Repository: spytensor/plants_disease_detection
Branch: master
Commit: 8155dc2f55c3
Files: 13
Total size: 26.8 KB
Directory structure:
gitextract_xat58g1e/
├── README.md
├── config.py
├── data/
│ ├── temp/
│ │ ├── images/
│ │ │ └── .gitkeep
│ │ └── labels/
│ │ └── .gitkeep
│ ├── test/
│ │ └── .gitkeep
│ └── train/
│ └── .gitkeep
├── data_aug.py
├── dataset/
│ └── dataloader.py
├── main.py
├── models/
│ ├── __init__.py
│ └── model.py
├── move.py
└── utils.py
================================================
FILE CONTENTS
================================================
================================================
FILE: README.md
================================================
### 声明:开源只是为了方便大家交流学习,数据请勿用于商业用途!!!!转载或解读请注明出处,谢谢!
**背景**
很早之前开源过 pytorch 进行图像分类的代码([从实例掌握 pytorch 进行图像分类](http://spytensor.com/index.php/archives/21/)),历时两个多月的学习和总结,近期也做了升级。在此基础上写了一个 Ai Challenger 农作物竞赛的 baseline 供大家交流。
**2018 年 12 月 13 日更新**
新增数据集下载链接:[百度网盘]( https://pan.baidu.com/s/16f1nQchS-zBtzSWn9Guyyg ) 提取码:iksk
数据集是 10 月 23 日 更新后的新数据集,包含训练集、验证集、测试集A/B.
另外最近有同学拿到类似的数据,想做分类的任务,但是这份代码是针对这次比赛开源的,在数据读取方式上会有区别,对于新手来说不太友好,我开源了一份针对图像分类任务的代码,并附上简单教程,相信看完后能比较轻松使用 pytorch 进行图像分类。
教程: [从实例掌握 pytorch 进行图像分类](http://www.spytensor.com/index.php/archives/21/)
代码: [pytorch-image-classification](https://github.com/spytensor/pytorch-image-classification)
**2018年 10 月 30 日更新**
新增 `data_aug.py` 用于线下数据增强,由于时间问题,这个比赛不再做啦,这些增强方式大家有需要可以研究一下,支持的增强方式:
- 高斯噪声
- 亮度变化
- 左右翻转
- 上下翻转
- 色彩抖动
- 对比度变化
- 锐度变化
注:对比度增强在可视化后,主观感觉特征更明显了,目前我还未跑完。提醒一下,如果做了对比度增强,在测试集的时候最好也做一下。
个人博客:[超杰](http://spytensor.com/)
比赛地址:[农作物病害检测](https://challenger.ai/competition/pdr2018)
完整代码地址:[plants_disease_detection](https://github.com/spytensor/plants_disease_detection)
注:
欢迎大佬学习交流啊,这份代码可改进的地方太多了,
如果大佬们有啥改进的意见请指导!
联系方式:zhuchaojie@buaa.edu.cn
**成绩**:线上 0.8805,线下0.875,由于划分存在随机性,可能复现会出现波动,已经尽可能排除随机种子的干扰了。
## 提醒
`main.py` 中的test函数已经修正,执行后在 `./submit/`中会得到提交格式的 json 文件,现已支持 Focalloss 和交叉验证,需要的自行修改一下就可以了。
依赖中的 pytorch 版本请保持一致,不然可能会有一些小 BUG。
### 1. 依赖
python3.6 pytorch0.4.1
### 2. 关于数据的处理
首先说明,使用的数据为官方更新后的数据,并做了一个统计分析(下文会给出),最后决定删除第 44 类和第 45 类。
并且由于数据分布的原因,我将 train 和 val 数据集合并后,采用随机划分。
数据增强方式:
- RandomRotation(30)
- RandomHorizontalFlip()
- RandomVerticalFlip()
- RandomAffine(45)
图片尺寸选择了 650,暂时没有对这个尺寸进行调优(毕竟太忙了。。)
### 3. 模型选择
模型目前就尝试了 resnet50,后续有卡的话再说吧。。。
### 4. 超参数设置
详情在 config.py 中
### 5.使用方法
- 第一步:将测试集图片复制到 `data/test/` 下
- 第二步:将训练集合验证集中的图片都复制到 `data/temp/images/` 下,将两个 `json` 文件放到 `data/temp/labels/` 下
- 执行 move.py 文件
- 执行 main.py 进行训练
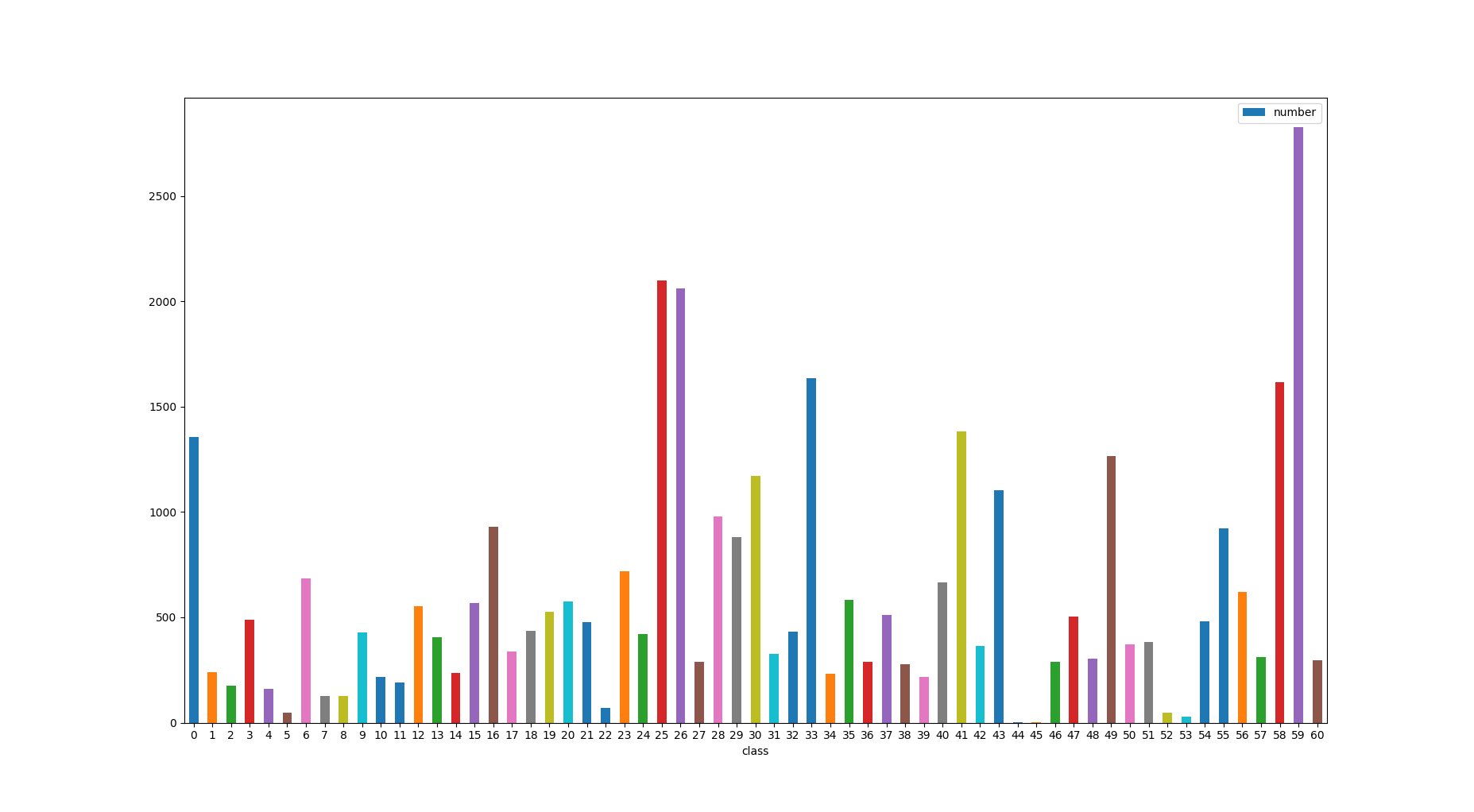
### 6.数据分布图
训练集
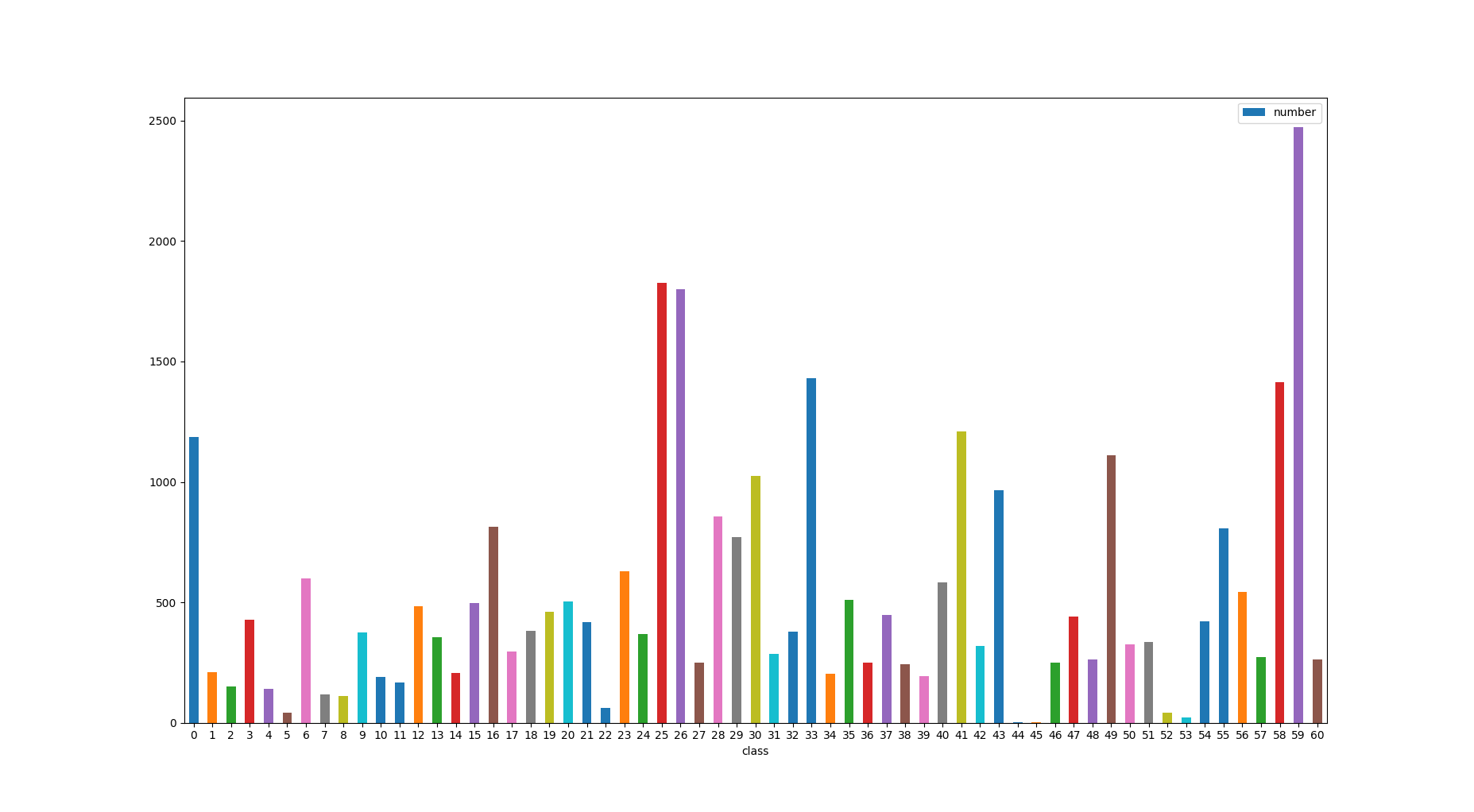
验证集
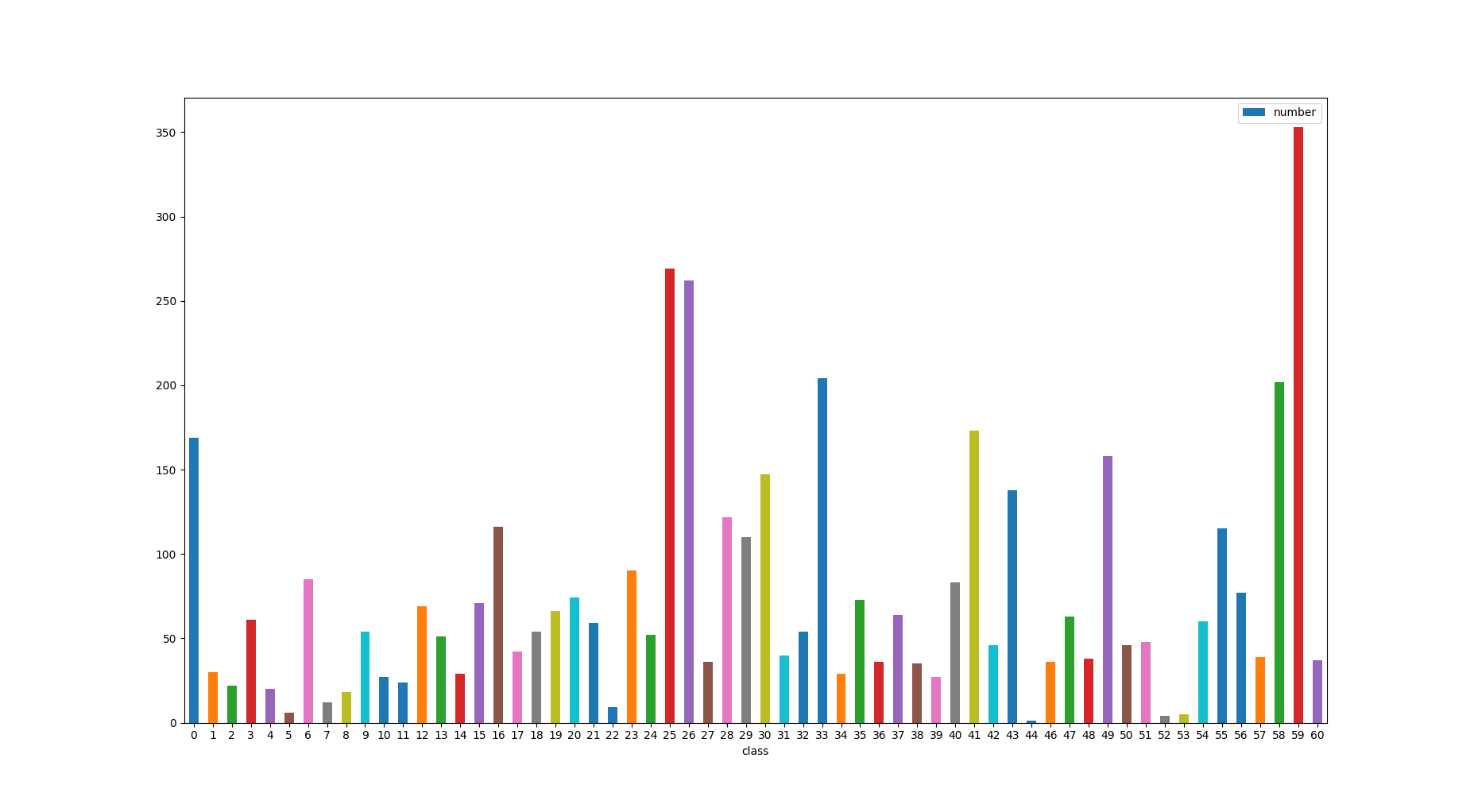
全部数据集
================================================
FILE: config.py
================================================
class DefaultConfigs(object):
#1.string parameters
train_data = "./data/train/"
test_data = "./data/test/"
val_data = "no"
model_name = "resnet50"
weights = "./checkpoints/"
best_models = weights + "best_model/"
submit = "./submit/"
logs = "./logs/"
gpus = "1"
#2.numeric parameters
epochs = 40
batch_size = 8
img_height = 650
img_weight = 650
num_classes = 59
seed = 888
lr = 1e-4
lr_decay = 1e-4
weight_decay = 1e-4
config = DefaultConfigs()
================================================
FILE: data/temp/images/.gitkeep
================================================
================================================
FILE: data/temp/labels/.gitkeep
================================================
================================================
FILE: data/test/.gitkeep
================================================
================================================
FILE: data/train/.gitkeep
================================================
================================================
FILE: data_aug.py
================================================
from PIL import Image,ImageEnhance,ImageFilter,ImageOps
import os
import shutil
import numpy as np
import cv2
import random
from skimage.util import random_noise
from skimage import exposure
image_number = 0
raw_path = "./data/train/"
new_path = "./aug/train/"
# 加高斯噪声
def addNoise(img):
'''
注意:输出的像素是[0,1]之间,所以乘以5得到[0,255]之间
'''
return random_noise(img, mode='gaussian', seed=13, clip=True)*255
def changeLight(img):
rate = random.uniform(0.5, 1.5)
# print(rate)
img = exposure.adjust_gamma(img, rate) #大于1为调暗,小于1为调亮;1.05
return img
try:
for i in range(59):
os.makedirs(new_path + os.sep + str(i))
except:
pass
for raw_dir_name in range(59):
raw_dir_name = str(raw_dir_name)
saved_image_path = new_path + raw_dir_name+"/"
raw_image_path = raw_path + raw_dir_name+"/"
if not os.path.exists(saved_image_path):
os.mkdir(saved_image_path)
raw_image_file_name = os.listdir(raw_image_path)
raw_image_file_path = []
for i in raw_image_file_name:
raw_image_file_path.append(raw_image_path+i)
for x in raw_image_file_path:
img = Image.open(x)
cv_image = cv2.imread(x)
# 高斯噪声
gau_image = addNoise(cv_image)
# 随机改变
light = changeLight(cv_image)
light_and_gau = addNoise(light)
cv2.imwrite(saved_image_path + "gau_" + os.path.basename(x),gau_image)
cv2.imwrite(saved_image_path + "light_" + os.path.basename(x),light)
cv2.imwrite(saved_image_path + "gau_light" + os.path.basename(x),light_and_gau)
#img = img.resize((800,600))
#1.翻转
img_flip_left_right = img.transpose(Image.FLIP_LEFT_RIGHT)
img_flip_top_bottom = img.transpose(Image.FLIP_TOP_BOTTOM)
#2.旋转
#img_rotate_90 = img.transpose(Image.ROTATE_90)
#img_rotate_180 = img.transpose(Image.ROTATE_180)
#img_rotate_270 = img.transpose(Image.ROTATE_270)
#img_rotate_90_left = img_flip_left_right.transpose(Image.ROTATE_90)
#img_rotate_270_left = img_flip_left_right.transpose(Image.ROTATE_270)
#3.亮度
#enh_bri = ImageEnhance.Brightness(img)
#brightness = 1.5
#image_brightened = enh_bri.enhance(brightness)
#4.色彩
#enh_col = ImageEnhance.Color(img)
#color = 1.5
#image_colored = enh_col.enhance(color)
#5.对比度
enh_con = ImageEnhance.Contrast(img)
contrast = 1.5
image_contrasted = enh_con.enhance(contrast)
#6.锐度
#enh_sha = ImageEnhance.Sharpness(img)
#sharpness = 3.0
#image_sharped = enh_sha.enhance(sharpness)
#保存
img.save(saved_image_path + os.path.basename(x))
img_flip_left_right.save(saved_image_path + "left_right_" + os.path.basename(x))
img_flip_top_bottom.save(saved_image_path + "top_bottom_" + os.path.basename(x))
#img_rotate_90.save(saved_image_path + "rotate_90_" + os.path.basename(x))
#img_rotate_180.save(saved_image_path + "rotate_180_" + os.path.basename(x))
#img_rotate_270.save(saved_image_path + "rotate_270_" + os.path.basename(x))
#img_rotate_90_left.save(saved_image_path + "rotate_90_left_" + os.path.basename(x))
#img_rotate_270_left.save(saved_image_path + "rotate_270_left_" + os.path.basename(x))
#image_brightened.save(saved_image_path + "brighted_" + os.path.basename(x))
#image_colored.save(saved_image_path + "colored_" + os.path.basename(x))
image_contrasted.save(saved_image_path + "contrasted_" + os.path.basename(x))
#image_sharped.save(saved_image_path + "sharped_" + os.path.basename(x))
image_number += 1
print("convert pictur" "es :%s size:%s mode:%s" % (image_number, img.size, img.mode))
================================================
FILE: dataset/dataloader.py
================================================
from torch.utils.data import Dataset
from torchvision import transforms as T
from config import config
from PIL import Image
from itertools import chain
from glob import glob
from tqdm import tqdm
import random
import numpy as np
import pandas as pd
import os
import cv2
import torch
#1.set random seed
random.seed(config.seed)
np.random.seed(config.seed)
torch.manual_seed(config.seed)
torch.cuda.manual_seed_all(config.seed)
#2.define dataset
class ChaojieDataset(Dataset):
def __init__(self,label_list,transforms=None,train=True,test=False):
self.test = test
self.train = train
imgs = []
if self.test:
for index,row in label_list.iterrows():
imgs.append((row["filename"]))
self.imgs = imgs
else:
for index,row in label_list.iterrows():
imgs.append((row["filename"],row["label"]))
self.imgs = imgs
if transforms is None:
if self.test or not train:
self.transforms = T.Compose([
T.Resize((config.img_weight,config.img_height)),
T.ToTensor(),
T.Normalize(mean = [0.485,0.456,0.406],
std = [0.229,0.224,0.225])])
else:
self.transforms = T.Compose([
T.Resize((config.img_weight,config.img_height)),
T.RandomRotation(30),
T.RandomHorizontalFlip(),
T.RandomVerticalFlip(),
T.RandomAffine(45),
T.ToTensor(),
T.Normalize(mean = [0.485,0.456,0.406],
std = [0.229,0.224,0.225])])
else:
self.transforms = transforms
def __getitem__(self,index):
if self.test:
filename = self.imgs[index]
img = Image.open(filename)
img = self.transforms(img)
return img,filename
else:
filename,label = self.imgs[index]
img = Image.open(filename)
img = self.transforms(img)
return img,label
def __len__(self):
return len(self.imgs)
def collate_fn(batch):
imgs = []
label = []
for sample in batch:
imgs.append(sample[0])
label.append(sample[1])
return torch.stack(imgs, 0), \
label
def get_files(root,mode):
#for test
if mode == "test":
files = []
for img in os.listdir(root):
files.append(root + img)
files = pd.DataFrame({"filename":files})
return files
elif mode != "test":
#for train and val
all_data_path,labels = [],[]
image_folders = list(map(lambda x:root+x,os.listdir(root)))
jpg_image_1 = list(map(lambda x:glob(x+"/*.jpg"),image_folders))
jpg_image_2 = list(map(lambda x:glob(x+"/*.JPG"),image_folders))
all_images = list(chain.from_iterable(jpg_image_1 + jpg_image_2))
print("loading train dataset")
for file in tqdm(all_images):
all_data_path.append(file)
labels.append(int(file.split("/")[-2]))
all_files = pd.DataFrame({"filename":all_data_path,"label":labels})
return all_files
else:
print("check the mode please!")
================================================
FILE: main.py
================================================
import os
import random
import time
import json
import torch
import torchvision
import numpy as np
import pandas as pd
import warnings
from datetime import datetime
from torch import nn,optim
from config import config
from collections import OrderedDict
from torch.autograd import Variable
from torch.utils.data import DataLoader
from dataset.dataloader import *
from sklearn.model_selection import train_test_split,StratifiedKFold
from timeit import default_timer as timer
from models.model import *
from utils import *
#1. set random.seed and cudnn performance
random.seed(config.seed)
np.random.seed(config.seed)
torch.manual_seed(config.seed)
torch.cuda.manual_seed_all(config.seed)
os.environ["CUDA_VISIBLE_DEVICES"] = config.gpus
torch.backends.cudnn.benchmark = True
warnings.filterwarnings('ignore')
#2. evaluate func
def evaluate(val_loader,model,criterion):
#2.1 define meters
losses = AverageMeter()
top1 = AverageMeter()
top2 = AverageMeter()
#2.2 switch to evaluate mode and confirm model has been transfered to cuda
model.cuda()
model.eval()
with torch.no_grad():
for i,(input,target) in enumerate(val_loader):
input = Variable(input).cuda()
target = Variable(torch.from_numpy(np.array(target)).long()).cuda()
#target = Variable(target).cuda()
#2.2.1 compute output
output = model(input)
loss = criterion(output,target)
#2.2.2 measure accuracy and record loss
precision1,precision2 = accuracy(output,target,topk=(1,2))
losses.update(loss.item(),input.size(0))
top1.update(precision1[0],input.size(0))
top2.update(precision2[0],input.size(0))
return [losses.avg,top1.avg,top2.avg]
#3. test model on public dataset and save the probability matrix
def test(test_loader,model,folds):
#3.1 confirm the model converted to cuda
csv_map = OrderedDict({"filename":[],"probability":[]})
model.cuda()
model.eval()
with open("./submit/baseline.json","w",encoding="utf-8") as f :
submit_results = []
for i,(input,filepath) in enumerate(tqdm(test_loader)):
#3.2 change everything to cuda and get only basename
filepath = [os.path.basename(x) for x in filepath]
with torch.no_grad():
image_var = Variable(input).cuda()
#3.3.output
#print(filepath)
#print(input,input.shape)
y_pred = model(image_var)
#print(y_pred.shape)
smax = nn.Softmax(1)
smax_out = smax(y_pred)
#3.4 save probability to csv files
csv_map["filename"].extend(filepath)
for output in smax_out:
prob = ";".join([str(i) for i in output.data.tolist()])
csv_map["probability"].append(prob)
result = pd.DataFrame(csv_map)
result["probability"] = result["probability"].map(lambda x : [float(i) for i in x.split(";")])
for index, row in result.iterrows():
pred_label = np.argmax(row['probability'])
if pred_label > 43:
pred_label = pred_label + 2
submit_results.append({"image_id":row['filename'],"disease_class":pred_label})
json.dump(submit_results,f,ensure_ascii=False,cls = MyEncoder)
#4. more details to build main function
def main():
fold = 0
#4.1 mkdirs
if not os.path.exists(config.submit):
os.mkdir(config.submit)
if not os.path.exists(config.weights):
os.mkdir(config.weights)
if not os.path.exists(config.best_models):
os.mkdir(config.best_models)
if not os.path.exists(config.logs):
os.mkdir(config.logs)
if not os.path.exists(config.weights + config.model_name + os.sep +str(fold) + os.sep):
os.makedirs(config.weights + config.model_name + os.sep +str(fold) + os.sep)
if not os.path.exists(config.best_models + config.model_name + os.sep +str(fold) + os.sep):
os.makedirs(config.best_models + config.model_name + os.sep +str(fold) + os.sep)
#4.2 get model and optimizer
model = get_net()
#model = torch.nn.DataParallel(model)
model.cuda()
#optimizer = optim.SGD(model.parameters(),lr = config.lr,momentum=0.9,weight_decay=config.weight_decay)
optimizer = optim.Adam(model.parameters(),lr = config.lr,amsgrad=True,weight_decay=config.weight_decay)
criterion = nn.CrossEntropyLoss().cuda()
#criterion = FocalLoss().cuda()
log = Logger()
log.open(config.logs + "log_train.txt",mode="a")
log.write("\n----------------------------------------------- [START %s] %s\n\n" % (datetime.now().strftime('%Y-%m-%d %H:%M:%S'), '-' * 51))
#4.3 some parameters for K-fold and restart model
start_epoch = 0
best_precision1 = 0
best_precision_save = 0
resume = False
#4.4 restart the training process
if resume:
checkpoint = torch.load(config.best_models + str(fold) + "/model_best.pth.tar")
start_epoch = checkpoint["epoch"]
fold = checkpoint["fold"]
best_precision1 = checkpoint["best_precision1"]
model.load_state_dict(checkpoint["state_dict"])
optimizer.load_state_dict(checkpoint["optimizer"])
#4.5 get files and split for K-fold dataset
#4.5.1 read files
train_ = get_files(config.train_data,"train")
#val_data_list = get_files(config.val_data,"val")
test_files = get_files(config.test_data,"test")
"""
#4.5.2 split
split_fold = StratifiedKFold(n_splits=3)
folds_indexes = split_fold.split(X=origin_files["filename"],y=origin_files["label"])
folds_indexes = np.array(list(folds_indexes))
fold_index = folds_indexes[fold]
#4.5.3 using fold index to split for train data and val data
train_data_list = pd.concat([origin_files["filename"][fold_index[0]],origin_files["label"][fold_index[0]]],axis=1)
val_data_list = pd.concat([origin_files["filename"][fold_index[1]],origin_files["label"][fold_index[1]]],axis=1)
"""
train_data_list,val_data_list = train_test_split(train_,test_size = 0.15,stratify=train_["label"])
#4.5.4 load dataset
train_dataloader = DataLoader(ChaojieDataset(train_data_list),batch_size=config.batch_size,shuffle=True,collate_fn=collate_fn,pin_memory=True)
val_dataloader = DataLoader(ChaojieDataset(val_data_list,train=False),batch_size=config.batch_size,shuffle=True,collate_fn=collate_fn,pin_memory=False)
test_dataloader = DataLoader(ChaojieDataset(test_files,test=True),batch_size=1,shuffle=False,pin_memory=False)
#scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer,"max",verbose=1,patience=3)
scheduler = optim.lr_scheduler.StepLR(optimizer,step_size = 10,gamma=0.1)
#4.5.5.1 define metrics
train_losses = AverageMeter()
train_top1 = AverageMeter()
train_top2 = AverageMeter()
valid_loss = [np.inf,0,0]
model.train()
#logs
log.write('** start training here! **\n')
log.write(' |------------ VALID -------------|----------- TRAIN -------------|------Accuracy------|------------|\n')
log.write('lr iter epoch | loss top-1 top-2 | loss top-1 top-2 | Current Best | time |\n')
log.write('-------------------------------------------------------------------------------------------------------------------------------\n')
#4.5.5 train
start = timer()
for epoch in range(start_epoch,config.epochs):
scheduler.step(epoch)
# train
#global iter
for iter,(input,target) in enumerate(train_dataloader):
#4.5.5 switch to continue train process
model.train()
input = Variable(input).cuda()
target = Variable(torch.from_numpy(np.array(target)).long()).cuda()
#target = Variable(target).cuda()
output = model(input)
loss = criterion(output,target)
precision1_train,precision2_train = accuracy(output,target,topk=(1,2))
train_losses.update(loss.item(),input.size(0))
train_top1.update(precision1_train[0],input.size(0))
train_top2.update(precision2_train[0],input.size(0))
#backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
lr = get_learning_rate(optimizer)
print('\r',end='',flush=True)
print('%0.4f %5.1f %6.1f | %0.3f %0.3f %0.3f | %0.3f %0.3f %0.3f | %s | %s' % (\
lr, iter/len(train_dataloader) + epoch, epoch,
valid_loss[0], valid_loss[1], valid_loss[2],
train_losses.avg, train_top1.avg, train_top2.avg,str(best_precision_save),
time_to_str((timer() - start),'min'))
, end='',flush=True)
#evaluate
lr = get_learning_rate(optimizer)
#evaluate every half epoch
valid_loss = evaluate(val_dataloader,model,criterion)
is_best = valid_loss[1] > best_precision1
best_precision1 = max(valid_loss[1],best_precision1)
try:
best_precision_save = best_precision1.cpu().data.numpy()
except:
pass
save_checkpoint({
"epoch":epoch + 1,
"model_name":config.model_name,
"state_dict":model.state_dict(),
"best_precision1":best_precision1,
"optimizer":optimizer.state_dict(),
"fold":fold,
"valid_loss":valid_loss,
},is_best,fold)
#adjust learning rate
#scheduler.step(valid_loss[1])
print("\r",end="",flush=True)
log.write('%0.4f %5.1f %6.1f | %0.3f %0.3f %0.3f | %0.3f %0.3f %0.3f | %s | %s' % (\
lr, 0 + epoch, epoch,
valid_loss[0], valid_loss[1], valid_loss[2],
train_losses.avg, train_top1.avg, train_top2.avg, str(best_precision_save),
time_to_str((timer() - start),'min'))
)
log.write('\n')
time.sleep(0.01)
best_model = torch.load(config.best_models + os.sep+config.model_name+os.sep+ str(fold) +os.sep+ 'model_best.pth.tar')
model.load_state_dict(best_model["state_dict"])
test(test_dataloader,model,fold)
if __name__ =="__main__":
main()
================================================
FILE: models/__init__.py
================================================
================================================
FILE: models/model.py
================================================
import torchvision
import torch.nn.functional as F
from torch import nn
from config import config
def generate_model():
class DenseModel(nn.Module):
def __init__(self, pretrained_model):
super(DenseModel, self).__init__()
self.classifier = nn.Linear(pretrained_model.classifier.in_features, config.num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal(m.weight)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.bias.data.zero_()
self.features = pretrained_model.features
self.layer1 = pretrained_model.features._modules['denseblock1']
self.layer2 = pretrained_model.features._modules['denseblock2']
self.layer3 = pretrained_model.features._modules['denseblock3']
self.layer4 = pretrained_model.features._modules['denseblock4']
def forward(self, x):
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.avg_pool2d(out, kernel_size=8).view(features.size(0), -1)
out = F.sigmoid(self.classifier(out))
return out
return DenseModel(torchvision.models.densenet169(pretrained=True))
def get_net():
#return MyModel(torchvision.models.resnet101(pretrained = True))
model = torchvision.models.resnet50(pretrained = True)
#for param in model.parameters():
# param.requires_grad = False
model.avgpool = nn.AdaptiveAvgPool2d(1)
model.fc = nn.Linear(2048,config.num_classes)
return model
================================================
FILE: move.py
================================================
import json
import shutil
import os
from glob import glob
from tqdm import tqdm
try:
for i in range(0,59):
os.mkdir("./data/train/" + str(i))
except:
pass
file_train = json.load(open("./data/temp/labels/AgriculturalDisease_train_annotations.json","r",encoding="utf-8"))
file_val = json.load(open("./data/temp/labels/AgriculturalDisease_validation_annotations.json","r",encoding="utf-8"))
file_list = file_train + file_val
for file in tqdm(file_list):
filename = file["image_id"]
origin_path = "./data/temp/images/" + filename
ids = file["disease_class"]
if ids == 44:
continue
if ids == 45:
continue
if ids > 45:
ids = ids -2
save_path = "./data/train/" + str(ids) + "/"
shutil.copy(origin_path,save_path)
================================================
FILE: utils.py
================================================
import shutil
import torch
import sys
import os
import json
import numpy as np
from config import config
from torch import nn
import torch.nn.functional as F
def save_checkpoint(state, is_best,fold):
filename = config.weights + config.model_name + os.sep +str(fold) + os.sep + "_checkpoint.pth.tar"
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, config.best_models + config.model_name+ os.sep +str(fold) + os.sep + 'model_best.pth.tar')
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 3 epochs"""
lr = config.lr * (0.1 ** (epoch // 3))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
def schedule(current_epoch, current_lrs, **logs):
lrs = [1e-3, 1e-4, 0.5e-4, 1e-5, 0.5e-5]
epochs = [0, 1, 6, 8, 12]
for lr, epoch in zip(lrs, epochs):
if current_epoch >= epoch:
current_lrs[5] = lr
if current_epoch >= 2:
current_lrs[4] = lr * 1
current_lrs[3] = lr * 1
current_lrs[2] = lr * 1
current_lrs[1] = lr * 1
current_lrs[0] = lr * 0.1
return current_lrs
def accuracy(output, target, topk=(1,)):
"""Computes the accuracy over the k top predictions for the specified values of k"""
with torch.no_grad():
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0, keepdim=True)
res.append(correct_k.mul_(100.0 / batch_size))
return res
class Logger(object):
def __init__(self):
self.terminal = sys.stdout #stdout
self.file = None
def open(self, file, mode=None):
if mode is None: mode ='w'
self.file = open(file, mode)
def write(self, message, is_terminal=1, is_file=1 ):
if '\r' in message: is_file=0
if is_terminal == 1:
self.terminal.write(message)
self.terminal.flush()
#time.sleep(1)
if is_file == 1:
self.file.write(message)
self.file.flush()
def flush(self):
# this flush method is needed for python 3 compatibility.
# this handles the flush command by doing nothing.
# you might want to specify some extra behavior here.
pass
def get_learning_rate(optimizer):
lr=[]
for param_group in optimizer.param_groups:
lr +=[ param_group['lr'] ]
#assert(len(lr)==1) #we support only one param_group
lr = lr[0]
return lr
def time_to_str(t, mode='min'):
if mode=='min':
t = int(t)/60
hr = t//60
min = t%60
return '%2d hr %02d min'%(hr,min)
elif mode=='sec':
t = int(t)
min = t//60
sec = t%60
return '%2d min %02d sec'%(min,sec)
else:
raise NotImplementedError
class FocalLoss(nn.Module):
def __init__(self, focusing_param=2, balance_param=0.25):
super(FocalLoss, self).__init__()
self.focusing_param = focusing_param
self.balance_param = balance_param
def forward(self, output, target):
cross_entropy = F.cross_entropy(output, target)
cross_entropy_log = torch.log(cross_entropy)
logpt = - F.cross_entropy(output, target)
pt = torch.exp(logpt)
focal_loss = -((1 - pt) ** self.focusing_param) * logpt
balanced_focal_loss = self.balance_param * focal_loss
return balanced_focal_loss
class MyEncoder(json.JSONEncoder):
def default(self, obj):
if isinstance(obj, np.integer):
return int(obj)
elif isinstance(obj, np.floating):
return float(obj)
elif isinstance(obj, np.ndarray):
return obj.tolist()
else:
return super(MyEncoder, self).default(obj)
gitextract_xat58g1e/ ├── README.md ├── config.py ├── data/ │ ├── temp/ │ │ ├── images/ │ │ │ └── .gitkeep │ │ └── labels/ │ │ └── .gitkeep │ ├── test/ │ │ └── .gitkeep │ └── train/ │ └── .gitkeep ├── data_aug.py ├── dataset/ │ └── dataloader.py ├── main.py ├── models/ │ ├── __init__.py │ └── model.py ├── move.py └── utils.py
SYMBOL INDEX (34 symbols across 6 files)
FILE: config.py
class DefaultConfigs (line 1) | class DefaultConfigs(object):
FILE: data_aug.py
function addNoise (line 18) | def addNoise(img):
function changeLight (line 24) | def changeLight(img):
FILE: dataset/dataloader.py
class ChaojieDataset (line 22) | class ChaojieDataset(Dataset):
method __init__ (line 23) | def __init__(self,label_list,transforms=None,train=True,test=False):
method __getitem__ (line 54) | def __getitem__(self,index):
method __len__ (line 65) | def __len__(self):
function collate_fn (line 68) | def collate_fn(batch):
function get_files (line 78) | def get_files(root,mode):
FILE: main.py
function evaluate (line 32) | def evaluate(val_loader,model,criterion):
function test (line 58) | def test(test_loader,model,folds):
function main (line 92) | def main():
FILE: models/model.py
function generate_model (line 6) | def generate_model():
function get_net (line 36) | def get_net():
FILE: utils.py
function save_checkpoint (line 10) | def save_checkpoint(state, is_best,fold):
class AverageMeter (line 16) | class AverageMeter(object):
method __init__ (line 18) | def __init__(self):
method reset (line 21) | def reset(self):
method update (line 27) | def update(self, val, n=1):
function adjust_learning_rate (line 33) | def adjust_learning_rate(optimizer, epoch):
function schedule (line 40) | def schedule(current_epoch, current_lrs, **logs):
function accuracy (line 54) | def accuracy(output, target, topk=(1,)):
class Logger (line 70) | class Logger(object):
method __init__ (line 71) | def __init__(self):
method open (line 75) | def open(self, file, mode=None):
method write (line 79) | def write(self, message, is_terminal=1, is_file=1 ):
method flush (line 91) | def flush(self):
function get_learning_rate (line 97) | def get_learning_rate(optimizer):
function time_to_str (line 108) | def time_to_str(t, mode='min'):
class FocalLoss (line 126) | class FocalLoss(nn.Module):
method __init__ (line 128) | def __init__(self, focusing_param=2, balance_param=0.25):
method forward (line 134) | def forward(self, output, target):
class MyEncoder (line 147) | class MyEncoder(json.JSONEncoder):
method default (line 148) | def default(self, obj):
Condensed preview — 13 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (31K chars).
[
{
"path": "README.md",
"chars": 2068,
"preview": "### 声明:开源只是为了方便大家交流学习,数据请勿用于商业用途!!!!转载或解读请注明出处,谢谢!\n\n**背景**\n\n很早之前开源过 pytorch 进行图像分类的代码([从实例掌握 pytorch 进行图像分类](http://spyt"
},
{
"path": "config.py",
"chars": 526,
"preview": "class DefaultConfigs(object):\n #1.string parameters\n train_data = \"./data/train/\"\n test_data = \"./data/test/\"\n "
},
{
"path": "data/temp/images/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "data/temp/labels/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "data/test/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "data/train/.gitkeep",
"chars": 0,
"preview": ""
},
{
"path": "data_aug.py",
"chars": 3846,
"preview": "from PIL import Image,ImageEnhance,ImageFilter,ImageOps\nimport os\nimport shutil\nimport numpy as np\nimport cv2\nimport ran"
},
{
"path": "dataset/dataloader.py",
"chars": 3349,
"preview": "from torch.utils.data import Dataset\nfrom torchvision import transforms as T \nfrom config import config\nfrom PIL import "
},
{
"path": "main.py",
"chars": 10608,
"preview": "import os \nimport random \nimport time\nimport json\nimport torch\nimport torchvision\nimport numpy as np \nimport pandas as p"
},
{
"path": "models/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "models/model.py",
"chars": 1744,
"preview": "import torchvision\nimport torch.nn.functional as F \nfrom torch import nn\nfrom config import config\n\ndef generate_model()"
},
{
"path": "move.py",
"chars": 788,
"preview": "import json\nimport shutil\nimport os\nfrom glob import glob\nfrom tqdm import tqdm\n\ntry:\n for i in range(0,59):\n "
},
{
"path": "utils.py",
"chars": 4486,
"preview": "import shutil\nimport torch\nimport sys\nimport os\nimport json\nimport numpy as np\nfrom config import config\nfrom torch impo"
}
]
About this extraction
This page contains the full source code of the spytensor/plants_disease_detection GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 13 files (26.8 KB), approximately 7.6k tokens, and a symbol index with 34 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.