse:ga,iant:da,nary:da,ghty:da,uent:da,erer:ya,bury:Ca,dorf:ka,esty:ka,wych:Ca,dale:Ca,folk:Ca,vale:Ca,abad:Ca,sham:Ca,wick:Ca,view:Ca},{elist:ya,holic:pa,phite:pa,tized:fa,urned:fa,eased:fa,ances:va,bound:da,ettes:va,fully:ba,ishes:ma,ities:va,marek:Pa,nssen:Pa,ology:ka,osome:pa,tment:pa,ports:va,rough:da,tches:ma,tieth:"Ordinal",tures:va,wards:ba,where:ba,archy:ka,pathy:ka,opoly:ka,embly:ka,phate:ka,ndent:pa,scent:pa,onist:ya,anist:ya,alist:ya,olist:ya,icist:ya,ounce:ga,iable:da,borne:da,gnant:da,inant:da,igent:da,atory:da,rient:pa,dient:pa,maker:ya,burgh:Ca,mouth:Ca,ceter:Ca,ville:Ca,hurst:Ca,stead:Ca,endon:Ca,brook:Ca,shire:Ca,worth:ka,field:"ProperNoun",ridge:Ca},{auskas:Pa,parent:pa,cedent:pa,ionary:pa,cklist:pa,brooke:Ca,keeper:ya,logist:ya,teenth:"Value",worker:ya,master:ya,writer:ya,brough:Ca,cester:Ca,ington:Ca,cliffe:Ca,ingham:Ca},{chester:Ca,logists:ya,opoulos:Pa,borough:Ca,sdottir:Pa}];const xa="Adjective",Ia="Noun",Ta="Verb";var Da=[null,null,{},{neo:Ia,bio:Ia,"de-":Ta,"re-":Ta,"un-":Ta,"ex-":Ia},{anti:Ia,auto:Ia,faux:xa,hexa:Ia,kilo:Ia,mono:Ia,nano:Ia,octa:Ia,poly:Ia,semi:xa,tele:Ia,"pro-":xa,"mis-":Ta,"dis-":Ta,"pre-":xa},{anglo:Ia,centi:Ia,ethno:Ia,ferro:Ia,grand:Ia,hepta:Ia,hydro:Ia,intro:Ia,macro:Ia,micro:Ia,milli:Ia,nitro:Ia,penta:Ia,quasi:xa,radio:Ia,tetra:Ia,"omni-":xa,"post-":xa},{pseudo:xa,"extra-":xa,"hyper-":xa,"inter-":xa,"intra-":xa,"deca-":xa},{electro:Ia}];const Ha="Adjective",Ea="Infinitive",Ga="PresentTense",Oa="Singular",Fa="PastTense",Va="Adverb",za="Expression",Ba="Actor",Sa="Verb",$a="Noun",Ma="LastName";var La={a:[[/.[aeiou]na$/,$a,"tuna"],[/.[oau][wvl]ska$/,Ma],[/.[^aeiou]ica$/,Oa,"harmonica"],[/^([hyj]a+)+$/,za,"haha"]],c:[[/.[^aeiou]ic$/,Ha]],d:[[/[aeiou](pp|ll|ss|ff|gg|tt|rr|bb|nn|mm)ed$/,Fa,"popped"],[/.[aeo]{2}[bdgmnprvz]ed$/,Fa,"rammed"],[/.[aeiou][sg]hed$/,Fa,"gushed"],[/.[aeiou]red$/,Fa,"hired"],[/.[aeiou]r?ried$/,Fa,"hurried"],[/[^aeiou]ard$/,Oa,"steward"],[/[aeiou][^aeiou]id$/,Ha,""],[/.[vrl]id$/,Ha,"livid"],[/..led$/,Fa,"hurled"],[/.[iao]sed$/,Fa,""],[/[aeiou]n?[cs]ed$/,Fa,""],[/[aeiou][rl]?[mnf]ed$/,Fa,""],[/[aeiou][ns]?c?ked$/,Fa,"bunked"],[/[aeiou]gned$/,Fa],[/[aeiou][nl]?ged$/,Fa],[/.[tdbwxyz]ed$/,Fa],[/[^aeiou][aeiou][tvx]ed$/,Fa],[/.[cdflmnprstv]ied$/,Fa,"emptied"]],e:[[/.[lnr]ize$/,Ea,"antagonize"],[/.[^aeiou]ise$/,Ea,"antagonise"],[/.[aeiou]te$/,Ea,"bite"],[/.[^aeiou][ai]ble$/,Ha,"fixable"],[/.[^aeiou]eable$/,Ha,"maleable"],[/.[ts]ive$/,Ha,"festive"],[/[a-z]-like$/,Ha,"woman-like"]],h:[[/.[^aeiouf]ish$/,Ha,"cornish"],[/.v[iy]ch$/,Ma,"..ovich"],[/^ug?h+$/,za,"ughh"],[/^uh[ -]?oh$/,za,"uhoh"],[/[a-z]-ish$/,Ha,"cartoon-ish"]],i:[[/.[oau][wvl]ski$/,Ma,"polish-male"]],k:[[/^(k){2}$/,za,"kkkk"]],l:[[/.[gl]ial$/,Ha,"familial"],[/.[^aeiou]ful$/,Ha,"fitful"],[/.[nrtumcd]al$/,Ha,"natal"],[/.[^aeiou][ei]al$/,Ha,"familial"]],m:[[/.[^aeiou]ium$/,Oa,"magnesium"],[/[^aeiou]ism$/,Oa,"schism"],[/^[hu]m+$/,za,"hmm"],[/^\d+ ?[ap]m$/,"Date","3am"]],n:[[/.[lsrnpb]ian$/,Ha,"republican"],[/[^aeiou]ician$/,Ba,"musician"],[/[aeiou][ktrp]in'$/,"Gerund","cookin'"]],o:[[/^no+$/,za,"noooo"],[/^(yo)+$/,za,"yoo"],[/^wo{2,}[pt]?$/,za,"woop"]],r:[[/.[bdfklmst]ler$/,"Noun"],[/[aeiou][pns]er$/,Oa],[/[^i]fer$/,Ea],[/.[^aeiou][ao]pher$/,Ba],[/.[lk]er$/,"Noun"],[/.ier$/,"Comparative"]],t:[[/.[di]est$/,"Superlative"],[/.[icldtgrv]ent$/,Ha],[/[aeiou].*ist$/,Ha],[/^[a-z]et$/,Sa]],s:[[/.[^aeiou]ises$/,Ga],[/.[rln]ates$/,Ga],[/.[^z]ens$/,Sa],[/.[lstrn]us$/,Oa],[/.[aeiou]sks$/,Ga],[/.[aeiou]kes$/,Ga],[/[aeiou][^aeiou]is$/,Oa],[/[a-z]'s$/,$a],[/^yes+$/,za]],v:[[/.[^aeiou][ai][kln]ov$/,Ma]],y:[[/.[cts]hy$/,Ha],[/.[st]ty$/,Ha],[/.[tnl]ary$/,Ha],[/.[oe]ry$/,Oa],[/[rdntkbhs]ly$/,Va],[/.(gg|bb|zz)ly$/,Ha],[/...lly$/,Va],[/.[gk]y$/,Ha],[/[bszmp]{2}y$/,Ha],[/.[ai]my$/,Ha],[/[ea]{2}zy$/,Ha],[/.[^aeiou]ity$/,Oa]]};const Ka="Verb",Ja="Noun";var Wa={leftTags:[["Adjective",Ja],["Possessive",Ja],["Determiner",Ja],["Adverb",Ka],["Pronoun",Ka],["Value",Ja],["Ordinal",Ja],["Modal",Ka],["Superlative",Ja],["Demonym",Ja],["Honorific","Person"]],leftWords:[["i",Ka],["first",Ja],["it",Ka],["there",Ka],["not",Ka],["because",Ja],["if",Ja],["but",Ja],["who",Ka],["this",Ja],["his",Ja],["when",Ja],["you",Ka],["very","Adjective"],["old",Ja],["never",Ka],["before",Ja],["a",Ja],["the",Ja],["been",Ka]],rightTags:[["Copula",Ja],["PastTense",Ja],["Conjunction",Ja],["Modal",Ja]],rightWords:[["there",Ka],["me",Ka],["man","Adjective"],["him",Ka],["it",Ka],["were",Ja],["took",Ja],["himself",Ka],["went",Ja],["who",Ja],["jr","Person"]]},qa={fwd:"3:ser,ier¦1er:h,t,f,l,n¦1r:e¦2er:ss,or,om",both:"3er:ver,ear,alm¦3ner:hin¦3ter:lat¦2mer:im¦2er:ng,rm,mb¦2ber:ib¦2ger:ig¦1er:w,p,k,d¦ier:y",rev:"1:tter,yer¦2:uer,ver,ffer,oner,eler,ller,iler,ster,cer,uler,sher,ener,gher,aner,adder,nter,eter,rter,hter,rner,fter¦3:oser,ooler,eafer,user,airer,bler,maler,tler,eater,uger,rger,ainer,urer,ealer,icher,pler,emner,icter,nser,iser¦4:arser,viner,ucher,rosser,somer,ndomer,moter,oother,uarer,hiter¦5:nuiner,esser,emier¦ar:urther",ex:"worse:bad¦better:good¦4er:fair,gray,poor¦1urther:far¦3ter:fat,hot,wet¦3der:mad,sad¦3er:shy,fun¦4der:glad¦:¦4r:cute,dire,fake,fine,free,lame,late,pale,rare,ripe,rude,safe,sore,tame,wide¦5r:eerie,stale"},Ua={fwd:"1:nning,tting,rring,pping,eing,mming,gging,dding,bbing,kking¦2:eking,oling,eling,eming¦3:velling,siting,uiting,fiting,loting,geting,ialing,celling¦4:graming",both:"1:aing,iing,fing,xing,ying,oing,hing,wing¦2:tzing,rping,izzing,bting,mning,sping,wling,rling,wding,rbing,uping,lming,wning,mping,oning,lting,mbing,lking,fting,hting,sking,gning,pting,cking,ening,nking,iling,eping,ering,rting,rming,cting,lping,ssing,nting,nding,lding,sting,rning,rding,rking¦3:belling,siping,toming,yaking,uaking,oaning,auling,ooping,aiding,naping,euring,tolling,uzzing,ganing,haning,ualing,halling,iasing,auding,ieting,ceting,ouling,voring,ralling,garing,joring,oaming,oaking,roring,nelling,ooring,uelling,eaming,ooding,eaping,eeting,ooting,ooming,xiting,keting,ooking,ulling,airing,oaring,biting,outing,oiting,earing,naling,oading,eeding,ouring,eaking,aiming,illing,oining,eaning,onging,ealing,aining,eading¦4:thoming,melling,aboring,ivoting,weating,dfilling,onoring,eriting,imiting,tialling,rgining,otoring,linging,winging,lleting,louding,spelling,mpelling,heating,feating,opelling,choring,welling,ymaking,ctoring,calling,peating,iloring,laiting,utoring,uditing,mmaking,loating,iciting,waiting,mbating,voiding,otalling,nsoring,nselling,ocusing,itoring,eloping¦5:rselling,umpeting,atrolling,treating,tselling,rpreting,pringing,ummeting,ossoming,elmaking,eselling,rediting,totyping,onmaking,rfeiting,ntrolling¦5e:chmaking,dkeeping,severing,erouting,ecreting,ephoning,uthoring,ravening,reathing,pediting,erfering,eotyping,fringing,entoring,ombining,ompeting¦4e:emaking,eething,twining,rruling,chuting,xciting,rseding,scoping,edoring,pinging,lunging,agining,craping,pleting,eleting,nciting,nfining,ncoding,tponing,ecoding,writing,esaling,nvening,gnoring,evoting,mpeding,rvening,dhering,mpiling,storing,nviting,ploring¦3e:tining,nuring,saking,miring,haling,ceding,xuding,rining,nuting,laring,caring,miling,riding,hoking,piring,lading,curing,uading,noting,taping,futing,paring,hading,loding,siring,guring,vading,voking,during,niting,laning,caping,luting,muting,ruding,ciding,juring,laming,caling,hining,uoting,liding,ciling,duling,tuting,puting,cuting,coring,uiding,tiring,turing,siding,rading,enging,haping,buting,lining,taking,anging,haring,uiring,coming,mining,moting,suring,viding,luding¦2e:tring,zling,uging,oging,gling,iging,vring,fling,lging,obing,psing,pling,ubing,cling,dling,wsing,iking,rsing,dging,kling,ysing,tling,rging,eging,nsing,uning,osing,uming,using,ibing,bling,aging,ising,asing,ating¦2ie:rlying¦1e:zing,uing,cing,ving",rev:"ying:ie¦1ing:se,ke,te,we,ne,re,de,pe,me,le,c,he¦2ing:ll,ng,dd,ee,ye,oe,rg,us¦2ning:un¦2ging:og,ag,ug,ig,eg¦2ming:um¦2bing:ub,ab,eb,ob¦3ning:lan,can,hin,pin,win¦3ring:cur,lur,tir,tar,pur,car¦3ing:ait,del,eel,fin,eat,oat,eem,lel,ool,ein,uin¦3ping:rop,rap,top,uip,wap,hip,hop,lap,rip,cap¦3ming:tem,wim,rim,kim,lim¦3ting:mat,cut,pot,lit,lot,hat,set,pit,put¦3ding:hed,bed,bid¦3king:rek¦3ling:cil,pel¦3bing:rib¦4ning:egin¦4ing:isit,ruit,ilot,nsit,dget,rkel,ival,rcel¦4ring:efer,nfer¦4ting:rmit,mmit,ysit,dmit,emit,bmit,tfit,gret¦4ling:evel,xcel,ivel¦4ding:hred¦5ing:arget,posit,rofit¦5ring:nsfer¦5ting:nsmit,orget,cquit¦5ling:ancel,istil",ex:"3:adding,eating,aiming,aiding,airing,outing,gassing,setting,getting,putting,cutting,winning,sitting,betting,mapping,tapping,letting,bidding,hitting,tanning,netting,popping,fitting,capping,lapping,barring,banning,vetting,topping,rotting,tipping,potting,wetting,pitting,dipping,budding,hemming,pinning,jetting,kidding,padding,podding,sipping,wedding,bedding,donning,warring,penning,gutting,cueing,wadding,petting,ripping,napping,matting,tinning,binning,dimming,hopping,mopping,nodding,panning,rapping,ridding,sinning¦4:selling,falling,calling,waiting,editing,telling,rolling,heating,boating,hanging,beating,coating,singing,tolling,felling,polling,discing,seating,voiding,gelling,yelling,baiting,reining,ruining,seeking,spanning,stepping,knitting,emitting,slipping,quitting,dialing,omitting,clipping,shutting,skinning,abutting,flipping,trotting,cramming,fretting,suiting¦5:bringing,treating,spelling,stalling,trolling,expelling,rivaling,wringing,deterring,singeing,befitting,refitting¦6:enrolling,distilling,scrolling,strolling,caucusing,travelling¦7:installing,redefining,stencilling,recharging,overeating,benefiting,unraveling,programing¦9:reprogramming¦is:being¦2e:using,aging,owing¦3e:making,taking,coming,noting,hiring,filing,coding,citing,doping,baking,coping,hoping,lading,caring,naming,voting,riding,mining,curing,lining,ruling,typing,boring,dining,firing,hiding,piling,taping,waning,baling,boning,faring,honing,wiping,luring,timing,wading,piping,fading,biting,zoning,daring,waking,gaming,raking,ceding,tiring,coking,wining,joking,paring,gaping,poking,pining,coring,liming,toting,roping,wiring,aching¦4e:writing,storing,eroding,framing,smoking,tasting,wasting,phoning,shaking,abiding,braking,flaking,pasting,priming,shoring,sloping,withing,hinging¦5e:defining,refining,renaming,swathing,fringing,reciting¦1ie:dying,tying,lying,vying¦7e:sunbathing"},Ra={fwd:"1:mt¦2:llen¦3:iven,aken¦:ne¦y:in",both:"1:wn¦2:me,aten¦3:seen,bidden,isen¦4:roven,asten¦3l:pilt¦3d:uilt¦2e:itten¦1im:wum¦1eak:poken¦1ine:hone¦1ose:osen¦1in:gun¦1ake:woken¦ear:orn¦eal:olen¦eeze:ozen¦et:otten¦ink:unk¦ing:ung",rev:"2:un¦oken:eak¦ought:eek¦oven:eave¦1ne:o¦1own:ly¦1den:de¦1in:ay¦2t:am¦2n:ee¦3en:all¦4n:rive,sake,take¦5n:rgive",ex:"2:been¦3:seen,run¦4:given,taken¦5:shaken¦2eak:broken¦1ive:dove¦2y:flown¦3e:hidden,ridden¦1eek:sought¦1ake:woken¦1eave:woven"},Qa={fwd:"1:oes¦1ve:as",both:"1:xes¦2:zzes,ches,shes,sses¦3:iases¦2y:llies,plies¦1y:cies,bies,ties,vies,nies,pies,dies,ries,fies¦:s",rev:"1ies:ly¦2es:us,go,do¦3es:cho,eto",ex:"2:does,goes¦3:gasses¦5:focuses¦is:are¦3y:relies¦2y:flies¦2ve:has"},Za={fwd:"1st:e¦1est:l,m,f,s¦1iest:cey¦2est:or,ir¦3est:ver",both:"4:east¦5:hwest¦5lest:erful¦4est:weet,lgar,tter,oung¦4most:uter¦3est:ger,der,rey,iet,ong,ear¦3test:lat¦3most:ner¦2est:pt,ft,nt,ct,rt,ht¦2test:it¦2gest:ig¦1est:b,k,n,p,h,d,w¦iest:y",rev:"1:ttest,nnest,yest¦2:sest,stest,rmest,cest,vest,lmest,olest,ilest,ulest,ssest,imest,uest¦3:rgest,eatest,oorest,plest,allest,urest,iefest,uelest,blest,ugest,amest,yalest,ealest,illest,tlest,itest¦4:cerest,eriest,somest,rmalest,ndomest,motest,uarest,tiffest¦5:leverest,rangest¦ar:urthest¦3ey:riciest",ex:"best:good¦worst:bad¦5est:great¦4est:fast,full,fair,dull¦3test:hot,wet,fat¦4nest:thin¦1urthest:far¦3est:gay,shy,ill¦4test:neat¦4st:late,wide,fine,safe,cute,fake,pale,rare,rude,sore,ripe,dire¦6st:severe"},_a={fwd:"1:tistic,eable,lful,sful,ting,tty¦2:onate,rtable,geous,ced,seful,ctful¦3:ortive,ented¦arity:ear¦y:etic¦fulness:begone¦1ity:re¦1y:tiful,gic¦2ity:ile,imous,ilous,ime¦2ion:ated¦2eness:iving¦2y:trious¦2ation:iring¦2tion:vant¦3ion:ect¦3ce:mant,mantic¦3tion:irable¦3y:est,estic¦3m:mistic,listic¦3ess:ning¦4n:utious¦4on:rative,native,vative,ective¦4ce:erant",both:"1:king,wing¦2:alous,ltuous,oyful,rdous¦3:gorous,ectable,werful,amatic¦4:oised,usical,agical,raceful,ocused,lined,ightful¦5ness:stful,lding,itous,nuous,ulous,otous,nable,gious,ayful,rvous,ntous,lsive,peful,entle,ciful,osive,leful,isive,ncise,reful,mious¦5ty:ivacious¦5ties:ubtle¦5ce:ilient,adiant,atient¦5cy:icient¦5sm:gmatic¦5on:sessive,dictive¦5ity:pular,sonal,eative,entic¦5sity:uminous¦5ism:conic¦5nce:mperate¦5ility:mitable¦5ment:xcited¦5n:bitious¦4cy:brant,etent,curate¦4ility:erable,acable,icable,ptable¦4ty:nacious,aive,oyal,dacious¦4n:icious¦4ce:vient,erent,stent,ndent,dient,quent,ident¦4ness:adic,ound,hing,pant,sant,oing,oist,tute¦4icity:imple¦4ment:fined,mused¦4ism:otic¦4ry:dantic¦4ity:tund,eral¦4edness:hand¦4on:uitive¦4lity:pitable¦4sm:eroic,namic¦4sity:nerous¦3th:arm¦3ility:pable,bable,dable,iable¦3cy:hant,nant,icate¦3ness:red,hin,nse,ict,iet,ite,oud,ind,ied,rce¦3ion:lute¦3ity:ual,gal,volous,ial¦3ce:sent,fensive,lant,gant,gent,lent,dant¦3on:asive¦3m:fist,sistic,iastic¦3y:terious,xurious,ronic,tastic¦3ur:amorous¦3e:tunate¦3ation:mined¦3sy:rteous¦3ty:ain¦3ry:ave¦3ment:azed¦2ness:de,on,ue,rn,ur,ft,rp,pe,om,ge,rd,od,ay,ss,er,ll,oy,ap,ht,ld,ad,rt¦2inousness:umous¦2ity:neous,ene,id,ane¦2cy:bate,late¦2ation:ized¦2ility:oble,ible¦2y:odic¦2e:oving,aring¦2s:ost¦2itude:pt¦2dom:ee¦2ance:uring¦2tion:reet¦2ion:oted¦2sion:ending¦2liness:an¦2or:rdent¦1th:ung¦1e:uable¦1ness:w,h,k,f¦1ility:mble¦1or:vent¦1ement:ging¦1tiquity:ncient¦1ment:hed¦verty:or¦ength:ong¦eat:ot¦pth:ep¦iness:y",rev:"",ex:"5:forceful,humorous¦8:charismatic¦13:understanding¦5ity:active¦11ness:adventurous,inquisitive,resourceful¦8on:aggressive,automatic,perceptive¦7ness:amorous,fatuous,furtive,ominous,serious¦5ness:ample,sweet¦12ness:apprehensive,cantankerous,contemptuous,ostentatious¦13ness:argumentative,conscientious¦9ness:assertive,facetious,imperious,inventive,oblivious,rapacious,receptive,seditious,whimsical¦10ness:attractive,expressive,impressive,loquacious,salubrious,thoughtful¦3edom:boring¦4ness:calm,fast,keen,tame¦8ness:cheerful,gracious,specious,spurious,timorous,unctuous¦5sity:curious¦9ion:deliberate¦8ion:desperate¦6e:expensive¦7ce:fragrant¦3y:furious¦9ility:ineluctable¦6ism:mystical¦8ity:physical,proactive,sensitive,vertical¦5cy:pliant¦7ity:positive¦9ity:practical¦12ism:professional¦6ce:prudent¦3ness:red¦6cy:vagrant¦3dom:wise"};const Xa=function(e="",t={}){let n=function(e,t={}){return t.hasOwnProperty(e)?t[e]:null}(e,t.ex);return n=n||function(e,t=[]){for(let n=0;n=1;r-=1){let o=e.length-r,a=e.substring(o,e.length);if(!0===t.hasOwnProperty(a))return e.slice(0,o)+t[a];if(!0===n.hasOwnProperty(a))return e.slice(0,o)+n[a]}return t.hasOwnProperty("")?e+t[""]:n.hasOwnProperty("")?e+n[""]:null}(e,t.fwd,t.both),n=n||e,n},Ya=function(e){return Object.entries(e).reduce(((e,t)=>(e[t[1]]=t[0],e)),{})},ei=function(e={}){return{reversed:!0,both:Ya(e.both),ex:Ya(e.ex),fwd:e.rev||{}}},ti=/^([0-9]+)/,ni=function(e){let t=function(e){let t={};return e.split("¦").forEach((e=>{let[n,r]=e.split(":");r=(r||"").split(","),r.forEach((e=>{t[e]=n}))})),t}(e);return Object.keys(t).reduce(((e,n)=>(e[n]=function(e="",t=""){let n=(t=String(t)).match(ti);if(null===n)return t;let r=Number(n[1])||0;return e.substring(0,r)+t.replace(ti,"")}(n,t[n]),e)),{})},ri=function(e={}){return"string"==typeof e&&(e=JSON.parse(e)),e.fwd=ni(e.fwd||""),e.both=ni(e.both||""),e.rev=ni(e.rev||""),e.ex=ni(e.ex||""),e},oi=ri({fwd:"1:tted,wed,gged,nned,een,rred,pped,yed,bbed,oed,dded,rd,wn,mmed¦2:eed,nded,et,hted,st,oled,ut,emed,eled,lded,ken,rt,nked,apt,ant,eped,eked¦3:eared,eat,eaded,nelled,ealt,eeded,ooted,eaked,eaned,eeted,mited,bid,uit,ead,uited,ealed,geted,velled,ialed,belled¦4:ebuted,hined,comed¦y:ied¦ome:ame¦ear:ore¦ind:ound¦ing:ung,ang¦ep:pt¦ink:ank,unk¦ig:ug¦all:ell¦ee:aw¦ive:ave¦eeze:oze¦old:eld¦ave:ft¦ake:ook¦ell:old¦ite:ote¦ide:ode¦ine:one¦in:un,on¦eal:ole¦im:am¦ie:ay¦and:ood¦1ise:rose¦1eak:roke¦1ing:rought¦1ive:rove¦1el:elt¦1id:bade¦1et:got¦1y:aid¦1it:sat¦3e:lid¦3d:pent",both:"1:aed,fed,xed,hed¦2:sged,xted,wled,rped,lked,kied,lmed,lped,uped,bted,rbed,rked,wned,rled,mped,fted,mned,mbed,zzed,omed,ened,cked,gned,lted,sked,ued,zed,nted,ered,rted,rmed,ced,sted,rned,ssed,rded,pted,ved,cted¦3:cled,eined,siped,ooned,uked,ymed,jored,ouded,ioted,oaned,lged,asped,iged,mured,oided,eiled,yped,taled,moned,yled,lit,kled,oaked,gled,naled,fled,uined,oared,valled,koned,soned,aided,obed,ibed,meted,nicked,rored,micked,keted,vred,ooped,oaded,rited,aired,auled,filled,ouled,ooded,ceted,tolled,oited,bited,aped,tled,vored,dled,eamed,nsed,rsed,sited,owded,pled,sored,rged,osed,pelled,oured,psed,oated,loned,aimed,illed,eured,tred,ioned,celled,bled,wsed,ooked,oiled,itzed,iked,iased,onged,ased,ailed,uned,umed,ained,auded,nulled,ysed,eged,ised,aged,oined,ated,used,dged,doned¦4:ntied,efited,uaked,caded,fired,roped,halled,roked,himed,culed,tared,lared,tuted,uared,routed,pited,naked,miled,houted,helled,hared,cored,caled,tired,peated,futed,ciled,called,tined,moted,filed,sided,poned,iloted,honed,lleted,huted,ruled,cured,named,preted,vaded,sured,talled,haled,peded,gined,nited,uided,ramed,feited,laked,gured,ctored,unged,pired,cuted,voked,eloped,ralled,rined,coded,icited,vided,uaded,voted,mined,sired,noted,lined,nselled,luted,jured,fided,puted,piled,pared,olored,cided,hoked,enged,tured,geoned,cotted,lamed,uiled,waited,udited,anged,luded,mired,uired,raded¦5:modelled,izzled,eleted,umpeted,ailored,rseded,treated,eduled,ecited,rammed,eceded,atrolled,nitored,basted,twined,itialled,ncited,gnored,ploded,xcited,nrolled,namelled,plored,efeated,redited,ntrolled,nfined,pleted,llided,lcined,eathed,ibuted,lloted,dhered,cceded¦3ad:sled¦2aw:drew¦2ot:hot¦2ke:made¦2ow:hrew,grew¦2ose:hose¦2d:ilt¦2in:egan¦1un:ran¦1ink:hought¦1ick:tuck¦1ike:ruck¦1eak:poke,nuck¦1it:pat¦1o:did¦1ow:new¦1ake:woke¦go:went",rev:"3:rst,hed,hut,cut,set¦4:tbid¦5:dcast,eread,pread,erbid¦ought:uy,eek¦1ied:ny,ly,dy,ry,fy,py,vy,by,ty,cy¦1ung:ling,ting,wing¦1pt:eep¦1ank:rink¦1ore:bear,wear¦1ave:give¦1oze:reeze¦1ound:rind,wind¦1ook:take,hake¦1aw:see¦1old:sell¦1ote:rite¦1ole:teal¦1unk:tink¦1am:wim¦1ay:lie¦1ood:tand¦1eld:hold¦2d:he,ge,re,le,leed,ne,reed,be,ye,lee,pe,we¦2ed:dd,oy,or,ey,gg,rr,us,ew,to¦2ame:ecome,rcome¦2ped:ap¦2ged:ag,og,ug,eg¦2bed:ub,ab,ib,ob¦2lt:neel¦2id:pay¦2ang:pring¦2ove:trive¦2med:um¦2ode:rride¦2at:ysit¦3ted:mit,hat,mat,lat,pot,rot,bat¦3ed:low,end,tow,und,ond,eem,lay,cho,dow,xit,eld,ald,uld,law,lel,eat,oll,ray,ank,fin,oam,out,how,iek,tay,haw,ait,vet,say,cay,bow¦3d:ste,ede,ode,ete,ree,ude,ame,oke,ote,ime,ute,ade¦3red:lur,cur,pur,car¦3ped:hop,rop,uip,rip,lip,tep,top¦3ded:bed,rod,kid¦3ade:orbid¦3led:uel¦3ned:lan,can,kin,pan,tun¦3med:rim,lim¦4ted:quit,llot¦4ed:pear,rrow,rand,lean,mand,anel,pand,reet,link,abel,evel,imit,ceed,ruit,mind,peal,veal,hool,head,pell,well,mell,uell,band,hear,weak¦4led:nnel,qual,ebel,ivel¦4red:nfer,efer,sfer¦4n:sake,trew¦4d:ntee¦4ded:hred¦4ned:rpin¦5ed:light,nceal,right,ndear,arget,hread,eight,rtial,eboot¦5d:edite,nvite¦5ted:egret¦5led:ravel",ex:"2:been,upped¦3:added,aged,aided,aimed,aired,bid,died,dyed,egged,erred,eyed,fit,gassed,hit,lied,owed,pent,pied,tied,used,vied,oiled,outed,banned,barred,bet,canned,cut,dipped,donned,ended,feed,inked,jarred,let,manned,mowed,netted,padded,panned,pitted,popped,potted,put,set,sewn,sowed,tanned,tipped,topped,vowed,weed,bowed,jammed,binned,dimmed,hopped,mopped,nodded,pinned,rigged,sinned,towed,vetted¦4:ached,baked,baled,boned,bored,called,caned,cared,ceded,cited,coded,cored,cubed,cured,dared,dined,edited,exited,faked,fared,filed,fined,fired,fuelled,gamed,gelled,hired,hoped,joked,lined,mined,named,noted,piled,poked,polled,pored,pulled,reaped,roamed,rolled,ruled,seated,shed,sided,timed,tolled,toned,voted,waited,walled,waned,winged,wiped,wired,zoned,yelled,tamed,lubed,roped,faded,mired,caked,honed,banged,culled,heated,raked,welled,banded,beat,cast,cooled,cost,dealt,feared,folded,footed,handed,headed,heard,hurt,knitted,landed,leaked,leapt,linked,meant,minded,molded,neared,needed,peaked,plodded,plotted,pooled,quit,read,rooted,sealed,seeded,seeped,shipped,shunned,skimmed,slammed,sparred,stemmed,stirred,suited,thinned,twinned,swayed,winked,dialed,abutted,blotted,fretted,healed,heeded,peeled,reeled¦5:basted,cheated,equalled,eroded,exiled,focused,opined,pleated,primed,quoted,scouted,shored,sloped,smoked,sniped,spelled,spouted,routed,staked,stored,swelled,tasted,treated,wasted,smelled,dwelled,honored,prided,quelled,eloped,scared,coveted,sweated,breaded,cleared,debuted,deterred,freaked,modeled,pleaded,rebutted,speeded¦6:anchored,defined,endured,impaled,invited,refined,revered,strolled,cringed,recast,thrust,unfolded¦7:authored,combined,competed,conceded,convened,excreted,extruded,redefined,restored,secreted,rescinded,welcomed¦8:expedited,infringed¦9:interfered,intervened,persevered¦10:contravened¦eat:ate¦is:was¦go:went¦are:were¦3d:bent,lent,rent,sent¦3e:bit,fled,hid,lost¦3ed:bled,bred¦2ow:blew,grew¦1uy:bought¦2tch:caught¦1o:did¦1ive:dove,gave¦2aw:drew¦2ed:fed¦2y:flew,laid,paid,said¦1ight:fought¦1et:got¦2ve:had¦1ang:hung¦2ad:led¦2ght:lit¦2ke:made¦2et:met¦1un:ran¦1ise:rose¦1it:sat¦1eek:sought¦1each:taught¦1ake:woke,took¦1eave:wove¦2ise:arose¦1ear:bore,tore,wore¦1ind:bound,found,wound¦2eak:broke¦2ing:brought,wrung¦1ome:came¦2ive:drove¦1ig:dug¦1all:fell¦2el:felt¦4et:forgot¦1old:held¦2ave:left¦1ing:rang,sang¦1ide:rode¦1ink:sank¦1ee:saw¦2ine:shone¦4e:slid¦1ell:sold,told¦4d:spent¦2in:spun¦1in:won"}),ai=ri(Qa),ii=ri(Ua),si=ri(Ra),li=ei(oi),ui=ei(ai),ci=ei(ii),hi=ei(si),di=ri(qa),gi=ri(Za);var mi={fromPast:oi,fromPresent:ai,fromGerund:ii,fromParticiple:si,toPast:li,toPresent:ui,toGerund:ci,toParticiple:hi,toComparative:di,toSuperlative:gi,fromComparative:ei(di),fromSuperlative:ei(gi),adjToNoun:ri(_a)},pi=["academy","administration","agence","agences","agencies","agency","airlines","airways","army","assoc","associates","association","assurance","authority","autorite","aviation","bank","banque","board","boys","brands","brewery","brotherhood","brothers","bureau","cafe","co","caisse","capital","care","cathedral","center","centre","chemicals","choir","chronicle","church","circus","clinic","clinique","club","co","coalition","coffee","collective","college","commission","committee","communications","community","company","comprehensive","computers","confederation","conference","conseil","consulting","containers","corporation","corps","corp","council","crew","data","departement","department","departments","design","development","directorate","division","drilling","education","eglise","electric","electricity","energy","ensemble","enterprise","enterprises","entertainment","estate","etat","faculty","faction","federation","financial","fm","foundation","fund","gas","gazette","girls","government","group","guild","herald","holdings","hospital","hotel","hotels","inc","industries","institut","institute","institutes","insurance","international","interstate","investment","investments","investors","journal","laboratory","labs","llc","ltd","limited","machines","magazine","management","marine","marketing","markets","media","memorial","ministere","ministry","military","mobile","motor","motors","musee","museum","news","observatory","office","oil","optical","orchestra","organization","partners","partnership","petrol","petroleum","pharmacare","pharmaceutical","pharmaceuticals","pizza","plc","police","politburo","polytechnic","post","power","press","productions","quartet","radio","reserve","resources","restaurant","restaurants","savings","school","securities","service","services","societe","subsidiary","society","sons","subcommittee","syndicat","systems","telecommunications","telegraph","television","times","tribunal","tv","union","university","utilities","workers"].reduce(((e,t)=>(e[t]=!0,e)),{}),fi=["atoll","basin","bay","beach","bluff","bog","camp","canyon","canyons","cape","cave","caves","cliffs","coast","cove","coves","crater","crossing","creek","desert","dune","dunes","downs","estates","escarpment","estuary","falls","fjord","fjords","forest","forests","glacier","gorge","gorges","grove","gulf","gully","highland","heights","hollow","hill","hills","inlet","island","islands","isthmus","junction","knoll","lagoon","lake","lakeshore","marsh","marshes","mount","mountain","mountains","narrows","peninsula","plains","plateau","pond","rapids","ravine","reef","reefs","ridge","river","rivers","sandhill","shoal","shore","shoreline","shores","strait","straits","springs","stream","swamp","tombolo","trail","trails","trench","valley","vallies","village","volcano","waterfall","watershed","wetland","woods","acres","burough","county","district","municipality","prefecture","province","region","reservation","state","territory","borough","metropolis","downtown","uptown","midtown","city","town","township","hamlet","country","kingdom","enclave","neighbourhood","neighborhood","kingdom","ward","zone","airport","amphitheater","arch","arena","auditorium","bar","barn","basilica","battlefield","bridge","building","castle","centre","coliseum","cineplex","complex","dam","farm","field","fort","garden","gardens","gymnasium","hall","house","levee","library","manor","memorial","monument","museum","gallery","palace","pillar","pits","plantation","playhouse","quarry","sportsfield","sportsplex","stadium","terrace","terraces","theater","tower","park","parks","site","ranch","raceway","sportsplex","ave","st","street","rd","road","lane","landing","crescent","cr","way","tr","terrace","avenue"].reduce(((e,t)=>(e[t]=!0,e)),{}),bi=[[/([^v])ies$/i,"$1y"],[/(ise)s$/i,"$1"],[/(kn|[^o]l|w)ives$/i,"$1ife"],[/^((?:ca|e|ha|(?:our|them|your)?se|she|wo)l|lea|loa|shea|thie)ves$/i,"$1f"],[/^(dwar|handkerchie|hoo|scar|whar)ves$/i,"$1f"],[/(antenn|formul|nebul|vertebr|vit)ae$/i,"$1a"],[/(octop|vir|radi|nucle|fung|cact|stimul)(i)$/i,"$1us"],[/(buffal|tomat|tornad)(oes)$/i,"$1o"],[/(ause)s$/i,"$1"],[/(ease)s$/i,"$1"],[/(ious)es$/i,"$1"],[/(ouse)s$/i,"$1"],[/(ose)s$/i,"$1"],[/(..ase)s$/i,"$1"],[/(..[aeiu]s)es$/i,"$1"],[/(vert|ind|cort)(ices)$/i,"$1ex"],[/(matr|append)(ices)$/i,"$1ix"],[/([xo]|ch|ss|sh)es$/i,"$1"],[/men$/i,"man"],[/(n)ews$/i,"$1ews"],[/([ti])a$/i,"$1um"],[/([^aeiouy]|qu)ies$/i,"$1y"],[/(s)eries$/i,"$1eries"],[/(m)ovies$/i,"$1ovie"],[/(cris|ax|test)es$/i,"$1is"],[/(alias|status)es$/i,"$1"],[/(ss)$/i,"$1"],[/(ic)s$/i,"$1"],[/s$/i,""]];const vi=function(e,t){const{irregularPlurals:n}=t.two,r=(o=n,Object.keys(o).reduce(((e,t)=>(e[o[t]]=t,e)),{}));var o;if(r.hasOwnProperty(e))return r[e];for(let t=0;t(wi[t].forEach((n=>e[n]=t)),e)),{});const ki=function(e){const t=e.substring(e.length-3);if(!0===wi.hasOwnProperty(t))return wi[t];const n=e.substring(e.length-2);if(!0===wi.hasOwnProperty(n))return wi[n];return"s"===e.substring(e.length-1)?"PresentTense":null},Pi={are:"be",were:"be",been:"be",is:"be",am:"be",was:"be",be:"be",being:"be"},Ai=function(e,t,n){const{fromPast:r,fromPresent:o,fromGerund:a,fromParticiple:i}=t.two.models,{prefix:s,verb:l,particle:u}=function(e,t){let n="",r={};t.one&&t.one.prefixes&&(r=t.one.prefixes);let[o,a]=e.split(/ /);return a&&!0===r[o]&&(n=o,o=a,a=""),{prefix:n,verb:o,particle:a}}(e,t);let c="";if(n||(n=ki(e)),Pi.hasOwnProperty(e))c=Pi[e];else if("Participle"===n)c=Xa(l,i);else if("PastTense"===n)c=Xa(l,r);else if("PresentTense"===n)c=Xa(l,o);else{if("Gerund"!==n)return e;c=Xa(l,a)}return u&&(c+=" "+u),s&&(c=s+" "+c),c},Ci=function(e,t){const{toPast:n,toPresent:r,toGerund:o,toParticiple:a}=t.two.models;if("be"===e)return{Infinitive:e,Gerund:"being",PastTense:"was",PresentTense:"is"};const[i,s]=(e=>/ /.test(e)?e.split(/ /):[e,""])(e),l={Infinitive:i,PastTense:Xa(i,n),PresentTense:Xa(i,r),Gerund:Xa(i,o),FutureTense:"will "+i};let u=Xa(i,a);if(u!==e&&u!==l.PastTense){const n=t.one.lexicon||{};"Participle"!==n[u]&&"Adjective"!==n[u]||("play"===e&&(u="played"),l.Participle=u)}return s&&Object.keys(l).forEach((e=>{l[e]+=" "+s})),l};var Ni={toInfinitive:Ai,conjugate:Ci,all:function(e,t){const n=Ci(e,t);return delete n.FutureTense,Object.values(n).filter((e=>e))}};const ji=function(e,t){const n=t.two.models.toSuperlative;return Xa(e,n)},xi=function(e,t){const n=t.two.models.toComparative;return Xa(e,n)},Ii=function(e="",t=[]){const n=e.length;for(let r=n<=6?n-1:6;r>=1;r-=1){const o=e.substring(n-r,e.length);if(!0===t[o.length].hasOwnProperty(o)){return e.slice(0,n-r)+t[o.length][o]}}return null},Ti="ically",Di=new Set(["analyt"+Ti,"chem"+Ti,"class"+Ti,"clin"+Ti,"crit"+Ti,"ecolog"+Ti,"electr"+Ti,"empir"+Ti,"frant"+Ti,"grammat"+Ti,"ident"+Ti,"ideolog"+Ti,"log"+Ti,"mag"+Ti,"mathemat"+Ti,"mechan"+Ti,"med"+Ti,"method"+Ti,"method"+Ti,"mus"+Ti,"phys"+Ti,"phys"+Ti,"polit"+Ti,"pract"+Ti,"rad"+Ti,"satir"+Ti,"statist"+Ti,"techn"+Ti,"technolog"+Ti,"theoret"+Ti,"typ"+Ti,"vert"+Ti,"whims"+Ti]),Hi=[null,{},{ly:""},{ily:"y",bly:"ble",ply:"ple"},{ally:"al",rply:"rp"},{ually:"ual",ially:"ial",cally:"cal",eally:"eal",rally:"ral",nally:"nal",mally:"mal",eeply:"eep",eaply:"eap"},{ically:"ic"}],Ei=new Set(["early","only","hourly","daily","weekly","monthly","yearly","mostly","duly","unduly","especially","undoubtedly","conversely","namely","exceedingly","presumably","accordingly","overly","best","latter","little","long","low"]),Gi={wholly:"whole",fully:"full",truly:"true",gently:"gentle",singly:"single",customarily:"customary",idly:"idle",publically:"public",quickly:"quick",superbly:"superb",cynically:"cynical",well:"good"},Oi=[null,{y:"ily"},{ly:"ly",ic:"ically"},{ial:"ially",ual:"ually",tle:"tly",ble:"bly",ple:"ply",ary:"arily"},{},{},{}],Fi={cool:"cooly",whole:"wholly",full:"fully",good:"well",idle:"idly",public:"publicly",single:"singly",special:"especially"},Vi=function(e){if(Fi.hasOwnProperty(e))return Fi[e];let t=Ii(e,Oi);return t||(t=e+"ly"),t};var zi={toSuperlative:ji,toComparative:xi,toAdverb:Vi,toNoun:function(e,t){const n=t.two.models.adjToNoun;return Xa(e,n)},fromAdverb:function(e){return e.endsWith("ly")?Di.has(e)?e.replace(/ically/,"ical"):Ei.has(e)?null:Gi.hasOwnProperty(e)?Gi[e]:Ii(e,Hi)||e:null},fromSuperlative:function(e,t){const n=t.two.models.fromSuperlative;return Xa(e,n)},fromComparative:function(e,t){const n=t.two.models.fromComparative;return Xa(e,n)},all:function(e,t){let n=[e];return n.push(ji(e,t)),n.push(xi(e,t)),n.push(Vi(e)),n=n.filter((e=>e)),n=new Set(n),Array.from(n)}},Bi={noun:yi,verb:Ni,adjective:zi},Si={Singular:(e,t,n,r)=>{const o=r.one.lexicon,a=n.two.transform.noun.toPlural(e,r);o[a]||(t[a]=t[a]||"Plural")},Actor:(e,t,n,r)=>{const o=r.one.lexicon,a=n.two.transform.noun.toPlural(e,r);o[a]||(t[a]=t[a]||["Plural","Actor"])},Comparable:(e,t,n,r)=>{const o=r.one.lexicon,{toSuperlative:a,toComparative:i}=n.two.transform.adjective,s=a(e,r);o[s]||(t[s]=t[s]||"Superlative");const l=i(e,r);o[l]||(t[l]=t[l]||"Comparative"),t[e]="Adjective"},Demonym:(e,t,n,r)=>{const o=n.two.transform.noun.toPlural(e,r);t[o]=t[o]||["Demonym","Plural"]},Infinitive:(e,t,n,r)=>{const o=r.one.lexicon,a=n.two.transform.verb.conjugate(e,r);Object.entries(a).forEach((e=>{o[e[1]]||t[e[1]]||"FutureTense"===e[0]||(t[e[1]]=e[0])}))},PhrasalVerb:(e,t,n,r)=>{const o=r.one.lexicon;t[e]=["PhrasalVerb","Infinitive"];const a=r.one._multiCache,[i,s]=e.split(" ");o[i]||(t[i]=t[i]||"Infinitive");const l=n.two.transform.verb.conjugate(i,r);delete l.FutureTense,Object.entries(l).forEach((e=>{if("Actor"===e[0]||""===e[1])return;t[e[1]]||o[e[1]]||(t[e[1]]=e[0]),a[e[1]]=2;const n=e[1]+" "+s;t[n]=t[n]||[e[0],"PhrasalVerb"]}))},Multiple:(e,t)=>{t[e]=["Multiple","Cardinal"],t[e+"th"]=["Multiple","Ordinal"],t[e+"ths"]=["Multiple","Fraction"]},Cardinal:(e,t)=>{t[e]=["TextValue","Cardinal"]},Ordinal:(e,t)=>{t[e]=["TextValue","Ordinal"],t[e+"s"]=["TextValue","Fraction"]},Place:(e,t)=>{t[e]=["Place","ProperNoun"]},Region:(e,t)=>{t[e]=["Region","ProperNoun"]}};const $i={e:["mice","louse","antennae","formulae","nebulae","vertebrae","vitae"],i:["tia","octopi","viri","radii","nuclei","fungi","cacti","stimuli"],n:["men"],t:["feet"]},Mi=new Set(["israelis","menus","logos"]),Li=["bus","mas","was","ias","xas","vas","cis","lis","nis","ois","ris","sis","tis","xis","aus","cus","eus","fus","gus","ius","lus","nus","das","ous","pus","rus","sus","tus","xus","aos","igos","ados","ogos","'s","ss"],Ki=function(e){if(!e||e.length<=3)return!1;if(Mi.has(e))return!0;const t=e[e.length-1];return $i.hasOwnProperty(t)?$i[t].find((t=>e.endsWith(t))):"s"===t&&!Li.find((t=>e.endsWith(t)))};var Ji={two:{quickSplit:function(e){const t=/[,:;]/,n=[];return e.forEach((e=>{let r=0;e.forEach(((o,a)=>{t.test(o.post)&&function(e,t){const n=/^[0-9]+$/,r=e[t];if(!r)return!1;const o=new Set(["may","april","august","jan"]);if("like"===r.normal||o.has(r.normal))return!1;if(r.tags.has("Place")||r.tags.has("Date"))return!1;if(e[t-1]){const n=e[t-1];if(n.tags.has("Date")||o.has(n.normal))return!1;if(n.tags.has("Adjective")||r.tags.has("Adjective"))return!1}const a=r.normal;return 1!==a.length&&2!==a.length&&4!==a.length||!n.test(a)}(e,a+1)&&(n.push(e.slice(r,a+1)),r=a+1)})),r{const i=e[t],s=(t=(t=t.toLowerCase().trim()).replace(/'s\b/,"")).split(/ /);s.length>1&&(void 0===a[s[0]]||s.length>a[s[0]])&&(a[s[0]]=s.length),!0===Si.hasOwnProperty(i)&&Si[i](t,o,n,r),o[t]=o[t]||i})),delete o[""],delete o.null,delete o[" "],{lex:o,_multi:a}},transform:Bi,looksPlural:Ki}};const Wi={one:{lexicon:{}},two:{models:mi}},qi={"Actor|Verb":"Actor","Adj|Gerund":"Adjective","Adj|Noun":"Adjective","Adj|Past":"Adjective","Adj|Present":"Adjective","Noun|Verb":"Singular","Noun|Gerund":"Gerund","Person|Noun":"Noun","Person|Date":"Month","Person|Verb":"FirstName","Person|Place":"Person","Person|Adj":"Comparative","Plural|Verb":"Plural","Unit|Noun":"Noun"},Ui=function(e,t){const n={model:t,methods:Ji},{lex:r,_multi:o}=Ji.two.expandLexicon(e,n);return Object.assign(t.one.lexicon,r),Object.assign(t.one._multiCache,o),t},Ri=function(e,t,n){const r=Ci(e,Wi);t[r.PastTense]=t[r.PastTense]||"PastTense",t[r.Gerund]=t[r.Gerund]||"Gerund",!0===n&&(t[r.PresentTense]=t[r.PresentTense]||"PresentTense")},Qi=function(e,t,n){const r=ji(e,n);t[r]=t[r]||"Superlative";const o=xi(e,n);t[o]=t[o]||"Comparative"},Zi=function(e,t){const n={},r=t.one.lexicon;return Object.keys(e).forEach((o=>{const a=e[o];if(n[o]=qi[a],"Noun|Verb"!==a&&"Person|Verb"!==a&&"Actor|Verb"!==a||Ri(o,r,!1),"Adj|Present"===a&&(Ri(o,r,!0),Qi(o,r,t)),"Person|Adj"===a&&Qi(o,r,t),"Adj|Gerund"===a||"Noun|Gerund"===a){const e=Ai(o,Wi,"Gerund");r[e]||(n[e]="Infinitive")}if("Noun|Gerund"!==a&&"Adj|Noun"!==a&&"Person|Noun"!==a||function(e,t,n){const r=Ao(e,n);t[r]=t[r]||"Plural"}(o,r,t),"Adj|Past"===a){const e=Ai(o,Wi,"PastTense");r[e]||(n[e]="Infinitive")}})),t=Ui(n,t)};let _i={one:{_multiCache:{},lexicon:No,frozenLex:{"20th century fox":"Organization","7 eleven":"Organization","motel 6":"Organization","excuse me":"Expression","financial times":"Organization","guns n roses":"Organization","la z boy":"Organization","labour party":"Organization","new kids on the block":"Organization","new york times":"Organization","the guess who":"Organization","thin lizzy":"Organization","prime minister":"Actor","free market":"Singular","lay up":"Singular","living room":"Singular","living rooms":"Plural","spin off":"Singular","appeal court":"Uncountable","cold war":"Uncountable","gene pool":"Uncountable","machine learning":"Uncountable","nail polish":"Uncountable","time off":"Uncountable","take part":"Infinitive","bill gates":"Person","doctor who":"Person","dr who":"Person","he man":"Person","iron man":"Person","kid cudi":"Person","run dmc":"Person","rush limbaugh":"Person","snow white":"Person","tiger woods":"Person","brand new":"Adjective","en route":"Adjective","left wing":"Adjective","off guard":"Adjective","on board":"Adjective","part time":"Adjective","right wing":"Adjective","so called":"Adjective","spot on":"Adjective","straight forward":"Adjective","super duper":"Adjective","tip top":"Adjective","top notch":"Adjective","up to date":"Adjective","win win":"Adjective","brooklyn nets":"SportsTeam","chicago bears":"SportsTeam","houston astros":"SportsTeam","houston dynamo":"SportsTeam","houston rockets":"SportsTeam","houston texans":"SportsTeam","minnesota twins":"SportsTeam","orlando magic":"SportsTeam","san antonio spurs":"SportsTeam","san diego chargers":"SportsTeam","san diego padres":"SportsTeam","iron maiden":"ProperNoun","isle of man":"Country","united states":"Country","united states of america":"Country","prince edward island":"Region","cedar breaks":"Place","cedar falls":"Place","point blank":"Adverb","tiny bit":"Adverb","by the time":"Conjunction","no matter":"Conjunction","civil wars":"Plural","credit cards":"Plural","default rates":"Plural","free markets":"Plural","head starts":"Plural","home runs":"Plural","lay ups":"Plural","phone calls":"Plural","press releases":"Plural","record labels":"Plural","soft serves":"Plural","student loans":"Plural","tax returns":"Plural","tv shows":"Plural","video games":"Plural","took part":"PastTense","takes part":"PresentTense","taking part":"Gerund","taken part":"Participle","light bulb":"Noun","rush hour":"Noun","fluid ounce":"Unit","the rolling stones":"Organization"}},two:{irregularPlurals:ho,models:mi,suffixPatterns:ja,prefixPatterns:Da,endsWith:La,neighbours:Wa,regexNormal:[[/^[\w.]+@[\w.]+\.[a-z]{2,3}$/,"Email"],[/^(https?:\/\/|www\.)+\w+\.[a-z]{2,3}/,"Url","http.."],[/^[a-z0-9./].+\.(com|net|gov|org|ly|edu|info|biz|dev|ru|jp|de|in|uk|br|io|ai)/,"Url",".com"],[/^[PMCE]ST$/,"Timezone","EST"],[/^ma?c'[a-z]{3}/,"LastName","mc'neil"],[/^o'[a-z]{3}/,"LastName","o'connor"],[/^ma?cd[aeiou][a-z]{3}/,"LastName","mcdonald"],[/^(lol)+[sz]$/,"Expression","lol"],[/^wo{2,}a*h?$/,"Expression","wooah"],[/^(hee?){2,}h?$/,"Expression","hehe"],[/^(un|de|re)\\-[a-z\u00C0-\u00FF]{2}/,"Verb","un-vite"],[/^(m|k|cm|km)\/(s|h|hr)$/,"Unit","5 k/m"],[/^(ug|ng|mg)\/(l|m3|ft3)$/,"Unit","ug/L"],[/[^:/]\/\p{Letter}/u,"SlashedTerm","love/hate"]],regexText:[[/^#[\p{Number}_]*\p{Letter}/u,"HashTag"],[/^@\w{2,}$/,"AtMention"],[/^([A-Z]\.){2}[A-Z]?/i,["Acronym","Noun"],"F.B.I"],[/.{3}[lkmnp]in['‘’‛‵′`´]$/,"Gerund","chillin'"],[/.{4}s['‘’‛‵′`´]$/,"Possessive","flanders'"],[/^[\p{Emoji_Presentation}\p{Extended_Pictographic}]/u,"Emoji","emoji-class"]],regexNumbers:[[/^@1?[0-9](am|pm)$/i,"Time","3pm"],[/^@1?[0-9]:[0-9]{2}(am|pm)?$/i,"Time","3:30pm"],[/^'[0-9]{2}$/,"Year"],[/^[012]?[0-9](:[0-5][0-9])(:[0-5][0-9])$/,"Time","3:12:31"],[/^[012]?[0-9](:[0-5][0-9])?(:[0-5][0-9])? ?(am|pm)$/i,"Time","1:12pm"],[/^[012]?[0-9](:[0-5][0-9])(:[0-5][0-9])? ?(am|pm)?$/i,"Time","1:12:31pm"],[/^[0-9]{4}-[0-9]{2}-[0-9]{2}T[0-9]{2}:[0-9]{2}/i,"Date","iso-date"],[/^[0-9]{1,4}-[0-9]{1,2}-[0-9]{1,4}$/,"Date","iso-dash"],[/^[0-9]{1,4}\/[0-9]{1,2}\/([0-9]{4}|[0-9]{2})$/,"Date","iso-slash"],[/^[0-9]{1,4}\.[0-9]{1,2}\.[0-9]{1,4}$/,"Date","iso-dot"],[/^[0-9]{1,4}-[a-z]{2,9}-[0-9]{1,4}$/i,"Date","12-dec-2019"],[/^utc ?[+-]?[0-9]+$/,"Timezone","utc-9"],[/^(gmt|utc)[+-][0-9]{1,2}$/i,"Timezone","gmt-3"],[/^[0-9]{3}-[0-9]{4}$/,"PhoneNumber","421-0029"],[/^(\+?[0-9][ -])?[0-9]{3}[ -]?[0-9]{3}-[0-9]{4}$/,"PhoneNumber","1-800-"],[/^[-+]?\p{Currency_Symbol}[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?([kmb]|bn)?\+?$/u,["Money","Value"],"$5.30"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?\p{Currency_Symbol}\+?$/u,["Money","Value"],"5.30£"],[/^[-+]?[$£]?[0-9]([0-9,.])+(usd|eur|jpy|gbp|cad|aud|chf|cny|hkd|nzd|kr|rub)$/i,["Money","Value"],"$400usd"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?\+?$/,["Cardinal","NumericValue"],"5,999"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?(st|nd|rd|r?th)$/,["Ordinal","NumericValue"],"53rd"],[/^\.[0-9]+\+?$/,["Cardinal","NumericValue"],".73th"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?%\+?$/,["Percent","Cardinal","NumericValue"],"-4%"],[/^\.[0-9]+%$/,["Percent","Cardinal","NumericValue"],".3%"],[/^[0-9]{1,4}\/[0-9]{1,4}(st|nd|rd|th)?s?$/,["Fraction","NumericValue"],"2/3rds"],[/^[0-9.]{1,3}[a-z]{0,2}[-–—][0-9]{1,3}[a-z]{0,2}$/,["Value","NumberRange"],"3-4"],[/^[0-9]{1,2}(:[0-9][0-9])?(am|pm)? ?[-–—] ?[0-9]{1,2}(:[0-9][0-9])?(am|pm)$/,["Time","NumberRange"],"3-4pm"],[/^[0-9.]+([a-z°]{1,4})$/,"NumericValue","9km"]],switches:jo,clues:ca,uncountable:{},orgWords:pi,placeWords:fi}};_i=function(e){return e=function(e,t){return Object.keys(e).forEach((n=>{"Uncountable"===e[n]&&(t.two.uncountable[n]=!0,e[n]="Uncountable")})),t}((e=Ui(e.one.lexicon,e)).one.lexicon,e),e=function(e){const{irregularPlurals:t}=e.two,{lexicon:n}=e.one;return Object.entries(t).forEach((e=>{n[e[0]]=n[e[0]]||"Singular",n[e[1]]=n[e[1]]||"Plural"})),e}(e=Zi(e.two.switches,e)),e}(_i);const Xi=function(e,t,n,r){const o=r.methods.one.setTag;"-"===e[t].post&&e[t+1]&&o([e[t],e[t+1]],"Hyphenated",r,null,"1-punct-hyphen''")},Yi=/^(under|over|mis|re|un|dis|semi)-?/,es=function(e,t,n){const r=n.two.switches,o=e[t];if(r.hasOwnProperty(o.normal))o.switch=r[o.normal];else if(Yi.test(o.normal)){const e=o.normal.replace(Yi,"");e.length>3&&r.hasOwnProperty(e)&&(o.switch=r[e])}},ts=function(e,t,n){if(!t||0===t.length)return;if(!0===e.frozen)return;const r="undefined"!=typeof process&&process.env?process.env:self.env||{};r&&r.DEBUG_TAGS&&((e,t,n="")=>{const r=e.text||"["+e.implicit+"]";var o;"string"!=typeof t&&t.length>2&&(t=t.slice(0,2).join(", #")+" +"),t="string"!=typeof t?t.join(", #"):t,console.log(` ${(o=r,"�[33m�[3m"+o+"�[0m").padEnd(24)} �[32m→�[0m #${t.padEnd(22)} ${(e=>"�[3m"+e+"�[0m")(n)}`)})(e,t,n),e.tags=e.tags||new Set,"string"==typeof t?e.tags.add(t):t.forEach((t=>e.tags.add(t)))},ns=["Acronym","Abbreviation","ProperNoun","Uncountable","Possessive","Pronoun","Activity","Honorific","Month"],rs=function(e,t,n){const r=e[t],o=Array.from(r.tags);for(let e=0;ee.tags.has(t)))||(Ki(e.normal)?ts(e,"Plural","3-plural-guess"):ts(e,"Singular","3-singular-guess"))}(r),function(e){const t=e.tags;if(t.has("Verb")&&1===t.size){const t=ki(e.normal);t&&ts(e,t,"3-verb-tense-guess")}}(r)},os=/^\p{Lu}[\p{Ll}'’]/u,as=/[0-9]/,is=["Date","Month","WeekDay","Unit","Expression"],ss=/[IVX]/,ls=/^[IVXLCDM]{2,}$/,us=/^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$/,cs={li:!0,dc:!0,md:!0,dm:!0,ml:!0},hs=function(e,t,n){const r=e[t];r.index=r.index||[0,0];const o=r.index[1],a=r.text||"";return 0!==o&&!0===os.test(a)&&!1===as.test(a)?is.find((e=>r.tags.has(e)))||r.pre.match(/["']$/)||"the"===r.normal?null:(rs(e,t,n),r.tags.has("Noun")||r.frozen||r.tags.clear(),ts(r,"ProperNoun","2-titlecase"),!0):a.length>=2&&ls.test(a)&&ss.test(a)&&us.test(a)&&!cs[r.normal]?(ts(r,"RomanNumeral","2-xvii"),!0):null},ds=function(e="",t=[]){const n=e.length;let r=7;n<=r&&(r=n-1);for(let o=r;o>1;o-=1){const r=e.substring(n-o,n);if(!0===t[r.length].hasOwnProperty(r)){return t[r.length][r]}}return null},gs=function(e,t,n){const r=e[t];if(0===r.tags.size){let e=ds(r.normal,n.two.suffixPatterns);if(null!==e)return ts(r,e,"2-suffix"),r.confidence=.7,!0;if(r.implicit&&(e=ds(r.implicit,n.two.suffixPatterns),null!==e))return ts(r,e,"2-implicit-suffix"),r.confidence=.7,!0}return null},ms=/['‘’‛‵′`´]/,ps=function(e,t){for(let n=0;nn-3&&(r=n-3);for(let n=r;n>2;n-=1){const r=e.substring(0,n);if(!0===t[r.length].hasOwnProperty(r))return t[r.length][r]}return null}(r.normal,n.two.prefixPatterns);if(null!==e)return ts(r,e,"2-prefix"),r.confidence=.5,!0}return null},vs=new Set(["in","on","by","until","for","to","during","throughout","through","within","before","after","of","this","next","last","circa","around","post","pre","budget","classic","plan","may"]),ys=function(e){if(!e)return!1;const t=e.normal||e.implicit;return!!vs.has(t)||(!!(e.tags.has("Date")||e.tags.has("Month")||e.tags.has("WeekDay")||e.tags.has("Year"))||!!e.tags.has("ProperNoun"))},ws=function(e){return!!e&&(!!e.tags.has("Ordinal")||(!!(e.tags.has("Cardinal")&&e.normal.length<3)||("is"===e.normal||"was"===e.normal)))},ks=function(e){return e&&(e.tags.has("Date")||e.tags.has("Month")||e.tags.has("WeekDay")||e.tags.has("Year"))},Ps=function(e,t){const n=e[t];if(n.tags.has("NumericValue")&&n.tags.has("Cardinal")&&4===n.normal.length){const r=Number(n.normal);if(r&&!isNaN(r)&&r>1400&&r<2100){const o=e[t-1],a=e[t+1];if(ys(o)||ys(a))return ts(n,"Year","2-tagYear");if(r>=1920&&r<2025){if(ws(o)||ws(a))return ts(n,"Year","2-tagYear-close");if(ks(e[t-2])||ks(e[t+2]))return ts(n,"Year","2-tagYear-far");if(o&&(o.tags.has("Determiner")||o.tags.has("Possessive"))&&a&&a.tags.has("Noun")&&!a.tags.has("Plural"))return ts(n,"Year","2-tagYear-noun")}}}return null},As=function(e,t,n,r){const o=r.methods.one.setTag,a=e[t],i=["PastTense","PresentTense","Auxiliary","Modal","Particle"];if(a.tags.has("Verb")){i.find((e=>a.tags.has(e)))||o([a],"Infinitive",r,null,"2-verb-type''")}},Cs=/^[A-Z]('s|,)?$/,Ns=/^[A-Z-]+$/,js=/^[A-Z]+s$/,xs=/([A-Z]\.)+[A-Z]?,?$/,Is=/[A-Z]{2,}('s|,)?$/,Ts=/([a-z]\.)+[a-z]\.?$/,Ds={I:!0,A:!0},Hs={la:!0,ny:!0,us:!0,dc:!0,gb:!0},Es=function(e,t,n){const r=e[t];return r.tags.has("RomanNumeral")||r.tags.has("Acronym")||r.frozen?null:function(e,t){let n=e.text;if(!1===Ns.test(n)){if(!(n.length>3&&!0===js.test(n)))return!1;n=n.replace(/s$/,"")}return!(n.length>5||Ds.hasOwnProperty(n)||t.one.lexicon.hasOwnProperty(e.normal)||!0!==xs.test(n)&&!0!==Ts.test(n)&&!0!==Cs.test(n)&&!0!==Is.test(n))}(r,n)?(r.tags.clear(),ts(r,["Acronym","Noun"],"3-no-period-acronym"),!0===Hs[r.normal]&&ts(r,"Place","3-place-acronym"),!0===js.test(r.text)&&ts(r,"Plural","3-plural-acronym"),!0):!Ds.hasOwnProperty(r.text)&&Cs.test(r.text)?(r.tags.clear(),ts(r,["Acronym","Noun"],"3-one-letter-acronym"),!0):r.tags.has("Organization")&&r.text.length<=3?(ts(r,"Acronym","3-org-acronym"),!0):r.tags.has("Organization")&&Ns.test(r.text)&&r.text.length<=6?(ts(r,"Acronym","3-titlecase-acronym"),!0):null},Gs=function(e,t){if(!e)return null;const n=t.find((t=>e.normal===t[0]));return n?n[1]:null},Os=function(e,t){if(!e)return null;const n=t.find((t=>e.tags.has(t[0])));return n?n[1]:null},Fs=function(e,t,n){const{leftTags:r,leftWords:o,rightWords:a,rightTags:i}=n.two.neighbours,s=e[t];if(0===s.tags.size){let l=null;if(l=l||Gs(e[t-1],o),l=l||Gs(e[t+1],a),l=l||Os(e[t-1],r),l=l||Os(e[t+1],i),l)return ts(s,l,"3-[neighbour]"),rs(e,t,n),e[t].confidence=.2,!0}return null},Vs=function(e,t,n){return!!e&&(!e.tags.has("FirstName")&&!e.tags.has("Place")&&(!!(e.tags.has("ProperNoun")||e.tags.has("Organization")||e.tags.has("Acronym"))||!(n||(r=e.text,!/^\p{Lu}[\p{Ll}'’]/u.test(r)))&&(0!==t||e.tags.has("Singular"))));var r},zs=function(e,t,n,r){const o=n.model.two.orgWords,a=n.methods.one.setTag,i=e[t];if(!0===o[i.machine||i.normal]&&Vs(e[t-1],t-1,r)){a([e[t]],"Organization",n,null,"3-[org-word]");for(let o=t;o>=0&&Vs(e[o],o,r);o-=1)a([e[o]],"Organization",n,null,"3-[org-word]")}return null},Bs=/'s$/,Ss=new Set(["athletic","city","community","eastern","federal","financial","great","historic","historical","local","memorial","municipal","national","northern","provincial","southern","state","western","spring","pine","sunset","view","oak","maple","spruce","cedar","willow"]),$s=new Set(["center","centre","way","range","bar","bridge","field","pit"]),Ms=function(e,t,n){if(!e)return!1;const r=e.tags;return!(r.has("Organization")||r.has("Possessive")||Bs.test(e.normal))&&(!(!r.has("ProperNoun")&&!r.has("Place"))||!(n||(o=e.text,!/^\p{Lu}[\p{Ll}'’]/u.test(o)))&&(0!==t||r.has("Singular")));var o},Ls=function(e,t,n,r){const o=n.model.two.placeWords,a=n.methods.one.setTag,i=e[t],s=i.machine||i.normal;if(!0===o[s]){for(let o=t-1;o>=0;o-=1)if(!Ss.has(e[o].normal)){if(!Ms(e[o],o,r))break;a(e.slice(o,t+1),"Place",n,null,"3-[place-of-foo]")}if($s.has(s))return!1;for(let o=t+1;oe[t].tags.has("ProperNoun")&&Js.test(e[t].text)?"Noun":null,qs=(e,t,n)=>0!==t||e[1]?null:n,Us={"Adj|Gerund":(e,t)=>Ws(e,t),"Adj|Noun":(e,t)=>Ws(e,t)||function(e,t){return!e[t+1]&&e[t-1]&&e[t-1].tags.has("Determiner")?"Noun":null}(e,t),"Actor|Verb":(e,t)=>Ws(e,t),"Adj|Past":(e,t)=>Ws(e,t),"Adj|Present":(e,t)=>Ws(e,t),"Noun|Gerund":(e,t)=>Ws(e,t),"Noun|Verb":(e,t)=>t>0&&Ws(e,t)||qs(e,t,"Infinitive"),"Plural|Verb":(e,t)=>Ws(e,t)||qs(e,t,"PresentTense")||function(e,t,n){return 0===t&&e.length>3?n:null}(e,t,"Plural"),"Person|Noun":(e,t)=>Ws(e,t),"Person|Verb":(e,t)=>0!==t?Ws(e,t):null,"Person|Adj":(e,t)=>0===t&&e.length>1||Ws(e,t)?"Person":null},Rs="undefined"!=typeof process&&process.env?process.env:self.env||{},Qs=/^(under|over|mis|re|un|dis|semi)-?/,Zs=(e,t)=>{if(!e||!t)return null;const n=e.normal||e.implicit;let r=null;return t.hasOwnProperty(n)&&(r=t[n]),r&&Rs.DEBUG_TAGS&&console.log(`\n �[2m�[3m ↓ - '${n}' �[0m`),r},_s=(e,t={},n)=>{if(!e||!t)return null;const r=Array.from(e.tags).sort(((e,t)=>(n[e]?n[e].parents.length:0)>(n[t]?n[t].parents.length:0)?-1:1));let o=r.find((e=>t[e]));return o&&Rs.DEBUG_TAGS&&console.log(` �[2m�[3m ↓ - '${e.normal||e.implicit}' (#${o}) �[0m`),o=t[o],o},Xs=function(e,t,n){const r=n.model,o=n.methods.one.setTag,{switches:a,clues:i}=r.two,s=e[t];let l=s.normal||s.implicit||"";if(Qs.test(l)&&!a[l]&&(l=l.replace(Qs,"")),s.switch){const a=s.switch;if(s.tags.has("Acronym")||s.tags.has("PhrasalVerb"))return;let u=function(e,t,n,r){if(!n)return null;const o="also"!==e[t-1]?.text?t-1:Math.max(0,t-2),a=r.one.tagSet;let i=Zs(e[t+1],n.afterWords);return i=i||Zs(e[o],n.beforeWords),i=i||_s(e[o],n.beforeTags,a),i=i||_s(e[t+1],n.afterTags,a),i}(e,t,i[a],r);Us[a]&&(u=Us[a](e,t)||u),u?(o([s],u,n,null,`3-[switch] (${a})`),rs(e,t,r)):Rs.DEBUG_TAGS&&console.log(`\n -> X - '${l}' : (${a}) `)}},Ys={there:!0,this:!0,it:!0,him:!0,her:!0,us:!0},el=function(e){if(e.filter((e=>!e.tags.has("ProperNoun"))).length<=3)return!1;const t=/^[a-z]/;return e.every((e=>!t.test(e.text)))},tl=function(e,t,n,r){for(let o=0;o=2){if(e.length<4&&!Ys[e[1].normal])return;if(!o.tags.has("PhrasalVerb")&&r.hasOwnProperty(o.normal))return;(e[1].tags.has("Noun")||e[1].tags.has("Determiner"))&&(e.slice(1,3).some((e=>e.tags.has("Verb")))&&!o.tags.has("#PhrasalVerb")||n([o],"Imperative",t,null,"3-[imperative]"))}}(e,n)},rl={Possessive:e=>{let t=e.machine||e.normal||e.text;return t=t.replace(/'s$/,""),t},Plural:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.noun.toSingular(n,t.model)},Copula:()=>"is",PastTense:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.verb.toInfinitive(n,t.model,"PastTense")},Gerund:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.verb.toInfinitive(n,t.model,"Gerund")},PresentTense:(e,t)=>{const n=e.machine||e.normal||e.text;return e.tags.has("Infinitive")?n:t.methods.two.transform.verb.toInfinitive(n,t.model,"PresentTense")},Comparative:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.adjective.fromComparative(n,t.model)},Superlative:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.adjective.fromSuperlative(n,t.model)},Adverb:(e,t)=>{const{fromAdverb:n}=t.methods.two.transform.adjective;return n(e.machine||e.normal||e.text)}},ol={Adverb:"RB",Comparative:"JJR",Superlative:"JJS",Adjective:"JJ",TO:"Conjunction",Modal:"MD",Auxiliary:"MD",Gerund:"VBG",PastTense:"VBD",Participle:"VBN",PresentTense:"VBZ",Infinitive:"VB",Particle:"RP",Verb:"VB",Pronoun:"PRP",Cardinal:"CD",Conjunction:"CC",Determiner:"DT",Preposition:"IN",QuestionWord:"WP",Expression:"UH",Possessive:"POS",ProperNoun:"NNP",Person:"NNP",Place:"NNP",Organization:"NNP",Singular:"NN",Plural:"NNS",Noun:"NN",There:"EX"};var al={preTagger:function(e){const{methods:t,model:n,world:r}=e,o=e.docs;!function(e,t,n){e.forEach((e=>{!function(e,t,n,r){const o=r.methods.one.setTag;if(e.length>=3){const t=/:/;if(e[0].post.match(t)){const t=e[1];if(t.tags.has("Value")||t.tags.has("Email")||t.tags.has("PhoneNumber"))return;o([e[0]],"Expression",r,null,"2-punct-colon''")}}}(e,0,0,n)}))}(o,0,r);const a=t.two.quickSplit(o);for(let e=0;e{for(let r=0;r{e.forEach((e=>{e.penn=function(e){if(e.tags.has("ProperNoun")&&e.tags.has("Plural"))return"NNPS";if(e.tags.has("Possessive")&&e.tags.has("Pronoun"))return"PRP$";if("there"===e.normal)return"EX";if("to"===e.normal)return"TO";const t=e.tagRank||[];for(let e=0;e{e.implicit=e.normal,e.text="",e.normal=""}));for(let e=0;e(e.implicit=e.text,e.machine=e.text,e.pre="",e.post="",e.text="",e.normal="",e.index=[r,o+t],e))),n[0]&&(n[0].pre=e[r][o].pre,n[n.length-1].post=e[r][o].post,n[0].text=e[r][o].text,n[0].normal=e[r][o].normal),e[r].splice(o,1,...n))},fl=/'/,bl=new Set(["been","become"]),vl=new Set(["what","how","when","if","too"]),yl=new Set(["too","also","enough"]),wl=function(e,t){const n=e[t].normal.split(fl)[0];if("let"===n)return[n,"us"];if("there"===n){const r=e[t+1];if(r&&r.tags.has("Plural"))return[n,"are"]}return"has"===((e,t)=>{for(let n=t+1;n{for(let n=t+1;n0&&(n-=1),e[a]&&(a+=1),o.ptrs=[[0,n,a]],o.compute(["freeze","lexicon","preTagger","unfreeze"]),function(e){e.forEach(((e,t)=>{e.index&&(e.index[1]=t)}))}(e)},Hl={d:(e,t)=>Cl(e,t),t:(e,t)=>function(e,t){if("ain't"===e[t].normal||"aint"===e[t].normal){if(e[t+1]&&"never"===e[t+1].normal)return["have"];const n=function(e,t){for(let n=t-1;n>=0;n-=1)if(e[n].tags.has("Noun")||e[n].tags.has("Pronoun")||e[n].tags.has("Plural")||e[n].tags.has("Singular"))return e[n];return null}(e,t);if(n){if("we"===n.normal||"they"===n.normal)return["are","not"];if("i"===n.normal)return["am","not"];if(n.tags&&n.tags.has("Plural"))return["are","not"]}return["is","not"]}return[e[t].normal.replace(/n't/,""),"not"]}(e,t),s:(e,t,n)=>((e,t)=>{const n=e[t];if(Nl.hasOwnProperty(n.machine||n.normal))return!1;if(n.tags.has("Possessive"))return!0;if(n.tags.has("QuestionWord"))return!1;if("he's"===n.normal||"she's"===n.normal)return!1;const r=e[t+1];if(!r)return!0;if("it's"===n.normal)return!!r.tags.has("#Noun");if("Noun|Gerund"==r.switch){const r=e[t+2];return r?!!r.tags.has("Copula")||("on"===r.normal||r.normal,!1):!(!n.tags.has("Actor")&&!n.tags.has("ProperNoun"))}if(r.tags.has("Verb"))return!!r.tags.has("Infinitive")||!r.tags.has("Gerund")&&!!r.tags.has("PresentTense");if("Adj|Noun"===r.switch){const n=e[t+2];if(!n)return!1;if(Il.has(n.normal))return!0;if(xl.has(n.normal))return!1}if(r.tags.has("Noun")){const e=r.machine||r.normal;return!("here"===e||"there"===e||"everywhere"===e||r.tags.has("Possessive")||r.tags.has("ProperNoun")&&!n.tags.has("ProperNoun"))}if(e[t-1]&&!0===jl[e[t-1].normal])return!0;if(r.tags.has("Adjective")){const n=e[t+2];if(!n)return!1;if(n.tags.has("Noun")&&!n.tags.has("Pronoun")){const e=r.normal;return"above"!==e&&"below"!==e&&"behind"!==e}return"Noun|Verb"===n.switch}return!!r.tags.has("Value")})(e,t)?n.methods.one.setTag([e[t]],"Possessive",n,null,"2-contraction"):wl(e,t)},El=function(e,t){const n=t.fromText(e.join(" "));return n.compute("id"),n.docs[0]};var Gl={contractionTwo:e=>{const{world:t,document:n}=e;n.forEach(((r,o)=>{for(let a=r.length-1;a>=0;a-=1){if(r[a].implicit)continue;let i=null;!0===Tl.test(r[a].normal)&&(i=r[a].normal.split(Tl)[1]);let s=null;Hl.hasOwnProperty(i)&&(s=Hl[i](r,a,t)),s&&(s=El(s,e),pl(n,[o,a],s),Dl(n[o],e,a,s.length))}}))}},Ol={compute:Gl,api:function(e){class Contractions extends e{constructor(e,t,n){super(e,t,n),this.viewType="Contraction"}expand(){return this.docs.forEach((e=>{const t=ml.test(e[0].text);e.forEach(((t,n)=>{t.text=t.implicit||"",delete t.implicit,ne.toUpperCase()))}(e[0].text))})),this.compute("normal"),this}}e.prototype.contractions=function(){const e=this.match("@hasContraction+");return new Contractions(this.document,e.pointer)},e.prototype.contract=gl},hooks:["contractionTwo"]};const Fl="(hard|fast|late|early|high|right|deep|close|direct)";const Vl="(i|we|they)";const zl=[].concat([{match:"(got|were|was|is|are|am) (#PastTense|#Participle)",tag:"Passive",reason:"got-walked"},{match:"(was|were|is|are|am) being (#PastTense|#Participle)",tag:"Passive",reason:"was-being"},{match:"(had|have|has) been (#PastTense|#Participle)",tag:"Passive",reason:"had-been"},{match:"will be being? (#PastTense|#Participle)",tag:"Passive",reason:"will-be-cleaned"},{match:"#Noun [(#PastTense|#Participle)] by (the|a) #Noun",group:0,tag:"Passive",reason:"suffered-by"}],[{match:"[(all|both)] #Determiner #Noun",group:0,tag:"Noun",reason:"all-noun"},{match:"#Copula [(just|alone)]$",group:0,tag:"Adjective",reason:"not-adverb"},{match:"#Singular is #Adverb? [#PastTense$]",group:0,tag:"Adjective",reason:"is-filled"},{match:"[#PastTense] #Singular is",group:0,tag:"Adjective",reason:"smoked-poutine"},{match:"[#PastTense] #Plural are",group:0,tag:"Adjective",reason:"baked-onions"},{match:"well [#PastTense]",group:0,tag:"Adjective",reason:"well-made"},{match:"#Copula [fucked up?]",group:0,tag:"Adjective",reason:"swears-adjective"},{match:"#Singular (seems|appears) #Adverb? [#PastTense$]",group:0,tag:"Adjective",reason:"seems-filled"},{match:"#Copula #Adjective? [(out|in|through)]$",group:0,tag:"Adjective",reason:"still-out"},{match:"^[#Adjective] (the|your) #Noun",group:0,notIf:"(all|even)",tag:"Infinitive",reason:"shut-the"},{match:"the [said] #Noun",group:0,tag:"Adjective",reason:"the-said-card"},{match:"[#Hyphenated (#Hyphenated && #PastTense)] (#Noun|#Conjunction)",group:0,tag:"Adjective",notIf:"#Adverb",reason:"faith-based"},{match:"[#Hyphenated (#Hyphenated && #Gerund)] (#Noun|#Conjunction)",group:0,tag:"Adjective",notIf:"#Adverb",reason:"self-driving"},{match:"[#PastTense (#Hyphenated && #PhrasalVerb)] (#Noun|#Conjunction)",group:0,tag:"Adjective",reason:"dammed-up"},{match:"(#Hyphenated && #Value) fold",tag:"Adjective",reason:"two-fold"},{match:"must (#Hyphenated && #Infinitive)",tag:"Adjective",reason:"must-win"},{match:"(#Hyphenated && #Infinitive) #Hyphenated",tag:"Adjective",notIf:"#PhrasalVerb",reason:"vacuum-sealed"},{match:"too much",tag:"Adverb Adjective",reason:"bit-4"},{match:"a bit much",tag:"Determiner Adverb Adjective",reason:"bit-3"},{match:"[(un|contra|extra|inter|intra|macro|micro|mid|mis|mono|multi|pre|sub|tri|ex)] #Adjective",group:0,tag:["Adjective","Prefix"],reason:"un-skilled"}],[{match:"#Adverb [#Adverb] (and|or|then)",group:0,tag:"Adjective",reason:"kinda-sparkly-and"},{match:"[(dark|bright|flat|light|soft|pale|dead|dim|faux|little|wee|sheer|most|near|good|extra|all)] #Adjective",group:0,tag:"Adverb",reason:"dark-green"},{match:"#Copula [far too] #Adjective",group:0,tag:"Adverb",reason:"far-too"},{match:"#Copula [still] (in|#Gerund|#Adjective)",group:0,tag:"Adverb",reason:"was-still-walking"},{match:`#Plural ${Fl}`,tag:"#PresentTense #Adverb",reason:"studies-hard"},{match:`#Verb [${Fl}] !#Noun?`,group:0,notIf:"(#Copula|get|got|getting|become|became|becoming|feel|feels|feeling|#Determiner|#Preposition)",tag:"Adverb",reason:"shops-direct"},{match:"[#Plural] a lot",tag:"PresentTense",reason:"studies-a-lot"}],[{match:"as [#Gerund] as",group:0,tag:"Adjective",reason:"as-gerund-as"},{match:"more [#Gerund] than",group:0,tag:"Adjective",reason:"more-gerund-than"},{match:"(so|very|extremely) [#Gerund]",group:0,tag:"Adjective",reason:"so-gerund"},{match:"(found|found) it #Adverb? [#Gerund]",group:0,tag:"Adjective",reason:"found-it-gerund"},{match:"a (little|bit|wee) bit? [#Gerund]",group:0,tag:"Adjective",reason:"a-bit-gerund"},{match:"#Gerund [#Gerund]",group:0,tag:"Adjective",notIf:"(impersonating|practicing|considering|assuming)",reason:"looking-annoying"},{match:"(looked|look|looks) #Adverb? [%Adj|Gerund%]",group:0,tag:"Adjective",notIf:"(impersonating|practicing|considering|assuming)",reason:"looked-amazing"},{match:"[%Adj|Gerund%] #Determiner",group:0,tag:"Gerund",reason:"developing-a"},{match:"#Possessive [%Adj|Gerund%] #Noun",group:0,tag:"Adjective",reason:"leading-manufacturer"},{match:"%Noun|Gerund% %Adj|Gerund%",tag:"Gerund #Adjective",reason:"meaning-alluring"},{match:"(face|embrace|reveal|stop|start|resume) %Adj|Gerund%",tag:"#PresentTense #Adjective",reason:"face-shocking"},{match:"(are|were) [%Adj|Gerund%] #Plural",group:0,tag:"Adjective",reason:"are-enduring-symbols"}],[{match:"#Determiner [#Adjective] #Copula",group:0,tag:"Noun",reason:"the-adj-is"},{match:"#Adjective [#Adjective] #Copula",group:0,tag:"Noun",reason:"adj-adj-is"},{match:"(his|its) [%Adj|Noun%]",group:0,tag:"Noun",notIf:"#Hyphenated",reason:"his-fine"},{match:"#Copula #Adverb? [all]",group:0,tag:"Noun",reason:"is-all"},{match:"(have|had) [#Adjective] #Preposition .",group:0,tag:"Noun",reason:"have-fun"},{match:"#Gerund (giant|capital|center|zone|application)",tag:"Noun",reason:"brewing-giant"},{match:"#Preposition (a|an) [#Adjective]$",group:0,tag:"Noun",reason:"an-instant"},{match:"no [#Adjective] #Modal",group:0,tag:"Noun",reason:"no-golden"},{match:"[brand #Gerund?] new",group:0,tag:"Adverb",reason:"brand-new"},{match:"(#Determiner|#Comparative|new|different) [kind]",group:0,tag:"Noun",reason:"some-kind"},{match:"#Possessive [%Adj|Noun%] #Noun",group:0,tag:"Adjective",reason:"her-favourite"},{match:"must && #Hyphenated .",tag:"Adjective",reason:"must-win"},{match:"#Determiner [#Adjective]$",tag:"Noun",notIf:"(this|that|#Comparative|#Superlative)",reason:"the-south"},{match:"(#Noun && #Hyphenated) (#Adjective && #Hyphenated)",tag:"Adjective",notIf:"(this|that|#Comparative|#Superlative)",reason:"company-wide"},{match:"#Determiner [#Adjective] (#Copula|#Determiner)",notIf:"(#Comparative|#Superlative)",group:0,tag:"Noun",reason:"the-poor"},{match:"[%Adj|Noun%] #Noun",notIf:"(#Pronoun|#ProperNoun)",group:0,tag:"Adjective",reason:"stable-foundations"}],[{match:"[still] #Adjective",group:0,tag:"Adverb",reason:"still-advb"},{match:"[still] #Verb",group:0,tag:"Adverb",reason:"still-verb"},{match:"[so] #Adjective",group:0,tag:"Adverb",reason:"so-adv"},{match:"[way] #Comparative",group:0,tag:"Adverb",reason:"way-adj"},{match:"[way] #Adverb #Adjective",group:0,tag:"Adverb",reason:"way-too-adj"},{match:"[all] #Verb",group:0,tag:"Adverb",reason:"all-verb"},{match:"#Verb [like]",group:0,notIf:"(#Modal|#PhrasalVerb)",tag:"Adverb",reason:"verb-like"},{match:"(barely|hardly) even",tag:"Adverb",reason:"barely-even"},{match:"[even] #Verb",group:0,tag:"Adverb",reason:"even-walk"},{match:"[even] #Comparative",group:0,tag:"Adverb",reason:"even-worse"},{match:"[even] (#Determiner|#Possessive)",group:0,tag:"#Adverb",reason:"even-the"},{match:"even left",tag:"#Adverb #Verb",reason:"even-left"},{match:"[way] #Adjective",group:0,tag:"#Adverb",reason:"way-over"},{match:"#PresentTense [(hard|quick|bright|slow|fast|backwards|forwards)]",notIf:"#Copula",group:0,tag:"Adverb",reason:"lazy-ly"},{match:"[much] #Adjective",group:0,tag:"Adverb",reason:"bit-1"},{match:"#Copula [#Adverb]$",group:0,tag:"Adjective",reason:"is-well"},{match:"a [(little|bit|wee) bit?] #Adjective",group:0,tag:"Adverb",reason:"a-bit-cold"},{match:"[(super|pretty)] #Adjective",group:0,tag:"Adverb",reason:"super-strong"},{match:"(become|fall|grow) #Adverb? [#PastTense]",group:0,tag:"Adjective",reason:"overly-weakened"},{match:"(a|an) #Adverb [#Participle] #Noun",group:0,tag:"Adjective",reason:"completely-beaten"},{match:"#Determiner #Adverb? [close]",group:0,tag:"Adjective",reason:"a-close"},{match:"#Gerund #Adverb? [close]",group:0,tag:"Adverb",notIf:"(getting|becoming|feeling)",reason:"being-close"},{match:"(the|those|these|a|an) [#Participle] #Noun",group:0,tag:"Adjective",reason:"blown-motor"},{match:"(#PresentTense|#PastTense) [back]",group:0,tag:"Adverb",notIf:"(#PhrasalVerb|#Copula)",reason:"charge-back"},{match:"#Verb [around]",group:0,tag:"Adverb",notIf:"#PhrasalVerb",reason:"send-around"},{match:"[later] #PresentTense",group:0,tag:"Adverb",reason:"later-say"},{match:"#Determiner [well] !#PastTense?",group:0,tag:"Noun",reason:"the-well"},{match:"#Adjective [enough]",group:0,tag:"Adverb",reason:"high-enough"}],[{match:"[sun] the #Ordinal",tag:"WeekDay",reason:"sun-the-5th"},{match:"[sun] #Date",group:0,tag:"WeekDay",reason:"sun-feb"},{match:"#Date (on|this|next|last|during)? [sun]",group:0,tag:"WeekDay",reason:"1pm-sun"},{match:"(in|by|before|during|on|until|after|of|within|all) [sat]",group:0,tag:"WeekDay",reason:"sat"},{match:"(in|by|before|during|on|until|after|of|within|all) [wed]",group:0,tag:"WeekDay",reason:"wed"},{match:"(in|by|before|during|on|until|after|of|within|all) [march]",group:0,tag:"Month",reason:"march"},{match:"[sat] #Date",group:0,tag:"WeekDay",reason:"sat-feb"},{match:"#Preposition [(march|may)]",group:0,tag:"Month",reason:"in-month"},{match:"(this|next|last) (march|may) !#Infinitive?",tag:"#Date #Month",reason:"this-month"},{match:"(march|may) the? #Value",tag:"#Month #Date #Date",reason:"march-5th"},{match:"#Value of? (march|may)",tag:"#Date #Date #Month",reason:"5th-of-march"},{match:"[(march|may)] .? #Date",group:0,tag:"Month",reason:"march-and-feb"},{match:"#Date .? [(march|may)]",group:0,tag:"Month",reason:"feb-and-march"},{match:"#Adverb [(march|may)]",group:0,tag:"Verb",reason:"quickly-march"},{match:"[(march|may)] #Adverb",group:0,tag:"Verb",reason:"march-quickly"},{match:"#Value (am|pm)",tag:"Time",reason:"2-am"}],[{match:"#Holiday (day|eve)",tag:"Holiday",reason:"holiday-day"},{match:"#Value of #Month",tag:"Date",reason:"value-of-month"},{match:"#Cardinal #Month",tag:"Date",reason:"cardinal-month"},{match:"#Month #Value to #Value",tag:"Date",reason:"value-to-value"},{match:"#Month the #Value",tag:"Date",reason:"month-the-value"},{match:"(#WeekDay|#Month) #Value",tag:"Date",reason:"date-value"},{match:"#Value (#WeekDay|#Month)",tag:"Date",reason:"value-date"},{match:"(#TextValue && #Date) #TextValue",tag:"Date",reason:"textvalue-date"},{match:"#Month #NumberRange",tag:"Date",reason:"aug 20-21"},{match:"#WeekDay #Month #Ordinal",tag:"Date",reason:"week mm-dd"},{match:"#Month #Ordinal #Cardinal",tag:"Date",reason:"mm-dd-yyy"},{match:"(#Place|#Demonmym|#Time) (standard|daylight|central|mountain)? time",tag:"Timezone",reason:"std-time"},{match:"(eastern|mountain|pacific|central|atlantic) (standard|daylight|summer)? time",tag:"Timezone",reason:"eastern-time"},{match:"#Time [(eastern|mountain|pacific|central|est|pst|gmt)]",group:0,tag:"Timezone",reason:"5pm-central"},{match:"(central|western|eastern) european time",tag:"Timezone",reason:"cet"}],[{match:"(the|any) [more]",group:0,tag:"Singular",reason:"more-noun"},{match:"[more] #Noun",group:0,tag:"Adjective",reason:"more-noun"},{match:"(right|rights) of .",tag:"Noun",reason:"right-of"},{match:"a [bit]",group:0,tag:"Singular",reason:"bit-2"},{match:"a [must]",group:0,tag:"Singular",reason:"must-2"},{match:"(we|us) [all]",group:0,tag:"Noun",reason:"we all"},{match:"due to [#Verb]",group:0,tag:"Noun",reason:"due-to"},{match:"some [#Verb] #Plural",group:0,tag:"Noun",reason:"determiner6"},{match:"#Possessive #Ordinal [#PastTense]",group:0,tag:"Noun",reason:"first-thought"},{match:"(the|this|those|these) #Adjective [%Verb|Noun%]",group:0,tag:"Noun",notIf:"#Copula",reason:"the-adj-verb"},{match:"(the|this|those|these) #Adverb #Adjective [#Verb]",group:0,tag:"Noun",reason:"determiner4"},{match:"the [#Verb] #Preposition .",group:0,tag:"Noun",reason:"determiner1"},{match:"(a|an|the) [#Verb] of",group:0,tag:"Noun",reason:"the-verb-of"},{match:"#Determiner #Noun of [#Verb]",group:0,tag:"Noun",notIf:"#Gerund",reason:"noun-of-noun"},{match:"#PastTense #Preposition [#PresentTense]",group:0,notIf:"#Gerund",tag:"Noun",reason:"ended-in-ruins"},{match:"#Conjunction [u]",group:0,tag:"Pronoun",reason:"u-pronoun-2"},{match:"[u] #Verb",group:0,tag:"Pronoun",reason:"u-pronoun-1"},{match:"#Determiner [(western|eastern|northern|southern|central)] #Noun",group:0,tag:"Noun",reason:"western-line"},{match:"(#Singular && @hasHyphen) #PresentTense",tag:"Noun",reason:"hyphen-verb"},{match:"is no [#Verb]",group:0,tag:"Noun",reason:"is-no-verb"},{match:"do [so]",group:0,tag:"Noun",reason:"so-noun"},{match:"#Determiner [(shit|damn|hell)]",group:0,tag:"Noun",reason:"swears-noun"},{match:"to [(shit|hell)]",group:0,tag:"Noun",reason:"to-swears"},{match:"(the|these) [#Singular] (were|are)",group:0,tag:"Plural",reason:"singular-were"},{match:"a #Noun+ or #Adverb+? [#Verb]",group:0,tag:"Noun",reason:"noun-or-noun"},{match:"(the|those|these|a|an) #Adjective? [#PresentTense #Particle?]",group:0,tag:"Noun",notIf:"(seem|appear|include|#Gerund|#Copula)",reason:"det-inf"},{match:"#Noun #Actor",tag:"Actor",notIf:"(#Person|#Pronoun)",reason:"thing-doer"},{match:"#Gerund #Actor",tag:"Actor",reason:"gerund-doer"},{match:"co #Singular",tag:"Actor",reason:"co-noun"},{match:"[#Noun+] #Actor",group:0,tag:"Actor",notIf:"(#Honorific|#Pronoun|#Possessive)",reason:"air-traffic-controller"},{match:"(urban|cardiac|cardiovascular|respiratory|medical|clinical|visual|graphic|creative|dental|exotic|fine|certified|registered|technical|virtual|professional|amateur|junior|senior|special|pharmaceutical|theoretical)+ #Noun? #Actor",tag:"Actor",reason:"fine-artist"},{match:"#Noun+ (coach|chef|king|engineer|fellow|personality|boy|girl|man|woman|master)",tag:"Actor",reason:"dance-coach"},{match:"chief . officer",tag:"Actor",reason:"chief-x-officer"},{match:"chief of #Noun+",tag:"Actor",reason:"chief-of-police"},{match:"senior? vice? president of #Noun+",tag:"Actor",reason:"president-of"},{match:"#Determiner [sun]",group:0,tag:"Singular",reason:"the-sun"},{match:"#Verb (a|an) [#Value]$",group:0,tag:"Singular",reason:"did-a-value"},{match:"the [(can|will|may)]",group:0,tag:"Singular",reason:"the can"},{match:"#FirstName #Acronym? (#Possessive && #LastName)",tag:"Possessive",reason:"name-poss"},{match:"#Organization+ #Possessive",tag:"Possessive",reason:"org-possessive"},{match:"#Place+ #Possessive",tag:"Possessive",reason:"place-possessive"},{match:"#Possessive #PresentTense #Particle?",notIf:"(#Gerund|her)",tag:"Noun",reason:"possessive-verb"},{match:"(my|our|their|her|his|its) [(#Plural && #Actor)] #Noun",tag:"Possessive",reason:"my-dads"},{match:"#Value of a [second]",group:0,unTag:"Value",tag:"Singular",reason:"10th-of-a-second"},{match:"#Value [seconds]",group:0,unTag:"Value",tag:"Plural",reason:"10-seconds"},{match:"in [#Infinitive]",group:0,tag:"Singular",reason:"in-age"},{match:"a [#Adjective] #Preposition",group:0,tag:"Noun",reason:"a-minor-in"},{match:"#Determiner [#Singular] said",group:0,tag:"Actor",reason:"the-actor-said"},{match:"#Determiner #Noun [(feel|sense|process|rush|side|bomb|bully|challenge|cover|crush|dump|exchange|flow|function|issue|lecture|limit|march|process)] !(#Preposition|to|#Adverb)?",group:0,tag:"Noun",reason:"the-noun-sense"},{match:"[#PresentTense] (of|by|for) (a|an|the) #Noun #Copula",group:0,tag:"Plural",reason:"photographs-of"},{match:"#Infinitive and [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"fight and win"},{match:"#Noun and [#Verb] and #Noun",group:0,tag:"Noun",reason:"peace-and-flowers"},{match:"the #Cardinal [%Adj|Noun%]",group:0,tag:"Noun",reason:"the-1992-classic"},{match:"#Copula the [%Adj|Noun%] #Noun",group:0,tag:"Adjective",reason:"the-premier-university"},{match:"i #Verb [me] #Noun",group:0,tag:"Possessive",reason:"scottish-me"},{match:"[#PresentTense] (music|class|lesson|night|party|festival|league|ceremony)",group:0,tag:"Noun",reason:"dance-music"},{match:"[wit] (me|it)",group:0,tag:"Presposition",reason:"wit-me"},{match:"#PastTense #Possessive [#Verb]",group:0,tag:"Noun",notIf:"(saw|made)",reason:"left-her-boots"},{match:"#Value [%Plural|Verb%]",group:0,tag:"Plural",notIf:"(one|1|a|an)",reason:"35-signs"},{match:"had [#PresentTense]",group:0,tag:"Noun",notIf:"(#Gerund|come|become)",reason:"had-time"},{match:"%Adj|Noun% %Noun|Verb%",tag:"#Adjective #Noun",notIf:"#ProperNoun #Noun",reason:"instant-access"},{match:"#Determiner [%Adj|Noun%] #Conjunction",group:0,tag:"Noun",reason:"a-rep-to"},{match:"#Adjective #Noun [%Plural|Verb%]$",group:0,tag:"Plural",notIf:"#Pronoun",reason:"near-death-experiences"},{match:"#Possessive #Noun [%Plural|Verb%]$",group:0,tag:"Plural",reason:"your-guild-colors"}],[{match:"(this|that|the|a|an) [#Gerund #Infinitive]",group:0,tag:"Singular",reason:"the-planning-process"},{match:"(that|the) [#Gerund #PresentTense]",group:0,ifNo:"#Copula",tag:"Plural",reason:"the-paving-stones"},{match:"#Determiner [#Gerund] #Noun",group:0,tag:"Adjective",reason:"the-gerund-noun"},{match:"#Pronoun #Infinitive [#Gerund] #PresentTense",group:0,tag:"Noun",reason:"tipping-sucks"},{match:"#Adjective [#Gerund]",group:0,tag:"Noun",notIf:"(still|even|just)",reason:"early-warning"},{match:"[#Gerund] #Adverb? not? #Copula",group:0,tag:"Activity",reason:"gerund-copula"},{match:"#Copula [(#Gerund|#Activity)] #Copula",group:0,tag:"Gerund",reason:"are-doing-is"},{match:"[#Gerund] #Modal",group:0,tag:"Activity",reason:"gerund-modal"},{match:"#Singular for [%Noun|Gerund%]",group:0,tag:"Gerund",reason:"noun-for-gerund"},{match:"#Comparative (for|at) [%Noun|Gerund%]",group:0,tag:"Gerund",reason:"better-for-gerund"},{match:"#PresentTense the [#Gerund]",group:0,tag:"Noun",reason:"keep-the-touching"}],[{match:"#Infinitive (this|that|the) [#Infinitive]",group:0,tag:"Noun",reason:"do-this-dance"},{match:"#Gerund #Determiner [#Infinitive]",group:0,tag:"Noun",reason:"running-a-show"},{match:"#Determiner (only|further|just|more|backward) [#Infinitive]",group:0,tag:"Noun",reason:"the-only-reason"},{match:"(the|this|a|an) [#Infinitive] #Adverb? #Verb",group:0,tag:"Noun",reason:"determiner5"},{match:"#Determiner #Adjective #Adjective? [#Infinitive]",group:0,tag:"Noun",reason:"a-nice-inf"},{match:"#Determiner #Demonym [#PresentTense]",group:0,tag:"Noun",reason:"mexican-train"},{match:"#Adjective #Noun+ [#Infinitive] #Copula",group:0,tag:"Noun",reason:"career-move"},{match:"at some [#Infinitive]",group:0,tag:"Noun",reason:"at-some-inf"},{match:"(go|goes|went) to [#Infinitive]",group:0,tag:"Noun",reason:"goes-to-verb"},{match:"(a|an) #Adjective? #Noun [#Infinitive] (#Preposition|#Noun)",group:0,notIf:"from",tag:"Noun",reason:"a-noun-inf"},{match:"(a|an) #Noun [#Infinitive]$",group:0,tag:"Noun",reason:"a-noun-inf2"},{match:"#Gerund #Adjective? for [#Infinitive]",group:0,tag:"Noun",reason:"running-for"},{match:"about [#Infinitive]",group:0,tag:"Singular",reason:"about-love"},{match:"#Plural on [#Infinitive]",group:0,tag:"Noun",reason:"on-stage"},{match:"any [#Infinitive]",group:0,tag:"Noun",reason:"any-charge"},{match:"no [#Infinitive]",group:0,tag:"Noun",reason:"no-doubt"},{match:"number of [#PresentTense]",group:0,tag:"Noun",reason:"number-of-x"},{match:"(taught|teaches|learns|learned) [#PresentTense]",group:0,tag:"Noun",reason:"teaches-x"},{match:"(try|use|attempt|build|make) [#Verb #Particle?]",notIf:"(#Copula|#Noun|sure|fun|up)",group:0,tag:"Noun",reason:"do-verb"},{match:"^[#Infinitive] (is|was)",group:0,tag:"Noun",reason:"checkmate-is"},{match:"#Infinitive much [#Infinitive]",group:0,tag:"Noun",reason:"get-much"},{match:"[cause] #Pronoun #Verb",group:0,tag:"Conjunction",reason:"cause-cuz"},{match:"the #Singular [#Infinitive] #Noun",group:0,tag:"Noun",notIf:"#Pronoun",reason:"cardio-dance"},{match:"#Determiner #Modal [#Noun]",group:0,tag:"PresentTense",reason:"should-smoke"},{match:"this [#Plural]",group:0,tag:"PresentTense",notIf:"(#Preposition|#Date)",reason:"this-verbs"},{match:"#Noun that [#Plural]",group:0,tag:"PresentTense",notIf:"(#Preposition|#Pronoun|way)",reason:"voice-that-rocks"},{match:"that [#Plural] to",group:0,tag:"PresentTense",notIf:"#Preposition",reason:"that-leads-to"},{match:"(let|make|made) (him|her|it|#Person|#Place|#Organization)+ [#Singular] (a|an|the|it)",group:0,tag:"Infinitive",reason:"let-him-glue"},{match:"#Verb (all|every|each|most|some|no) [#PresentTense]",notIf:"#Modal",group:0,tag:"Noun",reason:"all-presentTense"},{match:"(had|have|#PastTense) #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"better",reason:"adj-presentTense"},{match:"#Value #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"one-big-reason"},{match:"#PastTense #Adjective+ [#PresentTense]",group:0,tag:"Noun",notIf:"(#Copula|better)",reason:"won-wide-support"},{match:"(many|few|several|couple) [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"many-poses"},{match:"#Determiner #Adverb #Adjective [%Noun|Verb%]",group:0,tag:"Noun",notIf:"#Copula",reason:"very-big-dream"},{match:"from #Noun to [%Noun|Verb%]",group:0,tag:"Noun",reason:"start-to-finish"},{match:"(for|with|of) #Noun (and|or|not) [%Noun|Verb%]",group:0,tag:"Noun",notIf:"#Pronoun",reason:"for-food-and-gas"},{match:"#Adjective #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"adorable-little-store"},{match:"#Gerund #Adverb? #Comparative [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"higher-costs"},{match:"(#Noun && @hasComma) #Noun (and|or) [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"noun-list"},{match:"(many|any|some|several) [#PresentTense] for",group:0,tag:"Noun",reason:"any-verbs-for"},{match:"to #PresentTense #Noun [#PresentTense] #Preposition",group:0,tag:"Noun",reason:"gas-exchange"},{match:"#PastTense (until|as|through|without) [#PresentTense]",group:0,tag:"Noun",reason:"waited-until-release"},{match:"#Gerund like #Adjective? [#PresentTense]",group:0,tag:"Plural",reason:"like-hot-cakes"},{match:"some #Adjective [#PresentTense]",group:0,tag:"Noun",reason:"some-reason"},{match:"for some [#PresentTense]",group:0,tag:"Noun",reason:"for-some-reason"},{match:"(same|some|the|that|a) kind of [#PresentTense]",group:0,tag:"Noun",reason:"some-kind-of"},{match:"(same|some|the|that|a) type of [#PresentTense]",group:0,tag:"Noun",reason:"some-type-of"},{match:"#Gerund #Adjective #Preposition [#PresentTense]",group:0,tag:"Noun",reason:"doing-better-for-x"},{match:"(get|got|have) #Comparative [#PresentTense]",group:0,tag:"Noun",reason:"got-better-aim"},{match:"whose [#PresentTense] #Copula",group:0,tag:"Noun",reason:"whos-name-was"},{match:"#PhrasalVerb #Particle #Preposition [#PresentTense]",group:0,tag:"Noun",reason:"given-up-on-x"},{match:"there (are|were) #Adjective? [#PresentTense]",group:0,tag:"Plural",reason:"there-are"},{match:"#Value [#PresentTense] of",group:0,notIf:"(one|1|#Copula|#Infinitive)",tag:"Plural",reason:"2-trains"},{match:"[#PresentTense] (are|were) #Adjective",group:0,tag:"Plural",reason:"compromises-are-possible"},{match:"^[(hope|guess|thought|think)] #Pronoun #Verb",group:0,tag:"Infinitive",reason:"suppose-i"},{match:"#Possessive #Adjective [#Verb]",group:0,tag:"Noun",notIf:"#Copula",reason:"our-full-support"},{match:"[(tastes|smells)] #Adverb? #Adjective",group:0,tag:"PresentTense",reason:"tastes-good"},{match:"#Copula #Gerund [#PresentTense] !by?",group:0,tag:"Noun",notIf:"going",reason:"ignoring-commute"},{match:"#Determiner #Adjective? [(shed|thought|rose|bid|saw|spelt)]",group:0,tag:"Noun",reason:"noun-past"},{match:"how to [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"how-to-noun"},{match:"which [%Noun|Verb%] #Noun",group:0,tag:"Infinitive",reason:"which-boost-it"},{match:"#Gerund [%Plural|Verb%]",group:0,tag:"Plural",reason:"asking-questions"},{match:"(ready|available|difficult|hard|easy|made|attempt|try) to [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"ready-to-noun"},{match:"(bring|went|go|drive|run|bike) to [%Noun|Verb%]",group:0,tag:"Noun",reason:"bring-to-noun"},{match:"#Modal #Noun [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"would-you-look"},{match:"#Copula just [#Infinitive]",group:0,tag:"Noun",reason:"is-just-spam"},{match:"^%Noun|Verb% %Plural|Verb%",tag:"Imperative #Plural",reason:"request-copies"},{match:"#Adjective #Plural and [%Plural|Verb%]",group:0,tag:"#Plural",reason:"pickles-and-drinks"},{match:"#Determiner #Year [#Verb]",group:0,tag:"Noun",reason:"the-1968-film"},{match:"#Determiner [#PhrasalVerb #Particle]",group:0,tag:"Noun",reason:"the-break-up"},{match:"#Determiner [%Adj|Noun%] #Noun",group:0,tag:"Adjective",notIf:"(#Pronoun|#Possessive|#ProperNoun)",reason:"the-individual-goals"},{match:"[%Noun|Verb%] or #Infinitive",group:0,tag:"Infinitive",reason:"work-or-prepare"},{match:"to #Infinitive [#PresentTense]",group:0,tag:"Noun",notIf:"(#Gerund|#Copula|help)",reason:"to-give-thanks"},{match:"[#Noun] me",group:0,tag:"Verb",reason:"kills-me"},{match:"%Plural|Verb% %Plural|Verb%",tag:"#PresentTense #Plural",reason:"removes-wrinkles"}],[{match:"#Money and #Money #Currency?",tag:"Money",reason:"money-and-money"},{match:"#Value #Currency [and] #Value (cents|ore|centavos|sens)",group:0,tag:"money",reason:"and-5-cents"},{match:"#Value (mark|rand|won|rub|ore)",tag:"#Money #Currency",reason:"4-mark"},{match:"a pound",tag:"#Money #Unit",reason:"a-pound"},{match:"#Value (pound|pounds)",tag:"#Money #Unit",reason:"4-pounds"}],[{match:"[(half|quarter)] of? (a|an)",group:0,tag:"Fraction",reason:"millionth"},{match:"#Adverb [half]",group:0,tag:"Fraction",reason:"nearly-half"},{match:"[half] the",group:0,tag:"Fraction",reason:"half-the"},{match:"#Cardinal and a half",tag:"Fraction",reason:"and-a-half"},{match:"#Value (halves|halfs|quarters)",tag:"Fraction",reason:"two-halves"},{match:"a #Ordinal",tag:"Fraction",reason:"a-quarter"},{match:"[#Cardinal+] (#Fraction && /s$/)",tag:"Fraction",reason:"seven-fifths"},{match:"[#Cardinal+ #Ordinal] of .",group:0,tag:"Fraction",reason:"ordinal-of"},{match:"[(#NumericValue && #Ordinal)] of .",group:0,tag:"Fraction",reason:"num-ordinal-of"},{match:"(a|one) #Cardinal?+ #Ordinal",tag:"Fraction",reason:"a-ordinal"},{match:"#Cardinal+ out? of every? #Cardinal",tag:"Fraction",reason:"out-of"}],[{match:"#Cardinal [second]",tag:"Unit",reason:"one-second"},{match:"!once? [(a|an)] (#Duration|hundred|thousand|million|billion|trillion)",group:0,tag:"Value",reason:"a-is-one"},{match:"1 #Value #PhoneNumber",tag:"PhoneNumber",reason:"1-800-Value"},{match:"#NumericValue #PhoneNumber",tag:"PhoneNumber",reason:"(800) PhoneNumber"},{match:"#Demonym #Currency",tag:"Currency",reason:"demonym-currency"},{match:"#Value [(buck|bucks|grand)]",group:0,tag:"Currency",reason:"value-bucks"},{match:"[#Value+] #Currency",group:0,tag:"Money",reason:"15 usd"},{match:"[second] #Noun",group:0,tag:"Ordinal",reason:"second-noun"},{match:"#Value+ [#Currency]",group:0,tag:"Unit",reason:"5-yan"},{match:"#Value [(foot|feet)]",group:0,tag:"Unit",reason:"foot-unit"},{match:"#Value [#Abbreviation]",group:0,tag:"Unit",reason:"value-abbr"},{match:"#Value [k]",group:0,tag:"Unit",reason:"value-k"},{match:"#Unit an hour",tag:"Unit",reason:"unit-an-hour"},{match:"(minus|negative) #Value",tag:"Value",reason:"minus-value"},{match:"#Value (point|decimal) #Value",tag:"Value",reason:"value-point-value"},{match:"#Determiner [(half|quarter)] #Ordinal",group:0,tag:"Value",reason:"half-ordinal"},{match:"#Multiple+ and #Value",tag:"Value",reason:"magnitude-and-value"},{match:"#Value #Unit [(per|an) (hr|hour|sec|second|min|minute)]",group:0,tag:"Unit",reason:"12-miles-per-second"},{match:"#Value [(square|cubic)] #Unit",group:0,tag:"Unit",reason:"square-miles"}],[{match:"#Copula [(#Noun|#PresentTense)] #LastName",group:0,tag:"FirstName",reason:"copula-noun-lastname"},{match:"(sister|pope|brother|father|aunt|uncle|grandpa|grandfather|grandma) #ProperNoun",tag:"Person",reason:"lady-titlecase",safe:!0},{match:"#FirstName [#Determiner #Noun] #LastName",group:0,tag:"Person",reason:"first-noun-last"},{match:"#ProperNoun (b|c|d|e|f|g|h|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z) #ProperNoun",tag:"Person",reason:"titlecase-acronym-titlecase",safe:!0},{match:"#Acronym #LastName",tag:"Person",reason:"acronym-lastname",safe:!0},{match:"#Person (jr|sr|md)",tag:"Person",reason:"person-honorific"},{match:"#Honorific #Acronym",tag:"Person",reason:"Honorific-TitleCase"},{match:"#Person #Person the? #RomanNumeral",tag:"Person",reason:"roman-numeral"},{match:"#FirstName [/^[^aiurck]$/]",group:0,tag:["Acronym","Person"],reason:"john-e"},{match:"#Noun van der? #Noun",tag:"Person",reason:"van der noun",safe:!0},{match:"(king|queen|prince|saint|lady) of #Noun",tag:"Person",reason:"king-of-noun",safe:!0},{match:"(prince|lady) #Place",tag:"Person",reason:"lady-place"},{match:"(king|queen|prince|saint) #ProperNoun",tag:"Person",notIf:"#Place",reason:"saint-foo"},{match:"al (#Person|#ProperNoun)",tag:"Person",reason:"al-borlen",safe:!0},{match:"#FirstName de #Noun",tag:"Person",reason:"bill-de-noun"},{match:"#FirstName (bin|al) #Noun",tag:"Person",reason:"bill-al-noun"},{match:"#FirstName #Acronym #ProperNoun",tag:"Person",reason:"bill-acronym-title"},{match:"#FirstName #FirstName #ProperNoun",tag:"Person",reason:"bill-firstname-title"},{match:"#Honorific #FirstName? #ProperNoun",tag:"Person",reason:"dr-john-Title"},{match:"#FirstName the #Adjective",tag:"Person",reason:"name-the-great"},{match:"#ProperNoun (van|al|bin) #ProperNoun",tag:"Person",reason:"title-van-title",safe:!0},{match:"#ProperNoun (de|du) la? #ProperNoun",tag:"Person",notIf:"#Place",reason:"title-de-title"},{match:"#Singular #Acronym #LastName",tag:"#FirstName #Person .",reason:"title-acro-noun",safe:!0},{match:"[#ProperNoun] #Person",group:0,tag:"Person",reason:"proper-person",safe:!0},{match:"#Person [#ProperNoun #ProperNoun]",group:0,tag:"Person",notIf:"#Possessive",reason:"three-name-person",safe:!0},{match:"#FirstName #Acronym? [#ProperNoun]",group:0,tag:"LastName",notIf:"#Possessive",reason:"firstname-titlecase"},{match:"#FirstName [#FirstName]",group:0,tag:"LastName",reason:"firstname-firstname"},{match:"#FirstName #Acronym #Noun",tag:"Person",reason:"n-acro-noun",safe:!0},{match:"#FirstName [(de|di|du|van|von)] #Person",group:0,tag:"LastName",reason:"de-firstname"},{match:"[(lieutenant|corporal|sergeant|captain|qeen|king|admiral|major|colonel|marshal|president|queen|king)+] #ProperNoun",group:0,tag:"Honorific",reason:"seargeant-john"},{match:"[(private|general|major|rear|prime|field|count|miss)] #Honorific? #Person",group:0,tag:["Honorific","Person"],reason:"ambg-honorifics"},{match:"#Honorific #FirstName [#Singular]",group:0,tag:"LastName",notIf:"#Possessive",reason:"dr-john-foo",safe:!0},{match:"[(his|her) (majesty|honour|worship|excellency|honorable)] #Person",group:0,tag:"Honorific",reason:"his-excellency"},{match:"#Honorific #Actor",tag:"Honorific",reason:"Lieutenant colonel"},{match:"(first|second|third|1st|2nd|3rd) #Actor",tag:"Honorific",reason:"first lady"},{match:"#Person #RomanNumeral",tag:"Person",reason:"louis-IV"}],[{match:"#FirstName #Noun$",tag:". #LastName",notIf:"(#Possessive|#Organization|#Place|#Pronoun|@hasTitleCase)",reason:"firstname-noun"},{match:"%Person|Date% #Acronym? #ProperNoun",tag:"Person",reason:"jan-thierson"},{match:"%Person|Noun% #Acronym? #ProperNoun",tag:"Person",reason:"switch-person",safe:!0},{match:"%Person|Noun% #Organization",tag:"Organization",reason:"olive-garden"},{match:"%Person|Verb% #Acronym? #ProperNoun",tag:"Person",reason:"verb-propernoun",ifNo:"#Actor"},{match:"[%Person|Verb%] (will|had|has|said|says|told|did|learned|wants|wanted)",group:0,tag:"Person",reason:"person-said"},{match:"[%Person|Place%] (harbor|harbour|pier|town|city|place|dump|landfill)",group:0,tag:"Place",reason:"sydney-harbour"},{match:"(west|east|north|south) [%Person|Place%]",group:0,tag:"Place",reason:"east-sydney"},{match:"#Modal [%Person|Verb%]",group:0,tag:"Verb",reason:"would-mark"},{match:"#Adverb [%Person|Verb%]",group:0,tag:"Verb",reason:"really-mark"},{match:"[%Person|Verb%] (#Adverb|#Comparative)",group:0,tag:"Verb",reason:"drew-closer"},{match:"%Person|Verb% #Person",tag:"Person",reason:"rob-smith"},{match:"%Person|Verb% #Acronym #ProperNoun",tag:"Person",reason:"rob-a-smith"},{match:"[will] #Verb",group:0,tag:"Modal",reason:"will-verb"},{match:"(will && @isTitleCase) #ProperNoun",tag:"Person",reason:"will-name"},{match:"(#FirstName && !#Possessive) [#Singular] #Verb",group:0,safe:!0,tag:"LastName",reason:"jack-layton"},{match:"^[#Singular] #Person #Verb",group:0,safe:!0,tag:"Person",reason:"sherwood-anderson"},{match:"(a|an) [#Person]$",group:0,unTag:"Person",reason:"a-warhol"}],[{match:"#Copula (pretty|dead|full|well|sure) (#Adjective|#Noun)",tag:"#Copula #Adverb #Adjective",reason:"sometimes-adverb"},{match:"(#Pronoun|#Person) (had|#Adverb)? [better] #PresentTense",group:0,tag:"Modal",reason:"i-better"},{match:"(#Modal|i|they|we|do) not? [like]",group:0,tag:"PresentTense",reason:"modal-like"},{match:"#Noun #Adverb? [left]",group:0,tag:"PastTense",reason:"left-verb"},{match:"will #Adverb? not? #Adverb? [be] #Gerund",group:0,tag:"Copula",reason:"will-be-copula"},{match:"will #Adverb? not? #Adverb? [be] #Adjective",group:0,tag:"Copula",reason:"be-copula"},{match:"[march] (up|down|back|toward)",notIf:"#Date",group:0,tag:"Infinitive",reason:"march-to"},{match:"#Modal [march]",group:0,tag:"Infinitive",reason:"must-march"},{match:"[may] be",group:0,tag:"Verb",reason:"may-be"},{match:"[(subject|subjects|subjected)] to",group:0,tag:"Verb",reason:"subject to"},{match:"[home] to",group:0,tag:"PresentTense",reason:"home to"},{match:"[open] #Determiner",group:0,tag:"Infinitive",reason:"open-the"},{match:"(were|was) being [#PresentTense]",group:0,tag:"PastTense",reason:"was-being"},{match:"(had|has|have) [been /en$/]",group:0,tag:"Auxiliary Participle",reason:"had-been-broken"},{match:"(had|has|have) [been /ed$/]",group:0,tag:"Auxiliary PastTense",reason:"had-been-smoked"},{match:"(had|has) #Adverb? [been] #Adverb? #PastTense",group:0,tag:"Auxiliary",reason:"had-been-adj"},{match:"(had|has) to [#Noun] (#Determiner|#Possessive)",group:0,tag:"Infinitive",reason:"had-to-noun"},{match:"have [#PresentTense]",group:0,tag:"PastTense",notIf:"(come|gotten)",reason:"have-read"},{match:"(does|will|#Modal) that [work]",group:0,tag:"PastTense",reason:"does-that-work"},{match:"[(sound|sounds)] #Adjective",group:0,tag:"PresentTense",reason:"sounds-fun"},{match:"[(look|looks)] #Adjective",group:0,tag:"PresentTense",reason:"looks-good"},{match:"[(start|starts|stop|stops|begin|begins)] #Gerund",group:0,tag:"Verb",reason:"starts-thinking"},{match:"(have|had) read",tag:"Modal #PastTense",reason:"read-read"},{match:"(is|was|were) [(under|over) #PastTense]",group:0,tag:"Adverb Adjective",reason:"was-under-cooked"},{match:"[shit] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear1-verb"},{match:"[damn] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear2-verb"},{match:"[fuck] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear3-verb"},{match:"#Plural that %Noun|Verb%",tag:". #Preposition #Infinitive",reason:"jobs-that-work"},{match:"[works] for me",group:0,tag:"PresentTense",reason:"works-for-me"},{match:"as #Pronoun [please]",group:0,tag:"Infinitive",reason:"as-we-please"},{match:"[(co|mis|de|inter|intra|pre|re|un|out|under|over|counter)] #Verb",group:0,tag:["Verb","Prefix"],notIf:"(#Copula|#PhrasalVerb)",reason:"co-write"},{match:"#PastTense and [%Adj|Past%]",group:0,tag:"PastTense",reason:"dressed-and-left"},{match:"[%Adj|Past%] and #PastTense",group:0,tag:"PastTense",reason:"dressed-and-left"},{match:"#Copula #Pronoun [%Adj|Past%]",group:0,tag:"Adjective",reason:"is-he-stoked"},{match:"to [%Noun|Verb%] #Preposition",group:0,tag:"Infinitive",reason:"to-dream-of"}],[{match:"(slowly|quickly) [#Adjective]",group:0,tag:"Verb",reason:"slowly-adj"},{match:"does (#Adverb|not)? [#Adjective]",group:0,tag:"PresentTense",reason:"does-mean"},{match:"[(fine|okay|cool|ok)] by me",group:0,tag:"Adjective",reason:"okay-by-me"},{match:"i (#Adverb|do)? not? [mean]",group:0,tag:"PresentTense",reason:"i-mean"},{match:"will #Adjective",tag:"Auxiliary Infinitive",reason:"will-adj"},{match:"#Pronoun [#Adjective] #Determiner #Adjective? #Noun",group:0,tag:"Verb",reason:"he-adj-the"},{match:"#Copula [%Adj|Present%] to #Verb",group:0,tag:"Verb",reason:"adj-to"},{match:"#Copula [#Adjective] (well|badly|quickly|slowly)",group:0,tag:"Verb",reason:"done-well"},{match:"#Adjective and [#Gerund] !#Preposition?",group:0,tag:"Adjective",reason:"rude-and-x"},{match:"#Copula #Adverb? (over|under) [#PastTense]",group:0,tag:"Adjective",reason:"over-cooked"},{match:"#Copula #Adjective+ (and|or) [#PastTense]$",group:0,tag:"Adjective",reason:"bland-and-overcooked"},{match:"got #Adverb? [#PastTense] of",group:0,tag:"Adjective",reason:"got-tired-of"},{match:"(seem|seems|seemed|appear|appeared|appears|feel|feels|felt|sound|sounds|sounded) (#Adverb|#Adjective)? [#PastTense]",group:0,tag:"Adjective",reason:"felt-loved"},{match:"(seem|feel|seemed|felt) [#PastTense #Particle?]",group:0,tag:"Adjective",reason:"seem-confused"},{match:"a (bit|little|tad) [#PastTense #Particle?]",group:0,tag:"Adjective",reason:"a-bit-confused"},{match:"not be [%Adj|Past% #Particle?]",group:0,tag:"Adjective",reason:"do-not-be-confused"},{match:"#Copula just [%Adj|Past% #Particle?]",group:0,tag:"Adjective",reason:"is-just-right"},{match:"as [#Infinitive] as",group:0,tag:"Adjective",reason:"as-pale-as"},{match:"[%Adj|Past%] and #Adjective",group:0,tag:"Adjective",reason:"faled-and-oppressive"},{match:"or [#PastTense] #Noun",group:0,tag:"Adjective",notIf:"(#Copula|#Pronoun)",reason:"or-heightened-emotion"},{match:"(become|became|becoming|becomes) [#Verb]",group:0,tag:"Adjective",reason:"become-verb"},{match:"#Possessive [#PastTense] #Noun",group:0,tag:"Adjective",reason:"declared-intentions"},{match:"#Copula #Pronoun [%Adj|Present%]",group:0,tag:"Adjective",reason:"is-he-cool"},{match:"#Copula [%Adj|Past%] with",group:0,tag:"Adjective",notIf:"(associated|worn|baked|aged|armed|bound|fried|loaded|mixed|packed|pumped|filled|sealed)",reason:"is-crowded-with"},{match:"#Copula #Adverb? [%Adj|Present%]$",group:0,tag:"Adjective",reason:"was-empty$"}],[{match:"will (#Adverb|not)+? [have] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"will-have-vb"},{match:"[#Copula] (#Adverb|not)+? (#Gerund|#PastTense)",group:0,tag:"Auxiliary",reason:"copula-walking"},{match:"[(#Modal|did)+] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"modal-verb"},{match:"#Modal (#Adverb|not)+? [have] (#Adverb|not)+? [had] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"would-have"},{match:"[(has|had)] (#Adverb|not)+? #PastTense",group:0,tag:"Auxiliary",reason:"had-walked"},{match:"[(do|does|did|will|have|had|has|got)] (not|#Adverb)+? #Verb",group:0,tag:"Auxiliary",reason:"have-had"},{match:"[about to] #Adverb? #Verb",group:0,tag:["Auxiliary","Verb"],reason:"about-to"},{match:"#Modal (#Adverb|not)+? [be] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"would-be"},{match:"[(#Modal|had|has)] (#Adverb|not)+? [been] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"had-been"},{match:"[(be|being|been)] #Participle",group:0,tag:"Auxiliary",reason:"being-driven"},{match:"[may] #Adverb? #Infinitive",group:0,tag:"Auxiliary",reason:"may-want"},{match:"#Copula (#Adverb|not)+? [(be|being|been)] #Adverb+? #PastTense",group:0,tag:"Auxiliary",reason:"being-walked"},{match:"will [be] #PastTense",group:0,tag:"Auxiliary",reason:"will-be-x"},{match:"[(be|been)] (#Adverb|not)+? #Gerund",group:0,tag:"Auxiliary",reason:"been-walking"},{match:"[used to] #PresentTense",group:0,tag:"Auxiliary",reason:"used-to-walk"},{match:"#Copula (#Adverb|not)+? [going to] #Adverb+? #PresentTense",group:0,tag:"Auxiliary",reason:"going-to-walk"},{match:"#Imperative [(me|him|her)]",group:0,tag:"Reflexive",reason:"tell-him"},{match:"(is|was) #Adverb? [no]",group:0,tag:"Negative",reason:"is-no"},{match:"[(been|had|became|came)] #PastTense",group:0,notIf:"#PhrasalVerb",tag:"Auxiliary",reason:"been-told"},{match:"[(being|having|getting)] #Verb",group:0,tag:"Auxiliary",reason:"being-born"},{match:"[be] #Gerund",group:0,tag:"Auxiliary",reason:"be-walking"},{match:"[better] #PresentTense",group:0,tag:"Modal",notIf:"(#Copula|#Gerund)",reason:"better-go"},{match:"even better",tag:"Adverb #Comparative",reason:"even-better"}],[{match:"(#Verb && @hasHyphen) up",tag:"PhrasalVerb",reason:"foo-up"},{match:"(#Verb && @hasHyphen) off",tag:"PhrasalVerb",reason:"foo-off"},{match:"(#Verb && @hasHyphen) over",tag:"PhrasalVerb",reason:"foo-over"},{match:"(#Verb && @hasHyphen) out",tag:"PhrasalVerb",reason:"foo-out"},{match:"[#Verb (in|out|up|down|off|back)] (on|in)",notIf:"#Copula",tag:"PhrasalVerb Particle",reason:"walk-in-on"},{match:"(lived|went|crept|go) [on] for",group:0,tag:"PhrasalVerb",reason:"went-on"},{match:"#Verb (up|down|in|on|for)$",tag:"PhrasalVerb #Particle",notIf:"#PhrasalVerb",reason:"come-down$"},{match:"help [(stop|end|make|start)]",group:0,tag:"Infinitive",reason:"help-stop"},{match:"#PhrasalVerb (in && #Particle) #Determiner",tag:"#Verb #Preposition #Determiner",unTag:"PhrasalVerb",reason:"work-in-the"},{match:"[(stop|start|finish|help)] #Gerund",group:0,tag:"Infinitive",reason:"start-listening"},{match:"#Verb (him|her|it|us|himself|herself|itself|everything|something) [(up|down)]",group:0,tag:"Adverb",reason:"phrasal-pronoun-advb"}],[{match:"^do not? [#Infinitive #Particle?]",notIf:Vl,group:0,tag:"Imperative",reason:"do-eat"},{match:"^please do? not? [#Infinitive #Particle?]",group:0,tag:"Imperative",reason:"please-go"},{match:"^just do? not? [#Infinitive #Particle?]",group:0,tag:"Imperative",reason:"just-go"},{match:"^[#Infinitive] it #Comparative",notIf:Vl,group:0,tag:"Imperative",reason:"do-it-better"},{match:"^[#Infinitive] it (please|now|again|plz)",notIf:Vl,group:0,tag:"Imperative",reason:"do-it-please"},{match:"^[#Infinitive] (#Adjective|#Adverb)$",group:0,tag:"Imperative",notIf:"(so|such|rather|enough)",reason:"go-quickly"},{match:"^[#Infinitive] (up|down|over) #Determiner",group:0,tag:"Imperative",reason:"turn-down"},{match:"^[#Infinitive] (your|my|the|a|an|any|each|every|some|more|with|on)",group:0,notIf:"like",tag:"Imperative",reason:"eat-my-shorts"},{match:"^[#Infinitive] (him|her|it|us|me|there)",group:0,tag:"Imperative",reason:"tell-him"},{match:"^[#Infinitive] #Adjective #Noun$",group:0,tag:"Imperative",reason:"avoid-loud-noises"},{match:"^[#Infinitive] (#Adjective|#Adverb)? and #Infinitive",group:0,tag:"Imperative",reason:"call-and-reserve"},{match:"^(go|stop|wait|hurry) please?$",tag:"Imperative",reason:"go"},{match:"^(somebody|everybody) [#Infinitive]",group:0,tag:"Imperative",reason:"somebody-call"},{match:"^let (us|me) [#Infinitive]",group:0,tag:"Imperative",reason:"lets-leave"},{match:"^[(shut|close|open|start|stop|end|keep)] #Determiner #Noun",group:0,tag:"Imperative",reason:"shut-the-door"},{match:"^[#PhrasalVerb #Particle] #Determiner #Noun",group:0,tag:"Imperative",reason:"turn-off-the-light"},{match:"^[go] to .",group:0,tag:"Imperative",reason:"go-to-toronto"},{match:"^#Modal you [#Infinitive]",group:0,tag:"Imperative",reason:"would-you-"},{match:"^never [#Infinitive]",group:0,tag:"Imperative",reason:"never-stop"},{match:"^come #Infinitive",tag:"Imperative",notIf:"on",reason:"come-have"},{match:"^come and? #Infinitive",tag:"Imperative . Imperative",notIf:"#PhrasalVerb",reason:"come-and-have"},{match:"^stay (out|away|back)",tag:"Imperative",reason:"stay-away"},{match:"^[(stay|be|keep)] #Adjective",group:0,tag:"Imperative",reason:"stay-cool"},{match:"^[keep it] #Adjective",group:0,tag:"Imperative",reason:"keep-it-cool"},{match:"^do not [#Infinitive]",group:0,tag:"Imperative",reason:"do-not-be"},{match:"[#Infinitive] (yourself|yourselves)",group:0,tag:"Imperative",reason:"allow-yourself"},{match:"[#Infinitive] what .",group:0,tag:"Imperative",reason:"look-what"},{match:"^[#Infinitive] #Gerund",group:0,tag:"Imperative",reason:"keep-playing"},{match:"^[#Infinitive] (to|for|into|toward|here|there)",group:0,tag:"Imperative",reason:"go-to"},{match:"^[#Infinitive] (and|or) #Infinitive",group:0,tag:"Imperative",reason:"inf-and-inf"},{match:"^[%Noun|Verb%] to",group:0,tag:"Imperative",reason:"commit-to"},{match:"^[#Infinitive] #Adjective? #Singular #Singular",group:0,tag:"Imperative",reason:"maintain-eye-contact"},{match:"do not (forget|omit|neglect) to [#Infinitive]",group:0,tag:"Imperative",reason:"do-not-forget"},{match:"^[(ask|wear|pay|look|help|show|watch|act|fix|kill|stop|start|turn|try|win)] #Noun",group:0,tag:"Imperative",reason:"pay-attention"}],[{match:"(that|which) were [%Adj|Gerund%]",group:0,tag:"Gerund",reason:"that-were-growing"},{match:"#Gerund [#Gerund] #Plural",group:0,tag:"Adjective",reason:"hard-working-fam"}],[{match:"u r",tag:"#Pronoun #Copula",reason:"u r"},{match:"#Noun [(who|whom)]",group:0,tag:"Determiner",reason:"captain-who"},{match:"[had] #Noun+ #PastTense",group:0,tag:"Condition",reason:"had-he"},{match:"[were] #Noun+ to #Infinitive",group:0,tag:"Condition",reason:"were-he"},{match:"some sort of",tag:"Adjective Noun Conjunction",reason:"some-sort-of"},{match:"of some sort",tag:"Conjunction Adjective Noun",reason:"of-some-sort"},{match:"[such] (a|an|is)? #Noun",group:0,tag:"Determiner",reason:"such-skill"},{match:"[right] (before|after|in|into|to|toward)",group:0,tag:"#Adverb",reason:"right-into"},{match:"#Preposition [about]",group:0,tag:"Adjective",reason:"at-about"},{match:"(are|#Modal|see|do|for) [ya]",group:0,tag:"Pronoun",reason:"are-ya"},{match:"[long live] .",group:0,tag:"#Adjective #Infinitive",reason:"long-live"},{match:"[plenty] of",group:0,tag:"#Uncountable",reason:"plenty-of"},{match:"(always|nearly|barely|practically) [there]",group:0,tag:"Adjective",reason:"always-there"},{match:"[there] (#Adverb|#Pronoun)? #Copula",group:0,tag:"There",reason:"there-is"},{match:"#Copula [there] .",group:0,tag:"There",reason:"is-there"},{match:"#Modal #Adverb? [there]",group:0,tag:"There",reason:"should-there"},{match:"^[do] (you|we|they)",group:0,tag:"QuestionWord",reason:"do-you"},{match:"^[does] (he|she|it|#ProperNoun)",group:0,tag:"QuestionWord",reason:"does-he"},{match:"#Determiner #Noun+ [who] #Verb",group:0,tag:"Preposition",reason:"the-x-who"},{match:"#Determiner #Noun+ [which] #Verb",group:0,tag:"Preposition",reason:"the-x-which"},{match:"a [while]",group:0,tag:"Noun",reason:"a-while"},{match:"guess who",tag:"#Infinitive #QuestionWord",reason:"guess-who"},{match:"[fucking] !#Verb",group:0,tag:"#Gerund",reason:"f-as-gerund"}],[{match:"university of #Place",tag:"Organization",reason:"university-of-Foo"},{match:"#Noun (&|n) #Noun",tag:"Organization",reason:"Noun-&-Noun"},{match:"#Organization of the? #ProperNoun",tag:"Organization",reason:"org-of-place",safe:!0},{match:"#Organization #Country",tag:"Organization",reason:"org-country"},{match:"#ProperNoun #Organization",tag:"Organization",notIf:"#FirstName",reason:"titlecase-org"},{match:"#ProperNoun (ltd|co|inc|dept|assn|bros)",tag:"Organization",reason:"org-abbrv"},{match:"the [#Acronym]",group:0,tag:"Organization",reason:"the-acronym",safe:!0},{match:"government of the? [#Place+]",tag:"Organization",reason:"government-of-x"},{match:"(health|school|commerce) board",tag:"Organization",reason:"school-board"},{match:"(nominating|special|conference|executive|steering|central|congressional) committee",tag:"Organization",reason:"special-comittee"},{match:"(world|global|international|national|#Demonym) #Organization",tag:"Organization",reason:"global-org"},{match:"#Noun+ (public|private) school",tag:"School",reason:"noun-public-school"},{match:"#Place+ #SportsTeam",tag:"SportsTeam",reason:"place-sportsteam"},{match:"(dc|atlanta|minnesota|manchester|newcastle|sheffield) united",tag:"SportsTeam",reason:"united-sportsteam"},{match:"#Place+ fc",tag:"SportsTeam",reason:"fc-sportsteam"},{match:"#Place+ #Noun{0,2} (club|society|group|team|committee|commission|association|guild|crew)",tag:"Organization",reason:"place-noun-society"}],[{match:"(west|north|south|east|western|northern|southern|eastern)+ #Place",tag:"Region",reason:"west-norfolk"},{match:"#City [(al|ak|az|ar|ca|ct|dc|fl|ga|id|il|nv|nh|nj|ny|oh|pa|sc|tn|tx|ut|vt|pr)]",group:0,tag:"Region",reason:"us-state"},{match:"portland [or]",group:0,tag:"Region",reason:"portland-or"},{match:"#ProperNoun+ (cliff|place|range|pit|place|point|room|grounds|ruins)",tag:"Place",reason:"foo-point"},{match:"in [#ProperNoun] #Place",group:0,tag:"Place",reason:"propernoun-place"},{match:"#Value #Noun (st|street|rd|road|crescent|cr|way|tr|terrace|avenue|ave)",tag:"Address",reason:"address-st"},{match:"(port|mount|mt) #ProperName",tag:"Place",reason:"port-name"}],[{match:"[so] #Noun",group:0,tag:"Conjunction",reason:"so-conj"},{match:"[(who|what|where|why|how|when)] #Noun #Copula #Adverb? (#Verb|#Adjective)",group:0,tag:"Conjunction",reason:"how-he-is-x"},{match:"#Copula [(who|what|where|why|how|when)] #Noun",group:0,tag:"Conjunction",reason:"when-he"},{match:"#Verb [that] #Pronoun",group:0,tag:"Conjunction",reason:"said-that-he"},{match:"#Noun [that] #Copula",group:0,tag:"Conjunction",reason:"that-are"},{match:"#Noun [that] #Verb #Adjective",group:0,tag:"Conjunction",reason:"that-seem"},{match:"#Noun #Copula not? [that] #Adjective",group:0,tag:"Adverb",reason:"that-adj"},{match:"#Verb #Adverb? #Noun [(that|which)]",group:0,tag:"Preposition",reason:"that-prep"},{match:"@hasComma [which] (#Pronoun|#Verb)",group:0,tag:"Preposition",reason:"which-copula"},{match:"#Noun [like] #Noun",group:0,tag:"Preposition",reason:"noun-like"},{match:"^[like] #Determiner",group:0,tag:"Preposition",reason:"like-the"},{match:"a #Noun [like] (#Noun|#Determiner)",group:0,tag:"Preposition",reason:"a-noun-like"},{match:"#Adverb [like]",group:0,tag:"Verb",reason:"really-like"},{match:"(not|nothing|never) [like]",group:0,tag:"Preposition",reason:"nothing-like"},{match:"#Infinitive #Pronoun [like]",group:0,tag:"Preposition",reason:"treat-them-like"},{match:"[#QuestionWord] (#Pronoun|#Determiner)",group:0,tag:"Preposition",reason:"how-he"},{match:"[#QuestionWord] #Participle",group:0,tag:"Preposition",reason:"when-stolen"},{match:"[how] (#Determiner|#Copula|#Modal|#PastTense)",group:0,tag:"QuestionWord",reason:"how-is"},{match:"#Plural [(who|which|when)] .",group:0,tag:"Preposition",reason:"people-who"}],[{match:"holy (shit|fuck|hell)",tag:"Expression",reason:"swears-expression"},{match:"^[(well|so|okay|now)] !#Adjective?",group:0,tag:"Expression",reason:"well-"},{match:"^come on",tag:"Expression",reason:"come-on"},{match:"(say|says|said) [sorry]",group:0,tag:"Expression",reason:"say-sorry"},{match:"^(ok|alright|shoot|hell|anyways)",tag:"Expression",reason:"ok-"},{match:"^(say && @hasComma)",tag:"Expression",reason:"say-"},{match:"^(like && @hasComma)",tag:"Expression",reason:"like-"},{match:"^[(dude|man|girl)] #Pronoun",group:0,tag:"Expression",reason:"dude-i"}]);let Bl=null;var Sl={postTagger:function(e){const{world:t}=e,{model:n,methods:r}=t;Bl=Bl||r.one.buildNet(n.two.matches,t);const o=r.two.quickSplit(e.document).map((e=>{const t=e[0];return[t.index[0],t.index[1],t.index[1]+e.length]})),a=e.update(o);return a.cache(),a.sweep(Bl),e.uncache(),e.unfreeze(),e},tagger:e=>e.compute(["freeze","lexicon","preTagger","postTagger","unfreeze"])};const $l={api:function(e){e.prototype.confidence=function(){let e=0,t=0;return this.docs.forEach((n=>{n.forEach((n=>{t+=1,e+=n.confidence||1}))})),0===t?1:(e=>Math.round(100*e)/100)(e/t)},e.prototype.tagger=function(){return this.compute(["tagger"])}},compute:Sl,model:{two:{matches:zl}},hooks:["postTagger"]},Ml=function(e,t){const n=function(e){return Object.keys(e.hooks).filter((e=>!e.startsWith("#")&&!e.startsWith("%")))}(t);if(0===n.length)return e;e._cache||e.cache();const r=e._cache;return e.filter(((e,t)=>n.some((e=>r[t].has(e)))))};var Ll={lib:{lazy:function(e,t){let n=t;"string"==typeof t&&(n=this.buildNet([{match:t}]));const r=this.tokenize(e),o=Ml(r,n);return o.found?(o.compute(["index","tagger"]),o.match(t)):r.none()}}};const Kl=function(e,t,n){let r=e.split(/ /g).map((e=>e.toLowerCase().trim()));r=r.filter((e=>e)),r=r.map((e=>`{${e}}`)).join(" ");let o=this.match(r);return n&&(o=o.if(n)),o.has("#Verb")?function(e,t){let n=t;return e.forEach((e=>{e.has("#Infinitive")||(n=function(e,t){const n=(0,e.methods.two.transform.verb.conjugate)(t,e.model);return e.has("#Gerund")?n.Gerund:e.has("#PastTense")?n.PastTense:e.has("#PresentTense")?n.PresentTense:e.has("#Gerund")?n.Gerund:t}(e,t)),e.replaceWith(n)})),e}(o,t):o.has("#Noun")?function(e,t){let n=t;e.has("#Plural")&&(n=(0,e.methods.two.transform.noun.toPlural)(t,e.model));e.replaceWith(n,{possessives:!0})}(o,t):o.has("#Adverb")?function(e,t){const{toAdverb:n}=e.methods.two.transform.adjective,r=n(t);r&&e.replaceWith(r)}(o,t):o.has("#Adjective")?function(e,t){const{toComparative:n,toSuperlative:r}=e.methods.two.transform.adjective;let o=t;e.has("#Comparative")?o=n(o,e.model):e.has("#Superlative")&&(o=r(o,e.model)),o&&e.replaceWith(o)}(o,t):this};var Jl={api:function(e){e.prototype.swap=Kl}};h.plugin(cl),h.plugin(Ol),h.plugin($l),h.plugin(Ll),h.plugin(Jl);const Wl=function(e){const{fromComparative:t,fromSuperlative:n}=e.methods.two.transform.adjective,r=e.text("normal");return e.has("#Comparative")?t(r,e.model):e.has("#Superlative")?n(r,e.model):r};var ql={api:function(e){class Adjectives extends e{constructor(e,t,n){super(e,t,n),this.viewType="Adjectives"}json(e={}){const{toAdverb:t,toNoun:n,toSuperlative:r,toComparative:o}=this.methods.two.transform.adjective;return e.normal=!0,this.map((a=>{const i=a.toView().json(e)[0]||{},s=Wl(a);return i.adjective={adverb:t(s,this.model),noun:n(s,this.model),superlative:r(s,this.model),comparative:o(s,this.model)},i}),[])}adverbs(){return this.before("#Adverb+$").concat(this.after("^#Adverb+"))}conjugate(e){const{toComparative:t,toSuperlative:n,toNoun:r,toAdverb:o}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const a=Wl(e);return{Adjective:a,Comparative:t(a,this.model),Superlative:n(a,this.model),Noun:r(a,this.model),Adverb:o(a,this.model)}}),[])}toComparative(e){const{toComparative:t}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const n=Wl(e),r=t(n,this.model);return e.replaceWith(r)}))}toSuperlative(e){const{toSuperlative:t}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const n=Wl(e),r=t(n,this.model);return e.replaceWith(r)}))}toAdverb(e){const{toAdverb:t}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const n=Wl(e),r=t(n,this.model);return e.replaceWith(r)}))}toNoun(e){const{toNoun:t}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const n=Wl(e),r=t(n,this.model);return e.replaceWith(r)}))}}e.prototype.adjectives=function(e){let t=this.match("#Adjective");return t=t.getNth(e),new Adjectives(t.document,t.pointer)},e.prototype.superlatives=function(e){let t=this.match("#Superlative");return t=t.getNth(e),new Adjectives(t.document,t.pointer)},e.prototype.comparatives=function(e){let t=this.match("#Comparative");return t=t.getNth(e),new Adjectives(t.document,t.pointer)}}};var Ul={api:function(e){class Adverbs extends e{constructor(e,t,n){super(e,t,n),this.viewType="Adverbs"}conjugate(e){return this.getNth(e).map((e=>{const t=function(e){return e.compute("root").text("root")}(e);return{Adverb:e.text("normal"),Adjective:t}}),[])}json(e={}){const t=this.methods.two.transform.adjective.fromAdverb;return e.normal=!0,this.map((n=>{const r=n.toView().json(e)[0]||{};return r.adverb={adjective:t(r.normal)},r}),[])}}e.prototype.adverbs=function(e){let t=this.match("#Adverb");return t=t.getNth(e),new Adverbs(t.document,t.pointer)}}};const Rl=function(e){let t=this;t=function(e){let t=e.parentheses();return t=t.filter((e=>e.wordCount()>=3&&e.has("#Verb")&&e.has("#Noun"))),e.splitOn(t)}(t),t=function(e){let t=e.quotations();return t=t.filter((e=>e.wordCount()>=3&&e.has("#Verb")&&e.has("#Noun"))),e.splitOn(t)}(t),t=function(e){let t=e.match("@hasComma");return t=t.filter((e=>{if(1===e.growLeft(".").wordCount())return!1;if(1===e.growRight(". .").wordCount())return!1;let t=e.grow(".");return t=t.ifNo("@hasComma @hasComma"),t=t.ifNo("@hasComma (and|or) ."),t=t.ifNo("(#City && @hasComma) #Country"),t=t.ifNo("(#WeekDay && @hasComma) #Date"),t=t.ifNo("(#Date+ && @hasComma) #Value"),t=t.ifNo("(#Adjective && @hasComma) #Adjective"),t.found})),e.splitAfter(t)}(t),t=t.splitAfter("(@hasEllipses|@hasSemicolon|@hasDash|@hasColon)"),t=t.splitAfter("^#Pronoun (said|says)"),t=t.splitBefore("(said|says) #ProperNoun$"),t=t.splitBefore(". . if .{4}"),t=t.splitBefore("and while"),t=t.splitBefore("now that"),t=t.splitBefore("ever since"),t=t.splitBefore("(supposing|although)"),t=t.splitBefore("even (while|if|though)"),t=t.splitBefore("(whereas|whose)"),t=t.splitBefore("as (though|if)"),t=t.splitBefore("(til|until)");const n=t.match("#Verb .* [but] .* #Verb",0);n.found&&(t=t.splitBefore(n));const r=t.if("if .{2,9} then .").match("then");return t=t.splitBefore(r),"number"==typeof e&&(t=t.get(e)),t},Ql={this:"Noun",then:"Pivot"},Zl=[{match:"[that] #Determiner #Noun",group:0,chunk:"Pivot"},{match:"#PastTense [that]",group:0,chunk:"Pivot"},{match:"[so] #Determiner",group:0,chunk:"Pivot"},{match:"#Copula #Adverb+? [#Adjective]",group:0,chunk:"Adjective"},{match:"#Adjective and #Adjective",chunk:"Adjective"},{match:"#Adverb+ and #Adverb #Verb",chunk:"Verb"},{match:"#Gerund #Adjective$",chunk:"Verb"},{match:"#Gerund to #Verb",chunk:"Verb"},{match:"#PresentTense and #PresentTense",chunk:"Verb"},{match:"#Adverb #Negative",chunk:"Verb"},{match:"(want|wants|wanted) to #Infinitive",chunk:"Verb"},{match:"#Verb #Reflexive",chunk:"Verb"},{match:"#Verb [to] #Adverb? #Infinitive",group:0,chunk:"Verb"},{match:"[#Preposition] #Gerund",group:0,chunk:"Verb"},{match:"#Infinitive [that] ",group:0,chunk:"Verb"},{match:"#Noun of #Determiner? #Noun",chunk:"Noun"},{match:"#Value+ #Adverb? #Adjective",chunk:"Noun"},{match:"the [#Adjective] #Noun",chunk:"Noun"},{match:"#Singular in #Determiner? #Singular",chunk:"Noun"},{match:"#Plural [in] #Determiner? #Noun",group:0,chunk:"Pivot"},{match:"#Noun and #Determiner? #Noun",notIf:"(#Possessive|#Pronoun)",chunk:"Noun"}];let _l=null;const Xl=function(e,t){if(("undefined"!=typeof process&&process.env?process.env:self.env||{}).DEBUG_CHUNKS){const n=(e.normal+"'").padEnd(8);console.log(` | '${n} → �[34m${t.padEnd(12)}�[0m �[2m -fallback- �[0m`)}e.chunk=t};var Yl={chunks:function(e){const{document:t,world:n}=e;!function(e){for(let t=0;t{for(let r=0;r{if("Verb"===e.chunk){const t=e.terms.find((e=>e.tags.has("Verb")));t||e.terms.forEach((e=>e.chunk=null))}}))}(t)}},eu={compute:Yl,api:function(e){class Chunks extends e{constructor(e,t,n){super(e,t,n),this.viewType="Chunks"}isVerb(){return this.filter((e=>e.has("")))}isNoun(){return this.filter((e=>e.has("")))}isAdjective(){return this.filter((e=>e.has("")))}isPivot(){return this.filter((e=>e.has("")))}debug(){return this.toView().debug("chunks"),this}update(e){const t=new Chunks(this.document,e);return t._cache=this._cache,t}}e.prototype.chunks=function(e){let t=function(e){const t=[];let n=null;return e.clauses().docs.forEach((e=>{e.forEach((e=>{e.chunk&&e.chunk===n?t[t.length-1][2]=e.index[1]+1:(n=e.chunk,t.push([e.index[0],e.index[1],e.index[1]+1]))})),n=null})),e.update(t)}(this);return t=t.getNth(e),new Chunks(this.document,t.pointer)},e.prototype.clauses=Rl},hooks:["chunks"]};const tu=/\./g,nu=/\(/,ru=/\)/,ou=function(e,t){for(;t{e[0].pre=e[0].pre.replace(nu,"");const t=e[e.length-1];t.post=t.post.replace(ru,"")})),e}(this)}}e.prototype.parentheses=function(e){let t=function(e){const t=[];return e.docs.forEach((e=>{for(let n=0;n{e[0].pre=e[0].pre.replace(lu,"");const t=e[e.length-1];t.post=t.post.replace(uu,"")}))}(this)}}e.prototype.quotations=function(e){let t=function(e){const t=[];return e.docs.forEach((e=>{for(let n=0;n{e.forEach((e=>{e.text=e.text.replace(tu,""),e.normal=e.normal.replace(tu,"")}))})),this}addPeriods(){return this.docs.forEach((e=>{e.forEach((e=>{e.text=e.text.replace(tu,""),e.normal=e.normal.replace(tu,""),e.text=e.text.split("").join(".")+".",e.normal=e.normal.split("").join(".")+"."}))})),this}}e.prototype.acronyms=function(e){let t=this.match("#Acronym");return t=t.getNth(e),new Acronyms(t.document,t.pointer)}}(e),au(e),function(e){class Possessives extends e{constructor(e,t,n){super(e,t,n),this.viewType="Possessives"}strip(){return this.docs.forEach((e=>{e.forEach((e=>{e.text=e.text.replace(iu,""),e.normal=e.normal.replace(iu,"")}))})),this}}e.prototype.possessives=function(e){let t=function(e){let t=e.match("#Possessive+");return t.has("#Person")&&(t=t.growLeft("#Person+")),t.has("#Place")&&(t=t.growLeft("#Place+")),t.has("#Organization")&&(t=t.growLeft("#Organization+")),t}(this);return t=t.getNth(e),new Possessives(t.document,t.pointer)}}(e),hu(e),function(e){gu.forEach((t=>{e.prototype[t[0]]=function(e){const n=this.match(t[1]);return"number"==typeof e?n.get(e):n}})),e.prototype.phoneNumbers=du,mu.forEach((t=>{e.prototype[t[0]]=e.prototype[t[1]]}))}(e),function(e){class Slashes extends e{constructor(e,t,n){super(e,t,n),this.viewType="Slashes"}split(){return this.map((e=>{const t=e.text().split(pu);return(e=e.replaceWith(t.join(" "))).growRight("("+t.join("|")+")+")}))}}e.prototype.slashes=function(e){let t=this.match("#SlashedTerm");return t=t.getNth(e),new Slashes(t.document,t.pointer)}}(e)}};const bu=function(e,t){e.docs.forEach((e=>{e.forEach(t)}))};var vu={case:e=>{bu(e,(e=>{e.text=e.text.toLowerCase()}))},unicode:e=>{const t=e.world,n=t.methods.one.killUnicode;bu(e,(e=>e.text=n(e.text,t)))},whitespace:e=>{bu(e,(e=>{e.post=e.post.replace(/\s+/g," "),e.post=e.post.replace(/\s([.,?!:;])/g,"$1"),e.pre=e.pre.replace(/\s+/g,"")}))},punctuation:e=>{bu(e,(e=>{e.post=e.post.replace(/[–—-]/g," "),e.post=e.post.replace(/[,:;]/g,""),e.post=e.post.replace(/\.{2,}/g,""),e.post=e.post.replace(/\?{2,}/g,"?"),e.post=e.post.replace(/!{2,}/g,"!"),e.post=e.post.replace(/\?!+/g,"?")}));const t=e.docs,n=t[t.length-1];if(n&&n.length>0){const e=n[n.length-1];e.post=e.post.replace(/ /g,"")}},contractions:e=>{e.contractions().expand()},acronyms:e=>{e.acronyms().strip()},parentheses:e=>{e.parentheses().strip()},possessives:e=>{e.possessives().strip()},quotations:e=>{e.quotations().strip()},emoji:e=>{e.emojis().remove()},honorifics:e=>{e.match("#Honorific+ #Person").honorifics().remove()},adverbs:e=>{e.adverbs().remove()},nouns:e=>{e.nouns().toSingular()},verbs:e=>{e.verbs().toInfinitive()},numbers:e=>{e.numbers().toNumber()},debullet:e=>{const t=/^\s*([-–—*•])\s*$/;return e.docs.forEach((e=>{t.test(e[0].pre)&&(e[0].pre=e[0].pre.replace(t,""))})),e}};const yu=e=>e.split("|").reduce(((e,t)=>(e[t]=!0,e)),{}),wu="unicode|punctuation|whitespace|acronyms",ku="|case|contractions|parentheses|quotations|emoji|honorifics|debullet",Pu={light:yu(wu),medium:yu(wu+ku),heavy:yu(wu+ku+"|possessives|adverbs|nouns|verbs")};var Au={api:function(e){e.prototype.normalize=function(e="light"){return"string"==typeof e&&(e=Pu[e]),Object.keys(e).forEach((t=>{vu.hasOwnProperty(t)&&vu[t](this,e[t])})),this}}};const Cu=["after","although","as if","as long as","as","because","before","even if","even though","ever since","if","in order that","provided that","since","so that","than","that","though","unless","until","what","whatever","when","whenever","where","whereas","wherever","whether","which","whichever","who","whoever","whom","whomever","whose"],Nu=function(e){if(e.before("#Preposition$").found)return!0;if(!e.before().found)return!1;for(let t=0;t3&&n.endsWith("s")&&!n.endsWith("ss")},xu=function(e){const t=function(e){let t=e.clone();return t=t.match("#Noun+"),t=t.remove("(#Adjective|#Preposition|#Determiner|#Value)"),t=t.not("#Possessive"),t=t.first(),t.found?t:e}(e);return{determiner:e.match("#Determiner").eq(0),adjectives:e.match("#Adjective"),number:e.values(),isPlural:ju(e,t),isSubordinate:Nu(e),root:t}},Iu=e=>e.text(),Tu=e=>e.json({terms:!1,normal:!0}).map((e=>e.normal)),Du=function(e){if(!e.found)return null;const t=e.values(0);if(t.found){return(t.parse()[0]||{}).num}return null},Hu=function(e){return!e.has("^(#Uncountable|#ProperNoun|#Place|#Pronoun|#Acronym)+$")},Eu={tags:!0},Gu={tags:!0};var Ou={api:function(e){class Nouns extends e{constructor(e,t,n){super(e,t,n),this.viewType="Nouns"}parse(e){return this.getNth(e).map(xu)}json(e){const t="object"==typeof e?e:{};return this.getNth(e).map((e=>{const n=e.toView().json(t)[0]||{};return t&&!1!==t.noun&&(n.noun=function(e){const t=xu(e);return{root:Iu(t.root),number:Du(t.number),determiner:Iu(t.determiner),adjectives:Tu(t.adjectives),isPlural:t.isPlural,isSubordinate:t.isSubordinate}}(e)),n}),[])}conjugate(e){const t=this.world.methods.two.transform.noun;return this.getNth(e).map((e=>{const n=xu(e),r=n.root.compute("root").text("root"),o={Singular:r};return Hu(n.root)&&(o.Plural=t.toPlural(r,this.model)),o.Singular===o.Plural&&delete o.Plural,o}),[])}isPlural(e){const t=this.filter((e=>xu(e).isPlural));return t.getNth(e)}isSingular(e){const t=this.filter((e=>!xu(e).isPlural));return t.getNth(e)}adjectives(e){let t=this.update([]);return this.forEach((e=>{const n=xu(e).adjectives;n.found&&(t=t.concat(n))})),t.getNth(e)}toPlural(e){return this.getNth(e).map((e=>function(e,t){if(!0===t.isPlural)return e;if(t.root.has("#Possessive")&&(t.root=t.root.possessives().strip()),!Hu(t.root))return e;const{methods:n,model:r}=e.world,{toPlural:o}=n.two.transform.noun,a=o(t.root.text({keepPunct:!1}),r);e.match(t.root).replaceWith(a,Eu).tag("Plural","toPlural"),t.determiner.has("(a|an)")&&e.remove(t.determiner);const i=t.root.after("not? #Adverb+? [#Copula]",0);return i.found&&(i.has("is")?e.replace(i,"are"):i.has("was")&&e.replace(i,"were")),e}(e,xu(e))))}toSingular(e){return this.getNth(e).map((e=>function(e,t){if(!1===t.isPlural)return e;const{methods:n,model:r}=e.world,{toSingular:o}=n.two.transform.noun,a=o(t.root.text("normal"),r);return e.replace(t.root,a,Gu).tag("Singular","toPlural"),e}(e,xu(e))))}update(e){const t=new Nouns(this.document,e);return t._cache=this._cache,t}}e.prototype.nouns=function(e){let t=function(e){let t=e.clauses().match(""),n=t.match("@hasComma");return n=n.not("#Place"),n.found&&(t=t.splitAfter(n)),t=t.splitOn("#Expression"),t=t.splitOn("(he|she|we|you|they|i)"),t=t.splitOn("(#Noun|#Adjective) [(he|him|she|it)]",0),t=t.splitOn("[(he|him|she|it)] (#Determiner|#Value)",0),t=t.splitBefore("#Noun [(the|a|an)] #Adjective? #Noun",0),t=t.splitOn("[(here|there)] #Noun",0),t=t.splitOn("[#Noun] (here|there)",0),t=t.splitBefore("(our|my|their|your)"),t=t.splitOn("#Noun [#Determiner]",0),t=t.if("#Noun"),t}(this);return t=t.getNth(e),new Nouns(this.document,t.pointer)}}};var Fu={ones:{zeroth:0,first:1,second:2,third:3,fourth:4,fifth:5,sixth:6,seventh:7,eighth:8,ninth:9,zero:0,one:1,two:2,three:3,four:4,five:5,six:6,seven:7,eight:8,nine:9},teens:{tenth:10,eleventh:11,twelfth:12,thirteenth:13,fourteenth:14,fifteenth:15,sixteenth:16,seventeenth:17,eighteenth:18,nineteenth:19,ten:10,eleven:11,twelve:12,thirteen:13,fourteen:14,fifteen:15,sixteen:16,seventeen:17,eighteen:18,nineteen:19},tens:{twentieth:20,thirtieth:30,fortieth:40,fourtieth:40,fiftieth:50,sixtieth:60,seventieth:70,eightieth:80,ninetieth:90,twenty:20,thirty:30,forty:40,fourty:40,fifty:50,sixty:60,seventy:70,eighty:80,ninety:90},multiples:{hundredth:100,thousandth:1e3,millionth:1e6,billionth:1e9,trillionth:1e12,quadrillionth:1e15,quintillionth:1e18,sextillionth:1e21,septillionth:1e24,hundred:100,thousand:1e3,million:1e6,billion:1e9,trillion:1e12,quadrillion:1e15,quintillion:1e18,sextillion:1e21,septillion:1e24,grand:1e3}};const Vu=(e,t)=>{if(Fu.ones.hasOwnProperty(e)){if(t.ones||t.teens)return!1}else if(Fu.teens.hasOwnProperty(e)){if(t.ones||t.teens||t.tens)return!1}else if(Fu.tens.hasOwnProperty(e)&&(t.ones||t.teens||t.tens))return!1;return!0},zu=function(e){let t="0.";for(let n=0;ne=(e=(e=(e=(e=(e=(e=(e=e.replace(/1st$/,"1")).replace(/2nd$/,"2")).replace(/3rd$/,"3")).replace(/([4567890])r?th$/,"$1")).replace(/^[$€¥£¢]/,"")).replace(/[%$€¥£¢]$/,"")).replace(/,/g,"")).replace(/([0-9])([a-z\u00C0-\u00FF]{1,2})$/,"$1"),Su=/^([0-9,. ]+)\/([0-9,. ]+)$/,$u={"a few":3,"a couple":2,"a dozen":12,"two dozen":24,zero:0},Mu=e=>Object.keys(e).reduce(((t,n)=>t+=e[n]),0),Lu=function(e){if(!0===$u.hasOwnProperty(e))return $u[e];if("a"===e||"an"===e)return 1;const t=(e=>{const t=[{reg:/^(minus|negative)[\s-]/i,mult:-1},{reg:/^(a\s)?half[\s-](of\s)?/i,mult:.5}];for(let n=0;n#Value+] out of every? [#Value+]");if(!0!==t.found)return null;let{num:n,den:r}=t.groups();return n&&r?(n=Ju(n),r=Ju(r),n&&r&&"number"==typeof n&&"number"==typeof r?{numerator:n,denominator:r}:null):null}(e)||function(e){const t=e.match("[(#Cardinal|a)+] [#Fraction+]");if(!0!==t.found)return null;let{num:n,den:r}=t.groups();n=n.has("a")?1:Ju(n);let o=r.text("reduced");return Ku.test(o)&&(o=o.replace(Ku,""),r=r.replaceWith(o)),r=Wu.hasOwnProperty(o)?Wu[o]:Ju(r),"number"==typeof n&&"number"==typeof r?{numerator:n,denominator:r}:null}(e)||function(e){const t=e.match("^#Ordinal$");if(!0!==t.found)return null;if(e.lookAhead("^of ."))return{numerator:1,denominator:Ju(t)};return null}(e)||null;return null!==t&&t.numerator&&t.denominator&&(t.decimal=t.numerator/t.denominator,t.decimal=(e=>{const t=Math.round(1e3*e)/1e3;return 0===t&&0!==e?e:t})(t.decimal)),t},Uu=function(e){if(e<1e6)return String(e);let t;return t="number"==typeof e?e.toFixed(0):e,-1===t.indexOf("e+")?t:t.replace(".","").split("e+").reduce((function(e,t){return e+Array(t-e.length+2).join(0)}))},Ru=[["ninety",90],["eighty",80],["seventy",70],["sixty",60],["fifty",50],["forty",40],["thirty",30],["twenty",20]],Qu=["","one","two","three","four","five","six","seven","eight","nine","ten","eleven","twelve","thirteen","fourteen","fifteen","sixteen","seventeen","eighteen","nineteen"],Zu=[[1e24,"septillion"],[1e20,"hundred sextillion"],[1e21,"sextillion"],[1e20,"hundred quintillion"],[1e18,"quintillion"],[1e17,"hundred quadrillion"],[1e15,"quadrillion"],[1e14,"hundred trillion"],[1e12,"trillion"],[1e11,"hundred billion"],[1e9,"billion"],[1e8,"hundred million"],[1e6,"million"],[1e5,"hundred thousand"],[1e3,"thousand"],[100,"hundred"],[1,"one"]],_u=function(e){const t=[];if(e>100)return t;for(let n=0;n=Ru[n][1]&&(e-=Ru[n][1],t.push(Ru[n][0]));return Qu[e]&&t.push(Qu[e]),t},Xu=function(e){let t=e.num;if(0===t||"0"===t)return"zero";t>1e21&&(t=Uu(t));let n=[];t<0&&(n.push("minus"),t=Math.abs(t));const r=function(e){let t=e;const n=[];return Zu.forEach((r=>{if(e>=r[0]){const e=Math.floor(t/r[0]);t-=e*r[0],e&&n.push({unit:r[1],count:e})}})),n}(t);for(let e=0;e1&&n.push("and")),n=n.concat(_u(r[e].count)),n.push(t)}return n=n.concat((e=>{const t=["zero","one","two","three","four","five","six","seven","eight","nine"],n=[],r=Uu(e).match(/\.([0-9]+)/);if(!r||!r[0])return n;n.push("point");const o=r[0].split("");for(let e=0;ee)),0===n.length&&(n[0]=""),n.join(" ")},Yu={one:"first",two:"second",three:"third",five:"fifth",eight:"eighth",nine:"ninth",twelve:"twelfth",twenty:"twentieth",thirty:"thirtieth",forty:"fortieth",fourty:"fourtieth",fifty:"fiftieth",sixty:"sixtieth",seventy:"seventieth",eighty:"eightieth",ninety:"ninetieth"},ec=e=>{const t=Xu(e).split(" "),n=t[t.length-1];return Yu.hasOwnProperty(n)?t[t.length-1]=Yu[n]:t[t.length-1]=n.replace(/y$/,"i")+"th",t.join(" ")},tc=function(e){class Fractions extends e{constructor(e,t,n){super(e,t,n),this.viewType="Fractions"}parse(e){return this.getNth(e).map(qu)}get(e){return this.getNth(e).map(qu)}json(e){return this.getNth(e).map((t=>{const n=t.toView().json(e)[0],r=qu(t);return n.fraction=r,n}),[])}toDecimal(e){return this.getNth(e).forEach((e=>{const{decimal:t}=qu(e);(e=e.replaceWith(String(t),!0)).tag("NumericValue"),e.unTag("Fraction")})),this}toFraction(e){return this.getNth(e).forEach((e=>{const t=qu(e);if(t&&"number"==typeof t.numerator&&"number"==typeof t.denominator){const n=`${t.numerator}/${t.denominator}`;this.replace(e,n)}})),this}toOrdinal(e){return this.getNth(e).forEach((e=>{let t=function(e){if(!e.numerator||!e.denominator)return"";const t=Xu({num:e.numerator});let n=ec({num:e.denominator});return 2===e.denominator&&(n="half"),t&&n?(1!==e.numerator&&(n+="s"),`${t} ${n}`):""}(qu(e));e.after("^#Noun").found&&(t+=" of"),e.replaceWith(t)})),this}toCardinal(e){return this.getNth(e).forEach((e=>{const t=function(e){return e.numerator&&e.denominator?`${Xu({num:e.numerator})} out of ${Xu({num:e.denominator})}`:""}(qu(e));e.replaceWith(t)})),this}toPercentage(e){return this.getNth(e).forEach((e=>{const{decimal:t}=qu(e);let n=100*t;n=Math.round(100*n)/100,e.replaceWith(`${n}%`)})),this}}e.prototype.fractions=function(e){let t=function(e,t){let n=e.match("#Fraction+");return n=n.filter((e=>!e.lookBehind("#Value and$").found)),n=n.notIf("#Value seconds"),n}(this);return t=t.getNth(e),new Fractions(this.document,t.pointer)}},nc="twenty|thirty|forty|fifty|sixty|seventy|eighty|ninety|fourty",rc=function(e){let t=e.match("#Value+");if(t.has("#NumericValue #NumericValue")&&(t.has("#Value @hasComma #Value")?t.splitAfter("@hasComma"):t.has("#NumericValue #Fraction")?t.splitAfter("#NumericValue #Fraction"):t=t.splitAfter("#NumericValue")),t.has("#Value #Value #Value")&&!t.has("#Multiple")&&t.has("("+nc+") #Cardinal #Cardinal")&&(t=t.splitAfter("("+nc+") #Cardinal")),t.has("#Value #Value")){t.has("#NumericValue #NumericValue")&&(t=t.splitOn("#Year")),t.has("("+nc+") (eleven|twelve|thirteen|fourteen|fifteen|sixteen|seventeen|eighteen|nineteen)")&&(t=t.splitAfter("("+nc+")"));const e=t.match("#Cardinal #Cardinal");if(e.found&&!t.has("(point|decimal|#Fraction)")&&!e.has("#Cardinal (#Multiple|point|decimal)")){const n=t.has(`(one|two|three|four|five|six|seven|eight|nine) (${nc})`),r=e.has("("+nc+") #Cardinal"),o=e.has("#Multiple #Value");n||r||o||e.terms().forEach((e=>{t=t.splitOn(e)}))}t.match("#Ordinal #Ordinal").match("#TextValue").found&&!t.has("#Multiple")&&(t.has("("+nc+") #Ordinal")||(t=t.splitAfter("#Ordinal"))),t=t.splitBefore("#Ordinal [#Cardinal]",0),t.has("#TextValue #NumericValue")&&!t.has("("+nc+"|#Multiple)")&&(t=t.splitBefore("#TextValue #NumericValue"))}return t=t.splitAfter("#NumberRange"),t=t.splitBefore("#Year"),t},oc=function(e){if("string"==typeof e)return{num:Lu(e)};let t=e.text("reduced");const n=e.growRight("#Unit").match("#Unit$").text("machine"),r=/[0-9],[0-9]/.test(e.text("text"));if(1===e.terms().length&&!e.has("#Multiple")){const o=function(e,t){const n=(e=e.replace(/,/g,"")).split(/([0-9.,]*)/);let[r,o]=n,a=n.slice(2).join("");return""!==o&&t.length<2?(o=Number(o||e),"number"!=typeof o&&(o=null),a=a||"","st"!==a&&"nd"!==a&&"rd"!==a&&"th"!==a||(a=""),{prefix:r||"",num:o,suffix:a}):null}(t,e);if(null!==o)return o.hasComma=r,o.unit=n,o}let o=e.match("#Fraction{2,}$");o=!1===o.found?e.match("^#Fraction$"):o;let a=null;o.found&&(o.has("#Value and #Value #Fraction")&&(o=o.match("and #Value #Fraction")),a=qu(o),t=(e=(e=e.not(o)).not("and$")).text("reduced"));let i=0;return t&&(i=Lu(t)||0),a&&a.decimal&&(i+=a.decimal),{hasComma:r,prefix:"",num:i,suffix:"",isOrdinal:e.has("#Ordinal"),isText:e.has("#TextValue"),isFraction:e.has("#Fraction"),isMoney:e.has("#Money"),unit:n}},ac={"¢":"cents",$:"dollars","£":"pounds","¥":"yen","€":"euros","₡":"colón","฿":"baht","₭":"kip","₩":"won","₹":"rupees","₽":"ruble","₺":"liras"},ic={"%":"percent","°":"degrees"},sc=function(e){const t={suffix:"",prefix:e.prefix};return ac.hasOwnProperty(e.prefix)&&(t.suffix+=" "+ac[e.prefix],t.prefix=""),ic.hasOwnProperty(e.suffix)&&(t.suffix+=" "+ic[e.suffix]),t.suffix&&1===e.num&&(t.suffix=t.suffix.replace(/s$/,"")),!t.suffix&&e.suffix&&(t.suffix+=" "+e.suffix),t},lc=function(e,t){if("TextOrdinal"===t){const{prefix:t,suffix:n}=sc(e);return t+ec(e)+n}if("Ordinal"===t)return e.prefix+function(e){const t=e.num;if(!t&&0!==t)return null;const n=t%100;if(n>10&&n<20)return String(t)+"th";const r={0:"th",1:"st",2:"nd",3:"rd"};let o=Uu(t);const a=o.slice(o.length-1,o.length);return o+=r[a]?r[a]:"th",o}(e)+e.suffix;if("TextCardinal"===t){const{prefix:t,suffix:n}=sc(e);return t+Xu(e)+n}let n=e.num;return e.hasComma&&(n=n.toLocaleString()),e.prefix+String(n)+e.suffix},uc=function(e){if("string"==typeof e||"number"==typeof e){const t={};return t[e]=!0,t}return t=e,"[object Array]"===Object.prototype.toString.call(t)?e.reduce(((e,t)=>(e[t]=!0,e)),{}):e||{};var t},cc=function(e){class Numbers extends e{constructor(e,t,n){super(e,t,n),this.viewType="Numbers"}parse(e){return this.getNth(e).map(oc)}get(e){return this.getNth(e).map(oc).map((e=>e.num))}json(e){const t="object"==typeof e?e:{};return this.getNth(e).map((e=>{const n=e.toView().json(t)[0],r=oc(e);return n.number={prefix:r.prefix,num:r.num,suffix:r.suffix,hasComma:r.hasComma,unit:r.unit},n}),[])}units(){return this.growRight("#Unit").match("#Unit$")}isUnit(e){return function(e,t={}){return t=uc(t),e.filter((e=>{const{unit:n}=oc(e);return!(!n||!0!==t[n])}))}(this,e)}isOrdinal(){return this.if("#Ordinal")}isCardinal(){return this.if("#Cardinal")}toNumber(){const e=this.map((e=>{if(!this.has("#TextValue"))return e;const t=oc(e);if(null===t.num)return e;const n=e.has("#Ordinal")?"Ordinal":"Cardinal",r=lc(t,n);return e.replaceWith(r,{tags:!0}),e.tag("NumericValue")}));return new Numbers(e.document,e.pointer)}toLocaleString(){return this.forEach((e=>{const t=oc(e);if(null===t.num)return;let n=t.num.toLocaleString();if(e.has("#Ordinal")){const e=lc(t,"Ordinal").match(/[a-z]+$/);e&&(n+=e[0]||"")}e.replaceWith(n,{tags:!0})})),this}toText(){const e=this.map((e=>{if(e.has("#TextValue"))return e;const t=oc(e);if(null===t.num)return e;const n=e.has("#Ordinal")?"TextOrdinal":"TextCardinal",r=lc(t,n);return e.replaceWith(r,{tags:!0}),e.tag("TextValue"),e}));return new Numbers(e.document,e.pointer)}toCardinal(){const e=this.map((e=>{if(!e.has("#Ordinal"))return e;const t=oc(e);if(null===t.num)return e;const n=e.has("#TextValue")?"TextCardinal":"Cardinal",r=lc(t,n);return e.replaceWith(r,{tags:!0}),e.tag("Cardinal"),e}));return new Numbers(e.document,e.pointer)}toOrdinal(){const e=this.map((e=>{if(e.has("#Ordinal"))return e;const t=oc(e);if(null===t.num)return e;const n=e.has("#TextValue")?"TextOrdinal":"Ordinal",r=lc(t,n);return e.replaceWith(r,{tags:!0}),e.tag("Ordinal"),e}));return new Numbers(e.document,e.pointer)}isEqual(e){return this.filter((t=>oc(t).num===e))}greaterThan(e){return this.filter((t=>oc(t).num>e))}lessThan(e){return this.filter((t=>oc(t).num{const r=oc(n).num;return r>e&&r{const n=oc(t);if(n.num=e,null===n.num)return t;let r=t.has("#Ordinal")?"Ordinal":"Cardinal";t.has("#TextValue")&&(r=t.has("#Ordinal")?"TextOrdinal":"TextCardinal");let o=lc(n,r);return n.hasComma&&"Cardinal"===r&&(o=Number(o).toLocaleString()),(t=t.not("#Currency")).replaceWith(o,{tags:!0}),t}));return new Numbers(t.document,t.pointer)}add(e){if(!e)return this;"string"==typeof e&&(e=oc(e).num);const t=this.map((t=>{const n=oc(t);if(null===n.num)return t;n.num+=e;let r=t.has("#Ordinal")?"Ordinal":"Cardinal";n.isText&&(r=t.has("#Ordinal")?"TextOrdinal":"TextCardinal");const o=lc(n,r);return t.replaceWith(o,{tags:!0}),t}));return new Numbers(t.document,t.pointer)}subtract(e,t){return this.add(-1*e,t)}increment(e){return this.add(1,e)}decrement(e){return this.add(-1,e)}update(e){const t=new Numbers(this.document,e);return t._cache=this._cache,t}}Numbers.prototype.toNice=Numbers.prototype.toLocaleString,Numbers.prototype.isBetween=Numbers.prototype.between,Numbers.prototype.minus=Numbers.prototype.subtract,Numbers.prototype.plus=Numbers.prototype.add,Numbers.prototype.equals=Numbers.prototype.isEqual,e.prototype.numbers=function(e){let t=rc(this);return t=t.getNth(e),new Numbers(this.document,t.pointer)},e.prototype.percentages=function(e){let t=rc(this);return t=t.filter((e=>e.has("#Percent")||e.after("^percent"))),t=t.getNth(e),new Numbers(this.document,t.pointer)},e.prototype.money=function(e){let t=rc(this);return t=t.filter((e=>e.has("#Money")||e.after("^#Currency"))),t=t.getNth(e),new Numbers(this.document,t.pointer)},e.prototype.values=e.prototype.numbers};var hc={api:function(e){tc(e),cc(e)}};const dc={people:!0,emails:!0,phoneNumbers:!0,places:!0},gc=function(e={}){return!1!==(e=Object.assign({},dc,e)).people&&this.people().replaceWith("██████████"),!1!==e.emails&&this.emails().replaceWith("██████████"),!1!==e.places&&this.places().replaceWith("██████████"),!1!==e.phoneNumbers&&this.phoneNumbers().replaceWith("███████"),this},mc={api:function(e){e.prototype.redact=gc}},pc=function(e){let t=null;return e.has("#PastTense")?t="PastTense":e.has("#FutureTense")?t="FutureTense":e.has("#PresentTense")&&(t="PresentTense"),{tense:t}},fc=function(e){const t=function(e){let t=e;return 1===t.length?t:(t=t.if("#Verb"),1===t.length?t:(t=t.ifNo("(after|although|as|because|before|if|since|than|that|though|when|whenever|where|whereas|wherever|whether|while|why|unless|until|once)"),t=t.ifNo("^even (if|though)"),t=t.ifNo("^so that"),t=t.ifNo("^rather than"),t=t.ifNo("^provided that"),1===t.length?t:(t=t.ifNo("(that|which|whichever|who|whoever|whom|whose|whomever)"),1===t.length?t:(t=t.ifNo("(^despite|^during|^before|^through|^throughout)"),1===t.length?t:(t=t.ifNo("^#Gerund"),1===t.length?t:(0===t.length&&(t=e),t.eq(0)))))))}(e.clauses()),n=t.chunks();let r=e.none(),o=e.none(),a=e.none();return n.forEach(((e,t)=>{0!==t||e.has("")?o.found||!e.has("")?o.found&&(a=a.concat(e)):o=e:r=e})),o.found&&!r.found&&(r=o.before("+").first()),{subj:r,verb:o,pred:a,grammar:pc(o)}};var bc={api:function(e){class Sentences extends e{constructor(e,t,n){super(e,t,n),this.viewType="Sentences"}json(e={}){return this.map((t=>{const n=t.toView().json(e)[0]||{},{subj:r,verb:o,pred:a,grammar:i}=fc(t);return n.sentence={subject:r.text("normal"),verb:o.text("normal"),predicate:a.text("normal"),grammar:i},n}),[])}toPastTense(e){return this.getNth(e).map((e=>(fc(e),function(e){let t=e.verbs();const n=t.eq(0);if(n.has("#PastTense"))return e;if(n.toPastTense(),t.length>1){t=t.slice(1),t=t.filter((e=>!e.lookBehind("to$").found)),t=t.if("#PresentTense"),t=t.notIf("#Gerund");const n=e.match("to #Verb+ #Conjunction #Verb").terms();t=t.not(n),t.found&&t.verbs().toPastTense()}return e}(e))))}toPresentTense(e){return this.getNth(e).map((e=>(fc(e),function(e){let t=e.verbs();return t.eq(0).toPresentTense(),t.length>1&&(t=t.slice(1),t=t.filter((e=>!e.lookBehind("to$").found)),t=t.notIf("#Gerund"),t.found&&t.verbs().toPresentTense()),e}(e))))}toFutureTense(e){return this.getNth(e).map((e=>(fc(e),e=function(e){let t=e.verbs();if(t.eq(0).toFutureTense(),t=(e=e.fullSentence()).verbs(),t.length>1){t=t.slice(1);const e=t.filter((e=>!(e.lookBehind("to$").found||!e.has("#Copula #Gerund")&&(e.has("#Gerund")||!e.has("#Copula")&&e.has("#PresentTense")&&!e.has("#Infinitive")&&e.lookBefore("(he|she|it|that|which)$").found))));e.found&&e.forEach((e=>{if(e.has("#Copula"))return e.match("was").replaceWith("is"),void e.match("is").replaceWith("will be");e.toInfinitive()}))}return e}(e),e)))}toInfinitive(e){return this.getNth(e).map((e=>(fc(e),function(e){return e.verbs().toInfinitive(),e}(e))))}toNegative(e){return this.getNth(e).map((e=>(fc(e),function(e){return e.verbs().first().toNegative().compute("chunks"),e}(e))))}toPositive(e){return this.getNth(e).map((e=>(fc(e),function(e){return e.verbs().first().toPositive().compute("chunks"),e}(e))))}isQuestion(e){return this.questions(e)}isExclamation(e){const t=this.filter((e=>e.lastTerm().has("@hasExclamation")));return t.getNth(e)}isStatement(e){const t=this.filter((e=>!e.isExclamation().found&&!e.isQuestion().found));return t.getNth(e)}update(e){const t=new Sentences(this.document,e);return t._cache=this._cache,t}}Sentences.prototype.toPresent=Sentences.prototype.toPresentTense,Sentences.prototype.toPast=Sentences.prototype.toPastTense,Sentences.prototype.toFuture=Sentences.prototype.toFutureTense;const t={sentences:function(e){let t=this.map((e=>e.fullSentence()));return t=t.getNth(e),new Sentences(this.document,t.pointer)},questions:function(e){const t=function(e){const t=/\?/,{document:n}=e;return e.filter((e=>{const r=e.docs[0]||[],o=r[r.length-1];return!(!o||n[o.index[0]].length!==r.length)&&(!!t.test(o.post)||function(e){const t=e.clauses();return!(/\.\.$/.test(e.out("text"))||e.has("^#QuestionWord")&&e.has("@hasComma")||!e.has("or not$")&&!e.has("^#QuestionWord")&&!e.has("^(do|does|did|is|was|can|could|will|would|may) #Noun")&&!e.has("^(have|must) you")&&!t.has("(do|does|is|was) #Noun+ #Adverb? (#Adjective|#Infinitive)$"))}(e))}))}(this);return t.getNth(e)}};Object.assign(e.prototype,t)}};const vc=function(e){const t={};t.firstName=e.match("#FirstName+"),t.lastName=e.match("#LastName+"),t.honorific=e.match("#Honorific+");const n=t.lastName,r=t.firstName;return r.found&&n.found||r.found||n.found||!e.has("^#Honorific .$")||(t.lastName=e.match(".$")),t},yc="male",wc="female",kc={mr:yc,mrs:wc,miss:wc,madam:wc,king:yc,queen:wc,duke:yc,duchess:wc,baron:yc,baroness:wc,count:yc,countess:wc,prince:yc,princess:wc,sire:yc,dame:wc,lady:wc,ayatullah:yc,congressman:yc,congresswoman:wc,"first lady":wc,mx:null},Pc=function(e,t){const{firstName:n,honorific:r}=e;if(n.has("#FemaleName"))return wc;if(n.has("#MaleName"))return yc;if(r.found){let e=r.text("normal");if(e=e.replace(/\./g,""),kc.hasOwnProperty(e))return kc[e];if(/^her /.test(e))return wc;if(/^his /.test(e))return yc}const o=t.after();if(!o.has("#Person")&&o.has("#Pronoun")){const e=o.match("#Pronoun");if(e.has("(they|their)"))return null;const t=e.has("(he|his)"),n=e.has("(she|her|hers)");if(t&&!n)return yc;if(n&&!t)return wc}return null},Ac=function(e){const t=this.clauses();let n=t.people();return n=n.concat(t.places()),n=n.concat(t.organizations()),n=n.not("(someone|man|woman|mother|brother|sister|father)"),n=n.sort("seq"),n=n.getNth(e),n};var Cc={api:function(e){!function(e){class People extends e{constructor(e,t,n){super(e,t,n),this.viewType="People"}parse(e){return this.getNth(e).map(vc)}json(e){const t="object"==typeof e?e:{};return this.getNth(e).map((e=>{const n=e.toView().json(t)[0],r=vc(e);return n.person={firstName:r.firstName.text("normal"),lastName:r.lastName.text("normal"),honorific:r.honorific.text("normal"),presumed_gender:Pc(r,e)},n}),[])}presumedMale(){return this.filter((e=>e.has("(#MaleName|mr|mister|sr|jr|king|pope|prince|sir)")))}presumedFemale(){return this.filter((e=>e.has("(#FemaleName|mrs|miss|queen|princess|madam)")))}update(e){const t=new People(this.document,e);return t._cache=this._cache,t}}e.prototype.people=function(e){let t=function(e){let t=e.splitAfter("@hasComma");t=t.match("#Honorific+? #Person+");const n=t.match("#Possessive").notIf("(his|her)");return t=t.splitAfter(n),t}(this);return t=t.getNth(e),new People(this.document,t.pointer)}}(e),function(e){e.prototype.places=function(t){let n=function(e){let t=e.match("(#Place|#Address)+"),n=t.match("@hasComma");return n=n.filter((e=>!!e.has("(asia|africa|europe|america)$")||!e.has("(#City|#Region|#ProperNoun)$")||!e.after("^(#Country|#Region)").found)),t=t.splitAfter(n),t}(this);return n=n.getNth(t),new e(this.document,n.pointer)}}(e),function(e){e.prototype.organizations=function(e){return this.match("#Organization+").getNth(e)}}(e),function(e){e.prototype.topics=Ac}(e)}};const Nc=function(e,t){const n={pre:e.none(),post:e.none()};if(!e.has("#Adverb"))return n;const r=e.splitOn(t);return 3===r.length?{pre:r.eq(0).adverbs(),post:r.eq(2).adverbs()}:r.eq(0).isDoc(t)?(n.post=r.eq(1).adverbs(),n):(n.pre=r.eq(0).adverbs(),n)},jc=function(e,t){const n=e.splitBefore(t);if(n.length<=1)return e.none();let r=n.eq(0);return r=r.not("(#Adverb|#Negative|#Prefix)"),r},xc=function(e){return e.match("#Negative")},Ic=function(e){if(!e.has("(#Particle|#PhrasalVerb)"))return{verb:e.none(),particle:e.none()};const t=e.match("#Particle$");return{verb:e.not(t),particle:t}},Tc=function(e){const t=e.clone();t.contractions().expand();const n=function(e){let t=e;return e.wordCount()>1&&(t=e.not("(#Negative|#Auxiliary|#Modal|#Adverb|#Prefix)")),t.length>1&&!t.has("#Phrasal #Particle")&&(t=t.last()),t=t.not("(want|wants|wanted) to"),t.found||(t=e.not("#Negative")),t}(t);return{root:n,prefix:t.match("#Prefix"),adverbs:Nc(t,n),auxiliary:jc(t,n),negative:xc(t),phrasal:Ic(n)}},Dc={tense:"PresentTense"},Hc={conditional:!0},Ec={tense:"FutureTense"},Gc={progressive:!0},Oc={tense:"PastTense"},Fc={complete:!0,progressive:!1},Vc={passive:!0},zc=function(e){const t={};return e.forEach((e=>{Object.assign(t,e)})),t},Bc={imperative:[["#Imperative",[]]],"want-infinitive":[["^(want|wants|wanted) to #Infinitive$",[Dc]],["^wanted to #Infinitive$",[Oc]],["^will want to #Infinitive$",[Ec]]],"gerund-phrase":[["^#PastTense #Gerund$",[Oc]],["^#PresentTense #Gerund$",[Dc]],["^#Infinitive #Gerund$",[Dc]],["^will #Infinitive #Gerund$",[Ec]],["^have #PastTense #Gerund$",[Oc]],["^will have #PastTense #Gerund$",[Oc]]],"simple-present":[["^#PresentTense$",[Dc]],["^#Infinitive$",[Dc]]],"simple-past":[["^#PastTense$",[Oc]]],"simple-future":[["^will #Adverb? #Infinitive",[Ec]]],"present-progressive":[["^(is|are|am) #Gerund$",[Dc,Gc]]],"past-progressive":[["^(was|were) #Gerund$",[Oc,Gc]]],"future-progressive":[["^will be #Gerund$",[Ec,Gc]]],"present-perfect":[["^(has|have) #PastTense$",[Oc,Fc]]],"past-perfect":[["^had #PastTense$",[Oc,Fc]],["^had #PastTense to #Infinitive",[Oc,Fc]]],"future-perfect":[["^will have #PastTense$",[Ec,Fc]]],"present-perfect-progressive":[["^(has|have) been #Gerund$",[Oc,Gc]]],"past-perfect-progressive":[["^had been #Gerund$",[Oc,Gc]]],"future-perfect-progressive":[["^will have been #Gerund$",[Ec,Gc]]],"passive-past":[["(got|were|was) #Passive",[Oc,Vc]],["^(was|were) being #Passive",[Oc,Vc]],["^(had|have) been #Passive",[Oc,Vc]]],"passive-present":[["^(is|are|am) #Passive",[Dc,Vc]],["^(is|are|am) being #Passive",[Dc,Vc]],["^has been #Passive",[Dc,Vc]]],"passive-future":[["will have been #Passive",[Ec,Vc,Hc]],["will be being? #Passive",[Ec,Vc,Hc]]],"present-conditional":[["would be #PastTense",[Dc,Hc]]],"past-conditional":[["would have been #PastTense",[Oc,Hc]]],"auxiliary-future":[["(is|are|am|was) going to (#Infinitive|#PresentTense)",[Ec]]],"auxiliary-past":[["^did #Infinitive$",[Oc,{plural:!1}]],["^used to #Infinitive$",[Oc,Fc]]],"auxiliary-present":[["^(does|do) #Infinitive$",[Dc,Fc,{plural:!0}]]],"modal-past":[["^(could|must|should|shall) have #PastTense$",[Oc]]],"modal-infinitive":[["^#Modal #Infinitive$",[]]],infinitive:[["^#Infinitive$",[]]]},Sc=[];Object.keys(Bc).map((e=>{Bc[e].forEach((t=>{Sc.push({name:e,match:t[0],data:zc(t[1])})}))}));const $c=function(e,t){const n={};e=function(e,t){return e=e.clone(),t.adverbs.post&&t.adverbs.post.found&&e.remove(t.adverbs.post),t.adverbs.pre&&t.adverbs.pre.found&&e.remove(t.adverbs.pre),e.has("#Negative")&&(e=e.remove("#Negative")),e.has("#Prefix")&&(e=e.remove("#Prefix")),t.root.has("#PhrasalVerb #Particle")&&e.remove("#Particle$"),e.not("#Adverb")}(e,t);for(let t=0;t!(e.has("^(if|unless|while|but|for|per|at|by|that|which|who|from)")||t>0&&e.has("^#Verb . #Noun+$")||t>0&&e.has("^#Adverb")))),0===t.length?e:t}(t);const n=t.nouns();let r=n.last();const o=r.match("(i|he|she|we|you|they)");if(o.found)return o.nouns();let a=n.if("^(that|this|those)");return a.found||!1===n.found&&(a=t.match("^(that|this|those)"),a.found)?a:(r=n.last(),Mc(r)&&(n.remove(r),r=n.last()),Mc(r)&&(n.remove(r),r=n.last()),r)}(e);return{subject:t,plural:Lc(t,e)}},Jc=e=>e,Wc=(e,t)=>{const n=Kc(e),r=n.subject;return!(!r.has("i")&&!r.has("we"))||n.plural},qc=function(e,t){if(e.has("were"))return"are";const{subject:n,plural:r}=Kc(e);return n.has("i")?"am":n.has("we")||r?"are":"is"},Uc=function(e,t){const n=Kc(e),r=n.subject;return r.has("i")||r.has("we")||n.plural?"do":"does"},Rc=function(e){return e.has("#Infinitive")?"Infinitive":e.has("#Participle")?"Participle":e.has("#PastTense")?"PastTense":e.has("#Gerund")?"Gerund":e.has("#PresentTense")?"PresentTense":void 0},Qc=function(e,t){const{toInfinitive:n}=e.methods.two.transform.verb;let r=t.root.text({keepPunct:!1});return r=n(r,e.model,Rc(e)),r&&e.replace(t.root,r),e},Zc=e=>e.has("will not")?e.replace("will not","have not"):e.remove("will"),_c=function(e){if(!e||!e.isView)return[];return e.json({normal:!0,terms:!1,text:!1}).map((e=>e.normal))},Xc=function(e){return e&&e.isView?e.text("normal"):""},Yc=function(e){const{toInfinitive:t}=e.methods.two.transform.verb;return t(e.text("normal"),e.model,Rc(e))},eh={tags:!0},th={tags:!0},nh={noAux:(e,t)=>(t.auxiliary.found&&(e=e.remove(t.auxiliary)),e),simple:(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,o=t.root;if(o.has("#Modal"))return e;let a=o.text({keepPunct:!1});a=r(a,e.model,Rc(o));return a=n(a,e.model).PastTense,a="been"===a?"was":a,"was"===a&&(a=((e,t)=>{const{subject:n,plural:r}=Kc(e);return r||n.has("we")?"were":"was"})(e)),a&&e.replace(o,a,th),e},both:function(e,t){return t.negative.found?(e.replace("will","did"),e):(e=nh.simple(e,t),e=nh.noAux(e,t))},hasHad:e=>(e.replace("has","had",th),e),hasParticiple:(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,o=t.root;let a=o.text("normal");return a=r(a,e.model,Rc(o)),n(a,e.model).Participle}},rh={infinitive:nh.simple,"simple-present":nh.simple,"simple-past":Jc,"simple-future":nh.both,"present-progressive":e=>(e.replace("are","were",th),e.replace("(is|are|am)","was",th),e),"past-progressive":Jc,"future-progressive":(e,t)=>(e.match(t.root).insertBefore("was"),e.remove("(will|be)"),e),"present-perfect":nh.hasHad,"past-perfect":Jc,"future-perfect":(e,t)=>(e.match(t.root).insertBefore("had"),e.has("will")&&(e=Zc(e)),e.remove("have"),e),"present-perfect-progressive":nh.hasHad,"past-perfect-progressive":Jc,"future-perfect-progressive":e=>(e.remove("will"),e.replace("have","had",th),e),"passive-past":e=>(e.replace("have","had",th),e),"passive-present":e=>(e.replace("(is|are)","was",th),e),"passive-future":(e,t)=>(t.auxiliary.has("will be")&&(e.match(t.root).insertBefore("had been"),e.remove("(will|be)")),t.auxiliary.has("will have been")&&(e.replace("have","had",th),e.remove("will")),e),"present-conditional":e=>(e.replace("be","have been"),e),"past-conditional":Jc,"auxiliary-future":e=>(e.replace("(is|are|am)","was",th),e),"auxiliary-past":Jc,"auxiliary-present":e=>(e.replace("(do|does)","did",th),e),"modal-infinitive":(e,t)=>(e.has("can")?e.replace("can","could",th):(nh.simple(e,t),e.match("#Modal").insertAfter("have").tag("Auxiliary")),e),"modal-past":Jc,"want-infinitive":e=>(e.replace("(want|wants)","wanted",th),e.remove("will"),e),"gerund-phrase":(e,t)=>(t.root=t.root.not("#Gerund$"),nh.simple(e,t),Zc(e),e)},oh=function(e,t){const n=Kc(e),r=n.subject;return r.has("(i|we|you)")?"have":!1===n.plural||r.has("he")||r.has("she")||r.has("#Person")?"has":"have"},ah=(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,{root:o,auxiliary:a}=t;if(o.has("#Modal"))return e;let i=o.text({keepPunct:!1});i=r(i,e.model,Rc(o));const s=n(i,e.model);if(i=s.Participle||s.PastTense,i){e=e.replace(o,i);const t=oh(e);e.prepend(t).match(t).tag("Auxiliary"),e.remove(a)}return e},ih={infinitive:ah,"simple-present":ah,"simple-future":(e,t)=>e.replace("will",oh(e)),"present-perfect":Jc,"past-perfect":Jc,"future-perfect":(e,t)=>e.replace("will have",oh(e)),"present-perfect-progressive":Jc,"past-perfect-progressive":Jc,"future-perfect-progressive":Jc},sh={tags:!0},lh=(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,o=t.root;let a=o.text("normal");return a=r(a,e.model,Rc(o)),!1===Wc(e)&&(a=n(a,e.model).PresentTense),o.has("#Copula")&&(a=qc(e)),a&&(e=e.replace(o,a,sh)).not("#Particle").tag("PresentTense"),e},uh=(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,o=t.root;let a=o.text("normal");return a=r(a,e.model,Rc(o)),!1===Wc(e)&&(a=n(a,e.model).Gerund),a&&(e=e.replace(o,a,sh)).not("#Particle").tag("Gerund"),e},ch={infinitive:lh,"simple-present":(e,t)=>{const{conjugate:n}=e.methods.two.transform.verb,{root:r}=t;if(!r.has("#Infinitive"))return lh(e,t);{const t=Kc(e).subject;if(Wc(e)||t.has("i"))return e;const o=r.text("normal"),a=n(o,e.model).PresentTense;o!==a&&e.replace(r,a,sh)}return e},"simple-past":lh,"simple-future":(e,t)=>{const{root:n,auxiliary:r}=t;if(r.has("will")&&n.has("be")){const t=qc(e);e.replace(n,t),(e=e.remove("will")).replace("not "+t,t+" not")}else lh(e,t),e=e.remove("will");return e},"present-progressive":Jc,"past-progressive":(e,t)=>{const n=qc(e);return e.replace("(were|was)",n,sh)},"future-progressive":e=>(e.match("will").insertBefore("is"),e.remove("be"),e.remove("will")),"present-perfect":(e,t)=>(lh(e,t),e=e.remove("(have|had|has)")),"past-perfect":(e,t)=>{const n=Kc(e).subject;return Wc(e)||n.has("i")?((e=Qc(e,t)).remove("had"),e):(e.replace("had","has",sh),e)},"future-perfect":e=>(e.match("will").insertBefore("has"),e.remove("have").remove("will")),"present-perfect-progressive":Jc,"past-perfect-progressive":e=>e.replace("had","has",sh),"future-perfect-progressive":e=>(e.match("will").insertBefore("has"),e.remove("have").remove("will")),"passive-past":(e,t)=>{const n=qc(e);return e.has("(had|have|has)")&&e.has("been")?(e.replace("(had|have|has)",n,sh),e.replace("been","being"),e):e.replace("(got|was|were)",n)},"passive-present":Jc,"passive-future":e=>(e.replace("will","is"),e.replace("be","being")),"present-conditional":Jc,"past-conditional":e=>(e.replace("been","be"),e.remove("have")),"auxiliary-future":(e,t)=>(uh(e,t),e.remove("(going|to)"),e),"auxiliary-past":(e,t)=>{if(t.auxiliary.has("did")){const n=Uc(e);return e.replace(t.auxiliary,n),e}return uh(e,t),e.replace(t.auxiliary,"is"),e},"auxiliary-present":Jc,"modal-infinitive":Jc,"modal-past":(e,t)=>(((e,t)=>{const{toInfinitive:n}=e.methods.two.transform.verb,r=t.root;let o=t.root.text("normal");o=n(o,e.model,Rc(r)),o&&(e=e.replace(t.root,o,sh))})(e,t),e.remove("have")),"gerund-phrase":(e,t)=>(t.root=t.root.not("#Gerund$"),lh(e,t),e.remove("(will|have)")),"want-infinitive":(e,t)=>{let n="wants";return Wc(e)&&(n="want"),e.replace("(want|wanted|wants)",n,sh),e.remove("will"),e}},hh={tags:!0},dh=(e,t)=>{const{toInfinitive:n}=e.methods.two.transform.verb,{root:r,auxiliary:o}=t;if(r.has("#Modal"))return e;let a=r.text("normal");return a=n(a,e.model,Rc(r)),a&&(e=e.replace(r,a,hh)).not("#Particle").tag("Verb"),e.prepend("will").match("will").tag("Auxiliary"),e.remove(o),e},gh=(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,{root:o,auxiliary:a}=t;let i=o.text("normal");return i=r(i,e.model,Rc(o)),i&&(i=n(i,e.model).Gerund,e.replace(o,i,hh),e.not("#Particle").tag("PresentTense")),e.remove(a),e.prepend("will be").match("will be").tag("Auxiliary"),e},mh={infinitive:dh,"simple-present":dh,"simple-past":dh,"simple-future":Jc,"present-progressive":gh,"past-progressive":gh,"future-progressive":Jc,"present-perfect":e=>(e.match("(have|has)").replaceWith("will have"),e),"past-perfect":e=>e.replace("(had|has)","will have"),"future-perfect":Jc,"present-perfect-progressive":e=>e.replace("has","will have"),"past-perfect-progressive":e=>e.replace("had","will have"),"future-perfect-progressive":Jc,"passive-past":e=>e.has("got")?e.replace("got","will get"):e.has("(was|were)")?(e.replace("(was|were)","will be"),e.remove("being")):e.has("(have|has|had) been")?e.replace("(have|has|had) been","will be"):e,"passive-present":e=>(e.replace("being","will be"),e.remove("(is|are|am)"),e),"passive-future":Jc,"present-conditional":e=>e.replace("would","will"),"past-conditional":e=>e.replace("would","will"),"auxiliary-future":Jc,"auxiliary-past":e=>e.has("used")&&e.has("to")?(e.replace("used","will"),e.remove("to")):(e.replace("did","will"),e),"auxiliary-present":e=>e.replace("(do|does)","will"),"modal-infinitive":Jc,"modal-past":Jc,"gerund-phrase":(e,t)=>(t.root=t.root.not("#Gerund$"),dh(e,t),e.remove("(had|have)")),"want-infinitive":e=>(e.replace("(want|wants|wanted)","will want"),e)},ph={tags:!0},fh={tags:!0},bh=function(e,t){const n=Uc(e);return e.prepend(n+" not"),e},vh=function(e){let t=e.match("be");return t.found?(t.prepend("not"),e):(t=e.match("(is|was|am|are|will|were)"),t.found?(t.append("not"),e):e)},yh=e=>e.has("(is|was|am|are|will|were|be)"),wh={"simple-present":(e,t)=>!0===yh(e)?vh(e):(e=Qc(e,t),e=bh(e)),"simple-past":(e,t)=>!0===yh(e)?vh(e):((e=Qc(e,t)).prepend("did not"),e),imperative:e=>(e.prepend("do not"),e),infinitive:(e,t)=>!0===yh(e)?vh(e):bh(e),"passive-past":e=>{if(e.has("got"))return e.replace("got","get",fh),e.prepend("did not"),e;const t=e.match("(was|were|had|have)");return t.found&&t.append("not"),e},"auxiliary-past":e=>{if(e.has("used"))return e.prepend("did not"),e;const t=e.match("(did|does|do)");return t.found&&t.append("not"),e},"want-infinitive":(e,t)=>e=(e=bh(e)).replace("wants","want",fh)};var kh={api:function(e){class Verbs extends e{constructor(e,t,n){super(e,t,n),this.viewType="Verbs"}parse(e){return this.getNth(e).map(Tc)}json(e,t){const n=this.getNth(t).map((t=>{const n=t.toView().json(e)[0]||{};return n.verb=function(e){const t=Tc(e);e=e.clone().toView();const n=$c(e,t);return{root:t.root.text(),preAdverbs:_c(t.adverbs.pre),postAdverbs:_c(t.adverbs.post),auxiliary:Xc(t.auxiliary),negative:t.negative.found,prefix:Xc(t.prefix),infinitive:Yc(t.root),grammar:n}}(t),n}),[]);return n}subjects(e){return this.getNth(e).map((e=>(Tc(e),Kc(e).subject)))}adverbs(e){return this.getNth(e).map((e=>e.match("#Adverb")))}isSingular(e){return this.getNth(e).filter((e=>!0!==Kc(e).plural))}isPlural(e){return this.getNth(e).filter((e=>!0===Kc(e).plural))}isImperative(e){return this.getNth(e).filter((e=>e.has("#Imperative")))}toInfinitive(e){return this.getNth(e).map((e=>{const t=Tc(e);return function(e,t){const{toInfinitive:n}=e.methods.two.transform.verb,{root:r,auxiliary:o}=t,a=o.terms().harden();let i=r.text("normal");if(i=n(i,e.model,Rc(r)),i&&e.replace(r,i,eh).tag("Verb").firstTerm().tag("Infinitive"),a.found&&e.remove(a),t.negative.found){e.has("not")||e.prepend("not");const t=Uc(e);e.prepend(t)}return e.fullSentence().compute(["freeze","lexicon","preTagger","postTagger","unfreeze","chunks"]),e}(e,t,$c(e,t).form)}))}toPresentTense(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t,n){return ch.hasOwnProperty(n)?((e=ch[n](e,t)).fullSentence().compute(["tagger","chunks"]),e):e}(e,t,n.form)}))}toPastTense(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t,n){return rh.hasOwnProperty(n)?((e=rh[n](e,t)).fullSentence().compute(["tagger","chunks"]),e):e}(e,t,n.form)}))}toFutureTense(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t,n){return e.has("will")||e.has("going to")?e:mh.hasOwnProperty(n)?((e=mh[n](e,t)).fullSentence().compute(["tagger","chunks"]),e):e}(e,t,n.form)}))}toGerund(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t){const{toInfinitive:n,conjugate:r}=e.methods.two.transform.verb,{root:o,auxiliary:a}=t;if(e.has("#Gerund"))return e;let i=o.text("normal");i=n(i,e.model,Rc(o));const s=r(i,e.model).Gerund;if(s){const t=qc(e);e.replace(o,s,ph),e.remove(a),e.prepend(t)}return e.replace("not is","is not"),e.replace("not are","are not"),e.fullSentence().compute(["tagger","chunks"]),e}(e,t,n.form)}))}toPastParticiple(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t,n){return ih.hasOwnProperty(n)?((e=ih[n](e,t)).fullSentence().compute(["tagger","chunks"]),e):((e=ah(e,t)).fullSentence().compute(["tagger","chunks"]),e)}(e,t,n.form)}))}conjugate(e){const{conjugate:t,toInfinitive:n}=this.world.methods.two.transform.verb;return this.getNth(e).map((e=>{const r=Tc(e),o=$c(e,r);"imperative"===o.form&&(o.form="simple-present");let a=r.root.text("normal");if(!r.root.has("#Infinitive")){const t=Rc(r.root);a=n(a,e.model,t)||a}return t(a,e.model)}),[])}isNegative(){return this.if("#Negative")}isPositive(){return this.ifNo("#Negative")}toPositive(){const e=this.match("do not #Verb");return e.found&&e.remove("do not"),this.remove("#Negative")}toNegative(e){return this.getNth(e).map((e=>{const t=Tc(e);return function(e,t,n){if(e.has("#Negative"))return e;if(wh.hasOwnProperty(n))return wh[n](e,t);let r=e.matchOne("be");return r.found?(r.prepend("not"),e):!0===yh(e)?vh(e):(r=e.matchOne("(will|had|have|has|did|does|do|#Modal)"),r.found?(r.append("not"),e):e)}(e,t,$c(e,t).form)}))}update(e){const t=new Verbs(this.document,e);return t._cache=this._cache,t}}Verbs.prototype.toPast=Verbs.prototype.toPastTense,Verbs.prototype.toPresent=Verbs.prototype.toPresentTense,Verbs.prototype.toFuture=Verbs.prototype.toFutureTense,e.prototype.verbs=function(e){let t=function(e){let t=e.match("");return t=t.not("#Conjunction"),t=t.not("#Preposition"),t=t.splitAfter("@hasComma"),t=t.splitAfter("[(do|did|am|was|is|will)] (is|was)",0),t=t.splitBefore("(#Verb && !#Copula) [being] #Verb",0),t=t.splitBefore("#Verb [to be] #Verb",0),t=t.splitAfter("[help] #PresentTense",0),t=t.splitBefore("(#PresentTense|#PastTense) [#Copula]$",0),t=t.splitBefore("(#PresentTense|#PastTense) [will be]$",0),t=t.splitBefore("(#PresentTense|#PastTense) [(had|has)]",0),t=t.not("#Reflexive$"),t=t.not("#Adjective"),t=t.splitAfter("[#PastTense] #PastTense",0),t=t.splitAfter("[#PastTense] #Auxiliary+ #PastTense",0),t=t.splitAfter("#Copula [#Gerund] #PastTense",0),t=t.if("#Verb"),t.has("(#Verb && !#Auxiliary) #Adverb+? #Copula")&&(t=t.splitBefore("#Copula")),t}(this);return t=t.getNth(e),new Verbs(this.document,t.pointer)}}};const Ph=function(e,t){const n=t.match(e);if(n.found){const e=n.pronouns().refersTo();if(e.found)return e}return t.none()},Ah=function(e){if(!e.found)return e;const[t]=e.fullPointer[0];return t&&t>0?e.update([[t-1]]):e.none()},Ch=function(e,t){let n=e.people();return n=function(e,t){return"m"===t?e.filter((e=>!e.presumedFemale().found)):"f"===t?e.filter((e=>!e.presumedMale().found)):e}(n,t),n.found?n.last():(n=e.nouns("#Actor"),n.found?n.last():"f"===t?Ph("(she|her|hers)",e):"m"===t?Ph("(he|him|his)",e):e.none())},Nh=function(e){const t=e.nouns();let n=t.isPlural().notIf("#Pronoun");if(n.found)return n.last();const r=Ph("(they|their|theirs)",e);return r.found?r:(n=t.match("(somebody|nobody|everybody|anybody|someone|noone|everyone|anyone)"),n.found?n.last():e.none())},jh=function(e,t){let n=e.before(),r=t(n);return r.found?r:(n=Ah(e),r=t(n),r.found?r:(n=Ah(n),r=t(n),r.found?r:e.none()))};var xh={compute:{coreference:function(e){e.pronouns().if("(he|him|his|she|her|hers|they|their|theirs|it|its)").forEach((e=>{let t=null;e.has("(he|him|his)")?t=jh(e,(e=>Ch(e,"m"))):e.has("(she|her|hers)")?t=jh(e,(e=>Ch(e,"f"))):e.has("(they|their|theirs)")&&(t=jh(e,Nh)),t&&t.found&&function(e,t){t&&t.found&&(e.docs[0][0].reference=t.ptrs[0])}(e,t)}))}},api:function(e){class Pronouns extends e{constructor(e,t,n){super(e,t,n),this.viewType="Pronouns"}hasReference(){return this.compute("coreference"),this.filter((e=>e.docs[0][0].reference))}refersTo(){return this.compute("coreference"),this.map((e=>{if(!e.found)return e.none();const t=e.docs[0][0];return t.reference?e.update([t.reference]):e.none()}))}update(e){const t=new Pronouns(this.document,e);return t._cache=this._cache,t}}e.prototype.pronouns=function(e){let t=this.match("#Pronoun");return t=t.getNth(e),new Pronouns(t.document,t.pointer)}}};return h.plugin(ql),h.plugin(Ul),h.plugin(eu),h.plugin(xh),h.plugin(fu),h.plugin(Au),h.plugin(Ou),h.plugin(hc),h.plugin(mc),h.plugin(bc),h.plugin(Cc),h.plugin(kh),h}));
================================================
FILE: builds/one/compromise-one.cjs
================================================
!function(t,e){"object"==typeof exports&&"undefined"!=typeof module?module.exports=e():"function"==typeof define&&define.amd?define(e):(t="undefined"!=typeof globalThis?globalThis:t||self).nlp=e()}(this,(function(){"use strict";var t={methods:{one:{},two:{},three:{},four:{}},model:{one:{},two:{},three:{}},compute:{},hooks:[]};const e={compute:function(t){const{world:e}=this,n=e.compute;return"string"==typeof t&&n.hasOwnProperty(t)?n[t](this):(t=>"[object Array]"===Object.prototype.toString.call(t))(t)?t.forEach((o=>{e.compute.hasOwnProperty(o)?n[o](this):console.warn("no compute:",t)})):"function"==typeof t?t(this):console.warn("no compute:",t),this}};var n={forEach:function(t){return this.fullPointer.forEach(((e,n)=>{const o=this.update([e]);t(o,n)})),this},map:function(t,e){const n=this.fullPointer.map(((e,n)=>{const o=this.update([e]),r=t(o,n);return void 0===r?this.none():r}));if(0===n.length)return e||this.update([]);if(void 0!==n[0]){if("string"==typeof n[0])return n;if("object"==typeof n[0]&&(null===n[0]||!n[0].isView))return n}let o=[];return n.forEach((t=>{o=o.concat(t.fullPointer)})),this.toView(o)},filter:function(t){let e=this.fullPointer;e=e.filter(((e,n)=>{const o=this.update([e]);return t(o,n)}));return this.update(e)},find:function(t){const e=this.fullPointer.find(((e,n)=>{const o=this.update([e]);return t(o,n)}));return this.update([e])},some:function(t){return this.fullPointer.some(((e,n)=>{const o=this.update([e]);return t(o,n)}))},random:function(t=1){let e=this.fullPointer,n=Math.floor(Math.random()*e.length);return n+t>this.length&&(n=this.length-t,n=n<0?0:n),e=e.slice(n,n+t),this.update(e)}};const o={termList:function(){return this.methods.one.termList(this.docs)},terms:function(t){const e=this.match(".");return"number"==typeof t?e.eq(t):e},groups:function(t){if(t||0===t)return this.update(this._groups[t]||[]);const e={};return Object.keys(this._groups).forEach((t=>{e[t]=this.update(this._groups[t])})),e},eq:function(t){let e=this.pointer;return e||(e=this.docs.map(((t,e)=>[e]))),e[t]?this.update([e[t]]):this.none()},first:function(){return this.eq(0)},last:function(){const t=this.fullPointer.length-1;return this.eq(t)},firstTerms:function(){return this.match("^.")},lastTerms:function(){return this.match(".$")},slice:function(t,e){let n=this.pointer||this.docs.map(((t,e)=>[e]));return n=n.slice(t,e),this.update(n)},all:function(){return this.update().toView()},fullSentences:function(){const t=this.fullPointer.map((t=>[t[0]]));return this.update(t).toView()},none:function(){return this.update([])},isDoc:function(t){if(!t||!t.isView)return!1;const e=this.fullPointer,n=t.fullPointer;return!e.length!==n.length&&e.every(((t,e)=>!!n[e]&&(t[0]===n[e][0]&&t[1]===n[e][1]&&t[2]===n[e][2])))},wordCount:function(){return this.docs.reduce(((t,e)=>(t+=e.filter((t=>""!==t.text)).length,t)),0)},isFull:function(){const t=this.pointer;if(!t)return!0;if(0===t.length||0!==t[0][0])return!1;let e=0,n=0;return this.document.forEach((t=>e+=t.length)),this.docs.forEach((t=>n+=t.length)),e===n},getNth:function(t){return"number"==typeof t?this.eq(t):"string"==typeof t?this.if(t):this}};o.group=o.groups,o.fullSentence=o.fullSentences,o.sentence=o.fullSentences,o.lastTerm=o.lastTerms,o.firstTerm=o.firstTerms;const r=Object.assign({},o,e,n);r.get=r.eq;class View{constructor(e,n,o={}){[["document",e],["world",t],["_groups",o],["_cache",null],["viewType","View"]].forEach((t=>{Object.defineProperty(this,t[0],{value:t[1],writable:!0})})),this.ptrs=n}get docs(){let e=this.document;return this.ptrs&&(e=t.methods.one.getDoc(this.ptrs,this.document)),e}get pointer(){return this.ptrs}get methods(){return this.world.methods}get model(){return this.world.model}get hooks(){return this.world.hooks}get isView(){return!0}get found(){return this.docs.length>0}get length(){return this.docs.length}get fullPointer(){const{docs:t,ptrs:e,document:n}=this,o=e||t.map(((t,e)=>[e]));return o.map((t=>{let[e,o,r,s,i]=t;return o=o||0,r=r||(n[e]||[]).length,n[e]&&n[e][o]&&(s=s||n[e][o].id,n[e][r-1]&&(i=i||n[e][r-1].id)),[e,o,r,s,i]}))}update(t){const e=new View(this.document,t);if(this._cache&&t&&t.length>0){const n=[];t.forEach(((t,e)=>{const[o,r,s]=t;(1===t.length||0===r&&this.document[o].length===s)&&(n[e]=this._cache[o])})),n.length>0&&(e._cache=n)}return e.world=this.world,e}toView(t){return new View(this.document,t||this.pointer)}fromText(t){const{methods:e}=this,n=e.one.tokenize.fromString(t,this.world),o=new View(n);return o.world=this.world,o.compute(["normal","freeze","lexicon"]),this.world.compute.preTagger&&o.compute("preTagger"),o.compute("unfreeze"),o}clone(){let t=this.document.slice(0);t=t.map((t=>t.map((t=>((t=Object.assign({},t)).tags=new Set(t.tags),t)))));const e=this.update(this.pointer);return e.document=t,e._cache=this._cache,e}}Object.assign(View.prototype,r);const s=function(t){return t&&"object"==typeof t&&!Array.isArray(t)};function i(t,e){if(s(e))for(const n in e)s(e[n])?(t[n]||Object.assign(t,{[n]:{}}),i(t[n],e[n])):Object.assign(t,{[n]:e[n]});return t}const c=function(t,e,n,o){if(r=t,"[object Array]"===Object.prototype.toString.call(r))return void t.forEach((t=>c(t,e,n,o)));var r;const{methods:s,model:u,compute:a,hooks:l}=e;t.methods&&function(t,e){for(const n in e)t[n]=t[n]||{},Object.assign(t[n],e[n])}(s,t.methods),t.model&&i(u,t.model),t.irregulars&&function(t,e){const n=t.two.models||{};Object.keys(e).forEach((t=>{e[t].pastTense&&(n.toPast&&(n.toPast.ex[t]=e[t].pastTense),n.fromPast&&(n.fromPast.ex[e[t].pastTense]=t)),e[t].presentTense&&(n.toPresent&&(n.toPresent.ex[t]=e[t].presentTense),n.fromPresent&&(n.fromPresent.ex[e[t].presentTense]=t)),e[t].gerund&&(n.toGerund&&(n.toGerund.ex[t]=e[t].gerund),n.fromGerund&&(n.fromGerund.ex[e[t].gerund]=t)),e[t].comparative&&(n.toComparative&&(n.toComparative.ex[t]=e[t].comparative),n.fromComparative&&(n.fromComparative.ex[e[t].comparative]=t)),e[t].superlative&&(n.toSuperlative&&(n.toSuperlative.ex[t]=e[t].superlative),n.fromSuperlative&&(n.fromSuperlative.ex[e[t].superlative]=t))}))}(u,t.irregulars),t.compute&&Object.assign(a,t.compute),l&&(e.hooks=l.concat(t.hooks||[])),t.api&&t.api(n),t.lib&&Object.keys(t.lib).forEach((e=>o[e]=t.lib[e])),t.tags&&o.addTags(t.tags),t.words&&o.addWords(t.words),t.frozen&&o.addWords(t.frozen,!0),t.mutate&&t.mutate(e,o)},u=function(t){return"[object Array]"===Object.prototype.toString.call(t)},a=function(t,e,n){const{methods:o}=n,r=new e([]);if(r.world=n,"number"==typeof t&&(t=String(t)),!t)return r;if("string"==typeof t){return new e(o.one.tokenize.fromString(t,n))}if(s=t,"[object Object]"===Object.prototype.toString.call(s)&&t.isView)return new e(t.document,t.ptrs);var s;if(u(t)){if(u(t[0])){const n=t.map((t=>t.map((t=>({text:t,normal:t,pre:"",post:" ",tags:new Set})))));return new e(n)}const n=t.map((t=>t.terms.map((t=>(u(t.tags)&&(t.tags=new Set(t.tags)),t)))));return new e(n)}return r},l=Object.assign({},t),h=function(t,e){e&&h.addWords(e);const n=a(t,View,l);return t&&n.compute(l.hooks),n};Object.defineProperty(h,"_world",{value:l,writable:!0}),h.tokenize=function(t,e){const{compute:n}=this._world;e&&h.addWords(e);const o=a(t,View,l);return n.contractions&&o.compute(["alias","normal","machine","contractions"]),o},h.plugin=function(t){return c(t,this._world,View,this),this},h.extend=h.plugin,h.world=function(){return this._world},h.model=function(){return this._world.model},h.methods=function(){return this._world.methods},h.hooks=function(){return this._world.hooks},h.verbose=function(t){const e="undefined"!=typeof process&&process.env?process.env:self.env||{};return e.DEBUG_TAGS="tagger"===t||!0===t||"",e.DEBUG_MATCH="match"===t||!0===t||"",e.DEBUG_CHUNKS="chunker"===t||!0===t||"",this},h.version="14.15.0";var f={one:{cacheDoc:function(t){const e=t.map((t=>{const e=new Set;return t.forEach((t=>{""!==t.normal&&e.add(t.normal),t.switch&&e.add(`%${t.switch}%`),t.implicit&&e.add(t.implicit),t.machine&&e.add(t.machine),t.root&&e.add(t.root),t.alias&&t.alias.forEach((t=>e.add(t)));const n=Array.from(t.tags);for(let t=0;t/^\p{Lu}[\p{Ll}'’]/u.test(t)||/^\p{Lu}$/u.test(t),w=(t,e,n)=>{if(n.forEach((t=>t.dirty=!0)),t){const o=[e,0].concat(n);Array.prototype.splice.apply(t,o)}return t},y=function(t){const e=t[t.length-1];!e||/ $/.test(e.post)||/[-–—]/.test(e.post)||(e.post+=" ")},b=(t,e,n)=>{const o=/[-.?!,;:)–—'"]/g,r=t[e-1];if(!r)return;const s=r.post;if(o.test(s)){const t=s.match(o).join(""),e=n[n.length-1];e.post=t+e.post,r.post=r.post.replace(o,"")}},v=function(t,e,n,o){const[r,s,i]=e;0===s||i===o[r].length?y(n):(y(n),y([t[e[1]]])),function(t,e,n){const o=t[e];if(0!==e||!m(o.text))return;n[0].text=n[0].text.replace(/^\p{Ll}/u,(t=>t.toUpperCase()));const r=t[e];r.tags.has("ProperNoun")||r.tags.has("Acronym")||m(r.text)&&r.text.length>1&&(r.text=(s=r.text,s.replace(/^\p{Lu}/u,(t=>t.toLowerCase()))));var s}(t,s,n),w(t,s,n)};let x=0;const j=t=>(t=t.length<3?"0"+t:t).length<3?"0"+t:t,E=function(t){let[e,n]=t.index||[0,0];x+=1,x=x>46655?0:x,e=e>46655?0:e,n=n>1294?0:n;let o=j(x.toString(36));o+=j(e.toString(36));let r=n.toString(36);r=r.length<2?"0"+r:r,o+=r;return o+=parseInt(36*Math.random(),10).toString(36),t.normal+"|"+o.toUpperCase()},O=function(t){if(t.has("@hasContraction")&&"function"==typeof t.contractions){t.grow("@hasContraction").contractions().expand()}},k=t=>"[object Array]"===Object.prototype.toString.call(t),P=function(t,e,n){const{document:o,world:r}=e;e.uncache();const s=e.fullPointer,i=e.fullPointer;e.forEach(((c,u)=>{const a=c.fullPointer[0],[l]=a,h=o[l];let f=function(t,e){const{methods:n}=e;return"string"==typeof t?n.one.tokenize.fromString(t,e)[0]:"object"==typeof t&&t.isView?t.clone().docs[0]||[]:k(t)?k(t[0])?t[0]:t:[]}(t,r);0!==f.length&&(f=function(t){return t.map((t=>(t.id=E(t),t)))}(f),n?(O(e.update([a]).firstTerm()),v(h,a,f,o)):(O(e.update([a]).lastTerm()),function(t,e,n,o){const[r,,s]=e,i=(o[r]||[]).length;st.replace(/^\p{Ll}/u,(t=>t.toUpperCase())),$=t=>t.replace(/^\p{Lu}/u,(t=>t.toLowerCase()));z.replaceWith=function(t,e={}){let n=this.fullPointer;const o=this;if(this.uncache(),"function"==typeof t)return function(t,e,n){return t.forEach((t=>{const o=e(t);t.replaceWith(o,n)})),t}(o,t,e);const r=o.docs[0];if(!r)return o;const s=e.possessives&&r[r.length-1].tags.has("Possessive"),i=e.case&&(c=r[0].text,/^\p{Lu}[\p{Ll}'’]/u.test(c)||/^\p{Lu}$/u.test(c));var c;t=function(t,e){if("string"!=typeof t)return t;const n=e.groups();return t=t.replace(S,(t=>{const e=t.replace(/\$/,"");return n.hasOwnProperty(e)?n[e].text():t})),t}(t,o);const u=this.update(n);n=n.map((t=>t.slice(0,3)));const a=(u.docs[0]||[]).map((t=>Array.from(t.tags))),l=u.docs[0][0].pre,h=u.docs[0][u.docs[0].length-1].post;if("string"==typeof t&&(t=this.fromText(t).compute("id")),o.insertAfter(t),u.has("@hasContraction")&&o.contractions){o.grow("@hasContraction+").contractions().expand()}if(o.delete(u),s){const t=o.docs[0],e=t[t.length-1];e.tags.has("Possessive")||(e.text+="'s",e.normal+="'s",e.tags.add("Possessive"))}if(l&&o.docs[0]&&(o.docs[0][0].pre=l),h&&o.docs[0]){const t=o.docs[0][o.docs[0].length-1];t.post.trim()||(t.post=h)}const f=o.toView(n).compute(["index","freeze","lexicon"]);if(f.world.compute.preTagger&&f.compute("preTagger"),f.compute("unfreeze"),e.tags&&f.terms().forEach(((t,e)=>{t.tagSafe(a[e])})),!f.docs[0]||!f.docs[0][0])return f;if(e.case){const t=i?A:$;f.docs[0][0].text=t(f.docs[0][0].text)}return f},z.replace=function(t,e,n){if(t&&!e)return this.replaceWith(t,n);const o=this.match(t);return o.found?(this.soften(),o.replaceWith(e,n)):this};const T={remove:function(t){const{indexN:e}=this.methods.one.pointer;this.uncache();let n=this.all(),o=this;t&&(n=this,o=this.match(t));const r=!n.ptrs;if(o.has("@hasContraction")&&o.contractions){o.grow("@hasContraction").contractions().expand()}let s=n.fullPointer;const i=o.fullPointer.reverse(),c=function(t,e){e.forEach((e=>{const[n,o,r]=e,s=r-o;t[n]&&(r===t[n].length&&r>1&&function(t,e){const n=t.length-1,o=t[n],r=t[n-e];r&&o&&(r.post+=o.post,r.post=r.post.replace(/ +([.?!,;:])/,"$1"),r.post=r.post.replace(/[,;:]+([.?!])/,"$1"))}(t[n],s),t[n].splice(o,s))}));for(let e=t.length-1;e>=0;e-=1)if(0===t[e].length&&(t.splice(e,1),e===t.length&&t[e-1])){const n=t[e-1],o=n[n.length-1];o&&(o.post=o.post.trimEnd())}return t}(this.document,i);if(s=function(t,e){return t=t.map((t=>{const[n]=t;return e[n]?(e[n].forEach((e=>{const n=e[2]-e[1];t[1]<=e[1]&&t[2]>=e[2]&&(t[2]-=n)})),t):t})),t.forEach(((e,n)=>{if(0===e[1]&&0==e[2])for(let e=n+1;et[2]-t[1]>0))).map((t=>(t[3]=null,t[4]=null,t)))}(s,e(i)),n.ptrs=s,n.document=c,n.compute("index"),r&&(n.ptrs=void 0),!t)return this.ptrs=[],n.none();return n.toView(s)}};T.delete=T.remove;const C={pre:function(t,e){return void 0===t&&this.found?this.docs[0][0].pre:(this.docs.forEach((n=>{const o=n[0];!0===e?o.pre+=t:o.pre=t})),this)},post:function(t,e){if(void 0===t){const t=this.docs[this.docs.length-1];return t[t.length-1].post}return this.docs.forEach((n=>{const o=n[n.length-1];!0===e?o.post+=t:o.post=t})),this},trim:function(){if(!this.found)return this;const t=this.docs,e=t[0][0];e.pre=e.pre.trimStart();const n=t[t.length-1],o=n[n.length-1];return o.post=o.post.trimEnd(),this},hyphenate:function(){return this.docs.forEach((t=>{t.forEach(((e,n)=>{0!==n&&(e.pre=""),t[n+1]&&(e.post="-")}))})),this},dehyphenate:function(){const t=/[-–—]/;return this.docs.forEach((e=>{e.forEach((e=>{t.test(e.post)&&(e.post=" ")}))})),this},toQuotations:function(t,e){return t=t||'"',e=e||'"',this.docs.forEach((n=>{n[0].pre=t+n[0].pre;const o=n[n.length-1];o.post=e+o.post})),this},toParentheses:function(t,e){return t=t||"(",e=e||")",this.docs.forEach((n=>{n[0].pre=t+n[0].pre;const o=n[n.length-1];o.post=e+o.post})),this}};C.deHyphenate=C.dehyphenate,C.toQuotation=C.toQuotations;var L={alpha:(t,e)=>t.normale.normal?1:0,length:(t,e)=>{const n=t.normal.trim().length,o=e.normal.trim().length;return no?-1:0},wordCount:(t,e)=>t.wordse.words?-1:0,sequential:(t,e)=>t[0]e[0]?-1:t[1]>e[1]?1:-1,byFreq:function(t){const e={};return t.forEach((t=>{e[t.normal]=e[t.normal]||0,e[t.normal]+=1})),t.sort(((t,n)=>{const o=e[t.normal],r=e[n.normal];return or?-1:0})),t}};const N=new Set(["index","sequence","seq","sequential","chron","chronological"]),V=new Set(["freq","frequency","topk","repeats"]),F=new Set(["alpha","alphabetical"]);var q={unique:function(){const t=new Set;return this.filter((e=>{const n=e.text("machine");return!t.has(n)&&(t.add(n),!0)}))},reverse:function(){let t=this.pointer||this.docs.map(((t,e)=>[e]));return t=[].concat(t),t=t.reverse(),this._cache&&(this._cache=this._cache.reverse()),this.update(t)},sort:function(t){const{docs:e,pointer:n}=this;if(this.uncache(),"function"==typeof t)return function(t,e){let n=t.fullPointer;return n=n.sort(((n,o)=>(n=t.update([n]),o=t.update([o]),e(n,o)))),t.ptrs=n,t}(this,t);t=t||"alpha";const o=n||e.map(((t,e)=>[e]));let r=e.map(((t,e)=>({index:e,words:t.length,normal:t.map((t=>t.machine||t.normal||"")).join(" "),pointer:o[e]})));return N.has(t)&&(t="sequential"),F.has(t)&&(t="alpha"),V.has(t)?(r=L.byFreq(r),this.update(r.map((t=>t.pointer)))):"function"==typeof L[t]?(r=r.sort(L[t]),this.update(r.map((t=>t.pointer)))):this}};const G=function(t,e){if(t.length>0){const e=t[t.length-1],n=e[e.length-1];!1===/ /.test(n.post)&&(n.post+=" ")}return t=t.concat(e)};var B={concat:function(t){if("string"==typeof t){const e=this.fromText(t);if(this.found&&this.ptrs){const t=this.fullPointer,n=t[t.length-1][0];this.document.splice(n,0,...e.document)}else this.document=this.document.concat(e.document);return this.all().compute("index")}if("object"==typeof t&&t.isView)return function(t,e){if(t.document===e.document){const n=t.fullPointer.concat(e.fullPointer);return t.toView(n).compute("index")}return e.fullPointer.forEach((e=>{e[0]+=t.document.length})),t.document=G(t.document,e.docs),t.all()}(this,t);if(e=t,"[object Array]"===Object.prototype.toString.call(e)){const e=G(this.document,t);return this.document=e,this.all()}var e;return this}};var D={harden:function(){return this.ptrs=this.fullPointer,this},soften:function(){let t=this.ptrs;return!t||t.length<1||(t=t.map((t=>t.slice(0,3))),this.ptrs=t),this}};const M=Object.assign({},{toLowerCase:function(){return this.termList().forEach((t=>{t.text=t.text.toLowerCase()})),this},toUpperCase:function(){return this.termList().forEach((t=>{t.text=t.text.toUpperCase()})),this},toTitleCase:function(){return this.termList().forEach((t=>{t.text=t.text.replace(/^ *[a-z\u00C0-\u00FF]/,(t=>t.toUpperCase()))})),this},toCamelCase:function(){return this.docs.forEach((t=>{t.forEach(((e,n)=>{0!==n&&(e.text=e.text.replace(/^ *[a-z\u00C0-\u00FF]/,(t=>t.toUpperCase()))),n!==t.length-1&&(e.post="")}))})),this}},_,z,T,C,q,B,D),U={id:function(t){const e=t.docs;for(let t=0;t(t.implicit=t.text,t.machine=t.text,t.pre="",t.post="",t.text="",t.normal="",t.index=[o,r+e],t))),n[0]&&(n[0].pre=t[o][r].pre,n[n.length-1].post=t[o][r].post,n[0].text=t[o][r].text,n[0].normal=t[o][r].normal),t[o].splice(r,1,...n))},H=/'/,Z=new Set(["what","how","when","where","why"]),K=new Set(["be","go","start","think","need"]),J=new Set(["been","gone"]),X=/'/,Y=/(e|é|aison|sion|tion)$/,tt=/(age|isme|acle|ege|oire)$/;var et=(t,e)=>["je",t[e].normal.split(X)[1]],nt=(t,e)=>{const n=t[e].normal.split(X)[1];return n&&n.endsWith("e")?["la",n]:["le",n]},ot=(t,e)=>{const n=t[e].normal.split(X)[1];return n&&Y.test(n)&&!tt.test(n)?["du",n]:n&&n.endsWith("s")?["des",n]:["de",n]};const rt=/^([0-9.]{1,4}[a-z]{0,2}) ?[-–—] ?([0-9]{1,4}[a-z]{0,2})$/i,st=/^([0-9]{1,2}(:[0-9][0-9])?(am|pm)?) ?[-–—] ?([0-9]{1,2}(:[0-9][0-9])?(am|pm)?)$/i,it=/^[0-9]{3}-[0-9]{4}$/,ct=function(t,e){const n=t[e];let o=n.text.match(rt);return null!==o?!0===n.tags.has("PhoneNumber")||it.test(n.text)?null:[o[1],"to",o[2]]:(o=n.text.match(st),null!==o?[o[1],"to",o[4]]:null)},ut=/^([+-]?[0-9][.,0-9]*)([a-z°²³µ/]+)$/,at=function(t,e,n){const o=n.model.one.numberSuffixes||{},r=t[e].text.match(ut);if(null!==r){const t=r[2].toLowerCase().trim();return o.hasOwnProperty(t)?null:[r[1],t]}return null},lt=/'/,ht=/^[0-9][^-–—]*[-–—].*?[0-9]/,ft=function(t,e,n,o){const r=e.update();r.document=[t];let s=n+o;n>0&&(n-=1),t[s]&&(s+=1),r.ptrs=[[0,n,s]]},pt={t:(t,e)=>function(t,e){return"ain't"===t[e].normal||"aint"===t[e].normal?null:[t[e].normal.replace(/n't/,""),"not"]}(t,e),d:(t,e)=>function(t,e){const n=t[e].normal.split(H)[0];if(Z.has(n))return[n,"did"];if(t[e+1]){if(J.has(t[e+1].normal))return[n,"had"];if(K.has(t[e+1].normal))return[n,"would"]}return null}(t,e)},dt={j:(t,e)=>et(t,e),l:(t,e)=>nt(t,e),d:(t,e)=>ot(t,e)},mt=function(t,e,n,o){for(let r=0;r2)return s.out.concat(o)}return null},gt=function(t,e){const n=e.fromText(t.join(" "));return n.compute(["id","alias"]),n.docs[0]},wt=function(t,e){for(let n=e+1;n<5&&t[n];n+=1)if("been"===t[n].normal)return["there","has"];return["there","is"]};var yt={contractions:t=>{const{world:e,document:n}=t,{model:o,methods:r}=e,s=o.one.contractions||[];n.forEach(((o,i)=>{for(let c=o.length-1;c>=0;c-=1){let u=null,a=null;if(!0===lt.test(o[c].normal)){const t=o[c].normal.split(lt);u=t[0],a=t[1]}let l=mt(s,o[c],u,a);!l&&pt.hasOwnProperty(a)&&(l=pt[a](o,c,e)),!l&&dt.hasOwnProperty(u)&&(l=dt[u](o,c)),"there"===u&&"s"===a&&(l=wt(o,c)),l?(l=gt(l,t),Q(n,[i,c],l),ft(n[i],t,c,l.length)):ht.test(o[c].normal)?(l=ct(o,c),l&&(l=gt(l,t),Q(n,[i,c],l),r.one.setTag(l,"NumberRange",e),l[2]&&l[2].tags.has("Time")&&r.one.setTag([l[0]],"Time",e,null,"time-range"),ft(n[i],t,c,l.length))):(l=at(o,c,e),l&&(l=gt(l,t),Q(n,[i,c],l),r.one.setTag([l[1]],"Unit",e,null,"contraction-unit")))}}))}};const bt={model:R,compute:yt,hooks:["contractions"]},vt=function(t){const e=t.world,{model:n,methods:o}=t.world,r=o.one.setTag,{frozenLex:s}=n.one,i=n.one._multiCache||{};t.docs.forEach((t=>{for(let n=0;nn;o-=1){const i=t.slice(n,o+1),c=i.map((t=>t.machine||t.normal)).join(" ");!0!==s.hasOwnProperty(c)||(r(i,s[c],e,!1,"1-frozen-multi-lexicon"),i.forEach((t=>t.frozen=!0)))}}void 0!==s[c]&&s.hasOwnProperty(c)&&(r([o],s[c],e,!1,"1-freeze-lexicon"),o.frozen=!0)}}))};const xt=t=>"�[34m"+t+"�[0m",jt=t=>"�[3m�[2m"+t+"�[0m",Et=function(t){t.docs.forEach((t=>{console.log(xt("\n ┌─────────")),t.forEach((t=>{let e=` ${jt("│")} `;const n=t.implicit||t.text||"-";!0===t.frozen?e+=`${xt(n)} ❄️`:e+=jt(n),console.log(e)}))}))};var Ot={compute:{frozen:vt,freeze:vt,unfreeze:function(t){return t.docs.forEach((t=>{t.forEach((t=>{delete t.frozen}))})),t}},mutate:t=>{const e=t.methods.one;e.termMethods.isFrozen=t=>!0===t.frozen,e.debug.freeze=Et,e.debug.frozen=Et},api:function(t){t.prototype.freeze=function(){return this.docs.forEach((t=>{t.forEach((t=>{t.frozen=!0}))})),this},t.prototype.unfreeze=function(){this.compute("unfreeze")},t.prototype.isFrozen=function(){return this.match("@isFrozen+")}},hooks:["freeze"]};const kt=function(t,e,n){const{model:o,methods:r}=n,s=r.one.setTag,i=o.one._multiCache||{},{lexicon:c}=o.one||{},u=t[e],a=u.machine||u.normal;if(void 0!==i[a]&&t[e+1]){for(let o=e+i[a]-1;o>e;o-=1){const r=t.slice(e,o+1);if(r.length<=1)return!1;const i=r.map((t=>t.machine||t.normal)).join(" ");if(!0===c.hasOwnProperty(i)){const t=c[i];return s(r,t,n,!1,"1-multi-lexicon"),!t||2!==t.length||"PhrasalVerb"!==t[0]&&"PhrasalVerb"!==t[1]||s([r[1]],"Particle",n,!1,"1-phrasal-particle"),!0}}return!1}return null},Pt=/^(under|over|mis|re|un|dis|semi|pre|post)-?/,_t=new Set(["Verb","Infinitive","PastTense","Gerund","PresentTense","Adjective","Participle"]),St=function(t,e,n){const{model:o,methods:r}=n,s=r.one.setTag,{lexicon:i}=o.one,c=t[e],u=c.machine||c.normal;if(void 0!==i[u]&&i.hasOwnProperty(u))return s([c],i[u],n,!1,"1-lexicon"),!0;if(c.alias){const t=c.alias.find((t=>i.hasOwnProperty(t)));if(t)return s([c],i[t],n,!1,"1-lexicon-alias"),!0}if(!0===Pt.test(u)){const t=u.replace(Pt,"");if(i.hasOwnProperty(t)&&t.length>3&&_t.has(i[t]))return s([c],i[t],n,!1,"1-lexicon-prefix"),!0}return null};var zt={lexicon:function(t){const e=t.world;t.docs.forEach((t=>{for(let n=0;n{const r=t[o],s=(o=(o=o.toLowerCase().trim()).replace(/'s\b/,"")).split(/ /);s.length>1&&(void 0===n[s[0]]||s.length>n[s[0]])&&(n[s[0]]=s.length),e[o]=e[o]||r})),delete e[""],delete e.null,delete e[" "],{lex:e,_multi:n}}}};var $t={addWords:function(t,e=!1){const n=this.world(),{methods:o,model:r}=n;if(!t)return;if(Object.keys(t).forEach((e=>{"string"==typeof t[e]&&t[e].startsWith("#")&&(t[e]=t[e].replace(/^#/,""))})),!0===e){const{lex:e,_multi:s}=o.one.expandLexicon(t,n);return Object.assign(r.one._multiCache,s),void Object.assign(r.one.frozenLex,e)}if(o.two.expandLexicon){const{lex:e,_multi:s}=o.two.expandLexicon(t,n);Object.assign(r.one.lexicon,e),Object.assign(r.one._multiCache,s)}const{lex:s,_multi:i}=o.one.expandLexicon(t,n);Object.assign(r.one.lexicon,s),Object.assign(r.one._multiCache,i)}};var Tt={model:{one:{lexicon:{},_multiCache:{},frozenLex:{}}},methods:At,compute:zt,lib:$t,hooks:["lexicon"]};const Ct=function(t,e){const n=[{}],o=[null],r=[0],s=[];let i=0;t.forEach((function(t){let r=0;const s=function(t,e){const{methods:n,model:o}=e,r=n.one.tokenize.splitTerms(t,o).map((t=>n.one.tokenize.splitWhitespace(t,o)));return r.map((t=>t.text.toLowerCase()))}(t,e);for(let t=0;t0&&!n[i].hasOwnProperty(u);)i=r[i];if(n.hasOwnProperty(i)){const t=n[i][u];r[a]=t,o[t]&&(o[a]=o[a]||[],o[a]=o[a].concat(o[t]))}else r[a]=0}}return{goNext:n,endAs:o,failTo:r}},Lt=function(t,e,n){let o=0;const r=[];for(let s=0;s0&&(void 0===e.goNext[o]||!e.goNext[o].hasOwnProperty(i));)o=e.failTo[o]||0;if(e.goNext[o].hasOwnProperty(i)&&(o=e.goNext[o][i],e.endAs[o])){const n=e.endAs[o];for(let e=0;e{for(let n=t.length-1;n>=0;n-=1)if(t[n]!==e)return t=t.slice(0,n+1);return t},Ft={buildTrie:function(t){return function(t){return t.goNext=t.goNext.map((t=>{if(0!==Object.keys(t).length)return t})),t.goNext=Vt(t.goNext,void 0),t.failTo=Vt(t.failTo,0),t.endAs=Vt(t.endAs,null),t}(Ct(t,this.world()))}};Ft.compile=Ft.buildTrie;var qt={api:function(t){t.prototype.lookup=function(t,e={}){if(!t)return this.none();"string"==typeof t&&(t=[t]);var n;let o=function(t,e,n){let o=[];n.form=n.form||"normal";const r=t.docs;if(!e.goNext||!e.goNext[0])return console.error("Compromise invalid lookup trie"),t.none();const s=Object.keys(e.goNext[0]);for(let i=0;i0&&(o=o.concat(u))}return t.update(o)}(this,(n=t,"[object Object]"===Object.prototype.toString.call(n)?t:Ct(t,this.world)),e);return o=o.settle(),o}},lib:Ft};const Gt=function(t,e){return e?(t.forEach((t=>{const n=t[0];e[n]&&(t[0]=e[n][0],t[1]+=e[n][1],t[2]+=e[n][1])})),t):t},Bt=function(t,e){let{ptrs:n}=t;const{byGroup:o}=t;return n=Gt(n,e),Object.keys(o).forEach((t=>{o[t]=Gt(o[t],e)})),{ptrs:n,byGroup:o}},Dt=function(t,e,n){const o=n.methods.one;return"number"==typeof t&&(t=String(t)),"string"==typeof t&&(t=o.killUnicode(t,n),t=o.parseMatch(t,e,n)),t},Mt=t=>"[object Object]"===Object.prototype.toString.call(t),Ut=t=>t&&Mt(t)&&!0===t.isView,Wt=t=>t&&Mt(t)&&!0===t.isNet;var It={matchOne:function(t,e,n){const o=this.methods.one;if(Ut(t))return this.intersection(t).eq(0);if(Wt(t))return this.sweep(t,{tagger:!1,matchOne:!0}).view;const r={regs:t=Dt(t,n,this.world),group:e,justOne:!0},s=o.match(this.docs,r,this._cache),{ptrs:i,byGroup:c}=Bt(s,this.fullPointer),u=this.toView(i);return u._groups=c,u},match:function(t,e,n){const o=this.methods.one;if(Ut(t))return this.intersection(t);if(Wt(t))return this.sweep(t,{tagger:!1}).view.settle();const r={regs:t=Dt(t,n,this.world),group:e},s=o.match(this.docs,r,this._cache),{ptrs:i,byGroup:c}=Bt(s,this.fullPointer),u=this.toView(i);return u._groups=c,u},has:function(t,e,n){const o=this.methods.one;if(Ut(t)){return this.intersection(t).fullPointer.length>0}if(Wt(t))return this.sweep(t,{tagger:!1}).view.found;const r={regs:t=Dt(t,n,this.world),group:e,justOne:!0};return o.match(this.docs,r,this._cache).ptrs.length>0},if:function(t,e,n){const o=this.methods.one;if(Ut(t))return this.filter((e=>e.intersection(t).found));if(Wt(t)){const e=this.sweep(t,{tagger:!1}).view.settle();return this.if(e)}const r={regs:t=Dt(t,n,this.world),group:e,justOne:!0};let s=this.fullPointer;const i=this._cache||[];s=s.filter(((t,e)=>{const n=this.update([t]);return o.match(n.docs,r,i[e]).ptrs.length>0}));const c=this.update(s);return this._cache&&(c._cache=s.map((t=>i[t[0]]))),c},ifNo:function(t,e,n){const{methods:o}=this,r=o.one;if(Ut(t))return this.filter((e=>!e.intersection(t).found));if(Wt(t)){const e=this.sweep(t,{tagger:!1}).view.settle();return this.ifNo(e)}t=Dt(t,n,this.world);const s=this._cache||[],i=this.filter(((n,o)=>{const i={regs:t,group:e,justOne:!0};return 0===r.match(n.docs,i,s[o]).ptrs.length}));return this._cache&&(i._cache=i.ptrs.map((t=>s[t[0]]))),i}};var Rt={before:function(t,e,n){const{indexN:o}=this.methods.one.pointer,r=[],s=o(this.fullPointer);Object.keys(s).forEach((t=>{const e=s[t].sort(((t,e)=>t[1]>e[1]?1:-1))[0];e[1]>0&&r.push([e[0],0,e[1]])}));const i=this.toView(r);return t?i.match(t,e,n):i},after:function(t,e,n){const{indexN:o}=this.methods.one.pointer,r=[],s=o(this.fullPointer),i=this.document;Object.keys(s).forEach((t=>{const e=s[t].sort(((t,e)=>t[1]>e[1]?-1:1))[0],[n,,o]=e;o{const s=n.before(t,e);if(s.found){const t=s.terms();o[r][1]-=t.length,o[r][3]=t.docs[0][0].id}})),this.update(o)},growRight:function(t,e,n){"string"==typeof t&&(t=this.world.methods.one.parseMatch(t,n,this.world)),t[0].start=!0;const o=this.fullPointer;return this.forEach(((n,r)=>{const s=n.after(t,e);if(s.found){const t=s.terms();o[r][2]+=t.length,o[r][4]=null}})),this.update(o)},grow:function(t,e,n){return this.growRight(t,e,n).growLeft(t,e,n)}};const Qt=function(t,e){return[t[0],t[1],e[2]]},Ht=(t,e,n)=>{return"string"==typeof t||(o=t,"[object Array]"===Object.prototype.toString.call(o))?e.match(t,n):t||e.none();var o},Zt=function(t,e){const[n,o,r]=t;return e.document[n]&&e.document[n][o]&&(t[3]=t[3]||e.document[n][o].id,e.document[n][r-1]&&(t[4]=t[4]||e.document[n][r-1].id)),t},Kt={splitOn:function(t,e){const{splitAll:n}=this.methods.one.pointer,o=Ht(t,this,e).fullPointer,r=n(this.fullPointer,o);let s=[];return r.forEach((t=>{s.push(t.passthrough),s.push(t.before),s.push(t.match),s.push(t.after)})),s=s.filter((t=>t)),s=s.map((t=>Zt(t,this))),this.update(s)},splitBefore:function(t,e){const{splitAll:n}=this.methods.one.pointer,o=Ht(t,this,e).fullPointer,r=n(this.fullPointer,o);for(let t=0;t{s.push(t.passthrough),s.push(t.before),t.match&&t.after?s.push(Qt(t.match,t.after)):s.push(t.match)})),s=s.filter((t=>t)),s=s.map((t=>Zt(t,this))),this.update(s)},splitAfter:function(t,e){const{splitAll:n}=this.methods.one.pointer,o=Ht(t,this,e).fullPointer,r=n(this.fullPointer,o);let s=[];return r.forEach((t=>{s.push(t.passthrough),t.before&&t.match?s.push(Qt(t.before,t.match)):(s.push(t.before),s.push(t.match)),s.push(t.after)})),s=s.filter((t=>t)),s=s.map((t=>Zt(t,this))),this.update(s)}};Kt.split=Kt.splitAfter;const Jt=function(t,e){return!(!t||!e)&&(t[0]===e[0]&&t[2]===e[1])},Xt=function(t,e,n){const o=t.world,r=o.methods.one.parseMatch;n=n||"^.";const s=r(e=e||".$",{},o),i=r(n,{},o);s[s.length-1].end=!0,i[0].start=!0;const c=t.fullPointer,u=[c[0]];for(let e=1;e)?\/.*?[^\\/]\/[?\]+*$~]*)(?:\s|$)/,ne=/([!~[^]*(?:<[^<]*>)?\([^)]+[^\\)]\)[?\]+*$~]*)(?:\s|$)/,oe=/ /g,re=t=>/^[![^]*(<[^<]*>)?\//.test(t)&&/\/[?\]+*$~]*$/.test(t),se=function(t){return t=(t=t.map((t=>t.trim()))).filter((t=>t))},ie=/\{([0-9]+)?(, *[0-9]*)?\}/,ce=/&&/,ue=new RegExp(/^<\s*(\S+)\s*>/),ae=t=>t.charAt(0).toUpperCase()+t.substring(1),le=t=>t.charAt(t.length-1),he=t=>t.charAt(0),fe=t=>t.substring(1),pe=t=>t.substring(0,t.length-1),de=function(t){return t=fe(t),t=pe(t)},me=function(t,e){const n={};for(let o=0;o<2;o+=1){if("$"===le(t)&&(n.end=!0,t=pe(t)),"^"===he(t)&&(n.start=!0,t=fe(t)),"?"===le(t)&&(n.optional=!0,t=pe(t)),("["===he(t)||"]"===le(t))&&(n.group=null,"["===he(t)&&(n.groupStart=!0),"]"===le(t)&&(n.groupEnd=!0),t=(t=t.replace(/^\[/,"")).replace(/\]$/,""),"<"===he(t))){const e=ue.exec(t);e.length>=2&&(n.group=e[1],t=t.replace(e[0],""))}if("+"===le(t)&&(n.greedy=!0,t=pe(t)),"*"!==t&&"*"===le(t)&&"\\*"!==t&&(n.greedy=!0,t=pe(t)),"!"===he(t)&&(n.negative=!0,t=fe(t)),"~"===he(t)&&"~"===le(t)&&t.length>2&&(t=de(t),n.fuzzy=!0,n.min=e.fuzzy||.85,!1===/\(/.test(t)))return n.word=t,n;if("/"===he(t)&&"/"===le(t))return t=de(t),e.caseSensitive&&(n.use="text"),n.regex=new RegExp(t),n;if(!0===ie.test(t)&&(t=t.replace(ie,((t,e,o)=>(void 0===o?(n.min=Number(e),n.max=Number(e)):(o=o.replace(/, */,""),void 0===e?(n.min=0,n.max=Number(o)):(n.min=Number(e),n.max=Number(o||999))),n.greedy=!0,n.min||(n.optional=!0),"")))),"("===he(t)&&")"===le(t)){ce.test(t)?(n.choices=t.split(ce),n.operator="and"):(n.choices=t.split("|"),n.operator="or"),n.choices[0]=fe(n.choices[0]);const o=n.choices.length-1;n.choices[o]=pe(n.choices[o]),n.choices=n.choices.map((t=>t.trim())),n.choices=n.choices.filter((t=>t)),n.choices=n.choices.map((t=>t.split(/ /g).map((t=>me(t,e))))),t=""}if("{"===he(t)&&"}"===le(t)){if(t=de(t),n.root=t,/\//.test(t)){const t=n.root.split(/\//);n.root=t[0],n.pos=t[1],"adj"===n.pos&&(n.pos="Adjective"),n.pos=n.pos.charAt(0).toUpperCase()+n.pos.substr(1).toLowerCase(),void 0!==t[2]&&(n.sense=t[2])}return n}if("<"===he(t)&&">"===le(t))return t=de(t),n.chunk=ae(t),n.greedy=!0,n;if("%"===he(t)&&"%"===le(t))return t=de(t),n.switch=t,n}return"#"===he(t)?(n.tag=fe(t),n.tag=ae(n.tag),n):"@"===he(t)?(n.method=fe(t),n):"."===t?(n.anything=!0,n):"*"===t?(n.anything=!0,n.greedy=!0,n.optional=!0,n):(t&&(t=(t=t.replace("\\*","*")).replace("\\.","."),e.caseSensitive?n.use="text":t=t.toLowerCase(),n.word=t),n)},ge=/[a-z0-9][-–—][a-z]/i,we=function(t,e){const{all:n}=e.methods.two.transform.verb||{},o=t.root;return n?n(o,e.model):[]},ye=function(t,e){const{all:n}=e.methods.two.transform.noun||{};return n?n(t.root,e.model):[t.root]},be=function(t,e){const{all:n}=e.methods.two.transform.adjective||{};return n?n(t.root,e.model):[t.root]},ve=function(t){return t=function(t){let e=0,n=null;for(let o=0;o(t.fuzzy&&t.choices&&t.choices.forEach((e=>{1===e.length&&e[0].word&&(e[0].fuzzy=!0,e[0].min=t.min)})),t)))}(t=t.map((t=>{if(void 0!==t.choices){if("or"!==t.operator)return t;if(!0===t.fuzzy)return t;!0===t.choices.every((t=>{if(1!==t.length)return!1;const e=t[0];return!0!==e.fuzzy&&!e.start&&!e.end&&void 0!==e.word&&!0!==e.negative&&!0!==e.optional&&!0!==e.method}))&&(t.fastOr=new Set,t.choices.forEach((e=>{t.fastOr.add(e[0].word)})),delete t.choices)}return t}))),t},xe=function(t,e){for(const n of e)if(t.has(n))return!0;return!1},je=function(t,e){for(let n=0;nn?o:n)+1;if(Math.abs(n-o)>(r||100))return r||100;const s=[];for(let t=0;t4)return n;u=e[i-1],a=c===u?0:1,l=s[r-1][i]+1,(h=s[r][i-1]+1)1&&i>1&&c===e[i-2]&&t[r-2]===u&&(h=s[r-2][i-2]+a)-1!==t.post.indexOf(e),ze={hasQuote:t=>Oe.test(t.pre)||ke.test(t.post),hasComma:t=>Se(t,","),hasPeriod:t=>!0===Se(t,".")&&!1===Se(t,"..."),hasExclamation:t=>Se(t,"!"),hasQuestionMark:t=>Se(t,"?")||Se(t,"¿"),hasEllipses:t=>Se(t,"..")||Se(t,"…"),hasSemicolon:t=>Se(t,";"),hasColon:t=>Se(t,":"),hasSlash:t=>/\//.test(t.text),hasHyphen:t=>Pe.test(t.post)||Pe.test(t.pre),hasDash:t=>_e.test(t.post)||_e.test(t.pre),hasContraction:t=>Boolean(t.implicit),isAcronym:t=>t.tags.has("Acronym"),isKnown:t=>t.tags.size>0,isTitleCase:t=>/^\p{Lu}[a-z'\u00C0-\u00FF]/u.test(t.text),isUpperCase:t=>/^\p{Lu}+$/u.test(t.text)};ze.hasQuotation=ze.hasQuote;let Ae=function(){};Ae=function(t,e,n,o){const r=function(t,e,n,o){if(!0===e.anything)return!0;if(!0===e.start&&0!==n)return!1;if(!0===e.end&&n!==o-1)return!1;if(void 0!==e.id&&e.id===t.id)return!0;if(void 0!==e.word){if(e.use)return e.word===t[e.use];if(null!==t.machine&&t.machine===e.word)return!0;if(void 0!==t.alias&&t.alias.hasOwnProperty(e.word))return!0;if(!0===e.fuzzy){if(e.word===t.root)return!0;if(Ee(e.word,t.normal)>=e.min)return!0}return!(!t.alias||!t.alias.some((t=>t===e.word)))||e.word===t.text||e.word===t.normal}if(void 0!==e.tag)return!0===t.tags.has(e.tag);if(void 0!==e.method)return"function"==typeof ze[e.method]&&!0===ze[e.method](t);if(void 0!==e.pre)return t.pre&&t.pre.includes(e.pre);if(void 0!==e.post)return t.post&&t.post.includes(e.post);if(void 0!==e.regex){let n=t.normal;return e.use&&(n=t[e.use]),e.regex.test(n)}if(void 0!==e.chunk)return t.chunk===e.chunk;if(void 0!==e.switch)return t.switch===e.switch;if(void 0!==e.machine)return t.normal===e.machine||t.machine===e.machine||t.root===e.machine;if(void 0!==e.sense)return t.sense===e.sense;if(void 0!==e.fastOr){if(e.pos&&!t.tags.has(e.pos))return null;const n=t.root||t.implicit||t.machine||t.normal;return e.fastOr.has(n)||e.fastOr.has(t.text)}return void 0!==e.choices&&("and"===e.operator?e.choices.every((e=>Ae(t,e,n,o))):e.choices.some((e=>Ae(t,e,n,o))))}(t,e,n,o);return!0===e.negative?!r:r};const $e=function(t,e){if(!0===t.end&&!0===t.greedy&&e.start_i+e.tn.max)return t.t=t.t+n.max,!0;if(!0===t.hasGroup){Te(t,t.t).length=o-t.t}return t.t=o,!0},Le=function(t,e=0){const n=t.regs[t.r];let o=!1;for(let s=0;s{let r=0;const s=t.t+o+e+r;if(void 0===t.terms[s])return!1;const i=Ae(t.terms[s],n,s+t.start_i,t.phrase_length);if(!0===i&&!0===n.greedy)for(let e=1;e{const o=n.every(((e,n)=>{const o=t.t+n;return void 0!==t.terms[o]&&Ae(t.terms[o],e,o,t.phrase_length)}));return!0===o&&n.length>e&&(e=n.length),o}))&&e}(t);if(o){if(!0===n.negative)return null;if(!0===t.hasGroup){Te(t,t.t).length+=o}if(!0===n.end){const e=t.phrase_length-1;if(t.t+t.start_i!==e)return null}return t.t+=o,!0}return!!n.optional||null},Fe=function(t){const{regs:e}=t,n=e[t.r],o=Object.assign({},n);o.negative=!1;if(Ae(t.terms[t.t],o,t.start_i+t.t,t.phrase_length))return!1;if(n.optional){const n=e[t.r+1];if(n){if(Ae(t.terms[t.t],n,t.start_i+t.t,t.phrase_length))t.r+=1;else if(n.optional&&e[t.r+2]){Ae(t.terms[t.t],e[t.r+2],t.start_i+t.t,t.phrase_length)&&(t.r+=2)}}}return n.greedy?function(t,e,n){let o=0;for(let r=t.t;ro||(t.t+=o,0))}(t,o,e[t.r+1]):(t.t+=1,!0)},qe=function(t){const{regs:e,phrase_length:n}=t,o=e[t.r];return t.t=function(t,e){const n=Object.assign({},t.regs[t.r],{start:!1,end:!1}),o=t.t;for(;t.tt.t?null:!0!==o.end||t.start_i+t.t===n||null},Ge=function(t){const{regs:e}=t,n=e[t.r],o=t.terms[t.t],r=t.t;if(n.optional&&e[t.r+1]&&n.negative)return!0;if(n.optional&&e[t.r+1]&&function(t){const{regs:e}=t,n=e[t.r],o=t.terms[t.t],r=Ae(o,e[t.r+1],t.start_i+t.t,t.phrase_length);if(n.negative||r){const n=t.terms[t.t+1];n&&Ae(n,e[t.r+1],t.start_i+t.t,t.phrase_length)||(t.r+=1)}}(t),o.implicit&&t.terms[t.t+1]&&function(t){const e=t.terms[t.t],n=t.regs[t.r];if(e.implicit&&t.terms[t.t+1]){if(!t.terms[t.t+1].implicit)return;n.word===e.normal&&(t.t+=1),"hasContraction"===n.method&&(t.t+=1)}}(t),t.t+=1,!0===n.end&&t.t!==t.terms.length&&!0!==n.greedy)return null;if(!0===n.greedy){if(!qe(t))return null}return!0===t.hasGroup&&function(t,e){const n=t.regs[t.r],o=Te(t,e);t.t>1&&n.greedy?o.length+=t.t-e:o.length++}(t,r),!0},Be=function(t,e,n,o){if(0===t.length||0===e.length)return null;const r={t:0,terms:t,r:0,regs:e,groups:{},start_i:n,phrase_length:o,inGroup:null};for(;r.r!t.optional)))break;return null}if(!0===t.anything&&!0===t.greedy){if(!Ce(r))return null;continue}if(void 0!==t.choices&&"or"===t.operator){if(!Ne(r))return null;continue}if(void 0!==t.choices&&"and"===t.operator){if(!Ve(r))return null;continue}if(!0===t.anything){if(t.negative&&t.anything)return null;if(!Ge(r))return null;continue}if(!0===$e(t,r)){if(!Ge(r))return null;continue}if(t.negative){if(!Fe(r))return null;continue}if(!0!==Ae(r.terms[r.t],t,r.start_i+r.t,r.phrase_length)){if(!0!==t.optional)return null}else{if(!Ge(r))return null}}const s=[null,n,r.t+n];if(s[1]===s[2])return null;const i={};return Object.keys(r.groups).forEach((t=>{const e=r.groups[t],o=n+e.start;i[t]=[null,o,o+e.length]})),{pointer:s,groups:i}},De=function(t,e){return t.pointer[0]=e,Object.keys(t.groups).forEach((n=>{t.groups[n][0]=e})),t},Me=function(t,e,n){let o=Be(t,e,0,t.length);return o?(o=De(o,n),o):null},Ue={one:{termMethods:ze,parseMatch:function(t,e,n){if(null==t||""===t)return[];e=e||{},"number"==typeof t&&(t=String(t));let o=function(t){const e=t.split(ee);let n=[];e.forEach((t=>{re(t)?n.push(t):n=n.concat(t.split(ne))})),n=se(n);let o=[];return n.forEach((t=>{(t=>/^[![^]*(<[^<]*>)?\(/.test(t)&&/\)[?\]+*$~]*$/.test(t))(t)||re(t)?o.push(t):o=o.concat(t.split(oe))})),o=se(o),o}(t);return o=o.map((t=>me(t,e))),o=function(t,e){const n=e.model.one.prefixes;for(let e=t.length-1;e>=0;e-=1){const o=t[e];if(o.word&&ge.test(o.word)){let r=o.word.split(/[-–—]/g);if(n.hasOwnProperty(r[0]))continue;r=r.filter((t=>t)).reverse(),t.splice(e,1),r.forEach((n=>{const r=Object.assign({},o);r.word=n,t.splice(e,0,r)}))}}return t}(o,n),o=function(t,e){return t.map((t=>{if(t.root)if(e.methods.two&&e.methods.two.transform){let n=[];t.pos?"Verb"===t.pos?n=n.concat(we(t,e)):"Noun"===t.pos?n=n.concat(ye(t,e)):"Adjective"===t.pos&&(n=n.concat(be(t,e))):(n=n.concat(we(t,e)),n=n.concat(ye(t,e)),n=n.concat(be(t,e))),n=n.filter((t=>t)),n.length>0&&(t.operator="or",t.fastOr=new Set(n))}else t.machine=t.root,delete t.id,delete t.root;return t}))}(o,n),o=ve(o),o},match:function(t,e,n){n=n||[];const{regs:o,group:r,justOne:s}=e;let i=[];if(!o||0===o.length)return{ptrs:[],byGroup:{}};const c=o.filter((t=>!0!==t.optional&&!0!==t.negative)).length;t:for(let e=0;et&&(t=Math.abs(n-1))}}else{const t=Me(r,o,e);t&&i.push(t)}}return!0===o[o.length-1].end&&(i=i.filter((e=>{const n=e.pointer[0];return t[n].length===e.pointer[2]}))),e.notIf&&(i=function(t,e,n){return t=t.filter((t=>{const[o,r,s]=t.pointer,i=n[o].slice(r,s);for(let t=0;t{t.groups[e]&&n.push(t.groups[e])})):t.forEach((t=>{n.push(t.pointer),Object.keys(t.groups).forEach((e=>{o[e]=o[e]||[],o[e].push(t.groups[e])}))}))),{ptrs:n,byGroup:o}}(i,r),i.ptrs.forEach((e=>{const[n,o,r]=e;e[3]=t[n][o].id,e[4]=t[n][r-1].id})),i}}};var We={api:function(t){Object.assign(t.prototype,te)},methods:Ue,lib:{parseMatch:function(t,e){const n=this.world(),o=n.methods.one.killUnicode;return o&&(t=o(t,n)),n.methods.one.parseMatch(t,e,n)}}};const Ie=/^\../,Re=/^#./,Qe=function(t,e){const n={},o={};return Object.keys(e).forEach((r=>{let s=e[r];const i=function(t){let e="",n=" ";return t=t.replace(/&/g,"&").replace(//g,">").replace(/"/g,""").replace(/'/g,"'"),Ie.test(t)?e=``),e+=">",{start:e,end:n}}(r);"string"==typeof s&&(s=t.match(s)),s.docs.forEach((t=>{if(t.every((t=>t.implicit)))return;const e=t[0].id;n[e]=n[e]||[],n[e].push(i.start);const r=t[t.length-1].id;o[r]=o[r]||[],o[r].push(i.end)}))})),{starts:n,ends:o}};var He={html:function(t){const{starts:e,ends:n}=Qe(this,t);let o="";return this.docs.forEach((t=>{for(let r=0;r{let n=t.pre||"",r=t.post||"";"some"===e.punctuation&&(n=n.replace(Ke,""),Xe.test(r)&&(r=" "),r=r.replace(Je,""),r=r.replace(/\?!+/,"?"),r=r.replace(/!+/,"!"),r=r.replace(/\?+/,"?"),r=r.replace(/\.{2,}/,""),t.tags.has("Abbreviation")&&(r=r.replace(/\./,""))),"some"===e.whitespace&&(n=n.replace(/\s/,""),r=r.replace(/\s+/," ")),e.keepPunct||(n=n.replace(Ke,""),r="-"===r?" ":r.replace(Ze,""));let s=t[e.form||"text"]||t.normal||"";"implicit"===e.form&&(s=t.implicit||t.text),"root"===e.form&&t.implicit&&(s=t.root||t.implicit||t.normal),"machine"!==e.form&&"implicit"!==e.form&&"root"!==e.form||!t.implicit||r&&Ye.test(r)||(r+=" "),o+=n+s+r})),!1===n&&(o=o.trim()),!0===e.lowerCase&&(o=o.toLowerCase()),o},en={text:{form:"text"},normal:{whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"normal"},machine:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"none",unicode:"some",form:"machine"},root:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"root"},implicit:{form:"implicit"}};en.clean=en.normal,en.reduced=en.root;const nn=[];let on=0;for(;on<64;)nn[on]=0|4294967296*Math.sin(++on%Math.PI);const rn=function(t){let e,n,o,r=decodeURI(encodeURI(t))+"",s=r.length;const i=[e=1732584193,n=4023233417,~e,~n],c=[];for(t=--s/4+2|15,c[--t]=8*s;~s;)c[s>>2]|=r.charCodeAt(s)<<8*s--;for(on=r=0;on>4]+nn[r]+~~c[on|15&[r,5*r+1,3*r+5,7*r][s]])<<(s=[7,12,17,22,5,9,14,20,4,11,16,23,6,10,15,21][4*s+r++%4])|o>>>-s),e,n])e=0|s[1],n=s[2];for(r=4;r;)i[--r]+=s[r]}for(t="";r<32;)t+=(i[r>>3]>>4*(1^r++)&15).toString(16);return t},sn={text:!0,terms:!0},cn={case:"none",unicode:"some",form:"machine",punctuation:"some"},un=function(t,e){return Object.assign({},t,e)},an={text:t=>tn(t,{keepPunct:!0},!1),normal:t=>tn(t,un(en.normal,{keepPunct:!0}),!1),implicit:t=>tn(t,un(en.implicit,{keepPunct:!0}),!1),machine:t=>tn(t,cn,!1),root:t=>tn(t,un(cn,{form:"root"}),!1),hash:t=>rn(tn(t,{keepPunct:!0},!1)),offset:t=>{const e=an.text(t).length;return{index:t[0].offset.index,start:t[0].offset.start,length:e}},terms:t=>t.map((t=>{const e=Object.assign({},t);return e.tags=Array.from(t.tags),e})),confidence:(t,e,n)=>e.eq(n).confidence(),syllables:(t,e,n)=>e.eq(n).syllables(),sentence:(t,e,n)=>e.eq(n).fullSentence().text(),dirty:t=>t.some((t=>!0===t.dirty))};an.sentences=an.sentence,an.clean=an.normal,an.reduced=an.root;const ln={json:function(t){const e=(n=this,"string"==typeof(o=(o=t)||{})&&(o={}),(o=Object.assign({},sn,o)).offset&&n.compute("offset"),n.docs.map(((t,e)=>{const r={};return Object.keys(o).forEach((s=>{o[s]&&an[s]&&(r[s]=an[s](t,n,e))})),r})));var n,o;return"number"==typeof t?e[t]:e}};ln.data=ln.json;const hn=function(t){const e=t.pre||"",n=t.post||"";return e+t.text+n},fn=function(t,e){const n=function(t,e){const n={};return Object.keys(e).forEach((o=>{t.match(o).fullPointer.forEach((t=>{n[t[3]]={fn:e[o],end:t[2]}}))})),n}(t,e);let o="";return t.docs.forEach(((e,r)=>{for(let s=0;st.reduce(((t,e)=>t+e.pre+e.text+e.post),"").trim()));return t.filter((t=>t))}if("freq"===t||"frequency"===t||"topk"===t)return function(t){const e={};t.forEach((t=>{e[t]=e[t]||0,e[t]+=1}));const n=Object.keys(e).map((t=>({normal:t,count:e[t]})));return n.sort(((t,e)=>t.count>e.count?-1:0))}(this.json({normal:!0}).map((t=>t.normal)));if("terms"===t){let t=[];return this.docs.forEach((e=>{let n=e.map((t=>t.text));n=n.filter((t=>t)),t=t.concat(n)})),t}return"tags"===t?this.docs.map((t=>t.reduce(((t,e)=>(t[e.implicit||e.normal]=Array.from(e.tags),t)),{}))):"debug"===t?this.debug():this.text()},wrap:function(t){return fn(this,t)}};var dn={text:function(t){let e={};var n;if(t&&"string"==typeof t&&en.hasOwnProperty(t)?e=Object.assign({},en[t]):t&&(n=t,"[object Object]"===Object.prototype.toString.call(n))&&(e=Object.assign({},t)),void 0!==e.keepSpace||this.isFull()||(e.keepSpace=!1),void 0===e.keepEndPunct&&this.pointer){const t=this.pointer[0];t&&t[1]?e.keepEndPunct=!1:e.keepEndPunct=!0}return void 0===e.keepPunct&&(e.keepPunct=!0),void 0===e.keepSpace&&(e.keepSpace=!0),function(t,e){let n="";if(!t||!t[0]||!t[0][0])return n;for(let o=0;o"�[32m"+t+gn,red:t=>"�[31m"+t+gn,blue:t=>"�[34m"+t+gn,magenta:t=>"�[35m"+t+gn,cyan:t=>"�[36m"+t+gn,yellow:t=>"�[33m"+t+gn,black:t=>"�[30m"+t+gn,dim:t=>"�[2m"+t+gn,i:t=>"�[3m"+t+gn},yn={tags:function(t){const{docs:e,model:n}=t;0===e.length&&console.log(wn.blue("\n ──────")),e.forEach((e=>{console.log(wn.blue("\n ┌─────────")),e.forEach((e=>{const o=[...e.tags||[]];let r=e.text||"-";e.sense&&(r=`{${e.normal}/${e.sense}}`),e.implicit&&(r="["+e.implicit+"]"),r=wn.yellow(r);let s="'"+r+"'";if(e.reference){const n=t.update([e.reference]).text("normal");s+=` - ${wn.dim(wn.i("["+n+"]"))}`}s=s.padEnd(18);const i=wn.blue(" │ ")+wn.i(s)+" - "+function(t,e){return e.one.tagSet&&(t=t.map((t=>{if(!e.one.tagSet.hasOwnProperty(t))return t;const n=e.one.tagSet[t].color||"blue";return wn[n](t)}))),t.join(", ")}(o,n);console.log(i)}))})),console.log("\n")},clientSide:function(t){console.log("%c -=-=- ","background-color:#6699cc;"),t.forEach((t=>{console.groupCollapsed(t.text());const e=t.docs[0].map((t=>{let e=t.text||"-";t.implicit&&(e="["+t.implicit+"]");return{text:e,tags:"["+Array.from(t.tags).join(", ")+"]"}}));console.table(e,["text","tags"]),console.groupEnd()}))},chunks:function(t){const{docs:e}=t;console.log(""),e.forEach((t=>{const e=[];t.forEach((t=>{"Noun"===t.chunk?e.push(wn.blue(t.implicit||t.normal)):"Verb"===t.chunk?e.push(wn.green(t.implicit||t.normal)):"Adjective"===t.chunk?e.push(wn.yellow(t.implicit||t.normal)):"Pivot"===t.chunk?e.push(wn.red(t.implicit||t.normal)):e.push(t.implicit||t.normal)})),console.log(e.join(" "),"\n")})),console.log("\n")},highlight:function(t){if(!t.found)return;const e={};t.fullPointer.forEach((t=>{e[t[0]]=e[t[0]]||[],e[t[0]].push(t)})),Object.keys(e).forEach((n=>{let o=t.update([[Number(n)]]).text();t.update(e[n]).json({offset:!0}).forEach(((t,e)=>{o=function(t,e,n){const o=((t,e,n)=>{const o=9*n,r=e.start+o,s=r+e.length;return[t.substring(0,r),t.substring(r,s),t.substring(s,t.length)]})(t,e,n);return`${o[0]}${wn.blue(o[1])}${o[2]}`}(o,t.offset,e)})),console.log(o)})),console.log("\n")}};var bn={api:function(t){Object.assign(t.prototype,mn)},methods:{one:{hash:rn,debug:yn}}};const vn=function(t,e){if(t[0]!==e[0])return!1;const[,n,o]=t,[,r,s]=e;return n<=r&&o>r||r<=n&&s>n},xn=function(t){const e={};return t.forEach((t=>{e[t[0]]=e[t[0]]||[],e[t[0]].push(t)})),e},jn=function(t,e){const n=xn(e),o=[];return t.forEach((t=>{const[e]=t;let r=n[e]||[];if(r=r.filter((e=>function(t,e){return t[1]<=e[1]&&e[2]<=t[2]}(t,e))),0===r.length)return void o.push({passthrough:t});r=r.sort(((t,e)=>t[1]-e[1]));let s=t;r.forEach(((t,e)=>{const n=function(t,e){const[n,o]=t,r=e[1],s=e[2],i={};if(os&&(i.after=[n,s,t[2]]),i}(s,t);r[e+1]?(o.push({before:n.before,match:n.match}),n.after&&(s=n.after)):o.push(n)}))})),o};var En={one:{termList:function(t){const e=[];for(let n=0;n{if(!o)return;let[s,i,c,u,a]=o,l=e[s]||[];if(void 0===i&&(i=0),void 0===c&&(c=l.length),!u||l[i]&&l[i].id===u)l=l.slice(i,c);else{const n=function(t,e,n){for(let o=0;o<20;o+=1){if(e[n-o]){const r=e[n-o].findIndex((e=>e.id===t));if(-1!==r)return[n-o,r]}if(e[n+o]){const r=e[n+o].findIndex((e=>e.id===t));if(-1!==r)return[n+o,r]}}return null}(u,e,s);if(null!==n){const o=c-i;l=e[n[0]].slice(n[1],n[1]+o);const s=l[0]?l[0].id:null;t[r]=[n[0],n[1],n[1]+o,s]}}0!==l.length&&i!==c&&(a&&l[l.length-1].id!==a&&(l=function(t,e){const[n,o,,,r]=t,s=e[n],i=s.findIndex((t=>t.id===r));return-1===i?(t[2]=e[n].length,t[4]=s.length?s[s.length-1].id:null):t[2]=i,e[n].slice(o,t[2]+1)}(o,e)),n.push(l))})),n=n.filter((t=>t.length>0)),n},pointer:{indexN:xn,splitAll:jn}}};const On=function(t,e){const n=t.concat(e),o=xn(n);let r=[];return n.forEach((t=>{const[e]=t;if(1===o[e].length)return void r.push(t);const n=o[e].filter((e=>vn(t,e)));n.push(t);const s=function(t){let e=t[0][1],n=t[0][2];return t.forEach((t=>{t[1]n&&(n=t[2])})),[t[0][0],e,n]}(n);r.push(s)})),r=function(t){const e={};for(let n=0;n{t.passthrough&&n.push(t.passthrough),t.before&&n.push(t.before),t.after&&n.push(t.after)})),n},Pn=(t,e)=>{return"string"==typeof t||(n=t,"[object Array]"===Object.prototype.toString.call(n))?e.match(t):t||e.none();var n},_n=function(t,e){return t.map((t=>{const[n,o]=t;return e[n]&&e[n][o]&&(t[3]=e[n][o].id),t}))},Sn={union:function(t){t=Pn(t,this);let e=On(this.fullPointer,t.fullPointer);return e=_n(e,this.document),this.toView(e)}};Sn.and=Sn.union,Sn.intersection=function(t){t=Pn(t,this);let e=function(t,e){const n=xn(e),o=[];return t.forEach((t=>{let e=n[t[0]]||[];e=e.filter((e=>vn(t,e))),0!==e.length&&e.forEach((e=>{const n=function(t,e){const n=t[1]e[2]?e[2]:t[2];return n{t=On(t,[e])})),t=_n(t,this.document),this.update(t)};var zn={methods:En,api:function(t){Object.assign(t.prototype,Sn)}};const An=function(t){return!0===t.optional||!0===t.negative?null:t.tag?"#"+t.tag:t.word?t.word:t.switch?`%${t.switch}%`:null},$n=function(t,e){const n=e.methods.one.parseMatch;return t.forEach((t=>{t.regs=n(t.match,{},e),"string"==typeof t.ifNo&&(t.ifNo=[t.ifNo]),t.notIf&&(t.notIf=n(t.notIf,{},e)),t.needs=function(t){const e=[];return t.forEach((t=>{e.push(An(t)),"and"===t.operator&&t.choices&&t.choices.forEach((t=>{t.forEach((t=>{e.push(An(t))}))}))})),e.filter((t=>t))}(t.regs);const{wants:o,count:r}=function(t){const e=[];let n=0;return t.forEach((t=>{"or"!==t.operator||t.optional||t.negative||(t.fastOr&&Array.from(t.fastOr).forEach((t=>{e.push(t)})),t.choices&&t.choices.forEach((t=>{t.forEach((t=>{const n=An(t);n&&e.push(n)}))})),n+=1)})),{wants:e,count:n}}(t.regs);t.wants=o,t.minWant=r,t.minWords=t.regs.filter((t=>!t.optional)).length})),t};var Tn={buildNet:function(t,e){t=$n(t,e);const n={};t.forEach((t=>{t.needs.forEach((e=>{n[e]=Array.isArray(n[e])?n[e]:[],n[e].push(t)})),t.wants.forEach((e=>{n[e]=Array.isArray(n[e])?n[e]:[],n[e].push(t)}))})),Object.keys(n).forEach((t=>{const e={};n[t]=n[t].filter((t=>"boolean"!=typeof e[t.match]&&(e[t.match]=!0,!0)))}));const o=t.filter((t=>0===t.needs.length&&0===t.wants.length));return{hooks:n,always:o}},bulkMatch:function(t,e,n,o={}){const r=n.one.cacheDoc(t);let s=function(t,e){return t.map(((n,o)=>{let r=[];Object.keys(e).forEach((n=>{t[o].has(n)&&(r=r.concat(e[n]))}));const s={};return r=r.filter((t=>"boolean"!=typeof s[t.match]&&(s[t.match]=!0,!0))),r}))}(r,e.hooks);s=function(t,e){return t.map(((t,n)=>{const o=e[n];return(t=(t=t.filter((t=>t.needs.every((t=>o.has(t)))))).filter((t=>void 0===t.ifNo||!0!==t.ifNo.some((t=>o.has(t)))))).filter((t=>0===t.wants.length||t.wants.filter((t=>o.has(t))).length>=t.minWant))}))}(s,r),e.always.length>0&&(s=s.map((t=>t.concat(e.always)))),s=function(t,e){return t.map(((t,n)=>{const o=e[n].length;return t=t.filter((t=>o>=t.minWords)),t}))}(s,t);const i=function(t,e,n,o,r){const s=[];for(let n=0;n0&&(u.ptrs.forEach((t=>{t[0]=n;const e=Object.assign({},c,{pointer:t});void 0!==c.unTag&&(e.unTag=c.unTag),s.push(e)})),!0===r.matchOne))return[s[0]]}return s}(s,t,0,n,o);return i},bulkTagger:function(t,e,n){const{model:o,methods:r}=n,{getDoc:s,setTag:i,unTag:c}=r.one,u=r.two.looksPlural;if(0===t.length)return t;return("undefined"!=typeof process&&process.env?process.env:self.env||{}).DEBUG_TAGS&&console.log(`\n\n �[32m→ ${t.length} post-tagger:�[0m`),t.map((t=>{if(!t.tag&&!t.chunk&&!t.unTag)return;const r=t.reason||t.match,a=s([t.pointer],e)[0];if(!0===t.safe){if(!1===function(t,e,n){const o=n.one.tagSet;if(!o.hasOwnProperty(e))return!0;const r=o[e].not||[];for(let e=0;et.frozen=!0))}void 0!==t.unTag&&c(a,t.unTag,n,t.safe,r),t.chunk&&a.forEach((e=>e.chunk=t.chunk))}))}},Cn={lib:{buildNet:function(t){const e=this.methods().one.buildNet(t,this.world());return e.isNet=!0,e}},api:function(t){t.prototype.sweep=function(t,e={}){const{world:n,docs:o}=this,{methods:r}=n;let s=r.one.bulkMatch(o,t,this.methods,e);!1!==e.tagger&&r.one.bulkTagger(s,o,this.world),s=s.map((t=>{const e=t.pointer,n=o[e[0]][e[1]],r=e[2]-e[1];return n.index&&(t.pointer=[n.index[0],n.index[1],e[1]+r]),t}));const i=s.map((t=>t.pointer));return s=s.map((t=>(t.view=this.update([t.pointer]),delete t.regs,delete t.needs,delete t.pointer,delete t._expanded,t))),{view:this.update(i),found:s}}},methods:{one:Tn}};const Ln=/ /,Nn=function(t,e){"Noun"===e&&(t.chunk=e),"Verb"===e&&(t.chunk=e)},Vn=function(t,e,n,o){if(!0===t.tags.has(e))return null;if("."===e)return null;!0===t.frozen&&(o=!0);const r=n[e];if(r){if(r.not&&r.not.length>0)for(let e=0;e0)for(let e=0;e{const o=t.map((t=>t.text||"["+t.implicit+"]")).join(" ");var r;"string"!=typeof e&&e.length>2&&(e=e.slice(0,2).join(", #")+" +"),e="string"!=typeof e?e.join(", #"):e,console.log(` ${(r=o,"�[33m�[3m"+r+"�[0m").padEnd(24)} �[32m→�[0m #${e.padEnd(22)} ${(t=>"�[3m"+t+"�[0m")(n)}`)})(t,e,r),!0!=(c=e,"[object Array]"===Object.prototype.toString.call(c)))if("string"==typeof e)if(e=e.trim(),Ln.test(e))!function(t,e,n,o){const r=e.split(Ln);t.forEach(((t,e)=>{let s=r[e];s&&(s=s.replace(/^#/,""),Vn(t,s,n,o))}))}(t,e,s,o);else{e=e.replace(/^#/,"");for(let n=0;nFn(t,e,n,o)))},qn=function(t){return t.children=t.children||[],t._cache=t._cache||{},t.props=t.props||{},t._cache.parents=t._cache.parents||[],t._cache.children=t._cache.children||[],t},Gn=/^ *(#|\/\/)/,Bn=function(t){let e=t.trim().split(/->/),n=[];e.forEach((t=>{n=n.concat(function(t){if(!(t=t.trim()))return null;if(/^\[/.test(t)&&/\]$/.test(t)){let e=(t=(t=t.replace(/^\[/,"")).replace(/\]$/,"")).split(/,/);return e=e.map((t=>t.trim())).filter((t=>t)),e=e.map((t=>qn({id:t}))),e}return[qn({id:t})]}(t))})),n=n.filter((t=>t));let o=n[0];for(let t=1;t{let n=[],o=[t];for(;o.length>0;){let t=o.pop();n.push(t),t.children&&t.children.forEach((n=>{e&&e(t,n),o.push(n)}))}return n},Mn=t=>"[object Array]"===Object.prototype.toString.call(t),Un=t=>(t=t||"").trim(),Wn=function(t=[]){return"string"==typeof t?function(t){let e=t.split(/\r?\n/),n=[];e.forEach((t=>{if(!t.trim()||Gn.test(t))return;let e=(t=>{const e=/^( {2}|\t)/;let n=0;for(;e.test(t);)t=t.replace(e,""),n+=1;return n})(t);n.push({indent:e,node:Bn(t)})}));let o=function(t){let e={children:[]};return t.forEach(((n,o)=>{0===n.indent?e.children=e.children.concat(n.node):t[o-1]&&function(t,e){let n=t[e].indent;for(;e>=0;e-=1)if(t[e].indent{e[t.id]=t}));let n=qn({});return t.forEach((t=>{if((t=qn(t)).parent)if(e.hasOwnProperty(t.parent)){let n=e[t.parent];delete t.parent,n.children.push(t)}else console.warn(`[Grad] - missing node '${t.parent}'`);else n.children.push(t)})),n}(t):(Dn(e=t).forEach(qn),e);var e},In=function(t,e){let n="-> ";e&&(n=(t=>"�[2m"+t+"�[0m")("→ "));let o="";return Dn(t).forEach(((t,r)=>{let s=t.id||"";if(e&&(s=(t=>"�[31m"+t+"�[0m")(s)),0===r&&!t.id)return;let i=t._cache.parents.length;o+=" ".repeat(i)+n+s+"\n"})),o},Rn=function(t){let e=Dn(t);e.forEach((t=>{delete(t=Object.assign({},t)).children}));let n=e[0];return n&&!n.id&&0===Object.keys(n.props).length&&e.shift(),e},Qn={text:In,txt:In,array:Rn,flat:Rn},Hn=function(t,e){return"nested"===e||"json"===e?t:"debug"===e?(console.log(In(t,!0)),null):Qn.hasOwnProperty(e)?Qn[e](t):t},Zn=t=>{Dn(t,((t,e)=>{t.id&&(t._cache.parents=t._cache.parents||[],e._cache.parents=t._cache.parents.concat([t.id]))}))},Kn=/\//;class g{constructor(t={}){Object.defineProperty(this,"json",{enumerable:!1,value:t,writable:!0})}get children(){return this.json.children}get id(){return this.json.id}get found(){return this.json.id||this.json.children.length>0}props(t={}){let e=this.json.props||{};return"string"==typeof t&&(e[t]=!0),this.json.props=Object.assign(e,t),this}get(t){if(t=Un(t),!Kn.test(t)){let e=this.json.children.find((e=>e.id===t));return new g(e)}let e=((t,e)=>{let n=(t=>"string"!=typeof t?t:(t=t.replace(/^\//,"")).split(/\//))(e=e||"");for(let e=0;et.id===n[e]));if(!o)return null;t=o}return t})(this.json,t)||qn({});return new g(e)}add(t,e={}){if(Mn(t))return t.forEach((t=>this.add(Un(t),e))),this;t=Un(t);let n=qn({id:t,props:e});return this.json.children.push(n),new g(n)}remove(t){return t=Un(t),this.json.children=this.json.children.filter((e=>e.id!==t)),this}nodes(){return Dn(this.json).map((t=>(delete(t=Object.assign({},t)).children,t)))}cache(){return(t=>{let e=Dn(t,((t,e)=>{t.id&&(t._cache.parents=t._cache.parents||[],t._cache.children=t._cache.children||[],e._cache.parents=t._cache.parents.concat([t.id]))})),n={};e.forEach((t=>{t.id&&(n[t.id]=t)})),e.forEach((t=>{t._cache.parents.forEach((e=>{n.hasOwnProperty(e)&&n[e]._cache.children.push(t.id)}))})),t._cache.children=Object.keys(n)})(this.json),this}list(){return Dn(this.json)}fillDown(){var t;return t=this.json,Dn(t,((t,e)=>{e.props=((t,e)=>(Object.keys(e).forEach((n=>{if(e[n]instanceof Set){let o=t[n]||new Set;t[n]=new Set([...o,...e[n]])}else if((t=>t&&"object"==typeof t&&!Array.isArray(t))(e[n])){let o=t[n]||{};t[n]=Object.assign({},e[n],o)}else Mn(e[n])?t[n]=e[n].concat(t[n]||[]):void 0===t[n]&&(t[n]=e[n])})),t))(e.props,t.props)})),this}depth(){Zn(this.json);let t=Dn(this.json),e=t.length>1?1:0;return t.forEach((t=>{if(0===t._cache.parents.length)return;let n=t._cache.parents.length+1;n>e&&(e=n)})),e}out(t){return Zn(this.json),Hn(this.json,t)}debug(){return Zn(this.json),Hn(this.json,"debug"),this}}const Jn=function(t){let e=Wn(t);return new g(e)};Jn.prototype.plugin=function(t){t(this)};const Xn={Noun:"blue",Verb:"green",Negative:"green",Date:"red",Value:"red",Adjective:"magenta",Preposition:"cyan",Conjunction:"cyan",Determiner:"cyan",Hyphenated:"cyan",Adverb:"cyan"},Yn=function(t){if(Xn.hasOwnProperty(t.id))return Xn[t.id];if(Xn.hasOwnProperty(t.is))return Xn[t.is];const e=t._cache.parents.find((t=>Xn[t]));return Xn[e]},to=function(t){return t?"string"==typeof t?[t]:t:[]},eo=function(t,e){return t=function(t,e){return Object.keys(t).forEach((n=>{t[n].isA&&(t[n].is=t[n].isA),t[n].notA&&(t[n].not=t[n].notA),t[n].is&&"string"==typeof t[n].is&&(e.hasOwnProperty(t[n].is)||t.hasOwnProperty(t[n].is)||(t[t[n].is]={})),t[n].not&&"string"==typeof t[n].not&&!t.hasOwnProperty(t[n].not)&&(e.hasOwnProperty(t[n].not)||t.hasOwnProperty(t[n].not)||(t[t[n].not]={}))})),t}(t,e),Object.keys(t).forEach((e=>{t[e].children=to(t[e].children),t[e].not=to(t[e].not)})),Object.keys(t).forEach((e=>{(t[e].not||[]).forEach((n=>{t[n]&&t[n].not&&t[n].not.push(e)}))})),t};var no={one:{setTag:Fn,unTag:function(t,e,n){e=e.trim().replace(/^#/,"");for(let o=0;o0)for(let t=0;t0&&(t=function(t){return Object.keys(t).forEach((e=>{t[e]=Object.assign({},t[e]),t[e].novel=!0})),t}(t)),t=eo(t,e);const n=function(t){const e=Object.keys(t).map((e=>{const n=t[e],o={not:new Set(n.not),also:n.also,is:n.is,novel:n.novel};return{id:e,parent:n.is,props:o,children:[]}}));return Jn(e).cache().fillDown().out("array")}(Object.assign({},e,t)),o=function(t){const e={};return t.forEach((t=>{const{not:n,also:o,is:r,novel:s}=t.props;let i=t._cache.parents;o&&(i=i.concat(o)),e[t.id]={is:r,not:n,novel:s,also:o,parents:i,children:t._cache.children,color:Yn(t)}})),Object.keys(e).forEach((t=>{const n=new Set(e[t].not);e[t].not.forEach((t=>{e[t]&&e[t].children.forEach((t=>n.add(t)))})),e[t].not=Array.from(n)})),e}(n);return o},canBe:function(t,e,n){if(!n.hasOwnProperty(e))return!0;const o=n[e].not||[];for(let e=0;er.one.setTag(o,t,i,n,e))):r.one.setTag(o,t,i,n,e),this.uncache(),this},tagSafe:function(t,e=""){return this.tag(t,e,!0)},unTag:function(t,e){if(!this.found||!t)return this;const n=this.termList();if(0===n.length)return this;const{methods:o,verbose:r,model:s}=this;!0===r&&console.log(" - ",t,e||"");const i=s.one.tagSet;return oo(t)?t.forEach((t=>o.one.unTag(n,t,i))):o.one.unTag(n,t,i),this.uncache(),this},canBe:function(t){t=t.replace(/^#/,"");const e=this.model.one.tagSet,n=this.methods.one.canBe,o=[];this.document.forEach(((r,s)=>{r.forEach(((r,i)=>{n(r,t,e)||o.push([s,i,i+1])}))}));const r=this.update(o);return this.difference(r)}};var so={addTags:function(t){const{model:e,methods:n}=this.world(),o=e.one.tagSet,r=(0,n.one.addTags)(t,o);return e.one.tagSet=r,this}};const io=new Set(["Auxiliary","Possessive"]);var co={model:{one:{tagSet:{}}},compute:{tagRank:function(t){const{document:e,world:n}=t,o=n.model.one.tagSet;e.forEach((t=>{t.forEach((t=>{const e=Array.from(t.tags);t.tagRank=function(t,e){return t=t.sort(((t,n)=>{if(io.has(t)||!e.hasOwnProperty(n))return 1;if(io.has(n)||!e.hasOwnProperty(t))return-1;let o=e[t].children||[];const r=o.length;return o=e[n].children||[],r-o.length})),t}(e,o)}))}))}},methods:no,api:function(t){Object.assign(t.prototype,ro)},lib:so};const uo=/([.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s)/g,ao=/^[.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s$/,lo=/((?:\r?\n|\r)+)/,ho=/[a-z0-9\u00C0-\u00FF\u00a9\u00ae\u2000-\u3300\ud000-\udfff]/i,fo=/\S/,po=function(t){return Boolean(t.match(/\n$/))},mo={'"':'"',""":""","“":"”","‟":"”","„":"”","⹂":"”","‚":"’","«":"»","‹":"›","‵":"′","‶":"″","‷":"‴","〝":"〞","〟":"〞"},go=RegExp("["+Object.keys(mo).join("")+"]","g"),wo=RegExp("["+Object.values(mo).join("")+"]","g"),yo=function(t){if(!t)return!1;const e=t.match(wo);return null!==e&&1===e.length},bo=/\(/g,vo=/\)/g,xo=/\S/,jo=/^\s+/,Eo=function(t,e){const n=t.split(/[-–—]/);if(n.length<=1)return!1;const{prefixes:o,suffixes:r}=e.one;if(1===n[0].length&&/[a-z]/i.test(n[0]))return!1;if(o.hasOwnProperty(n[0]))return!1;if(n[1]=n[1].trim().replace(/[.?!]$/,""),r.hasOwnProperty(n[1]))return!1;if(!0===/^([a-z\u00C0-\u00FF`"'/]+)[-–—]([a-z0-9\u00C0-\u00FF].*)/i.test(t))return!0;return!0===/^[('"]?([0-9]{1,4})[-–—]([a-z\u00C0-\u00FF`"'/-]+[)'"]?$)/i.test(t)},Oo=function(t){const e=[],n=t.split(/[-–—]/);let o="-";const r=t.match(/[-–—]/);r&&r[0]&&(o=r);for(let t=0;t(t[e]=!0,t)),{});const Ao=/\p{Letter}/u,$o=/[\p{Number}\p{Currency_Symbol}]/u,To=/^[a-z]\.([a-z]\.)+/i,Co=/[sn]['’]$/,Lo=/([A-Z]\.)+[A-Z]?,?$/,No=/^[A-Z]\.,?$/,Vo=/[A-Z]{2,}('s|,)?$/,Fo=/([a-z]\.)+[a-z]\.?$/,qo=function(t){return function(t){return!0===Lo.test(t)||!0===Fo.test(t)||!0===No.test(t)||!0===Vo.test(t)}(t)&&(t=t.replace(/\./g,"")),t},Go=function(t,e){const n=e.methods.one.killUnicode;let o=t.text||"";o=function(t){const e=t=(t=(t=t||"").toLowerCase()).trim();return t=(t=(t=t.replace(/[,;.!?]+$/,"")).replace(/\u2026/g,"...")).replace(/\u2013/g,"-"),!1===/^[:;]/.test(t)&&(t=(t=(t=t.replace(/\.{3,}$/g,"")).replace(/[",.!:;?)]+$/g,"")).replace(/^['"(]+/g,"")),""===(t=(t=t.replace(/[\u200B-\u200D\uFEFF]/g,"")).trim())&&(t=e),t.replace(/([0-9]),([0-9])/g,"$1$2")}(o),o=n(o,e),o=qo(o),t.normal=o},Bo=/[ .][A-Z]\.? *$/i,Do=/(?:\u2026|\.{2,}) *$/,Mo=/\p{L}/u,Uo=/\. *$/,Wo=/^[A-Z]\. $/;var Io={one:{killUnicode:function(t,e){const n=e.model.one.unicode||{},o=(t=t||"").split("");return o.forEach(((t,e)=>{n[t]&&(o[e]=n[t])})),o.join("")},tokenize:{splitSentences:function(t,e){if(t=t||"",!(t=String(t))||"string"!=typeof t||!1===xo.test(t))return[];const n=function(t){const e=[],n=t.split(lo);for(let t=0;t0&&(r.push(s),t[e]=""):t[e+1]=s+(t[e+1]||"")}return r}(o,e),o=function(t){const e=[];for(let n=0;n0?(n[n.length-1]+=s,n.push(e)):n.push(s+e),s=""):s+=e}return s&&(0===n.length&&(n[0]=""),n[n.length-1]+=s),n=function(t){for(let e=1;et)),n},splitWhitespace:(t,e)=>{const{str:n,pre:o,post:r}=function(t,e){const{prePunctuation:n,postPunctuation:o,emoticons:r}=e.one;let s=t,i="",c="";const u=Array.from(t);if(r.hasOwnProperty(t.trim()))return{str:t.trim(),pre:i,post:" "};let a=u.length;for(let t=0;t(c=t||"",""))),t=s,i=""),{str:t,pre:i,post:c}}(t,e);return{text:n,pre:o,post:r,tags:new Set}},fromString:function(t,e){const{methods:n,model:o}=e,{splitSentences:r,splitTerms:s,splitWhitespace:i}=n.one.tokenize;return t=r(t=t||"",e).map((t=>{let n=s(t,o);return n=n.map((t=>i(t,o))),n.forEach((t=>{Go(t,e)})),n})),t}}}};const Ro={},Qo={};[[["approx","apt","bc","cyn","eg","esp","est","etc","ex","exp","prob","pron","gal","min","pseud","fig","jd","lat","lng","vol","fm","def","misc","plz","ea","ps","sec","pt","pref","pl","pp","qt","fr","sq","nee","ss","tel","temp","vet","ver","fem","masc","eng","adj","vb","rb","inf","situ","vivo","vitro","wr"]],[["dl","ml","gal","qt","pt","tbl","tsp","tbsp","km","dm","cm","mm","mi","td","hr","hrs","kg","hg","dg","cg","mg","µg","lb","oz","sq ft","hz","mps","mph","kmph","kb","mb","tb","lx","lm","fl oz","yb"],"Unit"],[["ad","al","arc","ba","bl","ca","cca","col","corp","ft","fy","ie","lit","ma","md","pd","tce"],"Noun"],[["adj","adm","adv","asst","atty","bldg","brig","capt","cmdr","comdr","cpl","det","dr","esq","gen","gov","hon","jr","llb","lt","maj","messrs","mlle","mme","mr","mrs","ms","mstr","phd","prof","pvt","rep","reps","res","rev","sen","sens","sfc","sgt","sir","sr","supt","surg"],"Honorific"],[["jan","feb","mar","apr","jun","jul","aug","sep","sept","oct","nov","dec"],"Month"],[["dept","univ","assn","bros","inc","ltd","co"],"Organization"],[["rd","st","dist","mt","ave","blvd","cl","cres","hwy","ariz","cal","calif","colo","conn","fla","fl","ga","ida","ia","kan","kans","minn","neb","nebr","okla","penna","penn","pa","dak","tenn","tex","ut","vt","va","wis","wisc","wy","wyo","usafa","alta","ont","que","sask"],"Place"]].forEach((t=>{t[0].forEach((e=>{Ro[e]=!0,Qo[e]="Abbreviation",void 0!==t[1]&&(Qo[e]=[Qo[e],t[1]])}))}));var Ho=["anti","bi","co","contra","de","extra","infra","inter","intra","macro","micro","mis","mono","multi","peri","pre","pro","proto","pseudo","re","sub","supra","trans","tri","un","out","ex"].reduce(((t,e)=>(t[e]=!0,t)),{});const Zo={"!":"¡","?":"¿Ɂ",'"':'“”"❝❞',"'":"‘‛❛❜’","-":"—–",a:"ªÀÁÂÃÄÅàáâãäåĀāĂ㥹ǍǎǞǟǠǡǺǻȀȁȂȃȦȧȺΆΑΔΛάαλАаѦѧӐӑӒӓƛæ",b:"ßþƀƁƂƃƄƅɃΒβϐϦБВЪЬвъьѢѣҌҍ",c:"¢©ÇçĆćĈĉĊċČčƆƇƈȻȼͻͼϲϹϽϾСсєҀҁҪҫ",d:"ÐĎďĐđƉƊȡƋƌ",e:"ÈÉÊËèéêëĒēĔĕĖėĘęĚěƐȄȅȆȇȨȩɆɇΈΕΞΣέεξϵЀЁЕеѐёҼҽҾҿӖӗễ",f:"ƑƒϜϝӺӻҒғſ",g:"ĜĝĞğĠġĢģƓǤǥǦǧǴǵ",h:"ĤĥĦħƕǶȞȟΉΗЂЊЋНнђћҢңҤҥҺһӉӊ",I:"ÌÍÎÏ",i:"ìíîïĨĩĪīĬĭĮįİıƖƗȈȉȊȋΊΐΪίιϊІЇіїi̇",j:"ĴĵǰȷɈɉϳЈј",k:"ĶķĸƘƙǨǩΚκЌЖКжкќҚқҜҝҞҟҠҡ",l:"ĹĺĻļĽľĿŀŁłƚƪǀǏǐȴȽΙӀӏ",m:"ΜϺϻМмӍӎ",n:"ÑñŃńŅņŇňʼnŊŋƝƞǸǹȠȵΝΠήηϞЍИЙЛПийлпѝҊҋӅӆӢӣӤӥπ",o:"ÒÓÔÕÖØðòóôõöøŌōŎŏŐőƟƠơǑǒǪǫǬǭǾǿȌȍȎȏȪȫȬȭȮȯȰȱΌΘΟθοσόϕϘϙϬϴОФоѲѳӦӧӨөӪӫ",p:"ƤΡρϷϸϼРрҎҏÞ",q:"Ɋɋ",r:"ŔŕŖŗŘřƦȐȑȒȓɌɍЃГЯгяѓҐґ",s:"ŚśŜŝŞşŠšƧƨȘșȿЅѕ",t:"ŢţŤťŦŧƫƬƭƮȚțȶȾΓΤτϮТт",u:"ÙÚÛÜùúûüŨũŪūŬŭŮůŰűŲųƯưƱƲǓǔǕǖǗǘǙǚǛǜȔȕȖȗɄΰυϋύ",v:"νѴѵѶѷ",w:"ŴŵƜωώϖϢϣШЩшщѡѿ",x:"×ΧχϗϰХхҲҳӼӽӾӿ",y:"ÝýÿŶŷŸƳƴȲȳɎɏΎΥΫγψϒϓϔЎУучўѰѱҮүҰұӮӯӰӱӲӳ",z:"ŹźŻżŽžƵƶȤȥɀΖ"},Ko={};Object.keys(Zo).forEach((function(t){Zo[t].split("").forEach((function(e){Ko[e]=t}))}));const Jo=/\//,Xo=/[a-z]\.[a-z]/i,Yo=/[0-9]/,tr=function(t,e){const n=t.normal||t.text||t.machine,o=e.model.one.aliases;if(o.hasOwnProperty(n)&&(t.alias=t.alias||[],t.alias.push(o[n])),Jo.test(n)&&!Xo.test(n)&&!Yo.test(n)){const e=n.split(Jo);e.length<=3&&e.forEach((e=>{""!==(e=e.trim())&&(t.alias=t.alias||[],t.alias.push(e))}))}return t},er=/^\p{Letter}+-\p{Letter}+$/u,nr=function(t){let e=t.implicit||t.normal||t.text;e=e.replace(/['’]s$/,""),e=e.replace(/s['’]$/,"s"),e=e.replace(/([aeiou][ktrp])in'$/,"$1ing"),er.test(e)&&(e=e.replace(/-/g,"")),e=e.replace(/^[#@]/,""),e!==t.normal&&(t.machine=e)},or=function(t,e){const n=t.docs;for(let o=0;oor(t,tr),machine:t=>or(t,nr),normal:t=>or(t,Go),freq:function(t){const e=t.docs,n={};for(let t=0;t{let i=(t=t.toLowerCase().trim()).length;e.max&&i>e.max&&(i=e.max);for(let c=e.min;c{delete o[t]})),o}(t,e,this.world());return Object.keys(r).forEach((t=>{n.one.typeahead.hasOwnProperty(t)?delete n.one.typeahead[t]:n.one.typeahead[t]=r[t]})),this}};var lr={model:{one:{typeahead:{}}},api:function(t){t.prototype.autoFill=cr},lib:ar,compute:ir,hooks:["typeahead"]};return h.extend(W),h.extend(bn),h.extend(We),h.extend(zn),h.extend(co),h.plugin(bt),h.extend(sr),h.extend(Ot),h.plugin(d),h.extend(qt),h.extend(lr),h.extend(Tt),h.extend(Cn),h}));
================================================
FILE: builds/one/compromise-one.mjs
================================================
var t={methods:{one:{},two:{},three:{},four:{}},model:{one:{},two:{},three:{}},compute:{},hooks:[]};const e={compute:function(t){const{world:e}=this,n=e.compute;return"string"==typeof t&&n.hasOwnProperty(t)?n[t](this):(t=>"[object Array]"===Object.prototype.toString.call(t))(t)?t.forEach((o=>{e.compute.hasOwnProperty(o)?n[o](this):console.warn("no compute:",t)})):"function"==typeof t?t(this):console.warn("no compute:",t),this}};var n={forEach:function(t){return this.fullPointer.forEach(((e,n)=>{const o=this.update([e]);t(o,n)})),this},map:function(t,e){const n=this.fullPointer.map(((e,n)=>{const o=this.update([e]),r=t(o,n);return void 0===r?this.none():r}));if(0===n.length)return e||this.update([]);if(void 0!==n[0]){if("string"==typeof n[0])return n;if("object"==typeof n[0]&&(null===n[0]||!n[0].isView))return n}let o=[];return n.forEach((t=>{o=o.concat(t.fullPointer)})),this.toView(o)},filter:function(t){let e=this.fullPointer;e=e.filter(((e,n)=>{const o=this.update([e]);return t(o,n)}));return this.update(e)},find:function(t){const e=this.fullPointer.find(((e,n)=>{const o=this.update([e]);return t(o,n)}));return this.update([e])},some:function(t){return this.fullPointer.some(((e,n)=>{const o=this.update([e]);return t(o,n)}))},random:function(t=1){let e=this.fullPointer,n=Math.floor(Math.random()*e.length);return n+t>this.length&&(n=this.length-t,n=n<0?0:n),e=e.slice(n,n+t),this.update(e)}};const o={termList:function(){return this.methods.one.termList(this.docs)},terms:function(t){const e=this.match(".");return"number"==typeof t?e.eq(t):e},groups:function(t){if(t||0===t)return this.update(this._groups[t]||[]);const e={};return Object.keys(this._groups).forEach((t=>{e[t]=this.update(this._groups[t])})),e},eq:function(t){let e=this.pointer;return e||(e=this.docs.map(((t,e)=>[e]))),e[t]?this.update([e[t]]):this.none()},first:function(){return this.eq(0)},last:function(){const t=this.fullPointer.length-1;return this.eq(t)},firstTerms:function(){return this.match("^.")},lastTerms:function(){return this.match(".$")},slice:function(t,e){let n=this.pointer||this.docs.map(((t,e)=>[e]));return n=n.slice(t,e),this.update(n)},all:function(){return this.update().toView()},fullSentences:function(){const t=this.fullPointer.map((t=>[t[0]]));return this.update(t).toView()},none:function(){return this.update([])},isDoc:function(t){if(!t||!t.isView)return!1;const e=this.fullPointer,n=t.fullPointer;return!e.length!==n.length&&e.every(((t,e)=>!!n[e]&&(t[0]===n[e][0]&&t[1]===n[e][1]&&t[2]===n[e][2])))},wordCount:function(){return this.docs.reduce(((t,e)=>(t+=e.filter((t=>""!==t.text)).length,t)),0)},isFull:function(){const t=this.pointer;if(!t)return!0;if(0===t.length||0!==t[0][0])return!1;let e=0,n=0;return this.document.forEach((t=>e+=t.length)),this.docs.forEach((t=>n+=t.length)),e===n},getNth:function(t){return"number"==typeof t?this.eq(t):"string"==typeof t?this.if(t):this}};o.group=o.groups,o.fullSentence=o.fullSentences,o.sentence=o.fullSentences,o.lastTerm=o.lastTerms,o.firstTerm=o.firstTerms;const r=Object.assign({},o,e,n);r.get=r.eq;class View{constructor(e,n,o={}){[["document",e],["world",t],["_groups",o],["_cache",null],["viewType","View"]].forEach((t=>{Object.defineProperty(this,t[0],{value:t[1],writable:!0})})),this.ptrs=n}get docs(){let e=this.document;return this.ptrs&&(e=t.methods.one.getDoc(this.ptrs,this.document)),e}get pointer(){return this.ptrs}get methods(){return this.world.methods}get model(){return this.world.model}get hooks(){return this.world.hooks}get isView(){return!0}get found(){return this.docs.length>0}get length(){return this.docs.length}get fullPointer(){const{docs:t,ptrs:e,document:n}=this,o=e||t.map(((t,e)=>[e]));return o.map((t=>{let[e,o,r,s,i]=t;return o=o||0,r=r||(n[e]||[]).length,n[e]&&n[e][o]&&(s=s||n[e][o].id,n[e][r-1]&&(i=i||n[e][r-1].id)),[e,o,r,s,i]}))}update(t){const e=new View(this.document,t);if(this._cache&&t&&t.length>0){const n=[];t.forEach(((t,e)=>{const[o,r,s]=t;(1===t.length||0===r&&this.document[o].length===s)&&(n[e]=this._cache[o])})),n.length>0&&(e._cache=n)}return e.world=this.world,e}toView(t){return new View(this.document,t||this.pointer)}fromText(t){const{methods:e}=this,n=e.one.tokenize.fromString(t,this.world),o=new View(n);return o.world=this.world,o.compute(["normal","freeze","lexicon"]),this.world.compute.preTagger&&o.compute("preTagger"),o.compute("unfreeze"),o}clone(){let t=this.document.slice(0);t=t.map((t=>t.map((t=>((t=Object.assign({},t)).tags=new Set(t.tags),t)))));const e=this.update(this.pointer);return e.document=t,e._cache=this._cache,e}}Object.assign(View.prototype,r);const s=function(t){return t&&"object"==typeof t&&!Array.isArray(t)};function i(t,e){if(s(e))for(const n in e)s(e[n])?(t[n]||Object.assign(t,{[n]:{}}),i(t[n],e[n])):Object.assign(t,{[n]:e[n]});return t}const c=function(t,e,n,o){if(r=t,"[object Array]"===Object.prototype.toString.call(r))return void t.forEach((t=>c(t,e,n,o)));var r;const{methods:s,model:u,compute:a,hooks:l}=e;t.methods&&function(t,e){for(const n in e)t[n]=t[n]||{},Object.assign(t[n],e[n])}(s,t.methods),t.model&&i(u,t.model),t.irregulars&&function(t,e){const n=t.two.models||{};Object.keys(e).forEach((t=>{e[t].pastTense&&(n.toPast&&(n.toPast.ex[t]=e[t].pastTense),n.fromPast&&(n.fromPast.ex[e[t].pastTense]=t)),e[t].presentTense&&(n.toPresent&&(n.toPresent.ex[t]=e[t].presentTense),n.fromPresent&&(n.fromPresent.ex[e[t].presentTense]=t)),e[t].gerund&&(n.toGerund&&(n.toGerund.ex[t]=e[t].gerund),n.fromGerund&&(n.fromGerund.ex[e[t].gerund]=t)),e[t].comparative&&(n.toComparative&&(n.toComparative.ex[t]=e[t].comparative),n.fromComparative&&(n.fromComparative.ex[e[t].comparative]=t)),e[t].superlative&&(n.toSuperlative&&(n.toSuperlative.ex[t]=e[t].superlative),n.fromSuperlative&&(n.fromSuperlative.ex[e[t].superlative]=t))}))}(u,t.irregulars),t.compute&&Object.assign(a,t.compute),l&&(e.hooks=l.concat(t.hooks||[])),t.api&&t.api(n),t.lib&&Object.keys(t.lib).forEach((e=>o[e]=t.lib[e])),t.tags&&o.addTags(t.tags),t.words&&o.addWords(t.words),t.frozen&&o.addWords(t.frozen,!0),t.mutate&&t.mutate(e,o)},u=function(t){return"[object Array]"===Object.prototype.toString.call(t)},a=function(t,e,n){const{methods:o}=n,r=new e([]);if(r.world=n,"number"==typeof t&&(t=String(t)),!t)return r;if("string"==typeof t){return new e(o.one.tokenize.fromString(t,n))}if(s=t,"[object Object]"===Object.prototype.toString.call(s)&&t.isView)return new e(t.document,t.ptrs);var s;if(u(t)){if(u(t[0])){const n=t.map((t=>t.map((t=>({text:t,normal:t,pre:"",post:" ",tags:new Set})))));return new e(n)}const n=t.map((t=>t.terms.map((t=>(u(t.tags)&&(t.tags=new Set(t.tags)),t)))));return new e(n)}return r},l=Object.assign({},t),h=function(t,e){e&&h.addWords(e);const n=a(t,View,l);return t&&n.compute(l.hooks),n};Object.defineProperty(h,"_world",{value:l,writable:!0}),h.tokenize=function(t,e){const{compute:n}=this._world;e&&h.addWords(e);const o=a(t,View,l);return n.contractions&&o.compute(["alias","normal","machine","contractions"]),o},h.plugin=function(t){return c(t,this._world,View,this),this},h.extend=h.plugin,h.world=function(){return this._world},h.model=function(){return this._world.model},h.methods=function(){return this._world.methods},h.hooks=function(){return this._world.hooks},h.verbose=function(t){const e="undefined"!=typeof process&&process.env?process.env:self.env||{};return e.DEBUG_TAGS="tagger"===t||!0===t||"",e.DEBUG_MATCH="match"===t||!0===t||"",e.DEBUG_CHUNKS="chunker"===t||!0===t||"",this},h.version="14.15.0";var f={one:{cacheDoc:function(t){const e=t.map((t=>{const e=new Set;return t.forEach((t=>{""!==t.normal&&e.add(t.normal),t.switch&&e.add(`%${t.switch}%`),t.implicit&&e.add(t.implicit),t.machine&&e.add(t.machine),t.root&&e.add(t.root),t.alias&&t.alias.forEach((t=>e.add(t)));const n=Array.from(t.tags);for(let t=0;t/^\p{Lu}[\p{Ll}'’]/u.test(t)||/^\p{Lu}$/u.test(t),w=(t,e,n)=>{if(n.forEach((t=>t.dirty=!0)),t){const o=[e,0].concat(n);Array.prototype.splice.apply(t,o)}return t},b=function(t){const e=t[t.length-1];!e||/ $/.test(e.post)||/[-–—]/.test(e.post)||(e.post+=" ")},y=(t,e,n)=>{const o=/[-.?!,;:)–—'"]/g,r=t[e-1];if(!r)return;const s=r.post;if(o.test(s)){const t=s.match(o).join(""),e=n[n.length-1];e.post=t+e.post,r.post=r.post.replace(o,"")}},v=function(t,e,n,o){const[r,s,i]=e;0===s||i===o[r].length?b(n):(b(n),b([t[e[1]]])),function(t,e,n){const o=t[e];if(0!==e||!m(o.text))return;n[0].text=n[0].text.replace(/^\p{Ll}/u,(t=>t.toUpperCase()));const r=t[e];r.tags.has("ProperNoun")||r.tags.has("Acronym")||m(r.text)&&r.text.length>1&&(r.text=(s=r.text,s.replace(/^\p{Lu}/u,(t=>t.toLowerCase()))));var s}(t,s,n),w(t,s,n)};let x=0;const j=t=>(t=t.length<3?"0"+t:t).length<3?"0"+t:t,E=function(t){let[e,n]=t.index||[0,0];x+=1,x=x>46655?0:x,e=e>46655?0:e,n=n>1294?0:n;let o=j(x.toString(36));o+=j(e.toString(36));let r=n.toString(36);r=r.length<2?"0"+r:r,o+=r;return o+=parseInt(36*Math.random(),10).toString(36),t.normal+"|"+o.toUpperCase()},O=function(t){if(t.has("@hasContraction")&&"function"==typeof t.contractions){t.grow("@hasContraction").contractions().expand()}},k=t=>"[object Array]"===Object.prototype.toString.call(t),P=function(t,e,n){const{document:o,world:r}=e;e.uncache();const s=e.fullPointer,i=e.fullPointer;e.forEach(((c,u)=>{const a=c.fullPointer[0],[l]=a,h=o[l];let f=function(t,e){const{methods:n}=e;return"string"==typeof t?n.one.tokenize.fromString(t,e)[0]:"object"==typeof t&&t.isView?t.clone().docs[0]||[]:k(t)?k(t[0])?t[0]:t:[]}(t,r);0!==f.length&&(f=function(t){return t.map((t=>(t.id=E(t),t)))}(f),n?(O(e.update([a]).firstTerm()),v(h,a,f,o)):(O(e.update([a]).lastTerm()),function(t,e,n,o){const[r,,s]=e,i=(o[r]||[]).length;st.replace(/^\p{Ll}/u,(t=>t.toUpperCase())),$=t=>t.replace(/^\p{Lu}/u,(t=>t.toLowerCase()));z.replaceWith=function(t,e={}){let n=this.fullPointer;const o=this;if(this.uncache(),"function"==typeof t)return function(t,e,n){return t.forEach((t=>{const o=e(t);t.replaceWith(o,n)})),t}(o,t,e);const r=o.docs[0];if(!r)return o;const s=e.possessives&&r[r.length-1].tags.has("Possessive"),i=e.case&&(c=r[0].text,/^\p{Lu}[\p{Ll}'’]/u.test(c)||/^\p{Lu}$/u.test(c));var c;t=function(t,e){if("string"!=typeof t)return t;const n=e.groups();return t=t.replace(S,(t=>{const e=t.replace(/\$/,"");return n.hasOwnProperty(e)?n[e].text():t})),t}(t,o);const u=this.update(n);n=n.map((t=>t.slice(0,3)));const a=(u.docs[0]||[]).map((t=>Array.from(t.tags))),l=u.docs[0][0].pre,h=u.docs[0][u.docs[0].length-1].post;if("string"==typeof t&&(t=this.fromText(t).compute("id")),o.insertAfter(t),u.has("@hasContraction")&&o.contractions){o.grow("@hasContraction+").contractions().expand()}if(o.delete(u),s){const t=o.docs[0],e=t[t.length-1];e.tags.has("Possessive")||(e.text+="'s",e.normal+="'s",e.tags.add("Possessive"))}if(l&&o.docs[0]&&(o.docs[0][0].pre=l),h&&o.docs[0]){const t=o.docs[0][o.docs[0].length-1];t.post.trim()||(t.post=h)}const f=o.toView(n).compute(["index","freeze","lexicon"]);if(f.world.compute.preTagger&&f.compute("preTagger"),f.compute("unfreeze"),e.tags&&f.terms().forEach(((t,e)=>{t.tagSafe(a[e])})),!f.docs[0]||!f.docs[0][0])return f;if(e.case){const t=i?A:$;f.docs[0][0].text=t(f.docs[0][0].text)}return f},z.replace=function(t,e,n){if(t&&!e)return this.replaceWith(t,n);const o=this.match(t);return o.found?(this.soften(),o.replaceWith(e,n)):this};const T={remove:function(t){const{indexN:e}=this.methods.one.pointer;this.uncache();let n=this.all(),o=this;t&&(n=this,o=this.match(t));const r=!n.ptrs;if(o.has("@hasContraction")&&o.contractions){o.grow("@hasContraction").contractions().expand()}let s=n.fullPointer;const i=o.fullPointer.reverse(),c=function(t,e){e.forEach((e=>{const[n,o,r]=e,s=r-o;t[n]&&(r===t[n].length&&r>1&&function(t,e){const n=t.length-1,o=t[n],r=t[n-e];r&&o&&(r.post+=o.post,r.post=r.post.replace(/ +([.?!,;:])/,"$1"),r.post=r.post.replace(/[,;:]+([.?!])/,"$1"))}(t[n],s),t[n].splice(o,s))}));for(let e=t.length-1;e>=0;e-=1)if(0===t[e].length&&(t.splice(e,1),e===t.length&&t[e-1])){const n=t[e-1],o=n[n.length-1];o&&(o.post=o.post.trimEnd())}return t}(this.document,i);if(s=function(t,e){return t=t.map((t=>{const[n]=t;return e[n]?(e[n].forEach((e=>{const n=e[2]-e[1];t[1]<=e[1]&&t[2]>=e[2]&&(t[2]-=n)})),t):t})),t.forEach(((e,n)=>{if(0===e[1]&&0==e[2])for(let e=n+1;et[2]-t[1]>0))).map((t=>(t[3]=null,t[4]=null,t)))}(s,e(i)),n.ptrs=s,n.document=c,n.compute("index"),r&&(n.ptrs=void 0),!t)return this.ptrs=[],n.none();return n.toView(s)}};T.delete=T.remove;const C={pre:function(t,e){return void 0===t&&this.found?this.docs[0][0].pre:(this.docs.forEach((n=>{const o=n[0];!0===e?o.pre+=t:o.pre=t})),this)},post:function(t,e){if(void 0===t){const t=this.docs[this.docs.length-1];return t[t.length-1].post}return this.docs.forEach((n=>{const o=n[n.length-1];!0===e?o.post+=t:o.post=t})),this},trim:function(){if(!this.found)return this;const t=this.docs,e=t[0][0];e.pre=e.pre.trimStart();const n=t[t.length-1],o=n[n.length-1];return o.post=o.post.trimEnd(),this},hyphenate:function(){return this.docs.forEach((t=>{t.forEach(((e,n)=>{0!==n&&(e.pre=""),t[n+1]&&(e.post="-")}))})),this},dehyphenate:function(){const t=/[-–—]/;return this.docs.forEach((e=>{e.forEach((e=>{t.test(e.post)&&(e.post=" ")}))})),this},toQuotations:function(t,e){return t=t||'"',e=e||'"',this.docs.forEach((n=>{n[0].pre=t+n[0].pre;const o=n[n.length-1];o.post=e+o.post})),this},toParentheses:function(t,e){return t=t||"(",e=e||")",this.docs.forEach((n=>{n[0].pre=t+n[0].pre;const o=n[n.length-1];o.post=e+o.post})),this}};C.deHyphenate=C.dehyphenate,C.toQuotation=C.toQuotations;var L={alpha:(t,e)=>t.normale.normal?1:0,length:(t,e)=>{const n=t.normal.trim().length,o=e.normal.trim().length;return no?-1:0},wordCount:(t,e)=>t.wordse.words?-1:0,sequential:(t,e)=>t[0]e[0]?-1:t[1]>e[1]?1:-1,byFreq:function(t){const e={};return t.forEach((t=>{e[t.normal]=e[t.normal]||0,e[t.normal]+=1})),t.sort(((t,n)=>{const o=e[t.normal],r=e[n.normal];return or?-1:0})),t}};const N=new Set(["index","sequence","seq","sequential","chron","chronological"]),V=new Set(["freq","frequency","topk","repeats"]),F=new Set(["alpha","alphabetical"]);var q={unique:function(){const t=new Set;return this.filter((e=>{const n=e.text("machine");return!t.has(n)&&(t.add(n),!0)}))},reverse:function(){let t=this.pointer||this.docs.map(((t,e)=>[e]));return t=[].concat(t),t=t.reverse(),this._cache&&(this._cache=this._cache.reverse()),this.update(t)},sort:function(t){const{docs:e,pointer:n}=this;if(this.uncache(),"function"==typeof t)return function(t,e){let n=t.fullPointer;return n=n.sort(((n,o)=>(n=t.update([n]),o=t.update([o]),e(n,o)))),t.ptrs=n,t}(this,t);t=t||"alpha";const o=n||e.map(((t,e)=>[e]));let r=e.map(((t,e)=>({index:e,words:t.length,normal:t.map((t=>t.machine||t.normal||"")).join(" "),pointer:o[e]})));return N.has(t)&&(t="sequential"),F.has(t)&&(t="alpha"),V.has(t)?(r=L.byFreq(r),this.update(r.map((t=>t.pointer)))):"function"==typeof L[t]?(r=r.sort(L[t]),this.update(r.map((t=>t.pointer)))):this}};const G=function(t,e){if(t.length>0){const e=t[t.length-1],n=e[e.length-1];!1===/ /.test(n.post)&&(n.post+=" ")}return t=t.concat(e)};var B={concat:function(t){if("string"==typeof t){const e=this.fromText(t);if(this.found&&this.ptrs){const t=this.fullPointer,n=t[t.length-1][0];this.document.splice(n,0,...e.document)}else this.document=this.document.concat(e.document);return this.all().compute("index")}if("object"==typeof t&&t.isView)return function(t,e){if(t.document===e.document){const n=t.fullPointer.concat(e.fullPointer);return t.toView(n).compute("index")}return e.fullPointer.forEach((e=>{e[0]+=t.document.length})),t.document=G(t.document,e.docs),t.all()}(this,t);if(e=t,"[object Array]"===Object.prototype.toString.call(e)){const e=G(this.document,t);return this.document=e,this.all()}var e;return this}};var D={harden:function(){return this.ptrs=this.fullPointer,this},soften:function(){let t=this.ptrs;return!t||t.length<1||(t=t.map((t=>t.slice(0,3))),this.ptrs=t),this}};const M=Object.assign({},{toLowerCase:function(){return this.termList().forEach((t=>{t.text=t.text.toLowerCase()})),this},toUpperCase:function(){return this.termList().forEach((t=>{t.text=t.text.toUpperCase()})),this},toTitleCase:function(){return this.termList().forEach((t=>{t.text=t.text.replace(/^ *[a-z\u00C0-\u00FF]/,(t=>t.toUpperCase()))})),this},toCamelCase:function(){return this.docs.forEach((t=>{t.forEach(((e,n)=>{0!==n&&(e.text=e.text.replace(/^ *[a-z\u00C0-\u00FF]/,(t=>t.toUpperCase()))),n!==t.length-1&&(e.post="")}))})),this}},_,z,T,C,q,B,D),U={id:function(t){const e=t.docs;for(let t=0;t(t.implicit=t.text,t.machine=t.text,t.pre="",t.post="",t.text="",t.normal="",t.index=[o,r+e],t))),n[0]&&(n[0].pre=t[o][r].pre,n[n.length-1].post=t[o][r].post,n[0].text=t[o][r].text,n[0].normal=t[o][r].normal),t[o].splice(r,1,...n))},H=/'/,Z=new Set(["what","how","when","where","why"]),K=new Set(["be","go","start","think","need"]),J=new Set(["been","gone"]),X=/'/,Y=/(e|é|aison|sion|tion)$/,tt=/(age|isme|acle|ege|oire)$/;var et=(t,e)=>["je",t[e].normal.split(X)[1]],nt=(t,e)=>{const n=t[e].normal.split(X)[1];return n&&n.endsWith("e")?["la",n]:["le",n]},ot=(t,e)=>{const n=t[e].normal.split(X)[1];return n&&Y.test(n)&&!tt.test(n)?["du",n]:n&&n.endsWith("s")?["des",n]:["de",n]};const rt=/^([0-9.]{1,4}[a-z]{0,2}) ?[-–—] ?([0-9]{1,4}[a-z]{0,2})$/i,st=/^([0-9]{1,2}(:[0-9][0-9])?(am|pm)?) ?[-–—] ?([0-9]{1,2}(:[0-9][0-9])?(am|pm)?)$/i,it=/^[0-9]{3}-[0-9]{4}$/,ct=function(t,e){const n=t[e];let o=n.text.match(rt);return null!==o?!0===n.tags.has("PhoneNumber")||it.test(n.text)?null:[o[1],"to",o[2]]:(o=n.text.match(st),null!==o?[o[1],"to",o[4]]:null)},ut=/^([+-]?[0-9][.,0-9]*)([a-z°²³µ/]+)$/,at=function(t,e,n){const o=n.model.one.numberSuffixes||{},r=t[e].text.match(ut);if(null!==r){const t=r[2].toLowerCase().trim();return o.hasOwnProperty(t)?null:[r[1],t]}return null},lt=/'/,ht=/^[0-9][^-–—]*[-–—].*?[0-9]/,ft=function(t,e,n,o){const r=e.update();r.document=[t];let s=n+o;n>0&&(n-=1),t[s]&&(s+=1),r.ptrs=[[0,n,s]]},pt={t:(t,e)=>function(t,e){return"ain't"===t[e].normal||"aint"===t[e].normal?null:[t[e].normal.replace(/n't/,""),"not"]}(t,e),d:(t,e)=>function(t,e){const n=t[e].normal.split(H)[0];if(Z.has(n))return[n,"did"];if(t[e+1]){if(J.has(t[e+1].normal))return[n,"had"];if(K.has(t[e+1].normal))return[n,"would"]}return null}(t,e)},dt={j:(t,e)=>et(t,e),l:(t,e)=>nt(t,e),d:(t,e)=>ot(t,e)},mt=function(t,e,n,o){for(let r=0;r2)return s.out.concat(o)}return null},gt=function(t,e){const n=e.fromText(t.join(" "));return n.compute(["id","alias"]),n.docs[0]},wt=function(t,e){for(let n=e+1;n<5&&t[n];n+=1)if("been"===t[n].normal)return["there","has"];return["there","is"]};var bt={contractions:t=>{const{world:e,document:n}=t,{model:o,methods:r}=e,s=o.one.contractions||[];n.forEach(((o,i)=>{for(let c=o.length-1;c>=0;c-=1){let u=null,a=null;if(!0===lt.test(o[c].normal)){const t=o[c].normal.split(lt);u=t[0],a=t[1]}let l=mt(s,o[c],u,a);!l&&pt.hasOwnProperty(a)&&(l=pt[a](o,c,e)),!l&&dt.hasOwnProperty(u)&&(l=dt[u](o,c)),"there"===u&&"s"===a&&(l=wt(o,c)),l?(l=gt(l,t),Q(n,[i,c],l),ft(n[i],t,c,l.length)):ht.test(o[c].normal)?(l=ct(o,c),l&&(l=gt(l,t),Q(n,[i,c],l),r.one.setTag(l,"NumberRange",e),l[2]&&l[2].tags.has("Time")&&r.one.setTag([l[0]],"Time",e,null,"time-range"),ft(n[i],t,c,l.length))):(l=at(o,c,e),l&&(l=gt(l,t),Q(n,[i,c],l),r.one.setTag([l[1]],"Unit",e,null,"contraction-unit")))}}))}};const yt={model:R,compute:bt,hooks:["contractions"]},vt=function(t){const e=t.world,{model:n,methods:o}=t.world,r=o.one.setTag,{frozenLex:s}=n.one,i=n.one._multiCache||{};t.docs.forEach((t=>{for(let n=0;nn;o-=1){const i=t.slice(n,o+1),c=i.map((t=>t.machine||t.normal)).join(" ");!0!==s.hasOwnProperty(c)||(r(i,s[c],e,!1,"1-frozen-multi-lexicon"),i.forEach((t=>t.frozen=!0)))}}void 0!==s[c]&&s.hasOwnProperty(c)&&(r([o],s[c],e,!1,"1-freeze-lexicon"),o.frozen=!0)}}))};const xt=t=>"�[34m"+t+"�[0m",jt=t=>"�[3m�[2m"+t+"�[0m",Et=function(t){t.docs.forEach((t=>{console.log(xt("\n ┌─────────")),t.forEach((t=>{let e=` ${jt("│")} `;const n=t.implicit||t.text||"-";!0===t.frozen?e+=`${xt(n)} ❄️`:e+=jt(n),console.log(e)}))}))};var Ot={compute:{frozen:vt,freeze:vt,unfreeze:function(t){return t.docs.forEach((t=>{t.forEach((t=>{delete t.frozen}))})),t}},mutate:t=>{const e=t.methods.one;e.termMethods.isFrozen=t=>!0===t.frozen,e.debug.freeze=Et,e.debug.frozen=Et},api:function(t){t.prototype.freeze=function(){return this.docs.forEach((t=>{t.forEach((t=>{t.frozen=!0}))})),this},t.prototype.unfreeze=function(){this.compute("unfreeze")},t.prototype.isFrozen=function(){return this.match("@isFrozen+")}},hooks:["freeze"]};const kt=function(t,e,n){const{model:o,methods:r}=n,s=r.one.setTag,i=o.one._multiCache||{},{lexicon:c}=o.one||{},u=t[e],a=u.machine||u.normal;if(void 0!==i[a]&&t[e+1]){for(let o=e+i[a]-1;o>e;o-=1){const r=t.slice(e,o+1);if(r.length<=1)return!1;const i=r.map((t=>t.machine||t.normal)).join(" ");if(!0===c.hasOwnProperty(i)){const t=c[i];return s(r,t,n,!1,"1-multi-lexicon"),!t||2!==t.length||"PhrasalVerb"!==t[0]&&"PhrasalVerb"!==t[1]||s([r[1]],"Particle",n,!1,"1-phrasal-particle"),!0}}return!1}return null},Pt=/^(under|over|mis|re|un|dis|semi|pre|post)-?/,_t=new Set(["Verb","Infinitive","PastTense","Gerund","PresentTense","Adjective","Participle"]),St=function(t,e,n){const{model:o,methods:r}=n,s=r.one.setTag,{lexicon:i}=o.one,c=t[e],u=c.machine||c.normal;if(void 0!==i[u]&&i.hasOwnProperty(u))return s([c],i[u],n,!1,"1-lexicon"),!0;if(c.alias){const t=c.alias.find((t=>i.hasOwnProperty(t)));if(t)return s([c],i[t],n,!1,"1-lexicon-alias"),!0}if(!0===Pt.test(u)){const t=u.replace(Pt,"");if(i.hasOwnProperty(t)&&t.length>3&&_t.has(i[t]))return s([c],i[t],n,!1,"1-lexicon-prefix"),!0}return null};var zt={lexicon:function(t){const e=t.world;t.docs.forEach((t=>{for(let n=0;n{const r=t[o],s=(o=(o=o.toLowerCase().trim()).replace(/'s\b/,"")).split(/ /);s.length>1&&(void 0===n[s[0]]||s.length>n[s[0]])&&(n[s[0]]=s.length),e[o]=e[o]||r})),delete e[""],delete e.null,delete e[" "],{lex:e,_multi:n}}}};var $t={addWords:function(t,e=!1){const n=this.world(),{methods:o,model:r}=n;if(!t)return;if(Object.keys(t).forEach((e=>{"string"==typeof t[e]&&t[e].startsWith("#")&&(t[e]=t[e].replace(/^#/,""))})),!0===e){const{lex:e,_multi:s}=o.one.expandLexicon(t,n);return Object.assign(r.one._multiCache,s),void Object.assign(r.one.frozenLex,e)}if(o.two.expandLexicon){const{lex:e,_multi:s}=o.two.expandLexicon(t,n);Object.assign(r.one.lexicon,e),Object.assign(r.one._multiCache,s)}const{lex:s,_multi:i}=o.one.expandLexicon(t,n);Object.assign(r.one.lexicon,s),Object.assign(r.one._multiCache,i)}};var Tt={model:{one:{lexicon:{},_multiCache:{},frozenLex:{}}},methods:At,compute:zt,lib:$t,hooks:["lexicon"]};const Ct=function(t,e){const n=[{}],o=[null],r=[0],s=[];let i=0;t.forEach((function(t){let r=0;const s=function(t,e){const{methods:n,model:o}=e,r=n.one.tokenize.splitTerms(t,o).map((t=>n.one.tokenize.splitWhitespace(t,o)));return r.map((t=>t.text.toLowerCase()))}(t,e);for(let t=0;t0&&!n[i].hasOwnProperty(u);)i=r[i];if(n.hasOwnProperty(i)){const t=n[i][u];r[a]=t,o[t]&&(o[a]=o[a]||[],o[a]=o[a].concat(o[t]))}else r[a]=0}}return{goNext:n,endAs:o,failTo:r}},Lt=function(t,e,n){let o=0;const r=[];for(let s=0;s0&&(void 0===e.goNext[o]||!e.goNext[o].hasOwnProperty(i));)o=e.failTo[o]||0;if(e.goNext[o].hasOwnProperty(i)&&(o=e.goNext[o][i],e.endAs[o])){const n=e.endAs[o];for(let e=0;e{for(let n=t.length-1;n>=0;n-=1)if(t[n]!==e)return t=t.slice(0,n+1);return t},Ft={buildTrie:function(t){return function(t){return t.goNext=t.goNext.map((t=>{if(0!==Object.keys(t).length)return t})),t.goNext=Vt(t.goNext,void 0),t.failTo=Vt(t.failTo,0),t.endAs=Vt(t.endAs,null),t}(Ct(t,this.world()))}};Ft.compile=Ft.buildTrie;var qt={api:function(t){t.prototype.lookup=function(t,e={}){if(!t)return this.none();"string"==typeof t&&(t=[t]);var n;let o=function(t,e,n){let o=[];n.form=n.form||"normal";const r=t.docs;if(!e.goNext||!e.goNext[0])return console.error("Compromise invalid lookup trie"),t.none();const s=Object.keys(e.goNext[0]);for(let i=0;i0&&(o=o.concat(u))}return t.update(o)}(this,(n=t,"[object Object]"===Object.prototype.toString.call(n)?t:Ct(t,this.world)),e);return o=o.settle(),o}},lib:Ft};const Gt=function(t,e){return e?(t.forEach((t=>{const n=t[0];e[n]&&(t[0]=e[n][0],t[1]+=e[n][1],t[2]+=e[n][1])})),t):t},Bt=function(t,e){let{ptrs:n}=t;const{byGroup:o}=t;return n=Gt(n,e),Object.keys(o).forEach((t=>{o[t]=Gt(o[t],e)})),{ptrs:n,byGroup:o}},Dt=function(t,e,n){const o=n.methods.one;return"number"==typeof t&&(t=String(t)),"string"==typeof t&&(t=o.killUnicode(t,n),t=o.parseMatch(t,e,n)),t},Mt=t=>"[object Object]"===Object.prototype.toString.call(t),Ut=t=>t&&Mt(t)&&!0===t.isView,Wt=t=>t&&Mt(t)&&!0===t.isNet;var It={matchOne:function(t,e,n){const o=this.methods.one;if(Ut(t))return this.intersection(t).eq(0);if(Wt(t))return this.sweep(t,{tagger:!1,matchOne:!0}).view;const r={regs:t=Dt(t,n,this.world),group:e,justOne:!0},s=o.match(this.docs,r,this._cache),{ptrs:i,byGroup:c}=Bt(s,this.fullPointer),u=this.toView(i);return u._groups=c,u},match:function(t,e,n){const o=this.methods.one;if(Ut(t))return this.intersection(t);if(Wt(t))return this.sweep(t,{tagger:!1}).view.settle();const r={regs:t=Dt(t,n,this.world),group:e},s=o.match(this.docs,r,this._cache),{ptrs:i,byGroup:c}=Bt(s,this.fullPointer),u=this.toView(i);return u._groups=c,u},has:function(t,e,n){const o=this.methods.one;if(Ut(t)){return this.intersection(t).fullPointer.length>0}if(Wt(t))return this.sweep(t,{tagger:!1}).view.found;const r={regs:t=Dt(t,n,this.world),group:e,justOne:!0};return o.match(this.docs,r,this._cache).ptrs.length>0},if:function(t,e,n){const o=this.methods.one;if(Ut(t))return this.filter((e=>e.intersection(t).found));if(Wt(t)){const e=this.sweep(t,{tagger:!1}).view.settle();return this.if(e)}const r={regs:t=Dt(t,n,this.world),group:e,justOne:!0};let s=this.fullPointer;const i=this._cache||[];s=s.filter(((t,e)=>{const n=this.update([t]);return o.match(n.docs,r,i[e]).ptrs.length>0}));const c=this.update(s);return this._cache&&(c._cache=s.map((t=>i[t[0]]))),c},ifNo:function(t,e,n){const{methods:o}=this,r=o.one;if(Ut(t))return this.filter((e=>!e.intersection(t).found));if(Wt(t)){const e=this.sweep(t,{tagger:!1}).view.settle();return this.ifNo(e)}t=Dt(t,n,this.world);const s=this._cache||[],i=this.filter(((n,o)=>{const i={regs:t,group:e,justOne:!0};return 0===r.match(n.docs,i,s[o]).ptrs.length}));return this._cache&&(i._cache=i.ptrs.map((t=>s[t[0]]))),i}};var Rt={before:function(t,e,n){const{indexN:o}=this.methods.one.pointer,r=[],s=o(this.fullPointer);Object.keys(s).forEach((t=>{const e=s[t].sort(((t,e)=>t[1]>e[1]?1:-1))[0];e[1]>0&&r.push([e[0],0,e[1]])}));const i=this.toView(r);return t?i.match(t,e,n):i},after:function(t,e,n){const{indexN:o}=this.methods.one.pointer,r=[],s=o(this.fullPointer),i=this.document;Object.keys(s).forEach((t=>{const e=s[t].sort(((t,e)=>t[1]>e[1]?-1:1))[0],[n,,o]=e;o{const s=n.before(t,e);if(s.found){const t=s.terms();o[r][1]-=t.length,o[r][3]=t.docs[0][0].id}})),this.update(o)},growRight:function(t,e,n){"string"==typeof t&&(t=this.world.methods.one.parseMatch(t,n,this.world)),t[0].start=!0;const o=this.fullPointer;return this.forEach(((n,r)=>{const s=n.after(t,e);if(s.found){const t=s.terms();o[r][2]+=t.length,o[r][4]=null}})),this.update(o)},grow:function(t,e,n){return this.growRight(t,e,n).growLeft(t,e,n)}};const Qt=function(t,e){return[t[0],t[1],e[2]]},Ht=(t,e,n)=>{return"string"==typeof t||(o=t,"[object Array]"===Object.prototype.toString.call(o))?e.match(t,n):t||e.none();var o},Zt=function(t,e){const[n,o,r]=t;return e.document[n]&&e.document[n][o]&&(t[3]=t[3]||e.document[n][o].id,e.document[n][r-1]&&(t[4]=t[4]||e.document[n][r-1].id)),t},Kt={splitOn:function(t,e){const{splitAll:n}=this.methods.one.pointer,o=Ht(t,this,e).fullPointer,r=n(this.fullPointer,o);let s=[];return r.forEach((t=>{s.push(t.passthrough),s.push(t.before),s.push(t.match),s.push(t.after)})),s=s.filter((t=>t)),s=s.map((t=>Zt(t,this))),this.update(s)},splitBefore:function(t,e){const{splitAll:n}=this.methods.one.pointer,o=Ht(t,this,e).fullPointer,r=n(this.fullPointer,o);for(let t=0;t{s.push(t.passthrough),s.push(t.before),t.match&&t.after?s.push(Qt(t.match,t.after)):s.push(t.match)})),s=s.filter((t=>t)),s=s.map((t=>Zt(t,this))),this.update(s)},splitAfter:function(t,e){const{splitAll:n}=this.methods.one.pointer,o=Ht(t,this,e).fullPointer,r=n(this.fullPointer,o);let s=[];return r.forEach((t=>{s.push(t.passthrough),t.before&&t.match?s.push(Qt(t.before,t.match)):(s.push(t.before),s.push(t.match)),s.push(t.after)})),s=s.filter((t=>t)),s=s.map((t=>Zt(t,this))),this.update(s)}};Kt.split=Kt.splitAfter;const Jt=function(t,e){return!(!t||!e)&&(t[0]===e[0]&&t[2]===e[1])},Xt=function(t,e,n){const o=t.world,r=o.methods.one.parseMatch;n=n||"^.";const s=r(e=e||".$",{},o),i=r(n,{},o);s[s.length-1].end=!0,i[0].start=!0;const c=t.fullPointer,u=[c[0]];for(let e=1;e)?\/.*?[^\\/]\/[?\]+*$~]*)(?:\s|$)/,ne=/([!~[^]*(?:<[^<]*>)?\([^)]+[^\\)]\)[?\]+*$~]*)(?:\s|$)/,oe=/ /g,re=t=>/^[![^]*(<[^<]*>)?\//.test(t)&&/\/[?\]+*$~]*$/.test(t),se=function(t){return t=(t=t.map((t=>t.trim()))).filter((t=>t))},ie=/\{([0-9]+)?(, *[0-9]*)?\}/,ce=/&&/,ue=new RegExp(/^<\s*(\S+)\s*>/),ae=t=>t.charAt(0).toUpperCase()+t.substring(1),le=t=>t.charAt(t.length-1),he=t=>t.charAt(0),fe=t=>t.substring(1),pe=t=>t.substring(0,t.length-1),de=function(t){return t=fe(t),t=pe(t)},me=function(t,e){const n={};for(let o=0;o<2;o+=1){if("$"===le(t)&&(n.end=!0,t=pe(t)),"^"===he(t)&&(n.start=!0,t=fe(t)),"?"===le(t)&&(n.optional=!0,t=pe(t)),("["===he(t)||"]"===le(t))&&(n.group=null,"["===he(t)&&(n.groupStart=!0),"]"===le(t)&&(n.groupEnd=!0),t=(t=t.replace(/^\[/,"")).replace(/\]$/,""),"<"===he(t))){const e=ue.exec(t);e.length>=2&&(n.group=e[1],t=t.replace(e[0],""))}if("+"===le(t)&&(n.greedy=!0,t=pe(t)),"*"!==t&&"*"===le(t)&&"\\*"!==t&&(n.greedy=!0,t=pe(t)),"!"===he(t)&&(n.negative=!0,t=fe(t)),"~"===he(t)&&"~"===le(t)&&t.length>2&&(t=de(t),n.fuzzy=!0,n.min=e.fuzzy||.85,!1===/\(/.test(t)))return n.word=t,n;if("/"===he(t)&&"/"===le(t))return t=de(t),e.caseSensitive&&(n.use="text"),n.regex=new RegExp(t),n;if(!0===ie.test(t)&&(t=t.replace(ie,((t,e,o)=>(void 0===o?(n.min=Number(e),n.max=Number(e)):(o=o.replace(/, */,""),void 0===e?(n.min=0,n.max=Number(o)):(n.min=Number(e),n.max=Number(o||999))),n.greedy=!0,n.min||(n.optional=!0),"")))),"("===he(t)&&")"===le(t)){ce.test(t)?(n.choices=t.split(ce),n.operator="and"):(n.choices=t.split("|"),n.operator="or"),n.choices[0]=fe(n.choices[0]);const o=n.choices.length-1;n.choices[o]=pe(n.choices[o]),n.choices=n.choices.map((t=>t.trim())),n.choices=n.choices.filter((t=>t)),n.choices=n.choices.map((t=>t.split(/ /g).map((t=>me(t,e))))),t=""}if("{"===he(t)&&"}"===le(t)){if(t=de(t),n.root=t,/\//.test(t)){const t=n.root.split(/\//);n.root=t[0],n.pos=t[1],"adj"===n.pos&&(n.pos="Adjective"),n.pos=n.pos.charAt(0).toUpperCase()+n.pos.substr(1).toLowerCase(),void 0!==t[2]&&(n.sense=t[2])}return n}if("<"===he(t)&&">"===le(t))return t=de(t),n.chunk=ae(t),n.greedy=!0,n;if("%"===he(t)&&"%"===le(t))return t=de(t),n.switch=t,n}return"#"===he(t)?(n.tag=fe(t),n.tag=ae(n.tag),n):"@"===he(t)?(n.method=fe(t),n):"."===t?(n.anything=!0,n):"*"===t?(n.anything=!0,n.greedy=!0,n.optional=!0,n):(t&&(t=(t=t.replace("\\*","*")).replace("\\.","."),e.caseSensitive?n.use="text":t=t.toLowerCase(),n.word=t),n)},ge=/[a-z0-9][-–—][a-z]/i,we=function(t,e){const{all:n}=e.methods.two.transform.verb||{},o=t.root;return n?n(o,e.model):[]},be=function(t,e){const{all:n}=e.methods.two.transform.noun||{};return n?n(t.root,e.model):[t.root]},ye=function(t,e){const{all:n}=e.methods.two.transform.adjective||{};return n?n(t.root,e.model):[t.root]},ve=function(t){return t=function(t){let e=0,n=null;for(let o=0;o(t.fuzzy&&t.choices&&t.choices.forEach((e=>{1===e.length&&e[0].word&&(e[0].fuzzy=!0,e[0].min=t.min)})),t)))}(t=t.map((t=>{if(void 0!==t.choices){if("or"!==t.operator)return t;if(!0===t.fuzzy)return t;!0===t.choices.every((t=>{if(1!==t.length)return!1;const e=t[0];return!0!==e.fuzzy&&!e.start&&!e.end&&void 0!==e.word&&!0!==e.negative&&!0!==e.optional&&!0!==e.method}))&&(t.fastOr=new Set,t.choices.forEach((e=>{t.fastOr.add(e[0].word)})),delete t.choices)}return t}))),t},xe=function(t,e){for(const n of e)if(t.has(n))return!0;return!1},je=function(t,e){for(let n=0;nn?o:n)+1;if(Math.abs(n-o)>(r||100))return r||100;const s=[];for(let t=0;t4)return n;u=e[i-1],a=c===u?0:1,l=s[r-1][i]+1,(h=s[r][i-1]+1)1&&i>1&&c===e[i-2]&&t[r-2]===u&&(h=s[r-2][i-2]+a)-1!==t.post.indexOf(e),ze={hasQuote:t=>Oe.test(t.pre)||ke.test(t.post),hasComma:t=>Se(t,","),hasPeriod:t=>!0===Se(t,".")&&!1===Se(t,"..."),hasExclamation:t=>Se(t,"!"),hasQuestionMark:t=>Se(t,"?")||Se(t,"¿"),hasEllipses:t=>Se(t,"..")||Se(t,"…"),hasSemicolon:t=>Se(t,";"),hasColon:t=>Se(t,":"),hasSlash:t=>/\//.test(t.text),hasHyphen:t=>Pe.test(t.post)||Pe.test(t.pre),hasDash:t=>_e.test(t.post)||_e.test(t.pre),hasContraction:t=>Boolean(t.implicit),isAcronym:t=>t.tags.has("Acronym"),isKnown:t=>t.tags.size>0,isTitleCase:t=>/^\p{Lu}[a-z'\u00C0-\u00FF]/u.test(t.text),isUpperCase:t=>/^\p{Lu}+$/u.test(t.text)};ze.hasQuotation=ze.hasQuote;let Ae=function(){};Ae=function(t,e,n,o){const r=function(t,e,n,o){if(!0===e.anything)return!0;if(!0===e.start&&0!==n)return!1;if(!0===e.end&&n!==o-1)return!1;if(void 0!==e.id&&e.id===t.id)return!0;if(void 0!==e.word){if(e.use)return e.word===t[e.use];if(null!==t.machine&&t.machine===e.word)return!0;if(void 0!==t.alias&&t.alias.hasOwnProperty(e.word))return!0;if(!0===e.fuzzy){if(e.word===t.root)return!0;if(Ee(e.word,t.normal)>=e.min)return!0}return!(!t.alias||!t.alias.some((t=>t===e.word)))||e.word===t.text||e.word===t.normal}if(void 0!==e.tag)return!0===t.tags.has(e.tag);if(void 0!==e.method)return"function"==typeof ze[e.method]&&!0===ze[e.method](t);if(void 0!==e.pre)return t.pre&&t.pre.includes(e.pre);if(void 0!==e.post)return t.post&&t.post.includes(e.post);if(void 0!==e.regex){let n=t.normal;return e.use&&(n=t[e.use]),e.regex.test(n)}if(void 0!==e.chunk)return t.chunk===e.chunk;if(void 0!==e.switch)return t.switch===e.switch;if(void 0!==e.machine)return t.normal===e.machine||t.machine===e.machine||t.root===e.machine;if(void 0!==e.sense)return t.sense===e.sense;if(void 0!==e.fastOr){if(e.pos&&!t.tags.has(e.pos))return null;const n=t.root||t.implicit||t.machine||t.normal;return e.fastOr.has(n)||e.fastOr.has(t.text)}return void 0!==e.choices&&("and"===e.operator?e.choices.every((e=>Ae(t,e,n,o))):e.choices.some((e=>Ae(t,e,n,o))))}(t,e,n,o);return!0===e.negative?!r:r};const $e=function(t,e){if(!0===t.end&&!0===t.greedy&&e.start_i+e.tn.max)return t.t=t.t+n.max,!0;if(!0===t.hasGroup){Te(t,t.t).length=o-t.t}return t.t=o,!0},Le=function(t,e=0){const n=t.regs[t.r];let o=!1;for(let s=0;s{let r=0;const s=t.t+o+e+r;if(void 0===t.terms[s])return!1;const i=Ae(t.terms[s],n,s+t.start_i,t.phrase_length);if(!0===i&&!0===n.greedy)for(let e=1;e{const o=n.every(((e,n)=>{const o=t.t+n;return void 0!==t.terms[o]&&Ae(t.terms[o],e,o,t.phrase_length)}));return!0===o&&n.length>e&&(e=n.length),o}))&&e}(t);if(o){if(!0===n.negative)return null;if(!0===t.hasGroup){Te(t,t.t).length+=o}if(!0===n.end){const e=t.phrase_length-1;if(t.t+t.start_i!==e)return null}return t.t+=o,!0}return!!n.optional||null},Fe=function(t){const{regs:e}=t,n=e[t.r],o=Object.assign({},n);o.negative=!1;if(Ae(t.terms[t.t],o,t.start_i+t.t,t.phrase_length))return!1;if(n.optional){const n=e[t.r+1];if(n){if(Ae(t.terms[t.t],n,t.start_i+t.t,t.phrase_length))t.r+=1;else if(n.optional&&e[t.r+2]){Ae(t.terms[t.t],e[t.r+2],t.start_i+t.t,t.phrase_length)&&(t.r+=2)}}}return n.greedy?function(t,e,n){let o=0;for(let r=t.t;ro||(t.t+=o,0))}(t,o,e[t.r+1]):(t.t+=1,!0)},qe=function(t){const{regs:e,phrase_length:n}=t,o=e[t.r];return t.t=function(t,e){const n=Object.assign({},t.regs[t.r],{start:!1,end:!1}),o=t.t;for(;t.tt.t?null:!0!==o.end||t.start_i+t.t===n||null},Ge=function(t){const{regs:e}=t,n=e[t.r],o=t.terms[t.t],r=t.t;if(n.optional&&e[t.r+1]&&n.negative)return!0;if(n.optional&&e[t.r+1]&&function(t){const{regs:e}=t,n=e[t.r],o=t.terms[t.t],r=Ae(o,e[t.r+1],t.start_i+t.t,t.phrase_length);if(n.negative||r){const n=t.terms[t.t+1];n&&Ae(n,e[t.r+1],t.start_i+t.t,t.phrase_length)||(t.r+=1)}}(t),o.implicit&&t.terms[t.t+1]&&function(t){const e=t.terms[t.t],n=t.regs[t.r];if(e.implicit&&t.terms[t.t+1]){if(!t.terms[t.t+1].implicit)return;n.word===e.normal&&(t.t+=1),"hasContraction"===n.method&&(t.t+=1)}}(t),t.t+=1,!0===n.end&&t.t!==t.terms.length&&!0!==n.greedy)return null;if(!0===n.greedy){if(!qe(t))return null}return!0===t.hasGroup&&function(t,e){const n=t.regs[t.r],o=Te(t,e);t.t>1&&n.greedy?o.length+=t.t-e:o.length++}(t,r),!0},Be=function(t,e,n,o){if(0===t.length||0===e.length)return null;const r={t:0,terms:t,r:0,regs:e,groups:{},start_i:n,phrase_length:o,inGroup:null};for(;r.r!t.optional)))break;return null}if(!0===t.anything&&!0===t.greedy){if(!Ce(r))return null;continue}if(void 0!==t.choices&&"or"===t.operator){if(!Ne(r))return null;continue}if(void 0!==t.choices&&"and"===t.operator){if(!Ve(r))return null;continue}if(!0===t.anything){if(t.negative&&t.anything)return null;if(!Ge(r))return null;continue}if(!0===$e(t,r)){if(!Ge(r))return null;continue}if(t.negative){if(!Fe(r))return null;continue}if(!0!==Ae(r.terms[r.t],t,r.start_i+r.t,r.phrase_length)){if(!0!==t.optional)return null}else{if(!Ge(r))return null}}const s=[null,n,r.t+n];if(s[1]===s[2])return null;const i={};return Object.keys(r.groups).forEach((t=>{const e=r.groups[t],o=n+e.start;i[t]=[null,o,o+e.length]})),{pointer:s,groups:i}},De=function(t,e){return t.pointer[0]=e,Object.keys(t.groups).forEach((n=>{t.groups[n][0]=e})),t},Me=function(t,e,n){let o=Be(t,e,0,t.length);return o?(o=De(o,n),o):null},Ue={one:{termMethods:ze,parseMatch:function(t,e,n){if(null==t||""===t)return[];e=e||{},"number"==typeof t&&(t=String(t));let o=function(t){const e=t.split(ee);let n=[];e.forEach((t=>{re(t)?n.push(t):n=n.concat(t.split(ne))})),n=se(n);let o=[];return n.forEach((t=>{(t=>/^[![^]*(<[^<]*>)?\(/.test(t)&&/\)[?\]+*$~]*$/.test(t))(t)||re(t)?o.push(t):o=o.concat(t.split(oe))})),o=se(o),o}(t);return o=o.map((t=>me(t,e))),o=function(t,e){const n=e.model.one.prefixes;for(let e=t.length-1;e>=0;e-=1){const o=t[e];if(o.word&&ge.test(o.word)){let r=o.word.split(/[-–—]/g);if(n.hasOwnProperty(r[0]))continue;r=r.filter((t=>t)).reverse(),t.splice(e,1),r.forEach((n=>{const r=Object.assign({},o);r.word=n,t.splice(e,0,r)}))}}return t}(o,n),o=function(t,e){return t.map((t=>{if(t.root)if(e.methods.two&&e.methods.two.transform){let n=[];t.pos?"Verb"===t.pos?n=n.concat(we(t,e)):"Noun"===t.pos?n=n.concat(be(t,e)):"Adjective"===t.pos&&(n=n.concat(ye(t,e))):(n=n.concat(we(t,e)),n=n.concat(be(t,e)),n=n.concat(ye(t,e))),n=n.filter((t=>t)),n.length>0&&(t.operator="or",t.fastOr=new Set(n))}else t.machine=t.root,delete t.id,delete t.root;return t}))}(o,n),o=ve(o),o},match:function(t,e,n){n=n||[];const{regs:o,group:r,justOne:s}=e;let i=[];if(!o||0===o.length)return{ptrs:[],byGroup:{}};const c=o.filter((t=>!0!==t.optional&&!0!==t.negative)).length;t:for(let e=0;et&&(t=Math.abs(n-1))}}else{const t=Me(r,o,e);t&&i.push(t)}}return!0===o[o.length-1].end&&(i=i.filter((e=>{const n=e.pointer[0];return t[n].length===e.pointer[2]}))),e.notIf&&(i=function(t,e,n){return t=t.filter((t=>{const[o,r,s]=t.pointer,i=n[o].slice(r,s);for(let t=0;t{t.groups[e]&&n.push(t.groups[e])})):t.forEach((t=>{n.push(t.pointer),Object.keys(t.groups).forEach((e=>{o[e]=o[e]||[],o[e].push(t.groups[e])}))}))),{ptrs:n,byGroup:o}}(i,r),i.ptrs.forEach((e=>{const[n,o,r]=e;e[3]=t[n][o].id,e[4]=t[n][r-1].id})),i}}};var We={api:function(t){Object.assign(t.prototype,te)},methods:Ue,lib:{parseMatch:function(t,e){const n=this.world(),o=n.methods.one.killUnicode;return o&&(t=o(t,n)),n.methods.one.parseMatch(t,e,n)}}};const Ie=/^\../,Re=/^#./,Qe=function(t,e){const n={},o={};return Object.keys(e).forEach((r=>{let s=e[r];const i=function(t){let e="",n=" ";return t=t.replace(/&/g,"&").replace(//g,">").replace(/"/g,""").replace(/'/g,"'"),Ie.test(t)?e=``),e+=">",{start:e,end:n}}(r);"string"==typeof s&&(s=t.match(s)),s.docs.forEach((t=>{if(t.every((t=>t.implicit)))return;const e=t[0].id;n[e]=n[e]||[],n[e].push(i.start);const r=t[t.length-1].id;o[r]=o[r]||[],o[r].push(i.end)}))})),{starts:n,ends:o}};var He={html:function(t){const{starts:e,ends:n}=Qe(this,t);let o="";return this.docs.forEach((t=>{for(let r=0;r{let n=t.pre||"",r=t.post||"";"some"===e.punctuation&&(n=n.replace(Ke,""),Xe.test(r)&&(r=" "),r=r.replace(Je,""),r=r.replace(/\?!+/,"?"),r=r.replace(/!+/,"!"),r=r.replace(/\?+/,"?"),r=r.replace(/\.{2,}/,""),t.tags.has("Abbreviation")&&(r=r.replace(/\./,""))),"some"===e.whitespace&&(n=n.replace(/\s/,""),r=r.replace(/\s+/," ")),e.keepPunct||(n=n.replace(Ke,""),r="-"===r?" ":r.replace(Ze,""));let s=t[e.form||"text"]||t.normal||"";"implicit"===e.form&&(s=t.implicit||t.text),"root"===e.form&&t.implicit&&(s=t.root||t.implicit||t.normal),"machine"!==e.form&&"implicit"!==e.form&&"root"!==e.form||!t.implicit||r&&Ye.test(r)||(r+=" "),o+=n+s+r})),!1===n&&(o=o.trim()),!0===e.lowerCase&&(o=o.toLowerCase()),o},en={text:{form:"text"},normal:{whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"normal"},machine:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"none",unicode:"some",form:"machine"},root:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"root"},implicit:{form:"implicit"}};en.clean=en.normal,en.reduced=en.root;const nn=[];let on=0;for(;on<64;)nn[on]=0|4294967296*Math.sin(++on%Math.PI);const rn=function(t){let e,n,o,r=decodeURI(encodeURI(t))+"",s=r.length;const i=[e=1732584193,n=4023233417,~e,~n],c=[];for(t=--s/4+2|15,c[--t]=8*s;~s;)c[s>>2]|=r.charCodeAt(s)<<8*s--;for(on=r=0;on>4]+nn[r]+~~c[on|15&[r,5*r+1,3*r+5,7*r][s]])<<(s=[7,12,17,22,5,9,14,20,4,11,16,23,6,10,15,21][4*s+r++%4])|o>>>-s),e,n])e=0|s[1],n=s[2];for(r=4;r;)i[--r]+=s[r]}for(t="";r<32;)t+=(i[r>>3]>>4*(1^r++)&15).toString(16);return t},sn={text:!0,terms:!0},cn={case:"none",unicode:"some",form:"machine",punctuation:"some"},un=function(t,e){return Object.assign({},t,e)},an={text:t=>tn(t,{keepPunct:!0},!1),normal:t=>tn(t,un(en.normal,{keepPunct:!0}),!1),implicit:t=>tn(t,un(en.implicit,{keepPunct:!0}),!1),machine:t=>tn(t,cn,!1),root:t=>tn(t,un(cn,{form:"root"}),!1),hash:t=>rn(tn(t,{keepPunct:!0},!1)),offset:t=>{const e=an.text(t).length;return{index:t[0].offset.index,start:t[0].offset.start,length:e}},terms:t=>t.map((t=>{const e=Object.assign({},t);return e.tags=Array.from(t.tags),e})),confidence:(t,e,n)=>e.eq(n).confidence(),syllables:(t,e,n)=>e.eq(n).syllables(),sentence:(t,e,n)=>e.eq(n).fullSentence().text(),dirty:t=>t.some((t=>!0===t.dirty))};an.sentences=an.sentence,an.clean=an.normal,an.reduced=an.root;const ln={json:function(t){const e=(n=this,"string"==typeof(o=(o=t)||{})&&(o={}),(o=Object.assign({},sn,o)).offset&&n.compute("offset"),n.docs.map(((t,e)=>{const r={};return Object.keys(o).forEach((s=>{o[s]&&an[s]&&(r[s]=an[s](t,n,e))})),r})));var n,o;return"number"==typeof t?e[t]:e}};ln.data=ln.json;const hn=function(t){const e=t.pre||"",n=t.post||"";return e+t.text+n},fn=function(t,e){const n=function(t,e){const n={};return Object.keys(e).forEach((o=>{t.match(o).fullPointer.forEach((t=>{n[t[3]]={fn:e[o],end:t[2]}}))})),n}(t,e);let o="";return t.docs.forEach(((e,r)=>{for(let s=0;st.reduce(((t,e)=>t+e.pre+e.text+e.post),"").trim()));return t.filter((t=>t))}if("freq"===t||"frequency"===t||"topk"===t)return function(t){const e={};t.forEach((t=>{e[t]=e[t]||0,e[t]+=1}));const n=Object.keys(e).map((t=>({normal:t,count:e[t]})));return n.sort(((t,e)=>t.count>e.count?-1:0))}(this.json({normal:!0}).map((t=>t.normal)));if("terms"===t){let t=[];return this.docs.forEach((e=>{let n=e.map((t=>t.text));n=n.filter((t=>t)),t=t.concat(n)})),t}return"tags"===t?this.docs.map((t=>t.reduce(((t,e)=>(t[e.implicit||e.normal]=Array.from(e.tags),t)),{}))):"debug"===t?this.debug():this.text()},wrap:function(t){return fn(this,t)}};var dn={text:function(t){let e={};var n;if(t&&"string"==typeof t&&en.hasOwnProperty(t)?e=Object.assign({},en[t]):t&&(n=t,"[object Object]"===Object.prototype.toString.call(n))&&(e=Object.assign({},t)),void 0!==e.keepSpace||this.isFull()||(e.keepSpace=!1),void 0===e.keepEndPunct&&this.pointer){const t=this.pointer[0];t&&t[1]?e.keepEndPunct=!1:e.keepEndPunct=!0}return void 0===e.keepPunct&&(e.keepPunct=!0),void 0===e.keepSpace&&(e.keepSpace=!0),function(t,e){let n="";if(!t||!t[0]||!t[0][0])return n;for(let o=0;o"�[32m"+t+gn,red:t=>"�[31m"+t+gn,blue:t=>"�[34m"+t+gn,magenta:t=>"�[35m"+t+gn,cyan:t=>"�[36m"+t+gn,yellow:t=>"�[33m"+t+gn,black:t=>"�[30m"+t+gn,dim:t=>"�[2m"+t+gn,i:t=>"�[3m"+t+gn},bn={tags:function(t){const{docs:e,model:n}=t;0===e.length&&console.log(wn.blue("\n ──────")),e.forEach((e=>{console.log(wn.blue("\n ┌─────────")),e.forEach((e=>{const o=[...e.tags||[]];let r=e.text||"-";e.sense&&(r=`{${e.normal}/${e.sense}}`),e.implicit&&(r="["+e.implicit+"]"),r=wn.yellow(r);let s="'"+r+"'";if(e.reference){const n=t.update([e.reference]).text("normal");s+=` - ${wn.dim(wn.i("["+n+"]"))}`}s=s.padEnd(18);const i=wn.blue(" │ ")+wn.i(s)+" - "+function(t,e){return e.one.tagSet&&(t=t.map((t=>{if(!e.one.tagSet.hasOwnProperty(t))return t;const n=e.one.tagSet[t].color||"blue";return wn[n](t)}))),t.join(", ")}(o,n);console.log(i)}))})),console.log("\n")},clientSide:function(t){console.log("%c -=-=- ","background-color:#6699cc;"),t.forEach((t=>{console.groupCollapsed(t.text());const e=t.docs[0].map((t=>{let e=t.text||"-";t.implicit&&(e="["+t.implicit+"]");return{text:e,tags:"["+Array.from(t.tags).join(", ")+"]"}}));console.table(e,["text","tags"]),console.groupEnd()}))},chunks:function(t){const{docs:e}=t;console.log(""),e.forEach((t=>{const e=[];t.forEach((t=>{"Noun"===t.chunk?e.push(wn.blue(t.implicit||t.normal)):"Verb"===t.chunk?e.push(wn.green(t.implicit||t.normal)):"Adjective"===t.chunk?e.push(wn.yellow(t.implicit||t.normal)):"Pivot"===t.chunk?e.push(wn.red(t.implicit||t.normal)):e.push(t.implicit||t.normal)})),console.log(e.join(" "),"\n")})),console.log("\n")},highlight:function(t){if(!t.found)return;const e={};t.fullPointer.forEach((t=>{e[t[0]]=e[t[0]]||[],e[t[0]].push(t)})),Object.keys(e).forEach((n=>{let o=t.update([[Number(n)]]).text();t.update(e[n]).json({offset:!0}).forEach(((t,e)=>{o=function(t,e,n){const o=((t,e,n)=>{const o=9*n,r=e.start+o,s=r+e.length;return[t.substring(0,r),t.substring(r,s),t.substring(s,t.length)]})(t,e,n);return`${o[0]}${wn.blue(o[1])}${o[2]}`}(o,t.offset,e)})),console.log(o)})),console.log("\n")}};var yn={api:function(t){Object.assign(t.prototype,mn)},methods:{one:{hash:rn,debug:bn}}};const vn=function(t,e){if(t[0]!==e[0])return!1;const[,n,o]=t,[,r,s]=e;return n<=r&&o>r||r<=n&&s>n},xn=function(t){const e={};return t.forEach((t=>{e[t[0]]=e[t[0]]||[],e[t[0]].push(t)})),e},jn=function(t,e){const n=xn(e),o=[];return t.forEach((t=>{const[e]=t;let r=n[e]||[];if(r=r.filter((e=>function(t,e){return t[1]<=e[1]&&e[2]<=t[2]}(t,e))),0===r.length)return void o.push({passthrough:t});r=r.sort(((t,e)=>t[1]-e[1]));let s=t;r.forEach(((t,e)=>{const n=function(t,e){const[n,o]=t,r=e[1],s=e[2],i={};if(os&&(i.after=[n,s,t[2]]),i}(s,t);r[e+1]?(o.push({before:n.before,match:n.match}),n.after&&(s=n.after)):o.push(n)}))})),o};var En={one:{termList:function(t){const e=[];for(let n=0;n{if(!o)return;let[s,i,c,u,a]=o,l=e[s]||[];if(void 0===i&&(i=0),void 0===c&&(c=l.length),!u||l[i]&&l[i].id===u)l=l.slice(i,c);else{const n=function(t,e,n){for(let o=0;o<20;o+=1){if(e[n-o]){const r=e[n-o].findIndex((e=>e.id===t));if(-1!==r)return[n-o,r]}if(e[n+o]){const r=e[n+o].findIndex((e=>e.id===t));if(-1!==r)return[n+o,r]}}return null}(u,e,s);if(null!==n){const o=c-i;l=e[n[0]].slice(n[1],n[1]+o);const s=l[0]?l[0].id:null;t[r]=[n[0],n[1],n[1]+o,s]}}0!==l.length&&i!==c&&(a&&l[l.length-1].id!==a&&(l=function(t,e){const[n,o,,,r]=t,s=e[n],i=s.findIndex((t=>t.id===r));return-1===i?(t[2]=e[n].length,t[4]=s.length?s[s.length-1].id:null):t[2]=i,e[n].slice(o,t[2]+1)}(o,e)),n.push(l))})),n=n.filter((t=>t.length>0)),n},pointer:{indexN:xn,splitAll:jn}}};const On=function(t,e){const n=t.concat(e),o=xn(n);let r=[];return n.forEach((t=>{const[e]=t;if(1===o[e].length)return void r.push(t);const n=o[e].filter((e=>vn(t,e)));n.push(t);const s=function(t){let e=t[0][1],n=t[0][2];return t.forEach((t=>{t[1]n&&(n=t[2])})),[t[0][0],e,n]}(n);r.push(s)})),r=function(t){const e={};for(let n=0;n{t.passthrough&&n.push(t.passthrough),t.before&&n.push(t.before),t.after&&n.push(t.after)})),n},Pn=(t,e)=>{return"string"==typeof t||(n=t,"[object Array]"===Object.prototype.toString.call(n))?e.match(t):t||e.none();var n},_n=function(t,e){return t.map((t=>{const[n,o]=t;return e[n]&&e[n][o]&&(t[3]=e[n][o].id),t}))},Sn={union:function(t){t=Pn(t,this);let e=On(this.fullPointer,t.fullPointer);return e=_n(e,this.document),this.toView(e)}};Sn.and=Sn.union,Sn.intersection=function(t){t=Pn(t,this);let e=function(t,e){const n=xn(e),o=[];return t.forEach((t=>{let e=n[t[0]]||[];e=e.filter((e=>vn(t,e))),0!==e.length&&e.forEach((e=>{const n=function(t,e){const n=t[1]e[2]?e[2]:t[2];return n{t=On(t,[e])})),t=_n(t,this.document),this.update(t)};var zn={methods:En,api:function(t){Object.assign(t.prototype,Sn)}};const An=function(t){return!0===t.optional||!0===t.negative?null:t.tag?"#"+t.tag:t.word?t.word:t.switch?`%${t.switch}%`:null},$n=function(t,e){const n=e.methods.one.parseMatch;return t.forEach((t=>{t.regs=n(t.match,{},e),"string"==typeof t.ifNo&&(t.ifNo=[t.ifNo]),t.notIf&&(t.notIf=n(t.notIf,{},e)),t.needs=function(t){const e=[];return t.forEach((t=>{e.push(An(t)),"and"===t.operator&&t.choices&&t.choices.forEach((t=>{t.forEach((t=>{e.push(An(t))}))}))})),e.filter((t=>t))}(t.regs);const{wants:o,count:r}=function(t){const e=[];let n=0;return t.forEach((t=>{"or"!==t.operator||t.optional||t.negative||(t.fastOr&&Array.from(t.fastOr).forEach((t=>{e.push(t)})),t.choices&&t.choices.forEach((t=>{t.forEach((t=>{const n=An(t);n&&e.push(n)}))})),n+=1)})),{wants:e,count:n}}(t.regs);t.wants=o,t.minWant=r,t.minWords=t.regs.filter((t=>!t.optional)).length})),t};var Tn={buildNet:function(t,e){t=$n(t,e);const n={};t.forEach((t=>{t.needs.forEach((e=>{n[e]=Array.isArray(n[e])?n[e]:[],n[e].push(t)})),t.wants.forEach((e=>{n[e]=Array.isArray(n[e])?n[e]:[],n[e].push(t)}))})),Object.keys(n).forEach((t=>{const e={};n[t]=n[t].filter((t=>"boolean"!=typeof e[t.match]&&(e[t.match]=!0,!0)))}));const o=t.filter((t=>0===t.needs.length&&0===t.wants.length));return{hooks:n,always:o}},bulkMatch:function(t,e,n,o={}){const r=n.one.cacheDoc(t);let s=function(t,e){return t.map(((n,o)=>{let r=[];Object.keys(e).forEach((n=>{t[o].has(n)&&(r=r.concat(e[n]))}));const s={};return r=r.filter((t=>"boolean"!=typeof s[t.match]&&(s[t.match]=!0,!0))),r}))}(r,e.hooks);s=function(t,e){return t.map(((t,n)=>{const o=e[n];return(t=(t=t.filter((t=>t.needs.every((t=>o.has(t)))))).filter((t=>void 0===t.ifNo||!0!==t.ifNo.some((t=>o.has(t)))))).filter((t=>0===t.wants.length||t.wants.filter((t=>o.has(t))).length>=t.minWant))}))}(s,r),e.always.length>0&&(s=s.map((t=>t.concat(e.always)))),s=function(t,e){return t.map(((t,n)=>{const o=e[n].length;return t=t.filter((t=>o>=t.minWords)),t}))}(s,t);const i=function(t,e,n,o,r){const s=[];for(let n=0;n0&&(u.ptrs.forEach((t=>{t[0]=n;const e=Object.assign({},c,{pointer:t});void 0!==c.unTag&&(e.unTag=c.unTag),s.push(e)})),!0===r.matchOne))return[s[0]]}return s}(s,t,0,n,o);return i},bulkTagger:function(t,e,n){const{model:o,methods:r}=n,{getDoc:s,setTag:i,unTag:c}=r.one,u=r.two.looksPlural;if(0===t.length)return t;return("undefined"!=typeof process&&process.env?process.env:self.env||{}).DEBUG_TAGS&&console.log(`\n\n �[32m→ ${t.length} post-tagger:�[0m`),t.map((t=>{if(!t.tag&&!t.chunk&&!t.unTag)return;const r=t.reason||t.match,a=s([t.pointer],e)[0];if(!0===t.safe){if(!1===function(t,e,n){const o=n.one.tagSet;if(!o.hasOwnProperty(e))return!0;const r=o[e].not||[];for(let e=0;et.frozen=!0))}void 0!==t.unTag&&c(a,t.unTag,n,t.safe,r),t.chunk&&a.forEach((e=>e.chunk=t.chunk))}))}},Cn={lib:{buildNet:function(t){const e=this.methods().one.buildNet(t,this.world());return e.isNet=!0,e}},api:function(t){t.prototype.sweep=function(t,e={}){const{world:n,docs:o}=this,{methods:r}=n;let s=r.one.bulkMatch(o,t,this.methods,e);!1!==e.tagger&&r.one.bulkTagger(s,o,this.world),s=s.map((t=>{const e=t.pointer,n=o[e[0]][e[1]],r=e[2]-e[1];return n.index&&(t.pointer=[n.index[0],n.index[1],e[1]+r]),t}));const i=s.map((t=>t.pointer));return s=s.map((t=>(t.view=this.update([t.pointer]),delete t.regs,delete t.needs,delete t.pointer,delete t._expanded,t))),{view:this.update(i),found:s}}},methods:{one:Tn}};const Ln=/ /,Nn=function(t,e){"Noun"===e&&(t.chunk=e),"Verb"===e&&(t.chunk=e)},Vn=function(t,e,n,o){if(!0===t.tags.has(e))return null;if("."===e)return null;!0===t.frozen&&(o=!0);const r=n[e];if(r){if(r.not&&r.not.length>0)for(let e=0;e0)for(let e=0;e{const o=t.map((t=>t.text||"["+t.implicit+"]")).join(" ");var r;"string"!=typeof e&&e.length>2&&(e=e.slice(0,2).join(", #")+" +"),e="string"!=typeof e?e.join(", #"):e,console.log(` ${(r=o,"�[33m�[3m"+r+"�[0m").padEnd(24)} �[32m→�[0m #${e.padEnd(22)} ${(t=>"�[3m"+t+"�[0m")(n)}`)})(t,e,r),!0!=(c=e,"[object Array]"===Object.prototype.toString.call(c)))if("string"==typeof e)if(e=e.trim(),Ln.test(e))!function(t,e,n,o){const r=e.split(Ln);t.forEach(((t,e)=>{let s=r[e];s&&(s=s.replace(/^#/,""),Vn(t,s,n,o))}))}(t,e,s,o);else{e=e.replace(/^#/,"");for(let n=0;nFn(t,e,n,o)))},qn=function(t){return t.children=t.children||[],t._cache=t._cache||{},t.props=t.props||{},t._cache.parents=t._cache.parents||[],t._cache.children=t._cache.children||[],t},Gn=/^ *(#|\/\/)/,Bn=function(t){let e=t.trim().split(/->/),n=[];e.forEach((t=>{n=n.concat(function(t){if(!(t=t.trim()))return null;if(/^\[/.test(t)&&/\]$/.test(t)){let e=(t=(t=t.replace(/^\[/,"")).replace(/\]$/,"")).split(/,/);return e=e.map((t=>t.trim())).filter((t=>t)),e=e.map((t=>qn({id:t}))),e}return[qn({id:t})]}(t))})),n=n.filter((t=>t));let o=n[0];for(let t=1;t{let n=[],o=[t];for(;o.length>0;){let t=o.pop();n.push(t),t.children&&t.children.forEach((n=>{e&&e(t,n),o.push(n)}))}return n},Mn=t=>"[object Array]"===Object.prototype.toString.call(t),Un=t=>(t=t||"").trim(),Wn=function(t=[]){return"string"==typeof t?function(t){let e=t.split(/\r?\n/),n=[];e.forEach((t=>{if(!t.trim()||Gn.test(t))return;let e=(t=>{const e=/^( {2}|\t)/;let n=0;for(;e.test(t);)t=t.replace(e,""),n+=1;return n})(t);n.push({indent:e,node:Bn(t)})}));let o=function(t){let e={children:[]};return t.forEach(((n,o)=>{0===n.indent?e.children=e.children.concat(n.node):t[o-1]&&function(t,e){let n=t[e].indent;for(;e>=0;e-=1)if(t[e].indent{e[t.id]=t}));let n=qn({});return t.forEach((t=>{if((t=qn(t)).parent)if(e.hasOwnProperty(t.parent)){let n=e[t.parent];delete t.parent,n.children.push(t)}else console.warn(`[Grad] - missing node '${t.parent}'`);else n.children.push(t)})),n}(t):(Dn(e=t).forEach(qn),e);var e},In=function(t,e){let n="-> ";e&&(n=(t=>"�[2m"+t+"�[0m")("→ "));let o="";return Dn(t).forEach(((t,r)=>{let s=t.id||"";if(e&&(s=(t=>"�[31m"+t+"�[0m")(s)),0===r&&!t.id)return;let i=t._cache.parents.length;o+=" ".repeat(i)+n+s+"\n"})),o},Rn=function(t){let e=Dn(t);e.forEach((t=>{delete(t=Object.assign({},t)).children}));let n=e[0];return n&&!n.id&&0===Object.keys(n.props).length&&e.shift(),e},Qn={text:In,txt:In,array:Rn,flat:Rn},Hn=function(t,e){return"nested"===e||"json"===e?t:"debug"===e?(console.log(In(t,!0)),null):Qn.hasOwnProperty(e)?Qn[e](t):t},Zn=t=>{Dn(t,((t,e)=>{t.id&&(t._cache.parents=t._cache.parents||[],e._cache.parents=t._cache.parents.concat([t.id]))}))},Kn=/\//;class g{constructor(t={}){Object.defineProperty(this,"json",{enumerable:!1,value:t,writable:!0})}get children(){return this.json.children}get id(){return this.json.id}get found(){return this.json.id||this.json.children.length>0}props(t={}){let e=this.json.props||{};return"string"==typeof t&&(e[t]=!0),this.json.props=Object.assign(e,t),this}get(t){if(t=Un(t),!Kn.test(t)){let e=this.json.children.find((e=>e.id===t));return new g(e)}let e=((t,e)=>{let n=(t=>"string"!=typeof t?t:(t=t.replace(/^\//,"")).split(/\//))(e=e||"");for(let e=0;et.id===n[e]));if(!o)return null;t=o}return t})(this.json,t)||qn({});return new g(e)}add(t,e={}){if(Mn(t))return t.forEach((t=>this.add(Un(t),e))),this;t=Un(t);let n=qn({id:t,props:e});return this.json.children.push(n),new g(n)}remove(t){return t=Un(t),this.json.children=this.json.children.filter((e=>e.id!==t)),this}nodes(){return Dn(this.json).map((t=>(delete(t=Object.assign({},t)).children,t)))}cache(){return(t=>{let e=Dn(t,((t,e)=>{t.id&&(t._cache.parents=t._cache.parents||[],t._cache.children=t._cache.children||[],e._cache.parents=t._cache.parents.concat([t.id]))})),n={};e.forEach((t=>{t.id&&(n[t.id]=t)})),e.forEach((t=>{t._cache.parents.forEach((e=>{n.hasOwnProperty(e)&&n[e]._cache.children.push(t.id)}))})),t._cache.children=Object.keys(n)})(this.json),this}list(){return Dn(this.json)}fillDown(){var t;return t=this.json,Dn(t,((t,e)=>{e.props=((t,e)=>(Object.keys(e).forEach((n=>{if(e[n]instanceof Set){let o=t[n]||new Set;t[n]=new Set([...o,...e[n]])}else if((t=>t&&"object"==typeof t&&!Array.isArray(t))(e[n])){let o=t[n]||{};t[n]=Object.assign({},e[n],o)}else Mn(e[n])?t[n]=e[n].concat(t[n]||[]):void 0===t[n]&&(t[n]=e[n])})),t))(e.props,t.props)})),this}depth(){Zn(this.json);let t=Dn(this.json),e=t.length>1?1:0;return t.forEach((t=>{if(0===t._cache.parents.length)return;let n=t._cache.parents.length+1;n>e&&(e=n)})),e}out(t){return Zn(this.json),Hn(this.json,t)}debug(){return Zn(this.json),Hn(this.json,"debug"),this}}const Jn=function(t){let e=Wn(t);return new g(e)};Jn.prototype.plugin=function(t){t(this)};const Xn={Noun:"blue",Verb:"green",Negative:"green",Date:"red",Value:"red",Adjective:"magenta",Preposition:"cyan",Conjunction:"cyan",Determiner:"cyan",Hyphenated:"cyan",Adverb:"cyan"},Yn=function(t){if(Xn.hasOwnProperty(t.id))return Xn[t.id];if(Xn.hasOwnProperty(t.is))return Xn[t.is];const e=t._cache.parents.find((t=>Xn[t]));return Xn[e]},to=function(t){return t?"string"==typeof t?[t]:t:[]},eo=function(t,e){return t=function(t,e){return Object.keys(t).forEach((n=>{t[n].isA&&(t[n].is=t[n].isA),t[n].notA&&(t[n].not=t[n].notA),t[n].is&&"string"==typeof t[n].is&&(e.hasOwnProperty(t[n].is)||t.hasOwnProperty(t[n].is)||(t[t[n].is]={})),t[n].not&&"string"==typeof t[n].not&&!t.hasOwnProperty(t[n].not)&&(e.hasOwnProperty(t[n].not)||t.hasOwnProperty(t[n].not)||(t[t[n].not]={}))})),t}(t,e),Object.keys(t).forEach((e=>{t[e].children=to(t[e].children),t[e].not=to(t[e].not)})),Object.keys(t).forEach((e=>{(t[e].not||[]).forEach((n=>{t[n]&&t[n].not&&t[n].not.push(e)}))})),t};var no={one:{setTag:Fn,unTag:function(t,e,n){e=e.trim().replace(/^#/,"");for(let o=0;o0)for(let t=0;t0&&(t=function(t){return Object.keys(t).forEach((e=>{t[e]=Object.assign({},t[e]),t[e].novel=!0})),t}(t)),t=eo(t,e);const n=function(t){const e=Object.keys(t).map((e=>{const n=t[e],o={not:new Set(n.not),also:n.also,is:n.is,novel:n.novel};return{id:e,parent:n.is,props:o,children:[]}}));return Jn(e).cache().fillDown().out("array")}(Object.assign({},e,t)),o=function(t){const e={};return t.forEach((t=>{const{not:n,also:o,is:r,novel:s}=t.props;let i=t._cache.parents;o&&(i=i.concat(o)),e[t.id]={is:r,not:n,novel:s,also:o,parents:i,children:t._cache.children,color:Yn(t)}})),Object.keys(e).forEach((t=>{const n=new Set(e[t].not);e[t].not.forEach((t=>{e[t]&&e[t].children.forEach((t=>n.add(t)))})),e[t].not=Array.from(n)})),e}(n);return o},canBe:function(t,e,n){if(!n.hasOwnProperty(e))return!0;const o=n[e].not||[];for(let e=0;er.one.setTag(o,t,i,n,e))):r.one.setTag(o,t,i,n,e),this.uncache(),this},tagSafe:function(t,e=""){return this.tag(t,e,!0)},unTag:function(t,e){if(!this.found||!t)return this;const n=this.termList();if(0===n.length)return this;const{methods:o,verbose:r,model:s}=this;!0===r&&console.log(" - ",t,e||"");const i=s.one.tagSet;return oo(t)?t.forEach((t=>o.one.unTag(n,t,i))):o.one.unTag(n,t,i),this.uncache(),this},canBe:function(t){t=t.replace(/^#/,"");const e=this.model.one.tagSet,n=this.methods.one.canBe,o=[];this.document.forEach(((r,s)=>{r.forEach(((r,i)=>{n(r,t,e)||o.push([s,i,i+1])}))}));const r=this.update(o);return this.difference(r)}};var so={addTags:function(t){const{model:e,methods:n}=this.world(),o=e.one.tagSet,r=(0,n.one.addTags)(t,o);return e.one.tagSet=r,this}};const io=new Set(["Auxiliary","Possessive"]);var co={model:{one:{tagSet:{}}},compute:{tagRank:function(t){const{document:e,world:n}=t,o=n.model.one.tagSet;e.forEach((t=>{t.forEach((t=>{const e=Array.from(t.tags);t.tagRank=function(t,e){return t=t.sort(((t,n)=>{if(io.has(t)||!e.hasOwnProperty(n))return 1;if(io.has(n)||!e.hasOwnProperty(t))return-1;let o=e[t].children||[];const r=o.length;return o=e[n].children||[],r-o.length})),t}(e,o)}))}))}},methods:no,api:function(t){Object.assign(t.prototype,ro)},lib:so};const uo=/([.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s)/g,ao=/^[.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s$/,lo=/((?:\r?\n|\r)+)/,ho=/[a-z0-9\u00C0-\u00FF\u00a9\u00ae\u2000-\u3300\ud000-\udfff]/i,fo=/\S/,po=function(t){return Boolean(t.match(/\n$/))},mo={'"':'"',""":""","“":"”","‟":"”","„":"”","⹂":"”","‚":"’","«":"»","‹":"›","‵":"′","‶":"″","‷":"‴","〝":"〞","〟":"〞"},go=RegExp("["+Object.keys(mo).join("")+"]","g"),wo=RegExp("["+Object.values(mo).join("")+"]","g"),bo=function(t){if(!t)return!1;const e=t.match(wo);return null!==e&&1===e.length},yo=/\(/g,vo=/\)/g,xo=/\S/,jo=/^\s+/,Eo=function(t,e){const n=t.split(/[-–—]/);if(n.length<=1)return!1;const{prefixes:o,suffixes:r}=e.one;if(1===n[0].length&&/[a-z]/i.test(n[0]))return!1;if(o.hasOwnProperty(n[0]))return!1;if(n[1]=n[1].trim().replace(/[.?!]$/,""),r.hasOwnProperty(n[1]))return!1;if(!0===/^([a-z\u00C0-\u00FF`"'/]+)[-–—]([a-z0-9\u00C0-\u00FF].*)/i.test(t))return!0;return!0===/^[('"]?([0-9]{1,4})[-–—]([a-z\u00C0-\u00FF`"'/-]+[)'"]?$)/i.test(t)},Oo=function(t){const e=[],n=t.split(/[-–—]/);let o="-";const r=t.match(/[-–—]/);r&&r[0]&&(o=r);for(let t=0;t(t[e]=!0,t)),{});const Ao=/\p{Letter}/u,$o=/[\p{Number}\p{Currency_Symbol}]/u,To=/^[a-z]\.([a-z]\.)+/i,Co=/[sn]['’]$/,Lo=/([A-Z]\.)+[A-Z]?,?$/,No=/^[A-Z]\.,?$/,Vo=/[A-Z]{2,}('s|,)?$/,Fo=/([a-z]\.)+[a-z]\.?$/,qo=function(t){return function(t){return!0===Lo.test(t)||!0===Fo.test(t)||!0===No.test(t)||!0===Vo.test(t)}(t)&&(t=t.replace(/\./g,"")),t},Go=function(t,e){const n=e.methods.one.killUnicode;let o=t.text||"";o=function(t){const e=t=(t=(t=t||"").toLowerCase()).trim();return t=(t=(t=t.replace(/[,;.!?]+$/,"")).replace(/\u2026/g,"...")).replace(/\u2013/g,"-"),!1===/^[:;]/.test(t)&&(t=(t=(t=t.replace(/\.{3,}$/g,"")).replace(/[",.!:;?)]+$/g,"")).replace(/^['"(]+/g,"")),""===(t=(t=t.replace(/[\u200B-\u200D\uFEFF]/g,"")).trim())&&(t=e),t.replace(/([0-9]),([0-9])/g,"$1$2")}(o),o=n(o,e),o=qo(o),t.normal=o},Bo=/[ .][A-Z]\.? *$/i,Do=/(?:\u2026|\.{2,}) *$/,Mo=/\p{L}/u,Uo=/\. *$/,Wo=/^[A-Z]\. $/;var Io={one:{killUnicode:function(t,e){const n=e.model.one.unicode||{},o=(t=t||"").split("");return o.forEach(((t,e)=>{n[t]&&(o[e]=n[t])})),o.join("")},tokenize:{splitSentences:function(t,e){if(t=t||"",!(t=String(t))||"string"!=typeof t||!1===xo.test(t))return[];const n=function(t){const e=[],n=t.split(lo);for(let t=0;t0&&(r.push(s),t[e]=""):t[e+1]=s+(t[e+1]||"")}return r}(o,e),o=function(t){const e=[];for(let n=0;n0?(n[n.length-1]+=s,n.push(e)):n.push(s+e),s=""):s+=e}return s&&(0===n.length&&(n[0]=""),n[n.length-1]+=s),n=function(t){for(let e=1;et)),n},splitWhitespace:(t,e)=>{const{str:n,pre:o,post:r}=function(t,e){const{prePunctuation:n,postPunctuation:o,emoticons:r}=e.one;let s=t,i="",c="";const u=Array.from(t);if(r.hasOwnProperty(t.trim()))return{str:t.trim(),pre:i,post:" "};let a=u.length;for(let t=0;t(c=t||"",""))),t=s,i=""),{str:t,pre:i,post:c}}(t,e);return{text:n,pre:o,post:r,tags:new Set}},fromString:function(t,e){const{methods:n,model:o}=e,{splitSentences:r,splitTerms:s,splitWhitespace:i}=n.one.tokenize;return t=r(t=t||"",e).map((t=>{let n=s(t,o);return n=n.map((t=>i(t,o))),n.forEach((t=>{Go(t,e)})),n})),t}}}};const Ro={},Qo={};[[["approx","apt","bc","cyn","eg","esp","est","etc","ex","exp","prob","pron","gal","min","pseud","fig","jd","lat","lng","vol","fm","def","misc","plz","ea","ps","sec","pt","pref","pl","pp","qt","fr","sq","nee","ss","tel","temp","vet","ver","fem","masc","eng","adj","vb","rb","inf","situ","vivo","vitro","wr"]],[["dl","ml","gal","qt","pt","tbl","tsp","tbsp","km","dm","cm","mm","mi","td","hr","hrs","kg","hg","dg","cg","mg","µg","lb","oz","sq ft","hz","mps","mph","kmph","kb","mb","tb","lx","lm","fl oz","yb"],"Unit"],[["ad","al","arc","ba","bl","ca","cca","col","corp","ft","fy","ie","lit","ma","md","pd","tce"],"Noun"],[["adj","adm","adv","asst","atty","bldg","brig","capt","cmdr","comdr","cpl","det","dr","esq","gen","gov","hon","jr","llb","lt","maj","messrs","mlle","mme","mr","mrs","ms","mstr","phd","prof","pvt","rep","reps","res","rev","sen","sens","sfc","sgt","sir","sr","supt","surg"],"Honorific"],[["jan","feb","mar","apr","jun","jul","aug","sep","sept","oct","nov","dec"],"Month"],[["dept","univ","assn","bros","inc","ltd","co"],"Organization"],[["rd","st","dist","mt","ave","blvd","cl","cres","hwy","ariz","cal","calif","colo","conn","fla","fl","ga","ida","ia","kan","kans","minn","neb","nebr","okla","penna","penn","pa","dak","tenn","tex","ut","vt","va","wis","wisc","wy","wyo","usafa","alta","ont","que","sask"],"Place"]].forEach((t=>{t[0].forEach((e=>{Ro[e]=!0,Qo[e]="Abbreviation",void 0!==t[1]&&(Qo[e]=[Qo[e],t[1]])}))}));var Ho=["anti","bi","co","contra","de","extra","infra","inter","intra","macro","micro","mis","mono","multi","peri","pre","pro","proto","pseudo","re","sub","supra","trans","tri","un","out","ex"].reduce(((t,e)=>(t[e]=!0,t)),{});const Zo={"!":"¡","?":"¿Ɂ",'"':'“”"❝❞',"'":"‘‛❛❜’","-":"—–",a:"ªÀÁÂÃÄÅàáâãäåĀāĂ㥹ǍǎǞǟǠǡǺǻȀȁȂȃȦȧȺΆΑΔΛάαλАаѦѧӐӑӒӓƛæ",b:"ßþƀƁƂƃƄƅɃΒβϐϦБВЪЬвъьѢѣҌҍ",c:"¢©ÇçĆćĈĉĊċČčƆƇƈȻȼͻͼϲϹϽϾСсєҀҁҪҫ",d:"ÐĎďĐđƉƊȡƋƌ",e:"ÈÉÊËèéêëĒēĔĕĖėĘęĚěƐȄȅȆȇȨȩɆɇΈΕΞΣέεξϵЀЁЕеѐёҼҽҾҿӖӗễ",f:"ƑƒϜϝӺӻҒғſ",g:"ĜĝĞğĠġĢģƓǤǥǦǧǴǵ",h:"ĤĥĦħƕǶȞȟΉΗЂЊЋНнђћҢңҤҥҺһӉӊ",I:"ÌÍÎÏ",i:"ìíîïĨĩĪīĬĭĮįİıƖƗȈȉȊȋΊΐΪίιϊІЇіїi̇",j:"ĴĵǰȷɈɉϳЈј",k:"ĶķĸƘƙǨǩΚκЌЖКжкќҚқҜҝҞҟҠҡ",l:"ĹĺĻļĽľĿŀŁłƚƪǀǏǐȴȽΙӀӏ",m:"ΜϺϻМмӍӎ",n:"ÑñŃńŅņŇňʼnŊŋƝƞǸǹȠȵΝΠήηϞЍИЙЛПийлпѝҊҋӅӆӢӣӤӥπ",o:"ÒÓÔÕÖØðòóôõöøŌōŎŏŐőƟƠơǑǒǪǫǬǭǾǿȌȍȎȏȪȫȬȭȮȯȰȱΌΘΟθοσόϕϘϙϬϴОФоѲѳӦӧӨөӪӫ",p:"ƤΡρϷϸϼРрҎҏÞ",q:"Ɋɋ",r:"ŔŕŖŗŘřƦȐȑȒȓɌɍЃГЯгяѓҐґ",s:"ŚśŜŝŞşŠšƧƨȘșȿЅѕ",t:"ŢţŤťŦŧƫƬƭƮȚțȶȾΓΤτϮТт",u:"ÙÚÛÜùúûüŨũŪūŬŭŮůŰűŲųƯưƱƲǓǔǕǖǗǘǙǚǛǜȔȕȖȗɄΰυϋύ",v:"νѴѵѶѷ",w:"ŴŵƜωώϖϢϣШЩшщѡѿ",x:"×ΧχϗϰХхҲҳӼӽӾӿ",y:"ÝýÿŶŷŸƳƴȲȳɎɏΎΥΫγψϒϓϔЎУучўѰѱҮүҰұӮӯӰӱӲӳ",z:"ŹźŻżŽžƵƶȤȥɀΖ"},Ko={};Object.keys(Zo).forEach((function(t){Zo[t].split("").forEach((function(e){Ko[e]=t}))}));const Jo=/\//,Xo=/[a-z]\.[a-z]/i,Yo=/[0-9]/,tr=function(t,e){const n=t.normal||t.text||t.machine,o=e.model.one.aliases;if(o.hasOwnProperty(n)&&(t.alias=t.alias||[],t.alias.push(o[n])),Jo.test(n)&&!Xo.test(n)&&!Yo.test(n)){const e=n.split(Jo);e.length<=3&&e.forEach((e=>{""!==(e=e.trim())&&(t.alias=t.alias||[],t.alias.push(e))}))}return t},er=/^\p{Letter}+-\p{Letter}+$/u,nr=function(t){let e=t.implicit||t.normal||t.text;e=e.replace(/['’]s$/,""),e=e.replace(/s['’]$/,"s"),e=e.replace(/([aeiou][ktrp])in'$/,"$1ing"),er.test(e)&&(e=e.replace(/-/g,"")),e=e.replace(/^[#@]/,""),e!==t.normal&&(t.machine=e)},or=function(t,e){const n=t.docs;for(let o=0;oor(t,tr),machine:t=>or(t,nr),normal:t=>or(t,Go),freq:function(t){const e=t.docs,n={};for(let t=0;t{let i=(t=t.toLowerCase().trim()).length;e.max&&i>e.max&&(i=e.max);for(let c=e.min;c{delete o[t]})),o}(t,e,this.world());return Object.keys(r).forEach((t=>{n.one.typeahead.hasOwnProperty(t)?delete n.one.typeahead[t]:n.one.typeahead[t]=r[t]})),this}};var lr={model:{one:{typeahead:{}}},api:function(t){t.prototype.autoFill=cr},lib:ar,compute:ir,hooks:["typeahead"]};h.extend(W),h.extend(yn),h.extend(We),h.extend(zn),h.extend(co),h.plugin(yt),h.extend(sr),h.extend(Ot),h.plugin(d),h.extend(qt),h.extend(lr),h.extend(Tt),h.extend(Cn);export{h as default};
================================================
FILE: builds/three/compromise-three.cjs
================================================
!function(e,t){"object"==typeof exports&&"undefined"!=typeof module?module.exports=t():"function"==typeof define&&define.amd?define(t):(e="undefined"!=typeof globalThis?globalThis:e||self).nlp=t()}(this,(function(){"use strict";var e={methods:{one:{},two:{},three:{},four:{}},model:{one:{},two:{},three:{}},compute:{},hooks:[]};const t={compute:function(e){const{world:t}=this,n=t.compute;return"string"==typeof e&&n.hasOwnProperty(e)?n[e](this):(e=>"[object Array]"===Object.prototype.toString.call(e))(e)?e.forEach((r=>{t.compute.hasOwnProperty(r)?n[r](this):console.warn("no compute:",e)})):"function"==typeof e?e(this):console.warn("no compute:",e),this}};var n={forEach:function(e){return this.fullPointer.forEach(((t,n)=>{const r=this.update([t]);e(r,n)})),this},map:function(e,t){const n=this.fullPointer.map(((t,n)=>{const r=this.update([t]),o=e(r,n);return void 0===o?this.none():o}));if(0===n.length)return t||this.update([]);if(void 0!==n[0]){if("string"==typeof n[0])return n;if("object"==typeof n[0]&&(null===n[0]||!n[0].isView))return n}let r=[];return n.forEach((e=>{r=r.concat(e.fullPointer)})),this.toView(r)},filter:function(e){let t=this.fullPointer;t=t.filter(((t,n)=>{const r=this.update([t]);return e(r,n)}));return this.update(t)},find:function(e){const t=this.fullPointer.find(((t,n)=>{const r=this.update([t]);return e(r,n)}));return this.update([t])},some:function(e){return this.fullPointer.some(((t,n)=>{const r=this.update([t]);return e(r,n)}))},random:function(e=1){let t=this.fullPointer,n=Math.floor(Math.random()*t.length);return n+e>this.length&&(n=this.length-e,n=n<0?0:n),t=t.slice(n,n+e),this.update(t)}};const r={termList:function(){return this.methods.one.termList(this.docs)},terms:function(e){const t=this.match(".");return"number"==typeof e?t.eq(e):t},groups:function(e){if(e||0===e)return this.update(this._groups[e]||[]);const t={};return Object.keys(this._groups).forEach((e=>{t[e]=this.update(this._groups[e])})),t},eq:function(e){let t=this.pointer;return t||(t=this.docs.map(((e,t)=>[t]))),t[e]?this.update([t[e]]):this.none()},first:function(){return this.eq(0)},last:function(){const e=this.fullPointer.length-1;return this.eq(e)},firstTerms:function(){return this.match("^.")},lastTerms:function(){return this.match(".$")},slice:function(e,t){let n=this.pointer||this.docs.map(((e,t)=>[t]));return n=n.slice(e,t),this.update(n)},all:function(){return this.update().toView()},fullSentences:function(){const e=this.fullPointer.map((e=>[e[0]]));return this.update(e).toView()},none:function(){return this.update([])},isDoc:function(e){if(!e||!e.isView)return!1;const t=this.fullPointer,n=e.fullPointer;return!t.length!==n.length&&t.every(((e,t)=>!!n[t]&&(e[0]===n[t][0]&&e[1]===n[t][1]&&e[2]===n[t][2])))},wordCount:function(){return this.docs.reduce(((e,t)=>(e+=t.filter((e=>""!==e.text)).length,e)),0)},isFull:function(){const e=this.pointer;if(!e)return!0;if(0===e.length||0!==e[0][0])return!1;let t=0,n=0;return this.document.forEach((e=>t+=e.length)),this.docs.forEach((e=>n+=e.length)),t===n},getNth:function(e){return"number"==typeof e?this.eq(e):"string"==typeof e?this.if(e):this}};r.group=r.groups,r.fullSentence=r.fullSentences,r.sentence=r.fullSentences,r.lastTerm=r.lastTerms,r.firstTerm=r.firstTerms;const o=Object.assign({},r,t,n);o.get=o.eq;class View{constructor(t,n,r={}){[["document",t],["world",e],["_groups",r],["_cache",null],["viewType","View"]].forEach((e=>{Object.defineProperty(this,e[0],{value:e[1],writable:!0})})),this.ptrs=n}get docs(){let t=this.document;return this.ptrs&&(t=e.methods.one.getDoc(this.ptrs,this.document)),t}get pointer(){return this.ptrs}get methods(){return this.world.methods}get model(){return this.world.model}get hooks(){return this.world.hooks}get isView(){return!0}get found(){return this.docs.length>0}get length(){return this.docs.length}get fullPointer(){const{docs:e,ptrs:t,document:n}=this,r=t||e.map(((e,t)=>[t]));return r.map((e=>{let[t,r,o,a,i]=e;return r=r||0,o=o||(n[t]||[]).length,n[t]&&n[t][r]&&(a=a||n[t][r].id,n[t][o-1]&&(i=i||n[t][o-1].id)),[t,r,o,a,i]}))}update(e){const t=new View(this.document,e);if(this._cache&&e&&e.length>0){const n=[];e.forEach(((e,t)=>{const[r,o,a]=e;(1===e.length||0===o&&this.document[r].length===a)&&(n[t]=this._cache[r])})),n.length>0&&(t._cache=n)}return t.world=this.world,t}toView(e){return new View(this.document,e||this.pointer)}fromText(e){const{methods:t}=this,n=t.one.tokenize.fromString(e,this.world),r=new View(n);return r.world=this.world,r.compute(["normal","freeze","lexicon"]),this.world.compute.preTagger&&r.compute("preTagger"),r.compute("unfreeze"),r}clone(){let e=this.document.slice(0);e=e.map((e=>e.map((e=>((e=Object.assign({},e)).tags=new Set(e.tags),e)))));const t=this.update(this.pointer);return t.document=e,t._cache=this._cache,t}}Object.assign(View.prototype,o);const a=function(e){return e&&"object"==typeof e&&!Array.isArray(e)};function i(e,t){if(a(t))for(const n in t)a(t[n])?(e[n]||Object.assign(e,{[n]:{}}),i(e[n],t[n])):Object.assign(e,{[n]:t[n]});return e}const s=function(e,t,n,r){if(o=e,"[object Array]"===Object.prototype.toString.call(o))return void e.forEach((e=>s(e,t,n,r)));var o;const{methods:a,model:l,compute:u,hooks:c}=t;e.methods&&function(e,t){for(const n in t)e[n]=e[n]||{},Object.assign(e[n],t[n])}(a,e.methods),e.model&&i(l,e.model),e.irregulars&&function(e,t){const n=e.two.models||{};Object.keys(t).forEach((e=>{t[e].pastTense&&(n.toPast&&(n.toPast.ex[e]=t[e].pastTense),n.fromPast&&(n.fromPast.ex[t[e].pastTense]=e)),t[e].presentTense&&(n.toPresent&&(n.toPresent.ex[e]=t[e].presentTense),n.fromPresent&&(n.fromPresent.ex[t[e].presentTense]=e)),t[e].gerund&&(n.toGerund&&(n.toGerund.ex[e]=t[e].gerund),n.fromGerund&&(n.fromGerund.ex[t[e].gerund]=e)),t[e].comparative&&(n.toComparative&&(n.toComparative.ex[e]=t[e].comparative),n.fromComparative&&(n.fromComparative.ex[t[e].comparative]=e)),t[e].superlative&&(n.toSuperlative&&(n.toSuperlative.ex[e]=t[e].superlative),n.fromSuperlative&&(n.fromSuperlative.ex[t[e].superlative]=e))}))}(l,e.irregulars),e.compute&&Object.assign(u,e.compute),c&&(t.hooks=c.concat(e.hooks||[])),e.api&&e.api(n),e.lib&&Object.keys(e.lib).forEach((t=>r[t]=e.lib[t])),e.tags&&r.addTags(e.tags),e.words&&r.addWords(e.words),e.frozen&&r.addWords(e.frozen,!0),e.mutate&&e.mutate(t,r)},l=function(e){return"[object Array]"===Object.prototype.toString.call(e)},u=function(e,t,n){const{methods:r}=n,o=new t([]);if(o.world=n,"number"==typeof e&&(e=String(e)),!e)return o;if("string"==typeof e){return new t(r.one.tokenize.fromString(e,n))}if(a=e,"[object Object]"===Object.prototype.toString.call(a)&&e.isView)return new t(e.document,e.ptrs);var a;if(l(e)){if(l(e[0])){const n=e.map((e=>e.map((e=>({text:e,normal:e,pre:"",post:" ",tags:new Set})))));return new t(n)}const n=e.map((e=>e.terms.map((e=>(l(e.tags)&&(e.tags=new Set(e.tags)),e)))));return new t(n)}return o},c=Object.assign({},e),h=function(e,t){t&&h.addWords(t);const n=u(e,View,c);return e&&n.compute(c.hooks),n};Object.defineProperty(h,"_world",{value:c,writable:!0}),h.tokenize=function(e,t){const{compute:n}=this._world;t&&h.addWords(t);const r=u(e,View,c);return n.contractions&&r.compute(["alias","normal","machine","contractions"]),r},h.plugin=function(e){return s(e,this._world,View,this),this},h.extend=h.plugin,h.world=function(){return this._world},h.model=function(){return this._world.model},h.methods=function(){return this._world.methods},h.hooks=function(){return this._world.hooks},h.verbose=function(e){const t="undefined"!=typeof process&&process.env?process.env:self.env||{};return t.DEBUG_TAGS="tagger"===e||!0===e||"",t.DEBUG_MATCH="match"===e||!0===e||"",t.DEBUG_CHUNKS="chunker"===e||!0===e||"",this},h.version="14.15.0";var d={one:{cacheDoc:function(e){const t=e.map((e=>{const t=new Set;return e.forEach((e=>{""!==e.normal&&t.add(e.normal),e.switch&&t.add(`%${e.switch}%`),e.implicit&&t.add(e.implicit),e.machine&&t.add(e.machine),e.root&&t.add(e.root),e.alias&&e.alias.forEach((e=>t.add(e)));const n=Array.from(e.tags);for(let e=0;e/^\p{Lu}[\p{Ll}'’]/u.test(e)||/^\p{Lu}$/u.test(e),b=(e,t,n)=>{if(n.forEach((e=>e.dirty=!0)),e){const r=[t,0].concat(n);Array.prototype.splice.apply(e,r)}return e},v=function(e){const t=e[e.length-1];!t||/ $/.test(t.post)||/[-–—]/.test(t.post)||(t.post+=" ")},y=(e,t,n)=>{const r=/[-.?!,;:)–—'"]/g,o=e[t-1];if(!o)return;const a=o.post;if(r.test(a)){const e=a.match(r).join(""),t=n[n.length-1];t.post=e+t.post,o.post=o.post.replace(r,"")}},w=function(e,t,n,r){const[o,a,i]=t;0===a||i===r[o].length?v(n):(v(n),v([e[t[1]]])),function(e,t,n){const r=e[t];if(0!==t||!f(r.text))return;n[0].text=n[0].text.replace(/^\p{Ll}/u,(e=>e.toUpperCase()));const o=e[t];o.tags.has("ProperNoun")||o.tags.has("Acronym")||f(o.text)&&o.text.length>1&&(o.text=(a=o.text,a.replace(/^\p{Lu}/u,(e=>e.toLowerCase()))));var a}(e,a,n),b(e,a,n)};let k=0;const P=e=>(e=e.length<3?"0"+e:e).length<3?"0"+e:e,A=function(e){let[t,n]=e.index||[0,0];k+=1,k=k>46655?0:k,t=t>46655?0:t,n=n>1294?0:n;let r=P(k.toString(36));r+=P(t.toString(36));let o=n.toString(36);o=o.length<2?"0"+o:o,r+=o;return r+=parseInt(36*Math.random(),10).toString(36),e.normal+"|"+r.toUpperCase()},C=function(e){if(e.has("@hasContraction")&&"function"==typeof e.contractions){e.grow("@hasContraction").contractions().expand()}},N=e=>"[object Array]"===Object.prototype.toString.call(e),j=function(e,t,n){const{document:r,world:o}=t;t.uncache();const a=t.fullPointer,i=t.fullPointer;t.forEach(((s,l)=>{const u=s.fullPointer[0],[c]=u,h=r[c];let d=function(e,t){const{methods:n}=t;return"string"==typeof e?n.one.tokenize.fromString(e,t)[0]:"object"==typeof e&&e.isView?e.clone().docs[0]||[]:N(e)?N(e[0])?e[0]:e:[]}(e,o);0!==d.length&&(d=function(e){return e.map((e=>(e.id=A(e),e)))}(d),n?(C(t.update([u]).firstTerm()),w(h,u,d,r)):(C(t.update([u]).lastTerm()),function(e,t,n,r){const[o,,a]=t,i=(r[o]||[]).length;ae.replace(/^\p{Ll}/u,(e=>e.toUpperCase())),H=e=>e.replace(/^\p{Lu}/u,(e=>e.toLowerCase()));T.replaceWith=function(e,t={}){let n=this.fullPointer;const r=this;if(this.uncache(),"function"==typeof e)return function(e,t,n){return e.forEach((e=>{const r=t(e);e.replaceWith(r,n)})),e}(r,e,t);const o=r.docs[0];if(!o)return r;const a=t.possessives&&o[o.length-1].tags.has("Possessive"),i=t.case&&(s=o[0].text,/^\p{Lu}[\p{Ll}'’]/u.test(s)||/^\p{Lu}$/u.test(s));var s;e=function(e,t){if("string"!=typeof e)return e;const n=t.groups();return e=e.replace(I,(e=>{const t=e.replace(/\$/,"");return n.hasOwnProperty(t)?n[t].text():e})),e}(e,r);const l=this.update(n);n=n.map((e=>e.slice(0,3)));const u=(l.docs[0]||[]).map((e=>Array.from(e.tags))),c=l.docs[0][0].pre,h=l.docs[0][l.docs[0].length-1].post;if("string"==typeof e&&(e=this.fromText(e).compute("id")),r.insertAfter(e),l.has("@hasContraction")&&r.contractions){r.grow("@hasContraction+").contractions().expand()}if(r.delete(l),a){const e=r.docs[0],t=e[e.length-1];t.tags.has("Possessive")||(t.text+="'s",t.normal+="'s",t.tags.add("Possessive"))}if(c&&r.docs[0]&&(r.docs[0][0].pre=c),h&&r.docs[0]){const e=r.docs[0][r.docs[0].length-1];e.post.trim()||(e.post=h)}const d=r.toView(n).compute(["index","freeze","lexicon"]);if(d.world.compute.preTagger&&d.compute("preTagger"),d.compute("unfreeze"),t.tags&&d.terms().forEach(((e,t)=>{e.tagSafe(u[t])})),!d.docs[0]||!d.docs[0][0])return d;if(t.case){const e=i?D:H;d.docs[0][0].text=e(d.docs[0][0].text)}return d},T.replace=function(e,t,n){if(e&&!t)return this.replaceWith(e,n);const r=this.match(e);return r.found?(this.soften(),r.replaceWith(t,n)):this};const E={remove:function(e){const{indexN:t}=this.methods.one.pointer;this.uncache();let n=this.all(),r=this;e&&(n=this,r=this.match(e));const o=!n.ptrs;if(r.has("@hasContraction")&&r.contractions){r.grow("@hasContraction").contractions().expand()}let a=n.fullPointer;const i=r.fullPointer.reverse(),s=function(e,t){t.forEach((t=>{const[n,r,o]=t,a=o-r;e[n]&&(o===e[n].length&&o>1&&function(e,t){const n=e.length-1,r=e[n],o=e[n-t];o&&r&&(o.post+=r.post,o.post=o.post.replace(/ +([.?!,;:])/,"$1"),o.post=o.post.replace(/[,;:]+([.?!])/,"$1"))}(e[n],a),e[n].splice(r,a))}));for(let t=e.length-1;t>=0;t-=1)if(0===e[t].length&&(e.splice(t,1),t===e.length&&e[t-1])){const n=e[t-1],r=n[n.length-1];r&&(r.post=r.post.trimEnd())}return e}(this.document,i);if(a=function(e,t){return e=e.map((e=>{const[n]=e;return t[n]?(t[n].forEach((t=>{const n=t[2]-t[1];e[1]<=t[1]&&e[2]>=t[2]&&(e[2]-=n)})),e):e})),e.forEach(((t,n)=>{if(0===t[1]&&0==t[2])for(let t=n+1;te[2]-e[1]>0))).map((e=>(e[3]=null,e[4]=null,e)))}(a,t(i)),n.ptrs=a,n.document=s,n.compute("index"),o&&(n.ptrs=void 0),!e)return this.ptrs=[],n.none();return n.toView(a)}};E.delete=E.remove;const G={pre:function(e,t){return void 0===e&&this.found?this.docs[0][0].pre:(this.docs.forEach((n=>{const r=n[0];!0===t?r.pre+=e:r.pre=e})),this)},post:function(e,t){if(void 0===e){const e=this.docs[this.docs.length-1];return e[e.length-1].post}return this.docs.forEach((n=>{const r=n[n.length-1];!0===t?r.post+=e:r.post=e})),this},trim:function(){if(!this.found)return this;const e=this.docs,t=e[0][0];t.pre=t.pre.trimStart();const n=e[e.length-1],r=n[n.length-1];return r.post=r.post.trimEnd(),this},hyphenate:function(){return this.docs.forEach((e=>{e.forEach(((t,n)=>{0!==n&&(t.pre=""),e[n+1]&&(t.post="-")}))})),this},dehyphenate:function(){const e=/[-–—]/;return this.docs.forEach((t=>{t.forEach((t=>{e.test(t.post)&&(t.post=" ")}))})),this},toQuotations:function(e,t){return e=e||'"',t=t||'"',this.docs.forEach((n=>{n[0].pre=e+n[0].pre;const r=n[n.length-1];r.post=t+r.post})),this},toParentheses:function(e,t){return e=e||"(",t=t||")",this.docs.forEach((n=>{n[0].pre=e+n[0].pre;const r=n[n.length-1];r.post=t+r.post})),this}};G.deHyphenate=G.dehyphenate,G.toQuotation=G.toQuotations;var O={alpha:(e,t)=>e.normalt.normal?1:0,length:(e,t)=>{const n=e.normal.trim().length,r=t.normal.trim().length;return nr?-1:0},wordCount:(e,t)=>e.wordst.words?-1:0,sequential:(e,t)=>e[0]t[0]?-1:e[1]>t[1]?1:-1,byFreq:function(e){const t={};return e.forEach((e=>{t[e.normal]=t[e.normal]||0,t[e.normal]+=1})),e.sort(((e,n)=>{const r=t[e.normal],o=t[n.normal];return ro?-1:0})),e}};const F=new Set(["index","sequence","seq","sequential","chron","chronological"]),V=new Set(["freq","frequency","topk","repeats"]),z=new Set(["alpha","alphabetical"]);var B={unique:function(){const e=new Set,t=this.filter((t=>{const n=t.text("machine");return!e.has(n)&&(e.add(n),!0)}));return t},reverse:function(){let e=this.pointer||this.docs.map(((e,t)=>[t]));return e=[].concat(e),e=e.reverse(),this._cache&&(this._cache=this._cache.reverse()),this.update(e)},sort:function(e){const{docs:t,pointer:n}=this;if(this.uncache(),"function"==typeof e)return function(e,t){let n=e.fullPointer;return n=n.sort(((n,r)=>(n=e.update([n]),r=e.update([r]),t(n,r)))),e.ptrs=n,e}(this,e);e=e||"alpha";const r=n||t.map(((e,t)=>[t]));let o=t.map(((e,t)=>({index:t,words:e.length,normal:e.map((e=>e.machine||e.normal||"")).join(" "),pointer:r[t]})));return F.has(e)&&(e="sequential"),z.has(e)&&(e="alpha"),V.has(e)?(o=O.byFreq(o),this.update(o.map((e=>e.pointer)))):"function"==typeof O[e]?(o=o.sort(O[e]),this.update(o.map((e=>e.pointer)))):this}};const S=function(e,t){if(e.length>0){const t=e[e.length-1],n=t[t.length-1];!1===/ /.test(n.post)&&(n.post+=" ")}return e=e.concat(t)};var $={concat:function(e){if("string"==typeof e){const t=this.fromText(e);if(this.found&&this.ptrs){const e=this.fullPointer,n=e[e.length-1][0];this.document.splice(n,0,...t.document)}else this.document=this.document.concat(t.document);return this.all().compute("index")}if("object"==typeof e&&e.isView)return function(e,t){if(e.document===t.document){const n=e.fullPointer.concat(t.fullPointer);return e.toView(n).compute("index")}return t.fullPointer.forEach((t=>{t[0]+=e.document.length})),e.document=S(e.document,t.docs),e.all()}(this,e);if(t=e,"[object Array]"===Object.prototype.toString.call(t)){const t=S(this.document,e);return this.document=t,this.all()}var t;return this}};var M={harden:function(){return this.ptrs=this.fullPointer,this},soften:function(){let e=this.ptrs;return!e||e.length<1||(e=e.map((e=>e.slice(0,3))),this.ptrs=e),this}};const L=Object.assign({},{toLowerCase:function(){return this.termList().forEach((e=>{e.text=e.text.toLowerCase()})),this},toUpperCase:function(){return this.termList().forEach((e=>{e.text=e.text.toUpperCase()})),this},toTitleCase:function(){return this.termList().forEach((e=>{e.text=e.text.replace(/^ *[a-z\u00C0-\u00FF]/,(e=>e.toUpperCase()))})),this},toCamelCase:function(){return this.docs.forEach((e=>{e.forEach(((t,n)=>{0!==n&&(t.text=t.text.replace(/^ *[a-z\u00C0-\u00FF]/,(e=>e.toUpperCase()))),n!==e.length-1&&(t.post="")}))})),this}},x,T,E,G,B,$,M),K={id:function(e){const t=e.docs;for(let e=0;e(e.implicit=e.text,e.machine=e.text,e.pre="",e.post="",e.text="",e.normal="",e.index=[r,o+t],e))),n[0]&&(n[0].pre=e[r][o].pre,n[n.length-1].post=e[r][o].post,n[0].text=e[r][o].text,n[0].normal=e[r][o].normal),e[r].splice(o,1,...n))},R=/'/,Q=new Set(["what","how","when","where","why"]),Z=new Set(["be","go","start","think","need"]),_=new Set(["been","gone"]),X=/'/,Y=/(e|é|aison|sion|tion)$/,ee=/(age|isme|acle|ege|oire)$/;var te=(e,t)=>["je",e[t].normal.split(X)[1]],ne=(e,t)=>{const n=e[t].normal.split(X)[1];return n&&n.endsWith("e")?["la",n]:["le",n]},re=(e,t)=>{const n=e[t].normal.split(X)[1];return n&&Y.test(n)&&!ee.test(n)?["du",n]:n&&n.endsWith("s")?["des",n]:["de",n]};const oe=/^([0-9.]{1,4}[a-z]{0,2}) ?[-–—] ?([0-9]{1,4}[a-z]{0,2})$/i,ae=/^([0-9]{1,2}(:[0-9][0-9])?(am|pm)?) ?[-–—] ?([0-9]{1,2}(:[0-9][0-9])?(am|pm)?)$/i,ie=/^[0-9]{3}-[0-9]{4}$/,se=function(e,t){const n=e[t];let r=n.text.match(oe);return null!==r?!0===n.tags.has("PhoneNumber")||ie.test(n.text)?null:[r[1],"to",r[2]]:(r=n.text.match(ae),null!==r?[r[1],"to",r[4]]:null)},le=/^([+-]?[0-9][.,0-9]*)([a-z°²³µ/]+)$/,ue=function(e,t,n){const r=n.model.one.numberSuffixes||{},o=e[t].text.match(le);if(null!==o){const e=o[2].toLowerCase().trim();return r.hasOwnProperty(e)?null:[o[1],e]}return null},ce=/'/,he=/^[0-9][^-–—]*[-–—].*?[0-9]/,de=function(e,t,n,r){const o=t.update();o.document=[e];let a=n+r;n>0&&(n-=1),e[a]&&(a+=1),o.ptrs=[[0,n,a]]},ge={t:(e,t)=>function(e,t){return"ain't"===e[t].normal||"aint"===e[t].normal?null:[e[t].normal.replace(/n't/,""),"not"]}(e,t),d:(e,t)=>function(e,t){const n=e[t].normal.split(R)[0];if(Q.has(n))return[n,"did"];if(e[t+1]){if(_.has(e[t+1].normal))return[n,"had"];if(Z.has(e[t+1].normal))return[n,"would"]}return null}(e,t)},me={j:(e,t)=>te(e,t),l:(e,t)=>ne(e,t),d:(e,t)=>re(e,t)},pe=function(e,t,n,r){for(let o=0;o2)return a.out.concat(r)}return null},fe=function(e,t){const n=t.fromText(e.join(" "));return n.compute(["id","alias"]),n.docs[0]},be=function(e,t){for(let n=t+1;n<5&&e[n];n+=1)if("been"===e[n].normal)return["there","has"];return["there","is"]};var ve={contractions:e=>{const{world:t,document:n}=e,{model:r,methods:o}=t,a=r.one.contractions||[];n.forEach(((r,i)=>{for(let s=r.length-1;s>=0;s-=1){let l=null,u=null;if(!0===ce.test(r[s].normal)){const e=r[s].normal.split(ce);l=e[0],u=e[1]}let c=pe(a,r[s],l,u);!c&&ge.hasOwnProperty(u)&&(c=ge[u](r,s,t)),!c&&me.hasOwnProperty(l)&&(c=me[l](r,s)),"there"===l&&"s"===u&&(c=be(r,s)),c?(c=fe(c,e),U(n,[i,s],c),de(n[i],e,s,c.length)):he.test(r[s].normal)?(c=se(r,s),c&&(c=fe(c,e),U(n,[i,s],c),o.one.setTag(c,"NumberRange",t),c[2]&&c[2].tags.has("Time")&&o.one.setTag([c[0]],"Time",t,null,"time-range"),de(n[i],e,s,c.length))):(c=ue(r,s,t),c&&(c=fe(c,e),U(n,[i,s],c),o.one.setTag([c[1]],"Unit",t,null,"contraction-unit")))}}))}};const ye={model:q,compute:ve,hooks:["contractions"]},we=function(e){const t=e.world,{model:n,methods:r}=e.world,o=r.one.setTag,{frozenLex:a}=n.one,i=n.one._multiCache||{};e.docs.forEach((e=>{for(let n=0;nn;r-=1){const i=e.slice(n,r+1),s=i.map((e=>e.machine||e.normal)).join(" ");!0!==a.hasOwnProperty(s)||(o(i,a[s],t,!1,"1-frozen-multi-lexicon"),i.forEach((e=>e.frozen=!0)))}}void 0!==a[s]&&a.hasOwnProperty(s)&&(o([r],a[s],t,!1,"1-freeze-lexicon"),r.frozen=!0)}}))};const ke=e=>"�[34m"+e+"�[0m",Pe=e=>"�[3m�[2m"+e+"�[0m",Ae=function(e){e.docs.forEach((e=>{console.log(ke("\n ┌─────────")),e.forEach((e=>{let t=` ${Pe("│")} `;const n=e.implicit||e.text||"-";!0===e.frozen?t+=`${ke(n)} ❄️`:t+=Pe(n),console.log(t)}))}))};var Ce={compute:{frozen:we,freeze:we,unfreeze:function(e){return e.docs.forEach((e=>{e.forEach((e=>{delete e.frozen}))})),e}},mutate:e=>{const t=e.methods.one;t.termMethods.isFrozen=e=>!0===e.frozen,t.debug.freeze=Ae,t.debug.frozen=Ae},api:function(e){e.prototype.freeze=function(){return this.docs.forEach((e=>{e.forEach((e=>{e.frozen=!0}))})),this},e.prototype.unfreeze=function(){this.compute("unfreeze")},e.prototype.isFrozen=function(){return this.match("@isFrozen+")}},hooks:["freeze"]};const Ne=function(e,t,n){const{model:r,methods:o}=n,a=o.one.setTag,i=r.one._multiCache||{},{lexicon:s}=r.one||{},l=e[t],u=l.machine||l.normal;if(void 0!==i[u]&&e[t+1]){for(let r=t+i[u]-1;r>t;r-=1){const o=e.slice(t,r+1);if(o.length<=1)return!1;const i=o.map((e=>e.machine||e.normal)).join(" ");if(!0===s.hasOwnProperty(i)){const e=s[i];return a(o,e,n,!1,"1-multi-lexicon"),!e||2!==e.length||"PhrasalVerb"!==e[0]&&"PhrasalVerb"!==e[1]||a([o[1]],"Particle",n,!1,"1-phrasal-particle"),!0}}return!1}return null},je=/^(under|over|mis|re|un|dis|semi|pre|post)-?/,xe=new Set(["Verb","Infinitive","PastTense","Gerund","PresentTense","Adjective","Participle"]),Ie=function(e,t,n){const{model:r,methods:o}=n,a=o.one.setTag,{lexicon:i}=r.one,s=e[t],l=s.machine||s.normal;if(void 0!==i[l]&&i.hasOwnProperty(l))return a([s],i[l],n,!1,"1-lexicon"),!0;if(s.alias){const e=s.alias.find((e=>i.hasOwnProperty(e)));if(e)return a([s],i[e],n,!1,"1-lexicon-alias"),!0}if(!0===je.test(l)){const e=l.replace(je,"");if(i.hasOwnProperty(e)&&e.length>3&&xe.has(i[e]))return a([s],i[e],n,!1,"1-lexicon-prefix"),!0}return null};var Te={lexicon:function(e){const t=e.world;e.docs.forEach((e=>{for(let n=0;n{const o=e[r],a=(r=(r=r.toLowerCase().trim()).replace(/'s\b/,"")).split(/ /);a.length>1&&(void 0===n[a[0]]||a.length>n[a[0]])&&(n[a[0]]=a.length),t[r]=t[r]||o})),delete t[""],delete t.null,delete t[" "],{lex:t,_multi:n}}}};var He={addWords:function(e,t=!1){const n=this.world(),{methods:r,model:o}=n;if(!e)return;if(Object.keys(e).forEach((t=>{"string"==typeof e[t]&&e[t].startsWith("#")&&(e[t]=e[t].replace(/^#/,""))})),!0===t){const{lex:t,_multi:a}=r.one.expandLexicon(e,n);return Object.assign(o.one._multiCache,a),void Object.assign(o.one.frozenLex,t)}if(r.two.expandLexicon){const{lex:t,_multi:a}=r.two.expandLexicon(e,n);Object.assign(o.one.lexicon,t),Object.assign(o.one._multiCache,a)}const{lex:a,_multi:i}=r.one.expandLexicon(e,n);Object.assign(o.one.lexicon,a),Object.assign(o.one._multiCache,i)}};var Ee={model:{one:{lexicon:{},_multiCache:{},frozenLex:{}}},methods:De,compute:Te,lib:He,hooks:["lexicon"]};const Ge=function(e,t){const n=[{}],r=[null],o=[0],a=[];let i=0;e.forEach((function(e){let o=0;const a=function(e,t){const{methods:n,model:r}=t,o=n.one.tokenize.splitTerms(e,r).map((e=>n.one.tokenize.splitWhitespace(e,r)));return o.map((e=>e.text.toLowerCase()))}(e,t);for(let e=0;e0&&!n[i].hasOwnProperty(l);)i=o[i];if(n.hasOwnProperty(i)){const e=n[i][l];o[u]=e,r[e]&&(r[u]=r[u]||[],r[u]=r[u].concat(r[e]))}else o[u]=0}}return{goNext:n,endAs:r,failTo:o}},Oe=function(e,t,n){let r=0;const o=[];for(let a=0;a0&&(void 0===t.goNext[r]||!t.goNext[r].hasOwnProperty(i));)r=t.failTo[r]||0;if(t.goNext[r].hasOwnProperty(i)&&(r=t.goNext[r][i],t.endAs[r])){const n=t.endAs[r];for(let t=0;t{for(let n=e.length-1;n>=0;n-=1)if(e[n]!==t)return e=e.slice(0,n+1);return e},ze={buildTrie:function(e){return function(e){return e.goNext=e.goNext.map((e=>{if(0!==Object.keys(e).length)return e})),e.goNext=Ve(e.goNext,void 0),e.failTo=Ve(e.failTo,0),e.endAs=Ve(e.endAs,null),e}(Ge(e,this.world()))}};ze.compile=ze.buildTrie;var Be={api:function(e){e.prototype.lookup=function(e,t={}){if(!e)return this.none();"string"==typeof e&&(e=[e]);var n;let r=function(e,t,n){let r=[];n.form=n.form||"normal";const o=e.docs;if(!t.goNext||!t.goNext[0])return console.error("Compromise invalid lookup trie"),e.none();const a=Object.keys(t.goNext[0]);for(let i=0;i0&&(r=r.concat(l))}return e.update(r)}(this,(n=e,"[object Object]"===Object.prototype.toString.call(n)?e:Ge(e,this.world)),t);return r=r.settle(),r}},lib:ze};const Se=function(e,t){return t?(e.forEach((e=>{const n=e[0];t[n]&&(e[0]=t[n][0],e[1]+=t[n][1],e[2]+=t[n][1])})),e):e},$e=function(e,t){let{ptrs:n}=e;const{byGroup:r}=e;return n=Se(n,t),Object.keys(r).forEach((e=>{r[e]=Se(r[e],t)})),{ptrs:n,byGroup:r}},Me=function(e,t,n){const r=n.methods.one;return"number"==typeof e&&(e=String(e)),"string"==typeof e&&(e=r.killUnicode(e,n),e=r.parseMatch(e,t,n)),e},Le=e=>"[object Object]"===Object.prototype.toString.call(e),Ke=e=>e&&Le(e)&&!0===e.isView,Je=e=>e&&Le(e)&&!0===e.isNet;var We={matchOne:function(e,t,n){const r=this.methods.one;if(Ke(e))return this.intersection(e).eq(0);if(Je(e))return this.sweep(e,{tagger:!1,matchOne:!0}).view;const o={regs:e=Me(e,n,this.world),group:t,justOne:!0},a=r.match(this.docs,o,this._cache),{ptrs:i,byGroup:s}=$e(a,this.fullPointer),l=this.toView(i);return l._groups=s,l},match:function(e,t,n){const r=this.methods.one;if(Ke(e))return this.intersection(e);if(Je(e))return this.sweep(e,{tagger:!1}).view.settle();const o={regs:e=Me(e,n,this.world),group:t},a=r.match(this.docs,o,this._cache),{ptrs:i,byGroup:s}=$e(a,this.fullPointer),l=this.toView(i);return l._groups=s,l},has:function(e,t,n){const r=this.methods.one;if(Ke(e)){return this.intersection(e).fullPointer.length>0}if(Je(e))return this.sweep(e,{tagger:!1}).view.found;const o={regs:e=Me(e,n,this.world),group:t,justOne:!0};return r.match(this.docs,o,this._cache).ptrs.length>0},if:function(e,t,n){const r=this.methods.one;if(Ke(e))return this.filter((t=>t.intersection(e).found));if(Je(e)){const t=this.sweep(e,{tagger:!1}).view.settle();return this.if(t)}const o={regs:e=Me(e,n,this.world),group:t,justOne:!0};let a=this.fullPointer;const i=this._cache||[];a=a.filter(((e,t)=>{const n=this.update([e]);return r.match(n.docs,o,i[t]).ptrs.length>0}));const s=this.update(a);return this._cache&&(s._cache=a.map((e=>i[e[0]]))),s},ifNo:function(e,t,n){const{methods:r}=this,o=r.one;if(Ke(e))return this.filter((t=>!t.intersection(e).found));if(Je(e)){const t=this.sweep(e,{tagger:!1}).view.settle();return this.ifNo(t)}e=Me(e,n,this.world);const a=this._cache||[],i=this.filter(((n,r)=>{const i={regs:e,group:t,justOne:!0};return 0===o.match(n.docs,i,a[r]).ptrs.length}));return this._cache&&(i._cache=i.ptrs.map((e=>a[e[0]]))),i}};var qe={before:function(e,t,n){const{indexN:r}=this.methods.one.pointer,o=[],a=r(this.fullPointer);Object.keys(a).forEach((e=>{const t=a[e].sort(((e,t)=>e[1]>t[1]?1:-1))[0];t[1]>0&&o.push([t[0],0,t[1]])}));const i=this.toView(o);return e?i.match(e,t,n):i},after:function(e,t,n){const{indexN:r}=this.methods.one.pointer,o=[],a=r(this.fullPointer),i=this.document;Object.keys(a).forEach((e=>{const t=a[e].sort(((e,t)=>e[1]>t[1]?-1:1))[0],[n,,r]=t;r{const a=n.before(e,t);if(a.found){const e=a.terms();r[o][1]-=e.length,r[o][3]=e.docs[0][0].id}})),this.update(r)},growRight:function(e,t,n){"string"==typeof e&&(e=this.world.methods.one.parseMatch(e,n,this.world)),e[0].start=!0;const r=this.fullPointer;return this.forEach(((n,o)=>{const a=n.after(e,t);if(a.found){const e=a.terms();r[o][2]+=e.length,r[o][4]=null}})),this.update(r)},grow:function(e,t,n){return this.growRight(e,t,n).growLeft(e,t,n)}};const Ue=function(e,t){return[e[0],e[1],t[2]]},Re=(e,t,n)=>{return"string"==typeof e||(r=e,"[object Array]"===Object.prototype.toString.call(r))?t.match(e,n):e||t.none();var r},Qe=function(e,t){const[n,r,o]=e;return t.document[n]&&t.document[n][r]&&(e[3]=e[3]||t.document[n][r].id,t.document[n][o-1]&&(e[4]=e[4]||t.document[n][o-1].id)),e},Ze={splitOn:function(e,t){const{splitAll:n}=this.methods.one.pointer,r=Re(e,this,t).fullPointer,o=n(this.fullPointer,r);let a=[];return o.forEach((e=>{a.push(e.passthrough),a.push(e.before),a.push(e.match),a.push(e.after)})),a=a.filter((e=>e)),a=a.map((e=>Qe(e,this))),this.update(a)},splitBefore:function(e,t){const{splitAll:n}=this.methods.one.pointer,r=Re(e,this,t).fullPointer,o=n(this.fullPointer,r);for(let e=0;e{a.push(e.passthrough),a.push(e.before),e.match&&e.after?a.push(Ue(e.match,e.after)):a.push(e.match)})),a=a.filter((e=>e)),a=a.map((e=>Qe(e,this))),this.update(a)},splitAfter:function(e,t){const{splitAll:n}=this.methods.one.pointer,r=Re(e,this,t).fullPointer,o=n(this.fullPointer,r);let a=[];return o.forEach((e=>{a.push(e.passthrough),e.before&&e.match?a.push(Ue(e.before,e.match)):(a.push(e.before),a.push(e.match)),a.push(e.after)})),a=a.filter((e=>e)),a=a.map((e=>Qe(e,this))),this.update(a)}};Ze.split=Ze.splitAfter;const _e=function(e,t){return!(!e||!t)&&(e[0]===t[0]&&e[2]===t[1])},Xe=function(e,t,n){const r=e.world,o=r.methods.one.parseMatch;n=n||"^.";const a=o(t=t||".$",{},r),i=o(n,{},r);a[a.length-1].end=!0,i[0].start=!0;const s=e.fullPointer,l=[s[0]];for(let t=1;t)?\/.*?[^\\/]\/[?\]+*$~]*)(?:\s|$)/,nt=/([!~[^]*(?:<[^<]*>)?\([^)]+[^\\)]\)[?\]+*$~]*)(?:\s|$)/,rt=/ /g,ot=e=>/^[![^]*(<[^<]*>)?\//.test(e)&&/\/[?\]+*$~]*$/.test(e),at=function(e){return e=(e=e.map((e=>e.trim()))).filter((e=>e))},it=/\{([0-9]+)?(, *[0-9]*)?\}/,st=/&&/,lt=new RegExp(/^<\s*(\S+)\s*>/),ut=e=>e.charAt(0).toUpperCase()+e.substring(1),ct=e=>e.charAt(e.length-1),ht=e=>e.charAt(0),dt=e=>e.substring(1),gt=e=>e.substring(0,e.length-1),mt=function(e){return e=dt(e),e=gt(e)},pt=function(e,t){const n={};for(let r=0;r<2;r+=1){if("$"===ct(e)&&(n.end=!0,e=gt(e)),"^"===ht(e)&&(n.start=!0,e=dt(e)),"?"===ct(e)&&(n.optional=!0,e=gt(e)),("["===ht(e)||"]"===ct(e))&&(n.group=null,"["===ht(e)&&(n.groupStart=!0),"]"===ct(e)&&(n.groupEnd=!0),e=(e=e.replace(/^\[/,"")).replace(/\]$/,""),"<"===ht(e))){const t=lt.exec(e);t.length>=2&&(n.group=t[1],e=e.replace(t[0],""))}if("+"===ct(e)&&(n.greedy=!0,e=gt(e)),"*"!==e&&"*"===ct(e)&&"\\*"!==e&&(n.greedy=!0,e=gt(e)),"!"===ht(e)&&(n.negative=!0,e=dt(e)),"~"===ht(e)&&"~"===ct(e)&&e.length>2&&(e=mt(e),n.fuzzy=!0,n.min=t.fuzzy||.85,!1===/\(/.test(e)))return n.word=e,n;if("/"===ht(e)&&"/"===ct(e))return e=mt(e),t.caseSensitive&&(n.use="text"),n.regex=new RegExp(e),n;if(!0===it.test(e)&&(e=e.replace(it,((e,t,r)=>(void 0===r?(n.min=Number(t),n.max=Number(t)):(r=r.replace(/, */,""),void 0===t?(n.min=0,n.max=Number(r)):(n.min=Number(t),n.max=Number(r||999))),n.greedy=!0,n.min||(n.optional=!0),"")))),"("===ht(e)&&")"===ct(e)){st.test(e)?(n.choices=e.split(st),n.operator="and"):(n.choices=e.split("|"),n.operator="or"),n.choices[0]=dt(n.choices[0]);const r=n.choices.length-1;n.choices[r]=gt(n.choices[r]),n.choices=n.choices.map((e=>e.trim())),n.choices=n.choices.filter((e=>e)),n.choices=n.choices.map((e=>e.split(/ /g).map((e=>pt(e,t))))),e=""}if("{"===ht(e)&&"}"===ct(e)){if(e=mt(e),n.root=e,/\//.test(e)){const e=n.root.split(/\//);n.root=e[0],n.pos=e[1],"adj"===n.pos&&(n.pos="Adjective"),n.pos=n.pos.charAt(0).toUpperCase()+n.pos.substr(1).toLowerCase(),void 0!==e[2]&&(n.sense=e[2])}return n}if("<"===ht(e)&&">"===ct(e))return e=mt(e),n.chunk=ut(e),n.greedy=!0,n;if("%"===ht(e)&&"%"===ct(e))return e=mt(e),n.switch=e,n}return"#"===ht(e)?(n.tag=dt(e),n.tag=ut(n.tag),n):"@"===ht(e)?(n.method=dt(e),n):"."===e?(n.anything=!0,n):"*"===e?(n.anything=!0,n.greedy=!0,n.optional=!0,n):(e&&(e=(e=e.replace("\\*","*")).replace("\\.","."),t.caseSensitive?n.use="text":e=e.toLowerCase(),n.word=e),n)},ft=/[a-z0-9][-–—][a-z]/i,bt=function(e,t){const{all:n}=t.methods.two.transform.verb||{},r=e.root;return n?n(r,t.model):[]},vt=function(e,t){const{all:n}=t.methods.two.transform.noun||{};return n?n(e.root,t.model):[e.root]},yt=function(e,t){const{all:n}=t.methods.two.transform.adjective||{};return n?n(e.root,t.model):[e.root]},wt=function(e){return e=function(e){let t=0,n=null;for(let r=0;r(e.fuzzy&&e.choices&&e.choices.forEach((t=>{1===t.length&&t[0].word&&(t[0].fuzzy=!0,t[0].min=e.min)})),e)))}(e=e.map((e=>{if(void 0!==e.choices){if("or"!==e.operator)return e;if(!0===e.fuzzy)return e;!0===e.choices.every((e=>{if(1!==e.length)return!1;const t=e[0];return!0!==t.fuzzy&&!t.start&&!t.end&&void 0!==t.word&&!0!==t.negative&&!0!==t.optional&&!0!==t.method}))&&(e.fastOr=new Set,e.choices.forEach((t=>{e.fastOr.add(t[0].word)})),delete e.choices)}return e}))),e},kt=function(e,t){for(const n of t)if(e.has(n))return!0;return!1},Pt=function(e,t){for(let n=0;nn?r:n)+1;if(Math.abs(n-r)>(o||100))return o||100;const a=[];for(let e=0;e4)return n;l=t[i-1],u=s===l?0:1,c=a[o-1][i]+1,(h=a[o][i-1]+1)1&&i>1&&s===t[i-2]&&e[o-2]===l&&(h=a[o-2][i-2]+u)-1!==e.post.indexOf(t),Tt={hasQuote:e=>Ct.test(e.pre)||Nt.test(e.post),hasComma:e=>It(e,","),hasPeriod:e=>!0===It(e,".")&&!1===It(e,"..."),hasExclamation:e=>It(e,"!"),hasQuestionMark:e=>It(e,"?")||It(e,"¿"),hasEllipses:e=>It(e,"..")||It(e,"…"),hasSemicolon:e=>It(e,";"),hasColon:e=>It(e,":"),hasSlash:e=>/\//.test(e.text),hasHyphen:e=>jt.test(e.post)||jt.test(e.pre),hasDash:e=>xt.test(e.post)||xt.test(e.pre),hasContraction:e=>Boolean(e.implicit),isAcronym:e=>e.tags.has("Acronym"),isKnown:e=>e.tags.size>0,isTitleCase:e=>/^\p{Lu}[a-z'\u00C0-\u00FF]/u.test(e.text),isUpperCase:e=>/^\p{Lu}+$/u.test(e.text)};Tt.hasQuotation=Tt.hasQuote;let Dt=function(){};Dt=function(e,t,n,r){const o=function(e,t,n,r){if(!0===t.anything)return!0;if(!0===t.start&&0!==n)return!1;if(!0===t.end&&n!==r-1)return!1;if(void 0!==t.id&&t.id===e.id)return!0;if(void 0!==t.word){if(t.use)return t.word===e[t.use];if(null!==e.machine&&e.machine===t.word)return!0;if(void 0!==e.alias&&e.alias.hasOwnProperty(t.word))return!0;if(!0===t.fuzzy){if(t.word===e.root)return!0;if(At(t.word,e.normal)>=t.min)return!0}return!(!e.alias||!e.alias.some((e=>e===t.word)))||t.word===e.text||t.word===e.normal}if(void 0!==t.tag)return!0===e.tags.has(t.tag);if(void 0!==t.method)return"function"==typeof Tt[t.method]&&!0===Tt[t.method](e);if(void 0!==t.pre)return e.pre&&e.pre.includes(t.pre);if(void 0!==t.post)return e.post&&e.post.includes(t.post);if(void 0!==t.regex){let n=e.normal;return t.use&&(n=e[t.use]),t.regex.test(n)}if(void 0!==t.chunk)return e.chunk===t.chunk;if(void 0!==t.switch)return e.switch===t.switch;if(void 0!==t.machine)return e.normal===t.machine||e.machine===t.machine||e.root===t.machine;if(void 0!==t.sense)return e.sense===t.sense;if(void 0!==t.fastOr){if(t.pos&&!e.tags.has(t.pos))return null;const n=e.root||e.implicit||e.machine||e.normal;return t.fastOr.has(n)||t.fastOr.has(e.text)}return void 0!==t.choices&&("and"===t.operator?t.choices.every((t=>Dt(e,t,n,r))):t.choices.some((t=>Dt(e,t,n,r))))}(e,t,n,r);return!0===t.negative?!o:o};const Ht=function(e,t){if(!0===e.end&&!0===e.greedy&&t.start_i+t.tn.max)return e.t=e.t+n.max,!0;if(!0===e.hasGroup){Et(e,e.t).length=r-e.t}return e.t=r,!0},Ot=function(e,t=0){const n=e.regs[e.r];let r=!1;for(let a=0;a{let o=0;const a=e.t+r+t+o;if(void 0===e.terms[a])return!1;const i=Dt(e.terms[a],n,a+e.start_i,e.phrase_length);if(!0===i&&!0===n.greedy)for(let t=1;t{const r=n.every(((t,n)=>{const r=e.t+n;return void 0!==e.terms[r]&&Dt(e.terms[r],t,r,e.phrase_length)}));return!0===r&&n.length>t&&(t=n.length),r}))&&t}(e);if(r){if(!0===n.negative)return null;if(!0===e.hasGroup){Et(e,e.t).length+=r}if(!0===n.end){const t=e.phrase_length-1;if(e.t+e.start_i!==t)return null}return e.t+=r,!0}return!!n.optional||null},zt=function(e){const{regs:t}=e,n=t[e.r],r=Object.assign({},n);r.negative=!1;if(Dt(e.terms[e.t],r,e.start_i+e.t,e.phrase_length))return!1;if(n.optional){const n=t[e.r+1];if(n){if(Dt(e.terms[e.t],n,e.start_i+e.t,e.phrase_length))e.r+=1;else if(n.optional&&t[e.r+2]){Dt(e.terms[e.t],t[e.r+2],e.start_i+e.t,e.phrase_length)&&(e.r+=2)}}}return n.greedy?function(e,t,n){let r=0;for(let o=e.t;or||(e.t+=r,0))}(e,r,t[e.r+1]):(e.t+=1,!0)},Bt=function(e){const{regs:t,phrase_length:n}=e,r=t[e.r];return e.t=function(e,t){const n=Object.assign({},e.regs[e.r],{start:!1,end:!1}),r=e.t;for(;e.te.t?null:!0!==r.end||e.start_i+e.t===n||null},St=function(e){const{regs:t}=e,n=t[e.r],r=e.terms[e.t],o=e.t;if(n.optional&&t[e.r+1]&&n.negative)return!0;if(n.optional&&t[e.r+1]&&function(e){const{regs:t}=e,n=t[e.r],r=e.terms[e.t],o=Dt(r,t[e.r+1],e.start_i+e.t,e.phrase_length);if(n.negative||o){const n=e.terms[e.t+1];n&&Dt(n,t[e.r+1],e.start_i+e.t,e.phrase_length)||(e.r+=1)}}(e),r.implicit&&e.terms[e.t+1]&&function(e){const t=e.terms[e.t],n=e.regs[e.r];if(t.implicit&&e.terms[e.t+1]){if(!e.terms[e.t+1].implicit)return;n.word===t.normal&&(e.t+=1),"hasContraction"===n.method&&(e.t+=1)}}(e),e.t+=1,!0===n.end&&e.t!==e.terms.length&&!0!==n.greedy)return null;if(!0===n.greedy){if(!Bt(e))return null}return!0===e.hasGroup&&function(e,t){const n=e.regs[e.r],r=Et(e,t);e.t>1&&n.greedy?r.length+=e.t-t:r.length++}(e,o),!0},$t=function(e,t,n,r){if(0===e.length||0===t.length)return null;const o={t:0,terms:e,r:0,regs:t,groups:{},start_i:n,phrase_length:r,inGroup:null};for(;o.r!e.optional)))break;return null}if(!0===e.anything&&!0===e.greedy){if(!Gt(o))return null;continue}if(void 0!==e.choices&&"or"===e.operator){if(!Ft(o))return null;continue}if(void 0!==e.choices&&"and"===e.operator){if(!Vt(o))return null;continue}if(!0===e.anything){if(e.negative&&e.anything)return null;if(!St(o))return null;continue}if(!0===Ht(e,o)){if(!St(o))return null;continue}if(e.negative){if(!zt(o))return null;continue}if(!0!==Dt(o.terms[o.t],e,o.start_i+o.t,o.phrase_length)){if(!0!==e.optional)return null}else{if(!St(o))return null}}const a=[null,n,o.t+n];if(a[1]===a[2])return null;const i={};return Object.keys(o.groups).forEach((e=>{const t=o.groups[e],r=n+t.start;i[e]=[null,r,r+t.length]})),{pointer:a,groups:i}},Mt=function(e,t){return e.pointer[0]=t,Object.keys(e.groups).forEach((n=>{e.groups[n][0]=t})),e},Lt=function(e,t,n){let r=$t(e,t,0,e.length);return r?(r=Mt(r,n),r):null},Kt={one:{termMethods:Tt,parseMatch:function(e,t,n){if(null==e||""===e)return[];t=t||{},"number"==typeof e&&(e=String(e));let r=function(e){const t=e.split(tt);let n=[];t.forEach((e=>{ot(e)?n.push(e):n=n.concat(e.split(nt))})),n=at(n);let r=[];return n.forEach((e=>{(e=>/^[![^]*(<[^<]*>)?\(/.test(e)&&/\)[?\]+*$~]*$/.test(e))(e)||ot(e)?r.push(e):r=r.concat(e.split(rt))})),r=at(r),r}(e);return r=r.map((e=>pt(e,t))),r=function(e,t){const n=t.model.one.prefixes;for(let t=e.length-1;t>=0;t-=1){const r=e[t];if(r.word&&ft.test(r.word)){let o=r.word.split(/[-–—]/g);if(n.hasOwnProperty(o[0]))continue;o=o.filter((e=>e)).reverse(),e.splice(t,1),o.forEach((n=>{const o=Object.assign({},r);o.word=n,e.splice(t,0,o)}))}}return e}(r,n),r=function(e,t){return e.map((e=>{if(e.root)if(t.methods.two&&t.methods.two.transform){let n=[];e.pos?"Verb"===e.pos?n=n.concat(bt(e,t)):"Noun"===e.pos?n=n.concat(vt(e,t)):"Adjective"===e.pos&&(n=n.concat(yt(e,t))):(n=n.concat(bt(e,t)),n=n.concat(vt(e,t)),n=n.concat(yt(e,t))),n=n.filter((e=>e)),n.length>0&&(e.operator="or",e.fastOr=new Set(n))}else e.machine=e.root,delete e.id,delete e.root;return e}))}(r,n),r=wt(r),r},match:function(e,t,n){n=n||[];const{regs:r,group:o,justOne:a}=t;let i=[];if(!r||0===r.length)return{ptrs:[],byGroup:{}};const s=r.filter((e=>!0!==e.optional&&!0!==e.negative)).length;e:for(let t=0;te&&(e=Math.abs(n-1))}}else{const e=Lt(o,r,t);e&&i.push(e)}}return!0===r[r.length-1].end&&(i=i.filter((t=>{const n=t.pointer[0];return e[n].length===t.pointer[2]}))),t.notIf&&(i=function(e,t,n){return e=e.filter((e=>{const[r,o,a]=e.pointer,i=n[r].slice(o,a);for(let e=0;e{e.groups[t]&&n.push(e.groups[t])})):e.forEach((e=>{n.push(e.pointer),Object.keys(e.groups).forEach((t=>{r[t]=r[t]||[],r[t].push(e.groups[t])}))}))),{ptrs:n,byGroup:r}}(i,o),i.ptrs.forEach((t=>{const[n,r,o]=t;t[3]=e[n][r].id,t[4]=e[n][o-1].id})),i}}};var Jt={api:function(e){Object.assign(e.prototype,et)},methods:Kt,lib:{parseMatch:function(e,t){const n=this.world(),r=n.methods.one.killUnicode;return r&&(e=r(e,n)),n.methods.one.parseMatch(e,t,n)}}};const Wt=/^\../,qt=/^#./,Ut=function(e,t){const n={},r={};return Object.keys(t).forEach((o=>{let a=t[o];const i=function(e){let t="",n=" ";return e=e.replace(/&/g,"&").replace(//g,">").replace(/"/g,""").replace(/'/g,"'"),Wt.test(e)?t=``),t+=">",{start:t,end:n}}(o);"string"==typeof a&&(a=e.match(a)),a.docs.forEach((e=>{if(e.every((e=>e.implicit)))return;const t=e[0].id;n[t]=n[t]||[],n[t].push(i.start);const o=e[e.length-1].id;r[o]=r[o]||[],r[o].push(i.end)}))})),{starts:n,ends:r}};var Rt={html:function(e){const{starts:t,ends:n}=Ut(this,e);let r="";return this.docs.forEach((e=>{for(let o=0;o{let n=e.pre||"",o=e.post||"";"some"===t.punctuation&&(n=n.replace(Zt,""),Xt.test(o)&&(o=" "),o=o.replace(_t,""),o=o.replace(/\?!+/,"?"),o=o.replace(/!+/,"!"),o=o.replace(/\?+/,"?"),o=o.replace(/\.{2,}/,""),e.tags.has("Abbreviation")&&(o=o.replace(/\./,""))),"some"===t.whitespace&&(n=n.replace(/\s/,""),o=o.replace(/\s+/," ")),t.keepPunct||(n=n.replace(Zt,""),o="-"===o?" ":o.replace(Qt,""));let a=e[t.form||"text"]||e.normal||"";"implicit"===t.form&&(a=e.implicit||e.text),"root"===t.form&&e.implicit&&(a=e.root||e.implicit||e.normal),"machine"!==t.form&&"implicit"!==t.form&&"root"!==t.form||!e.implicit||o&&Yt.test(o)||(o+=" "),r+=n+a+o})),!1===n&&(r=r.trim()),!0===t.lowerCase&&(r=r.toLowerCase()),r},tn={text:{form:"text"},normal:{whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"normal"},machine:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"none",unicode:"some",form:"machine"},root:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"root"},implicit:{form:"implicit"}};tn.clean=tn.normal,tn.reduced=tn.root;const nn=[];let rn=0;for(;rn<64;)nn[rn]=0|4294967296*Math.sin(++rn%Math.PI);const on=function(e){let t,n,r,o=decodeURI(encodeURI(e))+"",a=o.length;const i=[t=1732584193,n=4023233417,~t,~n],s=[];for(e=--a/4+2|15,s[--e]=8*a;~a;)s[a>>2]|=o.charCodeAt(a)<<8*a--;for(rn=o=0;rn>4]+nn[o]+~~s[rn|15&[o,5*o+1,3*o+5,7*o][a]])<<(a=[7,12,17,22,5,9,14,20,4,11,16,23,6,10,15,21][4*a+o++%4])|r>>>-a),t,n])t=0|a[1],n=a[2];for(o=4;o;)i[--o]+=a[o]}for(e="";o<32;)e+=(i[o>>3]>>4*(1^o++)&15).toString(16);return e},an={text:!0,terms:!0},sn={case:"none",unicode:"some",form:"machine",punctuation:"some"},ln=function(e,t){return Object.assign({},e,t)},un={text:e=>en(e,{keepPunct:!0},!1),normal:e=>en(e,ln(tn.normal,{keepPunct:!0}),!1),implicit:e=>en(e,ln(tn.implicit,{keepPunct:!0}),!1),machine:e=>en(e,sn,!1),root:e=>en(e,ln(sn,{form:"root"}),!1),hash:e=>on(en(e,{keepPunct:!0},!1)),offset:e=>{const t=un.text(e).length;return{index:e[0].offset.index,start:e[0].offset.start,length:t}},terms:e=>e.map((e=>{const t=Object.assign({},e);return t.tags=Array.from(e.tags),t})),confidence:(e,t,n)=>t.eq(n).confidence(),syllables:(e,t,n)=>t.eq(n).syllables(),sentence:(e,t,n)=>t.eq(n).fullSentence().text(),dirty:e=>e.some((e=>!0===e.dirty))};un.sentences=un.sentence,un.clean=un.normal,un.reduced=un.root;const cn={json:function(e){const t=(n=this,"string"==typeof(r=(r=e)||{})&&(r={}),(r=Object.assign({},an,r)).offset&&n.compute("offset"),n.docs.map(((e,t)=>{const o={};return Object.keys(r).forEach((a=>{r[a]&&un[a]&&(o[a]=un[a](e,n,t))})),o})));var n,r;return"number"==typeof e?t[e]:t}};cn.data=cn.json;const hn=function(e){const t=e.pre||"",n=e.post||"";return t+e.text+n},dn=function(e,t){const n=function(e,t){const n={};return Object.keys(t).forEach((r=>{e.match(r).fullPointer.forEach((e=>{n[e[3]]={fn:t[r],end:e[2]}}))})),n}(e,t);let r="";return e.docs.forEach(((t,o)=>{for(let a=0;ae.reduce(((e,t)=>e+t.pre+t.text+t.post),"").trim()));return e.filter((e=>e))}if("freq"===e||"frequency"===e||"topk"===e)return function(e){const t={};e.forEach((e=>{t[e]=t[e]||0,t[e]+=1}));const n=Object.keys(t).map((e=>({normal:e,count:t[e]})));return n.sort(((e,t)=>e.count>t.count?-1:0))}(this.json({normal:!0}).map((e=>e.normal)));if("terms"===e){let e=[];return this.docs.forEach((t=>{let n=t.map((e=>e.text));n=n.filter((e=>e)),e=e.concat(n)})),e}return"tags"===e?this.docs.map((e=>e.reduce(((e,t)=>(e[t.implicit||t.normal]=Array.from(t.tags),e)),{}))):"debug"===e?this.debug():this.text()},wrap:function(e){return dn(this,e)}};var mn={text:function(e){let t={};var n;if(e&&"string"==typeof e&&tn.hasOwnProperty(e)?t=Object.assign({},tn[e]):e&&(n=e,"[object Object]"===Object.prototype.toString.call(n))&&(t=Object.assign({},e)),void 0!==t.keepSpace||this.isFull()||(t.keepSpace=!1),void 0===t.keepEndPunct&&this.pointer){const e=this.pointer[0];e&&e[1]?t.keepEndPunct=!1:t.keepEndPunct=!0}return void 0===t.keepPunct&&(t.keepPunct=!0),void 0===t.keepSpace&&(t.keepSpace=!0),function(e,t){let n="";if(!e||!e[0]||!e[0][0])return n;for(let r=0;r"�[32m"+e+fn,red:e=>"�[31m"+e+fn,blue:e=>"�[34m"+e+fn,magenta:e=>"�[35m"+e+fn,cyan:e=>"�[36m"+e+fn,yellow:e=>"�[33m"+e+fn,black:e=>"�[30m"+e+fn,dim:e=>"�[2m"+e+fn,i:e=>"�[3m"+e+fn},vn={tags:function(e){const{docs:t,model:n}=e;0===t.length&&console.log(bn.blue("\n ──────")),t.forEach((t=>{console.log(bn.blue("\n ┌─────────")),t.forEach((t=>{const r=[...t.tags||[]];let o=t.text||"-";t.sense&&(o=`{${t.normal}/${t.sense}}`),t.implicit&&(o="["+t.implicit+"]"),o=bn.yellow(o);let a="'"+o+"'";if(t.reference){const n=e.update([t.reference]).text("normal");a+=` - ${bn.dim(bn.i("["+n+"]"))}`}a=a.padEnd(18);const i=bn.blue(" │ ")+bn.i(a)+" - "+function(e,t){return t.one.tagSet&&(e=e.map((e=>{if(!t.one.tagSet.hasOwnProperty(e))return e;const n=t.one.tagSet[e].color||"blue";return bn[n](e)}))),e.join(", ")}(r,n);console.log(i)}))})),console.log("\n")},clientSide:function(e){console.log("%c -=-=- ","background-color:#6699cc;"),e.forEach((e=>{console.groupCollapsed(e.text());const t=e.docs[0].map((e=>{let t=e.text||"-";e.implicit&&(t="["+e.implicit+"]");return{text:t,tags:"["+Array.from(e.tags).join(", ")+"]"}}));console.table(t,["text","tags"]),console.groupEnd()}))},chunks:function(e){const{docs:t}=e;console.log(""),t.forEach((e=>{const t=[];e.forEach((e=>{"Noun"===e.chunk?t.push(bn.blue(e.implicit||e.normal)):"Verb"===e.chunk?t.push(bn.green(e.implicit||e.normal)):"Adjective"===e.chunk?t.push(bn.yellow(e.implicit||e.normal)):"Pivot"===e.chunk?t.push(bn.red(e.implicit||e.normal)):t.push(e.implicit||e.normal)})),console.log(t.join(" "),"\n")})),console.log("\n")},highlight:function(e){if(!e.found)return;const t={};e.fullPointer.forEach((e=>{t[e[0]]=t[e[0]]||[],t[e[0]].push(e)})),Object.keys(t).forEach((n=>{let r=e.update([[Number(n)]]).text();e.update(t[n]).json({offset:!0}).forEach(((e,t)=>{r=function(e,t,n){const r=((e,t,n)=>{const r=9*n,o=t.start+r,a=o+t.length;return[e.substring(0,o),e.substring(o,a),e.substring(a,e.length)]})(e,t,n);return`${r[0]}${bn.blue(r[1])}${r[2]}`}(r,e.offset,t)})),console.log(r)})),console.log("\n")}};var yn={api:function(e){Object.assign(e.prototype,pn)},methods:{one:{hash:on,debug:vn}}};const wn=function(e,t){if(e[0]!==t[0])return!1;const[,n,r]=e,[,o,a]=t;return n<=o&&r>o||o<=n&&a>n},kn=function(e){const t={};return e.forEach((e=>{t[e[0]]=t[e[0]]||[],t[e[0]].push(e)})),t},Pn=function(e,t){const n=kn(t),r=[];return e.forEach((e=>{const[t]=e;let o=n[t]||[];if(o=o.filter((t=>function(e,t){return e[1]<=t[1]&&t[2]<=e[2]}(e,t))),0===o.length)return void r.push({passthrough:e});o=o.sort(((e,t)=>e[1]-t[1]));let a=e;o.forEach(((e,t)=>{const n=function(e,t){const[n,r]=e,o=t[1],a=t[2],i={};if(ra&&(i.after=[n,a,e[2]]),i}(a,e);o[t+1]?(r.push({before:n.before,match:n.match}),n.after&&(a=n.after)):r.push(n)}))})),r};var An={one:{termList:function(e){const t=[];for(let n=0;n{if(!r)return;let[a,i,s,l,u]=r,c=t[a]||[];if(void 0===i&&(i=0),void 0===s&&(s=c.length),!l||c[i]&&c[i].id===l)c=c.slice(i,s);else{const n=function(e,t,n){for(let r=0;r<20;r+=1){if(t[n-r]){const o=t[n-r].findIndex((t=>t.id===e));if(-1!==o)return[n-r,o]}if(t[n+r]){const o=t[n+r].findIndex((t=>t.id===e));if(-1!==o)return[n+r,o]}}return null}(l,t,a);if(null!==n){const r=s-i;c=t[n[0]].slice(n[1],n[1]+r);const a=c[0]?c[0].id:null;e[o]=[n[0],n[1],n[1]+r,a]}}0!==c.length&&i!==s&&(u&&c[c.length-1].id!==u&&(c=function(e,t){const[n,r,,,o]=e,a=t[n],i=a.findIndex((e=>e.id===o));return-1===i?(e[2]=t[n].length,e[4]=a.length?a[a.length-1].id:null):e[2]=i,t[n].slice(r,e[2]+1)}(r,t)),n.push(c))})),n=n.filter((e=>e.length>0)),n},pointer:{indexN:kn,splitAll:Pn}}};const Cn=function(e,t){const n=e.concat(t),r=kn(n);let o=[];return n.forEach((e=>{const[t]=e;if(1===r[t].length)return void o.push(e);const n=r[t].filter((t=>wn(e,t)));n.push(e);const a=function(e){let t=e[0][1],n=e[0][2];return e.forEach((e=>{e[1]n&&(n=e[2])})),[e[0][0],t,n]}(n);o.push(a)})),o=function(e){const t={};for(let n=0;n{e.passthrough&&n.push(e.passthrough),e.before&&n.push(e.before),e.after&&n.push(e.after)})),n},jn=(e,t)=>{return"string"==typeof e||(n=e,"[object Array]"===Object.prototype.toString.call(n))?t.match(e):e||t.none();var n},xn=function(e,t){return e.map((e=>{const[n,r]=e;return t[n]&&t[n][r]&&(e[3]=t[n][r].id),e}))},In={union:function(e){e=jn(e,this);let t=Cn(this.fullPointer,e.fullPointer);return t=xn(t,this.document),this.toView(t)}};In.and=In.union,In.intersection=function(e){e=jn(e,this);let t=function(e,t){const n=kn(t),r=[];return e.forEach((e=>{let t=n[e[0]]||[];t=t.filter((t=>wn(e,t))),0!==t.length&&t.forEach((t=>{const n=function(e,t){const n=e[1]t[2]?t[2]:e[2];return n{e=Cn(e,[t])})),e=xn(e,this.document),this.update(e)};var Tn={methods:An,api:function(e){Object.assign(e.prototype,In)}};const Dn=function(e){return!0===e.optional||!0===e.negative?null:e.tag?"#"+e.tag:e.word?e.word:e.switch?`%${e.switch}%`:null},Hn=function(e,t){const n=t.methods.one.parseMatch;return e.forEach((e=>{e.regs=n(e.match,{},t),"string"==typeof e.ifNo&&(e.ifNo=[e.ifNo]),e.notIf&&(e.notIf=n(e.notIf,{},t)),e.needs=function(e){const t=[];return e.forEach((e=>{t.push(Dn(e)),"and"===e.operator&&e.choices&&e.choices.forEach((e=>{e.forEach((e=>{t.push(Dn(e))}))}))})),t.filter((e=>e))}(e.regs);const{wants:r,count:o}=function(e){const t=[];let n=0;return e.forEach((e=>{"or"!==e.operator||e.optional||e.negative||(e.fastOr&&Array.from(e.fastOr).forEach((e=>{t.push(e)})),e.choices&&e.choices.forEach((e=>{e.forEach((e=>{const n=Dn(e);n&&t.push(n)}))})),n+=1)})),{wants:t,count:n}}(e.regs);e.wants=r,e.minWant=o,e.minWords=e.regs.filter((e=>!e.optional)).length})),e};var En={buildNet:function(e,t){e=Hn(e,t);const n={};e.forEach((e=>{e.needs.forEach((t=>{n[t]=Array.isArray(n[t])?n[t]:[],n[t].push(e)})),e.wants.forEach((t=>{n[t]=Array.isArray(n[t])?n[t]:[],n[t].push(e)}))})),Object.keys(n).forEach((e=>{const t={};n[e]=n[e].filter((e=>"boolean"!=typeof t[e.match]&&(t[e.match]=!0,!0)))}));const r=e.filter((e=>0===e.needs.length&&0===e.wants.length));return{hooks:n,always:r}},bulkMatch:function(e,t,n,r={}){const o=n.one.cacheDoc(e);let a=function(e,t){return e.map(((n,r)=>{let o=[];Object.keys(t).forEach((n=>{e[r].has(n)&&(o=o.concat(t[n]))}));const a={};return o=o.filter((e=>"boolean"!=typeof a[e.match]&&(a[e.match]=!0,!0))),o}))}(o,t.hooks);a=function(e,t){return e.map(((e,n)=>{const r=t[n];return(e=(e=e.filter((e=>e.needs.every((e=>r.has(e)))))).filter((e=>void 0===e.ifNo||!0!==e.ifNo.some((e=>r.has(e)))))).filter((e=>0===e.wants.length||e.wants.filter((e=>r.has(e))).length>=e.minWant))}))}(a,o),t.always.length>0&&(a=a.map((e=>e.concat(t.always)))),a=function(e,t){return e.map(((e,n)=>{const r=t[n].length;return e=e.filter((e=>r>=e.minWords)),e}))}(a,e);const i=function(e,t,n,r,o){const a=[];for(let n=0;n0&&(l.ptrs.forEach((e=>{e[0]=n;const t=Object.assign({},s,{pointer:e});void 0!==s.unTag&&(t.unTag=s.unTag),a.push(t)})),!0===o.matchOne))return[a[0]]}return a}(a,e,0,n,r);return i},bulkTagger:function(e,t,n){const{model:r,methods:o}=n,{getDoc:a,setTag:i,unTag:s}=o.one,l=o.two.looksPlural;if(0===e.length)return e;return("undefined"!=typeof process&&process.env?process.env:self.env||{}).DEBUG_TAGS&&console.log(`\n\n �[32m→ ${e.length} post-tagger:�[0m`),e.map((e=>{if(!e.tag&&!e.chunk&&!e.unTag)return;const o=e.reason||e.match,u=a([e.pointer],t)[0];if(!0===e.safe){if(!1===function(e,t,n){const r=n.one.tagSet;if(!r.hasOwnProperty(t))return!0;const o=r[t].not||[];for(let t=0;te.frozen=!0))}void 0!==e.unTag&&s(u,e.unTag,n,e.safe,o),e.chunk&&u.forEach((t=>t.chunk=e.chunk))}))}},Gn={lib:{buildNet:function(e){const t=this.methods().one.buildNet(e,this.world());return t.isNet=!0,t}},api:function(e){e.prototype.sweep=function(e,t={}){const{world:n,docs:r}=this,{methods:o}=n;let a=o.one.bulkMatch(r,e,this.methods,t);!1!==t.tagger&&o.one.bulkTagger(a,r,this.world),a=a.map((e=>{const t=e.pointer,n=r[t[0]][t[1]],o=t[2]-t[1];return n.index&&(e.pointer=[n.index[0],n.index[1],t[1]+o]),e}));const i=a.map((e=>e.pointer));return a=a.map((e=>(e.view=this.update([e.pointer]),delete e.regs,delete e.needs,delete e.pointer,delete e._expanded,e))),{view:this.update(i),found:a}}},methods:{one:En}};const On=/ /,Fn=function(e,t){"Noun"===t&&(e.chunk=t),"Verb"===t&&(e.chunk=t)},Vn=function(e,t,n,r){if(!0===e.tags.has(t))return null;if("."===t)return null;!0===e.frozen&&(r=!0);const o=n[t];if(o){if(o.not&&o.not.length>0)for(let t=0;t0)for(let t=0;t{const r=e.map((e=>e.text||"["+e.implicit+"]")).join(" ");var o;"string"!=typeof t&&t.length>2&&(t=t.slice(0,2).join(", #")+" +"),t="string"!=typeof t?t.join(", #"):t,console.log(` ${(o=r,"�[33m�[3m"+o+"�[0m").padEnd(24)} �[32m→�[0m #${t.padEnd(22)} ${(e=>"�[3m"+e+"�[0m")(n)}`)})(e,t,o),!0!=(s=t,"[object Array]"===Object.prototype.toString.call(s)))if("string"==typeof t)if(t=t.trim(),On.test(t))!function(e,t,n,r){const o=t.split(On);e.forEach(((e,t)=>{let a=o[t];a&&(a=a.replace(/^#/,""),Vn(e,a,n,r))}))}(e,t,a,r);else{t=t.replace(/^#/,"");for(let n=0;nzn(e,t,n,r)))},Bn=function(e){return e.children=e.children||[],e._cache=e._cache||{},e.props=e.props||{},e._cache.parents=e._cache.parents||[],e._cache.children=e._cache.children||[],e},Sn=/^ *(#|\/\/)/,$n=function(e){let t=e.trim().split(/->/),n=[];t.forEach((e=>{n=n.concat(function(e){if(!(e=e.trim()))return null;if(/^\[/.test(e)&&/\]$/.test(e)){let t=(e=(e=e.replace(/^\[/,"")).replace(/\]$/,"")).split(/,/);return t=t.map((e=>e.trim())).filter((e=>e)),t=t.map((e=>Bn({id:e}))),t}return[Bn({id:e})]}(e))})),n=n.filter((e=>e));let r=n[0];for(let e=1;e{let n=[],r=[e];for(;r.length>0;){let e=r.pop();n.push(e),e.children&&e.children.forEach((n=>{t&&t(e,n),r.push(n)}))}return n},Ln=e=>"[object Array]"===Object.prototype.toString.call(e),Kn=e=>(e=e||"").trim(),Jn=function(e=[]){return"string"==typeof e?function(e){let t=e.split(/\r?\n/),n=[];t.forEach((e=>{if(!e.trim()||Sn.test(e))return;let t=(e=>{const t=/^( {2}|\t)/;let n=0;for(;t.test(e);)e=e.replace(t,""),n+=1;return n})(e);n.push({indent:t,node:$n(e)})}));let r=function(e){let t={children:[]};return e.forEach(((n,r)=>{0===n.indent?t.children=t.children.concat(n.node):e[r-1]&&function(e,t){let n=e[t].indent;for(;t>=0;t-=1)if(e[t].indent{t[e.id]=e}));let n=Bn({});return e.forEach((e=>{if((e=Bn(e)).parent)if(t.hasOwnProperty(e.parent)){let n=t[e.parent];delete e.parent,n.children.push(e)}else console.warn(`[Grad] - missing node '${e.parent}'`);else n.children.push(e)})),n}(e):(Mn(t=e).forEach(Bn),t);var t},Wn=function(e,t){let n="-> ";t&&(n=(e=>"�[2m"+e+"�[0m")("→ "));let r="";return Mn(e).forEach(((e,o)=>{let a=e.id||"";if(t&&(a=(e=>"�[31m"+e+"�[0m")(a)),0===o&&!e.id)return;let i=e._cache.parents.length;r+=" ".repeat(i)+n+a+"\n"})),r},qn=function(e){let t=Mn(e);t.forEach((e=>{delete(e=Object.assign({},e)).children}));let n=t[0];return n&&!n.id&&0===Object.keys(n.props).length&&t.shift(),t},Un={text:Wn,txt:Wn,array:qn,flat:qn},Rn=function(e,t){return"nested"===t||"json"===t?e:"debug"===t?(console.log(Wn(e,!0)),null):Un.hasOwnProperty(t)?Un[t](e):e},Qn=e=>{Mn(e,((e,t)=>{e.id&&(e._cache.parents=e._cache.parents||[],t._cache.parents=e._cache.parents.concat([e.id]))}))},Zn=/\//;let _n=class g{constructor(e={}){Object.defineProperty(this,"json",{enumerable:!1,value:e,writable:!0})}get children(){return this.json.children}get id(){return this.json.id}get found(){return this.json.id||this.json.children.length>0}props(e={}){let t=this.json.props||{};return"string"==typeof e&&(t[e]=!0),this.json.props=Object.assign(t,e),this}get(e){if(e=Kn(e),!Zn.test(e)){let t=this.json.children.find((t=>t.id===e));return new g(t)}let t=((e,t)=>{let n=(e=>"string"!=typeof e?e:(e=e.replace(/^\//,"")).split(/\//))(t=t||"");for(let t=0;te.id===n[t]));if(!r)return null;e=r}return e})(this.json,e)||Bn({});return new g(t)}add(e,t={}){if(Ln(e))return e.forEach((e=>this.add(Kn(e),t))),this;e=Kn(e);let n=Bn({id:e,props:t});return this.json.children.push(n),new g(n)}remove(e){return e=Kn(e),this.json.children=this.json.children.filter((t=>t.id!==e)),this}nodes(){return Mn(this.json).map((e=>(delete(e=Object.assign({},e)).children,e)))}cache(){return(e=>{let t=Mn(e,((e,t)=>{e.id&&(e._cache.parents=e._cache.parents||[],e._cache.children=e._cache.children||[],t._cache.parents=e._cache.parents.concat([e.id]))})),n={};t.forEach((e=>{e.id&&(n[e.id]=e)})),t.forEach((e=>{e._cache.parents.forEach((t=>{n.hasOwnProperty(t)&&n[t]._cache.children.push(e.id)}))})),e._cache.children=Object.keys(n)})(this.json),this}list(){return Mn(this.json)}fillDown(){var e;return e=this.json,Mn(e,((e,t)=>{t.props=((e,t)=>(Object.keys(t).forEach((n=>{if(t[n]instanceof Set){let r=e[n]||new Set;e[n]=new Set([...r,...t[n]])}else if((e=>e&&"object"==typeof e&&!Array.isArray(e))(t[n])){let r=e[n]||{};e[n]=Object.assign({},t[n],r)}else Ln(t[n])?e[n]=t[n].concat(e[n]||[]):void 0===e[n]&&(e[n]=t[n])})),e))(t.props,e.props)})),this}depth(){Qn(this.json);let e=Mn(this.json),t=e.length>1?1:0;return e.forEach((e=>{if(0===e._cache.parents.length)return;let n=e._cache.parents.length+1;n>t&&(t=n)})),t}out(e){return Qn(this.json),Rn(this.json,e)}debug(){return Qn(this.json),Rn(this.json,"debug"),this}};const Xn=function(e){let t=Jn(e);return new _n(t)};Xn.prototype.plugin=function(e){e(this)};const Yn={Noun:"blue",Verb:"green",Negative:"green",Date:"red",Value:"red",Adjective:"magenta",Preposition:"cyan",Conjunction:"cyan",Determiner:"cyan",Hyphenated:"cyan",Adverb:"cyan"},er=function(e){if(Yn.hasOwnProperty(e.id))return Yn[e.id];if(Yn.hasOwnProperty(e.is))return Yn[e.is];const t=e._cache.parents.find((e=>Yn[e]));return Yn[t]},tr=function(e){return e?"string"==typeof e?[e]:e:[]},nr=function(e,t){return e=function(e,t){return Object.keys(e).forEach((n=>{e[n].isA&&(e[n].is=e[n].isA),e[n].notA&&(e[n].not=e[n].notA),e[n].is&&"string"==typeof e[n].is&&(t.hasOwnProperty(e[n].is)||e.hasOwnProperty(e[n].is)||(e[e[n].is]={})),e[n].not&&"string"==typeof e[n].not&&!e.hasOwnProperty(e[n].not)&&(t.hasOwnProperty(e[n].not)||e.hasOwnProperty(e[n].not)||(e[e[n].not]={}))})),e}(e,t),Object.keys(e).forEach((t=>{e[t].children=tr(e[t].children),e[t].not=tr(e[t].not)})),Object.keys(e).forEach((t=>{(e[t].not||[]).forEach((n=>{e[n]&&e[n].not&&e[n].not.push(t)}))})),e};var rr={one:{setTag:zn,unTag:function(e,t,n){t=t.trim().replace(/^#/,"");for(let r=0;r0)for(let e=0;e0&&(e=function(e){return Object.keys(e).forEach((t=>{e[t]=Object.assign({},e[t]),e[t].novel=!0})),e}(e)),e=nr(e,t);const n=function(e){const t=Object.keys(e).map((t=>{const n=e[t],r={not:new Set(n.not),also:n.also,is:n.is,novel:n.novel};return{id:t,parent:n.is,props:r,children:[]}}));return Xn(t).cache().fillDown().out("array")}(Object.assign({},t,e)),r=function(e){const t={};return e.forEach((e=>{const{not:n,also:r,is:o,novel:a}=e.props;let i=e._cache.parents;r&&(i=i.concat(r)),t[e.id]={is:o,not:n,novel:a,also:r,parents:i,children:e._cache.children,color:er(e)}})),Object.keys(t).forEach((e=>{const n=new Set(t[e].not);t[e].not.forEach((e=>{t[e]&&t[e].children.forEach((e=>n.add(e)))})),t[e].not=Array.from(n)})),t}(n);return r},canBe:function(e,t,n){if(!n.hasOwnProperty(t))return!0;const r=n[t].not||[];for(let t=0;to.one.setTag(r,e,i,n,t))):o.one.setTag(r,e,i,n,t),this.uncache(),this},tagSafe:function(e,t=""){return this.tag(e,t,!0)},unTag:function(e,t){if(!this.found||!e)return this;const n=this.termList();if(0===n.length)return this;const{methods:r,verbose:o,model:a}=this;!0===o&&console.log(" - ",e,t||"");const i=a.one.tagSet;return or(e)?e.forEach((e=>r.one.unTag(n,e,i))):r.one.unTag(n,e,i),this.uncache(),this},canBe:function(e){e=e.replace(/^#/,"");const t=this.model.one.tagSet,n=this.methods.one.canBe,r=[];this.document.forEach(((o,a)=>{o.forEach(((o,i)=>{n(o,e,t)||r.push([a,i,i+1])}))}));const o=this.update(r);return this.difference(o)}};var ir={addTags:function(e){const{model:t,methods:n}=this.world(),r=t.one.tagSet,o=(0,n.one.addTags)(e,r);return t.one.tagSet=o,this}};const sr=new Set(["Auxiliary","Possessive"]);var lr={model:{one:{tagSet:{}}},compute:{tagRank:function(e){const{document:t,world:n}=e,r=n.model.one.tagSet;t.forEach((e=>{e.forEach((e=>{const t=Array.from(e.tags);e.tagRank=function(e,t){return e=e.sort(((e,n)=>{if(sr.has(e)||!t.hasOwnProperty(n))return 1;if(sr.has(n)||!t.hasOwnProperty(e))return-1;let r=t[e].children||[];const o=r.length;return r=t[n].children||[],o-r.length})),e}(t,r)}))}))}},methods:rr,api:function(e){Object.assign(e.prototype,ar)},lib:ir};const ur=/([.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s)/g,cr=/^[.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s$/,hr=/((?:\r?\n|\r)+)/,dr=/[a-z0-9\u00C0-\u00FF\u00a9\u00ae\u2000-\u3300\ud000-\udfff]/i,gr=/\S/,mr=function(e){return Boolean(e.match(/\n$/))},pr={'"':'"',""":""","“":"”","‟":"”","„":"”","⹂":"”","‚":"’","«":"»","‹":"›","‵":"′","‶":"″","‷":"‴","〝":"〞","〟":"〞"},fr=RegExp("["+Object.keys(pr).join("")+"]","g"),br=RegExp("["+Object.values(pr).join("")+"]","g"),vr=function(e){if(!e)return!1;const t=e.match(br);return null!==t&&1===t.length},yr=/\(/g,wr=/\)/g,kr=/\S/,Pr=/^\s+/,Ar=function(e,t){const n=e.split(/[-–—]/);if(n.length<=1)return!1;const{prefixes:r,suffixes:o}=t.one;if(1===n[0].length&&/[a-z]/i.test(n[0]))return!1;if(r.hasOwnProperty(n[0]))return!1;if(n[1]=n[1].trim().replace(/[.?!]$/,""),o.hasOwnProperty(n[1]))return!1;if(!0===/^([a-z\u00C0-\u00FF`"'/]+)[-–—]([a-z0-9\u00C0-\u00FF].*)/i.test(e))return!0;return!0===/^[('"]?([0-9]{1,4})[-–—]([a-z\u00C0-\u00FF`"'/-]+[)'"]?$)/i.test(e)},Cr=function(e){const t=[],n=e.split(/[-–—]/);let r="-";const o=e.match(/[-–—]/);o&&o[0]&&(r=o);for(let e=0;e(e[t]=!0,e)),{});const Dr=/\p{Letter}/u,Hr=/[\p{Number}\p{Currency_Symbol}]/u,Er=/^[a-z]\.([a-z]\.)+/i,Gr=/[sn]['’]$/,Or=/([A-Z]\.)+[A-Z]?,?$/,Fr=/^[A-Z]\.,?$/,Vr=/[A-Z]{2,}('s|,)?$/,zr=/([a-z]\.)+[a-z]\.?$/,Br=function(e){return function(e){return!0===Or.test(e)||!0===zr.test(e)||!0===Fr.test(e)||!0===Vr.test(e)}(e)&&(e=e.replace(/\./g,"")),e},Sr=function(e,t){const n=t.methods.one.killUnicode;let r=e.text||"";r=function(e){const t=e=(e=(e=e||"").toLowerCase()).trim();return e=(e=(e=e.replace(/[,;.!?]+$/,"")).replace(/\u2026/g,"...")).replace(/\u2013/g,"-"),!1===/^[:;]/.test(e)&&(e=(e=(e=e.replace(/\.{3,}$/g,"")).replace(/[",.!:;?)]+$/g,"")).replace(/^['"(]+/g,"")),""===(e=(e=e.replace(/[\u200B-\u200D\uFEFF]/g,"")).trim())&&(e=t),e.replace(/([0-9]),([0-9])/g,"$1$2")}(r),r=n(r,t),r=Br(r),e.normal=r},$r=/[ .][A-Z]\.? *$/i,Mr=/(?:\u2026|\.{2,}) *$/,Lr=/\p{L}/u,Kr=/\. *$/,Jr=/^[A-Z]\. $/;var Wr={one:{killUnicode:function(e,t){const n=t.model.one.unicode||{},r=(e=e||"").split("");return r.forEach(((e,t)=>{n[e]&&(r[t]=n[e])})),r.join("")},tokenize:{splitSentences:function(e,t){if(e=e||"",!(e=String(e))||"string"!=typeof e||!1===kr.test(e))return[];const n=function(e){const t=[],n=e.split(hr);for(let e=0;e0&&(o.push(a),e[t]=""):e[t+1]=a+(e[t+1]||"")}return o}(r,t),r=function(e){const t=[];for(let n=0;n0?(n[n.length-1]+=a,n.push(t)):n.push(a+t),a=""):a+=t}return a&&(0===n.length&&(n[0]=""),n[n.length-1]+=a),n=function(e){for(let t=1;te)),n},splitWhitespace:(e,t)=>{const{str:n,pre:r,post:o}=function(e,t){const{prePunctuation:n,postPunctuation:r,emoticons:o}=t.one;let a=e,i="",s="";const l=Array.from(e);if(o.hasOwnProperty(e.trim()))return{str:e.trim(),pre:i,post:" "};let u=l.length;for(let e=0;e(s=e||"",""))),e=a,i=""),{str:e,pre:i,post:s}}(e,t);return{text:n,pre:r,post:o,tags:new Set}},fromString:function(e,t){const{methods:n,model:r}=t,{splitSentences:o,splitTerms:a,splitWhitespace:i}=n.one.tokenize;return e=o(e=e||"",t).map((e=>{let n=a(e,r);return n=n.map((e=>i(e,r))),n.forEach((e=>{Sr(e,t)})),n})),e}}}};const qr={},Ur={};[[["approx","apt","bc","cyn","eg","esp","est","etc","ex","exp","prob","pron","gal","min","pseud","fig","jd","lat","lng","vol","fm","def","misc","plz","ea","ps","sec","pt","pref","pl","pp","qt","fr","sq","nee","ss","tel","temp","vet","ver","fem","masc","eng","adj","vb","rb","inf","situ","vivo","vitro","wr"]],[["dl","ml","gal","qt","pt","tbl","tsp","tbsp","km","dm","cm","mm","mi","td","hr","hrs","kg","hg","dg","cg","mg","µg","lb","oz","sq ft","hz","mps","mph","kmph","kb","mb","tb","lx","lm","fl oz","yb"],"Unit"],[["ad","al","arc","ba","bl","ca","cca","col","corp","ft","fy","ie","lit","ma","md","pd","tce"],"Noun"],[["adj","adm","adv","asst","atty","bldg","brig","capt","cmdr","comdr","cpl","det","dr","esq","gen","gov","hon","jr","llb","lt","maj","messrs","mlle","mme","mr","mrs","ms","mstr","phd","prof","pvt","rep","reps","res","rev","sen","sens","sfc","sgt","sir","sr","supt","surg"],"Honorific"],[["jan","feb","mar","apr","jun","jul","aug","sep","sept","oct","nov","dec"],"Month"],[["dept","univ","assn","bros","inc","ltd","co"],"Organization"],[["rd","st","dist","mt","ave","blvd","cl","cres","hwy","ariz","cal","calif","colo","conn","fla","fl","ga","ida","ia","kan","kans","minn","neb","nebr","okla","penna","penn","pa","dak","tenn","tex","ut","vt","va","wis","wisc","wy","wyo","usafa","alta","ont","que","sask"],"Place"]].forEach((e=>{e[0].forEach((t=>{qr[t]=!0,Ur[t]="Abbreviation",void 0!==e[1]&&(Ur[t]=[Ur[t],e[1]])}))}));var Rr=["anti","bi","co","contra","de","extra","infra","inter","intra","macro","micro","mis","mono","multi","peri","pre","pro","proto","pseudo","re","sub","supra","trans","tri","un","out","ex"].reduce(((e,t)=>(e[t]=!0,e)),{});const Qr={"!":"¡","?":"¿Ɂ",'"':'“”"❝❞',"'":"‘‛❛❜’","-":"—–",a:"ªÀÁÂÃÄÅàáâãäåĀāĂ㥹ǍǎǞǟǠǡǺǻȀȁȂȃȦȧȺΆΑΔΛάαλАаѦѧӐӑӒӓƛæ",b:"ßþƀƁƂƃƄƅɃΒβϐϦБВЪЬвъьѢѣҌҍ",c:"¢©ÇçĆćĈĉĊċČčƆƇƈȻȼͻͼϲϹϽϾСсєҀҁҪҫ",d:"ÐĎďĐđƉƊȡƋƌ",e:"ÈÉÊËèéêëĒēĔĕĖėĘęĚěƐȄȅȆȇȨȩɆɇΈΕΞΣέεξϵЀЁЕеѐёҼҽҾҿӖӗễ",f:"ƑƒϜϝӺӻҒғſ",g:"ĜĝĞğĠġĢģƓǤǥǦǧǴǵ",h:"ĤĥĦħƕǶȞȟΉΗЂЊЋНнђћҢңҤҥҺһӉӊ",I:"ÌÍÎÏ",i:"ìíîïĨĩĪīĬĭĮįİıƖƗȈȉȊȋΊΐΪίιϊІЇіїi̇",j:"ĴĵǰȷɈɉϳЈј",k:"ĶķĸƘƙǨǩΚκЌЖКжкќҚқҜҝҞҟҠҡ",l:"ĹĺĻļĽľĿŀŁłƚƪǀǏǐȴȽΙӀӏ",m:"ΜϺϻМмӍӎ",n:"ÑñŃńŅņŇňʼnŊŋƝƞǸǹȠȵΝΠήηϞЍИЙЛПийлпѝҊҋӅӆӢӣӤӥπ",o:"ÒÓÔÕÖØðòóôõöøŌōŎŏŐőƟƠơǑǒǪǫǬǭǾǿȌȍȎȏȪȫȬȭȮȯȰȱΌΘΟθοσόϕϘϙϬϴОФоѲѳӦӧӨөӪӫ",p:"ƤΡρϷϸϼРрҎҏÞ",q:"Ɋɋ",r:"ŔŕŖŗŘřƦȐȑȒȓɌɍЃГЯгяѓҐґ",s:"ŚśŜŝŞşŠšƧƨȘșȿЅѕ",t:"ŢţŤťŦŧƫƬƭƮȚțȶȾΓΤτϮТт",u:"ÙÚÛÜùúûüŨũŪūŬŭŮůŰűŲųƯưƱƲǓǔǕǖǗǘǙǚǛǜȔȕȖȗɄΰυϋύ",v:"νѴѵѶѷ",w:"ŴŵƜωώϖϢϣШЩшщѡѿ",x:"×ΧχϗϰХхҲҳӼӽӾӿ",y:"ÝýÿŶŷŸƳƴȲȳɎɏΎΥΫγψϒϓϔЎУучўѰѱҮүҰұӮӯӰӱӲӳ",z:"ŹźŻżŽžƵƶȤȥɀΖ"},Zr={};Object.keys(Qr).forEach((function(e){Qr[e].split("").forEach((function(t){Zr[t]=e}))}));const _r=/\//,Xr=/[a-z]\.[a-z]/i,Yr=/[0-9]/,eo=function(e,t){const n=e.normal||e.text||e.machine,r=t.model.one.aliases;if(r.hasOwnProperty(n)&&(e.alias=e.alias||[],e.alias.push(r[n])),_r.test(n)&&!Xr.test(n)&&!Yr.test(n)){const t=n.split(_r);t.length<=3&&t.forEach((t=>{""!==(t=t.trim())&&(e.alias=e.alias||[],e.alias.push(t))}))}return e},to=/^\p{Letter}+-\p{Letter}+$/u,no=function(e){let t=e.implicit||e.normal||e.text;t=t.replace(/['’]s$/,""),t=t.replace(/s['’]$/,"s"),t=t.replace(/([aeiou][ktrp])in'$/,"$1ing"),to.test(t)&&(t=t.replace(/-/g,"")),t=t.replace(/^[#@]/,""),t!==e.normal&&(e.machine=t)},ro=function(e,t){const n=e.docs;for(let r=0;rro(e,eo),machine:e=>ro(e,no),normal:e=>ro(e,Sr),freq:function(e){const t=e.docs,n={};for(let e=0;e{let i=(e=e.toLowerCase().trim()).length;t.max&&i>t.max&&(i=t.max);for(let s=t.min;s{delete r[e]})),r}(e,t,this.world());return Object.keys(o).forEach((e=>{n.one.typeahead.hasOwnProperty(e)?delete n.one.typeahead[e]:n.one.typeahead[e]=o[e]})),this}};var co={model:{one:{typeahead:{}}},api:function(e){e.prototype.autoFill=so},lib:uo,compute:io,hooks:["typeahead"]};h.extend(J),h.extend(yn),h.extend(Jt),h.extend(Tn),h.extend(lr),h.plugin(ye),h.extend(ao),h.extend(Ce),h.plugin(p),h.extend(Be),h.extend(co),h.extend(Ee),h.extend(Gn);var ho={addendum:"addenda",corpus:"corpora",criterion:"criteria",curriculum:"curricula",genus:"genera",memorandum:"memoranda",opus:"opera",ovum:"ova",phenomenon:"phenomena",referendum:"referenda",alga:"algae",alumna:"alumnae",antenna:"antennae",formula:"formulae",larva:"larvae",nebula:"nebulae",vertebra:"vertebrae",analysis:"analyses",axis:"axes",diagnosis:"diagnoses",parenthesis:"parentheses",prognosis:"prognoses",synopsis:"synopses",thesis:"theses",neurosis:"neuroses",appendix:"appendices",index:"indices",matrix:"matrices",ox:"oxen",sex:"sexes",alumnus:"alumni",bacillus:"bacilli",cactus:"cacti",fungus:"fungi",hippopotamus:"hippopotami",libretto:"libretti",modulus:"moduli",nucleus:"nuclei",octopus:"octopi",radius:"radii",stimulus:"stimuli",syllabus:"syllabi",cookie:"cookies",calorie:"calories",auntie:"aunties",movie:"movies",pie:"pies",rookie:"rookies",tie:"ties",zombie:"zombies",leaf:"leaves",loaf:"loaves",thief:"thieves",foot:"feet",goose:"geese",tooth:"teeth",beau:"beaux",chateau:"chateaux",tableau:"tableaux",bus:"buses",gas:"gases",circus:"circuses",crisis:"crises",virus:"viruses",database:"databases",excuse:"excuses",abuse:"abuses",avocado:"avocados",barracks:"barracks",child:"children",clothes:"clothes",echo:"echoes",embargo:"embargoes",epoch:"epochs",deer:"deer",halo:"halos",man:"men",woman:"women",mosquito:"mosquitoes",mouse:"mice",person:"people",quiz:"quizzes",rodeo:"rodeos",shoe:"shoes",sombrero:"sombreros",stomach:"stomachs",tornado:"tornados",tuxedo:"tuxedos",volcano:"volcanoes"},go={Comparative:"true¦bett1f0;arth0ew0in0;er",Superlative:"true¦earlier",PresentTense:"true¦bests,sounds",Condition:"true¦lest,unless",PastTense:"true¦began,came,d4had,kneel3l2m0sa4we1;ea0sg2;nt;eap0i0;ed;id",Participle:"true¦0:09;a06b01cZdXeat0fSgQhPoJprov0rHs7t6u4w1;ak0ithdra02o2r1;i02uY;k0v0;nd1pr04;ergoJoJ;ak0hHo3;e9h7lain,o6p5t4un3w1;o1um;rn;g,k;ol0reS;iQok0;ught,wn;ak0o1runk;ne,wn;en,wn;ewriNi1uJ;dd0s0;ut3ver1;do4se0t1;ak0h2;do2g1;roG;ne;ast0i7;iv0o1;ne,tt0;all0loBor1;bi3g2s1;ak0e0;iv0o9;dd0;ove,r1;a5eamt,iv0;hos0lu1;ng;e4i3lo2ui1;lt;wn;tt0;at0en,gun;r2w1;ak0ok0;is0;en",Gerund:"true¦accord0be0doin,go0result0stain0;ing",Expression:"true¦a0Yb0Uc0Sd0Oe0Mfarew0Lg0FhZjeez,lWmVnToOpLsJtIuFvEw7y0;a5e3i1u0;ck,p;k04p0;ee,pee;a0p,s;!h;!a,h,y;a5h2o1t0;af,f;rd up,w;atsoever,e1o0;a,ops;e,w;hoo,t;ery w06oi0L;gh,h0;! 0h,m;huh,oh;here nPsk,ut tut;h0ic;eesh,hh,it,oo;ff,h1l0ow,sst;ease,s,z;ew,ooey;h1i,mg,o0uch,w,y;h,o,ps;! 0h;hTmy go0wT;d,sh;a7evertheless,o0;!pe;eh,mm;ah,eh,m1ol0;!s;ao,fao;aCeBi9o2u0;h,mph,rra0zzC;h,y;l1o0;r6y9;la,y0;! 0;c1moCsmok0;es;ow;!p hip hoor0;ay;ck,e,llo,y;ha1i,lleluj0;ah;!ha;ah,ee4o1r0;eat scott,r;l1od0sh; grief,bye;ly;! whiz;ell;e0h,t cetera,ureka,ww,xcuse me;k,p;'oh,a0rat,uh;m0ng;mit,n0;!it;mon,o0;ngratulations,wabunga;a2oo1r0tw,ye;avo,r;!ya;h,m; 1h0ka,las,men,rgh,ye;!a,em,h,oy;la",Negative:"true¦n0;ever,o0;n,t",QuestionWord:"true¦how3wh0;at,e1ich,o0y;!m,se;n,re; come,'s",Reflexive:"true¦h4it5my5o1the0your2;ir1m1;ne3ur0;sel0;f,ves;er0im0;self",Plural:"true¦dick0gre0ones,records;ens","Unit|Noun":"true¦cEfDgChBinchAk9lb,m6newt5oz,p4qt,t1y0;ardEd;able1b0ea1sp;!l,sp;spo1;a,t,x;on9;!b,g,i1l,m,p0;h,s;!les;!b,elvin,g,m;!es;g,z;al,b;eet,oot,t;m,up0;!s",Value:"true¦a few",Imperative:"true¦bewa0come he0;re","Plural|Verb":"true¦leaves",Demonym:"true¦0:15;1:12;a0Vb0Oc0Dd0Ce08f07g04h02iYjVkTlPmLnIomHpEqatari,rCs7t5u4v3welAz2;am0Gimbabwe0;enezuel0ietnam0I;gAkrai1;aiwTex0hai,rinida0Ju2;ni0Prkmen;a5cotti4e3ingapoOlovak,oma0Spaniard,udRw2y0W;ede,iss;negal0Cr09;sh;mo0uT;o5us0Jw2;and0;a2eru0Fhilippi0Nortugu07uerto r0S;kist3lesti1na2raguay0;ma1;ani;ami00i2orweP;caragu0geri2;an,en;a3ex0Lo2;ngo0Drocc0;cedo1la2;gasy,y07;a4eb9i2;b2thua1;e0Cy0;o,t01;azakh,eny0o2uwaiI;re0;a2orda1;ma0Ap2;anO;celandic,nd4r2sraeli,ta01vo05;a2iB;ni0qi;i0oneU;aiAin2ondur0unO;di;amEe2hanai0reek,uatemal0;or2rm0;gi0;ilipino,ren8;cuadoVgyp4mira3ngli2sto1thiopi0urope0;shm0;ti;ti0;aPominUut3;a9h6o4roat3ub0ze2;ch;!i0;lom2ngol5;bi0;a6i2;le0n2;ese;lifor1m2na3;bo2eroo1;di0;angladeshi,el6o4r3ul2;gaE;azi9it;li2s1;vi0;aru2gi0;si0;fAl7merBngol0r5si0us2;sie,tr2;a2i0;li0;genti2me1;ne;ba1ge2;ri0;ni0;gh0r2;ic0;an",Organization:"true¦0:4Q;a3Tb3Bc2Od2He2Df27g1Zh1Ti1Pj1Nk1Ll1Gm12n0Po0Mp0Cqu0Br02sTtHuCv9w3xiaomi,y1;amaha,m1Bou1w1B;gov,tu3C;a4e2iki1orld trade organizati33;leaRped0O;lls fargo,st1;fie2Hinghou2R;l1rner br3U;gree3Jl street journ2Im1E;an halOeriz2Xisa,o1;dafo2Yl1;kswagMvo;b4kip,n2ps,s1;a tod3Aps;es3Mi1;lev3Fted natio3C;er,s; mobi32aco beRd bOe9gi frida3Lh3im horto3Amz,o1witt3D;shi49y1;ota,s r 05;e 1in lizzy;b3carpen3Jdaily ma3Dguess w2holli0s1w2;mashing pumpki35uprem0;ho;ea1lack eyed pe3Xyr0Q;ch bo3Dtl0;l2n3Qs1xas instrumen1U;co,la m1F;efoni0Kus;a8cientology,e5ieme2Ymirnoff,np,o3pice gir6quare0Ata1ubaru;rbuc1to34;ks;ny,undgard1;en;a2x pisto1;ls;g1Wrs;few2Minsbur31lesfor03msu2E;adiohead,b8e4o1yana3C;man empi1Xyal 1;b1dutch she4;ank;a3d 1max,vl20;bu1c2Ahot chili peppe2Ylobst2N;ll;ders dige1Ll madrid;c,s;ant3Aizn2Q;a8bs,e5fiz2Ihilip4i3r1;emier 1udenti1D;leagTo2K;nk floyd,zza hut; morrBs;psi2tro1uge0E;br33chi0Tn33;!co;lant2Un1yp16; 2ason27da2P;ld navy,pec,range juli2xf1;am;us;aAb9e6fl,h5i4o1sa,vid3wa;k2tre dame,vart1;is;ia;ke,ntendo,ss0QvZ;l,s;c,st1Otflix,w1; 1sweek;kids on the block,york0D;a,c;nd22s2t1;ional aca2Po,we0U;a,c02d0S;aDcdonalCe9i6lb,o3tv,y1;spa1;ce;b1Tnsanto,ody blu0t1;ley cr1or0T;ue;c2t1;as,subisO;helin,rosoft;dica2rcedes benz,talli1;ca;id,re;ds;cs milk,tt19z24;a3e1g,ittle caesa1P; ore09novo,x1;is,mark,us; 1bour party;pres0Dz boy;atv,fc,kk,lm,m1od1O;art;iffy lu0Roy divisi0Jpmorgan1sa;! cha09;bm,hop,k3n1tv;g,te1;l,rpol;ea;a5ewlett pack1Vi3o1sbc,yundai;me dep1n1P;ot;tac1zbollah;hi;lliburt08sbro;eneral 6hq,ithub,l5mb,o2reen d0Ou1;cci,ns n ros0;ldman sachs,o1;dye1g0H;ar;axo smith kli04encoW;electr0Nm1;oto0Z;a5bi,c barcelo4da,edex,i2leetwood m03o1rito l0G;rd,xcY;at,fa,nancial1restoZ; tim0;na;cebook,nnie mae;b0Asa,u3xxon1; m1m1;ob0J;!rosceptics;aiml0De5isney,o4u1;nkin donu2po0Zran dur1;an;ts;j,w jon0;a,f lepp12ll,peche mode,r spieg02stiny's chi1;ld;aJbc,hFiDloudflaCnn,o3r1;aigsli5eedence clearwater reviv1ossra09;al;c7inba6l4m1o0Est09;ca2p1;aq;st;dplSg1;ate;se;a c1o chanQ;ola;re;a,sco1tigroup;! systems;ev2i1;ck fil a,na daily;r1y;on;d2pital o1rls jr;ne;bury,ill1;ac;aEbc,eBf9l5mw,ni,o1p,rexiteeU;ei3mbardiIston 1;glo1pizza;be;ng;o2ue c1;roV;ckbuster video,omingda1;le; g1g1;oodriL;cht2e ge0rkshire hathaw1;ay;el;cardi,idu,nana republ3s1xt5y5;f,kin robbi1;ns;ic;bYcTdidSerosmith,iRlKmEnheuser busDol,ppleAr6s4u3v2y1;er;is,on;di,todesk;hland o1sociated E;il;b3g2m1;co;os;ys; compu1be0;te1;rs;ch;c,d,erican3t1;!r1;ak; ex1;pre1;ss; 5catel2ta1;ir;! lu1;ce1;nt;jazeera,qae1;da;g,rbnb;as;/dc,a3er,tivision1;! blizz1;ard;demy of scienc0;es;ba",Possessive:"true¦its,my,our0thy;!s","Noun|Verb":"true¦0:9W;1:AA;2:96;3:A3;4:9R;5:A2;6:9K;7:8N;8:7L;9:A8;A:93;B:8D;C:8X;a9Ob8Qc7Id6Re6Gf5Sg5Hh55i4Xj4Uk4Rl4Em40n3Vo3Sp2Squ2Rr21s0Jt02u00vVwGyFzD;ip,oD;ne,om;awn,e6Fie68;aOeMhJiHoErD;ap,e9Oink2;nd0rDuC;kDry,sh5Hth;!shop;ck,nDpe,re,sh;!d,g;e86iD;p,sD;k,p0t2;aDed,lco8W;r,th0;it,lk,rEsDt4ve,x;h,te;!ehou1ra9;aGen5FiFoD;iDmAte,w;ce,d;be,ew,sA;cuum,l4B;pDr7;da5gra6Elo6A;aReQhrPiOoMrGuEwiDy5Z;n,st;nDrn;e,n7O;aGeFiEoDu6;t,ub2;bu5ck4Jgg0m,p;at,k,nd;ck,de,in,nsDp,v7J;f0i8R;ll,ne,p,r4Yss,t94uD;ch,r;ck,de,e,le,me,p,re;e5Wow,u6;ar,e,ll,mp0st,xt;g,lDng2rg7Ps5x;k,ly;a0Sc0Ne0Kh0Fi0Dk0Cl0Am08n06o05pXquaBtKuFwD;ea88iD;ng,pe,t4;bGit,m,ppErD;fa3ge,pri1v2U;lDo6S;e6Py;!je8;aMeLiKoHrEuDy2;dy,ff,mb2;a85eEiDo5Pugg2;ke,ng;am,ss,t4;ckEop,p,rD;e,m;ing,pi2;ck,nk,t4;er,m,p;ck,ff,ge,in,ke,lEmp,nd,p2rDte,y;!e,t;k,l;aJeIiHlGoFrDur,y;ay,e56inDu3;g,k2;ns8Bt;a5Qit;ll,n,r87te;ed,ll;m,n,rk;b,uC;aDee1Tow;ke,p;a5Je4FiDo53;le,rk;eep,iDou4;ce,p,t;ateboa7Ii;de,gnDl2Vnk,p,ze;!al;aGeFiEoDuff2;ck,p,re,w;ft,p,v0;d,i3Ylt0;ck,de,pe,re,ve;aEed,nDrv1It;se,t2N;l,r4t;aGhedu2oBrD;aEeDibb2o3Z;en,w;pe,t4;le,n,r2M;cDfegua72il,mp2;k,rifi3;aZeHhy6LiGoEuD;b,in,le,n,s5X;a6ck,ll,oDpe,u5;f,t;de,ng,ot,p,s1W;aTcSdo,el,fQgPje8lOmMnLo17pJque6sFturn,vDwa6V;eDi27;al,r1;er74oFpe8tEuD;lt,me;!a55;l71rt;air,eaDly,o53;l,t;dezvo2Zt;aDedy;ke,rk;ea1i4G;a6Iist0r5N;act6Yer1Vo71uD;nd,se;a38o6F;ch,s6G;c1Dge,iEke,lly,nDp1Wt1W;ge,k,t;n,se;es6Biv0;a04e00hYiXlToNrEsy4uD;mp,n4rcha1sh;aKeIiHoDu4O;be,ceFdu3fi2grDje8mi1p,te6;amDe6W;!me;ed,ss;ce,de,nt;sDy;er6Cs;cti3i1;iHlFoEp,re,sDuCw0;e,i5Yt;l,p;iDl;ce,sh;nt,s5V;aEce,e32uD;g,mp,n7;ce,nDy;!t;ck,le,n17pe,tNvot;a1oD;ne,tograph;ak,eFnErDt;fu55mA;!c32;!l,r;ckJiInHrFsEtDu1y;ch,e9;s,te;k,tD;!y;!ic;nt,r,se;!a7;bje8ff0il,oErDutli3Qver4B;bAd0ie9;ze;a4ReFoDur1;d,tD;e,i3;ed,gle8tD;!work;aMeKiIoEuD;rd0;ck,d3Rld,nEp,uDve;nt,th;it5EkD;ey;lk,n4Brr5CsDx;s,ta2B;asuBn4UrDss;ge,it;il,nFp,rk3WsEtD;ch,t0;h,k,t0;da5n0oeuvB;aLeJiHoEuD;mp,st;aEbby,ck,g,oDve;k,t;d,n;cDe,ft,mAnIst;en1k;aDc0Pe4vK;ch,d,k,p,se;bFcEnd,p,t4uD;gh,n4;e,k;el,o2U;eEiDno4E;ck,d,ll,ss;el,y;aEo1OuD;i3mp;m,zz;mpJnEr46ssD;ue;c1Rdex,fluGha2k,se2HteDvoi3;nt,rD;e6fa3viD;ew;en3;a8le2A;aJeHiGoEuD;g,nt;l3Ano2Dok,pDr1u1;!e;ghli1Fke,nt,re,t;aDd7lp;d,t;ck,mGndFrEsh,tDu9;ch,e;bo3Xm,ne4Eve6;!le;!m0;aMear,ift,lKossJrFuD;arDe4Alp,n;antee,d;aFiEoDumb2;uCwth;ll,nd,p;de,sp;ip;aBoDue;ss,w;g,in,me,ng,s,te,ze;aZeWiRlNoJrFuD;ck,el,nDss,zz;c38d;aEoDy;st,wn;cDgme,me,nchi1;tuB;cFg,il,ld,rD;ce,e29mDwa31;!at;us;aFe0Vip,oDy;at,ck,od,wD;!er;g,ke,me,re,sh,vo1E;eGgFlEnDre,sh,t,x;an3i0Q;e,m,t0;ht,uB;ld;aEeDn3;d,l;r,tuB;ce,il,ll,rm,vo2W;cho,d7ffe8nMsKxFyeD;!baD;ll;cGerci1hFpDtra8;eriDo0W;en3me9;au6ibA;el,han7u1;caDtima5;pe;count0d,vy;a01eSiMoJrEuDye;b,el,mp,pli2X;aGeFiEoD;ne,p;ft,ll,nk,p,ve;am,ss;ft,g,in;cEd7ubt,wnloD;ad;k,u0E;ge6p,sFt4vD;e,iDor3;de;char7gui1h,liEpD;at4lay,u5;ke;al,bKcJfeIlGmaCposAsEtaD;il;e07iD;gn,re;ay,ega5iD;ght;at,ct;li04rea1;a5ut;b,ma7n3rDte;e,t;a0Eent0Dh06irc2l03oKrFuD;be,e,rDt;b,e,l,ve;aGeFoEuDy;sh;p,ss,wd;dAep;ck,ft,sh;at,de,in,lTmMnFordina5py,re,st,uDv0;gh,nDp2rt;s01t;ceHdu8fli8glomeIsFtDveN;a8rD;a6ol;e9tru8;ct;ntDrn;ra5;bHfoGmFpD;leDouCromi1;me9;aCe9it,u5;rt;at,iD;ne;lap1oD;r,ur;aEiDoud,ub;ck,p;im,w;aEeDip;at,ck,er;iGllen7nErD;ge,m,t;ge,nD;el;n,r;er,re;ke,ll,mp,noe,pGrXsFtEuDve;se,ti0I;alog,ch;h,t;!tuB;re;a03eZiXlToPrHuEyD;pa11;bb2ck2dgEff0mp,rDst,zz;den,n;et;anJeHiFoadEuD;i1sh;ca6;be,d7;ge;aDed;ch,k;ch,d;aFg,mb,nEoDrd0tt2x,ycott;k,st,t;d,e;rd,st;aFeCiDoYur;nk,tz;nd;me;as,d,ke,nd,opsy,tD;!ch,e;aFef,lt,nDt;d,efA;it;r,t;ck,il,lan3nIrFsEtt2;le;e,h;!gDk;aDe;in;!d,g,k;bu1c05dZge,iYlVnTppQrLsIttGucEwaD;rd;tiD;on;aDempt;ck;k,sD;i6ocia5;st;chFmD;!oD;ur;!iD;ve;eEroa4;ch;al;chDg0sw0;or;aEt0;er;rm;d,m,r;dreHvD;an3oD;ca5;te;ce;ss;cDe,he,t;eFoD;rd,u9;nt;nt,ss;se",Actor:"true¦0:7B;1:7G;2:6A;3:7F;4:7O;5:7K;a6Nb62c4Ud4Be41f3Sg3Bh30i2Uj2Qkin2Pl2Km26n1Zo1Sp0Vqu0Tr0JsQtJuHvEw8yo6;gi,ut6;h,ub0;aAe9i8o7r6;estl0it0;m2rk0;fe,nn0t2Bza2H;atherm2ld0;ge earn0it0nder0rri1;eter7i6oyF;ll5Qp,s3Z;an,ina2U;n6s0;c6Uder03;aoisea23e9herapi5iktok0o8r6ut1yco6S;a6endseLo43;d0mp,nscri0Bvel0;ddl0u1G;a0Qchn7en6na4st0;ag0;i3Oo0D;aiXcUeRhPiMki0mu26oJpGquaFtBu7wee6;p0theart;lt2per7r6;f0ge6Iviv1;h6inten0Ist5Ivis1;ero,um2;a8ep7r6;ang0eam0;bro2Nc2Ofa2Nmo2Nsi20;ff0tesm2;tt0;ec7ir2Do6;kesp59u0M;ia5Jt3;l7me6An,rcere6ul;r,ss;di0oi5;n7s6;sy,t0;g0n0;am2ephe1Iow6;girl,m2r2Q;cretInior cit3Fr6;gea4v6;a4it1;hol4Xi7reen6ulpt1;wr2C;e01on;l1nt;aEe9o8u6;l0nn6;er up,ingE;g40le mod3Zof0;a4Zc8fug2Ppo32searQv6;ere4Uolution6;ary;e6luYru22;ptio3T;bbi,dic5Vpp0;arter6e2Z;back;aYeWhSiRlOoKr8sycho7u6;nk,p31;logi5;aGeDiBo6;d9fess1g7ph47s6;pe2Ktitu51;en6ramm0;it1y;igy,uc0;est4Nme mini0Unce6s3E;!ss;a7si6;de4;ch0;ctiti39nk0P;dca0Oet,li6pula50rnst42;c2Itic6;al scie6i2;nti5;a6umb0;nn0y6;er,ma4Lwright;lgrim,one0;a8iloso7otogra7ra6ysi1V;se;ph0;ntom,rmaci5;r6ssi1T;form0s4O;i3El,nel3Yr8st1tr6wn;i6on;arWot;ent4Wi42tn0;ccupa4ffBp8r7ut6;ca5l0B;ac4Iganiz0ig2Fph2;er3t6;i1Jomet6;ri5;ic0spring;aBe9ie4Xo7u6;n,rser3J;b6mad,vi4V;le2Vo4D;i6mesis,phew;ce,ghb1;nny,rr3t1X;aEeDiAo7u6yst1Y;m8si16;der3gul,m7n6th0;arDk;!my;ni7s6;f02s0Jt0;on,st0;chan1Qnt1rcha4;gi9k0n8rtyr,t6y1;e,riar6;ch;ag0iac;ci2stra3I;a7e2Aieutena4o6;rd,s0v0;bor0d7ndlo6ss,urea3Fwy0ym2;rd;!y;!s28;e8o7u6;ggl0;gg0urna2U;st0;c3Hdol,llu3Ummigra4n6; l9c1Qfa4habi42nov3s7ve6;nt1stig3;pe0Nt6;a1Fig3ru0M;aw;airFeBistoAo8u6ygie1K;man6sba2H;!ita8;bo,st6usekN;age,e3P;ri2;ir,r6;m7o6;!ine;it;dress0sty2C;aLeIhostGirl26ladi3oCrand7u6;e5ru;c9daug0Jfa8m7pa6s2Y;!re4;a,o6;th0;hi1B;al7d6lf0;!de3A;ie,k6te26;eep0;!wr6;it0;isha,n6;i6tl04;us;mbl0rden0;aDella,iAo7r6;eela2Nie1P;e,re6ster pare4;be1Hm2r6st0;unn0;an2ZgZlmm17nanci0r6tt0;e6st la2H; marsh2OfigXm2;rm0th0;conoEdDlectriCm8n7x6;amin0cellency,i2A;emy,trepreneur,vironmenta1J;c8p6;er1loye6;e,r;ee;ci2;it1;mi5;aKeBi8ork,ri7u6we02;de,tche2H;ft0v0;ct3eti7plom2Hre6va;ct1;ci2ti2;aDcor3fencCi0InAput9s7tectLvel6;op0;ce1Ge6ign0;rt0;ee,y;iz6;en;em2;c1Ml0;d8nc0redev7ug6;ht0;il;!dy;a06e04fo,hXitizenWlToBr9u6;r3stomer6;! representat6;ive;e3it6;ic;lJmGnAord9rpor1Nu7w6;boy,ork0;n6ri0;ciTte1Q;in3;fidantAgressSs9t6;e0Kr6;ibut1o6;ll0;tab13ul1O;!e;edi2m6pos0rade;a0EeQissi6;on0;leag8on7um6;ni5;el;ue;e6own;an0r6;ic,k;!s;a9e7i6um;ld;erle6f;ad0;ir7nce6plFract0;ll1;m2wI;lebri6o;ty;dBptAr6shi0;e7pe6;nt0;r,t6;ak0;ain;et;aMeLiJlogg0oErBu6;dd0Fild0rgl9siness6;m2p7w6;om2;ers05;ar;i7o6;!k0th0;cklay0de,gadi0;hemi2oge8y6;!frie6;nd;ym2;an;cyc6sR;li5;atbox0ings;by,nk0r6;b0on7te6;nd0;!e07;c04dWge4nQpLrHsFtAu7yatull6;ah;nt7t6;h1oG;!ie;h8t6;e6orney;nda4;ie5le6;te;sis00tron6;aut,om0;chbis8isto7tis6;an,t;crU;hop;ost9p6;ari6rentiS;ti6;on;le;a9cest1im3nou8y6;bo6;dy;nc0;ly5rc6;hi5;mi8v6;entur0is1;er;ni7r6;al;str3;at1;or;counBquaintanArob9t6;ivi5or,re6;ss;st;at;ce;ta4;nt","Adj|Noun":"true¦0:16;a1Db17c0Ud0Re0Mf0Dg0Ah08i06ju05l02mWnUoSpNrIsBt7u4v1watershed;a1ision0Z;gabo4nilla,ria1;b0Vnt;ndergr1pstairs;adua14ou1;nd;a3e1oken,ri0;en,r1;min0rori13;boo,n;age,e5ilv0Flack,o3quat,ta2u1well;bordina0Xper5;b0Lndard;ciali0Yl1vereign;e,ve16;cret,n1ri0;ior;a4e2ou1ubbiL;nd,tiY;ar,bBl0Wnt0p1side11;resent0Vublican;ci0Qsh;a4eriodic0last0Zotenti0r1;emi2incip0o1;!fession0;er,um;rall4st,tie0U;ff1pposi0Hv0;ens0Oi0C;agg01ov1uts;el;a5e3iniatJo1;bi01der07r1;al,t0;di1tr0N;an,um;le,riG;attOi2u1;sh;ber0ght,qC;stice,veniT;de0mpressioYn1;cumbe0Edividu0no0Dsta0Eterim;alf,o1umdrum;bby,melF;en2old,ra1;ph0Bve;er0ious;a7e5i4l3u1;git03t1;ure;uid;ne;llow,m1;aFiL;ir,t,vo1;riOuriO;l3p00x1;c1ecutUpeV;ess;d1iK;er;ar2e1;mographUrivO;k,l2;hiGlassSo2rude,unn1;ing;m5n1operK;creCstitueOte2vertab1;le;mpor1nt;ary;ic,m2p1;anion,lex;er2u1;ni8;ci0;al;e5lank,o4r1;i2u1;te;ef;ttom,urgeois;st;cadem9d6l2ntarct9r1;ab,ct8;e3tern1;at1;ive;rt;oles1ult;ce1;nt;ic","Adj|Past":"true¦0:4Q;1:4C;2:4H;3:4E;a44b3Tc36d2Je29f20g1Wh1Si1Jj1Gkno1Fl1Am15n12o0Xp0Mqu0Kr08sLtEuAv9w4yellow0;a7ea6o4rinkl0;r4u3Y;n,ri0;k31th3;rp0sh0tZ;ari0e1O;n5p4s0;d1li1Rset;cov3derstood,i4;fi0t0;a8e3Rhr7i6ouTr4urn0wi4C;a4imm0ou2G;ck0in0pp0;ed,r0;eat2Qi37;m0nn0r4;get0ni2T;aOcKeIhGimFm0Hoak0pDt7u4;bsid3Ogge44s4;pe4ta2Y;ct0nd0;a8e7i2Eok0r5u4;ff0mp0nn0;ength2Hip4;ed,p0;am0reotyp0;in0t0;eci4ik0oH;al3Efi0;pRul1;a4ock0ut;d0r0;a4c1Jle2t31;l0s3Ut0;a6or5r4;at4e25;ch0;r0tt3;t4ut0;is2Mur1;aEe5o4;tt0;cAdJf2Bg9je2l8m0Knew0p7qu6s4;eTpe2t4;or0ri2;e3Dir0;e1lac0;at0e2Q;i0Rul1;eiv0o4ycl0;mme2Lrd0v3;in0lli0ti2A;a4ot0;li28;aCer30iBlAo9r5u4;mp0zzl0;e6i2Oo4;ce2Fd4lo1Anou30pos0te2v0;uc0;fe1CocCp0Iss0;i2Kli1L;ann0e2CuS;ck0erc0ss0;ck0i2Hr4st0;allLk0;bse7c6pp13rgan2Dver4;lo4whelm0;ok0;cupi0;rv0;aJe5o4;t0uri1A;ed0gle2;a6e5ix0o4ut0ys1N;di1Nt15u26;as0Clt0;n4rk0;ag0ufact0A;e6i5o4;ad0ck0st,v0;cens0m04st0;ft,v4;el0;tt0wn;a5o15u4;dg0s1B;gg0;llumSmpAn4sol1;br0cre1Ldebt0f8jZspir0t5v4;it0olv0;e4ox0Y;gr1n4re23;d0si15;e2l1o1Wuri1;li0o01r4;ov0;a6e1o4um03;ok0r4;ri0Z;mm3rm0;i6r5u4;a1Bid0;a0Ui0Rown;ft0;aAe9i8l6oc0Ir4;a4i0oz0Y;ctHg19m0;avo0Ju4;st3;ni08tt0x0;ar0;d0il0sc4;in1;dCl1mBn9quipp0s8x4;agger1c6p4te0T;a0Se4os0;ct0rie1D;it0;cap0tabliZ;cha0XgFha1As4;ur0;a0Zbarra0N;i0Buc1;aMeDi5r4;a01i0;gni08miniSre2s4;a9c6grun0Ft4;o4re0Hu17;rt0;iplWou4;nt0r4;ag0;bl0;cBdRf9l8p7ra6t5v4;elop0ot0;ail0ermQ;ng0;re07;ay0ight0;e4in0o0M;rr0;ay0enTor1;m5t0z4;ed,zl0;ag0p4;en0;aPeLhIlHo9r6u4;lt4r0stom03;iv1;a5owd0u4;sh0;ck0mp0;d0loAm7n4ok0v3;centr1f5s4troC;id3olid1;us0;b5pl4;ic1;in0;r0ur0;assi9os0utt3;ar5i4;ll0;g0m0;lebr1n6r4;ti4;fi0;tralJ;g0lcul1;aDewild3iCl9o7r5urn4;ed,t;ok4uis0;en;il0r0t4und;tl0;e5i4;nd0;ss0;as0;ffl0k0laMs0tt3;bPcNdKfIg0lFmaz0nDppBrm0ss9u5wa4;rd0;g5thor4;iz0;me4;nt0;o6u4;m0r0;li0re4;ci1;im1ticip1;at0;a5leg0t3;er0;rm0;fe2;ct0;ju5o7va4;nc0;st0;ce4knowledg0;pt0;and5so4;rb0;on0;ed",Singular:"true¦0:5J;1:5H;2:4W;3:4S;4:52;5:57;6:5L;7:56;8:5B;a52b4Lc3Nd35e2Xf2Og2Jh28in24j23k22l1Um1Ln1Ho1Bp0Rqu0Qr0FsZtMuHvCw9x r58yo yo;a9ha3Po3Q;f3i4Rt0Gy9;! arou39;arCeAideo ga2Qo9;cabu4Jl5C;gOr9t;di4Zt1Y;iety,ni4P;nBp30rAs 9;do43s5E;bani1in0;coordinat3Ader9;estima1to24we41; rex,aKeJhHiFoErBuAv9;! show;m2On2rntLto1D;agedy,ib9o4E;e,u9;n0ta46;ni1p2rq3L;c,er,m9;etF;ing9ree26;!y;am,mp3F;ct2le6x return;aNcMeKhor4QiJkHoGpin off,tDuBy9;ll9ner7st4T;ab2X;b9i1n28per bowl,rro1X;st3Ltot0;atAipe2Go1Lrate7udent9;! lo0I;i39u1;ft ser4Lmeo1I;elet5i9;ll,r3V;b38gn2Tte;ab2Jc9min3B;t,urity gua2N;e6ho2Y;bbatic0la3Jndwi0Qpi5;av5eDhetor2iAo9;de6om,w;tAv9;erb2C;e,u0;bDcBf9publ2r10spi1;er9orm3;e6r0;i9ord label;p2Ht0;a1u46;estion mark,ot2F;aPeMhoLiIlGoErAu9yram1F;ddi3HpErpo1Js3J;eBo9;bl3Zs9;pe3Jta1;dic1Rmi1Fp1Qroga8ss relea1F;p9rt0;py;a9ebisci1;q2Dte;cn2eAg9;!gy;!r;ne call,tocoK;anut,dAr9t0yo1;cen3Jsp3K;al,est0;nop4rAt9;e,hog5;adi11i2V;atme0bj3FcBpia1rde0thers,utspok5ve9wn3;n,r9;ti0Pview;cuAe9;an;pi3;arBitAot9umb3;a2Fhi2R;e,ra1;cot2ra8;aFeCiAo9ur0;nopo4p18rni2Nsq1Rti36uld;c,li11n0As9tt5;chief,si34;dAnu,t9;al,i3;al,ic;gna1mm0nd15rsupi0te9yf4;ri0;aDegCiBu9;ddi1n9;ch;me,p09; Be0M;bor14y9; 9er;up;eyno1itt5;el4ourn0;cBdices,itia8ni25sAtel0Lvert9;eb1J;e28titu1;en8i2T;aIeEighDoAu9;man right,s22;me9rmoFsp1Ftb0K;! r9;un; scho0YriY;a9i1N;d9v5; start,pho9;ne;ndful,sh brown,v5ze;aBelat0Ilaci3r9ul4yp1S;an9enadi3id;a1Cd slam,ny;df4r9;l2ni1I;aGeti1HiFlu1oCrAun9;er0;ee market,i9onti3;ga1;l4ur9;so9;me;ePref4;br2mi4;conoFffi7gg,lecto0Rmbas1EnCpidem2s1Zth2venBxAyel9;id;ampZempl0Nte6;i19t;er7terp9;ri9;se;my;eLiEoBr9ump tru0U;agonf4i9;er,ve thru;cAg7i4or,ssi3wn9;side;to0EumenE;aEgniDnn3sAvide9;nd;conte6incen8p9tri11;osi9;ti0C;ta0H;le0X;athBcAf9ni0terre6;ault 05err0;al,im0;!b9;ed;aWeThMiLlJoDr9;edit caBuc9;ib9;le;rd;efficDke,lCmmuniqLnsApi3rr0t0Xus9yo1;in;erv9uI;ato02;ic,lQ;ie6;er7i9oth;e6n2;ty,vil wM;aDeqCick5ocoBr9;istmas car9ysanthemum;ol;la1;ue;ndeli3racteri9;st2;iAllEr9;e0tifica1;liZ;hi3nFpErCt9ucus;erpi9hedr0;ll9;ar;!bohyd9ri3;ra1;it0;aAe,nib0t9;on;l,ry;aMeLiop2leJoHrDu9;nny,r9tterf4;g9i0;la9;ry;eakAi9;ck;fa9throB;st;dy,ro9wl;ugh;mi9;sh;an,l4;nkiArri3;er;ng;cSdMlInFppeti1rDsBtt2utop9;sy;ic;ce6pe9;ct;r9sen0;ay;ecAoma4tiA;ly;do1;i5l9;er7y;gy;en; hominDjAvan9;tage;ec8;ti9;ve;em;cCeAqui9;tt0;ta1;te;iAru0;al;de6;nt","Person|Noun":"true¦a0Eb07c03dWeUfQgOhLjHkiGlFmCnBolive,p7r4s3trini06v1wa0;ng,rd,tts;an,enus,iol0;a,et;ky,onPumm09;ay,e1o0uby;bin,d,se;ed,x;a2e1o0;l,tt04;aLnJ;dYge,tR;at,orm;a0eloW;t0x,ya;!s;a9eo,iH;ng,tP;a2e1o0;lGy;an,w3;de,smi4y;a0erb,iOolBuntR;ll,z0;el;ail,e0iLuy;ne;a1ern,i0lo;elds,nn;ith,n0;ny;a0dEmir,ula,ve;rl;a4e3i1j,ol0;ly;ck,x0;ie;an,ja;i0wn;sy;am,h0liff,rystal;a0in,ristian;mbers,ri0;ty;a4e3i2o,r0ud;an0ook;dy;ll;nedict,rg;k0nks;er;l0rt;fredo,ma","Actor|Verb":"true¦aCb8c5doctor,engineAfool,g3host,judge,m2nerd,p1recruit,scout,ushAvolunteAwi0;mp,tneA;arent,ilot;an,ime;eek,oof,r0uide;adu8oom;ha1o0;ach,nscript,ok;mpion,uffeur;o2u0;lly,tch0;er;ss;ddi1ffili0rchite1;ate;ct",MaleName:"true¦0:H6;1:FZ;2:DS;3:GQ;4:CZ;5:FV;6:GM;7:FP;8:GW;9:ET;A:C2;B:GD;aF8bE1cCQdBMeASfA1g8Yh88i7Uj6Sk6Bl5Mm48n3So3Ip33qu31r26s1Et0Ru0Ov0CwTxSyHzC;aCor0;cChC1karia,nAT;!hDkC;!aF6;!ar7CeF5;aJevgenBSoEuC;en,rFVsCu3FvEF;if,uf;nDs6OusC;ouf,s6N;aCg;s,tC;an,h0;hli,nCrosE1ss09;is,nC;!iBU;avi2ho5;aPeNiDoCyaEL;jcieBJlfgang,odrFutR;lFnC;f8TsC;lCt1;ow;bGey,frEhe4QlC;aE5iCy;am,e,s;ed8iC;d,ed;eAur;i,ndeD2rn2sC;!l9t1;lDyC;l1ne;lDtC;!er;aCHy;aKernDAiFladDoC;jteB0lodymyr;!iC;mFQsDB;cFha0ktBZnceDrgCOvC;a0ek;!nC;t,zo;!e4StBV;lCnC7sily;!entC;in9J;ghE2lCm70nax,ri,sm0;riCyss87;ch,k;aWeRhNiLoGrEuDyC;!l2roEDs1;n6r6E;avD0eCist0oy,um0;ntCRvBKy;bFdAWmCny;!asDmCoharu;aFFie,y;!z;iA6y;mCt4;!my,othy;adEeoDia0SomC;!as;!dor91;!de4;dFrC;enBKrC;anBJeCy;ll,nBI;!dy;dgh,ha,iCnn2req,tsu5V;cDAka;aYcotWeThPiMlobod0oKpenc2tEurDvenAEyCzym1;ed,lvest2;aj,e9V;anFeDuC;!aA;fan17phEQvCwaA;e77ie;!islaCl9;v,w;lom1rBuC;leymaDHta;dDgmu9UlCm1yabonga;as,v8B;!dhart8Yn9;aEeClo75;lCrm0;d1t1;h9Jne,qu1Jun,wn,yne;aDbastiEDk2Yl5Mpp,rgCth,ymoCU;e1Dio;m4n;!tC;!ie,y;eDPlFmEnCq67tosCMul;dCj2UtiA5;e01ro;!iATkeB6mC4u5;!ik,vato9K;aZeUheC8iRoGuDyC;an,ou;b99dDf4peAssC;!elEG;ol00y;an,bLc7MdJel,geIh0lHmGnEry,sDyC;!ce;ar7Ocoe,s;!aCnBU;ld,n;an,eo;a7Ef;l7Jr;e3Eg2n9olfo,riC;go;bBNeDH;cCl9;ar87c86h54kCo;!ey,ie,y;cFeA3gDid,ubByCza;an8Ln06;g85iC;naC6s;ep;ch8Kfa5hHin2je8HlGmFndEoHpha5sDul,wi36yC;an,mo8O;h9Im4;alDSol3O;iD0on;f,ph;ul;e9CinC;cy,t1;aOeLhilJiFrCyoG;aDeC;m,st1;ka85v2O;eDoC;tr;r8GtC;er,ro;!ipCl6H;!p6U;dCLrcy,tC;ar,e9JrC;!o7;b9Udra8So9UscAHtri62ulCv8I;!ie,o7;ctav6Ji2lImHndrBRrGsDtCum6wB;is,to;aDc6k6m0vCwaBE;al79;ma;i,vR;ar,er;aDeksandr,ivC;er,i2;f,v;aNeLguyBiFoCu3O;aDel,j4l0ma0rC;beAm0;h,m;cFels,g5i9EkDlC;es,s;!au,h96l78olaC;!i,y;hCkCol76;ol75;al,d,il,ls1vC;ilAF;hom,tC;e,hC;anCy;!a5i5;aYeViLoGuDyC;l4Nr1;hamDr84staC;fa,p6E;ed,mG;di10e,hamEis4JntDritz,sCussa;es,he;e,y;ad,ed,mC;ad,ed;cGgu5hai,kFlEnDtchC;!e8O;a9Pik;house,o7t1;ae73eC3ha8Iolaj;ah,hDkC;!ey,y;aDeC;al,l;el,l;hDlv3rC;le,ri8Ev4T;di,met;ay0c00gn4hWjd,ks2NlTmadZnSrKsXtDuric7VxC;imilBKwe8B;eHhEi69tCus,y69;!eo,hCia7;ew,i67;eDiC;as,eu,s;us,w;j,o;cHiGkFlEqu8Qsha83tCv3;iCy;!m,n;in,on;el,o7us;a6Yo7us;!elCin,o7us;!l8o;frAEi5Zny,u5;achDcoCik;lm;ai,y;amDdi,e5VmC;oud;adCm6W;ou;aulCi9P;ay;aWeOiMloyd,oJuDyC;le,nd1;cFdEiDkCth2uk;a7e;gi,s,z;ov7Cv6Hw6H;!as,iC;a6Een;g0nn52renDuCvA4we7D;!iS;!zo;am,n4oC;n5r;a9Yevi,la5KnHoFst2thaEvC;eCi;nte;bo;nCpo8V;!a82el,id;!nC;aAy;mEnd1rDsz73urenCwr6K;ce,t;ry,s;ar,beAont;aOeIhalHiFla4onr63rDu5SylC;e,s;istCzysztof;i0oph2;er0ngsl9p,rC;ilA9k,ollos;ed,id;en0iGnDrmCv4Z;it;!dDnCt1;e2Ny;ri4Z;r,th;cp2j4mEna8BrDsp6them,uC;ri;im,l;al,il;a03eXiVoFuC;an,lCst3;en,iC;an,en,o,us;aQeOhKkub4AnIrGsDzC;ef;eDhCi9Wue;!ua;!f,ph;dCge;i,on;!aCny;h,s,th6J;anDnC;!ath6Hie,n72;!nC;!es;!l,sCy;ph;o,qu3;an,mC;!i,m6V;d,ffFns,rCs4;a7JemDmai7QoCry;me,ni1H;i9Dy;!e73rC;ey,y;cKdBkImHrEsDvi2yC;dBs1;on,p2;ed,oDrCv67;e6Qod;d,s61;al,es5Wis1;a,e,oCub;b,v;ob,qu13;aTbNchiMgLke53lija,nuKonut,rIsEtCv0;ai,suC;ki;aDha0i8XmaCsac;el,il;ac,iaC;h,s;a,vinCw3;!g;k,nngu6X;nac1Xor;ka;ai,rahC;im;aReLoIuCyd6;beAgGmFsC;eyDsC;a3e3;in,n;ber5W;h,o;m2raDsse3wC;a5Pie;c49t1K;a0Qct3XiGnDrC;beAman08;dr7VrC;iCy2N;!k,q1R;n0Tt3S;bKlJmza,nIo,rEsDyC;a5KdB;an,s0;lEo67r2IuCv9;hi5Hki,tC;a,o;an,ey;k,s;!im;ib;a08e00iUlenToQrMuCyorgy;iHnFsC;!taC;f,vC;!e,o;n6tC;er,h2;do,lC;herDlC;auCerQ;me;aEegCov2;!g,orC;!io,y;dy,h7C;dfr9nza3XrDttfC;ri6C;an,d47;!n;acoGlEno,oCuseppe;rgiCvan6O;!o,s;be6Ies,lC;es;mo;oFrC;aDha4HrCt;it,y;ld,rd8;ffErgC;!e7iCy;!os;!r9;bElBrCv3;eCla1Nr4Hth,y;th;e,rC;e3YielC;!i4;aXeSiQlOorrest,rCyod2E;aHedFiC;edDtC;s,z;ri18;!d42eri11riC;ck,k;nCs2;cEkC;ie,lC;in,yn;esLisC;!co,z3M;etch2oC;ri0yd;d5lConn;ip;deriFliEng,rC;dinaCg4nan0B;nd8;pe,x;co;bCdi,hd;iEriC;ce,zC;io;an,en,o;benez2dZfrYit0lTmMnJo3rFsteb0th0ugenEvCymBzra;an,eCge4D;ns,re3K;!e;gi,iDnCrol,v3w3;est8ie,st;cCk;!h,k;o0DriCzo;co,qC;ue;aHerGiDmC;aGe3A;lCrh0;!iC;a10o,s;s1y;nu5;beAd1iEliDm2t1viCwood;n,s;ot28s;!as,j5Hot,sC;ha;a3en;!dGg6mFoDua2QwC;a2Pin;arC;do;oZuZ;ie;a04eTiOmitrNoFrag0uEwDylC;an,l0;ay3Hig4D;a3Gdl9nc0st3;minFnDri0ugCvydGy2S;!lF;!a36nCov0;e1Eie,y;go,iDykC;as;cCk;!k;i,y;armuFetDll1mitri7neCon,rk;sh;er,m6riC;ch;id;andLepak,j0lbeAmetri4nIon,rGsEvDwCxt2;ay30ey;en,in;hawn,moC;nd;ek,riC;ck;is,nC;is,y;rt;re;an,le,mKnIrEvC;e,iC;!d;en,iEne0PrCyl;eCin,yl;l45n;n,o,us;!iCny;el,lo;iCon;an,en,on;a0Fe0Ch03iar0lRoJrFuDyrC;il,us;rtC;!is;aEistC;iaCob12;no;ig;dy,lInErC;ey,neliCy;s,us;nEor,rDstaC;nt3;ad;or;by,e,in,l3t1;aHeEiCyde;fCnt,ve;fo0Xt1;menDt4;us;s,t;rFuDyC;!t1;dCs;e,io;enC;ce;aHeGrisC;!toC;phCs;!eC;!r;st2t;d,rCs;b5leC;s,y;cDdrCs6;ic;il;lHmFrC;ey,lDroCy;ll;!o7t1;er1iC;lo;!eb,v3;a09eZiVjorn,laUoSrEuCyr1;ddy,rtKst2;er;aKeFiEuDyC;an,ce,on;ce,no;an,ce;nDtC;!t;dDtC;!on;an,on;dFnC;dDisC;lav;en,on;!foOl9y;bby,gd0rCyd;is;i0Lke;bElDshC;al;al,lL;ek;nIrCshoi;at,nEtC;!raC;m,nd;aDhaCie;rd;rd8;!iDjam3nCs1;ie,y;to;kaMlazs,nHrC;n9rDtC;!holomew;eCy;tt;ey;dCeD;ar,iC;le;ar1Nb1Dd16fon15gust3hm12i0Zja0Yl0Bm07nTputsiSrGsaFugustEveDyCziz;a0kh0;ry;o,us;hi;aMchiKiJjun,mHnEon,tCy0;em,hCie,ur8;ur;aDoC;!ld;ud,v;aCin;an,nd8;!el,ki;baCe;ld;ta;aq;aMdHgel8tCw6;hoFoC;iDnC;!i8y;ne;ny;er7rCy;eDzC;ej;!as,i,j,s,w;!s;s,tolC;iCy;!y;ar,iEmaCos;nu5r;el;ne,r,t;aVbSdBeJfHiGl01onFphonsEt1vC;aPin;on;e,o;so,zo;!sR;!onZrC;ed;c,jaHksFssaHxC;!andC;er,rC;e,os,u;andCei;ar,er,r;ndC;ro;en;eDrecC;ht;rt8;dd3in,n,sC;taC;ir;ni;dDm6;ar;an,en;ad,eC;d,t;in;so;aGi,olErDvC;ik;ian8;f8ph;!o;mCn;!a;dGeFraDuC;!bakr,lfazl;hCm;am;!l;allFel,oulaye,ulC;!lDrahm0;an;ah,o;ah;av,on",Uncountable:"true¦0:2E;1:2L;2:33;a2Ub2Lc29d22e1Rf1Ng1Eh16i11j0Yk0Wl0Rm0Hn0Do0Cp03rZsLt9uran2Jv7w3you gu0E;a5his17i4oo3;d,l;ldlife,ne;rm8t1;apor,ernacul29i3;neg28ol1Otae;eDhBiAo8r4un3yranny;a,gst1B;aff2Oea1Ko4ue nor3;th;o08u3;bleshoot2Ose1Tt;night,othpas1Vwn3;foEsfoE;me off,n;er3und1;e,mod2S;a,nnis;aDcCeBhAi9ki8o7p6t4u3weepstak0;g1Unshi2Hshi;ati08e3;am,el;ace2Keci0;ap,cc1meth2C;n,ttl0;lk;eep,ingl0or1C;lf,na1Gri0;ene1Kisso1C;d0Wfe2l4nd,t3;i0Iurn;m1Ut;abi0e4ic3;e,ke15;c3i01laxa11search;ogni10rea10;a9e8hys7luto,o5re3ut2;amble,mis0s3ten20;en1Zs0L;l3rk;i28l0EyH; 16i28;a24tr0F;nt3ti0M;i0s;bstetri24vercrowd1Qxyg09;a5e4owada3utella;ys;ptu1Ows;il poliZtional securi2;aAe8o5u3;m3s1H;ps;n3o1K;ey,o3;gamy;a3cha0Elancholy,rchandi1Htallurgy;sl0t;chine3g1Aj1Hrs,thema1Q; learn1Cry;aught1e6i5ogi4u3;ck,g12;c,s1M;ce,ghtn18nguis1LteratWv1;ath1isVss;ara0EindergartPn3;icke0Aowled0Y;e3upit1;a3llyfiGwel0G;ns;ce,gnor6mp5n3;forma00ter3;net,sta07;atiSort3rov;an18;a7e6isto09o3ung1;ckey,mework,ne4o3rseradi8spitali2use arrest;ky;s2y;adquarteXre;ir,libut,ppiHs3;hi3te;sh;ene8l6o5r3um,ymnas11;a3eZ;niUss;lf,re;ut3yce0F;en; 3ti0W;edit0Hpo3;ol;aNicFlour,o4urnit3;ure;od,rgive3uri1wl;ness;arCcono0LducaBlectr9n7quip8thi0Pvery6x3;ist4per3;ti0B;en0J;body,o08th07;joy3tertain3;ment;ici2o3;ni0H;tiS;nings,th;emi02i6o4raugh3ynas2;ts;pe,wnstai3;rs;abet0ce,s3;honZrepu3;te;aDelciChAivi07l8o3urrency;al,ld w6mmenta5n3ral,ttIuscoB;fusiHt 3;ed;ry;ar;assi01oth0;es;aos,e3;eMwK;us;d,rO;a8i6lood,owlHread5u3;ntGtt1;er;!th;lliarJs3;on;g3ss;ga3;ge;cKdviJeroGirFmBn6ppeal court,r4spi3thleL;rin;ithmet3sen3;ic;i6y3;o4th3;ing;ne;se;en5n3;es2;ty;ds;craft;bi8d3nau7;yna3;mi6;ce;id,ous3;ti3;cs",Infinitive:"true¦0:9G;1:9T;2:AD;3:90;4:9Z;5:84;6:AH;7:A9;8:92;9:A0;A:AG;B:AI;C:9V;D:8R;E:8O;F:97;G:6H;H:7D;a94b8Hc7Jd68e4Zf4Mg4Gh4Ai3Qj3Nk3Kl3Bm34nou48o2Vp2Equ2Dr1Es0CtZuTvRwI;aOeNiLors5rI;eJiI;ng,te;ak,st3;d5e8TthI;draw,er;a2d,ep;i2ke,nIrn;d1t;aIie;liADniAry;nJpI;ho8Llift;cov1dJear8Hfound8DlIplug,rav82tie,ve94;eaAo3X;erIo;cut,go,staAFvalA3w2G;aSeQhNoMrIu73;aIe72;ffi3Smp3nsI;aBfo7CpI;i8oD;pp3ugh5;aJiJrIwaD;eat5i2;nk;aImA0;ch,se;ck3ilor,keImp1r8L;! paD;a0Ic0He0Fh0Bi0Al08mugg3n07o05p02qu01tUuLwI;aJeeIim;p,t5;ll7Wy;bNccMffLggeCmmKppJrI;mouFpa6Zvi2;o0re6Y;ari0on;er,i4;e7Numb;li9KmJsiIveD;de,st;er9it;aMe8MiKrI;ang3eIi2;ng27w;fIng;f5le;b,gg1rI;t3ve;a4AiA;a4UeJit,l7DoI;il,of;ak,nd;lIot7Kw;icEve;atGeak,i0O;aIi6;m,y;ft,ng,t;aKi6CoJriIun;nk,v6Q;ot,rt5;ke,rp5tt1;eIll,nd,que8Gv1w;!k,m;aven9ul8W;dd5tis1Iy;a0FeKiJoI;am,t,ut;d,p5;a0Ab08c06d05f01group,hea00iZjoi4lXmWnVpTq3MsOtMup,vI;amp,eJiIo3B;sEve;l,rI;e,t;i8rI;ie2ofE;eLiKpo8PtIurfa4;o24rI;aHiBuctu8;de,gn,st;mb3nt;el,hra0lIreseF;a4e71;d1ew,o07;aHe3Fo2;a7eFiIo6Jy;e2nq41ve;mbur0nf38;r0t;inKleBocus,rJuI;el,rbiA;aBeA;an4e;aBu4;ei2k8Bla43oIyc3;gni39nci3up,v1;oot,uI;ff;ct,d,liIp;se,ze;tt3viA;aAenGit,o7;aWerUinpoiFlumm1LoTrLuI;b47ke,niArIt;poDsuI;aFe;eMoI;cKd,fe4XhibEmo7noJpo0sp1tru6vI;e,i6o5L;un4;la3Nu8;aGclu6dJf1occupy,sup0JvI;a6BeF;etermi4TiB;aGllu7rtr5Ksse4Q;cei2fo4NiAmea7plex,sIva6;eve8iCua6;mp1rItrol,ve;a6It6E;bOccuNmEpMutLverIwe;l07sJtu6Yu0wI;helm;ee,h1F;gr5Cnu2Cpa4;era7i4Ipo0;py,r;ey,seItaH;r2ss;aMe0ViJoIultiply;leCu6Pw;micJnIspla4;ce,g3us;!k;iIke,na9;m,ntaH;aPeLiIo0u3N;ke,ng1quIv5;eIi6S;fy;aKnIss5;d,gI;th5;rn,ve;ng2Gu1N;eep,idnJnI;e4Cow;ap;oHuI;gg3xtaI;po0;gno8mVnIrk;cTdRfQgeChPitia7ju8q1CsNtKun6EvI;a6eIo11;nt,rt,st;erJimi6BoxiPrI;odu4u6;aBn,pr03ru6C;iCpi8tIu8;all,il,ruB;abEibE;eCo3Eu0;iIul9;ca7;i7lu6;b5Xmer0pI;aLer4Uin9ly,oJrI;e3Ais6Bo2;rt,se,veI;riA;le,rt;aLeKiIoiCuD;de,jaInd1;ck;ar,iT;mp1ng,pp5raIve;ng5Mss;ath1et,iMle27oLrI;aJeIow;et;b,pp3ze;!ve5A;gg3ve;aTer45i5RlSorMrJuI;lf4Cndrai0r48;eJiIolic;ght5;e0Qsh5;b3XeLfeEgJsI;a3Dee;eIi2;!t;clo0go,shIwa4Z;ad3F;att1ee,i36;lt1st5;a0OdEl0Mm0FnXquip,rWsVtGvTxI;aRcPeDhOiNpJtIu6;ing0Yol;eKi8lIo0un9;aHoI;it,re;ct,di7l;st,t;a3oDu3B;e30lI;a10u6;lt,mi28;alua7oI;ke,l2;chew,pou0tab19;a0u4U;aYcVdTfSgQhan4joy,lPqOrNsuMtKvI;e0YisI;a9i50;er,i4rI;aHenGuC;e,re;iGol0F;ui8;ar9iC;a9eIra2ulf;nd1;or4;ang1oIu8;r0w;irc3lo0ou0ErJuI;mb1;oaGy4D;b3ct;bKer9pI;hasiIow1;ze;aKody,rI;a4oiI;d1l;lm,rk;ap0eBuI;ci40de;rIt;ma0Rn;a0Re04iKo,rIwind3;aw,ed9oI;wn;agno0e,ff1g,mi2Kne,sLvI;eIul9;rIst;ge,t;aWbVcQlod9mant3pNru3TsMtI;iIoDu37;lJngI;uiA;!l;ol2ua6;eJlIo0ro2;a4ea0;n0r0;a2Xe36lKoIu0S;uIv1;ra9;aIo0;im;a3Kur0;b3rm;af5b01cVduBep5fUliTmQnOpMrLsiCtaGvI;eIol2;lop;ch;a20i2;aDiBloIoD;re,y;oIy;te,un4;eJoI;liA;an;mEv1;a4i0Ao06raud,y;ei2iMla8oKrI;ee,yI;!pt;de,mIup3;missi34po0;de,ma7ph1;aJrief,uI;g,nk;rk;mp5rk5uF;a0Dea0h0Ai09l08oKrIurta1G;a2ea7ipp3uI;mb3;ales4e04habEinci6ll03m00nIrro6;cXdUfQju8no7qu1sLtKvI;eIin4;ne,r9y;aHin2Bribu7;er2iLoli2Epi8tJuI;lt,me;itu7raH;in;d1st;eKiJoIroFu0;rm;de,gu8rm;ss;eJoI;ne;mn,n0;eIlu6ur;al,i2;buCe,men4pI;eIi3ly;l,te;eBi6u6;r4xiC;ean0iT;rcumveFte;eJirp,oI;o0p;riAw;ncIre5t1ulk;el;a02eSi6lQoPrKuI;iXrIy;st,y;aLeaKiJoad5;en;ng;stfeLtX;ke;il,l11mba0WrrMth1;eIow;ed;!coQfrie1LgPhMliLqueaKstJtrIwild1;ay;ow;th;e2tt3;a2eJoI;ld;ad;!in,ui3;me;bysEckfi8ff3tI;he;b15c0Rd0Iff0Ggree,l0Cm09n03ppZrXsQttOuMvJwaE;it;eDoI;id;rt;gIto0X;meF;aIeCraB;ch,in;pi8sJtoI;niA;aKeIi04u8;mb3rt,ss;le;il;re;g0Hi0ou0rI;an9i2;eaKly,oiFrI;ai0o2;nt;r,se;aMi0GnJtI;icipa7;eJoIul;un4y;al;ly0;aJu0;se;lga08ze;iKlI;e9oIu6;t,w;gn;ix,oI;rd;a03jNmiKoJsoI;rb;pt,rn;niIt;st1;er;ouJuC;st;rn;cLhie2knowled9quiItiva7;es4re;ce;ge;eQliOoKrJusI;e,tom;ue;mIst;moJpI;any,liA;da7;ma7;te;pt;andPduBet,i6oKsI;coKol2;ve;liArt,uI;nd;sh;de;ct;on",Person:"true¦0:1Q;a29b1Zc1Md1Ee18f15g13h0Ri0Qj0Nk0Jl0Gm09n06o05p00rPsItCusain bolt,v9w4xzibit,y1;anni,oko on2uji,v1;an,es;en,o;a3ednesday adams,i2o1;lfram,o0Q;ll ferrell,z khalifa;lt disn1Qr1;hol,r0G;a2i1oltai06;n dies0Zrginia wo17;lentino rossi,n goG;a4h3i2ripp,u1yra banks;lZpac shakur;ger woods,mba07;eresa may,or;kashi,t1ylor;um,ya1B;a5carlett johanss0h4i3lobodan milosevic,no2ocr1Lpider1uperm0Fwami; m0Em0E;op dogg,w whi1H;egfried,nbad;akespeaTerlock holm1Sia labeouf;ddam hussa16nt1;a cla11ig9;aAe6i5o3u1za;mi,n dmc,paul,sh limbau1;gh;bin hood,d stew16nald1thko;in0Mo;han0Yngo starr,valdo;ese witherspo0i1mbrandt;ll2nh1;old;ey,y;chmaninoff,ffi,iJshid,y roma1H;a4e3i2la16o1uff daddy;cahont0Ie;lar,p19;le,rZ;lm17ris hilt0;leg,prah winfr0Sra;a2e1iles cra1Bostradam0J; yo,l5tt06wmQ;pole0s;a5e4i2o1ubar03;by,lie5net,rriss0N;randa ju1tt romn0M;ly;rl0GssiaB;cklemo1rkov,s0ta hari,ya angelou;re;ady gaga,e1ibera0Pu;bron jam0Xch wale1e;sa;anye west,e3i1obe bryant;d cudi,efer suther1;la0P;ats,sha;a2effers0fk,k rowling,rr tolki1;en;ck the ripp0Mwaharlal nehru,y z;liTnez,ron m7;a7e5i3u1;lk hog5mphrey1sa01;! bog05;l1tl0H;de; m1dwig,nry 4;an;ile selassFlle ber4m3rrison1;! 1;ford;id,mo09;ry;ast0iannis,o1;odwPtye;ergus0lorence nightinga08r1;an1ederic chopN;s,z;ff5m2nya,ustaXzeki1;el;eril lagasse,i1;le zatop1nem;ek;ie;a6e4i2octor w1rake;ho;ck w1ego maradoC;olf;g1mi lovaOnzel washingt0;as;l1nHrth vadR;ai lNt0;a8h5lint0o1thulhu;n1olio;an,fuci1;us;on;aucKop2ristian baMy1;na;in;millo,ptain beefhe4r1;dinal wols2son1;! palmF;ey;art;a8e5hatt,i3oHro1;ck,n1;te;ll g1ng crosby;atB;ck,nazir bhut2rtil,yon1;ce;to;nksy,rack ob1;ama;l 6r3shton kutch2vril lavig8yn ra1;nd;er;chimed2istot1;le;es;capo2paci1;no;ne",Adjective:"true¦0:AI;1:BS;2:BI;3:BA;4:A8;5:84;6:AV;7:AN;8:AF;9:7H;A:BQ;B:AY;C:BC;D:BH;E:9Y;aA2b9Ec8Fd7We79f6Ng6Eh61i4Xj4Wk4Tl4Im41n3Po36p2Oquart7Pr2Ds1Dt14uSvOwFye29;aMeKhIiHoF;man5oFrth7G;dADzy;despreB1n w97s86;acked1UoleF;!sa6;ather1PeFll o70ste1D;!k5;nt1Ist6Ate4;aHeGiFola5T;bBUce versa,gi3Lle;ng67rsa5R;ca1gBSluAV;lt0PnLpHrGsFttermoBL;ef9Ku3;b96ge1; Hb32pGsFtiAH;ca6ide d4R;er,i85;f52to da2;a0Fbeco0Hc0Bd04e02f01gu1XheaBGiXkn4OmUnTopp06pRrNsJtHus0wF;aFiel3K;nt0rra0P;app0eXoF;ld,uS;eHi37o5ApGuF;perv06spec39;e1ok9O;en,ttl0;eFu5;cogn06gul2RlGqu84sF;erv0olv0;at0en33;aFrecede0E;id,rallel0;am0otic0;aFet;rri0tF;ch0;nFq26vers3;sur0terFv7U;eFrupt0;st0;air,inish0orese98;mploy0n7Ov97xpF;ect0lain0;eHisFocume01ue;clFput0;os0;cid0rF;!a8Scov9ha8Jlyi8nea8Gprivileg0sMwF;aFei9I;t9y;hGircumcFonvin2U;is0;aFeck0;lleng0rt0;b20ppea85ssuGttend0uthorF;iz0;mi8;i4Ara;aLeIhoHip 25oGrF;anspare1encha1i2;geth9leADp notch,rpB;rny,ugh6H;ena8DmpGrFs6U;r49tia4;eCo8P;leFst4M;nt0;a0Dc09e07h06i04ki03l01mug,nobbi4XoVpRqueami4XtKuFymb94;bHccinAi generis,pFr5;erFre7N;! dup9b,vi70;du0li7Lp6IsFurb7J;eq9Atanda9X;aKeJi16o2QrGubboFy4Q;rn;aightFin5GungS; fFfF;or7V;adfa9Pri6;lwa6Ftu82;arHeGir6NlendBot Fry;on;c3Qe1S;k5se; call0lImb9phistic16rHuFviV;ndFth1B;proof;dBry;dFub6; o2A;e60ipF;pe4shod;ll0n d7R;g2HnF;ceEg6ist9;am3Se9;co1Zem5lfFn6Are7; suf4Xi43;aGholFient3A;ar5;rlFt4A;et;cr0me,tisfac7F;aOeIheumatoBiGoF;bu8Ztt7Gy3;ghtFv3; 1Sf6X;cJdu8PlInown0pro69sGtF;ard0;is47oF;lu2na1;e1Suc45;alcit8Xe1ondi2;bBci3mpa1;aSePicayu7laOoNrGuF;bl7Tnjabi;eKiIoF;b7VfGmi49pFxi2M;er,ort81;a7uD;maFor,sti7va2;!ry;ciDexis0Ima2CpaB;in55puli8G;cBid;ac2Ynt 3IrFti2;ma40tFv7W;!i3Z;i2YrFss7R;anoBtF; 5XiF;al,s5V;bSffQkPld OnMrLth9utKverF;!aIbMdHhGni75seas,t,wF;ei74rou74;a63e7A;ue;ll;do1Ger,si6A;d3Qg2Aotu5Z; bFbFe on o7g3Uli7;oa80;fashion0school;!ay; gua7XbFha5Uli7;eat;eHligGsF;ce7er0So1C;at0;diFse;a1e1;aOeNiMoGuF;anc0de; moEnHrthFt6V;!eFwe7L;a7Krn;chaGdescri7Iprof30sF;top;la1;ght5;arby,cessa4ighbor5wlyw0xt;k0usiaFv3;ti8;aQeNiLoHuF;dIltiF;facet0p6;deHlGnFot,rbBst;ochro4Xth5;dy;rn,st;ddle ag0nF;dbloZi,or;ag9diocEga,naGrFtropolit4Q;e,ry;ci8;cIgenta,inHj0Fkeshift,mmGnFri4Oscu61ver18;da5Dy;ali4Lo4U;!stream;abEho;aOeLiIoFumberi8;ngFuti1R;stan3RtF;erm,i4H;ghtGteraF;l,ry,te;heart0wei5O;ft JgFss9th3;al,eFi0M;nda4;nguBps0te5;apGind5noF;wi8;ut;ad0itte4uniW;ce co0Hgno6Mll0Cm04nHpso 2UrF;a2releF;va1; ZaYcoWdReQfOgrNhibi4Ri05nMoLsHtFvalu5M;aAeF;nDrdepe2K;a7iGolFuboI;ub6ve1;de,gF;nifica1;rdi5N;a2er;own;eriIiLluenVrF;ar0eq5H;pt,rt;eHiGoFul1O;or;e,reA;fiFpe26termi5E;ni2;mpFnsideCrreA;le2;ccuCdeq5Ene,ppr4J;fFsitu,vitro;ro1;mJpF;arHeGl15oFrop9;li2r11;n2LrfeA;ti3;aGeFi18;d4BnD;tuE;egGiF;c0YteC;al,iF;tiF;ma2;ld;aOelNiLoFuma7;a4meInHrrGsFur5;ti6;if4E;e58o3U; ma3GsF;ick;ghfalut2HspF;an49;li00pf33;i4llow0ndGrdFtM; 05coEworki8;sy,y;aLener44iga3Blob3oKrGuF;il1Nng ho;aFea1Fizzl0;cGtF;ef2Vis;ef2U;ld3Aod;iFuc2D;nf2R;aVeSiQlOoJrF;aGeFil5ug3;q43tf2O;gFnt3S;i6ra1;lk13oHrF; keeps,eFge0Vm9tu41;g0Ei2Ds3R;liF;sh;ag4Mowe4uF;e1or45;e4nF;al,i2;d Gmini7rF;ti6ve1;up;bl0lDmIr Fst pac0ux;oGreacF;hi8;ff;ed,ili0R;aXfVlTmQnOqu3rMthere3veryday,xF;aApIquisi2traHuF;be48lF;ta1;!va2L;edRlF;icF;it;eAstF;whi6; Famor0ough,tiE;rou2sui2;erGiF;ne1;ge1;dFe2Aoq34;er5;ficF;ie1;g9sF;t,ygF;oi8;er;aWeMiHoGrFue;ea4owY;ci6mina1ne,r31ti8ubQ;dact2Jfficult,m,sGverF;ge1se;creGePjoi1paCtF;a1inA;et,te; Nadp0WceMfiLgeneCliJmuEpeIreliAsGvoF;id,ut;pFtitu2ul1L;eCoF;nde1;ca2ghF;tf13;a1ni2;as0;facto;i5ngero0I;ar0Ce09h07i06l05oOrIuF;rmudgeon5stoma4teF;sy;ly;aIeHu1EystalF; cleFli7;ar;epy;fFv17z0;ty;erUgTloSmPnGrpoCunterclVveFy;rt;cLdJgr21jIsHtrF;aFi2;dic0Yry;eq1Yta1;oi1ug3;escenFuN;di8;a1QeFiD;it0;atoDmensuCpF;ass1SulF;so4;ni3ss3;e1niza1;ci1J;ockwiD;rcumspeAvil;eFintzy;e4wy;leGrtaF;in;ba2;diac,ef00;a00ePiLliJoGrFuck nak0;and new,isk,on22;gGldface,naF; fi05fi05;us;nd,tF;he;gGpartisFzarE;an;tiF;me;autifOhiNlLnHsFyoN;iWtselF;li8;eGiFt;gn;aFfi03;th;at0oF;v0w;nd;ul;ckwards,rF;e,rT; priori,b13c0Zd0Tf0Ng0Ihe0Hl09mp6nt06pZrTsQttracti0MuLvIwF;aGkF;wa1B;ke,re;ant garGeraF;ge;de;diIsteEtF;heFoimmu7;nt07;re;to4;hGlFtu2;eep;en;bitIchiv3roHtF;ifiFsy;ci3;ga1;ra4;ry;pFt;aHetizi8rF;oprF;ia2;llFre1;ed,i8;ng;iquFsy;at0e;ed;cohKiJkaHl,oGriFterX;ght;ne,of;li7;ne;ke,ve;olF;ic;ad;ain07gressiIi6rF;eeF;ab6;le;ve;fGraB;id;ectGlF;ue1;ioF;na2; JaIeGvF;erD;pt,qF;ua2;ma1;hoc,infinitum;cuCquiGtu3u2;al;esce1;ra2;erSjeAlPoNrKsGuF;nda1;e1olu2trF;aAuD;se;te;eaGuF;pt;st;aFve;rd;aFe;ze;ct;ra1;nt",Pronoun:"true¦elle,h3i2me,she,th0us,we,you;e0ou;e,m,y;!l,t;e,im",Preposition:"true¦aPbMcLdKexcept,fIinGmid,notwithstandiWoDpXqua,sCt7u4v2w0;/o,hereSith0;! whHin,oW;ersus,i0;a,s a vis;n1p0;!on;like,til;h1ill,oward0;!s;an,ereby,r0;ough0u;!oM;ans,ince,o that,uch G;f1n0ut;!to;!f;! 0to;effect,part;or,r0;om;espite,own,u3;hez,irca;ar1e0oBy;sides,tween;ri7;bo8cross,ft7lo6m4propos,round,s1t0;!op;! 0;a whole,long 0;as;id0ong0;!st;ng;er;ut",SportsTeam:"true¦0:18;1:1E;2:1D;3:14;a1Db15c0Sd0Kfc dallas,g0Ihouston 0Hindiana0Gjacksonville jagua0k0El0Am01new UoRpKqueens parkJreal salt lake,sBt6utah jazz,vancouver whitecaps,w4yW;ashington 4h10;natio1Mredski2wizar0W;ampa bay 7e6o4;ronto 4ttenham hotspur;blue ja0Mrapto0;nnessee tita2xasD;buccanee0ra0K;a8eattle 6porting kansas0Wt4; louis 4oke0V;c1Drams;marine0s4;eah13ounH;cramento Rn 4;antonio spu0diego 4francisco gJjose earthquak1;char08paB; ran07;a9h6ittsburgh 5ortland t4;imbe0rail blaze0;pirat1steele0;il4oenix su2;adelphia 4li1;eagl1philNunE;dr1;akland 4klahoma city thunder,rlando magic;athle0Lrai4;de0;england 8orleans 7york 4;g5je3knYme3red bul0Xy4;anke1;ian3;pelica2sain3;patrio3revolut4;ion;anchEeAi4ontreal impact;ami 8lwaukee b7nnesota 4;t5vi4;kings;imberwolv1wi2;rewe0uc0J;dolphi2heat,marli2;mphis grizz4ts;li1;a6eic5os angeles 4;clippe0dodFlaB;esterV; galaxy,ke0;ansas city 4nF;chiefs,roya0D; pace0polis col3;astr05dynamo,rocke3texa2;olden state warrio0reen bay pac4;ke0;allas 8e4i04od6;nver 6troit 4;lio2pisto2ti4;ge0;broncYnugge3;cowbo5maver4;icZ;ys;arEelLhAincinnati 8leveland 6ol4;orado r4umbus crew sc;api7ocki1;brow2cavalie0guar4in4;dia2;bengaVre4;ds;arlotte horAicago 4;b5cubs,fire,wh4;iteB;ea0ulQ;diff4olina panthe0; city;altimore Alackburn rove0oston 6rooklyn 4uffalo bilN;ne3;ts;cel5red4; sox;tics;rs;oriol1rave2;rizona Ast8tlanta 4;brav1falco2h4;awA;ns;es;on villa,r4;os;c6di4;amondbac4;ks;ardi4;na4;ls",Unit:"true¦a07b04cXdWexVfTgRhePinYjoule0BkMlJmDnan08oCp9quart0Bsq ft,t7volts,w6y2ze3°1µ0;g,s;c,f,n;dVear1o0;ttR; 0s 0;old;att,b;erNon0;!ne02;ascals,e1i0;cXnt00;rcent,tJ;hms,unceY;/s,e4i0m²,²,³;/h,cro2l0;e0liK;!²;grLsR;gCtJ;it1u0;menQx;erPreP;b5elvins,ilo1m0notO;/h,ph,²;!byGgrEmCs;ct0rtzL;aJogrC;allonJb0ig3rB;ps;a0emtEl oz,t4;hrenheit,radG;aby9;eci3m1;aratDe1m0oulombD;²,³;lsius,nti0;gr2lit1m0;et0;er8;am7;b1y0;te5;l,ps;c2tt0;os0;econd1;re0;!s","Noun|Gerund":"true¦0:3O;1:3M;2:3N;3:3D;4:32;5:2V;6:3E;7:3K;8:36;9:3J;A:3B;a3Pb37c2Jd27e23f1Vg1Sh1Mi1Ij1Gk1Dl18m13n11o0Wp0Pques0Sr0EsTtNunderMvKwFyDzB;eroi0oB;ni0o3P;aw2eB;ar2l3;aEed4hispe5i5oCrB;ap8est3i1;n0ErB;ki0r31;i1r2s9tc9;isualizi0oB;lunt1Vti0;stan4ta6;aFeDhin6iCraBy8;c6di0i2vel1M;mi0p8;aBs1;c9si0;l6n2s1;aUcReQhOiMkatKl2Wmo6nowJpeItFuCwB;ea5im37;b35f0FrB;fi0vB;e2Mi2J;aAoryt1KrCuB;d2KfS;etc9ugg3;l3n4;bCi0;ebBi0;oar4;gnBnAt1;a3i0;ip8oB;p8rte2u1;a1r27t1;hCo5reBulp1;a2Qe2;edu3oo3;i3yi0;aKeEi4oCuB;li0n2;oBwi0;fi0;aFcEhear7laxi0nDpor1sB;pon4tructB;r2Iu5;de5;or4yc3;di0so2;p8ti0;aFeacek20laEoCrBublis9;a1Teten4in1oces7;iso2siB;tio2;n2yi0;ckaAin1rB;ki0t1O;fEpeDrganiCvB;erco24ula1;si0zi0;ni0ra1;fe5;avi0QeBur7;gotia1twor6;aDeCi2oB;de3nito5;a2dita1e1ssaA;int0XnBrke1;ifUufactu5;aEeaDiBodAyi0;cen7f1mi1stB;e2i0;r2si0;n4ug9;iCnB;ea4it1;c6l3;ogAuB;dAgg3stif12;ci0llust0VmDnBro2;nova1sp0NterBven1;ac1vie02;agi2plo4;aDea1iCoBun1;l4w3;ki0ri0;nd3rB;roWvB;es1;aCene0Lli4rBui4;ee1ie0N;rde2the5;aHeGiDlCorBros1un4;e0Pmat1;ir1oo4;gh1lCnBs9;anZdi0;i0li0;e3nX;r0Zscina1;a1du01nCxB;erci7plo5;chan1di0ginB;ee5;aLeHiGoub1rCum8wB;el3;aDeCiB;bb3n6vi0;a0Qs7;wi0;rTscoDvi0;ba1coZlBvelo8;eCiB;ve5;ga1;nGti0;aVelebUhSlPoDrBur3yc3;aBos7yi0;f1w3;aLdi0lJmFnBo6pi0ve5;dDsCvinB;ci0;trBul1;uc1;muniDpB;lBo7;ai2;ca1;lBo5;ec1;c9ti0;ap8eaCimToBubT;ni0t9;ni0ri0;aBee5;n1t1;ra1;m8rCs1te5;ri0;vi0;aPeNitMlLoGrDuB;dge1il4llBr8;yi0;an4eat9oadB;cas1;di0;a1mEokB;i0kB;ee8;pi0;bi0;es7oa1;c9i0;gin2lonAt1;gi0;bysit1c6ki0tt3;li0;ki0;bando2cGdverti7gi0pproac9rgDssuCtB;trac1;mi0;ui0;hi0;si0;coun1ti0;ti0;ni0;ng",PhrasalVerb:"true¦0:92;1:96;2:8H;3:8V;4:8A;5:83;6:85;7:98;8:90;9:8G;A:8X;B:8R;C:8U;D:8S;E:70;F:97;G:8Y;H:81;I:7H;J:79;a9Fb7Uc6Rd6Le6Jf5Ig50h4Biron0j47k40l3Em31n2Yo2Wp2Cquiet Hr1Xs0KtZuXvacuu6QwNyammerBzK;ero Dip LonK;e0k0;by,ov9up;aQeMhLiKor0Mrit19;mp0n3Fpe0r5s5;ackAeel Di0S;aLiKn33;gh 3Wrd0;n Dr K;do1in,oJ;it 79k5lk Lrm 69sh Kt83v60;aw3do1o7up;aw3in,oC;rgeBsK;e 2herE;a00eYhViRoQrMuKypP;ckErn K;do1in,oJup;aLiKot0y 30;ckl7Zp F;ck HdK;e 5Y;n7Wp 3Es5K;ck MdLe Kghten 6me0p o0Rre0;aw3ba4do1in,up;e Iy 2;by,oG;ink Lrow K;aw3ba4in,up;ba4ov9up;aKe 77ll62;m 2r 5M;ckBke Llk K;ov9shit,u47;aKba4do1in,leave,o4Dup;ba4ft9pa69w3;a0Vc0Te0Mh0Ii0Fl09m08n07o06p01quar5GtQuOwK;earMiK;ngLtch K;aw3ba4o8K; by;cKi6Bm 2ss0;k 64;aReQiPoNrKud35;aigh2Det75iK;ke 7Sng K;al6Yup;p Krm2F;by,in,oG;c3Ln3Lr 2tc4O;p F;c3Jmp0nd LrKveAy 2O;e Ht 2L;ba4do1up;ar3GeNiMlLrKurB;ead0ingBuc5;a49it 6H;c5ll o3Cn 2;ak Fe1Xll0;a3Bber 2rt0und like;ap 5Vow Duggl5;ash 6Noke0;eep NiKow 6;cLp K;o6Dup;e 68;in,oK;ff,v9;de19gn 4NnKt 6Gz5;gKkE; al6Ale0;aMoKu5W;ot Kut0w 7M;aw3ba4f48oC;c2WdeEk6EveA;e Pll1Nnd Orv5tK; Ktl5J;do1foLin,o7upK;!on;ot,r5Z;aw3ba4do1in,o33up;oCto;al66out0rK;ap65ew 6J;ilAv5;aXeUiSoOuK;b 5Yle0n Kstl5;aLba4do1inKo2Ith4Nu5P;!to;c2Xr8w3;ll Mot LpeAuK;g3Ind17;a2Wf3Po7;ar8in,o7up;ng 68p oKs5;ff,p18;aKelAinEnt0;c6Hd K;o4Dup;c27t0;aZeYiWlToQrOsyc35uK;ll Mn5Kt K;aKba4do1in,oJto47up;pa4Dw3;a3Jdo1in,o21to45up;attleBess KiNop 2;ah2Fon;iLp Kr4Zu1Gwer 6N;do1in,o6Nup;nt0;aLuK;gEmp 6;ce u20y 6D;ck Kg0le 4An 6p5B;oJup;el 5NncilE;c53ir 39n0ss MtLy K;ba4oG; Hc2R;aw3ba4in,oJ;pKw4Y;e4Xt D;aLerd0oK;dAt53;il Hrrow H;aTeQiPoLuK;ddl5ll I;c1FnkeyMp 6uthAve K;aKdo1in,o4Lup;l4Nw3; wi4K;ss0x 2;asur5e3SlLss K;a21up;t 6;ke Ln 6rKs2Ax0;k 6ryA;do,fun,oCsure,up;a02eViQoLuK;ck0st I;aNc4Fg MoKse0;k Kse4D;aft9ba4do1forw37in56o0Zu46;in,oJ;d 6;e NghtMnLsKve 00;ten F;e 2k 2; 2e46;ar8do1in;aMt LvelK; oC;do1go,in,o7up;nEve K;in,oK;pKut;en;c5p 2sh LtchBughAy K;do1o59;in4Po7;eMick Lnock K;do1oCup;oCup;eLy K;in,up;l Ip K;aw3ba4do1f04in,oJto,up;aMoLuK;ic5mpE;ke3St H;c43zz 2;a01eWiToPuK;nLrrKsh 6;y 2;keLt K;ar8do1;r H;lKneErse3K;d Ke 2;ba4dKfast,o0Cup;ear,o1;de Lt K;ba4on,up;aw3o7;aKlp0;d Ml Ir Kt 2;fKof;rom;f11in,o03uW;cPm 2nLsh0ve Kz2P;at,it,to;d Lg KkerP;do1in,o2Tup;do1in,oK;ut,v9;k 2;aZeTive Rloss IoMrLunK; f0S;ab hold,in43ow 2U; Kof 2I;aMb1Mit,oLr8th1IuK;nd9;ff,n,v9;bo7ft9hQw3;aw3bKdo1in,oJrise,up,w3;a4ir2H;ar 6ek0t K;aLb1Fdo1in,oKr8up;ff,n,ut,v9;cLhKl2Fr8t,w3;ead;ross;d aKng 2;bo7;a0Ee07iYlUoQrMuK;ck Ke2N;ar8up;eLighten KownBy 2;aw3oG;eKshe27; 2z5;g 2lMol Krk I;aKwi20;bo7r8;d 6low 2;aLeKip0;sh0;g 6ke0mKrKtten H;e F;gRlPnNrLsKzzle0;h F;e Km 2;aw3ba4up;d0isK;h 2;e Kl 1T;aw3fPin,o7;ht ba4ure0;ePnLsK;s 2;cMd K;fKoG;or;e D;d04l 2;cNll Krm0t1G;aLbKdo1in,o09sho0Eth08victim;a4ehi2O;pa0C;e K;do1oGup;at Kdge0nd 12y5;in,o7up;aOi1HoNrK;aLess 6op KuN;aw3b03in,oC;gBwB; Ile0ubl1B;m 2;a0Ah05l02oOrLut K;aw3ba4do1oCup;ackBeep LoKy0;ss Dwd0;by,do1in,o0Uup;me NoLuntK; o2A;k 6l K;do1oG;aRbQforOin,oNtKu0O;hLoKrue;geth9;rough;ff,ut,v9;th,wK;ard;a4y;paKr8w3;rt;eaLose K;in,oCup;n 6r F;aNeLiK;ll0pE;ck Der Kw F;on,up;t 2;lRncel0rOsMtch LveE; in;o1Nup;h Dt K;doubt,oG;ry LvK;e 08;aw3oJ;l Km H;aLba4do1oJup;ff,n,ut;r8w3;a0Ve0MiteAl0Fo04rQuK;bblNckl05il0Dlk 6ndl05rLsKtMy FzzA;t 00;n 0HsK;t D;e I;ov9;anWeaUiLush K;oGup;ghQng K;aNba4do1forMin,oLuK;nd9p;n,ut;th;bo7lKr8w3;ong;teK;n 2;k K;do1in,o7up;ch0;arTg 6iRn5oPrNssMttlLunce Kx D;aw3ba4;e 6; ar8;e H;do1;k Dt 2;e 2;l 6;do1up;d 2;aPeed0oKurt0;cMw K;aw3ba4do1o7up;ck;k K;in,oC;ck0nk0stA; oQaNef 2lt0nd K;do1ov9up;er;up;r Lt K;do1in,oCup;do1o7;ff,nK;to;ck Pil0nMrgLsK;h D;ainBe D;g DkB; on;in,o7;aw3do1in,oCup;ff,ut;ay;ct FdQir0sk MuctionA; oG;ff;ar8o7;ouK;nd; o7;d K;do1oKup;ff,n;wn;o7up;ut",ProperNoun:"true¦aIbDc8dalhousHe7f5gosford,h4iron maiden,kirby,landsdowne,m2nis,r1s0wembF;herwood,paldiB;iel,othwe1;cgi0ercedes,issy;ll;intBudsB;airview,lorence,ra0;mpt9nco;lmo,uro;a1h0;arlt6es5risti;rl0talina;et4i0;ng;arb3e0;et1nt0rke0;ley;on;ie;bid,jax","Person|Place":"true¦a8d6h4jordan,k3orlando,s1vi0;ctor9rgin9;a0ydney;lvador,mara,ntia4;ent,obe;amil0ous0;ton;arw2ie0;go;lexandr1ust0;in;ia",LastName:"true¦0:BR;1:BF;2:B5;3:BH;4:AX;5:9Y;6:B6;7:BK;8:B0;9:AV;A:AL;B:8Q;C:8G;D:7K;E:BM;F:AH;aBDb9Zc8Wd88e81f7Kg6Wh64i60j5Lk4Vl4Dm39n2Wo2Op25quispe,r1Ls0Pt0Ev03wTxSyKzG;aIhGimmerm6A;aGou,u;ng,o;khar5ytsE;aKeun9BiHoGun;koya32shiBU;!lG;diGmaz;rim,z;maGng;da,g52mo83sGzaC;aChiBV;iao,u;aLeJiHoGright,u;jcA5lff,ng;lGmm0nkl0sniewsC;kiB1liams33s3;bGiss,lt0;b,er,st0;a6Vgn0lHtG;anabe,s3;k0sh,tG;e2Non;aLeKiHoGukD;gt,lk5roby5;dHllalGnogr3Kr1Css0val3S;ba,ob1W;al,ov4;lasHsel8W;lJn dIrgBEsHzG;qu7;ilyEqu7siljE;en b6Aijk,yk;enzueAIverde;aPeix1VhKi2j8ka43oJrIsui,uG;om5UrG;c2n0un1;an,emblA7ynisC;dorAMlst3Km4rrAth;atch0i8UoG;mHrG;are84laci79;ps3sG;en,on;hirDkah9Mnaka,te,varA;a06ch01eYhUiRmOoMtIuHvGzabo;en9Jobod3N;ar7bot4lliv2zuC;aIeHoG;i7Bj4AyanAB;ele,in2FpheBvens25;l8rm0;kol5lovy5re7Tsa,to,uG;ng,sa;iGy72;rn5tG;!h;l71mHnGrbu;at9cla9Egh;moBo7M;aIeGimizu;hu,vchG;en8Luk;la,r1G;gu9infe5YmGoh,pulveA7rra5P;jGyG;on5;evi6iltz,miHneid0roed0uGwarz;be3Elz;dHtG;!t,z;!t;ar4Th8ito,ka4OlJnGr4saCto,unde19v4;ch7dHtGz;a5Le,os;b53e16;as,ihDm4Po0Y;aVeSiPoJuHyG;a6oo,u;bio,iz,sG;so,u;bKc8Fdrigue67ge10j9YmJosevelt,sItHux,wG;e,li6;a9Ch;enb4Usi;a54e4L;erts15i93;bei4JcHes,vGzzo;as,e9;ci,hards12;ag2es,iHut0yG;es,nol5N;s,t0;dImHnGsmu97v6C;tan1;ir7os;ic,u;aUeOhMiJoHrGut8;asad,if6Zochazk27;lishc2GpGrti72u10we76;e3Aov51;cHe45nG;as,to;as70hl0;aGillips;k,m,n6I;a3Hde3Wete0Bna,rJtG;ersHrovGters54;!a,ic;!en,on;eGic,kiBss3;i9ra,tz,z;h86k,padopoulIrk0tHvG;ic,l4N;el,te39;os;bMconn2Ag2TlJnei6PrHsbor6XweBzG;dem7Rturk;ella4DtGwe6N;ega,iz;iGof7Hs8I;vGyn1R;ei9;aSri1;aPeNiJoGune50ym2;rHvGwak;ak4Qik5otn66;odahl,r4S;cholsZeHkolGls4Jx3;ic,ov84;ls1miG;!n1;ils3mG;co4Xec;gy,kaGray2sh,var38;jiGmu9shiG;ma;a07c04eZiWoMuHyeG;rs;lJnIrGssoli6S;atGp03r7C;i,ov4;oz,te58;d0l0;h2lOnNo0RrHsGza1A;er,s;aKeJiIoz5risHtG;e56on;!on;!n7K;au,i9no,t5J;!lA;r1Btgome59;i3El0;cracFhhail5kkeHlG;l0os64;ls1;hmeJiIj30lHn3Krci0ssiGyer2N;!er;n0Po;er,j0;dDti;cartHlG;aughl8e2;hy;dQe7Egnu68i0jer3TkPmNnMrItHyG;er,r;ei,ic,su21thews;iHkDquAroqu8tinG;ez,s;a5Xc,nG;!o;ci5Vn;a5UmG;ad5;ar5e6Kin1;rig77s1;aVeOiLoJuHyG;!nch;k4nGo;d,gu;mbarGpe3Fvr4we;di;!nGu,yana2B;coln,dG;b21holm,strom;bedEfeKhIitn0kaHn8rGw35;oy;!j;m11tG;in1on1;bvGvG;re;iGmmy,ng,rs2Qu,voie,ws3;ne,t1F;aZeYh2iWlUnez50oNrJuHvar2woG;k,n;cerGmar68znets5;a,o34;aHem0isGyeziu;h23t3O;m0sni4Fus3KvG;ch4O;bay57ch,rh0Usk16vaIwalGzl5;czGsC;yk;cIlG;!cGen4K;huk;!ev4ic,s;e8uiveG;rt;eff0kGl4mu9nnun1;ucF;ll0nnedy;hn,llKminsCne,pIrHstra3Qto,ur,yGzl5;a,s0;j0Rls22;l2oG;or;oe;aPenOha6im14oHuG;ng,r4;e32hInHrge32u6vG;anD;es,ss3;anHnsG;en,on,t3;nesGs1R;en,s1;kiBnings,s1;cJkob4EnGrv0E;kDsG;en,sG;en0Ion;ks3obs2A;brahimDglesi5Nke5Fl0Qno07oneIshikHto,vanoG;u,v54;awa;scu;aVeOiNjaltal8oIrist50uG;!aGb0ghAynh;m2ng;a6dz4fIjgaa3Hk,lHpUrGwe,x3X;ak1Gvat;mAt;er,fm3WmG;ann;ggiBtchcock;iJmingw4BnHrGss;nand7re9;deGriks1;rs3;kkiHnG;on1;la,n1;dz4g1lvoQmOns0ZqNrMsJuIwHyG;asFes;kiB;g1ng;anHhiG;mo14;i,ov0J;di6p0r10t;ue;alaG;in1;rs1;aVeorgUheorghe,iSjonRoLrJuGw3;errGnnar3Co,staf3Ctierr7zm2;a,eG;ro;ayli6ee2Lg4iffithGub0;!s;lIme0UnHodGrbachE;e,m2;calvAzale0S;dGubE;bGs0E;erg;aj,i;bs3l,mGordaO;en7;iev3U;gnMlJmaIndFo,rGsFuthi0;cGdn0za;ia;ge;eaHlG;agh0i,o;no;e,on;aVerQiLjeldsted,lKoIrHuG;chs,entAji41ll0;eem2iedm2;ntaGrt8urni0wl0;na;emi6orA;lipIsHtzgeraG;ld;ch0h0;ovG;!ic;hatDnanIrG;arGei9;a,i;deY;ov4;b0rre1D;dKinsJriksIsGvaB;cob3GpGtra3D;inoza,osiQ;en,s3;te8;er,is3warG;ds;aXePiNjurhuMoKrisco15uHvorakG;!oT;arte,boHmitru,nn,rGt3C;and,ic;is;g2he0Omingu7nErd1ItG;to;us;aGcki2Hmitr2Ossanayake,x3;s,z; JbnaIlHmirGrvisFvi,w2;!ov4;gado,ic;th;bo0groot,jo6lHsilGvriA;va;a cruz,e3uG;ca;hl,mcevsCnIt2WviG;dGes,s;ov,s3;ielsGku22;!en;ki;a0Be06hRiobQlarkPoIrGunningh1H;awfo0RivGuz;elli;h1lKntJoIrGs2Nx;byn,reG;a,ia;ke,p0;i,rer2K;em2liB;ns;!e;anu;aOeMiu,oIristGu6we;eGiaG;ns1;i,ng,p9uHwGy;!dH;dGng;huJ;!n,onGu6;!g;kJnIpm2ttHudhGv7;ry;erjee,o14;!d,g;ma,raboG;rty;bJl0Cng4rG;eghetHnG;a,y;ti;an,ota1C;cerAlder3mpbeLrIstGvadi0B;iGro;llo;doHl0Er,t0uGvalho;so;so,zo;ll;a0Fe01hYiXlUoNrKuIyG;rLtyG;qi;chan2rG;ke,ns;ank5iem,oGyant;oks,wG;ne;gdan5nIruya,su,uchaHyKziG;c,n5;rd;darGik;enG;ko;ov;aGond15;nco,zG;ev4;ancFshw16;a08oGuiy2;umGwmG;ik;ckRethov1gu,ktPnNrG;gJisInG;ascoGds1;ni;ha;er,mG;anG;!n;gtGit7nP;ss3;asF;hi;er,hG;am;b4ch,ez,hRiley,kk0ldw8nMrIshHtAu0;es;ir;bInHtlGua;ett;es,i0;ieYosa;dGik;a9yoG;padhyG;ay;ra;k,ng;ic;bb0Acos09d07g04kht05lZnPrLsl2tJyG;aHd8;in;la;chis3kiG;ns3;aImstro6sl2;an;ng;ujo,ya;dJgelHsaG;ri;ovG;!a;ersJov,reG;aGjEws;ss1;en;en,on,s3;on;eksejEiyEmeiIvG;ar7es;ez;da;ev;arwHuilG;ar;al;ams,l0;er;ta;as",Ordinal:"true¦eBf7nin5s3t0zeroE;enDhir1we0;lfCn7;d,t3;e0ixt8;cond,vent7;et0th;e6ie7;i2o0;r0urt3;tie4;ft1rst;ight0lev1;e0h,ie1;en0;th",Cardinal:"true¦bEeBf5mEnine7one,s4t0zero;en,h2rDw0;e0o;lve,n5;irt6ousands,ree;even2ix2;i3o0;r1ur0;!t2;ty;ft0ve;e2y;ight0lev1;!e0y;en;illions",Multiple:"true¦b3hundred,m3qu2se1t0;housand,r2;pt1xt1;adr0int0;illion",City:"true¦0:74;1:61;2:6G;3:6J;4:5S;a68b53c4Id48e44f3Wg3Hh39i31j2Wk2Fl23m1Mn1Co19p0Wq0Ur0Os05tRuQvLwDxiBy9z5;a7h5i4Muri4O;a5e5ongsh0;ng3H;greb,nzib5G;ang2e5okoha3Sunfu;katerin3Hrev0;a5n0Q;m5Hn;arsBeAi6roclBu5;h0xi,zh5P;c7n5;d5nipeg,terth4;hoek,s1L;hi5Zkl3A;l63xford;aw;a8e6i5ladivost5Molgogr6L;en3lni6S;ni22r5;o3saill4N;lenc4Wncouv3Sr3ughn;lan bat1Crumqi,trecht;aFbilisi,eEheDiBo9r7u5;l21n63r5;in,ku;i5ondh62;es51poli;kyo,m2Zron1Pulo5;n,uS;an5jua3l2Tmisoa6Bra3;j4Tshui; hag62ssaloni2H;gucigal26hr0l av1U;briz,i6llinn,mpe56ng5rtu,shk2R;i3Esh0;an,chu1n0p2Eyu0;aEeDh8kopje,owe1Gt7u5;ra5zh4X;ba0Ht;aten is55ockholm,rasbou67uttga2V;an8e6i5;jiazhua1llo1m5Xy0;f50n5;ya1zh4H;gh3Kt4Q;att45o1Vv44;cramen16int ClBn5o paulo,ppo3Rrajevo; 7aa,t5;a 5o domin3E;a3fe,m1M;antonio,die3Cfrancisco,j5ped3Nsalvad0J;o5u0;se;em,t lake ci5Fz25;lou58peters24;a9e8i6o5;me,t59;ga,o5yadh;! de janei3F;cife,ims,nn3Jykjavik;b4Sip4lei2Inc2Pwalpindi;ingdao,u5;ez2i0Q;aFeEhDiCo9r7u6yong5;ya1;eb59ya1;a5etor3M;g52to;rt5zn0; 5la4Co;au prin0Melizabe24sa03;ls3Prae5Atts26;iladelph3Gnom pe1Aoenix;ki1tah tik3E;dua,lerYnaji,r4Ot5;na,r32;ak44des0Km1Mr6s5ttawa;a3Vlo;an,d06;a7ew5ing2Fovosibir1Jyc; 5cast36;del24orlea44taip14;g8iro4Wn5pl2Wshv33v0;ch6ji1t5;es,o1;a1o1;a6o5p4;ya;no,sa0W;aEeCi9o6u5;mb2Ani26sc3Y;gadishu,nt6s5;c13ul;evideo,pelli1Rre2Z;ami,l6n14s5;kolc,sissauga;an,waukee;cca,d5lbour2Mmph41ndo1Cssi3;an,ell2Xi3;cau,drAkass2Sl9n8r5shh4A;aca6ib5rakesh,se2L;or;i1Sy;a4EchFdal0Zi47;mo;id;aDeAi8o6u5vSy2;anMckn0Odhia3;n5s angel26;d2g bea1N;brev2Be3Lma5nz,sb2verpo28;!ss27; ma39i5;c5pzig;est16; p6g5ho2Wn0Cusan24;os;az,la33;aHharFiClaipeBo9rak0Du7y5;iv,o5;to;ala lump4n5;mi1sh0;hi0Hlka2Xpavog4si5wlo2;ce;da;ev,n5rkuk;gst2sha5;sa;k5toum;iv;bHdu3llakuric0Qmpa3Fn6ohsiu1ra5un1Iwaguc0Q;c0Pj;d5o,p4;ah1Ty;a7e6i5ohannesV;l1Vn0;dd36rusalem;ip4k5;ar2H;bad0mph1OnArkutUs7taXz5;mir,tapala5;pa;fah0l6tanb5;ul;am2Zi2H;che2d5;ianap2Mo20;aAe7o5yder2W; chi mi5ms,nolulu;nh;f6lsin5rakli2;ki;ei;ifa,lifax,mCn5rb1Dva3;g8nov01oi;aFdanEenDhCiPlasgBo9raz,u5;a5jr23;dal6ng5yaquil;zh1J;aja2Oupe;ld coa1Bthen5;bu2S;ow;ent;e0Uoa;sk;lw7n5za;dhi5gt1E;nag0U;ay;aisal29es,o8r6ukuya5;ma;ankfu5esno;rt;rt5sh0; wor6ale5;za;th;d5indhov0Pl paso;in5mont2;bur5;gh;aBe8ha0Xisp4o7resd0Lu5;b5esseldorf,nkirk,rb0shanbe;ai,l0I;ha,nggu0rtmu13;hradSl6nv5troit;er;hi;donghIe6k09l5masc1Zr es sala1KugavpiY;i0lU;gu,je2;aJebu,hAleve0Vo5raio02uriti1Q;lo7n6penhag0Ar5;do1Ok;akKst0V;gUm5;bo;aBen8i6ongqi1ristchur5;ch;ang m7ca5ttago1;go;g6n5;ai;du,zho1;ng5ttogr14;ch8sha,zh07;gliari,i9lga8mayenJn6pe town,r5tanO;acCdiff;ber1Ac5;un;ry;ro;aWeNhKirmingh0WoJr9u5;chareTdapeTenos air7r5s0tu0;g5sa;as;es;a9is6usse5;ls;ba6t5;ol;ne;sil8tisla7zzav5;il5;le;va;ia;goZst2;op6ubaneshw5;ar;al;iCl9ng8r5;g6l5n;in;en;aluru,hazi;fa6grade,o horizon5;te;st;ji1rut;ghd0BkFn9ot8r7s6yan n4;ur;el,r07;celo3i,ranquil09;ou;du1g6ja lu5;ka;alo6k5;ok;re;ng;ers5u;field;a05b02cc01ddis aba00gartaZhmedXizawl,lSmPnHqa00rEsBt7uck5;la5;nd;he7l5;an5;ta;ns;h5unci2;dod,gab5;at;li5;ngt2;on;a8c5kaOtwerp;hora6o3;na;ge;h7p5;ol5;is;eim;aravati,m0s5;terd5;am; 7buquerq6eppo,giers,ma5;ty;ue;basrah al qadim5mawsil al jadid5;ah;ab5;ad;la;ba;ra;idj0u dha5;bi;an;lbo6rh5;us;rg",Region:"true¦0:2O;1:2L;2:2U;3:2F;a2Sb2Fc21d1Wes1Vf1Tg1Oh1Ki1Fj1Bk16l13m0Sn09o07pYqVrSsJtEuBverAw6y4zacatec2W;akut0o0Fu4;cat1k09;a5est 4isconsin,yomi1O;bengal,virgin0;rwick3shington4;! dc;acruz,mont;dmurt0t4;ah,tar4; 2Pa12;a6e5laxca1Vripu21u4;scaEva;langa2nnessee,x2J;bas10m4smQtar29;aulip2Hil nadu;a9elang07i7o5taf16u4ylh1J;ff02rr09s1E;me1Gno1Uuth 4;cZdY;ber0c4kkim,naloa;hu1ily;n5rawak,skatchew1xo4;ny; luis potosi,ta catari2;a4hodeA;j4ngp0C;asth1shahi;ingh29u4;e4intana roo;bec,en6retaro;aAe6rince edward4unjab; i4;sl0G;i,n5r4;ak,nambu0F;a0Rnsylv4;an0;ha0Pra4;!na;axa0Zdisha,h4klaho21ntar4reg7ss0Dx0I;io;aLeEo6u4;evo le4nav0X;on;r4tt18va scot0;f9mandy,th4; 4ampton3;c6d5yo4;rk3;ako1O;aroli2;olk;bras1Nva0Dw4; 6foundland4;! and labrad4;or;brunswick,hamp3jers5mexiTyork4;! state;ey;galPyarit;aAeghala0Mi6o4;nta2r4;dov0elos;ch6dlanDn5ss4zor11;issippi,ouri;as geraPneso18;ig1oac1;dhy12harasht0Gine,lac07ni5r4ssachusetts;anhao,i el,ylG;p4toba;ur;anca3e4incoln3ouisI;e4iR;ds;a6e5h4omi;aka06ul2;dah,lant1ntucky,ra01;bardino,lmyk0ns0Qr4;achay,el0nata0X;alis6har4iangxi;kh4;and;co;daho,llino7n4owa;d5gush4;et0;ia2;is;a6ert5i4un1;dalFm0D;ford3;mp3rya2waii;ansu,eorg0lou7oa,u4;an4izhou,jarat;ajuato,gdo4;ng;cester3;lori4uji1;da;sex;ageUe7o5uran4;go;rs4;et;lawaMrby3;aFeaEh9o4rim08umbr0;ahui7l6nnectic5rsi4ventry;ca;ut;i03orado;la;e5hattisgarh,i4uvash0;apRhuahua;chn5rke4;ss0;ya;ra;lGm4;bridge3peche;a9ihar,r8u4;ck4ryat0;ingham3;shi4;re;emen,itish columb0;h0ja cal8lk7s4v7;hkorto4que;st1;an;ar0;iforn0;ia;dygHguascalientes,lBndhr9r5ss4;am;izo2kans5un4;achal 7;as;na;a 4;pradesh;a6ber5t4;ai;ta;ba5s4;ka;ma;ea",Place:"true¦0:4T;1:4V;2:44;3:4B;4:3I;a4Eb3Gc2Td2Ge26f25g1Vh1Ji1Fk1Cl14m0Vn0No0Jp08r04sTtNuLvJw7y5;a5o0Syz;kut1Bngtze;aDeChitBi9o5upatki,ycom2P;ki26o5;d5l1B;b3Ps5;i4to3Y;c0SllowbroCn5;c2Qgh2;by,chur1P;ed0ntw3Gs22;ke6r3St5;erf1f1; is0Gf3V;auxha3Mirgin is0Jost5;ok;laanbaatar,pto5xb3E;n,wn;a9eotihuac43h7ive49o6ru2Nsarskoe selo,u5;l2Dzigo47;nto,rquay,tt2J;am3e 5orn3E;bronx,hamptons;hiti,j mah0Iu1N;aEcotts bluff,eCfo,herbroQoApring9t7u5yd2F;dbu1Wn5;der03set3B;aff1ock2Nr5;atf1oud;hi37w24;ho,uth5; 1Iam1Zwo3E;a5i2O;f2Tt0;int lawrence riv3Pkhal2D;ayleigh,ed7i5oc1Z;chmo1Eo gran4ver5;be1Dfr09si4; s39cliffe,hi2Y;aCe9h8i5ompeii,utn2;c6ne5tcai2T; 2Pc0G;keri13t0;l,x;k,lh2mbr6n5r2J;n1Hzance;oke;cif38pahanaumokuak30r5;k5then0;si4w1K;ak7r6x5;f1l2X;ange county,d,f1inoco;mTw1G;e8i1Uo5;r5tt2N;th5wi0E; 0Sam19;uschwanste1Pw5; eng6a5h2market,po36;rk;la0P;a8co,e6i5uc;dt1Yll0Z;adow5ko0H;lands;chu picchu,gad2Ridsto1Ql8n7ple6r5;kh2; g1Cw11;hatt2Osf2B;ibu,t0ve1Z;a8e7gw,hr,in5owlOynd02;coln memori5dl2C;al;asi4w3;kefr7mbe1On5s,x;ca2Ig5si05;f1l27t0;ont;azan kreml14e6itchen2Gosrae,rasnoyar5ul;sk;ns0Hs1U;ax,cn,lf1n6ps5st;wiN;d5glew0Lverness;ian27ochina;aDeBi6kg,nd,ov5unti2H;d,enweep;gh6llc5;reL;bu03l5;and5;!s;r5yw0C;ef1tf1;libu24mp6r5stings;f1lem,row;stead,t0;aDodavari,r5uelph;avenAe5imsS;at 8en5; 6f1Fwi5;ch;acr3vall1H;brita0Flak3;hur5;st;ng3y villa0W;airhavHco,ra;aAgli9nf17ppi8u7ver6x5;et1Lf1;glad3t0;rope,st0;ng;nt0;rls1Ls5;t 5;e5si4;nd;aCe9fw,ig8o7ryd6u5xb;mfri3nstab00rh2tt0;en;nca18rcKv19wnt0B;by;n6r5vonpo1D;ry;!h2;nu8r5;l6t5;f1moor;ingt0;be;aLdg,eIgk,hClBo5royd0;l6m5rnwa0B;pt0;c7lingw6osse5;um;ood;he0S;earwat0St;a8el6i5uuk;chen itza,mney ro07natSricahua;m0Zt5;enh2;mor5rlottetPth2;ro;dar 5ntervilA;breaks,faZg5;rove;ld9m8r5versh2;lis6rizo pla5;in;le;bLpbellf1;weQ;aZcn,eNingl01kk,lackLolt0r5uckV;aGiAo5;ckt0ok5wns cany0;lyn,s5;i4to5;ne;de;dge6gh5;am,t0;n6t5;own;or5;th;ceb6m5;lNpt0;rid5;ge;bu5pool,wa8;rn;aconsfEdf1lBr9verly7x5;hi5;ll; hi5;lls;wi5;ck; air,l5;ingh2;am;ie5;ld;ltimore,rnsl6tters5;ea;ey;bLct0driadic,frica,ginJlGmFn9rc8s7tl6yleOzor3;es;!ant8;hcroft,ia; de triomphe,t6;adyr,ca8dov9tarct5;ic5; oce5;an;st5;er;ericas,s;be6dersh5hambra,list0;ot;rt0;cou5;rt;bot7i5;ngd0;on;sf1;ord",Country:"true¦0:38;1:2L;2:3B;a2Xb2Ec22d1Ye1Sf1Mg1Ch1Ai14j12k0Zl0Um0Gn05om2pZqat1KrXsKtCu7v5wal4yemTz3;a25imbabwe;es,lis and futu2Y;a3enezue32ietnam;nuatu,tican city;gTk6nited 4ruXs3zbeE; 2Ca,sr;arab emirat0Kkingdom,states3;! of am2Y;!raiV;a8haCimor les0Co7rinidad 5u3;nis0rk3valu;ey,me2Zs and caic1V;and t3t3;oba1L;go,kel10nga;iw2ji3nz2T;ki2V;aDcotl1eCi9lov8o6pa2Dri lanka,u5w3yr0;az3edAitzerl1;il1;d2riname;lomon1Xmal0uth 3;afr2KkMsud2;ak0en0;erra leoFn3;gapo1Yt maart3;en;negLrb0ychellZ;int 3moa,n marino,udi arab0;hele26luc0mart21;epublic of ir0Eom2Euss0w3;an27;a4eIhilippinUitcairn1Mo3uerto riN;l1rtugF;ki2Dl4nama,pua new0Vra3;gu7;au,esti3;ne;aBe9i7or3;folk1Ith4w3;ay; k3ern mariana1D;or0O;caragua,ger3ue;!ia;p3ther1Aw zeal1;al;mib0u3;ru;a7exi6icro0Bo3yanm06;ldova,n3roc5zambA;a4gol0t3;enegro,serrat;co;cAdagasc01l7r5urit4yot3;te;an0i16;shall0Xtin3;ique;a4div3i,ta;es;wi,ys0;ao,ed02;a6e5i3uxembourg;b3echtenste12thu1G;er0ya;ban0Isotho;os,tv0;azakh1Fe4iriba04o3uwait,yrgyz1F;rXsovo;eling0Knya;a3erG;ma16p2;c7nd6r4s3taly,vory coast;le of m2rael;a3el1;n,q;ia,oJ;el1;aiTon3ungary;dur0Ng kong;aBermany,ha0QibraltAre8u3;a6ern5inea3ya0P;! biss3;au;sey;deloupe,m,tema0Q;e3na0N;ce,nl1;ar;bUmb0;a7i6r3;ance,ench 3;guia0Epoly3;nes0;ji,nl1;lklandUroeU;ast tim7cu6gypt,l salv6ngl1quatorial4ritr5st3thiop0;on0; guin3;ea;ad3;or;enmark,jibou5ominica4r con3;go;!n C;ti;aBentral african Ah8o5roat0u4yprRzech3; 9ia;ba,racao;c4lo3morQngo brazzaville,okGsta r04te de ivoiL;mb0;osE;i3ristmasG;le,na;republic;m3naUpe verde,ymanA;bod0ero3;on;aGeDhut2o9r5u3;lgar0r3;kina faso,ma,undi;azil,itish 3unei;virgin3; is3;lands;liv0nai5snia and herzegoviHtswaHuvet3; isl1;and;re;l3n8rmuG;ar3gium,ize;us;h4ngladesh,rbad3;os;am4ra3;in;as;fghaGlDmBn6r4ustr3zerbaij2;al0ia;genti3men0uba;na;dorra,g5t3;arct7igua and barbu3;da;o3uil3;la;er3;ica;b3ger0;an0;ia;ni3;st2;an",FirstName:"true¦aTblair,cQdOfrancoZgabMhinaLilya,jHkClBm6ni4quinn,re3s0;h0umit,yd;ay,e0iloh;a,lby;g9ne;co,ko0;!s;a1el0ina,org6;!okuhF;ds,naia,r1tt0xiB;i,y;ion,lo;ashawn,eif,uca;a3e1ir0rM;an;lsFn0rry;dall,yat5;i,sD;a0essIie,ude;i1m0;ie,mG;me;ta;rie0y;le;arcy,ev0;an,on;as1h0;arl8eyenne;ey,sidy;drien,kira,l4nd1ubr0vi;ey;i,r0;a,e0;a,y;ex2f1o0;is;ie;ei,is",WeekDay:"true¦fri2mon2s1t0wednesd3;hurs1ues1;aturd1und1;!d0;ay0;!s",Month:"true¦dec0february,july,nov0octo1sept0;em0;ber",Date:"true¦ago,on4som4t1week0yesterd5; end,ends;mr1o0;d2morrow;!w;ed0;ay",Duration:"true¦centurAd8h7m5q4se3w1y0;ear8r8;eek0k7;!end,s;ason,c5;tr,uarter;i0onth3;llisecond2nute2;our1r1;ay0ecade0;!s;ies,y",FemaleName:"true¦0:J7;1:JB;2:IJ;3:IK;4:J1;5:IO;6:JS;7:JO;8:HB;9:JK;A:H4;B:I2;C:IT;D:JH;E:IX;F:BA;G:I4;aGTbFLcDRdD0eBMfB4gADh9Ti9Gj8Dk7Cl5Wm48n3Lo3Hp33qu32r29s15t0Eu0Cv02wVxiTyOzH;aLeIineb,oHsof3;e3Sf3la,ra;h2iKlIna,ynH;ab,ep;da,ma;da,h2iHra;nab;aKeJi0FolB7uIvH;et8onDP;i0na;le0sen3;el,gm3Hn,rGLs8W;aoHme0nyi;m5XyAD;aMendDZhiDGiH;dele9lJnH;if48niHo0;e,f47;a,helmi0lHma;a,ow;ka0nB;aNeKiHusa5;ck84kIl8oleAviH;anFenJ4;ky,toriBK;da,lA8rHs0;a,nHoniH9;a,iFR;leHnesH9;nILrH;i1y;g9rHs6xHA;su5te;aYeUhRiNoLrIuHy2;i,la;acJ3iHu0J;c3na,sH;hFta;nHr0F;iFya;aJffaEOnHs6;a,gtiH;ng;!nFSra;aIeHomasi0;a,l9Oo8Ares1;l3ndolwethu;g9Fo88rIssH;!a,ie;eHi,ri7;sa,za;bOlMmKnIrHs6tia0wa0;a60yn;iHya;a,ka,s6;arFe2iHm77ra;!ka;a,iH;a,t6;at6it6;a0Ecarlett,e0AhWiSkye,neza0oQri,tNuIyH;bIGlvi1;ha,mayIJniAsIzH;an3Net8ie,y;anHi7;!a,e,nH;aCe;aIeH;fan4l5Dphan6E;cI5r5;b3fiAAm0LnHphi1;d2ia,ja,ya;er2lJmon1nIobh8QtH;a,i;dy;lETv3;aMeIirHo0risFDy5;a,lDM;ba,e0i5lJrH;iHr6Jyl;!d8Ifa;ia,lDZ;hd,iMki2nJrIu0w0yH;la,ma,na;i,le9on,ron,yn;aIda,ia,nHon;a,on;!ya;k6mH;!aa;lJrItaye82vH;da,inj;e0ife;en1i0ma;anA9bLd5Oh1SiBkKlJmInd2rHs6vannaC;aCi0;ant6i2;lDOma,ome;ee0in8Tu2;in1ri0;a05eZhXiUoHuthDM;bScRghQl8LnPsJwIxH;anB3ie,y;an,e0;aIeHie,lD;ann7ll1marDGtA;!lHnn1;iHyn;e,nH;a,dF;da,i,na;ayy8G;hel67io;bDRerAyn;a,cIkHmas,nFta,ya;ki,o;h8Xki;ea,iannGMoH;da,n1P;an0bJemFgi0iInHta,y0;a8Bee;han86na;a,eH;cHkaC;a,ca;bi0chIe,i0mo0nHquETy0;di,ia;aERelHiB;!e,le;een4ia0;aPeOhMiLoJrHute6A;iHudenCV;scil3LyamvaB;lHrt3;i0ly;a,paluk;ilome0oebe,ylH;is,lis;ggy,nelope,r5t2;ige,m0VnKo5rvaDMtIulH;a,et8in1;ricHt4T;a,e,ia;do2i07;ctav3dIfD3is6ksa0lHphD3umC5yunbileg;a,ga,iv3;eHvAF;l3t8;aWeUiMoIurHy5;!ay,ul;a,eJor,rIuH;f,r;aCeEma;ll1mi;aNcLhariBQkKlaJna,sHta,vi;anHha;ur;!y;a,iDZki;hoGk9YolH;a,e4P;!mh;hir,lHna,risDEsreE;!a,iDDlBV;asuMdLh3i6Dl5nKomi7rgEVtH;aHhal4;lHs6;i1ya;cy,et8;e9iF0ya;nngu2X;a0Ackenz4e02iMoJrignayani,uriDJyH;a,rH;a,iOlNna,tG;bi0i2llBJnH;a,iH;ca,ka,qD9;a,cUdo4ZkaTlOmi,nMrItzi,yH;ar;aJiIlH;anET;am;!l,nB;dy,eHh,n4;nhGrva;aKdJe0iCUlH;iHy;cent,e;red;!gros;!e5;ae5hH;ae5el3Z;ag5DgNi,lKrH;edi7AiIjem,on,yH;em,l;em,sCG;an4iHliCF;nHsCJ;a,da;!an,han;b09cASd07e,g05ha,i04ja,l02n00rLsoum5YtKuIv84xBKyHz4;bell,ra,soBB;d7rH;a,eE;h8Gild1t4;a,cUgQiKjor4l7Un4s6tJwa,yH;!aHbe6Xja9lAE;m,nBL;a,ha,in1;!aJbCGeIja,lDna,sHt63;!a,ol,sa;!l1D;!h,mInH;!a,e,n1;!awit,i;arJeIie,oHr48ueri8;!t;!ry;et46i3B;el4Xi7Cy;dHon,ue5;akranAy;ak,en,iHlo3S;a,ka,nB;a,re,s4te;daHg4;!l3E;alDd4elHge,isDJon0;ei9in1yn;el,le;a0Ne0CiXoQuLyH;d3la,nH;!a,dIe2OnHsCT;!a,e2N;a,sCR;aD4cJel0Pis1lIna,pHz;e,iA;a,u,wa;iHy;a0Se,ja,l2NnB;is,l1UrItt1LuHvel4;el5is1;aKeIi7na,rH;aADi7;lHn1tA;ei;!in1;aTbb9HdSepa,lNnKsJvIzH;!a,be5Ret8z4;!ia;a,et8;!a,dH;a,sHy;ay,ey,i,y;a,iJja,lH;iHy;aA8e;!aH;!nF;ia,ya;!nH;!a,ne;aPda,e0iNjYla,nMoKsJtHx93y5;iHt4;c3t3;e2PlCO;la,nHra;a,ie,o2;a,or1;a,gh,laH;!ni;!h,nH;a,d2e,n5V;cOdon9DiNkes6mi9Gna,rMtJurIvHxmi,y5;ern1in3;a,e5Aie,yn;as6iIoH;nya,ya;fa,s6;a,isA9;a,la;ey,ie,y;a04eZhXiOlASoNrJyH;lHra;a,ee,ie;istHy6I;a,en,iIyH;!na;!e,n5F;nul,ri,urtnB8;aOerNlB7mJrHzzy;a,stH;en,in;!berlImernH;aq;eHi,y;e,y;a,stE;!na,ra;aHei2ongordzol;dij1w5;el7UiKjsi,lJnIrH;a,i,ri;d2na,za;ey,i,lBLs4y;ra,s6;biAcARdiat7MeBAiSlQmPnyakuma1DrNss6NtKviAyH;!e,lH;a,eH;e,i8T;!a6HeIhHi4TlDri0y;ar8Her8Hie,leErBAy;!lyn8Ori0;a,en,iHl5Xoli0yn;!ma,nFs95;a5il1;ei8Mi,lH;e,ie;a,tl6O;a0AeZiWoOuH;anMdLlHst88;es,iH;a8NeHs8X;!n9tH;!a,te;e5Mi3My;a,iA;!anNcelDdMelGhan7VleLni,sIva0yH;a,ce;eHie;fHlDph7Y;a,in1;en,n1;i7y;!a,e,n45;lHng;!i1DlH;!i1C;anNle0nKrJsH;i8JsH;!e,i8I;i,ri;!a,elGif2CnH;a,et8iHy;!e,f2A;a,eJiInH;a,eIiH;e,n1;!t8;cMda,mi,nIque4YsminFvie2y9zH;min7;a7eIiH;ce,e,n1s;!lHs82t0F;e,le;inIk6HlDquelH;in1yn;da,ta;da,lRmPnOo0rNsIvaHwo0zaro;!a0lu,na;aJiIlaHob89;!n9R;do2;belHdo2;!a,e,l3B;a7Ben1i0ma;di2es,gr72ji;a9elBogH;en1;a,e9iHo0se;a0na;aSeOiJoHus7Kyacin2C;da,ll4rten24snH;a,i9U;lImaH;ri;aIdHlaI;a,egard;ry;ath1BiJlInrietArmi9sH;sa,t1A;en2Uga,mi;di;bi2Fil8MlNnMrJsItHwa,yl8M;i5Tt4;n60ti;iHmo51ri53;etH;!te;aCnaC;a,ey,l4;a02eWiRlPoNrKunJwH;enHyne1R;!dolD;ay,el;acieIetHiselB;a,chE;!la;ld1CogooH;sh;adys,enHor3yn2K;a,da,na;aKgi,lIna,ov8EselHta;a,e,le;da,liH;an;!n0;mLnJorgIrH;ald5Si,m3Etrud7;et8i4X;a,eHna;s29vieve;ma;bIle,mHrnet,yG;al5Si5;iIrielH;a,l1;!ja;aTeQiPlorOoz3rH;anJeIiH;da,eB;da,ja;!cH;esIiHoi0P;n1s66;!ca;a,enc3;en,o0;lIn0rnH;anB;ec3ic3;jr,nArKtHy7;emIiHma,oumaA;ha,ma,n;eh;ah,iBrah,za0;cr4Rd0Re0Qi0Pk0Ol07mXn54rUsOtNuMvHwa;aKelIiH;!e,ta;inFyn;!a;!ngel4V;geni1ni47;h5Yien9ta;mLperanKtH;eIhHrel5;er;l31r7;za;a,eralB;iHma,ne4Lyn;cHka,n;a,ka;aPeNiKmH;aHe21ie,y;!li9nuH;elG;lHn1;e7iHy;a,e,ja;lHrald;da,y;!nue5;aWeUiNlMma,no2oKsJvH;a,iH;na,ra;a,ie;iHuiH;se;a,en,ie,y;a0c3da,e,f,nMsJzaH;!betHveA;e,h;aHe,ka;!beH;th;!a,or;anor,nH;!a,i;!in1na;ate1Rta;leEs6;vi;eIiHna,wi0;e,th;l,n;aYeMh3iLjeneKoH;lor5Vminiq4Ln3FrHtt4;a,eEis,la,othHthy;ea,y;ba;an09naCon9ya;anQbPde,eOiMlJmetr3nHsir5M;a,iH;ce,se;a,iIla,orHphi9;es,is;a,l6F;dHrdH;re;!d5Ena;!b2ForaCraC;a,d2nH;!a,e;hl3i0l0GmNnLphn1rIvi1WyH;le,na;a,by,cIia,lH;a,en1;ey,ie;a,et8iH;!ca,el1Aka,z;arHia;is;a0Re0Nh04i02lUoJristIynH;di,th3;al,i0;lPnMrIurH;tn1D;aJd2OiHn2Ori9;!nH;a,e,n1;!l4;cepci5Cn4sH;tanHuelo;ce,za;eHleE;en,t8;aJeoIotH;il54;!pat2;ir7rJudH;et8iH;a,ne;a,e,iH;ce,sZ;a2er2ndH;i,y;aReNloe,rH;isJyH;stH;al;sy,tH;a1Sen,iHy;an1e,n1;deJlseIrH;!i7yl;a,y;li9;nMrH;isKlImH;ai9;a,eHot8;n1t8;!sa;d2elGtH;al,elG;cIlH;es8i47;el3ilH;e,ia,y;itlYlXmilWndVrMsKtHy5;aIeIhHri0;er1IleErDy;ri0;a38sH;a37ie;a,iOlLmeJolIrH;ie,ol;!e,in1yn;lHn;!a,la;a,eIie,otHy;a,ta;ne,y;na,s1X;a0Ii0I;a,e,l1;isAl4;in,yn;a0Ke02iZlXoUrH;andi7eRiJoIyH;an0nn;nwDoke;an3HdgMgiLtH;n31tH;!aInH;ey,i,y;ny;d,t8;etH;!t7;an0e,nH;da,na;bbi7glarIlo07nH;iAn4;ka;ancHythe;a,he;an1Clja0nHsm3M;iAtH;ou;aWcVlinUniArPssOtJulaCvH;!erlH;ey,y;hJsy,tH;e,iHy7;e,na;!anH;ie,y;!ie;nItHyl;ha,ie;adIiH;ce;et8i9;ay,da;ca,ky;!triH;ce,z;rbJyaH;rmH;aa;a2o2ra;a2Ub2Od25g21i1Sj5l18m0Zn0Boi,r06sWtVuPvOwa,yIzH;ra,u0;aKes6gJlIn,seH;!l;in;un;!nH;a,na;a,i2K;drLguJrIsteH;ja;el3;stH;in1;a,ey,i,y;aahua,he0;hIi2Gja,miAs2DtrH;id;aMlIraqHt21;at;eIi7yH;!n;e,iHy;gh;!nH;ti;iJleIo6piA;ta;en,n1t8;aHelG;!n1J;a01dje5eZgViTjRnKohito,toHya;inet8nH;el5ia;te;!aKeIiHmJ;e,ka;!mHtt7;ar4;!belIliHmU;sa;!l1;a,eliH;ca;ka,sHta;a,sa;elHie;a,iH;a,ca,n1qH;ue;!tH;a,te;!bImHstasiMya;ar3;el;aLberKeliJiHy;e,l3naH;!ta;a,ja;!ly;hGiIl3nB;da;a,ra;le;aWba,ePiMlKthJyH;a,c3sH;a,on,sa;ea;iHys0N;e,s0M;a,cIn1sHza;a,e,ha,on,sa;e,ia,ja;c3is6jaKksaKna,sJxH;aHia;!nd2;ia,saH;nd2;ra;ia;i0nIyH;ah,na;a,is,naCoud;la;c6da,leEmNnLsH;haClH;inHyY;g,n;!h;a,o,slH;ey;ee;en;at6g4nIusH;ti0;es;ie;aWdiTelMrH;eJiH;anMenH;a,e,ne;an0;na;!aLeKiIyH;nn;a,n1;a,e;!ne;!iH;de;e,lDsH;on;yn;!lH;i9yn;ne;aKbIiHrL;!e,gaK;ey,i7y;!e;gaH;il;dKliyJradhIs6;ha;ya;ah;a,ya",Honorific:"true¦director1field marsh2lieutenant1rear0sergeant major,vice0; admir1; gener0;al","Adj|Gerund":"true¦0:3F;1:3H;2:31;3:2X;4:35;5:33;6:3C;7:2Z;8:36;9:29;a33b2Tc2Bd1Te1If19g12h0Zi0Rl0Nm0Gnu0Fo0Ap04rYsKtEuBvAw1Ayiel3;ar6e08;nBpA;l1Rs0B;fol3n1Zsett2;aEeDhrBi4ouc7rAwis0;e0Bif2oub2us0yi1;ea1SiA;l2vi1;l2mp0rr1J;nt1Vxi1;aMcreec7enten2NhLkyrocke0lo0Vmi2oJpHtDuBweA;e0Ul2;pp2ArA;gi1pri5roun3;aBea8iAri2Hun9;mula0r4;gge4rA;t2vi1;ark2eAraw2;e3llb2F;aAot7;ki1ri1;i9oc29;dYtisf6;aEeBive0oAus7;a4l2;assu4defi9fres7ig9juve07mai9s0vAwar3;ea2italiAol1G;si1zi1;gi1ll6mb2vi1;a6eDier23lun1VrAun2C;eBoA;mi5vo1Z;ce3s5vai2;n3rpleA;xi1;ffCpWutBverAwi1;arc7lap04p0Pri3whel8;goi1l6st1J;en3sA;et0;m2Jrtu4;aEeDiCoBuAyst0L;mb2;t1Jvi1;s5tiga0;an1Rl0n3smeri26;dAtu4;de9;aCeaBiAo0U;fesa0Tvi1;di1ni1;c1Fg19s0;llumiGmFnArri0R;cDfurHsCtBviA;go23ti1;e1Oimi21oxica0rig0V;pi4ul0;orpo20r0K;po5;na0;eaBorr02umilA;ia0;li1rtwar8;lFrA;atiDipCoBuelA;i1li1;undbrea10wi1;pi1;f6ng;a4ea8;a3etc7it0lEoCrBulfA;il2;ee1FighXust1L;rAun3;ebo3thco8;aCoA;a0wA;e4i1;mi1tte4;lectrJmHnExA;aCci0hBis0pA;an3lo3;aOila1B;c0spe1A;ab2coura0CdBergi13ga0Clive9ric7s02tA;hral2i0J;ea4u4;barras5er09pA;owe4;if6;aQeIiBrA;if0;sAzz6;aEgDhearCsen0tA;rAur11;ac0es5;te9;us0;ppoin0r8;biliGcDfi9gra3ligh0mBpres5sAvasG;erE;an3ea9orA;ali0L;a6eiBli9rA;ea5;vi1;ta0;maPri1s7un0zz2;aPhMlo5oAripp2ut0;mGnArrespon3;cer9fDspi4tA;inBrA;as0ibu0ol2;ui1;lic0u5;ni1;fDmCpA;eAromi5;l2ti1;an3;or0;aAil2;llenAnAr8;gi1;l8ptAri1;iva0;aff2eGin3lFoDrBuA;d3st2;eathtaAui5;ki1;gg2i2o8ri1unA;ci1;in3;co8wiA;lAtc7;de4;bsorVcOgonMlJmHnno6ppea2rFsA;pi4su4toA;nBun3;di1;is7;hi1;res0;li1;aFu5;si1;ar8lu4;ri1;mi1;iAzi1;zi1;cAhi1;eleDomA;moBpan6;yi1;da0;ra0;ti1;bi1;ng",Comparable:"true¦0:3C;1:3Q;2:3F;a3Tb3Cc33d2Te2Mf2Ag1Wh1Li1Fj1Ek1Bl13m0Xn0So0Rp0Iqu0Gr07sHtCug0vAw4y3za0Q;el10ouN;ary,e6hi5i3ry;ck0Cde,l3n1ry,se;d,y;ny,te;a3i3R;k,ry;a3erda2ulgar;gue,in,st;a6en2Xhi5i4ouZr3;anqu2Cen1ue;dy,g36me0ny;ck,rs28;ll,me,rt,wd3I;aRcaPeOhMiLkin0BlImGoEpDt6u4w3;eet,ift;b3dd0Wperfi21rre28;sta26t21;a8e7iff,r4u3;pUr1;a4ict,o3;ng;ig2Vn0N;a1ep,rn;le,rk,te0;e1Si2Vright0;ci1Yft,l3on,re;emn,id;a3el0;ll,rt;e4i3y;g2Mm0Z;ek,nd2T;ck24l0mp1L;a3iRrill,y;dy,l01rp;ve0Jxy;n1Jr3;ce,y;d,fe,int0l1Hv0V;a8e6i5o3ude;mantic,o19sy,u3;gh;pe,t1P;a3d,mo0A;dy,l;gg4iFndom,p3re,w;id;ed;ai2i3;ck,et;hoAi1Fl9o8r5u3;ny,r3;e,p11;egna2ic4o3;fouSud;ey,k0;liXor;ain,easa2;ny;dd,i0ld,ranL;aive,e5i4o3u14;b0Sisy,rm0Ysy;bb0ce,mb0R;a3r1w;r,t;ad,e5ild,o4u3;nda12te;ist,o1;a4ek,l3;low;s0ty;a8e7i6o3ucky;f0Jn4o15u3ve0w10y0N;d,sy;e0g;ke0l,mp,tt0Eve0;e1Qwd;me,r3te;ge;e4i3;nd;en;ol0ui19;cy,ll,n3;secu6t3;e3ima4;llege2rmedia3;te;re;aAe7i6o5u3;ge,m3ng1C;bYid;me0t;gh,l0;a3fXsita2;dy,rWv3;en0y;nd13ppy,r3;d3sh;!y;aFenEhCiBlAoofy,r3;a8e6i5o3ue0Z;o3ss;vy;m,s0;at,e3y;dy,n;nd,y;ad,ib,ooD;a2d1;a3o3;st0;tDuiS;u1y;aCeebBi9l8o6r5u3;ll,n3r0N;!ny;aCesh,iend0;a3nd,rmD;my;at,ir7;erce,nan3;ci9;le;r,ul3;ty;a6erie,sse4v3xtre0B;il;nti3;al;r4s3;tern,y;ly,th0;appZe9i5ru4u3;mb;nk;r5vi4z3;zy;ne;e,ty;a3ep,n9;d3f,r;!ly;agey,h8l7o5r4u3;dd0r0te;isp,uel;ar3ld,mmon,st0ward0zy;se;evKou1;e3il0;ap,e3;sy;aHiFlCoAr5u3;ff,r0sy;ly;a6i3oad;g4llia2;nt;ht;sh,ve;ld,un3;cy;a4o3ue;nd,o1;ck,nd;g,tt3;er;d,ld,w1;dy;bsu6ng5we3;so3;me;ry;rd",Adverb:"true¦a08b05d00eYfSheQinPjustOkinda,likewiZmMnJoEpCquite,r9s5t2u0very,well;ltima01p0; to,wards5;h1iny bit,o0wiO;o,t6;en,us;eldom,o0uch;!me1rt0; of;how,times,w0C;a1e0;alS;ndomRth05;ar excellenEer0oint blank; Lhaps;f3n0utright;ce0ly;! 0;ag05moX; courGten;ewJo0; longWt 0;onHwithstand9;aybe,eanwhiNore0;!ovT;! aboX;deed,steY;lla,n0;ce;or3u0;ck1l9rther0;!moK;ing; 0evK;exampCgood,suH;n mas0vI;se;e0irect2; 2fini0;te0;ly;juAtrop;ackward,y 0;far,no0; means,w; GbroFd nauseam,gEl7ny5part,s4t 2w0;ay,hi0;le;be7l0mo7wor7;arge,ea6; soon,i4;mo0way;re;l 3mo2ongsi1ready,so,togeth0ways;er;de;st;b1t0;hat;ut;ain;ad;lot,posteriori",Conjunction:"true¦aXbTcReNhowMiEjust00noBo9p8supposing,t5wh0yet;e1il0o3;e,st;n1re0thN; if,by,vM;evL;h0il,o;erefOo0;!uU;lus,rovided th9;r0therwiM;! not; mattEr,w0;! 0;since,th4w7;f4n0; 0asmuch;as mIcaForder t0;h0o;at;! 0;only,t0w0;hen;!ev3;ith2ven0;! 0;if,tB;er;o0uz;s,z;e0ut,y the time;cau1f0;ore;se;lt3nd,s 0;far1if,m0soon1t2;uch0; as;hou0;gh",Currency:"true¦$,aud,bQcOdJeurIfHgbp,hkd,iGjpy,kElDp8r7s3usd,x2y1z0¢,£,¥,ден,лв,руб,฿,₡,₨,€,₭,﷼;lotyQł;en,uanP;af,of;h0t5;e0il5;k0q0;elK;oubleJp,upeeJ;e2ound st0;er0;lingG;n0soF;ceEnies;empi7i7;n,r0wanzaCyatC;!onaBw;ls,nr;ori7ranc9;!os;en3i2kk,o0;b0ll2;ra5;me4n0rham4;ar3;e0ny;nt1;aht,itcoin0;!s",Determiner:"true¦aBboth,d9e6few,le5mu8neiDplenty,s4th2various,wh0;at0ich0;evC;a0e4is,ose;!t;everal,ome;!ast,s;a1l0very;!se;ch;e0u;!s;!n0;!o0y;th0;er","Adj|Present":"true¦a07b04cVdQeNfJhollIidRlEmCnarrIoBp9qua8r7s3t2uttFw0;aKet,ro0;ng,u08;endChin;e2hort,l1mooth,our,pa9tray,u0;re,speU;i2ow;cu6da02leSpaN;eplica01i02;ck;aHerfePr0;eseUime,omV;bscu1pen,wn;atu0e3odeH;re;a2e1ive,ow0;er;an;st,y;ow;a2i1oul,r0;ee,inge;rm;iIke,ncy,st;l1mpty,x0;emHpress;abo4ic7;amp,e2i1oub0ry,ull;le;ffu9re6;fu8libe0;raE;alm,l5o0;mpleCn3ol,rr1unterfe0;it;e0u7;ct;juga8sum7;ea1o0;se;n,r;ankru1lu0;nt;pt;li2pproxi0rticula1;ma0;te;ght","Person|Adj":"true¦b3du2earnest,frank,mi2r0san1woo1;an0ich,u1;dy;sty;ella,rown",Modal:"true¦c5lets,m4ought3sh1w0;ill,o5;a0o4;ll,nt;! to,a;ight,ust;an,o0;uld",Verb:"true¦born,cannot,gonna,has,keep tabs,msg","Person|Verb":"true¦b8ch7dr6foster,gra5ja9lan4ma2ni9ollie,p1rob,s0wade;kip,pike,t5ue;at,eg,ier2;ck,r0;k,shal;ce;ce,nt;ew;ase,u1;iff,l1ob,u0;ck;aze,ossom","Person|Date":"true¦a2j0sep;an0une;!uary;p0ugust,v0;ril"};const mo=36,po="0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ",fo=po.split("").reduce((function(e,t,n){return e[t]=n,e}),{});var bo=function(e){if(void 0!==fo[e])return fo[e];let t=0,n=1,r=mo,o=1;for(;n=0;n--,o*=mo){let r=e.charCodeAt(n)-48;r>10&&(r-=7),t+=r*o}return t};const vo=function(e,t,n){const r=bo(t);return r{let a=e.nodes[r];"!"===a[0]&&(t.push(o),a=a.slice(1));const i=a.split(/([A-Z0-9,]+)/g);for(let a=0;a{const t=function(e){if(!e)return{};const t=e.split("|").reduce(((e,t)=>{const n=t.split("¦");return e[n[0]]=n[1],e}),{}),n={};return Object.keys(t).forEach((function(e){const r=yo(t[e]);"true"===e&&(e=!0);for(let t=0;t{if(jo[t]=e,"Noun|Verb"===e){const e=Ao(t,xo);jo[e]="Plural|Verb"}})):Object.keys(t).forEach((t=>{No[t]=e}))})),[":(",":)",":P",":p",":O",";(",";)",";P",";p",";O",":3",":|",":/",":\\",":$",":*",":@",":-(",":-)",":-P",":-p",":-O",":-3",":-|",":-/",":-\\",":-$",":-*",":-@",":^(",":^)",":^P",":^p",":^O",":^3",":^|",":^/",":^\\",":^$",":^*",":^@","):","(:","$:","*:",")-:","(-:","$-:","*-:",")^:","(^:","$^:","*^:","<3","No[e]="Emoticon")),delete No[""],delete No.null,delete No[" "];const Io="Singular";var To={beforeTags:{Determiner:Io,Possessive:Io,Acronym:Io,Noun:Io,Adjective:Io,PresentTense:Io,Gerund:Io,PastTense:Io,Infinitive:Io,Date:Io,Ordinal:Io,Demonym:Io},afterTags:{Value:Io,Modal:Io,Copula:Io,PresentTense:Io,PastTense:Io,Demonym:Io,Actor:Io},beforeWords:{the:Io,with:Io,without:Io,of:Io,for:Io,any:Io,all:Io,on:Io,cut:Io,cuts:Io,increase:Io,decrease:Io,raise:Io,drop:Io,save:Io,saved:Io,saves:Io,make:Io,makes:Io,made:Io,minus:Io,plus:Io,than:Io,another:Io,versus:Io,neither:Io,about:Io,favorite:Io,best:Io,daily:Io,weekly:Io,linear:Io,binary:Io,mobile:Io,lexical:Io,technical:Io,computer:Io,scientific:Io,security:Io,government:Io,popular:Io,formal:Io,no:Io,more:Io,one:Io,let:Io,her:Io,his:Io,their:Io,our:Io,us:Io,sheer:Io,monthly:Io,yearly:Io,current:Io,previous:Io,upcoming:Io,last:Io,next:Io,main:Io,initial:Io,final:Io,beginning:Io,end:Io,top:Io,bottom:Io,future:Io,past:Io,major:Io,minor:Io,side:Io,central:Io,peripheral:Io,public:Io,private:Io},afterWords:{of:Io,system:Io,aid:Io,method:Io,utility:Io,tool:Io,reform:Io,therapy:Io,philosophy:Io,room:Io,authority:Io,says:Io,said:Io,wants:Io,wanted:Io,is:Io,did:Io,do:Io,can:Io,wise:Io}};const Do="Infinitive";var Ho={beforeTags:{Modal:Do,Adverb:Do,Negative:Do,Plural:Do},afterTags:{Determiner:Do,Adverb:Do,Possessive:Do,Reflexive:Do,Preposition:Do,Cardinal:Do,Comparative:Do,Superlative:Do},beforeWords:{i:Do,we:Do,you:Do,they:Do,to:Do,please:Do,will:Do,have:Do,had:Do,would:Do,could:Do,should:Do,do:Do,did:Do,does:Do,can:Do,must:Do,us:Do,me:Do,let:Do,even:Do,when:Do,help:Do,he:Do,she:Do,it:Do,being:Do,bi:Do,co:Do,contra:Do,de:Do,inter:Do,intra:Do,mis:Do,pre:Do,out:Do,counter:Do,nobody:Do,somebody:Do,anybody:Do,everybody:Do},afterWords:{the:Do,me:Do,you:Do,him:Do,us:Do,her:Do,his:Do,them:Do,they:Do,it:Do,himself:Do,herself:Do,itself:Do,myself:Do,ourselves:Do,themselves:Do,something:Do,anything:Do,a:Do,an:Do,up:Do,down:Do,by:Do,out:Do,off:Do,under:Do,what:Do,all:Do,to:Do,because:Do,although:Do,how:Do,otherwise:Do,together:Do,though:Do,into:Do,yet:Do,more:Do,here:Do,there:Do,away:Do}};const Eo={beforeTags:Object.assign({},Ho.beforeTags,To.beforeTags,{}),afterTags:Object.assign({},Ho.afterTags,To.afterTags,{}),beforeWords:Object.assign({},Ho.beforeWords,To.beforeWords,{}),afterWords:Object.assign({},Ho.afterWords,To.afterWords,{})},Go="Adjective";var Oo={beforeTags:{Determiner:Go,Possessive:Go,Hyphenated:Go},afterTags:{Adjective:Go},beforeWords:{seem:Go,seemed:Go,seems:Go,feel:Go,feels:Go,felt:Go,stay:Go,appear:Go,appears:Go,appeared:Go,also:Go,over:Go,under:Go,too:Go,it:Go,but:Go,still:Go,really:Go,quite:Go,well:Go,very:Go,truly:Go,how:Go,deeply:Go,hella:Go,profoundly:Go,extremely:Go,so:Go,badly:Go,mostly:Go,totally:Go,awfully:Go,rather:Go,nothing:Go,something:Go,anything:Go,not:Go,me:Go,is:Go,face:Go,faces:Go,faced:Go,look:Go,looks:Go,looked:Go,reveal:Go,reveals:Go,revealed:Go,sound:Go,sounded:Go,sounds:Go,remains:Go,remained:Go,prove:Go,proves:Go,proved:Go,becomes:Go,stays:Go,tastes:Go,taste:Go,smells:Go,smell:Go,gets:Go,grows:Go,as:Go,rings:Go,radiates:Go,conveys:Go,convey:Go,conveyed:Go,of:Go},afterWords:{too:Go,also:Go,or:Go,enough:Go,as:Go}};const Fo="Gerund";var Vo={beforeTags:{Adverb:Fo,Preposition:Fo,Conjunction:Fo},afterTags:{Adverb:Fo,Possessive:Fo,Person:Fo,Pronoun:Fo,Determiner:Fo,Copula:Fo,Preposition:Fo,Conjunction:Fo,Comparative:Fo},beforeWords:{been:Fo,keep:Fo,continue:Fo,stop:Fo,am:Fo,be:Fo,me:Fo,began:Fo,start:Fo,starts:Fo,started:Fo,stops:Fo,stopped:Fo,help:Fo,helps:Fo,avoid:Fo,avoids:Fo,love:Fo,loves:Fo,loved:Fo,hate:Fo,hates:Fo,hated:Fo},afterWords:{you:Fo,me:Fo,her:Fo,him:Fo,his:Fo,them:Fo,their:Fo,it:Fo,this:Fo,there:Fo,on:Fo,about:Fo,for:Fo,up:Fo,down:Fo}};const zo="Gerund",Bo="Adjective",So={beforeTags:Object.assign({},Oo.beforeTags,Vo.beforeTags,{Imperative:zo,Infinitive:Bo,Plural:zo}),afterTags:Object.assign({},Oo.afterTags,Vo.afterTags,{Noun:Bo}),beforeWords:Object.assign({},Oo.beforeWords,Vo.beforeWords,{is:Bo,are:zo,was:Bo,of:Bo,suggest:zo,suggests:zo,suggested:zo,recommend:zo,recommends:zo,recommended:zo,imagine:zo,imagines:zo,imagined:zo,consider:zo,considered:zo,considering:zo,resist:zo,resists:zo,resisted:zo,avoid:zo,avoided:zo,avoiding:zo,except:Bo,accept:Bo,assess:zo,explore:zo,fear:zo,fears:zo,appreciate:zo,question:zo,help:zo,embrace:zo,with:Bo}),afterWords:Object.assign({},Oo.afterWords,Vo.afterWords,{to:zo,not:zo,the:zo})},$o={beforeTags:{Determiner:void 0,Cardinal:"Noun",PhrasalVerb:"Adjective"},afterTags:{}},Mo={beforeTags:Object.assign({},Oo.beforeTags,To.beforeTags,$o.beforeTags),afterTags:Object.assign({},Oo.afterTags,To.afterTags,$o.afterTags),beforeWords:Object.assign({},Oo.beforeWords,To.beforeWords,{are:"Adjective",is:"Adjective",was:"Adjective",be:"Adjective",off:"Adjective",out:"Adjective"}),afterWords:Object.assign({},Oo.afterWords,To.afterWords)},Lo="PastTense",Ko="Adjective",Jo={beforeTags:{Adverb:Lo,Pronoun:Lo,ProperNoun:Lo,Auxiliary:Lo,Noun:Lo},afterTags:{Possessive:Lo,Pronoun:Lo,Determiner:Lo,Adverb:Lo,Comparative:Lo,Date:Lo,Gerund:Lo},beforeWords:{be:Lo,who:Lo,get:Ko,had:Lo,has:Lo,have:Lo,been:Lo,it:Lo,as:Lo,for:Ko,more:Ko,always:Ko},afterWords:{by:Lo,back:Lo,out:Lo,in:Lo,up:Lo,down:Lo,before:Lo,after:Lo,for:Lo,the:Lo,with:Lo,as:Lo,on:Lo,at:Lo,between:Lo,to:Lo,into:Lo,us:Lo,them:Lo,his:Lo,her:Lo,their:Lo,our:Lo,me:Lo,about:Ko}};var Wo={beforeTags:Object.assign({},Oo.beforeTags,Jo.beforeTags),afterTags:Object.assign({},Oo.afterTags,Jo.afterTags),beforeWords:Object.assign({},Oo.beforeWords,Jo.beforeWords),afterWords:Object.assign({},Oo.afterWords,Jo.afterWords)};const qo={afterTags:{Noun:"Adjective",Conjunction:void 0}},Uo={beforeTags:Object.assign({},Oo.beforeTags,Ho.beforeTags,{Adverb:void 0,Negative:void 0}),afterTags:Object.assign({},Oo.afterTags,Ho.afterTags,qo.afterTags),beforeWords:Object.assign({},Oo.beforeWords,Ho.beforeWords,{have:void 0,had:void 0,not:void 0,went:"Adjective",goes:"Adjective",got:"Adjective",be:"Adjective"}),afterWords:Object.assign({},Oo.afterWords,Ho.afterWords,{to:void 0,as:"Adjective"})},Ro={Copula:"Gerund",PastTense:"Gerund",PresentTense:"Gerund",Infinitive:"Gerund"},Qo={Value:"Gerund"},Zo={are:"Gerund",were:"Gerund",be:"Gerund",no:"Gerund",without:"Gerund",you:"Gerund",we:"Gerund",they:"Gerund",he:"Gerund",she:"Gerund",us:"Gerund",them:"Gerund"},_o={the:"Gerund",this:"Gerund",that:"Gerund",me:"Gerund",us:"Gerund",them:"Gerund"},Xo={beforeTags:Object.assign({},Vo.beforeTags,To.beforeTags,Ro),afterTags:Object.assign({},Vo.afterTags,To.afterTags,Qo),beforeWords:Object.assign({},Vo.beforeWords,To.beforeWords,Zo),afterWords:Object.assign({},Vo.afterWords,To.afterWords,_o)},Yo="Singular",ea="Infinitive",ta={beforeTags:Object.assign({},Ho.beforeTags,To.beforeTags,{Adjective:Yo,Particle:Yo}),afterTags:Object.assign({},Ho.afterTags,To.afterTags,{ProperNoun:ea,Gerund:ea,Adjective:ea,Copula:Yo}),beforeWords:Object.assign({},Ho.beforeWords,To.beforeWords,{is:Yo,was:Yo,of:Yo,have:null}),afterWords:Object.assign({},Ho.afterWords,To.afterWords,{instead:ea,about:ea,his:ea,her:ea,to:null,by:null,in:null})},na="Person";var ra={beforeTags:{Honorific:na,Person:na},afterTags:{Person:na,ProperNoun:na,Verb:na},beforeWords:{hi:na,hey:na,yo:na,dear:na,hello:na},afterWords:{said:na,says:na,told:na,tells:na,feels:na,felt:na,seems:na,thinks:na,thought:na,spends:na,spendt:na,plays:na,played:na,sing:na,sang:na,learn:na,learned:na,wants:na,wanted:na}};const oa="Month",aa={beforeTags:{Date:oa,Value:oa},afterTags:{Date:oa,Value:oa},beforeWords:{by:oa,in:oa,on:oa,during:oa,after:oa,before:oa,between:oa,until:oa,til:oa,sometime:oa,of:oa,this:oa,next:oa,last:oa,previous:oa,following:oa,with:"Person"},afterWords:{sometime:oa,in:oa,of:oa,until:oa,the:oa}};var ia={beforeTags:Object.assign({},ra.beforeTags,aa.beforeTags),afterTags:Object.assign({},ra.afterTags,aa.afterTags),beforeWords:Object.assign({},ra.beforeWords,aa.beforeWords),afterWords:Object.assign({},ra.afterWords,aa.afterWords)};const sa="Place",la={beforeTags:{Place:sa},afterTags:{Place:sa,Abbreviation:sa},beforeWords:{in:sa,by:sa,near:sa,from:sa,to:sa},afterWords:{in:sa,by:sa,near:sa,from:sa,to:sa,government:sa,council:sa,region:sa,city:sa}},ua="Unit",ca={"Actor|Verb":Eo,"Adj|Gerund":So,"Adj|Noun":Mo,"Adj|Past":Wo,"Adj|Present":Uo,"Noun|Verb":ta,"Noun|Gerund":Xo,"Person|Noun":{beforeTags:Object.assign({},To.beforeTags,ra.beforeTags),afterTags:Object.assign({},To.afterTags,ra.afterTags),beforeWords:Object.assign({},To.beforeWords,ra.beforeWords,{i:"Infinitive",we:"Infinitive"}),afterWords:Object.assign({},To.afterWords,ra.afterWords)},"Person|Date":ia,"Person|Verb":{beforeTags:Object.assign({},To.beforeTags,ra.beforeTags,Ho.beforeTags),afterTags:Object.assign({},To.afterTags,ra.afterTags,Ho.afterTags),beforeWords:Object.assign({},To.beforeWords,ra.beforeWords,Ho.beforeWords),afterWords:Object.assign({},To.afterWords,ra.afterWords,Ho.afterWords)},"Person|Place":{beforeTags:Object.assign({},la.beforeTags,ra.beforeTags),afterTags:Object.assign({},la.afterTags,ra.afterTags),beforeWords:Object.assign({},la.beforeWords,ra.beforeWords),afterWords:Object.assign({},la.afterWords,ra.afterWords)},"Person|Adj":{beforeTags:Object.assign({},ra.beforeTags,Oo.beforeTags),afterTags:Object.assign({},ra.afterTags,Oo.afterTags),beforeWords:Object.assign({},ra.beforeWords,Oo.beforeWords),afterWords:Object.assign({},ra.afterWords,Oo.afterWords)},"Unit|Noun":{beforeTags:{Value:ua},afterTags:{},beforeWords:{per:ua,every:ua,each:ua,square:ua,cubic:ua,sq:ua,metric:ua},afterWords:{per:ua,squared:ua,cubed:ua,long:ua}}},ha=(e,t)=>{const n=Object.keys(e).reduce(((t,n)=>(t[n]="Infinitive"===e[n]?"PresentTense":"Plural",t)),{});return Object.assign(n,t)};ca["Plural|Verb"]={beforeWords:ha(ca["Noun|Verb"].beforeWords,{had:"Plural",have:"Plural"}),afterWords:ha(ca["Noun|Verb"].afterWords,{his:"PresentTense",her:"PresentTense",its:"PresentTense",in:null,to:null,is:"PresentTense",by:"PresentTense"}),beforeTags:ha(ca["Noun|Verb"].beforeTags,{Conjunction:"PresentTense",Noun:void 0,ProperNoun:"PresentTense"}),afterTags:ha(ca["Noun|Verb"].afterTags,{Gerund:"Plural",Noun:"PresentTense",Value:"PresentTense"})};const da="Adjective",ga="Infinitive",ma="PresentTense",pa="Singular",fa="PastTense",ba="Adverb",va="Plural",ya="Actor",wa="Verb",ka="Noun",Pa="LastName",Aa="Modal",Ca="Place",Na="Participle";var ja=[null,null,{ea:pa,ia:ka,ic:da,ly:ba,"'n":wa,"'t":wa},{oed:fa,ued:fa,xed:fa," so":ba,"'ll":Aa,"'re":"Copula",azy:da,eer:ka,end:wa,ped:fa,ffy:da,ify:ga,ing:"Gerund",ize:ga,ibe:ga,lar:da,mum:da,nes:ma,nny:da,ous:da,que:da,ger:ka,ber:ka,rol:pa,sis:pa,ogy:pa,oid:pa,ian:pa,zes:ma,eld:fa,ken:Na,ven:Na,ten:Na,ect:ga,ict:ga,ign:ga,oze:ga,ful:da,bal:da,ton:ka,pur:Ca},{amed:fa,aped:fa,ched:fa,lked:fa,rked:fa,reed:fa,nded:fa,mned:da,cted:fa,dged:fa,ield:pa,akis:Pa,cede:ga,chuk:Pa,czyk:Pa,ects:ma,iend:pa,ends:wa,enko:Pa,ette:pa,iary:pa,wner:pa,fies:ma,fore:ba,gate:ga,gone:da,ices:va,ints:va,ruct:ga,ines:va,ions:va,ners:va,pers:va,lers:va,less:da,llen:da,made:da,nsen:Pa,oses:ma,ould:Aa,some:da,sson:Pa,ians:va,tion:pa,tage:ka,ique:pa,tive:da,tors:ka,vice:pa,lier:pa,fier:pa,wned:fa,gent:pa,tist:ya,pist:ya,rist:ya,mist:ya,yist:ya,vist:ya,ists:ya,lite:pa,site:pa,rite:pa,mite:pa,bite:pa,mate:pa,date:pa,ndal:pa,vent:pa,uist:ya,gist:ya,note:pa,cide:pa,ence:pa,wide:da,vide:ga,ract:ga,duce:ga,pose:ga,eive:ga,lyze:ga,lyse:ga,iant:da,nary:da,ghty:da,uent:da,erer:ya,bury:Ca,dorf:ka,esty:ka,wych:Ca,dale:Ca,folk:Ca,vale:Ca,abad:Ca,sham:Ca,wick:Ca,view:Ca},{elist:ya,holic:pa,phite:pa,tized:fa,urned:fa,eased:fa,ances:va,bound:da,ettes:va,fully:ba,ishes:ma,ities:va,marek:Pa,nssen:Pa,ology:ka,osome:pa,tment:pa,ports:va,rough:da,tches:ma,tieth:"Ordinal",tures:va,wards:ba,where:ba,archy:ka,pathy:ka,opoly:ka,embly:ka,phate:ka,ndent:pa,scent:pa,onist:ya,anist:ya,alist:ya,olist:ya,icist:ya,ounce:ga,iable:da,borne:da,gnant:da,inant:da,igent:da,atory:da,rient:pa,dient:pa,maker:ya,burgh:Ca,mouth:Ca,ceter:Ca,ville:Ca,hurst:Ca,stead:Ca,endon:Ca,brook:Ca,shire:Ca,worth:ka,field:"ProperNoun",ridge:Ca},{auskas:Pa,parent:pa,cedent:pa,ionary:pa,cklist:pa,brooke:Ca,keeper:ya,logist:ya,teenth:"Value",worker:ya,master:ya,writer:ya,brough:Ca,cester:Ca,ington:Ca,cliffe:Ca,ingham:Ca},{chester:Ca,logists:ya,opoulos:Pa,borough:Ca,sdottir:Pa}];const xa="Adjective",Ia="Noun",Ta="Verb";var Da=[null,null,{},{neo:Ia,bio:Ia,"de-":Ta,"re-":Ta,"un-":Ta,"ex-":Ia},{anti:Ia,auto:Ia,faux:xa,hexa:Ia,kilo:Ia,mono:Ia,nano:Ia,octa:Ia,poly:Ia,semi:xa,tele:Ia,"pro-":xa,"mis-":Ta,"dis-":Ta,"pre-":xa},{anglo:Ia,centi:Ia,ethno:Ia,ferro:Ia,grand:Ia,hepta:Ia,hydro:Ia,intro:Ia,macro:Ia,micro:Ia,milli:Ia,nitro:Ia,penta:Ia,quasi:xa,radio:Ia,tetra:Ia,"omni-":xa,"post-":xa},{pseudo:xa,"extra-":xa,"hyper-":xa,"inter-":xa,"intra-":xa,"deca-":xa},{electro:Ia}];const Ha="Adjective",Ea="Infinitive",Ga="PresentTense",Oa="Singular",Fa="PastTense",Va="Adverb",za="Expression",Ba="Actor",Sa="Verb",$a="Noun",Ma="LastName";var La={a:[[/.[aeiou]na$/,$a,"tuna"],[/.[oau][wvl]ska$/,Ma],[/.[^aeiou]ica$/,Oa,"harmonica"],[/^([hyj]a+)+$/,za,"haha"]],c:[[/.[^aeiou]ic$/,Ha]],d:[[/[aeiou](pp|ll|ss|ff|gg|tt|rr|bb|nn|mm)ed$/,Fa,"popped"],[/.[aeo]{2}[bdgmnprvz]ed$/,Fa,"rammed"],[/.[aeiou][sg]hed$/,Fa,"gushed"],[/.[aeiou]red$/,Fa,"hired"],[/.[aeiou]r?ried$/,Fa,"hurried"],[/[^aeiou]ard$/,Oa,"steward"],[/[aeiou][^aeiou]id$/,Ha,""],[/.[vrl]id$/,Ha,"livid"],[/..led$/,Fa,"hurled"],[/.[iao]sed$/,Fa,""],[/[aeiou]n?[cs]ed$/,Fa,""],[/[aeiou][rl]?[mnf]ed$/,Fa,""],[/[aeiou][ns]?c?ked$/,Fa,"bunked"],[/[aeiou]gned$/,Fa],[/[aeiou][nl]?ged$/,Fa],[/.[tdbwxyz]ed$/,Fa],[/[^aeiou][aeiou][tvx]ed$/,Fa],[/.[cdflmnprstv]ied$/,Fa,"emptied"]],e:[[/.[lnr]ize$/,Ea,"antagonize"],[/.[^aeiou]ise$/,Ea,"antagonise"],[/.[aeiou]te$/,Ea,"bite"],[/.[^aeiou][ai]ble$/,Ha,"fixable"],[/.[^aeiou]eable$/,Ha,"maleable"],[/.[ts]ive$/,Ha,"festive"],[/[a-z]-like$/,Ha,"woman-like"]],h:[[/.[^aeiouf]ish$/,Ha,"cornish"],[/.v[iy]ch$/,Ma,"..ovich"],[/^ug?h+$/,za,"ughh"],[/^uh[ -]?oh$/,za,"uhoh"],[/[a-z]-ish$/,Ha,"cartoon-ish"]],i:[[/.[oau][wvl]ski$/,Ma,"polish-male"]],k:[[/^(k){2}$/,za,"kkkk"]],l:[[/.[gl]ial$/,Ha,"familial"],[/.[^aeiou]ful$/,Ha,"fitful"],[/.[nrtumcd]al$/,Ha,"natal"],[/.[^aeiou][ei]al$/,Ha,"familial"]],m:[[/.[^aeiou]ium$/,Oa,"magnesium"],[/[^aeiou]ism$/,Oa,"schism"],[/^[hu]m+$/,za,"hmm"],[/^\d+ ?[ap]m$/,"Date","3am"]],n:[[/.[lsrnpb]ian$/,Ha,"republican"],[/[^aeiou]ician$/,Ba,"musician"],[/[aeiou][ktrp]in'$/,"Gerund","cookin'"]],o:[[/^no+$/,za,"noooo"],[/^(yo)+$/,za,"yoo"],[/^wo{2,}[pt]?$/,za,"woop"]],r:[[/.[bdfklmst]ler$/,"Noun"],[/[aeiou][pns]er$/,Oa],[/[^i]fer$/,Ea],[/.[^aeiou][ao]pher$/,Ba],[/.[lk]er$/,"Noun"],[/.ier$/,"Comparative"]],t:[[/.[di]est$/,"Superlative"],[/.[icldtgrv]ent$/,Ha],[/[aeiou].*ist$/,Ha],[/^[a-z]et$/,Sa]],s:[[/.[^aeiou]ises$/,Ga],[/.[rln]ates$/,Ga],[/.[^z]ens$/,Sa],[/.[lstrn]us$/,Oa],[/.[aeiou]sks$/,Ga],[/.[aeiou]kes$/,Ga],[/[aeiou][^aeiou]is$/,Oa],[/[a-z]'s$/,$a],[/^yes+$/,za]],v:[[/.[^aeiou][ai][kln]ov$/,Ma]],y:[[/.[cts]hy$/,Ha],[/.[st]ty$/,Ha],[/.[tnl]ary$/,Ha],[/.[oe]ry$/,Oa],[/[rdntkbhs]ly$/,Va],[/.(gg|bb|zz)ly$/,Ha],[/...lly$/,Va],[/.[gk]y$/,Ha],[/[bszmp]{2}y$/,Ha],[/.[ai]my$/,Ha],[/[ea]{2}zy$/,Ha],[/.[^aeiou]ity$/,Oa]]};const Ka="Verb",Ja="Noun";var Wa={leftTags:[["Adjective",Ja],["Possessive",Ja],["Determiner",Ja],["Adverb",Ka],["Pronoun",Ka],["Value",Ja],["Ordinal",Ja],["Modal",Ka],["Superlative",Ja],["Demonym",Ja],["Honorific","Person"]],leftWords:[["i",Ka],["first",Ja],["it",Ka],["there",Ka],["not",Ka],["because",Ja],["if",Ja],["but",Ja],["who",Ka],["this",Ja],["his",Ja],["when",Ja],["you",Ka],["very","Adjective"],["old",Ja],["never",Ka],["before",Ja],["a",Ja],["the",Ja],["been",Ka]],rightTags:[["Copula",Ja],["PastTense",Ja],["Conjunction",Ja],["Modal",Ja]],rightWords:[["there",Ka],["me",Ka],["man","Adjective"],["him",Ka],["it",Ka],["were",Ja],["took",Ja],["himself",Ka],["went",Ja],["who",Ja],["jr","Person"]]},qa={fwd:"3:ser,ier¦1er:h,t,f,l,n¦1r:e¦2er:ss,or,om",both:"3er:ver,ear,alm¦3ner:hin¦3ter:lat¦2mer:im¦2er:ng,rm,mb¦2ber:ib¦2ger:ig¦1er:w,p,k,d¦ier:y",rev:"1:tter,yer¦2:uer,ver,ffer,oner,eler,ller,iler,ster,cer,uler,sher,ener,gher,aner,adder,nter,eter,rter,hter,rner,fter¦3:oser,ooler,eafer,user,airer,bler,maler,tler,eater,uger,rger,ainer,urer,ealer,icher,pler,emner,icter,nser,iser¦4:arser,viner,ucher,rosser,somer,ndomer,moter,oother,uarer,hiter¦5:nuiner,esser,emier¦ar:urther",ex:"worse:bad¦better:good¦4er:fair,gray,poor¦1urther:far¦3ter:fat,hot,wet¦3der:mad,sad¦3er:shy,fun¦4der:glad¦:¦4r:cute,dire,fake,fine,free,lame,late,pale,rare,ripe,rude,safe,sore,tame,wide¦5r:eerie,stale"},Ua={fwd:"1:nning,tting,rring,pping,eing,mming,gging,dding,bbing,kking¦2:eking,oling,eling,eming¦3:velling,siting,uiting,fiting,loting,geting,ialing,celling¦4:graming",both:"1:aing,iing,fing,xing,ying,oing,hing,wing¦2:tzing,rping,izzing,bting,mning,sping,wling,rling,wding,rbing,uping,lming,wning,mping,oning,lting,mbing,lking,fting,hting,sking,gning,pting,cking,ening,nking,iling,eping,ering,rting,rming,cting,lping,ssing,nting,nding,lding,sting,rning,rding,rking¦3:belling,siping,toming,yaking,uaking,oaning,auling,ooping,aiding,naping,euring,tolling,uzzing,ganing,haning,ualing,halling,iasing,auding,ieting,ceting,ouling,voring,ralling,garing,joring,oaming,oaking,roring,nelling,ooring,uelling,eaming,ooding,eaping,eeting,ooting,ooming,xiting,keting,ooking,ulling,airing,oaring,biting,outing,oiting,earing,naling,oading,eeding,ouring,eaking,aiming,illing,oining,eaning,onging,ealing,aining,eading¦4:thoming,melling,aboring,ivoting,weating,dfilling,onoring,eriting,imiting,tialling,rgining,otoring,linging,winging,lleting,louding,spelling,mpelling,heating,feating,opelling,choring,welling,ymaking,ctoring,calling,peating,iloring,laiting,utoring,uditing,mmaking,loating,iciting,waiting,mbating,voiding,otalling,nsoring,nselling,ocusing,itoring,eloping¦5:rselling,umpeting,atrolling,treating,tselling,rpreting,pringing,ummeting,ossoming,elmaking,eselling,rediting,totyping,onmaking,rfeiting,ntrolling¦5e:chmaking,dkeeping,severing,erouting,ecreting,ephoning,uthoring,ravening,reathing,pediting,erfering,eotyping,fringing,entoring,ombining,ompeting¦4e:emaking,eething,twining,rruling,chuting,xciting,rseding,scoping,edoring,pinging,lunging,agining,craping,pleting,eleting,nciting,nfining,ncoding,tponing,ecoding,writing,esaling,nvening,gnoring,evoting,mpeding,rvening,dhering,mpiling,storing,nviting,ploring¦3e:tining,nuring,saking,miring,haling,ceding,xuding,rining,nuting,laring,caring,miling,riding,hoking,piring,lading,curing,uading,noting,taping,futing,paring,hading,loding,siring,guring,vading,voking,during,niting,laning,caping,luting,muting,ruding,ciding,juring,laming,caling,hining,uoting,liding,ciling,duling,tuting,puting,cuting,coring,uiding,tiring,turing,siding,rading,enging,haping,buting,lining,taking,anging,haring,uiring,coming,mining,moting,suring,viding,luding¦2e:tring,zling,uging,oging,gling,iging,vring,fling,lging,obing,psing,pling,ubing,cling,dling,wsing,iking,rsing,dging,kling,ysing,tling,rging,eging,nsing,uning,osing,uming,using,ibing,bling,aging,ising,asing,ating¦2ie:rlying¦1e:zing,uing,cing,ving",rev:"ying:ie¦1ing:se,ke,te,we,ne,re,de,pe,me,le,c,he¦2ing:ll,ng,dd,ee,ye,oe,rg,us¦2ning:un¦2ging:og,ag,ug,ig,eg¦2ming:um¦2bing:ub,ab,eb,ob¦3ning:lan,can,hin,pin,win¦3ring:cur,lur,tir,tar,pur,car¦3ing:ait,del,eel,fin,eat,oat,eem,lel,ool,ein,uin¦3ping:rop,rap,top,uip,wap,hip,hop,lap,rip,cap¦3ming:tem,wim,rim,kim,lim¦3ting:mat,cut,pot,lit,lot,hat,set,pit,put¦3ding:hed,bed,bid¦3king:rek¦3ling:cil,pel¦3bing:rib¦4ning:egin¦4ing:isit,ruit,ilot,nsit,dget,rkel,ival,rcel¦4ring:efer,nfer¦4ting:rmit,mmit,ysit,dmit,emit,bmit,tfit,gret¦4ling:evel,xcel,ivel¦4ding:hred¦5ing:arget,posit,rofit¦5ring:nsfer¦5ting:nsmit,orget,cquit¦5ling:ancel,istil",ex:"3:adding,eating,aiming,aiding,airing,outing,gassing,setting,getting,putting,cutting,winning,sitting,betting,mapping,tapping,letting,bidding,hitting,tanning,netting,popping,fitting,capping,lapping,barring,banning,vetting,topping,rotting,tipping,potting,wetting,pitting,dipping,budding,hemming,pinning,jetting,kidding,padding,podding,sipping,wedding,bedding,donning,warring,penning,gutting,cueing,wadding,petting,ripping,napping,matting,tinning,binning,dimming,hopping,mopping,nodding,panning,rapping,ridding,sinning¦4:selling,falling,calling,waiting,editing,telling,rolling,heating,boating,hanging,beating,coating,singing,tolling,felling,polling,discing,seating,voiding,gelling,yelling,baiting,reining,ruining,seeking,spanning,stepping,knitting,emitting,slipping,quitting,dialing,omitting,clipping,shutting,skinning,abutting,flipping,trotting,cramming,fretting,suiting¦5:bringing,treating,spelling,stalling,trolling,expelling,rivaling,wringing,deterring,singeing,befitting,refitting¦6:enrolling,distilling,scrolling,strolling,caucusing,travelling¦7:installing,redefining,stencilling,recharging,overeating,benefiting,unraveling,programing¦9:reprogramming¦is:being¦2e:using,aging,owing¦3e:making,taking,coming,noting,hiring,filing,coding,citing,doping,baking,coping,hoping,lading,caring,naming,voting,riding,mining,curing,lining,ruling,typing,boring,dining,firing,hiding,piling,taping,waning,baling,boning,faring,honing,wiping,luring,timing,wading,piping,fading,biting,zoning,daring,waking,gaming,raking,ceding,tiring,coking,wining,joking,paring,gaping,poking,pining,coring,liming,toting,roping,wiring,aching¦4e:writing,storing,eroding,framing,smoking,tasting,wasting,phoning,shaking,abiding,braking,flaking,pasting,priming,shoring,sloping,withing,hinging¦5e:defining,refining,renaming,swathing,fringing,reciting¦1ie:dying,tying,lying,vying¦7e:sunbathing"},Ra={fwd:"1:mt¦2:llen¦3:iven,aken¦:ne¦y:in",both:"1:wn¦2:me,aten¦3:seen,bidden,isen¦4:roven,asten¦3l:pilt¦3d:uilt¦2e:itten¦1im:wum¦1eak:poken¦1ine:hone¦1ose:osen¦1in:gun¦1ake:woken¦ear:orn¦eal:olen¦eeze:ozen¦et:otten¦ink:unk¦ing:ung",rev:"2:un¦oken:eak¦ought:eek¦oven:eave¦1ne:o¦1own:ly¦1den:de¦1in:ay¦2t:am¦2n:ee¦3en:all¦4n:rive,sake,take¦5n:rgive",ex:"2:been¦3:seen,run¦4:given,taken¦5:shaken¦2eak:broken¦1ive:dove¦2y:flown¦3e:hidden,ridden¦1eek:sought¦1ake:woken¦1eave:woven"},Qa={fwd:"1:oes¦1ve:as",both:"1:xes¦2:zzes,ches,shes,sses¦3:iases¦2y:llies,plies¦1y:cies,bies,ties,vies,nies,pies,dies,ries,fies¦:s",rev:"1ies:ly¦2es:us,go,do¦3es:cho,eto",ex:"2:does,goes¦3:gasses¦5:focuses¦is:are¦3y:relies¦2y:flies¦2ve:has"},Za={fwd:"1st:e¦1est:l,m,f,s¦1iest:cey¦2est:or,ir¦3est:ver",both:"4:east¦5:hwest¦5lest:erful¦4est:weet,lgar,tter,oung¦4most:uter¦3est:ger,der,rey,iet,ong,ear¦3test:lat¦3most:ner¦2est:pt,ft,nt,ct,rt,ht¦2test:it¦2gest:ig¦1est:b,k,n,p,h,d,w¦iest:y",rev:"1:ttest,nnest,yest¦2:sest,stest,rmest,cest,vest,lmest,olest,ilest,ulest,ssest,imest,uest¦3:rgest,eatest,oorest,plest,allest,urest,iefest,uelest,blest,ugest,amest,yalest,ealest,illest,tlest,itest¦4:cerest,eriest,somest,rmalest,ndomest,motest,uarest,tiffest¦5:leverest,rangest¦ar:urthest¦3ey:riciest",ex:"best:good¦worst:bad¦5est:great¦4est:fast,full,fair,dull¦3test:hot,wet,fat¦4nest:thin¦1urthest:far¦3est:gay,shy,ill¦4test:neat¦4st:late,wide,fine,safe,cute,fake,pale,rare,rude,sore,ripe,dire¦6st:severe"},_a={fwd:"1:tistic,eable,lful,sful,ting,tty¦2:onate,rtable,geous,ced,seful,ctful¦3:ortive,ented¦arity:ear¦y:etic¦fulness:begone¦1ity:re¦1y:tiful,gic¦2ity:ile,imous,ilous,ime¦2ion:ated¦2eness:iving¦2y:trious¦2ation:iring¦2tion:vant¦3ion:ect¦3ce:mant,mantic¦3tion:irable¦3y:est,estic¦3m:mistic,listic¦3ess:ning¦4n:utious¦4on:rative,native,vative,ective¦4ce:erant",both:"1:king,wing¦2:alous,ltuous,oyful,rdous¦3:gorous,ectable,werful,amatic¦4:oised,usical,agical,raceful,ocused,lined,ightful¦5ness:stful,lding,itous,nuous,ulous,otous,nable,gious,ayful,rvous,ntous,lsive,peful,entle,ciful,osive,leful,isive,ncise,reful,mious¦5ty:ivacious¦5ties:ubtle¦5ce:ilient,adiant,atient¦5cy:icient¦5sm:gmatic¦5on:sessive,dictive¦5ity:pular,sonal,eative,entic¦5sity:uminous¦5ism:conic¦5nce:mperate¦5ility:mitable¦5ment:xcited¦5n:bitious¦4cy:brant,etent,curate¦4ility:erable,acable,icable,ptable¦4ty:nacious,aive,oyal,dacious¦4n:icious¦4ce:vient,erent,stent,ndent,dient,quent,ident¦4ness:adic,ound,hing,pant,sant,oing,oist,tute¦4icity:imple¦4ment:fined,mused¦4ism:otic¦4ry:dantic¦4ity:tund,eral¦4edness:hand¦4on:uitive¦4lity:pitable¦4sm:eroic,namic¦4sity:nerous¦3th:arm¦3ility:pable,bable,dable,iable¦3cy:hant,nant,icate¦3ness:red,hin,nse,ict,iet,ite,oud,ind,ied,rce¦3ion:lute¦3ity:ual,gal,volous,ial¦3ce:sent,fensive,lant,gant,gent,lent,dant¦3on:asive¦3m:fist,sistic,iastic¦3y:terious,xurious,ronic,tastic¦3ur:amorous¦3e:tunate¦3ation:mined¦3sy:rteous¦3ty:ain¦3ry:ave¦3ment:azed¦2ness:de,on,ue,rn,ur,ft,rp,pe,om,ge,rd,od,ay,ss,er,ll,oy,ap,ht,ld,ad,rt¦2inousness:umous¦2ity:neous,ene,id,ane¦2cy:bate,late¦2ation:ized¦2ility:oble,ible¦2y:odic¦2e:oving,aring¦2s:ost¦2itude:pt¦2dom:ee¦2ance:uring¦2tion:reet¦2ion:oted¦2sion:ending¦2liness:an¦2or:rdent¦1th:ung¦1e:uable¦1ness:w,h,k,f¦1ility:mble¦1or:vent¦1ement:ging¦1tiquity:ncient¦1ment:hed¦verty:or¦ength:ong¦eat:ot¦pth:ep¦iness:y",rev:"",ex:"5:forceful,humorous¦8:charismatic¦13:understanding¦5ity:active¦11ness:adventurous,inquisitive,resourceful¦8on:aggressive,automatic,perceptive¦7ness:amorous,fatuous,furtive,ominous,serious¦5ness:ample,sweet¦12ness:apprehensive,cantankerous,contemptuous,ostentatious¦13ness:argumentative,conscientious¦9ness:assertive,facetious,imperious,inventive,oblivious,rapacious,receptive,seditious,whimsical¦10ness:attractive,expressive,impressive,loquacious,salubrious,thoughtful¦3edom:boring¦4ness:calm,fast,keen,tame¦8ness:cheerful,gracious,specious,spurious,timorous,unctuous¦5sity:curious¦9ion:deliberate¦8ion:desperate¦6e:expensive¦7ce:fragrant¦3y:furious¦9ility:ineluctable¦6ism:mystical¦8ity:physical,proactive,sensitive,vertical¦5cy:pliant¦7ity:positive¦9ity:practical¦12ism:professional¦6ce:prudent¦3ness:red¦6cy:vagrant¦3dom:wise"};const Xa=function(e="",t={}){let n=function(e,t={}){return t.hasOwnProperty(e)?t[e]:null}(e,t.ex);return n=n||function(e,t=[]){for(let n=0;n=1;r-=1){let o=e.length-r,a=e.substring(o,e.length);if(!0===t.hasOwnProperty(a))return e.slice(0,o)+t[a];if(!0===n.hasOwnProperty(a))return e.slice(0,o)+n[a]}return t.hasOwnProperty("")?e+t[""]:n.hasOwnProperty("")?e+n[""]:null}(e,t.fwd,t.both),n=n||e,n},Ya=function(e){return Object.entries(e).reduce(((e,t)=>(e[t[1]]=t[0],e)),{})},ei=function(e={}){return{reversed:!0,both:Ya(e.both),ex:Ya(e.ex),fwd:e.rev||{}}},ti=/^([0-9]+)/,ni=function(e){let t=function(e){let t={};return e.split("¦").forEach((e=>{let[n,r]=e.split(":");r=(r||"").split(","),r.forEach((e=>{t[e]=n}))})),t}(e);return Object.keys(t).reduce(((e,n)=>(e[n]=function(e="",t=""){let n=(t=String(t)).match(ti);if(null===n)return t;let r=Number(n[1])||0;return e.substring(0,r)+t.replace(ti,"")}(n,t[n]),e)),{})},ri=function(e={}){return"string"==typeof e&&(e=JSON.parse(e)),e.fwd=ni(e.fwd||""),e.both=ni(e.both||""),e.rev=ni(e.rev||""),e.ex=ni(e.ex||""),e},oi=ri({fwd:"1:tted,wed,gged,nned,een,rred,pped,yed,bbed,oed,dded,rd,wn,mmed¦2:eed,nded,et,hted,st,oled,ut,emed,eled,lded,ken,rt,nked,apt,ant,eped,eked¦3:eared,eat,eaded,nelled,ealt,eeded,ooted,eaked,eaned,eeted,mited,bid,uit,ead,uited,ealed,geted,velled,ialed,belled¦4:ebuted,hined,comed¦y:ied¦ome:ame¦ear:ore¦ind:ound¦ing:ung,ang¦ep:pt¦ink:ank,unk¦ig:ug¦all:ell¦ee:aw¦ive:ave¦eeze:oze¦old:eld¦ave:ft¦ake:ook¦ell:old¦ite:ote¦ide:ode¦ine:one¦in:un,on¦eal:ole¦im:am¦ie:ay¦and:ood¦1ise:rose¦1eak:roke¦1ing:rought¦1ive:rove¦1el:elt¦1id:bade¦1et:got¦1y:aid¦1it:sat¦3e:lid¦3d:pent",both:"1:aed,fed,xed,hed¦2:sged,xted,wled,rped,lked,kied,lmed,lped,uped,bted,rbed,rked,wned,rled,mped,fted,mned,mbed,zzed,omed,ened,cked,gned,lted,sked,ued,zed,nted,ered,rted,rmed,ced,sted,rned,ssed,rded,pted,ved,cted¦3:cled,eined,siped,ooned,uked,ymed,jored,ouded,ioted,oaned,lged,asped,iged,mured,oided,eiled,yped,taled,moned,yled,lit,kled,oaked,gled,naled,fled,uined,oared,valled,koned,soned,aided,obed,ibed,meted,nicked,rored,micked,keted,vred,ooped,oaded,rited,aired,auled,filled,ouled,ooded,ceted,tolled,oited,bited,aped,tled,vored,dled,eamed,nsed,rsed,sited,owded,pled,sored,rged,osed,pelled,oured,psed,oated,loned,aimed,illed,eured,tred,ioned,celled,bled,wsed,ooked,oiled,itzed,iked,iased,onged,ased,ailed,uned,umed,ained,auded,nulled,ysed,eged,ised,aged,oined,ated,used,dged,doned¦4:ntied,efited,uaked,caded,fired,roped,halled,roked,himed,culed,tared,lared,tuted,uared,routed,pited,naked,miled,houted,helled,hared,cored,caled,tired,peated,futed,ciled,called,tined,moted,filed,sided,poned,iloted,honed,lleted,huted,ruled,cured,named,preted,vaded,sured,talled,haled,peded,gined,nited,uided,ramed,feited,laked,gured,ctored,unged,pired,cuted,voked,eloped,ralled,rined,coded,icited,vided,uaded,voted,mined,sired,noted,lined,nselled,luted,jured,fided,puted,piled,pared,olored,cided,hoked,enged,tured,geoned,cotted,lamed,uiled,waited,udited,anged,luded,mired,uired,raded¦5:modelled,izzled,eleted,umpeted,ailored,rseded,treated,eduled,ecited,rammed,eceded,atrolled,nitored,basted,twined,itialled,ncited,gnored,ploded,xcited,nrolled,namelled,plored,efeated,redited,ntrolled,nfined,pleted,llided,lcined,eathed,ibuted,lloted,dhered,cceded¦3ad:sled¦2aw:drew¦2ot:hot¦2ke:made¦2ow:hrew,grew¦2ose:hose¦2d:ilt¦2in:egan¦1un:ran¦1ink:hought¦1ick:tuck¦1ike:ruck¦1eak:poke,nuck¦1it:pat¦1o:did¦1ow:new¦1ake:woke¦go:went",rev:"3:rst,hed,hut,cut,set¦4:tbid¦5:dcast,eread,pread,erbid¦ought:uy,eek¦1ied:ny,ly,dy,ry,fy,py,vy,by,ty,cy¦1ung:ling,ting,wing¦1pt:eep¦1ank:rink¦1ore:bear,wear¦1ave:give¦1oze:reeze¦1ound:rind,wind¦1ook:take,hake¦1aw:see¦1old:sell¦1ote:rite¦1ole:teal¦1unk:tink¦1am:wim¦1ay:lie¦1ood:tand¦1eld:hold¦2d:he,ge,re,le,leed,ne,reed,be,ye,lee,pe,we¦2ed:dd,oy,or,ey,gg,rr,us,ew,to¦2ame:ecome,rcome¦2ped:ap¦2ged:ag,og,ug,eg¦2bed:ub,ab,ib,ob¦2lt:neel¦2id:pay¦2ang:pring¦2ove:trive¦2med:um¦2ode:rride¦2at:ysit¦3ted:mit,hat,mat,lat,pot,rot,bat¦3ed:low,end,tow,und,ond,eem,lay,cho,dow,xit,eld,ald,uld,law,lel,eat,oll,ray,ank,fin,oam,out,how,iek,tay,haw,ait,vet,say,cay,bow¦3d:ste,ede,ode,ete,ree,ude,ame,oke,ote,ime,ute,ade¦3red:lur,cur,pur,car¦3ped:hop,rop,uip,rip,lip,tep,top¦3ded:bed,rod,kid¦3ade:orbid¦3led:uel¦3ned:lan,can,kin,pan,tun¦3med:rim,lim¦4ted:quit,llot¦4ed:pear,rrow,rand,lean,mand,anel,pand,reet,link,abel,evel,imit,ceed,ruit,mind,peal,veal,hool,head,pell,well,mell,uell,band,hear,weak¦4led:nnel,qual,ebel,ivel¦4red:nfer,efer,sfer¦4n:sake,trew¦4d:ntee¦4ded:hred¦4ned:rpin¦5ed:light,nceal,right,ndear,arget,hread,eight,rtial,eboot¦5d:edite,nvite¦5ted:egret¦5led:ravel",ex:"2:been,upped¦3:added,aged,aided,aimed,aired,bid,died,dyed,egged,erred,eyed,fit,gassed,hit,lied,owed,pent,pied,tied,used,vied,oiled,outed,banned,barred,bet,canned,cut,dipped,donned,ended,feed,inked,jarred,let,manned,mowed,netted,padded,panned,pitted,popped,potted,put,set,sewn,sowed,tanned,tipped,topped,vowed,weed,bowed,jammed,binned,dimmed,hopped,mopped,nodded,pinned,rigged,sinned,towed,vetted¦4:ached,baked,baled,boned,bored,called,caned,cared,ceded,cited,coded,cored,cubed,cured,dared,dined,edited,exited,faked,fared,filed,fined,fired,fuelled,gamed,gelled,hired,hoped,joked,lined,mined,named,noted,piled,poked,polled,pored,pulled,reaped,roamed,rolled,ruled,seated,shed,sided,timed,tolled,toned,voted,waited,walled,waned,winged,wiped,wired,zoned,yelled,tamed,lubed,roped,faded,mired,caked,honed,banged,culled,heated,raked,welled,banded,beat,cast,cooled,cost,dealt,feared,folded,footed,handed,headed,heard,hurt,knitted,landed,leaked,leapt,linked,meant,minded,molded,neared,needed,peaked,plodded,plotted,pooled,quit,read,rooted,sealed,seeded,seeped,shipped,shunned,skimmed,slammed,sparred,stemmed,stirred,suited,thinned,twinned,swayed,winked,dialed,abutted,blotted,fretted,healed,heeded,peeled,reeled¦5:basted,cheated,equalled,eroded,exiled,focused,opined,pleated,primed,quoted,scouted,shored,sloped,smoked,sniped,spelled,spouted,routed,staked,stored,swelled,tasted,treated,wasted,smelled,dwelled,honored,prided,quelled,eloped,scared,coveted,sweated,breaded,cleared,debuted,deterred,freaked,modeled,pleaded,rebutted,speeded¦6:anchored,defined,endured,impaled,invited,refined,revered,strolled,cringed,recast,thrust,unfolded¦7:authored,combined,competed,conceded,convened,excreted,extruded,redefined,restored,secreted,rescinded,welcomed¦8:expedited,infringed¦9:interfered,intervened,persevered¦10:contravened¦eat:ate¦is:was¦go:went¦are:were¦3d:bent,lent,rent,sent¦3e:bit,fled,hid,lost¦3ed:bled,bred¦2ow:blew,grew¦1uy:bought¦2tch:caught¦1o:did¦1ive:dove,gave¦2aw:drew¦2ed:fed¦2y:flew,laid,paid,said¦1ight:fought¦1et:got¦2ve:had¦1ang:hung¦2ad:led¦2ght:lit¦2ke:made¦2et:met¦1un:ran¦1ise:rose¦1it:sat¦1eek:sought¦1each:taught¦1ake:woke,took¦1eave:wove¦2ise:arose¦1ear:bore,tore,wore¦1ind:bound,found,wound¦2eak:broke¦2ing:brought,wrung¦1ome:came¦2ive:drove¦1ig:dug¦1all:fell¦2el:felt¦4et:forgot¦1old:held¦2ave:left¦1ing:rang,sang¦1ide:rode¦1ink:sank¦1ee:saw¦2ine:shone¦4e:slid¦1ell:sold,told¦4d:spent¦2in:spun¦1in:won"}),ai=ri(Qa),ii=ri(Ua),si=ri(Ra),li=ei(oi),ui=ei(ai),ci=ei(ii),hi=ei(si),di=ri(qa),gi=ri(Za);var mi={fromPast:oi,fromPresent:ai,fromGerund:ii,fromParticiple:si,toPast:li,toPresent:ui,toGerund:ci,toParticiple:hi,toComparative:di,toSuperlative:gi,fromComparative:ei(di),fromSuperlative:ei(gi),adjToNoun:ri(_a)},pi=["academy","administration","agence","agences","agencies","agency","airlines","airways","army","assoc","associates","association","assurance","authority","autorite","aviation","bank","banque","board","boys","brands","brewery","brotherhood","brothers","bureau","cafe","co","caisse","capital","care","cathedral","center","centre","chemicals","choir","chronicle","church","circus","clinic","clinique","club","co","coalition","coffee","collective","college","commission","committee","communications","community","company","comprehensive","computers","confederation","conference","conseil","consulting","containers","corporation","corps","corp","council","crew","data","departement","department","departments","design","development","directorate","division","drilling","education","eglise","electric","electricity","energy","ensemble","enterprise","enterprises","entertainment","estate","etat","faculty","faction","federation","financial","fm","foundation","fund","gas","gazette","girls","government","group","guild","herald","holdings","hospital","hotel","hotels","inc","industries","institut","institute","institutes","insurance","international","interstate","investment","investments","investors","journal","laboratory","labs","llc","ltd","limited","machines","magazine","management","marine","marketing","markets","media","memorial","ministere","ministry","military","mobile","motor","motors","musee","museum","news","observatory","office","oil","optical","orchestra","organization","partners","partnership","petrol","petroleum","pharmacare","pharmaceutical","pharmaceuticals","pizza","plc","police","politburo","polytechnic","post","power","press","productions","quartet","radio","reserve","resources","restaurant","restaurants","savings","school","securities","service","services","societe","subsidiary","society","sons","subcommittee","syndicat","systems","telecommunications","telegraph","television","times","tribunal","tv","union","university","utilities","workers"].reduce(((e,t)=>(e[t]=!0,e)),{}),fi=["atoll","basin","bay","beach","bluff","bog","camp","canyon","canyons","cape","cave","caves","cliffs","coast","cove","coves","crater","crossing","creek","desert","dune","dunes","downs","estates","escarpment","estuary","falls","fjord","fjords","forest","forests","glacier","gorge","gorges","grove","gulf","gully","highland","heights","hollow","hill","hills","inlet","island","islands","isthmus","junction","knoll","lagoon","lake","lakeshore","marsh","marshes","mount","mountain","mountains","narrows","peninsula","plains","plateau","pond","rapids","ravine","reef","reefs","ridge","river","rivers","sandhill","shoal","shore","shoreline","shores","strait","straits","springs","stream","swamp","tombolo","trail","trails","trench","valley","vallies","village","volcano","waterfall","watershed","wetland","woods","acres","burough","county","district","municipality","prefecture","province","region","reservation","state","territory","borough","metropolis","downtown","uptown","midtown","city","town","township","hamlet","country","kingdom","enclave","neighbourhood","neighborhood","kingdom","ward","zone","airport","amphitheater","arch","arena","auditorium","bar","barn","basilica","battlefield","bridge","building","castle","centre","coliseum","cineplex","complex","dam","farm","field","fort","garden","gardens","gymnasium","hall","house","levee","library","manor","memorial","monument","museum","gallery","palace","pillar","pits","plantation","playhouse","quarry","sportsfield","sportsplex","stadium","terrace","terraces","theater","tower","park","parks","site","ranch","raceway","sportsplex","ave","st","street","rd","road","lane","landing","crescent","cr","way","tr","terrace","avenue"].reduce(((e,t)=>(e[t]=!0,e)),{}),bi=[[/([^v])ies$/i,"$1y"],[/(ise)s$/i,"$1"],[/(kn|[^o]l|w)ives$/i,"$1ife"],[/^((?:ca|e|ha|(?:our|them|your)?se|she|wo)l|lea|loa|shea|thie)ves$/i,"$1f"],[/^(dwar|handkerchie|hoo|scar|whar)ves$/i,"$1f"],[/(antenn|formul|nebul|vertebr|vit)ae$/i,"$1a"],[/(octop|vir|radi|nucle|fung|cact|stimul)(i)$/i,"$1us"],[/(buffal|tomat|tornad)(oes)$/i,"$1o"],[/(ause)s$/i,"$1"],[/(ease)s$/i,"$1"],[/(ious)es$/i,"$1"],[/(ouse)s$/i,"$1"],[/(ose)s$/i,"$1"],[/(..ase)s$/i,"$1"],[/(..[aeiu]s)es$/i,"$1"],[/(vert|ind|cort)(ices)$/i,"$1ex"],[/(matr|append)(ices)$/i,"$1ix"],[/([xo]|ch|ss|sh)es$/i,"$1"],[/men$/i,"man"],[/(n)ews$/i,"$1ews"],[/([ti])a$/i,"$1um"],[/([^aeiouy]|qu)ies$/i,"$1y"],[/(s)eries$/i,"$1eries"],[/(m)ovies$/i,"$1ovie"],[/(cris|ax|test)es$/i,"$1is"],[/(alias|status)es$/i,"$1"],[/(ss)$/i,"$1"],[/(ic)s$/i,"$1"],[/s$/i,""]];const vi=function(e,t){const{irregularPlurals:n}=t.two,r=(o=n,Object.keys(o).reduce(((e,t)=>(e[o[t]]=t,e)),{}));var o;if(r.hasOwnProperty(e))return r[e];for(let t=0;t(wi[t].forEach((n=>e[n]=t)),e)),{});const ki=function(e){const t=e.substring(e.length-3);if(!0===wi.hasOwnProperty(t))return wi[t];const n=e.substring(e.length-2);if(!0===wi.hasOwnProperty(n))return wi[n];return"s"===e.substring(e.length-1)?"PresentTense":null},Pi={are:"be",were:"be",been:"be",is:"be",am:"be",was:"be",be:"be",being:"be"},Ai=function(e,t,n){const{fromPast:r,fromPresent:o,fromGerund:a,fromParticiple:i}=t.two.models,{prefix:s,verb:l,particle:u}=function(e,t){let n="",r={};t.one&&t.one.prefixes&&(r=t.one.prefixes);let[o,a]=e.split(/ /);return a&&!0===r[o]&&(n=o,o=a,a=""),{prefix:n,verb:o,particle:a}}(e,t);let c="";if(n||(n=ki(e)),Pi.hasOwnProperty(e))c=Pi[e];else if("Participle"===n)c=Xa(l,i);else if("PastTense"===n)c=Xa(l,r);else if("PresentTense"===n)c=Xa(l,o);else{if("Gerund"!==n)return e;c=Xa(l,a)}return u&&(c+=" "+u),s&&(c=s+" "+c),c},Ci=function(e,t){const{toPast:n,toPresent:r,toGerund:o,toParticiple:a}=t.two.models;if("be"===e)return{Infinitive:e,Gerund:"being",PastTense:"was",PresentTense:"is"};const[i,s]=(e=>/ /.test(e)?e.split(/ /):[e,""])(e),l={Infinitive:i,PastTense:Xa(i,n),PresentTense:Xa(i,r),Gerund:Xa(i,o),FutureTense:"will "+i};let u=Xa(i,a);if(u!==e&&u!==l.PastTense){const n=t.one.lexicon||{};"Participle"!==n[u]&&"Adjective"!==n[u]||("play"===e&&(u="played"),l.Participle=u)}return s&&Object.keys(l).forEach((e=>{l[e]+=" "+s})),l};var Ni={toInfinitive:Ai,conjugate:Ci,all:function(e,t){const n=Ci(e,t);return delete n.FutureTense,Object.values(n).filter((e=>e))}};const ji=function(e,t){const n=t.two.models.toSuperlative;return Xa(e,n)},xi=function(e,t){const n=t.two.models.toComparative;return Xa(e,n)},Ii=function(e="",t=[]){const n=e.length;for(let r=n<=6?n-1:6;r>=1;r-=1){const o=e.substring(n-r,e.length);if(!0===t[o.length].hasOwnProperty(o)){return e.slice(0,n-r)+t[o.length][o]}}return null},Ti="ically",Di=new Set(["analyt"+Ti,"chem"+Ti,"class"+Ti,"clin"+Ti,"crit"+Ti,"ecolog"+Ti,"electr"+Ti,"empir"+Ti,"frant"+Ti,"grammat"+Ti,"ident"+Ti,"ideolog"+Ti,"log"+Ti,"mag"+Ti,"mathemat"+Ti,"mechan"+Ti,"med"+Ti,"method"+Ti,"method"+Ti,"mus"+Ti,"phys"+Ti,"phys"+Ti,"polit"+Ti,"pract"+Ti,"rad"+Ti,"satir"+Ti,"statist"+Ti,"techn"+Ti,"technolog"+Ti,"theoret"+Ti,"typ"+Ti,"vert"+Ti,"whims"+Ti]),Hi=[null,{},{ly:""},{ily:"y",bly:"ble",ply:"ple"},{ally:"al",rply:"rp"},{ually:"ual",ially:"ial",cally:"cal",eally:"eal",rally:"ral",nally:"nal",mally:"mal",eeply:"eep",eaply:"eap"},{ically:"ic"}],Ei=new Set(["early","only","hourly","daily","weekly","monthly","yearly","mostly","duly","unduly","especially","undoubtedly","conversely","namely","exceedingly","presumably","accordingly","overly","best","latter","little","long","low"]),Gi={wholly:"whole",fully:"full",truly:"true",gently:"gentle",singly:"single",customarily:"customary",idly:"idle",publically:"public",quickly:"quick",superbly:"superb",cynically:"cynical",well:"good"},Oi=[null,{y:"ily"},{ly:"ly",ic:"ically"},{ial:"ially",ual:"ually",tle:"tly",ble:"bly",ple:"ply",ary:"arily"},{},{},{}],Fi={cool:"cooly",whole:"wholly",full:"fully",good:"well",idle:"idly",public:"publicly",single:"singly",special:"especially"},Vi=function(e){if(Fi.hasOwnProperty(e))return Fi[e];let t=Ii(e,Oi);return t||(t=e+"ly"),t};var zi={toSuperlative:ji,toComparative:xi,toAdverb:Vi,toNoun:function(e,t){const n=t.two.models.adjToNoun;return Xa(e,n)},fromAdverb:function(e){return e.endsWith("ly")?Di.has(e)?e.replace(/ically/,"ical"):Ei.has(e)?null:Gi.hasOwnProperty(e)?Gi[e]:Ii(e,Hi)||e:null},fromSuperlative:function(e,t){const n=t.two.models.fromSuperlative;return Xa(e,n)},fromComparative:function(e,t){const n=t.two.models.fromComparative;return Xa(e,n)},all:function(e,t){let n=[e];return n.push(ji(e,t)),n.push(xi(e,t)),n.push(Vi(e)),n=n.filter((e=>e)),n=new Set(n),Array.from(n)}},Bi={noun:yi,verb:Ni,adjective:zi},Si={Singular:(e,t,n,r)=>{const o=r.one.lexicon,a=n.two.transform.noun.toPlural(e,r);o[a]||(t[a]=t[a]||"Plural")},Actor:(e,t,n,r)=>{const o=r.one.lexicon,a=n.two.transform.noun.toPlural(e,r);o[a]||(t[a]=t[a]||["Plural","Actor"])},Comparable:(e,t,n,r)=>{const o=r.one.lexicon,{toSuperlative:a,toComparative:i}=n.two.transform.adjective,s=a(e,r);o[s]||(t[s]=t[s]||"Superlative");const l=i(e,r);o[l]||(t[l]=t[l]||"Comparative"),t[e]="Adjective"},Demonym:(e,t,n,r)=>{const o=n.two.transform.noun.toPlural(e,r);t[o]=t[o]||["Demonym","Plural"]},Infinitive:(e,t,n,r)=>{const o=r.one.lexicon,a=n.two.transform.verb.conjugate(e,r);Object.entries(a).forEach((e=>{o[e[1]]||t[e[1]]||"FutureTense"===e[0]||(t[e[1]]=e[0])}))},PhrasalVerb:(e,t,n,r)=>{const o=r.one.lexicon;t[e]=["PhrasalVerb","Infinitive"];const a=r.one._multiCache,[i,s]=e.split(" ");o[i]||(t[i]=t[i]||"Infinitive");const l=n.two.transform.verb.conjugate(i,r);delete l.FutureTense,Object.entries(l).forEach((e=>{if("Actor"===e[0]||""===e[1])return;t[e[1]]||o[e[1]]||(t[e[1]]=e[0]),a[e[1]]=2;const n=e[1]+" "+s;t[n]=t[n]||[e[0],"PhrasalVerb"]}))},Multiple:(e,t)=>{t[e]=["Multiple","Cardinal"],t[e+"th"]=["Multiple","Ordinal"],t[e+"ths"]=["Multiple","Fraction"]},Cardinal:(e,t)=>{t[e]=["TextValue","Cardinal"]},Ordinal:(e,t)=>{t[e]=["TextValue","Ordinal"],t[e+"s"]=["TextValue","Fraction"]},Place:(e,t)=>{t[e]=["Place","ProperNoun"]},Region:(e,t)=>{t[e]=["Region","ProperNoun"]}};const $i={e:["mice","louse","antennae","formulae","nebulae","vertebrae","vitae"],i:["tia","octopi","viri","radii","nuclei","fungi","cacti","stimuli"],n:["men"],t:["feet"]},Mi=new Set(["israelis","menus","logos"]),Li=["bus","mas","was","ias","xas","vas","cis","lis","nis","ois","ris","sis","tis","xis","aus","cus","eus","fus","gus","ius","lus","nus","das","ous","pus","rus","sus","tus","xus","aos","igos","ados","ogos","'s","ss"],Ki=function(e){if(!e||e.length<=3)return!1;if(Mi.has(e))return!0;const t=e[e.length-1];return $i.hasOwnProperty(t)?$i[t].find((t=>e.endsWith(t))):"s"===t&&!Li.find((t=>e.endsWith(t)))};var Ji={two:{quickSplit:function(e){const t=/[,:;]/,n=[];return e.forEach((e=>{let r=0;e.forEach(((o,a)=>{t.test(o.post)&&function(e,t){const n=/^[0-9]+$/,r=e[t];if(!r)return!1;const o=new Set(["may","april","august","jan"]);if("like"===r.normal||o.has(r.normal))return!1;if(r.tags.has("Place")||r.tags.has("Date"))return!1;if(e[t-1]){const n=e[t-1];if(n.tags.has("Date")||o.has(n.normal))return!1;if(n.tags.has("Adjective")||r.tags.has("Adjective"))return!1}const a=r.normal;return 1!==a.length&&2!==a.length&&4!==a.length||!n.test(a)}(e,a+1)&&(n.push(e.slice(r,a+1)),r=a+1)})),r{const i=e[t],s=(t=(t=t.toLowerCase().trim()).replace(/'s\b/,"")).split(/ /);s.length>1&&(void 0===a[s[0]]||s.length>a[s[0]])&&(a[s[0]]=s.length),!0===Si.hasOwnProperty(i)&&Si[i](t,o,n,r),o[t]=o[t]||i})),delete o[""],delete o.null,delete o[" "],{lex:o,_multi:a}},transform:Bi,looksPlural:Ki}};const Wi={one:{lexicon:{}},two:{models:mi}},qi={"Actor|Verb":"Actor","Adj|Gerund":"Adjective","Adj|Noun":"Adjective","Adj|Past":"Adjective","Adj|Present":"Adjective","Noun|Verb":"Singular","Noun|Gerund":"Gerund","Person|Noun":"Noun","Person|Date":"Month","Person|Verb":"FirstName","Person|Place":"Person","Person|Adj":"Comparative","Plural|Verb":"Plural","Unit|Noun":"Noun"},Ui=function(e,t){const n={model:t,methods:Ji},{lex:r,_multi:o}=Ji.two.expandLexicon(e,n);return Object.assign(t.one.lexicon,r),Object.assign(t.one._multiCache,o),t},Ri=function(e,t,n){const r=Ci(e,Wi);t[r.PastTense]=t[r.PastTense]||"PastTense",t[r.Gerund]=t[r.Gerund]||"Gerund",!0===n&&(t[r.PresentTense]=t[r.PresentTense]||"PresentTense")},Qi=function(e,t,n){const r=ji(e,n);t[r]=t[r]||"Superlative";const o=xi(e,n);t[o]=t[o]||"Comparative"},Zi=function(e,t){const n={},r=t.one.lexicon;return Object.keys(e).forEach((o=>{const a=e[o];if(n[o]=qi[a],"Noun|Verb"!==a&&"Person|Verb"!==a&&"Actor|Verb"!==a||Ri(o,r,!1),"Adj|Present"===a&&(Ri(o,r,!0),Qi(o,r,t)),"Person|Adj"===a&&Qi(o,r,t),"Adj|Gerund"===a||"Noun|Gerund"===a){const e=Ai(o,Wi,"Gerund");r[e]||(n[e]="Infinitive")}if("Noun|Gerund"!==a&&"Adj|Noun"!==a&&"Person|Noun"!==a||function(e,t,n){const r=Ao(e,n);t[r]=t[r]||"Plural"}(o,r,t),"Adj|Past"===a){const e=Ai(o,Wi,"PastTense");r[e]||(n[e]="Infinitive")}})),t=Ui(n,t)};let _i={one:{_multiCache:{},lexicon:No,frozenLex:{"20th century fox":"Organization","7 eleven":"Organization","motel 6":"Organization","excuse me":"Expression","financial times":"Organization","guns n roses":"Organization","la z boy":"Organization","labour party":"Organization","new kids on the block":"Organization","new york times":"Organization","the guess who":"Organization","thin lizzy":"Organization","prime minister":"Actor","free market":"Singular","lay up":"Singular","living room":"Singular","living rooms":"Plural","spin off":"Singular","appeal court":"Uncountable","cold war":"Uncountable","gene pool":"Uncountable","machine learning":"Uncountable","nail polish":"Uncountable","time off":"Uncountable","take part":"Infinitive","bill gates":"Person","doctor who":"Person","dr who":"Person","he man":"Person","iron man":"Person","kid cudi":"Person","run dmc":"Person","rush limbaugh":"Person","snow white":"Person","tiger woods":"Person","brand new":"Adjective","en route":"Adjective","left wing":"Adjective","off guard":"Adjective","on board":"Adjective","part time":"Adjective","right wing":"Adjective","so called":"Adjective","spot on":"Adjective","straight forward":"Adjective","super duper":"Adjective","tip top":"Adjective","top notch":"Adjective","up to date":"Adjective","win win":"Adjective","brooklyn nets":"SportsTeam","chicago bears":"SportsTeam","houston astros":"SportsTeam","houston dynamo":"SportsTeam","houston rockets":"SportsTeam","houston texans":"SportsTeam","minnesota twins":"SportsTeam","orlando magic":"SportsTeam","san antonio spurs":"SportsTeam","san diego chargers":"SportsTeam","san diego padres":"SportsTeam","iron maiden":"ProperNoun","isle of man":"Country","united states":"Country","united states of america":"Country","prince edward island":"Region","cedar breaks":"Place","cedar falls":"Place","point blank":"Adverb","tiny bit":"Adverb","by the time":"Conjunction","no matter":"Conjunction","civil wars":"Plural","credit cards":"Plural","default rates":"Plural","free markets":"Plural","head starts":"Plural","home runs":"Plural","lay ups":"Plural","phone calls":"Plural","press releases":"Plural","record labels":"Plural","soft serves":"Plural","student loans":"Plural","tax returns":"Plural","tv shows":"Plural","video games":"Plural","took part":"PastTense","takes part":"PresentTense","taking part":"Gerund","taken part":"Participle","light bulb":"Noun","rush hour":"Noun","fluid ounce":"Unit","the rolling stones":"Organization"}},two:{irregularPlurals:ho,models:mi,suffixPatterns:ja,prefixPatterns:Da,endsWith:La,neighbours:Wa,regexNormal:[[/^[\w.]+@[\w.]+\.[a-z]{2,3}$/,"Email"],[/^(https?:\/\/|www\.)+\w+\.[a-z]{2,3}/,"Url","http.."],[/^[a-z0-9./].+\.(com|net|gov|org|ly|edu|info|biz|dev|ru|jp|de|in|uk|br|io|ai)/,"Url",".com"],[/^[PMCE]ST$/,"Timezone","EST"],[/^ma?c'[a-z]{3}/,"LastName","mc'neil"],[/^o'[a-z]{3}/,"LastName","o'connor"],[/^ma?cd[aeiou][a-z]{3}/,"LastName","mcdonald"],[/^(lol)+[sz]$/,"Expression","lol"],[/^wo{2,}a*h?$/,"Expression","wooah"],[/^(hee?){2,}h?$/,"Expression","hehe"],[/^(un|de|re)\\-[a-z\u00C0-\u00FF]{2}/,"Verb","un-vite"],[/^(m|k|cm|km)\/(s|h|hr)$/,"Unit","5 k/m"],[/^(ug|ng|mg)\/(l|m3|ft3)$/,"Unit","ug/L"],[/[^:/]\/\p{Letter}/u,"SlashedTerm","love/hate"]],regexText:[[/^#[\p{Number}_]*\p{Letter}/u,"HashTag"],[/^@\w{2,}$/,"AtMention"],[/^([A-Z]\.){2}[A-Z]?/i,["Acronym","Noun"],"F.B.I"],[/.{3}[lkmnp]in['‘’‛‵′`´]$/,"Gerund","chillin'"],[/.{4}s['‘’‛‵′`´]$/,"Possessive","flanders'"],[/^[\p{Emoji_Presentation}\p{Extended_Pictographic}]/u,"Emoji","emoji-class"]],regexNumbers:[[/^@1?[0-9](am|pm)$/i,"Time","3pm"],[/^@1?[0-9]:[0-9]{2}(am|pm)?$/i,"Time","3:30pm"],[/^'[0-9]{2}$/,"Year"],[/^[012]?[0-9](:[0-5][0-9])(:[0-5][0-9])$/,"Time","3:12:31"],[/^[012]?[0-9](:[0-5][0-9])?(:[0-5][0-9])? ?(am|pm)$/i,"Time","1:12pm"],[/^[012]?[0-9](:[0-5][0-9])(:[0-5][0-9])? ?(am|pm)?$/i,"Time","1:12:31pm"],[/^[0-9]{4}-[0-9]{2}-[0-9]{2}T[0-9]{2}:[0-9]{2}/i,"Date","iso-date"],[/^[0-9]{1,4}-[0-9]{1,2}-[0-9]{1,4}$/,"Date","iso-dash"],[/^[0-9]{1,4}\/[0-9]{1,2}\/([0-9]{4}|[0-9]{2})$/,"Date","iso-slash"],[/^[0-9]{1,4}\.[0-9]{1,2}\.[0-9]{1,4}$/,"Date","iso-dot"],[/^[0-9]{1,4}-[a-z]{2,9}-[0-9]{1,4}$/i,"Date","12-dec-2019"],[/^utc ?[+-]?[0-9]+$/,"Timezone","utc-9"],[/^(gmt|utc)[+-][0-9]{1,2}$/i,"Timezone","gmt-3"],[/^[0-9]{3}-[0-9]{4}$/,"PhoneNumber","421-0029"],[/^(\+?[0-9][ -])?[0-9]{3}[ -]?[0-9]{3}-[0-9]{4}$/,"PhoneNumber","1-800-"],[/^[-+]?\p{Currency_Symbol}[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?([kmb]|bn)?\+?$/u,["Money","Value"],"$5.30"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?\p{Currency_Symbol}\+?$/u,["Money","Value"],"5.30£"],[/^[-+]?[$£]?[0-9]([0-9,.])+(usd|eur|jpy|gbp|cad|aud|chf|cny|hkd|nzd|kr|rub)$/i,["Money","Value"],"$400usd"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?\+?$/,["Cardinal","NumericValue"],"5,999"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?(st|nd|rd|r?th)$/,["Ordinal","NumericValue"],"53rd"],[/^\.[0-9]+\+?$/,["Cardinal","NumericValue"],".73th"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?%\+?$/,["Percent","Cardinal","NumericValue"],"-4%"],[/^\.[0-9]+%$/,["Percent","Cardinal","NumericValue"],".3%"],[/^[0-9]{1,4}\/[0-9]{1,4}(st|nd|rd|th)?s?$/,["Fraction","NumericValue"],"2/3rds"],[/^[0-9.]{1,3}[a-z]{0,2}[-–—][0-9]{1,3}[a-z]{0,2}$/,["Value","NumberRange"],"3-4"],[/^[0-9]{1,2}(:[0-9][0-9])?(am|pm)? ?[-–—] ?[0-9]{1,2}(:[0-9][0-9])?(am|pm)$/,["Time","NumberRange"],"3-4pm"],[/^[0-9.]+([a-z°]{1,4})$/,"NumericValue","9km"]],switches:jo,clues:ca,uncountable:{},orgWords:pi,placeWords:fi}};_i=function(e){return e=function(e,t){return Object.keys(e).forEach((n=>{"Uncountable"===e[n]&&(t.two.uncountable[n]=!0,e[n]="Uncountable")})),t}((e=Ui(e.one.lexicon,e)).one.lexicon,e),e=function(e){const{irregularPlurals:t}=e.two,{lexicon:n}=e.one;return Object.entries(t).forEach((e=>{n[e[0]]=n[e[0]]||"Singular",n[e[1]]=n[e[1]]||"Plural"})),e}(e=Zi(e.two.switches,e)),e}(_i);const Xi=function(e,t,n,r){const o=r.methods.one.setTag;"-"===e[t].post&&e[t+1]&&o([e[t],e[t+1]],"Hyphenated",r,null,"1-punct-hyphen''")},Yi=/^(under|over|mis|re|un|dis|semi)-?/,es=function(e,t,n){const r=n.two.switches,o=e[t];if(r.hasOwnProperty(o.normal))o.switch=r[o.normal];else if(Yi.test(o.normal)){const e=o.normal.replace(Yi,"");e.length>3&&r.hasOwnProperty(e)&&(o.switch=r[e])}},ts=function(e,t,n){if(!t||0===t.length)return;if(!0===e.frozen)return;const r="undefined"!=typeof process&&process.env?process.env:self.env||{};r&&r.DEBUG_TAGS&&((e,t,n="")=>{const r=e.text||"["+e.implicit+"]";var o;"string"!=typeof t&&t.length>2&&(t=t.slice(0,2).join(", #")+" +"),t="string"!=typeof t?t.join(", #"):t,console.log(` ${(o=r,"�[33m�[3m"+o+"�[0m").padEnd(24)} �[32m→�[0m #${t.padEnd(22)} ${(e=>"�[3m"+e+"�[0m")(n)}`)})(e,t,n),e.tags=e.tags||new Set,"string"==typeof t?e.tags.add(t):t.forEach((t=>e.tags.add(t)))},ns=["Acronym","Abbreviation","ProperNoun","Uncountable","Possessive","Pronoun","Activity","Honorific","Month"],rs=function(e,t,n){const r=e[t],o=Array.from(r.tags);for(let e=0;ee.tags.has(t)))||(Ki(e.normal)?ts(e,"Plural","3-plural-guess"):ts(e,"Singular","3-singular-guess"))}(r),function(e){const t=e.tags;if(t.has("Verb")&&1===t.size){const t=ki(e.normal);t&&ts(e,t,"3-verb-tense-guess")}}(r)},os=/^\p{Lu}[\p{Ll}'’]/u,as=/[0-9]/,is=["Date","Month","WeekDay","Unit","Expression"],ss=/[IVX]/,ls=/^[IVXLCDM]{2,}$/,us=/^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$/,cs={li:!0,dc:!0,md:!0,dm:!0,ml:!0},hs=function(e,t,n){const r=e[t];r.index=r.index||[0,0];const o=r.index[1],a=r.text||"";return 0!==o&&!0===os.test(a)&&!1===as.test(a)?is.find((e=>r.tags.has(e)))||r.pre.match(/["']$/)||"the"===r.normal?null:(rs(e,t,n),r.tags.has("Noun")||r.frozen||r.tags.clear(),ts(r,"ProperNoun","2-titlecase"),!0):a.length>=2&&ls.test(a)&&ss.test(a)&&us.test(a)&&!cs[r.normal]?(ts(r,"RomanNumeral","2-xvii"),!0):null},ds=function(e="",t=[]){const n=e.length;let r=7;n<=r&&(r=n-1);for(let o=r;o>1;o-=1){const r=e.substring(n-o,n);if(!0===t[r.length].hasOwnProperty(r)){return t[r.length][r]}}return null},gs=function(e,t,n){const r=e[t];if(0===r.tags.size){let e=ds(r.normal,n.two.suffixPatterns);if(null!==e)return ts(r,e,"2-suffix"),r.confidence=.7,!0;if(r.implicit&&(e=ds(r.implicit,n.two.suffixPatterns),null!==e))return ts(r,e,"2-implicit-suffix"),r.confidence=.7,!0}return null},ms=/['‘’‛‵′`´]/,ps=function(e,t){for(let n=0;nn-3&&(r=n-3);for(let n=r;n>2;n-=1){const r=e.substring(0,n);if(!0===t[r.length].hasOwnProperty(r))return t[r.length][r]}return null}(r.normal,n.two.prefixPatterns);if(null!==e)return ts(r,e,"2-prefix"),r.confidence=.5,!0}return null},vs=new Set(["in","on","by","until","for","to","during","throughout","through","within","before","after","of","this","next","last","circa","around","post","pre","budget","classic","plan","may"]),ys=function(e){if(!e)return!1;const t=e.normal||e.implicit;return!!vs.has(t)||(!!(e.tags.has("Date")||e.tags.has("Month")||e.tags.has("WeekDay")||e.tags.has("Year"))||!!e.tags.has("ProperNoun"))},ws=function(e){return!!e&&(!!e.tags.has("Ordinal")||(!!(e.tags.has("Cardinal")&&e.normal.length<3)||("is"===e.normal||"was"===e.normal)))},ks=function(e){return e&&(e.tags.has("Date")||e.tags.has("Month")||e.tags.has("WeekDay")||e.tags.has("Year"))},Ps=function(e,t){const n=e[t];if(n.tags.has("NumericValue")&&n.tags.has("Cardinal")&&4===n.normal.length){const r=Number(n.normal);if(r&&!isNaN(r)&&r>1400&&r<2100){const o=e[t-1],a=e[t+1];if(ys(o)||ys(a))return ts(n,"Year","2-tagYear");if(r>=1920&&r<2025){if(ws(o)||ws(a))return ts(n,"Year","2-tagYear-close");if(ks(e[t-2])||ks(e[t+2]))return ts(n,"Year","2-tagYear-far");if(o&&(o.tags.has("Determiner")||o.tags.has("Possessive"))&&a&&a.tags.has("Noun")&&!a.tags.has("Plural"))return ts(n,"Year","2-tagYear-noun")}}}return null},As=function(e,t,n,r){const o=r.methods.one.setTag,a=e[t],i=["PastTense","PresentTense","Auxiliary","Modal","Particle"];if(a.tags.has("Verb")){i.find((e=>a.tags.has(e)))||o([a],"Infinitive",r,null,"2-verb-type''")}},Cs=/^[A-Z]('s|,)?$/,Ns=/^[A-Z-]+$/,js=/^[A-Z]+s$/,xs=/([A-Z]\.)+[A-Z]?,?$/,Is=/[A-Z]{2,}('s|,)?$/,Ts=/([a-z]\.)+[a-z]\.?$/,Ds={I:!0,A:!0},Hs={la:!0,ny:!0,us:!0,dc:!0,gb:!0},Es=function(e,t,n){const r=e[t];return r.tags.has("RomanNumeral")||r.tags.has("Acronym")||r.frozen?null:function(e,t){let n=e.text;if(!1===Ns.test(n)){if(!(n.length>3&&!0===js.test(n)))return!1;n=n.replace(/s$/,"")}return!(n.length>5||Ds.hasOwnProperty(n)||t.one.lexicon.hasOwnProperty(e.normal)||!0!==xs.test(n)&&!0!==Ts.test(n)&&!0!==Cs.test(n)&&!0!==Is.test(n))}(r,n)?(r.tags.clear(),ts(r,["Acronym","Noun"],"3-no-period-acronym"),!0===Hs[r.normal]&&ts(r,"Place","3-place-acronym"),!0===js.test(r.text)&&ts(r,"Plural","3-plural-acronym"),!0):!Ds.hasOwnProperty(r.text)&&Cs.test(r.text)?(r.tags.clear(),ts(r,["Acronym","Noun"],"3-one-letter-acronym"),!0):r.tags.has("Organization")&&r.text.length<=3?(ts(r,"Acronym","3-org-acronym"),!0):r.tags.has("Organization")&&Ns.test(r.text)&&r.text.length<=6?(ts(r,"Acronym","3-titlecase-acronym"),!0):null},Gs=function(e,t){if(!e)return null;const n=t.find((t=>e.normal===t[0]));return n?n[1]:null},Os=function(e,t){if(!e)return null;const n=t.find((t=>e.tags.has(t[0])));return n?n[1]:null},Fs=function(e,t,n){const{leftTags:r,leftWords:o,rightWords:a,rightTags:i}=n.two.neighbours,s=e[t];if(0===s.tags.size){let l=null;if(l=l||Gs(e[t-1],o),l=l||Gs(e[t+1],a),l=l||Os(e[t-1],r),l=l||Os(e[t+1],i),l)return ts(s,l,"3-[neighbour]"),rs(e,t,n),e[t].confidence=.2,!0}return null},Vs=function(e,t,n){return!!e&&(!e.tags.has("FirstName")&&!e.tags.has("Place")&&(!!(e.tags.has("ProperNoun")||e.tags.has("Organization")||e.tags.has("Acronym"))||!(n||(r=e.text,!/^\p{Lu}[\p{Ll}'’]/u.test(r)))&&(0!==t||e.tags.has("Singular"))));var r},zs=function(e,t,n,r){const o=n.model.two.orgWords,a=n.methods.one.setTag,i=e[t];if(!0===o[i.machine||i.normal]&&Vs(e[t-1],t-1,r)){a([e[t]],"Organization",n,null,"3-[org-word]");for(let o=t;o>=0&&Vs(e[o],o,r);o-=1)a([e[o]],"Organization",n,null,"3-[org-word]")}return null},Bs=/'s$/,Ss=new Set(["athletic","city","community","eastern","federal","financial","great","historic","historical","local","memorial","municipal","national","northern","provincial","southern","state","western","spring","pine","sunset","view","oak","maple","spruce","cedar","willow"]),$s=new Set(["center","centre","way","range","bar","bridge","field","pit"]),Ms=function(e,t,n){if(!e)return!1;const r=e.tags;return!(r.has("Organization")||r.has("Possessive")||Bs.test(e.normal))&&(!(!r.has("ProperNoun")&&!r.has("Place"))||!(n||(o=e.text,!/^\p{Lu}[\p{Ll}'’]/u.test(o)))&&(0!==t||r.has("Singular")));var o},Ls=function(e,t,n,r){const o=n.model.two.placeWords,a=n.methods.one.setTag,i=e[t],s=i.machine||i.normal;if(!0===o[s]){for(let o=t-1;o>=0;o-=1)if(!Ss.has(e[o].normal)){if(!Ms(e[o],o,r))break;a(e.slice(o,t+1),"Place",n,null,"3-[place-of-foo]")}if($s.has(s))return!1;for(let o=t+1;oe[t].tags.has("ProperNoun")&&Js.test(e[t].text)?"Noun":null,qs=(e,t,n)=>0!==t||e[1]?null:n,Us={"Adj|Gerund":(e,t)=>Ws(e,t),"Adj|Noun":(e,t)=>Ws(e,t)||function(e,t){return!e[t+1]&&e[t-1]&&e[t-1].tags.has("Determiner")?"Noun":null}(e,t),"Actor|Verb":(e,t)=>Ws(e,t),"Adj|Past":(e,t)=>Ws(e,t),"Adj|Present":(e,t)=>Ws(e,t),"Noun|Gerund":(e,t)=>Ws(e,t),"Noun|Verb":(e,t)=>t>0&&Ws(e,t)||qs(e,t,"Infinitive"),"Plural|Verb":(e,t)=>Ws(e,t)||qs(e,t,"PresentTense")||function(e,t,n){return 0===t&&e.length>3?n:null}(e,t,"Plural"),"Person|Noun":(e,t)=>Ws(e,t),"Person|Verb":(e,t)=>0!==t?Ws(e,t):null,"Person|Adj":(e,t)=>0===t&&e.length>1||Ws(e,t)?"Person":null},Rs="undefined"!=typeof process&&process.env?process.env:self.env||{},Qs=/^(under|over|mis|re|un|dis|semi)-?/,Zs=(e,t)=>{if(!e||!t)return null;const n=e.normal||e.implicit;let r=null;return t.hasOwnProperty(n)&&(r=t[n]),r&&Rs.DEBUG_TAGS&&console.log(`\n �[2m�[3m ↓ - '${n}' �[0m`),r},_s=(e,t={},n)=>{if(!e||!t)return null;const r=Array.from(e.tags).sort(((e,t)=>(n[e]?n[e].parents.length:0)>(n[t]?n[t].parents.length:0)?-1:1));let o=r.find((e=>t[e]));return o&&Rs.DEBUG_TAGS&&console.log(` �[2m�[3m ↓ - '${e.normal||e.implicit}' (#${o}) �[0m`),o=t[o],o},Xs=function(e,t,n){const r=n.model,o=n.methods.one.setTag,{switches:a,clues:i}=r.two,s=e[t];let l=s.normal||s.implicit||"";if(Qs.test(l)&&!a[l]&&(l=l.replace(Qs,"")),s.switch){const a=s.switch;if(s.tags.has("Acronym")||s.tags.has("PhrasalVerb"))return;let u=function(e,t,n,r){if(!n)return null;const o="also"!==e[t-1]?.text?t-1:Math.max(0,t-2),a=r.one.tagSet;let i=Zs(e[t+1],n.afterWords);return i=i||Zs(e[o],n.beforeWords),i=i||_s(e[o],n.beforeTags,a),i=i||_s(e[t+1],n.afterTags,a),i}(e,t,i[a],r);Us[a]&&(u=Us[a](e,t)||u),u?(o([s],u,n,null,`3-[switch] (${a})`),rs(e,t,r)):Rs.DEBUG_TAGS&&console.log(`\n -> X - '${l}' : (${a}) `)}},Ys={there:!0,this:!0,it:!0,him:!0,her:!0,us:!0},el=function(e){if(e.filter((e=>!e.tags.has("ProperNoun"))).length<=3)return!1;const t=/^[a-z]/;return e.every((e=>!t.test(e.text)))},tl=function(e,t,n,r){for(let o=0;o=2){if(e.length<4&&!Ys[e[1].normal])return;if(!o.tags.has("PhrasalVerb")&&r.hasOwnProperty(o.normal))return;(e[1].tags.has("Noun")||e[1].tags.has("Determiner"))&&(e.slice(1,3).some((e=>e.tags.has("Verb")))&&!o.tags.has("#PhrasalVerb")||n([o],"Imperative",t,null,"3-[imperative]"))}}(e,n)},rl={Possessive:e=>{let t=e.machine||e.normal||e.text;return t=t.replace(/'s$/,""),t},Plural:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.noun.toSingular(n,t.model)},Copula:()=>"is",PastTense:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.verb.toInfinitive(n,t.model,"PastTense")},Gerund:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.verb.toInfinitive(n,t.model,"Gerund")},PresentTense:(e,t)=>{const n=e.machine||e.normal||e.text;return e.tags.has("Infinitive")?n:t.methods.two.transform.verb.toInfinitive(n,t.model,"PresentTense")},Comparative:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.adjective.fromComparative(n,t.model)},Superlative:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.adjective.fromSuperlative(n,t.model)},Adverb:(e,t)=>{const{fromAdverb:n}=t.methods.two.transform.adjective;return n(e.machine||e.normal||e.text)}},ol={Adverb:"RB",Comparative:"JJR",Superlative:"JJS",Adjective:"JJ",TO:"Conjunction",Modal:"MD",Auxiliary:"MD",Gerund:"VBG",PastTense:"VBD",Participle:"VBN",PresentTense:"VBZ",Infinitive:"VB",Particle:"RP",Verb:"VB",Pronoun:"PRP",Cardinal:"CD",Conjunction:"CC",Determiner:"DT",Preposition:"IN",QuestionWord:"WP",Expression:"UH",Possessive:"POS",ProperNoun:"NNP",Person:"NNP",Place:"NNP",Organization:"NNP",Singular:"NN",Plural:"NNS",Noun:"NN",There:"EX"};var al={preTagger:function(e){const{methods:t,model:n,world:r}=e,o=e.docs;!function(e,t,n){e.forEach((e=>{!function(e,t,n,r){const o=r.methods.one.setTag;if(e.length>=3){const t=/:/;if(e[0].post.match(t)){const t=e[1];if(t.tags.has("Value")||t.tags.has("Email")||t.tags.has("PhoneNumber"))return;o([e[0]],"Expression",r,null,"2-punct-colon''")}}}(e,0,0,n)}))}(o,0,r);const a=t.two.quickSplit(o);for(let e=0;e{for(let r=0;r{e.forEach((e=>{e.penn=function(e){if(e.tags.has("ProperNoun")&&e.tags.has("Plural"))return"NNPS";if(e.tags.has("Possessive")&&e.tags.has("Pronoun"))return"PRP$";if("there"===e.normal)return"EX";if("to"===e.normal)return"TO";const t=e.tagRank||[];for(let e=0;e{e.implicit=e.normal,e.text="",e.normal=""}));for(let e=0;e(e.implicit=e.text,e.machine=e.text,e.pre="",e.post="",e.text="",e.normal="",e.index=[r,o+t],e))),n[0]&&(n[0].pre=e[r][o].pre,n[n.length-1].post=e[r][o].post,n[0].text=e[r][o].text,n[0].normal=e[r][o].normal),e[r].splice(o,1,...n))},fl=/'/,bl=new Set(["been","become"]),vl=new Set(["what","how","when","if","too"]),yl=new Set(["too","also","enough"]),wl=function(e,t){const n=e[t].normal.split(fl)[0];if("let"===n)return[n,"us"];if("there"===n){const r=e[t+1];if(r&&r.tags.has("Plural"))return[n,"are"]}return"has"===((e,t)=>{for(let n=t+1;n{for(let n=t+1;n0&&(n-=1),e[a]&&(a+=1),o.ptrs=[[0,n,a]],o.compute(["freeze","lexicon","preTagger","unfreeze"]),function(e){e.forEach(((e,t)=>{e.index&&(e.index[1]=t)}))}(e)},Hl={d:(e,t)=>Cl(e,t),t:(e,t)=>function(e,t){if("ain't"===e[t].normal||"aint"===e[t].normal){if(e[t+1]&&"never"===e[t+1].normal)return["have"];const n=function(e,t){for(let n=t-1;n>=0;n-=1)if(e[n].tags.has("Noun")||e[n].tags.has("Pronoun")||e[n].tags.has("Plural")||e[n].tags.has("Singular"))return e[n];return null}(e,t);if(n){if("we"===n.normal||"they"===n.normal)return["are","not"];if("i"===n.normal)return["am","not"];if(n.tags&&n.tags.has("Plural"))return["are","not"]}return["is","not"]}return[e[t].normal.replace(/n't/,""),"not"]}(e,t),s:(e,t,n)=>((e,t)=>{const n=e[t];if(Nl.hasOwnProperty(n.machine||n.normal))return!1;if(n.tags.has("Possessive"))return!0;if(n.tags.has("QuestionWord"))return!1;if("he's"===n.normal||"she's"===n.normal)return!1;const r=e[t+1];if(!r)return!0;if("it's"===n.normal)return!!r.tags.has("#Noun");if("Noun|Gerund"==r.switch){const r=e[t+2];return r?!!r.tags.has("Copula")||("on"===r.normal||r.normal,!1):!(!n.tags.has("Actor")&&!n.tags.has("ProperNoun"))}if(r.tags.has("Verb"))return!!r.tags.has("Infinitive")||!r.tags.has("Gerund")&&!!r.tags.has("PresentTense");if("Adj|Noun"===r.switch){const n=e[t+2];if(!n)return!1;if(Il.has(n.normal))return!0;if(xl.has(n.normal))return!1}if(r.tags.has("Noun")){const e=r.machine||r.normal;return!("here"===e||"there"===e||"everywhere"===e||r.tags.has("Possessive")||r.tags.has("ProperNoun")&&!n.tags.has("ProperNoun"))}if(e[t-1]&&!0===jl[e[t-1].normal])return!0;if(r.tags.has("Adjective")){const n=e[t+2];if(!n)return!1;if(n.tags.has("Noun")&&!n.tags.has("Pronoun")){const e=r.normal;return"above"!==e&&"below"!==e&&"behind"!==e}return"Noun|Verb"===n.switch}return!!r.tags.has("Value")})(e,t)?n.methods.one.setTag([e[t]],"Possessive",n,null,"2-contraction"):wl(e,t)},El=function(e,t){const n=t.fromText(e.join(" "));return n.compute("id"),n.docs[0]};var Gl={contractionTwo:e=>{const{world:t,document:n}=e;n.forEach(((r,o)=>{for(let a=r.length-1;a>=0;a-=1){if(r[a].implicit)continue;let i=null;!0===Tl.test(r[a].normal)&&(i=r[a].normal.split(Tl)[1]);let s=null;Hl.hasOwnProperty(i)&&(s=Hl[i](r,a,t)),s&&(s=El(s,e),pl(n,[o,a],s),Dl(n[o],e,a,s.length))}}))}},Ol={compute:Gl,api:function(e){class Contractions extends e{constructor(e,t,n){super(e,t,n),this.viewType="Contraction"}expand(){return this.docs.forEach((e=>{const t=ml.test(e[0].text);e.forEach(((t,n)=>{t.text=t.implicit||"",delete t.implicit,ne.toUpperCase()))}(e[0].text))})),this.compute("normal"),this}}e.prototype.contractions=function(){const e=this.match("@hasContraction+");return new Contractions(this.document,e.pointer)},e.prototype.contract=gl},hooks:["contractionTwo"]};const Fl="(hard|fast|late|early|high|right|deep|close|direct)";const Vl="(i|we|they)";const zl=[].concat([{match:"(got|were|was|is|are|am) (#PastTense|#Participle)",tag:"Passive",reason:"got-walked"},{match:"(was|were|is|are|am) being (#PastTense|#Participle)",tag:"Passive",reason:"was-being"},{match:"(had|have|has) been (#PastTense|#Participle)",tag:"Passive",reason:"had-been"},{match:"will be being? (#PastTense|#Participle)",tag:"Passive",reason:"will-be-cleaned"},{match:"#Noun [(#PastTense|#Participle)] by (the|a) #Noun",group:0,tag:"Passive",reason:"suffered-by"}],[{match:"[(all|both)] #Determiner #Noun",group:0,tag:"Noun",reason:"all-noun"},{match:"#Copula [(just|alone)]$",group:0,tag:"Adjective",reason:"not-adverb"},{match:"#Singular is #Adverb? [#PastTense$]",group:0,tag:"Adjective",reason:"is-filled"},{match:"[#PastTense] #Singular is",group:0,tag:"Adjective",reason:"smoked-poutine"},{match:"[#PastTense] #Plural are",group:0,tag:"Adjective",reason:"baked-onions"},{match:"well [#PastTense]",group:0,tag:"Adjective",reason:"well-made"},{match:"#Copula [fucked up?]",group:0,tag:"Adjective",reason:"swears-adjective"},{match:"#Singular (seems|appears) #Adverb? [#PastTense$]",group:0,tag:"Adjective",reason:"seems-filled"},{match:"#Copula #Adjective? [(out|in|through)]$",group:0,tag:"Adjective",reason:"still-out"},{match:"^[#Adjective] (the|your) #Noun",group:0,notIf:"(all|even)",tag:"Infinitive",reason:"shut-the"},{match:"the [said] #Noun",group:0,tag:"Adjective",reason:"the-said-card"},{match:"[#Hyphenated (#Hyphenated && #PastTense)] (#Noun|#Conjunction)",group:0,tag:"Adjective",notIf:"#Adverb",reason:"faith-based"},{match:"[#Hyphenated (#Hyphenated && #Gerund)] (#Noun|#Conjunction)",group:0,tag:"Adjective",notIf:"#Adverb",reason:"self-driving"},{match:"[#PastTense (#Hyphenated && #PhrasalVerb)] (#Noun|#Conjunction)",group:0,tag:"Adjective",reason:"dammed-up"},{match:"(#Hyphenated && #Value) fold",tag:"Adjective",reason:"two-fold"},{match:"must (#Hyphenated && #Infinitive)",tag:"Adjective",reason:"must-win"},{match:"(#Hyphenated && #Infinitive) #Hyphenated",tag:"Adjective",notIf:"#PhrasalVerb",reason:"vacuum-sealed"},{match:"too much",tag:"Adverb Adjective",reason:"bit-4"},{match:"a bit much",tag:"Determiner Adverb Adjective",reason:"bit-3"},{match:"[(un|contra|extra|inter|intra|macro|micro|mid|mis|mono|multi|pre|sub|tri|ex)] #Adjective",group:0,tag:["Adjective","Prefix"],reason:"un-skilled"}],[{match:"#Adverb [#Adverb] (and|or|then)",group:0,tag:"Adjective",reason:"kinda-sparkly-and"},{match:"[(dark|bright|flat|light|soft|pale|dead|dim|faux|little|wee|sheer|most|near|good|extra|all)] #Adjective",group:0,tag:"Adverb",reason:"dark-green"},{match:"#Copula [far too] #Adjective",group:0,tag:"Adverb",reason:"far-too"},{match:"#Copula [still] (in|#Gerund|#Adjective)",group:0,tag:"Adverb",reason:"was-still-walking"},{match:`#Plural ${Fl}`,tag:"#PresentTense #Adverb",reason:"studies-hard"},{match:`#Verb [${Fl}] !#Noun?`,group:0,notIf:"(#Copula|get|got|getting|become|became|becoming|feel|feels|feeling|#Determiner|#Preposition)",tag:"Adverb",reason:"shops-direct"},{match:"[#Plural] a lot",tag:"PresentTense",reason:"studies-a-lot"}],[{match:"as [#Gerund] as",group:0,tag:"Adjective",reason:"as-gerund-as"},{match:"more [#Gerund] than",group:0,tag:"Adjective",reason:"more-gerund-than"},{match:"(so|very|extremely) [#Gerund]",group:0,tag:"Adjective",reason:"so-gerund"},{match:"(found|found) it #Adverb? [#Gerund]",group:0,tag:"Adjective",reason:"found-it-gerund"},{match:"a (little|bit|wee) bit? [#Gerund]",group:0,tag:"Adjective",reason:"a-bit-gerund"},{match:"#Gerund [#Gerund]",group:0,tag:"Adjective",notIf:"(impersonating|practicing|considering|assuming)",reason:"looking-annoying"},{match:"(looked|look|looks) #Adverb? [%Adj|Gerund%]",group:0,tag:"Adjective",notIf:"(impersonating|practicing|considering|assuming)",reason:"looked-amazing"},{match:"[%Adj|Gerund%] #Determiner",group:0,tag:"Gerund",reason:"developing-a"},{match:"#Possessive [%Adj|Gerund%] #Noun",group:0,tag:"Adjective",reason:"leading-manufacturer"},{match:"%Noun|Gerund% %Adj|Gerund%",tag:"Gerund #Adjective",reason:"meaning-alluring"},{match:"(face|embrace|reveal|stop|start|resume) %Adj|Gerund%",tag:"#PresentTense #Adjective",reason:"face-shocking"},{match:"(are|were) [%Adj|Gerund%] #Plural",group:0,tag:"Adjective",reason:"are-enduring-symbols"}],[{match:"#Determiner [#Adjective] #Copula",group:0,tag:"Noun",reason:"the-adj-is"},{match:"#Adjective [#Adjective] #Copula",group:0,tag:"Noun",reason:"adj-adj-is"},{match:"(his|its) [%Adj|Noun%]",group:0,tag:"Noun",notIf:"#Hyphenated",reason:"his-fine"},{match:"#Copula #Adverb? [all]",group:0,tag:"Noun",reason:"is-all"},{match:"(have|had) [#Adjective] #Preposition .",group:0,tag:"Noun",reason:"have-fun"},{match:"#Gerund (giant|capital|center|zone|application)",tag:"Noun",reason:"brewing-giant"},{match:"#Preposition (a|an) [#Adjective]$",group:0,tag:"Noun",reason:"an-instant"},{match:"no [#Adjective] #Modal",group:0,tag:"Noun",reason:"no-golden"},{match:"[brand #Gerund?] new",group:0,tag:"Adverb",reason:"brand-new"},{match:"(#Determiner|#Comparative|new|different) [kind]",group:0,tag:"Noun",reason:"some-kind"},{match:"#Possessive [%Adj|Noun%] #Noun",group:0,tag:"Adjective",reason:"her-favourite"},{match:"must && #Hyphenated .",tag:"Adjective",reason:"must-win"},{match:"#Determiner [#Adjective]$",tag:"Noun",notIf:"(this|that|#Comparative|#Superlative)",reason:"the-south"},{match:"(#Noun && #Hyphenated) (#Adjective && #Hyphenated)",tag:"Adjective",notIf:"(this|that|#Comparative|#Superlative)",reason:"company-wide"},{match:"#Determiner [#Adjective] (#Copula|#Determiner)",notIf:"(#Comparative|#Superlative)",group:0,tag:"Noun",reason:"the-poor"},{match:"[%Adj|Noun%] #Noun",notIf:"(#Pronoun|#ProperNoun)",group:0,tag:"Adjective",reason:"stable-foundations"}],[{match:"[still] #Adjective",group:0,tag:"Adverb",reason:"still-advb"},{match:"[still] #Verb",group:0,tag:"Adverb",reason:"still-verb"},{match:"[so] #Adjective",group:0,tag:"Adverb",reason:"so-adv"},{match:"[way] #Comparative",group:0,tag:"Adverb",reason:"way-adj"},{match:"[way] #Adverb #Adjective",group:0,tag:"Adverb",reason:"way-too-adj"},{match:"[all] #Verb",group:0,tag:"Adverb",reason:"all-verb"},{match:"#Verb [like]",group:0,notIf:"(#Modal|#PhrasalVerb)",tag:"Adverb",reason:"verb-like"},{match:"(barely|hardly) even",tag:"Adverb",reason:"barely-even"},{match:"[even] #Verb",group:0,tag:"Adverb",reason:"even-walk"},{match:"[even] #Comparative",group:0,tag:"Adverb",reason:"even-worse"},{match:"[even] (#Determiner|#Possessive)",group:0,tag:"#Adverb",reason:"even-the"},{match:"even left",tag:"#Adverb #Verb",reason:"even-left"},{match:"[way] #Adjective",group:0,tag:"#Adverb",reason:"way-over"},{match:"#PresentTense [(hard|quick|bright|slow|fast|backwards|forwards)]",notIf:"#Copula",group:0,tag:"Adverb",reason:"lazy-ly"},{match:"[much] #Adjective",group:0,tag:"Adverb",reason:"bit-1"},{match:"#Copula [#Adverb]$",group:0,tag:"Adjective",reason:"is-well"},{match:"a [(little|bit|wee) bit?] #Adjective",group:0,tag:"Adverb",reason:"a-bit-cold"},{match:"[(super|pretty)] #Adjective",group:0,tag:"Adverb",reason:"super-strong"},{match:"(become|fall|grow) #Adverb? [#PastTense]",group:0,tag:"Adjective",reason:"overly-weakened"},{match:"(a|an) #Adverb [#Participle] #Noun",group:0,tag:"Adjective",reason:"completely-beaten"},{match:"#Determiner #Adverb? [close]",group:0,tag:"Adjective",reason:"a-close"},{match:"#Gerund #Adverb? [close]",group:0,tag:"Adverb",notIf:"(getting|becoming|feeling)",reason:"being-close"},{match:"(the|those|these|a|an) [#Participle] #Noun",group:0,tag:"Adjective",reason:"blown-motor"},{match:"(#PresentTense|#PastTense) [back]",group:0,tag:"Adverb",notIf:"(#PhrasalVerb|#Copula)",reason:"charge-back"},{match:"#Verb [around]",group:0,tag:"Adverb",notIf:"#PhrasalVerb",reason:"send-around"},{match:"[later] #PresentTense",group:0,tag:"Adverb",reason:"later-say"},{match:"#Determiner [well] !#PastTense?",group:0,tag:"Noun",reason:"the-well"},{match:"#Adjective [enough]",group:0,tag:"Adverb",reason:"high-enough"}],[{match:"[sun] the #Ordinal",tag:"WeekDay",reason:"sun-the-5th"},{match:"[sun] #Date",group:0,tag:"WeekDay",reason:"sun-feb"},{match:"#Date (on|this|next|last|during)? [sun]",group:0,tag:"WeekDay",reason:"1pm-sun"},{match:"(in|by|before|during|on|until|after|of|within|all) [sat]",group:0,tag:"WeekDay",reason:"sat"},{match:"(in|by|before|during|on|until|after|of|within|all) [wed]",group:0,tag:"WeekDay",reason:"wed"},{match:"(in|by|before|during|on|until|after|of|within|all) [march]",group:0,tag:"Month",reason:"march"},{match:"[sat] #Date",group:0,tag:"WeekDay",reason:"sat-feb"},{match:"#Preposition [(march|may)]",group:0,tag:"Month",reason:"in-month"},{match:"(this|next|last) (march|may) !#Infinitive?",tag:"#Date #Month",reason:"this-month"},{match:"(march|may) the? #Value",tag:"#Month #Date #Date",reason:"march-5th"},{match:"#Value of? (march|may)",tag:"#Date #Date #Month",reason:"5th-of-march"},{match:"[(march|may)] .? #Date",group:0,tag:"Month",reason:"march-and-feb"},{match:"#Date .? [(march|may)]",group:0,tag:"Month",reason:"feb-and-march"},{match:"#Adverb [(march|may)]",group:0,tag:"Verb",reason:"quickly-march"},{match:"[(march|may)] #Adverb",group:0,tag:"Verb",reason:"march-quickly"},{match:"#Value (am|pm)",tag:"Time",reason:"2-am"}],[{match:"#Holiday (day|eve)",tag:"Holiday",reason:"holiday-day"},{match:"#Value of #Month",tag:"Date",reason:"value-of-month"},{match:"#Cardinal #Month",tag:"Date",reason:"cardinal-month"},{match:"#Month #Value to #Value",tag:"Date",reason:"value-to-value"},{match:"#Month the #Value",tag:"Date",reason:"month-the-value"},{match:"(#WeekDay|#Month) #Value",tag:"Date",reason:"date-value"},{match:"#Value (#WeekDay|#Month)",tag:"Date",reason:"value-date"},{match:"(#TextValue && #Date) #TextValue",tag:"Date",reason:"textvalue-date"},{match:"#Month #NumberRange",tag:"Date",reason:"aug 20-21"},{match:"#WeekDay #Month #Ordinal",tag:"Date",reason:"week mm-dd"},{match:"#Month #Ordinal #Cardinal",tag:"Date",reason:"mm-dd-yyy"},{match:"(#Place|#Demonmym|#Time) (standard|daylight|central|mountain)? time",tag:"Timezone",reason:"std-time"},{match:"(eastern|mountain|pacific|central|atlantic) (standard|daylight|summer)? time",tag:"Timezone",reason:"eastern-time"},{match:"#Time [(eastern|mountain|pacific|central|est|pst|gmt)]",group:0,tag:"Timezone",reason:"5pm-central"},{match:"(central|western|eastern) european time",tag:"Timezone",reason:"cet"}],[{match:"(the|any) [more]",group:0,tag:"Singular",reason:"more-noun"},{match:"[more] #Noun",group:0,tag:"Adjective",reason:"more-noun"},{match:"(right|rights) of .",tag:"Noun",reason:"right-of"},{match:"a [bit]",group:0,tag:"Singular",reason:"bit-2"},{match:"a [must]",group:0,tag:"Singular",reason:"must-2"},{match:"(we|us) [all]",group:0,tag:"Noun",reason:"we all"},{match:"due to [#Verb]",group:0,tag:"Noun",reason:"due-to"},{match:"some [#Verb] #Plural",group:0,tag:"Noun",reason:"determiner6"},{match:"#Possessive #Ordinal [#PastTense]",group:0,tag:"Noun",reason:"first-thought"},{match:"(the|this|those|these) #Adjective [%Verb|Noun%]",group:0,tag:"Noun",notIf:"#Copula",reason:"the-adj-verb"},{match:"(the|this|those|these) #Adverb #Adjective [#Verb]",group:0,tag:"Noun",reason:"determiner4"},{match:"the [#Verb] #Preposition .",group:0,tag:"Noun",reason:"determiner1"},{match:"(a|an|the) [#Verb] of",group:0,tag:"Noun",reason:"the-verb-of"},{match:"#Determiner #Noun of [#Verb]",group:0,tag:"Noun",notIf:"#Gerund",reason:"noun-of-noun"},{match:"#PastTense #Preposition [#PresentTense]",group:0,notIf:"#Gerund",tag:"Noun",reason:"ended-in-ruins"},{match:"#Conjunction [u]",group:0,tag:"Pronoun",reason:"u-pronoun-2"},{match:"[u] #Verb",group:0,tag:"Pronoun",reason:"u-pronoun-1"},{match:"#Determiner [(western|eastern|northern|southern|central)] #Noun",group:0,tag:"Noun",reason:"western-line"},{match:"(#Singular && @hasHyphen) #PresentTense",tag:"Noun",reason:"hyphen-verb"},{match:"is no [#Verb]",group:0,tag:"Noun",reason:"is-no-verb"},{match:"do [so]",group:0,tag:"Noun",reason:"so-noun"},{match:"#Determiner [(shit|damn|hell)]",group:0,tag:"Noun",reason:"swears-noun"},{match:"to [(shit|hell)]",group:0,tag:"Noun",reason:"to-swears"},{match:"(the|these) [#Singular] (were|are)",group:0,tag:"Plural",reason:"singular-were"},{match:"a #Noun+ or #Adverb+? [#Verb]",group:0,tag:"Noun",reason:"noun-or-noun"},{match:"(the|those|these|a|an) #Adjective? [#PresentTense #Particle?]",group:0,tag:"Noun",notIf:"(seem|appear|include|#Gerund|#Copula)",reason:"det-inf"},{match:"#Noun #Actor",tag:"Actor",notIf:"(#Person|#Pronoun)",reason:"thing-doer"},{match:"#Gerund #Actor",tag:"Actor",reason:"gerund-doer"},{match:"co #Singular",tag:"Actor",reason:"co-noun"},{match:"[#Noun+] #Actor",group:0,tag:"Actor",notIf:"(#Honorific|#Pronoun|#Possessive)",reason:"air-traffic-controller"},{match:"(urban|cardiac|cardiovascular|respiratory|medical|clinical|visual|graphic|creative|dental|exotic|fine|certified|registered|technical|virtual|professional|amateur|junior|senior|special|pharmaceutical|theoretical)+ #Noun? #Actor",tag:"Actor",reason:"fine-artist"},{match:"#Noun+ (coach|chef|king|engineer|fellow|personality|boy|girl|man|woman|master)",tag:"Actor",reason:"dance-coach"},{match:"chief . officer",tag:"Actor",reason:"chief-x-officer"},{match:"chief of #Noun+",tag:"Actor",reason:"chief-of-police"},{match:"senior? vice? president of #Noun+",tag:"Actor",reason:"president-of"},{match:"#Determiner [sun]",group:0,tag:"Singular",reason:"the-sun"},{match:"#Verb (a|an) [#Value]$",group:0,tag:"Singular",reason:"did-a-value"},{match:"the [(can|will|may)]",group:0,tag:"Singular",reason:"the can"},{match:"#FirstName #Acronym? (#Possessive && #LastName)",tag:"Possessive",reason:"name-poss"},{match:"#Organization+ #Possessive",tag:"Possessive",reason:"org-possessive"},{match:"#Place+ #Possessive",tag:"Possessive",reason:"place-possessive"},{match:"#Possessive #PresentTense #Particle?",notIf:"(#Gerund|her)",tag:"Noun",reason:"possessive-verb"},{match:"(my|our|their|her|his|its) [(#Plural && #Actor)] #Noun",tag:"Possessive",reason:"my-dads"},{match:"#Value of a [second]",group:0,unTag:"Value",tag:"Singular",reason:"10th-of-a-second"},{match:"#Value [seconds]",group:0,unTag:"Value",tag:"Plural",reason:"10-seconds"},{match:"in [#Infinitive]",group:0,tag:"Singular",reason:"in-age"},{match:"a [#Adjective] #Preposition",group:0,tag:"Noun",reason:"a-minor-in"},{match:"#Determiner [#Singular] said",group:0,tag:"Actor",reason:"the-actor-said"},{match:"#Determiner #Noun [(feel|sense|process|rush|side|bomb|bully|challenge|cover|crush|dump|exchange|flow|function|issue|lecture|limit|march|process)] !(#Preposition|to|#Adverb)?",group:0,tag:"Noun",reason:"the-noun-sense"},{match:"[#PresentTense] (of|by|for) (a|an|the) #Noun #Copula",group:0,tag:"Plural",reason:"photographs-of"},{match:"#Infinitive and [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"fight and win"},{match:"#Noun and [#Verb] and #Noun",group:0,tag:"Noun",reason:"peace-and-flowers"},{match:"the #Cardinal [%Adj|Noun%]",group:0,tag:"Noun",reason:"the-1992-classic"},{match:"#Copula the [%Adj|Noun%] #Noun",group:0,tag:"Adjective",reason:"the-premier-university"},{match:"i #Verb [me] #Noun",group:0,tag:"Possessive",reason:"scottish-me"},{match:"[#PresentTense] (music|class|lesson|night|party|festival|league|ceremony)",group:0,tag:"Noun",reason:"dance-music"},{match:"[wit] (me|it)",group:0,tag:"Presposition",reason:"wit-me"},{match:"#PastTense #Possessive [#Verb]",group:0,tag:"Noun",notIf:"(saw|made)",reason:"left-her-boots"},{match:"#Value [%Plural|Verb%]",group:0,tag:"Plural",notIf:"(one|1|a|an)",reason:"35-signs"},{match:"had [#PresentTense]",group:0,tag:"Noun",notIf:"(#Gerund|come|become)",reason:"had-time"},{match:"%Adj|Noun% %Noun|Verb%",tag:"#Adjective #Noun",notIf:"#ProperNoun #Noun",reason:"instant-access"},{match:"#Determiner [%Adj|Noun%] #Conjunction",group:0,tag:"Noun",reason:"a-rep-to"},{match:"#Adjective #Noun [%Plural|Verb%]$",group:0,tag:"Plural",notIf:"#Pronoun",reason:"near-death-experiences"},{match:"#Possessive #Noun [%Plural|Verb%]$",group:0,tag:"Plural",reason:"your-guild-colors"}],[{match:"(this|that|the|a|an) [#Gerund #Infinitive]",group:0,tag:"Singular",reason:"the-planning-process"},{match:"(that|the) [#Gerund #PresentTense]",group:0,ifNo:"#Copula",tag:"Plural",reason:"the-paving-stones"},{match:"#Determiner [#Gerund] #Noun",group:0,tag:"Adjective",reason:"the-gerund-noun"},{match:"#Pronoun #Infinitive [#Gerund] #PresentTense",group:0,tag:"Noun",reason:"tipping-sucks"},{match:"#Adjective [#Gerund]",group:0,tag:"Noun",notIf:"(still|even|just)",reason:"early-warning"},{match:"[#Gerund] #Adverb? not? #Copula",group:0,tag:"Activity",reason:"gerund-copula"},{match:"#Copula [(#Gerund|#Activity)] #Copula",group:0,tag:"Gerund",reason:"are-doing-is"},{match:"[#Gerund] #Modal",group:0,tag:"Activity",reason:"gerund-modal"},{match:"#Singular for [%Noun|Gerund%]",group:0,tag:"Gerund",reason:"noun-for-gerund"},{match:"#Comparative (for|at) [%Noun|Gerund%]",group:0,tag:"Gerund",reason:"better-for-gerund"},{match:"#PresentTense the [#Gerund]",group:0,tag:"Noun",reason:"keep-the-touching"}],[{match:"#Infinitive (this|that|the) [#Infinitive]",group:0,tag:"Noun",reason:"do-this-dance"},{match:"#Gerund #Determiner [#Infinitive]",group:0,tag:"Noun",reason:"running-a-show"},{match:"#Determiner (only|further|just|more|backward) [#Infinitive]",group:0,tag:"Noun",reason:"the-only-reason"},{match:"(the|this|a|an) [#Infinitive] #Adverb? #Verb",group:0,tag:"Noun",reason:"determiner5"},{match:"#Determiner #Adjective #Adjective? [#Infinitive]",group:0,tag:"Noun",reason:"a-nice-inf"},{match:"#Determiner #Demonym [#PresentTense]",group:0,tag:"Noun",reason:"mexican-train"},{match:"#Adjective #Noun+ [#Infinitive] #Copula",group:0,tag:"Noun",reason:"career-move"},{match:"at some [#Infinitive]",group:0,tag:"Noun",reason:"at-some-inf"},{match:"(go|goes|went) to [#Infinitive]",group:0,tag:"Noun",reason:"goes-to-verb"},{match:"(a|an) #Adjective? #Noun [#Infinitive] (#Preposition|#Noun)",group:0,notIf:"from",tag:"Noun",reason:"a-noun-inf"},{match:"(a|an) #Noun [#Infinitive]$",group:0,tag:"Noun",reason:"a-noun-inf2"},{match:"#Gerund #Adjective? for [#Infinitive]",group:0,tag:"Noun",reason:"running-for"},{match:"about [#Infinitive]",group:0,tag:"Singular",reason:"about-love"},{match:"#Plural on [#Infinitive]",group:0,tag:"Noun",reason:"on-stage"},{match:"any [#Infinitive]",group:0,tag:"Noun",reason:"any-charge"},{match:"no [#Infinitive]",group:0,tag:"Noun",reason:"no-doubt"},{match:"number of [#PresentTense]",group:0,tag:"Noun",reason:"number-of-x"},{match:"(taught|teaches|learns|learned) [#PresentTense]",group:0,tag:"Noun",reason:"teaches-x"},{match:"(try|use|attempt|build|make) [#Verb #Particle?]",notIf:"(#Copula|#Noun|sure|fun|up)",group:0,tag:"Noun",reason:"do-verb"},{match:"^[#Infinitive] (is|was)",group:0,tag:"Noun",reason:"checkmate-is"},{match:"#Infinitive much [#Infinitive]",group:0,tag:"Noun",reason:"get-much"},{match:"[cause] #Pronoun #Verb",group:0,tag:"Conjunction",reason:"cause-cuz"},{match:"the #Singular [#Infinitive] #Noun",group:0,tag:"Noun",notIf:"#Pronoun",reason:"cardio-dance"},{match:"#Determiner #Modal [#Noun]",group:0,tag:"PresentTense",reason:"should-smoke"},{match:"this [#Plural]",group:0,tag:"PresentTense",notIf:"(#Preposition|#Date)",reason:"this-verbs"},{match:"#Noun that [#Plural]",group:0,tag:"PresentTense",notIf:"(#Preposition|#Pronoun|way)",reason:"voice-that-rocks"},{match:"that [#Plural] to",group:0,tag:"PresentTense",notIf:"#Preposition",reason:"that-leads-to"},{match:"(let|make|made) (him|her|it|#Person|#Place|#Organization)+ [#Singular] (a|an|the|it)",group:0,tag:"Infinitive",reason:"let-him-glue"},{match:"#Verb (all|every|each|most|some|no) [#PresentTense]",notIf:"#Modal",group:0,tag:"Noun",reason:"all-presentTense"},{match:"(had|have|#PastTense) #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"better",reason:"adj-presentTense"},{match:"#Value #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"one-big-reason"},{match:"#PastTense #Adjective+ [#PresentTense]",group:0,tag:"Noun",notIf:"(#Copula|better)",reason:"won-wide-support"},{match:"(many|few|several|couple) [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"many-poses"},{match:"#Determiner #Adverb #Adjective [%Noun|Verb%]",group:0,tag:"Noun",notIf:"#Copula",reason:"very-big-dream"},{match:"from #Noun to [%Noun|Verb%]",group:0,tag:"Noun",reason:"start-to-finish"},{match:"(for|with|of) #Noun (and|or|not) [%Noun|Verb%]",group:0,tag:"Noun",notIf:"#Pronoun",reason:"for-food-and-gas"},{match:"#Adjective #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"adorable-little-store"},{match:"#Gerund #Adverb? #Comparative [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"higher-costs"},{match:"(#Noun && @hasComma) #Noun (and|or) [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"noun-list"},{match:"(many|any|some|several) [#PresentTense] for",group:0,tag:"Noun",reason:"any-verbs-for"},{match:"to #PresentTense #Noun [#PresentTense] #Preposition",group:0,tag:"Noun",reason:"gas-exchange"},{match:"#PastTense (until|as|through|without) [#PresentTense]",group:0,tag:"Noun",reason:"waited-until-release"},{match:"#Gerund like #Adjective? [#PresentTense]",group:0,tag:"Plural",reason:"like-hot-cakes"},{match:"some #Adjective [#PresentTense]",group:0,tag:"Noun",reason:"some-reason"},{match:"for some [#PresentTense]",group:0,tag:"Noun",reason:"for-some-reason"},{match:"(same|some|the|that|a) kind of [#PresentTense]",group:0,tag:"Noun",reason:"some-kind-of"},{match:"(same|some|the|that|a) type of [#PresentTense]",group:0,tag:"Noun",reason:"some-type-of"},{match:"#Gerund #Adjective #Preposition [#PresentTense]",group:0,tag:"Noun",reason:"doing-better-for-x"},{match:"(get|got|have) #Comparative [#PresentTense]",group:0,tag:"Noun",reason:"got-better-aim"},{match:"whose [#PresentTense] #Copula",group:0,tag:"Noun",reason:"whos-name-was"},{match:"#PhrasalVerb #Particle #Preposition [#PresentTense]",group:0,tag:"Noun",reason:"given-up-on-x"},{match:"there (are|were) #Adjective? [#PresentTense]",group:0,tag:"Plural",reason:"there-are"},{match:"#Value [#PresentTense] of",group:0,notIf:"(one|1|#Copula|#Infinitive)",tag:"Plural",reason:"2-trains"},{match:"[#PresentTense] (are|were) #Adjective",group:0,tag:"Plural",reason:"compromises-are-possible"},{match:"^[(hope|guess|thought|think)] #Pronoun #Verb",group:0,tag:"Infinitive",reason:"suppose-i"},{match:"#Possessive #Adjective [#Verb]",group:0,tag:"Noun",notIf:"#Copula",reason:"our-full-support"},{match:"[(tastes|smells)] #Adverb? #Adjective",group:0,tag:"PresentTense",reason:"tastes-good"},{match:"#Copula #Gerund [#PresentTense] !by?",group:0,tag:"Noun",notIf:"going",reason:"ignoring-commute"},{match:"#Determiner #Adjective? [(shed|thought|rose|bid|saw|spelt)]",group:0,tag:"Noun",reason:"noun-past"},{match:"how to [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"how-to-noun"},{match:"which [%Noun|Verb%] #Noun",group:0,tag:"Infinitive",reason:"which-boost-it"},{match:"#Gerund [%Plural|Verb%]",group:0,tag:"Plural",reason:"asking-questions"},{match:"(ready|available|difficult|hard|easy|made|attempt|try) to [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"ready-to-noun"},{match:"(bring|went|go|drive|run|bike) to [%Noun|Verb%]",group:0,tag:"Noun",reason:"bring-to-noun"},{match:"#Modal #Noun [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"would-you-look"},{match:"#Copula just [#Infinitive]",group:0,tag:"Noun",reason:"is-just-spam"},{match:"^%Noun|Verb% %Plural|Verb%",tag:"Imperative #Plural",reason:"request-copies"},{match:"#Adjective #Plural and [%Plural|Verb%]",group:0,tag:"#Plural",reason:"pickles-and-drinks"},{match:"#Determiner #Year [#Verb]",group:0,tag:"Noun",reason:"the-1968-film"},{match:"#Determiner [#PhrasalVerb #Particle]",group:0,tag:"Noun",reason:"the-break-up"},{match:"#Determiner [%Adj|Noun%] #Noun",group:0,tag:"Adjective",notIf:"(#Pronoun|#Possessive|#ProperNoun)",reason:"the-individual-goals"},{match:"[%Noun|Verb%] or #Infinitive",group:0,tag:"Infinitive",reason:"work-or-prepare"},{match:"to #Infinitive [#PresentTense]",group:0,tag:"Noun",notIf:"(#Gerund|#Copula|help)",reason:"to-give-thanks"},{match:"[#Noun] me",group:0,tag:"Verb",reason:"kills-me"},{match:"%Plural|Verb% %Plural|Verb%",tag:"#PresentTense #Plural",reason:"removes-wrinkles"}],[{match:"#Money and #Money #Currency?",tag:"Money",reason:"money-and-money"},{match:"#Value #Currency [and] #Value (cents|ore|centavos|sens)",group:0,tag:"money",reason:"and-5-cents"},{match:"#Value (mark|rand|won|rub|ore)",tag:"#Money #Currency",reason:"4-mark"},{match:"a pound",tag:"#Money #Unit",reason:"a-pound"},{match:"#Value (pound|pounds)",tag:"#Money #Unit",reason:"4-pounds"}],[{match:"[(half|quarter)] of? (a|an)",group:0,tag:"Fraction",reason:"millionth"},{match:"#Adverb [half]",group:0,tag:"Fraction",reason:"nearly-half"},{match:"[half] the",group:0,tag:"Fraction",reason:"half-the"},{match:"#Cardinal and a half",tag:"Fraction",reason:"and-a-half"},{match:"#Value (halves|halfs|quarters)",tag:"Fraction",reason:"two-halves"},{match:"a #Ordinal",tag:"Fraction",reason:"a-quarter"},{match:"[#Cardinal+] (#Fraction && /s$/)",tag:"Fraction",reason:"seven-fifths"},{match:"[#Cardinal+ #Ordinal] of .",group:0,tag:"Fraction",reason:"ordinal-of"},{match:"[(#NumericValue && #Ordinal)] of .",group:0,tag:"Fraction",reason:"num-ordinal-of"},{match:"(a|one) #Cardinal?+ #Ordinal",tag:"Fraction",reason:"a-ordinal"},{match:"#Cardinal+ out? of every? #Cardinal",tag:"Fraction",reason:"out-of"}],[{match:"#Cardinal [second]",tag:"Unit",reason:"one-second"},{match:"!once? [(a|an)] (#Duration|hundred|thousand|million|billion|trillion)",group:0,tag:"Value",reason:"a-is-one"},{match:"1 #Value #PhoneNumber",tag:"PhoneNumber",reason:"1-800-Value"},{match:"#NumericValue #PhoneNumber",tag:"PhoneNumber",reason:"(800) PhoneNumber"},{match:"#Demonym #Currency",tag:"Currency",reason:"demonym-currency"},{match:"#Value [(buck|bucks|grand)]",group:0,tag:"Currency",reason:"value-bucks"},{match:"[#Value+] #Currency",group:0,tag:"Money",reason:"15 usd"},{match:"[second] #Noun",group:0,tag:"Ordinal",reason:"second-noun"},{match:"#Value+ [#Currency]",group:0,tag:"Unit",reason:"5-yan"},{match:"#Value [(foot|feet)]",group:0,tag:"Unit",reason:"foot-unit"},{match:"#Value [#Abbreviation]",group:0,tag:"Unit",reason:"value-abbr"},{match:"#Value [k]",group:0,tag:"Unit",reason:"value-k"},{match:"#Unit an hour",tag:"Unit",reason:"unit-an-hour"},{match:"(minus|negative) #Value",tag:"Value",reason:"minus-value"},{match:"#Value (point|decimal) #Value",tag:"Value",reason:"value-point-value"},{match:"#Determiner [(half|quarter)] #Ordinal",group:0,tag:"Value",reason:"half-ordinal"},{match:"#Multiple+ and #Value",tag:"Value",reason:"magnitude-and-value"},{match:"#Value #Unit [(per|an) (hr|hour|sec|second|min|minute)]",group:0,tag:"Unit",reason:"12-miles-per-second"},{match:"#Value [(square|cubic)] #Unit",group:0,tag:"Unit",reason:"square-miles"}],[{match:"#Copula [(#Noun|#PresentTense)] #LastName",group:0,tag:"FirstName",reason:"copula-noun-lastname"},{match:"(sister|pope|brother|father|aunt|uncle|grandpa|grandfather|grandma) #ProperNoun",tag:"Person",reason:"lady-titlecase",safe:!0},{match:"#FirstName [#Determiner #Noun] #LastName",group:0,tag:"Person",reason:"first-noun-last"},{match:"#ProperNoun (b|c|d|e|f|g|h|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z) #ProperNoun",tag:"Person",reason:"titlecase-acronym-titlecase",safe:!0},{match:"#Acronym #LastName",tag:"Person",reason:"acronym-lastname",safe:!0},{match:"#Person (jr|sr|md)",tag:"Person",reason:"person-honorific"},{match:"#Honorific #Acronym",tag:"Person",reason:"Honorific-TitleCase"},{match:"#Person #Person the? #RomanNumeral",tag:"Person",reason:"roman-numeral"},{match:"#FirstName [/^[^aiurck]$/]",group:0,tag:["Acronym","Person"],reason:"john-e"},{match:"#Noun van der? #Noun",tag:"Person",reason:"van der noun",safe:!0},{match:"(king|queen|prince|saint|lady) of #Noun",tag:"Person",reason:"king-of-noun",safe:!0},{match:"(prince|lady) #Place",tag:"Person",reason:"lady-place"},{match:"(king|queen|prince|saint) #ProperNoun",tag:"Person",notIf:"#Place",reason:"saint-foo"},{match:"al (#Person|#ProperNoun)",tag:"Person",reason:"al-borlen",safe:!0},{match:"#FirstName de #Noun",tag:"Person",reason:"bill-de-noun"},{match:"#FirstName (bin|al) #Noun",tag:"Person",reason:"bill-al-noun"},{match:"#FirstName #Acronym #ProperNoun",tag:"Person",reason:"bill-acronym-title"},{match:"#FirstName #FirstName #ProperNoun",tag:"Person",reason:"bill-firstname-title"},{match:"#Honorific #FirstName? #ProperNoun",tag:"Person",reason:"dr-john-Title"},{match:"#FirstName the #Adjective",tag:"Person",reason:"name-the-great"},{match:"#ProperNoun (van|al|bin) #ProperNoun",tag:"Person",reason:"title-van-title",safe:!0},{match:"#ProperNoun (de|du) la? #ProperNoun",tag:"Person",notIf:"#Place",reason:"title-de-title"},{match:"#Singular #Acronym #LastName",tag:"#FirstName #Person .",reason:"title-acro-noun",safe:!0},{match:"[#ProperNoun] #Person",group:0,tag:"Person",reason:"proper-person",safe:!0},{match:"#Person [#ProperNoun #ProperNoun]",group:0,tag:"Person",notIf:"#Possessive",reason:"three-name-person",safe:!0},{match:"#FirstName #Acronym? [#ProperNoun]",group:0,tag:"LastName",notIf:"#Possessive",reason:"firstname-titlecase"},{match:"#FirstName [#FirstName]",group:0,tag:"LastName",reason:"firstname-firstname"},{match:"#FirstName #Acronym #Noun",tag:"Person",reason:"n-acro-noun",safe:!0},{match:"#FirstName [(de|di|du|van|von)] #Person",group:0,tag:"LastName",reason:"de-firstname"},{match:"[(lieutenant|corporal|sergeant|captain|qeen|king|admiral|major|colonel|marshal|president|queen|king)+] #ProperNoun",group:0,tag:"Honorific",reason:"seargeant-john"},{match:"[(private|general|major|rear|prime|field|count|miss)] #Honorific? #Person",group:0,tag:["Honorific","Person"],reason:"ambg-honorifics"},{match:"#Honorific #FirstName [#Singular]",group:0,tag:"LastName",notIf:"#Possessive",reason:"dr-john-foo",safe:!0},{match:"[(his|her) (majesty|honour|worship|excellency|honorable)] #Person",group:0,tag:"Honorific",reason:"his-excellency"},{match:"#Honorific #Actor",tag:"Honorific",reason:"Lieutenant colonel"},{match:"(first|second|third|1st|2nd|3rd) #Actor",tag:"Honorific",reason:"first lady"},{match:"#Person #RomanNumeral",tag:"Person",reason:"louis-IV"}],[{match:"#FirstName #Noun$",tag:". #LastName",notIf:"(#Possessive|#Organization|#Place|#Pronoun|@hasTitleCase)",reason:"firstname-noun"},{match:"%Person|Date% #Acronym? #ProperNoun",tag:"Person",reason:"jan-thierson"},{match:"%Person|Noun% #Acronym? #ProperNoun",tag:"Person",reason:"switch-person",safe:!0},{match:"%Person|Noun% #Organization",tag:"Organization",reason:"olive-garden"},{match:"%Person|Verb% #Acronym? #ProperNoun",tag:"Person",reason:"verb-propernoun",ifNo:"#Actor"},{match:"[%Person|Verb%] (will|had|has|said|says|told|did|learned|wants|wanted)",group:0,tag:"Person",reason:"person-said"},{match:"[%Person|Place%] (harbor|harbour|pier|town|city|place|dump|landfill)",group:0,tag:"Place",reason:"sydney-harbour"},{match:"(west|east|north|south) [%Person|Place%]",group:0,tag:"Place",reason:"east-sydney"},{match:"#Modal [%Person|Verb%]",group:0,tag:"Verb",reason:"would-mark"},{match:"#Adverb [%Person|Verb%]",group:0,tag:"Verb",reason:"really-mark"},{match:"[%Person|Verb%] (#Adverb|#Comparative)",group:0,tag:"Verb",reason:"drew-closer"},{match:"%Person|Verb% #Person",tag:"Person",reason:"rob-smith"},{match:"%Person|Verb% #Acronym #ProperNoun",tag:"Person",reason:"rob-a-smith"},{match:"[will] #Verb",group:0,tag:"Modal",reason:"will-verb"},{match:"(will && @isTitleCase) #ProperNoun",tag:"Person",reason:"will-name"},{match:"(#FirstName && !#Possessive) [#Singular] #Verb",group:0,safe:!0,tag:"LastName",reason:"jack-layton"},{match:"^[#Singular] #Person #Verb",group:0,safe:!0,tag:"Person",reason:"sherwood-anderson"},{match:"(a|an) [#Person]$",group:0,unTag:"Person",reason:"a-warhol"}],[{match:"#Copula (pretty|dead|full|well|sure) (#Adjective|#Noun)",tag:"#Copula #Adverb #Adjective",reason:"sometimes-adverb"},{match:"(#Pronoun|#Person) (had|#Adverb)? [better] #PresentTense",group:0,tag:"Modal",reason:"i-better"},{match:"(#Modal|i|they|we|do) not? [like]",group:0,tag:"PresentTense",reason:"modal-like"},{match:"#Noun #Adverb? [left]",group:0,tag:"PastTense",reason:"left-verb"},{match:"will #Adverb? not? #Adverb? [be] #Gerund",group:0,tag:"Copula",reason:"will-be-copula"},{match:"will #Adverb? not? #Adverb? [be] #Adjective",group:0,tag:"Copula",reason:"be-copula"},{match:"[march] (up|down|back|toward)",notIf:"#Date",group:0,tag:"Infinitive",reason:"march-to"},{match:"#Modal [march]",group:0,tag:"Infinitive",reason:"must-march"},{match:"[may] be",group:0,tag:"Verb",reason:"may-be"},{match:"[(subject|subjects|subjected)] to",group:0,tag:"Verb",reason:"subject to"},{match:"[home] to",group:0,tag:"PresentTense",reason:"home to"},{match:"[open] #Determiner",group:0,tag:"Infinitive",reason:"open-the"},{match:"(were|was) being [#PresentTense]",group:0,tag:"PastTense",reason:"was-being"},{match:"(had|has|have) [been /en$/]",group:0,tag:"Auxiliary Participle",reason:"had-been-broken"},{match:"(had|has|have) [been /ed$/]",group:0,tag:"Auxiliary PastTense",reason:"had-been-smoked"},{match:"(had|has) #Adverb? [been] #Adverb? #PastTense",group:0,tag:"Auxiliary",reason:"had-been-adj"},{match:"(had|has) to [#Noun] (#Determiner|#Possessive)",group:0,tag:"Infinitive",reason:"had-to-noun"},{match:"have [#PresentTense]",group:0,tag:"PastTense",notIf:"(come|gotten)",reason:"have-read"},{match:"(does|will|#Modal) that [work]",group:0,tag:"PastTense",reason:"does-that-work"},{match:"[(sound|sounds)] #Adjective",group:0,tag:"PresentTense",reason:"sounds-fun"},{match:"[(look|looks)] #Adjective",group:0,tag:"PresentTense",reason:"looks-good"},{match:"[(start|starts|stop|stops|begin|begins)] #Gerund",group:0,tag:"Verb",reason:"starts-thinking"},{match:"(have|had) read",tag:"Modal #PastTense",reason:"read-read"},{match:"(is|was|were) [(under|over) #PastTense]",group:0,tag:"Adverb Adjective",reason:"was-under-cooked"},{match:"[shit] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear1-verb"},{match:"[damn] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear2-verb"},{match:"[fuck] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear3-verb"},{match:"#Plural that %Noun|Verb%",tag:". #Preposition #Infinitive",reason:"jobs-that-work"},{match:"[works] for me",group:0,tag:"PresentTense",reason:"works-for-me"},{match:"as #Pronoun [please]",group:0,tag:"Infinitive",reason:"as-we-please"},{match:"[(co|mis|de|inter|intra|pre|re|un|out|under|over|counter)] #Verb",group:0,tag:["Verb","Prefix"],notIf:"(#Copula|#PhrasalVerb)",reason:"co-write"},{match:"#PastTense and [%Adj|Past%]",group:0,tag:"PastTense",reason:"dressed-and-left"},{match:"[%Adj|Past%] and #PastTense",group:0,tag:"PastTense",reason:"dressed-and-left"},{match:"#Copula #Pronoun [%Adj|Past%]",group:0,tag:"Adjective",reason:"is-he-stoked"},{match:"to [%Noun|Verb%] #Preposition",group:0,tag:"Infinitive",reason:"to-dream-of"}],[{match:"(slowly|quickly) [#Adjective]",group:0,tag:"Verb",reason:"slowly-adj"},{match:"does (#Adverb|not)? [#Adjective]",group:0,tag:"PresentTense",reason:"does-mean"},{match:"[(fine|okay|cool|ok)] by me",group:0,tag:"Adjective",reason:"okay-by-me"},{match:"i (#Adverb|do)? not? [mean]",group:0,tag:"PresentTense",reason:"i-mean"},{match:"will #Adjective",tag:"Auxiliary Infinitive",reason:"will-adj"},{match:"#Pronoun [#Adjective] #Determiner #Adjective? #Noun",group:0,tag:"Verb",reason:"he-adj-the"},{match:"#Copula [%Adj|Present%] to #Verb",group:0,tag:"Verb",reason:"adj-to"},{match:"#Copula [#Adjective] (well|badly|quickly|slowly)",group:0,tag:"Verb",reason:"done-well"},{match:"#Adjective and [#Gerund] !#Preposition?",group:0,tag:"Adjective",reason:"rude-and-x"},{match:"#Copula #Adverb? (over|under) [#PastTense]",group:0,tag:"Adjective",reason:"over-cooked"},{match:"#Copula #Adjective+ (and|or) [#PastTense]$",group:0,tag:"Adjective",reason:"bland-and-overcooked"},{match:"got #Adverb? [#PastTense] of",group:0,tag:"Adjective",reason:"got-tired-of"},{match:"(seem|seems|seemed|appear|appeared|appears|feel|feels|felt|sound|sounds|sounded) (#Adverb|#Adjective)? [#PastTense]",group:0,tag:"Adjective",reason:"felt-loved"},{match:"(seem|feel|seemed|felt) [#PastTense #Particle?]",group:0,tag:"Adjective",reason:"seem-confused"},{match:"a (bit|little|tad) [#PastTense #Particle?]",group:0,tag:"Adjective",reason:"a-bit-confused"},{match:"not be [%Adj|Past% #Particle?]",group:0,tag:"Adjective",reason:"do-not-be-confused"},{match:"#Copula just [%Adj|Past% #Particle?]",group:0,tag:"Adjective",reason:"is-just-right"},{match:"as [#Infinitive] as",group:0,tag:"Adjective",reason:"as-pale-as"},{match:"[%Adj|Past%] and #Adjective",group:0,tag:"Adjective",reason:"faled-and-oppressive"},{match:"or [#PastTense] #Noun",group:0,tag:"Adjective",notIf:"(#Copula|#Pronoun)",reason:"or-heightened-emotion"},{match:"(become|became|becoming|becomes) [#Verb]",group:0,tag:"Adjective",reason:"become-verb"},{match:"#Possessive [#PastTense] #Noun",group:0,tag:"Adjective",reason:"declared-intentions"},{match:"#Copula #Pronoun [%Adj|Present%]",group:0,tag:"Adjective",reason:"is-he-cool"},{match:"#Copula [%Adj|Past%] with",group:0,tag:"Adjective",notIf:"(associated|worn|baked|aged|armed|bound|fried|loaded|mixed|packed|pumped|filled|sealed)",reason:"is-crowded-with"},{match:"#Copula #Adverb? [%Adj|Present%]$",group:0,tag:"Adjective",reason:"was-empty$"}],[{match:"will (#Adverb|not)+? [have] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"will-have-vb"},{match:"[#Copula] (#Adverb|not)+? (#Gerund|#PastTense)",group:0,tag:"Auxiliary",reason:"copula-walking"},{match:"[(#Modal|did)+] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"modal-verb"},{match:"#Modal (#Adverb|not)+? [have] (#Adverb|not)+? [had] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"would-have"},{match:"[(has|had)] (#Adverb|not)+? #PastTense",group:0,tag:"Auxiliary",reason:"had-walked"},{match:"[(do|does|did|will|have|had|has|got)] (not|#Adverb)+? #Verb",group:0,tag:"Auxiliary",reason:"have-had"},{match:"[about to] #Adverb? #Verb",group:0,tag:["Auxiliary","Verb"],reason:"about-to"},{match:"#Modal (#Adverb|not)+? [be] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"would-be"},{match:"[(#Modal|had|has)] (#Adverb|not)+? [been] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"had-been"},{match:"[(be|being|been)] #Participle",group:0,tag:"Auxiliary",reason:"being-driven"},{match:"[may] #Adverb? #Infinitive",group:0,tag:"Auxiliary",reason:"may-want"},{match:"#Copula (#Adverb|not)+? [(be|being|been)] #Adverb+? #PastTense",group:0,tag:"Auxiliary",reason:"being-walked"},{match:"will [be] #PastTense",group:0,tag:"Auxiliary",reason:"will-be-x"},{match:"[(be|been)] (#Adverb|not)+? #Gerund",group:0,tag:"Auxiliary",reason:"been-walking"},{match:"[used to] #PresentTense",group:0,tag:"Auxiliary",reason:"used-to-walk"},{match:"#Copula (#Adverb|not)+? [going to] #Adverb+? #PresentTense",group:0,tag:"Auxiliary",reason:"going-to-walk"},{match:"#Imperative [(me|him|her)]",group:0,tag:"Reflexive",reason:"tell-him"},{match:"(is|was) #Adverb? [no]",group:0,tag:"Negative",reason:"is-no"},{match:"[(been|had|became|came)] #PastTense",group:0,notIf:"#PhrasalVerb",tag:"Auxiliary",reason:"been-told"},{match:"[(being|having|getting)] #Verb",group:0,tag:"Auxiliary",reason:"being-born"},{match:"[be] #Gerund",group:0,tag:"Auxiliary",reason:"be-walking"},{match:"[better] #PresentTense",group:0,tag:"Modal",notIf:"(#Copula|#Gerund)",reason:"better-go"},{match:"even better",tag:"Adverb #Comparative",reason:"even-better"}],[{match:"(#Verb && @hasHyphen) up",tag:"PhrasalVerb",reason:"foo-up"},{match:"(#Verb && @hasHyphen) off",tag:"PhrasalVerb",reason:"foo-off"},{match:"(#Verb && @hasHyphen) over",tag:"PhrasalVerb",reason:"foo-over"},{match:"(#Verb && @hasHyphen) out",tag:"PhrasalVerb",reason:"foo-out"},{match:"[#Verb (in|out|up|down|off|back)] (on|in)",notIf:"#Copula",tag:"PhrasalVerb Particle",reason:"walk-in-on"},{match:"(lived|went|crept|go) [on] for",group:0,tag:"PhrasalVerb",reason:"went-on"},{match:"#Verb (up|down|in|on|for)$",tag:"PhrasalVerb #Particle",notIf:"#PhrasalVerb",reason:"come-down$"},{match:"help [(stop|end|make|start)]",group:0,tag:"Infinitive",reason:"help-stop"},{match:"#PhrasalVerb (in && #Particle) #Determiner",tag:"#Verb #Preposition #Determiner",unTag:"PhrasalVerb",reason:"work-in-the"},{match:"[(stop|start|finish|help)] #Gerund",group:0,tag:"Infinitive",reason:"start-listening"},{match:"#Verb (him|her|it|us|himself|herself|itself|everything|something) [(up|down)]",group:0,tag:"Adverb",reason:"phrasal-pronoun-advb"}],[{match:"^do not? [#Infinitive #Particle?]",notIf:Vl,group:0,tag:"Imperative",reason:"do-eat"},{match:"^please do? not? [#Infinitive #Particle?]",group:0,tag:"Imperative",reason:"please-go"},{match:"^just do? not? [#Infinitive #Particle?]",group:0,tag:"Imperative",reason:"just-go"},{match:"^[#Infinitive] it #Comparative",notIf:Vl,group:0,tag:"Imperative",reason:"do-it-better"},{match:"^[#Infinitive] it (please|now|again|plz)",notIf:Vl,group:0,tag:"Imperative",reason:"do-it-please"},{match:"^[#Infinitive] (#Adjective|#Adverb)$",group:0,tag:"Imperative",notIf:"(so|such|rather|enough)",reason:"go-quickly"},{match:"^[#Infinitive] (up|down|over) #Determiner",group:0,tag:"Imperative",reason:"turn-down"},{match:"^[#Infinitive] (your|my|the|a|an|any|each|every|some|more|with|on)",group:0,notIf:"like",tag:"Imperative",reason:"eat-my-shorts"},{match:"^[#Infinitive] (him|her|it|us|me|there)",group:0,tag:"Imperative",reason:"tell-him"},{match:"^[#Infinitive] #Adjective #Noun$",group:0,tag:"Imperative",reason:"avoid-loud-noises"},{match:"^[#Infinitive] (#Adjective|#Adverb)? and #Infinitive",group:0,tag:"Imperative",reason:"call-and-reserve"},{match:"^(go|stop|wait|hurry) please?$",tag:"Imperative",reason:"go"},{match:"^(somebody|everybody) [#Infinitive]",group:0,tag:"Imperative",reason:"somebody-call"},{match:"^let (us|me) [#Infinitive]",group:0,tag:"Imperative",reason:"lets-leave"},{match:"^[(shut|close|open|start|stop|end|keep)] #Determiner #Noun",group:0,tag:"Imperative",reason:"shut-the-door"},{match:"^[#PhrasalVerb #Particle] #Determiner #Noun",group:0,tag:"Imperative",reason:"turn-off-the-light"},{match:"^[go] to .",group:0,tag:"Imperative",reason:"go-to-toronto"},{match:"^#Modal you [#Infinitive]",group:0,tag:"Imperative",reason:"would-you-"},{match:"^never [#Infinitive]",group:0,tag:"Imperative",reason:"never-stop"},{match:"^come #Infinitive",tag:"Imperative",notIf:"on",reason:"come-have"},{match:"^come and? #Infinitive",tag:"Imperative . Imperative",notIf:"#PhrasalVerb",reason:"come-and-have"},{match:"^stay (out|away|back)",tag:"Imperative",reason:"stay-away"},{match:"^[(stay|be|keep)] #Adjective",group:0,tag:"Imperative",reason:"stay-cool"},{match:"^[keep it] #Adjective",group:0,tag:"Imperative",reason:"keep-it-cool"},{match:"^do not [#Infinitive]",group:0,tag:"Imperative",reason:"do-not-be"},{match:"[#Infinitive] (yourself|yourselves)",group:0,tag:"Imperative",reason:"allow-yourself"},{match:"[#Infinitive] what .",group:0,tag:"Imperative",reason:"look-what"},{match:"^[#Infinitive] #Gerund",group:0,tag:"Imperative",reason:"keep-playing"},{match:"^[#Infinitive] (to|for|into|toward|here|there)",group:0,tag:"Imperative",reason:"go-to"},{match:"^[#Infinitive] (and|or) #Infinitive",group:0,tag:"Imperative",reason:"inf-and-inf"},{match:"^[%Noun|Verb%] to",group:0,tag:"Imperative",reason:"commit-to"},{match:"^[#Infinitive] #Adjective? #Singular #Singular",group:0,tag:"Imperative",reason:"maintain-eye-contact"},{match:"do not (forget|omit|neglect) to [#Infinitive]",group:0,tag:"Imperative",reason:"do-not-forget"},{match:"^[(ask|wear|pay|look|help|show|watch|act|fix|kill|stop|start|turn|try|win)] #Noun",group:0,tag:"Imperative",reason:"pay-attention"}],[{match:"(that|which) were [%Adj|Gerund%]",group:0,tag:"Gerund",reason:"that-were-growing"},{match:"#Gerund [#Gerund] #Plural",group:0,tag:"Adjective",reason:"hard-working-fam"}],[{match:"u r",tag:"#Pronoun #Copula",reason:"u r"},{match:"#Noun [(who|whom)]",group:0,tag:"Determiner",reason:"captain-who"},{match:"[had] #Noun+ #PastTense",group:0,tag:"Condition",reason:"had-he"},{match:"[were] #Noun+ to #Infinitive",group:0,tag:"Condition",reason:"were-he"},{match:"some sort of",tag:"Adjective Noun Conjunction",reason:"some-sort-of"},{match:"of some sort",tag:"Conjunction Adjective Noun",reason:"of-some-sort"},{match:"[such] (a|an|is)? #Noun",group:0,tag:"Determiner",reason:"such-skill"},{match:"[right] (before|after|in|into|to|toward)",group:0,tag:"#Adverb",reason:"right-into"},{match:"#Preposition [about]",group:0,tag:"Adjective",reason:"at-about"},{match:"(are|#Modal|see|do|for) [ya]",group:0,tag:"Pronoun",reason:"are-ya"},{match:"[long live] .",group:0,tag:"#Adjective #Infinitive",reason:"long-live"},{match:"[plenty] of",group:0,tag:"#Uncountable",reason:"plenty-of"},{match:"(always|nearly|barely|practically) [there]",group:0,tag:"Adjective",reason:"always-there"},{match:"[there] (#Adverb|#Pronoun)? #Copula",group:0,tag:"There",reason:"there-is"},{match:"#Copula [there] .",group:0,tag:"There",reason:"is-there"},{match:"#Modal #Adverb? [there]",group:0,tag:"There",reason:"should-there"},{match:"^[do] (you|we|they)",group:0,tag:"QuestionWord",reason:"do-you"},{match:"^[does] (he|she|it|#ProperNoun)",group:0,tag:"QuestionWord",reason:"does-he"},{match:"#Determiner #Noun+ [who] #Verb",group:0,tag:"Preposition",reason:"the-x-who"},{match:"#Determiner #Noun+ [which] #Verb",group:0,tag:"Preposition",reason:"the-x-which"},{match:"a [while]",group:0,tag:"Noun",reason:"a-while"},{match:"guess who",tag:"#Infinitive #QuestionWord",reason:"guess-who"},{match:"[fucking] !#Verb",group:0,tag:"#Gerund",reason:"f-as-gerund"}],[{match:"university of #Place",tag:"Organization",reason:"university-of-Foo"},{match:"#Noun (&|n) #Noun",tag:"Organization",reason:"Noun-&-Noun"},{match:"#Organization of the? #ProperNoun",tag:"Organization",reason:"org-of-place",safe:!0},{match:"#Organization #Country",tag:"Organization",reason:"org-country"},{match:"#ProperNoun #Organization",tag:"Organization",notIf:"#FirstName",reason:"titlecase-org"},{match:"#ProperNoun (ltd|co|inc|dept|assn|bros)",tag:"Organization",reason:"org-abbrv"},{match:"the [#Acronym]",group:0,tag:"Organization",reason:"the-acronym",safe:!0},{match:"government of the? [#Place+]",tag:"Organization",reason:"government-of-x"},{match:"(health|school|commerce) board",tag:"Organization",reason:"school-board"},{match:"(nominating|special|conference|executive|steering|central|congressional) committee",tag:"Organization",reason:"special-comittee"},{match:"(world|global|international|national|#Demonym) #Organization",tag:"Organization",reason:"global-org"},{match:"#Noun+ (public|private) school",tag:"School",reason:"noun-public-school"},{match:"#Place+ #SportsTeam",tag:"SportsTeam",reason:"place-sportsteam"},{match:"(dc|atlanta|minnesota|manchester|newcastle|sheffield) united",tag:"SportsTeam",reason:"united-sportsteam"},{match:"#Place+ fc",tag:"SportsTeam",reason:"fc-sportsteam"},{match:"#Place+ #Noun{0,2} (club|society|group|team|committee|commission|association|guild|crew)",tag:"Organization",reason:"place-noun-society"}],[{match:"(west|north|south|east|western|northern|southern|eastern)+ #Place",tag:"Region",reason:"west-norfolk"},{match:"#City [(al|ak|az|ar|ca|ct|dc|fl|ga|id|il|nv|nh|nj|ny|oh|pa|sc|tn|tx|ut|vt|pr)]",group:0,tag:"Region",reason:"us-state"},{match:"portland [or]",group:0,tag:"Region",reason:"portland-or"},{match:"#ProperNoun+ (cliff|place|range|pit|place|point|room|grounds|ruins)",tag:"Place",reason:"foo-point"},{match:"in [#ProperNoun] #Place",group:0,tag:"Place",reason:"propernoun-place"},{match:"#Value #Noun (st|street|rd|road|crescent|cr|way|tr|terrace|avenue|ave)",tag:"Address",reason:"address-st"},{match:"(port|mount|mt) #ProperName",tag:"Place",reason:"port-name"}],[{match:"[so] #Noun",group:0,tag:"Conjunction",reason:"so-conj"},{match:"[(who|what|where|why|how|when)] #Noun #Copula #Adverb? (#Verb|#Adjective)",group:0,tag:"Conjunction",reason:"how-he-is-x"},{match:"#Copula [(who|what|where|why|how|when)] #Noun",group:0,tag:"Conjunction",reason:"when-he"},{match:"#Verb [that] #Pronoun",group:0,tag:"Conjunction",reason:"said-that-he"},{match:"#Noun [that] #Copula",group:0,tag:"Conjunction",reason:"that-are"},{match:"#Noun [that] #Verb #Adjective",group:0,tag:"Conjunction",reason:"that-seem"},{match:"#Noun #Copula not? [that] #Adjective",group:0,tag:"Adverb",reason:"that-adj"},{match:"#Verb #Adverb? #Noun [(that|which)]",group:0,tag:"Preposition",reason:"that-prep"},{match:"@hasComma [which] (#Pronoun|#Verb)",group:0,tag:"Preposition",reason:"which-copula"},{match:"#Noun [like] #Noun",group:0,tag:"Preposition",reason:"noun-like"},{match:"^[like] #Determiner",group:0,tag:"Preposition",reason:"like-the"},{match:"a #Noun [like] (#Noun|#Determiner)",group:0,tag:"Preposition",reason:"a-noun-like"},{match:"#Adverb [like]",group:0,tag:"Verb",reason:"really-like"},{match:"(not|nothing|never) [like]",group:0,tag:"Preposition",reason:"nothing-like"},{match:"#Infinitive #Pronoun [like]",group:0,tag:"Preposition",reason:"treat-them-like"},{match:"[#QuestionWord] (#Pronoun|#Determiner)",group:0,tag:"Preposition",reason:"how-he"},{match:"[#QuestionWord] #Participle",group:0,tag:"Preposition",reason:"when-stolen"},{match:"[how] (#Determiner|#Copula|#Modal|#PastTense)",group:0,tag:"QuestionWord",reason:"how-is"},{match:"#Plural [(who|which|when)] .",group:0,tag:"Preposition",reason:"people-who"}],[{match:"holy (shit|fuck|hell)",tag:"Expression",reason:"swears-expression"},{match:"^[(well|so|okay|now)] !#Adjective?",group:0,tag:"Expression",reason:"well-"},{match:"^come on",tag:"Expression",reason:"come-on"},{match:"(say|says|said) [sorry]",group:0,tag:"Expression",reason:"say-sorry"},{match:"^(ok|alright|shoot|hell|anyways)",tag:"Expression",reason:"ok-"},{match:"^(say && @hasComma)",tag:"Expression",reason:"say-"},{match:"^(like && @hasComma)",tag:"Expression",reason:"like-"},{match:"^[(dude|man|girl)] #Pronoun",group:0,tag:"Expression",reason:"dude-i"}]);let Bl=null;var Sl={postTagger:function(e){const{world:t}=e,{model:n,methods:r}=t;Bl=Bl||r.one.buildNet(n.two.matches,t);const o=r.two.quickSplit(e.document).map((e=>{const t=e[0];return[t.index[0],t.index[1],t.index[1]+e.length]})),a=e.update(o);return a.cache(),a.sweep(Bl),e.uncache(),e.unfreeze(),e},tagger:e=>e.compute(["freeze","lexicon","preTagger","postTagger","unfreeze"])};const $l={api:function(e){e.prototype.confidence=function(){let e=0,t=0;return this.docs.forEach((n=>{n.forEach((n=>{t+=1,e+=n.confidence||1}))})),0===t?1:(e=>Math.round(100*e)/100)(e/t)},e.prototype.tagger=function(){return this.compute(["tagger"])}},compute:Sl,model:{two:{matches:zl}},hooks:["postTagger"]},Ml=function(e,t){const n=function(e){return Object.keys(e.hooks).filter((e=>!e.startsWith("#")&&!e.startsWith("%")))}(t);if(0===n.length)return e;e._cache||e.cache();const r=e._cache;return e.filter(((e,t)=>n.some((e=>r[t].has(e)))))};var Ll={lib:{lazy:function(e,t){let n=t;"string"==typeof t&&(n=this.buildNet([{match:t}]));const r=this.tokenize(e),o=Ml(r,n);return o.found?(o.compute(["index","tagger"]),o.match(t)):r.none()}}};const Kl=function(e,t,n){let r=e.split(/ /g).map((e=>e.toLowerCase().trim()));r=r.filter((e=>e)),r=r.map((e=>`{${e}}`)).join(" ");let o=this.match(r);return n&&(o=o.if(n)),o.has("#Verb")?function(e,t){let n=t;return e.forEach((e=>{e.has("#Infinitive")||(n=function(e,t){const n=(0,e.methods.two.transform.verb.conjugate)(t,e.model);return e.has("#Gerund")?n.Gerund:e.has("#PastTense")?n.PastTense:e.has("#PresentTense")?n.PresentTense:e.has("#Gerund")?n.Gerund:t}(e,t)),e.replaceWith(n)})),e}(o,t):o.has("#Noun")?function(e,t){let n=t;e.has("#Plural")&&(n=(0,e.methods.two.transform.noun.toPlural)(t,e.model));e.replaceWith(n,{possessives:!0})}(o,t):o.has("#Adverb")?function(e,t){const{toAdverb:n}=e.methods.two.transform.adjective,r=n(t);r&&e.replaceWith(r)}(o,t):o.has("#Adjective")?function(e,t){const{toComparative:n,toSuperlative:r}=e.methods.two.transform.adjective;let o=t;e.has("#Comparative")?o=n(o,e.model):e.has("#Superlative")&&(o=r(o,e.model)),o&&e.replaceWith(o)}(o,t):this};var Jl={api:function(e){e.prototype.swap=Kl}};h.plugin(cl),h.plugin(Ol),h.plugin($l),h.plugin(Ll),h.plugin(Jl);const Wl=function(e){const{fromComparative:t,fromSuperlative:n}=e.methods.two.transform.adjective,r=e.text("normal");return e.has("#Comparative")?t(r,e.model):e.has("#Superlative")?n(r,e.model):r};var ql={api:function(e){class Adjectives extends e{constructor(e,t,n){super(e,t,n),this.viewType="Adjectives"}json(e={}){const{toAdverb:t,toNoun:n,toSuperlative:r,toComparative:o}=this.methods.two.transform.adjective;return e.normal=!0,this.map((a=>{const i=a.toView().json(e)[0]||{},s=Wl(a);return i.adjective={adverb:t(s,this.model),noun:n(s,this.model),superlative:r(s,this.model),comparative:o(s,this.model)},i}),[])}adverbs(){return this.before("#Adverb+$").concat(this.after("^#Adverb+"))}conjugate(e){const{toComparative:t,toSuperlative:n,toNoun:r,toAdverb:o}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const a=Wl(e);return{Adjective:a,Comparative:t(a,this.model),Superlative:n(a,this.model),Noun:r(a,this.model),Adverb:o(a,this.model)}}),[])}toComparative(e){const{toComparative:t}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const n=Wl(e),r=t(n,this.model);return e.replaceWith(r)}))}toSuperlative(e){const{toSuperlative:t}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const n=Wl(e),r=t(n,this.model);return e.replaceWith(r)}))}toAdverb(e){const{toAdverb:t}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const n=Wl(e),r=t(n,this.model);return e.replaceWith(r)}))}toNoun(e){const{toNoun:t}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const n=Wl(e),r=t(n,this.model);return e.replaceWith(r)}))}}e.prototype.adjectives=function(e){let t=this.match("#Adjective");return t=t.getNth(e),new Adjectives(t.document,t.pointer)},e.prototype.superlatives=function(e){let t=this.match("#Superlative");return t=t.getNth(e),new Adjectives(t.document,t.pointer)},e.prototype.comparatives=function(e){let t=this.match("#Comparative");return t=t.getNth(e),new Adjectives(t.document,t.pointer)}}};var Ul={api:function(e){class Adverbs extends e{constructor(e,t,n){super(e,t,n),this.viewType="Adverbs"}conjugate(e){return this.getNth(e).map((e=>{const t=function(e){return e.compute("root").text("root")}(e);return{Adverb:e.text("normal"),Adjective:t}}),[])}json(e={}){const t=this.methods.two.transform.adjective.fromAdverb;return e.normal=!0,this.map((n=>{const r=n.toView().json(e)[0]||{};return r.adverb={adjective:t(r.normal)},r}),[])}}e.prototype.adverbs=function(e){let t=this.match("#Adverb");return t=t.getNth(e),new Adverbs(t.document,t.pointer)}}};const Rl=function(e){let t=this;t=function(e){let t=e.parentheses();return t=t.filter((e=>e.wordCount()>=3&&e.has("#Verb")&&e.has("#Noun"))),e.splitOn(t)}(t),t=function(e){let t=e.quotations();return t=t.filter((e=>e.wordCount()>=3&&e.has("#Verb")&&e.has("#Noun"))),e.splitOn(t)}(t),t=function(e){let t=e.match("@hasComma");return t=t.filter((e=>{if(1===e.growLeft(".").wordCount())return!1;if(1===e.growRight(". .").wordCount())return!1;let t=e.grow(".");return t=t.ifNo("@hasComma @hasComma"),t=t.ifNo("@hasComma (and|or) ."),t=t.ifNo("(#City && @hasComma) #Country"),t=t.ifNo("(#WeekDay && @hasComma) #Date"),t=t.ifNo("(#Date+ && @hasComma) #Value"),t=t.ifNo("(#Adjective && @hasComma) #Adjective"),t.found})),e.splitAfter(t)}(t),t=t.splitAfter("(@hasEllipses|@hasSemicolon|@hasDash|@hasColon)"),t=t.splitAfter("^#Pronoun (said|says)"),t=t.splitBefore("(said|says) #ProperNoun$"),t=t.splitBefore(". . if .{4}"),t=t.splitBefore("and while"),t=t.splitBefore("now that"),t=t.splitBefore("ever since"),t=t.splitBefore("(supposing|although)"),t=t.splitBefore("even (while|if|though)"),t=t.splitBefore("(whereas|whose)"),t=t.splitBefore("as (though|if)"),t=t.splitBefore("(til|until)");const n=t.match("#Verb .* [but] .* #Verb",0);n.found&&(t=t.splitBefore(n));const r=t.if("if .{2,9} then .").match("then");return t=t.splitBefore(r),"number"==typeof e&&(t=t.get(e)),t},Ql={this:"Noun",then:"Pivot"},Zl=[{match:"[that] #Determiner #Noun",group:0,chunk:"Pivot"},{match:"#PastTense [that]",group:0,chunk:"Pivot"},{match:"[so] #Determiner",group:0,chunk:"Pivot"},{match:"#Copula #Adverb+? [#Adjective]",group:0,chunk:"Adjective"},{match:"#Adjective and #Adjective",chunk:"Adjective"},{match:"#Adverb+ and #Adverb #Verb",chunk:"Verb"},{match:"#Gerund #Adjective$",chunk:"Verb"},{match:"#Gerund to #Verb",chunk:"Verb"},{match:"#PresentTense and #PresentTense",chunk:"Verb"},{match:"#Adverb #Negative",chunk:"Verb"},{match:"(want|wants|wanted) to #Infinitive",chunk:"Verb"},{match:"#Verb #Reflexive",chunk:"Verb"},{match:"#Verb [to] #Adverb? #Infinitive",group:0,chunk:"Verb"},{match:"[#Preposition] #Gerund",group:0,chunk:"Verb"},{match:"#Infinitive [that] ",group:0,chunk:"Verb"},{match:"#Noun of #Determiner? #Noun",chunk:"Noun"},{match:"#Value+ #Adverb? #Adjective",chunk:"Noun"},{match:"the [#Adjective] #Noun",chunk:"Noun"},{match:"#Singular in #Determiner? #Singular",chunk:"Noun"},{match:"#Plural [in] #Determiner? #Noun",group:0,chunk:"Pivot"},{match:"#Noun and #Determiner? #Noun",notIf:"(#Possessive|#Pronoun)",chunk:"Noun"}];let _l=null;const Xl=function(e,t){if(("undefined"!=typeof process&&process.env?process.env:self.env||{}).DEBUG_CHUNKS){const n=(e.normal+"'").padEnd(8);console.log(` | '${n} → �[34m${t.padEnd(12)}�[0m �[2m -fallback- �[0m`)}e.chunk=t};var Yl={chunks:function(e){const{document:t,world:n}=e;!function(e){for(let t=0;t{for(let r=0;r{if("Verb"===e.chunk){const t=e.terms.find((e=>e.tags.has("Verb")));t||e.terms.forEach((e=>e.chunk=null))}}))}(t)}},eu={compute:Yl,api:function(e){class Chunks extends e{constructor(e,t,n){super(e,t,n),this.viewType="Chunks"}isVerb(){return this.filter((e=>e.has("")))}isNoun(){return this.filter((e=>e.has("")))}isAdjective(){return this.filter((e=>e.has("")))}isPivot(){return this.filter((e=>e.has("")))}debug(){return this.toView().debug("chunks"),this}update(e){const t=new Chunks(this.document,e);return t._cache=this._cache,t}}e.prototype.chunks=function(e){let t=function(e){const t=[];let n=null;return e.clauses().docs.forEach((e=>{e.forEach((e=>{e.chunk&&e.chunk===n?t[t.length-1][2]=e.index[1]+1:(n=e.chunk,t.push([e.index[0],e.index[1],e.index[1]+1]))})),n=null})),e.update(t)}(this);return t=t.getNth(e),new Chunks(this.document,t.pointer)},e.prototype.clauses=Rl},hooks:["chunks"]};const tu=/\./g,nu=/\(/,ru=/\)/,ou=function(e,t){for(;t{e[0].pre=e[0].pre.replace(nu,"");const t=e[e.length-1];t.post=t.post.replace(ru,"")})),e}(this)}}e.prototype.parentheses=function(e){let t=function(e){const t=[];return e.docs.forEach((e=>{for(let n=0;n{e[0].pre=e[0].pre.replace(lu,"");const t=e[e.length-1];t.post=t.post.replace(uu,"")}))}(this)}}e.prototype.quotations=function(e){let t=function(e){const t=[];return e.docs.forEach((e=>{for(let n=0;n{e.forEach((e=>{e.text=e.text.replace(tu,""),e.normal=e.normal.replace(tu,"")}))})),this}addPeriods(){return this.docs.forEach((e=>{e.forEach((e=>{e.text=e.text.replace(tu,""),e.normal=e.normal.replace(tu,""),e.text=e.text.split("").join(".")+".",e.normal=e.normal.split("").join(".")+"."}))})),this}}e.prototype.acronyms=function(e){let t=this.match("#Acronym");return t=t.getNth(e),new Acronyms(t.document,t.pointer)}}(e),au(e),function(e){class Possessives extends e{constructor(e,t,n){super(e,t,n),this.viewType="Possessives"}strip(){return this.docs.forEach((e=>{e.forEach((e=>{e.text=e.text.replace(iu,""),e.normal=e.normal.replace(iu,"")}))})),this}}e.prototype.possessives=function(e){let t=function(e){let t=e.match("#Possessive+");return t.has("#Person")&&(t=t.growLeft("#Person+")),t.has("#Place")&&(t=t.growLeft("#Place+")),t.has("#Organization")&&(t=t.growLeft("#Organization+")),t}(this);return t=t.getNth(e),new Possessives(t.document,t.pointer)}}(e),hu(e),function(e){gu.forEach((t=>{e.prototype[t[0]]=function(e){const n=this.match(t[1]);return"number"==typeof e?n.get(e):n}})),e.prototype.phoneNumbers=du,mu.forEach((t=>{e.prototype[t[0]]=e.prototype[t[1]]}))}(e),function(e){class Slashes extends e{constructor(e,t,n){super(e,t,n),this.viewType="Slashes"}split(){return this.map((e=>{const t=e.text().split(pu);return(e=e.replaceWith(t.join(" "))).growRight("("+t.join("|")+")+")}))}}e.prototype.slashes=function(e){let t=this.match("#SlashedTerm");return t=t.getNth(e),new Slashes(t.document,t.pointer)}}(e)}};const bu=function(e,t){e.docs.forEach((e=>{e.forEach(t)}))};var vu={case:e=>{bu(e,(e=>{e.text=e.text.toLowerCase()}))},unicode:e=>{const t=e.world,n=t.methods.one.killUnicode;bu(e,(e=>e.text=n(e.text,t)))},whitespace:e=>{bu(e,(e=>{e.post=e.post.replace(/\s+/g," "),e.post=e.post.replace(/\s([.,?!:;])/g,"$1"),e.pre=e.pre.replace(/\s+/g,"")}))},punctuation:e=>{bu(e,(e=>{e.post=e.post.replace(/[–—-]/g," "),e.post=e.post.replace(/[,:;]/g,""),e.post=e.post.replace(/\.{2,}/g,""),e.post=e.post.replace(/\?{2,}/g,"?"),e.post=e.post.replace(/!{2,}/g,"!"),e.post=e.post.replace(/\?!+/g,"?")}));const t=e.docs,n=t[t.length-1];if(n&&n.length>0){const e=n[n.length-1];e.post=e.post.replace(/ /g,"")}},contractions:e=>{e.contractions().expand()},acronyms:e=>{e.acronyms().strip()},parentheses:e=>{e.parentheses().strip()},possessives:e=>{e.possessives().strip()},quotations:e=>{e.quotations().strip()},emoji:e=>{e.emojis().remove()},honorifics:e=>{e.match("#Honorific+ #Person").honorifics().remove()},adverbs:e=>{e.adverbs().remove()},nouns:e=>{e.nouns().toSingular()},verbs:e=>{e.verbs().toInfinitive()},numbers:e=>{e.numbers().toNumber()},debullet:e=>{const t=/^\s*([-–—*•])\s*$/;return e.docs.forEach((e=>{t.test(e[0].pre)&&(e[0].pre=e[0].pre.replace(t,""))})),e}};const yu=e=>e.split("|").reduce(((e,t)=>(e[t]=!0,e)),{}),wu="unicode|punctuation|whitespace|acronyms",ku="|case|contractions|parentheses|quotations|emoji|honorifics|debullet",Pu={light:yu(wu),medium:yu(wu+ku),heavy:yu(wu+ku+"|possessives|adverbs|nouns|verbs")};var Au={api:function(e){e.prototype.normalize=function(e="light"){return"string"==typeof e&&(e=Pu[e]),Object.keys(e).forEach((t=>{vu.hasOwnProperty(t)&&vu[t](this,e[t])})),this}}};const Cu=["after","although","as if","as long as","as","because","before","even if","even though","ever since","if","in order that","provided that","since","so that","than","that","though","unless","until","what","whatever","when","whenever","where","whereas","wherever","whether","which","whichever","who","whoever","whom","whomever","whose"],Nu=function(e){if(e.before("#Preposition$").found)return!0;if(!e.before().found)return!1;for(let t=0;t3&&n.endsWith("s")&&!n.endsWith("ss")},xu=function(e){const t=function(e){let t=e.clone();return t=t.match("#Noun+"),t=t.remove("(#Adjective|#Preposition|#Determiner|#Value)"),t=t.not("#Possessive"),t=t.first(),t.found?t:e}(e);return{determiner:e.match("#Determiner").eq(0),adjectives:e.match("#Adjective"),number:e.values(),isPlural:ju(e,t),isSubordinate:Nu(e),root:t}},Iu=e=>e.text(),Tu=e=>e.json({terms:!1,normal:!0}).map((e=>e.normal)),Du=function(e){if(!e.found)return null;const t=e.values(0);if(t.found){return(t.parse()[0]||{}).num}return null},Hu=function(e){return!e.has("^(#Uncountable|#ProperNoun|#Place|#Pronoun|#Acronym)+$")},Eu={tags:!0},Gu={tags:!0};var Ou={api:function(e){class Nouns extends e{constructor(e,t,n){super(e,t,n),this.viewType="Nouns"}parse(e){return this.getNth(e).map(xu)}json(e){const t="object"==typeof e?e:{};return this.getNth(e).map((e=>{const n=e.toView().json(t)[0]||{};return t&&!1!==t.noun&&(n.noun=function(e){const t=xu(e);return{root:Iu(t.root),number:Du(t.number),determiner:Iu(t.determiner),adjectives:Tu(t.adjectives),isPlural:t.isPlural,isSubordinate:t.isSubordinate}}(e)),n}),[])}conjugate(e){const t=this.world.methods.two.transform.noun;return this.getNth(e).map((e=>{const n=xu(e),r=n.root.compute("root").text("root"),o={Singular:r};return Hu(n.root)&&(o.Plural=t.toPlural(r,this.model)),o.Singular===o.Plural&&delete o.Plural,o}),[])}isPlural(e){const t=this.filter((e=>xu(e).isPlural));return t.getNth(e)}isSingular(e){const t=this.filter((e=>!xu(e).isPlural));return t.getNth(e)}adjectives(e){let t=this.update([]);return this.forEach((e=>{const n=xu(e).adjectives;n.found&&(t=t.concat(n))})),t.getNth(e)}toPlural(e){return this.getNth(e).map((e=>function(e,t){if(!0===t.isPlural)return e;if(t.root.has("#Possessive")&&(t.root=t.root.possessives().strip()),!Hu(t.root))return e;const{methods:n,model:r}=e.world,{toPlural:o}=n.two.transform.noun,a=o(t.root.text({keepPunct:!1}),r);e.match(t.root).replaceWith(a,Eu).tag("Plural","toPlural"),t.determiner.has("(a|an)")&&e.remove(t.determiner);const i=t.root.after("not? #Adverb+? [#Copula]",0);return i.found&&(i.has("is")?e.replace(i,"are"):i.has("was")&&e.replace(i,"were")),e}(e,xu(e))))}toSingular(e){return this.getNth(e).map((e=>function(e,t){if(!1===t.isPlural)return e;const{methods:n,model:r}=e.world,{toSingular:o}=n.two.transform.noun,a=o(t.root.text("normal"),r);return e.replace(t.root,a,Gu).tag("Singular","toPlural"),e}(e,xu(e))))}update(e){const t=new Nouns(this.document,e);return t._cache=this._cache,t}}e.prototype.nouns=function(e){let t=function(e){let t=e.clauses().match(""),n=t.match("@hasComma");return n=n.not("#Place"),n.found&&(t=t.splitAfter(n)),t=t.splitOn("#Expression"),t=t.splitOn("(he|she|we|you|they|i)"),t=t.splitOn("(#Noun|#Adjective) [(he|him|she|it)]",0),t=t.splitOn("[(he|him|she|it)] (#Determiner|#Value)",0),t=t.splitBefore("#Noun [(the|a|an)] #Adjective? #Noun",0),t=t.splitOn("[(here|there)] #Noun",0),t=t.splitOn("[#Noun] (here|there)",0),t=t.splitBefore("(our|my|their|your)"),t=t.splitOn("#Noun [#Determiner]",0),t=t.if("#Noun"),t}(this);return t=t.getNth(e),new Nouns(this.document,t.pointer)}}};var Fu={ones:{zeroth:0,first:1,second:2,third:3,fourth:4,fifth:5,sixth:6,seventh:7,eighth:8,ninth:9,zero:0,one:1,two:2,three:3,four:4,five:5,six:6,seven:7,eight:8,nine:9},teens:{tenth:10,eleventh:11,twelfth:12,thirteenth:13,fourteenth:14,fifteenth:15,sixteenth:16,seventeenth:17,eighteenth:18,nineteenth:19,ten:10,eleven:11,twelve:12,thirteen:13,fourteen:14,fifteen:15,sixteen:16,seventeen:17,eighteen:18,nineteen:19},tens:{twentieth:20,thirtieth:30,fortieth:40,fourtieth:40,fiftieth:50,sixtieth:60,seventieth:70,eightieth:80,ninetieth:90,twenty:20,thirty:30,forty:40,fourty:40,fifty:50,sixty:60,seventy:70,eighty:80,ninety:90},multiples:{hundredth:100,thousandth:1e3,millionth:1e6,billionth:1e9,trillionth:1e12,quadrillionth:1e15,quintillionth:1e18,sextillionth:1e21,septillionth:1e24,hundred:100,thousand:1e3,million:1e6,billion:1e9,trillion:1e12,quadrillion:1e15,quintillion:1e18,sextillion:1e21,septillion:1e24,grand:1e3}};const Vu=(e,t)=>{if(Fu.ones.hasOwnProperty(e)){if(t.ones||t.teens)return!1}else if(Fu.teens.hasOwnProperty(e)){if(t.ones||t.teens||t.tens)return!1}else if(Fu.tens.hasOwnProperty(e)&&(t.ones||t.teens||t.tens))return!1;return!0},zu=function(e){let t="0.";for(let n=0;ne=(e=(e=(e=(e=(e=(e=(e=e.replace(/1st$/,"1")).replace(/2nd$/,"2")).replace(/3rd$/,"3")).replace(/([4567890])r?th$/,"$1")).replace(/^[$€¥£¢]/,"")).replace(/[%$€¥£¢]$/,"")).replace(/,/g,"")).replace(/([0-9])([a-z\u00C0-\u00FF]{1,2})$/,"$1"),Su=/^([0-9,. ]+)\/([0-9,. ]+)$/,$u={"a few":3,"a couple":2,"a dozen":12,"two dozen":24,zero:0},Mu=e=>Object.keys(e).reduce(((t,n)=>t+=e[n]),0),Lu=function(e){if(!0===$u.hasOwnProperty(e))return $u[e];if("a"===e||"an"===e)return 1;const t=(e=>{const t=[{reg:/^(minus|negative)[\s-]/i,mult:-1},{reg:/^(a\s)?half[\s-](of\s)?/i,mult:.5}];for(let n=0;n#Value+] out of every? [#Value+]");if(!0!==t.found)return null;let{num:n,den:r}=t.groups();return n&&r?(n=Ju(n),r=Ju(r),n&&r&&"number"==typeof n&&"number"==typeof r?{numerator:n,denominator:r}:null):null}(e)||function(e){const t=e.match("[(#Cardinal|a)+] [#Fraction+]");if(!0!==t.found)return null;let{num:n,den:r}=t.groups();n=n.has("a")?1:Ju(n);let o=r.text("reduced");return Ku.test(o)&&(o=o.replace(Ku,""),r=r.replaceWith(o)),r=Wu.hasOwnProperty(o)?Wu[o]:Ju(r),"number"==typeof n&&"number"==typeof r?{numerator:n,denominator:r}:null}(e)||function(e){const t=e.match("^#Ordinal$");if(!0!==t.found)return null;if(e.lookAhead("^of ."))return{numerator:1,denominator:Ju(t)};return null}(e)||null;return null!==t&&t.numerator&&t.denominator&&(t.decimal=t.numerator/t.denominator,t.decimal=(e=>{const t=Math.round(1e3*e)/1e3;return 0===t&&0!==e?e:t})(t.decimal)),t},Uu=function(e){if(e<1e6)return String(e);let t;return t="number"==typeof e?e.toFixed(0):e,-1===t.indexOf("e+")?t:t.replace(".","").split("e+").reduce((function(e,t){return e+Array(t-e.length+2).join(0)}))},Ru=[["ninety",90],["eighty",80],["seventy",70],["sixty",60],["fifty",50],["forty",40],["thirty",30],["twenty",20]],Qu=["","one","two","three","four","five","six","seven","eight","nine","ten","eleven","twelve","thirteen","fourteen","fifteen","sixteen","seventeen","eighteen","nineteen"],Zu=[[1e24,"septillion"],[1e20,"hundred sextillion"],[1e21,"sextillion"],[1e20,"hundred quintillion"],[1e18,"quintillion"],[1e17,"hundred quadrillion"],[1e15,"quadrillion"],[1e14,"hundred trillion"],[1e12,"trillion"],[1e11,"hundred billion"],[1e9,"billion"],[1e8,"hundred million"],[1e6,"million"],[1e5,"hundred thousand"],[1e3,"thousand"],[100,"hundred"],[1,"one"]],_u=function(e){const t=[];if(e>100)return t;for(let n=0;n=Ru[n][1]&&(e-=Ru[n][1],t.push(Ru[n][0]));return Qu[e]&&t.push(Qu[e]),t},Xu=function(e){let t=e.num;if(0===t||"0"===t)return"zero";t>1e21&&(t=Uu(t));let n=[];t<0&&(n.push("minus"),t=Math.abs(t));const r=function(e){let t=e;const n=[];return Zu.forEach((r=>{if(e>=r[0]){const e=Math.floor(t/r[0]);t-=e*r[0],e&&n.push({unit:r[1],count:e})}})),n}(t);for(let e=0;e1&&n.push("and")),n=n.concat(_u(r[e].count)),n.push(t)}return n=n.concat((e=>{const t=["zero","one","two","three","four","five","six","seven","eight","nine"],n=[],r=Uu(e).match(/\.([0-9]+)/);if(!r||!r[0])return n;n.push("point");const o=r[0].split("");for(let e=0;ee)),0===n.length&&(n[0]=""),n.join(" ")},Yu={one:"first",two:"second",three:"third",five:"fifth",eight:"eighth",nine:"ninth",twelve:"twelfth",twenty:"twentieth",thirty:"thirtieth",forty:"fortieth",fourty:"fourtieth",fifty:"fiftieth",sixty:"sixtieth",seventy:"seventieth",eighty:"eightieth",ninety:"ninetieth"},ec=e=>{const t=Xu(e).split(" "),n=t[t.length-1];return Yu.hasOwnProperty(n)?t[t.length-1]=Yu[n]:t[t.length-1]=n.replace(/y$/,"i")+"th",t.join(" ")},tc=function(e){class Fractions extends e{constructor(e,t,n){super(e,t,n),this.viewType="Fractions"}parse(e){return this.getNth(e).map(qu)}get(e){return this.getNth(e).map(qu)}json(e){return this.getNth(e).map((t=>{const n=t.toView().json(e)[0],r=qu(t);return n.fraction=r,n}),[])}toDecimal(e){return this.getNth(e).forEach((e=>{const{decimal:t}=qu(e);(e=e.replaceWith(String(t),!0)).tag("NumericValue"),e.unTag("Fraction")})),this}toFraction(e){return this.getNth(e).forEach((e=>{const t=qu(e);if(t&&"number"==typeof t.numerator&&"number"==typeof t.denominator){const n=`${t.numerator}/${t.denominator}`;this.replace(e,n)}})),this}toOrdinal(e){return this.getNth(e).forEach((e=>{let t=function(e){if(!e.numerator||!e.denominator)return"";const t=Xu({num:e.numerator});let n=ec({num:e.denominator});return 2===e.denominator&&(n="half"),t&&n?(1!==e.numerator&&(n+="s"),`${t} ${n}`):""}(qu(e));e.after("^#Noun").found&&(t+=" of"),e.replaceWith(t)})),this}toCardinal(e){return this.getNth(e).forEach((e=>{const t=function(e){return e.numerator&&e.denominator?`${Xu({num:e.numerator})} out of ${Xu({num:e.denominator})}`:""}(qu(e));e.replaceWith(t)})),this}toPercentage(e){return this.getNth(e).forEach((e=>{const{decimal:t}=qu(e);let n=100*t;n=Math.round(100*n)/100,e.replaceWith(`${n}%`)})),this}}e.prototype.fractions=function(e){let t=function(e,t){let n=e.match("#Fraction+");return n=n.filter((e=>!e.lookBehind("#Value and$").found)),n=n.notIf("#Value seconds"),n}(this);return t=t.getNth(e),new Fractions(this.document,t.pointer)}},nc="twenty|thirty|forty|fifty|sixty|seventy|eighty|ninety|fourty",rc=function(e){let t=e.match("#Value+");if(t.has("#NumericValue #NumericValue")&&(t.has("#Value @hasComma #Value")?t.splitAfter("@hasComma"):t.has("#NumericValue #Fraction")?t.splitAfter("#NumericValue #Fraction"):t=t.splitAfter("#NumericValue")),t.has("#Value #Value #Value")&&!t.has("#Multiple")&&t.has("("+nc+") #Cardinal #Cardinal")&&(t=t.splitAfter("("+nc+") #Cardinal")),t.has("#Value #Value")){t.has("#NumericValue #NumericValue")&&(t=t.splitOn("#Year")),t.has("("+nc+") (eleven|twelve|thirteen|fourteen|fifteen|sixteen|seventeen|eighteen|nineteen)")&&(t=t.splitAfter("("+nc+")"));const e=t.match("#Cardinal #Cardinal");if(e.found&&!t.has("(point|decimal|#Fraction)")&&!e.has("#Cardinal (#Multiple|point|decimal)")){const n=t.has(`(one|two|three|four|five|six|seven|eight|nine) (${nc})`),r=e.has("("+nc+") #Cardinal"),o=e.has("#Multiple #Value");n||r||o||e.terms().forEach((e=>{t=t.splitOn(e)}))}t.match("#Ordinal #Ordinal").match("#TextValue").found&&!t.has("#Multiple")&&(t.has("("+nc+") #Ordinal")||(t=t.splitAfter("#Ordinal"))),t=t.splitBefore("#Ordinal [#Cardinal]",0),t.has("#TextValue #NumericValue")&&!t.has("("+nc+"|#Multiple)")&&(t=t.splitBefore("#TextValue #NumericValue"))}return t=t.splitAfter("#NumberRange"),t=t.splitBefore("#Year"),t},oc=function(e){if("string"==typeof e)return{num:Lu(e)};let t=e.text("reduced");const n=e.growRight("#Unit").match("#Unit$").text("machine"),r=/[0-9],[0-9]/.test(e.text("text"));if(1===e.terms().length&&!e.has("#Multiple")){const o=function(e,t){const n=(e=e.replace(/,/g,"")).split(/([0-9.,]*)/);let[r,o]=n,a=n.slice(2).join("");return""!==o&&t.length<2?(o=Number(o||e),"number"!=typeof o&&(o=null),a=a||"","st"!==a&&"nd"!==a&&"rd"!==a&&"th"!==a||(a=""),{prefix:r||"",num:o,suffix:a}):null}(t,e);if(null!==o)return o.hasComma=r,o.unit=n,o}let o=e.match("#Fraction{2,}$");o=!1===o.found?e.match("^#Fraction$"):o;let a=null;o.found&&(o.has("#Value and #Value #Fraction")&&(o=o.match("and #Value #Fraction")),a=qu(o),t=(e=(e=e.not(o)).not("and$")).text("reduced"));let i=0;return t&&(i=Lu(t)||0),a&&a.decimal&&(i+=a.decimal),{hasComma:r,prefix:"",num:i,suffix:"",isOrdinal:e.has("#Ordinal"),isText:e.has("#TextValue"),isFraction:e.has("#Fraction"),isMoney:e.has("#Money"),unit:n}},ac={"¢":"cents",$:"dollars","£":"pounds","¥":"yen","€":"euros","₡":"colón","฿":"baht","₭":"kip","₩":"won","₹":"rupees","₽":"ruble","₺":"liras"},ic={"%":"percent","°":"degrees"},sc=function(e){const t={suffix:"",prefix:e.prefix};return ac.hasOwnProperty(e.prefix)&&(t.suffix+=" "+ac[e.prefix],t.prefix=""),ic.hasOwnProperty(e.suffix)&&(t.suffix+=" "+ic[e.suffix]),t.suffix&&1===e.num&&(t.suffix=t.suffix.replace(/s$/,"")),!t.suffix&&e.suffix&&(t.suffix+=" "+e.suffix),t},lc=function(e,t){if("TextOrdinal"===t){const{prefix:t,suffix:n}=sc(e);return t+ec(e)+n}if("Ordinal"===t)return e.prefix+function(e){const t=e.num;if(!t&&0!==t)return null;const n=t%100;if(n>10&&n<20)return String(t)+"th";const r={0:"th",1:"st",2:"nd",3:"rd"};let o=Uu(t);const a=o.slice(o.length-1,o.length);return o+=r[a]?r[a]:"th",o}(e)+e.suffix;if("TextCardinal"===t){const{prefix:t,suffix:n}=sc(e);return t+Xu(e)+n}let n=e.num;return e.hasComma&&(n=n.toLocaleString()),e.prefix+String(n)+e.suffix},uc=function(e){if("string"==typeof e||"number"==typeof e){const t={};return t[e]=!0,t}return t=e,"[object Array]"===Object.prototype.toString.call(t)?e.reduce(((e,t)=>(e[t]=!0,e)),{}):e||{};var t},cc=function(e){class Numbers extends e{constructor(e,t,n){super(e,t,n),this.viewType="Numbers"}parse(e){return this.getNth(e).map(oc)}get(e){return this.getNth(e).map(oc).map((e=>e.num))}json(e){const t="object"==typeof e?e:{};return this.getNth(e).map((e=>{const n=e.toView().json(t)[0],r=oc(e);return n.number={prefix:r.prefix,num:r.num,suffix:r.suffix,hasComma:r.hasComma,unit:r.unit},n}),[])}units(){return this.growRight("#Unit").match("#Unit$")}isUnit(e){return function(e,t={}){return t=uc(t),e.filter((e=>{const{unit:n}=oc(e);return!(!n||!0!==t[n])}))}(this,e)}isOrdinal(){return this.if("#Ordinal")}isCardinal(){return this.if("#Cardinal")}toNumber(){const e=this.map((e=>{if(!this.has("#TextValue"))return e;const t=oc(e);if(null===t.num)return e;const n=e.has("#Ordinal")?"Ordinal":"Cardinal",r=lc(t,n);return e.replaceWith(r,{tags:!0}),e.tag("NumericValue")}));return new Numbers(e.document,e.pointer)}toLocaleString(){return this.forEach((e=>{const t=oc(e);if(null===t.num)return;let n=t.num.toLocaleString();if(e.has("#Ordinal")){const e=lc(t,"Ordinal").match(/[a-z]+$/);e&&(n+=e[0]||"")}e.replaceWith(n,{tags:!0})})),this}toText(){const e=this.map((e=>{if(e.has("#TextValue"))return e;const t=oc(e);if(null===t.num)return e;const n=e.has("#Ordinal")?"TextOrdinal":"TextCardinal",r=lc(t,n);return e.replaceWith(r,{tags:!0}),e.tag("TextValue"),e}));return new Numbers(e.document,e.pointer)}toCardinal(){const e=this.map((e=>{if(!e.has("#Ordinal"))return e;const t=oc(e);if(null===t.num)return e;const n=e.has("#TextValue")?"TextCardinal":"Cardinal",r=lc(t,n);return e.replaceWith(r,{tags:!0}),e.tag("Cardinal"),e}));return new Numbers(e.document,e.pointer)}toOrdinal(){const e=this.map((e=>{if(e.has("#Ordinal"))return e;const t=oc(e);if(null===t.num)return e;const n=e.has("#TextValue")?"TextOrdinal":"Ordinal",r=lc(t,n);return e.replaceWith(r,{tags:!0}),e.tag("Ordinal"),e}));return new Numbers(e.document,e.pointer)}isEqual(e){return this.filter((t=>oc(t).num===e))}greaterThan(e){return this.filter((t=>oc(t).num>e))}lessThan(e){return this.filter((t=>oc(t).num{const r=oc(n).num;return r>e&&r{const n=oc(t);if(n.num=e,null===n.num)return t;let r=t.has("#Ordinal")?"Ordinal":"Cardinal";t.has("#TextValue")&&(r=t.has("#Ordinal")?"TextOrdinal":"TextCardinal");let o=lc(n,r);return n.hasComma&&"Cardinal"===r&&(o=Number(o).toLocaleString()),(t=t.not("#Currency")).replaceWith(o,{tags:!0}),t}));return new Numbers(t.document,t.pointer)}add(e){if(!e)return this;"string"==typeof e&&(e=oc(e).num);const t=this.map((t=>{const n=oc(t);if(null===n.num)return t;n.num+=e;let r=t.has("#Ordinal")?"Ordinal":"Cardinal";n.isText&&(r=t.has("#Ordinal")?"TextOrdinal":"TextCardinal");const o=lc(n,r);return t.replaceWith(o,{tags:!0}),t}));return new Numbers(t.document,t.pointer)}subtract(e,t){return this.add(-1*e,t)}increment(e){return this.add(1,e)}decrement(e){return this.add(-1,e)}update(e){const t=new Numbers(this.document,e);return t._cache=this._cache,t}}Numbers.prototype.toNice=Numbers.prototype.toLocaleString,Numbers.prototype.isBetween=Numbers.prototype.between,Numbers.prototype.minus=Numbers.prototype.subtract,Numbers.prototype.plus=Numbers.prototype.add,Numbers.prototype.equals=Numbers.prototype.isEqual,e.prototype.numbers=function(e){let t=rc(this);return t=t.getNth(e),new Numbers(this.document,t.pointer)},e.prototype.percentages=function(e){let t=rc(this);return t=t.filter((e=>e.has("#Percent")||e.after("^percent"))),t=t.getNth(e),new Numbers(this.document,t.pointer)},e.prototype.money=function(e){let t=rc(this);return t=t.filter((e=>e.has("#Money")||e.after("^#Currency"))),t=t.getNth(e),new Numbers(this.document,t.pointer)},e.prototype.values=e.prototype.numbers};var hc={api:function(e){tc(e),cc(e)}};const dc={people:!0,emails:!0,phoneNumbers:!0,places:!0},gc=function(e={}){return!1!==(e=Object.assign({},dc,e)).people&&this.people().replaceWith("██████████"),!1!==e.emails&&this.emails().replaceWith("██████████"),!1!==e.places&&this.places().replaceWith("██████████"),!1!==e.phoneNumbers&&this.phoneNumbers().replaceWith("███████"),this},mc={api:function(e){e.prototype.redact=gc}},pc=function(e){let t=null;return e.has("#PastTense")?t="PastTense":e.has("#FutureTense")?t="FutureTense":e.has("#PresentTense")&&(t="PresentTense"),{tense:t}},fc=function(e){const t=function(e){let t=e;return 1===t.length?t:(t=t.if("#Verb"),1===t.length?t:(t=t.ifNo("(after|although|as|because|before|if|since|than|that|though|when|whenever|where|whereas|wherever|whether|while|why|unless|until|once)"),t=t.ifNo("^even (if|though)"),t=t.ifNo("^so that"),t=t.ifNo("^rather than"),t=t.ifNo("^provided that"),1===t.length?t:(t=t.ifNo("(that|which|whichever|who|whoever|whom|whose|whomever)"),1===t.length?t:(t=t.ifNo("(^despite|^during|^before|^through|^throughout)"),1===t.length?t:(t=t.ifNo("^#Gerund"),1===t.length?t:(0===t.length&&(t=e),t.eq(0)))))))}(e.clauses()),n=t.chunks();let r=e.none(),o=e.none(),a=e.none();return n.forEach(((e,t)=>{0!==t||e.has("")?o.found||!e.has("")?o.found&&(a=a.concat(e)):o=e:r=e})),o.found&&!r.found&&(r=o.before("+").first()),{subj:r,verb:o,pred:a,grammar:pc(o)}};var bc={api:function(e){class Sentences extends e{constructor(e,t,n){super(e,t,n),this.viewType="Sentences"}json(e={}){return this.map((t=>{const n=t.toView().json(e)[0]||{},{subj:r,verb:o,pred:a,grammar:i}=fc(t);return n.sentence={subject:r.text("normal"),verb:o.text("normal"),predicate:a.text("normal"),grammar:i},n}),[])}toPastTense(e){return this.getNth(e).map((e=>(fc(e),function(e){let t=e.verbs();const n=t.eq(0);if(n.has("#PastTense"))return e;if(n.toPastTense(),t.length>1){t=t.slice(1),t=t.filter((e=>!e.lookBehind("to$").found)),t=t.if("#PresentTense"),t=t.notIf("#Gerund");const n=e.match("to #Verb+ #Conjunction #Verb").terms();t=t.not(n),t.found&&t.verbs().toPastTense()}return e}(e))))}toPresentTense(e){return this.getNth(e).map((e=>(fc(e),function(e){let t=e.verbs();return t.eq(0).toPresentTense(),t.length>1&&(t=t.slice(1),t=t.filter((e=>!e.lookBehind("to$").found)),t=t.notIf("#Gerund"),t.found&&t.verbs().toPresentTense()),e}(e))))}toFutureTense(e){return this.getNth(e).map((e=>(fc(e),e=function(e){let t=e.verbs();if(t.eq(0).toFutureTense(),t=(e=e.fullSentence()).verbs(),t.length>1){t=t.slice(1);const e=t.filter((e=>!(e.lookBehind("to$").found||!e.has("#Copula #Gerund")&&(e.has("#Gerund")||!e.has("#Copula")&&e.has("#PresentTense")&&!e.has("#Infinitive")&&e.lookBefore("(he|she|it|that|which)$").found))));e.found&&e.forEach((e=>{if(e.has("#Copula"))return e.match("was").replaceWith("is"),void e.match("is").replaceWith("will be");e.toInfinitive()}))}return e}(e),e)))}toInfinitive(e){return this.getNth(e).map((e=>(fc(e),function(e){return e.verbs().toInfinitive(),e}(e))))}toNegative(e){return this.getNth(e).map((e=>(fc(e),function(e){return e.verbs().first().toNegative().compute("chunks"),e}(e))))}toPositive(e){return this.getNth(e).map((e=>(fc(e),function(e){return e.verbs().first().toPositive().compute("chunks"),e}(e))))}isQuestion(e){return this.questions(e)}isExclamation(e){const t=this.filter((e=>e.lastTerm().has("@hasExclamation")));return t.getNth(e)}isStatement(e){const t=this.filter((e=>!e.isExclamation().found&&!e.isQuestion().found));return t.getNth(e)}update(e){const t=new Sentences(this.document,e);return t._cache=this._cache,t}}Sentences.prototype.toPresent=Sentences.prototype.toPresentTense,Sentences.prototype.toPast=Sentences.prototype.toPastTense,Sentences.prototype.toFuture=Sentences.prototype.toFutureTense;const t={sentences:function(e){let t=this.map((e=>e.fullSentence()));return t=t.getNth(e),new Sentences(this.document,t.pointer)},questions:function(e){const t=function(e){const t=/\?/,{document:n}=e;return e.filter((e=>{const r=e.docs[0]||[],o=r[r.length-1];return!(!o||n[o.index[0]].length!==r.length)&&(!!t.test(o.post)||function(e){const t=e.clauses();return!(/\.\.$/.test(e.out("text"))||e.has("^#QuestionWord")&&e.has("@hasComma")||!e.has("or not$")&&!e.has("^#QuestionWord")&&!e.has("^(do|does|did|is|was|can|could|will|would|may) #Noun")&&!e.has("^(have|must) you")&&!t.has("(do|does|is|was) #Noun+ #Adverb? (#Adjective|#Infinitive)$"))}(e))}))}(this);return t.getNth(e)}};Object.assign(e.prototype,t)}};const vc=function(e){const t={};t.firstName=e.match("#FirstName+"),t.lastName=e.match("#LastName+"),t.honorific=e.match("#Honorific+");const n=t.lastName,r=t.firstName;return r.found&&n.found||r.found||n.found||!e.has("^#Honorific .$")||(t.lastName=e.match(".$")),t},yc="male",wc="female",kc={mr:yc,mrs:wc,miss:wc,madam:wc,king:yc,queen:wc,duke:yc,duchess:wc,baron:yc,baroness:wc,count:yc,countess:wc,prince:yc,princess:wc,sire:yc,dame:wc,lady:wc,ayatullah:yc,congressman:yc,congresswoman:wc,"first lady":wc,mx:null},Pc=function(e,t){const{firstName:n,honorific:r}=e;if(n.has("#FemaleName"))return wc;if(n.has("#MaleName"))return yc;if(r.found){let e=r.text("normal");if(e=e.replace(/\./g,""),kc.hasOwnProperty(e))return kc[e];if(/^her /.test(e))return wc;if(/^his /.test(e))return yc}const o=t.after();if(!o.has("#Person")&&o.has("#Pronoun")){const e=o.match("#Pronoun");if(e.has("(they|their)"))return null;const t=e.has("(he|his)"),n=e.has("(she|her|hers)");if(t&&!n)return yc;if(n&&!t)return wc}return null},Ac=function(e){const t=this.clauses();let n=t.people();return n=n.concat(t.places()),n=n.concat(t.organizations()),n=n.not("(someone|man|woman|mother|brother|sister|father)"),n=n.sort("seq"),n=n.getNth(e),n};var Cc={api:function(e){!function(e){class People extends e{constructor(e,t,n){super(e,t,n),this.viewType="People"}parse(e){return this.getNth(e).map(vc)}json(e){const t="object"==typeof e?e:{};return this.getNth(e).map((e=>{const n=e.toView().json(t)[0],r=vc(e);return n.person={firstName:r.firstName.text("normal"),lastName:r.lastName.text("normal"),honorific:r.honorific.text("normal"),presumed_gender:Pc(r,e)},n}),[])}presumedMale(){return this.filter((e=>e.has("(#MaleName|mr|mister|sr|jr|king|pope|prince|sir)")))}presumedFemale(){return this.filter((e=>e.has("(#FemaleName|mrs|miss|queen|princess|madam)")))}update(e){const t=new People(this.document,e);return t._cache=this._cache,t}}e.prototype.people=function(e){let t=function(e){let t=e.splitAfter("@hasComma");t=t.match("#Honorific+? #Person+");const n=t.match("#Possessive").notIf("(his|her)");return t=t.splitAfter(n),t}(this);return t=t.getNth(e),new People(this.document,t.pointer)}}(e),function(e){e.prototype.places=function(t){let n=function(e){let t=e.match("(#Place|#Address)+"),n=t.match("@hasComma");return n=n.filter((e=>!!e.has("(asia|africa|europe|america)$")||!e.has("(#City|#Region|#ProperNoun)$")||!e.after("^(#Country|#Region)").found)),t=t.splitAfter(n),t}(this);return n=n.getNth(t),new e(this.document,n.pointer)}}(e),function(e){e.prototype.organizations=function(e){return this.match("#Organization+").getNth(e)}}(e),function(e){e.prototype.topics=Ac}(e)}};const Nc=function(e,t){const n={pre:e.none(),post:e.none()};if(!e.has("#Adverb"))return n;const r=e.splitOn(t);return 3===r.length?{pre:r.eq(0).adverbs(),post:r.eq(2).adverbs()}:r.eq(0).isDoc(t)?(n.post=r.eq(1).adverbs(),n):(n.pre=r.eq(0).adverbs(),n)},jc=function(e,t){const n=e.splitBefore(t);if(n.length<=1)return e.none();let r=n.eq(0);return r=r.not("(#Adverb|#Negative|#Prefix)"),r},xc=function(e){return e.match("#Negative")},Ic=function(e){if(!e.has("(#Particle|#PhrasalVerb)"))return{verb:e.none(),particle:e.none()};const t=e.match("#Particle$");return{verb:e.not(t),particle:t}},Tc=function(e){const t=e.clone();t.contractions().expand();const n=function(e){let t=e;return e.wordCount()>1&&(t=e.not("(#Negative|#Auxiliary|#Modal|#Adverb|#Prefix)")),t.length>1&&!t.has("#Phrasal #Particle")&&(t=t.last()),t=t.not("(want|wants|wanted) to"),t.found||(t=e.not("#Negative")),t}(t);return{root:n,prefix:t.match("#Prefix"),adverbs:Nc(t,n),auxiliary:jc(t,n),negative:xc(t),phrasal:Ic(n)}},Dc={tense:"PresentTense"},Hc={conditional:!0},Ec={tense:"FutureTense"},Gc={progressive:!0},Oc={tense:"PastTense"},Fc={complete:!0,progressive:!1},Vc={passive:!0},zc=function(e){const t={};return e.forEach((e=>{Object.assign(t,e)})),t},Bc={imperative:[["#Imperative",[]]],"want-infinitive":[["^(want|wants|wanted) to #Infinitive$",[Dc]],["^wanted to #Infinitive$",[Oc]],["^will want to #Infinitive$",[Ec]]],"gerund-phrase":[["^#PastTense #Gerund$",[Oc]],["^#PresentTense #Gerund$",[Dc]],["^#Infinitive #Gerund$",[Dc]],["^will #Infinitive #Gerund$",[Ec]],["^have #PastTense #Gerund$",[Oc]],["^will have #PastTense #Gerund$",[Oc]]],"simple-present":[["^#PresentTense$",[Dc]],["^#Infinitive$",[Dc]]],"simple-past":[["^#PastTense$",[Oc]]],"simple-future":[["^will #Adverb? #Infinitive",[Ec]]],"present-progressive":[["^(is|are|am) #Gerund$",[Dc,Gc]]],"past-progressive":[["^(was|were) #Gerund$",[Oc,Gc]]],"future-progressive":[["^will be #Gerund$",[Ec,Gc]]],"present-perfect":[["^(has|have) #PastTense$",[Oc,Fc]]],"past-perfect":[["^had #PastTense$",[Oc,Fc]],["^had #PastTense to #Infinitive",[Oc,Fc]]],"future-perfect":[["^will have #PastTense$",[Ec,Fc]]],"present-perfect-progressive":[["^(has|have) been #Gerund$",[Oc,Gc]]],"past-perfect-progressive":[["^had been #Gerund$",[Oc,Gc]]],"future-perfect-progressive":[["^will have been #Gerund$",[Ec,Gc]]],"passive-past":[["(got|were|was) #Passive",[Oc,Vc]],["^(was|were) being #Passive",[Oc,Vc]],["^(had|have) been #Passive",[Oc,Vc]]],"passive-present":[["^(is|are|am) #Passive",[Dc,Vc]],["^(is|are|am) being #Passive",[Dc,Vc]],["^has been #Passive",[Dc,Vc]]],"passive-future":[["will have been #Passive",[Ec,Vc,Hc]],["will be being? #Passive",[Ec,Vc,Hc]]],"present-conditional":[["would be #PastTense",[Dc,Hc]]],"past-conditional":[["would have been #PastTense",[Oc,Hc]]],"auxiliary-future":[["(is|are|am|was) going to (#Infinitive|#PresentTense)",[Ec]]],"auxiliary-past":[["^did #Infinitive$",[Oc,{plural:!1}]],["^used to #Infinitive$",[Oc,Fc]]],"auxiliary-present":[["^(does|do) #Infinitive$",[Dc,Fc,{plural:!0}]]],"modal-past":[["^(could|must|should|shall) have #PastTense$",[Oc]]],"modal-infinitive":[["^#Modal #Infinitive$",[]]],infinitive:[["^#Infinitive$",[]]]},Sc=[];Object.keys(Bc).map((e=>{Bc[e].forEach((t=>{Sc.push({name:e,match:t[0],data:zc(t[1])})}))}));const $c=function(e,t){const n={};e=function(e,t){return e=e.clone(),t.adverbs.post&&t.adverbs.post.found&&e.remove(t.adverbs.post),t.adverbs.pre&&t.adverbs.pre.found&&e.remove(t.adverbs.pre),e.has("#Negative")&&(e=e.remove("#Negative")),e.has("#Prefix")&&(e=e.remove("#Prefix")),t.root.has("#PhrasalVerb #Particle")&&e.remove("#Particle$"),e.not("#Adverb")}(e,t);for(let t=0;t!(e.has("^(if|unless|while|but|for|per|at|by|that|which|who|from)")||t>0&&e.has("^#Verb . #Noun+$")||t>0&&e.has("^#Adverb")))),0===t.length?e:t}(t);const n=t.nouns();let r=n.last();const o=r.match("(i|he|she|we|you|they)");if(o.found)return o.nouns();let a=n.if("^(that|this|those)");return a.found||!1===n.found&&(a=t.match("^(that|this|those)"),a.found)?a:(r=n.last(),Mc(r)&&(n.remove(r),r=n.last()),Mc(r)&&(n.remove(r),r=n.last()),r)}(e);return{subject:t,plural:Lc(t,e)}},Jc=e=>e,Wc=(e,t)=>{const n=Kc(e),r=n.subject;return!(!r.has("i")&&!r.has("we"))||n.plural},qc=function(e,t){if(e.has("were"))return"are";const{subject:n,plural:r}=Kc(e);return n.has("i")?"am":n.has("we")||r?"are":"is"},Uc=function(e,t){const n=Kc(e),r=n.subject;return r.has("i")||r.has("we")||n.plural?"do":"does"},Rc=function(e){return e.has("#Infinitive")?"Infinitive":e.has("#Participle")?"Participle":e.has("#PastTense")?"PastTense":e.has("#Gerund")?"Gerund":e.has("#PresentTense")?"PresentTense":void 0},Qc=function(e,t){const{toInfinitive:n}=e.methods.two.transform.verb;let r=t.root.text({keepPunct:!1});return r=n(r,e.model,Rc(e)),r&&e.replace(t.root,r),e},Zc=e=>e.has("will not")?e.replace("will not","have not"):e.remove("will"),_c=function(e){if(!e||!e.isView)return[];return e.json({normal:!0,terms:!1,text:!1}).map((e=>e.normal))},Xc=function(e){return e&&e.isView?e.text("normal"):""},Yc=function(e){const{toInfinitive:t}=e.methods.two.transform.verb;return t(e.text("normal"),e.model,Rc(e))},eh={tags:!0},th={tags:!0},nh={noAux:(e,t)=>(t.auxiliary.found&&(e=e.remove(t.auxiliary)),e),simple:(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,o=t.root;if(o.has("#Modal"))return e;let a=o.text({keepPunct:!1});a=r(a,e.model,Rc(o));return a=n(a,e.model).PastTense,a="been"===a?"was":a,"was"===a&&(a=((e,t)=>{const{subject:n,plural:r}=Kc(e);return r||n.has("we")?"were":"was"})(e)),a&&e.replace(o,a,th),e},both:function(e,t){return t.negative.found?(e.replace("will","did"),e):(e=nh.simple(e,t),e=nh.noAux(e,t))},hasHad:e=>(e.replace("has","had",th),e),hasParticiple:(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,o=t.root;let a=o.text("normal");return a=r(a,e.model,Rc(o)),n(a,e.model).Participle}},rh={infinitive:nh.simple,"simple-present":nh.simple,"simple-past":Jc,"simple-future":nh.both,"present-progressive":e=>(e.replace("are","were",th),e.replace("(is|are|am)","was",th),e),"past-progressive":Jc,"future-progressive":(e,t)=>(e.match(t.root).insertBefore("was"),e.remove("(will|be)"),e),"present-perfect":nh.hasHad,"past-perfect":Jc,"future-perfect":(e,t)=>(e.match(t.root).insertBefore("had"),e.has("will")&&(e=Zc(e)),e.remove("have"),e),"present-perfect-progressive":nh.hasHad,"past-perfect-progressive":Jc,"future-perfect-progressive":e=>(e.remove("will"),e.replace("have","had",th),e),"passive-past":e=>(e.replace("have","had",th),e),"passive-present":e=>(e.replace("(is|are)","was",th),e),"passive-future":(e,t)=>(t.auxiliary.has("will be")&&(e.match(t.root).insertBefore("had been"),e.remove("(will|be)")),t.auxiliary.has("will have been")&&(e.replace("have","had",th),e.remove("will")),e),"present-conditional":e=>(e.replace("be","have been"),e),"past-conditional":Jc,"auxiliary-future":e=>(e.replace("(is|are|am)","was",th),e),"auxiliary-past":Jc,"auxiliary-present":e=>(e.replace("(do|does)","did",th),e),"modal-infinitive":(e,t)=>(e.has("can")?e.replace("can","could",th):(nh.simple(e,t),e.match("#Modal").insertAfter("have").tag("Auxiliary")),e),"modal-past":Jc,"want-infinitive":e=>(e.replace("(want|wants)","wanted",th),e.remove("will"),e),"gerund-phrase":(e,t)=>(t.root=t.root.not("#Gerund$"),nh.simple(e,t),Zc(e),e)},oh=function(e,t){const n=Kc(e),r=n.subject;return r.has("(i|we|you)")?"have":!1===n.plural||r.has("he")||r.has("she")||r.has("#Person")?"has":"have"},ah=(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,{root:o,auxiliary:a}=t;if(o.has("#Modal"))return e;let i=o.text({keepPunct:!1});i=r(i,e.model,Rc(o));const s=n(i,e.model);if(i=s.Participle||s.PastTense,i){e=e.replace(o,i);const t=oh(e);e.prepend(t).match(t).tag("Auxiliary"),e.remove(a)}return e},ih={infinitive:ah,"simple-present":ah,"simple-future":(e,t)=>e.replace("will",oh(e)),"present-perfect":Jc,"past-perfect":Jc,"future-perfect":(e,t)=>e.replace("will have",oh(e)),"present-perfect-progressive":Jc,"past-perfect-progressive":Jc,"future-perfect-progressive":Jc},sh={tags:!0},lh=(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,o=t.root;let a=o.text("normal");return a=r(a,e.model,Rc(o)),!1===Wc(e)&&(a=n(a,e.model).PresentTense),o.has("#Copula")&&(a=qc(e)),a&&(e=e.replace(o,a,sh)).not("#Particle").tag("PresentTense"),e},uh=(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,o=t.root;let a=o.text("normal");return a=r(a,e.model,Rc(o)),!1===Wc(e)&&(a=n(a,e.model).Gerund),a&&(e=e.replace(o,a,sh)).not("#Particle").tag("Gerund"),e},ch={infinitive:lh,"simple-present":(e,t)=>{const{conjugate:n}=e.methods.two.transform.verb,{root:r}=t;if(!r.has("#Infinitive"))return lh(e,t);{const t=Kc(e).subject;if(Wc(e)||t.has("i"))return e;const o=r.text("normal"),a=n(o,e.model).PresentTense;o!==a&&e.replace(r,a,sh)}return e},"simple-past":lh,"simple-future":(e,t)=>{const{root:n,auxiliary:r}=t;if(r.has("will")&&n.has("be")){const t=qc(e);e.replace(n,t),(e=e.remove("will")).replace("not "+t,t+" not")}else lh(e,t),e=e.remove("will");return e},"present-progressive":Jc,"past-progressive":(e,t)=>{const n=qc(e);return e.replace("(were|was)",n,sh)},"future-progressive":e=>(e.match("will").insertBefore("is"),e.remove("be"),e.remove("will")),"present-perfect":(e,t)=>(lh(e,t),e=e.remove("(have|had|has)")),"past-perfect":(e,t)=>{const n=Kc(e).subject;return Wc(e)||n.has("i")?((e=Qc(e,t)).remove("had"),e):(e.replace("had","has",sh),e)},"future-perfect":e=>(e.match("will").insertBefore("has"),e.remove("have").remove("will")),"present-perfect-progressive":Jc,"past-perfect-progressive":e=>e.replace("had","has",sh),"future-perfect-progressive":e=>(e.match("will").insertBefore("has"),e.remove("have").remove("will")),"passive-past":(e,t)=>{const n=qc(e);return e.has("(had|have|has)")&&e.has("been")?(e.replace("(had|have|has)",n,sh),e.replace("been","being"),e):e.replace("(got|was|were)",n)},"passive-present":Jc,"passive-future":e=>(e.replace("will","is"),e.replace("be","being")),"present-conditional":Jc,"past-conditional":e=>(e.replace("been","be"),e.remove("have")),"auxiliary-future":(e,t)=>(uh(e,t),e.remove("(going|to)"),e),"auxiliary-past":(e,t)=>{if(t.auxiliary.has("did")){const n=Uc(e);return e.replace(t.auxiliary,n),e}return uh(e,t),e.replace(t.auxiliary,"is"),e},"auxiliary-present":Jc,"modal-infinitive":Jc,"modal-past":(e,t)=>(((e,t)=>{const{toInfinitive:n}=e.methods.two.transform.verb,r=t.root;let o=t.root.text("normal");o=n(o,e.model,Rc(r)),o&&(e=e.replace(t.root,o,sh))})(e,t),e.remove("have")),"gerund-phrase":(e,t)=>(t.root=t.root.not("#Gerund$"),lh(e,t),e.remove("(will|have)")),"want-infinitive":(e,t)=>{let n="wants";return Wc(e)&&(n="want"),e.replace("(want|wanted|wants)",n,sh),e.remove("will"),e}},hh={tags:!0},dh=(e,t)=>{const{toInfinitive:n}=e.methods.two.transform.verb,{root:r,auxiliary:o}=t;if(r.has("#Modal"))return e;let a=r.text("normal");return a=n(a,e.model,Rc(r)),a&&(e=e.replace(r,a,hh)).not("#Particle").tag("Verb"),e.prepend("will").match("will").tag("Auxiliary"),e.remove(o),e},gh=(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,{root:o,auxiliary:a}=t;let i=o.text("normal");return i=r(i,e.model,Rc(o)),i&&(i=n(i,e.model).Gerund,e.replace(o,i,hh),e.not("#Particle").tag("PresentTense")),e.remove(a),e.prepend("will be").match("will be").tag("Auxiliary"),e},mh={infinitive:dh,"simple-present":dh,"simple-past":dh,"simple-future":Jc,"present-progressive":gh,"past-progressive":gh,"future-progressive":Jc,"present-perfect":e=>(e.match("(have|has)").replaceWith("will have"),e),"past-perfect":e=>e.replace("(had|has)","will have"),"future-perfect":Jc,"present-perfect-progressive":e=>e.replace("has","will have"),"past-perfect-progressive":e=>e.replace("had","will have"),"future-perfect-progressive":Jc,"passive-past":e=>e.has("got")?e.replace("got","will get"):e.has("(was|were)")?(e.replace("(was|were)","will be"),e.remove("being")):e.has("(have|has|had) been")?e.replace("(have|has|had) been","will be"):e,"passive-present":e=>(e.replace("being","will be"),e.remove("(is|are|am)"),e),"passive-future":Jc,"present-conditional":e=>e.replace("would","will"),"past-conditional":e=>e.replace("would","will"),"auxiliary-future":Jc,"auxiliary-past":e=>e.has("used")&&e.has("to")?(e.replace("used","will"),e.remove("to")):(e.replace("did","will"),e),"auxiliary-present":e=>e.replace("(do|does)","will"),"modal-infinitive":Jc,"modal-past":Jc,"gerund-phrase":(e,t)=>(t.root=t.root.not("#Gerund$"),dh(e,t),e.remove("(had|have)")),"want-infinitive":e=>(e.replace("(want|wants|wanted)","will want"),e)},ph={tags:!0},fh={tags:!0},bh=function(e,t){const n=Uc(e);return e.prepend(n+" not"),e},vh=function(e){let t=e.match("be");return t.found?(t.prepend("not"),e):(t=e.match("(is|was|am|are|will|were)"),t.found?(t.append("not"),e):e)},yh=e=>e.has("(is|was|am|are|will|were|be)"),wh={"simple-present":(e,t)=>!0===yh(e)?vh(e):(e=Qc(e,t),e=bh(e)),"simple-past":(e,t)=>!0===yh(e)?vh(e):((e=Qc(e,t)).prepend("did not"),e),imperative:e=>(e.prepend("do not"),e),infinitive:(e,t)=>!0===yh(e)?vh(e):bh(e),"passive-past":e=>{if(e.has("got"))return e.replace("got","get",fh),e.prepend("did not"),e;const t=e.match("(was|were|had|have)");return t.found&&t.append("not"),e},"auxiliary-past":e=>{if(e.has("used"))return e.prepend("did not"),e;const t=e.match("(did|does|do)");return t.found&&t.append("not"),e},"want-infinitive":(e,t)=>e=(e=bh(e)).replace("wants","want",fh)};var kh={api:function(e){class Verbs extends e{constructor(e,t,n){super(e,t,n),this.viewType="Verbs"}parse(e){return this.getNth(e).map(Tc)}json(e,t){const n=this.getNth(t).map((t=>{const n=t.toView().json(e)[0]||{};return n.verb=function(e){const t=Tc(e);e=e.clone().toView();const n=$c(e,t);return{root:t.root.text(),preAdverbs:_c(t.adverbs.pre),postAdverbs:_c(t.adverbs.post),auxiliary:Xc(t.auxiliary),negative:t.negative.found,prefix:Xc(t.prefix),infinitive:Yc(t.root),grammar:n}}(t),n}),[]);return n}subjects(e){return this.getNth(e).map((e=>(Tc(e),Kc(e).subject)))}adverbs(e){return this.getNth(e).map((e=>e.match("#Adverb")))}isSingular(e){return this.getNth(e).filter((e=>!0!==Kc(e).plural))}isPlural(e){return this.getNth(e).filter((e=>!0===Kc(e).plural))}isImperative(e){return this.getNth(e).filter((e=>e.has("#Imperative")))}toInfinitive(e){return this.getNth(e).map((e=>{const t=Tc(e);return function(e,t){const{toInfinitive:n}=e.methods.two.transform.verb,{root:r,auxiliary:o}=t,a=o.terms().harden();let i=r.text("normal");if(i=n(i,e.model,Rc(r)),i&&e.replace(r,i,eh).tag("Verb").firstTerm().tag("Infinitive"),a.found&&e.remove(a),t.negative.found){e.has("not")||e.prepend("not");const t=Uc(e);e.prepend(t)}return e.fullSentence().compute(["freeze","lexicon","preTagger","postTagger","unfreeze","chunks"]),e}(e,t,$c(e,t).form)}))}toPresentTense(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t,n){return ch.hasOwnProperty(n)?((e=ch[n](e,t)).fullSentence().compute(["tagger","chunks"]),e):e}(e,t,n.form)}))}toPastTense(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t,n){return rh.hasOwnProperty(n)?((e=rh[n](e,t)).fullSentence().compute(["tagger","chunks"]),e):e}(e,t,n.form)}))}toFutureTense(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t,n){return e.has("will")||e.has("going to")?e:mh.hasOwnProperty(n)?((e=mh[n](e,t)).fullSentence().compute(["tagger","chunks"]),e):e}(e,t,n.form)}))}toGerund(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t){const{toInfinitive:n,conjugate:r}=e.methods.two.transform.verb,{root:o,auxiliary:a}=t;if(e.has("#Gerund"))return e;let i=o.text("normal");i=n(i,e.model,Rc(o));const s=r(i,e.model).Gerund;if(s){const t=qc(e);e.replace(o,s,ph),e.remove(a),e.prepend(t)}return e.replace("not is","is not"),e.replace("not are","are not"),e.fullSentence().compute(["tagger","chunks"]),e}(e,t,n.form)}))}toPastParticiple(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t,n){return ih.hasOwnProperty(n)?((e=ih[n](e,t)).fullSentence().compute(["tagger","chunks"]),e):((e=ah(e,t)).fullSentence().compute(["tagger","chunks"]),e)}(e,t,n.form)}))}conjugate(e){const{conjugate:t,toInfinitive:n}=this.world.methods.two.transform.verb;return this.getNth(e).map((e=>{const r=Tc(e),o=$c(e,r);"imperative"===o.form&&(o.form="simple-present");let a=r.root.text("normal");if(!r.root.has("#Infinitive")){const t=Rc(r.root);a=n(a,e.model,t)||a}return t(a,e.model)}),[])}isNegative(){return this.if("#Negative")}isPositive(){return this.ifNo("#Negative")}toPositive(){const e=this.match("do not #Verb");return e.found&&e.remove("do not"),this.remove("#Negative")}toNegative(e){return this.getNth(e).map((e=>{const t=Tc(e);return function(e,t,n){if(e.has("#Negative"))return e;if(wh.hasOwnProperty(n))return wh[n](e,t);let r=e.matchOne("be");return r.found?(r.prepend("not"),e):!0===yh(e)?vh(e):(r=e.matchOne("(will|had|have|has|did|does|do|#Modal)"),r.found?(r.append("not"),e):e)}(e,t,$c(e,t).form)}))}update(e){const t=new Verbs(this.document,e);return t._cache=this._cache,t}}Verbs.prototype.toPast=Verbs.prototype.toPastTense,Verbs.prototype.toPresent=Verbs.prototype.toPresentTense,Verbs.prototype.toFuture=Verbs.prototype.toFutureTense,e.prototype.verbs=function(e){let t=function(e){let t=e.match("");return t=t.not("#Conjunction"),t=t.not("#Preposition"),t=t.splitAfter("@hasComma"),t=t.splitAfter("[(do|did|am|was|is|will)] (is|was)",0),t=t.splitBefore("(#Verb && !#Copula) [being] #Verb",0),t=t.splitBefore("#Verb [to be] #Verb",0),t=t.splitAfter("[help] #PresentTense",0),t=t.splitBefore("(#PresentTense|#PastTense) [#Copula]$",0),t=t.splitBefore("(#PresentTense|#PastTense) [will be]$",0),t=t.splitBefore("(#PresentTense|#PastTense) [(had|has)]",0),t=t.not("#Reflexive$"),t=t.not("#Adjective"),t=t.splitAfter("[#PastTense] #PastTense",0),t=t.splitAfter("[#PastTense] #Auxiliary+ #PastTense",0),t=t.splitAfter("#Copula [#Gerund] #PastTense",0),t=t.if("#Verb"),t.has("(#Verb && !#Auxiliary) #Adverb+? #Copula")&&(t=t.splitBefore("#Copula")),t}(this);return t=t.getNth(e),new Verbs(this.document,t.pointer)}}};const Ph=function(e,t){const n=t.match(e);if(n.found){const e=n.pronouns().refersTo();if(e.found)return e}return t.none()},Ah=function(e){if(!e.found)return e;const[t]=e.fullPointer[0];return t&&t>0?e.update([[t-1]]):e.none()},Ch=function(e,t){let n=e.people();return n=function(e,t){return"m"===t?e.filter((e=>!e.presumedFemale().found)):"f"===t?e.filter((e=>!e.presumedMale().found)):e}(n,t),n.found?n.last():(n=e.nouns("#Actor"),n.found?n.last():"f"===t?Ph("(she|her|hers)",e):"m"===t?Ph("(he|him|his)",e):e.none())},Nh=function(e){const t=e.nouns();let n=t.isPlural().notIf("#Pronoun");if(n.found)return n.last();const r=Ph("(they|their|theirs)",e);return r.found?r:(n=t.match("(somebody|nobody|everybody|anybody|someone|noone|everyone|anyone)"),n.found?n.last():e.none())},jh=function(e,t){let n=e.before(),r=t(n);return r.found?r:(n=Ah(e),r=t(n),r.found?r:(n=Ah(n),r=t(n),r.found?r:e.none()))};var xh={compute:{coreference:function(e){e.pronouns().if("(he|him|his|she|her|hers|they|their|theirs|it|its)").forEach((e=>{let t=null;e.has("(he|him|his)")?t=jh(e,(e=>Ch(e,"m"))):e.has("(she|her|hers)")?t=jh(e,(e=>Ch(e,"f"))):e.has("(they|their|theirs)")&&(t=jh(e,Nh)),t&&t.found&&function(e,t){t&&t.found&&(e.docs[0][0].reference=t.ptrs[0])}(e,t)}))}},api:function(e){class Pronouns extends e{constructor(e,t,n){super(e,t,n),this.viewType="Pronouns"}hasReference(){return this.compute("coreference"),this.filter((e=>e.docs[0][0].reference))}refersTo(){return this.compute("coreference"),this.map((e=>{if(!e.found)return e.none();const t=e.docs[0][0];return t.reference?e.update([t.reference]):e.none()}))}update(e){const t=new Pronouns(this.document,e);return t._cache=this._cache,t}}e.prototype.pronouns=function(e){let t=this.match("#Pronoun");return t=t.getNth(e),new Pronouns(t.document,t.pointer)}}};return h.plugin(ql),h.plugin(Ul),h.plugin(eu),h.plugin(xh),h.plugin(fu),h.plugin(Au),h.plugin(Ou),h.plugin(hc),h.plugin(mc),h.plugin(bc),h.plugin(Cc),h.plugin(kh),h}));
================================================
FILE: builds/three/compromise-three.mjs
================================================
var e={methods:{one:{},two:{},three:{},four:{}},model:{one:{},two:{},three:{}},compute:{},hooks:[]};const t={compute:function(e){const{world:t}=this,n=t.compute;return"string"==typeof e&&n.hasOwnProperty(e)?n[e](this):(e=>"[object Array]"===Object.prototype.toString.call(e))(e)?e.forEach((r=>{t.compute.hasOwnProperty(r)?n[r](this):console.warn("no compute:",e)})):"function"==typeof e?e(this):console.warn("no compute:",e),this}};var n={forEach:function(e){return this.fullPointer.forEach(((t,n)=>{const r=this.update([t]);e(r,n)})),this},map:function(e,t){const n=this.fullPointer.map(((t,n)=>{const r=this.update([t]),o=e(r,n);return void 0===o?this.none():o}));if(0===n.length)return t||this.update([]);if(void 0!==n[0]){if("string"==typeof n[0])return n;if("object"==typeof n[0]&&(null===n[0]||!n[0].isView))return n}let r=[];return n.forEach((e=>{r=r.concat(e.fullPointer)})),this.toView(r)},filter:function(e){let t=this.fullPointer;t=t.filter(((t,n)=>{const r=this.update([t]);return e(r,n)}));return this.update(t)},find:function(e){const t=this.fullPointer.find(((t,n)=>{const r=this.update([t]);return e(r,n)}));return this.update([t])},some:function(e){return this.fullPointer.some(((t,n)=>{const r=this.update([t]);return e(r,n)}))},random:function(e=1){let t=this.fullPointer,n=Math.floor(Math.random()*t.length);return n+e>this.length&&(n=this.length-e,n=n<0?0:n),t=t.slice(n,n+e),this.update(t)}};const r={termList:function(){return this.methods.one.termList(this.docs)},terms:function(e){const t=this.match(".");return"number"==typeof e?t.eq(e):t},groups:function(e){if(e||0===e)return this.update(this._groups[e]||[]);const t={};return Object.keys(this._groups).forEach((e=>{t[e]=this.update(this._groups[e])})),t},eq:function(e){let t=this.pointer;return t||(t=this.docs.map(((e,t)=>[t]))),t[e]?this.update([t[e]]):this.none()},first:function(){return this.eq(0)},last:function(){const e=this.fullPointer.length-1;return this.eq(e)},firstTerms:function(){return this.match("^.")},lastTerms:function(){return this.match(".$")},slice:function(e,t){let n=this.pointer||this.docs.map(((e,t)=>[t]));return n=n.slice(e,t),this.update(n)},all:function(){return this.update().toView()},fullSentences:function(){const e=this.fullPointer.map((e=>[e[0]]));return this.update(e).toView()},none:function(){return this.update([])},isDoc:function(e){if(!e||!e.isView)return!1;const t=this.fullPointer,n=e.fullPointer;return!t.length!==n.length&&t.every(((e,t)=>!!n[t]&&(e[0]===n[t][0]&&e[1]===n[t][1]&&e[2]===n[t][2])))},wordCount:function(){return this.docs.reduce(((e,t)=>(e+=t.filter((e=>""!==e.text)).length,e)),0)},isFull:function(){const e=this.pointer;if(!e)return!0;if(0===e.length||0!==e[0][0])return!1;let t=0,n=0;return this.document.forEach((e=>t+=e.length)),this.docs.forEach((e=>n+=e.length)),t===n},getNth:function(e){return"number"==typeof e?this.eq(e):"string"==typeof e?this.if(e):this}};r.group=r.groups,r.fullSentence=r.fullSentences,r.sentence=r.fullSentences,r.lastTerm=r.lastTerms,r.firstTerm=r.firstTerms;const o=Object.assign({},r,t,n);o.get=o.eq;class View{constructor(t,n,r={}){[["document",t],["world",e],["_groups",r],["_cache",null],["viewType","View"]].forEach((e=>{Object.defineProperty(this,e[0],{value:e[1],writable:!0})})),this.ptrs=n}get docs(){let t=this.document;return this.ptrs&&(t=e.methods.one.getDoc(this.ptrs,this.document)),t}get pointer(){return this.ptrs}get methods(){return this.world.methods}get model(){return this.world.model}get hooks(){return this.world.hooks}get isView(){return!0}get found(){return this.docs.length>0}get length(){return this.docs.length}get fullPointer(){const{docs:e,ptrs:t,document:n}=this,r=t||e.map(((e,t)=>[t]));return r.map((e=>{let[t,r,o,a,i]=e;return r=r||0,o=o||(n[t]||[]).length,n[t]&&n[t][r]&&(a=a||n[t][r].id,n[t][o-1]&&(i=i||n[t][o-1].id)),[t,r,o,a,i]}))}update(e){const t=new View(this.document,e);if(this._cache&&e&&e.length>0){const n=[];e.forEach(((e,t)=>{const[r,o,a]=e;(1===e.length||0===o&&this.document[r].length===a)&&(n[t]=this._cache[r])})),n.length>0&&(t._cache=n)}return t.world=this.world,t}toView(e){return new View(this.document,e||this.pointer)}fromText(e){const{methods:t}=this,n=t.one.tokenize.fromString(e,this.world),r=new View(n);return r.world=this.world,r.compute(["normal","freeze","lexicon"]),this.world.compute.preTagger&&r.compute("preTagger"),r.compute("unfreeze"),r}clone(){let e=this.document.slice(0);e=e.map((e=>e.map((e=>((e=Object.assign({},e)).tags=new Set(e.tags),e)))));const t=this.update(this.pointer);return t.document=e,t._cache=this._cache,t}}Object.assign(View.prototype,o);const a=function(e){return e&&"object"==typeof e&&!Array.isArray(e)};function i(e,t){if(a(t))for(const n in t)a(t[n])?(e[n]||Object.assign(e,{[n]:{}}),i(e[n],t[n])):Object.assign(e,{[n]:t[n]});return e}const s=function(e,t,n,r){if(o=e,"[object Array]"===Object.prototype.toString.call(o))return void e.forEach((e=>s(e,t,n,r)));var o;const{methods:a,model:l,compute:u,hooks:c}=t;e.methods&&function(e,t){for(const n in t)e[n]=e[n]||{},Object.assign(e[n],t[n])}(a,e.methods),e.model&&i(l,e.model),e.irregulars&&function(e,t){const n=e.two.models||{};Object.keys(t).forEach((e=>{t[e].pastTense&&(n.toPast&&(n.toPast.ex[e]=t[e].pastTense),n.fromPast&&(n.fromPast.ex[t[e].pastTense]=e)),t[e].presentTense&&(n.toPresent&&(n.toPresent.ex[e]=t[e].presentTense),n.fromPresent&&(n.fromPresent.ex[t[e].presentTense]=e)),t[e].gerund&&(n.toGerund&&(n.toGerund.ex[e]=t[e].gerund),n.fromGerund&&(n.fromGerund.ex[t[e].gerund]=e)),t[e].comparative&&(n.toComparative&&(n.toComparative.ex[e]=t[e].comparative),n.fromComparative&&(n.fromComparative.ex[t[e].comparative]=e)),t[e].superlative&&(n.toSuperlative&&(n.toSuperlative.ex[e]=t[e].superlative),n.fromSuperlative&&(n.fromSuperlative.ex[t[e].superlative]=e))}))}(l,e.irregulars),e.compute&&Object.assign(u,e.compute),c&&(t.hooks=c.concat(e.hooks||[])),e.api&&e.api(n),e.lib&&Object.keys(e.lib).forEach((t=>r[t]=e.lib[t])),e.tags&&r.addTags(e.tags),e.words&&r.addWords(e.words),e.frozen&&r.addWords(e.frozen,!0),e.mutate&&e.mutate(t,r)},l=function(e){return"[object Array]"===Object.prototype.toString.call(e)},u=function(e,t,n){const{methods:r}=n,o=new t([]);if(o.world=n,"number"==typeof e&&(e=String(e)),!e)return o;if("string"==typeof e){return new t(r.one.tokenize.fromString(e,n))}if(a=e,"[object Object]"===Object.prototype.toString.call(a)&&e.isView)return new t(e.document,e.ptrs);var a;if(l(e)){if(l(e[0])){const n=e.map((e=>e.map((e=>({text:e,normal:e,pre:"",post:" ",tags:new Set})))));return new t(n)}const n=e.map((e=>e.terms.map((e=>(l(e.tags)&&(e.tags=new Set(e.tags)),e)))));return new t(n)}return o},c=Object.assign({},e),h=function(e,t){t&&h.addWords(t);const n=u(e,View,c);return e&&n.compute(c.hooks),n};Object.defineProperty(h,"_world",{value:c,writable:!0}),h.tokenize=function(e,t){const{compute:n}=this._world;t&&h.addWords(t);const r=u(e,View,c);return n.contractions&&r.compute(["alias","normal","machine","contractions"]),r},h.plugin=function(e){return s(e,this._world,View,this),this},h.extend=h.plugin,h.world=function(){return this._world},h.model=function(){return this._world.model},h.methods=function(){return this._world.methods},h.hooks=function(){return this._world.hooks},h.verbose=function(e){const t="undefined"!=typeof process&&process.env?process.env:self.env||{};return t.DEBUG_TAGS="tagger"===e||!0===e||"",t.DEBUG_MATCH="match"===e||!0===e||"",t.DEBUG_CHUNKS="chunker"===e||!0===e||"",this},h.version="14.15.0";var d={one:{cacheDoc:function(e){const t=e.map((e=>{const t=new Set;return e.forEach((e=>{""!==e.normal&&t.add(e.normal),e.switch&&t.add(`%${e.switch}%`),e.implicit&&t.add(e.implicit),e.machine&&t.add(e.machine),e.root&&t.add(e.root),e.alias&&e.alias.forEach((e=>t.add(e)));const n=Array.from(e.tags);for(let e=0;e/^\p{Lu}[\p{Ll}'’]/u.test(e)||/^\p{Lu}$/u.test(e),b=(e,t,n)=>{if(n.forEach((e=>e.dirty=!0)),e){const r=[t,0].concat(n);Array.prototype.splice.apply(e,r)}return e},v=function(e){const t=e[e.length-1];!t||/ $/.test(t.post)||/[-–—]/.test(t.post)||(t.post+=" ")},y=(e,t,n)=>{const r=/[-.?!,;:)–—'"]/g,o=e[t-1];if(!o)return;const a=o.post;if(r.test(a)){const e=a.match(r).join(""),t=n[n.length-1];t.post=e+t.post,o.post=o.post.replace(r,"")}},w=function(e,t,n,r){const[o,a,i]=t;0===a||i===r[o].length?v(n):(v(n),v([e[t[1]]])),function(e,t,n){const r=e[t];if(0!==t||!f(r.text))return;n[0].text=n[0].text.replace(/^\p{Ll}/u,(e=>e.toUpperCase()));const o=e[t];o.tags.has("ProperNoun")||o.tags.has("Acronym")||f(o.text)&&o.text.length>1&&(o.text=(a=o.text,a.replace(/^\p{Lu}/u,(e=>e.toLowerCase()))));var a}(e,a,n),b(e,a,n)};let k=0;const P=e=>(e=e.length<3?"0"+e:e).length<3?"0"+e:e,A=function(e){let[t,n]=e.index||[0,0];k+=1,k=k>46655?0:k,t=t>46655?0:t,n=n>1294?0:n;let r=P(k.toString(36));r+=P(t.toString(36));let o=n.toString(36);o=o.length<2?"0"+o:o,r+=o;return r+=parseInt(36*Math.random(),10).toString(36),e.normal+"|"+r.toUpperCase()},C=function(e){if(e.has("@hasContraction")&&"function"==typeof e.contractions){e.grow("@hasContraction").contractions().expand()}},N=e=>"[object Array]"===Object.prototype.toString.call(e),j=function(e,t,n){const{document:r,world:o}=t;t.uncache();const a=t.fullPointer,i=t.fullPointer;t.forEach(((s,l)=>{const u=s.fullPointer[0],[c]=u,h=r[c];let d=function(e,t){const{methods:n}=t;return"string"==typeof e?n.one.tokenize.fromString(e,t)[0]:"object"==typeof e&&e.isView?e.clone().docs[0]||[]:N(e)?N(e[0])?e[0]:e:[]}(e,o);0!==d.length&&(d=function(e){return e.map((e=>(e.id=A(e),e)))}(d),n?(C(t.update([u]).firstTerm()),w(h,u,d,r)):(C(t.update([u]).lastTerm()),function(e,t,n,r){const[o,,a]=t,i=(r[o]||[]).length;ae.replace(/^\p{Ll}/u,(e=>e.toUpperCase())),H=e=>e.replace(/^\p{Lu}/u,(e=>e.toLowerCase()));T.replaceWith=function(e,t={}){let n=this.fullPointer;const r=this;if(this.uncache(),"function"==typeof e)return function(e,t,n){return e.forEach((e=>{const r=t(e);e.replaceWith(r,n)})),e}(r,e,t);const o=r.docs[0];if(!o)return r;const a=t.possessives&&o[o.length-1].tags.has("Possessive"),i=t.case&&(s=o[0].text,/^\p{Lu}[\p{Ll}'’]/u.test(s)||/^\p{Lu}$/u.test(s));var s;e=function(e,t){if("string"!=typeof e)return e;const n=t.groups();return e=e.replace(I,(e=>{const t=e.replace(/\$/,"");return n.hasOwnProperty(t)?n[t].text():e})),e}(e,r);const l=this.update(n);n=n.map((e=>e.slice(0,3)));const u=(l.docs[0]||[]).map((e=>Array.from(e.tags))),c=l.docs[0][0].pre,h=l.docs[0][l.docs[0].length-1].post;if("string"==typeof e&&(e=this.fromText(e).compute("id")),r.insertAfter(e),l.has("@hasContraction")&&r.contractions){r.grow("@hasContraction+").contractions().expand()}if(r.delete(l),a){const e=r.docs[0],t=e[e.length-1];t.tags.has("Possessive")||(t.text+="'s",t.normal+="'s",t.tags.add("Possessive"))}if(c&&r.docs[0]&&(r.docs[0][0].pre=c),h&&r.docs[0]){const e=r.docs[0][r.docs[0].length-1];e.post.trim()||(e.post=h)}const d=r.toView(n).compute(["index","freeze","lexicon"]);if(d.world.compute.preTagger&&d.compute("preTagger"),d.compute("unfreeze"),t.tags&&d.terms().forEach(((e,t)=>{e.tagSafe(u[t])})),!d.docs[0]||!d.docs[0][0])return d;if(t.case){const e=i?D:H;d.docs[0][0].text=e(d.docs[0][0].text)}return d},T.replace=function(e,t,n){if(e&&!t)return this.replaceWith(e,n);const r=this.match(e);return r.found?(this.soften(),r.replaceWith(t,n)):this};const E={remove:function(e){const{indexN:t}=this.methods.one.pointer;this.uncache();let n=this.all(),r=this;e&&(n=this,r=this.match(e));const o=!n.ptrs;if(r.has("@hasContraction")&&r.contractions){r.grow("@hasContraction").contractions().expand()}let a=n.fullPointer;const i=r.fullPointer.reverse(),s=function(e,t){t.forEach((t=>{const[n,r,o]=t,a=o-r;e[n]&&(o===e[n].length&&o>1&&function(e,t){const n=e.length-1,r=e[n],o=e[n-t];o&&r&&(o.post+=r.post,o.post=o.post.replace(/ +([.?!,;:])/,"$1"),o.post=o.post.replace(/[,;:]+([.?!])/,"$1"))}(e[n],a),e[n].splice(r,a))}));for(let t=e.length-1;t>=0;t-=1)if(0===e[t].length&&(e.splice(t,1),t===e.length&&e[t-1])){const n=e[t-1],r=n[n.length-1];r&&(r.post=r.post.trimEnd())}return e}(this.document,i);if(a=function(e,t){return e=e.map((e=>{const[n]=e;return t[n]?(t[n].forEach((t=>{const n=t[2]-t[1];e[1]<=t[1]&&e[2]>=t[2]&&(e[2]-=n)})),e):e})),e.forEach(((t,n)=>{if(0===t[1]&&0==t[2])for(let t=n+1;te[2]-e[1]>0))).map((e=>(e[3]=null,e[4]=null,e)))}(a,t(i)),n.ptrs=a,n.document=s,n.compute("index"),o&&(n.ptrs=void 0),!e)return this.ptrs=[],n.none();return n.toView(a)}};E.delete=E.remove;const G={pre:function(e,t){return void 0===e&&this.found?this.docs[0][0].pre:(this.docs.forEach((n=>{const r=n[0];!0===t?r.pre+=e:r.pre=e})),this)},post:function(e,t){if(void 0===e){const e=this.docs[this.docs.length-1];return e[e.length-1].post}return this.docs.forEach((n=>{const r=n[n.length-1];!0===t?r.post+=e:r.post=e})),this},trim:function(){if(!this.found)return this;const e=this.docs,t=e[0][0];t.pre=t.pre.trimStart();const n=e[e.length-1],r=n[n.length-1];return r.post=r.post.trimEnd(),this},hyphenate:function(){return this.docs.forEach((e=>{e.forEach(((t,n)=>{0!==n&&(t.pre=""),e[n+1]&&(t.post="-")}))})),this},dehyphenate:function(){const e=/[-–—]/;return this.docs.forEach((t=>{t.forEach((t=>{e.test(t.post)&&(t.post=" ")}))})),this},toQuotations:function(e,t){return e=e||'"',t=t||'"',this.docs.forEach((n=>{n[0].pre=e+n[0].pre;const r=n[n.length-1];r.post=t+r.post})),this},toParentheses:function(e,t){return e=e||"(",t=t||")",this.docs.forEach((n=>{n[0].pre=e+n[0].pre;const r=n[n.length-1];r.post=t+r.post})),this}};G.deHyphenate=G.dehyphenate,G.toQuotation=G.toQuotations;var O={alpha:(e,t)=>e.normalt.normal?1:0,length:(e,t)=>{const n=e.normal.trim().length,r=t.normal.trim().length;return nr?-1:0},wordCount:(e,t)=>e.wordst.words?-1:0,sequential:(e,t)=>e[0]t[0]?-1:e[1]>t[1]?1:-1,byFreq:function(e){const t={};return e.forEach((e=>{t[e.normal]=t[e.normal]||0,t[e.normal]+=1})),e.sort(((e,n)=>{const r=t[e.normal],o=t[n.normal];return ro?-1:0})),e}};const F=new Set(["index","sequence","seq","sequential","chron","chronological"]),V=new Set(["freq","frequency","topk","repeats"]),z=new Set(["alpha","alphabetical"]);var B={unique:function(){const e=new Set,t=this.filter((t=>{const n=t.text("machine");return!e.has(n)&&(e.add(n),!0)}));return t},reverse:function(){let e=this.pointer||this.docs.map(((e,t)=>[t]));return e=[].concat(e),e=e.reverse(),this._cache&&(this._cache=this._cache.reverse()),this.update(e)},sort:function(e){const{docs:t,pointer:n}=this;if(this.uncache(),"function"==typeof e)return function(e,t){let n=e.fullPointer;return n=n.sort(((n,r)=>(n=e.update([n]),r=e.update([r]),t(n,r)))),e.ptrs=n,e}(this,e);e=e||"alpha";const r=n||t.map(((e,t)=>[t]));let o=t.map(((e,t)=>({index:t,words:e.length,normal:e.map((e=>e.machine||e.normal||"")).join(" "),pointer:r[t]})));return F.has(e)&&(e="sequential"),z.has(e)&&(e="alpha"),V.has(e)?(o=O.byFreq(o),this.update(o.map((e=>e.pointer)))):"function"==typeof O[e]?(o=o.sort(O[e]),this.update(o.map((e=>e.pointer)))):this}};const S=function(e,t){if(e.length>0){const t=e[e.length-1],n=t[t.length-1];!1===/ /.test(n.post)&&(n.post+=" ")}return e=e.concat(t)};var $={concat:function(e){if("string"==typeof e){const t=this.fromText(e);if(this.found&&this.ptrs){const e=this.fullPointer,n=e[e.length-1][0];this.document.splice(n,0,...t.document)}else this.document=this.document.concat(t.document);return this.all().compute("index")}if("object"==typeof e&&e.isView)return function(e,t){if(e.document===t.document){const n=e.fullPointer.concat(t.fullPointer);return e.toView(n).compute("index")}return t.fullPointer.forEach((t=>{t[0]+=e.document.length})),e.document=S(e.document,t.docs),e.all()}(this,e);if(t=e,"[object Array]"===Object.prototype.toString.call(t)){const t=S(this.document,e);return this.document=t,this.all()}var t;return this}};var M={harden:function(){return this.ptrs=this.fullPointer,this},soften:function(){let e=this.ptrs;return!e||e.length<1||(e=e.map((e=>e.slice(0,3))),this.ptrs=e),this}};const L=Object.assign({},{toLowerCase:function(){return this.termList().forEach((e=>{e.text=e.text.toLowerCase()})),this},toUpperCase:function(){return this.termList().forEach((e=>{e.text=e.text.toUpperCase()})),this},toTitleCase:function(){return this.termList().forEach((e=>{e.text=e.text.replace(/^ *[a-z\u00C0-\u00FF]/,(e=>e.toUpperCase()))})),this},toCamelCase:function(){return this.docs.forEach((e=>{e.forEach(((t,n)=>{0!==n&&(t.text=t.text.replace(/^ *[a-z\u00C0-\u00FF]/,(e=>e.toUpperCase()))),n!==e.length-1&&(t.post="")}))})),this}},x,T,E,G,B,$,M),K={id:function(e){const t=e.docs;for(let e=0;e(e.implicit=e.text,e.machine=e.text,e.pre="",e.post="",e.text="",e.normal="",e.index=[r,o+t],e))),n[0]&&(n[0].pre=e[r][o].pre,n[n.length-1].post=e[r][o].post,n[0].text=e[r][o].text,n[0].normal=e[r][o].normal),e[r].splice(o,1,...n))},R=/'/,Q=new Set(["what","how","when","where","why"]),Z=new Set(["be","go","start","think","need"]),_=new Set(["been","gone"]),X=/'/,Y=/(e|é|aison|sion|tion)$/,ee=/(age|isme|acle|ege|oire)$/;var te=(e,t)=>["je",e[t].normal.split(X)[1]],ne=(e,t)=>{const n=e[t].normal.split(X)[1];return n&&n.endsWith("e")?["la",n]:["le",n]},re=(e,t)=>{const n=e[t].normal.split(X)[1];return n&&Y.test(n)&&!ee.test(n)?["du",n]:n&&n.endsWith("s")?["des",n]:["de",n]};const oe=/^([0-9.]{1,4}[a-z]{0,2}) ?[-–—] ?([0-9]{1,4}[a-z]{0,2})$/i,ae=/^([0-9]{1,2}(:[0-9][0-9])?(am|pm)?) ?[-–—] ?([0-9]{1,2}(:[0-9][0-9])?(am|pm)?)$/i,ie=/^[0-9]{3}-[0-9]{4}$/,se=function(e,t){const n=e[t];let r=n.text.match(oe);return null!==r?!0===n.tags.has("PhoneNumber")||ie.test(n.text)?null:[r[1],"to",r[2]]:(r=n.text.match(ae),null!==r?[r[1],"to",r[4]]:null)},le=/^([+-]?[0-9][.,0-9]*)([a-z°²³µ/]+)$/,ue=function(e,t,n){const r=n.model.one.numberSuffixes||{},o=e[t].text.match(le);if(null!==o){const e=o[2].toLowerCase().trim();return r.hasOwnProperty(e)?null:[o[1],e]}return null},ce=/'/,he=/^[0-9][^-–—]*[-–—].*?[0-9]/,de=function(e,t,n,r){const o=t.update();o.document=[e];let a=n+r;n>0&&(n-=1),e[a]&&(a+=1),o.ptrs=[[0,n,a]]},ge={t:(e,t)=>function(e,t){return"ain't"===e[t].normal||"aint"===e[t].normal?null:[e[t].normal.replace(/n't/,""),"not"]}(e,t),d:(e,t)=>function(e,t){const n=e[t].normal.split(R)[0];if(Q.has(n))return[n,"did"];if(e[t+1]){if(_.has(e[t+1].normal))return[n,"had"];if(Z.has(e[t+1].normal))return[n,"would"]}return null}(e,t)},me={j:(e,t)=>te(e,t),l:(e,t)=>ne(e,t),d:(e,t)=>re(e,t)},pe=function(e,t,n,r){for(let o=0;o2)return a.out.concat(r)}return null},fe=function(e,t){const n=t.fromText(e.join(" "));return n.compute(["id","alias"]),n.docs[0]},be=function(e,t){for(let n=t+1;n<5&&e[n];n+=1)if("been"===e[n].normal)return["there","has"];return["there","is"]};var ve={contractions:e=>{const{world:t,document:n}=e,{model:r,methods:o}=t,a=r.one.contractions||[];n.forEach(((r,i)=>{for(let s=r.length-1;s>=0;s-=1){let l=null,u=null;if(!0===ce.test(r[s].normal)){const e=r[s].normal.split(ce);l=e[0],u=e[1]}let c=pe(a,r[s],l,u);!c&&ge.hasOwnProperty(u)&&(c=ge[u](r,s,t)),!c&&me.hasOwnProperty(l)&&(c=me[l](r,s)),"there"===l&&"s"===u&&(c=be(r,s)),c?(c=fe(c,e),U(n,[i,s],c),de(n[i],e,s,c.length)):he.test(r[s].normal)?(c=se(r,s),c&&(c=fe(c,e),U(n,[i,s],c),o.one.setTag(c,"NumberRange",t),c[2]&&c[2].tags.has("Time")&&o.one.setTag([c[0]],"Time",t,null,"time-range"),de(n[i],e,s,c.length))):(c=ue(r,s,t),c&&(c=fe(c,e),U(n,[i,s],c),o.one.setTag([c[1]],"Unit",t,null,"contraction-unit")))}}))}};const ye={model:q,compute:ve,hooks:["contractions"]},we=function(e){const t=e.world,{model:n,methods:r}=e.world,o=r.one.setTag,{frozenLex:a}=n.one,i=n.one._multiCache||{};e.docs.forEach((e=>{for(let n=0;nn;r-=1){const i=e.slice(n,r+1),s=i.map((e=>e.machine||e.normal)).join(" ");!0!==a.hasOwnProperty(s)||(o(i,a[s],t,!1,"1-frozen-multi-lexicon"),i.forEach((e=>e.frozen=!0)))}}void 0!==a[s]&&a.hasOwnProperty(s)&&(o([r],a[s],t,!1,"1-freeze-lexicon"),r.frozen=!0)}}))};const ke=e=>"�[34m"+e+"�[0m",Pe=e=>"�[3m�[2m"+e+"�[0m",Ae=function(e){e.docs.forEach((e=>{console.log(ke("\n ┌─────────")),e.forEach((e=>{let t=` ${Pe("│")} `;const n=e.implicit||e.text||"-";!0===e.frozen?t+=`${ke(n)} ❄️`:t+=Pe(n),console.log(t)}))}))};var Ce={compute:{frozen:we,freeze:we,unfreeze:function(e){return e.docs.forEach((e=>{e.forEach((e=>{delete e.frozen}))})),e}},mutate:e=>{const t=e.methods.one;t.termMethods.isFrozen=e=>!0===e.frozen,t.debug.freeze=Ae,t.debug.frozen=Ae},api:function(e){e.prototype.freeze=function(){return this.docs.forEach((e=>{e.forEach((e=>{e.frozen=!0}))})),this},e.prototype.unfreeze=function(){this.compute("unfreeze")},e.prototype.isFrozen=function(){return this.match("@isFrozen+")}},hooks:["freeze"]};const Ne=function(e,t,n){const{model:r,methods:o}=n,a=o.one.setTag,i=r.one._multiCache||{},{lexicon:s}=r.one||{},l=e[t],u=l.machine||l.normal;if(void 0!==i[u]&&e[t+1]){for(let r=t+i[u]-1;r>t;r-=1){const o=e.slice(t,r+1);if(o.length<=1)return!1;const i=o.map((e=>e.machine||e.normal)).join(" ");if(!0===s.hasOwnProperty(i)){const e=s[i];return a(o,e,n,!1,"1-multi-lexicon"),!e||2!==e.length||"PhrasalVerb"!==e[0]&&"PhrasalVerb"!==e[1]||a([o[1]],"Particle",n,!1,"1-phrasal-particle"),!0}}return!1}return null},je=/^(under|over|mis|re|un|dis|semi|pre|post)-?/,xe=new Set(["Verb","Infinitive","PastTense","Gerund","PresentTense","Adjective","Participle"]),Ie=function(e,t,n){const{model:r,methods:o}=n,a=o.one.setTag,{lexicon:i}=r.one,s=e[t],l=s.machine||s.normal;if(void 0!==i[l]&&i.hasOwnProperty(l))return a([s],i[l],n,!1,"1-lexicon"),!0;if(s.alias){const e=s.alias.find((e=>i.hasOwnProperty(e)));if(e)return a([s],i[e],n,!1,"1-lexicon-alias"),!0}if(!0===je.test(l)){const e=l.replace(je,"");if(i.hasOwnProperty(e)&&e.length>3&&xe.has(i[e]))return a([s],i[e],n,!1,"1-lexicon-prefix"),!0}return null};var Te={lexicon:function(e){const t=e.world;e.docs.forEach((e=>{for(let n=0;n{const o=e[r],a=(r=(r=r.toLowerCase().trim()).replace(/'s\b/,"")).split(/ /);a.length>1&&(void 0===n[a[0]]||a.length>n[a[0]])&&(n[a[0]]=a.length),t[r]=t[r]||o})),delete t[""],delete t.null,delete t[" "],{lex:t,_multi:n}}}};var He={addWords:function(e,t=!1){const n=this.world(),{methods:r,model:o}=n;if(!e)return;if(Object.keys(e).forEach((t=>{"string"==typeof e[t]&&e[t].startsWith("#")&&(e[t]=e[t].replace(/^#/,""))})),!0===t){const{lex:t,_multi:a}=r.one.expandLexicon(e,n);return Object.assign(o.one._multiCache,a),void Object.assign(o.one.frozenLex,t)}if(r.two.expandLexicon){const{lex:t,_multi:a}=r.two.expandLexicon(e,n);Object.assign(o.one.lexicon,t),Object.assign(o.one._multiCache,a)}const{lex:a,_multi:i}=r.one.expandLexicon(e,n);Object.assign(o.one.lexicon,a),Object.assign(o.one._multiCache,i)}};var Ee={model:{one:{lexicon:{},_multiCache:{},frozenLex:{}}},methods:De,compute:Te,lib:He,hooks:["lexicon"]};const Ge=function(e,t){const n=[{}],r=[null],o=[0],a=[];let i=0;e.forEach((function(e){let o=0;const a=function(e,t){const{methods:n,model:r}=t,o=n.one.tokenize.splitTerms(e,r).map((e=>n.one.tokenize.splitWhitespace(e,r)));return o.map((e=>e.text.toLowerCase()))}(e,t);for(let e=0;e0&&!n[i].hasOwnProperty(l);)i=o[i];if(n.hasOwnProperty(i)){const e=n[i][l];o[u]=e,r[e]&&(r[u]=r[u]||[],r[u]=r[u].concat(r[e]))}else o[u]=0}}return{goNext:n,endAs:r,failTo:o}},Oe=function(e,t,n){let r=0;const o=[];for(let a=0;a0&&(void 0===t.goNext[r]||!t.goNext[r].hasOwnProperty(i));)r=t.failTo[r]||0;if(t.goNext[r].hasOwnProperty(i)&&(r=t.goNext[r][i],t.endAs[r])){const n=t.endAs[r];for(let t=0;t{for(let n=e.length-1;n>=0;n-=1)if(e[n]!==t)return e=e.slice(0,n+1);return e},ze={buildTrie:function(e){return function(e){return e.goNext=e.goNext.map((e=>{if(0!==Object.keys(e).length)return e})),e.goNext=Ve(e.goNext,void 0),e.failTo=Ve(e.failTo,0),e.endAs=Ve(e.endAs,null),e}(Ge(e,this.world()))}};ze.compile=ze.buildTrie;var Be={api:function(e){e.prototype.lookup=function(e,t={}){if(!e)return this.none();"string"==typeof e&&(e=[e]);var n;let r=function(e,t,n){let r=[];n.form=n.form||"normal";const o=e.docs;if(!t.goNext||!t.goNext[0])return console.error("Compromise invalid lookup trie"),e.none();const a=Object.keys(t.goNext[0]);for(let i=0;i0&&(r=r.concat(l))}return e.update(r)}(this,(n=e,"[object Object]"===Object.prototype.toString.call(n)?e:Ge(e,this.world)),t);return r=r.settle(),r}},lib:ze};const Se=function(e,t){return t?(e.forEach((e=>{const n=e[0];t[n]&&(e[0]=t[n][0],e[1]+=t[n][1],e[2]+=t[n][1])})),e):e},$e=function(e,t){let{ptrs:n}=e;const{byGroup:r}=e;return n=Se(n,t),Object.keys(r).forEach((e=>{r[e]=Se(r[e],t)})),{ptrs:n,byGroup:r}},Me=function(e,t,n){const r=n.methods.one;return"number"==typeof e&&(e=String(e)),"string"==typeof e&&(e=r.killUnicode(e,n),e=r.parseMatch(e,t,n)),e},Le=e=>"[object Object]"===Object.prototype.toString.call(e),Ke=e=>e&&Le(e)&&!0===e.isView,Je=e=>e&&Le(e)&&!0===e.isNet;var We={matchOne:function(e,t,n){const r=this.methods.one;if(Ke(e))return this.intersection(e).eq(0);if(Je(e))return this.sweep(e,{tagger:!1,matchOne:!0}).view;const o={regs:e=Me(e,n,this.world),group:t,justOne:!0},a=r.match(this.docs,o,this._cache),{ptrs:i,byGroup:s}=$e(a,this.fullPointer),l=this.toView(i);return l._groups=s,l},match:function(e,t,n){const r=this.methods.one;if(Ke(e))return this.intersection(e);if(Je(e))return this.sweep(e,{tagger:!1}).view.settle();const o={regs:e=Me(e,n,this.world),group:t},a=r.match(this.docs,o,this._cache),{ptrs:i,byGroup:s}=$e(a,this.fullPointer),l=this.toView(i);return l._groups=s,l},has:function(e,t,n){const r=this.methods.one;if(Ke(e)){return this.intersection(e).fullPointer.length>0}if(Je(e))return this.sweep(e,{tagger:!1}).view.found;const o={regs:e=Me(e,n,this.world),group:t,justOne:!0};return r.match(this.docs,o,this._cache).ptrs.length>0},if:function(e,t,n){const r=this.methods.one;if(Ke(e))return this.filter((t=>t.intersection(e).found));if(Je(e)){const t=this.sweep(e,{tagger:!1}).view.settle();return this.if(t)}const o={regs:e=Me(e,n,this.world),group:t,justOne:!0};let a=this.fullPointer;const i=this._cache||[];a=a.filter(((e,t)=>{const n=this.update([e]);return r.match(n.docs,o,i[t]).ptrs.length>0}));const s=this.update(a);return this._cache&&(s._cache=a.map((e=>i[e[0]]))),s},ifNo:function(e,t,n){const{methods:r}=this,o=r.one;if(Ke(e))return this.filter((t=>!t.intersection(e).found));if(Je(e)){const t=this.sweep(e,{tagger:!1}).view.settle();return this.ifNo(t)}e=Me(e,n,this.world);const a=this._cache||[],i=this.filter(((n,r)=>{const i={regs:e,group:t,justOne:!0};return 0===o.match(n.docs,i,a[r]).ptrs.length}));return this._cache&&(i._cache=i.ptrs.map((e=>a[e[0]]))),i}};var qe={before:function(e,t,n){const{indexN:r}=this.methods.one.pointer,o=[],a=r(this.fullPointer);Object.keys(a).forEach((e=>{const t=a[e].sort(((e,t)=>e[1]>t[1]?1:-1))[0];t[1]>0&&o.push([t[0],0,t[1]])}));const i=this.toView(o);return e?i.match(e,t,n):i},after:function(e,t,n){const{indexN:r}=this.methods.one.pointer,o=[],a=r(this.fullPointer),i=this.document;Object.keys(a).forEach((e=>{const t=a[e].sort(((e,t)=>e[1]>t[1]?-1:1))[0],[n,,r]=t;r{const a=n.before(e,t);if(a.found){const e=a.terms();r[o][1]-=e.length,r[o][3]=e.docs[0][0].id}})),this.update(r)},growRight:function(e,t,n){"string"==typeof e&&(e=this.world.methods.one.parseMatch(e,n,this.world)),e[0].start=!0;const r=this.fullPointer;return this.forEach(((n,o)=>{const a=n.after(e,t);if(a.found){const e=a.terms();r[o][2]+=e.length,r[o][4]=null}})),this.update(r)},grow:function(e,t,n){return this.growRight(e,t,n).growLeft(e,t,n)}};const Ue=function(e,t){return[e[0],e[1],t[2]]},Re=(e,t,n)=>{return"string"==typeof e||(r=e,"[object Array]"===Object.prototype.toString.call(r))?t.match(e,n):e||t.none();var r},Qe=function(e,t){const[n,r,o]=e;return t.document[n]&&t.document[n][r]&&(e[3]=e[3]||t.document[n][r].id,t.document[n][o-1]&&(e[4]=e[4]||t.document[n][o-1].id)),e},Ze={splitOn:function(e,t){const{splitAll:n}=this.methods.one.pointer,r=Re(e,this,t).fullPointer,o=n(this.fullPointer,r);let a=[];return o.forEach((e=>{a.push(e.passthrough),a.push(e.before),a.push(e.match),a.push(e.after)})),a=a.filter((e=>e)),a=a.map((e=>Qe(e,this))),this.update(a)},splitBefore:function(e,t){const{splitAll:n}=this.methods.one.pointer,r=Re(e,this,t).fullPointer,o=n(this.fullPointer,r);for(let e=0;e{a.push(e.passthrough),a.push(e.before),e.match&&e.after?a.push(Ue(e.match,e.after)):a.push(e.match)})),a=a.filter((e=>e)),a=a.map((e=>Qe(e,this))),this.update(a)},splitAfter:function(e,t){const{splitAll:n}=this.methods.one.pointer,r=Re(e,this,t).fullPointer,o=n(this.fullPointer,r);let a=[];return o.forEach((e=>{a.push(e.passthrough),e.before&&e.match?a.push(Ue(e.before,e.match)):(a.push(e.before),a.push(e.match)),a.push(e.after)})),a=a.filter((e=>e)),a=a.map((e=>Qe(e,this))),this.update(a)}};Ze.split=Ze.splitAfter;const _e=function(e,t){return!(!e||!t)&&(e[0]===t[0]&&e[2]===t[1])},Xe=function(e,t,n){const r=e.world,o=r.methods.one.parseMatch;n=n||"^.";const a=o(t=t||".$",{},r),i=o(n,{},r);a[a.length-1].end=!0,i[0].start=!0;const s=e.fullPointer,l=[s[0]];for(let t=1;t)?\/.*?[^\\/]\/[?\]+*$~]*)(?:\s|$)/,nt=/([!~[^]*(?:<[^<]*>)?\([^)]+[^\\)]\)[?\]+*$~]*)(?:\s|$)/,rt=/ /g,ot=e=>/^[![^]*(<[^<]*>)?\//.test(e)&&/\/[?\]+*$~]*$/.test(e),at=function(e){return e=(e=e.map((e=>e.trim()))).filter((e=>e))},it=/\{([0-9]+)?(, *[0-9]*)?\}/,st=/&&/,lt=new RegExp(/^<\s*(\S+)\s*>/),ut=e=>e.charAt(0).toUpperCase()+e.substring(1),ct=e=>e.charAt(e.length-1),ht=e=>e.charAt(0),dt=e=>e.substring(1),gt=e=>e.substring(0,e.length-1),mt=function(e){return e=dt(e),e=gt(e)},pt=function(e,t){const n={};for(let r=0;r<2;r+=1){if("$"===ct(e)&&(n.end=!0,e=gt(e)),"^"===ht(e)&&(n.start=!0,e=dt(e)),"?"===ct(e)&&(n.optional=!0,e=gt(e)),("["===ht(e)||"]"===ct(e))&&(n.group=null,"["===ht(e)&&(n.groupStart=!0),"]"===ct(e)&&(n.groupEnd=!0),e=(e=e.replace(/^\[/,"")).replace(/\]$/,""),"<"===ht(e))){const t=lt.exec(e);t.length>=2&&(n.group=t[1],e=e.replace(t[0],""))}if("+"===ct(e)&&(n.greedy=!0,e=gt(e)),"*"!==e&&"*"===ct(e)&&"\\*"!==e&&(n.greedy=!0,e=gt(e)),"!"===ht(e)&&(n.negative=!0,e=dt(e)),"~"===ht(e)&&"~"===ct(e)&&e.length>2&&(e=mt(e),n.fuzzy=!0,n.min=t.fuzzy||.85,!1===/\(/.test(e)))return n.word=e,n;if("/"===ht(e)&&"/"===ct(e))return e=mt(e),t.caseSensitive&&(n.use="text"),n.regex=new RegExp(e),n;if(!0===it.test(e)&&(e=e.replace(it,((e,t,r)=>(void 0===r?(n.min=Number(t),n.max=Number(t)):(r=r.replace(/, */,""),void 0===t?(n.min=0,n.max=Number(r)):(n.min=Number(t),n.max=Number(r||999))),n.greedy=!0,n.min||(n.optional=!0),"")))),"("===ht(e)&&")"===ct(e)){st.test(e)?(n.choices=e.split(st),n.operator="and"):(n.choices=e.split("|"),n.operator="or"),n.choices[0]=dt(n.choices[0]);const r=n.choices.length-1;n.choices[r]=gt(n.choices[r]),n.choices=n.choices.map((e=>e.trim())),n.choices=n.choices.filter((e=>e)),n.choices=n.choices.map((e=>e.split(/ /g).map((e=>pt(e,t))))),e=""}if("{"===ht(e)&&"}"===ct(e)){if(e=mt(e),n.root=e,/\//.test(e)){const e=n.root.split(/\//);n.root=e[0],n.pos=e[1],"adj"===n.pos&&(n.pos="Adjective"),n.pos=n.pos.charAt(0).toUpperCase()+n.pos.substr(1).toLowerCase(),void 0!==e[2]&&(n.sense=e[2])}return n}if("<"===ht(e)&&">"===ct(e))return e=mt(e),n.chunk=ut(e),n.greedy=!0,n;if("%"===ht(e)&&"%"===ct(e))return e=mt(e),n.switch=e,n}return"#"===ht(e)?(n.tag=dt(e),n.tag=ut(n.tag),n):"@"===ht(e)?(n.method=dt(e),n):"."===e?(n.anything=!0,n):"*"===e?(n.anything=!0,n.greedy=!0,n.optional=!0,n):(e&&(e=(e=e.replace("\\*","*")).replace("\\.","."),t.caseSensitive?n.use="text":e=e.toLowerCase(),n.word=e),n)},ft=/[a-z0-9][-–—][a-z]/i,bt=function(e,t){const{all:n}=t.methods.two.transform.verb||{},r=e.root;return n?n(r,t.model):[]},vt=function(e,t){const{all:n}=t.methods.two.transform.noun||{};return n?n(e.root,t.model):[e.root]},yt=function(e,t){const{all:n}=t.methods.two.transform.adjective||{};return n?n(e.root,t.model):[e.root]},wt=function(e){return e=function(e){let t=0,n=null;for(let r=0;r(e.fuzzy&&e.choices&&e.choices.forEach((t=>{1===t.length&&t[0].word&&(t[0].fuzzy=!0,t[0].min=e.min)})),e)))}(e=e.map((e=>{if(void 0!==e.choices){if("or"!==e.operator)return e;if(!0===e.fuzzy)return e;!0===e.choices.every((e=>{if(1!==e.length)return!1;const t=e[0];return!0!==t.fuzzy&&!t.start&&!t.end&&void 0!==t.word&&!0!==t.negative&&!0!==t.optional&&!0!==t.method}))&&(e.fastOr=new Set,e.choices.forEach((t=>{e.fastOr.add(t[0].word)})),delete e.choices)}return e}))),e},kt=function(e,t){for(const n of t)if(e.has(n))return!0;return!1},Pt=function(e,t){for(let n=0;nn?r:n)+1;if(Math.abs(n-r)>(o||100))return o||100;const a=[];for(let e=0;e4)return n;l=t[i-1],u=s===l?0:1,c=a[o-1][i]+1,(h=a[o][i-1]+1)1&&i>1&&s===t[i-2]&&e[o-2]===l&&(h=a[o-2][i-2]+u)-1!==e.post.indexOf(t),Tt={hasQuote:e=>Ct.test(e.pre)||Nt.test(e.post),hasComma:e=>It(e,","),hasPeriod:e=>!0===It(e,".")&&!1===It(e,"..."),hasExclamation:e=>It(e,"!"),hasQuestionMark:e=>It(e,"?")||It(e,"¿"),hasEllipses:e=>It(e,"..")||It(e,"…"),hasSemicolon:e=>It(e,";"),hasColon:e=>It(e,":"),hasSlash:e=>/\//.test(e.text),hasHyphen:e=>jt.test(e.post)||jt.test(e.pre),hasDash:e=>xt.test(e.post)||xt.test(e.pre),hasContraction:e=>Boolean(e.implicit),isAcronym:e=>e.tags.has("Acronym"),isKnown:e=>e.tags.size>0,isTitleCase:e=>/^\p{Lu}[a-z'\u00C0-\u00FF]/u.test(e.text),isUpperCase:e=>/^\p{Lu}+$/u.test(e.text)};Tt.hasQuotation=Tt.hasQuote;let Dt=function(){};Dt=function(e,t,n,r){const o=function(e,t,n,r){if(!0===t.anything)return!0;if(!0===t.start&&0!==n)return!1;if(!0===t.end&&n!==r-1)return!1;if(void 0!==t.id&&t.id===e.id)return!0;if(void 0!==t.word){if(t.use)return t.word===e[t.use];if(null!==e.machine&&e.machine===t.word)return!0;if(void 0!==e.alias&&e.alias.hasOwnProperty(t.word))return!0;if(!0===t.fuzzy){if(t.word===e.root)return!0;if(At(t.word,e.normal)>=t.min)return!0}return!(!e.alias||!e.alias.some((e=>e===t.word)))||t.word===e.text||t.word===e.normal}if(void 0!==t.tag)return!0===e.tags.has(t.tag);if(void 0!==t.method)return"function"==typeof Tt[t.method]&&!0===Tt[t.method](e);if(void 0!==t.pre)return e.pre&&e.pre.includes(t.pre);if(void 0!==t.post)return e.post&&e.post.includes(t.post);if(void 0!==t.regex){let n=e.normal;return t.use&&(n=e[t.use]),t.regex.test(n)}if(void 0!==t.chunk)return e.chunk===t.chunk;if(void 0!==t.switch)return e.switch===t.switch;if(void 0!==t.machine)return e.normal===t.machine||e.machine===t.machine||e.root===t.machine;if(void 0!==t.sense)return e.sense===t.sense;if(void 0!==t.fastOr){if(t.pos&&!e.tags.has(t.pos))return null;const n=e.root||e.implicit||e.machine||e.normal;return t.fastOr.has(n)||t.fastOr.has(e.text)}return void 0!==t.choices&&("and"===t.operator?t.choices.every((t=>Dt(e,t,n,r))):t.choices.some((t=>Dt(e,t,n,r))))}(e,t,n,r);return!0===t.negative?!o:o};const Ht=function(e,t){if(!0===e.end&&!0===e.greedy&&t.start_i+t.tn.max)return e.t=e.t+n.max,!0;if(!0===e.hasGroup){Et(e,e.t).length=r-e.t}return e.t=r,!0},Ot=function(e,t=0){const n=e.regs[e.r];let r=!1;for(let a=0;a{let o=0;const a=e.t+r+t+o;if(void 0===e.terms[a])return!1;const i=Dt(e.terms[a],n,a+e.start_i,e.phrase_length);if(!0===i&&!0===n.greedy)for(let t=1;t{const r=n.every(((t,n)=>{const r=e.t+n;return void 0!==e.terms[r]&&Dt(e.terms[r],t,r,e.phrase_length)}));return!0===r&&n.length>t&&(t=n.length),r}))&&t}(e);if(r){if(!0===n.negative)return null;if(!0===e.hasGroup){Et(e,e.t).length+=r}if(!0===n.end){const t=e.phrase_length-1;if(e.t+e.start_i!==t)return null}return e.t+=r,!0}return!!n.optional||null},zt=function(e){const{regs:t}=e,n=t[e.r],r=Object.assign({},n);r.negative=!1;if(Dt(e.terms[e.t],r,e.start_i+e.t,e.phrase_length))return!1;if(n.optional){const n=t[e.r+1];if(n){if(Dt(e.terms[e.t],n,e.start_i+e.t,e.phrase_length))e.r+=1;else if(n.optional&&t[e.r+2]){Dt(e.terms[e.t],t[e.r+2],e.start_i+e.t,e.phrase_length)&&(e.r+=2)}}}return n.greedy?function(e,t,n){let r=0;for(let o=e.t;or||(e.t+=r,0))}(e,r,t[e.r+1]):(e.t+=1,!0)},Bt=function(e){const{regs:t,phrase_length:n}=e,r=t[e.r];return e.t=function(e,t){const n=Object.assign({},e.regs[e.r],{start:!1,end:!1}),r=e.t;for(;e.te.t?null:!0!==r.end||e.start_i+e.t===n||null},St=function(e){const{regs:t}=e,n=t[e.r],r=e.terms[e.t],o=e.t;if(n.optional&&t[e.r+1]&&n.negative)return!0;if(n.optional&&t[e.r+1]&&function(e){const{regs:t}=e,n=t[e.r],r=e.terms[e.t],o=Dt(r,t[e.r+1],e.start_i+e.t,e.phrase_length);if(n.negative||o){const n=e.terms[e.t+1];n&&Dt(n,t[e.r+1],e.start_i+e.t,e.phrase_length)||(e.r+=1)}}(e),r.implicit&&e.terms[e.t+1]&&function(e){const t=e.terms[e.t],n=e.regs[e.r];if(t.implicit&&e.terms[e.t+1]){if(!e.terms[e.t+1].implicit)return;n.word===t.normal&&(e.t+=1),"hasContraction"===n.method&&(e.t+=1)}}(e),e.t+=1,!0===n.end&&e.t!==e.terms.length&&!0!==n.greedy)return null;if(!0===n.greedy){if(!Bt(e))return null}return!0===e.hasGroup&&function(e,t){const n=e.regs[e.r],r=Et(e,t);e.t>1&&n.greedy?r.length+=e.t-t:r.length++}(e,o),!0},$t=function(e,t,n,r){if(0===e.length||0===t.length)return null;const o={t:0,terms:e,r:0,regs:t,groups:{},start_i:n,phrase_length:r,inGroup:null};for(;o.r!e.optional)))break;return null}if(!0===e.anything&&!0===e.greedy){if(!Gt(o))return null;continue}if(void 0!==e.choices&&"or"===e.operator){if(!Ft(o))return null;continue}if(void 0!==e.choices&&"and"===e.operator){if(!Vt(o))return null;continue}if(!0===e.anything){if(e.negative&&e.anything)return null;if(!St(o))return null;continue}if(!0===Ht(e,o)){if(!St(o))return null;continue}if(e.negative){if(!zt(o))return null;continue}if(!0!==Dt(o.terms[o.t],e,o.start_i+o.t,o.phrase_length)){if(!0!==e.optional)return null}else{if(!St(o))return null}}const a=[null,n,o.t+n];if(a[1]===a[2])return null;const i={};return Object.keys(o.groups).forEach((e=>{const t=o.groups[e],r=n+t.start;i[e]=[null,r,r+t.length]})),{pointer:a,groups:i}},Mt=function(e,t){return e.pointer[0]=t,Object.keys(e.groups).forEach((n=>{e.groups[n][0]=t})),e},Lt=function(e,t,n){let r=$t(e,t,0,e.length);return r?(r=Mt(r,n),r):null},Kt={one:{termMethods:Tt,parseMatch:function(e,t,n){if(null==e||""===e)return[];t=t||{},"number"==typeof e&&(e=String(e));let r=function(e){const t=e.split(tt);let n=[];t.forEach((e=>{ot(e)?n.push(e):n=n.concat(e.split(nt))})),n=at(n);let r=[];return n.forEach((e=>{(e=>/^[![^]*(<[^<]*>)?\(/.test(e)&&/\)[?\]+*$~]*$/.test(e))(e)||ot(e)?r.push(e):r=r.concat(e.split(rt))})),r=at(r),r}(e);return r=r.map((e=>pt(e,t))),r=function(e,t){const n=t.model.one.prefixes;for(let t=e.length-1;t>=0;t-=1){const r=e[t];if(r.word&&ft.test(r.word)){let o=r.word.split(/[-–—]/g);if(n.hasOwnProperty(o[0]))continue;o=o.filter((e=>e)).reverse(),e.splice(t,1),o.forEach((n=>{const o=Object.assign({},r);o.word=n,e.splice(t,0,o)}))}}return e}(r,n),r=function(e,t){return e.map((e=>{if(e.root)if(t.methods.two&&t.methods.two.transform){let n=[];e.pos?"Verb"===e.pos?n=n.concat(bt(e,t)):"Noun"===e.pos?n=n.concat(vt(e,t)):"Adjective"===e.pos&&(n=n.concat(yt(e,t))):(n=n.concat(bt(e,t)),n=n.concat(vt(e,t)),n=n.concat(yt(e,t))),n=n.filter((e=>e)),n.length>0&&(e.operator="or",e.fastOr=new Set(n))}else e.machine=e.root,delete e.id,delete e.root;return e}))}(r,n),r=wt(r),r},match:function(e,t,n){n=n||[];const{regs:r,group:o,justOne:a}=t;let i=[];if(!r||0===r.length)return{ptrs:[],byGroup:{}};const s=r.filter((e=>!0!==e.optional&&!0!==e.negative)).length;e:for(let t=0;te&&(e=Math.abs(n-1))}}else{const e=Lt(o,r,t);e&&i.push(e)}}return!0===r[r.length-1].end&&(i=i.filter((t=>{const n=t.pointer[0];return e[n].length===t.pointer[2]}))),t.notIf&&(i=function(e,t,n){return e=e.filter((e=>{const[r,o,a]=e.pointer,i=n[r].slice(o,a);for(let e=0;e{e.groups[t]&&n.push(e.groups[t])})):e.forEach((e=>{n.push(e.pointer),Object.keys(e.groups).forEach((t=>{r[t]=r[t]||[],r[t].push(e.groups[t])}))}))),{ptrs:n,byGroup:r}}(i,o),i.ptrs.forEach((t=>{const[n,r,o]=t;t[3]=e[n][r].id,t[4]=e[n][o-1].id})),i}}};var Jt={api:function(e){Object.assign(e.prototype,et)},methods:Kt,lib:{parseMatch:function(e,t){const n=this.world(),r=n.methods.one.killUnicode;return r&&(e=r(e,n)),n.methods.one.parseMatch(e,t,n)}}};const Wt=/^\../,qt=/^#./,Ut=function(e,t){const n={},r={};return Object.keys(t).forEach((o=>{let a=t[o];const i=function(e){let t="",n=" ";return e=e.replace(/&/g,"&").replace(//g,">").replace(/"/g,""").replace(/'/g,"'"),Wt.test(e)?t=``),t+=">",{start:t,end:n}}(o);"string"==typeof a&&(a=e.match(a)),a.docs.forEach((e=>{if(e.every((e=>e.implicit)))return;const t=e[0].id;n[t]=n[t]||[],n[t].push(i.start);const o=e[e.length-1].id;r[o]=r[o]||[],r[o].push(i.end)}))})),{starts:n,ends:r}};var Rt={html:function(e){const{starts:t,ends:n}=Ut(this,e);let r="";return this.docs.forEach((e=>{for(let o=0;o{let n=e.pre||"",o=e.post||"";"some"===t.punctuation&&(n=n.replace(Zt,""),Xt.test(o)&&(o=" "),o=o.replace(_t,""),o=o.replace(/\?!+/,"?"),o=o.replace(/!+/,"!"),o=o.replace(/\?+/,"?"),o=o.replace(/\.{2,}/,""),e.tags.has("Abbreviation")&&(o=o.replace(/\./,""))),"some"===t.whitespace&&(n=n.replace(/\s/,""),o=o.replace(/\s+/," ")),t.keepPunct||(n=n.replace(Zt,""),o="-"===o?" ":o.replace(Qt,""));let a=e[t.form||"text"]||e.normal||"";"implicit"===t.form&&(a=e.implicit||e.text),"root"===t.form&&e.implicit&&(a=e.root||e.implicit||e.normal),"machine"!==t.form&&"implicit"!==t.form&&"root"!==t.form||!e.implicit||o&&Yt.test(o)||(o+=" "),r+=n+a+o})),!1===n&&(r=r.trim()),!0===t.lowerCase&&(r=r.toLowerCase()),r},tn={text:{form:"text"},normal:{whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"normal"},machine:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"none",unicode:"some",form:"machine"},root:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"root"},implicit:{form:"implicit"}};tn.clean=tn.normal,tn.reduced=tn.root;const nn=[];let rn=0;for(;rn<64;)nn[rn]=0|4294967296*Math.sin(++rn%Math.PI);const on=function(e){let t,n,r,o=decodeURI(encodeURI(e))+"",a=o.length;const i=[t=1732584193,n=4023233417,~t,~n],s=[];for(e=--a/4+2|15,s[--e]=8*a;~a;)s[a>>2]|=o.charCodeAt(a)<<8*a--;for(rn=o=0;rn>4]+nn[o]+~~s[rn|15&[o,5*o+1,3*o+5,7*o][a]])<<(a=[7,12,17,22,5,9,14,20,4,11,16,23,6,10,15,21][4*a+o++%4])|r>>>-a),t,n])t=0|a[1],n=a[2];for(o=4;o;)i[--o]+=a[o]}for(e="";o<32;)e+=(i[o>>3]>>4*(1^o++)&15).toString(16);return e},an={text:!0,terms:!0},sn={case:"none",unicode:"some",form:"machine",punctuation:"some"},ln=function(e,t){return Object.assign({},e,t)},un={text:e=>en(e,{keepPunct:!0},!1),normal:e=>en(e,ln(tn.normal,{keepPunct:!0}),!1),implicit:e=>en(e,ln(tn.implicit,{keepPunct:!0}),!1),machine:e=>en(e,sn,!1),root:e=>en(e,ln(sn,{form:"root"}),!1),hash:e=>on(en(e,{keepPunct:!0},!1)),offset:e=>{const t=un.text(e).length;return{index:e[0].offset.index,start:e[0].offset.start,length:t}},terms:e=>e.map((e=>{const t=Object.assign({},e);return t.tags=Array.from(e.tags),t})),confidence:(e,t,n)=>t.eq(n).confidence(),syllables:(e,t,n)=>t.eq(n).syllables(),sentence:(e,t,n)=>t.eq(n).fullSentence().text(),dirty:e=>e.some((e=>!0===e.dirty))};un.sentences=un.sentence,un.clean=un.normal,un.reduced=un.root;const cn={json:function(e){const t=(n=this,"string"==typeof(r=(r=e)||{})&&(r={}),(r=Object.assign({},an,r)).offset&&n.compute("offset"),n.docs.map(((e,t)=>{const o={};return Object.keys(r).forEach((a=>{r[a]&&un[a]&&(o[a]=un[a](e,n,t))})),o})));var n,r;return"number"==typeof e?t[e]:t}};cn.data=cn.json;const hn=function(e){const t=e.pre||"",n=e.post||"";return t+e.text+n},dn=function(e,t){const n=function(e,t){const n={};return Object.keys(t).forEach((r=>{e.match(r).fullPointer.forEach((e=>{n[e[3]]={fn:t[r],end:e[2]}}))})),n}(e,t);let r="";return e.docs.forEach(((t,o)=>{for(let a=0;ae.reduce(((e,t)=>e+t.pre+t.text+t.post),"").trim()));return e.filter((e=>e))}if("freq"===e||"frequency"===e||"topk"===e)return function(e){const t={};e.forEach((e=>{t[e]=t[e]||0,t[e]+=1}));const n=Object.keys(t).map((e=>({normal:e,count:t[e]})));return n.sort(((e,t)=>e.count>t.count?-1:0))}(this.json({normal:!0}).map((e=>e.normal)));if("terms"===e){let e=[];return this.docs.forEach((t=>{let n=t.map((e=>e.text));n=n.filter((e=>e)),e=e.concat(n)})),e}return"tags"===e?this.docs.map((e=>e.reduce(((e,t)=>(e[t.implicit||t.normal]=Array.from(t.tags),e)),{}))):"debug"===e?this.debug():this.text()},wrap:function(e){return dn(this,e)}};var mn={text:function(e){let t={};var n;if(e&&"string"==typeof e&&tn.hasOwnProperty(e)?t=Object.assign({},tn[e]):e&&(n=e,"[object Object]"===Object.prototype.toString.call(n))&&(t=Object.assign({},e)),void 0!==t.keepSpace||this.isFull()||(t.keepSpace=!1),void 0===t.keepEndPunct&&this.pointer){const e=this.pointer[0];e&&e[1]?t.keepEndPunct=!1:t.keepEndPunct=!0}return void 0===t.keepPunct&&(t.keepPunct=!0),void 0===t.keepSpace&&(t.keepSpace=!0),function(e,t){let n="";if(!e||!e[0]||!e[0][0])return n;for(let r=0;r"�[32m"+e+fn,red:e=>"�[31m"+e+fn,blue:e=>"�[34m"+e+fn,magenta:e=>"�[35m"+e+fn,cyan:e=>"�[36m"+e+fn,yellow:e=>"�[33m"+e+fn,black:e=>"�[30m"+e+fn,dim:e=>"�[2m"+e+fn,i:e=>"�[3m"+e+fn},vn={tags:function(e){const{docs:t,model:n}=e;0===t.length&&console.log(bn.blue("\n ──────")),t.forEach((t=>{console.log(bn.blue("\n ┌─────────")),t.forEach((t=>{const r=[...t.tags||[]];let o=t.text||"-";t.sense&&(o=`{${t.normal}/${t.sense}}`),t.implicit&&(o="["+t.implicit+"]"),o=bn.yellow(o);let a="'"+o+"'";if(t.reference){const n=e.update([t.reference]).text("normal");a+=` - ${bn.dim(bn.i("["+n+"]"))}`}a=a.padEnd(18);const i=bn.blue(" │ ")+bn.i(a)+" - "+function(e,t){return t.one.tagSet&&(e=e.map((e=>{if(!t.one.tagSet.hasOwnProperty(e))return e;const n=t.one.tagSet[e].color||"blue";return bn[n](e)}))),e.join(", ")}(r,n);console.log(i)}))})),console.log("\n")},clientSide:function(e){console.log("%c -=-=- ","background-color:#6699cc;"),e.forEach((e=>{console.groupCollapsed(e.text());const t=e.docs[0].map((e=>{let t=e.text||"-";e.implicit&&(t="["+e.implicit+"]");return{text:t,tags:"["+Array.from(e.tags).join(", ")+"]"}}));console.table(t,["text","tags"]),console.groupEnd()}))},chunks:function(e){const{docs:t}=e;console.log(""),t.forEach((e=>{const t=[];e.forEach((e=>{"Noun"===e.chunk?t.push(bn.blue(e.implicit||e.normal)):"Verb"===e.chunk?t.push(bn.green(e.implicit||e.normal)):"Adjective"===e.chunk?t.push(bn.yellow(e.implicit||e.normal)):"Pivot"===e.chunk?t.push(bn.red(e.implicit||e.normal)):t.push(e.implicit||e.normal)})),console.log(t.join(" "),"\n")})),console.log("\n")},highlight:function(e){if(!e.found)return;const t={};e.fullPointer.forEach((e=>{t[e[0]]=t[e[0]]||[],t[e[0]].push(e)})),Object.keys(t).forEach((n=>{let r=e.update([[Number(n)]]).text();e.update(t[n]).json({offset:!0}).forEach(((e,t)=>{r=function(e,t,n){const r=((e,t,n)=>{const r=9*n,o=t.start+r,a=o+t.length;return[e.substring(0,o),e.substring(o,a),e.substring(a,e.length)]})(e,t,n);return`${r[0]}${bn.blue(r[1])}${r[2]}`}(r,e.offset,t)})),console.log(r)})),console.log("\n")}};var yn={api:function(e){Object.assign(e.prototype,pn)},methods:{one:{hash:on,debug:vn}}};const wn=function(e,t){if(e[0]!==t[0])return!1;const[,n,r]=e,[,o,a]=t;return n<=o&&r>o||o<=n&&a>n},kn=function(e){const t={};return e.forEach((e=>{t[e[0]]=t[e[0]]||[],t[e[0]].push(e)})),t},Pn=function(e,t){const n=kn(t),r=[];return e.forEach((e=>{const[t]=e;let o=n[t]||[];if(o=o.filter((t=>function(e,t){return e[1]<=t[1]&&t[2]<=e[2]}(e,t))),0===o.length)return void r.push({passthrough:e});o=o.sort(((e,t)=>e[1]-t[1]));let a=e;o.forEach(((e,t)=>{const n=function(e,t){const[n,r]=e,o=t[1],a=t[2],i={};if(ra&&(i.after=[n,a,e[2]]),i}(a,e);o[t+1]?(r.push({before:n.before,match:n.match}),n.after&&(a=n.after)):r.push(n)}))})),r};var An={one:{termList:function(e){const t=[];for(let n=0;n{if(!r)return;let[a,i,s,l,u]=r,c=t[a]||[];if(void 0===i&&(i=0),void 0===s&&(s=c.length),!l||c[i]&&c[i].id===l)c=c.slice(i,s);else{const n=function(e,t,n){for(let r=0;r<20;r+=1){if(t[n-r]){const o=t[n-r].findIndex((t=>t.id===e));if(-1!==o)return[n-r,o]}if(t[n+r]){const o=t[n+r].findIndex((t=>t.id===e));if(-1!==o)return[n+r,o]}}return null}(l,t,a);if(null!==n){const r=s-i;c=t[n[0]].slice(n[1],n[1]+r);const a=c[0]?c[0].id:null;e[o]=[n[0],n[1],n[1]+r,a]}}0!==c.length&&i!==s&&(u&&c[c.length-1].id!==u&&(c=function(e,t){const[n,r,,,o]=e,a=t[n],i=a.findIndex((e=>e.id===o));return-1===i?(e[2]=t[n].length,e[4]=a.length?a[a.length-1].id:null):e[2]=i,t[n].slice(r,e[2]+1)}(r,t)),n.push(c))})),n=n.filter((e=>e.length>0)),n},pointer:{indexN:kn,splitAll:Pn}}};const Cn=function(e,t){const n=e.concat(t),r=kn(n);let o=[];return n.forEach((e=>{const[t]=e;if(1===r[t].length)return void o.push(e);const n=r[t].filter((t=>wn(e,t)));n.push(e);const a=function(e){let t=e[0][1],n=e[0][2];return e.forEach((e=>{e[1]n&&(n=e[2])})),[e[0][0],t,n]}(n);o.push(a)})),o=function(e){const t={};for(let n=0;n{e.passthrough&&n.push(e.passthrough),e.before&&n.push(e.before),e.after&&n.push(e.after)})),n},jn=(e,t)=>{return"string"==typeof e||(n=e,"[object Array]"===Object.prototype.toString.call(n))?t.match(e):e||t.none();var n},xn=function(e,t){return e.map((e=>{const[n,r]=e;return t[n]&&t[n][r]&&(e[3]=t[n][r].id),e}))},In={union:function(e){e=jn(e,this);let t=Cn(this.fullPointer,e.fullPointer);return t=xn(t,this.document),this.toView(t)}};In.and=In.union,In.intersection=function(e){e=jn(e,this);let t=function(e,t){const n=kn(t),r=[];return e.forEach((e=>{let t=n[e[0]]||[];t=t.filter((t=>wn(e,t))),0!==t.length&&t.forEach((t=>{const n=function(e,t){const n=e[1]t[2]?t[2]:e[2];return n{e=Cn(e,[t])})),e=xn(e,this.document),this.update(e)};var Tn={methods:An,api:function(e){Object.assign(e.prototype,In)}};const Dn=function(e){return!0===e.optional||!0===e.negative?null:e.tag?"#"+e.tag:e.word?e.word:e.switch?`%${e.switch}%`:null},Hn=function(e,t){const n=t.methods.one.parseMatch;return e.forEach((e=>{e.regs=n(e.match,{},t),"string"==typeof e.ifNo&&(e.ifNo=[e.ifNo]),e.notIf&&(e.notIf=n(e.notIf,{},t)),e.needs=function(e){const t=[];return e.forEach((e=>{t.push(Dn(e)),"and"===e.operator&&e.choices&&e.choices.forEach((e=>{e.forEach((e=>{t.push(Dn(e))}))}))})),t.filter((e=>e))}(e.regs);const{wants:r,count:o}=function(e){const t=[];let n=0;return e.forEach((e=>{"or"!==e.operator||e.optional||e.negative||(e.fastOr&&Array.from(e.fastOr).forEach((e=>{t.push(e)})),e.choices&&e.choices.forEach((e=>{e.forEach((e=>{const n=Dn(e);n&&t.push(n)}))})),n+=1)})),{wants:t,count:n}}(e.regs);e.wants=r,e.minWant=o,e.minWords=e.regs.filter((e=>!e.optional)).length})),e};var En={buildNet:function(e,t){e=Hn(e,t);const n={};e.forEach((e=>{e.needs.forEach((t=>{n[t]=Array.isArray(n[t])?n[t]:[],n[t].push(e)})),e.wants.forEach((t=>{n[t]=Array.isArray(n[t])?n[t]:[],n[t].push(e)}))})),Object.keys(n).forEach((e=>{const t={};n[e]=n[e].filter((e=>"boolean"!=typeof t[e.match]&&(t[e.match]=!0,!0)))}));const r=e.filter((e=>0===e.needs.length&&0===e.wants.length));return{hooks:n,always:r}},bulkMatch:function(e,t,n,r={}){const o=n.one.cacheDoc(e);let a=function(e,t){return e.map(((n,r)=>{let o=[];Object.keys(t).forEach((n=>{e[r].has(n)&&(o=o.concat(t[n]))}));const a={};return o=o.filter((e=>"boolean"!=typeof a[e.match]&&(a[e.match]=!0,!0))),o}))}(o,t.hooks);a=function(e,t){return e.map(((e,n)=>{const r=t[n];return(e=(e=e.filter((e=>e.needs.every((e=>r.has(e)))))).filter((e=>void 0===e.ifNo||!0!==e.ifNo.some((e=>r.has(e)))))).filter((e=>0===e.wants.length||e.wants.filter((e=>r.has(e))).length>=e.minWant))}))}(a,o),t.always.length>0&&(a=a.map((e=>e.concat(t.always)))),a=function(e,t){return e.map(((e,n)=>{const r=t[n].length;return e=e.filter((e=>r>=e.minWords)),e}))}(a,e);const i=function(e,t,n,r,o){const a=[];for(let n=0;n0&&(l.ptrs.forEach((e=>{e[0]=n;const t=Object.assign({},s,{pointer:e});void 0!==s.unTag&&(t.unTag=s.unTag),a.push(t)})),!0===o.matchOne))return[a[0]]}return a}(a,e,0,n,r);return i},bulkTagger:function(e,t,n){const{model:r,methods:o}=n,{getDoc:a,setTag:i,unTag:s}=o.one,l=o.two.looksPlural;if(0===e.length)return e;return("undefined"!=typeof process&&process.env?process.env:self.env||{}).DEBUG_TAGS&&console.log(`\n\n �[32m→ ${e.length} post-tagger:�[0m`),e.map((e=>{if(!e.tag&&!e.chunk&&!e.unTag)return;const o=e.reason||e.match,u=a([e.pointer],t)[0];if(!0===e.safe){if(!1===function(e,t,n){const r=n.one.tagSet;if(!r.hasOwnProperty(t))return!0;const o=r[t].not||[];for(let t=0;te.frozen=!0))}void 0!==e.unTag&&s(u,e.unTag,n,e.safe,o),e.chunk&&u.forEach((t=>t.chunk=e.chunk))}))}},Gn={lib:{buildNet:function(e){const t=this.methods().one.buildNet(e,this.world());return t.isNet=!0,t}},api:function(e){e.prototype.sweep=function(e,t={}){const{world:n,docs:r}=this,{methods:o}=n;let a=o.one.bulkMatch(r,e,this.methods,t);!1!==t.tagger&&o.one.bulkTagger(a,r,this.world),a=a.map((e=>{const t=e.pointer,n=r[t[0]][t[1]],o=t[2]-t[1];return n.index&&(e.pointer=[n.index[0],n.index[1],t[1]+o]),e}));const i=a.map((e=>e.pointer));return a=a.map((e=>(e.view=this.update([e.pointer]),delete e.regs,delete e.needs,delete e.pointer,delete e._expanded,e))),{view:this.update(i),found:a}}},methods:{one:En}};const On=/ /,Fn=function(e,t){"Noun"===t&&(e.chunk=t),"Verb"===t&&(e.chunk=t)},Vn=function(e,t,n,r){if(!0===e.tags.has(t))return null;if("."===t)return null;!0===e.frozen&&(r=!0);const o=n[t];if(o){if(o.not&&o.not.length>0)for(let t=0;t0)for(let t=0;t{const r=e.map((e=>e.text||"["+e.implicit+"]")).join(" ");var o;"string"!=typeof t&&t.length>2&&(t=t.slice(0,2).join(", #")+" +"),t="string"!=typeof t?t.join(", #"):t,console.log(` ${(o=r,"�[33m�[3m"+o+"�[0m").padEnd(24)} �[32m→�[0m #${t.padEnd(22)} ${(e=>"�[3m"+e+"�[0m")(n)}`)})(e,t,o),!0!=(s=t,"[object Array]"===Object.prototype.toString.call(s)))if("string"==typeof t)if(t=t.trim(),On.test(t))!function(e,t,n,r){const o=t.split(On);e.forEach(((e,t)=>{let a=o[t];a&&(a=a.replace(/^#/,""),Vn(e,a,n,r))}))}(e,t,a,r);else{t=t.replace(/^#/,"");for(let n=0;nzn(e,t,n,r)))},Bn=function(e){return e.children=e.children||[],e._cache=e._cache||{},e.props=e.props||{},e._cache.parents=e._cache.parents||[],e._cache.children=e._cache.children||[],e},Sn=/^ *(#|\/\/)/,$n=function(e){let t=e.trim().split(/->/),n=[];t.forEach((e=>{n=n.concat(function(e){if(!(e=e.trim()))return null;if(/^\[/.test(e)&&/\]$/.test(e)){let t=(e=(e=e.replace(/^\[/,"")).replace(/\]$/,"")).split(/,/);return t=t.map((e=>e.trim())).filter((e=>e)),t=t.map((e=>Bn({id:e}))),t}return[Bn({id:e})]}(e))})),n=n.filter((e=>e));let r=n[0];for(let e=1;e{let n=[],r=[e];for(;r.length>0;){let e=r.pop();n.push(e),e.children&&e.children.forEach((n=>{t&&t(e,n),r.push(n)}))}return n},Ln=e=>"[object Array]"===Object.prototype.toString.call(e),Kn=e=>(e=e||"").trim(),Jn=function(e=[]){return"string"==typeof e?function(e){let t=e.split(/\r?\n/),n=[];t.forEach((e=>{if(!e.trim()||Sn.test(e))return;let t=(e=>{const t=/^( {2}|\t)/;let n=0;for(;t.test(e);)e=e.replace(t,""),n+=1;return n})(e);n.push({indent:t,node:$n(e)})}));let r=function(e){let t={children:[]};return e.forEach(((n,r)=>{0===n.indent?t.children=t.children.concat(n.node):e[r-1]&&function(e,t){let n=e[t].indent;for(;t>=0;t-=1)if(e[t].indent{t[e.id]=e}));let n=Bn({});return e.forEach((e=>{if((e=Bn(e)).parent)if(t.hasOwnProperty(e.parent)){let n=t[e.parent];delete e.parent,n.children.push(e)}else console.warn(`[Grad] - missing node '${e.parent}'`);else n.children.push(e)})),n}(e):(Mn(t=e).forEach(Bn),t);var t},Wn=function(e,t){let n="-> ";t&&(n=(e=>"�[2m"+e+"�[0m")("→ "));let r="";return Mn(e).forEach(((e,o)=>{let a=e.id||"";if(t&&(a=(e=>"�[31m"+e+"�[0m")(a)),0===o&&!e.id)return;let i=e._cache.parents.length;r+=" ".repeat(i)+n+a+"\n"})),r},qn=function(e){let t=Mn(e);t.forEach((e=>{delete(e=Object.assign({},e)).children}));let n=t[0];return n&&!n.id&&0===Object.keys(n.props).length&&t.shift(),t},Un={text:Wn,txt:Wn,array:qn,flat:qn},Rn=function(e,t){return"nested"===t||"json"===t?e:"debug"===t?(console.log(Wn(e,!0)),null):Un.hasOwnProperty(t)?Un[t](e):e},Qn=e=>{Mn(e,((e,t)=>{e.id&&(e._cache.parents=e._cache.parents||[],t._cache.parents=e._cache.parents.concat([e.id]))}))},Zn=/\//;let _n=class g{constructor(e={}){Object.defineProperty(this,"json",{enumerable:!1,value:e,writable:!0})}get children(){return this.json.children}get id(){return this.json.id}get found(){return this.json.id||this.json.children.length>0}props(e={}){let t=this.json.props||{};return"string"==typeof e&&(t[e]=!0),this.json.props=Object.assign(t,e),this}get(e){if(e=Kn(e),!Zn.test(e)){let t=this.json.children.find((t=>t.id===e));return new g(t)}let t=((e,t)=>{let n=(e=>"string"!=typeof e?e:(e=e.replace(/^\//,"")).split(/\//))(t=t||"");for(let t=0;te.id===n[t]));if(!r)return null;e=r}return e})(this.json,e)||Bn({});return new g(t)}add(e,t={}){if(Ln(e))return e.forEach((e=>this.add(Kn(e),t))),this;e=Kn(e);let n=Bn({id:e,props:t});return this.json.children.push(n),new g(n)}remove(e){return e=Kn(e),this.json.children=this.json.children.filter((t=>t.id!==e)),this}nodes(){return Mn(this.json).map((e=>(delete(e=Object.assign({},e)).children,e)))}cache(){return(e=>{let t=Mn(e,((e,t)=>{e.id&&(e._cache.parents=e._cache.parents||[],e._cache.children=e._cache.children||[],t._cache.parents=e._cache.parents.concat([e.id]))})),n={};t.forEach((e=>{e.id&&(n[e.id]=e)})),t.forEach((e=>{e._cache.parents.forEach((t=>{n.hasOwnProperty(t)&&n[t]._cache.children.push(e.id)}))})),e._cache.children=Object.keys(n)})(this.json),this}list(){return Mn(this.json)}fillDown(){var e;return e=this.json,Mn(e,((e,t)=>{t.props=((e,t)=>(Object.keys(t).forEach((n=>{if(t[n]instanceof Set){let r=e[n]||new Set;e[n]=new Set([...r,...t[n]])}else if((e=>e&&"object"==typeof e&&!Array.isArray(e))(t[n])){let r=e[n]||{};e[n]=Object.assign({},t[n],r)}else Ln(t[n])?e[n]=t[n].concat(e[n]||[]):void 0===e[n]&&(e[n]=t[n])})),e))(t.props,e.props)})),this}depth(){Qn(this.json);let e=Mn(this.json),t=e.length>1?1:0;return e.forEach((e=>{if(0===e._cache.parents.length)return;let n=e._cache.parents.length+1;n>t&&(t=n)})),t}out(e){return Qn(this.json),Rn(this.json,e)}debug(){return Qn(this.json),Rn(this.json,"debug"),this}};const Xn=function(e){let t=Jn(e);return new _n(t)};Xn.prototype.plugin=function(e){e(this)};const Yn={Noun:"blue",Verb:"green",Negative:"green",Date:"red",Value:"red",Adjective:"magenta",Preposition:"cyan",Conjunction:"cyan",Determiner:"cyan",Hyphenated:"cyan",Adverb:"cyan"},er=function(e){if(Yn.hasOwnProperty(e.id))return Yn[e.id];if(Yn.hasOwnProperty(e.is))return Yn[e.is];const t=e._cache.parents.find((e=>Yn[e]));return Yn[t]},tr=function(e){return e?"string"==typeof e?[e]:e:[]},nr=function(e,t){return e=function(e,t){return Object.keys(e).forEach((n=>{e[n].isA&&(e[n].is=e[n].isA),e[n].notA&&(e[n].not=e[n].notA),e[n].is&&"string"==typeof e[n].is&&(t.hasOwnProperty(e[n].is)||e.hasOwnProperty(e[n].is)||(e[e[n].is]={})),e[n].not&&"string"==typeof e[n].not&&!e.hasOwnProperty(e[n].not)&&(t.hasOwnProperty(e[n].not)||e.hasOwnProperty(e[n].not)||(e[e[n].not]={}))})),e}(e,t),Object.keys(e).forEach((t=>{e[t].children=tr(e[t].children),e[t].not=tr(e[t].not)})),Object.keys(e).forEach((t=>{(e[t].not||[]).forEach((n=>{e[n]&&e[n].not&&e[n].not.push(t)}))})),e};var rr={one:{setTag:zn,unTag:function(e,t,n){t=t.trim().replace(/^#/,"");for(let r=0;r0)for(let e=0;e0&&(e=function(e){return Object.keys(e).forEach((t=>{e[t]=Object.assign({},e[t]),e[t].novel=!0})),e}(e)),e=nr(e,t);const n=function(e){const t=Object.keys(e).map((t=>{const n=e[t],r={not:new Set(n.not),also:n.also,is:n.is,novel:n.novel};return{id:t,parent:n.is,props:r,children:[]}}));return Xn(t).cache().fillDown().out("array")}(Object.assign({},t,e)),r=function(e){const t={};return e.forEach((e=>{const{not:n,also:r,is:o,novel:a}=e.props;let i=e._cache.parents;r&&(i=i.concat(r)),t[e.id]={is:o,not:n,novel:a,also:r,parents:i,children:e._cache.children,color:er(e)}})),Object.keys(t).forEach((e=>{const n=new Set(t[e].not);t[e].not.forEach((e=>{t[e]&&t[e].children.forEach((e=>n.add(e)))})),t[e].not=Array.from(n)})),t}(n);return r},canBe:function(e,t,n){if(!n.hasOwnProperty(t))return!0;const r=n[t].not||[];for(let t=0;to.one.setTag(r,e,i,n,t))):o.one.setTag(r,e,i,n,t),this.uncache(),this},tagSafe:function(e,t=""){return this.tag(e,t,!0)},unTag:function(e,t){if(!this.found||!e)return this;const n=this.termList();if(0===n.length)return this;const{methods:r,verbose:o,model:a}=this;!0===o&&console.log(" - ",e,t||"");const i=a.one.tagSet;return or(e)?e.forEach((e=>r.one.unTag(n,e,i))):r.one.unTag(n,e,i),this.uncache(),this},canBe:function(e){e=e.replace(/^#/,"");const t=this.model.one.tagSet,n=this.methods.one.canBe,r=[];this.document.forEach(((o,a)=>{o.forEach(((o,i)=>{n(o,e,t)||r.push([a,i,i+1])}))}));const o=this.update(r);return this.difference(o)}};var ir={addTags:function(e){const{model:t,methods:n}=this.world(),r=t.one.tagSet,o=(0,n.one.addTags)(e,r);return t.one.tagSet=o,this}};const sr=new Set(["Auxiliary","Possessive"]);var lr={model:{one:{tagSet:{}}},compute:{tagRank:function(e){const{document:t,world:n}=e,r=n.model.one.tagSet;t.forEach((e=>{e.forEach((e=>{const t=Array.from(e.tags);e.tagRank=function(e,t){return e=e.sort(((e,n)=>{if(sr.has(e)||!t.hasOwnProperty(n))return 1;if(sr.has(n)||!t.hasOwnProperty(e))return-1;let r=t[e].children||[];const o=r.length;return r=t[n].children||[],o-r.length})),e}(t,r)}))}))}},methods:rr,api:function(e){Object.assign(e.prototype,ar)},lib:ir};const ur=/([.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s)/g,cr=/^[.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s$/,hr=/((?:\r?\n|\r)+)/,dr=/[a-z0-9\u00C0-\u00FF\u00a9\u00ae\u2000-\u3300\ud000-\udfff]/i,gr=/\S/,mr=function(e){return Boolean(e.match(/\n$/))},pr={'"':'"',""":""","“":"”","‟":"”","„":"”","⹂":"”","‚":"’","«":"»","‹":"›","‵":"′","‶":"″","‷":"‴","〝":"〞","〟":"〞"},fr=RegExp("["+Object.keys(pr).join("")+"]","g"),br=RegExp("["+Object.values(pr).join("")+"]","g"),vr=function(e){if(!e)return!1;const t=e.match(br);return null!==t&&1===t.length},yr=/\(/g,wr=/\)/g,kr=/\S/,Pr=/^\s+/,Ar=function(e,t){const n=e.split(/[-–—]/);if(n.length<=1)return!1;const{prefixes:r,suffixes:o}=t.one;if(1===n[0].length&&/[a-z]/i.test(n[0]))return!1;if(r.hasOwnProperty(n[0]))return!1;if(n[1]=n[1].trim().replace(/[.?!]$/,""),o.hasOwnProperty(n[1]))return!1;if(!0===/^([a-z\u00C0-\u00FF`"'/]+)[-–—]([a-z0-9\u00C0-\u00FF].*)/i.test(e))return!0;return!0===/^[('"]?([0-9]{1,4})[-–—]([a-z\u00C0-\u00FF`"'/-]+[)'"]?$)/i.test(e)},Cr=function(e){const t=[],n=e.split(/[-–—]/);let r="-";const o=e.match(/[-–—]/);o&&o[0]&&(r=o);for(let e=0;e(e[t]=!0,e)),{});const Dr=/\p{Letter}/u,Hr=/[\p{Number}\p{Currency_Symbol}]/u,Er=/^[a-z]\.([a-z]\.)+/i,Gr=/[sn]['’]$/,Or=/([A-Z]\.)+[A-Z]?,?$/,Fr=/^[A-Z]\.,?$/,Vr=/[A-Z]{2,}('s|,)?$/,zr=/([a-z]\.)+[a-z]\.?$/,Br=function(e){return function(e){return!0===Or.test(e)||!0===zr.test(e)||!0===Fr.test(e)||!0===Vr.test(e)}(e)&&(e=e.replace(/\./g,"")),e},Sr=function(e,t){const n=t.methods.one.killUnicode;let r=e.text||"";r=function(e){const t=e=(e=(e=e||"").toLowerCase()).trim();return e=(e=(e=e.replace(/[,;.!?]+$/,"")).replace(/\u2026/g,"...")).replace(/\u2013/g,"-"),!1===/^[:;]/.test(e)&&(e=(e=(e=e.replace(/\.{3,}$/g,"")).replace(/[",.!:;?)]+$/g,"")).replace(/^['"(]+/g,"")),""===(e=(e=e.replace(/[\u200B-\u200D\uFEFF]/g,"")).trim())&&(e=t),e.replace(/([0-9]),([0-9])/g,"$1$2")}(r),r=n(r,t),r=Br(r),e.normal=r},$r=/[ .][A-Z]\.? *$/i,Mr=/(?:\u2026|\.{2,}) *$/,Lr=/\p{L}/u,Kr=/\. *$/,Jr=/^[A-Z]\. $/;var Wr={one:{killUnicode:function(e,t){const n=t.model.one.unicode||{},r=(e=e||"").split("");return r.forEach(((e,t)=>{n[e]&&(r[t]=n[e])})),r.join("")},tokenize:{splitSentences:function(e,t){if(e=e||"",!(e=String(e))||"string"!=typeof e||!1===kr.test(e))return[];const n=function(e){const t=[],n=e.split(hr);for(let e=0;e0&&(o.push(a),e[t]=""):e[t+1]=a+(e[t+1]||"")}return o}(r,t),r=function(e){const t=[];for(let n=0;n0?(n[n.length-1]+=a,n.push(t)):n.push(a+t),a=""):a+=t}return a&&(0===n.length&&(n[0]=""),n[n.length-1]+=a),n=function(e){for(let t=1;te)),n},splitWhitespace:(e,t)=>{const{str:n,pre:r,post:o}=function(e,t){const{prePunctuation:n,postPunctuation:r,emoticons:o}=t.one;let a=e,i="",s="";const l=Array.from(e);if(o.hasOwnProperty(e.trim()))return{str:e.trim(),pre:i,post:" "};let u=l.length;for(let e=0;e(s=e||"",""))),e=a,i=""),{str:e,pre:i,post:s}}(e,t);return{text:n,pre:r,post:o,tags:new Set}},fromString:function(e,t){const{methods:n,model:r}=t,{splitSentences:o,splitTerms:a,splitWhitespace:i}=n.one.tokenize;return e=o(e=e||"",t).map((e=>{let n=a(e,r);return n=n.map((e=>i(e,r))),n.forEach((e=>{Sr(e,t)})),n})),e}}}};const qr={},Ur={};[[["approx","apt","bc","cyn","eg","esp","est","etc","ex","exp","prob","pron","gal","min","pseud","fig","jd","lat","lng","vol","fm","def","misc","plz","ea","ps","sec","pt","pref","pl","pp","qt","fr","sq","nee","ss","tel","temp","vet","ver","fem","masc","eng","adj","vb","rb","inf","situ","vivo","vitro","wr"]],[["dl","ml","gal","qt","pt","tbl","tsp","tbsp","km","dm","cm","mm","mi","td","hr","hrs","kg","hg","dg","cg","mg","µg","lb","oz","sq ft","hz","mps","mph","kmph","kb","mb","tb","lx","lm","fl oz","yb"],"Unit"],[["ad","al","arc","ba","bl","ca","cca","col","corp","ft","fy","ie","lit","ma","md","pd","tce"],"Noun"],[["adj","adm","adv","asst","atty","bldg","brig","capt","cmdr","comdr","cpl","det","dr","esq","gen","gov","hon","jr","llb","lt","maj","messrs","mlle","mme","mr","mrs","ms","mstr","phd","prof","pvt","rep","reps","res","rev","sen","sens","sfc","sgt","sir","sr","supt","surg"],"Honorific"],[["jan","feb","mar","apr","jun","jul","aug","sep","sept","oct","nov","dec"],"Month"],[["dept","univ","assn","bros","inc","ltd","co"],"Organization"],[["rd","st","dist","mt","ave","blvd","cl","cres","hwy","ariz","cal","calif","colo","conn","fla","fl","ga","ida","ia","kan","kans","minn","neb","nebr","okla","penna","penn","pa","dak","tenn","tex","ut","vt","va","wis","wisc","wy","wyo","usafa","alta","ont","que","sask"],"Place"]].forEach((e=>{e[0].forEach((t=>{qr[t]=!0,Ur[t]="Abbreviation",void 0!==e[1]&&(Ur[t]=[Ur[t],e[1]])}))}));var Rr=["anti","bi","co","contra","de","extra","infra","inter","intra","macro","micro","mis","mono","multi","peri","pre","pro","proto","pseudo","re","sub","supra","trans","tri","un","out","ex"].reduce(((e,t)=>(e[t]=!0,e)),{});const Qr={"!":"¡","?":"¿Ɂ",'"':'“”"❝❞',"'":"‘‛❛❜’","-":"—–",a:"ªÀÁÂÃÄÅàáâãäåĀāĂ㥹ǍǎǞǟǠǡǺǻȀȁȂȃȦȧȺΆΑΔΛάαλАаѦѧӐӑӒӓƛæ",b:"ßþƀƁƂƃƄƅɃΒβϐϦБВЪЬвъьѢѣҌҍ",c:"¢©ÇçĆćĈĉĊċČčƆƇƈȻȼͻͼϲϹϽϾСсєҀҁҪҫ",d:"ÐĎďĐđƉƊȡƋƌ",e:"ÈÉÊËèéêëĒēĔĕĖėĘęĚěƐȄȅȆȇȨȩɆɇΈΕΞΣέεξϵЀЁЕеѐёҼҽҾҿӖӗễ",f:"ƑƒϜϝӺӻҒғſ",g:"ĜĝĞğĠġĢģƓǤǥǦǧǴǵ",h:"ĤĥĦħƕǶȞȟΉΗЂЊЋНнђћҢңҤҥҺһӉӊ",I:"ÌÍÎÏ",i:"ìíîïĨĩĪīĬĭĮįİıƖƗȈȉȊȋΊΐΪίιϊІЇіїi̇",j:"ĴĵǰȷɈɉϳЈј",k:"ĶķĸƘƙǨǩΚκЌЖКжкќҚқҜҝҞҟҠҡ",l:"ĹĺĻļĽľĿŀŁłƚƪǀǏǐȴȽΙӀӏ",m:"ΜϺϻМмӍӎ",n:"ÑñŃńŅņŇňʼnŊŋƝƞǸǹȠȵΝΠήηϞЍИЙЛПийлпѝҊҋӅӆӢӣӤӥπ",o:"ÒÓÔÕÖØðòóôõöøŌōŎŏŐőƟƠơǑǒǪǫǬǭǾǿȌȍȎȏȪȫȬȭȮȯȰȱΌΘΟθοσόϕϘϙϬϴОФоѲѳӦӧӨөӪӫ",p:"ƤΡρϷϸϼРрҎҏÞ",q:"Ɋɋ",r:"ŔŕŖŗŘřƦȐȑȒȓɌɍЃГЯгяѓҐґ",s:"ŚśŜŝŞşŠšƧƨȘșȿЅѕ",t:"ŢţŤťŦŧƫƬƭƮȚțȶȾΓΤτϮТт",u:"ÙÚÛÜùúûüŨũŪūŬŭŮůŰűŲųƯưƱƲǓǔǕǖǗǘǙǚǛǜȔȕȖȗɄΰυϋύ",v:"νѴѵѶѷ",w:"ŴŵƜωώϖϢϣШЩшщѡѿ",x:"×ΧχϗϰХхҲҳӼӽӾӿ",y:"ÝýÿŶŷŸƳƴȲȳɎɏΎΥΫγψϒϓϔЎУучўѰѱҮүҰұӮӯӰӱӲӳ",z:"ŹźŻżŽžƵƶȤȥɀΖ"},Zr={};Object.keys(Qr).forEach((function(e){Qr[e].split("").forEach((function(t){Zr[t]=e}))}));const _r=/\//,Xr=/[a-z]\.[a-z]/i,Yr=/[0-9]/,eo=function(e,t){const n=e.normal||e.text||e.machine,r=t.model.one.aliases;if(r.hasOwnProperty(n)&&(e.alias=e.alias||[],e.alias.push(r[n])),_r.test(n)&&!Xr.test(n)&&!Yr.test(n)){const t=n.split(_r);t.length<=3&&t.forEach((t=>{""!==(t=t.trim())&&(e.alias=e.alias||[],e.alias.push(t))}))}return e},to=/^\p{Letter}+-\p{Letter}+$/u,no=function(e){let t=e.implicit||e.normal||e.text;t=t.replace(/['’]s$/,""),t=t.replace(/s['’]$/,"s"),t=t.replace(/([aeiou][ktrp])in'$/,"$1ing"),to.test(t)&&(t=t.replace(/-/g,"")),t=t.replace(/^[#@]/,""),t!==e.normal&&(e.machine=t)},ro=function(e,t){const n=e.docs;for(let r=0;rro(e,eo),machine:e=>ro(e,no),normal:e=>ro(e,Sr),freq:function(e){const t=e.docs,n={};for(let e=0;e{let i=(e=e.toLowerCase().trim()).length;t.max&&i>t.max&&(i=t.max);for(let s=t.min;s{delete r[e]})),r}(e,t,this.world());return Object.keys(o).forEach((e=>{n.one.typeahead.hasOwnProperty(e)?delete n.one.typeahead[e]:n.one.typeahead[e]=o[e]})),this}};var co={model:{one:{typeahead:{}}},api:function(e){e.prototype.autoFill=so},lib:uo,compute:io,hooks:["typeahead"]};h.extend(J),h.extend(yn),h.extend(Jt),h.extend(Tn),h.extend(lr),h.plugin(ye),h.extend(ao),h.extend(Ce),h.plugin(p),h.extend(Be),h.extend(co),h.extend(Ee),h.extend(Gn);var ho={addendum:"addenda",corpus:"corpora",criterion:"criteria",curriculum:"curricula",genus:"genera",memorandum:"memoranda",opus:"opera",ovum:"ova",phenomenon:"phenomena",referendum:"referenda",alga:"algae",alumna:"alumnae",antenna:"antennae",formula:"formulae",larva:"larvae",nebula:"nebulae",vertebra:"vertebrae",analysis:"analyses",axis:"axes",diagnosis:"diagnoses",parenthesis:"parentheses",prognosis:"prognoses",synopsis:"synopses",thesis:"theses",neurosis:"neuroses",appendix:"appendices",index:"indices",matrix:"matrices",ox:"oxen",sex:"sexes",alumnus:"alumni",bacillus:"bacilli",cactus:"cacti",fungus:"fungi",hippopotamus:"hippopotami",libretto:"libretti",modulus:"moduli",nucleus:"nuclei",octopus:"octopi",radius:"radii",stimulus:"stimuli",syllabus:"syllabi",cookie:"cookies",calorie:"calories",auntie:"aunties",movie:"movies",pie:"pies",rookie:"rookies",tie:"ties",zombie:"zombies",leaf:"leaves",loaf:"loaves",thief:"thieves",foot:"feet",goose:"geese",tooth:"teeth",beau:"beaux",chateau:"chateaux",tableau:"tableaux",bus:"buses",gas:"gases",circus:"circuses",crisis:"crises",virus:"viruses",database:"databases",excuse:"excuses",abuse:"abuses",avocado:"avocados",barracks:"barracks",child:"children",clothes:"clothes",echo:"echoes",embargo:"embargoes",epoch:"epochs",deer:"deer",halo:"halos",man:"men",woman:"women",mosquito:"mosquitoes",mouse:"mice",person:"people",quiz:"quizzes",rodeo:"rodeos",shoe:"shoes",sombrero:"sombreros",stomach:"stomachs",tornado:"tornados",tuxedo:"tuxedos",volcano:"volcanoes"},go={Comparative:"true¦bett1f0;arth0ew0in0;er",Superlative:"true¦earlier",PresentTense:"true¦bests,sounds",Condition:"true¦lest,unless",PastTense:"true¦began,came,d4had,kneel3l2m0sa4we1;ea0sg2;nt;eap0i0;ed;id",Participle:"true¦0:09;a06b01cZdXeat0fSgQhPoJprov0rHs7t6u4w1;ak0ithdra02o2r1;i02uY;k0v0;nd1pr04;ergoJoJ;ak0hHo3;e9h7lain,o6p5t4un3w1;o1um;rn;g,k;ol0reS;iQok0;ught,wn;ak0o1runk;ne,wn;en,wn;ewriNi1uJ;dd0s0;ut3ver1;do4se0t1;ak0h2;do2g1;roG;ne;ast0i7;iv0o1;ne,tt0;all0loBor1;bi3g2s1;ak0e0;iv0o9;dd0;ove,r1;a5eamt,iv0;hos0lu1;ng;e4i3lo2ui1;lt;wn;tt0;at0en,gun;r2w1;ak0ok0;is0;en",Gerund:"true¦accord0be0doin,go0result0stain0;ing",Expression:"true¦a0Yb0Uc0Sd0Oe0Mfarew0Lg0FhZjeez,lWmVnToOpLsJtIuFvEw7y0;a5e3i1u0;ck,p;k04p0;ee,pee;a0p,s;!h;!a,h,y;a5h2o1t0;af,f;rd up,w;atsoever,e1o0;a,ops;e,w;hoo,t;ery w06oi0L;gh,h0;! 0h,m;huh,oh;here nPsk,ut tut;h0ic;eesh,hh,it,oo;ff,h1l0ow,sst;ease,s,z;ew,ooey;h1i,mg,o0uch,w,y;h,o,ps;! 0h;hTmy go0wT;d,sh;a7evertheless,o0;!pe;eh,mm;ah,eh,m1ol0;!s;ao,fao;aCeBi9o2u0;h,mph,rra0zzC;h,y;l1o0;r6y9;la,y0;! 0;c1moCsmok0;es;ow;!p hip hoor0;ay;ck,e,llo,y;ha1i,lleluj0;ah;!ha;ah,ee4o1r0;eat scott,r;l1od0sh; grief,bye;ly;! whiz;ell;e0h,t cetera,ureka,ww,xcuse me;k,p;'oh,a0rat,uh;m0ng;mit,n0;!it;mon,o0;ngratulations,wabunga;a2oo1r0tw,ye;avo,r;!ya;h,m; 1h0ka,las,men,rgh,ye;!a,em,h,oy;la",Negative:"true¦n0;ever,o0;n,t",QuestionWord:"true¦how3wh0;at,e1ich,o0y;!m,se;n,re; come,'s",Reflexive:"true¦h4it5my5o1the0your2;ir1m1;ne3ur0;sel0;f,ves;er0im0;self",Plural:"true¦dick0gre0ones,records;ens","Unit|Noun":"true¦cEfDgChBinchAk9lb,m6newt5oz,p4qt,t1y0;ardEd;able1b0ea1sp;!l,sp;spo1;a,t,x;on9;!b,g,i1l,m,p0;h,s;!les;!b,elvin,g,m;!es;g,z;al,b;eet,oot,t;m,up0;!s",Value:"true¦a few",Imperative:"true¦bewa0come he0;re","Plural|Verb":"true¦leaves",Demonym:"true¦0:15;1:12;a0Vb0Oc0Dd0Ce08f07g04h02iYjVkTlPmLnIomHpEqatari,rCs7t5u4v3welAz2;am0Gimbabwe0;enezuel0ietnam0I;gAkrai1;aiwTex0hai,rinida0Ju2;ni0Prkmen;a5cotti4e3ingapoOlovak,oma0Spaniard,udRw2y0W;ede,iss;negal0Cr09;sh;mo0uT;o5us0Jw2;and0;a2eru0Fhilippi0Nortugu07uerto r0S;kist3lesti1na2raguay0;ma1;ani;ami00i2orweP;caragu0geri2;an,en;a3ex0Lo2;ngo0Drocc0;cedo1la2;gasy,y07;a4eb9i2;b2thua1;e0Cy0;o,t01;azakh,eny0o2uwaiI;re0;a2orda1;ma0Ap2;anO;celandic,nd4r2sraeli,ta01vo05;a2iB;ni0qi;i0oneU;aiAin2ondur0unO;di;amEe2hanai0reek,uatemal0;or2rm0;gi0;ilipino,ren8;cuadoVgyp4mira3ngli2sto1thiopi0urope0;shm0;ti;ti0;aPominUut3;a9h6o4roat3ub0ze2;ch;!i0;lom2ngol5;bi0;a6i2;le0n2;ese;lifor1m2na3;bo2eroo1;di0;angladeshi,el6o4r3ul2;gaE;azi9it;li2s1;vi0;aru2gi0;si0;fAl7merBngol0r5si0us2;sie,tr2;a2i0;li0;genti2me1;ne;ba1ge2;ri0;ni0;gh0r2;ic0;an",Organization:"true¦0:4Q;a3Tb3Bc2Od2He2Df27g1Zh1Ti1Pj1Nk1Ll1Gm12n0Po0Mp0Cqu0Br02sTtHuCv9w3xiaomi,y1;amaha,m1Bou1w1B;gov,tu3C;a4e2iki1orld trade organizati33;leaRped0O;lls fargo,st1;fie2Hinghou2R;l1rner br3U;gree3Jl street journ2Im1E;an halOeriz2Xisa,o1;dafo2Yl1;kswagMvo;b4kip,n2ps,s1;a tod3Aps;es3Mi1;lev3Fted natio3C;er,s; mobi32aco beRd bOe9gi frida3Lh3im horto3Amz,o1witt3D;shi49y1;ota,s r 05;e 1in lizzy;b3carpen3Jdaily ma3Dguess w2holli0s1w2;mashing pumpki35uprem0;ho;ea1lack eyed pe3Xyr0Q;ch bo3Dtl0;l2n3Qs1xas instrumen1U;co,la m1F;efoni0Kus;a8cientology,e5ieme2Ymirnoff,np,o3pice gir6quare0Ata1ubaru;rbuc1to34;ks;ny,undgard1;en;a2x pisto1;ls;g1Wrs;few2Minsbur31lesfor03msu2E;adiohead,b8e4o1yana3C;man empi1Xyal 1;b1dutch she4;ank;a3d 1max,vl20;bu1c2Ahot chili peppe2Ylobst2N;ll;ders dige1Ll madrid;c,s;ant3Aizn2Q;a8bs,e5fiz2Ihilip4i3r1;emier 1udenti1D;leagTo2K;nk floyd,zza hut; morrBs;psi2tro1uge0E;br33chi0Tn33;!co;lant2Un1yp16; 2ason27da2P;ld navy,pec,range juli2xf1;am;us;aAb9e6fl,h5i4o1sa,vid3wa;k2tre dame,vart1;is;ia;ke,ntendo,ss0QvZ;l,s;c,st1Otflix,w1; 1sweek;kids on the block,york0D;a,c;nd22s2t1;ional aca2Po,we0U;a,c02d0S;aDcdonalCe9i6lb,o3tv,y1;spa1;ce;b1Tnsanto,ody blu0t1;ley cr1or0T;ue;c2t1;as,subisO;helin,rosoft;dica2rcedes benz,talli1;ca;id,re;ds;cs milk,tt19z24;a3e1g,ittle caesa1P; ore09novo,x1;is,mark,us; 1bour party;pres0Dz boy;atv,fc,kk,lm,m1od1O;art;iffy lu0Roy divisi0Jpmorgan1sa;! cha09;bm,hop,k3n1tv;g,te1;l,rpol;ea;a5ewlett pack1Vi3o1sbc,yundai;me dep1n1P;ot;tac1zbollah;hi;lliburt08sbro;eneral 6hq,ithub,l5mb,o2reen d0Ou1;cci,ns n ros0;ldman sachs,o1;dye1g0H;ar;axo smith kli04encoW;electr0Nm1;oto0Z;a5bi,c barcelo4da,edex,i2leetwood m03o1rito l0G;rd,xcY;at,fa,nancial1restoZ; tim0;na;cebook,nnie mae;b0Asa,u3xxon1; m1m1;ob0J;!rosceptics;aiml0De5isney,o4u1;nkin donu2po0Zran dur1;an;ts;j,w jon0;a,f lepp12ll,peche mode,r spieg02stiny's chi1;ld;aJbc,hFiDloudflaCnn,o3r1;aigsli5eedence clearwater reviv1ossra09;al;c7inba6l4m1o0Est09;ca2p1;aq;st;dplSg1;ate;se;a c1o chanQ;ola;re;a,sco1tigroup;! systems;ev2i1;ck fil a,na daily;r1y;on;d2pital o1rls jr;ne;bury,ill1;ac;aEbc,eBf9l5mw,ni,o1p,rexiteeU;ei3mbardiIston 1;glo1pizza;be;ng;o2ue c1;roV;ckbuster video,omingda1;le; g1g1;oodriL;cht2e ge0rkshire hathaw1;ay;el;cardi,idu,nana republ3s1xt5y5;f,kin robbi1;ns;ic;bYcTdidSerosmith,iRlKmEnheuser busDol,ppleAr6s4u3v2y1;er;is,on;di,todesk;hland o1sociated E;il;b3g2m1;co;os;ys; compu1be0;te1;rs;ch;c,d,erican3t1;!r1;ak; ex1;pre1;ss; 5catel2ta1;ir;! lu1;ce1;nt;jazeera,qae1;da;g,rbnb;as;/dc,a3er,tivision1;! blizz1;ard;demy of scienc0;es;ba",Possessive:"true¦its,my,our0thy;!s","Noun|Verb":"true¦0:9W;1:AA;2:96;3:A3;4:9R;5:A2;6:9K;7:8N;8:7L;9:A8;A:93;B:8D;C:8X;a9Ob8Qc7Id6Re6Gf5Sg5Hh55i4Xj4Uk4Rl4Em40n3Vo3Sp2Squ2Rr21s0Jt02u00vVwGyFzD;ip,oD;ne,om;awn,e6Fie68;aOeMhJiHoErD;ap,e9Oink2;nd0rDuC;kDry,sh5Hth;!shop;ck,nDpe,re,sh;!d,g;e86iD;p,sD;k,p0t2;aDed,lco8W;r,th0;it,lk,rEsDt4ve,x;h,te;!ehou1ra9;aGen5FiFoD;iDmAte,w;ce,d;be,ew,sA;cuum,l4B;pDr7;da5gra6Elo6A;aReQhrPiOoMrGuEwiDy5Z;n,st;nDrn;e,n7O;aGeFiEoDu6;t,ub2;bu5ck4Jgg0m,p;at,k,nd;ck,de,in,nsDp,v7J;f0i8R;ll,ne,p,r4Yss,t94uD;ch,r;ck,de,e,le,me,p,re;e5Wow,u6;ar,e,ll,mp0st,xt;g,lDng2rg7Ps5x;k,ly;a0Sc0Ne0Kh0Fi0Dk0Cl0Am08n06o05pXquaBtKuFwD;ea88iD;ng,pe,t4;bGit,m,ppErD;fa3ge,pri1v2U;lDo6S;e6Py;!je8;aMeLiKoHrEuDy2;dy,ff,mb2;a85eEiDo5Pugg2;ke,ng;am,ss,t4;ckEop,p,rD;e,m;ing,pi2;ck,nk,t4;er,m,p;ck,ff,ge,in,ke,lEmp,nd,p2rDte,y;!e,t;k,l;aJeIiHlGoFrDur,y;ay,e56inDu3;g,k2;ns8Bt;a5Qit;ll,n,r87te;ed,ll;m,n,rk;b,uC;aDee1Tow;ke,p;a5Je4FiDo53;le,rk;eep,iDou4;ce,p,t;ateboa7Ii;de,gnDl2Vnk,p,ze;!al;aGeFiEoDuff2;ck,p,re,w;ft,p,v0;d,i3Ylt0;ck,de,pe,re,ve;aEed,nDrv1It;se,t2N;l,r4t;aGhedu2oBrD;aEeDibb2o3Z;en,w;pe,t4;le,n,r2M;cDfegua72il,mp2;k,rifi3;aZeHhy6LiGoEuD;b,in,le,n,s5X;a6ck,ll,oDpe,u5;f,t;de,ng,ot,p,s1W;aTcSdo,el,fQgPje8lOmMnLo17pJque6sFturn,vDwa6V;eDi27;al,r1;er74oFpe8tEuD;lt,me;!a55;l71rt;air,eaDly,o53;l,t;dezvo2Zt;aDedy;ke,rk;ea1i4G;a6Iist0r5N;act6Yer1Vo71uD;nd,se;a38o6F;ch,s6G;c1Dge,iEke,lly,nDp1Wt1W;ge,k,t;n,se;es6Biv0;a04e00hYiXlToNrEsy4uD;mp,n4rcha1sh;aKeIiHoDu4O;be,ceFdu3fi2grDje8mi1p,te6;amDe6W;!me;ed,ss;ce,de,nt;sDy;er6Cs;cti3i1;iHlFoEp,re,sDuCw0;e,i5Yt;l,p;iDl;ce,sh;nt,s5V;aEce,e32uD;g,mp,n7;ce,nDy;!t;ck,le,n17pe,tNvot;a1oD;ne,tograph;ak,eFnErDt;fu55mA;!c32;!l,r;ckJiInHrFsEtDu1y;ch,e9;s,te;k,tD;!y;!ic;nt,r,se;!a7;bje8ff0il,oErDutli3Qver4B;bAd0ie9;ze;a4ReFoDur1;d,tD;e,i3;ed,gle8tD;!work;aMeKiIoEuD;rd0;ck,d3Rld,nEp,uDve;nt,th;it5EkD;ey;lk,n4Brr5CsDx;s,ta2B;asuBn4UrDss;ge,it;il,nFp,rk3WsEtD;ch,t0;h,k,t0;da5n0oeuvB;aLeJiHoEuD;mp,st;aEbby,ck,g,oDve;k,t;d,n;cDe,ft,mAnIst;en1k;aDc0Pe4vK;ch,d,k,p,se;bFcEnd,p,t4uD;gh,n4;e,k;el,o2U;eEiDno4E;ck,d,ll,ss;el,y;aEo1OuD;i3mp;m,zz;mpJnEr46ssD;ue;c1Rdex,fluGha2k,se2HteDvoi3;nt,rD;e6fa3viD;ew;en3;a8le2A;aJeHiGoEuD;g,nt;l3Ano2Dok,pDr1u1;!e;ghli1Fke,nt,re,t;aDd7lp;d,t;ck,mGndFrEsh,tDu9;ch,e;bo3Xm,ne4Eve6;!le;!m0;aMear,ift,lKossJrFuD;arDe4Alp,n;antee,d;aFiEoDumb2;uCwth;ll,nd,p;de,sp;ip;aBoDue;ss,w;g,in,me,ng,s,te,ze;aZeWiRlNoJrFuD;ck,el,nDss,zz;c38d;aEoDy;st,wn;cDgme,me,nchi1;tuB;cFg,il,ld,rD;ce,e29mDwa31;!at;us;aFe0Vip,oDy;at,ck,od,wD;!er;g,ke,me,re,sh,vo1E;eGgFlEnDre,sh,t,x;an3i0Q;e,m,t0;ht,uB;ld;aEeDn3;d,l;r,tuB;ce,il,ll,rm,vo2W;cho,d7ffe8nMsKxFyeD;!baD;ll;cGerci1hFpDtra8;eriDo0W;en3me9;au6ibA;el,han7u1;caDtima5;pe;count0d,vy;a01eSiMoJrEuDye;b,el,mp,pli2X;aGeFiEoD;ne,p;ft,ll,nk,p,ve;am,ss;ft,g,in;cEd7ubt,wnloD;ad;k,u0E;ge6p,sFt4vD;e,iDor3;de;char7gui1h,liEpD;at4lay,u5;ke;al,bKcJfeIlGmaCposAsEtaD;il;e07iD;gn,re;ay,ega5iD;ght;at,ct;li04rea1;a5ut;b,ma7n3rDte;e,t;a0Eent0Dh06irc2l03oKrFuD;be,e,rDt;b,e,l,ve;aGeFoEuDy;sh;p,ss,wd;dAep;ck,ft,sh;at,de,in,lTmMnFordina5py,re,st,uDv0;gh,nDp2rt;s01t;ceHdu8fli8glomeIsFtDveN;a8rD;a6ol;e9tru8;ct;ntDrn;ra5;bHfoGmFpD;leDouCromi1;me9;aCe9it,u5;rt;at,iD;ne;lap1oD;r,ur;aEiDoud,ub;ck,p;im,w;aEeDip;at,ck,er;iGllen7nErD;ge,m,t;ge,nD;el;n,r;er,re;ke,ll,mp,noe,pGrXsFtEuDve;se,ti0I;alog,ch;h,t;!tuB;re;a03eZiXlToPrHuEyD;pa11;bb2ck2dgEff0mp,rDst,zz;den,n;et;anJeHiFoadEuD;i1sh;ca6;be,d7;ge;aDed;ch,k;ch,d;aFg,mb,nEoDrd0tt2x,ycott;k,st,t;d,e;rd,st;aFeCiDoYur;nk,tz;nd;me;as,d,ke,nd,opsy,tD;!ch,e;aFef,lt,nDt;d,efA;it;r,t;ck,il,lan3nIrFsEtt2;le;e,h;!gDk;aDe;in;!d,g,k;bu1c05dZge,iYlVnTppQrLsIttGucEwaD;rd;tiD;on;aDempt;ck;k,sD;i6ocia5;st;chFmD;!oD;ur;!iD;ve;eEroa4;ch;al;chDg0sw0;or;aEt0;er;rm;d,m,r;dreHvD;an3oD;ca5;te;ce;ss;cDe,he,t;eFoD;rd,u9;nt;nt,ss;se",Actor:"true¦0:7B;1:7G;2:6A;3:7F;4:7O;5:7K;a6Nb62c4Ud4Be41f3Sg3Bh30i2Uj2Qkin2Pl2Km26n1Zo1Sp0Vqu0Tr0JsQtJuHvEw8yo6;gi,ut6;h,ub0;aAe9i8o7r6;estl0it0;m2rk0;fe,nn0t2Bza2H;atherm2ld0;ge earn0it0nder0rri1;eter7i6oyF;ll5Qp,s3Z;an,ina2U;n6s0;c6Uder03;aoisea23e9herapi5iktok0o8r6ut1yco6S;a6endseLo43;d0mp,nscri0Bvel0;ddl0u1G;a0Qchn7en6na4st0;ag0;i3Oo0D;aiXcUeRhPiMki0mu26oJpGquaFtBu7wee6;p0theart;lt2per7r6;f0ge6Iviv1;h6inten0Ist5Ivis1;ero,um2;a8ep7r6;ang0eam0;bro2Nc2Ofa2Nmo2Nsi20;ff0tesm2;tt0;ec7ir2Do6;kesp59u0M;ia5Jt3;l7me6An,rcere6ul;r,ss;di0oi5;n7s6;sy,t0;g0n0;am2ephe1Iow6;girl,m2r2Q;cretInior cit3Fr6;gea4v6;a4it1;hol4Xi7reen6ulpt1;wr2C;e01on;l1nt;aEe9o8u6;l0nn6;er up,ingE;g40le mod3Zof0;a4Zc8fug2Ppo32searQv6;ere4Uolution6;ary;e6luYru22;ptio3T;bbi,dic5Vpp0;arter6e2Z;back;aYeWhSiRlOoKr8sycho7u6;nk,p31;logi5;aGeDiBo6;d9fess1g7ph47s6;pe2Ktitu51;en6ramm0;it1y;igy,uc0;est4Nme mini0Unce6s3E;!ss;a7si6;de4;ch0;ctiti39nk0P;dca0Oet,li6pula50rnst42;c2Itic6;al scie6i2;nti5;a6umb0;nn0y6;er,ma4Lwright;lgrim,one0;a8iloso7otogra7ra6ysi1V;se;ph0;ntom,rmaci5;r6ssi1T;form0s4O;i3El,nel3Yr8st1tr6wn;i6on;arWot;ent4Wi42tn0;ccupa4ffBp8r7ut6;ca5l0B;ac4Iganiz0ig2Fph2;er3t6;i1Jomet6;ri5;ic0spring;aBe9ie4Xo7u6;n,rser3J;b6mad,vi4V;le2Vo4D;i6mesis,phew;ce,ghb1;nny,rr3t1X;aEeDiAo7u6yst1Y;m8si16;der3gul,m7n6th0;arDk;!my;ni7s6;f02s0Jt0;on,st0;chan1Qnt1rcha4;gi9k0n8rtyr,t6y1;e,riar6;ch;ag0iac;ci2stra3I;a7e2Aieutena4o6;rd,s0v0;bor0d7ndlo6ss,urea3Fwy0ym2;rd;!y;!s28;e8o7u6;ggl0;gg0urna2U;st0;c3Hdol,llu3Ummigra4n6; l9c1Qfa4habi42nov3s7ve6;nt1stig3;pe0Nt6;a1Fig3ru0M;aw;airFeBistoAo8u6ygie1K;man6sba2H;!ita8;bo,st6usekN;age,e3P;ri2;ir,r6;m7o6;!ine;it;dress0sty2C;aLeIhostGirl26ladi3oCrand7u6;e5ru;c9daug0Jfa8m7pa6s2Y;!re4;a,o6;th0;hi1B;al7d6lf0;!de3A;ie,k6te26;eep0;!wr6;it0;isha,n6;i6tl04;us;mbl0rden0;aDella,iAo7r6;eela2Nie1P;e,re6ster pare4;be1Hm2r6st0;unn0;an2ZgZlmm17nanci0r6tt0;e6st la2H; marsh2OfigXm2;rm0th0;conoEdDlectriCm8n7x6;amin0cellency,i2A;emy,trepreneur,vironmenta1J;c8p6;er1loye6;e,r;ee;ci2;it1;mi5;aKeBi8ork,ri7u6we02;de,tche2H;ft0v0;ct3eti7plom2Hre6va;ct1;ci2ti2;aDcor3fencCi0InAput9s7tectLvel6;op0;ce1Ge6ign0;rt0;ee,y;iz6;en;em2;c1Ml0;d8nc0redev7ug6;ht0;il;!dy;a06e04fo,hXitizenWlToBr9u6;r3stomer6;! representat6;ive;e3it6;ic;lJmGnAord9rpor1Nu7w6;boy,ork0;n6ri0;ciTte1Q;in3;fidantAgressSs9t6;e0Kr6;ibut1o6;ll0;tab13ul1O;!e;edi2m6pos0rade;a0EeQissi6;on0;leag8on7um6;ni5;el;ue;e6own;an0r6;ic,k;!s;a9e7i6um;ld;erle6f;ad0;ir7nce6plFract0;ll1;m2wI;lebri6o;ty;dBptAr6shi0;e7pe6;nt0;r,t6;ak0;ain;et;aMeLiJlogg0oErBu6;dd0Fild0rgl9siness6;m2p7w6;om2;ers05;ar;i7o6;!k0th0;cklay0de,gadi0;hemi2oge8y6;!frie6;nd;ym2;an;cyc6sR;li5;atbox0ings;by,nk0r6;b0on7te6;nd0;!e07;c04dWge4nQpLrHsFtAu7yatull6;ah;nt7t6;h1oG;!ie;h8t6;e6orney;nda4;ie5le6;te;sis00tron6;aut,om0;chbis8isto7tis6;an,t;crU;hop;ost9p6;ari6rentiS;ti6;on;le;a9cest1im3nou8y6;bo6;dy;nc0;ly5rc6;hi5;mi8v6;entur0is1;er;ni7r6;al;str3;at1;or;counBquaintanArob9t6;ivi5or,re6;ss;st;at;ce;ta4;nt","Adj|Noun":"true¦0:16;a1Db17c0Ud0Re0Mf0Dg0Ah08i06ju05l02mWnUoSpNrIsBt7u4v1watershed;a1ision0Z;gabo4nilla,ria1;b0Vnt;ndergr1pstairs;adua14ou1;nd;a3e1oken,ri0;en,r1;min0rori13;boo,n;age,e5ilv0Flack,o3quat,ta2u1well;bordina0Xper5;b0Lndard;ciali0Yl1vereign;e,ve16;cret,n1ri0;ior;a4e2ou1ubbiL;nd,tiY;ar,bBl0Wnt0p1side11;resent0Vublican;ci0Qsh;a4eriodic0last0Zotenti0r1;emi2incip0o1;!fession0;er,um;rall4st,tie0U;ff1pposi0Hv0;ens0Oi0C;agg01ov1uts;el;a5e3iniatJo1;bi01der07r1;al,t0;di1tr0N;an,um;le,riG;attOi2u1;sh;ber0ght,qC;stice,veniT;de0mpressioYn1;cumbe0Edividu0no0Dsta0Eterim;alf,o1umdrum;bby,melF;en2old,ra1;ph0Bve;er0ious;a7e5i4l3u1;git03t1;ure;uid;ne;llow,m1;aFiL;ir,t,vo1;riOuriO;l3p00x1;c1ecutUpeV;ess;d1iK;er;ar2e1;mographUrivO;k,l2;hiGlassSo2rude,unn1;ing;m5n1operK;creCstitueOte2vertab1;le;mpor1nt;ary;ic,m2p1;anion,lex;er2u1;ni8;ci0;al;e5lank,o4r1;i2u1;te;ef;ttom,urgeois;st;cadem9d6l2ntarct9r1;ab,ct8;e3tern1;at1;ive;rt;oles1ult;ce1;nt;ic","Adj|Past":"true¦0:4Q;1:4C;2:4H;3:4E;a44b3Tc36d2Je29f20g1Wh1Si1Jj1Gkno1Fl1Am15n12o0Xp0Mqu0Kr08sLtEuAv9w4yellow0;a7ea6o4rinkl0;r4u3Y;n,ri0;k31th3;rp0sh0tZ;ari0e1O;n5p4s0;d1li1Rset;cov3derstood,i4;fi0t0;a8e3Rhr7i6ouTr4urn0wi4C;a4imm0ou2G;ck0in0pp0;ed,r0;eat2Qi37;m0nn0r4;get0ni2T;aOcKeIhGimFm0Hoak0pDt7u4;bsid3Ogge44s4;pe4ta2Y;ct0nd0;a8e7i2Eok0r5u4;ff0mp0nn0;ength2Hip4;ed,p0;am0reotyp0;in0t0;eci4ik0oH;al3Efi0;pRul1;a4ock0ut;d0r0;a4c1Jle2t31;l0s3Ut0;a6or5r4;at4e25;ch0;r0tt3;t4ut0;is2Mur1;aEe5o4;tt0;cAdJf2Bg9je2l8m0Knew0p7qu6s4;eTpe2t4;or0ri2;e3Dir0;e1lac0;at0e2Q;i0Rul1;eiv0o4ycl0;mme2Lrd0v3;in0lli0ti2A;a4ot0;li28;aCer30iBlAo9r5u4;mp0zzl0;e6i2Oo4;ce2Fd4lo1Anou30pos0te2v0;uc0;fe1CocCp0Iss0;i2Kli1L;ann0e2CuS;ck0erc0ss0;ck0i2Hr4st0;allLk0;bse7c6pp13rgan2Dver4;lo4whelm0;ok0;cupi0;rv0;aJe5o4;t0uri1A;ed0gle2;a6e5ix0o4ut0ys1N;di1Nt15u26;as0Clt0;n4rk0;ag0ufact0A;e6i5o4;ad0ck0st,v0;cens0m04st0;ft,v4;el0;tt0wn;a5o15u4;dg0s1B;gg0;llumSmpAn4sol1;br0cre1Ldebt0f8jZspir0t5v4;it0olv0;e4ox0Y;gr1n4re23;d0si15;e2l1o1Wuri1;li0o01r4;ov0;a6e1o4um03;ok0r4;ri0Z;mm3rm0;i6r5u4;a1Bid0;a0Ui0Rown;ft0;aAe9i8l6oc0Ir4;a4i0oz0Y;ctHg19m0;avo0Ju4;st3;ni08tt0x0;ar0;d0il0sc4;in1;dCl1mBn9quipp0s8x4;agger1c6p4te0T;a0Se4os0;ct0rie1D;it0;cap0tabliZ;cha0XgFha1As4;ur0;a0Zbarra0N;i0Buc1;aMeDi5r4;a01i0;gni08miniSre2s4;a9c6grun0Ft4;o4re0Hu17;rt0;iplWou4;nt0r4;ag0;bl0;cBdRf9l8p7ra6t5v4;elop0ot0;ail0ermQ;ng0;re07;ay0ight0;e4in0o0M;rr0;ay0enTor1;m5t0z4;ed,zl0;ag0p4;en0;aPeLhIlHo9r6u4;lt4r0stom03;iv1;a5owd0u4;sh0;ck0mp0;d0loAm7n4ok0v3;centr1f5s4troC;id3olid1;us0;b5pl4;ic1;in0;r0ur0;assi9os0utt3;ar5i4;ll0;g0m0;lebr1n6r4;ti4;fi0;tralJ;g0lcul1;aDewild3iCl9o7r5urn4;ed,t;ok4uis0;en;il0r0t4und;tl0;e5i4;nd0;ss0;as0;ffl0k0laMs0tt3;bPcNdKfIg0lFmaz0nDppBrm0ss9u5wa4;rd0;g5thor4;iz0;me4;nt0;o6u4;m0r0;li0re4;ci1;im1ticip1;at0;a5leg0t3;er0;rm0;fe2;ct0;ju5o7va4;nc0;st0;ce4knowledg0;pt0;and5so4;rb0;on0;ed",Singular:"true¦0:5J;1:5H;2:4W;3:4S;4:52;5:57;6:5L;7:56;8:5B;a52b4Lc3Nd35e2Xf2Og2Jh28in24j23k22l1Um1Ln1Ho1Bp0Rqu0Qr0FsZtMuHvCw9x r58yo yo;a9ha3Po3Q;f3i4Rt0Gy9;! arou39;arCeAideo ga2Qo9;cabu4Jl5C;gOr9t;di4Zt1Y;iety,ni4P;nBp30rAs 9;do43s5E;bani1in0;coordinat3Ader9;estima1to24we41; rex,aKeJhHiFoErBuAv9;! show;m2On2rntLto1D;agedy,ib9o4E;e,u9;n0ta46;ni1p2rq3L;c,er,m9;etF;ing9ree26;!y;am,mp3F;ct2le6x return;aNcMeKhor4QiJkHoGpin off,tDuBy9;ll9ner7st4T;ab2X;b9i1n28per bowl,rro1X;st3Ltot0;atAipe2Go1Lrate7udent9;! lo0I;i39u1;ft ser4Lmeo1I;elet5i9;ll,r3V;b38gn2Tte;ab2Jc9min3B;t,urity gua2N;e6ho2Y;bbatic0la3Jndwi0Qpi5;av5eDhetor2iAo9;de6om,w;tAv9;erb2C;e,u0;bDcBf9publ2r10spi1;er9orm3;e6r0;i9ord label;p2Ht0;a1u46;estion mark,ot2F;aPeMhoLiIlGoErAu9yram1F;ddi3HpErpo1Js3J;eBo9;bl3Zs9;pe3Jta1;dic1Rmi1Fp1Qroga8ss relea1F;p9rt0;py;a9ebisci1;q2Dte;cn2eAg9;!gy;!r;ne call,tocoK;anut,dAr9t0yo1;cen3Jsp3K;al,est0;nop4rAt9;e,hog5;adi11i2V;atme0bj3FcBpia1rde0thers,utspok5ve9wn3;n,r9;ti0Pview;cuAe9;an;pi3;arBitAot9umb3;a2Fhi2R;e,ra1;cot2ra8;aFeCiAo9ur0;nopo4p18rni2Nsq1Rti36uld;c,li11n0As9tt5;chief,si34;dAnu,t9;al,i3;al,ic;gna1mm0nd15rsupi0te9yf4;ri0;aDegCiBu9;ddi1n9;ch;me,p09; Be0M;bor14y9; 9er;up;eyno1itt5;el4ourn0;cBdices,itia8ni25sAtel0Lvert9;eb1J;e28titu1;en8i2T;aIeEighDoAu9;man right,s22;me9rmoFsp1Ftb0K;! r9;un; scho0YriY;a9i1N;d9v5; start,pho9;ne;ndful,sh brown,v5ze;aBelat0Ilaci3r9ul4yp1S;an9enadi3id;a1Cd slam,ny;df4r9;l2ni1I;aGeti1HiFlu1oCrAun9;er0;ee market,i9onti3;ga1;l4ur9;so9;me;ePref4;br2mi4;conoFffi7gg,lecto0Rmbas1EnCpidem2s1Zth2venBxAyel9;id;ampZempl0Nte6;i19t;er7terp9;ri9;se;my;eLiEoBr9ump tru0U;agonf4i9;er,ve thru;cAg7i4or,ssi3wn9;side;to0EumenE;aEgniDnn3sAvide9;nd;conte6incen8p9tri11;osi9;ti0C;ta0H;le0X;athBcAf9ni0terre6;ault 05err0;al,im0;!b9;ed;aWeThMiLlJoDr9;edit caBuc9;ib9;le;rd;efficDke,lCmmuniqLnsApi3rr0t0Xus9yo1;in;erv9uI;ato02;ic,lQ;ie6;er7i9oth;e6n2;ty,vil wM;aDeqCick5ocoBr9;istmas car9ysanthemum;ol;la1;ue;ndeli3racteri9;st2;iAllEr9;e0tifica1;liZ;hi3nFpErCt9ucus;erpi9hedr0;ll9;ar;!bohyd9ri3;ra1;it0;aAe,nib0t9;on;l,ry;aMeLiop2leJoHrDu9;nny,r9tterf4;g9i0;la9;ry;eakAi9;ck;fa9throB;st;dy,ro9wl;ugh;mi9;sh;an,l4;nkiArri3;er;ng;cSdMlInFppeti1rDsBtt2utop9;sy;ic;ce6pe9;ct;r9sen0;ay;ecAoma4tiA;ly;do1;i5l9;er7y;gy;en; hominDjAvan9;tage;ec8;ti9;ve;em;cCeAqui9;tt0;ta1;te;iAru0;al;de6;nt","Person|Noun":"true¦a0Eb07c03dWeUfQgOhLjHkiGlFmCnBolive,p7r4s3trini06v1wa0;ng,rd,tts;an,enus,iol0;a,et;ky,onPumm09;ay,e1o0uby;bin,d,se;ed,x;a2e1o0;l,tt04;aLnJ;dYge,tR;at,orm;a0eloW;t0x,ya;!s;a9eo,iH;ng,tP;a2e1o0;lGy;an,w3;de,smi4y;a0erb,iOolBuntR;ll,z0;el;ail,e0iLuy;ne;a1ern,i0lo;elds,nn;ith,n0;ny;a0dEmir,ula,ve;rl;a4e3i1j,ol0;ly;ck,x0;ie;an,ja;i0wn;sy;am,h0liff,rystal;a0in,ristian;mbers,ri0;ty;a4e3i2o,r0ud;an0ook;dy;ll;nedict,rg;k0nks;er;l0rt;fredo,ma","Actor|Verb":"true¦aCb8c5doctor,engineAfool,g3host,judge,m2nerd,p1recruit,scout,ushAvolunteAwi0;mp,tneA;arent,ilot;an,ime;eek,oof,r0uide;adu8oom;ha1o0;ach,nscript,ok;mpion,uffeur;o2u0;lly,tch0;er;ss;ddi1ffili0rchite1;ate;ct",MaleName:"true¦0:H6;1:FZ;2:DS;3:GQ;4:CZ;5:FV;6:GM;7:FP;8:GW;9:ET;A:C2;B:GD;aF8bE1cCQdBMeASfA1g8Yh88i7Uj6Sk6Bl5Mm48n3So3Ip33qu31r26s1Et0Ru0Ov0CwTxSyHzC;aCor0;cChC1karia,nAT;!hDkC;!aF6;!ar7CeF5;aJevgenBSoEuC;en,rFVsCu3FvEF;if,uf;nDs6OusC;ouf,s6N;aCg;s,tC;an,h0;hli,nCrosE1ss09;is,nC;!iBU;avi2ho5;aPeNiDoCyaEL;jcieBJlfgang,odrFutR;lFnC;f8TsC;lCt1;ow;bGey,frEhe4QlC;aE5iCy;am,e,s;ed8iC;d,ed;eAur;i,ndeD2rn2sC;!l9t1;lDyC;l1ne;lDtC;!er;aCHy;aKernDAiFladDoC;jteB0lodymyr;!iC;mFQsDB;cFha0ktBZnceDrgCOvC;a0ek;!nC;t,zo;!e4StBV;lCnC7sily;!entC;in9J;ghE2lCm70nax,ri,sm0;riCyss87;ch,k;aWeRhNiLoGrEuDyC;!l2roEDs1;n6r6E;avD0eCist0oy,um0;ntCRvBKy;bFdAWmCny;!asDmCoharu;aFFie,y;!z;iA6y;mCt4;!my,othy;adEeoDia0SomC;!as;!dor91;!de4;dFrC;enBKrC;anBJeCy;ll,nBI;!dy;dgh,ha,iCnn2req,tsu5V;cDAka;aYcotWeThPiMlobod0oKpenc2tEurDvenAEyCzym1;ed,lvest2;aj,e9V;anFeDuC;!aA;fan17phEQvCwaA;e77ie;!islaCl9;v,w;lom1rBuC;leymaDHta;dDgmu9UlCm1yabonga;as,v8B;!dhart8Yn9;aEeClo75;lCrm0;d1t1;h9Jne,qu1Jun,wn,yne;aDbastiEDk2Yl5Mpp,rgCth,ymoCU;e1Dio;m4n;!tC;!ie,y;eDPlFmEnCq67tosCMul;dCj2UtiA5;e01ro;!iATkeB6mC4u5;!ik,vato9K;aZeUheC8iRoGuDyC;an,ou;b99dDf4peAssC;!elEG;ol00y;an,bLc7MdJel,geIh0lHmGnEry,sDyC;!ce;ar7Ocoe,s;!aCnBU;ld,n;an,eo;a7Ef;l7Jr;e3Eg2n9olfo,riC;go;bBNeDH;cCl9;ar87c86h54kCo;!ey,ie,y;cFeA3gDid,ubByCza;an8Ln06;g85iC;naC6s;ep;ch8Kfa5hHin2je8HlGmFndEoHpha5sDul,wi36yC;an,mo8O;h9Im4;alDSol3O;iD0on;f,ph;ul;e9CinC;cy,t1;aOeLhilJiFrCyoG;aDeC;m,st1;ka85v2O;eDoC;tr;r8GtC;er,ro;!ipCl6H;!p6U;dCLrcy,tC;ar,e9JrC;!o7;b9Udra8So9UscAHtri62ulCv8I;!ie,o7;ctav6Ji2lImHndrBRrGsDtCum6wB;is,to;aDc6k6m0vCwaBE;al79;ma;i,vR;ar,er;aDeksandr,ivC;er,i2;f,v;aNeLguyBiFoCu3O;aDel,j4l0ma0rC;beAm0;h,m;cFels,g5i9EkDlC;es,s;!au,h96l78olaC;!i,y;hCkCol76;ol75;al,d,il,ls1vC;ilAF;hom,tC;e,hC;anCy;!a5i5;aYeViLoGuDyC;l4Nr1;hamDr84staC;fa,p6E;ed,mG;di10e,hamEis4JntDritz,sCussa;es,he;e,y;ad,ed,mC;ad,ed;cGgu5hai,kFlEnDtchC;!e8O;a9Pik;house,o7t1;ae73eC3ha8Iolaj;ah,hDkC;!ey,y;aDeC;al,l;el,l;hDlv3rC;le,ri8Ev4T;di,met;ay0c00gn4hWjd,ks2NlTmadZnSrKsXtDuric7VxC;imilBKwe8B;eHhEi69tCus,y69;!eo,hCia7;ew,i67;eDiC;as,eu,s;us,w;j,o;cHiGkFlEqu8Qsha83tCv3;iCy;!m,n;in,on;el,o7us;a6Yo7us;!elCin,o7us;!l8o;frAEi5Zny,u5;achDcoCik;lm;ai,y;amDdi,e5VmC;oud;adCm6W;ou;aulCi9P;ay;aWeOiMloyd,oJuDyC;le,nd1;cFdEiDkCth2uk;a7e;gi,s,z;ov7Cv6Hw6H;!as,iC;a6Een;g0nn52renDuCvA4we7D;!iS;!zo;am,n4oC;n5r;a9Yevi,la5KnHoFst2thaEvC;eCi;nte;bo;nCpo8V;!a82el,id;!nC;aAy;mEnd1rDsz73urenCwr6K;ce,t;ry,s;ar,beAont;aOeIhalHiFla4onr63rDu5SylC;e,s;istCzysztof;i0oph2;er0ngsl9p,rC;ilA9k,ollos;ed,id;en0iGnDrmCv4Z;it;!dDnCt1;e2Ny;ri4Z;r,th;cp2j4mEna8BrDsp6them,uC;ri;im,l;al,il;a03eXiVoFuC;an,lCst3;en,iC;an,en,o,us;aQeOhKkub4AnIrGsDzC;ef;eDhCi9Wue;!ua;!f,ph;dCge;i,on;!aCny;h,s,th6J;anDnC;!ath6Hie,n72;!nC;!es;!l,sCy;ph;o,qu3;an,mC;!i,m6V;d,ffFns,rCs4;a7JemDmai7QoCry;me,ni1H;i9Dy;!e73rC;ey,y;cKdBkImHrEsDvi2yC;dBs1;on,p2;ed,oDrCv67;e6Qod;d,s61;al,es5Wis1;a,e,oCub;b,v;ob,qu13;aTbNchiMgLke53lija,nuKonut,rIsEtCv0;ai,suC;ki;aDha0i8XmaCsac;el,il;ac,iaC;h,s;a,vinCw3;!g;k,nngu6X;nac1Xor;ka;ai,rahC;im;aReLoIuCyd6;beAgGmFsC;eyDsC;a3e3;in,n;ber5W;h,o;m2raDsse3wC;a5Pie;c49t1K;a0Qct3XiGnDrC;beAman08;dr7VrC;iCy2N;!k,q1R;n0Tt3S;bKlJmza,nIo,rEsDyC;a5KdB;an,s0;lEo67r2IuCv9;hi5Hki,tC;a,o;an,ey;k,s;!im;ib;a08e00iUlenToQrMuCyorgy;iHnFsC;!taC;f,vC;!e,o;n6tC;er,h2;do,lC;herDlC;auCerQ;me;aEegCov2;!g,orC;!io,y;dy,h7C;dfr9nza3XrDttfC;ri6C;an,d47;!n;acoGlEno,oCuseppe;rgiCvan6O;!o,s;be6Ies,lC;es;mo;oFrC;aDha4HrCt;it,y;ld,rd8;ffErgC;!e7iCy;!os;!r9;bElBrCv3;eCla1Nr4Hth,y;th;e,rC;e3YielC;!i4;aXeSiQlOorrest,rCyod2E;aHedFiC;edDtC;s,z;ri18;!d42eri11riC;ck,k;nCs2;cEkC;ie,lC;in,yn;esLisC;!co,z3M;etch2oC;ri0yd;d5lConn;ip;deriFliEng,rC;dinaCg4nan0B;nd8;pe,x;co;bCdi,hd;iEriC;ce,zC;io;an,en,o;benez2dZfrYit0lTmMnJo3rFsteb0th0ugenEvCymBzra;an,eCge4D;ns,re3K;!e;gi,iDnCrol,v3w3;est8ie,st;cCk;!h,k;o0DriCzo;co,qC;ue;aHerGiDmC;aGe3A;lCrh0;!iC;a10o,s;s1y;nu5;beAd1iEliDm2t1viCwood;n,s;ot28s;!as,j5Hot,sC;ha;a3en;!dGg6mFoDua2QwC;a2Pin;arC;do;oZuZ;ie;a04eTiOmitrNoFrag0uEwDylC;an,l0;ay3Hig4D;a3Gdl9nc0st3;minFnDri0ugCvydGy2S;!lF;!a36nCov0;e1Eie,y;go,iDykC;as;cCk;!k;i,y;armuFetDll1mitri7neCon,rk;sh;er,m6riC;ch;id;andLepak,j0lbeAmetri4nIon,rGsEvDwCxt2;ay30ey;en,in;hawn,moC;nd;ek,riC;ck;is,nC;is,y;rt;re;an,le,mKnIrEvC;e,iC;!d;en,iEne0PrCyl;eCin,yl;l45n;n,o,us;!iCny;el,lo;iCon;an,en,on;a0Fe0Ch03iar0lRoJrFuDyrC;il,us;rtC;!is;aEistC;iaCob12;no;ig;dy,lInErC;ey,neliCy;s,us;nEor,rDstaC;nt3;ad;or;by,e,in,l3t1;aHeEiCyde;fCnt,ve;fo0Xt1;menDt4;us;s,t;rFuDyC;!t1;dCs;e,io;enC;ce;aHeGrisC;!toC;phCs;!eC;!r;st2t;d,rCs;b5leC;s,y;cDdrCs6;ic;il;lHmFrC;ey,lDroCy;ll;!o7t1;er1iC;lo;!eb,v3;a09eZiVjorn,laUoSrEuCyr1;ddy,rtKst2;er;aKeFiEuDyC;an,ce,on;ce,no;an,ce;nDtC;!t;dDtC;!on;an,on;dFnC;dDisC;lav;en,on;!foOl9y;bby,gd0rCyd;is;i0Lke;bElDshC;al;al,lL;ek;nIrCshoi;at,nEtC;!raC;m,nd;aDhaCie;rd;rd8;!iDjam3nCs1;ie,y;to;kaMlazs,nHrC;n9rDtC;!holomew;eCy;tt;ey;dCeD;ar,iC;le;ar1Nb1Dd16fon15gust3hm12i0Zja0Yl0Bm07nTputsiSrGsaFugustEveDyCziz;a0kh0;ry;o,us;hi;aMchiKiJjun,mHnEon,tCy0;em,hCie,ur8;ur;aDoC;!ld;ud,v;aCin;an,nd8;!el,ki;baCe;ld;ta;aq;aMdHgel8tCw6;hoFoC;iDnC;!i8y;ne;ny;er7rCy;eDzC;ej;!as,i,j,s,w;!s;s,tolC;iCy;!y;ar,iEmaCos;nu5r;el;ne,r,t;aVbSdBeJfHiGl01onFphonsEt1vC;aPin;on;e,o;so,zo;!sR;!onZrC;ed;c,jaHksFssaHxC;!andC;er,rC;e,os,u;andCei;ar,er,r;ndC;ro;en;eDrecC;ht;rt8;dd3in,n,sC;taC;ir;ni;dDm6;ar;an,en;ad,eC;d,t;in;so;aGi,olErDvC;ik;ian8;f8ph;!o;mCn;!a;dGeFraDuC;!bakr,lfazl;hCm;am;!l;allFel,oulaye,ulC;!lDrahm0;an;ah,o;ah;av,on",Uncountable:"true¦0:2E;1:2L;2:33;a2Ub2Lc29d22e1Rf1Ng1Eh16i11j0Yk0Wl0Rm0Hn0Do0Cp03rZsLt9uran2Jv7w3you gu0E;a5his17i4oo3;d,l;ldlife,ne;rm8t1;apor,ernacul29i3;neg28ol1Otae;eDhBiAo8r4un3yranny;a,gst1B;aff2Oea1Ko4ue nor3;th;o08u3;bleshoot2Ose1Tt;night,othpas1Vwn3;foEsfoE;me off,n;er3und1;e,mod2S;a,nnis;aDcCeBhAi9ki8o7p6t4u3weepstak0;g1Unshi2Hshi;ati08e3;am,el;ace2Keci0;ap,cc1meth2C;n,ttl0;lk;eep,ingl0or1C;lf,na1Gri0;ene1Kisso1C;d0Wfe2l4nd,t3;i0Iurn;m1Ut;abi0e4ic3;e,ke15;c3i01laxa11search;ogni10rea10;a9e8hys7luto,o5re3ut2;amble,mis0s3ten20;en1Zs0L;l3rk;i28l0EyH; 16i28;a24tr0F;nt3ti0M;i0s;bstetri24vercrowd1Qxyg09;a5e4owada3utella;ys;ptu1Ows;il poliZtional securi2;aAe8o5u3;m3s1H;ps;n3o1K;ey,o3;gamy;a3cha0Elancholy,rchandi1Htallurgy;sl0t;chine3g1Aj1Hrs,thema1Q; learn1Cry;aught1e6i5ogi4u3;ck,g12;c,s1M;ce,ghtn18nguis1LteratWv1;ath1isVss;ara0EindergartPn3;icke0Aowled0Y;e3upit1;a3llyfiGwel0G;ns;ce,gnor6mp5n3;forma00ter3;net,sta07;atiSort3rov;an18;a7e6isto09o3ung1;ckey,mework,ne4o3rseradi8spitali2use arrest;ky;s2y;adquarteXre;ir,libut,ppiHs3;hi3te;sh;ene8l6o5r3um,ymnas11;a3eZ;niUss;lf,re;ut3yce0F;en; 3ti0W;edit0Hpo3;ol;aNicFlour,o4urnit3;ure;od,rgive3uri1wl;ness;arCcono0LducaBlectr9n7quip8thi0Pvery6x3;ist4per3;ti0B;en0J;body,o08th07;joy3tertain3;ment;ici2o3;ni0H;tiS;nings,th;emi02i6o4raugh3ynas2;ts;pe,wnstai3;rs;abet0ce,s3;honZrepu3;te;aDelciChAivi07l8o3urrency;al,ld w6mmenta5n3ral,ttIuscoB;fusiHt 3;ed;ry;ar;assi01oth0;es;aos,e3;eMwK;us;d,rO;a8i6lood,owlHread5u3;ntGtt1;er;!th;lliarJs3;on;g3ss;ga3;ge;cKdviJeroGirFmBn6ppeal court,r4spi3thleL;rin;ithmet3sen3;ic;i6y3;o4th3;ing;ne;se;en5n3;es2;ty;ds;craft;bi8d3nau7;yna3;mi6;ce;id,ous3;ti3;cs",Infinitive:"true¦0:9G;1:9T;2:AD;3:90;4:9Z;5:84;6:AH;7:A9;8:92;9:A0;A:AG;B:AI;C:9V;D:8R;E:8O;F:97;G:6H;H:7D;a94b8Hc7Jd68e4Zf4Mg4Gh4Ai3Qj3Nk3Kl3Bm34nou48o2Vp2Equ2Dr1Es0CtZuTvRwI;aOeNiLors5rI;eJiI;ng,te;ak,st3;d5e8TthI;draw,er;a2d,ep;i2ke,nIrn;d1t;aIie;liADniAry;nJpI;ho8Llift;cov1dJear8Hfound8DlIplug,rav82tie,ve94;eaAo3X;erIo;cut,go,staAFvalA3w2G;aSeQhNoMrIu73;aIe72;ffi3Smp3nsI;aBfo7CpI;i8oD;pp3ugh5;aJiJrIwaD;eat5i2;nk;aImA0;ch,se;ck3ilor,keImp1r8L;! paD;a0Ic0He0Fh0Bi0Al08mugg3n07o05p02qu01tUuLwI;aJeeIim;p,t5;ll7Wy;bNccMffLggeCmmKppJrI;mouFpa6Zvi2;o0re6Y;ari0on;er,i4;e7Numb;li9KmJsiIveD;de,st;er9it;aMe8MiKrI;ang3eIi2;ng27w;fIng;f5le;b,gg1rI;t3ve;a4AiA;a4UeJit,l7DoI;il,of;ak,nd;lIot7Kw;icEve;atGeak,i0O;aIi6;m,y;ft,ng,t;aKi6CoJriIun;nk,v6Q;ot,rt5;ke,rp5tt1;eIll,nd,que8Gv1w;!k,m;aven9ul8W;dd5tis1Iy;a0FeKiJoI;am,t,ut;d,p5;a0Ab08c06d05f01group,hea00iZjoi4lXmWnVpTq3MsOtMup,vI;amp,eJiIo3B;sEve;l,rI;e,t;i8rI;ie2ofE;eLiKpo8PtIurfa4;o24rI;aHiBuctu8;de,gn,st;mb3nt;el,hra0lIreseF;a4e71;d1ew,o07;aHe3Fo2;a7eFiIo6Jy;e2nq41ve;mbur0nf38;r0t;inKleBocus,rJuI;el,rbiA;aBeA;an4e;aBu4;ei2k8Bla43oIyc3;gni39nci3up,v1;oot,uI;ff;ct,d,liIp;se,ze;tt3viA;aAenGit,o7;aWerUinpoiFlumm1LoTrLuI;b47ke,niArIt;poDsuI;aFe;eMoI;cKd,fe4XhibEmo7noJpo0sp1tru6vI;e,i6o5L;un4;la3Nu8;aGclu6dJf1occupy,sup0JvI;a6BeF;etermi4TiB;aGllu7rtr5Ksse4Q;cei2fo4NiAmea7plex,sIva6;eve8iCua6;mp1rItrol,ve;a6It6E;bOccuNmEpMutLverIwe;l07sJtu6Yu0wI;helm;ee,h1F;gr5Cnu2Cpa4;era7i4Ipo0;py,r;ey,seItaH;r2ss;aMe0ViJoIultiply;leCu6Pw;micJnIspla4;ce,g3us;!k;iIke,na9;m,ntaH;aPeLiIo0u3N;ke,ng1quIv5;eIi6S;fy;aKnIss5;d,gI;th5;rn,ve;ng2Gu1N;eep,idnJnI;e4Cow;ap;oHuI;gg3xtaI;po0;gno8mVnIrk;cTdRfQgeChPitia7ju8q1CsNtKun6EvI;a6eIo11;nt,rt,st;erJimi6BoxiPrI;odu4u6;aBn,pr03ru6C;iCpi8tIu8;all,il,ruB;abEibE;eCo3Eu0;iIul9;ca7;i7lu6;b5Xmer0pI;aLer4Uin9ly,oJrI;e3Ais6Bo2;rt,se,veI;riA;le,rt;aLeKiIoiCuD;de,jaInd1;ck;ar,iT;mp1ng,pp5raIve;ng5Mss;ath1et,iMle27oLrI;aJeIow;et;b,pp3ze;!ve5A;gg3ve;aTer45i5RlSorMrJuI;lf4Cndrai0r48;eJiIolic;ght5;e0Qsh5;b3XeLfeEgJsI;a3Dee;eIi2;!t;clo0go,shIwa4Z;ad3F;att1ee,i36;lt1st5;a0OdEl0Mm0FnXquip,rWsVtGvTxI;aRcPeDhOiNpJtIu6;ing0Yol;eKi8lIo0un9;aHoI;it,re;ct,di7l;st,t;a3oDu3B;e30lI;a10u6;lt,mi28;alua7oI;ke,l2;chew,pou0tab19;a0u4U;aYcVdTfSgQhan4joy,lPqOrNsuMtKvI;e0YisI;a9i50;er,i4rI;aHenGuC;e,re;iGol0F;ui8;ar9iC;a9eIra2ulf;nd1;or4;ang1oIu8;r0w;irc3lo0ou0ErJuI;mb1;oaGy4D;b3ct;bKer9pI;hasiIow1;ze;aKody,rI;a4oiI;d1l;lm,rk;ap0eBuI;ci40de;rIt;ma0Rn;a0Re04iKo,rIwind3;aw,ed9oI;wn;agno0e,ff1g,mi2Kne,sLvI;eIul9;rIst;ge,t;aWbVcQlod9mant3pNru3TsMtI;iIoDu37;lJngI;uiA;!l;ol2ua6;eJlIo0ro2;a4ea0;n0r0;a2Xe36lKoIu0S;uIv1;ra9;aIo0;im;a3Kur0;b3rm;af5b01cVduBep5fUliTmQnOpMrLsiCtaGvI;eIol2;lop;ch;a20i2;aDiBloIoD;re,y;oIy;te,un4;eJoI;liA;an;mEv1;a4i0Ao06raud,y;ei2iMla8oKrI;ee,yI;!pt;de,mIup3;missi34po0;de,ma7ph1;aJrief,uI;g,nk;rk;mp5rk5uF;a0Dea0h0Ai09l08oKrIurta1G;a2ea7ipp3uI;mb3;ales4e04habEinci6ll03m00nIrro6;cXdUfQju8no7qu1sLtKvI;eIin4;ne,r9y;aHin2Bribu7;er2iLoli2Epi8tJuI;lt,me;itu7raH;in;d1st;eKiJoIroFu0;rm;de,gu8rm;ss;eJoI;ne;mn,n0;eIlu6ur;al,i2;buCe,men4pI;eIi3ly;l,te;eBi6u6;r4xiC;ean0iT;rcumveFte;eJirp,oI;o0p;riAw;ncIre5t1ulk;el;a02eSi6lQoPrKuI;iXrIy;st,y;aLeaKiJoad5;en;ng;stfeLtX;ke;il,l11mba0WrrMth1;eIow;ed;!coQfrie1LgPhMliLqueaKstJtrIwild1;ay;ow;th;e2tt3;a2eJoI;ld;ad;!in,ui3;me;bysEckfi8ff3tI;he;b15c0Rd0Iff0Ggree,l0Cm09n03ppZrXsQttOuMvJwaE;it;eDoI;id;rt;gIto0X;meF;aIeCraB;ch,in;pi8sJtoI;niA;aKeIi04u8;mb3rt,ss;le;il;re;g0Hi0ou0rI;an9i2;eaKly,oiFrI;ai0o2;nt;r,se;aMi0GnJtI;icipa7;eJoIul;un4y;al;ly0;aJu0;se;lga08ze;iKlI;e9oIu6;t,w;gn;ix,oI;rd;a03jNmiKoJsoI;rb;pt,rn;niIt;st1;er;ouJuC;st;rn;cLhie2knowled9quiItiva7;es4re;ce;ge;eQliOoKrJusI;e,tom;ue;mIst;moJpI;any,liA;da7;ma7;te;pt;andPduBet,i6oKsI;coKol2;ve;liArt,uI;nd;sh;de;ct;on",Person:"true¦0:1Q;a29b1Zc1Md1Ee18f15g13h0Ri0Qj0Nk0Jl0Gm09n06o05p00rPsItCusain bolt,v9w4xzibit,y1;anni,oko on2uji,v1;an,es;en,o;a3ednesday adams,i2o1;lfram,o0Q;ll ferrell,z khalifa;lt disn1Qr1;hol,r0G;a2i1oltai06;n dies0Zrginia wo17;lentino rossi,n goG;a4h3i2ripp,u1yra banks;lZpac shakur;ger woods,mba07;eresa may,or;kashi,t1ylor;um,ya1B;a5carlett johanss0h4i3lobodan milosevic,no2ocr1Lpider1uperm0Fwami; m0Em0E;op dogg,w whi1H;egfried,nbad;akespeaTerlock holm1Sia labeouf;ddam hussa16nt1;a cla11ig9;aAe6i5o3u1za;mi,n dmc,paul,sh limbau1;gh;bin hood,d stew16nald1thko;in0Mo;han0Yngo starr,valdo;ese witherspo0i1mbrandt;ll2nh1;old;ey,y;chmaninoff,ffi,iJshid,y roma1H;a4e3i2la16o1uff daddy;cahont0Ie;lar,p19;le,rZ;lm17ris hilt0;leg,prah winfr0Sra;a2e1iles cra1Bostradam0J; yo,l5tt06wmQ;pole0s;a5e4i2o1ubar03;by,lie5net,rriss0N;randa ju1tt romn0M;ly;rl0GssiaB;cklemo1rkov,s0ta hari,ya angelou;re;ady gaga,e1ibera0Pu;bron jam0Xch wale1e;sa;anye west,e3i1obe bryant;d cudi,efer suther1;la0P;ats,sha;a2effers0fk,k rowling,rr tolki1;en;ck the ripp0Mwaharlal nehru,y z;liTnez,ron m7;a7e5i3u1;lk hog5mphrey1sa01;! bog05;l1tl0H;de; m1dwig,nry 4;an;ile selassFlle ber4m3rrison1;! 1;ford;id,mo09;ry;ast0iannis,o1;odwPtye;ergus0lorence nightinga08r1;an1ederic chopN;s,z;ff5m2nya,ustaXzeki1;el;eril lagasse,i1;le zatop1nem;ek;ie;a6e4i2octor w1rake;ho;ck w1ego maradoC;olf;g1mi lovaOnzel washingt0;as;l1nHrth vadR;ai lNt0;a8h5lint0o1thulhu;n1olio;an,fuci1;us;on;aucKop2ristian baMy1;na;in;millo,ptain beefhe4r1;dinal wols2son1;! palmF;ey;art;a8e5hatt,i3oHro1;ck,n1;te;ll g1ng crosby;atB;ck,nazir bhut2rtil,yon1;ce;to;nksy,rack ob1;ama;l 6r3shton kutch2vril lavig8yn ra1;nd;er;chimed2istot1;le;es;capo2paci1;no;ne",Adjective:"true¦0:AI;1:BS;2:BI;3:BA;4:A8;5:84;6:AV;7:AN;8:AF;9:7H;A:BQ;B:AY;C:BC;D:BH;E:9Y;aA2b9Ec8Fd7We79f6Ng6Eh61i4Xj4Wk4Tl4Im41n3Po36p2Oquart7Pr2Ds1Dt14uSvOwFye29;aMeKhIiHoF;man5oFrth7G;dADzy;despreB1n w97s86;acked1UoleF;!sa6;ather1PeFll o70ste1D;!k5;nt1Ist6Ate4;aHeGiFola5T;bBUce versa,gi3Lle;ng67rsa5R;ca1gBSluAV;lt0PnLpHrGsFttermoBL;ef9Ku3;b96ge1; Hb32pGsFtiAH;ca6ide d4R;er,i85;f52to da2;a0Fbeco0Hc0Bd04e02f01gu1XheaBGiXkn4OmUnTopp06pRrNsJtHus0wF;aFiel3K;nt0rra0P;app0eXoF;ld,uS;eHi37o5ApGuF;perv06spec39;e1ok9O;en,ttl0;eFu5;cogn06gul2RlGqu84sF;erv0olv0;at0en33;aFrecede0E;id,rallel0;am0otic0;aFet;rri0tF;ch0;nFq26vers3;sur0terFv7U;eFrupt0;st0;air,inish0orese98;mploy0n7Ov97xpF;ect0lain0;eHisFocume01ue;clFput0;os0;cid0rF;!a8Scov9ha8Jlyi8nea8Gprivileg0sMwF;aFei9I;t9y;hGircumcFonvin2U;is0;aFeck0;lleng0rt0;b20ppea85ssuGttend0uthorF;iz0;mi8;i4Ara;aLeIhoHip 25oGrF;anspare1encha1i2;geth9leADp notch,rpB;rny,ugh6H;ena8DmpGrFs6U;r49tia4;eCo8P;leFst4M;nt0;a0Dc09e07h06i04ki03l01mug,nobbi4XoVpRqueami4XtKuFymb94;bHccinAi generis,pFr5;erFre7N;! dup9b,vi70;du0li7Lp6IsFurb7J;eq9Atanda9X;aKeJi16o2QrGubboFy4Q;rn;aightFin5GungS; fFfF;or7V;adfa9Pri6;lwa6Ftu82;arHeGir6NlendBot Fry;on;c3Qe1S;k5se; call0lImb9phistic16rHuFviV;ndFth1B;proof;dBry;dFub6; o2A;e60ipF;pe4shod;ll0n d7R;g2HnF;ceEg6ist9;am3Se9;co1Zem5lfFn6Are7; suf4Xi43;aGholFient3A;ar5;rlFt4A;et;cr0me,tisfac7F;aOeIheumatoBiGoF;bu8Ztt7Gy3;ghtFv3; 1Sf6X;cJdu8PlInown0pro69sGtF;ard0;is47oF;lu2na1;e1Suc45;alcit8Xe1ondi2;bBci3mpa1;aSePicayu7laOoNrGuF;bl7Tnjabi;eKiIoF;b7VfGmi49pFxi2M;er,ort81;a7uD;maFor,sti7va2;!ry;ciDexis0Ima2CpaB;in55puli8G;cBid;ac2Ynt 3IrFti2;ma40tFv7W;!i3Z;i2YrFss7R;anoBtF; 5XiF;al,s5V;bSffQkPld OnMrLth9utKverF;!aIbMdHhGni75seas,t,wF;ei74rou74;a63e7A;ue;ll;do1Ger,si6A;d3Qg2Aotu5Z; bFbFe on o7g3Uli7;oa80;fashion0school;!ay; gua7XbFha5Uli7;eat;eHligGsF;ce7er0So1C;at0;diFse;a1e1;aOeNiMoGuF;anc0de; moEnHrthFt6V;!eFwe7L;a7Krn;chaGdescri7Iprof30sF;top;la1;ght5;arby,cessa4ighbor5wlyw0xt;k0usiaFv3;ti8;aQeNiLoHuF;dIltiF;facet0p6;deHlGnFot,rbBst;ochro4Xth5;dy;rn,st;ddle ag0nF;dbloZi,or;ag9diocEga,naGrFtropolit4Q;e,ry;ci8;cIgenta,inHj0Fkeshift,mmGnFri4Oscu61ver18;da5Dy;ali4Lo4U;!stream;abEho;aOeLiIoFumberi8;ngFuti1R;stan3RtF;erm,i4H;ghtGteraF;l,ry,te;heart0wei5O;ft JgFss9th3;al,eFi0M;nda4;nguBps0te5;apGind5noF;wi8;ut;ad0itte4uniW;ce co0Hgno6Mll0Cm04nHpso 2UrF;a2releF;va1; ZaYcoWdReQfOgrNhibi4Ri05nMoLsHtFvalu5M;aAeF;nDrdepe2K;a7iGolFuboI;ub6ve1;de,gF;nifica1;rdi5N;a2er;own;eriIiLluenVrF;ar0eq5H;pt,rt;eHiGoFul1O;or;e,reA;fiFpe26termi5E;ni2;mpFnsideCrreA;le2;ccuCdeq5Ene,ppr4J;fFsitu,vitro;ro1;mJpF;arHeGl15oFrop9;li2r11;n2LrfeA;ti3;aGeFi18;d4BnD;tuE;egGiF;c0YteC;al,iF;tiF;ma2;ld;aOelNiLoFuma7;a4meInHrrGsFur5;ti6;if4E;e58o3U; ma3GsF;ick;ghfalut2HspF;an49;li00pf33;i4llow0ndGrdFtM; 05coEworki8;sy,y;aLener44iga3Blob3oKrGuF;il1Nng ho;aFea1Fizzl0;cGtF;ef2Vis;ef2U;ld3Aod;iFuc2D;nf2R;aVeSiQlOoJrF;aGeFil5ug3;q43tf2O;gFnt3S;i6ra1;lk13oHrF; keeps,eFge0Vm9tu41;g0Ei2Ds3R;liF;sh;ag4Mowe4uF;e1or45;e4nF;al,i2;d Gmini7rF;ti6ve1;up;bl0lDmIr Fst pac0ux;oGreacF;hi8;ff;ed,ili0R;aXfVlTmQnOqu3rMthere3veryday,xF;aApIquisi2traHuF;be48lF;ta1;!va2L;edRlF;icF;it;eAstF;whi6; Famor0ough,tiE;rou2sui2;erGiF;ne1;ge1;dFe2Aoq34;er5;ficF;ie1;g9sF;t,ygF;oi8;er;aWeMiHoGrFue;ea4owY;ci6mina1ne,r31ti8ubQ;dact2Jfficult,m,sGverF;ge1se;creGePjoi1paCtF;a1inA;et,te; Nadp0WceMfiLgeneCliJmuEpeIreliAsGvoF;id,ut;pFtitu2ul1L;eCoF;nde1;ca2ghF;tf13;a1ni2;as0;facto;i5ngero0I;ar0Ce09h07i06l05oOrIuF;rmudgeon5stoma4teF;sy;ly;aIeHu1EystalF; cleFli7;ar;epy;fFv17z0;ty;erUgTloSmPnGrpoCunterclVveFy;rt;cLdJgr21jIsHtrF;aFi2;dic0Yry;eq1Yta1;oi1ug3;escenFuN;di8;a1QeFiD;it0;atoDmensuCpF;ass1SulF;so4;ni3ss3;e1niza1;ci1J;ockwiD;rcumspeAvil;eFintzy;e4wy;leGrtaF;in;ba2;diac,ef00;a00ePiLliJoGrFuck nak0;and new,isk,on22;gGldface,naF; fi05fi05;us;nd,tF;he;gGpartisFzarE;an;tiF;me;autifOhiNlLnHsFyoN;iWtselF;li8;eGiFt;gn;aFfi03;th;at0oF;v0w;nd;ul;ckwards,rF;e,rT; priori,b13c0Zd0Tf0Ng0Ihe0Hl09mp6nt06pZrTsQttracti0MuLvIwF;aGkF;wa1B;ke,re;ant garGeraF;ge;de;diIsteEtF;heFoimmu7;nt07;re;to4;hGlFtu2;eep;en;bitIchiv3roHtF;ifiFsy;ci3;ga1;ra4;ry;pFt;aHetizi8rF;oprF;ia2;llFre1;ed,i8;ng;iquFsy;at0e;ed;cohKiJkaHl,oGriFterX;ght;ne,of;li7;ne;ke,ve;olF;ic;ad;ain07gressiIi6rF;eeF;ab6;le;ve;fGraB;id;ectGlF;ue1;ioF;na2; JaIeGvF;erD;pt,qF;ua2;ma1;hoc,infinitum;cuCquiGtu3u2;al;esce1;ra2;erSjeAlPoNrKsGuF;nda1;e1olu2trF;aAuD;se;te;eaGuF;pt;st;aFve;rd;aFe;ze;ct;ra1;nt",Pronoun:"true¦elle,h3i2me,she,th0us,we,you;e0ou;e,m,y;!l,t;e,im",Preposition:"true¦aPbMcLdKexcept,fIinGmid,notwithstandiWoDpXqua,sCt7u4v2w0;/o,hereSith0;! whHin,oW;ersus,i0;a,s a vis;n1p0;!on;like,til;h1ill,oward0;!s;an,ereby,r0;ough0u;!oM;ans,ince,o that,uch G;f1n0ut;!to;!f;! 0to;effect,part;or,r0;om;espite,own,u3;hez,irca;ar1e0oBy;sides,tween;ri7;bo8cross,ft7lo6m4propos,round,s1t0;!op;! 0;a whole,long 0;as;id0ong0;!st;ng;er;ut",SportsTeam:"true¦0:18;1:1E;2:1D;3:14;a1Db15c0Sd0Kfc dallas,g0Ihouston 0Hindiana0Gjacksonville jagua0k0El0Am01new UoRpKqueens parkJreal salt lake,sBt6utah jazz,vancouver whitecaps,w4yW;ashington 4h10;natio1Mredski2wizar0W;ampa bay 7e6o4;ronto 4ttenham hotspur;blue ja0Mrapto0;nnessee tita2xasD;buccanee0ra0K;a8eattle 6porting kansas0Wt4; louis 4oke0V;c1Drams;marine0s4;eah13ounH;cramento Rn 4;antonio spu0diego 4francisco gJjose earthquak1;char08paB; ran07;a9h6ittsburgh 5ortland t4;imbe0rail blaze0;pirat1steele0;il4oenix su2;adelphia 4li1;eagl1philNunE;dr1;akland 4klahoma city thunder,rlando magic;athle0Lrai4;de0;england 8orleans 7york 4;g5je3knYme3red bul0Xy4;anke1;ian3;pelica2sain3;patrio3revolut4;ion;anchEeAi4ontreal impact;ami 8lwaukee b7nnesota 4;t5vi4;kings;imberwolv1wi2;rewe0uc0J;dolphi2heat,marli2;mphis grizz4ts;li1;a6eic5os angeles 4;clippe0dodFlaB;esterV; galaxy,ke0;ansas city 4nF;chiefs,roya0D; pace0polis col3;astr05dynamo,rocke3texa2;olden state warrio0reen bay pac4;ke0;allas 8e4i04od6;nver 6troit 4;lio2pisto2ti4;ge0;broncYnugge3;cowbo5maver4;icZ;ys;arEelLhAincinnati 8leveland 6ol4;orado r4umbus crew sc;api7ocki1;brow2cavalie0guar4in4;dia2;bengaVre4;ds;arlotte horAicago 4;b5cubs,fire,wh4;iteB;ea0ulQ;diff4olina panthe0; city;altimore Alackburn rove0oston 6rooklyn 4uffalo bilN;ne3;ts;cel5red4; sox;tics;rs;oriol1rave2;rizona Ast8tlanta 4;brav1falco2h4;awA;ns;es;on villa,r4;os;c6di4;amondbac4;ks;ardi4;na4;ls",Unit:"true¦a07b04cXdWexVfTgRhePinYjoule0BkMlJmDnan08oCp9quart0Bsq ft,t7volts,w6y2ze3°1µ0;g,s;c,f,n;dVear1o0;ttR; 0s 0;old;att,b;erNon0;!ne02;ascals,e1i0;cXnt00;rcent,tJ;hms,unceY;/s,e4i0m²,²,³;/h,cro2l0;e0liK;!²;grLsR;gCtJ;it1u0;menQx;erPreP;b5elvins,ilo1m0notO;/h,ph,²;!byGgrEmCs;ct0rtzL;aJogrC;allonJb0ig3rB;ps;a0emtEl oz,t4;hrenheit,radG;aby9;eci3m1;aratDe1m0oulombD;²,³;lsius,nti0;gr2lit1m0;et0;er8;am7;b1y0;te5;l,ps;c2tt0;os0;econd1;re0;!s","Noun|Gerund":"true¦0:3O;1:3M;2:3N;3:3D;4:32;5:2V;6:3E;7:3K;8:36;9:3J;A:3B;a3Pb37c2Jd27e23f1Vg1Sh1Mi1Ij1Gk1Dl18m13n11o0Wp0Pques0Sr0EsTtNunderMvKwFyDzB;eroi0oB;ni0o3P;aw2eB;ar2l3;aEed4hispe5i5oCrB;ap8est3i1;n0ErB;ki0r31;i1r2s9tc9;isualizi0oB;lunt1Vti0;stan4ta6;aFeDhin6iCraBy8;c6di0i2vel1M;mi0p8;aBs1;c9si0;l6n2s1;aUcReQhOiMkatKl2Wmo6nowJpeItFuCwB;ea5im37;b35f0FrB;fi0vB;e2Mi2J;aAoryt1KrCuB;d2KfS;etc9ugg3;l3n4;bCi0;ebBi0;oar4;gnBnAt1;a3i0;ip8oB;p8rte2u1;a1r27t1;hCo5reBulp1;a2Qe2;edu3oo3;i3yi0;aKeEi4oCuB;li0n2;oBwi0;fi0;aFcEhear7laxi0nDpor1sB;pon4tructB;r2Iu5;de5;or4yc3;di0so2;p8ti0;aFeacek20laEoCrBublis9;a1Teten4in1oces7;iso2siB;tio2;n2yi0;ckaAin1rB;ki0t1O;fEpeDrganiCvB;erco24ula1;si0zi0;ni0ra1;fe5;avi0QeBur7;gotia1twor6;aDeCi2oB;de3nito5;a2dita1e1ssaA;int0XnBrke1;ifUufactu5;aEeaDiBodAyi0;cen7f1mi1stB;e2i0;r2si0;n4ug9;iCnB;ea4it1;c6l3;ogAuB;dAgg3stif12;ci0llust0VmDnBro2;nova1sp0NterBven1;ac1vie02;agi2plo4;aDea1iCoBun1;l4w3;ki0ri0;nd3rB;roWvB;es1;aCene0Lli4rBui4;ee1ie0N;rde2the5;aHeGiDlCorBros1un4;e0Pmat1;ir1oo4;gh1lCnBs9;anZdi0;i0li0;e3nX;r0Zscina1;a1du01nCxB;erci7plo5;chan1di0ginB;ee5;aLeHiGoub1rCum8wB;el3;aDeCiB;bb3n6vi0;a0Qs7;wi0;rTscoDvi0;ba1coZlBvelo8;eCiB;ve5;ga1;nGti0;aVelebUhSlPoDrBur3yc3;aBos7yi0;f1w3;aLdi0lJmFnBo6pi0ve5;dDsCvinB;ci0;trBul1;uc1;muniDpB;lBo7;ai2;ca1;lBo5;ec1;c9ti0;ap8eaCimToBubT;ni0t9;ni0ri0;aBee5;n1t1;ra1;m8rCs1te5;ri0;vi0;aPeNitMlLoGrDuB;dge1il4llBr8;yi0;an4eat9oadB;cas1;di0;a1mEokB;i0kB;ee8;pi0;bi0;es7oa1;c9i0;gin2lonAt1;gi0;bysit1c6ki0tt3;li0;ki0;bando2cGdverti7gi0pproac9rgDssuCtB;trac1;mi0;ui0;hi0;si0;coun1ti0;ti0;ni0;ng",PhrasalVerb:"true¦0:92;1:96;2:8H;3:8V;4:8A;5:83;6:85;7:98;8:90;9:8G;A:8X;B:8R;C:8U;D:8S;E:70;F:97;G:8Y;H:81;I:7H;J:79;a9Fb7Uc6Rd6Le6Jf5Ig50h4Biron0j47k40l3Em31n2Yo2Wp2Cquiet Hr1Xs0KtZuXvacuu6QwNyammerBzK;ero Dip LonK;e0k0;by,ov9up;aQeMhLiKor0Mrit19;mp0n3Fpe0r5s5;ackAeel Di0S;aLiKn33;gh 3Wrd0;n Dr K;do1in,oJ;it 79k5lk Lrm 69sh Kt83v60;aw3do1o7up;aw3in,oC;rgeBsK;e 2herE;a00eYhViRoQrMuKypP;ckErn K;do1in,oJup;aLiKot0y 30;ckl7Zp F;ck HdK;e 5Y;n7Wp 3Es5K;ck MdLe Kghten 6me0p o0Rre0;aw3ba4do1in,up;e Iy 2;by,oG;ink Lrow K;aw3ba4in,up;ba4ov9up;aKe 77ll62;m 2r 5M;ckBke Llk K;ov9shit,u47;aKba4do1in,leave,o4Dup;ba4ft9pa69w3;a0Vc0Te0Mh0Ii0Fl09m08n07o06p01quar5GtQuOwK;earMiK;ngLtch K;aw3ba4o8K; by;cKi6Bm 2ss0;k 64;aReQiPoNrKud35;aigh2Det75iK;ke 7Sng K;al6Yup;p Krm2F;by,in,oG;c3Ln3Lr 2tc4O;p F;c3Jmp0nd LrKveAy 2O;e Ht 2L;ba4do1up;ar3GeNiMlLrKurB;ead0ingBuc5;a49it 6H;c5ll o3Cn 2;ak Fe1Xll0;a3Bber 2rt0und like;ap 5Vow Duggl5;ash 6Noke0;eep NiKow 6;cLp K;o6Dup;e 68;in,oK;ff,v9;de19gn 4NnKt 6Gz5;gKkE; al6Ale0;aMoKu5W;ot Kut0w 7M;aw3ba4f48oC;c2WdeEk6EveA;e Pll1Nnd Orv5tK; Ktl5J;do1foLin,o7upK;!on;ot,r5Z;aw3ba4do1in,o33up;oCto;al66out0rK;ap65ew 6J;ilAv5;aXeUiSoOuK;b 5Yle0n Kstl5;aLba4do1inKo2Ith4Nu5P;!to;c2Xr8w3;ll Mot LpeAuK;g3Ind17;a2Wf3Po7;ar8in,o7up;ng 68p oKs5;ff,p18;aKelAinEnt0;c6Hd K;o4Dup;c27t0;aZeYiWlToQrOsyc35uK;ll Mn5Kt K;aKba4do1in,oJto47up;pa4Dw3;a3Jdo1in,o21to45up;attleBess KiNop 2;ah2Fon;iLp Kr4Zu1Gwer 6N;do1in,o6Nup;nt0;aLuK;gEmp 6;ce u20y 6D;ck Kg0le 4An 6p5B;oJup;el 5NncilE;c53ir 39n0ss MtLy K;ba4oG; Hc2R;aw3ba4in,oJ;pKw4Y;e4Xt D;aLerd0oK;dAt53;il Hrrow H;aTeQiPoLuK;ddl5ll I;c1FnkeyMp 6uthAve K;aKdo1in,o4Lup;l4Nw3; wi4K;ss0x 2;asur5e3SlLss K;a21up;t 6;ke Ln 6rKs2Ax0;k 6ryA;do,fun,oCsure,up;a02eViQoLuK;ck0st I;aNc4Fg MoKse0;k Kse4D;aft9ba4do1forw37in56o0Zu46;in,oJ;d 6;e NghtMnLsKve 00;ten F;e 2k 2; 2e46;ar8do1in;aMt LvelK; oC;do1go,in,o7up;nEve K;in,oK;pKut;en;c5p 2sh LtchBughAy K;do1o59;in4Po7;eMick Lnock K;do1oCup;oCup;eLy K;in,up;l Ip K;aw3ba4do1f04in,oJto,up;aMoLuK;ic5mpE;ke3St H;c43zz 2;a01eWiToPuK;nLrrKsh 6;y 2;keLt K;ar8do1;r H;lKneErse3K;d Ke 2;ba4dKfast,o0Cup;ear,o1;de Lt K;ba4on,up;aw3o7;aKlp0;d Ml Ir Kt 2;fKof;rom;f11in,o03uW;cPm 2nLsh0ve Kz2P;at,it,to;d Lg KkerP;do1in,o2Tup;do1in,oK;ut,v9;k 2;aZeTive Rloss IoMrLunK; f0S;ab hold,in43ow 2U; Kof 2I;aMb1Mit,oLr8th1IuK;nd9;ff,n,v9;bo7ft9hQw3;aw3bKdo1in,oJrise,up,w3;a4ir2H;ar 6ek0t K;aLb1Fdo1in,oKr8up;ff,n,ut,v9;cLhKl2Fr8t,w3;ead;ross;d aKng 2;bo7;a0Ee07iYlUoQrMuK;ck Ke2N;ar8up;eLighten KownBy 2;aw3oG;eKshe27; 2z5;g 2lMol Krk I;aKwi20;bo7r8;d 6low 2;aLeKip0;sh0;g 6ke0mKrKtten H;e F;gRlPnNrLsKzzle0;h F;e Km 2;aw3ba4up;d0isK;h 2;e Kl 1T;aw3fPin,o7;ht ba4ure0;ePnLsK;s 2;cMd K;fKoG;or;e D;d04l 2;cNll Krm0t1G;aLbKdo1in,o09sho0Eth08victim;a4ehi2O;pa0C;e K;do1oGup;at Kdge0nd 12y5;in,o7up;aOi1HoNrK;aLess 6op KuN;aw3b03in,oC;gBwB; Ile0ubl1B;m 2;a0Ah05l02oOrLut K;aw3ba4do1oCup;ackBeep LoKy0;ss Dwd0;by,do1in,o0Uup;me NoLuntK; o2A;k 6l K;do1oG;aRbQforOin,oNtKu0O;hLoKrue;geth9;rough;ff,ut,v9;th,wK;ard;a4y;paKr8w3;rt;eaLose K;in,oCup;n 6r F;aNeLiK;ll0pE;ck Der Kw F;on,up;t 2;lRncel0rOsMtch LveE; in;o1Nup;h Dt K;doubt,oG;ry LvK;e 08;aw3oJ;l Km H;aLba4do1oJup;ff,n,ut;r8w3;a0Ve0MiteAl0Fo04rQuK;bblNckl05il0Dlk 6ndl05rLsKtMy FzzA;t 00;n 0HsK;t D;e I;ov9;anWeaUiLush K;oGup;ghQng K;aNba4do1forMin,oLuK;nd9p;n,ut;th;bo7lKr8w3;ong;teK;n 2;k K;do1in,o7up;ch0;arTg 6iRn5oPrNssMttlLunce Kx D;aw3ba4;e 6; ar8;e H;do1;k Dt 2;e 2;l 6;do1up;d 2;aPeed0oKurt0;cMw K;aw3ba4do1o7up;ck;k K;in,oC;ck0nk0stA; oQaNef 2lt0nd K;do1ov9up;er;up;r Lt K;do1in,oCup;do1o7;ff,nK;to;ck Pil0nMrgLsK;h D;ainBe D;g DkB; on;in,o7;aw3do1in,oCup;ff,ut;ay;ct FdQir0sk MuctionA; oG;ff;ar8o7;ouK;nd; o7;d K;do1oKup;ff,n;wn;o7up;ut",ProperNoun:"true¦aIbDc8dalhousHe7f5gosford,h4iron maiden,kirby,landsdowne,m2nis,r1s0wembF;herwood,paldiB;iel,othwe1;cgi0ercedes,issy;ll;intBudsB;airview,lorence,ra0;mpt9nco;lmo,uro;a1h0;arlt6es5risti;rl0talina;et4i0;ng;arb3e0;et1nt0rke0;ley;on;ie;bid,jax","Person|Place":"true¦a8d6h4jordan,k3orlando,s1vi0;ctor9rgin9;a0ydney;lvador,mara,ntia4;ent,obe;amil0ous0;ton;arw2ie0;go;lexandr1ust0;in;ia",LastName:"true¦0:BR;1:BF;2:B5;3:BH;4:AX;5:9Y;6:B6;7:BK;8:B0;9:AV;A:AL;B:8Q;C:8G;D:7K;E:BM;F:AH;aBDb9Zc8Wd88e81f7Kg6Wh64i60j5Lk4Vl4Dm39n2Wo2Op25quispe,r1Ls0Pt0Ev03wTxSyKzG;aIhGimmerm6A;aGou,u;ng,o;khar5ytsE;aKeun9BiHoGun;koya32shiBU;!lG;diGmaz;rim,z;maGng;da,g52mo83sGzaC;aChiBV;iao,u;aLeJiHoGright,u;jcA5lff,ng;lGmm0nkl0sniewsC;kiB1liams33s3;bGiss,lt0;b,er,st0;a6Vgn0lHtG;anabe,s3;k0sh,tG;e2Non;aLeKiHoGukD;gt,lk5roby5;dHllalGnogr3Kr1Css0val3S;ba,ob1W;al,ov4;lasHsel8W;lJn dIrgBEsHzG;qu7;ilyEqu7siljE;en b6Aijk,yk;enzueAIverde;aPeix1VhKi2j8ka43oJrIsui,uG;om5UrG;c2n0un1;an,emblA7ynisC;dorAMlst3Km4rrAth;atch0i8UoG;mHrG;are84laci79;ps3sG;en,on;hirDkah9Mnaka,te,varA;a06ch01eYhUiRmOoMtIuHvGzabo;en9Jobod3N;ar7bot4lliv2zuC;aIeHoG;i7Bj4AyanAB;ele,in2FpheBvens25;l8rm0;kol5lovy5re7Tsa,to,uG;ng,sa;iGy72;rn5tG;!h;l71mHnGrbu;at9cla9Egh;moBo7M;aIeGimizu;hu,vchG;en8Luk;la,r1G;gu9infe5YmGoh,pulveA7rra5P;jGyG;on5;evi6iltz,miHneid0roed0uGwarz;be3Elz;dHtG;!t,z;!t;ar4Th8ito,ka4OlJnGr4saCto,unde19v4;ch7dHtGz;a5Le,os;b53e16;as,ihDm4Po0Y;aVeSiPoJuHyG;a6oo,u;bio,iz,sG;so,u;bKc8Fdrigue67ge10j9YmJosevelt,sItHux,wG;e,li6;a9Ch;enb4Usi;a54e4L;erts15i93;bei4JcHes,vGzzo;as,e9;ci,hards12;ag2es,iHut0yG;es,nol5N;s,t0;dImHnGsmu97v6C;tan1;ir7os;ic,u;aUeOhMiJoHrGut8;asad,if6Zochazk27;lishc2GpGrti72u10we76;e3Aov51;cHe45nG;as,to;as70hl0;aGillips;k,m,n6I;a3Hde3Wete0Bna,rJtG;ersHrovGters54;!a,ic;!en,on;eGic,kiBss3;i9ra,tz,z;h86k,padopoulIrk0tHvG;ic,l4N;el,te39;os;bMconn2Ag2TlJnei6PrHsbor6XweBzG;dem7Rturk;ella4DtGwe6N;ega,iz;iGof7Hs8I;vGyn1R;ei9;aSri1;aPeNiJoGune50ym2;rHvGwak;ak4Qik5otn66;odahl,r4S;cholsZeHkolGls4Jx3;ic,ov84;ls1miG;!n1;ils3mG;co4Xec;gy,kaGray2sh,var38;jiGmu9shiG;ma;a07c04eZiWoMuHyeG;rs;lJnIrGssoli6S;atGp03r7C;i,ov4;oz,te58;d0l0;h2lOnNo0RrHsGza1A;er,s;aKeJiIoz5risHtG;e56on;!on;!n7K;au,i9no,t5J;!lA;r1Btgome59;i3El0;cracFhhail5kkeHlG;l0os64;ls1;hmeJiIj30lHn3Krci0ssiGyer2N;!er;n0Po;er,j0;dDti;cartHlG;aughl8e2;hy;dQe7Egnu68i0jer3TkPmNnMrItHyG;er,r;ei,ic,su21thews;iHkDquAroqu8tinG;ez,s;a5Xc,nG;!o;ci5Vn;a5UmG;ad5;ar5e6Kin1;rig77s1;aVeOiLoJuHyG;!nch;k4nGo;d,gu;mbarGpe3Fvr4we;di;!nGu,yana2B;coln,dG;b21holm,strom;bedEfeKhIitn0kaHn8rGw35;oy;!j;m11tG;in1on1;bvGvG;re;iGmmy,ng,rs2Qu,voie,ws3;ne,t1F;aZeYh2iWlUnez50oNrJuHvar2woG;k,n;cerGmar68znets5;a,o34;aHem0isGyeziu;h23t3O;m0sni4Fus3KvG;ch4O;bay57ch,rh0Usk16vaIwalGzl5;czGsC;yk;cIlG;!cGen4K;huk;!ev4ic,s;e8uiveG;rt;eff0kGl4mu9nnun1;ucF;ll0nnedy;hn,llKminsCne,pIrHstra3Qto,ur,yGzl5;a,s0;j0Rls22;l2oG;or;oe;aPenOha6im14oHuG;ng,r4;e32hInHrge32u6vG;anD;es,ss3;anHnsG;en,on,t3;nesGs1R;en,s1;kiBnings,s1;cJkob4EnGrv0E;kDsG;en,sG;en0Ion;ks3obs2A;brahimDglesi5Nke5Fl0Qno07oneIshikHto,vanoG;u,v54;awa;scu;aVeOiNjaltal8oIrist50uG;!aGb0ghAynh;m2ng;a6dz4fIjgaa3Hk,lHpUrGwe,x3X;ak1Gvat;mAt;er,fm3WmG;ann;ggiBtchcock;iJmingw4BnHrGss;nand7re9;deGriks1;rs3;kkiHnG;on1;la,n1;dz4g1lvoQmOns0ZqNrMsJuIwHyG;asFes;kiB;g1ng;anHhiG;mo14;i,ov0J;di6p0r10t;ue;alaG;in1;rs1;aVeorgUheorghe,iSjonRoLrJuGw3;errGnnar3Co,staf3Ctierr7zm2;a,eG;ro;ayli6ee2Lg4iffithGub0;!s;lIme0UnHodGrbachE;e,m2;calvAzale0S;dGubE;bGs0E;erg;aj,i;bs3l,mGordaO;en7;iev3U;gnMlJmaIndFo,rGsFuthi0;cGdn0za;ia;ge;eaHlG;agh0i,o;no;e,on;aVerQiLjeldsted,lKoIrHuG;chs,entAji41ll0;eem2iedm2;ntaGrt8urni0wl0;na;emi6orA;lipIsHtzgeraG;ld;ch0h0;ovG;!ic;hatDnanIrG;arGei9;a,i;deY;ov4;b0rre1D;dKinsJriksIsGvaB;cob3GpGtra3D;inoza,osiQ;en,s3;te8;er,is3warG;ds;aXePiNjurhuMoKrisco15uHvorakG;!oT;arte,boHmitru,nn,rGt3C;and,ic;is;g2he0Omingu7nErd1ItG;to;us;aGcki2Hmitr2Ossanayake,x3;s,z; JbnaIlHmirGrvisFvi,w2;!ov4;gado,ic;th;bo0groot,jo6lHsilGvriA;va;a cruz,e3uG;ca;hl,mcevsCnIt2WviG;dGes,s;ov,s3;ielsGku22;!en;ki;a0Be06hRiobQlarkPoIrGunningh1H;awfo0RivGuz;elli;h1lKntJoIrGs2Nx;byn,reG;a,ia;ke,p0;i,rer2K;em2liB;ns;!e;anu;aOeMiu,oIristGu6we;eGiaG;ns1;i,ng,p9uHwGy;!dH;dGng;huJ;!n,onGu6;!g;kJnIpm2ttHudhGv7;ry;erjee,o14;!d,g;ma,raboG;rty;bJl0Cng4rG;eghetHnG;a,y;ti;an,ota1C;cerAlder3mpbeLrIstGvadi0B;iGro;llo;doHl0Er,t0uGvalho;so;so,zo;ll;a0Fe01hYiXlUoNrKuIyG;rLtyG;qi;chan2rG;ke,ns;ank5iem,oGyant;oks,wG;ne;gdan5nIruya,su,uchaHyKziG;c,n5;rd;darGik;enG;ko;ov;aGond15;nco,zG;ev4;ancFshw16;a08oGuiy2;umGwmG;ik;ckRethov1gu,ktPnNrG;gJisInG;ascoGds1;ni;ha;er,mG;anG;!n;gtGit7nP;ss3;asF;hi;er,hG;am;b4ch,ez,hRiley,kk0ldw8nMrIshHtAu0;es;ir;bInHtlGua;ett;es,i0;ieYosa;dGik;a9yoG;padhyG;ay;ra;k,ng;ic;bb0Acos09d07g04kht05lZnPrLsl2tJyG;aHd8;in;la;chis3kiG;ns3;aImstro6sl2;an;ng;ujo,ya;dJgelHsaG;ri;ovG;!a;ersJov,reG;aGjEws;ss1;en;en,on,s3;on;eksejEiyEmeiIvG;ar7es;ez;da;ev;arwHuilG;ar;al;ams,l0;er;ta;as",Ordinal:"true¦eBf7nin5s3t0zeroE;enDhir1we0;lfCn7;d,t3;e0ixt8;cond,vent7;et0th;e6ie7;i2o0;r0urt3;tie4;ft1rst;ight0lev1;e0h,ie1;en0;th",Cardinal:"true¦bEeBf5mEnine7one,s4t0zero;en,h2rDw0;e0o;lve,n5;irt6ousands,ree;even2ix2;i3o0;r1ur0;!t2;ty;ft0ve;e2y;ight0lev1;!e0y;en;illions",Multiple:"true¦b3hundred,m3qu2se1t0;housand,r2;pt1xt1;adr0int0;illion",City:"true¦0:74;1:61;2:6G;3:6J;4:5S;a68b53c4Id48e44f3Wg3Hh39i31j2Wk2Fl23m1Mn1Co19p0Wq0Ur0Os05tRuQvLwDxiBy9z5;a7h5i4Muri4O;a5e5ongsh0;ng3H;greb,nzib5G;ang2e5okoha3Sunfu;katerin3Hrev0;a5n0Q;m5Hn;arsBeAi6roclBu5;h0xi,zh5P;c7n5;d5nipeg,terth4;hoek,s1L;hi5Zkl3A;l63xford;aw;a8e6i5ladivost5Molgogr6L;en3lni6S;ni22r5;o3saill4N;lenc4Wncouv3Sr3ughn;lan bat1Crumqi,trecht;aFbilisi,eEheDiBo9r7u5;l21n63r5;in,ku;i5ondh62;es51poli;kyo,m2Zron1Pulo5;n,uS;an5jua3l2Tmisoa6Bra3;j4Tshui; hag62ssaloni2H;gucigal26hr0l av1U;briz,i6llinn,mpe56ng5rtu,shk2R;i3Esh0;an,chu1n0p2Eyu0;aEeDh8kopje,owe1Gt7u5;ra5zh4X;ba0Ht;aten is55ockholm,rasbou67uttga2V;an8e6i5;jiazhua1llo1m5Xy0;f50n5;ya1zh4H;gh3Kt4Q;att45o1Vv44;cramen16int ClBn5o paulo,ppo3Rrajevo; 7aa,t5;a 5o domin3E;a3fe,m1M;antonio,die3Cfrancisco,j5ped3Nsalvad0J;o5u0;se;em,t lake ci5Fz25;lou58peters24;a9e8i6o5;me,t59;ga,o5yadh;! de janei3F;cife,ims,nn3Jykjavik;b4Sip4lei2Inc2Pwalpindi;ingdao,u5;ez2i0Q;aFeEhDiCo9r7u6yong5;ya1;eb59ya1;a5etor3M;g52to;rt5zn0; 5la4Co;au prin0Melizabe24sa03;ls3Prae5Atts26;iladelph3Gnom pe1Aoenix;ki1tah tik3E;dua,lerYnaji,r4Ot5;na,r32;ak44des0Km1Mr6s5ttawa;a3Vlo;an,d06;a7ew5ing2Fovosibir1Jyc; 5cast36;del24orlea44taip14;g8iro4Wn5pl2Wshv33v0;ch6ji1t5;es,o1;a1o1;a6o5p4;ya;no,sa0W;aEeCi9o6u5;mb2Ani26sc3Y;gadishu,nt6s5;c13ul;evideo,pelli1Rre2Z;ami,l6n14s5;kolc,sissauga;an,waukee;cca,d5lbour2Mmph41ndo1Cssi3;an,ell2Xi3;cau,drAkass2Sl9n8r5shh4A;aca6ib5rakesh,se2L;or;i1Sy;a4EchFdal0Zi47;mo;id;aDeAi8o6u5vSy2;anMckn0Odhia3;n5s angel26;d2g bea1N;brev2Be3Lma5nz,sb2verpo28;!ss27; ma39i5;c5pzig;est16; p6g5ho2Wn0Cusan24;os;az,la33;aHharFiClaipeBo9rak0Du7y5;iv,o5;to;ala lump4n5;mi1sh0;hi0Hlka2Xpavog4si5wlo2;ce;da;ev,n5rkuk;gst2sha5;sa;k5toum;iv;bHdu3llakuric0Qmpa3Fn6ohsiu1ra5un1Iwaguc0Q;c0Pj;d5o,p4;ah1Ty;a7e6i5ohannesV;l1Vn0;dd36rusalem;ip4k5;ar2H;bad0mph1OnArkutUs7taXz5;mir,tapala5;pa;fah0l6tanb5;ul;am2Zi2H;che2d5;ianap2Mo20;aAe7o5yder2W; chi mi5ms,nolulu;nh;f6lsin5rakli2;ki;ei;ifa,lifax,mCn5rb1Dva3;g8nov01oi;aFdanEenDhCiPlasgBo9raz,u5;a5jr23;dal6ng5yaquil;zh1J;aja2Oupe;ld coa1Bthen5;bu2S;ow;ent;e0Uoa;sk;lw7n5za;dhi5gt1E;nag0U;ay;aisal29es,o8r6ukuya5;ma;ankfu5esno;rt;rt5sh0; wor6ale5;za;th;d5indhov0Pl paso;in5mont2;bur5;gh;aBe8ha0Xisp4o7resd0Lu5;b5esseldorf,nkirk,rb0shanbe;ai,l0I;ha,nggu0rtmu13;hradSl6nv5troit;er;hi;donghIe6k09l5masc1Zr es sala1KugavpiY;i0lU;gu,je2;aJebu,hAleve0Vo5raio02uriti1Q;lo7n6penhag0Ar5;do1Ok;akKst0V;gUm5;bo;aBen8i6ongqi1ristchur5;ch;ang m7ca5ttago1;go;g6n5;ai;du,zho1;ng5ttogr14;ch8sha,zh07;gliari,i9lga8mayenJn6pe town,r5tanO;acCdiff;ber1Ac5;un;ry;ro;aWeNhKirmingh0WoJr9u5;chareTdapeTenos air7r5s0tu0;g5sa;as;es;a9is6usse5;ls;ba6t5;ol;ne;sil8tisla7zzav5;il5;le;va;ia;goZst2;op6ubaneshw5;ar;al;iCl9ng8r5;g6l5n;in;en;aluru,hazi;fa6grade,o horizon5;te;st;ji1rut;ghd0BkFn9ot8r7s6yan n4;ur;el,r07;celo3i,ranquil09;ou;du1g6ja lu5;ka;alo6k5;ok;re;ng;ers5u;field;a05b02cc01ddis aba00gartaZhmedXizawl,lSmPnHqa00rEsBt7uck5;la5;nd;he7l5;an5;ta;ns;h5unci2;dod,gab5;at;li5;ngt2;on;a8c5kaOtwerp;hora6o3;na;ge;h7p5;ol5;is;eim;aravati,m0s5;terd5;am; 7buquerq6eppo,giers,ma5;ty;ue;basrah al qadim5mawsil al jadid5;ah;ab5;ad;la;ba;ra;idj0u dha5;bi;an;lbo6rh5;us;rg",Region:"true¦0:2O;1:2L;2:2U;3:2F;a2Sb2Fc21d1Wes1Vf1Tg1Oh1Ki1Fj1Bk16l13m0Sn09o07pYqVrSsJtEuBverAw6y4zacatec2W;akut0o0Fu4;cat1k09;a5est 4isconsin,yomi1O;bengal,virgin0;rwick3shington4;! dc;acruz,mont;dmurt0t4;ah,tar4; 2Pa12;a6e5laxca1Vripu21u4;scaEva;langa2nnessee,x2J;bas10m4smQtar29;aulip2Hil nadu;a9elang07i7o5taf16u4ylh1J;ff02rr09s1E;me1Gno1Uuth 4;cZdY;ber0c4kkim,naloa;hu1ily;n5rawak,skatchew1xo4;ny; luis potosi,ta catari2;a4hodeA;j4ngp0C;asth1shahi;ingh29u4;e4intana roo;bec,en6retaro;aAe6rince edward4unjab; i4;sl0G;i,n5r4;ak,nambu0F;a0Rnsylv4;an0;ha0Pra4;!na;axa0Zdisha,h4klaho21ntar4reg7ss0Dx0I;io;aLeEo6u4;evo le4nav0X;on;r4tt18va scot0;f9mandy,th4; 4ampton3;c6d5yo4;rk3;ako1O;aroli2;olk;bras1Nva0Dw4; 6foundland4;! and labrad4;or;brunswick,hamp3jers5mexiTyork4;! state;ey;galPyarit;aAeghala0Mi6o4;nta2r4;dov0elos;ch6dlanDn5ss4zor11;issippi,ouri;as geraPneso18;ig1oac1;dhy12harasht0Gine,lac07ni5r4ssachusetts;anhao,i el,ylG;p4toba;ur;anca3e4incoln3ouisI;e4iR;ds;a6e5h4omi;aka06ul2;dah,lant1ntucky,ra01;bardino,lmyk0ns0Qr4;achay,el0nata0X;alis6har4iangxi;kh4;and;co;daho,llino7n4owa;d5gush4;et0;ia2;is;a6ert5i4un1;dalFm0D;ford3;mp3rya2waii;ansu,eorg0lou7oa,u4;an4izhou,jarat;ajuato,gdo4;ng;cester3;lori4uji1;da;sex;ageUe7o5uran4;go;rs4;et;lawaMrby3;aFeaEh9o4rim08umbr0;ahui7l6nnectic5rsi4ventry;ca;ut;i03orado;la;e5hattisgarh,i4uvash0;apRhuahua;chn5rke4;ss0;ya;ra;lGm4;bridge3peche;a9ihar,r8u4;ck4ryat0;ingham3;shi4;re;emen,itish columb0;h0ja cal8lk7s4v7;hkorto4que;st1;an;ar0;iforn0;ia;dygHguascalientes,lBndhr9r5ss4;am;izo2kans5un4;achal 7;as;na;a 4;pradesh;a6ber5t4;ai;ta;ba5s4;ka;ma;ea",Place:"true¦0:4T;1:4V;2:44;3:4B;4:3I;a4Eb3Gc2Td2Ge26f25g1Vh1Ji1Fk1Cl14m0Vn0No0Jp08r04sTtNuLvJw7y5;a5o0Syz;kut1Bngtze;aDeChitBi9o5upatki,ycom2P;ki26o5;d5l1B;b3Ps5;i4to3Y;c0SllowbroCn5;c2Qgh2;by,chur1P;ed0ntw3Gs22;ke6r3St5;erf1f1; is0Gf3V;auxha3Mirgin is0Jost5;ok;laanbaatar,pto5xb3E;n,wn;a9eotihuac43h7ive49o6ru2Nsarskoe selo,u5;l2Dzigo47;nto,rquay,tt2J;am3e 5orn3E;bronx,hamptons;hiti,j mah0Iu1N;aEcotts bluff,eCfo,herbroQoApring9t7u5yd2F;dbu1Wn5;der03set3B;aff1ock2Nr5;atf1oud;hi37w24;ho,uth5; 1Iam1Zwo3E;a5i2O;f2Tt0;int lawrence riv3Pkhal2D;ayleigh,ed7i5oc1Z;chmo1Eo gran4ver5;be1Dfr09si4; s39cliffe,hi2Y;aCe9h8i5ompeii,utn2;c6ne5tcai2T; 2Pc0G;keri13t0;l,x;k,lh2mbr6n5r2J;n1Hzance;oke;cif38pahanaumokuak30r5;k5then0;si4w1K;ak7r6x5;f1l2X;ange county,d,f1inoco;mTw1G;e8i1Uo5;r5tt2N;th5wi0E; 0Sam19;uschwanste1Pw5; eng6a5h2market,po36;rk;la0P;a8co,e6i5uc;dt1Yll0Z;adow5ko0H;lands;chu picchu,gad2Ridsto1Ql8n7ple6r5;kh2; g1Cw11;hatt2Osf2B;ibu,t0ve1Z;a8e7gw,hr,in5owlOynd02;coln memori5dl2C;al;asi4w3;kefr7mbe1On5s,x;ca2Ig5si05;f1l27t0;ont;azan kreml14e6itchen2Gosrae,rasnoyar5ul;sk;ns0Hs1U;ax,cn,lf1n6ps5st;wiN;d5glew0Lverness;ian27ochina;aDeBi6kg,nd,ov5unti2H;d,enweep;gh6llc5;reL;bu03l5;and5;!s;r5yw0C;ef1tf1;libu24mp6r5stings;f1lem,row;stead,t0;aDodavari,r5uelph;avenAe5imsS;at 8en5; 6f1Fwi5;ch;acr3vall1H;brita0Flak3;hur5;st;ng3y villa0W;airhavHco,ra;aAgli9nf17ppi8u7ver6x5;et1Lf1;glad3t0;rope,st0;ng;nt0;rls1Ls5;t 5;e5si4;nd;aCe9fw,ig8o7ryd6u5xb;mfri3nstab00rh2tt0;en;nca18rcKv19wnt0B;by;n6r5vonpo1D;ry;!h2;nu8r5;l6t5;f1moor;ingt0;be;aLdg,eIgk,hClBo5royd0;l6m5rnwa0B;pt0;c7lingw6osse5;um;ood;he0S;earwat0St;a8el6i5uuk;chen itza,mney ro07natSricahua;m0Zt5;enh2;mor5rlottetPth2;ro;dar 5ntervilA;breaks,faZg5;rove;ld9m8r5versh2;lis6rizo pla5;in;le;bLpbellf1;weQ;aZcn,eNingl01kk,lackLolt0r5uckV;aGiAo5;ckt0ok5wns cany0;lyn,s5;i4to5;ne;de;dge6gh5;am,t0;n6t5;own;or5;th;ceb6m5;lNpt0;rid5;ge;bu5pool,wa8;rn;aconsfEdf1lBr9verly7x5;hi5;ll; hi5;lls;wi5;ck; air,l5;ingh2;am;ie5;ld;ltimore,rnsl6tters5;ea;ey;bLct0driadic,frica,ginJlGmFn9rc8s7tl6yleOzor3;es;!ant8;hcroft,ia; de triomphe,t6;adyr,ca8dov9tarct5;ic5; oce5;an;st5;er;ericas,s;be6dersh5hambra,list0;ot;rt0;cou5;rt;bot7i5;ngd0;on;sf1;ord",Country:"true¦0:38;1:2L;2:3B;a2Xb2Ec22d1Ye1Sf1Mg1Ch1Ai14j12k0Zl0Um0Gn05om2pZqat1KrXsKtCu7v5wal4yemTz3;a25imbabwe;es,lis and futu2Y;a3enezue32ietnam;nuatu,tican city;gTk6nited 4ruXs3zbeE; 2Ca,sr;arab emirat0Kkingdom,states3;! of am2Y;!raiV;a8haCimor les0Co7rinidad 5u3;nis0rk3valu;ey,me2Zs and caic1V;and t3t3;oba1L;go,kel10nga;iw2ji3nz2T;ki2V;aDcotl1eCi9lov8o6pa2Dri lanka,u5w3yr0;az3edAitzerl1;il1;d2riname;lomon1Xmal0uth 3;afr2KkMsud2;ak0en0;erra leoFn3;gapo1Yt maart3;en;negLrb0ychellZ;int 3moa,n marino,udi arab0;hele26luc0mart21;epublic of ir0Eom2Euss0w3;an27;a4eIhilippinUitcairn1Mo3uerto riN;l1rtugF;ki2Dl4nama,pua new0Vra3;gu7;au,esti3;ne;aBe9i7or3;folk1Ith4w3;ay; k3ern mariana1D;or0O;caragua,ger3ue;!ia;p3ther1Aw zeal1;al;mib0u3;ru;a7exi6icro0Bo3yanm06;ldova,n3roc5zambA;a4gol0t3;enegro,serrat;co;cAdagasc01l7r5urit4yot3;te;an0i16;shall0Xtin3;ique;a4div3i,ta;es;wi,ys0;ao,ed02;a6e5i3uxembourg;b3echtenste12thu1G;er0ya;ban0Isotho;os,tv0;azakh1Fe4iriba04o3uwait,yrgyz1F;rXsovo;eling0Knya;a3erG;ma16p2;c7nd6r4s3taly,vory coast;le of m2rael;a3el1;n,q;ia,oJ;el1;aiTon3ungary;dur0Ng kong;aBermany,ha0QibraltAre8u3;a6ern5inea3ya0P;! biss3;au;sey;deloupe,m,tema0Q;e3na0N;ce,nl1;ar;bUmb0;a7i6r3;ance,ench 3;guia0Epoly3;nes0;ji,nl1;lklandUroeU;ast tim7cu6gypt,l salv6ngl1quatorial4ritr5st3thiop0;on0; guin3;ea;ad3;or;enmark,jibou5ominica4r con3;go;!n C;ti;aBentral african Ah8o5roat0u4yprRzech3; 9ia;ba,racao;c4lo3morQngo brazzaville,okGsta r04te de ivoiL;mb0;osE;i3ristmasG;le,na;republic;m3naUpe verde,ymanA;bod0ero3;on;aGeDhut2o9r5u3;lgar0r3;kina faso,ma,undi;azil,itish 3unei;virgin3; is3;lands;liv0nai5snia and herzegoviHtswaHuvet3; isl1;and;re;l3n8rmuG;ar3gium,ize;us;h4ngladesh,rbad3;os;am4ra3;in;as;fghaGlDmBn6r4ustr3zerbaij2;al0ia;genti3men0uba;na;dorra,g5t3;arct7igua and barbu3;da;o3uil3;la;er3;ica;b3ger0;an0;ia;ni3;st2;an",FirstName:"true¦aTblair,cQdOfrancoZgabMhinaLilya,jHkClBm6ni4quinn,re3s0;h0umit,yd;ay,e0iloh;a,lby;g9ne;co,ko0;!s;a1el0ina,org6;!okuhF;ds,naia,r1tt0xiB;i,y;ion,lo;ashawn,eif,uca;a3e1ir0rM;an;lsFn0rry;dall,yat5;i,sD;a0essIie,ude;i1m0;ie,mG;me;ta;rie0y;le;arcy,ev0;an,on;as1h0;arl8eyenne;ey,sidy;drien,kira,l4nd1ubr0vi;ey;i,r0;a,e0;a,y;ex2f1o0;is;ie;ei,is",WeekDay:"true¦fri2mon2s1t0wednesd3;hurs1ues1;aturd1und1;!d0;ay0;!s",Month:"true¦dec0february,july,nov0octo1sept0;em0;ber",Date:"true¦ago,on4som4t1week0yesterd5; end,ends;mr1o0;d2morrow;!w;ed0;ay",Duration:"true¦centurAd8h7m5q4se3w1y0;ear8r8;eek0k7;!end,s;ason,c5;tr,uarter;i0onth3;llisecond2nute2;our1r1;ay0ecade0;!s;ies,y",FemaleName:"true¦0:J7;1:JB;2:IJ;3:IK;4:J1;5:IO;6:JS;7:JO;8:HB;9:JK;A:H4;B:I2;C:IT;D:JH;E:IX;F:BA;G:I4;aGTbFLcDRdD0eBMfB4gADh9Ti9Gj8Dk7Cl5Wm48n3Lo3Hp33qu32r29s15t0Eu0Cv02wVxiTyOzH;aLeIineb,oHsof3;e3Sf3la,ra;h2iKlIna,ynH;ab,ep;da,ma;da,h2iHra;nab;aKeJi0FolB7uIvH;et8onDP;i0na;le0sen3;el,gm3Hn,rGLs8W;aoHme0nyi;m5XyAD;aMendDZhiDGiH;dele9lJnH;if48niHo0;e,f47;a,helmi0lHma;a,ow;ka0nB;aNeKiHusa5;ck84kIl8oleAviH;anFenJ4;ky,toriBK;da,lA8rHs0;a,nHoniH9;a,iFR;leHnesH9;nILrH;i1y;g9rHs6xHA;su5te;aYeUhRiNoLrIuHy2;i,la;acJ3iHu0J;c3na,sH;hFta;nHr0F;iFya;aJffaEOnHs6;a,gtiH;ng;!nFSra;aIeHomasi0;a,l9Oo8Ares1;l3ndolwethu;g9Fo88rIssH;!a,ie;eHi,ri7;sa,za;bOlMmKnIrHs6tia0wa0;a60yn;iHya;a,ka,s6;arFe2iHm77ra;!ka;a,iH;a,t6;at6it6;a0Ecarlett,e0AhWiSkye,neza0oQri,tNuIyH;bIGlvi1;ha,mayIJniAsIzH;an3Net8ie,y;anHi7;!a,e,nH;aCe;aIeH;fan4l5Dphan6E;cI5r5;b3fiAAm0LnHphi1;d2ia,ja,ya;er2lJmon1nIobh8QtH;a,i;dy;lETv3;aMeIirHo0risFDy5;a,lDM;ba,e0i5lJrH;iHr6Jyl;!d8Ifa;ia,lDZ;hd,iMki2nJrIu0w0yH;la,ma,na;i,le9on,ron,yn;aIda,ia,nHon;a,on;!ya;k6mH;!aa;lJrItaye82vH;da,inj;e0ife;en1i0ma;anA9bLd5Oh1SiBkKlJmInd2rHs6vannaC;aCi0;ant6i2;lDOma,ome;ee0in8Tu2;in1ri0;a05eZhXiUoHuthDM;bScRghQl8LnPsJwIxH;anB3ie,y;an,e0;aIeHie,lD;ann7ll1marDGtA;!lHnn1;iHyn;e,nH;a,dF;da,i,na;ayy8G;hel67io;bDRerAyn;a,cIkHmas,nFta,ya;ki,o;h8Xki;ea,iannGMoH;da,n1P;an0bJemFgi0iInHta,y0;a8Bee;han86na;a,eH;cHkaC;a,ca;bi0chIe,i0mo0nHquETy0;di,ia;aERelHiB;!e,le;een4ia0;aPeOhMiLoJrHute6A;iHudenCV;scil3LyamvaB;lHrt3;i0ly;a,paluk;ilome0oebe,ylH;is,lis;ggy,nelope,r5t2;ige,m0VnKo5rvaDMtIulH;a,et8in1;ricHt4T;a,e,ia;do2i07;ctav3dIfD3is6ksa0lHphD3umC5yunbileg;a,ga,iv3;eHvAF;l3t8;aWeUiMoIurHy5;!ay,ul;a,eJor,rIuH;f,r;aCeEma;ll1mi;aNcLhariBQkKlaJna,sHta,vi;anHha;ur;!y;a,iDZki;hoGk9YolH;a,e4P;!mh;hir,lHna,risDEsreE;!a,iDDlBV;asuMdLh3i6Dl5nKomi7rgEVtH;aHhal4;lHs6;i1ya;cy,et8;e9iF0ya;nngu2X;a0Ackenz4e02iMoJrignayani,uriDJyH;a,rH;a,iOlNna,tG;bi0i2llBJnH;a,iH;ca,ka,qD9;a,cUdo4ZkaTlOmi,nMrItzi,yH;ar;aJiIlH;anET;am;!l,nB;dy,eHh,n4;nhGrva;aKdJe0iCUlH;iHy;cent,e;red;!gros;!e5;ae5hH;ae5el3Z;ag5DgNi,lKrH;edi7AiIjem,on,yH;em,l;em,sCG;an4iHliCF;nHsCJ;a,da;!an,han;b09cASd07e,g05ha,i04ja,l02n00rLsoum5YtKuIv84xBKyHz4;bell,ra,soBB;d7rH;a,eE;h8Gild1t4;a,cUgQiKjor4l7Un4s6tJwa,yH;!aHbe6Xja9lAE;m,nBL;a,ha,in1;!aJbCGeIja,lDna,sHt63;!a,ol,sa;!l1D;!h,mInH;!a,e,n1;!awit,i;arJeIie,oHr48ueri8;!t;!ry;et46i3B;el4Xi7Cy;dHon,ue5;akranAy;ak,en,iHlo3S;a,ka,nB;a,re,s4te;daHg4;!l3E;alDd4elHge,isDJon0;ei9in1yn;el,le;a0Ne0CiXoQuLyH;d3la,nH;!a,dIe2OnHsCT;!a,e2N;a,sCR;aD4cJel0Pis1lIna,pHz;e,iA;a,u,wa;iHy;a0Se,ja,l2NnB;is,l1UrItt1LuHvel4;el5is1;aKeIi7na,rH;aADi7;lHn1tA;ei;!in1;aTbb9HdSepa,lNnKsJvIzH;!a,be5Ret8z4;!ia;a,et8;!a,dH;a,sHy;ay,ey,i,y;a,iJja,lH;iHy;aA8e;!aH;!nF;ia,ya;!nH;!a,ne;aPda,e0iNjYla,nMoKsJtHx93y5;iHt4;c3t3;e2PlCO;la,nHra;a,ie,o2;a,or1;a,gh,laH;!ni;!h,nH;a,d2e,n5V;cOdon9DiNkes6mi9Gna,rMtJurIvHxmi,y5;ern1in3;a,e5Aie,yn;as6iIoH;nya,ya;fa,s6;a,isA9;a,la;ey,ie,y;a04eZhXiOlASoNrJyH;lHra;a,ee,ie;istHy6I;a,en,iIyH;!na;!e,n5F;nul,ri,urtnB8;aOerNlB7mJrHzzy;a,stH;en,in;!berlImernH;aq;eHi,y;e,y;a,stE;!na,ra;aHei2ongordzol;dij1w5;el7UiKjsi,lJnIrH;a,i,ri;d2na,za;ey,i,lBLs4y;ra,s6;biAcARdiat7MeBAiSlQmPnyakuma1DrNss6NtKviAyH;!e,lH;a,eH;e,i8T;!a6HeIhHi4TlDri0y;ar8Her8Hie,leErBAy;!lyn8Ori0;a,en,iHl5Xoli0yn;!ma,nFs95;a5il1;ei8Mi,lH;e,ie;a,tl6O;a0AeZiWoOuH;anMdLlHst88;es,iH;a8NeHs8X;!n9tH;!a,te;e5Mi3My;a,iA;!anNcelDdMelGhan7VleLni,sIva0yH;a,ce;eHie;fHlDph7Y;a,in1;en,n1;i7y;!a,e,n45;lHng;!i1DlH;!i1C;anNle0nKrJsH;i8JsH;!e,i8I;i,ri;!a,elGif2CnH;a,et8iHy;!e,f2A;a,eJiInH;a,eIiH;e,n1;!t8;cMda,mi,nIque4YsminFvie2y9zH;min7;a7eIiH;ce,e,n1s;!lHs82t0F;e,le;inIk6HlDquelH;in1yn;da,ta;da,lRmPnOo0rNsIvaHwo0zaro;!a0lu,na;aJiIlaHob89;!n9R;do2;belHdo2;!a,e,l3B;a7Ben1i0ma;di2es,gr72ji;a9elBogH;en1;a,e9iHo0se;a0na;aSeOiJoHus7Kyacin2C;da,ll4rten24snH;a,i9U;lImaH;ri;aIdHlaI;a,egard;ry;ath1BiJlInrietArmi9sH;sa,t1A;en2Uga,mi;di;bi2Fil8MlNnMrJsItHwa,yl8M;i5Tt4;n60ti;iHmo51ri53;etH;!te;aCnaC;a,ey,l4;a02eWiRlPoNrKunJwH;enHyne1R;!dolD;ay,el;acieIetHiselB;a,chE;!la;ld1CogooH;sh;adys,enHor3yn2K;a,da,na;aKgi,lIna,ov8EselHta;a,e,le;da,liH;an;!n0;mLnJorgIrH;ald5Si,m3Etrud7;et8i4X;a,eHna;s29vieve;ma;bIle,mHrnet,yG;al5Si5;iIrielH;a,l1;!ja;aTeQiPlorOoz3rH;anJeIiH;da,eB;da,ja;!cH;esIiHoi0P;n1s66;!ca;a,enc3;en,o0;lIn0rnH;anB;ec3ic3;jr,nArKtHy7;emIiHma,oumaA;ha,ma,n;eh;ah,iBrah,za0;cr4Rd0Re0Qi0Pk0Ol07mXn54rUsOtNuMvHwa;aKelIiH;!e,ta;inFyn;!a;!ngel4V;geni1ni47;h5Yien9ta;mLperanKtH;eIhHrel5;er;l31r7;za;a,eralB;iHma,ne4Lyn;cHka,n;a,ka;aPeNiKmH;aHe21ie,y;!li9nuH;elG;lHn1;e7iHy;a,e,ja;lHrald;da,y;!nue5;aWeUiNlMma,no2oKsJvH;a,iH;na,ra;a,ie;iHuiH;se;a,en,ie,y;a0c3da,e,f,nMsJzaH;!betHveA;e,h;aHe,ka;!beH;th;!a,or;anor,nH;!a,i;!in1na;ate1Rta;leEs6;vi;eIiHna,wi0;e,th;l,n;aYeMh3iLjeneKoH;lor5Vminiq4Ln3FrHtt4;a,eEis,la,othHthy;ea,y;ba;an09naCon9ya;anQbPde,eOiMlJmetr3nHsir5M;a,iH;ce,se;a,iIla,orHphi9;es,is;a,l6F;dHrdH;re;!d5Ena;!b2ForaCraC;a,d2nH;!a,e;hl3i0l0GmNnLphn1rIvi1WyH;le,na;a,by,cIia,lH;a,en1;ey,ie;a,et8iH;!ca,el1Aka,z;arHia;is;a0Re0Nh04i02lUoJristIynH;di,th3;al,i0;lPnMrIurH;tn1D;aJd2OiHn2Ori9;!nH;a,e,n1;!l4;cepci5Cn4sH;tanHuelo;ce,za;eHleE;en,t8;aJeoIotH;il54;!pat2;ir7rJudH;et8iH;a,ne;a,e,iH;ce,sZ;a2er2ndH;i,y;aReNloe,rH;isJyH;stH;al;sy,tH;a1Sen,iHy;an1e,n1;deJlseIrH;!i7yl;a,y;li9;nMrH;isKlImH;ai9;a,eHot8;n1t8;!sa;d2elGtH;al,elG;cIlH;es8i47;el3ilH;e,ia,y;itlYlXmilWndVrMsKtHy5;aIeIhHri0;er1IleErDy;ri0;a38sH;a37ie;a,iOlLmeJolIrH;ie,ol;!e,in1yn;lHn;!a,la;a,eIie,otHy;a,ta;ne,y;na,s1X;a0Ii0I;a,e,l1;isAl4;in,yn;a0Ke02iZlXoUrH;andi7eRiJoIyH;an0nn;nwDoke;an3HdgMgiLtH;n31tH;!aInH;ey,i,y;ny;d,t8;etH;!t7;an0e,nH;da,na;bbi7glarIlo07nH;iAn4;ka;ancHythe;a,he;an1Clja0nHsm3M;iAtH;ou;aWcVlinUniArPssOtJulaCvH;!erlH;ey,y;hJsy,tH;e,iHy7;e,na;!anH;ie,y;!ie;nItHyl;ha,ie;adIiH;ce;et8i9;ay,da;ca,ky;!triH;ce,z;rbJyaH;rmH;aa;a2o2ra;a2Ub2Od25g21i1Sj5l18m0Zn0Boi,r06sWtVuPvOwa,yIzH;ra,u0;aKes6gJlIn,seH;!l;in;un;!nH;a,na;a,i2K;drLguJrIsteH;ja;el3;stH;in1;a,ey,i,y;aahua,he0;hIi2Gja,miAs2DtrH;id;aMlIraqHt21;at;eIi7yH;!n;e,iHy;gh;!nH;ti;iJleIo6piA;ta;en,n1t8;aHelG;!n1J;a01dje5eZgViTjRnKohito,toHya;inet8nH;el5ia;te;!aKeIiHmJ;e,ka;!mHtt7;ar4;!belIliHmU;sa;!l1;a,eliH;ca;ka,sHta;a,sa;elHie;a,iH;a,ca,n1qH;ue;!tH;a,te;!bImHstasiMya;ar3;el;aLberKeliJiHy;e,l3naH;!ta;a,ja;!ly;hGiIl3nB;da;a,ra;le;aWba,ePiMlKthJyH;a,c3sH;a,on,sa;ea;iHys0N;e,s0M;a,cIn1sHza;a,e,ha,on,sa;e,ia,ja;c3is6jaKksaKna,sJxH;aHia;!nd2;ia,saH;nd2;ra;ia;i0nIyH;ah,na;a,is,naCoud;la;c6da,leEmNnLsH;haClH;inHyY;g,n;!h;a,o,slH;ey;ee;en;at6g4nIusH;ti0;es;ie;aWdiTelMrH;eJiH;anMenH;a,e,ne;an0;na;!aLeKiIyH;nn;a,n1;a,e;!ne;!iH;de;e,lDsH;on;yn;!lH;i9yn;ne;aKbIiHrL;!e,gaK;ey,i7y;!e;gaH;il;dKliyJradhIs6;ha;ya;ah;a,ya",Honorific:"true¦director1field marsh2lieutenant1rear0sergeant major,vice0; admir1; gener0;al","Adj|Gerund":"true¦0:3F;1:3H;2:31;3:2X;4:35;5:33;6:3C;7:2Z;8:36;9:29;a33b2Tc2Bd1Te1If19g12h0Zi0Rl0Nm0Gnu0Fo0Ap04rYsKtEuBvAw1Ayiel3;ar6e08;nBpA;l1Rs0B;fol3n1Zsett2;aEeDhrBi4ouc7rAwis0;e0Bif2oub2us0yi1;ea1SiA;l2vi1;l2mp0rr1J;nt1Vxi1;aMcreec7enten2NhLkyrocke0lo0Vmi2oJpHtDuBweA;e0Ul2;pp2ArA;gi1pri5roun3;aBea8iAri2Hun9;mula0r4;gge4rA;t2vi1;ark2eAraw2;e3llb2F;aAot7;ki1ri1;i9oc29;dYtisf6;aEeBive0oAus7;a4l2;assu4defi9fres7ig9juve07mai9s0vAwar3;ea2italiAol1G;si1zi1;gi1ll6mb2vi1;a6eDier23lun1VrAun2C;eBoA;mi5vo1Z;ce3s5vai2;n3rpleA;xi1;ffCpWutBverAwi1;arc7lap04p0Pri3whel8;goi1l6st1J;en3sA;et0;m2Jrtu4;aEeDiCoBuAyst0L;mb2;t1Jvi1;s5tiga0;an1Rl0n3smeri26;dAtu4;de9;aCeaBiAo0U;fesa0Tvi1;di1ni1;c1Fg19s0;llumiGmFnArri0R;cDfurHsCtBviA;go23ti1;e1Oimi21oxica0rig0V;pi4ul0;orpo20r0K;po5;na0;eaBorr02umilA;ia0;li1rtwar8;lFrA;atiDipCoBuelA;i1li1;undbrea10wi1;pi1;f6ng;a4ea8;a3etc7it0lEoCrBulfA;il2;ee1FighXust1L;rAun3;ebo3thco8;aCoA;a0wA;e4i1;mi1tte4;lectrJmHnExA;aCci0hBis0pA;an3lo3;aOila1B;c0spe1A;ab2coura0CdBergi13ga0Clive9ric7s02tA;hral2i0J;ea4u4;barras5er09pA;owe4;if6;aQeIiBrA;if0;sAzz6;aEgDhearCsen0tA;rAur11;ac0es5;te9;us0;ppoin0r8;biliGcDfi9gra3ligh0mBpres5sAvasG;erE;an3ea9orA;ali0L;a6eiBli9rA;ea5;vi1;ta0;maPri1s7un0zz2;aPhMlo5oAripp2ut0;mGnArrespon3;cer9fDspi4tA;inBrA;as0ibu0ol2;ui1;lic0u5;ni1;fDmCpA;eAromi5;l2ti1;an3;or0;aAil2;llenAnAr8;gi1;l8ptAri1;iva0;aff2eGin3lFoDrBuA;d3st2;eathtaAui5;ki1;gg2i2o8ri1unA;ci1;in3;co8wiA;lAtc7;de4;bsorVcOgonMlJmHnno6ppea2rFsA;pi4su4toA;nBun3;di1;is7;hi1;res0;li1;aFu5;si1;ar8lu4;ri1;mi1;iAzi1;zi1;cAhi1;eleDomA;moBpan6;yi1;da0;ra0;ti1;bi1;ng",Comparable:"true¦0:3C;1:3Q;2:3F;a3Tb3Cc33d2Te2Mf2Ag1Wh1Li1Fj1Ek1Bl13m0Xn0So0Rp0Iqu0Gr07sHtCug0vAw4y3za0Q;el10ouN;ary,e6hi5i3ry;ck0Cde,l3n1ry,se;d,y;ny,te;a3i3R;k,ry;a3erda2ulgar;gue,in,st;a6en2Xhi5i4ouZr3;anqu2Cen1ue;dy,g36me0ny;ck,rs28;ll,me,rt,wd3I;aRcaPeOhMiLkin0BlImGoEpDt6u4w3;eet,ift;b3dd0Wperfi21rre28;sta26t21;a8e7iff,r4u3;pUr1;a4ict,o3;ng;ig2Vn0N;a1ep,rn;le,rk,te0;e1Si2Vright0;ci1Yft,l3on,re;emn,id;a3el0;ll,rt;e4i3y;g2Mm0Z;ek,nd2T;ck24l0mp1L;a3iRrill,y;dy,l01rp;ve0Jxy;n1Jr3;ce,y;d,fe,int0l1Hv0V;a8e6i5o3ude;mantic,o19sy,u3;gh;pe,t1P;a3d,mo0A;dy,l;gg4iFndom,p3re,w;id;ed;ai2i3;ck,et;hoAi1Fl9o8r5u3;ny,r3;e,p11;egna2ic4o3;fouSud;ey,k0;liXor;ain,easa2;ny;dd,i0ld,ranL;aive,e5i4o3u14;b0Sisy,rm0Ysy;bb0ce,mb0R;a3r1w;r,t;ad,e5ild,o4u3;nda12te;ist,o1;a4ek,l3;low;s0ty;a8e7i6o3ucky;f0Jn4o15u3ve0w10y0N;d,sy;e0g;ke0l,mp,tt0Eve0;e1Qwd;me,r3te;ge;e4i3;nd;en;ol0ui19;cy,ll,n3;secu6t3;e3ima4;llege2rmedia3;te;re;aAe7i6o5u3;ge,m3ng1C;bYid;me0t;gh,l0;a3fXsita2;dy,rWv3;en0y;nd13ppy,r3;d3sh;!y;aFenEhCiBlAoofy,r3;a8e6i5o3ue0Z;o3ss;vy;m,s0;at,e3y;dy,n;nd,y;ad,ib,ooD;a2d1;a3o3;st0;tDuiS;u1y;aCeebBi9l8o6r5u3;ll,n3r0N;!ny;aCesh,iend0;a3nd,rmD;my;at,ir7;erce,nan3;ci9;le;r,ul3;ty;a6erie,sse4v3xtre0B;il;nti3;al;r4s3;tern,y;ly,th0;appZe9i5ru4u3;mb;nk;r5vi4z3;zy;ne;e,ty;a3ep,n9;d3f,r;!ly;agey,h8l7o5r4u3;dd0r0te;isp,uel;ar3ld,mmon,st0ward0zy;se;evKou1;e3il0;ap,e3;sy;aHiFlCoAr5u3;ff,r0sy;ly;a6i3oad;g4llia2;nt;ht;sh,ve;ld,un3;cy;a4o3ue;nd,o1;ck,nd;g,tt3;er;d,ld,w1;dy;bsu6ng5we3;so3;me;ry;rd",Adverb:"true¦a08b05d00eYfSheQinPjustOkinda,likewiZmMnJoEpCquite,r9s5t2u0very,well;ltima01p0; to,wards5;h1iny bit,o0wiO;o,t6;en,us;eldom,o0uch;!me1rt0; of;how,times,w0C;a1e0;alS;ndomRth05;ar excellenEer0oint blank; Lhaps;f3n0utright;ce0ly;! 0;ag05moX; courGten;ewJo0; longWt 0;onHwithstand9;aybe,eanwhiNore0;!ovT;! aboX;deed,steY;lla,n0;ce;or3u0;ck1l9rther0;!moK;ing; 0evK;exampCgood,suH;n mas0vI;se;e0irect2; 2fini0;te0;ly;juAtrop;ackward,y 0;far,no0; means,w; GbroFd nauseam,gEl7ny5part,s4t 2w0;ay,hi0;le;be7l0mo7wor7;arge,ea6; soon,i4;mo0way;re;l 3mo2ongsi1ready,so,togeth0ways;er;de;st;b1t0;hat;ut;ain;ad;lot,posteriori",Conjunction:"true¦aXbTcReNhowMiEjust00noBo9p8supposing,t5wh0yet;e1il0o3;e,st;n1re0thN; if,by,vM;evL;h0il,o;erefOo0;!uU;lus,rovided th9;r0therwiM;! not; mattEr,w0;! 0;since,th4w7;f4n0; 0asmuch;as mIcaForder t0;h0o;at;! 0;only,t0w0;hen;!ev3;ith2ven0;! 0;if,tB;er;o0uz;s,z;e0ut,y the time;cau1f0;ore;se;lt3nd,s 0;far1if,m0soon1t2;uch0; as;hou0;gh",Currency:"true¦$,aud,bQcOdJeurIfHgbp,hkd,iGjpy,kElDp8r7s3usd,x2y1z0¢,£,¥,ден,лв,руб,฿,₡,₨,€,₭,﷼;lotyQł;en,uanP;af,of;h0t5;e0il5;k0q0;elK;oubleJp,upeeJ;e2ound st0;er0;lingG;n0soF;ceEnies;empi7i7;n,r0wanzaCyatC;!onaBw;ls,nr;ori7ranc9;!os;en3i2kk,o0;b0ll2;ra5;me4n0rham4;ar3;e0ny;nt1;aht,itcoin0;!s",Determiner:"true¦aBboth,d9e6few,le5mu8neiDplenty,s4th2various,wh0;at0ich0;evC;a0e4is,ose;!t;everal,ome;!ast,s;a1l0very;!se;ch;e0u;!s;!n0;!o0y;th0;er","Adj|Present":"true¦a07b04cVdQeNfJhollIidRlEmCnarrIoBp9qua8r7s3t2uttFw0;aKet,ro0;ng,u08;endChin;e2hort,l1mooth,our,pa9tray,u0;re,speU;i2ow;cu6da02leSpaN;eplica01i02;ck;aHerfePr0;eseUime,omV;bscu1pen,wn;atu0e3odeH;re;a2e1ive,ow0;er;an;st,y;ow;a2i1oul,r0;ee,inge;rm;iIke,ncy,st;l1mpty,x0;emHpress;abo4ic7;amp,e2i1oub0ry,ull;le;ffu9re6;fu8libe0;raE;alm,l5o0;mpleCn3ol,rr1unterfe0;it;e0u7;ct;juga8sum7;ea1o0;se;n,r;ankru1lu0;nt;pt;li2pproxi0rticula1;ma0;te;ght","Person|Adj":"true¦b3du2earnest,frank,mi2r0san1woo1;an0ich,u1;dy;sty;ella,rown",Modal:"true¦c5lets,m4ought3sh1w0;ill,o5;a0o4;ll,nt;! to,a;ight,ust;an,o0;uld",Verb:"true¦born,cannot,gonna,has,keep tabs,msg","Person|Verb":"true¦b8ch7dr6foster,gra5ja9lan4ma2ni9ollie,p1rob,s0wade;kip,pike,t5ue;at,eg,ier2;ck,r0;k,shal;ce;ce,nt;ew;ase,u1;iff,l1ob,u0;ck;aze,ossom","Person|Date":"true¦a2j0sep;an0une;!uary;p0ugust,v0;ril"};const mo=36,po="0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ",fo=po.split("").reduce((function(e,t,n){return e[t]=n,e}),{});var bo=function(e){if(void 0!==fo[e])return fo[e];let t=0,n=1,r=mo,o=1;for(;n=0;n--,o*=mo){let r=e.charCodeAt(n)-48;r>10&&(r-=7),t+=r*o}return t};const vo=function(e,t,n){const r=bo(t);return r{let a=e.nodes[r];"!"===a[0]&&(t.push(o),a=a.slice(1));const i=a.split(/([A-Z0-9,]+)/g);for(let a=0;a{const t=function(e){if(!e)return{};const t=e.split("|").reduce(((e,t)=>{const n=t.split("¦");return e[n[0]]=n[1],e}),{}),n={};return Object.keys(t).forEach((function(e){const r=yo(t[e]);"true"===e&&(e=!0);for(let t=0;t{if(jo[t]=e,"Noun|Verb"===e){const e=Ao(t,xo);jo[e]="Plural|Verb"}})):Object.keys(t).forEach((t=>{No[t]=e}))})),[":(",":)",":P",":p",":O",";(",";)",";P",";p",";O",":3",":|",":/",":\\",":$",":*",":@",":-(",":-)",":-P",":-p",":-O",":-3",":-|",":-/",":-\\",":-$",":-*",":-@",":^(",":^)",":^P",":^p",":^O",":^3",":^|",":^/",":^\\",":^$",":^*",":^@","):","(:","$:","*:",")-:","(-:","$-:","*-:",")^:","(^:","$^:","*^:","<3","No[e]="Emoticon")),delete No[""],delete No.null,delete No[" "];const Io="Singular";var To={beforeTags:{Determiner:Io,Possessive:Io,Acronym:Io,Noun:Io,Adjective:Io,PresentTense:Io,Gerund:Io,PastTense:Io,Infinitive:Io,Date:Io,Ordinal:Io,Demonym:Io},afterTags:{Value:Io,Modal:Io,Copula:Io,PresentTense:Io,PastTense:Io,Demonym:Io,Actor:Io},beforeWords:{the:Io,with:Io,without:Io,of:Io,for:Io,any:Io,all:Io,on:Io,cut:Io,cuts:Io,increase:Io,decrease:Io,raise:Io,drop:Io,save:Io,saved:Io,saves:Io,make:Io,makes:Io,made:Io,minus:Io,plus:Io,than:Io,another:Io,versus:Io,neither:Io,about:Io,favorite:Io,best:Io,daily:Io,weekly:Io,linear:Io,binary:Io,mobile:Io,lexical:Io,technical:Io,computer:Io,scientific:Io,security:Io,government:Io,popular:Io,formal:Io,no:Io,more:Io,one:Io,let:Io,her:Io,his:Io,their:Io,our:Io,us:Io,sheer:Io,monthly:Io,yearly:Io,current:Io,previous:Io,upcoming:Io,last:Io,next:Io,main:Io,initial:Io,final:Io,beginning:Io,end:Io,top:Io,bottom:Io,future:Io,past:Io,major:Io,minor:Io,side:Io,central:Io,peripheral:Io,public:Io,private:Io},afterWords:{of:Io,system:Io,aid:Io,method:Io,utility:Io,tool:Io,reform:Io,therapy:Io,philosophy:Io,room:Io,authority:Io,says:Io,said:Io,wants:Io,wanted:Io,is:Io,did:Io,do:Io,can:Io,wise:Io}};const Do="Infinitive";var Ho={beforeTags:{Modal:Do,Adverb:Do,Negative:Do,Plural:Do},afterTags:{Determiner:Do,Adverb:Do,Possessive:Do,Reflexive:Do,Preposition:Do,Cardinal:Do,Comparative:Do,Superlative:Do},beforeWords:{i:Do,we:Do,you:Do,they:Do,to:Do,please:Do,will:Do,have:Do,had:Do,would:Do,could:Do,should:Do,do:Do,did:Do,does:Do,can:Do,must:Do,us:Do,me:Do,let:Do,even:Do,when:Do,help:Do,he:Do,she:Do,it:Do,being:Do,bi:Do,co:Do,contra:Do,de:Do,inter:Do,intra:Do,mis:Do,pre:Do,out:Do,counter:Do,nobody:Do,somebody:Do,anybody:Do,everybody:Do},afterWords:{the:Do,me:Do,you:Do,him:Do,us:Do,her:Do,his:Do,them:Do,they:Do,it:Do,himself:Do,herself:Do,itself:Do,myself:Do,ourselves:Do,themselves:Do,something:Do,anything:Do,a:Do,an:Do,up:Do,down:Do,by:Do,out:Do,off:Do,under:Do,what:Do,all:Do,to:Do,because:Do,although:Do,how:Do,otherwise:Do,together:Do,though:Do,into:Do,yet:Do,more:Do,here:Do,there:Do,away:Do}};const Eo={beforeTags:Object.assign({},Ho.beforeTags,To.beforeTags,{}),afterTags:Object.assign({},Ho.afterTags,To.afterTags,{}),beforeWords:Object.assign({},Ho.beforeWords,To.beforeWords,{}),afterWords:Object.assign({},Ho.afterWords,To.afterWords,{})},Go="Adjective";var Oo={beforeTags:{Determiner:Go,Possessive:Go,Hyphenated:Go},afterTags:{Adjective:Go},beforeWords:{seem:Go,seemed:Go,seems:Go,feel:Go,feels:Go,felt:Go,stay:Go,appear:Go,appears:Go,appeared:Go,also:Go,over:Go,under:Go,too:Go,it:Go,but:Go,still:Go,really:Go,quite:Go,well:Go,very:Go,truly:Go,how:Go,deeply:Go,hella:Go,profoundly:Go,extremely:Go,so:Go,badly:Go,mostly:Go,totally:Go,awfully:Go,rather:Go,nothing:Go,something:Go,anything:Go,not:Go,me:Go,is:Go,face:Go,faces:Go,faced:Go,look:Go,looks:Go,looked:Go,reveal:Go,reveals:Go,revealed:Go,sound:Go,sounded:Go,sounds:Go,remains:Go,remained:Go,prove:Go,proves:Go,proved:Go,becomes:Go,stays:Go,tastes:Go,taste:Go,smells:Go,smell:Go,gets:Go,grows:Go,as:Go,rings:Go,radiates:Go,conveys:Go,convey:Go,conveyed:Go,of:Go},afterWords:{too:Go,also:Go,or:Go,enough:Go,as:Go}};const Fo="Gerund";var Vo={beforeTags:{Adverb:Fo,Preposition:Fo,Conjunction:Fo},afterTags:{Adverb:Fo,Possessive:Fo,Person:Fo,Pronoun:Fo,Determiner:Fo,Copula:Fo,Preposition:Fo,Conjunction:Fo,Comparative:Fo},beforeWords:{been:Fo,keep:Fo,continue:Fo,stop:Fo,am:Fo,be:Fo,me:Fo,began:Fo,start:Fo,starts:Fo,started:Fo,stops:Fo,stopped:Fo,help:Fo,helps:Fo,avoid:Fo,avoids:Fo,love:Fo,loves:Fo,loved:Fo,hate:Fo,hates:Fo,hated:Fo},afterWords:{you:Fo,me:Fo,her:Fo,him:Fo,his:Fo,them:Fo,their:Fo,it:Fo,this:Fo,there:Fo,on:Fo,about:Fo,for:Fo,up:Fo,down:Fo}};const zo="Gerund",Bo="Adjective",So={beforeTags:Object.assign({},Oo.beforeTags,Vo.beforeTags,{Imperative:zo,Infinitive:Bo,Plural:zo}),afterTags:Object.assign({},Oo.afterTags,Vo.afterTags,{Noun:Bo}),beforeWords:Object.assign({},Oo.beforeWords,Vo.beforeWords,{is:Bo,are:zo,was:Bo,of:Bo,suggest:zo,suggests:zo,suggested:zo,recommend:zo,recommends:zo,recommended:zo,imagine:zo,imagines:zo,imagined:zo,consider:zo,considered:zo,considering:zo,resist:zo,resists:zo,resisted:zo,avoid:zo,avoided:zo,avoiding:zo,except:Bo,accept:Bo,assess:zo,explore:zo,fear:zo,fears:zo,appreciate:zo,question:zo,help:zo,embrace:zo,with:Bo}),afterWords:Object.assign({},Oo.afterWords,Vo.afterWords,{to:zo,not:zo,the:zo})},$o={beforeTags:{Determiner:void 0,Cardinal:"Noun",PhrasalVerb:"Adjective"},afterTags:{}},Mo={beforeTags:Object.assign({},Oo.beforeTags,To.beforeTags,$o.beforeTags),afterTags:Object.assign({},Oo.afterTags,To.afterTags,$o.afterTags),beforeWords:Object.assign({},Oo.beforeWords,To.beforeWords,{are:"Adjective",is:"Adjective",was:"Adjective",be:"Adjective",off:"Adjective",out:"Adjective"}),afterWords:Object.assign({},Oo.afterWords,To.afterWords)},Lo="PastTense",Ko="Adjective",Jo={beforeTags:{Adverb:Lo,Pronoun:Lo,ProperNoun:Lo,Auxiliary:Lo,Noun:Lo},afterTags:{Possessive:Lo,Pronoun:Lo,Determiner:Lo,Adverb:Lo,Comparative:Lo,Date:Lo,Gerund:Lo},beforeWords:{be:Lo,who:Lo,get:Ko,had:Lo,has:Lo,have:Lo,been:Lo,it:Lo,as:Lo,for:Ko,more:Ko,always:Ko},afterWords:{by:Lo,back:Lo,out:Lo,in:Lo,up:Lo,down:Lo,before:Lo,after:Lo,for:Lo,the:Lo,with:Lo,as:Lo,on:Lo,at:Lo,between:Lo,to:Lo,into:Lo,us:Lo,them:Lo,his:Lo,her:Lo,their:Lo,our:Lo,me:Lo,about:Ko}};var Wo={beforeTags:Object.assign({},Oo.beforeTags,Jo.beforeTags),afterTags:Object.assign({},Oo.afterTags,Jo.afterTags),beforeWords:Object.assign({},Oo.beforeWords,Jo.beforeWords),afterWords:Object.assign({},Oo.afterWords,Jo.afterWords)};const qo={afterTags:{Noun:"Adjective",Conjunction:void 0}},Uo={beforeTags:Object.assign({},Oo.beforeTags,Ho.beforeTags,{Adverb:void 0,Negative:void 0}),afterTags:Object.assign({},Oo.afterTags,Ho.afterTags,qo.afterTags),beforeWords:Object.assign({},Oo.beforeWords,Ho.beforeWords,{have:void 0,had:void 0,not:void 0,went:"Adjective",goes:"Adjective",got:"Adjective",be:"Adjective"}),afterWords:Object.assign({},Oo.afterWords,Ho.afterWords,{to:void 0,as:"Adjective"})},Ro={Copula:"Gerund",PastTense:"Gerund",PresentTense:"Gerund",Infinitive:"Gerund"},Qo={Value:"Gerund"},Zo={are:"Gerund",were:"Gerund",be:"Gerund",no:"Gerund",without:"Gerund",you:"Gerund",we:"Gerund",they:"Gerund",he:"Gerund",she:"Gerund",us:"Gerund",them:"Gerund"},_o={the:"Gerund",this:"Gerund",that:"Gerund",me:"Gerund",us:"Gerund",them:"Gerund"},Xo={beforeTags:Object.assign({},Vo.beforeTags,To.beforeTags,Ro),afterTags:Object.assign({},Vo.afterTags,To.afterTags,Qo),beforeWords:Object.assign({},Vo.beforeWords,To.beforeWords,Zo),afterWords:Object.assign({},Vo.afterWords,To.afterWords,_o)},Yo="Singular",ea="Infinitive",ta={beforeTags:Object.assign({},Ho.beforeTags,To.beforeTags,{Adjective:Yo,Particle:Yo}),afterTags:Object.assign({},Ho.afterTags,To.afterTags,{ProperNoun:ea,Gerund:ea,Adjective:ea,Copula:Yo}),beforeWords:Object.assign({},Ho.beforeWords,To.beforeWords,{is:Yo,was:Yo,of:Yo,have:null}),afterWords:Object.assign({},Ho.afterWords,To.afterWords,{instead:ea,about:ea,his:ea,her:ea,to:null,by:null,in:null})},na="Person";var ra={beforeTags:{Honorific:na,Person:na},afterTags:{Person:na,ProperNoun:na,Verb:na},beforeWords:{hi:na,hey:na,yo:na,dear:na,hello:na},afterWords:{said:na,says:na,told:na,tells:na,feels:na,felt:na,seems:na,thinks:na,thought:na,spends:na,spendt:na,plays:na,played:na,sing:na,sang:na,learn:na,learned:na,wants:na,wanted:na}};const oa="Month",aa={beforeTags:{Date:oa,Value:oa},afterTags:{Date:oa,Value:oa},beforeWords:{by:oa,in:oa,on:oa,during:oa,after:oa,before:oa,between:oa,until:oa,til:oa,sometime:oa,of:oa,this:oa,next:oa,last:oa,previous:oa,following:oa,with:"Person"},afterWords:{sometime:oa,in:oa,of:oa,until:oa,the:oa}};var ia={beforeTags:Object.assign({},ra.beforeTags,aa.beforeTags),afterTags:Object.assign({},ra.afterTags,aa.afterTags),beforeWords:Object.assign({},ra.beforeWords,aa.beforeWords),afterWords:Object.assign({},ra.afterWords,aa.afterWords)};const sa="Place",la={beforeTags:{Place:sa},afterTags:{Place:sa,Abbreviation:sa},beforeWords:{in:sa,by:sa,near:sa,from:sa,to:sa},afterWords:{in:sa,by:sa,near:sa,from:sa,to:sa,government:sa,council:sa,region:sa,city:sa}},ua="Unit",ca={"Actor|Verb":Eo,"Adj|Gerund":So,"Adj|Noun":Mo,"Adj|Past":Wo,"Adj|Present":Uo,"Noun|Verb":ta,"Noun|Gerund":Xo,"Person|Noun":{beforeTags:Object.assign({},To.beforeTags,ra.beforeTags),afterTags:Object.assign({},To.afterTags,ra.afterTags),beforeWords:Object.assign({},To.beforeWords,ra.beforeWords,{i:"Infinitive",we:"Infinitive"}),afterWords:Object.assign({},To.afterWords,ra.afterWords)},"Person|Date":ia,"Person|Verb":{beforeTags:Object.assign({},To.beforeTags,ra.beforeTags,Ho.beforeTags),afterTags:Object.assign({},To.afterTags,ra.afterTags,Ho.afterTags),beforeWords:Object.assign({},To.beforeWords,ra.beforeWords,Ho.beforeWords),afterWords:Object.assign({},To.afterWords,ra.afterWords,Ho.afterWords)},"Person|Place":{beforeTags:Object.assign({},la.beforeTags,ra.beforeTags),afterTags:Object.assign({},la.afterTags,ra.afterTags),beforeWords:Object.assign({},la.beforeWords,ra.beforeWords),afterWords:Object.assign({},la.afterWords,ra.afterWords)},"Person|Adj":{beforeTags:Object.assign({},ra.beforeTags,Oo.beforeTags),afterTags:Object.assign({},ra.afterTags,Oo.afterTags),beforeWords:Object.assign({},ra.beforeWords,Oo.beforeWords),afterWords:Object.assign({},ra.afterWords,Oo.afterWords)},"Unit|Noun":{beforeTags:{Value:ua},afterTags:{},beforeWords:{per:ua,every:ua,each:ua,square:ua,cubic:ua,sq:ua,metric:ua},afterWords:{per:ua,squared:ua,cubed:ua,long:ua}}},ha=(e,t)=>{const n=Object.keys(e).reduce(((t,n)=>(t[n]="Infinitive"===e[n]?"PresentTense":"Plural",t)),{});return Object.assign(n,t)};ca["Plural|Verb"]={beforeWords:ha(ca["Noun|Verb"].beforeWords,{had:"Plural",have:"Plural"}),afterWords:ha(ca["Noun|Verb"].afterWords,{his:"PresentTense",her:"PresentTense",its:"PresentTense",in:null,to:null,is:"PresentTense",by:"PresentTense"}),beforeTags:ha(ca["Noun|Verb"].beforeTags,{Conjunction:"PresentTense",Noun:void 0,ProperNoun:"PresentTense"}),afterTags:ha(ca["Noun|Verb"].afterTags,{Gerund:"Plural",Noun:"PresentTense",Value:"PresentTense"})};const da="Adjective",ga="Infinitive",ma="PresentTense",pa="Singular",fa="PastTense",ba="Adverb",va="Plural",ya="Actor",wa="Verb",ka="Noun",Pa="LastName",Aa="Modal",Ca="Place",Na="Participle";var ja=[null,null,{ea:pa,ia:ka,ic:da,ly:ba,"'n":wa,"'t":wa},{oed:fa,ued:fa,xed:fa," so":ba,"'ll":Aa,"'re":"Copula",azy:da,eer:ka,end:wa,ped:fa,ffy:da,ify:ga,ing:"Gerund",ize:ga,ibe:ga,lar:da,mum:da,nes:ma,nny:da,ous:da,que:da,ger:ka,ber:ka,rol:pa,sis:pa,ogy:pa,oid:pa,ian:pa,zes:ma,eld:fa,ken:Na,ven:Na,ten:Na,ect:ga,ict:ga,ign:ga,oze:ga,ful:da,bal:da,ton:ka,pur:Ca},{amed:fa,aped:fa,ched:fa,lked:fa,rked:fa,reed:fa,nded:fa,mned:da,cted:fa,dged:fa,ield:pa,akis:Pa,cede:ga,chuk:Pa,czyk:Pa,ects:ma,iend:pa,ends:wa,enko:Pa,ette:pa,iary:pa,wner:pa,fies:ma,fore:ba,gate:ga,gone:da,ices:va,ints:va,ruct:ga,ines:va,ions:va,ners:va,pers:va,lers:va,less:da,llen:da,made:da,nsen:Pa,oses:ma,ould:Aa,some:da,sson:Pa,ians:va,tion:pa,tage:ka,ique:pa,tive:da,tors:ka,vice:pa,lier:pa,fier:pa,wned:fa,gent:pa,tist:ya,pist:ya,rist:ya,mist:ya,yist:ya,vist:ya,ists:ya,lite:pa,site:pa,rite:pa,mite:pa,bite:pa,mate:pa,date:pa,ndal:pa,vent:pa,uist:ya,gist:ya,note:pa,cide:pa,ence:pa,wide:da,vide:ga,ract:ga,duce:ga,pose:ga,eive:ga,lyze:ga,lyse:ga,iant:da,nary:da,ghty:da,uent:da,erer:ya,bury:Ca,dorf:ka,esty:ka,wych:Ca,dale:Ca,folk:Ca,vale:Ca,abad:Ca,sham:Ca,wick:Ca,view:Ca},{elist:ya,holic:pa,phite:pa,tized:fa,urned:fa,eased:fa,ances:va,bound:da,ettes:va,fully:ba,ishes:ma,ities:va,marek:Pa,nssen:Pa,ology:ka,osome:pa,tment:pa,ports:va,rough:da,tches:ma,tieth:"Ordinal",tures:va,wards:ba,where:ba,archy:ka,pathy:ka,opoly:ka,embly:ka,phate:ka,ndent:pa,scent:pa,onist:ya,anist:ya,alist:ya,olist:ya,icist:ya,ounce:ga,iable:da,borne:da,gnant:da,inant:da,igent:da,atory:da,rient:pa,dient:pa,maker:ya,burgh:Ca,mouth:Ca,ceter:Ca,ville:Ca,hurst:Ca,stead:Ca,endon:Ca,brook:Ca,shire:Ca,worth:ka,field:"ProperNoun",ridge:Ca},{auskas:Pa,parent:pa,cedent:pa,ionary:pa,cklist:pa,brooke:Ca,keeper:ya,logist:ya,teenth:"Value",worker:ya,master:ya,writer:ya,brough:Ca,cester:Ca,ington:Ca,cliffe:Ca,ingham:Ca},{chester:Ca,logists:ya,opoulos:Pa,borough:Ca,sdottir:Pa}];const xa="Adjective",Ia="Noun",Ta="Verb";var Da=[null,null,{},{neo:Ia,bio:Ia,"de-":Ta,"re-":Ta,"un-":Ta,"ex-":Ia},{anti:Ia,auto:Ia,faux:xa,hexa:Ia,kilo:Ia,mono:Ia,nano:Ia,octa:Ia,poly:Ia,semi:xa,tele:Ia,"pro-":xa,"mis-":Ta,"dis-":Ta,"pre-":xa},{anglo:Ia,centi:Ia,ethno:Ia,ferro:Ia,grand:Ia,hepta:Ia,hydro:Ia,intro:Ia,macro:Ia,micro:Ia,milli:Ia,nitro:Ia,penta:Ia,quasi:xa,radio:Ia,tetra:Ia,"omni-":xa,"post-":xa},{pseudo:xa,"extra-":xa,"hyper-":xa,"inter-":xa,"intra-":xa,"deca-":xa},{electro:Ia}];const Ha="Adjective",Ea="Infinitive",Ga="PresentTense",Oa="Singular",Fa="PastTense",Va="Adverb",za="Expression",Ba="Actor",Sa="Verb",$a="Noun",Ma="LastName";var La={a:[[/.[aeiou]na$/,$a,"tuna"],[/.[oau][wvl]ska$/,Ma],[/.[^aeiou]ica$/,Oa,"harmonica"],[/^([hyj]a+)+$/,za,"haha"]],c:[[/.[^aeiou]ic$/,Ha]],d:[[/[aeiou](pp|ll|ss|ff|gg|tt|rr|bb|nn|mm)ed$/,Fa,"popped"],[/.[aeo]{2}[bdgmnprvz]ed$/,Fa,"rammed"],[/.[aeiou][sg]hed$/,Fa,"gushed"],[/.[aeiou]red$/,Fa,"hired"],[/.[aeiou]r?ried$/,Fa,"hurried"],[/[^aeiou]ard$/,Oa,"steward"],[/[aeiou][^aeiou]id$/,Ha,""],[/.[vrl]id$/,Ha,"livid"],[/..led$/,Fa,"hurled"],[/.[iao]sed$/,Fa,""],[/[aeiou]n?[cs]ed$/,Fa,""],[/[aeiou][rl]?[mnf]ed$/,Fa,""],[/[aeiou][ns]?c?ked$/,Fa,"bunked"],[/[aeiou]gned$/,Fa],[/[aeiou][nl]?ged$/,Fa],[/.[tdbwxyz]ed$/,Fa],[/[^aeiou][aeiou][tvx]ed$/,Fa],[/.[cdflmnprstv]ied$/,Fa,"emptied"]],e:[[/.[lnr]ize$/,Ea,"antagonize"],[/.[^aeiou]ise$/,Ea,"antagonise"],[/.[aeiou]te$/,Ea,"bite"],[/.[^aeiou][ai]ble$/,Ha,"fixable"],[/.[^aeiou]eable$/,Ha,"maleable"],[/.[ts]ive$/,Ha,"festive"],[/[a-z]-like$/,Ha,"woman-like"]],h:[[/.[^aeiouf]ish$/,Ha,"cornish"],[/.v[iy]ch$/,Ma,"..ovich"],[/^ug?h+$/,za,"ughh"],[/^uh[ -]?oh$/,za,"uhoh"],[/[a-z]-ish$/,Ha,"cartoon-ish"]],i:[[/.[oau][wvl]ski$/,Ma,"polish-male"]],k:[[/^(k){2}$/,za,"kkkk"]],l:[[/.[gl]ial$/,Ha,"familial"],[/.[^aeiou]ful$/,Ha,"fitful"],[/.[nrtumcd]al$/,Ha,"natal"],[/.[^aeiou][ei]al$/,Ha,"familial"]],m:[[/.[^aeiou]ium$/,Oa,"magnesium"],[/[^aeiou]ism$/,Oa,"schism"],[/^[hu]m+$/,za,"hmm"],[/^\d+ ?[ap]m$/,"Date","3am"]],n:[[/.[lsrnpb]ian$/,Ha,"republican"],[/[^aeiou]ician$/,Ba,"musician"],[/[aeiou][ktrp]in'$/,"Gerund","cookin'"]],o:[[/^no+$/,za,"noooo"],[/^(yo)+$/,za,"yoo"],[/^wo{2,}[pt]?$/,za,"woop"]],r:[[/.[bdfklmst]ler$/,"Noun"],[/[aeiou][pns]er$/,Oa],[/[^i]fer$/,Ea],[/.[^aeiou][ao]pher$/,Ba],[/.[lk]er$/,"Noun"],[/.ier$/,"Comparative"]],t:[[/.[di]est$/,"Superlative"],[/.[icldtgrv]ent$/,Ha],[/[aeiou].*ist$/,Ha],[/^[a-z]et$/,Sa]],s:[[/.[^aeiou]ises$/,Ga],[/.[rln]ates$/,Ga],[/.[^z]ens$/,Sa],[/.[lstrn]us$/,Oa],[/.[aeiou]sks$/,Ga],[/.[aeiou]kes$/,Ga],[/[aeiou][^aeiou]is$/,Oa],[/[a-z]'s$/,$a],[/^yes+$/,za]],v:[[/.[^aeiou][ai][kln]ov$/,Ma]],y:[[/.[cts]hy$/,Ha],[/.[st]ty$/,Ha],[/.[tnl]ary$/,Ha],[/.[oe]ry$/,Oa],[/[rdntkbhs]ly$/,Va],[/.(gg|bb|zz)ly$/,Ha],[/...lly$/,Va],[/.[gk]y$/,Ha],[/[bszmp]{2}y$/,Ha],[/.[ai]my$/,Ha],[/[ea]{2}zy$/,Ha],[/.[^aeiou]ity$/,Oa]]};const Ka="Verb",Ja="Noun";var Wa={leftTags:[["Adjective",Ja],["Possessive",Ja],["Determiner",Ja],["Adverb",Ka],["Pronoun",Ka],["Value",Ja],["Ordinal",Ja],["Modal",Ka],["Superlative",Ja],["Demonym",Ja],["Honorific","Person"]],leftWords:[["i",Ka],["first",Ja],["it",Ka],["there",Ka],["not",Ka],["because",Ja],["if",Ja],["but",Ja],["who",Ka],["this",Ja],["his",Ja],["when",Ja],["you",Ka],["very","Adjective"],["old",Ja],["never",Ka],["before",Ja],["a",Ja],["the",Ja],["been",Ka]],rightTags:[["Copula",Ja],["PastTense",Ja],["Conjunction",Ja],["Modal",Ja]],rightWords:[["there",Ka],["me",Ka],["man","Adjective"],["him",Ka],["it",Ka],["were",Ja],["took",Ja],["himself",Ka],["went",Ja],["who",Ja],["jr","Person"]]},qa={fwd:"3:ser,ier¦1er:h,t,f,l,n¦1r:e¦2er:ss,or,om",both:"3er:ver,ear,alm¦3ner:hin¦3ter:lat¦2mer:im¦2er:ng,rm,mb¦2ber:ib¦2ger:ig¦1er:w,p,k,d¦ier:y",rev:"1:tter,yer¦2:uer,ver,ffer,oner,eler,ller,iler,ster,cer,uler,sher,ener,gher,aner,adder,nter,eter,rter,hter,rner,fter¦3:oser,ooler,eafer,user,airer,bler,maler,tler,eater,uger,rger,ainer,urer,ealer,icher,pler,emner,icter,nser,iser¦4:arser,viner,ucher,rosser,somer,ndomer,moter,oother,uarer,hiter¦5:nuiner,esser,emier¦ar:urther",ex:"worse:bad¦better:good¦4er:fair,gray,poor¦1urther:far¦3ter:fat,hot,wet¦3der:mad,sad¦3er:shy,fun¦4der:glad¦:¦4r:cute,dire,fake,fine,free,lame,late,pale,rare,ripe,rude,safe,sore,tame,wide¦5r:eerie,stale"},Ua={fwd:"1:nning,tting,rring,pping,eing,mming,gging,dding,bbing,kking¦2:eking,oling,eling,eming¦3:velling,siting,uiting,fiting,loting,geting,ialing,celling¦4:graming",both:"1:aing,iing,fing,xing,ying,oing,hing,wing¦2:tzing,rping,izzing,bting,mning,sping,wling,rling,wding,rbing,uping,lming,wning,mping,oning,lting,mbing,lking,fting,hting,sking,gning,pting,cking,ening,nking,iling,eping,ering,rting,rming,cting,lping,ssing,nting,nding,lding,sting,rning,rding,rking¦3:belling,siping,toming,yaking,uaking,oaning,auling,ooping,aiding,naping,euring,tolling,uzzing,ganing,haning,ualing,halling,iasing,auding,ieting,ceting,ouling,voring,ralling,garing,joring,oaming,oaking,roring,nelling,ooring,uelling,eaming,ooding,eaping,eeting,ooting,ooming,xiting,keting,ooking,ulling,airing,oaring,biting,outing,oiting,earing,naling,oading,eeding,ouring,eaking,aiming,illing,oining,eaning,onging,ealing,aining,eading¦4:thoming,melling,aboring,ivoting,weating,dfilling,onoring,eriting,imiting,tialling,rgining,otoring,linging,winging,lleting,louding,spelling,mpelling,heating,feating,opelling,choring,welling,ymaking,ctoring,calling,peating,iloring,laiting,utoring,uditing,mmaking,loating,iciting,waiting,mbating,voiding,otalling,nsoring,nselling,ocusing,itoring,eloping¦5:rselling,umpeting,atrolling,treating,tselling,rpreting,pringing,ummeting,ossoming,elmaking,eselling,rediting,totyping,onmaking,rfeiting,ntrolling¦5e:chmaking,dkeeping,severing,erouting,ecreting,ephoning,uthoring,ravening,reathing,pediting,erfering,eotyping,fringing,entoring,ombining,ompeting¦4e:emaking,eething,twining,rruling,chuting,xciting,rseding,scoping,edoring,pinging,lunging,agining,craping,pleting,eleting,nciting,nfining,ncoding,tponing,ecoding,writing,esaling,nvening,gnoring,evoting,mpeding,rvening,dhering,mpiling,storing,nviting,ploring¦3e:tining,nuring,saking,miring,haling,ceding,xuding,rining,nuting,laring,caring,miling,riding,hoking,piring,lading,curing,uading,noting,taping,futing,paring,hading,loding,siring,guring,vading,voking,during,niting,laning,caping,luting,muting,ruding,ciding,juring,laming,caling,hining,uoting,liding,ciling,duling,tuting,puting,cuting,coring,uiding,tiring,turing,siding,rading,enging,haping,buting,lining,taking,anging,haring,uiring,coming,mining,moting,suring,viding,luding¦2e:tring,zling,uging,oging,gling,iging,vring,fling,lging,obing,psing,pling,ubing,cling,dling,wsing,iking,rsing,dging,kling,ysing,tling,rging,eging,nsing,uning,osing,uming,using,ibing,bling,aging,ising,asing,ating¦2ie:rlying¦1e:zing,uing,cing,ving",rev:"ying:ie¦1ing:se,ke,te,we,ne,re,de,pe,me,le,c,he¦2ing:ll,ng,dd,ee,ye,oe,rg,us¦2ning:un¦2ging:og,ag,ug,ig,eg¦2ming:um¦2bing:ub,ab,eb,ob¦3ning:lan,can,hin,pin,win¦3ring:cur,lur,tir,tar,pur,car¦3ing:ait,del,eel,fin,eat,oat,eem,lel,ool,ein,uin¦3ping:rop,rap,top,uip,wap,hip,hop,lap,rip,cap¦3ming:tem,wim,rim,kim,lim¦3ting:mat,cut,pot,lit,lot,hat,set,pit,put¦3ding:hed,bed,bid¦3king:rek¦3ling:cil,pel¦3bing:rib¦4ning:egin¦4ing:isit,ruit,ilot,nsit,dget,rkel,ival,rcel¦4ring:efer,nfer¦4ting:rmit,mmit,ysit,dmit,emit,bmit,tfit,gret¦4ling:evel,xcel,ivel¦4ding:hred¦5ing:arget,posit,rofit¦5ring:nsfer¦5ting:nsmit,orget,cquit¦5ling:ancel,istil",ex:"3:adding,eating,aiming,aiding,airing,outing,gassing,setting,getting,putting,cutting,winning,sitting,betting,mapping,tapping,letting,bidding,hitting,tanning,netting,popping,fitting,capping,lapping,barring,banning,vetting,topping,rotting,tipping,potting,wetting,pitting,dipping,budding,hemming,pinning,jetting,kidding,padding,podding,sipping,wedding,bedding,donning,warring,penning,gutting,cueing,wadding,petting,ripping,napping,matting,tinning,binning,dimming,hopping,mopping,nodding,panning,rapping,ridding,sinning¦4:selling,falling,calling,waiting,editing,telling,rolling,heating,boating,hanging,beating,coating,singing,tolling,felling,polling,discing,seating,voiding,gelling,yelling,baiting,reining,ruining,seeking,spanning,stepping,knitting,emitting,slipping,quitting,dialing,omitting,clipping,shutting,skinning,abutting,flipping,trotting,cramming,fretting,suiting¦5:bringing,treating,spelling,stalling,trolling,expelling,rivaling,wringing,deterring,singeing,befitting,refitting¦6:enrolling,distilling,scrolling,strolling,caucusing,travelling¦7:installing,redefining,stencilling,recharging,overeating,benefiting,unraveling,programing¦9:reprogramming¦is:being¦2e:using,aging,owing¦3e:making,taking,coming,noting,hiring,filing,coding,citing,doping,baking,coping,hoping,lading,caring,naming,voting,riding,mining,curing,lining,ruling,typing,boring,dining,firing,hiding,piling,taping,waning,baling,boning,faring,honing,wiping,luring,timing,wading,piping,fading,biting,zoning,daring,waking,gaming,raking,ceding,tiring,coking,wining,joking,paring,gaping,poking,pining,coring,liming,toting,roping,wiring,aching¦4e:writing,storing,eroding,framing,smoking,tasting,wasting,phoning,shaking,abiding,braking,flaking,pasting,priming,shoring,sloping,withing,hinging¦5e:defining,refining,renaming,swathing,fringing,reciting¦1ie:dying,tying,lying,vying¦7e:sunbathing"},Ra={fwd:"1:mt¦2:llen¦3:iven,aken¦:ne¦y:in",both:"1:wn¦2:me,aten¦3:seen,bidden,isen¦4:roven,asten¦3l:pilt¦3d:uilt¦2e:itten¦1im:wum¦1eak:poken¦1ine:hone¦1ose:osen¦1in:gun¦1ake:woken¦ear:orn¦eal:olen¦eeze:ozen¦et:otten¦ink:unk¦ing:ung",rev:"2:un¦oken:eak¦ought:eek¦oven:eave¦1ne:o¦1own:ly¦1den:de¦1in:ay¦2t:am¦2n:ee¦3en:all¦4n:rive,sake,take¦5n:rgive",ex:"2:been¦3:seen,run¦4:given,taken¦5:shaken¦2eak:broken¦1ive:dove¦2y:flown¦3e:hidden,ridden¦1eek:sought¦1ake:woken¦1eave:woven"},Qa={fwd:"1:oes¦1ve:as",both:"1:xes¦2:zzes,ches,shes,sses¦3:iases¦2y:llies,plies¦1y:cies,bies,ties,vies,nies,pies,dies,ries,fies¦:s",rev:"1ies:ly¦2es:us,go,do¦3es:cho,eto",ex:"2:does,goes¦3:gasses¦5:focuses¦is:are¦3y:relies¦2y:flies¦2ve:has"},Za={fwd:"1st:e¦1est:l,m,f,s¦1iest:cey¦2est:or,ir¦3est:ver",both:"4:east¦5:hwest¦5lest:erful¦4est:weet,lgar,tter,oung¦4most:uter¦3est:ger,der,rey,iet,ong,ear¦3test:lat¦3most:ner¦2est:pt,ft,nt,ct,rt,ht¦2test:it¦2gest:ig¦1est:b,k,n,p,h,d,w¦iest:y",rev:"1:ttest,nnest,yest¦2:sest,stest,rmest,cest,vest,lmest,olest,ilest,ulest,ssest,imest,uest¦3:rgest,eatest,oorest,plest,allest,urest,iefest,uelest,blest,ugest,amest,yalest,ealest,illest,tlest,itest¦4:cerest,eriest,somest,rmalest,ndomest,motest,uarest,tiffest¦5:leverest,rangest¦ar:urthest¦3ey:riciest",ex:"best:good¦worst:bad¦5est:great¦4est:fast,full,fair,dull¦3test:hot,wet,fat¦4nest:thin¦1urthest:far¦3est:gay,shy,ill¦4test:neat¦4st:late,wide,fine,safe,cute,fake,pale,rare,rude,sore,ripe,dire¦6st:severe"},_a={fwd:"1:tistic,eable,lful,sful,ting,tty¦2:onate,rtable,geous,ced,seful,ctful¦3:ortive,ented¦arity:ear¦y:etic¦fulness:begone¦1ity:re¦1y:tiful,gic¦2ity:ile,imous,ilous,ime¦2ion:ated¦2eness:iving¦2y:trious¦2ation:iring¦2tion:vant¦3ion:ect¦3ce:mant,mantic¦3tion:irable¦3y:est,estic¦3m:mistic,listic¦3ess:ning¦4n:utious¦4on:rative,native,vative,ective¦4ce:erant",both:"1:king,wing¦2:alous,ltuous,oyful,rdous¦3:gorous,ectable,werful,amatic¦4:oised,usical,agical,raceful,ocused,lined,ightful¦5ness:stful,lding,itous,nuous,ulous,otous,nable,gious,ayful,rvous,ntous,lsive,peful,entle,ciful,osive,leful,isive,ncise,reful,mious¦5ty:ivacious¦5ties:ubtle¦5ce:ilient,adiant,atient¦5cy:icient¦5sm:gmatic¦5on:sessive,dictive¦5ity:pular,sonal,eative,entic¦5sity:uminous¦5ism:conic¦5nce:mperate¦5ility:mitable¦5ment:xcited¦5n:bitious¦4cy:brant,etent,curate¦4ility:erable,acable,icable,ptable¦4ty:nacious,aive,oyal,dacious¦4n:icious¦4ce:vient,erent,stent,ndent,dient,quent,ident¦4ness:adic,ound,hing,pant,sant,oing,oist,tute¦4icity:imple¦4ment:fined,mused¦4ism:otic¦4ry:dantic¦4ity:tund,eral¦4edness:hand¦4on:uitive¦4lity:pitable¦4sm:eroic,namic¦4sity:nerous¦3th:arm¦3ility:pable,bable,dable,iable¦3cy:hant,nant,icate¦3ness:red,hin,nse,ict,iet,ite,oud,ind,ied,rce¦3ion:lute¦3ity:ual,gal,volous,ial¦3ce:sent,fensive,lant,gant,gent,lent,dant¦3on:asive¦3m:fist,sistic,iastic¦3y:terious,xurious,ronic,tastic¦3ur:amorous¦3e:tunate¦3ation:mined¦3sy:rteous¦3ty:ain¦3ry:ave¦3ment:azed¦2ness:de,on,ue,rn,ur,ft,rp,pe,om,ge,rd,od,ay,ss,er,ll,oy,ap,ht,ld,ad,rt¦2inousness:umous¦2ity:neous,ene,id,ane¦2cy:bate,late¦2ation:ized¦2ility:oble,ible¦2y:odic¦2e:oving,aring¦2s:ost¦2itude:pt¦2dom:ee¦2ance:uring¦2tion:reet¦2ion:oted¦2sion:ending¦2liness:an¦2or:rdent¦1th:ung¦1e:uable¦1ness:w,h,k,f¦1ility:mble¦1or:vent¦1ement:ging¦1tiquity:ncient¦1ment:hed¦verty:or¦ength:ong¦eat:ot¦pth:ep¦iness:y",rev:"",ex:"5:forceful,humorous¦8:charismatic¦13:understanding¦5ity:active¦11ness:adventurous,inquisitive,resourceful¦8on:aggressive,automatic,perceptive¦7ness:amorous,fatuous,furtive,ominous,serious¦5ness:ample,sweet¦12ness:apprehensive,cantankerous,contemptuous,ostentatious¦13ness:argumentative,conscientious¦9ness:assertive,facetious,imperious,inventive,oblivious,rapacious,receptive,seditious,whimsical¦10ness:attractive,expressive,impressive,loquacious,salubrious,thoughtful¦3edom:boring¦4ness:calm,fast,keen,tame¦8ness:cheerful,gracious,specious,spurious,timorous,unctuous¦5sity:curious¦9ion:deliberate¦8ion:desperate¦6e:expensive¦7ce:fragrant¦3y:furious¦9ility:ineluctable¦6ism:mystical¦8ity:physical,proactive,sensitive,vertical¦5cy:pliant¦7ity:positive¦9ity:practical¦12ism:professional¦6ce:prudent¦3ness:red¦6cy:vagrant¦3dom:wise"};const Xa=function(e="",t={}){let n=function(e,t={}){return t.hasOwnProperty(e)?t[e]:null}(e,t.ex);return n=n||function(e,t=[]){for(let n=0;n=1;r-=1){let o=e.length-r,a=e.substring(o,e.length);if(!0===t.hasOwnProperty(a))return e.slice(0,o)+t[a];if(!0===n.hasOwnProperty(a))return e.slice(0,o)+n[a]}return t.hasOwnProperty("")?e+t[""]:n.hasOwnProperty("")?e+n[""]:null}(e,t.fwd,t.both),n=n||e,n},Ya=function(e){return Object.entries(e).reduce(((e,t)=>(e[t[1]]=t[0],e)),{})},ei=function(e={}){return{reversed:!0,both:Ya(e.both),ex:Ya(e.ex),fwd:e.rev||{}}},ti=/^([0-9]+)/,ni=function(e){let t=function(e){let t={};return e.split("¦").forEach((e=>{let[n,r]=e.split(":");r=(r||"").split(","),r.forEach((e=>{t[e]=n}))})),t}(e);return Object.keys(t).reduce(((e,n)=>(e[n]=function(e="",t=""){let n=(t=String(t)).match(ti);if(null===n)return t;let r=Number(n[1])||0;return e.substring(0,r)+t.replace(ti,"")}(n,t[n]),e)),{})},ri=function(e={}){return"string"==typeof e&&(e=JSON.parse(e)),e.fwd=ni(e.fwd||""),e.both=ni(e.both||""),e.rev=ni(e.rev||""),e.ex=ni(e.ex||""),e},oi=ri({fwd:"1:tted,wed,gged,nned,een,rred,pped,yed,bbed,oed,dded,rd,wn,mmed¦2:eed,nded,et,hted,st,oled,ut,emed,eled,lded,ken,rt,nked,apt,ant,eped,eked¦3:eared,eat,eaded,nelled,ealt,eeded,ooted,eaked,eaned,eeted,mited,bid,uit,ead,uited,ealed,geted,velled,ialed,belled¦4:ebuted,hined,comed¦y:ied¦ome:ame¦ear:ore¦ind:ound¦ing:ung,ang¦ep:pt¦ink:ank,unk¦ig:ug¦all:ell¦ee:aw¦ive:ave¦eeze:oze¦old:eld¦ave:ft¦ake:ook¦ell:old¦ite:ote¦ide:ode¦ine:one¦in:un,on¦eal:ole¦im:am¦ie:ay¦and:ood¦1ise:rose¦1eak:roke¦1ing:rought¦1ive:rove¦1el:elt¦1id:bade¦1et:got¦1y:aid¦1it:sat¦3e:lid¦3d:pent",both:"1:aed,fed,xed,hed¦2:sged,xted,wled,rped,lked,kied,lmed,lped,uped,bted,rbed,rked,wned,rled,mped,fted,mned,mbed,zzed,omed,ened,cked,gned,lted,sked,ued,zed,nted,ered,rted,rmed,ced,sted,rned,ssed,rded,pted,ved,cted¦3:cled,eined,siped,ooned,uked,ymed,jored,ouded,ioted,oaned,lged,asped,iged,mured,oided,eiled,yped,taled,moned,yled,lit,kled,oaked,gled,naled,fled,uined,oared,valled,koned,soned,aided,obed,ibed,meted,nicked,rored,micked,keted,vred,ooped,oaded,rited,aired,auled,filled,ouled,ooded,ceted,tolled,oited,bited,aped,tled,vored,dled,eamed,nsed,rsed,sited,owded,pled,sored,rged,osed,pelled,oured,psed,oated,loned,aimed,illed,eured,tred,ioned,celled,bled,wsed,ooked,oiled,itzed,iked,iased,onged,ased,ailed,uned,umed,ained,auded,nulled,ysed,eged,ised,aged,oined,ated,used,dged,doned¦4:ntied,efited,uaked,caded,fired,roped,halled,roked,himed,culed,tared,lared,tuted,uared,routed,pited,naked,miled,houted,helled,hared,cored,caled,tired,peated,futed,ciled,called,tined,moted,filed,sided,poned,iloted,honed,lleted,huted,ruled,cured,named,preted,vaded,sured,talled,haled,peded,gined,nited,uided,ramed,feited,laked,gured,ctored,unged,pired,cuted,voked,eloped,ralled,rined,coded,icited,vided,uaded,voted,mined,sired,noted,lined,nselled,luted,jured,fided,puted,piled,pared,olored,cided,hoked,enged,tured,geoned,cotted,lamed,uiled,waited,udited,anged,luded,mired,uired,raded¦5:modelled,izzled,eleted,umpeted,ailored,rseded,treated,eduled,ecited,rammed,eceded,atrolled,nitored,basted,twined,itialled,ncited,gnored,ploded,xcited,nrolled,namelled,plored,efeated,redited,ntrolled,nfined,pleted,llided,lcined,eathed,ibuted,lloted,dhered,cceded¦3ad:sled¦2aw:drew¦2ot:hot¦2ke:made¦2ow:hrew,grew¦2ose:hose¦2d:ilt¦2in:egan¦1un:ran¦1ink:hought¦1ick:tuck¦1ike:ruck¦1eak:poke,nuck¦1it:pat¦1o:did¦1ow:new¦1ake:woke¦go:went",rev:"3:rst,hed,hut,cut,set¦4:tbid¦5:dcast,eread,pread,erbid¦ought:uy,eek¦1ied:ny,ly,dy,ry,fy,py,vy,by,ty,cy¦1ung:ling,ting,wing¦1pt:eep¦1ank:rink¦1ore:bear,wear¦1ave:give¦1oze:reeze¦1ound:rind,wind¦1ook:take,hake¦1aw:see¦1old:sell¦1ote:rite¦1ole:teal¦1unk:tink¦1am:wim¦1ay:lie¦1ood:tand¦1eld:hold¦2d:he,ge,re,le,leed,ne,reed,be,ye,lee,pe,we¦2ed:dd,oy,or,ey,gg,rr,us,ew,to¦2ame:ecome,rcome¦2ped:ap¦2ged:ag,og,ug,eg¦2bed:ub,ab,ib,ob¦2lt:neel¦2id:pay¦2ang:pring¦2ove:trive¦2med:um¦2ode:rride¦2at:ysit¦3ted:mit,hat,mat,lat,pot,rot,bat¦3ed:low,end,tow,und,ond,eem,lay,cho,dow,xit,eld,ald,uld,law,lel,eat,oll,ray,ank,fin,oam,out,how,iek,tay,haw,ait,vet,say,cay,bow¦3d:ste,ede,ode,ete,ree,ude,ame,oke,ote,ime,ute,ade¦3red:lur,cur,pur,car¦3ped:hop,rop,uip,rip,lip,tep,top¦3ded:bed,rod,kid¦3ade:orbid¦3led:uel¦3ned:lan,can,kin,pan,tun¦3med:rim,lim¦4ted:quit,llot¦4ed:pear,rrow,rand,lean,mand,anel,pand,reet,link,abel,evel,imit,ceed,ruit,mind,peal,veal,hool,head,pell,well,mell,uell,band,hear,weak¦4led:nnel,qual,ebel,ivel¦4red:nfer,efer,sfer¦4n:sake,trew¦4d:ntee¦4ded:hred¦4ned:rpin¦5ed:light,nceal,right,ndear,arget,hread,eight,rtial,eboot¦5d:edite,nvite¦5ted:egret¦5led:ravel",ex:"2:been,upped¦3:added,aged,aided,aimed,aired,bid,died,dyed,egged,erred,eyed,fit,gassed,hit,lied,owed,pent,pied,tied,used,vied,oiled,outed,banned,barred,bet,canned,cut,dipped,donned,ended,feed,inked,jarred,let,manned,mowed,netted,padded,panned,pitted,popped,potted,put,set,sewn,sowed,tanned,tipped,topped,vowed,weed,bowed,jammed,binned,dimmed,hopped,mopped,nodded,pinned,rigged,sinned,towed,vetted¦4:ached,baked,baled,boned,bored,called,caned,cared,ceded,cited,coded,cored,cubed,cured,dared,dined,edited,exited,faked,fared,filed,fined,fired,fuelled,gamed,gelled,hired,hoped,joked,lined,mined,named,noted,piled,poked,polled,pored,pulled,reaped,roamed,rolled,ruled,seated,shed,sided,timed,tolled,toned,voted,waited,walled,waned,winged,wiped,wired,zoned,yelled,tamed,lubed,roped,faded,mired,caked,honed,banged,culled,heated,raked,welled,banded,beat,cast,cooled,cost,dealt,feared,folded,footed,handed,headed,heard,hurt,knitted,landed,leaked,leapt,linked,meant,minded,molded,neared,needed,peaked,plodded,plotted,pooled,quit,read,rooted,sealed,seeded,seeped,shipped,shunned,skimmed,slammed,sparred,stemmed,stirred,suited,thinned,twinned,swayed,winked,dialed,abutted,blotted,fretted,healed,heeded,peeled,reeled¦5:basted,cheated,equalled,eroded,exiled,focused,opined,pleated,primed,quoted,scouted,shored,sloped,smoked,sniped,spelled,spouted,routed,staked,stored,swelled,tasted,treated,wasted,smelled,dwelled,honored,prided,quelled,eloped,scared,coveted,sweated,breaded,cleared,debuted,deterred,freaked,modeled,pleaded,rebutted,speeded¦6:anchored,defined,endured,impaled,invited,refined,revered,strolled,cringed,recast,thrust,unfolded¦7:authored,combined,competed,conceded,convened,excreted,extruded,redefined,restored,secreted,rescinded,welcomed¦8:expedited,infringed¦9:interfered,intervened,persevered¦10:contravened¦eat:ate¦is:was¦go:went¦are:were¦3d:bent,lent,rent,sent¦3e:bit,fled,hid,lost¦3ed:bled,bred¦2ow:blew,grew¦1uy:bought¦2tch:caught¦1o:did¦1ive:dove,gave¦2aw:drew¦2ed:fed¦2y:flew,laid,paid,said¦1ight:fought¦1et:got¦2ve:had¦1ang:hung¦2ad:led¦2ght:lit¦2ke:made¦2et:met¦1un:ran¦1ise:rose¦1it:sat¦1eek:sought¦1each:taught¦1ake:woke,took¦1eave:wove¦2ise:arose¦1ear:bore,tore,wore¦1ind:bound,found,wound¦2eak:broke¦2ing:brought,wrung¦1ome:came¦2ive:drove¦1ig:dug¦1all:fell¦2el:felt¦4et:forgot¦1old:held¦2ave:left¦1ing:rang,sang¦1ide:rode¦1ink:sank¦1ee:saw¦2ine:shone¦4e:slid¦1ell:sold,told¦4d:spent¦2in:spun¦1in:won"}),ai=ri(Qa),ii=ri(Ua),si=ri(Ra),li=ei(oi),ui=ei(ai),ci=ei(ii),hi=ei(si),di=ri(qa),gi=ri(Za);var mi={fromPast:oi,fromPresent:ai,fromGerund:ii,fromParticiple:si,toPast:li,toPresent:ui,toGerund:ci,toParticiple:hi,toComparative:di,toSuperlative:gi,fromComparative:ei(di),fromSuperlative:ei(gi),adjToNoun:ri(_a)},pi=["academy","administration","agence","agences","agencies","agency","airlines","airways","army","assoc","associates","association","assurance","authority","autorite","aviation","bank","banque","board","boys","brands","brewery","brotherhood","brothers","bureau","cafe","co","caisse","capital","care","cathedral","center","centre","chemicals","choir","chronicle","church","circus","clinic","clinique","club","co","coalition","coffee","collective","college","commission","committee","communications","community","company","comprehensive","computers","confederation","conference","conseil","consulting","containers","corporation","corps","corp","council","crew","data","departement","department","departments","design","development","directorate","division","drilling","education","eglise","electric","electricity","energy","ensemble","enterprise","enterprises","entertainment","estate","etat","faculty","faction","federation","financial","fm","foundation","fund","gas","gazette","girls","government","group","guild","herald","holdings","hospital","hotel","hotels","inc","industries","institut","institute","institutes","insurance","international","interstate","investment","investments","investors","journal","laboratory","labs","llc","ltd","limited","machines","magazine","management","marine","marketing","markets","media","memorial","ministere","ministry","military","mobile","motor","motors","musee","museum","news","observatory","office","oil","optical","orchestra","organization","partners","partnership","petrol","petroleum","pharmacare","pharmaceutical","pharmaceuticals","pizza","plc","police","politburo","polytechnic","post","power","press","productions","quartet","radio","reserve","resources","restaurant","restaurants","savings","school","securities","service","services","societe","subsidiary","society","sons","subcommittee","syndicat","systems","telecommunications","telegraph","television","times","tribunal","tv","union","university","utilities","workers"].reduce(((e,t)=>(e[t]=!0,e)),{}),fi=["atoll","basin","bay","beach","bluff","bog","camp","canyon","canyons","cape","cave","caves","cliffs","coast","cove","coves","crater","crossing","creek","desert","dune","dunes","downs","estates","escarpment","estuary","falls","fjord","fjords","forest","forests","glacier","gorge","gorges","grove","gulf","gully","highland","heights","hollow","hill","hills","inlet","island","islands","isthmus","junction","knoll","lagoon","lake","lakeshore","marsh","marshes","mount","mountain","mountains","narrows","peninsula","plains","plateau","pond","rapids","ravine","reef","reefs","ridge","river","rivers","sandhill","shoal","shore","shoreline","shores","strait","straits","springs","stream","swamp","tombolo","trail","trails","trench","valley","vallies","village","volcano","waterfall","watershed","wetland","woods","acres","burough","county","district","municipality","prefecture","province","region","reservation","state","territory","borough","metropolis","downtown","uptown","midtown","city","town","township","hamlet","country","kingdom","enclave","neighbourhood","neighborhood","kingdom","ward","zone","airport","amphitheater","arch","arena","auditorium","bar","barn","basilica","battlefield","bridge","building","castle","centre","coliseum","cineplex","complex","dam","farm","field","fort","garden","gardens","gymnasium","hall","house","levee","library","manor","memorial","monument","museum","gallery","palace","pillar","pits","plantation","playhouse","quarry","sportsfield","sportsplex","stadium","terrace","terraces","theater","tower","park","parks","site","ranch","raceway","sportsplex","ave","st","street","rd","road","lane","landing","crescent","cr","way","tr","terrace","avenue"].reduce(((e,t)=>(e[t]=!0,e)),{}),bi=[[/([^v])ies$/i,"$1y"],[/(ise)s$/i,"$1"],[/(kn|[^o]l|w)ives$/i,"$1ife"],[/^((?:ca|e|ha|(?:our|them|your)?se|she|wo)l|lea|loa|shea|thie)ves$/i,"$1f"],[/^(dwar|handkerchie|hoo|scar|whar)ves$/i,"$1f"],[/(antenn|formul|nebul|vertebr|vit)ae$/i,"$1a"],[/(octop|vir|radi|nucle|fung|cact|stimul)(i)$/i,"$1us"],[/(buffal|tomat|tornad)(oes)$/i,"$1o"],[/(ause)s$/i,"$1"],[/(ease)s$/i,"$1"],[/(ious)es$/i,"$1"],[/(ouse)s$/i,"$1"],[/(ose)s$/i,"$1"],[/(..ase)s$/i,"$1"],[/(..[aeiu]s)es$/i,"$1"],[/(vert|ind|cort)(ices)$/i,"$1ex"],[/(matr|append)(ices)$/i,"$1ix"],[/([xo]|ch|ss|sh)es$/i,"$1"],[/men$/i,"man"],[/(n)ews$/i,"$1ews"],[/([ti])a$/i,"$1um"],[/([^aeiouy]|qu)ies$/i,"$1y"],[/(s)eries$/i,"$1eries"],[/(m)ovies$/i,"$1ovie"],[/(cris|ax|test)es$/i,"$1is"],[/(alias|status)es$/i,"$1"],[/(ss)$/i,"$1"],[/(ic)s$/i,"$1"],[/s$/i,""]];const vi=function(e,t){const{irregularPlurals:n}=t.two,r=(o=n,Object.keys(o).reduce(((e,t)=>(e[o[t]]=t,e)),{}));var o;if(r.hasOwnProperty(e))return r[e];for(let t=0;t(wi[t].forEach((n=>e[n]=t)),e)),{});const ki=function(e){const t=e.substring(e.length-3);if(!0===wi.hasOwnProperty(t))return wi[t];const n=e.substring(e.length-2);if(!0===wi.hasOwnProperty(n))return wi[n];return"s"===e.substring(e.length-1)?"PresentTense":null},Pi={are:"be",were:"be",been:"be",is:"be",am:"be",was:"be",be:"be",being:"be"},Ai=function(e,t,n){const{fromPast:r,fromPresent:o,fromGerund:a,fromParticiple:i}=t.two.models,{prefix:s,verb:l,particle:u}=function(e,t){let n="",r={};t.one&&t.one.prefixes&&(r=t.one.prefixes);let[o,a]=e.split(/ /);return a&&!0===r[o]&&(n=o,o=a,a=""),{prefix:n,verb:o,particle:a}}(e,t);let c="";if(n||(n=ki(e)),Pi.hasOwnProperty(e))c=Pi[e];else if("Participle"===n)c=Xa(l,i);else if("PastTense"===n)c=Xa(l,r);else if("PresentTense"===n)c=Xa(l,o);else{if("Gerund"!==n)return e;c=Xa(l,a)}return u&&(c+=" "+u),s&&(c=s+" "+c),c},Ci=function(e,t){const{toPast:n,toPresent:r,toGerund:o,toParticiple:a}=t.two.models;if("be"===e)return{Infinitive:e,Gerund:"being",PastTense:"was",PresentTense:"is"};const[i,s]=(e=>/ /.test(e)?e.split(/ /):[e,""])(e),l={Infinitive:i,PastTense:Xa(i,n),PresentTense:Xa(i,r),Gerund:Xa(i,o),FutureTense:"will "+i};let u=Xa(i,a);if(u!==e&&u!==l.PastTense){const n=t.one.lexicon||{};"Participle"!==n[u]&&"Adjective"!==n[u]||("play"===e&&(u="played"),l.Participle=u)}return s&&Object.keys(l).forEach((e=>{l[e]+=" "+s})),l};var Ni={toInfinitive:Ai,conjugate:Ci,all:function(e,t){const n=Ci(e,t);return delete n.FutureTense,Object.values(n).filter((e=>e))}};const ji=function(e,t){const n=t.two.models.toSuperlative;return Xa(e,n)},xi=function(e,t){const n=t.two.models.toComparative;return Xa(e,n)},Ii=function(e="",t=[]){const n=e.length;for(let r=n<=6?n-1:6;r>=1;r-=1){const o=e.substring(n-r,e.length);if(!0===t[o.length].hasOwnProperty(o)){return e.slice(0,n-r)+t[o.length][o]}}return null},Ti="ically",Di=new Set(["analyt"+Ti,"chem"+Ti,"class"+Ti,"clin"+Ti,"crit"+Ti,"ecolog"+Ti,"electr"+Ti,"empir"+Ti,"frant"+Ti,"grammat"+Ti,"ident"+Ti,"ideolog"+Ti,"log"+Ti,"mag"+Ti,"mathemat"+Ti,"mechan"+Ti,"med"+Ti,"method"+Ti,"method"+Ti,"mus"+Ti,"phys"+Ti,"phys"+Ti,"polit"+Ti,"pract"+Ti,"rad"+Ti,"satir"+Ti,"statist"+Ti,"techn"+Ti,"technolog"+Ti,"theoret"+Ti,"typ"+Ti,"vert"+Ti,"whims"+Ti]),Hi=[null,{},{ly:""},{ily:"y",bly:"ble",ply:"ple"},{ally:"al",rply:"rp"},{ually:"ual",ially:"ial",cally:"cal",eally:"eal",rally:"ral",nally:"nal",mally:"mal",eeply:"eep",eaply:"eap"},{ically:"ic"}],Ei=new Set(["early","only","hourly","daily","weekly","monthly","yearly","mostly","duly","unduly","especially","undoubtedly","conversely","namely","exceedingly","presumably","accordingly","overly","best","latter","little","long","low"]),Gi={wholly:"whole",fully:"full",truly:"true",gently:"gentle",singly:"single",customarily:"customary",idly:"idle",publically:"public",quickly:"quick",superbly:"superb",cynically:"cynical",well:"good"},Oi=[null,{y:"ily"},{ly:"ly",ic:"ically"},{ial:"ially",ual:"ually",tle:"tly",ble:"bly",ple:"ply",ary:"arily"},{},{},{}],Fi={cool:"cooly",whole:"wholly",full:"fully",good:"well",idle:"idly",public:"publicly",single:"singly",special:"especially"},Vi=function(e){if(Fi.hasOwnProperty(e))return Fi[e];let t=Ii(e,Oi);return t||(t=e+"ly"),t};var zi={toSuperlative:ji,toComparative:xi,toAdverb:Vi,toNoun:function(e,t){const n=t.two.models.adjToNoun;return Xa(e,n)},fromAdverb:function(e){return e.endsWith("ly")?Di.has(e)?e.replace(/ically/,"ical"):Ei.has(e)?null:Gi.hasOwnProperty(e)?Gi[e]:Ii(e,Hi)||e:null},fromSuperlative:function(e,t){const n=t.two.models.fromSuperlative;return Xa(e,n)},fromComparative:function(e,t){const n=t.two.models.fromComparative;return Xa(e,n)},all:function(e,t){let n=[e];return n.push(ji(e,t)),n.push(xi(e,t)),n.push(Vi(e)),n=n.filter((e=>e)),n=new Set(n),Array.from(n)}},Bi={noun:yi,verb:Ni,adjective:zi},Si={Singular:(e,t,n,r)=>{const o=r.one.lexicon,a=n.two.transform.noun.toPlural(e,r);o[a]||(t[a]=t[a]||"Plural")},Actor:(e,t,n,r)=>{const o=r.one.lexicon,a=n.two.transform.noun.toPlural(e,r);o[a]||(t[a]=t[a]||["Plural","Actor"])},Comparable:(e,t,n,r)=>{const o=r.one.lexicon,{toSuperlative:a,toComparative:i}=n.two.transform.adjective,s=a(e,r);o[s]||(t[s]=t[s]||"Superlative");const l=i(e,r);o[l]||(t[l]=t[l]||"Comparative"),t[e]="Adjective"},Demonym:(e,t,n,r)=>{const o=n.two.transform.noun.toPlural(e,r);t[o]=t[o]||["Demonym","Plural"]},Infinitive:(e,t,n,r)=>{const o=r.one.lexicon,a=n.two.transform.verb.conjugate(e,r);Object.entries(a).forEach((e=>{o[e[1]]||t[e[1]]||"FutureTense"===e[0]||(t[e[1]]=e[0])}))},PhrasalVerb:(e,t,n,r)=>{const o=r.one.lexicon;t[e]=["PhrasalVerb","Infinitive"];const a=r.one._multiCache,[i,s]=e.split(" ");o[i]||(t[i]=t[i]||"Infinitive");const l=n.two.transform.verb.conjugate(i,r);delete l.FutureTense,Object.entries(l).forEach((e=>{if("Actor"===e[0]||""===e[1])return;t[e[1]]||o[e[1]]||(t[e[1]]=e[0]),a[e[1]]=2;const n=e[1]+" "+s;t[n]=t[n]||[e[0],"PhrasalVerb"]}))},Multiple:(e,t)=>{t[e]=["Multiple","Cardinal"],t[e+"th"]=["Multiple","Ordinal"],t[e+"ths"]=["Multiple","Fraction"]},Cardinal:(e,t)=>{t[e]=["TextValue","Cardinal"]},Ordinal:(e,t)=>{t[e]=["TextValue","Ordinal"],t[e+"s"]=["TextValue","Fraction"]},Place:(e,t)=>{t[e]=["Place","ProperNoun"]},Region:(e,t)=>{t[e]=["Region","ProperNoun"]}};const $i={e:["mice","louse","antennae","formulae","nebulae","vertebrae","vitae"],i:["tia","octopi","viri","radii","nuclei","fungi","cacti","stimuli"],n:["men"],t:["feet"]},Mi=new Set(["israelis","menus","logos"]),Li=["bus","mas","was","ias","xas","vas","cis","lis","nis","ois","ris","sis","tis","xis","aus","cus","eus","fus","gus","ius","lus","nus","das","ous","pus","rus","sus","tus","xus","aos","igos","ados","ogos","'s","ss"],Ki=function(e){if(!e||e.length<=3)return!1;if(Mi.has(e))return!0;const t=e[e.length-1];return $i.hasOwnProperty(t)?$i[t].find((t=>e.endsWith(t))):"s"===t&&!Li.find((t=>e.endsWith(t)))};var Ji={two:{quickSplit:function(e){const t=/[,:;]/,n=[];return e.forEach((e=>{let r=0;e.forEach(((o,a)=>{t.test(o.post)&&function(e,t){const n=/^[0-9]+$/,r=e[t];if(!r)return!1;const o=new Set(["may","april","august","jan"]);if("like"===r.normal||o.has(r.normal))return!1;if(r.tags.has("Place")||r.tags.has("Date"))return!1;if(e[t-1]){const n=e[t-1];if(n.tags.has("Date")||o.has(n.normal))return!1;if(n.tags.has("Adjective")||r.tags.has("Adjective"))return!1}const a=r.normal;return 1!==a.length&&2!==a.length&&4!==a.length||!n.test(a)}(e,a+1)&&(n.push(e.slice(r,a+1)),r=a+1)})),r{const i=e[t],s=(t=(t=t.toLowerCase().trim()).replace(/'s\b/,"")).split(/ /);s.length>1&&(void 0===a[s[0]]||s.length>a[s[0]])&&(a[s[0]]=s.length),!0===Si.hasOwnProperty(i)&&Si[i](t,o,n,r),o[t]=o[t]||i})),delete o[""],delete o.null,delete o[" "],{lex:o,_multi:a}},transform:Bi,looksPlural:Ki}};const Wi={one:{lexicon:{}},two:{models:mi}},qi={"Actor|Verb":"Actor","Adj|Gerund":"Adjective","Adj|Noun":"Adjective","Adj|Past":"Adjective","Adj|Present":"Adjective","Noun|Verb":"Singular","Noun|Gerund":"Gerund","Person|Noun":"Noun","Person|Date":"Month","Person|Verb":"FirstName","Person|Place":"Person","Person|Adj":"Comparative","Plural|Verb":"Plural","Unit|Noun":"Noun"},Ui=function(e,t){const n={model:t,methods:Ji},{lex:r,_multi:o}=Ji.two.expandLexicon(e,n);return Object.assign(t.one.lexicon,r),Object.assign(t.one._multiCache,o),t},Ri=function(e,t,n){const r=Ci(e,Wi);t[r.PastTense]=t[r.PastTense]||"PastTense",t[r.Gerund]=t[r.Gerund]||"Gerund",!0===n&&(t[r.PresentTense]=t[r.PresentTense]||"PresentTense")},Qi=function(e,t,n){const r=ji(e,n);t[r]=t[r]||"Superlative";const o=xi(e,n);t[o]=t[o]||"Comparative"},Zi=function(e,t){const n={},r=t.one.lexicon;return Object.keys(e).forEach((o=>{const a=e[o];if(n[o]=qi[a],"Noun|Verb"!==a&&"Person|Verb"!==a&&"Actor|Verb"!==a||Ri(o,r,!1),"Adj|Present"===a&&(Ri(o,r,!0),Qi(o,r,t)),"Person|Adj"===a&&Qi(o,r,t),"Adj|Gerund"===a||"Noun|Gerund"===a){const e=Ai(o,Wi,"Gerund");r[e]||(n[e]="Infinitive")}if("Noun|Gerund"!==a&&"Adj|Noun"!==a&&"Person|Noun"!==a||function(e,t,n){const r=Ao(e,n);t[r]=t[r]||"Plural"}(o,r,t),"Adj|Past"===a){const e=Ai(o,Wi,"PastTense");r[e]||(n[e]="Infinitive")}})),t=Ui(n,t)};let _i={one:{_multiCache:{},lexicon:No,frozenLex:{"20th century fox":"Organization","7 eleven":"Organization","motel 6":"Organization","excuse me":"Expression","financial times":"Organization","guns n roses":"Organization","la z boy":"Organization","labour party":"Organization","new kids on the block":"Organization","new york times":"Organization","the guess who":"Organization","thin lizzy":"Organization","prime minister":"Actor","free market":"Singular","lay up":"Singular","living room":"Singular","living rooms":"Plural","spin off":"Singular","appeal court":"Uncountable","cold war":"Uncountable","gene pool":"Uncountable","machine learning":"Uncountable","nail polish":"Uncountable","time off":"Uncountable","take part":"Infinitive","bill gates":"Person","doctor who":"Person","dr who":"Person","he man":"Person","iron man":"Person","kid cudi":"Person","run dmc":"Person","rush limbaugh":"Person","snow white":"Person","tiger woods":"Person","brand new":"Adjective","en route":"Adjective","left wing":"Adjective","off guard":"Adjective","on board":"Adjective","part time":"Adjective","right wing":"Adjective","so called":"Adjective","spot on":"Adjective","straight forward":"Adjective","super duper":"Adjective","tip top":"Adjective","top notch":"Adjective","up to date":"Adjective","win win":"Adjective","brooklyn nets":"SportsTeam","chicago bears":"SportsTeam","houston astros":"SportsTeam","houston dynamo":"SportsTeam","houston rockets":"SportsTeam","houston texans":"SportsTeam","minnesota twins":"SportsTeam","orlando magic":"SportsTeam","san antonio spurs":"SportsTeam","san diego chargers":"SportsTeam","san diego padres":"SportsTeam","iron maiden":"ProperNoun","isle of man":"Country","united states":"Country","united states of america":"Country","prince edward island":"Region","cedar breaks":"Place","cedar falls":"Place","point blank":"Adverb","tiny bit":"Adverb","by the time":"Conjunction","no matter":"Conjunction","civil wars":"Plural","credit cards":"Plural","default rates":"Plural","free markets":"Plural","head starts":"Plural","home runs":"Plural","lay ups":"Plural","phone calls":"Plural","press releases":"Plural","record labels":"Plural","soft serves":"Plural","student loans":"Plural","tax returns":"Plural","tv shows":"Plural","video games":"Plural","took part":"PastTense","takes part":"PresentTense","taking part":"Gerund","taken part":"Participle","light bulb":"Noun","rush hour":"Noun","fluid ounce":"Unit","the rolling stones":"Organization"}},two:{irregularPlurals:ho,models:mi,suffixPatterns:ja,prefixPatterns:Da,endsWith:La,neighbours:Wa,regexNormal:[[/^[\w.]+@[\w.]+\.[a-z]{2,3}$/,"Email"],[/^(https?:\/\/|www\.)+\w+\.[a-z]{2,3}/,"Url","http.."],[/^[a-z0-9./].+\.(com|net|gov|org|ly|edu|info|biz|dev|ru|jp|de|in|uk|br|io|ai)/,"Url",".com"],[/^[PMCE]ST$/,"Timezone","EST"],[/^ma?c'[a-z]{3}/,"LastName","mc'neil"],[/^o'[a-z]{3}/,"LastName","o'connor"],[/^ma?cd[aeiou][a-z]{3}/,"LastName","mcdonald"],[/^(lol)+[sz]$/,"Expression","lol"],[/^wo{2,}a*h?$/,"Expression","wooah"],[/^(hee?){2,}h?$/,"Expression","hehe"],[/^(un|de|re)\\-[a-z\u00C0-\u00FF]{2}/,"Verb","un-vite"],[/^(m|k|cm|km)\/(s|h|hr)$/,"Unit","5 k/m"],[/^(ug|ng|mg)\/(l|m3|ft3)$/,"Unit","ug/L"],[/[^:/]\/\p{Letter}/u,"SlashedTerm","love/hate"]],regexText:[[/^#[\p{Number}_]*\p{Letter}/u,"HashTag"],[/^@\w{2,}$/,"AtMention"],[/^([A-Z]\.){2}[A-Z]?/i,["Acronym","Noun"],"F.B.I"],[/.{3}[lkmnp]in['‘’‛‵′`´]$/,"Gerund","chillin'"],[/.{4}s['‘’‛‵′`´]$/,"Possessive","flanders'"],[/^[\p{Emoji_Presentation}\p{Extended_Pictographic}]/u,"Emoji","emoji-class"]],regexNumbers:[[/^@1?[0-9](am|pm)$/i,"Time","3pm"],[/^@1?[0-9]:[0-9]{2}(am|pm)?$/i,"Time","3:30pm"],[/^'[0-9]{2}$/,"Year"],[/^[012]?[0-9](:[0-5][0-9])(:[0-5][0-9])$/,"Time","3:12:31"],[/^[012]?[0-9](:[0-5][0-9])?(:[0-5][0-9])? ?(am|pm)$/i,"Time","1:12pm"],[/^[012]?[0-9](:[0-5][0-9])(:[0-5][0-9])? ?(am|pm)?$/i,"Time","1:12:31pm"],[/^[0-9]{4}-[0-9]{2}-[0-9]{2}T[0-9]{2}:[0-9]{2}/i,"Date","iso-date"],[/^[0-9]{1,4}-[0-9]{1,2}-[0-9]{1,4}$/,"Date","iso-dash"],[/^[0-9]{1,4}\/[0-9]{1,2}\/([0-9]{4}|[0-9]{2})$/,"Date","iso-slash"],[/^[0-9]{1,4}\.[0-9]{1,2}\.[0-9]{1,4}$/,"Date","iso-dot"],[/^[0-9]{1,4}-[a-z]{2,9}-[0-9]{1,4}$/i,"Date","12-dec-2019"],[/^utc ?[+-]?[0-9]+$/,"Timezone","utc-9"],[/^(gmt|utc)[+-][0-9]{1,2}$/i,"Timezone","gmt-3"],[/^[0-9]{3}-[0-9]{4}$/,"PhoneNumber","421-0029"],[/^(\+?[0-9][ -])?[0-9]{3}[ -]?[0-9]{3}-[0-9]{4}$/,"PhoneNumber","1-800-"],[/^[-+]?\p{Currency_Symbol}[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?([kmb]|bn)?\+?$/u,["Money","Value"],"$5.30"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?\p{Currency_Symbol}\+?$/u,["Money","Value"],"5.30£"],[/^[-+]?[$£]?[0-9]([0-9,.])+(usd|eur|jpy|gbp|cad|aud|chf|cny|hkd|nzd|kr|rub)$/i,["Money","Value"],"$400usd"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?\+?$/,["Cardinal","NumericValue"],"5,999"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?(st|nd|rd|r?th)$/,["Ordinal","NumericValue"],"53rd"],[/^\.[0-9]+\+?$/,["Cardinal","NumericValue"],".73th"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?%\+?$/,["Percent","Cardinal","NumericValue"],"-4%"],[/^\.[0-9]+%$/,["Percent","Cardinal","NumericValue"],".3%"],[/^[0-9]{1,4}\/[0-9]{1,4}(st|nd|rd|th)?s?$/,["Fraction","NumericValue"],"2/3rds"],[/^[0-9.]{1,3}[a-z]{0,2}[-–—][0-9]{1,3}[a-z]{0,2}$/,["Value","NumberRange"],"3-4"],[/^[0-9]{1,2}(:[0-9][0-9])?(am|pm)? ?[-–—] ?[0-9]{1,2}(:[0-9][0-9])?(am|pm)$/,["Time","NumberRange"],"3-4pm"],[/^[0-9.]+([a-z°]{1,4})$/,"NumericValue","9km"]],switches:jo,clues:ca,uncountable:{},orgWords:pi,placeWords:fi}};_i=function(e){return e=function(e,t){return Object.keys(e).forEach((n=>{"Uncountable"===e[n]&&(t.two.uncountable[n]=!0,e[n]="Uncountable")})),t}((e=Ui(e.one.lexicon,e)).one.lexicon,e),e=function(e){const{irregularPlurals:t}=e.two,{lexicon:n}=e.one;return Object.entries(t).forEach((e=>{n[e[0]]=n[e[0]]||"Singular",n[e[1]]=n[e[1]]||"Plural"})),e}(e=Zi(e.two.switches,e)),e}(_i);const Xi=function(e,t,n,r){const o=r.methods.one.setTag;"-"===e[t].post&&e[t+1]&&o([e[t],e[t+1]],"Hyphenated",r,null,"1-punct-hyphen''")},Yi=/^(under|over|mis|re|un|dis|semi)-?/,es=function(e,t,n){const r=n.two.switches,o=e[t];if(r.hasOwnProperty(o.normal))o.switch=r[o.normal];else if(Yi.test(o.normal)){const e=o.normal.replace(Yi,"");e.length>3&&r.hasOwnProperty(e)&&(o.switch=r[e])}},ts=function(e,t,n){if(!t||0===t.length)return;if(!0===e.frozen)return;const r="undefined"!=typeof process&&process.env?process.env:self.env||{};r&&r.DEBUG_TAGS&&((e,t,n="")=>{const r=e.text||"["+e.implicit+"]";var o;"string"!=typeof t&&t.length>2&&(t=t.slice(0,2).join(", #")+" +"),t="string"!=typeof t?t.join(", #"):t,console.log(` ${(o=r,"�[33m�[3m"+o+"�[0m").padEnd(24)} �[32m→�[0m #${t.padEnd(22)} ${(e=>"�[3m"+e+"�[0m")(n)}`)})(e,t,n),e.tags=e.tags||new Set,"string"==typeof t?e.tags.add(t):t.forEach((t=>e.tags.add(t)))},ns=["Acronym","Abbreviation","ProperNoun","Uncountable","Possessive","Pronoun","Activity","Honorific","Month"],rs=function(e,t,n){const r=e[t],o=Array.from(r.tags);for(let e=0;ee.tags.has(t)))||(Ki(e.normal)?ts(e,"Plural","3-plural-guess"):ts(e,"Singular","3-singular-guess"))}(r),function(e){const t=e.tags;if(t.has("Verb")&&1===t.size){const t=ki(e.normal);t&&ts(e,t,"3-verb-tense-guess")}}(r)},os=/^\p{Lu}[\p{Ll}'’]/u,as=/[0-9]/,is=["Date","Month","WeekDay","Unit","Expression"],ss=/[IVX]/,ls=/^[IVXLCDM]{2,}$/,us=/^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$/,cs={li:!0,dc:!0,md:!0,dm:!0,ml:!0},hs=function(e,t,n){const r=e[t];r.index=r.index||[0,0];const o=r.index[1],a=r.text||"";return 0!==o&&!0===os.test(a)&&!1===as.test(a)?is.find((e=>r.tags.has(e)))||r.pre.match(/["']$/)||"the"===r.normal?null:(rs(e,t,n),r.tags.has("Noun")||r.frozen||r.tags.clear(),ts(r,"ProperNoun","2-titlecase"),!0):a.length>=2&&ls.test(a)&&ss.test(a)&&us.test(a)&&!cs[r.normal]?(ts(r,"RomanNumeral","2-xvii"),!0):null},ds=function(e="",t=[]){const n=e.length;let r=7;n<=r&&(r=n-1);for(let o=r;o>1;o-=1){const r=e.substring(n-o,n);if(!0===t[r.length].hasOwnProperty(r)){return t[r.length][r]}}return null},gs=function(e,t,n){const r=e[t];if(0===r.tags.size){let e=ds(r.normal,n.two.suffixPatterns);if(null!==e)return ts(r,e,"2-suffix"),r.confidence=.7,!0;if(r.implicit&&(e=ds(r.implicit,n.two.suffixPatterns),null!==e))return ts(r,e,"2-implicit-suffix"),r.confidence=.7,!0}return null},ms=/['‘’‛‵′`´]/,ps=function(e,t){for(let n=0;nn-3&&(r=n-3);for(let n=r;n>2;n-=1){const r=e.substring(0,n);if(!0===t[r.length].hasOwnProperty(r))return t[r.length][r]}return null}(r.normal,n.two.prefixPatterns);if(null!==e)return ts(r,e,"2-prefix"),r.confidence=.5,!0}return null},vs=new Set(["in","on","by","until","for","to","during","throughout","through","within","before","after","of","this","next","last","circa","around","post","pre","budget","classic","plan","may"]),ys=function(e){if(!e)return!1;const t=e.normal||e.implicit;return!!vs.has(t)||(!!(e.tags.has("Date")||e.tags.has("Month")||e.tags.has("WeekDay")||e.tags.has("Year"))||!!e.tags.has("ProperNoun"))},ws=function(e){return!!e&&(!!e.tags.has("Ordinal")||(!!(e.tags.has("Cardinal")&&e.normal.length<3)||("is"===e.normal||"was"===e.normal)))},ks=function(e){return e&&(e.tags.has("Date")||e.tags.has("Month")||e.tags.has("WeekDay")||e.tags.has("Year"))},Ps=function(e,t){const n=e[t];if(n.tags.has("NumericValue")&&n.tags.has("Cardinal")&&4===n.normal.length){const r=Number(n.normal);if(r&&!isNaN(r)&&r>1400&&r<2100){const o=e[t-1],a=e[t+1];if(ys(o)||ys(a))return ts(n,"Year","2-tagYear");if(r>=1920&&r<2025){if(ws(o)||ws(a))return ts(n,"Year","2-tagYear-close");if(ks(e[t-2])||ks(e[t+2]))return ts(n,"Year","2-tagYear-far");if(o&&(o.tags.has("Determiner")||o.tags.has("Possessive"))&&a&&a.tags.has("Noun")&&!a.tags.has("Plural"))return ts(n,"Year","2-tagYear-noun")}}}return null},As=function(e,t,n,r){const o=r.methods.one.setTag,a=e[t],i=["PastTense","PresentTense","Auxiliary","Modal","Particle"];if(a.tags.has("Verb")){i.find((e=>a.tags.has(e)))||o([a],"Infinitive",r,null,"2-verb-type''")}},Cs=/^[A-Z]('s|,)?$/,Ns=/^[A-Z-]+$/,js=/^[A-Z]+s$/,xs=/([A-Z]\.)+[A-Z]?,?$/,Is=/[A-Z]{2,}('s|,)?$/,Ts=/([a-z]\.)+[a-z]\.?$/,Ds={I:!0,A:!0},Hs={la:!0,ny:!0,us:!0,dc:!0,gb:!0},Es=function(e,t,n){const r=e[t];return r.tags.has("RomanNumeral")||r.tags.has("Acronym")||r.frozen?null:function(e,t){let n=e.text;if(!1===Ns.test(n)){if(!(n.length>3&&!0===js.test(n)))return!1;n=n.replace(/s$/,"")}return!(n.length>5||Ds.hasOwnProperty(n)||t.one.lexicon.hasOwnProperty(e.normal)||!0!==xs.test(n)&&!0!==Ts.test(n)&&!0!==Cs.test(n)&&!0!==Is.test(n))}(r,n)?(r.tags.clear(),ts(r,["Acronym","Noun"],"3-no-period-acronym"),!0===Hs[r.normal]&&ts(r,"Place","3-place-acronym"),!0===js.test(r.text)&&ts(r,"Plural","3-plural-acronym"),!0):!Ds.hasOwnProperty(r.text)&&Cs.test(r.text)?(r.tags.clear(),ts(r,["Acronym","Noun"],"3-one-letter-acronym"),!0):r.tags.has("Organization")&&r.text.length<=3?(ts(r,"Acronym","3-org-acronym"),!0):r.tags.has("Organization")&&Ns.test(r.text)&&r.text.length<=6?(ts(r,"Acronym","3-titlecase-acronym"),!0):null},Gs=function(e,t){if(!e)return null;const n=t.find((t=>e.normal===t[0]));return n?n[1]:null},Os=function(e,t){if(!e)return null;const n=t.find((t=>e.tags.has(t[0])));return n?n[1]:null},Fs=function(e,t,n){const{leftTags:r,leftWords:o,rightWords:a,rightTags:i}=n.two.neighbours,s=e[t];if(0===s.tags.size){let l=null;if(l=l||Gs(e[t-1],o),l=l||Gs(e[t+1],a),l=l||Os(e[t-1],r),l=l||Os(e[t+1],i),l)return ts(s,l,"3-[neighbour]"),rs(e,t,n),e[t].confidence=.2,!0}return null},Vs=function(e,t,n){return!!e&&(!e.tags.has("FirstName")&&!e.tags.has("Place")&&(!!(e.tags.has("ProperNoun")||e.tags.has("Organization")||e.tags.has("Acronym"))||!(n||(r=e.text,!/^\p{Lu}[\p{Ll}'’]/u.test(r)))&&(0!==t||e.tags.has("Singular"))));var r},zs=function(e,t,n,r){const o=n.model.two.orgWords,a=n.methods.one.setTag,i=e[t];if(!0===o[i.machine||i.normal]&&Vs(e[t-1],t-1,r)){a([e[t]],"Organization",n,null,"3-[org-word]");for(let o=t;o>=0&&Vs(e[o],o,r);o-=1)a([e[o]],"Organization",n,null,"3-[org-word]")}return null},Bs=/'s$/,Ss=new Set(["athletic","city","community","eastern","federal","financial","great","historic","historical","local","memorial","municipal","national","northern","provincial","southern","state","western","spring","pine","sunset","view","oak","maple","spruce","cedar","willow"]),$s=new Set(["center","centre","way","range","bar","bridge","field","pit"]),Ms=function(e,t,n){if(!e)return!1;const r=e.tags;return!(r.has("Organization")||r.has("Possessive")||Bs.test(e.normal))&&(!(!r.has("ProperNoun")&&!r.has("Place"))||!(n||(o=e.text,!/^\p{Lu}[\p{Ll}'’]/u.test(o)))&&(0!==t||r.has("Singular")));var o},Ls=function(e,t,n,r){const o=n.model.two.placeWords,a=n.methods.one.setTag,i=e[t],s=i.machine||i.normal;if(!0===o[s]){for(let o=t-1;o>=0;o-=1)if(!Ss.has(e[o].normal)){if(!Ms(e[o],o,r))break;a(e.slice(o,t+1),"Place",n,null,"3-[place-of-foo]")}if($s.has(s))return!1;for(let o=t+1;oe[t].tags.has("ProperNoun")&&Js.test(e[t].text)?"Noun":null,qs=(e,t,n)=>0!==t||e[1]?null:n,Us={"Adj|Gerund":(e,t)=>Ws(e,t),"Adj|Noun":(e,t)=>Ws(e,t)||function(e,t){return!e[t+1]&&e[t-1]&&e[t-1].tags.has("Determiner")?"Noun":null}(e,t),"Actor|Verb":(e,t)=>Ws(e,t),"Adj|Past":(e,t)=>Ws(e,t),"Adj|Present":(e,t)=>Ws(e,t),"Noun|Gerund":(e,t)=>Ws(e,t),"Noun|Verb":(e,t)=>t>0&&Ws(e,t)||qs(e,t,"Infinitive"),"Plural|Verb":(e,t)=>Ws(e,t)||qs(e,t,"PresentTense")||function(e,t,n){return 0===t&&e.length>3?n:null}(e,t,"Plural"),"Person|Noun":(e,t)=>Ws(e,t),"Person|Verb":(e,t)=>0!==t?Ws(e,t):null,"Person|Adj":(e,t)=>0===t&&e.length>1||Ws(e,t)?"Person":null},Rs="undefined"!=typeof process&&process.env?process.env:self.env||{},Qs=/^(under|over|mis|re|un|dis|semi)-?/,Zs=(e,t)=>{if(!e||!t)return null;const n=e.normal||e.implicit;let r=null;return t.hasOwnProperty(n)&&(r=t[n]),r&&Rs.DEBUG_TAGS&&console.log(`\n �[2m�[3m ↓ - '${n}' �[0m`),r},_s=(e,t={},n)=>{if(!e||!t)return null;const r=Array.from(e.tags).sort(((e,t)=>(n[e]?n[e].parents.length:0)>(n[t]?n[t].parents.length:0)?-1:1));let o=r.find((e=>t[e]));return o&&Rs.DEBUG_TAGS&&console.log(` �[2m�[3m ↓ - '${e.normal||e.implicit}' (#${o}) �[0m`),o=t[o],o},Xs=function(e,t,n){const r=n.model,o=n.methods.one.setTag,{switches:a,clues:i}=r.two,s=e[t];let l=s.normal||s.implicit||"";if(Qs.test(l)&&!a[l]&&(l=l.replace(Qs,"")),s.switch){const a=s.switch;if(s.tags.has("Acronym")||s.tags.has("PhrasalVerb"))return;let u=function(e,t,n,r){if(!n)return null;const o="also"!==e[t-1]?.text?t-1:Math.max(0,t-2),a=r.one.tagSet;let i=Zs(e[t+1],n.afterWords);return i=i||Zs(e[o],n.beforeWords),i=i||_s(e[o],n.beforeTags,a),i=i||_s(e[t+1],n.afterTags,a),i}(e,t,i[a],r);Us[a]&&(u=Us[a](e,t)||u),u?(o([s],u,n,null,`3-[switch] (${a})`),rs(e,t,r)):Rs.DEBUG_TAGS&&console.log(`\n -> X - '${l}' : (${a}) `)}},Ys={there:!0,this:!0,it:!0,him:!0,her:!0,us:!0},el=function(e){if(e.filter((e=>!e.tags.has("ProperNoun"))).length<=3)return!1;const t=/^[a-z]/;return e.every((e=>!t.test(e.text)))},tl=function(e,t,n,r){for(let o=0;o=2){if(e.length<4&&!Ys[e[1].normal])return;if(!o.tags.has("PhrasalVerb")&&r.hasOwnProperty(o.normal))return;(e[1].tags.has("Noun")||e[1].tags.has("Determiner"))&&(e.slice(1,3).some((e=>e.tags.has("Verb")))&&!o.tags.has("#PhrasalVerb")||n([o],"Imperative",t,null,"3-[imperative]"))}}(e,n)},rl={Possessive:e=>{let t=e.machine||e.normal||e.text;return t=t.replace(/'s$/,""),t},Plural:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.noun.toSingular(n,t.model)},Copula:()=>"is",PastTense:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.verb.toInfinitive(n,t.model,"PastTense")},Gerund:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.verb.toInfinitive(n,t.model,"Gerund")},PresentTense:(e,t)=>{const n=e.machine||e.normal||e.text;return e.tags.has("Infinitive")?n:t.methods.two.transform.verb.toInfinitive(n,t.model,"PresentTense")},Comparative:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.adjective.fromComparative(n,t.model)},Superlative:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.adjective.fromSuperlative(n,t.model)},Adverb:(e,t)=>{const{fromAdverb:n}=t.methods.two.transform.adjective;return n(e.machine||e.normal||e.text)}},ol={Adverb:"RB",Comparative:"JJR",Superlative:"JJS",Adjective:"JJ",TO:"Conjunction",Modal:"MD",Auxiliary:"MD",Gerund:"VBG",PastTense:"VBD",Participle:"VBN",PresentTense:"VBZ",Infinitive:"VB",Particle:"RP",Verb:"VB",Pronoun:"PRP",Cardinal:"CD",Conjunction:"CC",Determiner:"DT",Preposition:"IN",QuestionWord:"WP",Expression:"UH",Possessive:"POS",ProperNoun:"NNP",Person:"NNP",Place:"NNP",Organization:"NNP",Singular:"NN",Plural:"NNS",Noun:"NN",There:"EX"};var al={preTagger:function(e){const{methods:t,model:n,world:r}=e,o=e.docs;!function(e,t,n){e.forEach((e=>{!function(e,t,n,r){const o=r.methods.one.setTag;if(e.length>=3){const t=/:/;if(e[0].post.match(t)){const t=e[1];if(t.tags.has("Value")||t.tags.has("Email")||t.tags.has("PhoneNumber"))return;o([e[0]],"Expression",r,null,"2-punct-colon''")}}}(e,0,0,n)}))}(o,0,r);const a=t.two.quickSplit(o);for(let e=0;e{for(let r=0;r{e.forEach((e=>{e.penn=function(e){if(e.tags.has("ProperNoun")&&e.tags.has("Plural"))return"NNPS";if(e.tags.has("Possessive")&&e.tags.has("Pronoun"))return"PRP$";if("there"===e.normal)return"EX";if("to"===e.normal)return"TO";const t=e.tagRank||[];for(let e=0;e{e.implicit=e.normal,e.text="",e.normal=""}));for(let e=0;e(e.implicit=e.text,e.machine=e.text,e.pre="",e.post="",e.text="",e.normal="",e.index=[r,o+t],e))),n[0]&&(n[0].pre=e[r][o].pre,n[n.length-1].post=e[r][o].post,n[0].text=e[r][o].text,n[0].normal=e[r][o].normal),e[r].splice(o,1,...n))},fl=/'/,bl=new Set(["been","become"]),vl=new Set(["what","how","when","if","too"]),yl=new Set(["too","also","enough"]),wl=function(e,t){const n=e[t].normal.split(fl)[0];if("let"===n)return[n,"us"];if("there"===n){const r=e[t+1];if(r&&r.tags.has("Plural"))return[n,"are"]}return"has"===((e,t)=>{for(let n=t+1;n{for(let n=t+1;n0&&(n-=1),e[a]&&(a+=1),o.ptrs=[[0,n,a]],o.compute(["freeze","lexicon","preTagger","unfreeze"]),function(e){e.forEach(((e,t)=>{e.index&&(e.index[1]=t)}))}(e)},Hl={d:(e,t)=>Cl(e,t),t:(e,t)=>function(e,t){if("ain't"===e[t].normal||"aint"===e[t].normal){if(e[t+1]&&"never"===e[t+1].normal)return["have"];const n=function(e,t){for(let n=t-1;n>=0;n-=1)if(e[n].tags.has("Noun")||e[n].tags.has("Pronoun")||e[n].tags.has("Plural")||e[n].tags.has("Singular"))return e[n];return null}(e,t);if(n){if("we"===n.normal||"they"===n.normal)return["are","not"];if("i"===n.normal)return["am","not"];if(n.tags&&n.tags.has("Plural"))return["are","not"]}return["is","not"]}return[e[t].normal.replace(/n't/,""),"not"]}(e,t),s:(e,t,n)=>((e,t)=>{const n=e[t];if(Nl.hasOwnProperty(n.machine||n.normal))return!1;if(n.tags.has("Possessive"))return!0;if(n.tags.has("QuestionWord"))return!1;if("he's"===n.normal||"she's"===n.normal)return!1;const r=e[t+1];if(!r)return!0;if("it's"===n.normal)return!!r.tags.has("#Noun");if("Noun|Gerund"==r.switch){const r=e[t+2];return r?!!r.tags.has("Copula")||("on"===r.normal||r.normal,!1):!(!n.tags.has("Actor")&&!n.tags.has("ProperNoun"))}if(r.tags.has("Verb"))return!!r.tags.has("Infinitive")||!r.tags.has("Gerund")&&!!r.tags.has("PresentTense");if("Adj|Noun"===r.switch){const n=e[t+2];if(!n)return!1;if(Il.has(n.normal))return!0;if(xl.has(n.normal))return!1}if(r.tags.has("Noun")){const e=r.machine||r.normal;return!("here"===e||"there"===e||"everywhere"===e||r.tags.has("Possessive")||r.tags.has("ProperNoun")&&!n.tags.has("ProperNoun"))}if(e[t-1]&&!0===jl[e[t-1].normal])return!0;if(r.tags.has("Adjective")){const n=e[t+2];if(!n)return!1;if(n.tags.has("Noun")&&!n.tags.has("Pronoun")){const e=r.normal;return"above"!==e&&"below"!==e&&"behind"!==e}return"Noun|Verb"===n.switch}return!!r.tags.has("Value")})(e,t)?n.methods.one.setTag([e[t]],"Possessive",n,null,"2-contraction"):wl(e,t)},El=function(e,t){const n=t.fromText(e.join(" "));return n.compute("id"),n.docs[0]};var Gl={contractionTwo:e=>{const{world:t,document:n}=e;n.forEach(((r,o)=>{for(let a=r.length-1;a>=0;a-=1){if(r[a].implicit)continue;let i=null;!0===Tl.test(r[a].normal)&&(i=r[a].normal.split(Tl)[1]);let s=null;Hl.hasOwnProperty(i)&&(s=Hl[i](r,a,t)),s&&(s=El(s,e),pl(n,[o,a],s),Dl(n[o],e,a,s.length))}}))}},Ol={compute:Gl,api:function(e){class Contractions extends e{constructor(e,t,n){super(e,t,n),this.viewType="Contraction"}expand(){return this.docs.forEach((e=>{const t=ml.test(e[0].text);e.forEach(((t,n)=>{t.text=t.implicit||"",delete t.implicit,ne.toUpperCase()))}(e[0].text))})),this.compute("normal"),this}}e.prototype.contractions=function(){const e=this.match("@hasContraction+");return new Contractions(this.document,e.pointer)},e.prototype.contract=gl},hooks:["contractionTwo"]};const Fl="(hard|fast|late|early|high|right|deep|close|direct)";const Vl="(i|we|they)";const zl=[].concat([{match:"(got|were|was|is|are|am) (#PastTense|#Participle)",tag:"Passive",reason:"got-walked"},{match:"(was|were|is|are|am) being (#PastTense|#Participle)",tag:"Passive",reason:"was-being"},{match:"(had|have|has) been (#PastTense|#Participle)",tag:"Passive",reason:"had-been"},{match:"will be being? (#PastTense|#Participle)",tag:"Passive",reason:"will-be-cleaned"},{match:"#Noun [(#PastTense|#Participle)] by (the|a) #Noun",group:0,tag:"Passive",reason:"suffered-by"}],[{match:"[(all|both)] #Determiner #Noun",group:0,tag:"Noun",reason:"all-noun"},{match:"#Copula [(just|alone)]$",group:0,tag:"Adjective",reason:"not-adverb"},{match:"#Singular is #Adverb? [#PastTense$]",group:0,tag:"Adjective",reason:"is-filled"},{match:"[#PastTense] #Singular is",group:0,tag:"Adjective",reason:"smoked-poutine"},{match:"[#PastTense] #Plural are",group:0,tag:"Adjective",reason:"baked-onions"},{match:"well [#PastTense]",group:0,tag:"Adjective",reason:"well-made"},{match:"#Copula [fucked up?]",group:0,tag:"Adjective",reason:"swears-adjective"},{match:"#Singular (seems|appears) #Adverb? [#PastTense$]",group:0,tag:"Adjective",reason:"seems-filled"},{match:"#Copula #Adjective? [(out|in|through)]$",group:0,tag:"Adjective",reason:"still-out"},{match:"^[#Adjective] (the|your) #Noun",group:0,notIf:"(all|even)",tag:"Infinitive",reason:"shut-the"},{match:"the [said] #Noun",group:0,tag:"Adjective",reason:"the-said-card"},{match:"[#Hyphenated (#Hyphenated && #PastTense)] (#Noun|#Conjunction)",group:0,tag:"Adjective",notIf:"#Adverb",reason:"faith-based"},{match:"[#Hyphenated (#Hyphenated && #Gerund)] (#Noun|#Conjunction)",group:0,tag:"Adjective",notIf:"#Adverb",reason:"self-driving"},{match:"[#PastTense (#Hyphenated && #PhrasalVerb)] (#Noun|#Conjunction)",group:0,tag:"Adjective",reason:"dammed-up"},{match:"(#Hyphenated && #Value) fold",tag:"Adjective",reason:"two-fold"},{match:"must (#Hyphenated && #Infinitive)",tag:"Adjective",reason:"must-win"},{match:"(#Hyphenated && #Infinitive) #Hyphenated",tag:"Adjective",notIf:"#PhrasalVerb",reason:"vacuum-sealed"},{match:"too much",tag:"Adverb Adjective",reason:"bit-4"},{match:"a bit much",tag:"Determiner Adverb Adjective",reason:"bit-3"},{match:"[(un|contra|extra|inter|intra|macro|micro|mid|mis|mono|multi|pre|sub|tri|ex)] #Adjective",group:0,tag:["Adjective","Prefix"],reason:"un-skilled"}],[{match:"#Adverb [#Adverb] (and|or|then)",group:0,tag:"Adjective",reason:"kinda-sparkly-and"},{match:"[(dark|bright|flat|light|soft|pale|dead|dim|faux|little|wee|sheer|most|near|good|extra|all)] #Adjective",group:0,tag:"Adverb",reason:"dark-green"},{match:"#Copula [far too] #Adjective",group:0,tag:"Adverb",reason:"far-too"},{match:"#Copula [still] (in|#Gerund|#Adjective)",group:0,tag:"Adverb",reason:"was-still-walking"},{match:`#Plural ${Fl}`,tag:"#PresentTense #Adverb",reason:"studies-hard"},{match:`#Verb [${Fl}] !#Noun?`,group:0,notIf:"(#Copula|get|got|getting|become|became|becoming|feel|feels|feeling|#Determiner|#Preposition)",tag:"Adverb",reason:"shops-direct"},{match:"[#Plural] a lot",tag:"PresentTense",reason:"studies-a-lot"}],[{match:"as [#Gerund] as",group:0,tag:"Adjective",reason:"as-gerund-as"},{match:"more [#Gerund] than",group:0,tag:"Adjective",reason:"more-gerund-than"},{match:"(so|very|extremely) [#Gerund]",group:0,tag:"Adjective",reason:"so-gerund"},{match:"(found|found) it #Adverb? [#Gerund]",group:0,tag:"Adjective",reason:"found-it-gerund"},{match:"a (little|bit|wee) bit? [#Gerund]",group:0,tag:"Adjective",reason:"a-bit-gerund"},{match:"#Gerund [#Gerund]",group:0,tag:"Adjective",notIf:"(impersonating|practicing|considering|assuming)",reason:"looking-annoying"},{match:"(looked|look|looks) #Adverb? [%Adj|Gerund%]",group:0,tag:"Adjective",notIf:"(impersonating|practicing|considering|assuming)",reason:"looked-amazing"},{match:"[%Adj|Gerund%] #Determiner",group:0,tag:"Gerund",reason:"developing-a"},{match:"#Possessive [%Adj|Gerund%] #Noun",group:0,tag:"Adjective",reason:"leading-manufacturer"},{match:"%Noun|Gerund% %Adj|Gerund%",tag:"Gerund #Adjective",reason:"meaning-alluring"},{match:"(face|embrace|reveal|stop|start|resume) %Adj|Gerund%",tag:"#PresentTense #Adjective",reason:"face-shocking"},{match:"(are|were) [%Adj|Gerund%] #Plural",group:0,tag:"Adjective",reason:"are-enduring-symbols"}],[{match:"#Determiner [#Adjective] #Copula",group:0,tag:"Noun",reason:"the-adj-is"},{match:"#Adjective [#Adjective] #Copula",group:0,tag:"Noun",reason:"adj-adj-is"},{match:"(his|its) [%Adj|Noun%]",group:0,tag:"Noun",notIf:"#Hyphenated",reason:"his-fine"},{match:"#Copula #Adverb? [all]",group:0,tag:"Noun",reason:"is-all"},{match:"(have|had) [#Adjective] #Preposition .",group:0,tag:"Noun",reason:"have-fun"},{match:"#Gerund (giant|capital|center|zone|application)",tag:"Noun",reason:"brewing-giant"},{match:"#Preposition (a|an) [#Adjective]$",group:0,tag:"Noun",reason:"an-instant"},{match:"no [#Adjective] #Modal",group:0,tag:"Noun",reason:"no-golden"},{match:"[brand #Gerund?] new",group:0,tag:"Adverb",reason:"brand-new"},{match:"(#Determiner|#Comparative|new|different) [kind]",group:0,tag:"Noun",reason:"some-kind"},{match:"#Possessive [%Adj|Noun%] #Noun",group:0,tag:"Adjective",reason:"her-favourite"},{match:"must && #Hyphenated .",tag:"Adjective",reason:"must-win"},{match:"#Determiner [#Adjective]$",tag:"Noun",notIf:"(this|that|#Comparative|#Superlative)",reason:"the-south"},{match:"(#Noun && #Hyphenated) (#Adjective && #Hyphenated)",tag:"Adjective",notIf:"(this|that|#Comparative|#Superlative)",reason:"company-wide"},{match:"#Determiner [#Adjective] (#Copula|#Determiner)",notIf:"(#Comparative|#Superlative)",group:0,tag:"Noun",reason:"the-poor"},{match:"[%Adj|Noun%] #Noun",notIf:"(#Pronoun|#ProperNoun)",group:0,tag:"Adjective",reason:"stable-foundations"}],[{match:"[still] #Adjective",group:0,tag:"Adverb",reason:"still-advb"},{match:"[still] #Verb",group:0,tag:"Adverb",reason:"still-verb"},{match:"[so] #Adjective",group:0,tag:"Adverb",reason:"so-adv"},{match:"[way] #Comparative",group:0,tag:"Adverb",reason:"way-adj"},{match:"[way] #Adverb #Adjective",group:0,tag:"Adverb",reason:"way-too-adj"},{match:"[all] #Verb",group:0,tag:"Adverb",reason:"all-verb"},{match:"#Verb [like]",group:0,notIf:"(#Modal|#PhrasalVerb)",tag:"Adverb",reason:"verb-like"},{match:"(barely|hardly) even",tag:"Adverb",reason:"barely-even"},{match:"[even] #Verb",group:0,tag:"Adverb",reason:"even-walk"},{match:"[even] #Comparative",group:0,tag:"Adverb",reason:"even-worse"},{match:"[even] (#Determiner|#Possessive)",group:0,tag:"#Adverb",reason:"even-the"},{match:"even left",tag:"#Adverb #Verb",reason:"even-left"},{match:"[way] #Adjective",group:0,tag:"#Adverb",reason:"way-over"},{match:"#PresentTense [(hard|quick|bright|slow|fast|backwards|forwards)]",notIf:"#Copula",group:0,tag:"Adverb",reason:"lazy-ly"},{match:"[much] #Adjective",group:0,tag:"Adverb",reason:"bit-1"},{match:"#Copula [#Adverb]$",group:0,tag:"Adjective",reason:"is-well"},{match:"a [(little|bit|wee) bit?] #Adjective",group:0,tag:"Adverb",reason:"a-bit-cold"},{match:"[(super|pretty)] #Adjective",group:0,tag:"Adverb",reason:"super-strong"},{match:"(become|fall|grow) #Adverb? [#PastTense]",group:0,tag:"Adjective",reason:"overly-weakened"},{match:"(a|an) #Adverb [#Participle] #Noun",group:0,tag:"Adjective",reason:"completely-beaten"},{match:"#Determiner #Adverb? [close]",group:0,tag:"Adjective",reason:"a-close"},{match:"#Gerund #Adverb? [close]",group:0,tag:"Adverb",notIf:"(getting|becoming|feeling)",reason:"being-close"},{match:"(the|those|these|a|an) [#Participle] #Noun",group:0,tag:"Adjective",reason:"blown-motor"},{match:"(#PresentTense|#PastTense) [back]",group:0,tag:"Adverb",notIf:"(#PhrasalVerb|#Copula)",reason:"charge-back"},{match:"#Verb [around]",group:0,tag:"Adverb",notIf:"#PhrasalVerb",reason:"send-around"},{match:"[later] #PresentTense",group:0,tag:"Adverb",reason:"later-say"},{match:"#Determiner [well] !#PastTense?",group:0,tag:"Noun",reason:"the-well"},{match:"#Adjective [enough]",group:0,tag:"Adverb",reason:"high-enough"}],[{match:"[sun] the #Ordinal",tag:"WeekDay",reason:"sun-the-5th"},{match:"[sun] #Date",group:0,tag:"WeekDay",reason:"sun-feb"},{match:"#Date (on|this|next|last|during)? [sun]",group:0,tag:"WeekDay",reason:"1pm-sun"},{match:"(in|by|before|during|on|until|after|of|within|all) [sat]",group:0,tag:"WeekDay",reason:"sat"},{match:"(in|by|before|during|on|until|after|of|within|all) [wed]",group:0,tag:"WeekDay",reason:"wed"},{match:"(in|by|before|during|on|until|after|of|within|all) [march]",group:0,tag:"Month",reason:"march"},{match:"[sat] #Date",group:0,tag:"WeekDay",reason:"sat-feb"},{match:"#Preposition [(march|may)]",group:0,tag:"Month",reason:"in-month"},{match:"(this|next|last) (march|may) !#Infinitive?",tag:"#Date #Month",reason:"this-month"},{match:"(march|may) the? #Value",tag:"#Month #Date #Date",reason:"march-5th"},{match:"#Value of? (march|may)",tag:"#Date #Date #Month",reason:"5th-of-march"},{match:"[(march|may)] .? #Date",group:0,tag:"Month",reason:"march-and-feb"},{match:"#Date .? [(march|may)]",group:0,tag:"Month",reason:"feb-and-march"},{match:"#Adverb [(march|may)]",group:0,tag:"Verb",reason:"quickly-march"},{match:"[(march|may)] #Adverb",group:0,tag:"Verb",reason:"march-quickly"},{match:"#Value (am|pm)",tag:"Time",reason:"2-am"}],[{match:"#Holiday (day|eve)",tag:"Holiday",reason:"holiday-day"},{match:"#Value of #Month",tag:"Date",reason:"value-of-month"},{match:"#Cardinal #Month",tag:"Date",reason:"cardinal-month"},{match:"#Month #Value to #Value",tag:"Date",reason:"value-to-value"},{match:"#Month the #Value",tag:"Date",reason:"month-the-value"},{match:"(#WeekDay|#Month) #Value",tag:"Date",reason:"date-value"},{match:"#Value (#WeekDay|#Month)",tag:"Date",reason:"value-date"},{match:"(#TextValue && #Date) #TextValue",tag:"Date",reason:"textvalue-date"},{match:"#Month #NumberRange",tag:"Date",reason:"aug 20-21"},{match:"#WeekDay #Month #Ordinal",tag:"Date",reason:"week mm-dd"},{match:"#Month #Ordinal #Cardinal",tag:"Date",reason:"mm-dd-yyy"},{match:"(#Place|#Demonmym|#Time) (standard|daylight|central|mountain)? time",tag:"Timezone",reason:"std-time"},{match:"(eastern|mountain|pacific|central|atlantic) (standard|daylight|summer)? time",tag:"Timezone",reason:"eastern-time"},{match:"#Time [(eastern|mountain|pacific|central|est|pst|gmt)]",group:0,tag:"Timezone",reason:"5pm-central"},{match:"(central|western|eastern) european time",tag:"Timezone",reason:"cet"}],[{match:"(the|any) [more]",group:0,tag:"Singular",reason:"more-noun"},{match:"[more] #Noun",group:0,tag:"Adjective",reason:"more-noun"},{match:"(right|rights) of .",tag:"Noun",reason:"right-of"},{match:"a [bit]",group:0,tag:"Singular",reason:"bit-2"},{match:"a [must]",group:0,tag:"Singular",reason:"must-2"},{match:"(we|us) [all]",group:0,tag:"Noun",reason:"we all"},{match:"due to [#Verb]",group:0,tag:"Noun",reason:"due-to"},{match:"some [#Verb] #Plural",group:0,tag:"Noun",reason:"determiner6"},{match:"#Possessive #Ordinal [#PastTense]",group:0,tag:"Noun",reason:"first-thought"},{match:"(the|this|those|these) #Adjective [%Verb|Noun%]",group:0,tag:"Noun",notIf:"#Copula",reason:"the-adj-verb"},{match:"(the|this|those|these) #Adverb #Adjective [#Verb]",group:0,tag:"Noun",reason:"determiner4"},{match:"the [#Verb] #Preposition .",group:0,tag:"Noun",reason:"determiner1"},{match:"(a|an|the) [#Verb] of",group:0,tag:"Noun",reason:"the-verb-of"},{match:"#Determiner #Noun of [#Verb]",group:0,tag:"Noun",notIf:"#Gerund",reason:"noun-of-noun"},{match:"#PastTense #Preposition [#PresentTense]",group:0,notIf:"#Gerund",tag:"Noun",reason:"ended-in-ruins"},{match:"#Conjunction [u]",group:0,tag:"Pronoun",reason:"u-pronoun-2"},{match:"[u] #Verb",group:0,tag:"Pronoun",reason:"u-pronoun-1"},{match:"#Determiner [(western|eastern|northern|southern|central)] #Noun",group:0,tag:"Noun",reason:"western-line"},{match:"(#Singular && @hasHyphen) #PresentTense",tag:"Noun",reason:"hyphen-verb"},{match:"is no [#Verb]",group:0,tag:"Noun",reason:"is-no-verb"},{match:"do [so]",group:0,tag:"Noun",reason:"so-noun"},{match:"#Determiner [(shit|damn|hell)]",group:0,tag:"Noun",reason:"swears-noun"},{match:"to [(shit|hell)]",group:0,tag:"Noun",reason:"to-swears"},{match:"(the|these) [#Singular] (were|are)",group:0,tag:"Plural",reason:"singular-were"},{match:"a #Noun+ or #Adverb+? [#Verb]",group:0,tag:"Noun",reason:"noun-or-noun"},{match:"(the|those|these|a|an) #Adjective? [#PresentTense #Particle?]",group:0,tag:"Noun",notIf:"(seem|appear|include|#Gerund|#Copula)",reason:"det-inf"},{match:"#Noun #Actor",tag:"Actor",notIf:"(#Person|#Pronoun)",reason:"thing-doer"},{match:"#Gerund #Actor",tag:"Actor",reason:"gerund-doer"},{match:"co #Singular",tag:"Actor",reason:"co-noun"},{match:"[#Noun+] #Actor",group:0,tag:"Actor",notIf:"(#Honorific|#Pronoun|#Possessive)",reason:"air-traffic-controller"},{match:"(urban|cardiac|cardiovascular|respiratory|medical|clinical|visual|graphic|creative|dental|exotic|fine|certified|registered|technical|virtual|professional|amateur|junior|senior|special|pharmaceutical|theoretical)+ #Noun? #Actor",tag:"Actor",reason:"fine-artist"},{match:"#Noun+ (coach|chef|king|engineer|fellow|personality|boy|girl|man|woman|master)",tag:"Actor",reason:"dance-coach"},{match:"chief . officer",tag:"Actor",reason:"chief-x-officer"},{match:"chief of #Noun+",tag:"Actor",reason:"chief-of-police"},{match:"senior? vice? president of #Noun+",tag:"Actor",reason:"president-of"},{match:"#Determiner [sun]",group:0,tag:"Singular",reason:"the-sun"},{match:"#Verb (a|an) [#Value]$",group:0,tag:"Singular",reason:"did-a-value"},{match:"the [(can|will|may)]",group:0,tag:"Singular",reason:"the can"},{match:"#FirstName #Acronym? (#Possessive && #LastName)",tag:"Possessive",reason:"name-poss"},{match:"#Organization+ #Possessive",tag:"Possessive",reason:"org-possessive"},{match:"#Place+ #Possessive",tag:"Possessive",reason:"place-possessive"},{match:"#Possessive #PresentTense #Particle?",notIf:"(#Gerund|her)",tag:"Noun",reason:"possessive-verb"},{match:"(my|our|their|her|his|its) [(#Plural && #Actor)] #Noun",tag:"Possessive",reason:"my-dads"},{match:"#Value of a [second]",group:0,unTag:"Value",tag:"Singular",reason:"10th-of-a-second"},{match:"#Value [seconds]",group:0,unTag:"Value",tag:"Plural",reason:"10-seconds"},{match:"in [#Infinitive]",group:0,tag:"Singular",reason:"in-age"},{match:"a [#Adjective] #Preposition",group:0,tag:"Noun",reason:"a-minor-in"},{match:"#Determiner [#Singular] said",group:0,tag:"Actor",reason:"the-actor-said"},{match:"#Determiner #Noun [(feel|sense|process|rush|side|bomb|bully|challenge|cover|crush|dump|exchange|flow|function|issue|lecture|limit|march|process)] !(#Preposition|to|#Adverb)?",group:0,tag:"Noun",reason:"the-noun-sense"},{match:"[#PresentTense] (of|by|for) (a|an|the) #Noun #Copula",group:0,tag:"Plural",reason:"photographs-of"},{match:"#Infinitive and [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"fight and win"},{match:"#Noun and [#Verb] and #Noun",group:0,tag:"Noun",reason:"peace-and-flowers"},{match:"the #Cardinal [%Adj|Noun%]",group:0,tag:"Noun",reason:"the-1992-classic"},{match:"#Copula the [%Adj|Noun%] #Noun",group:0,tag:"Adjective",reason:"the-premier-university"},{match:"i #Verb [me] #Noun",group:0,tag:"Possessive",reason:"scottish-me"},{match:"[#PresentTense] (music|class|lesson|night|party|festival|league|ceremony)",group:0,tag:"Noun",reason:"dance-music"},{match:"[wit] (me|it)",group:0,tag:"Presposition",reason:"wit-me"},{match:"#PastTense #Possessive [#Verb]",group:0,tag:"Noun",notIf:"(saw|made)",reason:"left-her-boots"},{match:"#Value [%Plural|Verb%]",group:0,tag:"Plural",notIf:"(one|1|a|an)",reason:"35-signs"},{match:"had [#PresentTense]",group:0,tag:"Noun",notIf:"(#Gerund|come|become)",reason:"had-time"},{match:"%Adj|Noun% %Noun|Verb%",tag:"#Adjective #Noun",notIf:"#ProperNoun #Noun",reason:"instant-access"},{match:"#Determiner [%Adj|Noun%] #Conjunction",group:0,tag:"Noun",reason:"a-rep-to"},{match:"#Adjective #Noun [%Plural|Verb%]$",group:0,tag:"Plural",notIf:"#Pronoun",reason:"near-death-experiences"},{match:"#Possessive #Noun [%Plural|Verb%]$",group:0,tag:"Plural",reason:"your-guild-colors"}],[{match:"(this|that|the|a|an) [#Gerund #Infinitive]",group:0,tag:"Singular",reason:"the-planning-process"},{match:"(that|the) [#Gerund #PresentTense]",group:0,ifNo:"#Copula",tag:"Plural",reason:"the-paving-stones"},{match:"#Determiner [#Gerund] #Noun",group:0,tag:"Adjective",reason:"the-gerund-noun"},{match:"#Pronoun #Infinitive [#Gerund] #PresentTense",group:0,tag:"Noun",reason:"tipping-sucks"},{match:"#Adjective [#Gerund]",group:0,tag:"Noun",notIf:"(still|even|just)",reason:"early-warning"},{match:"[#Gerund] #Adverb? not? #Copula",group:0,tag:"Activity",reason:"gerund-copula"},{match:"#Copula [(#Gerund|#Activity)] #Copula",group:0,tag:"Gerund",reason:"are-doing-is"},{match:"[#Gerund] #Modal",group:0,tag:"Activity",reason:"gerund-modal"},{match:"#Singular for [%Noun|Gerund%]",group:0,tag:"Gerund",reason:"noun-for-gerund"},{match:"#Comparative (for|at) [%Noun|Gerund%]",group:0,tag:"Gerund",reason:"better-for-gerund"},{match:"#PresentTense the [#Gerund]",group:0,tag:"Noun",reason:"keep-the-touching"}],[{match:"#Infinitive (this|that|the) [#Infinitive]",group:0,tag:"Noun",reason:"do-this-dance"},{match:"#Gerund #Determiner [#Infinitive]",group:0,tag:"Noun",reason:"running-a-show"},{match:"#Determiner (only|further|just|more|backward) [#Infinitive]",group:0,tag:"Noun",reason:"the-only-reason"},{match:"(the|this|a|an) [#Infinitive] #Adverb? #Verb",group:0,tag:"Noun",reason:"determiner5"},{match:"#Determiner #Adjective #Adjective? [#Infinitive]",group:0,tag:"Noun",reason:"a-nice-inf"},{match:"#Determiner #Demonym [#PresentTense]",group:0,tag:"Noun",reason:"mexican-train"},{match:"#Adjective #Noun+ [#Infinitive] #Copula",group:0,tag:"Noun",reason:"career-move"},{match:"at some [#Infinitive]",group:0,tag:"Noun",reason:"at-some-inf"},{match:"(go|goes|went) to [#Infinitive]",group:0,tag:"Noun",reason:"goes-to-verb"},{match:"(a|an) #Adjective? #Noun [#Infinitive] (#Preposition|#Noun)",group:0,notIf:"from",tag:"Noun",reason:"a-noun-inf"},{match:"(a|an) #Noun [#Infinitive]$",group:0,tag:"Noun",reason:"a-noun-inf2"},{match:"#Gerund #Adjective? for [#Infinitive]",group:0,tag:"Noun",reason:"running-for"},{match:"about [#Infinitive]",group:0,tag:"Singular",reason:"about-love"},{match:"#Plural on [#Infinitive]",group:0,tag:"Noun",reason:"on-stage"},{match:"any [#Infinitive]",group:0,tag:"Noun",reason:"any-charge"},{match:"no [#Infinitive]",group:0,tag:"Noun",reason:"no-doubt"},{match:"number of [#PresentTense]",group:0,tag:"Noun",reason:"number-of-x"},{match:"(taught|teaches|learns|learned) [#PresentTense]",group:0,tag:"Noun",reason:"teaches-x"},{match:"(try|use|attempt|build|make) [#Verb #Particle?]",notIf:"(#Copula|#Noun|sure|fun|up)",group:0,tag:"Noun",reason:"do-verb"},{match:"^[#Infinitive] (is|was)",group:0,tag:"Noun",reason:"checkmate-is"},{match:"#Infinitive much [#Infinitive]",group:0,tag:"Noun",reason:"get-much"},{match:"[cause] #Pronoun #Verb",group:0,tag:"Conjunction",reason:"cause-cuz"},{match:"the #Singular [#Infinitive] #Noun",group:0,tag:"Noun",notIf:"#Pronoun",reason:"cardio-dance"},{match:"#Determiner #Modal [#Noun]",group:0,tag:"PresentTense",reason:"should-smoke"},{match:"this [#Plural]",group:0,tag:"PresentTense",notIf:"(#Preposition|#Date)",reason:"this-verbs"},{match:"#Noun that [#Plural]",group:0,tag:"PresentTense",notIf:"(#Preposition|#Pronoun|way)",reason:"voice-that-rocks"},{match:"that [#Plural] to",group:0,tag:"PresentTense",notIf:"#Preposition",reason:"that-leads-to"},{match:"(let|make|made) (him|her|it|#Person|#Place|#Organization)+ [#Singular] (a|an|the|it)",group:0,tag:"Infinitive",reason:"let-him-glue"},{match:"#Verb (all|every|each|most|some|no) [#PresentTense]",notIf:"#Modal",group:0,tag:"Noun",reason:"all-presentTense"},{match:"(had|have|#PastTense) #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"better",reason:"adj-presentTense"},{match:"#Value #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"one-big-reason"},{match:"#PastTense #Adjective+ [#PresentTense]",group:0,tag:"Noun",notIf:"(#Copula|better)",reason:"won-wide-support"},{match:"(many|few|several|couple) [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"many-poses"},{match:"#Determiner #Adverb #Adjective [%Noun|Verb%]",group:0,tag:"Noun",notIf:"#Copula",reason:"very-big-dream"},{match:"from #Noun to [%Noun|Verb%]",group:0,tag:"Noun",reason:"start-to-finish"},{match:"(for|with|of) #Noun (and|or|not) [%Noun|Verb%]",group:0,tag:"Noun",notIf:"#Pronoun",reason:"for-food-and-gas"},{match:"#Adjective #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"adorable-little-store"},{match:"#Gerund #Adverb? #Comparative [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"higher-costs"},{match:"(#Noun && @hasComma) #Noun (and|or) [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"noun-list"},{match:"(many|any|some|several) [#PresentTense] for",group:0,tag:"Noun",reason:"any-verbs-for"},{match:"to #PresentTense #Noun [#PresentTense] #Preposition",group:0,tag:"Noun",reason:"gas-exchange"},{match:"#PastTense (until|as|through|without) [#PresentTense]",group:0,tag:"Noun",reason:"waited-until-release"},{match:"#Gerund like #Adjective? [#PresentTense]",group:0,tag:"Plural",reason:"like-hot-cakes"},{match:"some #Adjective [#PresentTense]",group:0,tag:"Noun",reason:"some-reason"},{match:"for some [#PresentTense]",group:0,tag:"Noun",reason:"for-some-reason"},{match:"(same|some|the|that|a) kind of [#PresentTense]",group:0,tag:"Noun",reason:"some-kind-of"},{match:"(same|some|the|that|a) type of [#PresentTense]",group:0,tag:"Noun",reason:"some-type-of"},{match:"#Gerund #Adjective #Preposition [#PresentTense]",group:0,tag:"Noun",reason:"doing-better-for-x"},{match:"(get|got|have) #Comparative [#PresentTense]",group:0,tag:"Noun",reason:"got-better-aim"},{match:"whose [#PresentTense] #Copula",group:0,tag:"Noun",reason:"whos-name-was"},{match:"#PhrasalVerb #Particle #Preposition [#PresentTense]",group:0,tag:"Noun",reason:"given-up-on-x"},{match:"there (are|were) #Adjective? [#PresentTense]",group:0,tag:"Plural",reason:"there-are"},{match:"#Value [#PresentTense] of",group:0,notIf:"(one|1|#Copula|#Infinitive)",tag:"Plural",reason:"2-trains"},{match:"[#PresentTense] (are|were) #Adjective",group:0,tag:"Plural",reason:"compromises-are-possible"},{match:"^[(hope|guess|thought|think)] #Pronoun #Verb",group:0,tag:"Infinitive",reason:"suppose-i"},{match:"#Possessive #Adjective [#Verb]",group:0,tag:"Noun",notIf:"#Copula",reason:"our-full-support"},{match:"[(tastes|smells)] #Adverb? #Adjective",group:0,tag:"PresentTense",reason:"tastes-good"},{match:"#Copula #Gerund [#PresentTense] !by?",group:0,tag:"Noun",notIf:"going",reason:"ignoring-commute"},{match:"#Determiner #Adjective? [(shed|thought|rose|bid|saw|spelt)]",group:0,tag:"Noun",reason:"noun-past"},{match:"how to [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"how-to-noun"},{match:"which [%Noun|Verb%] #Noun",group:0,tag:"Infinitive",reason:"which-boost-it"},{match:"#Gerund [%Plural|Verb%]",group:0,tag:"Plural",reason:"asking-questions"},{match:"(ready|available|difficult|hard|easy|made|attempt|try) to [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"ready-to-noun"},{match:"(bring|went|go|drive|run|bike) to [%Noun|Verb%]",group:0,tag:"Noun",reason:"bring-to-noun"},{match:"#Modal #Noun [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"would-you-look"},{match:"#Copula just [#Infinitive]",group:0,tag:"Noun",reason:"is-just-spam"},{match:"^%Noun|Verb% %Plural|Verb%",tag:"Imperative #Plural",reason:"request-copies"},{match:"#Adjective #Plural and [%Plural|Verb%]",group:0,tag:"#Plural",reason:"pickles-and-drinks"},{match:"#Determiner #Year [#Verb]",group:0,tag:"Noun",reason:"the-1968-film"},{match:"#Determiner [#PhrasalVerb #Particle]",group:0,tag:"Noun",reason:"the-break-up"},{match:"#Determiner [%Adj|Noun%] #Noun",group:0,tag:"Adjective",notIf:"(#Pronoun|#Possessive|#ProperNoun)",reason:"the-individual-goals"},{match:"[%Noun|Verb%] or #Infinitive",group:0,tag:"Infinitive",reason:"work-or-prepare"},{match:"to #Infinitive [#PresentTense]",group:0,tag:"Noun",notIf:"(#Gerund|#Copula|help)",reason:"to-give-thanks"},{match:"[#Noun] me",group:0,tag:"Verb",reason:"kills-me"},{match:"%Plural|Verb% %Plural|Verb%",tag:"#PresentTense #Plural",reason:"removes-wrinkles"}],[{match:"#Money and #Money #Currency?",tag:"Money",reason:"money-and-money"},{match:"#Value #Currency [and] #Value (cents|ore|centavos|sens)",group:0,tag:"money",reason:"and-5-cents"},{match:"#Value (mark|rand|won|rub|ore)",tag:"#Money #Currency",reason:"4-mark"},{match:"a pound",tag:"#Money #Unit",reason:"a-pound"},{match:"#Value (pound|pounds)",tag:"#Money #Unit",reason:"4-pounds"}],[{match:"[(half|quarter)] of? (a|an)",group:0,tag:"Fraction",reason:"millionth"},{match:"#Adverb [half]",group:0,tag:"Fraction",reason:"nearly-half"},{match:"[half] the",group:0,tag:"Fraction",reason:"half-the"},{match:"#Cardinal and a half",tag:"Fraction",reason:"and-a-half"},{match:"#Value (halves|halfs|quarters)",tag:"Fraction",reason:"two-halves"},{match:"a #Ordinal",tag:"Fraction",reason:"a-quarter"},{match:"[#Cardinal+] (#Fraction && /s$/)",tag:"Fraction",reason:"seven-fifths"},{match:"[#Cardinal+ #Ordinal] of .",group:0,tag:"Fraction",reason:"ordinal-of"},{match:"[(#NumericValue && #Ordinal)] of .",group:0,tag:"Fraction",reason:"num-ordinal-of"},{match:"(a|one) #Cardinal?+ #Ordinal",tag:"Fraction",reason:"a-ordinal"},{match:"#Cardinal+ out? of every? #Cardinal",tag:"Fraction",reason:"out-of"}],[{match:"#Cardinal [second]",tag:"Unit",reason:"one-second"},{match:"!once? [(a|an)] (#Duration|hundred|thousand|million|billion|trillion)",group:0,tag:"Value",reason:"a-is-one"},{match:"1 #Value #PhoneNumber",tag:"PhoneNumber",reason:"1-800-Value"},{match:"#NumericValue #PhoneNumber",tag:"PhoneNumber",reason:"(800) PhoneNumber"},{match:"#Demonym #Currency",tag:"Currency",reason:"demonym-currency"},{match:"#Value [(buck|bucks|grand)]",group:0,tag:"Currency",reason:"value-bucks"},{match:"[#Value+] #Currency",group:0,tag:"Money",reason:"15 usd"},{match:"[second] #Noun",group:0,tag:"Ordinal",reason:"second-noun"},{match:"#Value+ [#Currency]",group:0,tag:"Unit",reason:"5-yan"},{match:"#Value [(foot|feet)]",group:0,tag:"Unit",reason:"foot-unit"},{match:"#Value [#Abbreviation]",group:0,tag:"Unit",reason:"value-abbr"},{match:"#Value [k]",group:0,tag:"Unit",reason:"value-k"},{match:"#Unit an hour",tag:"Unit",reason:"unit-an-hour"},{match:"(minus|negative) #Value",tag:"Value",reason:"minus-value"},{match:"#Value (point|decimal) #Value",tag:"Value",reason:"value-point-value"},{match:"#Determiner [(half|quarter)] #Ordinal",group:0,tag:"Value",reason:"half-ordinal"},{match:"#Multiple+ and #Value",tag:"Value",reason:"magnitude-and-value"},{match:"#Value #Unit [(per|an) (hr|hour|sec|second|min|minute)]",group:0,tag:"Unit",reason:"12-miles-per-second"},{match:"#Value [(square|cubic)] #Unit",group:0,tag:"Unit",reason:"square-miles"}],[{match:"#Copula [(#Noun|#PresentTense)] #LastName",group:0,tag:"FirstName",reason:"copula-noun-lastname"},{match:"(sister|pope|brother|father|aunt|uncle|grandpa|grandfather|grandma) #ProperNoun",tag:"Person",reason:"lady-titlecase",safe:!0},{match:"#FirstName [#Determiner #Noun] #LastName",group:0,tag:"Person",reason:"first-noun-last"},{match:"#ProperNoun (b|c|d|e|f|g|h|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z) #ProperNoun",tag:"Person",reason:"titlecase-acronym-titlecase",safe:!0},{match:"#Acronym #LastName",tag:"Person",reason:"acronym-lastname",safe:!0},{match:"#Person (jr|sr|md)",tag:"Person",reason:"person-honorific"},{match:"#Honorific #Acronym",tag:"Person",reason:"Honorific-TitleCase"},{match:"#Person #Person the? #RomanNumeral",tag:"Person",reason:"roman-numeral"},{match:"#FirstName [/^[^aiurck]$/]",group:0,tag:["Acronym","Person"],reason:"john-e"},{match:"#Noun van der? #Noun",tag:"Person",reason:"van der noun",safe:!0},{match:"(king|queen|prince|saint|lady) of #Noun",tag:"Person",reason:"king-of-noun",safe:!0},{match:"(prince|lady) #Place",tag:"Person",reason:"lady-place"},{match:"(king|queen|prince|saint) #ProperNoun",tag:"Person",notIf:"#Place",reason:"saint-foo"},{match:"al (#Person|#ProperNoun)",tag:"Person",reason:"al-borlen",safe:!0},{match:"#FirstName de #Noun",tag:"Person",reason:"bill-de-noun"},{match:"#FirstName (bin|al) #Noun",tag:"Person",reason:"bill-al-noun"},{match:"#FirstName #Acronym #ProperNoun",tag:"Person",reason:"bill-acronym-title"},{match:"#FirstName #FirstName #ProperNoun",tag:"Person",reason:"bill-firstname-title"},{match:"#Honorific #FirstName? #ProperNoun",tag:"Person",reason:"dr-john-Title"},{match:"#FirstName the #Adjective",tag:"Person",reason:"name-the-great"},{match:"#ProperNoun (van|al|bin) #ProperNoun",tag:"Person",reason:"title-van-title",safe:!0},{match:"#ProperNoun (de|du) la? #ProperNoun",tag:"Person",notIf:"#Place",reason:"title-de-title"},{match:"#Singular #Acronym #LastName",tag:"#FirstName #Person .",reason:"title-acro-noun",safe:!0},{match:"[#ProperNoun] #Person",group:0,tag:"Person",reason:"proper-person",safe:!0},{match:"#Person [#ProperNoun #ProperNoun]",group:0,tag:"Person",notIf:"#Possessive",reason:"three-name-person",safe:!0},{match:"#FirstName #Acronym? [#ProperNoun]",group:0,tag:"LastName",notIf:"#Possessive",reason:"firstname-titlecase"},{match:"#FirstName [#FirstName]",group:0,tag:"LastName",reason:"firstname-firstname"},{match:"#FirstName #Acronym #Noun",tag:"Person",reason:"n-acro-noun",safe:!0},{match:"#FirstName [(de|di|du|van|von)] #Person",group:0,tag:"LastName",reason:"de-firstname"},{match:"[(lieutenant|corporal|sergeant|captain|qeen|king|admiral|major|colonel|marshal|president|queen|king)+] #ProperNoun",group:0,tag:"Honorific",reason:"seargeant-john"},{match:"[(private|general|major|rear|prime|field|count|miss)] #Honorific? #Person",group:0,tag:["Honorific","Person"],reason:"ambg-honorifics"},{match:"#Honorific #FirstName [#Singular]",group:0,tag:"LastName",notIf:"#Possessive",reason:"dr-john-foo",safe:!0},{match:"[(his|her) (majesty|honour|worship|excellency|honorable)] #Person",group:0,tag:"Honorific",reason:"his-excellency"},{match:"#Honorific #Actor",tag:"Honorific",reason:"Lieutenant colonel"},{match:"(first|second|third|1st|2nd|3rd) #Actor",tag:"Honorific",reason:"first lady"},{match:"#Person #RomanNumeral",tag:"Person",reason:"louis-IV"}],[{match:"#FirstName #Noun$",tag:". #LastName",notIf:"(#Possessive|#Organization|#Place|#Pronoun|@hasTitleCase)",reason:"firstname-noun"},{match:"%Person|Date% #Acronym? #ProperNoun",tag:"Person",reason:"jan-thierson"},{match:"%Person|Noun% #Acronym? #ProperNoun",tag:"Person",reason:"switch-person",safe:!0},{match:"%Person|Noun% #Organization",tag:"Organization",reason:"olive-garden"},{match:"%Person|Verb% #Acronym? #ProperNoun",tag:"Person",reason:"verb-propernoun",ifNo:"#Actor"},{match:"[%Person|Verb%] (will|had|has|said|says|told|did|learned|wants|wanted)",group:0,tag:"Person",reason:"person-said"},{match:"[%Person|Place%] (harbor|harbour|pier|town|city|place|dump|landfill)",group:0,tag:"Place",reason:"sydney-harbour"},{match:"(west|east|north|south) [%Person|Place%]",group:0,tag:"Place",reason:"east-sydney"},{match:"#Modal [%Person|Verb%]",group:0,tag:"Verb",reason:"would-mark"},{match:"#Adverb [%Person|Verb%]",group:0,tag:"Verb",reason:"really-mark"},{match:"[%Person|Verb%] (#Adverb|#Comparative)",group:0,tag:"Verb",reason:"drew-closer"},{match:"%Person|Verb% #Person",tag:"Person",reason:"rob-smith"},{match:"%Person|Verb% #Acronym #ProperNoun",tag:"Person",reason:"rob-a-smith"},{match:"[will] #Verb",group:0,tag:"Modal",reason:"will-verb"},{match:"(will && @isTitleCase) #ProperNoun",tag:"Person",reason:"will-name"},{match:"(#FirstName && !#Possessive) [#Singular] #Verb",group:0,safe:!0,tag:"LastName",reason:"jack-layton"},{match:"^[#Singular] #Person #Verb",group:0,safe:!0,tag:"Person",reason:"sherwood-anderson"},{match:"(a|an) [#Person]$",group:0,unTag:"Person",reason:"a-warhol"}],[{match:"#Copula (pretty|dead|full|well|sure) (#Adjective|#Noun)",tag:"#Copula #Adverb #Adjective",reason:"sometimes-adverb"},{match:"(#Pronoun|#Person) (had|#Adverb)? [better] #PresentTense",group:0,tag:"Modal",reason:"i-better"},{match:"(#Modal|i|they|we|do) not? [like]",group:0,tag:"PresentTense",reason:"modal-like"},{match:"#Noun #Adverb? [left]",group:0,tag:"PastTense",reason:"left-verb"},{match:"will #Adverb? not? #Adverb? [be] #Gerund",group:0,tag:"Copula",reason:"will-be-copula"},{match:"will #Adverb? not? #Adverb? [be] #Adjective",group:0,tag:"Copula",reason:"be-copula"},{match:"[march] (up|down|back|toward)",notIf:"#Date",group:0,tag:"Infinitive",reason:"march-to"},{match:"#Modal [march]",group:0,tag:"Infinitive",reason:"must-march"},{match:"[may] be",group:0,tag:"Verb",reason:"may-be"},{match:"[(subject|subjects|subjected)] to",group:0,tag:"Verb",reason:"subject to"},{match:"[home] to",group:0,tag:"PresentTense",reason:"home to"},{match:"[open] #Determiner",group:0,tag:"Infinitive",reason:"open-the"},{match:"(were|was) being [#PresentTense]",group:0,tag:"PastTense",reason:"was-being"},{match:"(had|has|have) [been /en$/]",group:0,tag:"Auxiliary Participle",reason:"had-been-broken"},{match:"(had|has|have) [been /ed$/]",group:0,tag:"Auxiliary PastTense",reason:"had-been-smoked"},{match:"(had|has) #Adverb? [been] #Adverb? #PastTense",group:0,tag:"Auxiliary",reason:"had-been-adj"},{match:"(had|has) to [#Noun] (#Determiner|#Possessive)",group:0,tag:"Infinitive",reason:"had-to-noun"},{match:"have [#PresentTense]",group:0,tag:"PastTense",notIf:"(come|gotten)",reason:"have-read"},{match:"(does|will|#Modal) that [work]",group:0,tag:"PastTense",reason:"does-that-work"},{match:"[(sound|sounds)] #Adjective",group:0,tag:"PresentTense",reason:"sounds-fun"},{match:"[(look|looks)] #Adjective",group:0,tag:"PresentTense",reason:"looks-good"},{match:"[(start|starts|stop|stops|begin|begins)] #Gerund",group:0,tag:"Verb",reason:"starts-thinking"},{match:"(have|had) read",tag:"Modal #PastTense",reason:"read-read"},{match:"(is|was|were) [(under|over) #PastTense]",group:0,tag:"Adverb Adjective",reason:"was-under-cooked"},{match:"[shit] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear1-verb"},{match:"[damn] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear2-verb"},{match:"[fuck] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear3-verb"},{match:"#Plural that %Noun|Verb%",tag:". #Preposition #Infinitive",reason:"jobs-that-work"},{match:"[works] for me",group:0,tag:"PresentTense",reason:"works-for-me"},{match:"as #Pronoun [please]",group:0,tag:"Infinitive",reason:"as-we-please"},{match:"[(co|mis|de|inter|intra|pre|re|un|out|under|over|counter)] #Verb",group:0,tag:["Verb","Prefix"],notIf:"(#Copula|#PhrasalVerb)",reason:"co-write"},{match:"#PastTense and [%Adj|Past%]",group:0,tag:"PastTense",reason:"dressed-and-left"},{match:"[%Adj|Past%] and #PastTense",group:0,tag:"PastTense",reason:"dressed-and-left"},{match:"#Copula #Pronoun [%Adj|Past%]",group:0,tag:"Adjective",reason:"is-he-stoked"},{match:"to [%Noun|Verb%] #Preposition",group:0,tag:"Infinitive",reason:"to-dream-of"}],[{match:"(slowly|quickly) [#Adjective]",group:0,tag:"Verb",reason:"slowly-adj"},{match:"does (#Adverb|not)? [#Adjective]",group:0,tag:"PresentTense",reason:"does-mean"},{match:"[(fine|okay|cool|ok)] by me",group:0,tag:"Adjective",reason:"okay-by-me"},{match:"i (#Adverb|do)? not? [mean]",group:0,tag:"PresentTense",reason:"i-mean"},{match:"will #Adjective",tag:"Auxiliary Infinitive",reason:"will-adj"},{match:"#Pronoun [#Adjective] #Determiner #Adjective? #Noun",group:0,tag:"Verb",reason:"he-adj-the"},{match:"#Copula [%Adj|Present%] to #Verb",group:0,tag:"Verb",reason:"adj-to"},{match:"#Copula [#Adjective] (well|badly|quickly|slowly)",group:0,tag:"Verb",reason:"done-well"},{match:"#Adjective and [#Gerund] !#Preposition?",group:0,tag:"Adjective",reason:"rude-and-x"},{match:"#Copula #Adverb? (over|under) [#PastTense]",group:0,tag:"Adjective",reason:"over-cooked"},{match:"#Copula #Adjective+ (and|or) [#PastTense]$",group:0,tag:"Adjective",reason:"bland-and-overcooked"},{match:"got #Adverb? [#PastTense] of",group:0,tag:"Adjective",reason:"got-tired-of"},{match:"(seem|seems|seemed|appear|appeared|appears|feel|feels|felt|sound|sounds|sounded) (#Adverb|#Adjective)? [#PastTense]",group:0,tag:"Adjective",reason:"felt-loved"},{match:"(seem|feel|seemed|felt) [#PastTense #Particle?]",group:0,tag:"Adjective",reason:"seem-confused"},{match:"a (bit|little|tad) [#PastTense #Particle?]",group:0,tag:"Adjective",reason:"a-bit-confused"},{match:"not be [%Adj|Past% #Particle?]",group:0,tag:"Adjective",reason:"do-not-be-confused"},{match:"#Copula just [%Adj|Past% #Particle?]",group:0,tag:"Adjective",reason:"is-just-right"},{match:"as [#Infinitive] as",group:0,tag:"Adjective",reason:"as-pale-as"},{match:"[%Adj|Past%] and #Adjective",group:0,tag:"Adjective",reason:"faled-and-oppressive"},{match:"or [#PastTense] #Noun",group:0,tag:"Adjective",notIf:"(#Copula|#Pronoun)",reason:"or-heightened-emotion"},{match:"(become|became|becoming|becomes) [#Verb]",group:0,tag:"Adjective",reason:"become-verb"},{match:"#Possessive [#PastTense] #Noun",group:0,tag:"Adjective",reason:"declared-intentions"},{match:"#Copula #Pronoun [%Adj|Present%]",group:0,tag:"Adjective",reason:"is-he-cool"},{match:"#Copula [%Adj|Past%] with",group:0,tag:"Adjective",notIf:"(associated|worn|baked|aged|armed|bound|fried|loaded|mixed|packed|pumped|filled|sealed)",reason:"is-crowded-with"},{match:"#Copula #Adverb? [%Adj|Present%]$",group:0,tag:"Adjective",reason:"was-empty$"}],[{match:"will (#Adverb|not)+? [have] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"will-have-vb"},{match:"[#Copula] (#Adverb|not)+? (#Gerund|#PastTense)",group:0,tag:"Auxiliary",reason:"copula-walking"},{match:"[(#Modal|did)+] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"modal-verb"},{match:"#Modal (#Adverb|not)+? [have] (#Adverb|not)+? [had] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"would-have"},{match:"[(has|had)] (#Adverb|not)+? #PastTense",group:0,tag:"Auxiliary",reason:"had-walked"},{match:"[(do|does|did|will|have|had|has|got)] (not|#Adverb)+? #Verb",group:0,tag:"Auxiliary",reason:"have-had"},{match:"[about to] #Adverb? #Verb",group:0,tag:["Auxiliary","Verb"],reason:"about-to"},{match:"#Modal (#Adverb|not)+? [be] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"would-be"},{match:"[(#Modal|had|has)] (#Adverb|not)+? [been] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"had-been"},{match:"[(be|being|been)] #Participle",group:0,tag:"Auxiliary",reason:"being-driven"},{match:"[may] #Adverb? #Infinitive",group:0,tag:"Auxiliary",reason:"may-want"},{match:"#Copula (#Adverb|not)+? [(be|being|been)] #Adverb+? #PastTense",group:0,tag:"Auxiliary",reason:"being-walked"},{match:"will [be] #PastTense",group:0,tag:"Auxiliary",reason:"will-be-x"},{match:"[(be|been)] (#Adverb|not)+? #Gerund",group:0,tag:"Auxiliary",reason:"been-walking"},{match:"[used to] #PresentTense",group:0,tag:"Auxiliary",reason:"used-to-walk"},{match:"#Copula (#Adverb|not)+? [going to] #Adverb+? #PresentTense",group:0,tag:"Auxiliary",reason:"going-to-walk"},{match:"#Imperative [(me|him|her)]",group:0,tag:"Reflexive",reason:"tell-him"},{match:"(is|was) #Adverb? [no]",group:0,tag:"Negative",reason:"is-no"},{match:"[(been|had|became|came)] #PastTense",group:0,notIf:"#PhrasalVerb",tag:"Auxiliary",reason:"been-told"},{match:"[(being|having|getting)] #Verb",group:0,tag:"Auxiliary",reason:"being-born"},{match:"[be] #Gerund",group:0,tag:"Auxiliary",reason:"be-walking"},{match:"[better] #PresentTense",group:0,tag:"Modal",notIf:"(#Copula|#Gerund)",reason:"better-go"},{match:"even better",tag:"Adverb #Comparative",reason:"even-better"}],[{match:"(#Verb && @hasHyphen) up",tag:"PhrasalVerb",reason:"foo-up"},{match:"(#Verb && @hasHyphen) off",tag:"PhrasalVerb",reason:"foo-off"},{match:"(#Verb && @hasHyphen) over",tag:"PhrasalVerb",reason:"foo-over"},{match:"(#Verb && @hasHyphen) out",tag:"PhrasalVerb",reason:"foo-out"},{match:"[#Verb (in|out|up|down|off|back)] (on|in)",notIf:"#Copula",tag:"PhrasalVerb Particle",reason:"walk-in-on"},{match:"(lived|went|crept|go) [on] for",group:0,tag:"PhrasalVerb",reason:"went-on"},{match:"#Verb (up|down|in|on|for)$",tag:"PhrasalVerb #Particle",notIf:"#PhrasalVerb",reason:"come-down$"},{match:"help [(stop|end|make|start)]",group:0,tag:"Infinitive",reason:"help-stop"},{match:"#PhrasalVerb (in && #Particle) #Determiner",tag:"#Verb #Preposition #Determiner",unTag:"PhrasalVerb",reason:"work-in-the"},{match:"[(stop|start|finish|help)] #Gerund",group:0,tag:"Infinitive",reason:"start-listening"},{match:"#Verb (him|her|it|us|himself|herself|itself|everything|something) [(up|down)]",group:0,tag:"Adverb",reason:"phrasal-pronoun-advb"}],[{match:"^do not? [#Infinitive #Particle?]",notIf:Vl,group:0,tag:"Imperative",reason:"do-eat"},{match:"^please do? not? [#Infinitive #Particle?]",group:0,tag:"Imperative",reason:"please-go"},{match:"^just do? not? [#Infinitive #Particle?]",group:0,tag:"Imperative",reason:"just-go"},{match:"^[#Infinitive] it #Comparative",notIf:Vl,group:0,tag:"Imperative",reason:"do-it-better"},{match:"^[#Infinitive] it (please|now|again|plz)",notIf:Vl,group:0,tag:"Imperative",reason:"do-it-please"},{match:"^[#Infinitive] (#Adjective|#Adverb)$",group:0,tag:"Imperative",notIf:"(so|such|rather|enough)",reason:"go-quickly"},{match:"^[#Infinitive] (up|down|over) #Determiner",group:0,tag:"Imperative",reason:"turn-down"},{match:"^[#Infinitive] (your|my|the|a|an|any|each|every|some|more|with|on)",group:0,notIf:"like",tag:"Imperative",reason:"eat-my-shorts"},{match:"^[#Infinitive] (him|her|it|us|me|there)",group:0,tag:"Imperative",reason:"tell-him"},{match:"^[#Infinitive] #Adjective #Noun$",group:0,tag:"Imperative",reason:"avoid-loud-noises"},{match:"^[#Infinitive] (#Adjective|#Adverb)? and #Infinitive",group:0,tag:"Imperative",reason:"call-and-reserve"},{match:"^(go|stop|wait|hurry) please?$",tag:"Imperative",reason:"go"},{match:"^(somebody|everybody) [#Infinitive]",group:0,tag:"Imperative",reason:"somebody-call"},{match:"^let (us|me) [#Infinitive]",group:0,tag:"Imperative",reason:"lets-leave"},{match:"^[(shut|close|open|start|stop|end|keep)] #Determiner #Noun",group:0,tag:"Imperative",reason:"shut-the-door"},{match:"^[#PhrasalVerb #Particle] #Determiner #Noun",group:0,tag:"Imperative",reason:"turn-off-the-light"},{match:"^[go] to .",group:0,tag:"Imperative",reason:"go-to-toronto"},{match:"^#Modal you [#Infinitive]",group:0,tag:"Imperative",reason:"would-you-"},{match:"^never [#Infinitive]",group:0,tag:"Imperative",reason:"never-stop"},{match:"^come #Infinitive",tag:"Imperative",notIf:"on",reason:"come-have"},{match:"^come and? #Infinitive",tag:"Imperative . Imperative",notIf:"#PhrasalVerb",reason:"come-and-have"},{match:"^stay (out|away|back)",tag:"Imperative",reason:"stay-away"},{match:"^[(stay|be|keep)] #Adjective",group:0,tag:"Imperative",reason:"stay-cool"},{match:"^[keep it] #Adjective",group:0,tag:"Imperative",reason:"keep-it-cool"},{match:"^do not [#Infinitive]",group:0,tag:"Imperative",reason:"do-not-be"},{match:"[#Infinitive] (yourself|yourselves)",group:0,tag:"Imperative",reason:"allow-yourself"},{match:"[#Infinitive] what .",group:0,tag:"Imperative",reason:"look-what"},{match:"^[#Infinitive] #Gerund",group:0,tag:"Imperative",reason:"keep-playing"},{match:"^[#Infinitive] (to|for|into|toward|here|there)",group:0,tag:"Imperative",reason:"go-to"},{match:"^[#Infinitive] (and|or) #Infinitive",group:0,tag:"Imperative",reason:"inf-and-inf"},{match:"^[%Noun|Verb%] to",group:0,tag:"Imperative",reason:"commit-to"},{match:"^[#Infinitive] #Adjective? #Singular #Singular",group:0,tag:"Imperative",reason:"maintain-eye-contact"},{match:"do not (forget|omit|neglect) to [#Infinitive]",group:0,tag:"Imperative",reason:"do-not-forget"},{match:"^[(ask|wear|pay|look|help|show|watch|act|fix|kill|stop|start|turn|try|win)] #Noun",group:0,tag:"Imperative",reason:"pay-attention"}],[{match:"(that|which) were [%Adj|Gerund%]",group:0,tag:"Gerund",reason:"that-were-growing"},{match:"#Gerund [#Gerund] #Plural",group:0,tag:"Adjective",reason:"hard-working-fam"}],[{match:"u r",tag:"#Pronoun #Copula",reason:"u r"},{match:"#Noun [(who|whom)]",group:0,tag:"Determiner",reason:"captain-who"},{match:"[had] #Noun+ #PastTense",group:0,tag:"Condition",reason:"had-he"},{match:"[were] #Noun+ to #Infinitive",group:0,tag:"Condition",reason:"were-he"},{match:"some sort of",tag:"Adjective Noun Conjunction",reason:"some-sort-of"},{match:"of some sort",tag:"Conjunction Adjective Noun",reason:"of-some-sort"},{match:"[such] (a|an|is)? #Noun",group:0,tag:"Determiner",reason:"such-skill"},{match:"[right] (before|after|in|into|to|toward)",group:0,tag:"#Adverb",reason:"right-into"},{match:"#Preposition [about]",group:0,tag:"Adjective",reason:"at-about"},{match:"(are|#Modal|see|do|for) [ya]",group:0,tag:"Pronoun",reason:"are-ya"},{match:"[long live] .",group:0,tag:"#Adjective #Infinitive",reason:"long-live"},{match:"[plenty] of",group:0,tag:"#Uncountable",reason:"plenty-of"},{match:"(always|nearly|barely|practically) [there]",group:0,tag:"Adjective",reason:"always-there"},{match:"[there] (#Adverb|#Pronoun)? #Copula",group:0,tag:"There",reason:"there-is"},{match:"#Copula [there] .",group:0,tag:"There",reason:"is-there"},{match:"#Modal #Adverb? [there]",group:0,tag:"There",reason:"should-there"},{match:"^[do] (you|we|they)",group:0,tag:"QuestionWord",reason:"do-you"},{match:"^[does] (he|she|it|#ProperNoun)",group:0,tag:"QuestionWord",reason:"does-he"},{match:"#Determiner #Noun+ [who] #Verb",group:0,tag:"Preposition",reason:"the-x-who"},{match:"#Determiner #Noun+ [which] #Verb",group:0,tag:"Preposition",reason:"the-x-which"},{match:"a [while]",group:0,tag:"Noun",reason:"a-while"},{match:"guess who",tag:"#Infinitive #QuestionWord",reason:"guess-who"},{match:"[fucking] !#Verb",group:0,tag:"#Gerund",reason:"f-as-gerund"}],[{match:"university of #Place",tag:"Organization",reason:"university-of-Foo"},{match:"#Noun (&|n) #Noun",tag:"Organization",reason:"Noun-&-Noun"},{match:"#Organization of the? #ProperNoun",tag:"Organization",reason:"org-of-place",safe:!0},{match:"#Organization #Country",tag:"Organization",reason:"org-country"},{match:"#ProperNoun #Organization",tag:"Organization",notIf:"#FirstName",reason:"titlecase-org"},{match:"#ProperNoun (ltd|co|inc|dept|assn|bros)",tag:"Organization",reason:"org-abbrv"},{match:"the [#Acronym]",group:0,tag:"Organization",reason:"the-acronym",safe:!0},{match:"government of the? [#Place+]",tag:"Organization",reason:"government-of-x"},{match:"(health|school|commerce) board",tag:"Organization",reason:"school-board"},{match:"(nominating|special|conference|executive|steering|central|congressional) committee",tag:"Organization",reason:"special-comittee"},{match:"(world|global|international|national|#Demonym) #Organization",tag:"Organization",reason:"global-org"},{match:"#Noun+ (public|private) school",tag:"School",reason:"noun-public-school"},{match:"#Place+ #SportsTeam",tag:"SportsTeam",reason:"place-sportsteam"},{match:"(dc|atlanta|minnesota|manchester|newcastle|sheffield) united",tag:"SportsTeam",reason:"united-sportsteam"},{match:"#Place+ fc",tag:"SportsTeam",reason:"fc-sportsteam"},{match:"#Place+ #Noun{0,2} (club|society|group|team|committee|commission|association|guild|crew)",tag:"Organization",reason:"place-noun-society"}],[{match:"(west|north|south|east|western|northern|southern|eastern)+ #Place",tag:"Region",reason:"west-norfolk"},{match:"#City [(al|ak|az|ar|ca|ct|dc|fl|ga|id|il|nv|nh|nj|ny|oh|pa|sc|tn|tx|ut|vt|pr)]",group:0,tag:"Region",reason:"us-state"},{match:"portland [or]",group:0,tag:"Region",reason:"portland-or"},{match:"#ProperNoun+ (cliff|place|range|pit|place|point|room|grounds|ruins)",tag:"Place",reason:"foo-point"},{match:"in [#ProperNoun] #Place",group:0,tag:"Place",reason:"propernoun-place"},{match:"#Value #Noun (st|street|rd|road|crescent|cr|way|tr|terrace|avenue|ave)",tag:"Address",reason:"address-st"},{match:"(port|mount|mt) #ProperName",tag:"Place",reason:"port-name"}],[{match:"[so] #Noun",group:0,tag:"Conjunction",reason:"so-conj"},{match:"[(who|what|where|why|how|when)] #Noun #Copula #Adverb? (#Verb|#Adjective)",group:0,tag:"Conjunction",reason:"how-he-is-x"},{match:"#Copula [(who|what|where|why|how|when)] #Noun",group:0,tag:"Conjunction",reason:"when-he"},{match:"#Verb [that] #Pronoun",group:0,tag:"Conjunction",reason:"said-that-he"},{match:"#Noun [that] #Copula",group:0,tag:"Conjunction",reason:"that-are"},{match:"#Noun [that] #Verb #Adjective",group:0,tag:"Conjunction",reason:"that-seem"},{match:"#Noun #Copula not? [that] #Adjective",group:0,tag:"Adverb",reason:"that-adj"},{match:"#Verb #Adverb? #Noun [(that|which)]",group:0,tag:"Preposition",reason:"that-prep"},{match:"@hasComma [which] (#Pronoun|#Verb)",group:0,tag:"Preposition",reason:"which-copula"},{match:"#Noun [like] #Noun",group:0,tag:"Preposition",reason:"noun-like"},{match:"^[like] #Determiner",group:0,tag:"Preposition",reason:"like-the"},{match:"a #Noun [like] (#Noun|#Determiner)",group:0,tag:"Preposition",reason:"a-noun-like"},{match:"#Adverb [like]",group:0,tag:"Verb",reason:"really-like"},{match:"(not|nothing|never) [like]",group:0,tag:"Preposition",reason:"nothing-like"},{match:"#Infinitive #Pronoun [like]",group:0,tag:"Preposition",reason:"treat-them-like"},{match:"[#QuestionWord] (#Pronoun|#Determiner)",group:0,tag:"Preposition",reason:"how-he"},{match:"[#QuestionWord] #Participle",group:0,tag:"Preposition",reason:"when-stolen"},{match:"[how] (#Determiner|#Copula|#Modal|#PastTense)",group:0,tag:"QuestionWord",reason:"how-is"},{match:"#Plural [(who|which|when)] .",group:0,tag:"Preposition",reason:"people-who"}],[{match:"holy (shit|fuck|hell)",tag:"Expression",reason:"swears-expression"},{match:"^[(well|so|okay|now)] !#Adjective?",group:0,tag:"Expression",reason:"well-"},{match:"^come on",tag:"Expression",reason:"come-on"},{match:"(say|says|said) [sorry]",group:0,tag:"Expression",reason:"say-sorry"},{match:"^(ok|alright|shoot|hell|anyways)",tag:"Expression",reason:"ok-"},{match:"^(say && @hasComma)",tag:"Expression",reason:"say-"},{match:"^(like && @hasComma)",tag:"Expression",reason:"like-"},{match:"^[(dude|man|girl)] #Pronoun",group:0,tag:"Expression",reason:"dude-i"}]);let Bl=null;var Sl={postTagger:function(e){const{world:t}=e,{model:n,methods:r}=t;Bl=Bl||r.one.buildNet(n.two.matches,t);const o=r.two.quickSplit(e.document).map((e=>{const t=e[0];return[t.index[0],t.index[1],t.index[1]+e.length]})),a=e.update(o);return a.cache(),a.sweep(Bl),e.uncache(),e.unfreeze(),e},tagger:e=>e.compute(["freeze","lexicon","preTagger","postTagger","unfreeze"])};const $l={api:function(e){e.prototype.confidence=function(){let e=0,t=0;return this.docs.forEach((n=>{n.forEach((n=>{t+=1,e+=n.confidence||1}))})),0===t?1:(e=>Math.round(100*e)/100)(e/t)},e.prototype.tagger=function(){return this.compute(["tagger"])}},compute:Sl,model:{two:{matches:zl}},hooks:["postTagger"]},Ml=function(e,t){const n=function(e){return Object.keys(e.hooks).filter((e=>!e.startsWith("#")&&!e.startsWith("%")))}(t);if(0===n.length)return e;e._cache||e.cache();const r=e._cache;return e.filter(((e,t)=>n.some((e=>r[t].has(e)))))};var Ll={lib:{lazy:function(e,t){let n=t;"string"==typeof t&&(n=this.buildNet([{match:t}]));const r=this.tokenize(e),o=Ml(r,n);return o.found?(o.compute(["index","tagger"]),o.match(t)):r.none()}}};const Kl=function(e,t,n){let r=e.split(/ /g).map((e=>e.toLowerCase().trim()));r=r.filter((e=>e)),r=r.map((e=>`{${e}}`)).join(" ");let o=this.match(r);return n&&(o=o.if(n)),o.has("#Verb")?function(e,t){let n=t;return e.forEach((e=>{e.has("#Infinitive")||(n=function(e,t){const n=(0,e.methods.two.transform.verb.conjugate)(t,e.model);return e.has("#Gerund")?n.Gerund:e.has("#PastTense")?n.PastTense:e.has("#PresentTense")?n.PresentTense:e.has("#Gerund")?n.Gerund:t}(e,t)),e.replaceWith(n)})),e}(o,t):o.has("#Noun")?function(e,t){let n=t;e.has("#Plural")&&(n=(0,e.methods.two.transform.noun.toPlural)(t,e.model));e.replaceWith(n,{possessives:!0})}(o,t):o.has("#Adverb")?function(e,t){const{toAdverb:n}=e.methods.two.transform.adjective,r=n(t);r&&e.replaceWith(r)}(o,t):o.has("#Adjective")?function(e,t){const{toComparative:n,toSuperlative:r}=e.methods.two.transform.adjective;let o=t;e.has("#Comparative")?o=n(o,e.model):e.has("#Superlative")&&(o=r(o,e.model)),o&&e.replaceWith(o)}(o,t):this};var Jl={api:function(e){e.prototype.swap=Kl}};h.plugin(cl),h.plugin(Ol),h.plugin($l),h.plugin(Ll),h.plugin(Jl);const Wl=function(e){const{fromComparative:t,fromSuperlative:n}=e.methods.two.transform.adjective,r=e.text("normal");return e.has("#Comparative")?t(r,e.model):e.has("#Superlative")?n(r,e.model):r};var ql={api:function(e){class Adjectives extends e{constructor(e,t,n){super(e,t,n),this.viewType="Adjectives"}json(e={}){const{toAdverb:t,toNoun:n,toSuperlative:r,toComparative:o}=this.methods.two.transform.adjective;return e.normal=!0,this.map((a=>{const i=a.toView().json(e)[0]||{},s=Wl(a);return i.adjective={adverb:t(s,this.model),noun:n(s,this.model),superlative:r(s,this.model),comparative:o(s,this.model)},i}),[])}adverbs(){return this.before("#Adverb+$").concat(this.after("^#Adverb+"))}conjugate(e){const{toComparative:t,toSuperlative:n,toNoun:r,toAdverb:o}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const a=Wl(e);return{Adjective:a,Comparative:t(a,this.model),Superlative:n(a,this.model),Noun:r(a,this.model),Adverb:o(a,this.model)}}),[])}toComparative(e){const{toComparative:t}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const n=Wl(e),r=t(n,this.model);return e.replaceWith(r)}))}toSuperlative(e){const{toSuperlative:t}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const n=Wl(e),r=t(n,this.model);return e.replaceWith(r)}))}toAdverb(e){const{toAdverb:t}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const n=Wl(e),r=t(n,this.model);return e.replaceWith(r)}))}toNoun(e){const{toNoun:t}=this.methods.two.transform.adjective;return this.getNth(e).map((e=>{const n=Wl(e),r=t(n,this.model);return e.replaceWith(r)}))}}e.prototype.adjectives=function(e){let t=this.match("#Adjective");return t=t.getNth(e),new Adjectives(t.document,t.pointer)},e.prototype.superlatives=function(e){let t=this.match("#Superlative");return t=t.getNth(e),new Adjectives(t.document,t.pointer)},e.prototype.comparatives=function(e){let t=this.match("#Comparative");return t=t.getNth(e),new Adjectives(t.document,t.pointer)}}};var Ul={api:function(e){class Adverbs extends e{constructor(e,t,n){super(e,t,n),this.viewType="Adverbs"}conjugate(e){return this.getNth(e).map((e=>{const t=function(e){return e.compute("root").text("root")}(e);return{Adverb:e.text("normal"),Adjective:t}}),[])}json(e={}){const t=this.methods.two.transform.adjective.fromAdverb;return e.normal=!0,this.map((n=>{const r=n.toView().json(e)[0]||{};return r.adverb={adjective:t(r.normal)},r}),[])}}e.prototype.adverbs=function(e){let t=this.match("#Adverb");return t=t.getNth(e),new Adverbs(t.document,t.pointer)}}};const Rl=function(e){let t=this;t=function(e){let t=e.parentheses();return t=t.filter((e=>e.wordCount()>=3&&e.has("#Verb")&&e.has("#Noun"))),e.splitOn(t)}(t),t=function(e){let t=e.quotations();return t=t.filter((e=>e.wordCount()>=3&&e.has("#Verb")&&e.has("#Noun"))),e.splitOn(t)}(t),t=function(e){let t=e.match("@hasComma");return t=t.filter((e=>{if(1===e.growLeft(".").wordCount())return!1;if(1===e.growRight(". .").wordCount())return!1;let t=e.grow(".");return t=t.ifNo("@hasComma @hasComma"),t=t.ifNo("@hasComma (and|or) ."),t=t.ifNo("(#City && @hasComma) #Country"),t=t.ifNo("(#WeekDay && @hasComma) #Date"),t=t.ifNo("(#Date+ && @hasComma) #Value"),t=t.ifNo("(#Adjective && @hasComma) #Adjective"),t.found})),e.splitAfter(t)}(t),t=t.splitAfter("(@hasEllipses|@hasSemicolon|@hasDash|@hasColon)"),t=t.splitAfter("^#Pronoun (said|says)"),t=t.splitBefore("(said|says) #ProperNoun$"),t=t.splitBefore(". . if .{4}"),t=t.splitBefore("and while"),t=t.splitBefore("now that"),t=t.splitBefore("ever since"),t=t.splitBefore("(supposing|although)"),t=t.splitBefore("even (while|if|though)"),t=t.splitBefore("(whereas|whose)"),t=t.splitBefore("as (though|if)"),t=t.splitBefore("(til|until)");const n=t.match("#Verb .* [but] .* #Verb",0);n.found&&(t=t.splitBefore(n));const r=t.if("if .{2,9} then .").match("then");return t=t.splitBefore(r),"number"==typeof e&&(t=t.get(e)),t},Ql={this:"Noun",then:"Pivot"},Zl=[{match:"[that] #Determiner #Noun",group:0,chunk:"Pivot"},{match:"#PastTense [that]",group:0,chunk:"Pivot"},{match:"[so] #Determiner",group:0,chunk:"Pivot"},{match:"#Copula #Adverb+? [#Adjective]",group:0,chunk:"Adjective"},{match:"#Adjective and #Adjective",chunk:"Adjective"},{match:"#Adverb+ and #Adverb #Verb",chunk:"Verb"},{match:"#Gerund #Adjective$",chunk:"Verb"},{match:"#Gerund to #Verb",chunk:"Verb"},{match:"#PresentTense and #PresentTense",chunk:"Verb"},{match:"#Adverb #Negative",chunk:"Verb"},{match:"(want|wants|wanted) to #Infinitive",chunk:"Verb"},{match:"#Verb #Reflexive",chunk:"Verb"},{match:"#Verb [to] #Adverb? #Infinitive",group:0,chunk:"Verb"},{match:"[#Preposition] #Gerund",group:0,chunk:"Verb"},{match:"#Infinitive [that] ",group:0,chunk:"Verb"},{match:"#Noun of #Determiner? #Noun",chunk:"Noun"},{match:"#Value+ #Adverb? #Adjective",chunk:"Noun"},{match:"the [#Adjective] #Noun",chunk:"Noun"},{match:"#Singular in #Determiner? #Singular",chunk:"Noun"},{match:"#Plural [in] #Determiner? #Noun",group:0,chunk:"Pivot"},{match:"#Noun and #Determiner? #Noun",notIf:"(#Possessive|#Pronoun)",chunk:"Noun"}];let _l=null;const Xl=function(e,t){if(("undefined"!=typeof process&&process.env?process.env:self.env||{}).DEBUG_CHUNKS){const n=(e.normal+"'").padEnd(8);console.log(` | '${n} → �[34m${t.padEnd(12)}�[0m �[2m -fallback- �[0m`)}e.chunk=t};var Yl={chunks:function(e){const{document:t,world:n}=e;!function(e){for(let t=0;t{for(let r=0;r{if("Verb"===e.chunk){const t=e.terms.find((e=>e.tags.has("Verb")));t||e.terms.forEach((e=>e.chunk=null))}}))}(t)}},eu={compute:Yl,api:function(e){class Chunks extends e{constructor(e,t,n){super(e,t,n),this.viewType="Chunks"}isVerb(){return this.filter((e=>e.has("")))}isNoun(){return this.filter((e=>e.has("")))}isAdjective(){return this.filter((e=>e.has("")))}isPivot(){return this.filter((e=>e.has("")))}debug(){return this.toView().debug("chunks"),this}update(e){const t=new Chunks(this.document,e);return t._cache=this._cache,t}}e.prototype.chunks=function(e){let t=function(e){const t=[];let n=null;return e.clauses().docs.forEach((e=>{e.forEach((e=>{e.chunk&&e.chunk===n?t[t.length-1][2]=e.index[1]+1:(n=e.chunk,t.push([e.index[0],e.index[1],e.index[1]+1]))})),n=null})),e.update(t)}(this);return t=t.getNth(e),new Chunks(this.document,t.pointer)},e.prototype.clauses=Rl},hooks:["chunks"]};const tu=/\./g,nu=/\(/,ru=/\)/,ou=function(e,t){for(;t{e[0].pre=e[0].pre.replace(nu,"");const t=e[e.length-1];t.post=t.post.replace(ru,"")})),e}(this)}}e.prototype.parentheses=function(e){let t=function(e){const t=[];return e.docs.forEach((e=>{for(let n=0;n{e[0].pre=e[0].pre.replace(lu,"");const t=e[e.length-1];t.post=t.post.replace(uu,"")}))}(this)}}e.prototype.quotations=function(e){let t=function(e){const t=[];return e.docs.forEach((e=>{for(let n=0;n{e.forEach((e=>{e.text=e.text.replace(tu,""),e.normal=e.normal.replace(tu,"")}))})),this}addPeriods(){return this.docs.forEach((e=>{e.forEach((e=>{e.text=e.text.replace(tu,""),e.normal=e.normal.replace(tu,""),e.text=e.text.split("").join(".")+".",e.normal=e.normal.split("").join(".")+"."}))})),this}}e.prototype.acronyms=function(e){let t=this.match("#Acronym");return t=t.getNth(e),new Acronyms(t.document,t.pointer)}}(e),au(e),function(e){class Possessives extends e{constructor(e,t,n){super(e,t,n),this.viewType="Possessives"}strip(){return this.docs.forEach((e=>{e.forEach((e=>{e.text=e.text.replace(iu,""),e.normal=e.normal.replace(iu,"")}))})),this}}e.prototype.possessives=function(e){let t=function(e){let t=e.match("#Possessive+");return t.has("#Person")&&(t=t.growLeft("#Person+")),t.has("#Place")&&(t=t.growLeft("#Place+")),t.has("#Organization")&&(t=t.growLeft("#Organization+")),t}(this);return t=t.getNth(e),new Possessives(t.document,t.pointer)}}(e),hu(e),function(e){gu.forEach((t=>{e.prototype[t[0]]=function(e){const n=this.match(t[1]);return"number"==typeof e?n.get(e):n}})),e.prototype.phoneNumbers=du,mu.forEach((t=>{e.prototype[t[0]]=e.prototype[t[1]]}))}(e),function(e){class Slashes extends e{constructor(e,t,n){super(e,t,n),this.viewType="Slashes"}split(){return this.map((e=>{const t=e.text().split(pu);return(e=e.replaceWith(t.join(" "))).growRight("("+t.join("|")+")+")}))}}e.prototype.slashes=function(e){let t=this.match("#SlashedTerm");return t=t.getNth(e),new Slashes(t.document,t.pointer)}}(e)}};const bu=function(e,t){e.docs.forEach((e=>{e.forEach(t)}))};var vu={case:e=>{bu(e,(e=>{e.text=e.text.toLowerCase()}))},unicode:e=>{const t=e.world,n=t.methods.one.killUnicode;bu(e,(e=>e.text=n(e.text,t)))},whitespace:e=>{bu(e,(e=>{e.post=e.post.replace(/\s+/g," "),e.post=e.post.replace(/\s([.,?!:;])/g,"$1"),e.pre=e.pre.replace(/\s+/g,"")}))},punctuation:e=>{bu(e,(e=>{e.post=e.post.replace(/[–—-]/g," "),e.post=e.post.replace(/[,:;]/g,""),e.post=e.post.replace(/\.{2,}/g,""),e.post=e.post.replace(/\?{2,}/g,"?"),e.post=e.post.replace(/!{2,}/g,"!"),e.post=e.post.replace(/\?!+/g,"?")}));const t=e.docs,n=t[t.length-1];if(n&&n.length>0){const e=n[n.length-1];e.post=e.post.replace(/ /g,"")}},contractions:e=>{e.contractions().expand()},acronyms:e=>{e.acronyms().strip()},parentheses:e=>{e.parentheses().strip()},possessives:e=>{e.possessives().strip()},quotations:e=>{e.quotations().strip()},emoji:e=>{e.emojis().remove()},honorifics:e=>{e.match("#Honorific+ #Person").honorifics().remove()},adverbs:e=>{e.adverbs().remove()},nouns:e=>{e.nouns().toSingular()},verbs:e=>{e.verbs().toInfinitive()},numbers:e=>{e.numbers().toNumber()},debullet:e=>{const t=/^\s*([-–—*•])\s*$/;return e.docs.forEach((e=>{t.test(e[0].pre)&&(e[0].pre=e[0].pre.replace(t,""))})),e}};const yu=e=>e.split("|").reduce(((e,t)=>(e[t]=!0,e)),{}),wu="unicode|punctuation|whitespace|acronyms",ku="|case|contractions|parentheses|quotations|emoji|honorifics|debullet",Pu={light:yu(wu),medium:yu(wu+ku),heavy:yu(wu+ku+"|possessives|adverbs|nouns|verbs")};var Au={api:function(e){e.prototype.normalize=function(e="light"){return"string"==typeof e&&(e=Pu[e]),Object.keys(e).forEach((t=>{vu.hasOwnProperty(t)&&vu[t](this,e[t])})),this}}};const Cu=["after","although","as if","as long as","as","because","before","even if","even though","ever since","if","in order that","provided that","since","so that","than","that","though","unless","until","what","whatever","when","whenever","where","whereas","wherever","whether","which","whichever","who","whoever","whom","whomever","whose"],Nu=function(e){if(e.before("#Preposition$").found)return!0;if(!e.before().found)return!1;for(let t=0;t3&&n.endsWith("s")&&!n.endsWith("ss")},xu=function(e){const t=function(e){let t=e.clone();return t=t.match("#Noun+"),t=t.remove("(#Adjective|#Preposition|#Determiner|#Value)"),t=t.not("#Possessive"),t=t.first(),t.found?t:e}(e);return{determiner:e.match("#Determiner").eq(0),adjectives:e.match("#Adjective"),number:e.values(),isPlural:ju(e,t),isSubordinate:Nu(e),root:t}},Iu=e=>e.text(),Tu=e=>e.json({terms:!1,normal:!0}).map((e=>e.normal)),Du=function(e){if(!e.found)return null;const t=e.values(0);if(t.found){return(t.parse()[0]||{}).num}return null},Hu=function(e){return!e.has("^(#Uncountable|#ProperNoun|#Place|#Pronoun|#Acronym)+$")},Eu={tags:!0},Gu={tags:!0};var Ou={api:function(e){class Nouns extends e{constructor(e,t,n){super(e,t,n),this.viewType="Nouns"}parse(e){return this.getNth(e).map(xu)}json(e){const t="object"==typeof e?e:{};return this.getNth(e).map((e=>{const n=e.toView().json(t)[0]||{};return t&&!1!==t.noun&&(n.noun=function(e){const t=xu(e);return{root:Iu(t.root),number:Du(t.number),determiner:Iu(t.determiner),adjectives:Tu(t.adjectives),isPlural:t.isPlural,isSubordinate:t.isSubordinate}}(e)),n}),[])}conjugate(e){const t=this.world.methods.two.transform.noun;return this.getNth(e).map((e=>{const n=xu(e),r=n.root.compute("root").text("root"),o={Singular:r};return Hu(n.root)&&(o.Plural=t.toPlural(r,this.model)),o.Singular===o.Plural&&delete o.Plural,o}),[])}isPlural(e){const t=this.filter((e=>xu(e).isPlural));return t.getNth(e)}isSingular(e){const t=this.filter((e=>!xu(e).isPlural));return t.getNth(e)}adjectives(e){let t=this.update([]);return this.forEach((e=>{const n=xu(e).adjectives;n.found&&(t=t.concat(n))})),t.getNth(e)}toPlural(e){return this.getNth(e).map((e=>function(e,t){if(!0===t.isPlural)return e;if(t.root.has("#Possessive")&&(t.root=t.root.possessives().strip()),!Hu(t.root))return e;const{methods:n,model:r}=e.world,{toPlural:o}=n.two.transform.noun,a=o(t.root.text({keepPunct:!1}),r);e.match(t.root).replaceWith(a,Eu).tag("Plural","toPlural"),t.determiner.has("(a|an)")&&e.remove(t.determiner);const i=t.root.after("not? #Adverb+? [#Copula]",0);return i.found&&(i.has("is")?e.replace(i,"are"):i.has("was")&&e.replace(i,"were")),e}(e,xu(e))))}toSingular(e){return this.getNth(e).map((e=>function(e,t){if(!1===t.isPlural)return e;const{methods:n,model:r}=e.world,{toSingular:o}=n.two.transform.noun,a=o(t.root.text("normal"),r);return e.replace(t.root,a,Gu).tag("Singular","toPlural"),e}(e,xu(e))))}update(e){const t=new Nouns(this.document,e);return t._cache=this._cache,t}}e.prototype.nouns=function(e){let t=function(e){let t=e.clauses().match(""),n=t.match("@hasComma");return n=n.not("#Place"),n.found&&(t=t.splitAfter(n)),t=t.splitOn("#Expression"),t=t.splitOn("(he|she|we|you|they|i)"),t=t.splitOn("(#Noun|#Adjective) [(he|him|she|it)]",0),t=t.splitOn("[(he|him|she|it)] (#Determiner|#Value)",0),t=t.splitBefore("#Noun [(the|a|an)] #Adjective? #Noun",0),t=t.splitOn("[(here|there)] #Noun",0),t=t.splitOn("[#Noun] (here|there)",0),t=t.splitBefore("(our|my|their|your)"),t=t.splitOn("#Noun [#Determiner]",0),t=t.if("#Noun"),t}(this);return t=t.getNth(e),new Nouns(this.document,t.pointer)}}};var Fu={ones:{zeroth:0,first:1,second:2,third:3,fourth:4,fifth:5,sixth:6,seventh:7,eighth:8,ninth:9,zero:0,one:1,two:2,three:3,four:4,five:5,six:6,seven:7,eight:8,nine:9},teens:{tenth:10,eleventh:11,twelfth:12,thirteenth:13,fourteenth:14,fifteenth:15,sixteenth:16,seventeenth:17,eighteenth:18,nineteenth:19,ten:10,eleven:11,twelve:12,thirteen:13,fourteen:14,fifteen:15,sixteen:16,seventeen:17,eighteen:18,nineteen:19},tens:{twentieth:20,thirtieth:30,fortieth:40,fourtieth:40,fiftieth:50,sixtieth:60,seventieth:70,eightieth:80,ninetieth:90,twenty:20,thirty:30,forty:40,fourty:40,fifty:50,sixty:60,seventy:70,eighty:80,ninety:90},multiples:{hundredth:100,thousandth:1e3,millionth:1e6,billionth:1e9,trillionth:1e12,quadrillionth:1e15,quintillionth:1e18,sextillionth:1e21,septillionth:1e24,hundred:100,thousand:1e3,million:1e6,billion:1e9,trillion:1e12,quadrillion:1e15,quintillion:1e18,sextillion:1e21,septillion:1e24,grand:1e3}};const Vu=(e,t)=>{if(Fu.ones.hasOwnProperty(e)){if(t.ones||t.teens)return!1}else if(Fu.teens.hasOwnProperty(e)){if(t.ones||t.teens||t.tens)return!1}else if(Fu.tens.hasOwnProperty(e)&&(t.ones||t.teens||t.tens))return!1;return!0},zu=function(e){let t="0.";for(let n=0;ne=(e=(e=(e=(e=(e=(e=(e=e.replace(/1st$/,"1")).replace(/2nd$/,"2")).replace(/3rd$/,"3")).replace(/([4567890])r?th$/,"$1")).replace(/^[$€¥£¢]/,"")).replace(/[%$€¥£¢]$/,"")).replace(/,/g,"")).replace(/([0-9])([a-z\u00C0-\u00FF]{1,2})$/,"$1"),Su=/^([0-9,. ]+)\/([0-9,. ]+)$/,$u={"a few":3,"a couple":2,"a dozen":12,"two dozen":24,zero:0},Mu=e=>Object.keys(e).reduce(((t,n)=>t+=e[n]),0),Lu=function(e){if(!0===$u.hasOwnProperty(e))return $u[e];if("a"===e||"an"===e)return 1;const t=(e=>{const t=[{reg:/^(minus|negative)[\s-]/i,mult:-1},{reg:/^(a\s)?half[\s-](of\s)?/i,mult:.5}];for(let n=0;n#Value+] out of every? [#Value+]");if(!0!==t.found)return null;let{num:n,den:r}=t.groups();return n&&r?(n=Ju(n),r=Ju(r),n&&r&&"number"==typeof n&&"number"==typeof r?{numerator:n,denominator:r}:null):null}(e)||function(e){const t=e.match("[(#Cardinal|a)+] [#Fraction+]");if(!0!==t.found)return null;let{num:n,den:r}=t.groups();n=n.has("a")?1:Ju(n);let o=r.text("reduced");return Ku.test(o)&&(o=o.replace(Ku,""),r=r.replaceWith(o)),r=Wu.hasOwnProperty(o)?Wu[o]:Ju(r),"number"==typeof n&&"number"==typeof r?{numerator:n,denominator:r}:null}(e)||function(e){const t=e.match("^#Ordinal$");if(!0!==t.found)return null;if(e.lookAhead("^of ."))return{numerator:1,denominator:Ju(t)};return null}(e)||null;return null!==t&&t.numerator&&t.denominator&&(t.decimal=t.numerator/t.denominator,t.decimal=(e=>{const t=Math.round(1e3*e)/1e3;return 0===t&&0!==e?e:t})(t.decimal)),t},Uu=function(e){if(e<1e6)return String(e);let t;return t="number"==typeof e?e.toFixed(0):e,-1===t.indexOf("e+")?t:t.replace(".","").split("e+").reduce((function(e,t){return e+Array(t-e.length+2).join(0)}))},Ru=[["ninety",90],["eighty",80],["seventy",70],["sixty",60],["fifty",50],["forty",40],["thirty",30],["twenty",20]],Qu=["","one","two","three","four","five","six","seven","eight","nine","ten","eleven","twelve","thirteen","fourteen","fifteen","sixteen","seventeen","eighteen","nineteen"],Zu=[[1e24,"septillion"],[1e20,"hundred sextillion"],[1e21,"sextillion"],[1e20,"hundred quintillion"],[1e18,"quintillion"],[1e17,"hundred quadrillion"],[1e15,"quadrillion"],[1e14,"hundred trillion"],[1e12,"trillion"],[1e11,"hundred billion"],[1e9,"billion"],[1e8,"hundred million"],[1e6,"million"],[1e5,"hundred thousand"],[1e3,"thousand"],[100,"hundred"],[1,"one"]],_u=function(e){const t=[];if(e>100)return t;for(let n=0;n=Ru[n][1]&&(e-=Ru[n][1],t.push(Ru[n][0]));return Qu[e]&&t.push(Qu[e]),t},Xu=function(e){let t=e.num;if(0===t||"0"===t)return"zero";t>1e21&&(t=Uu(t));let n=[];t<0&&(n.push("minus"),t=Math.abs(t));const r=function(e){let t=e;const n=[];return Zu.forEach((r=>{if(e>=r[0]){const e=Math.floor(t/r[0]);t-=e*r[0],e&&n.push({unit:r[1],count:e})}})),n}(t);for(let e=0;e1&&n.push("and")),n=n.concat(_u(r[e].count)),n.push(t)}return n=n.concat((e=>{const t=["zero","one","two","three","four","five","six","seven","eight","nine"],n=[],r=Uu(e).match(/\.([0-9]+)/);if(!r||!r[0])return n;n.push("point");const o=r[0].split("");for(let e=0;ee)),0===n.length&&(n[0]=""),n.join(" ")},Yu={one:"first",two:"second",three:"third",five:"fifth",eight:"eighth",nine:"ninth",twelve:"twelfth",twenty:"twentieth",thirty:"thirtieth",forty:"fortieth",fourty:"fourtieth",fifty:"fiftieth",sixty:"sixtieth",seventy:"seventieth",eighty:"eightieth",ninety:"ninetieth"},ec=e=>{const t=Xu(e).split(" "),n=t[t.length-1];return Yu.hasOwnProperty(n)?t[t.length-1]=Yu[n]:t[t.length-1]=n.replace(/y$/,"i")+"th",t.join(" ")},tc=function(e){class Fractions extends e{constructor(e,t,n){super(e,t,n),this.viewType="Fractions"}parse(e){return this.getNth(e).map(qu)}get(e){return this.getNth(e).map(qu)}json(e){return this.getNth(e).map((t=>{const n=t.toView().json(e)[0],r=qu(t);return n.fraction=r,n}),[])}toDecimal(e){return this.getNth(e).forEach((e=>{const{decimal:t}=qu(e);(e=e.replaceWith(String(t),!0)).tag("NumericValue"),e.unTag("Fraction")})),this}toFraction(e){return this.getNth(e).forEach((e=>{const t=qu(e);if(t&&"number"==typeof t.numerator&&"number"==typeof t.denominator){const n=`${t.numerator}/${t.denominator}`;this.replace(e,n)}})),this}toOrdinal(e){return this.getNth(e).forEach((e=>{let t=function(e){if(!e.numerator||!e.denominator)return"";const t=Xu({num:e.numerator});let n=ec({num:e.denominator});return 2===e.denominator&&(n="half"),t&&n?(1!==e.numerator&&(n+="s"),`${t} ${n}`):""}(qu(e));e.after("^#Noun").found&&(t+=" of"),e.replaceWith(t)})),this}toCardinal(e){return this.getNth(e).forEach((e=>{const t=function(e){return e.numerator&&e.denominator?`${Xu({num:e.numerator})} out of ${Xu({num:e.denominator})}`:""}(qu(e));e.replaceWith(t)})),this}toPercentage(e){return this.getNth(e).forEach((e=>{const{decimal:t}=qu(e);let n=100*t;n=Math.round(100*n)/100,e.replaceWith(`${n}%`)})),this}}e.prototype.fractions=function(e){let t=function(e,t){let n=e.match("#Fraction+");return n=n.filter((e=>!e.lookBehind("#Value and$").found)),n=n.notIf("#Value seconds"),n}(this);return t=t.getNth(e),new Fractions(this.document,t.pointer)}},nc="twenty|thirty|forty|fifty|sixty|seventy|eighty|ninety|fourty",rc=function(e){let t=e.match("#Value+");if(t.has("#NumericValue #NumericValue")&&(t.has("#Value @hasComma #Value")?t.splitAfter("@hasComma"):t.has("#NumericValue #Fraction")?t.splitAfter("#NumericValue #Fraction"):t=t.splitAfter("#NumericValue")),t.has("#Value #Value #Value")&&!t.has("#Multiple")&&t.has("("+nc+") #Cardinal #Cardinal")&&(t=t.splitAfter("("+nc+") #Cardinal")),t.has("#Value #Value")){t.has("#NumericValue #NumericValue")&&(t=t.splitOn("#Year")),t.has("("+nc+") (eleven|twelve|thirteen|fourteen|fifteen|sixteen|seventeen|eighteen|nineteen)")&&(t=t.splitAfter("("+nc+")"));const e=t.match("#Cardinal #Cardinal");if(e.found&&!t.has("(point|decimal|#Fraction)")&&!e.has("#Cardinal (#Multiple|point|decimal)")){const n=t.has(`(one|two|three|four|five|six|seven|eight|nine) (${nc})`),r=e.has("("+nc+") #Cardinal"),o=e.has("#Multiple #Value");n||r||o||e.terms().forEach((e=>{t=t.splitOn(e)}))}t.match("#Ordinal #Ordinal").match("#TextValue").found&&!t.has("#Multiple")&&(t.has("("+nc+") #Ordinal")||(t=t.splitAfter("#Ordinal"))),t=t.splitBefore("#Ordinal [#Cardinal]",0),t.has("#TextValue #NumericValue")&&!t.has("("+nc+"|#Multiple)")&&(t=t.splitBefore("#TextValue #NumericValue"))}return t=t.splitAfter("#NumberRange"),t=t.splitBefore("#Year"),t},oc=function(e){if("string"==typeof e)return{num:Lu(e)};let t=e.text("reduced");const n=e.growRight("#Unit").match("#Unit$").text("machine"),r=/[0-9],[0-9]/.test(e.text("text"));if(1===e.terms().length&&!e.has("#Multiple")){const o=function(e,t){const n=(e=e.replace(/,/g,"")).split(/([0-9.,]*)/);let[r,o]=n,a=n.slice(2).join("");return""!==o&&t.length<2?(o=Number(o||e),"number"!=typeof o&&(o=null),a=a||"","st"!==a&&"nd"!==a&&"rd"!==a&&"th"!==a||(a=""),{prefix:r||"",num:o,suffix:a}):null}(t,e);if(null!==o)return o.hasComma=r,o.unit=n,o}let o=e.match("#Fraction{2,}$");o=!1===o.found?e.match("^#Fraction$"):o;let a=null;o.found&&(o.has("#Value and #Value #Fraction")&&(o=o.match("and #Value #Fraction")),a=qu(o),t=(e=(e=e.not(o)).not("and$")).text("reduced"));let i=0;return t&&(i=Lu(t)||0),a&&a.decimal&&(i+=a.decimal),{hasComma:r,prefix:"",num:i,suffix:"",isOrdinal:e.has("#Ordinal"),isText:e.has("#TextValue"),isFraction:e.has("#Fraction"),isMoney:e.has("#Money"),unit:n}},ac={"¢":"cents",$:"dollars","£":"pounds","¥":"yen","€":"euros","₡":"colón","฿":"baht","₭":"kip","₩":"won","₹":"rupees","₽":"ruble","₺":"liras"},ic={"%":"percent","°":"degrees"},sc=function(e){const t={suffix:"",prefix:e.prefix};return ac.hasOwnProperty(e.prefix)&&(t.suffix+=" "+ac[e.prefix],t.prefix=""),ic.hasOwnProperty(e.suffix)&&(t.suffix+=" "+ic[e.suffix]),t.suffix&&1===e.num&&(t.suffix=t.suffix.replace(/s$/,"")),!t.suffix&&e.suffix&&(t.suffix+=" "+e.suffix),t},lc=function(e,t){if("TextOrdinal"===t){const{prefix:t,suffix:n}=sc(e);return t+ec(e)+n}if("Ordinal"===t)return e.prefix+function(e){const t=e.num;if(!t&&0!==t)return null;const n=t%100;if(n>10&&n<20)return String(t)+"th";const r={0:"th",1:"st",2:"nd",3:"rd"};let o=Uu(t);const a=o.slice(o.length-1,o.length);return o+=r[a]?r[a]:"th",o}(e)+e.suffix;if("TextCardinal"===t){const{prefix:t,suffix:n}=sc(e);return t+Xu(e)+n}let n=e.num;return e.hasComma&&(n=n.toLocaleString()),e.prefix+String(n)+e.suffix},uc=function(e){if("string"==typeof e||"number"==typeof e){const t={};return t[e]=!0,t}return t=e,"[object Array]"===Object.prototype.toString.call(t)?e.reduce(((e,t)=>(e[t]=!0,e)),{}):e||{};var t},cc=function(e){class Numbers extends e{constructor(e,t,n){super(e,t,n),this.viewType="Numbers"}parse(e){return this.getNth(e).map(oc)}get(e){return this.getNth(e).map(oc).map((e=>e.num))}json(e){const t="object"==typeof e?e:{};return this.getNth(e).map((e=>{const n=e.toView().json(t)[0],r=oc(e);return n.number={prefix:r.prefix,num:r.num,suffix:r.suffix,hasComma:r.hasComma,unit:r.unit},n}),[])}units(){return this.growRight("#Unit").match("#Unit$")}isUnit(e){return function(e,t={}){return t=uc(t),e.filter((e=>{const{unit:n}=oc(e);return!(!n||!0!==t[n])}))}(this,e)}isOrdinal(){return this.if("#Ordinal")}isCardinal(){return this.if("#Cardinal")}toNumber(){const e=this.map((e=>{if(!this.has("#TextValue"))return e;const t=oc(e);if(null===t.num)return e;const n=e.has("#Ordinal")?"Ordinal":"Cardinal",r=lc(t,n);return e.replaceWith(r,{tags:!0}),e.tag("NumericValue")}));return new Numbers(e.document,e.pointer)}toLocaleString(){return this.forEach((e=>{const t=oc(e);if(null===t.num)return;let n=t.num.toLocaleString();if(e.has("#Ordinal")){const e=lc(t,"Ordinal").match(/[a-z]+$/);e&&(n+=e[0]||"")}e.replaceWith(n,{tags:!0})})),this}toText(){const e=this.map((e=>{if(e.has("#TextValue"))return e;const t=oc(e);if(null===t.num)return e;const n=e.has("#Ordinal")?"TextOrdinal":"TextCardinal",r=lc(t,n);return e.replaceWith(r,{tags:!0}),e.tag("TextValue"),e}));return new Numbers(e.document,e.pointer)}toCardinal(){const e=this.map((e=>{if(!e.has("#Ordinal"))return e;const t=oc(e);if(null===t.num)return e;const n=e.has("#TextValue")?"TextCardinal":"Cardinal",r=lc(t,n);return e.replaceWith(r,{tags:!0}),e.tag("Cardinal"),e}));return new Numbers(e.document,e.pointer)}toOrdinal(){const e=this.map((e=>{if(e.has("#Ordinal"))return e;const t=oc(e);if(null===t.num)return e;const n=e.has("#TextValue")?"TextOrdinal":"Ordinal",r=lc(t,n);return e.replaceWith(r,{tags:!0}),e.tag("Ordinal"),e}));return new Numbers(e.document,e.pointer)}isEqual(e){return this.filter((t=>oc(t).num===e))}greaterThan(e){return this.filter((t=>oc(t).num>e))}lessThan(e){return this.filter((t=>oc(t).num{const r=oc(n).num;return r>e&&r{const n=oc(t);if(n.num=e,null===n.num)return t;let r=t.has("#Ordinal")?"Ordinal":"Cardinal";t.has("#TextValue")&&(r=t.has("#Ordinal")?"TextOrdinal":"TextCardinal");let o=lc(n,r);return n.hasComma&&"Cardinal"===r&&(o=Number(o).toLocaleString()),(t=t.not("#Currency")).replaceWith(o,{tags:!0}),t}));return new Numbers(t.document,t.pointer)}add(e){if(!e)return this;"string"==typeof e&&(e=oc(e).num);const t=this.map((t=>{const n=oc(t);if(null===n.num)return t;n.num+=e;let r=t.has("#Ordinal")?"Ordinal":"Cardinal";n.isText&&(r=t.has("#Ordinal")?"TextOrdinal":"TextCardinal");const o=lc(n,r);return t.replaceWith(o,{tags:!0}),t}));return new Numbers(t.document,t.pointer)}subtract(e,t){return this.add(-1*e,t)}increment(e){return this.add(1,e)}decrement(e){return this.add(-1,e)}update(e){const t=new Numbers(this.document,e);return t._cache=this._cache,t}}Numbers.prototype.toNice=Numbers.prototype.toLocaleString,Numbers.prototype.isBetween=Numbers.prototype.between,Numbers.prototype.minus=Numbers.prototype.subtract,Numbers.prototype.plus=Numbers.prototype.add,Numbers.prototype.equals=Numbers.prototype.isEqual,e.prototype.numbers=function(e){let t=rc(this);return t=t.getNth(e),new Numbers(this.document,t.pointer)},e.prototype.percentages=function(e){let t=rc(this);return t=t.filter((e=>e.has("#Percent")||e.after("^percent"))),t=t.getNth(e),new Numbers(this.document,t.pointer)},e.prototype.money=function(e){let t=rc(this);return t=t.filter((e=>e.has("#Money")||e.after("^#Currency"))),t=t.getNth(e),new Numbers(this.document,t.pointer)},e.prototype.values=e.prototype.numbers};var hc={api:function(e){tc(e),cc(e)}};const dc={people:!0,emails:!0,phoneNumbers:!0,places:!0},gc=function(e={}){return!1!==(e=Object.assign({},dc,e)).people&&this.people().replaceWith("██████████"),!1!==e.emails&&this.emails().replaceWith("██████████"),!1!==e.places&&this.places().replaceWith("██████████"),!1!==e.phoneNumbers&&this.phoneNumbers().replaceWith("███████"),this},mc={api:function(e){e.prototype.redact=gc}},pc=function(e){let t=null;return e.has("#PastTense")?t="PastTense":e.has("#FutureTense")?t="FutureTense":e.has("#PresentTense")&&(t="PresentTense"),{tense:t}},fc=function(e){const t=function(e){let t=e;return 1===t.length?t:(t=t.if("#Verb"),1===t.length?t:(t=t.ifNo("(after|although|as|because|before|if|since|than|that|though|when|whenever|where|whereas|wherever|whether|while|why|unless|until|once)"),t=t.ifNo("^even (if|though)"),t=t.ifNo("^so that"),t=t.ifNo("^rather than"),t=t.ifNo("^provided that"),1===t.length?t:(t=t.ifNo("(that|which|whichever|who|whoever|whom|whose|whomever)"),1===t.length?t:(t=t.ifNo("(^despite|^during|^before|^through|^throughout)"),1===t.length?t:(t=t.ifNo("^#Gerund"),1===t.length?t:(0===t.length&&(t=e),t.eq(0)))))))}(e.clauses()),n=t.chunks();let r=e.none(),o=e.none(),a=e.none();return n.forEach(((e,t)=>{0!==t||e.has("")?o.found||!e.has("")?o.found&&(a=a.concat(e)):o=e:r=e})),o.found&&!r.found&&(r=o.before("+").first()),{subj:r,verb:o,pred:a,grammar:pc(o)}};var bc={api:function(e){class Sentences extends e{constructor(e,t,n){super(e,t,n),this.viewType="Sentences"}json(e={}){return this.map((t=>{const n=t.toView().json(e)[0]||{},{subj:r,verb:o,pred:a,grammar:i}=fc(t);return n.sentence={subject:r.text("normal"),verb:o.text("normal"),predicate:a.text("normal"),grammar:i},n}),[])}toPastTense(e){return this.getNth(e).map((e=>(fc(e),function(e){let t=e.verbs();const n=t.eq(0);if(n.has("#PastTense"))return e;if(n.toPastTense(),t.length>1){t=t.slice(1),t=t.filter((e=>!e.lookBehind("to$").found)),t=t.if("#PresentTense"),t=t.notIf("#Gerund");const n=e.match("to #Verb+ #Conjunction #Verb").terms();t=t.not(n),t.found&&t.verbs().toPastTense()}return e}(e))))}toPresentTense(e){return this.getNth(e).map((e=>(fc(e),function(e){let t=e.verbs();return t.eq(0).toPresentTense(),t.length>1&&(t=t.slice(1),t=t.filter((e=>!e.lookBehind("to$").found)),t=t.notIf("#Gerund"),t.found&&t.verbs().toPresentTense()),e}(e))))}toFutureTense(e){return this.getNth(e).map((e=>(fc(e),e=function(e){let t=e.verbs();if(t.eq(0).toFutureTense(),t=(e=e.fullSentence()).verbs(),t.length>1){t=t.slice(1);const e=t.filter((e=>!(e.lookBehind("to$").found||!e.has("#Copula #Gerund")&&(e.has("#Gerund")||!e.has("#Copula")&&e.has("#PresentTense")&&!e.has("#Infinitive")&&e.lookBefore("(he|she|it|that|which)$").found))));e.found&&e.forEach((e=>{if(e.has("#Copula"))return e.match("was").replaceWith("is"),void e.match("is").replaceWith("will be");e.toInfinitive()}))}return e}(e),e)))}toInfinitive(e){return this.getNth(e).map((e=>(fc(e),function(e){return e.verbs().toInfinitive(),e}(e))))}toNegative(e){return this.getNth(e).map((e=>(fc(e),function(e){return e.verbs().first().toNegative().compute("chunks"),e}(e))))}toPositive(e){return this.getNth(e).map((e=>(fc(e),function(e){return e.verbs().first().toPositive().compute("chunks"),e}(e))))}isQuestion(e){return this.questions(e)}isExclamation(e){const t=this.filter((e=>e.lastTerm().has("@hasExclamation")));return t.getNth(e)}isStatement(e){const t=this.filter((e=>!e.isExclamation().found&&!e.isQuestion().found));return t.getNth(e)}update(e){const t=new Sentences(this.document,e);return t._cache=this._cache,t}}Sentences.prototype.toPresent=Sentences.prototype.toPresentTense,Sentences.prototype.toPast=Sentences.prototype.toPastTense,Sentences.prototype.toFuture=Sentences.prototype.toFutureTense;const t={sentences:function(e){let t=this.map((e=>e.fullSentence()));return t=t.getNth(e),new Sentences(this.document,t.pointer)},questions:function(e){const t=function(e){const t=/\?/,{document:n}=e;return e.filter((e=>{const r=e.docs[0]||[],o=r[r.length-1];return!(!o||n[o.index[0]].length!==r.length)&&(!!t.test(o.post)||function(e){const t=e.clauses();return!(/\.\.$/.test(e.out("text"))||e.has("^#QuestionWord")&&e.has("@hasComma")||!e.has("or not$")&&!e.has("^#QuestionWord")&&!e.has("^(do|does|did|is|was|can|could|will|would|may) #Noun")&&!e.has("^(have|must) you")&&!t.has("(do|does|is|was) #Noun+ #Adverb? (#Adjective|#Infinitive)$"))}(e))}))}(this);return t.getNth(e)}};Object.assign(e.prototype,t)}};const vc=function(e){const t={};t.firstName=e.match("#FirstName+"),t.lastName=e.match("#LastName+"),t.honorific=e.match("#Honorific+");const n=t.lastName,r=t.firstName;return r.found&&n.found||r.found||n.found||!e.has("^#Honorific .$")||(t.lastName=e.match(".$")),t},yc="male",wc="female",kc={mr:yc,mrs:wc,miss:wc,madam:wc,king:yc,queen:wc,duke:yc,duchess:wc,baron:yc,baroness:wc,count:yc,countess:wc,prince:yc,princess:wc,sire:yc,dame:wc,lady:wc,ayatullah:yc,congressman:yc,congresswoman:wc,"first lady":wc,mx:null},Pc=function(e,t){const{firstName:n,honorific:r}=e;if(n.has("#FemaleName"))return wc;if(n.has("#MaleName"))return yc;if(r.found){let e=r.text("normal");if(e=e.replace(/\./g,""),kc.hasOwnProperty(e))return kc[e];if(/^her /.test(e))return wc;if(/^his /.test(e))return yc}const o=t.after();if(!o.has("#Person")&&o.has("#Pronoun")){const e=o.match("#Pronoun");if(e.has("(they|their)"))return null;const t=e.has("(he|his)"),n=e.has("(she|her|hers)");if(t&&!n)return yc;if(n&&!t)return wc}return null},Ac=function(e){const t=this.clauses();let n=t.people();return n=n.concat(t.places()),n=n.concat(t.organizations()),n=n.not("(someone|man|woman|mother|brother|sister|father)"),n=n.sort("seq"),n=n.getNth(e),n};var Cc={api:function(e){!function(e){class People extends e{constructor(e,t,n){super(e,t,n),this.viewType="People"}parse(e){return this.getNth(e).map(vc)}json(e){const t="object"==typeof e?e:{};return this.getNth(e).map((e=>{const n=e.toView().json(t)[0],r=vc(e);return n.person={firstName:r.firstName.text("normal"),lastName:r.lastName.text("normal"),honorific:r.honorific.text("normal"),presumed_gender:Pc(r,e)},n}),[])}presumedMale(){return this.filter((e=>e.has("(#MaleName|mr|mister|sr|jr|king|pope|prince|sir)")))}presumedFemale(){return this.filter((e=>e.has("(#FemaleName|mrs|miss|queen|princess|madam)")))}update(e){const t=new People(this.document,e);return t._cache=this._cache,t}}e.prototype.people=function(e){let t=function(e){let t=e.splitAfter("@hasComma");t=t.match("#Honorific+? #Person+");const n=t.match("#Possessive").notIf("(his|her)");return t=t.splitAfter(n),t}(this);return t=t.getNth(e),new People(this.document,t.pointer)}}(e),function(e){e.prototype.places=function(t){let n=function(e){let t=e.match("(#Place|#Address)+"),n=t.match("@hasComma");return n=n.filter((e=>!!e.has("(asia|africa|europe|america)$")||!e.has("(#City|#Region|#ProperNoun)$")||!e.after("^(#Country|#Region)").found)),t=t.splitAfter(n),t}(this);return n=n.getNth(t),new e(this.document,n.pointer)}}(e),function(e){e.prototype.organizations=function(e){return this.match("#Organization+").getNth(e)}}(e),function(e){e.prototype.topics=Ac}(e)}};const Nc=function(e,t){const n={pre:e.none(),post:e.none()};if(!e.has("#Adverb"))return n;const r=e.splitOn(t);return 3===r.length?{pre:r.eq(0).adverbs(),post:r.eq(2).adverbs()}:r.eq(0).isDoc(t)?(n.post=r.eq(1).adverbs(),n):(n.pre=r.eq(0).adverbs(),n)},jc=function(e,t){const n=e.splitBefore(t);if(n.length<=1)return e.none();let r=n.eq(0);return r=r.not("(#Adverb|#Negative|#Prefix)"),r},xc=function(e){return e.match("#Negative")},Ic=function(e){if(!e.has("(#Particle|#PhrasalVerb)"))return{verb:e.none(),particle:e.none()};const t=e.match("#Particle$");return{verb:e.not(t),particle:t}},Tc=function(e){const t=e.clone();t.contractions().expand();const n=function(e){let t=e;return e.wordCount()>1&&(t=e.not("(#Negative|#Auxiliary|#Modal|#Adverb|#Prefix)")),t.length>1&&!t.has("#Phrasal #Particle")&&(t=t.last()),t=t.not("(want|wants|wanted) to"),t.found||(t=e.not("#Negative")),t}(t);return{root:n,prefix:t.match("#Prefix"),adverbs:Nc(t,n),auxiliary:jc(t,n),negative:xc(t),phrasal:Ic(n)}},Dc={tense:"PresentTense"},Hc={conditional:!0},Ec={tense:"FutureTense"},Gc={progressive:!0},Oc={tense:"PastTense"},Fc={complete:!0,progressive:!1},Vc={passive:!0},zc=function(e){const t={};return e.forEach((e=>{Object.assign(t,e)})),t},Bc={imperative:[["#Imperative",[]]],"want-infinitive":[["^(want|wants|wanted) to #Infinitive$",[Dc]],["^wanted to #Infinitive$",[Oc]],["^will want to #Infinitive$",[Ec]]],"gerund-phrase":[["^#PastTense #Gerund$",[Oc]],["^#PresentTense #Gerund$",[Dc]],["^#Infinitive #Gerund$",[Dc]],["^will #Infinitive #Gerund$",[Ec]],["^have #PastTense #Gerund$",[Oc]],["^will have #PastTense #Gerund$",[Oc]]],"simple-present":[["^#PresentTense$",[Dc]],["^#Infinitive$",[Dc]]],"simple-past":[["^#PastTense$",[Oc]]],"simple-future":[["^will #Adverb? #Infinitive",[Ec]]],"present-progressive":[["^(is|are|am) #Gerund$",[Dc,Gc]]],"past-progressive":[["^(was|were) #Gerund$",[Oc,Gc]]],"future-progressive":[["^will be #Gerund$",[Ec,Gc]]],"present-perfect":[["^(has|have) #PastTense$",[Oc,Fc]]],"past-perfect":[["^had #PastTense$",[Oc,Fc]],["^had #PastTense to #Infinitive",[Oc,Fc]]],"future-perfect":[["^will have #PastTense$",[Ec,Fc]]],"present-perfect-progressive":[["^(has|have) been #Gerund$",[Oc,Gc]]],"past-perfect-progressive":[["^had been #Gerund$",[Oc,Gc]]],"future-perfect-progressive":[["^will have been #Gerund$",[Ec,Gc]]],"passive-past":[["(got|were|was) #Passive",[Oc,Vc]],["^(was|were) being #Passive",[Oc,Vc]],["^(had|have) been #Passive",[Oc,Vc]]],"passive-present":[["^(is|are|am) #Passive",[Dc,Vc]],["^(is|are|am) being #Passive",[Dc,Vc]],["^has been #Passive",[Dc,Vc]]],"passive-future":[["will have been #Passive",[Ec,Vc,Hc]],["will be being? #Passive",[Ec,Vc,Hc]]],"present-conditional":[["would be #PastTense",[Dc,Hc]]],"past-conditional":[["would have been #PastTense",[Oc,Hc]]],"auxiliary-future":[["(is|are|am|was) going to (#Infinitive|#PresentTense)",[Ec]]],"auxiliary-past":[["^did #Infinitive$",[Oc,{plural:!1}]],["^used to #Infinitive$",[Oc,Fc]]],"auxiliary-present":[["^(does|do) #Infinitive$",[Dc,Fc,{plural:!0}]]],"modal-past":[["^(could|must|should|shall) have #PastTense$",[Oc]]],"modal-infinitive":[["^#Modal #Infinitive$",[]]],infinitive:[["^#Infinitive$",[]]]},Sc=[];Object.keys(Bc).map((e=>{Bc[e].forEach((t=>{Sc.push({name:e,match:t[0],data:zc(t[1])})}))}));const $c=function(e,t){const n={};e=function(e,t){return e=e.clone(),t.adverbs.post&&t.adverbs.post.found&&e.remove(t.adverbs.post),t.adverbs.pre&&t.adverbs.pre.found&&e.remove(t.adverbs.pre),e.has("#Negative")&&(e=e.remove("#Negative")),e.has("#Prefix")&&(e=e.remove("#Prefix")),t.root.has("#PhrasalVerb #Particle")&&e.remove("#Particle$"),e.not("#Adverb")}(e,t);for(let t=0;t!(e.has("^(if|unless|while|but|for|per|at|by|that|which|who|from)")||t>0&&e.has("^#Verb . #Noun+$")||t>0&&e.has("^#Adverb")))),0===t.length?e:t}(t);const n=t.nouns();let r=n.last();const o=r.match("(i|he|she|we|you|they)");if(o.found)return o.nouns();let a=n.if("^(that|this|those)");return a.found||!1===n.found&&(a=t.match("^(that|this|those)"),a.found)?a:(r=n.last(),Mc(r)&&(n.remove(r),r=n.last()),Mc(r)&&(n.remove(r),r=n.last()),r)}(e);return{subject:t,plural:Lc(t,e)}},Jc=e=>e,Wc=(e,t)=>{const n=Kc(e),r=n.subject;return!(!r.has("i")&&!r.has("we"))||n.plural},qc=function(e,t){if(e.has("were"))return"are";const{subject:n,plural:r}=Kc(e);return n.has("i")?"am":n.has("we")||r?"are":"is"},Uc=function(e,t){const n=Kc(e),r=n.subject;return r.has("i")||r.has("we")||n.plural?"do":"does"},Rc=function(e){return e.has("#Infinitive")?"Infinitive":e.has("#Participle")?"Participle":e.has("#PastTense")?"PastTense":e.has("#Gerund")?"Gerund":e.has("#PresentTense")?"PresentTense":void 0},Qc=function(e,t){const{toInfinitive:n}=e.methods.two.transform.verb;let r=t.root.text({keepPunct:!1});return r=n(r,e.model,Rc(e)),r&&e.replace(t.root,r),e},Zc=e=>e.has("will not")?e.replace("will not","have not"):e.remove("will"),_c=function(e){if(!e||!e.isView)return[];return e.json({normal:!0,terms:!1,text:!1}).map((e=>e.normal))},Xc=function(e){return e&&e.isView?e.text("normal"):""},Yc=function(e){const{toInfinitive:t}=e.methods.two.transform.verb;return t(e.text("normal"),e.model,Rc(e))},eh={tags:!0},th={tags:!0},nh={noAux:(e,t)=>(t.auxiliary.found&&(e=e.remove(t.auxiliary)),e),simple:(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,o=t.root;if(o.has("#Modal"))return e;let a=o.text({keepPunct:!1});a=r(a,e.model,Rc(o));return a=n(a,e.model).PastTense,a="been"===a?"was":a,"was"===a&&(a=((e,t)=>{const{subject:n,plural:r}=Kc(e);return r||n.has("we")?"were":"was"})(e)),a&&e.replace(o,a,th),e},both:function(e,t){return t.negative.found?(e.replace("will","did"),e):(e=nh.simple(e,t),e=nh.noAux(e,t))},hasHad:e=>(e.replace("has","had",th),e),hasParticiple:(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,o=t.root;let a=o.text("normal");return a=r(a,e.model,Rc(o)),n(a,e.model).Participle}},rh={infinitive:nh.simple,"simple-present":nh.simple,"simple-past":Jc,"simple-future":nh.both,"present-progressive":e=>(e.replace("are","were",th),e.replace("(is|are|am)","was",th),e),"past-progressive":Jc,"future-progressive":(e,t)=>(e.match(t.root).insertBefore("was"),e.remove("(will|be)"),e),"present-perfect":nh.hasHad,"past-perfect":Jc,"future-perfect":(e,t)=>(e.match(t.root).insertBefore("had"),e.has("will")&&(e=Zc(e)),e.remove("have"),e),"present-perfect-progressive":nh.hasHad,"past-perfect-progressive":Jc,"future-perfect-progressive":e=>(e.remove("will"),e.replace("have","had",th),e),"passive-past":e=>(e.replace("have","had",th),e),"passive-present":e=>(e.replace("(is|are)","was",th),e),"passive-future":(e,t)=>(t.auxiliary.has("will be")&&(e.match(t.root).insertBefore("had been"),e.remove("(will|be)")),t.auxiliary.has("will have been")&&(e.replace("have","had",th),e.remove("will")),e),"present-conditional":e=>(e.replace("be","have been"),e),"past-conditional":Jc,"auxiliary-future":e=>(e.replace("(is|are|am)","was",th),e),"auxiliary-past":Jc,"auxiliary-present":e=>(e.replace("(do|does)","did",th),e),"modal-infinitive":(e,t)=>(e.has("can")?e.replace("can","could",th):(nh.simple(e,t),e.match("#Modal").insertAfter("have").tag("Auxiliary")),e),"modal-past":Jc,"want-infinitive":e=>(e.replace("(want|wants)","wanted",th),e.remove("will"),e),"gerund-phrase":(e,t)=>(t.root=t.root.not("#Gerund$"),nh.simple(e,t),Zc(e),e)},oh=function(e,t){const n=Kc(e),r=n.subject;return r.has("(i|we|you)")?"have":!1===n.plural||r.has("he")||r.has("she")||r.has("#Person")?"has":"have"},ah=(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,{root:o,auxiliary:a}=t;if(o.has("#Modal"))return e;let i=o.text({keepPunct:!1});i=r(i,e.model,Rc(o));const s=n(i,e.model);if(i=s.Participle||s.PastTense,i){e=e.replace(o,i);const t=oh(e);e.prepend(t).match(t).tag("Auxiliary"),e.remove(a)}return e},ih={infinitive:ah,"simple-present":ah,"simple-future":(e,t)=>e.replace("will",oh(e)),"present-perfect":Jc,"past-perfect":Jc,"future-perfect":(e,t)=>e.replace("will have",oh(e)),"present-perfect-progressive":Jc,"past-perfect-progressive":Jc,"future-perfect-progressive":Jc},sh={tags:!0},lh=(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,o=t.root;let a=o.text("normal");return a=r(a,e.model,Rc(o)),!1===Wc(e)&&(a=n(a,e.model).PresentTense),o.has("#Copula")&&(a=qc(e)),a&&(e=e.replace(o,a,sh)).not("#Particle").tag("PresentTense"),e},uh=(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,o=t.root;let a=o.text("normal");return a=r(a,e.model,Rc(o)),!1===Wc(e)&&(a=n(a,e.model).Gerund),a&&(e=e.replace(o,a,sh)).not("#Particle").tag("Gerund"),e},ch={infinitive:lh,"simple-present":(e,t)=>{const{conjugate:n}=e.methods.two.transform.verb,{root:r}=t;if(!r.has("#Infinitive"))return lh(e,t);{const t=Kc(e).subject;if(Wc(e)||t.has("i"))return e;const o=r.text("normal"),a=n(o,e.model).PresentTense;o!==a&&e.replace(r,a,sh)}return e},"simple-past":lh,"simple-future":(e,t)=>{const{root:n,auxiliary:r}=t;if(r.has("will")&&n.has("be")){const t=qc(e);e.replace(n,t),(e=e.remove("will")).replace("not "+t,t+" not")}else lh(e,t),e=e.remove("will");return e},"present-progressive":Jc,"past-progressive":(e,t)=>{const n=qc(e);return e.replace("(were|was)",n,sh)},"future-progressive":e=>(e.match("will").insertBefore("is"),e.remove("be"),e.remove("will")),"present-perfect":(e,t)=>(lh(e,t),e=e.remove("(have|had|has)")),"past-perfect":(e,t)=>{const n=Kc(e).subject;return Wc(e)||n.has("i")?((e=Qc(e,t)).remove("had"),e):(e.replace("had","has",sh),e)},"future-perfect":e=>(e.match("will").insertBefore("has"),e.remove("have").remove("will")),"present-perfect-progressive":Jc,"past-perfect-progressive":e=>e.replace("had","has",sh),"future-perfect-progressive":e=>(e.match("will").insertBefore("has"),e.remove("have").remove("will")),"passive-past":(e,t)=>{const n=qc(e);return e.has("(had|have|has)")&&e.has("been")?(e.replace("(had|have|has)",n,sh),e.replace("been","being"),e):e.replace("(got|was|were)",n)},"passive-present":Jc,"passive-future":e=>(e.replace("will","is"),e.replace("be","being")),"present-conditional":Jc,"past-conditional":e=>(e.replace("been","be"),e.remove("have")),"auxiliary-future":(e,t)=>(uh(e,t),e.remove("(going|to)"),e),"auxiliary-past":(e,t)=>{if(t.auxiliary.has("did")){const n=Uc(e);return e.replace(t.auxiliary,n),e}return uh(e,t),e.replace(t.auxiliary,"is"),e},"auxiliary-present":Jc,"modal-infinitive":Jc,"modal-past":(e,t)=>(((e,t)=>{const{toInfinitive:n}=e.methods.two.transform.verb,r=t.root;let o=t.root.text("normal");o=n(o,e.model,Rc(r)),o&&(e=e.replace(t.root,o,sh))})(e,t),e.remove("have")),"gerund-phrase":(e,t)=>(t.root=t.root.not("#Gerund$"),lh(e,t),e.remove("(will|have)")),"want-infinitive":(e,t)=>{let n="wants";return Wc(e)&&(n="want"),e.replace("(want|wanted|wants)",n,sh),e.remove("will"),e}},hh={tags:!0},dh=(e,t)=>{const{toInfinitive:n}=e.methods.two.transform.verb,{root:r,auxiliary:o}=t;if(r.has("#Modal"))return e;let a=r.text("normal");return a=n(a,e.model,Rc(r)),a&&(e=e.replace(r,a,hh)).not("#Particle").tag("Verb"),e.prepend("will").match("will").tag("Auxiliary"),e.remove(o),e},gh=(e,t)=>{const{conjugate:n,toInfinitive:r}=e.methods.two.transform.verb,{root:o,auxiliary:a}=t;let i=o.text("normal");return i=r(i,e.model,Rc(o)),i&&(i=n(i,e.model).Gerund,e.replace(o,i,hh),e.not("#Particle").tag("PresentTense")),e.remove(a),e.prepend("will be").match("will be").tag("Auxiliary"),e},mh={infinitive:dh,"simple-present":dh,"simple-past":dh,"simple-future":Jc,"present-progressive":gh,"past-progressive":gh,"future-progressive":Jc,"present-perfect":e=>(e.match("(have|has)").replaceWith("will have"),e),"past-perfect":e=>e.replace("(had|has)","will have"),"future-perfect":Jc,"present-perfect-progressive":e=>e.replace("has","will have"),"past-perfect-progressive":e=>e.replace("had","will have"),"future-perfect-progressive":Jc,"passive-past":e=>e.has("got")?e.replace("got","will get"):e.has("(was|were)")?(e.replace("(was|were)","will be"),e.remove("being")):e.has("(have|has|had) been")?e.replace("(have|has|had) been","will be"):e,"passive-present":e=>(e.replace("being","will be"),e.remove("(is|are|am)"),e),"passive-future":Jc,"present-conditional":e=>e.replace("would","will"),"past-conditional":e=>e.replace("would","will"),"auxiliary-future":Jc,"auxiliary-past":e=>e.has("used")&&e.has("to")?(e.replace("used","will"),e.remove("to")):(e.replace("did","will"),e),"auxiliary-present":e=>e.replace("(do|does)","will"),"modal-infinitive":Jc,"modal-past":Jc,"gerund-phrase":(e,t)=>(t.root=t.root.not("#Gerund$"),dh(e,t),e.remove("(had|have)")),"want-infinitive":e=>(e.replace("(want|wants|wanted)","will want"),e)},ph={tags:!0},fh={tags:!0},bh=function(e,t){const n=Uc(e);return e.prepend(n+" not"),e},vh=function(e){let t=e.match("be");return t.found?(t.prepend("not"),e):(t=e.match("(is|was|am|are|will|were)"),t.found?(t.append("not"),e):e)},yh=e=>e.has("(is|was|am|are|will|were|be)"),wh={"simple-present":(e,t)=>!0===yh(e)?vh(e):(e=Qc(e,t),e=bh(e)),"simple-past":(e,t)=>!0===yh(e)?vh(e):((e=Qc(e,t)).prepend("did not"),e),imperative:e=>(e.prepend("do not"),e),infinitive:(e,t)=>!0===yh(e)?vh(e):bh(e),"passive-past":e=>{if(e.has("got"))return e.replace("got","get",fh),e.prepend("did not"),e;const t=e.match("(was|were|had|have)");return t.found&&t.append("not"),e},"auxiliary-past":e=>{if(e.has("used"))return e.prepend("did not"),e;const t=e.match("(did|does|do)");return t.found&&t.append("not"),e},"want-infinitive":(e,t)=>e=(e=bh(e)).replace("wants","want",fh)};var kh={api:function(e){class Verbs extends e{constructor(e,t,n){super(e,t,n),this.viewType="Verbs"}parse(e){return this.getNth(e).map(Tc)}json(e,t){const n=this.getNth(t).map((t=>{const n=t.toView().json(e)[0]||{};return n.verb=function(e){const t=Tc(e);e=e.clone().toView();const n=$c(e,t);return{root:t.root.text(),preAdverbs:_c(t.adverbs.pre),postAdverbs:_c(t.adverbs.post),auxiliary:Xc(t.auxiliary),negative:t.negative.found,prefix:Xc(t.prefix),infinitive:Yc(t.root),grammar:n}}(t),n}),[]);return n}subjects(e){return this.getNth(e).map((e=>(Tc(e),Kc(e).subject)))}adverbs(e){return this.getNth(e).map((e=>e.match("#Adverb")))}isSingular(e){return this.getNth(e).filter((e=>!0!==Kc(e).plural))}isPlural(e){return this.getNth(e).filter((e=>!0===Kc(e).plural))}isImperative(e){return this.getNth(e).filter((e=>e.has("#Imperative")))}toInfinitive(e){return this.getNth(e).map((e=>{const t=Tc(e);return function(e,t){const{toInfinitive:n}=e.methods.two.transform.verb,{root:r,auxiliary:o}=t,a=o.terms().harden();let i=r.text("normal");if(i=n(i,e.model,Rc(r)),i&&e.replace(r,i,eh).tag("Verb").firstTerm().tag("Infinitive"),a.found&&e.remove(a),t.negative.found){e.has("not")||e.prepend("not");const t=Uc(e);e.prepend(t)}return e.fullSentence().compute(["freeze","lexicon","preTagger","postTagger","unfreeze","chunks"]),e}(e,t,$c(e,t).form)}))}toPresentTense(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t,n){return ch.hasOwnProperty(n)?((e=ch[n](e,t)).fullSentence().compute(["tagger","chunks"]),e):e}(e,t,n.form)}))}toPastTense(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t,n){return rh.hasOwnProperty(n)?((e=rh[n](e,t)).fullSentence().compute(["tagger","chunks"]),e):e}(e,t,n.form)}))}toFutureTense(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t,n){return e.has("will")||e.has("going to")?e:mh.hasOwnProperty(n)?((e=mh[n](e,t)).fullSentence().compute(["tagger","chunks"]),e):e}(e,t,n.form)}))}toGerund(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t){const{toInfinitive:n,conjugate:r}=e.methods.two.transform.verb,{root:o,auxiliary:a}=t;if(e.has("#Gerund"))return e;let i=o.text("normal");i=n(i,e.model,Rc(o));const s=r(i,e.model).Gerund;if(s){const t=qc(e);e.replace(o,s,ph),e.remove(a),e.prepend(t)}return e.replace("not is","is not"),e.replace("not are","are not"),e.fullSentence().compute(["tagger","chunks"]),e}(e,t,n.form)}))}toPastParticiple(e){return this.getNth(e).map((e=>{const t=Tc(e),n=$c(e,t);return n.isInfinitive?e:function(e,t,n){return ih.hasOwnProperty(n)?((e=ih[n](e,t)).fullSentence().compute(["tagger","chunks"]),e):((e=ah(e,t)).fullSentence().compute(["tagger","chunks"]),e)}(e,t,n.form)}))}conjugate(e){const{conjugate:t,toInfinitive:n}=this.world.methods.two.transform.verb;return this.getNth(e).map((e=>{const r=Tc(e),o=$c(e,r);"imperative"===o.form&&(o.form="simple-present");let a=r.root.text("normal");if(!r.root.has("#Infinitive")){const t=Rc(r.root);a=n(a,e.model,t)||a}return t(a,e.model)}),[])}isNegative(){return this.if("#Negative")}isPositive(){return this.ifNo("#Negative")}toPositive(){const e=this.match("do not #Verb");return e.found&&e.remove("do not"),this.remove("#Negative")}toNegative(e){return this.getNth(e).map((e=>{const t=Tc(e);return function(e,t,n){if(e.has("#Negative"))return e;if(wh.hasOwnProperty(n))return wh[n](e,t);let r=e.matchOne("be");return r.found?(r.prepend("not"),e):!0===yh(e)?vh(e):(r=e.matchOne("(will|had|have|has|did|does|do|#Modal)"),r.found?(r.append("not"),e):e)}(e,t,$c(e,t).form)}))}update(e){const t=new Verbs(this.document,e);return t._cache=this._cache,t}}Verbs.prototype.toPast=Verbs.prototype.toPastTense,Verbs.prototype.toPresent=Verbs.prototype.toPresentTense,Verbs.prototype.toFuture=Verbs.prototype.toFutureTense,e.prototype.verbs=function(e){let t=function(e){let t=e.match("");return t=t.not("#Conjunction"),t=t.not("#Preposition"),t=t.splitAfter("@hasComma"),t=t.splitAfter("[(do|did|am|was|is|will)] (is|was)",0),t=t.splitBefore("(#Verb && !#Copula) [being] #Verb",0),t=t.splitBefore("#Verb [to be] #Verb",0),t=t.splitAfter("[help] #PresentTense",0),t=t.splitBefore("(#PresentTense|#PastTense) [#Copula]$",0),t=t.splitBefore("(#PresentTense|#PastTense) [will be]$",0),t=t.splitBefore("(#PresentTense|#PastTense) [(had|has)]",0),t=t.not("#Reflexive$"),t=t.not("#Adjective"),t=t.splitAfter("[#PastTense] #PastTense",0),t=t.splitAfter("[#PastTense] #Auxiliary+ #PastTense",0),t=t.splitAfter("#Copula [#Gerund] #PastTense",0),t=t.if("#Verb"),t.has("(#Verb && !#Auxiliary) #Adverb+? #Copula")&&(t=t.splitBefore("#Copula")),t}(this);return t=t.getNth(e),new Verbs(this.document,t.pointer)}}};const Ph=function(e,t){const n=t.match(e);if(n.found){const e=n.pronouns().refersTo();if(e.found)return e}return t.none()},Ah=function(e){if(!e.found)return e;const[t]=e.fullPointer[0];return t&&t>0?e.update([[t-1]]):e.none()},Ch=function(e,t){let n=e.people();return n=function(e,t){return"m"===t?e.filter((e=>!e.presumedFemale().found)):"f"===t?e.filter((e=>!e.presumedMale().found)):e}(n,t),n.found?n.last():(n=e.nouns("#Actor"),n.found?n.last():"f"===t?Ph("(she|her|hers)",e):"m"===t?Ph("(he|him|his)",e):e.none())},Nh=function(e){const t=e.nouns();let n=t.isPlural().notIf("#Pronoun");if(n.found)return n.last();const r=Ph("(they|their|theirs)",e);return r.found?r:(n=t.match("(somebody|nobody|everybody|anybody|someone|noone|everyone|anyone)"),n.found?n.last():e.none())},jh=function(e,t){let n=e.before(),r=t(n);return r.found?r:(n=Ah(e),r=t(n),r.found?r:(n=Ah(n),r=t(n),r.found?r:e.none()))};var xh={compute:{coreference:function(e){e.pronouns().if("(he|him|his|she|her|hers|they|their|theirs|it|its)").forEach((e=>{let t=null;e.has("(he|him|his)")?t=jh(e,(e=>Ch(e,"m"))):e.has("(she|her|hers)")?t=jh(e,(e=>Ch(e,"f"))):e.has("(they|their|theirs)")&&(t=jh(e,Nh)),t&&t.found&&function(e,t){t&&t.found&&(e.docs[0][0].reference=t.ptrs[0])}(e,t)}))}},api:function(e){class Pronouns extends e{constructor(e,t,n){super(e,t,n),this.viewType="Pronouns"}hasReference(){return this.compute("coreference"),this.filter((e=>e.docs[0][0].reference))}refersTo(){return this.compute("coreference"),this.map((e=>{if(!e.found)return e.none();const t=e.docs[0][0];return t.reference?e.update([t.reference]):e.none()}))}update(e){const t=new Pronouns(this.document,e);return t._cache=this._cache,t}}e.prototype.pronouns=function(e){let t=this.match("#Pronoun");return t=t.getNth(e),new Pronouns(t.document,t.pointer)}}};h.plugin(ql),h.plugin(Ul),h.plugin(eu),h.plugin(xh),h.plugin(fu),h.plugin(Au),h.plugin(Ou),h.plugin(hc),h.plugin(mc),h.plugin(bc),h.plugin(Cc),h.plugin(kh);export{h as default};
================================================
FILE: builds/two/compromise-two.cjs
================================================
!function(e,t){"object"==typeof exports&&"undefined"!=typeof module?module.exports=t():"function"==typeof define&&define.amd?define(t):(e="undefined"!=typeof globalThis?globalThis:e||self).nlp=t()}(this,(function(){"use strict";var e={methods:{one:{},two:{},three:{},four:{}},model:{one:{},two:{},three:{}},compute:{},hooks:[]};const t={compute:function(e){const{world:t}=this,n=t.compute;return"string"==typeof e&&n.hasOwnProperty(e)?n[e](this):(e=>"[object Array]"===Object.prototype.toString.call(e))(e)?e.forEach((a=>{t.compute.hasOwnProperty(a)?n[a](this):console.warn("no compute:",e)})):"function"==typeof e?e(this):console.warn("no compute:",e),this}};var n={forEach:function(e){return this.fullPointer.forEach(((t,n)=>{const a=this.update([t]);e(a,n)})),this},map:function(e,t){const n=this.fullPointer.map(((t,n)=>{const a=this.update([t]),r=e(a,n);return void 0===r?this.none():r}));if(0===n.length)return t||this.update([]);if(void 0!==n[0]){if("string"==typeof n[0])return n;if("object"==typeof n[0]&&(null===n[0]||!n[0].isView))return n}let a=[];return n.forEach((e=>{a=a.concat(e.fullPointer)})),this.toView(a)},filter:function(e){let t=this.fullPointer;t=t.filter(((t,n)=>{const a=this.update([t]);return e(a,n)}));return this.update(t)},find:function(e){const t=this.fullPointer.find(((t,n)=>{const a=this.update([t]);return e(a,n)}));return this.update([t])},some:function(e){return this.fullPointer.some(((t,n)=>{const a=this.update([t]);return e(a,n)}))},random:function(e=1){let t=this.fullPointer,n=Math.floor(Math.random()*t.length);return n+e>this.length&&(n=this.length-e,n=n<0?0:n),t=t.slice(n,n+e),this.update(t)}};const a={termList:function(){return this.methods.one.termList(this.docs)},terms:function(e){const t=this.match(".");return"number"==typeof e?t.eq(e):t},groups:function(e){if(e||0===e)return this.update(this._groups[e]||[]);const t={};return Object.keys(this._groups).forEach((e=>{t[e]=this.update(this._groups[e])})),t},eq:function(e){let t=this.pointer;return t||(t=this.docs.map(((e,t)=>[t]))),t[e]?this.update([t[e]]):this.none()},first:function(){return this.eq(0)},last:function(){const e=this.fullPointer.length-1;return this.eq(e)},firstTerms:function(){return this.match("^.")},lastTerms:function(){return this.match(".$")},slice:function(e,t){let n=this.pointer||this.docs.map(((e,t)=>[t]));return n=n.slice(e,t),this.update(n)},all:function(){return this.update().toView()},fullSentences:function(){const e=this.fullPointer.map((e=>[e[0]]));return this.update(e).toView()},none:function(){return this.update([])},isDoc:function(e){if(!e||!e.isView)return!1;const t=this.fullPointer,n=e.fullPointer;return!t.length!==n.length&&t.every(((e,t)=>!!n[t]&&(e[0]===n[t][0]&&e[1]===n[t][1]&&e[2]===n[t][2])))},wordCount:function(){return this.docs.reduce(((e,t)=>(e+=t.filter((e=>""!==e.text)).length,e)),0)},isFull:function(){const e=this.pointer;if(!e)return!0;if(0===e.length||0!==e[0][0])return!1;let t=0,n=0;return this.document.forEach((e=>t+=e.length)),this.docs.forEach((e=>n+=e.length)),t===n},getNth:function(e){return"number"==typeof e?this.eq(e):"string"==typeof e?this.if(e):this}};a.group=a.groups,a.fullSentence=a.fullSentences,a.sentence=a.fullSentences,a.lastTerm=a.lastTerms,a.firstTerm=a.firstTerms;const r=Object.assign({},a,t,n);r.get=r.eq;class View{constructor(t,n,a={}){[["document",t],["world",e],["_groups",a],["_cache",null],["viewType","View"]].forEach((e=>{Object.defineProperty(this,e[0],{value:e[1],writable:!0})})),this.ptrs=n}get docs(){let t=this.document;return this.ptrs&&(t=e.methods.one.getDoc(this.ptrs,this.document)),t}get pointer(){return this.ptrs}get methods(){return this.world.methods}get model(){return this.world.model}get hooks(){return this.world.hooks}get isView(){return!0}get found(){return this.docs.length>0}get length(){return this.docs.length}get fullPointer(){const{docs:e,ptrs:t,document:n}=this,a=t||e.map(((e,t)=>[t]));return a.map((e=>{let[t,a,r,o,i]=e;return a=a||0,r=r||(n[t]||[]).length,n[t]&&n[t][a]&&(o=o||n[t][a].id,n[t][r-1]&&(i=i||n[t][r-1].id)),[t,a,r,o,i]}))}update(e){const t=new View(this.document,e);if(this._cache&&e&&e.length>0){const n=[];e.forEach(((e,t)=>{const[a,r,o]=e;(1===e.length||0===r&&this.document[a].length===o)&&(n[t]=this._cache[a])})),n.length>0&&(t._cache=n)}return t.world=this.world,t}toView(e){return new View(this.document,e||this.pointer)}fromText(e){const{methods:t}=this,n=t.one.tokenize.fromString(e,this.world),a=new View(n);return a.world=this.world,a.compute(["normal","freeze","lexicon"]),this.world.compute.preTagger&&a.compute("preTagger"),a.compute("unfreeze"),a}clone(){let e=this.document.slice(0);e=e.map((e=>e.map((e=>((e=Object.assign({},e)).tags=new Set(e.tags),e)))));const t=this.update(this.pointer);return t.document=e,t._cache=this._cache,t}}Object.assign(View.prototype,r);const o=function(e){return e&&"object"==typeof e&&!Array.isArray(e)};function i(e,t){if(o(t))for(const n in t)o(t[n])?(e[n]||Object.assign(e,{[n]:{}}),i(e[n],t[n])):Object.assign(e,{[n]:t[n]});return e}const s=function(e,t,n,a){if(r=e,"[object Array]"===Object.prototype.toString.call(r))return void e.forEach((e=>s(e,t,n,a)));var r;const{methods:o,model:l,compute:u,hooks:c}=t;e.methods&&function(e,t){for(const n in t)e[n]=e[n]||{},Object.assign(e[n],t[n])}(o,e.methods),e.model&&i(l,e.model),e.irregulars&&function(e,t){const n=e.two.models||{};Object.keys(t).forEach((e=>{t[e].pastTense&&(n.toPast&&(n.toPast.ex[e]=t[e].pastTense),n.fromPast&&(n.fromPast.ex[t[e].pastTense]=e)),t[e].presentTense&&(n.toPresent&&(n.toPresent.ex[e]=t[e].presentTense),n.fromPresent&&(n.fromPresent.ex[t[e].presentTense]=e)),t[e].gerund&&(n.toGerund&&(n.toGerund.ex[e]=t[e].gerund),n.fromGerund&&(n.fromGerund.ex[t[e].gerund]=e)),t[e].comparative&&(n.toComparative&&(n.toComparative.ex[e]=t[e].comparative),n.fromComparative&&(n.fromComparative.ex[t[e].comparative]=e)),t[e].superlative&&(n.toSuperlative&&(n.toSuperlative.ex[e]=t[e].superlative),n.fromSuperlative&&(n.fromSuperlative.ex[t[e].superlative]=e))}))}(l,e.irregulars),e.compute&&Object.assign(u,e.compute),c&&(t.hooks=c.concat(e.hooks||[])),e.api&&e.api(n),e.lib&&Object.keys(e.lib).forEach((t=>a[t]=e.lib[t])),e.tags&&a.addTags(e.tags),e.words&&a.addWords(e.words),e.frozen&&a.addWords(e.frozen,!0),e.mutate&&e.mutate(t,a)},l=function(e){return"[object Array]"===Object.prototype.toString.call(e)},u=function(e,t,n){const{methods:a}=n,r=new t([]);if(r.world=n,"number"==typeof e&&(e=String(e)),!e)return r;if("string"==typeof e){return new t(a.one.tokenize.fromString(e,n))}if(o=e,"[object Object]"===Object.prototype.toString.call(o)&&e.isView)return new t(e.document,e.ptrs);var o;if(l(e)){if(l(e[0])){const n=e.map((e=>e.map((e=>({text:e,normal:e,pre:"",post:" ",tags:new Set})))));return new t(n)}const n=e.map((e=>e.terms.map((e=>(l(e.tags)&&(e.tags=new Set(e.tags)),e)))));return new t(n)}return r},c=Object.assign({},e),d=function(e,t){t&&d.addWords(t);const n=u(e,View,c);return e&&n.compute(c.hooks),n};Object.defineProperty(d,"_world",{value:c,writable:!0}),d.tokenize=function(e,t){const{compute:n}=this._world;t&&d.addWords(t);const a=u(e,View,c);return n.contractions&&a.compute(["alias","normal","machine","contractions"]),a},d.plugin=function(e){return s(e,this._world,View,this),this},d.extend=d.plugin,d.world=function(){return this._world},d.model=function(){return this._world.model},d.methods=function(){return this._world.methods},d.hooks=function(){return this._world.hooks},d.verbose=function(e){const t="undefined"!=typeof process&&process.env?process.env:self.env||{};return t.DEBUG_TAGS="tagger"===e||!0===e||"",t.DEBUG_MATCH="match"===e||!0===e||"",t.DEBUG_CHUNKS="chunker"===e||!0===e||"",this},d.version="14.15.0";var h={one:{cacheDoc:function(e){const t=e.map((e=>{const t=new Set;return e.forEach((e=>{""!==e.normal&&t.add(e.normal),e.switch&&t.add(`%${e.switch}%`),e.implicit&&t.add(e.implicit),e.machine&&t.add(e.machine),e.root&&t.add(e.root),e.alias&&e.alias.forEach((e=>t.add(e)));const n=Array.from(e.tags);for(let e=0;e/^\p{Lu}[\p{Ll}'’]/u.test(e)||/^\p{Lu}$/u.test(e),b=(e,t,n)=>{if(n.forEach((e=>e.dirty=!0)),e){const a=[t,0].concat(n);Array.prototype.splice.apply(e,a)}return e},y=function(e){const t=e[e.length-1];!t||/ $/.test(t.post)||/[-–—]/.test(t.post)||(t.post+=" ")},v=(e,t,n)=>{const a=/[-.?!,;:)–—'"]/g,r=e[t-1];if(!r)return;const o=r.post;if(a.test(o)){const e=o.match(a).join(""),t=n[n.length-1];t.post=e+t.post,r.post=r.post.replace(a,"")}},w=function(e,t,n,a){const[r,o,i]=t;0===o||i===a[r].length?y(n):(y(n),y([e[t[1]]])),function(e,t,n){const a=e[t];if(0!==t||!f(a.text))return;n[0].text=n[0].text.replace(/^\p{Ll}/u,(e=>e.toUpperCase()));const r=e[t];r.tags.has("ProperNoun")||r.tags.has("Acronym")||f(r.text)&&r.text.length>1&&(r.text=(o=r.text,o.replace(/^\p{Lu}/u,(e=>e.toLowerCase()))));var o}(e,o,n),b(e,o,n)};let k=0;const P=e=>(e=e.length<3?"0"+e:e).length<3?"0"+e:e,A=function(e){let[t,n]=e.index||[0,0];k+=1,k=k>46655?0:k,t=t>46655?0:t,n=n>1294?0:n;let a=P(k.toString(36));a+=P(t.toString(36));let r=n.toString(36);r=r.length<2?"0"+r:r,a+=r;return a+=parseInt(36*Math.random(),10).toString(36),e.normal+"|"+a.toUpperCase()},C=function(e){if(e.has("@hasContraction")&&"function"==typeof e.contractions){e.grow("@hasContraction").contractions().expand()}},j=e=>"[object Array]"===Object.prototype.toString.call(e),N=function(e,t,n){const{document:a,world:r}=t;t.uncache();const o=t.fullPointer,i=t.fullPointer;t.forEach(((s,l)=>{const u=s.fullPointer[0],[c]=u,d=a[c];let h=function(e,t){const{methods:n}=t;return"string"==typeof e?n.one.tokenize.fromString(e,t)[0]:"object"==typeof e&&e.isView?e.clone().docs[0]||[]:j(e)?j(e[0])?e[0]:e:[]}(e,r);0!==h.length&&(h=function(e){return e.map((e=>(e.id=A(e),e)))}(h),n?(C(t.update([u]).firstTerm()),w(d,u,h,a)):(C(t.update([u]).lastTerm()),function(e,t,n,a){const[r,,o]=t,i=(a[r]||[]).length;oe.replace(/^\p{Ll}/u,(e=>e.toUpperCase())),G=e=>e.replace(/^\p{Lu}/u,(e=>e.toLowerCase()));H.replaceWith=function(e,t={}){let n=this.fullPointer;const a=this;if(this.uncache(),"function"==typeof e)return function(e,t,n){return e.forEach((e=>{const a=t(e);e.replaceWith(a,n)})),e}(a,e,t);const r=a.docs[0];if(!r)return a;const o=t.possessives&&r[r.length-1].tags.has("Possessive"),i=t.case&&(s=r[0].text,/^\p{Lu}[\p{Ll}'’]/u.test(s)||/^\p{Lu}$/u.test(s));var s;e=function(e,t){if("string"!=typeof e)return e;const n=t.groups();return e=e.replace(D,(e=>{const t=e.replace(/\$/,"");return n.hasOwnProperty(t)?n[t].text():e})),e}(e,a);const l=this.update(n);n=n.map((e=>e.slice(0,3)));const u=(l.docs[0]||[]).map((e=>Array.from(e.tags))),c=l.docs[0][0].pre,d=l.docs[0][l.docs[0].length-1].post;if("string"==typeof e&&(e=this.fromText(e).compute("id")),a.insertAfter(e),l.has("@hasContraction")&&a.contractions){a.grow("@hasContraction+").contractions().expand()}if(a.delete(l),o){const e=a.docs[0],t=e[e.length-1];t.tags.has("Possessive")||(t.text+="'s",t.normal+="'s",t.tags.add("Possessive"))}if(c&&a.docs[0]&&(a.docs[0][0].pre=c),d&&a.docs[0]){const e=a.docs[0][a.docs[0].length-1];e.post.trim()||(e.post=d)}const h=a.toView(n).compute(["index","freeze","lexicon"]);if(h.world.compute.preTagger&&h.compute("preTagger"),h.compute("unfreeze"),t.tags&&h.terms().forEach(((e,t)=>{e.tagSafe(u[t])})),!h.docs[0]||!h.docs[0][0])return h;if(t.case){const e=i?T:G;h.docs[0][0].text=e(h.docs[0][0].text)}return h},H.replace=function(e,t,n){if(e&&!t)return this.replaceWith(e,n);const a=this.match(e);return a.found?(this.soften(),a.replaceWith(t,n)):this};const x={remove:function(e){const{indexN:t}=this.methods.one.pointer;this.uncache();let n=this.all(),a=this;e&&(n=this,a=this.match(e));const r=!n.ptrs;if(a.has("@hasContraction")&&a.contractions){a.grow("@hasContraction").contractions().expand()}let o=n.fullPointer;const i=a.fullPointer.reverse(),s=function(e,t){t.forEach((t=>{const[n,a,r]=t,o=r-a;e[n]&&(r===e[n].length&&r>1&&function(e,t){const n=e.length-1,a=e[n],r=e[n-t];r&&a&&(r.post+=a.post,r.post=r.post.replace(/ +([.?!,;:])/,"$1"),r.post=r.post.replace(/[,;:]+([.?!])/,"$1"))}(e[n],o),e[n].splice(a,o))}));for(let t=e.length-1;t>=0;t-=1)if(0===e[t].length&&(e.splice(t,1),t===e.length&&e[t-1])){const n=e[t-1],a=n[n.length-1];a&&(a.post=a.post.trimEnd())}return e}(this.document,i);if(o=function(e,t){return e=e.map((e=>{const[n]=e;return t[n]?(t[n].forEach((t=>{const n=t[2]-t[1];e[1]<=t[1]&&e[2]>=t[2]&&(e[2]-=n)})),e):e})),e.forEach(((t,n)=>{if(0===t[1]&&0==t[2])for(let t=n+1;te[2]-e[1]>0))).map((e=>(e[3]=null,e[4]=null,e)))}(o,t(i)),n.ptrs=o,n.document=s,n.compute("index"),r&&(n.ptrs=void 0),!e)return this.ptrs=[],n.none();return n.toView(o)}};x.delete=x.remove;const E={pre:function(e,t){return void 0===e&&this.found?this.docs[0][0].pre:(this.docs.forEach((n=>{const a=n[0];!0===t?a.pre+=e:a.pre=e})),this)},post:function(e,t){if(void 0===e){const e=this.docs[this.docs.length-1];return e[e.length-1].post}return this.docs.forEach((n=>{const a=n[n.length-1];!0===t?a.post+=e:a.post=e})),this},trim:function(){if(!this.found)return this;const e=this.docs,t=e[0][0];t.pre=t.pre.trimStart();const n=e[e.length-1],a=n[n.length-1];return a.post=a.post.trimEnd(),this},hyphenate:function(){return this.docs.forEach((e=>{e.forEach(((t,n)=>{0!==n&&(t.pre=""),e[n+1]&&(t.post="-")}))})),this},dehyphenate:function(){const e=/[-–—]/;return this.docs.forEach((t=>{t.forEach((t=>{e.test(t.post)&&(t.post=" ")}))})),this},toQuotations:function(e,t){return e=e||'"',t=t||'"',this.docs.forEach((n=>{n[0].pre=e+n[0].pre;const a=n[n.length-1];a.post=t+a.post})),this},toParentheses:function(e,t){return e=e||"(",t=t||")",this.docs.forEach((n=>{n[0].pre=e+n[0].pre;const a=n[n.length-1];a.post=t+a.post})),this}};E.deHyphenate=E.dehyphenate,E.toQuotation=E.toQuotations;var F={alpha:(e,t)=>e.normalt.normal?1:0,length:(e,t)=>{const n=e.normal.trim().length,a=t.normal.trim().length;return na?-1:0},wordCount:(e,t)=>e.wordst.words?-1:0,sequential:(e,t)=>e[0]t[0]?-1:e[1]>t[1]?1:-1,byFreq:function(e){const t={};return e.forEach((e=>{t[e.normal]=t[e.normal]||0,t[e.normal]+=1})),e.sort(((e,n)=>{const a=t[e.normal],r=t[n.normal];return ar?-1:0})),e}};const O=new Set(["index","sequence","seq","sequential","chron","chronological"]),z=new Set(["freq","frequency","topk","repeats"]),V=new Set(["alpha","alphabetical"]);var B={unique:function(){const e=new Set,t=this.filter((t=>{const n=t.text("machine");return!e.has(n)&&(e.add(n),!0)}));return t},reverse:function(){let e=this.pointer||this.docs.map(((e,t)=>[t]));return e=[].concat(e),e=e.reverse(),this._cache&&(this._cache=this._cache.reverse()),this.update(e)},sort:function(e){const{docs:t,pointer:n}=this;if(this.uncache(),"function"==typeof e)return function(e,t){let n=e.fullPointer;return n=n.sort(((n,a)=>(n=e.update([n]),a=e.update([a]),t(n,a)))),e.ptrs=n,e}(this,e);e=e||"alpha";const a=n||t.map(((e,t)=>[t]));let r=t.map(((e,t)=>({index:t,words:e.length,normal:e.map((e=>e.machine||e.normal||"")).join(" "),pointer:a[t]})));return O.has(e)&&(e="sequential"),V.has(e)&&(e="alpha"),z.has(e)?(r=F.byFreq(r),this.update(r.map((e=>e.pointer)))):"function"==typeof F[e]?(r=r.sort(F[e]),this.update(r.map((e=>e.pointer)))):this}};const S=function(e,t){if(e.length>0){const t=e[e.length-1],n=t[t.length-1];!1===/ /.test(n.post)&&(n.post+=" ")}return e=e.concat(t)};var K={concat:function(e){if("string"==typeof e){const t=this.fromText(e);if(this.found&&this.ptrs){const e=this.fullPointer,n=e[e.length-1][0];this.document.splice(n,0,...t.document)}else this.document=this.document.concat(t.document);return this.all().compute("index")}if("object"==typeof e&&e.isView)return function(e,t){if(e.document===t.document){const n=e.fullPointer.concat(t.fullPointer);return e.toView(n).compute("index")}return t.fullPointer.forEach((t=>{t[0]+=e.document.length})),e.document=S(e.document,t.docs),e.all()}(this,e);if(t=e,"[object Array]"===Object.prototype.toString.call(t)){const t=S(this.document,e);return this.document=t,this.all()}var t;return this}};var $={harden:function(){return this.ptrs=this.fullPointer,this},soften:function(){let e=this.ptrs;return!e||e.length<1||(e=e.map((e=>e.slice(0,3))),this.ptrs=e),this}};const L=Object.assign({},{toLowerCase:function(){return this.termList().forEach((e=>{e.text=e.text.toLowerCase()})),this},toUpperCase:function(){return this.termList().forEach((e=>{e.text=e.text.toUpperCase()})),this},toTitleCase:function(){return this.termList().forEach((e=>{e.text=e.text.replace(/^ *[a-z\u00C0-\u00FF]/,(e=>e.toUpperCase()))})),this},toCamelCase:function(){return this.docs.forEach((e=>{e.forEach(((t,n)=>{0!==n&&(t.text=t.text.replace(/^ *[a-z\u00C0-\u00FF]/,(e=>e.toUpperCase()))),n!==e.length-1&&(t.post="")}))})),this}},I,H,x,E,B,K,$),M={id:function(e){const t=e.docs;for(let e=0;e(e.implicit=e.text,e.machine=e.text,e.pre="",e.post="",e.text="",e.normal="",e.index=[a,r+t],e))),n[0]&&(n[0].pre=e[a][r].pre,n[n.length-1].post=e[a][r].post,n[0].text=e[a][r].text,n[0].normal=e[a][r].normal),e[a].splice(r,1,...n))},R=/'/,Q=new Set(["what","how","when","where","why"]),Z=new Set(["be","go","start","think","need"]),X=new Set(["been","gone"]),_=/'/,Y=/(e|é|aison|sion|tion)$/,ee=/(age|isme|acle|ege|oire)$/;var te=(e,t)=>["je",e[t].normal.split(_)[1]],ne=(e,t)=>{const n=e[t].normal.split(_)[1];return n&&n.endsWith("e")?["la",n]:["le",n]},ae=(e,t)=>{const n=e[t].normal.split(_)[1];return n&&Y.test(n)&&!ee.test(n)?["du",n]:n&&n.endsWith("s")?["des",n]:["de",n]};const re=/^([0-9.]{1,4}[a-z]{0,2}) ?[-–—] ?([0-9]{1,4}[a-z]{0,2})$/i,oe=/^([0-9]{1,2}(:[0-9][0-9])?(am|pm)?) ?[-–—] ?([0-9]{1,2}(:[0-9][0-9])?(am|pm)?)$/i,ie=/^[0-9]{3}-[0-9]{4}$/,se=function(e,t){const n=e[t];let a=n.text.match(re);return null!==a?!0===n.tags.has("PhoneNumber")||ie.test(n.text)?null:[a[1],"to",a[2]]:(a=n.text.match(oe),null!==a?[a[1],"to",a[4]]:null)},le=/^([+-]?[0-9][.,0-9]*)([a-z°²³µ/]+)$/,ue=function(e,t,n){const a=n.model.one.numberSuffixes||{},r=e[t].text.match(le);if(null!==r){const e=r[2].toLowerCase().trim();return a.hasOwnProperty(e)?null:[r[1],e]}return null},ce=/'/,de=/^[0-9][^-–—]*[-–—].*?[0-9]/,he=function(e,t,n,a){const r=t.update();r.document=[e];let o=n+a;n>0&&(n-=1),e[o]&&(o+=1),r.ptrs=[[0,n,o]]},ge={t:(e,t)=>function(e,t){return"ain't"===e[t].normal||"aint"===e[t].normal?null:[e[t].normal.replace(/n't/,""),"not"]}(e,t),d:(e,t)=>function(e,t){const n=e[t].normal.split(R)[0];if(Q.has(n))return[n,"did"];if(e[t+1]){if(X.has(e[t+1].normal))return[n,"had"];if(Z.has(e[t+1].normal))return[n,"would"]}return null}(e,t)},me={j:(e,t)=>te(e,t),l:(e,t)=>ne(e,t),d:(e,t)=>ae(e,t)},pe=function(e,t,n,a){for(let r=0;r2)return o.out.concat(a)}return null},fe=function(e,t){const n=t.fromText(e.join(" "));return n.compute(["id","alias"]),n.docs[0]},be=function(e,t){for(let n=t+1;n<5&&e[n];n+=1)if("been"===e[n].normal)return["there","has"];return["there","is"]};var ye={contractions:e=>{const{world:t,document:n}=e,{model:a,methods:r}=t,o=a.one.contractions||[];n.forEach(((a,i)=>{for(let s=a.length-1;s>=0;s-=1){let l=null,u=null;if(!0===ce.test(a[s].normal)){const e=a[s].normal.split(ce);l=e[0],u=e[1]}let c=pe(o,a[s],l,u);!c&&ge.hasOwnProperty(u)&&(c=ge[u](a,s,t)),!c&&me.hasOwnProperty(l)&&(c=me[l](a,s)),"there"===l&&"s"===u&&(c=be(a,s)),c?(c=fe(c,e),q(n,[i,s],c),he(n[i],e,s,c.length)):de.test(a[s].normal)?(c=se(a,s),c&&(c=fe(c,e),q(n,[i,s],c),r.one.setTag(c,"NumberRange",t),c[2]&&c[2].tags.has("Time")&&r.one.setTag([c[0]],"Time",t,null,"time-range"),he(n[i],e,s,c.length))):(c=ue(a,s,t),c&&(c=fe(c,e),q(n,[i,s],c),r.one.setTag([c[1]],"Unit",t,null,"contraction-unit")))}}))}};const ve={model:U,compute:ye,hooks:["contractions"]},we=function(e){const t=e.world,{model:n,methods:a}=e.world,r=a.one.setTag,{frozenLex:o}=n.one,i=n.one._multiCache||{};e.docs.forEach((e=>{for(let n=0;nn;a-=1){const i=e.slice(n,a+1),s=i.map((e=>e.machine||e.normal)).join(" ");!0!==o.hasOwnProperty(s)||(r(i,o[s],t,!1,"1-frozen-multi-lexicon"),i.forEach((e=>e.frozen=!0)))}}void 0!==o[s]&&o.hasOwnProperty(s)&&(r([a],o[s],t,!1,"1-freeze-lexicon"),a.frozen=!0)}}))};const ke=e=>"�[34m"+e+"�[0m",Pe=e=>"�[3m�[2m"+e+"�[0m",Ae=function(e){e.docs.forEach((e=>{console.log(ke("\n ┌─────────")),e.forEach((e=>{let t=` ${Pe("│")} `;const n=e.implicit||e.text||"-";!0===e.frozen?t+=`${ke(n)} ❄️`:t+=Pe(n),console.log(t)}))}))};var Ce={compute:{frozen:we,freeze:we,unfreeze:function(e){return e.docs.forEach((e=>{e.forEach((e=>{delete e.frozen}))})),e}},mutate:e=>{const t=e.methods.one;t.termMethods.isFrozen=e=>!0===e.frozen,t.debug.freeze=Ae,t.debug.frozen=Ae},api:function(e){e.prototype.freeze=function(){return this.docs.forEach((e=>{e.forEach((e=>{e.frozen=!0}))})),this},e.prototype.unfreeze=function(){this.compute("unfreeze")},e.prototype.isFrozen=function(){return this.match("@isFrozen+")}},hooks:["freeze"]};const je=function(e,t,n){const{model:a,methods:r}=n,o=r.one.setTag,i=a.one._multiCache||{},{lexicon:s}=a.one||{},l=e[t],u=l.machine||l.normal;if(void 0!==i[u]&&e[t+1]){for(let a=t+i[u]-1;a>t;a-=1){const r=e.slice(t,a+1);if(r.length<=1)return!1;const i=r.map((e=>e.machine||e.normal)).join(" ");if(!0===s.hasOwnProperty(i)){const e=s[i];return o(r,e,n,!1,"1-multi-lexicon"),!e||2!==e.length||"PhrasalVerb"!==e[0]&&"PhrasalVerb"!==e[1]||o([r[1]],"Particle",n,!1,"1-phrasal-particle"),!0}}return!1}return null},Ne=/^(under|over|mis|re|un|dis|semi|pre|post)-?/,Ie=new Set(["Verb","Infinitive","PastTense","Gerund","PresentTense","Adjective","Participle"]),De=function(e,t,n){const{model:a,methods:r}=n,o=r.one.setTag,{lexicon:i}=a.one,s=e[t],l=s.machine||s.normal;if(void 0!==i[l]&&i.hasOwnProperty(l))return o([s],i[l],n,!1,"1-lexicon"),!0;if(s.alias){const e=s.alias.find((e=>i.hasOwnProperty(e)));if(e)return o([s],i[e],n,!1,"1-lexicon-alias"),!0}if(!0===Ne.test(l)){const e=l.replace(Ne,"");if(i.hasOwnProperty(e)&&e.length>3&&Ie.has(i[e]))return o([s],i[e],n,!1,"1-lexicon-prefix"),!0}return null};var He={lexicon:function(e){const t=e.world;e.docs.forEach((e=>{for(let n=0;n{const r=e[a],o=(a=(a=a.toLowerCase().trim()).replace(/'s\b/,"")).split(/ /);o.length>1&&(void 0===n[o[0]]||o.length>n[o[0]])&&(n[o[0]]=o.length),t[a]=t[a]||r})),delete t[""],delete t.null,delete t[" "],{lex:t,_multi:n}}}};var Ge={addWords:function(e,t=!1){const n=this.world(),{methods:a,model:r}=n;if(!e)return;if(Object.keys(e).forEach((t=>{"string"==typeof e[t]&&e[t].startsWith("#")&&(e[t]=e[t].replace(/^#/,""))})),!0===t){const{lex:t,_multi:o}=a.one.expandLexicon(e,n);return Object.assign(r.one._multiCache,o),void Object.assign(r.one.frozenLex,t)}if(a.two.expandLexicon){const{lex:t,_multi:o}=a.two.expandLexicon(e,n);Object.assign(r.one.lexicon,t),Object.assign(r.one._multiCache,o)}const{lex:o,_multi:i}=a.one.expandLexicon(e,n);Object.assign(r.one.lexicon,o),Object.assign(r.one._multiCache,i)}};var xe={model:{one:{lexicon:{},_multiCache:{},frozenLex:{}}},methods:Te,compute:He,lib:Ge,hooks:["lexicon"]};const Ee=function(e,t){const n=[{}],a=[null],r=[0],o=[];let i=0;e.forEach((function(e){let r=0;const o=function(e,t){const{methods:n,model:a}=t,r=n.one.tokenize.splitTerms(e,a).map((e=>n.one.tokenize.splitWhitespace(e,a)));return r.map((e=>e.text.toLowerCase()))}(e,t);for(let e=0;e0&&!n[i].hasOwnProperty(l);)i=r[i];if(n.hasOwnProperty(i)){const e=n[i][l];r[u]=e,a[e]&&(a[u]=a[u]||[],a[u]=a[u].concat(a[e]))}else r[u]=0}}return{goNext:n,endAs:a,failTo:r}},Fe=function(e,t,n){let a=0;const r=[];for(let o=0;o0&&(void 0===t.goNext[a]||!t.goNext[a].hasOwnProperty(i));)a=t.failTo[a]||0;if(t.goNext[a].hasOwnProperty(i)&&(a=t.goNext[a][i],t.endAs[a])){const n=t.endAs[a];for(let t=0;t{for(let n=e.length-1;n>=0;n-=1)if(e[n]!==t)return e=e.slice(0,n+1);return e},Ve={buildTrie:function(e){return function(e){return e.goNext=e.goNext.map((e=>{if(0!==Object.keys(e).length)return e})),e.goNext=ze(e.goNext,void 0),e.failTo=ze(e.failTo,0),e.endAs=ze(e.endAs,null),e}(Ee(e,this.world()))}};Ve.compile=Ve.buildTrie;var Be={api:function(e){e.prototype.lookup=function(e,t={}){if(!e)return this.none();"string"==typeof e&&(e=[e]);var n;let a=function(e,t,n){let a=[];n.form=n.form||"normal";const r=e.docs;if(!t.goNext||!t.goNext[0])return console.error("Compromise invalid lookup trie"),e.none();const o=Object.keys(t.goNext[0]);for(let i=0;i0&&(a=a.concat(l))}return e.update(a)}(this,(n=e,"[object Object]"===Object.prototype.toString.call(n)?e:Ee(e,this.world)),t);return a=a.settle(),a}},lib:Ve};const Se=function(e,t){return t?(e.forEach((e=>{const n=e[0];t[n]&&(e[0]=t[n][0],e[1]+=t[n][1],e[2]+=t[n][1])})),e):e},Ke=function(e,t){let{ptrs:n}=e;const{byGroup:a}=e;return n=Se(n,t),Object.keys(a).forEach((e=>{a[e]=Se(a[e],t)})),{ptrs:n,byGroup:a}},$e=function(e,t,n){const a=n.methods.one;return"number"==typeof e&&(e=String(e)),"string"==typeof e&&(e=a.killUnicode(e,n),e=a.parseMatch(e,t,n)),e},Le=e=>"[object Object]"===Object.prototype.toString.call(e),Me=e=>e&&Le(e)&&!0===e.isView,Je=e=>e&&Le(e)&&!0===e.isNet;var We={matchOne:function(e,t,n){const a=this.methods.one;if(Me(e))return this.intersection(e).eq(0);if(Je(e))return this.sweep(e,{tagger:!1,matchOne:!0}).view;const r={regs:e=$e(e,n,this.world),group:t,justOne:!0},o=a.match(this.docs,r,this._cache),{ptrs:i,byGroup:s}=Ke(o,this.fullPointer),l=this.toView(i);return l._groups=s,l},match:function(e,t,n){const a=this.methods.one;if(Me(e))return this.intersection(e);if(Je(e))return this.sweep(e,{tagger:!1}).view.settle();const r={regs:e=$e(e,n,this.world),group:t},o=a.match(this.docs,r,this._cache),{ptrs:i,byGroup:s}=Ke(o,this.fullPointer),l=this.toView(i);return l._groups=s,l},has:function(e,t,n){const a=this.methods.one;if(Me(e)){return this.intersection(e).fullPointer.length>0}if(Je(e))return this.sweep(e,{tagger:!1}).view.found;const r={regs:e=$e(e,n,this.world),group:t,justOne:!0};return a.match(this.docs,r,this._cache).ptrs.length>0},if:function(e,t,n){const a=this.methods.one;if(Me(e))return this.filter((t=>t.intersection(e).found));if(Je(e)){const t=this.sweep(e,{tagger:!1}).view.settle();return this.if(t)}const r={regs:e=$e(e,n,this.world),group:t,justOne:!0};let o=this.fullPointer;const i=this._cache||[];o=o.filter(((e,t)=>{const n=this.update([e]);return a.match(n.docs,r,i[t]).ptrs.length>0}));const s=this.update(o);return this._cache&&(s._cache=o.map((e=>i[e[0]]))),s},ifNo:function(e,t,n){const{methods:a}=this,r=a.one;if(Me(e))return this.filter((t=>!t.intersection(e).found));if(Je(e)){const t=this.sweep(e,{tagger:!1}).view.settle();return this.ifNo(t)}e=$e(e,n,this.world);const o=this._cache||[],i=this.filter(((n,a)=>{const i={regs:e,group:t,justOne:!0};return 0===r.match(n.docs,i,o[a]).ptrs.length}));return this._cache&&(i._cache=i.ptrs.map((e=>o[e[0]]))),i}};var Ue={before:function(e,t,n){const{indexN:a}=this.methods.one.pointer,r=[],o=a(this.fullPointer);Object.keys(o).forEach((e=>{const t=o[e].sort(((e,t)=>e[1]>t[1]?1:-1))[0];t[1]>0&&r.push([t[0],0,t[1]])}));const i=this.toView(r);return e?i.match(e,t,n):i},after:function(e,t,n){const{indexN:a}=this.methods.one.pointer,r=[],o=a(this.fullPointer),i=this.document;Object.keys(o).forEach((e=>{const t=o[e].sort(((e,t)=>e[1]>t[1]?-1:1))[0],[n,,a]=t;a{const o=n.before(e,t);if(o.found){const e=o.terms();a[r][1]-=e.length,a[r][3]=e.docs[0][0].id}})),this.update(a)},growRight:function(e,t,n){"string"==typeof e&&(e=this.world.methods.one.parseMatch(e,n,this.world)),e[0].start=!0;const a=this.fullPointer;return this.forEach(((n,r)=>{const o=n.after(e,t);if(o.found){const e=o.terms();a[r][2]+=e.length,a[r][4]=null}})),this.update(a)},grow:function(e,t,n){return this.growRight(e,t,n).growLeft(e,t,n)}};const qe=function(e,t){return[e[0],e[1],t[2]]},Re=(e,t,n)=>{return"string"==typeof e||(a=e,"[object Array]"===Object.prototype.toString.call(a))?t.match(e,n):e||t.none();var a},Qe=function(e,t){const[n,a,r]=e;return t.document[n]&&t.document[n][a]&&(e[3]=e[3]||t.document[n][a].id,t.document[n][r-1]&&(e[4]=e[4]||t.document[n][r-1].id)),e},Ze={splitOn:function(e,t){const{splitAll:n}=this.methods.one.pointer,a=Re(e,this,t).fullPointer,r=n(this.fullPointer,a);let o=[];return r.forEach((e=>{o.push(e.passthrough),o.push(e.before),o.push(e.match),o.push(e.after)})),o=o.filter((e=>e)),o=o.map((e=>Qe(e,this))),this.update(o)},splitBefore:function(e,t){const{splitAll:n}=this.methods.one.pointer,a=Re(e,this,t).fullPointer,r=n(this.fullPointer,a);for(let e=0;e{o.push(e.passthrough),o.push(e.before),e.match&&e.after?o.push(qe(e.match,e.after)):o.push(e.match)})),o=o.filter((e=>e)),o=o.map((e=>Qe(e,this))),this.update(o)},splitAfter:function(e,t){const{splitAll:n}=this.methods.one.pointer,a=Re(e,this,t).fullPointer,r=n(this.fullPointer,a);let o=[];return r.forEach((e=>{o.push(e.passthrough),e.before&&e.match?o.push(qe(e.before,e.match)):(o.push(e.before),o.push(e.match)),o.push(e.after)})),o=o.filter((e=>e)),o=o.map((e=>Qe(e,this))),this.update(o)}};Ze.split=Ze.splitAfter;const Xe=function(e,t){return!(!e||!t)&&(e[0]===t[0]&&e[2]===t[1])},_e=function(e,t,n){const a=e.world,r=a.methods.one.parseMatch;n=n||"^.";const o=r(t=t||".$",{},a),i=r(n,{},a);o[o.length-1].end=!0,i[0].start=!0;const s=e.fullPointer,l=[s[0]];for(let t=1;t)?\/.*?[^\\/]\/[?\]+*$~]*)(?:\s|$)/,nt=/([!~[^]*(?:<[^<]*>)?\([^)]+[^\\)]\)[?\]+*$~]*)(?:\s|$)/,at=/ /g,rt=e=>/^[![^]*(<[^<]*>)?\//.test(e)&&/\/[?\]+*$~]*$/.test(e),ot=function(e){return e=(e=e.map((e=>e.trim()))).filter((e=>e))},it=/\{([0-9]+)?(, *[0-9]*)?\}/,st=/&&/,lt=new RegExp(/^<\s*(\S+)\s*>/),ut=e=>e.charAt(0).toUpperCase()+e.substring(1),ct=e=>e.charAt(e.length-1),dt=e=>e.charAt(0),ht=e=>e.substring(1),gt=e=>e.substring(0,e.length-1),mt=function(e){return e=ht(e),e=gt(e)},pt=function(e,t){const n={};for(let a=0;a<2;a+=1){if("$"===ct(e)&&(n.end=!0,e=gt(e)),"^"===dt(e)&&(n.start=!0,e=ht(e)),"?"===ct(e)&&(n.optional=!0,e=gt(e)),("["===dt(e)||"]"===ct(e))&&(n.group=null,"["===dt(e)&&(n.groupStart=!0),"]"===ct(e)&&(n.groupEnd=!0),e=(e=e.replace(/^\[/,"")).replace(/\]$/,""),"<"===dt(e))){const t=lt.exec(e);t.length>=2&&(n.group=t[1],e=e.replace(t[0],""))}if("+"===ct(e)&&(n.greedy=!0,e=gt(e)),"*"!==e&&"*"===ct(e)&&"\\*"!==e&&(n.greedy=!0,e=gt(e)),"!"===dt(e)&&(n.negative=!0,e=ht(e)),"~"===dt(e)&&"~"===ct(e)&&e.length>2&&(e=mt(e),n.fuzzy=!0,n.min=t.fuzzy||.85,!1===/\(/.test(e)))return n.word=e,n;if("/"===dt(e)&&"/"===ct(e))return e=mt(e),t.caseSensitive&&(n.use="text"),n.regex=new RegExp(e),n;if(!0===it.test(e)&&(e=e.replace(it,((e,t,a)=>(void 0===a?(n.min=Number(t),n.max=Number(t)):(a=a.replace(/, */,""),void 0===t?(n.min=0,n.max=Number(a)):(n.min=Number(t),n.max=Number(a||999))),n.greedy=!0,n.min||(n.optional=!0),"")))),"("===dt(e)&&")"===ct(e)){st.test(e)?(n.choices=e.split(st),n.operator="and"):(n.choices=e.split("|"),n.operator="or"),n.choices[0]=ht(n.choices[0]);const a=n.choices.length-1;n.choices[a]=gt(n.choices[a]),n.choices=n.choices.map((e=>e.trim())),n.choices=n.choices.filter((e=>e)),n.choices=n.choices.map((e=>e.split(/ /g).map((e=>pt(e,t))))),e=""}if("{"===dt(e)&&"}"===ct(e)){if(e=mt(e),n.root=e,/\//.test(e)){const e=n.root.split(/\//);n.root=e[0],n.pos=e[1],"adj"===n.pos&&(n.pos="Adjective"),n.pos=n.pos.charAt(0).toUpperCase()+n.pos.substr(1).toLowerCase(),void 0!==e[2]&&(n.sense=e[2])}return n}if("<"===dt(e)&&">"===ct(e))return e=mt(e),n.chunk=ut(e),n.greedy=!0,n;if("%"===dt(e)&&"%"===ct(e))return e=mt(e),n.switch=e,n}return"#"===dt(e)?(n.tag=ht(e),n.tag=ut(n.tag),n):"@"===dt(e)?(n.method=ht(e),n):"."===e?(n.anything=!0,n):"*"===e?(n.anything=!0,n.greedy=!0,n.optional=!0,n):(e&&(e=(e=e.replace("\\*","*")).replace("\\.","."),t.caseSensitive?n.use="text":e=e.toLowerCase(),n.word=e),n)},ft=/[a-z0-9][-–—][a-z]/i,bt=function(e,t){const{all:n}=t.methods.two.transform.verb||{},a=e.root;return n?n(a,t.model):[]},yt=function(e,t){const{all:n}=t.methods.two.transform.noun||{};return n?n(e.root,t.model):[e.root]},vt=function(e,t){const{all:n}=t.methods.two.transform.adjective||{};return n?n(e.root,t.model):[e.root]},wt=function(e){return e=function(e){let t=0,n=null;for(let a=0;a(e.fuzzy&&e.choices&&e.choices.forEach((t=>{1===t.length&&t[0].word&&(t[0].fuzzy=!0,t[0].min=e.min)})),e)))}(e=e.map((e=>{if(void 0!==e.choices){if("or"!==e.operator)return e;if(!0===e.fuzzy)return e;!0===e.choices.every((e=>{if(1!==e.length)return!1;const t=e[0];return!0!==t.fuzzy&&!t.start&&!t.end&&void 0!==t.word&&!0!==t.negative&&!0!==t.optional&&!0!==t.method}))&&(e.fastOr=new Set,e.choices.forEach((t=>{e.fastOr.add(t[0].word)})),delete e.choices)}return e}))),e},kt=function(e,t){for(const n of t)if(e.has(n))return!0;return!1},Pt=function(e,t){for(let n=0;nn?a:n)+1;if(Math.abs(n-a)>(r||100))return r||100;const o=[];for(let e=0;e4)return n;l=t[i-1],u=s===l?0:1,c=o[r-1][i]+1,(d=o[r][i-1]+1)1&&i>1&&s===t[i-2]&&e[r-2]===l&&(d=o[r-2][i-2]+u)-1!==e.post.indexOf(t),Ht={hasQuote:e=>Ct.test(e.pre)||jt.test(e.post),hasComma:e=>Dt(e,","),hasPeriod:e=>!0===Dt(e,".")&&!1===Dt(e,"..."),hasExclamation:e=>Dt(e,"!"),hasQuestionMark:e=>Dt(e,"?")||Dt(e,"¿"),hasEllipses:e=>Dt(e,"..")||Dt(e,"…"),hasSemicolon:e=>Dt(e,";"),hasColon:e=>Dt(e,":"),hasSlash:e=>/\//.test(e.text),hasHyphen:e=>Nt.test(e.post)||Nt.test(e.pre),hasDash:e=>It.test(e.post)||It.test(e.pre),hasContraction:e=>Boolean(e.implicit),isAcronym:e=>e.tags.has("Acronym"),isKnown:e=>e.tags.size>0,isTitleCase:e=>/^\p{Lu}[a-z'\u00C0-\u00FF]/u.test(e.text),isUpperCase:e=>/^\p{Lu}+$/u.test(e.text)};Ht.hasQuotation=Ht.hasQuote;let Tt=function(){};Tt=function(e,t,n,a){const r=function(e,t,n,a){if(!0===t.anything)return!0;if(!0===t.start&&0!==n)return!1;if(!0===t.end&&n!==a-1)return!1;if(void 0!==t.id&&t.id===e.id)return!0;if(void 0!==t.word){if(t.use)return t.word===e[t.use];if(null!==e.machine&&e.machine===t.word)return!0;if(void 0!==e.alias&&e.alias.hasOwnProperty(t.word))return!0;if(!0===t.fuzzy){if(t.word===e.root)return!0;if(At(t.word,e.normal)>=t.min)return!0}return!(!e.alias||!e.alias.some((e=>e===t.word)))||t.word===e.text||t.word===e.normal}if(void 0!==t.tag)return!0===e.tags.has(t.tag);if(void 0!==t.method)return"function"==typeof Ht[t.method]&&!0===Ht[t.method](e);if(void 0!==t.pre)return e.pre&&e.pre.includes(t.pre);if(void 0!==t.post)return e.post&&e.post.includes(t.post);if(void 0!==t.regex){let n=e.normal;return t.use&&(n=e[t.use]),t.regex.test(n)}if(void 0!==t.chunk)return e.chunk===t.chunk;if(void 0!==t.switch)return e.switch===t.switch;if(void 0!==t.machine)return e.normal===t.machine||e.machine===t.machine||e.root===t.machine;if(void 0!==t.sense)return e.sense===t.sense;if(void 0!==t.fastOr){if(t.pos&&!e.tags.has(t.pos))return null;const n=e.root||e.implicit||e.machine||e.normal;return t.fastOr.has(n)||t.fastOr.has(e.text)}return void 0!==t.choices&&("and"===t.operator?t.choices.every((t=>Tt(e,t,n,a))):t.choices.some((t=>Tt(e,t,n,a))))}(e,t,n,a);return!0===t.negative?!r:r};const Gt=function(e,t){if(!0===e.end&&!0===e.greedy&&t.start_i+t.tn.max)return e.t=e.t+n.max,!0;if(!0===e.hasGroup){xt(e,e.t).length=a-e.t}return e.t=a,!0},Ft=function(e,t=0){const n=e.regs[e.r];let a=!1;for(let o=0;o{let r=0;const o=e.t+a+t+r;if(void 0===e.terms[o])return!1;const i=Tt(e.terms[o],n,o+e.start_i,e.phrase_length);if(!0===i&&!0===n.greedy)for(let t=1;t{const a=n.every(((t,n)=>{const a=e.t+n;return void 0!==e.terms[a]&&Tt(e.terms[a],t,a,e.phrase_length)}));return!0===a&&n.length>t&&(t=n.length),a}))&&t}(e);if(a){if(!0===n.negative)return null;if(!0===e.hasGroup){xt(e,e.t).length+=a}if(!0===n.end){const t=e.phrase_length-1;if(e.t+e.start_i!==t)return null}return e.t+=a,!0}return!!n.optional||null},Vt=function(e){const{regs:t}=e,n=t[e.r],a=Object.assign({},n);a.negative=!1;if(Tt(e.terms[e.t],a,e.start_i+e.t,e.phrase_length))return!1;if(n.optional){const n=t[e.r+1];if(n){if(Tt(e.terms[e.t],n,e.start_i+e.t,e.phrase_length))e.r+=1;else if(n.optional&&t[e.r+2]){Tt(e.terms[e.t],t[e.r+2],e.start_i+e.t,e.phrase_length)&&(e.r+=2)}}}return n.greedy?function(e,t,n){let a=0;for(let r=e.t;ra||(e.t+=a,0))}(e,a,t[e.r+1]):(e.t+=1,!0)},Bt=function(e){const{regs:t,phrase_length:n}=e,a=t[e.r];return e.t=function(e,t){const n=Object.assign({},e.regs[e.r],{start:!1,end:!1}),a=e.t;for(;e.te.t?null:!0!==a.end||e.start_i+e.t===n||null},St=function(e){const{regs:t}=e,n=t[e.r],a=e.terms[e.t],r=e.t;if(n.optional&&t[e.r+1]&&n.negative)return!0;if(n.optional&&t[e.r+1]&&function(e){const{regs:t}=e,n=t[e.r],a=e.terms[e.t],r=Tt(a,t[e.r+1],e.start_i+e.t,e.phrase_length);if(n.negative||r){const n=e.terms[e.t+1];n&&Tt(n,t[e.r+1],e.start_i+e.t,e.phrase_length)||(e.r+=1)}}(e),a.implicit&&e.terms[e.t+1]&&function(e){const t=e.terms[e.t],n=e.regs[e.r];if(t.implicit&&e.terms[e.t+1]){if(!e.terms[e.t+1].implicit)return;n.word===t.normal&&(e.t+=1),"hasContraction"===n.method&&(e.t+=1)}}(e),e.t+=1,!0===n.end&&e.t!==e.terms.length&&!0!==n.greedy)return null;if(!0===n.greedy){if(!Bt(e))return null}return!0===e.hasGroup&&function(e,t){const n=e.regs[e.r],a=xt(e,t);e.t>1&&n.greedy?a.length+=e.t-t:a.length++}(e,r),!0},Kt=function(e,t,n,a){if(0===e.length||0===t.length)return null;const r={t:0,terms:e,r:0,regs:t,groups:{},start_i:n,phrase_length:a,inGroup:null};for(;r.r!e.optional)))break;return null}if(!0===e.anything&&!0===e.greedy){if(!Et(r))return null;continue}if(void 0!==e.choices&&"or"===e.operator){if(!Ot(r))return null;continue}if(void 0!==e.choices&&"and"===e.operator){if(!zt(r))return null;continue}if(!0===e.anything){if(e.negative&&e.anything)return null;if(!St(r))return null;continue}if(!0===Gt(e,r)){if(!St(r))return null;continue}if(e.negative){if(!Vt(r))return null;continue}if(!0!==Tt(r.terms[r.t],e,r.start_i+r.t,r.phrase_length)){if(!0!==e.optional)return null}else{if(!St(r))return null}}const o=[null,n,r.t+n];if(o[1]===o[2])return null;const i={};return Object.keys(r.groups).forEach((e=>{const t=r.groups[e],a=n+t.start;i[e]=[null,a,a+t.length]})),{pointer:o,groups:i}},$t=function(e,t){return e.pointer[0]=t,Object.keys(e.groups).forEach((n=>{e.groups[n][0]=t})),e},Lt=function(e,t,n){let a=Kt(e,t,0,e.length);return a?(a=$t(a,n),a):null},Mt={one:{termMethods:Ht,parseMatch:function(e,t,n){if(null==e||""===e)return[];t=t||{},"number"==typeof e&&(e=String(e));let a=function(e){const t=e.split(tt);let n=[];t.forEach((e=>{rt(e)?n.push(e):n=n.concat(e.split(nt))})),n=ot(n);let a=[];return n.forEach((e=>{(e=>/^[![^]*(<[^<]*>)?\(/.test(e)&&/\)[?\]+*$~]*$/.test(e))(e)||rt(e)?a.push(e):a=a.concat(e.split(at))})),a=ot(a),a}(e);return a=a.map((e=>pt(e,t))),a=function(e,t){const n=t.model.one.prefixes;for(let t=e.length-1;t>=0;t-=1){const a=e[t];if(a.word&&ft.test(a.word)){let r=a.word.split(/[-–—]/g);if(n.hasOwnProperty(r[0]))continue;r=r.filter((e=>e)).reverse(),e.splice(t,1),r.forEach((n=>{const r=Object.assign({},a);r.word=n,e.splice(t,0,r)}))}}return e}(a,n),a=function(e,t){return e.map((e=>{if(e.root)if(t.methods.two&&t.methods.two.transform){let n=[];e.pos?"Verb"===e.pos?n=n.concat(bt(e,t)):"Noun"===e.pos?n=n.concat(yt(e,t)):"Adjective"===e.pos&&(n=n.concat(vt(e,t))):(n=n.concat(bt(e,t)),n=n.concat(yt(e,t)),n=n.concat(vt(e,t))),n=n.filter((e=>e)),n.length>0&&(e.operator="or",e.fastOr=new Set(n))}else e.machine=e.root,delete e.id,delete e.root;return e}))}(a,n),a=wt(a),a},match:function(e,t,n){n=n||[];const{regs:a,group:r,justOne:o}=t;let i=[];if(!a||0===a.length)return{ptrs:[],byGroup:{}};const s=a.filter((e=>!0!==e.optional&&!0!==e.negative)).length;e:for(let t=0;te&&(e=Math.abs(n-1))}}else{const e=Lt(r,a,t);e&&i.push(e)}}return!0===a[a.length-1].end&&(i=i.filter((t=>{const n=t.pointer[0];return e[n].length===t.pointer[2]}))),t.notIf&&(i=function(e,t,n){return e=e.filter((e=>{const[a,r,o]=e.pointer,i=n[a].slice(r,o);for(let e=0;e{e.groups[t]&&n.push(e.groups[t])})):e.forEach((e=>{n.push(e.pointer),Object.keys(e.groups).forEach((t=>{a[t]=a[t]||[],a[t].push(e.groups[t])}))}))),{ptrs:n,byGroup:a}}(i,r),i.ptrs.forEach((t=>{const[n,a,r]=t;t[3]=e[n][a].id,t[4]=e[n][r-1].id})),i}}};var Jt={api:function(e){Object.assign(e.prototype,et)},methods:Mt,lib:{parseMatch:function(e,t){const n=this.world(),a=n.methods.one.killUnicode;return a&&(e=a(e,n)),n.methods.one.parseMatch(e,t,n)}}};const Wt=/^\../,Ut=/^#./,qt=function(e,t){const n={},a={};return Object.keys(t).forEach((r=>{let o=t[r];const i=function(e){let t="",n=" ";return e=e.replace(/&/g,"&").replace(//g,">").replace(/"/g,""").replace(/'/g,"'"),Wt.test(e)?t=``),t+=">",{start:t,end:n}}(r);"string"==typeof o&&(o=e.match(o)),o.docs.forEach((e=>{if(e.every((e=>e.implicit)))return;const t=e[0].id;n[t]=n[t]||[],n[t].push(i.start);const r=e[e.length-1].id;a[r]=a[r]||[],a[r].push(i.end)}))})),{starts:n,ends:a}};var Rt={html:function(e){const{starts:t,ends:n}=qt(this,e);let a="";return this.docs.forEach((e=>{for(let r=0;r{let n=e.pre||"",r=e.post||"";"some"===t.punctuation&&(n=n.replace(Zt,""),_t.test(r)&&(r=" "),r=r.replace(Xt,""),r=r.replace(/\?!+/,"?"),r=r.replace(/!+/,"!"),r=r.replace(/\?+/,"?"),r=r.replace(/\.{2,}/,""),e.tags.has("Abbreviation")&&(r=r.replace(/\./,""))),"some"===t.whitespace&&(n=n.replace(/\s/,""),r=r.replace(/\s+/," ")),t.keepPunct||(n=n.replace(Zt,""),r="-"===r?" ":r.replace(Qt,""));let o=e[t.form||"text"]||e.normal||"";"implicit"===t.form&&(o=e.implicit||e.text),"root"===t.form&&e.implicit&&(o=e.root||e.implicit||e.normal),"machine"!==t.form&&"implicit"!==t.form&&"root"!==t.form||!e.implicit||r&&Yt.test(r)||(r+=" "),a+=n+o+r})),!1===n&&(a=a.trim()),!0===t.lowerCase&&(a=a.toLowerCase()),a},tn={text:{form:"text"},normal:{whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"normal"},machine:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"none",unicode:"some",form:"machine"},root:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"root"},implicit:{form:"implicit"}};tn.clean=tn.normal,tn.reduced=tn.root;const nn=[];let an=0;for(;an<64;)nn[an]=0|4294967296*Math.sin(++an%Math.PI);const rn=function(e){let t,n,a,r=decodeURI(encodeURI(e))+"",o=r.length;const i=[t=1732584193,n=4023233417,~t,~n],s=[];for(e=--o/4+2|15,s[--e]=8*o;~o;)s[o>>2]|=r.charCodeAt(o)<<8*o--;for(an=r=0;an>4]+nn[r]+~~s[an|15&[r,5*r+1,3*r+5,7*r][o]])<<(o=[7,12,17,22,5,9,14,20,4,11,16,23,6,10,15,21][4*o+r++%4])|a>>>-o),t,n])t=0|o[1],n=o[2];for(r=4;r;)i[--r]+=o[r]}for(e="";r<32;)e+=(i[r>>3]>>4*(1^r++)&15).toString(16);return e},on={text:!0,terms:!0},sn={case:"none",unicode:"some",form:"machine",punctuation:"some"},ln=function(e,t){return Object.assign({},e,t)},un={text:e=>en(e,{keepPunct:!0},!1),normal:e=>en(e,ln(tn.normal,{keepPunct:!0}),!1),implicit:e=>en(e,ln(tn.implicit,{keepPunct:!0}),!1),machine:e=>en(e,sn,!1),root:e=>en(e,ln(sn,{form:"root"}),!1),hash:e=>rn(en(e,{keepPunct:!0},!1)),offset:e=>{const t=un.text(e).length;return{index:e[0].offset.index,start:e[0].offset.start,length:t}},terms:e=>e.map((e=>{const t=Object.assign({},e);return t.tags=Array.from(e.tags),t})),confidence:(e,t,n)=>t.eq(n).confidence(),syllables:(e,t,n)=>t.eq(n).syllables(),sentence:(e,t,n)=>t.eq(n).fullSentence().text(),dirty:e=>e.some((e=>!0===e.dirty))};un.sentences=un.sentence,un.clean=un.normal,un.reduced=un.root;const cn={json:function(e){const t=(n=this,"string"==typeof(a=(a=e)||{})&&(a={}),(a=Object.assign({},on,a)).offset&&n.compute("offset"),n.docs.map(((e,t)=>{const r={};return Object.keys(a).forEach((o=>{a[o]&&un[o]&&(r[o]=un[o](e,n,t))})),r})));var n,a;return"number"==typeof e?t[e]:t}};cn.data=cn.json;const dn=function(e){const t=e.pre||"",n=e.post||"";return t+e.text+n},hn=function(e,t){const n=function(e,t){const n={};return Object.keys(t).forEach((a=>{e.match(a).fullPointer.forEach((e=>{n[e[3]]={fn:t[a],end:e[2]}}))})),n}(e,t);let a="";return e.docs.forEach(((t,r)=>{for(let o=0;oe.reduce(((e,t)=>e+t.pre+t.text+t.post),"").trim()));return e.filter((e=>e))}if("freq"===e||"frequency"===e||"topk"===e)return function(e){const t={};e.forEach((e=>{t[e]=t[e]||0,t[e]+=1}));const n=Object.keys(t).map((e=>({normal:e,count:t[e]})));return n.sort(((e,t)=>e.count>t.count?-1:0))}(this.json({normal:!0}).map((e=>e.normal)));if("terms"===e){let e=[];return this.docs.forEach((t=>{let n=t.map((e=>e.text));n=n.filter((e=>e)),e=e.concat(n)})),e}return"tags"===e?this.docs.map((e=>e.reduce(((e,t)=>(e[t.implicit||t.normal]=Array.from(t.tags),e)),{}))):"debug"===e?this.debug():this.text()},wrap:function(e){return hn(this,e)}};var mn={text:function(e){let t={};var n;if(e&&"string"==typeof e&&tn.hasOwnProperty(e)?t=Object.assign({},tn[e]):e&&(n=e,"[object Object]"===Object.prototype.toString.call(n))&&(t=Object.assign({},e)),void 0!==t.keepSpace||this.isFull()||(t.keepSpace=!1),void 0===t.keepEndPunct&&this.pointer){const e=this.pointer[0];e&&e[1]?t.keepEndPunct=!1:t.keepEndPunct=!0}return void 0===t.keepPunct&&(t.keepPunct=!0),void 0===t.keepSpace&&(t.keepSpace=!0),function(e,t){let n="";if(!e||!e[0]||!e[0][0])return n;for(let a=0;a"�[32m"+e+fn,red:e=>"�[31m"+e+fn,blue:e=>"�[34m"+e+fn,magenta:e=>"�[35m"+e+fn,cyan:e=>"�[36m"+e+fn,yellow:e=>"�[33m"+e+fn,black:e=>"�[30m"+e+fn,dim:e=>"�[2m"+e+fn,i:e=>"�[3m"+e+fn},yn={tags:function(e){const{docs:t,model:n}=e;0===t.length&&console.log(bn.blue("\n ──────")),t.forEach((t=>{console.log(bn.blue("\n ┌─────────")),t.forEach((t=>{const a=[...t.tags||[]];let r=t.text||"-";t.sense&&(r=`{${t.normal}/${t.sense}}`),t.implicit&&(r="["+t.implicit+"]"),r=bn.yellow(r);let o="'"+r+"'";if(t.reference){const n=e.update([t.reference]).text("normal");o+=` - ${bn.dim(bn.i("["+n+"]"))}`}o=o.padEnd(18);const i=bn.blue(" │ ")+bn.i(o)+" - "+function(e,t){return t.one.tagSet&&(e=e.map((e=>{if(!t.one.tagSet.hasOwnProperty(e))return e;const n=t.one.tagSet[e].color||"blue";return bn[n](e)}))),e.join(", ")}(a,n);console.log(i)}))})),console.log("\n")},clientSide:function(e){console.log("%c -=-=- ","background-color:#6699cc;"),e.forEach((e=>{console.groupCollapsed(e.text());const t=e.docs[0].map((e=>{let t=e.text||"-";e.implicit&&(t="["+e.implicit+"]");return{text:t,tags:"["+Array.from(e.tags).join(", ")+"]"}}));console.table(t,["text","tags"]),console.groupEnd()}))},chunks:function(e){const{docs:t}=e;console.log(""),t.forEach((e=>{const t=[];e.forEach((e=>{"Noun"===e.chunk?t.push(bn.blue(e.implicit||e.normal)):"Verb"===e.chunk?t.push(bn.green(e.implicit||e.normal)):"Adjective"===e.chunk?t.push(bn.yellow(e.implicit||e.normal)):"Pivot"===e.chunk?t.push(bn.red(e.implicit||e.normal)):t.push(e.implicit||e.normal)})),console.log(t.join(" "),"\n")})),console.log("\n")},highlight:function(e){if(!e.found)return;const t={};e.fullPointer.forEach((e=>{t[e[0]]=t[e[0]]||[],t[e[0]].push(e)})),Object.keys(t).forEach((n=>{let a=e.update([[Number(n)]]).text();e.update(t[n]).json({offset:!0}).forEach(((e,t)=>{a=function(e,t,n){const a=((e,t,n)=>{const a=9*n,r=t.start+a,o=r+t.length;return[e.substring(0,r),e.substring(r,o),e.substring(o,e.length)]})(e,t,n);return`${a[0]}${bn.blue(a[1])}${a[2]}`}(a,e.offset,t)})),console.log(a)})),console.log("\n")}};var vn={api:function(e){Object.assign(e.prototype,pn)},methods:{one:{hash:rn,debug:yn}}};const wn=function(e,t){if(e[0]!==t[0])return!1;const[,n,a]=e,[,r,o]=t;return n<=r&&a>r||r<=n&&o>n},kn=function(e){const t={};return e.forEach((e=>{t[e[0]]=t[e[0]]||[],t[e[0]].push(e)})),t},Pn=function(e,t){const n=kn(t),a=[];return e.forEach((e=>{const[t]=e;let r=n[t]||[];if(r=r.filter((t=>function(e,t){return e[1]<=t[1]&&t[2]<=e[2]}(e,t))),0===r.length)return void a.push({passthrough:e});r=r.sort(((e,t)=>e[1]-t[1]));let o=e;r.forEach(((e,t)=>{const n=function(e,t){const[n,a]=e,r=t[1],o=t[2],i={};if(ao&&(i.after=[n,o,e[2]]),i}(o,e);r[t+1]?(a.push({before:n.before,match:n.match}),n.after&&(o=n.after)):a.push(n)}))})),a};var An={one:{termList:function(e){const t=[];for(let n=0;n{if(!a)return;let[o,i,s,l,u]=a,c=t[o]||[];if(void 0===i&&(i=0),void 0===s&&(s=c.length),!l||c[i]&&c[i].id===l)c=c.slice(i,s);else{const n=function(e,t,n){for(let a=0;a<20;a+=1){if(t[n-a]){const r=t[n-a].findIndex((t=>t.id===e));if(-1!==r)return[n-a,r]}if(t[n+a]){const r=t[n+a].findIndex((t=>t.id===e));if(-1!==r)return[n+a,r]}}return null}(l,t,o);if(null!==n){const a=s-i;c=t[n[0]].slice(n[1],n[1]+a);const o=c[0]?c[0].id:null;e[r]=[n[0],n[1],n[1]+a,o]}}0!==c.length&&i!==s&&(u&&c[c.length-1].id!==u&&(c=function(e,t){const[n,a,,,r]=e,o=t[n],i=o.findIndex((e=>e.id===r));return-1===i?(e[2]=t[n].length,e[4]=o.length?o[o.length-1].id:null):e[2]=i,t[n].slice(a,e[2]+1)}(a,t)),n.push(c))})),n=n.filter((e=>e.length>0)),n},pointer:{indexN:kn,splitAll:Pn}}};const Cn=function(e,t){const n=e.concat(t),a=kn(n);let r=[];return n.forEach((e=>{const[t]=e;if(1===a[t].length)return void r.push(e);const n=a[t].filter((t=>wn(e,t)));n.push(e);const o=function(e){let t=e[0][1],n=e[0][2];return e.forEach((e=>{e[1]n&&(n=e[2])})),[e[0][0],t,n]}(n);r.push(o)})),r=function(e){const t={};for(let n=0;n{e.passthrough&&n.push(e.passthrough),e.before&&n.push(e.before),e.after&&n.push(e.after)})),n},Nn=(e,t)=>{return"string"==typeof e||(n=e,"[object Array]"===Object.prototype.toString.call(n))?t.match(e):e||t.none();var n},In=function(e,t){return e.map((e=>{const[n,a]=e;return t[n]&&t[n][a]&&(e[3]=t[n][a].id),e}))},Dn={union:function(e){e=Nn(e,this);let t=Cn(this.fullPointer,e.fullPointer);return t=In(t,this.document),this.toView(t)}};Dn.and=Dn.union,Dn.intersection=function(e){e=Nn(e,this);let t=function(e,t){const n=kn(t),a=[];return e.forEach((e=>{let t=n[e[0]]||[];t=t.filter((t=>wn(e,t))),0!==t.length&&t.forEach((t=>{const n=function(e,t){const n=e[1]t[2]?t[2]:e[2];return n{e=Cn(e,[t])})),e=In(e,this.document),this.update(e)};var Hn={methods:An,api:function(e){Object.assign(e.prototype,Dn)}};const Tn=function(e){return!0===e.optional||!0===e.negative?null:e.tag?"#"+e.tag:e.word?e.word:e.switch?`%${e.switch}%`:null},Gn=function(e,t){const n=t.methods.one.parseMatch;return e.forEach((e=>{e.regs=n(e.match,{},t),"string"==typeof e.ifNo&&(e.ifNo=[e.ifNo]),e.notIf&&(e.notIf=n(e.notIf,{},t)),e.needs=function(e){const t=[];return e.forEach((e=>{t.push(Tn(e)),"and"===e.operator&&e.choices&&e.choices.forEach((e=>{e.forEach((e=>{t.push(Tn(e))}))}))})),t.filter((e=>e))}(e.regs);const{wants:a,count:r}=function(e){const t=[];let n=0;return e.forEach((e=>{"or"!==e.operator||e.optional||e.negative||(e.fastOr&&Array.from(e.fastOr).forEach((e=>{t.push(e)})),e.choices&&e.choices.forEach((e=>{e.forEach((e=>{const n=Tn(e);n&&t.push(n)}))})),n+=1)})),{wants:t,count:n}}(e.regs);e.wants=a,e.minWant=r,e.minWords=e.regs.filter((e=>!e.optional)).length})),e};var xn={buildNet:function(e,t){e=Gn(e,t);const n={};e.forEach((e=>{e.needs.forEach((t=>{n[t]=Array.isArray(n[t])?n[t]:[],n[t].push(e)})),e.wants.forEach((t=>{n[t]=Array.isArray(n[t])?n[t]:[],n[t].push(e)}))})),Object.keys(n).forEach((e=>{const t={};n[e]=n[e].filter((e=>"boolean"!=typeof t[e.match]&&(t[e.match]=!0,!0)))}));const a=e.filter((e=>0===e.needs.length&&0===e.wants.length));return{hooks:n,always:a}},bulkMatch:function(e,t,n,a={}){const r=n.one.cacheDoc(e);let o=function(e,t){return e.map(((n,a)=>{let r=[];Object.keys(t).forEach((n=>{e[a].has(n)&&(r=r.concat(t[n]))}));const o={};return r=r.filter((e=>"boolean"!=typeof o[e.match]&&(o[e.match]=!0,!0))),r}))}(r,t.hooks);o=function(e,t){return e.map(((e,n)=>{const a=t[n];return(e=(e=e.filter((e=>e.needs.every((e=>a.has(e)))))).filter((e=>void 0===e.ifNo||!0!==e.ifNo.some((e=>a.has(e)))))).filter((e=>0===e.wants.length||e.wants.filter((e=>a.has(e))).length>=e.minWant))}))}(o,r),t.always.length>0&&(o=o.map((e=>e.concat(t.always)))),o=function(e,t){return e.map(((e,n)=>{const a=t[n].length;return e=e.filter((e=>a>=e.minWords)),e}))}(o,e);const i=function(e,t,n,a,r){const o=[];for(let n=0;n0&&(l.ptrs.forEach((e=>{e[0]=n;const t=Object.assign({},s,{pointer:e});void 0!==s.unTag&&(t.unTag=s.unTag),o.push(t)})),!0===r.matchOne))return[o[0]]}return o}(o,e,0,n,a);return i},bulkTagger:function(e,t,n){const{model:a,methods:r}=n,{getDoc:o,setTag:i,unTag:s}=r.one,l=r.two.looksPlural;if(0===e.length)return e;return("undefined"!=typeof process&&process.env?process.env:self.env||{}).DEBUG_TAGS&&console.log(`\n\n �[32m→ ${e.length} post-tagger:�[0m`),e.map((e=>{if(!e.tag&&!e.chunk&&!e.unTag)return;const r=e.reason||e.match,u=o([e.pointer],t)[0];if(!0===e.safe){if(!1===function(e,t,n){const a=n.one.tagSet;if(!a.hasOwnProperty(t))return!0;const r=a[t].not||[];for(let t=0;te.frozen=!0))}void 0!==e.unTag&&s(u,e.unTag,n,e.safe,r),e.chunk&&u.forEach((t=>t.chunk=e.chunk))}))}},En={lib:{buildNet:function(e){const t=this.methods().one.buildNet(e,this.world());return t.isNet=!0,t}},api:function(e){e.prototype.sweep=function(e,t={}){const{world:n,docs:a}=this,{methods:r}=n;let o=r.one.bulkMatch(a,e,this.methods,t);!1!==t.tagger&&r.one.bulkTagger(o,a,this.world),o=o.map((e=>{const t=e.pointer,n=a[t[0]][t[1]],r=t[2]-t[1];return n.index&&(e.pointer=[n.index[0],n.index[1],t[1]+r]),e}));const i=o.map((e=>e.pointer));return o=o.map((e=>(e.view=this.update([e.pointer]),delete e.regs,delete e.needs,delete e.pointer,delete e._expanded,e))),{view:this.update(i),found:o}}},methods:{one:xn}};const Fn=/ /,On=function(e,t){"Noun"===t&&(e.chunk=t),"Verb"===t&&(e.chunk=t)},zn=function(e,t,n,a){if(!0===e.tags.has(t))return null;if("."===t)return null;!0===e.frozen&&(a=!0);const r=n[t];if(r){if(r.not&&r.not.length>0)for(let t=0;t0)for(let t=0;t{const a=e.map((e=>e.text||"["+e.implicit+"]")).join(" ");var r;"string"!=typeof t&&t.length>2&&(t=t.slice(0,2).join(", #")+" +"),t="string"!=typeof t?t.join(", #"):t,console.log(` ${(r=a,"�[33m�[3m"+r+"�[0m").padEnd(24)} �[32m→�[0m #${t.padEnd(22)} ${(e=>"�[3m"+e+"�[0m")(n)}`)})(e,t,r),!0!=(s=t,"[object Array]"===Object.prototype.toString.call(s)))if("string"==typeof t)if(t=t.trim(),Fn.test(t))!function(e,t,n,a){const r=t.split(Fn);e.forEach(((e,t)=>{let o=r[t];o&&(o=o.replace(/^#/,""),zn(e,o,n,a))}))}(e,t,o,a);else{t=t.replace(/^#/,"");for(let n=0;nVn(e,t,n,a)))},Bn=function(e){return e.children=e.children||[],e._cache=e._cache||{},e.props=e.props||{},e._cache.parents=e._cache.parents||[],e._cache.children=e._cache.children||[],e},Sn=/^ *(#|\/\/)/,Kn=function(e){let t=e.trim().split(/->/),n=[];t.forEach((e=>{n=n.concat(function(e){if(!(e=e.trim()))return null;if(/^\[/.test(e)&&/\]$/.test(e)){let t=(e=(e=e.replace(/^\[/,"")).replace(/\]$/,"")).split(/,/);return t=t.map((e=>e.trim())).filter((e=>e)),t=t.map((e=>Bn({id:e}))),t}return[Bn({id:e})]}(e))})),n=n.filter((e=>e));let a=n[0];for(let e=1;e{let n=[],a=[e];for(;a.length>0;){let e=a.pop();n.push(e),e.children&&e.children.forEach((n=>{t&&t(e,n),a.push(n)}))}return n},Ln=e=>"[object Array]"===Object.prototype.toString.call(e),Mn=e=>(e=e||"").trim(),Jn=function(e=[]){return"string"==typeof e?function(e){let t=e.split(/\r?\n/),n=[];t.forEach((e=>{if(!e.trim()||Sn.test(e))return;let t=(e=>{const t=/^( {2}|\t)/;let n=0;for(;t.test(e);)e=e.replace(t,""),n+=1;return n})(e);n.push({indent:t,node:Kn(e)})}));let a=function(e){let t={children:[]};return e.forEach(((n,a)=>{0===n.indent?t.children=t.children.concat(n.node):e[a-1]&&function(e,t){let n=e[t].indent;for(;t>=0;t-=1)if(e[t].indent{t[e.id]=e}));let n=Bn({});return e.forEach((e=>{if((e=Bn(e)).parent)if(t.hasOwnProperty(e.parent)){let n=t[e.parent];delete e.parent,n.children.push(e)}else console.warn(`[Grad] - missing node '${e.parent}'`);else n.children.push(e)})),n}(e):($n(t=e).forEach(Bn),t);var t},Wn=function(e,t){let n="-> ";t&&(n=(e=>"�[2m"+e+"�[0m")("→ "));let a="";return $n(e).forEach(((e,r)=>{let o=e.id||"";if(t&&(o=(e=>"�[31m"+e+"�[0m")(o)),0===r&&!e.id)return;let i=e._cache.parents.length;a+=" ".repeat(i)+n+o+"\n"})),a},Un=function(e){let t=$n(e);t.forEach((e=>{delete(e=Object.assign({},e)).children}));let n=t[0];return n&&!n.id&&0===Object.keys(n.props).length&&t.shift(),t},qn={text:Wn,txt:Wn,array:Un,flat:Un},Rn=function(e,t){return"nested"===t||"json"===t?e:"debug"===t?(console.log(Wn(e,!0)),null):qn.hasOwnProperty(t)?qn[t](e):e},Qn=e=>{$n(e,((e,t)=>{e.id&&(e._cache.parents=e._cache.parents||[],t._cache.parents=e._cache.parents.concat([e.id]))}))},Zn=/\//;let Xn=class g{constructor(e={}){Object.defineProperty(this,"json",{enumerable:!1,value:e,writable:!0})}get children(){return this.json.children}get id(){return this.json.id}get found(){return this.json.id||this.json.children.length>0}props(e={}){let t=this.json.props||{};return"string"==typeof e&&(t[e]=!0),this.json.props=Object.assign(t,e),this}get(e){if(e=Mn(e),!Zn.test(e)){let t=this.json.children.find((t=>t.id===e));return new g(t)}let t=((e,t)=>{let n=(e=>"string"!=typeof e?e:(e=e.replace(/^\//,"")).split(/\//))(t=t||"");for(let t=0;te.id===n[t]));if(!a)return null;e=a}return e})(this.json,e)||Bn({});return new g(t)}add(e,t={}){if(Ln(e))return e.forEach((e=>this.add(Mn(e),t))),this;e=Mn(e);let n=Bn({id:e,props:t});return this.json.children.push(n),new g(n)}remove(e){return e=Mn(e),this.json.children=this.json.children.filter((t=>t.id!==e)),this}nodes(){return $n(this.json).map((e=>(delete(e=Object.assign({},e)).children,e)))}cache(){return(e=>{let t=$n(e,((e,t)=>{e.id&&(e._cache.parents=e._cache.parents||[],e._cache.children=e._cache.children||[],t._cache.parents=e._cache.parents.concat([e.id]))})),n={};t.forEach((e=>{e.id&&(n[e.id]=e)})),t.forEach((e=>{e._cache.parents.forEach((t=>{n.hasOwnProperty(t)&&n[t]._cache.children.push(e.id)}))})),e._cache.children=Object.keys(n)})(this.json),this}list(){return $n(this.json)}fillDown(){var e;return e=this.json,$n(e,((e,t)=>{t.props=((e,t)=>(Object.keys(t).forEach((n=>{if(t[n]instanceof Set){let a=e[n]||new Set;e[n]=new Set([...a,...t[n]])}else if((e=>e&&"object"==typeof e&&!Array.isArray(e))(t[n])){let a=e[n]||{};e[n]=Object.assign({},t[n],a)}else Ln(t[n])?e[n]=t[n].concat(e[n]||[]):void 0===e[n]&&(e[n]=t[n])})),e))(t.props,e.props)})),this}depth(){Qn(this.json);let e=$n(this.json),t=e.length>1?1:0;return e.forEach((e=>{if(0===e._cache.parents.length)return;let n=e._cache.parents.length+1;n>t&&(t=n)})),t}out(e){return Qn(this.json),Rn(this.json,e)}debug(){return Qn(this.json),Rn(this.json,"debug"),this}};const _n=function(e){let t=Jn(e);return new Xn(t)};_n.prototype.plugin=function(e){e(this)};const Yn={Noun:"blue",Verb:"green",Negative:"green",Date:"red",Value:"red",Adjective:"magenta",Preposition:"cyan",Conjunction:"cyan",Determiner:"cyan",Hyphenated:"cyan",Adverb:"cyan"},ea=function(e){if(Yn.hasOwnProperty(e.id))return Yn[e.id];if(Yn.hasOwnProperty(e.is))return Yn[e.is];const t=e._cache.parents.find((e=>Yn[e]));return Yn[t]},ta=function(e){return e?"string"==typeof e?[e]:e:[]},na=function(e,t){return e=function(e,t){return Object.keys(e).forEach((n=>{e[n].isA&&(e[n].is=e[n].isA),e[n].notA&&(e[n].not=e[n].notA),e[n].is&&"string"==typeof e[n].is&&(t.hasOwnProperty(e[n].is)||e.hasOwnProperty(e[n].is)||(e[e[n].is]={})),e[n].not&&"string"==typeof e[n].not&&!e.hasOwnProperty(e[n].not)&&(t.hasOwnProperty(e[n].not)||e.hasOwnProperty(e[n].not)||(e[e[n].not]={}))})),e}(e,t),Object.keys(e).forEach((t=>{e[t].children=ta(e[t].children),e[t].not=ta(e[t].not)})),Object.keys(e).forEach((t=>{(e[t].not||[]).forEach((n=>{e[n]&&e[n].not&&e[n].not.push(t)}))})),e};var aa={one:{setTag:Vn,unTag:function(e,t,n){t=t.trim().replace(/^#/,"");for(let a=0;a0)for(let e=0;e0&&(e=function(e){return Object.keys(e).forEach((t=>{e[t]=Object.assign({},e[t]),e[t].novel=!0})),e}(e)),e=na(e,t);const n=function(e){const t=Object.keys(e).map((t=>{const n=e[t],a={not:new Set(n.not),also:n.also,is:n.is,novel:n.novel};return{id:t,parent:n.is,props:a,children:[]}}));return _n(t).cache().fillDown().out("array")}(Object.assign({},t,e)),a=function(e){const t={};return e.forEach((e=>{const{not:n,also:a,is:r,novel:o}=e.props;let i=e._cache.parents;a&&(i=i.concat(a)),t[e.id]={is:r,not:n,novel:o,also:a,parents:i,children:e._cache.children,color:ea(e)}})),Object.keys(t).forEach((e=>{const n=new Set(t[e].not);t[e].not.forEach((e=>{t[e]&&t[e].children.forEach((e=>n.add(e)))})),t[e].not=Array.from(n)})),t}(n);return a},canBe:function(e,t,n){if(!n.hasOwnProperty(t))return!0;const a=n[t].not||[];for(let t=0;tr.one.setTag(a,e,i,n,t))):r.one.setTag(a,e,i,n,t),this.uncache(),this},tagSafe:function(e,t=""){return this.tag(e,t,!0)},unTag:function(e,t){if(!this.found||!e)return this;const n=this.termList();if(0===n.length)return this;const{methods:a,verbose:r,model:o}=this;!0===r&&console.log(" - ",e,t||"");const i=o.one.tagSet;return ra(e)?e.forEach((e=>a.one.unTag(n,e,i))):a.one.unTag(n,e,i),this.uncache(),this},canBe:function(e){e=e.replace(/^#/,"");const t=this.model.one.tagSet,n=this.methods.one.canBe,a=[];this.document.forEach(((r,o)=>{r.forEach(((r,i)=>{n(r,e,t)||a.push([o,i,i+1])}))}));const r=this.update(a);return this.difference(r)}};var ia={addTags:function(e){const{model:t,methods:n}=this.world(),a=t.one.tagSet,r=(0,n.one.addTags)(e,a);return t.one.tagSet=r,this}};const sa=new Set(["Auxiliary","Possessive"]);var la={model:{one:{tagSet:{}}},compute:{tagRank:function(e){const{document:t,world:n}=e,a=n.model.one.tagSet;t.forEach((e=>{e.forEach((e=>{const t=Array.from(e.tags);e.tagRank=function(e,t){return e=e.sort(((e,n)=>{if(sa.has(e)||!t.hasOwnProperty(n))return 1;if(sa.has(n)||!t.hasOwnProperty(e))return-1;let a=t[e].children||[];const r=a.length;return a=t[n].children||[],r-a.length})),e}(t,a)}))}))}},methods:aa,api:function(e){Object.assign(e.prototype,oa)},lib:ia};const ua=/([.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s)/g,ca=/^[.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s$/,da=/((?:\r?\n|\r)+)/,ha=/[a-z0-9\u00C0-\u00FF\u00a9\u00ae\u2000-\u3300\ud000-\udfff]/i,ga=/\S/,ma=function(e){return Boolean(e.match(/\n$/))},pa={'"':'"',""":""","“":"”","‟":"”","„":"”","⹂":"”","‚":"’","«":"»","‹":"›","‵":"′","‶":"″","‷":"‴","〝":"〞","〟":"〞"},fa=RegExp("["+Object.keys(pa).join("")+"]","g"),ba=RegExp("["+Object.values(pa).join("")+"]","g"),ya=function(e){if(!e)return!1;const t=e.match(ba);return null!==t&&1===t.length},va=/\(/g,wa=/\)/g,ka=/\S/,Pa=/^\s+/,Aa=function(e,t){const n=e.split(/[-–—]/);if(n.length<=1)return!1;const{prefixes:a,suffixes:r}=t.one;if(1===n[0].length&&/[a-z]/i.test(n[0]))return!1;if(a.hasOwnProperty(n[0]))return!1;if(n[1]=n[1].trim().replace(/[.?!]$/,""),r.hasOwnProperty(n[1]))return!1;if(!0===/^([a-z\u00C0-\u00FF`"'/]+)[-–—]([a-z0-9\u00C0-\u00FF].*)/i.test(e))return!0;return!0===/^[('"]?([0-9]{1,4})[-–—]([a-z\u00C0-\u00FF`"'/-]+[)'"]?$)/i.test(e)},Ca=function(e){const t=[],n=e.split(/[-–—]/);let a="-";const r=e.match(/[-–—]/);r&&r[0]&&(a=r);for(let e=0;e(e[t]=!0,e)),{});const Ta=/\p{Letter}/u,Ga=/[\p{Number}\p{Currency_Symbol}]/u,xa=/^[a-z]\.([a-z]\.)+/i,Ea=/[sn]['’]$/,Fa=/([A-Z]\.)+[A-Z]?,?$/,Oa=/^[A-Z]\.,?$/,za=/[A-Z]{2,}('s|,)?$/,Va=/([a-z]\.)+[a-z]\.?$/,Ba=function(e){return function(e){return!0===Fa.test(e)||!0===Va.test(e)||!0===Oa.test(e)||!0===za.test(e)}(e)&&(e=e.replace(/\./g,"")),e},Sa=function(e,t){const n=t.methods.one.killUnicode;let a=e.text||"";a=function(e){const t=e=(e=(e=e||"").toLowerCase()).trim();return e=(e=(e=e.replace(/[,;.!?]+$/,"")).replace(/\u2026/g,"...")).replace(/\u2013/g,"-"),!1===/^[:;]/.test(e)&&(e=(e=(e=e.replace(/\.{3,}$/g,"")).replace(/[",.!:;?)]+$/g,"")).replace(/^['"(]+/g,"")),""===(e=(e=e.replace(/[\u200B-\u200D\uFEFF]/g,"")).trim())&&(e=t),e.replace(/([0-9]),([0-9])/g,"$1$2")}(a),a=n(a,t),a=Ba(a),e.normal=a},Ka=/[ .][A-Z]\.? *$/i,$a=/(?:\u2026|\.{2,}) *$/,La=/\p{L}/u,Ma=/\. *$/,Ja=/^[A-Z]\. $/;var Wa={one:{killUnicode:function(e,t){const n=t.model.one.unicode||{},a=(e=e||"").split("");return a.forEach(((e,t)=>{n[e]&&(a[t]=n[e])})),a.join("")},tokenize:{splitSentences:function(e,t){if(e=e||"",!(e=String(e))||"string"!=typeof e||!1===ka.test(e))return[];const n=function(e){const t=[],n=e.split(da);for(let e=0;e0&&(r.push(o),e[t]=""):e[t+1]=o+(e[t+1]||"")}return r}(a,t),a=function(e){const t=[];for(let n=0;n0?(n[n.length-1]+=o,n.push(t)):n.push(o+t),o=""):o+=t}return o&&(0===n.length&&(n[0]=""),n[n.length-1]+=o),n=function(e){for(let t=1;te)),n},splitWhitespace:(e,t)=>{const{str:n,pre:a,post:r}=function(e,t){const{prePunctuation:n,postPunctuation:a,emoticons:r}=t.one;let o=e,i="",s="";const l=Array.from(e);if(r.hasOwnProperty(e.trim()))return{str:e.trim(),pre:i,post:" "};let u=l.length;for(let e=0;e(s=e||"",""))),e=o,i=""),{str:e,pre:i,post:s}}(e,t);return{text:n,pre:a,post:r,tags:new Set}},fromString:function(e,t){const{methods:n,model:a}=t,{splitSentences:r,splitTerms:o,splitWhitespace:i}=n.one.tokenize;return e=r(e=e||"",t).map((e=>{let n=o(e,a);return n=n.map((e=>i(e,a))),n.forEach((e=>{Sa(e,t)})),n})),e}}}};const Ua={},qa={};[[["approx","apt","bc","cyn","eg","esp","est","etc","ex","exp","prob","pron","gal","min","pseud","fig","jd","lat","lng","vol","fm","def","misc","plz","ea","ps","sec","pt","pref","pl","pp","qt","fr","sq","nee","ss","tel","temp","vet","ver","fem","masc","eng","adj","vb","rb","inf","situ","vivo","vitro","wr"]],[["dl","ml","gal","qt","pt","tbl","tsp","tbsp","km","dm","cm","mm","mi","td","hr","hrs","kg","hg","dg","cg","mg","µg","lb","oz","sq ft","hz","mps","mph","kmph","kb","mb","tb","lx","lm","fl oz","yb"],"Unit"],[["ad","al","arc","ba","bl","ca","cca","col","corp","ft","fy","ie","lit","ma","md","pd","tce"],"Noun"],[["adj","adm","adv","asst","atty","bldg","brig","capt","cmdr","comdr","cpl","det","dr","esq","gen","gov","hon","jr","llb","lt","maj","messrs","mlle","mme","mr","mrs","ms","mstr","phd","prof","pvt","rep","reps","res","rev","sen","sens","sfc","sgt","sir","sr","supt","surg"],"Honorific"],[["jan","feb","mar","apr","jun","jul","aug","sep","sept","oct","nov","dec"],"Month"],[["dept","univ","assn","bros","inc","ltd","co"],"Organization"],[["rd","st","dist","mt","ave","blvd","cl","cres","hwy","ariz","cal","calif","colo","conn","fla","fl","ga","ida","ia","kan","kans","minn","neb","nebr","okla","penna","penn","pa","dak","tenn","tex","ut","vt","va","wis","wisc","wy","wyo","usafa","alta","ont","que","sask"],"Place"]].forEach((e=>{e[0].forEach((t=>{Ua[t]=!0,qa[t]="Abbreviation",void 0!==e[1]&&(qa[t]=[qa[t],e[1]])}))}));var Ra=["anti","bi","co","contra","de","extra","infra","inter","intra","macro","micro","mis","mono","multi","peri","pre","pro","proto","pseudo","re","sub","supra","trans","tri","un","out","ex"].reduce(((e,t)=>(e[t]=!0,e)),{});const Qa={"!":"¡","?":"¿Ɂ",'"':'“”"❝❞',"'":"‘‛❛❜’","-":"—–",a:"ªÀÁÂÃÄÅàáâãäåĀāĂ㥹ǍǎǞǟǠǡǺǻȀȁȂȃȦȧȺΆΑΔΛάαλАаѦѧӐӑӒӓƛæ",b:"ßþƀƁƂƃƄƅɃΒβϐϦБВЪЬвъьѢѣҌҍ",c:"¢©ÇçĆćĈĉĊċČčƆƇƈȻȼͻͼϲϹϽϾСсєҀҁҪҫ",d:"ÐĎďĐđƉƊȡƋƌ",e:"ÈÉÊËèéêëĒēĔĕĖėĘęĚěƐȄȅȆȇȨȩɆɇΈΕΞΣέεξϵЀЁЕеѐёҼҽҾҿӖӗễ",f:"ƑƒϜϝӺӻҒғſ",g:"ĜĝĞğĠġĢģƓǤǥǦǧǴǵ",h:"ĤĥĦħƕǶȞȟΉΗЂЊЋНнђћҢңҤҥҺһӉӊ",I:"ÌÍÎÏ",i:"ìíîïĨĩĪīĬĭĮįİıƖƗȈȉȊȋΊΐΪίιϊІЇіїi̇",j:"ĴĵǰȷɈɉϳЈј",k:"ĶķĸƘƙǨǩΚκЌЖКжкќҚқҜҝҞҟҠҡ",l:"ĹĺĻļĽľĿŀŁłƚƪǀǏǐȴȽΙӀӏ",m:"ΜϺϻМмӍӎ",n:"ÑñŃńŅņŇňʼnŊŋƝƞǸǹȠȵΝΠήηϞЍИЙЛПийлпѝҊҋӅӆӢӣӤӥπ",o:"ÒÓÔÕÖØðòóôõöøŌōŎŏŐőƟƠơǑǒǪǫǬǭǾǿȌȍȎȏȪȫȬȭȮȯȰȱΌΘΟθοσόϕϘϙϬϴОФоѲѳӦӧӨөӪӫ",p:"ƤΡρϷϸϼРрҎҏÞ",q:"Ɋɋ",r:"ŔŕŖŗŘřƦȐȑȒȓɌɍЃГЯгяѓҐґ",s:"ŚśŜŝŞşŠšƧƨȘșȿЅѕ",t:"ŢţŤťŦŧƫƬƭƮȚțȶȾΓΤτϮТт",u:"ÙÚÛÜùúûüŨũŪūŬŭŮůŰűŲųƯưƱƲǓǔǕǖǗǘǙǚǛǜȔȕȖȗɄΰυϋύ",v:"νѴѵѶѷ",w:"ŴŵƜωώϖϢϣШЩшщѡѿ",x:"×ΧχϗϰХхҲҳӼӽӾӿ",y:"ÝýÿŶŷŸƳƴȲȳɎɏΎΥΫγψϒϓϔЎУучўѰѱҮүҰұӮӯӰӱӲӳ",z:"ŹźŻżŽžƵƶȤȥɀΖ"},Za={};Object.keys(Qa).forEach((function(e){Qa[e].split("").forEach((function(t){Za[t]=e}))}));const Xa=/\//,_a=/[a-z]\.[a-z]/i,Ya=/[0-9]/,er=function(e,t){const n=e.normal||e.text||e.machine,a=t.model.one.aliases;if(a.hasOwnProperty(n)&&(e.alias=e.alias||[],e.alias.push(a[n])),Xa.test(n)&&!_a.test(n)&&!Ya.test(n)){const t=n.split(Xa);t.length<=3&&t.forEach((t=>{""!==(t=t.trim())&&(e.alias=e.alias||[],e.alias.push(t))}))}return e},tr=/^\p{Letter}+-\p{Letter}+$/u,nr=function(e){let t=e.implicit||e.normal||e.text;t=t.replace(/['’]s$/,""),t=t.replace(/s['’]$/,"s"),t=t.replace(/([aeiou][ktrp])in'$/,"$1ing"),tr.test(t)&&(t=t.replace(/-/g,"")),t=t.replace(/^[#@]/,""),t!==e.normal&&(e.machine=t)},ar=function(e,t){const n=e.docs;for(let a=0;aar(e,er),machine:e=>ar(e,nr),normal:e=>ar(e,Sa),freq:function(e){const t=e.docs,n={};for(let e=0;e{let i=(e=e.toLowerCase().trim()).length;t.max&&i>t.max&&(i=t.max);for(let s=t.min;s{delete a[e]})),a}(e,t,this.world());return Object.keys(r).forEach((e=>{n.one.typeahead.hasOwnProperty(e)?delete n.one.typeahead[e]:n.one.typeahead[e]=r[e]})),this}};var cr={model:{one:{typeahead:{}}},api:function(e){e.prototype.autoFill=sr},lib:ur,compute:ir,hooks:["typeahead"]};d.extend(J),d.extend(vn),d.extend(Jt),d.extend(Hn),d.extend(la),d.plugin(ve),d.extend(or),d.extend(Ce),d.plugin(p),d.extend(Be),d.extend(cr),d.extend(xe),d.extend(En);var dr={addendum:"addenda",corpus:"corpora",criterion:"criteria",curriculum:"curricula",genus:"genera",memorandum:"memoranda",opus:"opera",ovum:"ova",phenomenon:"phenomena",referendum:"referenda",alga:"algae",alumna:"alumnae",antenna:"antennae",formula:"formulae",larva:"larvae",nebula:"nebulae",vertebra:"vertebrae",analysis:"analyses",axis:"axes",diagnosis:"diagnoses",parenthesis:"parentheses",prognosis:"prognoses",synopsis:"synopses",thesis:"theses",neurosis:"neuroses",appendix:"appendices",index:"indices",matrix:"matrices",ox:"oxen",sex:"sexes",alumnus:"alumni",bacillus:"bacilli",cactus:"cacti",fungus:"fungi",hippopotamus:"hippopotami",libretto:"libretti",modulus:"moduli",nucleus:"nuclei",octopus:"octopi",radius:"radii",stimulus:"stimuli",syllabus:"syllabi",cookie:"cookies",calorie:"calories",auntie:"aunties",movie:"movies",pie:"pies",rookie:"rookies",tie:"ties",zombie:"zombies",leaf:"leaves",loaf:"loaves",thief:"thieves",foot:"feet",goose:"geese",tooth:"teeth",beau:"beaux",chateau:"chateaux",tableau:"tableaux",bus:"buses",gas:"gases",circus:"circuses",crisis:"crises",virus:"viruses",database:"databases",excuse:"excuses",abuse:"abuses",avocado:"avocados",barracks:"barracks",child:"children",clothes:"clothes",echo:"echoes",embargo:"embargoes",epoch:"epochs",deer:"deer",halo:"halos",man:"men",woman:"women",mosquito:"mosquitoes",mouse:"mice",person:"people",quiz:"quizzes",rodeo:"rodeos",shoe:"shoes",sombrero:"sombreros",stomach:"stomachs",tornado:"tornados",tuxedo:"tuxedos",volcano:"volcanoes"},hr={Comparative:"true¦bett1f0;arth0ew0in0;er",Superlative:"true¦earlier",PresentTense:"true¦bests,sounds",Condition:"true¦lest,unless",PastTense:"true¦began,came,d4had,kneel3l2m0sa4we1;ea0sg2;nt;eap0i0;ed;id",Participle:"true¦0:09;a06b01cZdXeat0fSgQhPoJprov0rHs7t6u4w1;ak0ithdra02o2r1;i02uY;k0v0;nd1pr04;ergoJoJ;ak0hHo3;e9h7lain,o6p5t4un3w1;o1um;rn;g,k;ol0reS;iQok0;ught,wn;ak0o1runk;ne,wn;en,wn;ewriNi1uJ;dd0s0;ut3ver1;do4se0t1;ak0h2;do2g1;roG;ne;ast0i7;iv0o1;ne,tt0;all0loBor1;bi3g2s1;ak0e0;iv0o9;dd0;ove,r1;a5eamt,iv0;hos0lu1;ng;e4i3lo2ui1;lt;wn;tt0;at0en,gun;r2w1;ak0ok0;is0;en",Gerund:"true¦accord0be0doin,go0result0stain0;ing",Expression:"true¦a0Yb0Uc0Sd0Oe0Mfarew0Lg0FhZjeez,lWmVnToOpLsJtIuFvEw7y0;a5e3i1u0;ck,p;k04p0;ee,pee;a0p,s;!h;!a,h,y;a5h2o1t0;af,f;rd up,w;atsoever,e1o0;a,ops;e,w;hoo,t;ery w06oi0L;gh,h0;! 0h,m;huh,oh;here nPsk,ut tut;h0ic;eesh,hh,it,oo;ff,h1l0ow,sst;ease,s,z;ew,ooey;h1i,mg,o0uch,w,y;h,o,ps;! 0h;hTmy go0wT;d,sh;a7evertheless,o0;!pe;eh,mm;ah,eh,m1ol0;!s;ao,fao;aCeBi9o2u0;h,mph,rra0zzC;h,y;l1o0;r6y9;la,y0;! 0;c1moCsmok0;es;ow;!p hip hoor0;ay;ck,e,llo,y;ha1i,lleluj0;ah;!ha;ah,ee4o1r0;eat scott,r;l1od0sh; grief,bye;ly;! whiz;ell;e0h,t cetera,ureka,ww,xcuse me;k,p;'oh,a0rat,uh;m0ng;mit,n0;!it;mon,o0;ngratulations,wabunga;a2oo1r0tw,ye;avo,r;!ya;h,m; 1h0ka,las,men,rgh,ye;!a,em,h,oy;la",Negative:"true¦n0;ever,o0;n,t",QuestionWord:"true¦how3wh0;at,e1ich,o0y;!m,se;n,re; come,'s",Reflexive:"true¦h4it5my5o1the0your2;ir1m1;ne3ur0;sel0;f,ves;er0im0;self",Plural:"true¦dick0gre0ones,records;ens","Unit|Noun":"true¦cEfDgChBinchAk9lb,m6newt5oz,p4qt,t1y0;ardEd;able1b0ea1sp;!l,sp;spo1;a,t,x;on9;!b,g,i1l,m,p0;h,s;!les;!b,elvin,g,m;!es;g,z;al,b;eet,oot,t;m,up0;!s",Value:"true¦a few",Imperative:"true¦bewa0come he0;re","Plural|Verb":"true¦leaves",Demonym:"true¦0:15;1:12;a0Vb0Oc0Dd0Ce08f07g04h02iYjVkTlPmLnIomHpEqatari,rCs7t5u4v3welAz2;am0Gimbabwe0;enezuel0ietnam0I;gAkrai1;aiwTex0hai,rinida0Ju2;ni0Prkmen;a5cotti4e3ingapoOlovak,oma0Spaniard,udRw2y0W;ede,iss;negal0Cr09;sh;mo0uT;o5us0Jw2;and0;a2eru0Fhilippi0Nortugu07uerto r0S;kist3lesti1na2raguay0;ma1;ani;ami00i2orweP;caragu0geri2;an,en;a3ex0Lo2;ngo0Drocc0;cedo1la2;gasy,y07;a4eb9i2;b2thua1;e0Cy0;o,t01;azakh,eny0o2uwaiI;re0;a2orda1;ma0Ap2;anO;celandic,nd4r2sraeli,ta01vo05;a2iB;ni0qi;i0oneU;aiAin2ondur0unO;di;amEe2hanai0reek,uatemal0;or2rm0;gi0;ilipino,ren8;cuadoVgyp4mira3ngli2sto1thiopi0urope0;shm0;ti;ti0;aPominUut3;a9h6o4roat3ub0ze2;ch;!i0;lom2ngol5;bi0;a6i2;le0n2;ese;lifor1m2na3;bo2eroo1;di0;angladeshi,el6o4r3ul2;gaE;azi9it;li2s1;vi0;aru2gi0;si0;fAl7merBngol0r5si0us2;sie,tr2;a2i0;li0;genti2me1;ne;ba1ge2;ri0;ni0;gh0r2;ic0;an",Organization:"true¦0:4Q;a3Tb3Bc2Od2He2Df27g1Zh1Ti1Pj1Nk1Ll1Gm12n0Po0Mp0Cqu0Br02sTtHuCv9w3xiaomi,y1;amaha,m1Bou1w1B;gov,tu3C;a4e2iki1orld trade organizati33;leaRped0O;lls fargo,st1;fie2Hinghou2R;l1rner br3U;gree3Jl street journ2Im1E;an halOeriz2Xisa,o1;dafo2Yl1;kswagMvo;b4kip,n2ps,s1;a tod3Aps;es3Mi1;lev3Fted natio3C;er,s; mobi32aco beRd bOe9gi frida3Lh3im horto3Amz,o1witt3D;shi49y1;ota,s r 05;e 1in lizzy;b3carpen3Jdaily ma3Dguess w2holli0s1w2;mashing pumpki35uprem0;ho;ea1lack eyed pe3Xyr0Q;ch bo3Dtl0;l2n3Qs1xas instrumen1U;co,la m1F;efoni0Kus;a8cientology,e5ieme2Ymirnoff,np,o3pice gir6quare0Ata1ubaru;rbuc1to34;ks;ny,undgard1;en;a2x pisto1;ls;g1Wrs;few2Minsbur31lesfor03msu2E;adiohead,b8e4o1yana3C;man empi1Xyal 1;b1dutch she4;ank;a3d 1max,vl20;bu1c2Ahot chili peppe2Ylobst2N;ll;ders dige1Ll madrid;c,s;ant3Aizn2Q;a8bs,e5fiz2Ihilip4i3r1;emier 1udenti1D;leagTo2K;nk floyd,zza hut; morrBs;psi2tro1uge0E;br33chi0Tn33;!co;lant2Un1yp16; 2ason27da2P;ld navy,pec,range juli2xf1;am;us;aAb9e6fl,h5i4o1sa,vid3wa;k2tre dame,vart1;is;ia;ke,ntendo,ss0QvZ;l,s;c,st1Otflix,w1; 1sweek;kids on the block,york0D;a,c;nd22s2t1;ional aca2Po,we0U;a,c02d0S;aDcdonalCe9i6lb,o3tv,y1;spa1;ce;b1Tnsanto,ody blu0t1;ley cr1or0T;ue;c2t1;as,subisO;helin,rosoft;dica2rcedes benz,talli1;ca;id,re;ds;cs milk,tt19z24;a3e1g,ittle caesa1P; ore09novo,x1;is,mark,us; 1bour party;pres0Dz boy;atv,fc,kk,lm,m1od1O;art;iffy lu0Roy divisi0Jpmorgan1sa;! cha09;bm,hop,k3n1tv;g,te1;l,rpol;ea;a5ewlett pack1Vi3o1sbc,yundai;me dep1n1P;ot;tac1zbollah;hi;lliburt08sbro;eneral 6hq,ithub,l5mb,o2reen d0Ou1;cci,ns n ros0;ldman sachs,o1;dye1g0H;ar;axo smith kli04encoW;electr0Nm1;oto0Z;a5bi,c barcelo4da,edex,i2leetwood m03o1rito l0G;rd,xcY;at,fa,nancial1restoZ; tim0;na;cebook,nnie mae;b0Asa,u3xxon1; m1m1;ob0J;!rosceptics;aiml0De5isney,o4u1;nkin donu2po0Zran dur1;an;ts;j,w jon0;a,f lepp12ll,peche mode,r spieg02stiny's chi1;ld;aJbc,hFiDloudflaCnn,o3r1;aigsli5eedence clearwater reviv1ossra09;al;c7inba6l4m1o0Est09;ca2p1;aq;st;dplSg1;ate;se;a c1o chanQ;ola;re;a,sco1tigroup;! systems;ev2i1;ck fil a,na daily;r1y;on;d2pital o1rls jr;ne;bury,ill1;ac;aEbc,eBf9l5mw,ni,o1p,rexiteeU;ei3mbardiIston 1;glo1pizza;be;ng;o2ue c1;roV;ckbuster video,omingda1;le; g1g1;oodriL;cht2e ge0rkshire hathaw1;ay;el;cardi,idu,nana republ3s1xt5y5;f,kin robbi1;ns;ic;bYcTdidSerosmith,iRlKmEnheuser busDol,ppleAr6s4u3v2y1;er;is,on;di,todesk;hland o1sociated E;il;b3g2m1;co;os;ys; compu1be0;te1;rs;ch;c,d,erican3t1;!r1;ak; ex1;pre1;ss; 5catel2ta1;ir;! lu1;ce1;nt;jazeera,qae1;da;g,rbnb;as;/dc,a3er,tivision1;! blizz1;ard;demy of scienc0;es;ba",Possessive:"true¦its,my,our0thy;!s","Noun|Verb":"true¦0:9W;1:AA;2:96;3:A3;4:9R;5:A2;6:9K;7:8N;8:7L;9:A8;A:93;B:8D;C:8X;a9Ob8Qc7Id6Re6Gf5Sg5Hh55i4Xj4Uk4Rl4Em40n3Vo3Sp2Squ2Rr21s0Jt02u00vVwGyFzD;ip,oD;ne,om;awn,e6Fie68;aOeMhJiHoErD;ap,e9Oink2;nd0rDuC;kDry,sh5Hth;!shop;ck,nDpe,re,sh;!d,g;e86iD;p,sD;k,p0t2;aDed,lco8W;r,th0;it,lk,rEsDt4ve,x;h,te;!ehou1ra9;aGen5FiFoD;iDmAte,w;ce,d;be,ew,sA;cuum,l4B;pDr7;da5gra6Elo6A;aReQhrPiOoMrGuEwiDy5Z;n,st;nDrn;e,n7O;aGeFiEoDu6;t,ub2;bu5ck4Jgg0m,p;at,k,nd;ck,de,in,nsDp,v7J;f0i8R;ll,ne,p,r4Yss,t94uD;ch,r;ck,de,e,le,me,p,re;e5Wow,u6;ar,e,ll,mp0st,xt;g,lDng2rg7Ps5x;k,ly;a0Sc0Ne0Kh0Fi0Dk0Cl0Am08n06o05pXquaBtKuFwD;ea88iD;ng,pe,t4;bGit,m,ppErD;fa3ge,pri1v2U;lDo6S;e6Py;!je8;aMeLiKoHrEuDy2;dy,ff,mb2;a85eEiDo5Pugg2;ke,ng;am,ss,t4;ckEop,p,rD;e,m;ing,pi2;ck,nk,t4;er,m,p;ck,ff,ge,in,ke,lEmp,nd,p2rDte,y;!e,t;k,l;aJeIiHlGoFrDur,y;ay,e56inDu3;g,k2;ns8Bt;a5Qit;ll,n,r87te;ed,ll;m,n,rk;b,uC;aDee1Tow;ke,p;a5Je4FiDo53;le,rk;eep,iDou4;ce,p,t;ateboa7Ii;de,gnDl2Vnk,p,ze;!al;aGeFiEoDuff2;ck,p,re,w;ft,p,v0;d,i3Ylt0;ck,de,pe,re,ve;aEed,nDrv1It;se,t2N;l,r4t;aGhedu2oBrD;aEeDibb2o3Z;en,w;pe,t4;le,n,r2M;cDfegua72il,mp2;k,rifi3;aZeHhy6LiGoEuD;b,in,le,n,s5X;a6ck,ll,oDpe,u5;f,t;de,ng,ot,p,s1W;aTcSdo,el,fQgPje8lOmMnLo17pJque6sFturn,vDwa6V;eDi27;al,r1;er74oFpe8tEuD;lt,me;!a55;l71rt;air,eaDly,o53;l,t;dezvo2Zt;aDedy;ke,rk;ea1i4G;a6Iist0r5N;act6Yer1Vo71uD;nd,se;a38o6F;ch,s6G;c1Dge,iEke,lly,nDp1Wt1W;ge,k,t;n,se;es6Biv0;a04e00hYiXlToNrEsy4uD;mp,n4rcha1sh;aKeIiHoDu4O;be,ceFdu3fi2grDje8mi1p,te6;amDe6W;!me;ed,ss;ce,de,nt;sDy;er6Cs;cti3i1;iHlFoEp,re,sDuCw0;e,i5Yt;l,p;iDl;ce,sh;nt,s5V;aEce,e32uD;g,mp,n7;ce,nDy;!t;ck,le,n17pe,tNvot;a1oD;ne,tograph;ak,eFnErDt;fu55mA;!c32;!l,r;ckJiInHrFsEtDu1y;ch,e9;s,te;k,tD;!y;!ic;nt,r,se;!a7;bje8ff0il,oErDutli3Qver4B;bAd0ie9;ze;a4ReFoDur1;d,tD;e,i3;ed,gle8tD;!work;aMeKiIoEuD;rd0;ck,d3Rld,nEp,uDve;nt,th;it5EkD;ey;lk,n4Brr5CsDx;s,ta2B;asuBn4UrDss;ge,it;il,nFp,rk3WsEtD;ch,t0;h,k,t0;da5n0oeuvB;aLeJiHoEuD;mp,st;aEbby,ck,g,oDve;k,t;d,n;cDe,ft,mAnIst;en1k;aDc0Pe4vK;ch,d,k,p,se;bFcEnd,p,t4uD;gh,n4;e,k;el,o2U;eEiDno4E;ck,d,ll,ss;el,y;aEo1OuD;i3mp;m,zz;mpJnEr46ssD;ue;c1Rdex,fluGha2k,se2HteDvoi3;nt,rD;e6fa3viD;ew;en3;a8le2A;aJeHiGoEuD;g,nt;l3Ano2Dok,pDr1u1;!e;ghli1Fke,nt,re,t;aDd7lp;d,t;ck,mGndFrEsh,tDu9;ch,e;bo3Xm,ne4Eve6;!le;!m0;aMear,ift,lKossJrFuD;arDe4Alp,n;antee,d;aFiEoDumb2;uCwth;ll,nd,p;de,sp;ip;aBoDue;ss,w;g,in,me,ng,s,te,ze;aZeWiRlNoJrFuD;ck,el,nDss,zz;c38d;aEoDy;st,wn;cDgme,me,nchi1;tuB;cFg,il,ld,rD;ce,e29mDwa31;!at;us;aFe0Vip,oDy;at,ck,od,wD;!er;g,ke,me,re,sh,vo1E;eGgFlEnDre,sh,t,x;an3i0Q;e,m,t0;ht,uB;ld;aEeDn3;d,l;r,tuB;ce,il,ll,rm,vo2W;cho,d7ffe8nMsKxFyeD;!baD;ll;cGerci1hFpDtra8;eriDo0W;en3me9;au6ibA;el,han7u1;caDtima5;pe;count0d,vy;a01eSiMoJrEuDye;b,el,mp,pli2X;aGeFiEoD;ne,p;ft,ll,nk,p,ve;am,ss;ft,g,in;cEd7ubt,wnloD;ad;k,u0E;ge6p,sFt4vD;e,iDor3;de;char7gui1h,liEpD;at4lay,u5;ke;al,bKcJfeIlGmaCposAsEtaD;il;e07iD;gn,re;ay,ega5iD;ght;at,ct;li04rea1;a5ut;b,ma7n3rDte;e,t;a0Eent0Dh06irc2l03oKrFuD;be,e,rDt;b,e,l,ve;aGeFoEuDy;sh;p,ss,wd;dAep;ck,ft,sh;at,de,in,lTmMnFordina5py,re,st,uDv0;gh,nDp2rt;s01t;ceHdu8fli8glomeIsFtDveN;a8rD;a6ol;e9tru8;ct;ntDrn;ra5;bHfoGmFpD;leDouCromi1;me9;aCe9it,u5;rt;at,iD;ne;lap1oD;r,ur;aEiDoud,ub;ck,p;im,w;aEeDip;at,ck,er;iGllen7nErD;ge,m,t;ge,nD;el;n,r;er,re;ke,ll,mp,noe,pGrXsFtEuDve;se,ti0I;alog,ch;h,t;!tuB;re;a03eZiXlToPrHuEyD;pa11;bb2ck2dgEff0mp,rDst,zz;den,n;et;anJeHiFoadEuD;i1sh;ca6;be,d7;ge;aDed;ch,k;ch,d;aFg,mb,nEoDrd0tt2x,ycott;k,st,t;d,e;rd,st;aFeCiDoYur;nk,tz;nd;me;as,d,ke,nd,opsy,tD;!ch,e;aFef,lt,nDt;d,efA;it;r,t;ck,il,lan3nIrFsEtt2;le;e,h;!gDk;aDe;in;!d,g,k;bu1c05dZge,iYlVnTppQrLsIttGucEwaD;rd;tiD;on;aDempt;ck;k,sD;i6ocia5;st;chFmD;!oD;ur;!iD;ve;eEroa4;ch;al;chDg0sw0;or;aEt0;er;rm;d,m,r;dreHvD;an3oD;ca5;te;ce;ss;cDe,he,t;eFoD;rd,u9;nt;nt,ss;se",Actor:"true¦0:7B;1:7G;2:6A;3:7F;4:7O;5:7K;a6Nb62c4Ud4Be41f3Sg3Bh30i2Uj2Qkin2Pl2Km26n1Zo1Sp0Vqu0Tr0JsQtJuHvEw8yo6;gi,ut6;h,ub0;aAe9i8o7r6;estl0it0;m2rk0;fe,nn0t2Bza2H;atherm2ld0;ge earn0it0nder0rri1;eter7i6oyF;ll5Qp,s3Z;an,ina2U;n6s0;c6Uder03;aoisea23e9herapi5iktok0o8r6ut1yco6S;a6endseLo43;d0mp,nscri0Bvel0;ddl0u1G;a0Qchn7en6na4st0;ag0;i3Oo0D;aiXcUeRhPiMki0mu26oJpGquaFtBu7wee6;p0theart;lt2per7r6;f0ge6Iviv1;h6inten0Ist5Ivis1;ero,um2;a8ep7r6;ang0eam0;bro2Nc2Ofa2Nmo2Nsi20;ff0tesm2;tt0;ec7ir2Do6;kesp59u0M;ia5Jt3;l7me6An,rcere6ul;r,ss;di0oi5;n7s6;sy,t0;g0n0;am2ephe1Iow6;girl,m2r2Q;cretInior cit3Fr6;gea4v6;a4it1;hol4Xi7reen6ulpt1;wr2C;e01on;l1nt;aEe9o8u6;l0nn6;er up,ingE;g40le mod3Zof0;a4Zc8fug2Ppo32searQv6;ere4Uolution6;ary;e6luYru22;ptio3T;bbi,dic5Vpp0;arter6e2Z;back;aYeWhSiRlOoKr8sycho7u6;nk,p31;logi5;aGeDiBo6;d9fess1g7ph47s6;pe2Ktitu51;en6ramm0;it1y;igy,uc0;est4Nme mini0Unce6s3E;!ss;a7si6;de4;ch0;ctiti39nk0P;dca0Oet,li6pula50rnst42;c2Itic6;al scie6i2;nti5;a6umb0;nn0y6;er,ma4Lwright;lgrim,one0;a8iloso7otogra7ra6ysi1V;se;ph0;ntom,rmaci5;r6ssi1T;form0s4O;i3El,nel3Yr8st1tr6wn;i6on;arWot;ent4Wi42tn0;ccupa4ffBp8r7ut6;ca5l0B;ac4Iganiz0ig2Fph2;er3t6;i1Jomet6;ri5;ic0spring;aBe9ie4Xo7u6;n,rser3J;b6mad,vi4V;le2Vo4D;i6mesis,phew;ce,ghb1;nny,rr3t1X;aEeDiAo7u6yst1Y;m8si16;der3gul,m7n6th0;arDk;!my;ni7s6;f02s0Jt0;on,st0;chan1Qnt1rcha4;gi9k0n8rtyr,t6y1;e,riar6;ch;ag0iac;ci2stra3I;a7e2Aieutena4o6;rd,s0v0;bor0d7ndlo6ss,urea3Fwy0ym2;rd;!y;!s28;e8o7u6;ggl0;gg0urna2U;st0;c3Hdol,llu3Ummigra4n6; l9c1Qfa4habi42nov3s7ve6;nt1stig3;pe0Nt6;a1Fig3ru0M;aw;airFeBistoAo8u6ygie1K;man6sba2H;!ita8;bo,st6usekN;age,e3P;ri2;ir,r6;m7o6;!ine;it;dress0sty2C;aLeIhostGirl26ladi3oCrand7u6;e5ru;c9daug0Jfa8m7pa6s2Y;!re4;a,o6;th0;hi1B;al7d6lf0;!de3A;ie,k6te26;eep0;!wr6;it0;isha,n6;i6tl04;us;mbl0rden0;aDella,iAo7r6;eela2Nie1P;e,re6ster pare4;be1Hm2r6st0;unn0;an2ZgZlmm17nanci0r6tt0;e6st la2H; marsh2OfigXm2;rm0th0;conoEdDlectriCm8n7x6;amin0cellency,i2A;emy,trepreneur,vironmenta1J;c8p6;er1loye6;e,r;ee;ci2;it1;mi5;aKeBi8ork,ri7u6we02;de,tche2H;ft0v0;ct3eti7plom2Hre6va;ct1;ci2ti2;aDcor3fencCi0InAput9s7tectLvel6;op0;ce1Ge6ign0;rt0;ee,y;iz6;en;em2;c1Ml0;d8nc0redev7ug6;ht0;il;!dy;a06e04fo,hXitizenWlToBr9u6;r3stomer6;! representat6;ive;e3it6;ic;lJmGnAord9rpor1Nu7w6;boy,ork0;n6ri0;ciTte1Q;in3;fidantAgressSs9t6;e0Kr6;ibut1o6;ll0;tab13ul1O;!e;edi2m6pos0rade;a0EeQissi6;on0;leag8on7um6;ni5;el;ue;e6own;an0r6;ic,k;!s;a9e7i6um;ld;erle6f;ad0;ir7nce6plFract0;ll1;m2wI;lebri6o;ty;dBptAr6shi0;e7pe6;nt0;r,t6;ak0;ain;et;aMeLiJlogg0oErBu6;dd0Fild0rgl9siness6;m2p7w6;om2;ers05;ar;i7o6;!k0th0;cklay0de,gadi0;hemi2oge8y6;!frie6;nd;ym2;an;cyc6sR;li5;atbox0ings;by,nk0r6;b0on7te6;nd0;!e07;c04dWge4nQpLrHsFtAu7yatull6;ah;nt7t6;h1oG;!ie;h8t6;e6orney;nda4;ie5le6;te;sis00tron6;aut,om0;chbis8isto7tis6;an,t;crU;hop;ost9p6;ari6rentiS;ti6;on;le;a9cest1im3nou8y6;bo6;dy;nc0;ly5rc6;hi5;mi8v6;entur0is1;er;ni7r6;al;str3;at1;or;counBquaintanArob9t6;ivi5or,re6;ss;st;at;ce;ta4;nt","Adj|Noun":"true¦0:16;a1Db17c0Ud0Re0Mf0Dg0Ah08i06ju05l02mWnUoSpNrIsBt7u4v1watershed;a1ision0Z;gabo4nilla,ria1;b0Vnt;ndergr1pstairs;adua14ou1;nd;a3e1oken,ri0;en,r1;min0rori13;boo,n;age,e5ilv0Flack,o3quat,ta2u1well;bordina0Xper5;b0Lndard;ciali0Yl1vereign;e,ve16;cret,n1ri0;ior;a4e2ou1ubbiL;nd,tiY;ar,bBl0Wnt0p1side11;resent0Vublican;ci0Qsh;a4eriodic0last0Zotenti0r1;emi2incip0o1;!fession0;er,um;rall4st,tie0U;ff1pposi0Hv0;ens0Oi0C;agg01ov1uts;el;a5e3iniatJo1;bi01der07r1;al,t0;di1tr0N;an,um;le,riG;attOi2u1;sh;ber0ght,qC;stice,veniT;de0mpressioYn1;cumbe0Edividu0no0Dsta0Eterim;alf,o1umdrum;bby,melF;en2old,ra1;ph0Bve;er0ious;a7e5i4l3u1;git03t1;ure;uid;ne;llow,m1;aFiL;ir,t,vo1;riOuriO;l3p00x1;c1ecutUpeV;ess;d1iK;er;ar2e1;mographUrivO;k,l2;hiGlassSo2rude,unn1;ing;m5n1operK;creCstitueOte2vertab1;le;mpor1nt;ary;ic,m2p1;anion,lex;er2u1;ni8;ci0;al;e5lank,o4r1;i2u1;te;ef;ttom,urgeois;st;cadem9d6l2ntarct9r1;ab,ct8;e3tern1;at1;ive;rt;oles1ult;ce1;nt;ic","Adj|Past":"true¦0:4Q;1:4C;2:4H;3:4E;a44b3Tc36d2Je29f20g1Wh1Si1Jj1Gkno1Fl1Am15n12o0Xp0Mqu0Kr08sLtEuAv9w4yellow0;a7ea6o4rinkl0;r4u3Y;n,ri0;k31th3;rp0sh0tZ;ari0e1O;n5p4s0;d1li1Rset;cov3derstood,i4;fi0t0;a8e3Rhr7i6ouTr4urn0wi4C;a4imm0ou2G;ck0in0pp0;ed,r0;eat2Qi37;m0nn0r4;get0ni2T;aOcKeIhGimFm0Hoak0pDt7u4;bsid3Ogge44s4;pe4ta2Y;ct0nd0;a8e7i2Eok0r5u4;ff0mp0nn0;ength2Hip4;ed,p0;am0reotyp0;in0t0;eci4ik0oH;al3Efi0;pRul1;a4ock0ut;d0r0;a4c1Jle2t31;l0s3Ut0;a6or5r4;at4e25;ch0;r0tt3;t4ut0;is2Mur1;aEe5o4;tt0;cAdJf2Bg9je2l8m0Knew0p7qu6s4;eTpe2t4;or0ri2;e3Dir0;e1lac0;at0e2Q;i0Rul1;eiv0o4ycl0;mme2Lrd0v3;in0lli0ti2A;a4ot0;li28;aCer30iBlAo9r5u4;mp0zzl0;e6i2Oo4;ce2Fd4lo1Anou30pos0te2v0;uc0;fe1CocCp0Iss0;i2Kli1L;ann0e2CuS;ck0erc0ss0;ck0i2Hr4st0;allLk0;bse7c6pp13rgan2Dver4;lo4whelm0;ok0;cupi0;rv0;aJe5o4;t0uri1A;ed0gle2;a6e5ix0o4ut0ys1N;di1Nt15u26;as0Clt0;n4rk0;ag0ufact0A;e6i5o4;ad0ck0st,v0;cens0m04st0;ft,v4;el0;tt0wn;a5o15u4;dg0s1B;gg0;llumSmpAn4sol1;br0cre1Ldebt0f8jZspir0t5v4;it0olv0;e4ox0Y;gr1n4re23;d0si15;e2l1o1Wuri1;li0o01r4;ov0;a6e1o4um03;ok0r4;ri0Z;mm3rm0;i6r5u4;a1Bid0;a0Ui0Rown;ft0;aAe9i8l6oc0Ir4;a4i0oz0Y;ctHg19m0;avo0Ju4;st3;ni08tt0x0;ar0;d0il0sc4;in1;dCl1mBn9quipp0s8x4;agger1c6p4te0T;a0Se4os0;ct0rie1D;it0;cap0tabliZ;cha0XgFha1As4;ur0;a0Zbarra0N;i0Buc1;aMeDi5r4;a01i0;gni08miniSre2s4;a9c6grun0Ft4;o4re0Hu17;rt0;iplWou4;nt0r4;ag0;bl0;cBdRf9l8p7ra6t5v4;elop0ot0;ail0ermQ;ng0;re07;ay0ight0;e4in0o0M;rr0;ay0enTor1;m5t0z4;ed,zl0;ag0p4;en0;aPeLhIlHo9r6u4;lt4r0stom03;iv1;a5owd0u4;sh0;ck0mp0;d0loAm7n4ok0v3;centr1f5s4troC;id3olid1;us0;b5pl4;ic1;in0;r0ur0;assi9os0utt3;ar5i4;ll0;g0m0;lebr1n6r4;ti4;fi0;tralJ;g0lcul1;aDewild3iCl9o7r5urn4;ed,t;ok4uis0;en;il0r0t4und;tl0;e5i4;nd0;ss0;as0;ffl0k0laMs0tt3;bPcNdKfIg0lFmaz0nDppBrm0ss9u5wa4;rd0;g5thor4;iz0;me4;nt0;o6u4;m0r0;li0re4;ci1;im1ticip1;at0;a5leg0t3;er0;rm0;fe2;ct0;ju5o7va4;nc0;st0;ce4knowledg0;pt0;and5so4;rb0;on0;ed",Singular:"true¦0:5J;1:5H;2:4W;3:4S;4:52;5:57;6:5L;7:56;8:5B;a52b4Lc3Nd35e2Xf2Og2Jh28in24j23k22l1Um1Ln1Ho1Bp0Rqu0Qr0FsZtMuHvCw9x r58yo yo;a9ha3Po3Q;f3i4Rt0Gy9;! arou39;arCeAideo ga2Qo9;cabu4Jl5C;gOr9t;di4Zt1Y;iety,ni4P;nBp30rAs 9;do43s5E;bani1in0;coordinat3Ader9;estima1to24we41; rex,aKeJhHiFoErBuAv9;! show;m2On2rntLto1D;agedy,ib9o4E;e,u9;n0ta46;ni1p2rq3L;c,er,m9;etF;ing9ree26;!y;am,mp3F;ct2le6x return;aNcMeKhor4QiJkHoGpin off,tDuBy9;ll9ner7st4T;ab2X;b9i1n28per bowl,rro1X;st3Ltot0;atAipe2Go1Lrate7udent9;! lo0I;i39u1;ft ser4Lmeo1I;elet5i9;ll,r3V;b38gn2Tte;ab2Jc9min3B;t,urity gua2N;e6ho2Y;bbatic0la3Jndwi0Qpi5;av5eDhetor2iAo9;de6om,w;tAv9;erb2C;e,u0;bDcBf9publ2r10spi1;er9orm3;e6r0;i9ord label;p2Ht0;a1u46;estion mark,ot2F;aPeMhoLiIlGoErAu9yram1F;ddi3HpErpo1Js3J;eBo9;bl3Zs9;pe3Jta1;dic1Rmi1Fp1Qroga8ss relea1F;p9rt0;py;a9ebisci1;q2Dte;cn2eAg9;!gy;!r;ne call,tocoK;anut,dAr9t0yo1;cen3Jsp3K;al,est0;nop4rAt9;e,hog5;adi11i2V;atme0bj3FcBpia1rde0thers,utspok5ve9wn3;n,r9;ti0Pview;cuAe9;an;pi3;arBitAot9umb3;a2Fhi2R;e,ra1;cot2ra8;aFeCiAo9ur0;nopo4p18rni2Nsq1Rti36uld;c,li11n0As9tt5;chief,si34;dAnu,t9;al,i3;al,ic;gna1mm0nd15rsupi0te9yf4;ri0;aDegCiBu9;ddi1n9;ch;me,p09; Be0M;bor14y9; 9er;up;eyno1itt5;el4ourn0;cBdices,itia8ni25sAtel0Lvert9;eb1J;e28titu1;en8i2T;aIeEighDoAu9;man right,s22;me9rmoFsp1Ftb0K;! r9;un; scho0YriY;a9i1N;d9v5; start,pho9;ne;ndful,sh brown,v5ze;aBelat0Ilaci3r9ul4yp1S;an9enadi3id;a1Cd slam,ny;df4r9;l2ni1I;aGeti1HiFlu1oCrAun9;er0;ee market,i9onti3;ga1;l4ur9;so9;me;ePref4;br2mi4;conoFffi7gg,lecto0Rmbas1EnCpidem2s1Zth2venBxAyel9;id;ampZempl0Nte6;i19t;er7terp9;ri9;se;my;eLiEoBr9ump tru0U;agonf4i9;er,ve thru;cAg7i4or,ssi3wn9;side;to0EumenE;aEgniDnn3sAvide9;nd;conte6incen8p9tri11;osi9;ti0C;ta0H;le0X;athBcAf9ni0terre6;ault 05err0;al,im0;!b9;ed;aWeThMiLlJoDr9;edit caBuc9;ib9;le;rd;efficDke,lCmmuniqLnsApi3rr0t0Xus9yo1;in;erv9uI;ato02;ic,lQ;ie6;er7i9oth;e6n2;ty,vil wM;aDeqCick5ocoBr9;istmas car9ysanthemum;ol;la1;ue;ndeli3racteri9;st2;iAllEr9;e0tifica1;liZ;hi3nFpErCt9ucus;erpi9hedr0;ll9;ar;!bohyd9ri3;ra1;it0;aAe,nib0t9;on;l,ry;aMeLiop2leJoHrDu9;nny,r9tterf4;g9i0;la9;ry;eakAi9;ck;fa9throB;st;dy,ro9wl;ugh;mi9;sh;an,l4;nkiArri3;er;ng;cSdMlInFppeti1rDsBtt2utop9;sy;ic;ce6pe9;ct;r9sen0;ay;ecAoma4tiA;ly;do1;i5l9;er7y;gy;en; hominDjAvan9;tage;ec8;ti9;ve;em;cCeAqui9;tt0;ta1;te;iAru0;al;de6;nt","Person|Noun":"true¦a0Eb07c03dWeUfQgOhLjHkiGlFmCnBolive,p7r4s3trini06v1wa0;ng,rd,tts;an,enus,iol0;a,et;ky,onPumm09;ay,e1o0uby;bin,d,se;ed,x;a2e1o0;l,tt04;aLnJ;dYge,tR;at,orm;a0eloW;t0x,ya;!s;a9eo,iH;ng,tP;a2e1o0;lGy;an,w3;de,smi4y;a0erb,iOolBuntR;ll,z0;el;ail,e0iLuy;ne;a1ern,i0lo;elds,nn;ith,n0;ny;a0dEmir,ula,ve;rl;a4e3i1j,ol0;ly;ck,x0;ie;an,ja;i0wn;sy;am,h0liff,rystal;a0in,ristian;mbers,ri0;ty;a4e3i2o,r0ud;an0ook;dy;ll;nedict,rg;k0nks;er;l0rt;fredo,ma","Actor|Verb":"true¦aCb8c5doctor,engineAfool,g3host,judge,m2nerd,p1recruit,scout,ushAvolunteAwi0;mp,tneA;arent,ilot;an,ime;eek,oof,r0uide;adu8oom;ha1o0;ach,nscript,ok;mpion,uffeur;o2u0;lly,tch0;er;ss;ddi1ffili0rchite1;ate;ct",MaleName:"true¦0:H6;1:FZ;2:DS;3:GQ;4:CZ;5:FV;6:GM;7:FP;8:GW;9:ET;A:C2;B:GD;aF8bE1cCQdBMeASfA1g8Yh88i7Uj6Sk6Bl5Mm48n3So3Ip33qu31r26s1Et0Ru0Ov0CwTxSyHzC;aCor0;cChC1karia,nAT;!hDkC;!aF6;!ar7CeF5;aJevgenBSoEuC;en,rFVsCu3FvEF;if,uf;nDs6OusC;ouf,s6N;aCg;s,tC;an,h0;hli,nCrosE1ss09;is,nC;!iBU;avi2ho5;aPeNiDoCyaEL;jcieBJlfgang,odrFutR;lFnC;f8TsC;lCt1;ow;bGey,frEhe4QlC;aE5iCy;am,e,s;ed8iC;d,ed;eAur;i,ndeD2rn2sC;!l9t1;lDyC;l1ne;lDtC;!er;aCHy;aKernDAiFladDoC;jteB0lodymyr;!iC;mFQsDB;cFha0ktBZnceDrgCOvC;a0ek;!nC;t,zo;!e4StBV;lCnC7sily;!entC;in9J;ghE2lCm70nax,ri,sm0;riCyss87;ch,k;aWeRhNiLoGrEuDyC;!l2roEDs1;n6r6E;avD0eCist0oy,um0;ntCRvBKy;bFdAWmCny;!asDmCoharu;aFFie,y;!z;iA6y;mCt4;!my,othy;adEeoDia0SomC;!as;!dor91;!de4;dFrC;enBKrC;anBJeCy;ll,nBI;!dy;dgh,ha,iCnn2req,tsu5V;cDAka;aYcotWeThPiMlobod0oKpenc2tEurDvenAEyCzym1;ed,lvest2;aj,e9V;anFeDuC;!aA;fan17phEQvCwaA;e77ie;!islaCl9;v,w;lom1rBuC;leymaDHta;dDgmu9UlCm1yabonga;as,v8B;!dhart8Yn9;aEeClo75;lCrm0;d1t1;h9Jne,qu1Jun,wn,yne;aDbastiEDk2Yl5Mpp,rgCth,ymoCU;e1Dio;m4n;!tC;!ie,y;eDPlFmEnCq67tosCMul;dCj2UtiA5;e01ro;!iATkeB6mC4u5;!ik,vato9K;aZeUheC8iRoGuDyC;an,ou;b99dDf4peAssC;!elEG;ol00y;an,bLc7MdJel,geIh0lHmGnEry,sDyC;!ce;ar7Ocoe,s;!aCnBU;ld,n;an,eo;a7Ef;l7Jr;e3Eg2n9olfo,riC;go;bBNeDH;cCl9;ar87c86h54kCo;!ey,ie,y;cFeA3gDid,ubByCza;an8Ln06;g85iC;naC6s;ep;ch8Kfa5hHin2je8HlGmFndEoHpha5sDul,wi36yC;an,mo8O;h9Im4;alDSol3O;iD0on;f,ph;ul;e9CinC;cy,t1;aOeLhilJiFrCyoG;aDeC;m,st1;ka85v2O;eDoC;tr;r8GtC;er,ro;!ipCl6H;!p6U;dCLrcy,tC;ar,e9JrC;!o7;b9Udra8So9UscAHtri62ulCv8I;!ie,o7;ctav6Ji2lImHndrBRrGsDtCum6wB;is,to;aDc6k6m0vCwaBE;al79;ma;i,vR;ar,er;aDeksandr,ivC;er,i2;f,v;aNeLguyBiFoCu3O;aDel,j4l0ma0rC;beAm0;h,m;cFels,g5i9EkDlC;es,s;!au,h96l78olaC;!i,y;hCkCol76;ol75;al,d,il,ls1vC;ilAF;hom,tC;e,hC;anCy;!a5i5;aYeViLoGuDyC;l4Nr1;hamDr84staC;fa,p6E;ed,mG;di10e,hamEis4JntDritz,sCussa;es,he;e,y;ad,ed,mC;ad,ed;cGgu5hai,kFlEnDtchC;!e8O;a9Pik;house,o7t1;ae73eC3ha8Iolaj;ah,hDkC;!ey,y;aDeC;al,l;el,l;hDlv3rC;le,ri8Ev4T;di,met;ay0c00gn4hWjd,ks2NlTmadZnSrKsXtDuric7VxC;imilBKwe8B;eHhEi69tCus,y69;!eo,hCia7;ew,i67;eDiC;as,eu,s;us,w;j,o;cHiGkFlEqu8Qsha83tCv3;iCy;!m,n;in,on;el,o7us;a6Yo7us;!elCin,o7us;!l8o;frAEi5Zny,u5;achDcoCik;lm;ai,y;amDdi,e5VmC;oud;adCm6W;ou;aulCi9P;ay;aWeOiMloyd,oJuDyC;le,nd1;cFdEiDkCth2uk;a7e;gi,s,z;ov7Cv6Hw6H;!as,iC;a6Een;g0nn52renDuCvA4we7D;!iS;!zo;am,n4oC;n5r;a9Yevi,la5KnHoFst2thaEvC;eCi;nte;bo;nCpo8V;!a82el,id;!nC;aAy;mEnd1rDsz73urenCwr6K;ce,t;ry,s;ar,beAont;aOeIhalHiFla4onr63rDu5SylC;e,s;istCzysztof;i0oph2;er0ngsl9p,rC;ilA9k,ollos;ed,id;en0iGnDrmCv4Z;it;!dDnCt1;e2Ny;ri4Z;r,th;cp2j4mEna8BrDsp6them,uC;ri;im,l;al,il;a03eXiVoFuC;an,lCst3;en,iC;an,en,o,us;aQeOhKkub4AnIrGsDzC;ef;eDhCi9Wue;!ua;!f,ph;dCge;i,on;!aCny;h,s,th6J;anDnC;!ath6Hie,n72;!nC;!es;!l,sCy;ph;o,qu3;an,mC;!i,m6V;d,ffFns,rCs4;a7JemDmai7QoCry;me,ni1H;i9Dy;!e73rC;ey,y;cKdBkImHrEsDvi2yC;dBs1;on,p2;ed,oDrCv67;e6Qod;d,s61;al,es5Wis1;a,e,oCub;b,v;ob,qu13;aTbNchiMgLke53lija,nuKonut,rIsEtCv0;ai,suC;ki;aDha0i8XmaCsac;el,il;ac,iaC;h,s;a,vinCw3;!g;k,nngu6X;nac1Xor;ka;ai,rahC;im;aReLoIuCyd6;beAgGmFsC;eyDsC;a3e3;in,n;ber5W;h,o;m2raDsse3wC;a5Pie;c49t1K;a0Qct3XiGnDrC;beAman08;dr7VrC;iCy2N;!k,q1R;n0Tt3S;bKlJmza,nIo,rEsDyC;a5KdB;an,s0;lEo67r2IuCv9;hi5Hki,tC;a,o;an,ey;k,s;!im;ib;a08e00iUlenToQrMuCyorgy;iHnFsC;!taC;f,vC;!e,o;n6tC;er,h2;do,lC;herDlC;auCerQ;me;aEegCov2;!g,orC;!io,y;dy,h7C;dfr9nza3XrDttfC;ri6C;an,d47;!n;acoGlEno,oCuseppe;rgiCvan6O;!o,s;be6Ies,lC;es;mo;oFrC;aDha4HrCt;it,y;ld,rd8;ffErgC;!e7iCy;!os;!r9;bElBrCv3;eCla1Nr4Hth,y;th;e,rC;e3YielC;!i4;aXeSiQlOorrest,rCyod2E;aHedFiC;edDtC;s,z;ri18;!d42eri11riC;ck,k;nCs2;cEkC;ie,lC;in,yn;esLisC;!co,z3M;etch2oC;ri0yd;d5lConn;ip;deriFliEng,rC;dinaCg4nan0B;nd8;pe,x;co;bCdi,hd;iEriC;ce,zC;io;an,en,o;benez2dZfrYit0lTmMnJo3rFsteb0th0ugenEvCymBzra;an,eCge4D;ns,re3K;!e;gi,iDnCrol,v3w3;est8ie,st;cCk;!h,k;o0DriCzo;co,qC;ue;aHerGiDmC;aGe3A;lCrh0;!iC;a10o,s;s1y;nu5;beAd1iEliDm2t1viCwood;n,s;ot28s;!as,j5Hot,sC;ha;a3en;!dGg6mFoDua2QwC;a2Pin;arC;do;oZuZ;ie;a04eTiOmitrNoFrag0uEwDylC;an,l0;ay3Hig4D;a3Gdl9nc0st3;minFnDri0ugCvydGy2S;!lF;!a36nCov0;e1Eie,y;go,iDykC;as;cCk;!k;i,y;armuFetDll1mitri7neCon,rk;sh;er,m6riC;ch;id;andLepak,j0lbeAmetri4nIon,rGsEvDwCxt2;ay30ey;en,in;hawn,moC;nd;ek,riC;ck;is,nC;is,y;rt;re;an,le,mKnIrEvC;e,iC;!d;en,iEne0PrCyl;eCin,yl;l45n;n,o,us;!iCny;el,lo;iCon;an,en,on;a0Fe0Ch03iar0lRoJrFuDyrC;il,us;rtC;!is;aEistC;iaCob12;no;ig;dy,lInErC;ey,neliCy;s,us;nEor,rDstaC;nt3;ad;or;by,e,in,l3t1;aHeEiCyde;fCnt,ve;fo0Xt1;menDt4;us;s,t;rFuDyC;!t1;dCs;e,io;enC;ce;aHeGrisC;!toC;phCs;!eC;!r;st2t;d,rCs;b5leC;s,y;cDdrCs6;ic;il;lHmFrC;ey,lDroCy;ll;!o7t1;er1iC;lo;!eb,v3;a09eZiVjorn,laUoSrEuCyr1;ddy,rtKst2;er;aKeFiEuDyC;an,ce,on;ce,no;an,ce;nDtC;!t;dDtC;!on;an,on;dFnC;dDisC;lav;en,on;!foOl9y;bby,gd0rCyd;is;i0Lke;bElDshC;al;al,lL;ek;nIrCshoi;at,nEtC;!raC;m,nd;aDhaCie;rd;rd8;!iDjam3nCs1;ie,y;to;kaMlazs,nHrC;n9rDtC;!holomew;eCy;tt;ey;dCeD;ar,iC;le;ar1Nb1Dd16fon15gust3hm12i0Zja0Yl0Bm07nTputsiSrGsaFugustEveDyCziz;a0kh0;ry;o,us;hi;aMchiKiJjun,mHnEon,tCy0;em,hCie,ur8;ur;aDoC;!ld;ud,v;aCin;an,nd8;!el,ki;baCe;ld;ta;aq;aMdHgel8tCw6;hoFoC;iDnC;!i8y;ne;ny;er7rCy;eDzC;ej;!as,i,j,s,w;!s;s,tolC;iCy;!y;ar,iEmaCos;nu5r;el;ne,r,t;aVbSdBeJfHiGl01onFphonsEt1vC;aPin;on;e,o;so,zo;!sR;!onZrC;ed;c,jaHksFssaHxC;!andC;er,rC;e,os,u;andCei;ar,er,r;ndC;ro;en;eDrecC;ht;rt8;dd3in,n,sC;taC;ir;ni;dDm6;ar;an,en;ad,eC;d,t;in;so;aGi,olErDvC;ik;ian8;f8ph;!o;mCn;!a;dGeFraDuC;!bakr,lfazl;hCm;am;!l;allFel,oulaye,ulC;!lDrahm0;an;ah,o;ah;av,on",Uncountable:"true¦0:2E;1:2L;2:33;a2Ub2Lc29d22e1Rf1Ng1Eh16i11j0Yk0Wl0Rm0Hn0Do0Cp03rZsLt9uran2Jv7w3you gu0E;a5his17i4oo3;d,l;ldlife,ne;rm8t1;apor,ernacul29i3;neg28ol1Otae;eDhBiAo8r4un3yranny;a,gst1B;aff2Oea1Ko4ue nor3;th;o08u3;bleshoot2Ose1Tt;night,othpas1Vwn3;foEsfoE;me off,n;er3und1;e,mod2S;a,nnis;aDcCeBhAi9ki8o7p6t4u3weepstak0;g1Unshi2Hshi;ati08e3;am,el;ace2Keci0;ap,cc1meth2C;n,ttl0;lk;eep,ingl0or1C;lf,na1Gri0;ene1Kisso1C;d0Wfe2l4nd,t3;i0Iurn;m1Ut;abi0e4ic3;e,ke15;c3i01laxa11search;ogni10rea10;a9e8hys7luto,o5re3ut2;amble,mis0s3ten20;en1Zs0L;l3rk;i28l0EyH; 16i28;a24tr0F;nt3ti0M;i0s;bstetri24vercrowd1Qxyg09;a5e4owada3utella;ys;ptu1Ows;il poliZtional securi2;aAe8o5u3;m3s1H;ps;n3o1K;ey,o3;gamy;a3cha0Elancholy,rchandi1Htallurgy;sl0t;chine3g1Aj1Hrs,thema1Q; learn1Cry;aught1e6i5ogi4u3;ck,g12;c,s1M;ce,ghtn18nguis1LteratWv1;ath1isVss;ara0EindergartPn3;icke0Aowled0Y;e3upit1;a3llyfiGwel0G;ns;ce,gnor6mp5n3;forma00ter3;net,sta07;atiSort3rov;an18;a7e6isto09o3ung1;ckey,mework,ne4o3rseradi8spitali2use arrest;ky;s2y;adquarteXre;ir,libut,ppiHs3;hi3te;sh;ene8l6o5r3um,ymnas11;a3eZ;niUss;lf,re;ut3yce0F;en; 3ti0W;edit0Hpo3;ol;aNicFlour,o4urnit3;ure;od,rgive3uri1wl;ness;arCcono0LducaBlectr9n7quip8thi0Pvery6x3;ist4per3;ti0B;en0J;body,o08th07;joy3tertain3;ment;ici2o3;ni0H;tiS;nings,th;emi02i6o4raugh3ynas2;ts;pe,wnstai3;rs;abet0ce,s3;honZrepu3;te;aDelciChAivi07l8o3urrency;al,ld w6mmenta5n3ral,ttIuscoB;fusiHt 3;ed;ry;ar;assi01oth0;es;aos,e3;eMwK;us;d,rO;a8i6lood,owlHread5u3;ntGtt1;er;!th;lliarJs3;on;g3ss;ga3;ge;cKdviJeroGirFmBn6ppeal court,r4spi3thleL;rin;ithmet3sen3;ic;i6y3;o4th3;ing;ne;se;en5n3;es2;ty;ds;craft;bi8d3nau7;yna3;mi6;ce;id,ous3;ti3;cs",Infinitive:"true¦0:9G;1:9T;2:AD;3:90;4:9Z;5:84;6:AH;7:A9;8:92;9:A0;A:AG;B:AI;C:9V;D:8R;E:8O;F:97;G:6H;H:7D;a94b8Hc7Jd68e4Zf4Mg4Gh4Ai3Qj3Nk3Kl3Bm34nou48o2Vp2Equ2Dr1Es0CtZuTvRwI;aOeNiLors5rI;eJiI;ng,te;ak,st3;d5e8TthI;draw,er;a2d,ep;i2ke,nIrn;d1t;aIie;liADniAry;nJpI;ho8Llift;cov1dJear8Hfound8DlIplug,rav82tie,ve94;eaAo3X;erIo;cut,go,staAFvalA3w2G;aSeQhNoMrIu73;aIe72;ffi3Smp3nsI;aBfo7CpI;i8oD;pp3ugh5;aJiJrIwaD;eat5i2;nk;aImA0;ch,se;ck3ilor,keImp1r8L;! paD;a0Ic0He0Fh0Bi0Al08mugg3n07o05p02qu01tUuLwI;aJeeIim;p,t5;ll7Wy;bNccMffLggeCmmKppJrI;mouFpa6Zvi2;o0re6Y;ari0on;er,i4;e7Numb;li9KmJsiIveD;de,st;er9it;aMe8MiKrI;ang3eIi2;ng27w;fIng;f5le;b,gg1rI;t3ve;a4AiA;a4UeJit,l7DoI;il,of;ak,nd;lIot7Kw;icEve;atGeak,i0O;aIi6;m,y;ft,ng,t;aKi6CoJriIun;nk,v6Q;ot,rt5;ke,rp5tt1;eIll,nd,que8Gv1w;!k,m;aven9ul8W;dd5tis1Iy;a0FeKiJoI;am,t,ut;d,p5;a0Ab08c06d05f01group,hea00iZjoi4lXmWnVpTq3MsOtMup,vI;amp,eJiIo3B;sEve;l,rI;e,t;i8rI;ie2ofE;eLiKpo8PtIurfa4;o24rI;aHiBuctu8;de,gn,st;mb3nt;el,hra0lIreseF;a4e71;d1ew,o07;aHe3Fo2;a7eFiIo6Jy;e2nq41ve;mbur0nf38;r0t;inKleBocus,rJuI;el,rbiA;aBeA;an4e;aBu4;ei2k8Bla43oIyc3;gni39nci3up,v1;oot,uI;ff;ct,d,liIp;se,ze;tt3viA;aAenGit,o7;aWerUinpoiFlumm1LoTrLuI;b47ke,niArIt;poDsuI;aFe;eMoI;cKd,fe4XhibEmo7noJpo0sp1tru6vI;e,i6o5L;un4;la3Nu8;aGclu6dJf1occupy,sup0JvI;a6BeF;etermi4TiB;aGllu7rtr5Ksse4Q;cei2fo4NiAmea7plex,sIva6;eve8iCua6;mp1rItrol,ve;a6It6E;bOccuNmEpMutLverIwe;l07sJtu6Yu0wI;helm;ee,h1F;gr5Cnu2Cpa4;era7i4Ipo0;py,r;ey,seItaH;r2ss;aMe0ViJoIultiply;leCu6Pw;micJnIspla4;ce,g3us;!k;iIke,na9;m,ntaH;aPeLiIo0u3N;ke,ng1quIv5;eIi6S;fy;aKnIss5;d,gI;th5;rn,ve;ng2Gu1N;eep,idnJnI;e4Cow;ap;oHuI;gg3xtaI;po0;gno8mVnIrk;cTdRfQgeChPitia7ju8q1CsNtKun6EvI;a6eIo11;nt,rt,st;erJimi6BoxiPrI;odu4u6;aBn,pr03ru6C;iCpi8tIu8;all,il,ruB;abEibE;eCo3Eu0;iIul9;ca7;i7lu6;b5Xmer0pI;aLer4Uin9ly,oJrI;e3Ais6Bo2;rt,se,veI;riA;le,rt;aLeKiIoiCuD;de,jaInd1;ck;ar,iT;mp1ng,pp5raIve;ng5Mss;ath1et,iMle27oLrI;aJeIow;et;b,pp3ze;!ve5A;gg3ve;aTer45i5RlSorMrJuI;lf4Cndrai0r48;eJiIolic;ght5;e0Qsh5;b3XeLfeEgJsI;a3Dee;eIi2;!t;clo0go,shIwa4Z;ad3F;att1ee,i36;lt1st5;a0OdEl0Mm0FnXquip,rWsVtGvTxI;aRcPeDhOiNpJtIu6;ing0Yol;eKi8lIo0un9;aHoI;it,re;ct,di7l;st,t;a3oDu3B;e30lI;a10u6;lt,mi28;alua7oI;ke,l2;chew,pou0tab19;a0u4U;aYcVdTfSgQhan4joy,lPqOrNsuMtKvI;e0YisI;a9i50;er,i4rI;aHenGuC;e,re;iGol0F;ui8;ar9iC;a9eIra2ulf;nd1;or4;ang1oIu8;r0w;irc3lo0ou0ErJuI;mb1;oaGy4D;b3ct;bKer9pI;hasiIow1;ze;aKody,rI;a4oiI;d1l;lm,rk;ap0eBuI;ci40de;rIt;ma0Rn;a0Re04iKo,rIwind3;aw,ed9oI;wn;agno0e,ff1g,mi2Kne,sLvI;eIul9;rIst;ge,t;aWbVcQlod9mant3pNru3TsMtI;iIoDu37;lJngI;uiA;!l;ol2ua6;eJlIo0ro2;a4ea0;n0r0;a2Xe36lKoIu0S;uIv1;ra9;aIo0;im;a3Kur0;b3rm;af5b01cVduBep5fUliTmQnOpMrLsiCtaGvI;eIol2;lop;ch;a20i2;aDiBloIoD;re,y;oIy;te,un4;eJoI;liA;an;mEv1;a4i0Ao06raud,y;ei2iMla8oKrI;ee,yI;!pt;de,mIup3;missi34po0;de,ma7ph1;aJrief,uI;g,nk;rk;mp5rk5uF;a0Dea0h0Ai09l08oKrIurta1G;a2ea7ipp3uI;mb3;ales4e04habEinci6ll03m00nIrro6;cXdUfQju8no7qu1sLtKvI;eIin4;ne,r9y;aHin2Bribu7;er2iLoli2Epi8tJuI;lt,me;itu7raH;in;d1st;eKiJoIroFu0;rm;de,gu8rm;ss;eJoI;ne;mn,n0;eIlu6ur;al,i2;buCe,men4pI;eIi3ly;l,te;eBi6u6;r4xiC;ean0iT;rcumveFte;eJirp,oI;o0p;riAw;ncIre5t1ulk;el;a02eSi6lQoPrKuI;iXrIy;st,y;aLeaKiJoad5;en;ng;stfeLtX;ke;il,l11mba0WrrMth1;eIow;ed;!coQfrie1LgPhMliLqueaKstJtrIwild1;ay;ow;th;e2tt3;a2eJoI;ld;ad;!in,ui3;me;bysEckfi8ff3tI;he;b15c0Rd0Iff0Ggree,l0Cm09n03ppZrXsQttOuMvJwaE;it;eDoI;id;rt;gIto0X;meF;aIeCraB;ch,in;pi8sJtoI;niA;aKeIi04u8;mb3rt,ss;le;il;re;g0Hi0ou0rI;an9i2;eaKly,oiFrI;ai0o2;nt;r,se;aMi0GnJtI;icipa7;eJoIul;un4y;al;ly0;aJu0;se;lga08ze;iKlI;e9oIu6;t,w;gn;ix,oI;rd;a03jNmiKoJsoI;rb;pt,rn;niIt;st1;er;ouJuC;st;rn;cLhie2knowled9quiItiva7;es4re;ce;ge;eQliOoKrJusI;e,tom;ue;mIst;moJpI;any,liA;da7;ma7;te;pt;andPduBet,i6oKsI;coKol2;ve;liArt,uI;nd;sh;de;ct;on",Person:"true¦0:1Q;a29b1Zc1Md1Ee18f15g13h0Ri0Qj0Nk0Jl0Gm09n06o05p00rPsItCusain bolt,v9w4xzibit,y1;anni,oko on2uji,v1;an,es;en,o;a3ednesday adams,i2o1;lfram,o0Q;ll ferrell,z khalifa;lt disn1Qr1;hol,r0G;a2i1oltai06;n dies0Zrginia wo17;lentino rossi,n goG;a4h3i2ripp,u1yra banks;lZpac shakur;ger woods,mba07;eresa may,or;kashi,t1ylor;um,ya1B;a5carlett johanss0h4i3lobodan milosevic,no2ocr1Lpider1uperm0Fwami; m0Em0E;op dogg,w whi1H;egfried,nbad;akespeaTerlock holm1Sia labeouf;ddam hussa16nt1;a cla11ig9;aAe6i5o3u1za;mi,n dmc,paul,sh limbau1;gh;bin hood,d stew16nald1thko;in0Mo;han0Yngo starr,valdo;ese witherspo0i1mbrandt;ll2nh1;old;ey,y;chmaninoff,ffi,iJshid,y roma1H;a4e3i2la16o1uff daddy;cahont0Ie;lar,p19;le,rZ;lm17ris hilt0;leg,prah winfr0Sra;a2e1iles cra1Bostradam0J; yo,l5tt06wmQ;pole0s;a5e4i2o1ubar03;by,lie5net,rriss0N;randa ju1tt romn0M;ly;rl0GssiaB;cklemo1rkov,s0ta hari,ya angelou;re;ady gaga,e1ibera0Pu;bron jam0Xch wale1e;sa;anye west,e3i1obe bryant;d cudi,efer suther1;la0P;ats,sha;a2effers0fk,k rowling,rr tolki1;en;ck the ripp0Mwaharlal nehru,y z;liTnez,ron m7;a7e5i3u1;lk hog5mphrey1sa01;! bog05;l1tl0H;de; m1dwig,nry 4;an;ile selassFlle ber4m3rrison1;! 1;ford;id,mo09;ry;ast0iannis,o1;odwPtye;ergus0lorence nightinga08r1;an1ederic chopN;s,z;ff5m2nya,ustaXzeki1;el;eril lagasse,i1;le zatop1nem;ek;ie;a6e4i2octor w1rake;ho;ck w1ego maradoC;olf;g1mi lovaOnzel washingt0;as;l1nHrth vadR;ai lNt0;a8h5lint0o1thulhu;n1olio;an,fuci1;us;on;aucKop2ristian baMy1;na;in;millo,ptain beefhe4r1;dinal wols2son1;! palmF;ey;art;a8e5hatt,i3oHro1;ck,n1;te;ll g1ng crosby;atB;ck,nazir bhut2rtil,yon1;ce;to;nksy,rack ob1;ama;l 6r3shton kutch2vril lavig8yn ra1;nd;er;chimed2istot1;le;es;capo2paci1;no;ne",Adjective:"true¦0:AI;1:BS;2:BI;3:BA;4:A8;5:84;6:AV;7:AN;8:AF;9:7H;A:BQ;B:AY;C:BC;D:BH;E:9Y;aA2b9Ec8Fd7We79f6Ng6Eh61i4Xj4Wk4Tl4Im41n3Po36p2Oquart7Pr2Ds1Dt14uSvOwFye29;aMeKhIiHoF;man5oFrth7G;dADzy;despreB1n w97s86;acked1UoleF;!sa6;ather1PeFll o70ste1D;!k5;nt1Ist6Ate4;aHeGiFola5T;bBUce versa,gi3Lle;ng67rsa5R;ca1gBSluAV;lt0PnLpHrGsFttermoBL;ef9Ku3;b96ge1; Hb32pGsFtiAH;ca6ide d4R;er,i85;f52to da2;a0Fbeco0Hc0Bd04e02f01gu1XheaBGiXkn4OmUnTopp06pRrNsJtHus0wF;aFiel3K;nt0rra0P;app0eXoF;ld,uS;eHi37o5ApGuF;perv06spec39;e1ok9O;en,ttl0;eFu5;cogn06gul2RlGqu84sF;erv0olv0;at0en33;aFrecede0E;id,rallel0;am0otic0;aFet;rri0tF;ch0;nFq26vers3;sur0terFv7U;eFrupt0;st0;air,inish0orese98;mploy0n7Ov97xpF;ect0lain0;eHisFocume01ue;clFput0;os0;cid0rF;!a8Scov9ha8Jlyi8nea8Gprivileg0sMwF;aFei9I;t9y;hGircumcFonvin2U;is0;aFeck0;lleng0rt0;b20ppea85ssuGttend0uthorF;iz0;mi8;i4Ara;aLeIhoHip 25oGrF;anspare1encha1i2;geth9leADp notch,rpB;rny,ugh6H;ena8DmpGrFs6U;r49tia4;eCo8P;leFst4M;nt0;a0Dc09e07h06i04ki03l01mug,nobbi4XoVpRqueami4XtKuFymb94;bHccinAi generis,pFr5;erFre7N;! dup9b,vi70;du0li7Lp6IsFurb7J;eq9Atanda9X;aKeJi16o2QrGubboFy4Q;rn;aightFin5GungS; fFfF;or7V;adfa9Pri6;lwa6Ftu82;arHeGir6NlendBot Fry;on;c3Qe1S;k5se; call0lImb9phistic16rHuFviV;ndFth1B;proof;dBry;dFub6; o2A;e60ipF;pe4shod;ll0n d7R;g2HnF;ceEg6ist9;am3Se9;co1Zem5lfFn6Are7; suf4Xi43;aGholFient3A;ar5;rlFt4A;et;cr0me,tisfac7F;aOeIheumatoBiGoF;bu8Ztt7Gy3;ghtFv3; 1Sf6X;cJdu8PlInown0pro69sGtF;ard0;is47oF;lu2na1;e1Suc45;alcit8Xe1ondi2;bBci3mpa1;aSePicayu7laOoNrGuF;bl7Tnjabi;eKiIoF;b7VfGmi49pFxi2M;er,ort81;a7uD;maFor,sti7va2;!ry;ciDexis0Ima2CpaB;in55puli8G;cBid;ac2Ynt 3IrFti2;ma40tFv7W;!i3Z;i2YrFss7R;anoBtF; 5XiF;al,s5V;bSffQkPld OnMrLth9utKverF;!aIbMdHhGni75seas,t,wF;ei74rou74;a63e7A;ue;ll;do1Ger,si6A;d3Qg2Aotu5Z; bFbFe on o7g3Uli7;oa80;fashion0school;!ay; gua7XbFha5Uli7;eat;eHligGsF;ce7er0So1C;at0;diFse;a1e1;aOeNiMoGuF;anc0de; moEnHrthFt6V;!eFwe7L;a7Krn;chaGdescri7Iprof30sF;top;la1;ght5;arby,cessa4ighbor5wlyw0xt;k0usiaFv3;ti8;aQeNiLoHuF;dIltiF;facet0p6;deHlGnFot,rbBst;ochro4Xth5;dy;rn,st;ddle ag0nF;dbloZi,or;ag9diocEga,naGrFtropolit4Q;e,ry;ci8;cIgenta,inHj0Fkeshift,mmGnFri4Oscu61ver18;da5Dy;ali4Lo4U;!stream;abEho;aOeLiIoFumberi8;ngFuti1R;stan3RtF;erm,i4H;ghtGteraF;l,ry,te;heart0wei5O;ft JgFss9th3;al,eFi0M;nda4;nguBps0te5;apGind5noF;wi8;ut;ad0itte4uniW;ce co0Hgno6Mll0Cm04nHpso 2UrF;a2releF;va1; ZaYcoWdReQfOgrNhibi4Ri05nMoLsHtFvalu5M;aAeF;nDrdepe2K;a7iGolFuboI;ub6ve1;de,gF;nifica1;rdi5N;a2er;own;eriIiLluenVrF;ar0eq5H;pt,rt;eHiGoFul1O;or;e,reA;fiFpe26termi5E;ni2;mpFnsideCrreA;le2;ccuCdeq5Ene,ppr4J;fFsitu,vitro;ro1;mJpF;arHeGl15oFrop9;li2r11;n2LrfeA;ti3;aGeFi18;d4BnD;tuE;egGiF;c0YteC;al,iF;tiF;ma2;ld;aOelNiLoFuma7;a4meInHrrGsFur5;ti6;if4E;e58o3U; ma3GsF;ick;ghfalut2HspF;an49;li00pf33;i4llow0ndGrdFtM; 05coEworki8;sy,y;aLener44iga3Blob3oKrGuF;il1Nng ho;aFea1Fizzl0;cGtF;ef2Vis;ef2U;ld3Aod;iFuc2D;nf2R;aVeSiQlOoJrF;aGeFil5ug3;q43tf2O;gFnt3S;i6ra1;lk13oHrF; keeps,eFge0Vm9tu41;g0Ei2Ds3R;liF;sh;ag4Mowe4uF;e1or45;e4nF;al,i2;d Gmini7rF;ti6ve1;up;bl0lDmIr Fst pac0ux;oGreacF;hi8;ff;ed,ili0R;aXfVlTmQnOqu3rMthere3veryday,xF;aApIquisi2traHuF;be48lF;ta1;!va2L;edRlF;icF;it;eAstF;whi6; Famor0ough,tiE;rou2sui2;erGiF;ne1;ge1;dFe2Aoq34;er5;ficF;ie1;g9sF;t,ygF;oi8;er;aWeMiHoGrFue;ea4owY;ci6mina1ne,r31ti8ubQ;dact2Jfficult,m,sGverF;ge1se;creGePjoi1paCtF;a1inA;et,te; Nadp0WceMfiLgeneCliJmuEpeIreliAsGvoF;id,ut;pFtitu2ul1L;eCoF;nde1;ca2ghF;tf13;a1ni2;as0;facto;i5ngero0I;ar0Ce09h07i06l05oOrIuF;rmudgeon5stoma4teF;sy;ly;aIeHu1EystalF; cleFli7;ar;epy;fFv17z0;ty;erUgTloSmPnGrpoCunterclVveFy;rt;cLdJgr21jIsHtrF;aFi2;dic0Yry;eq1Yta1;oi1ug3;escenFuN;di8;a1QeFiD;it0;atoDmensuCpF;ass1SulF;so4;ni3ss3;e1niza1;ci1J;ockwiD;rcumspeAvil;eFintzy;e4wy;leGrtaF;in;ba2;diac,ef00;a00ePiLliJoGrFuck nak0;and new,isk,on22;gGldface,naF; fi05fi05;us;nd,tF;he;gGpartisFzarE;an;tiF;me;autifOhiNlLnHsFyoN;iWtselF;li8;eGiFt;gn;aFfi03;th;at0oF;v0w;nd;ul;ckwards,rF;e,rT; priori,b13c0Zd0Tf0Ng0Ihe0Hl09mp6nt06pZrTsQttracti0MuLvIwF;aGkF;wa1B;ke,re;ant garGeraF;ge;de;diIsteEtF;heFoimmu7;nt07;re;to4;hGlFtu2;eep;en;bitIchiv3roHtF;ifiFsy;ci3;ga1;ra4;ry;pFt;aHetizi8rF;oprF;ia2;llFre1;ed,i8;ng;iquFsy;at0e;ed;cohKiJkaHl,oGriFterX;ght;ne,of;li7;ne;ke,ve;olF;ic;ad;ain07gressiIi6rF;eeF;ab6;le;ve;fGraB;id;ectGlF;ue1;ioF;na2; JaIeGvF;erD;pt,qF;ua2;ma1;hoc,infinitum;cuCquiGtu3u2;al;esce1;ra2;erSjeAlPoNrKsGuF;nda1;e1olu2trF;aAuD;se;te;eaGuF;pt;st;aFve;rd;aFe;ze;ct;ra1;nt",Pronoun:"true¦elle,h3i2me,she,th0us,we,you;e0ou;e,m,y;!l,t;e,im",Preposition:"true¦aPbMcLdKexcept,fIinGmid,notwithstandiWoDpXqua,sCt7u4v2w0;/o,hereSith0;! whHin,oW;ersus,i0;a,s a vis;n1p0;!on;like,til;h1ill,oward0;!s;an,ereby,r0;ough0u;!oM;ans,ince,o that,uch G;f1n0ut;!to;!f;! 0to;effect,part;or,r0;om;espite,own,u3;hez,irca;ar1e0oBy;sides,tween;ri7;bo8cross,ft7lo6m4propos,round,s1t0;!op;! 0;a whole,long 0;as;id0ong0;!st;ng;er;ut",SportsTeam:"true¦0:18;1:1E;2:1D;3:14;a1Db15c0Sd0Kfc dallas,g0Ihouston 0Hindiana0Gjacksonville jagua0k0El0Am01new UoRpKqueens parkJreal salt lake,sBt6utah jazz,vancouver whitecaps,w4yW;ashington 4h10;natio1Mredski2wizar0W;ampa bay 7e6o4;ronto 4ttenham hotspur;blue ja0Mrapto0;nnessee tita2xasD;buccanee0ra0K;a8eattle 6porting kansas0Wt4; louis 4oke0V;c1Drams;marine0s4;eah13ounH;cramento Rn 4;antonio spu0diego 4francisco gJjose earthquak1;char08paB; ran07;a9h6ittsburgh 5ortland t4;imbe0rail blaze0;pirat1steele0;il4oenix su2;adelphia 4li1;eagl1philNunE;dr1;akland 4klahoma city thunder,rlando magic;athle0Lrai4;de0;england 8orleans 7york 4;g5je3knYme3red bul0Xy4;anke1;ian3;pelica2sain3;patrio3revolut4;ion;anchEeAi4ontreal impact;ami 8lwaukee b7nnesota 4;t5vi4;kings;imberwolv1wi2;rewe0uc0J;dolphi2heat,marli2;mphis grizz4ts;li1;a6eic5os angeles 4;clippe0dodFlaB;esterV; galaxy,ke0;ansas city 4nF;chiefs,roya0D; pace0polis col3;astr05dynamo,rocke3texa2;olden state warrio0reen bay pac4;ke0;allas 8e4i04od6;nver 6troit 4;lio2pisto2ti4;ge0;broncYnugge3;cowbo5maver4;icZ;ys;arEelLhAincinnati 8leveland 6ol4;orado r4umbus crew sc;api7ocki1;brow2cavalie0guar4in4;dia2;bengaVre4;ds;arlotte horAicago 4;b5cubs,fire,wh4;iteB;ea0ulQ;diff4olina panthe0; city;altimore Alackburn rove0oston 6rooklyn 4uffalo bilN;ne3;ts;cel5red4; sox;tics;rs;oriol1rave2;rizona Ast8tlanta 4;brav1falco2h4;awA;ns;es;on villa,r4;os;c6di4;amondbac4;ks;ardi4;na4;ls",Unit:"true¦a07b04cXdWexVfTgRhePinYjoule0BkMlJmDnan08oCp9quart0Bsq ft,t7volts,w6y2ze3°1µ0;g,s;c,f,n;dVear1o0;ttR; 0s 0;old;att,b;erNon0;!ne02;ascals,e1i0;cXnt00;rcent,tJ;hms,unceY;/s,e4i0m²,²,³;/h,cro2l0;e0liK;!²;grLsR;gCtJ;it1u0;menQx;erPreP;b5elvins,ilo1m0notO;/h,ph,²;!byGgrEmCs;ct0rtzL;aJogrC;allonJb0ig3rB;ps;a0emtEl oz,t4;hrenheit,radG;aby9;eci3m1;aratDe1m0oulombD;²,³;lsius,nti0;gr2lit1m0;et0;er8;am7;b1y0;te5;l,ps;c2tt0;os0;econd1;re0;!s","Noun|Gerund":"true¦0:3O;1:3M;2:3N;3:3D;4:32;5:2V;6:3E;7:3K;8:36;9:3J;A:3B;a3Pb37c2Jd27e23f1Vg1Sh1Mi1Ij1Gk1Dl18m13n11o0Wp0Pques0Sr0EsTtNunderMvKwFyDzB;eroi0oB;ni0o3P;aw2eB;ar2l3;aEed4hispe5i5oCrB;ap8est3i1;n0ErB;ki0r31;i1r2s9tc9;isualizi0oB;lunt1Vti0;stan4ta6;aFeDhin6iCraBy8;c6di0i2vel1M;mi0p8;aBs1;c9si0;l6n2s1;aUcReQhOiMkatKl2Wmo6nowJpeItFuCwB;ea5im37;b35f0FrB;fi0vB;e2Mi2J;aAoryt1KrCuB;d2KfS;etc9ugg3;l3n4;bCi0;ebBi0;oar4;gnBnAt1;a3i0;ip8oB;p8rte2u1;a1r27t1;hCo5reBulp1;a2Qe2;edu3oo3;i3yi0;aKeEi4oCuB;li0n2;oBwi0;fi0;aFcEhear7laxi0nDpor1sB;pon4tructB;r2Iu5;de5;or4yc3;di0so2;p8ti0;aFeacek20laEoCrBublis9;a1Teten4in1oces7;iso2siB;tio2;n2yi0;ckaAin1rB;ki0t1O;fEpeDrganiCvB;erco24ula1;si0zi0;ni0ra1;fe5;avi0QeBur7;gotia1twor6;aDeCi2oB;de3nito5;a2dita1e1ssaA;int0XnBrke1;ifUufactu5;aEeaDiBodAyi0;cen7f1mi1stB;e2i0;r2si0;n4ug9;iCnB;ea4it1;c6l3;ogAuB;dAgg3stif12;ci0llust0VmDnBro2;nova1sp0NterBven1;ac1vie02;agi2plo4;aDea1iCoBun1;l4w3;ki0ri0;nd3rB;roWvB;es1;aCene0Lli4rBui4;ee1ie0N;rde2the5;aHeGiDlCorBros1un4;e0Pmat1;ir1oo4;gh1lCnBs9;anZdi0;i0li0;e3nX;r0Zscina1;a1du01nCxB;erci7plo5;chan1di0ginB;ee5;aLeHiGoub1rCum8wB;el3;aDeCiB;bb3n6vi0;a0Qs7;wi0;rTscoDvi0;ba1coZlBvelo8;eCiB;ve5;ga1;nGti0;aVelebUhSlPoDrBur3yc3;aBos7yi0;f1w3;aLdi0lJmFnBo6pi0ve5;dDsCvinB;ci0;trBul1;uc1;muniDpB;lBo7;ai2;ca1;lBo5;ec1;c9ti0;ap8eaCimToBubT;ni0t9;ni0ri0;aBee5;n1t1;ra1;m8rCs1te5;ri0;vi0;aPeNitMlLoGrDuB;dge1il4llBr8;yi0;an4eat9oadB;cas1;di0;a1mEokB;i0kB;ee8;pi0;bi0;es7oa1;c9i0;gin2lonAt1;gi0;bysit1c6ki0tt3;li0;ki0;bando2cGdverti7gi0pproac9rgDssuCtB;trac1;mi0;ui0;hi0;si0;coun1ti0;ti0;ni0;ng",PhrasalVerb:"true¦0:92;1:96;2:8H;3:8V;4:8A;5:83;6:85;7:98;8:90;9:8G;A:8X;B:8R;C:8U;D:8S;E:70;F:97;G:8Y;H:81;I:7H;J:79;a9Fb7Uc6Rd6Le6Jf5Ig50h4Biron0j47k40l3Em31n2Yo2Wp2Cquiet Hr1Xs0KtZuXvacuu6QwNyammerBzK;ero Dip LonK;e0k0;by,ov9up;aQeMhLiKor0Mrit19;mp0n3Fpe0r5s5;ackAeel Di0S;aLiKn33;gh 3Wrd0;n Dr K;do1in,oJ;it 79k5lk Lrm 69sh Kt83v60;aw3do1o7up;aw3in,oC;rgeBsK;e 2herE;a00eYhViRoQrMuKypP;ckErn K;do1in,oJup;aLiKot0y 30;ckl7Zp F;ck HdK;e 5Y;n7Wp 3Es5K;ck MdLe Kghten 6me0p o0Rre0;aw3ba4do1in,up;e Iy 2;by,oG;ink Lrow K;aw3ba4in,up;ba4ov9up;aKe 77ll62;m 2r 5M;ckBke Llk K;ov9shit,u47;aKba4do1in,leave,o4Dup;ba4ft9pa69w3;a0Vc0Te0Mh0Ii0Fl09m08n07o06p01quar5GtQuOwK;earMiK;ngLtch K;aw3ba4o8K; by;cKi6Bm 2ss0;k 64;aReQiPoNrKud35;aigh2Det75iK;ke 7Sng K;al6Yup;p Krm2F;by,in,oG;c3Ln3Lr 2tc4O;p F;c3Jmp0nd LrKveAy 2O;e Ht 2L;ba4do1up;ar3GeNiMlLrKurB;ead0ingBuc5;a49it 6H;c5ll o3Cn 2;ak Fe1Xll0;a3Bber 2rt0und like;ap 5Vow Duggl5;ash 6Noke0;eep NiKow 6;cLp K;o6Dup;e 68;in,oK;ff,v9;de19gn 4NnKt 6Gz5;gKkE; al6Ale0;aMoKu5W;ot Kut0w 7M;aw3ba4f48oC;c2WdeEk6EveA;e Pll1Nnd Orv5tK; Ktl5J;do1foLin,o7upK;!on;ot,r5Z;aw3ba4do1in,o33up;oCto;al66out0rK;ap65ew 6J;ilAv5;aXeUiSoOuK;b 5Yle0n Kstl5;aLba4do1inKo2Ith4Nu5P;!to;c2Xr8w3;ll Mot LpeAuK;g3Ind17;a2Wf3Po7;ar8in,o7up;ng 68p oKs5;ff,p18;aKelAinEnt0;c6Hd K;o4Dup;c27t0;aZeYiWlToQrOsyc35uK;ll Mn5Kt K;aKba4do1in,oJto47up;pa4Dw3;a3Jdo1in,o21to45up;attleBess KiNop 2;ah2Fon;iLp Kr4Zu1Gwer 6N;do1in,o6Nup;nt0;aLuK;gEmp 6;ce u20y 6D;ck Kg0le 4An 6p5B;oJup;el 5NncilE;c53ir 39n0ss MtLy K;ba4oG; Hc2R;aw3ba4in,oJ;pKw4Y;e4Xt D;aLerd0oK;dAt53;il Hrrow H;aTeQiPoLuK;ddl5ll I;c1FnkeyMp 6uthAve K;aKdo1in,o4Lup;l4Nw3; wi4K;ss0x 2;asur5e3SlLss K;a21up;t 6;ke Ln 6rKs2Ax0;k 6ryA;do,fun,oCsure,up;a02eViQoLuK;ck0st I;aNc4Fg MoKse0;k Kse4D;aft9ba4do1forw37in56o0Zu46;in,oJ;d 6;e NghtMnLsKve 00;ten F;e 2k 2; 2e46;ar8do1in;aMt LvelK; oC;do1go,in,o7up;nEve K;in,oK;pKut;en;c5p 2sh LtchBughAy K;do1o59;in4Po7;eMick Lnock K;do1oCup;oCup;eLy K;in,up;l Ip K;aw3ba4do1f04in,oJto,up;aMoLuK;ic5mpE;ke3St H;c43zz 2;a01eWiToPuK;nLrrKsh 6;y 2;keLt K;ar8do1;r H;lKneErse3K;d Ke 2;ba4dKfast,o0Cup;ear,o1;de Lt K;ba4on,up;aw3o7;aKlp0;d Ml Ir Kt 2;fKof;rom;f11in,o03uW;cPm 2nLsh0ve Kz2P;at,it,to;d Lg KkerP;do1in,o2Tup;do1in,oK;ut,v9;k 2;aZeTive Rloss IoMrLunK; f0S;ab hold,in43ow 2U; Kof 2I;aMb1Mit,oLr8th1IuK;nd9;ff,n,v9;bo7ft9hQw3;aw3bKdo1in,oJrise,up,w3;a4ir2H;ar 6ek0t K;aLb1Fdo1in,oKr8up;ff,n,ut,v9;cLhKl2Fr8t,w3;ead;ross;d aKng 2;bo7;a0Ee07iYlUoQrMuK;ck Ke2N;ar8up;eLighten KownBy 2;aw3oG;eKshe27; 2z5;g 2lMol Krk I;aKwi20;bo7r8;d 6low 2;aLeKip0;sh0;g 6ke0mKrKtten H;e F;gRlPnNrLsKzzle0;h F;e Km 2;aw3ba4up;d0isK;h 2;e Kl 1T;aw3fPin,o7;ht ba4ure0;ePnLsK;s 2;cMd K;fKoG;or;e D;d04l 2;cNll Krm0t1G;aLbKdo1in,o09sho0Eth08victim;a4ehi2O;pa0C;e K;do1oGup;at Kdge0nd 12y5;in,o7up;aOi1HoNrK;aLess 6op KuN;aw3b03in,oC;gBwB; Ile0ubl1B;m 2;a0Ah05l02oOrLut K;aw3ba4do1oCup;ackBeep LoKy0;ss Dwd0;by,do1in,o0Uup;me NoLuntK; o2A;k 6l K;do1oG;aRbQforOin,oNtKu0O;hLoKrue;geth9;rough;ff,ut,v9;th,wK;ard;a4y;paKr8w3;rt;eaLose K;in,oCup;n 6r F;aNeLiK;ll0pE;ck Der Kw F;on,up;t 2;lRncel0rOsMtch LveE; in;o1Nup;h Dt K;doubt,oG;ry LvK;e 08;aw3oJ;l Km H;aLba4do1oJup;ff,n,ut;r8w3;a0Ve0MiteAl0Fo04rQuK;bblNckl05il0Dlk 6ndl05rLsKtMy FzzA;t 00;n 0HsK;t D;e I;ov9;anWeaUiLush K;oGup;ghQng K;aNba4do1forMin,oLuK;nd9p;n,ut;th;bo7lKr8w3;ong;teK;n 2;k K;do1in,o7up;ch0;arTg 6iRn5oPrNssMttlLunce Kx D;aw3ba4;e 6; ar8;e H;do1;k Dt 2;e 2;l 6;do1up;d 2;aPeed0oKurt0;cMw K;aw3ba4do1o7up;ck;k K;in,oC;ck0nk0stA; oQaNef 2lt0nd K;do1ov9up;er;up;r Lt K;do1in,oCup;do1o7;ff,nK;to;ck Pil0nMrgLsK;h D;ainBe D;g DkB; on;in,o7;aw3do1in,oCup;ff,ut;ay;ct FdQir0sk MuctionA; oG;ff;ar8o7;ouK;nd; o7;d K;do1oKup;ff,n;wn;o7up;ut",ProperNoun:"true¦aIbDc8dalhousHe7f5gosford,h4iron maiden,kirby,landsdowne,m2nis,r1s0wembF;herwood,paldiB;iel,othwe1;cgi0ercedes,issy;ll;intBudsB;airview,lorence,ra0;mpt9nco;lmo,uro;a1h0;arlt6es5risti;rl0talina;et4i0;ng;arb3e0;et1nt0rke0;ley;on;ie;bid,jax","Person|Place":"true¦a8d6h4jordan,k3orlando,s1vi0;ctor9rgin9;a0ydney;lvador,mara,ntia4;ent,obe;amil0ous0;ton;arw2ie0;go;lexandr1ust0;in;ia",LastName:"true¦0:BR;1:BF;2:B5;3:BH;4:AX;5:9Y;6:B6;7:BK;8:B0;9:AV;A:AL;B:8Q;C:8G;D:7K;E:BM;F:AH;aBDb9Zc8Wd88e81f7Kg6Wh64i60j5Lk4Vl4Dm39n2Wo2Op25quispe,r1Ls0Pt0Ev03wTxSyKzG;aIhGimmerm6A;aGou,u;ng,o;khar5ytsE;aKeun9BiHoGun;koya32shiBU;!lG;diGmaz;rim,z;maGng;da,g52mo83sGzaC;aChiBV;iao,u;aLeJiHoGright,u;jcA5lff,ng;lGmm0nkl0sniewsC;kiB1liams33s3;bGiss,lt0;b,er,st0;a6Vgn0lHtG;anabe,s3;k0sh,tG;e2Non;aLeKiHoGukD;gt,lk5roby5;dHllalGnogr3Kr1Css0val3S;ba,ob1W;al,ov4;lasHsel8W;lJn dIrgBEsHzG;qu7;ilyEqu7siljE;en b6Aijk,yk;enzueAIverde;aPeix1VhKi2j8ka43oJrIsui,uG;om5UrG;c2n0un1;an,emblA7ynisC;dorAMlst3Km4rrAth;atch0i8UoG;mHrG;are84laci79;ps3sG;en,on;hirDkah9Mnaka,te,varA;a06ch01eYhUiRmOoMtIuHvGzabo;en9Jobod3N;ar7bot4lliv2zuC;aIeHoG;i7Bj4AyanAB;ele,in2FpheBvens25;l8rm0;kol5lovy5re7Tsa,to,uG;ng,sa;iGy72;rn5tG;!h;l71mHnGrbu;at9cla9Egh;moBo7M;aIeGimizu;hu,vchG;en8Luk;la,r1G;gu9infe5YmGoh,pulveA7rra5P;jGyG;on5;evi6iltz,miHneid0roed0uGwarz;be3Elz;dHtG;!t,z;!t;ar4Th8ito,ka4OlJnGr4saCto,unde19v4;ch7dHtGz;a5Le,os;b53e16;as,ihDm4Po0Y;aVeSiPoJuHyG;a6oo,u;bio,iz,sG;so,u;bKc8Fdrigue67ge10j9YmJosevelt,sItHux,wG;e,li6;a9Ch;enb4Usi;a54e4L;erts15i93;bei4JcHes,vGzzo;as,e9;ci,hards12;ag2es,iHut0yG;es,nol5N;s,t0;dImHnGsmu97v6C;tan1;ir7os;ic,u;aUeOhMiJoHrGut8;asad,if6Zochazk27;lishc2GpGrti72u10we76;e3Aov51;cHe45nG;as,to;as70hl0;aGillips;k,m,n6I;a3Hde3Wete0Bna,rJtG;ersHrovGters54;!a,ic;!en,on;eGic,kiBss3;i9ra,tz,z;h86k,padopoulIrk0tHvG;ic,l4N;el,te39;os;bMconn2Ag2TlJnei6PrHsbor6XweBzG;dem7Rturk;ella4DtGwe6N;ega,iz;iGof7Hs8I;vGyn1R;ei9;aSri1;aPeNiJoGune50ym2;rHvGwak;ak4Qik5otn66;odahl,r4S;cholsZeHkolGls4Jx3;ic,ov84;ls1miG;!n1;ils3mG;co4Xec;gy,kaGray2sh,var38;jiGmu9shiG;ma;a07c04eZiWoMuHyeG;rs;lJnIrGssoli6S;atGp03r7C;i,ov4;oz,te58;d0l0;h2lOnNo0RrHsGza1A;er,s;aKeJiIoz5risHtG;e56on;!on;!n7K;au,i9no,t5J;!lA;r1Btgome59;i3El0;cracFhhail5kkeHlG;l0os64;ls1;hmeJiIj30lHn3Krci0ssiGyer2N;!er;n0Po;er,j0;dDti;cartHlG;aughl8e2;hy;dQe7Egnu68i0jer3TkPmNnMrItHyG;er,r;ei,ic,su21thews;iHkDquAroqu8tinG;ez,s;a5Xc,nG;!o;ci5Vn;a5UmG;ad5;ar5e6Kin1;rig77s1;aVeOiLoJuHyG;!nch;k4nGo;d,gu;mbarGpe3Fvr4we;di;!nGu,yana2B;coln,dG;b21holm,strom;bedEfeKhIitn0kaHn8rGw35;oy;!j;m11tG;in1on1;bvGvG;re;iGmmy,ng,rs2Qu,voie,ws3;ne,t1F;aZeYh2iWlUnez50oNrJuHvar2woG;k,n;cerGmar68znets5;a,o34;aHem0isGyeziu;h23t3O;m0sni4Fus3KvG;ch4O;bay57ch,rh0Usk16vaIwalGzl5;czGsC;yk;cIlG;!cGen4K;huk;!ev4ic,s;e8uiveG;rt;eff0kGl4mu9nnun1;ucF;ll0nnedy;hn,llKminsCne,pIrHstra3Qto,ur,yGzl5;a,s0;j0Rls22;l2oG;or;oe;aPenOha6im14oHuG;ng,r4;e32hInHrge32u6vG;anD;es,ss3;anHnsG;en,on,t3;nesGs1R;en,s1;kiBnings,s1;cJkob4EnGrv0E;kDsG;en,sG;en0Ion;ks3obs2A;brahimDglesi5Nke5Fl0Qno07oneIshikHto,vanoG;u,v54;awa;scu;aVeOiNjaltal8oIrist50uG;!aGb0ghAynh;m2ng;a6dz4fIjgaa3Hk,lHpUrGwe,x3X;ak1Gvat;mAt;er,fm3WmG;ann;ggiBtchcock;iJmingw4BnHrGss;nand7re9;deGriks1;rs3;kkiHnG;on1;la,n1;dz4g1lvoQmOns0ZqNrMsJuIwHyG;asFes;kiB;g1ng;anHhiG;mo14;i,ov0J;di6p0r10t;ue;alaG;in1;rs1;aVeorgUheorghe,iSjonRoLrJuGw3;errGnnar3Co,staf3Ctierr7zm2;a,eG;ro;ayli6ee2Lg4iffithGub0;!s;lIme0UnHodGrbachE;e,m2;calvAzale0S;dGubE;bGs0E;erg;aj,i;bs3l,mGordaO;en7;iev3U;gnMlJmaIndFo,rGsFuthi0;cGdn0za;ia;ge;eaHlG;agh0i,o;no;e,on;aVerQiLjeldsted,lKoIrHuG;chs,entAji41ll0;eem2iedm2;ntaGrt8urni0wl0;na;emi6orA;lipIsHtzgeraG;ld;ch0h0;ovG;!ic;hatDnanIrG;arGei9;a,i;deY;ov4;b0rre1D;dKinsJriksIsGvaB;cob3GpGtra3D;inoza,osiQ;en,s3;te8;er,is3warG;ds;aXePiNjurhuMoKrisco15uHvorakG;!oT;arte,boHmitru,nn,rGt3C;and,ic;is;g2he0Omingu7nErd1ItG;to;us;aGcki2Hmitr2Ossanayake,x3;s,z; JbnaIlHmirGrvisFvi,w2;!ov4;gado,ic;th;bo0groot,jo6lHsilGvriA;va;a cruz,e3uG;ca;hl,mcevsCnIt2WviG;dGes,s;ov,s3;ielsGku22;!en;ki;a0Be06hRiobQlarkPoIrGunningh1H;awfo0RivGuz;elli;h1lKntJoIrGs2Nx;byn,reG;a,ia;ke,p0;i,rer2K;em2liB;ns;!e;anu;aOeMiu,oIristGu6we;eGiaG;ns1;i,ng,p9uHwGy;!dH;dGng;huJ;!n,onGu6;!g;kJnIpm2ttHudhGv7;ry;erjee,o14;!d,g;ma,raboG;rty;bJl0Cng4rG;eghetHnG;a,y;ti;an,ota1C;cerAlder3mpbeLrIstGvadi0B;iGro;llo;doHl0Er,t0uGvalho;so;so,zo;ll;a0Fe01hYiXlUoNrKuIyG;rLtyG;qi;chan2rG;ke,ns;ank5iem,oGyant;oks,wG;ne;gdan5nIruya,su,uchaHyKziG;c,n5;rd;darGik;enG;ko;ov;aGond15;nco,zG;ev4;ancFshw16;a08oGuiy2;umGwmG;ik;ckRethov1gu,ktPnNrG;gJisInG;ascoGds1;ni;ha;er,mG;anG;!n;gtGit7nP;ss3;asF;hi;er,hG;am;b4ch,ez,hRiley,kk0ldw8nMrIshHtAu0;es;ir;bInHtlGua;ett;es,i0;ieYosa;dGik;a9yoG;padhyG;ay;ra;k,ng;ic;bb0Acos09d07g04kht05lZnPrLsl2tJyG;aHd8;in;la;chis3kiG;ns3;aImstro6sl2;an;ng;ujo,ya;dJgelHsaG;ri;ovG;!a;ersJov,reG;aGjEws;ss1;en;en,on,s3;on;eksejEiyEmeiIvG;ar7es;ez;da;ev;arwHuilG;ar;al;ams,l0;er;ta;as",Ordinal:"true¦eBf7nin5s3t0zeroE;enDhir1we0;lfCn7;d,t3;e0ixt8;cond,vent7;et0th;e6ie7;i2o0;r0urt3;tie4;ft1rst;ight0lev1;e0h,ie1;en0;th",Cardinal:"true¦bEeBf5mEnine7one,s4t0zero;en,h2rDw0;e0o;lve,n5;irt6ousands,ree;even2ix2;i3o0;r1ur0;!t2;ty;ft0ve;e2y;ight0lev1;!e0y;en;illions",Multiple:"true¦b3hundred,m3qu2se1t0;housand,r2;pt1xt1;adr0int0;illion",City:"true¦0:74;1:61;2:6G;3:6J;4:5S;a68b53c4Id48e44f3Wg3Hh39i31j2Wk2Fl23m1Mn1Co19p0Wq0Ur0Os05tRuQvLwDxiBy9z5;a7h5i4Muri4O;a5e5ongsh0;ng3H;greb,nzib5G;ang2e5okoha3Sunfu;katerin3Hrev0;a5n0Q;m5Hn;arsBeAi6roclBu5;h0xi,zh5P;c7n5;d5nipeg,terth4;hoek,s1L;hi5Zkl3A;l63xford;aw;a8e6i5ladivost5Molgogr6L;en3lni6S;ni22r5;o3saill4N;lenc4Wncouv3Sr3ughn;lan bat1Crumqi,trecht;aFbilisi,eEheDiBo9r7u5;l21n63r5;in,ku;i5ondh62;es51poli;kyo,m2Zron1Pulo5;n,uS;an5jua3l2Tmisoa6Bra3;j4Tshui; hag62ssaloni2H;gucigal26hr0l av1U;briz,i6llinn,mpe56ng5rtu,shk2R;i3Esh0;an,chu1n0p2Eyu0;aEeDh8kopje,owe1Gt7u5;ra5zh4X;ba0Ht;aten is55ockholm,rasbou67uttga2V;an8e6i5;jiazhua1llo1m5Xy0;f50n5;ya1zh4H;gh3Kt4Q;att45o1Vv44;cramen16int ClBn5o paulo,ppo3Rrajevo; 7aa,t5;a 5o domin3E;a3fe,m1M;antonio,die3Cfrancisco,j5ped3Nsalvad0J;o5u0;se;em,t lake ci5Fz25;lou58peters24;a9e8i6o5;me,t59;ga,o5yadh;! de janei3F;cife,ims,nn3Jykjavik;b4Sip4lei2Inc2Pwalpindi;ingdao,u5;ez2i0Q;aFeEhDiCo9r7u6yong5;ya1;eb59ya1;a5etor3M;g52to;rt5zn0; 5la4Co;au prin0Melizabe24sa03;ls3Prae5Atts26;iladelph3Gnom pe1Aoenix;ki1tah tik3E;dua,lerYnaji,r4Ot5;na,r32;ak44des0Km1Mr6s5ttawa;a3Vlo;an,d06;a7ew5ing2Fovosibir1Jyc; 5cast36;del24orlea44taip14;g8iro4Wn5pl2Wshv33v0;ch6ji1t5;es,o1;a1o1;a6o5p4;ya;no,sa0W;aEeCi9o6u5;mb2Ani26sc3Y;gadishu,nt6s5;c13ul;evideo,pelli1Rre2Z;ami,l6n14s5;kolc,sissauga;an,waukee;cca,d5lbour2Mmph41ndo1Cssi3;an,ell2Xi3;cau,drAkass2Sl9n8r5shh4A;aca6ib5rakesh,se2L;or;i1Sy;a4EchFdal0Zi47;mo;id;aDeAi8o6u5vSy2;anMckn0Odhia3;n5s angel26;d2g bea1N;brev2Be3Lma5nz,sb2verpo28;!ss27; ma39i5;c5pzig;est16; p6g5ho2Wn0Cusan24;os;az,la33;aHharFiClaipeBo9rak0Du7y5;iv,o5;to;ala lump4n5;mi1sh0;hi0Hlka2Xpavog4si5wlo2;ce;da;ev,n5rkuk;gst2sha5;sa;k5toum;iv;bHdu3llakuric0Qmpa3Fn6ohsiu1ra5un1Iwaguc0Q;c0Pj;d5o,p4;ah1Ty;a7e6i5ohannesV;l1Vn0;dd36rusalem;ip4k5;ar2H;bad0mph1OnArkutUs7taXz5;mir,tapala5;pa;fah0l6tanb5;ul;am2Zi2H;che2d5;ianap2Mo20;aAe7o5yder2W; chi mi5ms,nolulu;nh;f6lsin5rakli2;ki;ei;ifa,lifax,mCn5rb1Dva3;g8nov01oi;aFdanEenDhCiPlasgBo9raz,u5;a5jr23;dal6ng5yaquil;zh1J;aja2Oupe;ld coa1Bthen5;bu2S;ow;ent;e0Uoa;sk;lw7n5za;dhi5gt1E;nag0U;ay;aisal29es,o8r6ukuya5;ma;ankfu5esno;rt;rt5sh0; wor6ale5;za;th;d5indhov0Pl paso;in5mont2;bur5;gh;aBe8ha0Xisp4o7resd0Lu5;b5esseldorf,nkirk,rb0shanbe;ai,l0I;ha,nggu0rtmu13;hradSl6nv5troit;er;hi;donghIe6k09l5masc1Zr es sala1KugavpiY;i0lU;gu,je2;aJebu,hAleve0Vo5raio02uriti1Q;lo7n6penhag0Ar5;do1Ok;akKst0V;gUm5;bo;aBen8i6ongqi1ristchur5;ch;ang m7ca5ttago1;go;g6n5;ai;du,zho1;ng5ttogr14;ch8sha,zh07;gliari,i9lga8mayenJn6pe town,r5tanO;acCdiff;ber1Ac5;un;ry;ro;aWeNhKirmingh0WoJr9u5;chareTdapeTenos air7r5s0tu0;g5sa;as;es;a9is6usse5;ls;ba6t5;ol;ne;sil8tisla7zzav5;il5;le;va;ia;goZst2;op6ubaneshw5;ar;al;iCl9ng8r5;g6l5n;in;en;aluru,hazi;fa6grade,o horizon5;te;st;ji1rut;ghd0BkFn9ot8r7s6yan n4;ur;el,r07;celo3i,ranquil09;ou;du1g6ja lu5;ka;alo6k5;ok;re;ng;ers5u;field;a05b02cc01ddis aba00gartaZhmedXizawl,lSmPnHqa00rEsBt7uck5;la5;nd;he7l5;an5;ta;ns;h5unci2;dod,gab5;at;li5;ngt2;on;a8c5kaOtwerp;hora6o3;na;ge;h7p5;ol5;is;eim;aravati,m0s5;terd5;am; 7buquerq6eppo,giers,ma5;ty;ue;basrah al qadim5mawsil al jadid5;ah;ab5;ad;la;ba;ra;idj0u dha5;bi;an;lbo6rh5;us;rg",Region:"true¦0:2O;1:2L;2:2U;3:2F;a2Sb2Fc21d1Wes1Vf1Tg1Oh1Ki1Fj1Bk16l13m0Sn09o07pYqVrSsJtEuBverAw6y4zacatec2W;akut0o0Fu4;cat1k09;a5est 4isconsin,yomi1O;bengal,virgin0;rwick3shington4;! dc;acruz,mont;dmurt0t4;ah,tar4; 2Pa12;a6e5laxca1Vripu21u4;scaEva;langa2nnessee,x2J;bas10m4smQtar29;aulip2Hil nadu;a9elang07i7o5taf16u4ylh1J;ff02rr09s1E;me1Gno1Uuth 4;cZdY;ber0c4kkim,naloa;hu1ily;n5rawak,skatchew1xo4;ny; luis potosi,ta catari2;a4hodeA;j4ngp0C;asth1shahi;ingh29u4;e4intana roo;bec,en6retaro;aAe6rince edward4unjab; i4;sl0G;i,n5r4;ak,nambu0F;a0Rnsylv4;an0;ha0Pra4;!na;axa0Zdisha,h4klaho21ntar4reg7ss0Dx0I;io;aLeEo6u4;evo le4nav0X;on;r4tt18va scot0;f9mandy,th4; 4ampton3;c6d5yo4;rk3;ako1O;aroli2;olk;bras1Nva0Dw4; 6foundland4;! and labrad4;or;brunswick,hamp3jers5mexiTyork4;! state;ey;galPyarit;aAeghala0Mi6o4;nta2r4;dov0elos;ch6dlanDn5ss4zor11;issippi,ouri;as geraPneso18;ig1oac1;dhy12harasht0Gine,lac07ni5r4ssachusetts;anhao,i el,ylG;p4toba;ur;anca3e4incoln3ouisI;e4iR;ds;a6e5h4omi;aka06ul2;dah,lant1ntucky,ra01;bardino,lmyk0ns0Qr4;achay,el0nata0X;alis6har4iangxi;kh4;and;co;daho,llino7n4owa;d5gush4;et0;ia2;is;a6ert5i4un1;dalFm0D;ford3;mp3rya2waii;ansu,eorg0lou7oa,u4;an4izhou,jarat;ajuato,gdo4;ng;cester3;lori4uji1;da;sex;ageUe7o5uran4;go;rs4;et;lawaMrby3;aFeaEh9o4rim08umbr0;ahui7l6nnectic5rsi4ventry;ca;ut;i03orado;la;e5hattisgarh,i4uvash0;apRhuahua;chn5rke4;ss0;ya;ra;lGm4;bridge3peche;a9ihar,r8u4;ck4ryat0;ingham3;shi4;re;emen,itish columb0;h0ja cal8lk7s4v7;hkorto4que;st1;an;ar0;iforn0;ia;dygHguascalientes,lBndhr9r5ss4;am;izo2kans5un4;achal 7;as;na;a 4;pradesh;a6ber5t4;ai;ta;ba5s4;ka;ma;ea",Place:"true¦0:4T;1:4V;2:44;3:4B;4:3I;a4Eb3Gc2Td2Ge26f25g1Vh1Ji1Fk1Cl14m0Vn0No0Jp08r04sTtNuLvJw7y5;a5o0Syz;kut1Bngtze;aDeChitBi9o5upatki,ycom2P;ki26o5;d5l1B;b3Ps5;i4to3Y;c0SllowbroCn5;c2Qgh2;by,chur1P;ed0ntw3Gs22;ke6r3St5;erf1f1; is0Gf3V;auxha3Mirgin is0Jost5;ok;laanbaatar,pto5xb3E;n,wn;a9eotihuac43h7ive49o6ru2Nsarskoe selo,u5;l2Dzigo47;nto,rquay,tt2J;am3e 5orn3E;bronx,hamptons;hiti,j mah0Iu1N;aEcotts bluff,eCfo,herbroQoApring9t7u5yd2F;dbu1Wn5;der03set3B;aff1ock2Nr5;atf1oud;hi37w24;ho,uth5; 1Iam1Zwo3E;a5i2O;f2Tt0;int lawrence riv3Pkhal2D;ayleigh,ed7i5oc1Z;chmo1Eo gran4ver5;be1Dfr09si4; s39cliffe,hi2Y;aCe9h8i5ompeii,utn2;c6ne5tcai2T; 2Pc0G;keri13t0;l,x;k,lh2mbr6n5r2J;n1Hzance;oke;cif38pahanaumokuak30r5;k5then0;si4w1K;ak7r6x5;f1l2X;ange county,d,f1inoco;mTw1G;e8i1Uo5;r5tt2N;th5wi0E; 0Sam19;uschwanste1Pw5; eng6a5h2market,po36;rk;la0P;a8co,e6i5uc;dt1Yll0Z;adow5ko0H;lands;chu picchu,gad2Ridsto1Ql8n7ple6r5;kh2; g1Cw11;hatt2Osf2B;ibu,t0ve1Z;a8e7gw,hr,in5owlOynd02;coln memori5dl2C;al;asi4w3;kefr7mbe1On5s,x;ca2Ig5si05;f1l27t0;ont;azan kreml14e6itchen2Gosrae,rasnoyar5ul;sk;ns0Hs1U;ax,cn,lf1n6ps5st;wiN;d5glew0Lverness;ian27ochina;aDeBi6kg,nd,ov5unti2H;d,enweep;gh6llc5;reL;bu03l5;and5;!s;r5yw0C;ef1tf1;libu24mp6r5stings;f1lem,row;stead,t0;aDodavari,r5uelph;avenAe5imsS;at 8en5; 6f1Fwi5;ch;acr3vall1H;brita0Flak3;hur5;st;ng3y villa0W;airhavHco,ra;aAgli9nf17ppi8u7ver6x5;et1Lf1;glad3t0;rope,st0;ng;nt0;rls1Ls5;t 5;e5si4;nd;aCe9fw,ig8o7ryd6u5xb;mfri3nstab00rh2tt0;en;nca18rcKv19wnt0B;by;n6r5vonpo1D;ry;!h2;nu8r5;l6t5;f1moor;ingt0;be;aLdg,eIgk,hClBo5royd0;l6m5rnwa0B;pt0;c7lingw6osse5;um;ood;he0S;earwat0St;a8el6i5uuk;chen itza,mney ro07natSricahua;m0Zt5;enh2;mor5rlottetPth2;ro;dar 5ntervilA;breaks,faZg5;rove;ld9m8r5versh2;lis6rizo pla5;in;le;bLpbellf1;weQ;aZcn,eNingl01kk,lackLolt0r5uckV;aGiAo5;ckt0ok5wns cany0;lyn,s5;i4to5;ne;de;dge6gh5;am,t0;n6t5;own;or5;th;ceb6m5;lNpt0;rid5;ge;bu5pool,wa8;rn;aconsfEdf1lBr9verly7x5;hi5;ll; hi5;lls;wi5;ck; air,l5;ingh2;am;ie5;ld;ltimore,rnsl6tters5;ea;ey;bLct0driadic,frica,ginJlGmFn9rc8s7tl6yleOzor3;es;!ant8;hcroft,ia; de triomphe,t6;adyr,ca8dov9tarct5;ic5; oce5;an;st5;er;ericas,s;be6dersh5hambra,list0;ot;rt0;cou5;rt;bot7i5;ngd0;on;sf1;ord",Country:"true¦0:38;1:2L;2:3B;a2Xb2Ec22d1Ye1Sf1Mg1Ch1Ai14j12k0Zl0Um0Gn05om2pZqat1KrXsKtCu7v5wal4yemTz3;a25imbabwe;es,lis and futu2Y;a3enezue32ietnam;nuatu,tican city;gTk6nited 4ruXs3zbeE; 2Ca,sr;arab emirat0Kkingdom,states3;! of am2Y;!raiV;a8haCimor les0Co7rinidad 5u3;nis0rk3valu;ey,me2Zs and caic1V;and t3t3;oba1L;go,kel10nga;iw2ji3nz2T;ki2V;aDcotl1eCi9lov8o6pa2Dri lanka,u5w3yr0;az3edAitzerl1;il1;d2riname;lomon1Xmal0uth 3;afr2KkMsud2;ak0en0;erra leoFn3;gapo1Yt maart3;en;negLrb0ychellZ;int 3moa,n marino,udi arab0;hele26luc0mart21;epublic of ir0Eom2Euss0w3;an27;a4eIhilippinUitcairn1Mo3uerto riN;l1rtugF;ki2Dl4nama,pua new0Vra3;gu7;au,esti3;ne;aBe9i7or3;folk1Ith4w3;ay; k3ern mariana1D;or0O;caragua,ger3ue;!ia;p3ther1Aw zeal1;al;mib0u3;ru;a7exi6icro0Bo3yanm06;ldova,n3roc5zambA;a4gol0t3;enegro,serrat;co;cAdagasc01l7r5urit4yot3;te;an0i16;shall0Xtin3;ique;a4div3i,ta;es;wi,ys0;ao,ed02;a6e5i3uxembourg;b3echtenste12thu1G;er0ya;ban0Isotho;os,tv0;azakh1Fe4iriba04o3uwait,yrgyz1F;rXsovo;eling0Knya;a3erG;ma16p2;c7nd6r4s3taly,vory coast;le of m2rael;a3el1;n,q;ia,oJ;el1;aiTon3ungary;dur0Ng kong;aBermany,ha0QibraltAre8u3;a6ern5inea3ya0P;! biss3;au;sey;deloupe,m,tema0Q;e3na0N;ce,nl1;ar;bUmb0;a7i6r3;ance,ench 3;guia0Epoly3;nes0;ji,nl1;lklandUroeU;ast tim7cu6gypt,l salv6ngl1quatorial4ritr5st3thiop0;on0; guin3;ea;ad3;or;enmark,jibou5ominica4r con3;go;!n C;ti;aBentral african Ah8o5roat0u4yprRzech3; 9ia;ba,racao;c4lo3morQngo brazzaville,okGsta r04te de ivoiL;mb0;osE;i3ristmasG;le,na;republic;m3naUpe verde,ymanA;bod0ero3;on;aGeDhut2o9r5u3;lgar0r3;kina faso,ma,undi;azil,itish 3unei;virgin3; is3;lands;liv0nai5snia and herzegoviHtswaHuvet3; isl1;and;re;l3n8rmuG;ar3gium,ize;us;h4ngladesh,rbad3;os;am4ra3;in;as;fghaGlDmBn6r4ustr3zerbaij2;al0ia;genti3men0uba;na;dorra,g5t3;arct7igua and barbu3;da;o3uil3;la;er3;ica;b3ger0;an0;ia;ni3;st2;an",FirstName:"true¦aTblair,cQdOfrancoZgabMhinaLilya,jHkClBm6ni4quinn,re3s0;h0umit,yd;ay,e0iloh;a,lby;g9ne;co,ko0;!s;a1el0ina,org6;!okuhF;ds,naia,r1tt0xiB;i,y;ion,lo;ashawn,eif,uca;a3e1ir0rM;an;lsFn0rry;dall,yat5;i,sD;a0essIie,ude;i1m0;ie,mG;me;ta;rie0y;le;arcy,ev0;an,on;as1h0;arl8eyenne;ey,sidy;drien,kira,l4nd1ubr0vi;ey;i,r0;a,e0;a,y;ex2f1o0;is;ie;ei,is",WeekDay:"true¦fri2mon2s1t0wednesd3;hurs1ues1;aturd1und1;!d0;ay0;!s",Month:"true¦dec0february,july,nov0octo1sept0;em0;ber",Date:"true¦ago,on4som4t1week0yesterd5; end,ends;mr1o0;d2morrow;!w;ed0;ay",Duration:"true¦centurAd8h7m5q4se3w1y0;ear8r8;eek0k7;!end,s;ason,c5;tr,uarter;i0onth3;llisecond2nute2;our1r1;ay0ecade0;!s;ies,y",FemaleName:"true¦0:J7;1:JB;2:IJ;3:IK;4:J1;5:IO;6:JS;7:JO;8:HB;9:JK;A:H4;B:I2;C:IT;D:JH;E:IX;F:BA;G:I4;aGTbFLcDRdD0eBMfB4gADh9Ti9Gj8Dk7Cl5Wm48n3Lo3Hp33qu32r29s15t0Eu0Cv02wVxiTyOzH;aLeIineb,oHsof3;e3Sf3la,ra;h2iKlIna,ynH;ab,ep;da,ma;da,h2iHra;nab;aKeJi0FolB7uIvH;et8onDP;i0na;le0sen3;el,gm3Hn,rGLs8W;aoHme0nyi;m5XyAD;aMendDZhiDGiH;dele9lJnH;if48niHo0;e,f47;a,helmi0lHma;a,ow;ka0nB;aNeKiHusa5;ck84kIl8oleAviH;anFenJ4;ky,toriBK;da,lA8rHs0;a,nHoniH9;a,iFR;leHnesH9;nILrH;i1y;g9rHs6xHA;su5te;aYeUhRiNoLrIuHy2;i,la;acJ3iHu0J;c3na,sH;hFta;nHr0F;iFya;aJffaEOnHs6;a,gtiH;ng;!nFSra;aIeHomasi0;a,l9Oo8Ares1;l3ndolwethu;g9Fo88rIssH;!a,ie;eHi,ri7;sa,za;bOlMmKnIrHs6tia0wa0;a60yn;iHya;a,ka,s6;arFe2iHm77ra;!ka;a,iH;a,t6;at6it6;a0Ecarlett,e0AhWiSkye,neza0oQri,tNuIyH;bIGlvi1;ha,mayIJniAsIzH;an3Net8ie,y;anHi7;!a,e,nH;aCe;aIeH;fan4l5Dphan6E;cI5r5;b3fiAAm0LnHphi1;d2ia,ja,ya;er2lJmon1nIobh8QtH;a,i;dy;lETv3;aMeIirHo0risFDy5;a,lDM;ba,e0i5lJrH;iHr6Jyl;!d8Ifa;ia,lDZ;hd,iMki2nJrIu0w0yH;la,ma,na;i,le9on,ron,yn;aIda,ia,nHon;a,on;!ya;k6mH;!aa;lJrItaye82vH;da,inj;e0ife;en1i0ma;anA9bLd5Oh1SiBkKlJmInd2rHs6vannaC;aCi0;ant6i2;lDOma,ome;ee0in8Tu2;in1ri0;a05eZhXiUoHuthDM;bScRghQl8LnPsJwIxH;anB3ie,y;an,e0;aIeHie,lD;ann7ll1marDGtA;!lHnn1;iHyn;e,nH;a,dF;da,i,na;ayy8G;hel67io;bDRerAyn;a,cIkHmas,nFta,ya;ki,o;h8Xki;ea,iannGMoH;da,n1P;an0bJemFgi0iInHta,y0;a8Bee;han86na;a,eH;cHkaC;a,ca;bi0chIe,i0mo0nHquETy0;di,ia;aERelHiB;!e,le;een4ia0;aPeOhMiLoJrHute6A;iHudenCV;scil3LyamvaB;lHrt3;i0ly;a,paluk;ilome0oebe,ylH;is,lis;ggy,nelope,r5t2;ige,m0VnKo5rvaDMtIulH;a,et8in1;ricHt4T;a,e,ia;do2i07;ctav3dIfD3is6ksa0lHphD3umC5yunbileg;a,ga,iv3;eHvAF;l3t8;aWeUiMoIurHy5;!ay,ul;a,eJor,rIuH;f,r;aCeEma;ll1mi;aNcLhariBQkKlaJna,sHta,vi;anHha;ur;!y;a,iDZki;hoGk9YolH;a,e4P;!mh;hir,lHna,risDEsreE;!a,iDDlBV;asuMdLh3i6Dl5nKomi7rgEVtH;aHhal4;lHs6;i1ya;cy,et8;e9iF0ya;nngu2X;a0Ackenz4e02iMoJrignayani,uriDJyH;a,rH;a,iOlNna,tG;bi0i2llBJnH;a,iH;ca,ka,qD9;a,cUdo4ZkaTlOmi,nMrItzi,yH;ar;aJiIlH;anET;am;!l,nB;dy,eHh,n4;nhGrva;aKdJe0iCUlH;iHy;cent,e;red;!gros;!e5;ae5hH;ae5el3Z;ag5DgNi,lKrH;edi7AiIjem,on,yH;em,l;em,sCG;an4iHliCF;nHsCJ;a,da;!an,han;b09cASd07e,g05ha,i04ja,l02n00rLsoum5YtKuIv84xBKyHz4;bell,ra,soBB;d7rH;a,eE;h8Gild1t4;a,cUgQiKjor4l7Un4s6tJwa,yH;!aHbe6Xja9lAE;m,nBL;a,ha,in1;!aJbCGeIja,lDna,sHt63;!a,ol,sa;!l1D;!h,mInH;!a,e,n1;!awit,i;arJeIie,oHr48ueri8;!t;!ry;et46i3B;el4Xi7Cy;dHon,ue5;akranAy;ak,en,iHlo3S;a,ka,nB;a,re,s4te;daHg4;!l3E;alDd4elHge,isDJon0;ei9in1yn;el,le;a0Ne0CiXoQuLyH;d3la,nH;!a,dIe2OnHsCT;!a,e2N;a,sCR;aD4cJel0Pis1lIna,pHz;e,iA;a,u,wa;iHy;a0Se,ja,l2NnB;is,l1UrItt1LuHvel4;el5is1;aKeIi7na,rH;aADi7;lHn1tA;ei;!in1;aTbb9HdSepa,lNnKsJvIzH;!a,be5Ret8z4;!ia;a,et8;!a,dH;a,sHy;ay,ey,i,y;a,iJja,lH;iHy;aA8e;!aH;!nF;ia,ya;!nH;!a,ne;aPda,e0iNjYla,nMoKsJtHx93y5;iHt4;c3t3;e2PlCO;la,nHra;a,ie,o2;a,or1;a,gh,laH;!ni;!h,nH;a,d2e,n5V;cOdon9DiNkes6mi9Gna,rMtJurIvHxmi,y5;ern1in3;a,e5Aie,yn;as6iIoH;nya,ya;fa,s6;a,isA9;a,la;ey,ie,y;a04eZhXiOlASoNrJyH;lHra;a,ee,ie;istHy6I;a,en,iIyH;!na;!e,n5F;nul,ri,urtnB8;aOerNlB7mJrHzzy;a,stH;en,in;!berlImernH;aq;eHi,y;e,y;a,stE;!na,ra;aHei2ongordzol;dij1w5;el7UiKjsi,lJnIrH;a,i,ri;d2na,za;ey,i,lBLs4y;ra,s6;biAcARdiat7MeBAiSlQmPnyakuma1DrNss6NtKviAyH;!e,lH;a,eH;e,i8T;!a6HeIhHi4TlDri0y;ar8Her8Hie,leErBAy;!lyn8Ori0;a,en,iHl5Xoli0yn;!ma,nFs95;a5il1;ei8Mi,lH;e,ie;a,tl6O;a0AeZiWoOuH;anMdLlHst88;es,iH;a8NeHs8X;!n9tH;!a,te;e5Mi3My;a,iA;!anNcelDdMelGhan7VleLni,sIva0yH;a,ce;eHie;fHlDph7Y;a,in1;en,n1;i7y;!a,e,n45;lHng;!i1DlH;!i1C;anNle0nKrJsH;i8JsH;!e,i8I;i,ri;!a,elGif2CnH;a,et8iHy;!e,f2A;a,eJiInH;a,eIiH;e,n1;!t8;cMda,mi,nIque4YsminFvie2y9zH;min7;a7eIiH;ce,e,n1s;!lHs82t0F;e,le;inIk6HlDquelH;in1yn;da,ta;da,lRmPnOo0rNsIvaHwo0zaro;!a0lu,na;aJiIlaHob89;!n9R;do2;belHdo2;!a,e,l3B;a7Ben1i0ma;di2es,gr72ji;a9elBogH;en1;a,e9iHo0se;a0na;aSeOiJoHus7Kyacin2C;da,ll4rten24snH;a,i9U;lImaH;ri;aIdHlaI;a,egard;ry;ath1BiJlInrietArmi9sH;sa,t1A;en2Uga,mi;di;bi2Fil8MlNnMrJsItHwa,yl8M;i5Tt4;n60ti;iHmo51ri53;etH;!te;aCnaC;a,ey,l4;a02eWiRlPoNrKunJwH;enHyne1R;!dolD;ay,el;acieIetHiselB;a,chE;!la;ld1CogooH;sh;adys,enHor3yn2K;a,da,na;aKgi,lIna,ov8EselHta;a,e,le;da,liH;an;!n0;mLnJorgIrH;ald5Si,m3Etrud7;et8i4X;a,eHna;s29vieve;ma;bIle,mHrnet,yG;al5Si5;iIrielH;a,l1;!ja;aTeQiPlorOoz3rH;anJeIiH;da,eB;da,ja;!cH;esIiHoi0P;n1s66;!ca;a,enc3;en,o0;lIn0rnH;anB;ec3ic3;jr,nArKtHy7;emIiHma,oumaA;ha,ma,n;eh;ah,iBrah,za0;cr4Rd0Re0Qi0Pk0Ol07mXn54rUsOtNuMvHwa;aKelIiH;!e,ta;inFyn;!a;!ngel4V;geni1ni47;h5Yien9ta;mLperanKtH;eIhHrel5;er;l31r7;za;a,eralB;iHma,ne4Lyn;cHka,n;a,ka;aPeNiKmH;aHe21ie,y;!li9nuH;elG;lHn1;e7iHy;a,e,ja;lHrald;da,y;!nue5;aWeUiNlMma,no2oKsJvH;a,iH;na,ra;a,ie;iHuiH;se;a,en,ie,y;a0c3da,e,f,nMsJzaH;!betHveA;e,h;aHe,ka;!beH;th;!a,or;anor,nH;!a,i;!in1na;ate1Rta;leEs6;vi;eIiHna,wi0;e,th;l,n;aYeMh3iLjeneKoH;lor5Vminiq4Ln3FrHtt4;a,eEis,la,othHthy;ea,y;ba;an09naCon9ya;anQbPde,eOiMlJmetr3nHsir5M;a,iH;ce,se;a,iIla,orHphi9;es,is;a,l6F;dHrdH;re;!d5Ena;!b2ForaCraC;a,d2nH;!a,e;hl3i0l0GmNnLphn1rIvi1WyH;le,na;a,by,cIia,lH;a,en1;ey,ie;a,et8iH;!ca,el1Aka,z;arHia;is;a0Re0Nh04i02lUoJristIynH;di,th3;al,i0;lPnMrIurH;tn1D;aJd2OiHn2Ori9;!nH;a,e,n1;!l4;cepci5Cn4sH;tanHuelo;ce,za;eHleE;en,t8;aJeoIotH;il54;!pat2;ir7rJudH;et8iH;a,ne;a,e,iH;ce,sZ;a2er2ndH;i,y;aReNloe,rH;isJyH;stH;al;sy,tH;a1Sen,iHy;an1e,n1;deJlseIrH;!i7yl;a,y;li9;nMrH;isKlImH;ai9;a,eHot8;n1t8;!sa;d2elGtH;al,elG;cIlH;es8i47;el3ilH;e,ia,y;itlYlXmilWndVrMsKtHy5;aIeIhHri0;er1IleErDy;ri0;a38sH;a37ie;a,iOlLmeJolIrH;ie,ol;!e,in1yn;lHn;!a,la;a,eIie,otHy;a,ta;ne,y;na,s1X;a0Ii0I;a,e,l1;isAl4;in,yn;a0Ke02iZlXoUrH;andi7eRiJoIyH;an0nn;nwDoke;an3HdgMgiLtH;n31tH;!aInH;ey,i,y;ny;d,t8;etH;!t7;an0e,nH;da,na;bbi7glarIlo07nH;iAn4;ka;ancHythe;a,he;an1Clja0nHsm3M;iAtH;ou;aWcVlinUniArPssOtJulaCvH;!erlH;ey,y;hJsy,tH;e,iHy7;e,na;!anH;ie,y;!ie;nItHyl;ha,ie;adIiH;ce;et8i9;ay,da;ca,ky;!triH;ce,z;rbJyaH;rmH;aa;a2o2ra;a2Ub2Od25g21i1Sj5l18m0Zn0Boi,r06sWtVuPvOwa,yIzH;ra,u0;aKes6gJlIn,seH;!l;in;un;!nH;a,na;a,i2K;drLguJrIsteH;ja;el3;stH;in1;a,ey,i,y;aahua,he0;hIi2Gja,miAs2DtrH;id;aMlIraqHt21;at;eIi7yH;!n;e,iHy;gh;!nH;ti;iJleIo6piA;ta;en,n1t8;aHelG;!n1J;a01dje5eZgViTjRnKohito,toHya;inet8nH;el5ia;te;!aKeIiHmJ;e,ka;!mHtt7;ar4;!belIliHmU;sa;!l1;a,eliH;ca;ka,sHta;a,sa;elHie;a,iH;a,ca,n1qH;ue;!tH;a,te;!bImHstasiMya;ar3;el;aLberKeliJiHy;e,l3naH;!ta;a,ja;!ly;hGiIl3nB;da;a,ra;le;aWba,ePiMlKthJyH;a,c3sH;a,on,sa;ea;iHys0N;e,s0M;a,cIn1sHza;a,e,ha,on,sa;e,ia,ja;c3is6jaKksaKna,sJxH;aHia;!nd2;ia,saH;nd2;ra;ia;i0nIyH;ah,na;a,is,naCoud;la;c6da,leEmNnLsH;haClH;inHyY;g,n;!h;a,o,slH;ey;ee;en;at6g4nIusH;ti0;es;ie;aWdiTelMrH;eJiH;anMenH;a,e,ne;an0;na;!aLeKiIyH;nn;a,n1;a,e;!ne;!iH;de;e,lDsH;on;yn;!lH;i9yn;ne;aKbIiHrL;!e,gaK;ey,i7y;!e;gaH;il;dKliyJradhIs6;ha;ya;ah;a,ya",Honorific:"true¦director1field marsh2lieutenant1rear0sergeant major,vice0; admir1; gener0;al","Adj|Gerund":"true¦0:3F;1:3H;2:31;3:2X;4:35;5:33;6:3C;7:2Z;8:36;9:29;a33b2Tc2Bd1Te1If19g12h0Zi0Rl0Nm0Gnu0Fo0Ap04rYsKtEuBvAw1Ayiel3;ar6e08;nBpA;l1Rs0B;fol3n1Zsett2;aEeDhrBi4ouc7rAwis0;e0Bif2oub2us0yi1;ea1SiA;l2vi1;l2mp0rr1J;nt1Vxi1;aMcreec7enten2NhLkyrocke0lo0Vmi2oJpHtDuBweA;e0Ul2;pp2ArA;gi1pri5roun3;aBea8iAri2Hun9;mula0r4;gge4rA;t2vi1;ark2eAraw2;e3llb2F;aAot7;ki1ri1;i9oc29;dYtisf6;aEeBive0oAus7;a4l2;assu4defi9fres7ig9juve07mai9s0vAwar3;ea2italiAol1G;si1zi1;gi1ll6mb2vi1;a6eDier23lun1VrAun2C;eBoA;mi5vo1Z;ce3s5vai2;n3rpleA;xi1;ffCpWutBverAwi1;arc7lap04p0Pri3whel8;goi1l6st1J;en3sA;et0;m2Jrtu4;aEeDiCoBuAyst0L;mb2;t1Jvi1;s5tiga0;an1Rl0n3smeri26;dAtu4;de9;aCeaBiAo0U;fesa0Tvi1;di1ni1;c1Fg19s0;llumiGmFnArri0R;cDfurHsCtBviA;go23ti1;e1Oimi21oxica0rig0V;pi4ul0;orpo20r0K;po5;na0;eaBorr02umilA;ia0;li1rtwar8;lFrA;atiDipCoBuelA;i1li1;undbrea10wi1;pi1;f6ng;a4ea8;a3etc7it0lEoCrBulfA;il2;ee1FighXust1L;rAun3;ebo3thco8;aCoA;a0wA;e4i1;mi1tte4;lectrJmHnExA;aCci0hBis0pA;an3lo3;aOila1B;c0spe1A;ab2coura0CdBergi13ga0Clive9ric7s02tA;hral2i0J;ea4u4;barras5er09pA;owe4;if6;aQeIiBrA;if0;sAzz6;aEgDhearCsen0tA;rAur11;ac0es5;te9;us0;ppoin0r8;biliGcDfi9gra3ligh0mBpres5sAvasG;erE;an3ea9orA;ali0L;a6eiBli9rA;ea5;vi1;ta0;maPri1s7un0zz2;aPhMlo5oAripp2ut0;mGnArrespon3;cer9fDspi4tA;inBrA;as0ibu0ol2;ui1;lic0u5;ni1;fDmCpA;eAromi5;l2ti1;an3;or0;aAil2;llenAnAr8;gi1;l8ptAri1;iva0;aff2eGin3lFoDrBuA;d3st2;eathtaAui5;ki1;gg2i2o8ri1unA;ci1;in3;co8wiA;lAtc7;de4;bsorVcOgonMlJmHnno6ppea2rFsA;pi4su4toA;nBun3;di1;is7;hi1;res0;li1;aFu5;si1;ar8lu4;ri1;mi1;iAzi1;zi1;cAhi1;eleDomA;moBpan6;yi1;da0;ra0;ti1;bi1;ng",Comparable:"true¦0:3C;1:3Q;2:3F;a3Tb3Cc33d2Te2Mf2Ag1Wh1Li1Fj1Ek1Bl13m0Xn0So0Rp0Iqu0Gr07sHtCug0vAw4y3za0Q;el10ouN;ary,e6hi5i3ry;ck0Cde,l3n1ry,se;d,y;ny,te;a3i3R;k,ry;a3erda2ulgar;gue,in,st;a6en2Xhi5i4ouZr3;anqu2Cen1ue;dy,g36me0ny;ck,rs28;ll,me,rt,wd3I;aRcaPeOhMiLkin0BlImGoEpDt6u4w3;eet,ift;b3dd0Wperfi21rre28;sta26t21;a8e7iff,r4u3;pUr1;a4ict,o3;ng;ig2Vn0N;a1ep,rn;le,rk,te0;e1Si2Vright0;ci1Yft,l3on,re;emn,id;a3el0;ll,rt;e4i3y;g2Mm0Z;ek,nd2T;ck24l0mp1L;a3iRrill,y;dy,l01rp;ve0Jxy;n1Jr3;ce,y;d,fe,int0l1Hv0V;a8e6i5o3ude;mantic,o19sy,u3;gh;pe,t1P;a3d,mo0A;dy,l;gg4iFndom,p3re,w;id;ed;ai2i3;ck,et;hoAi1Fl9o8r5u3;ny,r3;e,p11;egna2ic4o3;fouSud;ey,k0;liXor;ain,easa2;ny;dd,i0ld,ranL;aive,e5i4o3u14;b0Sisy,rm0Ysy;bb0ce,mb0R;a3r1w;r,t;ad,e5ild,o4u3;nda12te;ist,o1;a4ek,l3;low;s0ty;a8e7i6o3ucky;f0Jn4o15u3ve0w10y0N;d,sy;e0g;ke0l,mp,tt0Eve0;e1Qwd;me,r3te;ge;e4i3;nd;en;ol0ui19;cy,ll,n3;secu6t3;e3ima4;llege2rmedia3;te;re;aAe7i6o5u3;ge,m3ng1C;bYid;me0t;gh,l0;a3fXsita2;dy,rWv3;en0y;nd13ppy,r3;d3sh;!y;aFenEhCiBlAoofy,r3;a8e6i5o3ue0Z;o3ss;vy;m,s0;at,e3y;dy,n;nd,y;ad,ib,ooD;a2d1;a3o3;st0;tDuiS;u1y;aCeebBi9l8o6r5u3;ll,n3r0N;!ny;aCesh,iend0;a3nd,rmD;my;at,ir7;erce,nan3;ci9;le;r,ul3;ty;a6erie,sse4v3xtre0B;il;nti3;al;r4s3;tern,y;ly,th0;appZe9i5ru4u3;mb;nk;r5vi4z3;zy;ne;e,ty;a3ep,n9;d3f,r;!ly;agey,h8l7o5r4u3;dd0r0te;isp,uel;ar3ld,mmon,st0ward0zy;se;evKou1;e3il0;ap,e3;sy;aHiFlCoAr5u3;ff,r0sy;ly;a6i3oad;g4llia2;nt;ht;sh,ve;ld,un3;cy;a4o3ue;nd,o1;ck,nd;g,tt3;er;d,ld,w1;dy;bsu6ng5we3;so3;me;ry;rd",Adverb:"true¦a08b05d00eYfSheQinPjustOkinda,likewiZmMnJoEpCquite,r9s5t2u0very,well;ltima01p0; to,wards5;h1iny bit,o0wiO;o,t6;en,us;eldom,o0uch;!me1rt0; of;how,times,w0C;a1e0;alS;ndomRth05;ar excellenEer0oint blank; Lhaps;f3n0utright;ce0ly;! 0;ag05moX; courGten;ewJo0; longWt 0;onHwithstand9;aybe,eanwhiNore0;!ovT;! aboX;deed,steY;lla,n0;ce;or3u0;ck1l9rther0;!moK;ing; 0evK;exampCgood,suH;n mas0vI;se;e0irect2; 2fini0;te0;ly;juAtrop;ackward,y 0;far,no0; means,w; GbroFd nauseam,gEl7ny5part,s4t 2w0;ay,hi0;le;be7l0mo7wor7;arge,ea6; soon,i4;mo0way;re;l 3mo2ongsi1ready,so,togeth0ways;er;de;st;b1t0;hat;ut;ain;ad;lot,posteriori",Conjunction:"true¦aXbTcReNhowMiEjust00noBo9p8supposing,t5wh0yet;e1il0o3;e,st;n1re0thN; if,by,vM;evL;h0il,o;erefOo0;!uU;lus,rovided th9;r0therwiM;! not; mattEr,w0;! 0;since,th4w7;f4n0; 0asmuch;as mIcaForder t0;h0o;at;! 0;only,t0w0;hen;!ev3;ith2ven0;! 0;if,tB;er;o0uz;s,z;e0ut,y the time;cau1f0;ore;se;lt3nd,s 0;far1if,m0soon1t2;uch0; as;hou0;gh",Currency:"true¦$,aud,bQcOdJeurIfHgbp,hkd,iGjpy,kElDp8r7s3usd,x2y1z0¢,£,¥,ден,лв,руб,฿,₡,₨,€,₭,﷼;lotyQł;en,uanP;af,of;h0t5;e0il5;k0q0;elK;oubleJp,upeeJ;e2ound st0;er0;lingG;n0soF;ceEnies;empi7i7;n,r0wanzaCyatC;!onaBw;ls,nr;ori7ranc9;!os;en3i2kk,o0;b0ll2;ra5;me4n0rham4;ar3;e0ny;nt1;aht,itcoin0;!s",Determiner:"true¦aBboth,d9e6few,le5mu8neiDplenty,s4th2various,wh0;at0ich0;evC;a0e4is,ose;!t;everal,ome;!ast,s;a1l0very;!se;ch;e0u;!s;!n0;!o0y;th0;er","Adj|Present":"true¦a07b04cVdQeNfJhollIidRlEmCnarrIoBp9qua8r7s3t2uttFw0;aKet,ro0;ng,u08;endChin;e2hort,l1mooth,our,pa9tray,u0;re,speU;i2ow;cu6da02leSpaN;eplica01i02;ck;aHerfePr0;eseUime,omV;bscu1pen,wn;atu0e3odeH;re;a2e1ive,ow0;er;an;st,y;ow;a2i1oul,r0;ee,inge;rm;iIke,ncy,st;l1mpty,x0;emHpress;abo4ic7;amp,e2i1oub0ry,ull;le;ffu9re6;fu8libe0;raE;alm,l5o0;mpleCn3ol,rr1unterfe0;it;e0u7;ct;juga8sum7;ea1o0;se;n,r;ankru1lu0;nt;pt;li2pproxi0rticula1;ma0;te;ght","Person|Adj":"true¦b3du2earnest,frank,mi2r0san1woo1;an0ich,u1;dy;sty;ella,rown",Modal:"true¦c5lets,m4ought3sh1w0;ill,o5;a0o4;ll,nt;! to,a;ight,ust;an,o0;uld",Verb:"true¦born,cannot,gonna,has,keep tabs,msg","Person|Verb":"true¦b8ch7dr6foster,gra5ja9lan4ma2ni9ollie,p1rob,s0wade;kip,pike,t5ue;at,eg,ier2;ck,r0;k,shal;ce;ce,nt;ew;ase,u1;iff,l1ob,u0;ck;aze,ossom","Person|Date":"true¦a2j0sep;an0une;!uary;p0ugust,v0;ril"};const gr=36,mr="0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ",pr=mr.split("").reduce((function(e,t,n){return e[t]=n,e}),{});var fr=function(e){if(void 0!==pr[e])return pr[e];let t=0,n=1,a=gr,r=1;for(;n=0;n--,r*=gr){let a=e.charCodeAt(n)-48;a>10&&(a-=7),t+=a*r}return t};const br=function(e,t,n){const a=fr(t);return a{let o=e.nodes[a];"!"===o[0]&&(t.push(r),o=o.slice(1));const i=o.split(/([A-Z0-9,]+)/g);for(let o=0;o{const t=function(e){if(!e)return{};const t=e.split("|").reduce(((e,t)=>{const n=t.split("¦");return e[n[0]]=n[1],e}),{}),n={};return Object.keys(t).forEach((function(e){const a=yr(t[e]);"true"===e&&(e=!0);for(let t=0;t{if(jr[t]=e,"Noun|Verb"===e){const e=Pr(t,Nr);jr[e]="Plural|Verb"}})):Object.keys(t).forEach((t=>{Cr[t]=e}))})),[":(",":)",":P",":p",":O",";(",";)",";P",";p",";O",":3",":|",":/",":\\",":$",":*",":@",":-(",":-)",":-P",":-p",":-O",":-3",":-|",":-/",":-\\",":-$",":-*",":-@",":^(",":^)",":^P",":^p",":^O",":^3",":^|",":^/",":^\\",":^$",":^*",":^@","):","(:","$:","*:",")-:","(-:","$-:","*-:",")^:","(^:","$^:","*^:","<3","Cr[e]="Emoticon")),delete Cr[""],delete Cr.null,delete Cr[" "];const Ir="Singular";var Dr={beforeTags:{Determiner:Ir,Possessive:Ir,Acronym:Ir,Noun:Ir,Adjective:Ir,PresentTense:Ir,Gerund:Ir,PastTense:Ir,Infinitive:Ir,Date:Ir,Ordinal:Ir,Demonym:Ir},afterTags:{Value:Ir,Modal:Ir,Copula:Ir,PresentTense:Ir,PastTense:Ir,Demonym:Ir,Actor:Ir},beforeWords:{the:Ir,with:Ir,without:Ir,of:Ir,for:Ir,any:Ir,all:Ir,on:Ir,cut:Ir,cuts:Ir,increase:Ir,decrease:Ir,raise:Ir,drop:Ir,save:Ir,saved:Ir,saves:Ir,make:Ir,makes:Ir,made:Ir,minus:Ir,plus:Ir,than:Ir,another:Ir,versus:Ir,neither:Ir,about:Ir,favorite:Ir,best:Ir,daily:Ir,weekly:Ir,linear:Ir,binary:Ir,mobile:Ir,lexical:Ir,technical:Ir,computer:Ir,scientific:Ir,security:Ir,government:Ir,popular:Ir,formal:Ir,no:Ir,more:Ir,one:Ir,let:Ir,her:Ir,his:Ir,their:Ir,our:Ir,us:Ir,sheer:Ir,monthly:Ir,yearly:Ir,current:Ir,previous:Ir,upcoming:Ir,last:Ir,next:Ir,main:Ir,initial:Ir,final:Ir,beginning:Ir,end:Ir,top:Ir,bottom:Ir,future:Ir,past:Ir,major:Ir,minor:Ir,side:Ir,central:Ir,peripheral:Ir,public:Ir,private:Ir},afterWords:{of:Ir,system:Ir,aid:Ir,method:Ir,utility:Ir,tool:Ir,reform:Ir,therapy:Ir,philosophy:Ir,room:Ir,authority:Ir,says:Ir,said:Ir,wants:Ir,wanted:Ir,is:Ir,did:Ir,do:Ir,can:Ir,wise:Ir}};const Hr="Infinitive";var Tr={beforeTags:{Modal:Hr,Adverb:Hr,Negative:Hr,Plural:Hr},afterTags:{Determiner:Hr,Adverb:Hr,Possessive:Hr,Reflexive:Hr,Preposition:Hr,Cardinal:Hr,Comparative:Hr,Superlative:Hr},beforeWords:{i:Hr,we:Hr,you:Hr,they:Hr,to:Hr,please:Hr,will:Hr,have:Hr,had:Hr,would:Hr,could:Hr,should:Hr,do:Hr,did:Hr,does:Hr,can:Hr,must:Hr,us:Hr,me:Hr,let:Hr,even:Hr,when:Hr,help:Hr,he:Hr,she:Hr,it:Hr,being:Hr,bi:Hr,co:Hr,contra:Hr,de:Hr,inter:Hr,intra:Hr,mis:Hr,pre:Hr,out:Hr,counter:Hr,nobody:Hr,somebody:Hr,anybody:Hr,everybody:Hr},afterWords:{the:Hr,me:Hr,you:Hr,him:Hr,us:Hr,her:Hr,his:Hr,them:Hr,they:Hr,it:Hr,himself:Hr,herself:Hr,itself:Hr,myself:Hr,ourselves:Hr,themselves:Hr,something:Hr,anything:Hr,a:Hr,an:Hr,up:Hr,down:Hr,by:Hr,out:Hr,off:Hr,under:Hr,what:Hr,all:Hr,to:Hr,because:Hr,although:Hr,how:Hr,otherwise:Hr,together:Hr,though:Hr,into:Hr,yet:Hr,more:Hr,here:Hr,there:Hr,away:Hr}};const Gr={beforeTags:Object.assign({},Tr.beforeTags,Dr.beforeTags,{}),afterTags:Object.assign({},Tr.afterTags,Dr.afterTags,{}),beforeWords:Object.assign({},Tr.beforeWords,Dr.beforeWords,{}),afterWords:Object.assign({},Tr.afterWords,Dr.afterWords,{})},xr="Adjective";var Er={beforeTags:{Determiner:xr,Possessive:xr,Hyphenated:xr},afterTags:{Adjective:xr},beforeWords:{seem:xr,seemed:xr,seems:xr,feel:xr,feels:xr,felt:xr,stay:xr,appear:xr,appears:xr,appeared:xr,also:xr,over:xr,under:xr,too:xr,it:xr,but:xr,still:xr,really:xr,quite:xr,well:xr,very:xr,truly:xr,how:xr,deeply:xr,hella:xr,profoundly:xr,extremely:xr,so:xr,badly:xr,mostly:xr,totally:xr,awfully:xr,rather:xr,nothing:xr,something:xr,anything:xr,not:xr,me:xr,is:xr,face:xr,faces:xr,faced:xr,look:xr,looks:xr,looked:xr,reveal:xr,reveals:xr,revealed:xr,sound:xr,sounded:xr,sounds:xr,remains:xr,remained:xr,prove:xr,proves:xr,proved:xr,becomes:xr,stays:xr,tastes:xr,taste:xr,smells:xr,smell:xr,gets:xr,grows:xr,as:xr,rings:xr,radiates:xr,conveys:xr,convey:xr,conveyed:xr,of:xr},afterWords:{too:xr,also:xr,or:xr,enough:xr,as:xr}};const Fr="Gerund";var Or={beforeTags:{Adverb:Fr,Preposition:Fr,Conjunction:Fr},afterTags:{Adverb:Fr,Possessive:Fr,Person:Fr,Pronoun:Fr,Determiner:Fr,Copula:Fr,Preposition:Fr,Conjunction:Fr,Comparative:Fr},beforeWords:{been:Fr,keep:Fr,continue:Fr,stop:Fr,am:Fr,be:Fr,me:Fr,began:Fr,start:Fr,starts:Fr,started:Fr,stops:Fr,stopped:Fr,help:Fr,helps:Fr,avoid:Fr,avoids:Fr,love:Fr,loves:Fr,loved:Fr,hate:Fr,hates:Fr,hated:Fr},afterWords:{you:Fr,me:Fr,her:Fr,him:Fr,his:Fr,them:Fr,their:Fr,it:Fr,this:Fr,there:Fr,on:Fr,about:Fr,for:Fr,up:Fr,down:Fr}};const zr="Gerund",Vr="Adjective",Br={beforeTags:Object.assign({},Er.beforeTags,Or.beforeTags,{Imperative:zr,Infinitive:Vr,Plural:zr}),afterTags:Object.assign({},Er.afterTags,Or.afterTags,{Noun:Vr}),beforeWords:Object.assign({},Er.beforeWords,Or.beforeWords,{is:Vr,are:zr,was:Vr,of:Vr,suggest:zr,suggests:zr,suggested:zr,recommend:zr,recommends:zr,recommended:zr,imagine:zr,imagines:zr,imagined:zr,consider:zr,considered:zr,considering:zr,resist:zr,resists:zr,resisted:zr,avoid:zr,avoided:zr,avoiding:zr,except:Vr,accept:Vr,assess:zr,explore:zr,fear:zr,fears:zr,appreciate:zr,question:zr,help:zr,embrace:zr,with:Vr}),afterWords:Object.assign({},Er.afterWords,Or.afterWords,{to:zr,not:zr,the:zr})},Sr={beforeTags:{Determiner:void 0,Cardinal:"Noun",PhrasalVerb:"Adjective"},afterTags:{}},Kr={beforeTags:Object.assign({},Er.beforeTags,Dr.beforeTags,Sr.beforeTags),afterTags:Object.assign({},Er.afterTags,Dr.afterTags,Sr.afterTags),beforeWords:Object.assign({},Er.beforeWords,Dr.beforeWords,{are:"Adjective",is:"Adjective",was:"Adjective",be:"Adjective",off:"Adjective",out:"Adjective"}),afterWords:Object.assign({},Er.afterWords,Dr.afterWords)},$r="PastTense",Lr="Adjective",Mr={beforeTags:{Adverb:$r,Pronoun:$r,ProperNoun:$r,Auxiliary:$r,Noun:$r},afterTags:{Possessive:$r,Pronoun:$r,Determiner:$r,Adverb:$r,Comparative:$r,Date:$r,Gerund:$r},beforeWords:{be:$r,who:$r,get:Lr,had:$r,has:$r,have:$r,been:$r,it:$r,as:$r,for:Lr,more:Lr,always:Lr},afterWords:{by:$r,back:$r,out:$r,in:$r,up:$r,down:$r,before:$r,after:$r,for:$r,the:$r,with:$r,as:$r,on:$r,at:$r,between:$r,to:$r,into:$r,us:$r,them:$r,his:$r,her:$r,their:$r,our:$r,me:$r,about:Lr}};var Jr={beforeTags:Object.assign({},Er.beforeTags,Mr.beforeTags),afterTags:Object.assign({},Er.afterTags,Mr.afterTags),beforeWords:Object.assign({},Er.beforeWords,Mr.beforeWords),afterWords:Object.assign({},Er.afterWords,Mr.afterWords)};const Wr={afterTags:{Noun:"Adjective",Conjunction:void 0}},Ur={beforeTags:Object.assign({},Er.beforeTags,Tr.beforeTags,{Adverb:void 0,Negative:void 0}),afterTags:Object.assign({},Er.afterTags,Tr.afterTags,Wr.afterTags),beforeWords:Object.assign({},Er.beforeWords,Tr.beforeWords,{have:void 0,had:void 0,not:void 0,went:"Adjective",goes:"Adjective",got:"Adjective",be:"Adjective"}),afterWords:Object.assign({},Er.afterWords,Tr.afterWords,{to:void 0,as:"Adjective"})},qr={Copula:"Gerund",PastTense:"Gerund",PresentTense:"Gerund",Infinitive:"Gerund"},Rr={Value:"Gerund"},Qr={are:"Gerund",were:"Gerund",be:"Gerund",no:"Gerund",without:"Gerund",you:"Gerund",we:"Gerund",they:"Gerund",he:"Gerund",she:"Gerund",us:"Gerund",them:"Gerund"},Zr={the:"Gerund",this:"Gerund",that:"Gerund",me:"Gerund",us:"Gerund",them:"Gerund"},Xr={beforeTags:Object.assign({},Or.beforeTags,Dr.beforeTags,qr),afterTags:Object.assign({},Or.afterTags,Dr.afterTags,Rr),beforeWords:Object.assign({},Or.beforeWords,Dr.beforeWords,Qr),afterWords:Object.assign({},Or.afterWords,Dr.afterWords,Zr)},_r="Singular",Yr="Infinitive",eo={beforeTags:Object.assign({},Tr.beforeTags,Dr.beforeTags,{Adjective:_r,Particle:_r}),afterTags:Object.assign({},Tr.afterTags,Dr.afterTags,{ProperNoun:Yr,Gerund:Yr,Adjective:Yr,Copula:_r}),beforeWords:Object.assign({},Tr.beforeWords,Dr.beforeWords,{is:_r,was:_r,of:_r,have:null}),afterWords:Object.assign({},Tr.afterWords,Dr.afterWords,{instead:Yr,about:Yr,his:Yr,her:Yr,to:null,by:null,in:null})},to="Person";var no={beforeTags:{Honorific:to,Person:to},afterTags:{Person:to,ProperNoun:to,Verb:to},beforeWords:{hi:to,hey:to,yo:to,dear:to,hello:to},afterWords:{said:to,says:to,told:to,tells:to,feels:to,felt:to,seems:to,thinks:to,thought:to,spends:to,spendt:to,plays:to,played:to,sing:to,sang:to,learn:to,learned:to,wants:to,wanted:to}};const ao="Month",ro={beforeTags:{Date:ao,Value:ao},afterTags:{Date:ao,Value:ao},beforeWords:{by:ao,in:ao,on:ao,during:ao,after:ao,before:ao,between:ao,until:ao,til:ao,sometime:ao,of:ao,this:ao,next:ao,last:ao,previous:ao,following:ao,with:"Person"},afterWords:{sometime:ao,in:ao,of:ao,until:ao,the:ao}};var oo={beforeTags:Object.assign({},no.beforeTags,ro.beforeTags),afterTags:Object.assign({},no.afterTags,ro.afterTags),beforeWords:Object.assign({},no.beforeWords,ro.beforeWords),afterWords:Object.assign({},no.afterWords,ro.afterWords)};const io="Place",so={beforeTags:{Place:io},afterTags:{Place:io,Abbreviation:io},beforeWords:{in:io,by:io,near:io,from:io,to:io},afterWords:{in:io,by:io,near:io,from:io,to:io,government:io,council:io,region:io,city:io}},lo="Unit",uo={"Actor|Verb":Gr,"Adj|Gerund":Br,"Adj|Noun":Kr,"Adj|Past":Jr,"Adj|Present":Ur,"Noun|Verb":eo,"Noun|Gerund":Xr,"Person|Noun":{beforeTags:Object.assign({},Dr.beforeTags,no.beforeTags),afterTags:Object.assign({},Dr.afterTags,no.afterTags),beforeWords:Object.assign({},Dr.beforeWords,no.beforeWords,{i:"Infinitive",we:"Infinitive"}),afterWords:Object.assign({},Dr.afterWords,no.afterWords)},"Person|Date":oo,"Person|Verb":{beforeTags:Object.assign({},Dr.beforeTags,no.beforeTags,Tr.beforeTags),afterTags:Object.assign({},Dr.afterTags,no.afterTags,Tr.afterTags),beforeWords:Object.assign({},Dr.beforeWords,no.beforeWords,Tr.beforeWords),afterWords:Object.assign({},Dr.afterWords,no.afterWords,Tr.afterWords)},"Person|Place":{beforeTags:Object.assign({},so.beforeTags,no.beforeTags),afterTags:Object.assign({},so.afterTags,no.afterTags),beforeWords:Object.assign({},so.beforeWords,no.beforeWords),afterWords:Object.assign({},so.afterWords,no.afterWords)},"Person|Adj":{beforeTags:Object.assign({},no.beforeTags,Er.beforeTags),afterTags:Object.assign({},no.afterTags,Er.afterTags),beforeWords:Object.assign({},no.beforeWords,Er.beforeWords),afterWords:Object.assign({},no.afterWords,Er.afterWords)},"Unit|Noun":{beforeTags:{Value:lo},afterTags:{},beforeWords:{per:lo,every:lo,each:lo,square:lo,cubic:lo,sq:lo,metric:lo},afterWords:{per:lo,squared:lo,cubed:lo,long:lo}}},co=(e,t)=>{const n=Object.keys(e).reduce(((t,n)=>(t[n]="Infinitive"===e[n]?"PresentTense":"Plural",t)),{});return Object.assign(n,t)};uo["Plural|Verb"]={beforeWords:co(uo["Noun|Verb"].beforeWords,{had:"Plural",have:"Plural"}),afterWords:co(uo["Noun|Verb"].afterWords,{his:"PresentTense",her:"PresentTense",its:"PresentTense",in:null,to:null,is:"PresentTense",by:"PresentTense"}),beforeTags:co(uo["Noun|Verb"].beforeTags,{Conjunction:"PresentTense",Noun:void 0,ProperNoun:"PresentTense"}),afterTags:co(uo["Noun|Verb"].afterTags,{Gerund:"Plural",Noun:"PresentTense",Value:"PresentTense"})};const ho="Adjective",go="Infinitive",mo="PresentTense",po="Singular",fo="PastTense",bo="Adverb",yo="Plural",vo="Actor",wo="Verb",ko="Noun",Po="LastName",Ao="Modal",Co="Place",jo="Participle";var No=[null,null,{ea:po,ia:ko,ic:ho,ly:bo,"'n":wo,"'t":wo},{oed:fo,ued:fo,xed:fo," so":bo,"'ll":Ao,"'re":"Copula",azy:ho,eer:ko,end:wo,ped:fo,ffy:ho,ify:go,ing:"Gerund",ize:go,ibe:go,lar:ho,mum:ho,nes:mo,nny:ho,ous:ho,que:ho,ger:ko,ber:ko,rol:po,sis:po,ogy:po,oid:po,ian:po,zes:mo,eld:fo,ken:jo,ven:jo,ten:jo,ect:go,ict:go,ign:go,oze:go,ful:ho,bal:ho,ton:ko,pur:Co},{amed:fo,aped:fo,ched:fo,lked:fo,rked:fo,reed:fo,nded:fo,mned:ho,cted:fo,dged:fo,ield:po,akis:Po,cede:go,chuk:Po,czyk:Po,ects:mo,iend:po,ends:wo,enko:Po,ette:po,iary:po,wner:po,fies:mo,fore:bo,gate:go,gone:ho,ices:yo,ints:yo,ruct:go,ines:yo,ions:yo,ners:yo,pers:yo,lers:yo,less:ho,llen:ho,made:ho,nsen:Po,oses:mo,ould:Ao,some:ho,sson:Po,ians:yo,tion:po,tage:ko,ique:po,tive:ho,tors:ko,vice:po,lier:po,fier:po,wned:fo,gent:po,tist:vo,pist:vo,rist:vo,mist:vo,yist:vo,vist:vo,ists:vo,lite:po,site:po,rite:po,mite:po,bite:po,mate:po,date:po,ndal:po,vent:po,uist:vo,gist:vo,note:po,cide:po,ence:po,wide:ho,vide:go,ract:go,duce:go,pose:go,eive:go,lyze:go,lyse:go,iant:ho,nary:ho,ghty:ho,uent:ho,erer:vo,bury:Co,dorf:ko,esty:ko,wych:Co,dale:Co,folk:Co,vale:Co,abad:Co,sham:Co,wick:Co,view:Co},{elist:vo,holic:po,phite:po,tized:fo,urned:fo,eased:fo,ances:yo,bound:ho,ettes:yo,fully:bo,ishes:mo,ities:yo,marek:Po,nssen:Po,ology:ko,osome:po,tment:po,ports:yo,rough:ho,tches:mo,tieth:"Ordinal",tures:yo,wards:bo,where:bo,archy:ko,pathy:ko,opoly:ko,embly:ko,phate:ko,ndent:po,scent:po,onist:vo,anist:vo,alist:vo,olist:vo,icist:vo,ounce:go,iable:ho,borne:ho,gnant:ho,inant:ho,igent:ho,atory:ho,rient:po,dient:po,maker:vo,burgh:Co,mouth:Co,ceter:Co,ville:Co,hurst:Co,stead:Co,endon:Co,brook:Co,shire:Co,worth:ko,field:"ProperNoun",ridge:Co},{auskas:Po,parent:po,cedent:po,ionary:po,cklist:po,brooke:Co,keeper:vo,logist:vo,teenth:"Value",worker:vo,master:vo,writer:vo,brough:Co,cester:Co,ington:Co,cliffe:Co,ingham:Co},{chester:Co,logists:vo,opoulos:Po,borough:Co,sdottir:Po}];const Io="Adjective",Do="Noun",Ho="Verb";var To=[null,null,{},{neo:Do,bio:Do,"de-":Ho,"re-":Ho,"un-":Ho,"ex-":Do},{anti:Do,auto:Do,faux:Io,hexa:Do,kilo:Do,mono:Do,nano:Do,octa:Do,poly:Do,semi:Io,tele:Do,"pro-":Io,"mis-":Ho,"dis-":Ho,"pre-":Io},{anglo:Do,centi:Do,ethno:Do,ferro:Do,grand:Do,hepta:Do,hydro:Do,intro:Do,macro:Do,micro:Do,milli:Do,nitro:Do,penta:Do,quasi:Io,radio:Do,tetra:Do,"omni-":Io,"post-":Io},{pseudo:Io,"extra-":Io,"hyper-":Io,"inter-":Io,"intra-":Io,"deca-":Io},{electro:Do}];const Go="Adjective",xo="Infinitive",Eo="PresentTense",Fo="Singular",Oo="PastTense",zo="Adverb",Vo="Expression",Bo="Actor",So="Verb",Ko="Noun",$o="LastName";var Lo={a:[[/.[aeiou]na$/,Ko,"tuna"],[/.[oau][wvl]ska$/,$o],[/.[^aeiou]ica$/,Fo,"harmonica"],[/^([hyj]a+)+$/,Vo,"haha"]],c:[[/.[^aeiou]ic$/,Go]],d:[[/[aeiou](pp|ll|ss|ff|gg|tt|rr|bb|nn|mm)ed$/,Oo,"popped"],[/.[aeo]{2}[bdgmnprvz]ed$/,Oo,"rammed"],[/.[aeiou][sg]hed$/,Oo,"gushed"],[/.[aeiou]red$/,Oo,"hired"],[/.[aeiou]r?ried$/,Oo,"hurried"],[/[^aeiou]ard$/,Fo,"steward"],[/[aeiou][^aeiou]id$/,Go,""],[/.[vrl]id$/,Go,"livid"],[/..led$/,Oo,"hurled"],[/.[iao]sed$/,Oo,""],[/[aeiou]n?[cs]ed$/,Oo,""],[/[aeiou][rl]?[mnf]ed$/,Oo,""],[/[aeiou][ns]?c?ked$/,Oo,"bunked"],[/[aeiou]gned$/,Oo],[/[aeiou][nl]?ged$/,Oo],[/.[tdbwxyz]ed$/,Oo],[/[^aeiou][aeiou][tvx]ed$/,Oo],[/.[cdflmnprstv]ied$/,Oo,"emptied"]],e:[[/.[lnr]ize$/,xo,"antagonize"],[/.[^aeiou]ise$/,xo,"antagonise"],[/.[aeiou]te$/,xo,"bite"],[/.[^aeiou][ai]ble$/,Go,"fixable"],[/.[^aeiou]eable$/,Go,"maleable"],[/.[ts]ive$/,Go,"festive"],[/[a-z]-like$/,Go,"woman-like"]],h:[[/.[^aeiouf]ish$/,Go,"cornish"],[/.v[iy]ch$/,$o,"..ovich"],[/^ug?h+$/,Vo,"ughh"],[/^uh[ -]?oh$/,Vo,"uhoh"],[/[a-z]-ish$/,Go,"cartoon-ish"]],i:[[/.[oau][wvl]ski$/,$o,"polish-male"]],k:[[/^(k){2}$/,Vo,"kkkk"]],l:[[/.[gl]ial$/,Go,"familial"],[/.[^aeiou]ful$/,Go,"fitful"],[/.[nrtumcd]al$/,Go,"natal"],[/.[^aeiou][ei]al$/,Go,"familial"]],m:[[/.[^aeiou]ium$/,Fo,"magnesium"],[/[^aeiou]ism$/,Fo,"schism"],[/^[hu]m+$/,Vo,"hmm"],[/^\d+ ?[ap]m$/,"Date","3am"]],n:[[/.[lsrnpb]ian$/,Go,"republican"],[/[^aeiou]ician$/,Bo,"musician"],[/[aeiou][ktrp]in'$/,"Gerund","cookin'"]],o:[[/^no+$/,Vo,"noooo"],[/^(yo)+$/,Vo,"yoo"],[/^wo{2,}[pt]?$/,Vo,"woop"]],r:[[/.[bdfklmst]ler$/,"Noun"],[/[aeiou][pns]er$/,Fo],[/[^i]fer$/,xo],[/.[^aeiou][ao]pher$/,Bo],[/.[lk]er$/,"Noun"],[/.ier$/,"Comparative"]],t:[[/.[di]est$/,"Superlative"],[/.[icldtgrv]ent$/,Go],[/[aeiou].*ist$/,Go],[/^[a-z]et$/,So]],s:[[/.[^aeiou]ises$/,Eo],[/.[rln]ates$/,Eo],[/.[^z]ens$/,So],[/.[lstrn]us$/,Fo],[/.[aeiou]sks$/,Eo],[/.[aeiou]kes$/,Eo],[/[aeiou][^aeiou]is$/,Fo],[/[a-z]'s$/,Ko],[/^yes+$/,Vo]],v:[[/.[^aeiou][ai][kln]ov$/,$o]],y:[[/.[cts]hy$/,Go],[/.[st]ty$/,Go],[/.[tnl]ary$/,Go],[/.[oe]ry$/,Fo],[/[rdntkbhs]ly$/,zo],[/.(gg|bb|zz)ly$/,Go],[/...lly$/,zo],[/.[gk]y$/,Go],[/[bszmp]{2}y$/,Go],[/.[ai]my$/,Go],[/[ea]{2}zy$/,Go],[/.[^aeiou]ity$/,Fo]]};const Mo="Verb",Jo="Noun";var Wo={leftTags:[["Adjective",Jo],["Possessive",Jo],["Determiner",Jo],["Adverb",Mo],["Pronoun",Mo],["Value",Jo],["Ordinal",Jo],["Modal",Mo],["Superlative",Jo],["Demonym",Jo],["Honorific","Person"]],leftWords:[["i",Mo],["first",Jo],["it",Mo],["there",Mo],["not",Mo],["because",Jo],["if",Jo],["but",Jo],["who",Mo],["this",Jo],["his",Jo],["when",Jo],["you",Mo],["very","Adjective"],["old",Jo],["never",Mo],["before",Jo],["a",Jo],["the",Jo],["been",Mo]],rightTags:[["Copula",Jo],["PastTense",Jo],["Conjunction",Jo],["Modal",Jo]],rightWords:[["there",Mo],["me",Mo],["man","Adjective"],["him",Mo],["it",Mo],["were",Jo],["took",Jo],["himself",Mo],["went",Jo],["who",Jo],["jr","Person"]]},Uo={fwd:"3:ser,ier¦1er:h,t,f,l,n¦1r:e¦2er:ss,or,om",both:"3er:ver,ear,alm¦3ner:hin¦3ter:lat¦2mer:im¦2er:ng,rm,mb¦2ber:ib¦2ger:ig¦1er:w,p,k,d¦ier:y",rev:"1:tter,yer¦2:uer,ver,ffer,oner,eler,ller,iler,ster,cer,uler,sher,ener,gher,aner,adder,nter,eter,rter,hter,rner,fter¦3:oser,ooler,eafer,user,airer,bler,maler,tler,eater,uger,rger,ainer,urer,ealer,icher,pler,emner,icter,nser,iser¦4:arser,viner,ucher,rosser,somer,ndomer,moter,oother,uarer,hiter¦5:nuiner,esser,emier¦ar:urther",ex:"worse:bad¦better:good¦4er:fair,gray,poor¦1urther:far¦3ter:fat,hot,wet¦3der:mad,sad¦3er:shy,fun¦4der:glad¦:¦4r:cute,dire,fake,fine,free,lame,late,pale,rare,ripe,rude,safe,sore,tame,wide¦5r:eerie,stale"},qo={fwd:"1:nning,tting,rring,pping,eing,mming,gging,dding,bbing,kking¦2:eking,oling,eling,eming¦3:velling,siting,uiting,fiting,loting,geting,ialing,celling¦4:graming",both:"1:aing,iing,fing,xing,ying,oing,hing,wing¦2:tzing,rping,izzing,bting,mning,sping,wling,rling,wding,rbing,uping,lming,wning,mping,oning,lting,mbing,lking,fting,hting,sking,gning,pting,cking,ening,nking,iling,eping,ering,rting,rming,cting,lping,ssing,nting,nding,lding,sting,rning,rding,rking¦3:belling,siping,toming,yaking,uaking,oaning,auling,ooping,aiding,naping,euring,tolling,uzzing,ganing,haning,ualing,halling,iasing,auding,ieting,ceting,ouling,voring,ralling,garing,joring,oaming,oaking,roring,nelling,ooring,uelling,eaming,ooding,eaping,eeting,ooting,ooming,xiting,keting,ooking,ulling,airing,oaring,biting,outing,oiting,earing,naling,oading,eeding,ouring,eaking,aiming,illing,oining,eaning,onging,ealing,aining,eading¦4:thoming,melling,aboring,ivoting,weating,dfilling,onoring,eriting,imiting,tialling,rgining,otoring,linging,winging,lleting,louding,spelling,mpelling,heating,feating,opelling,choring,welling,ymaking,ctoring,calling,peating,iloring,laiting,utoring,uditing,mmaking,loating,iciting,waiting,mbating,voiding,otalling,nsoring,nselling,ocusing,itoring,eloping¦5:rselling,umpeting,atrolling,treating,tselling,rpreting,pringing,ummeting,ossoming,elmaking,eselling,rediting,totyping,onmaking,rfeiting,ntrolling¦5e:chmaking,dkeeping,severing,erouting,ecreting,ephoning,uthoring,ravening,reathing,pediting,erfering,eotyping,fringing,entoring,ombining,ompeting¦4e:emaking,eething,twining,rruling,chuting,xciting,rseding,scoping,edoring,pinging,lunging,agining,craping,pleting,eleting,nciting,nfining,ncoding,tponing,ecoding,writing,esaling,nvening,gnoring,evoting,mpeding,rvening,dhering,mpiling,storing,nviting,ploring¦3e:tining,nuring,saking,miring,haling,ceding,xuding,rining,nuting,laring,caring,miling,riding,hoking,piring,lading,curing,uading,noting,taping,futing,paring,hading,loding,siring,guring,vading,voking,during,niting,laning,caping,luting,muting,ruding,ciding,juring,laming,caling,hining,uoting,liding,ciling,duling,tuting,puting,cuting,coring,uiding,tiring,turing,siding,rading,enging,haping,buting,lining,taking,anging,haring,uiring,coming,mining,moting,suring,viding,luding¦2e:tring,zling,uging,oging,gling,iging,vring,fling,lging,obing,psing,pling,ubing,cling,dling,wsing,iking,rsing,dging,kling,ysing,tling,rging,eging,nsing,uning,osing,uming,using,ibing,bling,aging,ising,asing,ating¦2ie:rlying¦1e:zing,uing,cing,ving",rev:"ying:ie¦1ing:se,ke,te,we,ne,re,de,pe,me,le,c,he¦2ing:ll,ng,dd,ee,ye,oe,rg,us¦2ning:un¦2ging:og,ag,ug,ig,eg¦2ming:um¦2bing:ub,ab,eb,ob¦3ning:lan,can,hin,pin,win¦3ring:cur,lur,tir,tar,pur,car¦3ing:ait,del,eel,fin,eat,oat,eem,lel,ool,ein,uin¦3ping:rop,rap,top,uip,wap,hip,hop,lap,rip,cap¦3ming:tem,wim,rim,kim,lim¦3ting:mat,cut,pot,lit,lot,hat,set,pit,put¦3ding:hed,bed,bid¦3king:rek¦3ling:cil,pel¦3bing:rib¦4ning:egin¦4ing:isit,ruit,ilot,nsit,dget,rkel,ival,rcel¦4ring:efer,nfer¦4ting:rmit,mmit,ysit,dmit,emit,bmit,tfit,gret¦4ling:evel,xcel,ivel¦4ding:hred¦5ing:arget,posit,rofit¦5ring:nsfer¦5ting:nsmit,orget,cquit¦5ling:ancel,istil",ex:"3:adding,eating,aiming,aiding,airing,outing,gassing,setting,getting,putting,cutting,winning,sitting,betting,mapping,tapping,letting,bidding,hitting,tanning,netting,popping,fitting,capping,lapping,barring,banning,vetting,topping,rotting,tipping,potting,wetting,pitting,dipping,budding,hemming,pinning,jetting,kidding,padding,podding,sipping,wedding,bedding,donning,warring,penning,gutting,cueing,wadding,petting,ripping,napping,matting,tinning,binning,dimming,hopping,mopping,nodding,panning,rapping,ridding,sinning¦4:selling,falling,calling,waiting,editing,telling,rolling,heating,boating,hanging,beating,coating,singing,tolling,felling,polling,discing,seating,voiding,gelling,yelling,baiting,reining,ruining,seeking,spanning,stepping,knitting,emitting,slipping,quitting,dialing,omitting,clipping,shutting,skinning,abutting,flipping,trotting,cramming,fretting,suiting¦5:bringing,treating,spelling,stalling,trolling,expelling,rivaling,wringing,deterring,singeing,befitting,refitting¦6:enrolling,distilling,scrolling,strolling,caucusing,travelling¦7:installing,redefining,stencilling,recharging,overeating,benefiting,unraveling,programing¦9:reprogramming¦is:being¦2e:using,aging,owing¦3e:making,taking,coming,noting,hiring,filing,coding,citing,doping,baking,coping,hoping,lading,caring,naming,voting,riding,mining,curing,lining,ruling,typing,boring,dining,firing,hiding,piling,taping,waning,baling,boning,faring,honing,wiping,luring,timing,wading,piping,fading,biting,zoning,daring,waking,gaming,raking,ceding,tiring,coking,wining,joking,paring,gaping,poking,pining,coring,liming,toting,roping,wiring,aching¦4e:writing,storing,eroding,framing,smoking,tasting,wasting,phoning,shaking,abiding,braking,flaking,pasting,priming,shoring,sloping,withing,hinging¦5e:defining,refining,renaming,swathing,fringing,reciting¦1ie:dying,tying,lying,vying¦7e:sunbathing"},Ro={fwd:"1:mt¦2:llen¦3:iven,aken¦:ne¦y:in",both:"1:wn¦2:me,aten¦3:seen,bidden,isen¦4:roven,asten¦3l:pilt¦3d:uilt¦2e:itten¦1im:wum¦1eak:poken¦1ine:hone¦1ose:osen¦1in:gun¦1ake:woken¦ear:orn¦eal:olen¦eeze:ozen¦et:otten¦ink:unk¦ing:ung",rev:"2:un¦oken:eak¦ought:eek¦oven:eave¦1ne:o¦1own:ly¦1den:de¦1in:ay¦2t:am¦2n:ee¦3en:all¦4n:rive,sake,take¦5n:rgive",ex:"2:been¦3:seen,run¦4:given,taken¦5:shaken¦2eak:broken¦1ive:dove¦2y:flown¦3e:hidden,ridden¦1eek:sought¦1ake:woken¦1eave:woven"},Qo={fwd:"1:oes¦1ve:as",both:"1:xes¦2:zzes,ches,shes,sses¦3:iases¦2y:llies,plies¦1y:cies,bies,ties,vies,nies,pies,dies,ries,fies¦:s",rev:"1ies:ly¦2es:us,go,do¦3es:cho,eto",ex:"2:does,goes¦3:gasses¦5:focuses¦is:are¦3y:relies¦2y:flies¦2ve:has"},Zo={fwd:"1st:e¦1est:l,m,f,s¦1iest:cey¦2est:or,ir¦3est:ver",both:"4:east¦5:hwest¦5lest:erful¦4est:weet,lgar,tter,oung¦4most:uter¦3est:ger,der,rey,iet,ong,ear¦3test:lat¦3most:ner¦2est:pt,ft,nt,ct,rt,ht¦2test:it¦2gest:ig¦1est:b,k,n,p,h,d,w¦iest:y",rev:"1:ttest,nnest,yest¦2:sest,stest,rmest,cest,vest,lmest,olest,ilest,ulest,ssest,imest,uest¦3:rgest,eatest,oorest,plest,allest,urest,iefest,uelest,blest,ugest,amest,yalest,ealest,illest,tlest,itest¦4:cerest,eriest,somest,rmalest,ndomest,motest,uarest,tiffest¦5:leverest,rangest¦ar:urthest¦3ey:riciest",ex:"best:good¦worst:bad¦5est:great¦4est:fast,full,fair,dull¦3test:hot,wet,fat¦4nest:thin¦1urthest:far¦3est:gay,shy,ill¦4test:neat¦4st:late,wide,fine,safe,cute,fake,pale,rare,rude,sore,ripe,dire¦6st:severe"},Xo={fwd:"1:tistic,eable,lful,sful,ting,tty¦2:onate,rtable,geous,ced,seful,ctful¦3:ortive,ented¦arity:ear¦y:etic¦fulness:begone¦1ity:re¦1y:tiful,gic¦2ity:ile,imous,ilous,ime¦2ion:ated¦2eness:iving¦2y:trious¦2ation:iring¦2tion:vant¦3ion:ect¦3ce:mant,mantic¦3tion:irable¦3y:est,estic¦3m:mistic,listic¦3ess:ning¦4n:utious¦4on:rative,native,vative,ective¦4ce:erant",both:"1:king,wing¦2:alous,ltuous,oyful,rdous¦3:gorous,ectable,werful,amatic¦4:oised,usical,agical,raceful,ocused,lined,ightful¦5ness:stful,lding,itous,nuous,ulous,otous,nable,gious,ayful,rvous,ntous,lsive,peful,entle,ciful,osive,leful,isive,ncise,reful,mious¦5ty:ivacious¦5ties:ubtle¦5ce:ilient,adiant,atient¦5cy:icient¦5sm:gmatic¦5on:sessive,dictive¦5ity:pular,sonal,eative,entic¦5sity:uminous¦5ism:conic¦5nce:mperate¦5ility:mitable¦5ment:xcited¦5n:bitious¦4cy:brant,etent,curate¦4ility:erable,acable,icable,ptable¦4ty:nacious,aive,oyal,dacious¦4n:icious¦4ce:vient,erent,stent,ndent,dient,quent,ident¦4ness:adic,ound,hing,pant,sant,oing,oist,tute¦4icity:imple¦4ment:fined,mused¦4ism:otic¦4ry:dantic¦4ity:tund,eral¦4edness:hand¦4on:uitive¦4lity:pitable¦4sm:eroic,namic¦4sity:nerous¦3th:arm¦3ility:pable,bable,dable,iable¦3cy:hant,nant,icate¦3ness:red,hin,nse,ict,iet,ite,oud,ind,ied,rce¦3ion:lute¦3ity:ual,gal,volous,ial¦3ce:sent,fensive,lant,gant,gent,lent,dant¦3on:asive¦3m:fist,sistic,iastic¦3y:terious,xurious,ronic,tastic¦3ur:amorous¦3e:tunate¦3ation:mined¦3sy:rteous¦3ty:ain¦3ry:ave¦3ment:azed¦2ness:de,on,ue,rn,ur,ft,rp,pe,om,ge,rd,od,ay,ss,er,ll,oy,ap,ht,ld,ad,rt¦2inousness:umous¦2ity:neous,ene,id,ane¦2cy:bate,late¦2ation:ized¦2ility:oble,ible¦2y:odic¦2e:oving,aring¦2s:ost¦2itude:pt¦2dom:ee¦2ance:uring¦2tion:reet¦2ion:oted¦2sion:ending¦2liness:an¦2or:rdent¦1th:ung¦1e:uable¦1ness:w,h,k,f¦1ility:mble¦1or:vent¦1ement:ging¦1tiquity:ncient¦1ment:hed¦verty:or¦ength:ong¦eat:ot¦pth:ep¦iness:y",rev:"",ex:"5:forceful,humorous¦8:charismatic¦13:understanding¦5ity:active¦11ness:adventurous,inquisitive,resourceful¦8on:aggressive,automatic,perceptive¦7ness:amorous,fatuous,furtive,ominous,serious¦5ness:ample,sweet¦12ness:apprehensive,cantankerous,contemptuous,ostentatious¦13ness:argumentative,conscientious¦9ness:assertive,facetious,imperious,inventive,oblivious,rapacious,receptive,seditious,whimsical¦10ness:attractive,expressive,impressive,loquacious,salubrious,thoughtful¦3edom:boring¦4ness:calm,fast,keen,tame¦8ness:cheerful,gracious,specious,spurious,timorous,unctuous¦5sity:curious¦9ion:deliberate¦8ion:desperate¦6e:expensive¦7ce:fragrant¦3y:furious¦9ility:ineluctable¦6ism:mystical¦8ity:physical,proactive,sensitive,vertical¦5cy:pliant¦7ity:positive¦9ity:practical¦12ism:professional¦6ce:prudent¦3ness:red¦6cy:vagrant¦3dom:wise"};const _o=function(e="",t={}){let n=function(e,t={}){return t.hasOwnProperty(e)?t[e]:null}(e,t.ex);return n=n||function(e,t=[]){for(let n=0;n=1;a-=1){let r=e.length-a,o=e.substring(r,e.length);if(!0===t.hasOwnProperty(o))return e.slice(0,r)+t[o];if(!0===n.hasOwnProperty(o))return e.slice(0,r)+n[o]}return t.hasOwnProperty("")?e+t[""]:n.hasOwnProperty("")?e+n[""]:null}(e,t.fwd,t.both),n=n||e,n},Yo=function(e){return Object.entries(e).reduce(((e,t)=>(e[t[1]]=t[0],e)),{})},ei=function(e={}){return{reversed:!0,both:Yo(e.both),ex:Yo(e.ex),fwd:e.rev||{}}},ti=/^([0-9]+)/,ni=function(e){let t=function(e){let t={};return e.split("¦").forEach((e=>{let[n,a]=e.split(":");a=(a||"").split(","),a.forEach((e=>{t[e]=n}))})),t}(e);return Object.keys(t).reduce(((e,n)=>(e[n]=function(e="",t=""){let n=(t=String(t)).match(ti);if(null===n)return t;let a=Number(n[1])||0;return e.substring(0,a)+t.replace(ti,"")}(n,t[n]),e)),{})},ai=function(e={}){return"string"==typeof e&&(e=JSON.parse(e)),e.fwd=ni(e.fwd||""),e.both=ni(e.both||""),e.rev=ni(e.rev||""),e.ex=ni(e.ex||""),e},ri=ai({fwd:"1:tted,wed,gged,nned,een,rred,pped,yed,bbed,oed,dded,rd,wn,mmed¦2:eed,nded,et,hted,st,oled,ut,emed,eled,lded,ken,rt,nked,apt,ant,eped,eked¦3:eared,eat,eaded,nelled,ealt,eeded,ooted,eaked,eaned,eeted,mited,bid,uit,ead,uited,ealed,geted,velled,ialed,belled¦4:ebuted,hined,comed¦y:ied¦ome:ame¦ear:ore¦ind:ound¦ing:ung,ang¦ep:pt¦ink:ank,unk¦ig:ug¦all:ell¦ee:aw¦ive:ave¦eeze:oze¦old:eld¦ave:ft¦ake:ook¦ell:old¦ite:ote¦ide:ode¦ine:one¦in:un,on¦eal:ole¦im:am¦ie:ay¦and:ood¦1ise:rose¦1eak:roke¦1ing:rought¦1ive:rove¦1el:elt¦1id:bade¦1et:got¦1y:aid¦1it:sat¦3e:lid¦3d:pent",both:"1:aed,fed,xed,hed¦2:sged,xted,wled,rped,lked,kied,lmed,lped,uped,bted,rbed,rked,wned,rled,mped,fted,mned,mbed,zzed,omed,ened,cked,gned,lted,sked,ued,zed,nted,ered,rted,rmed,ced,sted,rned,ssed,rded,pted,ved,cted¦3:cled,eined,siped,ooned,uked,ymed,jored,ouded,ioted,oaned,lged,asped,iged,mured,oided,eiled,yped,taled,moned,yled,lit,kled,oaked,gled,naled,fled,uined,oared,valled,koned,soned,aided,obed,ibed,meted,nicked,rored,micked,keted,vred,ooped,oaded,rited,aired,auled,filled,ouled,ooded,ceted,tolled,oited,bited,aped,tled,vored,dled,eamed,nsed,rsed,sited,owded,pled,sored,rged,osed,pelled,oured,psed,oated,loned,aimed,illed,eured,tred,ioned,celled,bled,wsed,ooked,oiled,itzed,iked,iased,onged,ased,ailed,uned,umed,ained,auded,nulled,ysed,eged,ised,aged,oined,ated,used,dged,doned¦4:ntied,efited,uaked,caded,fired,roped,halled,roked,himed,culed,tared,lared,tuted,uared,routed,pited,naked,miled,houted,helled,hared,cored,caled,tired,peated,futed,ciled,called,tined,moted,filed,sided,poned,iloted,honed,lleted,huted,ruled,cured,named,preted,vaded,sured,talled,haled,peded,gined,nited,uided,ramed,feited,laked,gured,ctored,unged,pired,cuted,voked,eloped,ralled,rined,coded,icited,vided,uaded,voted,mined,sired,noted,lined,nselled,luted,jured,fided,puted,piled,pared,olored,cided,hoked,enged,tured,geoned,cotted,lamed,uiled,waited,udited,anged,luded,mired,uired,raded¦5:modelled,izzled,eleted,umpeted,ailored,rseded,treated,eduled,ecited,rammed,eceded,atrolled,nitored,basted,twined,itialled,ncited,gnored,ploded,xcited,nrolled,namelled,plored,efeated,redited,ntrolled,nfined,pleted,llided,lcined,eathed,ibuted,lloted,dhered,cceded¦3ad:sled¦2aw:drew¦2ot:hot¦2ke:made¦2ow:hrew,grew¦2ose:hose¦2d:ilt¦2in:egan¦1un:ran¦1ink:hought¦1ick:tuck¦1ike:ruck¦1eak:poke,nuck¦1it:pat¦1o:did¦1ow:new¦1ake:woke¦go:went",rev:"3:rst,hed,hut,cut,set¦4:tbid¦5:dcast,eread,pread,erbid¦ought:uy,eek¦1ied:ny,ly,dy,ry,fy,py,vy,by,ty,cy¦1ung:ling,ting,wing¦1pt:eep¦1ank:rink¦1ore:bear,wear¦1ave:give¦1oze:reeze¦1ound:rind,wind¦1ook:take,hake¦1aw:see¦1old:sell¦1ote:rite¦1ole:teal¦1unk:tink¦1am:wim¦1ay:lie¦1ood:tand¦1eld:hold¦2d:he,ge,re,le,leed,ne,reed,be,ye,lee,pe,we¦2ed:dd,oy,or,ey,gg,rr,us,ew,to¦2ame:ecome,rcome¦2ped:ap¦2ged:ag,og,ug,eg¦2bed:ub,ab,ib,ob¦2lt:neel¦2id:pay¦2ang:pring¦2ove:trive¦2med:um¦2ode:rride¦2at:ysit¦3ted:mit,hat,mat,lat,pot,rot,bat¦3ed:low,end,tow,und,ond,eem,lay,cho,dow,xit,eld,ald,uld,law,lel,eat,oll,ray,ank,fin,oam,out,how,iek,tay,haw,ait,vet,say,cay,bow¦3d:ste,ede,ode,ete,ree,ude,ame,oke,ote,ime,ute,ade¦3red:lur,cur,pur,car¦3ped:hop,rop,uip,rip,lip,tep,top¦3ded:bed,rod,kid¦3ade:orbid¦3led:uel¦3ned:lan,can,kin,pan,tun¦3med:rim,lim¦4ted:quit,llot¦4ed:pear,rrow,rand,lean,mand,anel,pand,reet,link,abel,evel,imit,ceed,ruit,mind,peal,veal,hool,head,pell,well,mell,uell,band,hear,weak¦4led:nnel,qual,ebel,ivel¦4red:nfer,efer,sfer¦4n:sake,trew¦4d:ntee¦4ded:hred¦4ned:rpin¦5ed:light,nceal,right,ndear,arget,hread,eight,rtial,eboot¦5d:edite,nvite¦5ted:egret¦5led:ravel",ex:"2:been,upped¦3:added,aged,aided,aimed,aired,bid,died,dyed,egged,erred,eyed,fit,gassed,hit,lied,owed,pent,pied,tied,used,vied,oiled,outed,banned,barred,bet,canned,cut,dipped,donned,ended,feed,inked,jarred,let,manned,mowed,netted,padded,panned,pitted,popped,potted,put,set,sewn,sowed,tanned,tipped,topped,vowed,weed,bowed,jammed,binned,dimmed,hopped,mopped,nodded,pinned,rigged,sinned,towed,vetted¦4:ached,baked,baled,boned,bored,called,caned,cared,ceded,cited,coded,cored,cubed,cured,dared,dined,edited,exited,faked,fared,filed,fined,fired,fuelled,gamed,gelled,hired,hoped,joked,lined,mined,named,noted,piled,poked,polled,pored,pulled,reaped,roamed,rolled,ruled,seated,shed,sided,timed,tolled,toned,voted,waited,walled,waned,winged,wiped,wired,zoned,yelled,tamed,lubed,roped,faded,mired,caked,honed,banged,culled,heated,raked,welled,banded,beat,cast,cooled,cost,dealt,feared,folded,footed,handed,headed,heard,hurt,knitted,landed,leaked,leapt,linked,meant,minded,molded,neared,needed,peaked,plodded,plotted,pooled,quit,read,rooted,sealed,seeded,seeped,shipped,shunned,skimmed,slammed,sparred,stemmed,stirred,suited,thinned,twinned,swayed,winked,dialed,abutted,blotted,fretted,healed,heeded,peeled,reeled¦5:basted,cheated,equalled,eroded,exiled,focused,opined,pleated,primed,quoted,scouted,shored,sloped,smoked,sniped,spelled,spouted,routed,staked,stored,swelled,tasted,treated,wasted,smelled,dwelled,honored,prided,quelled,eloped,scared,coveted,sweated,breaded,cleared,debuted,deterred,freaked,modeled,pleaded,rebutted,speeded¦6:anchored,defined,endured,impaled,invited,refined,revered,strolled,cringed,recast,thrust,unfolded¦7:authored,combined,competed,conceded,convened,excreted,extruded,redefined,restored,secreted,rescinded,welcomed¦8:expedited,infringed¦9:interfered,intervened,persevered¦10:contravened¦eat:ate¦is:was¦go:went¦are:were¦3d:bent,lent,rent,sent¦3e:bit,fled,hid,lost¦3ed:bled,bred¦2ow:blew,grew¦1uy:bought¦2tch:caught¦1o:did¦1ive:dove,gave¦2aw:drew¦2ed:fed¦2y:flew,laid,paid,said¦1ight:fought¦1et:got¦2ve:had¦1ang:hung¦2ad:led¦2ght:lit¦2ke:made¦2et:met¦1un:ran¦1ise:rose¦1it:sat¦1eek:sought¦1each:taught¦1ake:woke,took¦1eave:wove¦2ise:arose¦1ear:bore,tore,wore¦1ind:bound,found,wound¦2eak:broke¦2ing:brought,wrung¦1ome:came¦2ive:drove¦1ig:dug¦1all:fell¦2el:felt¦4et:forgot¦1old:held¦2ave:left¦1ing:rang,sang¦1ide:rode¦1ink:sank¦1ee:saw¦2ine:shone¦4e:slid¦1ell:sold,told¦4d:spent¦2in:spun¦1in:won"}),oi=ai(Qo),ii=ai(qo),si=ai(Ro),li=ei(ri),ui=ei(oi),ci=ei(ii),di=ei(si),hi=ai(Uo),gi=ai(Zo);var mi={fromPast:ri,fromPresent:oi,fromGerund:ii,fromParticiple:si,toPast:li,toPresent:ui,toGerund:ci,toParticiple:di,toComparative:hi,toSuperlative:gi,fromComparative:ei(hi),fromSuperlative:ei(gi),adjToNoun:ai(Xo)},pi=["academy","administration","agence","agences","agencies","agency","airlines","airways","army","assoc","associates","association","assurance","authority","autorite","aviation","bank","banque","board","boys","brands","brewery","brotherhood","brothers","bureau","cafe","co","caisse","capital","care","cathedral","center","centre","chemicals","choir","chronicle","church","circus","clinic","clinique","club","co","coalition","coffee","collective","college","commission","committee","communications","community","company","comprehensive","computers","confederation","conference","conseil","consulting","containers","corporation","corps","corp","council","crew","data","departement","department","departments","design","development","directorate","division","drilling","education","eglise","electric","electricity","energy","ensemble","enterprise","enterprises","entertainment","estate","etat","faculty","faction","federation","financial","fm","foundation","fund","gas","gazette","girls","government","group","guild","herald","holdings","hospital","hotel","hotels","inc","industries","institut","institute","institutes","insurance","international","interstate","investment","investments","investors","journal","laboratory","labs","llc","ltd","limited","machines","magazine","management","marine","marketing","markets","media","memorial","ministere","ministry","military","mobile","motor","motors","musee","museum","news","observatory","office","oil","optical","orchestra","organization","partners","partnership","petrol","petroleum","pharmacare","pharmaceutical","pharmaceuticals","pizza","plc","police","politburo","polytechnic","post","power","press","productions","quartet","radio","reserve","resources","restaurant","restaurants","savings","school","securities","service","services","societe","subsidiary","society","sons","subcommittee","syndicat","systems","telecommunications","telegraph","television","times","tribunal","tv","union","university","utilities","workers"].reduce(((e,t)=>(e[t]=!0,e)),{}),fi=["atoll","basin","bay","beach","bluff","bog","camp","canyon","canyons","cape","cave","caves","cliffs","coast","cove","coves","crater","crossing","creek","desert","dune","dunes","downs","estates","escarpment","estuary","falls","fjord","fjords","forest","forests","glacier","gorge","gorges","grove","gulf","gully","highland","heights","hollow","hill","hills","inlet","island","islands","isthmus","junction","knoll","lagoon","lake","lakeshore","marsh","marshes","mount","mountain","mountains","narrows","peninsula","plains","plateau","pond","rapids","ravine","reef","reefs","ridge","river","rivers","sandhill","shoal","shore","shoreline","shores","strait","straits","springs","stream","swamp","tombolo","trail","trails","trench","valley","vallies","village","volcano","waterfall","watershed","wetland","woods","acres","burough","county","district","municipality","prefecture","province","region","reservation","state","territory","borough","metropolis","downtown","uptown","midtown","city","town","township","hamlet","country","kingdom","enclave","neighbourhood","neighborhood","kingdom","ward","zone","airport","amphitheater","arch","arena","auditorium","bar","barn","basilica","battlefield","bridge","building","castle","centre","coliseum","cineplex","complex","dam","farm","field","fort","garden","gardens","gymnasium","hall","house","levee","library","manor","memorial","monument","museum","gallery","palace","pillar","pits","plantation","playhouse","quarry","sportsfield","sportsplex","stadium","terrace","terraces","theater","tower","park","parks","site","ranch","raceway","sportsplex","ave","st","street","rd","road","lane","landing","crescent","cr","way","tr","terrace","avenue"].reduce(((e,t)=>(e[t]=!0,e)),{}),bi=[[/([^v])ies$/i,"$1y"],[/(ise)s$/i,"$1"],[/(kn|[^o]l|w)ives$/i,"$1ife"],[/^((?:ca|e|ha|(?:our|them|your)?se|she|wo)l|lea|loa|shea|thie)ves$/i,"$1f"],[/^(dwar|handkerchie|hoo|scar|whar)ves$/i,"$1f"],[/(antenn|formul|nebul|vertebr|vit)ae$/i,"$1a"],[/(octop|vir|radi|nucle|fung|cact|stimul)(i)$/i,"$1us"],[/(buffal|tomat|tornad)(oes)$/i,"$1o"],[/(ause)s$/i,"$1"],[/(ease)s$/i,"$1"],[/(ious)es$/i,"$1"],[/(ouse)s$/i,"$1"],[/(ose)s$/i,"$1"],[/(..ase)s$/i,"$1"],[/(..[aeiu]s)es$/i,"$1"],[/(vert|ind|cort)(ices)$/i,"$1ex"],[/(matr|append)(ices)$/i,"$1ix"],[/([xo]|ch|ss|sh)es$/i,"$1"],[/men$/i,"man"],[/(n)ews$/i,"$1ews"],[/([ti])a$/i,"$1um"],[/([^aeiouy]|qu)ies$/i,"$1y"],[/(s)eries$/i,"$1eries"],[/(m)ovies$/i,"$1ovie"],[/(cris|ax|test)es$/i,"$1is"],[/(alias|status)es$/i,"$1"],[/(ss)$/i,"$1"],[/(ic)s$/i,"$1"],[/s$/i,""]];const yi=function(e,t){const{irregularPlurals:n}=t.two,a=(r=n,Object.keys(r).reduce(((e,t)=>(e[r[t]]=t,e)),{}));var r;if(a.hasOwnProperty(e))return a[e];for(let t=0;t(wi[t].forEach((n=>e[n]=t)),e)),{});const ki=function(e){const t=e.substring(e.length-3);if(!0===wi.hasOwnProperty(t))return wi[t];const n=e.substring(e.length-2);if(!0===wi.hasOwnProperty(n))return wi[n];return"s"===e.substring(e.length-1)?"PresentTense":null},Pi={are:"be",were:"be",been:"be",is:"be",am:"be",was:"be",be:"be",being:"be"},Ai=function(e,t,n){const{fromPast:a,fromPresent:r,fromGerund:o,fromParticiple:i}=t.two.models,{prefix:s,verb:l,particle:u}=function(e,t){let n="",a={};t.one&&t.one.prefixes&&(a=t.one.prefixes);let[r,o]=e.split(/ /);return o&&!0===a[r]&&(n=r,r=o,o=""),{prefix:n,verb:r,particle:o}}(e,t);let c="";if(n||(n=ki(e)),Pi.hasOwnProperty(e))c=Pi[e];else if("Participle"===n)c=_o(l,i);else if("PastTense"===n)c=_o(l,a);else if("PresentTense"===n)c=_o(l,r);else{if("Gerund"!==n)return e;c=_o(l,o)}return u&&(c+=" "+u),s&&(c=s+" "+c),c},Ci=function(e,t){const{toPast:n,toPresent:a,toGerund:r,toParticiple:o}=t.two.models;if("be"===e)return{Infinitive:e,Gerund:"being",PastTense:"was",PresentTense:"is"};const[i,s]=(e=>/ /.test(e)?e.split(/ /):[e,""])(e),l={Infinitive:i,PastTense:_o(i,n),PresentTense:_o(i,a),Gerund:_o(i,r),FutureTense:"will "+i};let u=_o(i,o);if(u!==e&&u!==l.PastTense){const n=t.one.lexicon||{};"Participle"!==n[u]&&"Adjective"!==n[u]||("play"===e&&(u="played"),l.Participle=u)}return s&&Object.keys(l).forEach((e=>{l[e]+=" "+s})),l};var ji={toInfinitive:Ai,conjugate:Ci,all:function(e,t){const n=Ci(e,t);return delete n.FutureTense,Object.values(n).filter((e=>e))}};const Ni=function(e,t){const n=t.two.models.toSuperlative;return _o(e,n)},Ii=function(e,t){const n=t.two.models.toComparative;return _o(e,n)},Di=function(e="",t=[]){const n=e.length;for(let a=n<=6?n-1:6;a>=1;a-=1){const r=e.substring(n-a,e.length);if(!0===t[r.length].hasOwnProperty(r)){return e.slice(0,n-a)+t[r.length][r]}}return null},Hi="ically",Ti=new Set(["analyt"+Hi,"chem"+Hi,"class"+Hi,"clin"+Hi,"crit"+Hi,"ecolog"+Hi,"electr"+Hi,"empir"+Hi,"frant"+Hi,"grammat"+Hi,"ident"+Hi,"ideolog"+Hi,"log"+Hi,"mag"+Hi,"mathemat"+Hi,"mechan"+Hi,"med"+Hi,"method"+Hi,"method"+Hi,"mus"+Hi,"phys"+Hi,"phys"+Hi,"polit"+Hi,"pract"+Hi,"rad"+Hi,"satir"+Hi,"statist"+Hi,"techn"+Hi,"technolog"+Hi,"theoret"+Hi,"typ"+Hi,"vert"+Hi,"whims"+Hi]),Gi=[null,{},{ly:""},{ily:"y",bly:"ble",ply:"ple"},{ally:"al",rply:"rp"},{ually:"ual",ially:"ial",cally:"cal",eally:"eal",rally:"ral",nally:"nal",mally:"mal",eeply:"eep",eaply:"eap"},{ically:"ic"}],xi=new Set(["early","only","hourly","daily","weekly","monthly","yearly","mostly","duly","unduly","especially","undoubtedly","conversely","namely","exceedingly","presumably","accordingly","overly","best","latter","little","long","low"]),Ei={wholly:"whole",fully:"full",truly:"true",gently:"gentle",singly:"single",customarily:"customary",idly:"idle",publically:"public",quickly:"quick",superbly:"superb",cynically:"cynical",well:"good"},Fi=[null,{y:"ily"},{ly:"ly",ic:"ically"},{ial:"ially",ual:"ually",tle:"tly",ble:"bly",ple:"ply",ary:"arily"},{},{},{}],Oi={cool:"cooly",whole:"wholly",full:"fully",good:"well",idle:"idly",public:"publicly",single:"singly",special:"especially"},zi=function(e){if(Oi.hasOwnProperty(e))return Oi[e];let t=Di(e,Fi);return t||(t=e+"ly"),t};var Vi={toSuperlative:Ni,toComparative:Ii,toAdverb:zi,toNoun:function(e,t){const n=t.two.models.adjToNoun;return _o(e,n)},fromAdverb:function(e){return e.endsWith("ly")?Ti.has(e)?e.replace(/ically/,"ical"):xi.has(e)?null:Ei.hasOwnProperty(e)?Ei[e]:Di(e,Gi)||e:null},fromSuperlative:function(e,t){const n=t.two.models.fromSuperlative;return _o(e,n)},fromComparative:function(e,t){const n=t.two.models.fromComparative;return _o(e,n)},all:function(e,t){let n=[e];return n.push(Ni(e,t)),n.push(Ii(e,t)),n.push(zi(e)),n=n.filter((e=>e)),n=new Set(n),Array.from(n)}},Bi={noun:vi,verb:ji,adjective:Vi},Si={Singular:(e,t,n,a)=>{const r=a.one.lexicon,o=n.two.transform.noun.toPlural(e,a);r[o]||(t[o]=t[o]||"Plural")},Actor:(e,t,n,a)=>{const r=a.one.lexicon,o=n.two.transform.noun.toPlural(e,a);r[o]||(t[o]=t[o]||["Plural","Actor"])},Comparable:(e,t,n,a)=>{const r=a.one.lexicon,{toSuperlative:o,toComparative:i}=n.two.transform.adjective,s=o(e,a);r[s]||(t[s]=t[s]||"Superlative");const l=i(e,a);r[l]||(t[l]=t[l]||"Comparative"),t[e]="Adjective"},Demonym:(e,t,n,a)=>{const r=n.two.transform.noun.toPlural(e,a);t[r]=t[r]||["Demonym","Plural"]},Infinitive:(e,t,n,a)=>{const r=a.one.lexicon,o=n.two.transform.verb.conjugate(e,a);Object.entries(o).forEach((e=>{r[e[1]]||t[e[1]]||"FutureTense"===e[0]||(t[e[1]]=e[0])}))},PhrasalVerb:(e,t,n,a)=>{const r=a.one.lexicon;t[e]=["PhrasalVerb","Infinitive"];const o=a.one._multiCache,[i,s]=e.split(" ");r[i]||(t[i]=t[i]||"Infinitive");const l=n.two.transform.verb.conjugate(i,a);delete l.FutureTense,Object.entries(l).forEach((e=>{if("Actor"===e[0]||""===e[1])return;t[e[1]]||r[e[1]]||(t[e[1]]=e[0]),o[e[1]]=2;const n=e[1]+" "+s;t[n]=t[n]||[e[0],"PhrasalVerb"]}))},Multiple:(e,t)=>{t[e]=["Multiple","Cardinal"],t[e+"th"]=["Multiple","Ordinal"],t[e+"ths"]=["Multiple","Fraction"]},Cardinal:(e,t)=>{t[e]=["TextValue","Cardinal"]},Ordinal:(e,t)=>{t[e]=["TextValue","Ordinal"],t[e+"s"]=["TextValue","Fraction"]},Place:(e,t)=>{t[e]=["Place","ProperNoun"]},Region:(e,t)=>{t[e]=["Region","ProperNoun"]}};const Ki={e:["mice","louse","antennae","formulae","nebulae","vertebrae","vitae"],i:["tia","octopi","viri","radii","nuclei","fungi","cacti","stimuli"],n:["men"],t:["feet"]},$i=new Set(["israelis","menus","logos"]),Li=["bus","mas","was","ias","xas","vas","cis","lis","nis","ois","ris","sis","tis","xis","aus","cus","eus","fus","gus","ius","lus","nus","das","ous","pus","rus","sus","tus","xus","aos","igos","ados","ogos","'s","ss"],Mi=function(e){if(!e||e.length<=3)return!1;if($i.has(e))return!0;const t=e[e.length-1];return Ki.hasOwnProperty(t)?Ki[t].find((t=>e.endsWith(t))):"s"===t&&!Li.find((t=>e.endsWith(t)))};var Ji={two:{quickSplit:function(e){const t=/[,:;]/,n=[];return e.forEach((e=>{let a=0;e.forEach(((r,o)=>{t.test(r.post)&&function(e,t){const n=/^[0-9]+$/,a=e[t];if(!a)return!1;const r=new Set(["may","april","august","jan"]);if("like"===a.normal||r.has(a.normal))return!1;if(a.tags.has("Place")||a.tags.has("Date"))return!1;if(e[t-1]){const n=e[t-1];if(n.tags.has("Date")||r.has(n.normal))return!1;if(n.tags.has("Adjective")||a.tags.has("Adjective"))return!1}const o=a.normal;return 1!==o.length&&2!==o.length&&4!==o.length||!n.test(o)}(e,o+1)&&(n.push(e.slice(a,o+1)),a=o+1)})),a{const i=e[t],s=(t=(t=t.toLowerCase().trim()).replace(/'s\b/,"")).split(/ /);s.length>1&&(void 0===o[s[0]]||s.length>o[s[0]])&&(o[s[0]]=s.length),!0===Si.hasOwnProperty(i)&&Si[i](t,r,n,a),r[t]=r[t]||i})),delete r[""],delete r.null,delete r[" "],{lex:r,_multi:o}},transform:Bi,looksPlural:Mi}};const Wi={one:{lexicon:{}},two:{models:mi}},Ui={"Actor|Verb":"Actor","Adj|Gerund":"Adjective","Adj|Noun":"Adjective","Adj|Past":"Adjective","Adj|Present":"Adjective","Noun|Verb":"Singular","Noun|Gerund":"Gerund","Person|Noun":"Noun","Person|Date":"Month","Person|Verb":"FirstName","Person|Place":"Person","Person|Adj":"Comparative","Plural|Verb":"Plural","Unit|Noun":"Noun"},qi=function(e,t){const n={model:t,methods:Ji},{lex:a,_multi:r}=Ji.two.expandLexicon(e,n);return Object.assign(t.one.lexicon,a),Object.assign(t.one._multiCache,r),t},Ri=function(e,t,n){const a=Ci(e,Wi);t[a.PastTense]=t[a.PastTense]||"PastTense",t[a.Gerund]=t[a.Gerund]||"Gerund",!0===n&&(t[a.PresentTense]=t[a.PresentTense]||"PresentTense")},Qi=function(e,t,n){const a=Ni(e,n);t[a]=t[a]||"Superlative";const r=Ii(e,n);t[r]=t[r]||"Comparative"},Zi=function(e,t){const n={},a=t.one.lexicon;return Object.keys(e).forEach((r=>{const o=e[r];if(n[r]=Ui[o],"Noun|Verb"!==o&&"Person|Verb"!==o&&"Actor|Verb"!==o||Ri(r,a,!1),"Adj|Present"===o&&(Ri(r,a,!0),Qi(r,a,t)),"Person|Adj"===o&&Qi(r,a,t),"Adj|Gerund"===o||"Noun|Gerund"===o){const e=Ai(r,Wi,"Gerund");a[e]||(n[e]="Infinitive")}if("Noun|Gerund"!==o&&"Adj|Noun"!==o&&"Person|Noun"!==o||function(e,t,n){const a=Pr(e,n);t[a]=t[a]||"Plural"}(r,a,t),"Adj|Past"===o){const e=Ai(r,Wi,"PastTense");a[e]||(n[e]="Infinitive")}})),t=qi(n,t)};let Xi={one:{_multiCache:{},lexicon:Cr,frozenLex:{"20th century fox":"Organization","7 eleven":"Organization","motel 6":"Organization","excuse me":"Expression","financial times":"Organization","guns n roses":"Organization","la z boy":"Organization","labour party":"Organization","new kids on the block":"Organization","new york times":"Organization","the guess who":"Organization","thin lizzy":"Organization","prime minister":"Actor","free market":"Singular","lay up":"Singular","living room":"Singular","living rooms":"Plural","spin off":"Singular","appeal court":"Uncountable","cold war":"Uncountable","gene pool":"Uncountable","machine learning":"Uncountable","nail polish":"Uncountable","time off":"Uncountable","take part":"Infinitive","bill gates":"Person","doctor who":"Person","dr who":"Person","he man":"Person","iron man":"Person","kid cudi":"Person","run dmc":"Person","rush limbaugh":"Person","snow white":"Person","tiger woods":"Person","brand new":"Adjective","en route":"Adjective","left wing":"Adjective","off guard":"Adjective","on board":"Adjective","part time":"Adjective","right wing":"Adjective","so called":"Adjective","spot on":"Adjective","straight forward":"Adjective","super duper":"Adjective","tip top":"Adjective","top notch":"Adjective","up to date":"Adjective","win win":"Adjective","brooklyn nets":"SportsTeam","chicago bears":"SportsTeam","houston astros":"SportsTeam","houston dynamo":"SportsTeam","houston rockets":"SportsTeam","houston texans":"SportsTeam","minnesota twins":"SportsTeam","orlando magic":"SportsTeam","san antonio spurs":"SportsTeam","san diego chargers":"SportsTeam","san diego padres":"SportsTeam","iron maiden":"ProperNoun","isle of man":"Country","united states":"Country","united states of america":"Country","prince edward island":"Region","cedar breaks":"Place","cedar falls":"Place","point blank":"Adverb","tiny bit":"Adverb","by the time":"Conjunction","no matter":"Conjunction","civil wars":"Plural","credit cards":"Plural","default rates":"Plural","free markets":"Plural","head starts":"Plural","home runs":"Plural","lay ups":"Plural","phone calls":"Plural","press releases":"Plural","record labels":"Plural","soft serves":"Plural","student loans":"Plural","tax returns":"Plural","tv shows":"Plural","video games":"Plural","took part":"PastTense","takes part":"PresentTense","taking part":"Gerund","taken part":"Participle","light bulb":"Noun","rush hour":"Noun","fluid ounce":"Unit","the rolling stones":"Organization"}},two:{irregularPlurals:dr,models:mi,suffixPatterns:No,prefixPatterns:To,endsWith:Lo,neighbours:Wo,regexNormal:[[/^[\w.]+@[\w.]+\.[a-z]{2,3}$/,"Email"],[/^(https?:\/\/|www\.)+\w+\.[a-z]{2,3}/,"Url","http.."],[/^[a-z0-9./].+\.(com|net|gov|org|ly|edu|info|biz|dev|ru|jp|de|in|uk|br|io|ai)/,"Url",".com"],[/^[PMCE]ST$/,"Timezone","EST"],[/^ma?c'[a-z]{3}/,"LastName","mc'neil"],[/^o'[a-z]{3}/,"LastName","o'connor"],[/^ma?cd[aeiou][a-z]{3}/,"LastName","mcdonald"],[/^(lol)+[sz]$/,"Expression","lol"],[/^wo{2,}a*h?$/,"Expression","wooah"],[/^(hee?){2,}h?$/,"Expression","hehe"],[/^(un|de|re)\\-[a-z\u00C0-\u00FF]{2}/,"Verb","un-vite"],[/^(m|k|cm|km)\/(s|h|hr)$/,"Unit","5 k/m"],[/^(ug|ng|mg)\/(l|m3|ft3)$/,"Unit","ug/L"],[/[^:/]\/\p{Letter}/u,"SlashedTerm","love/hate"]],regexText:[[/^#[\p{Number}_]*\p{Letter}/u,"HashTag"],[/^@\w{2,}$/,"AtMention"],[/^([A-Z]\.){2}[A-Z]?/i,["Acronym","Noun"],"F.B.I"],[/.{3}[lkmnp]in['‘’‛‵′`´]$/,"Gerund","chillin'"],[/.{4}s['‘’‛‵′`´]$/,"Possessive","flanders'"],[/^[\p{Emoji_Presentation}\p{Extended_Pictographic}]/u,"Emoji","emoji-class"]],regexNumbers:[[/^@1?[0-9](am|pm)$/i,"Time","3pm"],[/^@1?[0-9]:[0-9]{2}(am|pm)?$/i,"Time","3:30pm"],[/^'[0-9]{2}$/,"Year"],[/^[012]?[0-9](:[0-5][0-9])(:[0-5][0-9])$/,"Time","3:12:31"],[/^[012]?[0-9](:[0-5][0-9])?(:[0-5][0-9])? ?(am|pm)$/i,"Time","1:12pm"],[/^[012]?[0-9](:[0-5][0-9])(:[0-5][0-9])? ?(am|pm)?$/i,"Time","1:12:31pm"],[/^[0-9]{4}-[0-9]{2}-[0-9]{2}T[0-9]{2}:[0-9]{2}/i,"Date","iso-date"],[/^[0-9]{1,4}-[0-9]{1,2}-[0-9]{1,4}$/,"Date","iso-dash"],[/^[0-9]{1,4}\/[0-9]{1,2}\/([0-9]{4}|[0-9]{2})$/,"Date","iso-slash"],[/^[0-9]{1,4}\.[0-9]{1,2}\.[0-9]{1,4}$/,"Date","iso-dot"],[/^[0-9]{1,4}-[a-z]{2,9}-[0-9]{1,4}$/i,"Date","12-dec-2019"],[/^utc ?[+-]?[0-9]+$/,"Timezone","utc-9"],[/^(gmt|utc)[+-][0-9]{1,2}$/i,"Timezone","gmt-3"],[/^[0-9]{3}-[0-9]{4}$/,"PhoneNumber","421-0029"],[/^(\+?[0-9][ -])?[0-9]{3}[ -]?[0-9]{3}-[0-9]{4}$/,"PhoneNumber","1-800-"],[/^[-+]?\p{Currency_Symbol}[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?([kmb]|bn)?\+?$/u,["Money","Value"],"$5.30"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?\p{Currency_Symbol}\+?$/u,["Money","Value"],"5.30£"],[/^[-+]?[$£]?[0-9]([0-9,.])+(usd|eur|jpy|gbp|cad|aud|chf|cny|hkd|nzd|kr|rub)$/i,["Money","Value"],"$400usd"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?\+?$/,["Cardinal","NumericValue"],"5,999"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?(st|nd|rd|r?th)$/,["Ordinal","NumericValue"],"53rd"],[/^\.[0-9]+\+?$/,["Cardinal","NumericValue"],".73th"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?%\+?$/,["Percent","Cardinal","NumericValue"],"-4%"],[/^\.[0-9]+%$/,["Percent","Cardinal","NumericValue"],".3%"],[/^[0-9]{1,4}\/[0-9]{1,4}(st|nd|rd|th)?s?$/,["Fraction","NumericValue"],"2/3rds"],[/^[0-9.]{1,3}[a-z]{0,2}[-–—][0-9]{1,3}[a-z]{0,2}$/,["Value","NumberRange"],"3-4"],[/^[0-9]{1,2}(:[0-9][0-9])?(am|pm)? ?[-–—] ?[0-9]{1,2}(:[0-9][0-9])?(am|pm)$/,["Time","NumberRange"],"3-4pm"],[/^[0-9.]+([a-z°]{1,4})$/,"NumericValue","9km"]],switches:jr,clues:uo,uncountable:{},orgWords:pi,placeWords:fi}};Xi=function(e){return e=function(e,t){return Object.keys(e).forEach((n=>{"Uncountable"===e[n]&&(t.two.uncountable[n]=!0,e[n]="Uncountable")})),t}((e=qi(e.one.lexicon,e)).one.lexicon,e),e=function(e){const{irregularPlurals:t}=e.two,{lexicon:n}=e.one;return Object.entries(t).forEach((e=>{n[e[0]]=n[e[0]]||"Singular",n[e[1]]=n[e[1]]||"Plural"})),e}(e=Zi(e.two.switches,e)),e}(Xi);const _i=function(e,t,n,a){const r=a.methods.one.setTag;"-"===e[t].post&&e[t+1]&&r([e[t],e[t+1]],"Hyphenated",a,null,"1-punct-hyphen''")},Yi=/^(under|over|mis|re|un|dis|semi)-?/,es=function(e,t,n){const a=n.two.switches,r=e[t];if(a.hasOwnProperty(r.normal))r.switch=a[r.normal];else if(Yi.test(r.normal)){const e=r.normal.replace(Yi,"");e.length>3&&a.hasOwnProperty(e)&&(r.switch=a[e])}},ts=function(e,t,n){if(!t||0===t.length)return;if(!0===e.frozen)return;const a="undefined"!=typeof process&&process.env?process.env:self.env||{};a&&a.DEBUG_TAGS&&((e,t,n="")=>{const a=e.text||"["+e.implicit+"]";var r;"string"!=typeof t&&t.length>2&&(t=t.slice(0,2).join(", #")+" +"),t="string"!=typeof t?t.join(", #"):t,console.log(` ${(r=a,"�[33m�[3m"+r+"�[0m").padEnd(24)} �[32m→�[0m #${t.padEnd(22)} ${(e=>"�[3m"+e+"�[0m")(n)}`)})(e,t,n),e.tags=e.tags||new Set,"string"==typeof t?e.tags.add(t):t.forEach((t=>e.tags.add(t)))},ns=["Acronym","Abbreviation","ProperNoun","Uncountable","Possessive","Pronoun","Activity","Honorific","Month"],as=function(e,t,n){const a=e[t],r=Array.from(a.tags);for(let e=0;ee.tags.has(t)))||(Mi(e.normal)?ts(e,"Plural","3-plural-guess"):ts(e,"Singular","3-singular-guess"))}(a),function(e){const t=e.tags;if(t.has("Verb")&&1===t.size){const t=ki(e.normal);t&&ts(e,t,"3-verb-tense-guess")}}(a)},rs=/^\p{Lu}[\p{Ll}'’]/u,os=/[0-9]/,is=["Date","Month","WeekDay","Unit","Expression"],ss=/[IVX]/,ls=/^[IVXLCDM]{2,}$/,us=/^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$/,cs={li:!0,dc:!0,md:!0,dm:!0,ml:!0},ds=function(e,t,n){const a=e[t];a.index=a.index||[0,0];const r=a.index[1],o=a.text||"";return 0!==r&&!0===rs.test(o)&&!1===os.test(o)?is.find((e=>a.tags.has(e)))||a.pre.match(/["']$/)||"the"===a.normal?null:(as(e,t,n),a.tags.has("Noun")||a.frozen||a.tags.clear(),ts(a,"ProperNoun","2-titlecase"),!0):o.length>=2&&ls.test(o)&&ss.test(o)&&us.test(o)&&!cs[a.normal]?(ts(a,"RomanNumeral","2-xvii"),!0):null},hs=function(e="",t=[]){const n=e.length;let a=7;n<=a&&(a=n-1);for(let r=a;r>1;r-=1){const a=e.substring(n-r,n);if(!0===t[a.length].hasOwnProperty(a)){return t[a.length][a]}}return null},gs=function(e,t,n){const a=e[t];if(0===a.tags.size){let e=hs(a.normal,n.two.suffixPatterns);if(null!==e)return ts(a,e,"2-suffix"),a.confidence=.7,!0;if(a.implicit&&(e=hs(a.implicit,n.two.suffixPatterns),null!==e))return ts(a,e,"2-implicit-suffix"),a.confidence=.7,!0}return null},ms=/['‘’‛‵′`´]/,ps=function(e,t){for(let n=0;nn-3&&(a=n-3);for(let n=a;n>2;n-=1){const a=e.substring(0,n);if(!0===t[a.length].hasOwnProperty(a))return t[a.length][a]}return null}(a.normal,n.two.prefixPatterns);if(null!==e)return ts(a,e,"2-prefix"),a.confidence=.5,!0}return null},ys=new Set(["in","on","by","until","for","to","during","throughout","through","within","before","after","of","this","next","last","circa","around","post","pre","budget","classic","plan","may"]),vs=function(e){if(!e)return!1;const t=e.normal||e.implicit;return!!ys.has(t)||(!!(e.tags.has("Date")||e.tags.has("Month")||e.tags.has("WeekDay")||e.tags.has("Year"))||!!e.tags.has("ProperNoun"))},ws=function(e){return!!e&&(!!e.tags.has("Ordinal")||(!!(e.tags.has("Cardinal")&&e.normal.length<3)||("is"===e.normal||"was"===e.normal)))},ks=function(e){return e&&(e.tags.has("Date")||e.tags.has("Month")||e.tags.has("WeekDay")||e.tags.has("Year"))},Ps=function(e,t){const n=e[t];if(n.tags.has("NumericValue")&&n.tags.has("Cardinal")&&4===n.normal.length){const a=Number(n.normal);if(a&&!isNaN(a)&&a>1400&&a<2100){const r=e[t-1],o=e[t+1];if(vs(r)||vs(o))return ts(n,"Year","2-tagYear");if(a>=1920&&a<2025){if(ws(r)||ws(o))return ts(n,"Year","2-tagYear-close");if(ks(e[t-2])||ks(e[t+2]))return ts(n,"Year","2-tagYear-far");if(r&&(r.tags.has("Determiner")||r.tags.has("Possessive"))&&o&&o.tags.has("Noun")&&!o.tags.has("Plural"))return ts(n,"Year","2-tagYear-noun")}}}return null},As=function(e,t,n,a){const r=a.methods.one.setTag,o=e[t],i=["PastTense","PresentTense","Auxiliary","Modal","Particle"];if(o.tags.has("Verb")){i.find((e=>o.tags.has(e)))||r([o],"Infinitive",a,null,"2-verb-type''")}},Cs=/^[A-Z]('s|,)?$/,js=/^[A-Z-]+$/,Ns=/^[A-Z]+s$/,Is=/([A-Z]\.)+[A-Z]?,?$/,Ds=/[A-Z]{2,}('s|,)?$/,Hs=/([a-z]\.)+[a-z]\.?$/,Ts={I:!0,A:!0},Gs={la:!0,ny:!0,us:!0,dc:!0,gb:!0},xs=function(e,t,n){const a=e[t];return a.tags.has("RomanNumeral")||a.tags.has("Acronym")||a.frozen?null:function(e,t){let n=e.text;if(!1===js.test(n)){if(!(n.length>3&&!0===Ns.test(n)))return!1;n=n.replace(/s$/,"")}return!(n.length>5||Ts.hasOwnProperty(n)||t.one.lexicon.hasOwnProperty(e.normal)||!0!==Is.test(n)&&!0!==Hs.test(n)&&!0!==Cs.test(n)&&!0!==Ds.test(n))}(a,n)?(a.tags.clear(),ts(a,["Acronym","Noun"],"3-no-period-acronym"),!0===Gs[a.normal]&&ts(a,"Place","3-place-acronym"),!0===Ns.test(a.text)&&ts(a,"Plural","3-plural-acronym"),!0):!Ts.hasOwnProperty(a.text)&&Cs.test(a.text)?(a.tags.clear(),ts(a,["Acronym","Noun"],"3-one-letter-acronym"),!0):a.tags.has("Organization")&&a.text.length<=3?(ts(a,"Acronym","3-org-acronym"),!0):a.tags.has("Organization")&&js.test(a.text)&&a.text.length<=6?(ts(a,"Acronym","3-titlecase-acronym"),!0):null},Es=function(e,t){if(!e)return null;const n=t.find((t=>e.normal===t[0]));return n?n[1]:null},Fs=function(e,t){if(!e)return null;const n=t.find((t=>e.tags.has(t[0])));return n?n[1]:null},Os=function(e,t,n){const{leftTags:a,leftWords:r,rightWords:o,rightTags:i}=n.two.neighbours,s=e[t];if(0===s.tags.size){let l=null;if(l=l||Es(e[t-1],r),l=l||Es(e[t+1],o),l=l||Fs(e[t-1],a),l=l||Fs(e[t+1],i),l)return ts(s,l,"3-[neighbour]"),as(e,t,n),e[t].confidence=.2,!0}return null},zs=function(e,t,n){return!!e&&(!e.tags.has("FirstName")&&!e.tags.has("Place")&&(!!(e.tags.has("ProperNoun")||e.tags.has("Organization")||e.tags.has("Acronym"))||!(n||(a=e.text,!/^\p{Lu}[\p{Ll}'’]/u.test(a)))&&(0!==t||e.tags.has("Singular"))));var a},Vs=function(e,t,n,a){const r=n.model.two.orgWords,o=n.methods.one.setTag,i=e[t];if(!0===r[i.machine||i.normal]&&zs(e[t-1],t-1,a)){o([e[t]],"Organization",n,null,"3-[org-word]");for(let r=t;r>=0&&zs(e[r],r,a);r-=1)o([e[r]],"Organization",n,null,"3-[org-word]")}return null},Bs=/'s$/,Ss=new Set(["athletic","city","community","eastern","federal","financial","great","historic","historical","local","memorial","municipal","national","northern","provincial","southern","state","western","spring","pine","sunset","view","oak","maple","spruce","cedar","willow"]),Ks=new Set(["center","centre","way","range","bar","bridge","field","pit"]),$s=function(e,t,n){if(!e)return!1;const a=e.tags;return!(a.has("Organization")||a.has("Possessive")||Bs.test(e.normal))&&(!(!a.has("ProperNoun")&&!a.has("Place"))||!(n||(r=e.text,!/^\p{Lu}[\p{Ll}'’]/u.test(r)))&&(0!==t||a.has("Singular")));var r},Ls=function(e,t,n,a){const r=n.model.two.placeWords,o=n.methods.one.setTag,i=e[t],s=i.machine||i.normal;if(!0===r[s]){for(let r=t-1;r>=0;r-=1)if(!Ss.has(e[r].normal)){if(!$s(e[r],r,a))break;o(e.slice(r,t+1),"Place",n,null,"3-[place-of-foo]")}if(Ks.has(s))return!1;for(let r=t+1;re[t].tags.has("ProperNoun")&&Js.test(e[t].text)?"Noun":null,Us=(e,t,n)=>0!==t||e[1]?null:n,qs={"Adj|Gerund":(e,t)=>Ws(e,t),"Adj|Noun":(e,t)=>Ws(e,t)||function(e,t){return!e[t+1]&&e[t-1]&&e[t-1].tags.has("Determiner")?"Noun":null}(e,t),"Actor|Verb":(e,t)=>Ws(e,t),"Adj|Past":(e,t)=>Ws(e,t),"Adj|Present":(e,t)=>Ws(e,t),"Noun|Gerund":(e,t)=>Ws(e,t),"Noun|Verb":(e,t)=>t>0&&Ws(e,t)||Us(e,t,"Infinitive"),"Plural|Verb":(e,t)=>Ws(e,t)||Us(e,t,"PresentTense")||function(e,t,n){return 0===t&&e.length>3?n:null}(e,t,"Plural"),"Person|Noun":(e,t)=>Ws(e,t),"Person|Verb":(e,t)=>0!==t?Ws(e,t):null,"Person|Adj":(e,t)=>0===t&&e.length>1||Ws(e,t)?"Person":null},Rs="undefined"!=typeof process&&process.env?process.env:self.env||{},Qs=/^(under|over|mis|re|un|dis|semi)-?/,Zs=(e,t)=>{if(!e||!t)return null;const n=e.normal||e.implicit;let a=null;return t.hasOwnProperty(n)&&(a=t[n]),a&&Rs.DEBUG_TAGS&&console.log(`\n �[2m�[3m ↓ - '${n}' �[0m`),a},Xs=(e,t={},n)=>{if(!e||!t)return null;const a=Array.from(e.tags).sort(((e,t)=>(n[e]?n[e].parents.length:0)>(n[t]?n[t].parents.length:0)?-1:1));let r=a.find((e=>t[e]));return r&&Rs.DEBUG_TAGS&&console.log(` �[2m�[3m ↓ - '${e.normal||e.implicit}' (#${r}) �[0m`),r=t[r],r},_s=function(e,t,n){const a=n.model,r=n.methods.one.setTag,{switches:o,clues:i}=a.two,s=e[t];let l=s.normal||s.implicit||"";if(Qs.test(l)&&!o[l]&&(l=l.replace(Qs,"")),s.switch){const o=s.switch;if(s.tags.has("Acronym")||s.tags.has("PhrasalVerb"))return;let u=function(e,t,n,a){if(!n)return null;const r="also"!==e[t-1]?.text?t-1:Math.max(0,t-2),o=a.one.tagSet;let i=Zs(e[t+1],n.afterWords);return i=i||Zs(e[r],n.beforeWords),i=i||Xs(e[r],n.beforeTags,o),i=i||Xs(e[t+1],n.afterTags,o),i}(e,t,i[o],a);qs[o]&&(u=qs[o](e,t)||u),u?(r([s],u,n,null,`3-[switch] (${o})`),as(e,t,a)):Rs.DEBUG_TAGS&&console.log(`\n -> X - '${l}' : (${o}) `)}},Ys={there:!0,this:!0,it:!0,him:!0,her:!0,us:!0},el=function(e){if(e.filter((e=>!e.tags.has("ProperNoun"))).length<=3)return!1;const t=/^[a-z]/;return e.every((e=>!t.test(e.text)))},tl=function(e,t,n,a){for(let r=0;r=2){if(e.length<4&&!Ys[e[1].normal])return;if(!r.tags.has("PhrasalVerb")&&a.hasOwnProperty(r.normal))return;(e[1].tags.has("Noun")||e[1].tags.has("Determiner"))&&(e.slice(1,3).some((e=>e.tags.has("Verb")))&&!r.tags.has("#PhrasalVerb")||n([r],"Imperative",t,null,"3-[imperative]"))}}(e,n)},al={Possessive:e=>{let t=e.machine||e.normal||e.text;return t=t.replace(/'s$/,""),t},Plural:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.noun.toSingular(n,t.model)},Copula:()=>"is",PastTense:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.verb.toInfinitive(n,t.model,"PastTense")},Gerund:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.verb.toInfinitive(n,t.model,"Gerund")},PresentTense:(e,t)=>{const n=e.machine||e.normal||e.text;return e.tags.has("Infinitive")?n:t.methods.two.transform.verb.toInfinitive(n,t.model,"PresentTense")},Comparative:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.adjective.fromComparative(n,t.model)},Superlative:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.adjective.fromSuperlative(n,t.model)},Adverb:(e,t)=>{const{fromAdverb:n}=t.methods.two.transform.adjective;return n(e.machine||e.normal||e.text)}},rl={Adverb:"RB",Comparative:"JJR",Superlative:"JJS",Adjective:"JJ",TO:"Conjunction",Modal:"MD",Auxiliary:"MD",Gerund:"VBG",PastTense:"VBD",Participle:"VBN",PresentTense:"VBZ",Infinitive:"VB",Particle:"RP",Verb:"VB",Pronoun:"PRP",Cardinal:"CD",Conjunction:"CC",Determiner:"DT",Preposition:"IN",QuestionWord:"WP",Expression:"UH",Possessive:"POS",ProperNoun:"NNP",Person:"NNP",Place:"NNP",Organization:"NNP",Singular:"NN",Plural:"NNS",Noun:"NN",There:"EX"};var ol={preTagger:function(e){const{methods:t,model:n,world:a}=e,r=e.docs;!function(e,t,n){e.forEach((e=>{!function(e,t,n,a){const r=a.methods.one.setTag;if(e.length>=3){const t=/:/;if(e[0].post.match(t)){const t=e[1];if(t.tags.has("Value")||t.tags.has("Email")||t.tags.has("PhoneNumber"))return;r([e[0]],"Expression",a,null,"2-punct-colon''")}}}(e,0,0,n)}))}(r,0,a);const o=t.two.quickSplit(r);for(let e=0;e{for(let a=0;a{e.forEach((e=>{e.penn=function(e){if(e.tags.has("ProperNoun")&&e.tags.has("Plural"))return"NNPS";if(e.tags.has("Possessive")&&e.tags.has("Pronoun"))return"PRP$";if("there"===e.normal)return"EX";if("to"===e.normal)return"TO";const t=e.tagRank||[];for(let e=0;e{e.implicit=e.normal,e.text="",e.normal=""}));for(let e=0;e(e.implicit=e.text,e.machine=e.text,e.pre="",e.post="",e.text="",e.normal="",e.index=[a,r+t],e))),n[0]&&(n[0].pre=e[a][r].pre,n[n.length-1].post=e[a][r].post,n[0].text=e[a][r].text,n[0].normal=e[a][r].normal),e[a].splice(r,1,...n))},fl=/'/,bl=new Set(["been","become"]),yl=new Set(["what","how","when","if","too"]),vl=new Set(["too","also","enough"]),wl=function(e,t){const n=e[t].normal.split(fl)[0];if("let"===n)return[n,"us"];if("there"===n){const a=e[t+1];if(a&&a.tags.has("Plural"))return[n,"are"]}return"has"===((e,t)=>{for(let n=t+1;n{for(let n=t+1;n0&&(n-=1),e[o]&&(o+=1),r.ptrs=[[0,n,o]],r.compute(["freeze","lexicon","preTagger","unfreeze"]),function(e){e.forEach(((e,t)=>{e.index&&(e.index[1]=t)}))}(e)},Gl={d:(e,t)=>Cl(e,t),t:(e,t)=>function(e,t){if("ain't"===e[t].normal||"aint"===e[t].normal){if(e[t+1]&&"never"===e[t+1].normal)return["have"];const n=function(e,t){for(let n=t-1;n>=0;n-=1)if(e[n].tags.has("Noun")||e[n].tags.has("Pronoun")||e[n].tags.has("Plural")||e[n].tags.has("Singular"))return e[n];return null}(e,t);if(n){if("we"===n.normal||"they"===n.normal)return["are","not"];if("i"===n.normal)return["am","not"];if(n.tags&&n.tags.has("Plural"))return["are","not"]}return["is","not"]}return[e[t].normal.replace(/n't/,""),"not"]}(e,t),s:(e,t,n)=>((e,t)=>{const n=e[t];if(jl.hasOwnProperty(n.machine||n.normal))return!1;if(n.tags.has("Possessive"))return!0;if(n.tags.has("QuestionWord"))return!1;if("he's"===n.normal||"she's"===n.normal)return!1;const a=e[t+1];if(!a)return!0;if("it's"===n.normal)return!!a.tags.has("#Noun");if("Noun|Gerund"==a.switch){const a=e[t+2];return a?!!a.tags.has("Copula")||("on"===a.normal||a.normal,!1):!(!n.tags.has("Actor")&&!n.tags.has("ProperNoun"))}if(a.tags.has("Verb"))return!!a.tags.has("Infinitive")||!a.tags.has("Gerund")&&!!a.tags.has("PresentTense");if("Adj|Noun"===a.switch){const n=e[t+2];if(!n)return!1;if(Dl.has(n.normal))return!0;if(Il.has(n.normal))return!1}if(a.tags.has("Noun")){const e=a.machine||a.normal;return!("here"===e||"there"===e||"everywhere"===e||a.tags.has("Possessive")||a.tags.has("ProperNoun")&&!n.tags.has("ProperNoun"))}if(e[t-1]&&!0===Nl[e[t-1].normal])return!0;if(a.tags.has("Adjective")){const n=e[t+2];if(!n)return!1;if(n.tags.has("Noun")&&!n.tags.has("Pronoun")){const e=a.normal;return"above"!==e&&"below"!==e&&"behind"!==e}return"Noun|Verb"===n.switch}return!!a.tags.has("Value")})(e,t)?n.methods.one.setTag([e[t]],"Possessive",n,null,"2-contraction"):wl(e,t)},xl=function(e,t){const n=t.fromText(e.join(" "));return n.compute("id"),n.docs[0]};var El={contractionTwo:e=>{const{world:t,document:n}=e;n.forEach(((a,r)=>{for(let o=a.length-1;o>=0;o-=1){if(a[o].implicit)continue;let i=null;!0===Hl.test(a[o].normal)&&(i=a[o].normal.split(Hl)[1]);let s=null;Gl.hasOwnProperty(i)&&(s=Gl[i](a,o,t)),s&&(s=xl(s,e),pl(n,[r,o],s),Tl(n[r],e,o,s.length))}}))}},Fl={compute:El,api:function(e){class Contractions extends e{constructor(e,t,n){super(e,t,n),this.viewType="Contraction"}expand(){return this.docs.forEach((e=>{const t=ml.test(e[0].text);e.forEach(((t,n)=>{t.text=t.implicit||"",delete t.implicit,ne.toUpperCase()))}(e[0].text))})),this.compute("normal"),this}}e.prototype.contractions=function(){const e=this.match("@hasContraction+");return new Contractions(this.document,e.pointer)},e.prototype.contract=gl},hooks:["contractionTwo"]};const Ol="(hard|fast|late|early|high|right|deep|close|direct)";const zl="(i|we|they)";const Vl=[].concat([{match:"(got|were|was|is|are|am) (#PastTense|#Participle)",tag:"Passive",reason:"got-walked"},{match:"(was|were|is|are|am) being (#PastTense|#Participle)",tag:"Passive",reason:"was-being"},{match:"(had|have|has) been (#PastTense|#Participle)",tag:"Passive",reason:"had-been"},{match:"will be being? (#PastTense|#Participle)",tag:"Passive",reason:"will-be-cleaned"},{match:"#Noun [(#PastTense|#Participle)] by (the|a) #Noun",group:0,tag:"Passive",reason:"suffered-by"}],[{match:"[(all|both)] #Determiner #Noun",group:0,tag:"Noun",reason:"all-noun"},{match:"#Copula [(just|alone)]$",group:0,tag:"Adjective",reason:"not-adverb"},{match:"#Singular is #Adverb? [#PastTense$]",group:0,tag:"Adjective",reason:"is-filled"},{match:"[#PastTense] #Singular is",group:0,tag:"Adjective",reason:"smoked-poutine"},{match:"[#PastTense] #Plural are",group:0,tag:"Adjective",reason:"baked-onions"},{match:"well [#PastTense]",group:0,tag:"Adjective",reason:"well-made"},{match:"#Copula [fucked up?]",group:0,tag:"Adjective",reason:"swears-adjective"},{match:"#Singular (seems|appears) #Adverb? [#PastTense$]",group:0,tag:"Adjective",reason:"seems-filled"},{match:"#Copula #Adjective? [(out|in|through)]$",group:0,tag:"Adjective",reason:"still-out"},{match:"^[#Adjective] (the|your) #Noun",group:0,notIf:"(all|even)",tag:"Infinitive",reason:"shut-the"},{match:"the [said] #Noun",group:0,tag:"Adjective",reason:"the-said-card"},{match:"[#Hyphenated (#Hyphenated && #PastTense)] (#Noun|#Conjunction)",group:0,tag:"Adjective",notIf:"#Adverb",reason:"faith-based"},{match:"[#Hyphenated (#Hyphenated && #Gerund)] (#Noun|#Conjunction)",group:0,tag:"Adjective",notIf:"#Adverb",reason:"self-driving"},{match:"[#PastTense (#Hyphenated && #PhrasalVerb)] (#Noun|#Conjunction)",group:0,tag:"Adjective",reason:"dammed-up"},{match:"(#Hyphenated && #Value) fold",tag:"Adjective",reason:"two-fold"},{match:"must (#Hyphenated && #Infinitive)",tag:"Adjective",reason:"must-win"},{match:"(#Hyphenated && #Infinitive) #Hyphenated",tag:"Adjective",notIf:"#PhrasalVerb",reason:"vacuum-sealed"},{match:"too much",tag:"Adverb Adjective",reason:"bit-4"},{match:"a bit much",tag:"Determiner Adverb Adjective",reason:"bit-3"},{match:"[(un|contra|extra|inter|intra|macro|micro|mid|mis|mono|multi|pre|sub|tri|ex)] #Adjective",group:0,tag:["Adjective","Prefix"],reason:"un-skilled"}],[{match:"#Adverb [#Adverb] (and|or|then)",group:0,tag:"Adjective",reason:"kinda-sparkly-and"},{match:"[(dark|bright|flat|light|soft|pale|dead|dim|faux|little|wee|sheer|most|near|good|extra|all)] #Adjective",group:0,tag:"Adverb",reason:"dark-green"},{match:"#Copula [far too] #Adjective",group:0,tag:"Adverb",reason:"far-too"},{match:"#Copula [still] (in|#Gerund|#Adjective)",group:0,tag:"Adverb",reason:"was-still-walking"},{match:`#Plural ${Ol}`,tag:"#PresentTense #Adverb",reason:"studies-hard"},{match:`#Verb [${Ol}] !#Noun?`,group:0,notIf:"(#Copula|get|got|getting|become|became|becoming|feel|feels|feeling|#Determiner|#Preposition)",tag:"Adverb",reason:"shops-direct"},{match:"[#Plural] a lot",tag:"PresentTense",reason:"studies-a-lot"}],[{match:"as [#Gerund] as",group:0,tag:"Adjective",reason:"as-gerund-as"},{match:"more [#Gerund] than",group:0,tag:"Adjective",reason:"more-gerund-than"},{match:"(so|very|extremely) [#Gerund]",group:0,tag:"Adjective",reason:"so-gerund"},{match:"(found|found) it #Adverb? [#Gerund]",group:0,tag:"Adjective",reason:"found-it-gerund"},{match:"a (little|bit|wee) bit? [#Gerund]",group:0,tag:"Adjective",reason:"a-bit-gerund"},{match:"#Gerund [#Gerund]",group:0,tag:"Adjective",notIf:"(impersonating|practicing|considering|assuming)",reason:"looking-annoying"},{match:"(looked|look|looks) #Adverb? [%Adj|Gerund%]",group:0,tag:"Adjective",notIf:"(impersonating|practicing|considering|assuming)",reason:"looked-amazing"},{match:"[%Adj|Gerund%] #Determiner",group:0,tag:"Gerund",reason:"developing-a"},{match:"#Possessive [%Adj|Gerund%] #Noun",group:0,tag:"Adjective",reason:"leading-manufacturer"},{match:"%Noun|Gerund% %Adj|Gerund%",tag:"Gerund #Adjective",reason:"meaning-alluring"},{match:"(face|embrace|reveal|stop|start|resume) %Adj|Gerund%",tag:"#PresentTense #Adjective",reason:"face-shocking"},{match:"(are|were) [%Adj|Gerund%] #Plural",group:0,tag:"Adjective",reason:"are-enduring-symbols"}],[{match:"#Determiner [#Adjective] #Copula",group:0,tag:"Noun",reason:"the-adj-is"},{match:"#Adjective [#Adjective] #Copula",group:0,tag:"Noun",reason:"adj-adj-is"},{match:"(his|its) [%Adj|Noun%]",group:0,tag:"Noun",notIf:"#Hyphenated",reason:"his-fine"},{match:"#Copula #Adverb? [all]",group:0,tag:"Noun",reason:"is-all"},{match:"(have|had) [#Adjective] #Preposition .",group:0,tag:"Noun",reason:"have-fun"},{match:"#Gerund (giant|capital|center|zone|application)",tag:"Noun",reason:"brewing-giant"},{match:"#Preposition (a|an) [#Adjective]$",group:0,tag:"Noun",reason:"an-instant"},{match:"no [#Adjective] #Modal",group:0,tag:"Noun",reason:"no-golden"},{match:"[brand #Gerund?] new",group:0,tag:"Adverb",reason:"brand-new"},{match:"(#Determiner|#Comparative|new|different) [kind]",group:0,tag:"Noun",reason:"some-kind"},{match:"#Possessive [%Adj|Noun%] #Noun",group:0,tag:"Adjective",reason:"her-favourite"},{match:"must && #Hyphenated .",tag:"Adjective",reason:"must-win"},{match:"#Determiner [#Adjective]$",tag:"Noun",notIf:"(this|that|#Comparative|#Superlative)",reason:"the-south"},{match:"(#Noun && #Hyphenated) (#Adjective && #Hyphenated)",tag:"Adjective",notIf:"(this|that|#Comparative|#Superlative)",reason:"company-wide"},{match:"#Determiner [#Adjective] (#Copula|#Determiner)",notIf:"(#Comparative|#Superlative)",group:0,tag:"Noun",reason:"the-poor"},{match:"[%Adj|Noun%] #Noun",notIf:"(#Pronoun|#ProperNoun)",group:0,tag:"Adjective",reason:"stable-foundations"}],[{match:"[still] #Adjective",group:0,tag:"Adverb",reason:"still-advb"},{match:"[still] #Verb",group:0,tag:"Adverb",reason:"still-verb"},{match:"[so] #Adjective",group:0,tag:"Adverb",reason:"so-adv"},{match:"[way] #Comparative",group:0,tag:"Adverb",reason:"way-adj"},{match:"[way] #Adverb #Adjective",group:0,tag:"Adverb",reason:"way-too-adj"},{match:"[all] #Verb",group:0,tag:"Adverb",reason:"all-verb"},{match:"#Verb [like]",group:0,notIf:"(#Modal|#PhrasalVerb)",tag:"Adverb",reason:"verb-like"},{match:"(barely|hardly) even",tag:"Adverb",reason:"barely-even"},{match:"[even] #Verb",group:0,tag:"Adverb",reason:"even-walk"},{match:"[even] #Comparative",group:0,tag:"Adverb",reason:"even-worse"},{match:"[even] (#Determiner|#Possessive)",group:0,tag:"#Adverb",reason:"even-the"},{match:"even left",tag:"#Adverb #Verb",reason:"even-left"},{match:"[way] #Adjective",group:0,tag:"#Adverb",reason:"way-over"},{match:"#PresentTense [(hard|quick|bright|slow|fast|backwards|forwards)]",notIf:"#Copula",group:0,tag:"Adverb",reason:"lazy-ly"},{match:"[much] #Adjective",group:0,tag:"Adverb",reason:"bit-1"},{match:"#Copula [#Adverb]$",group:0,tag:"Adjective",reason:"is-well"},{match:"a [(little|bit|wee) bit?] #Adjective",group:0,tag:"Adverb",reason:"a-bit-cold"},{match:"[(super|pretty)] #Adjective",group:0,tag:"Adverb",reason:"super-strong"},{match:"(become|fall|grow) #Adverb? [#PastTense]",group:0,tag:"Adjective",reason:"overly-weakened"},{match:"(a|an) #Adverb [#Participle] #Noun",group:0,tag:"Adjective",reason:"completely-beaten"},{match:"#Determiner #Adverb? [close]",group:0,tag:"Adjective",reason:"a-close"},{match:"#Gerund #Adverb? [close]",group:0,tag:"Adverb",notIf:"(getting|becoming|feeling)",reason:"being-close"},{match:"(the|those|these|a|an) [#Participle] #Noun",group:0,tag:"Adjective",reason:"blown-motor"},{match:"(#PresentTense|#PastTense) [back]",group:0,tag:"Adverb",notIf:"(#PhrasalVerb|#Copula)",reason:"charge-back"},{match:"#Verb [around]",group:0,tag:"Adverb",notIf:"#PhrasalVerb",reason:"send-around"},{match:"[later] #PresentTense",group:0,tag:"Adverb",reason:"later-say"},{match:"#Determiner [well] !#PastTense?",group:0,tag:"Noun",reason:"the-well"},{match:"#Adjective [enough]",group:0,tag:"Adverb",reason:"high-enough"}],[{match:"[sun] the #Ordinal",tag:"WeekDay",reason:"sun-the-5th"},{match:"[sun] #Date",group:0,tag:"WeekDay",reason:"sun-feb"},{match:"#Date (on|this|next|last|during)? [sun]",group:0,tag:"WeekDay",reason:"1pm-sun"},{match:"(in|by|before|during|on|until|after|of|within|all) [sat]",group:0,tag:"WeekDay",reason:"sat"},{match:"(in|by|before|during|on|until|after|of|within|all) [wed]",group:0,tag:"WeekDay",reason:"wed"},{match:"(in|by|before|during|on|until|after|of|within|all) [march]",group:0,tag:"Month",reason:"march"},{match:"[sat] #Date",group:0,tag:"WeekDay",reason:"sat-feb"},{match:"#Preposition [(march|may)]",group:0,tag:"Month",reason:"in-month"},{match:"(this|next|last) (march|may) !#Infinitive?",tag:"#Date #Month",reason:"this-month"},{match:"(march|may) the? #Value",tag:"#Month #Date #Date",reason:"march-5th"},{match:"#Value of? (march|may)",tag:"#Date #Date #Month",reason:"5th-of-march"},{match:"[(march|may)] .? #Date",group:0,tag:"Month",reason:"march-and-feb"},{match:"#Date .? [(march|may)]",group:0,tag:"Month",reason:"feb-and-march"},{match:"#Adverb [(march|may)]",group:0,tag:"Verb",reason:"quickly-march"},{match:"[(march|may)] #Adverb",group:0,tag:"Verb",reason:"march-quickly"},{match:"#Value (am|pm)",tag:"Time",reason:"2-am"}],[{match:"#Holiday (day|eve)",tag:"Holiday",reason:"holiday-day"},{match:"#Value of #Month",tag:"Date",reason:"value-of-month"},{match:"#Cardinal #Month",tag:"Date",reason:"cardinal-month"},{match:"#Month #Value to #Value",tag:"Date",reason:"value-to-value"},{match:"#Month the #Value",tag:"Date",reason:"month-the-value"},{match:"(#WeekDay|#Month) #Value",tag:"Date",reason:"date-value"},{match:"#Value (#WeekDay|#Month)",tag:"Date",reason:"value-date"},{match:"(#TextValue && #Date) #TextValue",tag:"Date",reason:"textvalue-date"},{match:"#Month #NumberRange",tag:"Date",reason:"aug 20-21"},{match:"#WeekDay #Month #Ordinal",tag:"Date",reason:"week mm-dd"},{match:"#Month #Ordinal #Cardinal",tag:"Date",reason:"mm-dd-yyy"},{match:"(#Place|#Demonmym|#Time) (standard|daylight|central|mountain)? time",tag:"Timezone",reason:"std-time"},{match:"(eastern|mountain|pacific|central|atlantic) (standard|daylight|summer)? time",tag:"Timezone",reason:"eastern-time"},{match:"#Time [(eastern|mountain|pacific|central|est|pst|gmt)]",group:0,tag:"Timezone",reason:"5pm-central"},{match:"(central|western|eastern) european time",tag:"Timezone",reason:"cet"}],[{match:"(the|any) [more]",group:0,tag:"Singular",reason:"more-noun"},{match:"[more] #Noun",group:0,tag:"Adjective",reason:"more-noun"},{match:"(right|rights) of .",tag:"Noun",reason:"right-of"},{match:"a [bit]",group:0,tag:"Singular",reason:"bit-2"},{match:"a [must]",group:0,tag:"Singular",reason:"must-2"},{match:"(we|us) [all]",group:0,tag:"Noun",reason:"we all"},{match:"due to [#Verb]",group:0,tag:"Noun",reason:"due-to"},{match:"some [#Verb] #Plural",group:0,tag:"Noun",reason:"determiner6"},{match:"#Possessive #Ordinal [#PastTense]",group:0,tag:"Noun",reason:"first-thought"},{match:"(the|this|those|these) #Adjective [%Verb|Noun%]",group:0,tag:"Noun",notIf:"#Copula",reason:"the-adj-verb"},{match:"(the|this|those|these) #Adverb #Adjective [#Verb]",group:0,tag:"Noun",reason:"determiner4"},{match:"the [#Verb] #Preposition .",group:0,tag:"Noun",reason:"determiner1"},{match:"(a|an|the) [#Verb] of",group:0,tag:"Noun",reason:"the-verb-of"},{match:"#Determiner #Noun of [#Verb]",group:0,tag:"Noun",notIf:"#Gerund",reason:"noun-of-noun"},{match:"#PastTense #Preposition [#PresentTense]",group:0,notIf:"#Gerund",tag:"Noun",reason:"ended-in-ruins"},{match:"#Conjunction [u]",group:0,tag:"Pronoun",reason:"u-pronoun-2"},{match:"[u] #Verb",group:0,tag:"Pronoun",reason:"u-pronoun-1"},{match:"#Determiner [(western|eastern|northern|southern|central)] #Noun",group:0,tag:"Noun",reason:"western-line"},{match:"(#Singular && @hasHyphen) #PresentTense",tag:"Noun",reason:"hyphen-verb"},{match:"is no [#Verb]",group:0,tag:"Noun",reason:"is-no-verb"},{match:"do [so]",group:0,tag:"Noun",reason:"so-noun"},{match:"#Determiner [(shit|damn|hell)]",group:0,tag:"Noun",reason:"swears-noun"},{match:"to [(shit|hell)]",group:0,tag:"Noun",reason:"to-swears"},{match:"(the|these) [#Singular] (were|are)",group:0,tag:"Plural",reason:"singular-were"},{match:"a #Noun+ or #Adverb+? [#Verb]",group:0,tag:"Noun",reason:"noun-or-noun"},{match:"(the|those|these|a|an) #Adjective? [#PresentTense #Particle?]",group:0,tag:"Noun",notIf:"(seem|appear|include|#Gerund|#Copula)",reason:"det-inf"},{match:"#Noun #Actor",tag:"Actor",notIf:"(#Person|#Pronoun)",reason:"thing-doer"},{match:"#Gerund #Actor",tag:"Actor",reason:"gerund-doer"},{match:"co #Singular",tag:"Actor",reason:"co-noun"},{match:"[#Noun+] #Actor",group:0,tag:"Actor",notIf:"(#Honorific|#Pronoun|#Possessive)",reason:"air-traffic-controller"},{match:"(urban|cardiac|cardiovascular|respiratory|medical|clinical|visual|graphic|creative|dental|exotic|fine|certified|registered|technical|virtual|professional|amateur|junior|senior|special|pharmaceutical|theoretical)+ #Noun? #Actor",tag:"Actor",reason:"fine-artist"},{match:"#Noun+ (coach|chef|king|engineer|fellow|personality|boy|girl|man|woman|master)",tag:"Actor",reason:"dance-coach"},{match:"chief . officer",tag:"Actor",reason:"chief-x-officer"},{match:"chief of #Noun+",tag:"Actor",reason:"chief-of-police"},{match:"senior? vice? president of #Noun+",tag:"Actor",reason:"president-of"},{match:"#Determiner [sun]",group:0,tag:"Singular",reason:"the-sun"},{match:"#Verb (a|an) [#Value]$",group:0,tag:"Singular",reason:"did-a-value"},{match:"the [(can|will|may)]",group:0,tag:"Singular",reason:"the can"},{match:"#FirstName #Acronym? (#Possessive && #LastName)",tag:"Possessive",reason:"name-poss"},{match:"#Organization+ #Possessive",tag:"Possessive",reason:"org-possessive"},{match:"#Place+ #Possessive",tag:"Possessive",reason:"place-possessive"},{match:"#Possessive #PresentTense #Particle?",notIf:"(#Gerund|her)",tag:"Noun",reason:"possessive-verb"},{match:"(my|our|their|her|his|its) [(#Plural && #Actor)] #Noun",tag:"Possessive",reason:"my-dads"},{match:"#Value of a [second]",group:0,unTag:"Value",tag:"Singular",reason:"10th-of-a-second"},{match:"#Value [seconds]",group:0,unTag:"Value",tag:"Plural",reason:"10-seconds"},{match:"in [#Infinitive]",group:0,tag:"Singular",reason:"in-age"},{match:"a [#Adjective] #Preposition",group:0,tag:"Noun",reason:"a-minor-in"},{match:"#Determiner [#Singular] said",group:0,tag:"Actor",reason:"the-actor-said"},{match:"#Determiner #Noun [(feel|sense|process|rush|side|bomb|bully|challenge|cover|crush|dump|exchange|flow|function|issue|lecture|limit|march|process)] !(#Preposition|to|#Adverb)?",group:0,tag:"Noun",reason:"the-noun-sense"},{match:"[#PresentTense] (of|by|for) (a|an|the) #Noun #Copula",group:0,tag:"Plural",reason:"photographs-of"},{match:"#Infinitive and [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"fight and win"},{match:"#Noun and [#Verb] and #Noun",group:0,tag:"Noun",reason:"peace-and-flowers"},{match:"the #Cardinal [%Adj|Noun%]",group:0,tag:"Noun",reason:"the-1992-classic"},{match:"#Copula the [%Adj|Noun%] #Noun",group:0,tag:"Adjective",reason:"the-premier-university"},{match:"i #Verb [me] #Noun",group:0,tag:"Possessive",reason:"scottish-me"},{match:"[#PresentTense] (music|class|lesson|night|party|festival|league|ceremony)",group:0,tag:"Noun",reason:"dance-music"},{match:"[wit] (me|it)",group:0,tag:"Presposition",reason:"wit-me"},{match:"#PastTense #Possessive [#Verb]",group:0,tag:"Noun",notIf:"(saw|made)",reason:"left-her-boots"},{match:"#Value [%Plural|Verb%]",group:0,tag:"Plural",notIf:"(one|1|a|an)",reason:"35-signs"},{match:"had [#PresentTense]",group:0,tag:"Noun",notIf:"(#Gerund|come|become)",reason:"had-time"},{match:"%Adj|Noun% %Noun|Verb%",tag:"#Adjective #Noun",notIf:"#ProperNoun #Noun",reason:"instant-access"},{match:"#Determiner [%Adj|Noun%] #Conjunction",group:0,tag:"Noun",reason:"a-rep-to"},{match:"#Adjective #Noun [%Plural|Verb%]$",group:0,tag:"Plural",notIf:"#Pronoun",reason:"near-death-experiences"},{match:"#Possessive #Noun [%Plural|Verb%]$",group:0,tag:"Plural",reason:"your-guild-colors"}],[{match:"(this|that|the|a|an) [#Gerund #Infinitive]",group:0,tag:"Singular",reason:"the-planning-process"},{match:"(that|the) [#Gerund #PresentTense]",group:0,ifNo:"#Copula",tag:"Plural",reason:"the-paving-stones"},{match:"#Determiner [#Gerund] #Noun",group:0,tag:"Adjective",reason:"the-gerund-noun"},{match:"#Pronoun #Infinitive [#Gerund] #PresentTense",group:0,tag:"Noun",reason:"tipping-sucks"},{match:"#Adjective [#Gerund]",group:0,tag:"Noun",notIf:"(still|even|just)",reason:"early-warning"},{match:"[#Gerund] #Adverb? not? #Copula",group:0,tag:"Activity",reason:"gerund-copula"},{match:"#Copula [(#Gerund|#Activity)] #Copula",group:0,tag:"Gerund",reason:"are-doing-is"},{match:"[#Gerund] #Modal",group:0,tag:"Activity",reason:"gerund-modal"},{match:"#Singular for [%Noun|Gerund%]",group:0,tag:"Gerund",reason:"noun-for-gerund"},{match:"#Comparative (for|at) [%Noun|Gerund%]",group:0,tag:"Gerund",reason:"better-for-gerund"},{match:"#PresentTense the [#Gerund]",group:0,tag:"Noun",reason:"keep-the-touching"}],[{match:"#Infinitive (this|that|the) [#Infinitive]",group:0,tag:"Noun",reason:"do-this-dance"},{match:"#Gerund #Determiner [#Infinitive]",group:0,tag:"Noun",reason:"running-a-show"},{match:"#Determiner (only|further|just|more|backward) [#Infinitive]",group:0,tag:"Noun",reason:"the-only-reason"},{match:"(the|this|a|an) [#Infinitive] #Adverb? #Verb",group:0,tag:"Noun",reason:"determiner5"},{match:"#Determiner #Adjective #Adjective? [#Infinitive]",group:0,tag:"Noun",reason:"a-nice-inf"},{match:"#Determiner #Demonym [#PresentTense]",group:0,tag:"Noun",reason:"mexican-train"},{match:"#Adjective #Noun+ [#Infinitive] #Copula",group:0,tag:"Noun",reason:"career-move"},{match:"at some [#Infinitive]",group:0,tag:"Noun",reason:"at-some-inf"},{match:"(go|goes|went) to [#Infinitive]",group:0,tag:"Noun",reason:"goes-to-verb"},{match:"(a|an) #Adjective? #Noun [#Infinitive] (#Preposition|#Noun)",group:0,notIf:"from",tag:"Noun",reason:"a-noun-inf"},{match:"(a|an) #Noun [#Infinitive]$",group:0,tag:"Noun",reason:"a-noun-inf2"},{match:"#Gerund #Adjective? for [#Infinitive]",group:0,tag:"Noun",reason:"running-for"},{match:"about [#Infinitive]",group:0,tag:"Singular",reason:"about-love"},{match:"#Plural on [#Infinitive]",group:0,tag:"Noun",reason:"on-stage"},{match:"any [#Infinitive]",group:0,tag:"Noun",reason:"any-charge"},{match:"no [#Infinitive]",group:0,tag:"Noun",reason:"no-doubt"},{match:"number of [#PresentTense]",group:0,tag:"Noun",reason:"number-of-x"},{match:"(taught|teaches|learns|learned) [#PresentTense]",group:0,tag:"Noun",reason:"teaches-x"},{match:"(try|use|attempt|build|make) [#Verb #Particle?]",notIf:"(#Copula|#Noun|sure|fun|up)",group:0,tag:"Noun",reason:"do-verb"},{match:"^[#Infinitive] (is|was)",group:0,tag:"Noun",reason:"checkmate-is"},{match:"#Infinitive much [#Infinitive]",group:0,tag:"Noun",reason:"get-much"},{match:"[cause] #Pronoun #Verb",group:0,tag:"Conjunction",reason:"cause-cuz"},{match:"the #Singular [#Infinitive] #Noun",group:0,tag:"Noun",notIf:"#Pronoun",reason:"cardio-dance"},{match:"#Determiner #Modal [#Noun]",group:0,tag:"PresentTense",reason:"should-smoke"},{match:"this [#Plural]",group:0,tag:"PresentTense",notIf:"(#Preposition|#Date)",reason:"this-verbs"},{match:"#Noun that [#Plural]",group:0,tag:"PresentTense",notIf:"(#Preposition|#Pronoun|way)",reason:"voice-that-rocks"},{match:"that [#Plural] to",group:0,tag:"PresentTense",notIf:"#Preposition",reason:"that-leads-to"},{match:"(let|make|made) (him|her|it|#Person|#Place|#Organization)+ [#Singular] (a|an|the|it)",group:0,tag:"Infinitive",reason:"let-him-glue"},{match:"#Verb (all|every|each|most|some|no) [#PresentTense]",notIf:"#Modal",group:0,tag:"Noun",reason:"all-presentTense"},{match:"(had|have|#PastTense) #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"better",reason:"adj-presentTense"},{match:"#Value #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"one-big-reason"},{match:"#PastTense #Adjective+ [#PresentTense]",group:0,tag:"Noun",notIf:"(#Copula|better)",reason:"won-wide-support"},{match:"(many|few|several|couple) [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"many-poses"},{match:"#Determiner #Adverb #Adjective [%Noun|Verb%]",group:0,tag:"Noun",notIf:"#Copula",reason:"very-big-dream"},{match:"from #Noun to [%Noun|Verb%]",group:0,tag:"Noun",reason:"start-to-finish"},{match:"(for|with|of) #Noun (and|or|not) [%Noun|Verb%]",group:0,tag:"Noun",notIf:"#Pronoun",reason:"for-food-and-gas"},{match:"#Adjective #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"adorable-little-store"},{match:"#Gerund #Adverb? #Comparative [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"higher-costs"},{match:"(#Noun && @hasComma) #Noun (and|or) [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"noun-list"},{match:"(many|any|some|several) [#PresentTense] for",group:0,tag:"Noun",reason:"any-verbs-for"},{match:"to #PresentTense #Noun [#PresentTense] #Preposition",group:0,tag:"Noun",reason:"gas-exchange"},{match:"#PastTense (until|as|through|without) [#PresentTense]",group:0,tag:"Noun",reason:"waited-until-release"},{match:"#Gerund like #Adjective? [#PresentTense]",group:0,tag:"Plural",reason:"like-hot-cakes"},{match:"some #Adjective [#PresentTense]",group:0,tag:"Noun",reason:"some-reason"},{match:"for some [#PresentTense]",group:0,tag:"Noun",reason:"for-some-reason"},{match:"(same|some|the|that|a) kind of [#PresentTense]",group:0,tag:"Noun",reason:"some-kind-of"},{match:"(same|some|the|that|a) type of [#PresentTense]",group:0,tag:"Noun",reason:"some-type-of"},{match:"#Gerund #Adjective #Preposition [#PresentTense]",group:0,tag:"Noun",reason:"doing-better-for-x"},{match:"(get|got|have) #Comparative [#PresentTense]",group:0,tag:"Noun",reason:"got-better-aim"},{match:"whose [#PresentTense] #Copula",group:0,tag:"Noun",reason:"whos-name-was"},{match:"#PhrasalVerb #Particle #Preposition [#PresentTense]",group:0,tag:"Noun",reason:"given-up-on-x"},{match:"there (are|were) #Adjective? [#PresentTense]",group:0,tag:"Plural",reason:"there-are"},{match:"#Value [#PresentTense] of",group:0,notIf:"(one|1|#Copula|#Infinitive)",tag:"Plural",reason:"2-trains"},{match:"[#PresentTense] (are|were) #Adjective",group:0,tag:"Plural",reason:"compromises-are-possible"},{match:"^[(hope|guess|thought|think)] #Pronoun #Verb",group:0,tag:"Infinitive",reason:"suppose-i"},{match:"#Possessive #Adjective [#Verb]",group:0,tag:"Noun",notIf:"#Copula",reason:"our-full-support"},{match:"[(tastes|smells)] #Adverb? #Adjective",group:0,tag:"PresentTense",reason:"tastes-good"},{match:"#Copula #Gerund [#PresentTense] !by?",group:0,tag:"Noun",notIf:"going",reason:"ignoring-commute"},{match:"#Determiner #Adjective? [(shed|thought|rose|bid|saw|spelt)]",group:0,tag:"Noun",reason:"noun-past"},{match:"how to [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"how-to-noun"},{match:"which [%Noun|Verb%] #Noun",group:0,tag:"Infinitive",reason:"which-boost-it"},{match:"#Gerund [%Plural|Verb%]",group:0,tag:"Plural",reason:"asking-questions"},{match:"(ready|available|difficult|hard|easy|made|attempt|try) to [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"ready-to-noun"},{match:"(bring|went|go|drive|run|bike) to [%Noun|Verb%]",group:0,tag:"Noun",reason:"bring-to-noun"},{match:"#Modal #Noun [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"would-you-look"},{match:"#Copula just [#Infinitive]",group:0,tag:"Noun",reason:"is-just-spam"},{match:"^%Noun|Verb% %Plural|Verb%",tag:"Imperative #Plural",reason:"request-copies"},{match:"#Adjective #Plural and [%Plural|Verb%]",group:0,tag:"#Plural",reason:"pickles-and-drinks"},{match:"#Determiner #Year [#Verb]",group:0,tag:"Noun",reason:"the-1968-film"},{match:"#Determiner [#PhrasalVerb #Particle]",group:0,tag:"Noun",reason:"the-break-up"},{match:"#Determiner [%Adj|Noun%] #Noun",group:0,tag:"Adjective",notIf:"(#Pronoun|#Possessive|#ProperNoun)",reason:"the-individual-goals"},{match:"[%Noun|Verb%] or #Infinitive",group:0,tag:"Infinitive",reason:"work-or-prepare"},{match:"to #Infinitive [#PresentTense]",group:0,tag:"Noun",notIf:"(#Gerund|#Copula|help)",reason:"to-give-thanks"},{match:"[#Noun] me",group:0,tag:"Verb",reason:"kills-me"},{match:"%Plural|Verb% %Plural|Verb%",tag:"#PresentTense #Plural",reason:"removes-wrinkles"}],[{match:"#Money and #Money #Currency?",tag:"Money",reason:"money-and-money"},{match:"#Value #Currency [and] #Value (cents|ore|centavos|sens)",group:0,tag:"money",reason:"and-5-cents"},{match:"#Value (mark|rand|won|rub|ore)",tag:"#Money #Currency",reason:"4-mark"},{match:"a pound",tag:"#Money #Unit",reason:"a-pound"},{match:"#Value (pound|pounds)",tag:"#Money #Unit",reason:"4-pounds"}],[{match:"[(half|quarter)] of? (a|an)",group:0,tag:"Fraction",reason:"millionth"},{match:"#Adverb [half]",group:0,tag:"Fraction",reason:"nearly-half"},{match:"[half] the",group:0,tag:"Fraction",reason:"half-the"},{match:"#Cardinal and a half",tag:"Fraction",reason:"and-a-half"},{match:"#Value (halves|halfs|quarters)",tag:"Fraction",reason:"two-halves"},{match:"a #Ordinal",tag:"Fraction",reason:"a-quarter"},{match:"[#Cardinal+] (#Fraction && /s$/)",tag:"Fraction",reason:"seven-fifths"},{match:"[#Cardinal+ #Ordinal] of .",group:0,tag:"Fraction",reason:"ordinal-of"},{match:"[(#NumericValue && #Ordinal)] of .",group:0,tag:"Fraction",reason:"num-ordinal-of"},{match:"(a|one) #Cardinal?+ #Ordinal",tag:"Fraction",reason:"a-ordinal"},{match:"#Cardinal+ out? of every? #Cardinal",tag:"Fraction",reason:"out-of"}],[{match:"#Cardinal [second]",tag:"Unit",reason:"one-second"},{match:"!once? [(a|an)] (#Duration|hundred|thousand|million|billion|trillion)",group:0,tag:"Value",reason:"a-is-one"},{match:"1 #Value #PhoneNumber",tag:"PhoneNumber",reason:"1-800-Value"},{match:"#NumericValue #PhoneNumber",tag:"PhoneNumber",reason:"(800) PhoneNumber"},{match:"#Demonym #Currency",tag:"Currency",reason:"demonym-currency"},{match:"#Value [(buck|bucks|grand)]",group:0,tag:"Currency",reason:"value-bucks"},{match:"[#Value+] #Currency",group:0,tag:"Money",reason:"15 usd"},{match:"[second] #Noun",group:0,tag:"Ordinal",reason:"second-noun"},{match:"#Value+ [#Currency]",group:0,tag:"Unit",reason:"5-yan"},{match:"#Value [(foot|feet)]",group:0,tag:"Unit",reason:"foot-unit"},{match:"#Value [#Abbreviation]",group:0,tag:"Unit",reason:"value-abbr"},{match:"#Value [k]",group:0,tag:"Unit",reason:"value-k"},{match:"#Unit an hour",tag:"Unit",reason:"unit-an-hour"},{match:"(minus|negative) #Value",tag:"Value",reason:"minus-value"},{match:"#Value (point|decimal) #Value",tag:"Value",reason:"value-point-value"},{match:"#Determiner [(half|quarter)] #Ordinal",group:0,tag:"Value",reason:"half-ordinal"},{match:"#Multiple+ and #Value",tag:"Value",reason:"magnitude-and-value"},{match:"#Value #Unit [(per|an) (hr|hour|sec|second|min|minute)]",group:0,tag:"Unit",reason:"12-miles-per-second"},{match:"#Value [(square|cubic)] #Unit",group:0,tag:"Unit",reason:"square-miles"}],[{match:"#Copula [(#Noun|#PresentTense)] #LastName",group:0,tag:"FirstName",reason:"copula-noun-lastname"},{match:"(sister|pope|brother|father|aunt|uncle|grandpa|grandfather|grandma) #ProperNoun",tag:"Person",reason:"lady-titlecase",safe:!0},{match:"#FirstName [#Determiner #Noun] #LastName",group:0,tag:"Person",reason:"first-noun-last"},{match:"#ProperNoun (b|c|d|e|f|g|h|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z) #ProperNoun",tag:"Person",reason:"titlecase-acronym-titlecase",safe:!0},{match:"#Acronym #LastName",tag:"Person",reason:"acronym-lastname",safe:!0},{match:"#Person (jr|sr|md)",tag:"Person",reason:"person-honorific"},{match:"#Honorific #Acronym",tag:"Person",reason:"Honorific-TitleCase"},{match:"#Person #Person the? #RomanNumeral",tag:"Person",reason:"roman-numeral"},{match:"#FirstName [/^[^aiurck]$/]",group:0,tag:["Acronym","Person"],reason:"john-e"},{match:"#Noun van der? #Noun",tag:"Person",reason:"van der noun",safe:!0},{match:"(king|queen|prince|saint|lady) of #Noun",tag:"Person",reason:"king-of-noun",safe:!0},{match:"(prince|lady) #Place",tag:"Person",reason:"lady-place"},{match:"(king|queen|prince|saint) #ProperNoun",tag:"Person",notIf:"#Place",reason:"saint-foo"},{match:"al (#Person|#ProperNoun)",tag:"Person",reason:"al-borlen",safe:!0},{match:"#FirstName de #Noun",tag:"Person",reason:"bill-de-noun"},{match:"#FirstName (bin|al) #Noun",tag:"Person",reason:"bill-al-noun"},{match:"#FirstName #Acronym #ProperNoun",tag:"Person",reason:"bill-acronym-title"},{match:"#FirstName #FirstName #ProperNoun",tag:"Person",reason:"bill-firstname-title"},{match:"#Honorific #FirstName? #ProperNoun",tag:"Person",reason:"dr-john-Title"},{match:"#FirstName the #Adjective",tag:"Person",reason:"name-the-great"},{match:"#ProperNoun (van|al|bin) #ProperNoun",tag:"Person",reason:"title-van-title",safe:!0},{match:"#ProperNoun (de|du) la? #ProperNoun",tag:"Person",notIf:"#Place",reason:"title-de-title"},{match:"#Singular #Acronym #LastName",tag:"#FirstName #Person .",reason:"title-acro-noun",safe:!0},{match:"[#ProperNoun] #Person",group:0,tag:"Person",reason:"proper-person",safe:!0},{match:"#Person [#ProperNoun #ProperNoun]",group:0,tag:"Person",notIf:"#Possessive",reason:"three-name-person",safe:!0},{match:"#FirstName #Acronym? [#ProperNoun]",group:0,tag:"LastName",notIf:"#Possessive",reason:"firstname-titlecase"},{match:"#FirstName [#FirstName]",group:0,tag:"LastName",reason:"firstname-firstname"},{match:"#FirstName #Acronym #Noun",tag:"Person",reason:"n-acro-noun",safe:!0},{match:"#FirstName [(de|di|du|van|von)] #Person",group:0,tag:"LastName",reason:"de-firstname"},{match:"[(lieutenant|corporal|sergeant|captain|qeen|king|admiral|major|colonel|marshal|president|queen|king)+] #ProperNoun",group:0,tag:"Honorific",reason:"seargeant-john"},{match:"[(private|general|major|rear|prime|field|count|miss)] #Honorific? #Person",group:0,tag:["Honorific","Person"],reason:"ambg-honorifics"},{match:"#Honorific #FirstName [#Singular]",group:0,tag:"LastName",notIf:"#Possessive",reason:"dr-john-foo",safe:!0},{match:"[(his|her) (majesty|honour|worship|excellency|honorable)] #Person",group:0,tag:"Honorific",reason:"his-excellency"},{match:"#Honorific #Actor",tag:"Honorific",reason:"Lieutenant colonel"},{match:"(first|second|third|1st|2nd|3rd) #Actor",tag:"Honorific",reason:"first lady"},{match:"#Person #RomanNumeral",tag:"Person",reason:"louis-IV"}],[{match:"#FirstName #Noun$",tag:". #LastName",notIf:"(#Possessive|#Organization|#Place|#Pronoun|@hasTitleCase)",reason:"firstname-noun"},{match:"%Person|Date% #Acronym? #ProperNoun",tag:"Person",reason:"jan-thierson"},{match:"%Person|Noun% #Acronym? #ProperNoun",tag:"Person",reason:"switch-person",safe:!0},{match:"%Person|Noun% #Organization",tag:"Organization",reason:"olive-garden"},{match:"%Person|Verb% #Acronym? #ProperNoun",tag:"Person",reason:"verb-propernoun",ifNo:"#Actor"},{match:"[%Person|Verb%] (will|had|has|said|says|told|did|learned|wants|wanted)",group:0,tag:"Person",reason:"person-said"},{match:"[%Person|Place%] (harbor|harbour|pier|town|city|place|dump|landfill)",group:0,tag:"Place",reason:"sydney-harbour"},{match:"(west|east|north|south) [%Person|Place%]",group:0,tag:"Place",reason:"east-sydney"},{match:"#Modal [%Person|Verb%]",group:0,tag:"Verb",reason:"would-mark"},{match:"#Adverb [%Person|Verb%]",group:0,tag:"Verb",reason:"really-mark"},{match:"[%Person|Verb%] (#Adverb|#Comparative)",group:0,tag:"Verb",reason:"drew-closer"},{match:"%Person|Verb% #Person",tag:"Person",reason:"rob-smith"},{match:"%Person|Verb% #Acronym #ProperNoun",tag:"Person",reason:"rob-a-smith"},{match:"[will] #Verb",group:0,tag:"Modal",reason:"will-verb"},{match:"(will && @isTitleCase) #ProperNoun",tag:"Person",reason:"will-name"},{match:"(#FirstName && !#Possessive) [#Singular] #Verb",group:0,safe:!0,tag:"LastName",reason:"jack-layton"},{match:"^[#Singular] #Person #Verb",group:0,safe:!0,tag:"Person",reason:"sherwood-anderson"},{match:"(a|an) [#Person]$",group:0,unTag:"Person",reason:"a-warhol"}],[{match:"#Copula (pretty|dead|full|well|sure) (#Adjective|#Noun)",tag:"#Copula #Adverb #Adjective",reason:"sometimes-adverb"},{match:"(#Pronoun|#Person) (had|#Adverb)? [better] #PresentTense",group:0,tag:"Modal",reason:"i-better"},{match:"(#Modal|i|they|we|do) not? [like]",group:0,tag:"PresentTense",reason:"modal-like"},{match:"#Noun #Adverb? [left]",group:0,tag:"PastTense",reason:"left-verb"},{match:"will #Adverb? not? #Adverb? [be] #Gerund",group:0,tag:"Copula",reason:"will-be-copula"},{match:"will #Adverb? not? #Adverb? [be] #Adjective",group:0,tag:"Copula",reason:"be-copula"},{match:"[march] (up|down|back|toward)",notIf:"#Date",group:0,tag:"Infinitive",reason:"march-to"},{match:"#Modal [march]",group:0,tag:"Infinitive",reason:"must-march"},{match:"[may] be",group:0,tag:"Verb",reason:"may-be"},{match:"[(subject|subjects|subjected)] to",group:0,tag:"Verb",reason:"subject to"},{match:"[home] to",group:0,tag:"PresentTense",reason:"home to"},{match:"[open] #Determiner",group:0,tag:"Infinitive",reason:"open-the"},{match:"(were|was) being [#PresentTense]",group:0,tag:"PastTense",reason:"was-being"},{match:"(had|has|have) [been /en$/]",group:0,tag:"Auxiliary Participle",reason:"had-been-broken"},{match:"(had|has|have) [been /ed$/]",group:0,tag:"Auxiliary PastTense",reason:"had-been-smoked"},{match:"(had|has) #Adverb? [been] #Adverb? #PastTense",group:0,tag:"Auxiliary",reason:"had-been-adj"},{match:"(had|has) to [#Noun] (#Determiner|#Possessive)",group:0,tag:"Infinitive",reason:"had-to-noun"},{match:"have [#PresentTense]",group:0,tag:"PastTense",notIf:"(come|gotten)",reason:"have-read"},{match:"(does|will|#Modal) that [work]",group:0,tag:"PastTense",reason:"does-that-work"},{match:"[(sound|sounds)] #Adjective",group:0,tag:"PresentTense",reason:"sounds-fun"},{match:"[(look|looks)] #Adjective",group:0,tag:"PresentTense",reason:"looks-good"},{match:"[(start|starts|stop|stops|begin|begins)] #Gerund",group:0,tag:"Verb",reason:"starts-thinking"},{match:"(have|had) read",tag:"Modal #PastTense",reason:"read-read"},{match:"(is|was|were) [(under|over) #PastTense]",group:0,tag:"Adverb Adjective",reason:"was-under-cooked"},{match:"[shit] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear1-verb"},{match:"[damn] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear2-verb"},{match:"[fuck] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear3-verb"},{match:"#Plural that %Noun|Verb%",tag:". #Preposition #Infinitive",reason:"jobs-that-work"},{match:"[works] for me",group:0,tag:"PresentTense",reason:"works-for-me"},{match:"as #Pronoun [please]",group:0,tag:"Infinitive",reason:"as-we-please"},{match:"[(co|mis|de|inter|intra|pre|re|un|out|under|over|counter)] #Verb",group:0,tag:["Verb","Prefix"],notIf:"(#Copula|#PhrasalVerb)",reason:"co-write"},{match:"#PastTense and [%Adj|Past%]",group:0,tag:"PastTense",reason:"dressed-and-left"},{match:"[%Adj|Past%] and #PastTense",group:0,tag:"PastTense",reason:"dressed-and-left"},{match:"#Copula #Pronoun [%Adj|Past%]",group:0,tag:"Adjective",reason:"is-he-stoked"},{match:"to [%Noun|Verb%] #Preposition",group:0,tag:"Infinitive",reason:"to-dream-of"}],[{match:"(slowly|quickly) [#Adjective]",group:0,tag:"Verb",reason:"slowly-adj"},{match:"does (#Adverb|not)? [#Adjective]",group:0,tag:"PresentTense",reason:"does-mean"},{match:"[(fine|okay|cool|ok)] by me",group:0,tag:"Adjective",reason:"okay-by-me"},{match:"i (#Adverb|do)? not? [mean]",group:0,tag:"PresentTense",reason:"i-mean"},{match:"will #Adjective",tag:"Auxiliary Infinitive",reason:"will-adj"},{match:"#Pronoun [#Adjective] #Determiner #Adjective? #Noun",group:0,tag:"Verb",reason:"he-adj-the"},{match:"#Copula [%Adj|Present%] to #Verb",group:0,tag:"Verb",reason:"adj-to"},{match:"#Copula [#Adjective] (well|badly|quickly|slowly)",group:0,tag:"Verb",reason:"done-well"},{match:"#Adjective and [#Gerund] !#Preposition?",group:0,tag:"Adjective",reason:"rude-and-x"},{match:"#Copula #Adverb? (over|under) [#PastTense]",group:0,tag:"Adjective",reason:"over-cooked"},{match:"#Copula #Adjective+ (and|or) [#PastTense]$",group:0,tag:"Adjective",reason:"bland-and-overcooked"},{match:"got #Adverb? [#PastTense] of",group:0,tag:"Adjective",reason:"got-tired-of"},{match:"(seem|seems|seemed|appear|appeared|appears|feel|feels|felt|sound|sounds|sounded) (#Adverb|#Adjective)? [#PastTense]",group:0,tag:"Adjective",reason:"felt-loved"},{match:"(seem|feel|seemed|felt) [#PastTense #Particle?]",group:0,tag:"Adjective",reason:"seem-confused"},{match:"a (bit|little|tad) [#PastTense #Particle?]",group:0,tag:"Adjective",reason:"a-bit-confused"},{match:"not be [%Adj|Past% #Particle?]",group:0,tag:"Adjective",reason:"do-not-be-confused"},{match:"#Copula just [%Adj|Past% #Particle?]",group:0,tag:"Adjective",reason:"is-just-right"},{match:"as [#Infinitive] as",group:0,tag:"Adjective",reason:"as-pale-as"},{match:"[%Adj|Past%] and #Adjective",group:0,tag:"Adjective",reason:"faled-and-oppressive"},{match:"or [#PastTense] #Noun",group:0,tag:"Adjective",notIf:"(#Copula|#Pronoun)",reason:"or-heightened-emotion"},{match:"(become|became|becoming|becomes) [#Verb]",group:0,tag:"Adjective",reason:"become-verb"},{match:"#Possessive [#PastTense] #Noun",group:0,tag:"Adjective",reason:"declared-intentions"},{match:"#Copula #Pronoun [%Adj|Present%]",group:0,tag:"Adjective",reason:"is-he-cool"},{match:"#Copula [%Adj|Past%] with",group:0,tag:"Adjective",notIf:"(associated|worn|baked|aged|armed|bound|fried|loaded|mixed|packed|pumped|filled|sealed)",reason:"is-crowded-with"},{match:"#Copula #Adverb? [%Adj|Present%]$",group:0,tag:"Adjective",reason:"was-empty$"}],[{match:"will (#Adverb|not)+? [have] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"will-have-vb"},{match:"[#Copula] (#Adverb|not)+? (#Gerund|#PastTense)",group:0,tag:"Auxiliary",reason:"copula-walking"},{match:"[(#Modal|did)+] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"modal-verb"},{match:"#Modal (#Adverb|not)+? [have] (#Adverb|not)+? [had] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"would-have"},{match:"[(has|had)] (#Adverb|not)+? #PastTense",group:0,tag:"Auxiliary",reason:"had-walked"},{match:"[(do|does|did|will|have|had|has|got)] (not|#Adverb)+? #Verb",group:0,tag:"Auxiliary",reason:"have-had"},{match:"[about to] #Adverb? #Verb",group:0,tag:["Auxiliary","Verb"],reason:"about-to"},{match:"#Modal (#Adverb|not)+? [be] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"would-be"},{match:"[(#Modal|had|has)] (#Adverb|not)+? [been] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"had-been"},{match:"[(be|being|been)] #Participle",group:0,tag:"Auxiliary",reason:"being-driven"},{match:"[may] #Adverb? #Infinitive",group:0,tag:"Auxiliary",reason:"may-want"},{match:"#Copula (#Adverb|not)+? [(be|being|been)] #Adverb+? #PastTense",group:0,tag:"Auxiliary",reason:"being-walked"},{match:"will [be] #PastTense",group:0,tag:"Auxiliary",reason:"will-be-x"},{match:"[(be|been)] (#Adverb|not)+? #Gerund",group:0,tag:"Auxiliary",reason:"been-walking"},{match:"[used to] #PresentTense",group:0,tag:"Auxiliary",reason:"used-to-walk"},{match:"#Copula (#Adverb|not)+? [going to] #Adverb+? #PresentTense",group:0,tag:"Auxiliary",reason:"going-to-walk"},{match:"#Imperative [(me|him|her)]",group:0,tag:"Reflexive",reason:"tell-him"},{match:"(is|was) #Adverb? [no]",group:0,tag:"Negative",reason:"is-no"},{match:"[(been|had|became|came)] #PastTense",group:0,notIf:"#PhrasalVerb",tag:"Auxiliary",reason:"been-told"},{match:"[(being|having|getting)] #Verb",group:0,tag:"Auxiliary",reason:"being-born"},{match:"[be] #Gerund",group:0,tag:"Auxiliary",reason:"be-walking"},{match:"[better] #PresentTense",group:0,tag:"Modal",notIf:"(#Copula|#Gerund)",reason:"better-go"},{match:"even better",tag:"Adverb #Comparative",reason:"even-better"}],[{match:"(#Verb && @hasHyphen) up",tag:"PhrasalVerb",reason:"foo-up"},{match:"(#Verb && @hasHyphen) off",tag:"PhrasalVerb",reason:"foo-off"},{match:"(#Verb && @hasHyphen) over",tag:"PhrasalVerb",reason:"foo-over"},{match:"(#Verb && @hasHyphen) out",tag:"PhrasalVerb",reason:"foo-out"},{match:"[#Verb (in|out|up|down|off|back)] (on|in)",notIf:"#Copula",tag:"PhrasalVerb Particle",reason:"walk-in-on"},{match:"(lived|went|crept|go) [on] for",group:0,tag:"PhrasalVerb",reason:"went-on"},{match:"#Verb (up|down|in|on|for)$",tag:"PhrasalVerb #Particle",notIf:"#PhrasalVerb",reason:"come-down$"},{match:"help [(stop|end|make|start)]",group:0,tag:"Infinitive",reason:"help-stop"},{match:"#PhrasalVerb (in && #Particle) #Determiner",tag:"#Verb #Preposition #Determiner",unTag:"PhrasalVerb",reason:"work-in-the"},{match:"[(stop|start|finish|help)] #Gerund",group:0,tag:"Infinitive",reason:"start-listening"},{match:"#Verb (him|her|it|us|himself|herself|itself|everything|something) [(up|down)]",group:0,tag:"Adverb",reason:"phrasal-pronoun-advb"}],[{match:"^do not? [#Infinitive #Particle?]",notIf:zl,group:0,tag:"Imperative",reason:"do-eat"},{match:"^please do? not? [#Infinitive #Particle?]",group:0,tag:"Imperative",reason:"please-go"},{match:"^just do? not? [#Infinitive #Particle?]",group:0,tag:"Imperative",reason:"just-go"},{match:"^[#Infinitive] it #Comparative",notIf:zl,group:0,tag:"Imperative",reason:"do-it-better"},{match:"^[#Infinitive] it (please|now|again|plz)",notIf:zl,group:0,tag:"Imperative",reason:"do-it-please"},{match:"^[#Infinitive] (#Adjective|#Adverb)$",group:0,tag:"Imperative",notIf:"(so|such|rather|enough)",reason:"go-quickly"},{match:"^[#Infinitive] (up|down|over) #Determiner",group:0,tag:"Imperative",reason:"turn-down"},{match:"^[#Infinitive] (your|my|the|a|an|any|each|every|some|more|with|on)",group:0,notIf:"like",tag:"Imperative",reason:"eat-my-shorts"},{match:"^[#Infinitive] (him|her|it|us|me|there)",group:0,tag:"Imperative",reason:"tell-him"},{match:"^[#Infinitive] #Adjective #Noun$",group:0,tag:"Imperative",reason:"avoid-loud-noises"},{match:"^[#Infinitive] (#Adjective|#Adverb)? and #Infinitive",group:0,tag:"Imperative",reason:"call-and-reserve"},{match:"^(go|stop|wait|hurry) please?$",tag:"Imperative",reason:"go"},{match:"^(somebody|everybody) [#Infinitive]",group:0,tag:"Imperative",reason:"somebody-call"},{match:"^let (us|me) [#Infinitive]",group:0,tag:"Imperative",reason:"lets-leave"},{match:"^[(shut|close|open|start|stop|end|keep)] #Determiner #Noun",group:0,tag:"Imperative",reason:"shut-the-door"},{match:"^[#PhrasalVerb #Particle] #Determiner #Noun",group:0,tag:"Imperative",reason:"turn-off-the-light"},{match:"^[go] to .",group:0,tag:"Imperative",reason:"go-to-toronto"},{match:"^#Modal you [#Infinitive]",group:0,tag:"Imperative",reason:"would-you-"},{match:"^never [#Infinitive]",group:0,tag:"Imperative",reason:"never-stop"},{match:"^come #Infinitive",tag:"Imperative",notIf:"on",reason:"come-have"},{match:"^come and? #Infinitive",tag:"Imperative . Imperative",notIf:"#PhrasalVerb",reason:"come-and-have"},{match:"^stay (out|away|back)",tag:"Imperative",reason:"stay-away"},{match:"^[(stay|be|keep)] #Adjective",group:0,tag:"Imperative",reason:"stay-cool"},{match:"^[keep it] #Adjective",group:0,tag:"Imperative",reason:"keep-it-cool"},{match:"^do not [#Infinitive]",group:0,tag:"Imperative",reason:"do-not-be"},{match:"[#Infinitive] (yourself|yourselves)",group:0,tag:"Imperative",reason:"allow-yourself"},{match:"[#Infinitive] what .",group:0,tag:"Imperative",reason:"look-what"},{match:"^[#Infinitive] #Gerund",group:0,tag:"Imperative",reason:"keep-playing"},{match:"^[#Infinitive] (to|for|into|toward|here|there)",group:0,tag:"Imperative",reason:"go-to"},{match:"^[#Infinitive] (and|or) #Infinitive",group:0,tag:"Imperative",reason:"inf-and-inf"},{match:"^[%Noun|Verb%] to",group:0,tag:"Imperative",reason:"commit-to"},{match:"^[#Infinitive] #Adjective? #Singular #Singular",group:0,tag:"Imperative",reason:"maintain-eye-contact"},{match:"do not (forget|omit|neglect) to [#Infinitive]",group:0,tag:"Imperative",reason:"do-not-forget"},{match:"^[(ask|wear|pay|look|help|show|watch|act|fix|kill|stop|start|turn|try|win)] #Noun",group:0,tag:"Imperative",reason:"pay-attention"}],[{match:"(that|which) were [%Adj|Gerund%]",group:0,tag:"Gerund",reason:"that-were-growing"},{match:"#Gerund [#Gerund] #Plural",group:0,tag:"Adjective",reason:"hard-working-fam"}],[{match:"u r",tag:"#Pronoun #Copula",reason:"u r"},{match:"#Noun [(who|whom)]",group:0,tag:"Determiner",reason:"captain-who"},{match:"[had] #Noun+ #PastTense",group:0,tag:"Condition",reason:"had-he"},{match:"[were] #Noun+ to #Infinitive",group:0,tag:"Condition",reason:"were-he"},{match:"some sort of",tag:"Adjective Noun Conjunction",reason:"some-sort-of"},{match:"of some sort",tag:"Conjunction Adjective Noun",reason:"of-some-sort"},{match:"[such] (a|an|is)? #Noun",group:0,tag:"Determiner",reason:"such-skill"},{match:"[right] (before|after|in|into|to|toward)",group:0,tag:"#Adverb",reason:"right-into"},{match:"#Preposition [about]",group:0,tag:"Adjective",reason:"at-about"},{match:"(are|#Modal|see|do|for) [ya]",group:0,tag:"Pronoun",reason:"are-ya"},{match:"[long live] .",group:0,tag:"#Adjective #Infinitive",reason:"long-live"},{match:"[plenty] of",group:0,tag:"#Uncountable",reason:"plenty-of"},{match:"(always|nearly|barely|practically) [there]",group:0,tag:"Adjective",reason:"always-there"},{match:"[there] (#Adverb|#Pronoun)? #Copula",group:0,tag:"There",reason:"there-is"},{match:"#Copula [there] .",group:0,tag:"There",reason:"is-there"},{match:"#Modal #Adverb? [there]",group:0,tag:"There",reason:"should-there"},{match:"^[do] (you|we|they)",group:0,tag:"QuestionWord",reason:"do-you"},{match:"^[does] (he|she|it|#ProperNoun)",group:0,tag:"QuestionWord",reason:"does-he"},{match:"#Determiner #Noun+ [who] #Verb",group:0,tag:"Preposition",reason:"the-x-who"},{match:"#Determiner #Noun+ [which] #Verb",group:0,tag:"Preposition",reason:"the-x-which"},{match:"a [while]",group:0,tag:"Noun",reason:"a-while"},{match:"guess who",tag:"#Infinitive #QuestionWord",reason:"guess-who"},{match:"[fucking] !#Verb",group:0,tag:"#Gerund",reason:"f-as-gerund"}],[{match:"university of #Place",tag:"Organization",reason:"university-of-Foo"},{match:"#Noun (&|n) #Noun",tag:"Organization",reason:"Noun-&-Noun"},{match:"#Organization of the? #ProperNoun",tag:"Organization",reason:"org-of-place",safe:!0},{match:"#Organization #Country",tag:"Organization",reason:"org-country"},{match:"#ProperNoun #Organization",tag:"Organization",notIf:"#FirstName",reason:"titlecase-org"},{match:"#ProperNoun (ltd|co|inc|dept|assn|bros)",tag:"Organization",reason:"org-abbrv"},{match:"the [#Acronym]",group:0,tag:"Organization",reason:"the-acronym",safe:!0},{match:"government of the? [#Place+]",tag:"Organization",reason:"government-of-x"},{match:"(health|school|commerce) board",tag:"Organization",reason:"school-board"},{match:"(nominating|special|conference|executive|steering|central|congressional) committee",tag:"Organization",reason:"special-comittee"},{match:"(world|global|international|national|#Demonym) #Organization",tag:"Organization",reason:"global-org"},{match:"#Noun+ (public|private) school",tag:"School",reason:"noun-public-school"},{match:"#Place+ #SportsTeam",tag:"SportsTeam",reason:"place-sportsteam"},{match:"(dc|atlanta|minnesota|manchester|newcastle|sheffield) united",tag:"SportsTeam",reason:"united-sportsteam"},{match:"#Place+ fc",tag:"SportsTeam",reason:"fc-sportsteam"},{match:"#Place+ #Noun{0,2} (club|society|group|team|committee|commission|association|guild|crew)",tag:"Organization",reason:"place-noun-society"}],[{match:"(west|north|south|east|western|northern|southern|eastern)+ #Place",tag:"Region",reason:"west-norfolk"},{match:"#City [(al|ak|az|ar|ca|ct|dc|fl|ga|id|il|nv|nh|nj|ny|oh|pa|sc|tn|tx|ut|vt|pr)]",group:0,tag:"Region",reason:"us-state"},{match:"portland [or]",group:0,tag:"Region",reason:"portland-or"},{match:"#ProperNoun+ (cliff|place|range|pit|place|point|room|grounds|ruins)",tag:"Place",reason:"foo-point"},{match:"in [#ProperNoun] #Place",group:0,tag:"Place",reason:"propernoun-place"},{match:"#Value #Noun (st|street|rd|road|crescent|cr|way|tr|terrace|avenue|ave)",tag:"Address",reason:"address-st"},{match:"(port|mount|mt) #ProperName",tag:"Place",reason:"port-name"}],[{match:"[so] #Noun",group:0,tag:"Conjunction",reason:"so-conj"},{match:"[(who|what|where|why|how|when)] #Noun #Copula #Adverb? (#Verb|#Adjective)",group:0,tag:"Conjunction",reason:"how-he-is-x"},{match:"#Copula [(who|what|where|why|how|when)] #Noun",group:0,tag:"Conjunction",reason:"when-he"},{match:"#Verb [that] #Pronoun",group:0,tag:"Conjunction",reason:"said-that-he"},{match:"#Noun [that] #Copula",group:0,tag:"Conjunction",reason:"that-are"},{match:"#Noun [that] #Verb #Adjective",group:0,tag:"Conjunction",reason:"that-seem"},{match:"#Noun #Copula not? [that] #Adjective",group:0,tag:"Adverb",reason:"that-adj"},{match:"#Verb #Adverb? #Noun [(that|which)]",group:0,tag:"Preposition",reason:"that-prep"},{match:"@hasComma [which] (#Pronoun|#Verb)",group:0,tag:"Preposition",reason:"which-copula"},{match:"#Noun [like] #Noun",group:0,tag:"Preposition",reason:"noun-like"},{match:"^[like] #Determiner",group:0,tag:"Preposition",reason:"like-the"},{match:"a #Noun [like] (#Noun|#Determiner)",group:0,tag:"Preposition",reason:"a-noun-like"},{match:"#Adverb [like]",group:0,tag:"Verb",reason:"really-like"},{match:"(not|nothing|never) [like]",group:0,tag:"Preposition",reason:"nothing-like"},{match:"#Infinitive #Pronoun [like]",group:0,tag:"Preposition",reason:"treat-them-like"},{match:"[#QuestionWord] (#Pronoun|#Determiner)",group:0,tag:"Preposition",reason:"how-he"},{match:"[#QuestionWord] #Participle",group:0,tag:"Preposition",reason:"when-stolen"},{match:"[how] (#Determiner|#Copula|#Modal|#PastTense)",group:0,tag:"QuestionWord",reason:"how-is"},{match:"#Plural [(who|which|when)] .",group:0,tag:"Preposition",reason:"people-who"}],[{match:"holy (shit|fuck|hell)",tag:"Expression",reason:"swears-expression"},{match:"^[(well|so|okay|now)] !#Adjective?",group:0,tag:"Expression",reason:"well-"},{match:"^come on",tag:"Expression",reason:"come-on"},{match:"(say|says|said) [sorry]",group:0,tag:"Expression",reason:"say-sorry"},{match:"^(ok|alright|shoot|hell|anyways)",tag:"Expression",reason:"ok-"},{match:"^(say && @hasComma)",tag:"Expression",reason:"say-"},{match:"^(like && @hasComma)",tag:"Expression",reason:"like-"},{match:"^[(dude|man|girl)] #Pronoun",group:0,tag:"Expression",reason:"dude-i"}]);let Bl=null;var Sl={postTagger:function(e){const{world:t}=e,{model:n,methods:a}=t;Bl=Bl||a.one.buildNet(n.two.matches,t);const r=a.two.quickSplit(e.document).map((e=>{const t=e[0];return[t.index[0],t.index[1],t.index[1]+e.length]})),o=e.update(r);return o.cache(),o.sweep(Bl),e.uncache(),e.unfreeze(),e},tagger:e=>e.compute(["freeze","lexicon","preTagger","postTagger","unfreeze"])};const Kl={api:function(e){e.prototype.confidence=function(){let e=0,t=0;return this.docs.forEach((n=>{n.forEach((n=>{t+=1,e+=n.confidence||1}))})),0===t?1:(e=>Math.round(100*e)/100)(e/t)},e.prototype.tagger=function(){return this.compute(["tagger"])}},compute:Sl,model:{two:{matches:Vl}},hooks:["postTagger"]},$l=function(e,t){const n=function(e){return Object.keys(e.hooks).filter((e=>!e.startsWith("#")&&!e.startsWith("%")))}(t);if(0===n.length)return e;e._cache||e.cache();const a=e._cache;return e.filter(((e,t)=>n.some((e=>a[t].has(e)))))};var Ll={lib:{lazy:function(e,t){let n=t;"string"==typeof t&&(n=this.buildNet([{match:t}]));const a=this.tokenize(e),r=$l(a,n);return r.found?(r.compute(["index","tagger"]),r.match(t)):a.none()}}};const Ml=function(e,t,n){let a=e.split(/ /g).map((e=>e.toLowerCase().trim()));a=a.filter((e=>e)),a=a.map((e=>`{${e}}`)).join(" ");let r=this.match(a);return n&&(r=r.if(n)),r.has("#Verb")?function(e,t){let n=t;return e.forEach((e=>{e.has("#Infinitive")||(n=function(e,t){const n=(0,e.methods.two.transform.verb.conjugate)(t,e.model);return e.has("#Gerund")?n.Gerund:e.has("#PastTense")?n.PastTense:e.has("#PresentTense")?n.PresentTense:e.has("#Gerund")?n.Gerund:t}(e,t)),e.replaceWith(n)})),e}(r,t):r.has("#Noun")?function(e,t){let n=t;e.has("#Plural")&&(n=(0,e.methods.two.transform.noun.toPlural)(t,e.model));e.replaceWith(n,{possessives:!0})}(r,t):r.has("#Adverb")?function(e,t){const{toAdverb:n}=e.methods.two.transform.adjective,a=n(t);a&&e.replaceWith(a)}(r,t):r.has("#Adjective")?function(e,t){const{toComparative:n,toSuperlative:a}=e.methods.two.transform.adjective;let r=t;e.has("#Comparative")?r=n(r,e.model):e.has("#Superlative")&&(r=a(r,e.model)),r&&e.replaceWith(r)}(r,t):this};var Jl={api:function(e){e.prototype.swap=Ml}};return d.plugin(cl),d.plugin(Fl),d.plugin(Kl),d.plugin(Ll),d.plugin(Jl),d}));
================================================
FILE: builds/two/compromise-two.mjs
================================================
var e={methods:{one:{},two:{},three:{},four:{}},model:{one:{},two:{},three:{}},compute:{},hooks:[]};const t={compute:function(e){const{world:t}=this,n=t.compute;return"string"==typeof e&&n.hasOwnProperty(e)?n[e](this):(e=>"[object Array]"===Object.prototype.toString.call(e))(e)?e.forEach((a=>{t.compute.hasOwnProperty(a)?n[a](this):console.warn("no compute:",e)})):"function"==typeof e?e(this):console.warn("no compute:",e),this}};var n={forEach:function(e){return this.fullPointer.forEach(((t,n)=>{const a=this.update([t]);e(a,n)})),this},map:function(e,t){const n=this.fullPointer.map(((t,n)=>{const a=this.update([t]),r=e(a,n);return void 0===r?this.none():r}));if(0===n.length)return t||this.update([]);if(void 0!==n[0]){if("string"==typeof n[0])return n;if("object"==typeof n[0]&&(null===n[0]||!n[0].isView))return n}let a=[];return n.forEach((e=>{a=a.concat(e.fullPointer)})),this.toView(a)},filter:function(e){let t=this.fullPointer;t=t.filter(((t,n)=>{const a=this.update([t]);return e(a,n)}));return this.update(t)},find:function(e){const t=this.fullPointer.find(((t,n)=>{const a=this.update([t]);return e(a,n)}));return this.update([t])},some:function(e){return this.fullPointer.some(((t,n)=>{const a=this.update([t]);return e(a,n)}))},random:function(e=1){let t=this.fullPointer,n=Math.floor(Math.random()*t.length);return n+e>this.length&&(n=this.length-e,n=n<0?0:n),t=t.slice(n,n+e),this.update(t)}};const a={termList:function(){return this.methods.one.termList(this.docs)},terms:function(e){const t=this.match(".");return"number"==typeof e?t.eq(e):t},groups:function(e){if(e||0===e)return this.update(this._groups[e]||[]);const t={};return Object.keys(this._groups).forEach((e=>{t[e]=this.update(this._groups[e])})),t},eq:function(e){let t=this.pointer;return t||(t=this.docs.map(((e,t)=>[t]))),t[e]?this.update([t[e]]):this.none()},first:function(){return this.eq(0)},last:function(){const e=this.fullPointer.length-1;return this.eq(e)},firstTerms:function(){return this.match("^.")},lastTerms:function(){return this.match(".$")},slice:function(e,t){let n=this.pointer||this.docs.map(((e,t)=>[t]));return n=n.slice(e,t),this.update(n)},all:function(){return this.update().toView()},fullSentences:function(){const e=this.fullPointer.map((e=>[e[0]]));return this.update(e).toView()},none:function(){return this.update([])},isDoc:function(e){if(!e||!e.isView)return!1;const t=this.fullPointer,n=e.fullPointer;return!t.length!==n.length&&t.every(((e,t)=>!!n[t]&&(e[0]===n[t][0]&&e[1]===n[t][1]&&e[2]===n[t][2])))},wordCount:function(){return this.docs.reduce(((e,t)=>(e+=t.filter((e=>""!==e.text)).length,e)),0)},isFull:function(){const e=this.pointer;if(!e)return!0;if(0===e.length||0!==e[0][0])return!1;let t=0,n=0;return this.document.forEach((e=>t+=e.length)),this.docs.forEach((e=>n+=e.length)),t===n},getNth:function(e){return"number"==typeof e?this.eq(e):"string"==typeof e?this.if(e):this}};a.group=a.groups,a.fullSentence=a.fullSentences,a.sentence=a.fullSentences,a.lastTerm=a.lastTerms,a.firstTerm=a.firstTerms;const r=Object.assign({},a,t,n);r.get=r.eq;class View{constructor(t,n,a={}){[["document",t],["world",e],["_groups",a],["_cache",null],["viewType","View"]].forEach((e=>{Object.defineProperty(this,e[0],{value:e[1],writable:!0})})),this.ptrs=n}get docs(){let t=this.document;return this.ptrs&&(t=e.methods.one.getDoc(this.ptrs,this.document)),t}get pointer(){return this.ptrs}get methods(){return this.world.methods}get model(){return this.world.model}get hooks(){return this.world.hooks}get isView(){return!0}get found(){return this.docs.length>0}get length(){return this.docs.length}get fullPointer(){const{docs:e,ptrs:t,document:n}=this,a=t||e.map(((e,t)=>[t]));return a.map((e=>{let[t,a,r,o,i]=e;return a=a||0,r=r||(n[t]||[]).length,n[t]&&n[t][a]&&(o=o||n[t][a].id,n[t][r-1]&&(i=i||n[t][r-1].id)),[t,a,r,o,i]}))}update(e){const t=new View(this.document,e);if(this._cache&&e&&e.length>0){const n=[];e.forEach(((e,t)=>{const[a,r,o]=e;(1===e.length||0===r&&this.document[a].length===o)&&(n[t]=this._cache[a])})),n.length>0&&(t._cache=n)}return t.world=this.world,t}toView(e){return new View(this.document,e||this.pointer)}fromText(e){const{methods:t}=this,n=t.one.tokenize.fromString(e,this.world),a=new View(n);return a.world=this.world,a.compute(["normal","freeze","lexicon"]),this.world.compute.preTagger&&a.compute("preTagger"),a.compute("unfreeze"),a}clone(){let e=this.document.slice(0);e=e.map((e=>e.map((e=>((e=Object.assign({},e)).tags=new Set(e.tags),e)))));const t=this.update(this.pointer);return t.document=e,t._cache=this._cache,t}}Object.assign(View.prototype,r);const o=function(e){return e&&"object"==typeof e&&!Array.isArray(e)};function i(e,t){if(o(t))for(const n in t)o(t[n])?(e[n]||Object.assign(e,{[n]:{}}),i(e[n],t[n])):Object.assign(e,{[n]:t[n]});return e}const s=function(e,t,n,a){if(r=e,"[object Array]"===Object.prototype.toString.call(r))return void e.forEach((e=>s(e,t,n,a)));var r;const{methods:o,model:l,compute:u,hooks:c}=t;e.methods&&function(e,t){for(const n in t)e[n]=e[n]||{},Object.assign(e[n],t[n])}(o,e.methods),e.model&&i(l,e.model),e.irregulars&&function(e,t){const n=e.two.models||{};Object.keys(t).forEach((e=>{t[e].pastTense&&(n.toPast&&(n.toPast.ex[e]=t[e].pastTense),n.fromPast&&(n.fromPast.ex[t[e].pastTense]=e)),t[e].presentTense&&(n.toPresent&&(n.toPresent.ex[e]=t[e].presentTense),n.fromPresent&&(n.fromPresent.ex[t[e].presentTense]=e)),t[e].gerund&&(n.toGerund&&(n.toGerund.ex[e]=t[e].gerund),n.fromGerund&&(n.fromGerund.ex[t[e].gerund]=e)),t[e].comparative&&(n.toComparative&&(n.toComparative.ex[e]=t[e].comparative),n.fromComparative&&(n.fromComparative.ex[t[e].comparative]=e)),t[e].superlative&&(n.toSuperlative&&(n.toSuperlative.ex[e]=t[e].superlative),n.fromSuperlative&&(n.fromSuperlative.ex[t[e].superlative]=e))}))}(l,e.irregulars),e.compute&&Object.assign(u,e.compute),c&&(t.hooks=c.concat(e.hooks||[])),e.api&&e.api(n),e.lib&&Object.keys(e.lib).forEach((t=>a[t]=e.lib[t])),e.tags&&a.addTags(e.tags),e.words&&a.addWords(e.words),e.frozen&&a.addWords(e.frozen,!0),e.mutate&&e.mutate(t,a)},l=function(e){return"[object Array]"===Object.prototype.toString.call(e)},u=function(e,t,n){const{methods:a}=n,r=new t([]);if(r.world=n,"number"==typeof e&&(e=String(e)),!e)return r;if("string"==typeof e){return new t(a.one.tokenize.fromString(e,n))}if(o=e,"[object Object]"===Object.prototype.toString.call(o)&&e.isView)return new t(e.document,e.ptrs);var o;if(l(e)){if(l(e[0])){const n=e.map((e=>e.map((e=>({text:e,normal:e,pre:"",post:" ",tags:new Set})))));return new t(n)}const n=e.map((e=>e.terms.map((e=>(l(e.tags)&&(e.tags=new Set(e.tags)),e)))));return new t(n)}return r},c=Object.assign({},e),d=function(e,t){t&&d.addWords(t);const n=u(e,View,c);return e&&n.compute(c.hooks),n};Object.defineProperty(d,"_world",{value:c,writable:!0}),d.tokenize=function(e,t){const{compute:n}=this._world;t&&d.addWords(t);const a=u(e,View,c);return n.contractions&&a.compute(["alias","normal","machine","contractions"]),a},d.plugin=function(e){return s(e,this._world,View,this),this},d.extend=d.plugin,d.world=function(){return this._world},d.model=function(){return this._world.model},d.methods=function(){return this._world.methods},d.hooks=function(){return this._world.hooks},d.verbose=function(e){const t="undefined"!=typeof process&&process.env?process.env:self.env||{};return t.DEBUG_TAGS="tagger"===e||!0===e||"",t.DEBUG_MATCH="match"===e||!0===e||"",t.DEBUG_CHUNKS="chunker"===e||!0===e||"",this},d.version="14.15.0";var h={one:{cacheDoc:function(e){const t=e.map((e=>{const t=new Set;return e.forEach((e=>{""!==e.normal&&t.add(e.normal),e.switch&&t.add(`%${e.switch}%`),e.implicit&&t.add(e.implicit),e.machine&&t.add(e.machine),e.root&&t.add(e.root),e.alias&&e.alias.forEach((e=>t.add(e)));const n=Array.from(e.tags);for(let e=0;e/^\p{Lu}[\p{Ll}'’]/u.test(e)||/^\p{Lu}$/u.test(e),b=(e,t,n)=>{if(n.forEach((e=>e.dirty=!0)),e){const a=[t,0].concat(n);Array.prototype.splice.apply(e,a)}return e},y=function(e){const t=e[e.length-1];!t||/ $/.test(t.post)||/[-–—]/.test(t.post)||(t.post+=" ")},v=(e,t,n)=>{const a=/[-.?!,;:)–—'"]/g,r=e[t-1];if(!r)return;const o=r.post;if(a.test(o)){const e=o.match(a).join(""),t=n[n.length-1];t.post=e+t.post,r.post=r.post.replace(a,"")}},w=function(e,t,n,a){const[r,o,i]=t;0===o||i===a[r].length?y(n):(y(n),y([e[t[1]]])),function(e,t,n){const a=e[t];if(0!==t||!f(a.text))return;n[0].text=n[0].text.replace(/^\p{Ll}/u,(e=>e.toUpperCase()));const r=e[t];r.tags.has("ProperNoun")||r.tags.has("Acronym")||f(r.text)&&r.text.length>1&&(r.text=(o=r.text,o.replace(/^\p{Lu}/u,(e=>e.toLowerCase()))));var o}(e,o,n),b(e,o,n)};let k=0;const P=e=>(e=e.length<3?"0"+e:e).length<3?"0"+e:e,A=function(e){let[t,n]=e.index||[0,0];k+=1,k=k>46655?0:k,t=t>46655?0:t,n=n>1294?0:n;let a=P(k.toString(36));a+=P(t.toString(36));let r=n.toString(36);r=r.length<2?"0"+r:r,a+=r;return a+=parseInt(36*Math.random(),10).toString(36),e.normal+"|"+a.toUpperCase()},C=function(e){if(e.has("@hasContraction")&&"function"==typeof e.contractions){e.grow("@hasContraction").contractions().expand()}},j=e=>"[object Array]"===Object.prototype.toString.call(e),N=function(e,t,n){const{document:a,world:r}=t;t.uncache();const o=t.fullPointer,i=t.fullPointer;t.forEach(((s,l)=>{const u=s.fullPointer[0],[c]=u,d=a[c];let h=function(e,t){const{methods:n}=t;return"string"==typeof e?n.one.tokenize.fromString(e,t)[0]:"object"==typeof e&&e.isView?e.clone().docs[0]||[]:j(e)?j(e[0])?e[0]:e:[]}(e,r);0!==h.length&&(h=function(e){return e.map((e=>(e.id=A(e),e)))}(h),n?(C(t.update([u]).firstTerm()),w(d,u,h,a)):(C(t.update([u]).lastTerm()),function(e,t,n,a){const[r,,o]=t,i=(a[r]||[]).length;oe.replace(/^\p{Ll}/u,(e=>e.toUpperCase())),T=e=>e.replace(/^\p{Lu}/u,(e=>e.toLowerCase()));H.replaceWith=function(e,t={}){let n=this.fullPointer;const a=this;if(this.uncache(),"function"==typeof e)return function(e,t,n){return e.forEach((e=>{const a=t(e);e.replaceWith(a,n)})),e}(a,e,t);const r=a.docs[0];if(!r)return a;const o=t.possessives&&r[r.length-1].tags.has("Possessive"),i=t.case&&(s=r[0].text,/^\p{Lu}[\p{Ll}'’]/u.test(s)||/^\p{Lu}$/u.test(s));var s;e=function(e,t){if("string"!=typeof e)return e;const n=t.groups();return e=e.replace(D,(e=>{const t=e.replace(/\$/,"");return n.hasOwnProperty(t)?n[t].text():e})),e}(e,a);const l=this.update(n);n=n.map((e=>e.slice(0,3)));const u=(l.docs[0]||[]).map((e=>Array.from(e.tags))),c=l.docs[0][0].pre,d=l.docs[0][l.docs[0].length-1].post;if("string"==typeof e&&(e=this.fromText(e).compute("id")),a.insertAfter(e),l.has("@hasContraction")&&a.contractions){a.grow("@hasContraction+").contractions().expand()}if(a.delete(l),o){const e=a.docs[0],t=e[e.length-1];t.tags.has("Possessive")||(t.text+="'s",t.normal+="'s",t.tags.add("Possessive"))}if(c&&a.docs[0]&&(a.docs[0][0].pre=c),d&&a.docs[0]){const e=a.docs[0][a.docs[0].length-1];e.post.trim()||(e.post=d)}const h=a.toView(n).compute(["index","freeze","lexicon"]);if(h.world.compute.preTagger&&h.compute("preTagger"),h.compute("unfreeze"),t.tags&&h.terms().forEach(((e,t)=>{e.tagSafe(u[t])})),!h.docs[0]||!h.docs[0][0])return h;if(t.case){const e=i?G:T;h.docs[0][0].text=e(h.docs[0][0].text)}return h},H.replace=function(e,t,n){if(e&&!t)return this.replaceWith(e,n);const a=this.match(e);return a.found?(this.soften(),a.replaceWith(t,n)):this};const x={remove:function(e){const{indexN:t}=this.methods.one.pointer;this.uncache();let n=this.all(),a=this;e&&(n=this,a=this.match(e));const r=!n.ptrs;if(a.has("@hasContraction")&&a.contractions){a.grow("@hasContraction").contractions().expand()}let o=n.fullPointer;const i=a.fullPointer.reverse(),s=function(e,t){t.forEach((t=>{const[n,a,r]=t,o=r-a;e[n]&&(r===e[n].length&&r>1&&function(e,t){const n=e.length-1,a=e[n],r=e[n-t];r&&a&&(r.post+=a.post,r.post=r.post.replace(/ +([.?!,;:])/,"$1"),r.post=r.post.replace(/[,;:]+([.?!])/,"$1"))}(e[n],o),e[n].splice(a,o))}));for(let t=e.length-1;t>=0;t-=1)if(0===e[t].length&&(e.splice(t,1),t===e.length&&e[t-1])){const n=e[t-1],a=n[n.length-1];a&&(a.post=a.post.trimEnd())}return e}(this.document,i);if(o=function(e,t){return e=e.map((e=>{const[n]=e;return t[n]?(t[n].forEach((t=>{const n=t[2]-t[1];e[1]<=t[1]&&e[2]>=t[2]&&(e[2]-=n)})),e):e})),e.forEach(((t,n)=>{if(0===t[1]&&0==t[2])for(let t=n+1;te[2]-e[1]>0))).map((e=>(e[3]=null,e[4]=null,e)))}(o,t(i)),n.ptrs=o,n.document=s,n.compute("index"),r&&(n.ptrs=void 0),!e)return this.ptrs=[],n.none();return n.toView(o)}};x.delete=x.remove;const E={pre:function(e,t){return void 0===e&&this.found?this.docs[0][0].pre:(this.docs.forEach((n=>{const a=n[0];!0===t?a.pre+=e:a.pre=e})),this)},post:function(e,t){if(void 0===e){const e=this.docs[this.docs.length-1];return e[e.length-1].post}return this.docs.forEach((n=>{const a=n[n.length-1];!0===t?a.post+=e:a.post=e})),this},trim:function(){if(!this.found)return this;const e=this.docs,t=e[0][0];t.pre=t.pre.trimStart();const n=e[e.length-1],a=n[n.length-1];return a.post=a.post.trimEnd(),this},hyphenate:function(){return this.docs.forEach((e=>{e.forEach(((t,n)=>{0!==n&&(t.pre=""),e[n+1]&&(t.post="-")}))})),this},dehyphenate:function(){const e=/[-–—]/;return this.docs.forEach((t=>{t.forEach((t=>{e.test(t.post)&&(t.post=" ")}))})),this},toQuotations:function(e,t){return e=e||'"',t=t||'"',this.docs.forEach((n=>{n[0].pre=e+n[0].pre;const a=n[n.length-1];a.post=t+a.post})),this},toParentheses:function(e,t){return e=e||"(",t=t||")",this.docs.forEach((n=>{n[0].pre=e+n[0].pre;const a=n[n.length-1];a.post=t+a.post})),this}};E.deHyphenate=E.dehyphenate,E.toQuotation=E.toQuotations;var F={alpha:(e,t)=>e.normalt.normal?1:0,length:(e,t)=>{const n=e.normal.trim().length,a=t.normal.trim().length;return na?-1:0},wordCount:(e,t)=>e.wordst.words?-1:0,sequential:(e,t)=>e[0]t[0]?-1:e[1]>t[1]?1:-1,byFreq:function(e){const t={};return e.forEach((e=>{t[e.normal]=t[e.normal]||0,t[e.normal]+=1})),e.sort(((e,n)=>{const a=t[e.normal],r=t[n.normal];return ar?-1:0})),e}};const O=new Set(["index","sequence","seq","sequential","chron","chronological"]),z=new Set(["freq","frequency","topk","repeats"]),V=new Set(["alpha","alphabetical"]);var B={unique:function(){const e=new Set,t=this.filter((t=>{const n=t.text("machine");return!e.has(n)&&(e.add(n),!0)}));return t},reverse:function(){let e=this.pointer||this.docs.map(((e,t)=>[t]));return e=[].concat(e),e=e.reverse(),this._cache&&(this._cache=this._cache.reverse()),this.update(e)},sort:function(e){const{docs:t,pointer:n}=this;if(this.uncache(),"function"==typeof e)return function(e,t){let n=e.fullPointer;return n=n.sort(((n,a)=>(n=e.update([n]),a=e.update([a]),t(n,a)))),e.ptrs=n,e}(this,e);e=e||"alpha";const a=n||t.map(((e,t)=>[t]));let r=t.map(((e,t)=>({index:t,words:e.length,normal:e.map((e=>e.machine||e.normal||"")).join(" "),pointer:a[t]})));return O.has(e)&&(e="sequential"),V.has(e)&&(e="alpha"),z.has(e)?(r=F.byFreq(r),this.update(r.map((e=>e.pointer)))):"function"==typeof F[e]?(r=r.sort(F[e]),this.update(r.map((e=>e.pointer)))):this}};const S=function(e,t){if(e.length>0){const t=e[e.length-1],n=t[t.length-1];!1===/ /.test(n.post)&&(n.post+=" ")}return e=e.concat(t)};var K={concat:function(e){if("string"==typeof e){const t=this.fromText(e);if(this.found&&this.ptrs){const e=this.fullPointer,n=e[e.length-1][0];this.document.splice(n,0,...t.document)}else this.document=this.document.concat(t.document);return this.all().compute("index")}if("object"==typeof e&&e.isView)return function(e,t){if(e.document===t.document){const n=e.fullPointer.concat(t.fullPointer);return e.toView(n).compute("index")}return t.fullPointer.forEach((t=>{t[0]+=e.document.length})),e.document=S(e.document,t.docs),e.all()}(this,e);if(t=e,"[object Array]"===Object.prototype.toString.call(t)){const t=S(this.document,e);return this.document=t,this.all()}var t;return this}};var $={harden:function(){return this.ptrs=this.fullPointer,this},soften:function(){let e=this.ptrs;return!e||e.length<1||(e=e.map((e=>e.slice(0,3))),this.ptrs=e),this}};const L=Object.assign({},{toLowerCase:function(){return this.termList().forEach((e=>{e.text=e.text.toLowerCase()})),this},toUpperCase:function(){return this.termList().forEach((e=>{e.text=e.text.toUpperCase()})),this},toTitleCase:function(){return this.termList().forEach((e=>{e.text=e.text.replace(/^ *[a-z\u00C0-\u00FF]/,(e=>e.toUpperCase()))})),this},toCamelCase:function(){return this.docs.forEach((e=>{e.forEach(((t,n)=>{0!==n&&(t.text=t.text.replace(/^ *[a-z\u00C0-\u00FF]/,(e=>e.toUpperCase()))),n!==e.length-1&&(t.post="")}))})),this}},I,H,x,E,B,K,$),M={id:function(e){const t=e.docs;for(let e=0;e(e.implicit=e.text,e.machine=e.text,e.pre="",e.post="",e.text="",e.normal="",e.index=[a,r+t],e))),n[0]&&(n[0].pre=e[a][r].pre,n[n.length-1].post=e[a][r].post,n[0].text=e[a][r].text,n[0].normal=e[a][r].normal),e[a].splice(r,1,...n))},R=/'/,Q=new Set(["what","how","when","where","why"]),Z=new Set(["be","go","start","think","need"]),X=new Set(["been","gone"]),_=/'/,Y=/(e|é|aison|sion|tion)$/,ee=/(age|isme|acle|ege|oire)$/;var te=(e,t)=>["je",e[t].normal.split(_)[1]],ne=(e,t)=>{const n=e[t].normal.split(_)[1];return n&&n.endsWith("e")?["la",n]:["le",n]},ae=(e,t)=>{const n=e[t].normal.split(_)[1];return n&&Y.test(n)&&!ee.test(n)?["du",n]:n&&n.endsWith("s")?["des",n]:["de",n]};const re=/^([0-9.]{1,4}[a-z]{0,2}) ?[-–—] ?([0-9]{1,4}[a-z]{0,2})$/i,oe=/^([0-9]{1,2}(:[0-9][0-9])?(am|pm)?) ?[-–—] ?([0-9]{1,2}(:[0-9][0-9])?(am|pm)?)$/i,ie=/^[0-9]{3}-[0-9]{4}$/,se=function(e,t){const n=e[t];let a=n.text.match(re);return null!==a?!0===n.tags.has("PhoneNumber")||ie.test(n.text)?null:[a[1],"to",a[2]]:(a=n.text.match(oe),null!==a?[a[1],"to",a[4]]:null)},le=/^([+-]?[0-9][.,0-9]*)([a-z°²³µ/]+)$/,ue=function(e,t,n){const a=n.model.one.numberSuffixes||{},r=e[t].text.match(le);if(null!==r){const e=r[2].toLowerCase().trim();return a.hasOwnProperty(e)?null:[r[1],e]}return null},ce=/'/,de=/^[0-9][^-–—]*[-–—].*?[0-9]/,he=function(e,t,n,a){const r=t.update();r.document=[e];let o=n+a;n>0&&(n-=1),e[o]&&(o+=1),r.ptrs=[[0,n,o]]},ge={t:(e,t)=>function(e,t){return"ain't"===e[t].normal||"aint"===e[t].normal?null:[e[t].normal.replace(/n't/,""),"not"]}(e,t),d:(e,t)=>function(e,t){const n=e[t].normal.split(R)[0];if(Q.has(n))return[n,"did"];if(e[t+1]){if(X.has(e[t+1].normal))return[n,"had"];if(Z.has(e[t+1].normal))return[n,"would"]}return null}(e,t)},me={j:(e,t)=>te(e,t),l:(e,t)=>ne(e,t),d:(e,t)=>ae(e,t)},pe=function(e,t,n,a){for(let r=0;r2)return o.out.concat(a)}return null},fe=function(e,t){const n=t.fromText(e.join(" "));return n.compute(["id","alias"]),n.docs[0]},be=function(e,t){for(let n=t+1;n<5&&e[n];n+=1)if("been"===e[n].normal)return["there","has"];return["there","is"]};var ye={contractions:e=>{const{world:t,document:n}=e,{model:a,methods:r}=t,o=a.one.contractions||[];n.forEach(((a,i)=>{for(let s=a.length-1;s>=0;s-=1){let l=null,u=null;if(!0===ce.test(a[s].normal)){const e=a[s].normal.split(ce);l=e[0],u=e[1]}let c=pe(o,a[s],l,u);!c&&ge.hasOwnProperty(u)&&(c=ge[u](a,s,t)),!c&&me.hasOwnProperty(l)&&(c=me[l](a,s)),"there"===l&&"s"===u&&(c=be(a,s)),c?(c=fe(c,e),q(n,[i,s],c),he(n[i],e,s,c.length)):de.test(a[s].normal)?(c=se(a,s),c&&(c=fe(c,e),q(n,[i,s],c),r.one.setTag(c,"NumberRange",t),c[2]&&c[2].tags.has("Time")&&r.one.setTag([c[0]],"Time",t,null,"time-range"),he(n[i],e,s,c.length))):(c=ue(a,s,t),c&&(c=fe(c,e),q(n,[i,s],c),r.one.setTag([c[1]],"Unit",t,null,"contraction-unit")))}}))}};const ve={model:U,compute:ye,hooks:["contractions"]},we=function(e){const t=e.world,{model:n,methods:a}=e.world,r=a.one.setTag,{frozenLex:o}=n.one,i=n.one._multiCache||{};e.docs.forEach((e=>{for(let n=0;nn;a-=1){const i=e.slice(n,a+1),s=i.map((e=>e.machine||e.normal)).join(" ");!0!==o.hasOwnProperty(s)||(r(i,o[s],t,!1,"1-frozen-multi-lexicon"),i.forEach((e=>e.frozen=!0)))}}void 0!==o[s]&&o.hasOwnProperty(s)&&(r([a],o[s],t,!1,"1-freeze-lexicon"),a.frozen=!0)}}))};const ke=e=>"�[34m"+e+"�[0m",Pe=e=>"�[3m�[2m"+e+"�[0m",Ae=function(e){e.docs.forEach((e=>{console.log(ke("\n ┌─────────")),e.forEach((e=>{let t=` ${Pe("│")} `;const n=e.implicit||e.text||"-";!0===e.frozen?t+=`${ke(n)} ❄️`:t+=Pe(n),console.log(t)}))}))};var Ce={compute:{frozen:we,freeze:we,unfreeze:function(e){return e.docs.forEach((e=>{e.forEach((e=>{delete e.frozen}))})),e}},mutate:e=>{const t=e.methods.one;t.termMethods.isFrozen=e=>!0===e.frozen,t.debug.freeze=Ae,t.debug.frozen=Ae},api:function(e){e.prototype.freeze=function(){return this.docs.forEach((e=>{e.forEach((e=>{e.frozen=!0}))})),this},e.prototype.unfreeze=function(){this.compute("unfreeze")},e.prototype.isFrozen=function(){return this.match("@isFrozen+")}},hooks:["freeze"]};const je=function(e,t,n){const{model:a,methods:r}=n,o=r.one.setTag,i=a.one._multiCache||{},{lexicon:s}=a.one||{},l=e[t],u=l.machine||l.normal;if(void 0!==i[u]&&e[t+1]){for(let a=t+i[u]-1;a>t;a-=1){const r=e.slice(t,a+1);if(r.length<=1)return!1;const i=r.map((e=>e.machine||e.normal)).join(" ");if(!0===s.hasOwnProperty(i)){const e=s[i];return o(r,e,n,!1,"1-multi-lexicon"),!e||2!==e.length||"PhrasalVerb"!==e[0]&&"PhrasalVerb"!==e[1]||o([r[1]],"Particle",n,!1,"1-phrasal-particle"),!0}}return!1}return null},Ne=/^(under|over|mis|re|un|dis|semi|pre|post)-?/,Ie=new Set(["Verb","Infinitive","PastTense","Gerund","PresentTense","Adjective","Participle"]),De=function(e,t,n){const{model:a,methods:r}=n,o=r.one.setTag,{lexicon:i}=a.one,s=e[t],l=s.machine||s.normal;if(void 0!==i[l]&&i.hasOwnProperty(l))return o([s],i[l],n,!1,"1-lexicon"),!0;if(s.alias){const e=s.alias.find((e=>i.hasOwnProperty(e)));if(e)return o([s],i[e],n,!1,"1-lexicon-alias"),!0}if(!0===Ne.test(l)){const e=l.replace(Ne,"");if(i.hasOwnProperty(e)&&e.length>3&&Ie.has(i[e]))return o([s],i[e],n,!1,"1-lexicon-prefix"),!0}return null};var He={lexicon:function(e){const t=e.world;e.docs.forEach((e=>{for(let n=0;n{const r=e[a],o=(a=(a=a.toLowerCase().trim()).replace(/'s\b/,"")).split(/ /);o.length>1&&(void 0===n[o[0]]||o.length>n[o[0]])&&(n[o[0]]=o.length),t[a]=t[a]||r})),delete t[""],delete t.null,delete t[" "],{lex:t,_multi:n}}}};var Te={addWords:function(e,t=!1){const n=this.world(),{methods:a,model:r}=n;if(!e)return;if(Object.keys(e).forEach((t=>{"string"==typeof e[t]&&e[t].startsWith("#")&&(e[t]=e[t].replace(/^#/,""))})),!0===t){const{lex:t,_multi:o}=a.one.expandLexicon(e,n);return Object.assign(r.one._multiCache,o),void Object.assign(r.one.frozenLex,t)}if(a.two.expandLexicon){const{lex:t,_multi:o}=a.two.expandLexicon(e,n);Object.assign(r.one.lexicon,t),Object.assign(r.one._multiCache,o)}const{lex:o,_multi:i}=a.one.expandLexicon(e,n);Object.assign(r.one.lexicon,o),Object.assign(r.one._multiCache,i)}};var xe={model:{one:{lexicon:{},_multiCache:{},frozenLex:{}}},methods:Ge,compute:He,lib:Te,hooks:["lexicon"]};const Ee=function(e,t){const n=[{}],a=[null],r=[0],o=[];let i=0;e.forEach((function(e){let r=0;const o=function(e,t){const{methods:n,model:a}=t,r=n.one.tokenize.splitTerms(e,a).map((e=>n.one.tokenize.splitWhitespace(e,a)));return r.map((e=>e.text.toLowerCase()))}(e,t);for(let e=0;e0&&!n[i].hasOwnProperty(l);)i=r[i];if(n.hasOwnProperty(i)){const e=n[i][l];r[u]=e,a[e]&&(a[u]=a[u]||[],a[u]=a[u].concat(a[e]))}else r[u]=0}}return{goNext:n,endAs:a,failTo:r}},Fe=function(e,t,n){let a=0;const r=[];for(let o=0;o0&&(void 0===t.goNext[a]||!t.goNext[a].hasOwnProperty(i));)a=t.failTo[a]||0;if(t.goNext[a].hasOwnProperty(i)&&(a=t.goNext[a][i],t.endAs[a])){const n=t.endAs[a];for(let t=0;t{for(let n=e.length-1;n>=0;n-=1)if(e[n]!==t)return e=e.slice(0,n+1);return e},Ve={buildTrie:function(e){return function(e){return e.goNext=e.goNext.map((e=>{if(0!==Object.keys(e).length)return e})),e.goNext=ze(e.goNext,void 0),e.failTo=ze(e.failTo,0),e.endAs=ze(e.endAs,null),e}(Ee(e,this.world()))}};Ve.compile=Ve.buildTrie;var Be={api:function(e){e.prototype.lookup=function(e,t={}){if(!e)return this.none();"string"==typeof e&&(e=[e]);var n;let a=function(e,t,n){let a=[];n.form=n.form||"normal";const r=e.docs;if(!t.goNext||!t.goNext[0])return console.error("Compromise invalid lookup trie"),e.none();const o=Object.keys(t.goNext[0]);for(let i=0;i0&&(a=a.concat(l))}return e.update(a)}(this,(n=e,"[object Object]"===Object.prototype.toString.call(n)?e:Ee(e,this.world)),t);return a=a.settle(),a}},lib:Ve};const Se=function(e,t){return t?(e.forEach((e=>{const n=e[0];t[n]&&(e[0]=t[n][0],e[1]+=t[n][1],e[2]+=t[n][1])})),e):e},Ke=function(e,t){let{ptrs:n}=e;const{byGroup:a}=e;return n=Se(n,t),Object.keys(a).forEach((e=>{a[e]=Se(a[e],t)})),{ptrs:n,byGroup:a}},$e=function(e,t,n){const a=n.methods.one;return"number"==typeof e&&(e=String(e)),"string"==typeof e&&(e=a.killUnicode(e,n),e=a.parseMatch(e,t,n)),e},Le=e=>"[object Object]"===Object.prototype.toString.call(e),Me=e=>e&&Le(e)&&!0===e.isView,Je=e=>e&&Le(e)&&!0===e.isNet;var We={matchOne:function(e,t,n){const a=this.methods.one;if(Me(e))return this.intersection(e).eq(0);if(Je(e))return this.sweep(e,{tagger:!1,matchOne:!0}).view;const r={regs:e=$e(e,n,this.world),group:t,justOne:!0},o=a.match(this.docs,r,this._cache),{ptrs:i,byGroup:s}=Ke(o,this.fullPointer),l=this.toView(i);return l._groups=s,l},match:function(e,t,n){const a=this.methods.one;if(Me(e))return this.intersection(e);if(Je(e))return this.sweep(e,{tagger:!1}).view.settle();const r={regs:e=$e(e,n,this.world),group:t},o=a.match(this.docs,r,this._cache),{ptrs:i,byGroup:s}=Ke(o,this.fullPointer),l=this.toView(i);return l._groups=s,l},has:function(e,t,n){const a=this.methods.one;if(Me(e)){return this.intersection(e).fullPointer.length>0}if(Je(e))return this.sweep(e,{tagger:!1}).view.found;const r={regs:e=$e(e,n,this.world),group:t,justOne:!0};return a.match(this.docs,r,this._cache).ptrs.length>0},if:function(e,t,n){const a=this.methods.one;if(Me(e))return this.filter((t=>t.intersection(e).found));if(Je(e)){const t=this.sweep(e,{tagger:!1}).view.settle();return this.if(t)}const r={regs:e=$e(e,n,this.world),group:t,justOne:!0};let o=this.fullPointer;const i=this._cache||[];o=o.filter(((e,t)=>{const n=this.update([e]);return a.match(n.docs,r,i[t]).ptrs.length>0}));const s=this.update(o);return this._cache&&(s._cache=o.map((e=>i[e[0]]))),s},ifNo:function(e,t,n){const{methods:a}=this,r=a.one;if(Me(e))return this.filter((t=>!t.intersection(e).found));if(Je(e)){const t=this.sweep(e,{tagger:!1}).view.settle();return this.ifNo(t)}e=$e(e,n,this.world);const o=this._cache||[],i=this.filter(((n,a)=>{const i={regs:e,group:t,justOne:!0};return 0===r.match(n.docs,i,o[a]).ptrs.length}));return this._cache&&(i._cache=i.ptrs.map((e=>o[e[0]]))),i}};var Ue={before:function(e,t,n){const{indexN:a}=this.methods.one.pointer,r=[],o=a(this.fullPointer);Object.keys(o).forEach((e=>{const t=o[e].sort(((e,t)=>e[1]>t[1]?1:-1))[0];t[1]>0&&r.push([t[0],0,t[1]])}));const i=this.toView(r);return e?i.match(e,t,n):i},after:function(e,t,n){const{indexN:a}=this.methods.one.pointer,r=[],o=a(this.fullPointer),i=this.document;Object.keys(o).forEach((e=>{const t=o[e].sort(((e,t)=>e[1]>t[1]?-1:1))[0],[n,,a]=t;a{const o=n.before(e,t);if(o.found){const e=o.terms();a[r][1]-=e.length,a[r][3]=e.docs[0][0].id}})),this.update(a)},growRight:function(e,t,n){"string"==typeof e&&(e=this.world.methods.one.parseMatch(e,n,this.world)),e[0].start=!0;const a=this.fullPointer;return this.forEach(((n,r)=>{const o=n.after(e,t);if(o.found){const e=o.terms();a[r][2]+=e.length,a[r][4]=null}})),this.update(a)},grow:function(e,t,n){return this.growRight(e,t,n).growLeft(e,t,n)}};const qe=function(e,t){return[e[0],e[1],t[2]]},Re=(e,t,n)=>{return"string"==typeof e||(a=e,"[object Array]"===Object.prototype.toString.call(a))?t.match(e,n):e||t.none();var a},Qe=function(e,t){const[n,a,r]=e;return t.document[n]&&t.document[n][a]&&(e[3]=e[3]||t.document[n][a].id,t.document[n][r-1]&&(e[4]=e[4]||t.document[n][r-1].id)),e},Ze={splitOn:function(e,t){const{splitAll:n}=this.methods.one.pointer,a=Re(e,this,t).fullPointer,r=n(this.fullPointer,a);let o=[];return r.forEach((e=>{o.push(e.passthrough),o.push(e.before),o.push(e.match),o.push(e.after)})),o=o.filter((e=>e)),o=o.map((e=>Qe(e,this))),this.update(o)},splitBefore:function(e,t){const{splitAll:n}=this.methods.one.pointer,a=Re(e,this,t).fullPointer,r=n(this.fullPointer,a);for(let e=0;e{o.push(e.passthrough),o.push(e.before),e.match&&e.after?o.push(qe(e.match,e.after)):o.push(e.match)})),o=o.filter((e=>e)),o=o.map((e=>Qe(e,this))),this.update(o)},splitAfter:function(e,t){const{splitAll:n}=this.methods.one.pointer,a=Re(e,this,t).fullPointer,r=n(this.fullPointer,a);let o=[];return r.forEach((e=>{o.push(e.passthrough),e.before&&e.match?o.push(qe(e.before,e.match)):(o.push(e.before),o.push(e.match)),o.push(e.after)})),o=o.filter((e=>e)),o=o.map((e=>Qe(e,this))),this.update(o)}};Ze.split=Ze.splitAfter;const Xe=function(e,t){return!(!e||!t)&&(e[0]===t[0]&&e[2]===t[1])},_e=function(e,t,n){const a=e.world,r=a.methods.one.parseMatch;n=n||"^.";const o=r(t=t||".$",{},a),i=r(n,{},a);o[o.length-1].end=!0,i[0].start=!0;const s=e.fullPointer,l=[s[0]];for(let t=1;t)?\/.*?[^\\/]\/[?\]+*$~]*)(?:\s|$)/,nt=/([!~[^]*(?:<[^<]*>)?\([^)]+[^\\)]\)[?\]+*$~]*)(?:\s|$)/,at=/ /g,rt=e=>/^[![^]*(<[^<]*>)?\//.test(e)&&/\/[?\]+*$~]*$/.test(e),ot=function(e){return e=(e=e.map((e=>e.trim()))).filter((e=>e))},it=/\{([0-9]+)?(, *[0-9]*)?\}/,st=/&&/,lt=new RegExp(/^<\s*(\S+)\s*>/),ut=e=>e.charAt(0).toUpperCase()+e.substring(1),ct=e=>e.charAt(e.length-1),dt=e=>e.charAt(0),ht=e=>e.substring(1),gt=e=>e.substring(0,e.length-1),mt=function(e){return e=ht(e),e=gt(e)},pt=function(e,t){const n={};for(let a=0;a<2;a+=1){if("$"===ct(e)&&(n.end=!0,e=gt(e)),"^"===dt(e)&&(n.start=!0,e=ht(e)),"?"===ct(e)&&(n.optional=!0,e=gt(e)),("["===dt(e)||"]"===ct(e))&&(n.group=null,"["===dt(e)&&(n.groupStart=!0),"]"===ct(e)&&(n.groupEnd=!0),e=(e=e.replace(/^\[/,"")).replace(/\]$/,""),"<"===dt(e))){const t=lt.exec(e);t.length>=2&&(n.group=t[1],e=e.replace(t[0],""))}if("+"===ct(e)&&(n.greedy=!0,e=gt(e)),"*"!==e&&"*"===ct(e)&&"\\*"!==e&&(n.greedy=!0,e=gt(e)),"!"===dt(e)&&(n.negative=!0,e=ht(e)),"~"===dt(e)&&"~"===ct(e)&&e.length>2&&(e=mt(e),n.fuzzy=!0,n.min=t.fuzzy||.85,!1===/\(/.test(e)))return n.word=e,n;if("/"===dt(e)&&"/"===ct(e))return e=mt(e),t.caseSensitive&&(n.use="text"),n.regex=new RegExp(e),n;if(!0===it.test(e)&&(e=e.replace(it,((e,t,a)=>(void 0===a?(n.min=Number(t),n.max=Number(t)):(a=a.replace(/, */,""),void 0===t?(n.min=0,n.max=Number(a)):(n.min=Number(t),n.max=Number(a||999))),n.greedy=!0,n.min||(n.optional=!0),"")))),"("===dt(e)&&")"===ct(e)){st.test(e)?(n.choices=e.split(st),n.operator="and"):(n.choices=e.split("|"),n.operator="or"),n.choices[0]=ht(n.choices[0]);const a=n.choices.length-1;n.choices[a]=gt(n.choices[a]),n.choices=n.choices.map((e=>e.trim())),n.choices=n.choices.filter((e=>e)),n.choices=n.choices.map((e=>e.split(/ /g).map((e=>pt(e,t))))),e=""}if("{"===dt(e)&&"}"===ct(e)){if(e=mt(e),n.root=e,/\//.test(e)){const e=n.root.split(/\//);n.root=e[0],n.pos=e[1],"adj"===n.pos&&(n.pos="Adjective"),n.pos=n.pos.charAt(0).toUpperCase()+n.pos.substr(1).toLowerCase(),void 0!==e[2]&&(n.sense=e[2])}return n}if("<"===dt(e)&&">"===ct(e))return e=mt(e),n.chunk=ut(e),n.greedy=!0,n;if("%"===dt(e)&&"%"===ct(e))return e=mt(e),n.switch=e,n}return"#"===dt(e)?(n.tag=ht(e),n.tag=ut(n.tag),n):"@"===dt(e)?(n.method=ht(e),n):"."===e?(n.anything=!0,n):"*"===e?(n.anything=!0,n.greedy=!0,n.optional=!0,n):(e&&(e=(e=e.replace("\\*","*")).replace("\\.","."),t.caseSensitive?n.use="text":e=e.toLowerCase(),n.word=e),n)},ft=/[a-z0-9][-–—][a-z]/i,bt=function(e,t){const{all:n}=t.methods.two.transform.verb||{},a=e.root;return n?n(a,t.model):[]},yt=function(e,t){const{all:n}=t.methods.two.transform.noun||{};return n?n(e.root,t.model):[e.root]},vt=function(e,t){const{all:n}=t.methods.two.transform.adjective||{};return n?n(e.root,t.model):[e.root]},wt=function(e){return e=function(e){let t=0,n=null;for(let a=0;a(e.fuzzy&&e.choices&&e.choices.forEach((t=>{1===t.length&&t[0].word&&(t[0].fuzzy=!0,t[0].min=e.min)})),e)))}(e=e.map((e=>{if(void 0!==e.choices){if("or"!==e.operator)return e;if(!0===e.fuzzy)return e;!0===e.choices.every((e=>{if(1!==e.length)return!1;const t=e[0];return!0!==t.fuzzy&&!t.start&&!t.end&&void 0!==t.word&&!0!==t.negative&&!0!==t.optional&&!0!==t.method}))&&(e.fastOr=new Set,e.choices.forEach((t=>{e.fastOr.add(t[0].word)})),delete e.choices)}return e}))),e},kt=function(e,t){for(const n of t)if(e.has(n))return!0;return!1},Pt=function(e,t){for(let n=0;nn?a:n)+1;if(Math.abs(n-a)>(r||100))return r||100;const o=[];for(let e=0;e4)return n;l=t[i-1],u=s===l?0:1,c=o[r-1][i]+1,(d=o[r][i-1]+1)1&&i>1&&s===t[i-2]&&e[r-2]===l&&(d=o[r-2][i-2]+u)-1!==e.post.indexOf(t),Ht={hasQuote:e=>Ct.test(e.pre)||jt.test(e.post),hasComma:e=>Dt(e,","),hasPeriod:e=>!0===Dt(e,".")&&!1===Dt(e,"..."),hasExclamation:e=>Dt(e,"!"),hasQuestionMark:e=>Dt(e,"?")||Dt(e,"¿"),hasEllipses:e=>Dt(e,"..")||Dt(e,"…"),hasSemicolon:e=>Dt(e,";"),hasColon:e=>Dt(e,":"),hasSlash:e=>/\//.test(e.text),hasHyphen:e=>Nt.test(e.post)||Nt.test(e.pre),hasDash:e=>It.test(e.post)||It.test(e.pre),hasContraction:e=>Boolean(e.implicit),isAcronym:e=>e.tags.has("Acronym"),isKnown:e=>e.tags.size>0,isTitleCase:e=>/^\p{Lu}[a-z'\u00C0-\u00FF]/u.test(e.text),isUpperCase:e=>/^\p{Lu}+$/u.test(e.text)};Ht.hasQuotation=Ht.hasQuote;let Gt=function(){};Gt=function(e,t,n,a){const r=function(e,t,n,a){if(!0===t.anything)return!0;if(!0===t.start&&0!==n)return!1;if(!0===t.end&&n!==a-1)return!1;if(void 0!==t.id&&t.id===e.id)return!0;if(void 0!==t.word){if(t.use)return t.word===e[t.use];if(null!==e.machine&&e.machine===t.word)return!0;if(void 0!==e.alias&&e.alias.hasOwnProperty(t.word))return!0;if(!0===t.fuzzy){if(t.word===e.root)return!0;if(At(t.word,e.normal)>=t.min)return!0}return!(!e.alias||!e.alias.some((e=>e===t.word)))||t.word===e.text||t.word===e.normal}if(void 0!==t.tag)return!0===e.tags.has(t.tag);if(void 0!==t.method)return"function"==typeof Ht[t.method]&&!0===Ht[t.method](e);if(void 0!==t.pre)return e.pre&&e.pre.includes(t.pre);if(void 0!==t.post)return e.post&&e.post.includes(t.post);if(void 0!==t.regex){let n=e.normal;return t.use&&(n=e[t.use]),t.regex.test(n)}if(void 0!==t.chunk)return e.chunk===t.chunk;if(void 0!==t.switch)return e.switch===t.switch;if(void 0!==t.machine)return e.normal===t.machine||e.machine===t.machine||e.root===t.machine;if(void 0!==t.sense)return e.sense===t.sense;if(void 0!==t.fastOr){if(t.pos&&!e.tags.has(t.pos))return null;const n=e.root||e.implicit||e.machine||e.normal;return t.fastOr.has(n)||t.fastOr.has(e.text)}return void 0!==t.choices&&("and"===t.operator?t.choices.every((t=>Gt(e,t,n,a))):t.choices.some((t=>Gt(e,t,n,a))))}(e,t,n,a);return!0===t.negative?!r:r};const Tt=function(e,t){if(!0===e.end&&!0===e.greedy&&t.start_i+t.tn.max)return e.t=e.t+n.max,!0;if(!0===e.hasGroup){xt(e,e.t).length=a-e.t}return e.t=a,!0},Ft=function(e,t=0){const n=e.regs[e.r];let a=!1;for(let o=0;o{let r=0;const o=e.t+a+t+r;if(void 0===e.terms[o])return!1;const i=Gt(e.terms[o],n,o+e.start_i,e.phrase_length);if(!0===i&&!0===n.greedy)for(let t=1;t{const a=n.every(((t,n)=>{const a=e.t+n;return void 0!==e.terms[a]&&Gt(e.terms[a],t,a,e.phrase_length)}));return!0===a&&n.length>t&&(t=n.length),a}))&&t}(e);if(a){if(!0===n.negative)return null;if(!0===e.hasGroup){xt(e,e.t).length+=a}if(!0===n.end){const t=e.phrase_length-1;if(e.t+e.start_i!==t)return null}return e.t+=a,!0}return!!n.optional||null},Vt=function(e){const{regs:t}=e,n=t[e.r],a=Object.assign({},n);a.negative=!1;if(Gt(e.terms[e.t],a,e.start_i+e.t,e.phrase_length))return!1;if(n.optional){const n=t[e.r+1];if(n){if(Gt(e.terms[e.t],n,e.start_i+e.t,e.phrase_length))e.r+=1;else if(n.optional&&t[e.r+2]){Gt(e.terms[e.t],t[e.r+2],e.start_i+e.t,e.phrase_length)&&(e.r+=2)}}}return n.greedy?function(e,t,n){let a=0;for(let r=e.t;ra||(e.t+=a,0))}(e,a,t[e.r+1]):(e.t+=1,!0)},Bt=function(e){const{regs:t,phrase_length:n}=e,a=t[e.r];return e.t=function(e,t){const n=Object.assign({},e.regs[e.r],{start:!1,end:!1}),a=e.t;for(;e.te.t?null:!0!==a.end||e.start_i+e.t===n||null},St=function(e){const{regs:t}=e,n=t[e.r],a=e.terms[e.t],r=e.t;if(n.optional&&t[e.r+1]&&n.negative)return!0;if(n.optional&&t[e.r+1]&&function(e){const{regs:t}=e,n=t[e.r],a=e.terms[e.t],r=Gt(a,t[e.r+1],e.start_i+e.t,e.phrase_length);if(n.negative||r){const n=e.terms[e.t+1];n&&Gt(n,t[e.r+1],e.start_i+e.t,e.phrase_length)||(e.r+=1)}}(e),a.implicit&&e.terms[e.t+1]&&function(e){const t=e.terms[e.t],n=e.regs[e.r];if(t.implicit&&e.terms[e.t+1]){if(!e.terms[e.t+1].implicit)return;n.word===t.normal&&(e.t+=1),"hasContraction"===n.method&&(e.t+=1)}}(e),e.t+=1,!0===n.end&&e.t!==e.terms.length&&!0!==n.greedy)return null;if(!0===n.greedy){if(!Bt(e))return null}return!0===e.hasGroup&&function(e,t){const n=e.regs[e.r],a=xt(e,t);e.t>1&&n.greedy?a.length+=e.t-t:a.length++}(e,r),!0},Kt=function(e,t,n,a){if(0===e.length||0===t.length)return null;const r={t:0,terms:e,r:0,regs:t,groups:{},start_i:n,phrase_length:a,inGroup:null};for(;r.r!e.optional)))break;return null}if(!0===e.anything&&!0===e.greedy){if(!Et(r))return null;continue}if(void 0!==e.choices&&"or"===e.operator){if(!Ot(r))return null;continue}if(void 0!==e.choices&&"and"===e.operator){if(!zt(r))return null;continue}if(!0===e.anything){if(e.negative&&e.anything)return null;if(!St(r))return null;continue}if(!0===Tt(e,r)){if(!St(r))return null;continue}if(e.negative){if(!Vt(r))return null;continue}if(!0!==Gt(r.terms[r.t],e,r.start_i+r.t,r.phrase_length)){if(!0!==e.optional)return null}else{if(!St(r))return null}}const o=[null,n,r.t+n];if(o[1]===o[2])return null;const i={};return Object.keys(r.groups).forEach((e=>{const t=r.groups[e],a=n+t.start;i[e]=[null,a,a+t.length]})),{pointer:o,groups:i}},$t=function(e,t){return e.pointer[0]=t,Object.keys(e.groups).forEach((n=>{e.groups[n][0]=t})),e},Lt=function(e,t,n){let a=Kt(e,t,0,e.length);return a?(a=$t(a,n),a):null},Mt={one:{termMethods:Ht,parseMatch:function(e,t,n){if(null==e||""===e)return[];t=t||{},"number"==typeof e&&(e=String(e));let a=function(e){const t=e.split(tt);let n=[];t.forEach((e=>{rt(e)?n.push(e):n=n.concat(e.split(nt))})),n=ot(n);let a=[];return n.forEach((e=>{(e=>/^[![^]*(<[^<]*>)?\(/.test(e)&&/\)[?\]+*$~]*$/.test(e))(e)||rt(e)?a.push(e):a=a.concat(e.split(at))})),a=ot(a),a}(e);return a=a.map((e=>pt(e,t))),a=function(e,t){const n=t.model.one.prefixes;for(let t=e.length-1;t>=0;t-=1){const a=e[t];if(a.word&&ft.test(a.word)){let r=a.word.split(/[-–—]/g);if(n.hasOwnProperty(r[0]))continue;r=r.filter((e=>e)).reverse(),e.splice(t,1),r.forEach((n=>{const r=Object.assign({},a);r.word=n,e.splice(t,0,r)}))}}return e}(a,n),a=function(e,t){return e.map((e=>{if(e.root)if(t.methods.two&&t.methods.two.transform){let n=[];e.pos?"Verb"===e.pos?n=n.concat(bt(e,t)):"Noun"===e.pos?n=n.concat(yt(e,t)):"Adjective"===e.pos&&(n=n.concat(vt(e,t))):(n=n.concat(bt(e,t)),n=n.concat(yt(e,t)),n=n.concat(vt(e,t))),n=n.filter((e=>e)),n.length>0&&(e.operator="or",e.fastOr=new Set(n))}else e.machine=e.root,delete e.id,delete e.root;return e}))}(a,n),a=wt(a),a},match:function(e,t,n){n=n||[];const{regs:a,group:r,justOne:o}=t;let i=[];if(!a||0===a.length)return{ptrs:[],byGroup:{}};const s=a.filter((e=>!0!==e.optional&&!0!==e.negative)).length;e:for(let t=0;te&&(e=Math.abs(n-1))}}else{const e=Lt(r,a,t);e&&i.push(e)}}return!0===a[a.length-1].end&&(i=i.filter((t=>{const n=t.pointer[0];return e[n].length===t.pointer[2]}))),t.notIf&&(i=function(e,t,n){return e=e.filter((e=>{const[a,r,o]=e.pointer,i=n[a].slice(r,o);for(let e=0;e{e.groups[t]&&n.push(e.groups[t])})):e.forEach((e=>{n.push(e.pointer),Object.keys(e.groups).forEach((t=>{a[t]=a[t]||[],a[t].push(e.groups[t])}))}))),{ptrs:n,byGroup:a}}(i,r),i.ptrs.forEach((t=>{const[n,a,r]=t;t[3]=e[n][a].id,t[4]=e[n][r-1].id})),i}}};var Jt={api:function(e){Object.assign(e.prototype,et)},methods:Mt,lib:{parseMatch:function(e,t){const n=this.world(),a=n.methods.one.killUnicode;return a&&(e=a(e,n)),n.methods.one.parseMatch(e,t,n)}}};const Wt=/^\../,Ut=/^#./,qt=function(e,t){const n={},a={};return Object.keys(t).forEach((r=>{let o=t[r];const i=function(e){let t="",n=" ";return e=e.replace(/&/g,"&").replace(//g,">").replace(/"/g,""").replace(/'/g,"'"),Wt.test(e)?t=``),t+=">",{start:t,end:n}}(r);"string"==typeof o&&(o=e.match(o)),o.docs.forEach((e=>{if(e.every((e=>e.implicit)))return;const t=e[0].id;n[t]=n[t]||[],n[t].push(i.start);const r=e[e.length-1].id;a[r]=a[r]||[],a[r].push(i.end)}))})),{starts:n,ends:a}};var Rt={html:function(e){const{starts:t,ends:n}=qt(this,e);let a="";return this.docs.forEach((e=>{for(let r=0;r{let n=e.pre||"",r=e.post||"";"some"===t.punctuation&&(n=n.replace(Zt,""),_t.test(r)&&(r=" "),r=r.replace(Xt,""),r=r.replace(/\?!+/,"?"),r=r.replace(/!+/,"!"),r=r.replace(/\?+/,"?"),r=r.replace(/\.{2,}/,""),e.tags.has("Abbreviation")&&(r=r.replace(/\./,""))),"some"===t.whitespace&&(n=n.replace(/\s/,""),r=r.replace(/\s+/," ")),t.keepPunct||(n=n.replace(Zt,""),r="-"===r?" ":r.replace(Qt,""));let o=e[t.form||"text"]||e.normal||"";"implicit"===t.form&&(o=e.implicit||e.text),"root"===t.form&&e.implicit&&(o=e.root||e.implicit||e.normal),"machine"!==t.form&&"implicit"!==t.form&&"root"!==t.form||!e.implicit||r&&Yt.test(r)||(r+=" "),a+=n+o+r})),!1===n&&(a=a.trim()),!0===t.lowerCase&&(a=a.toLowerCase()),a},tn={text:{form:"text"},normal:{whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"normal"},machine:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"none",unicode:"some",form:"machine"},root:{keepSpace:!1,whitespace:"some",punctuation:"some",case:"some",unicode:"some",form:"root"},implicit:{form:"implicit"}};tn.clean=tn.normal,tn.reduced=tn.root;const nn=[];let an=0;for(;an<64;)nn[an]=0|4294967296*Math.sin(++an%Math.PI);const rn=function(e){let t,n,a,r=decodeURI(encodeURI(e))+"",o=r.length;const i=[t=1732584193,n=4023233417,~t,~n],s=[];for(e=--o/4+2|15,s[--e]=8*o;~o;)s[o>>2]|=r.charCodeAt(o)<<8*o--;for(an=r=0;an>4]+nn[r]+~~s[an|15&[r,5*r+1,3*r+5,7*r][o]])<<(o=[7,12,17,22,5,9,14,20,4,11,16,23,6,10,15,21][4*o+r++%4])|a>>>-o),t,n])t=0|o[1],n=o[2];for(r=4;r;)i[--r]+=o[r]}for(e="";r<32;)e+=(i[r>>3]>>4*(1^r++)&15).toString(16);return e},on={text:!0,terms:!0},sn={case:"none",unicode:"some",form:"machine",punctuation:"some"},ln=function(e,t){return Object.assign({},e,t)},un={text:e=>en(e,{keepPunct:!0},!1),normal:e=>en(e,ln(tn.normal,{keepPunct:!0}),!1),implicit:e=>en(e,ln(tn.implicit,{keepPunct:!0}),!1),machine:e=>en(e,sn,!1),root:e=>en(e,ln(sn,{form:"root"}),!1),hash:e=>rn(en(e,{keepPunct:!0},!1)),offset:e=>{const t=un.text(e).length;return{index:e[0].offset.index,start:e[0].offset.start,length:t}},terms:e=>e.map((e=>{const t=Object.assign({},e);return t.tags=Array.from(e.tags),t})),confidence:(e,t,n)=>t.eq(n).confidence(),syllables:(e,t,n)=>t.eq(n).syllables(),sentence:(e,t,n)=>t.eq(n).fullSentence().text(),dirty:e=>e.some((e=>!0===e.dirty))};un.sentences=un.sentence,un.clean=un.normal,un.reduced=un.root;const cn={json:function(e){const t=(n=this,"string"==typeof(a=(a=e)||{})&&(a={}),(a=Object.assign({},on,a)).offset&&n.compute("offset"),n.docs.map(((e,t)=>{const r={};return Object.keys(a).forEach((o=>{a[o]&&un[o]&&(r[o]=un[o](e,n,t))})),r})));var n,a;return"number"==typeof e?t[e]:t}};cn.data=cn.json;const dn=function(e){const t=e.pre||"",n=e.post||"";return t+e.text+n},hn=function(e,t){const n=function(e,t){const n={};return Object.keys(t).forEach((a=>{e.match(a).fullPointer.forEach((e=>{n[e[3]]={fn:t[a],end:e[2]}}))})),n}(e,t);let a="";return e.docs.forEach(((t,r)=>{for(let o=0;oe.reduce(((e,t)=>e+t.pre+t.text+t.post),"").trim()));return e.filter((e=>e))}if("freq"===e||"frequency"===e||"topk"===e)return function(e){const t={};e.forEach((e=>{t[e]=t[e]||0,t[e]+=1}));const n=Object.keys(t).map((e=>({normal:e,count:t[e]})));return n.sort(((e,t)=>e.count>t.count?-1:0))}(this.json({normal:!0}).map((e=>e.normal)));if("terms"===e){let e=[];return this.docs.forEach((t=>{let n=t.map((e=>e.text));n=n.filter((e=>e)),e=e.concat(n)})),e}return"tags"===e?this.docs.map((e=>e.reduce(((e,t)=>(e[t.implicit||t.normal]=Array.from(t.tags),e)),{}))):"debug"===e?this.debug():this.text()},wrap:function(e){return hn(this,e)}};var mn={text:function(e){let t={};var n;if(e&&"string"==typeof e&&tn.hasOwnProperty(e)?t=Object.assign({},tn[e]):e&&(n=e,"[object Object]"===Object.prototype.toString.call(n))&&(t=Object.assign({},e)),void 0!==t.keepSpace||this.isFull()||(t.keepSpace=!1),void 0===t.keepEndPunct&&this.pointer){const e=this.pointer[0];e&&e[1]?t.keepEndPunct=!1:t.keepEndPunct=!0}return void 0===t.keepPunct&&(t.keepPunct=!0),void 0===t.keepSpace&&(t.keepSpace=!0),function(e,t){let n="";if(!e||!e[0]||!e[0][0])return n;for(let a=0;a"�[32m"+e+fn,red:e=>"�[31m"+e+fn,blue:e=>"�[34m"+e+fn,magenta:e=>"�[35m"+e+fn,cyan:e=>"�[36m"+e+fn,yellow:e=>"�[33m"+e+fn,black:e=>"�[30m"+e+fn,dim:e=>"�[2m"+e+fn,i:e=>"�[3m"+e+fn},yn={tags:function(e){const{docs:t,model:n}=e;0===t.length&&console.log(bn.blue("\n ──────")),t.forEach((t=>{console.log(bn.blue("\n ┌─────────")),t.forEach((t=>{const a=[...t.tags||[]];let r=t.text||"-";t.sense&&(r=`{${t.normal}/${t.sense}}`),t.implicit&&(r="["+t.implicit+"]"),r=bn.yellow(r);let o="'"+r+"'";if(t.reference){const n=e.update([t.reference]).text("normal");o+=` - ${bn.dim(bn.i("["+n+"]"))}`}o=o.padEnd(18);const i=bn.blue(" │ ")+bn.i(o)+" - "+function(e,t){return t.one.tagSet&&(e=e.map((e=>{if(!t.one.tagSet.hasOwnProperty(e))return e;const n=t.one.tagSet[e].color||"blue";return bn[n](e)}))),e.join(", ")}(a,n);console.log(i)}))})),console.log("\n")},clientSide:function(e){console.log("%c -=-=- ","background-color:#6699cc;"),e.forEach((e=>{console.groupCollapsed(e.text());const t=e.docs[0].map((e=>{let t=e.text||"-";e.implicit&&(t="["+e.implicit+"]");return{text:t,tags:"["+Array.from(e.tags).join(", ")+"]"}}));console.table(t,["text","tags"]),console.groupEnd()}))},chunks:function(e){const{docs:t}=e;console.log(""),t.forEach((e=>{const t=[];e.forEach((e=>{"Noun"===e.chunk?t.push(bn.blue(e.implicit||e.normal)):"Verb"===e.chunk?t.push(bn.green(e.implicit||e.normal)):"Adjective"===e.chunk?t.push(bn.yellow(e.implicit||e.normal)):"Pivot"===e.chunk?t.push(bn.red(e.implicit||e.normal)):t.push(e.implicit||e.normal)})),console.log(t.join(" "),"\n")})),console.log("\n")},highlight:function(e){if(!e.found)return;const t={};e.fullPointer.forEach((e=>{t[e[0]]=t[e[0]]||[],t[e[0]].push(e)})),Object.keys(t).forEach((n=>{let a=e.update([[Number(n)]]).text();e.update(t[n]).json({offset:!0}).forEach(((e,t)=>{a=function(e,t,n){const a=((e,t,n)=>{const a=9*n,r=t.start+a,o=r+t.length;return[e.substring(0,r),e.substring(r,o),e.substring(o,e.length)]})(e,t,n);return`${a[0]}${bn.blue(a[1])}${a[2]}`}(a,e.offset,t)})),console.log(a)})),console.log("\n")}};var vn={api:function(e){Object.assign(e.prototype,pn)},methods:{one:{hash:rn,debug:yn}}};const wn=function(e,t){if(e[0]!==t[0])return!1;const[,n,a]=e,[,r,o]=t;return n<=r&&a>r||r<=n&&o>n},kn=function(e){const t={};return e.forEach((e=>{t[e[0]]=t[e[0]]||[],t[e[0]].push(e)})),t},Pn=function(e,t){const n=kn(t),a=[];return e.forEach((e=>{const[t]=e;let r=n[t]||[];if(r=r.filter((t=>function(e,t){return e[1]<=t[1]&&t[2]<=e[2]}(e,t))),0===r.length)return void a.push({passthrough:e});r=r.sort(((e,t)=>e[1]-t[1]));let o=e;r.forEach(((e,t)=>{const n=function(e,t){const[n,a]=e,r=t[1],o=t[2],i={};if(ao&&(i.after=[n,o,e[2]]),i}(o,e);r[t+1]?(a.push({before:n.before,match:n.match}),n.after&&(o=n.after)):a.push(n)}))})),a};var An={one:{termList:function(e){const t=[];for(let n=0;n{if(!a)return;let[o,i,s,l,u]=a,c=t[o]||[];if(void 0===i&&(i=0),void 0===s&&(s=c.length),!l||c[i]&&c[i].id===l)c=c.slice(i,s);else{const n=function(e,t,n){for(let a=0;a<20;a+=1){if(t[n-a]){const r=t[n-a].findIndex((t=>t.id===e));if(-1!==r)return[n-a,r]}if(t[n+a]){const r=t[n+a].findIndex((t=>t.id===e));if(-1!==r)return[n+a,r]}}return null}(l,t,o);if(null!==n){const a=s-i;c=t[n[0]].slice(n[1],n[1]+a);const o=c[0]?c[0].id:null;e[r]=[n[0],n[1],n[1]+a,o]}}0!==c.length&&i!==s&&(u&&c[c.length-1].id!==u&&(c=function(e,t){const[n,a,,,r]=e,o=t[n],i=o.findIndex((e=>e.id===r));return-1===i?(e[2]=t[n].length,e[4]=o.length?o[o.length-1].id:null):e[2]=i,t[n].slice(a,e[2]+1)}(a,t)),n.push(c))})),n=n.filter((e=>e.length>0)),n},pointer:{indexN:kn,splitAll:Pn}}};const Cn=function(e,t){const n=e.concat(t),a=kn(n);let r=[];return n.forEach((e=>{const[t]=e;if(1===a[t].length)return void r.push(e);const n=a[t].filter((t=>wn(e,t)));n.push(e);const o=function(e){let t=e[0][1],n=e[0][2];return e.forEach((e=>{e[1]n&&(n=e[2])})),[e[0][0],t,n]}(n);r.push(o)})),r=function(e){const t={};for(let n=0;n{e.passthrough&&n.push(e.passthrough),e.before&&n.push(e.before),e.after&&n.push(e.after)})),n},Nn=(e,t)=>{return"string"==typeof e||(n=e,"[object Array]"===Object.prototype.toString.call(n))?t.match(e):e||t.none();var n},In=function(e,t){return e.map((e=>{const[n,a]=e;return t[n]&&t[n][a]&&(e[3]=t[n][a].id),e}))},Dn={union:function(e){e=Nn(e,this);let t=Cn(this.fullPointer,e.fullPointer);return t=In(t,this.document),this.toView(t)}};Dn.and=Dn.union,Dn.intersection=function(e){e=Nn(e,this);let t=function(e,t){const n=kn(t),a=[];return e.forEach((e=>{let t=n[e[0]]||[];t=t.filter((t=>wn(e,t))),0!==t.length&&t.forEach((t=>{const n=function(e,t){const n=e[1]t[2]?t[2]:e[2];return n{e=Cn(e,[t])})),e=In(e,this.document),this.update(e)};var Hn={methods:An,api:function(e){Object.assign(e.prototype,Dn)}};const Gn=function(e){return!0===e.optional||!0===e.negative?null:e.tag?"#"+e.tag:e.word?e.word:e.switch?`%${e.switch}%`:null},Tn=function(e,t){const n=t.methods.one.parseMatch;return e.forEach((e=>{e.regs=n(e.match,{},t),"string"==typeof e.ifNo&&(e.ifNo=[e.ifNo]),e.notIf&&(e.notIf=n(e.notIf,{},t)),e.needs=function(e){const t=[];return e.forEach((e=>{t.push(Gn(e)),"and"===e.operator&&e.choices&&e.choices.forEach((e=>{e.forEach((e=>{t.push(Gn(e))}))}))})),t.filter((e=>e))}(e.regs);const{wants:a,count:r}=function(e){const t=[];let n=0;return e.forEach((e=>{"or"!==e.operator||e.optional||e.negative||(e.fastOr&&Array.from(e.fastOr).forEach((e=>{t.push(e)})),e.choices&&e.choices.forEach((e=>{e.forEach((e=>{const n=Gn(e);n&&t.push(n)}))})),n+=1)})),{wants:t,count:n}}(e.regs);e.wants=a,e.minWant=r,e.minWords=e.regs.filter((e=>!e.optional)).length})),e};var xn={buildNet:function(e,t){e=Tn(e,t);const n={};e.forEach((e=>{e.needs.forEach((t=>{n[t]=Array.isArray(n[t])?n[t]:[],n[t].push(e)})),e.wants.forEach((t=>{n[t]=Array.isArray(n[t])?n[t]:[],n[t].push(e)}))})),Object.keys(n).forEach((e=>{const t={};n[e]=n[e].filter((e=>"boolean"!=typeof t[e.match]&&(t[e.match]=!0,!0)))}));const a=e.filter((e=>0===e.needs.length&&0===e.wants.length));return{hooks:n,always:a}},bulkMatch:function(e,t,n,a={}){const r=n.one.cacheDoc(e);let o=function(e,t){return e.map(((n,a)=>{let r=[];Object.keys(t).forEach((n=>{e[a].has(n)&&(r=r.concat(t[n]))}));const o={};return r=r.filter((e=>"boolean"!=typeof o[e.match]&&(o[e.match]=!0,!0))),r}))}(r,t.hooks);o=function(e,t){return e.map(((e,n)=>{const a=t[n];return(e=(e=e.filter((e=>e.needs.every((e=>a.has(e)))))).filter((e=>void 0===e.ifNo||!0!==e.ifNo.some((e=>a.has(e)))))).filter((e=>0===e.wants.length||e.wants.filter((e=>a.has(e))).length>=e.minWant))}))}(o,r),t.always.length>0&&(o=o.map((e=>e.concat(t.always)))),o=function(e,t){return e.map(((e,n)=>{const a=t[n].length;return e=e.filter((e=>a>=e.minWords)),e}))}(o,e);const i=function(e,t,n,a,r){const o=[];for(let n=0;n0&&(l.ptrs.forEach((e=>{e[0]=n;const t=Object.assign({},s,{pointer:e});void 0!==s.unTag&&(t.unTag=s.unTag),o.push(t)})),!0===r.matchOne))return[o[0]]}return o}(o,e,0,n,a);return i},bulkTagger:function(e,t,n){const{model:a,methods:r}=n,{getDoc:o,setTag:i,unTag:s}=r.one,l=r.two.looksPlural;if(0===e.length)return e;return("undefined"!=typeof process&&process.env?process.env:self.env||{}).DEBUG_TAGS&&console.log(`\n\n �[32m→ ${e.length} post-tagger:�[0m`),e.map((e=>{if(!e.tag&&!e.chunk&&!e.unTag)return;const r=e.reason||e.match,u=o([e.pointer],t)[0];if(!0===e.safe){if(!1===function(e,t,n){const a=n.one.tagSet;if(!a.hasOwnProperty(t))return!0;const r=a[t].not||[];for(let t=0;te.frozen=!0))}void 0!==e.unTag&&s(u,e.unTag,n,e.safe,r),e.chunk&&u.forEach((t=>t.chunk=e.chunk))}))}},En={lib:{buildNet:function(e){const t=this.methods().one.buildNet(e,this.world());return t.isNet=!0,t}},api:function(e){e.prototype.sweep=function(e,t={}){const{world:n,docs:a}=this,{methods:r}=n;let o=r.one.bulkMatch(a,e,this.methods,t);!1!==t.tagger&&r.one.bulkTagger(o,a,this.world),o=o.map((e=>{const t=e.pointer,n=a[t[0]][t[1]],r=t[2]-t[1];return n.index&&(e.pointer=[n.index[0],n.index[1],t[1]+r]),e}));const i=o.map((e=>e.pointer));return o=o.map((e=>(e.view=this.update([e.pointer]),delete e.regs,delete e.needs,delete e.pointer,delete e._expanded,e))),{view:this.update(i),found:o}}},methods:{one:xn}};const Fn=/ /,On=function(e,t){"Noun"===t&&(e.chunk=t),"Verb"===t&&(e.chunk=t)},zn=function(e,t,n,a){if(!0===e.tags.has(t))return null;if("."===t)return null;!0===e.frozen&&(a=!0);const r=n[t];if(r){if(r.not&&r.not.length>0)for(let t=0;t0)for(let t=0;t{const a=e.map((e=>e.text||"["+e.implicit+"]")).join(" ");var r;"string"!=typeof t&&t.length>2&&(t=t.slice(0,2).join(", #")+" +"),t="string"!=typeof t?t.join(", #"):t,console.log(` ${(r=a,"�[33m�[3m"+r+"�[0m").padEnd(24)} �[32m→�[0m #${t.padEnd(22)} ${(e=>"�[3m"+e+"�[0m")(n)}`)})(e,t,r),!0!=(s=t,"[object Array]"===Object.prototype.toString.call(s)))if("string"==typeof t)if(t=t.trim(),Fn.test(t))!function(e,t,n,a){const r=t.split(Fn);e.forEach(((e,t)=>{let o=r[t];o&&(o=o.replace(/^#/,""),zn(e,o,n,a))}))}(e,t,o,a);else{t=t.replace(/^#/,"");for(let n=0;nVn(e,t,n,a)))},Bn=function(e){return e.children=e.children||[],e._cache=e._cache||{},e.props=e.props||{},e._cache.parents=e._cache.parents||[],e._cache.children=e._cache.children||[],e},Sn=/^ *(#|\/\/)/,Kn=function(e){let t=e.trim().split(/->/),n=[];t.forEach((e=>{n=n.concat(function(e){if(!(e=e.trim()))return null;if(/^\[/.test(e)&&/\]$/.test(e)){let t=(e=(e=e.replace(/^\[/,"")).replace(/\]$/,"")).split(/,/);return t=t.map((e=>e.trim())).filter((e=>e)),t=t.map((e=>Bn({id:e}))),t}return[Bn({id:e})]}(e))})),n=n.filter((e=>e));let a=n[0];for(let e=1;e{let n=[],a=[e];for(;a.length>0;){let e=a.pop();n.push(e),e.children&&e.children.forEach((n=>{t&&t(e,n),a.push(n)}))}return n},Ln=e=>"[object Array]"===Object.prototype.toString.call(e),Mn=e=>(e=e||"").trim(),Jn=function(e=[]){return"string"==typeof e?function(e){let t=e.split(/\r?\n/),n=[];t.forEach((e=>{if(!e.trim()||Sn.test(e))return;let t=(e=>{const t=/^( {2}|\t)/;let n=0;for(;t.test(e);)e=e.replace(t,""),n+=1;return n})(e);n.push({indent:t,node:Kn(e)})}));let a=function(e){let t={children:[]};return e.forEach(((n,a)=>{0===n.indent?t.children=t.children.concat(n.node):e[a-1]&&function(e,t){let n=e[t].indent;for(;t>=0;t-=1)if(e[t].indent{t[e.id]=e}));let n=Bn({});return e.forEach((e=>{if((e=Bn(e)).parent)if(t.hasOwnProperty(e.parent)){let n=t[e.parent];delete e.parent,n.children.push(e)}else console.warn(`[Grad] - missing node '${e.parent}'`);else n.children.push(e)})),n}(e):($n(t=e).forEach(Bn),t);var t},Wn=function(e,t){let n="-> ";t&&(n=(e=>"�[2m"+e+"�[0m")("→ "));let a="";return $n(e).forEach(((e,r)=>{let o=e.id||"";if(t&&(o=(e=>"�[31m"+e+"�[0m")(o)),0===r&&!e.id)return;let i=e._cache.parents.length;a+=" ".repeat(i)+n+o+"\n"})),a},Un=function(e){let t=$n(e);t.forEach((e=>{delete(e=Object.assign({},e)).children}));let n=t[0];return n&&!n.id&&0===Object.keys(n.props).length&&t.shift(),t},qn={text:Wn,txt:Wn,array:Un,flat:Un},Rn=function(e,t){return"nested"===t||"json"===t?e:"debug"===t?(console.log(Wn(e,!0)),null):qn.hasOwnProperty(t)?qn[t](e):e},Qn=e=>{$n(e,((e,t)=>{e.id&&(e._cache.parents=e._cache.parents||[],t._cache.parents=e._cache.parents.concat([e.id]))}))},Zn=/\//;let Xn=class g{constructor(e={}){Object.defineProperty(this,"json",{enumerable:!1,value:e,writable:!0})}get children(){return this.json.children}get id(){return this.json.id}get found(){return this.json.id||this.json.children.length>0}props(e={}){let t=this.json.props||{};return"string"==typeof e&&(t[e]=!0),this.json.props=Object.assign(t,e),this}get(e){if(e=Mn(e),!Zn.test(e)){let t=this.json.children.find((t=>t.id===e));return new g(t)}let t=((e,t)=>{let n=(e=>"string"!=typeof e?e:(e=e.replace(/^\//,"")).split(/\//))(t=t||"");for(let t=0;te.id===n[t]));if(!a)return null;e=a}return e})(this.json,e)||Bn({});return new g(t)}add(e,t={}){if(Ln(e))return e.forEach((e=>this.add(Mn(e),t))),this;e=Mn(e);let n=Bn({id:e,props:t});return this.json.children.push(n),new g(n)}remove(e){return e=Mn(e),this.json.children=this.json.children.filter((t=>t.id!==e)),this}nodes(){return $n(this.json).map((e=>(delete(e=Object.assign({},e)).children,e)))}cache(){return(e=>{let t=$n(e,((e,t)=>{e.id&&(e._cache.parents=e._cache.parents||[],e._cache.children=e._cache.children||[],t._cache.parents=e._cache.parents.concat([e.id]))})),n={};t.forEach((e=>{e.id&&(n[e.id]=e)})),t.forEach((e=>{e._cache.parents.forEach((t=>{n.hasOwnProperty(t)&&n[t]._cache.children.push(e.id)}))})),e._cache.children=Object.keys(n)})(this.json),this}list(){return $n(this.json)}fillDown(){var e;return e=this.json,$n(e,((e,t)=>{t.props=((e,t)=>(Object.keys(t).forEach((n=>{if(t[n]instanceof Set){let a=e[n]||new Set;e[n]=new Set([...a,...t[n]])}else if((e=>e&&"object"==typeof e&&!Array.isArray(e))(t[n])){let a=e[n]||{};e[n]=Object.assign({},t[n],a)}else Ln(t[n])?e[n]=t[n].concat(e[n]||[]):void 0===e[n]&&(e[n]=t[n])})),e))(t.props,e.props)})),this}depth(){Qn(this.json);let e=$n(this.json),t=e.length>1?1:0;return e.forEach((e=>{if(0===e._cache.parents.length)return;let n=e._cache.parents.length+1;n>t&&(t=n)})),t}out(e){return Qn(this.json),Rn(this.json,e)}debug(){return Qn(this.json),Rn(this.json,"debug"),this}};const _n=function(e){let t=Jn(e);return new Xn(t)};_n.prototype.plugin=function(e){e(this)};const Yn={Noun:"blue",Verb:"green",Negative:"green",Date:"red",Value:"red",Adjective:"magenta",Preposition:"cyan",Conjunction:"cyan",Determiner:"cyan",Hyphenated:"cyan",Adverb:"cyan"},ea=function(e){if(Yn.hasOwnProperty(e.id))return Yn[e.id];if(Yn.hasOwnProperty(e.is))return Yn[e.is];const t=e._cache.parents.find((e=>Yn[e]));return Yn[t]},ta=function(e){return e?"string"==typeof e?[e]:e:[]},na=function(e,t){return e=function(e,t){return Object.keys(e).forEach((n=>{e[n].isA&&(e[n].is=e[n].isA),e[n].notA&&(e[n].not=e[n].notA),e[n].is&&"string"==typeof e[n].is&&(t.hasOwnProperty(e[n].is)||e.hasOwnProperty(e[n].is)||(e[e[n].is]={})),e[n].not&&"string"==typeof e[n].not&&!e.hasOwnProperty(e[n].not)&&(t.hasOwnProperty(e[n].not)||e.hasOwnProperty(e[n].not)||(e[e[n].not]={}))})),e}(e,t),Object.keys(e).forEach((t=>{e[t].children=ta(e[t].children),e[t].not=ta(e[t].not)})),Object.keys(e).forEach((t=>{(e[t].not||[]).forEach((n=>{e[n]&&e[n].not&&e[n].not.push(t)}))})),e};var aa={one:{setTag:Vn,unTag:function(e,t,n){t=t.trim().replace(/^#/,"");for(let a=0;a0)for(let e=0;e0&&(e=function(e){return Object.keys(e).forEach((t=>{e[t]=Object.assign({},e[t]),e[t].novel=!0})),e}(e)),e=na(e,t);const n=function(e){const t=Object.keys(e).map((t=>{const n=e[t],a={not:new Set(n.not),also:n.also,is:n.is,novel:n.novel};return{id:t,parent:n.is,props:a,children:[]}}));return _n(t).cache().fillDown().out("array")}(Object.assign({},t,e)),a=function(e){const t={};return e.forEach((e=>{const{not:n,also:a,is:r,novel:o}=e.props;let i=e._cache.parents;a&&(i=i.concat(a)),t[e.id]={is:r,not:n,novel:o,also:a,parents:i,children:e._cache.children,color:ea(e)}})),Object.keys(t).forEach((e=>{const n=new Set(t[e].not);t[e].not.forEach((e=>{t[e]&&t[e].children.forEach((e=>n.add(e)))})),t[e].not=Array.from(n)})),t}(n);return a},canBe:function(e,t,n){if(!n.hasOwnProperty(t))return!0;const a=n[t].not||[];for(let t=0;tr.one.setTag(a,e,i,n,t))):r.one.setTag(a,e,i,n,t),this.uncache(),this},tagSafe:function(e,t=""){return this.tag(e,t,!0)},unTag:function(e,t){if(!this.found||!e)return this;const n=this.termList();if(0===n.length)return this;const{methods:a,verbose:r,model:o}=this;!0===r&&console.log(" - ",e,t||"");const i=o.one.tagSet;return ra(e)?e.forEach((e=>a.one.unTag(n,e,i))):a.one.unTag(n,e,i),this.uncache(),this},canBe:function(e){e=e.replace(/^#/,"");const t=this.model.one.tagSet,n=this.methods.one.canBe,a=[];this.document.forEach(((r,o)=>{r.forEach(((r,i)=>{n(r,e,t)||a.push([o,i,i+1])}))}));const r=this.update(a);return this.difference(r)}};var ia={addTags:function(e){const{model:t,methods:n}=this.world(),a=t.one.tagSet,r=(0,n.one.addTags)(e,a);return t.one.tagSet=r,this}};const sa=new Set(["Auxiliary","Possessive"]);var la={model:{one:{tagSet:{}}},compute:{tagRank:function(e){const{document:t,world:n}=e,a=n.model.one.tagSet;t.forEach((e=>{e.forEach((e=>{const t=Array.from(e.tags);e.tagRank=function(e,t){return e=e.sort(((e,n)=>{if(sa.has(e)||!t.hasOwnProperty(n))return 1;if(sa.has(n)||!t.hasOwnProperty(e))return-1;let a=t[e].children||[];const r=a.length;return a=t[n].children||[],r-a.length})),e}(t,a)}))}))}},methods:aa,api:function(e){Object.assign(e.prototype,oa)},lib:ia};const ua=/([.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s)/g,ca=/^[.!?\u203D\u2E18\u203C\u2047-\u2049\u3002]+\s$/,da=/((?:\r?\n|\r)+)/,ha=/[a-z0-9\u00C0-\u00FF\u00a9\u00ae\u2000-\u3300\ud000-\udfff]/i,ga=/\S/,ma=function(e){return Boolean(e.match(/\n$/))},pa={'"':'"',""":""","“":"”","‟":"”","„":"”","⹂":"”","‚":"’","«":"»","‹":"›","‵":"′","‶":"″","‷":"‴","〝":"〞","〟":"〞"},fa=RegExp("["+Object.keys(pa).join("")+"]","g"),ba=RegExp("["+Object.values(pa).join("")+"]","g"),ya=function(e){if(!e)return!1;const t=e.match(ba);return null!==t&&1===t.length},va=/\(/g,wa=/\)/g,ka=/\S/,Pa=/^\s+/,Aa=function(e,t){const n=e.split(/[-–—]/);if(n.length<=1)return!1;const{prefixes:a,suffixes:r}=t.one;if(1===n[0].length&&/[a-z]/i.test(n[0]))return!1;if(a.hasOwnProperty(n[0]))return!1;if(n[1]=n[1].trim().replace(/[.?!]$/,""),r.hasOwnProperty(n[1]))return!1;if(!0===/^([a-z\u00C0-\u00FF`"'/]+)[-–—]([a-z0-9\u00C0-\u00FF].*)/i.test(e))return!0;return!0===/^[('"]?([0-9]{1,4})[-–—]([a-z\u00C0-\u00FF`"'/-]+[)'"]?$)/i.test(e)},Ca=function(e){const t=[],n=e.split(/[-–—]/);let a="-";const r=e.match(/[-–—]/);r&&r[0]&&(a=r);for(let e=0;e(e[t]=!0,e)),{});const Ga=/\p{Letter}/u,Ta=/[\p{Number}\p{Currency_Symbol}]/u,xa=/^[a-z]\.([a-z]\.)+/i,Ea=/[sn]['’]$/,Fa=/([A-Z]\.)+[A-Z]?,?$/,Oa=/^[A-Z]\.,?$/,za=/[A-Z]{2,}('s|,)?$/,Va=/([a-z]\.)+[a-z]\.?$/,Ba=function(e){return function(e){return!0===Fa.test(e)||!0===Va.test(e)||!0===Oa.test(e)||!0===za.test(e)}(e)&&(e=e.replace(/\./g,"")),e},Sa=function(e,t){const n=t.methods.one.killUnicode;let a=e.text||"";a=function(e){const t=e=(e=(e=e||"").toLowerCase()).trim();return e=(e=(e=e.replace(/[,;.!?]+$/,"")).replace(/\u2026/g,"...")).replace(/\u2013/g,"-"),!1===/^[:;]/.test(e)&&(e=(e=(e=e.replace(/\.{3,}$/g,"")).replace(/[",.!:;?)]+$/g,"")).replace(/^['"(]+/g,"")),""===(e=(e=e.replace(/[\u200B-\u200D\uFEFF]/g,"")).trim())&&(e=t),e.replace(/([0-9]),([0-9])/g,"$1$2")}(a),a=n(a,t),a=Ba(a),e.normal=a},Ka=/[ .][A-Z]\.? *$/i,$a=/(?:\u2026|\.{2,}) *$/,La=/\p{L}/u,Ma=/\. *$/,Ja=/^[A-Z]\. $/;var Wa={one:{killUnicode:function(e,t){const n=t.model.one.unicode||{},a=(e=e||"").split("");return a.forEach(((e,t)=>{n[e]&&(a[t]=n[e])})),a.join("")},tokenize:{splitSentences:function(e,t){if(e=e||"",!(e=String(e))||"string"!=typeof e||!1===ka.test(e))return[];const n=function(e){const t=[],n=e.split(da);for(let e=0;e0&&(r.push(o),e[t]=""):e[t+1]=o+(e[t+1]||"")}return r}(a,t),a=function(e){const t=[];for(let n=0;n0?(n[n.length-1]+=o,n.push(t)):n.push(o+t),o=""):o+=t}return o&&(0===n.length&&(n[0]=""),n[n.length-1]+=o),n=function(e){for(let t=1;te)),n},splitWhitespace:(e,t)=>{const{str:n,pre:a,post:r}=function(e,t){const{prePunctuation:n,postPunctuation:a,emoticons:r}=t.one;let o=e,i="",s="";const l=Array.from(e);if(r.hasOwnProperty(e.trim()))return{str:e.trim(),pre:i,post:" "};let u=l.length;for(let e=0;e(s=e||"",""))),e=o,i=""),{str:e,pre:i,post:s}}(e,t);return{text:n,pre:a,post:r,tags:new Set}},fromString:function(e,t){const{methods:n,model:a}=t,{splitSentences:r,splitTerms:o,splitWhitespace:i}=n.one.tokenize;return e=r(e=e||"",t).map((e=>{let n=o(e,a);return n=n.map((e=>i(e,a))),n.forEach((e=>{Sa(e,t)})),n})),e}}}};const Ua={},qa={};[[["approx","apt","bc","cyn","eg","esp","est","etc","ex","exp","prob","pron","gal","min","pseud","fig","jd","lat","lng","vol","fm","def","misc","plz","ea","ps","sec","pt","pref","pl","pp","qt","fr","sq","nee","ss","tel","temp","vet","ver","fem","masc","eng","adj","vb","rb","inf","situ","vivo","vitro","wr"]],[["dl","ml","gal","qt","pt","tbl","tsp","tbsp","km","dm","cm","mm","mi","td","hr","hrs","kg","hg","dg","cg","mg","µg","lb","oz","sq ft","hz","mps","mph","kmph","kb","mb","tb","lx","lm","fl oz","yb"],"Unit"],[["ad","al","arc","ba","bl","ca","cca","col","corp","ft","fy","ie","lit","ma","md","pd","tce"],"Noun"],[["adj","adm","adv","asst","atty","bldg","brig","capt","cmdr","comdr","cpl","det","dr","esq","gen","gov","hon","jr","llb","lt","maj","messrs","mlle","mme","mr","mrs","ms","mstr","phd","prof","pvt","rep","reps","res","rev","sen","sens","sfc","sgt","sir","sr","supt","surg"],"Honorific"],[["jan","feb","mar","apr","jun","jul","aug","sep","sept","oct","nov","dec"],"Month"],[["dept","univ","assn","bros","inc","ltd","co"],"Organization"],[["rd","st","dist","mt","ave","blvd","cl","cres","hwy","ariz","cal","calif","colo","conn","fla","fl","ga","ida","ia","kan","kans","minn","neb","nebr","okla","penna","penn","pa","dak","tenn","tex","ut","vt","va","wis","wisc","wy","wyo","usafa","alta","ont","que","sask"],"Place"]].forEach((e=>{e[0].forEach((t=>{Ua[t]=!0,qa[t]="Abbreviation",void 0!==e[1]&&(qa[t]=[qa[t],e[1]])}))}));var Ra=["anti","bi","co","contra","de","extra","infra","inter","intra","macro","micro","mis","mono","multi","peri","pre","pro","proto","pseudo","re","sub","supra","trans","tri","un","out","ex"].reduce(((e,t)=>(e[t]=!0,e)),{});const Qa={"!":"¡","?":"¿Ɂ",'"':'“”"❝❞',"'":"‘‛❛❜’","-":"—–",a:"ªÀÁÂÃÄÅàáâãäåĀāĂ㥹ǍǎǞǟǠǡǺǻȀȁȂȃȦȧȺΆΑΔΛάαλАаѦѧӐӑӒӓƛæ",b:"ßþƀƁƂƃƄƅɃΒβϐϦБВЪЬвъьѢѣҌҍ",c:"¢©ÇçĆćĈĉĊċČčƆƇƈȻȼͻͼϲϹϽϾСсєҀҁҪҫ",d:"ÐĎďĐđƉƊȡƋƌ",e:"ÈÉÊËèéêëĒēĔĕĖėĘęĚěƐȄȅȆȇȨȩɆɇΈΕΞΣέεξϵЀЁЕеѐёҼҽҾҿӖӗễ",f:"ƑƒϜϝӺӻҒғſ",g:"ĜĝĞğĠġĢģƓǤǥǦǧǴǵ",h:"ĤĥĦħƕǶȞȟΉΗЂЊЋНнђћҢңҤҥҺһӉӊ",I:"ÌÍÎÏ",i:"ìíîïĨĩĪīĬĭĮįİıƖƗȈȉȊȋΊΐΪίιϊІЇіїi̇",j:"ĴĵǰȷɈɉϳЈј",k:"ĶķĸƘƙǨǩΚκЌЖКжкќҚқҜҝҞҟҠҡ",l:"ĹĺĻļĽľĿŀŁłƚƪǀǏǐȴȽΙӀӏ",m:"ΜϺϻМмӍӎ",n:"ÑñŃńŅņŇňʼnŊŋƝƞǸǹȠȵΝΠήηϞЍИЙЛПийлпѝҊҋӅӆӢӣӤӥπ",o:"ÒÓÔÕÖØðòóôõöøŌōŎŏŐőƟƠơǑǒǪǫǬǭǾǿȌȍȎȏȪȫȬȭȮȯȰȱΌΘΟθοσόϕϘϙϬϴОФоѲѳӦӧӨөӪӫ",p:"ƤΡρϷϸϼРрҎҏÞ",q:"Ɋɋ",r:"ŔŕŖŗŘřƦȐȑȒȓɌɍЃГЯгяѓҐґ",s:"ŚśŜŝŞşŠšƧƨȘșȿЅѕ",t:"ŢţŤťŦŧƫƬƭƮȚțȶȾΓΤτϮТт",u:"ÙÚÛÜùúûüŨũŪūŬŭŮůŰűŲųƯưƱƲǓǔǕǖǗǘǙǚǛǜȔȕȖȗɄΰυϋύ",v:"νѴѵѶѷ",w:"ŴŵƜωώϖϢϣШЩшщѡѿ",x:"×ΧχϗϰХхҲҳӼӽӾӿ",y:"ÝýÿŶŷŸƳƴȲȳɎɏΎΥΫγψϒϓϔЎУучўѰѱҮүҰұӮӯӰӱӲӳ",z:"ŹźŻżŽžƵƶȤȥɀΖ"},Za={};Object.keys(Qa).forEach((function(e){Qa[e].split("").forEach((function(t){Za[t]=e}))}));const Xa=/\//,_a=/[a-z]\.[a-z]/i,Ya=/[0-9]/,er=function(e,t){const n=e.normal||e.text||e.machine,a=t.model.one.aliases;if(a.hasOwnProperty(n)&&(e.alias=e.alias||[],e.alias.push(a[n])),Xa.test(n)&&!_a.test(n)&&!Ya.test(n)){const t=n.split(Xa);t.length<=3&&t.forEach((t=>{""!==(t=t.trim())&&(e.alias=e.alias||[],e.alias.push(t))}))}return e},tr=/^\p{Letter}+-\p{Letter}+$/u,nr=function(e){let t=e.implicit||e.normal||e.text;t=t.replace(/['’]s$/,""),t=t.replace(/s['’]$/,"s"),t=t.replace(/([aeiou][ktrp])in'$/,"$1ing"),tr.test(t)&&(t=t.replace(/-/g,"")),t=t.replace(/^[#@]/,""),t!==e.normal&&(e.machine=t)},ar=function(e,t){const n=e.docs;for(let a=0;aar(e,er),machine:e=>ar(e,nr),normal:e=>ar(e,Sa),freq:function(e){const t=e.docs,n={};for(let e=0;e{let i=(e=e.toLowerCase().trim()).length;t.max&&i>t.max&&(i=t.max);for(let s=t.min;s{delete a[e]})),a}(e,t,this.world());return Object.keys(r).forEach((e=>{n.one.typeahead.hasOwnProperty(e)?delete n.one.typeahead[e]:n.one.typeahead[e]=r[e]})),this}};var cr={model:{one:{typeahead:{}}},api:function(e){e.prototype.autoFill=sr},lib:ur,compute:ir,hooks:["typeahead"]};d.extend(J),d.extend(vn),d.extend(Jt),d.extend(Hn),d.extend(la),d.plugin(ve),d.extend(or),d.extend(Ce),d.plugin(p),d.extend(Be),d.extend(cr),d.extend(xe),d.extend(En);var dr={addendum:"addenda",corpus:"corpora",criterion:"criteria",curriculum:"curricula",genus:"genera",memorandum:"memoranda",opus:"opera",ovum:"ova",phenomenon:"phenomena",referendum:"referenda",alga:"algae",alumna:"alumnae",antenna:"antennae",formula:"formulae",larva:"larvae",nebula:"nebulae",vertebra:"vertebrae",analysis:"analyses",axis:"axes",diagnosis:"diagnoses",parenthesis:"parentheses",prognosis:"prognoses",synopsis:"synopses",thesis:"theses",neurosis:"neuroses",appendix:"appendices",index:"indices",matrix:"matrices",ox:"oxen",sex:"sexes",alumnus:"alumni",bacillus:"bacilli",cactus:"cacti",fungus:"fungi",hippopotamus:"hippopotami",libretto:"libretti",modulus:"moduli",nucleus:"nuclei",octopus:"octopi",radius:"radii",stimulus:"stimuli",syllabus:"syllabi",cookie:"cookies",calorie:"calories",auntie:"aunties",movie:"movies",pie:"pies",rookie:"rookies",tie:"ties",zombie:"zombies",leaf:"leaves",loaf:"loaves",thief:"thieves",foot:"feet",goose:"geese",tooth:"teeth",beau:"beaux",chateau:"chateaux",tableau:"tableaux",bus:"buses",gas:"gases",circus:"circuses",crisis:"crises",virus:"viruses",database:"databases",excuse:"excuses",abuse:"abuses",avocado:"avocados",barracks:"barracks",child:"children",clothes:"clothes",echo:"echoes",embargo:"embargoes",epoch:"epochs",deer:"deer",halo:"halos",man:"men",woman:"women",mosquito:"mosquitoes",mouse:"mice",person:"people",quiz:"quizzes",rodeo:"rodeos",shoe:"shoes",sombrero:"sombreros",stomach:"stomachs",tornado:"tornados",tuxedo:"tuxedos",volcano:"volcanoes"},hr={Comparative:"true¦bett1f0;arth0ew0in0;er",Superlative:"true¦earlier",PresentTense:"true¦bests,sounds",Condition:"true¦lest,unless",PastTense:"true¦began,came,d4had,kneel3l2m0sa4we1;ea0sg2;nt;eap0i0;ed;id",Participle:"true¦0:09;a06b01cZdXeat0fSgQhPoJprov0rHs7t6u4w1;ak0ithdra02o2r1;i02uY;k0v0;nd1pr04;ergoJoJ;ak0hHo3;e9h7lain,o6p5t4un3w1;o1um;rn;g,k;ol0reS;iQok0;ught,wn;ak0o1runk;ne,wn;en,wn;ewriNi1uJ;dd0s0;ut3ver1;do4se0t1;ak0h2;do2g1;roG;ne;ast0i7;iv0o1;ne,tt0;all0loBor1;bi3g2s1;ak0e0;iv0o9;dd0;ove,r1;a5eamt,iv0;hos0lu1;ng;e4i3lo2ui1;lt;wn;tt0;at0en,gun;r2w1;ak0ok0;is0;en",Gerund:"true¦accord0be0doin,go0result0stain0;ing",Expression:"true¦a0Yb0Uc0Sd0Oe0Mfarew0Lg0FhZjeez,lWmVnToOpLsJtIuFvEw7y0;a5e3i1u0;ck,p;k04p0;ee,pee;a0p,s;!h;!a,h,y;a5h2o1t0;af,f;rd up,w;atsoever,e1o0;a,ops;e,w;hoo,t;ery w06oi0L;gh,h0;! 0h,m;huh,oh;here nPsk,ut tut;h0ic;eesh,hh,it,oo;ff,h1l0ow,sst;ease,s,z;ew,ooey;h1i,mg,o0uch,w,y;h,o,ps;! 0h;hTmy go0wT;d,sh;a7evertheless,o0;!pe;eh,mm;ah,eh,m1ol0;!s;ao,fao;aCeBi9o2u0;h,mph,rra0zzC;h,y;l1o0;r6y9;la,y0;! 0;c1moCsmok0;es;ow;!p hip hoor0;ay;ck,e,llo,y;ha1i,lleluj0;ah;!ha;ah,ee4o1r0;eat scott,r;l1od0sh; grief,bye;ly;! whiz;ell;e0h,t cetera,ureka,ww,xcuse me;k,p;'oh,a0rat,uh;m0ng;mit,n0;!it;mon,o0;ngratulations,wabunga;a2oo1r0tw,ye;avo,r;!ya;h,m; 1h0ka,las,men,rgh,ye;!a,em,h,oy;la",Negative:"true¦n0;ever,o0;n,t",QuestionWord:"true¦how3wh0;at,e1ich,o0y;!m,se;n,re; come,'s",Reflexive:"true¦h4it5my5o1the0your2;ir1m1;ne3ur0;sel0;f,ves;er0im0;self",Plural:"true¦dick0gre0ones,records;ens","Unit|Noun":"true¦cEfDgChBinchAk9lb,m6newt5oz,p4qt,t1y0;ardEd;able1b0ea1sp;!l,sp;spo1;a,t,x;on9;!b,g,i1l,m,p0;h,s;!les;!b,elvin,g,m;!es;g,z;al,b;eet,oot,t;m,up0;!s",Value:"true¦a few",Imperative:"true¦bewa0come he0;re","Plural|Verb":"true¦leaves",Demonym:"true¦0:15;1:12;a0Vb0Oc0Dd0Ce08f07g04h02iYjVkTlPmLnIomHpEqatari,rCs7t5u4v3welAz2;am0Gimbabwe0;enezuel0ietnam0I;gAkrai1;aiwTex0hai,rinida0Ju2;ni0Prkmen;a5cotti4e3ingapoOlovak,oma0Spaniard,udRw2y0W;ede,iss;negal0Cr09;sh;mo0uT;o5us0Jw2;and0;a2eru0Fhilippi0Nortugu07uerto r0S;kist3lesti1na2raguay0;ma1;ani;ami00i2orweP;caragu0geri2;an,en;a3ex0Lo2;ngo0Drocc0;cedo1la2;gasy,y07;a4eb9i2;b2thua1;e0Cy0;o,t01;azakh,eny0o2uwaiI;re0;a2orda1;ma0Ap2;anO;celandic,nd4r2sraeli,ta01vo05;a2iB;ni0qi;i0oneU;aiAin2ondur0unO;di;amEe2hanai0reek,uatemal0;or2rm0;gi0;ilipino,ren8;cuadoVgyp4mira3ngli2sto1thiopi0urope0;shm0;ti;ti0;aPominUut3;a9h6o4roat3ub0ze2;ch;!i0;lom2ngol5;bi0;a6i2;le0n2;ese;lifor1m2na3;bo2eroo1;di0;angladeshi,el6o4r3ul2;gaE;azi9it;li2s1;vi0;aru2gi0;si0;fAl7merBngol0r5si0us2;sie,tr2;a2i0;li0;genti2me1;ne;ba1ge2;ri0;ni0;gh0r2;ic0;an",Organization:"true¦0:4Q;a3Tb3Bc2Od2He2Df27g1Zh1Ti1Pj1Nk1Ll1Gm12n0Po0Mp0Cqu0Br02sTtHuCv9w3xiaomi,y1;amaha,m1Bou1w1B;gov,tu3C;a4e2iki1orld trade organizati33;leaRped0O;lls fargo,st1;fie2Hinghou2R;l1rner br3U;gree3Jl street journ2Im1E;an halOeriz2Xisa,o1;dafo2Yl1;kswagMvo;b4kip,n2ps,s1;a tod3Aps;es3Mi1;lev3Fted natio3C;er,s; mobi32aco beRd bOe9gi frida3Lh3im horto3Amz,o1witt3D;shi49y1;ota,s r 05;e 1in lizzy;b3carpen3Jdaily ma3Dguess w2holli0s1w2;mashing pumpki35uprem0;ho;ea1lack eyed pe3Xyr0Q;ch bo3Dtl0;l2n3Qs1xas instrumen1U;co,la m1F;efoni0Kus;a8cientology,e5ieme2Ymirnoff,np,o3pice gir6quare0Ata1ubaru;rbuc1to34;ks;ny,undgard1;en;a2x pisto1;ls;g1Wrs;few2Minsbur31lesfor03msu2E;adiohead,b8e4o1yana3C;man empi1Xyal 1;b1dutch she4;ank;a3d 1max,vl20;bu1c2Ahot chili peppe2Ylobst2N;ll;ders dige1Ll madrid;c,s;ant3Aizn2Q;a8bs,e5fiz2Ihilip4i3r1;emier 1udenti1D;leagTo2K;nk floyd,zza hut; morrBs;psi2tro1uge0E;br33chi0Tn33;!co;lant2Un1yp16; 2ason27da2P;ld navy,pec,range juli2xf1;am;us;aAb9e6fl,h5i4o1sa,vid3wa;k2tre dame,vart1;is;ia;ke,ntendo,ss0QvZ;l,s;c,st1Otflix,w1; 1sweek;kids on the block,york0D;a,c;nd22s2t1;ional aca2Po,we0U;a,c02d0S;aDcdonalCe9i6lb,o3tv,y1;spa1;ce;b1Tnsanto,ody blu0t1;ley cr1or0T;ue;c2t1;as,subisO;helin,rosoft;dica2rcedes benz,talli1;ca;id,re;ds;cs milk,tt19z24;a3e1g,ittle caesa1P; ore09novo,x1;is,mark,us; 1bour party;pres0Dz boy;atv,fc,kk,lm,m1od1O;art;iffy lu0Roy divisi0Jpmorgan1sa;! cha09;bm,hop,k3n1tv;g,te1;l,rpol;ea;a5ewlett pack1Vi3o1sbc,yundai;me dep1n1P;ot;tac1zbollah;hi;lliburt08sbro;eneral 6hq,ithub,l5mb,o2reen d0Ou1;cci,ns n ros0;ldman sachs,o1;dye1g0H;ar;axo smith kli04encoW;electr0Nm1;oto0Z;a5bi,c barcelo4da,edex,i2leetwood m03o1rito l0G;rd,xcY;at,fa,nancial1restoZ; tim0;na;cebook,nnie mae;b0Asa,u3xxon1; m1m1;ob0J;!rosceptics;aiml0De5isney,o4u1;nkin donu2po0Zran dur1;an;ts;j,w jon0;a,f lepp12ll,peche mode,r spieg02stiny's chi1;ld;aJbc,hFiDloudflaCnn,o3r1;aigsli5eedence clearwater reviv1ossra09;al;c7inba6l4m1o0Est09;ca2p1;aq;st;dplSg1;ate;se;a c1o chanQ;ola;re;a,sco1tigroup;! systems;ev2i1;ck fil a,na daily;r1y;on;d2pital o1rls jr;ne;bury,ill1;ac;aEbc,eBf9l5mw,ni,o1p,rexiteeU;ei3mbardiIston 1;glo1pizza;be;ng;o2ue c1;roV;ckbuster video,omingda1;le; g1g1;oodriL;cht2e ge0rkshire hathaw1;ay;el;cardi,idu,nana republ3s1xt5y5;f,kin robbi1;ns;ic;bYcTdidSerosmith,iRlKmEnheuser busDol,ppleAr6s4u3v2y1;er;is,on;di,todesk;hland o1sociated E;il;b3g2m1;co;os;ys; compu1be0;te1;rs;ch;c,d,erican3t1;!r1;ak; ex1;pre1;ss; 5catel2ta1;ir;! lu1;ce1;nt;jazeera,qae1;da;g,rbnb;as;/dc,a3er,tivision1;! blizz1;ard;demy of scienc0;es;ba",Possessive:"true¦its,my,our0thy;!s","Noun|Verb":"true¦0:9W;1:AA;2:96;3:A3;4:9R;5:A2;6:9K;7:8N;8:7L;9:A8;A:93;B:8D;C:8X;a9Ob8Qc7Id6Re6Gf5Sg5Hh55i4Xj4Uk4Rl4Em40n3Vo3Sp2Squ2Rr21s0Jt02u00vVwGyFzD;ip,oD;ne,om;awn,e6Fie68;aOeMhJiHoErD;ap,e9Oink2;nd0rDuC;kDry,sh5Hth;!shop;ck,nDpe,re,sh;!d,g;e86iD;p,sD;k,p0t2;aDed,lco8W;r,th0;it,lk,rEsDt4ve,x;h,te;!ehou1ra9;aGen5FiFoD;iDmAte,w;ce,d;be,ew,sA;cuum,l4B;pDr7;da5gra6Elo6A;aReQhrPiOoMrGuEwiDy5Z;n,st;nDrn;e,n7O;aGeFiEoDu6;t,ub2;bu5ck4Jgg0m,p;at,k,nd;ck,de,in,nsDp,v7J;f0i8R;ll,ne,p,r4Yss,t94uD;ch,r;ck,de,e,le,me,p,re;e5Wow,u6;ar,e,ll,mp0st,xt;g,lDng2rg7Ps5x;k,ly;a0Sc0Ne0Kh0Fi0Dk0Cl0Am08n06o05pXquaBtKuFwD;ea88iD;ng,pe,t4;bGit,m,ppErD;fa3ge,pri1v2U;lDo6S;e6Py;!je8;aMeLiKoHrEuDy2;dy,ff,mb2;a85eEiDo5Pugg2;ke,ng;am,ss,t4;ckEop,p,rD;e,m;ing,pi2;ck,nk,t4;er,m,p;ck,ff,ge,in,ke,lEmp,nd,p2rDte,y;!e,t;k,l;aJeIiHlGoFrDur,y;ay,e56inDu3;g,k2;ns8Bt;a5Qit;ll,n,r87te;ed,ll;m,n,rk;b,uC;aDee1Tow;ke,p;a5Je4FiDo53;le,rk;eep,iDou4;ce,p,t;ateboa7Ii;de,gnDl2Vnk,p,ze;!al;aGeFiEoDuff2;ck,p,re,w;ft,p,v0;d,i3Ylt0;ck,de,pe,re,ve;aEed,nDrv1It;se,t2N;l,r4t;aGhedu2oBrD;aEeDibb2o3Z;en,w;pe,t4;le,n,r2M;cDfegua72il,mp2;k,rifi3;aZeHhy6LiGoEuD;b,in,le,n,s5X;a6ck,ll,oDpe,u5;f,t;de,ng,ot,p,s1W;aTcSdo,el,fQgPje8lOmMnLo17pJque6sFturn,vDwa6V;eDi27;al,r1;er74oFpe8tEuD;lt,me;!a55;l71rt;air,eaDly,o53;l,t;dezvo2Zt;aDedy;ke,rk;ea1i4G;a6Iist0r5N;act6Yer1Vo71uD;nd,se;a38o6F;ch,s6G;c1Dge,iEke,lly,nDp1Wt1W;ge,k,t;n,se;es6Biv0;a04e00hYiXlToNrEsy4uD;mp,n4rcha1sh;aKeIiHoDu4O;be,ceFdu3fi2grDje8mi1p,te6;amDe6W;!me;ed,ss;ce,de,nt;sDy;er6Cs;cti3i1;iHlFoEp,re,sDuCw0;e,i5Yt;l,p;iDl;ce,sh;nt,s5V;aEce,e32uD;g,mp,n7;ce,nDy;!t;ck,le,n17pe,tNvot;a1oD;ne,tograph;ak,eFnErDt;fu55mA;!c32;!l,r;ckJiInHrFsEtDu1y;ch,e9;s,te;k,tD;!y;!ic;nt,r,se;!a7;bje8ff0il,oErDutli3Qver4B;bAd0ie9;ze;a4ReFoDur1;d,tD;e,i3;ed,gle8tD;!work;aMeKiIoEuD;rd0;ck,d3Rld,nEp,uDve;nt,th;it5EkD;ey;lk,n4Brr5CsDx;s,ta2B;asuBn4UrDss;ge,it;il,nFp,rk3WsEtD;ch,t0;h,k,t0;da5n0oeuvB;aLeJiHoEuD;mp,st;aEbby,ck,g,oDve;k,t;d,n;cDe,ft,mAnIst;en1k;aDc0Pe4vK;ch,d,k,p,se;bFcEnd,p,t4uD;gh,n4;e,k;el,o2U;eEiDno4E;ck,d,ll,ss;el,y;aEo1OuD;i3mp;m,zz;mpJnEr46ssD;ue;c1Rdex,fluGha2k,se2HteDvoi3;nt,rD;e6fa3viD;ew;en3;a8le2A;aJeHiGoEuD;g,nt;l3Ano2Dok,pDr1u1;!e;ghli1Fke,nt,re,t;aDd7lp;d,t;ck,mGndFrEsh,tDu9;ch,e;bo3Xm,ne4Eve6;!le;!m0;aMear,ift,lKossJrFuD;arDe4Alp,n;antee,d;aFiEoDumb2;uCwth;ll,nd,p;de,sp;ip;aBoDue;ss,w;g,in,me,ng,s,te,ze;aZeWiRlNoJrFuD;ck,el,nDss,zz;c38d;aEoDy;st,wn;cDgme,me,nchi1;tuB;cFg,il,ld,rD;ce,e29mDwa31;!at;us;aFe0Vip,oDy;at,ck,od,wD;!er;g,ke,me,re,sh,vo1E;eGgFlEnDre,sh,t,x;an3i0Q;e,m,t0;ht,uB;ld;aEeDn3;d,l;r,tuB;ce,il,ll,rm,vo2W;cho,d7ffe8nMsKxFyeD;!baD;ll;cGerci1hFpDtra8;eriDo0W;en3me9;au6ibA;el,han7u1;caDtima5;pe;count0d,vy;a01eSiMoJrEuDye;b,el,mp,pli2X;aGeFiEoD;ne,p;ft,ll,nk,p,ve;am,ss;ft,g,in;cEd7ubt,wnloD;ad;k,u0E;ge6p,sFt4vD;e,iDor3;de;char7gui1h,liEpD;at4lay,u5;ke;al,bKcJfeIlGmaCposAsEtaD;il;e07iD;gn,re;ay,ega5iD;ght;at,ct;li04rea1;a5ut;b,ma7n3rDte;e,t;a0Eent0Dh06irc2l03oKrFuD;be,e,rDt;b,e,l,ve;aGeFoEuDy;sh;p,ss,wd;dAep;ck,ft,sh;at,de,in,lTmMnFordina5py,re,st,uDv0;gh,nDp2rt;s01t;ceHdu8fli8glomeIsFtDveN;a8rD;a6ol;e9tru8;ct;ntDrn;ra5;bHfoGmFpD;leDouCromi1;me9;aCe9it,u5;rt;at,iD;ne;lap1oD;r,ur;aEiDoud,ub;ck,p;im,w;aEeDip;at,ck,er;iGllen7nErD;ge,m,t;ge,nD;el;n,r;er,re;ke,ll,mp,noe,pGrXsFtEuDve;se,ti0I;alog,ch;h,t;!tuB;re;a03eZiXlToPrHuEyD;pa11;bb2ck2dgEff0mp,rDst,zz;den,n;et;anJeHiFoadEuD;i1sh;ca6;be,d7;ge;aDed;ch,k;ch,d;aFg,mb,nEoDrd0tt2x,ycott;k,st,t;d,e;rd,st;aFeCiDoYur;nk,tz;nd;me;as,d,ke,nd,opsy,tD;!ch,e;aFef,lt,nDt;d,efA;it;r,t;ck,il,lan3nIrFsEtt2;le;e,h;!gDk;aDe;in;!d,g,k;bu1c05dZge,iYlVnTppQrLsIttGucEwaD;rd;tiD;on;aDempt;ck;k,sD;i6ocia5;st;chFmD;!oD;ur;!iD;ve;eEroa4;ch;al;chDg0sw0;or;aEt0;er;rm;d,m,r;dreHvD;an3oD;ca5;te;ce;ss;cDe,he,t;eFoD;rd,u9;nt;nt,ss;se",Actor:"true¦0:7B;1:7G;2:6A;3:7F;4:7O;5:7K;a6Nb62c4Ud4Be41f3Sg3Bh30i2Uj2Qkin2Pl2Km26n1Zo1Sp0Vqu0Tr0JsQtJuHvEw8yo6;gi,ut6;h,ub0;aAe9i8o7r6;estl0it0;m2rk0;fe,nn0t2Bza2H;atherm2ld0;ge earn0it0nder0rri1;eter7i6oyF;ll5Qp,s3Z;an,ina2U;n6s0;c6Uder03;aoisea23e9herapi5iktok0o8r6ut1yco6S;a6endseLo43;d0mp,nscri0Bvel0;ddl0u1G;a0Qchn7en6na4st0;ag0;i3Oo0D;aiXcUeRhPiMki0mu26oJpGquaFtBu7wee6;p0theart;lt2per7r6;f0ge6Iviv1;h6inten0Ist5Ivis1;ero,um2;a8ep7r6;ang0eam0;bro2Nc2Ofa2Nmo2Nsi20;ff0tesm2;tt0;ec7ir2Do6;kesp59u0M;ia5Jt3;l7me6An,rcere6ul;r,ss;di0oi5;n7s6;sy,t0;g0n0;am2ephe1Iow6;girl,m2r2Q;cretInior cit3Fr6;gea4v6;a4it1;hol4Xi7reen6ulpt1;wr2C;e01on;l1nt;aEe9o8u6;l0nn6;er up,ingE;g40le mod3Zof0;a4Zc8fug2Ppo32searQv6;ere4Uolution6;ary;e6luYru22;ptio3T;bbi,dic5Vpp0;arter6e2Z;back;aYeWhSiRlOoKr8sycho7u6;nk,p31;logi5;aGeDiBo6;d9fess1g7ph47s6;pe2Ktitu51;en6ramm0;it1y;igy,uc0;est4Nme mini0Unce6s3E;!ss;a7si6;de4;ch0;ctiti39nk0P;dca0Oet,li6pula50rnst42;c2Itic6;al scie6i2;nti5;a6umb0;nn0y6;er,ma4Lwright;lgrim,one0;a8iloso7otogra7ra6ysi1V;se;ph0;ntom,rmaci5;r6ssi1T;form0s4O;i3El,nel3Yr8st1tr6wn;i6on;arWot;ent4Wi42tn0;ccupa4ffBp8r7ut6;ca5l0B;ac4Iganiz0ig2Fph2;er3t6;i1Jomet6;ri5;ic0spring;aBe9ie4Xo7u6;n,rser3J;b6mad,vi4V;le2Vo4D;i6mesis,phew;ce,ghb1;nny,rr3t1X;aEeDiAo7u6yst1Y;m8si16;der3gul,m7n6th0;arDk;!my;ni7s6;f02s0Jt0;on,st0;chan1Qnt1rcha4;gi9k0n8rtyr,t6y1;e,riar6;ch;ag0iac;ci2stra3I;a7e2Aieutena4o6;rd,s0v0;bor0d7ndlo6ss,urea3Fwy0ym2;rd;!y;!s28;e8o7u6;ggl0;gg0urna2U;st0;c3Hdol,llu3Ummigra4n6; l9c1Qfa4habi42nov3s7ve6;nt1stig3;pe0Nt6;a1Fig3ru0M;aw;airFeBistoAo8u6ygie1K;man6sba2H;!ita8;bo,st6usekN;age,e3P;ri2;ir,r6;m7o6;!ine;it;dress0sty2C;aLeIhostGirl26ladi3oCrand7u6;e5ru;c9daug0Jfa8m7pa6s2Y;!re4;a,o6;th0;hi1B;al7d6lf0;!de3A;ie,k6te26;eep0;!wr6;it0;isha,n6;i6tl04;us;mbl0rden0;aDella,iAo7r6;eela2Nie1P;e,re6ster pare4;be1Hm2r6st0;unn0;an2ZgZlmm17nanci0r6tt0;e6st la2H; marsh2OfigXm2;rm0th0;conoEdDlectriCm8n7x6;amin0cellency,i2A;emy,trepreneur,vironmenta1J;c8p6;er1loye6;e,r;ee;ci2;it1;mi5;aKeBi8ork,ri7u6we02;de,tche2H;ft0v0;ct3eti7plom2Hre6va;ct1;ci2ti2;aDcor3fencCi0InAput9s7tectLvel6;op0;ce1Ge6ign0;rt0;ee,y;iz6;en;em2;c1Ml0;d8nc0redev7ug6;ht0;il;!dy;a06e04fo,hXitizenWlToBr9u6;r3stomer6;! representat6;ive;e3it6;ic;lJmGnAord9rpor1Nu7w6;boy,ork0;n6ri0;ciTte1Q;in3;fidantAgressSs9t6;e0Kr6;ibut1o6;ll0;tab13ul1O;!e;edi2m6pos0rade;a0EeQissi6;on0;leag8on7um6;ni5;el;ue;e6own;an0r6;ic,k;!s;a9e7i6um;ld;erle6f;ad0;ir7nce6plFract0;ll1;m2wI;lebri6o;ty;dBptAr6shi0;e7pe6;nt0;r,t6;ak0;ain;et;aMeLiJlogg0oErBu6;dd0Fild0rgl9siness6;m2p7w6;om2;ers05;ar;i7o6;!k0th0;cklay0de,gadi0;hemi2oge8y6;!frie6;nd;ym2;an;cyc6sR;li5;atbox0ings;by,nk0r6;b0on7te6;nd0;!e07;c04dWge4nQpLrHsFtAu7yatull6;ah;nt7t6;h1oG;!ie;h8t6;e6orney;nda4;ie5le6;te;sis00tron6;aut,om0;chbis8isto7tis6;an,t;crU;hop;ost9p6;ari6rentiS;ti6;on;le;a9cest1im3nou8y6;bo6;dy;nc0;ly5rc6;hi5;mi8v6;entur0is1;er;ni7r6;al;str3;at1;or;counBquaintanArob9t6;ivi5or,re6;ss;st;at;ce;ta4;nt","Adj|Noun":"true¦0:16;a1Db17c0Ud0Re0Mf0Dg0Ah08i06ju05l02mWnUoSpNrIsBt7u4v1watershed;a1ision0Z;gabo4nilla,ria1;b0Vnt;ndergr1pstairs;adua14ou1;nd;a3e1oken,ri0;en,r1;min0rori13;boo,n;age,e5ilv0Flack,o3quat,ta2u1well;bordina0Xper5;b0Lndard;ciali0Yl1vereign;e,ve16;cret,n1ri0;ior;a4e2ou1ubbiL;nd,tiY;ar,bBl0Wnt0p1side11;resent0Vublican;ci0Qsh;a4eriodic0last0Zotenti0r1;emi2incip0o1;!fession0;er,um;rall4st,tie0U;ff1pposi0Hv0;ens0Oi0C;agg01ov1uts;el;a5e3iniatJo1;bi01der07r1;al,t0;di1tr0N;an,um;le,riG;attOi2u1;sh;ber0ght,qC;stice,veniT;de0mpressioYn1;cumbe0Edividu0no0Dsta0Eterim;alf,o1umdrum;bby,melF;en2old,ra1;ph0Bve;er0ious;a7e5i4l3u1;git03t1;ure;uid;ne;llow,m1;aFiL;ir,t,vo1;riOuriO;l3p00x1;c1ecutUpeV;ess;d1iK;er;ar2e1;mographUrivO;k,l2;hiGlassSo2rude,unn1;ing;m5n1operK;creCstitueOte2vertab1;le;mpor1nt;ary;ic,m2p1;anion,lex;er2u1;ni8;ci0;al;e5lank,o4r1;i2u1;te;ef;ttom,urgeois;st;cadem9d6l2ntarct9r1;ab,ct8;e3tern1;at1;ive;rt;oles1ult;ce1;nt;ic","Adj|Past":"true¦0:4Q;1:4C;2:4H;3:4E;a44b3Tc36d2Je29f20g1Wh1Si1Jj1Gkno1Fl1Am15n12o0Xp0Mqu0Kr08sLtEuAv9w4yellow0;a7ea6o4rinkl0;r4u3Y;n,ri0;k31th3;rp0sh0tZ;ari0e1O;n5p4s0;d1li1Rset;cov3derstood,i4;fi0t0;a8e3Rhr7i6ouTr4urn0wi4C;a4imm0ou2G;ck0in0pp0;ed,r0;eat2Qi37;m0nn0r4;get0ni2T;aOcKeIhGimFm0Hoak0pDt7u4;bsid3Ogge44s4;pe4ta2Y;ct0nd0;a8e7i2Eok0r5u4;ff0mp0nn0;ength2Hip4;ed,p0;am0reotyp0;in0t0;eci4ik0oH;al3Efi0;pRul1;a4ock0ut;d0r0;a4c1Jle2t31;l0s3Ut0;a6or5r4;at4e25;ch0;r0tt3;t4ut0;is2Mur1;aEe5o4;tt0;cAdJf2Bg9je2l8m0Knew0p7qu6s4;eTpe2t4;or0ri2;e3Dir0;e1lac0;at0e2Q;i0Rul1;eiv0o4ycl0;mme2Lrd0v3;in0lli0ti2A;a4ot0;li28;aCer30iBlAo9r5u4;mp0zzl0;e6i2Oo4;ce2Fd4lo1Anou30pos0te2v0;uc0;fe1CocCp0Iss0;i2Kli1L;ann0e2CuS;ck0erc0ss0;ck0i2Hr4st0;allLk0;bse7c6pp13rgan2Dver4;lo4whelm0;ok0;cupi0;rv0;aJe5o4;t0uri1A;ed0gle2;a6e5ix0o4ut0ys1N;di1Nt15u26;as0Clt0;n4rk0;ag0ufact0A;e6i5o4;ad0ck0st,v0;cens0m04st0;ft,v4;el0;tt0wn;a5o15u4;dg0s1B;gg0;llumSmpAn4sol1;br0cre1Ldebt0f8jZspir0t5v4;it0olv0;e4ox0Y;gr1n4re23;d0si15;e2l1o1Wuri1;li0o01r4;ov0;a6e1o4um03;ok0r4;ri0Z;mm3rm0;i6r5u4;a1Bid0;a0Ui0Rown;ft0;aAe9i8l6oc0Ir4;a4i0oz0Y;ctHg19m0;avo0Ju4;st3;ni08tt0x0;ar0;d0il0sc4;in1;dCl1mBn9quipp0s8x4;agger1c6p4te0T;a0Se4os0;ct0rie1D;it0;cap0tabliZ;cha0XgFha1As4;ur0;a0Zbarra0N;i0Buc1;aMeDi5r4;a01i0;gni08miniSre2s4;a9c6grun0Ft4;o4re0Hu17;rt0;iplWou4;nt0r4;ag0;bl0;cBdRf9l8p7ra6t5v4;elop0ot0;ail0ermQ;ng0;re07;ay0ight0;e4in0o0M;rr0;ay0enTor1;m5t0z4;ed,zl0;ag0p4;en0;aPeLhIlHo9r6u4;lt4r0stom03;iv1;a5owd0u4;sh0;ck0mp0;d0loAm7n4ok0v3;centr1f5s4troC;id3olid1;us0;b5pl4;ic1;in0;r0ur0;assi9os0utt3;ar5i4;ll0;g0m0;lebr1n6r4;ti4;fi0;tralJ;g0lcul1;aDewild3iCl9o7r5urn4;ed,t;ok4uis0;en;il0r0t4und;tl0;e5i4;nd0;ss0;as0;ffl0k0laMs0tt3;bPcNdKfIg0lFmaz0nDppBrm0ss9u5wa4;rd0;g5thor4;iz0;me4;nt0;o6u4;m0r0;li0re4;ci1;im1ticip1;at0;a5leg0t3;er0;rm0;fe2;ct0;ju5o7va4;nc0;st0;ce4knowledg0;pt0;and5so4;rb0;on0;ed",Singular:"true¦0:5J;1:5H;2:4W;3:4S;4:52;5:57;6:5L;7:56;8:5B;a52b4Lc3Nd35e2Xf2Og2Jh28in24j23k22l1Um1Ln1Ho1Bp0Rqu0Qr0FsZtMuHvCw9x r58yo yo;a9ha3Po3Q;f3i4Rt0Gy9;! arou39;arCeAideo ga2Qo9;cabu4Jl5C;gOr9t;di4Zt1Y;iety,ni4P;nBp30rAs 9;do43s5E;bani1in0;coordinat3Ader9;estima1to24we41; rex,aKeJhHiFoErBuAv9;! show;m2On2rntLto1D;agedy,ib9o4E;e,u9;n0ta46;ni1p2rq3L;c,er,m9;etF;ing9ree26;!y;am,mp3F;ct2le6x return;aNcMeKhor4QiJkHoGpin off,tDuBy9;ll9ner7st4T;ab2X;b9i1n28per bowl,rro1X;st3Ltot0;atAipe2Go1Lrate7udent9;! lo0I;i39u1;ft ser4Lmeo1I;elet5i9;ll,r3V;b38gn2Tte;ab2Jc9min3B;t,urity gua2N;e6ho2Y;bbatic0la3Jndwi0Qpi5;av5eDhetor2iAo9;de6om,w;tAv9;erb2C;e,u0;bDcBf9publ2r10spi1;er9orm3;e6r0;i9ord label;p2Ht0;a1u46;estion mark,ot2F;aPeMhoLiIlGoErAu9yram1F;ddi3HpErpo1Js3J;eBo9;bl3Zs9;pe3Jta1;dic1Rmi1Fp1Qroga8ss relea1F;p9rt0;py;a9ebisci1;q2Dte;cn2eAg9;!gy;!r;ne call,tocoK;anut,dAr9t0yo1;cen3Jsp3K;al,est0;nop4rAt9;e,hog5;adi11i2V;atme0bj3FcBpia1rde0thers,utspok5ve9wn3;n,r9;ti0Pview;cuAe9;an;pi3;arBitAot9umb3;a2Fhi2R;e,ra1;cot2ra8;aFeCiAo9ur0;nopo4p18rni2Nsq1Rti36uld;c,li11n0As9tt5;chief,si34;dAnu,t9;al,i3;al,ic;gna1mm0nd15rsupi0te9yf4;ri0;aDegCiBu9;ddi1n9;ch;me,p09; Be0M;bor14y9; 9er;up;eyno1itt5;el4ourn0;cBdices,itia8ni25sAtel0Lvert9;eb1J;e28titu1;en8i2T;aIeEighDoAu9;man right,s22;me9rmoFsp1Ftb0K;! r9;un; scho0YriY;a9i1N;d9v5; start,pho9;ne;ndful,sh brown,v5ze;aBelat0Ilaci3r9ul4yp1S;an9enadi3id;a1Cd slam,ny;df4r9;l2ni1I;aGeti1HiFlu1oCrAun9;er0;ee market,i9onti3;ga1;l4ur9;so9;me;ePref4;br2mi4;conoFffi7gg,lecto0Rmbas1EnCpidem2s1Zth2venBxAyel9;id;ampZempl0Nte6;i19t;er7terp9;ri9;se;my;eLiEoBr9ump tru0U;agonf4i9;er,ve thru;cAg7i4or,ssi3wn9;side;to0EumenE;aEgniDnn3sAvide9;nd;conte6incen8p9tri11;osi9;ti0C;ta0H;le0X;athBcAf9ni0terre6;ault 05err0;al,im0;!b9;ed;aWeThMiLlJoDr9;edit caBuc9;ib9;le;rd;efficDke,lCmmuniqLnsApi3rr0t0Xus9yo1;in;erv9uI;ato02;ic,lQ;ie6;er7i9oth;e6n2;ty,vil wM;aDeqCick5ocoBr9;istmas car9ysanthemum;ol;la1;ue;ndeli3racteri9;st2;iAllEr9;e0tifica1;liZ;hi3nFpErCt9ucus;erpi9hedr0;ll9;ar;!bohyd9ri3;ra1;it0;aAe,nib0t9;on;l,ry;aMeLiop2leJoHrDu9;nny,r9tterf4;g9i0;la9;ry;eakAi9;ck;fa9throB;st;dy,ro9wl;ugh;mi9;sh;an,l4;nkiArri3;er;ng;cSdMlInFppeti1rDsBtt2utop9;sy;ic;ce6pe9;ct;r9sen0;ay;ecAoma4tiA;ly;do1;i5l9;er7y;gy;en; hominDjAvan9;tage;ec8;ti9;ve;em;cCeAqui9;tt0;ta1;te;iAru0;al;de6;nt","Person|Noun":"true¦a0Eb07c03dWeUfQgOhLjHkiGlFmCnBolive,p7r4s3trini06v1wa0;ng,rd,tts;an,enus,iol0;a,et;ky,onPumm09;ay,e1o0uby;bin,d,se;ed,x;a2e1o0;l,tt04;aLnJ;dYge,tR;at,orm;a0eloW;t0x,ya;!s;a9eo,iH;ng,tP;a2e1o0;lGy;an,w3;de,smi4y;a0erb,iOolBuntR;ll,z0;el;ail,e0iLuy;ne;a1ern,i0lo;elds,nn;ith,n0;ny;a0dEmir,ula,ve;rl;a4e3i1j,ol0;ly;ck,x0;ie;an,ja;i0wn;sy;am,h0liff,rystal;a0in,ristian;mbers,ri0;ty;a4e3i2o,r0ud;an0ook;dy;ll;nedict,rg;k0nks;er;l0rt;fredo,ma","Actor|Verb":"true¦aCb8c5doctor,engineAfool,g3host,judge,m2nerd,p1recruit,scout,ushAvolunteAwi0;mp,tneA;arent,ilot;an,ime;eek,oof,r0uide;adu8oom;ha1o0;ach,nscript,ok;mpion,uffeur;o2u0;lly,tch0;er;ss;ddi1ffili0rchite1;ate;ct",MaleName:"true¦0:H6;1:FZ;2:DS;3:GQ;4:CZ;5:FV;6:GM;7:FP;8:GW;9:ET;A:C2;B:GD;aF8bE1cCQdBMeASfA1g8Yh88i7Uj6Sk6Bl5Mm48n3So3Ip33qu31r26s1Et0Ru0Ov0CwTxSyHzC;aCor0;cChC1karia,nAT;!hDkC;!aF6;!ar7CeF5;aJevgenBSoEuC;en,rFVsCu3FvEF;if,uf;nDs6OusC;ouf,s6N;aCg;s,tC;an,h0;hli,nCrosE1ss09;is,nC;!iBU;avi2ho5;aPeNiDoCyaEL;jcieBJlfgang,odrFutR;lFnC;f8TsC;lCt1;ow;bGey,frEhe4QlC;aE5iCy;am,e,s;ed8iC;d,ed;eAur;i,ndeD2rn2sC;!l9t1;lDyC;l1ne;lDtC;!er;aCHy;aKernDAiFladDoC;jteB0lodymyr;!iC;mFQsDB;cFha0ktBZnceDrgCOvC;a0ek;!nC;t,zo;!e4StBV;lCnC7sily;!entC;in9J;ghE2lCm70nax,ri,sm0;riCyss87;ch,k;aWeRhNiLoGrEuDyC;!l2roEDs1;n6r6E;avD0eCist0oy,um0;ntCRvBKy;bFdAWmCny;!asDmCoharu;aFFie,y;!z;iA6y;mCt4;!my,othy;adEeoDia0SomC;!as;!dor91;!de4;dFrC;enBKrC;anBJeCy;ll,nBI;!dy;dgh,ha,iCnn2req,tsu5V;cDAka;aYcotWeThPiMlobod0oKpenc2tEurDvenAEyCzym1;ed,lvest2;aj,e9V;anFeDuC;!aA;fan17phEQvCwaA;e77ie;!islaCl9;v,w;lom1rBuC;leymaDHta;dDgmu9UlCm1yabonga;as,v8B;!dhart8Yn9;aEeClo75;lCrm0;d1t1;h9Jne,qu1Jun,wn,yne;aDbastiEDk2Yl5Mpp,rgCth,ymoCU;e1Dio;m4n;!tC;!ie,y;eDPlFmEnCq67tosCMul;dCj2UtiA5;e01ro;!iATkeB6mC4u5;!ik,vato9K;aZeUheC8iRoGuDyC;an,ou;b99dDf4peAssC;!elEG;ol00y;an,bLc7MdJel,geIh0lHmGnEry,sDyC;!ce;ar7Ocoe,s;!aCnBU;ld,n;an,eo;a7Ef;l7Jr;e3Eg2n9olfo,riC;go;bBNeDH;cCl9;ar87c86h54kCo;!ey,ie,y;cFeA3gDid,ubByCza;an8Ln06;g85iC;naC6s;ep;ch8Kfa5hHin2je8HlGmFndEoHpha5sDul,wi36yC;an,mo8O;h9Im4;alDSol3O;iD0on;f,ph;ul;e9CinC;cy,t1;aOeLhilJiFrCyoG;aDeC;m,st1;ka85v2O;eDoC;tr;r8GtC;er,ro;!ipCl6H;!p6U;dCLrcy,tC;ar,e9JrC;!o7;b9Udra8So9UscAHtri62ulCv8I;!ie,o7;ctav6Ji2lImHndrBRrGsDtCum6wB;is,to;aDc6k6m0vCwaBE;al79;ma;i,vR;ar,er;aDeksandr,ivC;er,i2;f,v;aNeLguyBiFoCu3O;aDel,j4l0ma0rC;beAm0;h,m;cFels,g5i9EkDlC;es,s;!au,h96l78olaC;!i,y;hCkCol76;ol75;al,d,il,ls1vC;ilAF;hom,tC;e,hC;anCy;!a5i5;aYeViLoGuDyC;l4Nr1;hamDr84staC;fa,p6E;ed,mG;di10e,hamEis4JntDritz,sCussa;es,he;e,y;ad,ed,mC;ad,ed;cGgu5hai,kFlEnDtchC;!e8O;a9Pik;house,o7t1;ae73eC3ha8Iolaj;ah,hDkC;!ey,y;aDeC;al,l;el,l;hDlv3rC;le,ri8Ev4T;di,met;ay0c00gn4hWjd,ks2NlTmadZnSrKsXtDuric7VxC;imilBKwe8B;eHhEi69tCus,y69;!eo,hCia7;ew,i67;eDiC;as,eu,s;us,w;j,o;cHiGkFlEqu8Qsha83tCv3;iCy;!m,n;in,on;el,o7us;a6Yo7us;!elCin,o7us;!l8o;frAEi5Zny,u5;achDcoCik;lm;ai,y;amDdi,e5VmC;oud;adCm6W;ou;aulCi9P;ay;aWeOiMloyd,oJuDyC;le,nd1;cFdEiDkCth2uk;a7e;gi,s,z;ov7Cv6Hw6H;!as,iC;a6Een;g0nn52renDuCvA4we7D;!iS;!zo;am,n4oC;n5r;a9Yevi,la5KnHoFst2thaEvC;eCi;nte;bo;nCpo8V;!a82el,id;!nC;aAy;mEnd1rDsz73urenCwr6K;ce,t;ry,s;ar,beAont;aOeIhalHiFla4onr63rDu5SylC;e,s;istCzysztof;i0oph2;er0ngsl9p,rC;ilA9k,ollos;ed,id;en0iGnDrmCv4Z;it;!dDnCt1;e2Ny;ri4Z;r,th;cp2j4mEna8BrDsp6them,uC;ri;im,l;al,il;a03eXiVoFuC;an,lCst3;en,iC;an,en,o,us;aQeOhKkub4AnIrGsDzC;ef;eDhCi9Wue;!ua;!f,ph;dCge;i,on;!aCny;h,s,th6J;anDnC;!ath6Hie,n72;!nC;!es;!l,sCy;ph;o,qu3;an,mC;!i,m6V;d,ffFns,rCs4;a7JemDmai7QoCry;me,ni1H;i9Dy;!e73rC;ey,y;cKdBkImHrEsDvi2yC;dBs1;on,p2;ed,oDrCv67;e6Qod;d,s61;al,es5Wis1;a,e,oCub;b,v;ob,qu13;aTbNchiMgLke53lija,nuKonut,rIsEtCv0;ai,suC;ki;aDha0i8XmaCsac;el,il;ac,iaC;h,s;a,vinCw3;!g;k,nngu6X;nac1Xor;ka;ai,rahC;im;aReLoIuCyd6;beAgGmFsC;eyDsC;a3e3;in,n;ber5W;h,o;m2raDsse3wC;a5Pie;c49t1K;a0Qct3XiGnDrC;beAman08;dr7VrC;iCy2N;!k,q1R;n0Tt3S;bKlJmza,nIo,rEsDyC;a5KdB;an,s0;lEo67r2IuCv9;hi5Hki,tC;a,o;an,ey;k,s;!im;ib;a08e00iUlenToQrMuCyorgy;iHnFsC;!taC;f,vC;!e,o;n6tC;er,h2;do,lC;herDlC;auCerQ;me;aEegCov2;!g,orC;!io,y;dy,h7C;dfr9nza3XrDttfC;ri6C;an,d47;!n;acoGlEno,oCuseppe;rgiCvan6O;!o,s;be6Ies,lC;es;mo;oFrC;aDha4HrCt;it,y;ld,rd8;ffErgC;!e7iCy;!os;!r9;bElBrCv3;eCla1Nr4Hth,y;th;e,rC;e3YielC;!i4;aXeSiQlOorrest,rCyod2E;aHedFiC;edDtC;s,z;ri18;!d42eri11riC;ck,k;nCs2;cEkC;ie,lC;in,yn;esLisC;!co,z3M;etch2oC;ri0yd;d5lConn;ip;deriFliEng,rC;dinaCg4nan0B;nd8;pe,x;co;bCdi,hd;iEriC;ce,zC;io;an,en,o;benez2dZfrYit0lTmMnJo3rFsteb0th0ugenEvCymBzra;an,eCge4D;ns,re3K;!e;gi,iDnCrol,v3w3;est8ie,st;cCk;!h,k;o0DriCzo;co,qC;ue;aHerGiDmC;aGe3A;lCrh0;!iC;a10o,s;s1y;nu5;beAd1iEliDm2t1viCwood;n,s;ot28s;!as,j5Hot,sC;ha;a3en;!dGg6mFoDua2QwC;a2Pin;arC;do;oZuZ;ie;a04eTiOmitrNoFrag0uEwDylC;an,l0;ay3Hig4D;a3Gdl9nc0st3;minFnDri0ugCvydGy2S;!lF;!a36nCov0;e1Eie,y;go,iDykC;as;cCk;!k;i,y;armuFetDll1mitri7neCon,rk;sh;er,m6riC;ch;id;andLepak,j0lbeAmetri4nIon,rGsEvDwCxt2;ay30ey;en,in;hawn,moC;nd;ek,riC;ck;is,nC;is,y;rt;re;an,le,mKnIrEvC;e,iC;!d;en,iEne0PrCyl;eCin,yl;l45n;n,o,us;!iCny;el,lo;iCon;an,en,on;a0Fe0Ch03iar0lRoJrFuDyrC;il,us;rtC;!is;aEistC;iaCob12;no;ig;dy,lInErC;ey,neliCy;s,us;nEor,rDstaC;nt3;ad;or;by,e,in,l3t1;aHeEiCyde;fCnt,ve;fo0Xt1;menDt4;us;s,t;rFuDyC;!t1;dCs;e,io;enC;ce;aHeGrisC;!toC;phCs;!eC;!r;st2t;d,rCs;b5leC;s,y;cDdrCs6;ic;il;lHmFrC;ey,lDroCy;ll;!o7t1;er1iC;lo;!eb,v3;a09eZiVjorn,laUoSrEuCyr1;ddy,rtKst2;er;aKeFiEuDyC;an,ce,on;ce,no;an,ce;nDtC;!t;dDtC;!on;an,on;dFnC;dDisC;lav;en,on;!foOl9y;bby,gd0rCyd;is;i0Lke;bElDshC;al;al,lL;ek;nIrCshoi;at,nEtC;!raC;m,nd;aDhaCie;rd;rd8;!iDjam3nCs1;ie,y;to;kaMlazs,nHrC;n9rDtC;!holomew;eCy;tt;ey;dCeD;ar,iC;le;ar1Nb1Dd16fon15gust3hm12i0Zja0Yl0Bm07nTputsiSrGsaFugustEveDyCziz;a0kh0;ry;o,us;hi;aMchiKiJjun,mHnEon,tCy0;em,hCie,ur8;ur;aDoC;!ld;ud,v;aCin;an,nd8;!el,ki;baCe;ld;ta;aq;aMdHgel8tCw6;hoFoC;iDnC;!i8y;ne;ny;er7rCy;eDzC;ej;!as,i,j,s,w;!s;s,tolC;iCy;!y;ar,iEmaCos;nu5r;el;ne,r,t;aVbSdBeJfHiGl01onFphonsEt1vC;aPin;on;e,o;so,zo;!sR;!onZrC;ed;c,jaHksFssaHxC;!andC;er,rC;e,os,u;andCei;ar,er,r;ndC;ro;en;eDrecC;ht;rt8;dd3in,n,sC;taC;ir;ni;dDm6;ar;an,en;ad,eC;d,t;in;so;aGi,olErDvC;ik;ian8;f8ph;!o;mCn;!a;dGeFraDuC;!bakr,lfazl;hCm;am;!l;allFel,oulaye,ulC;!lDrahm0;an;ah,o;ah;av,on",Uncountable:"true¦0:2E;1:2L;2:33;a2Ub2Lc29d22e1Rf1Ng1Eh16i11j0Yk0Wl0Rm0Hn0Do0Cp03rZsLt9uran2Jv7w3you gu0E;a5his17i4oo3;d,l;ldlife,ne;rm8t1;apor,ernacul29i3;neg28ol1Otae;eDhBiAo8r4un3yranny;a,gst1B;aff2Oea1Ko4ue nor3;th;o08u3;bleshoot2Ose1Tt;night,othpas1Vwn3;foEsfoE;me off,n;er3und1;e,mod2S;a,nnis;aDcCeBhAi9ki8o7p6t4u3weepstak0;g1Unshi2Hshi;ati08e3;am,el;ace2Keci0;ap,cc1meth2C;n,ttl0;lk;eep,ingl0or1C;lf,na1Gri0;ene1Kisso1C;d0Wfe2l4nd,t3;i0Iurn;m1Ut;abi0e4ic3;e,ke15;c3i01laxa11search;ogni10rea10;a9e8hys7luto,o5re3ut2;amble,mis0s3ten20;en1Zs0L;l3rk;i28l0EyH; 16i28;a24tr0F;nt3ti0M;i0s;bstetri24vercrowd1Qxyg09;a5e4owada3utella;ys;ptu1Ows;il poliZtional securi2;aAe8o5u3;m3s1H;ps;n3o1K;ey,o3;gamy;a3cha0Elancholy,rchandi1Htallurgy;sl0t;chine3g1Aj1Hrs,thema1Q; learn1Cry;aught1e6i5ogi4u3;ck,g12;c,s1M;ce,ghtn18nguis1LteratWv1;ath1isVss;ara0EindergartPn3;icke0Aowled0Y;e3upit1;a3llyfiGwel0G;ns;ce,gnor6mp5n3;forma00ter3;net,sta07;atiSort3rov;an18;a7e6isto09o3ung1;ckey,mework,ne4o3rseradi8spitali2use arrest;ky;s2y;adquarteXre;ir,libut,ppiHs3;hi3te;sh;ene8l6o5r3um,ymnas11;a3eZ;niUss;lf,re;ut3yce0F;en; 3ti0W;edit0Hpo3;ol;aNicFlour,o4urnit3;ure;od,rgive3uri1wl;ness;arCcono0LducaBlectr9n7quip8thi0Pvery6x3;ist4per3;ti0B;en0J;body,o08th07;joy3tertain3;ment;ici2o3;ni0H;tiS;nings,th;emi02i6o4raugh3ynas2;ts;pe,wnstai3;rs;abet0ce,s3;honZrepu3;te;aDelciChAivi07l8o3urrency;al,ld w6mmenta5n3ral,ttIuscoB;fusiHt 3;ed;ry;ar;assi01oth0;es;aos,e3;eMwK;us;d,rO;a8i6lood,owlHread5u3;ntGtt1;er;!th;lliarJs3;on;g3ss;ga3;ge;cKdviJeroGirFmBn6ppeal court,r4spi3thleL;rin;ithmet3sen3;ic;i6y3;o4th3;ing;ne;se;en5n3;es2;ty;ds;craft;bi8d3nau7;yna3;mi6;ce;id,ous3;ti3;cs",Infinitive:"true¦0:9G;1:9T;2:AD;3:90;4:9Z;5:84;6:AH;7:A9;8:92;9:A0;A:AG;B:AI;C:9V;D:8R;E:8O;F:97;G:6H;H:7D;a94b8Hc7Jd68e4Zf4Mg4Gh4Ai3Qj3Nk3Kl3Bm34nou48o2Vp2Equ2Dr1Es0CtZuTvRwI;aOeNiLors5rI;eJiI;ng,te;ak,st3;d5e8TthI;draw,er;a2d,ep;i2ke,nIrn;d1t;aIie;liADniAry;nJpI;ho8Llift;cov1dJear8Hfound8DlIplug,rav82tie,ve94;eaAo3X;erIo;cut,go,staAFvalA3w2G;aSeQhNoMrIu73;aIe72;ffi3Smp3nsI;aBfo7CpI;i8oD;pp3ugh5;aJiJrIwaD;eat5i2;nk;aImA0;ch,se;ck3ilor,keImp1r8L;! paD;a0Ic0He0Fh0Bi0Al08mugg3n07o05p02qu01tUuLwI;aJeeIim;p,t5;ll7Wy;bNccMffLggeCmmKppJrI;mouFpa6Zvi2;o0re6Y;ari0on;er,i4;e7Numb;li9KmJsiIveD;de,st;er9it;aMe8MiKrI;ang3eIi2;ng27w;fIng;f5le;b,gg1rI;t3ve;a4AiA;a4UeJit,l7DoI;il,of;ak,nd;lIot7Kw;icEve;atGeak,i0O;aIi6;m,y;ft,ng,t;aKi6CoJriIun;nk,v6Q;ot,rt5;ke,rp5tt1;eIll,nd,que8Gv1w;!k,m;aven9ul8W;dd5tis1Iy;a0FeKiJoI;am,t,ut;d,p5;a0Ab08c06d05f01group,hea00iZjoi4lXmWnVpTq3MsOtMup,vI;amp,eJiIo3B;sEve;l,rI;e,t;i8rI;ie2ofE;eLiKpo8PtIurfa4;o24rI;aHiBuctu8;de,gn,st;mb3nt;el,hra0lIreseF;a4e71;d1ew,o07;aHe3Fo2;a7eFiIo6Jy;e2nq41ve;mbur0nf38;r0t;inKleBocus,rJuI;el,rbiA;aBeA;an4e;aBu4;ei2k8Bla43oIyc3;gni39nci3up,v1;oot,uI;ff;ct,d,liIp;se,ze;tt3viA;aAenGit,o7;aWerUinpoiFlumm1LoTrLuI;b47ke,niArIt;poDsuI;aFe;eMoI;cKd,fe4XhibEmo7noJpo0sp1tru6vI;e,i6o5L;un4;la3Nu8;aGclu6dJf1occupy,sup0JvI;a6BeF;etermi4TiB;aGllu7rtr5Ksse4Q;cei2fo4NiAmea7plex,sIva6;eve8iCua6;mp1rItrol,ve;a6It6E;bOccuNmEpMutLverIwe;l07sJtu6Yu0wI;helm;ee,h1F;gr5Cnu2Cpa4;era7i4Ipo0;py,r;ey,seItaH;r2ss;aMe0ViJoIultiply;leCu6Pw;micJnIspla4;ce,g3us;!k;iIke,na9;m,ntaH;aPeLiIo0u3N;ke,ng1quIv5;eIi6S;fy;aKnIss5;d,gI;th5;rn,ve;ng2Gu1N;eep,idnJnI;e4Cow;ap;oHuI;gg3xtaI;po0;gno8mVnIrk;cTdRfQgeChPitia7ju8q1CsNtKun6EvI;a6eIo11;nt,rt,st;erJimi6BoxiPrI;odu4u6;aBn,pr03ru6C;iCpi8tIu8;all,il,ruB;abEibE;eCo3Eu0;iIul9;ca7;i7lu6;b5Xmer0pI;aLer4Uin9ly,oJrI;e3Ais6Bo2;rt,se,veI;riA;le,rt;aLeKiIoiCuD;de,jaInd1;ck;ar,iT;mp1ng,pp5raIve;ng5Mss;ath1et,iMle27oLrI;aJeIow;et;b,pp3ze;!ve5A;gg3ve;aTer45i5RlSorMrJuI;lf4Cndrai0r48;eJiIolic;ght5;e0Qsh5;b3XeLfeEgJsI;a3Dee;eIi2;!t;clo0go,shIwa4Z;ad3F;att1ee,i36;lt1st5;a0OdEl0Mm0FnXquip,rWsVtGvTxI;aRcPeDhOiNpJtIu6;ing0Yol;eKi8lIo0un9;aHoI;it,re;ct,di7l;st,t;a3oDu3B;e30lI;a10u6;lt,mi28;alua7oI;ke,l2;chew,pou0tab19;a0u4U;aYcVdTfSgQhan4joy,lPqOrNsuMtKvI;e0YisI;a9i50;er,i4rI;aHenGuC;e,re;iGol0F;ui8;ar9iC;a9eIra2ulf;nd1;or4;ang1oIu8;r0w;irc3lo0ou0ErJuI;mb1;oaGy4D;b3ct;bKer9pI;hasiIow1;ze;aKody,rI;a4oiI;d1l;lm,rk;ap0eBuI;ci40de;rIt;ma0Rn;a0Re04iKo,rIwind3;aw,ed9oI;wn;agno0e,ff1g,mi2Kne,sLvI;eIul9;rIst;ge,t;aWbVcQlod9mant3pNru3TsMtI;iIoDu37;lJngI;uiA;!l;ol2ua6;eJlIo0ro2;a4ea0;n0r0;a2Xe36lKoIu0S;uIv1;ra9;aIo0;im;a3Kur0;b3rm;af5b01cVduBep5fUliTmQnOpMrLsiCtaGvI;eIol2;lop;ch;a20i2;aDiBloIoD;re,y;oIy;te,un4;eJoI;liA;an;mEv1;a4i0Ao06raud,y;ei2iMla8oKrI;ee,yI;!pt;de,mIup3;missi34po0;de,ma7ph1;aJrief,uI;g,nk;rk;mp5rk5uF;a0Dea0h0Ai09l08oKrIurta1G;a2ea7ipp3uI;mb3;ales4e04habEinci6ll03m00nIrro6;cXdUfQju8no7qu1sLtKvI;eIin4;ne,r9y;aHin2Bribu7;er2iLoli2Epi8tJuI;lt,me;itu7raH;in;d1st;eKiJoIroFu0;rm;de,gu8rm;ss;eJoI;ne;mn,n0;eIlu6ur;al,i2;buCe,men4pI;eIi3ly;l,te;eBi6u6;r4xiC;ean0iT;rcumveFte;eJirp,oI;o0p;riAw;ncIre5t1ulk;el;a02eSi6lQoPrKuI;iXrIy;st,y;aLeaKiJoad5;en;ng;stfeLtX;ke;il,l11mba0WrrMth1;eIow;ed;!coQfrie1LgPhMliLqueaKstJtrIwild1;ay;ow;th;e2tt3;a2eJoI;ld;ad;!in,ui3;me;bysEckfi8ff3tI;he;b15c0Rd0Iff0Ggree,l0Cm09n03ppZrXsQttOuMvJwaE;it;eDoI;id;rt;gIto0X;meF;aIeCraB;ch,in;pi8sJtoI;niA;aKeIi04u8;mb3rt,ss;le;il;re;g0Hi0ou0rI;an9i2;eaKly,oiFrI;ai0o2;nt;r,se;aMi0GnJtI;icipa7;eJoIul;un4y;al;ly0;aJu0;se;lga08ze;iKlI;e9oIu6;t,w;gn;ix,oI;rd;a03jNmiKoJsoI;rb;pt,rn;niIt;st1;er;ouJuC;st;rn;cLhie2knowled9quiItiva7;es4re;ce;ge;eQliOoKrJusI;e,tom;ue;mIst;moJpI;any,liA;da7;ma7;te;pt;andPduBet,i6oKsI;coKol2;ve;liArt,uI;nd;sh;de;ct;on",Person:"true¦0:1Q;a29b1Zc1Md1Ee18f15g13h0Ri0Qj0Nk0Jl0Gm09n06o05p00rPsItCusain bolt,v9w4xzibit,y1;anni,oko on2uji,v1;an,es;en,o;a3ednesday adams,i2o1;lfram,o0Q;ll ferrell,z khalifa;lt disn1Qr1;hol,r0G;a2i1oltai06;n dies0Zrginia wo17;lentino rossi,n goG;a4h3i2ripp,u1yra banks;lZpac shakur;ger woods,mba07;eresa may,or;kashi,t1ylor;um,ya1B;a5carlett johanss0h4i3lobodan milosevic,no2ocr1Lpider1uperm0Fwami; m0Em0E;op dogg,w whi1H;egfried,nbad;akespeaTerlock holm1Sia labeouf;ddam hussa16nt1;a cla11ig9;aAe6i5o3u1za;mi,n dmc,paul,sh limbau1;gh;bin hood,d stew16nald1thko;in0Mo;han0Yngo starr,valdo;ese witherspo0i1mbrandt;ll2nh1;old;ey,y;chmaninoff,ffi,iJshid,y roma1H;a4e3i2la16o1uff daddy;cahont0Ie;lar,p19;le,rZ;lm17ris hilt0;leg,prah winfr0Sra;a2e1iles cra1Bostradam0J; yo,l5tt06wmQ;pole0s;a5e4i2o1ubar03;by,lie5net,rriss0N;randa ju1tt romn0M;ly;rl0GssiaB;cklemo1rkov,s0ta hari,ya angelou;re;ady gaga,e1ibera0Pu;bron jam0Xch wale1e;sa;anye west,e3i1obe bryant;d cudi,efer suther1;la0P;ats,sha;a2effers0fk,k rowling,rr tolki1;en;ck the ripp0Mwaharlal nehru,y z;liTnez,ron m7;a7e5i3u1;lk hog5mphrey1sa01;! bog05;l1tl0H;de; m1dwig,nry 4;an;ile selassFlle ber4m3rrison1;! 1;ford;id,mo09;ry;ast0iannis,o1;odwPtye;ergus0lorence nightinga08r1;an1ederic chopN;s,z;ff5m2nya,ustaXzeki1;el;eril lagasse,i1;le zatop1nem;ek;ie;a6e4i2octor w1rake;ho;ck w1ego maradoC;olf;g1mi lovaOnzel washingt0;as;l1nHrth vadR;ai lNt0;a8h5lint0o1thulhu;n1olio;an,fuci1;us;on;aucKop2ristian baMy1;na;in;millo,ptain beefhe4r1;dinal wols2son1;! palmF;ey;art;a8e5hatt,i3oHro1;ck,n1;te;ll g1ng crosby;atB;ck,nazir bhut2rtil,yon1;ce;to;nksy,rack ob1;ama;l 6r3shton kutch2vril lavig8yn ra1;nd;er;chimed2istot1;le;es;capo2paci1;no;ne",Adjective:"true¦0:AI;1:BS;2:BI;3:BA;4:A8;5:84;6:AV;7:AN;8:AF;9:7H;A:BQ;B:AY;C:BC;D:BH;E:9Y;aA2b9Ec8Fd7We79f6Ng6Eh61i4Xj4Wk4Tl4Im41n3Po36p2Oquart7Pr2Ds1Dt14uSvOwFye29;aMeKhIiHoF;man5oFrth7G;dADzy;despreB1n w97s86;acked1UoleF;!sa6;ather1PeFll o70ste1D;!k5;nt1Ist6Ate4;aHeGiFola5T;bBUce versa,gi3Lle;ng67rsa5R;ca1gBSluAV;lt0PnLpHrGsFttermoBL;ef9Ku3;b96ge1; Hb32pGsFtiAH;ca6ide d4R;er,i85;f52to da2;a0Fbeco0Hc0Bd04e02f01gu1XheaBGiXkn4OmUnTopp06pRrNsJtHus0wF;aFiel3K;nt0rra0P;app0eXoF;ld,uS;eHi37o5ApGuF;perv06spec39;e1ok9O;en,ttl0;eFu5;cogn06gul2RlGqu84sF;erv0olv0;at0en33;aFrecede0E;id,rallel0;am0otic0;aFet;rri0tF;ch0;nFq26vers3;sur0terFv7U;eFrupt0;st0;air,inish0orese98;mploy0n7Ov97xpF;ect0lain0;eHisFocume01ue;clFput0;os0;cid0rF;!a8Scov9ha8Jlyi8nea8Gprivileg0sMwF;aFei9I;t9y;hGircumcFonvin2U;is0;aFeck0;lleng0rt0;b20ppea85ssuGttend0uthorF;iz0;mi8;i4Ara;aLeIhoHip 25oGrF;anspare1encha1i2;geth9leADp notch,rpB;rny,ugh6H;ena8DmpGrFs6U;r49tia4;eCo8P;leFst4M;nt0;a0Dc09e07h06i04ki03l01mug,nobbi4XoVpRqueami4XtKuFymb94;bHccinAi generis,pFr5;erFre7N;! dup9b,vi70;du0li7Lp6IsFurb7J;eq9Atanda9X;aKeJi16o2QrGubboFy4Q;rn;aightFin5GungS; fFfF;or7V;adfa9Pri6;lwa6Ftu82;arHeGir6NlendBot Fry;on;c3Qe1S;k5se; call0lImb9phistic16rHuFviV;ndFth1B;proof;dBry;dFub6; o2A;e60ipF;pe4shod;ll0n d7R;g2HnF;ceEg6ist9;am3Se9;co1Zem5lfFn6Are7; suf4Xi43;aGholFient3A;ar5;rlFt4A;et;cr0me,tisfac7F;aOeIheumatoBiGoF;bu8Ztt7Gy3;ghtFv3; 1Sf6X;cJdu8PlInown0pro69sGtF;ard0;is47oF;lu2na1;e1Suc45;alcit8Xe1ondi2;bBci3mpa1;aSePicayu7laOoNrGuF;bl7Tnjabi;eKiIoF;b7VfGmi49pFxi2M;er,ort81;a7uD;maFor,sti7va2;!ry;ciDexis0Ima2CpaB;in55puli8G;cBid;ac2Ynt 3IrFti2;ma40tFv7W;!i3Z;i2YrFss7R;anoBtF; 5XiF;al,s5V;bSffQkPld OnMrLth9utKverF;!aIbMdHhGni75seas,t,wF;ei74rou74;a63e7A;ue;ll;do1Ger,si6A;d3Qg2Aotu5Z; bFbFe on o7g3Uli7;oa80;fashion0school;!ay; gua7XbFha5Uli7;eat;eHligGsF;ce7er0So1C;at0;diFse;a1e1;aOeNiMoGuF;anc0de; moEnHrthFt6V;!eFwe7L;a7Krn;chaGdescri7Iprof30sF;top;la1;ght5;arby,cessa4ighbor5wlyw0xt;k0usiaFv3;ti8;aQeNiLoHuF;dIltiF;facet0p6;deHlGnFot,rbBst;ochro4Xth5;dy;rn,st;ddle ag0nF;dbloZi,or;ag9diocEga,naGrFtropolit4Q;e,ry;ci8;cIgenta,inHj0Fkeshift,mmGnFri4Oscu61ver18;da5Dy;ali4Lo4U;!stream;abEho;aOeLiIoFumberi8;ngFuti1R;stan3RtF;erm,i4H;ghtGteraF;l,ry,te;heart0wei5O;ft JgFss9th3;al,eFi0M;nda4;nguBps0te5;apGind5noF;wi8;ut;ad0itte4uniW;ce co0Hgno6Mll0Cm04nHpso 2UrF;a2releF;va1; ZaYcoWdReQfOgrNhibi4Ri05nMoLsHtFvalu5M;aAeF;nDrdepe2K;a7iGolFuboI;ub6ve1;de,gF;nifica1;rdi5N;a2er;own;eriIiLluenVrF;ar0eq5H;pt,rt;eHiGoFul1O;or;e,reA;fiFpe26termi5E;ni2;mpFnsideCrreA;le2;ccuCdeq5Ene,ppr4J;fFsitu,vitro;ro1;mJpF;arHeGl15oFrop9;li2r11;n2LrfeA;ti3;aGeFi18;d4BnD;tuE;egGiF;c0YteC;al,iF;tiF;ma2;ld;aOelNiLoFuma7;a4meInHrrGsFur5;ti6;if4E;e58o3U; ma3GsF;ick;ghfalut2HspF;an49;li00pf33;i4llow0ndGrdFtM; 05coEworki8;sy,y;aLener44iga3Blob3oKrGuF;il1Nng ho;aFea1Fizzl0;cGtF;ef2Vis;ef2U;ld3Aod;iFuc2D;nf2R;aVeSiQlOoJrF;aGeFil5ug3;q43tf2O;gFnt3S;i6ra1;lk13oHrF; keeps,eFge0Vm9tu41;g0Ei2Ds3R;liF;sh;ag4Mowe4uF;e1or45;e4nF;al,i2;d Gmini7rF;ti6ve1;up;bl0lDmIr Fst pac0ux;oGreacF;hi8;ff;ed,ili0R;aXfVlTmQnOqu3rMthere3veryday,xF;aApIquisi2traHuF;be48lF;ta1;!va2L;edRlF;icF;it;eAstF;whi6; Famor0ough,tiE;rou2sui2;erGiF;ne1;ge1;dFe2Aoq34;er5;ficF;ie1;g9sF;t,ygF;oi8;er;aWeMiHoGrFue;ea4owY;ci6mina1ne,r31ti8ubQ;dact2Jfficult,m,sGverF;ge1se;creGePjoi1paCtF;a1inA;et,te; Nadp0WceMfiLgeneCliJmuEpeIreliAsGvoF;id,ut;pFtitu2ul1L;eCoF;nde1;ca2ghF;tf13;a1ni2;as0;facto;i5ngero0I;ar0Ce09h07i06l05oOrIuF;rmudgeon5stoma4teF;sy;ly;aIeHu1EystalF; cleFli7;ar;epy;fFv17z0;ty;erUgTloSmPnGrpoCunterclVveFy;rt;cLdJgr21jIsHtrF;aFi2;dic0Yry;eq1Yta1;oi1ug3;escenFuN;di8;a1QeFiD;it0;atoDmensuCpF;ass1SulF;so4;ni3ss3;e1niza1;ci1J;ockwiD;rcumspeAvil;eFintzy;e4wy;leGrtaF;in;ba2;diac,ef00;a00ePiLliJoGrFuck nak0;and new,isk,on22;gGldface,naF; fi05fi05;us;nd,tF;he;gGpartisFzarE;an;tiF;me;autifOhiNlLnHsFyoN;iWtselF;li8;eGiFt;gn;aFfi03;th;at0oF;v0w;nd;ul;ckwards,rF;e,rT; priori,b13c0Zd0Tf0Ng0Ihe0Hl09mp6nt06pZrTsQttracti0MuLvIwF;aGkF;wa1B;ke,re;ant garGeraF;ge;de;diIsteEtF;heFoimmu7;nt07;re;to4;hGlFtu2;eep;en;bitIchiv3roHtF;ifiFsy;ci3;ga1;ra4;ry;pFt;aHetizi8rF;oprF;ia2;llFre1;ed,i8;ng;iquFsy;at0e;ed;cohKiJkaHl,oGriFterX;ght;ne,of;li7;ne;ke,ve;olF;ic;ad;ain07gressiIi6rF;eeF;ab6;le;ve;fGraB;id;ectGlF;ue1;ioF;na2; JaIeGvF;erD;pt,qF;ua2;ma1;hoc,infinitum;cuCquiGtu3u2;al;esce1;ra2;erSjeAlPoNrKsGuF;nda1;e1olu2trF;aAuD;se;te;eaGuF;pt;st;aFve;rd;aFe;ze;ct;ra1;nt",Pronoun:"true¦elle,h3i2me,she,th0us,we,you;e0ou;e,m,y;!l,t;e,im",Preposition:"true¦aPbMcLdKexcept,fIinGmid,notwithstandiWoDpXqua,sCt7u4v2w0;/o,hereSith0;! whHin,oW;ersus,i0;a,s a vis;n1p0;!on;like,til;h1ill,oward0;!s;an,ereby,r0;ough0u;!oM;ans,ince,o that,uch G;f1n0ut;!to;!f;! 0to;effect,part;or,r0;om;espite,own,u3;hez,irca;ar1e0oBy;sides,tween;ri7;bo8cross,ft7lo6m4propos,round,s1t0;!op;! 0;a whole,long 0;as;id0ong0;!st;ng;er;ut",SportsTeam:"true¦0:18;1:1E;2:1D;3:14;a1Db15c0Sd0Kfc dallas,g0Ihouston 0Hindiana0Gjacksonville jagua0k0El0Am01new UoRpKqueens parkJreal salt lake,sBt6utah jazz,vancouver whitecaps,w4yW;ashington 4h10;natio1Mredski2wizar0W;ampa bay 7e6o4;ronto 4ttenham hotspur;blue ja0Mrapto0;nnessee tita2xasD;buccanee0ra0K;a8eattle 6porting kansas0Wt4; louis 4oke0V;c1Drams;marine0s4;eah13ounH;cramento Rn 4;antonio spu0diego 4francisco gJjose earthquak1;char08paB; ran07;a9h6ittsburgh 5ortland t4;imbe0rail blaze0;pirat1steele0;il4oenix su2;adelphia 4li1;eagl1philNunE;dr1;akland 4klahoma city thunder,rlando magic;athle0Lrai4;de0;england 8orleans 7york 4;g5je3knYme3red bul0Xy4;anke1;ian3;pelica2sain3;patrio3revolut4;ion;anchEeAi4ontreal impact;ami 8lwaukee b7nnesota 4;t5vi4;kings;imberwolv1wi2;rewe0uc0J;dolphi2heat,marli2;mphis grizz4ts;li1;a6eic5os angeles 4;clippe0dodFlaB;esterV; galaxy,ke0;ansas city 4nF;chiefs,roya0D; pace0polis col3;astr05dynamo,rocke3texa2;olden state warrio0reen bay pac4;ke0;allas 8e4i04od6;nver 6troit 4;lio2pisto2ti4;ge0;broncYnugge3;cowbo5maver4;icZ;ys;arEelLhAincinnati 8leveland 6ol4;orado r4umbus crew sc;api7ocki1;brow2cavalie0guar4in4;dia2;bengaVre4;ds;arlotte horAicago 4;b5cubs,fire,wh4;iteB;ea0ulQ;diff4olina panthe0; city;altimore Alackburn rove0oston 6rooklyn 4uffalo bilN;ne3;ts;cel5red4; sox;tics;rs;oriol1rave2;rizona Ast8tlanta 4;brav1falco2h4;awA;ns;es;on villa,r4;os;c6di4;amondbac4;ks;ardi4;na4;ls",Unit:"true¦a07b04cXdWexVfTgRhePinYjoule0BkMlJmDnan08oCp9quart0Bsq ft,t7volts,w6y2ze3°1µ0;g,s;c,f,n;dVear1o0;ttR; 0s 0;old;att,b;erNon0;!ne02;ascals,e1i0;cXnt00;rcent,tJ;hms,unceY;/s,e4i0m²,²,³;/h,cro2l0;e0liK;!²;grLsR;gCtJ;it1u0;menQx;erPreP;b5elvins,ilo1m0notO;/h,ph,²;!byGgrEmCs;ct0rtzL;aJogrC;allonJb0ig3rB;ps;a0emtEl oz,t4;hrenheit,radG;aby9;eci3m1;aratDe1m0oulombD;²,³;lsius,nti0;gr2lit1m0;et0;er8;am7;b1y0;te5;l,ps;c2tt0;os0;econd1;re0;!s","Noun|Gerund":"true¦0:3O;1:3M;2:3N;3:3D;4:32;5:2V;6:3E;7:3K;8:36;9:3J;A:3B;a3Pb37c2Jd27e23f1Vg1Sh1Mi1Ij1Gk1Dl18m13n11o0Wp0Pques0Sr0EsTtNunderMvKwFyDzB;eroi0oB;ni0o3P;aw2eB;ar2l3;aEed4hispe5i5oCrB;ap8est3i1;n0ErB;ki0r31;i1r2s9tc9;isualizi0oB;lunt1Vti0;stan4ta6;aFeDhin6iCraBy8;c6di0i2vel1M;mi0p8;aBs1;c9si0;l6n2s1;aUcReQhOiMkatKl2Wmo6nowJpeItFuCwB;ea5im37;b35f0FrB;fi0vB;e2Mi2J;aAoryt1KrCuB;d2KfS;etc9ugg3;l3n4;bCi0;ebBi0;oar4;gnBnAt1;a3i0;ip8oB;p8rte2u1;a1r27t1;hCo5reBulp1;a2Qe2;edu3oo3;i3yi0;aKeEi4oCuB;li0n2;oBwi0;fi0;aFcEhear7laxi0nDpor1sB;pon4tructB;r2Iu5;de5;or4yc3;di0so2;p8ti0;aFeacek20laEoCrBublis9;a1Teten4in1oces7;iso2siB;tio2;n2yi0;ckaAin1rB;ki0t1O;fEpeDrganiCvB;erco24ula1;si0zi0;ni0ra1;fe5;avi0QeBur7;gotia1twor6;aDeCi2oB;de3nito5;a2dita1e1ssaA;int0XnBrke1;ifUufactu5;aEeaDiBodAyi0;cen7f1mi1stB;e2i0;r2si0;n4ug9;iCnB;ea4it1;c6l3;ogAuB;dAgg3stif12;ci0llust0VmDnBro2;nova1sp0NterBven1;ac1vie02;agi2plo4;aDea1iCoBun1;l4w3;ki0ri0;nd3rB;roWvB;es1;aCene0Lli4rBui4;ee1ie0N;rde2the5;aHeGiDlCorBros1un4;e0Pmat1;ir1oo4;gh1lCnBs9;anZdi0;i0li0;e3nX;r0Zscina1;a1du01nCxB;erci7plo5;chan1di0ginB;ee5;aLeHiGoub1rCum8wB;el3;aDeCiB;bb3n6vi0;a0Qs7;wi0;rTscoDvi0;ba1coZlBvelo8;eCiB;ve5;ga1;nGti0;aVelebUhSlPoDrBur3yc3;aBos7yi0;f1w3;aLdi0lJmFnBo6pi0ve5;dDsCvinB;ci0;trBul1;uc1;muniDpB;lBo7;ai2;ca1;lBo5;ec1;c9ti0;ap8eaCimToBubT;ni0t9;ni0ri0;aBee5;n1t1;ra1;m8rCs1te5;ri0;vi0;aPeNitMlLoGrDuB;dge1il4llBr8;yi0;an4eat9oadB;cas1;di0;a1mEokB;i0kB;ee8;pi0;bi0;es7oa1;c9i0;gin2lonAt1;gi0;bysit1c6ki0tt3;li0;ki0;bando2cGdverti7gi0pproac9rgDssuCtB;trac1;mi0;ui0;hi0;si0;coun1ti0;ti0;ni0;ng",PhrasalVerb:"true¦0:92;1:96;2:8H;3:8V;4:8A;5:83;6:85;7:98;8:90;9:8G;A:8X;B:8R;C:8U;D:8S;E:70;F:97;G:8Y;H:81;I:7H;J:79;a9Fb7Uc6Rd6Le6Jf5Ig50h4Biron0j47k40l3Em31n2Yo2Wp2Cquiet Hr1Xs0KtZuXvacuu6QwNyammerBzK;ero Dip LonK;e0k0;by,ov9up;aQeMhLiKor0Mrit19;mp0n3Fpe0r5s5;ackAeel Di0S;aLiKn33;gh 3Wrd0;n Dr K;do1in,oJ;it 79k5lk Lrm 69sh Kt83v60;aw3do1o7up;aw3in,oC;rgeBsK;e 2herE;a00eYhViRoQrMuKypP;ckErn K;do1in,oJup;aLiKot0y 30;ckl7Zp F;ck HdK;e 5Y;n7Wp 3Es5K;ck MdLe Kghten 6me0p o0Rre0;aw3ba4do1in,up;e Iy 2;by,oG;ink Lrow K;aw3ba4in,up;ba4ov9up;aKe 77ll62;m 2r 5M;ckBke Llk K;ov9shit,u47;aKba4do1in,leave,o4Dup;ba4ft9pa69w3;a0Vc0Te0Mh0Ii0Fl09m08n07o06p01quar5GtQuOwK;earMiK;ngLtch K;aw3ba4o8K; by;cKi6Bm 2ss0;k 64;aReQiPoNrKud35;aigh2Det75iK;ke 7Sng K;al6Yup;p Krm2F;by,in,oG;c3Ln3Lr 2tc4O;p F;c3Jmp0nd LrKveAy 2O;e Ht 2L;ba4do1up;ar3GeNiMlLrKurB;ead0ingBuc5;a49it 6H;c5ll o3Cn 2;ak Fe1Xll0;a3Bber 2rt0und like;ap 5Vow Duggl5;ash 6Noke0;eep NiKow 6;cLp K;o6Dup;e 68;in,oK;ff,v9;de19gn 4NnKt 6Gz5;gKkE; al6Ale0;aMoKu5W;ot Kut0w 7M;aw3ba4f48oC;c2WdeEk6EveA;e Pll1Nnd Orv5tK; Ktl5J;do1foLin,o7upK;!on;ot,r5Z;aw3ba4do1in,o33up;oCto;al66out0rK;ap65ew 6J;ilAv5;aXeUiSoOuK;b 5Yle0n Kstl5;aLba4do1inKo2Ith4Nu5P;!to;c2Xr8w3;ll Mot LpeAuK;g3Ind17;a2Wf3Po7;ar8in,o7up;ng 68p oKs5;ff,p18;aKelAinEnt0;c6Hd K;o4Dup;c27t0;aZeYiWlToQrOsyc35uK;ll Mn5Kt K;aKba4do1in,oJto47up;pa4Dw3;a3Jdo1in,o21to45up;attleBess KiNop 2;ah2Fon;iLp Kr4Zu1Gwer 6N;do1in,o6Nup;nt0;aLuK;gEmp 6;ce u20y 6D;ck Kg0le 4An 6p5B;oJup;el 5NncilE;c53ir 39n0ss MtLy K;ba4oG; Hc2R;aw3ba4in,oJ;pKw4Y;e4Xt D;aLerd0oK;dAt53;il Hrrow H;aTeQiPoLuK;ddl5ll I;c1FnkeyMp 6uthAve K;aKdo1in,o4Lup;l4Nw3; wi4K;ss0x 2;asur5e3SlLss K;a21up;t 6;ke Ln 6rKs2Ax0;k 6ryA;do,fun,oCsure,up;a02eViQoLuK;ck0st I;aNc4Fg MoKse0;k Kse4D;aft9ba4do1forw37in56o0Zu46;in,oJ;d 6;e NghtMnLsKve 00;ten F;e 2k 2; 2e46;ar8do1in;aMt LvelK; oC;do1go,in,o7up;nEve K;in,oK;pKut;en;c5p 2sh LtchBughAy K;do1o59;in4Po7;eMick Lnock K;do1oCup;oCup;eLy K;in,up;l Ip K;aw3ba4do1f04in,oJto,up;aMoLuK;ic5mpE;ke3St H;c43zz 2;a01eWiToPuK;nLrrKsh 6;y 2;keLt K;ar8do1;r H;lKneErse3K;d Ke 2;ba4dKfast,o0Cup;ear,o1;de Lt K;ba4on,up;aw3o7;aKlp0;d Ml Ir Kt 2;fKof;rom;f11in,o03uW;cPm 2nLsh0ve Kz2P;at,it,to;d Lg KkerP;do1in,o2Tup;do1in,oK;ut,v9;k 2;aZeTive Rloss IoMrLunK; f0S;ab hold,in43ow 2U; Kof 2I;aMb1Mit,oLr8th1IuK;nd9;ff,n,v9;bo7ft9hQw3;aw3bKdo1in,oJrise,up,w3;a4ir2H;ar 6ek0t K;aLb1Fdo1in,oKr8up;ff,n,ut,v9;cLhKl2Fr8t,w3;ead;ross;d aKng 2;bo7;a0Ee07iYlUoQrMuK;ck Ke2N;ar8up;eLighten KownBy 2;aw3oG;eKshe27; 2z5;g 2lMol Krk I;aKwi20;bo7r8;d 6low 2;aLeKip0;sh0;g 6ke0mKrKtten H;e F;gRlPnNrLsKzzle0;h F;e Km 2;aw3ba4up;d0isK;h 2;e Kl 1T;aw3fPin,o7;ht ba4ure0;ePnLsK;s 2;cMd K;fKoG;or;e D;d04l 2;cNll Krm0t1G;aLbKdo1in,o09sho0Eth08victim;a4ehi2O;pa0C;e K;do1oGup;at Kdge0nd 12y5;in,o7up;aOi1HoNrK;aLess 6op KuN;aw3b03in,oC;gBwB; Ile0ubl1B;m 2;a0Ah05l02oOrLut K;aw3ba4do1oCup;ackBeep LoKy0;ss Dwd0;by,do1in,o0Uup;me NoLuntK; o2A;k 6l K;do1oG;aRbQforOin,oNtKu0O;hLoKrue;geth9;rough;ff,ut,v9;th,wK;ard;a4y;paKr8w3;rt;eaLose K;in,oCup;n 6r F;aNeLiK;ll0pE;ck Der Kw F;on,up;t 2;lRncel0rOsMtch LveE; in;o1Nup;h Dt K;doubt,oG;ry LvK;e 08;aw3oJ;l Km H;aLba4do1oJup;ff,n,ut;r8w3;a0Ve0MiteAl0Fo04rQuK;bblNckl05il0Dlk 6ndl05rLsKtMy FzzA;t 00;n 0HsK;t D;e I;ov9;anWeaUiLush K;oGup;ghQng K;aNba4do1forMin,oLuK;nd9p;n,ut;th;bo7lKr8w3;ong;teK;n 2;k K;do1in,o7up;ch0;arTg 6iRn5oPrNssMttlLunce Kx D;aw3ba4;e 6; ar8;e H;do1;k Dt 2;e 2;l 6;do1up;d 2;aPeed0oKurt0;cMw K;aw3ba4do1o7up;ck;k K;in,oC;ck0nk0stA; oQaNef 2lt0nd K;do1ov9up;er;up;r Lt K;do1in,oCup;do1o7;ff,nK;to;ck Pil0nMrgLsK;h D;ainBe D;g DkB; on;in,o7;aw3do1in,oCup;ff,ut;ay;ct FdQir0sk MuctionA; oG;ff;ar8o7;ouK;nd; o7;d K;do1oKup;ff,n;wn;o7up;ut",ProperNoun:"true¦aIbDc8dalhousHe7f5gosford,h4iron maiden,kirby,landsdowne,m2nis,r1s0wembF;herwood,paldiB;iel,othwe1;cgi0ercedes,issy;ll;intBudsB;airview,lorence,ra0;mpt9nco;lmo,uro;a1h0;arlt6es5risti;rl0talina;et4i0;ng;arb3e0;et1nt0rke0;ley;on;ie;bid,jax","Person|Place":"true¦a8d6h4jordan,k3orlando,s1vi0;ctor9rgin9;a0ydney;lvador,mara,ntia4;ent,obe;amil0ous0;ton;arw2ie0;go;lexandr1ust0;in;ia",LastName:"true¦0:BR;1:BF;2:B5;3:BH;4:AX;5:9Y;6:B6;7:BK;8:B0;9:AV;A:AL;B:8Q;C:8G;D:7K;E:BM;F:AH;aBDb9Zc8Wd88e81f7Kg6Wh64i60j5Lk4Vl4Dm39n2Wo2Op25quispe,r1Ls0Pt0Ev03wTxSyKzG;aIhGimmerm6A;aGou,u;ng,o;khar5ytsE;aKeun9BiHoGun;koya32shiBU;!lG;diGmaz;rim,z;maGng;da,g52mo83sGzaC;aChiBV;iao,u;aLeJiHoGright,u;jcA5lff,ng;lGmm0nkl0sniewsC;kiB1liams33s3;bGiss,lt0;b,er,st0;a6Vgn0lHtG;anabe,s3;k0sh,tG;e2Non;aLeKiHoGukD;gt,lk5roby5;dHllalGnogr3Kr1Css0val3S;ba,ob1W;al,ov4;lasHsel8W;lJn dIrgBEsHzG;qu7;ilyEqu7siljE;en b6Aijk,yk;enzueAIverde;aPeix1VhKi2j8ka43oJrIsui,uG;om5UrG;c2n0un1;an,emblA7ynisC;dorAMlst3Km4rrAth;atch0i8UoG;mHrG;are84laci79;ps3sG;en,on;hirDkah9Mnaka,te,varA;a06ch01eYhUiRmOoMtIuHvGzabo;en9Jobod3N;ar7bot4lliv2zuC;aIeHoG;i7Bj4AyanAB;ele,in2FpheBvens25;l8rm0;kol5lovy5re7Tsa,to,uG;ng,sa;iGy72;rn5tG;!h;l71mHnGrbu;at9cla9Egh;moBo7M;aIeGimizu;hu,vchG;en8Luk;la,r1G;gu9infe5YmGoh,pulveA7rra5P;jGyG;on5;evi6iltz,miHneid0roed0uGwarz;be3Elz;dHtG;!t,z;!t;ar4Th8ito,ka4OlJnGr4saCto,unde19v4;ch7dHtGz;a5Le,os;b53e16;as,ihDm4Po0Y;aVeSiPoJuHyG;a6oo,u;bio,iz,sG;so,u;bKc8Fdrigue67ge10j9YmJosevelt,sItHux,wG;e,li6;a9Ch;enb4Usi;a54e4L;erts15i93;bei4JcHes,vGzzo;as,e9;ci,hards12;ag2es,iHut0yG;es,nol5N;s,t0;dImHnGsmu97v6C;tan1;ir7os;ic,u;aUeOhMiJoHrGut8;asad,if6Zochazk27;lishc2GpGrti72u10we76;e3Aov51;cHe45nG;as,to;as70hl0;aGillips;k,m,n6I;a3Hde3Wete0Bna,rJtG;ersHrovGters54;!a,ic;!en,on;eGic,kiBss3;i9ra,tz,z;h86k,padopoulIrk0tHvG;ic,l4N;el,te39;os;bMconn2Ag2TlJnei6PrHsbor6XweBzG;dem7Rturk;ella4DtGwe6N;ega,iz;iGof7Hs8I;vGyn1R;ei9;aSri1;aPeNiJoGune50ym2;rHvGwak;ak4Qik5otn66;odahl,r4S;cholsZeHkolGls4Jx3;ic,ov84;ls1miG;!n1;ils3mG;co4Xec;gy,kaGray2sh,var38;jiGmu9shiG;ma;a07c04eZiWoMuHyeG;rs;lJnIrGssoli6S;atGp03r7C;i,ov4;oz,te58;d0l0;h2lOnNo0RrHsGza1A;er,s;aKeJiIoz5risHtG;e56on;!on;!n7K;au,i9no,t5J;!lA;r1Btgome59;i3El0;cracFhhail5kkeHlG;l0os64;ls1;hmeJiIj30lHn3Krci0ssiGyer2N;!er;n0Po;er,j0;dDti;cartHlG;aughl8e2;hy;dQe7Egnu68i0jer3TkPmNnMrItHyG;er,r;ei,ic,su21thews;iHkDquAroqu8tinG;ez,s;a5Xc,nG;!o;ci5Vn;a5UmG;ad5;ar5e6Kin1;rig77s1;aVeOiLoJuHyG;!nch;k4nGo;d,gu;mbarGpe3Fvr4we;di;!nGu,yana2B;coln,dG;b21holm,strom;bedEfeKhIitn0kaHn8rGw35;oy;!j;m11tG;in1on1;bvGvG;re;iGmmy,ng,rs2Qu,voie,ws3;ne,t1F;aZeYh2iWlUnez50oNrJuHvar2woG;k,n;cerGmar68znets5;a,o34;aHem0isGyeziu;h23t3O;m0sni4Fus3KvG;ch4O;bay57ch,rh0Usk16vaIwalGzl5;czGsC;yk;cIlG;!cGen4K;huk;!ev4ic,s;e8uiveG;rt;eff0kGl4mu9nnun1;ucF;ll0nnedy;hn,llKminsCne,pIrHstra3Qto,ur,yGzl5;a,s0;j0Rls22;l2oG;or;oe;aPenOha6im14oHuG;ng,r4;e32hInHrge32u6vG;anD;es,ss3;anHnsG;en,on,t3;nesGs1R;en,s1;kiBnings,s1;cJkob4EnGrv0E;kDsG;en,sG;en0Ion;ks3obs2A;brahimDglesi5Nke5Fl0Qno07oneIshikHto,vanoG;u,v54;awa;scu;aVeOiNjaltal8oIrist50uG;!aGb0ghAynh;m2ng;a6dz4fIjgaa3Hk,lHpUrGwe,x3X;ak1Gvat;mAt;er,fm3WmG;ann;ggiBtchcock;iJmingw4BnHrGss;nand7re9;deGriks1;rs3;kkiHnG;on1;la,n1;dz4g1lvoQmOns0ZqNrMsJuIwHyG;asFes;kiB;g1ng;anHhiG;mo14;i,ov0J;di6p0r10t;ue;alaG;in1;rs1;aVeorgUheorghe,iSjonRoLrJuGw3;errGnnar3Co,staf3Ctierr7zm2;a,eG;ro;ayli6ee2Lg4iffithGub0;!s;lIme0UnHodGrbachE;e,m2;calvAzale0S;dGubE;bGs0E;erg;aj,i;bs3l,mGordaO;en7;iev3U;gnMlJmaIndFo,rGsFuthi0;cGdn0za;ia;ge;eaHlG;agh0i,o;no;e,on;aVerQiLjeldsted,lKoIrHuG;chs,entAji41ll0;eem2iedm2;ntaGrt8urni0wl0;na;emi6orA;lipIsHtzgeraG;ld;ch0h0;ovG;!ic;hatDnanIrG;arGei9;a,i;deY;ov4;b0rre1D;dKinsJriksIsGvaB;cob3GpGtra3D;inoza,osiQ;en,s3;te8;er,is3warG;ds;aXePiNjurhuMoKrisco15uHvorakG;!oT;arte,boHmitru,nn,rGt3C;and,ic;is;g2he0Omingu7nErd1ItG;to;us;aGcki2Hmitr2Ossanayake,x3;s,z; JbnaIlHmirGrvisFvi,w2;!ov4;gado,ic;th;bo0groot,jo6lHsilGvriA;va;a cruz,e3uG;ca;hl,mcevsCnIt2WviG;dGes,s;ov,s3;ielsGku22;!en;ki;a0Be06hRiobQlarkPoIrGunningh1H;awfo0RivGuz;elli;h1lKntJoIrGs2Nx;byn,reG;a,ia;ke,p0;i,rer2K;em2liB;ns;!e;anu;aOeMiu,oIristGu6we;eGiaG;ns1;i,ng,p9uHwGy;!dH;dGng;huJ;!n,onGu6;!g;kJnIpm2ttHudhGv7;ry;erjee,o14;!d,g;ma,raboG;rty;bJl0Cng4rG;eghetHnG;a,y;ti;an,ota1C;cerAlder3mpbeLrIstGvadi0B;iGro;llo;doHl0Er,t0uGvalho;so;so,zo;ll;a0Fe01hYiXlUoNrKuIyG;rLtyG;qi;chan2rG;ke,ns;ank5iem,oGyant;oks,wG;ne;gdan5nIruya,su,uchaHyKziG;c,n5;rd;darGik;enG;ko;ov;aGond15;nco,zG;ev4;ancFshw16;a08oGuiy2;umGwmG;ik;ckRethov1gu,ktPnNrG;gJisInG;ascoGds1;ni;ha;er,mG;anG;!n;gtGit7nP;ss3;asF;hi;er,hG;am;b4ch,ez,hRiley,kk0ldw8nMrIshHtAu0;es;ir;bInHtlGua;ett;es,i0;ieYosa;dGik;a9yoG;padhyG;ay;ra;k,ng;ic;bb0Acos09d07g04kht05lZnPrLsl2tJyG;aHd8;in;la;chis3kiG;ns3;aImstro6sl2;an;ng;ujo,ya;dJgelHsaG;ri;ovG;!a;ersJov,reG;aGjEws;ss1;en;en,on,s3;on;eksejEiyEmeiIvG;ar7es;ez;da;ev;arwHuilG;ar;al;ams,l0;er;ta;as",Ordinal:"true¦eBf7nin5s3t0zeroE;enDhir1we0;lfCn7;d,t3;e0ixt8;cond,vent7;et0th;e6ie7;i2o0;r0urt3;tie4;ft1rst;ight0lev1;e0h,ie1;en0;th",Cardinal:"true¦bEeBf5mEnine7one,s4t0zero;en,h2rDw0;e0o;lve,n5;irt6ousands,ree;even2ix2;i3o0;r1ur0;!t2;ty;ft0ve;e2y;ight0lev1;!e0y;en;illions",Multiple:"true¦b3hundred,m3qu2se1t0;housand,r2;pt1xt1;adr0int0;illion",City:"true¦0:74;1:61;2:6G;3:6J;4:5S;a68b53c4Id48e44f3Wg3Hh39i31j2Wk2Fl23m1Mn1Co19p0Wq0Ur0Os05tRuQvLwDxiBy9z5;a7h5i4Muri4O;a5e5ongsh0;ng3H;greb,nzib5G;ang2e5okoha3Sunfu;katerin3Hrev0;a5n0Q;m5Hn;arsBeAi6roclBu5;h0xi,zh5P;c7n5;d5nipeg,terth4;hoek,s1L;hi5Zkl3A;l63xford;aw;a8e6i5ladivost5Molgogr6L;en3lni6S;ni22r5;o3saill4N;lenc4Wncouv3Sr3ughn;lan bat1Crumqi,trecht;aFbilisi,eEheDiBo9r7u5;l21n63r5;in,ku;i5ondh62;es51poli;kyo,m2Zron1Pulo5;n,uS;an5jua3l2Tmisoa6Bra3;j4Tshui; hag62ssaloni2H;gucigal26hr0l av1U;briz,i6llinn,mpe56ng5rtu,shk2R;i3Esh0;an,chu1n0p2Eyu0;aEeDh8kopje,owe1Gt7u5;ra5zh4X;ba0Ht;aten is55ockholm,rasbou67uttga2V;an8e6i5;jiazhua1llo1m5Xy0;f50n5;ya1zh4H;gh3Kt4Q;att45o1Vv44;cramen16int ClBn5o paulo,ppo3Rrajevo; 7aa,t5;a 5o domin3E;a3fe,m1M;antonio,die3Cfrancisco,j5ped3Nsalvad0J;o5u0;se;em,t lake ci5Fz25;lou58peters24;a9e8i6o5;me,t59;ga,o5yadh;! de janei3F;cife,ims,nn3Jykjavik;b4Sip4lei2Inc2Pwalpindi;ingdao,u5;ez2i0Q;aFeEhDiCo9r7u6yong5;ya1;eb59ya1;a5etor3M;g52to;rt5zn0; 5la4Co;au prin0Melizabe24sa03;ls3Prae5Atts26;iladelph3Gnom pe1Aoenix;ki1tah tik3E;dua,lerYnaji,r4Ot5;na,r32;ak44des0Km1Mr6s5ttawa;a3Vlo;an,d06;a7ew5ing2Fovosibir1Jyc; 5cast36;del24orlea44taip14;g8iro4Wn5pl2Wshv33v0;ch6ji1t5;es,o1;a1o1;a6o5p4;ya;no,sa0W;aEeCi9o6u5;mb2Ani26sc3Y;gadishu,nt6s5;c13ul;evideo,pelli1Rre2Z;ami,l6n14s5;kolc,sissauga;an,waukee;cca,d5lbour2Mmph41ndo1Cssi3;an,ell2Xi3;cau,drAkass2Sl9n8r5shh4A;aca6ib5rakesh,se2L;or;i1Sy;a4EchFdal0Zi47;mo;id;aDeAi8o6u5vSy2;anMckn0Odhia3;n5s angel26;d2g bea1N;brev2Be3Lma5nz,sb2verpo28;!ss27; ma39i5;c5pzig;est16; p6g5ho2Wn0Cusan24;os;az,la33;aHharFiClaipeBo9rak0Du7y5;iv,o5;to;ala lump4n5;mi1sh0;hi0Hlka2Xpavog4si5wlo2;ce;da;ev,n5rkuk;gst2sha5;sa;k5toum;iv;bHdu3llakuric0Qmpa3Fn6ohsiu1ra5un1Iwaguc0Q;c0Pj;d5o,p4;ah1Ty;a7e6i5ohannesV;l1Vn0;dd36rusalem;ip4k5;ar2H;bad0mph1OnArkutUs7taXz5;mir,tapala5;pa;fah0l6tanb5;ul;am2Zi2H;che2d5;ianap2Mo20;aAe7o5yder2W; chi mi5ms,nolulu;nh;f6lsin5rakli2;ki;ei;ifa,lifax,mCn5rb1Dva3;g8nov01oi;aFdanEenDhCiPlasgBo9raz,u5;a5jr23;dal6ng5yaquil;zh1J;aja2Oupe;ld coa1Bthen5;bu2S;ow;ent;e0Uoa;sk;lw7n5za;dhi5gt1E;nag0U;ay;aisal29es,o8r6ukuya5;ma;ankfu5esno;rt;rt5sh0; wor6ale5;za;th;d5indhov0Pl paso;in5mont2;bur5;gh;aBe8ha0Xisp4o7resd0Lu5;b5esseldorf,nkirk,rb0shanbe;ai,l0I;ha,nggu0rtmu13;hradSl6nv5troit;er;hi;donghIe6k09l5masc1Zr es sala1KugavpiY;i0lU;gu,je2;aJebu,hAleve0Vo5raio02uriti1Q;lo7n6penhag0Ar5;do1Ok;akKst0V;gUm5;bo;aBen8i6ongqi1ristchur5;ch;ang m7ca5ttago1;go;g6n5;ai;du,zho1;ng5ttogr14;ch8sha,zh07;gliari,i9lga8mayenJn6pe town,r5tanO;acCdiff;ber1Ac5;un;ry;ro;aWeNhKirmingh0WoJr9u5;chareTdapeTenos air7r5s0tu0;g5sa;as;es;a9is6usse5;ls;ba6t5;ol;ne;sil8tisla7zzav5;il5;le;va;ia;goZst2;op6ubaneshw5;ar;al;iCl9ng8r5;g6l5n;in;en;aluru,hazi;fa6grade,o horizon5;te;st;ji1rut;ghd0BkFn9ot8r7s6yan n4;ur;el,r07;celo3i,ranquil09;ou;du1g6ja lu5;ka;alo6k5;ok;re;ng;ers5u;field;a05b02cc01ddis aba00gartaZhmedXizawl,lSmPnHqa00rEsBt7uck5;la5;nd;he7l5;an5;ta;ns;h5unci2;dod,gab5;at;li5;ngt2;on;a8c5kaOtwerp;hora6o3;na;ge;h7p5;ol5;is;eim;aravati,m0s5;terd5;am; 7buquerq6eppo,giers,ma5;ty;ue;basrah al qadim5mawsil al jadid5;ah;ab5;ad;la;ba;ra;idj0u dha5;bi;an;lbo6rh5;us;rg",Region:"true¦0:2O;1:2L;2:2U;3:2F;a2Sb2Fc21d1Wes1Vf1Tg1Oh1Ki1Fj1Bk16l13m0Sn09o07pYqVrSsJtEuBverAw6y4zacatec2W;akut0o0Fu4;cat1k09;a5est 4isconsin,yomi1O;bengal,virgin0;rwick3shington4;! dc;acruz,mont;dmurt0t4;ah,tar4; 2Pa12;a6e5laxca1Vripu21u4;scaEva;langa2nnessee,x2J;bas10m4smQtar29;aulip2Hil nadu;a9elang07i7o5taf16u4ylh1J;ff02rr09s1E;me1Gno1Uuth 4;cZdY;ber0c4kkim,naloa;hu1ily;n5rawak,skatchew1xo4;ny; luis potosi,ta catari2;a4hodeA;j4ngp0C;asth1shahi;ingh29u4;e4intana roo;bec,en6retaro;aAe6rince edward4unjab; i4;sl0G;i,n5r4;ak,nambu0F;a0Rnsylv4;an0;ha0Pra4;!na;axa0Zdisha,h4klaho21ntar4reg7ss0Dx0I;io;aLeEo6u4;evo le4nav0X;on;r4tt18va scot0;f9mandy,th4; 4ampton3;c6d5yo4;rk3;ako1O;aroli2;olk;bras1Nva0Dw4; 6foundland4;! and labrad4;or;brunswick,hamp3jers5mexiTyork4;! state;ey;galPyarit;aAeghala0Mi6o4;nta2r4;dov0elos;ch6dlanDn5ss4zor11;issippi,ouri;as geraPneso18;ig1oac1;dhy12harasht0Gine,lac07ni5r4ssachusetts;anhao,i el,ylG;p4toba;ur;anca3e4incoln3ouisI;e4iR;ds;a6e5h4omi;aka06ul2;dah,lant1ntucky,ra01;bardino,lmyk0ns0Qr4;achay,el0nata0X;alis6har4iangxi;kh4;and;co;daho,llino7n4owa;d5gush4;et0;ia2;is;a6ert5i4un1;dalFm0D;ford3;mp3rya2waii;ansu,eorg0lou7oa,u4;an4izhou,jarat;ajuato,gdo4;ng;cester3;lori4uji1;da;sex;ageUe7o5uran4;go;rs4;et;lawaMrby3;aFeaEh9o4rim08umbr0;ahui7l6nnectic5rsi4ventry;ca;ut;i03orado;la;e5hattisgarh,i4uvash0;apRhuahua;chn5rke4;ss0;ya;ra;lGm4;bridge3peche;a9ihar,r8u4;ck4ryat0;ingham3;shi4;re;emen,itish columb0;h0ja cal8lk7s4v7;hkorto4que;st1;an;ar0;iforn0;ia;dygHguascalientes,lBndhr9r5ss4;am;izo2kans5un4;achal 7;as;na;a 4;pradesh;a6ber5t4;ai;ta;ba5s4;ka;ma;ea",Place:"true¦0:4T;1:4V;2:44;3:4B;4:3I;a4Eb3Gc2Td2Ge26f25g1Vh1Ji1Fk1Cl14m0Vn0No0Jp08r04sTtNuLvJw7y5;a5o0Syz;kut1Bngtze;aDeChitBi9o5upatki,ycom2P;ki26o5;d5l1B;b3Ps5;i4to3Y;c0SllowbroCn5;c2Qgh2;by,chur1P;ed0ntw3Gs22;ke6r3St5;erf1f1; is0Gf3V;auxha3Mirgin is0Jost5;ok;laanbaatar,pto5xb3E;n,wn;a9eotihuac43h7ive49o6ru2Nsarskoe selo,u5;l2Dzigo47;nto,rquay,tt2J;am3e 5orn3E;bronx,hamptons;hiti,j mah0Iu1N;aEcotts bluff,eCfo,herbroQoApring9t7u5yd2F;dbu1Wn5;der03set3B;aff1ock2Nr5;atf1oud;hi37w24;ho,uth5; 1Iam1Zwo3E;a5i2O;f2Tt0;int lawrence riv3Pkhal2D;ayleigh,ed7i5oc1Z;chmo1Eo gran4ver5;be1Dfr09si4; s39cliffe,hi2Y;aCe9h8i5ompeii,utn2;c6ne5tcai2T; 2Pc0G;keri13t0;l,x;k,lh2mbr6n5r2J;n1Hzance;oke;cif38pahanaumokuak30r5;k5then0;si4w1K;ak7r6x5;f1l2X;ange county,d,f1inoco;mTw1G;e8i1Uo5;r5tt2N;th5wi0E; 0Sam19;uschwanste1Pw5; eng6a5h2market,po36;rk;la0P;a8co,e6i5uc;dt1Yll0Z;adow5ko0H;lands;chu picchu,gad2Ridsto1Ql8n7ple6r5;kh2; g1Cw11;hatt2Osf2B;ibu,t0ve1Z;a8e7gw,hr,in5owlOynd02;coln memori5dl2C;al;asi4w3;kefr7mbe1On5s,x;ca2Ig5si05;f1l27t0;ont;azan kreml14e6itchen2Gosrae,rasnoyar5ul;sk;ns0Hs1U;ax,cn,lf1n6ps5st;wiN;d5glew0Lverness;ian27ochina;aDeBi6kg,nd,ov5unti2H;d,enweep;gh6llc5;reL;bu03l5;and5;!s;r5yw0C;ef1tf1;libu24mp6r5stings;f1lem,row;stead,t0;aDodavari,r5uelph;avenAe5imsS;at 8en5; 6f1Fwi5;ch;acr3vall1H;brita0Flak3;hur5;st;ng3y villa0W;airhavHco,ra;aAgli9nf17ppi8u7ver6x5;et1Lf1;glad3t0;rope,st0;ng;nt0;rls1Ls5;t 5;e5si4;nd;aCe9fw,ig8o7ryd6u5xb;mfri3nstab00rh2tt0;en;nca18rcKv19wnt0B;by;n6r5vonpo1D;ry;!h2;nu8r5;l6t5;f1moor;ingt0;be;aLdg,eIgk,hClBo5royd0;l6m5rnwa0B;pt0;c7lingw6osse5;um;ood;he0S;earwat0St;a8el6i5uuk;chen itza,mney ro07natSricahua;m0Zt5;enh2;mor5rlottetPth2;ro;dar 5ntervilA;breaks,faZg5;rove;ld9m8r5versh2;lis6rizo pla5;in;le;bLpbellf1;weQ;aZcn,eNingl01kk,lackLolt0r5uckV;aGiAo5;ckt0ok5wns cany0;lyn,s5;i4to5;ne;de;dge6gh5;am,t0;n6t5;own;or5;th;ceb6m5;lNpt0;rid5;ge;bu5pool,wa8;rn;aconsfEdf1lBr9verly7x5;hi5;ll; hi5;lls;wi5;ck; air,l5;ingh2;am;ie5;ld;ltimore,rnsl6tters5;ea;ey;bLct0driadic,frica,ginJlGmFn9rc8s7tl6yleOzor3;es;!ant8;hcroft,ia; de triomphe,t6;adyr,ca8dov9tarct5;ic5; oce5;an;st5;er;ericas,s;be6dersh5hambra,list0;ot;rt0;cou5;rt;bot7i5;ngd0;on;sf1;ord",Country:"true¦0:38;1:2L;2:3B;a2Xb2Ec22d1Ye1Sf1Mg1Ch1Ai14j12k0Zl0Um0Gn05om2pZqat1KrXsKtCu7v5wal4yemTz3;a25imbabwe;es,lis and futu2Y;a3enezue32ietnam;nuatu,tican city;gTk6nited 4ruXs3zbeE; 2Ca,sr;arab emirat0Kkingdom,states3;! of am2Y;!raiV;a8haCimor les0Co7rinidad 5u3;nis0rk3valu;ey,me2Zs and caic1V;and t3t3;oba1L;go,kel10nga;iw2ji3nz2T;ki2V;aDcotl1eCi9lov8o6pa2Dri lanka,u5w3yr0;az3edAitzerl1;il1;d2riname;lomon1Xmal0uth 3;afr2KkMsud2;ak0en0;erra leoFn3;gapo1Yt maart3;en;negLrb0ychellZ;int 3moa,n marino,udi arab0;hele26luc0mart21;epublic of ir0Eom2Euss0w3;an27;a4eIhilippinUitcairn1Mo3uerto riN;l1rtugF;ki2Dl4nama,pua new0Vra3;gu7;au,esti3;ne;aBe9i7or3;folk1Ith4w3;ay; k3ern mariana1D;or0O;caragua,ger3ue;!ia;p3ther1Aw zeal1;al;mib0u3;ru;a7exi6icro0Bo3yanm06;ldova,n3roc5zambA;a4gol0t3;enegro,serrat;co;cAdagasc01l7r5urit4yot3;te;an0i16;shall0Xtin3;ique;a4div3i,ta;es;wi,ys0;ao,ed02;a6e5i3uxembourg;b3echtenste12thu1G;er0ya;ban0Isotho;os,tv0;azakh1Fe4iriba04o3uwait,yrgyz1F;rXsovo;eling0Knya;a3erG;ma16p2;c7nd6r4s3taly,vory coast;le of m2rael;a3el1;n,q;ia,oJ;el1;aiTon3ungary;dur0Ng kong;aBermany,ha0QibraltAre8u3;a6ern5inea3ya0P;! biss3;au;sey;deloupe,m,tema0Q;e3na0N;ce,nl1;ar;bUmb0;a7i6r3;ance,ench 3;guia0Epoly3;nes0;ji,nl1;lklandUroeU;ast tim7cu6gypt,l salv6ngl1quatorial4ritr5st3thiop0;on0; guin3;ea;ad3;or;enmark,jibou5ominica4r con3;go;!n C;ti;aBentral african Ah8o5roat0u4yprRzech3; 9ia;ba,racao;c4lo3morQngo brazzaville,okGsta r04te de ivoiL;mb0;osE;i3ristmasG;le,na;republic;m3naUpe verde,ymanA;bod0ero3;on;aGeDhut2o9r5u3;lgar0r3;kina faso,ma,undi;azil,itish 3unei;virgin3; is3;lands;liv0nai5snia and herzegoviHtswaHuvet3; isl1;and;re;l3n8rmuG;ar3gium,ize;us;h4ngladesh,rbad3;os;am4ra3;in;as;fghaGlDmBn6r4ustr3zerbaij2;al0ia;genti3men0uba;na;dorra,g5t3;arct7igua and barbu3;da;o3uil3;la;er3;ica;b3ger0;an0;ia;ni3;st2;an",FirstName:"true¦aTblair,cQdOfrancoZgabMhinaLilya,jHkClBm6ni4quinn,re3s0;h0umit,yd;ay,e0iloh;a,lby;g9ne;co,ko0;!s;a1el0ina,org6;!okuhF;ds,naia,r1tt0xiB;i,y;ion,lo;ashawn,eif,uca;a3e1ir0rM;an;lsFn0rry;dall,yat5;i,sD;a0essIie,ude;i1m0;ie,mG;me;ta;rie0y;le;arcy,ev0;an,on;as1h0;arl8eyenne;ey,sidy;drien,kira,l4nd1ubr0vi;ey;i,r0;a,e0;a,y;ex2f1o0;is;ie;ei,is",WeekDay:"true¦fri2mon2s1t0wednesd3;hurs1ues1;aturd1und1;!d0;ay0;!s",Month:"true¦dec0february,july,nov0octo1sept0;em0;ber",Date:"true¦ago,on4som4t1week0yesterd5; end,ends;mr1o0;d2morrow;!w;ed0;ay",Duration:"true¦centurAd8h7m5q4se3w1y0;ear8r8;eek0k7;!end,s;ason,c5;tr,uarter;i0onth3;llisecond2nute2;our1r1;ay0ecade0;!s;ies,y",FemaleName:"true¦0:J7;1:JB;2:IJ;3:IK;4:J1;5:IO;6:JS;7:JO;8:HB;9:JK;A:H4;B:I2;C:IT;D:JH;E:IX;F:BA;G:I4;aGTbFLcDRdD0eBMfB4gADh9Ti9Gj8Dk7Cl5Wm48n3Lo3Hp33qu32r29s15t0Eu0Cv02wVxiTyOzH;aLeIineb,oHsof3;e3Sf3la,ra;h2iKlIna,ynH;ab,ep;da,ma;da,h2iHra;nab;aKeJi0FolB7uIvH;et8onDP;i0na;le0sen3;el,gm3Hn,rGLs8W;aoHme0nyi;m5XyAD;aMendDZhiDGiH;dele9lJnH;if48niHo0;e,f47;a,helmi0lHma;a,ow;ka0nB;aNeKiHusa5;ck84kIl8oleAviH;anFenJ4;ky,toriBK;da,lA8rHs0;a,nHoniH9;a,iFR;leHnesH9;nILrH;i1y;g9rHs6xHA;su5te;aYeUhRiNoLrIuHy2;i,la;acJ3iHu0J;c3na,sH;hFta;nHr0F;iFya;aJffaEOnHs6;a,gtiH;ng;!nFSra;aIeHomasi0;a,l9Oo8Ares1;l3ndolwethu;g9Fo88rIssH;!a,ie;eHi,ri7;sa,za;bOlMmKnIrHs6tia0wa0;a60yn;iHya;a,ka,s6;arFe2iHm77ra;!ka;a,iH;a,t6;at6it6;a0Ecarlett,e0AhWiSkye,neza0oQri,tNuIyH;bIGlvi1;ha,mayIJniAsIzH;an3Net8ie,y;anHi7;!a,e,nH;aCe;aIeH;fan4l5Dphan6E;cI5r5;b3fiAAm0LnHphi1;d2ia,ja,ya;er2lJmon1nIobh8QtH;a,i;dy;lETv3;aMeIirHo0risFDy5;a,lDM;ba,e0i5lJrH;iHr6Jyl;!d8Ifa;ia,lDZ;hd,iMki2nJrIu0w0yH;la,ma,na;i,le9on,ron,yn;aIda,ia,nHon;a,on;!ya;k6mH;!aa;lJrItaye82vH;da,inj;e0ife;en1i0ma;anA9bLd5Oh1SiBkKlJmInd2rHs6vannaC;aCi0;ant6i2;lDOma,ome;ee0in8Tu2;in1ri0;a05eZhXiUoHuthDM;bScRghQl8LnPsJwIxH;anB3ie,y;an,e0;aIeHie,lD;ann7ll1marDGtA;!lHnn1;iHyn;e,nH;a,dF;da,i,na;ayy8G;hel67io;bDRerAyn;a,cIkHmas,nFta,ya;ki,o;h8Xki;ea,iannGMoH;da,n1P;an0bJemFgi0iInHta,y0;a8Bee;han86na;a,eH;cHkaC;a,ca;bi0chIe,i0mo0nHquETy0;di,ia;aERelHiB;!e,le;een4ia0;aPeOhMiLoJrHute6A;iHudenCV;scil3LyamvaB;lHrt3;i0ly;a,paluk;ilome0oebe,ylH;is,lis;ggy,nelope,r5t2;ige,m0VnKo5rvaDMtIulH;a,et8in1;ricHt4T;a,e,ia;do2i07;ctav3dIfD3is6ksa0lHphD3umC5yunbileg;a,ga,iv3;eHvAF;l3t8;aWeUiMoIurHy5;!ay,ul;a,eJor,rIuH;f,r;aCeEma;ll1mi;aNcLhariBQkKlaJna,sHta,vi;anHha;ur;!y;a,iDZki;hoGk9YolH;a,e4P;!mh;hir,lHna,risDEsreE;!a,iDDlBV;asuMdLh3i6Dl5nKomi7rgEVtH;aHhal4;lHs6;i1ya;cy,et8;e9iF0ya;nngu2X;a0Ackenz4e02iMoJrignayani,uriDJyH;a,rH;a,iOlNna,tG;bi0i2llBJnH;a,iH;ca,ka,qD9;a,cUdo4ZkaTlOmi,nMrItzi,yH;ar;aJiIlH;anET;am;!l,nB;dy,eHh,n4;nhGrva;aKdJe0iCUlH;iHy;cent,e;red;!gros;!e5;ae5hH;ae5el3Z;ag5DgNi,lKrH;edi7AiIjem,on,yH;em,l;em,sCG;an4iHliCF;nHsCJ;a,da;!an,han;b09cASd07e,g05ha,i04ja,l02n00rLsoum5YtKuIv84xBKyHz4;bell,ra,soBB;d7rH;a,eE;h8Gild1t4;a,cUgQiKjor4l7Un4s6tJwa,yH;!aHbe6Xja9lAE;m,nBL;a,ha,in1;!aJbCGeIja,lDna,sHt63;!a,ol,sa;!l1D;!h,mInH;!a,e,n1;!awit,i;arJeIie,oHr48ueri8;!t;!ry;et46i3B;el4Xi7Cy;dHon,ue5;akranAy;ak,en,iHlo3S;a,ka,nB;a,re,s4te;daHg4;!l3E;alDd4elHge,isDJon0;ei9in1yn;el,le;a0Ne0CiXoQuLyH;d3la,nH;!a,dIe2OnHsCT;!a,e2N;a,sCR;aD4cJel0Pis1lIna,pHz;e,iA;a,u,wa;iHy;a0Se,ja,l2NnB;is,l1UrItt1LuHvel4;el5is1;aKeIi7na,rH;aADi7;lHn1tA;ei;!in1;aTbb9HdSepa,lNnKsJvIzH;!a,be5Ret8z4;!ia;a,et8;!a,dH;a,sHy;ay,ey,i,y;a,iJja,lH;iHy;aA8e;!aH;!nF;ia,ya;!nH;!a,ne;aPda,e0iNjYla,nMoKsJtHx93y5;iHt4;c3t3;e2PlCO;la,nHra;a,ie,o2;a,or1;a,gh,laH;!ni;!h,nH;a,d2e,n5V;cOdon9DiNkes6mi9Gna,rMtJurIvHxmi,y5;ern1in3;a,e5Aie,yn;as6iIoH;nya,ya;fa,s6;a,isA9;a,la;ey,ie,y;a04eZhXiOlASoNrJyH;lHra;a,ee,ie;istHy6I;a,en,iIyH;!na;!e,n5F;nul,ri,urtnB8;aOerNlB7mJrHzzy;a,stH;en,in;!berlImernH;aq;eHi,y;e,y;a,stE;!na,ra;aHei2ongordzol;dij1w5;el7UiKjsi,lJnIrH;a,i,ri;d2na,za;ey,i,lBLs4y;ra,s6;biAcARdiat7MeBAiSlQmPnyakuma1DrNss6NtKviAyH;!e,lH;a,eH;e,i8T;!a6HeIhHi4TlDri0y;ar8Her8Hie,leErBAy;!lyn8Ori0;a,en,iHl5Xoli0yn;!ma,nFs95;a5il1;ei8Mi,lH;e,ie;a,tl6O;a0AeZiWoOuH;anMdLlHst88;es,iH;a8NeHs8X;!n9tH;!a,te;e5Mi3My;a,iA;!anNcelDdMelGhan7VleLni,sIva0yH;a,ce;eHie;fHlDph7Y;a,in1;en,n1;i7y;!a,e,n45;lHng;!i1DlH;!i1C;anNle0nKrJsH;i8JsH;!e,i8I;i,ri;!a,elGif2CnH;a,et8iHy;!e,f2A;a,eJiInH;a,eIiH;e,n1;!t8;cMda,mi,nIque4YsminFvie2y9zH;min7;a7eIiH;ce,e,n1s;!lHs82t0F;e,le;inIk6HlDquelH;in1yn;da,ta;da,lRmPnOo0rNsIvaHwo0zaro;!a0lu,na;aJiIlaHob89;!n9R;do2;belHdo2;!a,e,l3B;a7Ben1i0ma;di2es,gr72ji;a9elBogH;en1;a,e9iHo0se;a0na;aSeOiJoHus7Kyacin2C;da,ll4rten24snH;a,i9U;lImaH;ri;aIdHlaI;a,egard;ry;ath1BiJlInrietArmi9sH;sa,t1A;en2Uga,mi;di;bi2Fil8MlNnMrJsItHwa,yl8M;i5Tt4;n60ti;iHmo51ri53;etH;!te;aCnaC;a,ey,l4;a02eWiRlPoNrKunJwH;enHyne1R;!dolD;ay,el;acieIetHiselB;a,chE;!la;ld1CogooH;sh;adys,enHor3yn2K;a,da,na;aKgi,lIna,ov8EselHta;a,e,le;da,liH;an;!n0;mLnJorgIrH;ald5Si,m3Etrud7;et8i4X;a,eHna;s29vieve;ma;bIle,mHrnet,yG;al5Si5;iIrielH;a,l1;!ja;aTeQiPlorOoz3rH;anJeIiH;da,eB;da,ja;!cH;esIiHoi0P;n1s66;!ca;a,enc3;en,o0;lIn0rnH;anB;ec3ic3;jr,nArKtHy7;emIiHma,oumaA;ha,ma,n;eh;ah,iBrah,za0;cr4Rd0Re0Qi0Pk0Ol07mXn54rUsOtNuMvHwa;aKelIiH;!e,ta;inFyn;!a;!ngel4V;geni1ni47;h5Yien9ta;mLperanKtH;eIhHrel5;er;l31r7;za;a,eralB;iHma,ne4Lyn;cHka,n;a,ka;aPeNiKmH;aHe21ie,y;!li9nuH;elG;lHn1;e7iHy;a,e,ja;lHrald;da,y;!nue5;aWeUiNlMma,no2oKsJvH;a,iH;na,ra;a,ie;iHuiH;se;a,en,ie,y;a0c3da,e,f,nMsJzaH;!betHveA;e,h;aHe,ka;!beH;th;!a,or;anor,nH;!a,i;!in1na;ate1Rta;leEs6;vi;eIiHna,wi0;e,th;l,n;aYeMh3iLjeneKoH;lor5Vminiq4Ln3FrHtt4;a,eEis,la,othHthy;ea,y;ba;an09naCon9ya;anQbPde,eOiMlJmetr3nHsir5M;a,iH;ce,se;a,iIla,orHphi9;es,is;a,l6F;dHrdH;re;!d5Ena;!b2ForaCraC;a,d2nH;!a,e;hl3i0l0GmNnLphn1rIvi1WyH;le,na;a,by,cIia,lH;a,en1;ey,ie;a,et8iH;!ca,el1Aka,z;arHia;is;a0Re0Nh04i02lUoJristIynH;di,th3;al,i0;lPnMrIurH;tn1D;aJd2OiHn2Ori9;!nH;a,e,n1;!l4;cepci5Cn4sH;tanHuelo;ce,za;eHleE;en,t8;aJeoIotH;il54;!pat2;ir7rJudH;et8iH;a,ne;a,e,iH;ce,sZ;a2er2ndH;i,y;aReNloe,rH;isJyH;stH;al;sy,tH;a1Sen,iHy;an1e,n1;deJlseIrH;!i7yl;a,y;li9;nMrH;isKlImH;ai9;a,eHot8;n1t8;!sa;d2elGtH;al,elG;cIlH;es8i47;el3ilH;e,ia,y;itlYlXmilWndVrMsKtHy5;aIeIhHri0;er1IleErDy;ri0;a38sH;a37ie;a,iOlLmeJolIrH;ie,ol;!e,in1yn;lHn;!a,la;a,eIie,otHy;a,ta;ne,y;na,s1X;a0Ii0I;a,e,l1;isAl4;in,yn;a0Ke02iZlXoUrH;andi7eRiJoIyH;an0nn;nwDoke;an3HdgMgiLtH;n31tH;!aInH;ey,i,y;ny;d,t8;etH;!t7;an0e,nH;da,na;bbi7glarIlo07nH;iAn4;ka;ancHythe;a,he;an1Clja0nHsm3M;iAtH;ou;aWcVlinUniArPssOtJulaCvH;!erlH;ey,y;hJsy,tH;e,iHy7;e,na;!anH;ie,y;!ie;nItHyl;ha,ie;adIiH;ce;et8i9;ay,da;ca,ky;!triH;ce,z;rbJyaH;rmH;aa;a2o2ra;a2Ub2Od25g21i1Sj5l18m0Zn0Boi,r06sWtVuPvOwa,yIzH;ra,u0;aKes6gJlIn,seH;!l;in;un;!nH;a,na;a,i2K;drLguJrIsteH;ja;el3;stH;in1;a,ey,i,y;aahua,he0;hIi2Gja,miAs2DtrH;id;aMlIraqHt21;at;eIi7yH;!n;e,iHy;gh;!nH;ti;iJleIo6piA;ta;en,n1t8;aHelG;!n1J;a01dje5eZgViTjRnKohito,toHya;inet8nH;el5ia;te;!aKeIiHmJ;e,ka;!mHtt7;ar4;!belIliHmU;sa;!l1;a,eliH;ca;ka,sHta;a,sa;elHie;a,iH;a,ca,n1qH;ue;!tH;a,te;!bImHstasiMya;ar3;el;aLberKeliJiHy;e,l3naH;!ta;a,ja;!ly;hGiIl3nB;da;a,ra;le;aWba,ePiMlKthJyH;a,c3sH;a,on,sa;ea;iHys0N;e,s0M;a,cIn1sHza;a,e,ha,on,sa;e,ia,ja;c3is6jaKksaKna,sJxH;aHia;!nd2;ia,saH;nd2;ra;ia;i0nIyH;ah,na;a,is,naCoud;la;c6da,leEmNnLsH;haClH;inHyY;g,n;!h;a,o,slH;ey;ee;en;at6g4nIusH;ti0;es;ie;aWdiTelMrH;eJiH;anMenH;a,e,ne;an0;na;!aLeKiIyH;nn;a,n1;a,e;!ne;!iH;de;e,lDsH;on;yn;!lH;i9yn;ne;aKbIiHrL;!e,gaK;ey,i7y;!e;gaH;il;dKliyJradhIs6;ha;ya;ah;a,ya",Honorific:"true¦director1field marsh2lieutenant1rear0sergeant major,vice0; admir1; gener0;al","Adj|Gerund":"true¦0:3F;1:3H;2:31;3:2X;4:35;5:33;6:3C;7:2Z;8:36;9:29;a33b2Tc2Bd1Te1If19g12h0Zi0Rl0Nm0Gnu0Fo0Ap04rYsKtEuBvAw1Ayiel3;ar6e08;nBpA;l1Rs0B;fol3n1Zsett2;aEeDhrBi4ouc7rAwis0;e0Bif2oub2us0yi1;ea1SiA;l2vi1;l2mp0rr1J;nt1Vxi1;aMcreec7enten2NhLkyrocke0lo0Vmi2oJpHtDuBweA;e0Ul2;pp2ArA;gi1pri5roun3;aBea8iAri2Hun9;mula0r4;gge4rA;t2vi1;ark2eAraw2;e3llb2F;aAot7;ki1ri1;i9oc29;dYtisf6;aEeBive0oAus7;a4l2;assu4defi9fres7ig9juve07mai9s0vAwar3;ea2italiAol1G;si1zi1;gi1ll6mb2vi1;a6eDier23lun1VrAun2C;eBoA;mi5vo1Z;ce3s5vai2;n3rpleA;xi1;ffCpWutBverAwi1;arc7lap04p0Pri3whel8;goi1l6st1J;en3sA;et0;m2Jrtu4;aEeDiCoBuAyst0L;mb2;t1Jvi1;s5tiga0;an1Rl0n3smeri26;dAtu4;de9;aCeaBiAo0U;fesa0Tvi1;di1ni1;c1Fg19s0;llumiGmFnArri0R;cDfurHsCtBviA;go23ti1;e1Oimi21oxica0rig0V;pi4ul0;orpo20r0K;po5;na0;eaBorr02umilA;ia0;li1rtwar8;lFrA;atiDipCoBuelA;i1li1;undbrea10wi1;pi1;f6ng;a4ea8;a3etc7it0lEoCrBulfA;il2;ee1FighXust1L;rAun3;ebo3thco8;aCoA;a0wA;e4i1;mi1tte4;lectrJmHnExA;aCci0hBis0pA;an3lo3;aOila1B;c0spe1A;ab2coura0CdBergi13ga0Clive9ric7s02tA;hral2i0J;ea4u4;barras5er09pA;owe4;if6;aQeIiBrA;if0;sAzz6;aEgDhearCsen0tA;rAur11;ac0es5;te9;us0;ppoin0r8;biliGcDfi9gra3ligh0mBpres5sAvasG;erE;an3ea9orA;ali0L;a6eiBli9rA;ea5;vi1;ta0;maPri1s7un0zz2;aPhMlo5oAripp2ut0;mGnArrespon3;cer9fDspi4tA;inBrA;as0ibu0ol2;ui1;lic0u5;ni1;fDmCpA;eAromi5;l2ti1;an3;or0;aAil2;llenAnAr8;gi1;l8ptAri1;iva0;aff2eGin3lFoDrBuA;d3st2;eathtaAui5;ki1;gg2i2o8ri1unA;ci1;in3;co8wiA;lAtc7;de4;bsorVcOgonMlJmHnno6ppea2rFsA;pi4su4toA;nBun3;di1;is7;hi1;res0;li1;aFu5;si1;ar8lu4;ri1;mi1;iAzi1;zi1;cAhi1;eleDomA;moBpan6;yi1;da0;ra0;ti1;bi1;ng",Comparable:"true¦0:3C;1:3Q;2:3F;a3Tb3Cc33d2Te2Mf2Ag1Wh1Li1Fj1Ek1Bl13m0Xn0So0Rp0Iqu0Gr07sHtCug0vAw4y3za0Q;el10ouN;ary,e6hi5i3ry;ck0Cde,l3n1ry,se;d,y;ny,te;a3i3R;k,ry;a3erda2ulgar;gue,in,st;a6en2Xhi5i4ouZr3;anqu2Cen1ue;dy,g36me0ny;ck,rs28;ll,me,rt,wd3I;aRcaPeOhMiLkin0BlImGoEpDt6u4w3;eet,ift;b3dd0Wperfi21rre28;sta26t21;a8e7iff,r4u3;pUr1;a4ict,o3;ng;ig2Vn0N;a1ep,rn;le,rk,te0;e1Si2Vright0;ci1Yft,l3on,re;emn,id;a3el0;ll,rt;e4i3y;g2Mm0Z;ek,nd2T;ck24l0mp1L;a3iRrill,y;dy,l01rp;ve0Jxy;n1Jr3;ce,y;d,fe,int0l1Hv0V;a8e6i5o3ude;mantic,o19sy,u3;gh;pe,t1P;a3d,mo0A;dy,l;gg4iFndom,p3re,w;id;ed;ai2i3;ck,et;hoAi1Fl9o8r5u3;ny,r3;e,p11;egna2ic4o3;fouSud;ey,k0;liXor;ain,easa2;ny;dd,i0ld,ranL;aive,e5i4o3u14;b0Sisy,rm0Ysy;bb0ce,mb0R;a3r1w;r,t;ad,e5ild,o4u3;nda12te;ist,o1;a4ek,l3;low;s0ty;a8e7i6o3ucky;f0Jn4o15u3ve0w10y0N;d,sy;e0g;ke0l,mp,tt0Eve0;e1Qwd;me,r3te;ge;e4i3;nd;en;ol0ui19;cy,ll,n3;secu6t3;e3ima4;llege2rmedia3;te;re;aAe7i6o5u3;ge,m3ng1C;bYid;me0t;gh,l0;a3fXsita2;dy,rWv3;en0y;nd13ppy,r3;d3sh;!y;aFenEhCiBlAoofy,r3;a8e6i5o3ue0Z;o3ss;vy;m,s0;at,e3y;dy,n;nd,y;ad,ib,ooD;a2d1;a3o3;st0;tDuiS;u1y;aCeebBi9l8o6r5u3;ll,n3r0N;!ny;aCesh,iend0;a3nd,rmD;my;at,ir7;erce,nan3;ci9;le;r,ul3;ty;a6erie,sse4v3xtre0B;il;nti3;al;r4s3;tern,y;ly,th0;appZe9i5ru4u3;mb;nk;r5vi4z3;zy;ne;e,ty;a3ep,n9;d3f,r;!ly;agey,h8l7o5r4u3;dd0r0te;isp,uel;ar3ld,mmon,st0ward0zy;se;evKou1;e3il0;ap,e3;sy;aHiFlCoAr5u3;ff,r0sy;ly;a6i3oad;g4llia2;nt;ht;sh,ve;ld,un3;cy;a4o3ue;nd,o1;ck,nd;g,tt3;er;d,ld,w1;dy;bsu6ng5we3;so3;me;ry;rd",Adverb:"true¦a08b05d00eYfSheQinPjustOkinda,likewiZmMnJoEpCquite,r9s5t2u0very,well;ltima01p0; to,wards5;h1iny bit,o0wiO;o,t6;en,us;eldom,o0uch;!me1rt0; of;how,times,w0C;a1e0;alS;ndomRth05;ar excellenEer0oint blank; Lhaps;f3n0utright;ce0ly;! 0;ag05moX; courGten;ewJo0; longWt 0;onHwithstand9;aybe,eanwhiNore0;!ovT;! aboX;deed,steY;lla,n0;ce;or3u0;ck1l9rther0;!moK;ing; 0evK;exampCgood,suH;n mas0vI;se;e0irect2; 2fini0;te0;ly;juAtrop;ackward,y 0;far,no0; means,w; GbroFd nauseam,gEl7ny5part,s4t 2w0;ay,hi0;le;be7l0mo7wor7;arge,ea6; soon,i4;mo0way;re;l 3mo2ongsi1ready,so,togeth0ways;er;de;st;b1t0;hat;ut;ain;ad;lot,posteriori",Conjunction:"true¦aXbTcReNhowMiEjust00noBo9p8supposing,t5wh0yet;e1il0o3;e,st;n1re0thN; if,by,vM;evL;h0il,o;erefOo0;!uU;lus,rovided th9;r0therwiM;! not; mattEr,w0;! 0;since,th4w7;f4n0; 0asmuch;as mIcaForder t0;h0o;at;! 0;only,t0w0;hen;!ev3;ith2ven0;! 0;if,tB;er;o0uz;s,z;e0ut,y the time;cau1f0;ore;se;lt3nd,s 0;far1if,m0soon1t2;uch0; as;hou0;gh",Currency:"true¦$,aud,bQcOdJeurIfHgbp,hkd,iGjpy,kElDp8r7s3usd,x2y1z0¢,£,¥,ден,лв,руб,฿,₡,₨,€,₭,﷼;lotyQł;en,uanP;af,of;h0t5;e0il5;k0q0;elK;oubleJp,upeeJ;e2ound st0;er0;lingG;n0soF;ceEnies;empi7i7;n,r0wanzaCyatC;!onaBw;ls,nr;ori7ranc9;!os;en3i2kk,o0;b0ll2;ra5;me4n0rham4;ar3;e0ny;nt1;aht,itcoin0;!s",Determiner:"true¦aBboth,d9e6few,le5mu8neiDplenty,s4th2various,wh0;at0ich0;evC;a0e4is,ose;!t;everal,ome;!ast,s;a1l0very;!se;ch;e0u;!s;!n0;!o0y;th0;er","Adj|Present":"true¦a07b04cVdQeNfJhollIidRlEmCnarrIoBp9qua8r7s3t2uttFw0;aKet,ro0;ng,u08;endChin;e2hort,l1mooth,our,pa9tray,u0;re,speU;i2ow;cu6da02leSpaN;eplica01i02;ck;aHerfePr0;eseUime,omV;bscu1pen,wn;atu0e3odeH;re;a2e1ive,ow0;er;an;st,y;ow;a2i1oul,r0;ee,inge;rm;iIke,ncy,st;l1mpty,x0;emHpress;abo4ic7;amp,e2i1oub0ry,ull;le;ffu9re6;fu8libe0;raE;alm,l5o0;mpleCn3ol,rr1unterfe0;it;e0u7;ct;juga8sum7;ea1o0;se;n,r;ankru1lu0;nt;pt;li2pproxi0rticula1;ma0;te;ght","Person|Adj":"true¦b3du2earnest,frank,mi2r0san1woo1;an0ich,u1;dy;sty;ella,rown",Modal:"true¦c5lets,m4ought3sh1w0;ill,o5;a0o4;ll,nt;! to,a;ight,ust;an,o0;uld",Verb:"true¦born,cannot,gonna,has,keep tabs,msg","Person|Verb":"true¦b8ch7dr6foster,gra5ja9lan4ma2ni9ollie,p1rob,s0wade;kip,pike,t5ue;at,eg,ier2;ck,r0;k,shal;ce;ce,nt;ew;ase,u1;iff,l1ob,u0;ck;aze,ossom","Person|Date":"true¦a2j0sep;an0une;!uary;p0ugust,v0;ril"};const gr=36,mr="0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ",pr=mr.split("").reduce((function(e,t,n){return e[t]=n,e}),{});var fr=function(e){if(void 0!==pr[e])return pr[e];let t=0,n=1,a=gr,r=1;for(;n=0;n--,r*=gr){let a=e.charCodeAt(n)-48;a>10&&(a-=7),t+=a*r}return t};const br=function(e,t,n){const a=fr(t);return a{let o=e.nodes[a];"!"===o[0]&&(t.push(r),o=o.slice(1));const i=o.split(/([A-Z0-9,]+)/g);for(let o=0;o{const t=function(e){if(!e)return{};const t=e.split("|").reduce(((e,t)=>{const n=t.split("¦");return e[n[0]]=n[1],e}),{}),n={};return Object.keys(t).forEach((function(e){const a=yr(t[e]);"true"===e&&(e=!0);for(let t=0;t{if(jr[t]=e,"Noun|Verb"===e){const e=Pr(t,Nr);jr[e]="Plural|Verb"}})):Object.keys(t).forEach((t=>{Cr[t]=e}))})),[":(",":)",":P",":p",":O",";(",";)",";P",";p",";O",":3",":|",":/",":\\",":$",":*",":@",":-(",":-)",":-P",":-p",":-O",":-3",":-|",":-/",":-\\",":-$",":-*",":-@",":^(",":^)",":^P",":^p",":^O",":^3",":^|",":^/",":^\\",":^$",":^*",":^@","):","(:","$:","*:",")-:","(-:","$-:","*-:",")^:","(^:","$^:","*^:","<3","Cr[e]="Emoticon")),delete Cr[""],delete Cr.null,delete Cr[" "];const Ir="Singular";var Dr={beforeTags:{Determiner:Ir,Possessive:Ir,Acronym:Ir,Noun:Ir,Adjective:Ir,PresentTense:Ir,Gerund:Ir,PastTense:Ir,Infinitive:Ir,Date:Ir,Ordinal:Ir,Demonym:Ir},afterTags:{Value:Ir,Modal:Ir,Copula:Ir,PresentTense:Ir,PastTense:Ir,Demonym:Ir,Actor:Ir},beforeWords:{the:Ir,with:Ir,without:Ir,of:Ir,for:Ir,any:Ir,all:Ir,on:Ir,cut:Ir,cuts:Ir,increase:Ir,decrease:Ir,raise:Ir,drop:Ir,save:Ir,saved:Ir,saves:Ir,make:Ir,makes:Ir,made:Ir,minus:Ir,plus:Ir,than:Ir,another:Ir,versus:Ir,neither:Ir,about:Ir,favorite:Ir,best:Ir,daily:Ir,weekly:Ir,linear:Ir,binary:Ir,mobile:Ir,lexical:Ir,technical:Ir,computer:Ir,scientific:Ir,security:Ir,government:Ir,popular:Ir,formal:Ir,no:Ir,more:Ir,one:Ir,let:Ir,her:Ir,his:Ir,their:Ir,our:Ir,us:Ir,sheer:Ir,monthly:Ir,yearly:Ir,current:Ir,previous:Ir,upcoming:Ir,last:Ir,next:Ir,main:Ir,initial:Ir,final:Ir,beginning:Ir,end:Ir,top:Ir,bottom:Ir,future:Ir,past:Ir,major:Ir,minor:Ir,side:Ir,central:Ir,peripheral:Ir,public:Ir,private:Ir},afterWords:{of:Ir,system:Ir,aid:Ir,method:Ir,utility:Ir,tool:Ir,reform:Ir,therapy:Ir,philosophy:Ir,room:Ir,authority:Ir,says:Ir,said:Ir,wants:Ir,wanted:Ir,is:Ir,did:Ir,do:Ir,can:Ir,wise:Ir}};const Hr="Infinitive";var Gr={beforeTags:{Modal:Hr,Adverb:Hr,Negative:Hr,Plural:Hr},afterTags:{Determiner:Hr,Adverb:Hr,Possessive:Hr,Reflexive:Hr,Preposition:Hr,Cardinal:Hr,Comparative:Hr,Superlative:Hr},beforeWords:{i:Hr,we:Hr,you:Hr,they:Hr,to:Hr,please:Hr,will:Hr,have:Hr,had:Hr,would:Hr,could:Hr,should:Hr,do:Hr,did:Hr,does:Hr,can:Hr,must:Hr,us:Hr,me:Hr,let:Hr,even:Hr,when:Hr,help:Hr,he:Hr,she:Hr,it:Hr,being:Hr,bi:Hr,co:Hr,contra:Hr,de:Hr,inter:Hr,intra:Hr,mis:Hr,pre:Hr,out:Hr,counter:Hr,nobody:Hr,somebody:Hr,anybody:Hr,everybody:Hr},afterWords:{the:Hr,me:Hr,you:Hr,him:Hr,us:Hr,her:Hr,his:Hr,them:Hr,they:Hr,it:Hr,himself:Hr,herself:Hr,itself:Hr,myself:Hr,ourselves:Hr,themselves:Hr,something:Hr,anything:Hr,a:Hr,an:Hr,up:Hr,down:Hr,by:Hr,out:Hr,off:Hr,under:Hr,what:Hr,all:Hr,to:Hr,because:Hr,although:Hr,how:Hr,otherwise:Hr,together:Hr,though:Hr,into:Hr,yet:Hr,more:Hr,here:Hr,there:Hr,away:Hr}};const Tr={beforeTags:Object.assign({},Gr.beforeTags,Dr.beforeTags,{}),afterTags:Object.assign({},Gr.afterTags,Dr.afterTags,{}),beforeWords:Object.assign({},Gr.beforeWords,Dr.beforeWords,{}),afterWords:Object.assign({},Gr.afterWords,Dr.afterWords,{})},xr="Adjective";var Er={beforeTags:{Determiner:xr,Possessive:xr,Hyphenated:xr},afterTags:{Adjective:xr},beforeWords:{seem:xr,seemed:xr,seems:xr,feel:xr,feels:xr,felt:xr,stay:xr,appear:xr,appears:xr,appeared:xr,also:xr,over:xr,under:xr,too:xr,it:xr,but:xr,still:xr,really:xr,quite:xr,well:xr,very:xr,truly:xr,how:xr,deeply:xr,hella:xr,profoundly:xr,extremely:xr,so:xr,badly:xr,mostly:xr,totally:xr,awfully:xr,rather:xr,nothing:xr,something:xr,anything:xr,not:xr,me:xr,is:xr,face:xr,faces:xr,faced:xr,look:xr,looks:xr,looked:xr,reveal:xr,reveals:xr,revealed:xr,sound:xr,sounded:xr,sounds:xr,remains:xr,remained:xr,prove:xr,proves:xr,proved:xr,becomes:xr,stays:xr,tastes:xr,taste:xr,smells:xr,smell:xr,gets:xr,grows:xr,as:xr,rings:xr,radiates:xr,conveys:xr,convey:xr,conveyed:xr,of:xr},afterWords:{too:xr,also:xr,or:xr,enough:xr,as:xr}};const Fr="Gerund";var Or={beforeTags:{Adverb:Fr,Preposition:Fr,Conjunction:Fr},afterTags:{Adverb:Fr,Possessive:Fr,Person:Fr,Pronoun:Fr,Determiner:Fr,Copula:Fr,Preposition:Fr,Conjunction:Fr,Comparative:Fr},beforeWords:{been:Fr,keep:Fr,continue:Fr,stop:Fr,am:Fr,be:Fr,me:Fr,began:Fr,start:Fr,starts:Fr,started:Fr,stops:Fr,stopped:Fr,help:Fr,helps:Fr,avoid:Fr,avoids:Fr,love:Fr,loves:Fr,loved:Fr,hate:Fr,hates:Fr,hated:Fr},afterWords:{you:Fr,me:Fr,her:Fr,him:Fr,his:Fr,them:Fr,their:Fr,it:Fr,this:Fr,there:Fr,on:Fr,about:Fr,for:Fr,up:Fr,down:Fr}};const zr="Gerund",Vr="Adjective",Br={beforeTags:Object.assign({},Er.beforeTags,Or.beforeTags,{Imperative:zr,Infinitive:Vr,Plural:zr}),afterTags:Object.assign({},Er.afterTags,Or.afterTags,{Noun:Vr}),beforeWords:Object.assign({},Er.beforeWords,Or.beforeWords,{is:Vr,are:zr,was:Vr,of:Vr,suggest:zr,suggests:zr,suggested:zr,recommend:zr,recommends:zr,recommended:zr,imagine:zr,imagines:zr,imagined:zr,consider:zr,considered:zr,considering:zr,resist:zr,resists:zr,resisted:zr,avoid:zr,avoided:zr,avoiding:zr,except:Vr,accept:Vr,assess:zr,explore:zr,fear:zr,fears:zr,appreciate:zr,question:zr,help:zr,embrace:zr,with:Vr}),afterWords:Object.assign({},Er.afterWords,Or.afterWords,{to:zr,not:zr,the:zr})},Sr={beforeTags:{Determiner:void 0,Cardinal:"Noun",PhrasalVerb:"Adjective"},afterTags:{}},Kr={beforeTags:Object.assign({},Er.beforeTags,Dr.beforeTags,Sr.beforeTags),afterTags:Object.assign({},Er.afterTags,Dr.afterTags,Sr.afterTags),beforeWords:Object.assign({},Er.beforeWords,Dr.beforeWords,{are:"Adjective",is:"Adjective",was:"Adjective",be:"Adjective",off:"Adjective",out:"Adjective"}),afterWords:Object.assign({},Er.afterWords,Dr.afterWords)},$r="PastTense",Lr="Adjective",Mr={beforeTags:{Adverb:$r,Pronoun:$r,ProperNoun:$r,Auxiliary:$r,Noun:$r},afterTags:{Possessive:$r,Pronoun:$r,Determiner:$r,Adverb:$r,Comparative:$r,Date:$r,Gerund:$r},beforeWords:{be:$r,who:$r,get:Lr,had:$r,has:$r,have:$r,been:$r,it:$r,as:$r,for:Lr,more:Lr,always:Lr},afterWords:{by:$r,back:$r,out:$r,in:$r,up:$r,down:$r,before:$r,after:$r,for:$r,the:$r,with:$r,as:$r,on:$r,at:$r,between:$r,to:$r,into:$r,us:$r,them:$r,his:$r,her:$r,their:$r,our:$r,me:$r,about:Lr}};var Jr={beforeTags:Object.assign({},Er.beforeTags,Mr.beforeTags),afterTags:Object.assign({},Er.afterTags,Mr.afterTags),beforeWords:Object.assign({},Er.beforeWords,Mr.beforeWords),afterWords:Object.assign({},Er.afterWords,Mr.afterWords)};const Wr={afterTags:{Noun:"Adjective",Conjunction:void 0}},Ur={beforeTags:Object.assign({},Er.beforeTags,Gr.beforeTags,{Adverb:void 0,Negative:void 0}),afterTags:Object.assign({},Er.afterTags,Gr.afterTags,Wr.afterTags),beforeWords:Object.assign({},Er.beforeWords,Gr.beforeWords,{have:void 0,had:void 0,not:void 0,went:"Adjective",goes:"Adjective",got:"Adjective",be:"Adjective"}),afterWords:Object.assign({},Er.afterWords,Gr.afterWords,{to:void 0,as:"Adjective"})},qr={Copula:"Gerund",PastTense:"Gerund",PresentTense:"Gerund",Infinitive:"Gerund"},Rr={Value:"Gerund"},Qr={are:"Gerund",were:"Gerund",be:"Gerund",no:"Gerund",without:"Gerund",you:"Gerund",we:"Gerund",they:"Gerund",he:"Gerund",she:"Gerund",us:"Gerund",them:"Gerund"},Zr={the:"Gerund",this:"Gerund",that:"Gerund",me:"Gerund",us:"Gerund",them:"Gerund"},Xr={beforeTags:Object.assign({},Or.beforeTags,Dr.beforeTags,qr),afterTags:Object.assign({},Or.afterTags,Dr.afterTags,Rr),beforeWords:Object.assign({},Or.beforeWords,Dr.beforeWords,Qr),afterWords:Object.assign({},Or.afterWords,Dr.afterWords,Zr)},_r="Singular",Yr="Infinitive",eo={beforeTags:Object.assign({},Gr.beforeTags,Dr.beforeTags,{Adjective:_r,Particle:_r}),afterTags:Object.assign({},Gr.afterTags,Dr.afterTags,{ProperNoun:Yr,Gerund:Yr,Adjective:Yr,Copula:_r}),beforeWords:Object.assign({},Gr.beforeWords,Dr.beforeWords,{is:_r,was:_r,of:_r,have:null}),afterWords:Object.assign({},Gr.afterWords,Dr.afterWords,{instead:Yr,about:Yr,his:Yr,her:Yr,to:null,by:null,in:null})},to="Person";var no={beforeTags:{Honorific:to,Person:to},afterTags:{Person:to,ProperNoun:to,Verb:to},beforeWords:{hi:to,hey:to,yo:to,dear:to,hello:to},afterWords:{said:to,says:to,told:to,tells:to,feels:to,felt:to,seems:to,thinks:to,thought:to,spends:to,spendt:to,plays:to,played:to,sing:to,sang:to,learn:to,learned:to,wants:to,wanted:to}};const ao="Month",ro={beforeTags:{Date:ao,Value:ao},afterTags:{Date:ao,Value:ao},beforeWords:{by:ao,in:ao,on:ao,during:ao,after:ao,before:ao,between:ao,until:ao,til:ao,sometime:ao,of:ao,this:ao,next:ao,last:ao,previous:ao,following:ao,with:"Person"},afterWords:{sometime:ao,in:ao,of:ao,until:ao,the:ao}};var oo={beforeTags:Object.assign({},no.beforeTags,ro.beforeTags),afterTags:Object.assign({},no.afterTags,ro.afterTags),beforeWords:Object.assign({},no.beforeWords,ro.beforeWords),afterWords:Object.assign({},no.afterWords,ro.afterWords)};const io="Place",so={beforeTags:{Place:io},afterTags:{Place:io,Abbreviation:io},beforeWords:{in:io,by:io,near:io,from:io,to:io},afterWords:{in:io,by:io,near:io,from:io,to:io,government:io,council:io,region:io,city:io}},lo="Unit",uo={"Actor|Verb":Tr,"Adj|Gerund":Br,"Adj|Noun":Kr,"Adj|Past":Jr,"Adj|Present":Ur,"Noun|Verb":eo,"Noun|Gerund":Xr,"Person|Noun":{beforeTags:Object.assign({},Dr.beforeTags,no.beforeTags),afterTags:Object.assign({},Dr.afterTags,no.afterTags),beforeWords:Object.assign({},Dr.beforeWords,no.beforeWords,{i:"Infinitive",we:"Infinitive"}),afterWords:Object.assign({},Dr.afterWords,no.afterWords)},"Person|Date":oo,"Person|Verb":{beforeTags:Object.assign({},Dr.beforeTags,no.beforeTags,Gr.beforeTags),afterTags:Object.assign({},Dr.afterTags,no.afterTags,Gr.afterTags),beforeWords:Object.assign({},Dr.beforeWords,no.beforeWords,Gr.beforeWords),afterWords:Object.assign({},Dr.afterWords,no.afterWords,Gr.afterWords)},"Person|Place":{beforeTags:Object.assign({},so.beforeTags,no.beforeTags),afterTags:Object.assign({},so.afterTags,no.afterTags),beforeWords:Object.assign({},so.beforeWords,no.beforeWords),afterWords:Object.assign({},so.afterWords,no.afterWords)},"Person|Adj":{beforeTags:Object.assign({},no.beforeTags,Er.beforeTags),afterTags:Object.assign({},no.afterTags,Er.afterTags),beforeWords:Object.assign({},no.beforeWords,Er.beforeWords),afterWords:Object.assign({},no.afterWords,Er.afterWords)},"Unit|Noun":{beforeTags:{Value:lo},afterTags:{},beforeWords:{per:lo,every:lo,each:lo,square:lo,cubic:lo,sq:lo,metric:lo},afterWords:{per:lo,squared:lo,cubed:lo,long:lo}}},co=(e,t)=>{const n=Object.keys(e).reduce(((t,n)=>(t[n]="Infinitive"===e[n]?"PresentTense":"Plural",t)),{});return Object.assign(n,t)};uo["Plural|Verb"]={beforeWords:co(uo["Noun|Verb"].beforeWords,{had:"Plural",have:"Plural"}),afterWords:co(uo["Noun|Verb"].afterWords,{his:"PresentTense",her:"PresentTense",its:"PresentTense",in:null,to:null,is:"PresentTense",by:"PresentTense"}),beforeTags:co(uo["Noun|Verb"].beforeTags,{Conjunction:"PresentTense",Noun:void 0,ProperNoun:"PresentTense"}),afterTags:co(uo["Noun|Verb"].afterTags,{Gerund:"Plural",Noun:"PresentTense",Value:"PresentTense"})};const ho="Adjective",go="Infinitive",mo="PresentTense",po="Singular",fo="PastTense",bo="Adverb",yo="Plural",vo="Actor",wo="Verb",ko="Noun",Po="LastName",Ao="Modal",Co="Place",jo="Participle";var No=[null,null,{ea:po,ia:ko,ic:ho,ly:bo,"'n":wo,"'t":wo},{oed:fo,ued:fo,xed:fo," so":bo,"'ll":Ao,"'re":"Copula",azy:ho,eer:ko,end:wo,ped:fo,ffy:ho,ify:go,ing:"Gerund",ize:go,ibe:go,lar:ho,mum:ho,nes:mo,nny:ho,ous:ho,que:ho,ger:ko,ber:ko,rol:po,sis:po,ogy:po,oid:po,ian:po,zes:mo,eld:fo,ken:jo,ven:jo,ten:jo,ect:go,ict:go,ign:go,oze:go,ful:ho,bal:ho,ton:ko,pur:Co},{amed:fo,aped:fo,ched:fo,lked:fo,rked:fo,reed:fo,nded:fo,mned:ho,cted:fo,dged:fo,ield:po,akis:Po,cede:go,chuk:Po,czyk:Po,ects:mo,iend:po,ends:wo,enko:Po,ette:po,iary:po,wner:po,fies:mo,fore:bo,gate:go,gone:ho,ices:yo,ints:yo,ruct:go,ines:yo,ions:yo,ners:yo,pers:yo,lers:yo,less:ho,llen:ho,made:ho,nsen:Po,oses:mo,ould:Ao,some:ho,sson:Po,ians:yo,tion:po,tage:ko,ique:po,tive:ho,tors:ko,vice:po,lier:po,fier:po,wned:fo,gent:po,tist:vo,pist:vo,rist:vo,mist:vo,yist:vo,vist:vo,ists:vo,lite:po,site:po,rite:po,mite:po,bite:po,mate:po,date:po,ndal:po,vent:po,uist:vo,gist:vo,note:po,cide:po,ence:po,wide:ho,vide:go,ract:go,duce:go,pose:go,eive:go,lyze:go,lyse:go,iant:ho,nary:ho,ghty:ho,uent:ho,erer:vo,bury:Co,dorf:ko,esty:ko,wych:Co,dale:Co,folk:Co,vale:Co,abad:Co,sham:Co,wick:Co,view:Co},{elist:vo,holic:po,phite:po,tized:fo,urned:fo,eased:fo,ances:yo,bound:ho,ettes:yo,fully:bo,ishes:mo,ities:yo,marek:Po,nssen:Po,ology:ko,osome:po,tment:po,ports:yo,rough:ho,tches:mo,tieth:"Ordinal",tures:yo,wards:bo,where:bo,archy:ko,pathy:ko,opoly:ko,embly:ko,phate:ko,ndent:po,scent:po,onist:vo,anist:vo,alist:vo,olist:vo,icist:vo,ounce:go,iable:ho,borne:ho,gnant:ho,inant:ho,igent:ho,atory:ho,rient:po,dient:po,maker:vo,burgh:Co,mouth:Co,ceter:Co,ville:Co,hurst:Co,stead:Co,endon:Co,brook:Co,shire:Co,worth:ko,field:"ProperNoun",ridge:Co},{auskas:Po,parent:po,cedent:po,ionary:po,cklist:po,brooke:Co,keeper:vo,logist:vo,teenth:"Value",worker:vo,master:vo,writer:vo,brough:Co,cester:Co,ington:Co,cliffe:Co,ingham:Co},{chester:Co,logists:vo,opoulos:Po,borough:Co,sdottir:Po}];const Io="Adjective",Do="Noun",Ho="Verb";var Go=[null,null,{},{neo:Do,bio:Do,"de-":Ho,"re-":Ho,"un-":Ho,"ex-":Do},{anti:Do,auto:Do,faux:Io,hexa:Do,kilo:Do,mono:Do,nano:Do,octa:Do,poly:Do,semi:Io,tele:Do,"pro-":Io,"mis-":Ho,"dis-":Ho,"pre-":Io},{anglo:Do,centi:Do,ethno:Do,ferro:Do,grand:Do,hepta:Do,hydro:Do,intro:Do,macro:Do,micro:Do,milli:Do,nitro:Do,penta:Do,quasi:Io,radio:Do,tetra:Do,"omni-":Io,"post-":Io},{pseudo:Io,"extra-":Io,"hyper-":Io,"inter-":Io,"intra-":Io,"deca-":Io},{electro:Do}];const To="Adjective",xo="Infinitive",Eo="PresentTense",Fo="Singular",Oo="PastTense",zo="Adverb",Vo="Expression",Bo="Actor",So="Verb",Ko="Noun",$o="LastName";var Lo={a:[[/.[aeiou]na$/,Ko,"tuna"],[/.[oau][wvl]ska$/,$o],[/.[^aeiou]ica$/,Fo,"harmonica"],[/^([hyj]a+)+$/,Vo,"haha"]],c:[[/.[^aeiou]ic$/,To]],d:[[/[aeiou](pp|ll|ss|ff|gg|tt|rr|bb|nn|mm)ed$/,Oo,"popped"],[/.[aeo]{2}[bdgmnprvz]ed$/,Oo,"rammed"],[/.[aeiou][sg]hed$/,Oo,"gushed"],[/.[aeiou]red$/,Oo,"hired"],[/.[aeiou]r?ried$/,Oo,"hurried"],[/[^aeiou]ard$/,Fo,"steward"],[/[aeiou][^aeiou]id$/,To,""],[/.[vrl]id$/,To,"livid"],[/..led$/,Oo,"hurled"],[/.[iao]sed$/,Oo,""],[/[aeiou]n?[cs]ed$/,Oo,""],[/[aeiou][rl]?[mnf]ed$/,Oo,""],[/[aeiou][ns]?c?ked$/,Oo,"bunked"],[/[aeiou]gned$/,Oo],[/[aeiou][nl]?ged$/,Oo],[/.[tdbwxyz]ed$/,Oo],[/[^aeiou][aeiou][tvx]ed$/,Oo],[/.[cdflmnprstv]ied$/,Oo,"emptied"]],e:[[/.[lnr]ize$/,xo,"antagonize"],[/.[^aeiou]ise$/,xo,"antagonise"],[/.[aeiou]te$/,xo,"bite"],[/.[^aeiou][ai]ble$/,To,"fixable"],[/.[^aeiou]eable$/,To,"maleable"],[/.[ts]ive$/,To,"festive"],[/[a-z]-like$/,To,"woman-like"]],h:[[/.[^aeiouf]ish$/,To,"cornish"],[/.v[iy]ch$/,$o,"..ovich"],[/^ug?h+$/,Vo,"ughh"],[/^uh[ -]?oh$/,Vo,"uhoh"],[/[a-z]-ish$/,To,"cartoon-ish"]],i:[[/.[oau][wvl]ski$/,$o,"polish-male"]],k:[[/^(k){2}$/,Vo,"kkkk"]],l:[[/.[gl]ial$/,To,"familial"],[/.[^aeiou]ful$/,To,"fitful"],[/.[nrtumcd]al$/,To,"natal"],[/.[^aeiou][ei]al$/,To,"familial"]],m:[[/.[^aeiou]ium$/,Fo,"magnesium"],[/[^aeiou]ism$/,Fo,"schism"],[/^[hu]m+$/,Vo,"hmm"],[/^\d+ ?[ap]m$/,"Date","3am"]],n:[[/.[lsrnpb]ian$/,To,"republican"],[/[^aeiou]ician$/,Bo,"musician"],[/[aeiou][ktrp]in'$/,"Gerund","cookin'"]],o:[[/^no+$/,Vo,"noooo"],[/^(yo)+$/,Vo,"yoo"],[/^wo{2,}[pt]?$/,Vo,"woop"]],r:[[/.[bdfklmst]ler$/,"Noun"],[/[aeiou][pns]er$/,Fo],[/[^i]fer$/,xo],[/.[^aeiou][ao]pher$/,Bo],[/.[lk]er$/,"Noun"],[/.ier$/,"Comparative"]],t:[[/.[di]est$/,"Superlative"],[/.[icldtgrv]ent$/,To],[/[aeiou].*ist$/,To],[/^[a-z]et$/,So]],s:[[/.[^aeiou]ises$/,Eo],[/.[rln]ates$/,Eo],[/.[^z]ens$/,So],[/.[lstrn]us$/,Fo],[/.[aeiou]sks$/,Eo],[/.[aeiou]kes$/,Eo],[/[aeiou][^aeiou]is$/,Fo],[/[a-z]'s$/,Ko],[/^yes+$/,Vo]],v:[[/.[^aeiou][ai][kln]ov$/,$o]],y:[[/.[cts]hy$/,To],[/.[st]ty$/,To],[/.[tnl]ary$/,To],[/.[oe]ry$/,Fo],[/[rdntkbhs]ly$/,zo],[/.(gg|bb|zz)ly$/,To],[/...lly$/,zo],[/.[gk]y$/,To],[/[bszmp]{2}y$/,To],[/.[ai]my$/,To],[/[ea]{2}zy$/,To],[/.[^aeiou]ity$/,Fo]]};const Mo="Verb",Jo="Noun";var Wo={leftTags:[["Adjective",Jo],["Possessive",Jo],["Determiner",Jo],["Adverb",Mo],["Pronoun",Mo],["Value",Jo],["Ordinal",Jo],["Modal",Mo],["Superlative",Jo],["Demonym",Jo],["Honorific","Person"]],leftWords:[["i",Mo],["first",Jo],["it",Mo],["there",Mo],["not",Mo],["because",Jo],["if",Jo],["but",Jo],["who",Mo],["this",Jo],["his",Jo],["when",Jo],["you",Mo],["very","Adjective"],["old",Jo],["never",Mo],["before",Jo],["a",Jo],["the",Jo],["been",Mo]],rightTags:[["Copula",Jo],["PastTense",Jo],["Conjunction",Jo],["Modal",Jo]],rightWords:[["there",Mo],["me",Mo],["man","Adjective"],["him",Mo],["it",Mo],["were",Jo],["took",Jo],["himself",Mo],["went",Jo],["who",Jo],["jr","Person"]]},Uo={fwd:"3:ser,ier¦1er:h,t,f,l,n¦1r:e¦2er:ss,or,om",both:"3er:ver,ear,alm¦3ner:hin¦3ter:lat¦2mer:im¦2er:ng,rm,mb¦2ber:ib¦2ger:ig¦1er:w,p,k,d¦ier:y",rev:"1:tter,yer¦2:uer,ver,ffer,oner,eler,ller,iler,ster,cer,uler,sher,ener,gher,aner,adder,nter,eter,rter,hter,rner,fter¦3:oser,ooler,eafer,user,airer,bler,maler,tler,eater,uger,rger,ainer,urer,ealer,icher,pler,emner,icter,nser,iser¦4:arser,viner,ucher,rosser,somer,ndomer,moter,oother,uarer,hiter¦5:nuiner,esser,emier¦ar:urther",ex:"worse:bad¦better:good¦4er:fair,gray,poor¦1urther:far¦3ter:fat,hot,wet¦3der:mad,sad¦3er:shy,fun¦4der:glad¦:¦4r:cute,dire,fake,fine,free,lame,late,pale,rare,ripe,rude,safe,sore,tame,wide¦5r:eerie,stale"},qo={fwd:"1:nning,tting,rring,pping,eing,mming,gging,dding,bbing,kking¦2:eking,oling,eling,eming¦3:velling,siting,uiting,fiting,loting,geting,ialing,celling¦4:graming",both:"1:aing,iing,fing,xing,ying,oing,hing,wing¦2:tzing,rping,izzing,bting,mning,sping,wling,rling,wding,rbing,uping,lming,wning,mping,oning,lting,mbing,lking,fting,hting,sking,gning,pting,cking,ening,nking,iling,eping,ering,rting,rming,cting,lping,ssing,nting,nding,lding,sting,rning,rding,rking¦3:belling,siping,toming,yaking,uaking,oaning,auling,ooping,aiding,naping,euring,tolling,uzzing,ganing,haning,ualing,halling,iasing,auding,ieting,ceting,ouling,voring,ralling,garing,joring,oaming,oaking,roring,nelling,ooring,uelling,eaming,ooding,eaping,eeting,ooting,ooming,xiting,keting,ooking,ulling,airing,oaring,biting,outing,oiting,earing,naling,oading,eeding,ouring,eaking,aiming,illing,oining,eaning,onging,ealing,aining,eading¦4:thoming,melling,aboring,ivoting,weating,dfilling,onoring,eriting,imiting,tialling,rgining,otoring,linging,winging,lleting,louding,spelling,mpelling,heating,feating,opelling,choring,welling,ymaking,ctoring,calling,peating,iloring,laiting,utoring,uditing,mmaking,loating,iciting,waiting,mbating,voiding,otalling,nsoring,nselling,ocusing,itoring,eloping¦5:rselling,umpeting,atrolling,treating,tselling,rpreting,pringing,ummeting,ossoming,elmaking,eselling,rediting,totyping,onmaking,rfeiting,ntrolling¦5e:chmaking,dkeeping,severing,erouting,ecreting,ephoning,uthoring,ravening,reathing,pediting,erfering,eotyping,fringing,entoring,ombining,ompeting¦4e:emaking,eething,twining,rruling,chuting,xciting,rseding,scoping,edoring,pinging,lunging,agining,craping,pleting,eleting,nciting,nfining,ncoding,tponing,ecoding,writing,esaling,nvening,gnoring,evoting,mpeding,rvening,dhering,mpiling,storing,nviting,ploring¦3e:tining,nuring,saking,miring,haling,ceding,xuding,rining,nuting,laring,caring,miling,riding,hoking,piring,lading,curing,uading,noting,taping,futing,paring,hading,loding,siring,guring,vading,voking,during,niting,laning,caping,luting,muting,ruding,ciding,juring,laming,caling,hining,uoting,liding,ciling,duling,tuting,puting,cuting,coring,uiding,tiring,turing,siding,rading,enging,haping,buting,lining,taking,anging,haring,uiring,coming,mining,moting,suring,viding,luding¦2e:tring,zling,uging,oging,gling,iging,vring,fling,lging,obing,psing,pling,ubing,cling,dling,wsing,iking,rsing,dging,kling,ysing,tling,rging,eging,nsing,uning,osing,uming,using,ibing,bling,aging,ising,asing,ating¦2ie:rlying¦1e:zing,uing,cing,ving",rev:"ying:ie¦1ing:se,ke,te,we,ne,re,de,pe,me,le,c,he¦2ing:ll,ng,dd,ee,ye,oe,rg,us¦2ning:un¦2ging:og,ag,ug,ig,eg¦2ming:um¦2bing:ub,ab,eb,ob¦3ning:lan,can,hin,pin,win¦3ring:cur,lur,tir,tar,pur,car¦3ing:ait,del,eel,fin,eat,oat,eem,lel,ool,ein,uin¦3ping:rop,rap,top,uip,wap,hip,hop,lap,rip,cap¦3ming:tem,wim,rim,kim,lim¦3ting:mat,cut,pot,lit,lot,hat,set,pit,put¦3ding:hed,bed,bid¦3king:rek¦3ling:cil,pel¦3bing:rib¦4ning:egin¦4ing:isit,ruit,ilot,nsit,dget,rkel,ival,rcel¦4ring:efer,nfer¦4ting:rmit,mmit,ysit,dmit,emit,bmit,tfit,gret¦4ling:evel,xcel,ivel¦4ding:hred¦5ing:arget,posit,rofit¦5ring:nsfer¦5ting:nsmit,orget,cquit¦5ling:ancel,istil",ex:"3:adding,eating,aiming,aiding,airing,outing,gassing,setting,getting,putting,cutting,winning,sitting,betting,mapping,tapping,letting,bidding,hitting,tanning,netting,popping,fitting,capping,lapping,barring,banning,vetting,topping,rotting,tipping,potting,wetting,pitting,dipping,budding,hemming,pinning,jetting,kidding,padding,podding,sipping,wedding,bedding,donning,warring,penning,gutting,cueing,wadding,petting,ripping,napping,matting,tinning,binning,dimming,hopping,mopping,nodding,panning,rapping,ridding,sinning¦4:selling,falling,calling,waiting,editing,telling,rolling,heating,boating,hanging,beating,coating,singing,tolling,felling,polling,discing,seating,voiding,gelling,yelling,baiting,reining,ruining,seeking,spanning,stepping,knitting,emitting,slipping,quitting,dialing,omitting,clipping,shutting,skinning,abutting,flipping,trotting,cramming,fretting,suiting¦5:bringing,treating,spelling,stalling,trolling,expelling,rivaling,wringing,deterring,singeing,befitting,refitting¦6:enrolling,distilling,scrolling,strolling,caucusing,travelling¦7:installing,redefining,stencilling,recharging,overeating,benefiting,unraveling,programing¦9:reprogramming¦is:being¦2e:using,aging,owing¦3e:making,taking,coming,noting,hiring,filing,coding,citing,doping,baking,coping,hoping,lading,caring,naming,voting,riding,mining,curing,lining,ruling,typing,boring,dining,firing,hiding,piling,taping,waning,baling,boning,faring,honing,wiping,luring,timing,wading,piping,fading,biting,zoning,daring,waking,gaming,raking,ceding,tiring,coking,wining,joking,paring,gaping,poking,pining,coring,liming,toting,roping,wiring,aching¦4e:writing,storing,eroding,framing,smoking,tasting,wasting,phoning,shaking,abiding,braking,flaking,pasting,priming,shoring,sloping,withing,hinging¦5e:defining,refining,renaming,swathing,fringing,reciting¦1ie:dying,tying,lying,vying¦7e:sunbathing"},Ro={fwd:"1:mt¦2:llen¦3:iven,aken¦:ne¦y:in",both:"1:wn¦2:me,aten¦3:seen,bidden,isen¦4:roven,asten¦3l:pilt¦3d:uilt¦2e:itten¦1im:wum¦1eak:poken¦1ine:hone¦1ose:osen¦1in:gun¦1ake:woken¦ear:orn¦eal:olen¦eeze:ozen¦et:otten¦ink:unk¦ing:ung",rev:"2:un¦oken:eak¦ought:eek¦oven:eave¦1ne:o¦1own:ly¦1den:de¦1in:ay¦2t:am¦2n:ee¦3en:all¦4n:rive,sake,take¦5n:rgive",ex:"2:been¦3:seen,run¦4:given,taken¦5:shaken¦2eak:broken¦1ive:dove¦2y:flown¦3e:hidden,ridden¦1eek:sought¦1ake:woken¦1eave:woven"},Qo={fwd:"1:oes¦1ve:as",both:"1:xes¦2:zzes,ches,shes,sses¦3:iases¦2y:llies,plies¦1y:cies,bies,ties,vies,nies,pies,dies,ries,fies¦:s",rev:"1ies:ly¦2es:us,go,do¦3es:cho,eto",ex:"2:does,goes¦3:gasses¦5:focuses¦is:are¦3y:relies¦2y:flies¦2ve:has"},Zo={fwd:"1st:e¦1est:l,m,f,s¦1iest:cey¦2est:or,ir¦3est:ver",both:"4:east¦5:hwest¦5lest:erful¦4est:weet,lgar,tter,oung¦4most:uter¦3est:ger,der,rey,iet,ong,ear¦3test:lat¦3most:ner¦2est:pt,ft,nt,ct,rt,ht¦2test:it¦2gest:ig¦1est:b,k,n,p,h,d,w¦iest:y",rev:"1:ttest,nnest,yest¦2:sest,stest,rmest,cest,vest,lmest,olest,ilest,ulest,ssest,imest,uest¦3:rgest,eatest,oorest,plest,allest,urest,iefest,uelest,blest,ugest,amest,yalest,ealest,illest,tlest,itest¦4:cerest,eriest,somest,rmalest,ndomest,motest,uarest,tiffest¦5:leverest,rangest¦ar:urthest¦3ey:riciest",ex:"best:good¦worst:bad¦5est:great¦4est:fast,full,fair,dull¦3test:hot,wet,fat¦4nest:thin¦1urthest:far¦3est:gay,shy,ill¦4test:neat¦4st:late,wide,fine,safe,cute,fake,pale,rare,rude,sore,ripe,dire¦6st:severe"},Xo={fwd:"1:tistic,eable,lful,sful,ting,tty¦2:onate,rtable,geous,ced,seful,ctful¦3:ortive,ented¦arity:ear¦y:etic¦fulness:begone¦1ity:re¦1y:tiful,gic¦2ity:ile,imous,ilous,ime¦2ion:ated¦2eness:iving¦2y:trious¦2ation:iring¦2tion:vant¦3ion:ect¦3ce:mant,mantic¦3tion:irable¦3y:est,estic¦3m:mistic,listic¦3ess:ning¦4n:utious¦4on:rative,native,vative,ective¦4ce:erant",both:"1:king,wing¦2:alous,ltuous,oyful,rdous¦3:gorous,ectable,werful,amatic¦4:oised,usical,agical,raceful,ocused,lined,ightful¦5ness:stful,lding,itous,nuous,ulous,otous,nable,gious,ayful,rvous,ntous,lsive,peful,entle,ciful,osive,leful,isive,ncise,reful,mious¦5ty:ivacious¦5ties:ubtle¦5ce:ilient,adiant,atient¦5cy:icient¦5sm:gmatic¦5on:sessive,dictive¦5ity:pular,sonal,eative,entic¦5sity:uminous¦5ism:conic¦5nce:mperate¦5ility:mitable¦5ment:xcited¦5n:bitious¦4cy:brant,etent,curate¦4ility:erable,acable,icable,ptable¦4ty:nacious,aive,oyal,dacious¦4n:icious¦4ce:vient,erent,stent,ndent,dient,quent,ident¦4ness:adic,ound,hing,pant,sant,oing,oist,tute¦4icity:imple¦4ment:fined,mused¦4ism:otic¦4ry:dantic¦4ity:tund,eral¦4edness:hand¦4on:uitive¦4lity:pitable¦4sm:eroic,namic¦4sity:nerous¦3th:arm¦3ility:pable,bable,dable,iable¦3cy:hant,nant,icate¦3ness:red,hin,nse,ict,iet,ite,oud,ind,ied,rce¦3ion:lute¦3ity:ual,gal,volous,ial¦3ce:sent,fensive,lant,gant,gent,lent,dant¦3on:asive¦3m:fist,sistic,iastic¦3y:terious,xurious,ronic,tastic¦3ur:amorous¦3e:tunate¦3ation:mined¦3sy:rteous¦3ty:ain¦3ry:ave¦3ment:azed¦2ness:de,on,ue,rn,ur,ft,rp,pe,om,ge,rd,od,ay,ss,er,ll,oy,ap,ht,ld,ad,rt¦2inousness:umous¦2ity:neous,ene,id,ane¦2cy:bate,late¦2ation:ized¦2ility:oble,ible¦2y:odic¦2e:oving,aring¦2s:ost¦2itude:pt¦2dom:ee¦2ance:uring¦2tion:reet¦2ion:oted¦2sion:ending¦2liness:an¦2or:rdent¦1th:ung¦1e:uable¦1ness:w,h,k,f¦1ility:mble¦1or:vent¦1ement:ging¦1tiquity:ncient¦1ment:hed¦verty:or¦ength:ong¦eat:ot¦pth:ep¦iness:y",rev:"",ex:"5:forceful,humorous¦8:charismatic¦13:understanding¦5ity:active¦11ness:adventurous,inquisitive,resourceful¦8on:aggressive,automatic,perceptive¦7ness:amorous,fatuous,furtive,ominous,serious¦5ness:ample,sweet¦12ness:apprehensive,cantankerous,contemptuous,ostentatious¦13ness:argumentative,conscientious¦9ness:assertive,facetious,imperious,inventive,oblivious,rapacious,receptive,seditious,whimsical¦10ness:attractive,expressive,impressive,loquacious,salubrious,thoughtful¦3edom:boring¦4ness:calm,fast,keen,tame¦8ness:cheerful,gracious,specious,spurious,timorous,unctuous¦5sity:curious¦9ion:deliberate¦8ion:desperate¦6e:expensive¦7ce:fragrant¦3y:furious¦9ility:ineluctable¦6ism:mystical¦8ity:physical,proactive,sensitive,vertical¦5cy:pliant¦7ity:positive¦9ity:practical¦12ism:professional¦6ce:prudent¦3ness:red¦6cy:vagrant¦3dom:wise"};const _o=function(e="",t={}){let n=function(e,t={}){return t.hasOwnProperty(e)?t[e]:null}(e,t.ex);return n=n||function(e,t=[]){for(let n=0;n=1;a-=1){let r=e.length-a,o=e.substring(r,e.length);if(!0===t.hasOwnProperty(o))return e.slice(0,r)+t[o];if(!0===n.hasOwnProperty(o))return e.slice(0,r)+n[o]}return t.hasOwnProperty("")?e+t[""]:n.hasOwnProperty("")?e+n[""]:null}(e,t.fwd,t.both),n=n||e,n},Yo=function(e){return Object.entries(e).reduce(((e,t)=>(e[t[1]]=t[0],e)),{})},ei=function(e={}){return{reversed:!0,both:Yo(e.both),ex:Yo(e.ex),fwd:e.rev||{}}},ti=/^([0-9]+)/,ni=function(e){let t=function(e){let t={};return e.split("¦").forEach((e=>{let[n,a]=e.split(":");a=(a||"").split(","),a.forEach((e=>{t[e]=n}))})),t}(e);return Object.keys(t).reduce(((e,n)=>(e[n]=function(e="",t=""){let n=(t=String(t)).match(ti);if(null===n)return t;let a=Number(n[1])||0;return e.substring(0,a)+t.replace(ti,"")}(n,t[n]),e)),{})},ai=function(e={}){return"string"==typeof e&&(e=JSON.parse(e)),e.fwd=ni(e.fwd||""),e.both=ni(e.both||""),e.rev=ni(e.rev||""),e.ex=ni(e.ex||""),e},ri=ai({fwd:"1:tted,wed,gged,nned,een,rred,pped,yed,bbed,oed,dded,rd,wn,mmed¦2:eed,nded,et,hted,st,oled,ut,emed,eled,lded,ken,rt,nked,apt,ant,eped,eked¦3:eared,eat,eaded,nelled,ealt,eeded,ooted,eaked,eaned,eeted,mited,bid,uit,ead,uited,ealed,geted,velled,ialed,belled¦4:ebuted,hined,comed¦y:ied¦ome:ame¦ear:ore¦ind:ound¦ing:ung,ang¦ep:pt¦ink:ank,unk¦ig:ug¦all:ell¦ee:aw¦ive:ave¦eeze:oze¦old:eld¦ave:ft¦ake:ook¦ell:old¦ite:ote¦ide:ode¦ine:one¦in:un,on¦eal:ole¦im:am¦ie:ay¦and:ood¦1ise:rose¦1eak:roke¦1ing:rought¦1ive:rove¦1el:elt¦1id:bade¦1et:got¦1y:aid¦1it:sat¦3e:lid¦3d:pent",both:"1:aed,fed,xed,hed¦2:sged,xted,wled,rped,lked,kied,lmed,lped,uped,bted,rbed,rked,wned,rled,mped,fted,mned,mbed,zzed,omed,ened,cked,gned,lted,sked,ued,zed,nted,ered,rted,rmed,ced,sted,rned,ssed,rded,pted,ved,cted¦3:cled,eined,siped,ooned,uked,ymed,jored,ouded,ioted,oaned,lged,asped,iged,mured,oided,eiled,yped,taled,moned,yled,lit,kled,oaked,gled,naled,fled,uined,oared,valled,koned,soned,aided,obed,ibed,meted,nicked,rored,micked,keted,vred,ooped,oaded,rited,aired,auled,filled,ouled,ooded,ceted,tolled,oited,bited,aped,tled,vored,dled,eamed,nsed,rsed,sited,owded,pled,sored,rged,osed,pelled,oured,psed,oated,loned,aimed,illed,eured,tred,ioned,celled,bled,wsed,ooked,oiled,itzed,iked,iased,onged,ased,ailed,uned,umed,ained,auded,nulled,ysed,eged,ised,aged,oined,ated,used,dged,doned¦4:ntied,efited,uaked,caded,fired,roped,halled,roked,himed,culed,tared,lared,tuted,uared,routed,pited,naked,miled,houted,helled,hared,cored,caled,tired,peated,futed,ciled,called,tined,moted,filed,sided,poned,iloted,honed,lleted,huted,ruled,cured,named,preted,vaded,sured,talled,haled,peded,gined,nited,uided,ramed,feited,laked,gured,ctored,unged,pired,cuted,voked,eloped,ralled,rined,coded,icited,vided,uaded,voted,mined,sired,noted,lined,nselled,luted,jured,fided,puted,piled,pared,olored,cided,hoked,enged,tured,geoned,cotted,lamed,uiled,waited,udited,anged,luded,mired,uired,raded¦5:modelled,izzled,eleted,umpeted,ailored,rseded,treated,eduled,ecited,rammed,eceded,atrolled,nitored,basted,twined,itialled,ncited,gnored,ploded,xcited,nrolled,namelled,plored,efeated,redited,ntrolled,nfined,pleted,llided,lcined,eathed,ibuted,lloted,dhered,cceded¦3ad:sled¦2aw:drew¦2ot:hot¦2ke:made¦2ow:hrew,grew¦2ose:hose¦2d:ilt¦2in:egan¦1un:ran¦1ink:hought¦1ick:tuck¦1ike:ruck¦1eak:poke,nuck¦1it:pat¦1o:did¦1ow:new¦1ake:woke¦go:went",rev:"3:rst,hed,hut,cut,set¦4:tbid¦5:dcast,eread,pread,erbid¦ought:uy,eek¦1ied:ny,ly,dy,ry,fy,py,vy,by,ty,cy¦1ung:ling,ting,wing¦1pt:eep¦1ank:rink¦1ore:bear,wear¦1ave:give¦1oze:reeze¦1ound:rind,wind¦1ook:take,hake¦1aw:see¦1old:sell¦1ote:rite¦1ole:teal¦1unk:tink¦1am:wim¦1ay:lie¦1ood:tand¦1eld:hold¦2d:he,ge,re,le,leed,ne,reed,be,ye,lee,pe,we¦2ed:dd,oy,or,ey,gg,rr,us,ew,to¦2ame:ecome,rcome¦2ped:ap¦2ged:ag,og,ug,eg¦2bed:ub,ab,ib,ob¦2lt:neel¦2id:pay¦2ang:pring¦2ove:trive¦2med:um¦2ode:rride¦2at:ysit¦3ted:mit,hat,mat,lat,pot,rot,bat¦3ed:low,end,tow,und,ond,eem,lay,cho,dow,xit,eld,ald,uld,law,lel,eat,oll,ray,ank,fin,oam,out,how,iek,tay,haw,ait,vet,say,cay,bow¦3d:ste,ede,ode,ete,ree,ude,ame,oke,ote,ime,ute,ade¦3red:lur,cur,pur,car¦3ped:hop,rop,uip,rip,lip,tep,top¦3ded:bed,rod,kid¦3ade:orbid¦3led:uel¦3ned:lan,can,kin,pan,tun¦3med:rim,lim¦4ted:quit,llot¦4ed:pear,rrow,rand,lean,mand,anel,pand,reet,link,abel,evel,imit,ceed,ruit,mind,peal,veal,hool,head,pell,well,mell,uell,band,hear,weak¦4led:nnel,qual,ebel,ivel¦4red:nfer,efer,sfer¦4n:sake,trew¦4d:ntee¦4ded:hred¦4ned:rpin¦5ed:light,nceal,right,ndear,arget,hread,eight,rtial,eboot¦5d:edite,nvite¦5ted:egret¦5led:ravel",ex:"2:been,upped¦3:added,aged,aided,aimed,aired,bid,died,dyed,egged,erred,eyed,fit,gassed,hit,lied,owed,pent,pied,tied,used,vied,oiled,outed,banned,barred,bet,canned,cut,dipped,donned,ended,feed,inked,jarred,let,manned,mowed,netted,padded,panned,pitted,popped,potted,put,set,sewn,sowed,tanned,tipped,topped,vowed,weed,bowed,jammed,binned,dimmed,hopped,mopped,nodded,pinned,rigged,sinned,towed,vetted¦4:ached,baked,baled,boned,bored,called,caned,cared,ceded,cited,coded,cored,cubed,cured,dared,dined,edited,exited,faked,fared,filed,fined,fired,fuelled,gamed,gelled,hired,hoped,joked,lined,mined,named,noted,piled,poked,polled,pored,pulled,reaped,roamed,rolled,ruled,seated,shed,sided,timed,tolled,toned,voted,waited,walled,waned,winged,wiped,wired,zoned,yelled,tamed,lubed,roped,faded,mired,caked,honed,banged,culled,heated,raked,welled,banded,beat,cast,cooled,cost,dealt,feared,folded,footed,handed,headed,heard,hurt,knitted,landed,leaked,leapt,linked,meant,minded,molded,neared,needed,peaked,plodded,plotted,pooled,quit,read,rooted,sealed,seeded,seeped,shipped,shunned,skimmed,slammed,sparred,stemmed,stirred,suited,thinned,twinned,swayed,winked,dialed,abutted,blotted,fretted,healed,heeded,peeled,reeled¦5:basted,cheated,equalled,eroded,exiled,focused,opined,pleated,primed,quoted,scouted,shored,sloped,smoked,sniped,spelled,spouted,routed,staked,stored,swelled,tasted,treated,wasted,smelled,dwelled,honored,prided,quelled,eloped,scared,coveted,sweated,breaded,cleared,debuted,deterred,freaked,modeled,pleaded,rebutted,speeded¦6:anchored,defined,endured,impaled,invited,refined,revered,strolled,cringed,recast,thrust,unfolded¦7:authored,combined,competed,conceded,convened,excreted,extruded,redefined,restored,secreted,rescinded,welcomed¦8:expedited,infringed¦9:interfered,intervened,persevered¦10:contravened¦eat:ate¦is:was¦go:went¦are:were¦3d:bent,lent,rent,sent¦3e:bit,fled,hid,lost¦3ed:bled,bred¦2ow:blew,grew¦1uy:bought¦2tch:caught¦1o:did¦1ive:dove,gave¦2aw:drew¦2ed:fed¦2y:flew,laid,paid,said¦1ight:fought¦1et:got¦2ve:had¦1ang:hung¦2ad:led¦2ght:lit¦2ke:made¦2et:met¦1un:ran¦1ise:rose¦1it:sat¦1eek:sought¦1each:taught¦1ake:woke,took¦1eave:wove¦2ise:arose¦1ear:bore,tore,wore¦1ind:bound,found,wound¦2eak:broke¦2ing:brought,wrung¦1ome:came¦2ive:drove¦1ig:dug¦1all:fell¦2el:felt¦4et:forgot¦1old:held¦2ave:left¦1ing:rang,sang¦1ide:rode¦1ink:sank¦1ee:saw¦2ine:shone¦4e:slid¦1ell:sold,told¦4d:spent¦2in:spun¦1in:won"}),oi=ai(Qo),ii=ai(qo),si=ai(Ro),li=ei(ri),ui=ei(oi),ci=ei(ii),di=ei(si),hi=ai(Uo),gi=ai(Zo);var mi={fromPast:ri,fromPresent:oi,fromGerund:ii,fromParticiple:si,toPast:li,toPresent:ui,toGerund:ci,toParticiple:di,toComparative:hi,toSuperlative:gi,fromComparative:ei(hi),fromSuperlative:ei(gi),adjToNoun:ai(Xo)},pi=["academy","administration","agence","agences","agencies","agency","airlines","airways","army","assoc","associates","association","assurance","authority","autorite","aviation","bank","banque","board","boys","brands","brewery","brotherhood","brothers","bureau","cafe","co","caisse","capital","care","cathedral","center","centre","chemicals","choir","chronicle","church","circus","clinic","clinique","club","co","coalition","coffee","collective","college","commission","committee","communications","community","company","comprehensive","computers","confederation","conference","conseil","consulting","containers","corporation","corps","corp","council","crew","data","departement","department","departments","design","development","directorate","division","drilling","education","eglise","electric","electricity","energy","ensemble","enterprise","enterprises","entertainment","estate","etat","faculty","faction","federation","financial","fm","foundation","fund","gas","gazette","girls","government","group","guild","herald","holdings","hospital","hotel","hotels","inc","industries","institut","institute","institutes","insurance","international","interstate","investment","investments","investors","journal","laboratory","labs","llc","ltd","limited","machines","magazine","management","marine","marketing","markets","media","memorial","ministere","ministry","military","mobile","motor","motors","musee","museum","news","observatory","office","oil","optical","orchestra","organization","partners","partnership","petrol","petroleum","pharmacare","pharmaceutical","pharmaceuticals","pizza","plc","police","politburo","polytechnic","post","power","press","productions","quartet","radio","reserve","resources","restaurant","restaurants","savings","school","securities","service","services","societe","subsidiary","society","sons","subcommittee","syndicat","systems","telecommunications","telegraph","television","times","tribunal","tv","union","university","utilities","workers"].reduce(((e,t)=>(e[t]=!0,e)),{}),fi=["atoll","basin","bay","beach","bluff","bog","camp","canyon","canyons","cape","cave","caves","cliffs","coast","cove","coves","crater","crossing","creek","desert","dune","dunes","downs","estates","escarpment","estuary","falls","fjord","fjords","forest","forests","glacier","gorge","gorges","grove","gulf","gully","highland","heights","hollow","hill","hills","inlet","island","islands","isthmus","junction","knoll","lagoon","lake","lakeshore","marsh","marshes","mount","mountain","mountains","narrows","peninsula","plains","plateau","pond","rapids","ravine","reef","reefs","ridge","river","rivers","sandhill","shoal","shore","shoreline","shores","strait","straits","springs","stream","swamp","tombolo","trail","trails","trench","valley","vallies","village","volcano","waterfall","watershed","wetland","woods","acres","burough","county","district","municipality","prefecture","province","region","reservation","state","territory","borough","metropolis","downtown","uptown","midtown","city","town","township","hamlet","country","kingdom","enclave","neighbourhood","neighborhood","kingdom","ward","zone","airport","amphitheater","arch","arena","auditorium","bar","barn","basilica","battlefield","bridge","building","castle","centre","coliseum","cineplex","complex","dam","farm","field","fort","garden","gardens","gymnasium","hall","house","levee","library","manor","memorial","monument","museum","gallery","palace","pillar","pits","plantation","playhouse","quarry","sportsfield","sportsplex","stadium","terrace","terraces","theater","tower","park","parks","site","ranch","raceway","sportsplex","ave","st","street","rd","road","lane","landing","crescent","cr","way","tr","terrace","avenue"].reduce(((e,t)=>(e[t]=!0,e)),{}),bi=[[/([^v])ies$/i,"$1y"],[/(ise)s$/i,"$1"],[/(kn|[^o]l|w)ives$/i,"$1ife"],[/^((?:ca|e|ha|(?:our|them|your)?se|she|wo)l|lea|loa|shea|thie)ves$/i,"$1f"],[/^(dwar|handkerchie|hoo|scar|whar)ves$/i,"$1f"],[/(antenn|formul|nebul|vertebr|vit)ae$/i,"$1a"],[/(octop|vir|radi|nucle|fung|cact|stimul)(i)$/i,"$1us"],[/(buffal|tomat|tornad)(oes)$/i,"$1o"],[/(ause)s$/i,"$1"],[/(ease)s$/i,"$1"],[/(ious)es$/i,"$1"],[/(ouse)s$/i,"$1"],[/(ose)s$/i,"$1"],[/(..ase)s$/i,"$1"],[/(..[aeiu]s)es$/i,"$1"],[/(vert|ind|cort)(ices)$/i,"$1ex"],[/(matr|append)(ices)$/i,"$1ix"],[/([xo]|ch|ss|sh)es$/i,"$1"],[/men$/i,"man"],[/(n)ews$/i,"$1ews"],[/([ti])a$/i,"$1um"],[/([^aeiouy]|qu)ies$/i,"$1y"],[/(s)eries$/i,"$1eries"],[/(m)ovies$/i,"$1ovie"],[/(cris|ax|test)es$/i,"$1is"],[/(alias|status)es$/i,"$1"],[/(ss)$/i,"$1"],[/(ic)s$/i,"$1"],[/s$/i,""]];const yi=function(e,t){const{irregularPlurals:n}=t.two,a=(r=n,Object.keys(r).reduce(((e,t)=>(e[r[t]]=t,e)),{}));var r;if(a.hasOwnProperty(e))return a[e];for(let t=0;t(wi[t].forEach((n=>e[n]=t)),e)),{});const ki=function(e){const t=e.substring(e.length-3);if(!0===wi.hasOwnProperty(t))return wi[t];const n=e.substring(e.length-2);if(!0===wi.hasOwnProperty(n))return wi[n];return"s"===e.substring(e.length-1)?"PresentTense":null},Pi={are:"be",were:"be",been:"be",is:"be",am:"be",was:"be",be:"be",being:"be"},Ai=function(e,t,n){const{fromPast:a,fromPresent:r,fromGerund:o,fromParticiple:i}=t.two.models,{prefix:s,verb:l,particle:u}=function(e,t){let n="",a={};t.one&&t.one.prefixes&&(a=t.one.prefixes);let[r,o]=e.split(/ /);return o&&!0===a[r]&&(n=r,r=o,o=""),{prefix:n,verb:r,particle:o}}(e,t);let c="";if(n||(n=ki(e)),Pi.hasOwnProperty(e))c=Pi[e];else if("Participle"===n)c=_o(l,i);else if("PastTense"===n)c=_o(l,a);else if("PresentTense"===n)c=_o(l,r);else{if("Gerund"!==n)return e;c=_o(l,o)}return u&&(c+=" "+u),s&&(c=s+" "+c),c},Ci=function(e,t){const{toPast:n,toPresent:a,toGerund:r,toParticiple:o}=t.two.models;if("be"===e)return{Infinitive:e,Gerund:"being",PastTense:"was",PresentTense:"is"};const[i,s]=(e=>/ /.test(e)?e.split(/ /):[e,""])(e),l={Infinitive:i,PastTense:_o(i,n),PresentTense:_o(i,a),Gerund:_o(i,r),FutureTense:"will "+i};let u=_o(i,o);if(u!==e&&u!==l.PastTense){const n=t.one.lexicon||{};"Participle"!==n[u]&&"Adjective"!==n[u]||("play"===e&&(u="played"),l.Participle=u)}return s&&Object.keys(l).forEach((e=>{l[e]+=" "+s})),l};var ji={toInfinitive:Ai,conjugate:Ci,all:function(e,t){const n=Ci(e,t);return delete n.FutureTense,Object.values(n).filter((e=>e))}};const Ni=function(e,t){const n=t.two.models.toSuperlative;return _o(e,n)},Ii=function(e,t){const n=t.two.models.toComparative;return _o(e,n)},Di=function(e="",t=[]){const n=e.length;for(let a=n<=6?n-1:6;a>=1;a-=1){const r=e.substring(n-a,e.length);if(!0===t[r.length].hasOwnProperty(r)){return e.slice(0,n-a)+t[r.length][r]}}return null},Hi="ically",Gi=new Set(["analyt"+Hi,"chem"+Hi,"class"+Hi,"clin"+Hi,"crit"+Hi,"ecolog"+Hi,"electr"+Hi,"empir"+Hi,"frant"+Hi,"grammat"+Hi,"ident"+Hi,"ideolog"+Hi,"log"+Hi,"mag"+Hi,"mathemat"+Hi,"mechan"+Hi,"med"+Hi,"method"+Hi,"method"+Hi,"mus"+Hi,"phys"+Hi,"phys"+Hi,"polit"+Hi,"pract"+Hi,"rad"+Hi,"satir"+Hi,"statist"+Hi,"techn"+Hi,"technolog"+Hi,"theoret"+Hi,"typ"+Hi,"vert"+Hi,"whims"+Hi]),Ti=[null,{},{ly:""},{ily:"y",bly:"ble",ply:"ple"},{ally:"al",rply:"rp"},{ually:"ual",ially:"ial",cally:"cal",eally:"eal",rally:"ral",nally:"nal",mally:"mal",eeply:"eep",eaply:"eap"},{ically:"ic"}],xi=new Set(["early","only","hourly","daily","weekly","monthly","yearly","mostly","duly","unduly","especially","undoubtedly","conversely","namely","exceedingly","presumably","accordingly","overly","best","latter","little","long","low"]),Ei={wholly:"whole",fully:"full",truly:"true",gently:"gentle",singly:"single",customarily:"customary",idly:"idle",publically:"public",quickly:"quick",superbly:"superb",cynically:"cynical",well:"good"},Fi=[null,{y:"ily"},{ly:"ly",ic:"ically"},{ial:"ially",ual:"ually",tle:"tly",ble:"bly",ple:"ply",ary:"arily"},{},{},{}],Oi={cool:"cooly",whole:"wholly",full:"fully",good:"well",idle:"idly",public:"publicly",single:"singly",special:"especially"},zi=function(e){if(Oi.hasOwnProperty(e))return Oi[e];let t=Di(e,Fi);return t||(t=e+"ly"),t};var Vi={toSuperlative:Ni,toComparative:Ii,toAdverb:zi,toNoun:function(e,t){const n=t.two.models.adjToNoun;return _o(e,n)},fromAdverb:function(e){return e.endsWith("ly")?Gi.has(e)?e.replace(/ically/,"ical"):xi.has(e)?null:Ei.hasOwnProperty(e)?Ei[e]:Di(e,Ti)||e:null},fromSuperlative:function(e,t){const n=t.two.models.fromSuperlative;return _o(e,n)},fromComparative:function(e,t){const n=t.two.models.fromComparative;return _o(e,n)},all:function(e,t){let n=[e];return n.push(Ni(e,t)),n.push(Ii(e,t)),n.push(zi(e)),n=n.filter((e=>e)),n=new Set(n),Array.from(n)}},Bi={noun:vi,verb:ji,adjective:Vi},Si={Singular:(e,t,n,a)=>{const r=a.one.lexicon,o=n.two.transform.noun.toPlural(e,a);r[o]||(t[o]=t[o]||"Plural")},Actor:(e,t,n,a)=>{const r=a.one.lexicon,o=n.two.transform.noun.toPlural(e,a);r[o]||(t[o]=t[o]||["Plural","Actor"])},Comparable:(e,t,n,a)=>{const r=a.one.lexicon,{toSuperlative:o,toComparative:i}=n.two.transform.adjective,s=o(e,a);r[s]||(t[s]=t[s]||"Superlative");const l=i(e,a);r[l]||(t[l]=t[l]||"Comparative"),t[e]="Adjective"},Demonym:(e,t,n,a)=>{const r=n.two.transform.noun.toPlural(e,a);t[r]=t[r]||["Demonym","Plural"]},Infinitive:(e,t,n,a)=>{const r=a.one.lexicon,o=n.two.transform.verb.conjugate(e,a);Object.entries(o).forEach((e=>{r[e[1]]||t[e[1]]||"FutureTense"===e[0]||(t[e[1]]=e[0])}))},PhrasalVerb:(e,t,n,a)=>{const r=a.one.lexicon;t[e]=["PhrasalVerb","Infinitive"];const o=a.one._multiCache,[i,s]=e.split(" ");r[i]||(t[i]=t[i]||"Infinitive");const l=n.two.transform.verb.conjugate(i,a);delete l.FutureTense,Object.entries(l).forEach((e=>{if("Actor"===e[0]||""===e[1])return;t[e[1]]||r[e[1]]||(t[e[1]]=e[0]),o[e[1]]=2;const n=e[1]+" "+s;t[n]=t[n]||[e[0],"PhrasalVerb"]}))},Multiple:(e,t)=>{t[e]=["Multiple","Cardinal"],t[e+"th"]=["Multiple","Ordinal"],t[e+"ths"]=["Multiple","Fraction"]},Cardinal:(e,t)=>{t[e]=["TextValue","Cardinal"]},Ordinal:(e,t)=>{t[e]=["TextValue","Ordinal"],t[e+"s"]=["TextValue","Fraction"]},Place:(e,t)=>{t[e]=["Place","ProperNoun"]},Region:(e,t)=>{t[e]=["Region","ProperNoun"]}};const Ki={e:["mice","louse","antennae","formulae","nebulae","vertebrae","vitae"],i:["tia","octopi","viri","radii","nuclei","fungi","cacti","stimuli"],n:["men"],t:["feet"]},$i=new Set(["israelis","menus","logos"]),Li=["bus","mas","was","ias","xas","vas","cis","lis","nis","ois","ris","sis","tis","xis","aus","cus","eus","fus","gus","ius","lus","nus","das","ous","pus","rus","sus","tus","xus","aos","igos","ados","ogos","'s","ss"],Mi=function(e){if(!e||e.length<=3)return!1;if($i.has(e))return!0;const t=e[e.length-1];return Ki.hasOwnProperty(t)?Ki[t].find((t=>e.endsWith(t))):"s"===t&&!Li.find((t=>e.endsWith(t)))};var Ji={two:{quickSplit:function(e){const t=/[,:;]/,n=[];return e.forEach((e=>{let a=0;e.forEach(((r,o)=>{t.test(r.post)&&function(e,t){const n=/^[0-9]+$/,a=e[t];if(!a)return!1;const r=new Set(["may","april","august","jan"]);if("like"===a.normal||r.has(a.normal))return!1;if(a.tags.has("Place")||a.tags.has("Date"))return!1;if(e[t-1]){const n=e[t-1];if(n.tags.has("Date")||r.has(n.normal))return!1;if(n.tags.has("Adjective")||a.tags.has("Adjective"))return!1}const o=a.normal;return 1!==o.length&&2!==o.length&&4!==o.length||!n.test(o)}(e,o+1)&&(n.push(e.slice(a,o+1)),a=o+1)})),a{const i=e[t],s=(t=(t=t.toLowerCase().trim()).replace(/'s\b/,"")).split(/ /);s.length>1&&(void 0===o[s[0]]||s.length>o[s[0]])&&(o[s[0]]=s.length),!0===Si.hasOwnProperty(i)&&Si[i](t,r,n,a),r[t]=r[t]||i})),delete r[""],delete r.null,delete r[" "],{lex:r,_multi:o}},transform:Bi,looksPlural:Mi}};const Wi={one:{lexicon:{}},two:{models:mi}},Ui={"Actor|Verb":"Actor","Adj|Gerund":"Adjective","Adj|Noun":"Adjective","Adj|Past":"Adjective","Adj|Present":"Adjective","Noun|Verb":"Singular","Noun|Gerund":"Gerund","Person|Noun":"Noun","Person|Date":"Month","Person|Verb":"FirstName","Person|Place":"Person","Person|Adj":"Comparative","Plural|Verb":"Plural","Unit|Noun":"Noun"},qi=function(e,t){const n={model:t,methods:Ji},{lex:a,_multi:r}=Ji.two.expandLexicon(e,n);return Object.assign(t.one.lexicon,a),Object.assign(t.one._multiCache,r),t},Ri=function(e,t,n){const a=Ci(e,Wi);t[a.PastTense]=t[a.PastTense]||"PastTense",t[a.Gerund]=t[a.Gerund]||"Gerund",!0===n&&(t[a.PresentTense]=t[a.PresentTense]||"PresentTense")},Qi=function(e,t,n){const a=Ni(e,n);t[a]=t[a]||"Superlative";const r=Ii(e,n);t[r]=t[r]||"Comparative"},Zi=function(e,t){const n={},a=t.one.lexicon;return Object.keys(e).forEach((r=>{const o=e[r];if(n[r]=Ui[o],"Noun|Verb"!==o&&"Person|Verb"!==o&&"Actor|Verb"!==o||Ri(r,a,!1),"Adj|Present"===o&&(Ri(r,a,!0),Qi(r,a,t)),"Person|Adj"===o&&Qi(r,a,t),"Adj|Gerund"===o||"Noun|Gerund"===o){const e=Ai(r,Wi,"Gerund");a[e]||(n[e]="Infinitive")}if("Noun|Gerund"!==o&&"Adj|Noun"!==o&&"Person|Noun"!==o||function(e,t,n){const a=Pr(e,n);t[a]=t[a]||"Plural"}(r,a,t),"Adj|Past"===o){const e=Ai(r,Wi,"PastTense");a[e]||(n[e]="Infinitive")}})),t=qi(n,t)};let Xi={one:{_multiCache:{},lexicon:Cr,frozenLex:{"20th century fox":"Organization","7 eleven":"Organization","motel 6":"Organization","excuse me":"Expression","financial times":"Organization","guns n roses":"Organization","la z boy":"Organization","labour party":"Organization","new kids on the block":"Organization","new york times":"Organization","the guess who":"Organization","thin lizzy":"Organization","prime minister":"Actor","free market":"Singular","lay up":"Singular","living room":"Singular","living rooms":"Plural","spin off":"Singular","appeal court":"Uncountable","cold war":"Uncountable","gene pool":"Uncountable","machine learning":"Uncountable","nail polish":"Uncountable","time off":"Uncountable","take part":"Infinitive","bill gates":"Person","doctor who":"Person","dr who":"Person","he man":"Person","iron man":"Person","kid cudi":"Person","run dmc":"Person","rush limbaugh":"Person","snow white":"Person","tiger woods":"Person","brand new":"Adjective","en route":"Adjective","left wing":"Adjective","off guard":"Adjective","on board":"Adjective","part time":"Adjective","right wing":"Adjective","so called":"Adjective","spot on":"Adjective","straight forward":"Adjective","super duper":"Adjective","tip top":"Adjective","top notch":"Adjective","up to date":"Adjective","win win":"Adjective","brooklyn nets":"SportsTeam","chicago bears":"SportsTeam","houston astros":"SportsTeam","houston dynamo":"SportsTeam","houston rockets":"SportsTeam","houston texans":"SportsTeam","minnesota twins":"SportsTeam","orlando magic":"SportsTeam","san antonio spurs":"SportsTeam","san diego chargers":"SportsTeam","san diego padres":"SportsTeam","iron maiden":"ProperNoun","isle of man":"Country","united states":"Country","united states of america":"Country","prince edward island":"Region","cedar breaks":"Place","cedar falls":"Place","point blank":"Adverb","tiny bit":"Adverb","by the time":"Conjunction","no matter":"Conjunction","civil wars":"Plural","credit cards":"Plural","default rates":"Plural","free markets":"Plural","head starts":"Plural","home runs":"Plural","lay ups":"Plural","phone calls":"Plural","press releases":"Plural","record labels":"Plural","soft serves":"Plural","student loans":"Plural","tax returns":"Plural","tv shows":"Plural","video games":"Plural","took part":"PastTense","takes part":"PresentTense","taking part":"Gerund","taken part":"Participle","light bulb":"Noun","rush hour":"Noun","fluid ounce":"Unit","the rolling stones":"Organization"}},two:{irregularPlurals:dr,models:mi,suffixPatterns:No,prefixPatterns:Go,endsWith:Lo,neighbours:Wo,regexNormal:[[/^[\w.]+@[\w.]+\.[a-z]{2,3}$/,"Email"],[/^(https?:\/\/|www\.)+\w+\.[a-z]{2,3}/,"Url","http.."],[/^[a-z0-9./].+\.(com|net|gov|org|ly|edu|info|biz|dev|ru|jp|de|in|uk|br|io|ai)/,"Url",".com"],[/^[PMCE]ST$/,"Timezone","EST"],[/^ma?c'[a-z]{3}/,"LastName","mc'neil"],[/^o'[a-z]{3}/,"LastName","o'connor"],[/^ma?cd[aeiou][a-z]{3}/,"LastName","mcdonald"],[/^(lol)+[sz]$/,"Expression","lol"],[/^wo{2,}a*h?$/,"Expression","wooah"],[/^(hee?){2,}h?$/,"Expression","hehe"],[/^(un|de|re)\\-[a-z\u00C0-\u00FF]{2}/,"Verb","un-vite"],[/^(m|k|cm|km)\/(s|h|hr)$/,"Unit","5 k/m"],[/^(ug|ng|mg)\/(l|m3|ft3)$/,"Unit","ug/L"],[/[^:/]\/\p{Letter}/u,"SlashedTerm","love/hate"]],regexText:[[/^#[\p{Number}_]*\p{Letter}/u,"HashTag"],[/^@\w{2,}$/,"AtMention"],[/^([A-Z]\.){2}[A-Z]?/i,["Acronym","Noun"],"F.B.I"],[/.{3}[lkmnp]in['‘’‛‵′`´]$/,"Gerund","chillin'"],[/.{4}s['‘’‛‵′`´]$/,"Possessive","flanders'"],[/^[\p{Emoji_Presentation}\p{Extended_Pictographic}]/u,"Emoji","emoji-class"]],regexNumbers:[[/^@1?[0-9](am|pm)$/i,"Time","3pm"],[/^@1?[0-9]:[0-9]{2}(am|pm)?$/i,"Time","3:30pm"],[/^'[0-9]{2}$/,"Year"],[/^[012]?[0-9](:[0-5][0-9])(:[0-5][0-9])$/,"Time","3:12:31"],[/^[012]?[0-9](:[0-5][0-9])?(:[0-5][0-9])? ?(am|pm)$/i,"Time","1:12pm"],[/^[012]?[0-9](:[0-5][0-9])(:[0-5][0-9])? ?(am|pm)?$/i,"Time","1:12:31pm"],[/^[0-9]{4}-[0-9]{2}-[0-9]{2}T[0-9]{2}:[0-9]{2}/i,"Date","iso-date"],[/^[0-9]{1,4}-[0-9]{1,2}-[0-9]{1,4}$/,"Date","iso-dash"],[/^[0-9]{1,4}\/[0-9]{1,2}\/([0-9]{4}|[0-9]{2})$/,"Date","iso-slash"],[/^[0-9]{1,4}\.[0-9]{1,2}\.[0-9]{1,4}$/,"Date","iso-dot"],[/^[0-9]{1,4}-[a-z]{2,9}-[0-9]{1,4}$/i,"Date","12-dec-2019"],[/^utc ?[+-]?[0-9]+$/,"Timezone","utc-9"],[/^(gmt|utc)[+-][0-9]{1,2}$/i,"Timezone","gmt-3"],[/^[0-9]{3}-[0-9]{4}$/,"PhoneNumber","421-0029"],[/^(\+?[0-9][ -])?[0-9]{3}[ -]?[0-9]{3}-[0-9]{4}$/,"PhoneNumber","1-800-"],[/^[-+]?\p{Currency_Symbol}[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?([kmb]|bn)?\+?$/u,["Money","Value"],"$5.30"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?\p{Currency_Symbol}\+?$/u,["Money","Value"],"5.30£"],[/^[-+]?[$£]?[0-9]([0-9,.])+(usd|eur|jpy|gbp|cad|aud|chf|cny|hkd|nzd|kr|rub)$/i,["Money","Value"],"$400usd"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?\+?$/,["Cardinal","NumericValue"],"5,999"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?(st|nd|rd|r?th)$/,["Ordinal","NumericValue"],"53rd"],[/^\.[0-9]+\+?$/,["Cardinal","NumericValue"],".73th"],[/^[-+]?[0-9]+(,[0-9]{3})*(\.[0-9]+)?%\+?$/,["Percent","Cardinal","NumericValue"],"-4%"],[/^\.[0-9]+%$/,["Percent","Cardinal","NumericValue"],".3%"],[/^[0-9]{1,4}\/[0-9]{1,4}(st|nd|rd|th)?s?$/,["Fraction","NumericValue"],"2/3rds"],[/^[0-9.]{1,3}[a-z]{0,2}[-–—][0-9]{1,3}[a-z]{0,2}$/,["Value","NumberRange"],"3-4"],[/^[0-9]{1,2}(:[0-9][0-9])?(am|pm)? ?[-–—] ?[0-9]{1,2}(:[0-9][0-9])?(am|pm)$/,["Time","NumberRange"],"3-4pm"],[/^[0-9.]+([a-z°]{1,4})$/,"NumericValue","9km"]],switches:jr,clues:uo,uncountable:{},orgWords:pi,placeWords:fi}};Xi=function(e){return e=function(e,t){return Object.keys(e).forEach((n=>{"Uncountable"===e[n]&&(t.two.uncountable[n]=!0,e[n]="Uncountable")})),t}((e=qi(e.one.lexicon,e)).one.lexicon,e),e=function(e){const{irregularPlurals:t}=e.two,{lexicon:n}=e.one;return Object.entries(t).forEach((e=>{n[e[0]]=n[e[0]]||"Singular",n[e[1]]=n[e[1]]||"Plural"})),e}(e=Zi(e.two.switches,e)),e}(Xi);const _i=function(e,t,n,a){const r=a.methods.one.setTag;"-"===e[t].post&&e[t+1]&&r([e[t],e[t+1]],"Hyphenated",a,null,"1-punct-hyphen''")},Yi=/^(under|over|mis|re|un|dis|semi)-?/,es=function(e,t,n){const a=n.two.switches,r=e[t];if(a.hasOwnProperty(r.normal))r.switch=a[r.normal];else if(Yi.test(r.normal)){const e=r.normal.replace(Yi,"");e.length>3&&a.hasOwnProperty(e)&&(r.switch=a[e])}},ts=function(e,t,n){if(!t||0===t.length)return;if(!0===e.frozen)return;const a="undefined"!=typeof process&&process.env?process.env:self.env||{};a&&a.DEBUG_TAGS&&((e,t,n="")=>{const a=e.text||"["+e.implicit+"]";var r;"string"!=typeof t&&t.length>2&&(t=t.slice(0,2).join(", #")+" +"),t="string"!=typeof t?t.join(", #"):t,console.log(` ${(r=a,"�[33m�[3m"+r+"�[0m").padEnd(24)} �[32m→�[0m #${t.padEnd(22)} ${(e=>"�[3m"+e+"�[0m")(n)}`)})(e,t,n),e.tags=e.tags||new Set,"string"==typeof t?e.tags.add(t):t.forEach((t=>e.tags.add(t)))},ns=["Acronym","Abbreviation","ProperNoun","Uncountable","Possessive","Pronoun","Activity","Honorific","Month"],as=function(e,t,n){const a=e[t],r=Array.from(a.tags);for(let e=0;ee.tags.has(t)))||(Mi(e.normal)?ts(e,"Plural","3-plural-guess"):ts(e,"Singular","3-singular-guess"))}(a),function(e){const t=e.tags;if(t.has("Verb")&&1===t.size){const t=ki(e.normal);t&&ts(e,t,"3-verb-tense-guess")}}(a)},rs=/^\p{Lu}[\p{Ll}'’]/u,os=/[0-9]/,is=["Date","Month","WeekDay","Unit","Expression"],ss=/[IVX]/,ls=/^[IVXLCDM]{2,}$/,us=/^M{0,4}(CM|CD|D?C{0,3})(XC|XL|L?X{0,3})(IX|IV|V?I{0,3})$/,cs={li:!0,dc:!0,md:!0,dm:!0,ml:!0},ds=function(e,t,n){const a=e[t];a.index=a.index||[0,0];const r=a.index[1],o=a.text||"";return 0!==r&&!0===rs.test(o)&&!1===os.test(o)?is.find((e=>a.tags.has(e)))||a.pre.match(/["']$/)||"the"===a.normal?null:(as(e,t,n),a.tags.has("Noun")||a.frozen||a.tags.clear(),ts(a,"ProperNoun","2-titlecase"),!0):o.length>=2&&ls.test(o)&&ss.test(o)&&us.test(o)&&!cs[a.normal]?(ts(a,"RomanNumeral","2-xvii"),!0):null},hs=function(e="",t=[]){const n=e.length;let a=7;n<=a&&(a=n-1);for(let r=a;r>1;r-=1){const a=e.substring(n-r,n);if(!0===t[a.length].hasOwnProperty(a)){return t[a.length][a]}}return null},gs=function(e,t,n){const a=e[t];if(0===a.tags.size){let e=hs(a.normal,n.two.suffixPatterns);if(null!==e)return ts(a,e,"2-suffix"),a.confidence=.7,!0;if(a.implicit&&(e=hs(a.implicit,n.two.suffixPatterns),null!==e))return ts(a,e,"2-implicit-suffix"),a.confidence=.7,!0}return null},ms=/['‘’‛‵′`´]/,ps=function(e,t){for(let n=0;nn-3&&(a=n-3);for(let n=a;n>2;n-=1){const a=e.substring(0,n);if(!0===t[a.length].hasOwnProperty(a))return t[a.length][a]}return null}(a.normal,n.two.prefixPatterns);if(null!==e)return ts(a,e,"2-prefix"),a.confidence=.5,!0}return null},ys=new Set(["in","on","by","until","for","to","during","throughout","through","within","before","after","of","this","next","last","circa","around","post","pre","budget","classic","plan","may"]),vs=function(e){if(!e)return!1;const t=e.normal||e.implicit;return!!ys.has(t)||(!!(e.tags.has("Date")||e.tags.has("Month")||e.tags.has("WeekDay")||e.tags.has("Year"))||!!e.tags.has("ProperNoun"))},ws=function(e){return!!e&&(!!e.tags.has("Ordinal")||(!!(e.tags.has("Cardinal")&&e.normal.length<3)||("is"===e.normal||"was"===e.normal)))},ks=function(e){return e&&(e.tags.has("Date")||e.tags.has("Month")||e.tags.has("WeekDay")||e.tags.has("Year"))},Ps=function(e,t){const n=e[t];if(n.tags.has("NumericValue")&&n.tags.has("Cardinal")&&4===n.normal.length){const a=Number(n.normal);if(a&&!isNaN(a)&&a>1400&&a<2100){const r=e[t-1],o=e[t+1];if(vs(r)||vs(o))return ts(n,"Year","2-tagYear");if(a>=1920&&a<2025){if(ws(r)||ws(o))return ts(n,"Year","2-tagYear-close");if(ks(e[t-2])||ks(e[t+2]))return ts(n,"Year","2-tagYear-far");if(r&&(r.tags.has("Determiner")||r.tags.has("Possessive"))&&o&&o.tags.has("Noun")&&!o.tags.has("Plural"))return ts(n,"Year","2-tagYear-noun")}}}return null},As=function(e,t,n,a){const r=a.methods.one.setTag,o=e[t],i=["PastTense","PresentTense","Auxiliary","Modal","Particle"];if(o.tags.has("Verb")){i.find((e=>o.tags.has(e)))||r([o],"Infinitive",a,null,"2-verb-type''")}},Cs=/^[A-Z]('s|,)?$/,js=/^[A-Z-]+$/,Ns=/^[A-Z]+s$/,Is=/([A-Z]\.)+[A-Z]?,?$/,Ds=/[A-Z]{2,}('s|,)?$/,Hs=/([a-z]\.)+[a-z]\.?$/,Gs={I:!0,A:!0},Ts={la:!0,ny:!0,us:!0,dc:!0,gb:!0},xs=function(e,t,n){const a=e[t];return a.tags.has("RomanNumeral")||a.tags.has("Acronym")||a.frozen?null:function(e,t){let n=e.text;if(!1===js.test(n)){if(!(n.length>3&&!0===Ns.test(n)))return!1;n=n.replace(/s$/,"")}return!(n.length>5||Gs.hasOwnProperty(n)||t.one.lexicon.hasOwnProperty(e.normal)||!0!==Is.test(n)&&!0!==Hs.test(n)&&!0!==Cs.test(n)&&!0!==Ds.test(n))}(a,n)?(a.tags.clear(),ts(a,["Acronym","Noun"],"3-no-period-acronym"),!0===Ts[a.normal]&&ts(a,"Place","3-place-acronym"),!0===Ns.test(a.text)&&ts(a,"Plural","3-plural-acronym"),!0):!Gs.hasOwnProperty(a.text)&&Cs.test(a.text)?(a.tags.clear(),ts(a,["Acronym","Noun"],"3-one-letter-acronym"),!0):a.tags.has("Organization")&&a.text.length<=3?(ts(a,"Acronym","3-org-acronym"),!0):a.tags.has("Organization")&&js.test(a.text)&&a.text.length<=6?(ts(a,"Acronym","3-titlecase-acronym"),!0):null},Es=function(e,t){if(!e)return null;const n=t.find((t=>e.normal===t[0]));return n?n[1]:null},Fs=function(e,t){if(!e)return null;const n=t.find((t=>e.tags.has(t[0])));return n?n[1]:null},Os=function(e,t,n){const{leftTags:a,leftWords:r,rightWords:o,rightTags:i}=n.two.neighbours,s=e[t];if(0===s.tags.size){let l=null;if(l=l||Es(e[t-1],r),l=l||Es(e[t+1],o),l=l||Fs(e[t-1],a),l=l||Fs(e[t+1],i),l)return ts(s,l,"3-[neighbour]"),as(e,t,n),e[t].confidence=.2,!0}return null},zs=function(e,t,n){return!!e&&(!e.tags.has("FirstName")&&!e.tags.has("Place")&&(!!(e.tags.has("ProperNoun")||e.tags.has("Organization")||e.tags.has("Acronym"))||!(n||(a=e.text,!/^\p{Lu}[\p{Ll}'’]/u.test(a)))&&(0!==t||e.tags.has("Singular"))));var a},Vs=function(e,t,n,a){const r=n.model.two.orgWords,o=n.methods.one.setTag,i=e[t];if(!0===r[i.machine||i.normal]&&zs(e[t-1],t-1,a)){o([e[t]],"Organization",n,null,"3-[org-word]");for(let r=t;r>=0&&zs(e[r],r,a);r-=1)o([e[r]],"Organization",n,null,"3-[org-word]")}return null},Bs=/'s$/,Ss=new Set(["athletic","city","community","eastern","federal","financial","great","historic","historical","local","memorial","municipal","national","northern","provincial","southern","state","western","spring","pine","sunset","view","oak","maple","spruce","cedar","willow"]),Ks=new Set(["center","centre","way","range","bar","bridge","field","pit"]),$s=function(e,t,n){if(!e)return!1;const a=e.tags;return!(a.has("Organization")||a.has("Possessive")||Bs.test(e.normal))&&(!(!a.has("ProperNoun")&&!a.has("Place"))||!(n||(r=e.text,!/^\p{Lu}[\p{Ll}'’]/u.test(r)))&&(0!==t||a.has("Singular")));var r},Ls=function(e,t,n,a){const r=n.model.two.placeWords,o=n.methods.one.setTag,i=e[t],s=i.machine||i.normal;if(!0===r[s]){for(let r=t-1;r>=0;r-=1)if(!Ss.has(e[r].normal)){if(!$s(e[r],r,a))break;o(e.slice(r,t+1),"Place",n,null,"3-[place-of-foo]")}if(Ks.has(s))return!1;for(let r=t+1;re[t].tags.has("ProperNoun")&&Js.test(e[t].text)?"Noun":null,Us=(e,t,n)=>0!==t||e[1]?null:n,qs={"Adj|Gerund":(e,t)=>Ws(e,t),"Adj|Noun":(e,t)=>Ws(e,t)||function(e,t){return!e[t+1]&&e[t-1]&&e[t-1].tags.has("Determiner")?"Noun":null}(e,t),"Actor|Verb":(e,t)=>Ws(e,t),"Adj|Past":(e,t)=>Ws(e,t),"Adj|Present":(e,t)=>Ws(e,t),"Noun|Gerund":(e,t)=>Ws(e,t),"Noun|Verb":(e,t)=>t>0&&Ws(e,t)||Us(e,t,"Infinitive"),"Plural|Verb":(e,t)=>Ws(e,t)||Us(e,t,"PresentTense")||function(e,t,n){return 0===t&&e.length>3?n:null}(e,t,"Plural"),"Person|Noun":(e,t)=>Ws(e,t),"Person|Verb":(e,t)=>0!==t?Ws(e,t):null,"Person|Adj":(e,t)=>0===t&&e.length>1||Ws(e,t)?"Person":null},Rs="undefined"!=typeof process&&process.env?process.env:self.env||{},Qs=/^(under|over|mis|re|un|dis|semi)-?/,Zs=(e,t)=>{if(!e||!t)return null;const n=e.normal||e.implicit;let a=null;return t.hasOwnProperty(n)&&(a=t[n]),a&&Rs.DEBUG_TAGS&&console.log(`\n �[2m�[3m ↓ - '${n}' �[0m`),a},Xs=(e,t={},n)=>{if(!e||!t)return null;const a=Array.from(e.tags).sort(((e,t)=>(n[e]?n[e].parents.length:0)>(n[t]?n[t].parents.length:0)?-1:1));let r=a.find((e=>t[e]));return r&&Rs.DEBUG_TAGS&&console.log(` �[2m�[3m ↓ - '${e.normal||e.implicit}' (#${r}) �[0m`),r=t[r],r},_s=function(e,t,n){const a=n.model,r=n.methods.one.setTag,{switches:o,clues:i}=a.two,s=e[t];let l=s.normal||s.implicit||"";if(Qs.test(l)&&!o[l]&&(l=l.replace(Qs,"")),s.switch){const o=s.switch;if(s.tags.has("Acronym")||s.tags.has("PhrasalVerb"))return;let u=function(e,t,n,a){if(!n)return null;const r="also"!==e[t-1]?.text?t-1:Math.max(0,t-2),o=a.one.tagSet;let i=Zs(e[t+1],n.afterWords);return i=i||Zs(e[r],n.beforeWords),i=i||Xs(e[r],n.beforeTags,o),i=i||Xs(e[t+1],n.afterTags,o),i}(e,t,i[o],a);qs[o]&&(u=qs[o](e,t)||u),u?(r([s],u,n,null,`3-[switch] (${o})`),as(e,t,a)):Rs.DEBUG_TAGS&&console.log(`\n -> X - '${l}' : (${o}) `)}},Ys={there:!0,this:!0,it:!0,him:!0,her:!0,us:!0},el=function(e){if(e.filter((e=>!e.tags.has("ProperNoun"))).length<=3)return!1;const t=/^[a-z]/;return e.every((e=>!t.test(e.text)))},tl=function(e,t,n,a){for(let r=0;r=2){if(e.length<4&&!Ys[e[1].normal])return;if(!r.tags.has("PhrasalVerb")&&a.hasOwnProperty(r.normal))return;(e[1].tags.has("Noun")||e[1].tags.has("Determiner"))&&(e.slice(1,3).some((e=>e.tags.has("Verb")))&&!r.tags.has("#PhrasalVerb")||n([r],"Imperative",t,null,"3-[imperative]"))}}(e,n)},al={Possessive:e=>{let t=e.machine||e.normal||e.text;return t=t.replace(/'s$/,""),t},Plural:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.noun.toSingular(n,t.model)},Copula:()=>"is",PastTense:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.verb.toInfinitive(n,t.model,"PastTense")},Gerund:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.verb.toInfinitive(n,t.model,"Gerund")},PresentTense:(e,t)=>{const n=e.machine||e.normal||e.text;return e.tags.has("Infinitive")?n:t.methods.two.transform.verb.toInfinitive(n,t.model,"PresentTense")},Comparative:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.adjective.fromComparative(n,t.model)},Superlative:(e,t)=>{const n=e.machine||e.normal||e.text;return t.methods.two.transform.adjective.fromSuperlative(n,t.model)},Adverb:(e,t)=>{const{fromAdverb:n}=t.methods.two.transform.adjective;return n(e.machine||e.normal||e.text)}},rl={Adverb:"RB",Comparative:"JJR",Superlative:"JJS",Adjective:"JJ",TO:"Conjunction",Modal:"MD",Auxiliary:"MD",Gerund:"VBG",PastTense:"VBD",Participle:"VBN",PresentTense:"VBZ",Infinitive:"VB",Particle:"RP",Verb:"VB",Pronoun:"PRP",Cardinal:"CD",Conjunction:"CC",Determiner:"DT",Preposition:"IN",QuestionWord:"WP",Expression:"UH",Possessive:"POS",ProperNoun:"NNP",Person:"NNP",Place:"NNP",Organization:"NNP",Singular:"NN",Plural:"NNS",Noun:"NN",There:"EX"};var ol={preTagger:function(e){const{methods:t,model:n,world:a}=e,r=e.docs;!function(e,t,n){e.forEach((e=>{!function(e,t,n,a){const r=a.methods.one.setTag;if(e.length>=3){const t=/:/;if(e[0].post.match(t)){const t=e[1];if(t.tags.has("Value")||t.tags.has("Email")||t.tags.has("PhoneNumber"))return;r([e[0]],"Expression",a,null,"2-punct-colon''")}}}(e,0,0,n)}))}(r,0,a);const o=t.two.quickSplit(r);for(let e=0;e{for(let a=0;a{e.forEach((e=>{e.penn=function(e){if(e.tags.has("ProperNoun")&&e.tags.has("Plural"))return"NNPS";if(e.tags.has("Possessive")&&e.tags.has("Pronoun"))return"PRP$";if("there"===e.normal)return"EX";if("to"===e.normal)return"TO";const t=e.tagRank||[];for(let e=0;e{e.implicit=e.normal,e.text="",e.normal=""}));for(let e=0;e(e.implicit=e.text,e.machine=e.text,e.pre="",e.post="",e.text="",e.normal="",e.index=[a,r+t],e))),n[0]&&(n[0].pre=e[a][r].pre,n[n.length-1].post=e[a][r].post,n[0].text=e[a][r].text,n[0].normal=e[a][r].normal),e[a].splice(r,1,...n))},fl=/'/,bl=new Set(["been","become"]),yl=new Set(["what","how","when","if","too"]),vl=new Set(["too","also","enough"]),wl=function(e,t){const n=e[t].normal.split(fl)[0];if("let"===n)return[n,"us"];if("there"===n){const a=e[t+1];if(a&&a.tags.has("Plural"))return[n,"are"]}return"has"===((e,t)=>{for(let n=t+1;n{for(let n=t+1;n0&&(n-=1),e[o]&&(o+=1),r.ptrs=[[0,n,o]],r.compute(["freeze","lexicon","preTagger","unfreeze"]),function(e){e.forEach(((e,t)=>{e.index&&(e.index[1]=t)}))}(e)},Tl={d:(e,t)=>Cl(e,t),t:(e,t)=>function(e,t){if("ain't"===e[t].normal||"aint"===e[t].normal){if(e[t+1]&&"never"===e[t+1].normal)return["have"];const n=function(e,t){for(let n=t-1;n>=0;n-=1)if(e[n].tags.has("Noun")||e[n].tags.has("Pronoun")||e[n].tags.has("Plural")||e[n].tags.has("Singular"))return e[n];return null}(e,t);if(n){if("we"===n.normal||"they"===n.normal)return["are","not"];if("i"===n.normal)return["am","not"];if(n.tags&&n.tags.has("Plural"))return["are","not"]}return["is","not"]}return[e[t].normal.replace(/n't/,""),"not"]}(e,t),s:(e,t,n)=>((e,t)=>{const n=e[t];if(jl.hasOwnProperty(n.machine||n.normal))return!1;if(n.tags.has("Possessive"))return!0;if(n.tags.has("QuestionWord"))return!1;if("he's"===n.normal||"she's"===n.normal)return!1;const a=e[t+1];if(!a)return!0;if("it's"===n.normal)return!!a.tags.has("#Noun");if("Noun|Gerund"==a.switch){const a=e[t+2];return a?!!a.tags.has("Copula")||("on"===a.normal||a.normal,!1):!(!n.tags.has("Actor")&&!n.tags.has("ProperNoun"))}if(a.tags.has("Verb"))return!!a.tags.has("Infinitive")||!a.tags.has("Gerund")&&!!a.tags.has("PresentTense");if("Adj|Noun"===a.switch){const n=e[t+2];if(!n)return!1;if(Dl.has(n.normal))return!0;if(Il.has(n.normal))return!1}if(a.tags.has("Noun")){const e=a.machine||a.normal;return!("here"===e||"there"===e||"everywhere"===e||a.tags.has("Possessive")||a.tags.has("ProperNoun")&&!n.tags.has("ProperNoun"))}if(e[t-1]&&!0===Nl[e[t-1].normal])return!0;if(a.tags.has("Adjective")){const n=e[t+2];if(!n)return!1;if(n.tags.has("Noun")&&!n.tags.has("Pronoun")){const e=a.normal;return"above"!==e&&"below"!==e&&"behind"!==e}return"Noun|Verb"===n.switch}return!!a.tags.has("Value")})(e,t)?n.methods.one.setTag([e[t]],"Possessive",n,null,"2-contraction"):wl(e,t)},xl=function(e,t){const n=t.fromText(e.join(" "));return n.compute("id"),n.docs[0]};var El={contractionTwo:e=>{const{world:t,document:n}=e;n.forEach(((a,r)=>{for(let o=a.length-1;o>=0;o-=1){if(a[o].implicit)continue;let i=null;!0===Hl.test(a[o].normal)&&(i=a[o].normal.split(Hl)[1]);let s=null;Tl.hasOwnProperty(i)&&(s=Tl[i](a,o,t)),s&&(s=xl(s,e),pl(n,[r,o],s),Gl(n[r],e,o,s.length))}}))}},Fl={compute:El,api:function(e){class Contractions extends e{constructor(e,t,n){super(e,t,n),this.viewType="Contraction"}expand(){return this.docs.forEach((e=>{const t=ml.test(e[0].text);e.forEach(((t,n)=>{t.text=t.implicit||"",delete t.implicit,ne.toUpperCase()))}(e[0].text))})),this.compute("normal"),this}}e.prototype.contractions=function(){const e=this.match("@hasContraction+");return new Contractions(this.document,e.pointer)},e.prototype.contract=gl},hooks:["contractionTwo"]};const Ol="(hard|fast|late|early|high|right|deep|close|direct)";const zl="(i|we|they)";const Vl=[].concat([{match:"(got|were|was|is|are|am) (#PastTense|#Participle)",tag:"Passive",reason:"got-walked"},{match:"(was|were|is|are|am) being (#PastTense|#Participle)",tag:"Passive",reason:"was-being"},{match:"(had|have|has) been (#PastTense|#Participle)",tag:"Passive",reason:"had-been"},{match:"will be being? (#PastTense|#Participle)",tag:"Passive",reason:"will-be-cleaned"},{match:"#Noun [(#PastTense|#Participle)] by (the|a) #Noun",group:0,tag:"Passive",reason:"suffered-by"}],[{match:"[(all|both)] #Determiner #Noun",group:0,tag:"Noun",reason:"all-noun"},{match:"#Copula [(just|alone)]$",group:0,tag:"Adjective",reason:"not-adverb"},{match:"#Singular is #Adverb? [#PastTense$]",group:0,tag:"Adjective",reason:"is-filled"},{match:"[#PastTense] #Singular is",group:0,tag:"Adjective",reason:"smoked-poutine"},{match:"[#PastTense] #Plural are",group:0,tag:"Adjective",reason:"baked-onions"},{match:"well [#PastTense]",group:0,tag:"Adjective",reason:"well-made"},{match:"#Copula [fucked up?]",group:0,tag:"Adjective",reason:"swears-adjective"},{match:"#Singular (seems|appears) #Adverb? [#PastTense$]",group:0,tag:"Adjective",reason:"seems-filled"},{match:"#Copula #Adjective? [(out|in|through)]$",group:0,tag:"Adjective",reason:"still-out"},{match:"^[#Adjective] (the|your) #Noun",group:0,notIf:"(all|even)",tag:"Infinitive",reason:"shut-the"},{match:"the [said] #Noun",group:0,tag:"Adjective",reason:"the-said-card"},{match:"[#Hyphenated (#Hyphenated && #PastTense)] (#Noun|#Conjunction)",group:0,tag:"Adjective",notIf:"#Adverb",reason:"faith-based"},{match:"[#Hyphenated (#Hyphenated && #Gerund)] (#Noun|#Conjunction)",group:0,tag:"Adjective",notIf:"#Adverb",reason:"self-driving"},{match:"[#PastTense (#Hyphenated && #PhrasalVerb)] (#Noun|#Conjunction)",group:0,tag:"Adjective",reason:"dammed-up"},{match:"(#Hyphenated && #Value) fold",tag:"Adjective",reason:"two-fold"},{match:"must (#Hyphenated && #Infinitive)",tag:"Adjective",reason:"must-win"},{match:"(#Hyphenated && #Infinitive) #Hyphenated",tag:"Adjective",notIf:"#PhrasalVerb",reason:"vacuum-sealed"},{match:"too much",tag:"Adverb Adjective",reason:"bit-4"},{match:"a bit much",tag:"Determiner Adverb Adjective",reason:"bit-3"},{match:"[(un|contra|extra|inter|intra|macro|micro|mid|mis|mono|multi|pre|sub|tri|ex)] #Adjective",group:0,tag:["Adjective","Prefix"],reason:"un-skilled"}],[{match:"#Adverb [#Adverb] (and|or|then)",group:0,tag:"Adjective",reason:"kinda-sparkly-and"},{match:"[(dark|bright|flat|light|soft|pale|dead|dim|faux|little|wee|sheer|most|near|good|extra|all)] #Adjective",group:0,tag:"Adverb",reason:"dark-green"},{match:"#Copula [far too] #Adjective",group:0,tag:"Adverb",reason:"far-too"},{match:"#Copula [still] (in|#Gerund|#Adjective)",group:0,tag:"Adverb",reason:"was-still-walking"},{match:`#Plural ${Ol}`,tag:"#PresentTense #Adverb",reason:"studies-hard"},{match:`#Verb [${Ol}] !#Noun?`,group:0,notIf:"(#Copula|get|got|getting|become|became|becoming|feel|feels|feeling|#Determiner|#Preposition)",tag:"Adverb",reason:"shops-direct"},{match:"[#Plural] a lot",tag:"PresentTense",reason:"studies-a-lot"}],[{match:"as [#Gerund] as",group:0,tag:"Adjective",reason:"as-gerund-as"},{match:"more [#Gerund] than",group:0,tag:"Adjective",reason:"more-gerund-than"},{match:"(so|very|extremely) [#Gerund]",group:0,tag:"Adjective",reason:"so-gerund"},{match:"(found|found) it #Adverb? [#Gerund]",group:0,tag:"Adjective",reason:"found-it-gerund"},{match:"a (little|bit|wee) bit? [#Gerund]",group:0,tag:"Adjective",reason:"a-bit-gerund"},{match:"#Gerund [#Gerund]",group:0,tag:"Adjective",notIf:"(impersonating|practicing|considering|assuming)",reason:"looking-annoying"},{match:"(looked|look|looks) #Adverb? [%Adj|Gerund%]",group:0,tag:"Adjective",notIf:"(impersonating|practicing|considering|assuming)",reason:"looked-amazing"},{match:"[%Adj|Gerund%] #Determiner",group:0,tag:"Gerund",reason:"developing-a"},{match:"#Possessive [%Adj|Gerund%] #Noun",group:0,tag:"Adjective",reason:"leading-manufacturer"},{match:"%Noun|Gerund% %Adj|Gerund%",tag:"Gerund #Adjective",reason:"meaning-alluring"},{match:"(face|embrace|reveal|stop|start|resume) %Adj|Gerund%",tag:"#PresentTense #Adjective",reason:"face-shocking"},{match:"(are|were) [%Adj|Gerund%] #Plural",group:0,tag:"Adjective",reason:"are-enduring-symbols"}],[{match:"#Determiner [#Adjective] #Copula",group:0,tag:"Noun",reason:"the-adj-is"},{match:"#Adjective [#Adjective] #Copula",group:0,tag:"Noun",reason:"adj-adj-is"},{match:"(his|its) [%Adj|Noun%]",group:0,tag:"Noun",notIf:"#Hyphenated",reason:"his-fine"},{match:"#Copula #Adverb? [all]",group:0,tag:"Noun",reason:"is-all"},{match:"(have|had) [#Adjective] #Preposition .",group:0,tag:"Noun",reason:"have-fun"},{match:"#Gerund (giant|capital|center|zone|application)",tag:"Noun",reason:"brewing-giant"},{match:"#Preposition (a|an) [#Adjective]$",group:0,tag:"Noun",reason:"an-instant"},{match:"no [#Adjective] #Modal",group:0,tag:"Noun",reason:"no-golden"},{match:"[brand #Gerund?] new",group:0,tag:"Adverb",reason:"brand-new"},{match:"(#Determiner|#Comparative|new|different) [kind]",group:0,tag:"Noun",reason:"some-kind"},{match:"#Possessive [%Adj|Noun%] #Noun",group:0,tag:"Adjective",reason:"her-favourite"},{match:"must && #Hyphenated .",tag:"Adjective",reason:"must-win"},{match:"#Determiner [#Adjective]$",tag:"Noun",notIf:"(this|that|#Comparative|#Superlative)",reason:"the-south"},{match:"(#Noun && #Hyphenated) (#Adjective && #Hyphenated)",tag:"Adjective",notIf:"(this|that|#Comparative|#Superlative)",reason:"company-wide"},{match:"#Determiner [#Adjective] (#Copula|#Determiner)",notIf:"(#Comparative|#Superlative)",group:0,tag:"Noun",reason:"the-poor"},{match:"[%Adj|Noun%] #Noun",notIf:"(#Pronoun|#ProperNoun)",group:0,tag:"Adjective",reason:"stable-foundations"}],[{match:"[still] #Adjective",group:0,tag:"Adverb",reason:"still-advb"},{match:"[still] #Verb",group:0,tag:"Adverb",reason:"still-verb"},{match:"[so] #Adjective",group:0,tag:"Adverb",reason:"so-adv"},{match:"[way] #Comparative",group:0,tag:"Adverb",reason:"way-adj"},{match:"[way] #Adverb #Adjective",group:0,tag:"Adverb",reason:"way-too-adj"},{match:"[all] #Verb",group:0,tag:"Adverb",reason:"all-verb"},{match:"#Verb [like]",group:0,notIf:"(#Modal|#PhrasalVerb)",tag:"Adverb",reason:"verb-like"},{match:"(barely|hardly) even",tag:"Adverb",reason:"barely-even"},{match:"[even] #Verb",group:0,tag:"Adverb",reason:"even-walk"},{match:"[even] #Comparative",group:0,tag:"Adverb",reason:"even-worse"},{match:"[even] (#Determiner|#Possessive)",group:0,tag:"#Adverb",reason:"even-the"},{match:"even left",tag:"#Adverb #Verb",reason:"even-left"},{match:"[way] #Adjective",group:0,tag:"#Adverb",reason:"way-over"},{match:"#PresentTense [(hard|quick|bright|slow|fast|backwards|forwards)]",notIf:"#Copula",group:0,tag:"Adverb",reason:"lazy-ly"},{match:"[much] #Adjective",group:0,tag:"Adverb",reason:"bit-1"},{match:"#Copula [#Adverb]$",group:0,tag:"Adjective",reason:"is-well"},{match:"a [(little|bit|wee) bit?] #Adjective",group:0,tag:"Adverb",reason:"a-bit-cold"},{match:"[(super|pretty)] #Adjective",group:0,tag:"Adverb",reason:"super-strong"},{match:"(become|fall|grow) #Adverb? [#PastTense]",group:0,tag:"Adjective",reason:"overly-weakened"},{match:"(a|an) #Adverb [#Participle] #Noun",group:0,tag:"Adjective",reason:"completely-beaten"},{match:"#Determiner #Adverb? [close]",group:0,tag:"Adjective",reason:"a-close"},{match:"#Gerund #Adverb? [close]",group:0,tag:"Adverb",notIf:"(getting|becoming|feeling)",reason:"being-close"},{match:"(the|those|these|a|an) [#Participle] #Noun",group:0,tag:"Adjective",reason:"blown-motor"},{match:"(#PresentTense|#PastTense) [back]",group:0,tag:"Adverb",notIf:"(#PhrasalVerb|#Copula)",reason:"charge-back"},{match:"#Verb [around]",group:0,tag:"Adverb",notIf:"#PhrasalVerb",reason:"send-around"},{match:"[later] #PresentTense",group:0,tag:"Adverb",reason:"later-say"},{match:"#Determiner [well] !#PastTense?",group:0,tag:"Noun",reason:"the-well"},{match:"#Adjective [enough]",group:0,tag:"Adverb",reason:"high-enough"}],[{match:"[sun] the #Ordinal",tag:"WeekDay",reason:"sun-the-5th"},{match:"[sun] #Date",group:0,tag:"WeekDay",reason:"sun-feb"},{match:"#Date (on|this|next|last|during)? [sun]",group:0,tag:"WeekDay",reason:"1pm-sun"},{match:"(in|by|before|during|on|until|after|of|within|all) [sat]",group:0,tag:"WeekDay",reason:"sat"},{match:"(in|by|before|during|on|until|after|of|within|all) [wed]",group:0,tag:"WeekDay",reason:"wed"},{match:"(in|by|before|during|on|until|after|of|within|all) [march]",group:0,tag:"Month",reason:"march"},{match:"[sat] #Date",group:0,tag:"WeekDay",reason:"sat-feb"},{match:"#Preposition [(march|may)]",group:0,tag:"Month",reason:"in-month"},{match:"(this|next|last) (march|may) !#Infinitive?",tag:"#Date #Month",reason:"this-month"},{match:"(march|may) the? #Value",tag:"#Month #Date #Date",reason:"march-5th"},{match:"#Value of? (march|may)",tag:"#Date #Date #Month",reason:"5th-of-march"},{match:"[(march|may)] .? #Date",group:0,tag:"Month",reason:"march-and-feb"},{match:"#Date .? [(march|may)]",group:0,tag:"Month",reason:"feb-and-march"},{match:"#Adverb [(march|may)]",group:0,tag:"Verb",reason:"quickly-march"},{match:"[(march|may)] #Adverb",group:0,tag:"Verb",reason:"march-quickly"},{match:"#Value (am|pm)",tag:"Time",reason:"2-am"}],[{match:"#Holiday (day|eve)",tag:"Holiday",reason:"holiday-day"},{match:"#Value of #Month",tag:"Date",reason:"value-of-month"},{match:"#Cardinal #Month",tag:"Date",reason:"cardinal-month"},{match:"#Month #Value to #Value",tag:"Date",reason:"value-to-value"},{match:"#Month the #Value",tag:"Date",reason:"month-the-value"},{match:"(#WeekDay|#Month) #Value",tag:"Date",reason:"date-value"},{match:"#Value (#WeekDay|#Month)",tag:"Date",reason:"value-date"},{match:"(#TextValue && #Date) #TextValue",tag:"Date",reason:"textvalue-date"},{match:"#Month #NumberRange",tag:"Date",reason:"aug 20-21"},{match:"#WeekDay #Month #Ordinal",tag:"Date",reason:"week mm-dd"},{match:"#Month #Ordinal #Cardinal",tag:"Date",reason:"mm-dd-yyy"},{match:"(#Place|#Demonmym|#Time) (standard|daylight|central|mountain)? time",tag:"Timezone",reason:"std-time"},{match:"(eastern|mountain|pacific|central|atlantic) (standard|daylight|summer)? time",tag:"Timezone",reason:"eastern-time"},{match:"#Time [(eastern|mountain|pacific|central|est|pst|gmt)]",group:0,tag:"Timezone",reason:"5pm-central"},{match:"(central|western|eastern) european time",tag:"Timezone",reason:"cet"}],[{match:"(the|any) [more]",group:0,tag:"Singular",reason:"more-noun"},{match:"[more] #Noun",group:0,tag:"Adjective",reason:"more-noun"},{match:"(right|rights) of .",tag:"Noun",reason:"right-of"},{match:"a [bit]",group:0,tag:"Singular",reason:"bit-2"},{match:"a [must]",group:0,tag:"Singular",reason:"must-2"},{match:"(we|us) [all]",group:0,tag:"Noun",reason:"we all"},{match:"due to [#Verb]",group:0,tag:"Noun",reason:"due-to"},{match:"some [#Verb] #Plural",group:0,tag:"Noun",reason:"determiner6"},{match:"#Possessive #Ordinal [#PastTense]",group:0,tag:"Noun",reason:"first-thought"},{match:"(the|this|those|these) #Adjective [%Verb|Noun%]",group:0,tag:"Noun",notIf:"#Copula",reason:"the-adj-verb"},{match:"(the|this|those|these) #Adverb #Adjective [#Verb]",group:0,tag:"Noun",reason:"determiner4"},{match:"the [#Verb] #Preposition .",group:0,tag:"Noun",reason:"determiner1"},{match:"(a|an|the) [#Verb] of",group:0,tag:"Noun",reason:"the-verb-of"},{match:"#Determiner #Noun of [#Verb]",group:0,tag:"Noun",notIf:"#Gerund",reason:"noun-of-noun"},{match:"#PastTense #Preposition [#PresentTense]",group:0,notIf:"#Gerund",tag:"Noun",reason:"ended-in-ruins"},{match:"#Conjunction [u]",group:0,tag:"Pronoun",reason:"u-pronoun-2"},{match:"[u] #Verb",group:0,tag:"Pronoun",reason:"u-pronoun-1"},{match:"#Determiner [(western|eastern|northern|southern|central)] #Noun",group:0,tag:"Noun",reason:"western-line"},{match:"(#Singular && @hasHyphen) #PresentTense",tag:"Noun",reason:"hyphen-verb"},{match:"is no [#Verb]",group:0,tag:"Noun",reason:"is-no-verb"},{match:"do [so]",group:0,tag:"Noun",reason:"so-noun"},{match:"#Determiner [(shit|damn|hell)]",group:0,tag:"Noun",reason:"swears-noun"},{match:"to [(shit|hell)]",group:0,tag:"Noun",reason:"to-swears"},{match:"(the|these) [#Singular] (were|are)",group:0,tag:"Plural",reason:"singular-were"},{match:"a #Noun+ or #Adverb+? [#Verb]",group:0,tag:"Noun",reason:"noun-or-noun"},{match:"(the|those|these|a|an) #Adjective? [#PresentTense #Particle?]",group:0,tag:"Noun",notIf:"(seem|appear|include|#Gerund|#Copula)",reason:"det-inf"},{match:"#Noun #Actor",tag:"Actor",notIf:"(#Person|#Pronoun)",reason:"thing-doer"},{match:"#Gerund #Actor",tag:"Actor",reason:"gerund-doer"},{match:"co #Singular",tag:"Actor",reason:"co-noun"},{match:"[#Noun+] #Actor",group:0,tag:"Actor",notIf:"(#Honorific|#Pronoun|#Possessive)",reason:"air-traffic-controller"},{match:"(urban|cardiac|cardiovascular|respiratory|medical|clinical|visual|graphic|creative|dental|exotic|fine|certified|registered|technical|virtual|professional|amateur|junior|senior|special|pharmaceutical|theoretical)+ #Noun? #Actor",tag:"Actor",reason:"fine-artist"},{match:"#Noun+ (coach|chef|king|engineer|fellow|personality|boy|girl|man|woman|master)",tag:"Actor",reason:"dance-coach"},{match:"chief . officer",tag:"Actor",reason:"chief-x-officer"},{match:"chief of #Noun+",tag:"Actor",reason:"chief-of-police"},{match:"senior? vice? president of #Noun+",tag:"Actor",reason:"president-of"},{match:"#Determiner [sun]",group:0,tag:"Singular",reason:"the-sun"},{match:"#Verb (a|an) [#Value]$",group:0,tag:"Singular",reason:"did-a-value"},{match:"the [(can|will|may)]",group:0,tag:"Singular",reason:"the can"},{match:"#FirstName #Acronym? (#Possessive && #LastName)",tag:"Possessive",reason:"name-poss"},{match:"#Organization+ #Possessive",tag:"Possessive",reason:"org-possessive"},{match:"#Place+ #Possessive",tag:"Possessive",reason:"place-possessive"},{match:"#Possessive #PresentTense #Particle?",notIf:"(#Gerund|her)",tag:"Noun",reason:"possessive-verb"},{match:"(my|our|their|her|his|its) [(#Plural && #Actor)] #Noun",tag:"Possessive",reason:"my-dads"},{match:"#Value of a [second]",group:0,unTag:"Value",tag:"Singular",reason:"10th-of-a-second"},{match:"#Value [seconds]",group:0,unTag:"Value",tag:"Plural",reason:"10-seconds"},{match:"in [#Infinitive]",group:0,tag:"Singular",reason:"in-age"},{match:"a [#Adjective] #Preposition",group:0,tag:"Noun",reason:"a-minor-in"},{match:"#Determiner [#Singular] said",group:0,tag:"Actor",reason:"the-actor-said"},{match:"#Determiner #Noun [(feel|sense|process|rush|side|bomb|bully|challenge|cover|crush|dump|exchange|flow|function|issue|lecture|limit|march|process)] !(#Preposition|to|#Adverb)?",group:0,tag:"Noun",reason:"the-noun-sense"},{match:"[#PresentTense] (of|by|for) (a|an|the) #Noun #Copula",group:0,tag:"Plural",reason:"photographs-of"},{match:"#Infinitive and [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"fight and win"},{match:"#Noun and [#Verb] and #Noun",group:0,tag:"Noun",reason:"peace-and-flowers"},{match:"the #Cardinal [%Adj|Noun%]",group:0,tag:"Noun",reason:"the-1992-classic"},{match:"#Copula the [%Adj|Noun%] #Noun",group:0,tag:"Adjective",reason:"the-premier-university"},{match:"i #Verb [me] #Noun",group:0,tag:"Possessive",reason:"scottish-me"},{match:"[#PresentTense] (music|class|lesson|night|party|festival|league|ceremony)",group:0,tag:"Noun",reason:"dance-music"},{match:"[wit] (me|it)",group:0,tag:"Presposition",reason:"wit-me"},{match:"#PastTense #Possessive [#Verb]",group:0,tag:"Noun",notIf:"(saw|made)",reason:"left-her-boots"},{match:"#Value [%Plural|Verb%]",group:0,tag:"Plural",notIf:"(one|1|a|an)",reason:"35-signs"},{match:"had [#PresentTense]",group:0,tag:"Noun",notIf:"(#Gerund|come|become)",reason:"had-time"},{match:"%Adj|Noun% %Noun|Verb%",tag:"#Adjective #Noun",notIf:"#ProperNoun #Noun",reason:"instant-access"},{match:"#Determiner [%Adj|Noun%] #Conjunction",group:0,tag:"Noun",reason:"a-rep-to"},{match:"#Adjective #Noun [%Plural|Verb%]$",group:0,tag:"Plural",notIf:"#Pronoun",reason:"near-death-experiences"},{match:"#Possessive #Noun [%Plural|Verb%]$",group:0,tag:"Plural",reason:"your-guild-colors"}],[{match:"(this|that|the|a|an) [#Gerund #Infinitive]",group:0,tag:"Singular",reason:"the-planning-process"},{match:"(that|the) [#Gerund #PresentTense]",group:0,ifNo:"#Copula",tag:"Plural",reason:"the-paving-stones"},{match:"#Determiner [#Gerund] #Noun",group:0,tag:"Adjective",reason:"the-gerund-noun"},{match:"#Pronoun #Infinitive [#Gerund] #PresentTense",group:0,tag:"Noun",reason:"tipping-sucks"},{match:"#Adjective [#Gerund]",group:0,tag:"Noun",notIf:"(still|even|just)",reason:"early-warning"},{match:"[#Gerund] #Adverb? not? #Copula",group:0,tag:"Activity",reason:"gerund-copula"},{match:"#Copula [(#Gerund|#Activity)] #Copula",group:0,tag:"Gerund",reason:"are-doing-is"},{match:"[#Gerund] #Modal",group:0,tag:"Activity",reason:"gerund-modal"},{match:"#Singular for [%Noun|Gerund%]",group:0,tag:"Gerund",reason:"noun-for-gerund"},{match:"#Comparative (for|at) [%Noun|Gerund%]",group:0,tag:"Gerund",reason:"better-for-gerund"},{match:"#PresentTense the [#Gerund]",group:0,tag:"Noun",reason:"keep-the-touching"}],[{match:"#Infinitive (this|that|the) [#Infinitive]",group:0,tag:"Noun",reason:"do-this-dance"},{match:"#Gerund #Determiner [#Infinitive]",group:0,tag:"Noun",reason:"running-a-show"},{match:"#Determiner (only|further|just|more|backward) [#Infinitive]",group:0,tag:"Noun",reason:"the-only-reason"},{match:"(the|this|a|an) [#Infinitive] #Adverb? #Verb",group:0,tag:"Noun",reason:"determiner5"},{match:"#Determiner #Adjective #Adjective? [#Infinitive]",group:0,tag:"Noun",reason:"a-nice-inf"},{match:"#Determiner #Demonym [#PresentTense]",group:0,tag:"Noun",reason:"mexican-train"},{match:"#Adjective #Noun+ [#Infinitive] #Copula",group:0,tag:"Noun",reason:"career-move"},{match:"at some [#Infinitive]",group:0,tag:"Noun",reason:"at-some-inf"},{match:"(go|goes|went) to [#Infinitive]",group:0,tag:"Noun",reason:"goes-to-verb"},{match:"(a|an) #Adjective? #Noun [#Infinitive] (#Preposition|#Noun)",group:0,notIf:"from",tag:"Noun",reason:"a-noun-inf"},{match:"(a|an) #Noun [#Infinitive]$",group:0,tag:"Noun",reason:"a-noun-inf2"},{match:"#Gerund #Adjective? for [#Infinitive]",group:0,tag:"Noun",reason:"running-for"},{match:"about [#Infinitive]",group:0,tag:"Singular",reason:"about-love"},{match:"#Plural on [#Infinitive]",group:0,tag:"Noun",reason:"on-stage"},{match:"any [#Infinitive]",group:0,tag:"Noun",reason:"any-charge"},{match:"no [#Infinitive]",group:0,tag:"Noun",reason:"no-doubt"},{match:"number of [#PresentTense]",group:0,tag:"Noun",reason:"number-of-x"},{match:"(taught|teaches|learns|learned) [#PresentTense]",group:0,tag:"Noun",reason:"teaches-x"},{match:"(try|use|attempt|build|make) [#Verb #Particle?]",notIf:"(#Copula|#Noun|sure|fun|up)",group:0,tag:"Noun",reason:"do-verb"},{match:"^[#Infinitive] (is|was)",group:0,tag:"Noun",reason:"checkmate-is"},{match:"#Infinitive much [#Infinitive]",group:0,tag:"Noun",reason:"get-much"},{match:"[cause] #Pronoun #Verb",group:0,tag:"Conjunction",reason:"cause-cuz"},{match:"the #Singular [#Infinitive] #Noun",group:0,tag:"Noun",notIf:"#Pronoun",reason:"cardio-dance"},{match:"#Determiner #Modal [#Noun]",group:0,tag:"PresentTense",reason:"should-smoke"},{match:"this [#Plural]",group:0,tag:"PresentTense",notIf:"(#Preposition|#Date)",reason:"this-verbs"},{match:"#Noun that [#Plural]",group:0,tag:"PresentTense",notIf:"(#Preposition|#Pronoun|way)",reason:"voice-that-rocks"},{match:"that [#Plural] to",group:0,tag:"PresentTense",notIf:"#Preposition",reason:"that-leads-to"},{match:"(let|make|made) (him|her|it|#Person|#Place|#Organization)+ [#Singular] (a|an|the|it)",group:0,tag:"Infinitive",reason:"let-him-glue"},{match:"#Verb (all|every|each|most|some|no) [#PresentTense]",notIf:"#Modal",group:0,tag:"Noun",reason:"all-presentTense"},{match:"(had|have|#PastTense) #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"better",reason:"adj-presentTense"},{match:"#Value #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"one-big-reason"},{match:"#PastTense #Adjective+ [#PresentTense]",group:0,tag:"Noun",notIf:"(#Copula|better)",reason:"won-wide-support"},{match:"(many|few|several|couple) [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"many-poses"},{match:"#Determiner #Adverb #Adjective [%Noun|Verb%]",group:0,tag:"Noun",notIf:"#Copula",reason:"very-big-dream"},{match:"from #Noun to [%Noun|Verb%]",group:0,tag:"Noun",reason:"start-to-finish"},{match:"(for|with|of) #Noun (and|or|not) [%Noun|Verb%]",group:0,tag:"Noun",notIf:"#Pronoun",reason:"for-food-and-gas"},{match:"#Adjective #Adjective [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"adorable-little-store"},{match:"#Gerund #Adverb? #Comparative [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"higher-costs"},{match:"(#Noun && @hasComma) #Noun (and|or) [#PresentTense]",group:0,tag:"Noun",notIf:"#Copula",reason:"noun-list"},{match:"(many|any|some|several) [#PresentTense] for",group:0,tag:"Noun",reason:"any-verbs-for"},{match:"to #PresentTense #Noun [#PresentTense] #Preposition",group:0,tag:"Noun",reason:"gas-exchange"},{match:"#PastTense (until|as|through|without) [#PresentTense]",group:0,tag:"Noun",reason:"waited-until-release"},{match:"#Gerund like #Adjective? [#PresentTense]",group:0,tag:"Plural",reason:"like-hot-cakes"},{match:"some #Adjective [#PresentTense]",group:0,tag:"Noun",reason:"some-reason"},{match:"for some [#PresentTense]",group:0,tag:"Noun",reason:"for-some-reason"},{match:"(same|some|the|that|a) kind of [#PresentTense]",group:0,tag:"Noun",reason:"some-kind-of"},{match:"(same|some|the|that|a) type of [#PresentTense]",group:0,tag:"Noun",reason:"some-type-of"},{match:"#Gerund #Adjective #Preposition [#PresentTense]",group:0,tag:"Noun",reason:"doing-better-for-x"},{match:"(get|got|have) #Comparative [#PresentTense]",group:0,tag:"Noun",reason:"got-better-aim"},{match:"whose [#PresentTense] #Copula",group:0,tag:"Noun",reason:"whos-name-was"},{match:"#PhrasalVerb #Particle #Preposition [#PresentTense]",group:0,tag:"Noun",reason:"given-up-on-x"},{match:"there (are|were) #Adjective? [#PresentTense]",group:0,tag:"Plural",reason:"there-are"},{match:"#Value [#PresentTense] of",group:0,notIf:"(one|1|#Copula|#Infinitive)",tag:"Plural",reason:"2-trains"},{match:"[#PresentTense] (are|were) #Adjective",group:0,tag:"Plural",reason:"compromises-are-possible"},{match:"^[(hope|guess|thought|think)] #Pronoun #Verb",group:0,tag:"Infinitive",reason:"suppose-i"},{match:"#Possessive #Adjective [#Verb]",group:0,tag:"Noun",notIf:"#Copula",reason:"our-full-support"},{match:"[(tastes|smells)] #Adverb? #Adjective",group:0,tag:"PresentTense",reason:"tastes-good"},{match:"#Copula #Gerund [#PresentTense] !by?",group:0,tag:"Noun",notIf:"going",reason:"ignoring-commute"},{match:"#Determiner #Adjective? [(shed|thought|rose|bid|saw|spelt)]",group:0,tag:"Noun",reason:"noun-past"},{match:"how to [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"how-to-noun"},{match:"which [%Noun|Verb%] #Noun",group:0,tag:"Infinitive",reason:"which-boost-it"},{match:"#Gerund [%Plural|Verb%]",group:0,tag:"Plural",reason:"asking-questions"},{match:"(ready|available|difficult|hard|easy|made|attempt|try) to [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"ready-to-noun"},{match:"(bring|went|go|drive|run|bike) to [%Noun|Verb%]",group:0,tag:"Noun",reason:"bring-to-noun"},{match:"#Modal #Noun [%Noun|Verb%]",group:0,tag:"Infinitive",reason:"would-you-look"},{match:"#Copula just [#Infinitive]",group:0,tag:"Noun",reason:"is-just-spam"},{match:"^%Noun|Verb% %Plural|Verb%",tag:"Imperative #Plural",reason:"request-copies"},{match:"#Adjective #Plural and [%Plural|Verb%]",group:0,tag:"#Plural",reason:"pickles-and-drinks"},{match:"#Determiner #Year [#Verb]",group:0,tag:"Noun",reason:"the-1968-film"},{match:"#Determiner [#PhrasalVerb #Particle]",group:0,tag:"Noun",reason:"the-break-up"},{match:"#Determiner [%Adj|Noun%] #Noun",group:0,tag:"Adjective",notIf:"(#Pronoun|#Possessive|#ProperNoun)",reason:"the-individual-goals"},{match:"[%Noun|Verb%] or #Infinitive",group:0,tag:"Infinitive",reason:"work-or-prepare"},{match:"to #Infinitive [#PresentTense]",group:0,tag:"Noun",notIf:"(#Gerund|#Copula|help)",reason:"to-give-thanks"},{match:"[#Noun] me",group:0,tag:"Verb",reason:"kills-me"},{match:"%Plural|Verb% %Plural|Verb%",tag:"#PresentTense #Plural",reason:"removes-wrinkles"}],[{match:"#Money and #Money #Currency?",tag:"Money",reason:"money-and-money"},{match:"#Value #Currency [and] #Value (cents|ore|centavos|sens)",group:0,tag:"money",reason:"and-5-cents"},{match:"#Value (mark|rand|won|rub|ore)",tag:"#Money #Currency",reason:"4-mark"},{match:"a pound",tag:"#Money #Unit",reason:"a-pound"},{match:"#Value (pound|pounds)",tag:"#Money #Unit",reason:"4-pounds"}],[{match:"[(half|quarter)] of? (a|an)",group:0,tag:"Fraction",reason:"millionth"},{match:"#Adverb [half]",group:0,tag:"Fraction",reason:"nearly-half"},{match:"[half] the",group:0,tag:"Fraction",reason:"half-the"},{match:"#Cardinal and a half",tag:"Fraction",reason:"and-a-half"},{match:"#Value (halves|halfs|quarters)",tag:"Fraction",reason:"two-halves"},{match:"a #Ordinal",tag:"Fraction",reason:"a-quarter"},{match:"[#Cardinal+] (#Fraction && /s$/)",tag:"Fraction",reason:"seven-fifths"},{match:"[#Cardinal+ #Ordinal] of .",group:0,tag:"Fraction",reason:"ordinal-of"},{match:"[(#NumericValue && #Ordinal)] of .",group:0,tag:"Fraction",reason:"num-ordinal-of"},{match:"(a|one) #Cardinal?+ #Ordinal",tag:"Fraction",reason:"a-ordinal"},{match:"#Cardinal+ out? of every? #Cardinal",tag:"Fraction",reason:"out-of"}],[{match:"#Cardinal [second]",tag:"Unit",reason:"one-second"},{match:"!once? [(a|an)] (#Duration|hundred|thousand|million|billion|trillion)",group:0,tag:"Value",reason:"a-is-one"},{match:"1 #Value #PhoneNumber",tag:"PhoneNumber",reason:"1-800-Value"},{match:"#NumericValue #PhoneNumber",tag:"PhoneNumber",reason:"(800) PhoneNumber"},{match:"#Demonym #Currency",tag:"Currency",reason:"demonym-currency"},{match:"#Value [(buck|bucks|grand)]",group:0,tag:"Currency",reason:"value-bucks"},{match:"[#Value+] #Currency",group:0,tag:"Money",reason:"15 usd"},{match:"[second] #Noun",group:0,tag:"Ordinal",reason:"second-noun"},{match:"#Value+ [#Currency]",group:0,tag:"Unit",reason:"5-yan"},{match:"#Value [(foot|feet)]",group:0,tag:"Unit",reason:"foot-unit"},{match:"#Value [#Abbreviation]",group:0,tag:"Unit",reason:"value-abbr"},{match:"#Value [k]",group:0,tag:"Unit",reason:"value-k"},{match:"#Unit an hour",tag:"Unit",reason:"unit-an-hour"},{match:"(minus|negative) #Value",tag:"Value",reason:"minus-value"},{match:"#Value (point|decimal) #Value",tag:"Value",reason:"value-point-value"},{match:"#Determiner [(half|quarter)] #Ordinal",group:0,tag:"Value",reason:"half-ordinal"},{match:"#Multiple+ and #Value",tag:"Value",reason:"magnitude-and-value"},{match:"#Value #Unit [(per|an) (hr|hour|sec|second|min|minute)]",group:0,tag:"Unit",reason:"12-miles-per-second"},{match:"#Value [(square|cubic)] #Unit",group:0,tag:"Unit",reason:"square-miles"}],[{match:"#Copula [(#Noun|#PresentTense)] #LastName",group:0,tag:"FirstName",reason:"copula-noun-lastname"},{match:"(sister|pope|brother|father|aunt|uncle|grandpa|grandfather|grandma) #ProperNoun",tag:"Person",reason:"lady-titlecase",safe:!0},{match:"#FirstName [#Determiner #Noun] #LastName",group:0,tag:"Person",reason:"first-noun-last"},{match:"#ProperNoun (b|c|d|e|f|g|h|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z) #ProperNoun",tag:"Person",reason:"titlecase-acronym-titlecase",safe:!0},{match:"#Acronym #LastName",tag:"Person",reason:"acronym-lastname",safe:!0},{match:"#Person (jr|sr|md)",tag:"Person",reason:"person-honorific"},{match:"#Honorific #Acronym",tag:"Person",reason:"Honorific-TitleCase"},{match:"#Person #Person the? #RomanNumeral",tag:"Person",reason:"roman-numeral"},{match:"#FirstName [/^[^aiurck]$/]",group:0,tag:["Acronym","Person"],reason:"john-e"},{match:"#Noun van der? #Noun",tag:"Person",reason:"van der noun",safe:!0},{match:"(king|queen|prince|saint|lady) of #Noun",tag:"Person",reason:"king-of-noun",safe:!0},{match:"(prince|lady) #Place",tag:"Person",reason:"lady-place"},{match:"(king|queen|prince|saint) #ProperNoun",tag:"Person",notIf:"#Place",reason:"saint-foo"},{match:"al (#Person|#ProperNoun)",tag:"Person",reason:"al-borlen",safe:!0},{match:"#FirstName de #Noun",tag:"Person",reason:"bill-de-noun"},{match:"#FirstName (bin|al) #Noun",tag:"Person",reason:"bill-al-noun"},{match:"#FirstName #Acronym #ProperNoun",tag:"Person",reason:"bill-acronym-title"},{match:"#FirstName #FirstName #ProperNoun",tag:"Person",reason:"bill-firstname-title"},{match:"#Honorific #FirstName? #ProperNoun",tag:"Person",reason:"dr-john-Title"},{match:"#FirstName the #Adjective",tag:"Person",reason:"name-the-great"},{match:"#ProperNoun (van|al|bin) #ProperNoun",tag:"Person",reason:"title-van-title",safe:!0},{match:"#ProperNoun (de|du) la? #ProperNoun",tag:"Person",notIf:"#Place",reason:"title-de-title"},{match:"#Singular #Acronym #LastName",tag:"#FirstName #Person .",reason:"title-acro-noun",safe:!0},{match:"[#ProperNoun] #Person",group:0,tag:"Person",reason:"proper-person",safe:!0},{match:"#Person [#ProperNoun #ProperNoun]",group:0,tag:"Person",notIf:"#Possessive",reason:"three-name-person",safe:!0},{match:"#FirstName #Acronym? [#ProperNoun]",group:0,tag:"LastName",notIf:"#Possessive",reason:"firstname-titlecase"},{match:"#FirstName [#FirstName]",group:0,tag:"LastName",reason:"firstname-firstname"},{match:"#FirstName #Acronym #Noun",tag:"Person",reason:"n-acro-noun",safe:!0},{match:"#FirstName [(de|di|du|van|von)] #Person",group:0,tag:"LastName",reason:"de-firstname"},{match:"[(lieutenant|corporal|sergeant|captain|qeen|king|admiral|major|colonel|marshal|president|queen|king)+] #ProperNoun",group:0,tag:"Honorific",reason:"seargeant-john"},{match:"[(private|general|major|rear|prime|field|count|miss)] #Honorific? #Person",group:0,tag:["Honorific","Person"],reason:"ambg-honorifics"},{match:"#Honorific #FirstName [#Singular]",group:0,tag:"LastName",notIf:"#Possessive",reason:"dr-john-foo",safe:!0},{match:"[(his|her) (majesty|honour|worship|excellency|honorable)] #Person",group:0,tag:"Honorific",reason:"his-excellency"},{match:"#Honorific #Actor",tag:"Honorific",reason:"Lieutenant colonel"},{match:"(first|second|third|1st|2nd|3rd) #Actor",tag:"Honorific",reason:"first lady"},{match:"#Person #RomanNumeral",tag:"Person",reason:"louis-IV"}],[{match:"#FirstName #Noun$",tag:". #LastName",notIf:"(#Possessive|#Organization|#Place|#Pronoun|@hasTitleCase)",reason:"firstname-noun"},{match:"%Person|Date% #Acronym? #ProperNoun",tag:"Person",reason:"jan-thierson"},{match:"%Person|Noun% #Acronym? #ProperNoun",tag:"Person",reason:"switch-person",safe:!0},{match:"%Person|Noun% #Organization",tag:"Organization",reason:"olive-garden"},{match:"%Person|Verb% #Acronym? #ProperNoun",tag:"Person",reason:"verb-propernoun",ifNo:"#Actor"},{match:"[%Person|Verb%] (will|had|has|said|says|told|did|learned|wants|wanted)",group:0,tag:"Person",reason:"person-said"},{match:"[%Person|Place%] (harbor|harbour|pier|town|city|place|dump|landfill)",group:0,tag:"Place",reason:"sydney-harbour"},{match:"(west|east|north|south) [%Person|Place%]",group:0,tag:"Place",reason:"east-sydney"},{match:"#Modal [%Person|Verb%]",group:0,tag:"Verb",reason:"would-mark"},{match:"#Adverb [%Person|Verb%]",group:0,tag:"Verb",reason:"really-mark"},{match:"[%Person|Verb%] (#Adverb|#Comparative)",group:0,tag:"Verb",reason:"drew-closer"},{match:"%Person|Verb% #Person",tag:"Person",reason:"rob-smith"},{match:"%Person|Verb% #Acronym #ProperNoun",tag:"Person",reason:"rob-a-smith"},{match:"[will] #Verb",group:0,tag:"Modal",reason:"will-verb"},{match:"(will && @isTitleCase) #ProperNoun",tag:"Person",reason:"will-name"},{match:"(#FirstName && !#Possessive) [#Singular] #Verb",group:0,safe:!0,tag:"LastName",reason:"jack-layton"},{match:"^[#Singular] #Person #Verb",group:0,safe:!0,tag:"Person",reason:"sherwood-anderson"},{match:"(a|an) [#Person]$",group:0,unTag:"Person",reason:"a-warhol"}],[{match:"#Copula (pretty|dead|full|well|sure) (#Adjective|#Noun)",tag:"#Copula #Adverb #Adjective",reason:"sometimes-adverb"},{match:"(#Pronoun|#Person) (had|#Adverb)? [better] #PresentTense",group:0,tag:"Modal",reason:"i-better"},{match:"(#Modal|i|they|we|do) not? [like]",group:0,tag:"PresentTense",reason:"modal-like"},{match:"#Noun #Adverb? [left]",group:0,tag:"PastTense",reason:"left-verb"},{match:"will #Adverb? not? #Adverb? [be] #Gerund",group:0,tag:"Copula",reason:"will-be-copula"},{match:"will #Adverb? not? #Adverb? [be] #Adjective",group:0,tag:"Copula",reason:"be-copula"},{match:"[march] (up|down|back|toward)",notIf:"#Date",group:0,tag:"Infinitive",reason:"march-to"},{match:"#Modal [march]",group:0,tag:"Infinitive",reason:"must-march"},{match:"[may] be",group:0,tag:"Verb",reason:"may-be"},{match:"[(subject|subjects|subjected)] to",group:0,tag:"Verb",reason:"subject to"},{match:"[home] to",group:0,tag:"PresentTense",reason:"home to"},{match:"[open] #Determiner",group:0,tag:"Infinitive",reason:"open-the"},{match:"(were|was) being [#PresentTense]",group:0,tag:"PastTense",reason:"was-being"},{match:"(had|has|have) [been /en$/]",group:0,tag:"Auxiliary Participle",reason:"had-been-broken"},{match:"(had|has|have) [been /ed$/]",group:0,tag:"Auxiliary PastTense",reason:"had-been-smoked"},{match:"(had|has) #Adverb? [been] #Adverb? #PastTense",group:0,tag:"Auxiliary",reason:"had-been-adj"},{match:"(had|has) to [#Noun] (#Determiner|#Possessive)",group:0,tag:"Infinitive",reason:"had-to-noun"},{match:"have [#PresentTense]",group:0,tag:"PastTense",notIf:"(come|gotten)",reason:"have-read"},{match:"(does|will|#Modal) that [work]",group:0,tag:"PastTense",reason:"does-that-work"},{match:"[(sound|sounds)] #Adjective",group:0,tag:"PresentTense",reason:"sounds-fun"},{match:"[(look|looks)] #Adjective",group:0,tag:"PresentTense",reason:"looks-good"},{match:"[(start|starts|stop|stops|begin|begins)] #Gerund",group:0,tag:"Verb",reason:"starts-thinking"},{match:"(have|had) read",tag:"Modal #PastTense",reason:"read-read"},{match:"(is|was|were) [(under|over) #PastTense]",group:0,tag:"Adverb Adjective",reason:"was-under-cooked"},{match:"[shit] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear1-verb"},{match:"[damn] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear2-verb"},{match:"[fuck] (#Determiner|#Possessive|them)",group:0,tag:"Verb",reason:"swear3-verb"},{match:"#Plural that %Noun|Verb%",tag:". #Preposition #Infinitive",reason:"jobs-that-work"},{match:"[works] for me",group:0,tag:"PresentTense",reason:"works-for-me"},{match:"as #Pronoun [please]",group:0,tag:"Infinitive",reason:"as-we-please"},{match:"[(co|mis|de|inter|intra|pre|re|un|out|under|over|counter)] #Verb",group:0,tag:["Verb","Prefix"],notIf:"(#Copula|#PhrasalVerb)",reason:"co-write"},{match:"#PastTense and [%Adj|Past%]",group:0,tag:"PastTense",reason:"dressed-and-left"},{match:"[%Adj|Past%] and #PastTense",group:0,tag:"PastTense",reason:"dressed-and-left"},{match:"#Copula #Pronoun [%Adj|Past%]",group:0,tag:"Adjective",reason:"is-he-stoked"},{match:"to [%Noun|Verb%] #Preposition",group:0,tag:"Infinitive",reason:"to-dream-of"}],[{match:"(slowly|quickly) [#Adjective]",group:0,tag:"Verb",reason:"slowly-adj"},{match:"does (#Adverb|not)? [#Adjective]",group:0,tag:"PresentTense",reason:"does-mean"},{match:"[(fine|okay|cool|ok)] by me",group:0,tag:"Adjective",reason:"okay-by-me"},{match:"i (#Adverb|do)? not? [mean]",group:0,tag:"PresentTense",reason:"i-mean"},{match:"will #Adjective",tag:"Auxiliary Infinitive",reason:"will-adj"},{match:"#Pronoun [#Adjective] #Determiner #Adjective? #Noun",group:0,tag:"Verb",reason:"he-adj-the"},{match:"#Copula [%Adj|Present%] to #Verb",group:0,tag:"Verb",reason:"adj-to"},{match:"#Copula [#Adjective] (well|badly|quickly|slowly)",group:0,tag:"Verb",reason:"done-well"},{match:"#Adjective and [#Gerund] !#Preposition?",group:0,tag:"Adjective",reason:"rude-and-x"},{match:"#Copula #Adverb? (over|under) [#PastTense]",group:0,tag:"Adjective",reason:"over-cooked"},{match:"#Copula #Adjective+ (and|or) [#PastTense]$",group:0,tag:"Adjective",reason:"bland-and-overcooked"},{match:"got #Adverb? [#PastTense] of",group:0,tag:"Adjective",reason:"got-tired-of"},{match:"(seem|seems|seemed|appear|appeared|appears|feel|feels|felt|sound|sounds|sounded) (#Adverb|#Adjective)? [#PastTense]",group:0,tag:"Adjective",reason:"felt-loved"},{match:"(seem|feel|seemed|felt) [#PastTense #Particle?]",group:0,tag:"Adjective",reason:"seem-confused"},{match:"a (bit|little|tad) [#PastTense #Particle?]",group:0,tag:"Adjective",reason:"a-bit-confused"},{match:"not be [%Adj|Past% #Particle?]",group:0,tag:"Adjective",reason:"do-not-be-confused"},{match:"#Copula just [%Adj|Past% #Particle?]",group:0,tag:"Adjective",reason:"is-just-right"},{match:"as [#Infinitive] as",group:0,tag:"Adjective",reason:"as-pale-as"},{match:"[%Adj|Past%] and #Adjective",group:0,tag:"Adjective",reason:"faled-and-oppressive"},{match:"or [#PastTense] #Noun",group:0,tag:"Adjective",notIf:"(#Copula|#Pronoun)",reason:"or-heightened-emotion"},{match:"(become|became|becoming|becomes) [#Verb]",group:0,tag:"Adjective",reason:"become-verb"},{match:"#Possessive [#PastTense] #Noun",group:0,tag:"Adjective",reason:"declared-intentions"},{match:"#Copula #Pronoun [%Adj|Present%]",group:0,tag:"Adjective",reason:"is-he-cool"},{match:"#Copula [%Adj|Past%] with",group:0,tag:"Adjective",notIf:"(associated|worn|baked|aged|armed|bound|fried|loaded|mixed|packed|pumped|filled|sealed)",reason:"is-crowded-with"},{match:"#Copula #Adverb? [%Adj|Present%]$",group:0,tag:"Adjective",reason:"was-empty$"}],[{match:"will (#Adverb|not)+? [have] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"will-have-vb"},{match:"[#Copula] (#Adverb|not)+? (#Gerund|#PastTense)",group:0,tag:"Auxiliary",reason:"copula-walking"},{match:"[(#Modal|did)+] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"modal-verb"},{match:"#Modal (#Adverb|not)+? [have] (#Adverb|not)+? [had] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"would-have"},{match:"[(has|had)] (#Adverb|not)+? #PastTense",group:0,tag:"Auxiliary",reason:"had-walked"},{match:"[(do|does|did|will|have|had|has|got)] (not|#Adverb)+? #Verb",group:0,tag:"Auxiliary",reason:"have-had"},{match:"[about to] #Adverb? #Verb",group:0,tag:["Auxiliary","Verb"],reason:"about-to"},{match:"#Modal (#Adverb|not)+? [be] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"would-be"},{match:"[(#Modal|had|has)] (#Adverb|not)+? [been] (#Adverb|not)+? #Verb",group:0,tag:"Auxiliary",reason:"had-been"},{match:"[(be|being|been)] #Participle",group:0,tag:"Auxiliary",reason:"being-driven"},{match:"[may] #Adverb? #Infinitive",group:0,tag:"Auxiliary",reason:"may-want"},{match:"#Copula (#Adverb|not)+? [(be|being|been)] #Adverb+? #PastTense",group:0,tag:"Auxiliary",reason:"being-walked"},{match:"will [be] #PastTense",group:0,tag:"Auxiliary",reason:"will-be-x"},{match:"[(be|been)] (#Adverb|not)+? #Gerund",group:0,tag:"Auxiliary",reason:"been-walking"},{match:"[used to] #PresentTense",group:0,tag:"Auxiliary",reason:"used-to-walk"},{match:"#Copula (#Adverb|not)+? [going to] #Adverb+? #PresentTense",group:0,tag:"Auxiliary",reason:"going-to-walk"},{match:"#Imperative [(me|him|her)]",group:0,tag:"Reflexive",reason:"tell-him"},{match:"(is|was) #Adverb? [no]",group:0,tag:"Negative",reason:"is-no"},{match:"[(been|had|became|came)] #PastTense",group:0,notIf:"#PhrasalVerb",tag:"Auxiliary",reason:"been-told"},{match:"[(being|having|getting)] #Verb",group:0,tag:"Auxiliary",reason:"being-born"},{match:"[be] #Gerund",group:0,tag:"Auxiliary",reason:"be-walking"},{match:"[better] #PresentTense",group:0,tag:"Modal",notIf:"(#Copula|#Gerund)",reason:"better-go"},{match:"even better",tag:"Adverb #Comparative",reason:"even-better"}],[{match:"(#Verb && @hasHyphen) up",tag:"PhrasalVerb",reason:"foo-up"},{match:"(#Verb && @hasHyphen) off",tag:"PhrasalVerb",reason:"foo-off"},{match:"(#Verb && @hasHyphen) over",tag:"PhrasalVerb",reason:"foo-over"},{match:"(#Verb && @hasHyphen) out",tag:"PhrasalVerb",reason:"foo-out"},{match:"[#Verb (in|out|up|down|off|back)] (on|in)",notIf:"#Copula",tag:"PhrasalVerb Particle",reason:"walk-in-on"},{match:"(lived|went|crept|go) [on] for",group:0,tag:"PhrasalVerb",reason:"went-on"},{match:"#Verb (up|down|in|on|for)$",tag:"PhrasalVerb #Particle",notIf:"#PhrasalVerb",reason:"come-down$"},{match:"help [(stop|end|make|start)]",group:0,tag:"Infinitive",reason:"help-stop"},{match:"#PhrasalVerb (in && #Particle) #Determiner",tag:"#Verb #Preposition #Determiner",unTag:"PhrasalVerb",reason:"work-in-the"},{match:"[(stop|start|finish|help)] #Gerund",group:0,tag:"Infinitive",reason:"start-listening"},{match:"#Verb (him|her|it|us|himself|herself|itself|everything|something) [(up|down)]",group:0,tag:"Adverb",reason:"phrasal-pronoun-advb"}],[{match:"^do not? [#Infinitive #Particle?]",notIf:zl,group:0,tag:"Imperative",reason:"do-eat"},{match:"^please do? not? [#Infinitive #Particle?]",group:0,tag:"Imperative",reason:"please-go"},{match:"^just do? not? [#Infinitive #Particle?]",group:0,tag:"Imperative",reason:"just-go"},{match:"^[#Infinitive] it #Comparative",notIf:zl,group:0,tag:"Imperative",reason:"do-it-better"},{match:"^[#Infinitive] it (please|now|again|plz)",notIf:zl,group:0,tag:"Imperative",reason:"do-it-please"},{match:"^[#Infinitive] (#Adjective|#Adverb)$",group:0,tag:"Imperative",notIf:"(so|such|rather|enough)",reason:"go-quickly"},{match:"^[#Infinitive] (up|down|over) #Determiner",group:0,tag:"Imperative",reason:"turn-down"},{match:"^[#Infinitive] (your|my|the|a|an|any|each|every|some|more|with|on)",group:0,notIf:"like",tag:"Imperative",reason:"eat-my-shorts"},{match:"^[#Infinitive] (him|her|it|us|me|there)",group:0,tag:"Imperative",reason:"tell-him"},{match:"^[#Infinitive] #Adjective #Noun$",group:0,tag:"Imperative",reason:"avoid-loud-noises"},{match:"^[#Infinitive] (#Adjective|#Adverb)? and #Infinitive",group:0,tag:"Imperative",reason:"call-and-reserve"},{match:"^(go|stop|wait|hurry) please?$",tag:"Imperative",reason:"go"},{match:"^(somebody|everybody) [#Infinitive]",group:0,tag:"Imperative",reason:"somebody-call"},{match:"^let (us|me) [#Infinitive]",group:0,tag:"Imperative",reason:"lets-leave"},{match:"^[(shut|close|open|start|stop|end|keep)] #Determiner #Noun",group:0,tag:"Imperative",reason:"shut-the-door"},{match:"^[#PhrasalVerb #Particle] #Determiner #Noun",group:0,tag:"Imperative",reason:"turn-off-the-light"},{match:"^[go] to .",group:0,tag:"Imperative",reason:"go-to-toronto"},{match:"^#Modal you [#Infinitive]",group:0,tag:"Imperative",reason:"would-you-"},{match:"^never [#Infinitive]",group:0,tag:"Imperative",reason:"never-stop"},{match:"^come #Infinitive",tag:"Imperative",notIf:"on",reason:"come-have"},{match:"^come and? #Infinitive",tag:"Imperative . Imperative",notIf:"#PhrasalVerb",reason:"come-and-have"},{match:"^stay (out|away|back)",tag:"Imperative",reason:"stay-away"},{match:"^[(stay|be|keep)] #Adjective",group:0,tag:"Imperative",reason:"stay-cool"},{match:"^[keep it] #Adjective",group:0,tag:"Imperative",reason:"keep-it-cool"},{match:"^do not [#Infinitive]",group:0,tag:"Imperative",reason:"do-not-be"},{match:"[#Infinitive] (yourself|yourselves)",group:0,tag:"Imperative",reason:"allow-yourself"},{match:"[#Infinitive] what .",group:0,tag:"Imperative",reason:"look-what"},{match:"^[#Infinitive] #Gerund",group:0,tag:"Imperative",reason:"keep-playing"},{match:"^[#Infinitive] (to|for|into|toward|here|there)",group:0,tag:"Imperative",reason:"go-to"},{match:"^[#Infinitive] (and|or) #Infinitive",group:0,tag:"Imperative",reason:"inf-and-inf"},{match:"^[%Noun|Verb%] to",group:0,tag:"Imperative",reason:"commit-to"},{match:"^[#Infinitive] #Adjective? #Singular #Singular",group:0,tag:"Imperative",reason:"maintain-eye-contact"},{match:"do not (forget|omit|neglect) to [#Infinitive]",group:0,tag:"Imperative",reason:"do-not-forget"},{match:"^[(ask|wear|pay|look|help|show|watch|act|fix|kill|stop|start|turn|try|win)] #Noun",group:0,tag:"Imperative",reason:"pay-attention"}],[{match:"(that|which) were [%Adj|Gerund%]",group:0,tag:"Gerund",reason:"that-were-growing"},{match:"#Gerund [#Gerund] #Plural",group:0,tag:"Adjective",reason:"hard-working-fam"}],[{match:"u r",tag:"#Pronoun #Copula",reason:"u r"},{match:"#Noun [(who|whom)]",group:0,tag:"Determiner",reason:"captain-who"},{match:"[had] #Noun+ #PastTense",group:0,tag:"Condition",reason:"had-he"},{match:"[were] #Noun+ to #Infinitive",group:0,tag:"Condition",reason:"were-he"},{match:"some sort of",tag:"Adjective Noun Conjunction",reason:"some-sort-of"},{match:"of some sort",tag:"Conjunction Adjective Noun",reason:"of-some-sort"},{match:"[such] (a|an|is)? #Noun",group:0,tag:"Determiner",reason:"such-skill"},{match:"[right] (before|after|in|into|to|toward)",group:0,tag:"#Adverb",reason:"right-into"},{match:"#Preposition [about]",group:0,tag:"Adjective",reason:"at-about"},{match:"(are|#Modal|see|do|for) [ya]",group:0,tag:"Pronoun",reason:"are-ya"},{match:"[long live] .",group:0,tag:"#Adjective #Infinitive",reason:"long-live"},{match:"[plenty] of",group:0,tag:"#Uncountable",reason:"plenty-of"},{match:"(always|nearly|barely|practically) [there]",group:0,tag:"Adjective",reason:"always-there"},{match:"[there] (#Adverb|#Pronoun)? #Copula",group:0,tag:"There",reason:"there-is"},{match:"#Copula [there] .",group:0,tag:"There",reason:"is-there"},{match:"#Modal #Adverb? [there]",group:0,tag:"There",reason:"should-there"},{match:"^[do] (you|we|they)",group:0,tag:"QuestionWord",reason:"do-you"},{match:"^[does] (he|she|it|#ProperNoun)",group:0,tag:"QuestionWord",reason:"does-he"},{match:"#Determiner #Noun+ [who] #Verb",group:0,tag:"Preposition",reason:"the-x-who"},{match:"#Determiner #Noun+ [which] #Verb",group:0,tag:"Preposition",reason:"the-x-which"},{match:"a [while]",group:0,tag:"Noun",reason:"a-while"},{match:"guess who",tag:"#Infinitive #QuestionWord",reason:"guess-who"},{match:"[fucking] !#Verb",group:0,tag:"#Gerund",reason:"f-as-gerund"}],[{match:"university of #Place",tag:"Organization",reason:"university-of-Foo"},{match:"#Noun (&|n) #Noun",tag:"Organization",reason:"Noun-&-Noun"},{match:"#Organization of the? #ProperNoun",tag:"Organization",reason:"org-of-place",safe:!0},{match:"#Organization #Country",tag:"Organization",reason:"org-country"},{match:"#ProperNoun #Organization",tag:"Organization",notIf:"#FirstName",reason:"titlecase-org"},{match:"#ProperNoun (ltd|co|inc|dept|assn|bros)",tag:"Organization",reason:"org-abbrv"},{match:"the [#Acronym]",group:0,tag:"Organization",reason:"the-acronym",safe:!0},{match:"government of the? [#Place+]",tag:"Organization",reason:"government-of-x"},{match:"(health|school|commerce) board",tag:"Organization",reason:"school-board"},{match:"(nominating|special|conference|executive|steering|central|congressional) committee",tag:"Organization",reason:"special-comittee"},{match:"(world|global|international|national|#Demonym) #Organization",tag:"Organization",reason:"global-org"},{match:"#Noun+ (public|private) school",tag:"School",reason:"noun-public-school"},{match:"#Place+ #SportsTeam",tag:"SportsTeam",reason:"place-sportsteam"},{match:"(dc|atlanta|minnesota|manchester|newcastle|sheffield) united",tag:"SportsTeam",reason:"united-sportsteam"},{match:"#Place+ fc",tag:"SportsTeam",reason:"fc-sportsteam"},{match:"#Place+ #Noun{0,2} (club|society|group|team|committee|commission|association|guild|crew)",tag:"Organization",reason:"place-noun-society"}],[{match:"(west|north|south|east|western|northern|southern|eastern)+ #Place",tag:"Region",reason:"west-norfolk"},{match:"#City [(al|ak|az|ar|ca|ct|dc|fl|ga|id|il|nv|nh|nj|ny|oh|pa|sc|tn|tx|ut|vt|pr)]",group:0,tag:"Region",reason:"us-state"},{match:"portland [or]",group:0,tag:"Region",reason:"portland-or"},{match:"#ProperNoun+ (cliff|place|range|pit|place|point|room|grounds|ruins)",tag:"Place",reason:"foo-point"},{match:"in [#ProperNoun] #Place",group:0,tag:"Place",reason:"propernoun-place"},{match:"#Value #Noun (st|street|rd|road|crescent|cr|way|tr|terrace|avenue|ave)",tag:"Address",reason:"address-st"},{match:"(port|mount|mt) #ProperName",tag:"Place",reason:"port-name"}],[{match:"[so] #Noun",group:0,tag:"Conjunction",reason:"so-conj"},{match:"[(who|what|where|why|how|when)] #Noun #Copula #Adverb? (#Verb|#Adjective)",group:0,tag:"Conjunction",reason:"how-he-is-x"},{match:"#Copula [(who|what|where|why|how|when)] #Noun",group:0,tag:"Conjunction",reason:"when-he"},{match:"#Verb [that] #Pronoun",group:0,tag:"Conjunction",reason:"said-that-he"},{match:"#Noun [that] #Copula",group:0,tag:"Conjunction",reason:"that-are"},{match:"#Noun [that] #Verb #Adjective",group:0,tag:"Conjunction",reason:"that-seem"},{match:"#Noun #Copula not? [that] #Adjective",group:0,tag:"Adverb",reason:"that-adj"},{match:"#Verb #Adverb? #Noun [(that|which)]",group:0,tag:"Preposition",reason:"that-prep"},{match:"@hasComma [which] (#Pronoun|#Verb)",group:0,tag:"Preposition",reason:"which-copula"},{match:"#Noun [like] #Noun",group:0,tag:"Preposition",reason:"noun-like"},{match:"^[like] #Determiner",group:0,tag:"Preposition",reason:"like-the"},{match:"a #Noun [like] (#Noun|#Determiner)",group:0,tag:"Preposition",reason:"a-noun-like"},{match:"#Adverb [like]",group:0,tag:"Verb",reason:"really-like"},{match:"(not|nothing|never) [like]",group:0,tag:"Preposition",reason:"nothing-like"},{match:"#Infinitive #Pronoun [like]",group:0,tag:"Preposition",reason:"treat-them-like"},{match:"[#QuestionWord] (#Pronoun|#Determiner)",group:0,tag:"Preposition",reason:"how-he"},{match:"[#QuestionWord] #Participle",group:0,tag:"Preposition",reason:"when-stolen"},{match:"[how] (#Determiner|#Copula|#Modal|#PastTense)",group:0,tag:"QuestionWord",reason:"how-is"},{match:"#Plural [(who|which|when)] .",group:0,tag:"Preposition",reason:"people-who"}],[{match:"holy (shit|fuck|hell)",tag:"Expression",reason:"swears-expression"},{match:"^[(well|so|okay|now)] !#Adjective?",group:0,tag:"Expression",reason:"well-"},{match:"^come on",tag:"Expression",reason:"come-on"},{match:"(say|says|said) [sorry]",group:0,tag:"Expression",reason:"say-sorry"},{match:"^(ok|alright|shoot|hell|anyways)",tag:"Expression",reason:"ok-"},{match:"^(say && @hasComma)",tag:"Expression",reason:"say-"},{match:"^(like && @hasComma)",tag:"Expression",reason:"like-"},{match:"^[(dude|man|girl)] #Pronoun",group:0,tag:"Expression",reason:"dude-i"}]);let Bl=null;var Sl={postTagger:function(e){const{world:t}=e,{model:n,methods:a}=t;Bl=Bl||a.one.buildNet(n.two.matches,t);const r=a.two.quickSplit(e.document).map((e=>{const t=e[0];return[t.index[0],t.index[1],t.index[1]+e.length]})),o=e.update(r);return o.cache(),o.sweep(Bl),e.uncache(),e.unfreeze(),e},tagger:e=>e.compute(["freeze","lexicon","preTagger","postTagger","unfreeze"])};const Kl={api:function(e){e.prototype.confidence=function(){let e=0,t=0;return this.docs.forEach((n=>{n.forEach((n=>{t+=1,e+=n.confidence||1}))})),0===t?1:(e=>Math.round(100*e)/100)(e/t)},e.prototype.tagger=function(){return this.compute(["tagger"])}},compute:Sl,model:{two:{matches:Vl}},hooks:["postTagger"]},$l=function(e,t){const n=function(e){return Object.keys(e.hooks).filter((e=>!e.startsWith("#")&&!e.startsWith("%")))}(t);if(0===n.length)return e;e._cache||e.cache();const a=e._cache;return e.filter(((e,t)=>n.some((e=>a[t].has(e)))))};var Ll={lib:{lazy:function(e,t){let n=t;"string"==typeof t&&(n=this.buildNet([{match:t}]));const a=this.tokenize(e),r=$l(a,n);return r.found?(r.compute(["index","tagger"]),r.match(t)):a.none()}}};const Ml=function(e,t,n){let a=e.split(/ /g).map((e=>e.toLowerCase().trim()));a=a.filter((e=>e)),a=a.map((e=>`{${e}}`)).join(" ");let r=this.match(a);return n&&(r=r.if(n)),r.has("#Verb")?function(e,t){let n=t;return e.forEach((e=>{e.has("#Infinitive")||(n=function(e,t){const n=(0,e.methods.two.transform.verb.conjugate)(t,e.model);return e.has("#Gerund")?n.Gerund:e.has("#PastTense")?n.PastTense:e.has("#PresentTense")?n.PresentTense:e.has("#Gerund")?n.Gerund:t}(e,t)),e.replaceWith(n)})),e}(r,t):r.has("#Noun")?function(e,t){let n=t;e.has("#Plural")&&(n=(0,e.methods.two.transform.noun.toPlural)(t,e.model));e.replaceWith(n,{possessives:!0})}(r,t):r.has("#Adverb")?function(e,t){const{toAdverb:n}=e.methods.two.transform.adjective,a=n(t);a&&e.replaceWith(a)}(r,t):r.has("#Adjective")?function(e,t){const{toComparative:n,toSuperlative:a}=e.methods.two.transform.adjective;let r=t;e.has("#Comparative")?r=n(r,e.model):e.has("#Superlative")&&(r=a(r,e.model)),r&&e.replaceWith(r)}(r,t):this};var Jl={api:function(e){e.prototype.swap=Ml}};d.plugin(cl),d.plugin(Fl),d.plugin(Kl),d.plugin(Ll),d.plugin(Jl);export{d as default};
================================================
FILE: changelog.md
================================================
compromise uses semver, and pushes to npm and github frequently
- **Major** is a breaking api change - method or response changes that can cause runtime errors.
- **Minor** is a behaviour change - Tagging or grammar changes.
- **Patch** is an obvious, non-controversial bugfix.
While all _Major_ releases should be reviewed, our only _large_ releases are **v6** in 2016 **v12** in 2019 and **v14** in 2022. Others have been mostly incremental.
#### 14.15.0 [Feb 2026]
- **[update]** - support for Typescript 7 #1198
- **[update]** - dependencies
#### 14.14.5 [Dec 2025]
- **[fix]** - update types #1181
- **[update]** - add nelissa and gert #1180
- **[fix]** - sentence tokenization issues #1194 and #1193
- **[update]** - prefer const to let
- **[new]** - experimental cmd-k plugin
- **[update]** - dependencies
#### 14.14.4 [Jan 2025]
- **[fix]** - TypeScript & esm resolution #1165
#### 14.14.3 [Dec 2024]
- **[fix]** - another runtime error in punctuation replace #1150
- **[update]** - dependencies
#### 14.14.2 [Oct 2024]
- **[fix]** - runtime error in punctuation replace #1150
#### 14.14.1 [Oct 2024]
- **[update]** - compromise-dates 3.7.0
- **[fix]** - runtime error in number parser #1145
- **[update]** - dependencies
#### 14.14.0 [July 2024]
- **[new]** - .slashes() and .slashes().split() methods #1100
- **[fix]** - multiple contraction issue #1128
- **[fix]** - toNumbers() return values #1113
- **[fix]** - (plugins/wikipedia) - fix hard-coded path for #1116
- **[fix]** - (plugins/dates) - limit values in `mm/dd` format
- **[fix]** - (plugins/dates) params mutation #1109
- **[change]** - split people names by commas #1111
- **[change]** - typescript export update #1104
- **[update]** - eslint config format
- **[update]** - github actions
- **[update]** - dependencies
#### 14.13.0 [Apr 2024]
- **[new]** - .compute('freeze')
- **[new]** - .debug('freeze')
- **[change]** - allow 3-slashes in a word
#### 14.12.0 [Feb 2024]
- **[new]** - .payload() plugin
- **[new]** - `.numbers().isUnit()` method #1089
- **[change]** - update github workflow (thanks FDawgs!)
- **[fix]** - README issues (thanks track0x1!)
- **[fix]** - .has() inconsistency
- **[new]** - support adding debug methods via plugins
- **[change]** - remove deprecated .debug(object) support
- **[fix]** - parentheses() match issue
- **[fix]** - tokenization issue #1085
- **[new]** - `dates().isBefore()`, `dates().isBefore()` methods
- **[new]** - `.debug('dates')` method
- **[fix]** - lazy join() issue
- **[update]** - dependencies
#### 14.11.2 [Jan 2024]
- **[new]** - support for frozen lex in plugin object #1080
- **[fix]** - toggling options in .json()
- **[new]** - .join() and .joinIf() methods
- **[new]** - support freeze in sweep
- **[change]** - internal typescript improvements
- **[fix]** - tagging issues
- **[change]** - @hasEllipses must be following the word
- **[update]** - dependencies
#### 14.11.1 [Jan 2024]
- **[fix]** - missing words in html output (thanks ryan!)
- **[change]** - better #Possessive tagging for #1074
- **[change]** - improved is/has contraction classifier #1074
- **[change]** - fixes to subordinate clause identification #1072
- **[update]** - dependencies
#### 14.11.0 [Dec 2023]
- **[new]** - tagging `.freeze()` and `.unfreeze()` feature
- **[change]** - stronger deferal to internal lexicon
- **[change]** - support any-length phrases in lexicon
- **[fix]** - prevent missed overlapping lexicon phrases
- **[update]** - dependencies
#### 14.10.1 [Nov 2023]
- **[fix]** - abbreviation checks for sentence-tokenizer #1061
- **[change]** - improve person tagger #1059
- **[change]** - add #FutureTense tag
- **[fix]** - .out() runtime error #1056
- **[fix]** - punctuation loss in .not() #1022
- **[update]** - dependencies
#### 14.10.0 [Aug 2023]
- **[fix]** - verb conjugation fixes
- **[fix]** - tagger fixes
- **[change]** - align package.json with ESM module #1023
- **[fix]** - .splitBefore() bugfix
- **[fix]** - typescript+docs fixes #1023
- **[fix]** - subtle changes to .text() and .isFull()
- **[update]** - dependencies
#### 14.9.0 [May 2023]
- **[new]** - .verbs().toPastParticiple() method
- **[new]** - `.normalize({ debullet: true })` #1004
- **[change]** - typescript path changes (thanks @rotemdan !)
- **[fix]** - suffix tagging issues
- **[fix]** - match syntax issue #997
- **[change]** - keep possessive in replace #1011
- **[change]** - major improvements to adj.toNoun() conjugator
- **[fix]** - parsematch bug #997
- **[fix]** - "there's been" contraction
- **[new]** - .conjugate() methods on Noun/Adverb/Adjective classes
- **[new]** - add Gerund and PastParticiple to .verbs().conjugate() results
- **[new]** - option to keep possessives in .replace() #1011
- **[fix]** - tagger fix #998
- **[update]** - dependencies
#### 14.8.2 [Feb 2023]
- **[change]** - #Actor tagging - in advance of #565
- **[change]** - .noun() lumping changes - in advance of #565
- **[new]** - support japanese full-stop
- **[fix]** - number tagging #992
- **[update]** - dependencies
#### 14.8.1 [Dec 2022]
- **[fix]** - tagging fixes
- **[change]** - allow #Plural acronyms
- **[fix]** - allow root matches in fastOr
- **[fix]** - more flexible PhrasalVerb tagging
#### 14.8.0 [Dec 2022]
- **[fix]** - tagging fixes
- **[new]** - add Person .presumedMale(), .presumedFemale() methods
- **[new]** - add Pronoun class, .refersTo()
- **[new]** - add Noun.references()
- **[new]** - .nouns('spencer') shorthand as an if-match
- **[change]** - "[do] you .." etc now #QuestionWord
- **[new]** - add #Hyphenated tag
- **[fix]** - improved Auxiliary verb tagging
- **[update]** - dependencies
#### 14.7.1 [Nov 2022]
- **[fix]** - concat fix
- **[change]** - tagging fixes
- **[change]** - `{word/tag/sense}` sense-match syntax
#### 14.7.0 [Nov 2022]
- **[new]** - match term id
- **[change]** - tag text by default on .concat('')
- **[change]** - allow modifying term prePunctuation
- **[new]** - .wrap() method
- **[new]** - .isFull() method
- **[new]** - support full `notIf` matches on sweep
- **[fix]** - text params for #953
- **[fix]** - nouns().isSingular() missing
- **[change]** - one-character w/ dash tokenization #977
- **[change]** - allow setting `model.one.prePunctuation` + `postPunctuation`
- **[fix]** - compromise-paragraphs plugin
#### 14.6.0 [Oct 2022]
- **[change]** - move internal conjugation methods
- **[update]** - github scripts
- **[change]** - fixes to .clauses() parser
- **[change]** - an astrix is not a word
- **[new]** - @hasColon method
- **[new]** - @hasDash supports two dashes
- **[new]** - `#Passive` verb tag
- **[new]** - existential `#There` tag
- **[new]** - add tense info to sentence json
- **[fix]** - verb tokenization issues
- **[fix]** - .replace() issues
- **[update]** - dependencies
#### 14.5.2 [Oct 2022]
- **[fix]** - runtime error #965
- **[fix]** - misc possessive tagging issues
- **[update]** - dependencies
#### 14.5.1 [Oct 2022]
- **[fix]** - .remove() fixes
- **[change]** - support « angle quotes »
- **[update]** - dependencies
#### 14.5.0 [August 2022]
- **[fix]** - possible runtime error in setTag method
- **[change]** - make #Honorific always a #Person #951
- **[new]** - manually change conjugations/inflections from plugin #949
- **[new]** - `.adjectives().conjugate()` method
- **[update]** - dependencies
#### 14.4.5 [August 2022]
- **[fix]** - fix logic for greedy-negative matches - #936
- **[fix]** - fix tagging for 3-digit year iso dates - #868
- **[update]** - dependencies
#### 14.4.4 [August 2022]
- **[fix]** - support {root} matches without compromise/two
#### 14.4.3 [August 2022]
- **[fix]** - guard for toRoot methods in root match
- **[update]** - compromise-stats
#### 14.4.2 [July 2022]
- **[fix]** - hotfix for sentence tokenization issue #935
#### 14.4.1 [July 2022]
- **[change]** - improvements to negative-optional match logic - `!foo?`
- **[change]** - support short sentences embedded in quotes+parentheses
- **[change]** - faster sentence tokenizer
- **[change]** - ° symbol is not punctuation
- **[new]** - implement .swap() for comparative/superlative adjectives
- **[fix]** - sentence.toFuture() conjugation rules
- **[update]** - dependencies
#### 14.4.0 [July 2022]
- **[change]** - support root matches like '{walk}' work without doing .compute('root')
- **[change]** - split numbers+units '12km' as contraction - #919
- **[new]** - `.lazy(txt, match)` fast-scan method [1](https://observablehq.com/@spencermountain/compromise-performance)
- **[fix]** - support apostrophes in lexicon #932
- **[fix]** - support unTag property in sweep
- **[change]** - keep sentence caches, when still valid
- **[change]** - alias nlp.compile() to .buildTrie()
- **[fix]** - tagging fixes
- **[update]** - dependencies
_plugin-releases_: dates, speed, de-compromise
#### 14.3.1 [June 2022]
- **[fix]** - missed caches in .sweep()
- **[new]** - .out('hash') and `.json({hash:true})`
#### 14.3.0 [June 2022]
- **[fix]** - unwanted logging in compromise/one
- **[fix]** - dependency export path for react-native builds #928
- **[change]** - split hyphenated words in match syntax 'foo-bar'
- **[change]** - support 4-digit number-ranges (when not a phone number)
_plugin-releases_: dates
#### 14.2.1 [June 2022]
- **[fix]** - double-contraction issue #925
- **[fix]** - .not() memleak #926
#### 14.2.0 [June 2022]
- **[fix]** - speed improvements
- **[fix]** - bug with fast-or possessive matches
- **[fix]** - bug with slow-or end-matches
- **[change]** - no-longer attempt 's contractions in compromise/one
- **[new]** - flag novel tags in world.one.tagSet
- **[new]** - .sweep() and nlp.buildNet() methods
- **[new]** - some typescript support in plugins #918
- **[fix]** - better unicode support with Unicode property escapes
- **[fix]** - problems matching on cached documents
- **[fix]** - typescript fixes
- **[fix]** - suffix tagging issues
- **[fix]** - uncached matches missing in .sweep()
- **[fix]** - non-empty results when pointer is first repaired
- **[fix]** - nouns().toPlural() fix for #921
- **[fix]** - drop deprecated .subst() method internally
- **[new]** - some support for .numbers().units() again #919
#### 14.1.2 [April 2022]
- **[new]** - add .harden() .soften() undocumented methods
- **[fix]** - support pre-parsed matches in .has() .if() and .not()
- **[fix]** - contraction OR match issue
- **[fix]** - match-syntax min-max issue
- **[fix]** - normalized printout of abbreviations
- **[update]** - date plugin release
- **[update]** - dependencies
#### 14.1.1 [April 2022]
- **[fix]** - main property in package.json #911
#### 14.1.0 [April 2022]
- **[fix]** - client-side export format for plugins
- **[new]** - more adjective transformation methods
- **[new]** - emoji + emoticon tagger
- **[new]** - case-sensitive match option - `{caseSensitive:true}`
### 🚨 14.0.0 🚨 [March 2022]
Major release - see [Release Notes](https://github.com/spencermountain/compromise/releases/tag/14.0.0) for full details
- **[breaking]** - remove `.parent()` and `.parents()` chain - (use `.all()` instead)
- **[breaking]** - remove `@titleCase` alias (use @isTitleCase)
- **[breaking]** - remove '.get()' alias - use '.eq()'
- **[breaking]** - remove `.json(0)` shorthand - use `.json()[0]`
- **[breaking]** - remove `.tagger()` - use .compute('tagger')
- **[breaking]** - remove `.export()` -> .load() - use .json() -> nlp(json)
- **[breaking]** - remove `nlp.clone()`
- **[breaking]** - remove `.join()` _deprecated_
- **[breaking]** - remove `.lists()` _deprecated_
- **[breaking]** - remove `.segment()` _deprecated_
- **[breaking]** - remove `.sententences().toParticiple()` & `.verbs().toParticiple()`
- **[breaking]** - remove `.nouns().toPossessive()` & `.nouns().hasPlural()`
- **[breaking]** - remove array support in match methods - (use `.match().match()` instead)
- **[breaking]** - refactor `.out('freq')` output format - (uses `.compute('freq').terms().unique().json()` instead)
- **[breaking]** - change `.json()` result format for subsets
- **[change]** merge re-used capture-group names in one match
- **[change]** drop support for undocumented empty '.split()' methods - which used to split the parent
- **[change]** subtle changes to `.text('fmt')` formats
- **[change]** @hasContraction is no-longer secretly-greedy. use `@hasContraction{2}`
- **[change]** `.and()` now does a set 'union' operation of results (no overlaps)
- **[change]** bestTag is now `.compute('tagRank')`
- **[change]** `.sort()` is no longer in-place (its now immutable)
- **[change]** drop undocumented options param to `.replaceWith()` method
- **[change]** add match-group as 2nd param to split methods
- **[change]** remove #FutureTense tag - which is not really a thing in english
- **[change]** `.unique()` no-longer mutates parent
- **[change]** `.normalize()` inputs cleanup
- **[change]** drop agreement parameters in .numbers() methods
- **[change]** - less-magical money parsing - `nlp('50 cents').money().get()` is no-longer `0.5`
- **[change]** - .find() does not return undefined on an empty result anymore
- **[change]** - fuzzy matches must now be wrapped in tildes, like `~this~`
- **[new]** `.union()`, .intersection(), .difference() and .complement() methods
- **[new]** `.confidence()` method - approximate tagging confidence score for arbitrary selections
- **[new]** `.settle()` - remove overlaps in matches
- **[new]** `.isDoc()` - helper-method for comparing two views
- **[new]** `.none()` - helper-method for returning an empty view of the document
- **[new]** `.toView()` method - drop back to a normal Class instance
- **[new]** `.grow()` `.growLeft()` and `.growRight()` methods
- **[new]** add punctuation match support via pre/post params
- **[new]** add ambiguous empty .map() state as 2nd param
#### 13.11.3 [June 2021]
- **[fix]** - regex backtracing issue \#847 (thanks @srubin)
- misc tagging fixes
update deps
#### 13.11.2 [May 2021]
- **[fix]** - verbphrase conjugation fixes
- **[fix]** - verbphrase tagger fixes
- **[fix]** - url tagging regex improvements (thanks Axay!)
update deps
_plugin-releases_: dates
#### 13.11.1 [April 2021]
- **[fix]** - obscure runtime error in capture-groups
update deps
_plugin-releases_: typeahead
#### 13.11.0 [April 2021]
- **[change]** - use babel default build target (drop ie11 polyfill)
- **[change]** - dont compile esm build w/ babel anymore
- **[fix]** - sentence conjugation fixes
- **[fix]** - improvements to phrasal verbs
- **[change]** - keep tokenization for some more dashed suffixes like 'snail-like'
_plugin-releases_: dates, numbers, sentences
#### 13.10.7 [April 2021]
- **[change]** - tokenize '2 - 5' as NumerRange, like '2-5' is
- **[fix]** - edge-cases for URLs with numbers
- **[fix]** - some sentences.toPastTense() fixes
- **[fix]** - 'n weekends from now' math in plugin-date
_plugin-releases_: dates, sentences
#### 13.10.6 [April 2021]
- **[fix]** - support more time-ranges
_plugin-releases_: dates@2.0.2
#### 13.10.5 [March 2021]
- **[new]** - support Time-range like '3pm-4pm'
- **[change]** - cleanup some unicode regexes
_plugin-releases_: dates
#### 13.10.4 [March 2021]
- **[fix]** - match syntax tokenization fix
- **[change]** - improved performance monitoring
#### 13.10.3 [March 2021]
- **[fix]** - support complicated regular-expressions in match syntax
- improved performance testing
#### 13.10.2 [March 2021]
- **[fix]** - support matching implicit terms in (or|blocks)
- **[change]** - add #Timezone tag (from date-plugin)
- **[change]** - add many more cities and regions
#### 13.10.1 [March 2021]
- **[change]** - #Date terms can still be a #Conjunction
- **[new]** - #Imperative tag and `.verbs().isImperative()` method
- **[fix]** - some tagger issues
- update deps
_plugin-releases_: dates
#### 13.10.0 [Feb 2021]
- **[new]** - #Fraction tag and improved fraction support (thanks Jakeii!)
- **[fix]** - edge-case match issues with `!` syntax
- **[change]** - update deps
- updates for `compromise-dates@1.4.0`, `compromise-numbers@1.2.0`
#### 13.9.3 [Feb 2021]
- **[fix]** - fix weird ordering issue with named exports #815
#### 13.9.2 [Feb 2021]
- **[fix]** - typescript issue
#### 13.9.1 [Feb 2021]
- **[fix]** - matches over a contraction
- **[new]** - add 'implicit' text output
#### 13.9.0 [Feb 2021]
- **[new]** - World.addConjugations() method
- **[new]** - World.addPlurals() method
- **[new]** - start compromise-penn-tags plugin
- **[new]** - add fuzzy option to match commands
- **[new]** - support multiple-word matches in OR matches (a|b|foo bar|c)
- **[change] (internal)** - rename 'oneOf' match syntax to 'fastOr'
- **[change]** - use new export maps format
- **[fix]** - conjugations fixes #800
- **[fix]** - tokenization fixes #801
#### 13.8.0 [Dec 2020]
- **[change]** improved support for fractions in numbers-plugin #793
- **[change]** remove zero-width characters in normalized output #759
- **[change]** improved Person tagging with particles #794
- **[change]** improved i18n Person names
- **[change]** tagger+tokenization fixes
- **[change]** remove empty results from .out('array') #795
- **[change]** `.tokenize()` runs any postProcess() scripts from plugins
- **[change]** improved support for lowercase acronyms
- **[change]** - support years like '97
- **[change]** - change tokenizer for '20-aug'
- **[change]** - update deps of all plugins
- **[fix]** - NumberRange tagging issue #795
- **[fix]** - improved support for ordinal number ranges
- **[fix]** - improved regex support in match-syntax
- **[fix]** - improved support for ~soft~ match syntax #797
- **[fix]** - better handling of `{0,n}` match syntax
- **[new]** - new plugin `strict-match`
- **[new]** - set NounPhrase, VerbPhrase tags in nlp-sentences plugin
- **[new]** - `.phrases()` method in nlp-sentences plugin
- **[new]** - support `.apppend(doc)` and `.prepend(doc)`
- **[new]** - `values.normalize()` method
#### 13.7.0 [Oct 2020]
- **[change]** many misc tagging fixes
- 'if' is now a #Preposition
- possessive pronouns are #Pronoun and #Possessive
- more phrasal verbs
- make #Participle tag #PastTense
- favor #PastTense over #Participle interpretation in tagger
- **[change]** `@hasHyphen` returns false for sentence dashes
- a lot more testing
#### 13.6.0 [Oct 2020]
- **[new]** first-attempt at `verbs().subject()` method
- **[change]** avoid conjugating imperative tense - 'please close the door'
- **[change]** misc tagging fixes #786
- **[change]** .nouns() results split on quotations #783
- **[change]** NumberRange must be < 4 digits #735
- **[change]** reduction in #Person tag false-positives
#### 13.5.0 [Sep 2020]
- **[new]** add `.parseMatch()` method for pre-parsing match statements
#### 13.4.0 [Sep 2020]
- **[change]** stop including adverbs and some auxiliaries in `.conjugate()` results
- **[change]** .append() and .prepend() on an empty doc now creates a new doc
- **[new]** add `verbs().toParticiple()` method (add to observables/verb)
- **[new]** add `sentences().toParticiple()` method (add to observables/verb)
- **[fix]** some verb-tagging issues
- **[fix]** contractions issue in `.clone()`
- **[fix]** try harder to retain modal-verbs in conjugation - 'i should drive' no-longer becomes 'i will drive'
#### 13.3.2 [Aug 2020]
- fix for offset issue #771
- fix for `{min,max}` syntax #767
- typescript fixes
- update deps
#### 13.3.1 [June 2020]
-support unicode spaces for #759
- major improvements to `compromise-plugin-dates` (1.0.0)
#### 13.3.0 [June 2020]
- bugfixes (conjugation and tagging) 752, 737, 725, 751, 743 748, 755, 758, 706, 761
- support tokenized array as input
- update deps
- bugfix updates to `plugin-sentences`, and `plugin-dates`
#### 13.2.0 [May 2020]
- deprecate `.money()` and favour overloaded method in compromise-numbers plugin
- add `.percentages()` and `.fractions()` to compromise-numbers plugin
- add `.hasAfter()` and `.hasBefore()` methods
- change handling of slashes
- add `.world()` method to constructor
- add more abbreviations
- fix regex backtracking #739
- tokenize build:
- - remove conjugation and inflection data
- - remove conjugation and inflection functions
- remove sourcemap from build process (too big)
- improvements to `.numbers().units()`
- fix for linked-list runtime error #744 with contractions
#### 13.1.1
- fix `verbs.json()` runtime-error
- improve empty `.lists()` methods
- allow custom tag colors
- test new github action workflow
#### 13.1.0
- significant (~30%) speed up of parsing
- change sensitivity of input in `.lookup()` for major speed improvements.
- improved typescript types
- subtle changes to internal caching
- adds 'oneOf' match syntax param
- fixes `[word?]` syntax parsing
### 13.0.0 [Feb 2020]
_major changes to `.export()` and `[capture] group` match-syntax._
- **[breaking]** move .export() and .load() methods to plugin (compromise-export)
- - change .export() format - this hasn't worked properly since v12. (mis-parsed contractions) see #669
- **[breaking]** split `compromise-output` into `compromise-html` and `compromise-hash` plugins
- **[breaking]** `.match('foo [bar]')` no-longer returns 'bar'. (use `.match('foo [bar]', 0)`)
- **[breaking]** capture groups are no longer merged. `.match('[foo] [bar]')` returns two groups accessible with the new `.groups()` function
- **[breaking]** change `.sentences()` method to return only full-sentences of matches (use `.all()` instead)
modifications:
- **[fix]** - nlp.clone() - hasn't worked properly, since v12. (@Drache93)
- **[fix]** - issues with greedy capture [*] and [.+] -(@Drache93) 💛
- add whitespace properties (pre+post) to default json output (suppress with `.json({ whitespace: false })`)
- `.lookup({ key: val })` with an object now returns an object back ({val: Doc})
- add nlp constructor as a third param to `.extend()`
- support lexicon object param in tokenize - `.tokenize('my word', { word: 'tag' })`
- clean-up of scripts and tooling
- improved typescript types
- add support for some french contractions like `j'aime -> je aime`
- allow null results in `.map()` function
- better typescript support
- allow longer acronyms
- **[fix]** - offset length issue
- **[new]** - add new named-match syntax, with .groups() method (@Drache93)
- **[new]** - add `nlp.fromJSON()` method
- **[new]** - add a new `compromise-tokenize.js` build, without the tagger, or data included.
#### 12.3.0 [Jan 2020]
- prefer `@titleCase` instead of `#TitleCase` tag
- update dependencies
- fix case-sensitive paths
- fix greedy-start match condition regression #651
- fix single period sentence runtime error
- fix potentially-unsafe regexes
- improved tagging for '-ed' verbs (#616)
- improve support for auxilary-pastTense ('was lifted') verb-phrases
- more robust number-tagging regexes
- setup typescript types for plugins #661 (thanks @Drache93!)
- verb conjugation and tagger bugfixes
- disambiguate between acronyms & yelling
##### 12.2.1 [Dec 2019]
- fix 'aint' contraction
- make Doc.world writable
- update deps
- more tests
- fix shared period with acronym at end of sentence
- fix some mis-classification of contraction
- fix over-active emoji regex
- tag 'cookin', 'hootin' as `Gerund`
- support unicode single-quote symbols in contractions
#### 12.2.0 [Dec 2019]
- improved splitting in .nouns()
- add `.nouns().adjectives()` method
- add `concat` param to `.pre()` and `.post()`
- allow ellipses at start of term _"....so"_ in `@hasEllipses`
- fix matches with optional-end `foo?$` match syntax
- add typescript types for subsets
#### 12.1.0 [Nov 2019]
- add 'sideEffect:false' flag to build
- considerable speedup (20%) in tagger
- ensure trimming of whitespace for root/clean/reduced text formats
- fix client-side logging
- more flexible params to `replace()` and `replaceWith()`
### 12.0.0 :postal_horn: [Nov 2019]
- see **[Release Notes](https://github.com/spencermountain/compromise/wiki/v12-Release-Notes)**
#### 11.13.0
- support singular units in `.value()`
#### 11.11.0
- `.quotations()` no-longer return repeated results for nested quotes
- simplify quotation tagset
- `.out('normal')` no longer includes quotes or trailing-possessives
- improve `.debug()` on client-side
#### 11.10.0
- better honorific support, add `honorifics` feature to .normalize()
- elipses bugfixes
- replace unicode chars in `.normalize()` now by default
- `acronyms().stripPeriods()` and `acronyms().addPeriods()`
#### 11.9.0
- tag professions as `#Actor`
- add more behaviours to `.normalize()`
- support match-results as inputs to .match() and .not()
- support some us-state abbreviations like 'Phoeniz AZ'
#### 11.8.0
- add `nouns().toPossessive()`
- ngrams now remove empty-terms in contractions - fixes counting issue [#476](https://github.com/spencermountain/compromise/issues/476)
#### 11.7.0
- expose internal `sentences().isQuestion()` method
- `.join()` as an alias for `.flatten()`
- slightly different behavior for wildcards in capture-groups [pull/472](https://github.com/spencermountain/compromise/pull/472)
- `.possessives()` subset + `#Possessive` tagging fixes
- hide massive `world` output for console.log of a term
#### 11.6.0
- improve quotations() method
- add .parentheses() method
- add 'nickname' support to .people()
- 'will be #Adjective' now tagged as Copula
- include adverbs in verb conjugation (more) consistently
- `sentences().toContinuous()` and `verbs().toGerund()`
- some more aliases for jquery-like methods api
- move `getPunctuation`, `setPunctuation` from .sentence to main Text method
- rename internal `endPunctuation` to `getPunctuation`
- more consistent `cardinal/ordinal` tagging for values
#### 11.5.0
- add #Abbreviation tag
- add #ProperNoun tag
- fixes for noun inflection
##### 11.4.1
- include old ending punctuation in a `.replace()` cmd
##### 11.3.1
- almost-double the support for first-names
- changes to bestTag method
##### 11.2.1
- rolls-back some aggressive JustesonKatz stuff
- better support for emdash numberRange
- 'can\'t' contraction bugfix
- fix for dates().toShortForm()
#### 11.1.0
- add `#Multiple` Values tag, and changes to how invalid numbers like 'sixty fifteen hundred' are understood
- better em-dash/en-dash support
- better conjugate implicit verbs inside contractions - "i'm", "we've"
- nouns().articles() method
- neighborhoods as #Place
- support more complex noun-phrases with JustesonKatz in `.nouns()`
### v11
- support for persistent lexicon/tagset changes
- `addTags, addWords, addRegs, addPlurals, addConjugations` methods to extend native data
- - `.plugin()` method to wrap all of these into one
- - (removal of `.packWords()` method)
- more `.organizations()` matches
- regex-support in .match() - `nlp('it is waaaay cool').match('/aaa/').out()//'waaaay'`
- improved apostrophe-s disambiguation
- support whitespace before sentence boundary
- improved QuestionWord tagging, some `.questions()` without a question-mark
- phrasalVerb conjugation
- new #Activity tag for Gerunds as nouns 'walking is fun'
- change ngram params to an object `{size:int, max:int}`
- implement '[]' capture-group syntax in .match()
- bring-back `map, filter, foreach and reduce` methods
- set `.words()` as alias for .terms()
- `people().firstNames()`, `people().lastNames()`
- split-out comma-separated adverbs
##### 10.7.2
- fix for '.watch' reserved word in efrt
#### 10.7.0
- improved `places()` parsing
- improved `{min,max}` match syntax
- new `.out('match')` method
- quiet addition of .pack() and .unpack() for owen
#### 10.6.0
- move internal lexicon around, to support new format in v11
- added states & provinces as #Region
- added #Comparable tag for adjectives that conjugate
#### 10.5.0
- add increment/decrement/add/subtract methods to .values()
- add units(), noUnits() methods to .values()
- 'uncountable' nouns are no longer assumed to be singular
- money tag is no longer always a value
#### 10.4.0
- improved tagging of `VerbPhrase` and `Condition`
- fixes to contractions in sentence-changes - "i'm going -> i went"
- several verb conjugation fixes
- accept Terms & Result objects in .match() and .replace()
#### 10.3.0
- new `Percent` tag
- lump more units in with `.values()`
#### 10.2.0
- .trim() method,
- adjective tagging fixes
- some new .out() methods
#### 10.1.0
- fix return format of .isPlural(), so it acts like a match filter
- less-greedy date tagging & ambiguous month fixes
### v10
- cleanup & rename some `.value()` methods
- change lumping behaviour of lexicon terms with multiple words
- keep more former tags after a term replace method
- new `.random()` method
- new `.lessThan()`, `.greaterThan()`, `.equalTo()` methods
- new prefix/suffix/infix matches with `_ffix` syntax
- `tag()` supports a sequence of tags for a sequence of terms
- .match 'range' queries now use a real match - `#Adverb{2,4}`
- new `.before()` and `.after()` match methods
- removes `.lexicon()` method for many-lexicons concept
- changes params of `.replaceWith()` method to a 'keyTags' boolean
- improved .debug() and logging on client-side
#### 9.1.0
- pretty-real filesize reduction by swapping es6 classes for es5 inheritance
### v9.0.0
- rename `Term.tag` object to `Term.tags` so the `.tag()` method can work throughout more-consistently
- fix 'Auxillary' tag typo to 'Auxiliary'
- optimisation of .match(), and tagset - significant speedup!
- adds `.tagger()` method and cleanup extra params
- adds `wordStart` and `wordEnd` offsets to `.out('offset')` for whitespace+punctuation
- new `.has()` method for faster lookups
#### 8.2.0
- add `nlp.out('index')` method, 12 bugs
#### 8.1.0
- add `nlp.tokenize()` method for disabling pos-tagging of input
### v8.0.0
- less-ambitious date-parsing of nl-date forms
- filesize reduction using [efrt](https://github.com/nlp-compromise/efrt) data structure (254k -> 214k)
##### 7.0.15
- fix for IE9
### v7 :postal_horn:
- weee! [big change!](https://github.com/nlp-compromise/compromise/wiki/v7-Upgrade,-welcome) _npm package rename_
#### 6.5.0
- builds now using browserify + derequire()
#### 6.4.0
- re-written term-lumper logic
#### 6.3.0
- new nlp.lexicon({word:'POS'}) flow
### v6
- be consistent with `text.normal()`, `term.all_forms()`, `text.word_count()`. `text.normal()` includes sentence-terminators, like periods etc.
#### 5.2.0
- airport codes support, helper methods for specific POS
#### 5.1.0
- newlines split sentences
### v5
- Text methods now return this, instead of array of sentences
#### 4.12.0
- more-sensible responses for invalid, non-string inputs
#### 4.11.0
- 14 PRs, with fixes for currencies, pluralization, conjugation
#### 4.10.0
- Value.to_text() new method, fix "Posessive" POS typo
#### 4.9.0
- return of the text.spot() method (Re:#107)
#### 4.8.0
- more aggressive lumping of dates, like 'last week of february'
#### 4.7.0
- whitespace reproduction in .text() methods
#### 4.6.0
- move negate from sentence to verb & statement
#### 4.2.0
- rename 'implicit' to 'expansion' for smarter contractions
##### 4.1.3
- added readable-compression to adj, verbs (121kb -> 117kb)
#### 4.1.0
- hyphenated words are normalized into spaces
### v4.0.0
- grammar-aware match & replace functions
##### 3.0.2
- Statement & Question classes
### v3.0.0 Feb 2016
- split ngram, locale, and syllables into plugins in seperate repo
### 2.0.0 - Nov 2015
- es6 classes, babel building
- better test coverage
- ngram uses term tokenization, so that 'Tony Hawk' us one term, and not two
- more organized pos rules
- Pos tagging is done implicitly now once nlp.Text is run
- Entity spotting is split into .people(), .place(), .organisations()
- unicode normalisation is killed
- opaque two-letter tags are gone
- plugin support
- passive tense detection
- lexicon can be augmented third-party
- date parsing results are different
##### 1.1.0 - May 2015
- smarter handling of ambiguous contractions ("he's" -> ["he is", "he has"])
### v1.0.0 - May 2015
- added name genders and beginning of co-reference resolution ('Tony' -> 'he') API.
- small breaking change on `Noun.is_plural` and `Noun.is_entity`, affording significant pos() speedup. Bumped Major version for these changes.
##### 0.5.2 - May 2015
- Phrasal verbs ('step up'), firstnames and .people()
##### 0.4.0 - May 2015
- Major file-size reduction through refactoring
##### 0.3.0 - Jan 2015
- New NER choosing algorithm, better capitalisation logic, consolidated tests
##### 0.2.0 - Nov 2014
- Sentence class methods, client-side demos
================================================
FILE: data/README.md
================================================
hello!
here is the data compressed and compiled into the word models that compromise uses to understand text.
there are some things to note:
1. run `npm run pack` after making a change, to see changes appear.
2. lexicon words are lowercased and compressed with [efrt](https://github.com/spencermountain/efrt), some characters are reserved -`[0-9,;!:|¦]`
3. be careful adding ambiguous words - 'ray' should not be a #Person - it's a better fit for `./switches/person-date.js`
4. many word-lists have conjugations automatically applied to them - #Singular words are pluralized, etc.
the lexicon output data can be found in `./src/2-two/preTagger/model/lexicon/_data.js`
and the word-conjugation data can be found in `./src/2-two/preTagger/model/models/_data.js`
for more information, see the [compromise-lexicon docs](https://observablehq.com/@spencermountain/compromise-lexicon).
================================================
FILE: data/lexicon/adjectives/adjectives.js
================================================
//adjectives that don't conjugate to superlative/adverb/verb forms
export default [
'prima',
'ultra',
'extra',
'vice versa',
'magenta',
'superb',
'cardiac',
// -ic
'specific',
'terrific',
'horrific',
'scientific',
'public',
'symbolic',
'alcoholic',
'organic',
'hispanic',
'generic',
'didactic',
'gigantic',
'frantic',
'authentic',
'ad hoc',
'ahead',
'widespread',
// -ed
'nuanced',
'wounded',
'retarded',
'naked',
'buck naked',
'fabled',
'so called',
'old fashioned',
'sacred',
'deceased',
'diseased',
'lapsed',
'sophisticated',
'antiquated',
'spirited',
'talented',
'subdued',
'beloved',
'hallowed',
'crazed',
'infrared',
'grizzled',
'appalled',
'enamored',
'newlywed',
'famed',
'jaded',
'conceited',
// -id
'plaid',
'prepaid',
'afraid',
'rabid',
'placid',
'splendid',
'sordid',
'rheumatoid',
'devoid',
'torpid',
'languid',
'behind',
'blind',
'beyond',
'good',
'substandard',
'on board',
'aboard',
'onboard',
'off guard',
'awkward',
'forward',
'straight forward',
'straightforward',
'boldface',
'avant garde',
'home made',
'wee',
'teenage',
'average',
'awake',
'upscale',
'wholesale',
// -ble
'able',
'probable',
'foreseeable',
'notable',
'valuable',
'invaluable',
'soluble',
'insoluble',
'single',
// -ile
'fragile',
'worthwhile',
'sterile',
'volatile',
'versatile',
'fertile',
'hostile',
'whole',
'multiple',
'ample',
'same',
'supreme',
'part time',
'profane',
'humane',
'insane',
'obscene',
'serene',
// -ine
'alkaline',
'offline',
'crystalline',
'online',
'masculine',
'feminine',
'pristine',
'done',
'autoimmune',
'picayune',
'aware',
'macabre',
'sincere',
'mere',
'entire',
'bizarre',
'premature',
'immature',
'obese',
'precise',
'concise',
'false',
'immense',
'intense',
'sparse',
'adverse',
'diverse',
'perverse',
'profuse',
// -ate
'delicate',
'up to date',
'immediate',
'appropriate',
'inappropriate',
'legitimate',
'ultimate',
'insubordinate',
'indeterminate',
'innate',
'passionate',
'compassionate',
'proportionate',
'alternate',
'fortunate',
'disparate',
'degenerate',
'temperate',
'desperate',
'literate',
'illiterate',
'irate',
'accurate',
'inaccurate',
'commensurate',
'adequate',
'inadequate',
'private',
'obsolete',
'incomplete',
'discrete',
'recondite',
'impolite',
'finite',
'definite',
'indefinite',
'trite',
'petite',
'exquisite',
'en suite',
'acute',
'absolute',
'resolute',
'en route',
'due',
'concave',
'coercive',
'conducive',
'alive',
'aggressive',
'attractive',
'above',
'ablaze',
'bronze',
'well off',
'far off',
'aloof',
'soundproof',
'weatherproof',
// -ing
'menacing',
'longstanding',
'impending',
'far reaching',
'scathing',
'foregoing',
'ongoing',
'easygoing',
'lumbering',
'nausiating',
'preexisting',
'left wing',
'right wing',
'mindblowing',
'knowing',
'appetizing',
'appalling',
'smug',
// -ish
'snobbish',
'selfish',
'hellish',
'foolish',
'stylish',
'squeamish',
'loutish',
'mammoth',
'north',
'south',
'punjabi',
'mini',
'a priori',
'ok',
'brisk',
// -al
'global',
'ethereal',
'legal',
'illegal',
'conjugal',
'lethal',
'racial',
'beneficial',
'artificial',
'crucial',
'colonial',
'initial',
'influential',
'partial',
'impartial',
'final',
'literal',
'colossal',
'equal',
'usual',
'actual',
'archival',
'rival',
'royal',
// -el
'civil',
'all',
'overall',
'still',
'old school',
// -ful
'peaceful',
'graceful',
'vengeful',
'shameful',
'careful',
'useful',
'hateful',
'grateful',
'tasteful',
'wasteful',
'beautiful',
'gainful',
'painful',
'helpful',
'doubtful',
'forgetful',
'fretful',
'delightful',
'rightful',
'thoughtful',
'wistful',
'dim',
'longterm',
'ad infinitum',
'urban',
'suburban',
'mammalian',
'deadpan',
// -en
'wooden',
'barren',
'rotten',
'craven',
'proven',
'frozen',
'foreign',
'benign',
'main',
'certain',
'highfalutin',
'spot on',
'modern',
'northern',
'southern',
'western',
'upside down',
'gung ho',
'macho',
'in vitro',
'de facto',
'ipso facto',
'asleep',
'tip top',
'nonstop',
'fed up',
'hard up',
'familiar',
// -er
'somber',
'sheer',
'eager',
'together',
'other',
'former',
'inner',
'proper',
'improper',
'upper',
'super duper',
'super',
'lesser',
'outer',
'over',
'junior',
'inferior',
'prior',
'major',
'indoor',
'outdoor',
'backwards',
'sui generis',
'gratis',
'for keeps',
'bogus',
'dangerous',
'offbeat',
'upbeat',
// -ct
'abstract',
'intact',
'exact',
// 'perfect',
'imperfect',
'erect',
'indirect',
'incorrect',
'derelict',
'distinct',
'discreet',
'soviet',
'upset',
'makeshift',
'overweight',
'lightweight',
'overnight',
'uptight',
'overwrought',
'illicit',
'implicit',
'explicit',
'nonprofit',
'difficult',
// -ant
'vacant',
'significant',
'insignificant',
'abundant',
'redundant',
'extravagant',
'elegant',
'arrogant',
'obediant',
'defiant',
'nonchalant',
'vigilant',
'dormant',
'dominant',
'resonant',
'vibrant',
'exuberant',
'tolerant',
'flagrant',
'ignorant',
'aberrant',
'reluctant',
'exultant',
'important',
'distant',
'resistant',
'constant',
'relevant',
'irrelevant',
'observant',
'cognizant',
// -ent
'bent',
'fluorescent',
'interdependent',
'stringent',
'emergent',
'divergent',
'urgent',
'efficient',
'permanent',
'eminent',
'imminent',
'prominent',
'pertinent',
'apparent',
'transparent',
'absent',
'fluent',
'affluent',
'frequent',
'infrequent',
'subsequent',
'consequent',
'congruent',
'insolvent',
'conjoint',
'disjoint',
'in front',
'up front',
'moot',
'apt',
'adept',
'nondescript',
// 'exempt',
'abrupt',
'inert',
'overt',
'covert',
'east',
'abreast',
'steadfast',
'honest',
'populist',
'against',
'most',
'uttermost',
'robust',
'devout',
'kaput',
'next',
'in situ',
'brand new',
'below',
'faux',
'everyday',
'okay',
'nearby',
'muddy',
'speedy',
'moldy',
'handy',
'cutesy',
'creepy',
'sleepy',
'drowsy',
'folksy',
'handsy',
'fiery',
'flowery',
'cheery',
'chintzy',
// -ly
'kindly',
'monthly',
'daily',
'weekly',
'seemly',
'womanly',
'yearly',
'scholarly',
'elderly',
'orderly',
'quarterly',
'neighborly',
'hourly',
'surly',
'nightly',
'many',
'sparkly',
// 'approximately',
// 'fortunately',
'lately',
// 'ultimately',
// -ry
'legendary',
'secondary',
'dreary',
'tertiary',
'primary',
'customary',
'honorary',
'temporary',
'arbitrary',
'contrary',
'necessary',
'supervisory',
'sensory',
'mandatory',
'inhibitory',
'auditory',
'statutory',
'sorry',
'hairy',
'uppity',
'guilty',
'woozy',
// un-prefix that aren't verbs
'unabated',
'unappealing',
'unassuming',
'unattended',
'unauthorized',
'unbecoming',
'unchallenged',
'uncharted',
'unchecked',
'uncircumcised',
'unconvincing',
'undecided',
'under',
'underage',
'undercover',
'underhand',
'underlying',
'underneath',
'underprivileged',
'undersized',
'underwater',
'underway',
'underweight',
'undisclosed',
'undisputed',
'undocumented',
'undue',
'unemployed',
'unending',
'uneven',
'unexpected',
'unexplained',
'unfair',
'unfinished',
'unforeseen',
'unguarded',
'unheard',
'uninsured',
'uninterested',
'uninterrupted',
'uninvited',
'unique',
'universal',
'unknown',
'unmarried',
'unmatched',
'unmet',
'unnamed',
'unnoticed',
'unopposed',
'unpaid',
'unparalleled',
'unprecedented',
'unrecognized',
'unregulated',
'unrelated',
'unrelenting',
'unrequited',
'unreserved',
'unresolved',
'unruly',
'unseen',
'unsettled',
'unsightly',
'unsold',
'unspent',
'unspoken',
'unsupervised',
'unsuspecting',
'untapped',
'untested',
'untold',
'untouched',
'unused',
'unwanted',
'unwarranted',
'unwieldy',
'recent',
'overseas',
'monochrome',
'contradictory',
'satisfactory',
'skilled',
'antique',
'dependent',
'independent',
'modest',
// -ide
'bona fide',
'bonafide',
// -ate
'affectionate',
'celebate',
'corporate',
'illegitimate',
'inconsiderate',
'inordinate',
'proximate',
'renowned',
'beside',
'alright',
'top notch',
'self sufficient',
'middle aged',
'no more',
'ashen',
'scarlet',
'alone',
'homesick',
'longtime',
'bigtime',
'inside',
'outside',
'artsy',
'antsy',
'golden',
'bare',
'subpar',
'ingrown',
'agreeable',
'vile',
'mega',
'frilly',
'indulgent',
'win win',
'strung out',
'whacked out',
'crystal clear',
'skin deep',
'pent up',
'partisan',
'bipartisan',
'ice cold',
'one on one',
'ongoing',
'literary',
'beneath',
'alike',
'mainstream',
'metropolitan',
'overboard',
'mediocre',
'maritime',
'paranoid',
'compulsory',
'hardcore',
'clockwise',
'counterclockwise',
'multifaceted',
'lighthearted',
'belated',
'bestselling',
'breathtaking',
'infinite',
'southwest',
'northwest',
'southeast',
'northeast',
'indie',
'nude',
'destitute',
'obligated',
'naval',
'puzzled',
'overdue',
'overhand',
'overhead',
'hardworking',
'gauche',
'stout',
'abject',
'adamant',
'agile',
// 'articulate',
'astute',
'austere',
'blithe',
'circumspect',
'coy',
'eloquent',
'enough',
'expedient',
'fervent',
'fragrant',
'frugal',
'hoary',
'inane',
'inept',
'jittery',
'maverick',
'obedient',
'offhand',
'orotund',
'rampant',
'reprobate',
'sinister',
'slippery',
'stalwart',
'stubborn',
'sublime',
'thorny',
'trenchant',
'vagrant',
'wanton',
'meager',
'doting',
'crafty',
'morbid',
'acquiescent',
'despondent',
'slipshod',
'contrite',
'recalcitrant',
'merry',
'condescending',
'abstruse',
'erstwhile',
'comatose',
'desultory',
'pert',
'curmudgeonly',
'cogent',
'spry',
'demure',
'docile',
'watery',
'succinct',
'major',
'minor',
'fast paced',
'chewy',
'drunk',
'greasy',
'pointy',
'testy',
'sold out',
]
================================================
FILE: data/lexicon/adjectives/comparables.js
================================================
//adjectives that convert to superlative/comparative form
export default [
'absurd',
'angry',
'awesome',
'bad',
'bald',
'bawdy',
'big',
'bitter',
'black',
'bland',
'blond',
'bloody',
'blue',
'bold',
'bouncy',
'brash',
'brave',
'bright',
'brilliant',
'broad',
'brown',
'buff',
'burly',
'busy',
'cagey',
'cheap',
'cheesy',
'chilly',
'clever',
'cloudy',
'coarse',
'cold',
'common',
'costly',
'cowardly',
'cozy',
'crisp',
'cruel',
'cuddly',
'curly',
'cute',
'dapper',
'dark',
'dead',
'deadly',
'deaf',
'dear',
'deep',
'dense',
'dire',
'dirty',
'divine',
'dizzy',
'drunk',
'dumb',
'early',
'earthly',
'eastern',
'easy',
'eerie',
'essential',
'evil',
'extreme',
'far',
'faulty',
'feeble',
'fierce',
'financial',
'flat',
'flirty',
'foamy',
'fond',
'formal',
'frail',
'fresh',
'friendly',
'full',
'fun',
'funny',
'furry',
'gaudy',
'gay',
'gentle',
'genuine',
'ghastly',
'ghostly',
'giant',
'giddy',
'glad',
'glib',
'gloomy',
'goofy',
'grand',
'gray',
'great',
'greedy',
'green',
'grey',
'grim',
'grisly',
'groovy',
'gross',
'gruesome',
'handsome',
'happy',
'hard',
'hardy',
'harsh',
'heady',
'hearty',
'heavenly',
'heavy',
'hefty',
'hesitant',
'high',
'hilly',
'homely',
'hot',
'huge',
'humble',
'humid',
'hungry',
'icy',
'ill',
'insecure',
'intellegent',
'intermediate',
'intimate',
'jolly',
'juicy',
'keen',
'kind',
'lame',
'large',
'late',
'leery',
'lewd',
'likely',
'lil',
'limp',
'little',
'lively',
'lofty',
'lonely',
'long',
'loose',
'loud',
'lousy',
'lovely',
'low',
'lowly',
'loyal',
'lucky',
'mad',
'measly',
'meaty',
'meek',
'mellow',
'mild',
'moist',
'moody',
'mundane',
'mute',
'naive',
'near',
'neat',
'nerdy',
'new',
'nibbly',
'nice',
'nimble',
'noble',
'noisy',
'normal',
'nosy',
'numb',
'odd',
'oily',
'old',
'orange',
'phony',
'pink',
'plain',
'pleasant',
'polite',
'poor',
'pregnant',
'pricey',
'prickly',
'profound',
'proud',
'puny',
'pure',
'purple',
'quaint',
'quick',
'quiet',
'ragged',
'rainy',
'random',
'rapid',
'rare',
'raw',
'ready',
'real',
'red',
'remote',
'rich',
'ripe',
'ritzy',
'romantic',
'roomy',
'rosy',
'rough',
'round',
'rude',
'sad',
'safe',
'saintly',
'salty',
'savvy',
'scanty',
'scarce',
'scary',
'severe',
'sexy',
'shady',
'shallow',
'sharp',
'shiny',
'shrill',
'shy',
'sick',
'sickly',
'silly',
'simple',
'skinny',
'sleek',
'slender',
'slight',
'slim',
'slimy',
'sly',
'small',
'smart',
'smelly',
'social',
'soft',
'solemn',
'solid',
'soon',
'sore',
'special',
'spicy',
'sprightly',
'stale',
'stark',
'stately',
'steady',
'steep',
'stern',
'stiff',
'straight',
'strange',
'strict',
'strong',
'stupid',
'sturdy',
'substantial',
'subtle',
'sudden',
'superficial',
'surreal',
'sweet',
'swift',
'tall',
'tame',
'tart',
'tawdry',
'tense',
'thick',
'thirsty',
'tidy',
'tight',
'timely',
'tiny',
'tired',
'tough',
'tranquil',
'trendy',
'true',
'ugly',
'vague',
'vain',
'vast',
'verdant',
'vulgar',
'wary',
'weak',
'weary',
'weird',
'whiny',
'white',
'wicked',
'wide',
'wild',
'wily',
'windy',
'wiry',
'wise',
'wry',
'yellow',
'young',
'zany',
]
================================================
FILE: data/lexicon/dates/dates.js
================================================
// uncontroversial date words
export default [
'today',
'tomorrow',
'tmr',
'tmrw',
'yesterday',
'weekend',
'weekends',
'week end',
'ago',
'someday',
'oneday',
]
================================================
FILE: data/lexicon/dates/durations.js
================================================
export default [
'century',
'centuries',
'day',
'days',
'decade',
'decades',
'hour',
'hours',
'hr',
'hrs',
'millisecond',
'milliseconds',
'minute',
'minutes',
// 'min',
'month',
'months',
'sec',
'secs',
// 'week end',
'weekend',
'week',
'weeks',
'wk',
'wks',
'year',
'years',
'yr',
'yrs',
'quarter',
// 'quarters',
'qtr',
'season',
]
================================================
FILE: data/lexicon/dates/months.js
================================================
export default [
// 'january',
'february',
// 'april',
// 'june',
'july',
// 'august',
'september',
'october',
'november',
'december',
//abbreviations are elsewhere
]
================================================
FILE: data/lexicon/dates/weekdays.js
================================================
export default [
'monday',
'tuesday',
'wednesday',
'thursday',
'friday',
'saturday',
'sunday',
'mon',
'tues',
// 'wed',
'thurs',
'fri',
// 'sat',
// 'sun',
'mondays',
'tuesdays',
'wednesdays',
'thursdays',
'fridays',
'saturdays',
'sundays',
]
================================================
FILE: data/lexicon/index.js
================================================
//directory of files to pack with `node scripts/pack.js`
//they are stored in compressed form
import lex from './misc.js'
import demonyms from './nouns/demonyms.js'
import organizations from './nouns/organizations.js'
import possessives from './nouns/possessives.js'
import actors from './nouns/actors.js'
import pronouns from './nouns/pronouns.js'
import singulars from './nouns/singulars.js'
import sportsTeams from './nouns/sportsTeams.js'
import uncountables from './nouns/uncountables.js'
import properNouns from './nouns/properNouns.js'
import cities from './places/cities.js'
import countries from './places/countries.js'
import femaleNames from './people/femaleNames.js'
import firstnames from './people/firstnames.js'
import lastnames from './people/lastnames.js'
import maleNames from './people/maleNames.js'
import honorifics from './people/honorifics.js'
import people from './people/people.js'
import places from './places/places.js'
import regions from './places/regions.js'
import dates from './dates/dates.js'
import months from './dates/months.js'
import weekdays from './dates/weekdays.js'
import durations from './dates/durations.js'
import infinitives from './verbs/infinitives.js'
import modals from './verbs/modals.js'
import phrasals from './verbs/phrasals.js'
import verbs from './verbs/verbs.js'
import participles from './verbs/participles.js'
import adjectives from './adjectives/adjectives.js'
import comparables from './adjectives/comparables.js'
import units from './numbers/units.js'
import ordinals from './numbers/ordinals.js'
import cardinals from './numbers/cardinals.js'
import multiples from './numbers/multiples.js'
import adverbs from './misc/adverbs.js'
import conjunctions from './misc/conjunctions.js'
import currencies from './misc/currencies.js'
import determiners from './misc/determiners.js'
import expressions from './misc/expressions.js'
import prepositions from './misc/prepositions.js'
import actorVerb from './switches/actor-verb.js'
import adjGerund from './switches/adj-gerund.js'
import adjNoun from './switches/adj-noun.js'
import adjPast from './switches/adj-past.js'
import adjPresent from './switches/adj-present.js'
import nounVerb from './switches/noun-verb.js'
import nounGerund from './switches/noun-gerund.js'
import personNoun from './switches/person-noun.js'
import personDate from './switches/person-date.js'
import personVerb from './switches/person-verb.js'
import personPlace from './switches/person-place.js'
import personAdj from './switches/person-adj.js'
import unitNoun from './switches/unit-noun.js'
//add-in the generic, flat word-lists
const data = [
// nouns
[demonyms, 'Demonym'],
[organizations, 'Organization'],
[possessives, 'Possessive'],
[actors, 'Actor'],
[pronouns, 'Pronoun'],
[singulars, 'Singular'],
[sportsTeams, 'SportsTeam'],
[uncountables, 'Uncountable'],
[properNouns, 'ProperNoun'],
// numbers
[ordinals, 'Ordinal'],
[cardinals, 'Cardinal'],
[units, 'Unit'],
[multiples, 'Multiple'],
[cities, 'City'],
[countries, 'Country'],
[places, 'Place'],
[regions, 'Region'],
[weekdays, 'WeekDay'],
[months, 'Month'],
[dates, 'Date'],
[durations, 'Duration'],
[femaleNames, 'FemaleName'], //5kb
[firstnames, 'FirstName'],
[lastnames, 'LastName'], //3k
[maleNames, 'MaleName'], //5kb
[honorifics, 'Honorific'],
[people, 'Person'],
[adjectives, 'Adjective'],
[adverbs, 'Adverb'],
[conjunctions, 'Conjunction'],
[currencies, 'Currency'],
[determiners, 'Determiner'],
[expressions, 'Expression'],
[prepositions, 'Preposition'],
[comparables, 'Comparable'],
[infinitives, 'Infinitive'], //3kb
[modals, 'Modal'],
[verbs, 'Verb'],
[participles, 'Participle'],
[phrasals, 'PhrasalVerb'], //3kb
// switches - 10kb
[actorVerb, 'Actor|Verb'],
[adjGerund, 'Adj|Gerund'],
[adjNoun, 'Adj|Noun'],
[adjPast, 'Adj|Past'],
[adjPresent, 'Adj|Present'],
[nounVerb, 'Noun|Verb'],
[nounGerund, 'Noun|Gerund'],
[personNoun, 'Person|Noun'],
[personPlace, 'Person|Place'],
[personDate, 'Person|Date'],
[personVerb, 'Person|Verb'],
[personAdj, 'Person|Adj'],
[unitNoun, 'Unit|Noun'],
]
for (let i = 0; i < data.length; i++) {
const list = data[i][0]
for (let o = 0; o < list.length; o++) {
// log duplicates
// if (lex[list[o]]) {
// console.log(list[o] + ' ' + lex[list[o]] + ' ' + data[i][1])
// }
const str = list[o]
//do some linting
if (str.match(/[.,0-9-]/) || str.trim().toLowerCase() !== str) {
console.log(`'${str}'`) //eslint-disable-line
}
lex[str] = data[i][1]
}
}
export default lex
// console.log(Object.keys(lex).length);
// console.log(lex[`will want`])
================================================
FILE: data/lexicon/misc/adverbs.js
================================================
// most are generated from adjective list at runtime
export default [
'a lot',
'a posteriori',
'abroad',
'ad nauseam',
'again',
'all but',
'all that',
'almost',
'already',
'also',
'always',
'anymore',
'anyway',
'alongside',
'apart',
'aside',
'as soon',
'at best',
'at large',
'at least',
'at most',
'at worst',
'away',
'by far',
'by now',
'de jure',
'de trop',
'definitely',
'directly',
'en masse',
// 'enough',
'ever',
'for example',
'for good',
'for sure',
'forever',
'fully',
'further',
'furthermore',
'hence',
'indeed',
'instead',
'just about',
'just',
'likewise',
'kinda',
'maybe',
'meanwhile',
'awhile',
'more',
'moreover',
'newly',
'no longer',
'not only',
'not withstanding',
'of course',
'often',
'once again',
'once more',
'once',
'only',
'par excellence',
'per se',
'perhaps',
'point blank',
'quite',
'randomly',
'rather',
'really',
'so',
'somehow',
'sometimes',
'somewhat',
'sort of',
'seldom',
'such',
'then',
'thus',
'too',
'totally',
// 'toward',
'twice',
'up to',
'upwards of',
'tiny bit',
'very',
'well',
'backward',
'hella',
'by no means',
'altogether',
"outright",
'ultimately',
'fucking',
]
================================================
FILE: data/lexicon/misc/conjunctions.js
================================================
export default [
// 'after',
'although',
'and',
'as',
'as far as',
'as if',
// 'as long as',
'as much as',
'as soon as',
'as though',
'because',
'before',
'but',
'by the time',
'cuz',
'even',
'even if',
'even though',
'how',
'however',
'if',
'if only',
'if then',
'if when',
'inasmuch',
'in as much as',
'in case',
'in order that',
'in order to',
'just as',
'no matter',
'nor',
'now',
'now since',
'now that',
'now when',
'or',
'or not',
'otherwise',
'plus',
// 'provided',
'provided that',
'since',
// 'so that',
'supposing',
'than',
'therefore',
'tho',
'though',
// 'till',
'to',
// 'unless',
'until',
'til',
// 'versus',
// 'what',
// 'when',
'whenever',
// 'where',
// 'whereas',
'where if',
'wherever',
'whether',
'while',
'whilst',
'whoever',
// 'whose',
// 'why',
'yet',
'either',
"whereby",
"cos",
"coz",
]
================================================
FILE: data/lexicon/misc/currencies.js
================================================
export default [
'¢',
'$',
'£',
'¥',
'฿',
'₡',
'€',
'₭',
'₨',
'﷼',
'aud',
'baht',
'bitcoin',
'bitcoins',
'cent',
'cents',
'cny',
'denar',
'denars',
'dime',
'dimes',
'dinar',
'dinars',
'dirham',
'dirhams',
'dkk',
'dobra',
'dobras',
'dollar',
'dollars',
'eur',
'euros',
'forint',
'forints',
'franc',
'francs',
'gbp',
'hkd',
'inr',
'jpy',
'kn',
'kr',
'ils',
'krona',
'kronas',
'krw',
'kwanza',
'kwanzas',
'kyat',
'kyats',
'lempira',
'lempiras',
'lira',
'liras',
'pence',
'pences',
'pennies',
'peso',
'pesos',
'pound sterling',
'pound sterlings',
'rouble',
'roubles',
'rp',
'rupee',
'rupees',
'shekel',
'shekels',
'sheqel',
'sheqels',
'shilling',
'shillings',
'sterling',
'sterlings',
'usd',
'xaf',
'xof',
'yen',
'yuan',
'yuans',
'zł',
'zloty',
'zlotys',
'ден',
'лв',
'руб',
]
================================================
FILE: data/lexicon/misc/determiners.js
================================================
export default [
'a',
'an',
'another',
'any',
'both',
'each',
'else',
'every',
'few',
'least',
'much',
'neither',
'own',
'plenty',
'some',
'several',
'that',
'the',
'these',
'this',
'those',
'various',
'whatever',
'whichever',
'tha',
//some other languages (what could go wrong?)
// 'la',
'le',
'les',
'des',
'de',
'du',
'el',
]
================================================
FILE: data/lexicon/misc/expressions.js
================================================
// also called 'interjections'
export default [
'a la',
'ah',
'aha',
'ahem',
'ahoy',
'alas',
'amen',
'argh',
'bah',
'bam',
'boo',
'booya',
'bravo',
'brr',
'bye',
'congratulations',
'cowabunga',
'dammit',
'damn',
'damnit',
'dang',
'drat',
'duh',
'eek',
'eep',
'eh',
'et cetera',
'eww',
'fuck',
'gah',
'gee whiz',
'gee',
'golly',
'good grief',
'goodbye',
'gosh',
'great scott',
'grr',
'haha',
'hahaha',
'hai',
'hallelujah',
'hee',
'hello',
'hey',
'hi',
'hip hip hooray',
'holy cow',
'holy moly',
'holy smokes',
'holy',
'hooray',
'hooyah',
'huh',
'humph',
'hurrah',
'hurray',
'huzzah',
'jeez',
'lah',
'lmao',
'lmfao',
'lol',
'lols',
'meh',
'mmm',
'nah',
'nope',
'oh',
'ohh',
'oi',
'ooh',
'ooo',
'oops',
'ouch',
'ow',
'oy',
'pff',
'phew',
'phooey',
'please',
'plz',
'pow',
'psst',
'sheesh',
'shhh',
'shit',
'tsk',
'tut tut',
'ugh',
'uh huh',
'uh oh',
'uh',
'uhh',
'uhm',
'voila',
'wahoo',
'whee',
'whew',
'whoa',
'whoops',
'word up',
'wow',
'wtaf',
'wtf',
'ya',
'yaa',
// 'yahoo',
'yay',
'yeah',
'yep',
'yes',
'yikes',
'yipee',
'heck',
'yippee',
'yuck',
'yup',
`d'oh`,
'shoo',
'there now',
'aye',
'cmon', //come on
'excuse me',
'oh well',
'oh hell',
'oh my god',
'oh my gosh',
// 'thank you',
'whatsoever',
'btw',
'nevertheless',
'pls',
'ahh',
'sic',
'leh',
'wat',
'omg',
'aka',
'holla',
'very well',
'eureka',
'farewell',
'yea',
'nay',
'yah',
]
================================================
FILE: data/lexicon/misc/prepositions.js
================================================
export default [
'about',
'across',
'after',
'along',
'amid',
'amidst',
'among',
'amongst',
'apropos',
'around',
'as long as',
'as',
'at',
'atop',
'barring',
'besides',
'between',
'bout',
'by',
'chez',
'circa',
'despite',
'down',
'during',
'except',
'for',
'from',
'in',
'into',
'mid',
// 'midst',
'notwithstanding',
'of',
'off',
'on',
'onto',
'out',
'per',
'qua',
'sans',
'since',
'so that',
'such as',
'than',
'through',
'throughout',
'thereby',
'thru',
'till',
'toward',
'towards',
'unlike',
'until',
'up',
'upon',
'versus',
'via',
'vis a vis',
'w/o',
'whereas',
'with',
'with whom',
'within',
'without',
'as a whole',
'in part',
'in effect',
// `'o`,
// `a'`,
// `o'`,
]
================================================
FILE: data/lexicon/misc.js
================================================
export default {
better: 'Comparative',
farther: 'Comparative',
finer: 'Comparative',
fewer: 'Comparative',
earlier: 'Superlative',
sounds: 'PresentTense',
unless: 'Condition',
lest: 'Condition',
said: 'PastTense',
had: 'PastTense',
been: 'PastTense',
began: 'PastTense',
came: 'PastTense',
did: 'PastTense',
meant: 'PastTense',
went: 'PastTense',
taken: 'PastTense',
lied: 'PastTense',
going: 'Gerund',
being: 'Gerund',
according: 'Gerund',
resulting: 'Gerund',
staining: 'Gerund',
doin: 'Gerund',
no: 'Expression',
non: 'Negative',
never: 'Negative',
not: 'Negative',
where: 'QuestionWord',
why: 'QuestionWord',
when: 'QuestionWord',
who: 'QuestionWord',
whom: 'QuestionWord',
whose: 'QuestionWord',
what: 'QuestionWord',
which: 'QuestionWord',
"how's": 'QuestionWord',
'how come': 'QuestionWord',
'myself': 'Reflexive',
'yourself': 'Reflexive',
'yourselves': 'Reflexive',
'theirselves': 'Reflexive',
'himself': 'Reflexive',
'herself': 'Reflexive',
'oneself': 'Reflexive',
'itself': 'Reflexive',
'ourselves': 'Reflexive',
'themselves': 'Reflexive',
'theirself': 'Reflexive',
'ourself': 'Reflexive',
'themself': 'Reflexive',
//misc
records: 'Plural',
feet: 'Plural',
'a few': 'Value',
'ones': 'Plural', //those ones
'dickens': 'Plural',
'greens': 'Plural',
//
'come here': 'Imperative',
'beware': 'Imperative',
// 'go away': 'Imperative',
// 'hurry up': 'Imperative',
// 'make sure': 'Imperative',
// 'stand back': 'Imperative'
// 'subpar': 'Adjective'
// double-conjugations
'kneeled': 'PastTense',
'leaped': 'PastTense',
'msged': 'PastTense',
'bests': 'PresentTense',
// funny switches
'leaves': 'Plural|Verb'
}
================================================
FILE: data/lexicon/nouns/actors.js
================================================
//professions 'lawyer' that aren't covered by verb.to_actor()
export default [
'accountant',
'acquaintance',
'acrobat',
'activist',
'actor',
'actress',
'administrator',
'admiral',
'adolescent',
'adopted',
'adult',
'adventurer',
'advisor',
'agent',
'alien',
'ally',
'analyst',
'anarchist',
'ancestor',
'animator',
'announcer',
'anybody',
'apostle',
'apparition',
'apprentice',
'archbishop',
'aristocrat',
'artisan',
'artist',
'assistant',
'astronaut',
'astronomer',
'athiest',
'athlete',
'attendant',
'attorney',
'aunt',
'auntie',
'author',
'autocrat',
'ayatullah',
'baby',
'baker',
'banker',
'barber',
'baron',
'baroness',
'bartender',
'beatboxer',
'beings',
'creator',
'bicyclist',
'bishop',
'blogger',
'bohemian',
'boogeyman',
'boss',
'boy',
'boyfriend',
'bricklayer',
'bride',
'brigadier',
'bro',
'broker',
'brother',
'buddhist',
'buddy',
'builder',
'burglar',
'businessman',
'businessperson',
'businesswoman',
'butcher',
'cadet',
'captain',
'carer',
'caretaker',
'carpenter',
'cashier',
'celebrity',
'ceo',
'cfo',
'chairman',
'chairwoman',
'champion',
'chancellor',
'chaplain',
'character',
'cheerleader',
'chef',
'chief',
'child',
'chum',
'citizen',
'citizens',
'cleaner',
'cleric',
'clerk',
'client',
'clown',
'coworker',
'colleague',
'colonel',
'columnist',
'comedian',
'commander',
'commenter',
'commissioner',
'companion',
'composer',
'comrade',
'confidant',
'confidante',
'congressman',
'congresswoman',
'constable',
'consultant',
'contact',
'contender',
'contributor',
'controller',
'cook',
'coordinator',
'corporal',
'councillor',
'count',
'countess',
'courier',
'cousin',
'cowboy',
'critic',
'crowd',
'curator',
'customer representative',
'customer',
'dad',
'daddy',
'dancer',
'daredevil',
'darling',
'daughter',
'deacon',
'dealer',
'decorator',
'defenceman',
'deity',
'denizen',
'deputee',
'deputy',
'descendant',
'deserter',
'designer',
'detective',
'developer',
'dictator',
'dietician',
'dietitian',
'diplomat',
'director',
'diva',
'doctor',
'dork',
'drifter',
'driver',
'dude',
'dutchess',
'dweller',
'economist',
'editor',
'elder',
'electrician',
'emcee',
'emperor',
'employee',
'employer',
'enemy',
'engineer',
'entrepreneur',
'environmentalist',
'everybody',
'examiner',
'excellency',
'exile',
'family',
'farmer',
'father',
'fella',
'fellow',
'female',
'fiance',
'fighter',
'filmmaker',
'financier',
'fire marshal',
'firefighter',
'fireman',
'first lady',
'fitter',
'foe',
'forebear',
'foreman',
'forerunner',
'forester',
'foster parent',
'freelancer',
'friend',
'gal',
'gambler',
'gardener',
'geek',
'geisha',
'genius',
'gentleman',
'ghost',
'ghostwriter',
'girl',
'girlfriend',
'gladiator',
'goalie',
'goalkeeper',
'goaltender',
'god',
'goddess',
'golfer',
'grandchild',
'granddaughter',
'grandfather',
'grandma',
'grandmother',
'grandpa',
'grandparent',
'grandson',
'groom',
'guard',
'guest',
'guru',
'hairdresser',
'hairstylist',
'heir',
'hermit',
'hero',
'heroine',
'historian',
'hobo',
'host',
'hostage',
'hostess',
'housekeeper',
'human',
'humanitarian',
'hunter',
'husband',
'hygienist',
'icon',
'idol',
'illustrator',
'immigrant',
'in law',
'incel',
'individual',
'infant',
'inhabitant',
'innovator',
'inspector',
'installer',
'instigator',
'instructor',
'intern',
'inventor',
'investigator',
'jester',
'jogger',
'journalist',
'judge',
'juggler',
'kid',
'kin',
'king',
'kinsman',
'kinswoman',
'laborer',
'lad',
'lady',
'landlord',
'lass',
'laureate',
'lawyer',
'layman',
'leader',
'lieutenant',
'lord',
'loser',
'lover',
'magician',
'magistrate',
'magnate',
'maker',
'male',
'man',
'manager',
'maniac',
'martyr',
'mason',
'master',
'mate',
'matriarch',
'mayor',
'mechanic',
'mentor',
'merchant',
'minion',
'minister',
'misfit',
'missus',
'mister',
'model',
'moderator',
'mogul',
'mom',
'mommy',
'monarch',
'monk',
'mother',
'mum',
'mummy',
'musician',
'mystic',
'nanny',
'narrator',
'native',
'neice',
'neighbor',
'nemesis',
'nephew',
'nerd',
'niece',
'nobleman',
'noblewoman',
'nobody',
'nomad',
'novice',
'nun',
'nurse',
'nurseryman',
'occupant',
'officer',
'offspring',
'operator',
'optimist',
'optometrist',
'oracle',
'organizer',
'originator',
'orphan',
'outcast',
'outlaw',
'painter',
'pal',
'panellist',
'parent',
'parental',
'pariah',
'partner',
'pastor',
'patriarch',
'patriot',
'patron',
'pawn',
'peer',
'performer',
'person',
'pessimist',
'phantom',
'pharmacist',
'philosopher',
'photographer',
'phrase',
'physician',
'pilgrim',
'pilot',
'pioneer',
'planner',
'player',
'playmate',
'playwright',
'plumber',
'podcaster',
'poet',
'policeman',
'political scientist',
'politician',
'population',
'pornstar',
'practitioner',
'prankster',
'preacher',
'president',
'priest',
'priestess',
'prime minister',
'prince',
'princess',
'prisoner',
'prodigy',
'producer',
'professor',
'progenitor',
'progeny',
'programmer',
'prophet',
'prospector',
'prostitute',
'psychologist',
'punk',
'pupil',
'quarterback',
'queen',
'rabbi',
'radical',
'rapper',
'realist',
'receptionist',
'recluse',
'recruiter',
'refugee',
'relative',
'reporter',
'researcher',
'reverend',
'revolutionary',
'rival',
'rogue',
'role model',
'roofer',
'ruler',
'runner up',
'runningback',
'sailor',
'saint',
'scholar',
'scientist',
'scion',
'scout',
'screenwriter',
'sculptor',
'secretary',
'senior citizen',
'sergeant',
'servant',
'servitor',
'shaman',
'shepherd',
'showgirl',
'showman',
'showrunner',
'sibling',
'singer',
'sinner',
'sissy',
'sister',
'skier',
'smuggler',
'soldier',
'soloist',
'somebody',
'someone',
'son',
'sorcerer',
'sorceress',
'soul',
'sovereign',
'specialist',
'spectator',
'spirit',
'spokesperson',
'spouse',
'squatter',
'staffer',
'star',
'statesman',
'stepbrother',
'stepchild',
'stepfather',
'stepmother',
'stepsister',
'stranger',
'streamer',
'student',
'sultan',
'superhero',
'superhuman',
'superintendent',
'superstar',
'supervisor',
'surfer',
'surgeon',
'survivor',
'sweeper',
'sweetheart',
'taoiseach',
'teacher',
'technician',
'technologist',
'teen',
'teenager',
'tenant',
'tester',
'therapist',
'tiktoker',
'toddler',
'tourist',
'trader',
'tramp',
'transcriptionist',
'traveler',
'trendsetter',
'trooper',
'tutor',
'tycoon',
'uncle',
'underwriter',
'user',
'vagabond',
'veteran',
'veterinarian',
'villain',
'vip',
'visionary',
'visitor',
'voyager',
'wage earner',
'waiter',
'wanderer',
'warrior',
'weatherman',
'welder',
'wife',
'winner',
'witch',
'wizard',
'woman',
'worker',
'wrestler',
'writer',
'yogi',
'youth',
'youtuber',
]
================================================
FILE: data/lexicon/nouns/demonyms.js
================================================
//adjectival forms of place names, as adjectives.
export default [
'afghan',
'african',
'albanian',
'algerian',
'american',
'angolan',
'argentine',
'armenian',
'asian',
'aussie',
'australian',
'austrian',
'bangladeshi',
'belarusian',
'belgian',
'bolivian',
'bosnian',
'brazilian',
'brit',
'bulgarian',
'californian',
'cambodian',
'cameroonian',
'canadian',
'chadian',
'chilean',
'chinese',
'colombian',
'congolese',
'croat',
'croatian',
'cuban',
'czech',
'dane',
'dominican',
'dutch',
'ecuadorian',
'egyptian',
'emirati',
'englishman',
'estonian',
'ethiopian',
'european',
'filipino',
'french',
'gambian',
'georgian',
'german',
'ghanaian',
'greek',
'guatemalan',
'haitian',
'hindi',
'honduran',
'hungarian',
'icelandic',
'indian',
'indonesian',
'iranian',
'iraqi',
'irishman',
'israeli',
'italian',
'ivorian', // of Ivory Coast
'jamaican',
'japanese',
'jordanian',
'kazakh',
'kenyan',
'korean',
'kuwaiti',
'lao', // of Laos
'latvian',
'lebanese',
'liberian',
'libyan',
'lithuanian',
'macedonian',
'malagasy', // of Madagascar
'malaysian',
'mexican',
'mongolian',
'moroccan',
'namibian',
'nicaraguan',
'nigerian', // of Nigeria
'nigerien', // of Niger
'norwegian',
'omani',
'pakistani',
'palestinian',
'panamanian',
'paraguayan',
'peruvian',
'philippine',
'portuguese',
'puerto rican',
'qatari',
'romanian',
'russian',
'rwandan',
'samoan',
'saudi',
'scottish',
'senegalese',
'serbian',
'singaporean',
'slovak',
'somalian',
'spaniard',
'sudanese',
'swede',
'swiss',
'syrian',
'taiwanese',
'thai',
'texan',
'trinidadian',
'tunisian',
'turkmen',
'ugandan',
'ukrainian',
'venezuelan',
'vietnamese',
'welsh',
'zambian',
'zimbabwean',
// 'pole',
]
================================================
FILE: data/lexicon/nouns/organizations.js
================================================
//just a few named-organizations
//no acronyms needed. no product/brand pollution.
export default [
// 'abc',
'academy of sciences',
'acer',
'activision blizzard',
'activision',
'adidas',
'aig',
'airbnb',
'al jazeera',
'al qaeda',
'alcatel lucent',
'alcatel',
'altair',
'amc',
'amd',
'american express',
'amt',
'amtrak',
'anheuser busch',
'aol',
'apple computers',
'argos',
'armco',
'ashland oil',
'associated press',
'autodesk',
'avis',
'avon',
'ayer',
'baidu',
'banana republic',
'basf',
'baskin robbins',
'baxter',
'bayer',
'bbc',
'bechtel',
'berkshire hathaway',
'bf goodrich',
'bfgoodrich',
'blockbuster video',
'bloomingdale',
'blue cross',
'bmw',
'bni',
'boeing',
'bombardier',
'boston globe',
'boston pizza',
'bp',
'cadbury',
'capital one',
'cbc',
'chevron',
'chevy',
'chick fil a',
'china daily',
'cia',
'cisco systems',
'cisco',
'citigroup',
'cloudflare',
'cnn',
'coca cola',
'coinbase',
'colgate',
'comcast',
'compaq',
'coors',
'costco',
'craigslist',
'crossrail',
'daimler',
'dea',
'dell',
'der spiegel',
'disney',
'doj',
'dow jones',
'dunkin donuts',
'dupont',
'ebay',
'esa',
'eu',
'exxon mobil',
'exxonmobil',
'facebook',
'fannie mae',
'fbi',
'fda',
'fedex',
'fiat',
'financial times',
'firestone',
'ford',
'foxcon',
'frito lay',
'general electric',
'general motors',
'ghq',
'github',
'glaxo smith kline',
'glencore',
'gmb',
'goldman sachs',
'goodyear',
'google',
'gucci',
'hasbro',
'hewlett packard',
'hitachi',
'hizbollah',
'home depot',
'honda',
'hsbc',
'hyundai',
'ibm',
'ihop',
'ing',
'intel',
'interpol',
'itv',
'jiffy lube',
'jpmorgan chase',
'jpmorgan',
'jsa',
'katv',
'kfc',
'kkk',
'kmart',
'kodak',
'la presse',
'la z boy',
'labour party',
'lenovo',
'lexis',
'lexmark',
'lg',
'little caesars',
'mattel',
'mazda',
'mcdonalds',
'medicaid',
'medicare',
'mercedes benz',
'microsoft',
'mitas',
'mitsubishi',
'mlb',
'mobil',
'monsanto',
'motorola',
'mtv',
'myspace',
'nandos',
'nasa',
'nascar',
'nasdaq',
'national academy of sciences',
'nato',
'natwest',
'nba',
'nbc',
'nec',
'nestle',
'netflix',
'new york times',
'newsweek',
'nfl',
'nhl',
'nhs',
'nike',
'nintendo',
'nissan',
'nokia',
'notre dame',
'novartis',
'nsa',
'nvidia',
'nwa',
'old navy',
'opec',
'orange julius',
'oxfam',
'palantir',
'pan am',
'panasonic',
'panda express',
'paypal',
'pbs',
'pepsico',
'petrobras',
'petrochina',
'petronas',
'peugeot',
'pfizer',
'philip morris',
'pizza hut',
'premier oil',
'prudential',
'quantas',
'rbc',
'rbs',
'readers digest',
'red bull',
'red cross',
'red lobster',
'remax',
'revlon',
'royal bank',
'royal dutch shell',
'ryanair',
'safeway',
'salesforce',
'samsung',
'seagate',
'sears',
'siemens',
'snp',
'sony',
'squarespace',
'starbucks',
'statoil',
'subaru',
't mobile',
'taco bell',
'td bank',
'telefonica',
'telus',
'tencent',
'tesco',
'tesla motors',
'texas instruments',
'tgi fridays',
'the daily mail',
'tim hortons',
'tmz',
'toshiba',
'toyota',
'toys r us',
'twitter',
'uber',
'ubs',
'ukip',
'unesco',
'unilever',
'united nations',
'ups',
'usa today',
'usps',
'verizon',
'visa',
'vodafone',
'volkswagen',
'volvo',
'walgreens',
'wall street journal',
'walmart',
'warner bros',
'wells fargo',
'westfield',
'westinghouse',
'world trade organization',
'xiaomi',
'yahoo!',
'yamaha',
'ymca',
'yougov',
'youtube',
'ywca',
// 'mercedes',
`applebees`,
`applebees`,
`arbys`,
`carls jr`,
`le oreal`, //l'oreal
`macs milk`,
`mcdonalds`,
`quiznos`,
`sainsburys`,
//some bands
'abba',
'ac/dc',
'aerosmith',
'bee gees',
'coldplay',
'creedence clearwater revival',
'def leppard',
'depeche mode',
'duran duran',
'fleetwood mac',
'green day',
'guns n roses',
'joy division',
'metallica',
'moody blues',
'motley crue',
'new kids on the block',
'pink floyd',
// 'r.e.m.',
'radiohead',
'red hot chili peppers',
'sex pistols',
'soundgarden',
'spice girls',
'the beach boys',
'the beatles',
'the black eyed peas',
'the byrds',
'the carpenters',
'the guess who',
'the hollies',
// 'the rolling stones',
'the smashing pumpkins',
'the supremes',
'the who',
'thin lizzy',
// 'u2',
'van halen',
`destiny's child`,
// other groups
'eurosceptics',
'brexiteers',
'audi',
'bacardi',
'cadillac',
'coco chanel',
'fc barcelona',
'fifa',
'halliburton',
'ikea',
'klm',
'lexus',
// 'mcgill university',
'michelin',
'nivea',
'pepsi',
'philips',
'premier league',
'real madrid',
'roman empire',
'scientology',
'smirnoff',
'wikileaks',
'wikipedia',
]
================================================
FILE: data/lexicon/nouns/possessives.js
================================================
export default [
// 'her', //this one is check ambiguous
// 'hers',
// 'his',
'its',
'mine',
'my',
// 'none',
'our',
'ours',
'thy',
// 'their',
// 'theirs',
// 'your',
// 'yours',
]
================================================
FILE: data/lexicon/nouns/pronouns.js
================================================
export default [
'it',
'they',
'i',
'them',
'you',
'she',
'me',
'he',
'him',
'us',
'we',
'thou',
'thee',
'il',
'elle',
// `'em`,
]
================================================
FILE: data/lexicon/nouns/properNouns.js
================================================
// properNouns
export default [
'mercedes',
'barbie',
'catalina',
'christi',
'diego',
'elmo',
'franco',
'kirby',
'mickey',
'finn',
'missy',
'florence',
'stevens',
'abid',
'mcgill',
'hudson',
'chesley',
'carling',
'berkeley',
'beeton',
'carleton',
'ajax',
'weston',
'sherwood',
'wembley',
'hinton',
'bentley',
'landsdowne',
'brock',
'dalhousie',
'spalding',
'charlton',
'rothwell',
'gosford',
'frampton',
'fairview',
// currencies
'nis',
'riel',
'euro',
'iron maiden',
]
================================================
FILE: data/lexicon/nouns/relative-prounoun.js
================================================
export default [
'whatever',
'whatsoever',
'whichever',
'whichsoever',
'whoever',
'whom',
'whomever',
'whomsoever',
'whose',
'whosesoever',
'whosoever',
// 'that',
// 'when',
// 'which',
// 'who',
]
================================================
FILE: data/lexicon/nouns/singulars.js
================================================
//most nouns do not nead to be listed
// for whatever reasons, these look like not-nouns
// they are all inflected to add their plural form
export default [
// -ic
'medic',
'ethic',
'republic',
'colic',
'garlic',
'picnic',
'tunic',
'topic',
'fabric',
'rhetoric',
'tic',
'tactic',
'characteristic',
'statistic',
// -ed
'seabed',
'waterbed',
'riverbed',
'hotbed',
'moped',
'eyelid',
'pyramid',
'lipid',
'grid',
'dividend',
'stipend',
'way around',
'credit card',
'security guard',
'tribe',
'downside',
'upside',
'voltage',
'advantage',
'percentage',
'shortage',
'cottage',
'whale',
// -ble
'syllable',
'vegetable',
'timetable',
'turntable',
'crucible',
'mandible',
'example',
'home',
'someone',
'headphone',
'press release',
'premise',
'highrise',
'sunrise',
'purpose',
// -ate
'rebate',
'certificate',
'frigate',
'surrogate',
'opiate',
'chocolate',
'plate',
'template',
'consulate',
'pate',
'default rate',
'vertebrate',
'invertebrate',
'carbohydrate',
'electorate',
'doctorate',
'nitrate',
'substrate',
'acetate',
'us state',
'estate',
'prostate',
'plebiscite',
'luddite',
'urbanite',
'respite',
'rite',
'site',
'appetite',
'anecdote',
'antidote',
'keynote',
'coyote',
'flute',
'plaque',
'cheque',
'communique',
'torque',
'mosque',
// -ive
'prerogative',
'objective',
'disincentive',
'motive',
'haze',
'egg',
'pig',
// -ing
'pudding',
'thing',
'nothing',
'banking',
'ceiling',
'evening',
'morning',
'sibling',
'inning',
'lunch',
'breakthrough',
'trough',
'blemish',
'skirmish',
'garnish',
'varnish',
'death',
'question mark',
// -al
'accrual',
'acquittal',
'burial',
'capital',
'cathedral',
'cereal',
'corral',
'decal',
'deferral',
'denial',
'funeral',
'hospital',
'mammal',
'material',
'metal',
'mineral',
'mural',
'ordeal',
'pedestal',
'petal',
'portal',
'rebuttal',
'recital',
'referral',
'subtotal',
'tutorial',
'urinal',
'record label',
'skill',
'high school',
'christmas carol',
'handful',
'bowl',
'super bowl',
'team',
'grand slam',
'problem',
'ad hominem',
'system',
'room',
'chrysanthemum',
'bean',
'ocean',
'student loan',
'skeleten',
'kitten',
'heaven',
'raven',
'oven',
'cousin',
'gelatin',
'tax return',
'home run',
'cellar',
'us dollar',
'exemplar',
'civil war',
// -er
'number',
'wafer',
'glacier',
'grenadier',
'cahier',
'chandelier',
'pier',
'copier',
'photocopier',
'occupier',
'drier',
'tier',
'barrier',
'carrier',
'dossier',
'frontier',
'metier',
'reformer',
'dinner',
'door',
'indices',
'others',
'caucus',
'dialect',
'aspect',
'prospect',
'insect',
'intellect',
'verdict',
'district',
'free market',
'human right',
// -ent
'scent',
'ascent',
'incident',
'rodent',
'student',
'coefficient',
'client',
'quotient',
'talent',
'referent',
'deterrent',
'discontent',
'extent',
'event',
'head start',
'breakfast',
// -ist
'waist',
'bout',
'overview',
'tv show',
't rex',
'array',
'way',
'tragedy',
'body',
'doggy',
'effigy',
'clergy',
'allergy',
'energy',
'synergy',
// -ly
'anomaly',
'gadfly',
'firefly',
'dragonfly',
'butterfly',
'mayfly',
'family',
'doily',
'ally',
'belly',
'jelly',
'folly',
'gully',
'monopoly',
'panoply',
'tummy',
'economy',
'fanny',
'bunny',
'puppy',
// -ry
'salary',
'burglary',
'vocabulary',
'canary',
'granary',
'military',
'dignitary',
'documentary',
'notary',
'city',
'guy',
'school',
'bar',
'prediction',
'pie',
'rerun',
'menu',
'owner',
'coke',
'conservatory',
'caterpillar',
'collar',
'fetish',
'attic',
'borough',
'adjective',
'initiative',
'narrative',
'perspective',
'incentive',
'parish',
'tv',
'stone',
'tributary',
'flower',
'sandwich',
'x ray',
'dump truck',
'soft serve',
'car',
'strategy',
'piggy',
'thingy',
'peanut',
'accident',
'journal',
'tribunal',
'ritual',
'decimal',
'pedal',
'canal',
'alien',
'chicken',
'haven',
'mitten',
'pathogen',
'sapien',
'autopsy',
'embassy',
'pussy',
'spin off',
'lay up',
'leg up',
'poppy',
'epidemic',
'row',
'drive thru',
'hash brown',
// 'living room',
'seminar',
'variety',
'laboratory',
'programme',
'legend',
'fiend',
'cloth',
'institute',
'tonite',
'paradise',
'enterprise',
'lime',
'magnate',
'hormone',
'outspoken',
'medal',
'recipient',
'heist',
'signatory',
'narcotic',
'threesome',
'foursome',
'biopic',
'arsenal',
'oatmeal',
'sabbatical',
'missive',
'hussy',
'cane',
'overtime',
'preposition',
'disposition',
'stake',
'nite',
'prop',
'sect',
'mischief',
'marsupial',
'statute',
'mic',
'clinic',
'mould',
'peyote',
'gypsy',
'granny',
'vet',
'suite',
'uncoordinated',
'latch',
'deathbed',
'tunnel',
'intern',
'tribute',
'intent',
'undertone',
'underestimate',
'underwear',
'word',
'overview',
'yo yo',
'phone call',
'brick',
'cannibal',
'video game',
'layer',
'canton',
]
================================================
FILE: data/lexicon/nouns/sportsTeams.js
================================================
export default [
//mlb
'arizona diamondbacks',
'atlanta braves',
'baltimore orioles',
'boston red sox',
'chicago cubs',
'chicago white sox',
'cincinnati reds',
'cleveland indians',
'cleveland guardians',
'colorado rockies',
'detroit tigers',
'houston astros',
'miami marlins',
'milwaukee brewers',
'minnesota twins',
'oakland athletics',
'philadelphia phillies',
'pittsburgh pirates',
'seattle mariners',
'texas rangers',
'toronto blue jays',
'washington nationals',
'tampa bay rays',
'new york mets',
'new york yankees',
'san diego padres',
'kansas city royals',
'los angeles dodgers',
'san francisco giants',
'st louis cardinals',
'diamondbacks',
'white sox',
'astros',
'dodgers',
'mets',
'yankees',
'phillies',
'padres',
//nba
'boston celtics',
'brooklyn nets',
'new york knicks',
'toronto raptors',
'chicago bulls',
'cleveland cavaliers',
'detroit pistons',
'indiana pacers',
'milwaukee bucks',
'atlanta hawks',
'charlotte hornets',
'miami heat',
'orlando magic',
'washington wizards',
'dallas mavericks',
'houston rockets',
'memphis grizzlies',
'denver nuggets',
'utah jazz',
'minnesota timberwolves',
'new orleans pelicans',
'san antonio spurs',
'portland trail blazers',
'oklahoma city thunder',
'golden state warriors',
'los angeles clippers',
'los angeles lakers',
'phoenix suns',
'sacramento kings',
'knicks',
'lakers',
'celtics',
// 'philadelphia 76ers',
//nfl
'arizona cardinals',
'atlanta falcons',
'baltimore ravens',
'buffalo bills',
'carolina panthers',
'chicago bears',
'cincinnati bengals',
'cleveland browns',
'dallas cowboys',
'denver broncos',
'detroit lions',
'green bay packers',
'houston texans',
'indianapolis colts',
'jacksonville jaguars',
'kansas city chiefs',
'miami dolphins',
'minnesota vikings',
'new england patriots',
'new orleans saints',
'new york giants',
'new york jets',
'oakland raiders',
'philadelphia eagles',
'pittsburgh steelers',
'san diego chargers',
// 'san francisco 49ers',
'seattle seahawks',
'st louis rams',
'tampa bay buccaneers',
'tennessee titans',
'washington redskins',
//mls
'chicago fire',
'colorado rapids',
'columbus crew sc',
'fc dallas',
'houston dynamo',
'la galaxy',
'montreal impact',
'new england revolution',
'new york red bulls',
'philadelphia union',
'portland timbers',
'real salt lake',
'san jose earthquakes',
'seattle sounders',
'sporting kansas city',
'vancouver whitecaps',
// 'new york city fc',
// 'atlanta united',
// 'dc united',
// 'minnesota united',
//premier league soccer (mostly city+fc)
'aston villa',
'blackburn rovers',
'cardiff city',
'leicester city',
'manchester city',
'queens park rangers',
'stoke city',
'tottenham hotspur',
// 'sheffield united',
// 'manchester united',
// 'newcastle united',
// 'west ham united',
]
================================================
FILE: data/lexicon/nouns/uncountables.js
================================================
//common nouns that have no plural form. These are suprisingly rare
//used in noun.inflect(), and added as nouns in lexicon
export default [
'acid',
'acoustics',
'advice',
'aerobics',
'aerodynamics',
'aeronautics',
'aircraft',
'amends',
'amnesty',
'anger',
'anise',
'anyone',
'anything',
'appeal court',
'arithmetic',
'arsenic',
'aspirin',
'athletics',
'baggage',
'bass',
'billiards',
'bison',
'blood',
'bowling',
'bread',
'breadth',
'bunting',
'butter',
'cad',
'cards',
'celcius',
'chaos',
'cheese',
'chewing',
'civics',
'classics',
'clothes',
'coal',
'cold war',
'commentary',
'confusion',
'cont ed',
'coral',
'cotton',
'couscous',
'currency',
'debut',
'demise',
'diabetes',
'dice',
'dishonesty',
'disrepute',
'dope',
'downstairs',
'draughts',
'dynasty',
'earnings',
'economics',
'education',
'electricity',
'electronics',
'enjoyment',
'entertainment',
'equipment',
'ethics',
'everybody',
'everyone',
'everything',
'existence',
'expertise',
'fahrenheit',
'fate',
'feeling',
'fiction',
'fish',
'flour',
'food',
'forgiveness',
'fourier',
'fowl',
'furniture',
'gene editing',
'gene pool',
'genetics',
'gluten',
'glycerin',
'golf',
'gore',
'granite',
'grass',
'greed',
'gum',
'gymnastics',
'hair',
'halibut',
'happiness',
'hashish',
'haste',
'headquarters',
'here',
'hertz',
'history',
'hockey',
'homework',
'honesty',
'honey',
'hooky',
'horseradish',
'hospitality',
'house arrest',
'hunger',
'ice',
'ignorance',
'impatience',
'importance',
'improv',
'information',
'internet',
'interstate',
'jazz',
'jeans',
'jellyfish',
'jewelry',
'karate',
'kindergarten',
'knickers',
'knowledge',
'laughter',
'leather',
'leisure',
'less',
'lice',
'lightning',
'linguistics',
'literature',
'liver',
'logic',
'logistics',
'luck',
'luggage',
'machine learning',
'machinery',
'majesty',
'make up',
'mathematics',
'measles',
'meat',
'mechanics',
'merchandise',
'metallurgy',
'money',
'monogamy',
'moose',
'mumps',
'music',
'nail polish',
'national security',
'news',
'nowadays',
'obstetrics',
'overcrowding',
'oxygen',
'panties',
'pants',
'parking',
'patience',
'peace',
'petrol',
'phys ed',
'physics',
'plastic',
'politics',
'pollen',
'polygamy',
'pork',
'preamble',
'premises',
'presense',
'pressure',
'pretense',
'putty',
'rabies',
'recognition',
'recreation',
'reins',
'relaxation',
'research',
'rice',
'rickets',
'sadness',
'safety',
'salmon',
'salt',
'sand',
'satish',
'scenery',
'scissors',
'seating',
'self',
'senate',
'series',
'sheep',
'shingles',
'shopping',
'shorts',
'silk',
'silver',
'skin',
'skittles',
'soap',
'soccer',
'something',
'spacecraft',
'species',
'spite',
'static',
'statistics',
'steam',
'steel',
'sugar',
'sunshine',
'sushi',
'sweepstakes',
'tea',
'tennis',
'there',
'thermodynamics',
'thunder',
'time off',
'tin',
'tonight',
'toothpaste',
'townfolk',
'townsfolk',
'traffic',
'treatise',
'troops',
'trouble',
'troubleshooting',
'trousers',
'trout',
'true north',
'tuna',
'tungsten',
'tyranny',
'vernacular',
'vinegar',
'violence',
'vitae',
'warmth',
'water',
'whisky',
'wildlife',
'wine',
'wood',
'wool',
'you guys',
'nutella',
'vanilla',
'venus',
'earth',
'mars',
'jupiter',
'saturn',
'uranus',
'neptune',
'pluto',
'vapor',
'magic',
'melancholy',
// 'art',
// 'cash',
// 'clothing',
// 'gold',
// 'ground',
// 'justice',
// 'kelvin',
// 'mail',
// 'power',
// 'progress',
// 'snow',
// 'speed',
// 'spite',
// 'time',
// 'vanilla',
]
================================================
FILE: data/lexicon/numbers/cardinals.js
================================================
export default [
'zero',
'one',
'two',
'three',
'four',
'five',
'six',
'seven',
'eight',
'nine',
'ten',
'eleven',
'twelve',
'thirteen',
'fourteen',
'fifteen',
'sixteen',
'seventeen',
'eighteen',
'nineteen',
'twenty',
'thirty',
'forty',
'fourty',
'fifty',
'sixty',
'seventy',
'eighty',
'ninety',
// plural-multiples
'thousands',
'millions',
'billions',
'trillions',
]
================================================
FILE: data/lexicon/numbers/multiples.js
================================================
export default [
'hundred',
'thousand',
'million',
'billion',
'trillion',
'quadrillion',
'quintillion',
'sextillion',
'septillion',
]
================================================
FILE: data/lexicon/numbers/ordinals.js
================================================
export default [
'zeroth',
'first',
'second',
'third',
'fourth',
'fifth',
'sixth',
'seventh',
'eighth',
'ninth',
'tenth',
'eleventh',
'twelfth',
'thirteenth',
'fourteenth',
'fifteenth',
'sixteenth',
'seventeenth',
'eighteenth',
'nineteenth',
'twentieth',
'thirtieth',
'fortieth',
'fourtieth',
'fiftieth',
'sixtieth',
'seventieth',
'eightieth',
'ninetieth',
]
================================================
FILE: data/lexicon/numbers/units.js
================================================
// ambigous units are in ../switches/unit-noun.js
// units that are also abbreviations are in ../abbrev/units.js
export default [
'°c',
'celsius',
'°f',
'fahrenheit',
'kelvins',
'°n',
'm³',
'dm³',
'cm³',
'litre',
'litres',
'liter',
'liters',
'deciliter',
'deciliters',
'centiliter',
'centiliters',
'milliliter',
'milliliters',
'in³',
'ft³',
'yd³',
'gallon',
'gallons',
'bbl',
'pint',
'pints',
'quart',
'quarts',
'fl oz',
// 'fluid ounce',
// 'fluid ounces',
'kilometer',
'kilometers',
'meter',
'meters',
'decimeter',
'decimeters',
'centimeter',
'centimeters',
'millimeter',
'millimeters',
'mile',
'tonne',
'tonnes',
'kilo',
'kilos',
'kilogram',
'kilograms',
'hectogram',
'hectograms',
'gram',
'grams',
'decigram',
'decigrams',
'centigram',
'centigrams',
'milligram',
'milligrams',
'µg',
'microgram',
'micrograms',
'carat',
'carats',
'ounce',
'ounces',
'ton',
'km²',
'm²',
'dm²',
'cm²',
'mm²',
'hectare',
'hectares',
'mile²',
'in²',
'yd²',
'ft²',
'sq ft',
'acre',
'acres',
'hertz',
'hertzs',
'km/h',
'kmph',
'm/s',
'mi/h',
'knot',
'knots',
'byte',
'bytes',
'kilobyte',
'kilobytes',
'megabyte',
'megabytes',
'gigabyte',
'gigabytes',
'terabyte',
'terabytes',
'petabyte',
'petabytes',
'exabyte',
'exabytes',
'zettabyte',
'zettabytes',
'yottabyte',
'yottabytes',
'kbps',
'bbps',
'gbps',
'joule',
'joules',
'pascals',
'watt',
'watts',
'wb',
'coulomb',
'coulombs',
'volts',
'farad',
'farads',
'ohms',
'lux',
'lumen',
'lumens',
'µs',
'microsecond',
'microseconds',
'nanosecond',
'nanoseconds',
'picosecond',
'picoseconds',
'femtosecond',
'femtoseconds',
'attosecond',
'attoseconds',
'percent',
'year old',
'years old',
]
================================================
FILE: data/lexicon/people/femaleNames.js
================================================
//names with a distinctive signal that they identify as a female, internationally
export default [
'aada',
'aadya',
'aaliyah',
'aaradhya',
'aasha',
'abagail',
'abbey',
'abbi',
'abbie',
'abby',
'abi',
'abigail',
'abril',
'ada',
'adaline',
'adalyn',
'addie',
'addilyn',
'addison',
'adel',
'adela',
'adelaide',
'adele',
'adelene',
'adelia',
'adelina',
'adeline',
'adelynn',
'adreanna',
'adriana',
'adrianna',
'adrianne',
'adriena',
'adriene',
'adrienne',
'agatha',
'aggie',
'agnes',
'agustina',
'aicha',
'aida',
'aileen',
'aimee',
'aina',
'aino',
'ainsley',
'aisha',
'aishah',
'aisling',
'aislinn',
'aislynn',
'ajla',
'alaina',
'alana',
'alanis',
'alanna',
'alannah',
'alanoud',
'alayah',
'alayna',
'alba',
'alecia',
'aleisha',
'alejandra',
'aleksandra',
'alena',
'alesia',
'alessandra',
'alexa',
'alexandra',
'alexia',
'alia',
'alice',
'alicia',
'alicja',
'alina',
'aline',
'alisa',
'alise',
'alisha',
'alison',
'alissa',
'aliza',
'allie',
'allison',
'allyson',
'althea',
'alya',
'alycia',
'alysa',
'alyson',
'alyssa',
'amahle',
'amaia',
'amaira',
'amalia',
'amanda',
'amber',
'amberly',
'amelia',
'amelija',
'amie',
'amilia',
'amina',
'aminata',
'amy',
'ana',
'anabel',
'anamaria',
'anastasia',
'anastasija',
'anaya',
'andjela',
'ane',
'anette',
'angela',
'angelia',
'angelica',
'angelina',
'angeline',
'angelique',
'angie',
'anika',
'anisa',
'anissa',
'anita',
'anja',
'anjelica',
'ann',
'anna',
'annabel',
'annabella',
'annabelle',
'annalisa',
'annamaria',
'anne',
'annemarie',
'annette',
'annie',
'annika',
'annmarie',
'anohito',
'antoinette',
'antonella',
'antonia',
'anya',
'aoi',
'aria',
'ariana',
'arianna',
'arianne',
'arielle',
'arleen',
'arlena',
'arlene',
'arlette',
'aroha',
'arpita',
'asha',
'ashanti',
'ashlee',
'ashleigh',
'ashley',
'ashli',
'ashlie',
'ashly',
'ashlyn',
'ashraqat',
'ashton',
'asiya',
'asja',
'asmita',
'assil',
'astrid',
'ataahua',
'athena',
'audra',
'audrey',
'audri',
'audry',
'augustina',
'aurelia',
'austeja',
'ava',
'avigail',
'awa',
'aya',
'ayn',
'ayana',
'ayanna',
'ayesha',
'aygun',
'aylin',
'ayse',
'aysel',
'azra',
'azuna',
'barbara',
'barbora',
'barbra',
'bayarmaa',
'bea',
'beatrice',
'beatriz',
'becky',
'belinay',
'belinda',
'benita',
'bernadette',
'bernadine',
'bernice',
'bertha',
'beryl',
'bess',
'bessie',
'beth',
'bethanie',
'bethany',
'betsy',
'bette',
'bettie',
'bettina',
'betty',
'bettye',
'beula',
'beulah',
'bev',
'beverley',
'beverly',
'bianca',
'biljana',
'binita',
'bintou',
'bismah',
'blanca',
'blanche',
'blythe',
'bobbi',
'bobbie',
'boglarka',
'bolormaa',
'bonita',
'bonnie',
'brandi',
'brandie',
'breanna',
'bree',
'brenda',
'brenna',
'briana',
'brianna',
'brianne',
'bridget',
'bridgett',
'bridgette',
'brigid',
'britney',
'britt',
'brittany',
'brittney',
'brittni',
'brittny',
'bronwyn',
'brooke',
'bryanna',
'brynn',
'caitlin',
'caitlyn',
'calista',
'callie',
'camila',
'camile',
'camilla',
'camille',
'candace',
'candice',
'cara',
'carina',
'carissa',
'carla',
'carlene',
'carley',
'carlie',
'carlota',
'carly',
'carmel',
'carmela',
'carmella',
'carmen',
'carol',
'carole',
'carolina',
'caroline',
'carolyn',
'carrie',
'carrol',
'casandra',
'cassandra',
'cassie',
'catarina',
'caterina',
'catherina',
'catherine',
'cathleen',
'cathryn',
'cathy',
'catrina',
'cayla',
'cecelia',
'cecile',
'cecilia',
'cecily',
'celeste',
'celia',
'celina',
'celine',
'chandra',
'chanelle',
'chantal',
'chantelle',
'charis',
'charissa',
'charla',
'charlena',
'charlene',
'charlette',
'charlotte',
'charmaine',
'chedeline',
'chelsea',
'chelsey',
'cher',
'cheri',
'cherie',
'cheryl',
'chloe',
'chrissy',
'christa',
'christal',
'christen',
'christiana',
'christiane',
'christie',
'christina',
'christine',
'christy',
'chrystal',
'ciara',
'cierra',
'cindi',
'cindy',
'clair',
'claire',
'clara',
'clare',
'clarice',
'claris',
'clarissa',
'claudette',
'claudia',
'claudine',
'cleo',
'cleopatra',
'clotilde',
'coleen',
'colette',
'colleen',
'concepcion',
'connie',
'constance',
'constanza',
'consuelo',
'cora',
'coralie',
'cordelia',
'cori',
'corina',
'corine',
'corinna',
'corinne',
'cornelia',
'corrine',
'courtney',
'courtni',
'courtny',
'cristal',
'cristina',
'cyndi',
'cynthia',
'dahlia',
'daina',
'dalal',
'damaris',
'damia',
'dana',
'danette',
'dani',
'danica',
'daniela',
'daniele',
'daniella',
'danielle',
'danika',
'daniz',
'daphna',
'daphne',
'dara',
'darby',
'darcey',
'darcie',
'daria',
'darla',
'darlena',
'darlene',
'davida',
'davina',
'dayle',
'dayna',
'deana',
'deandra',
'deann',
'deanna',
'deanne',
'deb',
'debbie',
'debby',
'debora',
'deborah',
'debra',
'debrah',
'dede',
'dee',
'deedee',
'deena',
'deidre',
'deirdre',
'dela',
'delia',
'delilah',
'della',
'delores',
'deloris',
'delphine',
'demetria',
'dena',
'denice',
'denise',
'desiree',
'dhia',
'diana',
'diane',
'dianna',
'dianne',
'dina',
'dinah',
'dionne',
'diya',
'djeneba',
'dolores',
'dominique',
'dona',
'donna',
'dora',
'doreen',
'doris',
'dorla',
'dorothea',
'dorothy',
'dorthy',
'dottie',
'ecrin',
'edel',
'eden',
'edie',
'edith',
'edna',
'edwina',
'eevi',
'eileen',
'eisha',
'ekta',
'ela',
'elaina',
'elaine',
'elana',
'eleanor',
'elen',
'elena',
'eliana',
'elicia',
'elida',
'elif',
'elin',
'elina',
'elinor',
'elisa',
'elisabeth',
'elise',
'eliska',
'eliza',
'elizabete',
'elizabeth',
'elizaveta',
'ella',
'ellen',
'ellie',
'elly',
'elma',
'elnora',
'eloise',
'elouise',
'elsa',
'elsie',
'elva',
'elvina',
'elvira',
'ema',
'emelda',
'emely',
'emerald',
'emilee',
'emilia',
'emilie',
'emilija',
'emily',
'emina',
'emine',
'emmeline',
'emma',
'emmaline',
'emmie',
'emmy',
'enid',
'erica',
'ericka',
'erika',
'erin',
'erma',
'ernestina',
'ernestine',
'eryn',
'esma',
'esmeralda',
'esperanza',
'estela',
'estele',
'estella',
'estelle',
'ester',
'estere',
'esther',
'estrella',
'ethel',
'etta',
'eugenia',
'eugenie',
'eunice',
'eva',
'evangelina',
'evangeline',
'evelin',
'evelina',
'evelyn',
'evi',
'evie',
'evita',
'fajr',
'fanta',
'farah',
'farida',
'farrah',
'farzana',
'fatemeh',
'fatiha',
'fatima',
'fatin',
'fatma',
'fatoumata',
'fay',
'faye',
'felecia',
'felicia',
'fenna',
'fernanda',
'fien',
'fiona',
'flora',
'florencia',
'fozia',
'fran',
'frances',
'francesca',
'francina',
'francine',
'francisca',
'francoise',
'freda',
'freja',
'frida',
'frieda',
'gabija',
'gabriela',
'gabriella',
'gabrielle',
'gale',
'gamalat',
'gamila',
'garnet',
'gayle',
'gemma',
'gena',
'genesis',
'genevieve',
'genna',
'georgette',
'georgie',
'georgina',
'geraldina',
'geraldine',
'geri',
'germaine',
'gertrude',
'gia',
'gianna',
'gigi',
'gilda',
'gillian',
'gina',
'giovanna',
'gisela',
'gisele',
'giselle',
'gita',
'gladys',
'glena',
'glenda',
'glenna',
'gloria',
'glynis',
'golda',
'goldie',
'googoosh',
'gracie',
'graciela',
'greta',
'gretchen',
'griselda',
'gunay',
'gunel',
'gwen',
'gwendolyn',
'gwyneth',
'habiba',
'hailey',
'hala',
'haley',
'hallie',
'hana',
'hanah',
'hanna',
'hannah',
'hariet',
'hariette',
'harmony',
'harriet',
'harriett',
'harriette',
'hasnaa',
'hasti',
'hatice',
'hattie',
'hawa',
'hayley',
'heather',
'heidi',
'helen',
'helena',
'helene',
'helga',
'helmi',
'henrietta',
'hermine',
'hessa',
'hester',
'hilary',
'hilda',
'hildegard',
'hillary',
'himari',
'hoda',
'hollie',
'hortense',
'hosna',
'hosniya',
'hussa',
'hyacinth',
'ida',
'ila',
'ilene',
'iliana',
'ilina',
'ilona',
'ilse',
'imane',
'imelda',
'imogena',
'imogene',
'indira',
'ines',
'ingrid',
'inji',
'iona',
'irati',
'irena',
'irene',
'irina',
'irma',
'isabel',
'isabela',
'isabele',
'isabell',
'isabella',
'isabelle',
'isadora',
'isidora',
'isla',
'islande',
'isobel',
'iva',
'ivaana',
'ivalu',
'ivana',
'izaro',
'jacinda',
'jacinta',
'jackie',
'jaclyn',
'jacquelina',
'jacqueline',
'jacquelyn',
'jada',
'jami',
'jana',
'janae',
'jane',
'janele',
'janelle',
'janessa',
'janet',
'janette',
'janice',
'janie',
'janina',
'janine',
'janis',
'jaqueline',
'jasmin',
'jasmina',
'javiera',
'jayne',
'jazmin',
'jazmine',
'jeana',
'jeane',
'jeanette',
'jeanie',
'jeanina',
'jeanine',
'jeanna',
'jeanne',
'jeannette',
'jeannie',
'jeannina',
'jeannine',
'jelena',
'jen',
'jena',
'jenelle',
'jenifer',
'jenna',
'jennette',
'jenni',
'jennie',
'jennifer',
'jenny',
'jeri',
'jerri',
'jesica',
'jess',
'jesse',
'jessica',
'jil',
'jilian',
'jill',
'jillian',
'jing',
'jo',
'joan',
'joana',
'joane',
'joann',
'joanna',
'joanne',
'jocelyn',
'jodi',
'jodie',
'jody',
'joelle',
'johana',
'johanna',
'joleen',
'jolena',
'jolene',
'joni',
'josefa',
'josefina',
'josefine',
'joselyn',
'josephina',
'josephine',
'josie',
'jovana',
'joya',
'joyce',
'juana',
'juanita',
'judeline',
'judith',
'judy',
'julia',
'juliana',
'julianna',
'julianne',
'julie',
'julienne',
'juliet',
'julieta',
'juliette',
'julissa',
'justina',
'justine',
'kabita',
'kacey',
'kadiatou',
'kaede',
'kaia',
'kaitlin',
'kaitlyn',
'kaleigh',
'kali',
'kallie',
'kamala',
'kamila',
'kamile',
'kanyakumari',
'kara',
'karen',
'kari',
'karima',
'karin',
'karina',
'karissa',
'karla',
'karly',
'karolina',
'karyn',
'kassandra',
'kassie',
'katarina',
'kate',
'katelyn',
'katelynn',
'katerina',
'katharina',
'katharine',
'katherina',
'katherine',
'kathie',
'kathleen',
'kathrine',
'kathryn',
'kathy',
'kati',
'katia',
'katie',
'katlyn',
'katrina',
'katy',
'kavita',
'kay',
'kaye',
'kayla',
'kaylee',
'kayleigh',
'keeley',
'keely',
'keira',
'keisha',
'kejsi',
'keley',
'keli',
'kelley',
'kelli',
'kellie',
'kelly',
'kelsie',
'kely',
'kendra',
'kenna',
'kenza',
'kera',
'keri',
'kerri',
'khadija',
'khadije',
'khawla',
'kheira',
'khongordzol',
'kia',
'kiana',
'kiara',
'kiera',
'kiersten',
'kiley',
'kim',
'kimberlee',
'kimberley',
'kimberli',
'kimberly',
'kimmernaq',
'kira',
'kirsten',
'kirstin',
'kizzy',
'klea',
'konul',
'kori',
'kourtney',
'krista',
'kristen',
'kristi',
'kristie',
'kristin',
'kristina',
'kristine',
'kristy',
'kristyna',
'krystal',
'kyla',
'kylee',
'kylie',
'kyra',
'lacey',
'lacie',
'lacy',
'ladona',
'ladonna',
'laia',
'laila',
'lakesha',
'lamija',
'lana',
'lara',
'larissa',
'latasha',
'latifa',
'latisha',
'latonya',
'latoya',
'laura',
'laurel',
'lauren',
'laurie',
'lauryn',
'laverna',
'laverne',
'lavinia',
'laxmi',
'layla',
'lea',
'leah',
'leana',
'leandra',
'leane',
'leann',
'leanna',
'leanne',
'leda',
'leena',
'leia',
'leigh',
'leila',
'leilani',
'leja',
'lejla',
'lela',
'lena',
'lenora',
'lenore',
'leola',
'leona',
'leonie',
'leonora',
'leora',
'lesedi',
'lesley',
'lesli',
'leslie',
'lesly',
'leticia',
'letitia',
'lettie',
'lexie',
'leyla',
'lia',
'lian',
'liana',
'lianne',
'libbie',
'libby',
'lidia',
'lidya',
'liepa',
'lila',
'lili',
'lilia',
'lilian',
'liliana',
'lilja',
'lillia',
'lillian',
'lillie',
'lilly',
'lin',
'lina',
'linda',
'lindsay',
'lindsey',
'lindsi',
'lindsy',
'lindy',
'lisa',
'lisette',
'livia',
'liz',
'liza',
'lizbeth',
'lizette',
'lizzie',
'lois',
'lola',
'lolita',
'lora',
'loraina',
'loraine',
'lorelei',
'lorena',
'lorene',
'loretta',
'lori',
'lorie',
'lorna',
'lorraina',
'lorraine',
'lorri',
'lorrie',
'lotte',
'lottie',
'louella',
'louisa',
'louise',
'lovelie',
'luann',
'lucia',
'luciana',
'lucie',
'lucija',
'lucile',
'lucille',
'lucinda',
'lucy',
'luela',
'luella',
'luisa',
'lula',
'lulu',
'lulwa',
'luna',
'lupe',
'lupita',
'luz',
'lydia',
'lyla',
'lyn',
'lyna',
'lynda',
'lyndsey',
'lyne',
'lynette',
'lynn',
'lynna',
'lynne',
'lynnette',
'lynsey',
'mabel',
'mable',
'macie',
'macy',
'madalyn',
'maddie',
'madeleine',
'madelina',
'madeline',
'madelyn',
'madge',
'madison',
'madonna',
'mae',
'magda',
'magdalena',
'magdalene',
'maggie',
'maha',
'maia',
'maire',
'maisie',
'maite',
'maja',
'malak',
'malen',
'malia',
'malika',
'malinda',
'mallory',
'mandakranta',
'mandy',
'manon',
'manuela',
'mara',
'marcela',
'marcella',
'marcelle',
'marci',
'marcia',
'marcie',
'marcy',
'margaret',
'margarette',
'margarida',
'margarita',
'marge',
'margery',
'margie',
'margo',
'margot',
'margret',
'margrette',
'marguerite',
'mari',
'maria',
'mariah',
'mariam',
'mariamawit',
'mariami',
'marian',
'mariana',
'mariane',
'marianna',
'marianne',
'maribel',
'marie',
'mariela',
'mariella',
'marija',
'marilyn',
'marina',
'maris',
'marisa',
'marisol',
'marissa',
'maritza',
'marjorie',
'marla',
'marlena',
'marlene',
'marnie',
'marsha',
'marta',
'martha',
'martina',
'martine',
'marwa',
'mary',
'maryam',
'maryan',
'maryann',
'marybeth',
'maryjane',
'marylou',
'masoumeh',
'mathilde',
'matilda',
'matilde',
'mattie',
'maude',
'maura',
'maureen',
'mavis',
'maxina',
'maxine',
'maybell',
'mayra',
'maysoun',
'mazie',
'mckenzie',
'meagan',
'meg',
'megan',
'meghan',
'mei',
'melanie',
'melina',
'melinda',
'melisa',
'melissa',
'mellisa',
'meredith',
'meriem',
'merissa',
'merjem',
'meron',
'meryem',
'meryl',
'mia',
'micaela',
'michaela',
'michele',
'michelle',
'mika',
'mikaela',
'mila',
'milagros',
'mildred',
'milica',
'millicent',
'millie',
'milly',
'mimi',
'mindy',
'minenhle',
'minerva',
'minh',
'minnie',
'mira',
'miral',
'miranda',
'miriam',
'mirlande',
'mitzi',
'miyar',
'mobina',
'moira',
'mollie',
'molly',
'mona',
'monica',
'monika',
'monique',
'mrignayani',
'muriel',
'mya',
'myra',
'myrlande',
'myrna',
'myrtle',
'naasunnguaq',
'nadene',
'nadia',
'nadina',
'nadine',
'nahia',
'naima',
'nalla',
'nancy',
'nanette',
'naomi',
'naomie',
'narges',
'natalia',
'natalie',
'natasha',
'nathalie',
'nehir',
'nel',
'nela',
'nelisa',
'nell',
'nellie',
'nena',
'nerissa',
'nesreen',
'nia',
'niamh',
'nichole',
'nicki',
'nicky',
'nicola',
'nicole',
'nicolette',
'niharika',
'nika',
'niki',
'nikita',
'nikki',
'nila',
'nilay',
'nina',
'nisanur',
'nisha',
'nita',
'nivi',
'noa',
'noella',
'noelle',
'noemi',
'noor',
'nora',
'norah',
'noreen',
'norma',
'nouf',
'nour',
'nur',
'nuray',
'nurul',
'nyla',
'octavia',
'odelia',
'odette',
'odval',
'ofelia',
'oisha',
'ola',
'olga',
'olivia',
'ophelia',
'oumou',
'oyunbileg',
'paige',
'pam',
'pamela',
'pandora',
'paninnguaq',
'paola',
'parvati',
'patrica',
'patrice',
'patricia',
'patti',
'pattie',
'patty',
'paula',
'paulette',
'paulina',
'pauline',
'peggy',
'penelope',
'perla',
'petra',
'philomena',
'phoebe',
'phylis',
'phyllis',
'pipaluk',
'polly',
'portia',
'priscila',
'priscilla',
'priyamvada',
'prudence',
'puteri',
'queenie',
'quiana',
'rabina',
'rachael',
'rachel',
'rachele',
'rachelle',
'rachida',
'rae',
'raina',
'ramona',
'randi',
'rania',
'raquel',
'rayna',
'reanna',
'reba',
'rebecca',
'rebeka',
'rebekah',
'reem',
'reema',
'regina',
'reihaneh',
'reina',
'rena',
'renae',
'renata',
'renee',
'reta',
'reyna',
'rhea',
'rhiannon',
'rhoda',
'rhona',
'rhonda',
'ria',
'richelle',
'ricki',
'rikki',
'riko',
'rimas',
'rin',
'rina',
'rita',
'riya',
'robbin',
'roberta',
'robyn',
'rochele',
'rochelle',
'rocio',
'roghayyeh',
'rolanda',
'ronda',
'roni',
'ronna',
'rosa',
'rosalie',
'rosalina',
'rosalind',
'rosalinda',
'rosalyn',
'rosanna',
'rosanne',
'roseann',
'roseanne',
'rosella',
'roselle',
'rosemarie',
'rosemary',
'rosetta',
'rosie',
'roslyn',
'rowan',
'rowena',
'roxana',
'roxane',
'roxanna',
'roxanne',
'roxie',
'roxy',
'ruth',
'ruthie',
'saanvi',
'sabina',
'sabine',
'sabrina',
'sade',
'sadie',
'sahar',
'saida',
'sakeena',
'sakineh',
'sakura',
'sallie',
'sally',
'salma',
'salome',
'samantha',
'samira',
'sandra',
'sara',
'sarah',
'sarina',
'sasha',
'savanna',
'savannah',
'scarlett',
'selena',
'selene',
'selina',
'selma',
'serena',
'serife',
'setayesh',
'sevda',
'sevinj',
'shahd',
'shaikha',
'shaim',
'shaimaa',
'shakira',
'shana',
'shanaya',
'shanda',
'shania',
'shanna',
'shannon',
'shanon',
'shari',
'sharlene',
'sharon',
'sharron',
'shauna',
'shawna',
'shayla',
'shayma',
'shayna',
'sheba',
'sheena',
'sheila',
'shelia',
'shelley',
'shelly',
'sheri',
'sheridan',
'sherifa',
'sherri',
'sherrie',
'sherry',
'sheryl',
'shira',
'shirley',
'shirli',
'shirly',
'shona',
'shristi',
'shyla',
'sierra',
'sillin',
'silvia',
'simona',
'simone',
'sindy',
'siobhan',
'sita',
'siti',
'skye',
'snezana',
'sobia',
'sofia',
'sofie',
'sofija',
'somayyeh',
'sondra',
'sonia',
'sonja',
'sonya',
'sophia',
'sophie',
'stacey',
'staci',
'stacie',
'stacy',
'starla',
'stefanie',
'stela',
'stella',
'stephanie',
'suha',
'sumayah',
'sunita',
'susan',
'susana',
'susane',
'susanna',
'susannah',
'susanne',
'susi',
'susie',
'suzan',
'suzana',
'suzane',
'suzanna',
'suzanne',
'suzette',
'suzie',
'suzy',
'sybil',
'sylvia',
'sylvie',
'tabatha',
'tabitha',
'tala',
'talia',
'talitha',
'tamar',
'tamara',
'tamera',
'tami',
'tamika',
'tammi',
'tammie',
'tammy',
'tamra',
'tania',
'tanika',
'tanisha',
'tanya',
'tara',
'tarana',
'taryn',
'tasha',
'tatiana',
'tawana',
'tegan',
'teodora',
'teresa',
'tereza',
'teri',
'terri',
'terrie',
'tess',
'tessa',
'tessie',
'thalia',
'thandolwethu',
'thea',
'thelma',
'theodora',
'theresa',
'therese',
'thomasina',
'tia',
'tiana',
'tianna',
'tiara',
'tiffany',
'tina',
'tingting',
'tisha',
'toni',
'tonia',
'tonya',
'tora',
'tori',
'tracey',
'traci',
'tracie',
'tracy',
'tricia',
'trina',
'trish',
'trisha',
'trista',
'trudy',
'tui',
'tula',
'tyra',
'ugne',
'ursula',
'urte',
'uxue',
'valentina',
'valeria',
'valerie',
'valery',
'vanesa',
'vanessa',
'veda',
'velma',
'vera',
'verna',
'vernice',
'veronica',
'vesna',
'vicki',
'vickie',
'vicky',
'vikky',
'viktoria',
'viktorie',
'viktorija',
'vilte',
'violeta',
'vivian',
'viviana',
'vivien',
'vivienne',
'vusala',
'wakana',
'wanda',
'wendi',
'wendy',
'whitney',
'whitni',
'whitny',
'widelene',
'wila',
'wilhelmina',
'willa',
'willow',
'wilma',
'winifred',
'winnie',
'winnifred',
'winona',
'xiaomei',
'xiaoyan',
'ximena',
'xinyi',
'yael',
'yagmur',
'yan',
'yarin',
'yasmin',
'yasmine',
'yelena',
'yesenia',
'ying',
'yolanda',
'yuina',
'yuna',
'yvette',
'yvona',
'yvone',
'yvonna',
'yvonne',
'zada',
'zahra',
'zainab',
'zara',
'zehra',
'zeinab',
'zelda',
'zelma',
'zena',
'zeynab',
'zeynep',
'zineb',
'zoe',
'zoey',
'zofia',
'zola',
'zora',
'zsofia',
'abie',
'aneta',
'annett',
'augustine',
'becca',
'bertie',
'brigitte',
'carlotta',
'ekaterina',
'eleni',
'elie',
'emanuela',
'emile',
'emile',
'emmanuelle',
'etienne',
'ewa',
'gabi',
'gertrud',
'iwona',
'jacky',
'jules',
'kalle',
'kat',
'larisa',
'lex',
'liv',
'luise',
'maud',
'midori',
'milena',
'myriam',
'nadya',
'natalya',
'oksana',
'pia',
'polina',
'rebeca',
'sharyn',
'sri',
'stephane',
'usha',
// 'grace',
// 'lily',
// 'scarlet',
// 'victoria',
]
================================================
FILE: data/lexicon/people/firstnames.js
================================================
//ambiguously-gendered firstnames
//names commonly used in either gender
export default [
'alexis',
'andra',
'aubrey',
'blair',
'casey',
'cassidy',
'charlie',
'cheyenne',
'devan',
'devon',
'jamie',
'jammie',
'jessie',
'jude',
'kiran',
'kasey',
'kelsey',
'kenyatta',
'kerry',
'kris',
'lashawn',
'marion',
'marlo',
'mel',
'mina',
'morgan',
'nelly',
'quinn',
'regan',
'rene',
'shay',
'shea',
'shelby',
'shiloh',
'andrea',
'gabriele',
'hinata',
'jie',
'luca',
'manaia',
'melokuhle',
'sumit',
'gaby',
'jaime',
'kendall',
'syd',
'kai',
'kiril',
'leif',
'mads',
'matti',
'matty',
'maxime',
'nico',
'niko',
'nikos',
'adrien',
'alexei',
'andi',
'andrey',
'avi',
'darcy',
'ilya',
'werner',
'francois',
'friedrich',
'akira',
'alfie',
'alois',
]
================================================
FILE: data/lexicon/people/honorifics.js
================================================
export default [
'lieutenant general',
'field marshal',
'rear admiral',
'vice admiral',
'sergeant major',
'director general',
]
================================================
FILE: data/lexicon/people/lastnames.js
================================================
//a random copy+paste job from around the internet
//(dont mean to step on any toes)
//some countries have a higher lastname-signal than others
//this list is further augmented by some regexps, over in ./data/punct_rules.js
// https://en.wikipedia.org/wiki/List_of_most_common_surnames_in_Europe
export default [
'acosta',
'adams',
'aguilar',
'akhtar',
'aleksejev',
'aliyev',
'almeida',
'alvarez',
'alves',
'andersen',
'anderson',
'andersson',
'andov',
'andreassen',
'andrejev',
'angelov',
'angelova',
'araujo',
'araya',
'arslan',
'aslan',
'ayala',
'aydin',
'babic',
'bach',
'baez',
'bahk',
'bahng',
'bailey',
'bakker',
'bandara',
'bandyopadhyay',
'banik',
'barbieri',
'barbosa',
'barnes',
'barnier',
'barua',
'bauer',
'becker',
'beckham',
'beethoven',
'begu',
'bektashi',
'bengtsson',
'benitez',
'bennett',
'berger',
'bergmann',
'berisha',
'bernasconi',
'berndsen',
'bhak',
'bhang',
'bhoumik',
'bhowmik',
'bhuiyan',
'bianchi',
'bishwas',
'blanco',
'blazevic',
'blondal',
'bogdanov',
'bondarenko',
'bonik',
'boruya',
'bosu',
'bouchard',
'boyko',
'bozic',
'bozinov',
'brankov',
'briem',
'brooks',
'bryant',
'byrne',
'bytyqi',
'caceres',
'calderon',
'campbell',
'cardoso',
'cardozo',
'carter',
'caruso',
'carvalho',
'castillo',
'castro',
'cavadini',
'ceban',
'cebotari',
'celik',
'cengic',
'cereghetti',
'cerna',
'cerny',
'chakma',
'chakraborty',
'chan',
'chand',
'chang',
'chatterjee',
'chapman',
'chavez',
'che',
'chen',
'cheon',
'cheong',
'cheung',
'chiu',
'choi',
'chong',
'choung',
'chow',
'chowdhury',
'choy',
'christensen',
'christiansen',
'chung',
'chwe',
'ciobanu',
'clark',
'clarke',
'cohen',
'coleman',
'collins',
'conti',
'contreras',
'cooke',
'cooper',
'corbyn',
'correa',
'correia',
'costa',
'cox',
'crivelli',
'cruz',
'dahl',
'damcevski',
'danielsen',
'dankula',
'datta',
'davidov',
'davies',
'davis',
'de boer',
'de groot',
'de jong',
'de la cruz',
'de leon',
'de luca',
'de silva',
'de vries',
'debnath',
'delgado',
'delic',
'demir',
'demirovic',
'dervishi',
'devi',
'dewan',
'dias',
'diaz',
'dimitrov',
'dimitrova',
'dissanayake',
'djurhuus',
'dogan',
'doherty',
'dominguez',
'donev',
'dordevic',
'dotto',
'driscoll',
'duarte',
'dubois',
'dumitru',
'durand',
'duric',
'dutta',
'dvorak',
'dvorakova',
'eder',
'edison',
'edwards',
'einstein',
'eriksen',
'eriksson',
'escobar',
'espinoza',
'esposito',
'estrada',
'evans',
'faber',
'ferhatovic',
'fernandes',
'fernandez',
'ferrara',
'ferrari',
'ferreira',
'filipov',
'filipovic',
'fischer',
'fjeldsted',
'flores',
'fontana',
'fortin',
'fournier',
// 'franco',
'friedman',
'fuchs',
'fuentes',
'fujita',
'gagne',
'gagnon',
'galeano',
'gallagher',
'galli',
'gallo',
'gamage',
'gandhi',
'gao',
'garcia',
'garza',
'gashi',
'gauthier',
'georgiev',
'georgieva',
'gheorghe',
'gibson',
'gil',
'gimenez',
'giordano',
'gjonaj',
'gjoni',
'gorbachev',
'golubev',
'gomes',
'gomez',
'goncalves',
'gonzales',
'gonzalez',
'goode',
'goodman',
'grayling',
'grgic',
'griffiths',
'gruber',
'guo',
'gustafsson',
'gutierrez',
'guzman',
'gwon',
'hadzic',
'hagen',
'halvorsen',
'hamalainen',
'hansen',
'hansson',
'haque',
'harris',
'hasani',
'hasanov',
'hasanovic',
'hashimoto',
'haugen',
'haung',
'hayashi',
'hayes',
'heikkila',
'heikkinen',
'heinonen',
'hemingway',
'henderson',
'henriksen',
'hernandez',
'herrera',
'hitchcock',
'hjaltalin',
'hoang',
'hodzic',
'hofer',
'hoffmann',
'hojgaard',
'hok',
'horak',
'horakova',
'horvat',
'hoxha',
'hristov',
'hristova',
'hu',
'huaman',
'huang',
'huber',
'hughes',
'huynh',
'ibrahimovic',
'iglesias',
'ikeda',
'iliev',
'ilieva',
'inoue',
'ionescu',
'ishikawa',
'ito',
'ivanou',
'ivanov',
'ivanova',
'jackson',
'jacobsen',
'jakobsson',
'jansen',
'janssen',
'janssens',
'jansson',
'jarvinen',
'jenkins',
'jensen',
'jhang',
'jimenez',
'joensen',
'johannesen',
'johannessen',
'johansen',
'johansson',
'johnsen',
'johnson',
'johnston',
'jones',
'jonsson',
'jorgensen',
'joung',
'jovanovic',
'jung',
'juric',
'kahn',
'kalloe',
'kaminski',
'karjalainen',
'karlsen',
'karlsson',
'kastrati',
'kato',
'kaur',
'kaya',
'kayser',
'kazlov',
'kennedy',
'khan',
'kieffer',
'kilic',
'kimura',
'kinnunen',
'klein',
'kluivert',
'knezevic',
'kobayashi',
'korhonen',
'koskinen',
'kovac',
'kovacevic',
'kovacic',
'kovacs',
'koval',
'kovalchuk',
'kovalenko',
'kowalczyk',
'kowalski',
'kozlov',
'krasniqi',
'kravchenko',
'kremer',
'kristensen',
'kristiansen',
'kryeziu',
'kucera',
'kucerova',
'kumar',
'kumara',
'kuznetsov',
'kvaran',
'kwok',
'kwon',
'laine',
'laitinen',
'lammy',
'larsen',
'larsson',
'lau',
'lavoie',
'lebedev',
'lefebvre',
'lefevre',
'lehtinen',
'lehtonen',
'leitner',
'leka',
'lekaj',
'lenin',
'leroy',
'lewis',
'li',
'lincoln',
'lindberg',
'lindholm',
'liu',
'liyanage',
'lombardi',
'lopes',
'lopez',
'lovric',
'lukic',
'lund',
'lungu',
'luo',
'ly',
'lynch',
'madrigal',
'madsen',
'maeda',
'magnusson',
'maier',
'majerus',
'makela',
'makinen',
'mamani',
'mammadov',
'mancini',
'mariani',
'maric',
'marin',
'marino',
'markovic',
'marques',
'marroquin',
'martinez',
'martins',
'matei',
'matic',
'matsumoto',
'mayer',
'mayr',
'mccarthy',
'mclaughlin',
'mehmedovic',
'mehmeti',
'meijer',
'mejia',
'melnyk',
'melo',
'mendes',
'mendez',
'mercier',
'messi',
'messier',
'meyer',
'meyers',
'micrachi',
'mihhailov',
'mikkelsen',
'miller',
'mohan',
'molina',
'moller',
'moore',
'mora',
'morales',
'moreau',
'moreira',
'moreno',
'monroe',
'moretti',
'mori',
'morin',
'morina',
'morozov',
'morris',
'mortensen',
'moser',
'moss',
'mozart',
'mulder',
'muller',
'munoz',
'munteanu',
'murati',
'muratovic',
'murphy',
'murray',
'mussolini',
'nagy',
'nakajima',
'nakamura',
'nakashima',
'narayan',
'navarro',
'neilson',
'nemcova',
'nemec',
'nguyen',
'nielsen',
'niemi',
'nieminen',
'nikolic',
'nikolov',
'nikolova',
'nilsen',
'nilsson',
'nixon',
'norodahl',
'novak',
'novakova',
'novikov',
'novotna',
'novotny',
'nowak',
'nunes',
'nunez',
'nyman',
'obama',
'obrien',
'oconnor',
'ogawa',
'oliveira',
'oliynyk',
'olofsson',
'olsen',
'olsson',
'oneill',
'orellana',
'ortega',
'ortiz',
'orwell',
'ozdemir',
'ozturk',
'pahk',
'pahng',
'pak',
'parker',
'patel',
'patterson',
'pavic',
'pavlov',
'pavlovic',
'pedersen',
'peeters',
'pena',
'pereira',
'perera',
'peretz',
'perez',
'peric',
'persson',
'petersen',
'peterson',
'petrov',
'petrova',
'petrovic',
'pettersen',
'pettersson',
'phak',
'pham',
'phan',
'phang',
'phillips',
'picasso',
'pichler',
'piero',
'pinas',
'pinto',
'polishchuk',
'popescu',
'popov',
'popovic',
'portillo',
'poulsen',
'powell',
'prasad',
'prifti',
'prochazka',
'prochazkova',
'putin',
'quispe',
'radic',
'radu',
'ramirez',
'ramos',
'rantanen',
'rasmussen',
'ravelli',
'reagan',
'rees',
'reiter',
'reuter',
'reyes',
'ribeiro',
'ricci',
'richardson',
'ries',
'rivas',
'rivera',
'rizzo',
'roberts',
'robertson',
'robinson',
'rocha',
'rodrigues',
'rodriguez',
'rogers',
'rojas',
'romano',
'romero',
'roosevelt',
'rossi',
'rotari',
'roux',
'rowling',
'rubio',
'ruiz',
'russo',
'rusu',
'ryang',
'ryoo',
'ryu',
'saarinen',
'sahin',
'saito',
'salas',
'salihovic',
'salminen',
'salo',
'salonen',
'sanchez',
'sanders',
'santana',
'sante',
'santos',
'sanz',
'saric',
'sasaki',
'sato',
'savic',
'scheving',
'schiltz',
'schmid',
'schmidt',
'schmit',
'schmitz',
'schneider',
'schroeder',
'schulz',
'schwarz',
'seinfeld',
'segura',
'semjonov',
'semyonov',
'seoh',
'sepulveda',
'serrano',
'shala',
'sharma',
'shehu',
'shevchenko',
'shevchuk',
'shimizu',
'silva',
'simmons',
'simonsen',
'sinatra',
'singh',
'sirbu',
'smirnov',
'smit',
'smith',
'smyth',
'sokolov',
'solovyov',
'sorensen',
'sosa',
'soto',
'soung',
'sousa',
'stalin',
'starmer',
'steiner',
'stoica',
'stojanovic',
'stoyanov',
'stoyanova',
'suarez',
'subotic',
'sullivan',
'suzuki',
'svensson',
'svoboda',
'svobodova',
'szabo',
'tahirovic',
'takahashi',
'tanaka',
'teixeira',
'thatcher',
'thill',
'thompson',
'thomsen',
'thomson',
'thorarensen',
'thorlacius',
'tian',
'tjin',
'tkachenko',
'todorov',
'todorova',
'tolstoy',
'tomic',
'torres',
'toth',
'tran',
'tremblay',
'tryniski',
'tsui',
'tuominen',
'turcan',
'turner',
'turunen',
'valenzuela',
'valverde',
'van den berg',
'van dijk',
'van dyk',
'vargas',
'vasilyev',
'vasquez',
'vassiljev',
'vazquez',
'velasquez',
'vesela',
'vesely',
'vidovic',
'villalba',
'villalobos',
'vinogradov',
'virtanen',
'visser',
'vivaldi',
'volkov',
'vorobyov',
'vukovic',
'waage',
'wagner',
'walker',
'walsh',
// 'wang',
'watanabe',
'weber',
'weiss',
'welter',
'williams',
'wilson',
'wimmer',
'winkler',
'wisniewski',
'wojcik',
'wong',
'wright',
'wu',
'xiao',
'xu',
'yamada',
'yamaguchi',
'yamamoto',
'yamasaki',
'yamashita',
'yamazaki',
'yang',
'yeun',
'yeung',
'yi',
'yildirim',
'yildiz',
'yilmaz',
'yoshida',
'yun',
'zaytsev',
'zhang',
'zhao',
'zhou',
'zhu',
'atchison',
'dickinson',
'stevens',
'watson',
'koch',
'peters',
'jacobs',
'abbas',
'richards',
'fisher',
'kapoor',
'andrews',
'holmes',
'dixon',
'matthews',
'keller',
'armstrong',
'gibson',
'krishna',
'burns',
'browne',
'lang',
'mann',
'burke',
'davidson',
'reynolds',
'greene',
'roth',
'williamson',
'webb',
'choudhury',
'gardner',
'hart',
'morrison',
'carr',
'cunningham',
'lehmann',
'freeman',
'crawford',
'dunn',
'daniels',
'sakamoto',
'morton',
'agarwal',
'zimmermann',
'hawkins',
'kikuchi',
'ansari',
'carlsson',
'pearson',
'jennings',
'stephens',
'chopra',
'yokoyama',
'myers',
'saunders',
'papadopoulos',
'higgins',
'webster',
'wilkinson',
'kramer',
'bergman',
'meier',
'baldwin',
'stein',
'hopkins',
'stevenson',
'rosenberg',
'lindstrom',
'hoffman',
'mclean',
'wolff',
'vidal',
'kaplan',
'lawson',
'perkins',
'hofmann',
'krause',
'harper',
'bashir',
'bates',
'atkinson',
'walters',
'guerra',
'benson',
'nicholson',
'schmitt',
'schubert',
'holt',
'kane',
'fleming',
'gunnarsson',
'montgomery',
'hess',
'fowler',
'vogt',
'tavares',
'sinclair',
'milosevic',
'chattopadhyay',
'rowe',
'fuller',
'norris',
'jankovic',
'owens',
'adler',
'nash',
'steele',
'fitzgerald',
'lowe',
'osborne',
'kraus',
'tate',
'reis',
'buchanan',
'makarov',
'harding',
'goldberg',
'sandberg',
'griffith',
'guerrero',
'bartlett',
'zakharov',
'walton',
'farrell',
'olson',
'howe',
'goldstein',
'chaudhry',
'nichols',
]
================================================
FILE: data/lexicon/people/maleNames.js
================================================
//names with a distinctive signal that they identify as a male, internationally
// some are in ./switches/person-verb etc
export default [
'aarav',
'aaron',
'abdallah',
'abdel',
'abdoulaye',
'abdul',
'abdullah',
'abdullo',
'abdulrahman',
'abe',
'abel',
'abraham',
'abram',
'abu',
'abubakr',
'abulfazl',
'adam',
'adama',
'adan',
'adi',
'adolf',
'adolfo',
'adrian',
'advik',
'afonso',
'agustin',
'ahmad',
'ahmed',
'ahmet',
'aiden',
'aimar',
'ajani',
'alan',
'albert',
'alberto',
'alden',
'alec',
'alejandro',
'aleksandar',
'aleksander',
'alessandro',
'alex',
'alexander',
'alexandru',
'alfonso',
'alfred',
'ali',
'aladdin',
'allan',
'allen',
'alonso',
'alonzo',
'alphonso',
'alton',
'alvaro',
'alvin',
'amine',
'amir',
'amit',
'ammanuel',
'ammar',
'amos',
'anas',
'ander',
'andre',
'andreas',
'andrei',
'andres',
'andrew',
'andy',
'angel',
'angelo',
'anthony',
'antoine',
'anton',
'antoni',
'antonio',
'antony',
'aputsiaq',
'arata',
'archie',
'ari',
'ariel',
'ariki',
'arjun',
'armaan',
'armand',
'armando',
'arnav',
'arnold',
'aron',
'arthur',
'arturo',
'aryan',
'asahi',
'augustus',
'avery',
'ayaan',
'aykhan',
'aziz',
'bakary',
'balazs',
'bandar',
'bandile',
'banele',
'barney',
'barrett',
'barry',
'bart',
'ben',
'benito',
'benjamin',
'bennie',
'benny',
'berat',
'bernard',
'bernardo',
'bernie',
'bert',
'bertram',
'beshoi',
'bibek',
'bilal',
'billie',
'billy',
'bishal',
'blaine',
'blake',
'bobby',
'boris',
'boyd',
'brad',
'bradford',
'bradley',
'brady',
'branden',
'brandon',
'brendan',
'brendon',
'brent',
'brenton',
'bret',
'brett',
'brian',
'brice',
'bruce',
'bruno',
'bryan',
'bryce',
'bryon',
'buddy',
'burt',
'burton',
'byron',
'caleb',
'calvin',
'cameron',
'carey',
'carl',
'carlos',
'carlton',
'carroll',
'cary',
'cecil',
'cedric',
'cesar',
'chad',
'charbel',
'charles',
'charley',
'chas',
'chester',
'chris',
'christopher',
'ciaran',
'clarence',
'claude',
'clay',
'clayton',
'clement',
'cletus',
'clifford',
'clifton',
'clint',
'clyde',
'cody',
'colby',
'cole',
'colin',
'collin',
'colton',
'conor',
'conrad',
'corey',
'cornelius',
'cory',
'craig',
'cristobal',
'curt',
'curtis',
'cyril',
'cyrus',
'daan',
'dale',
'damian',
'damien',
'damion',
'damon',
'dan',
// 'dane',
'daniel',
'danny',
'daren',
'darin',
'dario',
'darius',
'darnell',
'darrel',
'darrell',
'darren',
'darrin',
'darryl',
'daryl',
'dave',
'davi',
'david',
'deandre',
'dejan',
'delbert',
'demetrius',
'denis',
'dennis',
'denny',
'deon',
'derek',
'derrick',
'deshawn',
'desmond',
'deven',
'devin',
'dewayne',
'dewey',
'dexter',
'diarmuid',
'dillon',
'dion',
'dirk',
'domingo',
'dominic',
'dominick',
'dominik',
'dominykas',
'don',
'donald',
'donnell',
'donnie',
'donny',
'donovan',
'dorian',
'doug',
'douglas',
'dovydas',
'doyle',
'dragan',
// 'drew',
'duane',
'dudley',
'duncan',
'dustin',
'dwayne',
'dwight',
'dylan',
'dyllan',
'dmitry',
'ebenezer',
'ed',
'eddie',
'edgar',
'edmond',
'edmund',
'edoardo',
'eduardo',
'edward',
'edwardo',
'edwin',
'efrain',
'efren',
'eitan',
'elbert',
'eldon',
'eli',
'elias',
'elijah',
'elisha',
'elliot',
'elliott',
'ellis',
'elmer',
'elton',
'elvin',
'elvis',
'elwood',
'emanuel',
'emerson',
'emery',
'emil',
'emilio',
'emilis',
'emirhan',
'emmanuel',
'emmett',
'enoch',
'enrique',
'enzo',
'eoin',
'ergi',
'eric',
'erick',
'erik',
'ernest',
'ernesto',
'ernie',
'errol',
'ervin',
'erwin',
'esteban',
'ethan',
'eugene',
'evan',
'evens',
'everett',
'eymen',
'ezra',
'fabian',
'fadi',
'fahd',
'federico',
'felipe',
'felix',
'feng',
'fernando',
'fidel',
'filip',
'fionn',
'fletcher',
'floyd',
'forrest',
'francesco',
'francis',
'francisco',
'franciszek',
'frankie',
'franklin',
'franklyn',
'fred',
'freddie',
'freddy',
'frederick',
'frederic',
'fredrick',
'fritz',
'gabreal',
'gabriel',
'gabrielius',
'galen',
'garland',
'garrett',
'garry',
'garth',
'gary',
'gavin',
'geoffrey',
'george',
'gerald',
'gerard',
'gerardo',
'gert',
'gerry',
'gilbert',
'gilberto',
'gino',
'giorgis',
'giovanni',
'glen',
'glenn',
'gonzalo',
'goran',
'gordon',
'grady',
'graham',
'greg',
'gregg',
'gregorio',
'gregory',
'grover',
'guilherme',
'guillermo',
'gus',
'gustavo',
'habib',
'hal',
'halim',
'hamza',
'hank',
'hans',
'hao',
'harlan',
'harley',
'harold',
'harry',
'haruhito',
'haruki',
'haruta',
'haruto',
'harvey',
'hasan',
'hassan',
'hayato',
'hayden',
'heath',
'hector',
'heitor',
'henri',
'henrique',
'henry',
'herbert',
'herman',
'homer',
'horace',
'hossein',
'howard',
'hubert',
'hugh',
'hugo',
'humberto',
'huseyin',
'huseyn',
'hussain',
'hussein',
'hydar',
'iain',
'ian',
'ibai',
'ibrahim',
'ichika',
'ignacio',
'igor',
'ike',
'iker',
'ilija',
'inuk',
'inunnguaq',
'ionut',
'ira',
'irvin',
'irving',
'irwin',
'isaac',
'isaiah',
'isaias',
'ishaan',
'isiah',
'ismael',
'ismail',
'issac',
'itai',
'itsuki',
'ivan',
// 'jack',
// 'jackson',
'jacob',
'jacques',
'jaden',
'jaka',
'jake',
'jakob',
'jakov',
'jakub',
'jamal',
'james',
'jameson',
'jamison',
'jared',
'jarod',
'jarrett',
'jarrod',
'jarvis',
'jason',
'jasper',
'javier',
'jayden',
'jayson',
'jed',
'jeff',
'jeffery',
'jeffrey',
'jeffry',
'jerald',
'jeremiah',
'jeremy',
'jermaine',
'jerome',
'jeronimo',
'jerry',
'jesus',
'jian',
'jim',
'jimmie',
'jimmy',
'jimi',
'joao',
'joaquin',
'joe',
'joel',
'joesph',
'joey',
'john',
'johnathan',
'johnathon',
'johnie',
'johnnie',
'johnny',
'jokubas',
'jon',
'jonah',
'jonas',
'jonathan',
'jonathon',
'jonny',
'jordi',
'jordon',
'jorge',
'jose',
'joseph',
'josh',
'joshua',
'josiah',
'josue',
'juan',
'julen',
'julian',
'julien',
'julio',
'julius',
'justin',
'kacper',
'kajus',
'kamal',
'kanata',
'karim',
'karl',
'kaspar',
'kathem',
'kauri',
'keenan',
'keir',
'keith',
'ken',
'kendrick',
'kenneth',
'kenny',
'kenton',
'kermit',
'keven',
'kevin',
'khaled',
'kieran',
'kip',
'kirk',
'kirollos',
'kristian',
'kristopher',
'kurt',
'kurtis',
'kyle',
'lamar',
'lamont',
'landon',
'larry',
'lars',
'laurence',
'lawrence',
'leandro',
'leevi',
'leland',
'len',
'lenny',
'leon',
'leonard',
'leonardo',
'leonel',
'lester',
'lethabo',
'levente',
'levi',
'liam',
'lionel',
'lior',
'lloyd',
'logan',
'lonnie',
'loren',
'lorenzo',
'lou',
'louie',
'louis',
'lovro',
'lowell',
'lucas',
'luciano',
'luigi',
'luis',
'luiz',
'luka',
'lukas',
'luke',
'luther',
'luuk',
'lyle',
'lyndon',
'maayan',
'macaulay',
// 'mack',
'mahamadou',
'mahammad',
'mahdi',
'mahesh',
'mahmoud',
'majd',
'maksim',
'malachai',
'malachy',
'malcolm',
'malik',
'mamadou',
'manish',
'manuel',
'marc',
'marcel',
'marcell',
'marco',
'marcos',
'marcus',
'mario',
// 'mark',
'markel',
'marko',
'markos',
'markus',
'marlin',
'marlon',
'marquis',
'marshall',
'marti',
'martim',
'martin',
'marty',
'marvin',
'matej',
'mateo',
'matheus',
'mathew',
'mathis',
'matias',
'matt',
'matteo',
'matthew',
'mattia',
'matus',
'matyas',
'maurice',
'mauricio',
'maximilian',
'maximiliano',
'maxwell',
'mehdi',
'mehmet',
'melvin',
'merle',
'merrill',
'mervin',
'micah',
'michael',
'michal',
'micheal',
'michel',
'micky',
'miguel',
'mihai',
'mikaere',
'mike',
'mikel',
'mikolaj',
'milhouse',
'milo',
'milos',
'milton',
'minato',
'minik',
'mitch',
'mitchell',
'modibo',
'moe',
'mohamad',
'mohamed',
'mohammad',
'mohammed',
'moises',
'monte',
'monty',
'moses',
'moshe',
'moussa',
'muhamed',
'muhammad',
'muhammed',
'murad',
'mustafa',
'mustapha',
'myles',
'myron',
'nahom',
'nate',
'nathan',
'nathanael',
'nathaniel',
'nathy',
'neal',
'ned',
'neil',
'nelson',
'neville',
'nicholas',
'nickolas',
'nicolas',
'nigel',
'niilo',
'nik',
'nikau',
'nikhil',
'nikola',
'niles',
'noah',
'noam',
'noel',
'nojus',
'nolan',
'nomaan',
'norbert',
'norman',
'nuka',
'octavio',
'oier',
'oliver',
'omar',
'omer',
'ondrej',
'ori',
'orville',
'osama',
'oscar',
'oskar',
'osman',
'osvaldo',
'otis',
'otto',
'oumar',
'owen',
'pablo',
'padraig',
'patrick',
'paul',
'paulo',
'paulos',
'pedro',
'percy',
'petar',
'pete',
'peter',
'petros',
'phil',
'philip',
'phillip',
'pierre',
'prakash',
'prem',
'preston',
'quentin',
'quincy',
'quinton',
'rachid',
'rafael',
'ralf',
'ralph',
'ramiro',
'ramon',
'randal',
'randall',
'randolph',
'raphael',
'rashad',
'rasmus',
'raul',
'rawiri',
'rayan',
'raymond',
'reggie',
'reginald',
'regis',
'reid',
'reuben',
'reyansh',
'reynaldo',
'reza',
'rhett',
'ricardo',
'riccardo',
'richard',
'richie',
'rick',
'rickey',
'rickie',
'ricky',
'rico',
'riley',
'roan',
'robbie',
'robby',
'robert',
'roberto',
'rocco',
'roderick',
'rodger',
'rodney',
'rodolfo',
'rodrigo',
'roel',
'rogelio',
'roger',
'rohan',
'roland',
'rolando',
'roman',
'romeo',
'ron',
'ronald',
'ronnie',
'ronny',
'rory',
'roscoe',
'ross',
'roy',
'royce',
'ruben',
'rubin',
'rudolph',
'rudy',
'rufus',
'rupert',
'russ',
'russel',
'russell',
'ryan',
'ryou',
'salik',
'salvatore',
'sam',
'samkelo',
'sammie',
'sammy',
'samuel',
'santino',
'saqib',
'saul',
'scot',
'scott',
'scottie',
'scotty',
'seamus',
'sean',
'sebastian',
'sekou',
'selim',
'sergei',
'sergio',
'seth',
'seymour',
'shahid',
'shane',
'shaquille',
'shaun',
'shawn',
'shayne',
'sheldon',
'shelton',
'sherman',
'sid',
'siddhartha',
'sidney',
'sigmund',
'silas',
'silvio',
'simon',
'siyabonga',
'solomon',
'souleymane',
'souta',
'spencer',
'stan',
'stanislaw',
'stanley',
'stefan',
'stephan',
'stephen',
'steve',
'steven',
// 'stevenson',
'stevie',
'stewart',
'stuart',
'suraj',
'sylvester',
'szymon',
'tadgh',
'taha',
'taichi',
'taika',
'tanner',
'tareq',
'tatsuki',
'ted',
'teddy',
'terence',
'terrance',
'terrell',
'terrence',
'terry',
'thad',
'thaddeus',
'theo',
'theodore',
'thiago',
'thom',
'thomas',
'tim',
'timmy',
'timothy',
'titus',
'tobias',
'toby',
'tod',
'todd',
'tom',
'tomas',
'tommaso',
'tommie',
'tommy',
'tomoharu',
'tony',
'travis',
'trent',
'trenton',
'trevor',
'trey',
'tristan',
'troy',
'truman',
'tunar',
'turki',
'ty',
'tyler',
'tyrone',
'tyson',
'ughur',
'ulysses',
'unax',
'usman',
'valentin',
'valentine',
'vance',
'vicente',
'victor',
'vihaan',
'viktor',
'vince',
'vincent',
'virgil',
'vivaan',
'vladimir',
'vojtech',
'wallace',
'wally',
'walt',
'walter',
'waylon',
'wayne',
'wei',
'wendell',
'wes',
'wesley',
'weston',
'wilbert',
'wilbur',
'wiley',
'wilfred',
'wilfredo',
'willard',
'william',
'willie',
'willis',
'winston',
'wojciech',
'wolfgang',
'woodrow',
'wout',
'wouter',
'wyatt',
'xavier',
'xhoel',
'yahli',
'yanis',
'yassin',
'yassine',
'yonas',
'yonatan',
'yonathan',
'yong',
'yosef',
'yousouf',
'youssef',
'yusif',
'yusuf',
'yuuma',
'yuval',
'zachariah',
'zachary',
'zachery',
'zack',
'zackary',
'zahid',
'zakaria',
'zan',
'zane',
'zoran',
'adolph',
'adriano',
'aidan',
'alain',
'alastair',
'albrecht',
'aleksandr',
'aleksei',
'alexandre',
'alexandros',
'alf',
'alistair',
'alphonse',
'amar',
'anatoli',
'anatoliy',
'anatoly',
'anders',
'andrej',
'andrzej',
'anwar',
'archibald',
'armin',
'arnaud',
'arno',
'artem',
'artie',
'artur',
'augusto',
'bartholomew',
'benson',
'bernhard',
'bertrand',
'bjorn',
'bogdan',
'branislav',
'buster',
'cal',
'camillo',
'camilo',
'carlo',
'chet',
'christoph',
'christophe',
'christos',
'claudio',
'claus',
'clemens',
'clive',
'connor',
'constantin',
'cornelis',
'cristiano',
'danilo',
'deepak',
'dieter',
'dietmar',
'dietrich',
'dimitri',
'dimitris',
'dinesh',
'dmitri',
'dmitry',
'ebenezer',
'eduard',
'eliot',
'emiliano',
'enrico',
'erich',
'ernst',
'eugen',
'evgeny',
'fabien',
'fabio',
'fabrice',
'fabrizio',
'ferdinand',
'ferdinando',
'fergus',
'florian',
'fraser',
'frederic',
'frederik',
'fredrik',
'friedrich',
'frits',
'fyodor',
'gabe',
'gareth',
'geoff',
'georg',
'georges',
'georgi',
'georgios',
'georgy',
'gerhard',
'gerrit',
'giacomo',
'giles',
'gilles',
'giorgi',
'giorgio',
'giuseppe',
'godfrey',
'gord',
'gottfried',
'gregor',
'guido',
'guillaume',
'gunnar',
'gunter',
'gunther',
'gustaf',
'gustav',
'gustave',
'gyorgy',
'hamid',
'harri',
'heinrich',
'hendrik',
'henrik',
'henryk',
'hermann',
'horacio',
'horatio',
'howie',
'humphrey',
'jaroslav',
'jens',
'johan',
'johann',
'johannes',
'josef',
'jozef',
'kamil',
'khalid',
'kingsley',
'kiril',
'kirill',
'klaus',
'konrad',
'krzysztof',
'kyls',
'lambert',
'laszlo',
'laurent',
'lennart',
'leonid',
'leopold',
'linus',
'luc',
'lucien',
'ludovic',
'ludvig',
'ludwig',
'maciej',
'magnus',
'manfred',
'manny',
'marcello',
'marcelo',
'marcin',
'mariano',
'marios',
'marius',
'masoud',
'mathias',
'mathieu',
'matthias',
'mattias',
'mervyn',
'mick',
'mickey',
'mikhail',
'moritz',
'nate',
'ned',
'newton',
'nguyen',
'niels',
'niklas',
'nikolai',
'nikolay',
'nils',
'norm',
'olaf',
'olav',
'oleksandr',
'olivier',
'oswald',
'paolo',
'pascal',
'patrik',
'paulie',
'pavel',
'pavlo',
'petr',
'petro',
'philipp',
'philippe',
'pieter',
'pietro',
'piotr',
'pravit',
'pyotr',
'rahul',
'rainer',
'rajesh',
'raoul',
'rashid',
'recep',
'reece',
'rolf',
'ronan',
'rosario',
'rudolf',
'saeed',
'sal',
'sami',
'samir',
'sandeep',
'sandro',
'sanjay',
'satoshi',
'sebastien',
'sepp',
'serge',
'sergei',
'sergey',
'shlomo',
'sigmund',
'silvio',
'slobodan',
'soren',
'stanislav',
'stefano',
'stefanos',
'stu',
'suresh',
'sven',
'svend',
'syed',
'theodor',
'tomasz',
'ulrich',
'ulrik',
'umberto',
'uri',
'val',
'vasily',
'vern',
'vernon',
'vic',
'vincenzo',
'vivek',
'vlad',
'vladislav',
'volodymyr',
'walt',
'werner',
'wilfrid',
'wilfried',
'wilhelm',
'willy',
'winfried',
'winslow',
'yann',
'yannick',
'yaroslav',
'yevgeni',
'yevgeny',
'yuen',
'yuri',
'yuriy',
'yury',
'zac',
'zach',
// 'chase',
]
================================================
FILE: data/lexicon/people/people.js
================================================
export default [
//famous people with names that are hard to recognize independendtly
//male
'hitler',
'ronaldo',
'ashton kutcher',
'barack obama',
'cardinal wolsey',
'carson palmer',
'denzel washington',
'dick wolf',
'emeril lagasse',
'hulk hogan',
'kanye west',
'kiefer sutherland',
'kobe bryant',
'lebron james',
'messiaen',
'mitt romney',
'mubarek',
'ray romano',
'rod stewart',
'ronaldinho',
'rush limbaugh',
'saddam hussain',
'slobodan milosevic',
'tiger woods',
'valentino rossi',
'van gogh',
'niles crane',
'run dmc',
// one-named artists/athletes
'dante',
'keats',
'shakespeare',
'poe',
'rumi',
'chaucer',
'bronte',
'voltaire',
'plato',
'socrates',
'aristotle',
'confucius',
'beyonce',
'liberace',
'beck',
'nas',
'nostradamus',
'xzibit',
'moby',
'coolio',
'banksy',
'sinbad',
'kesha',
'nelly',
'monet',
'moliere',
'rembrandt',
'warhol',
'degas',
'rothko',
'morrissey',
'bono',
'chyna',
'puff daddy',
'drake',
'enya',
'gotye',
'macklemore',
'ne yo',
'pele',
'raffi',
'rihanna',
'rivaldo',
'eminem',
'rupaul',
'rza',
'santigold',
'timbaland',
'yanni',
// 'will.i.am',
//tricky female names
'halle berry',
'jk rowling',
'oprah winfrey',
'paris hilton',
'reese witherspoon',
'scarlett johansson',
'theresa may',
'tyra banks',
'wednesday adams',
'miranda july',
'lady gaga',
//sometimes firstname, sometimes lastname
'brock',
'carson',
'clinton',
'dalton',
'harrison',
'tatum',
'effie',
'ezekiel',
'gaston',
'inez',
'jefferson',
'lee',
'nettie',
'ora',
'palmer',
'piper',
'humphrey',
'raisa',
// 'sung',
'taylor',
'reilly',
'warren',
'woode',
'al capone',
'al pacino',
'archimedes',
'avril lavigne',
'ayn rand',
'benazir bhutto',
'bill gates',
'bing crosby',
'captain beefheart',
'chopin',
'christian bale',
'conan',
'cthulhu',
'dalai lama',
'darth vader',
'demi lovato',
'diego maradona',
'doctor who',
'emile zatopek',
'florence nightingale',
'frederic chopin',
'haile selassie',
'harrison ford',
'he man',
'henry ford',
'humphrey bogart',
'iron man',
'jrr tolkien',
'jfk',
'jack the ripper',
'jawaharlal nehru',
'jay z',
'kid cudi',
'lech walesa',
'mata hari',
'maya angelou',
'merlin',
'napoleon',
'pocahontas',
'rachmaninoff',
'ringo starr',
'robin hood',
'santa claus',
'sherlock holmes',
'shia labeouf',
'snoop dogg',
'snow white',
'spider man',
'spiderman',
'superman',
'thor',
'tupac shakur',
'usain bolt',
'vin diesel',
'virginia woolf',
'walt disney',
'will ferrell',
'wiz khalifa',
'yoko onen',
'yoko ono',
// first+last names
'bertil',
'camillo',
'eustace',
'hedwig',
'hilde',
'ilias',
'oleg',
'pilar',
'reilley',
'reinhold',
'siegfried',
'swami',
'takashi',
'tatyana',
'tripp',
'tully',
'wolfram',
'yuji',
'yvan',
'yves',
'frans',
'franz',
'giannis',
'ferguson',
'rashid',
'newman',
'goodwin',
'bhatt',
'lu',
'markov',
'husain',
'hammond',
'hamid',
'perry',
'mason',
// '',
]
================================================
FILE: data/lexicon/places/cities.js
================================================
export default [
'aalborg',
'aarhus',
'abidjan',
'abu dhabi',
'ahmedabad',
'almaty',
'amman',
'amsterdam',
'ankara',
'antwerp',
'aqaba',
'ashdod',
'ashgabat',
'athens',
'auckland',
'baku',
'bangalore',
'bangkok',
'banja luka',
'barcelona',
'barranquilla',
'basel',
'beijing',
'beirut',
'belgrade',
'bergen',
'berlin',
'bern',
'birmingham',
'bogota',
'brasilia',
'bratislava',
'brisbane',
'brussels',
'bucharest',
'budapest',
'buenos aires',
'burgas',
'bursa',
'busan',
'cairo',
'calgary',
'cape town',
'caracas',
'cebu',
'chennai',
'chiang mai',
'chicago',
'chittagong',
'christchurch',
'cologne',
'colombo',
'constanta',
'copenhagen',
'cork',
'craiova',
'curitiba',
'daegu',
'daejeon',
'dakar',
'damascus',
'daugavpils',
'dhaka',
'doha',
'dublin',
'durban',
'dushanbe',
'edmonton',
'eindhoven',
'fes',
'frankfurt',
'galway',
'gdansk',
'geneva',
'genoa',
'ghent',
'giza',
'gothenburg',
'graz',
'guadalajara',
'guangzhou',
'haifa',
'hamburg',
// 'hamilton',
'hanoi',
'havana',
'helsinki',
'heraklion',
'ho chi minh',
'homs',
// 'houston',
'incheon',
'istanbul',
'jakarta',
'kabul',
'kampala',
'kandy',
'kaohsiung',
'karachi',
'karaj',
'kaunas',
'kharkiv',
'kiev',
'kingston',
'klaipeda',
// 'kobe',
'kopavogur',
'kosice',
'krakow',
'kuala lumpur',
'la plata',
'lausanne',
'liege',
'lima',
'limassol',
'linz',
'lisbon',
'liverpool',
'london',
'los angeles',
'lviv',
'lyon',
'madrid',
'malmo',
'manchester',
'mandalay',
'manila',
'maribor',
'marseille',
'medellin',
'melbourne',
'milan',
'minsk',
'miskolc',
'montevideo',
'montreal',
'moscow',
'mumbai',
'munich',
'nagoya',
'nantes',
'naples',
'navan',
'new delhi',
'new taipei',
'new york',
'odessa',
'osaka',
'oslo',
'ottawa',
'palermo',
'paris',
'patras',
'perth',
'petah tikva',
'philadelphia',
'phnom penh',
'phoenix',
'pilsen',
'piraeus',
'port elizabeth',
'porto',
'poznan',
'prague',
'pretoria',
'puebla',
'pyongyang',
'quito',
'reykjavik',
'riga',
'rio de janeiro',
'rome',
'rosario',
'rotterdam',
'saint petersburg',
// 'salvador',
'salzburg',
'san jose',
'san salvador',
// 'santiago',
'sapporo',
'seoul',
'seville',
'shanghai',
'shenzhen',
'skopje',
'stockholm',
'stuttgart',
// 'sydney',
'taichung',
'tainan',
'taipei',
'tallinn',
'tampere',
'tangier',
'tartu',
'tbilisi',
'tegucigalpa',
'tehran',
'tel aviv',
'the hague',
'thessaloniki',
'tianjin',
'tilburg',
'timisoara',
'tirana',
'tokyo',
'toronto',
'toulouse',
'trondheim',
'tunis',
'turin',
'turku',
'ulan bator',
'utrecht',
'valencia',
'vancouver',
'vaughn',
'varna',
'vernon',
'vienna',
'vilnius',
'warsaw',
'wellington',
'wexford',
'wicklow',
'winnipeg',
'winterthur',
'wroclaw',
'yangon',
'yekaterinburg',
'yerevan',
'yokohama',
'zagreb',
'zurich',
'delhi',
'sao paulo',
'wuhan',
'lagos',
'nyc',
'dongguan',
'kinshasa',
'chongqing',
'chengdu',
'baghdad',
'nanjing',
'nanchong',
'xian',
'lahore',
'shenyang',
'hangzhou',
'rio',
'harbin',
'taian',
'suzhou',
'shantou',
'bengaluru',
'kolkata',
'jinan',
'zhengzhou',
'riyadh',
'changchun',
'dalian',
'chattogram',
'kunming',
'qingdao',
'kano',
'foshan',
'puyang',
'ibadan',
'wuxi',
'xiamen',
'tianshui',
'ningbo',
'shiyan',
'taiyuan',
'tangshan',
'hefei',
'zibo',
'zhongshan',
'changsha',
'urumqi',
'dubai',
'surat',
'jeddah',
'shijiazhuang',
'kanpur',
'kyiv',
'luanda',
'quezon',
'addis ababa',
'nairobi',
'jaipur',
'dar es salaam',
'lanzhou',
'yunfu',
'basrah',
'mogadishu',
'faisalabad',
'izmir',
'izmir',
'lucknow',
'fortaleza',
'surabaya',
'belo horizonte',
'nanchang',
'mashhad',
'nagpur',
'maracaibo',
'santo domingo',
'al mawsil al jadidah',
'johannesburg',
'kowloon',
'al basrah al qadimah',
'dadonghai',
'medellin',
'tashkent',
'algiers',
'khartoum',
'accra',
'guayaquil',
'ordos',
'sanaa',
'jilin',
'camayenne',
'indore',
'iztapalapa',
'conakry',
'bayan nur',
'maracay',
'medan',
'rawalpindi',
'mosul',
'bandung',
'soweto',
'kallakurichi',
'rabat',
'aleppo',
'kunshan',
'patna',
'bhopal',
'manaus',
'xinyang',
'kaduna',
'isfahan',
'ludhiana',
'san diego',
'port au prince',
'brazzaville',
'baotou',
'tijuana',
'dallas',
'medina',
'tripoli',
'volgograd',
'omsk',
'mecca',
'makassar',
'asuncion',
'recife',
'san antonio',
'changzhou',
'mendoza',
'marrakesh',
'san francisco',
'la paz',
'jerusalem',
'fort worth',
'indianapolis',
'sarajevo',
'muscat',
'salem',
'sheffield',
'seattle',
'denver',
'el paso',
'detroit',
'islamabad',
'kirkuk',
'mississauga',
'boston',
'nantong',
'guadalupe',
'bristol',
'milwaukee',
'kyoto',
'cancun',
'portland',
'cordoba',
'tabriz',
'novosibirsk',
'benghazi',
'memphis',
'oran',
'glasgow',
'gold coast',
'zhangzhou',
'libreville',
'dortmund',
'vladivostok',
'irkutsk',
'duesseldorf',
'albuquerque',
'port said',
'nashville',
'macau',
'fresno',
'hannover',
'leicester',
'leipzig',
'sacramento',
'santa fe',
'dresden',
'tomsk',
'long beach',
'staten island',
'kawaguchi',
'cardiff',
'san juan',
'edinburgh',
'atlanta',
'miami',
'santa marta',
'oakland',
'nagasaki',
'gaza',
'newcastle',
'zanzibar',
'tulsa',
'kandahar',
'wichita',
'new orleans',
'arlington',
'cleveland',
'fukuyama',
'bakersfield',
'honolulu',
'canberra',
'halifax',
'nagano',
'anaheim',
'raleigh',
'santa ana',
'islington',
'anapolis',
'saint louis',
'butuan',
'pittsburgh',
'gujrat',
'anchorage',
'windsor',
'strasbourg',
'belfast',
'san pedro',
'windhoek',
'chengzhong',
'wuzhou',
'peking',
// india state-capitals
'agartala',
'aizawl',
'amaravati',
'bhubaneshwar',
'dehradun',
'dispur',
'gandhinagar',
'gangtok',
'hyderabad',
'imphal',
'itanagar',
'kohima',
'panaji',
'raipur',
'ranchi',
'shillong',
'shimla',
// relevant european cities
'venice',
'bari',
'catania',
'verona',
'messina',
'padua',
'prato',
'trieste',
'cagliari',
'ancona',
'rennes',
'reims',
'toulon',
'montpellier',
'le mans',
'dunkirk',
'versailles',
'salt lake city',
]
================================================
FILE: data/lexicon/places/countries.js
================================================
export default [
'afghanistan',
'albania',
'algeria',
'america',
'andorra',
'angola',
'anguilla',
'antarctica',
'antigua and barbuda',
'argentina',
'armenia',
'aruba',
'australia',
'austria',
'azerbaijan',
'bahamas',
'bahrain',
'bangladesh',
'barbados',
'belarus',
'belgium',
'belize',
'benin',
'bermuda',
'bhutan',
'bolivia',
'bonaire',
'bosnia and herzegovina',
'botswana',
'bouvet island',
'brazil',
'british virgin islands',
'brunei',
'bulgaria',
'burkina faso',
'burma',
'burundi',
'cambodia',
'cameroon',
'canada',
'cape verde',
'cayman islands',
'central african republic',
'chile',
'china',
'christmas island',
'cocos islands',
'colombia',
'comoros',
'congo brazzaville',
'cook islands',
'costa rica',
'croatia',
'cuba',
'curacao',
'cyprus',
'czech republic',
'czechia',
'denmark',
'djibouti',
'dominica',
'dominican republic',
'dr congo',
'east timor',
'ecuador',
'egypt',
'el salvador',
'england',
'equatorial guinea',
'eritrea',
'estonia',
'ethiopia',
'falkland islands',
'faroe islands',
'fiji',
'finland',
'france',
'french guiana',
'french polynesia',
'gabon',
'gambia',
'georgia',
'germany',
'ghana',
'gibraltar',
'greece',
'greenland',
'grenada',
'guadeloupe',
'guam',
'guatemala',
'guernsey',
'guinea bissau',
'guinea',
'guyana',
'haiti',
'honduras',
'hong kong',
'hungary',
'iceland',
'india',
'indonesia',
'iran',
'iraq',
'ireland',
'isle of man',
'israel',
'italy',
'ivory coast',
'jamaica',
'japan',
'jersey',
'kazakhstan',
'keeling islands',
'kenya',
'kiribati',
'kosovo',
'kuwait',
'kyrgyzstan',
'laos',
'latvia',
'lebanon',
'lesotho',
'liberia',
'libya',
'liechtenstein',
'lithuania',
'luxembourg',
'macao',
'macedonia',
'madagascar',
'malawi',
'malaysia',
'maldives',
'mali',
'malta',
'marshall islands',
'martinique',
'mauritania',
'mauritius',
'mayotte',
'mexico',
'micronesia',
'moldova',
'monaco',
'mongolia',
'montenegro',
'montserrat',
'morocco',
'mozambique',
'myanmar',
'namibia',
'nauru',
'nepal',
'netherlands',
'new zealand',
'nicaragua',
'niger',
'nigeria',
'niue',
'norfolk island',
'north korea',
'northern mariana islands',
'norway',
'oman',
'pakistan',
'palau',
'palestine',
'panama',
'papua new guinea',
'paraguay',
'peru',
'philippines',
'pitcairn islands',
'poland',
'portugal',
'puerto rico',
'qatar',
'republic of ireland',
'romania',
'russia',
'rwanda',
'saint helena',
'saint lucia',
'saint martin',
'samoa',
'san marino',
'saudi arabia',
'scotland',
'senegal',
'serbia',
'seychelles',
'sierra leone',
'singapore',
'sint maarten',
'slovakia',
'slovenia',
'solomon islands',
'somalia',
'south africa',
'south korea',
'korea',
'south sudan',
'spain',
'sri lanka',
'sudan',
'suriname',
'swaziland',
'sweden',
'switzerland',
'syria',
'taiwan',
'tajikistan',
'tanzania',
'thailand',
'timor leste',
'togo',
'tokelau',
'tonga',
'trinidad and tobago',
'trinidad tobago',
'tunisia',
'turkey',
'turkmenistan',
'turks and caicos islands',
'tuvalu',
'uk',
'us virgin islands',
'uganda',
'ukraine',
'united arab emirates',
'united kingdom',
'united states of america',
'united states',
'uruguay',
'usa',
'ussr',
'uzbekistan',
'vanuatu',
'vatican city',
'venezuela',
'vietnam',
'wales',
'wallis and futuna',
'yemen',
'zambia',
'zimbabwe',
`cote de ivoire`,
// 'jordan', //... or a name?
]
================================================
FILE: data/lexicon/places/places.js
================================================
export default [
//some of the busiest airports in the world from
//https://www.world-airport-codes.com/world-top-30-airports.html
'ams',
'atl',
'bcn',
'bkk',
'cdg',
'cgk',
'clt',
'den',
'dfw',
'dxb',
'fco',
'fra',
'hkg',
'hnd',
'iax',
'icn',
'ist',
'jfk',
'kul',
'las',
'lax',
'lgw',
'lhr',
'mco',
'muc',
'ord',
'pek',
'phl',
'phx',
'sfo',
'syd',
'yyz',
// bodies of water
'antarctic ocean',
'arctic ocean',
'atlantic ocean',
'everglades',
'great britain',
'great lakes',
'indian ocean',
'new england',
'pacific ocean',
'red sea',
'adriadic',
// rivers
'nile',
'ganges',
'mekong',
'thames',
'danube',
'yangtze',
'orinoco',
'seine',
'rio grande',
'godavari',
//continents
'africa',
'europe',
'americas',
'asia',
//some notable neighbourhoods (just #Place)
'midtown',
'downtown',
'uptown',
'the bronx',
'brooklyn',
'manhattan',
'greenwich',
'soho',
'harlem',
'chinatown',
'the hamptons',
'beverly hills',
'bel air',
'malibu',
'gay village',
'orange county',
'sunderland',
// places with their own timezones
'tahiti',
'chatham',
'pitcairn',
'azores',
'magadan',
'hovd',
'vostok',
'wake island',
'anadyr',
'ulaanbaatar',
'krasnoyarsk',
'indochina',
'yakutsk',
'chamorro',
'chuuk',
'kosrae',
'sakhalin',
// US national monuments
'alhambra',
'arc de triomphe',
'browns canyon',
'carrizo plain',
'cedar breaks',
'cedar falls',
'chichen itza',
'chimney rock',
'chiricahua',
'colosseum',
'hovenweep',
'kazan kremlin',
'lincoln memorial',
'machu picchu',
'neuschwanstein',
'papahanaumokuakea',
'parthenon',
'pompeii',
'taj mahal',
'teotihuacan',
'tonto',
'tsarskoe selo',
'tulum',
'tuzigoot',
'virgin islands',
'wupatki',
'cedar breaks',
'scotts bluff',
'saint lawrence river',
// generic place names
'west end',
'east end',
'north end',
'south end',
'west side',
'east side',
'north side',
'south side',
'brookside',
'brookstone',
'centerville',
'clearwater',
'cedar grove',
'fairhaven',
'green acres',
'highland',
'highlands',
'hillcrest',
'lakefront',
'lowlands',
'lowland',
'maplewood',
'meadowlands',
'midlands',
'oakmont',
'pinecrest',
'riverbend',
'riverfront',
'riverside',
'springhill',
'springwood',
'willowbrook',
'sunset hills',
'oakwood',
'parkside',
'green valley',
'maple grove',
'pine ridge',
'greenfield',
//misc notable british
'abbotsford',
'abingdon',
'acton',
'agincourt',
'alberton',
'aldershot',
'alliston',
'ancaster',
'andover',
'ashcroft',
'aylesford',
'baltimore',
'barnsley',
'battersea',
'beaconsfield',
'bedford',
'bellingham',
'berwick',
'bexhill',
'bingley',
'blackburn',
'blackpool',
'blackwall',
'bolton',
'bracebridge',
'bramley',
'brampton',
'bridgenorth',
'bridgetown',
'brigham',
'brighton',
'brockton',
'buckingham',
'caldwell',
'cambridge',
'campbellford',
'carlisle',
'caversham',
'charlottetown',
'chelmsford',
'cheltenham',
'colchester',
'collingwood',
'compton',
'cornwall',
'croydon',
'darlington',
'dartford',
'dartmoor',
'denham',
'derry',
'devonport',
'digby',
'doncaster',
'dorchester',
'dover',
'dryden',
'dumfries',
'dunstable',
'durham',
'dutton',
'earlscourt',
'eglinton',
'enfield',
'epping',
'euston',
'everton',
'exeter',
'exford',
'gravenhurst',
'grimsby',
'guelph',
'haliburton',
'hampstead',
'hampton',
'harford',
'harrow',
'hastings',
'hereford',
'hertford',
'heywood',
'highbury',
'huntingdon',
'ilford',
'inglewood',
'inverness',
'ipswich',
'kensington',
'keswick',
'kitchener',
'lambeth',
'lancaster',
'langford',
'langley',
'langton',
'lansing',
'leaside',
'lewes',
'lindley',
'lyndhurst',
'maidstone',
'malton',
'malvern',
'mansfield',
'markham',
'millington',
'newark',
'newham',
'newmarket',
'newport',
'northampton',
'norwich',
'nottingham',
'orford',
'oxford',
'oxley',
'parkwood',
'pelham',
'pembroke',
'pennington',
'penzance',
'perth',
'pickering',
'picton',
'putnam',
'rayleigh',
'redcliffe',
'redhill',
'richmond',
'rochester',
'seaforth',
'seaton',
'sherbrooke',
'southampton',
'southwold',
'stafford',
'stockwell',
'stratford',
'stroud',
'sudbury',
'sunderland',
'sydenham',
'taunton',
'thornhill',
'tiverton',
'torquay',
'tottenham',
'truro',
'upton',
'uxbridge',
'vauxhall',
'wakefield',
'warwick',
'waterford',
'watford',
'weedon',
'wentworth',
'whitby',
'whitchurch',
'wickham',
'winchester',
'wingham',
'woking',
'woodbridge',
'woodside',
'woodstock',
'woolwich',
'wycombe',
'york',
]
================================================
FILE: data/lexicon/places/regions.js
================================================
//some major 'second-level' administrative divisions
export default [
'alabama',
'alaska',
'arizona',
'arkansas',
'california',
'colorado',
'connecticut',
'delaware',
'florida',
'georgia',
'hawaii',
'idaho',
'illinois',
'indiana',
'iowa',
'kansas',
'kentucky',
'louisiana',
'maine',
'maryland',
'massachusetts',
'michigan',
'minnesota',
'mississippi',
'missouri',
'montana',
'nebraska',
'nevada',
'new hampshire',
'new jersey',
'new mexico',
'new york state',
'new york',
'north carolina',
'north dakota',
'ohio',
'oklahoma',
'oregon',
'pennsylvania',
'rhode island',
'south carolina',
'south dakota',
'tennessee',
'texas',
'utah',
'vermont',
'virginia',
'washington dc',
'washington',
'west virginia',
'wisconsin',
'wyoming',
//canada
'alberta',
'british columbia',
'manitoba',
'new brunswick',
'newfoundland',
'newfoundland and labrador',
'nova scotia',
'nunavut',
'ontario',
'prince edward island',
'pei',
'quebec',
'saskatchewan',
'yukon',
//australia
'norfolk',
'queensland',
'tasmania',
// 'victoria',
//china
'qinghai',
'sichuan',
'gansu',
'hunan',
'guangdong',
'guizhou',
'fujian',
'jiangxi',
//india
'andhra pradesh',
'arunachal pradesh',
'assam',
'bihar',
'chhattisgarh',
'goa',
'gujarat',
'haryana',
'himachal pradesh',
'jharkhand',
'karnataka',
'kerala',
'madhya pradesh',
'maharashtra',
'manipur',
'meghalaya',
'mizoram',
'nagaland',
'odisha',
'punjab',
'rajasthan',
'sikkim',
'tamil nadu',
'telangana',
'tripura',
'uttar pradesh',
'uttarakhand',
'west bengal',
//mexico
'aguascalientes',
'baja california',
'campeche',
'chiapas',
'chihuahua',
'coahuila',
'colima',
'durango',
'guanajuato',
'guerrero',
'hidalgo',
'jalisco',
'michoacan',
'morelos',
'nayarit',
'nuevo leon',
'oaxaca',
'queretaro',
'quintana roo',
'san luis potosi',
'sinaloa',
'sonora',
'tabasco',
'tamaulipas',
'tlaxcala',
'veracruz',
'yucatan',
'zacatecas',
//western-europe
'basque',
'bavaria',
'bremen',
'buckinghamshire',
'cambridgeshire',
'corsica',
'coventry',
'cumbria',
'derbyshire',
'dorset',
'essex',
'gloucestershire',
'hampshire',
'hertfordshire',
'lancashire',
'leeds',
'leicestershire',
'lincolnshire',
'midlands',
'normandy',
'north yorkshire',
'northamptonshire',
'nottinghamshire',
'oxfordshire',
'saxony',
'sicily',
'somerset',
'staffordshire',
'suffolk',
'surrey',
'sussex',
'tuscany',
'warwickshire',
'yorkshire',
//bangladesh
'rajshahi',
'rangpur',
'khulna',
'sylhet',
//brazil
'minas gerais',
'bahia',
'parana',
'pernambuco',
'ceara',
'para',
'maranhao',
'santa catarina',
//russia
'siberia',
'adygea',
'altai',
'bashkortostan',
'buryatia',
'dagestan',
'ingushetia',
'kabardino',
'balkaria',
'kalmykia',
'karachay',
'cherkessia',
'karelia',
'komi',
'mari el',
'mordovia',
'yakutia',
'ossetia',
'tatarstan',
'tuva',
'udmurtia',
'khakassia',
'chechnya',
'chuvashia',
'crimea',
// malaysia
'penang',
'pahang',
'perak',
'sarawak',
'selangor',
'malacca',
'kedah',
'kelantan',
]
================================================
FILE: data/lexicon/switches/actor-verb.js
================================================
// actor like 'the coach' or verb like 'coach a team'
// use noun-verb for sometimes-actors, like 'target', or 'star'
export default [
'addict',
'architect',
'advocate',
'affiliate',
'bitch',
'bully',
'boss',
'champion',
'chauffeur',
'coach',
'cook',
'doctor',
'butcher',
'delegate',
'engineer',
'fool',
'geek',
'goof',
'graduate',
'groom',
'guide',
'host',
'judge',
'man',
'mime',
'master',
'nerd',
'parent',
'pilot',
'recruit',
'scout',
'sponsor',
'spy',
'suspect',
'usher',
'volunteer',
'conscript',
'wimp',
'witness',
]
================================================
FILE: data/lexicon/switches/adj-gerund.js
================================================
// rallying the troops
// her rallying cry
export default [
'absorbing',
'accelerating',
'accompanying',
'aching',
'aging',
'agonizing',
'agonzing',
'alarming',
'alluring',
'amazing',
'amusing',
'annoying',
'appealing',
'arresting',
'aspiring',
'assuring',
'astonishing',
'astounding',
'baffling',
'becoming',
'bewildering',
'bewitching',
'binding',
'blinding',
'boiling',
'booming',
'boring',
'bouncing',
'breathtaking',
'bruising',
'budding',
'bustling',
'calming',
'captivating',
'caring',
'challenging',
'changing',
'charming',
'chilling',
'climbing',
'closing',
'comforting',
'commanding',
'compelling',
'competing',
'compromising',
'concerning',
'conflicting',
'confusing',
'conspiring',
'continuing',
'contrasting',
'contributing',
'controlling',
'convincing',
'corresponding',
'crippling',
'cutting',
'damaging',
'daring',
'dashing',
'daunting',
'dazzling',
'debilitating',
'decaying',
'deceiving',
'declining',
'decreasing',
'defining',
'degrading',
'delighting',
'demanding',
'demeaning',
'demoralizing',
'depressing',
'deserving',
'devastating',
'developing',
'disappointing',
'disarming',
'disgusting',
'disheartening',
'dissenting',
'distracting',
'distressing',
'disturbing',
'dizzying',
'drifting',
'electrifying',
'embarrassing',
'emerging',
'empowering',
'enabling',
'enchanting',
'encouraging',
'enduring',
'energizing',
'engaging',
'enlivening',
'enriching',
'ensuing',
'enthralling',
'enticing',
'exacting',
'exasperating',
'exciting',
'exhausting',
'exhilarating',
'existing',
'expanding',
'exploding',
'fading',
'fascinating',
'fetching',
'fitting',
'flaming',
'flattering',
'floating',
'flowering',
'flowing',
'foreboding',
'forthcoming',
'founding',
'freezing',
'frightening',
'frustrating',
'fulfilling',
'glaring',
'gleaming',
'gratifying',
'grating',
'gripping',
'groundbreaking',
'growing',
'grueling',
'gruelling',
'guiding',
'harrowing',
'healing',
'heartwarming',
'horrifying',
'humiliating',
'illuminating',
'imposing',
'incorporating',
'increasing',
'infuriating',
'inspiring',
'insulting',
'interesting',
'intimidating',
'intoxicating',
'intriguing',
'invigorating',
'inviting',
'irritating',
'judging',
'lacking',
'lagging',
'lasting',
'laughing',
'leaning',
'leading',
'learning',
'lifesaving',
'limiting',
'living',
'loving',
'maddening',
'maturing',
'meandering',
'melting',
'mending',
'mesmerizing',
// 'mind-altering',
'boggling',
'numbing',
'missing',
'mitigating',
'motivating',
'moving',
'mumbling',
'mystifying',
'nurturing',
'offending',
'offsetting',
'opposing',
'outgoing',
'outlying',
'outstanding',
'overarching',
'overlapping',
'overpowering',
'overriding',
'overwhelming',
'owing',
'paying',
'pending',
'perplexing',
'piercing',
'plunging',
'preceding',
'pressing',
'prevailing',
'promising',
'provoking',
'punishing',
'raging',
'rallying',
'rambling',
'raving',
'reassuring',
'redefining',
'refreshing',
'reigning',
'rejuvenating',
'relaxing',
'remaining',
'resting',
'revealing',
'revitalising',
'revitalizing',
'revolving',
'rewarding',
'riveting',
'roaring',
'rolling',
'running',
'rushing',
'saddening',
'satisfying',
'screaming',
'screeching',
'sentencing',
'shining',
'shocking',
'skyrocketing',
'sloping',
'smiling',
'soaking',
'soaring',
'soothing',
'sparkling',
'speeding',
'spellbinding',
'sprawling',
'staggering',
'startling',
'starving',
'steaming',
'stimulating',
'stirring',
'striking',
'stunning',
'supporting',
'surging',
'surprising',
'surrounding',
'sweeping',
'swelling',
'tantalizing',
'taxing',
'teasing',
'telling',
'tempting',
'terrifying',
'threatening',
'thrilling',
'thriving',
'tiring',
'touching',
'trembling',
'troubling',
'trusting',
'trying',
'twisting',
'unfolding',
'unnerving',
'unsettling',
'uplifting',
'upsetting',
'varying',
'vexing',
'willing',
'working',
'worrying',
'yielding',
'accommodating',
'trifling',
'endearing',
// prefixes
]
================================================
FILE: data/lexicon/switches/adj-noun.js
================================================
// the commercial market
// watching the commercial
export default [
'academic',
'adolescent',
'adult',
'alert',
'alternative',
'antarctic',
'arab',
'arctic',
'back',
'best',
'blank',
'bottom',
'bourgeois',
'brief',
'brute',
'chief',
'classic',
'comic',
'commercial',
'communist',
'companion',
'complex',
'concrete',
'content',
'constituent',
'contemporary',
'convertable',
'cooperative',
'crude',
'cunning',
'dark',
'darling',
'demographic',
'derivative',
'elder',
'elite',
'epic',
'excess',
'executive',
'expert',
'fair',
'fat',
'favorite',
'favourite',
'fellow',
'female',
'feminist',
'fine',
'firm',
'fluid',
'fugitive',
'future',
'general',
'genious',
'gold',
'graphic',
'grave',
'half',
'hobby',
'homeless',
'humdrum',
'ideal',
'impressionist',
'incumbent',
'individual',
'innocent',
'instant',
'interim',
'justice',
'juvenile',
'last',
'latter',
'left',
'liberal',
'light',
'liquid',
'lush',
'male',
'marine',
'median',
'medium',
'metric',
'miniature',
// 'major',
// 'minor',
'mobile',
'modernist',
'moral',
'mortal',
'nagging',
'novel',
'nuts',
'offensive',
'official',
'opposite',
'oval',
'parallel',
'past',
'patient',
'periodical',
'pet',
'plastic',
// 'poor',
'potential',
'premier',
'premium',
'present',
'principal',
'pro',
'professional',
'racist',
'rash',
'rear',
'rebel',
'relative',
'rental',
'representative',
'republican',
'resident',
// 'rich',
'right',
'round',
'routine',
'rubbish',
'sage',
'secret',
'senior',
'serial',
'silver',
'slack',
'socialist',
'sole',
'solvent',
'sound',
'sovereign',
'square',
'squat',
'stable',
'standard',
'subject',
'subordinate',
'superior',
'swell',
'taboo',
'tan',
'teen',
'terminal',
'terrorist',
'token',
'top',
'total',
'trial',
'undergraduate',
'underground',
'upstairs',
'vagabond',
'vanilla',
'variable',
'variant',
'visionary',
'void',
'watershed',
'welcome',
]
================================================
FILE: data/lexicon/switches/adj-past.js
================================================
// clues: [adj, past],
// fallback: 'Adjective',
export default [
'abandoned',
'absorbed',
'accepted',
'acknowledged',
'adjusted',
'adopted',
'advanced',
'affected',
'aged',
'alarmed',
'alleged',
'altered',
'amazed',
'animated',
'anticipated',
'applied',
'appreciated',
'armed',
'associated',
'assumed',
'assured',
'augmented',
'authorized',
'awarded',
'baffled',
'baked', //baked goods
'balanced',
'based', //modern slang
'battered',
'bewildered',
'biased',
'blessed',
'blinded',
'boiled',
'bored',
'bottled',
'bound',
'broken',
'bruised',
'burned',
'burnt',
'caged',
'calculated',
'celebrated',
'centralized',
'certified',
'charged',
'charmed',
'chilled',
'classified',
'closed',
'cluttered',
'coded',
'colored',
'coloured',
'combined',
'complicated',
'concentrated',
'confused',
'considered',
'consolidated',
'controlled',
'cooked',
'covered',
'cracked',
'cramped',
'crowded',
'crushed',
'cultivated',
'cured',
'customized',
'damaged',
'dampened',
'dated',
'dazed',
'dazzled',
'decayed',
'decentralized',
'decorated',
'dedicated',
'deferred',
'defined',
'deformed',
'delayed',
'delighted',
'depressed',
'deranged',
'detailed',
'determined',
'developed',
'devoted',
'dignified',
'diminished',
'directed',
'disabled',
'disciplined',
'discounted',
'discouraged',
'disgruntled',
'distorted',
'distressed',
'disturbed',
'drained',
'dried',
'edified',
'educated',
'elated',
'emaciated',
'embarrassed',
'enchanted',
'engaged',
'enhanced',
'ensured',
'equipped',
'escaped',
'established',
'exaggerated',
'excited',
'expanded',
'expected',
'experienced',
'exposed',
'extended',
'faded',
'failed',
'fascinated',
'feared',
'finished',
'fitted',
'fixed',
'flavored',
'flavoured',
'flustered',
'focused',
'fractured',
'fragmented',
'framed',
'fried',
'frozen',
'gifted',
'gratified',
'grilled',
'grown',
'guarded',
'guided',
'hammered',
'harmed',
'heated',
'hooked',
'horrified',
'humbled',
'illuminated',
'implied',
'imported',
'improved',
'inbred',
'increased',
'indebted',
'infected',
'inflated',
'informed',
'infuriated',
'injured',
'inspired',
'integrated',
'intended',
'intensified',
'interested',
'intoxicated',
'invited',
'involved',
'isolated',
'jagged',
'joined',
'judged',
'justified',
'knotted',
'known',
'lay',
'lead',
'left',
'leveled',
'licensed',
'limited',
'listed',
'loaded',
'locked',
'lost',
'loved',
'managed',
'manufactured',
'marked',
'measured',
'melted',
'mixed',
'modified',
'motivated',
'mounted',
'muted',
'mystified',
'nagged',
'needed',
'neglected',
'noted',
'nourished',
'observed',
'occupied',
'oppressed',
'organized',
'overlooked',
'overwhelmed',
'packed',
'painted',
'paralleled',
'parked',
'pasted',
'perfected',
'picked',
'pierced',
'pissed',
'planned',
'pleased',
'plugged',
'pointed',
'polished',
'preferred',
'preoccupied',
'prepared',
'pressed',
'printed',
'processed',
'produced',
'prolonged',
'pronounced',
'proposed',
'protected',
'proved',
'pumped',
'puzzled',
'qualified',
'quoted',
'rained',
'rallied',
'ratified',
'received',
'recommended',
'recorded',
'recovered',
'recycled',
'reduced',
'refined',
'registered',
'regulated',
'rejected',
'related',
'released',
'removed',
'renewed',
'repeated',
'replaced',
'requested',
'required',
'reserved',
'respected',
'restored',
'restricted',
'rotted',
'satisfied',
'saturated',
'sauted',
'scared',
'scattered',
'scorched',
'scratched',
'screened',
'sealed',
'seasoned',
'seated',
'secured',
'selected',
'settled',
'shaded',
'shared',
'shocked',
'shut',
'simplified',
'simulated',
'smoked',
'soaked',
'specialized',
'specified',
'spiked',
'spotted',
'stained',
'stated',
'steamed',
'stereotyped',
'stirred',
'stoked',
'strengthened',
'striped',
'stripped',
'stuffed',
'stumped',
'stunned',
'subsidized',
'suggested',
'suspected',
'suspended',
'sustained',
'tamed',
'tanned',
'targeted',
'tarnished',
'teased',
'threatened',
'thrilled',
'tied',
'tired',
'touched',
'tracked',
'trained',
'trapped',
'trimmed',
'troubled',
'turned',
'twisted',
'uncovered',
'understood',
'unified',
'united',
'updated',
'uplifted',
'upset',
'used',
'varied',
'verified',
'warped',
'washed',
'watched',
'weakened',
'weathered',
'wet',
'worn',
'worried',
'wounded',
'wrinkled',
'yellowed',
]
================================================
FILE: data/lexicon/switches/adj-present.js
================================================
// 'would mean' vs 'is mean'
export default [
'approximate',
'blunt',
'clean',
'complete',
'conjugate',
'cool',
'correct',
'damp',
'deliberate',
'diffuse',
'direct',
'double',
'dry',
'elaborate',
'empty',
'firm',
'free',
'hollow',
'idle',
'lay',//lay-people
'lean',
// 'light',
'live',
'mature',
'mean',
'moderate',
// 'near',
'narrow',
'obscure',
'open',
'own',
'pale',
'present',
'prime',
'prompt',
'quack',
'replicate',
'right',
'secure',
'sedate',
'select',
'separate',
'slick',
'slow',
'smooth',
'sour',
'spare',
'sure',
'suspect',
'thin',
'top',//top the chart
'total',
'utter',
'warm',
'wet',
'wound',
'wrong',
'express',
'elicit',
'fringe',
'consummate',
'defuse',
'wrought',
'counterfeit',
'alight',
'tender',
'lower',
'close',
'last',
'faint',
'bankrupt',
'corrupt',
'fast',
'short',
'foul',
'fake',
'fancy',
'clear',
'calm',
'dull',
'stray',
'perfect',
'exempt',
'articulate',
]
================================================
FILE: data/lexicon/switches/noun-gerund.js
================================================
// gerunds can be adjectives 'striking example'
// or nouns 'arguing', or 'operating room'
export default [
'abandoning',
'accounting',
'acting',
'advertising',
'aging',
'approaching',
'arguing',
'assuming',
'attracting',
'babysitting',
'backing',
'baking',
'battling',
'beginning',
'belonging',
'betting',
'bitching',
'biting',
'blessing',
'bloating',
'boating',
'bombing',
'booking',
'bookkeeping',
'branding',
'breathing',
'broadcasting',
'budgeting',
'building',
'bullying',
'burping',
'camping',
'carving',
'casting',
'catering',
'celebrating',
'chanting',
'chatting',
'cheering',
'clapping',
'cleaning',
'clearing',
'climbing',
'cloning',
'clothing',
'clubbing',
'coaching',
'coating',
'coding',
'collecting',
'coloring',
'communicating',
'complaining',
'composing',
'conducting',
'constructing',
'consulting',
'convincing',
'cooking',
'coping',
'covering',
'crafting',
'crawling',
'crossing',
'crying',
'curling',
'cycling',
'dancing',
'dating',
'debating',
'decorating',
'delegating',
'delivering',
'developing',
'directing',
'discovering',
'diving',
'doubting',
'drawing',
'dreaming',
'dressing',
'dribbling',
'drinking',
'driving',
'dumping',
'dwelling',
'eating',
'educating',
'enchanting',
'ending',
'engineering',
'exercising',
'exploring',
'farming',
'fascinating',
'feeling',
'fencing',
'fighting',
'filing',
'filling',
// 'filming',
'financing',
'finding',
'fishing',
'flirting',
'flooding',
'forecasting',
'formatting',
'frosting',
'funding',
'gardening',
'gathering',
'generating',
'gliding',
'greeting',
'grieving',
'guiding',
'handling',
'harrowing',
'harvesting',
'heating',
'hiking',
'hiring',
'holding',
'howling',
'hunting',
'icing',
'illustrating',
// 'imaging',
'imagining',
'imploding',
'innovating',
'inspecting',
'interacting',
'interviewing',
'inventing',
'ironing',
'jogging',
'judging',
'juggling',
'justifying',
'kicking',
'killing',
'kneading',
'knitting',
'landing',
'laughing',
'learning',
'leasing',
'licensing',
'lifting',
'limiting',
'listening',
'listing',
'lodging',
'lying',
'maintaining',
'manifesting',
'manufacturing',
'marketing',
'meaning',
'meditating',
'meeting',
'messaging',
'mining',
'modeling',
'monitoring',
'navigating',
'negotiating',
'networking',
'nursing',
'offering',
'opening',
'operating',
'organising',
'organizing',
'overcoming',
'ovulating',
'packaging',
'painting',
'parking',
'partying',
'peacekeeping',
'planning',
'playing',
'poisoning',
'positioning',
'praying',
'pretending',
'printing',
'processing',
'publishing',
'questioning',
'rapping',
'rating',
'reading',
'reasoning',
'recording',
'recycling',
'rehearsing',
'relaxing',
'rendering',
'reporting',
'responding',
'restructruing',
'restructuring',
'riding',
'roofing',
'rowing',
'ruling',
'running',
'sailing',
'saying',
'scheduling',
'schooling',
'scoring',
'screaming',
'screening',
'sculpting',
'seating',
'serving',
'setting',
'shipping',
'shopping',
'shortening',
'shouting',
'signaling',
'signing',
'singing',
'sitting',
'skateboarding',
'skating',
'sleeping',
'smoking',
'snowboarding',
'snowing',
'spelling',
'spending',
'staging',
'storytelling',
'stretching',
'struggling',
'studying',
'stuffing',
'subtracting',
'suffering',
'surfing',
'surveying',
'surviving',
'swearing',
'swimming',
'talking',
'tanning',
'tasting',
'teaching',
'teasing',
'testing',
'thinking',
'timing',
'tipping',
'tracking',
'trading',
'training',
'traveling',
'travelling',
'typing',
'understanding',
'undertaking',
'visualizing',
'volunteering',
'voting',
'waiting',
// 'walking',
'warning',
'washing',
'watching',
'wedding',
'whispering',
'wiring',
'wondering',
'working',
'worrying',
'wrapping',
'wrestling',
'writing',
'yawning',
'yearning',
'yelling',
'zeroing',
'zoning',
'zooming',
]
================================================
FILE: data/lexicon/switches/noun-verb.js
================================================
// words that can be infinitives or nouns
export default [
'abuse',
'accent',
'access',
'accord',
'account',
'ace',
'ache',
'act',
'address',
'advance',
'advocate',
'age',
'aid',
'aim',
'air',
'alarm',
'alter',
'anchor',
'anger',
'answer',
'appeal',
'approach',
'arch',
'archive',
'arm',
'armour',
'ask',
'assist',
'associate',
'attack',
'attempt',
'auction',
'award',
'back',
'bail',
'balance',
'ban',
'band',
'bang',
'bank',
'bar',
'bargain',
'barge',
'bark',
'base',
'bash',
'battle',
'bear',
'beat',
'beef',
'belt',
'bend',
'benefit',
'bet',
'bias',
'bid',
'bike',
'bill',
'bind',
'biopsy',
'bit',
'bitch',
'bite',
'blame',
'blend',
'blink',
'blitz',
'block',
'blur',
'board',
'boast',
'bog',
'bomb',
'bond',
'bone',
'book',
'boost',
'boot',
'border',
'bottle',
'box',
'boycott',
'branch',
'brand',
'breach',
'break',
'breed',
'bribe',
'bridge',
'broadcast',
'bruise',
'brush',
'bubble',
'buckle',
'budget',
'buffer',
'bump',
'burden',
'burn',
'bust',
'buzz',
'bypass',
'cake',
'call',
'camp',
'canoe',
'cap',
'capture',
'card',
'care',
'cash',
'cast',
'catalog',
'catch',
'cause',
'caution',
'cave',
'center',
'centre',
'chain',
'chair',
'challenge',
'change',
'channel',
'charge',
'charm',
'chart',
'chase',
'cheat',
'check',
'cheer',
'chip',
'circle',
'claim',
'claw',
'click',
'clip',
'cloud',
'club',
'coat',
'code',
'coin',
'collapse',
'color',
'colour',
'combat',
'combine',
'comfort',
'command',
'comment',
'commit',
'commute',
'complement',
'compound',
'compromise',
'concentrate',
'concern',
'conduct',
'conflict',
'conglomerate',
'consent',
'construct',
'contact',
'contrast',
'control',
'convert',
'coordinate',
'copy',
'core',
'cost',
'cough',
'counsel',
'count',
'couple',
'court',
'cover',
'crack',
'craft',
'crash',
'credit',
'creep',
'crop',
'cross',
'crowd',
'crush',
'cry',
'cube',
'cue',
'curb',
'cure',
'curl',
'curve',
'cut',
'dab',
'damage',
'dance',
'dare',
'dart',
'date',
'deal',
'debate',
'debut',
'decline',
'decrease',
'defeat',
'defect',
'delay',
'delegate',
'delight',
'demand',
'deposit',
'desert',
'design',
'desire',
'detail',
'digest',
'dip',
'discharge',
'disguise',
'dish',
'dislike',
'dispatch',
'display',
'dispute',
'ditch',
'dive',
'divide',
'divorce',
'dock',
'document',
'dodge',
'doubt',
'download',
'draft',
'drag',
'drain',
'dream',
'dress',
'drift',
'drill',
'drink',
'drip',
'drive',
'drone',
'drop',
'dub',
'duel',
'dump',
'duplicate',
'dye',
'echo',
'edge',
'effect',
'encounter',
'end',
'envy',
'escape',
'estimate',
'excel',
'exchange',
'excuse',
'exercise',
'exhaust',
'exhibit',
'experience',
'experiment',
'export',
'extract',
'eye',
'eyeball',
'face',
'fail',
'fall',
'farm',
'favour',
'fear',
'feature',
'feed',
'feel',
'fence',
'field',
'fight',
'figure',
'file',
'film',
'filter',
'finance',
'finish',
'fire',
'fish',
'fit',
'fix',
'flag',
'flake',
'flame',
'flare',
'flash',
'flavor',
'flavour',
'flesh',
'flip',
'float',
'flock',
'flood',
'flow',
'flower',
'fly',
'focus',
'fog',
'foil',
'fold',
'foot',
'force',
'forecast',
'form',
'format',
'forward',
'fracture',
'fragment',
'frame',
'franchise',
'frost',
'frown',
'fry',
'fuck',
'fuel',
'function',
'fund',
'fuss',
'fuzz',
'gag',
'gain',
'game',
'gang',
'gas',
'gate',
'gaze',
'gear',
'gift',
'glare',
'gloss',
'glow',
'glue',
'gossip',
'grade',
'grasp',
'grill',
'grind',
'grip',
'ground',
'growth',
'grumble',
'guarantee',
'guard',
'guess',
'gulp',
'gun',
'hack',
'ham',
'hammer',
'hand',
'handle',
'harbour',
'harm',
'harness',
'harvest',
'hash',
'hatch',
'hate',
'haunt',
'head',
'heat',
'hedge',
'help',
'highlight',
'hike',
'hint',
'hire',
'hit',
'hold',
'hole',
'honor',
'honour',
'hook',
'hop',
'hope',
'horse',
'house',
'hug',
'hunt',
'impact',
'implement',
'incline',
'increase',
'index',
'influence',
'inhale',
'ink',
'insert',
'intent',
'interest',
'interface',
'interview',
'invoice',
'iron',
'issue',
'jam',
'jazz',
'joke',
'juice',
'jump',
'keel',
'key',
'kick',
'kid',
'kill',
'kiss',
'knock',
'label',
'labor',
'labour',
'lace',
'lack',
'land',
'lap',
'latch',
'laugh',
'launch',
'leach',
'lead',
'leak',
'leap',
'lease',
'lecture',
'leech',
'level',
'levy',
'license',
'lick',
'lift',
'limit',
'line',
'link',
'list',
'load',
'loan',
'lobby',
'lock',
'log',
'look',
'loot',
'love',
'lump',
'lust',
'mail',
'mandate',
'manner',
'manoeuvre',
'map',
'market',
'mash',
'mask',
'master',
'match',
'matter',
'measure',
'mention',
'merge',
'merit',
'mess',
'milk',
'mind',
'mine',
'mirror',
'miss',
'mistake',
'mix',
'mock',
'model',
'mold',
'monitor',
'monkey',
'mop',
'mount',
'mouth',
'move',
'murder',
'name',
'need',
'neglect',
'net',
'network',
'nod',
'note',
'notice',
'nurse',
'object',
'offer',
'oil',
'ooze',
'orbit',
'order',
'orient',
'outline',
'overpass',
'pack',
'package',
'paint',
'pair',
'paise',
'pan',
'panic',
'park',
'part',
'party',
'pass',
'paste',
'patch',
'patent',
'pause',
'pay',
'peak',
'pee',
'peel',
'peer',
'pen',
'pencil',
'perfume',
'permit',
'pet',
'phase',
'phone',
'photograph',
'pick',
'pile',
'pin',
'pine',
'pipe',
'pit',
'pity',
'pivot',
'place',
'plan',
'plant',
'play',
'plce',
'plead',
'plug',
'plump',
'plunge',
'point',
'poison',
'police',
'polish',
'poll',
'pool',
'poop',
'pop',
'pore',
'pose',
'position',
'post',
'pound',
'power',
'practice',
'praise',
'preserve',
'press',
'prey',
'price',
'pride',
'print',
'probe',
'proceed',
'process',
'produce',
'profile',
'program',
'programme',
'progress',
'project',
'promise',
'prop',
'protest',
'prune',
'psych',
'pump',
'punch',
'purchase',
'push',
'question',
'quiver',
'race',
'rack',
'rage',
'rain',
'raise',
'rake',
'rally',
'range',
'rank',
'rant',
'rap',
'rape',
'rat',
'rate',
'reach',
'reason',
'recall',
'record',
'redo',
'reel',
'refactor',
'reference',
'reform',
'refund',
'refuse',
'regard',
'register',
'regret',
'reject',
'release',
'relish',
'remake',
'remark',
'remedy',
'rendezvous',
'rent',
'reorder',
'repair',
'repeal',
'repeat',
'reply',
'report',
'request',
'reserve',
'resolve',
'resort',
'respect',
'rest',
'restart',
'result',
'resume',
'return',
'reveal',
'reverse',
'review',
'reward',
'rhyme',
'ride',
'ring',
'riot',
'rip',
'rise',
'risk',
'roast',
'rock',
'roll',
'roof',
'root',
'rope',
'route',
'rub',
'ruin',
'rule',
'run',
'rush',
'rust',
'sack',
'sacrifice',
'safeguard',
'sail',
'sample',
'scale',
'scan',
'scar',
'scare',
'schedule',
'score',
'scrape',
'scratch',
'screen',
'screw',
'scribble',
'scroll',
'seal',
'search',
'seat',
'seed',
'sense',
'sentence',
'serve',
'service',
'set',
'shack',
'shade',
'shape',
'share',
'shave',
'shed',
'sheild',
'shelter',
'shift',
'ship',
'shiver',
'shock',
'shop',
'shore',
'show',
'shuffle',
'side',
'sign',
'signal',
'silence',
'sink',
'sip',
'size',
'skateboard',
'ski',
'skip',
'sleep',
'slice',
'slip',
'slit',
'slouch',
'smash',
'smell',
'smile',
'smirk',
'smoke',
'snake',
'snap',
'sneeze',
'snow',
'sob',
'sound',
'spam',
'span',
'spark',
'speed',
'spell',
'spill',
'spin',
'spiral',
'spite',
'splash',
'split',
'sponsor',
'spot',
'spray',
'spread',
'spring',
'sprinkle',
'spruce',
'spur',
'spy',
'square',
'stack',
'staff',
'stage',
'stain',
'stake',
'stalk',
'stall',
'stamp',
'stand',
'staple',
'star',
'stare',
'start',
'state',
'stay',
'steer',
'stem',
'step',
'stick',
'stink',
'stitch',
'stocking',
'stockpile',
'stoop',
'stop',
'store',
'storm',
'strain',
'stream',
'stress',
'stretch',
'strike',
'string',
'stroke',
'struggle',
'study',
'stuff',
'stumble',
'style',
'sub',
'subject',
'suit',
'sum',
'supplement',
'supply',
'support',
'surface',
'surge',
'surprise',
'survey',
'swear',
'sweat',
'swing',
'swipe',
'switch',
'tag',
'talk',
'tally',
'tangle',
'target',
'taste',
'tax',
'tear',
'tee',
'tell',
'temper',
'test',
'text',
'thread',
'throw',
'thrust',
'tick',
'tide',
'tie',
'tile',
'time',
'tip',
'tire',
'toll',
'tone',
'top',
'torture',
'toss',
'total',
'touch',
'tour',
'track',
'trade',
'train',
'transfer',
'transition',
'trap',
'travel',
'treat',
'trek',
'trend',
'tribute',
'trick',
'trickle',
'trigger',
'trim',
'trip',
'trot',
'trouble',
'trust',
'tune',
'tunnel',
'turn',
'twin',
'twist',
'type',
'update',
'upgrade',
'upload',
'urge',
'vacuum',
'value',
'venture',
'vibe',
'view',
'visit',
'voice',
'void',
'vomit',
'vote',
'vow',
'wait',
'walk',
'war',
'warehouse',
'warrant',
'wash',
'waste',
'watch',
'wave',
'wax',
'wear',
'weather',
'weed',
'welcome',
'wheel',
'whip',
'whisk',
'whisper',
'whistle',
'wick',
'win',
'wind',
'wing',
'wipe',
'wire',
'wish',
'wonder',
'work',
'workshop',
'worry',
'worship',
'worth',
'wound',
'wrap',
'wreck',
'wrinkle',
'yawn',
'yell',
'yield',
'zip',
'zone',
'zoom',
'lie',
// 'average',
// 'fast',
// 'try',
]
================================================
FILE: data/lexicon/switches/person-adj.js
================================================
export default [
'misty',
'rusty',
'dusty',
'rich',
'randy',
'sandy',
'earnest',
'frank',
// 'young',
'brown',
'bella',
'woody'
]
================================================
FILE: data/lexicon/switches/person-date.js
================================================
// person-names that can be dates
export default [
// clues: [person, date],
// fallback: 'Month',
'april', 'august', 'jan', 'january', 'june', 'sep', 'avril',
// 'may'
]
================================================
FILE: data/lexicon/switches/person-noun.js
================================================
// person-names that can be dates
export default [
// clues: [person, noun],
// fallback: 'Singular',
// words: [
'alfredo',
'alma',
'art',
'baker',
'benedict',
'berg',
'bill',
'brandy',
'brook',
'cam',
'charity',
'chin',
'christian',
'cliff',
'crystal',
'daisy',
'dawn',
'dean',
'deja',
'dick',
'dixie',
'dolly',
'earl',
'eddy',
'emir',
'eula',
'eve',
'faith',
'fern',
'flo',
'gail',
'gene',
'grant',
"guy",
'hall',
'hazel',
'hill',
'holly',
// 'hope',
'jade',
'jasmine',
'jay',
'jean',
'jewel',
'jolie',
'joy',
'kelvin',
'king',
'kitty',
'lane',
'leo',
'lily',
'max',
'maya',
'melody',
'miles',
'olive',
'patsy',
'page',
'pearl',
'penny',
'pol',
'ray',
'reed',
'rex',
'robin',
'rod',
'rose',
'ruby',
'sky',
'sonny',
'summer',
'trinity',
'van',
'viola',
'violet',
'wang',
'ward',
'venus',
"dj",
"paddy",
"herb",
"fanny",
"norm",
"bo",
"bud",
"finn",
"mat",
"mats",
"nat",
"hunter",
"ward",
"dean",
"gill",
"chambers",
"watts",
"banks",
"fields",
"miles",
"potter",
]
================================================
FILE: data/lexicon/switches/person-place.js
================================================
// cities
export default [
'alexandria',
'austin',
'darwin',
'diego',
'hamilton',
'houston',
'jordan',
'kent',
'kobe',
'orlando',
'salvador',
'samara',
'santiago',
'sydney',
'victoria',
'virginia',
]
================================================
FILE: data/lexicon/switches/person-verb.js
================================================
// words that can be a verb or a person's name
export default [
// clues: [person, verb],
// fallback: 'PresentTense', //maybe?
'biff',
'blaze',
'blossom',
'bob',
'buck',
'chase',
'chuck',
'drew',
'foster',
'grace',
'grant',
'jack',
'lance',
'mack',
'mark',
'marshal',
'nick',
'ollie',
'pat',
'peg',
'pierce',
'rob',
'spike',
'stew',
'sue',
'skip',
'wade',
// 'hope',
// 'trace',
// 'bill',
// 'will',
// 'sung'
// 'may'
// 'peter',
]
================================================
FILE: data/lexicon/switches/unit-noun.js
================================================
export default [
'cm',
'cup',
'cups',
'feet',
'foot',
'ft',
'gal',
'gb',
'hg',
'inch',
'inches',
'k',
'kb',
'kelvin',
'kg',
'kb',
'km',
'lb',
'm',
'mb',
'mg',
'mi',
'hz',
'mps',
'mph',
'miles',
'ml',
'mm',
'mph',
'newton',
'newtons',
'oz',
'pa',
// 'pound',
// 'pounds',
'pt',
'px',
'qt',
'tablespoon',
'tablespoons',
'tb',
'tbl',
'tbsp',
'teaspoon',
'teaspoons',
'tsp',
'yard',
'yards',
'yd',
]
================================================
FILE: data/lexicon/verbs/infinitives.js
================================================
export default [
'abandon',
'abet',
'abide',
'abolish',
'abort',
'abound',
'abscond',
'absolve',
'accept',
'acclimate',
'accommodate',
'accompany',
'accomplish',
'accost',
'accrue',
'accuse',
'accustom',
'achieve',
'acknowledge',
'acquiesce',
'acquire',
'activate',
'adapt',
'adjourn',
'adjust',
'administer',
'admit',
'adopt',
'adorn',
'adsorb',
'affix',
'afford',
'agree',
'align',
'allege',
'allot',
'allow',
'allude',
'amalgamate',
'amaze',
'amuse',
'analyse',
'animate',
'anneal',
'announce',
'annoy',
'annul',
'anticipate',
'appear',
'appease',
'apply',
'appoint',
'appraise',
'approve',
'argue',
'arise',
'arouse',
'arrange',
'arrive',
'aspire',
'assail',
'assemble',
'assert',
'assess',
'assign',
'assure',
'astonish',
'attach',
'attest',
'attract',
'augment',
'automate',
'avert',
'avoid',
'await',
'awaken',
'babysit',
'backfire',
'baffle',
'bathe',
'be',
'become',
'beg',
'begin',
'beguile',
'behave',
'behead',
'behold',
'believe',
'belittle',
'bequeath',
'bestow',
'betray',
'bewilder',
'bide',
'bleed',
'blow',
'boil',
'bolster',
'bombard',
'borrow',
'bother',
'brake',
'breastfeed',
'breathe',
'bring',
'broaden',
'build',
'burst',
'bury',
'buy',
'cancel',
'careen',
'cater',
'caulk',
'cease',
'cherish',
'chew',
'chirp',
'choose',
'chop',
'circumvent',
'cite',
'cleanse',
'cling',
'coalesce',
'coerce',
'coexist',
'cohabit',
'coincide',
'collect',
'collide',
'collude',
'combust',
'come',
'commence',
'compel',
'compete',
'compile',
'comply',
'conceal',
'conceive',
'conclude',
'concur',
'condemn',
'condense',
'condone',
'confess',
'confide',
'configure',
'confirm',
'conform',
'confront',
'confuse',
'conjure',
'connote',
'conquer',
'conserve',
'consider',
'consist',
'consolidate',
'conspire',
'constitute',
'consult',
'contain',
'continue',
'contribute',
'convene',
'converge',
'convey',
'convince',
'corrode',
'crave',
'create',
'cripple',
'crumble',
'curtail',
'dampen',
'darken',
'daunt',
'deafen',
'debark',
'debrief',
'debug',
'debunk',
'deceive',
'decide',
'decimate',
'decipher',
'declare',
'decode',
'decommission',
'decompose',
'decouple',
'decree',
'decry',
'decrypt',
'deduct',
'deepen',
'deface',
'define',
'deform',
'defraud',
'defy',
'delimit',
'deliver',
'demean',
'demolish',
'denote',
'denounce',
'deny',
'depart',
'depict',
'deplore',
'deploy',
'deport',
'derail',
'derive',
'desist',
'detach',
'develop',
'devolve',
'diagnose',
'die',
'differ',
'dig',
'diminish',
'dine',
'disable',
'disarm',
'disband',
'disburse',
'discard',
'discern',
'disclaim',
'disclose',
'discourage',
'discover',
'discuss',
'dislodge',
'dismantle',
'dispense',
'disperse',
'displace',
'displease',
'dispose',
'disprove',
'disrupt',
'dissolve',
'dissuade',
'distil',
'distill',
'distinguish',
'distort',
'disturb',
'diverge',
'divert',
'divest',
'divulge',
'do',
'draw',
'dredge',
'drown',
'dwindle',
'earmark',
'earn',
'eat',
'edit',
'elapse',
'elect',
'elucidate',
'elude',
'embalm',
'embark',
'embody',
'embrace',
'embroider',
'embroil',
'emerge',
'emphasize',
'empower',
'enable',
'enact',
'encircle',
'enclose',
'encourage',
'encroach',
'encrypt',
'encumber',
'endanger',
'endorse',
'endow',
'endure',
'enforce',
'engage',
'engender',
'engrave',
'engulf',
'enhance',
'enjoy',
'enlarge',
'enlist',
'enquire',
'enrich',
'enrol',
'enroll',
'ensue',
'ensure',
'enter',
'entice',
'entrain',
'entrench',
'entrust',
'envelop',
'envisage',
'envision',
'equip',
'erase',
'erupt',
'eschew',
'espouse',
'establish',
'etch',
'evaluate',
'evoke',
'evolve',
'exalt',
'examine',
'exceed',
'exclaim',
'exclude',
'exert',
'exhale',
'exhort',
'exhume',
'exist',
'exit',
'expect',
'expedite',
'expel',
'expire',
'explain',
'exploit',
'explore',
'expose',
'expunge',
'extinguish',
'extol',
'exude',
'falter',
'fasten',
'ferment',
'find',
'flatter',
'flee',
'fling',
'forbid',
'foreclose',
'forego',
'foreshadow',
'forewarn',
'forfeit',
'forge',
'forget',
'forgive',
'forsake',
'forsee',
'freeze',
'freshen',
'frighten',
'frolic',
'fulfil',
'fundraise',
'furnish',
'gather',
'get',
'give',
'glean',
'go',
'govern',
'grab',
'grapple',
'graze',
'greet',
'grow',
'hamper',
'hang',
'happen',
'harangue',
'harass',
'hasten',
'have',
'hear',
'heighten',
'hide',
'hijack',
'hinder',
'hoist',
'hurt',
'ignore',
'imbue',
'immerse',
'impale',
'impart',
'imperil',
'impinge',
'imply',
'import',
'impose',
'impoverish',
'impress',
'imprison',
'improve',
'incite',
'include',
'indicate',
'indulge',
'infest',
'inform',
'infuse',
'ingest',
'inhabit',
'inhibit',
'initiate',
'injure',
'inquire',
'insist',
'inspire',
'install',
'instil',
'instruct',
'insure',
'interact',
'intern',
'interpret',
'interrupt',
'intimidate',
'intoxicate',
'introduce',
'intrude',
'inundate',
'invade',
'invent',
'invert',
'invest',
'invoke',
'involve',
'irk',
'join',
'juggle',
'juxtapose',
'keep',
'kidnap',
'kneel',
'know',
'languish',
'launder',
'learn',
'leave',
'lend',
'lengthen',
'lessen',
'like',
'linger',
'liquefy',
'liquidate',
'liven',
'lose',
'lurk',
'maim',
'maintain',
'make',
'manage',
'meet',
'mimic',
'mimick',
'mince',
'mingle',
'minus',
'misplace',
'molest',
'mourn',
'mow',
'multiply',
'nourish',
'obey',
'observe',
'obsess',
'obtain',
'occupy',
'occur',
'omit',
'operate',
'opine',
'oppose',
'outgrow',
'outnumber',
'outpace',
'overlap',
'oversee',
'overshadow',
'overturn',
'overuse',
'overwhelm',
'owe',
'pamper',
'paralyse',
'participate',
'patrol',
'pave',
'perceive',
'perform',
'perish',
'permeate',
'perplex',
'persevere',
'persist',
'persuade',
'pervade',
'pinpoint',
'plummet',
'poach',
'pollute',
'portray',
'possess',
'preach',
'preclude',
'predetermine',
'predict',
'prefer',
'preoccupy',
'presuppose',
'prevail',
'prevent',
'proclaim',
'procure',
'prod',
'profess',
'prohibit',
'promote',
'pronounce',
'propose',
'prosper',
'protrude',
'prove',
'provide',
'provoke',
'publish',
'puke',
'punish',
'purport',
'pursuant',
'pursue',
'put',
'quash',
'quench',
'quit',
'quote',
'rattle',
'ravish',
'react',
'read',
'realise',
'realize',
'reap',
'reboot',
'rebuff',
'receive',
'reckon',
'reclaim',
'recognize',
'reconcile',
'recoup',
'recover',
'recycle',
'redact',
'reduce',
'refinance',
'refine',
'reflect',
'refocus',
'refract',
'refresh',
'refuel',
'refurbish',
'regroup',
'rehearse',
'reheat',
'reimburse',
'reinforce',
'rejoice',
'relate',
'relent',
'relieve',
'relinquish',
'relive',
'reload',
'rely',
'remain',
'remember',
'remove',
'render',
'renew',
'renounce',
'repel',
'rephrase',
'replace',
'replenish',
'replicate',
'represent',
'require',
'resemble',
'resent',
'reside',
'resign',
'resist',
'respond',
'restock',
'restrain',
'restrict',
'restructure',
'resurface',
'retire',
'retrieve',
'retrofit',
'reup', //'re-up'
'revamp',
'revel',
'revere',
'revert',
'revisit',
'revive',
'revoke',
'revolve',
'rid',
'ripen',
'roam',
'rot',
'rout',
'ruin',
'sadden',
'satisfy',
'say',
'scavenge',
'sculpt',
'see',
'seek',
'seem',
'sell',
'send',
'sequester',
'sever',
'sew',
'shake',
'sharpen',
'shatter',
'shine',
'shoot',
'shorten',
'shrink',
'shrivel',
'shun',
'sift',
'sing',
'sit',
'slam',
'slay',
'slide',
'smuggle',
'snatch',
'sneak',
'sniff',
'solicit',
'solve',
'soothe',
'sow',
'spawn',
'speak',
'spend',
'spit',
'splay',
'spoil',
'spoof',
'spring',
'squander',
'squish',
'stab',
'stagger',
'startle',
'starve',
'steal',
'stiffen',
'stifle',
'sting',
'strangle',
'strengthen',
'strew',
'strive',
'sublimate',
'submerge',
'submit',
'subside',
'subsist',
'subvert',
'succeed',
'succumb',
'suffer',
'suffice',
'suggest',
'summarise',
'summon',
'suppose',
'suppress',
'surmount',
'surpass',
'survive',
'swallow',
'sweep',
'sweeten',
'swim',
'tackle',
'tailor',
'take part',
'take',
'tamper',
'tarnish',
'teach',
'tease',
'tempt',
'thank',
'think',
'threaten',
'thrive',
'thwart',
'topple',
'toughen',
'traffick',
'trample',
'transact',
'transform',
'transpire',
'transport',
'tremble',
'tumble',
'uncover',
'undercut',
'undergo',
'understand',
'undervalue',
'underwhelm',
'undo',
'unearth',
'unfounded',
'unleash',
'unlock',
'unplug',
'unravel',
'untie',
'unveil',
'uphold',
'uplift',
'validate',
'vanish',
'vary',
'vie',
'waive',
'wake',
'wander',
'want',
'warn',
'weave',
'wed',
'weep',
'widen',
'wield',
'withdraw',
'wither',
'worsen',
'wreak',
'wrestle',
'wring',
'write',
'giggle',
'sway',
'constrain',
'abduct',
'attain',
'pound',
'consume',
'befriend',
]
================================================
FILE: data/lexicon/verbs/modals.js
================================================
export default [
'can',
'could',
'lets', //arguable
// 'may',
'might',
'must',
'ought to',
'ought',
'oughta',
'shall',
'shant',
'should',
'will',
'would',
]
================================================
FILE: data/lexicon/verbs/participles.js
================================================
export default [
// -- participle forms--
'arisen',
'awaken',
'awoken',
'beaten',
'been',
'begun',
'bitten',
'blown',
'broken',
'built',
'chosen',
'clung',
// 'done',
'dove',
'drawn',
'dreamt',
'driven',
// 'drunk',
'eaten',
'fallen',
'flown',
'forbidden',
'forgiven',
'forgotten',
'forsaken',
'forseen',
'frozen',
'given',
'gone',
'gotten',
'grown',
'hasten',
'hidden',
'known',
'outdone',
'outgrown',
'overdone',
'overseen',
'overtaken',
'overthrown',
'proven',
'rewritten',
'ridden',
'risen',
'rung',
'seen',
'sewn',
'shaken',
'shone',
'shown',
'shrunk',
'slain',
'sought',
'sown',
'spilt',
'spoken',
'stolen',
'strewn',
'sung',
'sunk',
'sworn',
'swum',
'taken',
'thrown',
'torn',
'undergone',
'undone',
'uprisen',
'waken',
'withdrawn',
'woken',
'worn',
'woven',
'written',
'wrung',
]
================================================
FILE: data/lexicon/verbs/phrasals.js
================================================
// phrasal verbs are two words that really mean one verb.
// 'beef up' is one verb, and not some direction of beefing.
// this seems like an inefficient way to store it, but the trie compresses by prefix
// the first-words are also conjugated as infinitives, so mind that
// by @spencermountain, 2015 mit
// many credits to http://www.allmyphrasalverbs.com/
export default [
'act out',
'air out',
'act up',
'add down',
'add off',
'add on',
'add up',
'ask around',
'ask out',
'auction off',
'back away',
'back down',
'back out',
'back off',
'back in',
'back up',
'bail out',
'bang in',
'bang out',
'bank on',
'bargain on',
'barge in',
'barge out',
'bash in',
'bash out',
'be off',
'be onto',
'belt out',
'bear out',
'bear down',
'beat down',
'beat in',
'beat off',
'beat out',
'beat up',
'beef up',
'bend down',
'bend over',
'bend up',
'bite off',
'black out',
'blank out',
'blast off',
'bleed out',
'block in',
'block off',
'block out',
'blow away',
'blow back',
'blow down',
'blow out',
'blow up',
'blurt out',
'board up',
'bore down',
'bog down',
'bog up',
'boil down',
'boil up',
'bone up',
'book in',
'book out',
'boot up',
'boss around',
'bottle down',
'bottle up',
'bounce away',
'bounce back',
'box in',
'box out',
'branch out',
'break down',
'break in',
'break out',
'break up',
'brighten up',
'bring about',
'bring along',
'bring around',
'bring away',
'bring back',
'bring down',
'bring forth',
'bring in',
'bring out',
'bring up',
'bring on',
'bring under',
'brush off',
'brush up',
'bubble over',
'buckle down',
'buckle up',
'build up',
'bulk down',
'bulk up',
'bundle down',
'bundle up',
'burn in',
'burn off',
'burn out',
'burst in',
'burst out',
'bust down',
'bust in',
'bust out',
'bust up',
'butt in',
'butt out',
'buy out',
'buy up',
'buzz off',
'call around',
'call away',
'call back',
'call down',
'call off',
'call on',
'call up',
'call out',
'calm down',
'cancel out',
'carry away',
'carry off',
'carry on',
'carry out',
'carve down',
'carve in',
'carve out',
'carve up',
'cash in',
'cash out',
'cast doubt',
'cast off',
'catch off',
'catch on',
'catch up',
'cave in',
'check in',
'check out',
'cheer on',
'cheer up',
'chat up',
'chew up',
'chew out',
'chill out',
'chip in',
'clean down',
'clean up',
'clear up',
'clear out',
'close up',
'close off',
'close out',
'close in',
'come apart',
'come around',
'come away',
'come back',
'come by',
'come forth',
'come forward',
'come in',
'come off',
'come up',
'come out',
'come over',
'come together',
'come through',
'come under',
'come true',
'cook down',
'cook up',
'cool down',
'cool off',
'count off',
'count on',
'crack on',
'creep by',
'creep down',
'creep in',
'creep on',
'creep out',
'creep up',
'cross in',
'crowd out',
'cross out',
'cry out',
'cut away',
'cut back',
'cut down',
'cut out',
'cut up',
'cut off',
'die down',
'dam up',
'dole out',
'do over',
'double down',
'double up',
'drum up',
'drag on',
'draw on',
'dress down',
'dress up',
'drop away',
'drop back',
'drop by',
'drop in',
'drop off',
'drop out',
'eat in',
'eat out',
'eat up',
'edge out',
'end off',
'end up',
'eye up',
'face down',
'face off',
'face up',
'fall apart',
'fall back',
'fall behind',
'fall down',
'fall in',
'fall off',
'fall out',
'fall over',
'fall through',
'fall short',
'fall victim',
'farm out',
'fatten up',
'feed off',
'feed on',
'feel up',
'fence in',
'fence out',
'fend for',
'fend off',
'fess up',
'fight back',
'figure out',
'file away',
'file for',
'file in',
'file out',
'fill down',
'fill in',
'fill out',
'fill up',
'find out',
'finish up',
'fire away',
'fire back',
'fire up',
'firm up',
'fish out',
'fish up',
'fizzle out',
'flag down',
'flag up',
'flake out',
'flame out',
'flame up',
'flare out',
'flare up',
'flatten down',
'flesh out',
'flip out',
'fork over',
'fold down',
'fold up',
'fog up',
'follow up',
'fool about',
'fool around',
'fool with',
'free up',
'freeze up',
'freshen up',
'frighten away',
'frighten off',
'frown on',
'fry up',
'fuck up',
'fuck around',
'fuel down',
'fuel up',
'gad about',
'gang up',
'gear down',
'gear up',
'geek out',
'get across',
'get ahead',
'get along',
'get around',
'get at',
'get away',
'get back',
'get by',
'get down',
'get in',
'get off',
'get on',
'get out',
'get over',
'get round',
'get up',
'give away',
'give back',
'give birth',
'give down',
'give in',
'give off',
'give on',
'give out',
'give rise',
'give up',
'give way',
'gloss over',
'go about',
'go after',
'go ahead',
'go away',
'go back',
'go by',
'go it',
'go off',
'go on',
'go over',
'go round',
'go through',
'go under',
'goof off',
'goof up',
'grind down',
'grind off',
'grind on',
'grind up',
'grow down',
'grow in',
'grow out',
'grow up',
'gun for',
'hack up',
'hash out',
'ham up',
'hand down',
'hand in',
'hand out',
'hand over',
'hang down',
'hang in',
'hang out',
'hang up',
'hang on',
'hanker for',
'have at',
'have it',
'have to',
'haze over',
'head in',
'head off',
'head on',
'head out',
'head over',
'head under',
'head for',
'heal over',
'hear from',
'hear of',
'heat up',
'help out',
'hide away',
'hide out',
'hit back',
'hit on',
'hit up',
'hold back',
'hold down',
'hold dear',
'hold fast',
'hold off',
'hold on',
'hold out',
'hold over',
'hold up',
'hole up',
'hone in',
'horse around',
'hunker down',
'hunt around',
'hunt down',
'hurry up',
'hush down',
'hush up',
'iron out',
'jack in',
'jack off',
'jack out',
'jazz up',
'joke around',
'jot down',
'juice up',
'jump in',
'keel over',
'keep away',
'keep back',
'keep down',
'keep from',
'keep in',
'keep off',
'keep on',
'keep out',
'keep to',
'keep up',
'key in',
'key up',
'kick off',
'kick out',
'kick up',
'knock down',
'knock off',
'knock out',
'knock up',
'lace up',
'lap up',
'lash into',
'lash out',
'latch on',
'laugh off',
'lay off',
'lay on',
'lay down',
'lean in',
'leave in',
'leave open',
'leave out',
'let down',
'let go',
'let in',
'let out',
'let up',
'level off',
'level out',
'lie around',
'lie down',
'lie in',
'light up',
'lighten up',
'line up',
'link up',
'listen out',
'listen up',
'live off',
'live up',
'live out',
'load down',
'load up',
'lock down',
'lock in',
'lock out',
'lock up',
'log in',
'log off',
'log on',
'log out',
'look after',
'look back',
'look down',
'look forward',
'look into',
'look over',
'look out',
'look under',
'look up',
'loosen up',
'lose out',
'luck out',
'lust over',
'make do',
'make off',
'make out',
'make up',
'make sure',
'make fun',
'man down',
'man up',
'mark down',
'mark up',
'marry off',
'mash up',
'max out',
'measure up',
'melt down',
'melt up',
'mess about',
'mess around',
'mess up',
'meet up',
'miss out',
'mix up',
'mock up',
'monkey with',
'mop down',
'mop up',
'mouth off',
'move along',
'move away',
'move down',
'move in',
'move out',
'move up',
'move on',
'muddle up',
'mull over',
'nail down',
'narrow down',
'nerd out',
'nod off',
'note down',
'open up',
'opt in',
'opt out',
'own up',
'pack down',
'pack in',
'pack out',
'pack up',
'pair down',
'pair off',
'pair up',
'pan out',
'pass away',
'pass back',
'pass in',
'pass off',
'pass on',
'pass out',
'pat down',
'patch up',
'pay back',
'pay off',
'peel in',
'peel off',
'peel out',
'pencil in',
'pick off',
'pick on',
'pick out',
'pick up',
'pig out',
'pile on',
'pile up',
'pin down',
'pin up',
'pipe down',
'pipe up',
'play around',
'play out',
'place under',
'plug in',
'plump down',
'plump up',
'point out',
'pop down',
'pop off',
'pop on',
'pop up',
'pop in',
'pore over',
'pour down',
'power down',
'power off',
'power on',
'power up',
'prattle on',
'press ahead',
'press on',
'print out',
'prop up',
'psych out',
'psych up',
'punch out',
'pull apart',
'pull down',
'pull in',
'pull out',
'pull together',
'pull up',
'pull over',
'put apart',
'put away',
'put back',
'put down',
'put in',
'put off',
'put on',
'put out',
'put together',
'put up',
'quiet down',
'rack up',
'rat out',
'reach in',
'reach out',
'read off',
'read out',
'read over',
'read up',
'reel off',
'rein in',
'rent out',
'rise up',
'ring in',
'ring off',
'ring out',
'rip off',
'rip open',
'rope off',
'roll around',
'roll in',
'roll out',
'roll up',
'root about',
'root for',
'root out',
'round out',
'rough up',
'round off',
'rub down',
'rub in',
'rub out',
'rub up',
'rule out',
'run across',
'run away',
'run back',
'run down',
'run in',
'run into',
'run out',
'run over',
'run through',
'run under',
'run up',
'run around',
'rustle up',
'sail off',
'save up',
'scale down',
'scale up',
'scout out',
'scrape down',
'scrape up',
'screw off',
'screw in',
'screw out',
'see off',
'see out',
'see to',
'sell off',
'sell out',
'send away',
'send back',
'send down',
'send in',
'send off',
'send on',
'send out',
'send over',
'send up',
'set down',
'set in',
'set out',
'set up',
'set forth',
'set upon',
'set foot',
'settle down',
'settle in',
'settle out',
'settle up',
'serve up',
'shack up',
'shade in',
'shake down',
'shake up',
'shave off',
'shoot away',
'shoot back',
'shoot for',
'shoot off',
'shoot out',
'shout out',
'show down',
'show off',
'show on',
'show up',
'shut in',
'shut out',
'shut up',
'shut down',
'side with',
'sign in',
'sign out',
'sign up',
'sink in',
'sing along',
'single out',
'sit down',
'sit in',
'sit out',
'sit up',
'size up',
'sleep in',
'sleep off',
'sleep over',
'slice off',
'slice up',
'slip up',
'slip on',
'slip out',
'slow down',
'slow up',
'smash down',
'smash in',
'smash out',
'smash up',
'smoke out',
'snuggle up',
'snap off',
'snap on',
'snap up',
'snow in',
'snow out',
'sober up',
'soak up',
'sort out',
'sound like',
'spark up',
'speed up',
'speed down',
'speak up',
'speak out',
'spell out',
'spill out',
'spill over',
'spin up',
'spice up',
'splash out',
'split off',
'split up',
'spread out',
'spring on',
'spruce up',
'spur on',
'square down',
'square off',
'square up',
'stack up',
'stamp out',
'stand back',
'stand down',
'stand up',
'start out',
'start up',
'start off',
'stare down',
'stave off',
'stay up',
'stay in',
'step up',
'step out',
'stink up',
'stir up',
'stitch up',
'stop by',
'stop in',
'stop off',
'storm off',
'storm out',
'stretch out',
'straighten out',
'straighten up',
'strike down',
'strike in',
'strike off',
'strike out',
'strike up',
'string up',
'string along',
'stick up',
'study up',
'suck in',
'suck off',
'suck out',
'suck up',
'suit up',
'sum up',
'suss out',
'swear by',
'swing by',
'switch away',
'switch back',
'switch off',
'switch on',
'tack on',
'take aback',
'take after',
'take apart',
'take away',
'take back',
'take down',
'take leave',
'take in',
'take off',
'take on',
'take out',
'take up',
'take over',
'talk over',
'talk shit',
'talk under',
'team up',
'tear down',
'tear off',
'tear up',
'tee off',
'tee up',
'tell off',
'tell on',
'think back',
'think over',
'think up',
'throw away',
'throw back',
'throw up',
'throw in',
'tick by',
'tick off',
'tide over',
'tidy up',
'tie away',
'tie back',
'tie down',
'tie in',
'tie up',
'tighten down',
'tighten up',
'time out',
'tip off',
'tip over',
'tire out',
'tone down',
'top down',
'top off',
'top out',
'top up',
'toss up',
'track down',
'trade in',
'trade out',
'trade up',
'trickle down',
'trip out',
'trip up',
'trot out',
'try in',
'try off',
'try on',
'try out',
'tuck in',
'turn down',
'turn in',
'turn off',
'turn on',
'turn out',
'turn up',
'type in',
'type out',
'type up',
'urge on',
'use up',
'usher in',
'vacuum up',
'wait off',
'wait on',
'wait up',
'wake up',
'walk away',
'walk in',
'walk off',
'walk out',
'warm in',
'warm out',
'warm up',
'wash away',
'wash down',
'wash out',
'wash up',
'watch out',
'wave in',
'wave out',
'wean in',
'wean out',
'wear down',
'wear in',
'wear off',
'wear on',
'wear out',
'weigh in',
'weigh up',
'weird out',
'went down',
'went up',
'whack off',
'wheel in',
'wheel out',
'whip out',
'whip up',
'wimp out',
'wind down',
'wind up',
'wipe out',
'wire up',
'wise up',
'work in',
'work off',
'work out',
'work up',
'write off',
'write up',
'yammer on',
'zero in',
'zero out',
'zip by',
'zip up',
'zip over',
'zone out',
'zonk out',
'grab hold',
]
================================================
FILE: data/lexicon/verbs/verbs.js
================================================
//verbs we shouldn't conjugate, for whatever reason
export default [
'has',
'keep tabs',
'born',
'cannot',
'gonna',
'msg',
'make sure',
]
================================================
FILE: data/pairs/AdjToNoun.js
================================================
export default [
['abject', 'abjection'],
['abstemious', 'abstemiousness'],
['abundant', 'abundance'],
['accomplished', 'accomplishment'],
['accurate', 'accuracy'],
['active', 'activity'],
['adamant', 'adamance'],
['adaptable', 'adaptability'],
['addictive', 'addiction'],
['admirable', 'admiration'],
['adventurous', 'adventurousness'],
['affectionate', 'affection'],
['aggressive', 'aggression'],
['agile', 'agility'],
['agitated', 'agitation'],
['alert', 'alertness'],
['aloof', 'aloofness'],
['amazed', 'amazement'],
['ambitious', 'ambition'],
['amiable', 'amiability'],
['amicable', 'amicability'],
['amorous', 'amorousness'],
['ample', 'ampleness'],
['amused', 'amusement'],
['amusing', 'amusement'],
['ancient', 'antiquity'],
['apprehensive', 'apprehensiveness'],
['ardent', 'ardor'],
['argumentative', 'argumentativeness'],
['articulate', 'articulacy'],
['artistic', 'art'],
['assertive', 'assertiveness'],
['astute', 'astuteness'],
['attractive', 'attractiveness'],
['audacious', 'audacity'],
['austere', 'austerity'],
['authentic', 'authenticity'],
['automatic', 'automation'],
['bad', 'badness'],
['beautiful', 'beauty'],
['benevolent', 'benevolence'],
['bold', 'boldness'],
['boring', 'boredom'],
['brave', 'bravery'],
['bright', 'brightness'],
['busy', 'business'],
['calm', 'calmness'],
['cantankerous', 'cantankerousness'],
['careful', 'carefulness'],
['caring', 'care'],
['cautious', 'caution'],
['certain', 'certainty'],
['charismatic', 'charisma'],
['cheap', 'cheapness'],
['cheerful', 'cheerfulness'],
['circumspect', 'circumspection'],
['clean', 'cleanliness'],
['clear', 'clarity'],
['clever', 'cleverness'],
['cold', 'coldness'],
['comfortable', 'comfort'],
['compassionate', 'compassion'],
['compatible', 'compatibility'],
['competent', 'competency'],
['concise', 'conciseness'],
['condescending', 'condescension'],
['confident', 'confidence'],
['congenial', 'congeniality'],
['conscientious', 'conscientiousness'],
['contemptuous', 'contemptuousness'],
['cooperative', 'cooperation'],
['courageous', 'courage'],
['courteous', 'courtesy'],
['coy', 'coyness'],
['creative', 'creativity'],
['credible', 'credibility'],
['curious', 'curiosity'],
['dark', 'darkness'],
['decisive', 'decisiveness'],
['dedicated', 'dedication'],
['deep', 'depth'],
['deliberate', 'deliberation'],
['delicate', 'delicacy'],
['delightful', 'delight'],
['dependable', 'dependability'],
['desperate', 'desperation'],
['determined', 'determination'],
['devoted', 'devotion'],
['diffident', 'diffidence'],
['diligent', 'diligence'],
['dirty', 'dirtiness'],
['disciplined', 'discipline'],
['discreet', 'discretion'],
['doleful', 'dolefulness'],
['dramatic', 'drama'],
['dull', 'dullness'],
['dynamic', 'dynamism'],
['eager', 'eagerness'],
['educated', 'education'],
['efficient', 'efficiency'],
['elegant', 'elegance'],
['eloquent', 'eloquence'],
['empathetic', 'empathy'],
['empty', 'emptiness'],
['enduring', 'endurance'],
['energetic', 'energy'],
['engaging', 'engagement'],
['enough', 'enoughness'],
['enthusiastic', 'enthusiasm'],
['excellent', 'excellence'],
['excited', 'excitement'],
['exciting', 'excitement'],
['exemplary', 'exemplariness'],
['expedient', 'expedience'],
['expensive', 'expense'],
['experienced', 'experience'],
['explosive', 'explosiveness'],
['expressive', 'expressiveness'],
['facetious', 'facetiousness'],
['fanciful', 'fancifulness'],
['fantastic', 'fantasy'],
['fast', 'fastness'],
['fatuous', 'fatuousness'],
['fearless', 'fearlessness'],
['fertile', 'fertility'],
['fervent', 'fervor'],
['fierce', 'fierceness'],
['flawless', 'flawlessness'],
['flexible', 'flexibility'],
['flowing', 'flow'],
['focused', 'focus'],
['forceful', 'force'],
['forgiving', 'forgiveness'],
['fortunate', 'fortune'],
['fragrant', 'fragrance'],
['frank', 'frankness'],
['free', 'freedom'],
['friendly', 'friendliness'],
['frivolous', 'frivolity'],
['frugal', 'frugality'],
['full', 'fullness'],
['funny', 'funniness'],
['furious', 'fury'],
['furry', 'furriness'],
['furtive', 'furtiveness'],
['gaudy', 'gaudiness'],
['gay', 'gayness'],
['generous', 'generosity'],
['gentle', 'gentleness'],
['ghastly', 'ghastliness'],
['glamorous', 'glamour'],
['glaring', 'glare'],
['glowing', 'glow'],
['good', 'goodness'],
['graceful', 'grace'],
['gracious', 'graciousness'],
['guileless', 'guilelessness'],
['gullible', 'gullibility'],
['hard', 'hardness'],
['hardworking', 'hardwork'],
['harried', 'harriedness'],
['harsh', 'harshness'],
['hazardous', 'hazard'],
['heavy', 'heaviness'],
['heroic', 'heroism'],
['hoary', 'hoariness'],
['honest', 'honesty'],
['hopeful', 'hopefulness'],
['hospitable', 'hospitality'],
['hot', 'heat'],
['huge', 'hugeness'],
['humble', 'humility'],
['humorous', 'humor'],
['iffy', 'iffiness'],
['imaginative', 'imagination'],
['impartial', 'impartiality'],
['imperfect', 'imperfection'],
['imperious', 'imperiousness'],
['imperturbable', 'imperturbability'],
['implacable', 'implacability'],
['impossible', 'impossibility'],
['impressive', 'impressiveness'],
['impulsive', 'impulsiveness'],
['inane', 'inanity'],
['independent', 'independence'],
['indolent', 'indolence'],
['industrious', 'industry'],
['ineluctable', 'ineluctability'],
['inept', 'ineptitude'],
['inimitable', 'inimitability'],
['innovative', 'innovation'],
['inquisitive', 'inquisitiveness'],
['insightful', 'insight'],
['inspiring', 'inspiration'],
['intelligent', 'intelligence'],
['intemperate', 'intemperance'],
['intrepid', 'intrepidity'],
['intuitive', 'intuition'],
['inventive', 'inventiveness'],
['ironic', 'irony'],
['jittery', 'jitteriness'],
['jovial', 'joviality'],
['joyful', 'joy'],
['joyous', 'joy'],
['keen', 'keenness'],
['kind', 'kindness'],
['knowledgeable', 'knowledge'],
['laconic', 'laconicism'],
['lavish', 'lavishness'],
['lazy', 'laziness'],
['legal', 'legality'],
['liberal', 'liberality'],
['light', 'lightness'],
['lively', 'liveliness'],
['lofty', 'loftiness'],
['long', 'length'],
['loquacious', 'loquaciousness'],
['lost', 'loss'],
['loud', 'loudness'],
['loving', 'love'],
['loyal', 'loyalty'],
['lucid', 'lucidity'],
['luminous', 'luminosity'],
['lush', 'lushness'],
['luxurious', 'luxury'],
['magical', 'magic'],
['magnanimous', 'magnanimity'],
['majestic', 'majesty'],
['mature', 'maturity'],
['maverick', 'maverickness'],
['mawkish', 'mawkishness'],
['melodic', 'melody'],
['meticulous', 'meticulousness'],
['mighty', 'mightiness'],
['modest', 'modesty'],
['moist', 'moistness'],
['momentous', 'momentousness'],
['motivated', 'motivation'],
['mundane', 'mundanity'],
['musical', 'music'],
['mysterious', 'mystery'],
['mystical', 'mysticism'],
['naive', 'naivety'],
['narcissistic', 'narcissism'],
['narrow', 'narrowness'],
['naughty', 'naughtiness'],
['nervous', 'nervousness'],
['noble', 'nobility'],
['nonchalant', 'nonchalance'],
['nurturing', 'nurturance'],
['obedient', 'obedience'],
['oblivious', 'obliviousness'],
['observant', 'observation'],
['offensive', 'offence'],
['offhand', 'offhandedness'],
['ominous', 'ominousness'],
['optimistic', 'optimism'],
['organized', 'organization'],
['orotund', 'orotundity'],
['ostentatious', 'ostentatiousness'],
['outgoing', 'outgoingness'],
['pacifist', 'pacifism'],
['passionate', 'passion'],
['patient', 'patience'],
['pedantic', 'pedantry'],
['peerless', 'peerlessness'],
['perceptive', 'perception'],
['perfect', 'perfection'],
['persistent', 'persistence'],
['personal', 'personality'],
['persuasive', 'persuasion'],
['physical', 'physicality'],
['placid', 'placidity'],
['playful', 'playfulness'],
['pleasant', 'pleasantness'],
['pliant', 'pliancy'],
['poignant', 'poignancy'],
['poised', 'poise'],
['polite', 'politeness'],
['poor', 'poverty'],
['popular', 'popularity'],
['positive', 'positivity'],
['possessive', 'possession'],
['powerful', 'power'],
['practical', 'practicality'],
['pragmatic', 'pragmatism'],
['present', 'presence'],
['proactive', 'proactivity'],
['prodigious', 'prodigiousness'],
['professional', 'professionalism'],
['proficient', 'proficiency'],
['proportionate', 'proportion'],
['protective', 'protection'],
['prudent', 'prudence'],
['punctual', 'punctuality'],
['purposeful', 'purpose'],
['querulous', 'querulousness'],
['quick', 'quickness'],
['quiet', 'quietness'],
['quixotic', 'quixoticism'],
['radiant', 'radiance'],
['rampant', 'rampantness'],
['random', 'randomness'],
['rapacious', 'rapaciousness'],
['ravishing', 'ravishingness'],
['ready', 'readiness'],
['realistic', 'realism'],
['reasonable', 'reasonableness'],
['receptive', 'receptiveness'],
['recondite', 'reconditeness'],
['red', 'redness'],
['refined', 'refinement'],
['relentless', 'relentlessness'],
['reliable', 'reliability'],
['reprobate', 'reprobacy'],
['resilient', 'resilience'],
['resolute', 'resolution'],
['resourceful', 'resourcefulness'],
['respectable', 'respect'],
['respectful', 'respect'],
['responsible', 'responsibility'],
['reverent', 'reverence'],
['rich', 'richness'],
['riotous', 'riotousness'],
['ripe', 'ripeness'],
['risible', 'risibility'],
['romantic', 'romance'],
['rough', 'roughness'],
['round', 'roundness'],
['sad', 'sadness'],
['salubrious', 'salubriousness'],
['scrupulous', 'scrupulousness'],
['scurrilous', 'scurrility'],
['seditious', 'seditiousness'],
['selfless', 'selflessness'],
['sensible', 'sensibility'],
['sensitive', 'sensitivity'],
['serene', 'serenity'],
['serious', 'seriousness'],
['sharp', 'sharpness'],
['shining', 'shininess'],
['short', 'shortness'],
['silent', 'silence'],
['simple', 'simplicity'],
['sincere', 'sincerity'],
['sinister', 'sinisterness'],
['skillful', 'skill'],
['slippery', 'slipperiness'],
['slow', 'slowness'],
['smooth', 'smoothness'],
['soft', 'softness'],
['solid', 'solidity'],
['soothing', 'soothingness'],
['sour', 'sourness'],
['specious', 'speciousness'],
['spiritual', 'spirituality'],
['spontaneous', 'spontaneity'],
['sporadic', 'sporadicness'],
['spurious', 'spuriousness'],
['stalwart', 'stalwartness'],
['stern', 'sternness'],
['straight', 'straightness'],
['strategic', 'strategy'],
['strict', 'strictness'],
['strong', 'strength'],
['stubborn', 'stubbornness'],
['sturdy', 'sturdiness'],
['sublime', 'sublimity'],
['subservient', 'subservience'],
['subtle', 'subtleties'],
['successful', 'success'],
['superficial', 'superficiality'],
['supportive', 'support'],
['suspicious', 'suspicion'],
['sweet', 'sweetness'],
['swift', 'swiftness'],
['sympathetic', 'sympathy'],
['tactful', 'tact'],
['talented', 'talent'],
['tall', 'tallness'],
['tame', 'tameness'],
['tart', 'tartness'],
['tawdry', 'tawdriness'],
['tenacious', 'tenacity'],
['tender', 'tenderness'],
['tense', 'tenseness'],
['tenuous', 'tenuousness'],
['thin', 'thinness'],
['thirsty', 'thirstiness'],
['thorny', 'thorniness'],
['thorough', 'thoroughness'],
['thoughtful', 'thoughtfulness'],
['tidy', 'tidiness'],
['timely', 'timeliness'],
['timid', 'timidity'],
['timorous', 'timorousness'],
['tiny', 'tininess'],
['tired', 'tiredness'],
['tireless', 'tirelessness'],
['tolerant', 'tolerance'],
['tough', 'toughness'],
['trenchant', 'trenchancy'],
['trusting', 'trust'],
['trustworthy', 'trustworthiness'],
['tumultuous', 'tumult'],
['ubiquitous', 'ubiquitousness'],
['unctuous', 'unctuousness'],
['understanding', 'understanding'],
['unflappable', 'unflappability'],
['unique', 'uniqueness'],
['unyielding', 'unyieldingness'],
['vagrant', 'vagrancy'],
['valuable', 'value'],
['vapid', 'vapidity'],
['venerable', 'venerability'],
['versatile', 'versatility'],
['vertical', 'verticality'],
['vibrant', 'vibrancy'],
['vigilant', 'vigilance'],
['vigorous', 'vigor'],
['vivacious', 'vivacity'],
['vixenish', 'vixenishness'],
['volatile', 'volatility'],
['volumous', 'voluminousness'],
['vulnerable', 'vulnerability'],
['wanton', 'wantonness'],
['warm', 'warmth'],
['weak', 'weakness'],
['whimsical', 'whimsicalness'],
['wide', 'wideness'],
['wily', 'wiliness'],
['wise', 'wisdom'],
['wistful', 'wistfulness'],
['witty', 'wit'],
['witty', 'wittiness'],
['woebegone', 'woefulness'],
['yielding', 'yieldingness'],
['young', 'youth'],
['zany', 'zaniness'],
['zealous', 'zeal'],
]
================================================
FILE: data/pairs/Comparative.js
================================================
export default [
['angry', 'angrier'],
['bad', 'worse'],
['bald', 'balder'],
['bawdy', 'bawdier'],
['big', 'bigger'],
['black', 'blacker'],
['bland', 'blander'],
['blond', 'blonder'],
['bloody', 'bloodier'],
['blue', 'bluer'],
['bold', 'bolder'],
['bouncy', 'bouncier'],
['brash', 'brasher'],
['brave', 'braver'],
['bright', 'brighter'],
['broad', 'broader'],
['buff', 'buffer'],
['burly', 'burlier'],
['busy', 'busier'],
['calm', 'calmer'],
['camp', 'camper'],
['catchy', 'catchier'],
['cheap', 'cheaper'],
['cheesy', 'cheesier'],
['chilly', 'chillier'],
['clean', 'cleaner'],
['clear', 'clearer'],
['close', 'closer'],
['cloudy', 'cloudier'],
['coarse', 'coarser'],
['cold', 'colder'],
['common', 'commoner'],
['cool', 'cooler'],
['costly', 'costlier'],
['cowardly', 'cowardlier'],
['cozy', 'cozier'],
['crisp', 'crisper'],
['cruel', 'crueler'],
['cuddly', 'cuddlier'],
['curly', 'curlier'],
['cute', 'cuter'],
['damp', 'damper'],
['dark', 'darker'],
['dead', 'deader'],
['deadly', 'deadlier'],
['deaf', 'deafer'],
['dear', 'dearer'],
['deep', 'deeper'],
['dense', 'denser'],
['diffuse', 'diffuser'],
['dire', 'direr'],
['dirty', 'dirtier'],
['divine', 'diviner'],
['drunk', 'drunker'],
['dry', 'drier'],
['dull', 'duller'],
['dumb', 'dumber'],
['early', 'earlier'],
['easy', 'easier'],
['eerie', 'eerier'],
['evil', 'eviler'],
['fair', 'fairer'],
['fake', 'faker'],
['fancy', 'fancier'],
['far', 'further'],
['fast', 'faster'],
['fat', 'fatter'],
['faulty', 'faultier'],
['feeble', 'feebler'],
['few', 'fewer'],
['fierce', 'fiercer'],
['fine', 'finer'],
['firm', 'firmer'],
['flat', 'flatter'],
['foamy', 'foamier'],
['fond', 'fonder'],
['formal', 'formaler'],
['foul', 'fouler'],
['frail', 'frailer'],
['free', 'freer'],
['fresh', 'fresher'],
['friendly', 'friendlier'],
['full', 'fuller'],
['fun', 'funer'],
['funny', 'funnier'],
['furry', 'furrier'],
['further', 'further'],
['gauche', 'gaucher'],
['gaudy', 'gaudier'],
['gay', 'gaier'],
['gentle', 'gentler'],
['genuine', 'genuiner'],
['ghastly', 'ghastlier'],
['ghostly', 'ghostlier'],
['giddy', 'giddier'],
['glib', 'glibber'],
['gloomy', 'gloomier'],
['gold', 'golder'],
['good', 'better'],
['goofy', 'goofier'],
['grand', 'grander'],
['gray', 'grayer'],
['great', 'greater'],
['green', 'greener'],
['grisly', 'grislier'],
['groovy', 'groovier'],
['gross', 'grosser'],
['gruesome', 'gruesomer'],
['handsome', 'handsomer'],
['happy', 'happier'],
['hard', 'harder'],
['hardy', 'hardier'],
['harsh', 'harsher'],
['heady', 'headier'],
['healthy', 'healthier'],
['heavy', 'heavier'],
['hefty', 'heftier'],
['high', 'higher'],
['hilly', 'hillier'],
['homely', 'homelier'],
['hot', 'hotter'],
['huge', 'huger'],
['humble', 'humbler'],
['humid', 'humider'],
['hungry', 'hungrier'],
['icy', 'icier'],
['ill', 'iller'],
['jolly', 'jollier'],
['juicy', 'juicier'],
['keen', 'keener'],
['kind', 'kinder'],
['lame', 'lamer'],
['large', 'larger'],
['late', 'later'],
['lean', 'leaner'],
['lengthy', 'lengthier'],
['lesser', 'lesser'],
['lewd', 'lewder'],
['light', 'lighter'],
['likely', 'likelier'],
['little', 'littler'],
['lively', 'livelier'],
['lofty', 'loftier'],
['lonely', 'lonelier'],
['long', 'longer'],
['loose', 'looser'],
['loud', 'louder'],
['lousy', 'lousier'],
['lovely', 'lovelier'],
['low', 'lower'],
['lucky', 'luckier'],
['mad', 'madder'],
['mean', 'meaner'],
['measly', 'measlier'],
['meaty', 'meatier'],
['meek', 'meeker'],
['mellow', 'mellower'],
['mild', 'milder'],
['moist', 'moister'],
['moody', 'moodier'],
['narrow', 'narrower'],
['nasty', 'nastier'],
['near', 'nearer'],
['neat', 'neater'],
['new', 'newer'],
['nice', 'nicer'],
['nimble', 'nimbler'],
['noble', 'nobler'],
['noisy', 'noisier'],
['normal', 'normaler'],
['nosy', 'nosier'],
['numb', 'number'],
['odd', 'odder'],
['oily', 'oilier'],
['old', 'older'],
['orient', 'orienter'],
['pale', 'paler'],
['phony', 'phonier'],
['pink', 'pinker'],
['plain', 'plainer'],
['poor', 'poorer'],
['premier', 'premier'],
['present', 'presenter'],
['prickly', 'pricklier'],
['proud', 'prouder'],
['puny', 'punier'],
['pure', 'purer'],
['quick', 'quicker'],
['quiet', 'quieter'],
['ragged', 'raggeder'],
['random', 'randomer'],
['rapid', 'rapider'],
['rare', 'rarer'],
['raw', 'rawer'],
['ready', 'readier'],
['real', 'realer'],
['remote', 'remoter'],
['rich', 'richer'],
['ripe', 'riper'],
['risky', 'riskier'],
['ritzy', 'ritzier'],
['roomy', 'roomier'],
['rosy', 'rosier'],
['rough', 'rougher'],
['round', 'rounder'],
['rude', 'ruder'],
['sad', 'sadder'],
['safe', 'safer'],
['saintly', 'saintlier'],
['salty', 'saltier'],
['savvy', 'savvier'],
['scarce', 'scarcer'],
['scary', 'scarier'],
['sexy', 'sexier'],
['shady', 'shadier'],
['shallow', 'shallower'],
['sharp', 'sharper'],
['shiny', 'shinier'],
['short', 'shorter'],
['shrill', 'shriller'],
['shy', 'shyer'],
['sick', 'sicker'],
['silly', 'sillier'],
['simple', 'simpler'],
['skinny', 'skinnier'],
['sleek', 'sleeker'],
['slight', 'slighter'],
['slim', 'slimmer'],
['slimy', 'slimier'],
['slow', 'slower'],
['sly', 'slier'],
['small', 'smaller'],
['smart', 'smarter'],
['smelly', 'smellier'],
['smooth', 'smoother'],
['soft', 'softer'],
['solemn', 'solemner'],
['solid', 'solider'],
['soon', 'sooner'],
['sore', 'sorer'],
['speedy', 'speedier'],
['spicy', 'spicier'],
['sprightly', 'sprightlier'],
['square', 'squarer'],
['stale', 'staler'],
['stark', 'starker'],
['steady', 'steadier'],
['steep', 'steeper'],
['stern', 'sterner'],
['stiff', 'stiffer'],
['straight', 'straighter'],
['strict', 'stricter'],
['strong', 'stronger'],
['stupid', 'stupider'],
['sturdy', 'sturdier'],
['subtle', 'subtler'],
['sudden', 'suddener'],
['surreal', 'surrealer'],
['sweet', 'sweeter'],
['swift', 'swifter'],
['tall', 'taller'],
['tame', 'tamer'],
['tart', 'tarter'],
['tawdry', 'tawdrier'],
['tense', 'tenser'],
['thick', 'thicker'],
['thin', 'thinner'],
['thirsty', 'thirstier'],
['tidy', 'tidier'],
['tight', 'tighter'],
['timely', 'timelier'],
['tiny', 'tinier'],
['tired', 'tireder'],
['tough', 'tougher'],
['tranquil', 'tranquiler'],
['trendy', 'trendier'],
['tricky', 'trickier'],
['trim', 'trimmer'],
['true', 'truer'],
['ugly', 'uglier'],
['unlikely', 'unlikelier'],
['untidy', 'untidier'],
['untrue', 'untruer'],
['vague', 'vaguer'],
['vain', 'vainer'],
['vast', 'vaster'],
['warm', 'warmer'],
['wary', 'warier'],
['weak', 'weaker'],
['wealthy', 'wealthier'],
['weary', 'wearier'],
['weird', 'weirder'],
['wet', 'wetter'],
['white', 'whiter'],
['wicked', 'wickeder'],
['wide', 'wider'],
['wild', 'wilder'],
['wily', 'wilier'],
['wise', 'wiser'],
['young', 'younger'],
['zany', 'zanier'],
['clever', 'cleverer'],
['glad', 'gladder'],
['neat', 'neater'],
['dim', 'dimmer'],
['', ''],
['', ''],
]
================================================
FILE: data/pairs/Gerund.js
================================================
export default [
['including', 'include'],
['following', 'follow'],
['being', 'is'],
['using', 'use'],
['working', 'work'],
['developing', 'develop'],
['providing', 'provide'],
['regarding', 'regard'],
['dumping', 'dump'],
['according', 'accord'],
['operating', 'operate'],
['making', 'make'],
['increasing', 'increase'],
['having', 'have'],
['supporting', 'support'],
['heading', 'head'],
['exceeding', 'exceed'],
['growing', 'grow'],
['concerning', 'concern'],
['reporting', 'report'],
['relating', 'relate'],
['leading', 'lead'],
['ensuring', 'ensure'],
['improving', 'improve'],
['meeting', 'meet'],
['existing', 'exist'],
['promoting', 'promote'],
['taking', 'take'],
['learning', 'learn'],
['originating', 'originate'],
['creating', 'create'],
['building', 'build'],
['resulting', 'result'],
['living', 'live'],
['funding', 'fund'],
['emerging', 'emerge'],
['involving', 'involve'],
['receiving', 'receive'],
['participating', 'participate'],
['representing', 'represent'],
['reducing', 'reduce'],
['determining', 'determine'],
['implementing', 'implement'],
['changing', 'change'],
['establishing', 'establish'],
['identifying', 'identify'],
['containing', 'contain'],
['doing', 'do'],
['looking', 'look'],
['addressing', 'address'],
['selling', 'sell'],
['excluding', 'exclude'],
['moving', 'move'],
['helping', 'help'],
['continuing', 'continue'],
['coming', 'come'],
['achieving', 'achieve'],
['going', 'go'],
['producing', 'produce'],
['respecting', 'respect'],
['depending', 'depend'],
['applying', 'apply'],
['planning', 'plan'],
['conducting', 'conduct'],
['managing', 'manage'],
['maintaining', 'maintain'],
['remaining', 'remain'],
['performing', 'perform'],
['dealing', 'deal'],
['seeking', 'seek'],
['contributing', 'contribute'],
['starting', 'start'],
['enhancing', 'enhance'],
['writing', 'write'],
['hosting', 'host'],
['strengthening', 'strengthen'],
['facing', 'face'],
['allowing', 'allow'],
['measuring', 'measure'],
['becoming', 'become'],
['affecting', 'affect'],
['finding', 'find'],
['offering', 'offer'],
['considering', 'consider'],
['beginning', 'begin'],
['setting', 'set'],
['aging', 'age'],
['bringing', 'bring'],
['keeping', 'keep'],
['monitoring', 'monitor'],
['requiring', 'require'],
['indicating', 'indicate'],
['giving', 'give'],
['preparing', 'prepare'],
['ending', 'end'],
['rising', 'rise'],
['sharing', 'share'],
['reaching', 'reach'],
['expanding', 'expand'],
['getting', 'get'],
['governing', 'govern'],
['assessing', 'assess'],
['granting', 'grant'],
['obtaining', 'obtain'],
['subsidizing', 'subsidize'],
['attending', 'attend'],
['entering', 'enter'],
['delivering', 'deliver'],
['arising', 'arise'],
['targeting', 'target'],
['travelling', 'travel'],
['fostering', 'foster'],
['carrying', 'carry'],
['encouraging', 'encourage'],
['underlying', 'underlie'],
['understanding', 'understand'],
['completing', 'complete'],
['covering', 'cover'],
['responding', 'respond'],
['visiting', 'visit'],
['importing', 'import'],
['protecting', 'protect'],
['reviewing', 'review'],
['owing', 'owe'],
['focusing', 'focus'],
['recognizing', 'recognize'],
['serving', 'serve'],
['facilitating', 'facilitate'],
['pertaining', 'pertain'],
['examining', 'examine'],
['enabling', 'enable'],
['evaluating', 'evaluate'],
['consisting', 'consist'],
['adding', 'add'],
['exporting', 'export'],
['investing', 'invest'],
['studying', 'study'],
['showing', 'show'],
['raising', 'raise'],
['ranging', 'range'],
['reflecting', 'reflect'],
['processing', 'process'],
['submitting', 'submit'],
['advancing', 'advance'],
['declining', 'decline'],
['surrounding', 'surround'],
['competing', 'compete'],
['preventing', 'prevent'],
['defining', 'define'],
['paying', 'pay'],
['undertaking', 'undertake'],
['speaking', 'speak'],
['acting', 'act'],
['holding', 'hold'],
['describing', 'describe'],
['training', 'train'],
['countervailing', 'countervail'],
['presenting', 'present'],
['evolving', 'evolve'],
['pending', 'pend'],
['assisting', 'assist'],
['requesting', 'request'],
['pursuing', 'pursue'],
['incorporating', 'incorporate'],
['noting', 'note'],
['coordinating', 'coordinate'],
['attracting', 'attract'],
['leaving', 'leave'],
['organizing', 'organize'],
['counselling', 'counsel'],
['playing', 'play'],
['trying', 'try'],
['causing', 'cause'],
['integrating', 'integrate'],
['belonging', 'belong'],
['collecting', 'collect'],
['administering', 'administer'],
['linking', 'link'],
['negotiating', 'negotiate'],
['putting', 'put'],
['limiting', 'limit'],
['cutting', 'cut'],
['occurring', 'occur'],
['falling', 'fall'],
['partnering', 'partner'],
['matching', 'match'],
['accessing', 'access'],
['experiencing', 'experience'],
['buying', 'buy'],
['exploring', 'explore'],
['calculating', 'calculate'],
['teaching', 'teach'],
['generating', 'generate'],
['varying', 'vary'],
['assuming', 'assume'],
['marking', 'mark'],
['calling', 'call'],
['driving', 'drive'],
['cleaning', 'clean'],
['selecting', 'select'],
['spending', 'spend'],
['engaging', 'engage'],
['returning', 'return'],
['comparing', 'compare'],
['running', 'run'],
['wishing', 'wish'],
['eliminating', 'eliminate'],
['demonstrating', 'demonstrate'],
['hiring', 'hire'],
['opening', 'open'],
['communicating', 'communicate'],
['arriving', 'arrive'],
['filing', 'file'],
['extending', 'extend'],
['controlling', 'control'],
['tracking', 'track'],
['handling', 'handle'],
['adopting', 'adopt'],
['preserving', 'preserve'],
['forming', 'form'],
['parenting', 'parent'],
['policing', 'police'],
['shipping', 'ship'],
['outlining', 'outline'],
['signing', 'sign'],
['introducing', 'introduce'],
['waiting', 'wait'],
['choosing', 'choose'],
['threatening', 'threaten'],
['stating', 'state'],
['celebrating', 'celebrate'],
['issuing', 'issue'],
['contacting', 'contact'],
['sending', 'send'],
['seeding', 'seed'],
['qualifying', 'qualify'],
['drawing', 'draw'],
['testing', 'test'],
['investigating', 'investigate'],
['distributing', 'distribute'],
['seeing', 'see'],
['saying', 'say'],
['asking', 'ask'],
['marketing', 'market'],
['weighing', 'weigh'],
['suggesting', 'suggest'],
['explaining', 'explain'],
['discussing', 'discuss'],
['accounting', 'account'],
['placing', 'place'],
['designing', 'design'],
['gaining', 'gain'],
['securing', 'secure'],
['removing', 'remove'],
['decreasing', 'decrease'],
['informing', 'inform'],
['turning', 'turn'],
['treating', 'treat'],
['thinking', 'think'],
['joining', 'join'],
['sponsoring', 'sponsor'],
['amending', 'amend'],
['searching', 'search'],
['retaining', 'retain'],
['fulfilling', 'fulfill'],
['influencing', 'influence'],
['reading', 'read'],
['missing', 'miss'],
['standing', 'stand'],
['estimating', 'estimate'],
['featuring', 'feature'],
['planting', 'plant'],
['shaping', 'shape'],
['reinforcing', 'reinforce'],
['combining', 'combine'],
['leveraging', 'leverage'],
['comprising', 'comprise'],
['analyzing', 'analyze'],
['purchasing', 'purchase'],
['updating', 'update'],
['highlighting', 'highlight'],
['consulting', 'consult'],
['recruiting', 'recruit'],
['knowing', 'know'],
['drafting', 'draft'],
['acquiring', 'acquire'],
['sustaining', 'sustain'],
['transferring', 'transfer'],
['confirming', 'confirm'],
['accepting', 'accept'],
['referring', 'refer'],
['grading', 'grade'],
['launching', 'launch'],
['replacing', 'replace'],
['filling', 'fill'],
['claiming', 'claim'],
['appearing', 'appear'],
['transporting', 'transport'],
['connecting', 'connect'],
['benefiting', 'benefit'],
['talking', 'talk'],
['collaborating', 'collaborate'],
['winning', 'win'],
['accompanying', 'accompany'],
['meaning', 'mean'],
['ordering', 'order'],
['hatching', 'hatch'],
['gathering', 'gather'],
['welcoming', 'welcome'],
['deciding', 'decide'],
['challenging', 'challenge'],
['posting', 'post'],
['losing', 'lose'],
['proposing', 'propose'],
['registering', 'register'],
['recording', 'record'],
['publishing', 'publish'],
['closing', 'close'],
['listening', 'listen'],
['translating', 'translate'],
['inviting', 'invite'],
['cropping', 'crop'],
['interpreting', 'interpret'],
['totalling', 'total'],
['attempting', 'attempt'],
['disseminating', 'disseminate'],
['tendering', 'tender'],
['crossing', 'cross'],
['maximizing', 'maximize'],
['employing', 'employ'],
['concluding', 'conclude'],
['profiling', 'profil'],
['breaking', 'break'],
['labelling', 'label'],
['prescribing', 'prescribe'],
['touring', 'tour'],
['adapting', 'adapt'],
['showcasing', 'showcase'],
['neighbouring', 'neighbour'],
['shifting', 'shift'],
['allocating', 'allocate'],
['authorizing', 'authorize'],
['resolving', 'resolve'],
['preceding', 'precede'],
['costing', 'cost'],
['approving', 'approve'],
['specifying', 'specify'],
['utilizing', 'utilize'],
['editing', 'edit'],
['branding', 'brand'],
['volunteering', 'volunteer'],
['pressing', 'press'],
['failing', 'fail'],
['upgrading', 'upgrade'],
['minimizing', 'minimize'],
['avoiding', 'avoid'],
['clarifying', 'clarify'],
['lacking', 'lack'],
['emphasizing', 'emphasize'],
['differing', 'differ'],
['initiating', 'initiate'],
['announcing', 'announce'],
['feeding', 'feed'],
['farming', 'farm'],
['stimulating', 'stimulate'],
['sitting', 'sit'],
['happening', 'happen'],
['educating', 'educate'],
['viewing', 'view'],
['exercising', 'exercise'],
['summarizing', 'summarize'],
['regulating', 'regulate'],
['residing', 'reside'],
['suffering', 'suffer'],
['commencing', 'commence'],
['permitting', 'permit'],
['advising', 'advise'],
['pruning', 'prune'],
['specializing', 'specialize'],
['expressing', 'express'],
['breeding', 'breed'],
['broadening', 'broaden'],
['supplying', 'supply'],
['drying', 'dry'],
['earning', 'earn'],
['licensing', 'license'],
['modeling', 'model'],
['contracting', 'contract'],
['financing', 'finance'],
['climbing', 'climb'],
['adjusting', 'adjust'],
['undergoing', 'undergo'],
['bridging', 'bridge'],
['screening', 'screen'],
['detailing', 'detail'],
['directing', 'direct'],
['proceeding', 'proceed'],
['capturing', 'capture'],
['mailing', 'mail'],
['demanding', 'demand'],
['bearing', 'bear'],
['outsourcing', 'outsource'],
['realizing', 'realize'],
['complying', 'comply'],
['documenting', 'document'],
['solving', 'solve'],
['passing', 'pass'],
['enforcing', 'enforce'],
['fighting', 'fight'],
['relying', 'rely'],
['watching', 'watch'],
['malting', 'malt'],
['mentoring', 'mentore'],
['clearing', 'clear'],
['balancing', 'balance'],
['overseeing', 'oversee'],
['broadcasting', 'broadcast'],
['acknowledging', 'acknowledge'],
['pooling', 'pool'],
['laying', 'lay'],
['transmitting', 'transmit'],
['eating', 'eat'],
['mixing', 'mix'],
['transforming', 'transform'],
['recommending', 'recommend'],
['packing', 'pack'],
['approaching', 'approach'],
['verifying', 'verify'],
['combating', 'combat'],
['renewing', 'renew'],
['spraying', 'spray'],
['stemming', 'stem'],
['averaging', 'average'],
['infringing', 'infringe'],
['releasing', 'release'],
['betting', 'bet'],
['distinguishing', 'distinguish'],
['lowering', 'lower'],
['networking', 'network'],
['binding', 'bind'],
['imposing', 'impose'],
['furthering', 'further'],
['attaining', 'attain'],
['committing', 'commit'],
['researching', 'research'],
['coding', 'code'],
['telling', 'tell'],
['checking', 'check'],
['wanting', 'want'],
['certifying', 'certify'],
['loading', 'load'],
['listing', 'list'],
['booking', 'book'],
['nurturing', 'nurture'],
['bullying', 'bully'],
['staying', 'stay'],
['sourcing', 'source'],
['dividing', 'divide'],
['streaming', 'stream'],
['crushing', 'crush'],
['benchmarking', 'benchmark'],
['restricting', 'restrict'],
['optimizing', 'optimize'],
['answering', 'answer'],
['rounding', 'round'],
['agreeing', 'agree'],
['recurring', 'recur'],
['designating', 'designate'],
['expecting', 'expect'],
['saving', 'save'],
['flowing', 'flow'],
['impacting', 'impact'],
['flying', 'fly'],
['awarding', 'award'],
['accelerating', 'accelerate'],
['spreading', 'spread'],
['prohibiting', 'prohibit'],
['restoring', 'restore'],
['functioning', 'function'],
['misleading', 'mislead'],
['streamlining', 'streamline'],
['citing', 'cite'],
['dying', 'die'],
['aiming', 'aim'],
['messaging', 'message'],
['reproducing', 'reproduce'],
['storing', 'store'],
['signaling', 'signal'],
['encompassing', 'encompass'],
['sporting', 'sport'],
['pumping', 'pump'],
['doping', 'dope'],
['sampling', 'sample'],
['revising', 'revise'],
['modifying', 'modify'],
['retiring', 'retire'],
['hearing', 'hear'],
['printing', 'print'],
['detecting', 'detect'],
['rolling', 'roll'],
['mounting', 'mount'],
['drinking', 'drink'],
['baking', 'bake'],
['dropping', 'drop'],
['converting', 'convert'],
['alleging', 'allege'],
['advocating', 'advocate'],
['welding', 'weld'],
['recovering', 'recover'],
['assembling', 'assemble'],
['struggling', 'struggle'],
['finishing', 'finish'],
['guiding', 'guide'],
['embracing', 'embrace'],
['cataloguing', 'catalogue'],
['stabilizing', 'stabilize'],
['modernizing', 'modernize'],
['awaiting', 'await'],
['steering', 'steer'],
['nominating', 'nominate'],
['ensuing', 'ensue'],
['wearing', 'wear'],
['carding', 'card'],
['clicking', 'click'],
['slowing', 'slow'],
['forecasting', 'forecast'],
['separating', 'separate'],
['consolidating', 'consolidate'],
['assigning', 'assign'],
['antidumping', 'antidump'],
['advertizing', 'advertize'],
['safeguarding', 'safeguard'],
['declaring', 'declare'],
['coping', 'cope'],
['scanning', 'scan'],
['forging', 'forge'],
['arguing', 'argue'],
['prevailing', 'prevail'],
['enriching', 'enrich'],
['questioning', 'question'],
['needing', 'need'],
['counting', 'count'],
['harmonizing', 'harmonize'],
['enjoying', 'enjoy'],
['shrinking', 'shrink'],
['unloading', 'unload'],
['constructing', 'construct'],
['walking', 'walk'],
['displaying', 'display'],
['interviewing', 'interview'],
['pushing', 'push'],
['proving', 'prove'],
['valuing', 'value'],
['locating', 'locate'],
['illustrating', 'illustrate'],
['mobilizing', 'mobilize'],
['multiplying', 'multiply'],
['dating', 'date'],
['shooting', 'shoot'],
['simplifying', 'simplify'],
['diminishing', 'diminish'],
['pointing', 'point'],
['boosting', 'boost'],
['promising', 'promise'],
['discovering', 'discover'],
['breastfeeding', 'breastfeed'],
['tabling', 'table'],
['hoping', 'hope'],
['diversifying', 'diversify'],
['offsetting', 'offset'],
['trapping', 'trap'],
['striving', 'strive'],
['cooperating', 'cooperate'],
['cooling', 'cool'],
['formulating', 'formulate'],
['switching', 'switch'],
['surviving', 'survive'],
['scouting', 'scout'],
['maturing', 'mature'],
['grinding', 'grind'],
['doubling', 'double'],
['renting', 'rent'],
['interacting', 'interact'],
['scoring', 'score'],
['departing', 'depart'],
['sealing', 'seal'],
['positioning', 'position'],
['stopping', 'stop'],
['commemorating', 'commemorate'],
['exposing', 'expose'],
['compiling', 'compile'],
['refining', 'refine'],
['exploiting', 'exploit'],
['adhering', 'adhere'],
['heating', 'heat'],
['intoxicating', 'intoxicate'],
['defending', 'defend'],
['casing', 'case'],
['lobbying', 'lobby'],
['feeling', 'feel'],
['routing', 'rout'],
['overcoming', 'overcome'],
['practising', 'practise'],
['compromising', 'compromise'],
['arranging', 'arrange'],
['terminating', 'terminate'],
['warehousing', 'warehouse'],
['commissioning', 'commission'],
['confronting', 'confront'],
['forcing', 'force'],
['anticipating', 'anticipate'],
['trending', 'trend'],
['appealing', 'appeal'],
['soliciting', 'solicit'],
['settling', 'settle'],
['tracing', 'trace'],
['counterfeiting', 'counterfeit'],
['floating', 'float'],
['analysing', 'analyse'],
['peacekeeping', 'peacekeep'],
['filtering', 'filter'],
['withdrawing', 'withdraw'],
['amounting', 'amount'],
['empowering', 'empower'],
['leaching', 'leach'],
['exchanging', 'exchange'],
['motivating', 'motivate'],
['predicting', 'predict'],
['escalating', 'escalate'],
['guaranteeing', 'guarantee'],
['aligning', 'align'],
['numbering', 'number'],
['spanning', 'span'],
['exhibiting', 'exhibit'],
['lading', 'lade'],
['assuring', 'assure'],
['washing', 'wash'],
['rendering', 'render'],
['bonding', 'bond'],
['insulating', 'insulate'],
['finalizing', 'finalize'],
['disclosing', 'disclose'],
['harming', 'harm'],
['practicing', 'practice'],
['burgeoning', 'burgeon'],
['manufacturing', 'manufacture'],
['supervising', 'supervise'],
['caring', 'care'],
['stamping', 'stamp'],
['coasting', 'coast'],
['circulating', 'circulate'],
['appointing', 'appoint'],
['pioneering', 'pioneer'],
['harnessing', 'harness'],
['charging', 'charge'],
['sorting', 'sort'],
['executing', 'execute'],
['projecting', 'project'],
['altering', 'alter'],
['mapping', 'map'],
['filmmaking', 'filmmak'],
['stereotyping', 'stereotype'],
['incurring', 'incur'],
['correcting', 'correct'],
['overwintering', 'overwinter'],
['structuring', 'structure'],
['favouring', 'favour'],
['tackling', 'tackle'],
['honouring', 'honour'],
['servicing', 'service'],
['soaring', 'soar'],
['deteriorating', 'deteriorate'],
['rotating', 'rotate'],
['mowing', 'mow'],
['believing', 'believe'],
['reforming', 'reform'],
['accommodating', 'accommodate'],
['concentrating', 'concentrate'],
['installing', 'install'],
['forwarding', 'forward'],
['intending', 'intend'],
['conserving', 'conserve'],
['presiding', 'preside'],
['emanating', 'emanate'],
['judging', 'judge'],
['sequencing', 'sequence'],
['withholding', 'withhold'],
['attesting', 'attest'],
['staffing', 'staff'],
['mentioning', 'mention'],
['computing', 'compute'],
['commenting', 'comment'],
['intervening', 'intervene'],
['capitalizing', 'capitalize'],
['logging', 'log'],
['progressing', 'progress'],
['denying', 'deny'],
['deepening', 'deepen'],
['picking', 'pick'],
['opposing', 'oppose'],
['distorting', 'distort'],
['nursing', 'nurse'],
['instituting', 'institute'],
['mitigating', 'mitigate'],
['trading', 'trade'],
['reversing', 'reverse'],
['decisionmaking', 'decisionmak'],
['fixing', 'fix'],
['deducting', 'deduct'],
['articulating', 'articulate'],
['delaying', 'delay'],
['mountaineering', 'mountaineer'],
['conveying', 'convey'],
['graduating', 'graduate'],
['rebuilding', 'rebuild'],
['validating', 'validate'],
['hiking', 'hike'],
['weakening', 'weaken'],
['eradicating', 'eradicate'],
['observing', 'observe'],
['classifying', 'classify'],
['scheduling', 'schedule'],
['naming', 'name'],
['reconciling', 'reconcile'],
['dispensing', 'dispense'],
['cultivating', 'cultivate'],
['satisfying', 'satisfy'],
['staging', 'stage'],
['inspecting', 'inspect'],
['stressing', 'stress'],
['revitalizing', 'revitalize'],
['blocking', 'block'],
['yielding', 'yield'],
['tapping', 'tap'],
['voting', 'vote'],
['packaging', 'package'],
['lodging', 'lodge'],
['killing', 'kill'],
['cloning', 'clon'],
['violating', 'violate'],
['accruing', 'accrue'],
['photocopying', 'photocopy'],
['riding', 'ride'],
['destroying', 'destroy'],
['retraining', 'retrain'],
['enacting', 'enact'],
['formatting', 'format'],
['succeeding', 'succeed'],
['subtracting', 'subtract'],
['merging', 'merge'],
['copying', 'copy'],
['officiating', 'officiate'],
['letting', 'let'],
['justifying', 'justify'],
['composting', 'compost'],
['possessing', 'possess'],
['lagging', 'lag'],
['differentiating', 'differentiate'],
['surveying', 'survey'],
['moulding', 'mould'],
['thanking', 'thank'],
['refusing', 'refuse'],
['bidding', 'bid'],
['striking', 'strike'],
['constituting', 'constitute'],
['widening', 'widen'],
['blending', 'blend'],
['innovating', 'innovate'],
['stocking', 'stock'],
['repairing', 'repair'],
['sawing', 'saw'],
['wrapping', 'wrap'],
['commercializing', 'commercialize'],
['ranking', 'rank'],
['posing', 'pose'],
['patenting', 'patent'],
['lending', 'lend'],
['inserting', 'insert'],
['appreciating', 'appreciate'],
['fuelling', 'fuel'],
['invoicing', 'invoice'],
['thinning', 'thin'],
['lingering', 'linger'],
['stepping', 'step'],
['sliding', 'slide'],
['drilling', 'drill'],
['notifying', 'notify'],
['founding', 'found'],
['surpassing', 'surpass'],
['impeding', 'impede'],
['complementing', 'complement'],
['depicting', 'depict'],
['lasting', 'last'],
['transplanting', 'transplant'],
['stacking', 'stack'],
['deriving', 'derive'],
['owning', 'own'],
['quoting', 'quote'],
['consuming', 'consume'],
['alternating', 'alternate'],
['prototyping', 'prototyp'],
['auditing', 'audit'],
['restructuring', 'restructure'],
['undermining', 'undermine'],
['exempting', 'exempt'],
['mulching', 'mulch'],
['dressing', 'dress'],
['hitting', 'hit'],
['phasing', 'phase'],
['pulling', 'pull'],
['weaving', 'weave'],
['milling', 'mill'],
['enrolling', 'enroll'],
['filming', 'film'],
['machining', 'machine'],
['healing', 'heal'],
['characterizing', 'characterize'],
['internationalizing', 'internationalize'],
['borrowing', 'borrow'],
['conferencing', 'conference'],
['sensing', 'sense'],
['peaking', 'peak'],
['contemplating', 'contemplate'],
['underpinning', 'underpin'],
['tanning', 'tan'],
['refrigerating', 'refrigerate'],
['devoting', 'devote'],
['harvesting', 'harvest'],
['championing', 'champion'],
['alleviating', 'alleviate'],
['compensating', 'compensate'],
['tying', 'tie'],
['decorating', 'decorate'],
['crosscutting', 'crosscut'],
['ignoring', 'ignore'],
['extracting', 'extract'],
['easing', 'ease'],
['dedicating', 'dedicate'],
['embarking', 'embark'],
['prompting', 'prompt'],
['cooking', 'cook'],
['eroding', 'erode'],
['narrowing', 'narrow'],
['occupying', 'occupy'],
['attaching', 'attach'],
['implying', 'imply'],
['duplicating', 'duplicate'],
['slaughtering', 'slaughter'],
['upholding', 'uphold'],
['affirming', 'affirm'],
['hauling', 'haul'],
['fluctuating', 'fluctuate'],
['lifting', 'lift'],
['convening', 'convene'],
['conforming', 'conform'],
['mining', 'mine'],
['rejecting', 'reject'],
['substantiating', 'substantiate'],
['liaising', 'liaise'],
['devising', 'devise'],
['navigating', 'navigate'],
['catching', 'catch'],
['revealing', 'reveal'],
['racing', 'race'],
['dampening', 'dampen'],
['nesting', 'nest'],
['resembling', 'resemble'],
['curing', 'cure'],
['disposing', 'dispose'],
['sounding', 'sound'],
['sweetening', 'sweeten'],
['sowing', 'sow'],
['tutoring', 'tutor'],
['pricing', 'price'],
['revisiting', 'revisit'],
['grouping', 'group'],
['substituting', 'substitute'],
['thriving', 'thrive'],
['hedging', 'hedge'],
['lining', 'line'],
['coaching', 'coach'],
['netting', 'net'],
['furnishing', 'furnish'],
['polishing', 'polish'],
['watering', 'water'],
['supplementing', 'supplement'],
['subscribing', 'subscribe'],
['spinning', 'spin'],
['synthesizing', 'synthesize'],
['rethinking', 'rethink'],
['intensifying', 'intensify'],
['reciprocating', 'reciprocate'],
['rescinding', 'rescind'],
['ratifying', 'ratify'],
['offending', 'offend'],
['charting', 'chart'],
['deploying', 'deploy'],
['nearing', 'near'],
['portraying', 'portray'],
['catering', 'cater'],
['damaging', 'damage'],
['casting', 'cast'],
['blowing', 'blow'],
['ruling', 'rule'],
['fleeing', 'flee'],
['culminating', 'culminate'],
['flowering', 'flower'],
['discharging', 'discharge'],
['converging', 'converge'],
['spotting', 'spot'],
['ticketing', 'ticket'],
['quantifying', 'quantify'],
['rating', 'rate'],
['aiding', 'aid'],
['bending', 'bend'],
['relieving', 'relieve'],
['quarrying', 'quarry'],
['levelling', 'level'],
['basing', 'base'],
['wholesaling', 'wholesale'],
['browsing', 'browse'],
['leasing', 'lease'],
['gauging', 'gauge'],
['purifying', 'purify'],
['interfering', 'interfere'],
['lubricating', 'lubricate'],
['exiting', 'exit'],
['preferring', 'prefer'],
['discouraging', 'discourage'],
['camping', 'camp'],
['spawning', 'spawn'],
['bundling', 'bundle'],
['conferring', 'confer'],
['touching', 'touch'],
['popping', 'pop'],
['effecting', 'effect'],
['inhibiting', 'inhibit'],
['chewing', 'chew'],
['underlining', 'underline'],
['debriefing', 'debrief'],
['contrasting', 'contrast'],
['stretching', 'stretch'],
['warning', 'warn'],
['summing', 'sum'],
['witnessing', 'witness'],
['disappearing', 'disappear'],
['chairing', 'chair'],
['mating', 'mate'],
['plaiting', 'plait'],
['divorcing', 'divorce'],
['piloting', 'pilot'],
['speeding', 'speed'],
['cancelling', 'cancel'],
['digitizing', 'digitize'],
['replicating', 'replicate'],
['affording', 'afford'],
['taxing', 'tax'],
['redefining', 'redefin'],
['opting', 'opt'],
['constraining', 'constrain'],
['publicizing', 'publicize'],
['burning', 'burn'],
['excavating', 'excavate'],
['consenting', 'consent'],
['grazing', 'graze'],
['yellowing', 'yellow'],
['ripening', 'ripen'],
['songwriting', 'songwrite'],
['standardizing', 'standardize'],
['reminding', 'remind'],
['remembering', 'remember'],
['repositioning', 'reposition'],
['tightening', 'tighten'],
['lessening', 'lessen'],
['circumventing', 'circumvent'],
['seizing', 'seize'],
['referencing', 'reference'],
['locking', 'lock'],
['sterilizing', 'sterilize'],
['dyeing', 'dye'],
['tending', 'tend'],
['videoconferencing', 'videoconference'],
['diagnosing', 'diagnose'],
['reacting', 'react'],
['descending', 'descend'],
['looming', 'loom'],
['waiving', 'waive'],
['surging', 'surge'],
['fitting', 'fit'],
['clustering', 'cluster'],
['lying', 'lie'],
['stalking', 'stalk'],
['wilting', 'wilt'],
['backing', 'back'],
['stitching', 'stitch'],
['tailoring', 'tailor'],
['rooting', 'root'],
['migrating', 'migrate'],
['hurting', 'hurt'],
['rebounding', 'rebound'],
['expediting', 'expedite'],
['unveiling', 'unveil'],
['canoeing', 'canoe'],
['accumulating', 'accumulate'],
['deterring', 'deter'],
['immigrating', 'immigrate'],
['attacking', 'attack'],
['reaffirming', 'reaffirm'],
['fencing', 'fence'],
['capping', 'cap'],
['colouring', 'colour'],
['germinating', 'germinate'],
['freezing', 'freeze'],
['remedying', 'remedy'],
['absorbing', 'absorb'],
['splitting', 'split'],
['boating', 'boat'],
['equipping', 'equip'],
['typing', 'type'],
['formalizing', 'formalize'],
['scaling', 'scale'],
['defaulting', 'default'],
['soldering', 'solder'],
['knitting', 'knit'],
['decoding', 'decode'],
['fishing', 'fish'],
['sacrificing', 'sacrifice'],
['renovating', 'renovate'],
['hanging', 'hang'],
['augmenting', 'augment'],
['relaxing', 'relax'],
['endorsing', 'endorse'],
['shortening', 'shorten'],
['recycling', 'recycle'],
['repeating', 'repeat'],
['hindering', 'hinder'],
['undercutting', 'undercut'],
['fingerprinting', 'fingerprint'],
['displacing', 'displace'],
['dismantling', 'dismantle'],
['emitting', 'emit'],
['countering', 'counter'],
['cracking', 'crack'],
['stunting', 'stunt'],
['flavouring', 'flavour'],
['scripting', 'script'],
['injecting', 'inject'],
['twinning', 'twin'],
['breathing', 'breathe'],
['boarding', 'board'],
['boiling', 'boil'],
['ticking', 'tick'],
['greeting', 'greet'],
['triggering', 'trigger'],
['rewarding', 'reward'],
['fruiting', 'fruit'],
['stipulating', 'stipulate'],
['threading', 'thread'],
['experimenting', 'experiment'],
['blurring', 'blur'],
['redesigning', 'redesign'],
['paging', 'page'],
['jumping', 'jump'],
['crowding', 'crowd'],
['associating', 'associate'],
['carving', 'carve'],
['freeing', 'free'],
['accomplishing', 'accomplish'],
['recalling', 'recall'],
['penetrating', 'penetrate'],
['tubing', 'tube'],
['stiffening', 'stiffen'],
['discriminating', 'discriminate'],
['framing', 'frame'],
['spearheading', 'spearhead'],
['disabling', 'disable'],
['keying', 'key'],
['flaming', 'flame'],
['tripling', 'triple'],
['sizing', 'size'],
['outpacing', 'outpace'],
['expiring', 'expire'],
['attributing', 'attribute'],
['skating', 'skate'],
['diverting', 'divert'],
['insisting', 'insist'],
['golfing', 'golf'],
['reaping', 'reap'],
['urging', 'urge'],
['winding', 'wind'],
['lighting', 'light'],
['signifying', 'signify'],
['debating', 'debate'],
['weighting', 'weight'],
['procuring', 'procure'],
['compounding', 'compound'],
['decommissioning', 'decommission'],
['embodying', 'embody'],
['dispersing', 'disperse'],
['boring', 'bore'],
['centralizing', 'centralize'],
['crafting', 'craft'],
['alerting', 'alert'],
['deferring', 'defer'],
['handing', 'hand'],
['curbing', 'curb'],
['discounting', 'discount'],
['asserting', 'assert'],
['shining', 'shine'],
['milking', 'milk'],
['grappling', 'grapple'],
['donating', 'donate'],
['tuning', 'tune'],
['proofreading', 'proofread'],
['lapsing', 'lapse'],
['slitting', 'slit'],
['ascending', 'ascend'],
['insuring', 'insure'],
['complicating', 'complicate'],
['dining', 'dine'],
['lapping', 'lap'],
['bathing', 'bath'],
['beating', 'beat'],
['stripping', 'strip'],
['transiting', 'transit'],
['tagging', 'tag'],
['plugging', 'plug'],
['mediating', 'mediate'],
['belting', 'belt'],
['injuring', 'injure'],
['reclaiming', 'reclaim'],
['repackaging', 'repackage'],
['rationing', 'ration'],
['retooling', 'retool'],
['subtitling', 'subtitle'],
['probing', 'probe'],
['draining', 'drain'],
['swimming', 'swim'],
['paving', 'pave'],
['complaining', 'complain'],
['overlapping', 'overlap'],
['administrating', 'administrate'],
['suspending', 'suspend'],
['barring', 'bar'],
['postponing', 'postpone'],
['moderating', 'moderate'],
['convincing', 'convince'],
['unwavering', 'unwaver'],
['unfolding', 'unfold'],
['manipulating', 'manipulate'],
['metering', 'meter'],
['disrupting', 'disrupt'],
['ranching', 'ranch'],
['mastering', 'master'],
['captioning', 'caption'],
['smelting', 'smelt'],
['tampering', 'tamper'],
['smoothing', 'smooth'],
['bleaching', 'bleach'],
['aggregating', 'aggregate'],
['arming', 'arm'],
['coinciding', 'coincide'],
['pairing', 'pair'],
['dwindling', 'dwindle'],
['docking', 'dock'],
['rafting', 'raft'],
['categorizing', 'categorize'],
['exerting', 'exert'],
['jeopardizing', 'jeopardize'],
['throwing', 'throw'],
['landscaping', 'landscape'],
['acceding', 'accede'],
['stealing', 'steal'],
['accrediting', 'accredit'],
['foregoing', 'forego'],
['sensitizing', 'sensitize'],
['dissolving', 'dissolve'],
['wrestling', 'wrestle'],
['extruding', 'extrude'],
['diverging', 'diverge'],
['grafting', 'graft'],
['fasting', 'fast'],
['transcribing', 'transcribe'],
['boxing', 'box'],
['detaining', 'detain'],
['forgetting', 'forget'],
['encoding', 'encode'],
['shedding', 'shed'],
['suppressing', 'suppress'],
['banning', 'ban'],
['stirring', 'stir'],
['gambling', 'gamble'],
['encountering', 'encounter'],
['simulating', 'simulate'],
['commuting', 'commute'],
['trimming', 'trim'],
['abandoning', 'abandon'],
['firing', 'fire'],
['scrambling', 'scramble'],
['ceasing', 'cease'],
['polluting', 'pollute'],
['precluding', 'preclude'],
['transacting', 'transact'],
['inducing', 'induce'],
['unpacking', 'unpack'],
['perforating', 'perforate'],
['licencing', 'licence'],
['realigning', 'realign'],
['splashing', 'splash'],
['decaying', 'decay'],
['coating', 'coat'],
['gluing', 'glue'],
['isolating', 'isolate'],
['blanketing', 'blanket'],
['slipping', 'slip'],
['worsening', 'worsen'],
['softening', 'soften'],
['escaping', 'escape'],
['drifting', 'drift'],
['hampering', 'hamper'],
['creeping', 'creep'],
['bolstering', 'bolster'],
['garnering', 'garner'],
['hiding', 'hide'],
['ionizing', 'ionize'],
['marrying', 'marry'],
['rebalancing', 'rebalance'],
['repaying', 'repay'],
['shearing', 'shear'],
['catalyzing', 'catalyze'],
['girdling', 'girdle'],
['confounding', 'confound'],
['piling', 'pile'],
['amplifying', 'amplify'],
['rationalizing', 'rationalize'],
['slicing', 'slice'],
['refreshing', 'refresh'],
['composing', 'compose'],
['astounding', 'astound'],
['discontinuing', 'discontinue'],
['subcontracting', 'subcontract'],
['underscoring', 'underscore'],
['shopping', 'shop'],
['flooding', 'flood'],
['abolishing', 'abolish'],
['factoring', 'factor'],
['conflicting', 'conflict'],
['towing', 'tow'],
['deserving', 'deserve'],
['sticking', 'stick'],
['embossing', 'emboss'],
['synchronizing', 'synchronize'],
['resuming', 'resume'],
['vetting', 'vet'],
['instructing', 'instruct'],
['calibrating', 'calibrate'],
['enclosing', 'enclose'],
['taping', 'tape'],
['ascertaining', 'ascertain'],
['predisposing', 'predispose'],
['farrowing', 'farrow'],
['planing', 'plane'],
['smoking', 'smoke'],
['activating', 'activate'],
['resorting', 'resort'],
['wondering', 'wonder'],
['neutralizing', 'neutralize'],
['automating', 'automate'],
['extenuating', 'extenuate'],
['relocating', 'relocate'],
['topping', 'top'],
['eliciting', 'elicit'],
['socializing', 'socialize'],
['trailing', 'trail'],
['enticing', 'entice'],
['dictating', 'dictate'],
['sleeping', 'sleep'],
['curling', 'curl'],
['starring', 'star'],
['babysitting', 'babysit'],
['solidifying', 'solidify'],
['uniting', 'unite'],
['aspiring', 'aspire'],
['trampling', 'trample'],
['teaming', 'team'],
['appraising', 'appraise'],
['delegating', 'delegate'],
['confining', 'confine'],
['fertilizing', 'fertilize'],
['reinstating', 'reinstate'],
['banding', 'band'],
['pickling', 'pickle'],
['tunnelling', 'tunnel'],
['piercing', 'pierce'],
['frying', 'fry'],
['redressing', 'redress'],
['engendering', 'engender'],
['prosecuting', 'prosecute'],
['sentencing', 'sentence'],
['depositing', 'deposit'],
['enduring', 'endure'],
['elevating', 'elevate'],
['rallying', 'rally'],
['flattening', 'flatten'],
['painting', 'paint'],
['dancing', 'dance'],
['airing', 'air'],
['gearing', 'gear'],
['ramping', 'ramp'],
['skyrocketing', 'skyrocket'],
['dominating', 'dominate'],
['tasting', 'taste'],
['pitching', 'pitch'],
['steaming', 'steam'],
['impairing', 'impair'],
['ventilating', 'ventilate'],
['damping', 'damp'],
['scouring', 'scour'],
['revoking', 'revoke'],
['contaminating', 'contaminate'],
['franchising', 'franchise'],
['deeming', 'deem'],
['zeroing', 'zero'],
['cohabiting', 'cohabit'],
['intersecting', 'intersect'],
['dubbing', 'dub'],
['merchandizing', 'merchandize'],
['adjudicating', 'adjudicate'],
['saluting', 'salute'],
['annealing', 'anneal'],
['dismissing', 'dismiss'],
['subjecting', 'subject'],
['excepting', 'except'],
['reorganizing', 'reorganize'],
['drumming', 'drum'],
['sanctioning', 'sanction'],
['elaborating', 'elaborate'],
['waning', 'wane'],
['restraining', 'restrain'],
['perpetuating', 'perpetuate'],
['curtailing', 'curtail'],
['illuminating', 'illuminate'],
['prolonging', 'prolong'],
['refuelling', 'refuel'],
['recognising', 'recognise'],
['brazing', 'braze'],
['galvanizing', 'galvanize'],
['amalgamating', 'amalgamate'],
['inciting', 'incite'],
['vending', 'vend'],
['reselling', 'resell'],
['customizing', 'customize'],
['canvassing', 'canvass'],
['microfilming', 'microfilm'],
['weeding', 'weed'],
['brokering', 'broker'],
['policymaking', 'policymak'],
['tilling', 'till'],
['rotting', 'rot'],
['melting', 'melt'],
['terracing', 'terrace'],
['sucking', 'suck'],
['reigning', 'reign'],
['aerating', 'aerate'],
['diluting', 'dilute'],
['backwashing', 'backwash'],
['admitting', 'admit'],
['underperforming', 'underperform'],
['resting', 'rest'],
['surfing', 'surf'],
['abusing', 'abuse'],
['interlocking', 'interlock'],
['embedding', 'embed'],
['billing', 'bill'],
['faxing', 'fax'],
['invading', 'invade'],
['distilling', 'distil'],
['swelling', 'swell'],
['tipping', 'tip'],
['electing', 'elect'],
['confusing', 'confuse'],
['reinvesting', 'reinvest'],
['spurring', 'spur'],
['hardening', 'harden'],
['bordering', 'border'],
['polarizing', 'polarize'],
['singing', 'sing'],
['resisting', 'resist'],
['necessitating', 'necessitate'],
['reopening', 'reopen'],
['pledging', 'pledge'],
['reshaping', 'reshape'],
['overarching', 'overarch'],
['wintering', 'winter'],
['modulating', 'modulate'],
['baling', 'bale'],
['threshing', 'thresh'],
['potting', 'pot'],
['landing', 'land'],
['remitting', 'remit'],
['sifting', 'sift'],
['penalizing', 'penalize'],
['boning', 'bone'],
['disregarding', 'disregard'],
['encapsulating', 'encapsulate'],
['rectifying', 'rectify'],
['concealing', 'conceal'],
['intercepting', 'intercept'],
['proclaiming', 'proclaim'],
['laminating', 'laminate'],
['figuring', 'figure'],
['paddling', 'paddle'],
['faring', 'fare'],
['depriving', 'deprive'],
['evidencing', 'evidence'],
['corresponding', 'correspond'],
['reeling', 'reel'],
['crimping', 'crimp'],
['edging', 'edge'],
['anchoring', 'anchor'],
['uncovering', 'uncover'],
['flourishing', 'flourish'],
['scratching', 'scratch'],
['honing', 'hone'],
['reinventing', 'reinvent'],
['mandating', 'mandate'],
['objecting', 'object'],
['revolving', 'revolve'],
['deleting', 'delete'],
['spelling', 'spell'],
['quitting', 'quit'],
['pouring', 'pour'],
['budgeting', 'budget'],
['teleconferencing', 'teleconference'],
['wasting', 'waste'],
['reallocating', 'reallocate'],
['sanding', 'sand'],
['shadowing', 'shadow'],
['punching', 'punch'],
['infecting', 'infect'],
['ploughing', 'plough'],
['disinfecting', 'disinfect'],
['wiping', 'wipe'],
['condensing', 'condense'],
['redistributing', 'redistribute'],
['housing', 'house'],
['fastening', 'fasten'],
['perfuming', 'perfume'],
['calendering', 'calender'],
['voicing', 'voice'],
['mooring', 'moor'],
['sinking', 'sink'],
['unlocking', 'unlock'],
['phoning', 'phone'],
['risking', 'risk'],
['heightening', 'heighten'],
['reserving', 'reserve'],
['breaching', 'breach'],
['depreciating', 'depreciate'],
['symbolizing', 'symbolize'],
['underwriting', 'underwrite'],
['regaining', 'regain'],
['depleting', 'deplete'],
['detracting', 'detract'],
['sprouting', 'sprout'],
['energizing', 'energize'],
['bagging', 'bag'],
['overturning', 'overturn'],
['entertaining', 'entertain'],
['provoking', 'provoke'],
['rehabilitating', 'rehabilitate'],
['fracturing', 'fracture'],
['desiring', 'desire'],
['retreading', 'retread'],
['steelmaking', 'steelmak'],
['revamping', 'revamp'],
['segregating', 'segregate'],
['crawling', 'crawl'],
['straightening', 'straighten'],
['worrying', 'worry'],
['perplexing', 'perplex'],
['conceptualizing', 'conceptualize'],
['monetizing', 'monetize'],
['watermarking', 'watermark'],
['humiliating', 'humiliate'],
['remanufacturing', 'remanufacture'],
['masking', 'mask'],
['dialing', 'dial'],
['exacerbating', 'exacerbate'],
['inspiring', 'inspire'],
['precipitating', 'precipitate'],
['equating', 'equate'],
['bypassing', 'bypass'],
['enlarging', 'enlarge'],
['omitting', 'omit'],
['liberalizing', 'liberalize'],
['luring', 'lure'],
['pressuring', 'pressure'],
['exploding', 'explode'],
['shaking', 'shake'],
['jogging', 'jog'],
['propelling', 'propel'],
['leaking', 'leak'],
['surrendering', 'surrender'],
['neglecting', 'neglect'],
['imparting', 'impart'],
['relaunching', 'relaunch'],
['channelling', 'channel'],
['remarking', 'remark'],
['forbidding', 'forbid'],
['disciplining', 'discipline'],
['roaming', 'roam'],
['clipping', 'clip'],
['arresting', 'arrest'],
['repealing', 'repeal'],
['expending', 'expend'],
['wetting', 'wet'],
['irrigating', 'irrigate'],
['decomposing', 'decompose'],
['renaming', 'rename'],
['ditching', 'ditch'],
['emptying', 'empty'],
['reassessing', 'reassess'],
['vaccinating', 'vaccinate'],
['bunching', 'bunch'],
['denigrating', 'denigrate'],
['sharpening', 'sharpen'],
['punishing', 'punish'],
['presuming', 'presume'],
['testifying', 'testify'],
['tolling', 'toll'],
['indexing', 'index'],
['retrieving', 'retrieve'],
['snowshoeing', 'snowshoe'],
['outperforming', 'outperform'],
['downsizing', 'downsize'],
['sparking', 'spark'],
['echoing', 'echo'],
['pinpointing', 'pinpoint'],
['reconsidering', 'reconsider'],
['overlooking', 'overlook'],
['relaying', 'relay'],
['enlisting', 'enlist'],
['perfecting', 'perfect'],
['branching', 'branch'],
['commending', 'commend'],
['pitting', 'pit'],
['defeating', 'defeat'],
['contravening', 'contravene'],
['congratulating', 'congratulate'],
['equalizing', 'equalize'],
['nourishing', 'nourish'],
['underfunding', 'underfund'],
['retailing', 'retail'],
['resurfacing', 'resurface'],
['plotting', 'plot'],
['lettering', 'letter'],
['burying', 'bury'],
['imputing', 'impute'],
['degrading', 'degrade'],
['flushing', 'flush'],
['crusting', 'crust'],
['spacing', 'space'],
['shading', 'shade'],
['notching', 'notch'],
['scalding', 'scald'],
['earmarking', 'earmark'],
['refilling', 'refill'],
['homogenizing', 'homogenize'],
['disputing', 'dispute'],
['kneading', 'knead'],
['sintering', 'sinter'],
['blinding', 'blind'],
['swearing', 'swear'],
['imaging', 'image'],
['rejuvenating', 'rejuvenate'],
['trawling', 'trawl'],
['abiding', 'abide'],
['plowing', 'plow'],
['scrutinizing', 'scrutinize'],
['segmenting', 'segment'],
['excelling', 'excel'],
['skiing', 'ski'],
['dreaming', 'dream'],
['exhilarating', 'exhilarate'],
['hunting', 'hunt'],
['disagreeing', 'disagree'],
['wandering', 'wander'],
['tilting', 'tilt'],
['rearing', 'rear'],
['overheating', 'overheat'],
['dipping', 'dip'],
['bustling', 'bustle'],
['swapping', 'swap'],
['recounting', 'recount'],
['erecting', 'erect'],
['redirecting', 'redirect'],
['halting', 'halt'],
['oscillating', 'oscillate'],
['stuffing', 'stuff'],
['quenching', 'quench'],
['noticing', 'notice'],
['reviving', 'revive'],
['refurbishing', 'refurbish'],
['vesting', 'vest'],
['invoking', 'invoke'],
['invalidating', 'invalidate'],
['compressing', 'compress'],
['venting', 'vent'],
['merchandising', 'merchandise'],
['divulging', 'divulge'],
['subsisting', 'subsist'],
['replying', 'reply'],
['flashing', 'flash'],
['straining', 'strain'],
['proofing', 'proof'],
['vaporizing', 'vaporize'],
['foraging', 'forage'],
['budding', 'bud'],
['staining', 'stain'],
['grooving', 'groove'],
['wounding', 'wound'],
['delineating', 'delineate'],
['lactating', 'lactate'],
['pleasing', 'please'],
['clotting', 'clot'],
['promulgating', 'promulgate'],
['legitimizing', 'legitimize'],
['demystifying', 'demystify'],
['pulping', 'pulp'],
['generalizing', 'generalize'],
['orienting', 'orient'],
['broaching', 'broach'],
['folding', 'fold'],
['birthing', 'birth'],
['braking', 'brake'],
['disfiguring', 'disfigure'],
['stifling', 'stifle'],
['boasting', 'boast'],
['timing', 'time'],
['reassuring', 'reassure'],
['vacationing', 'vacation'],
['sparing', 'spare'],
['regrouping', 'regroup'],
['tacking', 'tack'],
['chucking', 'chuck'],
['bleeding', 'bleed'],
['entrenching', 'entrench'],
['clamping', 'clamp'],
['cashing', 'cash'],
['gratifying', 'gratify'],
['maximising', 'maximise'],
['reprinting', 'reprint'],
['rinsing', 'rinse'],
['familiarizing', 'familiarize'],
['recouping', 'recoup'],
['cementing', 'cement'],
['scraping', 'scrape'],
['democratizing', 'democratize'],
['grasping', 'grasp'],
['defraying', 'defray'],
['normalizing', 'normalize'],
['weaning', 'wean'],
['extrapolating', 'extrapolate'],
['cycling', 'cycle'],
['disbursing', 'disburse'],
['endeavouring', 'endeavour'],
['molting', 'molt'],
['devolving', 'devolve'],
['blossoming', 'blossom'],
['wading', 'wade'],
['refuting', 'refute'],
['escorting', 'escort'],
['disembarking', 'disembark'],
['strapping', 'strap'],
['reclining', 'recline'],
['privatizing', 'privatize'],
['dredging', 'dredge'],
['abating', 'abate'],
['compelling', 'compel'],
['mirroring', 'mirror'],
['organising', 'organise'],
['warming', 'warm'],
['waving', 'wave'],
['tumbling', 'tumble'],
['battling', 'battle'],
['contending', 'contend'],
['intimidating', 'intimidate'],
['pampering', 'pamper'],
['lengthening', 'lengthen'],
['invigorating', 'invigorate'],
['spotlighting', 'spotlight'],
['apportioning', 'apportion'],
['authoring', 'authore'],
['persisting', 'persist'],
['tempering', 'temper'],
['preaching', 'preach'],
['vying', 'vie'],
['evaporating', 'evaporate'],
['crumbling', 'crumble'],
['bracing', 'brace'],
['bubbling', 'bubble'],
['grooming', 'groom'],
['reusing', 'reuse'],
['repatriating', 'repatriate'],
['unraveling', 'unravel'],
['piping', 'pipe'],
['engineering', 'engineer'],
['chipping', 'chip'],
['clogging', 'clog'],
['malfunctioning', 'malfunction'],
['alloying', 'alloy'],
['minding', 'mind'],
['appropriating', 'appropriate'],
['authenticating', 'authenticate'],
['videotaping', 'videotape'],
['warranting', 'warrant'],
['reprocessing', 'reprocess'],
['affixing', 'affix'],
['shattering', 'shatter'],
['falsifying', 'falsify'],
['bursting', 'burst'],
['reworking', 'rework'],
['renegotiating', 'renegotiate'],
['refocusing', 'refocus'],
['inventing', 'invent'],
['sculpting', 'sculpt'],
['economizing', 'economize'],
['encrypting', 'encrypt'],
['sheltering', 'shelter'],
['fogging', 'fog'],
['harrowing', 'harrow'],
['shredding', 'shred'],
['browning', 'brown'],
['bruising', 'bruise'],
['trucking', 'truck'],
['interrupting', 'interrupt'],
['denoting', 'denote'],
['surfacing', 'surface'],
['breading', 'bread'],
['fragmenting', 'fragment'],
['legislating', 'legislate'],
['frustrating', 'frustrate'],
['surprising', 'surprise'],
['gardening', 'garden'],
['bowling', 'bowl'],
['elucidating', 'elucidate'],
['blanking', 'blank'],
['stapling', 'staple'],
['felling', 'fell'],
['eviscerating', 'eviscerate'],
['imprinting', 'imprint'],
['hemming', 'hem'],
['sheeting', 'sheet'],
['puffing', 'puff'],
['kicking', 'kick'],
['imagining', 'imagine'],
['uttering', 'utter'],
['resubmitting', 'resubmit'],
['fallowing', 'fallow'],
['drowning', 'drown'],
['behaving', 'behave'],
['rewriting', 'rewrite'],
['polling', 'poll'],
['trekking', 'trek'],
['aggravating', 'aggravate'],
['hovering', 'hover'],
['encroaching', 'encroach'],
['persuading', 'persuade'],
['fading', 'fade'],
['stagnating', 'stagnate'],
['bucking', 'buck'],
['shutting', 'shut'],
['soaking', 'soak'],
['fearing', 'fear'],
['knocking', 'knock'],
['biting', 'bite'],
['banking', 'bank'],
['incubating', 'incubate'],
['globalizing', 'globalize'],
['thawing', 'thaw'],
['revolutionizing', 'revolutionize'],
['pounding', 'pound'],
['grabbing', 'grab'],
['delving', 'delve'],
['contesting', 'contest'],
['criticizing', 'criticize'],
['mourning', 'mourn'],
['manifesting', 'manifest'],
['decentralizing', 'decentralize'],
['reiterating', 'reiterate'],
['inquiring', 'inquire'],
['sewing', 'sew'],
['availing', 'avail'],
['relinquishing', 'relinquish'],
['silencing', 'silence'],
['patching', 'patch'],
['instilling', 'instill'],
['offloading', 'offload'],
['zoning', 'zone'],
['bolting', 'bolt'],
['meshing', 'mesh'],
['profiting', 'profit'],
['sequestering', 'sequester'],
['tabulating', 'tabulate'],
['dwarfing', 'dwarf'],
['bronzing', 'bronze'],
['digging', 'dig'],
['scarring', 'scar'],
['skinning', 'skin'],
['burrowing', 'burrow'],
['reorienting', 'reorient'],
['reasoning', 'reason'],
['grossing', 'gross'],
['reconditioning', 'recondition'],
['fermenting', 'ferment'],
['preexisting', 'preexist'],
['speculating', 'speculate'],
['averting', 'avert'],
['emulsifying', 'emulsify'],
['marinating', 'marinate'],
['marginalizing', 'marginalize'],
['smudging', 'smudge'],
['implicating', 'implicate'],
['vanishing', 'vanish'],
['engraving', 'engrave'],
['tearing', 'tear'],
['fusing', 'fuse'],
['slotting', 'slot'],
['concurring', 'concur'],
['spoofing', 'spoof'],
['decrypting', 'decrypt'],
['advertising', 'advertise'],
['interdicting', 'interdict'],
['foaming', 'foam'],
['dosing', 'dose'],
['interlining', 'interline'],
['burnishing', 'burnish'],
['singeing', 'singe'],
['electrogalvanizing', 'electrogalvanize'],
['trusting', 'trust'],
['overflowing', 'overflow'],
['immersing', 'immerse'],
['flocking', 'flock'],
['chatting', 'chat'],
['roughing', 'rough'],
['looping', 'loop'],
['outfitting', 'outfit'],
['receding', 'recede'],
['dragging', 'drag'],
['centering', 'center'],
['harbouring', 'harbour'],
['bumping', 'bump'],
['decelerating', 'decelerate'],
['venturing', 'venture'],
['alienating', 'alienate'],
['roasting', 'roast'],
['cabling', 'cable'],
['manoeuvring', 'manoeuvre'],
['occuring', 'occure'],
['firefighting', 'firefight'],
['chronicling', 'chronicle'],
['fabricating', 'fabricate'],
['obliging', 'oblige'],
['enlightening', 'enlighten'],
['rescheduling', 'reschedule'],
['destabilizing', 'destabilize'],
['resigning', 'resign'],
['caulking', 'caulk'],
['reordering', 'reorder'],
['diffusing', 'diffuse'],
['flooring', 'floor'],
['powering', 'power'],
['forgoing', 'forgo'],
['shoplifting', 'shoplift'],
['vulcanizing', 'vulcanize'],
['radiating', 'radiate'],
['subdividing', 'subdivide'],
['daunting', 'daunt'],
['uprooting', 'uproot'],
['discing', 'disc'],
['sanitizing', 'sanitize'],
['endangering', 'endanger'],
['buffering', 'buffer'],
['parking', 'park'],
['dispelling', 'dispel'],
['propagating', 'propagate'],
['fumigating', 'fumigate'],
['mottling', 'mottle'],
['lightening', 'lighten'],
['reapplying', 'reapply'],
['blaming', 'blame'],
['prejudging', 'prejudge'],
['flaking', 'flake'],
['depressing', 'depress'],
['trenching', 'trench'],
['dehydrating', 'dehydrate'],
['emulating', 'emulate'],
['conceiving', 'conceive'],
['hailing', 'hail'],
['unleashing', 'unleash'],
['upsetting', 'upset'],
['immunizing', 'immunize'],
['antagonizing', 'antagonize'],
['racking', 'rack'],
['typesetting', 'typeset'],
['hardworking', 'hardwork'],
['accentuating', 'accentuate'],
['awakening', 'awaken'],
['headlining', 'headline'],
['reprogramming', 'reprogram'],
['pasting', 'paste'],
['disassembling', 'disassemble'],
['assaulting', 'assault'],
['extinguishing', 'extinguish'],
['disobeying', 'disobey'],
['reuniting', 'reunite'],
['stigmatizing', 'stigmatize'],
['commingling', 'commingle'],
['icing', 'ice'],
['unlading', 'unlade'],
['detonating', 'detonate'],
['bunkering', 'bunker'],
['vulcanising', 'vulcanise'],
['descaling', 'descale'],
['priming', 'prime'],
['autoclaving', 'autoclave'],
['praising', 'praise'],
['twisting', 'twist'],
['scrubbing', 'scrub'],
['spilling', 'spill'],
['receipting', 'receipt'],
['telephoning', 'telephone'],
['bragging', 'brag'],
['replenishing', 'replenish'],
['materializing', 'materialize'],
['majoring', 'major'],
['sightseeing', 'sightsee'],
['emphasising', 'emphasise'],
['unwinding', 'unwind'],
['decompressing', 'decompress'],
['visualizing', 'visualize'],
['grounding', 'ground'],
['clouding', 'cloud'],
['actualizing', 'actualize'],
['stalling', 'stall'],
['billeting', 'billet'],
['lecturing', 'lecture'],
['conspiring', 'conspire'],
['rearranging', 'rearrange'],
['outstripping', 'outstrip'],
['interesting', 'interest'],
['plummeting', 'plummet'],
['plunging', 'plunge'],
['inflating', 'inflate'],
['corroborating', 'corroborate'],
['brightening', 'brighten'],
['raging', 'rage'],
['roving', 'rove'],
['stencilling', 'stencil'],
['rescuing', 'rescue'],
['daring', 'dare'],
['laughing', 'laugh'],
['busking', 'busk'],
['juggling', 'juggle'],
['sailing', 'sail'],
['predating', 'predate'],
['reconstructing', 'reconstruct'],
['conquering', 'conquer'],
['electroplating', 'electroplate'],
['alluding', 'allude'],
['nullifying', 'nullify'],
['contradicting', 'contradict'],
['recharging', 'recharg'],
['entitling', 'entitle'],
['impinging', 'impinge'],
['liquidating', 'liquidate'],
['tweaking', 'tweak'],
['optimising', 'optimise'],
['guarding', 'guard'],
['spying', 'spy'],
['conditioning', 'condition'],
['embalming', 'embalm'],
['choking', 'choke'],
['sweeping', 'sweep'],
['imitating', 'imitate'],
['counteracting', 'counteract'],
['deciphering', 'decipher'],
['overcrowding', 'overcrowd'],
['petitioning', 'petition'],
['pollinating', 'pollinate'],
['severing', 'sever'],
['secreting', 'secrete'],
['pasteurizing', 'pasteurize'],
['blasting', 'blast'],
['sugaring', 'sugar'],
['redeveloping', 'redevelop'],
['halving', 'halve'],
['culling', 'cull'],
['commanding', 'command'],
['whipping', 'whip'],
['bottling', 'bottle'],
['pinning', 'pin'],
['overlying', 'overlie'],
['infiltrating', 'infiltrate'],
['jetting', 'jet'],
['trembling', 'tremble'],
['swallowing', 'swallow'],
['stewing', 'stew'],
['brooding', 'brood'],
['evading', 'evade'],
['filleting', 'fillet'],
['unifying', 'unify'],
['teasing', 'tease'],
['approximating', 'approximate'],
['seating', 'seat'],
['rocking', 'rock'],
['briefing', 'brief'],
['waking', 'wake'],
['springing', 'spring'],
['dabbling', 'dabble'],
['prejudicing', 'prejudice'],
['harassing', 'harass'],
['mimicking', 'mimick'],
['chasing', 'chase'],
['crating', 'crate'],
['retouching', 'retouch'],
['hoisting', 'hoist'],
['institutionalizing', 'institutionalize'],
['condemning', 'condemn'],
['humbling', 'humble'],
['incapacitating', 'incapacitate'],
['corrupting', 'corrupt'],
['kneeling', 'kneel'],
['lashing', 'lash'],
['nailing', 'nail'],
['vibrating', 'vibrate'],
['reassembling', 'reassemble'],
['supercalendering', 'supercalender'],
['morticing', 'mortice'],
['banting', 'bant'],
['sheathing', 'sheath'],
['diving', 'dive'],
['abstracting', 'abstract'],
['scrolling', 'scroll'],
['kidding', 'kid'],
['transcending', 'transcend'],
['requisitioning', 'requisition'],
['cruising', 'cruise'],
['spiralling', 'spiral'],
['loosing', 'loose'],
['tramping', 'tramp'],
['liking', 'like'],
['laddering', 'ladder'],
['chanting', 'chant'],
['roaring', 'roar'],
['bouncing', 'bounce'],
['littering', 'litter'],
['paralleling', 'parallel'],
['photographing', 'photograph'],
['fetching', 'fetch'],
['cautioning', 'caution'],
['shoring', 'shore'],
['withstanding', 'withstand'],
['overriding', 'override'],
['inflicting', 'inflict'],
['squeezing', 'squeeze'],
['swinging', 'swing'],
['smiling', 'smile'],
['rushing', 'rush'],
['blazing', 'blaze'],
['swathing', 'swathe'],
['recirculating', 'recirculate'],
['bulking', 'bulk'],
['incriminating', 'incriminate'],
['liberating', 'liberate'],
['molding', 'mold'],
['endeavoring', 'endeavor'],
['inhabiting', 'inhabit'],
['faltering', 'falter'],
['befitting', 'befit'],
['grieving', 'grieve'],
['stevedoring', 'stevedore'],
['criminalizing', 'criminalize'],
['dusting', 'dust'],
['irritating', 'irritate'],
['gaming', 'game'],
['padding', 'pad'],
['computerizing', 'computerize'],
['underestimating', 'underestimate'],
['envisioning', 'envision'],
['clinging', 'cling'],
['purporting', 'purport'],
['reconfiguring', 'reconfigure'],
['configuring', 'configure'],
['oxidizing', 'oxidize'],
['screaming', 'scream'],
['levering', 'lever'],
['visioning', 'vision'],
['scaring', 'scare'],
['pecking', 'peck'],
['webbing', 'web'],
['pupating', 'pupate'],
['podding', 'pod'],
['silking', 'silk'],
['flecking', 'fleck'],
['raking', 'rake'],
['peeling', 'peel'],
['enunciating', 'enunciate'],
['mingling', 'mingle'],
['disintegrating', 'disintegrate'],
['fattening', 'fatten'],
['cumulating', 'cumulate'],
['grilling', 'grill'],
['ingesting', 'ingest'],
['fouling', 'foul'],
['inferring', 'infer'],
['refinancing', 'refinance'],
['ceding', 'cede'],
['suing', 'sue'],
['interrogating', 'interrogate'],
['contextualizing', 'contextualize'],
['crediting', 'credit'],
['overshooting', 'overshoot'],
['lumping', 'lump'],
['bewildering', 'bewilder'],
['redrafting', 'redraft'],
['firming', 'firm'],
['disallowing', 'disallow'],
['brimming', 'brim'],
['feasting', 'feast'],
['schooling', 'school'],
['minimising', 'minimise'],
['indemnifying', 'indemnify'],
['assimilating', 'assimilate'],
['gleaning', 'glean'],
['cataloging', 'cataloge'],
['pretending', 'pretend'],
['tailing', 'tail'],
['trafficking', 'traffick'],
['skewing', 'skew'],
['copyrighting', 'copyright'],
['publicising', 'publicise'],
['telecasting', 'telecast'],
['orchestrating', 'orchestrate'],
['erasing', 'erase'],
['sniffing', 'sniff'],
['dishwashing', 'dishwash'],
['faceting', 'facet'],
['immobilizing', 'immobilize'],
['telescoping', 'telescope'],
['interlacing', 'interlace'],
['plastering', 'plaster'],
['dieting', 'diet'],
['ameliorating', 'ameliorate'],
['dissecting', 'dissect'],
['shelving', 'shelve'],
['unforgiving', 'unforgive'],
['assaying', 'assay'],
['rerouting', 'reroute'],
['fringing', 'fringe'],
['reimbursing', 'reimburse'],
['reintroducing', 'reintroduce'],
['delighting', 'delight'],
['sipping', 'sip'],
['gliding', 'glide'],
['ballooning', 'balloon'],
['motoring', 'motor'],
['wedding', 'wed'],
['popularizing', 'popularize'],
['outing', 'out'],
['weathering', 'weather'],
['chopping', 'chop'],
['singling', 'single'],
['relegating', 'relegate'],
['industrializing', 'industrialize'],
['pegging', 'peg'],
['plaguing', 'plague'],
['refraining', 'refrain'],
['wooing', 'woo'],
['obstructing', 'obstruct'],
['stranding', 'strand'],
['staking', 'stake'],
['tiring', 'tire'],
['devouring', 'devour'],
['braising', 'braise'],
['marching', 'march'],
['streaking', 'streak'],
['hacking', 'hack'],
['quadrupling', 'quadruple'],
['animating', 'animate'],
['fashioning', 'fashion'],
['moisturizing', 'moisturize'],
['articling', 'article'],
['applauding', 'applaud'],
['appending', 'append'],
['entailing', 'entail'],
['superseding', 'supersede'],
['resurrecting', 'resurrect'],
['heeding', 'heed'],
['evoking', 'evoke'],
['deliberating', 'deliberate'],
['afflicting', 'afflict'],
['codifying', 'codify'],
['outlawing', 'outlaw'],
['disconcerting', 'disconcert'],
['biasing', 'bias'],
['deviating', 'deviate'],
['guessing', 'guess'],
['voiding', 'void'],
['abutting', 'abut'],
['leaning', 'lean'],
['masquerading', 'masquerade'],
['divesting', 'divest'],
['underpricing', 'underprice'],
['internalizing', 'internalize'],
['redeeming', 'redeem'],
['disentangling', 'disentangle'],
['flaring', 'flare'],
['coking', 'coke'],
['pirating', 'pirate'],
['unbundling', 'unbundle'],
['shielding', 'shield'],
['readying', 'ready'],
['chaining', 'chain'],
['protesting', 'protest'],
['backdating', 'backdate'],
['excusing', 'excuse'],
['queuing', 'queue'],
['rejoining', 'rejoin'],
['overburdening', 'overburden'],
['recreating', 'recreate'],
['prospering', 'prosper'],
['wagering', 'wager'],
['calving', 'calve'],
['gnawing', 'gnaw'],
['sloping', 'slope'],
['stratifying', 'stratify'],
['blooming', 'bloom'],
['smothering', 'smother'],
['hilling', 'hill'],
['chilling', 'chill'],
['thickening', 'thicken'],
['overspending', 'overspend'],
['pursing', 'purse'],
['itching', 'itch'],
['gelling', 'gell'],
['purging', 'purge'],
['combing', 'comb'],
['bartering', 'barter'],
['pelleting', 'pellet'],
['fobbing', 'fob'],
['perching', 'perch'],
['robbing', 'rob'],
['cribbing', 'crib'],
['predominating', 'predominate'],
['pollarding', 'pollard'],
['curving', 'curve'],
['margining', 'margin'],
['straying', 'stray'],
['auctioning', 'auction'],
['flipping', 'flip'],
['bedding', 'bed'],
['jointing', 'joint'],
['marshalling', 'marshal'],
['mutating', 'mutate'],
['mothering', 'mother'],
['hastening', 'hasten'],
['collapsing', 'collapse'],
['remunerating', 'remunerate'],
['postulating', 'postulate'],
['comprehending', 'comprehend'],
['equilibrating', 'equilibrate'],
['misinterpreting', 'misinterpret'],
['recasting', 'recast'],
['rehearsing', 'rehearse'],
['devaluing', 'devalue'],
['cheering', 'cheer'],
['donning', 'don'],
['mulling', 'mull'],
['exemplifying', 'exemplify'],
['acculturating', 'acculturate'],
['frequenting', 'frequent'],
['coproducing', 'coproduce'],
['equaling', 'equal'],
['legitimating', 'legitimate'],
['conciliating', 'conciliate'],
['interlinking', 'interlink'],
['electrifying', 'electrify'],
['succumbing', 'succumb'],
['rebating', 'rebate'],
['civilizing', 'civilize'],
['inaugurating', 'inaugurate'],
['interweaving', 'interweave'],
['butchering', 'butcher'],
['reinstituting', 'reinstitute'],
['embarrassing', 'embarrass'],
['denouncing', 'denounce'],
['misunderstanding', 'misunderstand'],
['bunking', 'bunk'],
['initialling', 'initial'],
['regenerating', 'regenerate'],
['conjuring', 'conjure'],
['smuggling', 'smuggle'],
['embroidering', 'embroider'],
['pinking', 'pink'],
['undervaluing', 'undervalue'],
['shaving', 'shave'],
['compacting', 'compact'],
['comminuting', 'comminute'],
['clinching', 'clinch'],
['agglomerating', 'agglomerate'],
['shafting', 'shaft'],
['bribing', 'bribe'],
['overeating', 'overeat'],
['relapsing', 'relapse'],
['individualizing', 'individualize'],
['complimenting', 'compliment'],
['orphaning', 'orphan'],
['culturing', 'culture'],
['coughing', 'cough'],
['downplaying', 'downplay'],
['scattering', 'scatter'],
['impressing', 'impress'],
['prospecting', 'prospect'],
['dispatching', 'dispatch'],
['overwhelming', 'overwhelm'],
['biking', 'bike'],
['slashing', 'slash'],
['rippling', 'ripple'],
['exciting', 'excite'],
['sunbathing', 'sunbathe'],
['summarising', 'summarise'],
['tobogganing', 'toboggan'],
['utilising', 'utilise'],
['sighting', 'sight'],
['fronting', 'front'],
['motorcycling', 'motorcycle'],
['outselling', 'outsell'],
['subduing', 'subdue'],
['outshining', 'outshine'],
['sketching', 'sketch'],
['reentering', 'reenter'],
['redeploying', 'redeploy'],
['outnumbering', 'outnumber'],
['gleaming', 'gleam'],
['warring', 'war'],
['penning', 'pen'],
['darkening', 'darken'],
['fluttering', 'flutter'],
['reverberating', 'reverberate'],
['previewing', 'preview'],
['buzzing', 'buzz'],
['haunting', 'haunt'],
['undulating', 'undulate'],
['smearing', 'smear'],
['flapping', 'flap'],
['crackling', 'crackle'],
['deafening', 'deafen'],
['labouring', 'labour'],
['parachuting', 'parachute'],
['snorkeling', 'snorkel'],
['gutting', 'gut'],
['downgrading', 'downgrade'],
['enshrining', 'enshrine'],
['rubbing', 'rub'],
['melding', 'meld'],
['propping', 'prop'],
['annoying', 'annoy'],
['gazing', 'gaze'],
['assenting', 'assent'],
['reciting', 'recite'],
['emigrating', 'emigrate'],
['ushering', 'usher'],
['arousing', 'arouse'],
['obeying', 'obey'],
['battering', 'batter'],
['distracting', 'distract'],
['obviating', 'obviate'],
['staggering', 'stagger'],
['hooking', 'hook'],
['reformulating', 'reformulate'],
['refunding', 'refund'],
['courting', 'court'],
['overcharging', 'overcharge'],
['cueing', 'cue'],
['floundering', 'flounder'],
['overshadowing', 'overshadow'],
['wining', 'wine'],
['tossing', 'toss'],
['annualizing', 'annualize'],
['envisaging', 'envisage'],
['seeming', 'seem'],
['restating', 'restate'],
['reunifying', 'reunify'],
['retreating', 'retreat'],
['grandfathering', 'grandfather'],
['quickening', 'quicken'],
['doubting', 'doubt'],
['disadvantaging', 'disadvantage'],
['obscuring', 'obscure'],
['seeping', 'seep'],
['intercropping', 'intercrop'],
['spitting', 'spit'],
['prying', 'pry'],
['shrivelling', 'shrivel'],
['metabolizing', 'metabolize'],
['puncturing', 'puncture'],
['exuding', 'exude'],
['protruding', 'protrude'],
['blackening', 'blacken'],
['rouging', 'rouge'],
['ridging', 'ridge'],
['stippling', 'stipple'],
['winnowing', 'winnow'],
['misusing', 'misuse'],
['programing', 'program'],
['deactivating', 'deactivate'],
['recalculating', 'recalculate'],
['paralyzing', 'paralyze'],
['colluding', 'collude'],
['demoralizing', 'demoralize'],
['specialising', 'specialise'],
['pasturing', 'pasture'],
['meatpacking', 'meatpack'],
['suckering', 'sucker'],
['infusing', 'infuse'],
['everchanging', 'everchange'],
['bargaining', 'bargain'],
['dialoguing', 'dialogue'],
['favoring', 'favor'],
['suffocating', 'suffocate'],
['berthing', 'berth'],
['disturbing', 'disturb'],
['resettling', 'resettle'],
['trolling', 'troll'],
['inactivating', 'inactivate'],
['clumping', 'clump'],
['rephrasing', 'rephrase'],
['dwelling', 'dwell'],
['cheating', 'cheat'],
['intermingling', 'intermingle'],
['roosting', 'roost'],
['ruffling', 'ruffle'],
['huddling', 'huddle'],
['quizzing', 'quiz'],
['militating', 'militate'],
['revitalising', 'revitalise'],
['eschewing', 'eschew'],
['glazing', 'glaze'],
['patrolling', 'patrol'],
['ankylosing', 'ankylose'],
['joking', 'joke'],
['bettering', 'better'],
['consummating', 'consummate'],
['proliferating', 'proliferate'],
['defusing', 'defuse'],
['deceiving', 'deceive'],
['cushioning', 'cushion'],
['extolling', 'extol'],
['crystallizing', 'crystallize'],
['localizing', 'localize'],
['subsidising', 'subsidise'],
['retarding', 'retard'],
['belittling', 'belittle'],
['dawning', 'dawn'],
['captivating', 'captivate'],
['modernising', 'modernise'],
['toasting', 'toast'],
['wowing', 'wow'],
['relearning', 'relearn'],
['instigating', 'instigate'],
['hijacking', 'hijack'],
['harmonising', 'harmonise'],
['delimiting', 'delimit'],
['distancing', 'distance'],
['dehumanizing', 'dehumanize'],
['reassigning', 'reassign'],
['privileging', 'privilege'],
['preceeding', 'preceed'],
['flattering', 'flatter'],
['endowing', 'endow'],
['trivializing', 'trivialize'],
['consigning', 'consign'],
['refitting', 'refit'],
['overprinting', 'overprint'],
['tallying', 'tally'],
['tantalizing', 'tantalize'],
['coupling', 'couple'],
['etching', 'etch'],
['salvaging', 'salvage'],
['entrusting', 'entrust'],
['chauffeuring', 'chauffeur'],
['withing', 'withe'],
['underachieving', 'underachieve'],
['backfilling', 'backfill'],
['campaigning', 'campaign'],
['coercing', 'coerce'],
['regretting', 'regret'],
['slapping', 'slap'],
['expelling', 'expel'],
['handcuffing', 'handcuff'],
['inheriting', 'inherit'],
['reestablishing', 'reestablish'],
['garnishing', 'garnish'],
['apprehending', 'apprehend'],
['kidnaping', 'kidnap'],
['reappraising', 'reappraise'],
['rewording', 'reword'],
['rowing', 'row'],
['refereeing', 'referee'],
['barking', 'bark'],
['kennelling', 'kennel'],
['screwing', 'screw'],
['cleaving', 'cleave'],
['impregnating', 'impregnate'],
['chambering', 'chamber'],
['strolling', 'stroll'],
['ironing', 'iron'],
['wadding', 'wad'],
['concatenating', 'concatenate'],
['tamping', 'tamp'],
['paring', 'pare'],
['collating', 'collate'],
['enveloping', 'envelop'],
['besetting', 'beset'],
['superceding', 'supercede'],
['piggybacking', 'piggyback'],
['graphing', 'graph'],
['stooping', 'stoop'],
['populating', 'populate'],
['sneezing', 'sneeze'],
['waging', 'wage'],
['pleading', 'plead'],
['disproving', 'disprove'],
['pinching', 'pinch'],
['presupposing', 'presuppose'],
['teeming', 'teem'],
['igniting', 'ignite'],
['rediscovering', 'rediscover'],
['demobilizing', 'demobilize'],
['finalising', 'finalise'],
['sizzling', 'sizzle'],
['flagging', 'flag'],
['magnifying', 'magnify'],
['perceiving', 'perceive'],
['procrastinating', 'procrastinate'],
['gifting', 'gift'],
['uncaring', 'uncare'],
['fascinating', 'fascinate'],
['tripping', 'trip'],
['honoring', 'honor'],
['flirting', 'flirt'],
['homebuilding', 'homebuild'],
['swooning', 'swoon'],
['sagging', 'sag'],
['gripping', 'grip'],
['erupting', 'erupt'],
['fledging', 'fledge'],
['deflating', 'deflate'],
['shocking', 'shock'],
['throttling', 'throttle'],
['shimmering', 'shimmer'],
['gaping', 'gape'],
['poking', 'poke'],
['petting', 'pet'],
['persevering', 'persevere'],
['raiding', 'raid'],
['decking', 'deck'],
['lulling', 'lull'],
['wailing', 'wail'],
['fiddling', 'fiddle'],
['howling', 'howl'],
['lurking', 'lurk'],
['hammering', 'hammer'],
['lugging', 'lug'],
['pining', 'pine'],
['leaping', 'leap'],
['whaling', 'whale'],
['swooping', 'swoop'],
['massing', 'mass'],
['buttressing', 'buttress'],
['evacuating', 'evacuate'],
['stabilising', 'stabilise'],
['ravaging', 'ravage'],
['staving', 'stave'],
['straddling', 'straddle'],
['cornering', 'corner'],
['bandaging', 'bandage'],
['inventorying', 'inventory'],
['acquainting', 'acquaint'],
['deprecating', 'deprecate'],
['summoning', 'summon'],
['adorning', 'adorn'],
['admiring', 'admire'],
['disqualifying', 'disqualify'],
['overruling', 'overrule'],
['maiming', 'maim'],
['adjourning', 'adjourn'],
['forsaking', 'forsake'],
['triumphing', 'triumph'],
['derogating', 'derogate'],
['shepherding', 'shepherd'],
['clamouring', 'clamour'],
['horrifying', 'horrify'],
['beefing', 'beef'],
['garnisheeing', 'garnishee'],
['dissipating', 'dissipate'],
['wording', 'word'],
['oversimplifying', 'oversimplify'],
['snooping', 'snoop'],
['overreaching', 'overreach'],
['preconditioning', 'precondition'],
['wrecking', 'wreck'],
['agonizing', 'agonize'],
['resonating', 'resonate'],
['thrilling', 'thrill'],
['bobbing', 'bob'],
['parting', 'part'],
['idling', 'idle'],
['sparging', 'sparge'],
['obligating', 'obligate'],
['arbitrating', 'arbitrate'],
['disguising', 'disguise'],
['unsatisfying', 'unsatisfy'],
['waxing', 'wax'],
['construing', 'construe'],
['submersing', 'submerse'],
['contouring', 'contour'],
['docketing', 'docket'],
['scorching', 'scorch'],
['raining', 'rain'],
['sensationalizing', 'sensationalize'],
['fixating', 'fixate'],
['advantaging', 'advantage'],
['wagging', 'wag'],
['trotting', 'trot'],
['pacing', 'pace'],
['manuring', 'manure'],
['haying', 'hay'],
['recordkeeping', 'recordkeepe'],
['coring', 'core'],
['grouting', 'grout'],
['strewing', 'strew'],
['loafing', 'loaf'],
['landfilling', 'landfil'],
['percolating', 'percolate'],
['forking', 'fork'],
['blunting', 'blunt'],
['defoliating', 'defoliate'],
['moulting', 'moult'],
['starving', 'starve'],
['infesting', 'infest'],
['liming', 'lime'],
['hollowing', 'hollow'],
['mounding', 'mound'],
['sweating', 'sweat'],
['drooping', 'droop'],
['wrinkling', 'wrinkle'],
['spoiling', 'spoil'],
['hoeing', 'hoe'],
['replanting', 'replant'],
['vectoring', 'vector'],
['understating', 'understate'],
['interceding', 'intercede'],
['rivaling', 'rival'],
['sparkling', 'sparkle'],
['oiling', 'oil'],
['fractionating', 'fractionate'],
['overestimating', 'overestimate'],
['flexing', 'flex'],
['reverting', 'revert'],
['diking', 'dike'],
['negating', 'negate'],
['overlaying', 'overlay'],
['grassing', 'grass'],
['dehorning', 'dehorn'],
['slumping', 'slump'],
['poisoning', 'poison'],
['heeling', 'heel'],
['deflecting', 'deflect'],
['overdosing', 'overdose'],
['thrusting', 'thrust'],
['stumbling', 'stumble'],
['poaching', 'poach'],
['interchanging', 'interchange'],
['portioning', 'portion'],
['exaggerating', 'exaggerate'],
['litigating', 'litigate'],
['mobilising', 'mobilise'],
['levying', 'levy'],
['overfeeding', 'overfeed'],
['coexisting', 'coexist'],
['tethering', 'tether'],
['allotting', 'allot'],
['adjoining', 'adjoin'],
['inclining', 'incline'],
['panting', 'pant'],
['impending', 'impend'],
['brewing', 'brew'],
['scavenging', 'scavenge'],
['trumpeting', 'trumpet'],
['outweighing', 'outweigh'],
['intertwining', 'intertwine'],
['toting', 'tote'],
['redrawing', 'redraw'],
['disenfranchising', 'disenfranchise'],
['supposing', 'suppose'],
['traversing', 'traverse'],
['overhauling', 'overhaul'],
['repurchasing', 'repurchase'],
['crowning', 'crown'],
['disdaining', 'disdain'],
['proselytizing', 'proselytize'],
['tainting', 'taint'],
['regressing', 'regress'],
['misreading', 'misread'],
['scrapping', 'scrap'],
['tiering', 'tier'],
['uplifting', 'uplift'],
['troubling', 'trouble'],
['pausing', 'pause'],
['clashing', 'clash'],
['piecing', 'piece'],
['disheartening', 'dishearten'],
['likening', 'liken'],
['transposing', 'transpose'],
['internalising', 'internalise'],
['decentralising', 'decentralise'],
['conversing', 'converse'],
['deducing', 'deduce'],
['chaperoning', 'chaperon'],
['memorizing', 'memorize'],
['begging', 'beg'],
['restarting', 'restart'],
['apologizing', 'apologize'],
['correlating', 'correlate'],
['abstaining', 'abstain'],
['bureaucratizing', 'bureaucratize'],
['plateauing', 'plateaue'],
['consecrating', 'consecrate'],
['reinvigorating', 'reinvigorate'],
['enslaving', 'enslave'],
['appeasing', 'appease'],
['constricting', 'constrict'],
['domesticating', 'domesticate'],
['multitasking', 'multitask'],
['remodeling', 'remodel'],
['touting', 'tout'],
['latching', 'latch'],
['cannibalizing', 'cannibalize'],
['numbing', 'numb'],
['begrudging', 'begrudge'],
['squandering', 'squander'],
['nonthreatening', 'nonthreaten'],
['insinuating', 'insinuate'],
['couching', 'couch'],
['exacting', 'exact'],
['recapitulating', 'recapitulate'],
['convoluting', 'convolute'],
['centralising', 'centralise'],
['amassing', 'amass'],
['affiliating', 'affiliate'],
['disclaiming', 'disclaim'],
['ascribing', 'ascribe'],
['tolerating', 'tolerate'],
['amortizing', 'amortize'],
['skimming', 'skim'],
['renouncing', 'renounce'],
['comporting', 'comport'],
['muddling', 'muddle'],
['usurping', 'usurp'],
['fractioning', 'fraction'],
['juxtaposing', 'juxtapose'],
['ripping', 'rip'],
['unscrambling', 'unscramble'],
['descrambling', 'descramble'],
['misappropriating', 'misappropriate'],
['scaffolding', 'scaffold'],
['jeopardising', 'jeopardise'],
['stationing', 'station'],
['encumbering', 'encumber'],
['roping', 'rope'],
['reheating', 'reheat'],
['underselling', 'undersell'],
['overtaking', 'overtake'],
['initializing', 'initialize'],
['perusing', 'peruse'],
['befriending', 'befriend'],
['cramming', 'cram'],
['intriguing', 'intrigue'],
['personalizing', 'personalize'],
['loaning', 'loan'],
['overloading', 'overload'],
['flanking', 'flank'],
['auditioning', 'audition'],
['rebroadcasting', 'rebroadcast'],
['parceling', 'parcel'],
['gentrifying', 'gentrify'],
['absolving', 'absolve'],
['pillaging', 'pillage'],
['bankrupting', 'bankrupt'],
['digitalizing', 'digitalize'],
['decreeing', 'decree'],
['teething', 'teethe'],
['centring', 'centre'],
['instating', 'instate'],
['righting', 'right'],
['taunting', 'taunt'],
['caucusing', 'caucus'],
['crashing', 'crash'],
['pondering', 'ponder'],
['flaunting', 'flaunt'],
['conscripting', 'conscript'],
['shouting', 'shout'],
['sobbing', 'sob'],
['fraying', 'fray'],
['disentitling', 'disentitle'],
['convicting', 'convict'],
['bequeathing', 'bequeath'],
['enumerating', 'enumerate'],
['quashing', 'quash'],
['mouthing', 'mouth'],
['abducting', 'abduct'],
['federating', 'federate'],
['remanding', 'remand'],
['incarcerating', 'incarcerate'],
['hazing', 'haze'],
['kissing', 'kiss'],
['perpetrating', 'perpetrate'],
['disarming', 'disarm'],
['bulging', 'bulge'],
['dovetailing', 'dovetail'],
['bicycling', 'bicycle'],
['anesthetizing', 'anesthetize'],
['menacing', 'menace'],
['scapegoating', 'scapegoate'],
['acquitting', 'acquit'],
['seasoning', 'season'],
['pivoting', 'pivot'],
['retracting', 'retract'],
['gunning', 'gun'],
['peening', 'peen'],
['flocculating', 'flocculate'],
['cleansing', 'cleanse'],
['lacing', 'lace'],
['hemstitching', 'hemstitch'],
['fulling', 'full'],
['napping', 'nap'],
['cubing', 'cube'],
['decontaminating', 'decontaminate'],
['dehumanising', 'dehumanise'],
['whitening', 'whiten'],
['superimposing', 'superimpose'],
['needling', 'needle'],
['recapping', 'recap'],
['matting', 'mat'],
['hewing', 'hew'],
['tufting', 'tuft'],
['wringing', 'wring'],
['tinning', 'tin'],
['wiring', 'wire'],
['bushing', 'bush'],
['granulating', 'granulate'],
['sieving', 'sieve'],
['debonding', 'debond'],
['splicing', 'splice'],
['beeping', 'beep'],
['underreporting', 'underreport'],
['booming', 'boom'],
['armouring', 'armour'],
['reaming', 'ream'],
['chamfering', 'chamfer'],
['superheating', 'superheat'],
['coiling', 'coil'],
['flanging', 'flange'],
['destining', 'destine'],
['demineralizing', 'demineralize'],
['laboring', 'labor'],
['coalescing', 'coalesce'],
['wheezing', 'wheeze'],
['coaxing', 'coax'],
['tapering', 'taper'],
['fooling', 'fool'],
['quaking', 'quak'],
['buckling', 'buckle'],
['characterising', 'characterise'],
['greying', 'grey'],
['crippling', 'cripple'],
['siphoning', 'siphon'],
['debilitating', 'debilitate'],
['lauding', 'laud'],
['perturbing', 'perturb'],
['unstinting', 'unstint'],
['desensitizing', 'desensitize'],
['inoculating', 'inoculate'],
['alarming', 'alarm'],
['depolarizing', 'depolarize'],
['crying', 'cry'],
['aching', 'ache'],
['glaring', 'glare'],
['stunning', 'stun'],
['blitzing', 'blitz'],
['bossing', 'boss'],
['fuzzing', 'fuzz'],
['gassing', 'gas'],
['glossing', 'gloss'],
['messing', 'mess'],
['smelling', 'smell'],
['yelling', 'yell'],
['peacemaking', 'peacemake'],
['fundraising', 'fundraise'],
['matchmaking', 'matchmake'],
['kayaking', 'kayak'],
// ["awakening", "awaken"],
["baiting", "bait"],
["binning", "bin"],
["bitting", "bite"],
["blotting", "blot"],
["canvassing", "canvass"],
["combatting", "combat"],
["compressing", "compress"],
["crowning", "crown"],
["customing", "custom"],
["dimming", "dim"],
// ["cross-checking", "cross-check"],
// ["double-checking", "double-check"],
["embedding", "embed"],
["encompassing", "encompass"],
["enlivening", "enliven"],
["enrolling", "enrol"],
["equalling", "equal"],
["expressing", "express"],
["fathoming", "fathom"],
// ["fine-tuning", "fine-tune"],
["fretting", "fret"],
["fulfilling", "fulfil"],
["gossiping", "gossip"],
["hastening", "hasten"],
["hinging", "hinge"],
["hopping", "hop"],
["inputting", "input"],
["instilling", "instil"],
// ["kick-starting", "kick-start"],
["massing", "mass"],
["mimicking", "mimic"],
["mopping", "mop"],
["nodding", "nod"],
["outputting", "output"],
["owning", "own"],
["panning", "pan"],
["rapping", "rap"],
["rebelling", "rebel"],
["refiting", "refit"],
["reining", "rein"],
["remodelling", "remodel"],
["repenting", "repent"],
["ridding", "rid"],
["ruining", "ruin"],
// ["self-destructing", "self-destruct"],
["shielding", "shield"],
["signalling", "signal"],
["sinning", "sin"],
["slimming", "slim"],
["subpoenaing", "subpoena"],
["suiting", "suit"],
["tilting", "tilt"],
["trespassing", "trespass"],
["withholding", "withhold"],
["witnessing", "witness"],
// ['', ''],
]
================================================
FILE: data/pairs/Participle.js
================================================
export default [
['arisen', 'arise'],
['awoken', 'awake'],
['beaten', 'beat'],
['been', 'be'],
['begun', 'begin'],
['become', 'become'],
['bitten', 'bite'],
['blown', 'blow'],
['broken', 'break'],
['built', 'build'],
['chosen', 'choose'],
['clung', 'cling'],
['come', 'come'],
['done', 'do'],
['dove', 'dive'],
['drawn', 'draw'],
['dreamt', 'dream'],
['driven', 'drive'],
['drunk', 'drink'],
['eaten', 'eat'],
['fallen', 'fall'],
['flown', 'fly'],
['forbidden', 'forbid'],
['forgiven', 'forgive'],
['forgotten', 'forget'],
['forsaken', 'forsake'],
['forseen', 'forsee'],
['frozen', 'freeze'],
['given', 'give'],
['gone', 'go'],
['gotten', 'get'],
['grown', 'grow'],
['hasten', 'haste'],
['hidden', 'hide'],
['known', 'know'],
['outdone', 'outdo'],
['outgrown', 'outgrow'],
['overdone', 'overdo'],
['overseen', 'oversee'],
['overtaken', 'overtake'],
['overthrown', 'overthrow'],
['proven', 'prove'],
['rewritten', 'rewrite'],
['ridden', 'ride'],
['risen', 'rise'],
['rung', 'ring'],
['seen', 'see'],
['sewn', 'sew'],
['shrunk', 'shrink'],
['shaken', 'shake'],
['shone', 'shine'],
['shown', 'show'],
['slain', 'slay'],
['sought', 'seek'],
['sown', 'sow'],
['spilt', 'spill'],
['spoken', 'speak'],
['stolen', 'steal'],
['strewn', 'strew'],
['run', 'run'],
['sung', 'sing'],
['sunk', 'sink'],
['sworn', 'swear'],
['swum', 'swim'],
['taken', 'take'],
['thrown', 'throw'],
['torn', 'tear'],
['undergone', 'undergo'],
['undone', 'undo'],
['uprisen', 'uprise'],
['woken', 'wake'],
['withdrawn', 'withdraw'],
['woken', 'wake'],
['worn', 'wear'],
['woven', 'weave'],
['written', 'write'],
['wrung', 'wring'],
['waken', 'wake'],
]
================================================
FILE: data/pairs/PastTense.js
================================================
export default [
['abandoned', 'abandon'],
['abated', 'abate'],
['abducted', 'abduct'],
['abolished', 'abolish'],
['abraded', 'abrade'],
['abridged', 'abridge'],
['absolved', 'absolve'],
['absorbed', 'absorb'],
['abstained', 'abstain'],
['abused', 'abuse'],
['acceded', 'accede'],
['accelerated', 'accelerate'],
['accepted', 'accept'],
['accessed', 'access'],
['accommodated', 'accommodate'],
['accompanied', 'accompany'],
['accomplished', 'accomplish'],
['accorded', 'accord'],
['accounted', 'account'],
['accredited', 'accredit'],
['accumulated', 'accumulate'],
['accused', 'accuse'],
['ached', 'ache'],
['achieved', 'achieve'],
['acknowledged', 'acknowledge'],
['acquired', 'acquire'],
['acquitted', 'acquit'],
['acted', 'act'],
['activated', 'activate'],
['adapted', 'adapt'],
['added', 'add'],
['addressed', 'address'],
['adduced', 'adduce'],
['adhered', 'adhere'],
['adjoined', 'adjoin'],
['adjourned', 'adjourn'],
['adjudicated', 'adjudicate'],
['adjusted', 'adjust'],
['administered', 'administer'],
['admired', 'admire'],
['admitted', 'admit'],
['adopted', 'adopt'],
['advanced', 'advance'],
['advantaged', 'advantage'],
['advertised', 'advertise'],
['advised', 'advise'],
['advocated', 'advocate'],
['aerated', 'aerate'],
['affected', 'affect'],
['affiliated', 'affiliate'],
['affirmed', 'affirm'],
['affixed', 'affix'],
['afflicted', 'afflict'],
['afforded', 'afford'],
['aged', 'age'],
['agglomerated', 'agglomerate'],
['aggravated', 'aggravate'],
['aggregated', 'aggregate'],
['aggrieved', 'aggrieve'],
['agreed', 'agree'],
['aided', 'aid'],
['aimed', 'aim'],
['aired', 'air'],
['alerted', 'alert'],
['aligned', 'align'],
['alleged', 'allege'],
['allied', 'ally'],
['allocated', 'allocate'],
['alloted', 'allote'],
['allotted', 'allot'],
['allowed', 'allow'],
['alloyed', 'alloy'],
['alluded', 'allude'],
['altered', 'alter'],
['amalgamated', 'amalgamate'],
['amassed', 'amass'],
['amended', 'amend'],
['amounted', 'amount'],
['analogized', 'analogize'],
['analysed', 'analyse'],
['analyzed', 'analyze'],
['anchored', 'anchor'],
['annexed', 'annex'],
['annotated', 'annotate'],
['announced', 'announce'],
['annulled', 'annul'],
['answered', 'answer'],
['anticipated', 'anticipate'],
['apologized', 'apologize'],
['appealed', 'appeal'],
['appeared', 'appear'],
['appeased', 'appease'],
['appended', 'append'],
['applauded', 'applaud'],
['applied', 'apply'],
['appointed', 'appoint'],
['apportioned', 'apportion'],
['appraised', 'appraise'],
['appreciated', 'appreciate'],
['apprised', 'apprise'],
['approached', 'approach'],
['appropriated', 'appropriate'],
['approved', 'approve'],
['approximated', 'approximate'],
['argued', 'argue'],
['arose', 'arise'],
['aroused', 'arouse'],
['arranged', 'arrange'],
['arrested', 'arrest'],
['arrived', 'arrive'],
['articulated', 'articulate'],
['ascended', 'ascend'],
['ascertained', 'ascertain'],
['asked', 'ask'],
['assailed', 'assail'],
['assaulted', 'assault'],
['assembled', 'assemble'],
['assented', 'assent'],
['asserted', 'assert'],
['assessed', 'assess'],
['assigned', 'assign'],
['assimilated', 'assimilate'],
['assisted', 'assist'],
['associated', 'associate'],
['assumed', 'assume'],
['assured', 'assure'],
['ate', 'eat'],
['attached', 'attach'],
['attacked', 'attack'],
['attained', 'attain'],
['attempted', 'attempt'],
['attended', 'attend'],
['attested', 'attest'],
['attracted', 'attract'],
['attributed', 'attribute'],
['attuned', 'attune'],
['auctioned', 'auction'],
['audited', 'audit'],
['augmented', 'augment'],
['authenticated', 'authenticate'],
['authored', 'authore'],
['authorised', 'authorise'],
['authorized', 'authorize'],
['autolyzed', 'autolyze'],
['availed', 'avail'],
['averaged', 'average'],
['avoided', 'avoid'],
['awaited', 'await'],
['awakened', 'awaken'],
['awarded', 'award'],
['awoke', 'awake'],
['backed', 'back'],
['bagged', 'bag'],
['baked', 'bake'],
['balanced', 'balance'],
['baled', 'bale'],
['banded', 'band'],
['banned', 'ban'],
['barred', 'bar'],
['based', 'base'],
['basted', 'baste'],
['battled', 'battle'],
['beat', 'beat'],
['became', 'become'],
['bedecked', 'bedeck'],
['been', 'be'],
['began', 'begin'],
['beguiled', 'beguile'],
['believed', 'believe'],
['belonged', 'belong'],
['benefited', 'benefit'],
['bent', 'bend'],
['bestowed', 'bestow'],
['bet', 'bet'],
['bettered', 'better'],
['biased', 'bias'],
['bid', 'bid'],
['biked', 'bike'],
['billed', 'bill'],
['bit', 'bite'],
['blamed', 'blame'],
['blasted', 'blast'],
['bleached', 'bleach'],
['bled', 'bleed'],
['blended', 'blend'],
['blew', 'blow'],
['blighted', 'blight'],
['blitzed', 'blitz'],
['bloated', 'bloat'],
['blocked', 'block'],
['blurred', 'blur'],
['blushed', 'blush'],
['boarded', 'board'],
['boasted', 'boast'],
['bodied', 'body'],
['boiled', 'boil'],
['bonded', 'bond'],
['boned', 'bone'],
['booked', 'book'],
['boomed', 'boom'],
['boosted', 'boost'],
['bore', 'bear'],
['bored', 'bore'],
['borrowed', 'borrow'],
['bossed', 'boss'],
['bothered', 'bother'],
['bought', 'buy'],
['bounced', 'bounce'],
['bound', 'bind'],
['boxed', 'box'],
['boycotted', 'boycott'],
['braised', 'braise'],
['branded', 'brand'],
['braved', 'brave'],
['brazed', 'braze'],
['breached', 'breach'],
['breaded', 'bread'],
['breathed', 'breathe'],
['bred', 'breed'],
['brewed', 'brew'],
['bridged', 'bridge'],
['briefed', 'brief'],
['brightened', 'brighten'],
['broadcast', 'broadcast'],
['broadened', 'broaden'],
['broke', 'break'],
['brokered', 'broker'],
['brought', 'bring'],
['browsed', 'browse'],
['built', 'build'],
['burgeoned', 'burgeon'],
['burned', 'burn'],
['burst', 'burst'],
['buzzed', 'buzz'],
['bypassed', 'bypass'],
['cabled', 'cable'],
['caged', 'cage'],
['calcined', 'calcine'],
['calculated', 'calculate'],
['calendered', 'calender'],
['calibrated', 'calibrate'],
['called', 'call'],
['came', 'come'],
['campaigned', 'campaign'],
['cancelled', 'cancel'],
['caned', 'cane'],
['canned', 'can'],
['canvassed', 'canvass'],
['capitalized', 'capitalize'],
['capped', 'cap'],
['captioned', 'caption'],
['captivated', 'captivate'],
['captured', 'capture'],
['carded', 'card'],
['cared', 'care'],
['carried', 'carry'],
['carved', 'carve'],
['cast', 'cast'],
['categorized', 'categorize'],
['catered', 'cater'],
['caught', 'catch'],
['caused', 'cause'],
['cautioned', 'caution'],
['ceased', 'cease'],
['ceded', 'cede'],
['celebrated', 'celebrate'],
['centered', 'center'],
['centralized', 'centralize'],
['centred', 'centre'],
['certificated', 'certificate'],
['certified', 'certify'],
['chained', 'chain'],
['chaired', 'chair'],
['challenged', 'challenge'],
['championed', 'champion'],
['changed', 'change'],
['channelled', 'channel'],
['characterized', 'characterize'],
['charged', 'charge'],
['charmed', 'charm'],
['chartered', 'charter'],
['chatted', 'chat'],
['chauffeured', 'chauffeur'],
['cheated', 'cheat'],
['checked', 'check'],
['cheered', 'cheer'],
['chilled', 'chill'],
['choked', 'choke'],
['chopped', 'chop'],
['chose', 'choose'],
['christened', 'christen'],
['circled', 'circle'],
['circulated', 'circulate'],
['circumvented', 'circumvent'],
['cited', 'cite'],
['claimed', 'claim'],
['clarified', 'clarify'],
['classified', 'classify'],
['cleaned', 'clean'],
['cleared', 'clear'],
['clicked', 'click'],
['climbed', 'climb'],
['clinched', 'clinch'],
['cloned', 'clon'],
['closed', 'close'],
['clung', 'cling'],
['clustered', 'cluster'],
['coached', 'coach'],
['coated', 'coat'],
['coded', 'code'],
['cohabited', 'cohabit'],
['coiled', 'coil'],
['coincided', 'coincide'],
['coined', 'coin'],
['collaborated', 'collaborate'],
['collapsed', 'collapse'],
['collected', 'collect'],
['collided', 'collide'],
['colonized', 'colonize'],
['colored', 'color'],
['coloured', 'colour'],
['combed', 'comb'],
['combined', 'combine'],
['commanded', 'command'],
['commemorated', 'commemorate'],
['commenced', 'commence'],
['commended', 'commend'],
['commented', 'comment'],
['commercialized', 'commercialize'],
['commissioned', 'commission'],
['committed', 'commit'],
['communicated', 'communicate'],
['compared', 'compare'],
['compelled', 'compel'],
['compensated', 'compensate'],
['competed', 'compete'],
['compiled', 'compile'],
['complained', 'complain'],
['complemented', 'complement'],
['completed', 'complete'],
['complied', 'comply'],
['complimented', 'compliment'],
['composed', 'compose'],
['composted', 'compost'],
['compounded', 'compound'],
['compressed', 'compress'],
['comprised', 'comprise'],
['compromised', 'compromise'],
['computed', 'compute'],
['computerized', 'computerize'],
['concealed', 'conceal'],
['conceded', 'concede'],
['conceived', 'conceive'],
['concentrated', 'concentrate'],
['conceptualized', 'conceptualize'],
['concerned', 'concern'],
['concluded', 'conclude'],
['concurred', 'concur'],
['condemned', 'condemn'],
['conducted', 'conduct'],
['conferred', 'confer'],
['confessed', 'confess'],
['confided', 'confide'],
['configured', 'configure'],
['confined', 'confine'],
['confirmed', 'confirm'],
['confiscated', 'confiscate'],
['confounded', 'confound'],
['confronted', 'confront'],
['congratulated', 'congratulate'],
['conjectured', 'conjecture'],
['conjugated', 'conjugate'],
['conjured', 'conjure'],
['connected', 'connect'],
['conquered', 'conquer'],
['consented', 'consent'],
['conserved', 'conserve'],
['considered', 'consider'],
['consigned', 'consign'],
['consisted', 'consist'],
['consolidated', 'consolidate'],
['constituted', 'constitute'],
['constructed', 'construct'],
['consulted', 'consult'],
['consumed', 'consume'],
['contacted', 'contact'],
['contained', 'contain'],
['contemplated', 'contemplate'],
['contended', 'contend'],
['contested', 'contest'],
['continued', 'continue'],
['contracted', 'contract'],
['contradicted', 'contradict'],
['contravened', 'contravene'],
['contributed', 'contribute'],
['controlled', 'control'],
['convened', 'convene'],
['converged', 'converge'],
['converted', 'convert'],
['conveyed', 'convey'],
['convicted', 'convict'],
['convinced', 'convince'],
['convoluted', 'convolute'],
['cooked', 'cook'],
['cooled', 'cool'],
['cooperated', 'cooperate'],
['coordinated', 'coordinate'],
['copied', 'copy'],
['coproduced', 'coproduce'],
['copyrighted', 'copyright'],
['cored', 'core'],
['corrected', 'correct'],
['correlated', 'correlate'],
['corresponded', 'correspond'],
['corroborated', 'corroborate'],
['corrugated', 'corrugate'],
['cosponsored', 'cosponsor'],
['cost', 'cost'],
['couched', 'couch'],
['counselled', 'counsel'],
['counted', 'count'],
['countered', 'counter'],
['countersigned', 'countersign'],
['coupled', 'couple'],
['covered', 'cover'],
['cracked', 'crack'],
['crafted', 'craft'],
['crashed', 'crash'],
['created', 'create'],
['credited', 'credit'],
['crept', 'creep'],
['crimped', 'crimp'],
['criticized', 'criticize'],
['cropped', 'crop'],
['crossed', 'cross'],
['crowded', 'crowd'],
['crystallized', 'crystallize'],
['cubed', 'cube'],
['culminated', 'culminate'],
['cultivated', 'cultivate'],
['cultured', 'culture'],
['curated', 'curate'],
['cured', 'cure'],
['curled', 'curl'],
['curtailed', 'curtail'],
['curved', 'curve'],
['customized', 'customize'],
['cut', 'cut'],
['damaged', 'damage'],
['dampened', 'dampen'],
['danced', 'dance'],
['dared', 'dare'],
['dated', 'date'],
['dawned', 'dawn'],
['dealt', 'deal'],
['debated', 'debate'],
['debited', 'debit'],
['debuted', 'debut'],
['decaffeinated', 'decaffeinate'],
['deceased', 'decease'],
['decelerated', 'decelerate'],
['decentralized', 'decentralize'],
['decided', 'decide'],
['declared', 'declare'],
['declined', 'decline'],
['decomposed', 'decompose'],
['decorated', 'decorate'],
['decreased', 'decrease'],
['decried', 'decry'],
['dedicated', 'dedicate'],
['deducted', 'deduct'],
['deemed', 'deem'],
['deepened', 'deepen'],
['defaulted', 'default'],
['defeated', 'defeat'],
['defended', 'defend'],
['deferred', 'defer'],
['defined', 'define'],
['deflated', 'deflate'],
['deflected', 'deflect'],
['degraded', 'degrade'],
['dehydrated', 'dehydrate'],
['delayed', 'delay'],
['delegated', 'delegate'],
['deliberated', 'deliberate'],
['delighted', 'delight'],
['delineated', 'delineate'],
['delivered', 'deliver'],
['demanded', 'demand'],
['demonstrated', 'demonstrate'],
['denatured', 'denature'],
['denied', 'deny'],
['denoted', 'denote'],
['denounced', 'denounce'],
['departed', 'depart'],
['depended', 'depend'],
['depicted', 'depict'],
['depleted', 'deplete'],
['deplored', 'deplore'],
['deployed', 'deploy'],
['deported', 'deport'],
['deposited', 'deposit'],
['depreciated', 'depreciate'],
['depressed', 'depress'],
['deprived', 'deprive'],
['deregulated', 'deregulate'],
['derived', 'derive'],
['descended', 'descend'],
['described', 'describe'],
['deserved', 'deserve'],
['desiccated', 'desiccate'],
['designated', 'designate'],
['designed', 'design'],
['desired', 'desire'],
['destined', 'destine'],
['destroyed', 'destroy'],
['detailed', 'detail'],
['detained', 'detain'],
['detected', 'detect'],
['determined', 'determine'],
['deterred', 'deter'],
['detracted', 'detract'],
['devalued', 'devalue'],
['devastated', 'devastate'],
['developed', 'develop'],
['devised', 'devise'],
['devolved', 'devolve'],
['devoted', 'devote'],
['diagnosed', 'diagnose'],
['diced', 'dice'],
['dictated', 'dictate'],
['did', 'do'],
['died', 'die'],
['differed', 'differ'],
['differentiated', 'differentiate'],
['digitized', 'digitize'],
['dined', 'dine'],
['dipped', 'dip'],
['directed', 'direct'],
['disabled', 'disable'],
['disadvantaged', 'disadvantage'],
['disagreed', 'disagree'],
['disallowed', 'disallow'],
['disappeared', 'disappear'],
['disbursed', 'disburse'],
['discharged', 'discharge'],
['disclosed', 'disclose'],
['discoloured', 'discolour'],
['discontinued', 'discontinue'],
['discounted', 'discount'],
['discouraged', 'discourage'],
['discovered', 'discover'],
['discriminated', 'discriminate'],
['discussed', 'discuss'],
['disembarked', 'disembark'],
['disenfranchised', 'disenfranchise'],
['disfavoured', 'disfavour'],
['disinfected', 'disinfect'],
['disliked', 'dislike'],
['dismantled', 'dismantle'],
['dismissed', 'dismiss'],
['disordered', 'disorder'],
['disorganized', 'disorganize'],
['dispelled', 'dispel'],
['dispensed', 'dispense'],
['dispersed', 'disperse'],
['displaced', 'displace'],
['displayed', 'display'],
['disposed', 'dispose'],
['disproved', 'disprove'],
['disputed', 'dispute'],
['disqualified', 'disqualify'],
['disregarded', 'disregard'],
['disrupted', 'disrupt'],
['dissatisfied', 'dissatisfy'],
['dissected', 'dissect'],
['disseminated', 'disseminate'],
['dissolved', 'dissolve'],
['dissuaded', 'dissuade'],
['distanced', 'distance'],
['distinguished', 'distinguish'],
['distorted', 'distort'],
['distributed', 'distribute'],
['disturbed', 'disturb'],
['diversified', 'diversify'],
['diverted', 'divert'],
['divested', 'divest'],
['divided', 'divide'],
['documented', 'document'],
['domiciled', 'domicile'],
['dominated', 'dominate'],
['donated', 'donate'],
['donned', 'don'],
['doubled', 'double'],
['doubted', 'doubt'],
['dove', 'dive'],
['downed', 'down'],
['downgraded', 'downgrade'],
['downsized', 'downsize'],
['drafted', 'draft'],
['dragged', 'drag'],
['drank', 'drink'],
['dreamed', 'dream'],
['dressed', 'dress'],
['drew', 'draw'],
['dried', 'dry'],
['drifted', 'drift'],
['drilled', 'drill'],
['dropped', 'drop'],
['drove', 'drive'],
['drowned', 'drown'],
['dubbed', 'dub'],
['dug', 'dig'],
['dumped', 'dump'],
['duplicated', 'duplicate'],
['dusted', 'dust'],
['dwindled', 'dwindle'],
['dyed', 'dye'],
['earmarked', 'earmark'],
['earned', 'earn'],
['eased', 'ease'],
['echoed', 'echo'],
['edged', 'edge'],
['edited', 'edit'],
['educated', 'educate'],
['effected', 'effect'],
['egged', 'egg'],
['elaborated', 'elaborate'],
['elected', 'elect'],
['elevated', 'elevate'],
['elicited', 'elicit'],
['eliminated', 'eliminate'],
['eluded', 'elude'],
['embarked', 'embark'],
['embedded', 'embed'],
['embodied', 'embody'],
['embossed', 'emboss'],
['embraced', 'embrace'],
['emerged', 'emerge'],
['emigrated', 'emigrate'],
['emitted', 'emit'],
['empaneled', 'empanel'],
['emphasised', 'emphasise'],
['emphasized', 'emphasize'],
['employed', 'employ'],
['empowered', 'empower'],
['enabled', 'enable'],
['enacted', 'enact'],
['enamelled', 'enamel'],
['enclosed', 'enclose'],
['encoded', 'encode'],
['encompassed', 'encompass'],
['encountered', 'encounter'],
['encouraged', 'encourage'],
['encroached', 'encroach'],
['encrypted', 'encrypt'],
['endangered', 'endanger'],
['endeared', 'endear'],
['endeavored', 'endeavor'],
['endeavoured', 'endeavour'],
['ended', 'end'],
['endorsed', 'endorse'],
['endowed', 'endow'],
['endured', 'endure'],
['enforced', 'enforce'],
['engaged', 'engage'],
['engendered', 'engender'],
['enhanced', 'enhance'],
['enjoyed', 'enjoy'],
['enlarged', 'enlarge'],
['enlisted', 'enlist'],
['enriched', 'enrich'],
['enrolled', 'enroll'],
['enshrined', 'enshrine'],
['ensued', 'ensue'],
['ensured', 'ensure'],
['entailed', 'entail'],
['entered', 'enter'],
['entertained', 'entertain'],
['enthralled', 'enthrall'],
['enticed', 'entice'],
['entitled', 'entitle'],
['entrenched', 'entrench'],
['entrusted', 'entrust'],
['entwined', 'entwine'],
['enumerated', 'enumerate'],
['enunciated', 'enunciate'],
['enveloped', 'envelop'],
['envisaged', 'envisage'],
['envisioned', 'envision'],
['equalized', 'equalize'],
['equalled', 'equal'],
['equated', 'equate'],
['equipped', 'equip'],
['erected', 'erect'],
['eroded', 'erode'],
['erred', 'err'],
['erupted', 'erupt'],
['escalated', 'escalate'],
['escaped', 'escape'],
['escorted', 'escort'],
['espoused', 'espouse'],
['established', 'establish'],
['estimated', 'estimate'],
['evaluated', 'evaluate'],
['evidenced', 'evidence'],
['eviscerated', 'eviscerate'],
['evoked', 'evoke'],
['evolved', 'evolve'],
['exacerbated', 'exacerbate'],
['examined', 'examine'],
['exasperated', 'exasperate'],
['excavated', 'excavate'],
['exceeded', 'exceed'],
['excepted', 'except'],
['exchanged', 'exchange'],
['excited', 'excite'],
['excluded', 'exclude'],
['excreted', 'excrete'],
['executed', 'execute'],
['exempted', 'exempt'],
['exercised', 'exercise'],
['exerted', 'exert'],
['exhausted', 'exhaust'],
['exhibited', 'exhibit'],
['exhorted', 'exhort'],
['exiled', 'exile'],
['existed', 'exist'],
['exited', 'exit'],
['expanded', 'expand'],
['expected', 'expect'],
['expedited', 'expedite'],
['expelled', 'expel'],
['expended', 'expend'],
['experienced', 'experience'],
['experimented', 'experiment'],
['expired', 'expire'],
['explained', 'explain'],
['exploded', 'explode'],
['exploited', 'exploit'],
['explored', 'explore'],
['exported', 'export'],
['exposed', 'expose'],
['expounded', 'expound'],
['expressed', 'express'],
['expunged', 'expunge'],
['extended', 'extend'],
['extolled', 'extol'],
['extracted', 'extract'],
['extruded', 'extrude'],
['eyed', 'eye'],
['faced', 'face'],
['faceted', 'facet'],
['facilitated', 'facilitate'],
['factored', 'factor'],
['failed', 'fail'],
['faked', 'fake'],
['familiarized', 'familiarize'],
['fared', 'fare'],
['farmed', 'farm'],
['fastened', 'fasten'],
['favored', 'favor'],
['favoured', 'favour'],
['faxed', 'fax'],
['feared', 'fear'],
['featured', 'feature'],
['fed', 'feed'],
['federated', 'federate'],
['feed', 'fee'],
['fell', 'fall'],
['felt', 'feel'],
['fielded', 'field'],
['figured', 'figure'],
['filed', 'file'],
['filled', 'fill'],
['finalized', 'finalize'],
['financed', 'finance'],
['fined', 'fine'],
['finished', 'finish'],
['fired', 'fire'],
['fished', 'fish'],
['fit', 'fit'],
['fixed', 'fix'],
['flagged', 'flag'],
['flaked', 'flake'],
['flanged', 'flange'],
['flattened', 'flatten'],
['flavored', 'flavor'],
['flavoured', 'flavour'],
['fled', 'flee'],
['flew', 'fly'],
['floated', 'float'],
['flooded', 'flood'],
['flourished', 'flourish'],
['flowed', 'flow'],
['fluctuated', 'fluctuate'],
['flung', 'fling'],
['focused', 'focus'],
['folded', 'fold'],
['followed', 'follow'],
['footed', 'foot'],
['forbade', 'forbid'],
['forbore', 'forbear'],
['forced', 'force'],
['forecasted', 'forecast'],
['foresaw', 'foresee'],
['forfeited', 'forfeit'],
['forgave', 'forgive'],
['forged', 'forge'],
['forgot', 'forget'],
['formalised', 'formalise'],
['formalized', 'formalize'],
['formatted', 'format'],
['formed', 'form'],
['formulated', 'formulate'],
['forsaken', 'forsake'],
['forwarded', 'forward'],
['fostered', 'foster'],
['fought', 'fight'],
['fouled', 'foul'],
['found', 'find'],
['founded', 'found'],
['fractionated', 'fractionate'],
['framed', 'frame'],
['freaked', 'freak'],
['freed', 'free'],
['froze', 'freeze'],
['frustrated', 'frustrate'],
['fuelled', 'fuel'],
['fulfilled', 'fulfil'],
['fulfilled', 'fulfill'],
['functioned', 'function'],
['funded', 'fund'],
['funnelled', 'funnel'],
['furnished', 'furnish'],
['furthered', 'further'],
['fuzzed', 'fuzz'],
['gained', 'gain'],
['galvanized', 'galvanize'],
['gamed', 'game'],
['garnered', 'garner'],
['gassed', 'gas'],
['gathered', 'gather'],
['gave', 'give'],
['gelled', 'gell'],
['generalized', 'generalize'],
['generated', 'generate'],
['gifted', 'gift'],
['glazed', 'glaze'],
['gleaned', 'glean'],
['glossed', 'gloss'],
['got', 'get'],
['governed', 'govern'],
['grabbed', 'grab'],
['graded', 'grade'],
['graduated', 'graduate'],
['granted', 'grant'],
['granulated', 'granulate'],
['grappled', 'grapple'],
['grassed', 'grass'],
['grated', 'grate'],
['gravitated', 'gravitate'],
['grazed', 'graze'],
['greeted', 'greet'],
['grew', 'grow'],
['gripped', 'grip'],
['grooved', 'groove'],
['grossed', 'gross'],
['ground', 'grind'],
['grounded', 'ground'],
['grouped', 'group'],
['guaranteed', 'guarantee'],
['guessed', 'guess'],
['guided', 'guide'],
['hacked', 'hack'],
['had', 'have'],
['hailed', 'hail'],
['halogenated', 'halogenate'],
['halted', 'halt'],
['hampered', 'hamper'],
['handed', 'hand'],
['handled', 'handle'],
['happened', 'happen'],
['harmed', 'harm'],
['harmonized', 'harmonize'],
['harnessed', 'harness'],
['harvested', 'harvest'],
['hatched', 'hatch'],
['hauled', 'haul'],
['headed', 'head'],
['heard', 'hear'],
['hearted', 'heart'],
['hedged', 'hedge'],
['heightened', 'heighten'],
['held', 'hold'],
['helped', 'help'],
['heralded', 'herald'],
['hid', 'hide'],
['highlighted', 'highlight'],
['hiked', 'hike'],
['hindered', 'hinder'],
['hired', 'hire'],
['hit', 'hit'],
['homogenized', 'homogenize'],
['honoured', 'honour'],
['hooked', 'hook'],
['hoped', 'hope'],
['hosted', 'host'],
['housed', 'house'],
['hovered', 'hover'],
['huddled', 'huddle'],
['hung', 'hang'],
['hurt', 'hurt'],
['hydrogenated', 'hydrogenate'],
['hypothesized', 'hypothesize'],
['idealized', 'idealize'],
['identified', 'identify'],
['idled', 'idle'],
['ignited', 'ignite'],
['ignored', 'ignore'],
['illuminated', 'illuminate'],
['illustrated', 'illustrate'],
['imagined', 'imagine'],
['immersed', 'immerse'],
['immigrated', 'immigrate'],
['immunized', 'immunize'],
['impacted', 'impact'],
['impaired', 'impair'],
['impaled', 'impale'],
['imparted', 'impart'],
['impeded', 'impede'],
['implanted', 'implant'],
['implemented', 'implement'],
['implied', 'imply'],
['imported', 'import'],
['imposed', 'impose'],
['impregnated', 'impregnate'],
['impressed', 'impress'],
['imprinted', 'imprint'],
['improved', 'improve'],
['improvised', 'improvise'],
['inactivated', 'inactivate'],
['inaugurated', 'inaugurate'],
['incarcerated', 'incarcerate'],
['incited', 'incite'],
['inclined', 'incline'],
['included', 'include'],
['incorporated', 'incorporate'],
['increased', 'increase'],
['incurred', 'incur'],
['indemnified', 'indemnify'],
['indented', 'indent'],
['indexed', 'index'],
['indicated', 'indicate'],
['indicted', 'indict'],
['individualized', 'individualize'],
['induced', 'induce'],
['industrialized', 'industrialize'],
['infected', 'infect'],
['inferred', 'infer'],
['infested', 'infest'],
['influenced', 'influence'],
['informed', 'inform'],
['infringed', 'infringe'],
['infused', 'infuse'],
['ingested', 'ingest'],
['inhabited', 'inhabit'],
['inhaled', 'inhale'],
['inherited', 'inherit'],
['inhibited', 'inhibit'],
['initialled', 'initial'],
['initiated', 'initiate'],
['injected', 'inject'],
['injured', 'injure'],
['inked', 'ink'],
['innovated', 'innovate'],
['inquired', 'inquire'],
['inserted', 'insert'],
['insisted', 'insist'],
['inspected', 'inspect'],
['inspired', 'inspire'],
['installed', 'install'],
['instigated', 'instigate'],
['instilled', 'instill'],
['instituted', 'institute'],
['institutionalized', 'institutionalize'],
['instructed', 'instruct'],
['insulated', 'insulate'],
['insured', 'insure'],
['integrated', 'integrate'],
['intended', 'intend'],
['intensified', 'intensify'],
['interacted', 'interact'],
['intercepted', 'intercept'],
['interested', 'interest'],
['interfered', 'interfere'],
['interlinked', 'interlink'],
['internalized', 'internalize'],
['internationalized', 'internationalize'],
['interned', 'intern'],
['interpreted', 'interpret'],
['interrelated', 'interrelate'],
['intersected', 'intersect'],
['intertwined', 'intertwine'],
['intervened', 'intervene'],
['interviewed', 'interview'],
['intoxicated', 'intoxicate'],
['introduced', 'introduce'],
['invaded', 'invade'],
['invalidated', 'invalidate'],
['invented', 'invent'],
['inventoried', 'inventory'],
['invested', 'invest'],
['investigated', 'investigate'],
['invited', 'invite'],
['invoiced', 'invoice'],
['invoked', 'invoke'],
['involved', 'involve'],
['irrigated', 'irrigate'],
['isolated', 'isolate'],
['issued', 'issue'],
['italicized', 'italicize'],
['itemized', 'itemize'],
['jarred', 'jar'],
['jeopardized', 'jeopardize'],
['jogged', 'jog'],
['joined', 'join'],
['joked', 'joke'],
['journeyed', 'journey'],
['judged', 'judge'],
['jumped', 'jump'],
['justified', 'justify'],
['kept', 'keep'],
['kicked', 'kick'],
['killed', 'kill'],
['kindled', 'kindle'],
['kissed', 'kiss'],
['knelt', 'kneel'],
['knew', 'know'],
['knitted', 'knit'],
['knocked', 'knock'],
['knurled', 'knurl'],
['labeled', 'label'],
['lacked', 'lack'],
['lacquered', 'lacquer'],
['lagged', 'lag'],
['laid', 'lay'],
['lambasted', 'lambaste'],
['lamented', 'lament'],
['laminated', 'laminate'],
['landed', 'land'],
['lapsed', 'lapse'],
['lasted', 'last'],
['lauded', 'laud'],
['laughed', 'laugh'],
['launched', 'launch'],
['layered', 'layer'],
['leached', 'leach'],
['leaked', 'leak'],
['leapt', 'leap'],
['learned', 'learn'],
['leased', 'lease'],
['lectured', 'lecture'],
['led', 'lead'],
['left', 'leave'],
['legislated', 'legislate'],
['legitimized', 'legitimize'],
['lent', 'lend'],
['lessened', 'lessen'],
['let', 'let'],
['leveled', 'level'],
['levelled', 'level'],
['levied', 'levy'],
['liaised', 'liaise'],
['liberalized', 'liberalize'],
['licenced', 'licence'],
['licensed', 'license'],
['lied', 'lie'],
['lifted', 'lift'],
['liked', 'like'],
['likened', 'liken'],
['limited', 'limit'],
['lined', 'line'],
['linked', 'link'],
['listed', 'list'],
['listened', 'listen'],
['lit', 'light'],
['lived', 'live'],
['loaded', 'load'],
['loaned', 'loan'],
['lobbied', 'lobby'],
['localized', 'localize'],
['located', 'locate'],
['locked', 'lock'],
['lodged', 'lodge'],
['logged', 'log'],
['looked', 'look'],
['looped', 'loop'],
['lost', 'lose'],
['loved', 'love'],
['lowered', 'lower'],
['lubricated', 'lubricate'],
['machined', 'machine'],
['made', 'make'],
['magnified', 'magnify'],
['mailed', 'mail'],
['maintained', 'maintain'],
['malted', 'malt'],
['managed', 'manage'],
['mandated', 'mandate'],
['manifested', 'manifest'],
['manipulated', 'manipulate'],
['manned', 'man'],
['manoeuvred', 'manoeuvre'],
['manufactured', 'manufacture'],
['mapped', 'map'],
['marginalized', 'marginalize'],
['marked', 'mark'],
['marketed', 'market'],
['married', 'marry'],
['masked', 'mask'],
['mastered', 'master'],
['matched', 'match'],
['materialized', 'materialize'],
['mattered', 'matter'],
['matured', 'mature'],
['maximized', 'maximize'],
['meant', 'mean'],
['measured', 'measure'],
['mediated', 'mediate'],
['melted', 'melt'],
['mentioned', 'mention'],
['mercerized', 'mercerize'],
['merged', 'merge'],
['messed', 'mess'],
['met', 'meet'],
['metallized', 'metallize'],
['microfilmed', 'microfilm'],
['migrated', 'migrate'],
['mimicked', 'mimic'],
['minced', 'mince'],
['minded', 'mind'],
['mined', 'mine'],
['minimized', 'minimize'],
['mirrored', 'mirror'],
['misinterpreted', 'misinterpret'],
['misrepresented', 'misrepresent'],
['missed', 'miss'],
['mistook', 'mistake'],
['misused', 'misuse'],
['mitigated', 'mitigate'],
['mixed', 'mix'],
['mobilized', 'mobilize'],
['modeled', 'model'],
['moderated', 'moderate'],
['modernized', 'modernize'],
['modified', 'modify'],
['modulated', 'modulate'],
['moistened', 'moisten'],
['molded', 'mold'],
['monitored', 'monitor'],
['motivated', 'motivate'],
['motorized', 'motorize'],
['moulded', 'mould'],
['mounted', 'mount'],
['moved', 'move'],
['mowed', 'mow'],
['multiplied', 'multiply'],
['named', 'name'],
['napped', 'nap'],
['narrated', 'narrate'],
['narrowed', 'narrow'],
['naturalized', 'naturalize'],
['navigated', 'navigate'],
['neared', 'near'],
['necessitated', 'necessitate'],
['needed', 'need'],
['negotiated', 'negotiate'],
['netted', 'net'],
['networked', 'network'],
['nicknamed', 'nickname'],
['nominated', 'nominate'],
['normalized', 'normalize'],
['nosed', 'nose'],
['notarized', 'notarize'],
['notched', 'notch'],
['noted', 'note'],
['noticed', 'notice'],
['notified', 'notify'],
['nourished', 'nourish'],
['numbered', 'number'],
['nurtured', 'nurture'],
['objected', 'object'],
['obligated', 'obligate'],
['obscured', 'obscure'],
['observed', 'observe'],
['obtained', 'obtain'],
['occupied', 'occupy'],
['occured', 'occure'],
['occurred', 'occur'],
['offended', 'offend'],
['offered', 'offer'],
['offset', 'offset'],
['omitted', 'omit'],
['oozed', 'ooze'],
['opened', 'open'],
['operated', 'operate'],
['opined', 'opine'],
['opposed', 'oppose'],
['oppressed', 'oppress'],
['opted', 'opt'],
['optimized', 'optimize'],
['ordered', 'order'],
['organised', 'organise'],
['organized', 'organize'],
['orientated', 'orientate'],
['oriented', 'orient'],
['originated', 'originate'],
['ousted', 'oust'],
['outbid', 'outbid'],
['outgrew', 'outgrow'],
['outlawed', 'outlaw'],
['outlined', 'outline'],
['outnumbered', 'outnumber'],
['outpaced', 'outpace'],
['outperformed', 'outperform'],
['outstripped', 'outstrip'],
['outweighed', 'outweigh'],
['overcame', 'overcome'],
['overhauled', 'overhaul'],
['overlapped', 'overlap'],
['overlooked', 'overlook'],
['overpaid', 'overpay'],
['overruled', 'overrule'],
['oversaw', 'oversee'],
['overstated', 'overstate'],
['overthrew', 'overthrow'],
['overtook', 'overtake'],
['overturned', 'overturn'],
['overvalued', 'overvalue'],
['overwhelmed', 'overwhelm'],
['owed', 'owe'],
['owned', 'own'],
['oxygenated', 'oxygenate'],
['packaged', 'package'],
['packed', 'pack'],
['padded', 'pad'],
['paid', 'pay'],
['painted', 'paint'],
['paired', 'pair'],
['panicked', 'panic'],
['panned', 'pan'],
['parachuted', 'parachute'],
['paralleled', 'parallel'],
['paraphrased', 'paraphrase'],
['pardoned', 'pardon'],
['parked', 'park'],
['participated', 'participate'],
['partnered', 'partner'],
['partook', 'partake'],
['passed', 'pass'],
['patented', 'patent'],
['patrolled', 'patrol'],
['paused', 'pause'],
['paved', 'pave'],
['peaked', 'peak'],
['pelleted', 'pellet'],
['penetrated', 'penetrate'],
['pent', 'pen'],
['peppered', 'pepper'],
['perceived', 'perceive'],
['perforated', 'perforate'],
['performed', 'perform'],
['perfumed', 'perfume'],
['perished', 'perish'],
['permeated', 'permeate'],
['permitted', 'permit'],
['persevered', 'persevere'],
['persisted', 'persist'],
['personified', 'personify'],
['persuaded', 'persuade'],
['pertained', 'pertain'],
['petitioned', 'petition'],
['phoned', 'phone'],
['photocopied', 'photocopy'],
['picked', 'pick'],
['pied', 'pie'],
['piled', 'pile'],
['piloted', 'pilot'],
['pioneered', 'pioneer'],
['piqued', 'pique'],
['pitched', 'pitch'],
['pitted', 'pit'],
['placed', 'place'],
['plagued', 'plague'],
['planned', 'plan'],
['planted', 'plant'],
['plated', 'plate'],
['played', 'play'],
['pleaded', 'plead'],
['pleased', 'please'],
['pleated', 'pleat'],
['pledged', 'pledge'],
['plodded', 'plod'],
['plotted', 'plot'],
['plugged', 'plug'],
['plummeted', 'plummet'],
['plunged', 'plunge'],
['pointed', 'point'],
['poked', 'poke'],
['polished', 'polish'],
['polled', 'poll'],
['polymerized', 'polymerize'],
['pondered', 'ponder'],
['pooled', 'pool'],
['popped', 'pop'],
['popularized', 'popularize'],
['pored', 'pore'],
['portrayed', 'portray'],
['posed', 'pose'],
['posited', 'posit'],
['positioned', 'position'],
['possessed', 'possess'],
['posted', 'post'],
['postponed', 'postpone'],
['postulated', 'postulate'],
['potted', 'pot'],
['poured', 'pour'],
['powered', 'power'],
['practiced', 'practice'],
['practised', 'practise'],
['praised', 'praise'],
['prayed', 'pray'],
['preached', 'preach'],
['preceded', 'precede'],
['precipitated', 'precipitate'],
['precluded', 'preclude'],
['predated', 'predate'],
['predetermined', 'predetermine'],
['predicted', 'predict'],
['predominated', 'predominate'],
['prefabricated', 'prefabricate'],
['preferred', 'prefer'],
['premiered', 'premier'],
['premised', 'premise'],
['preoccupied', 'preoccupy'],
['prepared', 'prepare'],
['prescribed', 'prescribe'],
['presented', 'present'],
['preserved', 'preserve'],
['presided', 'preside'],
['pressed', 'press'],
['pressurized', 'pressurize'],
['prevailed', 'prevail'],
['prevented', 'prevent'],
['pried', 'pry'],
['primed', 'prime'],
['printed', 'print'],
['probed', 'probe'],
['proceeded', 'proceed'],
['processed', 'process'],
['proclaimed', 'proclaim'],
['prodded', 'prod'],
['produced', 'produce'],
['proffered', 'proffer'],
['profiled', 'profile'],
['programmed', 'programme'],
['progressed', 'progress'],
['prohibited', 'prohibit'],
['projected', 'project'],
['prolonged', 'prolong'],
['promised', 'promise'],
['promoted', 'promote'],
['prompted', 'prompt'],
['promulgated', 'promulgate'],
['pronounced', 'pronounce'],
['proofed', 'proof'],
['propelled', 'propel'],
['proposed', 'propose'],
['prorated', 'prorate'],
['prosecuted', 'prosecute'],
['prospered', 'prosper'],
['protected', 'protect'],
['proved', 'prove'],
['provided', 'provide'],
['provoked', 'provoke'],
['pruned', 'prune'],
['published', 'publish'],
['pulled', 'pull'],
['pumped', 'pump'],
['punched', 'punch'],
['punctuated', 'punctuate'],
['purchased', 'purchase'],
['pursued', 'pursue'],
['pushed', 'push'],
['put', 'put'],
['qualified', 'qualify'],
['quarantined', 'quarantine'],
['quashed', 'quash'],
['queried', 'query'],
['questioned', 'question'],
['queued', 'queue'],
['quit', 'quit'],
['quoted', 'quote'],
['racked', 'rack'],
['radiated', 'radiate'],
['raged', 'rage'],
['raided', 'raid'],
['rained', 'rain'],
['raised', 'raise'],
['rallied', 'rally'],
['ran', 'run'],
['randomised', 'randomise'],
['randomized', 'randomize'],
['rang', 'ring'],
['ranged', 'range'],
['ranked', 'rank'],
['rated', 'rate'],
['ratified', 'ratify'],
['rationalized', 'rationalize'],
['ravaged', 'ravage'],
['reached', 'reach'],
['reacquired', 'reacquire'],
['reacted', 'react'],
['read', 'read'],
['reaffirmed', 'reaffirm'],
['realigned', 'realign'],
['realised', 'realise'],
['realized', 'realize'],
['reaped', 'reap'],
['reasoned', 'reason'],
['reasserted', 'reassert'],
['reassessed', 'reassess'],
['reassured', 'reassure'],
['rebated', 'rebate'],
['rebounded', 'rebound'],
['rebuilt', 'rebuild'],
['rebutted', 'rebut'],
['recalculated', 'recalculate'],
['recalled', 'recall'],
['recast', 'recast'],
['received', 'receive'],
['recited', 'recite'],
['reckoned', 'reckon'],
['reclaimed', 'reclaim'],
['reclassified', 'reclassify'],
['recognised', 'recognise'],
['recognized', 'recognize'],
['recommended', 'recommend'],
['reconciled', 'reconcile'],
['reconfigured', 'reconfigure'],
['reconfirmed', 'reconfirm'],
['reconsidered', 'reconsider'],
['recorded', 'record'],
['recounted', 'recount'],
['recovered', 'recover'],
['recreated', 'recreate'],
['recruited', 'recruit'],
['redefined', 'redefin'],
['redesigned', 'redesign'],
['redid', 'redo'],
['redirected', 'redirect'],
['redistributed', 'redistribute'],
['reduced', 'reduce'],
['reestablished', 'reestablish'],
['refereed', 'referee'],
['referenced', 'reference'],
['referred', 'refer'],
['refinanced', 'refinance'],
['refined', 'refine'],
['reflected', 'reflect'],
['refocused', 'refocuse'],
['reformed', 'reform'],
['refrigerated', 'refrigerate'],
['refunded', 'refund'],
['refused', 'refuse'],
['refuted', 'refute'],
['regained', 'regain'],
['regarded', 'regard'],
['registered', 'register'],
['regressed', 'regress'],
['regretted', 'regret'],
['regulated', 'regulate'],
['rehearsed', 'rehearse'],
['reigned', 'reign'],
['reimbursed', 'reimburse'],
['reinforced', 'reinforce'],
['reinstated', 'reinstate'],
['reintroduced', 'reintroduce'],
['reinvented', 'reinvent'],
['reinvested', 'reinvest'],
['reinvigorated', 'reinvigorate'],
['reissued', 'reissue'],
['reiterated', 'reiterate'],
['rejected', 'reject'],
['rejoined', 'rejoin'],
['related', 'relate'],
['relaunched', 'relaunch'],
['relaxed', 'relax'],
['relayed', 'relay'],
['released', 'release'],
['relied', 'rely'],
['relieved', 'relieve'],
['relinquished', 'relinquish'],
['relocated', 'relocate'],
['remade', 'remake'],
['remained', 'remain'],
['remanded', 'remand'],
['remarked', 'remark'],
['remembered', 'remember'],
['reminded', 'remind'],
['remitted', 'remit'],
['removed', 'remove'],
['renamed', 'rename'],
['rendered', 'render'],
['renegotiated', 'renegotiate'],
['renewed', 'renew'],
['renounced', 'renounce'],
['renovated', 'renovate'],
['rent', 'rend'],
['rented', 'rent'],
['reopened', 'reopen'],
['reordered', 'reorder'],
['reorganized', 'reorganize'],
['reoriented', 'reorient'],
['repaid', 'repay'],
['repatriated', 'repatriate'],
['repealed', 'repeal'],
['repeated', 'repeat'],
['replaced', 'replace'],
['replanted', 'replant'],
['replicated', 'replicate'],
['replied', 'reply'],
['reported', 'report'],
['represented', 'represent'],
['reprinted', 'reprint'],
['reproached', 'reproach'],
['reproduced', 'reproduce'],
['requested', 'request'],
['required', 'require'],
['reread', 'reread'],
['rescheduled', 'reschedule'],
['rescinded', 'rescind'],
['rescued', 'rescue'],
['researched', 'research'],
['resembled', 'resemble'],
['reserved', 'reserve'],
['resided', 'reside'],
['resigned', 'resign'],
['resisted', 'resist'],
['resold', 'resell'],
['resolved', 'resolve'],
['resonated', 'resonate'],
['respected', 'respect'],
['responded', 'respond'],
['restated', 'restate'],
['rested', 'rest'],
['restored', 'restore'],
['restricted', 'restrict'],
['restructured', 'restructure'],
['resubmitted', 'resubmit'],
['resulted', 'result'],
['resumed', 'resume'],
['retained', 'retain'],
['retired', 'retire'],
['retook', 'retake'],
['retraced', 'retrace'],
['retransmitted', 'retransmit'],
['retreated', 'retreat'],
['retrieved', 'retrieve'],
['returned', 'return'],
['revamped', 'revamp'],
['revealed', 'reveal'],
['revered', 'revere'],
['reversed', 'reverse'],
['reverted', 'revert'],
['reviewed', 'review'],
['revised', 'revise'],
['revisited', 'revisit'],
['revitalized', 'revitalize'],
['revived', 'revive'],
['revoked', 'revoke'],
['revolutionized', 'revolutionize'],
['revolved', 'revolve'],
['rewrote', 'rewrite'],
['ribbed', 'rib'],
['risked', 'risk'],
['rivalled', 'rival'],
['roamed', 'roam'],
['roared', 'roar'],
['roasted', 'roast'],
['robbed', 'rob'],
['rode', 'ride'],
['rolled', 'roll'],
['rooted', 'root'],
['rose', 'rise'],
['rotated', 'rotate'],
['rounded', 'round'],
['rubberized', 'rubberize'],
['ruined', 'ruin'],
['ruled', 'rule'],
['rushed', 'rush'],
['sacrificed', 'sacrifice'],
['said', 'say'],
['sailed', 'sail'],
['salted', 'salt'],
['saluted', 'salute'],
['sampled', 'sample'],
['sanctioned', 'sanction'],
['sang', 'sing'],
['sank', 'sink'],
['sat', 'sit'],
['satisfied', 'satisfy'],
['saturated', 'saturate'],
['saved', 'save'],
['saw', 'see'],
['scaled', 'scale'],
['scanned', 'scan'],
['scheduled', 'schedule'],
['schooled', 'school'],
['scored', 'score'],
['scouted', 'scout'],
['scrambled', 'scramble'],
['screened', 'screen'],
['screwed', 'screw'],
['sculptured', 'sculpture'],
['scutched', 'scutch'],
['sealed', 'seal'],
['searched', 'search'],
['seated', 'seat'],
['seconded', 'second'],
['secured', 'secure'],
['seeded', 'seed'],
['seemed', 'seem'],
['seeped', 'seep'],
['segmented', 'segment'],
['segregated', 'segregate'],
['seized', 'seize'],
['selected', 'select'],
['sensed', 'sense'],
['sensitized', 'sensitize'],
['sent', 'send'],
['sentenced', 'sentence'],
['separated', 'separate'],
['sequestered', 'sequester'],
['serrated', 'serrate'],
['served', 'serve'],
['serviced', 'service'],
['set', 'set'],
['settled', 'settle'],
['severed', 'sever'],
['sewn', 'sew'],
['shaped', 'shape'],
['shared', 'share'],
['shattered', 'shatter'],
['shaved', 'shave'],
['shed', 'shed'],
['shelled', 'shell'],
['sheltered', 'shelter'],
['shielded', 'shield'],
['shifted', 'shift'],
['shipped', 'ship'],
['shone', 'shine'],
['shook', 'shake'],
['shored', 'shore'],
['shortened', 'shorten'],
['shot', 'shoot'],
['shouted', 'shout'],
['shoved', 'shove'],
['showcased', 'showcase'],
['showed', 'show'],
['shrank', 'shrink'],
['shredded', 'shred'],
['shrieked', 'shriek'],
['shucked', 'shuck'],
['shuffled', 'shuffle'],
['shunned', 'shun'],
['shut', 'shut'],
['sided', 'side'],
['sidelined', 'sideline'],
['signaled', 'signal'],
['signed', 'sign'],
['signified', 'signify'],
['simplified', 'simplify'],
['simulated', 'simulate'],
['singled', 'single'],
['sized', 'size'],
['sketched', 'sketch'],
['skidded', 'skid'],
['skied', 'ski'],
['skimmed', 'skim'],
['skinned', 'skin'],
['skyrocketed', 'skyrocket'],
['slammed', 'slam'],
['slashed', 'slash'],
['slatted', 'slat'],
['slaughtered', 'slaughter'],
['slayed', 'slay'],
['slept', 'sleep'],
['sliced', 'slice'],
['slid', 'slide'],
['slipped', 'slip'],
['sloped', 'slope'],
['slowed', 'slow'],
['slumped', 'slump'],
['smiled', 'smile'],
['smoked', 'smoke'],
['smuggled', 'smuggle'],
['snaked', 'snake'],
['snarled', 'snarl'],
['sniped', 'snipe'],
['snuck', 'sneak'],
['soaked', 'soak'],
['soared', 'soar'],
['socked', 'sock'],
['softened', 'soften'],
['soiled', 'soil'],
['sold', 'sell'],
['solemnized', 'solemnize'],
['solicited', 'solicit'],
['solidified', 'solidify'],
['solved', 'solve'],
['sought', 'seek'],
['sounded', 'sound'],
['sowed', 'sow'],
['spaced', 'space'],
['spanned', 'span'],
['spared', 'spare'],
['sparked', 'spark'],
['sparred', 'spar'],
['spat', 'spit'],
['spawned', 'spawn'],
['spearheaded', 'spearhead'],
['specialised', 'specialise'],
['specialized', 'specialize'],
['specified', 'specify'],
['speckled', 'speckle'],
['speculated', 'speculate'],
['speeded', 'speed'],
['spelled', 'spell'],
['spent', 'spend'],
['spiked', 'spike'],
['spilled', 'spill'],
['spited', 'spite'],
['split', 'split'],
['spoke', 'speak'],
['sponsored', 'sponsor'],
['spotted', 'spot'],
['spouted', 'spout'],
['sprang', 'spring'],
['spread', 'spread'],
['sprinkled', 'sprinkle'],
['sprouted', 'sprout'],
['routed', 'route'],
['spun', 'spin'],
['spurred', 'spur'],
['squared', 'square'],
['squeezed', 'squeeze'],
['stabilized', 'stabilize'],
['stacked', 'stack'],
['staffed', 'staff'],
['staged', 'stage'],
['staggered', 'stagger'],
['stagnated', 'stagnate'],
['stained', 'stain'],
['staked', 'stake'],
['stalled', 'stall'],
['stamped', 'stamp'],
['standardized', 'standardize'],
['stapled', 'staple'],
['started', 'start'],
['stated', 'state'],
['stationed', 'station'],
['stayed', 'stay'],
['stemmed', 'stem'],
['stepped', 'step'],
['stifled', 'stifle'],
['stimulated', 'stimulate'],
['stipulated', 'stipulate'],
['stirred', 'stir'],
['stockpiled', 'stockpile'],
['stole', 'steal'],
['stood', 'stand'],
['stopped', 'stop'],
['stored', 'store'],
['stormed', 'storm'],
['stowed', 'stow'],
['straddled', 'straddle'],
['stratified', 'stratify'],
['streamed', 'stream'],
['streamlined', 'streamline'],
['strengthened', 'strengthen'],
['stressed', 'stress'],
['stretched', 'stretch'],
['strewn', 'strew'],
['stripped', 'strip'],
['strolled', 'stroll'],
['strove', 'strive'],
['struck', 'strike'],
['structured', 'structure'],
['struggled', 'struggle'],
['stuck', 'stick'],
['studied', 'study'],
['stuffed', 'stuff'],
['stumbled', 'stumble'],
['stunk', 'stink'],
['stunned', 'stun'],
['styled', 'style'],
['stylized', 'stylize'],
['subdivided', 'subdivide'],
['submerged', 'submerge'],
['submitted', 'submit'],
['subscribed', 'subscribe'],
['subsided', 'subside'],
['subsidized', 'subsidize'],
['substantiated', 'substantiate'],
['substituted', 'substitute'],
['subsumed', 'subsume'],
['succeeded', 'succeed'],
['succumbed', 'succumb'],
['sued', 'sue'],
['suffered', 'suffer'],
['suggested', 'suggest'],
['suited', 'suit'],
['sulphonated', 'sulphonate'],
['summarized', 'summarize'],
['summed', 'sum'],
['summoned', 'summon'],
['superseded', 'supersede'],
['supervised', 'supervise'],
['supplemented', 'supplement'],
['supplied', 'supply'],
['supported', 'support'],
['suppressed', 'suppress'],
['surfaced', 'surface'],
['surfed', 'surf'],
['surged', 'surge'],
['surmised', 'surmise'],
['surmounted', 'surmount'],
['surpassed', 'surpass'],
['surprised', 'surprise'],
['surrendered', 'surrender'],
['surrounded', 'surround'],
['surveyed', 'survey'],
['survived', 'survive'],
['suspected', 'suspect'],
['suspended', 'suspend'],
['sustained', 'sustain'],
['swam', 'swim'],
['sweetened', 'sweeten'],
['swelled', 'swell'],
['swept', 'sweep'],
['switched', 'switch'],
['swore', 'swear'],
['synthesized', 'synthesize'],
['systematized', 'systematize'],
['tabbed', 'tab'],
['tabled', 'table'],
['tabulated', 'tabulate'],
['tackled', 'tackle'],
['tagged', 'tag'],
['tailored', 'tailor'],
['talked', 'talk'],
['tallied', 'tally'],
['tanned', 'tan'],
['taped', 'tape'],
['tapered', 'taper'],
['tapped', 'tap'],
['targeted', 'target'],
['tarnished', 'tarnish'],
['tasked', 'task'],
['tasted', 'taste'],
['taught', 'teach'],
['taxed', 'tax'],
['teamed', 'team'],
['teetered', 'teeter'],
['telegraphed', 'telegraph'],
['telephoned', 'telephone'],
['tempted', 'tempt'],
['tended', 'tend'],
['tendered', 'tender'],
['termed', 'term'],
['terminated', 'terminate'],
['tested', 'test'],
['testified', 'testify'],
['thanked', 'thank'],
['thawed', 'thaw'],
['thinned', 'thin'],
['thought', 'think'],
['threaded', 'thread'],
['threatened', 'threaten'],
['threw', 'throw'],
['thrived', 'thrive'],
['thrust', 'thrust'],
['tied', 'tie'],
['tiered', 'tier'],
['tightened', 'tighten'],
['timed', 'time'],
['tipped', 'tip'],
['titled', 'title'],
['toasted', 'toast'],
['told', 'tell'],
['tolerated', 'tolerate'],
['tolled', 'toll'],
['toned', 'tone'],
['took', 'take'],
['topped', 'top'],
['tore', 'tear'],
['tossed', 'toss'],
['totaled', 'total'],
['touched', 'touch'],
['toured', 'tour'],
['traced', 'trace'],
['tracked', 'track'],
['traded', 'trade'],
['trafficked', 'traffick'],
['trailed', 'trail'],
['trained', 'train'],
['transacted', 'transact'],
['transferred', 'transfer'],
['transformed', 'transform'],
['transited', 'transit'],
['translated', 'translate'],
['transmitted', 'transmit'],
['transpired', 'transpire'],
['transported', 'transport'],
['travelled', 'travel'],
['treated', 'treat'],
['trended', 'trend'],
['tried', 'try'],
['triggered', 'trigger'],
['trimmed', 'trim'],
['tripled', 'triple'],
['trumpeted', 'trumpet'],
['truncated', 'truncate'],
['trusted', 'trust'],
['tufted', 'tuft'],
['tumbled', 'tumble'],
['tuned', 'tune'],
['turned', 'turn'],
['twinned', 'twin'],
['typed', 'type'],
['typified', 'typify'],
['uncovered', 'uncover'],
['underbid', 'underbid'],
['undercapitalized', 'undercapitalize'],
['undercut', 'undercut'],
['underdeveloped', 'underdevelop'],
['underestimated', 'underestimate'],
['underlay', 'underlie'],
['underlined', 'underline'],
['undermined', 'undermine'],
['underpaid', 'underpay'],
['underperformed', 'underperform'],
['underpinned', 'underpin'],
['underrepresented', 'underrepresent'],
['underscored', 'underscore'],
['undersigned', 'undersign'],
['understood', 'understand'],
['undertook', 'undertake'],
['underwent', 'undergo'],
['unearthed', 'unearth'],
['unfolded', 'unfold'],
['unified', 'unify'],
['unionized', 'unionize'],
['united', 'unite'],
['unleashed', 'unleash'],
['unloaded', 'unload'],
['unscrambled', 'unscramble'],
['unveiled', 'unveil'],
['updated', 'update'],
['upgraded', 'upgrade'],
['upheld', 'uphold'],
['upholstered', 'upholster'],
['uploaded', 'upload'],
['upped', 'up'],
['upset', 'upset'],
['urged', 'urge'],
['used', 'use'],
['ushered', 'usher'],
['utilized', 'utilize'],
['vaccinated', 'vaccinate'],
['validated', 'validate'],
['valued', 'value'],
['vanished', 'vanish'],
['vaporized', 'vaporize'],
['varied', 'vary'],
['varnished', 'varnish'],
['vegetated', 'vegetate'],
['vented', 'vent'],
['ventilated', 'ventilate'],
['ventured', 'venture'],
['verified', 'verify'],
['vibed', 'vibe'],
['vied', 'vie'],
['viewed', 'view'],
['violated', 'violate'],
['visited', 'visit'],
['voiced', 'voice'],
['voided', 'void'],
['volunteered', 'volunteer'],
['voted', 'vote'],
['vowed', 'vow'],
['vulcanized', 'vulcanize'],
['waited', 'wait'],
['waived', 'waive'],
['walked', 'walk'],
['walled', 'wall'],
['waned', 'wane'],
['wanted', 'want'],
['warehoused', 'warehouse'],
['warmed', 'warm'],
['warned', 'warn'],
['warranted', 'warrant'],
['was', 'is'],
['washed', 'wash'],
['wasted', 'waste'],
['watched', 'watch'],
['watered', 'water'],
['waxed', 'wax'],
['weakened', 'weaken'],
['weed', 'wee'],
['weighed', 'weigh'],
['weighted', 'weight'],
['welcomed', 'welcome'],
['welded', 'weld'],
['went', 'go'],
['wept', 'weep'],
['were', 'are'],
['whirled', 'whirl'],
['widened', 'widen'],
['widowed', 'widow'],
['winged', 'wing'],
['wiped', 'wipe'],
['wired', 'wire'],
['wished', 'wish'],
['withdrew', 'withdraw'],
['withheld', 'withhold'],
['withstood', 'withstand'],
['witnessed', 'witness'],
['woke', 'wake'],
['won', 'win'],
['wondered', 'wonder'],
['wore', 'wear'],
['worked', 'work'],
['worried', 'worry'],
['worsened', 'worsen'],
['wound', 'wind'],
['wove', 'weave'],
['wrapped', 'wrap'],
['wrestled', 'wrestle'],
['wrote', 'write'],
['wrung', 'wring'],
['yielded', 'yield'],
['zoned', 'zone'],
['smelled', 'smell'],
['chirped', 'chirp'],
['doomed', 'doom'],
['bowed', 'bow'],
['begged', 'beg'],
['chewed', 'chew'],
['flapped', 'flap'],
['murmured', 'murmur'],
['oiled', 'oil'],
['scarred', 'scar'],
['slapped', 'slap'],
['swayed', 'sway'],
['snapped', 'snap'],
['trotted', 'trot'],
['winked', 'wink'],
['yelled', 'yell'],
['jammed', 'jam'],
['courted', 'court'],
['emptied', 'empty'],
['deleted', 'delete'],
['secreted', 'secrete'],
['tamed', 'tame'],
['glared', 'glare'],
['impelled', 'impel'],
['dwelled', 'dwell'],
['honored', 'honor'],
['obliged', 'oblige'],
['lubed', 'lube'],
['stared', 'stare'],
['growled', 'growl'],
['gasped', 'gasp'],
['roped', 'rope'],
['ridiculed', 'ridicule'],
['prided', 'pride'],
['quelled', 'quell'],
['indulged', 'indulge'],
['eloped', 'elope'],
['chimed', 'chime'],
['raped', 'rape'],
['groaned', 'groan'],
['faded', 'fade'],
['dialed', 'dial'],
['stroked', 'stroke'],
['scared', 'scare'],
['marshalled', 'marshall'],
['waked', 'wake'],
['rioted', 'riot'],
['mired', 'mire'],
['texted', 'text'],
['equaled', 'equal'],
['caked', 'cake'],
['groped', 'grope'],
['honed', 'hone'],
['clouded', 'cloud'],
['backfired', 'backfire'],
['majored', 'major'],
['modelled', 'model'],
['sizzled', 'sizzle'],
['msged', 'msg'],
['txted', 'txt'],
['rhymed', 'rhyme'],
['sped', 'speed'],
['barricaded', 'barricade'],
['draped', 'drape'],
['cringed', 'cringe'],
['rebuked', 'rebuke'],
['chronicled', 'chronicle'],
['martialed', 'martial'],
['quaked', 'quake'],
['coveted', 'covet'],
['honeymooned', 'honeymoon'],
['accustomed', 'accustom'],
['befriended', 'befriend'],
["abutted", "abut"],
["apprehended", "apprehend"],
["assayed", "assay"],
["awakened", "awaken"],
["banged", "bang"],
["binned", "bin"],
["blinked", "blink"],
["blossomed", "blossom"],
["blotted", "blot"],
["canvassed", "canvass"],
["combatted", "combat"],
["comprehended", "comprehend"],
["compressed", "compress"],
// ["cross-checked", "cross-check"],
["crowned", "crown"],
["culled", "cull"],
["decayed", "decay"],
["dimmed", "dim"],
["disbanded", "disband"],
["elbowed", "elbow"],
["embedded", "embed"],
["encompassed", "encompass"],
["enlivened", "enliven"],
["enrolled", "enrol"],
["expressed", "express"],
["fancied", "fancy"],
["fathomed", "fathom"],
// ["fine-tuned", "fine-tune"],
["fitted", "fit"],
// ["forecast", "forecast"],
["forewent", "forego"],
["fretted", "fret"],
["gossiped", "gossip"],
["hastened", "hasten"],
["healed", "heal"],
["heated", "heat"],
["heeded", "heed"],
["hopped", "hop"],
["instilled", "instil"],
["kick-started", "kick-start"],
["labelled", "label"],
["levelled", "level"],
["massed", "mass"],
["mended", "mend"],
["misled", "mislead"],
["mopped", "mop"],
["nodded", "nod"],
["outed", "out"],
["outran", "outrun"],
["overrode", "override"],
["owned", "own"],
["peeled", "peel"],
["pinned", "pin"],
["raked", "rake"],
["rebelled", "rebel"],
["rebooted", "reboot"],
["reeled", "reel"],
["refited", "refit"],
["reined", "rein"],
["remodelled", "remodel"],
["repented", "repent"],
["rigged", "rig"],
// ["self-destructed", "self-destruct"],
["sewed", "sew"],
["sheared", "shear"],
["shielded", "shield"],
["signalled", "signal"],
["sinned", "sin"],
["skewed", "skew"],
["slew", "slay"],
["slimmed", "slim"],
["stewed", "stew"],
["stung", "sting"],
["subpoenaed", "subpoena"],
["sweated", "sweat"],
["swung", "swing"],
["swivelled", "swivel"],
["thrived", "thrive"],
["tilted", "tilt"],
["totalled", "total"],
["towed", "tow"],
["trespassed", "trespass"],
["tweaked", "tweak"],
["untied", "untie"],
["unwound", "unwind"],
["vetted", "vet"],
["vetoed", "veto"],
["withheld", "withhold"],
["witnessed", "witness"],
["welled", "well"],
["babysat", "babysit"],
["recycled", "recycle"],
// ['', ''],
]
================================================
FILE: data/pairs/PresentTense.js
================================================
export default [
['are', 'is'],
['has', 'have'],
['provides', 'provide'],
['does', 'do'],
['includes', 'include'],
['means', 'mean'],
['requires', 'require'],
['needs', 'need'],
['continues', 'continue'],
['supports', 'support'],
['allows', 'allow'],
['makes', 'make'],
['represents', 'represent'],
['follows', 'follow'],
['remains', 'remain'],
['offers', 'offer'],
['indicates', 'indicate'],
['appears', 'appear'],
['applies', 'apply'],
['contains', 'contain'],
['shows', 'show'],
['takes', 'take'],
['says', 'say'],
['suggests', 'suggest'],
['recognizes', 'recognize'],
['helps', 'help'],
['works', 'work'],
['reflects', 'reflect'],
['involves', 'involve'],
['consists', 'consist'],
['gives', 'give'],
['uses', 'use'],
['exists', 'exist'],
['presents', 'present'],
['comes', 'come'],
['agrees', 'agree'],
['outlines', 'outline'],
['refers', 'refer'],
['becomes', 'become'],
['aims', 'aim'],
['focuses', 'focus'],
['meets', 'meet'],
['occurs', 'occur'],
['recommends', 'recommend'],
['plans', 'plan'],
['promotes', 'promote'],
['covers', 'cover'],
['seems', 'seem'],
['contributes', 'contribute'],
['identifies', 'identify'],
['relates', 'relate'],
['receives', 'receive'],
['describes', 'describe'],
['ensures', 'ensure'],
['addresses', 'address'],
['encourages', 'encourage'],
['explains', 'explain'],
['serves', 'serve'],
['sets', 'set'],
['brings', 'bring'],
['believes', 'believe'],
['holds', 'hold'],
['depends', 'depend'],
['determines', 'determine'],
['plays', 'play'],
['states', 'state'],
['produces', 'produce'],
['seeks', 'seek'],
['considers', 'consider'],
['operates', 'operate'],
['reports', 'report'],
['enables', 'enable'],
['leads', 'lead'],
['constitutes', 'constitute'],
['varies', 'vary'],
['creates', 'create'],
['maintains', 'maintain'],
['goes', 'go'],
['proposes', 'propose'],
['increases', 'increase'],
['demonstrates', 'demonstrate'],
['notes', 'note'],
['affects', 'affect'],
['begins', 'begin'],
['establishes', 'establish'],
['exceeds', 'exceed'],
['administers', 'administer'],
['examines', 'examine'],
['defines', 'define'],
['wishes', 'wish'],
['reduces', 'reduce'],
['links', 'link'],
['develops', 'develop'],
['falls', 'fall'],
['intends', 'intend'],
['finds', 'find'],
['highlights', 'highlight'],
['assists', 'assist'],
['processes', 'process'],
['pays', 'pay'],
['wants', 'want'],
['causes', 'cause'],
['tends', 'tend'],
['builds', 'build'],
['calls', 'call'],
['illustrates', 'illustrate'],
['permits', 'permit'],
['expects', 'expect'],
['facilitates', 'facilitate'],
['reveals', 'reveal'],
['looks', 'look'],
['summarizes', 'summarize'],
['reviews', 'review'],
['adds', 'add'],
['confirms', 'confirm'],
['measures', 'measure'],
['raises', 'raise'],
['assumes', 'assume'],
['fails', 'fail'],
['acknowledges', 'acknowledge'],
['happens', 'happen'],
['comprises', 'comprise'],
['prohibits', 'prohibit'],
['conducts', 'conduct'],
['improves', 'improve'],
['faces', 'face'],
['concludes', 'conclude'],
['excludes', 'exclude'],
['implies', 'imply'],
['features', 'feature'],
['extends', 'extend'],
['controls', 'control'],
['estimates', 'estimate'],
['protects', 'protect'],
['specifies', 'specify'],
['manages', 'manage'],
['participates', 'participate'],
['relies', 'rely'],
['forms', 'form'],
['incorporates', 'incorporate'],
['places', 'place'],
['encompasses', 'encompass'],
['acts', 'act'],
['carries', 'carry'],
['lies', 'lie'],
['publishes', 'publish'],
['generates', 'generate'],
['delivers', 'deliver'],
['lists', 'list'],
['fosters', 'foster'],
['leaves', 'leave'],
['employs', 'employ'],
['emphasizes', 'emphasize'],
['starts', 'start'],
['stands', 'stand'],
['sells', 'sell'],
['enhances', 'enhance'],
['owns', 'own'],
['claims', 'claim'],
['costs', 'cost'],
['responds', 'respond'],
['feels', 'feel'],
['announces', 'announce'],
['hopes', 'hope'],
['discusses', 'discuss'],
['discloses', 'disclose'],
['respects', 'respect'],
['accounts', 'account'],
['collects', 'collect'],
['arises', 'arise'],
['prevents', 'prevent'],
['welcomes', 'welcome'],
['undertakes', 'undertake'],
['limits', 'limit'],
['speaks', 'speak'],
['sees', 'see'],
['puts', 'put'],
['accepts', 'accept'],
['gets', 'get'],
['runs', 'run'],
['reaches', 'reach'],
['ends', 'end'],
['stipulates', 'stipulate'],
['monitors', 'monitor'],
['stems', 'stem'],
['decides', 'decide'],
['imposes', 'impose'],
['compares', 'compare'],
['targets', 'target'],
['points', 'point'],
['knows', 'know'],
['commits', 'commit'],
['differs', 'differ'],
['ceases', 'cease'],
['submits', 'submit'],
['qualifies', 'qualify'],
['benefits', 'benefit'],
['values', 'value'],
['chooses', 'choose'],
['argues', 'argue'],
['explores', 'explore'],
['distributes', 'distribute'],
['coordinates', 'coordinate'],
['enters', 'enter'],
['keeps', 'keep'],
['sends', 'send'],
['guarantees', 'guarantee'],
['rests', 'rest'],
['strengthens', 'strengthen'],
['combines', 'combine'],
['moves', 'move'],
['retains', 'retain'],
['draws', 'draw'],
['prepares', 'prepare'],
['marks', 'mark'],
['strives', 'strive'],
['advises', 'advise'],
['authorizes', 'authorize'],
['opens', 'open'],
['arrives', 'arrive'],
['awards', 'award'],
['poses', 'pose'],
['asks', 'ask'],
['grants', 'grant'],
['projects', 'project'],
['directs', 'direct'],
['pertains', 'pertain'],
['files', 'file'],
['replaces', 'replace'],
['grows', 'grow'],
['attracts', 'attract'],
['results', 'result'],
['regards', 'regard'],
['supplies', 'supply'],
['centres', 'centre'],
['tells', 'tell'],
['invests', 'invest'],
['regulates', 'regulate'],
['funds', 'fund'],
['integrates', 'integrate'],
['corresponds', 'correspond'],
['performs', 'perform'],
['attempts', 'attempt'],
['complements', 'complement'],
['matters', 'matter'],
['introduces', 'introduce'],
['oversees', 'oversee'],
['concerns', 'concern'],
['turns', 'turn'],
['enjoys', 'enjoy'],
['changes', 'change'],
['references', 'reference'],
['understands', 'understand'],
['belongs', 'belong'],
['resides', 'reside'],
['challenges', 'challenge'],
['implements', 'implement'],
['releases', 'release'],
['ranks', 'rank'],
['extracts', 'extract'],
['informs', 'inform'],
['expires', 'expire'],
['alleges', 'allege'],
['invites', 'invite'],
['assesses', 'assess'],
['expands', 'expand'],
['captures', 'capture'],
['translates', 'translate'],
['interns', 'intern'],
['approves', 'approve'],
['imports', 'import'],
['dates', 'date'],
['approaches', 'approach'],
['celebrates', 'celebrate'],
['governs', 'govern'],
['reserves', 'reserve'],
['issues', 'issue'],
['fits', 'fit'],
['evaluates', 'evaluate'],
['feeds', 'feed'],
['deals', 'deal'],
['handles', 'handle'],
['eliminates', 'eliminate'],
['influences', 'influence'],
['sits', 'sit'],
['documents', 'document'],
['engages', 'engage'],
['lacks', 'lack'],
['complies', 'comply'],
['specializes', 'specialize'],
['impacts', 'impact'],
['matches', 'match'],
['equals', 'equal'],
['expresses', 'express'],
['dies', 'die'],
['visits', 'visit'],
['organizes', 'organize'],
['initiatives', 'initiative'],
['bears', 'bear'],
['rises', 'rise'],
['confers', 'confer'],
['entails', 'entail'],
['achieves', 'achieve'],
['obtains', 'obtain'],
['exhibits', 'exhibit'],
['hosts', 'host'],
['exports', 'export'],
['buys', 'buy'],
['satisfies', 'satisfy'],
['anticipates', 'anticipate'],
['allocates', 'allocate'],
['emerges', 'emerge'],
['studies', 'study'],
['spends', 'spend'],
['conforms', 'conform'],
['sections', 'section'],
['acquires', 'acquire'],
['flows', 'flow'],
['weeds', 'weed'],
['connects', 'connect'],
['passes', 'pass'],
['voyages', 'voyage'],
['reads', 'read'],
['steps', 'step'],
['removes', 'remove'],
['deems', 'deem'],
['tracks', 'track'],
['reinforces', 'reinforce'],
['requests', 'request'],
['exercises', 'exercise'],
['lives', 'live'],
['investigates', 'investigate'],
['concentrates', 'concentrate'],
['stresses', 'stress'],
['launches', 'launch'],
['favours', 'favour'],
['contends', 'contend'],
['consults', 'consult'],
['transfers', 'transfer'],
['restricts', 'restrict'],
['signs', 'sign'],
['embraces', 'embrace'],
['sponsors', 'sponsor'],
['underscores', 'underscore'],
['evolves', 'evolve'],
['attributes', 'attribute'],
['completes', 'complete'],
['reaffirms', 'reaffirm'],
['assigns', 'assign'],
['manufactures', 'manufacture'],
['designs', 'design'],
['occupies', 'occupy'],
['pursues', 'pursue'],
['overwinters', 'overwinter'],
['overlaps', 'overlap'],
['clarifies', 'clarify'],
['promises', 'promise'],
['derives', 'derive'],
['drives', 'drive'],
['programmes', 'programme'],
['teaches', 'teach'],
['urges', 'urge'],
['honours', 'honour'],
['tries', 'try'],
['chairs', 'chair'],
['aligns', 'align'],
['originates', 'originate'],
['designates', 'designate'],
['balances', 'balance'],
['heads', 'head'],
['transmits', 'transmit'],
['denotes', 'denote'],
['guides', 'guide'],
['views', 'view'],
['reminds', 'remind'],
['offsets', 'offset'],
['amounts', 'amount'],
['records', 'record'],
['experiences', 'experience'],
['deserves', 'deserve'],
['stimulates', 'stimulate'],
['predicts', 'predict'],
['distinguishes', 'distinguish'],
['decreases', 'decrease'],
['supersedes', 'supersede'],
['lasts', 'last'],
['houses', 'house'],
['affirms', 'affirm'],
['fulfills', 'fulfill'],
['demands', 'demand'],
['certifies', 'certify'],
['binds', 'bind'],
['charges', 'charge'],
['updates', 'update'],
['refuses', 'refuse'],
['minimizes', 'minimize'],
['forces', 'force'],
['displays', 'display'],
['signals', 'signal'],
['accompanies', 'accompany'],
['analyzes', 'analyze'],
['shares', 'share'],
['embodies', 'embody'],
['utilizes', 'utilize'],
['collaborates', 'collaborate'],
['disseminates', 'disseminate'],
['justifies', 'justify'],
['lends', 'lend'],
['proves', 'prove'],
['purchases', 'purchase'],
['answers', 'answer'],
['yields', 'yield'],
['returns', 'return'],
['breaks', 'break'],
['dominates', 'dominate'],
['competes', 'compete'],
['realizes', 'realize'],
['adopts', 'adopt'],
['services', 'service'],
['appreciates', 'appreciate'],
['terminates', 'terminate'],
['fills', 'fill'],
['thinks', 'think'],
['boasts', 'boast'],
['communicates', 'communicate'],
['ranges', 'range'],
['departs', 'depart'],
['threatens', 'threaten'],
['treats', 'treat'],
['possesses', 'possess'],
['coincides', 'coincide'],
['suffers', 'suffer'],
['showcases', 'showcase'],
['depicts', 'depict'],
['cuts', 'cut'],
['articulates', 'articulate'],
['lays', 'lay'],
['commences', 'commence'],
['joins', 'join'],
['negotiates', 'negotiate'],
['notifies', 'notify'],
['writes', 'write'],
['credits', 'credit'],
['markets', 'market'],
['spreads', 'spread'],
['broadcasts', 'broadcast'],
['films', 'film'],
['spans', 'span'],
['selects', 'select'],
['slips', 'slip'],
['declares', 'declare'],
['cites', 'cite'],
['observes', 'observe'],
['crosses', 'cross'],
['renders', 'render'],
['exemplifies', 'exemplify'],
['totals', 'total'],
['lowers', 'lower'],
['forecasts', 'forecast'],
['necessitates', 'necessitate'],
['mandates', 'mandate'],
['persists', 'persist'],
['recalls', 'recall'],
['counts', 'count'],
['mentions', 'mention'],
['climbs', 'climb'],
['mirrors', 'mirror'],
['preserves', 'preserve'],
['lets', 'let'],
['incurs', 'incur'],
['avoids', 'avoid'],
['gathers', 'gather'],
['drops', 'drop'],
['details', 'detail'],
['adjusts', 'adjust'],
['amends', 'amend'],
['attaches', 'attach'],
['kills', 'kill'],
['contacts', 'contact'],
['precludes', 'preclude'],
['prefers', 'prefer'],
['verifies', 'verify'],
['enriches', 'enrich'],
['attends', 'attend'],
['advances', 'advance'],
['travels', 'travel'],
['matures', 'mature'],
['earns', 'earn'],
['reiterates', 'reiterate'],
['progresses', 'progress'],
['adheres', 'adhere'],
['calculates', 'calculate'],
['affords', 'afford'],
['accommodates', 'accommodate'],
['initiates', 'initiate'],
['transports', 'transport'],
['wins', 'win'],
['insists', 'insist'],
['underlines', 'underline'],
['endorses', 'endorse'],
['proceeds', 'proceed'],
['contrasts', 'contrast'],
['attacks', 'attack'],
['posts', 'post'],
['resembles', 'resemble'],
['tests', 'test'],
['prevails', 'prevail'],
['envisions', 'envision'],
['infects', 'infect'],
['cruises', 'cruise'],
['diminishes', 'diminish'],
['loses', 'lose'],
['undergoes', 'undergo'],
['subsidizes', 'subsidize'],
['styles', 'style'],
['conveys', 'convey'],
['empowers', 'empower'],
['advocates', 'advocate'],
['stays', 'stay'],
['classifies', 'classify'],
['interacts', 'interact'],
['enforces', 'enforce'],
['signifies', 'signify'],
['interprets', 'interpret'],
['asserts', 'assert'],
['arranges', 'arrange'],
['portrays', 'portray'],
['prizes', 'prize'],
['assures', 'assure'],
['disclaims', 'disclaim'],
['undermines', 'undermine'],
['converts', 'convert'],
['hires', 'hire'],
['maximizes', 'maximize'],
['licenses', 'license'],
['appoints', 'appoint'],
['accelerates', 'accelerate'],
['slows', 'slow'],
['finishes', 'finish'],
['warrants', 'warrant'],
['violates', 'violate'],
['discovers', 'discover'],
['hears', 'hear'],
['lags', 'lag'],
['symbolizes', 'symbolize'],
['underlies', 'underlie'],
['accrues', 'accrue'],
['characterizes', 'characterize'],
['contravenes', 'contravene'],
['admits', 'admit'],
['consumes', 'consume'],
['survives', 'survive'],
['inspires', 'inspire'],
['registers', 'register'],
['succeeds', 'succeed'],
['compiles', 'compile'],
['expenditures', 'expenditure'],
['devotes', 'devote'],
['entitles', 'entitle'],
['denies', 'deny'],
['triggers', 'trigger'],
['disagrees', 'disagree'],
['alters', 'alter'],
['impedes', 'impede'],
['unveils', 'unveil'],
['questions', 'question'],
['revolves', 'revolve'],
['discourages', 'discourage'],
['secures', 'secure'],
['edits', 'edit'],
['unites', 'unite'],
['suspects', 'suspect'],
['thanks', 'thank'],
['prescribes', 'prescribe'],
['tours', 'tour'],
['owes', 'owe'],
['licences', 'licence'],
['unfolds', 'unfold'],
['comments', 'comment'],
['strikes', 'strike'],
['attains', 'attain'],
['infringes', 'infringe'],
['cooperates', 'cooperate'],
['simplifies', 'simplify'],
['regrets', 'regret'],
['flies', 'fly'],
['averages', 'average'],
['touches', 'touch'],
['applauds', 'applaud'],
['compensates', 'compensate'],
['supplements', 'supplement'],
['sizes', 'size'],
['forwards', 'forward'],
['analyses', 'analyse'],
['divides', 'divide'],
['dictates', 'dictate'],
['inhibits', 'inhibit'],
['reproduces', 'reproduce'],
['weighs', 'weigh'],
['rewards', 'reward'],
['exposes', 'expose'],
['withdraws', 'withdraw'],
['predominates', 'predominate'],
['boosts', 'boost'],
['destroys', 'destroy'],
['disciplines', 'discipline'],
['consolidates', 'consolidate'],
['approximates', 'approximate'],
['elects', 'elect'],
['trains', 'train'],
['shapes', 'shape'],
['educates', 'educate'],
['bases', 'base'],
['codes', 'code'],
['attests', 'attest'],
['ages', 'age'],
['rejects', 'reject'],
['stops', 'stop'],
['listens', 'listen'],
['saves', 'save'],
['figures', 'figure'],
['commends', 'commend'],
['commemorates', 'commemorate'],
['parts', 'part'],
['graduates', 'graduate'],
['motivates', 'motivate'],
['sustains', 'sustain'],
['ignores', 'ignore'],
['obliges', 'oblige'],
['flocks', 'flock'],
['effects', 'effect'],
['warns', 'warn'],
['bodes', 'bode'],
['recognises', 'recognise'],
['gains', 'gain'],
['positions', 'position'],
['liaises', 'liaise'],
['transforms', 'transform'],
['retires', 'retire'],
['exempts', 'exempt'],
['accomplishes', 'accomplish'],
['recruits', 'recruit'],
['underpins', 'underpin'],
['fulfils', 'fulfil'],
['perceives', 'perceive'],
['restores', 'restore'],
['broadens', 'broaden'],
['declines', 'decline'],
['accumulates', 'accumulate'],
['practises', 'practise'],
['alerts', 'alert'],
['congratulates', 'congratulate'],
['shifts', 'shift'],
['resonates', 'resonate'],
['maps', 'map'],
['surveys', 'survey'],
['sounds', 'sound'],
['learns', 'learn'],
['intervenes', 'intervene'],
['induces', 'induce'],
['hinders', 'hinder'],
['streamlines', 'streamline'],
['searches', 'search'],
['committees', 'committee'],
['outweighs', 'outweigh'],
['traces', 'trace'],
['interferes', 'interfere'],
['ents', 'ent'],
['weakens', 'weaken'],
['skirts', 'skirt'],
['risks', 'risk'],
['reimburses', 'reimburse'],
['cares', 'care'],
['finances', 'finance'],
['separates', 'separate'],
['hurts', 'hurt'],
['supervises', 'supervise'],
['stretches', 'stretch'],
['charts', 'chart'],
['complicates', 'complicate'],
['upholds', 'uphold'],
['remits', 'remit'],
['renews', 'renew'],
['excels', 'excel'],
['checks', 'check'],
['packages', 'package'],
['trips', 'trip'],
['likes', 'like'],
['instructs', 'instruct'],
['tubes', 'tube'],
['disappears', 'disappear'],
['presses', 'press'],
['exerts', 'exert'],
['transcends', 'transcend'],
['videotapes', 'videotape'],
['factors', 'factor'],
['reacts', 'react'],
['mixes', 'mix'],
['envisages', 'envisage'],
['sheds', 'shed'],
['closes', 'close'],
['relieves', 'relieve'],
['stabilizes', 'stabilize'],
['functions', 'function'],
['notices', 'notice'],
['catalogues', 'catalogue'],
['surrounds', 'surround'],
['inquires', 'inquire'],
['briefs', 'brief'],
['blouses', 'blouse'],
['resolves', 'resolve'],
['solicits', 'solicit'],
['surpasses', 'surpass'],
['hits', 'hit'],
['caters', 'cater'],
['recovers', 'recover'],
['purports', 'purport'],
['farms', 'farm'],
['aids', 'aid'],
['cultures', 'culture'],
['ties', 'tie'],
['presupposes', 'presuppose'],
['endeavours', 'endeavour'],
['widens', 'widen'],
['doubles', 'double'],
['suits', 'suit'],
['interests', 'interest'],
['thrives', 'thrive'],
['crafts', 'craft'],
['struggles', 'struggle'],
['furthers', 'further'],
['greets', 'greet'],
['proclaims', 'proclaim'],
['subjects', 'subject'],
['blocks', 'block'],
['interviews', 'interview'],
['unloads', 'unload'],
['clamps', 'clamp'],
['levies', 'levy'],
['lectures', 'lecture'],
['munitions', 'munition'],
['prints', 'print'],
['correlates', 'correlate'],
['walks', 'walk'],
['hinges', 'hinge'],
['springs', 'spring'],
['nurtures', 'nurture'],
['quotes', 'quote'],
['enacts', 'enact'],
['screens', 'screen'],
['leases', 'lease'],
['counsels', 'counsel'],
['concurs', 'concur'],
['lessons', 'lesson'],
['absorbs', 'absorb'],
['lambs', 'lamb'],
['manifests', 'manifest'],
['reprints', 'reprint'],
['optimizes', 'optimize'],
['routes', 'route'],
['prides', 'pride'],
['contracts', 'contract'],
['equates', 'equate'],
['types', 'type'],
['tables', 'table'],
['remembers', 'remember'],
['loves', 'love'],
['adapts', 'adapt'],
['replies', 'reply'],
['delineates', 'delineate'],
['drains', 'drain'],
['beetles', 'beetle'],
['bridges', 'bridge'],
['merits', 'merit'],
['screws', 'screw'],
['shakes', 'shake'],
['tops', 'top'],
['institutes', 'institute'],
['categorizes', 'categorize'],
['trails', 'trail'],
['desires', 'desire'],
['contents', 'content'],
['narrows', 'narrow'],
['executes', 'execute'],
['repeats', 'repeat'],
['sports', 'sport'],
['echoes', 'echo'],
['erodes', 'erode'],
['casts', 'cast'],
['connotes', 'connote'],
['fluctuates', 'fluctuate'],
['imparts', 'impart'],
['objects', 'object'],
['replicates', 'replicate'],
['hampers', 'hamper'],
['centers', 'center'],
['picks', 'pick'],
['capitalizes', 'capitalize'],
['differentiates', 'differentiate'],
['commissions', 'commission'],
['dedicates', 'dedicate'],
['trades', 'trade'],
['overcomes', 'overcome'],
['circumvents', 'circumvent'],
['detects', 'detect'],
['disposes', 'dispose'],
['opposes', 'oppose'],
['prompts', 'prompt'],
['borrows', 'borrow'],
['modifies', 'modify'],
['conserves', 'conserve'],
['mitigates', 'mitigate'],
['researches', 'research'],
['uncovers', 'uncover'],
['depreciates', 'depreciate'],
['encounters', 'encounter'],
['favors', 'favor'],
['fuels', 'fuel'],
['entertains', 'entertain'],
['pushes', 'push'],
['aspires', 'aspire'],
['subscribes', 'subscribe'],
['exacerbates', 'exacerbate'],
['settles', 'settle'],
['subsists', 'subsist'],
['misses', 'miss'],
['salts', 'salt'],
['simulates', 'simulate'],
['advertises', 'advertise'],
['rules', 'rule'],
['activates', 'activate'],
['appeals', 'appeal'],
['talks', 'talk'],
['damages', 'damage'],
['reverses', 'reverse'],
['pulls', 'pull'],
['assembles', 'assemble'],
['bestows', 'bestow'],
['contemplates', 'contemplate'],
['wears', 'wear'],
['elaborates', 'elaborate'],
['discounts', 'discount'],
['courses', 'course'],
['watches', 'watch'],
['mediates', 'mediate'],
['frames', 'frame'],
['cops', 'cop'],
['jackets', 'jacket'],
['begs', 'beg'],
['tools', 'tool'],
['sites', 'site'],
['recounts', 'recount'],
['masks', 'mask'],
['evokes', 'evoke'],
['surfaces', 'surface'],
['eases', 'ease'],
['tiers', 'tier'],
['paints', 'paint'],
['logs', 'log'],
['frees', 'free'],
['compounds', 'compound'],
['marries', 'marry'],
['derogates', 'derogate'],
['impairs', 'impair'],
['disrupts', 'disrupt'],
['corrects', 'correct'],
['defends', 'defend'],
['quantifies', 'quantify'],
['foresees', 'foresee'],
['streams', 'stream'],
['transacts', 'transact'],
['constrains', 'constrain'],
['exits', 'exit'],
['looms', 'loom'],
['mails', 'mail'],
['stages', 'stage'],
['labels', 'label'],
['hooks', 'hook'],
['dresses', 'dress'],
['shorts', 'short'],
['mars', 'mar'],
['cautions', 'caution'],
['plugs', 'plug'],
['convenes', 'convene'],
['forbids', 'forbid'],
['rents', 'rent'],
['speeds', 'speed'],
['intersects', 'intersect'],
['deprives', 'deprive'],
['testifies', 'testify'],
['formulates', 'formulate'],
['resigns', 'resign'],
['neglects', 'neglect'],
['corroborates', 'corroborate'],
['substantiates', 'substantiate'],
['spells', 'spell'],
['degrades', 'degrade'],
['inspects', 'inspect'],
['combs', 'comb'],
['worsens', 'worsen'],
['grains', 'grain'],
['purposes', 'purpose'],
['chapters', 'chapter'],
['saws', 'saw'],
['precedes', 'precede'],
['radios', 'radio'],
['prises', 'prise'],
['deploys', 'deploy'],
['injects', 'inject'],
['awaits', 'await'],
['fields', 'field'],
['summarises', 'summarise'],
['behaves', 'behave'],
['beats', 'beat'],
['pairs', 'pair'],
['boils', 'boil'],
['senses', 'sense'],
['accords', 'accord'],
['culminates', 'culminate'],
['structures', 'structure'],
['mobilizes', 'mobilize'],
['opts', 'opt'],
['budgets', 'budget'],
['equips', 'equip'],
['rots', 'rot'],
['privileges', 'privilege'],
['switches', 'switch'],
['ships', 'ship'],
['ensues', 'ensue'],
['outstrips', 'outstrip'],
['posits', 'posit'],
['confronts', 'confront'],
['diverts', 'divert'],
['honors', 'honor'],
['antiques', 'antique'],
['baffles', 'baffle'],
['gloves', 'glove'],
['enlists', 'enlist'],
['parties', 'party'],
['filters', 'filter'],
['stores', 'store'],
['encapsulates', 'encapsulate'],
['scales', 'scale'],
['insures', 'insure'],
['heats', 'heat'],
['bars', 'bar'],
['compromises', 'compromise'],
['exploits', 'exploit'],
['washes', 'wash'],
['cultivates', 'cultivate'],
['deepens', 'deepen'],
['praises', 'praise'],
['validates', 'validate'],
['upgrades', 'upgrade'],
['mimics', 'mimic'],
['abrogates', 'abrogate'],
['supposes', 'suppose'],
['detracts', 'detract'],
['predates', 'predate'],
['contradicts', 'contradict'],
['images', 'image'],
['soils', 'soil'],
['calves', 'calve'],
['dries', 'dry'],
['infests', 'infest'],
['strips', 'strip'],
['invoices', 'invoice'],
['disburses', 'disburse'],
['distorts', 'distort'],
['kernels', 'kernel'],
['deteriorates', 'deteriorate'],
['aggregates', 'aggregate'],
['nourishes', 'nourish'],
['encrypts', 'encrypt'],
['afflicts', 'afflict'],
['yarns', 'yarn'],
['burns', 'burn'],
['chronicles', 'chronicle'],
['amalgamates', 'amalgamate'],
['solves', 'solve'],
['partners', 'partner'],
['refines', 'refine'],
['conjures', 'conjure'],
['overlooks', 'overlook'],
['intensifies', 'intensify'],
['aliments', 'aliment'],
['lifts', 'lift'],
['gears', 'gear'],
['trends', 'trend'],
['salutes', 'salute'],
['isolates', 'isolate'],
['offends', 'offend'],
['doubts', 'doubt'],
['paves', 'pave'],
['commands', 'command'],
['drafts', 'draft'],
['inserts', 'insert'],
['requisitions', 'requisition'],
['crops', 'crop'],
['berries', 'berry'],
['suppresses', 'suppress'],
['cases', 'case'],
['harms', 'harm'],
['caps', 'cap'],
['diffuses', 'diffuse'],
['seals', 'seal'],
['defers', 'defer'],
['intercepts', 'intercept'],
['clears', 'clear'],
['nets', 'net'],
['backs', 'back'],
['copies', 'copy'],
['bills', 'bill'],
['revises', 'revise'],
['tutors', 'tutor'],
['fears', 'fear'],
['grades', 'grade'],
['reinvests', 'reinvest'],
['outpaces', 'outpace'],
['abounds', 'abound'],
['distils', 'distil'],
['reasons', 'reason'],
['disputes', 'dispute'],
['donates', 'donate'],
['evaporates', 'evaporate'],
['materializes', 'materialize'],
['stars', 'star'],
['channels', 'channel'],
['sums', 'sum'],
['permeates', 'permeate'],
['packs', 'pack'],
['installs', 'install'],
['overrides', 'override'],
['defeats', 'defeat'],
['medals', 'medal'],
['withholds', 'withhold'],
['pledges', 'pledge'],
['rolls', 'roll'],
['conceals', 'conceal'],
['displaces', 'displace'],
['outperforms', 'outperform'],
['emits', 'emit'],
['welds', 'weld'],
['bands', 'band'],
['conflicts', 'conflict'],
['formalizes', 'formalize'],
['oils', 'oil'],
['slugs', 'slug'],
['collapses', 'collapse'],
['catches', 'catch'],
['repays', 'repay'],
['duplicates', 'duplicate'],
['lessens', 'lessen'],
['interchanges', 'interchange'],
['compels', 'compel'],
['rows', 'row'],
['augments', 'augment'],
['postulates', 'postulate'],
['complains', 'complain'],
['consents', 'consent'],
['navigates', 'navigate'],
['chats', 'chat'],
['scans', 'scan'],
['shocks', 'shock'],
['suspends', 'suspend'],
['circulates', 'circulate'],
['wonders', 'wonder'],
['airs', 'air'],
['proscribes', 'proscribe'],
['conditions', 'condition'],
['games', 'game'],
['nominates', 'nominate'],
['detains', 'detain'],
['spills', 'spill'],
['embarks', 'embark'],
['orders', 'order'],
['kicks', 'kick'],
['rates', 'rate'],
['stews', 'stew'],
['reaps', 'reap'],
['avails', 'avail'],
['descends', 'descend'],
['remarks', 'remark'],
['innovates', 'innovate'],
['disperses', 'disperse'],
['constructs', 'construct'],
['disables', 'disable'],
['cleans', 'clean'],
['presumes', 'presume'],
['invokes', 'invoke'],
['fixes', 'fix'],
['sprouts', 'sprout'],
['sacrifices', 'sacrifice'],
['groups', 'group'],
['codifies', 'codify'],
['convicts', 'convict'],
['locks', 'lock'],
['teams', 'team'],
['multiplies', 'multiply'],
['remedies', 'remedy'],
['items', 'item'],
['copyrights', 'copyright'],
['fees', 'fee'],
['waives', 'waive'],
['elicits', 'elicit'],
['cancels', 'cancel'],
['pastures', 'pasture'],
['blights', 'blight'],
['deposits', 'deposit'],
['predisposes', 'predispose'],
['omits', 'omit'],
['counters', 'counter'],
['solidifies', 'solidify'],
['tolerates', 'tolerate'],
['empties', 'empty'],
['dampens', 'dampen'],
['curves', 'curve'],
['tackles', 'tackle'],
['rotates', 'rotate'],
['disadvantages', 'disadvantage'],
['reconciles', 'reconcile'],
['legislates', 'legislate'],
['provisions', 'provision'],
['pervades', 'pervade'],
['condemns', 'condemn'],
['dovetails', 'dovetail'],
['undercuts', 'undercut'],
['mounts', 'mount'],
['penalizes', 'penalize'],
['safeguards', 'safeguard'],
['entrenches', 'entrench'],
['authenticates', 'authenticate'],
['brevets', 'brevet'],
['adjudicates', 'adjudicate'],
['pads', 'pad'],
['rescinds', 'rescind'],
['stamps', 'stamp'],
['consigns', 'consign'],
['hats', 'hat'],
['halts', 'halt'],
['pillars', 'pillar'],
['practices', 'practice'],
['emanates', 'emanate'],
['retrofits', 'retrofit'],
['blends', 'blend'],
['repairs', 'repair'],
['retrieves', 'retrieve'],
['abandons', 'abandon'],
['names', 'name'],
['redistributes', 'redistribute'],
['automates', 'automate'],
['excites', 'excite'],
['tightens', 'tighten'],
['softens', 'soften'],
['fires', 'fire'],
['nears', 'near'],
['articles', 'article'],
['hangs', 'hang'],
['spurs', 'spur'],
['escapes', 'escape'],
['tips', 'tip'],
['throws', 'throw'],
['hails', 'hail'],
['sings', 'sing'],
['furnishes', 'furnish'],
['smiles', 'smile'],
['reverts', 'revert'],
['bypasses', 'bypass'],
['votes', 'vote'],
['harbours', 'harbour'],
['tailors', 'tailor'],
['proteins', 'protein'],
['resins', 'resin'],
['invades', 'invade'],
['escalates', 'escalate'],
['deters', 'deter'],
['resists', 'resist'],
['powers', 'power'],
['instills', 'instill'],
['audits', 'audit'],
['sands', 'sand'],
['gauges', 'gauge'],
['neighbours', 'neighbour'],
['synthesizes', 'synthesize'],
['voices', 'voice'],
['abides', 'abide'],
['earmarks', 'earmark'],
['fruits', 'fruit'],
['ducks', 'duck'],
['pods', 'pod'],
['shoots', 'shoot'],
['shrinks', 'shrink'],
['splits', 'split'],
['rings', 'ring'],
['nuts', 'nut'],
['sponges', 'sponge'],
['crushes', 'crush'],
['penetrates', 'penetrate'],
['vests', 'vest'],
['borders', 'border'],
['accentuates', 'accentuate'],
['heralds', 'herald'],
['obeys', 'obey'],
['parallels', 'parallel'],
['levers', 'lever'],
['rights', 'right'],
['hogs', 'hog'],
['steers', 'steer'],
['surprises', 'surprise'],
['jeopardizes', 'jeopardize'],
['infuses', 'infuse'],
['merges', 'merge'],
['dissipates', 'dissipate'],
['elapses', 'elapse'],
['fins', 'fin'],
['discriminates', 'discriminate'],
['seizes', 'seize'],
['revitalizes', 'revitalize'],
['enlightens', 'enlighten'],
['coproduces', 'coproduce'],
['formats', 'format'],
['suffices', 'suffice'],
['revokes', 'revoke'],
['programs', 'program'],
['scores', 'score'],
['inaugurates', 'inaugurate'],
['boards', 'board'],
['sensitizes', 'sensitize'],
['fuses', 'fuse'],
['pages', 'page'],
['demeans', 'demean'],
['dogs', 'dog'],
['expedites', 'expedite'],
['disorders', 'disorder'],
['plates', 'plate'],
['alloys', 'alloy'],
['bits', 'bit'],
['slats', 'slat'],
['relaunches', 'relaunch'],
['circumscribes', 'circumscribe'],
['mingles', 'mingle'],
['fairs', 'fair'],
['centralizes', 'centralize'],
['deletes', 'delete'],
['breaches', 'breach'],
['procures', 'procure'],
['seats', 'seat'],
['skews', 'skew'],
['interrupts', 'interrupt'],
['worries', 'worry'],
['cycles', 'cycle'],
['underestimates', 'underestimate'],
['probes', 'probe'],
['cools', 'cool'],
['illuminates', 'illuminate'],
['funnels', 'funnel'],
['fascinates', 'fascinate'],
['windows', 'window'],
['inspectors', 'inspector'],
['floats', 'float'],
['adorns', 'adorn'],
['oxidizes', 'oxidize'],
['cherishes', 'cherish'],
['sanctions', 'sanction'],
['obstructs', 'obstruct'],
['founds', 'found'],
['breathes', 'breathe'],
['epitomizes', 'epitomize'],
['endures', 'endure'],
['cries', 'cry'],
['meters', 'meter'],
['champions', 'champion'],
['endangers', 'endanger'],
['contours', 'contour'],
['abstracts', 'abstract'],
['surrenders', 'surrender'],
['enrols', 'enrol'],
['sticks', 'stick'],
['overlays', 'overlay'],
['cows', 'cow'],
['bans', 'ban'],
['delays', 'delay'],
['eats', 'eat'],
['warms', 'warm'],
['pellets', 'pellet'],
['wafers', 'wafer'],
['depresses', 'depress'],
['blurs', 'blur'],
['deviates', 'deviate'],
['discharges', 'discharge'],
['scouts', 'scout'],
['vents', 'vent'],
['mills', 'mill'],
['bids', 'bid'],
['garners', 'garner'],
['understates', 'understate'],
['eggs', 'egg'],
['pens', 'pen'],
['recreates', 'recreate'],
['amplifies', 'amplify'],
['judges', 'judge'],
['models', 'model'],
['accesses', 'access'],
['environs', 'environ'],
['pins', 'pin'],
['implicates', 'implicate'],
['enshrines', 'enshrine'],
['engenders', 'engender'],
['spikes', 'spike'],
['deplores', 'deplore'],
['reorganizes', 'reorganize'],
['entrusts', 'entrust'],
['abuses', 'abuse'],
['comports', 'comport'],
['organises', 'organise'],
['warehouses', 'warehouse'],
['forges', 'forge'],
['dispenses', 'dispense'],
['prosecutes', 'prosecute'],
['scissors', 'scissor'],
['queries', 'query'],
['bastes', 'baste'],
['stuffs', 'stuff'],
['elucidates', 'elucidate'],
['ascribes', 'ascribe'],
['encodes', 'encode'],
['prolongs', 'prolong'],
['leans', 'lean'],
['negates', 'negate'],
['officers', 'officer'],
['graves', 'grave'],
['propositions', 'proposition'],
['shingles', 'shingle'],
['readies', 'ready'],
['weaves', 'weave'],
['ponders', 'ponder'],
['sorts', 'sort'],
['augurs', 'augur'],
['unlocks', 'unlock'],
['cements', 'cement'],
['locates', 'locate'],
['criticizes', 'criticize'],
['disturbs', 'disturb'],
['subcontracts', 'subcontract'],
['emphasises', 'emphasise'],
['trusts', 'trust'],
['relaxes', 'relax'],
['resorts', 'resort'],
['pumps', 'pump'],
['waits', 'wait'],
['vacations', 'vacation'],
['jumps', 'jump'],
['escorts', 'escort'],
['inflates', 'inflate'],
['melts', 'melt'],
['buckles', 'buckle'],
['recycles', 'recycle'],
['wraps', 'wrap'],
['blooms', 'bloom'],
['smells', 'smell'],
['loads', 'load'],
['sketches', 'sketch'],
['jokes', 'joke'],
['erases', 'erase'],
['dimensions', 'dimension'],
['concedes', 'concede'],
['defies', 'defy'],
['plants', 'plant'],
['presides', 'preside'],
['belies', 'belie'],
['hastens', 'hasten'],
['bankrupts', 'bankrupt'],
['discontinues', 'discontinue'],
['redirects', 'redirect'],
['firms', 'firm'],
['discredits', 'discredit'],
['pressures', 'pressure'],
['footnotes', 'footnote'],
['exchanges', 'exchange'],
['photocopies', 'photocopy'],
['photographs', 'photograph'],
['instances', 'instance'],
['colours', 'colour'],
['perpetuates', 'perpetuate'],
['trees', 'tree'],
['rejoins', 'rejoin'],
['pales', 'pale'],
['migrates', 'migrate'],
['pupates', 'pupate'],
['yellows', 'yellow'],
['parasitizes', 'parasitize'],
['ripens', 'ripen'],
['encloses', 'enclose'],
['heals', 'heal'],
['preys', 'prey'],
['forfeits', 'forfeit'],
['keys', 'key'],
['arouses', 'arouse'],
['endeavors', 'endeavor'],
['specialises', 'specialise'],
['waxes', 'wax'],
['dissolves', 'dissolve'],
['insulates', 'insulate'],
['traps', 'trap'],
['slopes', 'slope'],
['heightens', 'heighten'],
['shuts', 'shut'],
['franchises', 'franchise'],
['indexes', 'index'],
['ameliorates', 'ameliorate'],
['triples', 'triple'],
['catalyzes', 'catalyze'],
['regroups', 'regroup'],
['holidays', 'holiday'],
['converges', 'converge'],
['swaps', 'swap'],
['exhausts', 'exhaust'],
['supplants', 'supplant'],
['reconvenes', 'reconvene'],
['modernizes', 'modernize'],
['leafs', 'leaf'],
['shines', 'shine'],
['familiarizes', 'familiarize'],
['tongues', 'tongue'],
['chances', 'chance'],
['numbers', 'number'],
['refrains', 'refrain'],
['fades', 'fade'],
['retails', 'retail'],
['ratifies', 'ratify'],
['alludes', 'allude'],
['enunciates', 'enunciate'],
['rouges', 'rouge'],
['embeds', 'embed'],
['decrypts', 'decrypt'],
['upsets', 'upset'],
['demotes', 'demote'],
['friends', 'friend'],
['wows', 'wow'],
['restates', 'restate'],
['conceives', 'conceive'],
['dwarfs', 'dwarf'],
['relocates', 'relocate'],
['infers', 'infer'],
['taboos', 'taboo'],
['expends', 'expend'],
['obligates', 'obligate'],
['combats', 'combat'],
['belittles', 'belittle'],
['conspires', 'conspire'],
['peoples', 'people'],
['conflates', 'conflate'],
['collates', 'collate'],
['shears', 'shear'],
['wheels', 'wheel'],
['conjugates', 'conjugate'],
['glazes', 'glaze'],
['taps', 'tap'],
['retorts', 'retort'],
['bottoms', 'bottom'],
['hikes', 'hike'],
['peddles', 'peddle'],
['mulls', 'mull'],
['rues', 'rue'],
['utilises', 'utilise'],
['pops', 'pop'],
['underwrites', 'underwrite'],
['stirs', 'stir'],
['aggravates', 'aggravate'],
['vies', 'vie'],
['sues', 'sue'],
['diverges', 'diverge'],
['situates', 'situate'],
['plots', 'plot'],
['billets', 'billet'],
['compliments', 'compliment'],
['pours', 'pour'],
['stocks', 'stock'],
['dares', 'dare'],
['skips', 'skip'],
['propagates', 'propagate'],
['breeds', 'breed'],
['typifies', 'typify'],
['liquefies', 'liquefy'],
['pinpoints', 'pinpoint'],
['winds', 'wind'],
['transpires', 'transpire'],
['disapproves', 'disapprove'],
['admires', 'admire'],
['gifts', 'gift'],
['finalizes', 'finalize'],
['floods', 'flood'],
['deducts', 'deduct'],
['prejudices', 'prejudice'],
['assents', 'assent'],
['revives', 'revive'],
['disqualifies', 'disqualify'],
['enquires', 'enquire'],
['refutes', 'refute'],
['pivots', 'pivot'],
['revisits', 'revisit'],
['calibrates', 'calibrate'],
['gasses', 'gas'],
['covenants', 'covenant'],
['supercedes', 'supercede'],
['harvests', 'harvest'],
['postpones', 'postpone'],
['reconsiders', 'reconsider'],
['invents', 'invent'],
['wipes', 'wipe'],
['confines', 'confine'],
['rekindles', 'rekindle'],
['fights', 'fight'],
['chains', 'chain'],
['enrolls', 'enroll'],
['rusts', 'rust'],
['manipulates', 'manipulate'],
['gouges', 'gouge'],
['germinates', 'germinate'],
['disintegrates', 'disintegrate'],
['obscures', 'obscure'],
['inhabits', 'inhabit'],
['sporulates', 'sporulate'],
['thickens', 'thicken'],
['coats', 'coat'],
['contaminates', 'contaminate'],
['fats', 'fat'],
['charters', 'charter'],
['bins', 'bin'],
['slices', 'slice'],
['thins', 'thin'],
['hives', 'hive'],
['depletes', 'deplete'],
['stations', 'station'],
['pits', 'pit'],
['closures', 'closure'],
['clogs', 'clog'],
['lengthens', 'lengthen'],
['needles', 'needle'],
['decomposes', 'decompose'],
['blankets', 'blanket'],
['corrodes', 'corrode'],
['stifles', 'stifle'],
['scares', 'scare'],
['hints', 'hint'],
['speculates', 'speculate'],
['frustrates', 'frustrate'],
['harmonizes', 'harmonize'],
['pools', 'pool'],
['tabulates', 'tabulate'],
['subsides', 'subside'],
['subtracts', 'subtract'],
['overstates', 'overstate'],
['characters', 'character'],
['paws', 'paw'],
['wages', 'wage'],
['resets', 'reset'],
['enumerates', 'enumerate'],
['peers', 'peer'],
['internalizes', 'internalize'],
['laughs', 'laugh'],
['coops', 'coop'],
['pretends', 'pretend'],
['errs', 'err'],
['allowances', 'allowance'],
['anchors', 'anchor'],
['weights', 'weight'],
['lunches', 'lunch'],
['checkers', 'checker'],
['redefines', 'redefine'],
['befits', 'befit'],
['disregards', 'disregard'],
['expertises', 'expertise'],
['spotlights', 'spotlight'],
['publicizes', 'publicize'],
['times', 'time'],
['premiers', 'premier'],
['champs', 'champ'],
['endows', 'endow'],
['symbols', 'symbol'],
['occasions', 'occasion'],
['lobbies', 'lobby'],
['refocuses', 'refocuse'],
['branches', 'branch'],
['dislikes', 'dislike'],
['freezes', 'freeze'],
['decodes', 'decode'],
['confounds', 'confound'],
['eludes', 'elude'],
['reasserts', 'reassert'],
['primes', 'prime'],
['relinquishes', 'relinquish'],
['overstocks', 'overstock'],
['excepts', 'except'],
['stalls', 'stall'],
['sails', 'sail'],
['arches', 'arch'],
['passages', 'passage'],
['recurs', 'recur'],
['trumps', 'trump'],
['frequents', 'frequent'],
['litigates', 'litigate'],
['abolishes', 'abolish'],
['defects', 'defect'],
['doses', 'dose'],
['chauffeurs', 'chauffeur'],
['teasels', 'teasel'],
['bitters', 'bitter'],
['rails', 'rail'],
['scrubs', 'scrub'],
['ornaments', 'ornament'],
['brackets', 'bracket'],
['traverses', 'traverse'],
['transits', 'transit'],
['excuses', 'excuse'],
['fulminates', 'fulminate'],
['torches', 'torch'],
['shovels', 'shovel'],
['eyelets', 'eyelet'],
['carillons', 'carillon'],
['garlands', 'garland'],
['reassures', 'reassure'],
['samples', 'sample'],
['resells', 'resell'],
['slates', 'slate'],
['referees', 'referee'],
['troubles', 'trouble'],
['inhales', 'inhale'],
['bullies', 'bully'],
['repeals', 'repeal'],
['quits', 'quit'],
['disobeys', 'disobey'],
['persuades', 'persuade'],
['reprises', 'reprise'],
['couches', 'couch'],
['disassociates', 'disassociate'],
['crashes', 'crash'],
[
'singles',
'single',
2
],
['scrutinizes', 'scrutinize'],
['realigns', 'realign'],
['entices', 'entice'],
['elevates', 'elevate'],
['awakens', 'awaken'],
['contests', 'contest'],
['schedules', 'schedule'],
['magnifies', 'magnify'],
['couples', 'couple'],
['fares', 'fare'],
['hovers', 'hover'],
['debuts', 'debut'],
['dazzles', 'dazzle'],
['patrols', 'patrol'],
['rumbles', 'rumble'],
['curls', 'curl'],
['glints', 'glint'],
['seduces', 'seduce'],
['steals', 'steal'],
['incinerates', 'incinerate'],
['sparks', 'spark'],
['chambers', 'chamber'],
['ascends', 'ascend'],
['clusters', 'cluster'],
['vaporizes', 'vaporize'],
['commercializes', 'commercialize'],
['dips', 'dip'],
['enthuses', 'enthuse'],
['restrains', 'restrain'],
['thwarts', 'thwart'],
['ripples', 'ripple'],
['saps', 'sap'],
['entraps', 'entrap'],
['humiliates', 'humiliate'],
['grounds', 'ground'],
['bowls', 'bowl'],
['appropriates', 'appropriate'],
['nullifies', 'nullify'],
['rubbers', 'rubber'],
['glues', 'glue'],
['polishes', 'polish'],
['inks', 'ink'],
['sifts', 'sift'],
['defrays', 'defray'],
['annotates', 'annotate'],
['associates', 'associate'],
['headlines', 'headline'],
['layers', 'layer'],
['accents', 'accent'],
['juggles', 'juggle'],
['skates', 'skate'],
['protests', 'protest'],
['patents', 'patent'],
['lapses', 'lapse'],
['gravitates', 'gravitate'],
['surnames', 'surname'],
['alarms', 'alarm'],
['imitates', 'imitate'],
['inconveniences', 'inconvenience'],
['doctors', 'doctor'],
['rebuilds', 'rebuild'],
['administrates', 'administrate'],
['sows', 'sow'],
['disentitles', 'disentitle'],
['bugs', 'bug'],
['sprays', 'spray'],
['stunts', 'stunt'],
['mates', 'mate'],
['defoliates', 'defoliate'],
['burrows', 'burrow'],
['alleviates', 'alleviate'],
['encroaches', 'encroach'],
['buries', 'bury'],
['secretes', 'secrete'],
['colonizes', 'colonize'],
['repels', 'repel'],
['injures', 'injure'],
['tastes', 'taste'],
['debriefs', 'debrief'],
['flakes', 'flake'],
['cakes', 'cake'],
['starches', 'starch'],
['pegs', 'peg'],
['diversifies', 'diversify'],
['hinnies', 'hinny'],
['seeds', 'seed'],
['sauces', 'sauce'],
['squeezes', 'squeeze'],
['overwhelms', 'overwhelm'],
['spices', 'spice'],
['militates', 'militate'],
['cups', 'cup'],
['exclaims', 'exclaim'],
['partakes', 'partake'],
['guesses', 'guess'],
['thaws', 'thaw'],
['leaches', 'leach'],
['zones', 'zone'],
['bolsters', 'bolster'],
['apportions', 'apportion'],
['surmises', 'surmise'],
['coils', 'coil'],
['lines', 'line'],
['slits', 'slit'],
['debunks', 'debunk'],
['overlies', 'overlie'],
['buffers', 'buffer'],
['shelves', 'shelve'],
['lands', 'land'],
['strains', 'strain'],
['stagnates', 'stagnate'],
['exaggerates', 'exaggerate'],
['hides', 'hide'],
['blunts', 'blunt'],
['rivals', 'rival'],
['minimises', 'minimise'],
['dwells', 'dwell'],
['nests', 'nest'],
['crumbles', 'crumble'],
['pans', 'pan'],
['wastes', 'waste'],
['disengages', 'disengage'],
['provokes', 'provoke'],
['disconnects', 'disconnect'],
['ministers', 'minister'],
['calendars', 'calendar'],
['reshapes', 'reshape'],
['mines', 'mine'],
['downplays', 'downplay'],
['burdens', 'burden'],
['handicaps', 'handicap'],
['alternates', 'alternate'],
['internationalizes', 'internationalize'],
['spawns', 'spawn'],
['propels', 'propel'],
['dismisses', 'dismiss'],
['neutralizes', 'neutralize'],
['sterilizes', 'sterilize'],
['sheets', 'sheet'],
['hypothesizes', 'hypothesize'],
['chases', 'chase'],
['unwinds', 'unwind'],
['incites', 'incite'],
['blames', 'blame'],
['overestimates', 'overestimate'],
['equalizes', 'equalize'],
['immunizes', 'immunize'],
['debits', 'debit'],
['forgoes', 'forgo'],
['advantages', 'advantage'],
['dreams', 'dream'],
['exacts', 'exact'],
['delves', 'delve'],
['relays', 'relay'],
['falters', 'falter'],
['institutionalizes', 'institutionalize'],
['inherits', 'inherit'],
['presages', 'presage'],
['outnumbers', 'outnumber'],
['convinces', 'convince'],
['bulletins', 'bulletin'],
['spearheads', 'spearhead'],
['personalizes', 'personalize'],
['volunteers', 'volunteer'],
['guests', 'guest'],
['battles', 'battle'],
['pockets', 'pocket'],
['expounds', 'expound'],
['legitimates', 'legitimate'],
['sidesteps', 'sidestep'],
['rosters', 'roster'],
['paroles', 'parole'],
['professes', 'profess'],
['prorates', 'prorate'],
['disallows', 'disallow'],
['engulfs', 'engulf'],
['straddles', 'straddle'],
['bespeaks', 'bespeak'],
['laments', 'lament'],
['discords', 'discord'],
['propitiates', 'propitiate'],
['recuperates', 'recuperate'],
['accedes', 'accede'],
['behooves', 'behoove'],
['legalizes', 'legalize'],
['analogizes', 'analogize'],
['lingers', 'linger'],
['traffics', 'traffic'],
['radiates', 'radiate'],
['clips', 'clip'],
['carts', 'cart'],
['trumpets', 'trumpet'],
['indemnifies', 'indemnify'],
['drags', 'drag'],
['collides', 'collide'],
['flags', 'flag'],
['chimes', 'chime'],
['saddles', 'saddle'],
['clubs', 'club'],
['rattles', 'rattle'],
['harbors', 'harbor'],
['ruins', 'ruin'],
['amazes', 'amaze'],
['revolts', 'revolt'],
['auditions', 'audition'],
['serenades', 'serenade'],
['disassembles', 'disassemble'],
['subsumes', 'subsume'],
['petitions', 'petition'],
['subsidises', 'subsidise'],
['longs', 'long'],
['treasures', 'treasure'],
['overemphasizes', 'overemphasize'],
['apprises', 'apprise'],
['initials', 'initial'],
['rides', 'ride'],
['marginalizes', 'marginalize'],
['slumps', 'slump'],
['premises', 'premise'],
['taints', 'taint'],
['mutualizes', 'mutualize'],
['digitizes', 'digitize'],
['apprehends', 'apprehend'],
['arrests', 'arrest'],
['amnesties', 'amnesty'],
['cosponsors', 'cosponsor'],
['mumps', 'mump'],
['orchestrates', 'orchestrate'],
['fortifies', 'fortify'],
['courts', 'court'],
['wards', 'ward'],
['plumes', 'plume'],
['cheats', 'cheat'],
['stables', 'stable'],
['delights', 'delight'],
['berths', 'berth'],
['clocks', 'clock'],
['cooks', 'cook'],
['roughs', 'rough'],
['slides', 'slide'],
['fastens', 'fasten'],
['repositions', 'reposition'],
['folds', 'fold'],
['encircles', 'encircle'],
['tows', 'tow'],
['defaces', 'deface'],
['mats', 'mat'],
['hoses', 'hose'],
['recalculates', 'recalculate'],
['docks', 'dock'],
['tires', 'tire'],
['disembarks', 'disembark'],
['belts', 'belt'],
['coins', 'coin'],
['offloads', 'offload'],
['stows', 'stow'],
['waters', 'water'],
['tents', 'tent'],
['jars', 'jar'],
['sulphonates', 'sulphonate'],
['burrs', 'burr'],
['plows', 'plow'],
['cranes', 'crane'],
['brushes', 'brush'],
['buoys', 'buoy'],
['roots', 'root'],
['powders', 'powder'],
['drills', 'drill'],
['blanks', 'blank'],
['cables', 'cable'],
['garments', 'garment'],
['pipes', 'pipe'],
['tiles', 'tile'],
['compresses', 'compress'],
['boots', 'boot'],
['cubes', 'cube'],
['mineralizes', 'mineralize'],
['regains', 'regain'],
['espouses', 'espouse'],
['arrays', 'array'],
['represses', 'repress'],
['assays', 'assay'],
['attenuates', 'attenuate'],
['modulates', 'modulate'],
['mutates', 'mutate'],
['popularizes', 'popularize'],
['dismantles', 'dismantle'],
['fuzzes', 'fuzz'],
['fizzes', 'fizz'],
['fizzles', 'fizzle'],
['impresses', 'impress'],
["awakens", "awaken"],
["biases", "bias"],
["compresses", "compress"],
["crowns", "crown"],
// ["cross-checks", "cross-check"],
// ["double-checks", "double-check"],
["embeds", "embed"],
["enlivens", "enliven"],
["expresses", "express"],
["fancies", "fancy"],
["hastens", "hasten"],
// ["fine-tunes", "fine-tune"],
// ["kick-starts", "kick-start"],
// ["self-destructs", "self-destruct"],
["owns", "own"],
["repents", "repent"],
["shed", "shed"],
["shields", "shield"],
["tilts", "tilt"],
["undoes", "undo"],
["vetoes", "veto"],
["withholds", "withhold"],
["witnesses", "witness"]
]
================================================
FILE: data/pairs/Superlative.js
================================================
export default [
['good', 'best'],
['least', 'least'],
['large', 'largest'],
['high', 'highest'],
['late', 'latest'],
['great', 'greatest'],
['low', 'lowest'],
['near', 'nearest'],
['big', 'biggest'],
['strong', 'strongest'],
['early', 'earliest'],
['old', 'oldest'],
['close', 'closest'],
['small', 'smallest'],
['fast', 'fastest'],
['bright', 'brightest'],
['new', 'newest'],
['bad', 'worst'],
['long', 'longest'],
['poor', 'poorest'],
['broad', 'broadest'],
['young', 'youngest'],
['wide', 'widest'],
['full', 'fullest'],
['fine', 'finest'],
['busy', 'busiest'],
['simple', 'simplest'],
['weak', 'weakest'],
['deep', 'deepest'],
['easy', 'easiest'],
['short', 'shortest'],
['safe', 'safest'],
['healthy', 'healthiest'],
['warm', 'warmest'],
['narrow', 'narrowest'],
['cheap', 'cheapest'],
['slight', 'slightest'],
['southwest', 'southwest'],
['heavy', 'heaviest'],
['few', 'fewest'],
['hard', 'hardest'],
['dry', 'driest'],
['strict', 'strictest'],
['slow', 'slowest'],
['hot', 'hottest'],
['clear', 'clearest'],
['rich', 'richest'],
['quick', 'quickest'],
['wealthy', 'wealthiest'],
['tough', 'toughest'],
['sharp', 'sharpest'],
['harsh', 'harshest'],
['tall', 'tallest'],
['proud', 'proudest'],
['wet', 'wettest'],
['deadly', 'deadliest'],
['fair', 'fairest'],
['wise', 'wisest'],
['pure', 'purest'],
['steep', 'steepest'],
['fresh', 'freshest'],
['sure', 'surest'],
['risky', 'riskiest'],
['common', 'commonest'],
['quiet', 'quietest'],
['green', 'greenest'],
['dirty', 'dirtiest'],
['wild', 'wildest'],
['thin', 'thinnest'],
['tight', 'tightest'],
['keen', 'keenest'],
['fit', 'fittest'],
['severe', 'severest'],
['costly', 'costliest'],
['happy', 'happiest'],
['sticky', 'stickiest'],
['fond', 'fondest'],
['sincere', 'sincerest'],
['hearty', 'heartiest'],
['lengthy', 'lengthiest'],
['soft', 'softest'],
['clean', 'cleanest'],
['straight', 'straightest'],
['loud', 'loudest'],
['bold', 'boldest'],
['tricky', 'trickiest'],
['bleak', 'bleakest'],
['kind', 'kindest'],
['nice', 'nicest'],
['nice', 'nicest'],
['late', 'latest'],
['hard', 'hardest'],
['inner', 'innermost'],
['outer', 'outermost'],
['far', 'furthest'],
['worse', 'worst'],
['bad', 'worst'],
['good', 'best'],
['big', 'biggest'],
['large', 'largest'],
['absurd', 'absurdest'],
['angry', 'angriest'],
['bad', 'worst'],
['bald', 'baldest'],
['bawdy', 'bawdiest'],
['big', 'biggest'],
['bitter', 'bitterest'],
['black', 'blackest'],
['bland', 'blandest'],
['blond', 'blondest'],
['bloody', 'bloodiest'],
['blue', 'bluest'],
['bold', 'boldest'],
['bouncy', 'bounciest'],
['brash', 'brashest'],
['brave', 'bravest'],
['brief', 'briefest'],
['brown', 'brownest'],
['burly', 'burliest'],
['busy', 'busiest'],
['calm', 'calmest'],
['cheap', 'cheapest'],
['cheesy', 'cheesiest'],
['chilly', 'chilliest'],
['clear', 'clearest'],
['clever', 'cleverest'],
['cloudy', 'cloudiest'],
['cold', 'coldest'],
['common', 'commonest'],
['cool', 'coolest'],
['costly', 'costliest'],
['cozy', 'coziest'],
['cruel', 'cruelest'],
['cuddly', 'cuddliest'],
['cute', 'cutest'],
['deadly', 'deadliest'],
['dear', 'dearest'],
['dense', 'densest'],
['dirty', 'dirtiest'],
['drunk', 'drunkest'],
['dull', 'dullest'],
['dumb', 'dumbest'],
['early', 'earliest'],
['earthly', 'earthliest'],
['eastern', 'easternest'],
['easy', 'easiest'],
['eerie', 'eeriest'],
['evil', 'evilest'],
['fair', 'fairest'],
['fake', 'fakest'],
['fancy', 'fanciest'],
['far', 'furthest'],
['faulty', 'faultiest'],
['feeble', 'feeblest'],
['fierce', 'fiercest'],
['fine', 'finest'],
['foamy', 'foamiest'],
['foul', 'foulest'],
['frail', 'frailest'],
['friendly', 'friendliest'],
['full', 'fullest'],
['funny', 'funniest'],
['furry', 'furriest'],
['gaudy', 'gaudiest'],
['gay', 'gayest'],
['gentle', 'gentlest'],
['ghastly', 'ghastliest'],
['ghostly', 'ghostliest'],
['giant', 'giantest'],
['giddy', 'giddiest'],
['glad', 'gladest'],
['glib', 'glibest'],
['gloomy', 'gloomiest'],
['goofy', 'goofiest'],
['grand', 'grandest'],
['gray', 'graiest'],
['green', 'greenest'],
['grey', 'greyest'],
['grisly', 'grisliest'],
['groovy', 'grooviest'],
['gross', 'grossest'],
['handsome', 'handsomest'],
['happy', 'happiest'],
['harsh', 'harshest'],
['heavenly', 'heavenliest'],
['heavy', 'heaviest'],
['hefty', 'heftiest'],
['high', 'highest'],
['hilly', 'hilliest'],
['homely', 'homeliest'],
['hot', 'hottest'],
['huge', 'hugest'],
['humble', 'humblest'],
['humid', 'humidest'],
['hungry', 'hungriest'],
['ill', 'illest'],
['instant', 'instantest'],
['jolly', 'jolliest'],
['juicy', 'juiciest'],
['keen', 'keenest'],
['kind', 'kindest'],
['lame', 'lamest'],
['large', 'largest'],
['late', 'latest'],
['lewd', 'lewdest'],
['likely', 'likeliest'],
['little', 'littlest'],
['lively', 'liveliest'],
['lofty', 'loftiest'],
['lonely', 'loneliest'],
['long', 'longest'],
['loud', 'loudest'],
['lousy', 'lousiest'],
['lovely', 'loveliest'],
['low', 'lowest'],
['lowly', 'lowliest'],
['loyal', 'loyalest'],
['lucky', 'luckiest'],
['mean', 'meanest'],
['meek', 'meekest'],
['mellow', 'mellowest'],
['mild', 'mildest'],
['moody', 'moodiest'],
['narrow', 'narrowest'],
['near', 'nearest'],
['neat', 'neattest'],
['new', 'newest'],
['nice', 'nicest'],
['nimble', 'nimblest'],
['noble', 'noblest'],
['noisy', 'noisiest'],
['normal', 'normalest'],
['nosy', 'nosiest'],
['odd', 'oddest'],
['oily', 'oiliest'],
['old', 'oldest'],
['pale', 'palest'],
['phony', 'phoniest'],
['plain', 'plainest'],
['pleasant', 'pleasantest'],
['poor', 'poorest'],
['pricey', 'priciest'],
['prickly', 'prickliest'],
['proud', 'proudest'],
['puny', 'puniest'],
['pure', 'purest'],
['quaint', 'quaintest'],
['random', 'randomest'],
['rapid', 'rapidest'],
['rare', 'rarest'],
['raw', 'rawest'],
['ready', 'readiest'],
['real', 'realest'],
['remote', 'remotest'],
['rich', 'richest'],
['ritzy', 'ritziest'],
['roomy', 'roomiest'],
['rosy', 'rosiest'],
['round', 'roundest'],
['rude', 'rudest'],
['safe', 'safest'],
['saintly', 'saintliest'],
['salty', 'saltiest'],
['savvy', 'savviest'],
['scary', 'scariest'],
['sexy', 'sexiest'],
['shady', 'shadiest'],
['shallow', 'shallowest'],
['shiny', 'shiniest'],
['shrill', 'shrillest'],
['shy', 'shyest'],
['silly', 'silliest'],
['simple', 'simplest'],
['skinny', 'skinniest'],
['sleek', 'sleekest'],
['slender', 'slenderest'],
['slight', 'slightest'],
['slim', 'slimest'],
['slimy', 'slimiest'],
['slow', 'slowest'],
['sly', 'sliest'],
['small', 'smallest'],
['smelly', 'smelliest'],
['solid', 'solidest'],
['soon', 'soonest'],
['sore', 'sorest'],
['spicy', 'spiciest'],
['sprightly', 'sprightliest'],
['square', 'squarest'],
['stark', 'starkest'],
['steady', 'steadiest'],
['stern', 'sternest'],
['strange', 'strangest'],
['strict', 'strictest'],
['strong', 'strongest'],
['stupid', 'stupidest'],
['sturdy', 'sturdiest'],
['subtle', 'subtlest'],
['sudden', 'suddenest'],
['swift', 'swiftest'],
['tall', 'tallest'],
['tame', 'tamest'],
['tart', 'tartest'],
['thirsty', 'thirstiest'],
['tidy', 'tidiest'],
['timely', 'timeliest'],
['tiny', 'tiniest'],
['tired', 'tiredest'],
['tranquil', 'tranquilest'],
['trendy', 'trendiest'],
['true', 'truest'],
['ugly', 'ugliest'],
['unlikely', 'unlikeliest'],
['untidy', 'untidiest'],
['vague', 'vaguest'],
['vulgar', 'vulgarest'],
['wary', 'wariest'],
['weary', 'weariest'],
['weird', 'weirdest'],
['wicked', 'wickedest'],
['wild', 'wildest'],
['wily', 'wiliest'],
['windy', 'windiest'],
['wiry', 'wiriest'],
['wise', 'wisest'],
['wry', 'wriest'],
['young', 'youngest'],
['zany', 'zaniest'],
['bright', 'brightest'],
['broad', 'broadest'],
['coarse', 'coarsest'],
['damp', 'dampest'],
['dark', 'darkest'],
['dead', 'deadest'],
['deep', 'deepest'],
['fast', 'fastest'],
['fat', 'fattest'],
['flat', 'flattest'],
['fresh', 'freshest'],
['great', 'greattest'],
['hard', 'hardest'],
['loose', 'loosest'],
['mad', 'madest'],
['quick', 'quickest'],
['quiet', 'quiettest'],
['red', 'redest'],
['ripe', 'ripest'],
['rough', 'roughest'],
['sad', 'sadest'],
['sharp', 'sharpest'],
['short', 'shortest'],
['sick', 'sickest'],
['smart', 'smartest'],
['soft', 'softest'],
['steep', 'steepest'],
['stiff', 'stiffest'],
['straight', 'straightest'],
['sweet', 'sweetest'],
['thick', 'thickest'],
['tight', 'tightest'],
['tough', 'toughest'],
['weak', 'weakest'],
['white', 'whitest'],
['wide', 'widest'],
['dire', 'direst'],
['polite', 'politest'],
['eager', 'eagerest'],
['prompt', 'promptest'],
['cheerful', 'cheerfullest'],
]
================================================
FILE: data/pairs/index.js
================================================
import Comparative from './Comparative.js'
import Gerund from './Gerund.js'
import Participle from './Participle.js'
import PastTense from './PastTense.js'
import PresentTense from './PresentTense.js'
import Superlative from './Superlative.js'
import AdjToNoun from './AdjToNoun.js'
export default {
Comparative,
Gerund,
Participle,
PastTense,
PresentTense,
Superlative,
AdjToNoun,
}
================================================
FILE: demos/performance.html
================================================
nlp-compromise stress-test
parse a bunch of large texts in the browser
start
================================================
FILE: demos/plugin.html
================================================
compromise plugin demo
web-worker demo
worker output:
================================================
FILE: eslint.config.js
================================================
import * as regexpPlugin from "eslint-plugin-regexp"
export default [
regexpPlugin.configs["flat/recommended"],
{
// "ignorePatterns": ["**/builds/*"],
"ignores": ["**/builds/*"],
"rules": {
"comma-dangle": [1, "only-multiline"],
"quotes": [0, "single", "avoid-escape"],
"max-nested-callbacks": [1, 4],
"max-params": [1, 5],
"consistent-return": 1,
"no-bitwise": 1,
"no-empty": 1,
"no-console": 1,
"no-duplicate-imports": 1,
"no-eval": 2,
"no-implied-eval": 2,
"no-mixed-operators": 2,
"no-multi-assign": 2,
"no-nested-ternary": 1,
"no-prototype-builtins": 0,
"no-self-compare": 1,
"no-sequences": 1,
"no-shadow": 2,
"no-unmodified-loop-condition": 1,
"no-use-before-define": 1,
"prefer-const": 1,
"radix": 1,
"no-unused-vars": 1,
"regexp/prefer-d": 0,
"regexp/prefer-w": 0,
"regexp/prefer-range": 0,
"regexp/no-unused-capturing-group": 0,
"eslint-comments/no-unused-disable": 0
}
},
]
================================================
FILE: one/package.json
================================================
{
"name": "compromise-one",
"version": "14.14.4",
"description": "",
"type": "module",
"module": "./../src/one.js",
"main": "./../src/one.js",
"types": "./../types/one.d.ts",
"exports": {
"./package.json": "./package.json",
".": {
"import": {
"types": "./../types/one/one.d.ts",
"default": "./../src/one.js"
},
"require": {
"types": "./../types/one.d.cts",
"default": "./../builds/one/compromise-one.cjs"
}
}
},
"author": "Spencer Kelly (http://spencermounta.in)",
"license": "MIT",
"sideEffects": true
}
================================================
FILE: package.json
================================================
{
"author": "Spencer Kelly (http://spencermounta.in)",
"name": "compromise",
"description": "modest natural language processing",
"version": "14.15.0",
"module": "./src/three.js",
"main": "./src/three.js",
"unpkg": "./builds/compromise.js",
"type": "module",
"sideEffects": false,
"types": "./types/three.d.ts",
"exports": {
".": {
"import": {
"types": "./types/three.d.ts",
"default": "./src/three.js"
},
"require": {
"types": "./types/three.d.cts",
"default": "./builds/three/compromise-three.cjs"
}
},
"./tokenize": {
"import": {
"types": "./types/one.d.ts",
"default": "./src/one.js"
},
"require": {
"types": "./types/one.d.cts",
"default": "./builds/one/compromise-one.cjs"
}
},
"./one": {
"import": {
"types": "./types/one.d.ts",
"default": "./src/one.js"
},
"require": {
"types": "./types/one.d.cts",
"default": "./builds/one/compromise-one.cjs"
}
},
"./two": {
"import": {
"types": "./types/two.d.ts",
"default": "./src/two.js"
},
"require": {
"types": "./types/two.d.cts",
"default": "./builds/two/compromise-two.cjs"
}
},
"./three": {
"import": {
"types": "./types/three.d.ts",
"default": "./src/three.js"
},
"require": {
"types": "./types/three.d.cts",
"default": "./builds/three/compromise-three.cjs"
}
},
"./misc": {
"types": "./types/misc.d.ts"
},
"./view/one": {
"types": "./types/view/one.d.ts"
},
"./view/two": {
"types": "./types/view/two.d.ts"
},
"./view/three": {
"types": "./types/view/three.d.ts"
}
},
"repository": {
"type": "git",
"url": "git://github.com/spencermountain/compromise.git"
},
"homepage": "https://github.com/spencermountain/compromise",
"engines": {
"node": ">=12.0.0"
},
"scripts": {
"build": "npm run version && rollup -c --silent",
"watch": "node --watch ./scratch.js",
"pack": "node ./scripts/pack.js",
"version": "node ./scripts/version.js",
"test": "tape \"./tests/**/*.test.js\" | tap-dancer",
"testb": "npm run test:smoke && cross-env TESTENV=prod npm run test",
"test:one": "tape \"./tests/one/**/*.test.js\" | tap-dancer",
"test:two": "tape \"./tests/two/**/*.test.js\" | tap-dancer",
"test:three": "tape \"./tests/three/**/*.test.js\" | tap-dancer",
"test:smoke": "tape \"./scripts/test/smoke.test.js\" | tap-dancer",
"test:plugins": "tape \"./plugins/**/tests/**/*.test.js\" | tap-dancer",
"stress": "node scripts/test/stress.js",
"debug": "node ./scripts/debug.js",
"match": "node ./scripts/match.js",
"coverage": "c8 -r lcov -n 'src/**/*' -n 'plugins/**/*' npm run test",
"perf": "node ./scripts/perf/index.js",
"flame": "clinic flame -- node ./scripts/perf/flame",
"lint": "eslint src",
"plugins:ci": "node ./scripts/plugins.js npm ci",
"plugins:build": "node ./scripts/plugins.js npm run build"
},
"files": [
"builds/",
"types/",
"src/",
"tokenize/",
"one/",
"two/",
"three/"
],
"keywords": [
"nlp"
],
"prettier": {
"trailingComma": "es5",
"tabWidth": 2,
"semi": false,
"singleQuote": true,
"printWidth": 120,
"arrowParens": "avoid"
},
"dependencies": {
"efrt": "2.7.0",
"grad-school": "0.0.5",
"suffix-thumb": "5.0.2"
},
"devDependencies": {
"@rollup/plugin-node-resolve": "16.0.3",
"@rollup/plugin-terser": "0.4.4",
"cross-env": "7.0.3",
"eslint": "9.39.1",
"eslint-plugin-regexp": "2.10.0",
"nlp-corpus": "4.4.0",
"rollup": "4.59.0",
"rollup-plugin-filesize-check": "1.2.0",
"shelljs": "0.10.0",
"tap-dancer": "0.3.4",
"tape": "5.9.0"
},
"eslintIgnore": [
"builds/*.js",
"*.ts",
"_old/**",
"_tests/**"
],
"license": "MIT"
}
================================================
FILE: plugins/_experiments/ast/README.md
================================================
attempt to create a [unist-formatted](https://github.com/syntax-tree/unist) Abstract Syntax Tree via some [dependency parsing](http://nlpprogress.com/english/dependency_parsing.html)
================================================
FILE: plugins/_experiments/ast/package.json
================================================
{
"name": "compromise-ast",
"description": "plugin for nlp-compromise",
"version": "0.0.0",
"author": "Spencer Kelly (http://spencermounta.in)",
"main": "./src/plugin.js",
"unpkg": "./builds/compromise-ast.min.js",
"module": "./builds/compromise-ast.mjs",
"type": "module",
"types": "index.d.ts",
"sideEffects": false,
"exports": {
".": {
"import": "./src/plugin.js",
"require": "./builds/compromise-ast.cjs"
}
},
"repository": {
"type": "git",
"url": "git://github.com/spencermountain/compromise.git"
},
"homepage": "https://github.com/spencermountain/compromise/tree/master/plugins/ast",
"scripts": {
"test": "tape \"./tests/**/*.test.js\" | tap-dancer --color always",
"testb": "TESTENV=prod tape \"./tests/**/*.test.js\" | tap-dancer --color always",
"watch": "node --watch ./scratch.js",
"build": "rollup -c --silent"
},
"eslintIgnore": [
"builds/*.js"
],
"files": [
"builds/",
"src/",
"index.d.ts"
],
"peerDependencies": {
"compromise": ">=14.0.0"
},
"dependencies": {},
"license": "MIT",
"devDependencies": {
"@rollup/plugin-commonjs": "^24.0.1"
}
}
================================================
FILE: plugins/_experiments/ast/scratch.js
================================================
import nlp from '../../../src/three.js'
import plg from './src/plugin.js'
nlp.plugin(plg)
let str = ''
str = `I prefer the morning flight through Denver. it was cool,
oh yeah nice`
const doc = nlp(str)
// console.log(doc.lines())
// let tree = doc.ast()
// console.dir(tree, { depth: 10 })
doc.chunks().debug('chunker')
================================================
FILE: plugins/_experiments/ast/src/ast.js
================================================
const chunkType = function (chunk) {
if (chunk.isVerb().found) {
return 'verbPhrase'
}
if (chunk.isNoun().found) {
return 'nounPhrase'
}
if (chunk.isPivot().found) {
return 'pivot'
}
if (chunk.isAdjective().found) {
return 'adjectivePhrase'
}
return null
}
const doWord = function (w) {
const term = w.docs[0][0]
const offset = term.offset
const node = {
type: 'word',
children: [],
position: {
start: { line: term.line + 1, column: null, offset: offset.start },
end: { line: term.line + 1, column: null, offset: offset.start + offset.length }
}
}
if (term.pre) {
node.children.push({
type: 'punct', value: term.pre, // data: { word: false }
})
}
node.children.push({
type: 'text', value: term.text, data: { normal: term.normal, tags: Array.from(term.tags) },
// position: { }
})
if (term.post) {
node.children.push({
type: 'punct', value: term.post, // data: { word: false }
})
}
return node
}
const doChunk = function (chunk) {
const type = chunkType(chunk)
const node = {
type: type,
children: chunk.terms().map(doWord),
// position: {}
}
return node
}
const doSentence = function (s) {
const node = {
type: 'sentence',
children: s.chunks().map(doChunk, []),
position: {}
}
return node
}
const toAst = function (doc) {
doc.compute(['chunks', 'offset', 'lines'])
const root = {
type: 'root',
children: doc.sentences().map(doSentence),
position: {}
}
return root
}
export default toAst
================================================
FILE: plugins/_experiments/ast/src/compute/index.js
================================================
export default {
lines: function (view) {
view.lines().forEach((arr, i) => {
arr.forEach(s => {
s.docs[0].forEach(term => {
term.line = i
})
})
})
}
}
================================================
FILE: plugins/_experiments/ast/src/lines.js
================================================
// return all newline-seperated sections in the document
const toLines = function (doc) {
const newLine = /\n/
const lines = [[]]
// a newline already splits a sentence,
// so it can only happen at the end of a sentence
doc.sentences().forEach(s => {
lines[lines.length - 1].push(s)
const terms = s.docs[0]
const end = terms[terms.length - 1]
if (newLine.test(end.post)) {
lines.push([])
}
})
// remove an empty last one
if (lines[lines.length - 1].length === 0) {
lines.pop()
}
return lines
}
export default toLines
================================================
FILE: plugins/_experiments/ast/src/plugin.js
================================================
import toAst from './ast.js'
import toLines from './lines.js'
import compute from './compute/index.js'
export default {
compute,
api: function (View) {
View.prototype.lines = function () {
return toLines(this)
}
View.prototype.ast = function (opts) {
return toAst(this, opts)
}
}
}
================================================
FILE: plugins/_experiments/cmd-k/README.md
================================================
npm install compromise-cmd-k
experimental plugins for command-prompt parsing
MIT
================================================
FILE: plugins/_experiments/cmd-k/package.json
================================================
{
"name": "compromise-cmd-k",
"description": "plugin for nlp-compromise",
"version": "0.0.1",
"author": "Spencer Kelly (http://spencermounta.in)",
"main": "./src/plugin.js",
"unpkg": "./builds/compromise-cmd-k.min.js",
"module": "./builds/compromise-cmd-k.mjs",
"type": "module",
"sideEffects": false,
"types": "./index.d.ts",
"exports": {
".": {
"import": "./src/plugin.js",
"require": "./builds/compromise-cmd-k.cjs",
"types": "./index.d.ts"
}
},
"repository": {
"type": "git",
"url": "git://github.com/spencermountain/compromise.git"
},
"homepage": "https://github.com/spencermountain/compromise/tree/master/plugins/dates",
"scripts": {
"test": "tape \"./tests/**/*.test.js\" | tap-dancer --color always",
"testb": "TESTENV=prod tape \"./tests/**/*.test.js\" | tap-dancer --color always",
"watch": "node --watch ./scratch.js",
"perf": "node ./scripts/perf.js",
"version": "node ./scripts/version.js",
"build": "npm run version && rollup -c --silent"
},
"files": [
"builds/",
"src/",
"index.d.ts"
],
"peerDependencies": {
"compromise": ">=14.2.0"
},
"dependencies": {},
"license": "MIT"
}
================================================
FILE: plugins/_experiments/cmd-k/scratch.js
================================================
/* eslint-disable no-console, no-unused-vars */
import nlp from '../../../src/three.js'
import plugin from './src/plugin.js'
nlp.extend(plugin)
let txt = '! i walk !ohyeah gh'
const doc = nlp(txt)
doc.searchBangs()
doc.debug()
================================================
FILE: plugins/_experiments/cmd-k/src/plugin.js
================================================
import searchBang from './searchBang.js'
import slashCmd from './slashCmd.js'
export default [searchBang, slashCmd]
================================================
FILE: plugins/_experiments/cmd-k/src/searchBang.js
================================================
// searchbang is a ! followed by a word
// it's a search engine shortcut
// !g is google, etc
const instaBangs = [
'g',
'gh',
'yt',
]
const searchBang = {
/** add a method */
api: (View) => {
View.prototype.searchBangs = function () {
return this.matchOne('#SearchBang+').text('normal')
}
},
/** add some tags */
tags: {
SearchBang: {
notA: ['Noun', 'Verb', 'Adjective'],
color: 'red'
},
},
/** add words to the stronger, more adamant lexicon */
frozen: instaBangs.reduce((h, str) => {
h[str] = 'SearchBang'
h['!' + str] = 'SearchBang'
return h
}, {}),
/** post-process tagger */
compute: {
tagBangs: (doc) => {
doc.match([{ word: '!' }]).tag('#SearchBang')
doc.match([{ pre: '!' }]).tag('#SearchBang')
doc.match([{ post: '!' }]).tag('#SearchBang')
}
},
/** run it on init */
hooks: ['tagBangs']
}
export default searchBang
================================================
FILE: plugins/_experiments/cmd-k/src/slashCmd.js
================================================
// slashCmds are / followed by a word
// they're a way to add custom commands
// "/me writes some bugs"
const slashCmd = {
/** add a method */
api: (View) => {
View.prototype.slashCmds = function () {
return this.matchOne('#SlashCmd+').text('normal')
}
},
/** add some tags */
tags: {
SlashCmd: {
notA: ['Noun', 'Verb', 'Adjective'],
color: 'yellow'
},
},
/** post-process tagger */
compute: {
tagSlashCmds: (doc) => {
doc.match([{ pre: '/' }]).not('#Number').tag('#SlashCmd')
}
},
/** run it on init */
hooks: ['tagSlashCmds']
}
export default slashCmd
================================================
FILE: plugins/_experiments/compress/README.md
================================================
they say that compression and intellegence are the same thing,
but I'm not small-enough to understand that.
================================================
FILE: plugins/_experiments/compress/src/index.js
================================================
import lz from './lz.js'
import fs from 'fs'
let string = fs.readFileSync('../../../plugins/speed/tests/files/freshPrince.txt').toString()
// string = "This is my compression test.";
// console.log("Size of sample is: " + string.length, '\n\n');
const compressed = lz.compress(string);
// console.log(string)
// console.log(compressed)
// console.log("\n\nSize of compressed sample is: " + compressed.length);
string = lz.decompress(compressed);
/*
[
text,
tag,
post,
pre
*/
================================================
FILE: plugins/_experiments/compress/src/lz.js
================================================
/* eslint-disable */
// Copyright (c) 2013 Pieroxy
// This work is free. You can redistribute it and/or modify it
// under the terms of the WTFPL, Version 2
// For more information see LICENSE.txt or http://www.wtfpl.net/
//
// For more information, the home page:
// http://pieroxy.net/blog/pages/lz-string/testing.html
//
// LZ-based compression algorithm, version 1.4.4
// private property
var f = String.fromCharCode;
var keyStrBase64 = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
var keyStrUriSafe = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+-$";
var baseReverseDic = {};
function getBaseValue(alphabet, character) {
if (!baseReverseDic[alphabet]) {
baseReverseDic[alphabet] = {};
for (var i = 0; i < alphabet.length; i++) {
baseReverseDic[alphabet][alphabet.charAt(i)] = i;
}
}
return baseReverseDic[alphabet][character];
}
var LZString = {
compressToBase64: function (input) {
if (input == null) return "";
var res = LZString._compress(input, 6, function (a) { return keyStrBase64.charAt(a); });
switch (res.length % 4) { // To produce valid Base64
default: // When could this happen ?
case 0: return res;
case 1: return res + "===";
case 2: return res + "==";
case 3: return res + "=";
}
},
decompressFromBase64: function (input) {
if (input == null) return "";
if (input == "") return null;
return LZString._decompress(input.length, 32, function (index) { return getBaseValue(keyStrBase64, input.charAt(index)); });
},
compressToUTF16: function (input) {
if (input == null) return "";
return LZString._compress(input, 15, function (a) { return f(a + 32); }) + " ";
},
decompressFromUTF16: function (compressed) {
if (compressed == null) return "";
if (compressed == "") return null;
return LZString._decompress(compressed.length, 16384, function (index) { return compressed.charCodeAt(index) - 32; });
},
//compress into a string that is already URI encoded
compressToEncodedURIComponent: function (input) {
if (input == null) return "";
return LZString._compress(input, 6, function (a) { return keyStrUriSafe.charAt(a); });
},
//decompress from an output of compressToEncodedURIComponent
decompressFromEncodedURIComponent: function (input) {
if (input == null) return "";
if (input == "") return null;
input = input.replace(/ /g, "+");
return LZString._decompress(input.length, 32, function (index) { return getBaseValue(keyStrUriSafe, input.charAt(index)); });
},
compress: function (uncompressed) {
return LZString._compress(uncompressed, 16, function (a) { return f(a); });
},
_compress: function (uncompressed, bitsPerChar, getCharFromInt) {
if (uncompressed == null) return "";
var i, value,
context_dictionary = {},
context_dictionaryToCreate = {},
context_c = "",
context_wc = "",
context_w = "",
context_enlargeIn = 2, // Compensate for the first entry which should not count
context_dictSize = 3,
context_numBits = 2,
context_data = [],
context_data_val = 0,
context_data_position = 0,
ii;
for (ii = 0; ii < uncompressed.length; ii += 1) {
context_c = uncompressed.charAt(ii);
if (!Object.prototype.hasOwnProperty.call(context_dictionary, context_c)) {
context_dictionary[context_c] = context_dictSize++;
context_dictionaryToCreate[context_c] = true;
}
context_wc = context_w + context_c;
if (Object.prototype.hasOwnProperty.call(context_dictionary, context_wc)) {
context_w = context_wc;
} else {
if (Object.prototype.hasOwnProperty.call(context_dictionaryToCreate, context_w)) {
if (context_w.charCodeAt(0) < 256) {
for (i = 0; i < context_numBits; i++) {
context_data_val = (context_data_val << 1);
if (context_data_position == bitsPerChar - 1) {
context_data_position = 0;
context_data.push(getCharFromInt(context_data_val));
context_data_val = 0;
} else {
context_data_position++;
}
}
value = context_w.charCodeAt(0);
for (i = 0; i < 8; i++) {
context_data_val = (context_data_val << 1) | (value & 1);
if (context_data_position == bitsPerChar - 1) {
context_data_position = 0;
context_data.push(getCharFromInt(context_data_val));
context_data_val = 0;
} else {
context_data_position++;
}
value = value >> 1;
}
} else {
value = 1;
for (i = 0; i < context_numBits; i++) {
context_data_val = (context_data_val << 1) | value;
if (context_data_position == bitsPerChar - 1) {
context_data_position = 0;
context_data.push(getCharFromInt(context_data_val));
context_data_val = 0;
} else {
context_data_position++;
}
value = 0;
}
value = context_w.charCodeAt(0);
for (i = 0; i < 16; i++) {
context_data_val = (context_data_val << 1) | (value & 1);
if (context_data_position == bitsPerChar - 1) {
context_data_position = 0;
context_data.push(getCharFromInt(context_data_val));
context_data_val = 0;
} else {
context_data_position++;
}
value = value >> 1;
}
}
context_enlargeIn--;
if (context_enlargeIn == 0) {
context_enlargeIn = Math.pow(2, context_numBits);
context_numBits++;
}
delete context_dictionaryToCreate[context_w];
} else {
value = context_dictionary[context_w];
for (i = 0; i < context_numBits; i++) {
context_data_val = (context_data_val << 1) | (value & 1);
if (context_data_position == bitsPerChar - 1) {
context_data_position = 0;
context_data.push(getCharFromInt(context_data_val));
context_data_val = 0;
} else {
context_data_position++;
}
value = value >> 1;
}
}
context_enlargeIn--;
if (context_enlargeIn == 0) {
context_enlargeIn = Math.pow(2, context_numBits);
context_numBits++;
}
// Add wc to the dictionary.
context_dictionary[context_wc] = context_dictSize++;
context_w = String(context_c);
}
}
// Output the code for w.
if (context_w !== "") {
if (Object.prototype.hasOwnProperty.call(context_dictionaryToCreate, context_w)) {
if (context_w.charCodeAt(0) < 256) {
for (i = 0; i < context_numBits; i++) {
context_data_val = (context_data_val << 1);
if (context_data_position == bitsPerChar - 1) {
context_data_position = 0;
context_data.push(getCharFromInt(context_data_val));
context_data_val = 0;
} else {
context_data_position++;
}
}
value = context_w.charCodeAt(0);
for (i = 0; i < 8; i++) {
context_data_val = (context_data_val << 1) | (value & 1);
if (context_data_position == bitsPerChar - 1) {
context_data_position = 0;
context_data.push(getCharFromInt(context_data_val));
context_data_val = 0;
} else {
context_data_position++;
}
value = value >> 1;
}
} else {
value = 1;
for (i = 0; i < context_numBits; i++) {
context_data_val = (context_data_val << 1) | value;
if (context_data_position == bitsPerChar - 1) {
context_data_position = 0;
context_data.push(getCharFromInt(context_data_val));
context_data_val = 0;
} else {
context_data_position++;
}
value = 0;
}
value = context_w.charCodeAt(0);
for (i = 0; i < 16; i++) {
context_data_val = (context_data_val << 1) | (value & 1);
if (context_data_position == bitsPerChar - 1) {
context_data_position = 0;
context_data.push(getCharFromInt(context_data_val));
context_data_val = 0;
} else {
context_data_position++;
}
value = value >> 1;
}
}
context_enlargeIn--;
if (context_enlargeIn == 0) {
context_enlargeIn = Math.pow(2, context_numBits);
context_numBits++;
}
delete context_dictionaryToCreate[context_w];
} else {
value = context_dictionary[context_w];
for (i = 0; i < context_numBits; i++) {
context_data_val = (context_data_val << 1) | (value & 1);
if (context_data_position == bitsPerChar - 1) {
context_data_position = 0;
context_data.push(getCharFromInt(context_data_val));
context_data_val = 0;
} else {
context_data_position++;
}
value = value >> 1;
}
}
context_enlargeIn--;
if (context_enlargeIn == 0) {
context_enlargeIn = Math.pow(2, context_numBits);
context_numBits++;
}
}
// Mark the end of the stream
value = 2;
for (i = 0; i < context_numBits; i++) {
context_data_val = (context_data_val << 1) | (value & 1);
if (context_data_position == bitsPerChar - 1) {
context_data_position = 0;
context_data.push(getCharFromInt(context_data_val));
context_data_val = 0;
} else {
context_data_position++;
}
value = value >> 1;
}
// Flush the last char
while (true) {
context_data_val = (context_data_val << 1);
if (context_data_position == bitsPerChar - 1) {
context_data.push(getCharFromInt(context_data_val));
break;
}
else context_data_position++;
}
return context_data.join('');
},
decompress: function (compressed) {
if (compressed == null) return "";
if (compressed == "") return null;
return LZString._decompress(compressed.length, 32768, function (index) { return compressed.charCodeAt(index); });
},
_decompress: function (length, resetValue, getNextValue) {
var dictionary = [],
next,
enlargeIn = 4,
dictSize = 4,
numBits = 3,
entry = "",
result = [],
i,
w,
bits, resb, maxpower, power,
c,
data = { val: getNextValue(0), position: resetValue, index: 1 };
for (i = 0; i < 3; i += 1) {
dictionary[i] = i;
}
bits = 0;
maxpower = Math.pow(2, 2);
power = 1;
while (power != maxpower) {
resb = data.val & data.position;
data.position >>= 1;
if (data.position == 0) {
data.position = resetValue;
data.val = getNextValue(data.index++);
}
bits |= (resb > 0 ? 1 : 0) * power;
power <<= 1;
}
switch (next = bits) {
case 0:
bits = 0;
maxpower = Math.pow(2, 8);
power = 1;
while (power != maxpower) {
resb = data.val & data.position;
data.position >>= 1;
if (data.position == 0) {
data.position = resetValue;
data.val = getNextValue(data.index++);
}
bits |= (resb > 0 ? 1 : 0) * power;
power <<= 1;
}
c = f(bits);
break;
case 1:
bits = 0;
maxpower = Math.pow(2, 16);
power = 1;
while (power != maxpower) {
resb = data.val & data.position;
data.position >>= 1;
if (data.position == 0) {
data.position = resetValue;
data.val = getNextValue(data.index++);
}
bits |= (resb > 0 ? 1 : 0) * power;
power <<= 1;
}
c = f(bits);
break;
case 2:
return "";
}
dictionary[3] = c;
w = c;
result.push(c);
while (true) {
if (data.index > length) {
return "";
}
bits = 0;
maxpower = Math.pow(2, numBits);
power = 1;
while (power != maxpower) {
resb = data.val & data.position;
data.position >>= 1;
if (data.position == 0) {
data.position = resetValue;
data.val = getNextValue(data.index++);
}
bits |= (resb > 0 ? 1 : 0) * power;
power <<= 1;
}
switch (c = bits) {
case 0:
bits = 0;
maxpower = Math.pow(2, 8);
power = 1;
while (power != maxpower) {
resb = data.val & data.position;
data.position >>= 1;
if (data.position == 0) {
data.position = resetValue;
data.val = getNextValue(data.index++);
}
bits |= (resb > 0 ? 1 : 0) * power;
power <<= 1;
}
dictionary[dictSize++] = f(bits);
c = dictSize - 1;
enlargeIn--;
break;
case 1:
bits = 0;
maxpower = Math.pow(2, 16);
power = 1;
while (power != maxpower) {
resb = data.val & data.position;
data.position >>= 1;
if (data.position == 0) {
data.position = resetValue;
data.val = getNextValue(data.index++);
}
bits |= (resb > 0 ? 1 : 0) * power;
power <<= 1;
}
dictionary[dictSize++] = f(bits);
c = dictSize - 1;
enlargeIn--;
break;
case 2:
return result.join('');
}
if (enlargeIn == 0) {
enlargeIn = Math.pow(2, numBits);
numBits++;
}
if (dictionary[c]) {
entry = dictionary[c];
} else {
if (c === dictSize) {
entry = w + w.charAt(0);
} else {
return null;
}
}
result.push(entry);
// Add w+entry[0] to the dictionary.
dictionary[dictSize++] = w + entry.charAt(0);
enlargeIn--;
w = entry;
if (enlargeIn == 0) {
enlargeIn = Math.pow(2, numBits);
numBits++;
}
}
}
};
export default LZString;
================================================
FILE: plugins/_experiments/markdown/README.md
================================================
experimental nlp on a [unified/remark](https://unifiedjs.com/) AST.
================================================
FILE: plugins/_experiments/markdown/package.json
================================================
{
"name": "compromise-markdown",
"description": "plugin for nlp-compromise",
"version": "0.0.0",
"author": "Spencer Kelly (http://spencermounta.in)",
"main": "./src/plugin.js",
"unpkg": "./builds/compromise-markdown.min.js",
"module": "./builds/compromise-markdown.mjs",
"type": "module",
"types": "index.d.ts",
"sideEffects": false,
"exports": {
".": {
"import": "./src/plugin.js",
"require": "./builds/compromise-markdown.cjs"
}
},
"repository": {
"type": "git",
"url": "git://github.com/spencermountain/compromise.git"
},
"homepage": "https://github.com/spencermountain/compromise/tree/master/plugins/markdown",
"scripts": {
"test": "tape \"./tests/**/*.test.js\" | tap-dancer --color always",
"testb": "TESTENV=prod tape \"./tests/**/*.test.js\" | tap-dancer --color always",
"watch": "node --watch ./scratch.js",
"build": "rollup -c --silent"
},
"eslintIgnore": [
"builds/*.js"
],
"files": [
"builds/",
"src/",
"index.d.ts"
],
"peerDependencies": {
"compromise": ">=14.0.0"
},
"dependencies": {
"hast-util-to-mdast": "^9.0.0",
"mdast-util-frontmatter": "^1.0.1",
"mdast-util-gfm-table": "^1.0.7",
"mdast-util-to-markdown": "^1.5.0",
"micromark-extension-gfm-table": "^1.0.5",
"unist-util-visit": "^4.1.2"
},
"license": "MIT",
"devDependencies": {
"@rollup/plugin-commonjs": "^24.0.1"
}
}
================================================
FILE: plugins/_experiments/markdown/scratch.js
================================================
/* eslint-disable */
import nlp from '../../../src/three.js'
import plg from './src/plugin.js'
nlp.plugin(plg)
let md = `is this [working](http://noitsnot.com) *again*? nope.
## oh yeah
and this is too
--
and **this** will be another section. i guess. \`inline stuff\`
\`\`\`
block stuff
\`\`\`
afterwards
> Alpha bravo charlie.
and then a cool:
* list 1
* list 2
* list 3
hello  world
`
md = `| cool | also | here | | |
|------|------|-------|---|---|
| one | two | three | | |
| four | five | | | |
| | | | | |`
md = `ok **cool** after.
below`
const doc = nlp.fromMarkdown(md)
console.log(doc)
================================================
FILE: plugins/_experiments/markdown/src/Wrap.js
================================================
================================================
FILE: plugins/_experiments/markdown/src/parse/crawl.js
================================================
// [a, b, a1, b1]
const breadthFirst = (root, fn) => {
const list = []
const queue = [root]
while (queue.length > 0) {
// get first
const node = queue.shift()
if (fn) {
fn(node)
}
// add to list
list.push(node)
// add kids to queue
if (node.children) {
node.children.forEach(n => {
// n._cache.parents = node._cache.parents + 1
queue.push(n)
})
}
}
return list
}
// [a, a1, b, b1]
const depthFirst = (root, fn) => {
const list = []
const queue = [root]
while (queue.length > 0) {
// get first
const node = queue.pop()
// add to list
list.push(node)
// add kids to queue
if (node.children) {
node.children.forEach(child => {
queue.push(child)
if (fn) {
fn(child)
}
})
}
}
return list
}
export { depthFirst, breadthFirst }
================================================
FILE: plugins/_experiments/markdown/src/parse/index.js
================================================
import { fromMarkdown } from 'mdast-util-from-markdown'
import { gfmTable } from 'micromark-extension-gfm-table'
import { gfmTableFromMarkdown } from 'mdast-util-gfm-table'
// import { frontmatterFromMarkdown, frontmatterToMarkdown } from 'mdast-util-frontmatter'
const parseMd = function (md) {
const tree = fromMarkdown(md, {
extensions: [gfmTable],
mdastExtensions: [gfmTableFromMarkdown]
})
return tree
}
export default parseMd
================================================
FILE: plugins/_experiments/markdown/src/parse/toPlaintext.js
================================================
// import { depthFirst, breadthFirst } from './crawl.js'
import { visit } from 'unist-util-visit'
// import uuid from './uuid.js'
const shouldBreak = {
heading: true,
paragraph: true,
code: true,
thematicBreak: true,
blockquote: true,
break: true,
image: true,
table: true,
tableRow: true,
tableCell: true
}
const skipText = {
code: true
}
const toPlaintext = function (tree) {
const texts = []
let current = ''
let startId = null
visit(tree, null, (node) => {
// n += 1
// node.id = node.type + '|' + uuid(n)
// console.log(node/.type, '|', node.value)
if (current && shouldBreak[node.type]) {
texts.push({
startId,
txt: current,
})
current = ''
startId = null
}
if (node.value && !skipText[node.type]) {
startId = startId || node.id
current += node.value
}
})
// add last one
if (current) {
texts.push({
startId,
txt: current,
})
}
return texts
}
export default toPlaintext
================================================
FILE: plugins/_experiments/markdown/src/parse/uuid.js
================================================
/*
unique & ordered term ids, based on time & term index
Base 36 (numbers+ascii)
3 digit 4,600
2 digit 1,200
1 digit 36
TTT|NNN|II|R
TTT -> 46 terms since load
NNN -> 46 thousand sentences (>1 inf-jest)
II -> 1,200 words in a sentence (nuts)
R -> 1-36 random number
novels:
avg 80,000 words
15 words per sentence
5,000 sentences
Infinite Jest:
36,247 sentences
https://en.wikipedia.org/wiki/List_of_longest_novels
collisions are more-likely after
46 seconds have passed,
and
after 46-thousand sentences
*/
let index = 0
const pad3 = (str) => {
str = str.length < 3 ? '0' + str : str
return str.length < 3 ? '0' + str : str
}
const toId = function (n) {
index += 1
//don't overflow index
index = index > 46655 ? 0 : index
//don't overflow sentences
n = n > 46655 ? 0 : n
// //don't overflow terms
// i = i > 1294 ? 0 : i
// 3 digits for time
let id = pad3(index.toString(36))
// 3 digit for sentence index (46k)
id += pad3(n.toString(36))
// 1 digit for term index (36)
// let tx = i.toString(36)
// tx = tx.length < 2 ? '0' + tx : tx //pad2
// id += tx
// 1 digit random number
const r = parseInt(Math.random() * 36, 10)
id += (r).toString(36)
return id.toUpperCase()
}
export default toId
// setInterval(() => console.log(toId(4, 12)), 100)
================================================
FILE: plugins/_experiments/markdown/src/plugin.js
================================================
// import { convertToHtml, parseHtml, printHtml } from './html/index.js'
// import { convertToMd, parseMd, printMd } from './md/index.js'
// import { fromMarkdown } from 'mdast-util-from-markdown'
import parse from './parse/index.js'
import toPlaintexts from './parse/toPlaintext.js'
import { visit } from 'unist-util-visit'
const cleanup = function (tree) {
let n = 0
visit(tree, null, (node) => {
node.id = String(n)
n += 1
delete node.position
})
return tree
}
export default {
lib: {
fromMarkdown: function (md = '') {
let tree = parse(md)
tree = cleanup(tree)
// console.dir(tree, { depth: 8 })
return toPlaintexts(tree)
}
}
}
================================================
FILE: plugins/_experiments/sentiment/README.md
================================================
experimental rule-based, compressed-data sentiment analysis by Scott Cram
================================================
FILE: plugins/_experiments/sentiment/package.json
================================================
{
"name": "compromise-sentiment",
"description": "plugin for nlp-compromise",
"version": "0.0.0",
"author": "Spencer Kelly (http://spencermounta.in)",
"main": "./src/plugin.js",
"unpkg": "./builds/compromise-sentiment.min.js",
"module": "./builds/compromise-sentiment.mjs",
"type": "module",
"types": "index.d.ts",
"sideEffects": false,
"exports": {
".": {
"import": "./src/plugin.js"
}
},
"repository": {
"type": "git",
"url": "git://github.com/spencermountain/compromise.git"
},
"homepage": "https://github.com/spencermountain/compromise/tree/master/plugins/sentiment",
"scripts": {
"test": "tape \"./tests/**/*.test.js\" | tap-dancer --color always",
"testb": "TESTENV=prod tape \"./tests/**/*.test.js\" | tap-dancer --color always",
"watch": "node --watch ./scratch.js",
"build": "rollup -c --silent"
},
"eslintIgnore": [
"builds/*.js"
],
"files": [
"builds/",
"src/",
"index.d.ts"
],
"peerDependencies": {
"compromise": ">=14.0.0"
},
"dependencies": {
"efrt": "^2.7.0"
},
"license": "MIT",
"devDependencies": {
"@rollup/plugin-commonjs": "^24.0.1"
}
}
================================================
FILE: plugins/_experiments/sentiment/scratch.js
================================================
import nlp from '../../../src/three.js'
import plg from './src/plugin.js'
nlp.plugin(plg)
const arr = [
"the acting was terrible",
"these pretzels are making me thirsty",
]
const res = nlp(arr[0]).sentiment()
console.log(res)
================================================
FILE: plugins/_experiments/sentiment/src/data/_pckd.js
================================================
/**
* pattern_en_packed
*
* Variable containing polarity, subjectivity, and intensity scores for selected opinion-based words in English, compressed with efrt 2.7.0
*
* @author Scott Cram
*
* Original version:
* @author Steven Loria
* @see {@link https://github.com/sloria/TextBlob/blob/dev/textblob/en/en-sentiment.xml|en-sentiment.xml}
*
* From xml file above, multiple occurences of the same word were replaced with single instance, and values were averaged to four decimal places.
* Resulting data was trimmed so as to only contain polarity, subjectivity and intensity scores.
* All apostrophes removed.
* Added all words from negation array below (with dummy values same as "wont", since they won't be used.)
* Converted to JSON object.
* Format for entries: "word": ["i1.0", "p0.0", "s0.1"]
* i denotes intensity score
* p denotes polarity score
* s denotes subjectivity score
*
* Alternative versions:
* @see {@link https://github.com/NaturalNode/natural/blob/master/lib/natural/sentiment/English/pattern-sentiment-en.json|pattern-sentiment-en.json (Another English language version)}
* @see {@link https://github.com/NaturalNode/natural/blob/master/lib/natural/sentiment/Dutch/pattern-sentiment-nl.json|pattern-sentiment-nl.json (Dutch language)}
* @see {@link https://github.com/NaturalNode/natural/blob/master/lib/natural/sentiment/French/pattern-sentiment-fr.json|pattern-sentiment-fr.json (French language)}
* @see {@link https://github.com/NaturalNode/natural/blob/master/lib/natural/sentiment/Italian/pattern-sentiment-it.json|pattern-sentiment-it.json (Italian language)}
*/
export default "i1.0¦0:N2;1:MG;2:N5;3:MX;4:M7;5:MQ;6:MP;7:M3;8:MY;9:KB;A:M1;B:JE;C:LP;D:L2;E:IX;F:II;G:KX;H:JO;I:IO;J:MW;K:LC;L:L0;aJTbIOcFQdE7eD0fBNgAShA7i8Wj8Rk8Pl7Xm6Sn6Io63p4Zqu4Vr46s22t1Hu0Fv09wPyM;aNellM4oungM;!er,iD;aawwnnnn,rn;a00eWhUiRoMro3tf;manJ0nPodKHrMu3Jw;kmanli89sNthM;!leJLwDFy;e,t;deCDky,t;de,lNnMse,tI;!ni3s;d,li3;addupwitdM2iMo6;ms9te;aOiN0lMre2st2Nt;coJLl-M;advis0intLVo3V;k,ltFB;cGSnPrOsM;nt,teM;!d,s;m,y;!ts;aPeterCiNoDDulM;gC5nG0;bCCcMoFLsu1t1vLL;io7tim;cu5JgA7pMrGst;id,orif5;gl0LltiK8nPppErOsMttE;eMu1;d LZfBleIW;bCinEK;a0Fb0Cc09d08e05f01grL5hYiVknown,likeI7nUorigF5pPreaOsNtMusu1w0;hink4race4;alt0chool0ettK8tirr0;d,liH;aL9lPrM;eNoM;ceDKpKD;cedeLZdi8B;ay4easa2;ec5Hotic0;l5Ompor8NnMq9Rvers1;spir0teM;lliFArrupt0;aNeM;altEHsiDP;mpG5pGG;aiOoMruitfB;cJErM;gett4tunateG5;r,t04;ngaGNvJ4xM;cell0pM;eUlHQ;eserv0ign78;ared-f68h85ivil,oMrit9ut;mMntroEWok0;fFKmGR;eNlMraH6;emLHinH8;fitKliHT;b6dultBPffeMnswFQppeJEsham0vow0waIA;ct0;iFLyM;!-duckJD;a05e01hXiVoSrNwMyp9;ist0o-dimen4I;aPeOiDKoub1AuM;e,tM;hfB;men8Hn9C;diESg5pp0;il1UneFpNt1uM;cIZgh;!-not9Uic1;dy,gGRny,reMt3U;d,soHU;anks,eOiNoughtMrillJ;-provoGPfB;ck,n,rd;atr9mHJoret9;chn9dGen1YnOrM;min3HrM;est5Di7X;!se;leKOme,steF;a1Mc1Je19h14i0Yk0Wl0Tm0Qo0Jp0DtYuNwMympathI6;e1Fi3N;bVcRddI3ffQit4pNrMspensH3;e,prisJre1;erNportiM;ng,ve;!b,fi8Xi57natD9;e3QocaK;ceNh,kM;erBJs;e2XssM;!fB;conscGjeC0norm1seqJOt6urbC;aWeTiRrOuMyliD;mb6nEWpidM;!iI;aMetCOiG1o3utK;ightMnH6;!forGZ;ff,nkM;er,s;adNll9SreotypM;ed,ic1;faJ3y;bBHinFle,ndaKArNtM;e-suppo57ic;k,tM;i3li3;aniDeOiritNlendJ2oMrightFW;ntanD2of;ed,u1;cMnt;iMtac2N;al,f5;bEci1ftRlPphOrLuM;nd,rHWthM;ern;ist9Hom28;e,iM;c91d;!-boBH;aNiMooAW;le6W;ll6Xrt;iNoM;pE3w;ck,gF6p7A;ept9iM;ll0ttiD;ckQgnifica2lPmNnMxth-graFH;ceG7g6istEks;il8YplM;e,iH;e2ly;!eDS;aPeEit,oNriMy;eDAll;ckJd7Brt,uMweL;ld2;dy,ky,llI1m,peFrp;aUcRizurBDlfQnOrNv2SxM;u1y;io7mE8;sMtim93;aCLiA;-acKiD;!ondNrMuFR;et;!aLhaHH;mFsI0;aMum;rMtGN;ey,y;dCPfe,me,rcaHtisM;fMyfi3;i0yi3;a07eTiQoNuM;de,iH5r1sG6thF;b0Afl,hypnol,maFPse,uM;ghMnd;!aFF;ch,dicu88ghtNp-oMsk-free,veK;ff;!-E2iHF;aYcXdWfresGAgUhaDlTmSpQsNtardMwarFS;!ed,s;ourcERpM;ectMoC2;ab6fBiIR;eMut4;lBCtiA;ark4inis2Wo8;atHWe3YigG;rets,uM;l7RrgitAE;!eeGWoubt4uI9;e2ogniz4;dy,liHsS;nNre,uMw;co7ncAL;coHEdom,k;estiOiM;ck,et,rC0xM;ot5;on4;a0Ie0Dh0Bi08l03oXrOsychoNuM;bl5re,taA;lFFt5;eRiQoM;fOlix,miNpMud,vA0;aganda,er;ne2si3;es0Ui1EouG9;ceFmaLor,sBSva8;acA6ciNdi3TgTse2tMvG;e2Sty;o7se;et5iPlOor,p0AsNtentMwerCR;!i1;iAsHH;ar,it9;gMntF;na2;aPeNodM;!di3;asMonaH;a2ed;cGBin,titud9IusH9;nMo7ty,vot1;heaMk;ds;antasmagMenomen1ilosoph80ys9;or5;aPeviDppeLrM;fe8MpMsAO;etuMlex0;alCW;cDCky;infBlRrNsMthEC;sioFDt;aOtiM;al,cM;ul6F;de,llel;e,p4;bYccaXdd,ffVkUld43nCNoz90pSrRthEutOverMwn;-the-top,aMbGKexcit0whelFH;ll;dF8rageNsM;iCPt5F;d,o7;di99ig9Fthodox;enC4po6ItimM;um;!ay;beFNeM;rs;siA1;ed8KjecAsMvG;e7Stacl8M;aSeQiGNoNumM;b,eFP;!b6nvio9CrNstalg5tM;!ab6;m1wegiC;ar,cMedFgaAithErve-racBWt,vEw,xt;essaL;iGKk0meFrrF1sIturalNuM;ghIseEO;!iH;a0Ee05iZoRuMysterG;ch,g4OltiNnda4CsMzak;ic1t2;lMp6;atM;er1;dQnPrNst,tl42uth-waM;te6G;alMe,on6U;!iDR;k3Yosyllab5;!eM;rMst;a8n;dQghIlPnNsMx0;er4fiCGplac0si3;dMim1or,us;-boggDKleC4;d,i9D;!d6;aSdiPlodrama,m7HnOrNsMtaphor9xDP;meriDFs4H;ciFe;a8Lt1;caNev1ocrM;e,iI;l,tiFR;gEnMsB7;!ingAI;d,gVin,jUlSnPrOsNtM;hemat9uC1;culi3IsiFMte4K;k0ri0ti1ve4V;nerB1oNq2VyM;!-sid0;ri1;adroit,eM;!vo83;or;ic9EnifiM;ce2;a09e05iVmao,oNuMyr5;c8Ysh;c1g9lSnQo9HsePuOvMw,y1;ab6eMi3;!d,ly;d,sy;rs,s;eAMgM;!-wiAB;!ol;ab6ceUfelSghtQkOmNnguiHtMve8Z;eCAt6;it0p;ab6eM;d,ly;!-heaM;rt0;iMo3;ke;ntG;aOftNgMn6Jss1P;al,endaLib6;!iD9;dBNst;me,rge1Xst67tNughMwfBzy;!ab6ed;eMtE;!r,st;ey,iM;ll0nd;aOewiDoy,uM;stMveni6;ifi0;ckassMil,mm0pane8M;!es;c0Vd0Rll0Qm0HnPrMs2tB2;iDon5rM;eleMi5O;va2; 0Ba0Ac06d02eYfWgenGhuma25i45nUsStMvenA;eMiBMrigui3;llOn8ErM;e57naM;l,ti7C;ectu1igentM;!sia;a1YecuAGpirMta2ulting7Z;a77i3;er,oM;ce2vaA;aMlexDJuriaK;mo7nti6tuC2;luOvQxpM;eMlic4reDF;d5LrieCV;ct4;eOiNomM;it4;e,spens4vidu1;ciph6Qpende2;alc8MoMredD9ur4;heDOmpNnMrruX;sistenci5Gven5D;ar4e6L;ppo33rticu90uspicG;good tMsto8W;as8;aginaAbeci6itati88mTpM;aRePlicOoMressCP;rMssD0;ta2;at0it 7X;cc4rceM;ptCW;s31t51;ane2en7G;!eg1;eOioM;cy,tM;!ic,s;al,ntifi4;ky,on5y;aVeTiSoOuMyster9;ge,mM;an,b6oBZ;llBGnestOrriMt;b6fM;ic,yi3;!-to-god;dd9TghSlarGnd6Pstor3Bt-and-mi8Z;aMro5;lt4YrtfeBVvy;d2haTlf,ndSpQrOs2teNve2zarM;do7;!d;dMsh;!er;hazaCEle8RpM;i6Dy;-held,so8Yy;!haM;!haM;!ha;a0Ee0Bi0Al07o02rNuM;ard0ilI;aYeUiRoPrNuM;d6Veso8R;!rM;!r;ss,tesqM;ue;eNm,pMtI;pi3;f,vo7;atNeMy;k,n;!eM;r,st;ndMph5tu0Z;!iloqAU;dforsak8Yld8YoNrM;g4Ny;dMfy;!y-gooM;dy;ad,oNuM;ey;b1om;a2ft0mmic5F;nMrmCtt4;er6Ct6uiM;ne;meMrgantuCw5By;!changE;*c6Wa0Le0Ii0Al05o00rSuM;ckQllOnNrtMtu7Z;hEiBK;!ny;! of life,-M;bodi0fleBFleng2B;!ed,i3;agi6ePiMostbitt8DustratJ;end6VgNnM;gy;h1Eid;eNnMqA4sh;ch;!-thin6JstM;an85;llowi3rMur21; su7KcOeign,getNmMtu97;er,ula5;fBt4;ed,ib6;aOippa2uMy;ffMid;!y;s34t,wM;ed,le72;c43endiDftie1RlSnPrNtMx0;!ti3;m,stM;!-st10;aNeM;!-loo62;l,n7U;l0t2V;aNeb6licMma6veriDw;ito7;rfB;bVci1iTke,l4TmRnQrOsNtIultFvorM;ed,i8;cinaKt;!-out,cMthermo92;e,ic1;at5taH;iliMo7;ar;lMnt,r;!ed,s,u6R;l0rNuM;lo7;ic8F;a0Qc0Nd0Lerie,ff0KgoiHl0Im0Gn08p5qu1r06ssen05th9uropeCv03xM;a00cXhWot5pSquiRtNubeM;ra2;eOin1BrM;aMe6I;!ordi2D;nUrn1;si8;eMlo6OresS;ct0nRriM;e90mM;ent1;au0YilaraK;eMitJu43;l2Ip31sM;si9U;ct,ggM;er7X;eryday,iM;de2l;ti1;ot5ron2CstwMudi8;hi6;dRerg6LgQigm5SjoyPlighOoNtM;ertai3OhusiaHi5Z;r64ugh;te3M;!ab6ed,i3;a3YliDros77;eaMle5K;ri3;o2KpM;ir9ty;abo8UeM;ct,ga2m2O;ecAi3;gy,uM;ca2E;centr5oM;l6DnomM;ic35;rlMsy;iEy;a11e0DiXoSrQuMynam5;dsvil6e,hNllMmb,sIuuh;!s;!hhM;!h;aMeadfBi0own0unk,y;g,m52;cum28es2meHnOubNwM;dy,n;le,tfB;e wiMt;th;a00dZffXgit1mWrUsMurn1;aRbelie06court1De0LguQhone78lik0possePtM;aNinTraug3XurM;bi3;nt,st4K;ss0;stJ;bl0ppointMst7I;ed,i3me2;eMty;ct;!-witt0;e8FiM;cu7Fde2;act5nt;lect1pha3A;ad08bau07c05ep,fZlVnomina1GpSsPtaOvMxtr1;asMelop0o6W;taK;il0;erNpe7OtrM;oyOucA;vi3;lNressM;!i3;or4;iMuxe;cNghtM;ed,fB;a8io7;eOiMt;cMni8;ie2;cMn2G;atM;es;e2reM;as0;ch0;!ly,pC;iNnge6Lrk,zM;ed,z55;ly,nI;a27e21h1Li1Kl17o01rTuMyn9;lPn1LrOsNtM;e,ti3;hy;io7re2si7F;iNtM;ur1;naL;aSeRiPoOuMyi3;ci1dMel,shJ;dy,e;ok0ss;mMsp,t9;in1;aAd6Qe1A;fIp,zy;ar1Ac0Qhe74l0Om0BnSol,rNsmopolitCuMw,zy;ld2ntFrtQ;iacPpNruptM;!ib6;o6HuM;le2;eo7;c00fYsUtPvM;eNinM;ci3;nZx;ePinOrM;iv0oM;versi1;ge2;mpo3Xst4;cGecr4SiMta2um41;dNsM;te2;er4;iMusJ;de2rm0;avo-convex,eMi0Ore8;iv4pM;tiM;on1;a,e-at-4fXic0DmVpM;eTlNreheM;ns5W;ainQePiM;c4EmM;enM;taL;te,x;ed,t;l3Ote2;ercialMon;!ism;ort4;d,lect5LoM;rfBss1;ky;aVeSoPuM;elessNmM;sy;ne1Y;s0udM;-covMle1W;er0;aMvE;nMr;!ly;ssMustrophob5;icMy;!al;nem1Qviliz0;aXeTiPopOrNurM;ni3;istiCon2N;py;ck2DlNneMtch46;se;diDlM;i3y;ap,eM;rNsM;ie3Sy;fBy;llenOngeFrM;acteriHiMmi3;sm1Bt4;gi3;aQlebr38ntOrM;emoni1taM;in;er,rM;al,ic;seF;cophoWlUnTpRrPsNtMuH;c2Bh36;t-irMu1;on;diac,eM;fBle0W;ab6tivM;aKe;d3Ct;cMm;ul4;no7;a0Ie0Ei0Cl03oZrNuM;d1Hsy;aUeathtaTiRoNuM;sh0t1;adMk1F;!-M;miM;nd0;ef,gMllia2tiD;ht;ki3;insiNsh,vM;ado,e;ck;diOgg0ilerpNld,nny,otleg,rJundF;le0A;la8;ly;aSeRi29oMue;nPodM;stNthirsIy;ty;ain0;de;ak,ch;ck,nMst0ta2;d,k;gMograph5ttEzar08;!gE;autifBco24efy,hi1YlNst,ttEwitc17;er;iMov0;ev4;ck,dRlmy,nQrOsNttlM;efB;e,ic,s;barMe;iCo7;al,d0g-up;!neM;ss;b34c2Qd2Aeriform,f20g1Whw,i1Tl1Gm15n12p0Qr0Gs0At06uXvVwNxiomM;at5;aSeQfBkOwM;!wM;!w;wa32;ul;aLsoM;me;re;ail4eraMid;ge;rea8strTtM;hPiHoM;biograph9noM;mo7;st5;eNorM;itaA;nt5;aliC;mospher5rocGtMyp9;enMracA;da2tiM;on-getKve;cQhPiCkew,sumpAtM;oMu8;nis04unM;di3;en;et5;bitUchaeRduo7e2oQre14tM;eOiM;fiMst5;ci1;siC;us0;olM;og9;ic1;raL;hon5pMt;aVeSlRoQrM;eciat1IoM;acNpria8xiM;ma8;hi3;r0Usi8;aud4icaA;aNtiM;zi3;li3;llJre2;gMnoyJxG;erMry;!ed;aRbPeNuM;si3;n4rM;icC;itG;io7;tMzi3;eurNoL;ry;!iD;sh;aWcohVg08iSlNterM;na8;-arouPeNusioM;ns;g0viM;at0;nd;enMve;!aK;ti3;ol5;rMs;mi3;nt,rM;ed,heM;ad0;ed,haOiNlM;ow;le,taA;st;fTloSoremPrM;aNicC;an;id;enM;tiM;on0;at;ab6irmaAlM;ue2;ama2dZeWjectiv1ministr4orUuTvM;aReM;ntuOrM;saAte2;ti0N;ro7;us;nc0;lt;ab6i3;ab6;pt,quateM;! M;to;ictMl0;ed,i0C;adem5cSquaiRross-the-bQtNuM;a8te;iNu1;al;ng,on,ve;oaX;nt0;eOomplNuM;ra8;ish0;ssM;ib6;le;ic;horYle,oXrUsNuM;nda2;enRoNuM;rd;lu8rbJ;ed,i3;ng;te;ce;iMupt;dg0;ed;ve;re2;nt|p0.0¦0:3I;1:2U;2:35;3:3K;4:3A;5:3E;6:3B;7:2W;8:2A;9:3J;a36b2Tc28d23e1Tf1Jg1Gh1Ei17j16key,l0Zm0Pn0No0Kp0Dqui0Cr06sQtJuFvDwByA;el3Foung1;estXhi3DoA;man2UoP;aAeter4isu0;porSri7st;ltima39nApp1rb4tt1;aBcr0AiAw6;nterrupt6vers0;vow6wa1S;eDhBiny,oAradi2B;p2t0;eAiJ;atr2m2Uoret2;chn2enBn,rrA;est0Jif3;!age;ame,eNhMiKmall1oHpFtaDuA;bBch,dAspense0L;den;consci7seque8urb4;ndaArK;rd;an29ecAiritu0;if3;lButhA;ern;e,id;le8mA;iIp5;e1ort;cond,lf-acAver0;ti9;eBomant3uA;r0ssi4;al1Yce8d,guClAminisce8spe2P;atAigi7;ed,i2T;lar;et,rky;aFers1IhEi7oCrAsych29ubl3;ese8iAop1;or,va29;igna8lAssib5t0R;it2;antasmagor3iloso20ys2;lp2Crallel;bBccasi1Bn1MpAutsi1Overall;en,posi23;je2Bvi7;ak6eAorwegi4umer7;cess0Wt,xt;aGeEiCoBuAysteri7;ltip5s2;de0Yr0;dAx6;!d5;diAtaphor2x1X;c0ev0;le,nAr0Cs09themat2;oAy-sid6;ri0;aCeBike17oA;c0w;ft,ss1;rg1stCtBwA;ful;er,t1;!i9;apa0Tew0Z;mFnAr0Yt1C;calcul1NdBevCi00n1s0JternaA;l,ti0M;epende8iBomA;it1K;e,vidu0;men0Nplicit in;and-held,eartfelt,istoricAum4;!al;eBia8lob0rA;a0Teek,itty,o07;n13rm4;aIema5iGluid,oErBuA;rth1tuQ;agi5eA;eAnch;-thinki9standi9;llowi9rmAurth;er,ula3;c04naA;l,n05;bricat6ci0rthermost;arli1ccentr3mo01nGqu0rstwhi5sDurope4xtA;eAra;nArn0;si17;pecial09sA;enA;ti0;gl05oBtiA;re;rm7ugh;ai03eCiBoAynam3;cumentGmest3ub5;ffere8git0urn0;ep,finiteAnominaOxtr0;!ly;athol3entrThPinem08lass2oFrDuA;linBnni9rA;re8si0T;ary;it2oAuK;ok6ss;arMmmerInCrpoBsmopolit4untleA;ss;ra08;cCsA;ta8;nt;avo-convex,epA;tiA;on0;ci0;iBrA;isti4onX;neA;se;al,ic;aKiGlEodiDrA;iAoad-mind6ush6;ef,tA;ish;ly;ank,onAue;de;gBograA;ph3;!g1;er;ck,nd6rbar7s3;ous;boXcSdOfKgJlternaImerLpproachi9rchaeGsi4tEuBxiomA;at3;strBtobiograA;ph2;ali4;mosphAyp2;er3;olog2;ic0;te;low;loat,oremention6rA;ic4;an;ed;diCministrA;ab5;le;ctiF;adem3tA;i9u0;al;ng;ic;ve|s0.1¦a0Cb08c00dXeTfPgOhNiLlJmDobjCp8respCs4t2un1w0;ants,orR;affect0Fco00origin0HprocXw0F;e0heoretTitular,wo-dimen8;chnSrrestE;e2ileHlippLmiQo1peHt0ucceeds;artKumbP;lKur0A;amXlf-actI;hantasmagor05olitNro0sychologN;fes1p0;aganda,er;sion07;ec2;a2edica1i0;lita00nus;ti04;le,n0ture;o0y-sidZ;ri00;augh,i0oses;nguiDteraU;cy,mplicit in,s0;nt;inderTumF;ettab6rey;ew,iftie2lu1ollow0reestand0;ing;id;th;mpir2rstwhi1xt0;ernOra;le;icM;extrLisposs1ome0rownJulls;stF;essH;a6ent5lo3osmopolit2r0ulturI;o0u7;okE;an;sCud0;less;er,r7;nt,thol6;a2ig,lue,o1ru0;sh7;dily,gg6;nd5re;bo7ct5djectiv6float,ll3mato2p0;hon0preciat3;ic;ry;eg0usions;ed;ion,u0;al;ve|s0.0¦0:1O;a1Gb1Cc10d0Re0Qf0Mg0Hh0Di09j07kill1Tl03mWnUoTpRrMsFtAu6v4w2y1;ellow,ou0J;aste1estHhi1Nooden;!d,s;a1eter1Oisu0;cuum,porif1R;n2pp0Fr1seZ;b1Lin0R;explain1Li1;nterrupt1Kvers0;e3h1oilet,rapp1J;e1i7;atr1Bmat1K;en1n;!aB;adi0Te6i5outh4pani0Yt2u1;burb1Ccce0O;anda1retch1C;rd;ern;nks,xth-gra0V;cond,izur0Ever0;e4o2u1;r0ssi15;hypnol,ugha1;ge;d,ha0Nlat0C;arallel,hiloso0Rr1;esent,ior,ov07;bstacl06ffers,pposi0Wverall;e1orwegi0Y;t,xt;a6e4id3on2u1;ltipWs0Qzak;key,osyllab0Y;!dU;di1x0R;c0ev0;rAthemat0L;a1eft,oc0;sti0Rt2w1;ful;er,tF;a1ewi06;il,pa03;mitation,n1ri04t0A;consistenciPdie,i2terna1;l,tM;ti0;a3i1;storic1t-and-miQ;!al;nd-held,rd5;amecha3e2lob0r1;eek,oM;n01rm09;ng1;er;a3inan3o1rench;rm1urth;er,ula08;ci0;ngliNurope02;aily,e4i3o1;cumentBub1;le;git0urn0;fec3nominat2stroy1;!iZ;ion0;at1;es;ardiac,h9lassNo5ro4u1;lin2rs1;ive;ary;ss;m1ncavo-convex,rporaK;a,mercial1;!i1;sm;i2r1;istiIonC;nese;ack,iographKl2oilerplaDriti1;sh;ank,on1;de;bsence,cEfAlterna9merBpproachiFr5siCtmosph4u1;str2tobiogra1;ph5;ali9;erC;chae1rest;olog1;ic0;al;te;oremention3r1;ic1;an;ed;adem2ti1;ng;ic|s0.9¦0:1T;1:1N;2:1M;a1Cb14c0Qd0Le0Df07g06h03iXjUkind,lSmPnNoMpJrGsBt8un4w3;elcome,ise,orth12ro1Q;asham0befit0Pchas1UdignTexcell0f5grad0ha4necess0Hpr3;eced7opiQ;mper0ppy;aith16ruit16;a3ren0O;l3ste0W;ent0;ensi1Jp6t5u3;bnorm0Aper3rpris0;fiOior;at14ereotyp0;ectac8ontane1;a4e3ofl;doub0Jleva2source0W;nk,re;ain0Uerplex0leon00o3rolix;p3wer0L;ular;bedIptimum,verexcit0;a3o0X;me0Hugh0N;annerly,i4o3;de0Vtley;gh0Knd0E;ate0TenCicen3ong-wind0;ti1;ackass4ust3;ifi0;!es;mpat7n3ron0L;auspici1credi0Md5exp4huma3tellige2;ne;ed4lica0K;ispensa0JomiZ;ie2;a4ero0Fonest3uge;!-to-god;nRte,zard1;orge1randiloque2;a7i6l5r4ull3; of life,-fledg0;ee-thinki0Kingy,ust8;ippa2y;ll0rst-st0H;bl0ir,nt7vor0;conomic9le7n5rot05x3;hila3perienc0ubera2;raE;orm1thusi3;ast01;ct,ment3;ary;al;anger1e4o3;ne with,ubtR;bauch0ft,l4p3;loraWressi05;ica09uxe;aDhBiviliz0lassy,o8r4ut3;ti02;a5u3;d3sB;dy;fGzy;cky,ntes4r3;pule2ruptiN;taM;ill3urniU;iTy;re4st-iron,tc3;hiR;less;a8eefy,l5o4ra3;insick,sh;nny,otleg;ast0ood3;thirs3y;ty;rbar1ttle3;ful;bsoKcJdCfAgha9hw,lgBmaziHnnoyiHpp7rtesian,s5ttenIuthoritaIww3;!w3;!w;cet3tuJ;ic;alliClauda3reciaD;ble;st;firmaAra3;id;dic8ept,o6ve3;ntur1rte2;nt;ous;ri3;ng;tive;ross-the-board,u5;lu4rb0;ed;te|s0.3¦aTbScPdMeHfEgreen,haha,lDmCpAre9s2thought-provokVundeservOv1w0;haddupwitdQonky;apid,e6;e3h0ucks;a1o0;rt,uldA;m,peless;cond0rmon;a0hand;ry;al,gurgitates;ar8erson9hilosophJi0reachy;nk,ous;asculine,odern;ow,ush;ail1luff,reque0;nt;!ed,s,ure;ar3ssen1x0;cruciating2ploitE;ti0;al;ly;evelop1is0;abl0tinct;ed;hitch1onc0;eiv7rete;at;est,usy;d2lienat1xiomat0;ic;ing;ministr1ult,vers0;ative;able|s0.2¦a09b06c02d00eZfVgrief,haUiRjoy,lQmKnHoFpDrAs8t6u3w0yarn;as0Fe1iAo0;nt,u02;ll-intentionVre0D;gly-duckl03n0s3;answerTe0fortunateS;ngag01ven;hanks,on0rouM;el00;milPob06poof,ta0will;inlYte-supportO;e1obot00ui0;ns;dunda03grets,moZ;erpetualJiBl0rofiterT;atitud1od;ld,oz0;es;e1o0;!t;ithVvV;e3i1u0;ch,ltilaterSstU;nor,s0;fire,placA;diocri0lodrama,ntPtaphorO;ty;augh7egNosers;mpercepti1n0;fatuat5telligentsia;ble;dLppinDsLveL;ix2orc2rustrat0un;ed,ing0;ly;ed;conomBrudiC;evoid,idFo0;esEnt;hoppy,inemat8luelessn5o0;mplain1u0;ldB;ed,t;adn1udd0;ing;ess;glow,i6ng5re6typ3u0;rea1tist0;ic;te;ic0;al;er;nt|s0.125¦bas2f1independent,occasional,s0;ame,pecif1;lat,oreign,uture;ic|s0.5¦a1Db14c0Vd0Se0Pf0Fg0Ch0Ai07l04mZnYoWpNquiMrJs8t5un3v1w0;himsEorthwhi19;a0ulner17;gue,ri0W;a0blem1Glike0Estirr1H;b15ppea1Cwa0F;e1houghtWiny,o0ruthWyp9;p,uchi1B;n0Urminal0A;afe,h8i7k5m4t1u0;bt10ch,dd03ffoca0GrprF;a1eaAi0;ff,nks;le,rt14;all0Uooth;ept0ill16;ic0W;mplist12nce03;a0od3y;ky,llow;andom,e0ip-off,omant0Z;a0deemi0Xminisce0Kspe6;dy;ck,xot0W;alp0Le7henomen0Oinheads,lausib0Mo4r0uW;e1ima0Com0;isi0S;di0g3;ct0H;i0te0C;g0n03;na0A;ace6ppe05;bvi02ffbeat,k0pGrdina04;!ay;ot0Aumer00;a3e1ild,o0;re,st;aning0re;ful;jor,ny;arg03ess03i1o0;usy,v03;ab03k02mp,tt03ve;con0Bdentifi01lleg04mplicat0Dn0;articula06terest0;ed,i08;ahahaha,ea0ighX;ltAvy;en1immicky,luey,old0reatV;en;erXuine;a8i7la5or3r1urt0;hRiZ;agiSesh,iend0;ly; su0gettP;re;s0wZ;hy;ne,t2;miliar,rce;arliIccentrTmpty,n1xhaus0;tiR;deariQergetRjoy,ough;efiniMi1u0;ll,mb;m,shon8;heesi7o0;ar5m3n1un0;tless;ceptionDsci0;ous;e-at-8ic,mon,plimenta0;ry;se;est;a6e2i1lata0;nt;gg1tt1;liev1tt0;er;ab0;le;n0ss;al;bridg7ccompl6lcohol5pp0;ea2licati1ropria0;te;ve;li0;ng;ic;ish0;ed|s0.3333¦adequate,brief,const0extensive,first,hidden,main,older,particular,quiet,realistic,subject,vibr0;ant|s0.6¦a0Ab08cZdReMfJgIhahahahaha,iEjamm0OlBmAn8orthodox,p7r6s3un2w0;arm,ell-off,o0;manly,r02;hesitati0Gknown,notic0L;ec1hrill,t0;ark,inker;!u03;aucReaso0Aisk-free,ude;eevish,loddi0Boor;a0onviolT;turalisWuseT;ark0DinimF;a04e1ifel0o0B;ike,o06;ftist,gi04;cky,n0;c0experie05flexi02tZ;ompa0u0;ra00;ood,uard05;a1rostbittRu0;ck,ll-bodi03;lIst;colog2n0rroneBth2veryday,xtinct;ig8joy0;aTiU;ic0;al;estrucFi5r3u0;h0sty,uuh;!hh0;!h;a0iSy;ma9;aphan0ffer4slikQ;ous;a5loud-coverOo0ryiJ;mpelliIn0;ci2secr1ting0vex;ent;atK;se;p1us0;tic;tiF;izar0road-mindF;re;cBd9larmi8me6pp3r1sh0we2;en;bitr0ousB;ary;etizi4ortion9rox0;ima0;te;na0;ble;ng;dict3equate to,va0;nc2;quaint1ti0;ve;ed|s0.25¦aDcAe8fic9juveni7logicCm5odd,p3re1s0usuC;eason5o6tel3upporting;c0ligious,petitive;e8ognizab4;ast,o0;lar;arri0ix0or6;ed;le;duca0qu3vide2xact;tion2;entr1onsiste0;nt;al;mateur,ware|s0.8¦a05b04cTdNeLfHgEhaphazard,iAl8m7p6re5s2tiOun0vulgar,well-advis08young07;blink05c0focus07think00;ared-for,ontroversiVut;arcasOh1kitt04t0uckerA;abb02eadfaF;it,ock03;putVtard02;ivotQrecise;aladroit,uggy;ikZo0;lol,ud,vY;diot2mpassBn0rrit1;corrupMfuri0;atT;!s;argantuan,entNrr0;!r0;!r;*2a0ree,u2;na8rthermo0;st;ckL;ffect0xcitK;ive;azKe4i1ow0;dy;dac1ffidJrty,s0;astrCbelievFturbF;tic;fenseless,servD;a6h5o1r0;ap,itic2;l0mfort5;lec1oss0;al;tib3;arit1ild7;cophon2lcul0ndid;ab0;le;ous;loodstain3right;bhorr3lleviat2mateur1nnoy2pposite,ttention-gett0;ing;ish;ed;ent|s1.0¦0:3W;1:3V;2:3T;3:36;4:40;5:3S;6:3P;a3Ib3Ac2Kd28e1Yf1Mg1Ch15i0Wkey,l0Tm0Jn0Go0Dp07qu05r01sMtJuDvBw7yaaawwnnnn;ac05e9it2Io7tf;nde1Rr7w;st,t2K;alt2Ji45;a1Ci7;c5o1Z;g29lti2Pn7tt0H;appetizi1believ4comAexpect0f8i7predict4real1Zsalt0usu6;nspir0q16;air,or7;gett4tuna2M;fort4mon;e8hril25ire38op-notch,r7wist0;emendo2oubl0;d5r0S;aJcaHeFhoc2XiEoDpCt9u7ympaW;p7rre6spens2R;erb,por3L;ereotyp22ri2Uu7ylD;n14pid7;!i1Y;irit0lend31;ft-boil0phist2Cr3D;cke10nist00;lf7ntiment6rious1Rxy;ish;r7t31;ey,y;d,tisf7;i0yi1;a9e8i7uthl10;dicu11ve2D;al1Jfres2Vpel18tardNwar2U;nc08unc1P;estion4ir7;ky;aBerfect,leas0oAr7sychot2T;e8icel0To7;fou0Fmine3ud;c5t1F;ss0Ktenti6we0O;thet2O;bsess0n19utrage8ver7wn;-the-top,whelmi1;d,o2;a8e7ice,ostalg2Kumb;cessa2Pedl0Krve-rac22;i2Ss17;aCe9i8oron7yster5;!s;nd-bogg13ser4;a7diocre,m2Pna1Frcil0F;g7ningl0E;er;d,g8levo0Mrve0Es7;si2Kte09;ic7nifice3;!al;a8egenda2Di7mao;ght-heart0ke0S;ugh4zy;de6ll,mAn7rreleva3; good tas16appo0Aconvenie3evit4famo2gen5nova2Cs7tDven2C;ane,pir7ul1H;a0Bi1;beci2DmAp7;o8ress7;ed,i28;rta3ssS;en1J;aBeartfe0Dilar5or8um7yster0M;oro2;ri7;b25f7;ic,yi1;nd1Hp7;lQpy;iFlad,oDr7uil0D;aBeateAi9otesq8u7;d0Ye1D;ue;evo2m,ppi1;st;nd;o7ry;dy-goody,fy;a3ft0;aEeCiAlawlForc9rig7unny;hte7id;ni1;ib1O;lt03n7;al,e-loo0S;a7eb1Llicito2;rf0X;bu9i3ke,mo2r8ultl7vori09;ess;!-out;lo2;erie,goFlEspecialOvil,x7;agger07ce9ot11presAqui8tr7;aordina16e0S;si02;l9p8s7;si17;tion6;le3;aboEega3;ist0T;aFeBi8r7;eadf0Hunk;fficu8m-witt0s7;gust09traught;lt;ad9finite9li8spe7vasta02;raP;c5ghtf0B;ly;in8zz7;li1;ty;aThNoDrAu8yn7;ic6;r5s7te;hy;e8u7;ci6de,el;a0Jepy;ld,mDn9r7urt8;iac7r0O;eo2;firm0sum8vin7;ci1;ma7;te;ic6pl7;ic7;at0;a9ee7;r7sy;fNy;llen8r7;ismatVmi1;gi1;ptiva8r7;efI;ti1;aDeCleBorAr7;aZeathta8illia3ut6;nt;ki1;ed,i1;ak,ch;autifAlov0witcI;se;bWdTff4gitaRirhead0las,musi1nLpKrtiHsDtCvBw7;e8f7kwaW;ul;so7;me;id;roc5tracL;sumpKto7;nis8un7;di1;hi1;fici6st7;ic;al;pall0t;g9x5;io2;us;ry;ng;ed;ti7;ve;or4;ab7;le;r8su7;rd;upt|s0.7¦aZbYcSdMeHfEhaDiAl7m6open-mind01p5respectPs4t3u1w0;ary,orkmanlike;n0sed to;adulteratYcriticNhealthy,ilaterNplay9settlQtrace9;hrillXirX;ecret,pright4uffers;lacid,retentiU;esmerizModer8;ight,o0;l,ne0;ly;maginat8n0;calcul0expressJnoceQ;abJ;r2tN;iendi1ortun0uckM;ate;sh;ffBn2x0;haustIpens0;ive;g0joyGtertain8;ag7ross7;e4i0udsvil9;alect2s0;appoint4taste0;ful;al;creas9ficieAlight9;heap,lean4o1red2unn0;ing;here7mprehens0nfus6;ib0;le;!ly;ang-up,ehind,oundless;dama2ir1utonom0;ous;ed;nt|s0.4¦a0Bbr0Ac03d00eWfTgShRiOlMmKnFpDr9s5tries,u3v2w0you05;et,ho0Di0;de,ld,n;itVocationV;glin05n0;avow0Ebra7paid,read,school0E;atisyfiZcum,h2imilar,lDmall,o1tr0;aight,uttiY;phomorRu09;owery,rie5;elat09ight1ou0;gh,nd;-mi0iB;nd06;ea0risUut3;ky;a2e0;ar,g0;ati00;k00rr0turF;ow;anque,esNo0;d,raliziJ;ea0oI;st;diocy,mmaneQn0; stock,competePdividu8eluctNsultingly,t0;ellectu7riguiE;ahaha,umbM;ame,raph6;a1everish,i0luffy,orgetD;rm,t;rcic2tty;nlighteni8p2xpe0;ctLriment0;al;ic;ark,e1i0;rect,sappointmeD;ad,ep;ap9easel5lum4o0urreB;lor2mple1nfusi0;ng;te,x;ful;sy;ess;avado,oken;cuate,g7l4skew,ttenda3v0;ail0erage;ab0;le;nt;i1l-arou0;nd;ve;ed|i2.¦definite1especi0re0serious1;al0;ly|s0.1667¦c3dynam5fema2half,in1mundane,p0slight;a1revious;coherent,ner;le;lass1o0;ntemporary,w;ic|s0.65¦cool,emotion0lyric,norm0sweet,true;al|s0.625¦able,entire,shady,weak|s0.75¦aKcGdEeDfabricIgBi9l8origin7poetLr6s4t2vivid,wi0;ll0nn0;ing;ot4ra0;dition3gH;h0loppy,uit5;arp,eer;emark3ich;al;ame,ovely;mpecc0ndecipher0;abC;odforsakAr0;eat,itty;dgy,ndless,xcit5;etail4is0;appoint3eas3;alm,elebr1laustrophob4o0;ntriv1zy;at0;ed;eriform,gi2li1mbitious,uthent0;ic;en;le|s0.6667¦b3compete2dece2insta2s0;e0uper;nsational,rious;nt;ad,lind,old|s0.0667¦l0public,social;ast,ess|s0.05¦missing,outside,subsequent,topical,victim|s0.1429¦limited,physical|s0.375¦accessible,due,other,private,s0;lick,traightforward|s0.0769¦regular|s0.3571¦conventional,plain,simple|s0.1333¦gloom,spiritual|s0.55¦criminal,full,responsible,subconscious|p-0.0125¦absence,vacuum|p-0.05¦arreDcCgAl9m8obstacl7p6rehash,s1un0well-intention5;affect4explain4thinka2;adism,eizur5ixth-grade,t0;r1um0;ble;ange,etch0;ed;assionate,erpetually;es;inor,onk2uzak;efti3ong;argantuan,r0;ey;ardiac,hangeless;st|p-0.1¦a0Nb0Jc09d00eXfVhaUiQjaPlNmJnGpErAs6t5u3w0yarn;as0Te1haddupwitdat,ide,o0;nt,u09;re0Rt;gly-duckli0Pn0rin03sed to;answer0Qbrand0Qcook0QfortunateUknown,proc00;on09ri02wo-dimensionG;e1hou04inks,lippi0Moft-boil0Op0tereotyp0Owill;e0Moof;c0riousQ;!ondhand;e2o0;bot0Ehypnol,ugh0;!age;grets,mo07;arti7eppe0Ai0ropaganda;nk,ty;e1o0;!t;ith03v03;ent2i0onosyllab06ust0A;lita04n0;im0us;al;i0oneB;a4felo04;il,mm05;cy,mmane03n0;articuSconsistenciGe0telligentsia;lucta0xperienc02;ble;dZrdRsZveZ;everish,luff,orgetMu0;ll-bodiYrZ;mpty,x0;cruciating0pectW;ly;e5i2o1r0ulls;ag,ownT;esRnt;dQs0;believiOposs0taP;essP;fec0void;at0;es;a7e4l3o0rushLurious;m1ntingeJu0;ldI;a,mercialism;osHuelessn2;as0nt7;el0;ess;nt,re0;ful;itt2oilerp0;la0;te;er;dversa8g7i6l3phon2r0skew;bitra0e5;ry;ic;armi1l0;eg2usions;ng;nt;ed;tive|p-0.2¦autist0Gb0Ac02dTeveryday,fRgPhNiKkill0FlImEnarrow,oCp9r8s5tr4un2wa0;n,ste0;!d,s;cared-for,e0notic0CoriginWschool0C;ngagiZvM;app0AoubP;h0ophomor0Atark;a0it,owery;m,pe05;edundaOightist,ound;l1re0;achy,dictabJ;atitud1od;oz0rthodox;es;e2i0;ndXs0;fire,placYsiM;diocriAssy;ead7imp,o0;ng-windVsers;mp1n0sC;cohereBfatuatT;atieAerceptib7;arLeavy,i0umb6;ndHt-and-miP;immicFre0;en;at0ew,irm,luffy,rustratingly,ull of life;ty;e6i1riLudsvil0;le;a2ffide1s0;ablIlikI;nt;lect0phanous;al;ad,stroy0;!i1;h4loud-cov3o1ryi0;ng;c0zy;ky;er8;i0oppy;ldi0tchat;sh;o1ra0;sh,vado;gg2und0;le0;ss;ed;ic|p0.3¦aMbonny,cCdistinct,eBf8g7int6l5mesmerizHp4raAs3u1vocationKw0;ins,orth;n0seJ;blinkEcontroversiH;miEolicitous,uccess;owerGroves;augh,ifelike;ellectuDriguA;amechanger,olden;or su1r0un;esh,ingy;re;conomic8le4nlighten5xcit5;alm,leanly,o0;lo5m0;e-at-ab3p0;ell1li0;mentary;ing;le;r1ss0;al;ful;bsorb0hw,pportion0uthoritative,ww;ed|p-0.1333¦active,cow,gloom,imitation|p0.1¦0:06;aYbVcLdJeHfFgettRiElBm9n8o7p6right-mind0s3titulUun2vit02w1youX;ild,ow;blemish0expect0hesitatiVread;arcaAe2o1tate-support0urpris0;ber,ft;amOnsitV;eaky,rofessionW;ffers,ld;aEeM;a1edicatRodest,ultilaterT;nque,rk0sculine,ture;i1oud,ush;ngui1teraN;st5;dentifiDn stock;ar,i1requeO;ftieth,x0;arly,mpiricLnigmat1p1rudiOxperimentL;ic;evelop0i1;m,rect;l7o2ul1;turG;mpleIn1;c2s1;cious,ider2;eiv1ise;able;assy,e2oud1;less;ar;almy,u1;ddi1sy;ng;bridg0c6d3ir0l2mato1rous0;ry;ive;ama2jectiv1ult;al;nt;ross-the-board,tion,ua1;te;ed|p-0.0333¦excuse,toilet|p-0.7¦a5ba4crude,disastr6frustrat3grr1merciless,painful,shock3u0vulgar;gly,nchaste;!r0;!r;ed;d,rbarian;bhorrent,nger,troci0;ous|p0.5¦0:13;a0Pbe0Nc0Fe09f06g04h02iYlUmNnot12oJpGrDs6t4unexce9w1;acky,e02i2or1;kmanlike,thwhi12;n08tty;o1ruthfM;p,uc0M;a5ex4incere,ki3ophistic0Qpirit0t2u1ympath07;ppor09re;at0Iriki0Nun03ylish;ll0;u0Ay;fe,tisf1;i0yi0J;e1ive09;dee6fres0Dput0Ospect1war7;ab0PfB;henomen04ivot04l2o0Jr1;eci0Komine0J;ausPeas0;k3utstan2verwhel1;mi0B;di0A;!ay;a4e2ind-bogg07o1;re,st;aningf1mor0D;ul;gic2n1;nerly,y;!al;atest,enie06i3ov1;ab09e1;!ly;ght-heart0k05;conSn1;corrupt8geni02no2spir1teresNvenH;ationKiV;ceZvaF;andsome,e1ilariZumorZ;althy;ift0lad,oofy,r1;and,eaJippiQ;a2itGorc1;ibX;mTvoriL;l5n1xotH;deariLerg3joy2tertai1;niK;abSed,iJ;etD;aboraFegaM;aptiva7ha6o2rea1uE;tive;hereJm2n1;fideIvinciD;ic1peG;al;llengiArismat5;ti9;lievFt1;ter;bFcquaint0d8giFirhead0llevi7pp3stonis2uthent1wwww;ic;hi4;ea2ropria1;te;li1;ng;at0;or5ve1;ntur3r1;te1;nt;ous;ab2;ed;le|p-0.125¦abrupt,due,e0foreign,other,sharp;ndless,xtreme|p0.2¦aKbeefy,cHeEfast,gentOhahaBi9leg8m6p5quixotGre3st2thanks,un1very,w0;ants,hoN;paid,usuD;ainless,raight;a0sponsibK;dy,l,soI;hilosophAromisL;od0uch;!ern;al,ibF;nt0ron6;ense,imaH;!ha0;!ha0;!ha;conom1thic0;al;ic;ap1on0;secr3vex;ab4tive;bso5ccomplish4dor6ll-around,me2pp0ttendant,urea7;etiz5reci0;at2;nab0;le;ed;lu1rb0;ing;te|s0.95¦a3barbarian,c2discourteous,gawky,lov6mouth-water6rose,successful,un0;i0pleasa4;mporta3ntellige3;hicken,ontroversial;b0fflue1;sorb1unda0;nt;ing|p-0.5¦a0Wb0Rc0Dd07e04fXgVhonest-to-god,iRjackassQlOmeNnMoLpJquestion0PraIs9t8u2v1w0yaaawwnnnn;a10ei11himsBro0Jtf;ague,ulner0N;n0se0L;a3c2f1i0likeCreaBsett0F;later0Inspir0N;air,ortunate;omfort0Iut;b0Isham0K;ediXiresome,roubl0Jwist0J;ad,car7elfish,hy,i3kept2or0Rt0uffocati0A;a0ereotyp1ink3;le,rt07;ic0A;l2mp1nist0;er;li4;ly;ey,y;ndom,uncH;leona0ower04sychot0G;st0F;bsess06ffbeat,ver-the-top;ame01eed01ostalg0D;aning00dioc5re;a0ouW;me,ughZ;!es;ll2n0rreleva03;auspiciDcurWexpedie02famDsecu0;re;!egS;o0ratuitAuilY;ody-gooDry;a3eebSla1orgettRr0;ighteJostbitt00;s0wS;hy;i0ke;l0nt;!ed,s;erie,ffiFrrone1x0;aggerApensS;ous;azKi3ow2runk,u0;hhh0uuh;!h;dy;dactOfficult,st0;asteful,urbi7;a8h3o0reepy;llectibBmplic1ntrivDr0;puleFrupt;atB;ee3il1ur0;ni1;li0;ng;sy;lcul2re1su0;al;less;ab0;le;l1or0rainsick;ed;ata1ind,oodthirs0;ty;nt;bsu5ng4s0wea4;cet2h1sumpt0;ive;en;ic;ry;rd|p0.6¦aOcJdeIeGfDhAimaginaSkind,l9motley,n8own,pop7r5s3t2un1w0;arm,ell-advisD;hamperCprecedentC;hrillBi9ren9;atisyfNmilAp0;ectac2ontaneF;e0ose;doubEsourceful;ular;ice,oD;ik4mao,ovH;a0onest;n0zard8;dy;i1ull-fledg0;ed;ne-lookBrst-strB;ffecBn0;gross9thusiastic;ft,luxe,serv8;a3hari1ourte0;ous;ta0;ble;ndid,tch3;bundant,cute,dept,ffirma3m1p0stound2;precia2t;az0us0;ing;tive|p0.375¦accessible,excited,f1original,poetic,rich,s0unique;ignificant,traightforward;amiliar,riendly|p0.4¦aUbScLdetail00eJfDgBhuge,i9justifi00li8mighNn7o6p4r3s2thought1un0well-off,youngish;adulteratZsaltZ;-provokWfP;ecuQmooth,ound,prightly,teadfast,uperf9;elevaBisk-frA;erplexVr0;ecise,imary;bedie8pen-mindT;aturaliAonviole7;centiNght;mporta5n0;comparaKdispensaK;enu0uardO;ine;a3i2lippa1ortunaNr0;ee;nt;llJt;bulEnta0r-out;stic;cological,n0;gagDjoy;he4ivilizEo2r0;af0edi8ushB;ty;m0nfirmB;forta5prehensi5;ap,erf0;ul;ang-up,izar0;re;ccura6dvanc5pp4ttenti2utonom1vaila0www;ble;ous;on-gett0ve;ing;licative,osi1;ed;te|s0.6333¦accurate,outdated|p-0.4¦aXbVcOdKexHfCgBi7n6o5p4rip-off,s2t1un0worG;appealiIfocSgrad00healthy,importaMnecessary,playQstirr00;erminally,hin,irZ;ecret,hri0;eky,ll;eevToor;utd4verexcitV;ause3erve-rackiC;mp1nf0rrit5;antiJlexibJ;assive,lic0;atQ;ame,luey,odforsaK;a1rustr0uck;ati5;l1rc0;e,ic9;se;haust0tinct;ed,i0;ng;e0usty;creasFf0;enseless,icie0;nt;a5heesiest,on1rimin0;al;f2test0;ab0;le;us7;cophonous,ustic;ehind,ootleg,ro0;ken;d2l1mateur0nnoy3pproximate;ish;as,gid;dict0equate to;ed|p-0.4667¦addled,maladroit|s0.8333¦addled,bland,c2easy,gratuitous,idiotic,l0sexu1tough;oy0ucky;al;lever,onfident|p0.3333¦a2bo1extraordinary,l0mi1pregnant,quick,super,tremendous,worthy;oyal,ucky;ld;dequate,rtistic|p-0.25¦a7excess6juveni5lazy,o4p3repetit6s1u0;nbelievab4su1;entiment0hady,lick,mall;al;ast,ointless;rdinary,verboard;le;ive;eriform,l0mateur,nxious;coholic,ien|p0.8¦a7bra8e4f3great,happy,intelligent,joy,lol2proud,rofl,un1w0;elcome,in;common,forgett7;!ol;avor2ly;lect,xp0;erienc0ressi2;ed;ff1ttracti0;ve;able|p0.65¦affluent|p-0.6¦aWbScMdCfAgr9hap7in6m5numb,prolix,s2tastel8un0;befitMdignifiTf0happy,propitiK;aithTruitT;cathiLt1u0;bnormUffers;abbiJinks,upidiC;eager,uggy;conveni9explicaJfuriaG;hazPl0;ess;andiloqu6udgiE;*ckiDiendish,uck0;ed,iC;anger8e5i0one with;m-wittGr3s0;appoint0easFtraught;i8m0;ent;ty;p1s0;perate,trucG;lora5ressi3;ous;hi4o2razy,ut0ynicB;ti0;ng;ld,rrupti0;ble;cken,lly;attle2l0;ast0oodstain0;ed;ful;fraid,g2rtifici1wkw0;ard;al;hast,ita0;tive|p-0.3¦alienatXbaVcOdLeIfGiElCmBnAp6r5s2thick,u0vap9wonF;gliVn0;deservFtraceable;cum,econdary,hoddy,low,ourEtruttUuck0;er0s;!s;aucKegurgitat7ude;inheads,l1r0;etentiIisMofiterP;ac0oddO;id;a9eg8;elodrama,oralizL;aAea9os0;es;c0diocy,nsultingly;ky;anatic,orc0;ed;dgy,xploit0;at0;ive;elica1ishone0uh;st;te;lum5o0;m1nfus7riace0;ous;mon,pl0;ain0ex;ed,t;sy;d0nal;ness;ing|p0.25¦aFcBe9f8h7interest6l5marri6p4recognizable,s1thr0w0;ill2;eason4tellar,u0;pport0rre7;ing;eaceful,retty;ogic4yr8;ed;igher,ot;irst,unny;ducation0vid3xact;al;o0risp;m1nsist0;ent;ic;mbitious,vid,ware|p-0.75¦anger1claustrophob0disappoint1trag0;ic;ed|s0.85¦a2b0deadpan,fascinat1hot,passionate,solicit3thin;almy,ecom0;ing;ngered,rdu0;ous|p-0.8¦aCbAcrap,d9egoistic,filthy,grie7ha6i4m2r0stupid,unappetizEvi3worthless;an0etardC;cor6k;alev0oron2;olent;diot0mbecile,napposi1;!s;te;f,v0;ous;ebauch3oubtful;ase,l0;ech,oody;nnoy1ppall0;ed;ing|p-0.35¦a0;ppalling,rduous|p0.05¦appare1bare,ceremoni0exubera1gener0inexpressible;al;nt|s0.35¦appare0ceremonial,dista0infantile,soft;nt|p0.7¦applaudable,bCchBdelightFe8f5go4h3l2mouth-waterEoptimum,s0talentFwise;kittish,u0;cceeds,perior,rprisC;aughCovC;appiness,ero6;od,rge1;a1elicit0;ous;bl7ir,scin1;rot1xhilar0;at4;ic;arm2eery;e0right;lov1witch0;ing;ed|p0.9¦artesian,brilliant,c2dainty,i0;deal,n0; good taste,credible;ast-iron,ushy|p0.55¦astute,controversial,suitable|p-0.15¦average,ba0dark,me0naughty,pale,ruins;ss|p1.0¦awesome,bBdeli8ex6f4greateCimpress3legendary,ma1p0superb,top-notch,wond2;erfect,rice4;gnific5rvel8st0;er6;ed,ive;ault0law0;less;cell0quisite;ent;ci1ght0;ful;ous;e0reathtaking;st|p-1.¦awEbCcruel,d9evil,gr8h4ins3m2nasty,outrage1pathet6ruthless,shockiDterri0vici1worst;b6fyiC;ous;enaciAiserab4;ane,ul7;orri0ysterical;b1f0;ic;le;im,uesome;evasta1isgust0read4;ed,i2;ti1;leak,ori0;ng;ful|p0.85¦beautiful|p0.45¦becoming|p-0.1667¦bla2h1less,mundane,odd,previous,s0typical,unpredictable;light,ubject;alf,idden;ck,nd|s0.4333¦black,full-length|p0.0625¦broad,major|s0.3125¦broad|p-0.875¦brutal|s0.8667¦casual,measly|p0.35¦c0full,sweet,true;elebrated,ool|p0.2143¦certain,large,pure,smart|s0.5714¦certain,special|s0.15¦changel0m0overboard,strange,wan;ess|p-0.0667¦characteristic,d0hollow,putative;epress,ry|s0.4667¦characteristic|p0.1667¦c2dece1main,old4particular,realist5s0vibra1;teady,upernatural;nt;l0ontemporary;ass1ev0;er;ic|p0.3667¦clean|s0.3833¦clear|p0.15¦concrete,normal|s0.45¦considerable|p0.95¦consummate|p-0.1429¦conventional|s0.4167¦crisp|p-0.9¦cruddy,f5h2inhumane,outrag4re0sicken3;pellent,tard0;!s;at1orrify0;ing;ed;earful,rigid|p0.75¦dazzling,impecc0remark0successful;able|p-0.8333¦deadly|p-0.55¦deadpan,g0indecipherable;awky,rotesque|s0.0333¦depress,excuse,hollow|p-0.65¦discourteous,un0;intellige0pleasa0;nt|p-0.1556¦down|s0.2889¦down|s0.07¦drag|p-0.4333¦dramatic|p-0.2917¦dull,hard|p-0.375¦dumb,incompetent,weak|p0.4333¦easy,strong|p0.6667¦excep0lively,sensa0;tional|p-0.3167¦failure|p0.4167¦fine,gay|p-0.025¦flat|p0.0333¦full-length,social|s0.5833¦gay|s0.5417¦hard|p0.16¦high|s0.54¦high|p-0.6667¦i0;diotic,mpossible|s0.875¦insecure,outstanding,si0;gnificant,lly|s0.4286¦large|s0.2667¦leaden|p-0.0714¦limited,single|p-0.1875¦little|p0.1364¦live,new|s0.9333¦lively,uncivil|p-0.0769¦loose|s0.2692¦loose|p-0.625¦mad|p-0.3125¦mean|s0.6875¦mean|p-0.5667¦measly|s0.4545¦new|p-0.24¦parade|s0.22¦parade|p-0.2143¦plain,stiff|p0.7333¦pleasant|s0.9667¦pleasant|p-0.0833¦polar|p0.2273¦positive|s0.5455¦positive|p0.0833¦profound|p-0.2308¦raw|s0.4615¦raw|p-0.3333¦ridicul2s0tense;eri1ha0ubtle;ky,llow;ous|p0.2857¦right|s0.5357¦right|p-0.225¦sermon,tame|p-0.7143¦sick|s0.8571¦sick|s0.2143¦single|p-0.4167¦sloppy|s0.6429¦smart|p-0.1571¦sour|s0.1143¦sour|p0.3571¦special|p0.8333¦splendid|s0.7333¦strong|s0.5667¦supernatural|s0.8889¦sure|s0.225¦tame|s0.475¦thick|p-0.1786¦tight|s0.2857¦tight|p-0.3889¦tough|p-0.7333¦uncivil|p-0.075¦victim|p0.125¦vivid|i1.5¦real|i1.3¦excruciatingly,very|i1.2¦frustratingly";
================================================
FILE: plugins/_experiments/sentiment/src/data/index.js
================================================
import { unpack } from 'efrt'
import pattern_en_packed from './_pckd.js'
// Decompress above data
const pattern_en = unpack(pattern_en_packed);
// Add some data efrt 2.7.0 compression can't handle yet
//
// Wait...you can add to a const? Yes!
// Ref: https://stackoverflow.com/a/23436563
const arrayInfo = ["i1.0", "p0.0", "s0.0"];
pattern_en['13th'] = arrayInfo;
pattern_en['20th'] = arrayInfo;
pattern_en['21st'] = arrayInfo;
pattern_en['2nd'] = arrayInfo;
pattern_en['3rd'] = arrayInfo;
// Sort all subarrays in alphabetical order
// resulting order and their corresponding
// indices will be:
// intensity [0]
// polarity [1]
// subjectivity [2]
Object.values(pattern_en).forEach(function (element) {
element.sort();
})
//console.log('pattern_en:', pattern_en);
// Find all keys from expanded pattern_en object
const pattern_en_keys = Object.keys(pattern_en);
//console.log('pattern_en_keys: ', pattern_en_keys);
// Find all intensifiers (keys whose values are not "i1.0") in pattern_en object
const intensifiers = Object.keys(pattern_en).filter(function (element) {
return (pattern_en[element][0] != "i1.0");
});
//console.log('intensifiers', intensifiers);
// Set up dictionary of negations
const negations = ['not', 'no', 'never', 'neither', 'havent', 'hasnt', 'hadnt', 'cant', 'couldnt', 'shouldnt', 'wasnt', 'wont', 'wouldnt', 'dont', 'doesnt', 'didnt', 'isnt', 'arent', 'aint', 'mustnt', 'werent'];
//console.log('negations: ', negations);
export { pattern_en, pattern_en_keys, intensifiers, negations }
================================================
FILE: plugins/_experiments/sentiment/src/emoji.js
================================================
import RegExpEscape from './escape.js'
/**
* emoticons
*
* Variable containing polarity scores for selected emoticons/smileys
*
* @author Scott Cram
*
* Original version:
* @author Steven Loria
* @see {@link https://github.com/sloria/TextBlob/blob/dev/textblob/_text.py|_text.py}
*
* From emoticons section of python file above, data was converted to JSON Object containing selected emoticons/smileys and their associated polarity scores
*/
const emoticons = { "<3": "1.00", "♥": "1.00", ">:D": "1.00", ":-D": "1.00", ":D": "1.00", "=-D": "1.00", "=D": "1.00", "X-D": "1.00", "x-D": "1.00", "XD": "1.00", "xD": "1.00", "8-D": "1.00", ">:P": "0.75", ":-P": "0.75", ":P": "0.75", ":-p": "0.75", ":p": "0.75", ":-b": "0.75", ":b": "0.75", ":c)": "0.75", ":o)": "0.75", ":^)": "0.75", ">:)": "0.50", ":-)": "0.50", ":)": "0.50", "=)": "0.50", "=]": "0.50", ":]": "0.50", ":}": "0.50", ":>": "0.50", ":3": "0.50", "8)": "0.50", "8-)": "0.50", ">;]": "0.25", ";-)": "0.25", ";)": "0.25", ";-]": "0.25", ";]": "0.25", ";D": "0.25", ";^)": "0.25", "*-)": "0.25", "*)": "0.25", ">:o": "0.05", ":-O": "0.05", ":O": "0.05", ":o": "0.05", ":-o": "0.05", "o_O": "0.05", "o.O": "0.05", "°O°": "0.05", "°o°": "0.05", ">:/": "-0.25", ":-/": "-0.25", ":/": "-0.25", ":\\": "-0.25", ">:\\": "-0.25", ":-.": "-0.25", ":-s": "-0.25", ":s": "-0.25", ":S": "-0.25", ":-S": "-0.25", ">.>": "-0.25", ">:[": "-0.75", ":-(": "-0.75", ":(": "-0.75", "=(": "-0.75", ":-[": "-0.75", ":[": "-0.75", ":{": "-0.75", ":-<": "-0.75", ":c": "-0.75", ":-c": "-0.75", "=/": "-0.75", ":'(": "-1.00", ":'''(": "-1.00", ";'(": "-1.00" };
//console.log('emoticons', emoticons);
// Combine all the keys from the emoticon object into a regex which match any of those emoticons
const emoticon_regex = new RegExp((RegExpEscape(Object.keys(emoticons).join(' '))).replace(/\\\s/g, '|'), 'g');
//console.log('emoticon_regex: ', emoticon_regex);
/**
* emojis
*
* Variable containing polarity scores for selected emojis
*
* @author Scott Cram
*
* Original version:
* @author P. Kralj Novak, J. Smailovic, B. Sluban, I. Mozetic
* @see {@link https://kt.ijs.si/data/Emoji_sentiment_ranking/|Emoji Sentiment Ranking v1.0}
*
* From emoji file above, data from Char and Sentiment score columns was used, and converted to JSON Object
*/
const emojis = { "😂": "0.221", "❤": "0.746", "♥": "0.657", "😍": "0.678", "😭": "-0.093", "😘": "0.701", "😊": "0.644", "👌": "0.563", "💕": "0.632", "👏": "0.520", "😁": "0.449", "☺": "0.657", "♡": "0.669", "👍": "0.521", "😩": "-0.368", "🙏": "0.417", "✌": "0.463", "😏": "0.332", "😉": "0.463", "🙌": "0.559", "🙈": "0.432", "💪": "0.555", "😄": "0.421", "😒": "-0.374", "💃": "0.734", "💖": "0.712", "😃": "0.557", "😔": "-0.146", "😱": "0.190", "🎉": "0.738", "😜": "0.455", "☯": "0.001", "🌸": "0.650", "💜": "0.654", "💙": "0.730", "✨": "0.351", "😳": "0.018", "💗": "0.657", "★": "0.283", "☀": "0.465", "😡": "-0.173", "😎": "0.491", "😢": "0.007", "💋": "0.691", "😋": "0.631", "🙊": "0.459", "😴": "-0.080", "🎶": "0.537", "💞": "0.739", "😌": "0.482", "🔥": "0.139", "💯": "0.120", "🔫": "-0.194", "💛": "0.709", "💁": "0.326", "💚": "0.656", "♫": "0.287", "😞": "-0.118", "😆": "0.409", "😝": "0.423", "😪": "-0.080", "😫": "-0.145", "😅": "0.178", "👊": "0.228", "💀": "-0.207", "😀": "0.568", "😚": "0.710", "😻": "0.619", "©": "0.117", "👀": "0.063", "💘": "0.683", "🐓": "0.028", "☕": "0.244", "👋": "0.413", "✋": "0.126", "🎊": "0.721", "🍕": "0.417", "❄": "0.506", "😥": "0.122", "😕": "-0.397", "💥": "0.148", "💔": "-0.121", "😤": "-0.209", "😈": "0.265", "✈": "0.415", "🔝": "0.474", "😰": "-0.020", "⚽": "0.616", "😑": "-0.311", "👑": "0.694", "😹": "0.141", "👉": "0.390", "🍃": "0.378", "🎁": "0.759", "😠": "-0.299", "🐧": "0.456", "🍀": "0.285", "🎈": "0.718", "🎅": "0.318", "😓": "-0.080", "😣": "-0.212", "😐": "-0.388", "✊": "0.429", "😨": "-0.140", "😖": "-0.155", "💤": "0.370", "💓": "0.664", "👎": "-0.188", "💦": "0.471", "✔": "0.270", "😷": "-0.169", "⚡": "0.177", "🙋": "0.485", "🎄": "0.531", "💩": "-0.116", "🎵": "0.500", "➡": "0.147", "😛": "0.601", "😬": "0.194", "👯": "0.439", "💎": "0.561", "🌿": "0.384", "🎂": "0.613", "🌟": "0.327", "🔮": "0.267", "❗": "0.100", "👫": "0.255", "🏆": "0.726", "✖": "0.311", "☝": "0.309", "😙": "0.778", "⛄": "0.521", "👅": "0.461", "♪": "0.534", "🍂": "0.547", "💏": "0.388", "🔪": "0.070", "🌴": "0.525", "👈": "0.424", "🌹": "0.600", "🙆": "0.500", "👻": "0.228", "💰": "0.251", "🍻": "0.512", "🙅": "-0.202", "🌞": "0.558", "🍁": "0.482", "⭐": "0.580", "▪": "0.198", "🎀": "0.629", "☷": "0.064", "🐷": "0.368", "🙉": "0.333", "🌺": "0.549", "💅": "0.388", "🐶": "0.576", "🌚": "0.464", "👽": "0.315", "🎤": "0.476", "👭": "0.463", "🎧": "0.414", "👆": "0.326", "🍸": "0.539", "🍷": "0.393", "®": "0.279", "🍉": "0.597", "😇": "0.587", "☑": "0.101", "🏃": "0.406", "😿": "-0.372", "💣": "0.007", "🍺": "0.493", "▶": "0.209", "😲": "-0.068", "🎸": "0.516", "🍹": "0.659", "💫": "0.500", "📚": "0.336", "😶": "-0.142", "🌷": "0.538", "💝": "0.644", "💨": "0.381", "🏈": "0.530", "💍": "0.478", "☔": "0.289", "👸": "0.605", "🍩": "0.382", "👾": "0.361", "☁": "0.308", "🌻": "0.570", "😵": "0.085", "📒": "0.038", "🐯": "0.476", "👼": "0.333", "🍔": "0.277", "😸": "0.410", "👶": "0.434", "💐": "0.735", "🌊": "0.500", "🍦": "0.459", "🍓": "0.670", "👇": "0.247", "💆": "0.221", "🍴": "0.537", "😧": "-0.063", "😮": "0.269", "🚫": "-0.440", "😽": "0.571", "🌈": "0.516", "🙀": "0.330", "⚠": "-0.066", "🎮": "0.427", "🍆": "0.402", "🍰": "0.448", "👐": "-0.023", "🙇": "0.140", "🍟": "0.302", "🍌": "0.435", "💑": "0.659", "👬": "-0.059", "🐣": "0.476", "🎃": "0.595", "😟": "0.072", "🐾": "0.605", "🎓": "0.563", "🏊": "0.575", "🍫": "0.152", "📷": "0.430", "👄": "0.474", "🌼": "0.779", "🚶": "-0.143", "🐱": "0.513", "🐸": "-0.080", "👿": "-0.534", "🚬": "0.521", "📖": "0.169", "🐒": "0.521", "🌍": "0.592", "🐥": "0.586", "🌀": "0.101", "🐼": "0.261", "🎥": "0.290", "💄": "0.435", "💸": "0.159", "⛔": "0.485", "🏀": "0.254", "💉": "0.358", "💟": "0.682", "🚗": "0.231", "😯": "0.123", "📝": "0.231", "♦": "0.453", "💭": "0.206", "🌙": "0.590", "🐟": "0.689", "👣": "0.344", "☞": "0.115", "✂": "-0.459", "🗿": "0.443", "🍝": "0.117", "👪": "-0.017", "🍭": "0.300", "🌃": "0.390", "❌": "0.271", "🐰": "0.586", "💊": "0.431", "🚨": "0.638", "😦": "-0.368", "🍪": "0.316", "🍣": "-0.232", "🎆": "0.709", "🎎": "0.907", "✅": "0.407", "👹": "0.058", "📱": "0.308", "🙍": "-0.327", "🍑": "0.250", "🎼": "0.327", "🔊": "0.404", "🌌": "0.520", "🍎": "0.320", "🐻": "0.440", "💇": "0.327", "♬": "0.245", "♚": "0.041", "🔴": "0.396", "🍱": "-0.313", "🍊": "0.417", "🍒": "0.313", "🐭": "0.688", "👟": "0.417", "🌎": "0.319", "🍍": "0.468", "🐮": "0.587", "📲": "0.239", "☼": "0.196", "🌅": "0.356", "👠": "0.356", "🌽": "0.444", "💧": "-0.159", "❓": "0.068", "🍬": "0.364", "😺": "0.395", "🐴": "0.070", "🚀": "0.488", "💢": "0.233", "🎬": "0.279", "🍧": "0.302", "🍜": "0.395", "🐏": "0.558", "🐘": "0.023", "👧": "0.140", "🏄": "0.524", "⬆": "0.286", "🍋": "0.244", "🆗": "0.537", "⚪": "0.450", "📺": "0.375", "🍅": "0.350", "⛅": "0.450", "🐢": "0.200", "👙": "0.500", "🏡": "0.436", "🌾": "0.538", "✏": "0.342", "🐬": "0.421", "🍤": "0.053", "♣": "0.342", "🐝": "0.211", "🌝": "0.189", "🔋": "-0.486", "🐍": "0.351", "♔": "0.541", "🍳": "0.028", "🔵": "0.306", "😾": "-0.333", "🌕": "0.556", "🐨": "0.444", "🔐": "0.333", "💿": "0.611", "🌳": "0.486", "👰": "0.486", "⚓": "0.571", "🚴": "0.657", "👗": "0.235", "➕": "0.529", "💬": "0.364", "🔜": "0.273", "🍨": "0.212", "💲": "0.242", "⛽": "0.152", "🍙": "0.281", "🍗": "0.063", "🍲": "0.125", "🍥": "-0.594", "♛": "0.188", "😼": "0.355", "🐙": "0.387", "👨": "0.516", "🍚": "0.452", "🍖": "0.129", "♨": "0.871", "🎹": "0.355", "♕": "0.387", "🚘": "0.067", "🍏": "0.067", "👩": "0.067", "👦": "0.133", "☠": "-0.033", "🐠": "0.414", "🚹": "0.690", "💵": "0.379", "👛": "0.357", "🚙": "0.036", "🌱": "0.571", "💻": "0.250", "🌏": "0.321", "👓": "0.296", "⚾": "-0.037", "🌲": "0.385", "👴": "0.231", "🏠": "0.500", "🍇": "0.269", "🍘": "0.385", "🍛": "0.038", "🐇": "0.231", "🔞": "-0.038", "👵": "0.423", "◀": "0.269", "🔙": "0.192", "🌵": "0.192", "🐽": "0.120", "🍮": "-0.120", "🎇": "0.680", "🐎": "0.400", "💶": "0.000", "🐤": "0.520", "🛀": "0.125", "🌑": "0.458", "🚲": "0.375", "🐑": "-0.167", "🏁": "0.500", "🍞": "0.042", "🎾": "0.542", "🈹": "0.292", "🐳": "0.130", "👮": "-0.348", "☹": "-0.522", "🐵": "0.478", "🗼": "0.522", "♠": "0.304", "👺": "-0.182", "🐚": "0.227", "👂": "-0.136", "🗽": "0.318", "🍵": "0.364", "🆒": "0.364", "🍯": "0.045", "🐺": "0.227", "🌓": "0.591", "🔒": "0.182", "👳": "0.619", "🌂": "0.238", "🚌": "0.190", "♩": "0.524", "🍡": "-0.048", "❥": "0.238", "🎡": "0.286", "💌": "0.500", "🐩": "0.350", "🌜": "0.500", "⌚": "0.200", "🚿": "0.600", "🐖": "0.150", "🔆": "0.550", "🌛": "0.550", "💂": "-0.150", "🐔": "0.300", "🙎": "-0.050", "🏩": "0.421", "🔨": "-0.105", "📢": "0.421", "🐦": "0.421", "🐲": "-0.053", "♻": "0.474", "🌘": "0.579", "🍐": "0.158", "🌔": "0.579", "👖": "0.333", "🚺": "0.167", "😗": "0.611", "🎭": "0.000", "🐄": "0.278", "🍢": "-0.111", "🎨": "0.167", "⬇": "0.389", "🚼": "0.556", "⛲": "0.056", "🌗": "0.611", "🌖": "0.611", "🔅": "0.833", "👜": "0.235", "🐌": "0.647", "💼": "0.529", "🚕": "0.000", "🐹": "0.294", "🌠": "0.529", "🐈": "0.294", "☎": "0.000", "🌁": "0.176", "⚫": "0.235", "♧": "0.471", "🏰": "0.294", "🚵": "0.353", "🎢": "0.471", "🎷": "0.647", "🎐": "0.176", "🌇": "0.500", "⏰": "0.438", "🚂": "0.250", "🎿": "0.375", "🆔": "0.750", "⛪": "0.125", "🌒": "0.563", "🐪": "0.563", "👔": "0.333", "🔱": "0.067", "🆓": "0.200", "🐋": "0.200", "🐛": "0.267", "👕": "0.400", "🚋": "0.067", "💳": "0.400", "🌆": "0.133", "🏧": "0.800", "💡": "0.600", "🔹": "0.133", "⬅": "0.467", "🍠": "0.000", "🐫": "0.333", "🏪": "0.067", "📹": "0.429", "👞": "0.429", "🚑": "0.071", "🆘": "0.071", "👚": "0.571", "🚍": "0.071", "🐂": "0.143", "🚣": "0.571", "✳": "0.000", "🏉": "0.500", "🗻": "0.571", "🐀": "0.143", "⛺": "0.462", "🐕": "0.231", "🏂": "0.385", "👡": "0.385", "📻": "0.308", "✒": "0.231", "🌰": "0.538", "🏢": "0.154", "🎒": "0.462", "🏫": "-0.231", "📴": "0.615", "🚢": "0.231", "🚚": "-0.077", "🐉": "0.154", "🐊": "0.077", "🔔": "0.769", "🏥": "0.250", "❔": "0.000", "🚖": "-0.083", "🃏": "0.083", "☛": "0.333", "💒": "0.500", "🚤": "0.333", "🐐": "0.417", "🔚": "0.333", "🎻": "0.333", "🔷": "0.167", "🚦": "0.083", "🔓": "0.083", "🎽": "0.417", "📅": "0.167", "🎺": "0.583", "🍈": "-0.333", "✉": "0.250", "🍼": "0.455", "📀": "0.091", "🚛": "-0.182", "📓": "0.182", "☉": "0.182", "💴": "-0.182", "🐃": "0.000", "➰": "-0.091", "🔌": "-0.091", "🍄": "0.000", "📕": "0.182", "📣": "0.364", "🚓": "0.273", "🐗": "0.455", "↪": "0.091", "⛳": "0.636", "👱": "0.100", "⏳": "0.000", "💺": "0.200", "🏇": "-0.100", "☻": "0.200", "📞": "0.400", "🌉": "0.500", "🚩": "-0.200", "✎": "0.500", "📃": "0.400", "🏨": "0.200", "📌": "-0.400", "♎": "-0.100", "💷": "0.400", "🚄": "0.500", "⛵": "0.500", "🔸": "0.200", "⌛": "0.100", "🚜": "0.700", "🐆": "0.300", "👒": "0.200", "❕": "0.200", "🔛": "0.400", "♢": "0.300", "👝": "0.333", "🎋": "0.444", "👥": "0.222", "📵": "0.111", "🐡": "0.222", "🏯": "0.111", "☂": "0.000", "🔭": "0.333", "🎪": "0.222", "🐜": "0.444", "♌": "0.556", "☐": "-0.667", "👷": "0.222", "🔈": "0.222", "📄": "0.667", "📍": "0.111", "🚐": "0.556", "🚔": "0.000", "🌋": "0.444", "📡": "0.222", "⏩": "0.111", "🚳": "0.667", "☾": "0.000", "🅰": "0.222", "📥": "0.000", "🔦": "0.000", "👤": "0.500", "🚁": "0.125", "🎠": "0.375", "🐁": "-0.250", "📗": "0.125", "☮": "0.000", "♂": "0.125", "📯": "-0.125", "🔩": "0.125", "👢": "0.500", "📰": "0.250", "📶": "0.250", "🚥": "0.000", "🌄": "0.125", "🗾": "0.250", "🔶": "0.250", "🏤": "0.250", "🎩": "0.250", "Ⓜ": "0.250", "🔧": "-0.375", "🐅": "0.125", "♮": "0.125", "🅾": "-0.125", "🔄": "0.000", "☄": "0.000", "☨": "0.000" };
//console.log('emojis: ', emojis);
// Create emoji regex object tjat matches the emojis from emojis object
const emoji_object_regex = new RegExp((RegExpEscape(Object.keys(emojis).join(' '))).replace(/\\\s/g, '|'), 'g');
//console.log('emoji_object_regex: ', emoji_object_regex);
// Create emoji regex object that matches all emojis
// Ref:
// How to strip emojis from string in JavaScript
// https://edvins.io/how-to-strip-emojis-from-string-in-java-script
const emoji_regex = new RegExp("([✀-➿-‑-⛿]|��|��|��)", 'g');
//console.log('emoji_regex: ', emoji_regex);
export { emoji_object_regex, emoji_regex, emoticon_regex, emoticons, emojis }
================================================
FILE: plugins/_experiments/sentiment/src/escape.js
================================================
/**
* Function to escape characters in preparation for conversion to regex
*
* @author Brian L
* @see {@link https://stackoverflow.com/a/7317957|Regex matching list of emoticons of various type}
*
* @param {string} text - The text to be escaped
*
* @returns {string} text - Input text with special regex characters escaped
*
*
*/
function RegExpEscape(text) {
return text.replace(/[-[\]{}()*+?.,\\^$|#\s]/g, "\\$&");
}
export default RegExpEscape
================================================
FILE: plugins/_experiments/sentiment/src/lib.js
================================================
import { intensifiers, negations } from './data/index.js'
// HELPER FUNCTIONS
/**
* Label the words of the input array as either 'negation', 'instensifier', 'opinion', or 'opinion!'
* ('opinion!' is an opinion word that is followed by an exclamation mark)
*
* @author Scott Cram
*
* @param {Array} inputArr - The array to be labeled
*
* @returns {Object} labelReturnObj - Object consisting of labeling results, including:
* @returns {Array} labelReturnObj.words - words from inputArr, less any exclamation marks
* @returns {Array} labelReturnObj.labels - array of word types that act as labels for each element in labelReturnObj.words
*/
function labelWordArray(inputArr) {
// Return error array if inputArr has no elements
if (inputArr.length === 0) { return { 'error': 'input array has no elements' } }
// Initialize variables
const labelReturnObj = { 'words': [], 'labels': [] };
let wordsArr = inputArr;
let labelsArr = [];
// Classify each word in Array as
// either 'em' (exclamation mark), negation', 'intensifier', or 'opinion'
inputArr.forEach(function (element, index) {
if (element.includes('!')) {
labelsArr[index] = 'em';
return;
}
if (negations.includes(element)) {
labelsArr[index] = 'negation';
return;
}
if (intensifiers.includes(element)) {
labelsArr[index] = 'intensifier';
return;
}
labelsArr[index] = 'opinion';
});
// In labelsArr, look for any instances of
// 'opinion' followed by 'em', and if found,
// convert 'opnion' to 'opinion!', remove 'em',
// and remove exclamation mark from wordsArr
for (let countdown = labelsArr.length - 1; countdown >= 0; countdown--) {
if (countdown < labelsArr.length - 1) {
if ((labelsArr[countdown] === 'opinion') && (labelsArr[countdown + 1] === 'em')) {
labelsArr[countdown] = 'opinion!';
labelsArr.splice(countdown + 1, 1);
wordsArr.splice(countdown + 1, 1);
}
}
}
// If there is not at least 1 'opinion' in
// labelsArr, then return object with error
if ((labelsArr.indexOf('opinion') < 0) && (labelsArr.indexOf('opinion!') < 0)) {
return { 'error': 'no opinion-based words found' };
}
// Each 'opinion'/'opinion!' is only modified
// by preceeding words, so ensure that the last
// item in wordsArr and labelArr is an 'opinion'/'opinion!'
wordsArr = wordsArr.slice(0, Math.max(labelsArr.lastIndexOf('opinion'), labelsArr.lastIndexOf('opinion!')) + 1);
labelsArr = labelsArr.slice(0, Math.max(labelsArr.lastIndexOf('opinion'), labelsArr.lastIndexOf('opinion!')) + 1);
labelReturnObj.words = wordsArr;
labelReturnObj.labels = labelsArr;
return labelReturnObj;
}
/**
* Find indices to split array at a given word
*
* @author Scott Cram
*
* @param {Array} startingArr - The array to be split
* @param {string} splitWord - The word at which split
*
* @returns {Array} splitPoints - Array of numbers that, when used in pairs for Array.splice(), cane be used to split the array so that only once occurence of splitWord appears
*
*
*/
function findArraySplitPoints(startingArr, splitWord) {
// Count how many times the splitWord occurs in startingArr
const howManySplitWords = startingArr.reduce(function (accumulator, currentValue) {
if (currentValue.match(splitWord) !== null) { accumulator++ }
return accumulator;
}, 0);
// If count is less than zero, return empty array
if (howManySplitWords < 1) {
return [];
}
// Using the above count of splitWord occurences,
// locate splice points for array
let startArrCount = 0;
let splitWordCount = 1; // We can now assume at least 1 occurence of splitWord
const splitPoints = [startArrCount];
startingArr.forEach(function (element, index) {
if ((element.match(splitWord) !== null) && (splitWordCount < howManySplitWords)) {
splitPoints.push(index + 1);
splitPoints.push(index + 1);
startArrCount = index + 1;
splitWordCount++;
return;
}
if ((element.match(splitWord) !== null) && (splitWordCount === howManySplitWords)) {
splitPoints.push(startingArr.length);
}
});
return splitPoints;
}
/**
* Chunk up included arrays into subarrays, with each subarray containing only one 'opinion'/'opinion!' and single preceeding negation and/or modifier
*
* @author Scott Cram
*
* @param {Array} wordsArr - Array of words to be chunked
* @param {Array} labelsArr - Array of labels to be chunked
*
* @returns {Object} chunks - Object consisting of chunking results, including:
* @returns {Array} chunks.words - words from inputArr, less any exclamation marks
* @returns {Array} chunks.labels - 2D array of word types
*/
function chunkArrays(wordsArr, labelsArr) {
// Initialize variables
const wordsArr2d = [];
const labelsArr2d = [];
const chunkReturnObj = { 'word_chunks': wordsArr2d, 'label_chunks': labelsArr2d };
// Find points where 'opinion'/'opinion!' can be split up in array,
// and store them in wordLocs (word locations)
const wordLocs = findArraySplitPoints(labelsArr, 'opinion');
// Use parameters stored in wordLocs array to
// create 2d arrays, grouping a 'opinion' with any
// preceeding negations and/or intensifiers.
for (let index = 0; index < wordLocs.length; index += 2) {
wordsArr2d.push(wordsArr.slice(wordLocs[index], wordLocs[index + 1]));
labelsArr2d.push(labelsArr.slice(wordLocs[index], wordLocs[index + 1]));
}
// Go through each subarray, and only keep
// 1 closest preceeding negation, as well as
// 1 closest preceeding intensifier
// Iterate through labelsArr2d to work with each subarray
labelsArr2d.forEach(function (element, index) {
// Create array to hold location of a
// single 'negation' (index 0), a
// single 'intensifier' (index 1), and
// 'opinion'/'opinion!'
const tempLocArr = [];
// Get values of last occurences of each type of words
tempLocArr.push(element.lastIndexOf('negation'));
tempLocArr.push(element.lastIndexOf('intensifier'));
tempLocArr.push(Math.max(element.lastIndexOf('opinion'), element.lastIndexOf('opinion!')));
// Filter words and labels down to just the items at the indices in tempLocArr
wordsArr2d[index] = wordsArr2d[index].filter(function (_, i) {
return tempLocArr.includes(i);
});
labelsArr2d[index] = labelsArr2d[index].filter(function (_, i) {
return tempLocArr.includes(i);
});
});
// chunkReturnObj = {'word_chunks': wordsArr2d, 'label_chunks': labelsArr2d};
chunkReturnObj.word_chunks = wordsArr2d;
chunkReturnObj.label_chunks = labelsArr2d;
return chunkReturnObj;
}
/**
* Limit a value inside a certain range
*
*
* Original version:
* @author w3resource
* @see {@link https://www.w3resource.com/javascript-exercises/JavaScript: Limit a value inside a certain range}
*
* @param {number} val - The value to be tested for range
* @param {number} min - The minimum amount in the desired range
* @param {number} max - The maximum amount in the desired range
*
* @returns {number} value - If the val input is within the range of min to max, val will be returned. If val is higher than max, then max will be returned. If val is lower than min, then min will be returned.
*
*/
function value_limit(val, min, max) {
return val < min ? min : (val > max ? max : val);
}
// Average all values in inputArr together
// or leave at 0, if array is empty.
function averageArray(inputArr) {
if (inputArr.length === 0) { return 0; }
return inputArr.reduce(function (accum, currentVal) {
return accum + currentVal;
}, 0) / inputArr.length;
}
export { labelWordArray, averageArray, value_limit, chunkArrays }
================================================
FILE: plugins/_experiments/sentiment/src/plugin.js
================================================
import { emoji_object_regex, emoji_regex, emoticon_regex, emoticons, emojis } from './emoji.js'
import { pattern_en, pattern_en_keys } from './data/index.js'
import { labelWordArray, averageArray, value_limit, chunkArrays } from './lib.js'
const sentimentComp = {
/** add a method */
api: (View) => {
View.prototype.sentiment = function (addMood = false, addSummary = false) {
//console.log('addMood: ', addMood);
//console.log('addSummary: ', addSummary);
// Ensure that inputStr is text
let inputStr = this.text();
const isInputValid = typeof inputStr === 'string';
if ((isInputValid === false) || (inputStr === '')) {
return { 'error': 'Input must be a string containing text.' };
}
// SET DEFAULTS
//
// Create default return object with scores of 0
const returnObj = { 'polarity': 0, 'subjectivity': 0 };
// Create default empty summary array
const summaryArr = [];
// INPUT STRING PROCESSING
//
// Remove sarcasm symbols [!] and (!), if present
inputStr = inputStr.replace(/\(!\)|\[!\]/g, '').replace(/\s+/g, ' ').trim();
// Create array of emoticons from input string
let emoticonArr = inputStr.match(emoticon_regex) || [];
//console.log('emoticonArr: ', emoticonArr);
// Create array of emoticon values using emoticonArr
let emoticonValArr = emoticonArr.map(function (element) { return parseFloat(emoticons[element]) }) || [];
//console.log('emoticonValArr: ', emoticonValArr);
// From inputText, get all the emojis which have scores
const emojisOnlyArr = inputStr.match(emoji_object_regex) || [];
//console.log('emojisOnlyArr: ', emojisOnlyArr);
// Get all the values of the emojis in emojisOnlyArr
const emojiValArr = emojisOnlyArr.map(function (element) { return parseFloat(emojis[element]) }) || [];
//console.log('emojiValArr: ', emojiValArr);
// Add emojisOnlyArr into emoticonArr
emoticonArr = emoticonArr.concat(emojisOnlyArr);
//console.log('emoticonArr: ', emoticonArr);
// Add emoticonValArr into emoticonValArr
emoticonValArr = emoticonValArr.concat(emojiValArr);
//console.log('emoticonValArr: ', emoticonValArr);
// Remove emoticons from inputStr,
// remove emojis,
// replace multiple exclamation marks with 1,
// remove apostrophes,
// and change entire string to lower case
inputStr = inputStr.replace(emoticon_regex, '').replace(emoji_regex, ' ').replace(/\s+/g, ' ').replace(/!{2,}/g, '!').replace(/['’]/g, '').trim().toLowerCase();
//console.log('inputStr: ', inputStr);
// From inputStr, create array containing only words listed in pattern_en or exclamation marks
const wordArr = (inputStr.match(/\w+|!/g)).filter(function (element) {
return (pattern_en_keys.includes(element) || element.includes('!'));
});
//console.log('wordArr: ', wordArr);
// Create array of labels of types of words in wordArr
const labelInfoObj = labelWordArray(wordArr);
//console.log('labelInfoObj: ', labelInfoObj);
// If wordArr is now empty,
// return an object with polarity and subjectivity of 0,
// as well as mood and summary information, if those flags
// are set
if ((wordArr.length === 0) || (labelInfoObj.hasOwnProperty('error'))) {
if (addMood === true) {
returnObj.mood = averageArray(emoticonValArr);
// If addSummary is true, add scored_icons
if (addSummary === true) {
const summaryObj = {};
summaryObj.scored_icons = emoticonArr;
summaryObj.mood = emoticonValArr;
summaryArr.push(summaryObj);
}
}
if (addSummary === true) { returnObj.summary = summaryArr; }
return returnObj;
}
// Since labelInfoObjn returned valid data,
// it's time to chunk the words and labels
// in groupd, each containing just 1
// 'opinion'/ 'opinion!', and the closest
// preceeding negation and intensifiers,
// if included
const chunkInfoObj = chunkArrays(labelInfoObj.words, labelInfoObj.labels);
//console.log('chunkInfoObj', chunkInfoObj);
const wordArr2d = chunkInfoObj.word_chunks;
const labelArr2d = chunkInfoObj.label_chunks;
// VALUE CALCULATION
//
// Create polarityArr and subjectivityArr arrays
// to hold individual calculation results before
// averaging them at the end.
const polarityValArr = [];
const subjectivityValArr = [];
// Iterate through arrays to calculate polarity and subjectivity
for (let index = 0; index < labelArr2d.length; index++) {
// Prepare this iteration's summary object
const summaryObject = {};
// Add scored_words index
summaryObject.scored_words = wordArr2d[index];
// If 'opinion!' exists, add '!' to scored_words array
if (labelArr2d[index].indexOf('opinion!') > -1) { summaryObject.scored_words.push('!'); }
// If a 'negation' exists, set value of multiplier
// to -0.5, otherwise, set it to 1
const negationMultiplier = labelArr2d[index].indexOf('negation') > -1 ? -0.5 : 1;
// If an 'intensifier' exists, calculate value,
// otherwise, default to 1
let intensityMultiplier = 1;
// Get index of location of intensifier for this index
const intensifierIndex = labelArr2d[index].indexOf('intensifier');
// If an intensifier exists...
if (intensifierIndex > -1) {
// ...get corresponding intensity score
// from pattern_en object
intensityMultiplier = parseFloat(pattern_en[wordArr2d[index][intensifierIndex]][0].replace(/i/g, ''));
// if negationMultiplier = -0.5, then
// use inverse of intensityMultiplier
if (negationMultiplier === -0.5) { intensityMultiplier = 1 / intensityMultiplier }
}
// Find 'opinion' or 'opinion!' in current array
const opinionLoc = Math.max(labelArr2d[index].indexOf('opinion'), labelArr2d[index].indexOf('opinion!'));
// If 'opinion!' is the current array,
// set exclamationMultiplier to 1.25,
// otherwise set it at 1
const exclamationMultiplier = labelArr2d[index].indexOf('opinion!') > -1 ? 1.25 : 1;
// Use location of 'opinion' in current array to
// get polarity and subjectivity values, and
// then multiply them by the appropriate multipliers
let polarityVal = (parseFloat(pattern_en[wordArr2d[index][opinionLoc]][1].replace(/p/g, ''))) * negationMultiplier * intensityMultiplier * exclamationMultiplier;
let subjectivityVal = (parseFloat(pattern_en[wordArr2d[index][opinionLoc]][2].replace(/s/g, ''))) * intensityMultiplier;
// Limit polarity to a range of -1 to 1
polarityVal = value_limit(polarityVal, -1, 1);
// Limit subjectiivity to a range of 0 to 1
subjectivityVal = value_limit(subjectivityVal, 0, 1);
polarityValArr.push(polarityVal);
subjectivityValArr.push(subjectivityVal);
// Add polarity and subjectivity of this iteration to summaryObject
summaryObject.polarity = polarityVal;
summaryObject.subjectivity = subjectivityVal;
// Add this iteration's information to summary array
summaryArr.push(summaryObject);
}
//console.log('polarityValArr', polarityValArr);
//console.log('subjectivityValArr', subjectivityValArr);
//console.log('summaryArr', summaryArr);
// Average values in arrays to get respective scores
const polarityScore = averageArray(polarityValArr);
const subjectivityScore = averageArray(subjectivityValArr);
returnObj.polarity = polarityScore;
returnObj.subjectivity = subjectivityScore;
if (addMood === true) {
returnObj.mood = averageArray(emoticonValArr);
// If addSummary is true, add scored_icons
if (addSummary === true) {
const summaryObj = {};
summaryObj.scored_icons = emoticonArr;
summaryObj.mood = emoticonValArr;
summaryArr.push(summaryObj);
}
}
if (addSummary === true) { returnObj.summary = summaryArr; }
return returnObj;
}
}
}
export default sentimentComp
================================================
FILE: plugins/_experiments/sentiment/test.js
================================================
/* eslint-disable */
import nlp from '../../../src/three.js'
import plg from './src/plugin.js'
nlp.plugin(plg)
// Tests
console.log("Test submissions to sentiment:");
console.log("");
console.log("INPUTS THAT RETURN ERRORS:");
console.log("-----");
console.log("No input:");
console.log("", nlp().sentiment());
// Expected result:
// {error: 'Input must be a string containing text.'}
console.log("-----");
console.log("Empty string:");
console.log("", nlp("").sentiment(""));
// Expected result:
// {error: 'Input must be a string containing text.'}
console.log("-----");
console.log("Object:");
console.log({ 'This': 'object', 'contains': 'words' }, nlp({ 'This': 'object', 'contains': 'words' }).sentiment());
console.log("-----");
// Expected result:
// {error: 'Input must be a string containing text.'}
console.log("");
console.log("BASIC EXPLANATIONS:");
console.log("-----");
console.log("Polarity is the negative or positive sentiment of the score, and ranges from -1.0 (negative sentiment) to 1.0 (positive sentiment). Neutral is anything around zero (usually -0.05 to 0.05).");
console.log("Subjectivity is a measure of how likely it is that the string is opinion-based, and ranges from 0 (not likely to be opinion-based) to 1.0 (highly likely to be opinion-based).");
console.log("-----");
console.log("sentiment looks for known opinion-based words. The following string has none:");
console.log("This movie exists.", nlp("This movie exists.").sentiment());
// Expected result:
// {polarity: 0, subjectivity: 0}
console.log("-----");
console.log("The following string has a single opinion-based word in it (\"good\"):");
console.log("This movie is good.", nlp("This movie is good.").sentiment());
// Expected result:
// {polarity: 0.7, subjectivity: 0.6}
console.log("-----");
console.log("The scores can be changed in several ways.");
console.log("This sentence adds the intensifier \"very\". Note how the scores change from above:");
console.log("This movie is very good.", nlp("This movie is very good.").sentiment());
// Expected result:
// {polarity: 0.9099999999999999, subjectivity: 0.78}
console.log("-----");
console.log("This sentence adds the negation \"not\". Note the effect of this on the scores:");
console.log("This movie is not good.", nlp("This movie is not good.").sentiment());
// Expected result:
// {polarity: -0.35, subjectivity: 0.6}
console.log("-----");
console.log("Adding an exclamation mark also affects scores:");
console.log("This movie is good!", nlp("This movie is good!").sentiment());
// Expected result:
// {polarity: 0.875, subjectivity: 0.6}
console.log("-----");
console.log("Combining a negation, intensifier, and an exclamation mark to the opinion-based word:");
console.log("This movie is not very good!", nlp("This movie is not very good!").sentiment());
// Expected result:
// {polarity: -0.33653846153846145, subjectivity: 0.46153846153846145}
console.log("-----");
console.log("However, sentiment only looks at the 1 closest preceeding negation (if present), the 1 closest preceeding intensifier (if present), and a single exclamation mark:");
console.log("This movie is not not really very good!!!!", nlp("This movie is not not really very good!!!!").sentiment());
// Expected result:
// {polarity: -0.33653846153846145, subjectivity: 0.46153846153846145}
console.log("-----");
console.log("If a negation and/or an intensifier follow the opinion-based word, they are ignored. The following sentence is scored as if (not very) didn't exist:");
console.log("This movie is good (not very).", nlp("This movie is good (not very).").sentiment());
// Expected result:
// {polarity: 0.7, subjectivity: 0.6}
console.log("-----");
console.log("Moving the (not very) phrase to before the opinion-based word makes a difference in the scores:");
console.log("This movie is (not very) good.", nlp("This movie is (not very) good.").sentiment());
// Expected result:
// {polarity: -0.26923076923076916, subjectivity: 0.46153846153846145}
console.log("-----");
console.log("");
console.log("MULTIPLE OPINION-BASED WORDS:");
console.log("-----");
console.log("Multiple opinion-based words can be used:");
console.log("It's not very good. In fact, it was bad.", nlp("It's not very good. In fact, it was bad.").sentiment());
// Expected result:
// {polarity: -0.48461538461538456, subjectivity: 0.5641192307692307}
console.log("-----");
console.log("When multiple opinion-based words are used, each opinion-based word is affected by the closest preceeding single negation and/or intensifier.");
console.log("The following sentence is scored differently than directly above because (not very) is attributed to the following opinion-based word (bad), rather than the opinion-based word before them (good):");
console.log("It's good (not very). In fact, it was bad.", nlp("It's good (not very). In fact, it was bad.").sentiment());
// Expected result:
// {polarity: 0.48461538461538456, subjectivity: 0.5564230769230769}
console.log("-----");
console.log("");
console.log("EMOJIS, EMOTIONS (\"SMILEYS\") AND MOOD:");
console.log("-----");
console.log("Here's a short text-style message, with no emojis or emoticons/smileys:");
console.log("Awesome. I love it!", nlp("Awesome. I love it!").sentiment());
// Expected result:
// {polarity: 0.8125, subjectivity: 0.8}
console.log("-----");
console.log("Polarity and subjectivity scores are measured solely from text, so they aren't affected by the includion of emojis or emoticons/smileys:");
console.log("Awesome. I love it!😍", nlp("Awesome. I love it!😍").sentiment());
// Expected result:
// {polarity: 0.8125, subjectivity: 0.8}
console.log("-----");
console.log("However, you can set the mood flag to true, and you'll see a mood score. The mood score is similar to polarity, but calculated from the emojis and emoticons/smileys.");
console.log("Just like polarity, mood can range from -1.0 (negative sentiment) to 1.0 (positive sentiment).");
console.log("Awesome. I love it!😍", nlp("Awesome. I love it!😍").sentiment(true));
// Expected result:
// {polarity: 0.8125, subjectivity: 0.8, mood: 0.678}
console.log("-----");
console.log("Naturally, you can use multiple emoticons/smileys, and this will change the mood score:");
console.log("Awesome.🎉 I love it! 🤗😍:-D", nlp("Awesome.🎉 I love it! 🤗😍:-D").sentiment(true));
// Expected result:
// {polarity: 0.8125, subjectivity: 0.8, mood: 0.8053333333333333}
console.log("-----");
console.log("You can even use mood score to detect cynicism, by noting when the polarity (text) is negative and mood (emoticons/smileys) is positive (or vice-versa):");
const sentimentVal = nlp("The movie wasn't that good.😉 ;-)").sentiment(true);
console.log("The movie wasn't that good.😉 ;-)", sentimentVal);
// Expected result:
// {polarity: -0.35, subjectivity: 0.6, mood: 0.35650000000000004}
console.log("If you detect situations like this, you can calculate the average of these two scores to get the true overall polarity:");
console.log("(" + sentimentVal.polarity + " + " + sentimentVal.mood + ") ÷ 2 = " + ((sentimentVal.polarity + sentimentVal.mood) / 2));
// Expected result:
// (-0.35 + 0.35650000000000004) ÷ 2 = 0.0032500000000000306
console.log("-----");
console.log("");
console.log("SUMMARY:");
console.log("-----");
console.log("The other flag that can be set is the summary flag.");
console.log("This summary includes which negation and intensifier (if any) were chunked together with which opinion-based word, as well as the polarity and subjectivity score of each chunk:");
console.log("It's not really very good.", nlp("It's not really very good.").sentiment(false, true));
// Expected result:
// {
// "polarity": -0.26923076923076916,
// "subjectivity": 0.46153846153846145,
// "summary": [
// {
// "scored_words": [
// "not",
// "very",
// "good"
// ],
// "polarity": -0.26923076923076916,
// "subjectivity": 0.46153846153846145
// }
// ]
// }
console.log("-----");
console.log("If you set both the mood flag and the summary flag to true, you can see each emoji, emoticon and how they were scored, as well:");
console.log("It's not really very good. 😦:-(", nlp("It's not really very good. 😦:-(").sentiment(true, true));
// {
// "polarity": -0.26923076923076916,
// "subjectivity": 0.46153846153846145,
// "mood": -0.5589999999999999,
// "summary": [
// {
// "scored_words": [
// "not",
// "very",
// "good"
// ],
// "polarity": -0.26923076923076916,
// "subjectivity": 0.46153846153846145
// },
// {
// "scored_icons": [
// ":-(",
// "😦"
// ],
// "mood": [
// -0.75,
// -0.368
// ]
// }
// ]
// }
console.log("-----");
console.log("If you set both the mood flag and the summary flag to true, but have no emojis or emoticons/smileys in the text, the scored emoticons and mood in the summary will simply be empty arrays:");
console.log("It's not really very good.", nlp("It's not really very good.").sentiment(true, true));
// Expected result:
// {
// "polarity": -0.26923076923076916,
// "subjectivity": 0.46153846153846145,
// "mood": 0,
// "summary": [
// {
// "scored_words": [
// "not",
// "very",
// "good"
// ],
// "polarity": -0.26923076923076916,
// "subjectivity": 0.46153846153846145
// },
// {
// "scored_icons": [],
// "mood": []
// }
// ]
// }
console.log("-----");
// Dependencies:
// https://unpkg.com/efrt@2.7.0/builds/efrt-unpack.min.js
// https://unpkg.com/compromise
================================================
FILE: plugins/dates/README.md
================================================
- including all informal text formats, and folksy shorthands.
•
Tokenization and
disambiguation with compromise.
_description_ | `Start` | `End` |
| ----------------------------------- | :-----------------------------------: | ---------------: | ---------------: |
| _march 2nd_ | | March 2, 12:00am | March 2, 11:59pm |
| _2 march_ | | '' | '' |
| _tues march 2_ | | '' | '' |
| _march the second_ | _natural-language number_ | '' | '' |
| _on the 2nd_ | _implicit months_ | '' | '' |
| _tuesday the 2nd_ | _date-reckoning_ | '' | '' |
| _iso formats_ | '' | '' |
| _2020-03-02_ | | '' | '' |
| _03-02-2020_ | _british formats_ | '' | '' |
| _03/02_ | | '' | '' |
| _2020.08.13_ | _alt-ISO_ | '' | '' |
| _calendar-holidays_ | Dec 24, 12:00am | Dec 24, 11:59pm |
| _easter_ | _astronomical holidays_ | -depends- | - |
| _q1_ | | Jan 1, 12:00am | Mar 31, 11:59pm |
| _weird iso-times_ | '' | '' |
| _two oclock_ | _written formats_ | '' | '' |
| _before 1_ | | '' | '' |
| _noon_ | | '' | '' |
| _at night_ | _informal daytimes_ | '' | '' |
| _in the morning_ | | '' | '' |
| _tomorrow evening_ | | '' | '' |
| _informal zone support_ | '' | '' |
| _est_ | _TZ shorthands_ | '' | '' |
| _peru time_ | | '' | '' |
| _..in beirut_ | _by location_ | '' | '' |
| _GMT+9_ | _by UTC/GMT offset_ | '' | '' |
| _-4h_ | '' | '' | '' |
| _Canada/Eastern_ | _IANA codes_ | '' | '' |
| _now+duration_ | '' | '' |
| _two days after june 6th_ | _date+duration_ | '' | '' |
| _2 weeks from now_ | | '' | '' |
| _2 weeks after june_ | | '' | '' |
| _2 years, 4 months, and 5 days ago_ | _complex durations_ | '' | '' |
| _a week and a half before_ | _written-out numbers_ | '' | '' |
| _a week friday_ | _idiom format_ | '' | '' |
| _up-against the ending_ | '' | '' |
| _start of next year_ | _lean-toward starting_ | '' | '' |
| _middle of q2 last year_ | _rough-center calculation_ | '' | '' |
| _explicit ranges_ | '' | '' |
| _from today to next haloween_ | | '' | '' |
| _aug 1 - aug 31_ | _dash-ranges_ | '' | '' |
| _22-23 February_ | | '' | '' |
| _today to next friday_ | | '' | '' |
| _during june_ | | '' | '' |
| _aug to june 1999_ | _shared range info_ | '' | '' |
| _before [2019]_ | _up-to a date_ | '' | '' |
| _by march_ | | '' | '' |
| _after february_ | _date-to-infinity_ | '' | '' |
| _n-repeating dates_ | |
| _any day in June_ | _repeating-date in range_ | June 1 ... | .. June 30 |
| _any wednesday this week_ | | '' | '' |
| _weekends in July_ | _more-complex interval_ | '' | '' |
| _every weekday until February_ | _interval until date_ | '' | '' |
_description_ | `Start` | `End` |
| ------------------------ | :--------------------------------------------: | :-----: | :---: |
| _middle of 2019/June_ | tries to find the sorta-center | June 15 | '' |
| _good friday 2025_ | tries to reckon astronomically-set holidays | '' | '' |
| _Oct 22 1975 2am in PST_ | historical DST changes (assumes current dates) | '' | '' |
_description_ | `Start` | `End` |
| ------------------------------------------- | :----------------------: | :-----: | :---: |
| _not this Saturday, but the Saturday after_ | self-reference logic | '' | '' |
| _3 years ago tomorrow_ | folksy short-hand | '' | '' |
| _2100_ | military time formats | '' | '' |
| _may 97_ | 'bare' 2-digit years | '' | '' |
1 -
Regular-expressions are too-brittle to parse dates.
2 -
Neural-nets are too-wonky to parse dates.
3 - A
corporation , or
startup is the wrong place to build a universal date-parser.
_dates_ , _times_ , _durations_ , and _intervals_ from natural language can be a solved-problem.
A rule-based, community open-source library - _one based on simple NLP_ - is the best way to build a natural language date parser - commercial, or otherwise - for the frontend, or the backend.
The _[match-syntax](https://observablehq.com/@spencermountain/compromise-match-syntax)_ is effective and easy, _javascript_ is prevailing, and the more people who contribute, the better.
compromise-date is sponsored by #Duration] [(after|before)]');
if (m.found) {
let unit = m.groups('unit').text('reduced');
// unit = unit.replace(/s$/, '')
let dir = m.groups('dir').text('reduced');
if (dir === 'after') {
result[unit] = 1;
} else if (dir === 'before') {
result[unit] = -1;
}
}
// in half an hour
m = shift.match('half (a|an) [#Duration]', 0);
if (m.found) {
let unit = parseUnit(m);
result[unit] = 0.5;
}
// a couple years
m = shift.match('a (few|couple) [#Duration]', 0);
if (m.found) {
let unit = parseUnit(m);
result[unit] = m.has('few') ? 3 : 2;
}
// finally, remove it from our text
m = doc.match('#DateShift+');
return { result, m }
};
/*
a 'counter' is a Unit determined after a point
* first hour of x
* 7th week in x
* last year in x
*
unlike a shift, like "2 weeks after x"
*/
const oneBased = {
minute: true,
};
const getCounter = function (doc) {
// 7th week of
let m = doc.match('[#Value] [#Duration+] (of|in)');
if (m.found) {
let obj = m.groups();
let num = obj.num.numbers().get()[0];
let unit = obj.unit.text('reduced');
let result = {
unit: unit,
num: Number(num) || 0,
};
// 0-based or 1-based units
if (!oneBased[unit]) {
result.num -= 1;
}
return { result, m }
}
// first week of
m = doc.match('[(first|initial|last|final)] [#Duration+] (of|in)');
if (m.found) {
let obj = m.groups();
let dir = obj.dir.text('reduced');
let unit = obj.unit.text('reduced');
if (dir === 'initial') {
dir = 'first';
}
if (dir === 'final') {
dir = 'last';
}
let result = {
unit: unit,
dir: dir,
};
return { result, m }
}
return { result: null, m: doc.none() }
};
const MSEC_IN_HOUR = 60 * 60 * 1000;
//convert our local date syntax a javascript UTC date
const toUtc = (dstChange, offset, year) => {
const [month, rest] = dstChange.split('/');
const [day, hour] = rest.split(':');
return Date.UTC(year, month - 1, day, hour) - (offset * MSEC_IN_HOUR)
};
// compare epoch with dst change events (in utc)
const inSummerTime = (epoch, start, end, summerOffset, winterOffset) => {
const year = new Date(epoch).getUTCFullYear();
const startUtc = toUtc(start, winterOffset, year);
const endUtc = toUtc(end, summerOffset, year);
// simple number comparison now
return epoch >= startUtc && epoch < endUtc
};
/* eslint-disable no-console */
// this method avoids having to do a full dst-calculation on every operation
// it reproduces some things in ./index.js, but speeds up spacetime considerably
const quickOffset = s => {
let zones = s.timezones;
let obj = zones[s.tz];
if (obj === undefined) {
console.warn("Warning: couldn't find timezone " + s.tz);
return 0
}
if (obj.dst === undefined) {
return obj.offset
}
//get our two possible offsets
let jul = obj.offset;
let dec = obj.offset + 1; // assume it's the same for now
if (obj.hem === 'n') {
dec = jul - 1;
}
let split = obj.dst.split('->');
let inSummer = inSummerTime(s.epoch, split[0], split[1], jul, dec);
if (inSummer === true) {
return jul
}
return dec
};
var data = {
"9|s": "2/dili,2/jayapura",
"9|n": "2/chita,2/khandyga,2/pyongyang,2/seoul,2/tokyo,2/yakutsk,11/palau,japan,rok",
"9.5|s|04/06:03->10/05:04": "4/adelaide,4/broken_hill,4/south,4/yancowinna",
"9.5|s": "4/darwin,4/north",
"8|s|03/13:01->10/02:00": "12/casey",
"8|s": "2/kuala_lumpur,2/makassar,2/singapore,4/perth,2/ujung_pandang,4/west,singapore",
"8|n": "2/brunei,2/hong_kong,2/irkutsk,2/kuching,2/macau,2/manila,2/shanghai,2/taipei,2/ulaanbaatar,2/chongqing,2/chungking,2/harbin,2/macao,2/ulan_bator,2/choibalsan,hongkong,prc,roc",
"8.75|s": "4/eucla",
"7|s": "12/davis,2/jakarta,9/christmas",
"7|n": "2/bangkok,2/barnaul,2/hovd,2/krasnoyarsk,2/novokuznetsk,2/novosibirsk,2/phnom_penh,2/pontianak,2/ho_chi_minh,2/tomsk,2/vientiane,2/saigon",
"6|s": "12/vostok",
"6|n": "2/almaty,2/bishkek,2/dhaka,2/omsk,2/qyzylorda,2/qostanay,2/thimphu,2/urumqi,9/chagos,2/dacca,2/kashgar,2/thimbu",
"6.5|n": "2/yangon,9/cocos,2/rangoon",
"5|s": "12/mawson,9/kerguelen",
"5|n": "2/aqtau,2/aqtobe,2/ashgabat,2/atyrau,2/dushanbe,2/karachi,2/oral,2/samarkand,2/tashkent,2/yekaterinburg,9/maldives,2/ashkhabad",
"5.75|n": "2/kathmandu,2/katmandu",
"5.5|n": "2/kolkata,2/colombo,2/calcutta",
"4|s": "9/reunion",
"4|n": "2/baku,2/dubai,2/muscat,2/tbilisi,2/yerevan,8/astrakhan,8/samara,8/saratov,8/ulyanovsk,8/volgograd,9/mahe,9/mauritius,2/volgograd",
"4.5|n": "2/kabul",
"3|s": "12/syowa,9/antananarivo",
"3|n|04/25:02->10/30:24": "0/cairo,egypt",
"3|n|04/12:04->10/25:02": "2/gaza,2/hebron",
"3|n|03/30:05->10/26:04": "2/famagusta,2/nicosia,8/athens,8/bucharest,8/helsinki,8/kyiv,8/mariehamn,8/riga,8/sofia,8/tallinn,8/uzhgorod,8/vilnius,8/zaporozhye,8/nicosia,8/kiev,eet",
"3|n|03/30:04->10/26:03": "8/chisinau,8/tiraspol",
"3|n|03/30:02->10/25:24": "2/beirut",
"3|n|03/28:04->10/26:02": "2/jerusalem,2/tel_aviv,israel",
"3|n": "0/addis_ababa,0/asmara,0/asmera,0/dar_es_salaam,0/djibouti,0/juba,0/kampala,0/mogadishu,0/nairobi,2/aden,2/amman,2/baghdad,2/bahrain,2/damascus,2/kuwait,2/qatar,2/riyadh,8/istanbul,8/kirov,8/minsk,8/moscow,8/simferopol,9/comoro,9/mayotte,2/istanbul,turkey,w-su",
"3.5|n": "2/tehran,iran",
"2|s|03/30:04->10/26:02": "12/troll",
"2|s": "0/gaborone,0/harare,0/johannesburg,0/lubumbashi,0/lusaka,0/maputo,0/maseru,0/mbabane",
"2|n|03/30:04->10/26:03": "0/ceuta,arctic/longyearbyen,8/amsterdam,8/andorra,8/belgrade,8/berlin,8/bratislava,8/brussels,8/budapest,8/busingen,8/copenhagen,8/gibraltar,8/ljubljana,8/luxembourg,8/madrid,8/malta,8/monaco,8/oslo,8/paris,8/podgorica,8/prague,8/rome,8/san_marino,8/sarajevo,8/skopje,8/stockholm,8/tirane,8/vaduz,8/vatican,8/vienna,8/warsaw,8/zagreb,8/zurich,3/jan_mayen,poland,cet,met",
"2|n": "0/blantyre,0/bujumbura,0/khartoum,0/kigali,0/tripoli,8/kaliningrad,libya",
"1|s": "0/brazzaville,0/kinshasa,0/luanda,0/windhoek",
"1|n|03/30:03->10/26:02": "3/canary,3/faroe,3/madeira,8/dublin,8/guernsey,8/isle_of_man,8/jersey,8/lisbon,8/london,3/faeroe,eire,8/belfast,gb-eire,gb,portugal,wet",
"1|n": "0/algiers,0/bangui,0/douala,0/lagos,0/libreville,0/malabo,0/ndjamena,0/niamey,0/porto-novo,0/tunis",
"14|n": "11/kiritimati",
"13|s": "11/apia,11/tongatapu",
"13|n": "11/enderbury,11/kanton,11/fakaofo",
"12|s|04/06:03->09/28:04": "12/mcmurdo,11/auckland,12/south_pole,nz",
"12|s": "11/fiji",
"12|n": "2/anadyr,2/kamchatka,2/srednekolymsk,11/funafuti,11/kwajalein,11/majuro,11/nauru,11/tarawa,11/wake,11/wallis,kwajalein",
"12.75|s|04/06:03->04/06:02": "11/chatham,nz-chat",
"11|s|04/06:03->10/05:04": "12/macquarie",
"11|s": "11/bougainville",
"11|n": "2/magadan,2/sakhalin,11/efate,11/guadalcanal,11/kosrae,11/noumea,11/pohnpei,11/ponape",
"11.5|n|04/06:03->10/05:04": "11/norfolk",
"10|s|04/06:03->10/05:04": "4/currie,4/hobart,4/melbourne,4/sydney,4/act,4/canberra,4/nsw,4/tasmania,4/victoria",
"10|s": "12/dumontdurville,4/brisbane,4/lindeman,11/port_moresby,4/queensland",
"10|n": "2/ust-nera,2/vladivostok,11/guam,11/saipan,11/chuuk,11/truk,11/yap",
"10.5|s|04/06:01->10/05:02": "4/lord_howe,4/lhi",
"0|s|02/23:03->04/06:04": "0/casablanca,0/el_aaiun",
"0|n|03/30:02->10/26:01": "3/azores",
"0|n|03/30:01->10/25:24": "1/scoresbysund",
"0|n": "0/abidjan,0/accra,0/bamako,0/banjul,0/bissau,0/conakry,0/dakar,0/freetown,0/lome,0/monrovia,0/nouakchott,0/ouagadougou,0/sao_tome,1/danmarkshavn,3/reykjavik,3/st_helena,13/gmt,13/utc,0/timbuktu,13/greenwich,13/uct,13/universal,13/zulu,gmt-0,gmt+0,gmt0,greenwich,iceland,uct,universal,utc,zulu,13/unknown,factory",
"-9|n|03/09:04->11/02:02": "1/adak,1/atka,us/aleutian",
"-9|n": "11/gambier",
"-9.5|n": "11/marquesas",
"-8|n|03/09:04->11/02:02": "1/anchorage,1/juneau,1/metlakatla,1/nome,1/sitka,1/yakutat,us/alaska",
"-8|n": "11/pitcairn",
"-7|n|03/09:04->11/02:02": "1/los_angeles,1/santa_isabel,1/tijuana,1/vancouver,1/ensenada,6/pacific,10/bajanorte,us/pacific-new,us/pacific",
"-7|n": "1/creston,1/dawson,1/dawson_creek,1/fort_nelson,1/hermosillo,1/mazatlan,1/phoenix,1/whitehorse,6/yukon,10/bajasur,us/arizona,mst",
"-6|s|04/05:22->09/06:24": "11/easter,7/easterisland",
"-6|n|04/07:02->10/27:02": "1/merida",
"-6|n|03/09:04->11/02:02": "1/boise,1/cambridge_bay,1/denver,1/edmonton,1/inuvik,1/north_dakota,1/ojinaga,1/ciudad_juarez,1/yellowknife,1/shiprock,6/mountain,navajo,us/mountain",
"-6|n": "1/bahia_banderas,1/belize,1/chihuahua,1/costa_rica,1/el_salvador,1/guatemala,1/managua,1/mexico_city,1/monterrey,1/regina,1/swift_current,1/tegucigalpa,11/galapagos,6/east-saskatchewan,6/saskatchewan,10/general",
"-5|s": "1/lima,1/rio_branco,1/porto_acre,5/acre",
"-5|n|03/09:04->11/02:02": "1/chicago,1/matamoros,1/menominee,1/rainy_river,1/rankin_inlet,1/resolute,1/winnipeg,1/indiana/knox,1/indiana/tell_city,1/north_dakota/beulah,1/north_dakota/center,1/north_dakota/new_salem,1/knox_in,6/central,us/central,us/indiana-starke",
"-5|n": "1/bogota,1/cancun,1/cayman,1/coral_harbour,1/eirunepe,1/guayaquil,1/jamaica,1/panama,1/atikokan,jamaica,est",
"-4|s|04/05:24->09/07:02": "1/santiago,7/continental",
"-4|s|03/22:24->10/05:02": "1/asuncion",
"-4|s": "1/campo_grande,1/cuiaba,1/la_paz,1/manaus,5/west",
"-4|n|03/09:04->11/02:02": "1/detroit,1/grand_turk,1/indiana,1/indianapolis,1/iqaluit,1/kentucky,1/louisville,1/montreal,1/nassau,1/new_york,1/nipigon,1/pangnirtung,1/port-au-prince,1/thunder_bay,1/toronto,1/indiana/marengo,1/indiana/petersburg,1/indiana/vevay,1/indiana/vincennes,1/indiana/winamac,1/kentucky/monticello,1/fort_wayne,1/indiana/indianapolis,1/kentucky/louisville,6/eastern,us/east-indiana,us/eastern,us/michigan",
"-4|n|03/09:02->11/02:01": "1/havana,cuba",
"-4|n": "1/anguilla,1/antigua,1/aruba,1/barbados,1/blanc-sablon,1/boa_vista,1/caracas,1/curacao,1/dominica,1/grenada,1/guadeloupe,1/guyana,1/kralendijk,1/lower_princes,1/marigot,1/martinique,1/montserrat,1/port_of_spain,1/porto_velho,1/puerto_rico,1/santo_domingo,1/st_barthelemy,1/st_kitts,1/st_lucia,1/st_thomas,1/st_vincent,1/tortola,1/virgin",
"-3|s": "1/argentina,1/buenos_aires,1/catamarca,1/cordoba,1/fortaleza,1/jujuy,1/mendoza,1/montevideo,1/punta_arenas,1/sao_paulo,12/palmer,12/rothera,3/stanley,1/argentina/la_rioja,1/argentina/rio_gallegos,1/argentina/salta,1/argentina/san_juan,1/argentina/san_luis,1/argentina/tucuman,1/argentina/ushuaia,1/argentina/comodrivadavia,1/argentina/buenos_aires,1/argentina/catamarca,1/argentina/cordoba,1/argentina/jujuy,1/argentina/mendoza,1/argentina/rosario,1/rosario,5/east",
"-3|n|03/09:04->11/02:02": "1/glace_bay,1/goose_bay,1/halifax,1/moncton,1/thule,3/bermuda,6/atlantic",
"-3|n": "1/araguaina,1/bahia,1/belem,1/cayenne,1/maceio,1/paramaribo,1/recife,1/santarem",
"-2|n|03/09:04->11/02:02": "1/miquelon",
"-2|n": "1/noronha,3/south_georgia,5/denoronha",
"-2.5|n|03/09:04->11/02:02": "1/st_johns,6/newfoundland",
"-1|n|03/30:01->10/25:24": "1/nuuk,1/godthab",
"-1|n": "3/cape_verde",
"-11|n": "11/midway,11/niue,11/pago_pago,11/samoa,us/samoa",
"-10|n": "11/honolulu,11/johnston,11/rarotonga,11/tahiti,us/hawaii,hst"
};
//prefixes for iana names..
var prefixes = [
'africa',
'america',
'asia',
'atlantic',
'australia',
'brazil',
'canada',
'chile',
'europe',
'indian',
'mexico',
'pacific',
'antarctica',
'etc'
];
let all = {};
Object.keys(data).forEach((k) => {
let split = k.split('|');
let obj = {
offset: Number(split[0]),
hem: split[1]
};
if (split[2]) {
obj.dst = split[2];
}
let names = data[k].split(',');
names.forEach((str) => {
str = str.replace(/(^[0-9]+)\//, (before, num) => {
num = Number(num);
return prefixes[num] + '/'
});
all[str] = obj;
});
});
all.utc = {
offset: 0,
hem: 'n' //default to northern hemisphere - (sorry!)
};
//add etc/gmt+n
for (let i = -14; i <= 14; i += 0.5) {
let num = i;
if (num > 0) {
num = '+' + num;
}
let name = 'etc/gmt' + num;
all[name] = {
offset: i * -1, //they're negative!
hem: 'n' //(sorry)
};
name = 'utc/gmt' + num; //this one too, why not.
all[name] = {
offset: i * -1,
hem: 'n'
};
}
//find the implicit iana code for this machine.
//safely query the Intl object
//based on - https://bitbucket.org/pellepim/jstimezonedetect/src
const fallbackTZ = 'utc'; //
//this Intl object is not supported often, yet
const safeIntl = () => {
if (typeof Intl === 'undefined' || typeof Intl.DateTimeFormat === 'undefined') {
return null
}
let format = Intl.DateTimeFormat();
if (typeof format === 'undefined' || typeof format.resolvedOptions === 'undefined') {
return null
}
let timezone = format.resolvedOptions().timeZone;
if (!timezone) {
return null
}
return timezone.toLowerCase()
};
const guessTz = () => {
let timezone = safeIntl();
if (timezone === null) {
return fallbackTZ
}
return timezone
};
const isOffset$1 = /(-?[0-9]+)h(rs)?/i;
const isNumber$1 = /(-?[0-9]+)/;
const utcOffset$1 = /utc([\-+]?[0-9]+)/i;
const gmtOffset$1 = /gmt([\-+]?[0-9]+)/i;
const toIana$1 = function (num) {
num = Number(num);
if (num >= -13 && num <= 13) {
num = num * -1; //it's opposite!
num = (num > 0 ? '+' : '') + num; //add plus sign
return 'etc/gmt' + num
}
return null
};
const parseOffset$2 = function (tz) {
// '+5hrs'
let m = tz.match(isOffset$1);
if (m !== null) {
return toIana$1(m[1])
}
// 'utc+5'
m = tz.match(utcOffset$1);
if (m !== null) {
return toIana$1(m[1])
}
// 'GMT-5' (not opposite)
m = tz.match(gmtOffset$1);
if (m !== null) {
let num = Number(m[1]) * -1;
return toIana$1(num)
}
// '+5'
m = tz.match(isNumber$1);
if (m !== null) {
return toIana$1(m[1])
}
return null
};
/* eslint-disable no-console */
let local = guessTz();
//add all the city names by themselves
const cities = Object.keys(all).reduce((h, k) => {
let city = k.split('/')[1] || '';
city = city.replace(/_/g, ' ');
h[city] = k;
return h
}, {});
//try to match these against iana form
const normalize$4 = (tz) => {
tz = tz.replace(/ time/g, '');
tz = tz.replace(/ (standard|daylight|summer)/g, '');
tz = tz.replace(/\b(east|west|north|south)ern/g, '$1');
tz = tz.replace(/\b(africa|america|australia)n/g, '$1');
tz = tz.replace(/\beuropean/g, 'europe');
tz = tz.replace(/islands/g, 'island');
return tz
};
// try our best to reconcile the timzone to this given string
const lookupTz = (str, zones) => {
if (!str) {
// guard if Intl response is unsupported (#397)
if (!zones.hasOwnProperty(local)) {
console.warn(`Unrecognized IANA id '${local}'. Setting fallback tz to UTC.`);
local = 'utc';
}
return local
}
if (typeof str !== 'string') {
console.error("Timezone must be a string - recieved: '", str, "'\n");
}
let tz = str.trim();
// let split = str.split('/')
//support long timezones like 'America/Argentina/Rio_Gallegos'
// if (split.length > 2 && zones.hasOwnProperty(tz) === false) {
// tz = split[0] + '/' + split[1]
// }
tz = tz.toLowerCase();
if (zones.hasOwnProperty(tz) === true) {
return tz
}
//lookup more loosely..
tz = normalize$4(tz);
if (zones.hasOwnProperty(tz) === true) {
return tz
}
//try city-names
if (cities.hasOwnProperty(tz) === true) {
return cities[tz]
}
// //try to parse '-5h'
if (/[0-9]/.test(tz) === true) {
let id = parseOffset$2(tz);
if (id) {
return id
}
}
throw new Error(
"Spacetime: Cannot find timezone named: '" + str + "'. Please enter an IANA timezone id."
)
};
//git:blame @JuliasCaesar https://www.timeanddate.com/date/leapyear.html
function isLeapYear(year) { return (year % 4 === 0 && year % 100 !== 0) || year % 400 === 0 }
// unsurprisingly-nasty `typeof date` call
function isDate(d) { return Object.prototype.toString.call(d) === '[object Date]' && !isNaN(d.valueOf()) }
function isArray$1(input) { return Object.prototype.toString.call(input) === '[object Array]' }
function isObject(input) { return Object.prototype.toString.call(input) === '[object Object]' }
function isBoolean(input) { return Object.prototype.toString.call(input) === '[object Boolean]' }
function zeroPad(str, len = 2) {
let pad = '0';
str = str + '';
return str.length >= len ? str : new Array(len - str.length + 1).join(pad) + str
}
function titleCase$1(str) {
if (!str) {
return ''
}
return str[0].toUpperCase() + str.substr(1)
}
function ordinal(i) {
let j = i % 10;
let k = i % 100;
if (j === 1 && k !== 11) {
return i + 'st'
}
if (j === 2 && k !== 12) {
return i + 'nd'
}
if (j === 3 && k !== 13) {
return i + 'rd'
}
return i + 'th'
}
//strip 'st' off '1st'..
function toCardinal(str) {
str = String(str);
str = str.replace(/([0-9])(st|nd|rd|th)$/i, '$1');
return parseInt(str, 10)
}
//used mostly for cleanup of unit names, like 'months'
function normalize$3(str = '') {
str = str.toLowerCase().trim();
str = str.replace(/ies$/, 'y'); //'centuries'
str = str.replace(/s$/, '');
str = str.replace(/-/g, '');
if (str === 'day' || str === 'days') {
return 'date'
}
if (str === 'min' || str === 'mins') {
return 'minute'
}
return str
}
function getEpoch(tmp) {
//support epoch
if (typeof tmp === 'number') {
return tmp
}
//suport date objects
if (isDate(tmp)) {
return tmp.getTime()
}
// support spacetime objects
if (tmp.epoch || tmp.epoch === 0) {
return tmp.epoch
}
return null
}
//make sure this input is a spacetime obj
function beADate(d, s) {
if (isObject(d) === false) {
return s.clone().set(d)
}
return d
}
function formatTimezone(offset, delimiter = '') {
const sign = offset > 0 ? '+' : '-';
const absOffset = Math.abs(offset);
const hours = zeroPad(parseInt('' + absOffset, 10));
const minutes = zeroPad((absOffset % 1) * 60);
return `${sign}${hours}${delimiter}${minutes}`
}
/* eslint-disable no-console */
const defaults$1 = {
year: new Date().getFullYear(),
month: 0,
date: 1
};
//support [2016, 03, 01] format
const parseArray$1 = (s, arr, today) => {
if (arr.length === 0) {
return s
}
let order = ['year', 'month', 'date', 'hour', 'minute', 'second', 'millisecond'];
for (let i = 0; i < order.length; i++) {
let num = arr[i] || today[order[i]] || defaults$1[order[i]] || 0;
s = s[order[i]](num);
}
return s
};
//support {year:2016, month:3} format
const parseObject$1 = (s, obj, today) => {
// if obj is empty, do nothing
if (Object.keys(obj).length === 0) {
return s
}
obj = Object.assign({}, defaults$1, today, obj);
let keys = Object.keys(obj);
for (let i = 0; i < keys.length; i++) {
let unit = keys[i];
//make sure we have this method
if (s[unit] === undefined || typeof s[unit] !== 'function') {
continue
}
//make sure the value is a number
if (obj[unit] === null || obj[unit] === undefined || obj[unit] === '') {
continue
}
let num = obj[unit] || today[unit] || defaults$1[unit] || 0;
s = s[unit](num);
}
return s
};
// this may seem like an arbitrary number, but it's 'within jan 1970'
// this is only really ambiguous until 2054 or so
const parseNumber$1 = function (s, input) {
const minimumEpoch = 2500000000;
// if the given epoch is really small, they've probably given seconds and not milliseconds
// anything below this number is likely (but not necessarily) a mistaken input.
if (input > 0 && input < minimumEpoch && s.silent === false) {
console.warn(' - Warning: You are setting the date to January 1970.');
console.warn(' - did input seconds instead of milliseconds?');
}
s.epoch = input;
return s
};
var fns = {
parseArray: parseArray$1,
parseObject: parseObject$1,
parseNumber: parseNumber$1
};
// pull in 'today' data for the baseline moment
const getNow = function (s) {
s.epoch = Date.now();
Object.keys(s._today || {}).forEach((k) => {
if (typeof s[k] === 'function') {
s = s[k](s._today[k]);
}
});
return s
};
const dates$4 = {
now: (s) => {
return getNow(s)
},
today: (s) => {
return getNow(s)
},
tonight: (s) => {
s = getNow(s);
s = s.hour(18); //6pm
return s
},
tomorrow: (s) => {
s = getNow(s);
s = s.add(1, 'day');
s = s.startOf('day');
return s
},
yesterday: (s) => {
s = getNow(s);
s = s.subtract(1, 'day');
s = s.startOf('day');
return s
},
christmas: (s) => {
let year = getNow(s).year();
s = s.set([year, 11, 25, 18, 0, 0]); // Dec 25
return s
},
'new years': (s) => {
let year = getNow(s).year();
s = s.set([year, 11, 31, 18, 0, 0]); // Dec 31
return s
}
};
dates$4['new years eve'] = dates$4['new years'];
//little cleanup..
const normalize$2 = function (str) {
// remove all day-names
str = str.replace(/\b(mon|tues?|wed|wednes|thur?s?|fri|sat|satur|sun)(day)?\b/i, '');
//remove ordinal ending
str = str.replace(/([0-9])(th|rd|st|nd)/, '$1');
str = str.replace(/,/g, '');
str = str.replace(/ +/g, ' ').trim();
return str
};
let o = {
millisecond: 1
};
o.second = 1000;
o.minute = 60000;
o.hour = 3.6e6; // dst is supported post-hoc
o.day = 8.64e7; //
o.date = o.day;
o.month = 8.64e7 * 29.5; //(average)
o.week = 6.048e8;
o.year = 3.154e10; // leap-years are supported post-hoc
//add plurals
Object.keys(o).forEach(k => {
o[k + 's'] = o[k];
});
/* eslint-disable no-console */
//basically, step-forward/backward until js Date object says we're there.
const walk = (s, n, fn, unit, previous) => {
let current = s.d[fn]();
if (current === n) {
return //already there
}
let startUnit = previous === null ? null : s.d[previous]();
let original = s.epoch;
//try to get it as close as we can
let diff = n - current;
s.epoch += o[unit] * diff;
//DST edge-case: if we are going many days, be a little conservative
// console.log(unit, diff)
if (unit === 'day') {
// s.epoch -= ms.minute
//but don't push it over a month
if (Math.abs(diff) > 28 && n < 28) {
s.epoch += o.hour;
}
}
// 1st time: oops, did we change previous unit? revert it.
if (previous !== null && startUnit !== s.d[previous]()) {
// console.warn('spacetime warning: missed setting ' + unit)
s.epoch = original;
// s.epoch += ms[unit] * diff * 0.89 // maybe try and make it close...?
}
//repair it if we've gone too far or something
//(go by half-steps, just in case)
const halfStep = o[unit] / 2;
while (s.d[fn]() < n) {
s.epoch += halfStep;
}
while (s.d[fn]() > n) {
s.epoch -= halfStep;
}
// 2nd time: did we change previous unit? revert it.
if (previous !== null && startUnit !== s.d[previous]()) {
// console.warn('spacetime warning: missed setting ' + unit)
s.epoch = original;
}
};
//find the desired date by a increment/check while loop
const units$5 = {
year: {
valid: (n) => n > -4000 && n < 4000,
walkTo: (s, n) => walk(s, n, 'getFullYear', 'year', null)
},
month: {
valid: (n) => n >= 0 && n <= 11,
walkTo: (s, n) => {
let d = s.d;
let current = d.getMonth();
let original = s.epoch;
let startUnit = d.getFullYear();
if (current === n) {
return
}
//try to get it as close as we can..
let diff = n - current;
s.epoch += o.day * (diff * 28); //special case
//oops, did we change the year? revert it.
if (startUnit !== s.d.getFullYear()) {
s.epoch = original;
}
//increment by day
while (s.d.getMonth() < n) {
s.epoch += o.day;
}
while (s.d.getMonth() > n) {
s.epoch -= o.day;
}
}
},
date: {
valid: (n) => n > 0 && n <= 31,
walkTo: (s, n) => walk(s, n, 'getDate', 'day', 'getMonth')
},
hour: {
valid: (n) => n >= 0 && n < 24,
walkTo: (s, n) => walk(s, n, 'getHours', 'hour', 'getDate')
},
minute: {
valid: (n) => n >= 0 && n < 60,
walkTo: (s, n) => walk(s, n, 'getMinutes', 'minute', 'getHours')
},
second: {
valid: (n) => n >= 0 && n < 60,
walkTo: (s, n) => {
//do this one directly
s.epoch = s.seconds(n).epoch;
}
},
millisecond: {
valid: (n) => n >= 0 && n < 1000,
walkTo: (s, n) => {
//do this one directly
s.epoch = s.milliseconds(n).epoch;
}
}
};
const walkTo = (s, wants) => {
let keys = Object.keys(units$5);
let old = s.clone();
for (let i = 0; i < keys.length; i++) {
let k = keys[i];
let n = wants[k];
if (n === undefined) {
n = old[k]();
}
if (typeof n === 'string') {
n = parseInt(n, 10);
}
//make-sure it's valid
if (!units$5[k].valid(n)) {
s.epoch = null;
if (s.silent === false) {
console.warn('invalid ' + k + ': ' + n);
}
return
}
units$5[k].walkTo(s, n);
}
return
};
const monthLengths = [
31, // January - 31 days
28, // February - 28 days in a common year and 29 days in leap years
31, // March - 31 days
30, // April - 30 days
31, // May - 31 days
30, // June - 30 days
31, // July - 31 days
31, // August - 31 days
30, // September - 30 days
31, // October - 31 days
30, // November - 30 days
31 // December - 31 days
];
// 28 - feb
// 30 - april, june, sept, nov
// 31 - jan, march, may, july, aug, oct, dec
let shortMonths = [
'jan',
'feb',
'mar',
'apr',
'may',
'jun',
'jul',
'aug',
'sep',
'oct',
'nov',
'dec'
];
let longMonths = [
'january',
'february',
'march',
'april',
'may',
'june',
'july',
'august',
'september',
'october',
'november',
'december'
];
function buildMapping() {
const obj = {
sep: 8 //support this format
};
for (let i = 0; i < shortMonths.length; i++) {
obj[shortMonths[i]] = i;
}
for (let i = 0; i < longMonths.length; i++) {
obj[longMonths[i]] = i;
}
return obj
}
function short$1() { return shortMonths }
function long$1() { return longMonths }
function mapping$3() { return buildMapping() }
function set$5(i18n) {
shortMonths = i18n.short || shortMonths;
longMonths = i18n.long || longMonths;
}
//pull-apart ISO offsets, like "+0100"
const parseOffset$1 = (s, offset) => {
if (!offset) {
return s
}
offset = offset.trim().toLowerCase();
// according to ISO8601, tz could be hh:mm, hhmm or hh
// so need few more steps before the calculation.
let num = 0;
// for (+-)hh:mm
if (/^[+-]?[0-9]{2}:[0-9]{2}$/.test(offset)) {
//support "+01:00"
if (/:00/.test(offset) === true) {
offset = offset.replace(/:00/, '');
}
//support "+01:30"
if (/:30/.test(offset) === true) {
offset = offset.replace(/:30/, '.5');
}
}
// for (+-)hhmm
if (/^[+-]?[0-9]{4}$/.test(offset)) {
offset = offset.replace(/30$/, '.5');
}
num = parseFloat(offset);
//divide by 100 or 10 - , "+0100", "+01"
if (Math.abs(num) > 100) {
num = num / 100;
}
//this is a fancy-move
if (num === 0 || offset === 'Z' || offset === 'z') {
s.tz = 'etc/gmt';
return s
}
//okay, try to match it to a utc timezone
//remember - this is opposite! a -5 offset maps to Etc/GMT+5 ¯\_(:/)_/¯
//https://askubuntu.com/questions/519550/why-is-the-8-timezone-called-gmt-8-in-the-filesystem
num *= -1;
if (num >= 0) {
num = '+' + num;
}
let tz = 'etc/gmt' + num;
let zones = s.timezones;
if (zones[tz]) {
// log a warning if we're over-writing a given timezone?
// console.log('changing timezone to: ' + tz)
s.tz = tz;
}
return s
};
// truncate any sub-millisecond values
const parseMs = function (str = '') {
str = String(str);
//js does not support sub-millisecond values
// so truncate these - 2021-11-02T19:55:30.087772
if (str.length > 3) {
str = str.substring(0, 3);
} else if (str.length === 1) {
// assume ms are zero-padded on the left
// but maybe not on the right.
// turn '.10' into '.100'
str = str + '00';
} else if (str.length === 2) {
str = str + '0';
}
return Number(str) || 0
};
const parseTime$1 = (s, str = '') => {
// remove all whitespace
str = str.replace(/^\s+/, '').toLowerCase();
//formal time format - 04:30.23
let arr = str.match(/([0-9]{1,2}):([0-9]{1,2}):?([0-9]{1,2})?[:.]?([0-9]{1,4})?/);
if (arr !== null) {
let [, h, m, sec, ms] = arr;
//validate it a little
h = Number(h);
if (h < 0 || h > 24) {
return s.startOf('day')
}
m = Number(m); //don't accept '5:3pm'
if (arr[2].length < 2 || m < 0 || m > 59) {
return s.startOf('day')
}
s = s.hour(h);
s = s.minute(m);
s = s.seconds(sec || 0);
s = s.millisecond(parseMs(ms));
//parse-out am/pm
let ampm = str.match(/[0-9] ?(am|pm)\b/);
if (ampm !== null && ampm[1]) {
s = s.ampm(ampm[1]);
}
return s
}
//try an informal form - 5pm (no minutes)
arr = str.match(/([0-9]+) ?(am|pm)/);
if (arr !== null && arr[1]) {
let h = Number(arr[1]);
//validate it a little..
if (h > 12 || h < 1) {
return s.startOf('day')
}
s = s.hour(arr[1] || 0);
s = s.ampm(arr[2]);
s = s.startOf('hour');
return s
}
//no time info found, use start-of-day
s = s.startOf('day');
return s
};
let months$1 = mapping$3();
//given a month, return whether day number exists in it
const validate$1 = (obj) => {
//invalid values
if (monthLengths.hasOwnProperty(obj.month) !== true) {
return false
}
//support leap-year in february
if (obj.month === 1) {
if (isLeapYear(obj.year) && obj.date <= 29) {
return true
} else {
return obj.date <= 28
}
}
//is this date too-big for this month?
let max = monthLengths[obj.month] || 0;
if (obj.date <= max) {
return true
}
return false
};
const parseYear = (str = '', today) => {
str = str.trim();
// parse '86 shorthand
if (/^'[0-9][0-9]$/.test(str) === true) {
let num = Number(str.replace(/'/, ''));
if (num > 50) {
return 1900 + num
}
return 2000 + num
}
let year = parseInt(str, 10);
// use a given year from options.today
if (!year && today) {
year = today.year;
}
// fallback to this year
year = year || new Date().getFullYear();
return year
};
const parseMonth = function (str) {
str = str.toLowerCase().trim();
if (str === 'sept') {
return months$1.sep
}
return months$1[str]
};
var ymd = [
// =====
// y-m-d
// =====
//iso-this 1998-05-30T22:00:00:000Z, iso-that 2017-04-03T08:00:00-0700
{
reg: /^(-?0{0,2}[0-9]{3,4})-([0-9]{1,2})-([0-9]{1,2})[T| ]([0-9.:]+)(Z|[0-9-+:]+)?$/i,
parse: (s, m) => {
let obj = {
year: m[1],
month: parseInt(m[2], 10) - 1,
date: m[3]
};
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
parseOffset$1(s, m[5]);
walkTo(s, obj);
s = parseTime$1(s, m[4]);
return s
}
},
//short-iso "2015-03-25" or "2015/03/25" or "2015/03/25 12:26:14 PM"
{
reg: /^([0-9]{4})[\-/. ]([0-9]{1,2})[\-/. ]([0-9]{1,2})( [0-9]{1,2}(:[0-9]{0,2})?(:[0-9]{0,3})? ?(am|pm)?)?$/i,
parse: (s, m) => {
let obj = {
year: m[1],
month: parseInt(m[2], 10) - 1,
date: parseInt(m[3], 10)
};
if (obj.month >= 12) {
//support yyyy/dd/mm (weird, but ok)
obj.date = parseInt(m[2], 10);
obj.month = parseInt(m[3], 10) - 1;
}
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = parseTime$1(s, m[4]);
return s
}
},
//text-month "2015-feb-25"
{
reg: /^([0-9]{4})[\-/. ]([a-z]+)[\-/. ]([0-9]{1,2})( [0-9]{1,2}(:[0-9]{0,2})?(:[0-9]{0,3})? ?(am|pm)?)?$/i,
parse: (s, m) => {
let obj = {
year: parseYear(m[1], s._today),
month: parseMonth(m[2]),
date: toCardinal(m[3] || '')
};
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = parseTime$1(s, m[4]);
return s
}
}
];
var mdy = [
// =====
// m-d-y
// =====
//mm/dd/yyyy - uk/canada "6/28/2019, 12:26:14 PM"
{
reg: /^([0-9]{1,2})[-/.]([0-9]{1,2})[\-/.]?([0-9]{4})?( [0-9]{1,2}:[0-9]{2}:?[0-9]{0,2} ?(am|pm|gmt))?$/i,
parse: (s, arr) => {
let month = parseInt(arr[1], 10) - 1;
let date = parseInt(arr[2], 10);
//support dd/mm/yyy
if (s.british || month >= 12) {
date = parseInt(arr[1], 10);
month = parseInt(arr[2], 10) - 1;
}
let obj = {
date,
month,
year: parseYear(arr[3], s._today) || new Date().getFullYear()
};
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = parseTime$1(s, arr[4]);
return s
}
},
//alt short format - "feb-25-2015"
{
reg: /^([a-z]+)[\-/. ]([0-9]{1,2})[\-/. ]?([0-9]{4}|'[0-9]{2})?( [0-9]{1,2}(:[0-9]{0,2})?(:[0-9]{0,3})? ?(am|pm)?)?$/i,
parse: (s, arr) => {
let obj = {
year: parseYear(arr[3], s._today),
month: parseMonth(arr[1]),
date: toCardinal(arr[2] || '')
};
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = parseTime$1(s, arr[4]);
return s
}
},
//Long "Mar 25 2015"
//February 22, 2017 15:30:00
{
reg: /^([a-z]+) ([0-9]{1,2})( [0-9]{4})?( ([0-9:]+( ?am| ?pm| ?gmt)?))?$/i,
parse: (s, arr) => {
let obj = {
year: parseYear(arr[3], s._today),
month: parseMonth(arr[1]),
date: toCardinal(arr[2] || '')
};
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = parseTime$1(s, arr[4]);
return s
}
},
// 'Sun Mar 14 15:09:48 +0000 2021'
{
reg: /^([a-z]+) ([0-9]{1,2}) ([0-9]{1,2}:[0-9]{2}:?[0-9]{0,2})( \+[0-9]{4})?( [0-9]{4})?$/i,
parse: (s, arr) => {
let [, month, date, time, tz, year] = arr;
let obj = {
year: parseYear(year, s._today),
month: parseMonth(month),
date: toCardinal(date || '')
};
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = parseOffset$1(s, tz);
s = parseTime$1(s, time);
return s
}
}
];
var dmy = [
// =====
// d-m-y
// =====
//common british format - "25-feb-2015"
{
reg: /^([0-9]{1,2})[-/]([a-z]+)[\-/]?([0-9]{4})?$/i,
parse: (s, m) => {
let obj = {
year: parseYear(m[3], s._today),
month: parseMonth(m[2]),
date: toCardinal(m[1] || '')
};
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = parseTime$1(s, m[4]);
return s
}
},
// "25 Mar 2015"
{
reg: /^([0-9]{1,2})( [a-z]+)( [0-9]{4}| '[0-9]{2})? ?([0-9]{1,2}:[0-9]{2}:?[0-9]{0,2} ?(am|pm|gmt))?$/i,
parse: (s, m) => {
let obj = {
year: parseYear(m[3], s._today),
month: parseMonth(m[2]),
date: toCardinal(m[1])
};
if (!obj.month || validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = parseTime$1(s, m[4]);
return s
}
},
// 01-jan-2020
{
reg: /^([0-9]{1,2})[. \-/]([a-z]+)[. \-/]([0-9]{4})?( [0-9]{1,2}(:[0-9]{0,2})?(:[0-9]{0,3})? ?(am|pm)?)?$/i,
parse: (s, m) => {
let obj = {
date: Number(m[1]),
month: parseMonth(m[2]),
year: Number(m[3])
};
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = s.startOf('day');
s = parseTime$1(s, m[4]);
return s
}
}
];
var misc = [
// =====
// no dates
// =====
// '2012-06' month-only
{
reg: /^([0-9]{4})[\-/]([0-9]{2})$/,
parse: (s, m) => {
let obj = {
year: m[1],
month: parseInt(m[2], 10) - 1,
date: 1
};
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = parseTime$1(s, m[4]);
return s
}
},
//February 2017 (implied date)
{
reg: /^([a-z]+) ([0-9]{4})$/i,
parse: (s, arr) => {
let obj = {
year: parseYear(arr[2], s._today),
month: parseMonth(arr[1]),
date: s._today.date || 1
};
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = parseTime$1(s, arr[4]);
return s
}
},
{
// 'q2 2002'
reg: /^(q[0-9])( of)?( [0-9]{4})?/i,
parse: (s, arr) => {
let quarter = arr[1] || '';
s = s.quarter(quarter);
let year = arr[3] || '';
if (year) {
year = year.trim();
s = s.year(year);
}
return s
}
},
{
// 'summer 2002'
reg: /^(spring|summer|winter|fall|autumn)( of)?( [0-9]{4})?/i,
parse: (s, arr) => {
let season = arr[1] || '';
s = s.season(season);
let year = arr[3] || '';
if (year) {
year = year.trim();
s = s.year(year);
}
return s
}
},
{
// '200bc'
reg: /^[0-9,]+ ?b\.?c\.?$/i,
parse: (s, arr) => {
let str = arr[0] || '';
//make year-negative
str = str.replace(/^([0-9,]+) ?b\.?c\.?$/i, '-$1');
let d = new Date();
let obj = {
year: parseInt(str.trim(), 10),
month: d.getMonth(),
date: d.getDate()
};
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = parseTime$1(s);
return s
}
},
{
// '200ad'
reg: /^[0-9,]+ ?(a\.?d\.?|c\.?e\.?)$/i,
parse: (s, arr) => {
let str = arr[0] || '';
//remove commas
str = str.replace(/,/g, '');
let d = new Date();
let obj = {
year: parseInt(str.trim(), 10),
month: d.getMonth(),
date: d.getDate()
};
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = parseTime$1(s);
return s
}
},
{
// '1992'
reg: /^[0-9]{4}( ?a\.?d\.?)?$/i,
parse: (s, arr) => {
let today = s._today;
// using today's date, but a new month is awkward.
if (today.month && !today.date) {
today.date = 1;
}
let d = new Date();
let obj = {
year: parseYear(arr[0], today),
month: today.month || d.getMonth(),
date: today.date || d.getDate()
};
if (validate$1(obj) === false) {
s.epoch = null;
return s
}
walkTo(s, obj);
s = parseTime$1(s);
return s
}
}
];
var parsers = [].concat(ymd, mdy, dmy, misc);
/* eslint-disable no-console */
const parseString = function (s, input, givenTz) {
// let parsers = s.parsers || []
//try each text-parse template, use the first good result
for (let i = 0; i < parsers.length; i++) {
let m = input.match(parsers[i].reg);
if (m) {
let res = parsers[i].parse(s, m, givenTz);
if (res !== null && res.isValid()) {
return res
}
}
}
if (s.silent === false) {
console.warn("Warning: couldn't parse date-string: '" + input + "'");
}
s.epoch = null;
return s
};
const { parseArray, parseObject, parseNumber } = fns;
//we have to actually parse these inputs ourselves
// - can't use built-in js parser ;(
//=========================================
// ISO Date "2015-03-25"
// Short Date "03/25/2015" or "2015/03/25"
// Long Date "Mar 25 2015" or "25 Mar 2015"
// Full Date "Wednesday March 25 2015"
//=========================================
const defaults = {
year: new Date().getFullYear(),
month: 0,
date: 1
};
//find the epoch from different input styles
const parseInput = (s, input) => {
let today = s._today || defaults;
//if we've been given a epoch number, it's easy
if (typeof input === 'number') {
return parseNumber(s, input)
}
//set tmp time
s.epoch = Date.now();
// overwrite tmp time with 'today' value, if exists
if (s._today && isObject(s._today) && Object.keys(s._today).length > 0) {
let res = parseObject(s, today, defaults);
if (res.isValid()) {
s.epoch = res.epoch;
}
}
// null input means 'now'
if (input === null || input === undefined || input === '') {
return s //k, we're good.
}
//support input of Date() object
if (isDate(input) === true) {
s.epoch = input.getTime();
return s
}
//support [2016, 03, 01] format
if (isArray$1(input) === true) {
s = parseArray(s, input, today);
return s
}
//support {year:2016, month:3} format
if (isObject(input) === true) {
//support spacetime object as input
if (input.epoch) {
s.epoch = input.epoch;
s.tz = input.tz;
return s
}
s = parseObject(s, input, today);
return s
}
//input as a string..
if (typeof input !== 'string') {
return s
}
//little cleanup..
input = normalize$2(input);
//try some known-words, like 'now'
if (dates$4.hasOwnProperty(input) === true) {
s = dates$4[input](s);
return s
}
//try each text-parse template, use the first good result
return parseString(s, input)
};
let shortDays = ['sun', 'mon', 'tue', 'wed', 'thu', 'fri', 'sat'];
let longDays = ['sunday', 'monday', 'tuesday', 'wednesday', 'thursday', 'friday', 'saturday'];
function short() { return shortDays }
function long() { return longDays }
function set$4(i18n) {
shortDays = i18n.short || shortDays;
longDays = i18n.long || longDays;
}
const aliases$1 = {
mo: 1,
tu: 2,
we: 3,
th: 4,
fr: 5,
sa: 6,
su: 7,
tues: 2,
weds: 3,
wedn: 3,
thur: 4,
thurs: 4
};
let titleCaseEnabled = true;
function useTitleCase() {
return titleCaseEnabled
}
function set$3(val) {
titleCaseEnabled = val;
}
// create the timezone offset part of an iso timestamp
// it's kind of nuts how involved this is
// "+01:00", "+0100", or simply "+01"
const isoOffset = s => {
let offset = s.timezone().current.offset;
return !offset ? 'Z' : formatTimezone(offset, ':')
};
const applyCaseFormat = (str) => {
if (useTitleCase()) {
return titleCase$1(str)
}
return str
};
// iso-year padding
const padYear = (num) => {
if (num >= 0) {
return zeroPad(num, 4)
} else {
num = Math.abs(num);
return '-' + zeroPad(num, 4)
}
};
const format = {
day: (s) => applyCaseFormat(s.dayName()),
'day-short': (s) => applyCaseFormat(short()[s.day()]),
'day-number': (s) => s.day(),
'day-ordinal': (s) => ordinal(s.day()),
'day-pad': (s) => zeroPad(s.day()),
date: (s) => s.date(),
'date-ordinal': (s) => ordinal(s.date()),
'date-pad': (s) => zeroPad(s.date()),
month: (s) => applyCaseFormat(s.monthName()),
'month-short': (s) => applyCaseFormat(short$1()[s.month()]),
'month-number': (s) => s.month(),
'month-ordinal': (s) => ordinal(s.month()),
'month-pad': (s) => zeroPad(s.month()),
'iso-month': (s) => zeroPad(s.month() + 1), //1-based months
year: (s) => {
let year = s.year();
if (year > 0) {
return year
}
year = Math.abs(year);
return year + ' BC'
},
'year-short': (s) => {
let year = s.year();
if (year > 0) {
return `'${String(s.year()).substr(2, 4)}`
}
year = Math.abs(year);
return year + ' BC'
},
'iso-year': (s) => {
let year = s.year();
let isNegative = year < 0;
let str = zeroPad(Math.abs(year), 4); //0-padded
if (isNegative) {
//negative years are for some reason 6-digits ('-00008')
str = zeroPad(str, 6);
str = '-' + str;
}
return str
},
time: (s) => s.time(),
'time-24': (s) => `${s.hour24()}:${zeroPad(s.minute())}`,
hour: (s) => s.hour12(),
'hour-pad': (s) => zeroPad(s.hour12()),
'hour-24': (s) => s.hour24(),
'hour-24-pad': (s) => zeroPad(s.hour24()),
minute: (s) => s.minute(),
'minute-pad': (s) => zeroPad(s.minute()),
second: (s) => s.second(),
'second-pad': (s) => zeroPad(s.second()),
millisecond: (s) => s.millisecond(),
'millisecond-pad': (s) => zeroPad(s.millisecond(), 3),
ampm: (s) => s.ampm(),
AMPM: (s) => s.ampm().toUpperCase(),
quarter: (s) => 'Q' + s.quarter(),
season: (s) => s.season(),
era: (s) => s.era(),
json: (s) => s.json(),
timezone: (s) => s.timezone().name,
offset: (s) => isoOffset(s),
numeric: (s) => `${s.year()}/${zeroPad(s.month() + 1)}/${zeroPad(s.date())}`, // yyyy/mm/dd
'numeric-us': (s) => `${zeroPad(s.month() + 1)}/${zeroPad(s.date())}/${s.year()}`, // mm/dd/yyyy
'numeric-uk': (s) => `${zeroPad(s.date())}/${zeroPad(s.month() + 1)}/${s.year()}`, //dd/mm/yyyy
'mm/dd': (s) => `${zeroPad(s.month() + 1)}/${zeroPad(s.date())}`, //mm/dd
// ... https://en.wikipedia.org/wiki/ISO_8601 ;(((
iso: (s) => {
let year = s.format('iso-year');
let month = zeroPad(s.month() + 1); //1-based months
let date = zeroPad(s.date());
let hour = zeroPad(s.h24());
let minute = zeroPad(s.minute());
let second = zeroPad(s.second());
let ms = zeroPad(s.millisecond(), 3);
let offset = isoOffset(s);
return `${year}-${month}-${date}T${hour}:${minute}:${second}.${ms}${offset}` //2018-03-09T08:50:00.000-05:00
},
'iso-short': (s) => {
let month = zeroPad(s.month() + 1); //1-based months
let date = zeroPad(s.date());
let year = padYear(s.year());
return `${year}-${month}-${date}` //2017-02-15
},
'iso-utc': (s) => {
return new Date(s.epoch).toISOString() //2017-03-08T19:45:28.367Z
},
//i made these up
nice: (s) => `${short$1()[s.month()]} ${ordinal(s.date())}, ${s.time()}`,
'nice-24': (s) =>
`${short$1()[s.month()]} ${ordinal(s.date())}, ${s.hour24()}:${zeroPad(
s.minute()
)}`,
'nice-year': (s) => `${short$1()[s.month()]} ${ordinal(s.date())}, ${s.year()}`,
'nice-day': (s) =>
`${short()[s.day()]} ${applyCaseFormat(short$1()[s.month()])} ${ordinal(
s.date()
)}`,
'nice-full': (s) =>
`${s.dayName()} ${applyCaseFormat(s.monthName())} ${ordinal(s.date())}, ${s.time()}`,
'nice-full-24': (s) =>
`${s.dayName()} ${applyCaseFormat(s.monthName())} ${ordinal(
s.date()
)}, ${s.hour24()}:${zeroPad(s.minute())}`
};
//aliases
const aliases = {
'day-name': 'day',
'month-name': 'month',
'iso 8601': 'iso',
'time-h24': 'time-24',
'time-12': 'time',
'time-h12': 'time',
tz: 'timezone',
'day-num': 'day-number',
'month-num': 'month-number',
'month-iso': 'iso-month',
'year-iso': 'iso-year',
'nice-short': 'nice',
'nice-short-24': 'nice-24',
mdy: 'numeric-us',
dmy: 'numeric-uk',
ymd: 'numeric',
'yyyy/mm/dd': 'numeric',
'mm/dd/yyyy': 'numeric-us',
'dd/mm/yyyy': 'numeric-us',
'little-endian': 'numeric-uk',
'big-endian': 'numeric',
'day-nice': 'nice-day'
};
Object.keys(aliases).forEach((k) => (format[k] = format[aliases[k]]));
const printFormat = (s, str = '') => {
//don't print anything if it's an invalid date
if (s.isValid() !== true) {
return ''
}
//support .format('month')
if (format.hasOwnProperty(str)) {
let out = format[str](s) || '';
if (str !== 'json') {
out = String(out);
if (str.toLowerCase() !== 'ampm') {
out = applyCaseFormat(out);
}
}
return out
}
//support '{hour}:{minute}' notation
if (str.indexOf('{') !== -1) {
let sections = /\{(.+?)\}/g;
str = str.replace(sections, (_, fmt) => {
fmt = fmt.trim();
if (fmt !== 'AMPM') {
fmt = fmt.toLowerCase();
}
if (format.hasOwnProperty(fmt)) {
let out = String(format[fmt](s));
if (fmt.toLowerCase() !== 'ampm') {
return applyCaseFormat(out)
}
return out
}
return ''
});
return str
}
return s.format('iso-short')
};
//parse this insane unix-time-templating thing, from the 19th century
//http://unicode.org/reports/tr35/tr35-25.html#Date_Format_Patterns
//time-symbols we support
const mapping$2 = {
G: (s) => s.era(),
GG: (s) => s.era(),
GGG: (s) => s.era(),
GGGG: (s) => (s.era() === 'AD' ? 'Anno Domini' : 'Before Christ'),
//year
y: (s) => s.year(),
yy: (s) => {
//last two chars
return zeroPad(Number(String(s.year()).substr(2, 4)))
},
yyy: (s) => s.year(),
yyyy: (s) => s.year(),
yyyyy: (s) => '0' + s.year(),
// u: (s) => {},//extended non-gregorian years
//quarter
Q: (s) => s.quarter(),
QQ: (s) => s.quarter(),
QQQ: (s) => s.quarter(),
QQQQ: (s) => s.quarter(),
//month
M: (s) => s.month() + 1,
MM: (s) => zeroPad(s.month() + 1),
MMM: (s) => s.format('month-short'),
MMMM: (s) => s.format('month'),
//week
w: (s) => s.week(),
ww: (s) => zeroPad(s.week()),
//week of month
// W: (s) => s.week(),
//date of month
d: (s) => s.date(),
dd: (s) => zeroPad(s.date()),
//date of year
D: (s) => s.dayOfYear(),
DD: (s) => zeroPad(s.dayOfYear()),
DDD: (s) => zeroPad(s.dayOfYear(), 3),
// F: (s) => {},//date of week in month
// g: (s) => {},//modified julian day
//day
E: (s) => s.format('day-short'),
EE: (s) => s.format('day-short'),
EEE: (s) => s.format('day-short'),
EEEE: (s) => s.format('day'),
EEEEE: (s) => s.format('day')[0],
e: (s) => s.day(),
ee: (s) => s.day(),
eee: (s) => s.format('day-short'),
eeee: (s) => s.format('day'),
eeeee: (s) => s.format('day')[0],
//am/pm
a: (s) => s.ampm().toUpperCase(),
aa: (s) => s.ampm().toUpperCase(),
aaa: (s) => s.ampm().toUpperCase(),
aaaa: (s) => s.ampm().toUpperCase(),
//hour
h: (s) => s.h12(),
hh: (s) => zeroPad(s.h12()),
H: (s) => s.hour(),
HH: (s) => zeroPad(s.hour()),
// j: (s) => {},//weird hour format
m: (s) => s.minute(),
mm: (s) => zeroPad(s.minute()),
s: (s) => s.second(),
ss: (s) => zeroPad(s.second()),
//milliseconds
SSS: (s) => zeroPad(s.millisecond(), 3),
//milliseconds in the day
A: (s) => s.epoch - s.startOf('day').epoch,
//timezone
z: (s) => s.timezone().name,
zz: (s) => s.timezone().name,
zzz: (s) => s.timezone().name,
zzzz: (s) => s.timezone().name,
Z: (s) => formatTimezone(s.timezone().current.offset),
ZZ: (s) => formatTimezone(s.timezone().current.offset),
ZZZ: (s) => formatTimezone(s.timezone().current.offset),
ZZZZ: (s) => formatTimezone(s.timezone().current.offset, ':')
};
const addAlias = (char, to, n) => {
let name = char;
let toName = to;
for (let i = 0; i < n; i += 1) {
mapping$2[name] = mapping$2[toName];
name += char;
toName += to;
}
};
addAlias('q', 'Q', 4);
addAlias('L', 'M', 4);
addAlias('Y', 'y', 4);
addAlias('c', 'e', 4);
addAlias('k', 'H', 2);
addAlias('K', 'h', 2);
addAlias('S', 's', 2);
addAlias('v', 'z', 4);
addAlias('V', 'Z', 4);
// support unix-style escaping with ' character
const escapeChars = function (arr) {
for (let i = 0; i < arr.length; i += 1) {
if (arr[i] === `'`) {
// greedy-search for next apostrophe
for (let o = i + 1; o < arr.length; o += 1) {
if (arr[o]) {
arr[i] += arr[o];
}
if (arr[o] === `'`) {
arr[o] = null;
break
}
arr[o] = null;
}
}
}
return arr.filter((ch) => ch)
};
//combine consecutive chars, like 'yyyy' as one.
const combineRepeated = function (arr) {
for (let i = 0; i < arr.length; i += 1) {
let c = arr[i];
// greedy-forward
for (let o = i + 1; o < arr.length; o += 1) {
if (arr[o] === c) {
arr[i] += arr[o];
arr[o] = null;
} else {
break
}
}
}
// '' means one apostrophe
arr = arr.filter((ch) => ch);
arr = arr.map((str) => {
if (str === `''`) {
str = `'`;
}
return str
});
return arr
};
const unixFmt = (s, str) => {
let arr = str.split('');
// support character escaping
arr = escapeChars(arr);
//combine 'yyyy' as string.
arr = combineRepeated(arr);
return arr.reduce((txt, c) => {
if (mapping$2[c] !== undefined) {
txt += mapping$2[c](s) || '';
} else {
// 'unescape'
if (/^'.+'$/.test(c)) {
c = c.replace(/'/g, '');
}
txt += c;
}
return txt
}, '')
};
const units$4 = ['year', 'season', 'quarter', 'month', 'week', 'day', 'quarterHour', 'hour', 'minute'];
const doUnit = function (s, k) {
let start = s.clone().startOf(k);
let end = s.clone().endOf(k);
let duration = end.epoch - start.epoch;
let percent = (s.epoch - start.epoch) / duration;
return parseFloat(percent.toFixed(2))
};
//how far it is along, from 0-1
const progress = (s, unit) => {
if (unit) {
unit = normalize$3(unit);
return doUnit(s, unit)
}
let obj = {};
units$4.forEach(k => {
obj[k] = doUnit(s, k);
});
return obj
};
/* eslint-disable no-console */
//round to either current, or +1 of this unit
const nearest = (s, unit) => {
//how far have we gone?
let prog = s.progress();
unit = normalize$3(unit);
//fix camel-case for this one
if (unit === 'quarterhour') {
unit = 'quarterHour';
}
if (prog[unit] !== undefined) {
// go forward one?
if (prog[unit] > 0.5) {
s = s.add(1, unit);
}
// go to start
s = s.startOf(unit);
} else if (s.silent === false) {
console.warn("no known unit '" + unit + "'");
}
return s
};
//increment until dates are the same
const climb = (a, b, unit) => {
let i = 0;
a = a.clone();
while (a.isBefore(b)) {
//do proper, expensive increment to catch all-the-tricks
a = a.add(1, unit);
i += 1;
}
//oops, we went too-far..
if (a.isAfter(b, unit)) {
i -= 1;
}
return i
};
// do a thurough +=1 on the unit, until they match
// for speed-reasons, only used on day, month, week.
const diffOne = (a, b, unit) => {
if (a.isBefore(b)) {
return climb(a, b, unit)
} else {
return climb(b, a, unit) * -1 //reverse it
}
};
// don't do anything too fancy here.
// 2020 - 2019 may be 1 year, or 0 years
// - '1 year difference' means 366 days during a leap year
const fastYear = (a, b) => {
let years = b.year() - a.year();
// should we decrement it by 1?
a = a.year(b.year());
if (a.isAfter(b)) {
years -= 1;
}
return years
};
// use a waterfall-method for computing a diff of any 'pre-knowable' units
// compute years, then compute months, etc..
// ... then ms-math for any very-small units
const diff = function (a, b) {
// an hour is always the same # of milliseconds
// so these units can be 'pre-calculated'
let msDiff = b.epoch - a.epoch;
let obj = {
milliseconds: msDiff,
seconds: parseInt(msDiff / 1000, 10)
};
obj.minutes = parseInt(obj.seconds / 60, 10);
obj.hours = parseInt(obj.minutes / 60, 10);
//do the year
let tmp = a.clone();
obj.years = fastYear(tmp, b);
tmp = a.add(obj.years, 'year');
//there's always 12 months in a year...
obj.months = obj.years * 12;
tmp = a.add(obj.months, 'month');
obj.months += diffOne(tmp, b, 'month');
// there's always 4 quarters in a year...
obj.quarters = obj.years * 4;
obj.quarters += parseInt((obj.months % 12) / 3, 10);
// there's always atleast 52 weeks in a year..
// (month * 4) isn't as close
obj.weeks = obj.years * 52;
tmp = a.add(obj.weeks, 'week');
obj.weeks += diffOne(tmp, b, 'week');
// there's always atleast 7 days in a week
obj.days = obj.weeks * 7;
tmp = a.add(obj.days, 'day');
obj.days += diffOne(tmp, b, 'day');
return obj
};
const reverseDiff = function (obj) {
Object.keys(obj).forEach((k) => {
obj[k] *= -1;
});
return obj
};
// this method counts a total # of each unit, between a, b.
// '1 month' means 28 days in february
// '1 year' means 366 days in a leap year
const main$1 = function (a, b, unit) {
b = beADate(b, a);
//reverse values, if necessary
let reversed = false;
if (a.isAfter(b)) {
let tmp = a;
a = b;
b = tmp;
reversed = true;
}
//compute them all (i know!)
let obj = diff(a, b);
if (reversed) {
obj = reverseDiff(obj);
}
//return just the requested unit
if (unit) {
//make sure it's plural-form
unit = normalize$3(unit);
if (/s$/.test(unit) !== true) {
unit += 's';
}
if (unit === 'dates') {
unit = 'days';
}
return obj[unit]
}
return obj
};
/*
ISO 8601 duration format
// https://en.wikipedia.org/wiki/ISO_8601#Durations
"P3Y6M4DT12H30M5S"
P the start of the duration representation.
Y the number of years.
M the number of months.
W the number of weeks.
D the number of days.
T of the representation.
H the number of hours.
M the number of minutes.
S the number of seconds.
*/
const fmt$1 = (n) => Math.abs(n) || 0;
const toISO = function (diff) {
let iso = 'P';
iso += fmt$1(diff.years) + 'Y';
iso += fmt$1(diff.months) + 'M';
iso += fmt$1(diff.days) + 'DT';
iso += fmt$1(diff.hours) + 'H';
iso += fmt$1(diff.minutes) + 'M';
iso += fmt$1(diff.seconds) + 'S';
return iso
};
//get number of hours/minutes... between the two dates
function getDiff(a, b) {
const isBefore = a.isBefore(b);
const later = isBefore ? b : a;
let earlier = isBefore ? a : b;
earlier = earlier.clone();
const diff = {
years: 0,
months: 0,
days: 0,
hours: 0,
minutes: 0,
seconds: 0
};
Object.keys(diff).forEach((unit) => {
if (earlier.isSame(later, unit)) {
return
}
let max = earlier.diff(later, unit);
earlier = earlier.add(max, unit);
diff[unit] = max;
});
//reverse it, if necessary
if (isBefore) {
Object.keys(diff).forEach((u) => {
if (diff[u] !== 0) {
diff[u] *= -1;
}
});
}
return diff
}
let units$3 = {
second: 'second',
seconds: 'seconds',
minute: 'minute',
minutes: 'minutes',
hour: 'hour',
hours: 'hours',
day: 'day',
days: 'days',
month: 'month',
months: 'months',
year: 'year',
years: 'years',
};
function unitsString(unit) {
return units$3[unit] || '';
}
function set$2(i18n = {}) {
units$3 = {
second: i18n.second || units$3.second,
seconds: i18n.seconds || units$3.seconds,
minute: i18n.minute || units$3.minute,
minutes: i18n.minutes || units$3.minutes,
hour: i18n.hour || units$3.hour,
hours: i18n.hours || units$3.hours,
day: i18n.day || units$3.day,
days: i18n.days || units$3.days,
month: i18n.month || units$3.month,
months: i18n.months || units$3.months,
year: i18n.year || units$3.year,
years: i18n.years || units$3.years,
};
}
let past = 'past';
let future = 'future';
let present = 'present';
let now = 'now';
let almost = 'almost';
let over = 'over';
let pastDistance = (value) => `${value} ago`;
let futureDistance = (value) => `in ${value}`;
function pastDistanceString(value) { return pastDistance(value) }
function futureDistanceString(value) { return futureDistance(value) }
function pastString() { return past }
function futureString() { return future }
function presentString() { return present }
function nowString() { return now }
function almostString() { return almost }
function overString() { return over }
function set$1(i18n) {
pastDistance = i18n.pastDistance || pastDistance;
futureDistance = i18n.futureDistance || futureDistance;
past = i18n.past || past;
future = i18n.future || future;
present = i18n.present || present;
now = i18n.now || now;
almost = i18n.almost || almost;
over = i18n.over || over;
}
//our conceptual 'break-points' for each unit
const qualifiers = {
months: {
almost: 10,
over: 4
},
days: {
almost: 25,
over: 10
},
hours: {
almost: 20,
over: 8
},
minutes: {
almost: 50,
over: 20
},
seconds: {
almost: 50,
over: 20
}
};
// Expects a plural unit arg
function pluralize(value, unit) {
if (value === 1) {
return value + ' ' + unitsString(unit.slice(0, -1))
}
return value + ' ' + unitsString(unit)
}
const toSoft = function (diff) {
let rounded = null;
let qualified = null;
let abbreviated = [];
let englishValues = [];
//go through each value and create its text-representation
Object.keys(diff).forEach((unit, i, units) => {
const value = Math.abs(diff[unit]);
if (value === 0) {
return
}
abbreviated.push(value + unit[0]);
const englishValue = pluralize(value, unit);
englishValues.push(englishValue);
if (!rounded) {
rounded = englishValue;
qualified = englishValue;
if (i > 4) {
return
}
//is it a 'almost' something, etc?
const nextUnit = units[i + 1];
const nextValue = Math.abs(diff[nextUnit]);
if (nextValue > qualifiers[nextUnit].almost) {
rounded = pluralize(value + 1, unit);
qualified = almostString() + ' ' + rounded;
} else if (nextValue > qualifiers[nextUnit].over) {
qualified = overString() + ' ' + englishValue;
}
}
});
return { qualified, rounded, abbreviated, englishValues }
};
//by spencermountain + Shaun Grady
//create the human-readable diff between the two dates
const since = (start, end) => {
end = beADate(end, start);
const diff = getDiff(start, end);
const isNow = Object.keys(diff).every((u) => !diff[u]);
if (isNow === true) {
return {
diff,
rounded: nowString(),
qualified: nowString(),
precise: nowString(),
abbreviated: [],
iso: 'P0Y0M0DT0H0M0S',
direction: presentString(),
}
}
let precise;
let direction = futureString();
let { rounded, qualified, englishValues, abbreviated } = toSoft(diff);
//make them into a string
precise = englishValues.splice(0, 2).join(', ');
//handle before/after logic
if (start.isAfter(end) === true) {
rounded = pastDistanceString(rounded);
qualified = pastDistanceString(qualified);
precise = pastDistanceString(precise);
direction = pastString();
} else {
rounded = futureDistanceString(rounded);
qualified = futureDistanceString(qualified);
precise = futureDistanceString(precise);
}
// https://en.wikipedia.org/wiki/ISO_8601#Durations
// P[n]Y[n]M[n]DT[n]H[n]M[n]S
let iso = toISO(diff);
return {
diff,
rounded,
qualified,
precise,
abbreviated,
iso,
direction,
}
};
//https://www.timeanddate.com/calendar/aboutseasons.html
// Spring - from March 1 to May 31;
// Summer - from June 1 to August 31;
// Fall (autumn) - from September 1 to November 30; and,
// Winter - from December 1 to February 28 (February 29 in a leap year).
const north = [
['spring', 2, 1],
['summer', 5, 1],
['fall', 8, 1],
['autumn', 8, 1],
['winter', 11, 1] //dec 1
];
const south = [
['fall', 2, 1],
['autumn', 2, 1],
['winter', 5, 1],
['spring', 8, 1],
['summer', 11, 1] //dec 1
];
var seasons$1 = { north, south };
var quarters = [
null,
[0, 1], //jan 1
[3, 1], //apr 1
[6, 1], //july 1
[9, 1] //oct 1
];
const units$2 = {
second: (s) => {
walkTo(s, {
millisecond: 0
});
return s
},
minute: (s) => {
walkTo(s, {
second: 0,
millisecond: 0
});
return s
},
quarterhour: (s) => {
let minute = s.minutes();
if (minute >= 45) {
s = s.minutes(45);
} else if (minute >= 30) {
s = s.minutes(30);
} else if (minute >= 15) {
s = s.minutes(15);
} else {
s = s.minutes(0);
}
walkTo(s, {
second: 0,
millisecond: 0
});
return s
},
hour: (s) => {
walkTo(s, {
minute: 0,
second: 0,
millisecond: 0
});
return s
},
day: (s) => {
walkTo(s, {
hour: 0,
minute: 0,
second: 0,
millisecond: 0
});
return s
},
week: (s) => {
let original = s.clone();
s = s.day(s._weekStart); //monday
if (s.isAfter(original)) {
s = s.subtract(1, 'week');
}
walkTo(s, {
hour: 0,
minute: 0,
second: 0,
millisecond: 0
});
return s
},
month: (s) => {
walkTo(s, {
date: 1,
hour: 0,
minute: 0,
second: 0,
millisecond: 0
});
return s
},
quarter: (s) => {
let q = s.quarter();
if (quarters[q]) {
walkTo(s, {
month: quarters[q][0],
date: quarters[q][1],
hour: 0,
minute: 0,
second: 0,
millisecond: 0
});
}
return s
},
season: (s) => {
let current = s.season();
let hem = 'north';
if (s.hemisphere() === 'South') {
hem = 'south';
}
for (let i = 0; i < seasons$1[hem].length; i++) {
if (seasons$1[hem][i][0] === current) {
//winter goes between years
let year = s.year();
if (current === 'winter' && s.month() < 3) {
year -= 1;
}
walkTo(s, {
year,
month: seasons$1[hem][i][1],
date: seasons$1[hem][i][2],
hour: 0,
minute: 0,
second: 0,
millisecond: 0
});
return s
}
}
return s
},
year: (s) => {
walkTo(s, {
month: 0,
date: 1,
hour: 0,
minute: 0,
second: 0,
millisecond: 0
});
return s
},
decade: (s) => {
s = s.startOf('year');
let year = s.year();
let decade = parseInt(year / 10, 10) * 10;
s = s.year(decade);
return s
},
century: (s) => {
s = s.startOf('year');
let year = s.year();
// near 0AD goes '-1 | +1'
let decade = parseInt(year / 100, 10) * 100;
s = s.year(decade);
return s
}
};
units$2.date = units$2.day;
const startOf = (a, unit) => {
let s = a.clone();
unit = normalize$3(unit);
if (units$2[unit]) {
return units$2[unit](s)
}
if (unit === 'summer' || unit === 'winter') {
s = s.season(unit);
return units$2.season(s)
}
return s
};
//piggy-backs off startOf
const endOf = (a, unit) => {
let s = a.clone();
unit = normalize$3(unit);
if (units$2[unit]) {
// go to beginning, go to next one, step back 1ms
s = units$2[unit](s); // startof
s = s.add(1, unit);
s = s.subtract(1, 'millisecond');
return s
}
return s
};
//is it 'wednesday'?
const isDay = function (unit) {
if (short().find((s) => s === unit)) {
return true
}
if (long().find((s) => s === unit)) {
return true
}
return false
};
// return a list of the weeks/months/days between a -> b
// returns spacetime objects in the timezone of the input
const every = function (start, unit, end, stepCount = 1) {
if (!unit || !end) {
return []
}
//cleanup unit param
unit = normalize$3(unit);
//cleanup to param
end = start.clone().set(end);
//swap them, if they're backwards
if (start.isAfter(end)) {
let tmp = start;
start = end;
end = tmp;
}
//prevent going beyond end if unit/stepCount > than the range
if (start.diff(end, unit) < stepCount) {
return []
}
//support 'every wednesday'
let d = start.clone();
if (isDay(unit)) {
d = d.next(unit);
unit = 'week';
} else {
let first = d.startOf(unit);
if (first.isBefore(start)) {
d = d.next(unit);
}
}
//okay, actually start doing it
let result = [];
while (d.isBefore(end)) {
result.push(d);
d = d.add(stepCount, unit);
}
return result
};
/* eslint-disable no-console */
const parseDst = dst => {
if (!dst) {
return []
}
return dst.split('->')
};
//iana codes are case-sensitive, technically
const titleCase = str => {
str = str[0].toUpperCase() + str.substr(1);
str = str.replace(/[/_-]([a-z])/gi, s => {
return s.toUpperCase()
});
str = str.replace(/_(of|es)_/i, (s) => s.toLowerCase());
str = str.replace(/\/gmt/i, '/GMT');
str = str.replace(/\/Dumontdurville$/i, '/DumontDUrville');
str = str.replace(/\/Mcmurdo$/i, '/McMurdo');
str = str.replace(/\/Port-au-prince$/i, '/Port-au-Prince');
return str
};
//get metadata about this timezone
const timezone = s => {
let zones = s.timezones;
let tz = s.tz;
if (zones.hasOwnProperty(tz) === false) {
tz = lookupTz(s.tz, zones);
}
if (tz === null) {
if (s.silent === false) {
console.warn("Warn: could not find given or local timezone - '" + s.tz + "'");
}
return {
current: {
epochShift: 0
}
}
}
let found = zones[tz];
let result = {
name: titleCase(tz),
hasDst: Boolean(found.dst),
default_offset: found.offset,
//do north-hemisphere version as default (sorry!)
hemisphere: found.hem === 's' ? 'South' : 'North',
current: {}
};
if (result.hasDst) {
let arr = parseDst(found.dst);
result.change = {
start: arr[0],
back: arr[1]
};
}
//find the offsets for summer/winter times
//(these variable names are north-centric)
let summer = found.offset; // (july)
let winter = summer; // (january) assume it's the same for now
if (result.hasDst === true) {
if (result.hemisphere === 'North') {
winter = summer - 1;
} else {
//southern hemisphere
winter = found.offset + 1;
}
}
//find out which offset to use right now
//use 'summer' time july-time
if (result.hasDst === false) {
result.current.offset = summer;
result.current.isDST = false;
} else if (inSummerTime(s.epoch, result.change.start, result.change.back, summer, winter) === true) {
result.current.offset = summer;
result.current.isDST = result.hemisphere === 'North'; //dst 'on' in winter in north
} else {
//use 'winter' january-time
result.current.offset = winter;
result.current.isDST = result.hemisphere === 'South'; //dst 'on' in summer in south
}
return result
};
/* eslint-disable no-console */
const units$1 = [
'century',
'decade',
'year',
'month',
'date',
'day',
'hour',
'minute',
'second',
'millisecond'
];
//the spacetime instance methods (also, the API)
const methods$4 = {
set: function (input, tz) {
let s = this.clone();
s = parseInput(s, input);
if (tz) {
this.tz = lookupTz(tz);
}
return s
},
timezone: function () {
return timezone(this)
},
isDST: function () {
return timezone(this).current.isDST
},
hasDST: function () {
return timezone(this).hasDst
},
offset: function () {
return timezone(this).current.offset * 60
},
hemisphere: function () {
return timezone(this).hemisphere
},
format: function (fmt) {
return printFormat(this, fmt)
},
unixFmt: function (fmt) {
return unixFmt(this, fmt)
},
startOf: function (unit) {
return startOf(this, unit)
},
endOf: function (unit) {
return endOf(this, unit)
},
leapYear: function () {
let year = this.year();
return isLeapYear(year)
},
progress: function (unit) {
return progress(this, unit)
},
nearest: function (unit) {
return nearest(this, unit)
},
diff: function (d, unit) {
return main$1(this, d, unit)
},
since: function (d) {
if (!d) {
d = this.clone().set();
}
return since(this, d)
},
next: function (unit) {
let s = this.add(1, unit);
return s.startOf(unit)
},
//the start of the previous year/week/century
last: function (unit) {
let s = this.subtract(1, unit);
return s.startOf(unit)
},
isValid: function () {
//null/undefined epochs
if (!this.epoch && this.epoch !== 0) {
return false
}
return !isNaN(this.d.getTime())
},
//travel to this timezone
goto: function (tz) {
let s = this.clone();
s.tz = lookupTz(tz, s.timezones); //science!
return s
},
//get each week/month/day between a -> b
every: function (unit, to, stepCount) {
// allow swapping these params:
if (typeof unit === 'object' && typeof to === 'string') {
let tmp = to;
to = unit;
unit = tmp;
}
return every(this, unit, to, stepCount)
},
isAwake: function () {
let hour = this.hour();
//10pm -> 8am
if (hour < 8 || hour > 22) {
return false
}
return true
},
isAsleep: function () {
return !this.isAwake()
},
daysInMonth: function () {
switch (this.month()) {
case 0:
return 31
case 1:
return this.leapYear() ? 29 : 28
case 2:
return 31
case 3:
return 30
case 4:
return 31
case 5:
return 30
case 6:
return 31
case 7:
return 31
case 8:
return 30
case 9:
return 31
case 10:
return 30
case 11:
return 31
default:
throw new Error('Invalid Month state.')
}
},
//pretty-printing
log: function () {
console.log('');
console.log(printFormat(this, 'nice-short'));
return this
},
logYear: function () {
console.log('');
console.log(printFormat(this, 'full-short'));
return this
},
json: function () {
return units$1.reduce((h, unit) => {
h[unit] = this[unit]();
return h
}, {})
},
debug: function () {
let tz = this.timezone();
let date = this.format('MM') + ' ' + this.format('date-ordinal') + ' ' + this.year();
date += '\n - ' + this.format('time');
console.log('\n\n', date + '\n - ' + tz.name + ' (' + tz.current.offset + ')');
return this
},
//alias of 'since' but opposite - like moment.js
from: function (d) {
d = this.clone().set(d);
return d.since(this)
},
fromNow: function () {
let d = this.clone().set(Date.now());
return d.since(this)
},
weekStart: function (input) {
//accept a number directly
if (typeof input === 'number') {
this._weekStart = input;
return this
}
if (typeof input === 'string') {
// accept 'wednesday'
input = input.toLowerCase().trim();
let num = short().indexOf(input);
if (num === -1) {
num = long().indexOf(input);
}
if (num === -1) {
num = 1; //go back to default
}
this._weekStart = num;
} else {
console.warn('Spacetime Error: Cannot understand .weekStart() input:', input);
}
return this
}
};
// aliases
methods$4.inDST = methods$4.isDST;
methods$4.round = methods$4.nearest;
methods$4.each = methods$4.every;
// javascript setX methods like setDate() can't be used because of the local bias
//these methods wrap around them.
const validate = (n) => {
//handle number as a string
if (typeof n === 'string') {
n = parseInt(n, 10);
}
return n
};
const order$1 = ['year', 'month', 'date', 'hour', 'minute', 'second', 'millisecond'];
//reduce hostile micro-changes when moving dates by millisecond
const confirm = (s, tmp, unit) => {
let n = order$1.indexOf(unit);
let arr = order$1.slice(n, order$1.length);
for (let i = 0; i < arr.length; i++) {
let want = tmp[arr[i]]();
s[arr[i]](want);
}
return s
};
// allow specifying setter direction
const fwdBkwd = function (s, old, goFwd, unit) {
if (goFwd === true && s.isBefore(old)) {
s = s.add(1, unit);
} else if (goFwd === false && s.isAfter(old)) {
s = s.minus(1, unit);
}
return s
};
const milliseconds = function (s, n) {
n = validate(n);
let current = s.millisecond();
let diff = current - n; //milliseconds to shift by
return s.epoch - diff
};
const seconds = function (s, n, goFwd) {
n = validate(n);
let old = s.clone();
let diff = s.second() - n;
let shift = diff * o.second;
s.epoch = s.epoch - shift;
s = fwdBkwd(s, old, goFwd, 'minute'); // specify direction
return s.epoch
};
const minutes = function (s, n, goFwd) {
n = validate(n);
let old = s.clone();
let diff = s.minute() - n;
let shift = diff * o.minute;
s.epoch -= shift;
confirm(s, old, 'second');
s = fwdBkwd(s, old, goFwd, 'hour'); // specify direction
return s.epoch
};
const hours = function (s, n, goFwd) {
n = validate(n);
if (n >= 24) {
n = 24;
} else if (n < 0) {
n = 0;
}
let old = s.clone();
let diff = s.hour() - n;
let shift = diff * o.hour;
s.epoch -= shift;
// oops, did we change the day?
if (s.date() !== old.date()) {
s = old.clone();
if (diff > 1) {
diff -= 1;
}
if (diff < 1) {
diff += 1;
}
shift = diff * o.hour;
s.epoch -= shift;
}
walkTo(s, {
hour: n
});
confirm(s, old, 'minute');
s = fwdBkwd(s, old, goFwd, 'day'); // specify direction
return s.epoch
};
const time = function (s, str, goFwd) {
let m = str.match(/([0-9]{1,2})[:h]([0-9]{1,2})(:[0-9]{1,2})? ?(am|pm)?/);
if (!m) {
//fallback to support just '2am'
m = str.match(/([0-9]{1,2}) ?(am|pm)/);
if (!m) {
return s.epoch
}
m.splice(2, 0, '0'); //add implicit 0 minutes
m.splice(3, 0, ''); //add implicit seconds
}
let h24 = false;
let hour = parseInt(m[1], 10);
let minute = parseInt(m[2], 10);
if (minute >= 60) {
minute = 59;
}
if (hour > 12) {
h24 = true;
}
//make the hour into proper 24h time
if (h24 === false) {
if (m[4] === 'am' && hour === 12) {
//12am is midnight
hour = 0;
}
if (m[4] === 'pm' && hour < 12) {
//12pm is noon
hour += 12;
}
}
// handle seconds
m[3] = m[3] || '';
m[3] = m[3].replace(/:/, '');
let sec = parseInt(m[3], 10) || 0;
let old = s.clone();
s = s.hour(hour);
s = s.minute(minute);
s = s.second(sec);
s = s.millisecond(0);
s = fwdBkwd(s, old, goFwd, 'day'); // specify direction
return s.epoch
};
const date = function (s, n, goFwd) {
n = validate(n);
//avoid setting february 31st
if (n > 28) {
let month = s.month();
let max = monthLengths[month];
// support leap day in february
if (month === 1 && n === 29 && isLeapYear(s.year())) {
max = 29;
}
if (n > max) {
n = max;
}
}
//avoid setting < 0
if (n <= 0) {
n = 1;
}
let old = s.clone();
walkTo(s, {
date: n
});
s = fwdBkwd(s, old, goFwd, 'month'); // specify direction
return s.epoch
};
const month = function (s, n, goFwd) {
if (typeof n === 'string') {
if (n === 'sept') {
n = 'sep';
}
n = mapping$3()[n.toLowerCase()];
}
n = validate(n);
//don't go past december
if (n >= 12) {
n = 11;
}
if (n <= 0) {
n = 0;
}
let d = s.date();
//there's no 30th of february, etc.
if (d > monthLengths[n]) {
//make it as close as we can..
d = monthLengths[n];
}
let old = s.clone();
walkTo(s, {
month: n,
d
});
s = fwdBkwd(s, old, goFwd, 'year'); // specify direction
return s.epoch
};
const year = function (s, n) {
// support '97
if (typeof n === 'string' && /^'[0-9]{2}$/.test(n)) {
n = n.replace(/'/, '').trim();
n = Number(n);
// '89 is 1989
if (n > 30) {
//change this in 10y
n = 1900 + n;
} else {
// '12 is 2012
n = 2000 + n;
}
}
n = validate(n);
walkTo(s, {
year: n
});
return s.epoch
};
const week = function (s, n, goFwd) {
let old = s.clone();
n = validate(n);
s = s.month(0);
s = s.date(1);
s = s.day('monday');
//first week starts first Thurs in Jan
// so mon dec 28th is 1st week
// so mon dec 29th is not the week
if (s.monthName() === 'december' && s.date() >= 28) {
s = s.add(1, 'week');
}
n -= 1; //1-based
s = s.add(n, 'weeks');
s = fwdBkwd(s, old, goFwd, 'year'); // specify direction
return s.epoch
};
const dayOfYear = function (s, n, goFwd) {
n = validate(n);
let old = s.clone();
n -= 1; //days are 1-based
if (n <= 0) {
n = 0;
} else if (n >= 365) {
if (isLeapYear(s.year())) {
n = 365;
} else {
n = 364;
}
}
s = s.startOf('year');
s = s.add(n, 'day');
confirm(s, old, 'hour');
s = fwdBkwd(s, old, goFwd, 'year'); // specify direction
return s.epoch
};
let morning = 'am';
let evening = 'pm';
function am() { return morning }
function pm() { return evening }
function set(i18n) {
morning = i18n.am || morning;
evening = i18n.pm || evening;
}
const methods$3 = {
millisecond: function (num) {
if (num !== undefined) {
let s = this.clone();
s.epoch = milliseconds(s, num);
return s
}
return this.d.getMilliseconds()
},
second: function (num, goFwd) {
if (num !== undefined) {
let s = this.clone();
s.epoch = seconds(s, num, goFwd);
return s
}
return this.d.getSeconds()
},
minute: function (num, goFwd) {
if (num !== undefined) {
let s = this.clone();
s.epoch = minutes(s, num, goFwd);
return s
}
return this.d.getMinutes()
},
hour: function (num, goFwd) {
let d = this.d;
if (num !== undefined) {
let s = this.clone();
s.epoch = hours(s, num, goFwd);
return s
}
return d.getHours()
},
//'3:30' is 3.5
hourFloat: function (num, goFwd) {
if (num !== undefined) {
let s = this.clone();
let minute = num % 1;
minute = minute * 60;
let hour = parseInt(num, 10);
s.epoch = hours(s, hour, goFwd);
s.epoch = minutes(s, minute, goFwd);
return s
}
let d = this.d;
let hour = d.getHours();
let minute = d.getMinutes();
minute = minute / 60;
return hour + minute
},
// hour in 12h format
hour12: function (str, goFwd) {
let d = this.d;
if (str !== undefined) {
let s = this.clone();
str = '' + str;
let m = str.match(/^([0-9]+)(am|pm)$/);
if (m) {
let hour = parseInt(m[1], 10);
if (m[2] === 'pm') {
hour += 12;
}
s.epoch = hours(s, hour, goFwd);
}
return s
}
//get the hour
let hour12 = d.getHours();
if (hour12 > 12) {
hour12 = hour12 - 12;
}
if (hour12 === 0) {
hour12 = 12;
}
return hour12
},
//some ambiguity here with 12/24h
time: function (str, goFwd) {
if (str !== undefined) {
let s = this.clone();
str = str.toLowerCase().trim();
s.epoch = time(s, str, goFwd);
return s
}
return `${this.h12()}:${zeroPad(this.minute())}${this.ampm()}`
},
// either 'am' or 'pm'
ampm: function (input, goFwd) {
// let which = 'am'
let which = am();
let hour = this.hour();
if (hour >= 12) {
// which = 'pm'
which = pm();
}
if (typeof input !== 'string') {
return which
}
//okay, we're doing a setter
let s = this.clone();
input = input.toLowerCase().trim();
//ampm should never change the day
// - so use `.hour(n)` instead of `.minus(12,'hour')`
if (hour >= 12 && input === 'am') {
//noon is 12pm
hour -= 12;
return s.hour(hour, goFwd)
}
if (hour < 12 && input === 'pm') {
hour += 12;
return s.hour(hour, goFwd)
}
return s
},
//some hard-coded times of day, like 'noon'
dayTime: function (str, goFwd) {
if (str !== undefined) {
const times = {
morning: '7:00',
breakfast: '7:00',
noon: '12:00',
lunch: '12:00',
afternoon: '14:00',
evening: '18:00',
dinner: '18:00',
night: '23:00',
midnight: '00:00'
};
let s = this.clone();
str = str || '';
str = str.toLowerCase();
if (times.hasOwnProperty(str) === true) {
s = s.time(times[str], goFwd);
}
return s
}
let h = this.hour();
if (h < 6) {
return 'night'
}
if (h < 12) {
//until noon
return 'morning'
}
if (h < 17) {
//until 5pm
return 'afternoon'
}
if (h < 22) {
//until 10pm
return 'evening'
}
return 'night'
},
//parse a proper iso string
iso: function (num) {
if (num !== undefined) {
return this.set(num)
}
return this.format('iso')
}
};
const methods$2 = {
// # day in the month
date: function (num, goFwd) {
if (num !== undefined) {
let s = this.clone();
num = parseInt(num, 10);
if (num) {
s.epoch = date(s, num, goFwd);
}
return s
}
return this.d.getDate()
},
//like 'wednesday' (hard!)
day: function (input, goFwd) {
if (input === undefined) {
return this.d.getDay()
}
let original = this.clone();
let want = input;
// accept 'wednesday'
if (typeof input === 'string') {
input = input.toLowerCase();
if (aliases$1.hasOwnProperty(input)) {
want = aliases$1[input];
} else {
want = short().indexOf(input);
if (want === -1) {
want = long().indexOf(input);
}
}
}
//move approx
let day = this.d.getDay();
let diff = day - want;
if (goFwd === true && diff > 0) {
diff = diff - 7;
}
if (goFwd === false && diff < 0) {
diff = diff + 7;
}
let s = this.subtract(diff, 'days');
//tighten it back up
walkTo(s, {
hour: original.hour(),
minute: original.minute(),
second: original.second()
});
return s
},
//these are helpful name-wrappers
dayName: function (input, goFwd) {
if (input === undefined) {
return long()[this.day()]
}
let s = this.clone();
s = s.day(input, goFwd);
return s
}
};
/* eslint-disable no-console */
const clearMinutes = (s) => {
s = s.minute(0);
s = s.second(0);
s = s.millisecond(1);
return s
};
const methods$1 = {
// day 0-366
dayOfYear: function (num, goFwd) {
if (num !== undefined) {
let s = this.clone();
s.epoch = dayOfYear(s, num, goFwd);
return s
}
//days since newyears - jan 1st is 1, jan 2nd is 2...
let sum = 0;
let month = this.d.getMonth();
let tmp;
//count the num days in each month
for (let i = 1; i <= month; i++) {
tmp = new Date();
tmp.setDate(1);
tmp.setFullYear(this.d.getFullYear()); //the year matters, because leap-years
tmp.setHours(1);
tmp.setMinutes(1);
tmp.setMonth(i);
tmp.setHours(-2); //the last day of the month
sum += tmp.getDate();
}
return sum + this.d.getDate()
},
//since the start of the year
week: function (num, goFwd) {
// week-setter
if (num !== undefined) {
let s = this.clone();
s.epoch = week(this, num, goFwd);
s = clearMinutes(s);
return s
}
//find-out which week it is
let tmp = this.clone();
tmp = tmp.month(0);
tmp = tmp.date(1);
tmp = clearMinutes(tmp);
tmp = tmp.day('monday');
//don't go into last-year
if (tmp.month() === 11 && tmp.date() >= 25) {
tmp = tmp.add(1, 'week');
}
// is first monday the 1st?
let toAdd = 1;
if (tmp.date() === 1) {
toAdd = 0;
}
tmp = tmp.minus(2, 'hours');
const thisOne = this.epoch;
//if the week technically hasn't started yet
if (tmp.epoch > thisOne) {
return 1
}
//speed it up, if we can
let i = 0;
let skipWeeks = this.month() * 4;
tmp.epoch += o.week * skipWeeks;
i += skipWeeks;
for (; i <= 52; i++) {
if (tmp.epoch > thisOne) {
return i + toAdd
}
tmp = tmp.add(1, 'week');
}
return 52
},
//either name or number
month: function (input, goFwd) {
if (input !== undefined) {
let s = this.clone();
s.epoch = month(s, input, goFwd);
return s
}
return this.d.getMonth()
},
//'january'
monthName: function (input, goFwd) {
if (input !== undefined) {
let s = this.clone();
s = s.month(input, goFwd);
return s
}
return long$1()[this.month()]
},
//q1, q2, q3, q4
quarter: function (num, goFwd) {
if (num !== undefined) {
if (typeof num === 'string') {
num = num.replace(/^q/i, '');
num = parseInt(num, 10);
}
if (quarters[num]) {
let s = this.clone();
let month = quarters[num][0];
s = s.month(month, goFwd);
s = s.date(1, goFwd);
s = s.startOf('day');
return s
}
}
let month = this.d.getMonth();
for (let i = 1; i < quarters.length; i++) {
if (month < quarters[i][0]) {
return i - 1
}
}
return 4
},
//spring, summer, winter, fall
season: function (input, goFwd) {
let hem = 'north';
if (this.hemisphere() === 'South') {
hem = 'south';
}
if (input !== undefined) { // setter
let s = this.clone();
for (let i = 0; i < seasons$1[hem].length; i++) {
if (input === seasons$1[hem][i][0]) {
s = s.month(seasons$1[hem][i][1], goFwd);
s = s.date(1);
s = s.startOf('day');
}
}
return s
}
let month = this.d.getMonth();
for (let i = 0; i < seasons$1[hem].length - 1; i++) {
if (month >= seasons$1[hem][i][1] && month < seasons$1[hem][i + 1][1]) {
return seasons$1[hem][i][0]
}
}
return hem === 'north' ? 'winter' : 'summer'
},
//the year number
year: function (num) {
if (num !== undefined) {
let s = this.clone();
s.epoch = year(s, num);
return s
}
return this.d.getFullYear()
},
//bc/ad years
era: function (str) {
if (str !== undefined) {
let s = this.clone();
str = str.toLowerCase();
//TODO: there is no year-0AD i think. may have off-by-1 error here
let year$1 = s.d.getFullYear();
//make '1992' into 1992bc..
if (str === 'bc' && year$1 > 0) {
s.epoch = year(s, year$1 * -1);
}
//make '1992bc' into '1992'
if (str === 'ad' && year$1 < 0) {
s.epoch = year(s, year$1 * -1);
}
return s
}
if (this.d.getFullYear() < 0) {
return 'BC'
}
return 'AD'
},
// 2019 -> 2010
decade: function (input) {
if (input !== undefined) {
input = String(input);
input = input.replace(/([0-9])'?s$/, '$1'); //1950's
input = input.replace(/([0-9])(th|rd|st|nd)/, '$1'); //fix ordinals
if (!input) {
console.warn('Spacetime: Invalid decade input');
return this
}
// assume 20th century?? for '70s'.
if (input.length === 2 && /[0-9][0-9]/.test(input)) {
input = '19' + input;
}
let year = Number(input);
if (isNaN(year)) {
return this
}
// round it down to the decade
year = Math.floor(year / 10) * 10;
return this.year(year) //.startOf('decade')
}
return this.startOf('decade').year()
},
// 1950 -> 19+1
century: function (input) {
if (input !== undefined) {
if (typeof input === 'string') {
input = input.replace(/([0-9])(th|rd|st|nd)/, '$1'); //fix ordinals
input = input.replace(/([0-9]+) ?(b\.?c\.?|a\.?d\.?)/i, (a, b, c) => {
if (c.match(/b\.?c\.?/i)) {
b = '-' + b;
}
return b
});
input = input.replace(/c$/, ''); //20thC
}
let year = Number(input);
if (isNaN(input)) {
console.warn('Spacetime: Invalid century input');
return this
}
// there is no century 0
if (year === 0) {
year = 1;
}
if (year >= 0) {
year = (year - 1) * 100;
} else {
year = (year + 1) * 100;
}
return this.year(year)
}
// century getter
let num = this.startOf('century').year();
num = Math.floor(num / 100);
if (num < 0) {
return num - 1
}
return num + 1
},
// 2019 -> 2+1
millenium: function (input) {
if (input !== undefined) {
if (typeof input === 'string') {
input = input.replace(/([0-9])(th|rd|st|nd)/, '$1'); //fix ordinals
input = Number(input);
if (isNaN(input)) {
console.warn('Spacetime: Invalid millenium input');
return this
}
}
if (input > 0) {
input -= 1;
}
let year = input * 1000;
// there is no year 0
if (year === 0) {
year = 1;
}
return this.year(year)
}
// get the current millenium
let num = Math.floor(this.year() / 1000);
if (num >= 0) {
num += 1;
}
return num
}
};
const methods = Object.assign({}, methods$3, methods$2, methods$1);
//aliases
methods.milliseconds = methods.millisecond;
methods.seconds = methods.second;
methods.minutes = methods.minute;
methods.hours = methods.hour;
methods.hour24 = methods.hour;
methods.h12 = methods.hour12;
methods.h24 = methods.hour24;
methods.days = methods.day;
const addMethods$4 = Space => {
//hook the methods into prototype
Object.keys(methods).forEach(k => {
Space.prototype[k] = methods[k];
});
};
const getMonthLength = function (month, year) {
if (month === 1 && isLeapYear(year)) {
return 29
}
return monthLengths[month]
};
//month is the one thing we 'model/compute'
//- because ms-shifting can be off by enough
const rollMonth = (want, old) => {
//increment year
if (want.month > 0) {
let years = parseInt(want.month / 12, 10);
want.year = old.year() + years;
want.month = want.month % 12;
} else if (want.month < 0) {
let m = Math.abs(want.month);
let years = parseInt(m / 12, 10);
if (m % 12 !== 0) {
years += 1;
}
want.year = old.year() - years;
//ignore extras
want.month = want.month % 12;
want.month = want.month + 12;
if (want.month === 12) {
want.month = 0;
}
}
return want
};
// briefly support day=-2 (this does not need to be perfect.)
const rollDaysDown = (want, old, sum) => {
want.year = old.year();
want.month = old.month();
let date = old.date();
want.date = date - Math.abs(sum);
while (want.date < 1) {
want.month -= 1;
if (want.month < 0) {
want.month = 11;
want.year -= 1;
}
let max = getMonthLength(want.month, want.year);
want.date += max;
}
return want
};
// briefly support day=33 (this does not need to be perfect.)
const rollDaysUp = (want, old, sum) => {
let year = old.year();
let month = old.month();
let max = getMonthLength(month, year);
while (sum > max) {
sum -= max;
month += 1;
if (month >= 12) {
month -= 12;
year += 1;
}
max = getMonthLength(month, year);
}
want.month = month;
want.date = sum;
return want
};
const months = rollMonth;
const days = rollDaysUp;
const daysBack = rollDaysDown;
// this logic is a bit of a mess,
// but briefly:
// millisecond-math, and some post-processing covers most-things
// we 'model' the calendar here only a little bit
// and that usually works-out...
const order = ['millisecond', 'second', 'minute', 'hour', 'date', 'month'];
let keep = {
second: order.slice(0, 1),
minute: order.slice(0, 2),
quarterhour: order.slice(0, 2),
hour: order.slice(0, 3),
date: order.slice(0, 4),
month: order.slice(0, 4),
quarter: order.slice(0, 4),
season: order.slice(0, 4),
year: order,
decade: order,
century: order
};
keep.week = keep.hour;
keep.season = keep.date;
keep.quarter = keep.date;
// Units need to be dst adjuested
const dstAwareUnits = {
year: true,
quarter: true,
season: true,
month: true,
week: true,
date: true
};
const keepDate = {
month: true,
quarter: true,
season: true,
year: true
};
const addMethods$3 = (SpaceTime) => {
SpaceTime.prototype.add = function (num, unit) {
let s = this.clone();
if (!unit || num === 0) {
return s //don't bother
}
let old = this.clone();
unit = normalize$3(unit);
if (unit === 'millisecond') {
s.epoch += num;
return s
}
// support 'fortnight' alias
if (unit === 'fortnight') {
num *= 2;
unit = 'week';
}
//move forward by the estimated milliseconds (rough)
if (o[unit]) {
s.epoch += o[unit] * num;
} else if (unit === 'week' || unit === 'weekend') {
s.epoch += o.day * (num * 7);
} else if (unit === 'quarter' || unit === 'season') {
s.epoch += o.month * (num * 3);
} else if (unit === 'quarterhour') {
s.epoch += o.minute * 15 * num;
}
//now ensure our milliseconds/etc are in-line
let want = {};
if (keep[unit]) {
keep[unit].forEach((u) => {
want[u] = old[u]();
});
}
if (dstAwareUnits[unit]) {
const diff = old.timezone().current.offset - s.timezone().current.offset;
s.epoch += diff * 3600 * 1000;
}
//ensure month/year has ticked-over
if (unit === 'month') {
want.month = old.month() + num;
//month is the one unit we 'model' directly
want = months(want, old);
}
//support coercing a week, too
if (unit === 'week') {
let sum = old.date() + (num * 7);
if (sum <= 28 && sum > 1) {
want.date = sum;
}
}
if (unit === 'weekend' && s.dayName() !== 'saturday') {
s = s.day('saturday', true); //ensure it's saturday
}
//support 25-hour day-changes on dst-changes
else if (unit === 'date') {
if (num < 0) {
want = daysBack(want, old, num);
} else {
//specify a naive date number, if it's easy to do...
let sum = old.date() + num;
// ok, model this one too
want = days(want, old, sum);
}
//manually punt it if we haven't moved at all..
if (num !== 0 && old.isSame(s, 'day')) {
want.date = old.date() + num;
}
}
// ensure a quarter is 3 months over
else if (unit === 'quarter') {
want.month = old.month() + (num * 3);
want.year = old.year();
// handle rollover
if (want.month < 0) {
let years = Math.floor(want.month / 12);
let remainder = want.month + (Math.abs(years) * 12);
want.month = remainder;
want.year += years;
} else if (want.month >= 12) {
let years = Math.floor(want.month / 12);
want.month = want.month % 12;
want.year += years;
}
want.date = old.date();
}
//ensure year has changed (leap-years)
else if (unit === 'year') {
let wantYear = old.year() + num;
let haveYear = s.year();
if (haveYear < wantYear) {
let toAdd = Math.floor(num / 4) || 1; //approx num of leap-days
s.epoch += Math.abs(o.day * toAdd);
} else if (haveYear > wantYear) {
let toAdd = Math.floor(num / 4) || 1; //approx num of leap-days
s.epoch += o.day * toAdd;
}
}
//these are easier
else if (unit === 'decade') {
want.year = s.year() + 10;
} else if (unit === 'century') {
want.year = s.year() + 100;
}
//keep current date, unless the month doesn't have it.
if (keepDate[unit]) {
let max = monthLengths[want.month];
want.date = old.date();
if (want.date > max) {
want.date = max;
}
}
if (Object.keys(want).length > 1) {
walkTo(s, want);
}
return s
};
//subtract is only add *-1
SpaceTime.prototype.subtract = function (num, unit) {
let s = this.clone();
return s.add(num * -1, unit)
};
//add aliases
SpaceTime.prototype.minus = SpaceTime.prototype.subtract;
SpaceTime.prototype.plus = SpaceTime.prototype.add;
};
//make a string, for easy comparison between dates
const print = {
millisecond: (s) => {
return s.epoch
},
second: (s) => {
return [s.year(), s.month(), s.date(), s.hour(), s.minute(), s.second()].join('-')
},
minute: (s) => {
return [s.year(), s.month(), s.date(), s.hour(), s.minute()].join('-')
},
hour: (s) => {
return [s.year(), s.month(), s.date(), s.hour()].join('-')
},
day: (s) => {
return [s.year(), s.month(), s.date()].join('-')
},
week: (s) => {
return [s.year(), s.week()].join('-')
},
month: (s) => {
return [s.year(), s.month()].join('-')
},
quarter: (s) => {
return [s.year(), s.quarter()].join('-')
},
year: (s) => {
return s.year()
}
};
print.date = print.day;
const addMethods$2 = (SpaceTime) => {
SpaceTime.prototype.isSame = function (b, unit, tzAware = true) {
let a = this;
if (!unit) {
return null
}
// support swapped params
if (typeof b === 'string' && typeof unit === 'object') {
let tmp = b;
b = unit;
unit = tmp;
}
if (typeof b === 'string' || typeof b === 'number') {
b = new SpaceTime(b, this.timezone.name);
}
//support 'seconds' aswell as 'second'
unit = unit.replace(/s$/, '');
// make them the same timezone for proper comparison
if (tzAware === true && a.tz !== b.tz) {
b = b.clone();
b.tz = a.tz;
}
if (print[unit]) {
return print[unit](a) === print[unit](b)
}
return null
};
};
const addMethods$1 = SpaceTime => {
const methods = {
isAfter: function (d) {
d = beADate(d, this);
let epoch = getEpoch(d);
if (epoch === null) {
return null
}
return this.epoch > epoch
},
isBefore: function (d) {
d = beADate(d, this);
let epoch = getEpoch(d);
if (epoch === null) {
return null
}
return this.epoch < epoch
},
isEqual: function (d) {
d = beADate(d, this);
let epoch = getEpoch(d);
if (epoch === null) {
return null
}
return this.epoch === epoch
},
isBetween: function (start, end, isInclusive = false) {
start = beADate(start, this);
end = beADate(end, this);
let startEpoch = getEpoch(start);
if (startEpoch === null) {
return null
}
let endEpoch = getEpoch(end);
if (endEpoch === null) {
return null
}
if (isInclusive) {
return this.isBetween(start, end) || this.isEqual(start) || this.isEqual(end);
}
return startEpoch < this.epoch && this.epoch < endEpoch
}
};
//hook them into proto
Object.keys(methods).forEach(k => {
SpaceTime.prototype[k] = methods[k];
});
};
const addMethods = SpaceTime => {
const methods = {
i18n: function (data) {
//change the day names
if (isObject(data.days)) {
set$4(data.days);
}
//change the month names
if (isObject(data.months)) {
set$5(data.months);
}
//change the display style of the month / day names
if (isBoolean(data.useTitleCase)) {
set$3(data.useTitleCase);
}
//change am and pm strings
if (isObject(data.ampm)) {
set(data.ampm);
}
//change distance strings
if(isObject(data.distance)){
set$1(data.distance);
}
//change units strings
if(isObject(data.units)){
set$2(data.units);
}
return this
}
};
//hook them into proto
Object.keys(methods).forEach(k => {
SpaceTime.prototype[k] = methods[k];
});
};
let timezones$1 = all;
// fake timezone-support, for fakers (es5 class)
const SpaceTime = function (input, tz, options = {}) {
// the holy moment
this.epoch = null;
// the shift for the given timezone
this.tz = lookupTz(tz, timezones$1);
// whether to output warnings to console
this.silent = typeof options.silent !== 'undefined' ? options.silent : true;
// favour british interpretation of 02/02/2018, etc
this.british = options.dmy || options.british;
// does the week start on sunday, or monday:
this._weekStart = 1; // default to monday
if (options.weekStart !== undefined) {
this._weekStart = options.weekStart;
}
// the reference today date object, (for testing)
this._today = {};
if (options.today !== undefined) {
this._today = options.today;
}
// dunno if this is a good idea, or not
// Object.defineProperty(this, 'parsers', {
// enumerable: false,
// writable: true,
// value: parsers
// })
// add getter/setters
Object.defineProperty(this, 'd', {
// return a js date object
get: function () {
let offset = quickOffset(this);
// every computer is somewhere- get this computer's built-in offset
let bias = new Date(this.epoch).getTimezoneOffset() || 0;
// movement
let shift = bias + (offset * 60); //in minutes
shift = shift * 60 * 1000; //in ms
// remove this computer's offset
let epoch = this.epoch + shift;
let d = new Date(epoch);
return d
}
});
// add this data on the object, to allow adding new timezones
Object.defineProperty(this, 'timezones', {
get: () => timezones$1,
set: (obj) => {
timezones$1 = obj;
return obj
}
});
// parse the various formats
let tmp = parseInput(this, input);
this.epoch = tmp.epoch;
if (tmp.tz) {
this.tz = tmp.tz;
}
};
// (add instance methods to prototype)
Object.keys(methods$4).forEach((k) => {
SpaceTime.prototype[k] = methods$4[k];
});
// ¯\_(ツ)_/¯
SpaceTime.prototype.clone = function () {
return new SpaceTime(this.epoch, this.tz, {
silent: this.silent,
weekStart: this._weekStart,
today: this._today,
parsers: this.parsers
})
};
/**
* @deprecated use toNativeDate()
* @returns native date object at the same epoch
*/
SpaceTime.prototype.toLocalDate = function () {
return this.toNativeDate()
};
/**
* @returns native date object at the same epoch
*/
SpaceTime.prototype.toNativeDate = function () {
return new Date(this.epoch)
};
// append more methods
addMethods$4(SpaceTime);
addMethods$3(SpaceTime);
addMethods$2(SpaceTime);
addMethods$1(SpaceTime);
addMethods(SpaceTime);
// const timezones = require('../data');
const whereIts = (a, b) => {
let start = new SpaceTime(null);
let end = new SpaceTime(null);
start = start.time(a);
//if b is undefined, use as 'within one hour'
if (b) {
end = end.time(b);
} else {
end = start.add(59, 'minutes');
}
let startHour = start.hour();
let endHour = end.hour();
let tzs = Object.keys(start.timezones).filter((tz) => {
if (tz.indexOf('/') === -1) {
return false
}
let m = new SpaceTime(null, tz);
let hour = m.hour();
//do 'calendar-compare' not real-time-compare
if (hour >= startHour && hour <= endHour) {
//test minutes too, if applicable
if (hour === startHour && m.minute() < start.minute()) {
return false
}
if (hour === endHour && m.minute() > end.minute()) {
return false
}
return true
}
return false
});
return tzs
};
var version$1 = '7.7.0';
const main = (input, tz, options) => new SpaceTime(input, tz, options);
// set all properties of a given 'today' object
const setToday = function (s) {
let today = s._today || {};
Object.keys(today).forEach((k) => {
s = s[k](today[k]);
});
return s
};
//some helper functions on the main method
main.now = (tz, options) => {
let s = new SpaceTime(new Date().getTime(), tz, options);
s = setToday(s);
return s
};
main.today = (tz, options) => {
let s = new SpaceTime(new Date().getTime(), tz, options);
s = setToday(s);
return s.startOf('day')
};
main.tomorrow = (tz, options) => {
let s = new SpaceTime(new Date().getTime(), tz, options);
s = setToday(s);
return s.add(1, 'day').startOf('day')
};
main.yesterday = (tz, options) => {
let s = new SpaceTime(new Date().getTime(), tz, options);
s = setToday(s);
return s.subtract(1, 'day').startOf('day')
};
main.extend = function (obj = {}) {
Object.keys(obj).forEach((k) => {
SpaceTime.prototype[k] = obj[k];
});
return this
};
main.timezones = function () {
let s = new SpaceTime();
return s.timezones
};
main.max = function (tz, options) {
let s = new SpaceTime(null, tz, options);
s.epoch = 8640000000000000;
return s
};
main.min = function (tz, options) {
let s = new SpaceTime(null, tz, options);
s.epoch = -8640000000000000;
return s
};
//find tz by time
main.whereIts = whereIts;
main.version = version$1;
//aliases:
main.plugin = main.extend;
// these should be added to model
const hardCoded = {
daybreak: '7:00am', //ergh
breakfast: '8:00am',
morning: '9:00am',
noon: '12:00pm',
midday: '12:00pm',
afternoon: '2:00pm',
lunchtime: '12:00pm',
evening: '6:00pm',
dinnertime: '6:00pm',
night: '8:00pm',
eod: '10:00pm',
midnight: '12:00am',
am: '9:00am', //tomorow am
pm: '5:00pm',
'early day': '8:00am',
'late at night': '11:00pm'
};
const minMap = {
quarter: 15,
half: 30,
};
// choose ambiguous ampm
const ampmChooser = function (s) {
let early = s.time('6:00am');
if (s.isBefore(early)) {
return s.ampm('pm')
}
return s
};
// parse 'twenty past 2'
const halfPast = function (m, s) {
let hour = m.match('#Cardinal$');
let punt = m.not(hour).match('(half|quarter|25|20|15|10|5)');
// get the mins, and the hour
hour = hour.text('reduced');
let mins = punt.text('reduced');
// support 'quarter'
if (minMap.hasOwnProperty(mins)) {
mins = minMap[mins];
}
let behind = m.has('to');
// apply it
s = s.hour(hour);
s = s.startOf('hour');
// assume 'half past 5' is 5pm
if (hour < 6) {
s = s.ampm('pm');
}
if (behind) {
s = s.subtract(mins, 'minutes');
} else {
s = s.add(mins, 'minutes');
}
return s
};
const parseTime = function (doc, context) {
let time = doc.match('(at|by|for|before|this|after)? #Time+');
// get the main part of the time
time = time.not('^(at|by|for|before|this|after)');
time = time.not('sharp');
time = time.not('on the dot');
let s = main.now(context.timezone);
let now = s.clone();
// check for known-times (like 'today')
let timeStr = time.not('in? the').text('reduced');
timeStr = timeStr.replace(/^@/, '');//@4pm
if (hardCoded.hasOwnProperty(timeStr)) {
return { result: hardCoded[timeStr], m: time }
}
// '5 oclock'
let m = time.match('^#Cardinal oclock (am|pm)?');
if (m.found) {
s = s.hour(m.text('reduced'));
s = s.startOf('hour');
if (s.isValid() && !s.isEqual(now)) {
let ampm = m.match('(am|pm)');
if (ampm.found) {
s = s.ampm(ampm.text('reduced'));
} else {
s = ampmChooser(s);
}
return { result: s.time(), m }
}
}
// 'quarter to two'
m = time.match('(half|quarter|25|20|15|10|5) (past|after|to) #Cardinal');
if (m.found) {
s = halfPast(m, s);
if (s.isValid() && !s.isEqual(now)) {
// choose ambiguous ampm
s = ampmChooser(s);
return { result: s.time(), m }
}
}
// 'twenty past'
m = time.match('[(half|quarter|25|20|15|10|5)] (past|after)');
if (m.found) {
let min = m.groups('min').text('reduced');
let d = main(context.today);
// support 'quarter', etc.
if (minMap.hasOwnProperty(min)) {
min = minMap[min];
}
d = d.next('hour').startOf('hour').minute(min);
if (d.isValid() && !d.isEqual(now)) {
return { result: d.time(), m }
}
}
// 'ten to'
m = time.match('[(half|quarter|25|20|15|10|5)] to');
if (m.found) {
let min = m.groups('min').text('reduced');
let d = main(context.today);
// support 'quarter', etc.
if (minMap.hasOwnProperty(min)) {
min = minMap[min];
}
d = d.next('hour').startOf('hour').minus(min, 'minutes');
if (d.isValid() && !d.isEqual(now)) {
return { result: d.time(), m }
}
}
// '4 in the evening'
m = time.match('[#Time] (in|at) the? [(morning|evening|night|nighttime)]');
if (m.found) {
let str = m.groups('time').text('normal');
if (/^[0-9]{1,2}$/.test(str)) {
s = s.hour(str); //3 in the morning
s = s.startOf('hour');
} else {
s = s.time(str); // 3:30 in the morning
}
if (s.isValid() && !s.isEqual(now)) {
let desc = m.groups('desc').text('reduced');
if (desc === 'evening' || desc === 'night') {
s = s.ampm('pm');
}
return { result: s.time(), m }
}
}
// 'this morning at 4'
m = time.match('this? [(morning|evening|tonight)] at [(#Cardinal|#Time)]');
if (m.found) {
let g = m.groups();
let str = g.time.text('reduced');
if (/^[0-9]{1,2}$/.test(str)) {
s = s.hour(str); //3
s = s.startOf('hour');
} else {
s = s.time(str); // 3:30
}
if (s.isValid() && !s.isEqual(now)) {
let desc = g.desc.text('reduced');
if (desc === 'morning') {
s = s.ampm('am');
}
if (desc === 'evening' || desc === 'tonight') {
s = s.ampm('pm');
}
return { result: s.time(), m }
}
}
// 'at 4' -> '4'
m = time.match('^#Cardinal$');
if (m.found) {
let str = m.text('reduced');
s = s.hour(str);
s = s.startOf('hour');
if (s.isValid() && !s.isEqual(now)) {
// choose ambiguous ampm
if (/(am|pm)/i.test(str) === false) {
s = ampmChooser(s);
}
return { result: s.time(), m }
}
}
// parse random a time like '4:54pm'
let str = time.text('reduced');
s = s.time(str);
if (s.isValid() && !s.isEqual(now)) {
// choose ambiguous ampm
if (/(am|pm)/i.test(str) === false) {
s = ampmChooser(s);
}
return { result: s.time(), m: time }
}
// should we fallback to a dayStart default?
if (context.dayStart) {
return { result: context.dayStart, m: doc.none() }
}
return { result: null, m: doc.none() }
};
// interpret 'this halloween' or 'next june'
const parseRelative = function (doc) {
// avoid parsing 'day after next'
if (doc.has('(next|last|this)$')) {
return { result: null, m: doc.none() }
}
// next monday
let m = doc.match('^this? (next|upcoming|coming)');
if (m.found) {
return { result: 'next', m }
}
// 'this past monday' is not-always 'last monday'
m = doc.match('^this? (past)');
if (m.found) {
return { result: 'this-past', m }
}
// last monday
m = doc.match('^this? (last|previous)');
if (m.found) {
return { result: 'last', m }
}
// this monday
m = doc.match('^(this|current)');
if (m.found) {
return { result: 'this', m }
}
return { result: null, m: doc.none() }
};
// 'start of october', 'middle of june 1st'
const parseSection = function (doc) {
// start of 2019
let m = doc.match('[(start|beginning) of] .', 0);
if (m.found) {
return { result: 'start', m }
}
// end of 2019
m = doc.match('[end of] .', 0);
if (m.found) {
return { result: 'end', m }
}
// middle of 2019
m = doc.match('[(middle|midpoint|center) of] .', 0);
if (m.found) {
return { result: 'middle', m }
}
return { result: null, m }
};
// some opinionated-but-common-sense timezone abbreviations
// these timezone abbreviations are wholly made-up by me, Spencer Kelly, with no expertise in geography
// generated humbly from https://github.com/spencermountain/spacetime-informal
const america$1 = 'America/';
const asia$1 = 'Asia/';
const europe$1 = 'Europe/';
const africa$1 = 'Africa/';
const aus$1 = 'Australia/';
const pac$1 = 'Pacific/';
const informal$1 = {
//europe
'british summer time': europe$1 + 'London',
bst: europe$1 + 'London',
'british time': europe$1 + 'London',
'britain time': europe$1 + 'London',
'irish summer time': europe$1 + 'Dublin',
'irish time': europe$1 + 'Dublin',
ireland: europe$1 + 'Dublin',
'central european time': europe$1 + 'Berlin',
cet: europe$1 + 'Berlin',
'central european summer time': europe$1 + 'Berlin',
cest: europe$1 + 'Berlin',
'central europe': europe$1 + 'Berlin',
'eastern european time': europe$1 + 'Riga',
eet: europe$1 + 'Riga',
'eastern european summer time': europe$1 + 'Riga',
eest: europe$1 + 'Riga',
'eastern europe time': europe$1 + 'Riga',
'western european time': europe$1 + 'Lisbon',
// wet: europe+'Lisbon',
'western european summer time': europe$1 + 'Lisbon',
// west: europe+'Lisbon',
'western europe': europe$1 + 'Lisbon',
'turkey standard time': europe$1 + 'Istanbul',
trt: europe$1 + 'Istanbul',
'turkish time': europe$1 + 'Istanbul',
//africa
etc: africa$1 + 'Freetown',
utc: africa$1 + 'Freetown',
'greenwich standard time': africa$1 + 'Freetown',
gmt: africa$1 + 'Freetown',
'east africa time': africa$1 + 'Nairobi',
// eat: africa+'Nairobi',
'east african time': africa$1 + 'Nairobi',
'eastern africa time': africa$1 + 'Nairobi',
'central africa time': africa$1 + 'Khartoum',
// cat: africa+'Khartoum',
'central african time': africa$1 + 'Khartoum',
'south africa standard time': africa$1 + 'Johannesburg',
sast: africa$1 + 'Johannesburg',
'southern africa': africa$1 + 'Johannesburg',
'south african': africa$1 + 'Johannesburg',
'west africa standard time': africa$1 + 'Lagos',
// wat: africa+'Lagos',
'western africa time': africa$1 + 'Lagos',
'west african time': africa$1 + 'Lagos',
'australian central standard time': aus$1 + 'Adelaide',
acst: aus$1 + 'Adelaide',
'australian central daylight time': aus$1 + 'Adelaide',
acdt: aus$1 + 'Adelaide',
'australia central': aus$1 + 'Adelaide',
'australian eastern standard time': aus$1 + 'Brisbane',
aest: aus$1 + 'Brisbane',
'australian eastern daylight time': aus$1 + 'Brisbane',
aedt: aus$1 + 'Brisbane',
'australia east': aus$1 + 'Brisbane',
'australian western standard time': aus$1 + 'Perth',
awst: aus$1 + 'Perth',
'australian western daylight time': aus$1 + 'Perth',
awdt: aus$1 + 'Perth',
'australia west': aus$1 + 'Perth',
'australian central western standard time': aus$1 + 'Eucla',
acwst: aus$1 + 'Eucla',
'australia central west': aus$1 + 'Eucla',
'lord howe standard time': aus$1 + 'Lord_Howe',
lhst: aus$1 + 'Lord_Howe',
'lord howe daylight time': aus$1 + 'Lord_Howe',
lhdt: aus$1 + 'Lord_Howe',
'russian standard time': europe$1 + 'Moscow',
msk: europe$1 + 'Moscow',
russian: europe$1 + 'Moscow',
//america
'central standard time': america$1 + 'Chicago',
'central time': america$1 + 'Chicago',
cst: america$1 + 'Havana',
'central daylight time': america$1 + 'Chicago',
cdt: america$1 + 'Havana',
'mountain standard time': america$1 + 'Denver',
'mountain time': america$1 + 'Denver',
mst: america$1 + 'Denver',
'mountain daylight time': america$1 + 'Denver',
mdt: america$1 + 'Denver',
'atlantic standard time': america$1 + 'Halifax',
'atlantic time': america$1 + 'Halifax',
ast: asia$1 + 'Baghdad',
'atlantic daylight time': america$1 + 'Halifax',
adt: america$1 + 'Halifax',
'eastern standard time': america$1 + 'New_York',
'eastern': america$1 + 'New_York',
'eastern time': america$1 + 'New_York',
est: america$1 + 'New_York',
'eastern daylight time': america$1 + 'New_York',
edt: america$1 + 'New_York',
'pacific time': america$1 + 'Los_Angeles',
'pacific standard time': america$1 + 'Los_Angeles',
pst: america$1 + 'Los_Angeles',
'pacific daylight time': america$1 + 'Los_Angeles',
pdt: america$1 + 'Los_Angeles',
'alaskan standard time': america$1 + 'Anchorage',
'alaskan time': america$1 + 'Anchorage',
ahst: america$1 + 'Anchorage',
'alaskan daylight time': america$1 + 'Anchorage',
ahdt: america$1 + 'Anchorage',
'hawaiian standard time': pac$1 + 'Honolulu',
'hawaiian time': pac$1 + 'Honolulu',
hst: pac$1 + 'Honolulu',
'aleutian time': pac$1 + 'Honolulu',
'hawaii time': pac$1 + 'Honolulu',
'newfoundland standard time': america$1 + 'St_Johns',
'newfoundland time': america$1 + 'St_Johns',
nst: america$1 + 'St_Johns',
'newfoundland daylight time': america$1 + 'St_Johns',
ndt: america$1 + 'St_Johns',
'brazil time': america$1 + 'Sao_Paulo',
brt: america$1 + 'Sao_Paulo',
'brasília': america$1 + 'Sao_Paulo',
brasilia: america$1 + 'Sao_Paulo',
'brazilian time': america$1 + 'Sao_Paulo',
'argentina time': america$1 + 'Buenos_Aires',
// art: a+'Buenos_Aires',
'argentinian time': america$1 + 'Buenos_Aires',
'amazon time': america$1 + 'Manaus',
amt: america$1 + 'Manaus',
'amazonian time': america$1 + 'Manaus',
'easter island standard time': 'Chile/Easterisland',
east: 'Chile/Easterisland',
'easter island summer time': 'Chile/Easterisland',
easst: 'Chile/Easterisland',
'venezuelan standard time': america$1 + 'Caracas',
'venezuelan time': america$1 + 'Caracas',
vet: america$1 + 'Caracas',
'venezuela time': america$1 + 'Caracas',
'paraguay time': america$1 + 'Asuncion',
pyt: america$1 + 'Asuncion',
'paraguay summer time': america$1 + 'Asuncion',
pyst: america$1 + 'Asuncion',
'cuba standard time': america$1 + 'Havana',
'cuba time': america$1 + 'Havana',
'cuba daylight time': america$1 + 'Havana',
'cuban time': america$1 + 'Havana',
'bolivia time': america$1 + 'La_Paz',
// bot: a+'La_Paz',
'bolivian time': america$1 + 'La_Paz',
'colombia time': america$1 + 'Bogota',
cot: america$1 + 'Bogota',
'colombian time': america$1 + 'Bogota',
'acre time': america$1 + 'Eirunepe',
// act: a+'Eirunepe',
'peru time': america$1 + 'Lima',
// pet: a+'Lima',
'chile standard time': america$1 + 'Punta_Arenas',
'chile time': america$1 + 'Punta_Arenas',
clst: america$1 + 'Punta_Arenas',
'chile summer time': america$1 + 'Punta_Arenas',
cldt: america$1 + 'Punta_Arenas',
'uruguay time': america$1 + 'Montevideo',
uyt: america$1 + 'Montevideo',
//asia
ist: asia$1 + 'Jerusalem',
'arabic standard time': asia$1 + 'Baghdad',
'arabic time': asia$1 + 'Baghdad',
'arab time': asia$1 + 'Baghdad',
'iran standard time': asia$1 + 'Tehran',
'iran time': asia$1 + 'Tehran',
irst: asia$1 + 'Tehran',
'iran daylight time': asia$1 + 'Tehran',
irdt: asia$1 + 'Tehran',
iranian: asia$1 + 'Tehran',
'pakistan standard time': asia$1 + 'Karachi',
'pakistan time': asia$1 + 'Karachi',
pkt: asia$1 + 'Karachi',
'india standard time': asia$1 + 'Kolkata',
'indian time': asia$1 + 'Kolkata',
'indochina time': asia$1 + 'Bangkok',
ict: asia$1 + 'Bangkok',
'south east asia': asia$1 + 'Bangkok',
'china standard time': asia$1 + 'Shanghai',
ct: asia$1 + 'Shanghai',
'chinese time': asia$1 + 'Shanghai',
'alma-ata time': asia$1 + 'Almaty',
almt: asia$1 + 'Almaty',
'oral time': asia$1 + 'Oral',
'orat time': asia$1 + 'Oral',
'yakutsk time': asia$1 + 'Yakutsk',
yakt: asia$1 + 'Yakutsk',
'gulf standard time': asia$1 + 'Dubai',
'gulf time': asia$1 + 'Dubai',
gst: asia$1 + 'Dubai',
uae: asia$1 + 'Dubai',
'hong kong time': asia$1 + 'Hong_Kong',
hkt: asia$1 + 'Hong_Kong',
'western indonesian time': asia$1 + 'Jakarta',
wib: asia$1 + 'Jakarta',
'indonesia time': asia$1 + 'Jakarta',
'central indonesian time': asia$1 + 'Makassar',
wita: asia$1 + 'Makassar',
'israel daylight time': asia$1 + 'Jerusalem',
idt: asia$1 + 'Jerusalem',
'israel standard time': asia$1 + 'Jerusalem',
'israel time': asia$1 + 'Jerusalem',
israeli: asia$1 + 'Jerusalem',
'krasnoyarsk time': asia$1 + 'Krasnoyarsk',
krat: asia$1 + 'Krasnoyarsk',
'malaysia time': asia$1 + 'Kuala_Lumpur',
myt: asia$1 + 'Kuala_Lumpur',
'singapore time': asia$1 + 'Singapore',
sgt: asia$1 + 'Singapore',
'korea standard time': asia$1 + 'Seoul',
'korea time': asia$1 + 'Seoul',
kst: asia$1 + 'Seoul',
'korean time': asia$1 + 'Seoul',
'uzbekistan time': asia$1 + 'Samarkand',
uzt: asia$1 + 'Samarkand',
'vladivostok time': asia$1 + 'Vladivostok',
vlat: asia$1 + 'Vladivostok',
//indian
'maldives time': 'Indian/Maldives',
mvt: 'Indian/Maldives',
'mauritius time': 'Indian/Mauritius',
mut: 'Indian/Mauritius',
// pacific
'marshall islands time': pac$1 + 'Kwajalein',
mht: pac$1 + 'Kwajalein',
'samoa standard time': pac$1 + 'Midway',
sst: pac$1 + 'Midway',
'somoan time': pac$1 + 'Midway',
'chamorro standard time': pac$1 + 'Guam',
chst: pac$1 + 'Guam',
'papua new guinea time': pac$1 + 'Bougainville',
pgt: pac$1 + 'Bougainville',
};
//add the official iana zonefile names
let iana$1 = main().timezones;
let formal$1 = Object.keys(iana$1).reduce((h, k) => {
h[k] = k;
return h
}, {});
var informal$2 = Object.assign({}, informal$1, formal$1);
const isOffset = /(-?[0-9]+)h(rs)?/i;
const isNumber = /(-?[0-9]+)/;
const utcOffset = /utc([-+]?[0-9]+)/i;
const gmtOffset = /gmt([-+]?[0-9]+)/i;
const toIana = function (num) {
num = Number(num);
if (num > -13 && num < 13) {
num = num * -1; //it's opposite!
num = (num > 0 ? '+' : '') + num; //add plus sign
return 'Etc/GMT' + num
}
return null
};
const parseOffset = function (tz) {
// '+5hrs'
let m = tz.match(isOffset);
if (m !== null) {
return toIana(m[1])
}
// 'utc+5'
m = tz.match(utcOffset);
if (m !== null) {
return toIana(m[1])
}
// 'GMT-5' (not opposite)
m = tz.match(gmtOffset);
if (m !== null) {
let num = Number(m[1]) * -1;
return toIana(num)
}
// '+5'
m = tz.match(isNumber);
if (m !== null) {
return toIana(m[1])
}
return null
};
const parseTimezone = function (doc) {
let m = doc.match('#Timezone+');
//remove prepositions
m = m.not('(in|for|by|near|at)');
let str = m.text('reduced');
// check our list of informal tz names
if (informal$2.hasOwnProperty(str)) {
return { result: informal$2[str], m }
}
let tz = parseOffset(str);
if (tz) {
return { result: tz, m }
}
return { result: null, m: doc.none() }
};
// pull-out 'thurs' from 'thurs next week'
const parseWeekday = function (doc) {
let day = doc.match('#WeekDay');
if (day.found && !doc.has('^#WeekDay$')) {
// handle relative-day logic elsewhere.
if (doc.has('(this|next|last) (next|upcoming|coming|past)? #WeekDay')) {
return { result: null, m: doc.none() }
}
return { result: day.text('reduced'), m: day }
}
return { result: null, m: doc.none() }
};
const cleanup = function (doc) {
// 'the fifth week ..'
doc = doc.not('[^the] !#Value', 0); // keep 'the 17th'
//
doc = doc.not('#Preposition$');
doc = doc.not('#Conjunction$');
doc = doc.not('sharp');
doc = doc.not('on the dot');
doc = doc.not('^(on|of)');
doc = doc.not('(next|last|this)$');
return doc
};
const tokenize = function (doc, context) {
// parse 'two weeks after'
let res = parseShift(doc);
let shift = res.result;
doc = doc.not(res.m);
// parse 'nth week of june'
res = getCounter(doc);
let counter = res.result;
doc = doc.not(res.m);
// parse 'eastern time'
res = parseTimezone(doc);
let tz = res.result;
doc = doc.not(res.m);
// parse '2pm'
res = parseTime(doc, context);
let time = res.result;
doc = doc.not(res.m);
// parse 'tuesday'
res = parseWeekday(doc);
let weekDay = res.result;
doc = doc.not(res.m);
// parse 'start of x'
res = parseSection(doc);
let section = res.result;
doc = doc.not(res.m);
// parse 'next x'
res = parseRelative(doc);
let rel = res.result;
doc = doc.not(res.m);
// cleanup remaining doc object
doc = cleanup(doc);
return {
shift,
counter,
tz,
time,
weekDay,
section,
rel,
doc
}
};
class Unit {
constructor(input, unit, context) {
this.unit = unit || 'day';
this.setTime = false;
context = context || {};
let today = {};
if (context.today) {
today = {
date: context.today.date(),
month: context.today.month(),
year: context.today.year(),
};
}
if (input && input.month === 'sept') {
input.month = 'sep';
}
// set it to the beginning of the given unit
let d = main(input, context.timezone, { today: today, dmy: context.dmy });
Object.defineProperty(this, 'd', {
enumerable: false,
writable: true,
value: d,
});
Object.defineProperty(this, 'context', {
enumerable: false,
writable: true,
value: context,
});
}
// make a new one
clone() {
let d = new Unit(this.d, this.unit, this.context);
d.setTime = this.setTime;
return d
}
log() {
console.log('--');//eslint-disable-line
this.d.log();
console.log('\n');//eslint-disable-line
return this
}
applyShift(obj = {}) {
Object.keys(obj).forEach((unit) => {
this.d = this.d.add(obj[unit], unit);
if (unit === 'hour' || unit === 'minute') {
this.setTime = true;
}
});
return this
}
applyTime(str) {
if (str) {
let justHour = /^[0-9]{1,2}$/;
if (justHour.test(str)) {
this.d = this.d.hour(str);
} else {
this.d = this.d.time(str);
}
// wiggle the best am/pm
let amPM = /[ap]m/.test(str);
if (!amPM) {
let tooEarly = this.d.time('6:00am');
if (this.d.isBefore(tooEarly)) {
this.d = this.d.ampm('pm');
}
let tooLate = this.d.time('10:00pm');
if (this.d.isAfter(tooLate)) {
this.d = this.d.ampm('am');
}
}
} else {
this.d = this.d.startOf('day'); //zero-out time
}
this.setTime = true;
return this
}
applyWeekDay(day) {
if (day) {
let epoch = this.d.epoch;
this.d = this.d.day(day);
if (this.d.epoch < epoch) {
this.d = this.d.add(1, 'week');
}
}
return this
}
applyRel(rel) {
if (rel === 'next') {
return this.next()
}
if (rel === 'last' || rel === 'this-past') {
// special 'this past' logic is handled in WeekDay
return this.last()
}
return this
}
applySection(section) {
if (section === 'start') {
return this.start()
}
if (section === 'end') {
return this.end()
}
if (section === 'middle') {
return this.middle()
}
return this
}
format(fmt) {
return this.d.format(fmt)
}
start() {
this.d = this.d.startOf(this.unit);
// do we have a custom day-start?
if (this.context.dayStart) {
this.d = this.d.time(this.context.dayStart);
}
return this
}
end() {
// do we have a custom day-end?
this.d = this.d.endOf(this.unit);
if (this.context.dayEnd) {
this.d = this.d.startOf('day');
let dayEnd = this.d.time(this.context.dayEnd);
if (dayEnd.isAfter(this.d)) {
this.d = dayEnd;
return this
}
}
return this
}
middle() {
let diff = this.d.diff(this.d.endOf(this.unit));
let minutes = Math.round(diff.minutes / 2);
this.d = this.d.add(minutes, 'minutes');
return this
}
// move it to 3/4s through
beforeEnd() {
let diff = this.d.startOf(this.unit).diff(this.d.endOf(this.unit));
let mins = Math.round(diff.minutes / 4);
this.d = this.d.endOf(this.unit);
this.d = this.d.minus(mins, 'minutes');
if (this.context.dayStart) {
this.d = this.d.time(this.context.dayStart);
}
return this
}
// the millescond before
before() {
this.d = this.d.minus(1, this.unit);
this.d = this.d.endOf(this.unit);
if (this.context.dayEnd) {
this.d = this.d.time(this.context.dayEnd);
}
return this
}
// 'after 2019'
after() {
this.d = this.d.add(1, this.unit);
this.d = this.d.startOf(this.unit);
return this
}
// tricky: 'next june' 'next tuesday'
next() {
this.d = this.d.add(1, this.unit);
this.d = this.d.startOf(this.unit);
return this
}
// tricky: 'last june' 'last tuesday'
last() {
this.d = this.d.minus(1, this.unit);
this.d = this.d.startOf(this.unit);
return this
}
}
class Day extends Unit {
constructor(input, unit, context) {
super(input, unit, context);
this.unit = 'day';
if (this.d.isValid()) {
this.d = this.d.startOf('day');
}
}
middle() {
this.d = this.d.time('10am');
return this
}
beforeEnd() {
this.d = this.d.time('2pm');
return this
}
}
// like 'feb 2'
class CalendarDate extends Day {
constructor(input, unit, context) {
super(input, unit, context);
this.unit = 'day';
if (this.d.isValid()) {
this.d = this.d.startOf('day');
}
}
next() {
this.d = this.d.add(1, 'year');
return this
}
last() {
this.d = this.d.minus(1, 'year');
return this
}
}
class WeekDay extends Day {
constructor(input, unit, context) {
super(input, unit, context);
this.unit = 'day';
this.isWeekDay = true; //cool.
// is the input just a weekday?
if (typeof input === 'string') {
this.d = main(context.today, context.timezone);
this.d = this.d.day(input);
// assume a wednesday in the future
if (this.d.isBefore(context.today)) {
this.d = this.d.add(7, 'days');
}
} else {
this.d = input;
}
this.weekDay = this.d.dayName();
if (this.d.isValid()) {
this.d = this.d.startOf('day');
}
}
// clone() {
// return new WeekDay(this.d, this.unit, this.context)
// }
next() {
this.d = this.d.add(7, 'days');
this.d = this.d.day(this.weekDay);
return this
}
last() {
this.d = this.d.minus(7, 'days');
this.d = this.d.day(this.weekDay);
return this
}
// the millescond before
before() {
this.d = this.d.minus(1, 'day');
this.d = this.d.endOf('day');
if (this.context.dayEnd) {
this.d = this.d.time(this.context.dayEnd);
}
return this
}
applyRel(rel) {
if (rel === 'next') {
let tooFar = this.context.today.endOf('week').add(1, 'week');
this.next();
// did we go too-far?
if (this.d.isAfter(tooFar)) {
this.last(); // go back
}
return this
}
// the closest-one backwards
if (rel === 'this-past') {
return this.last()
}
if (rel === 'last') {
let start = this.context.today.startOf('week');
this.last();
// are we still in 'this week' though?
if (this.d.isBefore(start) === false) {
this.last(); // do it again
}
return this
}
return this
}
}
// like 'haloween'
class Holiday extends CalendarDate {
constructor(input, unit, context) {
super(input, unit, context);
this.unit = 'day';
if (this.d.isValid()) {
this.d = this.d.startOf('day');
}
}
}
class Hour extends Unit {
constructor(input, unit, context) {
super(input, unit, context, true);
this.unit = 'hour';
if (this.d.isValid()) {
this.d = this.d.startOf('hour');
}
}
}
class Minute extends Unit {
constructor(input, unit, context) {
super(input, unit, context, true);
this.unit = 'minute';
if (this.d.isValid()) {
this.d = this.d.startOf('minute');
}
}
}
class Moment extends Unit {
constructor(input, unit, context) {
super(input, unit, context, true);
this.unit = 'millisecond';
}
}
// a specific month, like 'March'
class AnyMonth extends Unit {
constructor(input, unit, context) {
super(input, unit, context);
this.unit = 'month';
// set to beginning
if (this.d.isValid()) {
this.d = this.d.startOf(this.unit);
}
}
}
// a specific month, like 'March'
class Month extends Unit {
constructor(input, unit, context) {
super(input, unit, context);
this.unit = 'month';
// set to beginning
if (this.d.isValid()) {
this.d = this.d.startOf(this.unit);
}
}
next() {
this.d = this.d.add(1, 'year');
this.d = this.d.startOf('month');
return this
}
last() {
this.d = this.d.minus(1, 'year');
this.d = this.d.startOf('month');
return this
}
middle() {
this.d = this.d.add(15, 'days');
this.d = this.d.startOf('day');
return this
}
}
class AnyQuarter extends Unit {
constructor(input, unit, context) {
super(input, unit, context);
this.unit = 'quarter';
// set to beginning
if (this.d.isValid()) {
this.d = this.d.startOf(this.unit);
}
}
last() {
this.d = this.d.minus(1, 'quarter');
this.d = this.d.startOf(this.unit);
return this
}
}
class Quarter extends Unit {
constructor(input, unit, context) {
super(input, unit, context);
this.unit = 'quarter';
// set to beginning
if (this.d.isValid()) {
this.d = this.d.startOf(this.unit);
}
}
next() {
this.d = this.d.add(1, 'year');
this.d = this.d.startOf(this.unit);
return this
}
last() {
this.d = this.d.minus(1, 'year');
this.d = this.d.startOf(this.unit);
return this
}
}
class Season extends Unit {
constructor(input, unit, context) {
super(input, unit, context);
this.unit = 'season';
// set to beginning
if (this.d.isValid()) {
this.d = this.d.startOf(this.unit);
}
}
next() {
this.d = this.d.add(1, 'year');
this.d = this.d.startOf(this.unit);
return this
}
last() {
this.d = this.d.minus(1, 'year');
this.d = this.d.startOf(this.unit);
return this
}
}
class Year extends Unit {
constructor(input, unit, context) {
super(input, unit, context);
this.unit = 'year';
if (this.d.isValid()) {
this.d = this.d.startOf('year');
}
}
}
class Week extends Unit {
constructor(input, unit, context) {
super(input, unit, context);
this.unit = 'week';
if (this.d.isValid()) {
this.d = this.d.startOf('week');
}
}
clone() {
return new Week(this.d, this.unit, this.context)
}
middle() {
this.d = this.d.add(2, 'days'); //wednesday
return this
}
// move it to 3/4s through
beforeEnd() {
this.d = this.d.day('friday');
return this
}
}
//may need some work
class WeekEnd extends Unit {
constructor(input, unit, context) {
super(input, unit, context);
this.unit = 'week';
if (this.d.isValid()) {
this.d = this.d.day('saturday');
this.d = this.d.startOf('day');
}
}
start() {
this.d = this.d.day('saturday').startOf('day');
return this
}
// end() {
// this.d = this.d.day('sunday').endOf('day')
// return this
// }
next() {
this.d = this.d.add(1, this.unit);
this.d = this.d.startOf('weekend');
return this
}
last() {
this.d = this.d.minus(1, this.unit);
this.d = this.d.startOf('weekend');
return this
}
}
const knownWord = {
today: (context) => {
return new Day(context.today, null, context)
},
yesterday: (context) => {
return new Day(context.today.minus(1, 'day'), null, context)
},
tomorrow: (context) => {
return new Day(context.today.plus(1, 'day'), null, context)
},
eom: (context) => {
let d = context.today.endOf('month');
d = d.startOf('day');
return new Day(d, null, context)
},
// eod: (context) => {
// let d = context.today.endOf('day')
// d = d.startOf('hour').minus(4, 'hours') //rough
// return new Hour(d, null, context)
// },
eoy: (context) => {
let d = context.today.endOf('year');
d = d.startOf('day');
return new Day(d, null, context)
},
now: (context) => {
return new Moment(context.today, null, context) // should we set the current hour?
},
};
knownWord.tommorrow = knownWord.tomorrow;
knownWord.tmrw = knownWord.tomorrow;
knownWord.anytime = knownWord.today;
knownWord.sometime = knownWord.today;
const today = function (doc, context, parts) {
let unit = null;
// is it empty?
if (doc.found === false) {
// do we have just a time?
if (parts.time !== null) {
unit = new Moment(context.today, null, context); // choose today
}
//do we just have a shift?
if (parts.shift && Object.keys(parts.shift).length > 0) {
if (parts.shift.hour || parts.shift.minute) {
unit = new Moment(context.today, null, context); // choose now
} else {
unit = new Day(context.today, null, context); // choose today
}
}
}
// today, yesterday, tomorrow
let str = doc.text('reduced');
if (knownWord.hasOwnProperty(str) === true) {
return knownWord[str](context)
}
// day after next
if (str === 'next' && parts.shift && Object.keys(parts.shift).length > 0) {
return knownWord.tomorrow(context)
}
return unit
};
//yep,
const jan$1 = 'january';
const feb$1 = 'february';
const mar$1 = 'march';
const apr = 'april';
const may$1 = 'may';
const jun$1 = 'june';
const jul = 'july';
const aug = 'august';
const sep$1 = 'september';
const oct$1 = 'october';
const nov$1 = 'november';
const dec = 'december';
var fixed = {
'new years eve': [dec, 31],
'new years': [jan$1, 1],
'new years day': [jan$1, 1],
'inauguration day': [jan$1, 20],
'australia day': [jan$1, 26],
'national freedom day': [feb$1, 1],
'groundhog day': [feb$1, 2],
'rosa parks day': [feb$1, 4],
'valentines day': [feb$1, 14],
'saint valentines day': [feb$1, 14],
'st valentines day ': [feb$1, 14],
'saint patricks day': [mar$1, 17],
'st patricks day': [mar$1, 17],
'april fools': [apr, 1],
'april fools day': [apr, 1],
'emancipation day': [apr, 16],
'tax day': [apr, 15], //US
'labour day': [may$1, 1],
'cinco de mayo': [may$1, 5],
'national nurses day': [may$1, 6],
'harvey milk day': [may$1, 22],
'victoria day': [may$1, 24],
juneteenth: [jun$1, 19],
'canada day': [jul, 1],
'independence day': [jul, 4],
'independents day': [jul, 4],
'bastille day': [jul, 14],
'purple heart day': [aug, 7],
'womens equality day': [aug, 26],
'16 de septiembre': [sep$1, 16],
'dieciseis de septiembre': [sep$1, 16],
'grito de dolores': [sep$1, 16],
halloween: [oct$1, 31],
'all hallows eve': [oct$1, 31],
'day of the dead': [oct$1, 31], // Ranged holiday [nov, 2],
'dia de muertos': [oct$1, 31], // Ranged holiday [nov, 2],
'veterans day': [nov$1, 11],
'st andrews day': [nov$1, 30],
'saint andrews day': [nov$1, 30],
'all saints day': [nov$1, 1],
'all sts day': [nov$1, 1],
'armistice day': [nov$1, 11],
'rememberance day': [nov$1, 11],
'christmas eve': [dec, 24],
christmas: [dec, 25],
xmas: [dec, 25],
'boxing day': [dec, 26],
'st stephens day': [dec, 26],
'saint stephens day': [dec, 26],
// Fixed religious and cultural holidays
// Catholic + Christian
epiphany: [jan$1, 6],
'orthodox christmas day': [jan$1, 7],
'orthodox new year': [jan$1, 14],
'assumption of mary': [aug, 15],
'all souls day': [nov$1, 2],
'feast of the immaculate conception': [dec, 8],
'feast of our lady of guadalupe': [dec, 12],
// Kwanzaa
kwanzaa: [dec, 26], // Ranged holiday [jan, 1],
// Pagan / metal 🤘
imbolc: [feb$1, 2],
beltaine: [may$1, 1],
lughnassadh: [aug, 1],
samhain: [oct$1, 31]
};
// holidays that are the same date every year
const fixedDates$1 = function (str, normal, year, tz) {
if (fixed.hasOwnProperty(str) || fixed.hasOwnProperty(normal)) {
let arr = fixed[str] || fixed[normal] || [];
let s = main.now(tz);
s = s.year(year);
s = s.startOf('year');
s = s.month(arr[0]);
s = s.date(arr[1]);
if (s.isValid()) {
return s
}
}
return null
};
var fixedDates$2 = fixedDates$1;
//these are holidays on the 'nth weekday of month'
const jan = 'january';
const feb = 'february';
const mar = 'march';
// const apr = 'april'
const may = 'may';
const jun = 'june';
// const jul = 'july'
// const aug = 'august'
const sep = 'september';
const oct = 'october';
const nov = 'november';
// const dec = 'december'
const mon = 'monday';
// const tues = 'tuesday'
// const wed = 'wednesday'
const thurs = 'thursday';
const fri = 'friday';
// const sat = 'saturday'
const sun = 'sunday';
let holidays$3 = {
'martin luther king day': [3, mon, jan], //[third monday in january],
'presidents day': [3, mon, feb], //[third monday in february],
'commonwealth day': [2, mon, mar], //[second monday in march],
'mothers day': [2, sun, may], //[second Sunday in May],
'fathers day': [3, sun, jun], //[third Sunday in June],
'labor day': [1, mon, sep], //[first monday in september],
'columbus day': [2, mon, oct], //[second monday in october],
'canadian thanksgiving': [2, mon, oct], //[second monday in october],
thanksgiving: [4, thurs, nov], // [fourth Thursday in November],
'black friday': [4, fri, nov] //[fourth friday in november],
// 'memorial day': [may], //[last monday in may],
// 'us election': [nov], // [Tuesday following the first Monday in November],
// 'cyber monday': [nov]
// 'advent': [] // fourth Sunday before Christmas
};
// add aliases
holidays$3['turday day'] = holidays$3.thanksgiving;
holidays$3['indigenous peoples day'] = holidays$3['columbus day'];
holidays$3['mlk day'] = holidays$3['martin luther king day'];
var calendar = holidays$3;
// holidays that are the same date every year
const fixedDates = function (str, normal, year, tz) {
if (calendar.hasOwnProperty(str) || calendar.hasOwnProperty(normal)) {
let arr = calendar[str] || calendar[normal] || [];
let s = main.now(tz);
s = s.year(year);
// [3rd, 'monday', 'january']
s = s.month(arr[2]);
s = s.startOf('month');
// make it january
let month = s.month();
// make it the 1st monday
s = s.day(arr[1]);
if (s.month() !== month) {
s = s.add(1, 'week');
}
// make it nth monday
if (arr[0] > 1) {
s = s.add(arr[0] - 1, 'week');
}
if (s.isValid()) {
return s
}
}
return null
};
var nthWeekday = fixedDates;
// https://www.timeanddate.com/calendar/determining-easter-date.html
let dates$2 = {
easter: 0,
'ash wednesday': -46, // (46 days before easter)
'palm sunday': 7, // (1 week before easter)
'maundy thursday': -3, // (3 days before easter)
'good friday': -2, // (2 days before easter)
'holy saturday': -1, // (1 days before easter)
'easter saturday': -1, // (1 day before easter)
'easter monday': 1, // (1 day after easter)
'ascension day': 39, // (39 days after easter)
'whit sunday': 49, // / pentecost (49 days after easter)
'whit monday': 50, // (50 days after easter)
'trinity sunday': 65, // (56 days after easter)
'corpus christi': 60, // (60 days after easter)
'mardi gras': -47 //(47 days before easter)
};
dates$2['easter sunday'] = dates$2.easter;
dates$2.pentecost = dates$2['whit sunday'];
dates$2.whitsun = dates$2['whit sunday'];
var holidays$2 = dates$2;
// by John Dyer
// based on the algorithm by Oudin (1940) from http://www.tondering.dk/claus/cal/easter.php
const calcEaster = function (year) {
let f = Math.floor,
// Golden Number - 1
G = year % 19,
C = f(year / 100),
// related to Epact
H = (C - f(C / 4) - f((8 * C + 13) / 25) + 19 * G + 15) % 30,
// number of days from 21 March to the Paschal full moon
I = H - f(H / 28) * (1 - f(29 / (H + 1)) * f((21 - G) / 11)),
// weekday for the Paschal full moon
J = (year + f(year / 4) + I + 2 - C + f(C / 4)) % 7,
// number of days from 21 March to the Sunday on or before the Paschal full moon
L = I - J,
month = 3 + f((L + 40) / 44),
date = L + 28 - 31 * f(month / 4);
month = month === 4 ? 'April' : 'March';
return month + ' ' + date
};
var calcEaster$1 = calcEaster;
//calculate any holidays based on easter
const easterDates = function (str, normal, year, tz) {
if (holidays$2.hasOwnProperty(str) || holidays$2.hasOwnProperty(normal)) {
let days = holidays$2[str] || holidays$2[normal] || [];
let date = calcEaster$1(year);
if (!date) {
return null //no easter for this year
}
let e = main(date, tz);
e = e.year(year);
let s = e.add(days, 'day');
if (s.isValid()) {
return s
}
}
return null
};
var easterDates$1 = easterDates;
// http://www.astropixels.com/ephemeris/soleq2001.html
// years 2000-2100
const exceptions = {
spring: [
2003,
2007,
2044,
2048,
2052,
2056,
2060,
2064,
2068,
2072,
2076,
2077,
2080,
2081,
2084,
2085,
2088,
2089,
2092,
2093,
2096,
2097
],
summer: [
2021,
2016,
2020,
2024,
2028,
2032,
2036,
2040,
2041,
2044,
2045,
2048,
2049,
2052,
2053,
2056,
2057,
2060,
2061,
2064,
2065,
2068,
2069,
2070,
2072,
2073,
2074,
2076,
2077,
2078,
2080,
2081,
2082,
2084,
2085,
2086,
2088,
2089,
2090,
2092,
2093,
2094,
2096,
2097,
2098,
2099
],
fall: [
2002,
2003,
2004,
2006,
2007,
2010,
2011,
2014,
2015,
2018,
2019,
2022,
2023,
2026,
2027,
2031,
2035,
2039,
2043,
2047,
2051,
2055,
2059,
2092,
2096
],
winter: [
2002,
2003,
2006,
2007,
2011,
2015,
2019,
2023,
2027,
2031,
2035,
2039,
2043,
2080,
2084,
2088,
2092,
2096
]
};
const winter20th = [2080, 2084, 2088, 2092, 2096];
const calcSeasons = function (year) {
// most common defaults
let res = {
spring: 'March 20 ' + year,
summer: 'June 21 ' + year,
fall: 'Sept 22 ' + year,
winter: 'Dec 21 ' + year
};
if (exceptions.spring.indexOf(year) !== -1) {
res.spring = 'March 19 ' + year;
}
if (exceptions.summer.indexOf(year) !== -1) {
res.summer = 'June 20 ' + year;
}
if (exceptions.fall.indexOf(year) !== -1) {
res.fall = 'Sept 21 ' + year;
}
// winter can be 20th, 21st, or 22nd
if (exceptions.winter.indexOf(year) !== -1) {
res.winter = 'Dec 22 ' + year;
}
if (winter20th.indexOf(year) !== -1) {
res.winter = 'Dec 20 ' + year;
}
return res
};
var calcSeasons$1 = calcSeasons;
// these are properly calculated in ./lib/seasons
let dates$1 = {
'spring equinox': 'spring',
'summer solistice': 'summer',
'fall equinox': 'fall',
'winter solstice': 'winter'
};
// aliases
dates$1['march equinox'] = dates$1['spring equinox'];
dates$1['vernal equinox'] = dates$1['spring equinox'];
dates$1['ostara'] = dates$1['spring equinox'];
dates$1['june solstice'] = dates$1['summer solistice'];
dates$1['litha'] = dates$1['summer solistice'];
dates$1['autumn equinox'] = dates$1['fall equinox'];
dates$1['autumnal equinox'] = dates$1['fall equinox'];
dates$1['september equinox'] = dates$1['fall equinox'];
dates$1['sept equinox'] = dates$1['fall equinox'];
dates$1['mabon'] = dates$1['fall equinox'];
dates$1['december solstice'] = dates$1['winter solistice'];
dates$1['dec solstice'] = dates$1['winter solistice'];
dates$1['yule'] = dates$1['winter solistice'];
var holidays$1 = dates$1;
const astroDates = function (str, normal, year, tz) {
if (holidays$1.hasOwnProperty(str) || holidays$1.hasOwnProperty(normal)) {
let season = holidays$1[str] || holidays$1[normal];
let seasons = calcSeasons$1(year);
if (!season || !seasons || !seasons[season]) {
return null // couldn't figure it out
}
let s = main(seasons[season], tz);
if (s.isValid()) {
return s
}
}
return null
};
var astroDates$1 = astroDates;
let dates$3 = {
// Muslim holidays
'isra and miraj': 'april 13',
'lailat al-qadr': 'june 10',
'eid al-fitr': 'june 15',
'id al-Fitr': 'june 15',
'eid ul-Fitr': 'june 15',
ramadan: 'may 16', // Range holiday
'eid al-adha': 'sep 22',
muharram: 'sep 12',
'prophets birthday': 'nov 21'
};
var holidays$4 = dates$3;
// (lunar year is 354.36 days)
const dayDiff = -10.64;
const lunarDates = function (str, normal, year, tz) {
if (holidays$4.hasOwnProperty(str) || holidays$4.hasOwnProperty(normal)) {
let date = holidays$4[str] || holidays$4[normal] || [];
if (!date) {
return null
}
// start at 2018
let s = main(date + ' 2018', tz);
let diff = year - 2018;
let toAdd = diff * dayDiff;
s = s.add(toAdd, 'day');
s = s.startOf('day');
// now set the correct year
s = s.year(year);
if (s.isValid()) {
return s
}
}
return null
};
var lunarDates$1 = lunarDates;
const nowYear = main.now().year();
const spacetimeHoliday = function (str, year, tz) {
year = year || nowYear;
str = str || '';
str = String(str);
str = str.trim().toLowerCase();
str = str.replace(/'s/, 's'); // 'mother's day'
let normal = str.replace(/ day$/, '');
normal = normal.replace(/^the /, '');
normal = normal.replace(/^orthodox /, ''); //orthodox good friday
// try easier, unmoving holidays
let s = fixedDates$2(str, normal, year, tz);
if (s !== null) {
return s
}
// try 'nth monday' holidays
s = nthWeekday(str, normal, year, tz);
if (s !== null) {
return s
}
// easter-based holidays
s = easterDates$1(str, normal, year, tz);
if (s !== null) {
return s
}
// solar-based holidays
s = astroDates$1(str, normal, year, tz);
if (s !== null) {
return s
}
// mostly muslim holidays
s = lunarDates$1(str, normal, year, tz);
if (s !== null) {
return s
}
return null
};
const parseHoliday = function (doc, context) {
let unit = null;
let m = doc.match('[#Holiday+] [#Year?]');
let year = context.today.year();
if (m.groups('year').found) {
year = Number(m.groups('year').text('reduced')) || year;
}
let str = m.groups('holiday').text('reduced');
let s = spacetimeHoliday(str, year, context.timezone);
if (s !== null) {
// assume the year in the future..
if (s.isBefore(context.today) && year === context.today.year()) {
s = spacetimeHoliday(str, year + 1, context.timezone);
}
unit = new Holiday(s, null, context);
}
return unit
};
const mapping$1 = {
day: Day,
hour: Hour,
evening: Hour,
second: Moment,
milliscond: Moment,
instant: Moment,
minute: Minute,
week: Week,
weekend: WeekEnd,
month: AnyMonth,
quarter: AnyQuarter,
year: Year,
season: Season,
// set aliases
yr: Year,
qtr: AnyQuarter,
wk: Week,
sec: Moment,
hr: Hour,
};
let matchStr = `^(${Object.keys(mapping$1).join('|')})$`;
// when a unit of time is spoken of as 'this month' - instead of 'february'
const nextLast = function (doc, context) {
//this month, last quarter, next year
let m = doc.match(matchStr);
if (m.found === true) {
let str = m.text('reduced');
if (mapping$1.hasOwnProperty(str)) {
let Model = mapping$1[str];
if (!Model) {
return null
}
let unit = new Model(null, str, context);
return unit
}
}
//'next friday, last thursday'
m = doc.match('^#WeekDay$');
if (m.found === true) {
let str = m.text('reduced');
let unit = new WeekDay(str, null, context);
return unit
}
// tuesday next week
// m = doc.match('^#WeekDay (this|next)')
// if (m.found === true) {
// let str = m.text('reduced')
// let unit = new WeekDay(str, null, context)
// return unit
// }
return null
};
const fmtToday = function (context) {
return {
date: context.today.date(),
month: context.today.month(),
year: context.today.year(),
}
};
const parseYearly = function (doc, context) {
// support 'summer 2002'
let m = doc.match('(spring|summer|winter|fall|autumn) [#Year?]');
if (m.found) {
let str = doc.text('reduced');
let s = main(str, context.timezone, { today: fmtToday(context) });
let unit = new Season(s, null, context);
if (unit.d.isValid() === true) {
return unit
}
}
// support 'q4 2020'
m = doc.match('[#FinancialQuarter] [#Year?]');
if (m.found) {
let str = m.groups('q').text('reduced');
let s = main(str, context.timezone, { today: fmtToday(context) });
if (m.groups('year')) {
let year = Number(m.groups('year').text()) || context.today.year();
s = s.year(year);
}
let unit = new Quarter(s, null, context);
if (unit.d.isValid() === true) {
return unit
}
}
// support '4th quarter 2020'
m = doc.match('[#Value] quarter (of|in)? [#Year?]');
if (m.found) {
let q = m.groups('q').text('reduced');
let s = main(`q${q}`, context.timezone, { today: fmtToday(context) });
if (m.groups('year')) {
let year = Number(m.groups('year').text()) || context.today.year();
s = s.year(year);
}
let unit = new Quarter(s, null, context);
if (unit.d.isValid() === true) {
return unit
}
}
// support '2020'
m = doc.match('^#Year$');
if (m.found) {
let str = doc.text('reduced');
let s = main(null, context.timezone, { today: fmtToday(context) });
s = s.year(str);
let unit = new Year(s, null, context);
if (unit.d.isValid() === true) {
return unit
}
}
return null
};
// parse things like 'june 5th 2019'
// most of this is done in spacetime
const parseExplicit = function (doc, context) {
let impliedYear = context.today.year();
// 'fifth of june 1992'
// 'june the fifth 1992'
let m = doc.match('[#Value] of? [#Month] [#Year]');
if (!m.found) {
m = doc.match('[#Month] the? [#Value] [#Year]');
}
if (m.found) {
let obj = {
month: m.groups('month').text('reduced'),
date: m.groups('date').text('reduced'),
year: m.groups('year').text() || impliedYear,
};
let unit = new CalendarDate(obj, null, context);
if (unit.d.isValid() === true) {
return unit
}
}
// 'march 1992'
m = doc.match('[#Month] of? [#Year]');
if (m.found) {
let obj = {
month: m.groups('month').text('reduced'),
year: m.groups('year').text('reduced') || impliedYear,
};
let unit = new Month(obj, null, context);
if (unit.d.isValid() === true) {
return unit
}
}
// 'march 5th next year'
m = doc.match('[#Month] [#Value+]? of? the? [(this|next|last|current)] year');
if (m.found) {
let rel = m.groups('rel').text('reduced');
let year = impliedYear;
if (rel === 'next') {
year += 1;
} else if (rel === 'last') {
year -= 1;
}
let obj = {
month: m.groups('month').text('reduced'),
date: m.groups('date').numbers(0).get()[0],
year,
};
if (obj.date === undefined) {
obj.date = 1;
let unit = new Month(obj, null, context);
if (unit.d.isValid() === true) {
return unit
}
}
let unit = new CalendarDate(obj, null, context);
if (unit.d.isValid() === true) {
return unit
}
}
// '5th of next month'
m = doc.match('^the? [#Value+]? of? [(this|next|last|current)] month');
if (m.found) {
let month = context.today.month();
let rel = m.groups('rel').text('reduced');
if (rel === 'next') {
month += 1;
} else if (rel === 'last') {
month -= 1;
}
let obj = {
month,
date: m.groups('date').numbers(0).get()[0],
};
let unit = new CalendarDate(obj, null, context);
if (unit.d.isValid() === true) {
return unit
}
}
//no-years
// 'fifth of june'
m = doc.match('[#Value] of? [#Month]');
// 'june the fifth'
if (!m.found) {
m = doc.match('[#Month] the? [#Value]');
}
if (m.found) {
let obj = {
month: m.groups('month').text('reduced'),
date: m.groups('date').text('reduced'),
year: context.today.year(),
};
let unit = new CalendarDate(obj, null, context);
// assume 'feb' in the future
if (unit.d.month() < context.today.month()) {
obj.year += 1;
unit = new CalendarDate(obj, null, context);
}
if (unit.d.isValid() === true) {
return unit
}
}
// support 'december'
if (doc.has('#Month')) {
let obj = {
month: doc.match('#Month').text('reduced'),
date: 1, //assume 1st
year: context.today.year(),
};
let unit = new Month(obj, null, context);
// assume 'february' is always in the future
if (unit.d.month() < context.today.month()) {
obj.year += 1;
unit = new Month(obj, null, context);
}
if (unit.d.isValid() === true) {
return unit
}
}
// support 'thursday 21st'
m = doc.match('#WeekDay [#Value]');
if (m.found) {
let obj = {
month: context.today.month(),
date: m.groups('date').text('reduced'),
year: context.today.year(),
};
let unit = new CalendarDate(obj, null, context);
if (unit.d.isValid() === true) {
return unit
}
}
// support date-only 'the 21st'
m = doc.match('the [#Value]');
if (m.found) {
let obj = {
month: context.today.month(),
date: m.groups('date').text('reduced'),
year: context.today.year(),
};
let unit = new CalendarDate(obj, null, context);
if (unit.d.isValid() === true) {
// assume it's forward
if (unit.d.isBefore(context.today)) {
unit.d = unit.d.add(1, 'month');
}
return unit
}
}
// parse ISO as a Moment
m = doc.match('/[0-9]{4}-[0-9]{2}-[0-9]{2}t[0-9]{2}:/');
if (m.found) {
let str = doc.text('reduced');
let unit = new Moment(str, null, context);
if (unit.d.isValid() === true) {
return unit
}
}
let str = doc.text('reduced');
if (!str) {
return new Moment(context.today, null, context)
}
// punt it to spacetime, for the heavy-lifting
let unit = new Day(str, null, context);
// console.log(str, unit, context.today.year())
// did we find a date?
if (unit.d.isValid() === false) {
return null
}
return unit
};
const parse$3 = function (doc, context, parts) {
let unit = null;
//'in two days'
unit = unit || today(doc, context, parts);
// 'this haloween'
unit = unit || parseHoliday(doc, context);
// 'this month'
unit = unit || nextLast(doc, context);
// 'q2 2002'
unit = unit || parseYearly(doc, context);
// 'this june 2nd'
unit = unit || parseExplicit(doc, context);
return unit
};
const units = {
day: Day,
week: Week,
weekend: WeekEnd,
month: Month,
quarter: Quarter,
season: Season,
hour: Hour,
minute: Minute,
};
const applyCounter = function (unit, counter = {}) {
let Unit = units[counter.unit];
if (!Unit) {
return unit
}
let d = unit.d;
// support 'first' or 0th
if (counter.dir === 'first' || counter.num === 0) {
d = unit.start().d;
d = d.startOf(counter.unit);
} else if (counter.dir === 'last') {
d = d.endOf(unit.unit);
if (counter.unit === 'weekend') {
d = d.day('saturday', false);
} else {
d = d.startOf(counter.unit);
}
} else if (counter.num) {
if (counter.unit === 'weekend') {
d = d.day('saturday', true).add(1, 'day'); //fix bug
}
// support 'nth week', eg.
d = d.add(counter.num, counter.unit);
}
let u = new Unit(d, null, unit.context);
if (u.d.isValid() === true) {
return u
}
return unit //fallback
};
// apply all parsed {parts} to our unit date
const transform = function (unit, context, parts) {
if (!unit && parts.weekDay) {
unit = new WeekDay(parts.weekDay, null, context);
parts.weekDay = null;
}
// just don't bother
if (!unit) {
return null
}
// 2 days after..
if (parts.shift) {
let shift = parts.shift;
unit.applyShift(shift);
// allow shift to change our unit size
if (shift.hour || shift.minute) {
unit = new Moment(unit.d, null, unit.context);
} else if (shift.week || shift.day || shift.month) {
unit = new Day(unit.d, null, unit.context);
}
}
// wednesday next week
if (parts.weekDay && unit.unit !== 'day') {
unit.applyWeekDay(parts.weekDay);
unit = new WeekDay(unit.d, null, unit.context);
}
// this/next/last
if (parts.rel) {
unit.applyRel(parts.rel);
}
// end of
if (parts.section) {
unit.applySection(parts.section);
}
// at 5:40pm
if (parts.time) {
unit.applyTime(parts.time);
// unit = new Minute(unit.d, null, unit.context)
}
// apply counter
if (parts.counter && parts.counter.unit) {
unit = applyCounter(unit, parts.counter);
}
return unit
};
// import spacetime from 'spacetime'
const env$1 = typeof process === 'undefined' || !process.env ? self.env || {} : process.env;
const log$1 = parts => {
if (env$1.DEBUG_DATE) {
// console.log(parts)// eslint-disable-line
console.log(`\n==== '${parts.doc.text()}' =====`); // eslint-disable-line
Object.keys(parts).forEach(k => {
if (k !== 'doc' && parts[k]) {
console.log(k, parts[k]); // eslint-disable-line
}
});
parts.doc.debug(); // allow
}
};
const parseDate = function (doc, context) {
//parse-out any sections
let parts = tokenize(doc, context);
doc = parts.doc;
// logger
log$1(parts);
//apply our given timezone
if (parts.tz) {
context = Object.assign({}, context, { timezone: parts.tz });
// set timezone on any 'today' value, too
let iso = context.today.format('iso-short');
context.today = context.today.goto(context.timezone).set(iso);
}
// decide on a root date object
let unit = parse$3(doc, context, parts);
// apply all our parts
unit = transform(unit, context, parts);
return unit
};
const dayNames = {
mon: 'monday',
tue: 'tuesday',
tues: 'wednesday',
wed: 'wednesday',
thu: 'thursday',
fri: 'friday',
sat: 'saturday',
sun: 'sunday',
monday: 'monday',
tuesday: 'tuesday',
wednesday: 'wednesday',
thursday: 'thursday',
friday: 'friday',
saturday: 'saturday',
sunday: 'sunday',
};
// 'any tuesday' vs 'every tuesday'
const parseLogic = function (m) {
if (m.match('(every|each)').found) {
return 'AND'
}
if (m.match('(any|a)').found) {
return 'OR'
}
return null
};
// parse repeating dates, like 'every week'
const parseIntervals = function (doc, context) {
// 'every week'
let m = doc.match('[(every|any|each)] [other?] [#Duration] (starting|beginning|commencing)?');
if (m.found) {
let repeat = { interval: {} };
let unit = m.groups('unit').text('reduced');
repeat.interval[unit] = 1;
repeat.choose = parseLogic(m);
// 'every other week'
if (m.groups('skip').found) {
repeat.interval[unit] = 2;
}
doc = doc.remove(m);
return { repeat: repeat }
}
// 'every two weeks'
m = doc.match('[(every|any|each)] [#Value] [#Duration] (starting|beginning|commencing)?');
if (m.found) {
let repeat = { interval: {} };
let units = m.groups('unit');
units.nouns().toSingular();
let unit = units.text('reduced');
repeat.interval[unit] = m.groups('num').numbers().get()[0];
repeat.choose = parseLogic(m);
doc = doc.remove(m);
return { repeat: repeat }
}
// 'every friday'
m = doc.match('[(every|any|each|a)] [other?] [#WeekDay+] (starting|beginning|commencing)?');
if (m.found) {
let repeat = { interval: { day: 1 }, filter: { weekDays: {} } };
let str = m.groups('day').text('reduced');
str = dayNames[str]; //normalize it
if (str) {
repeat.filter.weekDays[str] = true;
repeat.choose = parseLogic(m);
doc = doc.remove(m);
return { repeat: repeat }
}
}
// 'every weekday'
m = doc.match(
'[(every|any|each|a)] [(weekday|week day|weekend|weekend day)] (starting|beginning|commencing)?'
);
if (m.found) {
let repeat = { interval: { day: 1 }, filter: { weekDays: {} } };
let day = m.groups('day');
if (day.has('(weekday|week day)')) {
repeat.filter.weekDays = {
monday: true,
tuesday: true,
wednesday: true,
thursday: true,
friday: true,
};
} else if (day.has('(weekend|weekend day)')) {
repeat.filter.weekDays = {
saturday: true,
sunday: true,
};
}
repeat.choose = parseLogic(m);
doc = doc.remove(m);
return { repeat: repeat }
}
// mondays
m = doc.match(
'[(mondays|tuesdays|wednesdays|thursdays|fridays|saturdays|sundays)] (at|near|after)? [#Time+?]'
);
if (m.found) {
let repeat = { interval: { day: 1 }, filter: { weekDays: {} } };
let str = m.groups('day').text('reduced');
str = str.replace(/s$/, '');
str = dayNames[str]; //normalize it
if (str) {
repeat.filter.weekDays[str] = true;
repeat.choose = 'OR';
doc = doc.remove(m);
let time = m.groups('time');
if (time.found) {
repeat.time = parseTime(time, context);
}
return { repeat: repeat }
}
}
return null
};
// somewhat-intellegent response to end-before-start situations
const reverseMaybe = function (obj) {
let start = obj.start;
let end = obj.end;
if (start.d.isAfter(end.d)) {
// wednesday to sunday -> move end up a week
if (start.isWeekDay && end.isWeekDay) {
obj.end.next();
return obj
}
// else, reverse them
let tmp = start;
obj.start = end;
obj.end = tmp;
}
return obj
};
const moveToPM = function (obj) {
let start = obj.start;
let end = obj.end;
if (start.d.isAfter(end.d)) {
if (end.d.hour() < 10) {
end.d = end.d.ampm('pm');
}
}
return obj
};
var doTwoTimes = [
{
// '3pm to 4pm january 5th'
match: '[#Time+] (to|until|upto|through|thru|and) [#Time+ #Date+]',
desc: '3pm to 4pm january 5th',
parse: (m, context) => {
let from = m.groups('from');
let to = m.groups('to');
let end = parseDate(to, context);
if (end) {
let start = end.clone();
start.applyTime(from.text('implicit'));
if (start) {
let obj = {
start: start,
end: end,
unit: 'time',
};
if (/(am|pm)/.test(to) === false) {
obj = moveToPM(obj);
}
obj = reverseMaybe(obj);
return obj
}
}
return null
},
},
{
// 'january from 3pm to 4pm'
match: '[#Date+] from [#Time] (to|until|upto|through|thru|and) [#Time+]',
desc: 'january from 3pm to 4pm',
parse: (m, context) => {
let main = m.groups('main');
let a = m.groups('a');
let b = m.groups('b');
main = parseDate(main, context);
if (main) {
main.applyTime(a.text('implicit'));
let end = main.clone();
end.applyTime(b.text('implicit'));
if (end) {
let obj = {
start: main,
end: end,
unit: 'time',
};
if (/(am|pm)/.test(b.text()) === false) {
obj = moveToPM(obj);
}
obj = reverseMaybe(obj);
return obj
}
}
return null
},
},
{
// 'january 5th 3pm to 4pm'
match: '[#Date+] (to|until|upto|through|thru|and) [#Time+]',
desc: 'january from 3pm to 4pm',
parse: (m, context) => {
let from = m.groups('from');
let to = m.groups('to');
from = parseDate(from, context);
if (from) {
let end = from.clone();
end.applyTime(to.text('implicit'));
if (end) {
let obj = {
start: from,
end: end,
unit: 'time',
};
if (/(am|pm)/.test(to.text()) === false) {
obj = moveToPM(obj);
}
obj = reverseMaybe(obj);
return obj
}
}
return null
},
},
];
// these are dates that produce two seperate dates,
// and not a start-end range.
var doCombos = [
{
// 'jan, or march 1999'
match: '^during? #Month+ (or|and) #Month [#Year]?',
desc: 'march or june',
parse: (m, context) => {
let before = m.match('^during? [#Month]', 0);
m = m.not('(or|and)');
let start = parseDate(before, context);
if (start) {
let result = [
{
start: start,
end: start.clone().end(),
unit: start.unit,
},
];
// add more run-on numbers?
let more = m.not(before);
if (more.found) {
more.match('#Month').forEach((month) => {
let s = parseDate(month, context);
// s.d = s.d.month(month.text('reduced'))
result.push({
start: s,
end: s.clone().end(),
unit: s.unit,
});
});
}
// apply the year
let year = m.match('#Year$');
if (year.found) {
year = year.text('reduced');
result.forEach((o) => {
o.start.d = o.start.d.year(year);
o.end.d = o.end.d.year(year);
});
}
return result
}
return null
},
},
{
// 'jan 5 or 8' - (one month, shared dates)
match: '^#Month #Value+ (or|and)? #Value$',
desc: 'jan 5 or 8',
parse: (m, context) => {
m = m.not('(or|and)');
let before = m.match('^#Month #Value');
let start = parseDate(before, context);
if (start) {
let result = [
{
start: start,
end: start.clone().end(),
unit: start.unit,
},
];
// add more run-on numbers?
let more = m.not(before);
if (more.found) {
more.match('#Value').forEach((v) => {
let s = start.clone();
s.d = s.d.date(v.text('reduced'));
result.push({
start: s,
end: s.clone().end(),
unit: s.unit,
});
});
}
return result
}
return null
},
},
{
// 'jan 5, 8' - (similar to above)
match: '^#Month+ #Value #Value+$',
desc: 'jan 5 8',
parse: (m, context) => {
let month = m.match('#Month');
let year = m.match('#Year');
m = m.not('#Year');
let results = [];
m.match('#Value').forEach((val) => {
val = val.clone();
let d = val.prepend(month.text());
if (year.found) {
d.append(year);
}
let start = parseDate(d, context);
if (start) {
results.push({
start: start,
end: start.clone().end(),
unit: start.unit,
});
}
});
return results
},
},
{
// '5 or 8 of jan' - (one month, shared dates)
match: '^#Value+ (or|and)? #Value of #Month #Year?$',
desc: '5 or 8 of Jan',
parse: (m, context) => {
let month = m.match('#Month');
let year = m.match('#Year');
m = m.not('#Year');
let results = [];
m.match('#Value').forEach((val) => {
let d = val.append(month);
if (year.found) {
d.append(year);
}
let start = parseDate(d, context);
if (start) {
results.push({
start: start,
end: start.clone().end(),
unit: start.unit,
});
}
});
return results
},
},
{
// 'june or july 2019'
match: '^!(between|from|during)? [#Date+] (and|or) [#Date+]$',
desc: 'A or B',
parse: (m, context) => {
let fromDoc = m.groups('from');
let toDoc = m.groups('to');
let from = parseDate(fromDoc, context);
let to = parseDate(toDoc, context);
if (from && to) {
return [
{
start: from,
end: from.clone().end(),
},
{
start: to,
end: to.clone().end(),
},
]
}
return null
},
},
];
var doDateRange = [
{
// month-ranges have some folksy rules
match: 'between [#Month] and [#Month] [#Year?]',
desc: 'between march and jan',
parse: (m, context) => {
let { start, end, year } = m.groups();
let y = year && year.found ? Number(year.text('reduced')) : context.today.year();
let obj = { month: start.text('reduced'), year: y };
let left = new Month(obj, null, context).start();
obj = { month: end.text('reduced'), year: y };
let right = new Month(obj, null, context).start();
if (left.d.isAfter(right.d)) {
return {
start: right,
end: left,
}
}
return {
start: left,
end: right,
}
},
},
{
// two explicit dates - 'between friday and sunday'
match: 'between [.+] and [.+]',
desc: 'between friday and sunday',
parse: (m, context) => {
let start = m.groups('start');
start = parseDate(start, context);
let end = m.groups('end');
end = parseDate(end, context);
if (start && end) {
end = end.before();
return {
start: start,
end: end,
}
}
return null
},
},
{
// two months, no year - 'june 5 to june 7'
match: '[#Month #Value] (to|through|thru) [#Month #Value] [#Year?]',
desc: 'june 5 to june 7',
parse: (m, context) => {
let res = m.groups();
let start = res.from;
if (res.year) {
start = start.append(res.year);
}
start = parseDate(start, context);
if (start) {
let end = res.to;
if (res.year) {
end = end.append(res.year);
}
end = parseDate(end, context);
if (end) {
// assume end is after start
if (start.d.isAfter(end.d)) {
end.d = end.d.add(1, 'year');
}
let obj = {
start: start,
end: end.end(),
};
return obj
}
}
return null
},
},
{
// one month, one year, first form - 'january 5 to 7 1998'
match: '[#Month] [#Value] (to|through|thru) [#Value] of? [#Year]',
desc: 'january 5 to 7 1998',
parse: (m, context) => {
let { month, from, to, year } = m.groups();
let year2 = year.clone();
let start = from.prepend(month).append(year);
start = parseDate(start, context);
if (start) {
let end = to.prepend(month).append(year2);
end = parseDate(end, context);
return {
start: start,
end: end.end(),
}
}
return null
},
},
{
// one month, one year, second form - '5 to 7 of january 1998'
match: '[#Value] (to|through|thru) [#Value of? #Month #Date+?]',
desc: '5 to 7 of january 1998',
parse: (m, context) => {
let to = m.groups('to');
to = parseDate(to, context);
if (to) {
let fromDate = m.groups('from');
let from = to.clone();
from.d = from.d.date(fromDate.text('implicit'));
return {
start: from,
end: to.end(),
}
}
return null
},
},
{
// one month, no year - 'january 5 to 7'
match: '[#Month #Value] (to|through|thru) [#Value]',
desc: 'january 5 to 7',
parse: (m, context) => {
let from = m.groups('from');
from = parseDate(from, context);
if (from) {
let toDate = m.groups('to');
let to = from.clone();
to.d = to.d.date(toDate.text('implicit'));
return {
start: from,
end: to.end(),
}
}
return null
},
},
{
// 'january to may 2020'
match: 'from? [#Month] (to|until|upto|through|thru) [#Month] [#Year]',
desc: 'january to may 2020',
parse: (m, context) => {
let from = m.groups('from');
let year = m.groups('year').numbers().get()[0];
let to = m.groups('to');
from = parseDate(from, context);
to = parseDate(to, context);
from.d = from.d.year(year);
to.d = to.d.year(year);
if (from && to) {
let obj = {
start: from,
end: to.end(),
};
// reverse the order?
obj = reverseMaybe(obj);
return obj
}
return null
},
},
{
// in 2 to 4 weeks
match: '^in [#Value] to [#Value] [(days|weeks|months|years)]',
desc: 'in 2 to 4 weeks',
parse: (m, context) => {
const { min, max, unit } = m.groups();
let start = new CalendarDate(context.today, null, context);
let end = start.clone();
const duration = unit.text('implicit');
start = start.applyShift({ [duration]: min.numbers().get()[0] });
end = end.applyShift({ [duration]: max.numbers().get()[0] });
return {
start: start,
end: end.end(),
}
},
},
{
// 2 to 4 weeks ago
match:
'[#Value] to [#Value] [(days|weeks|months|years)] (ago|before|earlier|prior)',
desc: '2 to 4 weeks ago',
parse: (m, context) => {
const { min, max, unit } = m.groups();
let start = new CalendarDate(context.today, null, context);
let end = start.clone();
const duration = unit.text('implicit');
start = start.applyShift({ [duration]: -max.numbers().get()[0] });
end = end.applyShift({ [duration]: -min.numbers().get()[0] });
return {
start: start,
end: end.end(),
}
},
},
{
// implicit range
match: '^until [#Date+]',
desc: 'until christmas',
parse: (m, context) => {
let to = m.groups('to');
to = parseDate(to, context);
if (to) {
let start = new CalendarDate(context.today, null, context);
return {
start: start,
end: to.start(),
}
}
return null
},
},
{
// second half of march
match: '[(1st|initial|2nd|latter)] half of [#Month] [#Year?]',
desc: 'second half of march',
parse: (m, context) => {
const { part, month, year } = m.groups();
let obj = {
month: month.text('reduced'),
date: 1, //assume 1st
year: year && year.found ? year.text('reduced') : context.today.year()
};
let unit = new Month(obj, null, context);
if (part.has('(1st|initial)')) {
return {
start: unit.start(),
end: unit.clone().middle(),
}
}
return {
start: unit.middle(),
end: unit.clone().end(),
}
},
},
];
const punt = function (unit, context) {
unit = unit.applyShift(context.punt);
return unit
};
var doOneDate = [
{
// 'from A to B'
match: 'from? [.+] (to|until|upto|through|thru) [.+]',
desc: 'from A to B',
parse: (m, context) => {
let from = m.groups('from');
let to = m.groups('to');
from = parseDate(from, context);
to = parseDate(to, context);
if (from && to) {
let obj = {
start: from,
end: to.end(),
};
obj = reverseMaybe(obj);
return obj
}
return null
},
},
{
// 'before june'
match: '^due? (by|before) [.+]',
desc: 'before june',
parse: (m, context) => {
m = m.group(0);
let unit = parseDate(m, context);
if (unit) {
let start = new Unit(context.today, null, context);
if (start.d.isAfter(unit.d)) {
start = unit.clone().applyShift({ weeks: -2 });
}
// end the night before
let end = unit.clone().applyShift({ day: -1 });
return {
start: start,
end: end.end(),
}
}
return null
},
},
{
// 'in june'
match: '^(on|in|at|@|during) [.+]',
desc: 'in june',
parse: (m, context) => {
m = m.group(0);
let unit = parseDate(m, context);
if (unit) {
return { start: unit, end: unit.clone().end(), unit: unit.unit }
}
return null
},
},
{
// 'after june'
match: '^(after|following) [.+]',
desc: 'after june',
parse: (m, context) => {
m = m.group(0);
let unit = parseDate(m, context);
if (unit) {
unit = unit.after();
return {
start: unit.clone(),
end: punt(unit.clone(), context),
}
}
return null
},
},
{
// 'middle of'
match: '^(middle|center|midpoint) of [.+]',
desc: 'middle of',
parse: (m, context) => {
m = m.group(0);
let unit = parseDate(m, context);
let start = unit.clone().middle();
let end = unit.beforeEnd();
if (unit) {
return {
start: start,
end: end,
}
}
return null
},
},
{
// 'tuesday after 5pm'
match: '.+ after #Time+$',
desc: 'tuesday after 5pm',
parse: (m, context) => {
let unit = parseDate(m, context);
if (unit) {
let start = unit.clone();
let end = unit.end();
return {
start: start,
end: end,
unit: 'time',
}
}
return null
},
},
{
// 'tuesday before noon'
match: '.+ before #Time+$',
desc: 'tuesday before noon',
parse: (m, context) => {
let unit = parseDate(m, context);
if (unit) {
let end = unit.clone();
let start = unit.start();
if (unit) {
return {
start: start,
end: end,
unit: 'time',
}
}
}
return null
},
},
];
const ranges = [].concat(doTwoTimes, doCombos, doDateRange, doOneDate);
const env = typeof process === 'undefined' || !process.env ? self.env || {} : process.env;
const log = msg => {
if (env.DEBUG_DATE) {
console.log(`\n \x1b[32m ${msg} \x1b[0m`); // eslint-disable-line
}
};
const isArray = function (arr) {
return Object.prototype.toString.call(arr) === '[object Array]'
};
//else, try whole thing, non ranges
const tryFull = function (doc, context) {
let res = {
start: null,
end: null,
};
if (!doc.found) {
return res
}
let unit = parseDate(doc, context);
if (unit) {
let end = unit.clone().end();
res = {
start: unit,
end: end,
unit: unit.setTime ? 'time' : unit.unit,
};
}
return res
};
const tryRanges = function (doc, context) {
// try each template in order
for (let i = 0; i < ranges.length; i += 1) {
let fmt = ranges[i];
let m = doc.match(fmt.match);
if (m.found) {
log(` ---[${fmt.desc}]---`);
let res = fmt.parse(m, context);
if (res !== null) {
// did it return more than one date?
if (!isArray(res)) {
res = [res];
}
return res
}
}
}
return null
};
// loop thru each range template
const parseRanges = function (m, context) {
// parse-out 'every week ..'
let repeats = parseIntervals(m, context) || {};
// try picking-apart ranges
let found = tryRanges(m, context);
if (!found) {
found = [tryFull(m, context)];
}
// add the repeat info to each date
found = found.map((o) => Object.assign({}, repeats, o));
// ensure start is not after end
found.forEach((res) => {
if (res.start && res.end && res.start.d.epoch > res.end.d.epoch) {
res.start = res.start.start();
}
});
return found
};
const normalize$1 = function (doc) {
if (!doc.numbers) {
console.warn(`\nCompromise warning: compromise/three must be used with compromise-dates plugin\n`); // eslint-disable-line
}
// normalize doc
doc = doc.clone();
doc.numbers().toNumber();
// expand 'aug 20-21'
doc.contractions().expand();
// 'week-end'
doc.replace('week end', 'weekend', true).tag('Date');
// 'a up to b'
doc.replace('up to', 'upto', true).tag('Date');
// 'a year ago'
if (doc.has('once (a|an) #Duration') === false) {
doc.match('[(a|an)] #Duration', 0).replaceWith('1', { tags: true }).compute('lexicon');
}
// jan - feb
doc.match('@hasDash').insertAfter('to').tag('Date');
return doc
};
const parse$2 = function (doc, context) {
// normalize context
context = context || {};
if (context.timezone === false) {
context.timezone = 'UTC';
}
context.today = context.today || main.now(context.timezone);
context.today = main(context.today, context.timezone);
doc = normalize$1(doc);
let res = parseRanges(doc, context);
return res
};
const getDuration = function (range) {
let end = range.end.d.add(1, 'millisecond');
let diff = end.since(range.start.d).diff;
delete diff.milliseconds;
delete diff.seconds;
return diff
};
const toJSON = function (range) {
if (!range.start) {
return {
start: null,
end: null,
timezone: null,
duration: {},
// range: null
}
}
let diff = range.end ? getDuration(range) : {};
return {
start: range.start.format('iso'),
end: range.end ? range.end.format('iso') : null,
timezone: range.start.d.format('timezone'),
duration: diff,
// range: getRange(diff)
}
};
const quickDate = function (view, str) {
let tmp = view.fromText(str);
let found = parse$2(tmp, view.opts)[0];
if (!found || !found.start || !found.start.d) {
return null
}
return found.start.d
};
const api$2 = function (View) {
class Dates extends View {
constructor(document, pointer, groups, opts = {}) {
super(document, pointer, groups);
this.viewType = 'Dates';
this.opts = Object.assign({}, opts);
}
get(n) {
let all = [];
this.forEach(m => {
parse$2(m, this.opts).forEach(res => {
let json = toJSON(res);
if (json.start) {
all.push(json);
}
});
});
if (typeof n === 'number') {
return all[n]
}
return all
}
json(opts = {}) {
return this.map(m => {
let json = m.toView().json(opts)[0] || {};
if (opts && opts.dates !== false) {
let parsed = parse$2(m, this.opts);
if (parsed.length > 0) {
json.dates = toJSON(parsed[0]);
}
}
return json
}, [])
}
/** replace date terms with a formatted date */
format(fmt) {
let found = this;
let res = found.map(m => {
let obj = parse$2(m, this.opts)[0] || {};
if (obj.start) {
let start = obj.start.d;
let str = start.format(fmt);
if (obj.end) {
let end = obj.end.d;
if (start.isSame(end, 'day') === false) {
str += ' to ' + end.format(fmt);
}
}
m.replaceWith(str);
}
return m
});
return new Dates(this.document, res.pointer, null, this.opts)
}
/** return only dates occuring before a given date */
isBefore(iso) {
let pivot = quickDate(this, iso);
return this.filter(m => {
let obj = parse$2(m, this.opts)[0] || {};
return obj.start && obj.start.d && obj.start.d.isBefore(pivot)
})
}
/** return only dates occuring after a given date */
isAfter(iso) {
let pivot = quickDate(this, iso);
return this.filter(m => {
let obj = parse$2(m, this.opts)[0] || {};
return obj.start && obj.start.d && obj.start.d.isAfter(pivot)
})
}
/** return only dates occuring after a given date */
isSame(unit, iso) {
let pivot = quickDate(this, iso);
return this.filter(m => {
let obj = parse$2(m, this.opts)[0] || {};
return obj.start && obj.start.d && obj.start.d.isSame(pivot, unit)
})
}
}
View.prototype.dates = function (opts) {
let m = findDate(this);
return new Dates(this.document, m.pointer, null, opts)
};
};
const normalize = function (doc) {
doc = doc.clone();
// 'four thirty' -> 4:30
let m = doc.match('#Time+').match('[#Cardinal] [(thirty|fifteen)]');
if (m.found) {
let hour = m.groups('hour');
let min = m.groups('min');
let num = hour.values().get()[0];
if (num > 0 && num <= 12) {
let mins = min.values().get()[0];
let str = `${num}:${mins}`;
m.replaceWith(str);
}
}
if (!doc.numbers) {
console.warn(`Warning: compromise .numbers() not loaded.\n This plugin requires >= v14`); //eslint-disable-line
} else {
// doc.numbers().normalize()
// convert 'two' to 2
let num = doc.numbers();
num.toNumber();
num.toCardinal(false);
}
// expand 'aug 20-21'
if (doc.contractions) {
doc.contractions().expand();
}
// remove adverbs
doc.adverbs().remove();
// 'week-end'
doc.replace('week end', 'weekend', true).tag('Date');
// 'a up to b'
doc.replace('up to', 'upto', true).tag('Date');
// 'a year ago'
if (doc.has('once (a|an) #Duration') === false) {
doc.match('[(a|an)] #Duration', 0).replaceWith('1').compute('lexicon');
// tagger(doc)
}
// 'in a few years'
// m = doc.match('in [a few] #Duration')
// if (m.found) {
// m.groups('0').replaceWith('2')
// tagger(doc)
// }
// jan - feb
doc.match('@hasDash').insertAfter('to').tag('Date');
return doc
};
const find = function (doc) {
return doc.match('#Time+ (am|pm)?')
};
const parse$1 = function (m, context = {}) {
m = normalize(m);
let res = parseTime(m, context);
if (!res.result) {
return { time: null, '24h': null }
}
let s = main.now().time(res.result);
return {
time: res.result,
'24h': s.format('time-24'),
hour: s.hour(),
minute: s.minute(),
}
};
const getNth = (doc, n) => (typeof n === 'number' ? doc.eq(n) : doc);
const api$1 = function (View) {
class Times extends View {
constructor(document, pointer, groups, opts) {
super(document, pointer, groups);
this.viewType = 'Times';
this.opts = opts || {};
}
format(fmt) {
let found = this;
let res = found.map(m => {
let obj = parse$1(m) || {};
if (obj.time) {
let s = main.now().time(obj.time);
let str = obj.time;
if (fmt === '24h') {
str = s.format('time-24');
} else {
str = s.format(fmt);
}
m = m.not('#Preposition');
m.replaceWith(str);
}
return m
});
return new Times(this.document, res.pointer, null, this.opts)
}
get(n) {
return getNth(this, n).map(parse$1)
}
json(opts = {}) {
return this.map(m => {
let json = m.toView().json(opts)[0] || {};
if (opts && opts.time !== false) {
json.time = parse$1(m);
}
return json
}, [])
}
}
View.prototype.times = function (n) {
let m = find(this);
m = getNth(m, n);
return new Times(this.document, m.pointer)
};
};
const known = {
century: true,
day: true,
decade: true,
hour: true,
millisecond: true,
minute: true,
month: true,
second: true,
weekend: true,
week: true,
year: true,
quarter: true,
season: true,
};
let mapping = {
m: 'minute',
h: 'hour',
hr: 'hour',
min: 'minute',
sec: 'second',
'week end': 'weekend',
wk: 'week',
yr: 'year',
qtr: 'quarter',
};
// add plurals
Object.keys(mapping).forEach((k) => {
mapping[k + 's'] = mapping[k];
});
const parse = function (doc) {
let duration = {};
//parse '8 minutes'
let twoWord = doc.match('#Value+ #Duration');
if (twoWord.found) {
twoWord.forEach((m) => {
let num = m.numbers().get()[0];
let unit = m.terms().last().text('reduced');
unit = unit.replace(/ies$/, 'y');
unit = unit.replace(/s$/, '');
// turn 'mins' into 'minute'
if (mapping.hasOwnProperty(unit)) {
unit = mapping[unit];
}
if (known.hasOwnProperty(unit) && num !== null) {
duration[unit] = num;
}
});
} else {
let oneWord = doc.match('(#Duration && /[0-9][a-z]+$/)');
if (oneWord.found) {
let str = doc.text();
let num = str.match(/([0-9]+)/);
let unit = str.match(/([a-z]+)/);
if (num && unit) {
num = num[0] || null;
unit = unit[0] || null;
if (mapping.hasOwnProperty(unit)) {
unit = mapping[unit];
}
if (known.hasOwnProperty(unit) && num !== null) {
duration[unit] = Number(num);
}
}
}
}
return duration
};
const addDurations = function (View) {
/** phrases like '2 months', or '2mins' */
class Durations extends View {
constructor(document, pointer, groups) {
super(document, pointer, groups);
this.context = {};
}
/** overload the original json with duration information */
json(opts = {}) {
return this.map(m => {
let json = m.toView().json(opts)[0] || {};
if (opts && opts.duration !== false) {
json.duration = parse(m);
}
return json
}, [])
}
/** easy getter for the time */
get(options) {
let arr = [];
this.forEach(doc => {
let res = parse(doc);
arr.push(res);
});
if (typeof options === 'number') {
return arr[options]
}
return arr
}
}
/** phrases like '2 months' */
View.prototype.durations = function (n) {
let m = this.match('#Value+ #Duration (and? #Value+ #Duration)?');
// not 'in 20 minutes'
m = m.notIf('#DateShift');
if (typeof n === 'number') {
m = m.eq(n);
}
return new Durations(this.document, m.pointer)
};
};
const api = function (View) {
api$2(View);
api$1(View);
addDurations(View);
};
//ambiguous 'may' and 'march'
// const preps = '(in|by|before|during|on|until|after|of|within|all)' //6
// const thisNext = '(last|next|this|previous|current|upcoming|coming)' //2
const sections$1 = '(start|end|middle|starting|ending|midpoint|beginning)'; //2
// const seasons = '(spring|summer|winter|fall|autumn)'
//ensure a year is approximately typical for common years
//please change in one thousand years
const tagYear = (m, reason) => {
if (m.found !== true) {
return
}
m.forEach((p) => {
let str = p.text('reduced');
let num = parseInt(str, 10);
if (num && num > 1000 && num < 3000) {
p.tag('Year', reason);
}
});
};
//same, but for less-confident values
const tagYearSafe = (m, reason) => {
if (m.found !== true) {
return
}
m.forEach((p) => {
let str = p.text('reduced');
let num = parseInt(str, 10);
if (num && num > 1900 && num < 2030) {
p.tag('Year', reason);
}
});
};
const tagDates = function (doc) {
doc
.match('(march|april|may) (and|to|or|through|until)? (march|april|may)')
.tag('Date')
.match('(march|april|may)')
.tag('Month', 'march|april|may');
// april should almost-always be a date
// doc.match('[april] !#LastName?', 0).tag('Month', 'april')
//year/cardinal tagging
let cardinal = doc.if('#Cardinal');
if (cardinal.found === true) {
let v = cardinal.match(`#Date #Value [#Cardinal]`, 0);
tagYear(v, 'date-value-year');
//scoops up a bunch
v = cardinal.match(`#Date [#Cardinal]`, 0);
tagYearSafe(v, 'date-year');
//middle of 1999
v = cardinal.match(`${sections$1} of [#Cardinal]`);
tagYearSafe(v, 'section-year');
//feb 8 2018
v = cardinal.match(`#Month #Value [#Cardinal]`, 0);
tagYear(v, 'month-value-year');
//feb 8 to 10th 2018
v = cardinal.match(`#Month #Value to #Value [#Cardinal]`, 0);
tagYear(v, 'month-range-year');
//in 1998
v = cardinal.match(`(in|of|by|during|before|starting|ending|for|year|since) [#Cardinal]`, 0);
tagYear(v, 'in-year-1');
//q2 2009
v = cardinal.match('(q1|q2|q3|q4) [#Cardinal]', 0);
tagYear(v, 'in-year-2');
//2nd quarter 2009
v = cardinal.match('#Ordinal quarter of? [#Cardinal]', 0);
tagYear(v, 'in-year-3');
//in the year 1998
v = cardinal.match('the year [#Cardinal]', 0);
tagYear(v, 'in-year-4');
//it was 1998
v = cardinal.match('it (is|was) [#Cardinal]', 0);
tagYearSafe(v, 'in-year-5');
// re-tag this part
cardinal.match(`${sections$1} of #Year`).tag('Date');
//between 1999 and 1998
let m = cardinal.match('between [#Cardinal] and [#Cardinal]');
tagYear(m.groups('0'), 'between-year-and-year-1');
tagYear(m.groups('1'), 'between-year-and-year-2');
}
//'2020' bare input
let m = doc.match('^/^20[012][0-9]$/$');
tagYearSafe(m, '2020-ish');
return doc
};
// 3-4 can be a time-range, sometimes
const tagTimeRange = function (m, reason) {
if (m.found) {
m.tag('Date', reason);
let nums = m.numbers().lessThan(31).ifNo('#Year');
nums.tag('#Time', reason);
}
};
//
const timeTagger = function (doc) {
let date = doc.if('#Date');
if (date.found) {
// ==time-ranges=
// --number-ranges--
let range = date.if('#NumberRange');
if (range.found) {
// 3-4 on tuesday
let m = range.match('[#NumberRange+] (on|by|at)? #WeekDay', 0);
tagTimeRange(m, '3-4-tuesday');
// 3-4 on march 2nd
m = range.match('[#NumberRange+] (on|by|at)? #Month #Value', 0);
tagTimeRange(m, '3-4 mar 3');
// 3-4pm
m = range.match('[#NumberRange] to (#NumberRange && #Time)', 0);
tagTimeRange(m, '3-4pm');
// 3pm-5
m = range.match('(#NumberRange && #Time) to [#NumberRange]', 0);
tagTimeRange(m, '3pm-4');
}
// from 4 to 5 tomorrow
let m = date.match('(from|between) #Cardinal and #Cardinal (in|on)? (#WeekDay|tomorrow|yesterday)');
tagTimeRange(m, 'from 9-5 tues');
// 9 to 5 tomorrow
m = doc.match('#Cardinal to #Cardinal (#WeekDay|tomorrow|yesterday)');
tagTimeRange(m, '9-5 tues');
// from 4 to 5pm
m = date.match('(from|between) [#NumericValue] (to|and) #Time', 0).tag('Time', '4-to-5pm');
tagTimeRange(m, 'from 9-5pm');
// wed from 3 to 4
m = date.match('(#WeekDay|tomorrow|yesterday) (from|between)? (#Cardinal|#Time) (and|to) (#Cardinal|#Time)');
tagTimeRange(m, 'tues 3-5');
// june 5 from 3 to 4
m = date.match('#Month #Value+ (from|between) [(#Cardinal|#Time) (and|to) (#Cardinal|#Time)]').group('time');
tagTimeRange(m, 'sep 4 from 9-5');
// 3pm to 4 on wednesday
m = date.match('#Time to #Cardinal on? #Date');
tagTimeRange(m, '3pm-4 wed');
// 3 to 4pm on wednesday
m = date.match('#Cardinal to #Time on? #Date');
tagTimeRange(m, '3-4pm wed');
// 3 to 4 on wednesday
m = date.match('#Cardinal to #Cardinal on? (#WeekDay|#Month #Value)');
tagTimeRange(m, '3-4 wed');
// 3 to 4 pm
// m = date.match('^#Cardinal to #Time')
// tagTimeRange(m, '3 to 4pm')
}
return doc
};
// timezone abbreviations
// (from spencermountain/timezone-soft)
const zones = [
'act',
'aft',
'akst',
'anat',
'art',
'azot',
'azt',
'bnt',
'bot',
'bt',
'cast',
'cat',
'cct',
'chast',
'chut',
'ckt',
'cvt',
'cxt',
'davt',
'eat',
'ect',
'fjt',
'fkst',
'fnt',
'gamt',
'get',
'gft',
'gilt',
'gyt',
'hast',
'hncu',
'hneg',
'hnnomx',
'hnog',
'hnpm',
'hnpmx',
'hntn',
'hovt',
'iot',
'irkt',
'jst',
'kgt',
'kost',
'lint',
'magt',
'mart',
'mawt',
'mmt',
'nct',
'nft',
'novt',
'npt',
'nrt',
'nut',
'nzst',
'omst',
'pet',
'pett',
'phot',
'phst',
'pont',
'pwt',
'ret',
'sakt',
'samt',
'sbt',
'sct',
'sret',
'srt',
'syot',
'taht',
'tft',
'tjt',
'tkt',
'tlt',
'tmt',
'tot',
'tvt',
'ulat',
'vut',
'wakt',
'wat',
'wet',
'wft',
'wit',
'wst',
'yekt',
].reduce((h, str) => {
h[str] = true;
return h
}, {});
const tagTz = function (doc) {
// 4pm PST
let m = doc.match('#Time [#Acronym]', 0);
if (m.found) {
let str = m.text('reduced');
if (zones[str] === true) {
m.tag('Timezone', 'tz-abbr');
}
}
};
const here = 'fix-tagger';
//
const fixUp = function (doc) {
//fixups
if (doc.has('#Date')) {
//first day by monday
let oops = doc.match('#Date+ by #Date+');
if (oops.found && !oops.has('^due')) {
oops.match('^#Date+').unTag('Date', 'by-monday');
}
let d = doc.match('#Date+');
//between june
if (d.has('^between') && !d.has('and .')) {
d.unTag('Date', here);
}
// log the hours
if (d.has('(minutes|seconds|weeks|hours|days|months)') && !d.has('#Value #Duration')) {
d.match('(minutes|seconds|weeks|hours|days|months)').unTag('Date', 'log-hours');
}
// about thanksgiving
if (d.has('about #Holiday')) {
d.match('about').unTag('#Date', 'about-thanksgiving');
}
// the day after next
d.match('#Date+').match('^the').unTag('Date');
}
return doc
};
const preps = '(in|by|before|during|on|until|after|of|within|all)'; //6
const thisNext = '(last|next|this|previous|current|upcoming|coming)'; //2
const sections = '(start|end|middle|starting|ending|midpoint|beginning|mid)'; //2
const seasons = '(spring|summer|winter|fall|autumn)';
const knownDate = '(yesterday|today|tomorrow)';
// { match: '', tag: '', reason:'' },
let matches = [
// in the evening
{ match: 'in the (night|evening|morning|afternoon|day|daytime)', tag: 'Time', reason: 'in-the-night' },
// 8 pm
{ match: '(#Value|#Time) (am|pm)', tag: 'Time', reason: 'value-ampm' },
// 2012-06
// { match: '/^[0-9]{4}-[0-9]{2}$/', tag: 'Date', reason: '2012-06' },
// 30mins
// { match: '/^[0-9]+(min|sec|hr|d)s?$/', tag: 'Duration', reason: '30min' },
// misc weekday words
{ match: '(tue|thu)', tag: 'WeekDay', reason: 'misc-weekday' },
//June 5-7th
{ match: `#Month #Date+`, tag: 'Date', reason: 'correction-numberRange' },
//5th of March
{ match: '#Value of #Month', tag: 'Date', unTag: 'Time', reason: 'value-of-month' },
//5 March
{ match: '#Cardinal #Month', tag: 'Date', reason: 'cardinal-month' },
//march 5 to 7
{ match: '#Month #Value (and|or|to)? #Value+', tag: 'Date', reason: 'value-to-value' },
//march the 12th
{ match: '#Month the #Value', tag: 'Date', reason: 'month-the-value' },
// march to april
{ match: '[(march|may)] to? #Date', group: 0, tag: 'Month', reason: 'march-to' },
// 'march'
{ match: '^(march|may)$', tag: 'Month', reason: 'single-march' },
//March or June
{ match: '#Month or #Month', tag: 'Date', reason: 'month-or-month' },
//june 7
{ match: '(#WeekDay|#Month) #Value', ifNo: '#Money', tag: 'Date', reason: 'date-value' },
//7 june
{ match: '#Value (#WeekDay|#Month)', ifNo: '#Money', tag: 'Date', reason: 'value-date' },
//may twenty five
// { match: '#TextValue #TextValue', if: '#Date', tag: '#Date', reason: 'textvalue-date' },
//two thursdays back
{ match: '#Value (#WeekDay|#Duration) back', tag: '#Date', reason: '3-back' },
//for 4 months
{ match: 'for #Value #Duration', tag: 'Date', reason: 'for-x-duration' },
//two days before
{ match: '#Value #Duration (before|ago|hence|back)', tag: 'Date', reason: 'val-duration-past' },
//for four days
{ match: `${preps}? #Value #Duration`, tag: 'Date', reason: 'value-duration' },
// 6-8 months
{ match: 'in? #Value to #Value #Duration time?', tag: 'Date', reason: '6-to-8-years' },
//two years old
{ match: '#Value #Duration old', unTag: 'Date', reason: 'val-years-old' },
//
{ match: `${preps}? ${thisNext} ${seasons}`, tag: 'Date', reason: 'thisNext-season' },
//
{ match: `the? ${sections} of ${seasons}`, tag: 'Date', reason: 'section-season' },
//
{ match: `${seasons} ${preps}? #Cardinal`, tag: 'Date', reason: 'season-year' },
//june the 5th
{ match: '#Date the? #Ordinal', tag: 'Date', reason: 'correction' },
//last month
{ match: `${thisNext} #Date`, tag: 'Date', reason: 'thisNext-date' },
//by 5 March
{ match: 'due? (by|before|after|until) #Date', tag: 'Date', reason: 'by' },
//next feb
{ match: '(last|next|this|previous|current|upcoming|coming|the) #Date', tag: 'Date', reason: 'next-feb' },
//start of june
{ match: `#Preposition? the? ${sections} of #Date`, tag: 'Date', reason: 'section-of' },
//fifth week in 1998
{ match: '#Ordinal #Duration in #Date', tag: 'Date', reason: 'duration-in' },
//early in june
{ match: '(early|late) (at|in)? the? #Date', tag: 'Time', reason: 'early-evening' },
//tomorrow before 3
{ match: '#Date [(by|before|after|at|@|about) #Cardinal]', group: 0, tag: 'Time', reason: 'date-before-Cardinal' },
//feb to june
{ match: '#Date (#Preposition|to) #Date', ifNo: '#Duration', tag: 'Date', reason: 'date-prep-date' },
//by 6pm
{ match: '(by|before|after|at|@|about) #Time', tag: 'Time', reason: 'preposition-time' },
// in 20mins
{ match: '(in|after) /^[0-9]+(min|sec|wk)s?/', tag: 'Date', reason: 'shift-units' },
//tuesday night
{ match: '#Date [(now|night|sometime)]', group: 0, tag: 'Time', reason: 'date-now' },
// 4 days from now
{ match: '(from|starting|until|by) now', tag: 'Date', reason: 'for-now' },
// every night
{ match: '(each|every) night', tag: 'Date', reason: 'for-now' },
//saturday am
{ match: '#Date [(am|pm)]', group: 0, tag: 'Time', reason: 'date-am' },
// mid-august
{ match: `[${sections}] #Date`, group: 0, tag: 'Date', reason: 'mid-sept' },
//june 5 to 7th
{ match: '#Month #Value to #Value of? #Year?', tag: 'Date', reason: 'june 5 to 7th' },
//5 to 7th june
{ match: '#Value to #Value of? #Month #Year?', tag: 'Date', reason: '5 to 7th june' },
//third week of may
{ match: '#Value #Duration of #Date', tag: 'Date', reason: 'third week of may' },
//two days after
{ match: '#Value+ #Duration (after|before|into|later|afterwards|ago)?', tag: 'Date', reason: 'two days after' },
//two days
{ match: '#Value #Date', tag: 'Date', reason: 'two days' },
//june 5th
{ match: '#Date #Value', tag: 'Date', reason: 'june 5th' },
//tuesday at 5
{ match: '#Date #Preposition #Value', tag: 'Date', reason: 'tuesday at 5' },
//tomorrow before 3
{ match: '#Date (after|before|during|on|in) #Value', tag: 'Date', reason: 'tomorrow before 3' },
//a year and a half
{ match: '#Value (year|month|week|day) and a half', tag: 'Date', reason: 'a year and a half' },
//5 and a half years
{ match: '#Value and a half (years|months|weeks|days)', tag: 'Date', reason: '5 and a half years' },
//on the fifth
{ match: 'on the #Ordinal', tag: 'Date', reason: 'on the fifth' },
// 'jan 5 or 8'
{ match: '#Month #Value+ (and|or) #Value', tag: 'Date', reason: 'date-or-date' },
// 5 or 8 of jan
{ match: '#Value+ (and|or) #Value of #Month ', tag: 'Date', reason: 'date-and-date' },
{ match: '(spring|summer|winter|fall|autumn|springtime|wintertime|summertime)', tag: 'Season', reason: 'date-tag1' },
{ match: '(q1|q2|q3|q4)', tag: 'FinancialQuarter', reason: 'date-tag2' },
{ match: '(this|next|last|current) quarter', tag: 'FinancialQuarter', reason: 'date-tag3' },
{ match: '(this|next|last|current) season', tag: 'Season', reason: 'date-tag4' },
//friday to sunday
{ match: '#Date #Preposition #Date', tag: 'Date', reason: 'friday to sunday' },
//once a day..
{ match: '(once|twice) (a|an|each) #Date', tag: 'Date', reason: 'once a day' },
//a year after..
{ match: 'a #Duration', tag: 'Date', reason: 'a year' },
//between x and y
{ match: '(between|from) #Date', tag: 'Date', reason: 'between x and y' },
{ match: '(to|until|upto) #Date', tag: 'Date', reason: 'between x and y2' },
{ match: 'between #Date+ and #Date+', tag: 'Date', reason: 'between x and y3' },
{ match: '#Month and #Month #Year', tag: 'Date', reason: 'x and y4' },
//day after next
{ match: 'the? #Date after next one?', tag: 'Date', reason: 'day after next' },
//approximately...
{ match: '(about|approx|approximately|around) #Date', tag: 'Date', reason: 'approximately june' },
// until june
{
match: '(by|until|on|in|at|during|over|every|each|due) the? #Date',
ifNo: '#PhrasalVerb',
tag: 'Date',
reason: 'until june',
},
// until last june
{
match: '(by|until|after|before|during|on|in|following|since) (next|this|last)? #Date',
ifNo: '#PhrasalVerb',
tag: 'Date',
reason: 'until last june',
},
//next september
{
match: 'this? (last|next|past|this|previous|current|upcoming|coming|the) #Date',
tag: 'Date',
reason: 'next september',
},
//starting this june
{ match: '(starting|beginning|ending) #Date', tag: 'Date', reason: 'starting this june' },
//start of june
{ match: 'the? (start|end|middle|beginning) of (last|next|this|the) #Date', tag: 'Date', reason: 'start of june' },
//this coming june
{ match: '(the|this) #Date', tag: 'Date', reason: 'this coming june' },
//january up to june
{ match: '#Date up to #Date', tag: 'Date', reason: 'january up to june' },
// 2 oclock
{ match: '#Cardinal oclock', tag: 'Time', reason: '2 oclock' },
// // 13h30
// { match: '/^[0-9]{2}h[0-9]{2}$/', tag: 'Time', reason: '13h30' },
// // 03/02
// { match: '/^[0-9]{2}/[0-9]{2}/', tag: 'Date', unTag: 'Value', reason: '03/02' },
// 3 in the morning
{ match: '#Value (in|at) the? (morning|evening|night|nighttime)', tag: 'Time', reason: '3 in the morning' },
// ten to seven
{
match: '(5|10|15|20|five|ten|fifteen|quarter|twenty|half) (after|past) #Cardinal',
tag: 'Time',
reason: 'ten to seven',
}, //add check for 1 to 1 etc.
// at 10 past
{
match: '(at|by|before) (5|10|15|20|five|ten|fifteen|twenty|quarter|half) (after|past|to)',
tag: 'Time',
reason: 'at-20-past',
},
// iso (2020-03-02T00:00:00.000Z)
// { match: '/^[0-9]{4}[:-][0-9]{2}[:-][0-9]{2}T[0-9]/', tag: 'Time', reason: 'iso-time-tag' },
// tuesday at 4
{ match: '#Date [at #Cardinal]', group: 0, ifNo: '#Year', tag: 'Time', reason: ' tuesday at 4' },
// half an hour
{ match: 'half an (hour|minute|second)', tag: 'Date', reason: 'half an hour' },
// in eastern time
{ match: '(in|for|by|near|at) #Timezone', tag: 'Date', reason: 'in eastern time' },
// 3pm to 4pm
{ match: '#Time to #Time', tag: 'Date', reason: '3pm to 4pm' },
// 4pm sharp
{ match: '#Time [(sharp|on the dot)]', group: 0, tag: 'Time', reason: '4pm sharp' },
// around four thirty
{
match: '(at|around|near|#Date) [#Cardinal (thirty|fifteen) (am|pm)?]',
group: 0,
tag: 'Time',
reason: 'around four thirty',
},
// four thirty am
{ match: '#Cardinal (thirty|fifteen) (am|pm)', tag: 'Time', reason: 'four thirty am' },
// four thirty tomorrow
{ match: '[#Cardinal (thirty|fifteen)] #Date', group: 0, tag: 'Time', reason: 'four thirty tomorrow' },
//anytime around 3
{ match: '(anytime|sometime) (before|after|near) [#Cardinal]', group: 0, tag: 'Time', reason: 'antime-after-3' },
//'two days before'/ 'nine weeks frow now'
{
match: '(#Cardinal|a|an) #Duration (before|after|ago|from|hence|back)',
tag: 'DateShift',
reason: 'nine weeks frow now',
},
// in two weeks
{ match: 'in (around|about|maybe|perhaps)? #Cardinal #Duration', tag: 'DateShift', reason: 'in two weeks' },
{ match: 'in (a|an) #Duration', tag: 'DateShift', reason: 'in a week' },
// an hour from now
{ match: '[(a|an) #Duration from] #Date', group: 0, tag: 'DateShift', reason: 'an hour from now' },
// a month ago
{ match: '(a|an) #Duration ago', tag: 'DateShift', reason: 'a month ago' },
// in half an hour
{ match: 'in half (a|an) #Duration', tag: 'DateShift', reason: 'in half an hour' },
// in a few weeks
{ match: 'in a (few|couple) of? #Duration', tag: 'DateShift', reason: 'in a few weeks' },
//two weeks and three days before
// { match: '#Cardinal #Duration and? #DateShift', tag: 'DateShift', reason: 'three days before' },
// { match: '#DateShift and #Cardinal #Duration', tag: 'DateShift', reason: 'date-shift' },
// 'day after tomorrow'
{ match: '[#Duration (after|before)] #Date', group: 0, tag: 'DateShift', reason: 'day after tomorrow' },
// july 3rd and 4th
{ match: '#Month #Ordinal and #Ordinal', tag: 'Date', reason: 'ord-and-ord' },
// every other week
{ match: 'every other #Duration', tag: 'Date', reason: 'every-other' },
// every weekend
{ match: '(every|any|each|a) (day|weekday|week day|weekend|weekend day)', tag: 'Date', reason: 'any-weekday' },
// any-wednesday
{ match: '(every|any|each|a) (#WeekDay)', tag: 'Date', reason: 'any-wednesday' },
// any week
{ match: '(every|any|each|a) (#Duration)', tag: 'Date', reason: 'any-week' },
// wed nov
{ match: '[(wed|sat)] (#Month|#Year|on|between|during|from)', group: 0, tag: 'WeekDay', reason: 'wed' },
//'spa day'
{ match: '^day$', unTag: 'Date', reason: 'spa-day' },
// tomorrow's meeting
{ match: '(in|of|by|for)? (#Possessive && #Date)', unTag: 'Date', reason: 'tomorrows meeting' },
//yesterday 7
{ match: `${knownDate} [#Value]$`, unTag: 'Date', group: 0, reason: 'yesterday-7' },
//7 yesterday
{ match: `^[#Value] ${knownDate}$`, group: 0, unTag: 'Date', reason: '7 yesterday' },
//friday yesterday
// { match: `#WeekDay+ ${knownDate}$`, unTag: 'Date').lastTerm(, tag:'Date', reason: 'fri-yesterday'},
//tomorrow on 5
{ match: `on #Cardinal$`, unTag: 'Date', reason: 'on 5' },
//this tomorrow
{ match: `[this] tomorrow`, group: 0, unTag: 'Date', reason: 'this-tomorrow' },
//q2 2019
{ match: `(q1|q2|q3|q4) #Year`, tag: 'Date', reason: 'q2 2016' },
//5 next week
{ match: `^[#Value] (this|next|last)`, group: 0, unTag: 'Date', reason: '4 next' },
//this month 7
{ match: `(last|this|next) #Duration [#Value]`, group: 0, unTag: 'Date', reason: 'this month 7' },
//7 this month
{ match: `[!#Month] #Value (last|this|next) #Date`, group: 0, unTag: 'Date', reason: '7 this month' },
// over the years
{ match: '(in|over) the #Duration #Date+?', unTag: 'Date', reason: 'over-the-duration' },
// second quarter of 2020
{ match: '#Ordinal quarter of? #Year', unTag: 'Fraction' },
// a month from now
{ match: '(from|by|before) now', unTag: 'Time', tag: 'Date' },
// 18th next month
{ match: '#Value of? (this|next|last) #Date', tag: 'Date' },
// first half of march
{ match: '(first|initial|second|latter) half of #Month', tag: 'Date' },
];
let net = null;
const doMatches = function (view) {
let { world } = view;
net = net || world.methods.one.buildNet(matches, world);
view.sweep(net);
};
// run each of the taggers
const compute = function (view) {
view.cache();
doMatches(view);
doMatches(view); // do it twice
tagDates(view);
timeTagger(view);
tagTz(view);
fixUp(view);
view.uncache();
// sorry, one more
view.match('#Cardinal #Duration and? #DateShift').tag('DateShift', 'three days before');
view.match('#DateShift and #Cardinal #Duration').tag('DateShift', 'three days and two weeks');
view.match('#Time [(sharp|on the dot)]').tag('Time', '4pm sharp');
// view.match('in #Adverb #DateShift').tag('Date', 'in-around-2-weeks')
return view
};
var compute$1 = {
dates: compute
};
var tags = {
FinancialQuarter: {
is: 'Date',
not: ['Fraction'],
},
// 'summer'
Season: {
is: 'Date',
},
// '1982'
Year: {
is: 'Date',
not: ['RomanNumeral'],
},
// 'easter'
Holiday: {
is: 'Date',
also: 'Noun',
},
// 'two weeks before'
DateShift: {
is: 'Date',
not: ['Timezone', 'Holiday'],
},
};
const america = 'America/';
const asia = 'Asia/';
const europe = 'Europe/';
const africa = 'Africa/';
const aus = 'Australia/';
const pac = 'Pacific/';
const informal = {
//europe
'british summer time': europe + 'London',
bst: europe + 'London',
'british time': europe + 'London',
'britain time': europe + 'London',
'irish summer time': europe + 'Dublin',
'irish time': europe + 'Dublin',
'central european time': europe + 'Berlin',
cet: europe + 'Berlin',
'central european summer time': europe + 'Berlin',
cest: europe + 'Berlin',
'central europe': europe + 'Berlin',
'eastern european time': europe + 'Riga',
eet: europe + 'Riga',
'eastern european summer time': europe + 'Riga',
eest: europe + 'Riga',
'eastern europe time': europe + 'Riga',
'western european time': europe + 'Lisbon',
'western european summer time': europe + 'Lisbon',
'turkey standard time': europe + 'Istanbul',
'turkish time': europe + 'Istanbul',
utc: africa + 'Freetown',
'greenwich standard time': africa + 'Freetown',
gmt: africa + 'Freetown',
//africa
'east africa time': africa + 'Nairobi',
'east african time': africa + 'Nairobi',
'eastern africa time': africa + 'Nairobi',
'central africa time': africa + 'Khartoum',
'central african time': africa + 'Khartoum',
'south africa standard time': africa + 'Johannesburg',
'west africa standard time': africa + 'Lagos',
'western africa time': africa + 'Lagos',
'west african time': africa + 'Lagos',
// australia
'australian central standard time': aus + 'Adelaide',
acst: aus + 'Adelaide',
'australian central daylight time': aus + 'Adelaide',
acdt: aus + 'Adelaide',
'australian eastern standard time': aus + 'Brisbane',
aest: aus + 'Brisbane',
'australian eastern daylight time': aus + 'Brisbane',
aedt: aus + 'Brisbane',
'australian western standard time': aus + 'Perth',
awst: aus + 'Perth',
'australian western daylight time': aus + 'Perth',
awdt: aus + 'Perth',
'australian central western standard time': aus + 'Eucla',
acwst: aus + 'Eucla',
'lord howe standard time': aus + 'Lord_Howe',
lhst: aus + 'Lord_Howe',
'lord howe daylight time': aus + 'Lord_Howe',
lhdt: aus + 'Lord_Howe',
'russian standard time': europe + 'Moscow',
msk: europe + 'Moscow',
//america
'central standard time': america + 'Chicago',
'central time': america + 'Chicago',
cst: america + 'Havana',
'central daylight time': america + 'Chicago',
cdt: america + 'Havana',
'mountain standard time': america + 'Denver',
'mountain time': america + 'Denver',
mst: america + 'Denver',
'mountain daylight time': america + 'Denver',
mdt: america + 'Denver',
'atlantic standard time': america + 'Halifax',
'atlantic time': america + 'Halifax',
ast: asia + 'Baghdad',
'atlantic daylight time': america + 'Halifax',
adt: america + 'Halifax',
'eastern standard time': america + 'New_York',
'eastern time': america + 'New_York',
est: america + 'New_York',
'eastern daylight time': america + 'New_York',
edt: america + 'New_York',
'pacific time': america + 'Los_Angeles',
'pacific standard time': america + 'Los_Angeles',
pst: america + 'Los_Angeles',
'pacific daylight time': america + 'Los_Angeles',
pdt: america + 'Los_Angeles',
'alaskan standard time': america + 'Anchorage',
'alaskan time': america + 'Anchorage',
ahst: america + 'Anchorage',
'alaskan daylight time': america + 'Anchorage',
ahdt: america + 'Anchorage',
'hawaiian standard time': pac + 'Honolulu',
'hawaiian time': pac + 'Honolulu',
hst: pac + 'Honolulu',
'aleutian time': pac + 'Honolulu',
'hawaii time': pac + 'Honolulu',
'newfoundland standard time': america + 'St_Johns',
'newfoundland time': america + 'St_Johns',
'newfoundland daylight time': america + 'St_Johns',
'brazil time': america + 'Sao_Paulo',
'brazilian time': america + 'Sao_Paulo',
'argentina time': america + 'Buenos_Aires',
'argentinian time': america + 'Buenos_Aires',
'amazon time': america + 'Manaus',
'amazonian time': america + 'Manaus',
'easter island standard time': 'Chile/Easterisland',
'easter island summer time': 'Chile/Easterisland',
easst: 'Chile/Easterisland',
'venezuelan standard time': america + 'Caracas',
'venezuelan time': america + 'Caracas',
'venezuela time': america + 'Caracas',
'paraguay time': america + 'Asuncion',
'paraguay summer time': america + 'Asuncion',
'cuba standard time': america + 'Havana',
'cuba time': america + 'Havana',
'cuba daylight time': america + 'Havana',
'cuban time': america + 'Havana',
'bolivia time': america + 'La_Paz',
'bolivian time': america + 'La_Paz',
'colombia time': america + 'Bogota',
'colombian time': america + 'Bogota',
'acre time': america + 'Eirunepe',
'peru time': america + 'Lima',
'chile standard time': america + 'Punta_Arenas',
'chile time': america + 'Punta_Arenas',
clst: america + 'Punta_Arenas',
'chile summer time': america + 'Punta_Arenas',
cldt: america + 'Punta_Arenas',
'uruguay time': america + 'Montevideo',
uyt: america + 'Montevideo',
//asia
'arabic standard time': asia + 'Baghdad',
'iran standard time': asia + 'Tehran',
'iran time': asia + 'Tehran',
'iran daylight time': asia + 'Tehran',
'pakistan standard time': asia + 'Karachi',
'pakistan time': asia + 'Karachi',
'india standard time': asia + 'Kolkata',
'indian time': asia + 'Kolkata',
'indochina time': asia + 'Bangkok',
'china standard time': asia + 'Shanghai',
'alma-ata time': asia + 'Almaty',
'oral time': asia + 'Oral',
'orat time': asia + 'Oral',
'yakutsk time': asia + 'Yakutsk',
yakt: asia + 'Yakutsk',
'gulf standard time': asia + 'Dubai',
'gulf time': asia + 'Dubai',
'hong kong time': asia + 'Hong_Kong',
'western indonesian time': asia + 'Jakarta',
'indonesia time': asia + 'Jakarta',
'central indonesian time': asia + 'Makassar',
'israel daylight time': asia + 'Jerusalem',
'israel standard time': asia + 'Jerusalem',
'israel time': asia + 'Jerusalem',
'krasnoyarsk time': asia + 'Krasnoyarsk',
'malaysia time': asia + 'Kuala_Lumpur',
'singapore time': asia + 'Singapore',
'korea standard time': asia + 'Seoul',
'korea time': asia + 'Seoul',
kst: asia + 'Seoul',
'korean time': asia + 'Seoul',
'uzbekistan time': asia + 'Samarkand',
'vladivostok time': asia + 'Vladivostok',
//indian
'maldives time': 'Indian/Maldives',
'mauritius time': 'Indian/Mauritius',
'marshall islands time': pac + 'Kwajalein',
'samoa standard time': pac + 'Midway',
'somoan time': pac + 'Midway',
'chamorro standard time': pac + 'Guam',
'papua new guinea time': pac + 'Bougainville',
};
//add the official iana zonefile names
let iana = main().timezones;
let formal = Object.keys(iana).reduce((h, k) => {
h[k] = k;
return h
}, {});
var timezones = Object.assign({}, informal, formal);
var dates = [
'weekday',
'summer',
'winter',
'autumn',
// 'some day',
// 'one day',
'all day',
// 'some point',
'eod',
'eom',
'eoy',
'standard time',
'daylight time',
'tommorrow',
];
var durations = [
'centuries',
'century',
'day',
'days',
'decade',
'decades',
'hour',
'hours',
'hr',
'hrs',
'millisecond',
'milliseconds',
'minute',
'minutes',
'min',
'mins',
'month',
'months',
'seconds',
'sec',
'secs',
'week end',
'week ends',
'weekend',
'weekends',
'week',
'weeks',
'wk',
'wks',
'year',
'years',
'yr',
'yrs',
'quarter',
// 'quarters',
'qtr',
'qtrs',
'season',
'seasons',
];
var holidays = [
'all hallows eve',
'all saints day',
'all sts day',
'april fools',
'armistice day',
'australia day',
'bastille day',
'boxing day',
'canada day',
'christmas eve',
'christmas',
'cinco de mayo',
'day of the dead',
'dia de muertos',
'dieciseis de septiembre',
'emancipation day',
'grito de dolores',
'groundhog day',
'halloween',
'harvey milk day',
'inauguration day',
'independence day',
'independents day',
'juneteenth',
'labour day',
'national freedom day',
'national nurses day',
'new years eve',
'new years',
'purple heart day',
'rememberance day',
'rosa parks day',
'saint andrews day',
'saint patricks day',
'saint stephens day',
'saint valentines day',
'st andrews day',
'st patricks day',
'st stephens day',
'st valentines day ',
'valentines day',
'valentines',
'veterans day',
'victoria day',
'womens equality day',
'xmas',
// Fixed religious and cultural holidays
// Catholic + Christian
'epiphany',
'orthodox christmas day',
'orthodox new year',
'assumption of mary',
'all souls day',
'feast of the immaculate conception',
'feast of our lady of guadalupe',
// Kwanzaa
'kwanzaa',
// Pagan / metal 🤘
'imbolc',
'beltaine',
'lughnassadh',
'samhain',
'martin luther king day',
'mlk day',
'presidents day',
'mardi gras',
'tax day',
'commonwealth day',
'mothers day',
'memorial day',
'fathers day',
'columbus day',
'indigenous peoples day',
'canadian thanksgiving',
'election day',
'thanksgiving',
't-day',
'turkey day',
'black friday',
'cyber monday',
// Astronomical religious and cultural holidays
'ash wednesday',
'palm sunday',
'maundy thursday',
'good friday',
'holy saturday',
'easter',
'easter sunday',
'easter monday',
'orthodox good friday',
'orthodox holy saturday',
'orthodox easter',
'orthodox easter monday',
'ascension day',
'pentecost',
'whitsunday',
'whit sunday',
'whit monday',
'trinity sunday',
'corpus christi',
'advent',
// Jewish
'tu bishvat',
'tu bshevat',
'purim',
'passover',
'yom hashoah',
'lag baomer',
'shavuot',
'tisha bav',
'rosh hashana',
'yom kippur',
'sukkot',
'shmini atzeret',
'simchat torah',
'chanukah',
'hanukkah',
// Muslim
'isra and miraj',
'lailat al-qadr',
'eid al-fitr',
'id al-Fitr',
'eid ul-Fitr',
'ramadan',
'eid al-adha',
'muharram',
'the prophets birthday',
'ostara',
'march equinox',
'vernal equinox',
'litha',
'june solistice',
'summer solistice',
'mabon',
'september equinox',
'fall equinox',
'autumnal equinox',
'yule',
'december solstice',
'winter solstice',
// Additional important holidays
'chinese new year',
'diwali',
];
var times = [
'noon',
'midnight',
'morning',
'tonight',
'evening',
'afternoon',
'breakfast time',
'lunchtime',
'dinnertime',
'midday',
'eod',
'oclock',
'oclock',
'at night',
// 'now',
// 'night',
// 'sometime',
// 'all day',
];
let lex = {
'a couple': 'Value',
thur: 'WeekDay',
thurs: 'WeekDay',
};
const add = function (arr, tag) {
arr.forEach(str => {
lex[str] = tag;
});
};
add(Object.keys(timezones), 'Timezone');
add(dates, 'Date');
add(durations, 'Duration');
add(holidays, 'Holiday');
add(times, 'Time');
var regex = [
// 30sec
[/^[0-9]+(min|sec|hr|d)s?$/i, 'Duration', '30min'],
// 2012-06
[/^[0-9]{4}-[0-9]{2}$/, 'Date', '2012-06'],
// 13h30
[/^[0-9]{2}h[0-9]{2}$/i, 'Time', '13h30'],
// @4:30
[/^@[0-9]+:[0-9]{2}$/, 'Time', '@5:30'],
// @4pm
[/^@[1-9]+(am|pm)$/, 'Time', '@5pm'],
// 03/02
[/^(?:0[1-9]|[12]\d|3[01])\/(?:0[1-9]|[12]\d|3[01])$/, 'Date', '03/02'],
// iso-time
// [/^[0-9]{4}[:-][0-9]{2}[:-][0-9]{2}T[0-9]/i, 'Time', 'iso-time-tag']
];
var version = '3.7.1';
/* eslint-disable no-console */
const fmt = iso => (iso ? main(iso).format('{nice-day} {year}') : '-');
// https://stackoverflow.com/questions/9781218/how-to-change-node-jss-console-font-color
const reset = '\x1b[0m';
//cheaper than requiring chalk
const cli = {
magenta: str => '\x1b[35m' + str + reset,
cyan: str => '\x1b[36m' + str + reset,
yellow: str => '\x1b[33m' + str + reset,
dim: str => '\x1b[2m' + str + reset,
i: str => '\x1b[3m' + str + reset,
};
const debug = function (view) {
view.dates().forEach(m => {
let res = m.dates().get()[0];
console.log('\n────────');
m.debug('highlight');
let msg = '';
if (res && res.start) {
msg = ' ' + cli.magenta(fmt(res.start));
}
if (res && res.end) {
msg += cli.dim(' → ') + cli.cyan(fmt(res.end));
}
console.log(msg + '\n');
});
};
var plugin = {
tags,
words: lex,
compute: compute$1,
api,
mutate: world => {
// add our regexes
world.model.two.regexText = world.model.two.regexText || [];
world.model.two.regexText = world.model.two.regexText.concat(regex);
// add our debug('dates') method
world.methods.one.debug = world.methods.one.debug || {};
world.methods.one.debug.dates = debug;
},
hooks: ['dates'],
version,
};
return plugin;
}));
================================================
FILE: plugins/dates/builds/compromise-dates.mjs
================================================
const e={second:!0,minute:!0,hour:!0,day:!0,week:!0,weekend:!0,month:!0,season:!0,quarter:!0,year:!0},t={wk:"week",min:"minute",sec:"second",weekend:"week"},a=function(e){let a=e.match("#Duration").text("normal");return a=a.replace(/s$/,""),t.hasOwnProperty(a)&&(a=t[a]),a},n={minute:!0},r=(e,t,a)=>{const[n,r]=e.split("/"),[i,o]=r.split(":");return Date.UTC(a,n-1,i,o)-36e5*t},i=(e,t,a,n,i)=>{const o=new Date(e).getUTCFullYear(),s=r(t,i,o),u=r(a,n,o);return e>=s&&e10/05:04":"4/adelaide,4/broken_hill,4/south,4/yancowinna","9.5|s":"4/darwin,4/north","8|s|03/13:01->10/02:00":"12/casey","8|s":"2/kuala_lumpur,2/makassar,2/singapore,4/perth,2/ujung_pandang,4/west,singapore","8|n":"2/brunei,2/hong_kong,2/irkutsk,2/kuching,2/macau,2/manila,2/shanghai,2/taipei,2/ulaanbaatar,2/chongqing,2/chungking,2/harbin,2/macao,2/ulan_bator,2/choibalsan,hongkong,prc,roc","8.75|s":"4/eucla","7|s":"12/davis,2/jakarta,9/christmas","7|n":"2/bangkok,2/barnaul,2/hovd,2/krasnoyarsk,2/novokuznetsk,2/novosibirsk,2/phnom_penh,2/pontianak,2/ho_chi_minh,2/tomsk,2/vientiane,2/saigon","6|s":"12/vostok","6|n":"2/almaty,2/bishkek,2/dhaka,2/omsk,2/qyzylorda,2/qostanay,2/thimphu,2/urumqi,9/chagos,2/dacca,2/kashgar,2/thimbu","6.5|n":"2/yangon,9/cocos,2/rangoon","5|s":"12/mawson,9/kerguelen","5|n":"2/aqtau,2/aqtobe,2/ashgabat,2/atyrau,2/dushanbe,2/karachi,2/oral,2/samarkand,2/tashkent,2/yekaterinburg,9/maldives,2/ashkhabad","5.75|n":"2/kathmandu,2/katmandu","5.5|n":"2/kolkata,2/colombo,2/calcutta","4|s":"9/reunion","4|n":"2/baku,2/dubai,2/muscat,2/tbilisi,2/yerevan,8/astrakhan,8/samara,8/saratov,8/ulyanovsk,8/volgograd,9/mahe,9/mauritius,2/volgograd","4.5|n":"2/kabul","3|s":"12/syowa,9/antananarivo","3|n|04/25:02->10/30:24":"0/cairo,egypt","3|n|04/12:04->10/25:02":"2/gaza,2/hebron","3|n|03/30:05->10/26:04":"2/famagusta,2/nicosia,8/athens,8/bucharest,8/helsinki,8/kyiv,8/mariehamn,8/riga,8/sofia,8/tallinn,8/uzhgorod,8/vilnius,8/zaporozhye,8/nicosia,8/kiev,eet","3|n|03/30:04->10/26:03":"8/chisinau,8/tiraspol","3|n|03/30:02->10/25:24":"2/beirut","3|n|03/28:04->10/26:02":"2/jerusalem,2/tel_aviv,israel","3|n":"0/addis_ababa,0/asmara,0/asmera,0/dar_es_salaam,0/djibouti,0/juba,0/kampala,0/mogadishu,0/nairobi,2/aden,2/amman,2/baghdad,2/bahrain,2/damascus,2/kuwait,2/qatar,2/riyadh,8/istanbul,8/kirov,8/minsk,8/moscow,8/simferopol,9/comoro,9/mayotte,2/istanbul,turkey,w-su","3.5|n":"2/tehran,iran","2|s|03/30:04->10/26:02":"12/troll","2|s":"0/gaborone,0/harare,0/johannesburg,0/lubumbashi,0/lusaka,0/maputo,0/maseru,0/mbabane","2|n|03/30:04->10/26:03":"0/ceuta,arctic/longyearbyen,8/amsterdam,8/andorra,8/belgrade,8/berlin,8/bratislava,8/brussels,8/budapest,8/busingen,8/copenhagen,8/gibraltar,8/ljubljana,8/luxembourg,8/madrid,8/malta,8/monaco,8/oslo,8/paris,8/podgorica,8/prague,8/rome,8/san_marino,8/sarajevo,8/skopje,8/stockholm,8/tirane,8/vaduz,8/vatican,8/vienna,8/warsaw,8/zagreb,8/zurich,3/jan_mayen,poland,cet,met","2|n":"0/blantyre,0/bujumbura,0/khartoum,0/kigali,0/tripoli,8/kaliningrad,libya","1|s":"0/brazzaville,0/kinshasa,0/luanda,0/windhoek","1|n|03/30:03->10/26:02":"3/canary,3/faroe,3/madeira,8/dublin,8/guernsey,8/isle_of_man,8/jersey,8/lisbon,8/london,3/faeroe,eire,8/belfast,gb-eire,gb,portugal,wet","1|n":"0/algiers,0/bangui,0/douala,0/lagos,0/libreville,0/malabo,0/ndjamena,0/niamey,0/porto-novo,0/tunis","14|n":"11/kiritimati","13|s":"11/apia,11/tongatapu","13|n":"11/enderbury,11/kanton,11/fakaofo","12|s|04/06:03->09/28:04":"12/mcmurdo,11/auckland,12/south_pole,nz","12|s":"11/fiji","12|n":"2/anadyr,2/kamchatka,2/srednekolymsk,11/funafuti,11/kwajalein,11/majuro,11/nauru,11/tarawa,11/wake,11/wallis,kwajalein","12.75|s|04/06:03->04/06:02":"11/chatham,nz-chat","11|s|04/06:03->10/05:04":"12/macquarie","11|s":"11/bougainville","11|n":"2/magadan,2/sakhalin,11/efate,11/guadalcanal,11/kosrae,11/noumea,11/pohnpei,11/ponape","11.5|n|04/06:03->10/05:04":"11/norfolk","10|s|04/06:03->10/05:04":"4/currie,4/hobart,4/melbourne,4/sydney,4/act,4/canberra,4/nsw,4/tasmania,4/victoria","10|s":"12/dumontdurville,4/brisbane,4/lindeman,11/port_moresby,4/queensland","10|n":"2/ust-nera,2/vladivostok,11/guam,11/saipan,11/chuuk,11/truk,11/yap","10.5|s|04/06:01->10/05:02":"4/lord_howe,4/lhi","0|s|02/23:03->04/06:04":"0/casablanca,0/el_aaiun","0|n|03/30:02->10/26:01":"3/azores","0|n|03/30:01->10/25:24":"1/scoresbysund","0|n":"0/abidjan,0/accra,0/bamako,0/banjul,0/bissau,0/conakry,0/dakar,0/freetown,0/lome,0/monrovia,0/nouakchott,0/ouagadougou,0/sao_tome,1/danmarkshavn,3/reykjavik,3/st_helena,13/gmt,13/utc,0/timbuktu,13/greenwich,13/uct,13/universal,13/zulu,gmt-0,gmt+0,gmt0,greenwich,iceland,uct,universal,utc,zulu,13/unknown,factory","-9|n|03/09:04->11/02:02":"1/adak,1/atka,us/aleutian","-9|n":"11/gambier","-9.5|n":"11/marquesas","-8|n|03/09:04->11/02:02":"1/anchorage,1/juneau,1/metlakatla,1/nome,1/sitka,1/yakutat,us/alaska","-8|n":"11/pitcairn","-7|n|03/09:04->11/02:02":"1/los_angeles,1/santa_isabel,1/tijuana,1/vancouver,1/ensenada,6/pacific,10/bajanorte,us/pacific-new,us/pacific","-7|n":"1/creston,1/dawson,1/dawson_creek,1/fort_nelson,1/hermosillo,1/mazatlan,1/phoenix,1/whitehorse,6/yukon,10/bajasur,us/arizona,mst","-6|s|04/05:22->09/06:24":"11/easter,7/easterisland","-6|n|04/07:02->10/27:02":"1/merida","-6|n|03/09:04->11/02:02":"1/boise,1/cambridge_bay,1/denver,1/edmonton,1/inuvik,1/north_dakota,1/ojinaga,1/ciudad_juarez,1/yellowknife,1/shiprock,6/mountain,navajo,us/mountain","-6|n":"1/bahia_banderas,1/belize,1/chihuahua,1/costa_rica,1/el_salvador,1/guatemala,1/managua,1/mexico_city,1/monterrey,1/regina,1/swift_current,1/tegucigalpa,11/galapagos,6/east-saskatchewan,6/saskatchewan,10/general","-5|s":"1/lima,1/rio_branco,1/porto_acre,5/acre","-5|n|03/09:04->11/02:02":"1/chicago,1/matamoros,1/menominee,1/rainy_river,1/rankin_inlet,1/resolute,1/winnipeg,1/indiana/knox,1/indiana/tell_city,1/north_dakota/beulah,1/north_dakota/center,1/north_dakota/new_salem,1/knox_in,6/central,us/central,us/indiana-starke","-5|n":"1/bogota,1/cancun,1/cayman,1/coral_harbour,1/eirunepe,1/guayaquil,1/jamaica,1/panama,1/atikokan,jamaica,est","-4|s|04/05:24->09/07:02":"1/santiago,7/continental","-4|s|03/22:24->10/05:02":"1/asuncion","-4|s":"1/campo_grande,1/cuiaba,1/la_paz,1/manaus,5/west","-4|n|03/09:04->11/02:02":"1/detroit,1/grand_turk,1/indiana,1/indianapolis,1/iqaluit,1/kentucky,1/louisville,1/montreal,1/nassau,1/new_york,1/nipigon,1/pangnirtung,1/port-au-prince,1/thunder_bay,1/toronto,1/indiana/marengo,1/indiana/petersburg,1/indiana/vevay,1/indiana/vincennes,1/indiana/winamac,1/kentucky/monticello,1/fort_wayne,1/indiana/indianapolis,1/kentucky/louisville,6/eastern,us/east-indiana,us/eastern,us/michigan","-4|n|03/09:02->11/02:01":"1/havana,cuba","-4|n":"1/anguilla,1/antigua,1/aruba,1/barbados,1/blanc-sablon,1/boa_vista,1/caracas,1/curacao,1/dominica,1/grenada,1/guadeloupe,1/guyana,1/kralendijk,1/lower_princes,1/marigot,1/martinique,1/montserrat,1/port_of_spain,1/porto_velho,1/puerto_rico,1/santo_domingo,1/st_barthelemy,1/st_kitts,1/st_lucia,1/st_thomas,1/st_vincent,1/tortola,1/virgin","-3|s":"1/argentina,1/buenos_aires,1/catamarca,1/cordoba,1/fortaleza,1/jujuy,1/mendoza,1/montevideo,1/punta_arenas,1/sao_paulo,12/palmer,12/rothera,3/stanley,1/argentina/la_rioja,1/argentina/rio_gallegos,1/argentina/salta,1/argentina/san_juan,1/argentina/san_luis,1/argentina/tucuman,1/argentina/ushuaia,1/argentina/comodrivadavia,1/argentina/buenos_aires,1/argentina/catamarca,1/argentina/cordoba,1/argentina/jujuy,1/argentina/mendoza,1/argentina/rosario,1/rosario,5/east","-3|n|03/09:04->11/02:02":"1/glace_bay,1/goose_bay,1/halifax,1/moncton,1/thule,3/bermuda,6/atlantic","-3|n":"1/araguaina,1/bahia,1/belem,1/cayenne,1/maceio,1/paramaribo,1/recife,1/santarem","-2|n|03/09:04->11/02:02":"1/miquelon","-2|n":"1/noronha,3/south_georgia,5/denoronha","-2.5|n|03/09:04->11/02:02":"1/st_johns,6/newfoundland","-1|n|03/30:01->10/25:24":"1/nuuk,1/godthab","-1|n":"3/cape_verde","-11|n":"11/midway,11/niue,11/pago_pago,11/samoa,us/samoa","-10|n":"11/honolulu,11/johnston,11/rarotonga,11/tahiti,us/hawaii,hst"},s=["africa","america","asia","atlantic","australia","brazil","canada","chile","europe","indian","mexico","pacific","antarctica","etc"];let u={};Object.keys(o).forEach((e=>{let t=e.split("|"),a={offset:Number(t[0]),hem:t[1]};t[2]&&(a.dst=t[2]),o[e].split(",").forEach((e=>{e=e.replace(/(^[0-9]+)\//,((e,t)=>(t=Number(t),s[t]+"/"))),u[e]=a}))})),u.utc={offset:0,hem:"n"};for(let e=-14;e<=14;e+=.5){let t=e;t>0&&(t="+"+t);let a="etc/gmt"+t;u[a]={offset:-1*e,hem:"n"},a="utc/gmt"+t,u[a]={offset:-1*e,hem:"n"}}const d=/(-?[0-9]+)h(rs)?/i,l=/(-?[0-9]+)/,h=/utc([\-+]?[0-9]+)/i,m=/gmt([\-+]?[0-9]+)/i,c=function(e){return(e=Number(e))>=-13&&e<=13?"etc/gmt"+(e=((e*=-1)>0?"+":"")+e):null};let f=(()=>{let e=(()=>{if("undefined"==typeof Intl||void 0===Intl.DateTimeFormat)return null;let e=Intl.DateTimeFormat();if(void 0===e||void 0===e.resolvedOptions)return null;let t=e.resolvedOptions().timeZone;return t?t.toLowerCase():null})();return null===e?"utc":e})();const y=Object.keys(u).reduce(((e,t)=>{let a=t.split("/")[1]||"";return a=a.replace(/_/g," "),e[a]=t,e}),{}),p=(e,t)=>{if(!e)return t.hasOwnProperty(f)||(console.warn(`Unrecognized IANA id '${f}'. Setting fallback tz to UTC.`),f="utc"),f;"string"!=typeof e&&console.error("Timezone must be a string - recieved: '",e,"'\n");let a=e.trim();if(a=a.toLowerCase(),!0===t.hasOwnProperty(a))return a;if(a=(e=>(e=(e=(e=(e=(e=e.replace(/ time/g,"")).replace(/ (standard|daylight|summer)/g,"")).replace(/\b(east|west|north|south)ern/g,"$1")).replace(/\b(africa|america|australia)n/g,"$1")).replace(/\beuropean/g,"europe")).replace(/islands/g,"island"))(a),!0===t.hasOwnProperty(a))return a;if(!0===y.hasOwnProperty(a))return y[a];if(!0===/[0-9]/.test(a)){let e=function(e){let t=e.match(d);if(null!==t)return c(t[1]);if(t=e.match(h),null!==t)return c(t[1]);if(t=e.match(m),null!==t){let e=-1*Number(t[1]);return c(e)}return t=e.match(l),null!==t?c(t[1]):null}(a);if(e)return e}throw new Error("Spacetime: Cannot find timezone named: '"+e+"'. Please enter an IANA timezone id.")};function g(e){return e%4==0&&e%100!=0||e%400==0}function w(e){return"[object Date]"===Object.prototype.toString.call(e)&&!isNaN(e.valueOf())}function b(e){return"[object Object]"===Object.prototype.toString.call(e)}function k(e,t=2){return(e+="").length>=t?e:new Array(t-e.length+1).join("0")+e}function D(e){let t=e%10,a=e%100;return 1===t&&11!==a?e+"st":2===t&&12!==a?e+"nd":3===t&&13!==a?e+"rd":e+"th"}function v(e){return e=(e=String(e)).replace(/([0-9])(st|nd|rd|th)$/i,"$1"),parseInt(e,10)}function x(e=""){return"day"===(e=(e=(e=(e=e.toLowerCase().trim()).replace(/ies$/,"y")).replace(/s$/,"")).replace(/-/g,""))||"days"===e?"date":"min"===e||"mins"===e?"minute":e}function O(e){return"number"==typeof e?e:w(e)?e.getTime():e.epoch||0===e.epoch?e.epoch:null}function M(e,t){return!1===b(e)?t.clone().set(e):e}function _(e,t=""){const a=e>0?"+":"-",n=Math.abs(e);return`${a}${k(parseInt(""+n,10))}${t}${k(n%1*60)}`}const j={year:(new Date).getFullYear(),month:0,date:1};var $={parseArray:(e,t,a)=>{if(0===t.length)return e;let n=["year","month","date","hour","minute","second","millisecond"];for(let r=0;r{if(0===Object.keys(t).length)return e;t=Object.assign({},j,a,t);let n=Object.keys(t);for(let r=0;r0&&t<25e8&&!1===e.silent&&(console.warn(" - Warning: You are setting the date to January 1970."),console.warn(" - did input seconds instead of milliseconds?")),e.epoch=t,e}};const z=function(e){return e.epoch=Date.now(),Object.keys(e._today||{}).forEach((t=>{"function"==typeof e[t]&&(e=e[t](e._today[t]))})),e},T={now:e=>z(e),today:e=>z(e),tonight:e=>e=(e=z(e)).hour(18),tomorrow:e=>e=(e=(e=z(e)).add(1,"day")).startOf("day"),yesterday:e=>e=(e=(e=z(e)).subtract(1,"day")).startOf("day"),christmas:e=>{let t=z(e).year();return e=e.set([t,11,25,18,0,0])},"new years":e=>{let t=z(e).year();return e=e.set([t,11,31,18,0,0])}};T["new years eve"]=T["new years"];let V={millisecond:1,second:1e3,minute:6e4,hour:36e5,day:864e5};V.date=V.day,V.month=25488e5,V.week=6048e5,V.year=3154e7,Object.keys(V).forEach((e=>{V[e+"s"]=V[e]}));const S=(e,t,a,n,r)=>{let i=e.d[a]();if(i===t)return;let o=null===r?null:e.d[r](),s=e.epoch,u=t-i;e.epoch+=V[n]*u,"day"===n&&Math.abs(u)>28&&t<28&&(e.epoch+=V.hour),null!==r&&o!==e.d[r]()&&(e.epoch=s);const d=V[n]/2;for(;e.d[a]()t;)e.epoch-=d;null!==r&&o!==e.d[r]()&&(e.epoch=s)},q={year:{valid:e=>e>-4e3&&e<4e3,walkTo:(e,t)=>S(e,t,"getFullYear","year",null)},month:{valid:e=>e>=0&&e<=11,walkTo:(e,t)=>{let a=e.d,n=a.getMonth(),r=e.epoch,i=a.getFullYear();if(n===t)return;let o=t-n;for(e.epoch+=V.day*(28*o),i!==e.d.getFullYear()&&(e.epoch=r);e.d.getMonth()t;)e.epoch-=V.day}},date:{valid:e=>e>0&&e<=31,walkTo:(e,t)=>S(e,t,"getDate","day","getMonth")},hour:{valid:e=>e>=0&&e<24,walkTo:(e,t)=>S(e,t,"getHours","hour","getDate")},minute:{valid:e=>e>=0&&e<60,walkTo:(e,t)=>S(e,t,"getMinutes","minute","getHours")},second:{valid:e=>e>=0&&e<60,walkTo:(e,t)=>{e.epoch=e.seconds(t).epoch}},millisecond:{valid:e=>e>=0&&e<1e3,walkTo:(e,t)=>{e.epoch=e.milliseconds(t).epoch}}},C=(e,t)=>{let a=Object.keys(q),n=e.clone();for(let r=0;r{if(!t)return e;t=t.trim().toLowerCase();let a=0;if(/^[+-]?[0-9]{2}:[0-9]{2}$/.test(t)&&(!0===/:00/.test(t)&&(t=t.replace(/:00/,"")),!0===/:30/.test(t)&&(t=t.replace(/:30/,".5"))),/^[+-]?[0-9]{4}$/.test(t)&&(t=t.replace(/30$/,".5")),a=parseFloat(t),Math.abs(a)>100&&(a/=100),0===a||"Z"===t||"z"===t)return e.tz="etc/gmt",e;a*=-1,a>=0&&(a="+"+a);let n="etc/gmt"+a;return e.timezones[n]&&(e.tz=n),e},H=(e,t="")=>{let a=(t=t.replace(/^\s+/,"").toLowerCase()).match(/([0-9]{1,2}):([0-9]{1,2}):?([0-9]{1,2})?[:.]?([0-9]{1,4})?/);if(null!==a){let[,n,r,i,o]=a;if(n=Number(n),n<0||n>24)return e.startOf("day");if(r=Number(r),a[2].length<2||r<0||r>59)return e.startOf("day");e=(e=(e=(e=e.hour(n)).minute(r)).seconds(i||0)).millisecond(function(e=""){return(e=String(e)).length>3?e=e.substring(0,3):1===e.length?e+="00":2===e.length&&(e+="0"),Number(e)||0}(o));let s=t.match(/[0-9] ?(am|pm)\b/);return null!==s&&s[1]&&(e=e.ampm(s[1])),e}if(a=t.match(/([0-9]+) ?(am|pm)/),null!==a&&a[1]){let t=Number(a[1]);return t>12||t<1?e.startOf("day"):e=(e=(e=e.hour(a[1]||0)).ampm(a[2])).startOf("hour")}return e=e.startOf("day")};let L=Y();const I=e=>{if(!0!==A.hasOwnProperty(e.month))return!1;if(1===e.month)return!!(g(e.year)&&e.date<=29)||e.date<=28;let t=A[e.month]||0;return e.date<=t},W=(e="",t)=>{if(e=e.trim(),!0===/^'[0-9][0-9]$/.test(e)){let t=Number(e.replace(/'/,""));return t>50?1900+t:2e3+t}let a=parseInt(e,10);return!a&&t&&(a=t.year),a=a||(new Date).getFullYear(),a},F=function(e){return"sept"===(e=e.toLowerCase().trim())?L.sep:L[e]};var J=[{reg:/^([0-9]{1,2})[-/.]([0-9]{1,2})[\-/.]?([0-9]{4})?( [0-9]{1,2}:[0-9]{2}:?[0-9]{0,2} ?(am|pm|gmt))?$/i,parse:(e,t)=>{let a=parseInt(t[1],10)-1,n=parseInt(t[2],10);(e.british||a>=12)&&(n=parseInt(t[1],10),a=parseInt(t[2],10)-1);let r={date:n,month:a,year:W(t[3],e._today)||(new Date).getFullYear()};return!1===I(r)?(e.epoch=null,e):(C(e,r),e=H(e,t[4]))}},{reg:/^([a-z]+)[\-/. ]([0-9]{1,2})[\-/. ]?([0-9]{4}|'[0-9]{2})?( [0-9]{1,2}(:[0-9]{0,2})?(:[0-9]{0,3})? ?(am|pm)?)?$/i,parse:(e,t)=>{let a={year:W(t[3],e._today),month:F(t[1]),date:v(t[2]||"")};return!1===I(a)?(e.epoch=null,e):(C(e,a),e=H(e,t[4]))}},{reg:/^([a-z]+) ([0-9]{1,2})( [0-9]{4})?( ([0-9:]+( ?am| ?pm| ?gmt)?))?$/i,parse:(e,t)=>{let a={year:W(t[3],e._today),month:F(t[1]),date:v(t[2]||"")};return!1===I(a)?(e.epoch=null,e):(C(e,a),e=H(e,t[4]))}},{reg:/^([a-z]+) ([0-9]{1,2}) ([0-9]{1,2}:[0-9]{2}:?[0-9]{0,2})( \+[0-9]{4})?( [0-9]{4})?$/i,parse:(e,t)=>{let[,a,n,r,i,o]=t,s={year:W(o,e._today),month:F(a),date:v(n||"")};return!1===I(s)?(e.epoch=null,e):(C(e,s),e=B(e,i),e=H(e,r))}}],U=[{reg:/^([0-9]{4})[\-/]([0-9]{2})$/,parse:(e,t)=>{let a={year:t[1],month:parseInt(t[2],10)-1,date:1};return!1===I(a)?(e.epoch=null,e):(C(e,a),e=H(e,t[4]))}},{reg:/^([a-z]+) ([0-9]{4})$/i,parse:(e,t)=>{let a={year:W(t[2],e._today),month:F(t[1]),date:e._today.date||1};return!1===I(a)?(e.epoch=null,e):(C(e,a),e=H(e,t[4]))}},{reg:/^(q[0-9])( of)?( [0-9]{4})?/i,parse:(e,t)=>{let a=t[1]||"";e=e.quarter(a);let n=t[3]||"";return n&&(n=n.trim(),e=e.year(n)),e}},{reg:/^(spring|summer|winter|fall|autumn)( of)?( [0-9]{4})?/i,parse:(e,t)=>{let a=t[1]||"";e=e.season(a);let n=t[3]||"";return n&&(n=n.trim(),e=e.year(n)),e}},{reg:/^[0-9,]+ ?b\.?c\.?$/i,parse:(e,t)=>{let a=t[0]||"";a=a.replace(/^([0-9,]+) ?b\.?c\.?$/i,"-$1");let n=new Date,r={year:parseInt(a.trim(),10),month:n.getMonth(),date:n.getDate()};return!1===I(r)?(e.epoch=null,e):(C(e,r),e=H(e))}},{reg:/^[0-9,]+ ?(a\.?d\.?|c\.?e\.?)$/i,parse:(e,t)=>{let a=t[0]||"";a=a.replace(/,/g,"");let n=new Date,r={year:parseInt(a.trim(),10),month:n.getMonth(),date:n.getDate()};return!1===I(r)?(e.epoch=null,e):(C(e,r),e=H(e))}},{reg:/^[0-9]{4}( ?a\.?d\.?)?$/i,parse:(e,t)=>{let a=e._today;a.month&&!a.date&&(a.date=1);let n=new Date,r={year:W(t[0],a),month:a.month||n.getMonth(),date:a.date||n.getDate()};return!1===I(r)?(e.epoch=null,e):(C(e,r),e=H(e))}}],K=[].concat([{reg:/^(-?0{0,2}[0-9]{3,4})-([0-9]{1,2})-([0-9]{1,2})[T| ]([0-9.:]+)(Z|[0-9-+:]+)?$/i,parse:(e,t)=>{let a={year:t[1],month:parseInt(t[2],10)-1,date:t[3]};return!1===I(a)?(e.epoch=null,e):(B(e,t[5]),C(e,a),e=H(e,t[4]))}},{reg:/^([0-9]{4})[\-/. ]([0-9]{1,2})[\-/. ]([0-9]{1,2})( [0-9]{1,2}(:[0-9]{0,2})?(:[0-9]{0,3})? ?(am|pm)?)?$/i,parse:(e,t)=>{let a={year:t[1],month:parseInt(t[2],10)-1,date:parseInt(t[3],10)};return a.month>=12&&(a.date=parseInt(t[2],10),a.month=parseInt(t[3],10)-1),!1===I(a)?(e.epoch=null,e):(C(e,a),e=H(e,t[4]))}},{reg:/^([0-9]{4})[\-/. ]([a-z]+)[\-/. ]([0-9]{1,2})( [0-9]{1,2}(:[0-9]{0,2})?(:[0-9]{0,3})? ?(am|pm)?)?$/i,parse:(e,t)=>{let a={year:W(t[1],e._today),month:F(t[2]),date:v(t[3]||"")};return!1===I(a)?(e.epoch=null,e):(C(e,a),e=H(e,t[4]))}}],J,[{reg:/^([0-9]{1,2})[-/]([a-z]+)[\-/]?([0-9]{4})?$/i,parse:(e,t)=>{let a={year:W(t[3],e._today),month:F(t[2]),date:v(t[1]||"")};return!1===I(a)?(e.epoch=null,e):(C(e,a),e=H(e,t[4]))}},{reg:/^([0-9]{1,2})( [a-z]+)( [0-9]{4}| '[0-9]{2})? ?([0-9]{1,2}:[0-9]{2}:?[0-9]{0,2} ?(am|pm|gmt))?$/i,parse:(e,t)=>{let a={year:W(t[3],e._today),month:F(t[2]),date:v(t[1])};return a.month&&!1!==I(a)?(C(e,a),e=H(e,t[4])):(e.epoch=null,e)}},{reg:/^([0-9]{1,2})[. \-/]([a-z]+)[. \-/]([0-9]{4})?( [0-9]{1,2}(:[0-9]{0,2})?(:[0-9]{0,3})? ?(am|pm)?)?$/i,parse:(e,t)=>{let a={date:Number(t[1]),month:F(t[2]),year:Number(t[3])};return!1===I(a)?(e.epoch=null,e):(C(e,a),e=e.startOf("day"),e=H(e,t[4]))}}],U);const{parseArray:Q,parseObject:R,parseNumber:G}=$,Z={year:(new Date).getFullYear(),month:0,date:1},X=(e,t)=>{let a=e._today||Z;if("number"==typeof t)return G(e,t);if(e.epoch=Date.now(),e._today&&b(e._today)&&Object.keys(e._today).length>0){let t=R(e,a,Z);t.isValid()&&(e.epoch=t.epoch)}return null==t||""===t?e:!0===w(t)?(e.epoch=t.getTime(),e):!0===function(e){return"[object Array]"===Object.prototype.toString.call(e)}(t)?e=Q(e,t,a):!0===b(t)?t.epoch?(e.epoch=t.epoch,e.tz=t.tz,e):e=R(e,t,a):"string"!=typeof t?e:(t=t.replace(/\b(mon|tues?|wed|wednes|thur?s?|fri|sat|satur|sun)(day)?\b/i,"").replace(/([0-9])(th|rd|st|nd)/,"$1").replace(/,/g,"").replace(/ +/g," ").trim(),!0===T.hasOwnProperty(t)?e=T[t](e):function(e,t,a){for(let n=0;n{let t=e.timezone().current.offset;return t?_(t,":"):"Z"},se=e=>ie?function(e){return e?e[0].toUpperCase()+e.substr(1):""}(e):e,ue={day:e=>se(e.dayName()),"day-short":e=>se(ae()[e.day()]),"day-number":e=>e.day(),"day-ordinal":e=>D(e.day()),"day-pad":e=>k(e.day()),date:e=>e.date(),"date-ordinal":e=>D(e.date()),"date-pad":e=>k(e.date()),month:e=>se(e.monthName()),"month-short":e=>se(P()[e.month()]),"month-number":e=>e.month(),"month-ordinal":e=>D(e.month()),"month-pad":e=>k(e.month()),"iso-month":e=>k(e.month()+1),year:e=>{let t=e.year();return t>0?t:(t=Math.abs(t),t+" BC")},"year-short":e=>{let t=e.year();return t>0?`'${String(e.year()).substr(2,4)}`:(t=Math.abs(t),t+" BC")},"iso-year":e=>{let t=e.year(),a=t<0,n=k(Math.abs(t),4);return a&&(n=k(n,6),n="-"+n),n},time:e=>e.time(),"time-24":e=>`${e.hour24()}:${k(e.minute())}`,hour:e=>e.hour12(),"hour-pad":e=>k(e.hour12()),"hour-24":e=>e.hour24(),"hour-24-pad":e=>k(e.hour24()),minute:e=>e.minute(),"minute-pad":e=>k(e.minute()),second:e=>e.second(),"second-pad":e=>k(e.second()),millisecond:e=>e.millisecond(),"millisecond-pad":e=>k(e.millisecond(),3),ampm:e=>e.ampm(),AMPM:e=>e.ampm().toUpperCase(),quarter:e=>"Q"+e.quarter(),season:e=>e.season(),era:e=>e.era(),json:e=>e.json(),timezone:e=>e.timezone().name,offset:e=>oe(e),numeric:e=>`${e.year()}/${k(e.month()+1)}/${k(e.date())}`,"numeric-us":e=>`${k(e.month()+1)}/${k(e.date())}/${e.year()}`,"numeric-uk":e=>`${k(e.date())}/${k(e.month()+1)}/${e.year()}`,"mm/dd":e=>`${k(e.month()+1)}/${k(e.date())}`,iso:e=>`${e.format("iso-year")}-${k(e.month()+1)}-${k(e.date())}T${k(e.h24())}:${k(e.minute())}:${k(e.second())}.${k(e.millisecond(),3)}${oe(e)}`,"iso-short":e=>{let t=k(e.month()+1),a=k(e.date());var n;return`${(n=e.year())>=0?k(n,4):"-"+k(n=Math.abs(n),4)}-${t}-${a}`},"iso-utc":e=>new Date(e.epoch).toISOString(),nice:e=>`${P()[e.month()]} ${D(e.date())}, ${e.time()}`,"nice-24":e=>`${P()[e.month()]} ${D(e.date())}, ${e.hour24()}:${k(e.minute())}`,"nice-year":e=>`${P()[e.month()]} ${D(e.date())}, ${e.year()}`,"nice-day":e=>`${ae()[e.day()]} ${se(P()[e.month()])} ${D(e.date())}`,"nice-full":e=>`${e.dayName()} ${se(e.monthName())} ${D(e.date())}, ${e.time()}`,"nice-full-24":e=>`${e.dayName()} ${se(e.monthName())} ${D(e.date())}, ${e.hour24()}:${k(e.minute())}`},de={"day-name":"day","month-name":"month","iso 8601":"iso","time-h24":"time-24","time-12":"time","time-h12":"time",tz:"timezone","day-num":"day-number","month-num":"month-number","month-iso":"iso-month","year-iso":"iso-year","nice-short":"nice","nice-short-24":"nice-24",mdy:"numeric-us",dmy:"numeric-uk",ymd:"numeric","yyyy/mm/dd":"numeric","mm/dd/yyyy":"numeric-us","dd/mm/yyyy":"numeric-us","little-endian":"numeric-uk","big-endian":"numeric","day-nice":"nice-day"};Object.keys(de).forEach((e=>ue[e]=ue[de[e]]));const le=(e,t="")=>{if(!0!==e.isValid())return"";if(ue.hasOwnProperty(t)){let a=ue[t](e)||"";return"json"!==t&&(a=String(a),"ampm"!==t.toLowerCase()&&(a=se(a))),a}if(-1!==t.indexOf("{")){let a=/\{(.+?)\}/g;return t=t.replace(a,((t,a)=>{if("AMPM"!==(a=a.trim())&&(a=a.toLowerCase()),ue.hasOwnProperty(a)){let t=String(ue[a](e));return"ampm"!==a.toLowerCase()?se(t):t}return""})),t}return e.format("iso-short")},he={G:e=>e.era(),GG:e=>e.era(),GGG:e=>e.era(),GGGG:e=>"AD"===e.era()?"Anno Domini":"Before Christ",y:e=>e.year(),yy:e=>k(Number(String(e.year()).substr(2,4))),yyy:e=>e.year(),yyyy:e=>e.year(),yyyyy:e=>"0"+e.year(),Q:e=>e.quarter(),QQ:e=>e.quarter(),QQQ:e=>e.quarter(),QQQQ:e=>e.quarter(),M:e=>e.month()+1,MM:e=>k(e.month()+1),MMM:e=>e.format("month-short"),MMMM:e=>e.format("month"),w:e=>e.week(),ww:e=>k(e.week()),d:e=>e.date(),dd:e=>k(e.date()),D:e=>e.dayOfYear(),DD:e=>k(e.dayOfYear()),DDD:e=>k(e.dayOfYear(),3),E:e=>e.format("day-short"),EE:e=>e.format("day-short"),EEE:e=>e.format("day-short"),EEEE:e=>e.format("day"),EEEEE:e=>e.format("day")[0],e:e=>e.day(),ee:e=>e.day(),eee:e=>e.format("day-short"),eeee:e=>e.format("day"),eeeee:e=>e.format("day")[0],a:e=>e.ampm().toUpperCase(),aa:e=>e.ampm().toUpperCase(),aaa:e=>e.ampm().toUpperCase(),aaaa:e=>e.ampm().toUpperCase(),h:e=>e.h12(),hh:e=>k(e.h12()),H:e=>e.hour(),HH:e=>k(e.hour()),m:e=>e.minute(),mm:e=>k(e.minute()),s:e=>e.second(),ss:e=>k(e.second()),SSS:e=>k(e.millisecond(),3),A:e=>e.epoch-e.startOf("day").epoch,z:e=>e.timezone().name,zz:e=>e.timezone().name,zzz:e=>e.timezone().name,zzzz:e=>e.timezone().name,Z:e=>_(e.timezone().current.offset),ZZ:e=>_(e.timezone().current.offset),ZZZ:e=>_(e.timezone().current.offset),ZZZZ:e=>_(e.timezone().current.offset,":")},me=(e,t,a)=>{let n=e,r=t;for(let i=0;i{let n=0;for(e=e.clone();e.isBefore(t);)e=e.add(1,a),n+=1;return e.isAfter(t,a)&&(n-=1),n},pe=(e,t,a)=>e.isBefore(t)?ye(e,t,a):-1*ye(t,e,a),ge=function(e,t,a){t=M(t,e);let n=!1;if(e.isAfter(t)){let a=e;e=t,t=a,n=!0}let r=function(e,t){let a=t.epoch-e.epoch,n={milliseconds:a,seconds:parseInt(a/1e3,10)};n.minutes=parseInt(n.seconds/60,10),n.hours=parseInt(n.minutes/60,10);let r=e.clone();return n.years=((e,t)=>{let a=t.year()-e.year();return(e=e.year(t.year())).isAfter(t)&&(a-=1),a})(r,t),r=e.add(n.years,"year"),n.months=12*n.years,r=e.add(n.months,"month"),n.months+=pe(r,t,"month"),n.quarters=4*n.years,n.quarters+=parseInt(n.months%12/3,10),n.weeks=52*n.years,r=e.add(n.weeks,"week"),n.weeks+=pe(r,t,"week"),n.days=7*n.weeks,r=e.add(n.days,"day"),n.days+=pe(r,t,"day"),n}(e,t);return n&&(r=function(e){return Object.keys(e).forEach((t=>{e[t]*=-1})),e}(r)),a?(a=x(a),!0!==/s$/.test(a)&&(a+="s"),"dates"===a&&(a="days"),r[a]):r},we=e=>Math.abs(e)||0;let be={second:"second",seconds:"seconds",minute:"minute",minutes:"minutes",hour:"hour",hours:"hours",day:"day",days:"days",month:"month",months:"months",year:"year",years:"years"};function ke(e){return be[e]||""}let De="past",ve="future",xe="present",Oe="now",Me="almost",_e="over",je=e=>`${e} ago`,$e=e=>`in ${e}`;function ze(e){return je(e)}function Te(e){return $e(e)}function Ve(){return Oe}const Se={months:{almost:10,over:4},days:{almost:25,over:10},hours:{almost:20,over:8},minutes:{almost:50,over:20},seconds:{almost:50,over:20}};function qe(e,t){return 1===e?e+" "+ke(t.slice(0,-1)):e+" "+ke(t)}const Ce=function(e){let t=null,a=null,n=[],r=[];return Object.keys(e).forEach(((i,o,s)=>{const u=Math.abs(e[i]);if(0===u)return;n.push(u+i[0]);const d=qe(u,i);if(r.push(d),!t){if(t=d,a=d,o>4)return;const n=s[o+1],r=Math.abs(e[n]);r>Se[n].almost?(t=qe(u+1,i),a=Me+" "+t):r>Se[n].over&&(a=_e+" "+d)}})),{qualified:a,rounded:t,abbreviated:n,englishValues:r}},Ae=(e,t)=>{const a=function(e,t){const a=e.isBefore(t),n=a?t:e;let r=a?e:t;r=r.clone();const i={years:0,months:0,days:0,hours:0,minutes:0,seconds:0};return Object.keys(i).forEach((e=>{if(r.isSame(n,e))return;let t=r.diff(n,e);r=r.add(t,e),i[e]=t})),a&&Object.keys(i).forEach((e=>{0!==i[e]&&(i[e]*=-1)})),i}(e,t=M(t,e));if(!0===Object.keys(a).every((e=>!a[e])))return{diff:a,rounded:Ve(),qualified:Ve(),precise:Ve(),abbreviated:[],iso:"P0Y0M0DT0H0M0S",direction:xe};let n,r=ve,{rounded:i,qualified:o,englishValues:s,abbreviated:u}=Ce(a);n=s.splice(0,2).join(", "),!0===e.isAfter(t)?(i=ze(i),o=ze(o),n=ze(n),r=De):(i=Te(i),o=Te(o),n=Te(n));let d=function(e){let t="P";return t+=we(e.years)+"Y",t+=we(e.months)+"M",t+=we(e.days)+"DT",t+=we(e.hours)+"H",t+=we(e.minutes)+"M",t+=we(e.seconds)+"S",t}(a);return{diff:a,rounded:i,qualified:o,precise:n,abbreviated:u,iso:d,direction:r}};var Ne={north:[["spring",2,1],["summer",5,1],["fall",8,1],["autumn",8,1],["winter",11,1]],south:[["fall",2,1],["autumn",2,1],["winter",5,1],["spring",8,1],["summer",11,1]]},Ee=[null,[0,1],[3,1],[6,1],[9,1]];const Pe={second:e=>(C(e,{millisecond:0}),e),minute:e=>(C(e,{second:0,millisecond:0}),e),quarterhour:e=>{let t=e.minutes();return e=t>=45?e.minutes(45):t>=30?e.minutes(30):t>=15?e.minutes(15):e.minutes(0),C(e,{second:0,millisecond:0}),e},hour:e=>(C(e,{minute:0,second:0,millisecond:0}),e),day:e=>(C(e,{hour:0,minute:0,second:0,millisecond:0}),e),week:e=>{let t=e.clone();return(e=e.day(e._weekStart)).isAfter(t)&&(e=e.subtract(1,"week")),C(e,{hour:0,minute:0,second:0,millisecond:0}),e},month:e=>(C(e,{date:1,hour:0,minute:0,second:0,millisecond:0}),e),quarter:e=>{let t=e.quarter();return Ee[t]&&C(e,{month:Ee[t][0],date:Ee[t][1],hour:0,minute:0,second:0,millisecond:0}),e},season:e=>{let t=e.season(),a="north";"South"===e.hemisphere()&&(a="south");for(let n=0;n(C(e,{month:0,date:1,hour:0,minute:0,second:0,millisecond:0}),e),decade:e=>{let t=(e=e.startOf("year")).year(),a=10*parseInt(t/10,10);return e=e.year(a)},century:e=>{let t=(e=e.startOf("year")).year(),a=100*parseInt(t/100,10);return e=e.year(a)}};Pe.date=Pe.day;const Ye=function(e,t,a,n=1){if(!t||!a)return[];if(t=x(t),a=e.clone().set(a),e.isAfter(a)){let t=e;e=a,a=t}if(e.diff(a,t)t===e))||!!ne().find((t=>t===e))}(t))r=r.next(t),t="week";else{r.startOf(t).isBefore(e)&&(r=r.next(t))}let i=[];for(;r.isBefore(a);)i.push(r),r=r.add(n,t);return i},Be=e=>{let t=e.timezones,a=e.tz;if(!1===t.hasOwnProperty(a)&&(a=p(e.tz,t)),null===a)return!1===e.silent&&console.warn("Warn: could not find given or local timezone - '"+e.tz+"'"),{current:{epochShift:0}};let n=t[a],r={name:(o=a,o=(o=(o=(o=(o=(o=(o=o[0].toUpperCase()+o.substr(1)).replace(/[/_-]([a-z])/gi,(e=>e.toUpperCase()))).replace(/_(of|es)_/i,(e=>e.toLowerCase()))).replace(/\/gmt/i,"/GMT")).replace(/\/Dumontdurville$/i,"/DumontDUrville")).replace(/\/Mcmurdo$/i,"/McMurdo")).replace(/\/Port-au-prince$/i,"/Port-au-Prince")),hasDst:Boolean(n.dst),default_offset:n.offset,hemisphere:"s"===n.hem?"South":"North",current:{}};var o,s;if(r.hasDst){let e=(s=n.dst)?s.split("->"):[];r.change={start:e[0],back:e[1]}}let u=n.offset,d=u;return!0===r.hasDst&&(d="North"===r.hemisphere?u-1:n.offset+1),!1===r.hasDst?(r.current.offset=u,r.current.isDST=!1):!0===i(e.epoch,r.change.start,r.change.back,u,d)?(r.current.offset=u,r.current.isDST="North"===r.hemisphere):(r.current.offset=d,r.current.isDST="South"===r.hemisphere),r},He=["century","decade","year","month","date","day","hour","minute","second","millisecond"],Le={set:function(e,t){let a=this.clone();return a=X(a,e),t&&(this.tz=p(t)),a},timezone:function(){return Be(this)},isDST:function(){return Be(this).current.isDST},hasDST:function(){return Be(this).hasDst},offset:function(){return 60*Be(this).current.offset},hemisphere:function(){return Be(this).hemisphere},format:function(e){return le(this,e)},unixFmt:function(e){return((e,t)=>{let a=t.split("");return a=function(e){for(let t=0;te))}(a),a=function(e){for(let t=0;te))).map((e=>("''"===e&&(e="'"),e)))}(a),a.reduce(((t,a)=>(void 0!==he[a]?t+=he[a](e)||"":(/^'.+'$/.test(a)&&(a=a.replace(/'/g,"")),t+=a),t)),"")})(this,e)},startOf:function(e){return((e,t)=>{let a=e.clone();return t=x(t),Pe[t]?Pe[t](a):"summer"===t||"winter"===t?(a=a.season(t),Pe.season(a)):a})(this,e)},endOf:function(e){return((e,t)=>{let a=e.clone();return t=x(t),Pe[t]?(a=Pe[t](a),a=a.add(1,t),a=a.subtract(1,"millisecond"),a):a})(this,e)},leapYear:function(){return g(this.year())},progress:function(e){return((e,t)=>{if(t)return t=x(t),fe(e,t);let a={};return ce.forEach((t=>{a[t]=fe(e,t)})),a})(this,e)},nearest:function(e){return((e,t)=>{let a=e.progress();return"quarterhour"===(t=x(t))&&(t="quarterHour"),void 0!==a[t]?(a[t]>.5&&(e=e.add(1,t)),e=e.startOf(t)):!1===e.silent&&console.warn("no known unit '"+t+"'"),e})(this,e)},diff:function(e,t){return ge(this,e,t)},since:function(e){return e||(e=this.clone().set()),Ae(this,e)},next:function(e){return this.add(1,e).startOf(e)},last:function(e){return this.subtract(1,e).startOf(e)},isValid:function(){return!(!this.epoch&&0!==this.epoch)&&!isNaN(this.d.getTime())},goto:function(e){let t=this.clone();return t.tz=p(e,t.timezones),t},every:function(e,t,a){if("object"==typeof e&&"string"==typeof t){let a=t;t=e,e=a}return Ye(this,e,t,a)},isAwake:function(){let e=this.hour();return!(e<8||e>22)},isAsleep:function(){return!this.isAwake()},daysInMonth:function(){switch(this.month()){case 0:case 2:case 4:case 6:case 7:case 9:case 11:return 31;case 1:return this.leapYear()?29:28;case 3:case 5:case 8:case 10:return 30;default:throw new Error("Invalid Month state.")}},log:function(){return console.log(""),console.log(le(this,"nice-short")),this},logYear:function(){return console.log(""),console.log(le(this,"full-short")),this},json:function(){return He.reduce(((e,t)=>(e[t]=this[t](),e)),{})},debug:function(){let e=this.timezone(),t=this.format("MM")+" "+this.format("date-ordinal")+" "+this.year();return t+="\n - "+this.format("time"),console.log("\n\n",t+"\n - "+e.name+" ("+e.current.offset+")"),this},from:function(e){return(e=this.clone().set(e)).since(this)},fromNow:function(){return this.clone().set(Date.now()).since(this)},weekStart:function(e){if("number"==typeof e)return this._weekStart=e,this;if("string"==typeof e){e=e.toLowerCase().trim();let t=ae().indexOf(e);-1===t&&(t=ne().indexOf(e)),-1===t&&(t=1),this._weekStart=t}else console.warn("Spacetime Error: Cannot understand .weekStart() input:",e);return this}};Le.inDST=Le.isDST,Le.round=Le.nearest,Le.each=Le.every;const Ie=e=>("string"==typeof e&&(e=parseInt(e,10)),e),We=["year","month","date","hour","minute","second","millisecond"],Fe=(e,t,a)=>{let n=We.indexOf(a),r=We.slice(n,We.length);for(let a=0;a=24?t=24:t<0&&(t=0);let n=e.clone(),r=e.hour()-t,i=r*V.hour;return e.epoch-=i,e.date()!==n.date()&&(e=n.clone(),r>1&&(r-=1),r<1&&(r+=1),i=r*V.hour,e.epoch-=i),C(e,{hour:t}),Fe(e,n,"minute"),(e=Je(e,n,a,"day")).epoch},Qe=function(e,t){return"string"==typeof t&&/^'[0-9]{2}$/.test(t)&&(t=t.replace(/'/,"").trim(),t=(t=Number(t))>30?1900+t:2e3+t),t=Ie(t),C(e,{year:t}),e.epoch};let Re="am",Ge="pm";const Ze={millisecond:function(e){if(void 0!==e){let t=this.clone();return t.epoch=function(e,t){t=Ie(t);let a=e.millisecond()-t;return e.epoch-a}(t,e),t}return this.d.getMilliseconds()},second:function(e,t){if(void 0!==e){let a=this.clone();return a.epoch=function(e,t,a){t=Ie(t);let n=e.clone(),r=(e.second()-t)*V.second;return e.epoch=e.epoch-r,(e=Je(e,n,a,"minute")).epoch}(a,e,t),a}return this.d.getSeconds()},minute:function(e,t){if(void 0!==e){let a=this.clone();return a.epoch=Ue(a,e,t),a}return this.d.getMinutes()},hour:function(e,t){let a=this.d;if(void 0!==e){let a=this.clone();return a.epoch=Ke(a,e,t),a}return a.getHours()},hourFloat:function(e,t){if(void 0!==e){let a=this.clone(),n=e%1;n*=60;let r=parseInt(e,10);return a.epoch=Ke(a,r,t),a.epoch=Ue(a,n,t),a}let a=this.d,n=a.getHours(),r=a.getMinutes();return r/=60,n+r},hour12:function(e,t){let a=this.d;if(void 0!==e){let a=this.clone(),n=(e=""+e).match(/^([0-9]+)(am|pm)$/);if(n){let e=parseInt(n[1],10);"pm"===n[2]&&(e+=12),a.epoch=Ke(a,e,t)}return a}let n=a.getHours();return n>12&&(n-=12),0===n&&(n=12),n},time:function(e,t){if(void 0!==e){let a=this.clone();return e=e.toLowerCase().trim(),a.epoch=function(e,t,a){let n=t.match(/([0-9]{1,2})[:h]([0-9]{1,2})(:[0-9]{1,2})? ?(am|pm)?/);if(!n){if(n=t.match(/([0-9]{1,2}) ?(am|pm)/),!n)return e.epoch;n.splice(2,0,"0"),n.splice(3,0,"")}let r=!1,i=parseInt(n[1],10),o=parseInt(n[2],10);o>=60&&(o=59),i>12&&(r=!0),!1===r&&("am"===n[4]&&12===i&&(i=0),"pm"===n[4]&&i<12&&(i+=12)),n[3]=n[3]||"",n[3]=n[3].replace(/:/,"");let s=parseInt(n[3],10)||0,u=e.clone();return e=(e=(e=(e=e.hour(i)).minute(o)).second(s)).millisecond(0),(e=Je(e,u,a,"day")).epoch}(a,e,t),a}return`${this.h12()}:${k(this.minute())}${this.ampm()}`},ampm:function(e,t){let a=Re,n=this.hour();if(n>=12&&(a=Ge),"string"!=typeof e)return a;let r=this.clone();return e=e.toLowerCase().trim(),n>=12&&"am"===e?(n-=12,r.hour(n,t)):n<12&&"pm"===e?(n+=12,r.hour(n,t)):r},dayTime:function(e,t){if(void 0!==e){const a={morning:"7:00",breakfast:"7:00",noon:"12:00",lunch:"12:00",afternoon:"14:00",evening:"18:00",dinner:"18:00",night:"23:00",midnight:"00:00"};let n=this.clone();return e=(e=e||"").toLowerCase(),!0===a.hasOwnProperty(e)&&(n=n.time(a[e],t)),n}let a=this.hour();return a<6?"night":a<12?"morning":a<17?"afternoon":a<22?"evening":"night"},iso:function(e){return void 0!==e?this.set(e):this.format("iso")}},Xe={date:function(e,t){if(void 0!==e){let a=this.clone();return(e=parseInt(e,10))&&(a.epoch=function(e,t,a){if((t=Ie(t))>28){let a=e.month(),n=A[a];1===a&&29===t&&g(e.year())&&(n=29),t>n&&(t=n)}t<=0&&(t=1);let n=e.clone();return C(e,{date:t}),(e=Je(e,n,a,"month")).epoch}(a,e,t)),a}return this.d.getDate()},day:function(e,t){if(void 0===e)return this.d.getDay();let a=this.clone(),n=e;"string"==typeof e&&(e=e.toLowerCase(),re.hasOwnProperty(e)?n=re[e]:(n=ae().indexOf(e),-1===n&&(n=ne().indexOf(e))));let r=this.d.getDay()-n;!0===t&&r>0&&(r-=7),!1===t&&r<0&&(r+=7);let i=this.subtract(r,"days");return C(i,{hour:a.hour(),minute:a.minute(),second:a.second()}),i},dayName:function(e,t){if(void 0===e)return ne()[this.day()];let a=this.clone();return a=a.day(e,t),a}},et=e=>e=(e=(e=e.minute(0)).second(0)).millisecond(1),tt={dayOfYear:function(e,t){if(void 0!==e){let a=this.clone();return a.epoch=function(e,t,a){t=Ie(t);let n=e.clone();return(t-=1)<=0?t=0:t>=365&&(t=g(e.year())?365:364),e=(e=e.startOf("year")).add(t,"day"),Fe(e,n,"hour"),(e=Je(e,n,a,"year")).epoch}(a,e,t),a}let a,n=0,r=this.d.getMonth();for(let e=1;e<=r;e++)a=new Date,a.setDate(1),a.setFullYear(this.d.getFullYear()),a.setHours(1),a.setMinutes(1),a.setMonth(e),a.setHours(-2),n+=a.getDate();return n+this.d.getDate()},week:function(e,t){if(void 0!==e){let a=this.clone();return a.epoch=function(e,t,a){let n=e.clone();return t=Ie(t),"december"===(e=(e=(e=e.month(0)).date(1)).day("monday")).monthName()&&e.date()>=28&&(e=e.add(1,"week")),t-=1,e=e.add(t,"weeks"),(e=Je(e,n,a,"year")).epoch}(this,e,t),a=et(a),a}let a=this.clone();a=a.month(0),a=a.date(1),a=et(a),a=a.day("monday"),11===a.month()&&a.date()>=25&&(a=a.add(1,"week"));let n=1;1===a.date()&&(n=0),a=a.minus(2,"hours");const r=this.epoch;if(a.epoch>r)return 1;let i=0,o=4*this.month();for(a.epoch+=V.week*o,i+=o;i<=52;i++){if(a.epoch>r)return i+n;a=a.add(1,"week")}return 52},month:function(e,t){if(void 0!==e){let a=this.clone();return a.epoch=function(e,t,a){"string"==typeof t&&("sept"===t&&(t="sep"),t=Y()[t.toLowerCase()]),(t=Ie(t))>=12&&(t=11),t<=0&&(t=0);let n=e.date();n>A[t]&&(n=A[t]);let r=e.clone();return C(e,{month:t,d:n}),(e=Je(e,r,a,"year")).epoch}(a,e,t),a}return this.d.getMonth()},monthName:function(e,t){if(void 0!==e){let a=this.clone();return a=a.month(e,t),a}return E[this.month()]},quarter:function(e,t){if(void 0!==e&&("string"==typeof e&&(e=e.replace(/^q/i,""),e=parseInt(e,10)),Ee[e])){let a=this.clone(),n=Ee[e][0];return a=a.month(n,t),a=a.date(1,t),a=a.startOf("day"),a}let a=this.d.getMonth();for(let e=1;e=Ne[a][e][1]&&n0&&(t.epoch=Qe(t,-1*a)),"ad"===e&&a<0&&(t.epoch=Qe(t,-1*a)),t}return this.d.getFullYear()<0?"BC":"AD"},decade:function(e){if(void 0!==e){if(!(e=(e=(e=String(e)).replace(/([0-9])'?s$/,"$1")).replace(/([0-9])(th|rd|st|nd)/,"$1")))return console.warn("Spacetime: Invalid decade input"),this;2===e.length&&/[0-9][0-9]/.test(e)&&(e="19"+e);let t=Number(e);return isNaN(t)?this:(t=10*Math.floor(t/10),this.year(t))}return this.startOf("decade").year()},century:function(e){if(void 0!==e){"string"==typeof e&&(e=(e=(e=e.replace(/([0-9])(th|rd|st|nd)/,"$1")).replace(/([0-9]+) ?(b\.?c\.?|a\.?d\.?)/i,((e,t,a)=>(a.match(/b\.?c\.?/i)&&(t="-"+t),t)))).replace(/c$/,""));let t=Number(e);return isNaN(e)?(console.warn("Spacetime: Invalid century input"),this):(0===t&&(t=1),t=t>=0?100*(t-1):100*(t+1),this.year(t))}let t=this.startOf("century").year();return t=Math.floor(t/100),t<0?t-1:t+1},millenium:function(e){if(void 0!==e){if("string"==typeof e&&(e=e.replace(/([0-9])(th|rd|st|nd)/,"$1"),e=Number(e),isNaN(e)))return console.warn("Spacetime: Invalid millenium input"),this;e>0&&(e-=1);let t=1e3*e;return 0===t&&(t=1),this.year(t)}let t=Math.floor(this.year()/1e3);return t>=0&&(t+=1),t}},at=Object.assign({},Ze,Xe,tt);at.milliseconds=at.millisecond,at.seconds=at.second,at.minutes=at.minute,at.hours=at.hour,at.hour24=at.hour,at.h12=at.hour12,at.h24=at.hour24,at.days=at.day;const nt=function(e,t){return 1===e&&g(t)?29:A[e]},rt=(e,t)=>{if(e.month>0){let a=parseInt(e.month/12,10);e.year=t.year()+a,e.month=e.month%12}else if(e.month<0){let a=Math.abs(e.month),n=parseInt(a/12,10);a%12!=0&&(n+=1),e.year=t.year()-n,e.month=e.month%12,e.month=e.month+12,12===e.month&&(e.month=0)}return e},it=(e,t,a)=>{let n=t.year(),r=t.month(),i=nt(r,n);for(;a>i;)a-=i,r+=1,r>=12&&(r-=12,n+=1),i=nt(r,n);return e.month=r,e.date=a,e},ot=(e,t,a)=>{e.year=t.year(),e.month=t.month();let n=t.date();for(e.date=n-Math.abs(a);e.date<1;){e.month-=1,e.month<0&&(e.month=11,e.year-=1);let t=nt(e.month,e.year);e.date+=t}return e},st=["millisecond","second","minute","hour","date","month"];let ut={second:st.slice(0,1),minute:st.slice(0,2),quarterhour:st.slice(0,2),hour:st.slice(0,3),date:st.slice(0,4),month:st.slice(0,4),quarter:st.slice(0,4),season:st.slice(0,4),year:st,decade:st,century:st};ut.week=ut.hour,ut.season=ut.date,ut.quarter=ut.date;const dt={year:!0,quarter:!0,season:!0,month:!0,week:!0,date:!0},lt={month:!0,quarter:!0,season:!0,year:!0},ht={millisecond:e=>e.epoch,second:e=>[e.year(),e.month(),e.date(),e.hour(),e.minute(),e.second()].join("-"),minute:e=>[e.year(),e.month(),e.date(),e.hour(),e.minute()].join("-"),hour:e=>[e.year(),e.month(),e.date(),e.hour()].join("-"),day:e=>[e.year(),e.month(),e.date()].join("-"),week:e=>[e.year(),e.week()].join("-"),month:e=>[e.year(),e.month()].join("-"),quarter:e=>[e.year(),e.quarter()].join("-"),year:e=>e.year()};ht.date=ht.day;let mt=u;const ct=function(e,t,a={}){this.epoch=null,this.tz=p(t,mt),this.silent=void 0===a.silent||a.silent,this.british=a.dmy||a.british,this._weekStart=1,void 0!==a.weekStart&&(this._weekStart=a.weekStart),this._today={},void 0!==a.today&&(this._today=a.today),Object.defineProperty(this,"d",{get:function(){let e=(e=>{let t=e.timezones[e.tz];if(void 0===t)return console.warn("Warning: couldn't find timezone "+e.tz),0;if(void 0===t.dst)return t.offset;let a=t.offset,n=t.offset+1;"n"===t.hem&&(n=a-1);let r=t.dst.split("->");return!0===i(e.epoch,r[0],r[1],a,n)?a:n})(this),t=(new Date(this.epoch).getTimezoneOffset()||0)+60*e;t=60*t*1e3;let a=this.epoch+t;return new Date(a)}}),Object.defineProperty(this,"timezones",{get:()=>mt,set:e=>(mt=e,e)});let n=X(this,e);this.epoch=n.epoch,n.tz&&(this.tz=n.tz)};var ft;Object.keys(Le).forEach((e=>{ct.prototype[e]=Le[e]})),ct.prototype.clone=function(){return new ct(this.epoch,this.tz,{silent:this.silent,weekStart:this._weekStart,today:this._today,parsers:this.parsers})},ct.prototype.toLocalDate=function(){return this.toNativeDate()},ct.prototype.toNativeDate=function(){return new Date(this.epoch)},ft=ct,Object.keys(at).forEach((e=>{ft.prototype[e]=at[e]})),(e=>{e.prototype.add=function(e,t){let a=this.clone();if(!t||0===e)return a;let n=this.clone();if("millisecond"===(t=x(t)))return a.epoch+=e,a;"fortnight"===t&&(e*=2,t="week"),V[t]?a.epoch+=V[t]*e:"week"===t||"weekend"===t?a.epoch+=V.day*(7*e):"quarter"===t||"season"===t?a.epoch+=V.month*(3*e):"quarterhour"===t&&(a.epoch+=15*V.minute*e);let r={};if(ut[t]&&ut[t].forEach((e=>{r[e]=n[e]()})),dt[t]){const e=n.timezone().current.offset-a.timezone().current.offset;a.epoch+=3600*e*1e3}if("month"===t&&(r.month=n.month()+e,r=rt(r,n)),"week"===t){let t=n.date()+7*e;t<=28&&t>1&&(r.date=t)}if("weekend"===t&&"saturday"!==a.dayName())a=a.day("saturday",!0);else if("date"===t){if(e<0)r=ot(r,n,e);else{let t=n.date()+e;r=it(r,n,t)}0!==e&&n.isSame(a,"day")&&(r.date=n.date()+e)}else if("quarter"===t){if(r.month=n.month()+3*e,r.year=n.year(),r.month<0){let e=Math.floor(r.month/12),t=r.month+12*Math.abs(e);r.month=t,r.year+=e}else if(r.month>=12){let e=Math.floor(r.month/12);r.month=r.month%12,r.year+=e}r.date=n.date()}else if("year"===t){let t=n.year()+e,r=a.year();if(rt){let t=Math.floor(e/4)||1;a.epoch+=V.day*t}}else"decade"===t?r.year=a.year()+10:"century"===t&&(r.year=a.year()+100);if(lt[t]){let e=A[r.month];r.date=n.date(),r.date>e&&(r.date=e)}return Object.keys(r).length>1&&C(a,r),a},e.prototype.subtract=function(e,t){return this.clone().add(-1*e,t)},e.prototype.minus=e.prototype.subtract,e.prototype.plus=e.prototype.add})(ct),(e=>{e.prototype.isSame=function(t,a,n=!0){let r=this;if(!a)return null;if("string"==typeof t&&"object"==typeof a){let e=t;t=a,a=e}return"string"!=typeof t&&"number"!=typeof t||(t=new e(t,this.timezone.name)),a=a.replace(/s$/,""),!0===n&&r.tz!==t.tz&&((t=t.clone()).tz=r.tz),ht[a]?ht[a](r)===ht[a](t):null}})(ct),(e=>{const t={isAfter:function(e){let t=O(e=M(e,this));return null===t?null:this.epoch>t},isBefore:function(e){let t=O(e=M(e,this));return null===t?null:this.epoch{e.prototype[a]=t[a]}))})(ct),(e=>{const t={i18n:function(e){var t,a,n;return b(e.days)&&(t=e.days,ee=t.short||ee,te=t.long||te),b(e.months)&&function(e){N=e.short||N,E=e.long||E}(e.months),n=e.useTitleCase,"[object Boolean]"===Object.prototype.toString.call(n)&&(a=e.useTitleCase,ie=a),b(e.ampm)&&function(e){Re=e.am||Re,Ge=e.pm||Ge}(e.ampm),b(e.distance)&&function(e){je=e.pastDistance||je,$e=e.futureDistance||$e,De=e.past||De,ve=e.future||ve,xe=e.present||xe,Oe=e.now||Oe,Me=e.almost||Me,_e=e.over||_e}(e.distance),b(e.units)&&function(e={}){be={second:e.second||be.second,seconds:e.seconds||be.seconds,minute:e.minute||be.minute,minutes:e.minutes||be.minutes,hour:e.hour||be.hour,hours:e.hours||be.hours,day:e.day||be.day,days:e.days||be.days,month:e.month||be.month,months:e.months||be.months,year:e.year||be.year,years:e.years||be.years}}(e.units),this}};Object.keys(t).forEach((a=>{e.prototype[a]=t[a]}))})(ct);const yt=(e,t,a)=>new ct(e,t,a),pt=function(e){let t=e._today||{};return Object.keys(t).forEach((a=>{e=e[a](t[a])})),e};yt.now=(e,t)=>{let a=new ct((new Date).getTime(),e,t);return a=pt(a),a},yt.today=(e,t)=>{let a=new ct((new Date).getTime(),e,t);return a=pt(a),a.startOf("day")},yt.tomorrow=(e,t)=>{let a=new ct((new Date).getTime(),e,t);return a=pt(a),a.add(1,"day").startOf("day")},yt.yesterday=(e,t)=>{let a=new ct((new Date).getTime(),e,t);return a=pt(a),a.subtract(1,"day").startOf("day")},yt.extend=function(e={}){return Object.keys(e).forEach((t=>{ct.prototype[t]=e[t]})),this},yt.timezones=function(){return(new ct).timezones},yt.max=function(e,t){let a=new ct(null,e,t);return a.epoch=864e13,a},yt.min=function(e,t){let a=new ct(null,e,t);return a.epoch=-864e13,a},yt.whereIts=(e,t)=>{let a=new ct(null),n=new ct(null);a=a.time(e),n=t?n.time(t):a.add(59,"minutes");let r=a.hour(),i=n.hour();return Object.keys(a.timezones).filter((e=>{if(-1===e.indexOf("/"))return!1;let t=new ct(null,e),o=t.hour();return o>=r&&o<=i&&(!(o===r&&t.minute()n.minute()))}))},yt.version="7.7.0",yt.plugin=yt.extend;const gt={daybreak:"7:00am",breakfast:"8:00am",morning:"9:00am",noon:"12:00pm",midday:"12:00pm",afternoon:"2:00pm",lunchtime:"12:00pm",evening:"6:00pm",dinnertime:"6:00pm",night:"8:00pm",eod:"10:00pm",midnight:"12:00am",am:"9:00am",pm:"5:00pm","early day":"8:00am","late at night":"11:00pm"},wt={quarter:15,half:30},bt=function(e){let t=e.time("6:00am");return e.isBefore(t)?e.ampm("pm"):e},kt=function(e,t){let a=e.match("(at|by|for|before|this|after)? #Time+");a=a.not("^(at|by|for|before|this|after)"),a=a.not("sharp"),a=a.not("on the dot");let n=yt.now(t.timezone),r=n.clone(),i=a.not("in? the").text("reduced");if(i=i.replace(/^@/,""),gt.hasOwnProperty(i))return{result:gt[i],m:a};let o=a.match("^#Cardinal oclock (am|pm)?");if(o.found&&(n=n.hour(o.text("reduced")),n=n.startOf("hour"),n.isValid()&&!n.isEqual(r))){let e=o.match("(am|pm)");return n=e.found?n.ampm(e.text("reduced")):bt(n),{result:n.time(),m:o}}if(o=a.match("(half|quarter|25|20|15|10|5) (past|after|to) #Cardinal"),o.found&&(n=function(e,t){let a=e.match("#Cardinal$"),n=e.not(a).match("(half|quarter|25|20|15|10|5)");a=a.text("reduced");let r=n.text("reduced");wt.hasOwnProperty(r)&&(r=wt[r]);let i=e.has("to");return t=(t=t.hour(a)).startOf("hour"),a<6&&(t=t.ampm("pm")),i?t.subtract(r,"minutes"):t.add(r,"minutes")}(o,n),n.isValid()&&!n.isEqual(r)))return n=bt(n),{result:n.time(),m:o};if(o=a.match("[(half|quarter|25|20|15|10|5)] (past|after)"),o.found){let e=o.groups("min").text("reduced"),a=yt(t.today);if(wt.hasOwnProperty(e)&&(e=wt[e]),a=a.next("hour").startOf("hour").minute(e),a.isValid()&&!a.isEqual(r))return{result:a.time(),m:o}}if(o=a.match("[(half|quarter|25|20|15|10|5)] to"),o.found){let e=o.groups("min").text("reduced"),a=yt(t.today);if(wt.hasOwnProperty(e)&&(e=wt[e]),a=a.next("hour").startOf("hour").minus(e,"minutes"),a.isValid()&&!a.isEqual(r))return{result:a.time(),m:o}}if(o=a.match("[#Time] (in|at) the? [(morning|evening|night|nighttime)]"),o.found){let e=o.groups("time").text("normal");if(/^[0-9]{1,2}$/.test(e)?(n=n.hour(e),n=n.startOf("hour")):n=n.time(e),n.isValid()&&!n.isEqual(r)){let e=o.groups("desc").text("reduced");return"evening"!==e&&"night"!==e||(n=n.ampm("pm")),{result:n.time(),m:o}}}if(o=a.match("this? [(morning|evening|tonight)] at [(#Cardinal|#Time)]"),o.found){let e=o.groups(),t=e.time.text("reduced");if(/^[0-9]{1,2}$/.test(t)?(n=n.hour(t),n=n.startOf("hour")):n=n.time(t),n.isValid()&&!n.isEqual(r)){let t=e.desc.text("reduced");return"morning"===t&&(n=n.ampm("am")),"evening"!==t&&"tonight"!==t||(n=n.ampm("pm")),{result:n.time(),m:o}}}if(o=a.match("^#Cardinal$"),o.found){let e=o.text("reduced");if(n=n.hour(e),n=n.startOf("hour"),n.isValid()&&!n.isEqual(r))return!1===/(am|pm)/i.test(e)&&(n=bt(n)),{result:n.time(),m:o}}let s=a.text("reduced");return n=n.time(s),n.isValid()&&!n.isEqual(r)?(!1===/(am|pm)/i.test(s)&&(n=bt(n)),{result:n.time(),m:a}):t.dayStart?{result:t.dayStart,m:e.none()}:{result:null,m:e.none()}},Dt="America/",vt="Asia/",xt="Europe/",Ot="Africa/",Mt="Australia/",_t="Pacific/",jt={"british summer time":xt+"London",bst:xt+"London","british time":xt+"London","britain time":xt+"London","irish summer time":xt+"Dublin","irish time":xt+"Dublin",ireland:xt+"Dublin","central european time":xt+"Berlin",cet:xt+"Berlin","central european summer time":xt+"Berlin",cest:xt+"Berlin","central europe":xt+"Berlin","eastern european time":xt+"Riga",eet:xt+"Riga","eastern european summer time":xt+"Riga",eest:xt+"Riga","eastern europe time":xt+"Riga","western european time":xt+"Lisbon","western european summer time":xt+"Lisbon","western europe":xt+"Lisbon","turkey standard time":xt+"Istanbul",trt:xt+"Istanbul","turkish time":xt+"Istanbul",etc:Ot+"Freetown",utc:Ot+"Freetown","greenwich standard time":Ot+"Freetown",gmt:Ot+"Freetown","east africa time":Ot+"Nairobi","east african time":Ot+"Nairobi","eastern africa time":Ot+"Nairobi","central africa time":Ot+"Khartoum","central african time":Ot+"Khartoum","south africa standard time":Ot+"Johannesburg",sast:Ot+"Johannesburg","southern africa":Ot+"Johannesburg","south african":Ot+"Johannesburg","west africa standard time":Ot+"Lagos","western africa time":Ot+"Lagos","west african time":Ot+"Lagos","australian central standard time":Mt+"Adelaide",acst:Mt+"Adelaide","australian central daylight time":Mt+"Adelaide",acdt:Mt+"Adelaide","australia central":Mt+"Adelaide","australian eastern standard time":Mt+"Brisbane",aest:Mt+"Brisbane","australian eastern daylight time":Mt+"Brisbane",aedt:Mt+"Brisbane","australia east":Mt+"Brisbane","australian western standard time":Mt+"Perth",awst:Mt+"Perth","australian western daylight time":Mt+"Perth",awdt:Mt+"Perth","australia west":Mt+"Perth","australian central western standard time":Mt+"Eucla",acwst:Mt+"Eucla","australia central west":Mt+"Eucla","lord howe standard time":Mt+"Lord_Howe",lhst:Mt+"Lord_Howe","lord howe daylight time":Mt+"Lord_Howe",lhdt:Mt+"Lord_Howe","russian standard time":xt+"Moscow",msk:xt+"Moscow",russian:xt+"Moscow","central standard time":Dt+"Chicago","central time":Dt+"Chicago",cst:Dt+"Havana","central daylight time":Dt+"Chicago",cdt:Dt+"Havana","mountain standard time":Dt+"Denver","mountain time":Dt+"Denver",mst:Dt+"Denver","mountain daylight time":Dt+"Denver",mdt:Dt+"Denver","atlantic standard time":Dt+"Halifax","atlantic time":Dt+"Halifax",ast:vt+"Baghdad","atlantic daylight time":Dt+"Halifax",adt:Dt+"Halifax","eastern standard time":Dt+"New_York",eastern:Dt+"New_York","eastern time":Dt+"New_York",est:Dt+"New_York","eastern daylight time":Dt+"New_York",edt:Dt+"New_York","pacific time":Dt+"Los_Angeles","pacific standard time":Dt+"Los_Angeles",pst:Dt+"Los_Angeles","pacific daylight time":Dt+"Los_Angeles",pdt:Dt+"Los_Angeles","alaskan standard time":Dt+"Anchorage","alaskan time":Dt+"Anchorage",ahst:Dt+"Anchorage","alaskan daylight time":Dt+"Anchorage",ahdt:Dt+"Anchorage","hawaiian standard time":_t+"Honolulu","hawaiian time":_t+"Honolulu",hst:_t+"Honolulu","aleutian time":_t+"Honolulu","hawaii time":_t+"Honolulu","newfoundland standard time":Dt+"St_Johns","newfoundland time":Dt+"St_Johns",nst:Dt+"St_Johns","newfoundland daylight time":Dt+"St_Johns",ndt:Dt+"St_Johns","brazil time":Dt+"Sao_Paulo",brt:Dt+"Sao_Paulo","brasília":Dt+"Sao_Paulo",brasilia:Dt+"Sao_Paulo","brazilian time":Dt+"Sao_Paulo","argentina time":Dt+"Buenos_Aires","argentinian time":Dt+"Buenos_Aires","amazon time":Dt+"Manaus",amt:Dt+"Manaus","amazonian time":Dt+"Manaus","easter island standard time":"Chile/Easterisland",east:"Chile/Easterisland","easter island summer time":"Chile/Easterisland",easst:"Chile/Easterisland","venezuelan standard time":Dt+"Caracas","venezuelan time":Dt+"Caracas",vet:Dt+"Caracas","venezuela time":Dt+"Caracas","paraguay time":Dt+"Asuncion",pyt:Dt+"Asuncion","paraguay summer time":Dt+"Asuncion",pyst:Dt+"Asuncion","cuba standard time":Dt+"Havana","cuba time":Dt+"Havana","cuba daylight time":Dt+"Havana","cuban time":Dt+"Havana","bolivia time":Dt+"La_Paz","bolivian time":Dt+"La_Paz","colombia time":Dt+"Bogota",cot:Dt+"Bogota","colombian time":Dt+"Bogota","acre time":Dt+"Eirunepe","peru time":Dt+"Lima","chile standard time":Dt+"Punta_Arenas","chile time":Dt+"Punta_Arenas",clst:Dt+"Punta_Arenas","chile summer time":Dt+"Punta_Arenas",cldt:Dt+"Punta_Arenas","uruguay time":Dt+"Montevideo",uyt:Dt+"Montevideo",ist:vt+"Jerusalem","arabic standard time":vt+"Baghdad","arabic time":vt+"Baghdad","arab time":vt+"Baghdad","iran standard time":vt+"Tehran","iran time":vt+"Tehran",irst:vt+"Tehran","iran daylight time":vt+"Tehran",irdt:vt+"Tehran",iranian:vt+"Tehran","pakistan standard time":vt+"Karachi","pakistan time":vt+"Karachi",pkt:vt+"Karachi","india standard time":vt+"Kolkata","indian time":vt+"Kolkata","indochina time":vt+"Bangkok",ict:vt+"Bangkok","south east asia":vt+"Bangkok","china standard time":vt+"Shanghai",ct:vt+"Shanghai","chinese time":vt+"Shanghai","alma-ata time":vt+"Almaty",almt:vt+"Almaty","oral time":vt+"Oral","orat time":vt+"Oral","yakutsk time":vt+"Yakutsk",yakt:vt+"Yakutsk","gulf standard time":vt+"Dubai","gulf time":vt+"Dubai",gst:vt+"Dubai",uae:vt+"Dubai","hong kong time":vt+"Hong_Kong",hkt:vt+"Hong_Kong","western indonesian time":vt+"Jakarta",wib:vt+"Jakarta","indonesia time":vt+"Jakarta","central indonesian time":vt+"Makassar",wita:vt+"Makassar","israel daylight time":vt+"Jerusalem",idt:vt+"Jerusalem","israel standard time":vt+"Jerusalem","israel time":vt+"Jerusalem",israeli:vt+"Jerusalem","krasnoyarsk time":vt+"Krasnoyarsk",krat:vt+"Krasnoyarsk","malaysia time":vt+"Kuala_Lumpur",myt:vt+"Kuala_Lumpur","singapore time":vt+"Singapore",sgt:vt+"Singapore","korea standard time":vt+"Seoul","korea time":vt+"Seoul",kst:vt+"Seoul","korean time":vt+"Seoul","uzbekistan time":vt+"Samarkand",uzt:vt+"Samarkand","vladivostok time":vt+"Vladivostok",vlat:vt+"Vladivostok","maldives time":"Indian/Maldives",mvt:"Indian/Maldives","mauritius time":"Indian/Mauritius",mut:"Indian/Mauritius","marshall islands time":_t+"Kwajalein",mht:_t+"Kwajalein","samoa standard time":_t+"Midway",sst:_t+"Midway","somoan time":_t+"Midway","chamorro standard time":_t+"Guam",chst:_t+"Guam","papua new guinea time":_t+"Bougainville",pgt:_t+"Bougainville"};let $t=yt().timezones,zt=Object.keys($t).reduce(((e,t)=>(e[t]=t,e)),{});var Tt=Object.assign({},jt,zt);const Vt=/(-?[0-9]+)h(rs)?/i,St=/(-?[0-9]+)/,qt=/utc([-+]?[0-9]+)/i,Ct=/gmt([-+]?[0-9]+)/i,At=function(e){return(e=Number(e))>-13&&e<13?"Etc/GMT"+(e=((e*=-1)>0?"+":"")+e):null},Nt=function(e){let t=e.match("#Timezone+");t=t.not("(in|for|by|near|at)");let a=t.text("reduced");if(Tt.hasOwnProperty(a))return{result:Tt[a],m:t};let n=function(e){let t=e.match(Vt);if(null!==t)return At(t[1]);if(t=e.match(qt),null!==t)return At(t[1]);if(t=e.match(Ct),null!==t){let e=-1*Number(t[1]);return At(e)}return t=e.match(St),null!==t?At(t[1]):null}(a);return n?{result:n,m:t}:{result:null,m:e.none()}},Et=function(t,r){let i=function(t){let n={},r=t.none(),i=t.match("#DateShift+");if(!1===i.found)return{res:n,m:r};if(i.match("#Cardinal #Duration").forEach((t=>{let r=t.match("#Cardinal").numbers().get()[0];if(r&&"number"==typeof r){let i=a(t);!0===e[i]&&(n[i]=r)}})),!0===i.has("(before|ago|hence|back)$")&&Object.keys(n).forEach((e=>n[e]*=-1)),r=i.match("#Cardinal #Duration"),i=i.not(r),r=i.match("[#Duration] [(after|before)]"),r.found){let e=r.groups("unit").text("reduced"),t=r.groups("dir").text("reduced");"after"===t?n[e]=1:"before"===t&&(n[e]=-1)}if(r=i.match("half (a|an) [#Duration]",0),r.found){let e=a(r);n[e]=.5}if(r=i.match("a (few|couple) [#Duration]",0),r.found){let e=a(r);n[e]=r.has("few")?3:2}return r=t.match("#DateShift+"),{result:n,m:r}}(t),o=i.result;i=function(e){let t=e.match("[#Value] [#Duration+] (of|in)");if(t.found){let e=t.groups(),a=e.num.numbers().get()[0],r=e.unit.text("reduced"),i={unit:r,num:Number(a)||0};return n[r]||(i.num-=1),{result:i,m:t}}if(t=e.match("[(first|initial|last|final)] [#Duration+] (of|in)"),t.found){let e=t.groups(),a=e.dir.text("reduced");return"initial"===a&&(a="first"),"final"===a&&(a="last"),{result:{unit:e.unit.text("reduced"),dir:a},m:t}}return{result:null,m:e.none()}}(t=t.not(i.m));let s=i.result;t=t.not(i.m),i=Nt(t);let u=i.result;t=t.not(i.m),i=kt(t,r);let d=i.result;i=function(e){let t=e.match("#WeekDay");return t.found&&!e.has("^#WeekDay$")?e.has("(this|next|last) (next|upcoming|coming|past)? #WeekDay")?{result:null,m:e.none()}:{result:t.text("reduced"),m:t}:{result:null,m:e.none()}}(t=t.not(i.m));let l=i.result;i=function(e){let t=e.match("[(start|beginning) of] .",0);return t.found?{result:"start",m:t}:(t=e.match("[end of] .",0),t.found?{result:"end",m:t}:(t=e.match("[(middle|midpoint|center) of] .",0),t.found?{result:"middle",m:t}:{result:null,m:t}))}(t=t.not(i.m));let h=i.result;return i=function(e){if(e.has("(next|last|this)$"))return{result:null,m:e.none()};let t=e.match("^this? (next|upcoming|coming)");return t.found?{result:"next",m:t}:(t=e.match("^this? (past)"),t.found?{result:"this-past",m:t}:(t=e.match("^this? (last|previous)"),t.found?{result:"last",m:t}:(t=e.match("^(this|current)"),t.found?{result:"this",m:t}:{result:null,m:e.none()})))}(t=t.not(i.m)),{shift:o,counter:s,tz:u,time:d,weekDay:l,section:h,rel:i.result,doc:t=function(e){return(e=(e=(e=(e=(e=(e=e.not("[^the] !#Value",0)).not("#Preposition$")).not("#Conjunction$")).not("sharp")).not("on the dot")).not("^(on|of)")).not("(next|last|this)$")}(t=t.not(i.m))}};class Unit{constructor(e,t,a){this.unit=t||"day",this.setTime=!1;let n={};(a=a||{}).today&&(n={date:a.today.date(),month:a.today.month(),year:a.today.year()}),e&&"sept"===e.month&&(e.month="sep");let r=yt(e,a.timezone,{today:n,dmy:a.dmy});Object.defineProperty(this,"d",{enumerable:!1,writable:!0,value:r}),Object.defineProperty(this,"context",{enumerable:!1,writable:!0,value:a})}clone(){let e=new Unit(this.d,this.unit,this.context);return e.setTime=this.setTime,e}log(){return console.log("--"),this.d.log(),console.log("\n"),this}applyShift(e={}){return Object.keys(e).forEach((t=>{this.d=this.d.add(e[t],t),"hour"!==t&&"minute"!==t||(this.setTime=!0)})),this}applyTime(e){if(e){if(/^[0-9]{1,2}$/.test(e)?this.d=this.d.hour(e):this.d=this.d.time(e),!/[ap]m/.test(e)){let e=this.d.time("6:00am");this.d.isBefore(e)&&(this.d=this.d.ampm("pm"));let t=this.d.time("10:00pm");this.d.isAfter(t)&&(this.d=this.d.ampm("am"))}}else this.d=this.d.startOf("day");return this.setTime=!0,this}applyWeekDay(e){if(e){let t=this.d.epoch;this.d=this.d.day(e),this.d.epochnew Day(e.today,null,e),yesterday:e=>new Day(e.today.minus(1,"day"),null,e),tomorrow:e=>new Day(e.today.plus(1,"day"),null,e),eom:e=>{let t=e.today.endOf("month");return t=t.startOf("day"),new Day(t,null,e)},eoy:e=>{let t=e.today.endOf("year");return t=t.startOf("day"),new Day(t,null,e)},now:e=>new Moment(e.today,null,e)};Pt.tommorrow=Pt.tomorrow,Pt.tmrw=Pt.tomorrow,Pt.anytime=Pt.today,Pt.sometime=Pt.today;const Yt="january",Bt="february",Ht="march",Lt="april",It="may",Wt="july",Ft="august",Jt="september",Ut="october",Kt="november",Qt="december";var Rt={"new years eve":[Qt,31],"new years":[Yt,1],"new years day":[Yt,1],"inauguration day":[Yt,20],"australia day":[Yt,26],"national freedom day":[Bt,1],"groundhog day":[Bt,2],"rosa parks day":[Bt,4],"valentines day":[Bt,14],"saint valentines day":[Bt,14],"st valentines day ":[Bt,14],"saint patricks day":[Ht,17],"st patricks day":[Ht,17],"april fools":[Lt,1],"april fools day":[Lt,1],"emancipation day":[Lt,16],"tax day":[Lt,15],"labour day":[It,1],"cinco de mayo":[It,5],"national nurses day":[It,6],"harvey milk day":[It,22],"victoria day":[It,24],juneteenth:["june",19],"canada day":[Wt,1],"independence day":[Wt,4],"independents day":[Wt,4],"bastille day":[Wt,14],"purple heart day":[Ft,7],"womens equality day":[Ft,26],"16 de septiembre":[Jt,16],"dieciseis de septiembre":[Jt,16],"grito de dolores":[Jt,16],halloween:[Ut,31],"all hallows eve":[Ut,31],"day of the dead":[Ut,31],"dia de muertos":[Ut,31],"veterans day":[Kt,11],"st andrews day":[Kt,30],"saint andrews day":[Kt,30],"all saints day":[Kt,1],"all sts day":[Kt,1],"armistice day":[Kt,11],"rememberance day":[Kt,11],"christmas eve":[Qt,24],christmas:[Qt,25],xmas:[Qt,25],"boxing day":[Qt,26],"st stephens day":[Qt,26],"saint stephens day":[Qt,26],epiphany:[Yt,6],"orthodox christmas day":[Yt,7],"orthodox new year":[Yt,14],"assumption of mary":[Ft,15],"all souls day":[Kt,2],"feast of the immaculate conception":[Qt,8],"feast of our lady of guadalupe":[Qt,12],kwanzaa:[Qt,26],imbolc:[Bt,2],beltaine:[It,1],lughnassadh:[Ft,1],samhain:[Ut,31]};var Gt=function(e,t,a,n){if(Rt.hasOwnProperty(e)||Rt.hasOwnProperty(t)){let r=Rt[e]||Rt[t]||[],i=yt.now(n);if(i=i.year(a),i=i.startOf("year"),i=i.month(r[0]),i=i.date(r[1]),i.isValid())return i}return null};const Zt="october",Xt="november",ea="monday",ta="sunday";let aa={"martin luther king day":[3,ea,"january"],"presidents day":[3,ea,"february"],"commonwealth day":[2,ea,"march"],"mothers day":[2,ta,"may"],"fathers day":[3,ta,"june"],"labor day":[1,ea,"september"],"columbus day":[2,ea,Zt],"canadian thanksgiving":[2,ea,Zt],thanksgiving:[4,"thursday",Xt],"black friday":[4,"friday",Xt]};aa["turday day"]=aa.thanksgiving,aa["indigenous peoples day"]=aa["columbus day"],aa["mlk day"]=aa["martin luther king day"];var na=aa;var ra=function(e,t,a,n){if(na.hasOwnProperty(e)||na.hasOwnProperty(t)){let r=na[e]||na[t]||[],i=yt.now(n);i=i.year(a),i=i.month(r[2]),i=i.startOf("month");let o=i.month();if(i=i.day(r[1]),i.month()!==o&&(i=i.add(1,"week")),r[0]>1&&(i=i.add(r[0]-1,"week")),i.isValid())return i}return null};let ia={easter:0,"ash wednesday":-46,"palm sunday":7,"maundy thursday":-3,"good friday":-2,"holy saturday":-1,"easter saturday":-1,"easter monday":1,"ascension day":39,"whit sunday":49,"whit monday":50,"trinity sunday":65,"corpus christi":60,"mardi gras":-47};ia["easter sunday"]=ia.easter,ia.pentecost=ia["whit sunday"],ia.whitsun=ia["whit sunday"];var oa=ia;var sa=function(e){let t=Math.floor,a=e%19,n=t(e/100),r=(n-t(n/4)-t((8*n+13)/25)+19*a+15)%30,i=r-t(r/28)*(1-t(29/(r+1))*t((21-a)/11)),o=i-(e+t(e/4)+i+2-n+t(n/4))%7,s=3+t((o+40)/44),u=o+28-31*t(s/4);return s=4===s?"April":"March",s+" "+u};var ua=function(e,t,a,n){if(oa.hasOwnProperty(e)||oa.hasOwnProperty(t)){let r=oa[e]||oa[t]||[],i=sa(a);if(!i)return null;let o=yt(i,n);o=o.year(a);let s=o.add(r,"day");if(s.isValid())return s}return null};const da={spring:[2003,2007,2044,2048,2052,2056,2060,2064,2068,2072,2076,2077,2080,2081,2084,2085,2088,2089,2092,2093,2096,2097],summer:[2021,2016,2020,2024,2028,2032,2036,2040,2041,2044,2045,2048,2049,2052,2053,2056,2057,2060,2061,2064,2065,2068,2069,2070,2072,2073,2074,2076,2077,2078,2080,2081,2082,2084,2085,2086,2088,2089,2090,2092,2093,2094,2096,2097,2098,2099],fall:[2002,2003,2004,2006,2007,2010,2011,2014,2015,2018,2019,2022,2023,2026,2027,2031,2035,2039,2043,2047,2051,2055,2059,2092,2096],winter:[2002,2003,2006,2007,2011,2015,2019,2023,2027,2031,2035,2039,2043,2080,2084,2088,2092,2096]},la=[2080,2084,2088,2092,2096];var ha=function(e){let t={spring:"March 20 "+e,summer:"June 21 "+e,fall:"Sept 22 "+e,winter:"Dec 21 "+e};return-1!==da.spring.indexOf(e)&&(t.spring="March 19 "+e),-1!==da.summer.indexOf(e)&&(t.summer="June 20 "+e),-1!==da.fall.indexOf(e)&&(t.fall="Sept 21 "+e),-1!==da.winter.indexOf(e)&&(t.winter="Dec 22 "+e),-1!==la.indexOf(e)&&(t.winter="Dec 20 "+e),t};let ma={"spring equinox":"spring","summer solistice":"summer","fall equinox":"fall","winter solstice":"winter"};ma["march equinox"]=ma["spring equinox"],ma["vernal equinox"]=ma["spring equinox"],ma.ostara=ma["spring equinox"],ma["june solstice"]=ma["summer solistice"],ma.litha=ma["summer solistice"],ma["autumn equinox"]=ma["fall equinox"],ma["autumnal equinox"]=ma["fall equinox"],ma["september equinox"]=ma["fall equinox"],ma["sept equinox"]=ma["fall equinox"],ma.mabon=ma["fall equinox"],ma["december solstice"]=ma["winter solistice"],ma["dec solstice"]=ma["winter solistice"],ma.yule=ma["winter solistice"];var ca=ma;var fa=function(e,t,a,n){if(ca.hasOwnProperty(e)||ca.hasOwnProperty(t)){let r=ca[e]||ca[t],i=ha(a);if(!r||!i||!i[r])return null;let o=yt(i[r],n);if(o.isValid())return o}return null};var ya={"isra and miraj":"april 13","lailat al-qadr":"june 10","eid al-fitr":"june 15","id al-Fitr":"june 15","eid ul-Fitr":"june 15",ramadan:"may 16","eid al-adha":"sep 22",muharram:"sep 12","prophets birthday":"nov 21"};var pa=function(e,t,a,n){if(ya.hasOwnProperty(e)||ya.hasOwnProperty(t)){let r=ya[e]||ya[t]||[];if(!r)return null;let i=yt(r+" 2018",n),o=-10.64*(a-2018);if(i=i.add(o,"day"),i=i.startOf("day"),i=i.year(a),i.isValid())return i}return null};const ga=yt.now().year(),wa=function(e,t,a){t=t||ga,e=e||"";let n=(e=(e=(e=String(e)).trim().toLowerCase()).replace(/'s/,"s")).replace(/ day$/,"");n=n.replace(/^the /,""),n=n.replace(/^orthodox /,"");let r=Gt(e,n,t,a);return null!==r?r:(r=ra(e,n,t,a),null!==r?r:(r=ua(e,n,t,a),null!==r?r:(r=fa(e,n,t,a),null!==r?r:(r=pa(e,n,t,a),null!==r?r:null))))},ba={day:Day,hour:Hour,evening:Hour,second:Moment,milliscond:Moment,instant:Moment,minute:Minute,week:Week,weekend:WeekEnd,month:class AnyMonth extends Unit{constructor(e,t,a){super(e,t,a),this.unit="month",this.d.isValid()&&(this.d=this.d.startOf(this.unit))}},quarter:AnyQuarter,year:Year,season:Season,yr:Year,qtr:AnyQuarter,wk:Week,sec:Moment,hr:Hour};let ka=`^(${Object.keys(ba).join("|")})$`;const Da=function(e){return{date:e.today.date(),month:e.today.month(),year:e.today.year()}},va=function(e,t,a){let n=null;return n=n||function(e,t,a){let n=null;!1===e.found&&(null!==a.time&&(n=new Moment(t.today,null,t)),a.shift&&Object.keys(a.shift).length>0&&(n=a.shift.hour||a.shift.minute?new Moment(t.today,null,t):new Day(t.today,null,t)));let r=e.text("reduced");return!0===Pt.hasOwnProperty(r)?Pt[r](t):"next"===r&&a.shift&&Object.keys(a.shift).length>0?Pt.tomorrow(t):n}(e,t,a),n=n||function(e,t){let a=null,n=e.match("[#Holiday+] [#Year?]"),r=t.today.year();n.groups("year").found&&(r=Number(n.groups("year").text("reduced"))||r);let i=n.groups("holiday").text("reduced"),o=wa(i,r,t.timezone);return null!==o&&(o.isBefore(t.today)&&r===t.today.year()&&(o=wa(i,r+1,t.timezone)),a=new Holiday(o,null,t)),a}(e,t),n=n||function(e,t){let a=e.match(ka);if(!0===a.found){let e=a.text("reduced");if(ba.hasOwnProperty(e)){let a=ba[e];return a?new a(null,e,t):null}}if(a=e.match("^#WeekDay$"),!0===a.found){let e=a.text("reduced");return new WeekDay(e,null,t)}return null}(e,t),n=n||function(e,t){let a=e.match("(spring|summer|winter|fall|autumn) [#Year?]");if(a.found){let a=e.text("reduced"),n=yt(a,t.timezone,{today:Da(t)}),r=new Season(n,null,t);if(!0===r.d.isValid())return r}if(a=e.match("[#FinancialQuarter] [#Year?]"),a.found){let e=a.groups("q").text("reduced"),n=yt(e,t.timezone,{today:Da(t)});if(a.groups("year")){let e=Number(a.groups("year").text())||t.today.year();n=n.year(e)}let r=new Quarter(n,null,t);if(!0===r.d.isValid())return r}if(a=e.match("[#Value] quarter (of|in)? [#Year?]"),a.found){let e=a.groups("q").text("reduced"),n=yt(`q${e}`,t.timezone,{today:Da(t)});if(a.groups("year")){let e=Number(a.groups("year").text())||t.today.year();n=n.year(e)}let r=new Quarter(n,null,t);if(!0===r.d.isValid())return r}if(a=e.match("^#Year$"),a.found){let a=e.text("reduced"),n=yt(null,t.timezone,{today:Da(t)});n=n.year(a);let r=new Year(n,null,t);if(!0===r.d.isValid())return r}return null}(e,t),n=n||function(e,t){let a=t.today.year(),n=e.match("[#Value] of? [#Month] [#Year]");if(n.found||(n=e.match("[#Month] the? [#Value] [#Year]")),n.found){let e={month:n.groups("month").text("reduced"),date:n.groups("date").text("reduced"),year:n.groups("year").text()||a},r=new CalendarDate(e,null,t);if(!0===r.d.isValid())return r}if(n=e.match("[#Month] of? [#Year]"),n.found){let e={month:n.groups("month").text("reduced"),year:n.groups("year").text("reduced")||a},r=new Month(e,null,t);if(!0===r.d.isValid())return r}if(n=e.match("[#Month] [#Value+]? of? the? [(this|next|last|current)] year"),n.found){let e=n.groups("rel").text("reduced"),r=a;"next"===e?r+=1:"last"===e&&(r-=1);let i={month:n.groups("month").text("reduced"),date:n.groups("date").numbers(0).get()[0],year:r};if(void 0===i.date){i.date=1;let e=new Month(i,null,t);if(!0===e.d.isValid())return e}let o=new CalendarDate(i,null,t);if(!0===o.d.isValid())return o}if(n=e.match("^the? [#Value+]? of? [(this|next|last|current)] month"),n.found){let e=t.today.month(),a=n.groups("rel").text("reduced");"next"===a?e+=1:"last"===a&&(e-=1);let r={month:e,date:n.groups("date").numbers(0).get()[0]},i=new CalendarDate(r,null,t);if(!0===i.d.isValid())return i}if(n=e.match("[#Value] of? [#Month]"),n.found||(n=e.match("[#Month] the? [#Value]")),n.found){let e={month:n.groups("month").text("reduced"),date:n.groups("date").text("reduced"),year:t.today.year()},a=new CalendarDate(e,null,t);if(a.d.month()#Value]"),n.found){let e={month:t.today.month(),date:n.groups("date").text("reduced"),year:t.today.year()},a=new CalendarDate(e,null,t);if(!0===a.d.isValid())return a}if(n=e.match("the [#Value]"),n.found){let e={month:t.today.month(),date:n.groups("date").text("reduced"),year:t.today.year()},a=new CalendarDate(e,null,t);if(!0===a.d.isValid())return a.d.isBefore(t.today)&&(a.d=a.d.add(1,"month")),a}if(n=e.match("/[0-9]{4}-[0-9]{2}-[0-9]{2}t[0-9]{2}:/"),n.found){let a=e.text("reduced"),n=new Moment(a,null,t);if(!0===n.d.isValid())return n}let r=e.text("reduced");if(!r)return new Moment(t.today,null,t);let i=new Day(r,null,t);return!1===i.d.isValid()?null:i}(e,t),n},xa={day:Day,week:Week,weekend:WeekEnd,month:Month,quarter:Quarter,season:Season,hour:Hour,minute:Minute},Oa=function(e,t,a){if(!e&&a.weekDay&&(e=new WeekDay(a.weekDay,null,t),a.weekDay=null),!e)return null;if(a.shift){let t=a.shift;e.applyShift(t),t.hour||t.minute?e=new Moment(e.d,null,e.context):(t.week||t.day||t.month)&&(e=new Day(e.d,null,e.context))}return a.weekDay&&"day"!==e.unit&&(e.applyWeekDay(a.weekDay),e=new WeekDay(e.d,null,e.context)),a.rel&&e.applyRel(a.rel),a.section&&e.applySection(a.section),a.time&&e.applyTime(a.time),a.counter&&a.counter.unit&&(e=function(e,t={}){let a=xa[t.unit];if(!a)return e;let n=e.d;"first"===t.dir||0===t.num?(n=e.start().d,n=n.startOf(t.unit)):"last"===t.dir?(n=n.endOf(e.unit),n="weekend"===t.unit?n.day("saturday",!1):n.startOf(t.unit)):t.num&&("weekend"===t.unit&&(n=n.day("saturday",!0).add(1,"day")),n=n.add(t.num,t.unit));let r=new a(n,null,e.context);return!0===r.d.isValid()?r:e}(e,a.counter)),e},Ma="undefined"!=typeof process&&process.env?process.env:self.env||{},_a=function(e,t){let a=Et(e,t);if(e=a.doc,(e=>{Ma.DEBUG_DATE&&(console.log(`\n==== '${e.doc.text()}' =====`),Object.keys(e).forEach((t=>{"doc"!==t&&e[t]&&console.log(t,e[t])})),e.doc.debug())})(a),a.tz){let e=(t=Object.assign({},t,{timezone:a.tz})).today.format("iso-short");t.today=t.today.goto(t.timezone).set(e)}let n=va(e,t,a);return n=Oa(n,t,a),n},ja={mon:"monday",tue:"tuesday",tues:"wednesday",wed:"wednesday",thu:"thursday",fri:"friday",sat:"saturday",sun:"sunday",monday:"monday",tuesday:"tuesday",wednesday:"wednesday",thursday:"thursday",friday:"friday",saturday:"saturday",sunday:"sunday"},$a=function(e){return e.match("(every|each)").found?"AND":e.match("(any|a)").found?"OR":null},za=function(e){let t=e.start,a=e.end;if(t.d.isAfter(a.d)){if(t.isWeekDay&&a.isWeekDay)return e.end.next(),e;let n=t;e.start=a,e.end=n}return e},Ta=function(e){let t=e.start,a=e.end;return t.d.isAfter(a.d)&&a.d.hour()<10&&(a.d=a.d.ampm("pm")),e};var Va=[{match:"[#Time+] (to|until|upto|through|thru|and) [#Time+ #Date+]",desc:"3pm to 4pm january 5th",parse:(e,t)=>{let a=e.groups("from"),n=e.groups("to"),r=_a(n,t);if(r){let e=r.clone();if(e.applyTime(a.text("implicit")),e){let t={start:e,end:r,unit:"time"};return!1===/(am|pm)/.test(n)&&(t=Ta(t)),t=za(t),t}}return null}},{match:"[#Date+] from [#Time] (to|until|upto|through|thru|and) [#Time+]",desc:"january from 3pm to 4pm",parse:(e,t)=>{let a=e.groups("main"),n=e.groups("a"),r=e.groups("b");if(a=_a(a,t),a){a.applyTime(n.text("implicit"));let e=a.clone();if(e.applyTime(r.text("implicit")),e){let t={start:a,end:e,unit:"time"};return!1===/(am|pm)/.test(r.text())&&(t=Ta(t)),t=za(t),t}}return null}},{match:"[#Date+] (to|until|upto|through|thru|and) [#Time+]",desc:"january from 3pm to 4pm",parse:(e,t)=>{let a=e.groups("from"),n=e.groups("to");if(a=_a(a,t),a){let e=a.clone();if(e.applyTime(n.text("implicit")),e){let t={start:a,end:e,unit:"time"};return!1===/(am|pm)/.test(n.text())&&(t=Ta(t)),t=za(t),t}}return null}}],Sa=[{match:"^during? #Month+ (or|and) #Month [#Year]?",desc:"march or june",parse:(e,t)=>{let a=e.match("^during? [#Month]",0);e=e.not("(or|and)");let n=_a(a,t);if(n){let r=[{start:n,end:n.clone().end(),unit:n.unit}],i=e.not(a);i.found&&i.match("#Month").forEach((e=>{let a=_a(e,t);r.push({start:a,end:a.clone().end(),unit:a.unit})}));let o=e.match("#Year$");return o.found&&(o=o.text("reduced"),r.forEach((e=>{e.start.d=e.start.d.year(o),e.end.d=e.end.d.year(o)}))),r}return null}},{match:"^#Month #Value+ (or|and)? #Value$",desc:"jan 5 or 8",parse:(e,t)=>{let a=(e=e.not("(or|and)")).match("^#Month #Value"),n=_a(a,t);if(n){let t=[{start:n,end:n.clone().end(),unit:n.unit}],r=e.not(a);return r.found&&r.match("#Value").forEach((e=>{let a=n.clone();a.d=a.d.date(e.text("reduced")),t.push({start:a,end:a.clone().end(),unit:a.unit})})),t}return null}},{match:"^#Month+ #Value #Value+$",desc:"jan 5 8",parse:(e,t)=>{let a=e.match("#Month"),n=e.match("#Year");e=e.not("#Year");let r=[];return e.match("#Value").forEach((e=>{let i=(e=e.clone()).prepend(a.text());n.found&&i.append(n);let o=_a(i,t);o&&r.push({start:o,end:o.clone().end(),unit:o.unit})})),r}},{match:"^#Value+ (or|and)? #Value of #Month #Year?$",desc:"5 or 8 of Jan",parse:(e,t)=>{let a=e.match("#Month"),n=e.match("#Year");e=e.not("#Year");let r=[];return e.match("#Value").forEach((e=>{let i=e.append(a);n.found&&i.append(n);let o=_a(i,t);o&&r.push({start:o,end:o.clone().end(),unit:o.unit})})),r}},{match:"^!(between|from|during)? [#Date+] (and|or) [#Date+]$",desc:"A or B",parse:(e,t)=>{let a=e.groups("from"),n=e.groups("to"),r=_a(a,t),i=_a(n,t);return r&&i?[{start:r,end:r.clone().end()},{start:i,end:i.clone().end()}]:null}}],qa=[{match:"between [#Month] and [#Month] [#Year?]",desc:"between march and jan",parse:(e,t)=>{let{start:a,end:n,year:r}=e.groups(),i=r&&r.found?Number(r.text("reduced")):t.today.year(),o={month:a.text("reduced"),year:i},s=new Month(o,null,t).start();o={month:n.text("reduced"),year:i};let u=new Month(o,null,t).start();return s.d.isAfter(u.d)?{start:u,end:s}:{start:s,end:u}}},{match:"between [ 




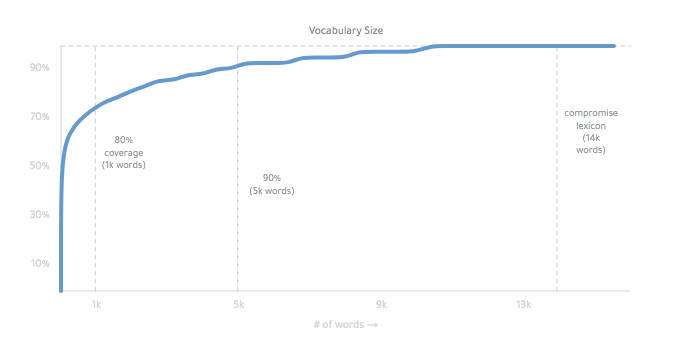



 **MIT** licenced
================================================
FILE: plugins/dates/builds/compromise-dates.cjs
================================================
(function (global, factory) {
typeof exports === 'object' && typeof module !== 'undefined' ? module.exports = factory() :
typeof define === 'function' && define.amd ? define(factory) :
(global = typeof globalThis !== 'undefined' ? globalThis : global || self, global.compromiseDates = factory());
})(this, (function () { 'use strict';
// chop things up into bite-size pieces
const split = function (dates) {
let m = null;
// don't split anything if it looks like a range
if (dates.has('^(between|within) #Date')) {
return dates
}
if (dates.has('#Month')) {
// 'june 5, june 10'
m = dates.match('[#Month #Value] and? #Month', 0).ifNo('@hasDash$');
if (m.found) {
dates = dates.splitAfter(m);
}
// '5 june, 10 june'
m = dates.match('[#Value #Month] and? #Value #Month', 0);
if (m.found) {
dates = dates.splitAfter(m);
}
// 'june, august'
m = dates.match('^[#Month] and? #Month #Ordinal?$', 0);
if (m.found) {
dates = dates.splitAfter(m);
}
// 'june 5th, june 10th'
m = dates.match('[#Month #Value] #Month', 0).ifNo('@hasDash$');
if (m.found) {
dates = dates.splitAfter(m);
}
}
if (dates.has('#WeekDay')) {
// 'tuesday, wednesday'
m = dates.match('^[#WeekDay] and? #WeekDay$', 0).ifNo('@hasDash$');
if (m.found) {
dates = dates.splitAfter(m);
}
// 'tuesday, wednesday, and friday'
m = dates.match('#WeekDay #WeekDay and? #WeekDay');
if (m.found) {
dates = dates.splitOn('#WeekDay');
}
// monday, wednesday
m = dates.match('[#WeekDay] (and|or|this|next)? #WeekDay', 0).ifNo('@hasDash$');
if (m.found) {
dates = dates.splitAfter('#WeekDay');
}
}
// next week tomorrow
m = dates.match('(this|next) #Duration [(today|tomorrow|yesterday)]', 0);
if (m.found) {
dates = dates.splitBefore(m);
}
// tomorrow 15 march
m = dates.match('[(today|tomorrow|yesterday)] #Value #Month', 0);
if (m.found) {
dates = dates.splitAfter(m);
}
// tomorrow yesterday
m = dates.match('[(today|tomorrow|yesterday)] (today|tomorrow|yesterday|#WeekDay)', 0).ifNo('@hasDash$');
if (m.found) {
dates = dates.splitAfter(m);
}
//1998 and 1999
m = dates.match('#Year [and] #Year', 0);
if (m.found) {
dates = dates.splitAfter(m);
}
// cleanup any splits
dates = dates.not('^and');
dates = dates.not('and$');
return dates
};
const findDate = function (doc) {
let dates = doc.match('#Date+');
// ignore only-durations like '20 minutes'
dates = dates.filter(m => {
let isDuration = m.has('^#Duration+$') || m.has('^#Value #Duration+$');
// allow 'q4', etc
if (isDuration === true && m.has('(#FinancialQuarter|quarter)')) {
return true
}
return isDuration === false
});
// 30 minutes on tuesday
let m = dates.match('[#Cardinal #Duration (in|on|this|next|during|for)] #Date', 0);
if (m.found) {
dates = dates.not(m);
}
// 30 minutes tuesday
m = dates.match('[#Cardinal #Duration] #WeekDay', 0);
if (m.found) {
dates = dates.not(m);
}
// tuesday for 30 mins
m = dates.match('#Date [for #Value #Duration]$', 0);
if (m.found) {
dates = dates.not(m);
}
// '20 minutes june 5th'
m = dates.match('[#Cardinal #Duration] #Date', 0); //but allow '20 minutes ago'
if (m.found && !dates.has('#Cardinal #Duration] (ago|from|before|after|back)')) {
dates = dates.not(m);
}
// for 20 minutes
m = dates.match('for #Cardinal #Duration');
if (m.found) {
dates = dates.not(m);
}
// 'one saturday'
dates = dates.notIf('^one (#WeekDay|#Month)$');
// tokenize the dates
dates = split(dates);
// $5 an hour
dates = dates.notIf('(#Money|#Percentage)');
dates = dates.notIf('^per #Duration');
return dates
};
const knownUnits = {
second: true,
minute: true,
hour: true,
day: true,
week: true,
weekend: true,
month: true,
season: true,
quarter: true,
year: true,
};
const aliases$2 = {
wk: 'week',
min: 'minute',
sec: 'second',
weekend: 'week', //for now...
};
const parseUnit = function (m) {
let unit = m.match('#Duration').text('normal');
unit = unit.replace(/s$/, '');
// support shorthands like 'min'
if (aliases$2.hasOwnProperty(unit)) {
unit = aliases$2[unit];
}
return unit
};
//turn '5 weeks before' to {weeks:5}
const parseShift = function (doc) {
let result = {};
let m = doc.none();
let shift = doc.match('#DateShift+');
if (shift.found === false) {
return { res: result, m }
}
// '5 weeks'
shift.match('#Cardinal #Duration').forEach((ts) => {
let num = ts.match('#Cardinal').numbers().get()[0];
if (num && typeof num === 'number') {
let unit = parseUnit(ts);
if (knownUnits[unit] === true) {
result[unit] = num;
}
}
});
//is it 2 weeks ago? → -2
if (shift.has('(before|ago|hence|back)$') === true) {
Object.keys(result).forEach((k) => (result[k] *= -1));
}
m = shift.match('#Cardinal #Duration');
shift = shift.not(m);
// supoprt '1 day after tomorrow'
m = shift.match('[
**MIT** licenced
================================================
FILE: plugins/dates/builds/compromise-dates.cjs
================================================
(function (global, factory) {
typeof exports === 'object' && typeof module !== 'undefined' ? module.exports = factory() :
typeof define === 'function' && define.amd ? define(factory) :
(global = typeof globalThis !== 'undefined' ? globalThis : global || self, global.compromiseDates = factory());
})(this, (function () { 'use strict';
// chop things up into bite-size pieces
const split = function (dates) {
let m = null;
// don't split anything if it looks like a range
if (dates.has('^(between|within) #Date')) {
return dates
}
if (dates.has('#Month')) {
// 'june 5, june 10'
m = dates.match('[#Month #Value] and? #Month', 0).ifNo('@hasDash$');
if (m.found) {
dates = dates.splitAfter(m);
}
// '5 june, 10 june'
m = dates.match('[#Value #Month] and? #Value #Month', 0);
if (m.found) {
dates = dates.splitAfter(m);
}
// 'june, august'
m = dates.match('^[#Month] and? #Month #Ordinal?$', 0);
if (m.found) {
dates = dates.splitAfter(m);
}
// 'june 5th, june 10th'
m = dates.match('[#Month #Value] #Month', 0).ifNo('@hasDash$');
if (m.found) {
dates = dates.splitAfter(m);
}
}
if (dates.has('#WeekDay')) {
// 'tuesday, wednesday'
m = dates.match('^[#WeekDay] and? #WeekDay$', 0).ifNo('@hasDash$');
if (m.found) {
dates = dates.splitAfter(m);
}
// 'tuesday, wednesday, and friday'
m = dates.match('#WeekDay #WeekDay and? #WeekDay');
if (m.found) {
dates = dates.splitOn('#WeekDay');
}
// monday, wednesday
m = dates.match('[#WeekDay] (and|or|this|next)? #WeekDay', 0).ifNo('@hasDash$');
if (m.found) {
dates = dates.splitAfter('#WeekDay');
}
}
// next week tomorrow
m = dates.match('(this|next) #Duration [(today|tomorrow|yesterday)]', 0);
if (m.found) {
dates = dates.splitBefore(m);
}
// tomorrow 15 march
m = dates.match('[(today|tomorrow|yesterday)] #Value #Month', 0);
if (m.found) {
dates = dates.splitAfter(m);
}
// tomorrow yesterday
m = dates.match('[(today|tomorrow|yesterday)] (today|tomorrow|yesterday|#WeekDay)', 0).ifNo('@hasDash$');
if (m.found) {
dates = dates.splitAfter(m);
}
//1998 and 1999
m = dates.match('#Year [and] #Year', 0);
if (m.found) {
dates = dates.splitAfter(m);
}
// cleanup any splits
dates = dates.not('^and');
dates = dates.not('and$');
return dates
};
const findDate = function (doc) {
let dates = doc.match('#Date+');
// ignore only-durations like '20 minutes'
dates = dates.filter(m => {
let isDuration = m.has('^#Duration+$') || m.has('^#Value #Duration+$');
// allow 'q4', etc
if (isDuration === true && m.has('(#FinancialQuarter|quarter)')) {
return true
}
return isDuration === false
});
// 30 minutes on tuesday
let m = dates.match('[#Cardinal #Duration (in|on|this|next|during|for)] #Date', 0);
if (m.found) {
dates = dates.not(m);
}
// 30 minutes tuesday
m = dates.match('[#Cardinal #Duration] #WeekDay', 0);
if (m.found) {
dates = dates.not(m);
}
// tuesday for 30 mins
m = dates.match('#Date [for #Value #Duration]$', 0);
if (m.found) {
dates = dates.not(m);
}
// '20 minutes june 5th'
m = dates.match('[#Cardinal #Duration] #Date', 0); //but allow '20 minutes ago'
if (m.found && !dates.has('#Cardinal #Duration] (ago|from|before|after|back)')) {
dates = dates.not(m);
}
// for 20 minutes
m = dates.match('for #Cardinal #Duration');
if (m.found) {
dates = dates.not(m);
}
// 'one saturday'
dates = dates.notIf('^one (#WeekDay|#Month)$');
// tokenize the dates
dates = split(dates);
// $5 an hour
dates = dates.notIf('(#Money|#Percentage)');
dates = dates.notIf('^per #Duration');
return dates
};
const knownUnits = {
second: true,
minute: true,
hour: true,
day: true,
week: true,
weekend: true,
month: true,
season: true,
quarter: true,
year: true,
};
const aliases$2 = {
wk: 'week',
min: 'minute',
sec: 'second',
weekend: 'week', //for now...
};
const parseUnit = function (m) {
let unit = m.match('#Duration').text('normal');
unit = unit.replace(/s$/, '');
// support shorthands like 'min'
if (aliases$2.hasOwnProperty(unit)) {
unit = aliases$2[unit];
}
return unit
};
//turn '5 weeks before' to {weeks:5}
const parseShift = function (doc) {
let result = {};
let m = doc.none();
let shift = doc.match('#DateShift+');
if (shift.found === false) {
return { res: result, m }
}
// '5 weeks'
shift.match('#Cardinal #Duration').forEach((ts) => {
let num = ts.match('#Cardinal').numbers().get()[0];
if (num && typeof num === 'number') {
let unit = parseUnit(ts);
if (knownUnits[unit] === true) {
result[unit] = num;
}
}
});
//is it 2 weeks ago? → -2
if (shift.has('(before|ago|hence|back)$') === true) {
Object.keys(result).forEach((k) => (result[k] *= -1));
}
m = shift.match('#Cardinal #Duration');
shift = shift.not(m);
// supoprt '1 day after tomorrow'
m = shift.match('[



