Repository: tmnhs/go-interview-resume
Branch: main
Commit: f4f3dbd824a8
Files: 147
Total size: 226.7 KB
Directory structure:
gitextract_a1362qft/
├── .gitignore
├── README.md
├── interview/
│ ├── MySQL.md
│ ├── go语言.md
│ ├── redis.md
│ ├── 代码编程(go语言实现).md
│ ├── 常见算法和模板.md
│ ├── 微服务.md
│ ├── 操作系统.md
│ ├── 架构设计.md
│ ├── 海量数据高频面试题.md
│ ├── 系统设计思路.md
│ └── 计算机网络.md
├── resume/
│ ├── 130套简历/
│ │ ├── 1【115套精品简历】/
│ │ │ └── word简历/
│ │ │ ├── 1.五百丁蓝黑色简历.docx
│ │ │ ├── 10.五百丁狼_背景样式简历.docx
│ │ │ ├── 100.紫色边简洁简历.docx
│ │ │ ├── 101.doc
│ │ │ ├── 102.docx
│ │ │ ├── 103.docx
│ │ │ ├── 104.doc
│ │ │ ├── 105.docx
│ │ │ ├── 106.doc
│ │ │ ├── 107.docx
│ │ │ ├── 108 .docx
│ │ │ ├── 109.doc
│ │ │ ├── 11.创意内容.docx
│ │ │ ├── 110 .docx
│ │ │ ├── 111.docx
│ │ │ ├── 112.doc
│ │ │ ├── 113.doc
│ │ │ ├── 114.doc
│ │ │ ├── 115.docx
│ │ │ ├── 12.淡蓝色时间轴.docx
│ │ │ ├── 13.时间轴黑蓝色块商务风.docx
│ │ │ ├── 14.淡绿色时间轴.docx
│ │ │ ├── 15.五百丁分隔简历.docx
│ │ │ ├── 16.多年经验-简洁线条.docx
│ │ │ ├── 17.方块背景简历.docx
│ │ │ ├── 18.分层简洁简历.docx
│ │ │ ├── 19.分条简洁.docx
│ │ │ ├── 2.五百丁沙漠背景样式简历.docx
│ │ │ ├── 20.规整分栏.docx
│ │ │ ├── 22.含icon蓝色边简历.docx
│ │ │ ├── 23.含icon-应届.docx
│ │ │ ├── 24.含公司logo.docx
│ │ │ ├── 25.黑白灰-多年经验.docx
│ │ │ ├── 26.黑白灰简洁简历.docx
│ │ │ ├── 27.黑粉商务风.docx
│ │ │ ├── 28.红白灰-多年经验.docx
│ │ │ ├── 29.红白色时间轴简历.docx
│ │ │ ├── 3.五百丁分割线简历.docx
│ │ │ ├── 30.传统极简简历.docx
│ │ │ ├── 31.红色肌理红色肌理风格.docx
│ │ │ ├── 32.红色简洁欧美.docx
│ │ │ ├── 33.红色时间轴简历.docx
│ │ │ ├── 34.灰蓝色时间轴.docx
│ │ │ ├── 35.极简英文简历.docx
│ │ │ ├── 36.简洁传统.docx
│ │ │ ├── 37.简洁红白色简历.docx
│ │ │ ├── 38.简洁橘色简历.docx
│ │ │ ├── 39.橘色简洁.docx
│ │ │ ├── 4..lowpoly风格.docx
│ │ │ ├── 40.酷黑.docx
│ │ │ ├── 41.酷黑炫彩.docx
│ │ │ ├── 42.蓝色框架简历.docx
│ │ │ ├── 43.蓝红绿时尚简历模板.docx
│ │ │ ├── 44.蓝灰色块基本款.docx
│ │ │ ├── 45.蓝色简洁.docx
│ │ │ ├── 46..豆瓣风格.docx
│ │ │ ├── 47.蓝色星空分隔简历.docx
│ │ │ ├── 48..传统两栏.docx
│ │ │ ├── 49.百科风格简历.docx
│ │ │ ├── 5.彩色时间轴简历.docx
│ │ │ ├── 50.鹰背景样式简历.docx
│ │ │ ├── 51黑色简洁模板.doc
│ │ │ ├── 52.黑白色块简历模板.doc
│ │ │ ├── 53.绿色边简历模板.doc
│ │ │ ├── 54.七彩花朵简历模板.doc
│ │ │ ├── 55.蓝色简洁大气简历模板.doc
│ │ │ ├── 56.黑白蓝简洁简历模板.doc
│ │ │ ├── 57.浅色几何背景.doc
│ │ │ ├── 58.橘色边简历模板.doc
│ │ │ ├── 59.蓝色边简历模板.doc
│ │ │ ├── 6.产品经理简历.docx
│ │ │ ├── 60.红色丝带.doc
│ │ │ ├── 61.浅色花朵背景.doc
│ │ │ ├── 62.红色边框简历模板.doc
│ │ │ ├── 63.米色背景简洁简历.doc
│ │ │ ├── 64.绿色叶子简历.doc
│ │ │ ├── 65.五百丁红黑色商务风中轴分布.docx
│ │ │ ├── 66.蓝色邮票简历.doc
│ │ │ ├── 67.浅绿色简洁简历.doc
│ │ │ ├── 68.深绿色简历.doc
│ │ │ ├── 69.淡紫色边框简历.doc
│ │ │ ├── 7.产品运营_数据分析-统计图.docx
│ │ │ ├── 70.红蓝色块模板.doc
│ │ │ ├── 71.简历常用icon-Word简历模板图标.docx
│ │ │ ├── 72.绿色多时间轴简历.docx
│ │ │ ├── 73.绿色极简简历.docx
│ │ │ ├── 74.绿色时尚模块.docx
│ │ │ ├── 75.蒙特里安-多年经验.docx
│ │ │ ├── 76.墨绿色可调技能环.docx
│ │ │ ├── 77.牛仔布肌理多年经验.docx
│ │ │ ├── 78.欧美毕业生简历.docx
│ │ │ ├── 79.欧美风简洁.docx
│ │ │ ├── 8.橙黄蓝-多年经验.docx
│ │ │ ├── 80.浅蓝色简洁.docx
│ │ │ ├── 81.清新素雅.docx
│ │ │ ├── 82.人力资源主管简历.docx
│ │ │ ├── 83.绿色条状简历 .docx
│ │ │ ├── 84.蓝色条纹状简历.docx
│ │ │ ├── 85.橘色条纹状简历.docx
│ │ │ ├── 86.绿色多彩商务.docx
│ │ │ ├── 87.蓝色多彩商务.docx
│ │ │ ├── 88.橘色多彩商务.docx
│ │ │ ├── 89.商业分析师简历-bing搜索风格.docx
│ │ │ ├── 9..IOS毛玻璃.docx
│ │ │ ├── 90..淡绿色商务简历.docx
│ │ │ ├── 91.时间轴黑绿色块商务风.docx
│ │ │ ├── 92.时间轴黑红色块商务风.docx
│ │ │ ├── 93.彩色史努比Snoopy .docx
│ │ │ ├── 94.纯色史努比Snoopy.docx
│ │ │ ├── 95无色简洁.docx
│ │ │ ├── 96.严肃规整.docx
│ │ │ ├── 97.英文蓝色简洁.docx
│ │ │ ├── 98.英文深紫色简历.docx
│ │ │ └── 99.中轴对称简历.docx
│ │ ├── 2【12套简历+封面+自荐信】/
│ │ │ └── word文档/
│ │ │ ├── 1.艺术类简历+封面+求职信模板.doc
│ │ │ ├── 10.蓝色极简【封面+简历+自荐信】.doc
│ │ │ ├── 11.蓝色商务简洁模板【简历+自荐信】.docx
│ │ │ ├── 12.桌面个人简历.doc
│ │ │ ├── 2.绿色树叶【简历封面+简历+自荐书】.doc
│ │ │ ├── 3.绿色树枝背景.doc
│ │ │ ├── 4.水墨风格【简历封面+简历+自荐信】.doc
│ │ │ ├── 5.清新花朵求职简历(封面+简历+自荐信).doc
│ │ │ ├── 6.树枝简洁【简历封面+简历+自荐信】.doc
│ │ │ ├── 7.紫色花朵【简历封面+简历+自荐信】.doc
│ │ │ ├── 8.【封面+求职简历+求职信】国风墨宝简历.doc
│ │ │ └── 9.兰花【简历封面+简历+自荐信】.doc
│ │ ├── 3【4套中英文简历】/
│ │ │ └── word文档/
│ │ │ ├── 1.蓝线黑框简洁进度条【中英文】.docx
│ │ │ ├── 2.【中英文简历】大气实用,秒抓HR眼球.doc
│ │ │ ├── 3.简历计划-中英文双版+求职信+作品集.doc
│ │ │ └── 4..暗红色中英文.docx
│ │ └── 如何插入照片.doc
│ └── 程序员推荐简历,简介明了.doc
├── 程序员推荐简历,简介明了.doc
└── 项目经历介绍.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
.DS_Store
.vscode
.idea
================================================
FILE: README.md
================================================
# go-interview-resume
> 这是本人整理的一些与**Golang后端研发**岗位相关的面试笔记,欢迎大家及时补充
>
> 当然并不局限于Golang研发岗位,笔记中还包括**计算机网络、操作系统、MySQL、Redis、系统设计**等八股文,其他语言岗位的也可以阅读
## 简历
>一些建议:
>
>**简介明了**:保持简历简洁明了,使用清晰的布局和格式,使得信息易于阅读。限制简历长度在一页或两页之内,但必须包含基本的个人信息,比如年龄、性别、电话、邮件以及教育经历
>
>**突出重点**:
>- **项目经验**:如果有相关的项目经验,可以列出项目的名称、时间、描述和您在项目中承担的角色和职责,最好别是那些烂大街的项目(点名某外卖、某论坛等),如果实在没有,可以参考我个人做的分布式定时任务管理平台[Crony](https://github.com/tmnhs/Crony) ,建议看看源码,不是很难,至于怎么在简历中写,可以参考[程序员推荐简历,简介明了](https://github.com/tmnhs/go-interview-resume/blob/main/resume/%E7%A8%8B%E5%BA%8F%E5%91%98%E6%8E%A8%E8%8D%90%E7%AE%80%E5%8E%86%EF%BC%8C%E7%AE%80%E4%BB%8B%E6%98%8E%E4%BA%86.doc) ,还有怎么在面试过程中介绍这个项目可以参考[项目经历介绍.md](https://github.com/tmnhs/go-interview-resume/blob/main/%E9%A1%B9%E7%9B%AE%E7%BB%8F%E5%8E%86%E4%BB%8B%E7%BB%8D.md)
>- **实习经历**:现在应届生如果没有实习经历真不好找工作了,建议大二或大三的时候找一份实习工作
>
- [130套简历](https://github.com/tmnhs/go-interview-resume/tree/main/resume/130%E5%A5%97%E7%AE%80%E5%8E%86)
- [程序员推荐简历,简介明了](https://github.com/tmnhs/go-interview-resume/blob/main/resume/%E7%A8%8B%E5%BA%8F%E5%91%98%E6%8E%A8%E8%8D%90%E7%AE%80%E5%8E%86%EF%BC%8C%E7%AE%80%E4%BB%8B%E6%98%8E%E4%BA%86.doc)
## 面试
> 整理的一些面试八股文,答案不一定准确,如果感觉不准确的可以自行在网上查找验证
>
> 其中❤表示重点
- [Go语言](https://github.com/tmnhs/go-interview-resume/blob/main/interview/go%E8%AF%AD%E8%A8%80.md)
Golang面试题,包括Go语言的**基础语法**、**垃圾回收**、**内存管理**、**GMP模型**以及**常见数据结构**(channel、map、select...)的底层原理等
推荐阅读[地鼠文档](https://www.topgoer.cn/), 可以在里面找到许多与go语言相关的文档
比如[Go专家编程](https://www.topgoer.cn/docs/gozhuanjia/gogfjhk) 、 [Go语言标准库](https://www.topgoer.cn/docs/golangstandard/golangstandard-1cmks9a4kaj3c) 等都值得阅读
- [代码编程](https://github.com/tmnhs/go-interview-resume/blob/main/interview/%E4%BB%A3%E7%A0%81%E7%BC%96%E7%A8%8B(go%E8%AF%AD%E8%A8%80%E5%AE%9E%E7%8E%B0).md)
面试过程中面试官可能要求实现的一些代码编程
比如:
- 两个协程交替打印10个字母和数字
- 启动 2个groutine 2秒后取消, 第一个协程1秒执行完,第二个协程3秒执行完
...
- [常见算法和模板](https://github.com/tmnhs/go-interview-resume/blob/main/interview/%E5%B8%B8%E8%A7%81%E7%AE%97%E6%B3%95%E5%92%8C%E6%A8%A1%E6%9D%BF.md)
一些常见算法的模板,比如**KMP、LRU算法、二分法、回溯法、分治法、滑动窗口**等
推荐阅读[algorithm-pattern](https://greyireland.gitbook.io/algorithm-pattern/) ,是基于Go语言的,阅读此文档可以解决面试中绝大部分算法题
- [MySQL](https://github.com/tmnhs/go-interview-resume/blob/main/interview/MySQL.md)
MySQL的一些面试题,包括:
- 存储引擎
- 索引及其优化
- 事务(MVCC)和锁
- 分库分表和主从复制
...
- [Redis](https://github.com/tmnhs/go-interview-resume/blob/main/interview/redis.md)
Redis面试题
包括**基本的数据类型、过期键的处理策略、持久化、集群、主从和哨兵**等
- [计算机网络](https://github.com/tmnhs/go-interview-resume/blob/main/interview/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C.md)
计算机网络相关面试题
比如**网络协议、TCP三次握手、四次挥手、http和https**等
- [操作系统](https://github.com/tmnhs/go-interview-resume/blob/main/interview/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F.md)
操作系统面试题
比如**线程、进程以及它们之间如何通信的、多路IO复用、内存**等
- [海量数据高频面试题](https://github.com/tmnhs/go-interview-resume/blob/main/interview/%E6%B5%B7%E9%87%8F%E6%95%B0%E6%8D%AE%E9%AB%98%E9%A2%91%E9%9D%A2%E8%AF%95%E9%A2%98.md)
在海量数据场景下的一些面试题,比如:
- 寻找热门查询,300万个查询字符串中统计最热门的10个
- 在2.5亿个整数中找出不重复的整数,内存空间不足以容纳这2.5亿个整数
- 在5亿个int找它们的中位数
...
- [微服务](https://github.com/tmnhs/go-interview-resume/blob/main/interview/%E5%BE%AE%E6%9C%8D%E5%8A%A1.md)
微服务场景下的面试题,比如服务治理、熔断和降级等
- [系统设计](https://github.com/tmnhs/go-interview-resume/blob/main/interview/%E7%B3%BB%E7%BB%9F%E8%AE%BE%E8%AE%A1%E6%80%9D%E8%B7%AF.md)
在某些特定场景下设计的面试题,比如:
- 分布式ID生成器
- 短网址系统
- 定时任务调度器
...
- [架构设计](https://github.com/tmnhs/go-interview-resume/blob/main/interview/%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1.md)
与架构设计相关的面试题,比如:
- 为什么要做多级缓存
- MQ中间件是如何实现消息可靠性投递的
...
还在更新中...
## 说明
本项目主要以简单问答的形式介绍面试八股文,如果想深入了解计算机网络、操作系统、数据库等,强烈推荐阅读[小林coding (xiaolincoding.com)](https://xiaolincoding.com/)
面试问题和答案大部分来自于网络,包括:
- [路人张的面试笔记](https://www.mianshi.online/)
- [地鼠文档](https://www.topgoer.cn/)
- [algorithm-pattern](https://greyireland.gitbook.io/algorithm-pattern/)
- 一些知乎上的文章
- [牛客上的面经](https://www.nowcoder.com/)
- [IT老齐-哔哩哔哩视频 (bilibili.com)](https://space.bilibili.com/359351574)
- 个人面经
答案不一定准确,欢迎大家提issues或者pull requests进行补充
================================================
FILE: interview/MySQL.md
================================================
## MySQL基础知识
### 1.什么是MySQL
MySQL是一个开源的关系型数据库管理系统,利用结构化查询语句SQL进行数据库管理
### 2.MySQL常用的存储引擎有什么?他们有什么区别
- InnoDB
InnoDB是MySQL默认的存储引擎,支持事务、行锁、外键、并发等操作,聚簇索引,
- MyISAM
MyISAM是MySQL5.1版本前的默认存储引擎,MyISAM的并发性很差,不支持事务、行锁、外键等操作,默认的锁的粒度为表级锁,非聚簇索引
- MEMORY:
所有的数据都在内存中,数据的处理速度快,但是安全性不高
- Archive:
如果只有INSERT和SELECT操作,可以选择Archive,Archive支持高并发的插入操作,但是本身不是事务安全的。Archive非常适合存储归档数据,如记录日志信息可以使用Archiv
### 3.数据库的三大范式是什么
- 第一范式:保证每列的原子性,数据表中的所有字段值都是不可分解的原子值
- 第二范式:保证表中每列都与主键相关
- 第三范式:保证每列都与主键直接相关而不是间接相关
### 4.❤MySQL的数据类型有哪些?
- 整数(TINYINT / SMALLINT / MEDIUMINT /INT / BIGINT)
- 浮点数(FLOAT / DOUBLE / DECIMAL【利用字符串,效率更低】)
- 字符串 (CHAR 【定长,未满补空格】 / VARCHAR 【可变,空间效率高,】):varchar更节省空间。应用场景:对于经常变更的数据使用char更好,char不容易产生碎片。**CHAR**的存取速度要比**VARCHAR**快得多,因为其长度固定,方便程序的存储与查找;但是CHAR为此付出的是空间的代价,因为其长度固定,所以难免会有多余的空格占位符占据空间,可以说是以空间换取时间效率,而VARCHAR则是以空间效率为首位的。
- 日期 (year / time /date / datetime【秒,8字节,与时区无关】 / timestamp【秒,四字节,与时区相关】):尽量使用timestamp,相比于datetime它有着更高的空间效率
## 索引
> 基本上问的最多的就是索引
>
> 一般面试官会问你对数据库索引了解的全部知识
>
> 只需要按照下面的问题大概讲一遍即可
>
> 百度提前批二面、得物一面、滴滴提前批一面
### 1.什么是索引
索引是对数据库表的一列或者多列的值进行排序的一种结构,使用索引可以快速访问数据库表中的特定信息
### 2.索引的优缺点
- 优点:
1.大大加快了数据检索的速度,
2.将随机I/O变成顺序I/O(因为B+数的叶子结点是连接在一起的),
3.可以加快表与表之间的连接
- 缺点:
1.创建索引和维护索引需要时间成本,这个成本随着数据量的增大而加大;
2.创建索引和维护索引需要空间成本,这个数据量越大,占用空间也越大;
3.会减低表的增删改的效率,因为每次操作都需要进行动态维护,导致时间变长
### 3.❤索引的数据结构?
索引的数据结构主要是B+树和哈希表,对应的索引分别是B+树索引和哈希索引。InnoDB引擎的索引主要是是B+树和哈希索引,默认的索引类型是B+树。
- B+树索引
1.所有的记录节点都是按照键值大小的顺序放在叶子节点,B+树具有有序性,并且所有的数据都存放在叶子节点,内部节点只有key值,没有value值
2.B+树的索引又可以分为主索引和辅助索引,其中主索引为聚簇索引,辅助索引为非聚簇索引,聚簇索引的叶子节点存储着完整的数据记录。非聚簇索引是以非主键的列作为B+数的键值所构成的B+数索引,非聚簇索引的叶子节点存储着主键值。使用非聚簇索引进行查询时会进行回标查询
- 哈希索引
哈希索引是基于哈希表实现的,对于每一行数据,存储引擎会对索引列通过哈希算法进行哈希计算得到哈希码,将哈希码作为哈希表额key值,将指向数据行的指针作为哈希表的value值。O(1) ,一般用于精准查找
### 4.Hash索引和B+树的区别
哈希表不支持排序,一般多用于精准的等值查找,存在哈希冲突,性能不稳定,B+树支持范围查询,模糊查询和多列索引最左前缀优先匹配,性能是相对稳定的,每次查询都是从根节点到叶子节点
### 5.索引的类型有哪些?
- FULLLTEXT:全文索引,查找文本内容,主要是用来解决模糊查询效率满低的问题
- 普通索引:基本的索引类型
- 唯一索引:数据列不允许重复,可以为NULL,索引列的值必须唯一
- 主键索引:数据列不允许重复,不能为NULL,一个表只能有一个
- 组合索引:多个列组成的索引,遵循最左前缀匹配原则
### 6.B数和B+树的区别?
- B树的内部节点和叶子节点都会存储键和值,而B+树的内部节点只有键没有值,叶子节点存放所有的键和值
- B+树的叶子节点是有序连接在一起的,方便顺序检索
### 7.❤数据库为什么使用B+树而不是B树?
- **范围检索:**B树只适用于随机检索,B+树适用于随机检索和顺序检索,因为B+树的叶子节点都是连接在一起的,支持范围检索
- **性能:**B+树性能更稳定,每次查询都是从根节点到叶子节点,而B树因为内部节点包含key值和数据的完整记录,所以每次查找的值可能在内部节点就已经找到
- **空间利用率:**B+树的空间利用率更高,因为B+树的内部节点只存储键(key),这样B+树的一个节点就可以存储更多的索引,从而是树的高度遍地,减少I/O次数,加快检索速度
### 8.什么是聚簇索引和非聚簇索引?
最主要区别是数据和索引是否分开存储
- 聚簇索引是将数据和索引放到一起存储,索引结构的叶子节点保留了**数据行**
- 非聚簇索引是将数据和索引分开存储,索引结构的叶子节点存储的是**指向数据行的地址**
### 9.非聚簇索引一定会进行回表查询?
可以通过**索引覆盖**解决非聚簇索引回表查询的问题。
如果查询的数据在辅助索引上完全能获取到便不需要回表查询。
例如一张个人信息表包含id、name、age等字段,假设聚簇索引是以id为键值建的索引,非聚簇索引是以name为键值构建的索引,select id ,name from user where name = 'zhangsan'
### 10.❤索引的使用场景(设计原则,如何优化)
- 对于**中大型表**建立索引非常有效,对于非常小的表,一帮全部表扫描速度更快些,索引列的基数越大,索引的效果越好
- 对于增删改非常少,而查询需求非常多的表,建立索引就很有必要了
- 多个字段经常被查询的话可以考虑组合索引
- 字段多并且字段值没有重复的时候可以考虑唯一索引
- 尽量使用**短索引**(前缀索引),尽量利用**最左前缀匹配原则**,对于较长的字符串进行索引的时候应该指定一个较短的前缀长度,因为较小的索引涉及的磁盘I/O较少,并且索引高速缓存中的块可以容纳更多的键值
### 11.如何创建/删除索引
- create index index_name on table_name(col_name);
- alter table table_name add index index_name(col_name);
- alter table table_name drop index index_name
- alter table table_name drop primary key
- drop index index_name on table_name;
### 12.使用索引查询是性能一定会提升吗?
不一定,因为创建和维护索引需要时间和空间上的代价,如果不合理的使用索引反而会是查询性能下降
### 13.什么是前缀索引
前缀索引是指对文本或者字符串的前几个字符建立索引,这样的索引长度更短,查询速度更快
使用场景:前缀区分度比较高的情况下
### 14.什么是最左匹配原则?
在建立组合索引时,从建立的索引最左边为起点开始连续匹配,遇到**范围查询**(>,<,between,like)会停止匹配
### 15.索引在什么情况下会失效?
- 条件中有or
- 使用like模糊查询以%开头的
- 在索引列上进行计算,使用函数,隐式转化,where a + 1 >100
- 对于组合索引,不遵循最左匹配原则
- 在索引字段上使用is null / is not null判断时会导致索引失败
### 16.❤数据库为什么使用B+树而不是红黑树?
> 百度提前批二面、得物一面
>
> 什么是红黑树?
>
> 红黑树(Red-Black Tree)是一种自平衡的二叉搜索树,它在插入和删除操作后通过重新调整树的结构来保持平衡,从而保证树的高度始终在可控范围内,保证了基本的搜索、插入和删除操作的时间复杂度都能保持在 O(log n) 级别。
>
> 红黑树的特点包括:
>
> 1. **节点颜色**:每个节点都有一个颜色,可以是红色或黑色。
> 2. **根节点和叶子节点特性**:根节点和叶子节点(NIL 节点,通常用于表示空节点)是黑色的。
> 3. **红色节点限制**:不能有两个连续的红色节点,即红色节点不能相邻。
> 4. **从任一节点到其每个叶子的路径都包含相同数目的黑色节点**:这保证了树的高度相对平衡,从而保证了搜索、插入和删除操作的平均时间复杂度。
>
> 红黑树的自平衡性质使得它适用于高效的查找、插入和删除操作,因此在许多编程语言的标准库中被广泛应用,如C++的STL中的`std::map`和`std::set`,以及Java的`TreeMap`和`TreeSet`等。红黑树的设计和调整策略相对复杂,但它确保了在最坏情况下的性能也能够保持在较高水平。
1. **磁盘IO优化**:B+树在设计上更适合数据库索引,因为它的节点结构能够更好地适应磁盘块的存储。B+树 的特点就是每层节点数目非常多,**层数很少**,目的就是为了就是**减少磁盘IO次数**。B+树的**内部节点存储的是键**,而叶子节点存储的是实际的数据或数据的引用。这种结构可以使得每个节点能够存储更多的键值,从而**减少磁盘IO的次数**,提高检索效率。
2. **范围查询优化**:数据库中的范围查询是很常见的操作,B+树天生就支持范围查询,因为叶子节点是一个有序的链表,范围查询可以通过遍历叶子节点实现。而红黑树则不具备这种天生的优势。
红黑树也是一种平衡二叉搜索树,它在某些情况下具有性能优势,但相对于B+树,在数据库索引的应用场景下,B+树更能满足数据库的需求,因此被广泛地用作数据库索引的数据结构。
> 为什么在内存中使用红黑树而不是B树?
>
> 1. **更低的内存占用和更简洁的节点结构**:B+树的内部节点要存储额外的指针,而红黑树只需要存储颜色标志和父节点指针,这在内存中可以节省空间。
> 2. **更快的查询性能**:由于内存访问速度较快,B+树叶子节点的顺序访问并不会像在磁盘上那样重要。而红黑树的平衡性质使得树的高度相对较小,查找性能相对较好。
> 3. **不需要额外的磁盘块管理**:B+树在磁盘中的设计考虑了磁盘块的大小和管理,而在内存中不需要这些考虑。红黑树的结构更为简单,适用于内存数据存储。
>
> 需要注意的是,B+树在数据库等涉及大规模数据存储的场景中的优势主要体现在磁盘IO优化、范围查询和排序操作等方面,而在内存中,红黑树的特性更符合内存数据的访问模式和性能需求。因此,在内存中使用红黑树通常是更合适的选择
## 事务
> 面试官提问:讲讲你对MySQL事务的理解
>
> 美团一面
### 1.什么是数据库的事务?
数据库事务是访问并可能操作各种数据项的一个数据库操作序列,这些要么全部执行,要么全部不执行
### 2.事务的四大特性?
- **原子性**:包含事务的操作要么全部执行成功,要么全部执行失败并回滚
- **一致性**:一致性是指事务在执行前后状态是一致的,保证事务按预期生效,即正确性
- **隔离性**:一个事务所进行的修改在最终提交之前,对其他事务是不可见的
- **持久性**:数据一旦提交,其所作的修改将永久的保存在数据库中
### 3.数据库的并发一致性问题
当多个事务并发执行时,可能出现以下问题
- **脏读**:事务A更新了数据,当时还没有提交,这时事务B读取到事务A更新后的数据,然后事务A回滚了,事务B读取的数据就成为脏数据了
- **不可重复读**:事务A对数据进行多次读取,事务B在事务A多次读取的过程中执行了更新操作并提交了,导致事务A多次读取到的数据并不一致
- **幻读**:事务A在读取数据后,事务B向事务A多次读取的数据中插入了几条数据,事务A再次读取数据是发现多了几条数据,和之前读取的数据不一致
- 丢失修改:事务A和事务B都对同一个数据进行修改,事务A先修改,事务B后修改,事务B的修改覆盖了事务A的修改
不可重复读和幻读的主要区别:在不可重复读中,发现数据不一致主要是数据被更行了;而在幻读中,发现数据不一致主要是数据增多了或者减少了
### 4.数据库的隔离级别有哪些?
- 未提交读:一个事务在提交前,它的修改对其他事务也是可见的
- 提交读:一个事务提交之后,它的修改才能被其他事务看到
- 可重复读:在同一个事务中多次读取到的数据是一致的
- 串行化:需要加锁实现,会强制事务串行执行
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
| ---- | ---- | ----- | ---- |
| 未提交读 | 允许 | 允许 | 允许 |
| 提交读 | 不允许 | 允许 | 允许 |
| 可重复读 | 不允许 | 不允许 | 允许 |
| 串行化 | 不允许 | 不允许 | 不允许 |
**MySQL的默认隔离级别是可重复读**
### 5.隔离级别是如何实现的?
事务的隔离机制主要是依靠锁机制和MVCC(多版本并发控制)实现的,提交读和可重复读可以通过MVCC实现,串行化可以通过锁机制实现
### 6.❤什么是MVCC?
MVCC(多版本并发控制)是一种控制并发的方法,MVCC的作用就是在**避免加锁**的情况下最大限度解决读写并发冲突的问题,它可以实现提交读和可重复读两个隔离级别
在了解MVCC机制之前需要介绍几个概念:
- ReadView(快照读):数据库中某一个时刻所有未提交事务的快照。
- 几个重要参数
- m_ids:表示生成ReadView时,当前系统正在活跃的读写事务的事务ID列表,数组里最小的id为min_id
- max_id:表示生成ReadView时,当前已创建的最大事务id
- 隐藏列
- 在InnoDB存储引擎中,它的聚簇索引记录中都包含两个必要的隐藏列,trx_id(事务id),roll_pointer(回滚指针)
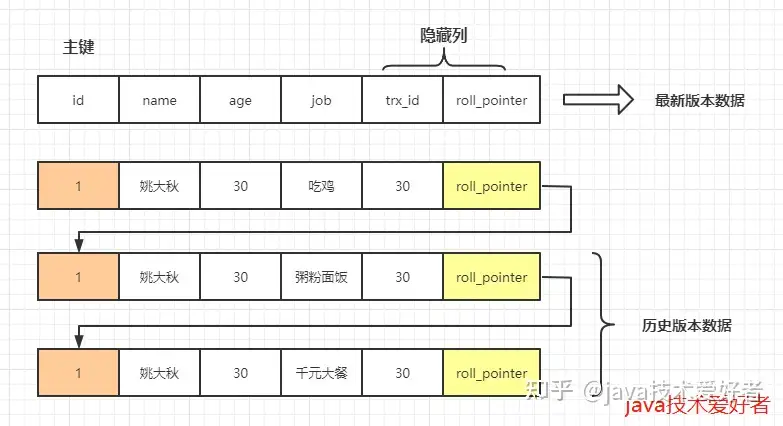
- undo日志
- MVCC使用到的快照会存储到Undo日志中,该日志通过回滚指针将一个一个数据行的所有快照连接起来。

**对比规则**:
1.如果落在绿色部分(trx_id < min_id),表示这个版本是已提交的事务生成的,这个数据是可见的
2.如果落在红色部分(trx_id>max_id),表示这个版本是有将来启动是事务生成的,是肯定不可见的
3.如果落在黄色(min_id <= trx_id <=max_id),分成两种情况
- 若row的trx_id在数组中,表示这个版本是由还没提交的事务生成的,不可见
- 若row的trx_id不在数组中,表示这个版本是已经提交了的事务生成的,可见
4.对于删除的情况可以认为是update的特殊情况,会将版本链上最新的数据复制一份,然后将trx_id修改成删除操作的trx_id,同时在该条记录的头信息里的(deleted_flag)标记为写上true,来表示当前记录已经被删除,在查询时按照上面的规则查到对应的记录若果delete_flag标记位为true,意味着已被删除,则不返回数据
**RC隔离级别的事务在每次查询开始时都会生成一个独立的 ReadView**。
**RR隔离级别的事务在第一次读取数据时生成ReadView,之后的查询都不会再生成,所以一个事务的查询结果每次都是一样的**。
### 7.❤既然用了MVCC,为什么还会出现幻读
> mvcc本身是通过trx_id(事务隐藏列)来实现的版本维护,不能读取到ReadView开启时还没提交的事务的记录。
>
> mysql里面实际上有两种读,
>
> 一种是“**快照读**”,比如我们使用select进行查询,就是快照读。在快照读的情况下不会产生幻读的问题。
>
> 另一种读则是“**当前读**”,例如delete,update,insert等语句,都需要满足**直接忽略事务号读取最新数据的要求**。
在快照读模式下可以解决幻读问题,但在当前读读模式下,仅仅依靠MVCC不能解决幻读问题,因为当前读必须获取最新数据
## 锁机制
### 1.什么是数据库的锁?
当数据库有并发事务的时候,保证数据访问顺序的机制成为锁机制
### 2.数据库的锁与隔离级别的关系?
| 隔离级别 | 实现方式 |
| ---- | -------------------- |
| 未提交读 | 总是读取最新的数据,无需加锁 |
| 提交读 | 读取数据时加共享锁,读取数据后释放 |
| 可重复读 | 读取数据时加共享锁,事务结束后释放共享锁 |
| 串行化 | 锁定整个范围的键,一直持有锁直到事结束 |
### 3.数据库锁的类型有哪些?
- 按粒度
| MySQL锁类别 | 资源开销 | 加锁速度 | 是否会出现死锁 | 锁的粒度 | 并发度 |
| -------- | ---- | ---- | ------- | ---- | ---- |
| **表级锁** | 小 | 快 | 不会 | 大 | 低 |
| 行级锁 | 大 | 慢 | 会 | 小 | 高 |
| 页级锁 | 一般 | 一般 | 不会 | 一般 | 一般 |
MyISAM默认采用**表级锁**,InnoDB默认采用**行级锁**。
- 从锁的类别上
- **共享锁**:又称读锁,一个事务对一个数据对象加了读锁,可以对这个数据对象进行读取操作,但不能进行更新操作。并且在加锁期间其他事务只能对这个数据对象加读锁,不能加写锁
- **排它锁**:又称写锁,一个事务对一个数据对象加了写锁,可以对这个对象进行读取和更新操作。加锁期间,其他事务不能对该数据对象进行加写锁或者读锁
### 4.MySQL中InnoDB引擎的行锁模式及其实如何实现的?
> 在存在行锁和表锁的时候,一个事务相对某个表加写锁,需要先检查是否有其他事务对这个表加了锁或者对这个表的某一行加了锁,对表的每一行都进行检测一次这是非常低效率的,为了解决这种问题,实现多粒度锁机制,InnoDB还有内部使用的意向锁,两种意向锁都是表锁。
**InnoDB实现了以下两种类型的行锁**
- 共享锁(S)
- 排他锁(X)
另外,为了允许行锁和表锁共存,提高效率,实现多粒度锁机制,InnoDB还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁。
- 意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的IS锁。
- 意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的IX锁。
**实现方式**
InnoDB的行锁是通过给索引上的**索引项加锁**实现的,如果没有索引,InnoDB将通过隐藏的的聚簇索引来对记录进行加锁。
行锁主要是分三种情况:
- Record lock 记录锁:对索引项加锁,存在于包括`主键索引`在内的`唯一索引`中,锁定单条索引记录。
- Grap lock 间隙锁:间隙锁基于`非唯一索引`,它`锁定一段范围内的索引记录`
- Next-key lock 临键锁:可以理解为一种特殊的间隙锁,也可以理解为一种特殊的算法。通过临建锁可以解决`幻读`的问题。 每个数据行上的`非唯一索引列`上都会存在一把临键锁,当某个事务持有该数据行的临键锁时,会锁住一段左开右闭区间的数据。需要强调的一点是,`InnoDB` 中`行级锁`是基于索引实现的,临键锁只与`非唯一索引列`有关,在`唯一索引列`(包括`主键列`)上不存在临键锁。
InnoDB行锁的特性:如果不通过索引条件检索数据,那么InnoDB将对表中的所有记录加锁,实际产生的效果和表锁是一样的
MVCC不能解决幻读问题,在可重复读隔离级别下,使用MVCC+Next-Key Locks可以解决幻读问题
### 5.❤什么是数据库的乐观锁和悲观锁,如何实现?
- 乐观锁(**读多写少**场景):系统假设数据的更新在大多数时候是不会产生的冲突的,所以数据库旨在**更新操作提交的时候对数据检测冲突**,如果存在冲突,则数据更新失败。
- 乐观锁实现方式:一般通过**版本号和CAS**(CompareAndSwap)算法实现
- 给表加一个版本号或时间戳的字段,读取数据时,将版本号一同读出,数据更新时,将版本号加1。
当我们提交数据更新时,判断当前的版本号与第一次读取出来的版本号是否相等。如果相等,则予以更新,否则认为数据过期,拒绝更新,让用户重新操作。
```sql
begin;
-- 查找最新版本号version
select nums, version from tb_goods_stock where goods_id = {$goods_id};
-- 根据version更新
update tb_goods_stock set nums = nums - {$num}, version = version + 1 where goods_id = {$goods_id} and version = {$version} and nums >= {$num};
```
- 函数公式:CAS(V,E,N)V:表示要更新的变量E:表示预期值N:表示新值
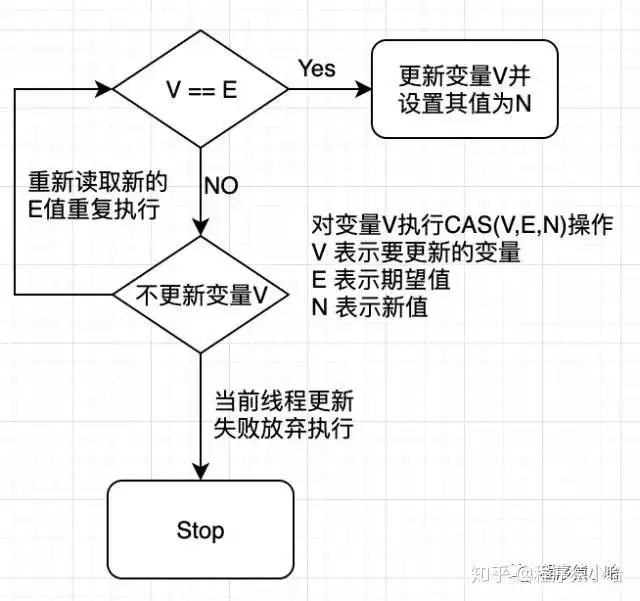
- 悲观锁(读少写多场景):鉴定会发生并发冲突,屏蔽一切可能违反数据完整性的操作。通俗讲就是每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会加上锁(在所有操作前都加锁)。
悲观锁实现方式:通过数据库的锁机制实现,对查询语句添加**for update**;
### 6.什么是死锁?如何避免?
死锁是**指两个或者两个以上进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象**。在MySQL中,MyISAM是一次获得锁需要的全部锁,要么全部满足,要么等待,所以不会出现死锁问题。在InnoDB中,除了单个SQL组成的事务外,锁都是逐步获得的,所以存在死锁问题。****
**如何避免**
- 以固定的顺序访问表和行
- 大事务更倾向于死锁,如果业务允许,**将大事务拆小**
- 在同一个事务中,尽可能做到一次锁定所需要的所有资源,减少死锁概率
- **降低隔离级别**。如果业务允许,将隔离级别调低也是较好的选择
- **为表添加合理的索引**,可以看到如果不走索引将会为表的每一行记录添加上锁,死锁的概率大大增大
## SQL语句基础知识
### 1.SQL语句主要分为哪几类?
- 数据定义语言DDL(Definition):Create\Drop\Alter
- 数据库查询语言DQL (Query): select
- 数据库操纵语言DML(Manipulation):insert/update/delete
- 数据控制功能DCL(Control):grant/revoke
### 2.SQL约束有哪些?
- 主键约束
- 唯一约束
- 外键约束
- Check约束
- 默认约束
### 3.什么是子查询?
把一个查询的结果在另一个查询中使用
- 标量子查询:
```sql
select * from user where age = (select max(age) from user)
```
- 列子查询:
```sql
select num1 from table1 where num1 > any (select num2 from table2)
```
- 行子查询:
```sql
select * from where (age,sex) = (select age ,sex from user where name = 'zhangsan')
```
- 表子查询:
```sql
select * from student where (name ,age ,sex ) in (select name,age,sex from class1)
```
### 4.❤了解MySQL的几种连接查询,内连接和外连接的区别?
- 外连接:取出连接表中匹配到的数据,匹配不到的也会保留,其值为NULL,left / right join
- 内连接:取出两张表中匹配到的数据,匹配不到的不保留
- 交叉连接:使用笛卡尔积的一种连接
### 5.MySQL中in 和exists 的区别是?
in和exists一般用于子查询
- 使用exists时会先进行**外表查询**,将查询到的每一行数据都带入内表查询中看是否满足条件;使用in一般会先进行**内表查询**获取结果集,然后对外表查询匹配结果集,返回数据。
- in在内表查询或者外表查询过程中都会用到索引
- exsits仅在内表查询时会用到索引
- **一般来说,当子查询的结果集比较大,外表较小时用exist效率更高;当子查询的结果较小,外表较大时,使用in效率更高。**
- 对于not in 和 not exists,not exists效率比not in 效率高,与子查询的结果集无关,因为not in 对于内外表都进行了 全表扫描,没有使用到索引。not exists的子查询中可以用到表上的索引
### 6.❤varchar 和 char 的区别?
- varchar 表示**变长**,char 表示**长度固定**,未满填充空格,超出国定长度则拒绝插入并提示错误信息
- **存储容量不同**。对char来说,最多能存放的字符个数为255.对于varchar,最多能存放的字符个数是65532
- **存储速度不同**。char长度固定,存储速度会比varchar快一些,但在空间上会占用额外的空间,属于一种空间换时间的策略。varchar空间利用率会更高些。
### 7.MySQL中int(10)、char(10)和varchar(10)的区别是?
int(10)表示显示数据的长度,而char(10)和varchar(10)表示的是存储数据的大小
### 8.drop、delete和truncate的区别
- drop删除整个表,数据行、索引都会被删除,不可回滚
- delete表结构还在,删除表的一部分或全部数据,可回滚
- truncate表结构还在,删除表的全部数据,不可回滚
### 9.union 和 union all 的区别?
union和union all的作用都是将两个结果集合并到一起。
- union会对结果**去重并排序**,union all 直接返回合并后的结果,不去重也不进行排序
- union all 的性能比union性能好
### 10.什么是临时表,什么时候会使用到临时表,什么时候删除临时表?
MySQL在执行SQL的时候会临时创建一些**存储中间结果集**的表,这种表被称为临时表,临时表只对当前连接可见,在连接关闭后,临时表会被删除并释放空间
临时表主要分为内存临时表(MEMORY存储引擎)和磁盘临时表(MyISAM存储引擎)。
一般在以下几种情况中会使用到临时表
- From 中的**子查询**
- **distinct**查询并加上order by
- order by 和group by 的子句不一样时
- 使用**union**查询是会产生临时表
### 11.大表数据查询如何进行优化?
- **索引优化**:通过添加索引后,查询的效率得到极大的提升,常用查询的查询时间从原来的几十秒下降到几秒。
- **SQL语句优化**,比如select *,在很多情况下要考虑索引的作用.
- **水平拆分**:水平拆分是指数据表行的拆分,如果表中的数据呈现出某一类特性,比如呈现时间特性,那么可以根据时间段将表拆分成多个。比如对id取模
- **垂直拆分**:垂直拆分是指数据表列的拆分,把一张列比较多的表拆分为多张表。表的记录并不多,但是字段却很长,表占用空间很大,检索表的时候需要执行大量的IO,严重降低了性能。这时需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。
- **使用中间表**:以空间换时间
- **使用缓存技术**:以空间换时间
- 固定长度的表访问起来更快
- 越小的列访问越快
### 12.了解慢日志查询吗?统计过慢查询吗?对慢查询如何优化
慢查询一般用于记录执行时间超过某个临界值的SQL语句的日志。
慢查询的统计主要由运维在做,会定期将业务中的慢查询反馈给我们。
如何优化:
- 分析语句的执行计划,查看SQL语句的**索引**是否命中
- 优化数据库的结构,将字段很多的表分解成多个表(**垂直拆分**),或者考虑建立**中间表**。
- **优化LIMIT分页**:对 limit 分页问题的性能优化方法,可以利用表的 **覆盖索引** 来加速分页查询,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快
```sql
//number为普通索引
select * from tb_a where number=1 limit 100000, 100;
--使用子查询优化:
将上面的语句改为
select * from tb_a where number = 1 and id >= (select id from tb_a where number = 1 limit 100000, 1) limit 100;
-- 使用 join 查询优化:
select * from tb_a as a inner join (select id from tb_a where number = 1 limit 100000, 100) as b on a.id = b.id where a.number = 1;
--使用 between ... and 优化:
select * from tb_a where number = 1 and id between 100000 and 100100 limit 100;
-- 使用 in 优化:
select * from tb_a where number = 1 and id in (select id from tb_a where number = 1 limit 100000, 100) limit 100;
-- 上面4种优化方式都是和 id 主键相关的,也就是说,这需要 id 是连续递增的
```
### 13.为什么要设置主键?
主键是唯一区分表中每一行的唯一标识,如果没有主键,更新或者删除表中特定行会很困难,因为不嫩准确地标识某一行
### 14.主键一般用自增ID还是UUID?
一般情况MySQL推荐使用**自增ID**。因为在MySQL中的InnoDB存储引擎中,主键索引是一种聚簇索引,主键索引的B+树的叶子节点按照顺序存储了主键值及数据,如果主键索引是自增ID,只需要按顺序往后排列即可,如果是UUID,ID是随机生成的,在**数据插入时会造成大量数据的移动,产生大量的内存碎片,造成插入性能的下降**。
使用自增ID的好处:
- 字段长度较uuid会**小**很多
- 数据库自动编号,按顺序存放,**利于检索**
- 无需担心主键重复问题
使用自增ID的缺点:
- 因为是自增,在某些业务场景天,容易被其他人查到业务量
- 发生数据迁移时,或者表合并时会非常麻烦
- 在**高并发**的场景下,竞争自增锁会减低数据库的吞吐能力
UUID:通用唯一标识码,基于当前时间、计数器和硬件标识等数据计算生成的
使用UUID的优点:
- 唯一标识,不会考虑重复问题,在数据拆分、合并时也能达到全局的唯一性
- 可以在应用层生成,提高数据库的吞吐能力
- 无需当心业务量泄露的问题
使用UUID的缺点:
- 因为UUID是随机生成的,所以会发生随机IO,影响插入速度,并且会造成硬盘的使用率较低
- UUID占用空间较大,建立的索引越多,造成的影响越大
- UUID之间比较大小较 自增ID慢不少,影响查询速度
### 15.字段为什么要设置成not null?
NULL和空值是不一样的,空值是不占用空间的,而NULL是占用空间的,所以字段设为not null后仍然可以插入空值
- NULL会影响**一些函数的统计**,比如count,遇到NULL值,这条记录不会统计在内
- B树不存储NULL,索引用不到NULL,会造成第一点中说的统计不到的问题
- Not In子查询在有NULL值的情况下返回的记过都是空值
- MySQL在进行比较的时候,**NULL会参与字段的比较**,因为NUll是一种比较特殊的数据类型,数据库在处理时需要进行特殊处理,增加了数据库处理记录的**复杂性**
### 16.如何优化查询过程中的数据访问?
从减少数据访问方面考虑:
- 正确使用**索引**,尽量做到索引覆盖
- 优化SQL执行计划
从返回更少的数据方面考虑:
- **数据分页处理**
- **只返回需要的字段**
从减少服务器CPU开销方面考虑:
- 合理使用排序
- 减少比较的操作
- **复杂运算在客户端处理**
从增加资源方面考虑:
- 客户端多进程并行访问
- 数据库并行处理
### 17.如何优化长难的查询语句?
- 将一个大的查询**分解**为多个小的查询
- 分解关联查询,使缓存的效率更高
### 18.如何优化LIMIT分页?
- **最大id查询法**
扫描意思呢?举个例子,我查询第一页的时候是limit 0,10 查询到的最后一条id是10,那么下一页的查询只需要查询id大于10的10条数据即可。
- **between...and**
```sql
select * from user where id BETWEEN 4000000 and 4000010
```


这种方式也只能适用于自增主键,并且id没有断裂,否者不推荐这种方式,我们发现使用BETWEEN AND的时候查询出来11条记录,也就是说BETWEEN AND包含了两边的边间条件。使用的时候需要特别注意一下。
- **索引覆盖**
可以利用表的 覆盖索引 来加速分页查询,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快。因为利用索引查找有优化算法,且数据块就在查询索引上面,不用再去找相关的数据块,这样节省了很多时间,也就是说,查询的数据就在索引上,不用再经过 回表 的操作。例如:
```sql
select id from tb_a where number=1 limit 100000, 100;
-- 改成
select * from tb_a where number = 1 and id >= (select id from tb_a where number = 1 limit 100000, 1) limit 100;
```
id 是主键索引(聚簇索引),number 是二级索引(非聚簇索引),二级索引的叶子结点上存储的是主键索引值,而我们只需要查询主键即可,因此就不用 回表 查询多一次。
### 19.如何优化UNION查询
如果不需要对结果集进行去重或者排序,建议使用UNION ALL ,会好一些
### 20.如何优化Where子句?
- 不要在where子句中使用!=和<>进行不等于判断,这样会导致放弃索引进行全表扫描
- 不要在where子句中使用null或者空值判断,尽量设置字段为Not NULL
- 尽量使用union all 代替 or
- 尽量少使用以“%”开头的模糊查询
- 在where 和 order by 涉及的列建立索引
- 尽量少使用in 或者 not in ,会进行全表扫描(待定)
- 避免在where子句中对字段进行表达式或者函数操作,会导致存储引擎放弃索引进而全表扫描
### 21.SQL语句执行很慢的原因是什么?
- 如果SQL语句只是偶尔执行很慢,可能是执行的时候遇到了锁,也可能是redo log日志写满了,要将redo log 中的数据同步到磁盘中去
- undo log(**回滚日志**):是 Innodb 存储引擎层生成的日志,实现了事务中的**原子性**,主要用于事务回滚和MVCC。
- redo log(**重做日志**):是 Innodb 存储引擎层生成的日志,实现了事务中的**持久性**,主要用于掉电等故障恢复;
- binlog (归档日志):是 Server 层生成的日志,主要用于**数据备份和主从复制**;
- 如果SQL语句一直很慢,可能是字段上没有索引或者字段有索引但是没用上索引
### 22.SQL语句的执行顺序?
```sql
select distinct
select_list
from
left_table
left join
right_table on join_condition
where
where_condition
group by
group_by_list
having
having_condition
order by
order_by_condition
limit
nums,nums2
from -> on -> join -> where -> group -> having ->select -> distinct -> order by
```
- from :首先对关键字两边的表以笛卡尔积的形式执行连接,并产生一个虚表。续表就是视图,数据会来自多张表的执行结果
- on: 对from连接的结果进行on过滤,并创建续虚拟表V2
- join:对on过滤后的左表添加进来,并创建新的虚拟表V3
- where: 对虚拟表V3进行where刷选,创建虚拟表V4
- group by :对V4中的记录进行分组操作,创建虚拟表V5
- having:对V5进行过滤,创建虚拟表V6
- select:将V6表中的结果按照select进行刷选,创建虚拟表V7
- distinct:对V7表中的结果进行去重操作,创建虚拟表V8,如果使用了group by 子句则无需使用distinct,因为分组的时候是将列中唯一的值分成一组,并且每组值返回一行记录,所以所有的记录都是不同的
- order by:对虚拟表V8中的结果进行排序
## 数据库优化
### 1.❤大表如何优化?
- 限定数据的范围:避免不带任何限制数据范围条件的查询语句。
- **读写分离**:主库负责写,从库负责读
- **垂直分表**:将一个表按照字段分成多个表,每个表存储其中一部分字段
- **水平分表**:在同一个数据库内,把一个表的数据按照一定规则拆分到多个表中
- **对单表进行优化**:对表中的字段、索引、查询SQL进行优化
- **添加缓存**
- **中间表**
### 2.什么是垂直分表、垂直分库、水平分表、水平分库?
- **垂直分表**:将一个表按照字段分成多个表,每一个表存储其中一部分字段。一般会将常用的字段放在一个表中,将不常用的字段放到另一张表中。
优势:
- 避免IO竞争减少锁表的概率。因为大的字段效率更低,第一个数据量大,需要读取的时间长;第二,大字段占用的空间更大,单页内存储的函数表少了,会使IO操作增多
- 可以更好的提升热门数据的查询效率
- **垂直分库**:按照**业务**对表进行分类,部署到不同的数据库上面,不同的数据库可以放到不同的服务器上面。
优势:
- 降低业务中的耦合,方便对不同的业务进行分级管理
- 可以提升IO、数据库连接数、解决单机硬件资源的瓶颈问题
垂直拆分的缺点
- **主键出现冗余**,需要管理冗余列
- 事务的处理变的复杂
- 仍然存在单数据量过大的问题
- 水平分表:在同一个数据库中,把同一个表的数据按照一定的规则拆分到多个表中。
优势:
- 解决了单表数据量过大的问题
- 避免IO竞争并减少锁表的概率
- 水平分库:把同一个表的数据按照一定的规则拆分到不同的数据库中,不同的数据库可以放到不同的服务器上面。
优势:
- 解决了单库大数据量的瓶颈问题
- IO冲突减少,锁的竞争减少,某个数据库出现问题不影响其他数据库(可用性),提高了系统的稳定系和可用性
水平拆分的缺点:
- 分片事务一致性难以解决
- 跨节点JOIN性能查,逻辑会变得复杂
- 数据扩展难度大,不易维护
在系统设计时根据业务耦合来确定垂直分库和垂直分表的方案,在数据访问压力不是特别大时应考虑缓存,读写分离等方法,若数据量很大,或持续增长可考虑水平分库分表,水平拆分所涉及的逻辑比较复杂,常见的方案有客户端架构和代理架构
### 3.❤分库分表后,ID键如何处理?
分库分表后不能每个表的ID都是从1开始,所以需要一个**全局ID**,设置全局ID主要有以下几种方法:
- **UUID**:优点:本地生成ID,不需要远程调用;全局唯一不重复。缺点:占用空间大,不适合做为索引
- **数据库自增ID**:在分库分表后使用数据库自增ID,需要一个专门用于生成主键的库,每次服务接收到请求,先向这个库中插入一条没有意义的数据,获取一个数据库自增的ID,利用这个ID去分库分表中写数据。优点:简单易实现。缺点:在高并发下存在瓶颈
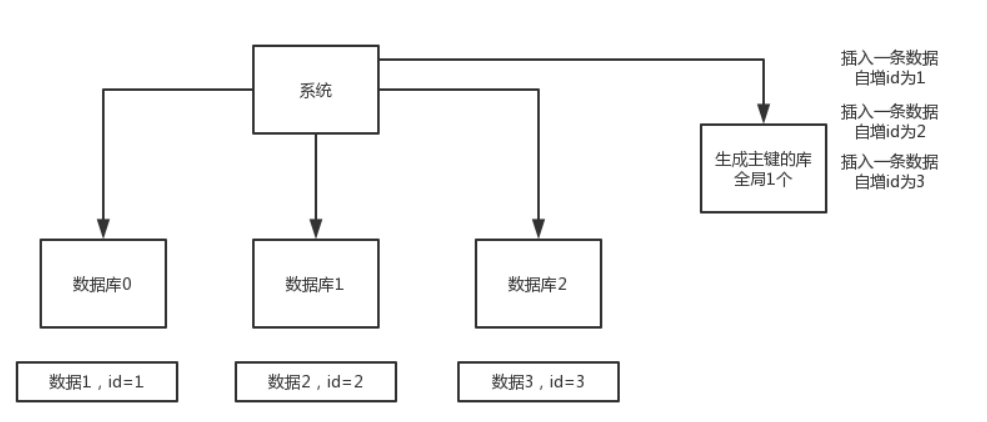
- **Redis生成ID**:有点:不依赖数据库,性能比较好。缺点:引入新的组件会使得系统复杂度增加
- Twitter的**snowflake算法**:是一个64位的long型的ID,其中有1bit作为毫秒数,41bit作为时间戳,10bit作为工作机器ID,12bit作为序列号。,因为二进制中的第一个bit为1的话为负数,当时ID不能为负数
- 美团的Leaf分布式ID生成系统:[Leaf——美团点评分布式ID生成系统 - 美团技术团队 (meituan.com)](https://tech.meituan.com/2017/04/21/mt-leaf.html)
### 4.❤MySQL的复制原理及流程?如何实现主从复制?
MySQL复制:为保证主服务器和从服务器的数据一致性,在向主服务器插入数据后,从服务器会自动将主服务器中修改的数据同步过来。
主从复制的原理:
主从复制主要有三个线程:binlog线程,I/O线程,SQL线程
- **binlog线程**:负责将主服务器上的数据更改写入到日志binary log中。
- **I/O线程**:负责从主服务器上读取二进制日志(binary log),并写入从服务器的中继日志(relay log)中
- **SQL线程**:负责读取中继日志,解析出主服务器中已经执行的数据更改并在从服务器中重放
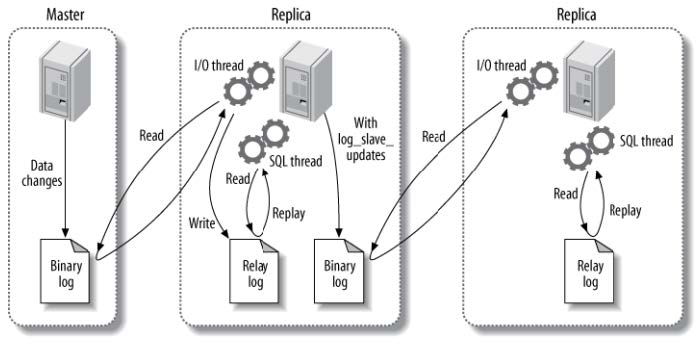
1.Master在每个事务更新数据完成之前,将操作记录写入到binary log中。
2.Slave从库连接Master主库,并且Master有多少个Slave就会创建多少个binglog dump线程。当Master节点的binlog发生变化时,binlog dump会通知所有的Slave,并将相应的binglog发送给Slave
3.I/O线程接收到binlog内容后,将其写入到中级日志(relay log)中。
4.SQL线程读取中级日志,并在从服务器中重放
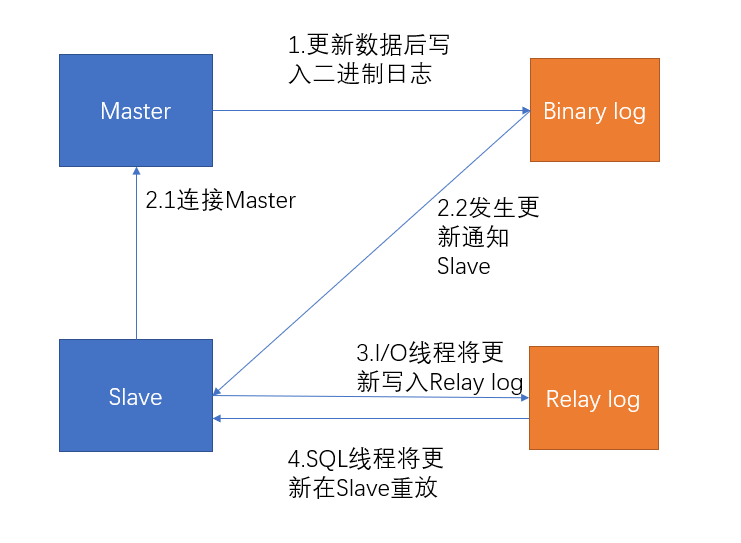
主从复制的作用:
- **高可用和故障转移**
- **负载均衡**
- **数据备份**
- 升级测试
### 5.了解读写分离吗?
读写分离主要是依赖于主从复制,主从复制为读写分离服务。
读写分离的优势:
- 主服务器负责写,从服务器负责读,缓解了锁的竞争
- 从服务器可以使用MyISAM,提升查询性能及节约系统开销
- 增加冗余,提高可用性
================================================
FILE: interview/go语言.md
================================================
# 基础语法
### 01 `=` 和 `:=` 的区别?
=是赋值变量,:=是定义变量。
### 02 指针的作用
一个指针可以指向任意变量的地址,它所指向的地址在32位或64位机器上分别**固定**占4或8个字节。指针的作用有:
- 获取变量的值
```go
import fmt
func main(){
a := 1
p := &a//取址&
fmt.Printf("%d\n", *p);//取值*
}
```
- 改变变量的值
```
// 交换函数
func swap(a, b *int) {
*a, *b = *b, *a
}
```
- 用指针替代值传入函数,比如类的接收器就是这样的。
```
type A struct{}
func (a *A) fun(){}
```
### 03 Go 允许多个返回值吗?多返回值怎么实现的?
可以。通常函数除了一般返回值还会返回一个error。
**实现原理**
> FP 栈底寄存器,指向一个函数栈的底部;PC 程序计数器,指向下一条执行指令;SB 指向静态数据的基指针,全局符号;SP 栈顶寄存器。
Go 传参和返回值是通过 FP+offset 实现,并且存储在调用函数的栈帧中。
### 04 Go 有异常类型吗?
有。Go用error类型代替try...catch语句,这样可以节省资源。同时增加代码可读性:
```
_, err := funcDemo()
if err != nil {
fmt.Println(err)
return
}
```
也可以用errors.New()来定义自己的异常。errors.Error()会返回异常的字符串表示。只要实现error接口就可以定义自己的异常,
```
type errorString struct {
s string
}
func (e *errorString) Error() string {
return e.s
}
// 多一个函数当作构造函数
func New(text string) error {
return &errorString{text}
}
```
### 05 ❤ 什么是协程(Goroutine)。进程、线程、协程有什么区别?(必问)
进程:是应用程序的启动实例,**进程是资源调度的基本单位**,运行一个可执行程序会创建一个或多个进程 。
线程:线程是程序执行(CPU调度)的基本单位,是轻量级的进程
协程:**用户态轻量级线程**,它是**线程调度的基本单位**。通常在函数前加上go关键字就能实现并发。一个Goroutine会以一个很小的栈启动2KB或4KB,当遇到栈空间不足时,栈会**自动伸缩**, 因此可以轻易实现成千上万个goroutine同时启动。
### 06 ❤ 如何高效地拼接字符串
拼接字符串的方式有:`+` , `fmt.Sprintf` , `strings.Builder`, `bytes.Buffer`, `strings.Join`
1 "+"
使用`+`操作符进行拼接时,会对字符串进行遍历,计算并开辟一个新的空间来存储原来的两个字符串。
2 fmt.Sprintf
由于采用了接口参数,必须要用反射获取值,因此有性能损耗。
3 strings.Builder:
用WriteString()进行拼接,内部实现是指针+切片,同时String()返回拼接后的字符串,它是直接把[]byte转换为string,从而避免变量拷贝。
4 bytes.Buffer
`bytes.Buffer`是一个一个缓冲`byte`类型的缓冲器,这个缓冲器里存放着都是`byte`,
`bytes.buffer`底层也是一个`[]byte`切片。
5 strings.join
`strings.join`也是基于`strings.builder`来实现的,并且可以自定义分隔符,在join方法内调用了b.Grow(n)方法,这个是进行初步的容量分配,而前面计算的n的长度就是我们要拼接的slice的长度,因为我们传入切片长度固定,所以提前进行容量分配可以减少内存分配,很高效。
**性能比较**:
strings.Join ≈ strings.Builder > bytes.Buffer > "+" > fmt.Sprintf
5种拼接方法的实例代码
```
func main(){
a := []string{"a", "b", "c"}
//方式1:+
ret := a[0] + a[1] + a[2]
//方式2:fmt.Sprintf
ret := fmt.Sprintf("%s%s%s", a[0],a[1],a[2])
//方式3:strings.Builder
var sb strings.Builder
sb.WriteString(a[0])
sb.WriteString(a[1])
sb.WriteString(a[2])
ret := sb.String()
//方式4:bytes.Buffer
buf := new(bytes.Buffer)
buf.Write(a[0])
buf.Write(a[1])
buf.Write(a[2])
ret := buf.String()
//方式5:strings.Join
ret := strings.Join(a,"")
}
```
> 参考资料:[字符串拼接性能及原理 | Go 语言高性能编程 | 极客兔兔](https://link.zhihu.com/?target=https%3A//geektutu.com/post/hpg-string-concat.html)
### 07 什么是 rune 类型
golang中的字符串底层实现是通过byte数组的,中文字符在unicode下占2个字节,在utf-8编码下占3个字节,而golang默认编码正好是utf-8
byte 等同于int8,常用来处理ascii字符
rune 等同于int32,常用来处理unicode或utf-8字符
```go
sample := "我爱GO"
runeSamp := []rune(sample)
runeSamp[0] = '你'
fmt.Println(string(runeSamp)) // "你爱GO"
fmt.Println(len(runeSamp)) // 4
```
### 08 如何判断 map 中是否包含某个 key ?
```go
var sample map[int]int
if _, ok := sample[10]; ok {
} else {
}
```
### 09 Go 支持默认参数或可选参数吗?
不支持。但是可以利用**结构体参数**,或者传入参数**切片数组**。
可选参数的话可以使用**选项模式**
```go
// 这个函数可以传入任意数量的整型参数
func sum(nums ...int) {
total := 0
for _, num := range nums {
total += num
}
fmt.Println(total)
}
```
### 10 defer 的执行顺序
defer执行顺序和调用顺序相反,类似于栈**后进先出**(LIFO)。
defer在return之后执行,但在函数退出之前,defer可以修改返回值(对于有名返回值)。下面是一个例子:
```go
func test() int {
i := 0
defer func() {
fmt.Println("defer1")
}()
defer func() {
i += 1
fmt.Println("defer2")
}()
return i
}
func main() {
fmt.Println("return", test())
}
// defer2
// defer1
// return 0
```
上面这个例子中,test返回值并没有修改,这是由于Go的返回机制决定的,执行Return语句后,Go会创建一个临时变量保存返回值。如果是有名返回(也就是指明返回值`func test() (i int)`)
```
func test() (i int) {
i = 0
defer func() {
i += 1
fmt.Println("defer2")
}()
return i
}
func main() {
fmt.Println("return", test())
}
// defer2
// return 1
```
这个例子中,返回值被修改了。对于有名返回值的函数,执行 return 语句时,并不会再创建临时变量保存,因此,defer 语句修改了 i,即对返回值产生了影响。
### 11 如何交换 2 个变量的值?
对于变量而言`a,b = b,a`; 对于指针而言`*a,*b = *b, *a`
### 12 Go 语言 tag 的用处?
tag可以为结构体成员提供属性。常见的:
1. json序列化或反序列化时字段的名称
2. db: sqlx模块中对应的数据库字段名
3. form: gin框架中对应的前端的数据字段名
4. binding: 搭配 form 使用, 默认如果没查找到结构体中的某个字段则不报错值为空, binding为 required 代表没找到返回错误给前端
### 13 ❤如何获取一个结构体的tag?tag是怎么实现的?
利用反射:
```go
import reflect
type Author struct {
Name int `json:"jsonname"`
Publications []string `json:"jsonpublication"`
}
func main() {
t := reflect.TypeOf(Author{})
for i := 0; i < t.NumField(); i++ {
s := t.Field(i).Tag
fmt.Println(s.Get("json"))
}
}
```
上述例子中,`reflect.TypeOf`方法获取对象的类型,之后`NumField()`获取结构体成员的数量。 通过`Field(i)`获取第i个成员的名字。 再通过其`Tag` 方法获得标签。
Go 中解析的 tag 是通过**反射**实现的。
### 14 如何判断 2 个字符串切片(slice) 是相等的?
`reflect.DeepEqual()` , 但反射非常影响性能。
### 15 结构体打印时,`%v` 和 `%+v` 的区别
`%v`输出结构体各成员的值;
`%+v`输出结构体各成员的**名称**和**值**;
`%#v`输出结构体名称和结构体各成员的名称和值
### 16 Go 语言中如何表示枚举值(enums)?
在常量中用iota可以表示枚举。iota从0开始。
```go
const (
B = 1 << (10 * iota)
KiB
MiB
GiB
TiB
PiB
EiB
)
```
### 17 空 struct{} 的用途
- 用map模拟一个set,那么就要把值置为struct{},struct{}本身不占任何空间,可以避免任何多余的内存分配。
```go
type Set map[string]struct{}
func main() {
set := make(Set)
for _, item := range []string{"A", "A", "B", "C"} {
set[item] = struct{}{}
}
fmt.Println(len(set)) // 3
if _, ok := set["A"]; ok {
fmt.Println("A exists") // A exists
}
}
```
- 有时候给通道发送一个空结构体实现并发控制,channel<-struct{}{},也是节省了空间。
```go
func main() {
ch := make(chan struct{}, 1)
go func() {
<-ch
// do something
}()
ch <- struct{}{}
// ...
}
```
- 仅有方法的结构体
```go
type Lamp struct{}
```
### **18 go里面的int和int32是同一个概念吗?**
不是一个概念!千万不能混淆。go语言中的int的大小是和操作系统位数相关的,如果是32位操作系统,int类型的大小就是4字节。如果是64位操作系统,int类型的大小就是8个字节。除此之外uint也与操作系统有关。
int8占1个字节,int16占2个字节,int32占4个字节,int64占8个字节。
### 19❤new和make的区别(基本必问)?
1)**作用变量类型**不同,new给string,int和数组分配内存,make给切片,map,channel分配内存;
2)**返回类型**不一样,new返回指向变量的指针,make返回变量本身;
3)new 分配的空间被清零(分配的内存置为零,也就是类型的零值)。make 分配空间后,会进行初始化,但是不是置为零值;
4) 字节的面试官还说了另外一个区别,就是分配的位置,在堆上还是在栈上?这块我比较模糊,大家可以自己探究下,我搜索出来的答案是golang会弱化分配的位置的概念,因为编译的时候会自动内存逃逸处理,懂的大佬帮忙补充下:make、new内存分配是在堆上还是在栈上?
### 20请你讲一下Go面向对象是如何实现的?
Go实现面向对象的两个关键是**struct和interface**。
封装:对于同一个包,对象对包内的文件可见;对不同的包,需要将对象以大写开头才是可见的。
[^封装]: 两层含义:一层含义是把对象的属性和行为看成一个密不可分的整体,将这两者“封装”在一个不可分割的独立单元(即对象)中;另一层含义指“信息隐藏”,把不需要让外界知道的信息隐藏起来,有些对象的属性及行为允许外界用户知道或使用,但不允许更改,而另一些属性或行为,则不允许外界知晓,或只允许使用对象的功能,而尽可能隐藏对象的功能实现细节。
继承:继承是编译时特征,在struct内加入所需要继承的类即可:
```
type A struct{}
type B struct{
A
}
```
多态:多态是运行时特征,Go多态通过interface来实现。类型和接口是松耦合的,某个类型的实例可以赋给它所实现的任意接口类型的变量。
[^多态]: 多态是同一个行为具有多个不同表现形式或形态的能力。
Go支持多重继承,就是在类型中嵌入所有必要的父类型。
### 21uint型变量值分别为 1,2,它们相减的结果是多少?
```
var a uint = 1
var b uint = 2
fmt.Println(a - b)
```
答案,结果会溢出,如果是32位系统,结果是2^32-1,如果是64位系统,结果2^64-1.
### 22讲一下go有没有函数在main之前执行?怎么用?
go的init函数在main函数之前执行
```go
func init() {
...
}
```
**怎么用**:
- 初始化不能采用初始化表达式初始化的变量;
- 程序运行前执行注册
- 实现sync.Once功能
- 不能被其它函数调用,init函数没有入口参数和返回值:
- 每个包可以有多个init函数,**每个源文件也可以有多个init函数**。
- 同一个包的init执行顺序,golang没有明确定义,编程时要注意程序不要依赖这个执行顺序。
- 不同包的init函数按照包导入的依赖关系决定执行顺序。
**go初始化**:
init()函数是go初始化的一部分,由runtime初始化每个导入的包,初始化不是按照从上到下的导入顺序,而是按照解析的依赖关系,没有依赖的包最先初始化。
每个包首先初始化包作用域的常量和变量(常量优先于变量),然后执行包的`init()`函数。
执行顺序:**import –> const –> var –>`init()`–>`main()**
### 23下面这句代码是什么作用,为什么要定义一个空值?
```
type GobCodec struct{
conn io.ReadWriteCloser
buf *bufio.Writer
dec *gob.Decoder
enc *gob.Encoder
}
type Codec interface {
io.Closer
ReadHeader(*Header) error
ReadBody(interface{}) error
Write(*Header, interface{}) error
}
var _ Codec = (*GobCodec)(nil)
```
答:将nil转换为*GobCodec类型,然后再转换为Codec接口,如果转换失败,说明*GobCodec没有实现Codec接口的所有方法,用来**判断GobCodec是否实现了Codec接口的所有方法**。
### 24如果若干个goroutine,有一个panic会怎么做?
有一个panic,那么剩余goroutine也会退出,程序退出。如果不想程序退出,那么必须通过调用 recover() 方法来捕获 panic 并恢复将要崩掉的程序。
> 参考理解:[goroutine配上panic会怎样](https://link.zhihu.com/?target=https%3A//blog.csdn.net/huorongbj/article/details/123013273)。
### 25defer可以捕获goroutine的子goroutine吗?
不可以。它们处于不同的调度器P中。对于子goroutine,必须通过recover()机制来进行恢复,然后结合日志进行打印(或者通过channel传递error),下面是一个例子:
```go
// 心跳函数
func Ping(ctx context.Context) error {
... code ...
go func() {
defer func() {
if r := recover(); r != nil {
log.Errorc(ctx, "ping panic: %v, stack: %v", r, string(debug.Stack()))
}
}()
... code ...
}()
... code ...
return nil
}
```
### 27channel 死锁的场景
> channle中的死锁,是指在程序的主线程中发生的情况,如果上述的情况发生在非主线程中,读取或者写入的情况是发生堵塞的,而不是死锁。实际上,阻塞情况省去了我们加锁的步骤,反而是更加有利于代码编写,要合理的利用阻塞。。
- 当一个`channel`中没有数据,而直接读取时,会发生死锁:
```go
q := make(chan int,2)
<-q
```
解决方案是采用select语句,再default放默认处理方式:
```
q := make(chan int,2)
select{
case val:=<-q:
default:
...
}
```
- 当channel数据满了,再尝试写数据会造成死锁:
```
q := make(chan int,2)
q<-1
q<-2
q<-3
```
解决方法,采用select
```
func main() {
q := make(chan int, 2)
q <- 1
q <- 2
select {
case q <- 3:
fmt.Println("ok")
default:
fmt.Println("wrong")
}
}
```
- 向一个关闭的channel写数据。(会panic)
注意:一个已经关闭的channel,只能读数据,不能写数据。
参考资料:[Golang关于channel死锁情况的汇总以及解决方案](https://link.zhihu.com/?target=https%3A//blog.csdn.net/qq_35976351/article/details/81984117)
### 28对已经关闭的chan进行读写会怎么样?
- 读已经关闭的chan能一直读到东西,但是读到的内容根据通道内关闭前是否有元素而不同。
- 如果chan关闭前,buffer内有元素还未读,会正确读到chan内的值,且返回的第二个bool值(是否读成功)为true。
- 如果chan关闭前,buffer内有元素已经被读完,chan内无值,接下来所有接收的值都会非阻塞直接成功,返回 channel 元素的零值,但是第二个bool值一直为false。
- 写已经关闭的chan会panic。
### 30 2 个 interface 可以比较吗 ?
Go 语言中,interface 的内部实现包含了 2 个字段,类型 `T` 和 值 `V`,interface 可以使用 `==` 或 `!=` 比较。2 个 interface 相等有以下 2 种情况
1. 两个 interface 均等于 nil(此时 V 和 T 都处于 unset 状态)
2. 类型 T 相同,且对应的值 V 相等。
看下面的例子:
```go
type Stu struct {
Name string
}
type StuInt interface{}
func main() {
var stu1, stu2 StuInt = &Stu{"Tom"}, &Stu{"Tom"}
var stu3, stu4 StuInt = Stu{"Tom"}, Stu{"Tom"}
fmt.Println(stu1 == stu2) // false
fmt.Println(stu3 == stu4) // true
}
```
`stu1` 和 `stu2` 对应的类型是 `*Stu`,值是 Stu 结构体的地址,两个地址不同,因此结果为 false。
`stu3` 和 `stu4` 对应的类型是 `Stu`,值是 Stu 结构体,且各字段相等,因此结果为 true。
### 31 2 个 nil 可能不相等吗?
可能不等。interface在运行时绑定值,只有值为nil接口值才为nil,但是与指针的nil不相等。举个例子:
```go
var p *int = nil
var i interface{} = nil
if(p == i){
fmt.Println("Equal")
}
```
两者并不相同。总结:**两个nil只有在类型相同时才相等**。
### 32 函数返回局部变量的指针是否安全?
这一点和C++不同,在Go里面返回局部变量的指针是安全的。因为Go会进行**逃逸分析**,如果发现局部变量的作用域超过该函数则会**把指针分配到堆区**,避免内存泄漏。
### 34 非接口的任意类型 T() 都能够调用 `*T` 的方法吗?反过来呢?
一个T类型的值可以调用*T类型声明的方法,当且仅当T是**可寻址的**。(比如被gc掉了)
反之:*T 可以调用T()的方法,因为指针可以解引用。
### 35 go slice是怎么扩容的?
如果当前容量小于1024,则判断所需容量是否大于原来容量2倍,如果大于,当前容量加上所需容量;否则当前容量乘2。
如果当前容量大于1024,则每次按照1.25倍速度递增容量,也就是每次加上cap/4。
### 36进程被kill,如何保证所有goroutine顺利退出
goroutine监听SIGKILL信号,一旦接收到SIGKILL,则立刻退出。可采用select方法。
```go
var wg = &sync.WaitGroup{}
func main() {
wg.Add(1)
go func() {
c1 := make(chan os.Signal, 1)
signal.Notify(c1,syscall.SIGKILL, syscall.SIGINT, syscall.SIGTERM, syscall.SIGQUIT)
fmt.Printf("goroutine 1 receive a signal : %v\n\n", <-c1)
wg.Done()
}()
wg.Wait()
fmt.Printf("all groutine done!\n")
}
```
### **37❤数组和切片的区别 (基本必问)**
**相同点:**
1)只能存储一组**相同类型**的数据结构
2)都是通过下标来访问,并且有容量长度,长度通过 len 获取,容量通过 cap 获取
**区别:**
1)数组是**定长**,访问和复制不能超过数组定义的长度,否则就会下标越界,切片长度和容量可以**自动扩容**
2)**数组是值类型,切片是引用类型**,每个切片都引用了一个底层数组,切片本身不能存储任何数据,都是这底层数组存储数据,所以修改切片的时候修改的是底层数组中的数据。切片一旦扩容,指向一个新的底层数组,内存地址也就随之改变
**简洁的回答:**
1)定义方式不一样 2)初始化方式不一样,数组需要指定大小,大小不改变 3)在函数传递中,数组切片。
```go
//数组的定义
var a1 [3]int
var a2 [...]int{1,2,3}
//切片的定义
var a1 []int
var a2 :=make([]int,3,5)
//数组的初始化
a1 := [...]int{1,2,3}
a2 := [5]int{1,2,3}
//切片的初始化
b:= make([]int,3,5)
```
### 38for range 的时候它的地址会发生变化么?
答:不会,在 for a,b := range c 遍历中, a 和 b 在内存中只会存在一份,即之后每次循环时遍历到的数据都是以**值覆盖**的方式赋给 a 和 b,a,b 的内存地址**始终不变**。由于有这个特性,for 循环里面如果开协程,不要直接把 a 或者 b 的地址传给协程。
解决办法:在每次循环时,创建一个**临时变量**。
### **39go defer,多个 defer 的顺序,defer 在什么时机会修改返回值?**
作用:defer延迟函数,释放资源,收尾工作;如释放锁,关闭文件,关闭链接;捕获panic;
避坑指南:defer函数紧跟在资源打开后面,否则defer可能得不到执行,导致内存泄露。
多个 defer 调用顺序是 **LIFO(后入先出)**,defer后的操作可以理解为压入栈中
defer,return,return value(函数返回值) 执行顺序:首先return,其次return value,最后defer。defer可以修改函数最终返回值,
修改时机:**有名返回值或者函数返回指针**
### **40调用函数传入结构体时,应该传值还是指针? (Golang 都是传值)**
> 值传递:指在调用函数时将实际参数复制一份传递到函数中,这样在函数中如果对参数进行修改,将不会影响到实际参数。
>
> 引用传递是指在调用函数时将实际参数的**地址**传递到函数中,那么在函数中对参数所进行的修改,将影响到实际参数
**在 Golang 中所有函数参数传递都是值拷贝**,传指针只是拷贝了一份**指针副本**,同时指向原对象。
在函数传参过程中,需要合理使用传值、传指针。一般情况下,需要改变原始对象值、传递大的结构体,传指针是最合适的,因为传一个内存地址的开销很小。反之,如果变量不可变更、map 或 slice 应该选择传值方式。
### **41讲讲 Go 的 slice 底层数据结构和一些特性?**
Go 的 slice 底层数据结构是由一个 **array 指针指向底层数组**,len 表示切片长度,cap 表示切片容量。
slice 的主要实现是**扩容**。对于 append 向 slice 添加元素时,假如 slice 容量够用,则追加新元素进去,slice.len++,返回原来的 slice。当原容量不够,则 slice 先扩容,扩容之后 slice 得到新的 slice,将元素追加进新的 slice,slice.len++,返回新的 slice。
对于切片的扩容规则:
当切片比较小时(容量小于 1024),则采用较大的扩容倍速进行扩容(新的扩容会是原来的 2 倍),避免频繁扩容,从而减少内存分配的次数和数据拷贝的代价。
当切片较大的时(原来的 slice 的容量大于或者等于 1024),采用较小的扩容倍速(新的扩容将扩大大于或者等于原来 1.25 倍),主要避免空间浪费,网上其实很多总结的是 1.25 倍,那是在不考虑内存对齐的情况下,实际上还要考虑内存对齐,扩容是大于或者等于 1.25 倍。
(关于刚才问的 slice 为什么传到函数内可能被修改,如果 slice 在函数内没有出现扩容,函数外和函数内 slice 变量指向是同一个数组,则函数内复制的 slice 变量值出现更改,函数外这个 slice 变量值也会被修改。如果 slice 在函数内出现扩容,则函数内变量的值会新生成一个数组(也就是新的 slice,而函数外的 slice 指向的还是原来的 slice,则函数内的修改不会影响函数外的 slice。)
## map相关
### 42map 使用注意的点,是否并发安全?
map的类型是map[key],key类型的key必须是可比较的,通常情况,会选择内建的基本类型,比如整数、字符串做key的类型。如果要使用struct作为key,要保证struct对象在逻辑上是不可变的。在Go语言中,map[key]函数返回结果可以是一个值,也可以是两个值。map是无序的,如果我们想要保证遍历map时元素有序,可以使用辅助的数据结构,例如orderedmap。
**第一,**一定要先**初始化**,否则panic
**第二,**map类型是容易发生**并发访问问题**的。不注意就容易发生程序运行时并发读写导致的panic。 Go语言内建的map对象不是线程安全的,并发读写的时候运行时会有检查,遇到并发问题就会导致panic。
### 43map 循环是有序的还是无序的?
**无序的,** map 因扩张⽽重新哈希时,各键值项存储位置都可能会发生改变,顺序自然也没法保证了,所以官方避免大家依赖顺序,直接打乱处理。就是 for range map 在开始处理循环逻辑的时候,就做了随机播种
### 44map 中删除一个 key,它的内存会释放么?(常问)
> 如果删除的元素是值类型,如int,float,bool,string以及数组和struct,map的内存不会自动释放
>
> 如果删除的元素是引用类型,如指针,slice,map,chan等,map的内存会自动释放,但释放的内存是子元素应用类型的内存占用
>
> 将map设置为nil后,内存被回收。
>
> **这个问题还需要大家去搜索下答案,我记得有不一样的说法,谨慎采用本题答案。**
以下是本人参考官方**https://github.com/golang/go/issues/20135**总结出来的,和上面的差不多,建议使用下面的说法
这个问题是关于哈希桶bucket的,包括标准桶和溢出桶。当从map中删除元素时,**map不会缩小哈希桶数或释放溢出桶**。**当元素被删除时,map将桶中的槽*清零* ,不会释放内存**。
键和值本身的空间不会被回收,因为该空间是哈希桶的一部分。只有键和值*引用*的东西才会被收集。
从理论上讲,map总是在增长。使用指针,我们能够收集指向的空间,但桶的大小永远不会。
### 4、怎么处理对 map 进行并发访问?有没有其他方案? 区别是什么?
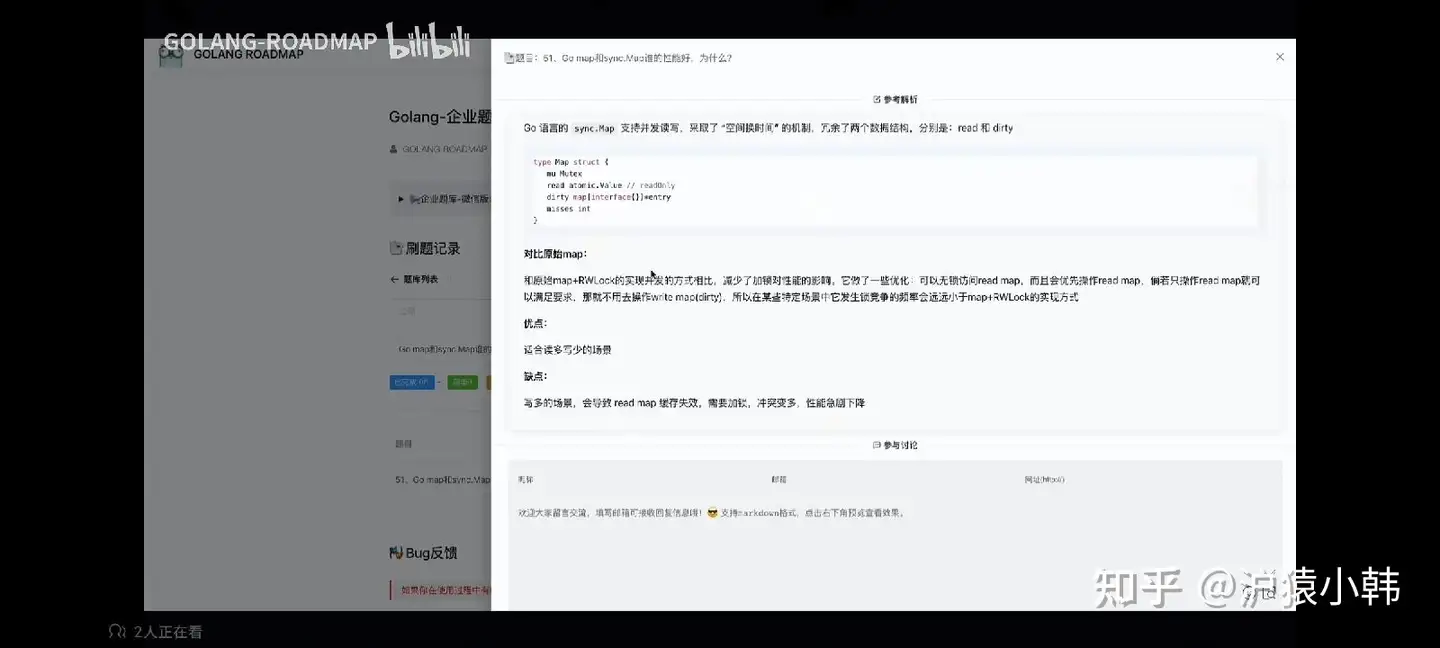
**方式一、使用内置sync.Map**
sync.Map支持并发读写,采取了**空间换时间**的机制,冗余了两个数据结构,分别是read和dirty
```go
type Map struct {
mu Mutex
// read contains the portion of the map's contents that are safe for
// concurrent access (with or without mu held).
// The read field itself is always safe to load, but must only be stored with
// mu held.
read atomic.Value // readOnly
// dirty contains the portion of the map's contents that require mu to be
// held. To ensure that the dirty map can be promoted to the read map quickly,
// it also includes all of the non-expunged entries in the read map.
dirty map[interface{}]*entry
misses int
}
```
和原始map+RWLock实现并发的方式相比,减少了加锁对性能的影响,它做了一些优化,可以**无锁访问**read map,而且会优先操作read map,在某些特定场景(读多写少)中,他发生锁竞争的频率会远远小于map+RWLock的实现方式
**方式二、使用读写锁实现并发安全map**
并发下写多读少的优先考虑带锁map,读多写少的优先考虑sync.map
### 45nil map 和空 map 有何不同?
> nil map和empty map的关系,就像nil slice和empty slice一样,两者都是空对象,未存储任何数据,但前者不指向底层数据结构,后者指向底层数据结构,只不过指向的底层对象是空对象。
>
> ```go
> package main
> func main() {
> var nil_map map[string]string
> println(nil_map)
>
> emp_map := map[string]string{}
> println(emp_map)
> }
> ```
**nil map 未初始化,等同于 var m map[string]int,空map是长度为空,空map表示map已经被初始化,只是长度为0,还并未赋于键值对,**
① 直接读取nil map:m[“a”] 并不会报错,会返回默认类型的空值
② 直接给nil map赋值:m[“a”] = 1 直接报错
③ 需要通过map == nil 来判断,是否为nil map
### 46slices能作为map类型的key吗?
当时被问的一脸懵逼,其实是这个问题的变种:golang 哪些类型可以作为map key?
答案是:**在golang规范中,可比较的类型都可以作为map key;**这个问题又延伸到在:golang规范中,哪些数据类型可以比较?
**不能作为map key 的类型包括:**
- slices
- maps
- functions
### 48讲讲 Go 中主协程如何等待其余协程退出?
答:Go 的 **sync.WaitGroup** 是等待一组协程结束,sync.WaitGroup 只有 3 个方法,Add()是添加计数,Done()减去一个计数,Wait()阻塞直到所有的任务完成。Go 里面还能通过有缓冲的 channel 实现其阻塞等待一组协程结束,这个不能保证一组 goroutine 按照顺序执行,可以并发执行协程。Go 里面能通过无缓冲的 channel 实现其阻塞等待一组协程结束,这个能保证一组 goroutine 按照顺序执行,但是不能并发执行。
**啰嗦一句:**循环智能二面,手写代码部分时,三个协程按交替顺序打印数字,最后题目做出来了,问我代码中Add()是什么意思,我回答的不是很清晰,这家公司就没有然后了。Add()表示协程计数,可以一次Add多个,如Add(3),可以多次Add(1);然后每个子协程必须调用done(),这样才能保证所有子协程结束,主协程才能结束。
### 49Go 语言中不同的类型如何比较是否相等?
答:像 string,int,float interface 等可以通过 reflect.DeepEqual 和等于号进行比较,像 slice,struct,map 则一般使用 reflect.DeepEqual 来检测是否相等。
### 50Go 中 uintptr 和 unsafe.Pointer 的区别?
- unsafe.Pointer 是通用指针类型,它不能参与计算,任何类型的指针都可以转化成 unsafe.Pointer,unsafe.Pointer 可以转化成任何类型的指针,uintptr 可以转换为 unsafe.Pointer,unsafe.Pointer 可以转换为 uintptr。
- uintptr 是指针运算的工具,但是它不能持有指针对象(意思就是它跟指针对象不能互相转换),unsafe.Pointer 是指针对象进行运算(也就是 uintptr)的桥梁。
### 51.问个小细节, JSON 标准库对 nil slice 和 空 slice 的处理是一致的吗?
首先Go的JSON 标准库对 nil slice 和 空 slice 的处理是**不一致**。
- slice := make([]int,0):slice不为nil,已经初始化,但是slice没有值,slice的底层的空间是空的。
- var slice []int :slice的值是nil,未初始化,可用于需要返回slice的函数,当函数出现异常的时候,保证函数依然会有nil的返回值。
# 实现原理
## GC垃圾回收和内存管理
### 01 ❤简述 Go 语言GC(垃圾回收)的工作原理
> 24届秋招go语言岗位基本必问
> - 引用计数:每个对象维护一个引用计数,当被引用对象被创建或被赋值给其他对象时引用计数自动加 +1;如果这个对象被销毁,则计数 -1 ,当计数为 0 时,回收该对象,Python,PHP等语言使用。
> - 优点:对象可以很快被回收,不会出现内存耗尽或到达阀值才回收。
> - 缺点:不能很好的处理循环引用
>
>
> - 分代收集:按照对象生命周期长短划分不同的代空间,生命周期长的放入老年代,短的放入新生代,不同代有不同的回收算法和回收频率,java使用。
> - 优点:回收性能好
> - 缺点:算法复杂
>
> 引用计数和分代收集了解即可
垃圾回收机制是Go一大特(nan)色(dian)。Go1.3采用**标记清除法**, Go1.5采用**三色标记法**,Go1.8采用**三色标记法+混合写屏障**。
**1.标记清除法**
分为两个阶段:标记和清除
标记阶段:从**根对象**开始迭代遍历所有被引用的对象,对能够通过引用遍历访问到的对象进行标记为“被引用”。
清除阶段:对没有标记过的内存进行回收(回收的同时可能伴有随便整理操作)。
弥补了引用计数的不足(频繁更新引用计数降低了性能+循环引用),缺点是需要暂停程序STW(每次启动垃圾回收都会暂停当前所有的代码执行,回收使系统响应能力大大减低)。
**2.三色标记法**:
- 初始状态下所有对象都是白色的(首先需要STW,做一些准备工作,比如开启写屏障)。
- 从根节点(包括**全局指针和 goroutine 栈上**的指针)开始遍历所有对象,把遍历到的对象变成灰色对象
- 遍历灰色对象,将灰色对象引用的对象也变成灰色对象,然后将遍历过的灰色对象变成黑色对象。
- 循环步骤3,直到灰色对象全部变黑色。
- 通过写屏障(write-barrier)检测对象有变化,重复以上操作
- 收集所有白色对象(垃圾)。
这种方法有一个缺陷,如果对象的引用被用户修改了,那么之前的标记就无效了。因此Go采用了**写屏障技术**,当对象新增或者更新会将其着色为灰色。
**3.STW (Stop The World)**
- 为了避免在 GC 的过程中,对象之间的引用关系发生新的变更,使得GC的结果发生错误(如GC过程中新增了一个引用,但是由于未扫描到该引用导致将被引用的对象清除了),停止所有正在运行的协程。
- STW对性能有一些影响,Golang目前已经可以做到1ms以下的STW。
**4.写屏障(Write Barrier)**
- 为了避免GC的过程中新修改的引用关系到GC的结果发生错误,我们需要进行STW。但是STW会影响程序的性能,所以我们要**通过写屏障技术尽可能地缩短STW的时间**。
基于插入写屏障和删除写屏障在结束时需要STW来重新扫描栈,带来性能瓶颈。
> 造成引用对象丢失的条件:
>
> 一个黑色的节点A新增了指向白色节点C的引用,并且白色节点C没有除了A之外的其他灰色节点的引用,或者存在但是在GC过程中被删除了。
>
> 以上两个条件需要同时满足:满足条件1时说明节点A已扫描完毕,A指向C的引用无法再被扫描到;满足条件2时说明白色节点C无其他灰色节点的引用了,即扫描结束后会被忽略 。
**混合写屏障**分为以下四步:
1. GC开始时,将栈上的全部对象标记为黑色(不需要二次扫描,无需STW);
2. GC期间,任何栈上创建的新对象均为黑色
3. 被删除引用的对象标记为灰色
4. 被添加引用的对象标记为灰色
总而言之就是确保黑色对象不能引用白色对象,这个改进直接使得GC时间从 2s降低到2us。
Golang gc 优化的核心就是尽量使得 STW(Stop The World) 的时间越来越短。
### 02 如何知道一个对象是分配在栈上还是堆上?
Go和C++不同,Go局部变量会进行**逃逸分析**。如果**变量离开作用域后没有被引用**,则**优先**分配到栈上,否则分配到堆上。那么如何判断是否发生了逃逸呢?
`go build -gcflags '-m -m -l' xxx.go`.
### 03❤golang的内存管理的原理清楚吗?简述go内存管理机制
> 得物、腾讯
golang内存管理基本是参考tcmalloc来进行的。go内存管理本质上是一个内存池,只不过内部做了很多优化:**自动伸缩内存池大小,合理的切割内存块**。
> 一些基本概念:
> 页Page:一块8K大小的内存空间。Go向操作系统申请和释放内存都是以页为单位的。
> span : 内存块,一个或多个连续的 page 组成一个 span 。如果把 page 比喻成工人, span 可看成是小队,工人被分成若干个队伍,不同的队伍干不同的活。
> sizeclass : 空间规格,每个 span 都带有一个 sizeclass ,标记着该 span 中的 page 应该如何使用。使用上面的比喻,就是 sizeclass 标志着 span 是一个什么样的队伍。
> object : 对象,用来存储一个变量数据内存空间,一个 span 在初始化时,会被切割成一堆等大的 object 。假设 object 的大小是 16B , span 大小是 8K ,那么就会把 span 中的 page 就会被初始化 8K / 16B = 512 个 object 。所谓内存分配,就是分配一个 object 出去。
**内存池mheap**
mheap 将从 OS 那里申请过来的内存初始化成一个大 `span`(sizeclass=0)。然后根据需要从这个大 `span` 中切出小 `span`,放在 mcentral 中来管理。大 `span` 由 `mheap.freelarge` 和 `mheap.busylarge` 等管理。如果 mcentral 中的 `span` 不够用了,会从 `mheap.freelarge` 上再切一块,如果 `mheap.freelarge` 空间不够,会再次从 OS 那里申请内存重复上述步骤。

mheap.spans :用来存储 page 和 span 信息,比如一个 span 的起始地址是多少,有几个 page,已使用了多大等等。
mheap.bitmap 存储着各个 span 中对象的标记信息,比如对象是否可回收等等。
mheap.arena_start : 将要分配给应用程序使用的空间。
**mcentral**
**mcentral是一个span链,用途相同的span会以链表的形式组织在一起存放在mcentral中**。这里用途用**sizeclass**来表示,就是该span存储哪种大小的对象。比如当分配一块大小为 `n` 的内存时,系统计算 `n` 应该使用哪种 `sizeclass`,然后根据 `sizeclass` 的值去找到一个可用的 `span` 来用作分配
找到合适的 span 后,会从中取一个 object 返回给上层使用。

**mcache**
> 从 mcache 上分配内存空间是不需要加锁的,因为在同一时间里,一个 P 只有一个线程在其上面运行,不可能出现竞争。没有了锁的限制,大大加速了内存分配。
为了提高内存并发申请效率,加入缓存层mcache。每一个mcache和处理器P对应。Go申请内存首先从P的mcache中分配,

答:
go语言内存管理本质上是一个内存池,只不过做了很多优化:自动伸缩内存池大小,合理的切割内存块等。go语言分配内存首先从处理器P的缓存层mcache中申请。mcache上分配内存空间不需要加锁,因为每一个mcache和一个处理器P对应,而一个P只有一个线程在其上面运行,不可能出现竞争,大大加速了内存分配,提高了内存并发申请效率。
如果mcache缓存中没有资源,则会向内存池mheap申请内存。mheap会将从操作系统申请的内存初始化成一个大span,大span由mheap.freelarge和mheap.busylarge管理,然后根据需要将大span按照sizeclass切割成小span放在mcentral中管理。mcentral是一条span链表,用途相同的span会以链表的形式组织在一起存放在mcentral中。go语言向mheap申请内存时首先会从mcentral中申请,系统计算所需内存应该使用哪种sizeclass,再根据sizeclass找的一个可用的span分配,从中取出一个object返回。如果mcentral中的span不够用了,会从mheap.freelarge上再切一块,如果mheap.freelarge空间不够,会再次从操作系统中申请内存进行分配。
> 参考资料:[Go 语言内存管理(二):Go 内存管理](https://link.zhihu.com/?target=https%3A//cloud.tencent.com/developer/article/1422392)
### 04goroutine什么情况会发生内存泄漏?如何定位排查内存泄露问题
在Go中内存泄露分为暂时性内存泄露和永久性内存泄露。
**暂时性内存泄露**
- 获取长字符串中的一段导致长字符串未释放
- 获取长slice中的一段导致长slice未释放
- 在长slice新建slice导致泄漏
string相比切片少了一个容量的cap字段,可以把string当成一个只读的切片类型。获取长string或者切片中的一段内容,由于新生成的对象和老的string或者切片共用一个内存空间,会导致老的string和切片资源暂时得不到释放,造成短暂的内存泄漏
**永久性内存泄露**
- goroutine永久阻塞而导致泄漏,互斥锁未释放或者造成死锁会造成内存泄漏
- time.Ticker未关闭导致泄漏
- 不正确使用Finalizer(Go版本的析构函数)导致泄漏
**排查方式:**
一般通过 pprof 是 Go 的性能分析工具,在程序运行过程中,可以记录程序的运行信息,可以是 CPU 使用情况、内存使用情况、goroutine 运行情况等,当需要性能调优或者定位 Bug 时候,这些记录的信息是相当重要。
### 05GC 中 stw 时机,各个阶段是如何解决的?
> 1)在开始新的一轮 GC 周期前,需要调用 gcWaitOnMark 方法上一轮 GC 的标记结束(含扫描终止、标记、或标记终止等)。
>
> 2)开始新的一轮 GC 周期,调用 gcStart 方法触发 GC 行为,开始扫描标记阶段。
>
> 3)需要调用 gcWaitOnMark 方法等待,直到当前 GC 周期的扫描、标记、标记终止完成。
>
> 4)需要调用 sweepone 方法,扫描未扫除的堆跨度,并持续扫除,保证清理完成。在等待扫除完毕前的阻塞时间,会调用 Gosched 让出。
>
> 5)在本轮 GC 已经基本完成后,会调用 mProf_PostSweep 方法。以此记录最后一次标记终止时的堆配置文件快照。
>
> 6)结束,释放 M。
- GC开始时进行STW,做一些准备工作,比如开启写屏障,扫描栈等
- 二次扫描:GC 迭代结束时(没有灰色节点),会对栈执行 STW,重新进行扫描清除白色节点。(STW 时间为 10-100ms)。如果开启混合写屏障,无需进行二次扫描
### 06❤GC 的触发时机?(初级必问)
初级必问,分为系统触发和手动触发。
1)gcTriggerHeap:当所分配的堆大小达到阈值(由控制器计算的触发堆的大小)时,将会触发。
2)gcTriggerTime:如果一定时间内没有触发,就会触发新的GC。时间周期以runtime.forcegcperiod 变量为准,默认 2 分钟。
3)gcTriggerCycle:如果没有开启 GC,则启动 GC。
4)手动触发的 runtime.GC 方法。
### 07❤知道 golang 的内存逃逸吗?什么情况下会发生内存逃逸?
1)**本该分配到栈上的变量,跑到了堆上,这就导致了内存逃逸。**2)栈是高地址到低地址,栈上的变量,函数结束后变量会跟着回收掉,不会有额外性能的开销。3)变量从栈逃逸到堆上,如果要回收掉,需要进行 gc,那么 gc 一定会带来额外的性能开销。编程语言不断优化 gc 算法,主要目的都是为了减少 gc 带来的额外性能开销,变量一旦逃逸会导致性能开销变大。
**内存逃逸的情况如下:**
1)方法内返回局部变量指针,且在方法外被引用。
2)向 channel 发送指针数据,在 slice 或 map 中存储指针。
3)在闭包中引用包外的值。
4)变量大小和类型不确定,变量分配的内存超过用户栈最大值
### 08Channel 分配在栈上还是堆上?哪些对象分配在堆上,哪些对象分配在栈上?
Channel 被设计用来实现协程间通信的组件,其作用域和生命周期不可能仅限于某个函数内部,所以 golang 直接将其分配在**堆**上
准确地说,你并不需要知道。Golang 中的变量只要被引用就一直会存活,存储在堆上还是栈上由内部实现决定而和具体的语法没有关系。
知道变量的存储位置确实和效率编程有关系。如果可能,Golang 编译器会将函数的局部变量分配到函数栈帧(stack frame)上。然而,如果编译器不能确保变量在函数 return 之后不再被引用,编译器就会将变量分配到堆上。而且,如果一个局部变量非常大,那么它也应该被分配到堆上而不是栈上。
当前情况下,如果一个变量被取地址,那么它就有可能被分配到堆上,然而,还要对这些变量做逃逸分析,如果函数 return 之后,变量不再被引用,则将其分配到栈上。
### 10介绍一下大对象小对象,为什么小对象多了会造成 gc 压力?
小于等于 32k 的对象就是小对象,其它都是大对象。一般小对象通过 mspan 分配内存;大对象则直接由 mheap 分配内存。通常小对象过多会导致 GC 三色法消耗过多的 CPU。优化思路是,减少对象分配。
小对象:如果申请小对象时,发现当前内存空间不存在空闲跨度时,将会需要调用 nextFree 方法获取新的可用的对象,可能会触发 GC 行为。
大对象:如果申请大于 32k 以上的大对象时,可能会触发 GC 行为。
## 协程调度GMP模型
### 01❤go如何进行调度的。GMP中状态流转。
> 24届秋招go语言岗位基本必问
> 我们知道,在高并发应用中频繁创建线程会造成不必要的开销,所以有了线程池。线程池中预先保存一定数量的线程,而新任务将不再以创建线程的方式去执行,而是将任务发布到任务队列,线程池中的线程不断地从任务队列中取出任务并执行,可以有效的减少线程创建和销毁所带来的开销。
>
> 下图展示一个典型的线程池:
>
> 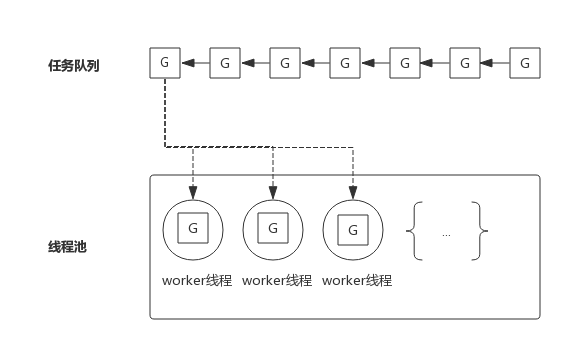
>
> 为了方便下面的叙述,我们把任务队列中的每一个任务称作G,而G往往代表一个函数。
> 线程池中的worker线程不断地从任务队列中取出任务并执行。而worker线程的调度则交给操作系统进行调度。
>
> 如果worker线程执行的G任务中发生系统调用,则操作系统会将该线程置为阻塞状态,也意味着该线程在怠工,也意味着消费任务队列的worker线程变少了,也就是说线程池消费任务队列的能力变弱了。
>
> 如果任务队列中的大部分任务都会进行系统调用,则会让这种状态恶化,大部分worker线程进入阻塞状态,从而任务队列中的任务产生堆积。
>
> 解决这个问题的一个思路就是重新审视线程池中线程的数量,增加线程池中线程数量可以一定程度上提高消费能力,但随着线程数量增多,由于**过多线程争抢CPU**,消费能力会有上限,甚至出现消费能力下降。 如下图所示:
>
> 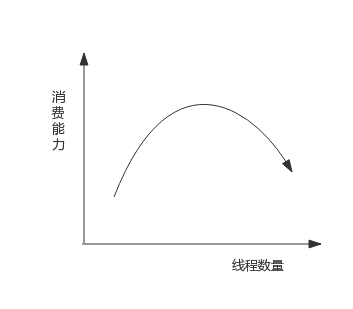
>
>
- G(Goroutine):即Go协程,每个go关键字都会创建一个协程。
- M(Machine):工作线程,在Go中称为Machine,数量对应真实的CPU数(真正干活的对象),M 的数量是不定的,由 Go Runtime 调整,为了防止创建过多 OS 线程导致系统调度不过来,目前默认最大限制为 10000 个。
- P(Processor):处理器(Go中定义的一个摡念,非CPU),包含运行Go代码的必要资源,用来调度 G 和 M 之间的关联关系,其数量可通过 GOMAXPROCS() 来设置,默认为核心数。但是不论 GOMAXPROCS 设置为多大,P 的数量最大为 256。
M必须拥有P才可以执行G中的代码,P含有一个包含多个G的队列,P可以调度G交由M执行。
调度器是M和G之间桥梁。
**go进行调度过程:**
- 某个线程尝试创建一个新的G,那么这个G就会被安排到这个线程的G本地队列LRQ中,如果LRQ满了,就会分配到全局队列GRQ中;
- 队列轮转:P 会周期性的将G调度到M中执行,执行一段时间后,保存上下文,将G放到队列尾部,然后从队列中再取出一个G进行调度。除此之外,P还会周期性的查看全局队列是否有G等待调度到M中执行。
- 系统调用:当G0即将进入系统调用时,M0将释放P,进而某个空闲的M1获取P,继续执行P队列中剩下的G。M1的来源有可能是M的缓存池,也可能是新建的。当G0系统调用结束后,如果有空闲的P,则获取一个P,继续执行G0。如果没有,则将G0放入全局队列,等待被其他的P调度。然后M0将进入缓存池睡眠。
### 02Go什么时候发生阻塞?阻塞时,调度器会怎么做。
- 用于**原子、互斥量或通道**操作导致goroutine阻塞,调度器将把当前阻塞的goroutine从本地运行队列**LRQ换出**,并重新调度其它goroutine;
- 由于**网络请求**和**IO**导致的阻塞,Go提供了网络轮询器(Netpoller)来处理,后台用epoll等技术实现IO多路复用。
其它回答:
- **channel阻塞**:当goroutine读写channel发生阻塞时,会调用gopark函数,该G脱离当前的M和P,调度器将新的G放入当前M。
- **系统调用**:当某个G由于系统调用陷入内核态,该P就会脱离当前M,此时P会更新自己的状态为Psyscall,M与G相互绑定,进行系统调用。结束以后,若该P状态还是Psyscall,则直接关联该M和G,否则使用闲置的处理器处理该G。
- **系统监控**:当某个G在P上运行的时间超过10ms时候,或者P处于Psyscall状态过长等情况就会调用retake函数,触发新的调度。
- **主动让出**:由于是协作式调度,该G会主动让出当前的P(通过GoSched),更新状态为Grunnable,该P会调度队列中的G运行。
> 更多关于netpoller的内容可以参看:[https://strikefreedom.top/go-netpoll-io-multiplexing-reactor](https://link.zhihu.com/?target=https%3A//strikefreedom.top/go-netpoll-io-multiplexing-reactor)
### 03Go中GMP有哪些状态?
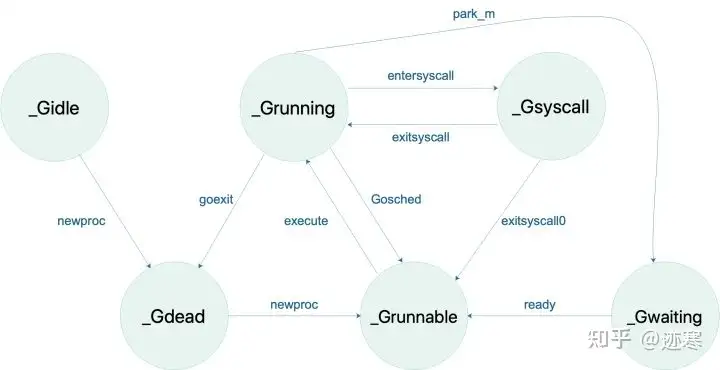
G的状态:
**_Gidle**:刚刚被分配并且还没有被初始化,值为0,为创建goroutine后的默认值
**_Grunnable**: 没有执行代码,没有栈的所有权,存储在运行队列中,可能在某个P的**本地队列或全局队列**中(如上图)。
**_Grunning**: 正在执行代码的goroutine,拥有栈的所有权(如上图)。
**_Gsyscall**:正在执行系统调用,拥有栈的所有权,与P脱离,但是与某个M绑定,会在调用结束后被分配到运行队列(如上图)。
**_Gwaiting**:被阻塞的goroutine,阻塞在某个channel的发送或者接收队列(如上图)。
**_Gdead**: 当前goroutine未被使用,没有执行代码,可能有分配的栈,分布在空闲列表gFree,可能是一个刚刚初始化的goroutine,也可能是执行了goexit退出的goroutine(如上图)。
**_Gcopystac**:栈正在被拷贝,没有执行代码,不在运行队列上,执行权在
**_Gscan** : GC 正在扫描栈空间,没有执行代码,可以与其他状态同时存在。
P的状态:
**_Pidle** :处理器没有运行用户代码或者调度器,被空闲队列或者改变其状态的结构持有,运行队列为空
**_Prunning** :被线程 M 持有,并且正在执行用户代码或者调度器(如上图)
**_Psyscall**:没有执行用户代码,当前线程陷入系统调用(如上图)
**_Pgcstop** :被线程 M 持有,当前处理器由于垃圾回收被停止
**_Pdead** :当前处理器已经不被使用
M的状态:
**自旋线程**:处于运行状态但是没有可执行goroutine的线程,数量最多为GOMAXPROC,若是数量大于GOMAXPROC就会进入休眠。
**非自旋线程**:处于运行状态有可执行goroutine的线程。
### 04GMP能不能去掉P层?会怎么样?
P层的作用
- 每个 P 有自己的本地队列,大幅度的减轻了对全局队列的直接依赖,所带来的效果就是锁竞争的减少。而 GM 模型的性能开销大头就是锁竞争。
- 每个 P 相对的平衡上,在 GMP 模型中也实现了 Work Stealing 算法,如果 P 的本地队列为空,则会从全局队列或其他 P 的本地队列中窃取可运行的 G 来运行,减少空转,提高了资源利用率。
参考资料:[https://juejin.cn/post/6968311281220583454](https://link.zhihu.com/?target=https%3A//juejin.cn/post/6968311281220583454)
### 05如果有一个G一直占用资源怎么办?什么是work stealing算法?
如果有个goroutine一直占用资源,那么GMP模型会**从正常模式转变为饥饿模式**(类似于mutex),允许其它goroutine使用work stealing抢占(禁用自旋锁)。
work stealing算法指,如果一个调度器P处于空闲状态,则会尝试从全局队列或其他 P 的本地队列中窃取可运行的 G 来运行,可以极大提高执行效率。
### **06go语言抢占式调度是如何抢占的?**
> 小红书一面
> 协作式调度依靠被调度方主动弃权;
>
> 抢占式调度则依靠调度器强制将被调度方被动中断。
>
> 参考
>
> https://blog.51cto.com/u_15107299/3935086
>
> https://go-interview.iswbm.com/c02/c02_05.html
**基于协作的抢占式调度**
1. 如果 sysmon 监控线程发现有个协程 A 执行时间太长了(或者 gc 场景,或者 stw 场景),那么会友好的在这个 A 协程的某个字段设置一个抢占标记 ;
2. 协程 A 在 call 一个函数的时候,会复用到扩容栈(morestack)的部分逻辑,检查到抢占标记之后,让出 cpu,切到调度主协程里;
但是这种调度并不完备,比如一个goroutine运行了很久,但是它并没有调用另一个函数,则它不会被抢占
**基于信号量抢占调度**
- M 注册一个 **SIGURG** 信号的处理函数:sighandler。
- sysmon 线程检测到执行时间过长的 goroutine 或者GC stw 时,会向相应的 M(或者说线程,每个线程对应一个 M)发送 SIGURG 信号。
- 收到信号后,内核执行 sighandler 函数,通过 **pushCall** 插入 asyncPreempt 函数调用。
- 回到当前 goroutine 执行 asyncPreempt 函数,通过 mcall 切到 g0 栈执行 gopreempt_m。
- 将当前 goroutine 插入到全局可运行队列,M 则继续寻找其他 goroutine 来运行。
- 被抢占的 goroutine 再次调度过来执行时,会继续原来的执行流。
### 07.Go语言GMP模型存在线程调度吗
> 滴滴24届提前批一面
Go语言的GMP模型中存在线程调度
当一个Goroutine发生阻塞时(例如等待I/O操作完成),Go运行时会将M与P解绑,从而让这个M可以去运行其他Goroutines,避免阻塞导致资源浪费。一旦Goroutine的阻塞状态解除,Go运行时会重新绑定M与P,使得该Goroutine可以继续执行。
所以,尽管Go语言的Goroutines看起来像是在单个线程上运行的,但实际上它们是由一组线程进行调度的,这些线程由Go运行时管理,可以实现高效的并发。
### 08.JAVA线程池和Go语言GMP模型的区别
> 滴滴24届提前批一面
**调度方式**:
- Java线程池:Java线程池的调度是由操作**系统内核**进行管理的,通过操作系统的线程调度器进行线程的切换。
- Go语言GMP模型:负责Goroutine的调度,在**用户态**执行,其中的M(线程)和P(处理器)组成的模型允许Goroutines在多个线程之间进行调度,使得在阻塞时能够更高效地切换执行。
**资源消耗**:
- Java线程池:每个Java线程都需要占用一定的内存和系统资源,线程切换需要上下文切换的开销。
- Go语言GMP模型:Goroutines相对较轻量,更容易创建和销毁。Go语言的运行时系统可以在少量的线程上同时运行大量的Goroutines,降低了资源消耗。
**阻塞和调度**:
- Java线程池:Java线程池在面临I/O阻塞时,可能会出现线程阻塞,导致资源浪费。线程的数量受限于操作系统的限制。
- Go语言GMP模型:Go语言中的Goroutine在面临I/O阻塞时,可以将线程释放给其他Goroutine使用,减少了阻塞带来的资源浪费。
### 09.Go语言的Goroutine与操作系统的线程有什么不同?
> 美团二面
1. **调度方式:**
- 协程的调度由 Go 语言的运行时系统负责,可以在用户态进行调度,以降低切换的开销。
- 操作系统线程的调度由操作系统内核负责,需要切换到内核态进行调度,是重量级的执行单元,创建和销毁线程涉及到较高的系统开销。
2. **创建和销毁成本:**
- 协程的创建和销毁成本非常低,内存占用较小,因此可以轻松创建大量的协程。
- 操作系统线程的创建和销毁成本较高,内存占用较大,因此需要谨慎使用大量线程。
3. **通信和同步:**
- 协程之间的通信和同步通常通过 Go 语言提供的**通道**(Channel)来实现,这是一种高度抽象的机制,用于避免竞态条件和协程之间的数据共享问题。
- 操作系统线程的通信和同步通常使用原始的线程同步机制,如**互斥锁、条件变**量等,更容易出现死锁和竞态条件。
## 常见数据结构的底层原理
### 01说说 atomic底层怎么实现的.
> 原子操作即是进行过程中不能被中断的操作,针对某个值的原子操作在被进行的过程中,CPU绝不会再去进行其他的针对该值的操作。为了实现这样的严谨性,原子操作仅会由一个**独立的CPU指令**代表和完成。原子操作是无锁的,常常直接通过CPU指令直接实现。 事实上,其它同步技术的实现常常依赖于原子操作。
>
> 具体的原子操作在不同的操作系统中实现是不同的。比如在Intel的CPU架构机器上,主要是使用总线锁的方式实现的。 大致的意思就是当一个CPU需要操作一个内存块的时候,向总线发送一个LOCK信号,所有CPU收到这个信号后就不对这个内存块进行操作了。 等待操作的CPU执行完操作后,发送UNLOCK信号,才结束。
> 在AMD的CPU架构机器上就是使用MESI一致性协议的方式来保证原子操作。 所以我们在看atomic源码的时候,我们看到它针对不同的操作系统有不同汇编语言文件。
atomic源码位于`sync\atomic`。通过阅读源码可知,atomic采用**CAS**(CompareAndSwap)的方式实现的。所谓CAS就是使用了CPU中的原子性操作(**独立的CPU指令**)。在操作共享变量的时候,CAS不需要对其进行加锁,而是通过类似于**乐观锁**的方式进行检测,总是假设被操作的值未曾改变(即与旧值相等),并一旦确认这个假设的真实性就立即进行值替换。
本质上是**不断占用CPU资源来避免加锁的开销**。
**原子操作与互斥锁的区别**
1)、互斥锁是一种数据结构,用来让一个线程执行程序的关键部分,完成互斥的多个操作。
2)、原子操作是针对某个值的单个互斥操作。
> 参考资料:[Go语言的原子操作atomic - 编程猎人](https://link.zhihu.com/?target=https%3A//www.programminghunter.com/article/37392193442/)
### 02channel底层实现?是否线程安全。
channel底层实现在`src/runtime/chan.go`中
```go
type hchan struct {
qcount uint // 当前队列中剩余元素个数
dataqsiz uint // 环形队列长度,即可以存放的元素个数
buf unsafe.Pointer // 环形队列指针,指向队列的内存
elemsize uint16 // 每个元素的大小
closed uint32 // 标识关闭状态
elemtype *_type // 元素类型
sendx uint // 队列下标,指示元素写入时存放到队列中的位置
recvx uint // 队列下标,指示元素从队列的该位置读出
recvq waitq // 等待读消息的goroutine队列
sendq waitq // 等待写消息的goroutine队列
lock mutex // 互斥锁,chan不允许并发读写
}
```
channel内部是一个环形队列。内部包含buf, sendx, recvx, lock ,recvq, sendq几个部分;
buf是有缓冲的channel所特有的结构,用来存储缓存数据,是个环形队列(循环链表);
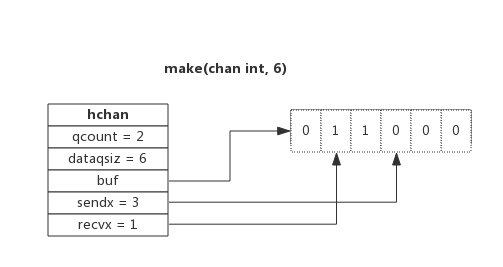
- sendx和recvx用于记录buf这个循环链表中的写入或者读取的index;
- lock是个互斥锁;
- recvq和sendq分别是接收(<-channel)或者发送(channel <- xxx)的goroutine抽象出来的结构体(sudog)的等待队列。被阻塞的goroutine将会挂在channel的等待队列中:
- 因读阻塞的goroutine会被向channel写入数据的goroutine唤醒;
- 因写阻塞的goroutine会被从channel读数据的goroutine唤醒;
channel是**线程安全**的。
简要回答:channel 的数据结构包含 qccount 当前队列中剩余元素个数,dataqsiz 环形队列长度,即可以存放的元素个数,buf 环形队列指针,elemsize 每个元素的大小,closed 标识关闭状态,elemtype 元素类型,sendx 队列下表,指示元素写入时存放到队列中的位置,recv 队列下表,指示元素从队列的该位置读出。recvq 等待读消息的 goroutine 队列,sendq 等待写消息的 goroutine 队列,lock 互斥锁,chan 不允许并发读写。
**无缓冲和有缓冲区别:** 管道没有缓冲区,从管道读数据会阻塞,直到有协程向管道中写入数据。同样,向管道写入数据也会阻塞,直到有协程从管道读取数据。管道有缓冲区但缓冲区没有数据,从管道读取数据也会阻塞,直到协程写入数据,如果管道满了,写数据也会阻塞,直到协程从缓冲区读取数据。
**channel 的一些特点** 1)、读写值 nil 管道会永久阻塞 2)、关闭的管道读数据仍然可以读数据 3)、往关闭的管道写数据会 panic 4)、关闭为 nil 的管道 panic 5)、关闭已经关闭的管道 panic
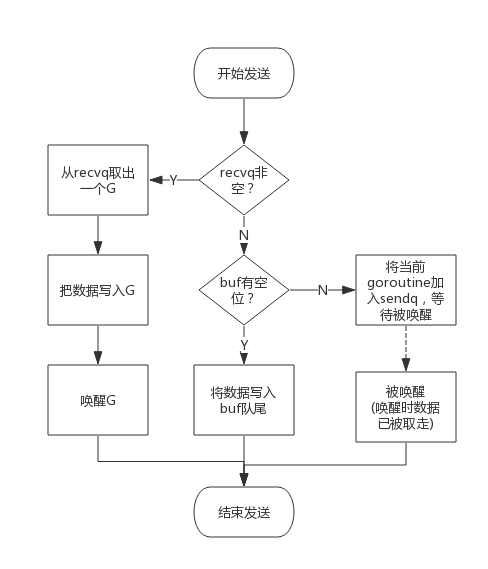
**向 channel 写数据的流程:**
- 如果等待接收队列 recvq 不为空,说明缓冲区中没有数据或者没有缓冲区,此时直接从 recvq 取出 G,并把数据写入,最后把该 G 唤醒,结束发送过程;
- 如果缓冲区中有空余位置,将数据写入缓冲区,结束发送过程;
- 如果缓冲区中没有空余位置,将待发送数据写入 G,将当前 G 加入 sendq,进入睡眠,等待被读 goroutine 唤醒;
**向 channel 读数据的流程:**
- 如果等待发送队列 sendq 不为空,且没有缓冲区,直接从 sendq 中取出 G,把 G 中数据读出,最后把 G 唤醒,结束读取过程;
- 如果等待发送队列 sendq 不为空,此时说明缓冲区已满,从缓冲区中首部读出数据,把 G 中数据写入缓冲区尾部,把 G 唤醒,结束读取过程;
- 如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程;否则将当前 goroutine 加入 recvq,进入睡眠,等待被写 goroutine 唤醒;
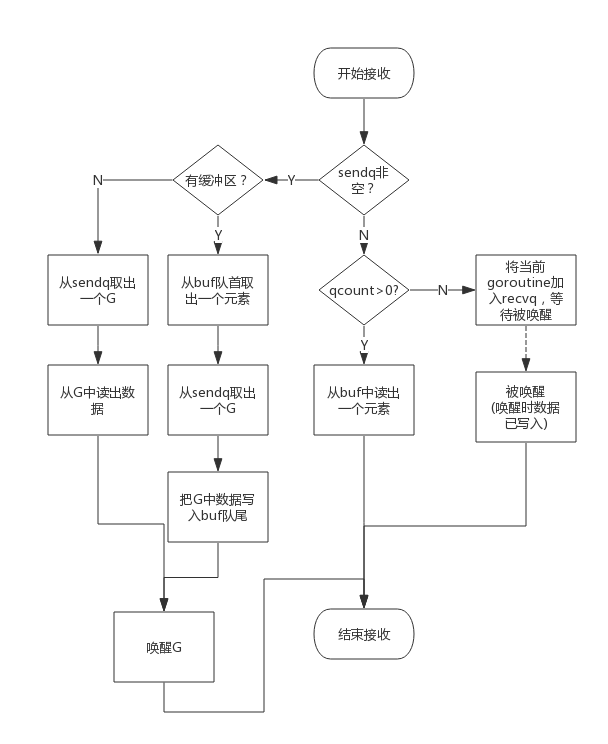
**使用场景:** **消息传递**、消息过滤,信号广播,**事件订阅与广播**,请求、响应转发,任务分发,结果汇总,**并发控制**,**限流**,**同步与异步**
> 参考资料:[Kitou:Golang 深度剖析 -- channel的底层实现](https://zhuanlan.zhihu.com/p/264305133)
### 03map的底层实现。怎样实现扩容的?
源码位于`src\runtime\map.go` 中。
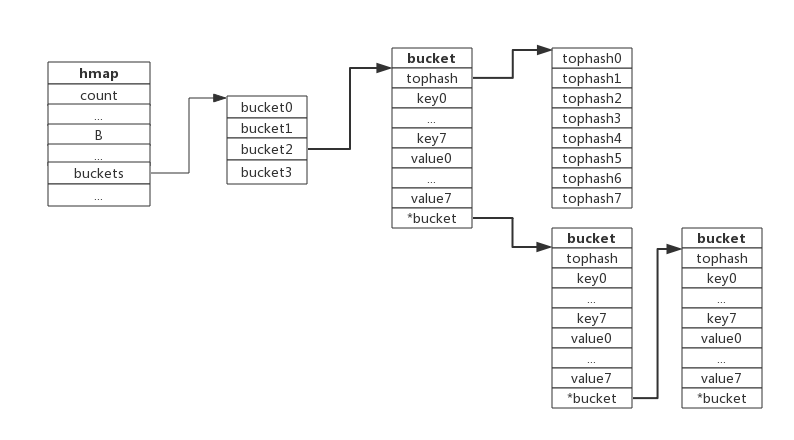
go的map和C++map不一样,底层实现是哈希表,包括两个部分:**hmap**和**bucket哈希桶**。
```go
type hmap struct {
count int // 当前保存的元素个数
...
B uint8
...
buckets unsafe.Pointer // bucket数组指针,数组的大小为2^B
...
}
//bucket数据结构由runtime/map.go:bmap定义:
type bmap struct {
tophash [8]uint8 //存储哈希值的高8位
data byte[1] //key value数据:key/key/key/.../value/value/value...
overflow *bmap //溢出bucket的地址
}
```
每个bucket可以存储8个键值对。
- tophash是个长度为8的数组,哈希值相同的键(准确的说是哈希值低位相同的键)存入当前bucket时会将哈希值的高位存储在该数组中,以方便后续匹配。
- data区存放的是key-value数据,存放顺序是key/key/key/…value/value/value,如此存放是为了节省字节对齐带来的空间浪费。
- overflow 指针指向的是下一个bucket,据此将所有冲突的键连接起来。
注意:上述中data和overflow并不是在结构体中显示定义的,而是直接通过指针运算进行访问的。
当有两个或以上数量的键被哈希到了同一个bucket时,我们称这些键发生了冲突。Go使用链地址法来解决键冲突。
由于每个bucket可以存放8个键值对,所以同一个bucket存放超过8个键值对时就会再创建一个键值对,用类似链表的方式将bucket连接起来。
**查找过程**如下:
1. 根据key值算出哈希值
2. 取哈希值低位与hmap.B取模确定bucket位置
3. 取哈希值高位在tophash数组中查询
4. 如果tophash[i]中存储值也哈希值相等,则去找到该bucket中的key值进行比较
5. 当前bucket没有找到,则继续从下个overflow的bucket中查找。
6. 如果当前处于搬迁过程,则优先从oldbuckets查找
注:如果查找不到,也不会返回空值,而是返回相应类型的0值。
**map 扩容**
> 询问map的底层实现的时候,扩容可以少讲或者省略,除非面试官问到扩容
>
> **触发条件**
>
> 1)负载因子超过阈值,源码里定义的阈值是 6.5。
>
> 负载因子用于衡量一个哈希表冲突情况,公式为:
>
> ```
> 负载因子 = 键数量/bucket数量
>
> ```
>
> 2)overflow数量 > 2^15时,也即overflow数量超过32768时。
**增量扩容**
当负载因子过大时,就新建一个bucket,新的bucket长度是原来的2倍,然后旧bucket数据搬迁到新的bucket。
考虑到如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,Go采用逐步搬迁策略,即每次访问map时都会触发一次搬迁,每次搬迁2个键值对。
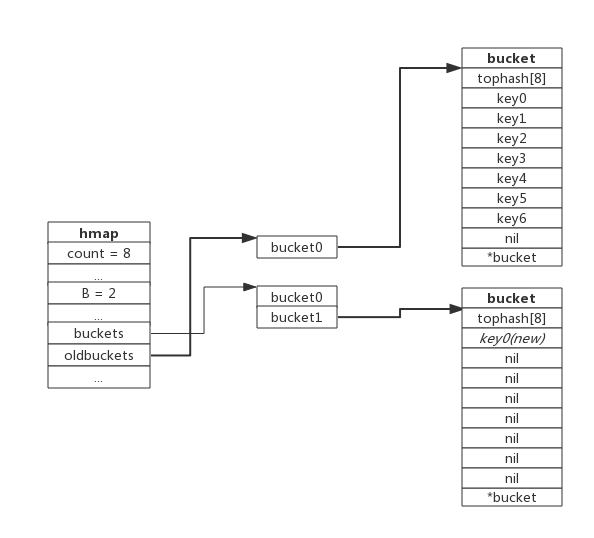
hmap数据结构中oldbuckets成员指身原bucket,而buckets指向了新申请的bucket。新的键值对被插入新的bucket中。
**等量扩容**
所谓等量扩容,实际上并不是扩大容量,**buckets数量不变**,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。
在极端场景下,比如不断地增删,而键值对正好集中在一小部分的bucket,这样会造成overflow的bucket数量增多,但负载因子又不高,从而无法执行增量搬迁的情况,如下图所示:
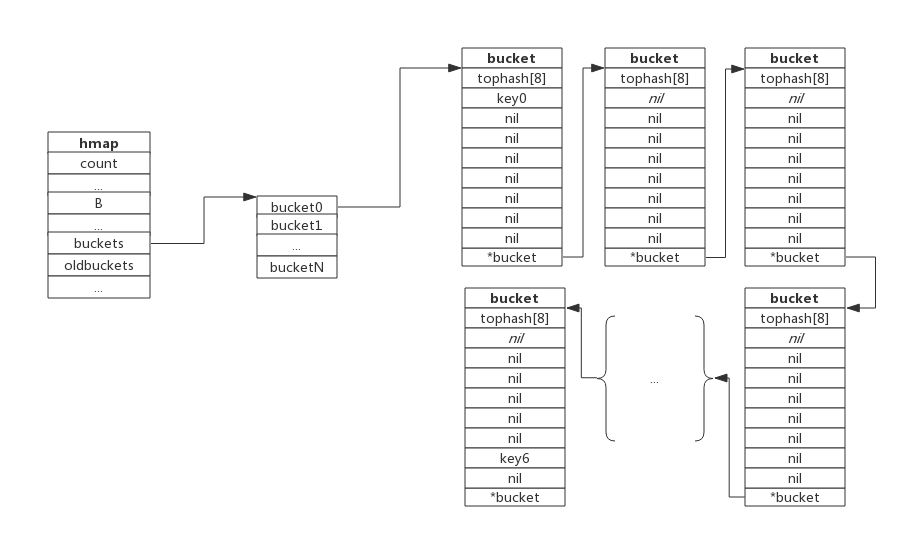
上图可见,overflow的bucket中大部分是空的,访问效率会很差。此时进行一次等量扩容,即buckets数量不变,经过重新组织后overflow的bucket数量会减少,即节省了空间又会提高访问效率。
### 04select的实现原理?讲讲select的一些特性
select源码位于`src\runtime\select.go`,最重要的`scase` 数据结构为:
```go
type scase struct {
c *hchan // chan
elem unsafe.Pointer // data element
}
```
scase.c为当前case语句所操作的channel指针,这也说明了一个case语句只能操作一个channel。
scase.elem表示缓冲区地址,根据scase.kind不同,有不同的用途:
- scase.kind == caseRecv : scase.elem表示读出channel的数据存放地址;
- scase.kind == caseSend : scase.elem表示将要写入channel的数据存放地址;
**select实现逻辑**
select的主要实现位于:`select.go`函数:
```go
func selectgo(cas0 *scase, order0 *uint16, ncases int) (int, bool)
{
//1. 锁定scase语句中所有的channel
//2. 按照随机顺序检测scase中的channel是否ready
// 2.1 如果case可读,则读取channel中数据,解锁所有的channel,然后返回(case index, true)
// 2.2 如果case可写,则将数据写入channel,解锁所有的channel,然后返回(case index, false)
// 2.3 所有case都未ready,则解锁所有的channel,然后返回(default index, false)
//3. 所有case都未ready,且没有default语句
// 3.1 将当前协程加入到所有channel的等待队列
// 3.2 当将协程转入阻塞,等待被唤醒
//4. 唤醒后返回channel对应的case index
// 4.1 如果是读操作,解锁所有的channel,然后返回(case index, true)
// 4.2 如果是写操作,解锁所有的channel,然后返回(case index, false)
}
```
函数参数:
- cas0为scase数组的首地址,selectgo()就是从这些scase中找出一个返回。
- order0为一个两倍cas0数组长度的buffer,保存scase随机序列pollorder和scase中channel地址序列lockorder
- pollorder:每次selectgo执行都会把scase序列打乱,以达到随机检测case的目的。
- lockorder:所有case语句中channel序列,以达到去重防止对channel加锁时重复加锁的目的。
- ncases表示scase数组的长度
函数返回值:
1. int: 选中case的编号,这个case编号跟代码一致
2. bool: 是否成功从channle中读取了数据,如果选中的case是从channel中读数据,则该返回值表示是否读取成功。
[^特别说明]: 对于读channel的case来说,如`case elem, ok := <-chan1:`, 如果channel有可能被其他协程关闭的情况下,一定要检测读取是否成功,因为close的channel也有可能返回,此时ok == false。
**select的特性**
1)select 操作至少要有一个 case 语句,出现读写 nil 的 channel 该分支会忽略,在 nil 的 channel 上操作则会报错。
2)select 仅支持管道,而且是单协程操作。
3)每个 case 语句仅能处理一个管道,要么读要么写。
4)多个 case 语句的执行顺序是随机的。
5)存在 default 语句,select 将不会阻塞,但是存在 default 会影响性能。
参考资料:[Go select的使用和实现原理](https://link.zhihu.com/?target=https%3A//www.cnblogs.com/wuyepeng/p/13910678.html%23%3A~%3Atext%3D%25E4%25B8%2580%25E3%2580%2581select%25E7%25AE%2580%25E4%25BB%258B.%25201.Go%25E7%259A%2584select%25E8%25AF%25AD%25E5%258F%25A5%25E6%2598%25AF%25E4%25B8%2580%25E7%25A7%258D%25E4%25BB%2585%25E8%2583%25BD%25E7%2594%25A8%25E4%25BA%258Echannl%25E5%258F%2591%25E9%2580%2581%25E5%2592%258C%25E6%258E%25A5%25E6%2594%25B6%25E6%25B6%2588%25E6%2581%25AF%25E7%259A%2584%25E4%25B8%2593%25E7%2594%25A8%25E8%25AF%25AD%25E5%258F%25A5%25EF%25BC%258C%25E6%25AD%25A4%25E8%25AF%25AD%25E5%258F%25A5%25E8%25BF%2590%25E8%25A1%258C%25E6%259C%259F%25E9%2597%25B4%25E6%2598%25AF%25E9%2598%25BB%25E5%25A1%259E%25E7%259A%2584%25EF%25BC%259B%25E5%25BD%2593select%25E4%25B8%25AD%25E6%25B2%25A1%25E6%259C%2589case%25E8%25AF%25AD%25E5%258F%25A5%25E7%259A%2584%25E6%2597%25B6%25E5%2580%2599%25EF%25BC%258C%25E4%25BC%259A%25E9%2598%25BB%25E5%25A1%259E%25E5%25BD%2593%25E5%2589%258Dgroutine%25E3%2580%2582.%25202.select%25E6%2598%25AFGolang%25E5%259C%25A8%25E8%25AF%25AD%25E8%25A8%2580%25E5%25B1%2582%25E9%259D%25A2%25E6%258F%2590%25E4%25BE%259B%25E7%259A%2584I%252FO%25E5%25A4%259A%25E8%25B7%25AF%25E5%25A4%258D%25E7%2594%25A8%25E7%259A%2584%25E6%259C%25BA%25E5%2588%25B6%25EF%25BC%258C%25E5%2585%25B6%25E4%25B8%2593%25E9%2597%25A8%25E7%2594%25A8%25E6%259D%25A5%25E6%25A3%2580%25E6%25B5%258B%25E5%25A4%259A%25E4%25B8%25AAchannel%25E6%2598%25AF%25E5%2590%25A6%25E5%2587%2586%25E5%25A4%2587%25E5%25AE%258C%25E6%25AF%2595%25EF%25BC%259A%25E5%258F%25AF%25E8%25AF%25BB%25E6%2588%2596%25E5%258F%25AF%25E5%2586%2599%25E3%2580%2582.%2C3.select%25E8%25AF%25AD%25E5%258F%25A5%25E4%25B8%25AD%25E9%2599%25A4default%25E5%25A4%2596%25EF%25BC%258C%25E6%25AF%258F%25E4%25B8%25AAcase%25E6%2593%258D%25E4%25BD%259C%25E4%25B8%2580%25E4%25B8%25AAchannel%25EF%25BC%258C%25E8%25A6%2581%25E4%25B9%2588%25E8%25AF%25BB%25E8%25A6%2581%25E4%25B9%2588%25E5%2586%2599.%25204.select%25E8%25AF%25AD%25E5%258F%25A5%25E4%25B8%25AD%25E9%2599%25A4default%25E5%25A4%2596%25EF%25BC%258C%25E5%2590%2584case%25E6%2589%25A7%25E8%25A1%258C%25E9%25A1%25BA%25E5%25BA%258F%25E6%2598%25AF%25E9%259A%258F%25E6%259C%25BA%25E7%259A%2584.%25205.select%25E8%25AF%25AD%25E5%258F%25A5%25E4%25B8%25AD%25E5%25A6%2582%25E6%259E%259C%25E6%25B2%25A1%25E6%259C%2589default%25E8%25AF%25AD%25E5%258F%25A5%25EF%25BC%258C%25E5%2588%2599%25E4%25BC%259A%25E9%2598%25BB%25E5%25A1%259E%25E7%25AD%2589%25E5%25BE%2585%25E4%25BB%25BB%25E4%25B8%2580case.%25206.select%25E8%25AF%25AD%25E5%258F%25A5%25E4%25B8%25AD%25E8%25AF%25BB%25E6%2593%258D%25E4%25BD%259C%25E8%25A6%2581%25E5%2588%25A4%25E6%2596%25AD%25E6%2598%25AF%25E5%2590%25A6%25E6%2588%2590%25E5%258A%259F%25E8%25AF%25BB%25E5%258F%2596%25EF%25BC%258C%25E5%2585%25B3%25E9%2597%25AD%25E7%259A%2584channel%25E4%25B9%259F%25E5%258F%25AF%25E4%25BB%25A5%25E8%25AF%25BB%25E5%258F%2596).
### 05go的interface怎么实现的?
go interface源码在`runtime\iface.go`中。
go的接口由两种类型实现`iface`和`eface`。iface是包含方法的接口,而eface不包含方法。
- `iface`
对应的数据结构是(位于`src\runtime\runtime2.go`):
```
type iface struct {
tab *itab
data unsafe.Pointer
}
```
可以简单理解为,tab表示接口的具体结构类型,而data是接口的值。
- itab:
```
type itab struct {
inter *interfacetype //此属性用于定位到具体interface
_type *_type //此属性用于定位到具体interface
hash uint32 // copy of _type.hash. Used for type switches.
_ [4]byte
fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter.
}
```
属性`interfacetype`类似于`_type`,其作用就是interface的公共描述,类似的还有`maptype`、`arraytype`、`chantype`…其都是各个结构的公共描述,可以理解为一种外在的表现信息。interfaetype和type唯一确定了接口类型,而hash用于查询和类型判断。fun表示方法集。
- `eface`
与iface基本一致,但是用`_type`直接表示类型,这样的话就无法使用方法。
```
type eface struct {
_type *_type
data unsafe.Pointer
}
```
这里篇幅有限,深入讨论可以看:[深入研究 Go interface 底层实现](https://link.zhihu.com/?target=https%3A//halfrost.com/go_interface/%23toc-1)
### 06go的reflect 底层实现
go reflect源码位于`src\reflect\`下面,作为一个库独立存在。反射是基于**接口**实现的。
Go反射有三大法则:
- 反射从**接口**映射到**反射对象;**
给定一个数据对象,可以将数据对象转化为反射对象`Type`和`Value`。
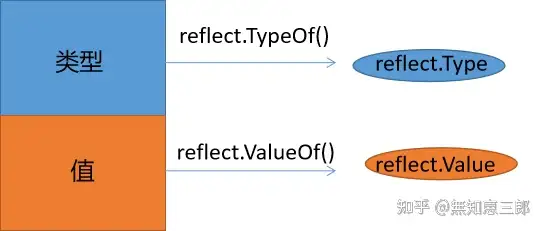
- 反射从**反射对象**映射到**接口值**;
给定的反射对象,可以转化为某种类型的数据对象。即法则一的逆向。
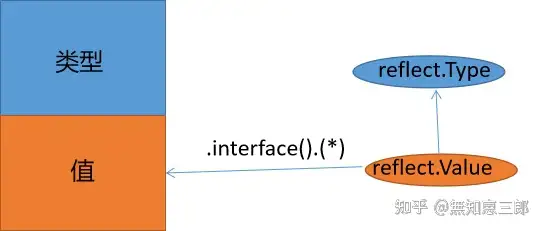
- 只有**值可以修改**(settable),才可以**修改**反射对象。
通过反射对象,可以修改原数据中的内容
Go反射基于上述三点实现。
type用于获取当前值的类型。value用于获取当前的值。
反射的意思是在运行时,能够动态知道给定数据对象的类型和结构,并有机会修改它!
现在一个数据对象,如何判断它是什么结构?
数据interface中保存有结构数据呀,只要想办法拿到该数据对应的内存地址,然后把该数据转成interface,通过查看interface中的类型结构,就可以知道该数据的结构了呀~
其实以上就是Go反射通俗的原理。
> 参考资料:[The Laws of Reflection](https://link.zhihu.com/?target=https%3A//go.dev/blog/laws-of-reflection), [图解go反射实现原理](https://link.zhihu.com/?target=https%3A//i6448038.github.io/2020/02/15/golang-reflection/)
### 07说说context包的作用?你用过哪些,原理知道吗?
`**context的作用就是在不同的goroutine之间同步请求特定的数据、取消信号以及处理请求的截止日期**。
**原理**
Go 的 Context 的数据结构包含 Deadline,Done,Err,Value,
Deadline 方法返回一个 time.Time,表示当前 Context 应该结束的时间,ok 则表示有结束时间,
Done 方法当 Context 被取消或者超时时候返回的一个 close 的 channel,告诉给 context 相关的函数要停止当前工作然后返回了,
Err 表示 context 被取消的原因,
Value 方法表示 context 实现共享数据存储的地方,是协程安全的。
```go
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}
```
**其主要的应用 :**
1:上下文控制,
2:多个 goroutine 之间的数据交互等,
3:超时控制:到某个时间点超时,过多久超时。
关于context原理,可以参看:[小白也能看懂的context包详解:从入门到精通](https://link.zhihu.com/?target=https%3A//cloud.tencent.com/developer/article/1900658)
### **08讲讲 Go 的 defer 底层数据结构和一些特性?**
答:每个 defer 语句都对应一个_defer 实例,多个实例使用指针连接起来形成一个单链表,保存在 gotoutine 数据结构中,每次插入_defer 实例,均插入到链表的头部,函数结束再一次从头部取出,从而形成后进先出的效果。
**defer 的规则总结**:
- 延迟函数的参数是 defer 语句出现的时候就已经确定了的。
- 延迟函数执行按照**后进先出**的顺序执行,即先出现的 defer 最后执行。
- 延迟函数可能操作**主函数的返回值**。
- 申请资源后立即使用 defer 关闭资源是个好习惯。
# 并发编程
### 01 ❤无缓冲的 channel 和有缓冲的 channel 的区别?
对于无缓冲区channel:
发送的数据如果没有被接收方接收,那么**发送方阻塞;**如果一直接收不到发送方的数据,**接收方阻塞**;
有缓冲的channel:
缓冲区满的时候发送方阻塞(写阻塞);缓冲区为空的时候接收方阻塞(读阻塞)。
两者的底层区别在于是否使用hchan.buf这个环形队列
### 02 为什么有协程泄露(Goroutine Leak)?
协程泄漏是指协程创建之后没有得到释放。主要原因有:
1. 缺少接收器,导致发送阻塞
2. 缺少发送器,导致接收阻塞
3. 死锁。多个协程由于竞争资源导致死锁。
4. 创建协程的没有回收。
### 03 Go 可以限制运行时操作系统线程的数量吗? 常见的goroutine操作函数有哪些?
可以,使用runtime.GOMAXROCS(num int)可以设置线程数目。该值默认为CPU逻辑核数,如果设的太大,会引起频繁的线程切换,降低性能。
runtime.Gosched(),用于让出CPU时间片,让出当前goroutine的执行权限,调度器安排其它等待的任务运行,并在下次某个时候从该位置恢复执行。
runtime.Goexit(),调用此函数会立即使当前的goroutine的运行终止(终止协程),而其它的goroutine并不会受此影响。runtime.Goexit在终止当前goroutine前会先执行此goroutine的还未执行的defer语句。请注意千万别在主函数调用runtime.Goexit,因为会引发panic。
### 04 如何控制协程数目。
> The GOMAXPROCS variable limits the number of operating system threads that can execute user-level Go code simultaneously. There is no limit to the number of threads that can be blocked in system calls on behalf of Go code; those do not count against the GOMAXPROCS limit.
从官方文档的解释可以看到,`GOMAXPROCS` 限制的是同时执行用户态 Go 代码的操作系统线程的数量,但是对于被系统调用阻塞的线程数量是没有限制的。`GOMAXPROCS` 的默认值等于 CPU 的**逻辑核数**,同一时间,一个核只能绑定一个线程,然后运行被调度的协程。因此对于 CPU 密集型的任务,若该值过大,例如设置为 CPU 逻辑核数的 2 倍,会增加线程切换的开销,降低性能。对于 I/O 密集型应用,适当地调大该值,可以提高 I/O 吞吐率。
另外对于协程,可以用带缓冲区的channel来控制,下面的例子是协程数为1024的例子
```go
var wg sync.WaitGroup
ch := make(chan struct{}, 1024)
for i:=0; i<20000; i++{
wg.Add(1)
ch<-struct{}{}
go func(){
defer wg.Done()
<-ch
}
}
wg.Wait()
```
此外还可以用**协程池**:其原理无外乎是将上述代码中通道和协程函数解耦,并封装成单独的结构体。常见第三方协程池库,比如[tunny](https://link.zhihu.com/?target=http%3A//github.com/Jeffail/tunny)等。
### 05❤mutex有几种模式?
> 加锁时,如果当前Locked位为1,说明该锁当前由其他协程持有,尝试加锁的协程并不是马上转入阻塞,而是会持续的探测Locked位是否变为0,这个过程即为自旋过程。
>
> 自旋时间很短,但如果在自旋过程中发现锁已被释放,那么协程可以立即获取锁。此时即便有协程被唤醒也无法获取锁,只能再次阻塞。
>
> 自旋的好处是,当加锁失败时不必立即转入阻塞,有一定机会获取到锁,这样**可以避免协程的切换**。
mutex有两种模式:**normal** 和 **starvation**
**正常模式**
默认情况下,Mutex的模式为normal。
该模式下,协程如果加锁不成功不会立即转入阻塞排队,而是判断是否满足自旋的条件,如果满足则会启动自旋过程,尝试抢锁。公平性:否。
**饥饿模式**
> 自旋过程中能抢到锁,一定意味着同一时刻有协程释放了锁,我们知道释放锁时如果发现有阻塞等待的协程,还会释放一个信号量来唤醒一个等待协程,被唤醒的协程得到CPU后开始运行,此时发现锁已被抢占了,自己只好再次阻塞,不过阻塞前会判断自上次阻塞到本次阻塞经过了多长时间,如果超过1ms的话,会将Mutex标记为"饥饿"模式,然后再阻塞。
处于饥饿模式下,不会启动自旋过程,也即一旦有协程释放了锁,那么一定会唤醒协程,被唤醒的协程将会成功获取锁,同时也会把等待计数减1。
在饥饿模式下,Mutex 的拥有者将直接把锁交给队列最前面的 waiter。新来的 goroutine 不会尝试获取锁,即使看起来锁没有被持有,它也不会去抢,也不会 spin(自旋),它会乖乖地加入到等待队列的尾部。 如果拥有 Mutex 的 waiter 发现下面两种情况的其中之一,它就会把这个 Mutex 转换成正常模式:
1. 此 waiter 已经是队列中的最后一个 waiter 了,没有其它的等待锁的 goroutine 了;
2. 此 waiter 的等待时间小于 1 毫秒。
公平性:是。
> 参考链接:[Go Mutex 饥饿模式](https://link.zhihu.com/?target=https%3A//blog.csdn.net/qq_37102984/article/details/115322706),[GO 互斥锁(Mutex)原理](https://link.zhihu.com/?target=https%3A//blog.csdn.net/baolingye/article/details/111357407%23%3A~%3Atext%3D%25E6%25AF%258F%25E4%25B8%25AAMutex%25E9%2583%25BD%2Ctarving%25E3%2580%2582)
### 06go竞态条件了解吗?
所谓竞态竞争,就是当**两个或以上的goroutine访问相同资源时候,对资源进行读/写。**
比如`var a int = 0`,有两个协程分别对a+=1,我们发现最后a不一定为2.这就是竞态竞争。
通常我们可以用`go run -race xx.go`来进行检测。
解决方法是,对临界区资源上**锁**,或者使用**原子操作**(atomics),原子操作的开销小于上锁。
### 07除了 mutex 以外还有那些方式安全读写共享变量?
- Golang中Goroutine 可以通过 Channel 进行安全读写共享变量。
- 可以用个数为 1 的信号量(semaphore)实现互斥
- 使用sync包,比如sync.Map
### 08悲观锁、乐观锁是什么?
**悲观锁**
悲观锁:当要对数据库中的一条数据进行修改的时候,为了避免同时被其他人修改,最好的办法就是直接对该数据进行加锁以防止并发。这种借助数据库锁机制,在修改数据之前先锁定,再修改的方式被称之为悲观并发控制【Pessimistic Concurrency Control,缩写“PCC”,又名“悲观锁”】。
**乐观锁**
乐观锁是相对悲观锁而言的,乐观锁假设数据一般情况不会造成冲突,所以在数据进行提交更新的时候,才会正式对数据的冲突与否进行检测,如果冲突,则返回给用户异常信息,让用户决定如何去做。乐观锁适用于**读多写少**的场景,这样可以提高程序的吞吐量
### 09goroutine 的自旋占用资源如何解决
自旋锁是指当一个线程在获取锁的时候,如果锁已经被其他线程获取,那么该线程将循环等待,然后不断地判断是否能够被成功获取,直到获取到锁才会退出循环。
**自旋的条件如下:**
1)还没自旋超过 **4** 次,
2)多核处理器,
3)GOMAXPROCS > 1,
4)p 上本地 goroutine 队列为空。
mutex 会让当前的 goroutine 去空转 CPU,在空转完后再次调用 CAS 方法去尝试性的占有锁资源,直到**不满足自旋条件**,则最终会加入到等待队列里。
### 10怎么控制并发数?
**第一,用缓冲通道**
根据通道中没有数据时读取操作陷入阻塞和通道已满时继续写入操作陷入阻塞的特性,正好实现控制并发数量。
```go
func main() {
count := 10 // 最大支持并发
sum := 100 // 任务总数
wg := sync.WaitGroup{} //控制主协程等待所有子协程执行完之后再退出。
c := make(chan struct{}, count) // 控制任务并发的chan
defer close(c)
for i:=0; i 参考资料:[gin框架实践连载八 | 如何优雅重启和停止 - 掘金](https://link.zhihu.com/?target=https%3A//juejin.cn/post/6867074626427502600%23heading-3),[优雅地关闭或重启 go web 项目](https://link.zhihu.com/?target=http%3A//www.phpxs.com/post/7186/)
### 02持久化怎么做的?
所谓持久化就是将要保存的字符串写到硬盘等设备。
- 最简单的方式就是采用ioutil的WriteFile()方法将字符串写到磁盘上,这种方法面临**格式化**方面的问题。
- 更好的做法是将数据按照**固定协议**进行组织再进行读写,比如JSON,XML,Gob,csv等。
- 如果要考虑**高并发**和**高可用**,必须把数据放入到**数据库**中,比如MySQL,PostgreDB,MongoDB等。
参考链接:[Golang 持久化](https://link.zhihu.com/?target=https%3A//www.jianshu.com/p/015aca3e11ae)
### 03GIN怎么做参数校验?
go采用validator包作参数校验。
它具有以下独特功能:
- 使用**验证tag或自定义validator**进行跨字段Field和跨结构体验证。
- 允许切片、数组和哈希表,多维字段的任何或所有级别进行校验。
- 能够对哈希表key和value进行验证
- 通过在验证之前确定它的基础类型来处理类型接口。
- 别名验证标签,允许将多个验证映射到单个标签,以便更轻松地定义结构体上的验证
- **gin web 框架的默认验证器**;
参考资料:[validator package - pkg.go.dev](https://link.zhihu.com/?target=https%3A//pkg.go.dev/github.com/go-playground/validator%23section-readme)
### 04中间件用过吗?
Middleware是Web的重要组成部分,中间件(通常)是一小段代码,它们接受一个请求,对其进行处理,每个中间件只处理一件事情,完成后将其传递给另一个中间件或最终处理程序,这样就做到了程序的解耦。
### 05进程挂了怎么办
> 首先需要问清挂了是指进程阻塞还是被kill了
>
> 当有客户端连接到 HTTP 服务器(或任何 TCP 服务器)并发送需要大量计算的请求时,每个请求都需要执行一些可能需要 “**任意时间才能完成”**代码。如果我们将这个耗时的代码隔离在一个函数中,我们就可以将此函数称为 **阻塞调用。**
>
> **也就是说,调用结果返回之前,当前线程会被挂起。**
>
> 简单的例子是查询数据库的函数或操作大图像文件的函数。在一个连接将由其自己的[专用线](https://www.zhihu.com/search?q=%E4%B8%93%E7%94%A8%E7%BA%BF&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra=%7B%22sourceType%22%3A%22answer%22%2C%22sourceId%22%3A2691425417%7D)程处理的旧模型中,这不是问题。但是在单个线程将处理数千个连接的新反应器模型中,只需要一个连接执行阻塞调用,就会影响和阻塞所有其他连接。
>
> 那么我们如何在不回到专用线程模型的情况下解决这个问题呢?
**解决方案1:线程并发**
你基本上使用CoralQueue将请求的工作(而不是请求本身)分配给固定数量的线程,这些线程同时执行(即并行)。假设您有 1000 个同时连接。除了拥有 1000 个并发线程(即不切实际 *的每个连接一个线程* 模型),您可以分析您的机器有多少可用的 CPU 内核并选择更少的[线程数](https://www.zhihu.com/search?q=%E7%BA%BF%E7%A8%8B%E6%95%B0&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra=%7B%22sourceType%22%3A%22answer%22%2C%22sourceId%22%3A2691425417%7D),比如说 4。这种架构将为您提供以下优点:
- 处理 HTTP 服务器请求的关键反应器线程永远不会阻塞,因为每个请求所需的工作将简单地添加到队列中,从而释放反应器线程以处理额外的传入 HTTP 请求。
- 即使一两个线程收到一个需要很长时间才能完成的请求,其他线程也可以继续排空队列中的请求。
如果你能提前猜到哪些请求会花费很长时间执行,你甚至可以将队列划分为通道,并为高优先级/快速请求设置一个快速通道,这样它们总能找到一个空闲线程来执行。
**解决方案2:分布式系统**
你可以使用分布式系统架构并利用异步网络调用,而不是在一台机器上使用有限的 CPU 内核做所有事情。这简化了处理请求的 HTTP 服务器,现在不需要任何额外的线程和并发队列。它可以在单个非阻塞反应器线程中完成所有操作。它是这样工作的:
- 您可以将此任务移动到另一个 *节点* (即另一个进程或机器)(通过负载均衡器),而不是在 HTTP 服务器本身上进行繁重的计算。
- 您可以简单地对负责繁重计算任务的节点进行异步网络调用,而不是使用 CoralQueue 跨线程分配工作。
- HTTP 服务器将 **异步等待** 来自繁重计算节点的响应。响应可能需要尽可能长的时间才能通过网络到达,因为 **HTTP 服务器永远不会阻塞**。
- HTTP 服务器只能使用一个线程来处理来自[外部客户](https://www.zhihu.com/search?q=%E5%A4%96%E9%83%A8%E5%AE%A2%E6%88%B7&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra=%7B%22sourceType%22%3A%22answer%22%2C%22sourceId%22%3A2691425417%7D)端的传入 HTTP 连接以及到执行繁重计算工作的[内部节点](https://www.zhihu.com/search?q=%E5%86%85%E9%83%A8%E8%8A%82%E7%82%B9&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra=%7B%22sourceType%22%3A%22answer%22%2C%22sourceId%22%3A2691425417%7D)的传出 HTTP 连接。
- 它的美妙之处在于,您可以通过根据需要简单地添加更多节点来进行扩展。故障转移和[负载平衡](https://www.zhihu.com/search?q=%E8%B4%9F%E8%BD%BD%E5%B9%B3%E8%A1%A1&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra=%7B%22sourceType%22%3A%22answer%22%2C%22sourceId%22%3A2691425417%7D)也变得微不足道。
### 06.nginx配置过吗,有哪些注意的点
> Nginx是一款轻量级的HTTP服务器,采用事件驱动的异步非阻塞处理方式框架,这让其具有极好的IO性能,时常用于服务端的反向代理和负载均衡。
**反向代理**
实现效果:使用 Nginx 反向代理,访问www.123.com直接跳转到127.0.0.1:8080
注意:此处如果要想从www.123.com跳转到本机指定的ip,需要修改本机的hosts文件。此处略过
配置代码
```nginx
server {
listen 80;
server_name www.123.com;
location / {
root html;
index index.html index.htm;
proxy_pass http://127.0.0.1:8080
}
}
```
如上配置,`Nginx`监听 `80`端口,访问域名为`www.123.com`(不加端口号时默认为 `80`端口),故访问该域名时会跳转到 `127.0.0.1:8080` 路径上。
反向代理还能解决**跨域**问题
**负载均衡**

几种方式:
- 轮询(默认)
- 加权轮询:weight 代表权重,默认为1,权重越高被分配的客户端越多。指定轮询几率,weight和访问比率成正比,用于后端服务器性能不均的情况。
- ip_hash:每个请求按访问ip的hash值分配,这样每个访问客户端会固定访问一个后端服务器,可以解决**会话Session丢失的问题**
- 最少连接
### 07.mq消费阻塞怎么办
消费阻塞主要有以下几个原因:
- 消费者的集群数量有问题
- 消费者的consumer group乱用,就是明明你不消费这个topic , 但是你的消费组名称取的跟别人正常消费的一样,这个时候,就会导致一部分队列分配到你这个节点身上,但是这些节点你本身又没有去消费,就会造成消费混乱
- 消费者线程阻塞
基于以上原因排查,基本上第一个可能性几乎没有,第二个需要开发者规范消费者的命令,第三个需要排查并修改代码(可能由于消费消息处理业务的时候,发起http请求,没有设置超时时间,导致在出现网络异常的情况下,程序直接僵死),重启服务
### 08.性能没达到预期,有什么解决方案
| 1 准备阶段
准备阶段是非常关键的一步,不能省略。
首先,需要对我们进行调优的对象进行详尽的了解,所谓知己知彼,百战不殆。
1. **对性能问题进行粗略评估,过滤一些因为低级的业务逻辑导致的性能问题**。譬如,线上应用日志级别不合理,可能会在大流量时导致 CPU 和磁盘的负载飙高,这种情况调整日志级别即可;
2. **了解应用的的总体架构**,比如应用的外部依赖和核心接口有哪些,使用了哪些组件(数据库MYSQL的查询优化和索引优化等的)和框架,哪些接口和模块的**使用率**较高,上下游的**数据链路**是怎么样的等;
3. **了解应用对应的服务器信息**,如服务器所在的**集群信息**、服务器的 **CPU/内存**信息、安装的 Linux 版本信息、服务器是容器还是虚拟机、所在宿主机混部后是否对当前应用有干扰等;
其次,我们需要获取基准数据,然后结合基准数据和当前的一些业务指标,确定此次性能优化的最终目标。
1. **使用基准测试工具获取系统细粒度指标**。可以使用若干 Linux 基准测试工具(eg. jmeter、ab、loadrunnerwrk、wrk等),得到文件系统、**磁盘 I/O**、网络等的性能报告。除此之外,类似 GC、Web 服务器、网卡流量等信息,如有必要也是需要了解记录的;
2. **通过压测工具或者压测平台**(如果有的话),对应用进行压力测试,获取当前应用的**宏观业务指标**,譬如:响应时间、吞吐量、TPS、QPS、消费速率(对于有 MQ 的应用)等。压力测试也可以省略,可以结合当前的实际业务和过往的监控数据,去统计当前的一些核心业务指标,如午高峰的服务 TPS。
3. **通过性能分析工具分析程序运行的性能**。比如使用pporf分析go语言代码执行的CPU和内存占用情况,锁定CPU占用较高的代码进行分析测试调优
| 2 测试阶段
进入到这一阶段,说明我们已经初步确定了应用性能瓶颈的所在,而且已经进行初步的调优了。**检测我们调优是否有效的方式,就是在仿真的条件下,对应用进行压力测试**。注意:由于 Java 有 JIT(just-in-time compilation)过程,因此压力测试时可能需要进行前期预热。
如果压力测试的结果符合了预期的调优目标,或者与基准数据相比,有很大的改善,则我们可以继续通过工具定位下一个瓶颈点,否则,则需要暂时排除这个瓶颈点,继续寻找下一个变量。
**注意事项**
在进行性能优化时,了解下面这些注意事项可以让我们少走一些弯路。
1. 性能瓶颈点通常呈现 **2/8 分布**,即80%的性能问题通常是由20%的性能瓶颈点导致的,2/8 原则也意味着并不是所有的性能问题都值得去优化;
2. 性能优化是一个渐进、迭代的过程,需要逐步、动态地进行。记录基准后,每次改变一个变量,引入多个变量会给我们的观测、优化过程造成干扰;
3. 不要过度追求应用的单机性能,如果单机表现良好,则应该从系统架构的角度去思考; 不要过度追求单一维度上的极致优化,如过度追求 CPU 的性能而忽略了内存方面的瓶颈;
4. 选择合适的性能优化工具,可以使得性能优化取得事半功倍的效果;
5. **整个应用的优化,应该与线上系统隔离,新的代码上线应该有降级方案**。
**瓶颈点分析工具箱**
> `pprof` 是 Go 语言中分析程序运行性能的工具,它能提供各种性能数据:
>
> 
性能优化其实就是找出应用存在性能瓶颈点,然后设法通过一些调优手段去缓解。性能瓶颈点的定位是较困难的,快速、直接地定位到瓶颈点,需要具备下面两个条件:
1. 恰到好处的工具;
2. 一定的性能优化经验。
工欲善其事,必先利其器,我们该如何选择合适的工具呢?不同的优化场景下,又该选择那些工具呢?
下面给出了一张更为实用的「性能优化工具图谱」,该图分别从系统层、应用层(含组件层)的角度出发,列举了我们在分析性能问题时首先需要关注的各项指标(其中?标注的是最需要关注的),这些点是最有可能出现性能瓶颈的地方。需要注意的是,一些低频的指标或工具,在图中并没有列出来,如 CPU 中断、索引节点使用、I/O事件跟踪等,这些低频点的排查思路较复杂,一般遇到的机会也不多,在这里我们聚焦最常见的一些就可以了。
对比上面的性能工具(Linux Performance Tools-full)图,下图的优势在于:把具体的工具同性能指标结合了起来,同时从不同的层次去描述了性能瓶颈点的分布,实用性和可操作性更强一些。系统层的工具分为CPU、内存、磁盘(含文件系统)、网络四个部分,工具集同性能工具(Linux Performance Tools-full)图中的工具基本一致。组件层和应用层中的工具构成为:JDK 提供的一些工具 + Trace 工具 + dump 分析工具 + Profiling 工具等。
这里就不具体介绍这些工具的具体用法了,我们可以使用 man 命令得到工具详尽的使用说明,除此之外,还有另外一个查询命令手册的方法:info。info 可以理解为 man 的详细版本,如果 man 的输出不太好理解,可以去参考 info 文档,命令太多,记不住也没必要记住。
### 09函数传递指针真的比传值效率高吗?
我们知道传递指针可以减少底层值的拷贝,可以提高效率,但是如果拷贝的数据量小,由于指针传递会产生逃逸,可能会使用堆,也可能会增加GC的负担,所以传递指针不一定是高效的。
### 10go里用过哪些设计模式 ?
> 参考[senghoo/golang-design-pattern: 设计模式 Golang实现-《研磨设计模式》读书笔记 (github.com)](https://github.com/senghoo/golang-design-pattern)
>
> 设计模式的六大原则
>
> 一、单一职责原则(Single Responsibility Principle)
>
> 二、开闭原则(Open-Closed Principle, OCP)
>
> 三、里氏代换原则(Liskov Substitution Principle, LSP)
>
> 四、依赖倒置原则(Dependence Inversion Principle,DIP)
>
> 五、接口隔离原则(Interface Segregation Principle, ISP)
>
> 六、迪米特法则(Law of Demeter, LoD)
- 简单工厂模式:`go` 语言没有构造函数一说,所以一般会定义 `NewXXX` 函数来初始化相关类。`NewXXX` 函数返回接口时就是简单工厂模式,也就是说 `Golang` 的一般推荐做法就是简单工厂。
- 单例模式:使用懒惰模式的单例模式(使用sync.Once.Do保证在需要时再加载),使用双重检查加锁保证线程安全
```go
package singleton
import "sync"
// Singleton 是单例模式接口,导出的
// 通过该接口可以避免 GetInstance 返回一个包私有类型的指针
type Singleton interface {
foo()
}
// singleton 是单例模式类,包私有的
type singleton struct{}
func (s singleton) foo() {}
var (
instance *singleton
once sync.Once
)
// GetInstance 用于获取单例模式对象
func GetInstance() Singleton {
once.Do(func() {
instance = &singleton{}
})
return instance
}
```
- 装饰者模式:有时候我们需要在一个类的基础上扩展另一个类,例如,一个披萨类,你可以在披萨类的基础上增加番茄披萨类和芝士披萨类。此时就可以使用装饰模式,简单来说,**装饰模式就是将对象封装到另一个对象中,用以为原对象绑定新的行为**。
```go
package decorator
type pizza interface {
getPrice() int
}
type base struct {}
func (p *base) getPrice() int {
return 15
}
type tomatoTopping struct {
pizza pizza
}
func (c *tomatoTopping) getPrice() int {
//装饰者模式
pizzaPrice := c.pizza.getPrice()
return pizzaPrice + 10
}
type cheeseTopping struct {
pizza pizza
}
func (c *cheeseTopping) getPrice() int {
//装饰者模式
pizzaPrice := c.pizza.getPrice()
return pizzaPrice + 20
}
```
- 代理模式:如果你需要在访问一个对象时,有一个像“代理”一样的角色,她可以在访问对象之前为你进行缓存检查、权限判断等访问控制,在访问对象之后为你进行结果缓存、日志记录等结果处理,那么就可以考虑使用代理模式。
```go
package proxy
import "fmt"
type Subject interface {
Proxy() string
}
// 代理
type Proxy struct {
real RealSubject
}
func (p Proxy) Proxy() string {
var res string
// 在调用真实对象之前,检查缓存,判断权限,等等
p.real.Pre()
// 调用真实对象
p.real.Real()
// 调用之后的操作,如缓存结果,对结果进行处理,等等
p.real.After()
return res
}
// 真实对象
type RealSubject struct{}
func (RealSubject) Real() {
fmt.Print("real")
}
func (RealSubject) Pre() {
fmt.Print("pre:")
}
func (RealSubject) After() {
fmt.Print(":after")
}
```
- 观察者模式:如果你需要在一个对象的状态被改变时,其他对象能作为其“观察者”而被通知,就可以使用观察者模式。
我们将自身的状态改变就会通知给其他对象的对象称为“发布者”,关注发布者状态变化的对象则称为“订阅者”。
```go
package observer
import "fmt"
// 发布者
type Subject struct {
observers []Observer
content string
}
func NewSubject() *Subject {
return &Subject{
observers: make([]Observer, 0),
}
}
// 添加订阅者
func (s *Subject) AddObserver(o Observer) {
s.observers = append(s.observers, o)
}
// 改变发布者的状态
func (s *Subject) UpdateContext(content string) {
s.content = content
s.notify()
}
// 通知订阅者接口
type Observer interface {
Do(*Subject)
}
func (s *Subject) notify() {
for _, o := range s.observers {
o.Do(s)
}
}
// 订阅者
type Reader struct {
name string
}
func NewReader(name string) *Reader {
return &Reader{
name: name,
}
}
func (r *Reader) Do(s *Subject) {
fmt.Println(r.name + " get " + s.content)
}
```
### 11go的调试/分析工具用过哪些。
go的自带工具链相当丰富,
- go cover : 测试代码覆盖率;
- godoc: 用于生成go文档;
- pprof:用于性能调优,针对cpu,内存和并发;
- race:用于竞争检测;
### 12grpc为啥好,基本原理是什么,和http比呢
官方介绍:gRPC 是一个现代开源的**高性能远程过程调用** (RPC) 框架,可以在**任何环境**中运行。它可以通过对负载平衡、跟踪、健康检查和身份验证的可插拔支持有效地连接数据中心内和跨数据中心的服务。它也适用于分布式计算的最后一英里,将设备、移动应用程序和浏览器连接到后端服务。
**原理**
- NettyServer 实例创建:gRPC 服务端创建,首先需要初始化 NettyServer,它是 gRPC 基于 Netty 4.1 HTTP/2 协议栈之上封装的 HTTP/2 服务端。NettyServer 实例由 NettyServerBuilder 的 buildTransportServer 方法构建,NettyServer 构建完成之后,监听指定的 Socket 地址,即可实现基于 HTTP/2 协议的请求消息接入。
- **绑定 IDL**(IDL是Interface description language的缩写,指接口描述语言,是[CORBA](https://baike.baidu.com/item/CORBA/2776997?fromModule=lemma_inlink)规范的一部分,是跨平台开发的基础) **定义的服务接口实现类**:gRPC 与其它一些 RPC 框架的差异点是服务接口实现类的调用并不是通过动态代理和反射机制,而是通过 proto 工具生成代码,在服务端启动时,将服务接口实现类实例注册到 gRPC 内部的服务注册中心上。请求消息接入之后,可以根据服务名和方法名,直接调用启动时注册的服务实例,而不需要通过反射的方式进行调用,性能更优。
- gRPC 服务实例(ServerImpl)构建:ServerImpl 负责整个 gRPC 服务端消息的调度和处理,创建 ServerImpl 实例过程中,会对服务端依赖的对象进行初始化,例如 Netty 的线程池资源、gRPC 的线程池、内部的服务注册类(InternalHandlerRegistry)等,ServerImpl 初始化完成之后,就可以调用 NettyServer 的 start 方法启动 HTTP/2 服务端,接收 gRPC 客户端的服务调用请求
- 服务端线程模型:**gRPC 的线程由 Netty 线程 + gRPC 应用线程组成**,它们之间的交互和切换比较复杂。gRPC 服务端调度线程为 SerializingExecutor,它实现了 Executor 和 Runnable 接口,通过外部传入的 Executor 对象,调度和处理 Runnable,同时内部又维护了一个任务队列 ConcurrentLinkedQueue,通过 run 方法循环处理队列中存放的 Runnable 。**gRPC 线程模型存在的一个缺点,就是在一次 RPC 调用过程中,做了多次 I/O 线程到应用线程之间的切换,频繁切换会导致性能下降**,这也是为什么 gRPC 性能比一些基于私有协议构建的 RPC 框架性能低的一个原因。尽管 gRPC 的性能已经比较优异,但是仍有一定的优化空间。
**优点**
- **生态好**:背靠Google。还有比如nginx也对grpc提供了支持,[参考链接](https://link.zhihu.com/?target=https%3A//nginx.org/en/docs/http/ngx_http_grpc_module.html)
- **跨语言**:跨语言,且自动生成sdk
- **协议可插拔:**不同的服务可能需要使用不同的消息通信类型和编码机制,例如,JSON、XML 和 Thirft, 所以协议应允许可插拔机制,还有负载均衡,服务发现,日志,监控等都支持可插拔机制
- **性能高**:比如protobuf性能高过json, 比如http2.0性能高过http1.1
- **强类型**:编译器就给你解决了很大一部分问题
- **流式处理(基于http2.0)**:支持客户端流式,服务端流式,双向流式
**区别:**
- rpc是**远程过程调用**,就是本地去调用一个远程的函数,而http是通过 **url**和符合**restful**风格的数据包去发送和获取数据;
- rpc的一般使用的编解码协议更加高效,比如grpc使用**protobuf**编解码。而http的一般使用json进行编解码,数据相比rpc更加直观,但是数据包也更大,效率低下;
- rpc一般用在服务内部的**相互调用**,而http则用于和**用户交互**;
**相似点**:
都有类似的机制,例如grpc的metadata机制和http的头机制作用相似,而且web框架,和rpc框架中都有拦截器的概念。grpc使用的是http2.0协议。
官网:[gRPC](https://link.zhihu.com/?target=https%3A//grpc.io/)
### 13.什么是死锁?如何避免?
> 腾讯一面
死锁是**指两个或者两个以上进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象**。
> 产生死锁的四个必要条件
>
> - 互斥条件:该资源任意一个时刻只由一个线程占用。
> - 请求与保持条件:一个进程因请求资源而阻塞时,对已获得的资源保持不放。
> - 不剥夺条件:线程已获得的资源在未使用完之前不能被其他线程强行剥夺,只有自己使用完毕后才释放资源。
> - 循环等待条件:若干进程之间形成一种头尾相接的循环等待资源关系。
如何避免死锁
针对四个必要条件,只要破坏其中一条,即可破坏死锁的产生。最常见的并且可行的就是**使用资源有序分配法,来破环循环等待条件**
- 破坏请求与保持条件 :**一次性申请所有的资源**。
- 破坏不剥夺条件 :占用部分资源的线程进一步申请其他资源时,如果申请不到,**可以主动释放它占有的资源。**
- 破坏循环等待条件 :**靠按序申请资源来预防**。按某一顺序申请资源,释放资源则反序释放。破坏循环等待条件。
# 总结
Go面试复习应该有所侧重,关注切片,通道,异常处理,Goroutine,GMP模型,字符串高效拼接,指针,反射,接口,sync。对于比较难懂的部分,GMP模型和GC和内存管理,应该主动去看**源码**,然后慢慢理解。业务代码写多了,自然就有理解了。
================================================
FILE: interview/redis.md
================================================
## Redis概述
### 1.什么是Redis?
Redis是一个基于内存的高性能的非关系型的键值对数据库,使用C语言编写
### 2.Redis的优缺点?
- 优点:
- **读写性能好**,读的速度可达11000次/s,写的速度可达81000次/s
- **支持数据持久化**,有AOF和RDB(默认)两种持久化方式
- Redis 默认开启RDB持久化方式,在指定的时间间隔内,执行指定次数的写操作,则将内存中的数据写入到磁盘中。
- AOF :Redis 默认不开启。它的出现是为了弥补RDB的不足(数据的不一致性),所以它采用日志的形式来记录每个**写操作**,并**追加**到文件中。Redis 重启的会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
- **数据结构丰富**,支持string、list、set、hash
- **支持事务**,redis所有的操作都是原子性的,并且还支持几个操作合并后的原子性执行,原子性值操作要么成功执行,要么失败不执行,不会只执行一部分
- **支持主从复制**,主机可以自动将数据同步到从机,进行读写分离
- 缺点:
- 因为Redis是将数据存到内存的,索引会收到内存大小的限制,不能用作海量数据的读写
- Redis不具备自动容错和恢复功能,主机或从机宕机会导致前端部分读写请求失败,需要重启机器或者手动切换前端的IP才可以
### 3.Redis和Memcached的区别和共同点?
相同点:
- 两者的读写性能都比较高
- 都是基于内存的数据库,通常被当做缓存使用
- 都有过期策略
- 都是基于C语言实现的
不同点:
| 不同点 | Redis | Memcache |
| ------ | ---------------------------------------- | ----------------- |
| 是否支持复制 | 支持主从复制 | 不支持复制 |
| key长度 | 长度最大为2GB | 长度为250个字节 |
| 数据类型 | 不仅支持key-value类型的数据,还支持hash、list、set、zset等数据类型的数据 | 仅支持key-value类型的数据 |
| 数据持久化 | 支持,将数据保存到磁盘 | 不支持 |
| 网络IO模型 | 单线程的多路IO复用模型 | 多线程的非常阻塞IO模式 |
| 集群 | 原生支持cluster模式集群 | 无原生 |
### 4.❤Redis是单线程还是多线程?Redis为什么这么快?
> oppo二面
Redis6.0之前是单线程的,为什么Redis6.0之前采用单线程而不是采用多线程
简单来说,就是Redis官方认为没有必要,**单线程的Redis的瓶颈通常在CPU的IO,而在使用Redis时几乎不存在CPU成为瓶颈的情况**。使用Redis主要的瓶颈在**内存和网络**,并且使用单线程也存在一些优点,比如系统的复杂度较低(实现简单并高效),可为维护性较高,避免了并发读写所带来的的一系列问题。
Redis为什么这么快主要有以下几个原因
- 运行在内存中
- 数据结构简单
- 使用**多路IO复用技术**
- **单线程实现**,单线程避免了线程切换、锁造成的性能开销
### 5.Redis6.0之后为什么引入了多线程?
前面也说了Redis的瓶颈在**内存和网路**,Redis6.0引入多线程主要是为了解决**网络IO**读写这个瓶颈,执行命令还是单线程执行,索引也不存在线程安全问题。
Redis6.0默认是否开启了多线程呢?
默认是没有开启的,如需开启,需要修改配置文件redis.conf:io-threads-do-reads no,no改为yes
### 6.❤Redis的数据类型有哪些?
> 需要牢记五大数据类型及其应用场景
Redis的常见的数据类型String、Hash、Set、List、ZSet。还有三种不那么常见的数据类型:Bitmap、HyperLogLog、Geospatial
| 数据类型 | 可以存储的值 | 可进行的操作 | 应用场景 |
| ------ | ----------------- | ---------------------- | ---------------------- |
| string | 字符串、整数、浮点数 | 对整数或浮点数可以进行自增、自减 | 键值对缓存及常规技术 |
| list | 列表(内部使用双向列表实现) | 向列表两端添加元素,或者获的列表的某一个片段 | 存储ID列表、消息队列 |
| set | 无序集合(内部使用值为空的散列表) | 增加/删除/获取元素,去交集并集 | 共同好友,共同关注(使用sinter命令)等 |
| zset | 有序集合(内部使用列表和跳表) | 添加、获取、删除元素、排名无序 | 排行榜,延时队列 |
| hash | 包含键值对的散列 | 添加、获取、移除单个键值对 | 常用于存储对象,比如购物车 |
**bitmap**:位图,是一个以位为单位的数组,数组中只能1或0,数组的下标叫偏移量。bitmap实现统计功能,更省空间。面试过程中常问的的布隆过滤器就用到这种数据结构,布隆过滤器可以判断出**哪些数据一定不在数据库中**,所以常用来解决Redis缓存穿透问题
**hyperloglog**: *['haɪpər]*是一种用于**统计基数** 的数据集合类型,
**Geospatial:**ˌ/dʒiːəʊˈspeɪʃəl/ 主要用于存储地理位置信息,常用于定位附近的人,打车距离的计算等。
### 7.❤Redis的数据结构有哪些?
> 小红书
- **简单动态字符串**:Redis的底层是用C语言编写,但Redis并没有直接使用C语言传统的字符串表示,而是构建了一种名为简单动态字符串的抽象类型。
- **链表**:链表提供了高效的节点重排能力,以及顺序性的结点访问方式,并且可以通过增删节点来灵活的调整链表的长度。链表是列表的底层实现之一
- **字典**:又称符号表、关联数组或映射
- **整数集合**:整数集合(intset)是集合键的底层实现之一,当一个集合只包含整数值元素,并且这个集合的元素数量不多时,Redis就会使用整数集合作为集合键的底层实现。
- **压缩列表(ziplist)**:压缩列表是Redis为了节约内存开发的,是由一系列特殊编码的连续内存组成的顺序型数据结构。
- **对象**:上面的是Redis的底层数据结构,但Redis并没有直接使用这些数据结构来实现键值对数据库,而是基于这些数据结构创建了一个对象系统,这个系统包含**字符串对象、列表对象、哈希对象、集合对象和有序集合对象**这五种类型的的对象
为什么不直接使用这些底层数据结构,而是要创建对象系统。对象系统主要有以下优点:
- 通过五种不同类型的对象,Redis可以在执行命令之前,根据对象的类型来判断一个对象是否可以给定的命令
- 我们可以针对不同的使用场景,为对象设置多种不同的数据结构实现,从而优化对象在不同场景下的使用效率
- 实现了基于**引用计数**的内存回收机制,当程序不再使用某个对象的时候,这个对象所占用的内存就会被自动释放,
- 还通过引用计数实现了对象共享机制,这一级至可以再适当的条件下,通过让多个数据库键共享一个对象来节约内存

- **跳跃表**(**面试**常问):跳跃表是一种有序数据结构,它通过在每个节点维持多个指向其他结点的指针,从而达到快速访问节点的目的。平均O(logN)、最坏O(N)复杂度的结点查找,还可以通过顺序性操作来批量处理节点。**跳跃表是有序集合键的底层实现之一** ,跳跃表还在集群节点中用作内部数据结构。跳跃表本质是一种空间换时间的策略,是一种可以进行二分查找的有序链表,**跳跃表在原有的有序链表上增加了多级索引,通过索引来实现快速查询**。跳表不仅能提高搜索性能,同时可以提高插入和删除操作的性能

建立一级索引:

对于理想的跳跃表,每先上一层索引节点数量都是下一层的1/2,跳跃表为O(logN),空间复杂度为O(N),虽然是空间换时间的策略,这里距离存储的知识数字,如果是存储比较大的对象,浪费的空间就不值一提了,因为索引节点只需要存储关键值和几个指针,并不需要存储对象
跳跃表相比于红黑树的优点(redis为什么用跳跃表而不是红黑树):
- **内存**占用更少,自定义参数化决定使用多少内存、查询性能至少不比红黑树差
- 简单更**容易**实现和维护
最后,说下Redis中的跳跃表和普通的跳跃表有什么区别?
- Redis中的跳跃表**分数(score)允许重复**,即跳跃表的key允许重复。如果分数重复,还需要根据数据内容来进行字典排序。普通的跳跃表是不支持的
- 第一层链表不是一个单向链表,而是一个**双向链表**。这是为了方便一倒序方式获取一个范围内的元素。
- 在Redis的跳跃表中可以很方便地计算出每个元素的**排名**
### 8.Redis的应用场景有哪些?
- **缓存**:Redis基于内存,读写速度非常快,并且有键过期功能和键淘汰策略,可以作为缓存使用
- **排行榜**:Redis提供的有序集合可以很方便地实现分布式的锁
- **分布式锁**:Redis的setnx功能来实现分布式的锁
- 社交功能:实现共同好友、共同关注等(sinter命令)
- 计数器(分布式ID生成):通过对String进行自增自减实现计数功能
- **消息队列**:Redis提供了发布、订阅、阻塞队列等功能,可以实现一个简单的消息队列
### 9.Redis是单线程的,如何提高CPU的利用率?
可以在一个服务器上部署多个Redis实例,把他们当作不同的服务器使用,在某些时候,无论如何一个服务器是不够的, 所以,如果你想使用多个CPU,你可以考虑一下**分片**(shard)。
## 过期键的删除策略
### 1.❤键的过期删除策略
> 联想一面
常见的过期删除策略时**惰性删除、定期删除、定时删除**
- **惰性删除**:只有访问这个键时才会检查他是否过期,如果过期则删除。优点:最大化地节约CPU资源。缺点:如果大量过期键没有被访问,会一直占用大量内存
- 定时删除:为每一个设置唾弃时间的key都创造一个定时器,到了过期时间就清除。优点:该策略可以立即清除过期的键。缺点:会占用大量CPU资源去处理过期的数据
- **定期删除**:每隔一段时间就对一些键进行检查,删除其中过期的键。该策略时惰性删除和定时删除的一个折中,既避免了占用大量CPU资源又避免了出现大量过期键不被清除占用内存的情况
Redis中同时使用了惰性删除和定期删除两种
### 2.❤Redis的内存淘汰机制是什么样
Redis是基于内存的,所以容量肯定是有限的,有效的内存淘汰机制对Redis非常重要的。
当存入的数据超过Redis最大允许内存后,会触发Redis的内存淘汰策略。在Redis4.0前一共有6种淘汰策略。
- noeviction:不删除策略,达到最大内存限制时,如果需要更多内存,直接返回错误信息。大多数写命令斗都会导致占用更多的内存
- allkeys-lru:所有的key通用,优先删除最近最少使用的key
**如何用go语言实现LRU(使用双向链表)**[146. LRU 缓存 - 力扣(Leetcode)](https://leetcode.cn/problems/lru-cache/description/)
```go
type LRUCache struct {
limit int
hashMap map[int]*Node
head,tail *Node
}
type Node struct{
key int
value int
pre *Node
next *Node
}
func NewNode(key , value int)*Node{
return &Node{
key:key,
value:value,
}
}
func Constructor(capacity int) LRUCache {
l:=LRUCache{
limit:capacity,
head:NewNode(0,0),
tail:NewNode(0,0),
hashMap:make(map[int]*Node),
}
l.head.next=l.tail
l.tail.pre=l.head
return l
}
func (this *LRUCache) Get(key int) int {
if node,ok:=this.hashMap[key];ok{
this.Refresh(node)
return node.value
}
return -1
}
func (this *LRUCache) Put(key int, value int) {
newNode:=NewNode(key,value)
if node,ok:=this.hashMap[key];ok{
node.value=value
this.Refresh(node)
}else{
this.hashMap[key]=newNode
this.AddNode(newNode)
if len(this.hashMap)>this.limit{
oldKey:=this.tail.pre.key
this.RemoveNode(this.tail.pre)
delete(this.hashMap,oldKey)
}
}
}
func (this *LRUCache) Refresh(node *Node) {
this.RemoveNode(node)
this.AddNode(node)
}
// 删除
func (this *LRUCache) RemoveNode(node *Node) {
node.pre.next=node.next
node.next.pre=node.pre
}
//每次添加头部
func (this *LRUCache) AddNode(node *Node) {
node.next=this.head.next
this.head.next.pre=node
node.pre=this.head
this.head.next=node
}
/**
- Your LRUCache object will be instantiated and called as such:
- obj := Constructor(capacity);
- param_1 := obj.Get(key);
- obj.Put(key,value);
*/
```
- allkeys-random:所有key通用;随机删除了一部分key
- volatile-lru:[ˈvɒlətaɪl] 只限于设置了expire的部分;优先删除最近最少使用的key
- volatile-random:只限于设置了expire的部分,随机删除最近最少使用的key
- volatile-ttl:只限于设置了expire的部分;优先删除剩余时间短的key
在Redis4.0之后可增加两个
- volatile-lfu:只限于设置了expire的部分;优先删除一些最不经常使用的键(Least Frequenly Used),淘汰最近访问频率最小的元素。
- allkeys-lfu:所有key通用,优先删除最不经常使用的键
## Redis的持久化
### 1.什么是Redis的持久化?
因为Redis是基于内存的,为了防止一些意外导致数据丢失,需要将数据持久化到磁盘上
### 2.Redis常见的持久化机制有哪些?有什么优缺点?
- **RDB** :Redis默认的持久化方式,按照一定的时间间隔将内存的数据以快照的形式保存到硬盘,恢复时是将快照读取到内存中。RDB持久化实际操作过程是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制压缩存储

优点:
- 适合对大规模的数据恢复,比AOF的启动效率高
- 只有一个文件dump.rdb,方便持久化
- 性能最大化,在开始持久化时,他唯一需要做的只是-------fork一个子进程,之后再由子进程完成这些持久化的工作,这样就可以极大地避免进程执行IO操作了。
缺点:
- 数据安全性低,在一定时间间隔内做一次备份,如果Redis突然宕机,会丢失最后一次快照修改
- 由于RDB是通过fork子进程来协助完成数据持久化工作的,因此当数据集较大时,可能会导致整个服务器停止服务几百毫秒,甚至是1秒
- **AOF** :AOF持久化以日志的形式记录服务器所处理的每一个写、删除操作,查询操作不会记录,以文本的方式记录,可以打开文件看到纤细的操作记录。

优点:
- 具备更高的安全性,Redis提供了3种同步策略,分别是每秒同步、每修改同步和不同步。相比RDB突然宕机丢失的数据会更少,每秒同步只会丢失一秒的数据,每修改同步不会丢失数据。
- 由于该机制对日志文件的写入操作采用的是append操作,因此在写入过程中即使出现宕机现象,也不会破坏日志文件中已经存在的内容。
- AOF包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作,可以通过该文件对完成数据的重建
缺点:
- 对于相同数量的数据集而言,AOF文件通常要大于RDB文件(如果AOF文件太大了怎么办?重写)。RDB在恢复大数据集时的速度比AOF的恢复速度要快
- 根据AOF选择同步策略的不同,效率也不同,但AOF在运行效率往往要慢于RDB
## Redis的事务
### 1.什么是Redis的事务
Redis的事务是一个单独的隔离操作,事务中的所有命令都会序列化、按顺序地执行。事务在执行过程中,不会被其他客户端发送来的命令请求所打断,所以Redis事务是在**一个队列中**,一次性、顺序性、排他性地执行一系列命令
Redis事务的主要作用就是**串联多个命令防止别的命令插队**
### 2.Redis事务的相关命令?
- discard:命令取消事务,放弃执行事务队列内的所有命令,恢复连接为非transaction模式,入股正在使用watch命令监视某个key,那么取消所有监视,等同于执行命令unwatch
- exec:执行事务队列内的所有命令
- multi:['mʌlti] 用于标记一个事务块的开始。
- unwatch,用于取消watch命令对所有key的监视。如果已经执行过了EXEC或DISCARD命令,则无需再执行UNWATCH命令,因为执行EXEC命令时,开始执行事务,WATCH命令也会生效,而 DISCARD命令在取消事务的同时也会取消所有对 key 的监视,所以不需要再执行UNWATCH命令了
- watch:用于标记要监视的key,以便有条件地执行事务,watch命令可以监控一个或多个键,一旦其中有一个键被修改,之后的事务就不会执行
### 3.Redis事务执行的三个阶段
1.开始事务(multi *['mʌltɪ]*)
2.命令入列
3.执行事务(exec)
### 4.Redis事务的特性
- Redis事务**不保证原子性**,单条的Redis命令是原子性的,但事务不能保证原子性
- Redis事务是有**隔离性**的,但是没有隔离级别,事务中所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送过来的命令请求所打断(**顺序性、排他性**)
- Redis事务**不支持回滚** ,Redis执行过程中的命令执行失败,其他命令仍然可以执行
### 5.Redis事务为什么不支持回滚?
在Redis的事务中,命令允许失败,但是Redis会继续执行其他的命令而不是回滚所有命令,是不支持回滚的
主要原因有以下两点:
- Redis命令简单,只在两种情况失败
- 语法错误的时候才失败(在命令输入的时候不检查语法)
- 要执行的key数据类型不匹配:这种错误实际上是编程错误,这应该在开发阶段被测试出来,而不是在生产上
- 因为不需要回滚,所以Redis**内部实现简单并高效**。(Redis为什么是单线程而不是多线程也用了这个思想,实现简单并且高效)
## Redis的集群、主从、哨兵
### 1.❤Redis集群的实现方案有哪些?
> 深信服一面
在说Redis集群前,先说为什么要使用Redis集群,Redis单机版主要有以下几个缺点:
- 不能保证数据的**可靠性**,服务部署在一台服务器上,一旦服务器宕机就不可用,
- **性能瓶颈**,内存容量有限,处理能力有限
Redis集群就是为了解决Redis单机版的一些问题,Redis集群主要是有以下几种方案**Redis主从模式** ,**Redis哨兵模式** ,**Redis自研** ,**Redis Cluster**
#### **Redis主从模式**
Redis单机版通过RDB或AOF持久化机制到硬盘上,但数据都存储在一台服务器上,并且读写都在同一服务器上(读写不分离),如果硬盘出现问题,则会导致数据不可用,为了避免这种问题,
Redis提供了复制功能,在master数据库中的数据更新后,自
动将更新的数据同步到slave数据库中,这就是主从模式的Redis集群,如下图:
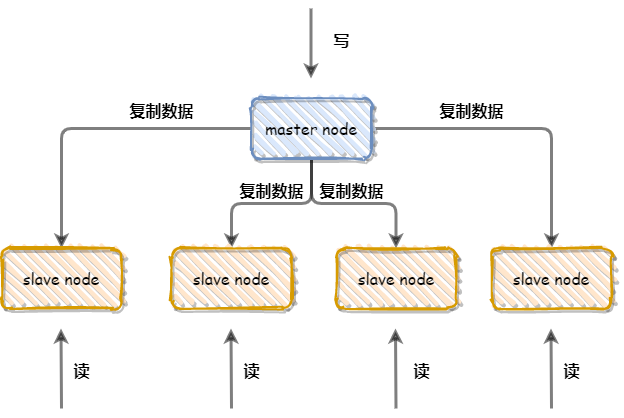
主从模式解决了Redis单机版存在的问题,但其本身也不是完美的,主要优缺点如下:
- **优点:**
- **高可靠性** ,在master数据库出现故障后,可以切换到salve数据库
- **读写分离**,slave库可以扩展master库节点的读能力,有效应对大并发量的读写操作
- **缺点:**
- 不具备自动容错和恢复能力,主节点故障,从节点需要手动升为主节点,可用性较低
#### **Redis哨兵模式**
为了解决主从模式的Redis集群不具备自动容错和恢复能力的问题,Redis从2.6开始提供哨兵模式
哨兵模式的核心还是主从复制,不过相比于主从模式,多了一个竞选机制(多了一个哨兵集群),从所有从节点中选出主节点,如下图:

哨兵模式相比于主从模式,主要多了一个哨兵集群,哨兵集群的主要作用如下:
- 监控所有服务器是否正常运行:通过发送命令返回监控服务器的运行状态(心跳),处理监控主服务器、从服务器外,哨兵之间也相互监控
- 故障切换:当哨兵监测到master宕机,会自动将某个slave切换到master,然后通过**发布订阅模式** 通知其他的从服务器,修改配置文件,让他们切换master。同时那台有问题的旧主也会变成新主的从节点,也就是说当旧的主节点即使恢复时,并不会恢复原来的主节点身份,而是作为新主节点的一个从节点
- **优点:**
- 哨兵模式是基于主从模式的,解决主从模式中master故障不可以自动切换master的问题
- **缺点:**
- 浪费资源,集群里所有节点保存的都是全量数据,数据量 过大时,主从同步会严重影响性能
- Redis主机宕机后,投片选举结束之前,谁也不知道主机和从机是谁,此时Redis也会开启保护机制,禁止写操作,直到选举出了新的Redis主机
- 只有一个master库执行写请求,写操作会单机性能瓶颈影响
#### **Redis自研**
哨兵模式虽然解决了主从模式存在的一些问题,但其本身也存在一些弊端,比如数据在每个Redis实例中都试试全量存储,极大地浪费了资源,为了解决这个问题,Redis提供了Redis Cluster,实现了数据分片存储,但Redis提供Redis Cluster之前,很多公司为了解决哨兵模式存在的问题,分别自行研发Redis集群方案:
- **客户端分片**
客户端分片是把分片的逻辑放在Redis客户端实现,通过Redis预先定义好的路由规则(使用哈希算法),把对Key的访问转发到不同的Redis实例中,查询数据时把返回结果回汇集。如下图:

**优点** :Redis实例彼此独立,相互无关联,每个Redis实例想单个服务器一样运行,非常容易线性扩展,系统的灵活性很强
**缺点:**
- Redis实例彼此独立,相互无关联,每个Redis实例像单服务器一样运行
- 运维成本比较高,集群的数据出了任何问题都需要运维人员和开发人员一起合作,减缓了解决问题的速度,增加了跨部门沟通的成本
- 在不同的客户端程序中,维护相同的路由分片逻辑成本巨大。比如java项目,go项目里共用一套Redis集群,路由分片逻辑分别需要写两套一样的逻辑,以后维护也是两套
- **代理分片** :
客户端分片的最大问题就是服务端Redis实例群拓扑结构有变化时,每个客户端都需要更新调整
为了解决这个问题,代理分片出现了,代理分片将客户端分片模块单独分了出来,作为Redis客户端和服务端的桥梁,如下图:
**优点**:解决了服务端Redis实例拓扑结构有变化时,每个客户端都需要更新调整的问题。
**缺点** :由于Redis客户端的每个请求都经过代理才能达到Redis服务器,这个过程中会产生**性能损失**
(常见的代理分片有Twitter开源的Redis代理Twemproxy和豌豆荚自主研发的Codis)
#### Redis Cluster
在Redis3.0中,Redis也提供了相应的解决方案,就是Redis Cluster
Redis Cluster是一种服务端Sharding技术,并没有采用一致性哈希,而是采用slot(槽)的概念,一共分成16384个槽。将请求发送到任意节点,接收到请求的结点会将查询请求发送到正确的结点上执行。
**一致性哈希**
首先对key计算出一个hash值,然后对2^32取模,将其范围抽象成一个**圆环**,使用CRC16算法计算出来的哈希值回落到圆环的某个地方
假设A、B、C三个Redis实例按照如图所示的位置分布在圆环上,通过上述介绍的方法计算出key的hash值,发现其落在了位置E,按照顺时针,这个key值应该分配到Redis实例A上。 如果此时Redis实例A挂了,会继续按照顺时针的方向,之前计算出在E位置的key会被分配到RedisB,而其他Redis实例则不受影响。
但一致性哈希也不是完美的,主要存在以下问题:**当Redis实例节点较少时,节点变化对整个哈希环中的数据影响较大,容易出现部分节点数据过多,部分节点数据过少的问题,出现数据倾斜的情况**,如下图(图片来源于网络),数据落在A节点和B节点的概率远大于B节点
为了解决这种问题,可以对一致性哈希算法引入**虚拟节点**(A#1,B#1,C#1),如下图(图片来源于网络)
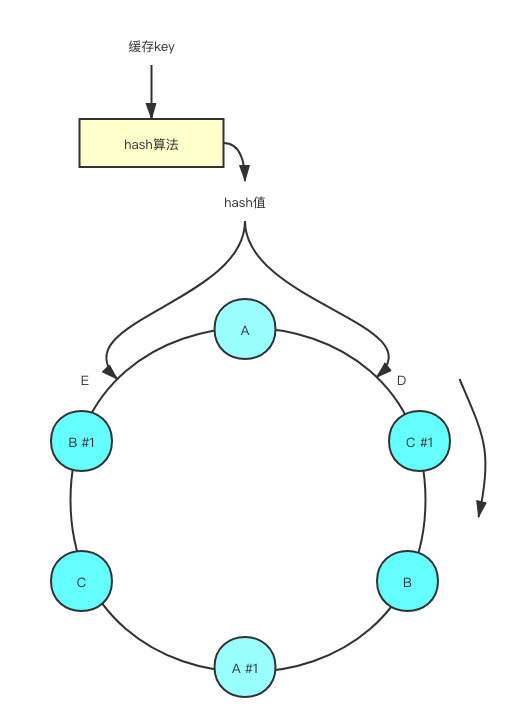
那这些虚拟节点有什么用呢?每个虚拟节点都会映射到真实节点,例如,计算出key的hash值后落入到了位置D,按照顺时针顺序,应该落到节点C#1这个虚拟节点上,因为虚拟节点会映射到真实节点,所以数据最终存储到节点C。
**Redis虚拟槽**
在Redis Cluster中并没有使用一致性哈希,而引进了虚拟槽。虚拟槽的原理和一致性哈希好像,Redis Cluster一共有2^14(16384)个槽,所有的master节点都会有一个范围比如0~1000,槽数是可以迁移的。master节点的slave节点不分配槽,只拥有读权限,其实虚拟槽也可以看成一致性哈希中的虚拟节点。
虚拟槽和一致性哈希算法的实现也很像,先通过CRC16算法计算出key的hash值,然后对16384取模,得到对应的槽位,根据槽找到对应的节点,如下图:
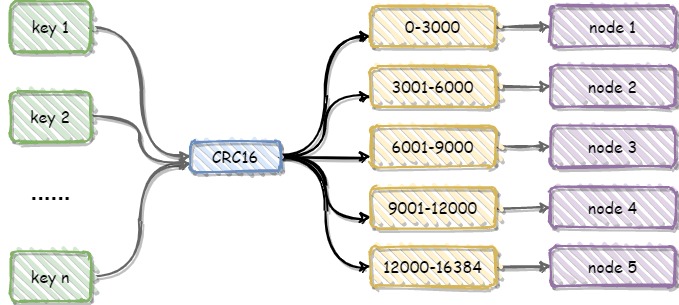
**优点:** **更加方便地添加和移除节点**,增加节点时,只需要把其他节点的某些哈希槽挪到新节点就可以了,当移除节点时,只需要把移除节点上的哈希槽挪到其他节点就行了,不需要停掉Redis任何一个节点的服务,采用一致性哈希算法时增加和移除节点需要rehash
Redis Cluster是一个去中心化的架构,不存在统一的配置,Redis Cluster的每个节点都保存了集群的配置信息,在Redis Cluster中,这个配置信息通过Redis Cluster Bus进行交互,并最后达成一致性。
配置信息的一致性主要是PING/PONG,每个节点向其他节点周期性的发送Ping/Pong消息。对于大规模的集群,如果每次Ping/Pong都携带者所有节点的信息,则网络开销会很大。此时Redis Cluster在每次Ping/Pong,只包含了随机一部分节点信息。由于交互比较频繁,集群的状态也会达到一致
在Cluster结构不发生变化时,各个节点通过gossip协议(Redis Cluster各个节点之间交换数据、通信采用的一种协议)在几轮交互后,便可以得知Cluster的结构信息,达到一致性的状态。但是当集群结构发生变化时(故障转移、分片迁移)时,有幸得知变更的节点会将自己的最新信息扩散到Cluster,并达到最终一致
Redis Bus是用于节点之间的信息交路,交互的信息有以下几个:
- 数据分片(slot)和节点的**对应关系**
- 集群中每个节点**可用状态**
- 集群结构发生变更时,通过一定的协议对**配置信息达成一致**。数据分片的迁移,主备切换、单点master的发现和其发生主备关系变更等,都会导致集群结构的变化
### 2.Redis主从架构中数据丢失吗?
Redis主从架构丢失数据主要有两种情况
- **异步复制同步丢失**
Redis主节点和从节点的复制是异步的,当主节点的数据未完全复制到从节点时就会发生宕机了,master内存中的数据会丢失
如果主节点开启持久化是否可以解决这个问题?
答案是**否定的**,在master发生宕机后,集群检测到主节点发生故障,重新选举新的主节点,如果就的主节点在故障恢复后重启,那么此时他需要同步新节点的数据,此时新的主节点的数据是空的(假设这段时间中没有数据写入)。那么旧主机点中的数据就会被刷新掉,此时数据还是会丢失
- **集群产生脑裂**
集群脑裂是指一个集群中有多个主节点,像一个人有两个大脑,到底听谁的
例如,由于网络原因,集群出现了分区,master和slave节点断开了联系,哨兵监测后认为主节点故障,重新选举从节点为主节点,但主节点可能并没有发生故障。此时客户端依然在旧的主节点上写数据,而新的主节点中没有数据,在发现这个问题之后,旧的主节点会被降为slave,并且开始同步新的master数据,那么之前的写入旧的主节点的数据被刷新掉,大量数据丢失。
### 3.如何解决Redis主从架构数据丢失的问题?
在Redis的配置文件中,有两个参数如下:
```yaml
min-slaves-to-write 1
min-slaves-max-lag 10
```
其中,min-slaves-to-write默认情况下是0,min-slaves-max-lag默认情况下是10。
上述参数表示至少有1个salve的与master的同步复制延迟不能超过10s,一旦所有的slave复制和同步的延迟达到了10s,那么此时master就不会接受任何请求。
通过降低min-slaves-max-lag参数的值,可以避免在发生故障时大量的数据丢失,一旦发现延迟超过了该值就不会往master中写入数据。
这种解决数据丢失的方法是降低系统的可用性来实现的。
### 4.Redis集群的主从复制过程是什么样的?
1.设置服务器的地址和端口号
2.建立套接字(建立主从服务器之间的连接)
3.发送Ping命令(检验套接字是否可用)
4.身份验证
5.命令传播(经过上面同步操作,此时主从的数据库状态其实已经一致了,许主服务器马上就接受到了新的写命令,执行完该命令后,主从的数据库状态又不一致。数据同步阶段完成后,主从节点进入命令传播阶段;在这个阶段主节点将自己执行的写命令发送给从节点,从节点接收命令并执行,从而保证主从节点数据的一致性)
### 5.简单解释下全量复制和部分复制?
在Redis2.8以前,从节点向主节点发送sync命令请求同步数据,此时的同步方式是全量复制;在Redis2.8及以后,从节点可以发送psync命令请求同步数据,此时根据主从节点当前状态的不同,同步方式可能是全量复制或部分复制。
- 全量复制:用于初次复制或其他无法进行部分复制的情况,将主节点中的所有数据都发送给从节点,是一个非常重型的操作。
- 部分复制:用于处理在主从复制中因网络闪退等原因造成数据丢失场景,当从节点再次连上主节点,如果条件允许,主节点会补发丢失数据给从节点,因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销。但需要注意,如果网络中断时间过长,造成主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制 。
### 6.Redis是如何保证主从服务器一直处于连接状态以及命令是否丢失
命令传播阶段,从服务器会利用**心跳检测机制**定时的向主服务发送消息。
### 7.因为网络原因在主从复制过程中停止复制会怎么样?
如果出现网络问题断开,**会自动重连,并且支持断点续传,接着上次复制的地方继续复制**,而不是重新复制一份。
### 8.Redis集群最大的节点个数是多少?为什么?
16384个,因为Redis集群采用哈希槽分片,而哈希槽总共有16384个。
由于其他设计折衷,一般情况下一个redis集群不会有超过**1000**个master节点
### 9.Redis集群是如何选择数据库的?
Redis集群目前无法做到数据库选择,默认在0数据库
### 10.Redis高可用方案如何实现?
- 数据持久化
- 主从模式
- 哨兵模式
- Redis集群(自研及Redis Cluster)
## Redis的分区
### 1.Redis分区的作用是什么?
- **扩展数据库容量**,可以利用多台机器的内存构建更大的数据库
- **扩展计算能力**,分区可以在多核和多计算机之间弹性扩展计算能力,在多计算机和网络适配器之间弹性扩展网络带宽
### 2.❤Redis分区有哪些实现方案?
在介绍Redis集群的实现方案时已经介绍过了客户端分区和代理分区,常见的Redis分区方案主要有以下三种:
- **客户端分区**:客户端决定数据被存到哪个Redis节点或者从哪个节点读取
- **代理分区**:客户端将请求发送到代理,而不是直接发送到Redis节点,代理根据分区策略将请求发送到Redis节点上
- **查询路由**:客户端随机请求任意一个Redis节点,这个Redis节点将请求转发到正确的Redis节点。Redis Cluster实现了一种混合形式的查询路由,并不是直接将请求从一个Redis节点转发到另一个Redis节点,而是在客户端的帮助下直接重定向到正确的redis节点
### **3.Redis分区的缺点?**
- **不支持多个键的操作**,例如不能操作映射在两个Redis实例上的两个集合的交叉集。(其实可以做到这一点,但是需要间接的解决)
- **不支持多个键的事务**
- Redis是以键来分区,因此不能使用单个大键对数据集进行分片,例如一个非常大的有序集
- **数据的处理会变得复杂**,比如你必须处理多个RDB和AOF文件,在多个实例和主机之间持久化你的数据
- 添加和删除节点也会变得复杂,例如通过在运行时添加和删除节点,Redis集群通常支持透明地再均衡数据,但是其他系统像客户端分区或者代理分区的特性就不支持该特性。不过Pre-sharding(预分片)可以在这方面提供帮助。
## Redis的分布式问题
### 1.什么是分布式锁?
锁在程序中的作用主要是同步,就是保证共享资源在同一时刻只能被同一个线程访问。 分布式锁则是为了保证在分布式场景下,共享资源在同一时刻只能被同一个线程访问,或者说是用来控制分布式系统之间同步访问共享资源。
### 2.分布式锁具有哪些特性?
- 互斥性:在任意时刻,同一条数据只能被一台机器上的一个线程执行
- 高可用性:当部分节点宕机后,客户端仍可以正常地获取锁和释放锁
- 独占性:加锁和解锁必须同一台服务器执行,不能在一个服务器上加锁,在另一个服务器上释放锁
- 防锁超时:如果客户端没有主动释放锁,服务器会在一定时间后自动释放锁, 防止客户端宕机或者网络异常导致宕机
### 3.❤分布式锁的实现方法?
> 百度提前批
基本思路就是要在整个系统中提供一个全局、唯一的获取锁的“东西”,然后每个系统在需要加锁时,都去问这个“东西”拿到一把锁,这样不同的系统拿到的就可以认为是同一把锁。 常见的分布式锁实现方案有三种:
###### **基于关系型数据库**:
> 它的基本原理和 Redis 的 SETNX 类似,其实就是创建一个分布式锁表,加锁后,我们就在表增加一条记录,释放锁即把该数据删掉
>
> 乐观锁和悲观锁
>
> 它同样存在一些问题:
>
> 1. 没有失效时间,容易导致死锁;
> 2. 依赖数据库的可用性,一旦数据库挂掉,锁就马上不可用;
> 3. 这把锁只能是非阻塞的,因为数据的 insert 操作,一旦插入失败就会直接报错。没有获得锁的线程并不会进入排队队列,要想再次获得锁就要再次触发获得锁操作;
> 4. 这把锁是非重入的,同一个线程在没有释放锁之前无法再次获得该锁。因为数据库中数据已经存在了。
**优点**:直接借助数据库容易理解
**缺点**: 在使用关系型数据库实现分布式锁的过程中会出现各种问题,例如数据库单点问题和可重入问题,并且在解决过程中会使得整个方案越来越复杂
###### **基于Redis**:
基本命令主要有:
- SETNX(SET If Not Exists):当且仅当 Key 不存在时,则可以设置,否则不做任何动作。
- SETEX:可以设置超时时间
其原理为:通过 SETNX 设置 Key-Value 来获得锁,随即进入死循环,每次循环判断,如果存在 Key 则继续循环,如果不存在 Key,则跳出循环,当前任务执行完成后,删除 Key 以释放锁。
这种方式可能会导致死锁,为了避免这种情况,需要设置**超时时间**。
**优点**:性能好,实现起来较为方便
**缺点**: key的过期时间设置难以确定,如何设置的失效时间太短,方法没等执行完,锁就自动释放了,那么就会产生并发问题。如果设置的时间太长,其他获取锁的线程就可能要平白的多等一段时间。 Redis的集群部署虽然能解决单点问题,但是并不是强一致性的,锁的不够健壮;高并发的情况下,如果两个线程同时进入循环,可能导致加锁失败。
**利用Redlock**
获取锁的步骤:
假设有N个redis节点,这些节点之间既没有主从,也没有集群关系。
- 客户端用相同的key和随机值在N 个节点上请求锁,请求锁的超时时间应小于锁自动释放时间。
- 当在(N/2+1)个(超过半数)redis上请求到锁的时候,才算是真正获取到了锁。
- 如果没有获取到锁,则把部分已锁的redis释放掉。
通过 Redlock 实现分布式锁比其他算法更加可靠
###### **基于zookeeper**:
> 实现是基于临时序号节点,每个客户端对某个方法加锁时,在 Zookeeper 上与该方法对应的指定节点的目录下,生成一个唯一的临时有序节点。 判断是否获取锁的方式很简单,只需要判断有序节点中序号最小的一个。 当释放锁的时候,只需将这个临时节点删除即可。同时,其可以避免服务宕机导致的锁无法释放,而产生的死锁问题。
锁分为两种:共享锁(读锁)和排他锁(写锁)
- 读锁:当有一个线程获取读锁后,其他线程也可以获取读锁,但是在读锁没有完全被释放之前,其他线程不能获取写锁。
- 写锁:当有一个线程获取写锁后,其他线程就无法获取读锁和写锁了。
zookeeper有一种节点类型叫做临时序号节点,它会按序号自增地创建临时节点,这正好可以作为分布式锁的实现工具。
读锁获取原理:
1、根据资源的id创建临时序号节点:/lock/mylockR0000000005 Read
2、获取/lock下的所有子节点,**判断比他小的节点是否全是读锁**,如果是读锁则获取锁成功
3、如果不是,则阻塞等待,**监听**自己的前一个节点。
4、当前面一个节点发生变更时,重新执行第二步操作。
写锁获取原理:
1、根据资源的id创建临时序号节点:/lock/mylockW0000000006 Write
2、获取 /lock 下所有子节点,**判断最小的节点是否为自己**,如果是则获锁成功
3、如果不是,则阻塞等待,**监听**自己的前一个节点
4、当前面一个节点发生变更时,重新执行第二步。
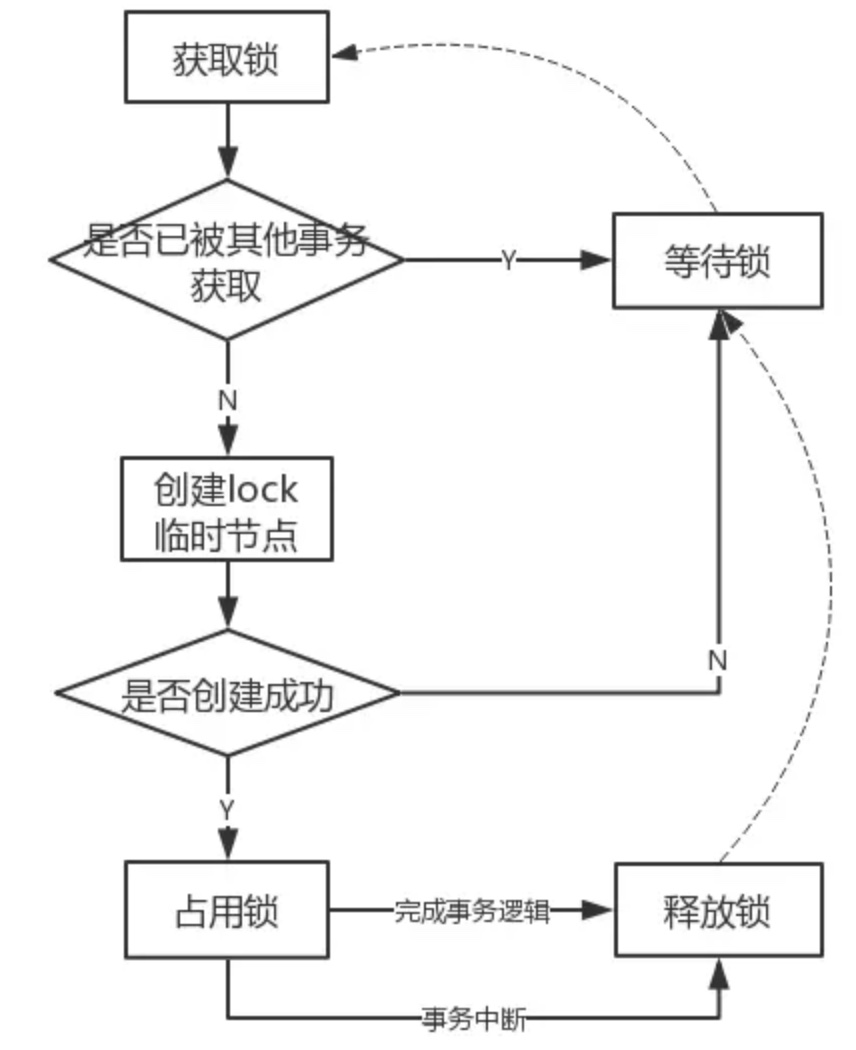
**优点**:有效地解决单点问题,**不可重入问**题,非阻塞问题以及锁无法释放的问题,实现起来较为简单。
**缺点**:性能上不如使用Redis实现分布式锁
### 4.❤Redis如何实现分布式锁?
Redis实现分布式锁的主要命令:SETNX,该命令的作用是当key不存在时设置key的值,当Key存在时,什么都不做。 但是这个简陋的分布式锁存在很多问题,并不能满足上述介绍的分布式锁的特性, 比如,当线程1执行到上图中执行业务这步时,业务代码突然出现异常了,无法进行删除锁这一步,那就完犊子了,死锁了,其他线程也无法获取到锁了(因为SETNX的特性)。
**改进方案1:设置超时时间**
其实这个问题很好解决,只需给锁设置一个**过期时间**就可以了,对key设置过期时间在Redis中是常规操作了。就是这个命令SET key value [EX seconds][PX milliseconds] [NX|XX] EX second: 设置键的过期时间为second秒; PX millisecond:设置键的过期时间为millisecond毫秒; NX:只在键不存在时,才对键进行设置操作; XX:只在键已经存在时,才对键进行设置操作; SET操作完成时,返回OK,否则返回nil。
那先现在这个方案就完美了吗?显然没有 例如,线程1获取到了锁,并设置了有效时间10秒,但线程1在执行业务时超过了10秒,锁到期自动释放了,在锁释放后,线程2又获取了锁,在线程2执行业务时,线程1执行完了,随后执行了删除锁这一步,但是线程1的锁早就到期自动释放了,他删除的是线程2的锁!!!
**改进方案2:超时时间+标识+守护线程**
其实看起来方案1的问题很容易解决,只需要把锁的过期时间设置的非常长,就可以避免这两个问题,但是这样并不可行,因为这样相当于回到最简陋的方案(会导致李四一直上不到厕所)。 那如何能让李四上到厕所,还不会让自己锁的门被张三打开门呢?
很简单,为锁加一个**标识**,例如生成一个UUID,作为锁的标识,每个线程获取锁时都会生成一个不同的UUID作为锁的标识,在进行删除锁时会进行判断,锁的标识和自己生成UUID相等时才进行删除操作,这样就避免线程1释放了线程2的锁。(相当于自己上自己的锁,不要计较为什么张三在李四上厕所时不需要李四的钥匙就能离开厕所这种事,上厕所和分布式锁逻辑并不完全相同,只是简单类比) 那怎么解决李四未等张三上完厕所就进厕所呢?(如何确定锁的过期时间)
可以在加锁时,先设置一个预估的过期时间,然后开启一个**守护线程**,定时去检测这个锁的失效时间,如果锁快要过期了,操作共享资源还未完成,那么就自动对锁进行续期,重新设置过期时间。 好了,张三和李四上厕所的解决了。 那此方案就没有其他问题了吗?其实还是有的,比如目前的分布式锁还不具备可重入性(同一线程可以重复获取锁,解决线程需要多次进入锁内执行任务的问题)
**改进方案3:计数**
参考其他重入锁的实现,可以通过对锁进行重入计数,加锁时加 1,解锁时减 1,当计数归 0 时才能释放锁。 那现在方案就没有问题了吗,其实还有 比如,线程1获取了锁,线程2没有获取到锁,那么线程2怎么知道线程1啥时候释放了锁,进而再去获取锁呢?
**改进方案4:客户端轮询**
方案3中问题的解决方案,一般以下两种解决方案:
可以通过客户端轮询的方式,就是线程2过一会就来看看是不是能获取锁了。这种方式比较消耗服务器资源,当并发量比较大时,会影响服务器的效率。
通过Redis的发布订阅功能,当获取锁失败时,订阅锁释放消息,获取锁成功后释放时,发送锁释放消息。 那现在这个方案完美了吗?也还没有 目前讨论的都是redis是单节点的情况,如果这个节点挂了,那么所有的客户端都获取不到锁了
**改进方案5:红锁**
> 为了实现多节点Redis的分布式锁,Redis的作者提出了RedLock算法。 这是RedLock算法官网的地址,https://redis.io/topics/distlock,英文好的建议直接看官方文档,
>
> **为什么基于故障转移实现的Redis分布式锁还不够用?**
>
> 官网中举了一个例子:
>
> 客户端A获得主服务器上的锁,然后主服务器向从服务器复制数据的过程中崩了,导致数据没有复制到从数据库中,这时会在从服务器中选出来一个升级为主服务器,但新的主服务器中并没有客户端A设置的锁。所以客户端B也可以获取到锁,违背了上面说的互斥性
>
> 这就解释为什么需要RedLock算法
Redlock获取锁的步骤:
假设有N个redis节点,这些节点之间既没有主从,也没有集群关系。
- 客户端用相同的key和随机值在N 个节点上请求锁,请求锁的超时时间应小于锁自动释放时间。
- 当在(N/2+1)个(超过半数)redis上请求到锁的时候,才算是真正获取到了锁。
- 如果没有获取到锁,则把部分已锁的redis释放掉。
**RedLock算法是异步的吗?**
可以看成**同步**算法,虽然没有跨进程的同步时钟,但每个进程(多个电脑)的本地时间仍然大致以相同的速度流动,与锁的自动释放时间相比,误差较小,将其忽略的话,则可以看成同步算法。
**RedLock失败重试**
当客户端无法获取到锁时,应该在随机时间后重试,并且理想的客户端应该并发地将所有命令用时发给所有Redis实例。对于已经获取锁的客户端要在完成任务后及时释放锁,这样其他客户端就不需要等锁自动过期后在获取。如果在获取锁后,在主动释放锁前无法连接到Redis实例,就只能等锁自动失效了。
**释放锁**
释放锁很简单,只要释放所有实例中的锁,不需要考虑是否释放成功(释放时会判断这个锁的value值是不是自己设置的,避免释放其他客户端设置的锁)
**RedLock的 Safety arguments**
- 假设客户端可以获取到大多数Redis实例,并且所有Redis实例具有相同的key和过期时间,但不同的Redis实例的key是不同的时间设置的(获取锁的时间不可能完全一致),所以过期时间也不同,假设获取第一个Redis实例的锁的时间为T1,最后一个为T2,则客户端获得锁的最小有效时间为key的有效时间-(T2-T1)-时钟漂移。
- 为什么需要获取一半以上的Redis实例的锁才算获取到锁成功呢?因为如果获取不到一半也算成功的话会导致多个客户端同时获取到锁,违背了互斥性
- 一个客户端锁定大多数Redis实例所需的时间大于或者接近锁的过期时间时,会认为锁无效,并解锁所有Redis实例
**RedLock崩溃的相关解决方法**
场景:客户端A在成功获取锁后,如果所有Redis重启,这时客户端B就可以再次获取到锁,违背了互斥性
解决方法:**开启AOF持久化**,可以解决这个问题,但是AOF同步到磁盘上的方式默认是每秒一次,如果1秒内断电,会导致1秒内的数据丢失,如果客户端是在这1秒内获得的锁,立即重启可能会导致锁的互斥性失效,解决方法是每次Redis无论因为什么原因停掉都要等key的过期时间到了在重启(**延迟重启**),这么做的缺点就是在等待重启这段时间内Redis处于关闭的状态。
### 5.Redis并发竞争key问题应该如何解决?
Redis并发竞争key就是多个客户端操作一个key,可能会导致数据出现问题,主要有以下几种解决办法:
- **乐观锁**,watch 命令可以方便的实现乐观锁。watch 命令会监视给定的每一个key,当 exec 时如果监视的任何一个key自从调用watch后发生过变化,则整个事务会回滚,不执行任何动作。不能在分片集群中使用
- **分布式锁**,适合分布式场景
- **时间戳**,适合有序场景,比如A想把key设置为1,B想把key设置为2,C想把key设置为3,对每个操作加上时间戳,写入前先比较自己的时间戳是不是早于现有记录的时间戳,如果早于,就不写入了
- **消息队列**,串行化处理
## Redis的缓存问题
### 1.❤说下什么是缓存雪崩、缓存穿透、缓存击穿,及它们的解决方案
> 这是一个非常高频的面试题,也非常容易掌握,比较麻烦的是总是分不清这三个哪个是哪个
**缓存雪崩**
缓存雪崩是指在某一个时刻出现大规模的缓存失效的情况,大量的请求直接打在数据库上面,可能会导致数据库宕机,如果这时重启数据库并不能解决根本问题,会再次造成缓存雪崩。
为什么会造成缓存雪崩?
一般来说,造成缓存雪崩主要有两种可能
- Redis宕机了
- 很多key采取了相同的过期时间
如何解决缓存雪崩?
- 为避免Redis宕机造成缓存雪崩,可以搭建Redis集群
- 尽量不要设置相同的过期时间,例如可以在原有的过期时间加上随机数
- 服务降级,当流量到达一定的阈值时,就直接返回“系统繁忙”之类的提示,防止过多的请求打在数据库上,这样虽然难用,但至少可以使用,避免直接把数据库搞挂
**缓存击穿**
缓存雪崩是大规模的key失效,而缓存击穿是一个热点的Key,有大并发集中对其进行访问,突然间这个Key失效了,导致大并发全部打在数据库上,导致数据库压力剧增,这种现象就叫做缓存击穿。 比较经典的例子是商品秒杀时,大量的用户在抢某个商品时,商品的key突然过期失效了,所有请求都到数据库上了。
如何解决缓存击穿
- 热点key不设置过期时间,避免key过期失效
- 加锁,如果缓存失效的情况,只有拿到锁才可以查询数据库,降低了在同一时刻打在数据库上的请求,防止数据库宕机,不过这样会导致系统的性能变差。
**缓存穿透**
缓存穿透是指用户的请求没有经过缓存而直接请求到数据库上了,比如用户请求的key在Redis中不存在,或者用户恶意伪造大量不存在的key进行请求,都可以绕过缓存,导致数据库压力太大挂掉。
如何解决缓存穿透
- **参数校验**,例如可以对用户id进行校验,直接拦截不合法的用户的请求
- **布隆过滤器**,布隆过滤器可以判断这个key在不在数据库中,特点是如果判断这个key不在数据库中,那么这个key一定不在数据库中,如果判断这个key在数据库中,也不能保证这个key一定在数据库中。就是会有少数的漏网之鱼,造成这种现象的原因是因为布隆过滤器中使用了hash算法,对key进行hash时,不同的key的hash值一定不同,但相同的hash的值不能说明这两个key相同。下面简单介绍下布隆过滤器,这个面试也常问。
布隆过滤器底层使用bit数组存储数据,该数组中的元素默认值是0。
布隆过滤器第一次初始化的时候,会把数据库中所有已存在的key,经过一系列的hash算法计算,算出每个key的位置,并将该位置的值置为1,为了减少哈希冲突的影响,可以对每个key进行多次hash计算,如下图
- 通过k个无偏hash函数计算得到k个hash值
- 依次取模数组长度,得到数组索引
- 判断索引处的值是否全部为1,如果全部为1则存在(这种存在可能是误判),如果存在一个0则必定不存在
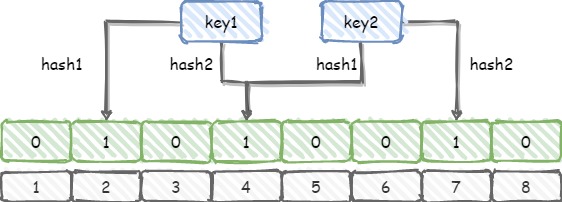
那使用布隆过滤器就可以完美解决问题了吗?当然没有,使用布隆过滤器解决缓存穿透问题的同时也带来了一些其他问题:
- 布隆过滤器存在误判的情况
- 布隆过滤器不支持删除,因为布隆过滤器中存的1可能涉及多个key,直接删除可能会影响到其他key,比如上图第四个位置的1就涉及两个key
- 如果数据库中数据更新同步到布隆过滤器时失败,布隆过滤器则会将本来正常的请求拦截住,这是非常致命的
先来看第一个问题,前面已经解释过了布隆过滤器存在误判的原因,就是不同的key的hash值可能相同。因为每个key要经过多次hash计算,恰好每次hash计算都和其他key的hash值相同的概率是很低的,有少数的漏网之鱼通过了布隆过滤器也不要紧,所以第一个问题不必担心。如果想要减少hash冲突导致的误判,可以适当**增加key的hash次数**。
第二个问题可以在布隆过滤器中以**计数**的方式存储,如下图
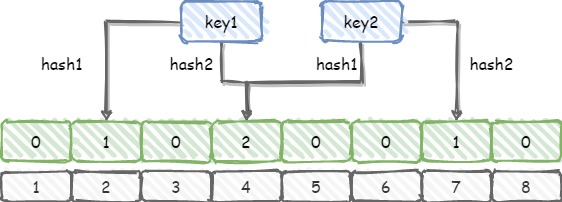
第三个问题出现概率不大,如果这种问题对业务影响很大,可以考虑其他解决缓存穿透的方法。
### 2.❤如何保证缓存与数据库双写时的数据一致性?
> 这是面试的高频题,需要好好掌握,这个问题是没有最优解的,只能数据一致性和性能之间找到一个最适合业务的平衡点
首先先来了解下一致性,在分布式系统中,一致性是指多副本问题中的数据一致性。一致性可以分为强一致性、弱一致性和最终一致性
强一致性:当更新操作完成之后,任何多个后续进程或者线程的访问都会返回最新的更新过的值。强一致性对用户比较友好,但对系统性能影响比较大。
弱一致性:系统并不保证后续进程或者线程的访问都会返回最新的更新过的值。
最终一致性:也是弱一致性的一种特殊形式,系统保证在没有后续更新的前提下,系统最终返回上一次更新操作的值。
**先更新数据库,后删除缓存**
这种方案也存在一个问题,如果更新数据库成功了,删除缓存时没有成功,那么后面每次读取缓存时都是错误的数据。
解决这个问题的办法是**删除重试机制**,常见的方案有利用消息队列和数据库的日志
利用**消息队列**实现删除重试机制,如下图
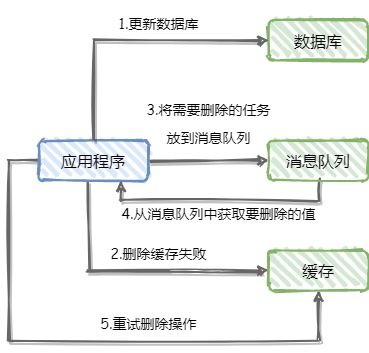
步骤在图中写的已经比较清除了,这里简单说下为什么使用消息队列,消息队列可以保证写到队列中的消息在成功消费之前不会消失,并且在第4步中获取消息时只有消费成功才会删除消息,否则会继续投递消息给应用程序,符合消息重试的要求。
但这个方案也有一些缺点,比如系统复杂度高,对业务代码入侵严重,这时可以采用订阅数据库日志的方法删除缓存。如下图
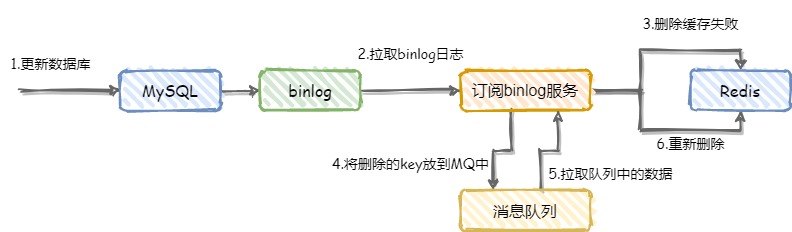
**先删除缓存,后更新数据库**
这种方案也存在一些问题,比如在并发环境下,有两个请求A和B,A是更新操作,B是查询操作
1.假设A请求先执行,会先删除缓存中的数据,然后去更新数据库
2.B请求查询缓存发现为空,会去查询数据库,并把这个值放到缓存中
3.在B查询数据库时A还没有完全更新成功,所以B查询并放到缓存中的是旧的值,并且以后每次查询缓存中的值都是错误的旧值
这种情况的解决方法通常是采用**延迟双删**,就是为保证A操作已经完成,最后再删除一次缓存

逻辑很简单,删除缓存后,休眠一会儿再删除一次缓存,虽然逻辑看起来简单,但实现起来并不容易,问题就出在延迟时间设置多少合适,延迟时间一般大于B操作读取数据库+写入缓存的时间,这个只能是估算,一般可以考虑读业务逻辑数据的耗时 + 几百毫秒。
在实际应用中,还是**先更新数据库后删除缓存**这种方案用的多些。
需要注意的是,无论哪种方案,如果数据库采取读写分离+主从复制延迟的话,即使采用先更新数据库后删除缓存也会出现类似先删除缓存后更新数据库中出现的问题,举个例子
1.A操作更新主库后,删除了缓存
2.B操作查询缓存没有查到数据,查询从库拿到旧值
3.主库将新值同步到从库
4.B操作将拿到的旧值写入缓存
这就造成了缓存中的是旧值,数据库中的是新值,解决方法还是上面说的延迟双删,延迟时间要大于主从复制的时间
### 3.一个字符串类型的值能存储最大容量是多少?
512MB
### 4.Redis如何实现大量数据的插入?
**使用Luke协议**
使用正常模式的Redis 客户端执行大量数据插入不是一个好主意:因为一个个的插入会有大量的时间浪费在每一个命令往返时间上。**使用管道(pipelining ** [paɪplaɪnɪŋ]**)是一种可行的办法**,但是在大量插入数据的同时又需要执行其他新命令时,这时读取数据的同时需要确保请可能快的的写入数据。
只有一小部分的客户端支持非阻塞输入/输出(non-blocking I/O),并且并不是所有客户端能以最大限度的提高吞吐量的高效的方式来分析答复。
从Redis 2.6开始`redis-cli`支持一种新的被称之为**pipe mode**的新模式用于执行大量数据插入工作。
使用redis-cli将有效的确保错误输出到Redis实例的标准输出里面。
**使用Redis协议**
它会非常简单的生成和解析Redis协议,Redis协议文档请参考Redis协议说明。 但是为了生成大量数据插入的目标,你需要了解每一个细节协议
### 5.如何通过Redis实现异步队列?
主要有两种方式
**RPUSH+ BLPOP**
第一种是使用List作为队列,通过RPUSH生产消息, LPOP消费消息
存在的问题:如果队列是空的,客户端会不停的pop,陷入死循环
解决方法:
- 当lpop没有消息时,可以使用sleep机制先休眠一段时间,然后再检查有没有消息。
- 可以使用BLPOP命令,在队列没有数据的时候,会立即进入休眠状态,一旦数据到来,则立刻醒过来。这种做法的缺点是只能提供一个消费者消费
**PUB/SUB**
第二种方法是**pub/sub**主题订阅模式,发送者(pub)发送消息,订阅者(sub)接收消息
存在的问题:消息的发布是无状态的,**无法保证到达**,如果订阅者在发送者发布消息时掉线,之后上线也无法接收发布者发送的消息
解决方法:使用消息队列
### 6.如何通过Redis实现延时队列?
先说下延时队列的使用场景:
- 常见的微信红包场景,A给B发红包,B没有收,1天后钱会退回原账户
- 电商的订单支付场景,订单在半小时内未支付会自动取消 上述场景
可以通过定时任务采用数据库/非关系型数据库轮询方案或延迟队列,现主要介绍下Redis实现的延迟队列
可以通过Redis的**zset**命令实现延迟队列,ZSET是Redis的有序集合,通过zadd score1 value1命令向内存中生产消息,并利用设置好的**时间戳**作为score进行排序,然后通过zrangebysocre 查询符合条件的所有待处理的任务,循环执行,也可以zrangebyscore key min max withscores limit 0 1 查询最早的一条任务,来进行消费,如下图(画的第二种,好画点)
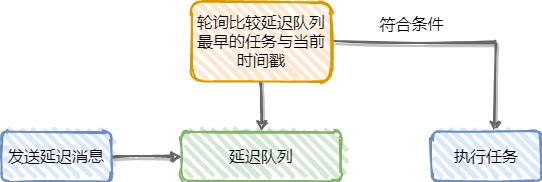
### 7.Redis回收使用什么算法?
Redis回收使用**LRU算法和引用计数法**
- LRU算法很常见,在学习操作系统时也经常看到,淘汰最长时间没有被使用的对象,LRU算法在手撕代码环节也经常出现,要提前背熟
- 引用计数法在学习JVM中也见过的,对于创建的每一个对象都有一个与之关联的计数器,这个计数器记录着该对象被使用的次数,当对象被一个新程序使用时,它的引用计数值会被增1,当对象不再被一个程序使用时,它的引用计数值会被减1,垃圾收集器在进行垃圾回收时,对扫描到的每一个对象判断一下计数器是否等于0,若等于0,就会释放该对象占用的内存空间,简单来说就是淘汰使用次数最少的对象(LFU算法)。
### 8.Redis 里面有1亿个 key,其中有 10 个 key 是包含 java,如何将它们全部找出来?
可以使用Redis的KEYS命令,用于查找所有匹配给定模式 pattern 的 key ,虽然时间复杂度为O(n),但常量时间相当小。
**注意**: 生产环境使用 KEYS命令需要非常小心,在大的数据库上执行命令会影响性能,KEYS指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个命令适合用来调试和特殊操作,像改变键空间布局。
不要在你的代码中使用 KEYS 。如果你需要一个寻找键空间中的key子集,考虑使用 **SCAN** 或 sets。
### 9.如何用Redis统计在线人数?
**方案一:使用集合**
每当一个用户上线时, 我们就执行以下 [SADD](http://redisdoc.com/set/sadd.html) 命令, 将它添加到在线用户名单当中:
```shell
SADD "online_users"
```
通过使用 [SISMEMBER](http://redisdoc.com/set/sismember.html) 命令, 我们可以检查一个指定的用户当前是否在线:
```shell
SISMEMBER "online_users"
```
而统计在线人数的工作则可以通过执行 [SCARD](http://redisdoc.com/set/scard.html) 命令来完成:
```shell
SCARD "online_users"
```
通过集合运算操作, 对不同时间段或者日期的在线用户名单进行聚合计算。 比如说, 通过 [SINTER](http://redisdoc.com/set/sinter.html) 或者 [SINTERSTORE](http://redisdoc.com/set/sinterstore.html) 命令, 我们可以计算出一周都有在线的用户:
```shell
SINTER "day_1_online_users" "day_2_online_users" ... "day_7_online_users"
```
**方案二:位图(常用方案)**
使用有序集合或者集合能够储存具体的在线用户名单, 但是却需要消耗大量的内存;
Redis 的位图就是一个由二进制位组成的数组, 通过将数组中的每个二进制位与用户 ID 进行一一对应, 我们可以使用位图去记录每个用户是否在线。
当一个用户上线时, 我们就使用 [SETBIT](http://redisdoc.com/string/setbit.html) 命令, 将这个用户对应的二进制位设置为 1 :
```shell
# 此处的 user_id 必须为数字,因为它会被用作索引
SETBIT "online_users" 1
```
通过使用 [GETBIT](http://redisdoc.com/string/getbit.html) 命令去检查一个二进制位的值是否为 1 , 我们可以知道指定的用户是否在线:
```shell
GETBIT "online_users"
```
而通过 [BITCOUNT](http://redisdoc.com/string/bitcount.html) 命令, 我们可以统计出位图中有多少个二进制位被设置成了 1 , 也即是有多少个用户在线:
```shell
BITCOUNT "online_users"
```
跟集合一样, 用户也能够对多个位图进行聚合计算 —— 通过 [BITOP](http://redisdoc.com/string/bitop.html) 命令, 用户可以对一个或多个位图执行逻辑并、逻辑或、逻辑异或或者逻辑非操作:
```shell
# 计算出 7 天都在线的用户
BITOP "AND" "7_days_both_online_users" "day_1_online_users" "day_2_online_users" ... "day_7_online_users"
# 计算出 7 在的在线用户总人数
BITOP "OR" "7_days_total_online_users" "day_1_online_users" "day_2_online_users" ... "day_7_online_users"
# 计算出两天当中只有其中一天在线的用户
BITOP "XOR" "only_one_day_online" "day_1_online_users" "day_2_online_users"
```
================================================
FILE: interview/代码编程(go语言实现).md
================================================
### 1.实现使用字符串函数名,调用函数。
思路:采用反射的Call方法实现。
```go
package main
import (
"fmt"
"reflect"
)
type Animal struct{
}
func (a *Animal) Eat(){
fmt.Println("Eat")
}
func main(){
a := Animal{}
reflect.ValueOf(&a).MethodByName("Eat").Call([]reflect.Value{})
}
```
### 2(Goroutine)有三个函数,分别打印"cat", "fish","dog"要求每一个函数都用一个goroutine,按照顺序打印100次。
此题目考察channel,**用三个无缓冲channel**,如果一个channel收到信号则通知下一个。
```go
package main
import (
"fmt"
"time"
)
var cat = make(chan struct{})
var fish = make(chan struct{})
var dog = make(chan struct{})
func Cat() {
<-cat
fmt.Println("cat")
fish <- struct{}{}
}
func Fish() {
<-fish
fmt.Println("fish")
dog <- struct{}{}
}
func Dog() {
<-dog
fmt.Println("dog")
cat <- struct{}{}
}
func main() {
for i := 0; i < 100; i++ {
go Cat()
go Fish()
go Dog()
}
cat <- struct{}{}
time.Sleep(2 * time.Second)
}
```
### 3两个协程交替打印10个字母和数字
思路:采用channel来协调goroutine之间顺序。
主线程一般要waitGroup等待协程退出,这里简化了一下直接sleep。
```go
package main
import (
"fmt"
"time"
)
var word = make(chan struct{}, 1)
var num = make(chan struct{}, 1)
func printNums() {
for i := 0; i < 10; i++ {
<-word
fmt.Println(1)
num <- struct{}{}
}
}
func printWords() {
for i := 0; i < 10; i++ {
<-num
fmt.Println("a")
word <- struct{}{}
}
}
func main() {
num <- struct{}{}
go printNums()
go printWords()
time.Sleep(time.Second * 1)
}
```
### 4启动 2个groutine 2秒后取消, 第一个协程1秒执行完,第二个协程3秒执行完。
思路:采用`ctx, _ := context.WithTimeout(context.Background(), time.Second*2)`实现2s取消。协程执行完后通过channel通知,是否超时。
```go
package main
import (
"context"
"fmt"
"time"
)
func f1(in chan struct{}) {
time.Sleep(1 * time.Second)
in <- struct{}{}
}
func f2(in chan struct{}) {
time.Sleep(3 * time.Second)
in <- struct{}{}
}
func main() {
ch1 := make(chan struct{})
ch2 := make(chan struct{})
ctx, _ := context.WithTimeout(context.Background(), 2*time.Second)
go func() {
go f1(ch1)
select {
case <-ctx.Done():
fmt.Println("f1 timeout")
break
case <-ch1:
fmt.Println("f1 done")
}
}()
go func() {
go f2(ch2)
select {
case <-ctx.Done():
fmt.Println("f2 timeout")
break
case <-ch2:
fmt.Println("f2 done")
}
}()
time.Sleep(time.Second * 5)
}
```
### 5当select监控多个chan同时到达就绪态时,如何先执行某个任务?
可以在子case再加一个for select语句。
```go
func priority_select(ch1, ch2 <-chan string) {
for {
select {
case val := <-ch1:
fmt.Println(val)
case val2 := <-ch2:
priority:
for {
select {
case val1 := <-ch1:
fmt.Println(val1)
default:
break priority
}
}
fmt.Println(val2)
}
}
}
```
### 6了解过选项模式吗?能否写一段代码实现一个函数选项模式?
选项模式是 go 语法所特有的,也是 go 语言的创始人所推崇的,**可以做到灵活的给接口提供参数,且参数的数量可以自定义,同时屏蔽了一些不需要对接口使用者的细节**。
```go
package main
import "fmt"
// 选项设计模式
// 问题:有一个结构体,定义一个函数,给结构体初始化
// 结构体
type Options struct {
str1 string
int1 int
}
// 声明一个函数类型的变量,用于传参
type Option func(opts *Options)
func InitOptions(opts ...Option) {
options := &Options{}
for _, opt := range opts {
opt(options)
}
fmt.Printf("options:%#v\n", options)
}
func WithString1(str string) Option {
return func(opts *Options) {
opts.str1 = str
}
}
func WithInt1(int1 int) Option {
return func(opts *Options) {
opts.int1 = int1
}
}
func main() {
InitOptions(WithString1("5lmh.com"),WithInt1(5))
}
```
### 7.请使用Go语言实现sync.WaitGroup的三个功能:Add、Done、Wait
> 24届滴滴提前批一面
在下面代码中,`cwg.done`是一个`chan struct{}`类型的通道,当调用`close(cwg.done)`时,会向该通道发送一个零值的结构体,表示通道已经关闭。在`<-cwg.done`这一行代码中,它会阻塞等待,直到收到通道关闭的信号。一旦通道被关闭,`<-cwg.done`将会立即返回,程序继续执行后续的操作。
在这个示例中,`cwg.Wait()`方法使用`<-cwg.done`来等待所有任务完成。由于`close(cwg.done)`在所有任务都完成时被调用,所以`<-cwg.done`会在所有任务都完成并且通道被关闭时立即返回。这确保了在所有任务完成后程序才会继续执行后续代码。
需要注意的是,在通道被关闭后,对该通道的任何接收操作(如`<-cwg.done`)都会立即返回零值。如果通道已经被关闭,再次对已关闭的通道进行接收操作不会阻塞,而是立即返回。这是Go语言的通道机制的特性。
```go
package main
import (
"fmt"
"sync/atomic"
"time"
)
type CustomWaitGroup struct {
count int32
done chan struct{}
}
func NewCustomWaitGroup() *CustomWaitGroup {
return &CustomWaitGroup{
count: 0,
done: make(chan struct{}),
}
}
func (cwg *CustomWaitGroup) Add(delta int) {
atomic.AddInt32(&cwg.count, int32(delta))
}
func (cwg *CustomWaitGroup) Done() {
if atomic.AddInt32(&cwg.count, -1) == 0 {
close(cwg.done)
}
}
func (cwg *CustomWaitGroup) Wait() {
<-cwg.done
}
func main() {
cwg := NewCustomWaitGroup()
for i := 0; i < 3; i++ {
cwg.Add(1)
go func(i int) {
defer cwg.Done()
fmt.Printf("Task %d started\n", i)
time.Sleep(time.Second * time.Duration(i))
fmt.Printf("Task %d completed\n", i)
}(i)
}
cwg.Wait()
fmt.Println("All tasks completed")
}
```
================================================
FILE: interview/常见算法和模板.md
================================================
> 参考
>
> [Introduction - algorithm-pattern (gitbook.io)](https://greyireland.gitbook.io/algorithm-pattern/)
## 一些常用库
### 切片
go 通过切片模拟栈和队列
**栈**
```go
// 创建栈
stack:=make([]int,0)
// push压入
stack=append(stack,10)
// pop弹出
v:=stack[len(stack)-1]
stack=stack[:len(stack)-1]
// 检查栈空
len(stack)==0
```
**队列**
```go
// 创建队列
queue:=make([]int,0)
// enqueue入队
queue=append(queue,10)
// dequeue出队
v:=queue[0]
queue=queue[1:]
// 长度0为空
len(queue)==0
```
**注意点**
- 参数传递,只能修改,不能新增或者删除原始数据
- 默认 s=s[0:len(s)],取下限不取上限,数学表示为:[)
### 字典
```go
// 创建
m:=make(map[string]int)
// 设置kv
m["hello"]=1
// 删除k
delete(m,"hello")
// 遍历
for k,v:=range m{
println(k,v)
}
```
注意点
- map 键需要可比较,不能为 slice、map、function
- map 值都有默认值,可以直接操作默认值,如:m[age]++ 值由 0 变为 1
- 比较两个 map 需要遍历,其中的 kv 是否相同,因为有默认值关系,所以需要检查 val 和 ok 两个值
### 标准库
**sort**
```go
// int排序
sort.Ints([]int{})
// 字符串排序
sort.Strings([]string{})
// 自定义排序
sort.Slice(s,func(i,j int)bool{return s[i] 参考
>
> [Go 数据结构和算法篇(十二):字符串匹配之 KMP 算法 - 极客书房 (geekr.dev)](https://geekr.dev/posts/go-knuth-morris-pratt-algorithm)
>
> [如何更好地理解和掌握 KMP 算法? - 知乎 (zhihu.com)](https://www.zhihu.com/question/21923021/answer/281346746)
>
> 如果实在看不懂,背下来
```go
package main
import "fmt"
// 生成 next 数组
func getNext(p string) []int {
next:=make([]int,len(p)+1)
next[0]=-1
i,j:=0,-1
for i need, window;
for (char c : t) need[c]++;
int left = 0, right = 0;
int valid = 0;
while (right < s.size()) {
// c 是将移入窗口的字符
char c = s[right];
// 右移窗口
right++;
// 进行窗口内数据的一系列更新
...
/*** debug 输出的位置 ***/
printf("window: [%d, %d)\n", left, right);
/********************/
// 判断左侧窗口是否要收缩
while (window needs shrink) {
// d 是将移出窗口的字符
char d = s[left];
// 左移窗口
left++;
// 进行窗口内数据的一系列更新
...
}
}
}
```
**练习**
[minimum-window-substring](https://leetcode-cn.com/problems/minimum-window-substring/)
[permutation-in-string](https://leetcode-cn.com/problems/permutation-in-string/)
[find-all-anagrams-in-a-string](https://leetcode-cn.com/problems/find-all-anagrams-in-a-string/)
[longest-substring-without-repeating-characters](https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/)
### 二分法
给一个**有序数组**和目标值,找第一次/最后一次/任何一次出现的索引,如果没有出现返回-1
模板四点要素
- 1、初始化:start=0、end=len-1
- 2、循环退出条件:start + 1 < end
- 3、比较中点和目标值:A[mid] ==、 <、> target
- 4、判断最后两个元素是否符合:A[start]、A[end] ? target
时间复杂度 O(logn),使用场景一般是有序数组的查找
> 给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
```go
// 二分搜索最常用模板
func search(nums []int, target int) int {
// 1、初始化start、end
start := 0
end := len(nums) - 1
// 2、处理for循环
for start+1 < end {
mid := start + (end-start)/2
// 3、比较a[mid]和target值
if nums[mid] == target {
end = mid
} else if nums[mid] < target {
start = mid
} else if nums[mid] > target {
end = mid
}
}
// 4、最后剩下两个元素,手动判断
if nums[start] == target {
return start
}
if nums[end] == target {
return end
}
return -1
}
```
大部分二分查找类的题目都可以用这个模板,然后做一点特殊逻辑即可
### 二叉树
**二叉树遍历**
**前序递归**
```go
func preorderTraversal(root *TreeNode) {
if root==nil{
return
}
// 先访问根再访问左右
fmt.Println(root.Val)
preorderTraversal(root.Left)
preorderTraversal(root.Right)
}
```
**前序非递归**
```go
// V3:通过非递归遍历
func preorderTraversal(root *TreeNode) []int {
// 非递归
if root == nil{
return nil
}
result:=make([]int,0)
stack:=make([]*TreeNode,0)
for root!=nil || len(stack)!=0{
for root !=nil{
// 前序遍历,所以先保存结果
result=append(result,root.Val)
stack=append(stack,root)
root=root.Left
}
// pop
node:=stack[len(stack)-1]
stack=stack[:len(stack)-1]
root=node.Right
}
return result
}
```
**中序非递归**
```go
// 思路:通过stack 保存已经访问的元素,用于原路返回
func inorderTraversal(root *TreeNode) []int {
result := make([]int, 0)
if root == nil {
return result
}
stack := make([]*TreeNode, 0)
for len(stack) > 0 || root != nil {
for root != nil {
stack = append(stack, root)
root = root.Left // 一直向左
}
// 弹出
val := stack[len(stack)-1]
stack = stack[:len(stack)-1]
result = append(result, val.Val)
root = val.Right
}
return result
}
```
**后序非递归**
```go
func postorderTraversal(root *TreeNode) []int {
// 通过lastVisit标识右子节点是否已经弹出
if root == nil {
return nil
}
result := make([]int, 0)
stack := make([]*TreeNode, 0)
var lastVisit *TreeNode
for root != nil || len(stack) != 0 {
for root != nil {
stack = append(stack, root)
root = root.Left
}
// 这里先看看,先不弹出
node:= stack[len(stack)-1]
// 根节点必须在右节点弹出之后,再弹出
if node.Right == nil || node.Right == lastVisit {
stack = stack[:len(stack)-1] // pop
result = append(result, node.Val)
// 标记当前这个节点已经弹出过
lastVisit = node
} else {
root = node.Right
}
}
return result
}
```
注意点
- 核心就是:根节点必须在右节点弹出之后,再弹出
**DFS深度搜索**
```go
type TreeNode struct {
Val int
Left *TreeNode
Right *TreeNode
}
func preorderTraversal(root *TreeNode) []int {
result := make([]int, 0)
dfs(root, &result)
return result
}
// V1:深度遍历,结果指针作为参数传入到函数内部
func dfs(root *TreeNode, result *[]int) {
if root == nil {
return
}
*result = append(*result, root.Val)
dfs(root.Left, result)
dfs(root.Right, result)
}
```
**DFS 深度搜索-从下向上(分治法)**
```go
// V2:通过分治法遍历
func preorderTraversal(root *TreeNode) []int {
result := divideAndConquer(root)
return result
}
func divideAndConquer(root *TreeNode) []int {
result := make([]int, 0)
// 返回条件(null & leaf)
if root == nil {
return result
}
// 分治(Divide)
left := divideAndConquer(root.Left)
right := divideAndConquer(root.Right)
// 合并结果(Conquer)
result = append(result, root.Val)
result = append(result, left...)
result = append(result, right...)
return result
}
```
注意点:
> DFS 深度搜索(从上到下) 和分治法区别:前者一般将最终结果通过指针参数传入,后者一般递归返回结果最后合并
**BFS 层次遍历**
```go
func levelOrder(root *TreeNode) [][]int {
// 通过上一层的长度确定下一层的元素
result := make([][]int, 0)
if root == nil {
return result
}
queue := make([]*TreeNode, 0)
queue = append(queue, root)
for len(queue) > 0 {
list := make([]int, 0)
// 为什么要取length?
// 记录当前层有多少元素(遍历当前层,再添加下一层)
l := len(queue)
for i := 0; i < l; i++ {
// 出队列
level := queue[0]
queue = queue[1:]
list = append(list, level.Val)
if level.Left != nil {
queue = append(queue, level.Left)
}
if level.Right != nil {
queue = append(queue, level.Right)
}
}
result = append(result, list)
}
return result
}
```
### 分治法
先分别处理局部,再合并结果
适用场景
- 快速排序
- 归并排序
- 二叉树相关问题
分治法模板
- 递归返回条件
- 分段处理
- 合并结果
```go
func traversal(root *TreeNode) ResultType {
// nil or leaf
if root == nil {
// do something and return
}
// Divide
ResultType left = traversal(root.Left)
ResultType right = traversal(root.Right)
// Conquer
ResultType result = Merge from left and right
return result
}
```
```go
// V2:通过分治法遍历二叉树
func preorderTraversal(root *TreeNode) []int {
result := divideAndConquer(root)
return result
}
func divideAndConquer(root *TreeNode) []int {
result := make([]int, 0)
// 返回条件(null & leaf)
if root == nil {
return result
}
// 分治(Divide)
left := divideAndConquer(root.Left)
right := divideAndConquer(root.Right)
// 合并结果(Conquer)
result = append(result, root.Val)
result = append(result, left...)
result = append(result, right...)
return result
}
```
### 排序
> 冒泡、插入、归并排序都是稳定的
###### **归并排序**
> tplink二面,当时用递归一下子写出来了,面试官就要求用非递归的方法
```go
func MergeSort(nums []int) []int {
return mergeSort(nums)
}
//递归方法
func mergeSort(nums []int) []int {
if len(nums) <= 1 {
return nums
}
// 分治法:divide 分为两段
mid := len(nums) / 2
left := mergeSort(nums[:mid])
right := mergeSort(nums[mid:])
// 合并两段数据
result := merge(left, right)
return result
}
func merge(left, right []int) (result []int) {
// 两边数组合并游标
l := 0
r := 0
// 注意不能越界
for l < len(left) && r < len(right) {
// 谁小合并谁
if left[l] > right[r] {
result = append(result, right[r])
r++
} else {
result = append(result, left[l])
l++
}
}
// 剩余部分合并
result = append(result, left[l:]...)
result = append(result, right[r:]...)
return
}
//非递归
func MergeSortNoRecursion(nums []int)[]int {
for k:=1;k=end{
return
}
tmp,i,j:=nums[begin],begin,end
for i=tmp{
j--
}
for i= 0; i-- {
sink(a, i, len(a))
}
// 3、交换a[0]和a[len(a)-1]
// 4、然后把前面这段数组继续下沉保持堆结构,如此循环即可
for i := len(a) - 1; i >= 1; i-- {
// 从后往前填充值
swap(a, 0, i)
// 前面的长度也减一
sink(a, 0, i)
}
return a
}
//大顶堆的排序
func sink(a []int, i int, length int) {
for {
// 左节点索引(从0开始,所以左节点为i*2+1)
l := i*2 + 1
// 右节点索引
r := i*2 + 2
// idx保存根、左、右三者之间较大值的索引
idx := i
// 存在左节点,左节点值较大,则取左节点
if l < length && a[l] > a[idx] {
idx = l
}
// 存在右节点,且值较大,取右节点
if r < length && a[r] > a[idx] {
idx = r
}
// 如果根节点较大,则不用下沉
if idx == i {
break
}
// 如果根节点较小,则交换值,并继续下沉
swap(a, i, idx)
// 继续下沉idx节点
i = idx
}
}
func swap(a []int, i, j int) {
a[i], a[j] = a[j], a[i]
}
```
###### **手写堆**
**方法一**
```go
package main
import "fmt"
func main() {
h := NewHeap()
h.Insert(1)
h.Insert(2)
h.Insert(3)
h.Insert(4)
h.Insert(5)
h.Insert(6)
h.Insert(7)
h.Insert(8)
h.Insert(9)
h.Print()
h.Remove()
h.Print()
h.Remove()
h.Print()
}
//实现大顶堆
type Heap struct {
data []int
size int
}
func NewHeap() Heap {
return Heap{
data: make([]int, 0),
size: 0,
}
}
func (h *Heap) Insert(x int) {
h.data = append(h.data, x)
h.size++
h.up(h.size - 1)
}
func (h *Heap) up(i int) {
for {
if i == 0 {
break
}
//父节点
p := (i - 1) / 2
if p >= 0 && h.data[p] >= h.data[i] {
break
}
h.data[p], h.data[i] = h.data[i], h.data[p]
i = p
}
}
func (h *Heap) Remove() int {
if h.size == 0 {
return -1
}
val := h.data[0]
h.data[0] = h.data[h.size-1]
h.data = h.data[:h.size-1]
h.size--
h.sink(0)
return val
}
func (h *Heap) sink(i int) {
for {
idx := i
l, r := 2*i+1, 2*i+2
if l < h.size && h.data[l] > h.data[idx] {
idx = l
}
if r < h.size && h.data[r] > h.data[idx] {
idx = r
}
if idx == i {
break
}
h.data[idx], h.data[i] = h.data[i], h.data[idx]
i = idx
}
}
func (h *Heap) Print() {
fmt.Println(h.data)
}
func HeapSort(arr []int) {
h := NewHeap()
for _, v := range arr {
h.Insert(v)
}
for i := len(arr) - 1; i >= 0; i-- {
arr[i] = h.Remove()
}
}
```
**方法二**
```go
// An IntHeap is a min-heap of ints.
type IntHeap []int
func (h IntHeap) Len() int { return len(h) }
func (h IntHeap) Less(i, j int) bool { return h[i] < h[j] }
func (h IntHeap) Swap(i, j int) { h[i], h[j] = h[j], h[i] }
func (h *IntHeap) Push(x interface{}) {
// Push and Pop use pointer receivers because they modify the slice's length,
// not just its contents.
*h = append(*h, x.(int))
}
func (h *IntHeap) Pop() interface{} {
old := *h
n := len(old)
x := old[n-1]
*h = old[0 : n-1]
return x
}
// This example inserts several ints into an IntHeap, checks the minimum,
// and removes them in order of priority.
func Example_intHeap() {
h := &IntHeap{2, 1, 5}
heap.Init(h)
heap.Push(h, 3)
fmt.Printf("minimum: %d\n", (*h)[0])
for h.Len() > 0 {
fmt.Printf("%d ", heap.Pop(h))
}
// Output:
// minimum: 1
// 1 2 3 5
}
```
### TopK问题
> 给你一个整数数组 `nums` 和一个整数 `k` ,请你返回其中出现频率前 `k` 高的元素。你可以按 **任意顺序** 返回答案。
>
> **示例 1:**
>
> ```
> 输入: nums = [1,1,1,2,2,3], k = 2
> 输出: [1,2]
> ```
>
> **示例 2:**
>
> ```
> 输入: nums = [1], k = 1
> 输出: [1]
> ```
```go
type Node struct{
Val int
Cnt int
}
func topKFrequent(nums []int, k int) []int {
m:=make(map[int]int,0)
for i:=0;i= 0; i-- {
sink(nums, i, len(nums))
}
}
// 维护小顶堆
func sink(nums []Node, i, length int) {
for{
l,r:=i*2+1,i*2+2
idx:=i
if l [146. LRU 缓存 - 力扣(Leetcode)](https://leetcode.cn/problems/lru-cache/description/)
>
> 腾讯和字节一面的算法题
```go
type LRUCache struct {
limit int
hashMap map[int]*Node
head,tail *Node
}
type Node struct{
key int
value int
pre *Node
next *Node
}
func NewNode(key , value int)*Node{
return &Node{
key:key,
value:value,
}
}
func Constructor(capacity int) LRUCache {
l:=LRUCache{
limit:capacity,
head:NewNode(0,0),
tail:NewNode(0,0),
hashMap:make(map[int]*Node),
}
//两个临时节点,更好操作
l.head.next=l.tail
l.tail.pre=l.head
return l
}
func (this *LRUCache) Get(key int) int {
if node,ok:=this.hashMap[key];ok{
this.Refresh(node)
return node.value
}
return -1
}
func (this *LRUCache) Put(key int, value int) {
newNode:=NewNode(key,value)
if node,ok:=this.hashMap[key];ok{
node.value=value
this.Refresh(node)
}else{
this.hashMap[key]=newNode
this.AddNode(newNode)
if len(this.hashMap)>this.limit{
oldKey:=this.tail.pre.key
this.RemoveNode(this.tail.pre)
delete(this.hashMap,oldKey)
}
}
}
func (this *LRUCache) Refresh(node *Node) {
this.RemoveNode(node)
this.AddNode(node)
}
// 删除
func (this *LRUCache) RemoveNode(node *Node) {
node.pre.next=node.next
node.next.pre=node.pre
}
//每次添加头部
func (this *LRUCache) AddNode(node *Node) {
node.next=this.head.next
this.head.next.pre=node
node.pre=this.head
this.head.next=node
}
/**
* Your LRUCache object will be instantiated and called as such:
* obj := Constructor(capacity);
* param_1 := obj.Get(key);
* obj.Put(key,value);
*/
```
### 背包问题
###### 01背包
> 有 `n` 个物品和一个大小为 `m` 的背包. 给定数组 `A` 表示每个物品的大小和数组 `V` 表示每个物品的价值.
>
> 问最多能装入背包的总价值是多大?
>
> 每个物品只能取一次
```go
func BackPack(m int, a []int, v []int) int {
// write your code here
//f[i]表示容量为i是背包的最大价值
n:=len(a)
f:=make([]int,m+1)
for i:=0;i=a[i-1];j--{
f[j]=max(f[j],f[j-a[i]]+v[i])
}
}
return f[m]
}
func max(a, b int)int{
if a>b{
return a
}
return b
}
```
###### 完全背包
> 有 `n` 个物品和一个大小为 `m` 的背包. 给定数组 `A` 表示每个物品的大小和数组 `V` 表示每个物品的价值.
>
> 问最多能装入背包的总价值是多大?
>
> 每个物品能取无数次
```go
func BackPack(m int, a []int, v []int) int {
// write your code here
//
n:=len(a)
f:=make([]int,m+1)
for i:=0;ib{
return a
}
return b
}
```
**背包递推公式**
问能否能装满背包(或者最多装多少):dp[j] = max(dp[j], dp[j - nums[i]] + nums[i]); ,对应题目如下:
- [动态规划:416.分割等和子集(opens new window)](https://programmercarl.com/0416.%E5%88%86%E5%89%B2%E7%AD%89%E5%92%8C%E5%AD%90%E9%9B%86.html)
- [动态规划:1049.最后一块石头的重量 II(opens new window)](https://programmercarl.com/1049.%E6%9C%80%E5%90%8E%E4%B8%80%E5%9D%97%E7%9F%B3%E5%A4%B4%E7%9A%84%E9%87%8D%E9%87%8FII.html)
问装满背包有几种方法:dp[j] += dp[j - nums[i]] ,对应题目如下:
- [动态规划:494.目标和(opens new window)](https://programmercarl.com/0494.%E7%9B%AE%E6%A0%87%E5%92%8C.html)
- [动态规划:518. 零钱兑换 II(opens new window)](https://programmercarl.com/0518.%E9%9B%B6%E9%92%B1%E5%85%91%E6%8D%A2II.html)
- [动态规划:377.组合总和Ⅳ(opens new window)](https://programmercarl.com/0377.%E7%BB%84%E5%90%88%E6%80%BB%E5%92%8C%E2%85%A3.html)
- [动态规划:70. 爬楼梯进阶版(完全背包)(opens new window)](https://programmercarl.com/0070.%E7%88%AC%E6%A5%BC%E6%A2%AF%E5%AE%8C%E5%85%A8%E8%83%8C%E5%8C%85%E7%89%88%E6%9C%AC.html)
问背包装满最大价值:dp[j] = max(dp[j], dp[j - weight[i]] + value[i]); ,对应题目如下:
- [动态规划:474.一和零(opens new window)](https://programmercarl.com/0474.%E4%B8%80%E5%92%8C%E9%9B%B6.html)
问装满背包所有物品的最小个数:dp[j] = min(dp[j - coins[i]] + 1, dp[j]); ,对应题目如下:
- [动态规划:322.零钱兑换(opens new window)](https://programmercarl.com/0322.%E9%9B%B6%E9%92%B1%E5%85%91%E6%8D%A2.html)
- [动态规划:279.完全平方数(opens new window)](https://programmercarl.com/0279.%E5%AE%8C%E5%85%A8%E5%B9%B3%E6%96%B9%E6%95%B0.html)
**遍历顺序**
**01背包**
在[动态规划:关于01背包问题,你该了解这些! (opens new window)](https://programmercarl.com/%E8%83%8C%E5%8C%85%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%8001%E8%83%8C%E5%8C%85-1.html)中我们讲解二维dp数组01背包先遍历物品还是先遍历背包都是可以的,且第二层for循环是从小到大遍历。
和[动态规划:关于01背包问题,你该了解这些!(滚动数组) (opens new window)](https://programmercarl.com/%E8%83%8C%E5%8C%85%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%8001%E8%83%8C%E5%8C%85-2.html)中,我们讲解一维dp数组01背包只能先遍历物品再遍历背包容量,且第二层for循环是从大到小遍历。
**一维dp数组的背包在遍历顺序上和二维dp数组实现的01背包其实是有很大差异的,大家需要注意!**
**完全背包**
说完01背包,再看看完全背包。
在[动态规划:关于完全背包,你该了解这些! (opens new window)](https://programmercarl.com/%E8%83%8C%E5%8C%85%E9%97%AE%E9%A2%98%E7%90%86%E8%AE%BA%E5%9F%BA%E7%A1%80%E5%AE%8C%E5%85%A8%E8%83%8C%E5%8C%85.html)中,讲解了纯完全背包的一维dp数组实现,先遍历物品还是先遍历背包都是可以的,且第二层for循环是从小到大遍历。
但是仅仅是纯完全背包的遍历顺序是这样的,题目稍有变化,两个for循环的先后顺序就不一样了。
**如果求组合数就是外层for循环遍历物品,内层for遍历背包**。
**如果求排列数就是外层for遍历背包,内层for循环遍历物品**。
相关题目如下:
- 求组合数:[动态规划:518.零钱兑换II(opens new window)](https://programmercarl.com/0518.%E9%9B%B6%E9%92%B1%E5%85%91%E6%8D%A2II.html)
- 求排列数:[动态规划:377. 组合总和 Ⅳ (opens new window)](https://mp.weixin.qq.com/s/Iixw0nahJWQgbqVNk8k6gA)、[动态规划:70. 爬楼梯进阶版(完全背包)(opens new window)](https://programmercarl.com/0070.%E7%88%AC%E6%A5%BC%E6%A2%AF%E5%AE%8C%E5%85%A8%E8%83%8C%E5%8C%85%E7%89%88%E6%9C%AC.html)
如果求最小数,那么两层for循环的先后顺序就无所谓了,相关题目如下:
- 求最小数:[动态规划:322. 零钱兑换 (opens new window)](https://programmercarl.com/0322.%E9%9B%B6%E9%92%B1%E5%85%91%E6%8D%A2.html)、[动态规划:279.完全平方数(opens new window)](https://programmercarl.com/0279.%E5%AE%8C%E5%85%A8%E5%B9%B3%E6%96%B9%E6%95%B0.html)
**对于背包问题,其实递推公式算是容易的,难是难在遍历顺序上,如果把遍历顺序搞透,才算是真正理解了**。
### 负载均衡算法
###### 平滑加权轮询算法
> ```
> SW(平滑加权)是一个包含加权项的结构体,并提供了选择加权项的方法。
> 用于平滑加权轮询均衡算法。该算法在Nginx中实现:
> https://github.com/phusion/nginx/commit/27e94984486058d73157038f7950a0a36ecc6e35。
> 算法如下:在每次选择peer时增加current_weight
> 根据每个符合条件的对等体的权重,选择当前权重最大的对等体
> 并将其current_weight减去分配的权重点总数
> 在同行。
> 对于{5,1,1}权重,给出了以下序列
> Current_weight 's:(a, a, b, a, c, a, a)
> ```
>
> 平滑加权还是有一个问题 这个算法第一次肯定是选择权重最高的实例 所以当出现比如切流更新权重之类的会导致重置blance状态的时候 在上游实例数足够多的情况下 有可能会把 权重最高的那个下游实例给打挂掉
```go
type WeightRoundRobinBalance struct {
curIndex int
rss []*WeightNode
}
type WeightNode struct {
weight int // 配置的权重,即在配置文件或初始化时约定好的每个节点的权重
currentWeight int //节点当前权重,会一直变化
effectiveWeight int //有效权重,初始值为weight, 通讯过程中发现节点异常,则-1 ,之后再次选取本节点,调用成功一次则+1,直达恢复到weight 。 用于健康检查,处理异常节点,降低其权重。
addr string // 服务器addr
}
/**
* @Author: yang
* @Description:添加服务
* @Date: 2021/4/7 15:36
*/
func (r *WeightRoundRobinBalance) Add (params ...string) error{
if len(params) != 2{
return errors.New("params len need 2")
}
// @Todo 获取值
addr := params[0]
parInt, err := strconv.ParseInt(params[1], 10, 64)
if err != nil {
return err
}
node := &WeightNode{
weight: int(parInt),
effectiveWeight: int(parInt), // 初始化時有效权重 = 配置权重值
currentWeight: int(parInt), // 初始化時当前权重 = 配置权重值
addr: addr,
}
r.rss = append(r.rss, node)
return nil
}
/**
* @Author: yang
* @Description:轮询获取服务
* @Date: 2021/4/7 15:36
*/
func (r *WeightRoundRobinBalance) Next () string {
// @Todo 没有服务
if len(r.rss) == 0 {
return ""
}
totalWeight := 0
var maxWeightNode *WeightNode
for key , node := range r.rss {
// @Todo 计算当前状态下所有节点的effectiveWeight之和totalWeight
totalWeight += node.effectiveWeight
// @Todo 计算currentWeight
node.currentWeight += node.effectiveWeight
// @Todo 寻找权重最大的
if maxWeightNode == nil || maxWeightNode.currentWeight < node.currentWeight {
maxWeightNode = node
r.curIndex = key
}
}
// @Todo 更新选中节点的currentWeight
maxWeightNode.currentWeight -= totalWeight
// @Todo 返回addr
return maxWeightNode.addr
}
```
###### 一致性哈希算法
> ```
> //consistent-hash:基于将每个对象映射到圆上的一个点(或等效地,
> //将每个对象映射到一个真实角度)。系统映射每个可用的机器(或其他存储桶)
> //到同一个圆上的多个伪随机分布点。
> ```
```go
package JiKe
import (
"errors"
"hash/crc32"
"sort"
"strconv"
"sync"
)
type Consistent struct {
//排序的hash虚拟结点
hashSortedNodes []uint32
//虚拟结点对应的结点信息
circle map[uint32]string
//已绑定的结点
nodes map[string]bool
//map读写锁
sync.RWMutex
//虚拟结点数
virtualNodeCount int
}
func (c *Consistent) hashKey(key string) uint32 {
return crc32.ChecksumIEEE([]byte(key))
}
func (c *Consistent) Add(node string, virtualNodeCount int) error {
if node == "" {
return nil
}
c.Lock()
defer c.Unlock()
if c.circle == nil {
c.circle = map[uint32]string{}
}
if c.nodes == nil {
c.nodes = map[string]bool{}
}
if _, ok := c.nodes[node]; ok {
return errors.New("node already existed")
}
c.nodes[node] = true
//增加虚拟结点
for i := 0; i < virtualNodeCount; i++ {
virtualKey := c.hashKey(node + strconv.Itoa(i))
c.circle[virtualKey] = node
c.hashSortedNodes = append(c.hashSortedNodes, virtualKey)
}
//虚拟结点排序
sort.Slice(c.hashSortedNodes, func(i, j int) bool {
return c.hashSortedNodes[i] < c.hashSortedNodes[j]
})
return nil
}
func (c *Consistent) GetNode(key string) string {
c.RLock()
defer c.RUnlock()
hash := c.hashKey(key)
i := c.getPosition(hash)
return c.circle[c.hashSortedNodes[i]]
}
func (c *Consistent) getPosition(hash uint32) int {
i := sort.Search(len(c.hashSortedNodes), func(i int) bool { return c.hashSortedNodes[i] >= hash })
if i < len(c.hashSortedNodes) {
if i == len(c.hashSortedNodes)-1 {
return 0
} else {
return i
}
} else {
return len(c.hashSortedNodes) - 1
}
}
//test
func Test_ConsistentHash(t *testing.T) {
virtualNodeList := []int{100, 150, 200}
//测试10台服务器
nodeNum := 10
//测试数据量100W
testCount := 1000000
for _, virtualNode := range virtualNodeList {
consistentHash := &Consistent{}
distributeMap := make(map[string]int64)
for i := 1; i <= nodeNum; i++ {
serverName := "172.17.0." + strconv.Itoa(i)
consistentHash.Add(serverName, virtualNode)
distributeMap[serverName] = 0
}
//测试100W个数据分布
for i := 0; i < testCount; i++ {
testName := "testName"
serverName := consistentHash.GetNode(testName + strconv.Itoa(i))
distributeMap[serverName] = distributeMap[serverName] + 1
}
var keys []string
var values []float64
for k, v := range distributeMap {
keys = append(keys, k)
values = append(values, float64(v))
}
sort.Strings(keys)
fmt.Printf("####测试%d个结点,一个结点有%d个虚拟结点,%d条测试数据\n", nodeNum, virtualNode, testCount)
for _, k := range keys {
fmt.Printf("服务器地址:%s 分布数据数:%d\n", k, distributeMap[k])
}
fmt.Printf("标准差:%f\n\n", getStandardDeviation(values))
}
}
//获取标准差
func getStandardDeviation(list []float64) float64 {
var total float64
for _, item := range list {
total += item
}
//平均值
avg := total / float64(len(list))
var dTotal float64
for _, value := range list {
dValue := value - avg
dTotal += dValue * dValue
}
return math.Sqrt(dTotal / avg)
}
```
### 循环队列(环形队列)
```go
package main
import "fmt"
type CircularQueue struct {
data []int
head int
tail int
size int
}
func NewCircularQueue(k int) CircularQueue {
return CircularQueue{
data: make([]int, k),
head: -1,
tail: -1,
size: k,
}
}
func (q *CircularQueue) Enqueue(val int) bool {
if q.IsFull() {
// 队列已满,覆盖队列最早进入的元素
if q.head == (q.tail+1)%q.size {
q.head = (q.head + 1) % q.size
}
}
// 添加元素到队列尾部
if q.IsEmpty() {
q.head = 0
}
q.tail = (q.tail + 1) % q.size
q.data[q.tail] = val
return true
}
func (q *CircularQueue) Dequeue() bool {
if q.IsEmpty() {
return false
}
if q.head == q.tail {
// 队列已空
q.head, q.tail = -1, -1
return true
}
q.head = (q.head + 1) % q.size
return true
}
func (q *CircularQueue) Front() int {
if q.IsEmpty() {
return -1
}
return q.data[q.head]
}
func (q *CircularQueue) Rear() int {
if q.IsEmpty() {
return -1
}
return q.data[q.tail]
}
func (q *CircularQueue) IsEmpty() bool {
return q.head == -1
}
func (q *CircularQueue) IsFull() bool {
return (q.tail+1)%q.size == q.head
}
func main(){
c:=NewCircularQueue(3)
c.Enqueue(1)
c.Enqueue(2)
c.Enqueue(3)
fmt.Print(c.data)
c.Enqueue(4)
fmt.Print(c.data)
}
```
================================================
FILE: interview/微服务.md
================================================
> 需要面试者有一定的大型项目经验经验,了解使用**微服务,etcd,gin,gorm,gRPC**等典型框架等模型或框架。
### 1.微服务了解吗?
微服务,又叫微服务架构,是一种软件架构方式。它将应用构建成一系列按业务领域划分模块的、小的自治服务。
在微服务架构中,每个服务都是自我包含的,并且实现了单一的业务功能。
简单来说,就是将一个系统按业务划分成多个子系统,每个子系统都是完整的,可独立运行的,子系统间的交互可通过HTTP协议进行通信(也可以采用消息队列来通信,如RoocketMQ,Kafaka等)。
微服务架构使应用程序更**易于扩展和更快地开发**,从而加速创新并缩短新功能的上市时间。
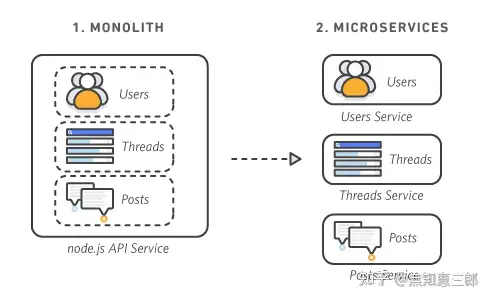
微服务有着**自主,专用,灵活性**等优点。
go语言常见的微服务框架有go-zero,go-micro等
> 参考资料:[什么是微服务?| AWS](https://link.zhihu.com/?target=https%3A//aws.amazon.com/cn/microservices/)
### 2.服务发现是怎么做的?
主要有两种服务发现机制:**客户端发现**和**服务端发现**。
**客户端发现模式**:
当我们使用客户端发现的时候,客户端负责决定可用服务实例的网络地址并且在集群中对请求负载均衡, 客户端访问**服务登记表**,也就是一个可用服务的数据库,然后客户端使用一种**负载均衡算法**选择一个可用的服务实例然后发起请求。该模式如下图所示:
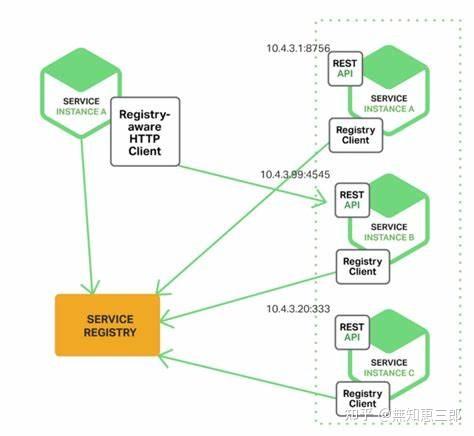客户端发现模式
服务实例的网络位置在启动时被记录到服务注册表,等实例终止时被删除。服务实例的注册信息通常使用心跳机制来定期刷新。
客户端发现模式优缺点兼有。这一模式相对直接,除了服务注册外,其它部分无需变动。此外,由于客户端知晓可用的服务实例,能针对特定应用实现智能负载均衡,比如使用哈希一致性。这种模式的一大缺点就是客户端与服务注册绑定,要针对服务端用到的每个编程语言和框架,实现客户端的服务发现逻辑。
**服务端发现模式**:客户端通过**负载均衡器**( 简单来说可以看成一个代理服务器)向某个服务提出请求,负载均衡器查询服务注册表,并将请求转发到可用的服务实例。如同客户端发现,服务实例在服务注册表中注册或注销。
Kubernetes 和 Marathon 这样的部署环境会在每个集群上运行一个代理,将代理用作服务端发现的负载均衡器。客户端使用主机 IP 地址和分配的端口通过代理将请求路由出去,向服务发送请求。代理将请求透明地转发到集群中可用的服务实例。
服务端发现模式兼具优缺点。它最大的优点是客户端无需关注发现的细节,只需要简单地向负载均衡器发送请求,这减少了编程语言框架需要完成的发现逻辑。这种模式也有缺点。除非负载均衡器由部署环境提供,否则会成为一个需要配置和管理的高可用系统组件。
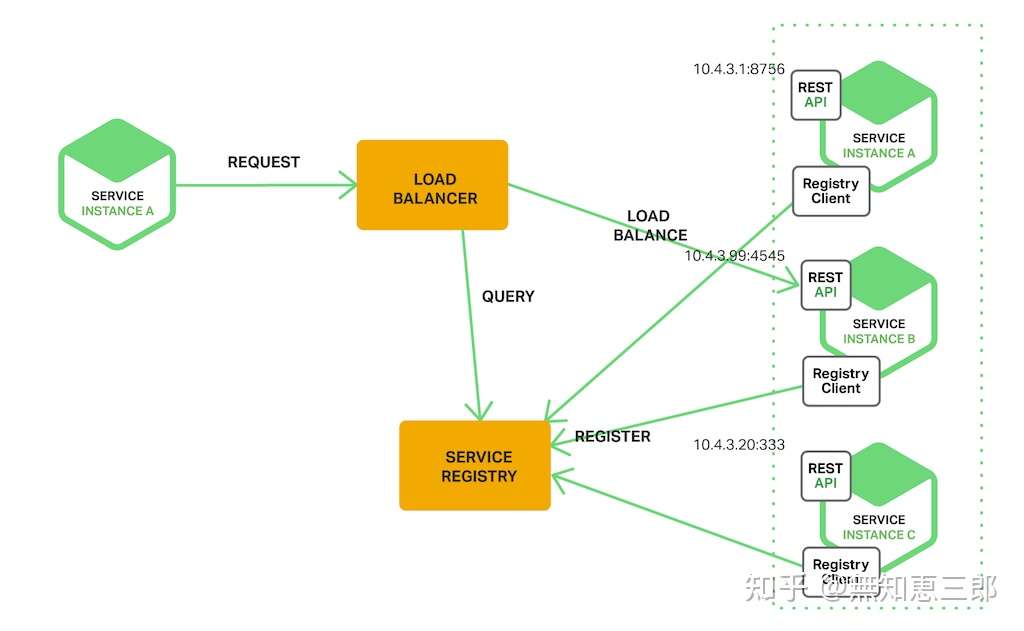
参考资料:[「Chris Richardson 微服务系列」服务发现的可行方案以及实践案例](https://link.zhihu.com/?target=http%3A//blog.daocloud.io/3289.html)
### 3.ETCD用过吗?
**etcd**是一个**高度一致**的**分布式键值存储**,它提供了一种可靠的方式来存储需要由分布式系统或机器集群访问的数据。它可以优雅地处理网络分区期间的领导者**选举**,即使在领导者节点中也可以容忍机器故障。
etcd 是用**Go语言**编写的,它具有出色的跨平台支持,小的二进制文件和强大的社区。
etcd机器之间的通信通过**Raft共识算法**处理。
### 4.etcd怎么搭建的,具体怎么用的
单机or集群部署
**写入数据**
```shell
etcdctl --endpoints=$ENDPOINTS put foo "Hello World"
```
**读取数据**
```shell
[root@etcd1 ~]# etcdctl --endpoints=$ENDPOINTS get foo
foo
Hello World
```
**通过前缀获取数据:**
```shell
#分别插入web1,web2,web3 三条数据
[root@etcd1 ~]# etcdctl --endpoints=$ENDPOINTS put web1 value1
OK
[root@etcd1 ~]# etcdctl --endpoints=$ENDPOINTS put web2 value2
OK
[root@etcd1 ~]# etcdctl --endpoints=$ENDPOINTS put web3 value3
OK
#通过web前缀获取这三条数据
[root@etcd1 ~]# etcdctl --endpoints=$ENDPOINTS get web --prefix
web1
value1
web2
value2
web3
value3
```
**删除数据**
```shell
[root@etcd1 ~]# etcdctl --endpoints=$ENDPOINTS del foo
1 #删除了1条数据
[root@etcd1 ~]# etcdctl --endpoints=$ENDPOINTS del web --prefix
3 #删除了3条数据
```
**事务写入**
```shell
#先插入一条数据
[root@etcd1 ~]# etcdctl --endpoints=$ENDPOINTS put user1 bad
OK
#开启事务
[root@etcd1 ~]# etcdctl --endpoints=$ENDPOINTS txn --interactive
#输入判断条件,两次回车
compares:
value("user1") = "good"
#如果user1 = good,则执行del user1
success requests (get, put, del):
del user1
#如果user1 != good,则执行put user1 verygood
failure requests (get, put, del):
put user1 verygood
FAILURE
OK
#由于user1原先不等于good,所以执行put user1 verygood
[root@etcd1 ~]# etcdctl --endpoints=$ENDPOINTS get user1
user1
verygood #现在user1的值已经被改为verygood
```
**监听**
watch用于获取监听信息的更改,并且支持持续地监听。在窗口1开启监听:
```
[root@etcd1 ~]# etcdctl --endpoints=$ENDPOINTS watch
```
另外开启一个窗口2写入数据:
```
etcdctl --endpoints=$ENDPOINTS put stock1 1000
```
此时窗口1会收到更新信息:
```
stock1
PUT
stock1
1000
```
也支持前缀监听:
```
etcdctl --endpoints=$ENDPOINTS watch stock --prefix
etcdctl --endpoints=$ENDPOINTS put stock1 10
etcdctl --endpoints=$ENDPOINTS put stock2 20
```
**租约**
lease用于设置key的TTL时间。
```
etcdctl --endpoints=$ENDPOINTS lease grant 300
# lease 2be7547fbc6a5afa granted with TTL(300s)
#创建数据,并指定lease
etcdctl --endpoints=$ENDPOINTS put sample value --lease=2be7547fbc6a5afa
#此时还可以获取到数据
etcdctl --endpoints=$ENDPOINTS get sample
#重置租约时间到原先指定的300s,会重复刷新
etcdctl --endpoints=$ENDPOINTS lease keep-alive 2be7547fbc6a5afa
#立即释放
etcdctl --endpoints=$ENDPOINTS lease revoke 2be7547fbc6a5afa
#租约到期或者直接revoke,就获取不到这个key了
etcdctl --endpoints=$ENDPOINTS get sample
```
### 5.熔断怎么做的
> 参考 [微服务的熔断原理与实现 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/269452010)
>
> 一个服务作为调用方调用另一个服务时,为了防止被调用服务出现问题进而导致调用服务出现问题,所以调用服务需要进行自我保护,而保护的常用手段就是*熔断*
>
> 服务治理中的熔断机制,指的是在发起服务调用的时候,如果被调用方返回的错误率超过一定的阈值,那么后续的请求将不会真正发起请求,而是在调用方直接返回错误
>
> 在这种模式下,服务调用方为每一个调用服务 (调用路径) 维护一个**状态机**,在这个状态机中有三个状态:
>
> - 关闭 (Closed):在这种状态下,我们需要一个计数器来记录调用失败的次数和总的请求次数,如果在某个时间窗口内,失败的失败率达到预设的阈值,则切换到断开状态,此时开启一个超时时间,当到达该时间则切换到半关闭状态,该超时时间是给了系统一次机会来修正导致调用失败的错误,以回到正常的工作状态。在关闭状态下,调用错误是基于时间的,在特定的时间间隔内会重置,这能够防止偶然错误导致熔断器进去断开状态
> - 打开 (Open):在该状态下,发起请求时会立即返回错误,一般会启动一个超时计时器,当计时器超时后,状态切换到半打开状态,也可以设置一个定时器,定期的探测服务是否恢复
> - 半打开 (Half-Open):在该状态下,允许应用程序一定数量的请求发往被调用服务,如果这些调用正常,那么可以认为被调用服务已经恢复正常,此时熔断器切换到关闭状态,同时需要重置计数。如果这部分仍有调用失败的情况,则认为被调用方仍然没有恢复,熔断器会切换到打开状态,然后重置计数器,半打开状态能够有效防止正在恢复中的服务被突然大量请求再次打垮
>
> 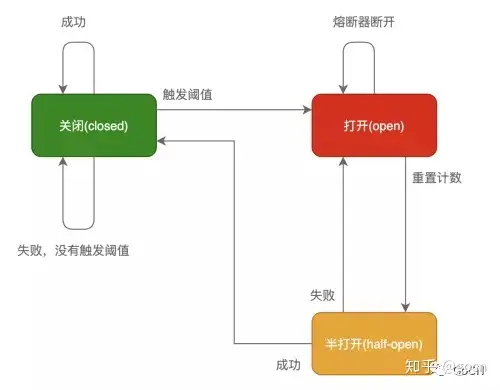
>
> 服务治理中引入熔断机制,使得系统更加**稳定和有弹性**,在系统从错误中恢复的时候提供稳定性,并且减少了错误对系统性能的影响,可以快速拒绝可能导致错误的服务调用,而不需要等待真正的错误返回
zRPC 中熔断器的实现参考了Google Sre 过载保护算法,该算法的原理如下:
- 请求数量 (requests):调用方发起请求的数量总和
- 请求接受数量 (accepts):被调用方正常处理的请求数量
在正常情况下,这两个值是相等的,随着被调用方服务出现异常开始拒绝请求,请求接受数量 (accepts) 的值开始逐渐小于请求数量 (requests),这个时候调用方可以继续发送请求,直到 requests = K * accepts,一旦超过这个限制,熔断器就回打开,新的请求会在本地以一定的概率被抛弃直接返回错误,概率的计算公式如下:
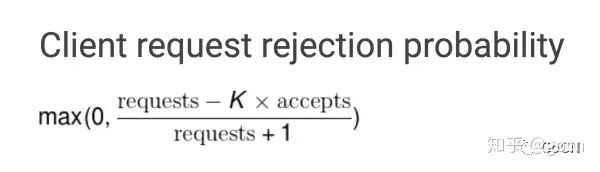
通过修改算法中的 K(倍值),可以调节熔断器的敏感度,当降低该倍值会使自适应熔断算法更敏感,当增加该倍值会使得自适应熔断算法降低敏感度,举例来说,假设将调用方的请求上限从 requests = 2 * acceptst 调整为 requests = 1.1 * accepts 那么就意味着调用方每十个请求之中就有一个请求会触发熔断
### 6.服务降级怎么搞
> 参考 [微服务架构-服务降级 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/58601445)
>
> 什么是服务降级?当服务器压力剧增的情况下,根据实际业务情况及流量,对一些服务和页面有策略的不处理或换种简单的方式处理,从而释放服务器资源以保证核心交易正常运作或高效运作。
>
> 使用场景
>
> 服务降级主要用于什么场景呢?当整个[微服务](https://link.zhihu.com/?target=https%3A//www.ironz.com/view/)架构整体的负载超出了预设的上限阈值或即将到来的流量预计将会超过预设的阈值时,为了保证重要或基本的服务能正常运行,我们可以将一些 不重要 或 不紧急 的服务或任务进行服务的 延迟使用 或 暂停使用。
**分布式开关**
根据上述需求,我们可以设置一个分布式开关,用于实现服务的降级,然后集中式管理开关配置信息即可。具体方案如下:
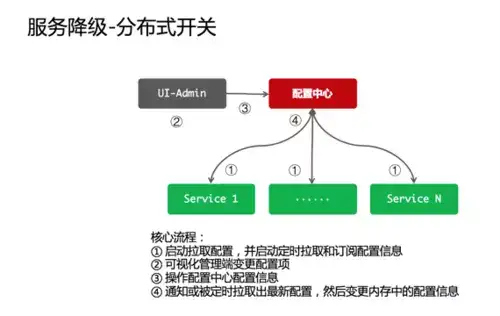
**自动降级**
超时降级 —— 主要配置好超时时间和超时重试次数和机制,并使用异步机制探测恢复情况
失败次数降级 —— 主要是一些不稳定的API,当失败调用次数达到一定阀值自动降级,同样要使用异步机制探测回复情况
故障降级 —— 如要调用的远程服务挂掉了(网络故障、DNS故障、HTTP服务返回错误的状态码和RPC服务抛出异常),则可以直接降级
限流降级 —— 当触发了限流超额时,可以使用暂时屏蔽的方式来进行短暂的屏蔽
当我们去秒杀或者抢购一些限购商品时,此时可能会因为访问量太大而导致系统崩溃,此时开发者会使用限流来进行限制访问量,当达到限流阀值,后续请求会被降级;降级后的处理方案可以是:排队页面(将用户导流到排队页面等一会重试)、无货(直接告知用户没货了)、错误页(如活动太火爆了,稍后重试)。
**降级处理方案**
页面降级 —— 可视化界面禁用点击按钮、调整静态页面
延迟服务 —— 如定时任务延迟处理、消息入MQ后延迟处理
写降级 —— 直接禁止相关写操作的服务请求
读降级 —— 直接禁止相关度的服务请求
缓存降级 —— 使用缓存方式来降级部分读频繁的服务接口
================================================
FILE: interview/操作系统.md
================================================
### 1.什么是操作系统?
操作系统是一组主管并控制计算机操作、运用和运行硬件、软件资源和提供公共服务来组织用户交互的相互关联的系统软件程序。
### 2.操作系统的功能
操作系统的功能主要可以分为以下5个部分
- 处理器管理,主要控制和管理CPU的工作
- 存储管理,主要进行内存的分配和管理
- 设备管理,主要管理基本的输入输出设备
- 文件管理,负责对计算机文件的组织、存储、操作和保护等
- 进程管理(作业管理),对计算机所进行的操作进行管理
### 3.什么是用户态和内核态
用户态和内核态是操作系统的两种运行状态,操作系统主要是为了对访问能力进行限制,用户态的权限较低,而内核态的权限较高
- 用户态:用户态运行的程序只能**受限地访问内存**,只能直接读取用户程序的数据,并且不允许访问外围设备,用户态下的 CPU 不允许**独占**,也就是说 CPU 能够被其他程序获取。
- 内核态:内核态运行的程序可以**访问计算机的任何数据和资源**,不受限制,包括外围设备,比如网卡、硬盘等。处于内核态的 CPU 可以从一个程序切换到另外一个程序,并且占用 CPU 不会发生**抢占**情况。
### 4.❤用户态和内核态是如何切换的?
先看为什么要进行切换
用户程序是跑在用户态下的,但有时候会遇到一些操作需要比较高的权限,比如申请内存等,这时候就需要转换到内核态去做。
内核态切换到用户态是通过设置程序状态字PSW
导致用户态切换到内核态最主要有**三种场景**
- **系统调用**,这是用户态进程主动要求切换到内核态的一种方式,用户态进程通过系统调用申请使用操作系统提供的服务程序完成工作。
- **异常**,当CPU执行运行在用户态下的程序时,发生了异常,这时会从当前的进程切换到处理异常的内核相关程序中,也就是从用户态切换到内核态,比如缺页异常
- **外围设备的中断**,当外围设备完成用户请求的操作后,会像CPU发出相应的中断信号,这时CPU会暂停执行下一条即将要执行的指令转而去执行与中断信号对应的处理程序
### 5.❤进程、线程和协程的区别和联系
> 腾讯、得物24届秋招
这三者的区别是一个比一个”小“的,一个进程可以包含多个线程,一个线程也可以包含多个协程。
- 进程:进程是资源调度的基本单位,运行一个可执行程序会创建一个或多个进程
- 线程:线程是程序执行的基本单位,是轻量级的进程
- 协程:用户态轻量级线程,是一种比线程更加轻量级的存在,协程是一个特殊的函数,这个函数可以在某个地方挂起,并且可以重新在挂起处继续运行
值得注意的是,一个线程内的多个协程的运行是串行的,一个进程可以有一个或多个线程,同一进程中的多个线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等。但同一进程中的多个线程有各自的调用栈和线程本地存储,下面看下具体的区别
| | 进程 | 线程 | 协程 |
| -------- | ------------------------ | --------------- | ----- |
| 切换者 | 操作系统 | 操作系统 | 用户 |
| 切换时机 | 操作系统的切换策略决定 | 操作系统的切换策略决定 | 用户决定 |
| 切换内容 | 页全局目录、内核栈、硬件上下文 | 内核栈、硬件上下文 | 硬件上下文 |
| 切换内容的保存 | 内核栈 | 内核栈 | 内核栈/堆 |
| **切换过程** | 用户态-内核态-用户态 | 用户态-内核态-用户态 | 用户态 |
| 并发问题 | 不同进程之间切换实现并发,各自占有CPU实现并行 | 一个进程内部的多个线程并发执行 | 串行执行 |
| **系统开销** | 很大 | 较小 | 很小 |
进程和线程的根本区别在于: **多进程中每个进程有自己的地址空间,线程则共享地址空间**。
### 6.Linux系统中一个进程可以创建多少线程
这个主要和系统的位数有关系
- 32位,用户态的虚拟空间只有 3G,假设创建一个线程需要占用 10M 虚拟内存,可以创建差不多 300 个(3G/10M)左右的线程
- 64位,用户态的虚拟空间只有 128T,假设创建一个线程需要占用 10M 虚拟内存,可以创建差不多1000多万(128T/10M)左右的线程,当然了,这只是理论,实际上还会受到系统的参数或性能限制,可能会远远小于这个数值,具体还得取决于那你的系统吸能怎么样
### 7.什么是临界区,如何解决冲突?
每个进程中访问临界资源的那段程序称为临界区,一次仅允许一个进程使用的资源称为临界资源。
解决冲突的办法:
- 如果有若干进程要求进入空闲的临界区,**一次仅允许一个进程进入**,如已有进程进入自己的临界区,则其它所有试图进入临界区的进程必须等待;
- 进入临界区的进程要在有限时间内退出。
- 如果进程不能进入自己的临界区,则应让出CPU,避免进程出现“忙等”现象
### 8.并发和并行有什么区别
- 并行:单位时间多个处理器同时处理多个任务。
- 并发:一个处理器处理多个任务,按时间片轮流处理多个任务。
### 9.什么是上下文切换?
上下文切换指的是内核操作系统的核心在CPU上对进程或者线程进行切换。
搞清楚上下文切换需要先搞清楚什么是上下文
CPU在开始执行任务时需要先知道从哪里去加载任务,从哪里开始执行,上下文的作用就是告诉CPU这些。(通常是由程序计数器和CPU寄存器来完成)
那为什么需要上下文切换呢?
一般线程的个数都大于 CPU 核心的个数,而一个 CPU 核心在任意时刻只能被一个线程使用,为了让这些线程都能得到有效执行,CPU 采取的策略是为每个线程分配时间片并轮转的形式,就是一个线程的时间片用完会退回到就绪态,其他线程继续运行,这个过程就是进行了一次上下文切换
上下文切换的步骤:
- 挂起一个进程,将这个进程在CPU中的状态(上下文信息)存储于内存的PCB(Process Control Block)中
- 在PCB中检索下一个进程的上下文并将其在CPU的寄存器中恢复
- 最后跳转到程序计数器所指的新位置,运行新任务
引起线程上下文切换的原因:
(1)当前正在执行的任务完成,系统的CPU正常调度下一个任务。
(2)当前正在执行的任务遇到I/O等阻塞操作,调度器挂起此任务,继续调度下一个任务。 (
(3)多个任务并发抢占锁资源,当前任务没有抢到锁资源,被调度器挂起,继续调度下一个任务。
(4)用户的代码挂起当前任务,比如线程执行yield()方法,让出CPU。
(5)硬件中断。
上下文切换可以分为**进程上下文切换、线程上下文切换、中断上下文切换**三种
- 进程上下文切换:进程上下文切换需要保存的东西比较多,花费的时间也比较多,进程的上下文主要包括虚拟内存、栈、全局变量、堆栈、寄存器等 线程上下文切换:
- 线程上下文切换时,虚拟内存和全局变量等资源都是共享的,线程的上下文包括栈和寄存器等,比寄存器少很多。
- 中断上下文切换:为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,然后调用中断处理程序,响应设备事件。中断上下文,只包括内核态中断服务程序执行所必需的状态,也就是 CPU 寄存器、内核堆栈、硬件中断参数等
### 10.进程有哪些状态?
进程的状态模型一般可以分为三态模型和五态模型,这里以五态模型为例,三态模型指**就绪、运行、阻塞**(等待) 进程一共有以下几个状态:
- 就绪状态::进程具备运行条件,等待系统分配处理器以便运行的状态。当进程已分配到除CPU以外的所有必要资源后,只要再获得CPU,便可立即执行,进程这时的状态称为就绪状态。在一个系统中处于就绪状态的进程可能有多个,通常将它们排成一个队列,称为就绪队列。
- 运⾏状态:进程占有处理器正在运行的状态。进程已获得CPU,其程序正在执行。在单处理机系统中,只有一个进程处于执行状态; 在多处理机系统中,则有多个进程处于执行状态。
- 阻塞状态:又称等待态,指进程不具备运行条件,正在等待某个时间完成的状态。一个进程正在等待某一事件发生(例如请求I/O而等待I/O完成等)而暂时停止运行,这时即使把处理机分配给进程也无法运行,故称该进程处于阻塞状态。
- 创建状态:对应于进程被创建时的状态,尚未进入就绪队列。创建一个进程需要通过两个步骤:1.为新进程分配所需要的资源和建立必要的管理信息。2.设置该进程为就绪态,并等待被调度执行。
- 结束状态::指进程完成任务到达正常结束点,或出现无法克服的错误而异常终止,或被操作系统及有终止权的进程所终止时所处的状态。 五种状态的转换过程如下:
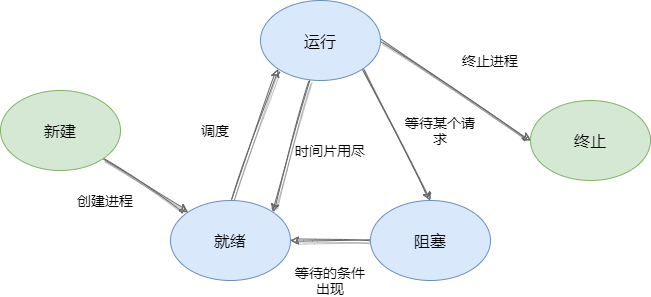
### 11.什么是僵尸进程?什么是孤儿进程?
僵尸进程是已完成且处于终止状态,但在进程表中却仍然存在的进程。
例如,当子进程比父进程先结束,而父进程又没有回收子进程,释放子进程占用的资源,此时子进程将成为一个僵尸进程 系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程. 此即为僵尸进程的危害,应当避免。
孤儿进程指的是在其父进程执行完成或被终止后仍继续运行的一类进程。这些孤儿进程将被init进程(进程号为1)所收养,并由init进程对它们完成状态收集工作。
当出现一个孤儿进程的时候,内核就把孤 儿进程的父进程设置为init,而init进程会循环地wait()它的已经退出的子进程。也就是说孤儿进程可以正常退出,因此孤儿进程并不会有什么危害
### 12.如何避免僵尸进程?
- 让僵尸进程的父进程来回收,父进程每隔一段时间来查询子进程是否结束并回收,调用wait()或者waitpid(),通知内核释放僵尸进程
- 采用信号SIGCHLD通知处理,并在信号处理程序中调用wait函数。父进程首先注册一个信号处理函数signal(SIGCHLD, sig_chld_handler),然后每当子进程退出的时候父进程都会受到SIGCHLD信号, 触发sig_chld_handler()函数,调用wait()函数等待子进程的退出。
- 让僵尸进程变成孤儿进程,由init回收。例如可以父进程首先创建子进程,子进程创建孙子进程,由孙子进程处理事务,而子进程再创建完孙子进程后,就退出。这样孙子进程就变成了孤儿进程。
### 13.❤进程有哪些调度算法?
> 腾讯24届秋招一面
先来说下什么是抢占式调度,什么式非抢占式调度
抢占式调度:现行进程在运行过程中,如果有重要或紧迫的进程到达(其状态必须为就绪),则现运行进程将被迫放弃处理器,系统将处理器立刻分配给新到达的进程
非抢占式调度:非抢占式让原来正在运行的进程继续运行,直至该进程完成或发生某种事件(如I/O请求),才主动放弃处理机
**先来先服务(FCFS,first come first served)**
非抢占式调度算法,这是最简单的一种调度算法,比较好理解,就是根据进程到达的先后顺序执行进程,不考虑等待时间和执行时间。
优点:公平,实现简单 缺点:比较有利于长作业,而不利于短作业
**时间片轮转(RR,Round-Robin)**
抢占式调度,给每个进程固定的执行时间,根据进程到达的先后顺序让进程在单位时间片内执行,执行完成后便调度下一个进程执行,适用于分时系统。
优点:兼顾长短作业 缺点:平均等待时间较长,上下文切换较费时
**短作业优先(SJF, Shortest Job First)**
非抢占式调度算法,对预计执行时间短的进程优先处理。对应的还有最短剩余时间优先算法,这是类似抢占式的短作业优先算法
优点:相比FCFS 算法,该算法可改善平均周转时间和平均带权周转时间,缩短进程的等待时间,提高系统的吞吐量
缺点:不利于长作业
**高响应比优先(HRRN,Highest Response Ratio Next)**
非抢占式调度算法,最高响应比是一种折中的算法,先来先服务主要考虑的是作业的等待时间而未考虑到作业的执行时间,短作业优先主要考虑的是作业的执行时间而未考虑作业等待时间。而最高响应比同时考虑到了两者,其响应比=(预估的进程执行时间+进程等待时间)/ 预估的进程执行时间,这就保证了等待时间相同的情况下,作业执行的时间越短,响应比越高,同时响应比会随着等待时间减小而变大,优先级会提高,能够避免饥饿现象,适用于批处理系统。
优点:兼顾长短作业 缺点:计算响应比开销大
**优先级调度算法**
抢占式调度算法,在进程等待队列中选择优先级最高的来执行。
**多级反馈队列(Multilevel Feedback Queue)**
抢占式调度算,这是一种将时间片轮转和优先级调度想结合的算法,把进程按优先级分成不同的队列,先按优先级调度,优先级相同的,按时间片轮转
优点:兼顾长短作业,有较好的响应时间,可行性强
### 14.线程和进程都怎么通信?
> 一般面试问的是进程间的通信
>
> 得物、滴滴
线程间通信:由于多线程共享地址空间和数据空间,所以多个线程间的通信是一个线程的数据可以直接提供给其他线程使用,而不必通过操作系统(也就是内核的调度)。
进程间的通信则不同,它的数据空间的独立性决定了它的通信相对比较复杂,需要通过操作系统。以前进程间的通信只能是单机版的,现在操作系统都继承了基于套接字(socket)的进程间的通信机制。这样进程间的通信就不局限于单台计算机了,实现了网络通信。
进程间的通信方式
- **管道( pipe )**:管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间使用。进程的亲缘关系通常是指父子进程关系。
- **有名管道 (namedpipe)** : 有名管道也是半双工的通信方式,但是它允许无亲缘关系进程间的通信。
- **信号量(semophore )** : 信号量是一个计数器,可以用来控制多个进程对共享资源的访问。它常作为一种锁机制,防止某进程正在访问共享资源时,其他进程也访问该资源。因此,主要作为进程间以及同一进程内不同线程之间的同步手段。
- **消息队列( messagequeue )** : 消息队列是由消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
- 信号 (sinal ) : 信号是一种比较复杂的通信方式,用于通知接收进程某个事件已经发生。
- **共享内存**(shared memory ) :共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问。共享内存是最快的 IPC 方式,它是针对其他进程间通信方式运行效率低而专门设计的。它往往与其他通信机制,如信号两,配合使用,来实现进程间的同步和通信。
- **套接字(socket )** : 套解口也是一种进程间通信机制,与其他通信机制不同的是,它可用于不同主机间的进程通信。
线程间的通信方式
- **锁机制**:包括互斥锁、条件变量、读写锁
- 互斥锁提供了以排他方式防止数据结构被并发修改的方法。
- 读写锁允许多个线程同时读共享数据,而对写操作是互斥的。
- 条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
- **信号量机制**(Semaphore):包括无名线程信号量和命名线程信号量
- **信号机制**(Signal):类似进程间的信号处理
- 线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的通信机制。
### 15.❤简述多路IO复用技术
> 参考https://www.jianshu.com/p/111f079315f5
IO 多路复用是一种同步 IO 模型,实现一个线程可以监视多个文件句柄;一旦某个文件句柄就绪,就能够通知应用程序进行相应的读写操作;没有文件句柄就绪时会阻塞应用程序,交出 cpu。
IO 是指网络 IO,多路指多个 [TCP](https://www.jianshu.com/p/cae79a66af4a) 连接(即 socket 或者 channel),复用指复用一个或几个[线程](https://www.jianshu.com/p/6a4947e27114)。意思说一个或一组线程处理多个 TCP 连接。最大优势是减少系统开销,不必创建过多的[进程/线程](https://www.jianshu.com/p/94b7c2ab84ac),也不必维护这些进程/线程。
IO 多路复用的三种实现方式:select、poll、epoll。
**select 机制**
1️⃣基本原理:
客户端操作服务器时就会产生这三种文件描述符(简称fd):writefds(写)、readfds(读)、和 exceptfds(异常)。select 会阻塞住监视 3 类文件描述符,等有数据、可读、可写、出异常或超时就会返回;返回后通过**遍历** fdset 整个数组来找到就绪的描述符 fd,然后进行对应的 IO 操作。
2️⃣优点:
几乎在所有的平台上支持,跨平台支持性好
3️⃣缺点:
1. 由于是采用轮询方式全盘扫描,会随着文件描述符 FD 数量增多而性能下降。
2. 每次调用 select(),都需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间)。
3. 单个进程打开的 FD 是有限制(通过`FD_SETSIZE`设置)的,默认是 1024 个,可修改宏定义,但是效率仍然慢。
**poll 机制**
1️⃣基本原理与 select 一致,也是**轮询+遍历**。唯一的区别就是 poll 没有**最大文件描述符限制**(使用[链表](https://www.jianshu.com/p/81a6ed0abeb8)的方式存储 fd)。
2️⃣poll 缺点
1. 由于是采用轮询方式全盘扫描,会随着文件描述符 FD 数量增多而性能下降。
2. 每次调用 select(),都需要把 fd 集合从用户态拷贝到内核态,并进行遍历(消息传递都是从内核到用户空间)。
**epoll机制**
1️⃣基本原理:
没有 fd 个数限制,用户态拷贝到内核态只需要一次,使用**时间通知机制**来触发。通过 epoll_ctl 注册 fd,一旦 fd 就绪就会通过 callback 回调机制来激活对应 fd,进行相关的 io 操作。
epoll 之所以高性能是得益于它的三个函数:
1. epoll_create() 系统启动时,在 Linux 内核里面申请一个基于**红黑树**结构的文件系统,返回 epoll 对象,也是一个 fd。
2. epoll_ctl() 每新建一个连接,都通过该函数操作 epoll 对象,在这个对象里面修改添加删除对应的链接 fd,绑定一个 callback 函数
3. epoll_wait() 轮训所有的callback集合,并完成对应的 IO 操作
2️⃣优点:
没 fd 这个限制,所支持的 FD 上限是操作系统的最大文件句柄数,1G 内存大概支持 10 万个句柄。效率提高,使用回调通知而不是轮询的方式,不会随着 FD 数目的增加效率下降。内核和用户空间 mmap 同一块内存实现(mmap 是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间)
3️⃣epoll缺点:
epoll 只能工作在 [linux](https://www.jianshu.com/p/95d087dc1a43) 下。
4️⃣epoll 应用:**redis、nginx**
### 16.简述进程切换的流程
1.切换页目录以使用新的地址空间
2.切换内核栈和硬件上下文
### 17.抢占是如何做到的
- **两种情况**
- 进程的时间片用完了,
- [优先级](https://so.csdn.net/so/search?q=%E4%BC%98%E5%85%88%E7%BA%A7&spm=1001.2101.3001.7020)更高的进程来争夺CPU了。
- **抢占的过程**分两步,第一步触发抢占,第二步执行抢占,这两步中间不一定是连续的,有些特殊情况下甚至会间隔相当长的时间:
1. 触发抢占:给正在CPU上运行的当前进程设置一个请求重新调度的标志(TIF_NEED_RESCHED),仅此而已,此时进程并没有切换。
2. 执行抢占:在随后的某个时刻,内核会检查TIF_NEED_RESCHED标志并调用schedule()执行抢占。
抢占只在某些特定的时机发生,这是内核的代码决定的。
- **抢占时机**: 让进程调用 `__schedule`, 分为用户态和内核态
- 用户态进程
- 时机-1: 从系统调用中返回, 返回过程中会调用 exit_to_usermode_loop, 检查 `_TIF_NEED_RESCHED`, 若打了标记, 则调用 schedule()
- 时机-2: 从中断中返回, 中断返回分为返回用户态和内核态(汇编代码: arch/x86/entry/entry_64.S), 返回用户态过程中会调用 exit_to_usermode_loop()->shcedule()
- 内核态进程
- 时机-1: 当内核从non-preemptible(禁止抢占)状态变成preemptible(允许抢占)的时候;
- 时机-2: 发生在中断返回, 也会调用 `__schedule`
### 18.什么是字节对齐
> 滴滴一面
所谓的字节对齐,就是各种类型的数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这个就是对齐。我们经常听说的对齐在N上(即一个变量在内存中占用N字节),它的含义就是数据的存放起始地址%N==0。
为什么要字节对齐?
各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。比如有些[架构](http://lib.csdn.net/base/16)的CPU,诸如SPARC在访问一个没有进行对齐的变量的时候会发生错误,那么在这种架构上必须编程必须保证字节对齐。
而有些平台对于没有进行对齐的数据进行存取时会产生效率的下降,如下:

### 19.什么是页表,页表的作用?
> 滴滴一面
页表是一种特殊的[数据结构](https://hd.nowcoder.com/link.html?target=https://baike.baidu.com/item/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84/1450),放在系统空间的页表区,存放逻辑页与物理页帧的对应关系。 每一个[进程](https://hd.nowcoder.com/link.html?target=https://baike.baidu.com/item/%E8%BF%9B%E7%A8%8B/382503)都拥有一个自己的页表,[PCB](https://hd.nowcoder.com/link.html?target=https://baike.baidu.com/item/PCB/16067368)表中有指针指向页表。
页表的作用:是内存非连续分区分配的基础,实现从[逻辑地址](https://so.csdn.net/so/search?q=%E9%80%BB%E8%BE%91%E5%9C%B0%E5%9D%80&spm=1001.2101.3001.7020)转化成物理地址。
为什么不直接使用物理内存?
- 安全风险:每个进程都可以访问0-4G的任意的内存空间,这也就意味着任意一个进程都能够去读写系统相关内存区域,如果是一个
木马病毒,那么他就能随意的修改内存空间,让设备直接瘫痪
- 用户可以访问任意的内存,寻址内存的每个字节,这样容易破坏操作系统,造成操作系统崩溃。
- 想要同时运行多个程序特别困难。
### 20.讲讲你对操作系统内存的理解
> 滴滴暑期实习一面
>
> [操作系统之内存管理,啃完的人都超神了!!! - 掘金 (juejin.cn)](https://juejin.cn/post/6942662689546059807#heading-17)
- **首先什么是内存**
- 内存就是许多 RAM 存储器的集合,就是将许多 RAM 存储器集成在一起的电路板。RAM 存储器的优点是存取速度快、读写方便。系统中会有一个或多个程序并发执行,也就是说会有多个程序的数据需要同时放到内存中。
- 系统会将程序编译链接成可执行模块加载进内存执行,有两种链接模式,静态链接(在程序运行之前,先将各目标模块及它们所需的库函数链接成一个完整的可执行文件(装入模块),即得到完整的逻辑地址,之后不再拆开)和动态链接(运行该目标模块时,才对它进行链接,用不到的模块不需要装入内存)。
- **内存分配。**
- 连续分配(在单一连续分配方式中,内存被分为系统区和用户区。内存中只能有一道用户程序,用户程序独占整个用户区空间。)
- 动态分区分配(在进程装入内存时, 根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需要)。
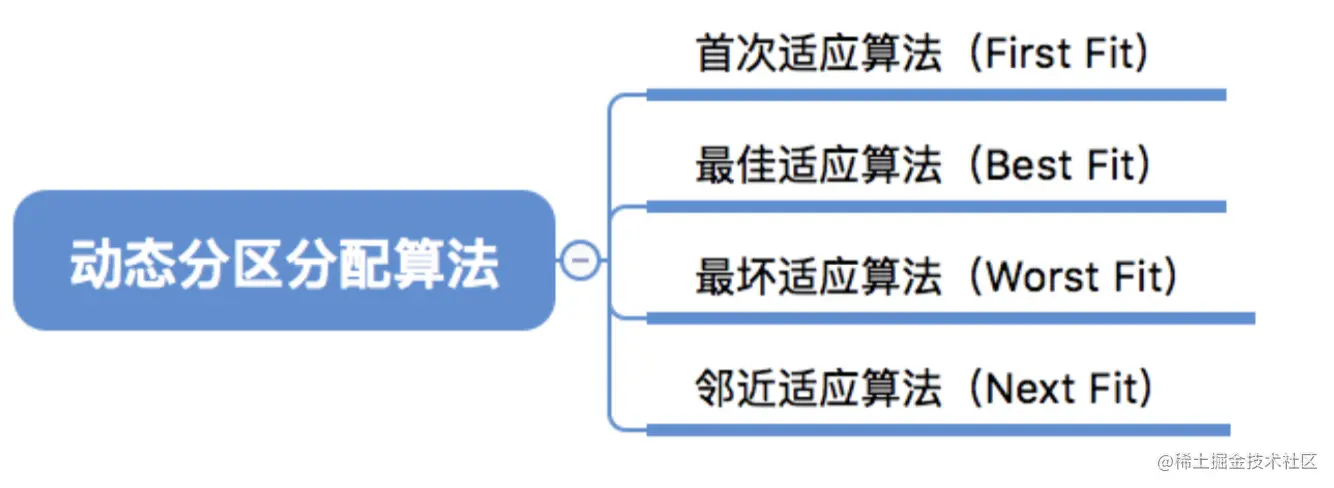
- **内存管理**
- 分页:操作系统会为每一个进程维护一张页表(pagetable),页表中记录着从逻辑地址到物理地址的映射,即页到帧的映射
- 快表(TLB):是一种访问速度比内存快很多的高速缓存(TLB不是内存!),用来存放最近访问的页表项的副本,可以加速地址变换的速度
- **虚拟地址**
- 虚拟内存的最大容量是由计算机的地址结构(CPU寻址范围)确定的,虚拟内存的实际容量 = min(内存和外存容量之和,CPU寻址范围)
- 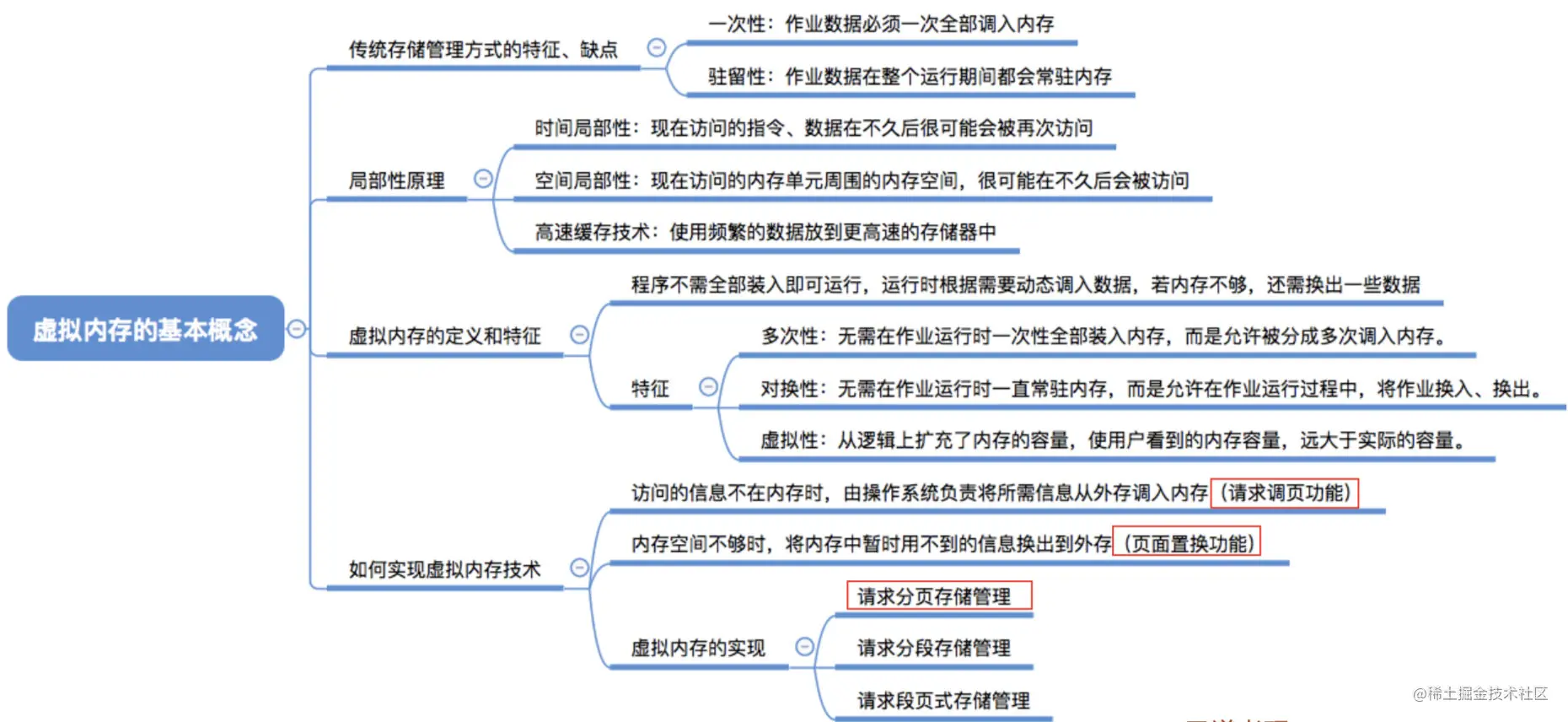
### 21.❤为什么要有虚拟内存(虚拟内存有什么作用)?
> 滴滴三面
- 虚拟内存可以使得进程对运行内存**超过物理内存**大小,因为程序运行符合局部性原理,CPU 访问内存会有很明显的重复访问的倾向性,对于那些没有被经常使用到的内存,我们可以把它换出到物理内存之外,比如硬盘上的 swap 区域。
- 由于每个进程都有自己的页表,所以每个进程的虚拟内存空间就是**相互独立**的。进程也没有办法访问其他进程的页表,所以这些页表是私有的,这就解决了多进程之间**地址冲突**的问题。
- 页表里的页表项中除了物理地址之外,还有一些标记属性的比特,比如控制一个页的读写权限,标记该页是否存在等。在内存访问方面,操作系统提供了更好的**安全性**。
### 22.操作系统内存紧张时会发生什么?
内核在给应用程序分配物理内存的时候,如果空闲物理内存不够,那么就会进行内存回收的工作,主要有两种方式:
- **后台内存回收**:在物理内存紧张的时候,会唤醒 kswapd 内核线程来回收内存,这个回收内存的过程**异步**的,不会阻塞进程的执行。
- **直接内存回收**:如果后台异步回收跟不上进程内存申请的速度,就会开始直接回收,这个回收内存的过程是**同步**的,会阻塞进程的执行。
可被回收的内存类型有文件页和匿名页:
- 文件页的回收:对于干净页是直接释放内存,这个操作不会影响性能,而对于脏页会先写回到磁盘再释放内存,这个操作会发生磁盘 I/O 的,这个操作是会影响系统性能的。
- 匿名页的回收:如果开启了 Swap 机制,那么 Swap 机制会将不常访问的匿名页换出到磁盘中,下次访问时,再从磁盘换入到内存中,这个操作是会影响系统性能的。
文件页和匿名页的回收都是基于 LRU 算法,也就是优先回收不常访问的内存。回收内存的操作基本都会发生磁盘 I/O 的,如果回收内存的操作很频繁,意味着磁盘 I/O 次数会很多,这个过程势必会影响系统的性能。
在经历完直接内存回收后,空闲的物理内存大小依然不够,那么就会触发 **OOM 机制**,OOM killer 就会根据每个进程的内存占用情况和 oom_score_adj 的值进行打分,得分最高的进程就会被首先杀掉。
我们可以通过调整进程的 /proc/[pid]/oom_score_adj 值,来降低被 OOM killer 杀掉的概率。
### 23.操作系统如何避免预读失效和缓存污染的问题?
**什么是预读机制:**
Linux 操作系统为基于 Page Cache 的读缓存机制提供**预读机制**,一个例子是:
- 应用程序只想读取磁盘上文件 A 的 offset 为 0-3KB 范围内的数据,由于磁盘的基本读写单位为 block(4KB),于是操作系统至少会读 0-4KB 的内容,这恰好可以在一个 page 中装下。
- 但是操作系统出于空间局部性原理(靠近当前被访问数据的数据,在未来很大概率会被访问到),会选择将磁盘块 offset [4KB,8KB)、[8KB,12KB) 以及 [12KB,16KB) 都加载到内存,于是额外在内存中申请了 3 个 page;
如果**这些被提前加载进来的页,并没有被访问**,相当于这个预读工作是白做了,这个就是**预读失效**。如果这些「预读页」如果一直不会被访问到,就会出现一个很奇怪的问题,**不会被访问的预读页却占用了 LRU 链表前排的位置,而末尾淘汰的页,可能是热点数据,这样就大大降低了缓存命中率** 。
**什么是缓存污染:**
当我们在批量读取数据的时候,由于数据被访问了一次,这些大量数据都会被加入到「活跃 LRU 链表」里,然后之前缓存在活跃 LRU 链表(或者 young 区域)里的热点数据全部都被淘汰了,**如果这些大量的数据在很长一段时间都不会被访问的话,那么整个活跃 LRU 链表(或者 young 区域)就被污染了**。
**解决问题:**
- Linux 操作系统实现两个了 LRU 链表:**活跃 LRU 链表(active list)和非活跃 LRU 链表(inactive list)**。
但是如果还是使用「只要数据被访问一次,就将数据加入到活跃 LRU 链表头部(或者 young 区域)」这种方式的话,那么**还存在缓存污染的问题**。
为了避免「缓存污染」造成的影响,Linux 操作系统提高了升级为热点数据的门槛:
- Linux 操作系统:在内存页被访问**第二次**的时候,才将页从 inactive list 升级到 active list 里。
通过提高了进入 active list的门槛后,就很好了避免缓存污染带来的影响。
### 24.进程写文件时,进程发生了崩溃,已写入的数据会丢失吗
当进程在写文件过程中发生崩溃时,已写入的数据有**可能会丢失**。这取决于文件系统和操作系统的特性以及应用程序的写入策略。
在一般情况下,当进程写入数据时,数据首先被缓存内核的 **page cache**,它是文件系统中用于缓存文件数据的缓冲,然后才会被操作系统写入磁盘。如果进程在数据被写入磁盘之前发生崩溃,那么这部分尚未写入磁盘的数据将会丢失。
要确保数据的持久化,可以采取以下措施:
1. **同步写入**:在写入数据后,可以使用操作系统提供的同步写入函数(如`fsync`或`fdatasync`)将数据立即刷写到磁盘。这样可以确保数据被持久化保存,但会影响性能,因为需要等待磁盘写入完成才能继续执行。
2. **缓冲区刷新**:使用缓冲区和缓冲区刷新策略,将数据缓存在内存中,并**定期**将缓冲区中的数据刷新到磁盘。可以通过设置适当的缓冲区大小和刷新策略来平衡性能和数据持久化的要求。在此方法下,仍然存在在进程崩溃前数据未被刷新到磁盘的风险。
3. 使用事务或日志:对于需要保证数据一致性和持久化的场景,可以使用事务或日志来记录数据的操作。通过将数据操作记录到事务日志中,即使在进程崩溃后,可以通过回滚或恢复日志来恢复之前的数据状态。比如Journaled 文件系统。
4. 定期备份:定期进行数据备份,将数据拷贝到其他存储介质或远程位置。这样即使在进程崩溃时,可以使用备份来恢复数据。比如RAID 阵列
需要根据具体的应用场景和数据重要性来选择适当的数据持久化策略。确保及时备份数据和采取适当的容灾措施是保护数据安全的重要措施之一。
### 25.多路IO复用中epoll机制的 LT 模式和 ET 模式
与 poll 的事件宏相比,epoll 新增了一个事件宏 **EPOLLET**,这就是所谓的**边缘触发模式**(**E**dge **T**rigger,ET),而默认的模式我们称为 **水平触发模式**(**L**evel **T**rigger,LT)。这两种模式的区别在于:
- 对于水平触发模式,**一个事件只要有,就会一直触发**;
- 对于边缘触发模式,**只有一个事件从无到有才会触发**。
以 **socket 的读事件**为例,对于水平模式,只要 socket 上有未读完的数据,就会一直产生 EPOLLIN 事件;而对于边缘模式,socket 上每新来一次数据就会触发一次,如果上一次触发后,未将 socket 上的数据读完,也不会再触发,除非再新来一次数据。对于 socket 写事件,如果 socket 的 TCP 窗口一直不饱和,会一直触发 EPOLLOUT 事件;而对于边缘模式,只会触发一次,除非 TCP 窗口由不饱和变成饱和再一次变成不饱和,才会再次触发 EPOLLOUT 事件。
边缘触发模式可以减少通知次数,适用于需要高效处理事件的场景,但需要确保在通知之后将所有就绪数据读取完毕。水平触发模式则更加简单,适用于处理非阻塞的场景,但需要在处理就绪事件时小心防止事件被重复通知。
需要注意的是,边缘触发模式需要更加细致的处理,以免错过就绪事件或者陷入死循环。对于初学者来说,水平触发模式更容易理解和使用。
================================================
FILE: interview/架构设计.md
================================================
### 1.什么是前后端分离,为什么现在绝大多数互联网公司使用的都是前后端分离架构?
前后端分离是指将应用程序的前端(用户界面、交互逻辑等)和后端(业务逻辑、数据处理、数据库操作等)分别开发、部署和维护,使得前端和后端可以独立开发、测试和部署,从而提高开发效率和质量。
**纯后端渲染架构的缺点**
- 前端团队无法单独调试
- 前后端职责不清,分工不明
- 不具备多端应用的潜力
**前后端分离架构的优点**
1. 提高开发效率:前后端分离使得前端和后端可以独立开发,无需等待对方完成工作,从而提高开发效率。前端开发人员可以专注于设计和开发用户界面和交互逻辑,而后端开发人员可以专注于业务逻辑和数据处理,减少了彼此之间的干扰和等待时间。
2. 支持多平台:前后端分离使得前端和后端可以独立部署和维护,从而支持多个平台和设备。例如,可以开发一个Web应用程序,同时支持PC端、移动端和平板电脑等设备,或者开发一个基于RESTful API的移动应用程序,从而可以支持不同类型的移动设备。
3. 提高应用程序的可扩展性:前后端分离使得前端和后端可以独立扩展,从而提高应用程序的可扩展性。例如,可以增加前端服务器的数量,以处理更多的用户请求;或者增加后端服务器的数量,以处理更多的业务逻辑和数据处理。
4. 提高应用程序的安全性:前后端分离使得前端和后端可以独立实现安全措施,从而提高应用程序的安全性。例如,可以在前端实现防止跨站点脚本攻击(XSS)的安全措施,而在后端实现防止SQL注入攻击的安全措施。
### 2.为什么大厂要做数据垂直分表
**垂直分表**:将一张大表按照“列”拆分为2张以上的小表,通过主外键关联获取数据。一般会将常用的字段放在一个表中,将不常用的字段放到另一张表中。
原因:
1. **业务解耦**:将多个业务模块拆分到不同的表中,可以减少表之间的耦合度,方便进行单独部署和维护,同时也有利于业务的扩展和迭代。
2. **性能优化**:将一个大表拆分成多个小表后,可以减小单表的数据量,提高查询速度和响应性能。同时也可以根据业务需求,将高频访问的字段和低频访问的字段分别放在不同的表中,从而达到提高查询性能的目的。通过将重要字段单独剥离出一张小表,让每一页能够容纳更多的行,进而缩小数据扫描的范围,提高执行效率。
3. 数据安全:将敏感数据和非敏感数据分别存储在不同的表中,可以提高数据的安全性和隐私保护,减少数据泄露的风险。
4. 节约成本:通过数据垂直分表,可以将不同类型的数据存储在不同的表中,从而避免了对同一张表进行频繁的DDL操作,减少数据库维护和升级的成本。
### 3.为什么要做多级缓存
> 多级缓存通常由几种不同类型的缓存组成,例如本地缓存、分布式缓存(redis)和CDN缓存等。多级缓存的主要目的是在提高数据访问速度的同时,减轻后端存储设备的负载,提高系统的可伸缩性和可用性。
>
> 1. 本地缓存:位于应用程序内存中,是最快的缓存层,可以快速响应读取请求,减少对后端存储的访问,提高系统的性能。
> 2. 分布式缓存:位于多个应用程序之间共享的缓存服务中,可以缓存经常被读取的数据,减轻后端存储设备的负载,提高系统的可伸缩性和可用性。
> 3. 后端存储:位于磁盘等后端存储设备中,用于持久化存储数据,当本地缓存和分布式缓存中没有命中需要的数据时,才会从后端存储中读取数据。
1. 提高系统的**性能和可用性**,从而满足系统的高并发、低延迟和高可靠性:一级缓存可以缓存热点数据,避免频繁访问数据库,提高系统响应速度;二级缓存可以缓存一些较少使用但又不适合放在一级缓存中的数据,进一步减轻数据库负载,提高系统性能。
2. 减轻数据库负载:多级缓存可以将热点数据缓存在内存中,避免频繁访问数据库,减轻数据库负载,提高数据库的稳定性和可靠性。
3. 改善用户体验:多级缓存可以大大缩短数据访问的响应时间,从而提高用户体验。
### 4.数据库水平分表按范围分表的优缺点
通常是按主键id进行范围分片
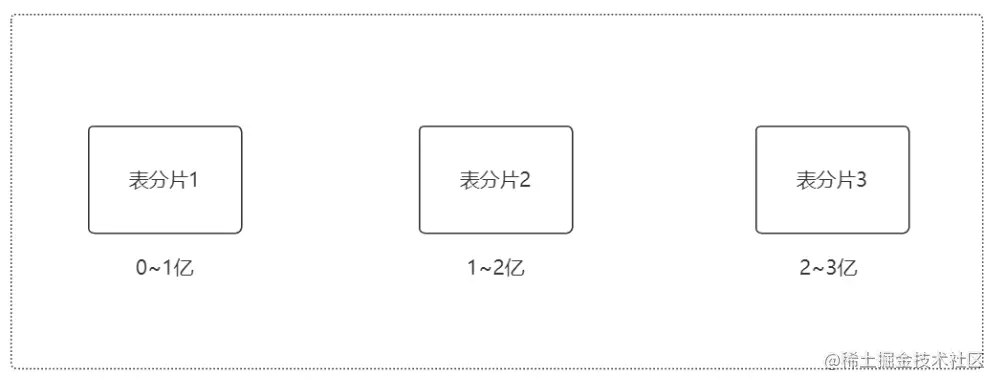
优点:
- 容易理解,易于扩展
缺点:
- 必须提前做好分片规划,会造成资源浪费
- 会产生“尾部热点”效应
### 5.MQ中间件是如何实现可靠性投递的
MQ中间件实现可靠性投递的主要方式是采用**ACK机制**。发送阶段,遇到高延迟,Producer会多次重发消息,直到Broker ACK确认,过程中Broker会自动去重,超时Producer产生异常,应用进行捕获提示。当消费者接收到消息时,需要发送一个ACK给MQ服务器,告诉服务器已经正确地接收到了消息。如果MQ服务器在一定时间内没有收到ACK,则认为该消息没有被正确处理,会将其重新投递给消费者,直到收到ACK为止。
此外,MQ中间件还会对消息进行**持久化处理**,保证消息在发送过程中不会丢失。Broker先刷盘再ack,即使ack失败消息不会丢失,多次重试直到Producer接收。
还可以使用**消息重试机制**、消费者负载均衡机制等。同时,为了防止消息被重复投递,MQ中间件还会使用消息去重机制(处理幂等性),保证每条消息只会被处理一次。
### 6.什么是最终一致性,有哪些手段可以保证最终一致性
最终一致性是指在分布式系统中,经过一段时间的数据同步和协调后,系统的所有副本最终达到一致的状态。
在分布式系统中,由于网络延迟、节点故障等原因,数据的复制和同步可能会有一定的延迟和不一致性。因此,最终一致性不要求系统的所有副本立即达到一致,而是允许一定的时间窗口来保证数据的最终一致性。
**如何保证:**
- **重试**
比如在订单系统和短信服务中,商家在每条订单下单后都会发送一条订单短信通知买家,订单系统和短信服务是两个独立的服务,那么应该如何保证每个订单都会发送短信呢?可以使用消息中间件MQ异步解耦,通过发布订阅以及MQ本身的重试机制保证服务的最终一致性

- **数据校对程序**
通过数据校对程序每隔一段时间抽取订单系统中未发送短信的订购进行补发(**补偿机制**)。

- **本地消息表**
和数据校对程序本质差不多

- **人工介入**
运维人员通过APM链路监控系统进行人工补偿

### 7.什么是单点登录,怎样设计(或者说具体流程是怎样的)
单点登录(Single Sign-On,简称SSO)是一种身份验证和授权机制,允许用户在多个应用系统中使用同一组凭据(如用户名和密码)进行登录,从而实现在不同系统之间的无缝登录体验。用户只需登录一次,即可在多个系统中自动登录,而无需为每个系统单独输入凭据。
**流程:**
- **同域**下的单点登录:
假如有三个网站sso.a.com、app1.a.com、app2.a.com
我们只要在sso.a.com登录,app1.a.com和app2.a.com就也登录了。
sso登录以后,可以将Cookie的域设置为顶域,即.a.com,这样所有子域的系统都可以访问到顶域的Cookie。
那么sso登录以后,app1和app2如何通过Cookie得到session呢,这里就需要将三个系统的session共享了。
说明一下,这并不是真正的单点登录。
- **不同域**下的单点登录:
假设有app1和app2两个系统(这两个系统都还没完成登录验证,并且是不同域的)以及一个统一认证中心SSO
1. 用户访问app1系统,app1系统是需要登录的,但用户现在没有登录。
2. 跳转到CAS server,即SSO登录系统。SSO系统也没有登录,弹出用户登录页。
3. 用户填写用户名、密码,SSO系统进行认证后,将登录状态写入SSO的session,浏览器(Browser)中写入SSO域下的Cookie。
4. SSO系统登录完成后会生成一个身份令牌**ST(Service Ticket)**,然后跳转到app1系统,同时将ST作为参数传递给app1系统。
5. app1系统拿到ST后,从后台向SSO发送请求,**验证**ST是否有效。
6. 验证通过后,app1系统将登录状态写入session并设置app1域下的Cookie。
至此,跨域单点登录就完成了。以后我们再访问app1系统时,app1就是已登录的。接下来是访问app2系统时的流程:
1. 用户访问app2系统,app2系统没有登录,跳转到SSO。
2. **由于SSO已经登录了,不需要重新登录认证**。
3. SSO生成ST,浏览器跳转到app2系统,并将ST作为参数传递给app2。
4. app2拿到ST,后台访问SSO,验证ST是否有效。
5. 验证成功后,app2将登录状态写入session,并在app2域下写入Cookie。
这样,app2系统不需要走登录流程,就已经是登录了。SSO,app1和app2在不同的域,它们之间的session不共享也是没问题的。
### 8.设计一个订单超时未支付关闭订单的解决方案(秒杀场景中)
> 字节二面
注意订单超时并不仅仅只是关闭订单,还需要减库存、通知等一些列操作
**方法一:扫表轮询**
此方案比较简单,我们只需要开一个定时任务扫描订单表,获取待支付状态的订单数据,判断订单是否超时,如果超时则关闭订单并进行减库存等操作。

缺点:
- 大量数据集,对**服务器内存**消耗大。
- 数据库频繁查询,订单量大的情况下,**IO**是瓶颈。
- 存在延迟,间隔短则耗资源,间隔长则时效性差,两者是一对矛盾。
- 不易控制,随着定时业务的增多和细化,每个业务都要对订单重复扫描,引发查询浪费
**方法二:懒删除**
我们只在用户查询订单的时候进行一个订单的校验,判断是否超时

缺点:
如果用户一直不查询订单,那么订单会被一直挂起,没有支付也没有取消,库存依旧占着。如果再业务上这种延迟操作不能接收,那么此方案也用不了
**方法三:消息队列**
通过消息队列中的延迟队列实现

优点:
- 可以随时在队列移除,实现实时取消订单,及时恢复订单占用的资源(如商品)
- 消息存储在mq中,不占用应用服务器资源
- 异步化处理,一旦处理能力不足,consumer集群可以很方便的扩容
缺点:
- 可能会导致消息大量堆积
- mq服务器一旦故障重启后,持久化的队列过期时间会被重新计算,造成精度不足
- 死信消息可能会导致监控系统频繁预警
**方法四:Redis实现**
利用redis的notify-keyspace-events,该选项默认为空,改为Ex开启过期事件,配置消息监听。每下一单在redis中放置一个key(如订单id),并设置过期时间

优点:
- 消息都存储在Redis中,不占用应用内存
- 外部redis存储,应用down机不会丢失数据
- 做集群扩展相当方便
- 依赖redis超时,时间准确度高
缺点:
- 订单量大时,每一单都要存储redis内存,需要大量redis服务器资源
### 9.如何避免订单重复提交支付?
- 前端的防抖处理
防止用户在快速点击时可能会提交两个一模一样的订单
我们可以在用户点击提交按钮时跳转到一个提交中的页面,防止用户重复提交。
- 服务端的幂等处理
- token机制
服务端生成一个token,可以存在redis中,并设置过期时间,用户在提交或支付订单前会获取该token,然后携带该token将请求发送给服务端,服务端会判断该token是否存在redis中,若存在,说明是第一次请求,处理该请求并删除token,若不存在,说明是重复提交的请求,不处理
- 根据订单号进行幂等处理
### 10.扫码登录到底是怎么实现的?

### 11.如何解决超卖问题?比如在秒杀商城的业务场景中
超卖问题指的是在并发环境下,多个用户同时购买同一商品或资源,导致库存数量超过实际可售数量的情况。为解决超卖问题,可以采取以下几种方法:
1. **悲观锁**(Pessimistic Locking):在并发访问资源时,使用锁机制对资源进行加锁,确保同一时间只有一个用户能够执行购买操作。比如,在数据库操作中使用行级锁或表级锁(select for update),限制并发访问。这种方法可以保证数据的一致性,但会降低系统的并发性能。
2. **乐观锁**(Optimistic Locking):在并发访问资源时,使用版本号或时间戳等机制进行乐观并发控制。每个用户在购买之前获取资源的版本号,并在购买时验证版本号是否仍然匹配。如果版本号匹配,则进行购买操作;如果不匹配,则表示资源已被其他用户修改,购买操作失败。这种方法避免了直接的加锁,提高了系统的并发性能,但需要处理并发冲突的情况。
```sql
-- 版本号实现乐观锁
select version from goods WHERE id= 1001;
update goods set num = num - 1, version = version + 1 WHERE id= 1001 AND num > 0 AND version = @version(上面查到的version);
```
3. **预减库存**:在用户下单前,先将商品的库存数量预先进行占用。当用户提交订单时,再对库存进行实际的扣减。这样可以确保即使在下单之后出现并发请求,预占的库存数量也会保留给该用户,避免了超卖问题。如果用户在一定时间内没有支付订单,则释放预占的库存。
在秒杀的情况下,高频率的去读写数据库,会严重造成性能问题。所以必须借助其他服务, 利用 redis 的单线程预减库存。比如商品有 100 件。那么可直接利用redis的原子性操作incre和decr。例如
每一个用户线程进来,key 值就incre,等减到 0 的时候,全部拒绝剩下的请求。
那么也就是只有 100 个线程会进入到后续操作。所以一定不会出现超卖的现象。
4. **队列和消息机制**:将用户的购买请求放入一个消息队列中,并使用消息机制逐个处理购买请求。这样可以保证每个购买请求按顺序进行处理,避免了并发导致的超卖问题。
5. **并发限制和限流**:在系统设计中,可以设置并发限制和限流机制,控制同时进行购买操作的用户数量。比如,使用令牌桶算法或漏桶算法对请求进行限制,确保系统能够处理合理数量的购买请求,避免超卖问题的发生。
> 令牌桶是一种控制请求访问速率的算法。
> 它具体工作原理是:系统以一定速率生成令牌并放到令牌桶里面。
> 然后所有的客户端请求进入到系统后,先从令牌桶里面获取令牌,成功获取到令牌表示
> 可以正常访问。
> 如果取不到令牌,说明请求流量大于令牌生成速率,也就是并发数超过系统承载的阈值,
> 就会触发限流的动作。
> 在流量较低的情况下,令牌桶可以缓存一定数量的令牌,所以令牌桶可以处理瞬时突发
> 流量。
需要根据具体业务场景和系统需求选择合适的解决方案,并进行适当的性能测试和调优,以确保系统的可靠性和稳定性。
### 12.什么是CAS,使用CAS(比如乐观搜)会有什么问题
**CAS(Compare and Swap)**是一种并发编程中常用的原子操作,用于实现多线程环境下的数据同步和共享资源的更新。CAS操作通常用于解决多线程并发情况下的竞态条件问题,例如在多个线程尝试修改同一个共享变量时可能出现的问题。
CAS操作的基本思想是比较共享变量的当前值与预期值,如果相同,则将新值写入共享变量。这个过程是原子的,不会被其他线程中断。如果共享变量的当前值与预期值不同,则表示在比较和更新之间有其他线程修改了变量,CAS操作会失败,不进行更新。
CAS操作的优点是**避免了传统的锁机制中的死锁和线程切换开销**,因为它是基于硬件级别的原子指令。然而,CAS操作也可能引发一些问题:
1. **ABA问题**:CAS操作只关心值是否一致,不关心值的变化历史。因此,即使在两次CAS之间值发生了变化,只要变化前后的值一致,CAS仍然会成功,导致一种被称为“ABA问题”的情况。解决方法包括使用版本号或标记来识别变化。
2. **自旋次数**:CAS操作失败时,通常会进行自旋尝试,不断重试直到成功或达到一定尝试次数。如果自旋次数过多,会增加CPU消耗,降低性能。
3. 竞态条件:尽管CAS操作可以解决一部分竞态条件,但并不能解决所有并发问题。在某些情况下,多个线程仍然可能同时访问共享资源,导致问题。
总之,CAS是一种有用的并发控制工具,但在使用过程中需要注意其局限性和可能引发的问题,同时根据实际情况进行合理的设计和调整。
### 13.什么是可重入锁,如何使用redis实现?
> 滴滴提前批二面
可重入锁是一种允许同一个线程或进程多次获取同一个锁的锁机制。当一个线程已经持有锁时,它可以多次重复获取锁,而不会造成死锁或资源冲突。可重入锁通常用于处理嵌套函数调用或递归函数中需要获取同一个锁的情况。
使用Redis实现可重入锁的基本思路如下:
1. 每个线程/进程持有一个唯一的标识(如线程ID或会话ID)作为锁的持有者标识。
2. 当获取锁时,将锁的持有者标识作为值写入到Redis的某个键。
3. 在获取锁之前,检查这个键的值是否已经被当前线程持有。如果是,则表示已经获取过锁,可以直接重入;如果不是,则进行正常的获取操作。
4. 在释放锁时,只有当锁的持有者标识与当前线程匹配时,才执行释放操作。
通过这种方式,Redis中的某个键表示锁,它的值记录了当前持有锁的线程/进程的标识。这样就可以实现可重入锁的效果。
需要注意的是,在实际应用中,需要考虑更多的并发和错误处理,以及锁的超时等问题。此外,Redis还提供了一些现成的分布式锁方案,如RedLock和Redsync,可以用于更复杂的分布式场景。
### 14.UUID实现的原理
> 小红书一面
UUID 的英文全称为 Universally Unique Identifier,即通用唯一识别码,它是由一组 16 个字节(128 位)组成的标识符,可以用于唯一地标识信息。UUID 的生成方式有多种,其中最为常用的是基于算法的 UUID 生成方式和基于硬件的 UUID 生成方式。
目前最常用的基于算法的 UUID 生成方式是基于时间戳的 UUID 生成方式。该方式基于当前时间戳和机器的 MAC 地址生成 UUID,它的算法流程如下:
1. 获取当前时间戳和机器的 MAC 地址;
2. 将当前时间戳转换为 UTC 时间,并计算出自 1582 年 10 月 15 日午夜(即格林威治标准时间 0 点)以来的纳秒数,将其存储在 UUID 的时间戳字段中;
3. 将机器的 MAC 地址哈希得到其中的 6 个字节作为 UUID 的节点字段;
4. 随机生成两个字节作为 UUID 的时钟序列字段;
5. 将时间戳、节点、时钟序列等信息组合起来,生成 UUID。
> 雪花算法的原理
>
> 雪花算法(Snowflake Algorithm)是一种用于生成分布式系统中唯一标识符的算法。它在分布式环境中广泛用于生成全局唯一的ID,通常用于数据库主键、消息队列、分布式锁等场景。雪花算法的核心思想是将一个64位的整数ID分解为不同的部分,每个部分表示不同的信息,以确保生成的ID在不同的节点和时间内是唯一的。以下是雪花算法的实现方法:
>
> **64位二进制结构**:
>
> 雪花算法生成的ID通常是一个64位的二进制数,可以分解成以下部分:
>
> - 1位符号位(不使用,一般为0,可保证ID为正数)
> - 41位时间戳,精确到毫秒级别
> - 10位机器ID(工作机器标识)
> - 12位序列号(同一毫秒内的序列号,支持4096个不同的ID)
>
> 1. **时间戳部分**:
>
> 时间戳部分用于记录生成ID的时间,通常是从一个固定的起始时间开始计算的毫秒数。这样可以确保在不同时间生成的ID不会发生冲突。需要注意的是,时间戳部分的位数需要足够长以支持未来的时间,以及防止时钟回拨引起的问题。
>
> 2. **机器ID部分**:
>
> 机器ID是为每个生成ID的节点分配的唯一标识符。这可以是一台机器的唯一编号或者在多机器环境中可以是一个机器组的标识。确保不同的节点有不同的机器ID,以防止冲突。
>
> 3. **序列号部分**:
>
> 序列号部分用于解决同一毫秒内生成ID的冲突问题。在同一毫秒内,可以生成4096(2^12)个不同的ID。当序列号部分达到最大值时,需要等待下一毫秒才能继续生成ID。
>
> **生成算法**:
>
> 雪花算法的生成过程可以简化如下:
>
> - 获取当前时间戳,精确到毫秒级别。
> - 如果当前时间小于上一次生成ID的时间戳,可以等待,直到下一毫秒。
> - 如果是同一毫秒内生成的ID,增加序列号。
> - 将各个部分的位合并,得到最终的64位ID。
>
> 雪花算法的关键是确保在分布式环境中生成的ID是唯一的,同时保证ID的有序性(根据时间戳部分)。每个节点需要分配一个唯一的机器ID,且需要保证时钟同步以避免时钟回拨引起的问题。因此,雪花算法的实现需要考虑分布式系统的特点和要求。不同的编程语言和库可以根据这个算法的思想来实现雪花算法。
### 15.如何确保一个请求到达服务器了
> 小红书一面
1. **使用确认响应(Acknowledgment Response)**:在客户端发送请求到服务器后,服务器在成功接收并处理请求后,向客户端发送一个确认响应。客户端可以等待服务器的确认响应,以确保请求已经成功到达服务器。
2. **使用消息队列**:如果您的应用程序使用消息队列系统,可以将请求发布到消息队列中,然后让服务器从队列中获取并处理请求。这种方式可以确保请求被传递给服务器,即使服务器当前不可用,请求也不会丢失。客户端可以等待服务器发送响应,或者使用异步机制轮询消息队列以获取响应。
3. **日志和监控**:在服务器端,您可以记录请求的到达时间和处理时间,并使用监控工具来跟踪请求的状态。这可以帮助您追踪请求的生命周期并检测到达服务器的问题。
4. **链路追踪:**
> 链路追踪是一种监控和诊断工具,可以帮助您追踪分布式应用程序中请求的传播路径。链路追踪通常使用唯一的标识符(链路追踪码)来关联请求的不同部分,从而跟踪请求的流程。以下是如何使用链路追踪来确保请求到达服务器的示例:
>
> 1. **生成链路追踪码**:在客户端发送请求之前,生成一个唯一的链路追踪码。这个码可以是UUID或任何其他全局唯一的标识符。
> 2. **将链路追踪码附加到请求**:将生成的链路追踪码附加到请求的头部或其他适当的位置。这个链路追踪码将随请求一起发送到服务器。
> 3. **服务器接收请求**:当服务器接收到请求时,它可以从请求中提取链路追踪码。
> 4. **处理请求**:服务器可以处理请求,并将链路追踪码传递给应用程序的不同组件或微服务。
> 5. **在请求的各个部分传递链路追踪码**:如果请求涉及多个服务或组件,确保链路追踪码在每个服务之间传递。这样,您就可以追踪请求在不同服务之间的传播路径。
> 6. **记录链路追踪信息**:每个服务在处理请求时,可以记录与链路追踪码相关的信息,如**处理时间、日志、错误**等。这些信息可以用于后续的监控和诊断。
> 7. **追踪请求的生命周期**:使用链路追踪工具,您可以查看请求的生命周期,了解请求从客户端到服务器的整个路径,并检查每个服务的性能和响应时间。
> 8. **错误检测和排查**:如果请求发生错误或延迟,您可以使用链路追踪来定位问题的根本原因,从而更容易进行故障排除。
### 16.跳表和红黑树应用场景有什么不同?
> 美团二面
**适合使用跳表的场景:**
1. **高效的范围查询:** 跳表对于范围查询(例如,查找某个范围内的元素)非常高效,因为它的多层级结构使得跳过不必要的部分成为可能。
2. **无序集合或有序集合的维护:** 跳表可以用于实现无序集合或有序集合,而不需要像红黑树那样复杂的平衡操作。
3. **并发数据结构:** 跳表的简单结构和无锁性质使其适合用作一种并发数据结构,多个线程可以并行地插入和删除节点。
**适合使用红黑树的场景:**
1. **关联容器:** 红黑树通常用于实现关联容器,例如 C++ 的 `std::map` 和 `std::set`,因为它提供了较为严格的平衡性保证,适用于通用情况下的键-值存储。
2. **数据库索引:** 许多数据库管理系统使用红黑树来实现索引结构,因为它们需要高度的平衡性和稳定的性能,尤其是在数据量大的情况下。
3. **文件系统:** 一些文件系统使用红黑树建立索引来维护文件和目录的结构,以便高效地进行文件查找和管理。
================================================
FILE: interview/海量数据高频面试题.md
================================================
### 1.海量日志数据,提取出某日访问百度次数最多的那个IP
题目的隐藏含义就是海量日志数据不能一次读取到内存中,否则直接用HashMap统计IP出现的频率(IP为key,频率为Value),然后按照频率排序就好了。
这道题的做法是先对文件遍历一遍,将一天访问百度的IP记录到一个单独的文件中,如果这个文件还是很大,可以对IP进行hash取余,将IP映射到多个文件中,然后利用HashMap统计每个文件中IP的频率,分别找到每个文件中评率最高的IP,再从这些IP中找到真题评率最高的IP
如果是频率最高的前N个怎么办?
这是可以利用HashMap统计每一个文件中IP的频率后,维护一个小顶堆,找到TopN。具体方法是:一次遍历每个小文件,构建一个小顶堆,堆大小为N。如果遍历到的IP的出现次数大于堆顶IP的出现次数,则用新IP替换堆顶的IP,然后重新调整为小顶堆,遍历结束后,小顶堆上的词就是出现频数自高的N个IP。
注:**TopN问题在手写代码也是高频题**,需要重点掌握,比如力扣215题:https://leetcode.cn/problems/kth-largest-element-in-an-array/comments/
### 2.寻找热门查询,300万个查询字符串中统计最热门的10个
> 题目详细描述:搜索引擎会通过日志文件把用户每次检索使用的所有查询串都记录下来,每个查询床的长度不超过 255 字节。假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门),请你统计最热门的10个查询串,要求使用的内存不能超过1G。
**方法一:分治+HashMap**
还是前面的老方法,先用Hash映射将查询字符串映射到多个小文件中,然后用HashMap统计每个小文件中查询字符串出现的频率(key为热门字符串,value为频率),找到每个小文件中的频率的最高的top10,最后通过一个小顶堆统计所有小文件中的top10
**方法二:直接用HashMap**
题目中写道,去重后只有300w条数据,每条查询不超过255字节,一共是729M,小于1G。所以可以直接遍历查询字符串,并存入到HashMap中(key为热门字符串,value为频率),通过小顶堆找到频率最高的top10
**方法三:前缀树**
知识把方法二种的HashMap换成了前缀树,在遍历字符串时,在前缀树中查找该字符串,如果找到,则将字节中保存的当前前缀的次数+1,没有找到则为这个字符串构建新节点,并将新构建的节点中的次数置为1。最后还是通过小顶堆找到频率最高的top10.
### 3.有一个1G大小的文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。
**分治+HashMap+小顶堆**
首先遍历文件,对每个词进行hash,比如hash(x)%5000,将所有词分别存入到5000个小的文件中,每个文件大概200kb左右,然后通过HashMap统计每个小文件中词的频率(key为词,value为频率)。对于每个遍历到的词,如果在HashMap中,则将value值+1,若不在HashMap中,则将词存入HashMap,并将值置为1。最后构建小顶堆,堆的大小 为100,找到频率最高的100个词
### 4.有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。要求你按照query的频度排序。
本题和前面的大同小异,首先遍历这10个文件,对每个query进行hash映射,将这些query重新映射到10个文件中,这是为了保证相同的query都在同一个文件中,然后再每个文件中分别使用HashMap统计query的频率,分别进行排序,最后通过归并排序将所有文件中的query排序中
### 5.给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
每个url是64字节,50亿*64大约等于300多个G,内存限制为4G,所有不能直接放入内存中
还是前面的**分治**思路,遍历文件a中的url,对url进行hash(url)%1000,将50亿的url分到1000个文件中存储(a1,a2,a3......)
,每个文件大约300多M,对文件b进行同样的操作,因为hash函数相同,所以相同的url必然会落到对应的文件中,比如文件a中的url与文件b中的url2相同,那么他们经过hash(url)%1000也是相同的。即url1落入第n个文件中,url2也会落到第n个文件中。
第二步是遍历a0中的url,存入HashMap中,同时遍历b0中的url,查看是否在HashSet中存在,如果存在则保存到单独的文件中。然后依次遍历a2、a3........,b2、b3..........
### 6.在2.5亿个整数中找出不重复的整数,内存空间不足以容纳这2.5亿个整数
**方法一:分治法**
先将2.5亿个整数通过hash取余,存到多个文件中,这时相同的整数会存入到同一个文件中。第二步是通过HashMap统计每个小文件中整数出现的频率(key为整数,value为频率),将所有value为1的整数存到单独的文件中,及为不重复的整数。
**方法二:位图法**
如果对布隆过滤器有了解的同学一定记得位图是什么,布隆过滤器在面试中也是经常问到的,下面简单说一下什么是位图?
简单来说,位图就是,用每一位来存放某种状态,通常是用来判断某个数据存不存在的。位图可以用数组实现的,数组的每一个元素的每一个二进制位都可以表示一个数据在或者不在,0表示数据存在,1表示数据不存在。如下,表示0-6中的元素,0-6中只有7个数,所以用7bit足以表示,例如5可以表示为
```txt
[0,0,0,0,0,1,0]
```
那为什么要使用位图,使用位图有什么好处呢?
使用位图可以大大缩短存储空间,一个int占用4byte,1byte=8bit,也就说本来4byte只能存1个整数,而现在4type可以存32个整数。
回到本题,要找出不重复的整数,那么一个整数可以有三种状态,即不存在、存在1次、存在多次,根据题目需要找出的是存在1次的
对于三种状态只用0或1肯定是表示不了的,所以可以用两位来表示整数的状态,00表示不存在,01表示存在1次,10表示存在多次。
具体做法,首先遍历 2.5 亿个整数,查看对应位图中对应的位,如果是 00,则变为 01,如果是 01 则变为 10,如果是 10 则保持不变。最后遍历位图,找出01对应的整数,即为2.5亿整数中只出现一次的整数
### 7.给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
> oppo二面
可以用分治法,然后遍历一遍,查看这个数是否在40亿个数中
不过这种判断某个数据是否存在,用**位图法**更合适,40亿个不重复的数需要40亿个bit,大约需要内存500多M,申请一个数组,遍历40亿个数,将对应的bit设置为1,然后查看需要查询的数的bit,如果为1,则表明在40亿个数中,如果为0,则表示不在40亿个数中。
### 8.已知某个文件内包含一些电话号码,每个号码为 8 位数字,统计不同号码的个数。
很明显,还是使用**位图法**最为简便,每个号码八位数,不考虑实际情况,一共有10^8种情况,也就是需要10^8位bit,大约需要内存100M。申请一个数组,遍历所有号码,将号码对应的bit置为1,最后统计bit位1的数量即为不同的号码数。
### 9.在5亿个int找它们的中位数
中位数是按顺序排列的一组数据中居于中间位置的数,如果观察值有偶数个,通常取最中间的两个数值的平均数作为中位数。 如果题目没有内存限制,只需将5亿个数直接读取到内存中,然后排序,找到中间的数即可
**方法一**
但排序的时间复杂度最快也得O(NlogN),想用空间换时间有没有什么好办法呢? 当然是有的,请看力扣295题(数据流的中位数),https://leetcode-cn.com/problems/find-median-from-data-stream/ 为了方便,这里贴出了一个高赞题解,原链接:https://leetcode-cn.com/problems/find-median-from-data-stream/solution/gong-shui-san-xie-jing-dian-shu-ju-jie-g-pqy8/
我们可以使用两个优先队列(堆)来维护整个数据流数据,令维护数据流左半边数据的优先队列(堆)为l,维护数据流右半边数据的优先队列(堆)为 r。
显然,为了可以在 O(1) 的复杂度内取得当前中位数,我们应当令 l 为大根堆,r为小根堆,并人为固定 l和r之前存在如下的大小关系:
当数据流元素数量为偶数:l 和r 大小相同,此时动态中位数为两者堆顶元素的平均值; 当数据流元素数量为奇数:l 比 r 多一,此时动态中位数为 l的堆顶原数。 为了满足上述说的奇偶性堆大小关系,在进行 addNum 时,我们应当分情况处理:
插入前两者大小相同,说明插入前数据流元素个数为偶数,插入后变为奇数。我们期望操作完达到「l的数量为r多一,同时双堆维持有序」,进一步分情况讨论:
如果r 为空,说明当前插入的是首个元素,直接添加到 l即可; 如果r不为空,且 num <= r.peek(),说明num 的插入位置不会在后半部分(不会在r中),直接加到l即可; 如果 r 不为空,且 num > r.peek(),说明 num的插入位置在后半部分,此时将r 的堆顶元素放到 l 中,再把 num放到 r(相当于从r中置换一位出来放到l中)。 插入前两者大小不同,说明前数据流元素个数为奇数,插入后变为偶数。我们期望操作完达到「l和r数量相等,同时双堆维持有序」,进一步分情况讨论(此时l必然比r 元素多一):
如果 num >= l.peek(),说明num的插入位置不会在前半部分(不会在 l中),直接添加到 r 即可。 如果 num < l.peek(),说明 num 的插入位置在前半部分,此时将 l 的堆顶元素放到r 中,再把 num 放入 l中(相等于从l 中替换一位出来当到r 中)。
**方法二**
当然如果内存不足怎么办,不能把数据全部放入内存
还是之前的老办法,分治法。但是这道题不能用hash映射的方法分流,因为这是无序的,而把数据打乱分散到不同文件中就找不到中位数了,所以需要一种按大小分流的方法。
首先遍历这5亿个数,遍历的时候将每个数转换位二进制,如果最高位为1存入文件1,最高位为0存入文件2,这样文件1中的数是一定比文件2中的小的。因为最高位是符号位,0表示正数,1表示负数
如果恰好文件1和文件2中的数都是2.5亿个,那么中位数则是文件1中的最小值和文件2中的最大值的平均值。
一般不会这么恰好,假设文件1中的数为2亿个,文件2中的数为3亿个,那么中位数是文件中的第五千万个数及下一个数的平均值。
那3亿个数还是不能一次读取进内存要怎么办?
还是使用这个方法根据次高位进行分流,并一直关注位数的位置,直到中位数所在的那部分数据大小可以直接放到内存中,然后对这部分排序,计算出中位数的值
================================================
FILE: interview/系统设计思路.md
================================================
## 面试回答系统设计题的思路
> [Introduction · 系统设计(System Design) (gitbooks.io)](https://soulmachine.gitbooks.io/system-design/content/cn/)
>
> 这部分内容主要参考了Github的一个国外的开源项目,写的很好,感兴趣的小伙伴可以去看看:https://github.com/donnemartin/system-design-primer
>
> 常见的系统设计题有设计一个秒杀系统、红包雨、URL短网址等,完成一个系统设计题大概需要分为四步。 需要注意的是,在面试过程中是比较紧张的,但遇到这种系统设计题,一定先不要急着回答,一定要先需要设计系统的一些使用场景。
>
> 1.第一步:向面试官不断提问,搞清楚系统的使用场景
>
> 系统的功能是什么
>
> 系统的目标群体是什么
>
> 系统的用户量有多大
>
> 希望每秒钟处理多少请求?
>
> 希望处理多少数据?
>
> 希望的读写比率?
>
> 第二步:创造一个高层级的设计
>
> 2.画出主要的组件和连接例如设计一个网络爬虫,这个是个完整的架构图,在这一步只需要画出一个抽象的架构图即可,不需要这么具体。
>
> 3.设计核心组件
>
> 对每一个核心组件进行具体地分析。例如,面试官让你设计一个url短网址,你需要考虑这些问题
>
> 生成并储存一个完整 url 的 hash
>
> - MD5和 Base62
> - Hash 碰撞
> - SQL 还是 NoSQL 数据库模型
> - 将一个 hashed url 翻译成完整的 url
> - 数据库查找
> - API 和面向对象设计
>
> 4.对系统进行优化
>
> 找到系统的瓶颈所在,对其进行优化,例如可以考虑水平扩展、数据库分片等等。
## 系统的一些性能指标
**响应时间**
响应时间指从发出请求开始到收到最后响应数据所需的时间,响应时间是系统最重要的性能指标其直观地反映了系统的“快慢”。
**并发数**
并发数指系统能够同时处理请求的数目,这个数字反映了系统的负载特性。
**吞吐量**
吞吐量指单位时间内系统处理的请求数量,体现系统的整体处理能力。
QPS(Query Per Second):服务器每秒可以执行的查询次数
TPS(Transaction Per Second):服务器每秒处理的事务数并发数=QPS*平均响应时间
**经常听到的一些系统活跃度的名词**
PV(Page View)
页面点击量或者浏览量,用户每次对网站中的每个页面访问均被记录一个PV,多次访问则会累计。
UV(Unique visitor)独立访客,统计一天内访问网站的用户数,一个用户多次访问网站算一个用户
IP(Internet Protocol)指一天内访问某站点的IP总数,以用户的IP地址作为统计的指标,相同IP多次访问某站点算一次
IP和UV的区别:在同一个IP地址下,两个不同的账号访问同一个站点,UV算两次,IP算一次
DAU(Daily Active User):日活跃用户数量。
MAU(monthly active users):月活跃用户人数。
**常用软件的QPS**
Nginx:一般Nginx的QPS是比较大的,单机的可达到30万
MySQL:对于读操作可达几百k,对于写操作更低,大概只有100k
Redis:大概在几万左右,像set命令甚至可达10万 Tomcat:单机
Tomcat 的QPS 在 2万左右。
Memcached:大概在几十万左右通过了解这些软件的QPS可以更清楚地找出系统的瓶颈所在。
### ❤1.分布式ID生成器
> 小红书、百度提前批
如何设计一个分布式ID生成器(Distributed ID Generator),并保证ID按时间粗略有序? 应用场景(Scenario) 现实中很多业务都有生成唯一ID的需求,例如: 用户ID 微博ID 聊天消息ID 帖子ID 订单ID需求(Needs)
这个ID往往会作为数据库主键,所以需要保证全局唯一。数据库会在这个字段上建立聚集索引(Clustered Index,参考 MySQL InnoDB),即该字段会影响各条数据再物理存储上的顺序。 ID还要尽可能短,节省内存,让数据库索引效率更高。基本上64位整数能够满足绝大多数的场景,但是如果能做到比64位更短那就更好了。需要根据具体业务进行分析,预估出ID的最大值,这个最大值通常比64位整数的上限小很多,于是我们可以用更少的bit表示这个ID。
查询的时候,往往有分页或者排序的需求,所以需要给每条数据添加一个时间字段,并在其上建立普通索引(Secondary Index)。但是普通索引的访问效率比聚集索引慢,如果能够让ID按照时间粗略有序,则可以省去这个时间字段。为什么不是按照时间精确有序呢?因为按照时间精确有序是做不到的,除非用一个单机算法,在分布式场景下做到精确有序性能一般很差。
这就引出了ID生成的三大核心需求:
全局唯一(unique)
按照时间粗略有序(sortable by time)
尽可能短
下面介绍一些常用的生成ID的方法。
**UUID**
用过MongoDB的人会知道,MongoDB会自动给每一条数据赋予一个唯一的ObjectId,保证不会重复,这是怎么做到的呢?实际上它用的是一种UUID算法,生成的ObjectId占12个字节,由以下几个部分组成,
4个字节表示的Unix timestamp,
3个字节表示的机器的ID
2个字节表示的进程ID
3个字节表示的计数器
UUID是一类算法的统称,具体有不同的实现。UUID的优点是每台机器可以独立产生ID,理论上保证不会重复,所以天然是分布式的,缺点是生成的ID太长,不仅占用内存,而且索引查询效率低。
**多台MySQL服务器**
既然MySQL可以产生自增ID,那么用多台MySQL服务器,能否组成一个高性能的分布式发号器呢? 显然可以。
假设用8台MySQL服务器协同工作,第一台MySQL初始值是1,每次自增8,第二台MySQL初始值是2,每次自增8,依次类推。前面用一个 round-robin load balancer 挡着,每来一个请求,由 round-robin balancer 随机地将请求发给8台MySQL中的任意一个,然后返回一个ID。
Flickr就是这么做的,仅仅使用了两台MySQL服务器。可见这个方法虽然简单无脑,但是性能足够好。不过要注意,在MySQL中,不需要把所有ID都存下来,每台机器只需要存一个MAX_ID就可以了。这需要用到MySQL的一个REPLACE INTO特性。
这个方法跟单台数据库比,缺点是ID是不是严格递增的,只是粗略递增的。不过这个问题不大,我们的目标是粗略有序,不需要严格递增。
**Twitter Snowflake**
比如 Twitter 有个成熟的开源项目,就是专门生成ID的,Twitter Snowflake 。Snowflake的核心算法如下
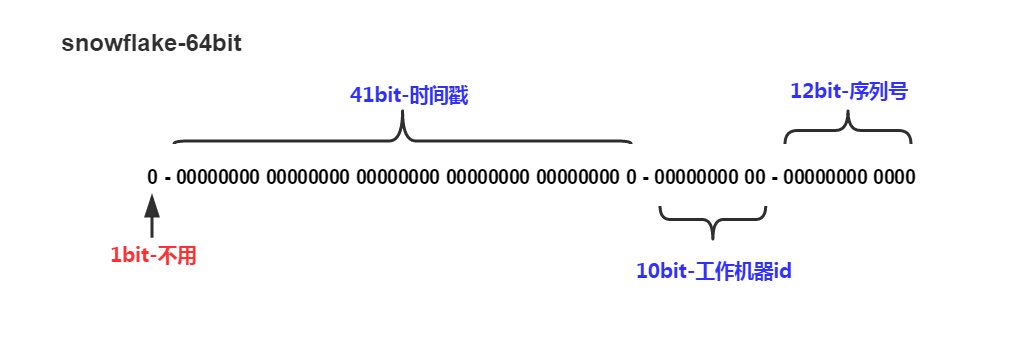
最高位不用,永远为0,其余三组bit占位均可浮动,看具体的业务需求而定。默认情况下41bit的时间戳可以支持该算法使用到2082年,10bit的工作机器id可以支持1023台机器,序列号支持1毫秒产生4095个自增序列id。
Instagram用了类似的方案,41位表示时间戳,13位表示shard Id(一个shard Id对应一台PostgreSQL机器),最低10位表示自增ID,怎么样,跟Snowflake的设计非常类似吧。这个方案用一个PostgreSQL集群代替了Twitter Snowflake 集群,优点是利用了现成的PostgreSQL,容易懂,维护方便。
有的面试官会问,如何让ID可以粗略的按照时间排序?上面的这种格式的ID,含有时间戳,且在高位,恰好满足要求。如果面试官又问,如何保证ID严格有序呢?在分布式这个场景下,是做不到的,要想高性能,只能做到粗略有序,无法保证严格有序。
注:这里列举了一些比较经典的系统设计题,并给出了解题思路,经典系统设计题部分内容来源于Gitbook,链接:https://github.com/donnemartin/system-design-primer
### **2.短网址系统**
如何设计一个短网址服务(TinyURL)?
**使用场景(Scenario)**
微博和Twitter都有140字数的限制,如果分享一个长网址,很容易就超出限制,发布出去。短网址服务可以把一个长网址变成短网址,方便在社交网络上传播。
**需求(Needs)**
很显然,要尽可能的短。长度设计为多少才合适呢?
**短网址的长度**
当前互联网上的网页总数大概是 45亿(参考 http://www.worldwidewebsize.com),45亿超过了 2^{32}=4294967296232=4294967296,但远远小于64位整数的上限值,那么用一个64位整数足够了。
微博的短网址服务用的是长度为7的字符串,这个字符串可以看做是62进制的数,那么最大能表示{62}^7=3521614606208627=3521614606208个网址,远远大于45亿。所以长度为7就足够了。 一个64位整数如何转化为字符串呢?,假设我们只是用大小写字母加数字,那么可以看做是62进制数,log_{62} {(2^{64}-1)}=10.7log62(264−1)=10.7,即字符串最长11就足够了。 实际生产中,还可以再短一点,比如新浪微博采用的长度就是7,因为 62^7=3521614606208627=3521614606208,这个量级远远超过互联网上的URL总数了,绝对够用了。
现代的web服务器(例如Apache, Nginx)大部分都区分URL里的大小写了,所以用大小写字母来区分不同的URL是没问题的。
因此,正确答案:**长度不超过7的字符串,由大小写字母加数字共62个字母组成**
一对一还是一对多映射?
一个长网址,对应一个短网址,还是可以对应多个短网址? 这也是个重大选择问题
一般而言,一个长网址,在不同的地点,不同的用户等情况下,生成的短网址应该不一样,这样,在后端数据库中,可以更好的进行数据分析。如果一个长网址与一个短网址一一对应,那么在数据库中,仅有一行数据,无法区分不同的来源,就无法做数据分析了。
以这个7位长度的短网址作为唯一ID,这个ID下可以挂各种信息,比如生成该网址的用户名,所在网站,HTTP头部的 User Agent等信息,收集了这些信息,才有可能在后面做大数据分析,挖掘数据的价值。短网址服务商的一大盈利来源就是这些数据。
**正确答案:一对多**
如何计算短网址
现在我们设定了短网址是一个长度为7的字符串,如何计算得到这个短网址呢? 最容易想到的办法是哈希,先hash得到一个64位整数,将它转化为62进制整,截取低7位即可。但是哈希算法会有冲突,如何处理冲突呢,又是一个麻烦。这个方法只是转移了矛盾,没有解决矛盾,抛弃。
**正确答案:分布式ID生成器**
**如何存储**
如果存储短网址和长网址的对应关系?以短网址为 primary key, 长网址为value, 可以用传统的关系数据库存起来,例如MySQL, PostgreSQL,也可以用任意一个分布式KV数据库,例如Redis, LevelDB。
如果你手痒想要手工设计这个存储,那就是另一个话题了,你需要完整地造一个KV存储引擎轮子。当前流行的KV存储引擎有LevelDB何RockDB,去读它们的源码吧
**301还是302重定向**
这也是一个有意思的问题。这个问题主要是考察你对301和302的理解,以及浏览器缓存机制的理解。
301是永久重定向,302是临时重定向。短地址一经生成就不会变化,所以用301是符合http语义的。但是如果用了301, Google,百度等搜索引擎,搜索的时候会直接展示真实地址,那我们就无法统计到短地址被点击的次数了,也无法收集用户的Cookie, User Agent 等信息,这些信息可以用来做很多有意思的大数据分析,也是短网址服务商的主要盈利来源。
所以,**正确答案是302重定向**。 可以抓包看看新浪微博的短网址是怎么做的,使用 Chrome 浏览器,访问这个URL http://t.cn/RX2VxjI,是我事先发微博自动生成的短网址。来抓包看看返回的结果是啥
TinyURL-302 可见新浪微博用的就是302临时重定向。
**预防攻击**
如果一些别有用心的黑客,短时间内向TinyURL服务器发送大量的请求,会迅速耗光ID,怎么办呢?
首先,限制IP的单日请求总数,超过阈值则直接拒绝服务。 光限制IP的请求数还不够,因为黑客一般手里有上百万台肉鸡的,IP地址大大的有,所以光限制IP作用不大。
可以用一台Redis作为缓存服务器,存储的不是 ID->长网址,而是 长网址->ID,仅存储一天以内的数据,用LRU机制进行淘汰。这样,如果黑客大量发同一个长网址过来,直接从缓存服务器里返回短网址即可,他就无法耗光我们的ID了。
### 3.定时任务调度器
请实现一个定时任务调度器,有很多任务,每个任务都有一个时间戳,任务会在该时间点开始执行。 定时执行任务是一个很常见的需求,例如Uber打车48小时后自动好评,淘宝购物15天后默认好评,等等。
**方案1: PriorityBlockingQueue + Polling** (轮询)
我们很快可以想到第一个办法:
用一个java.util.concurrent.PriorityBlockingQueue来作为优先队列。因为我们需要一个优先队列,又需要线程安全,用PriorityBlockingQueue再合适不过了。你也可以手工实现一个自己的PriorityBlockingQueue,用java.util.PriorityQueue + ReentrantLock,用一把锁把这个队列保护起来,就是线程安全的啦
对于生产者,可以用一个while(true),造一些随机任务塞进去 对于消费者,起一个线程,在 while(true)里每隔几秒检查一下队列,如果有任务,则取出来执行。
这个方案的确可行,总结起来就是轮询(polling)。轮询通常有个很大的缺点,就是时间间隔不好设置,间隔太长,任务无法及时处理,间隔太短,会很耗CPU。
**方案2: PriorityBlockingQueue + 时间差**
可以把方案1改进一下,while(true)里的逻辑变成: 偷看一下堆顶的元素,但并不取出来,如果该任务过期了,则取出来 如果没过期,则计算一下时间差,然后 sleep()该时间差 不再是 sleep() 一个固定间隔了,消除了轮询的缺点。 稍等!这个方案其实有个致命的缺陷,导致它比 PiorityBlockingQueue + Polling 更加不可用,这个缺点是什么呢?。。。
假设当前堆顶的任务在100秒后执行,消费者线程peek()偷看到了后,开始sleep 100秒,这时候一个新的任务插了进来,该任务在10秒后应该执行,但是由于消费者线程要睡眠100秒,这个新任务无法及时处理
**方案3:Go语言time包下的定时器实现方案**
golang使用最小堆(最小堆是满足除了根节点以外的每个节点都不小于其父节点的堆、四叉小顶堆)实现的定时器。golang []*****timer结构如下:
golang存储定时任务结构
addtimer在堆中插入一个值,然后保持最小堆的特性,其实这个结构本质就是最小优先队列的一个应用,**然后将时间转换一个绝对时间处理,通过睡眠和唤醒找出定时任务**
当我们通过 NewTimer、NewTicker 等方法创建定时器时,返回的是一个 Timer 对象。这个对象里有一个 runtimeTimer 字段的结构体,它在最后会被编译成 src/runtime/time.go 里的 timer 结构体。
而这个 timer 结构体就是真正有着定时处理逻辑的结构体。
一开始,timer 会被分配到一个全局的 timersBucket 时间桶。每当有 timer 被创建出来时,就会被分配到对应的时间桶里了。
为了不让所有的 timer 都集中到一个时间桶里,Go 会创建 64 个这样的时间桶,然后根据 当前 timer 所在的 Goroutine 的 P 的 id 去哈希到某个桶上:
```
// assignBucket 将创建好的 timer 关联到某个桶上
func (t *timer) assignBucket() *timersBucket {
id := uint8(getg().m.p.ptr().id) % timersLen
t.tb = &timers[id].timersBucket
return t.tb
}
```
接着 timersBucket 时间桶将会对这些 timer 进行一个最小堆的维护,每次会挑选出时间最快要达到的 timer。
如果挑选出来的 timer 时间还没到,那就会进行 sleep 休眠。
如果 timer 的时间到了,则执行 timer 上的函数,并且往 timer 的 channel 字段发送数据,以此来通知 timer 所在的 goroutine。
如果timer的时间还不到,但此时又添加另一个timer,此时会重新唤醒线程
**方案4: 时间轮(HashedWheelTimer)**
时间轮(HashedWheelTimer)其实很简单,就是一个循环队列,如下图所示,

上图是一个长度为8的循环队列,假设该时间轮精度为秒,即每秒走一格,像手表那样,走完一圈就是8秒。每个格子指向一个任务集合,时间轮无限循环,每转到一个格子,就扫描该格子下面的所有任务,把时间到期的任务取出来执行。
举个例子,假设指针当前正指向格子0,来了一个任务需要4秒后执行,那么这个任务就会放在格子s4下面,如果来了一个任务需要20秒后执行怎么?由于这个循环队列转一圈只需要8秒,这个任务需要多转2圈,所以这个任务的位置虽然依旧在格子4(20%8+0=4)下面,不过需要多转2圈后才执行。因此每个任务需要有一个字段记录需圈数,每转一圈就减1,减到0则立刻取出来执行。 怎么实现时间轮呢?Netty中已经有了一个时间轮的实现, HashedWheelTimer.java,可以参考它的源代码。 时间轮的优点是性能高,插入和删除的时间复杂度都是O(1)。
Linux 内核中的定时器采用的就是这个方案。
Follow up: 如何设计一个分布式的定时任务调度器呢? 答: Redis ZSet, RabbitMQ等
### 4❤.最近一个小时内访问频率最高的10个IP
实时输出最近一个小时内访问频率最高的10个IP,
要求:
实时输出
从当前时间向前数的1个小时
QPS可能会达到10W/s
这道题乍一看很像Top K 频繁项,是不是需要 Lossy Count 或 Count-Min Sketch 之类的算法呢?
其实杀鸡焉用牛刀,这道题用不着上述算法,请听我仔细分析。
- QPS是 10万/秒,即一秒内最高有 10万个请求,那么一个小时内就有 100000*3600=360000000≈2^{28.4},向上取整,大概是 2^{29}个请求,也不是很大。我们在内存中建立3600个HashMap< int , int>,放在一个数组里,每秒对应一个HashMap,IP地址为key, 出现次数作为value。这样,一个小时内最多有2^{29}个pair,每个pair占8字节,总内存大概是 2^{29} \times 8=2^{32}节,即4GB,单机完全可以存下。
- 同时还要新建一个固定大小为10的小根堆,用于存放当前出现次数最大的10个IP。堆顶是10个IP里频率最小的IP。
- 每次来一个请求,就把该秒对应的HashMap里对应的IP计数器增1,并查询该IP是否已经在堆中存在,
- 如果不存在,则把该IP在3600个HashMap的计数器加起来,与堆顶IP的出现次数进行比较,如果大于堆顶元素,则替换掉堆顶元素,如果小于,则什么也不做
- 如果已经存在,则把堆中该IP的计数器也增1,并调整堆
- 需要有一个后台常驻线程,每过一秒,把最旧的那个HashMap销毁,将存在于堆中的IP减少,并为当前这一秒新建一个HashMap,这样维持一个一小时的窗口。
- 每次查询top 10的IP地址时,把堆里10个IP地址返回来即可。
以上就是该方案的全部内容。 有的人问,可不可以用”IP + 时间”作为key, 把所有pair放在单个HashMap里?如果把所有数据放在一个HashMap里,有两个巨大的缺点,
- 第4步里,怎么淘汰掉一个小时前的pair呢?这时候后台线程只能每隔一秒,全量扫描这个HashMap里的所有pair,把过期数据删除,这是线性时间复杂度,很慢。
- 这时候HashMap里的key存放的是”IP + 时间”组合成的字符串,占用内存远远大于一个int。而前面的方案,不用存真正的时间,只需要开一个3600长度的数组来表示一个小时时间窗口。
### 5.key-Value存储引擎
请设计一个Key-Value存储引擎(Design a key-value store)。
这是一道频繁出现的题目,个人认为也是一道很好的题目,这题纵深非常深,内行的人可以讲的非常深。
首先讲两个术语,**数据库和存储引擎**。数据库往往是一个比较丰富完整的系统, 提供了SQL查询语言,事务和水平扩展等支持。然而存储引擎则是小而精, 纯粹专注于单机的读/写/存储。一般来说, 数据库底层往往会使用某种存储引擎。 、
目前开源的KV存储引擎中,RocksDB是流行的一个,MongoDB和MySQL底层可以切换成RocksDB, TiDB底层直接使用了RocksDB。大多数分布式数据库的底层不约而同的都选择了RocksDB。
RocksDB最初是从LevelDB进化而来的,我们先从简单一点的LevelDB入手,借鉴它的设计思路。
**LevelDB整体结构**
有一个反直觉的事情是,**内存随机写甚至比硬盘的顺序读还要慢**,磁盘随机写就更慢了,说明我们要避免随机写,最好设计成顺序写。因此好的KV存储引擎,都在尽量避免更新操作,把更新和删除操作转化为顺序写操作。
LevelDB采用了一种SSTable的数据结构来达到这个目的。 SSTable(Sorted String Table)就是一组按照key排序好的 key-value对, key和value都是字节数组。SSTable既可以在内存中,也可以在硬盘中。SSTable底层使用LSM Tree(Log-Structured Merge Tree)来存放有序的key-value对。
LevelDB整体由如下几个组成部分,
- MemTable。即内存中的SSTable,新数据会写入到这里,然后批量写入磁盘,以此提高写的吞吐量。
- Log文件。写MemTable前会写Log文件,即用WAL(Write Ahead Log)方式记录日志,如果机器突然掉电,内存中的MemTable丢失了,还可以通过日志恢复数据。WAL日志是很多传统数据库例如MySQL采用的技术,详细解释可以参考[数据库如何用 WAL 保证事务一致性? - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/24900322)。
- Immutable MemTable。内存中的MemTable达到指定的大小后,将不再接收新数据,同时会有新的MemTable产生,新数据写入到这个新的MemTable里,Immutable MemTable随后会写入硬盘,变成一个SST文件。
- SSTable文件。即硬盘上的SSTable,文件尾部追加了一块索引,记录key->offset,提高随机读的效率。SST文件为Level 0到Level N多层,每一层包含多个SST文件;单个SST文件容量随层次增加成倍增长;Level0的SST文件由Immutable MemTable直接Dump产生,其他Level的SST文件由其上一层的文件和本层文件归并产生。
- Manifest文件。 Manifest文件中记录SST文件在不同Level的分布,单个SST文件的最大最小key,以及其他一些LevelDB需要的元信息。
- Current文件。从上面的介绍可以看出,LevelDB启动时的首要任务就是找到当前的Manifest,而Manifest可能有多个。Current文件简单的记录了当前Manifest的文件名。
LevelDB的一些核心逻辑如下,
- 首先SST文件尾部的索引要放在内存中,这样读索引就不需要一次磁盘IO了
- 所有读要先查看MemTable,如果没有再查看内存中的索引
- 所有写操作只能写到MemTable, 因为SST文件不可修改
- 定期把Immutable MemTable写入硬盘,成为SSTable文件,同时新建一个MemTable会继续接收新来的写操作 定期对
- SSTable文件进行合并
- 由于硬盘上的SSTable文件是不可修改的,那怎么更新和删除数据呢?
- 对于更新操作,追加一个新的key-value对到文件尾部,由于读SSTable文件是从前向后读的,所以新数据会最先被读到;
- 对于删除操作,追加“墓碑”值(tombstone),表示删除该key,在定期合并SSTable文件时丢弃这些key, 即可删除这些key。
**Manifest文件**
Manifest文件记录各个SSTable各个文件的管理信息,比如该SST文件处于哪个Level,文件名称叫啥,最小key和最大key各自是多少,如下图所示,

**Log文件**
Log文件主要作用是系统发生故障时,能够保证不会丢失数据。因为在数据写入内存中的MemTable之前,会先写入Log文件,这样即使系统发生故障,MemTable中的数据没有来得及Dump到磁盘,LevelDB也可以根据log文件恢复内存中的MemTable,不会造成系统丢失数据。这个方式就叫做 WAL(Write Ahead Log),很多传统数据库例如MySQL也使用了WAL技术来记录日志。
每个Log文件由多个block组成,每个block大小为32K,读取和写入以block为基本单位。下图所示的Log文件包含3个Bloc

**SSTable**
**MemTable**
MemTable 是内存中的数据结构,存储的内容跟硬盘上的SSTable一样,只是格式不一样。Immutable MemTable的内存结构和Memtable是完全一样的,区别仅仅在于它是只读的,而MemTable则是允许写入和读取的。当MemTable写入的数据占用内存到达指定大小,则自动转换为Immutable Memtable,等待Dump到磁盘中,系统会自动生成一个新的MemTable供写操作写入新数据,理解了MemTable,那么Immutable MemTable自然不在话下。
MemTable里的数据是按照key有序的,因此当插入新数据时,需要把这个key-value对插入到合适的位置上,以保持key有序性。MemTable底层的核心数据结构是一个跳表(Skip List)。跳表是红黑树的一种替代数据结构,具有更高的写入速度,而且实现起来更加简单,请参考跳表(Skip List)[SkipList 跳表 - The time is passing - ITeye博客](https://www.iteye.com/blog/kenby-1187303)。
前面我们介绍了LevelDB的一些内存数据结构和文件,这里开始介绍一些动态操作,例如读取,写入,更新和删除数据,分层合并,错误恢复等操作。
**添加、更新和删除数据**
LevelDB写入新数据时,具体分为两个步骤:
- 将这个操作顺序追加到log文件末尾。尽管这是一个磁盘操作,但是文件的顺序写入效率还是跟高的,所以不会降低写入的速度
- 如果log文件写入成功,那么将这条key-value记录插入到内存中MemTable。
LevelDB更新一条记录时,并不会本地修改SST文件,而是会作为一条新数据写入MemTable,随后会写入SST文件,在SST文件合并过程中,新数据会处于文件尾部,而读取操作是从文件尾部倒着开始读的,所以新值一定会最先被读到。
LevelDB删除一条记录时,也不会修改SST文件,而是用一个特殊值(墓碑值,tombstone)作为value,将这个key-value对追加到SST文件尾部,在SST文件合并过程中,这种值的key都会被忽略掉。
核心思想就是把写操作转换为顺序追加,从而提高了写的效率。 **读取数据**
读操作使用了如下几个手段进行优化:
MemTable + SkipList
Binary Search(通过 manifest 文件)
页缓存
bloom filter
周期性分层合并
### 6.数据流采样

### 7.基数估计
如何计算数据流中不同元素的个数?例如,独立访客(Unique Visitor,简称UV)统计。这个问题称为基数估计(Cardinality Estimation),也是一个很经典的题目。
**方案1: HashSet**
首先最容易想到的办法是用HashSet,每来一个元素,就往里面塞,HashSet的大小就所求答案。但是在大数据的场景下,HashSet在单机内存中存不下。
**方案2: bitmap**
HashSet耗内存主要是由于存储了元素的真实值,可不可以不存储元素本身呢?bitmap就是这样一个方案,假设已经知道不同元素的个数的上限,即基数的最大值,设为N,则开一个长度为N的bit数组,地位跟HashSet一样。每个元素与bit数组的某一位一一对应,该位为1,表示此元素在集合中,为0表示不在集合中。那么bitmap中1的个数就是所求答案。
这个方案的缺点是,bitmap的长度与实际的基数无关,而是与基数的上限有关。假如要计算上限为1亿的基数,则需要12.5MB的bitmap,十个网站就需要125M。关键在于,这个内存使用与集合元素数量无关,即使一个网站仅仅有一个1UV,也要为其分配12.5MB内存。
实际上目前还没有发现在大数据场景中准确计算基数的高效算法,因此在不追求绝对准确的情况下,使用近似算法算是一个不错的解决方案。
**方案3: Linear Counting**

**方案4: LogLog Counting**

**方案5: HyperLogLog Counting**

### **8.频率估计**
如何计算数据流中任意元素的频率? 这个问题也是大数据场景下的一个经典问题,称为频率估计(Frequency Estimation)问题。
**方案1: HashMap**
用一个HashMap记录每个元素的出现次数,每来一个元素,就把相应的计数器增1。这个方法在大数据的场景下不可行,因为元素太多,单机内存无法存下这个巨大的HashMap。
**方案2: 数据分片 + HashMap**
既然单机内存存不下所有元素,一个很自然的改进就是使用多台机器。假设有8台机器,每台机器都有一个HashMap,第1台机器只处理hash(elem)%8==0的元素,第2台机器只处理hash(elem)%8==1的元素,以此类推。查询的时候,先计算这个元素在哪台机器上,然后去那台机器上的HashMap里取出计数器。 方案2能够scale, 但是依旧是把所有元素都存了下来,代价比较高。 如果允许近似计算,那么有很多高效的近似算法,单机就可以处理海量的数据。下面讲几个经典的近似算法。
**方案3: Count-Min Sketch**
Count-Min Sketch算法流程:
- 选定d个hash函数,开一个 dxm 的二维整数数组作为哈希表
- 对于每个元素,分别使用d个hash函数计算相应的哈希值,并对m取余,然后在对应的位置上增1,二维数组中的每个整数称为sketch
- 要查询某个元素的频率时,只需要取出d个sketch, 返回最小的那一个(其实d个sketch都是该元素的近似频率,返回任意一个都可以,该算法选择最小的那个)
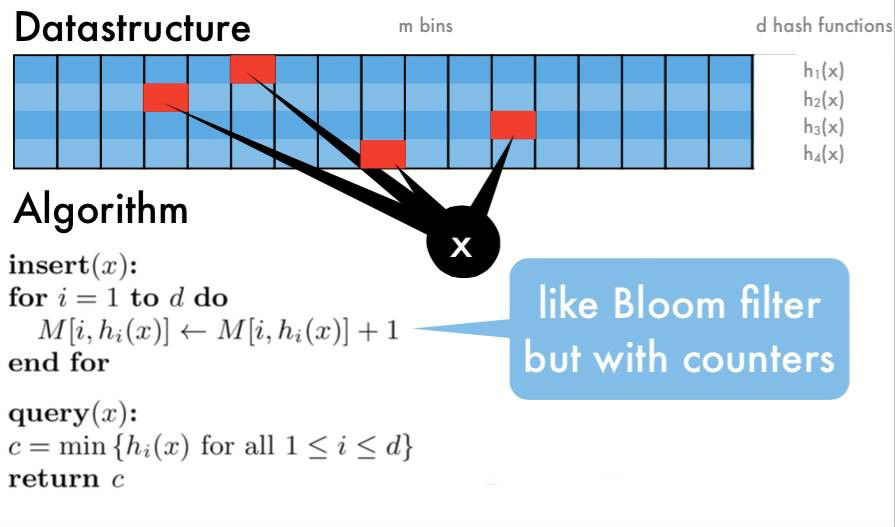
Count-Min Sketch 这个方法的思路和 Bloom Filter 比较类似,都是用多个hash函数来降低冲突。
空间复杂度O(dm)。Count-Min Sketch 需要开一个 dxm 大小的二位数组,所以空间复杂度是O(dm)
时间复杂度O(n)。Count-Min Sketch 只需要一遍扫描,所以时间复杂度是O(n) Count-Min Sketch算法的优点是省内存,缺点是对于出现次数比较少的元素,准确性很差,因为二维数组相比于原始数据来说还是太小,hash冲突比较严重,导致结果偏差比较大。
**方案4: Count-Mean-Min Sketch**
Count-Min Sketch算法对于低频的元素,结果不太准确,主要是因为hash冲突比较严重,产生了噪音,例如当m=20时,有1000个数hash到这个20桶,平均每个桶会收到50个数,这50个数的频率重叠在一块了。Count-Mean-Min Sketch 算法做了如下改进:
- 来了一个查询,按照 Count-Min Sketch的正常流程,取出它的d个sketch
- 对于每个hash函数,估算出一个噪音,噪音等于该行所有整数(除了被查询的这个元素)的平均值
- 用该行的sketch 减去该行的噪音,作为真正的sketch
- 返回d个sketch的中位数
算法能够显著的改善在长尾数据上的精确度。
### 9.❤Top k频繁项
> 深信服二面
寻找数据流中出现最频繁的k个元素(find top k frequent items in a data stream)。这个问题也称为 Heavy Hitters. 这题也是从实践中提炼而来的,例如搜索引擎的热搜榜,找出访问网站次数最多的前10个IP地址,等等。
**方案1: HashMap + Heap**
用一个 HashMap,存放所有元素出现的次数,用一个小根堆,容量为k,存放目前出现过的最频繁的k个元素,
- 每次从数据流来一个元素,如果在HashMap里已存在,则把对应的计数器增1,如果不存在,则插入,计数器初始化为1
- 在堆里查找该元素,如果找到,把堆里的计数器也增1,并调整堆;如果没有找到,把这个元素的次数跟堆顶元素比较,如果大于堆丁元素的出现次数,则把堆丁元素替换为该元素,并调整堆
- 空间复杂度O(n)。HashMap需要存放下所有元素,需要O(n)的空间,堆需要存放k个元素,需要O(k)的空间,跟O(n)相比可以忽略不计,总的时间复杂度是O(n) 时间复杂度O(n)。每次来一个新元素,需要在HashMap里查找一下,需要O(1)的时间;然后要在堆里查找一下,O(k)的时间,有可能需要调堆,又需要O(logk)的时间,总的时间复杂度是O(n(k+logk)),k是常量,所以可以看做是O(n)。
如果元素数量巨大,单机内存存不下,怎么办? 有两个办法,见方案2和3。
**方案2: 多机HashMap + Heap**
- 可以把数据进行分片。假设有8台机器,第1台机器只处理hash(elem)%8==0的元素,第2台机器只处理hash(elem)%8==1的元素,以此类推。
- 每台机器都有一个HashMap和一个 Heap, 各自独立计算出 top k 的元素
- 把每台机器的Heap,通过网络汇总到一台机器上,将多个Heap合并成一个Heap,就可以计算出总的 top k 个元素了
### 10.范围查询
给定一个无限的整数数据流,如何查询在某个范围内的元素出现的总次数?例如数据库常常需要SELECT count(v) WHERE v >= l AND v < u。这个经典的问题称为范围查询(Range Query)。
有一个简单方法,既然Count-Min Sketch可以计算每个元素的频率,那么我们把指定范围内所有元素的sketch加起来,不就是这个范围内元素出现的总数了吗?要注意,由于每个sketch都是近似值,多个近似值相加,误差会被放大,所以这个方法不可行。
解决的办法就是使用多个“分辨率”不同的Count-Min Sketch。第1个sketch每个格子存放单个元素的频率,第2个sketch每个格子存放2个元素的频率(做法很简答,把该元素的哈希值的最低位bit去掉,即右移一位,等价于除以2,再继续后续流程),第3个sketch每个格子存放4个元素的频率(哈希值右移2位即可),以此类推,最后一个sketch有2个格子,每个格子存放一半元素的频率总数,即第1个格子存放最高bit为0的元素的总次数,第2个格子存放最高bit为1的元素的总次数。Sketch的个数约等于log(不同元素的总数)。
- 插入元素时,算法伪代码如下,
```
def insert(x):
for i in range(1, d+1):
M1[i][h[i](x)] += 1
M2[i][h[i](x)/2] += 1
M3[i][h[i](x)/4] += 1
M4[i][h[i](x)/8] += 1
# ...
```
- 查询范围[l, u)时,从粗粒度到细粒度,找到多个区间,能够不重不漏完整覆盖区间[l, u),将这些sketch的值加起来,就是该范围内的元素总数。举个例子,给定某个范围,如下图所示,最粗粒度的那个sketch里找不到一个格子,就往细粒度找,最后找到第1个sketch的2个格子,第2个sketch的1个格子和第3个sketch的1个格子,共4个格子,能够不重不漏的覆盖整个范围,把4个红线部分的值加起来就是所求结果
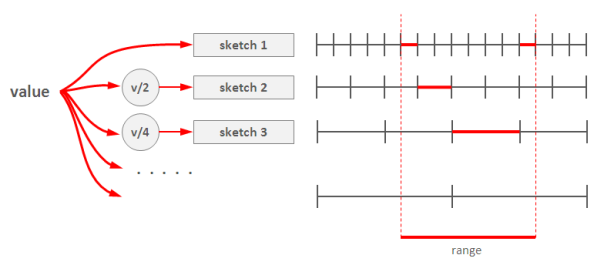
### 11.成员查询
给定一个无限的数据流和一个有限集合,如何判断数据流中的元素是否在这个集合中? 在实践中,我们经常需要判断一个元素是否在一个集合中,例如垃圾邮件过滤,爬虫的网址去重,等等。这题也是一道很经典的题目,称为成员查询(Membership Query)。
答案: **Bloom Filter**
### 12.设计预定系统的表结构。背景大概是用于预定KTV,考虑不同时段的库存和不同时段的价格
```sql
//只是单纯的表的字段,而且是主要字段,不建立索引
-- 预约用户表
create user table(
id bigint,
username varchar(32),
phone char(13), -- 手机号码,最重要的字段,一般都是用电话号码预约
...
)
//ktv房间表
create room table(
id bigint,
name char(5), -- 房间号,比如301 302等
grade tinyint, -- 大、中、小包厢
... -- 其他信息,比如最大容纳人数之类的
)
//预约表
create reservation table(
id bigint,
uid bigint, --预约用户Id
phone varchar(13),-- 预约用户的手机号码
rid bigint, --预约的房间Id
beginAt bigint,--预约开始时间
endAt bigint, --预约结束时间
amount float,-- 支付金额
...
)
//价格表
create prices table(
id bigint,
room_grade tinyint, //房间大小
prices float,//在beginAt~endAt之间每小时的价格
beginAt bigint,
endAt bigint,
)
```
### 13.商品秒杀
**业务场景**
秒杀业务的特点就是开售瞬间大量用户的涌入,例如双十一抢购,短时间内会有大量用户涌入系统,例如一种只有500件的商品会有几百万用户在同时抢购,而最终抢购成功的用户只有500人,大多数用户都是抢购失败。
**业务分析**
短时间内大量用户的高并发请求常常会压垮系统,而瓶颈就在于数据库,数据库每秒仅能支持几万的并发量,而对于抢购每秒百万千万的并发量根本不足以应对,所以要将请求尽量拦截在系统上游,层层削峰,来最大程度的缓解数据库的压力。
**解决方案**
- **前端优化**
1.**页面静态化**
对于变化不频繁的页面,如商品详情和订单详情页面,可进行页面静态化处理,数据通过接口从后端动态获取,实现前后端分离
2.**页面缓存**
对于变化频繁的页面,如商品列表页,可进行页面手动渲染,然后缓存到redis中,并设置过期时间
3.**图片验证码**
点击秒杀时,先让用户输入图片验证码,校验成功后才可进行秒杀
4.禁止重复提交
用户提交之后弹出遮罩或按钮置灰,来防止用户多次点击
-
**后端优化**
1.**利用缓存**
采用redis缓存,来减少对数据库的访问,系统启动时可把商品库存加载到redis中,在redis中预减库存,并把商品、订单、用户等信息保存到redis中
2.**流量削峰**
采用消息队列,来控制并发量,进行异步下单,把用户的下单请求发送给消息队列,当用户请求超过消息队列的最大数量时,直接抛弃用户请求或返回抢购失败页面
3.**限制访问次数**
利用redis的incr自增函数配合过期时间,限制同一用户在指定时间内的访问次数
4.秒杀接口隐藏
秒杀请求地址改为动态生成,临时请求,临时生成,防止恶意用户通过非法工具来请求秒杀接口
================================================
FILE: interview/计算机网络.md
================================================
### 1.什么是网络协议,为什么要对网络协议分层?
网络协议是计算机在通信过程中要遵循的一些约定好的规则。
网络分层的原因:
- 易于实现和维护,因为各层之间是独立的,层与层之间不会受到影响。
- 有利于标准化的制定
### 2.❤计算机网络的各层网络协议及作用
> 计算机网络体系可以大致分为一下三种,七层模型、五层模型和TCP/IP四层模型,一般面试能流畅回答出五层模型就可以了,表示层和会话层被问到的不多。
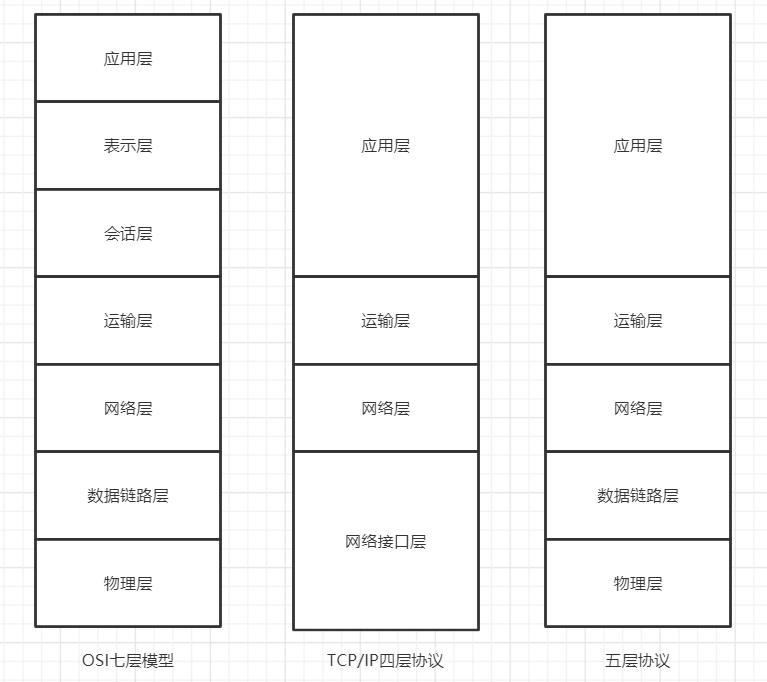
- **应用层**,**负责向用户提供一组应用程序**,常见的应用层协议有DNS,HTTP协议,FTP文件传输协议、SMTP等。而且应用层是工作在操作系统中的用户态,传输层及以下则工作在内核态。
- 表示层,表示层的主要作用是数据的表示、安全、压缩。可确保一个系统的应用层所发送的信息可以被另一个系统的应用层读取。
- 会话层,会话层的主要作用是建立通信链接,保持会话过程通信链接的畅通,同步两个节点之间的对话,决定通信是否被中断以及通信中断时决定从何处重新发送。
- **运输层**,传输层的主要作用是负责向两台**主机进程**之间的通信提供数据传输服务(**端到端的通信**)。传输层的协议主要有TCP、UDP。
- **网络层**,网络层的主要作用是选择合适的网间路由和交换结点,确保数据及时送达(**负责网络包的封装、分片、路由、转发**)。常见的协议有IP、ICMP。
- **数据链路层**,数据链路层的作用是在物理层提供比特流服务的基础上,建立相邻结点之间的数据链路,通过差错控制提供数据帧(Frame)在信道上无差错的传输,并进行各电路上的动作系列(**数据在相邻网络结点间的传输**)。 常见的协议有SDLC、HDLC、PPP、以太网等。
- **物理层**,物理层的主要作用是实现相邻计算机结点之间比特流的透明传输,并尽量屏蔽掉具体传输介质和物理设备的差异(**在线路上传输比特流**)。
### 3.URI和URL的区别?
- URI(Uniform Resource Identifier):中文全称为统一资源**标志**符,主要作用是唯一标识一个资源。
- URL(Uniform Resource Location):中文全称为统一资源**定位**符,主要作用是提供资源的路径。
有个经典的比喻是URI像是身份证,可以唯一标识一个人,而URL更像一个住址,可以通过URL找到这个人。
### 4.DNS的工作流程?
> 域名系统
**DNS是集群式的工作方式还是 单点式的,为什么?**
答案是**集群式的**,很容易想到的一个方案就是只用一个DNS服务器,包含了所有域名和IP地址的映射。尽管这种设计方式看起来很简单,但是缺点显而易见,如果这个唯一的DNS服务器出了故障,那么就全完了,因特网就几乎崩了。为了避免这种情况出现,DNS系统采用的是**分布式**的层次数据数据库模式,还有缓存的机制也能解决这种问题。
**DNS的工作流程**
> 主机向本地域名服务器的查询一般是采用递归查询,而本地域名服务器向根域名的查询一般是采用迭代查询。
>
> - 递归查询主机向本地域名发送查询请求报文,而本地域名服务器不知道该域名对应的IP地址时,本地域名会继续向根域名发送查询请求报文,不是通知主机自己向根域名发送查询请求报文。
>
>
> - 迭代查询是,本地域名服务器向根域名发出查询请求报文后,根域名不会继续向顶级域名服务器发送查询请求报文,而是通知本地域名服务器向顶级域名发送查询请求报文。
>
> 简单来说,递归查询就是,小明问了小红一个问题,小红不知道,但小红是个热心肠,小红就去问小王了,小王把答案告诉小红后,小红又去把答案告诉了小明。迭代查询就是,小明问了小红一个问题,小红也不知道,然后小红让小明去问小王,小明又去问小王了,小王把答案告诉了小明。
1.在浏览器中输入www.mianshi.online域名,操作系统会先检查自己本地的hosts文件是否有这个域名的映射关系,如果有,就先调用这个IP地址映射,完成域名解析。
2.如果hosts文件中没有,则查询本地DNS解析器缓存,如果有,则完成地址解析。
3.如果本地DNS解析器缓存中没有,则去查找本地DNS服务器,如果查到,完成解析。
4.如果没有,则本地服务器会向根域名服务器发起查询请求。根域名服务器会告诉本地域名服务器去查询哪个顶级域名服务器。
5.本地域名服务器向顶级域名服务器发起查询请求,顶级域名服务器会告诉本地域名服务器去查找哪个权限域名服务器。 本地域名服务器向权限域名服务器发起查询请求,权限域名服务器告诉本地域名服务器www.mianshi.online所对应的IP地址。
6.本地域名服务器告诉主机www.mianshi.online所对应的IP地址。
### 5.了解ARP协议吗?
ARP协议属于网络层的协议(地址解析协议),主要作用是**实现从IP地址转换为MAC地址**。在每个主机或者路由器中都建有一个ARP缓存表,表中有IP地址及IP地址对应的MAC地址。先来看一下什么时IP地址和MAC地址。
- IP地址:IP地址是指互联网协议地址,IP地址是IP协议提供的一种统一的地址格式,它为互联网上的每一个网络和每一台主机分配一个逻辑地址,以此来屏蔽物理地址的差异。
- MAC地址:MAC地址又称物理地址,由网络设备制造商生产时写在硬件内部,不可更改,并且每个以太网设备的MAC地址都是唯一的。
ARP的工作流程(面试时问ARP协议主要说这个就可以了):
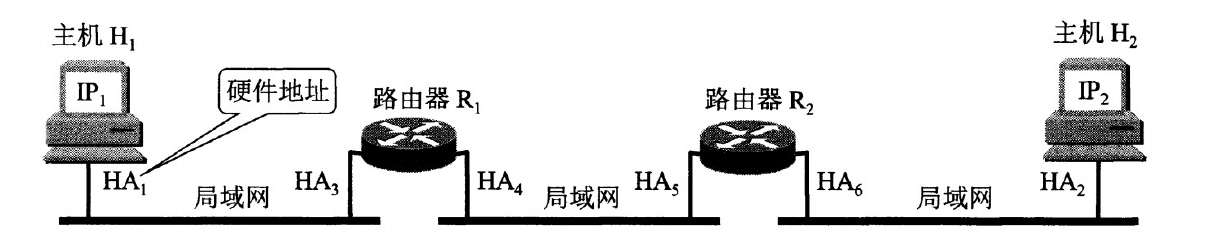
1. 在**局域网**内,主机A要向主机B发送IP数据报时,首先会在主机A的**ARP缓存表**中查找是否有IP地址及其对应的MAC地址,如果有,则将MAC地址写入到MAC帧的首部,并通过局域网将该MAC帧发送到MAC地址所在的主机B。
2. 如果主机A的ARP缓存表中没有主机B的IP地址及所对应的MAC地址,主机A会在局域网内**广播**发送一个ARP请求分组。局域网内的所有主机都会收到这个ARP请求分组。
3. 主机B在看到主机A发送的ARP请求分组中有自己的IP地址,会向主机A以**单播**的方式发送一个带有自己MAC地址的响应分组。
4. 主机A收到主机B的ARP响应分组后,会在ARP缓存表中写入主机B的IP地址及其IP地址对应的MAC地址。
5. 如果主机A和主机B**不在同一个局域网内**,即使知道主机B的MAC地址也是不能直接通信的,必须通过路由器转发到主机B的局域网才可以通过主机B的MAC地址找到主机B。并且主机A和主机B已经可以通信的情况下,主机A的ARP缓存表中寸的并不是主机B的IP地址及主机B的MAC地址,而是**主机B的IP地址及该通信链路上的下一跳路由器的MAC地址**。这就是上图中的源IP地址和目的IP地址一直不变,而MAC地址却随着链路的不同而改变。
### 6.有了IP地址,为什么还要用MAC地址?
简单来说,标识网络中的一台计算机,比较常用的就是IP地址和MAC地址,但计算机的IP地址可由用户自行更改,**管理起来相对困难**,而MAC地址不可更改,所以一般会把IP地址和MAC地址组合起来使用。具体是如何组合使用的在上面的ARP协议中已经讲的很清楚了。
那只用MAC地址不用IP地址可不可以呢?
其实也是不行的,因为在最早就是MAC地址先出现的,并且当时并不用IP地址,只用MAC地址,后来随着网络中的设备越来越多,整个路由过程越来越**复杂**,便出现了子网的概念。对于目的地址在其他子网的数据包,路由只需要将数据包送到那个子网即可,这个过程就是上面说的ARP协议。
那为什么要用IP地址呢?
是因为IP地址是和地域相关的,对于同一个子网上的设备,IP地址的前缀都是一样的,这样路由器通过IP地 址的前缀就知道设备在在哪个子网上了,而只用MAC地址的话,路由器则需要记住每个MAC地址在哪个子网,这需要路由器有极大的存储空间,是无法实现的。
IP地址可以比作为地址,MAC地址为收件人,在一次通信过程中,两者是缺一不可的。
### 7.说一说ping的过程?
ping是ICMP(网际控制报文协议)中的一个重要应用,ICMP是网络层的协议。ping的作用是测试两个主机的连通性。 ping的工作过程:
1.向目的主机发送多个ICMP请求报文
2.根据目的主机返回的回送报文的时间和成功响应的次数估算出数据包往返时间及丢包率。
### 8.路由器和交换机的区别?
| | 所属网络模型的层级 | 功能 |
| ---- | --------- | -------------------------------------- |
| 路由器 | 网络层 | 识别IP地址并根据IP地址转发数据包,维护数据表并基于数据表进行最佳路径选择 |
| 交换机 | 数据链路层 | 识别MAC地址并根据MAC地址转发数据帧 |
### 9.❤TCP与UDP有什么区别?
> 腾讯一面
| | 是否面向连接 | 可靠性 | 传输形式 | 传输效率 | 消耗资源 | 应用场景 | 首部字节 |
| ---- | ------ | ---- | ---- | ---- | ---- | ------- | ----- |
| TCP | 面向连接 | 可靠 | 字节流 | 慢 | 多 | 文件/邮件传输 | 20-60 |
| UDP | 无连接 | 不可靠 | | 快 | 少 | 视屏/语音传输 | 8 |
> ❤有时候面试还会问到TCP的首部都包含什么
TCP首部:前20个字节是固定的,后面又4n个字节是根据需要而增加的选项,最小长度为20个字节
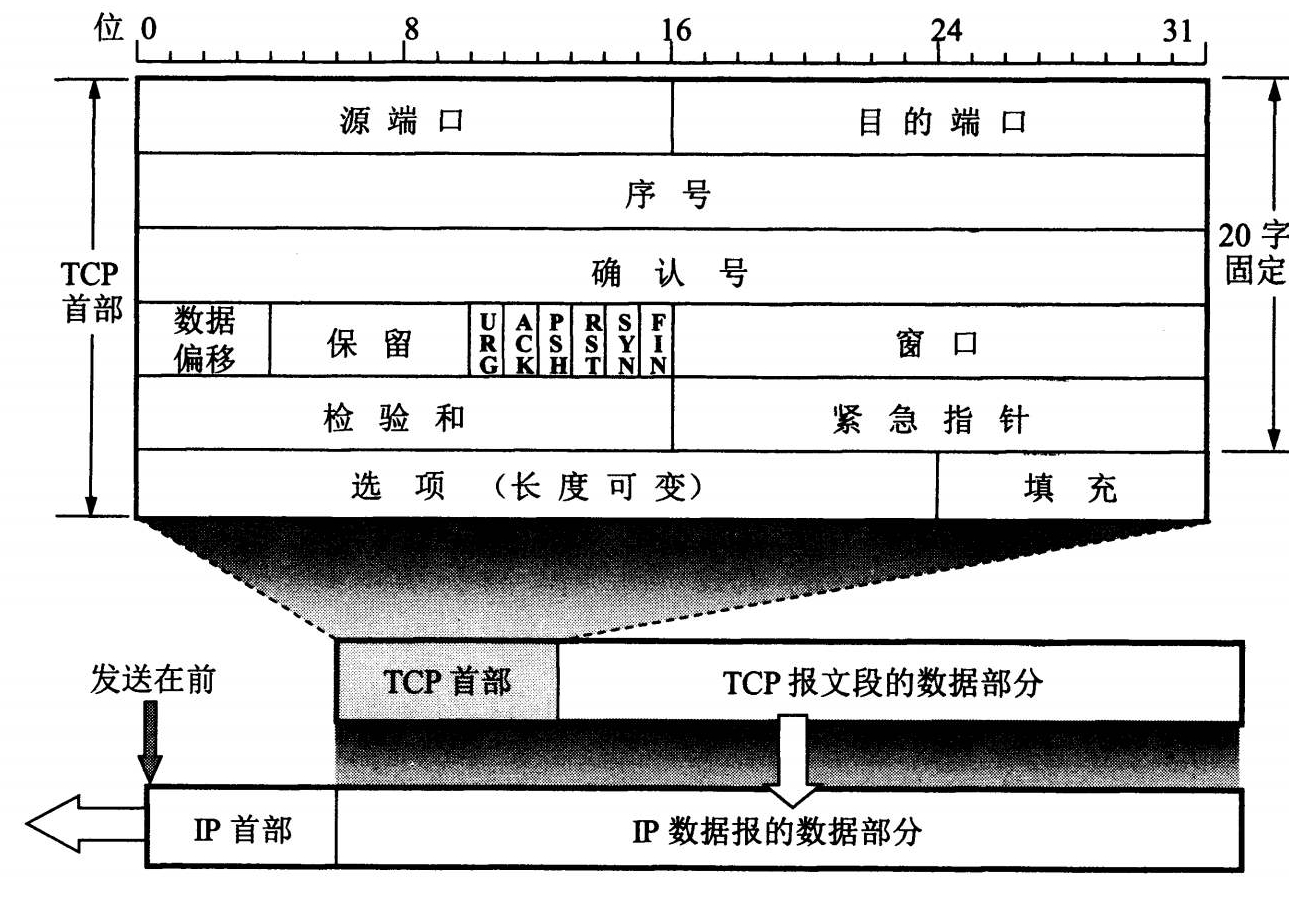
UDP的首部只有8个字节,源端口号、目的端口号、长度和校验和各两个字节。
### 10.❤TCP协议如何保证可靠传输
> 主要有校验和、序列号、超时重传、流量控制及拥塞避免等几种方法。
>
> 腾讯一面
- **校验和**:在发送方和接收端分别计算数据的校验和,如果两者不一致,则说明数据在传输的过程中出现了差错,TCP将丢弃和不确认次报文
- **序列号**:TCP会对每一个发送的字节进行编号,接收方接到数据后,会对发送方发送确认应答(ACK报文),并且这个ACK报文中带有相应的确认编号,告诉发送方,下一次发送的数据从编号多少开始发。如果发送方发送相同的数据,接收端也可以通过序列号判断出,直接将数据丢弃。
- **超时重传**:在上面说了序列号的作用,但如果发送方在发送数据后一段时间内(可以设置重传计时器规定这段时间)没有收到确认序号ACK,那么发送方就会重新发送数据。这里发送方没有收到ACK可以分两种情况,如果是发送方发送的数据包丢失了,接收方收到发送方重新发送的数据包后会马上给发送方发送ACK;如果是接收方之前接收到了发送方发送的数据包,而返回给发送方的ACK丢失了,这种情况,发送方重传后,接收方会直接丢弃发送方冲重传的数据包,然后再次发送ACK响应报文。如果数据被重发之后还是没有收到接收方的确认应答,则进行再次发送。此时,等待确认应答的时间将会以2倍、4倍的指数函数延长,直到最后关闭连接。
- **流量控制**:如果发送端发送的数据太快,接收端来不及接收就会出现丢包问题。为了解决这个问题,TCP协议利用了滑动窗口进行了流量控制。在TCP首部有一个16位字段大小的窗口,窗口的大小就是接收端接收数据缓冲区的剩余大小。接收端会在收到数据包后发送ACK报文时,将自己的窗口大小填入ACK中,发送方会根据ACK报文中的窗口大小进而控制发送速度。如果窗口大小为零,发送方会停止发送数据。
- **拥塞控制**:如果网络出现拥塞,则会产生丢包等问题,这时发送方会将丢失的数据包继续重传,网络拥塞会更加严重,所以在网络出现拥塞时应注意控制发送方的发送数据,降低整个网络的拥塞程度。拥塞控制主要有四部分组成:慢开始、拥塞避免、快重传、快恢复,如下图(图片来源于网络)。
这里的发送方会维护一个拥塞窗口的状态变量,它和流量控制的滑动窗口是不一样的,滑动窗口是根据接收方数据缓冲区大小确定的,而拥塞窗口是根据网络的拥塞情况动态确定的,一般来说发送方真实的发送窗口为滑动窗口和拥塞窗口中的最小值。
- **慢开始**:为了避免一开始发送大量的数据而产生网络阻塞,会先初始化cwnd为1,当收到ACK后到下一个传输轮次,cwnd为2,以此类推成指数形式增长。
- **拥塞避免**:因为cwnd的数量在慢开始是指数增长的,为了防止cwnd数量过大而导致网络阻塞,会设置一个慢开始的门限值ssthresh,当cwnd>=ssthresh时,进入到拥塞避免阶段,cwnd每个传输轮次加1。但网络出现超时,会将门限值ssthresh变为出现超时cwnd数值的一半,cwnd重新设置为1,如上图,在第12轮出现超时后,cwnd变为1,ssthresh变为12。
- **快重传**:在网络中如果出现超时或者阻塞,则按慢开始和拥塞避免算法进行调整。但如果只是丢失某一个报文段,如下图(图片来源于网络),则使用快重传算法。

但是根据快重传算法,要求在这种情况下,需要快速向发送端发送M2的确认报文,在发送方收到三个M2的确认报文后,无需等待重传计时器所设置的时间,可直接进行M3的重传,这就是快重传。
- **快恢复**:从上上图圈4可以看到,当发送收到三个重复的ACK,会进行快重传和快恢复。快恢复是指将ssthresh设置为发生快重传时的cwnd数量的一半,而cwnd不是设置为1而是设置为为门限值ssthresh,并开始拥塞避免阶段。
### 11.❤TCP的三次握手及四次挥手?
> 必考题
>
> 在介绍三次握手和四次挥手之前,先介绍一下TCP头部的一些常用字段。
>
> 序号:seq,占32位,用来标识从发送端到接收端发送的字节流。
>
> 确认号:ack,占32位,只有ACK标志位为1时,确认序号字段才有效,ack=seq+1。
>
> 标志位:
>
> SYN:发起一个新连接。
>
> FIN:释放一个连接。
>
> ACK:确认序号有效。
**三次握手**
> 三次握手的本质就是确定发送端和接收端具备收发信息的能力,在能流畅描述三次握手的流程及其中的字段含义作用的同时还需要记住每次握手时接收端和发送端的状态。这个比较容易忽略。
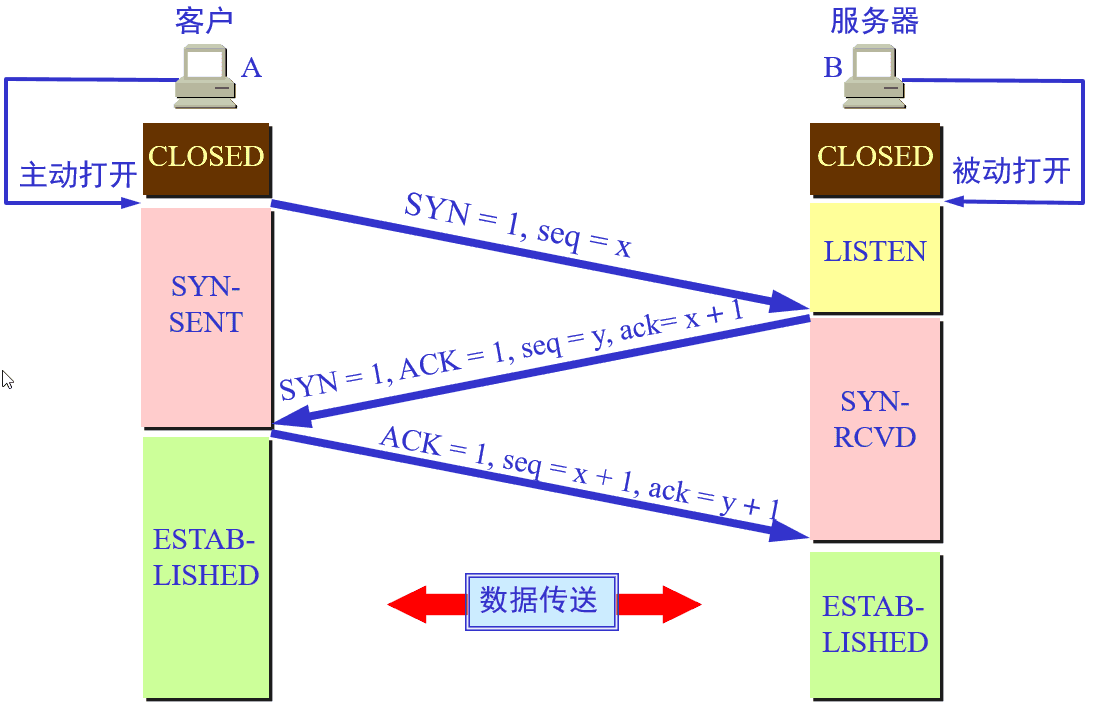
开始时客户端和服务端的状态都是CLOSE。
- 第一次握手:客户端向服务端发起建立连接请求,客户端会随机生成一个起始序列号x,客户端向服务端发送的字段中包含标志位**SYN=1**,序列号seq=x。客户端进入**SYN-SENT**状态
- 第二次握手:服务端在收到客户端发来的报文后,会随机生成一个服务端的起始序列号y,然后给客户端回复一段报文,其中包括标志位**SYN=1,ACK=1**,序列号**seq=y**,确认号**ack=x+1**。服务端进入**SYN-RCVD**状态(其中SYN=1表示要和客户端建立一个连接,ACK=1表示确认序号有效)
- 第三次握手:客户端收到服务端发来的报文后,会再向服务端发送报文,其中包含标志位ACK=1,序列号seq=x+1,确认号ack=y+1。客户端进入**ESTABLE-LISHED ** (əˈstabliSHt)阶段,服务端接收到报文后也会进入ESTABLE-LISHED阶段,开始数据传输。
**四次挥手**
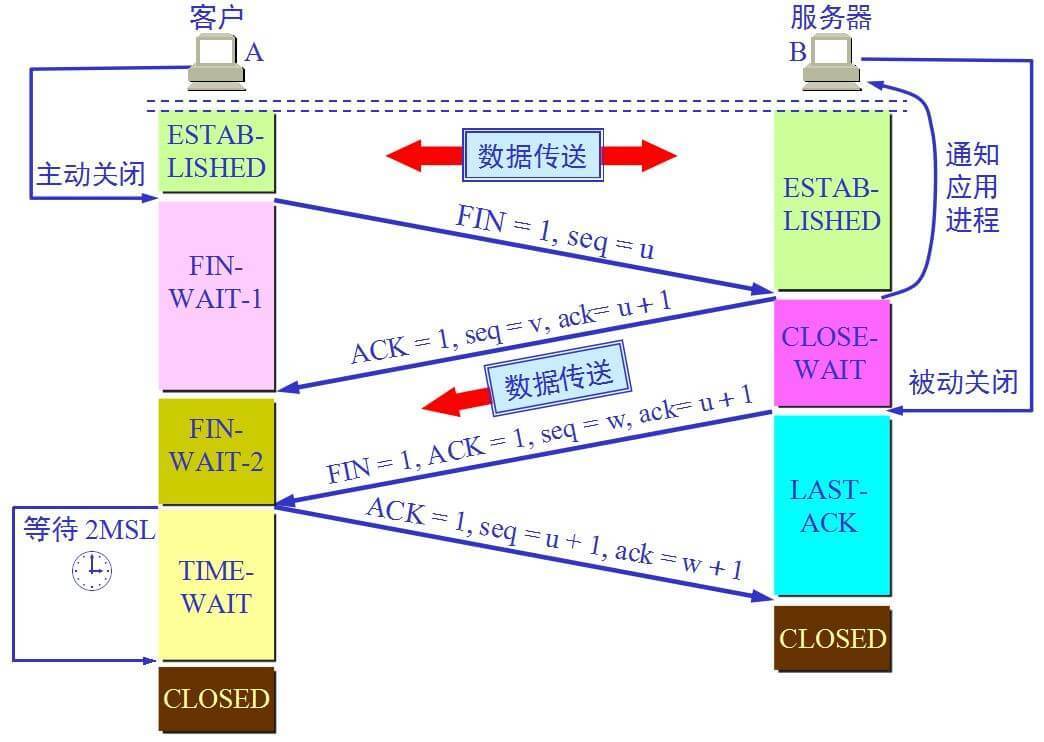
假设客户端首先发起的断开连接请求
- 第一次挥手:客户端向服务端发送的数据完成后,向服务端发起释放连接报文,报文包含标志位FIN=1,序列号seq=u。此时客户端只能接收数据,不能向服务端发送数据。
- 第二次挥手:服务端收到客户端的释放连接报文后,向客户端发送确认报文,包含标志位ACK=1,序列号seq=v,确认号ack=u+1。此时客户端到服务端的连接已经释放掉,客户端不能向服务端发送数据。但服务端到客户端的单向连接还能正常传输数据。
- 第三次挥手:服务端发送完数据后向客户端发出连接释放报文,报文包含标志位FIN=1,标志位ACK=1,序列号seq=w,确认号ack=u+1。
- 第四次挥手:客户端收到服务端发送的释放连接请求,向服务端发送确认报文,包含标志位ACK=1,序列号seq=u+1,确认号ack=w+1。
### 12.❤为什么TCP连接的时候是3次?两次或者四次是否可以?
不可以,主要从以下方面考虑(假设客户端是首先发起连接请求):
- **避免重复历史连接(主要原因)**
三次握手的**首要原因是为了防止旧的重复连接初始化造成混乱**

两次握手无法避免历史连接:
如果服务端接收到了一个**早已失效**的来自客户端的连接请求报文,会向客户端发送确认报文同意并立即建立TCP连接。但因为客户端并不需要向服务端发送数据,所以此次TCP连接没有意义。
- 同步双方的初始序列号
序列号在 TCP 连接中占据着非常重要的作用,所以当客户端发送携带「初始序列号」的 `SYN` 报文的时候,需要服务端回一个 `ACK` 应答报文,表示客户端的 SYN 报文已被服务端成功接收,那当服务端发送「初始序列号」给客户端的时候,依然也要得到客户端的应答回应,**这样一来一回,才能确保双方的初始序列号能被可靠的同步。**
- 避免资源浪费
如果只有「两次握手」,当客户端发生的 `SYN` 报文在网络中阻塞,客户端没有接收到 `ACK` 报文,就会重新发送 `SYN` ,**由于没有第三次握手,服务端不清楚客户端是否收到了自己回复的 ACK 报文,所以服务端每收到一个 SYN 就只能先主动建立一个连接**
如果客户端发送的 `SYN` 报文在网络中阻塞了,重复发送多次 `SYN` 报文,那么服务端在收到请求后就会**建立多个冗余的无效链接,造成不必要的资源浪费。**
至于四次握手,三次握手就已经理论上最少可靠连接建立,所以不需要使用更多的通信次数。
### 13.❤为什么TCP连接的时候是3次,关闭的时候却是4次?
因为需要**确保通信双方都能通知对方释放连接**
假设客户端发送完数据向服务端发送释放连接请求,当客户端并不知道,服务端是否已经发送完数据,所以此次断开的是客户端到服务端的单向连接,服务端返回给客户端确认报文后,服务端还能继续单向给客户端发送数据。当服务端发送完数据后还需要向客户端发送释放连接请求,客户端返回确认报文,TCP连接彻底关闭。所以断开TCP连接需要客户端和服务端分别通知对方并分别收到确认报文,一共需要四次。
### 14.TIME_WAIT和CLOSE_WAIT的区别在哪?
默认客户端首先发起断开连接请求
从图中可以看出
- CLOSE_WAIT是**被动**关闭形成的,当客户端发送FIN报文,服务端返回ACK报文后进入CLOSE_WAIT。
- TIME_WAIT是**主动**关闭形成的(等待2MSL),当第四次挥手完成后,客户端进入TIME_WAIT状态。

### 15.❤为什么客户端发出第四次挥手的确认报文后要等2MSL的时间才能释放TCP连接,或者问为什么需要TIME_WAIT?
> 客户端主动关闭连接时,会发送最后一个ack后,然后会进入TIME_WAIT状态,再停留2个MSL时间,进入CLOSED状态
>
> MSL就是maximum segment lifetime(最大分节生命期),这是一个IP数据包能在互联网上生存的最长时间,超过这个时间IP数据包将在网络中消失 。MSL在RFC 1122上建议是2分钟,而源自berkeley的TCP实现传统上使用30秒。
>
MSL的意思是报文的最长寿命,可以从两方面考虑:
- **防止新连接收到旧链接的TCP报文:** 防止历史连接中的数据,被后面相同四元组的连接错误的接收,客户端发送第四次挥手中的报文后,再经过2MSL,可使本次TCP连接中的所有报文全部消失,不会出现在下一个TCP连接中。 2*MSL 的时间足以保证两个方向上的数据都被丢弃,使得原来连接的数据包在网络中都自然消失,再出现的数据包一定是新连接上产生的。
- **防止连接关闭时四次挥手中的最后一次ACK丢失** :考虑丢包问题,如果第四挥手发送的报文在传输过程中丢失了,那么服务端没收到确认ack报文就会**重发**第三次挥手的报文。如果客户端发送完第四次挥手的确认报文后直接关闭,而这次报文又恰好丢失,则会造成服务端无法正常关闭。
### 16.如果已经建立了TCP连接,但是客户端突然出现故障了怎么办?
如果TCP连接已经建立,在通信过程中,客户端突然故障,那么服务端不会一直等下去,过一段时间就关闭连接了。具体原理是TCP有一个**保活机制**,主要用在服务器端,用于检测已建立TCP链接的客户端的状态,防止因客户端崩溃或者客户端网络不可达,而服务器端一直保持该TCP链接,占用服务器端的大量资源(因为Linux系统中可以创建的总TCP链接数是有限制的)。
保活机制原理:
设置TCP保活机制的保活时间keepIdle,即在TCP链接超过该时间没有任何数据交互时,发送**保活探测报文**;设置保活探测报文的发送时间间隔keepInterval;设置保活探测报文的总发送次数keepCount。如果在keepCount次的保活探测报文均没有收到客户端的回应,则服务器端即关闭与客户端的TCP链接。
具体细节请看这篇博客TCP通信过程中异常情况整理[TCP通信过程中异常情况整理_自由不死的博客-CSDN博客_tcp通讯故障](https://blog.csdn.net/yyc1023/article/details/80242815)。
### 17.❤HTTP和HTTPS的区别?
> 腾讯
| | HTTP | HTTPS |
| ------ | ---------- | ----------------------- |
| 端口 | 80 | 443 |
| 安全性 | 无加密,安全性较差 | 有加密机制,安全性较高 |
| 资源消耗 | 较少 | 由于加密处理,资源消耗更多 |
| 是否需要证书 | 不需要 | |
| 协议 | 运行在TCP协议之上 | 运行在SSL协议之上,SSL运行在TCP协议上 |
- HTTP 是超文本传输协议,信息是**明文传输**,存在安全风险的问题。HTTPS 则解决 HTTP 不安全的缺陷,在 TCP 和 HTTP 网络层之间加入了 SSL/TLS 安全协议,使得报文能够加密传输。
- HTTP 连接建立相对简单, TCP 三次握手之后便可进行 HTTP 的报文传输。而 HTTPS 在 TCP 三次握手之后,还需进行 SSL/TLS 的握手过程,才可进入加密报文传输。
- 两者的默认端口不一样,HTTP 默认端口号是 80,HTTPS 默认端口号是 443。
- HTTPS 协议需要向 CA(证书权威机构)申请数字证书,来保证服务器的身份是可信的。
### 18.什么是对称加密与非对称加密
- 对称加密对称加密指加密和解密使用**同一密钥**,优点是运算速度快,缺点是如何安全将密钥传输给另一方。常见的对称加密算法有DES、AES等等。
- 非对称加密非对称加密指的是加密和解密使用**不同**的密钥,一把公开的公钥,一把私有的私钥。公钥加密的信息只有私钥才能解密,私钥加密的信息只有公钥才能解密。优点解决了对称加密中存在的问题。缺点是运算速度较慢。常见的非对称加密算法有RSA、DSA、ECC等等。非对称加密的工作流程:A生成一对非堆成密钥,将公钥向所有人公开,B拿到A的公钥后使用A的公钥对信息加密后发送给A,经过加密的信息只有A手中的私钥能解密。这样B可以通过这种方式将自己的公钥加密后发送给A,两方建立起通信,可以通过对方的公钥加密要发送的信息,接收方用自己的私钥解密信息。
### 19.HTTPS的加密过程
上面已经介绍了对称加密和非对称加密的优缺点,HTTPS是将两者结合起来,使用的对称加密和非对称加密的混合加密算法。具体做法就是使用非对称加密来传输对称密钥来保证安全性,使用对称加密来保证通信的效率。
HTTPS的加密过程:
- 客户端向服务端发起第一次握手请求,告诉服务端客户端所支持的SSL的指定版本(协议版本号)、支持的加密算法以及一个客户端生成的随机数
- 服务端确认双方使用的加密方法,并给出数字证书、以及一个服务器生成的随机数
- 客户端确认数字证书有效,然后生成一个新的随机数,并使用数字证书中的公钥,加密这个随机数,发给服务端
- 服务端收到后利用自己的私钥解密信息,获得客户端发来的随机数。
- 客户端和服务端根据约定的加密方法,使用前三个随机数,生成“对话秘钥”(session key),用来加密接下来的整个对话过程。
上述流程存在的一个问题是客户端哪里来的数字认证机构的公钥,其实,在很多浏览器开发时,会内置常用数字证书认证机构的公钥。 流程图如下:
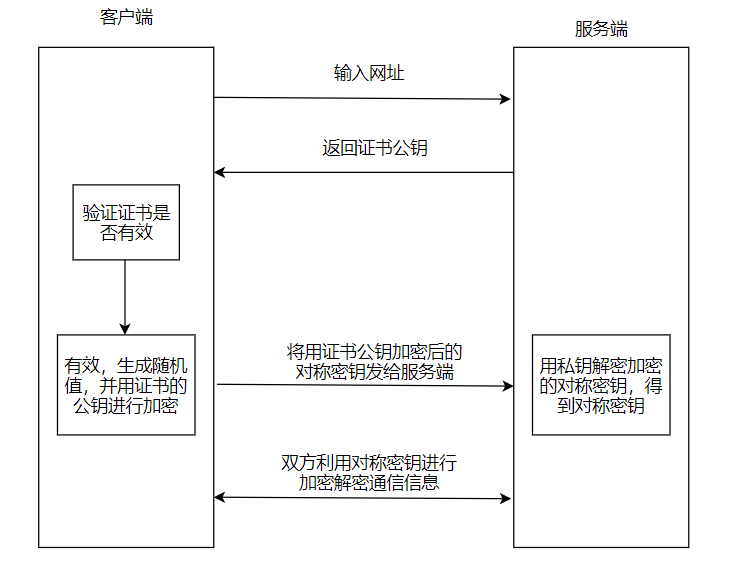
数字证书的工作流程:
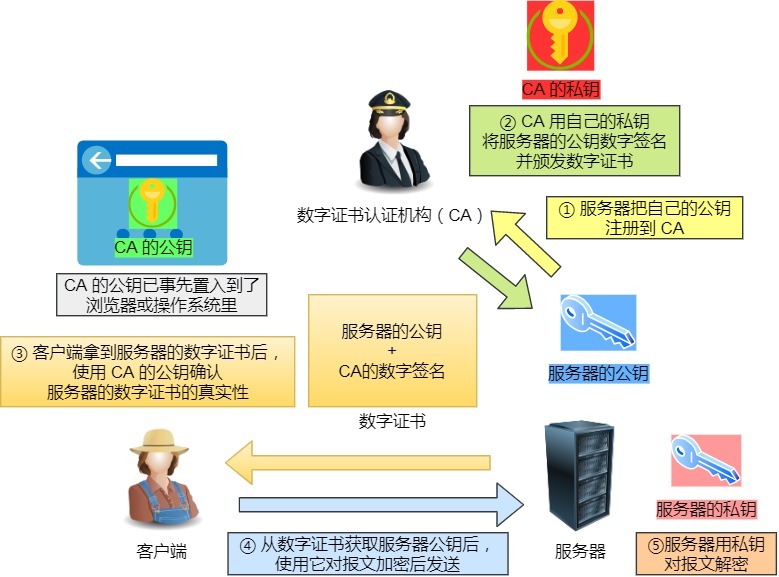
### 20.❤常用HTTP状态码?
> 这也是一个面试经常问的题目,背下来就行了
| 状态码 | 类别 |
| ---- | -------- |
| 1xx | 信息性状态码 |
| 2xx | 成功状态码 |
| 3xx | 重定向状态码 |
| 4xx | 客户端错误状态码 |
| 5xx | 服务端错误状态码 |
常见的HTTP状态码
**1XX**
- 100 Continue:表示正常,客户端可以继续发送请求
- 101 Switching Protocols:切换协议,服务器根据客户端的请求切换协议。
**2XX**
- **200** OK:请求成功,服务器返回的响应头都会有 body 数据
- **204** No Content:无内容,服务器成功处理,但未返回内容,与 200 OK 基本相同,但响应头没有 body 数据。
- **206** Partial Content:是应用于 HTTP 分块下载或断点续传,表示响应返回的 body 数据并不是资源的全部,而是其中的一部分,也是服务器处理成功的状态。
3XX
- **301** Moved Permanently:表示永久重定向,说明请求的资源已经不存在了,需改用新的 URL 再次访问。
- **302** Found:表示临时重定向,说明请求的资源还在,但暂时需要用另一个 URL 来访问。
4XX
- **400** Bad Request:客户端请求的报文有错误,但只是个笼统的错误。
- 401 Unauthorized:表示发送的请求需要有认证信息。
- **403** Forbidden:服务器禁止访问资源,并不是客户端的请求出错
- **404** Not Found:服务器无法根据客户端的请求找到资源。
**5XX**
- **500** Internal Server Error:服务器内部错误,与 400 类型,是个笼统通用的错误码,服务器发生了什么错误,我们并不知道。
- **501** Not Implemented:表示客户端请求的功能还不支持,类似“即将开业,敬请期待”的意思
- **502** Bad Gateway :通常是服务器作为网关或代理时返回的错误码,表示服务器自身工作正常,访问后端服务器发生了错误。
- **503** Service Unavailable:表示服务器当前很忙,暂时无法响应客户端,类似“网络服务正忙,请稍后重试”的意思。
### 21.常见的HTTP方法
| 方法 | 作用 |
| ------- | ------------------------ |
| GET | 获取资源 |
| POST | 传输数据,向服务器提交数据,对服务器数据进行更新 |
| PUT | 上传文件,向服务器添加数据 |
| DELETE | 删除文件 |
| HEAD | 和GET方法类似,但只返回报文实体主体部分 |
| PATCH | 对资源进行部分修改 |
| OPTIONS | 查询指定的URL支持的方法 |
| CONNECT | 要求用隧道协议连接代理 |
| TRACE | 服务器会将通行路径返回给客户端 |
### 22.❤GET和POST的区别
- **作用**: GET用于获取服务器上的资源,POST用于传输实体主体(修改服务器的资源)
- **参数位置**: GET的参数放在URL中,POST的参数存储在body中,并且GET方法提交的请求的URL中的数据最多是2048字节,POST请求没有大小限制。
- **安全性** :GET方法因为参数放在URL中,安全性相对于POST较差一些
- 幂等性: GET方法是具有幂等性的,而POST方法不具有幂等性。这里幂等性指客户端连续发出多次请求,收到的结果都是一样的.
### 23.HTTP 1.0、HTTP 1.1及HTTP 2.0的主要区别是什么
HTTP 1.0和HTTP 1.1的区别
- **长连接HTTP 1.1支持长连接和请求的流水线(管道网络传输)操作**。长连接是指不在需要每次请求都重新建立一次连接,HTTP 1.0默认使用短连接,每次请求都要重新建立一次TCP连接,资源消耗较大。请求的流水线操作是指客户端在收到HTTP的响应报文之前可以先发送新的请求报文,不支持请求的流水线操作需要等到收到HTTP的响应报文后才能继续发送新的请求报文。
- 缓存处理在HTTP 1.0中主要使用header中的If-Modified-Since,Expires作为缓存判断的标准,HTTP 1.1引入了Entity tag,If-Unmodified-Since, If-Match等更多可供选择的缓存头来控制缓存策略。
- **错误状态码**在HTTP 1.1新增了24个错误状态响应码
- HOST域在HTTP 1.0 中认为每台服务器都会绑定唯一的IP地址,所以,请求中的URL并没有传递主机名。但后来一台服务器上可能存在多个虚拟机,它们共享一个IP地址,所以HTTP 1.1中请求消息和响应消息都应该支持Host域。
- 带宽优化及网络连接的使用在HTTP 1.0中会存在浪费带宽的现象,主要是因为不支持断点续传功能,客户端只是需要某个对象的一部分,服务端却将整个对象都传了过来。在HTTP 1.1中请求头引入了range头域,它支持只请求资源的某个部分,返回的状态码为206。
HTTP 2.0的新特性
- **二进制格式**:HTTP 1.x的解析是基于文本,HTTP 2.0的解析采用二进制,实现方便,健壮性更好。
- **多路复用**:每一个request对应一个id,一个连接上可以有多个request,每个连接的request可以随机混在一起,这样接收方可以根据request的id将request归属到各自不同的服务端请求里。
- **header压缩**:在HTTP 1.x中,header携带大量信息,并且每次都需要重新发送,HTTP 2.0采用编码的方式减小了header的大小,同时通信双方各自缓存一份header fields表,避免了header的重复传输。
- **服务端推送**:客户端在请求一个资源时,会把相关资源一起发给客户端,这样客户端就不需要再次发起请求。
### 24.Session、Cookie和Token的主要区别
HTTP协议是无状态的,即服务器无法判断用户身份。Session和Cookie可以用来进行身份辨认。
- Cookie是保存在客户端一个小数据块,其中包含了用户信息。当客户端向服务端发起请求,服务端会像客户端浏览器发送一个Cookie,客户端会把Cookie存起来,当下次客户端再次请求服务端时,会携带上这个Cookie,服务端会通过这个Cookie来确定身份。
- Session是通过Cookie实现的,和Cookie不同的是,Session是存在服务端的。当客户端浏览器第一次访问服务器时,服务器会为浏览器创建一个sessionid,将sessionid放到Cookie中,存在客户端浏览器。比如浏览器访问的是购物网站,将一本《图解HTTP》放到了购物车,当浏览器再次访问服务器时,服务器会取出Cookie中的sessionid,并根据sessionid获取会话中的存储的信息,确认浏览器的身份是上次将《图解HTTP》放入到购物车那个用户。
- Token客户端在浏览器第一次访问服务端时,服务端生成的一串加密的字符串作为Token发给客户端浏览器,下次浏览器在访问服务端时携带token即可无需验证用户名和密码,省下来大量的资源开销。
**token可以通过将token加入请求参数或者请求头来抵抗csrf(跨站请求伪造攻击,盗用登录信息发起请求),cookie+session不行**
因为form 发起的 POST 请求并不受到浏览器同源策略的限制,因此可以任意地使用其他域的 Cookie 向其他域发送 POST 请求,形成 CSRF 攻击
cookie、session与token的真正区别下面为了方便记忆,做了一个表格进行对比。
| | 存放位置 | 占用空间 | 安全性 | 应用场景 |
| ------- | ------ | ---- | ---- | --------- |
| cookie | 客户端浏览器 | 小 | 较低 | 一般存放配置信息 |
| session | 服务端 | 多 | 较高 | 存放较为重要的信息 |
### 25.如果客户端禁止 cookie, session 还能用吗?
可以,Session的作用是在服务端来保持状态,通过sessionid来进行确认身份,但sessionid一般是通过Cookie来进行传递的。如果Cooike被禁用了,可以**通过在URL中传递sessionid**。
### 26.❤在浏览器输⼊url地址到显示主⻚的过程
> 面试超高频的一道题,一般能说清楚流程就可以。
- 对输入到浏览器的url进行DNS解析,将域名转换为IP地址(此时可以讲一讲DNS的解析过程,本机hosts文件->本地DNS服务器缓存->本地DNS服务器->根域名服务器发起迭代查询)。
- 通过ARP协议获取目的服务器的MAC地址,找到目的服务器(缓存->广播)
- 与目的服务器通过三次握手建立TCP连接
- 向目的服务器发送HTTP请求
- 服务器处理请求并返回HTTP报文
- 浏览器解析并渲染页面
### 27.❤tcp长连接和短连接的区别
所谓长连接,指在一个TCP连接上**可以连续发送多个数据包**,在TCP连接保持期间,如果没有数据包发送,需要双方发检测包以维持此连接,一般需要自己做在线维持。
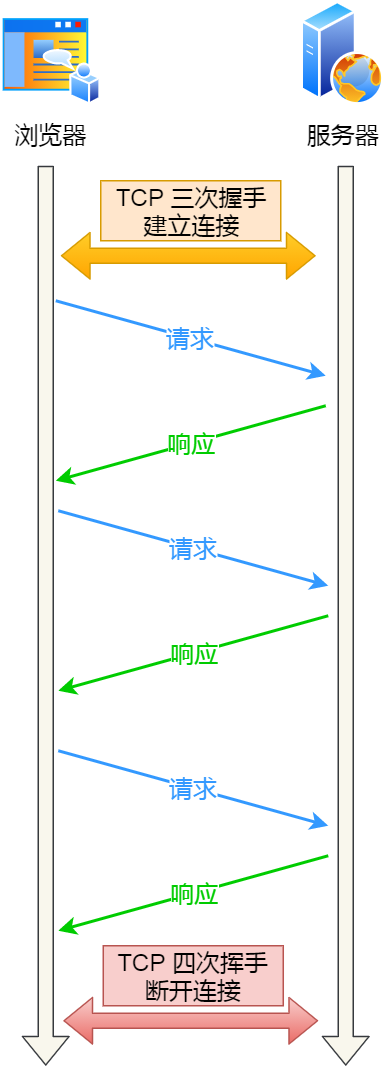
短连接是指通信双方有数据交互时,就建立一个TCP连接,数据发送完成后,则断开此TCP连接,一般银行都使用短连接。
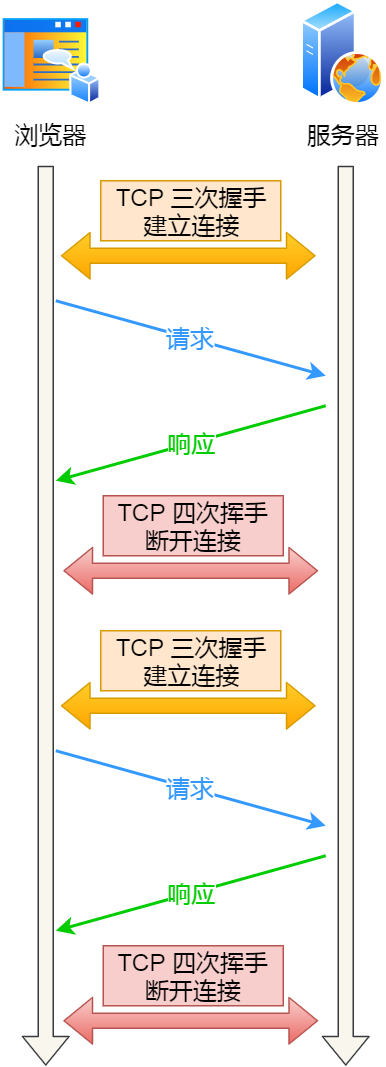
其实长连接是相对于通常的短连接而说的,也就是长时间保持客户端与服务端的连接状态。
使用场景:
**数据库的连接**用长连接, 如果用短连接频繁的通信会造成socket错误,而且频繁的socket 创建也是对资源的浪费。
WEB网站的**http服务**一般都用短链接,因为长连接对于服务端来说会耗费一定的资源
### 28.TCP 和 UDP 可以使用同一个端口吗?
**可以的**。
在数据链路层中,通过 MAC 地址来寻找局域网中的主机。在网际层中,通过 IP 地址来寻找网络中互连的主机或路由器。在传输层中,需要通过端口进行寻址,来识别同一计算机中同时通信的不同应用程序。
所以,传输层的「端口号」的作用,是为了区分同一个主机上不同应用程序的数据包。
传输层有两个传输协议分别是 TCP 和 UDP,在内核中是两个完全独立的软件模块。
当主机收到数据包后,可以在 IP 包头的「协议号」字段知道该数据包是 TCP/UDP,所以可以根据这个信息确定送给哪个模块(TCP/UDP)处理,送给 TCP/UDP 模块的报文根据「端口号」确定送给哪个应用程序处理。
因此,TCP/UDP 各自的端口号也相互独立,如 TCP 有一个 80 号端口,UDP 也可以有一个 80 号端口,二者并不冲突。
### 29.TCP连接中出现太多TIME_WAIT状态应该怎么办
> 小红书一面
当TCP连接中出现太多TIME_WAIT状态的情况时,可能会导致服务器资源耗尽或性能下降。TIME_WAIT状态是TCP连接正常关闭后的一种状态,用于确保在网络中的所有数据都被完全传输和处理。然而,**如果连接频繁关闭,就会产生大量的TIME_WAIT状态,这可能会占用服务器资源并影响性能。**以下是一些处理太多TIME_WAIT状态的方法:
1. 调整系统参数:
- **调整TIME_WAIT状态的超时时间**:您可以通过修改系统内核参数来缩短TIME_WAIT状态的超时时间,从而更快地释放这些资源。例如,可以调整`net.ipv4.tcp_fin_timeout`参数。
- 增加可用端口范围:通过扩大可用端口范围,可以减少TIME_WAIT状态的竞争,这可以通过修改`net.ipv4.ip_local_port_range`参数来实现。
2. **使用连接重用:**
- 考虑在应用程序中实现连接重用,而不是频繁地关闭和重新创建连接。这可以减少TIME_WAIT状态的生成,提高性能(比如tcp长连接)。
3. 负载均衡:
- 使用负载均衡器将请求分发到多个服务器实例,以分散TIME_WAIT状态的影响。这可以帮助分散TIME_WAIT状态的负载,从而减轻单个服务器的压力。
4. **使用连接池:**
- 对于数据库连接等资源密集型应用,使用连接池来管理连接,以减少连接的频繁创建和关闭。
5. 考虑TCP快速回收:
- 某些Linux内核版本支持TCP快速回收,它允许更快地回收TIME_WAIT状态的连接资源。您可以查看是否有此选项,并根据需要启用它。
请注意,在进行任何系统参数的更改时,务必小心,以免影响系统的稳定性和安全性。建议在测试环境中进行这些更改,并监控系统性能,以确保没有不良影响。不同的操作系统和内核版本可能有不同的参数名称和配置方法,因此您需要查阅相关文档以获得详细信息。
================================================
FILE: 项目经历介绍.md
================================================
## Crony分布式定时任务平台
> 这个项目其实是本人在XXXX公司实习时做的一个项目,感觉挺有意思,就自己写了一份代码(与原版还是有很大差别的,因为忘记了)上传到了github,可以看看源码,不是很难
>
> 具体的介绍可以看[tmnhs/Crony](https://github.com/tmnhs/Crony)
> 简历书写:
>
> - **技术栈: Go** + **MySQL** + **Etcd** + 公司自研微服务框架**Coa**
>
>
>
> - **项目简介:**对公司内部众多的定时任务进行集成化管理,提供可视化界面,支持**Coa**微服务(rpc)回调和多节点部署,提供任务加权轮询分配和故障转移等高可用功能
>
>
>
> - **功能实现:**
>
> 1.研读公司Coa微服务框架源码,熟悉其rpc调用流程、服务注册发现和负载均衡等,实现Coa微服务回调
>
> 2.项目采用中心化方案,分为调度中心和执行节点两个模块,调度中心通过Etcd实现服务发现、定时任务的分配、故障转移和大盘等功能,支持加权轮询分配
>
> 3.执行节点负责定时任务的执行,实现服务注册,支持http和微服务回调,将执行结果存入MySQL,支持重试、超时等配置,任务执行失败可邮件或飞书通知告警,实现日志收集,接入监控报警
>
> 4.研发go-sdk,允许接入go-sdk的微服务异步响应任务执行结果,并编写使用说明文档
>
>
> - **责任描述:**调研、输出技术方案,宣讲技术方案并答疑,负责完成执行节点模块和go-sdk的研发
>
>
>
>
> **简述:**
>
> 这是本人在XXX公司实习做的一个中台项目,公司在立项的时候讨论过为什么要专门做一个定时任务管理平台,因为公司过去开发的项目中存在许多定时任务,而代码写法都是采用见缝插针式的写法或者直接丢到task服务里面写。这样做存在很多问题,比如定时任务执行情况和执行时间没有统一管理,任务没有按时执行甚至失败了很久才发现,需要对应开发者结合代码和日志分析情况重试或排查,带来很高的维护成本。本项目旨在对公司内部众多的定时任务进行集成化管理,并提供可视化界面管理。
>
> 我们花了两三天时间完成对市面上开源定时任务平台(goland实现)的调研,通过对gocron和cronsun两个开源项目的分析(gocron不是分布式的,可用性不高,cronsun是分布式的,但是代码有点臃肿,不适合二次开发),最终决定自研。然后输出技术方案,并且答疑,之后开始研发测试。
>
> 总体上采用中心化系统架构,分为调度中心和执行节点两部分,通过ETCD实现服务注册与发现(此处可以讲一讲怎样实现的,或者和coa微服务架构怎样实现服务注册发现做比较...),MySQL实现持久化存储。
>
> - 其中调度中心实现服务发现、定时任务的分配(增删改查)和大盘功能,支持最少任务数量分配和加权轮询分配(默认)两种方式,还支持故障转移功能,一旦某个执行节点发生故障宕机了,调度中心会检测到并将该节点上的任务全部转移至其他正常的节点上。
>
>
> - 执行节点负责定时任务的执行,实现服务注册,支持http回调和微服务回调,将执行结果存入MySQL,支持重试、超时等配置,任务执行失败后可通过邮件或飞书通知对应开发人员,实现日志收集,接入监控报警(一旦定时任务执行的失败率过高会告警)。
>
>
> - 考虑到某些定时任务会执行很长时间,这时候执行节点不能一直等着,需要提供一个sdk的方法供调用方将异步执行结果返回给定时任务平台
>
> 如果在某个项目中想要启动一个定时任务,可以专门启动一个微服务或者API服务,在这个服务中,只需要负责该定时任务需要执行的方法,不负责时间调度(即不进行cron表达式的执行),由Crony定时任务平台负责时间调度,通知该服务执行。任务的执行结果支持同步和异步响应。同步即需要Crony定时任务平台同步等待回调结果返回,可以设置超时时间,若执行失败,在平台内部重试(再次通知),在多次重试都失败后,需要发邮件或者飞书通知特定的负责人任务执行失败。异步需要引入Crony平台的go-sdk将结果写入Mysql,此时需要平台将此任务的超时时间,重试次数传入,在微服务内部进行失败重试,重试失败后需要调用go-sdk(http调用)发邮件或者飞书告警。
>
> 可靠性说明:执行节点有多个,并且支持故障转移,调度中心只有一个,唯一不可靠的来源就是调度中心的单点故障,不过这个可以通过服务多实例和负载均衡预防
>
> **亮点:**
>
> - **分布式的**,中心化系统架构,支持多节点部署,提高系统的可用性和并发能力
> - 支持**故障转移**,提高系统的容错性
> - 支持定时任务**加权轮询**分配,支持**重试和超时**等配置,支持任务执行失败后可通过邮件或飞书**报警**通知对应负责人
> - **异步响应**任务执行结果,sdk的引入让执行节点无需同步等待服务返回,提高系统的资源利用率
>
> **遇到的困难:**
>
> - 微服务回调:这部分需要熟悉公司内部自研的微服务框架,通过阅读源码熟悉其rpc调用流程(待补充)
> - 如何实现服务注册与发现:使用etcd监听各个节点状态,实现服务注册和发现。当启动一个agent时,我们把服务的地址写进etcd,注册服务。同时绑定租约(lease),并以续租约(keep leases alive)的方式检测服务是否正常运行,从而实现健康检查。服务器需要在心跳周期之内向 etcd 发送数据包,表示自己能够正常工作。如果在规定的心跳周期内,etcd 没有收到心跳包,则表示该服务器异常,etcd 会将该服务器对应的信息进行删除。如果心跳包正常,但是服务器的租约周期结束,则需要重新申请新的租约,如果不申请,则 etcd 会删除对应租约的所有信息。
>
> 定时器的实现参考[(7条消息) Golang 定时任务 github/robfig/cron/v3 使用与源码解析_Junebao的博客-CSDN博客](https://blog.csdn.net/zjbyough/article/details/113853582)
>
> 其中上述corn/v3包的实现是基于go的time.Timer+排序数组,time.Timer底层是一个四叉小顶堆[Golang 定时器底层实现深度剖析 - 知乎 (zhihu.com)](https://zhuanlan.zhihu.com/p/149518569) ,至于为什么不直接使用time.Tricker,可能会跳过某次执行,当然这个也可以使用异步解决(go关键字)
>
> 基于go底层timer实现的定时任务管理性能不是很高,在一些追求性能的高并发场景(比如商品的订单取消(如果用户未支付,取消订单),qps可能达到百万级别)下显然不合适,但是本项目主要是用于公司内部运维的场景,比如数据的统计(在线时长、今日收益等),过期数据的清理(日志),并不追求性能
>
> 基于小顶堆的定时任务的添加和删除的时间复杂度都是O(logN),而基于时间轮算法实现的定时任务的添加和删除的时间复杂度都是O(1),在高并发和追求性能的定时任务显然使用时间轮算法实现更优
>
> 定时器的实现方式:小顶堆、红黑树、跳表、时间轮
#### 1)项目背景
MisU项目存在许多定时任务,过去的代码写法都是采取见缝插针式的写法或者直接丢到task服务里面写,存在以下问题
1. 服务多实例时执行定时任务要考虑抢占锁来争夺定时任务执行权,未抢到锁的任务计算资源被浪费了
2. 定时任务执行情况和执行时间没有统一管理,任务没有按时执行,甚至失败了很久才发现,需要对应开发者结合代码和日志分析情况重试或排查,带来很高的维护成本
#### 2)具体需求(模块化)
##### 1.管理平台模块(crony-web)(调度中心)
1. 实现对定时任务的增删改查和大盘功能(查询日志)
2. 新建任务支持http回调、微服务回调和本地化方案
3. 支持将任务通过轮询均匀调度到不同节点执行(每次选取任务数最少的节点)
##### 2.节点模块(corny-agent)
1. 实现多节点部署,支持当agent自身故障时,能够将任务转移至其他节点执行(故障转移)
2. 配置回调返回错误时,根据平台重试规则进行重试回调,当返回成功时认为通知成功
3. 实现监控报警,接入到mia监控报警平台,agent存活情况,执行任务失败数,重试数,超时数, 通知耗时
4. 对agent的任务执行情况进行日志收集,并且在管理平台进行查看
##### 3.sdk模块
1. 研发go-sdk,java-sdk,允许接入sdk的通知服务调用sdk异步响应任务执行结果
2. 编写使用说明文档
#### 3)拆解
1. 完成对市面上定时任务平台的调研(对gocron和cronsun开源项目进行调研)
2. 输出技术方案,确认是否使用开源二次修改或者自研
3. 宣讲技术方案,并且答疑
4. 研发测试,并且在测试环境灰度测试,并且压测确定稳定性
5. 灰度生产环境使用
#### 4)实现方案
##### 1.微服务(rpc)回调方案
1. 模拟coa(公司自研微服务框架)客户端对服务端进行连接,rpc调用
2. 在某个项目中,如果想要启动一个定时任务,可以专门启动一个微服务,在这个微服务中,只需要负责该定时任务需要执行的方法,不负责时间调度(即不进行cron表达式的执行),由Crony定时任务平台负责时间调度,通知改微服务执行。微服务回调支持同步和异步回调。同步即需要Crony定时任务平台同步等待回调结果返回,可以设置超时时间,若执行失败,在平台内部重试,在多次重试都失败后,需要发邮件或者飞书通知特定的负责人。异步需要引入Crony平台的go-sdk将结果(http调用)写入Mysql,此时需要平台将此任务的超时时间,重试次数传入,在微服务内部进行失败重试,重试失败后需要调用go-sdk(http调用)发邮件或者飞书告警。
##### 2.多agent部署方案
1. 使用etcd监听各个节点状态,实现服务注册和发现当启动一个agent时,我们把服务的地址写进etcd,注册服务。同时绑定租约(lease),并以续租约(keep leases alive)的方式检测服务是否正常运行,从而实现健康检查。服务器需要在心跳周期之内向 etcd 发送数据包,表示自己能够正常工作。如果在规定的心跳周期内,etcd 没有收到心跳包,则表示该服务器异常,etcd 会将该服务器对应的信息进行删除。如果心跳包正常,但是服务器的租约周期结束,则需要重新申请新的租约,如果不申请,则 etcd 会删除对应租约的所有信息。etcd主要存储了结点的存活情况
2. 在etcd结点注册一个watcher,agent改变后会通知etcd,用于处理 watch 请求。创建一个 serverWatchStream 结构体,开启两个 goroutine,其中 sendLoop 是用于发送 watch 消息,recvLoop 接收请求。其他agent如果订阅该服务就会知道
3. 在调度中心注册一个监听器,定时监听其他agent状态
##### 3.轮询调度方案
1. 有两种身份,调度中心和执行器(agent),调度中心分配任务,执行器执行任务
2. 每个agent有自己的任务调度器,调度中心将任务轮询均匀分配给各agent(将node的ip当作key注册到etcd上,每个agent持续监听各自的key值(create or modify),从这个key中获取分配的任务job)。调度中心维护一张各agent的任务表,新增任务时将任务添加到任务最少的节点上。调度中心监听到某节点挂掉时将该节点任务重新分配(故障转移)
##### 4.sdk方案
1. 模拟客户端进行coa回调,rpc任务执行方可能是异步的,因为定时任务都会执行很长时间,这时候invoke不能一直等着,需要提供一个sdk的方法供调用方将异步执行结果返回给定时任务平台
#### 5)可靠性说明
###### 1.crony-node节点
`crony-node `节点是负责调度和执行任务的,对于`crony-node `节点提供以下可靠性保障:
- `crony-node `被设计成一个常驻进程,追求稳定和高可用。
crony-node和etcd服务的连接中断了:
- 断开连接之前已经下发的任务会正常执行;
- 在断开连接期间新建、修改、删除的任务无法更新到节点;
- 会自动和`etcd`进行重连;
- 和`etcd`重新连接上后,会重新加载和该节点相关的全部任务,保证正确性;
- cron-node和数据库的连接中断了:
- ###### 所有任务依然会正常执行;
- 在断开连接期间`执行完成`的任务,日志会因为无法写入到数据库而看不到任务的执行记录和任务日志,不影响任务正常执行;
- 会自动和数据库进行重连,重连后执行记录和任务日志会正常写入数据库;
###### 2.crony-admin节点
`crony-admin`节点是负责管理任务、查看任务执行日志的,对于`Cronadmin`节点提供以下可靠性保障:
- crony-node进程崩溃了:
- 不影响`crony-node`节点和任务正常执行;
- 报警邮件无法发送;
- crony-admin和etcd
服务的连接中断了:
- `crony-admin`无法访问;
- 报警邮件无法发送;
- crony-admin和数据库服务的连接中断了:
- `crony-admin`无法访问;
- 报警邮件无法发送;
- 可以部署多个`crony-admin`节点,可以访问任一节点正常管理任务和查看日志;