Showing preview only (282K chars total). Download the full file or copy to clipboard to get everything.
Repository: tu-rbo/differentiable-particle-filters
Branch: master
Commit: 488f233a07f2
Files: 29
Total size: 270.3 KB
Directory structure:
gitextract_3zu9lda8/
├── LICENSE
├── README.md
├── experiments/
│ ├── __init__.py
│ ├── cross_evaluation.py
│ ├── cross_validation_kitti.py
│ ├── distributed_experiments.py
│ ├── evaluation_kitti.py
│ └── simple.py
├── methods/
│ ├── __init__.py
│ ├── dpf.py
│ ├── dpf_kitti.py
│ ├── odom.py
│ └── rnn.py
├── plotting/
│ ├── __init__.py
│ ├── ab_plot.py
│ ├── cross_plot.py
│ ├── lc_plot.py
│ ├── nt_plot.py
│ ├── plot_models.py
│ ├── plotting_kitti.py
│ └── swap_plot.py
├── setup.sh
└── utils/
├── __init__.py
├── data_utils.py
├── data_utils_kitti.py
├── exp_utils.py
├── exp_utils_kitti.py
├── method_utils.py
└── plotting_utils.py
================================================
FILE CONTENTS
================================================
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2018 Robotics and Biology Laboratory, TU Berlin
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
Differentiable Particle Filters
==================================================
Contact
------------------
Rico Jonschkowski (rico.jonschkowski@tu-berlin.de)
Introduction
------------
This repository contains our source code for differentiable particle filters (DPFs) described in the paper "Differentiable Particle Filters: End-to-End Learning with Algorithmic Priors" (Jonschkowski et al. 2018). This implementation is meant to complement the paper. Our goal is to enable others to reproduce our results and to build on our research by reusing our code. We do not include extensive explanations here -- these can be found in our paper https://arxiv.org/pdf/1805.11122.pdf.
If you are using this implementation in your research, please consider giving credit by citing our paper:
@article{jonschkowski18,
title = {{Differentiable Particle Filters: End-to-End Learning with Algorithmic Priors}},
booktitle = {{Proceedings of Robotics: Science and Systems (RSS)}},
author = {Jonschkowski, Rico and Rastogi, Divyam and Brock, Oliver},
year = {2018},
}
Dependencies
------------
Our code builds on python3 and the following libraries. *It is important that the libraries are installed for python3 not python2.*
numpy
sudo apt-get install python3-numpy
matplotlib
sudo apt-get install python3-matplotlib
TensorFlow --> https://www.tensorflow.org/install/, e.g.
pip3 install tensorflow
Sonnet --> https://github.com/deepmind/sonnet, e.g.
pip3 install dm-sonnet
Setup
-----
The setup script **downloads the data** for training and testing (~2.5GB) and **creates additional folders** (for logging etc.). To perform these steps, simply run the following commands in the main folder of the repository:
chmod +x setup.sh
./setup.sh
Usage
-----
After all dependencies are installed and setup is done, there is one more thing which needs to be done every time a new shell is opened before the code can be run. In the main repository folder, you need run the following command to append the parent directory to the PYTHONPATH. *Alternatively, you can import the project into the PyCharm IDE and and run `experiments/simple.py` from there. The need for running this command comes from how PyCharm handles relative imports and relative paths.*
export PYTHONPATH="${PYTHONPATH}:../"
After this is done, you can train and test a differentiable particle filter for global localization in maze 1 by running the following commands in the main folder:
cd experiments; python3 simple.py; cd ..
This command will first train the different models (motion model, observation likelihood estimator, and particle proposer) individually and then train them jointly end-to-end. The command line output will show the current losses on training and validation data (mean +- standard error), where ">>" indicates a new lowest validation loss. Training will stop if the best validation loss has not decreased for a while (e.g. 200 epochs). You should see something like this (the different plots are generated one after another):
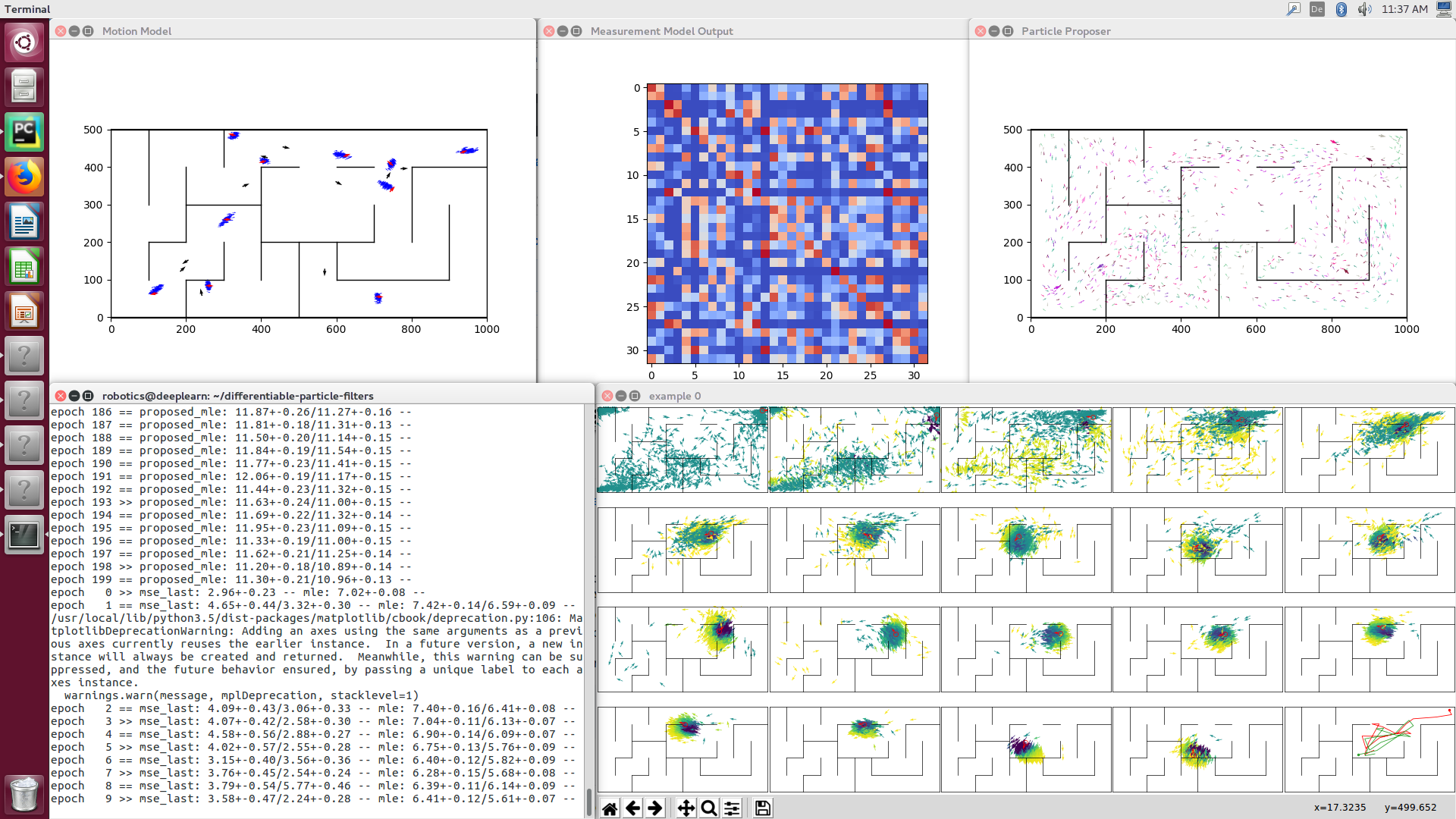
As next steps, you can play around with the hyperparameters in `utils/exp_utils.py`, go through the differentiable particle filter code in `methods/dpf.py`, and run other experiments, e.g. applying the filter to the KITTI visual odometry task by running the following command (if your computer has enough memory :D).
cd experiments; python3 cross_validation_kitti.py; cd ..
================================================
FILE: experiments/__init__.py
================================================
================================================
FILE: experiments/cross_evaluation.py
================================================
import pickle
import os
import numpy as np
from experiments.distributed_experiments import run_experiment, tracking_exp, planner_agent_exp, learning_curve_exp, noise_test_exp
def cross(logfile, cross_exp, exp_name='cr'):
# load data, choose correct task, method, num_episodes, noise_cond, seq_len
with open(logfile, 'rb') as f:
log = pickle.load(f)
model_path = '../models/' + log['exp_params'][0]['model_path'].split('/models/')[-1] # ['exp_params']['model_path]
print(model_path)
# these are actually already lists so we can pass them on directly
task = [log['exp_params'][0]['task']]
method = [log['exp_params'][0]['method']]
num_episodes = [log['exp_params'][0]['num_episodes']]
num_episodes = [log['exp_params'][0]['num_episodes']]
# define experiment you want to run
get_experiment_params, get_train_data_and_eval_iterator = cross_exp('../', exp_name=exp_name, id_extra='',
tasks=task, methods=method, episodes=num_episodes,
num_test_episodes=1000,
run=False)
run_experiment(get_experiment_params, get_train_data_and_eval_iterator, base_path='../', exp_name=exp_name, id_extra='', load_from_model_path=model_path)
def swapmodels(logfiles, noise_conds, exp_name='swap', flipmodules=False):
# expect logfiles to be a dict with two keys that match the noise conditions in noise_test,
# e.g. {'odom5_imgTG': [log1, log2], 'odom20_imgTG': [log1, log2]}
# noise_conds should be a list of the two conditions
# noise_conds = logfiles.keys()
model_paths = dict()
for c in noise_conds:
model_paths[c] = []
for i, logfile in enumerate(logfiles[c]):
with open(logfile, 'rb') as f:
log = pickle.load(f)
model_paths[c].append('../models/' + log['exp_params'][0]['model_path'].split('/models/')[-1])
# should be the same for all logfiles, not checked here
task = [log['exp_params'][0]['task']]
method = [log['exp_params'][0]['method']]
num_episodes = [log['exp_params'][0]['num_episodes']]
get_experiment_params, get_train_data_and_eval_iterator = noise_test_exp('../', exp_name=exp_name, id_extra='',
tasks=task, methods=method, episodes=num_episodes,
noise_conds=noise_conds,
num_test_episodes=1000,
run=False)
modules0 = ('mo_noise_generator', 'mo_transition_model')
modules1 = ('encoder', 'obs_like_estimator', 'particle_proposer')
if flipmodules:
modules0, modules1 = modules1, modules0
for variant, (path, module) in {
'orig_'+noise_conds[0]: (model_paths[noise_conds[0]][0], None),
'%s_%s' % (noise_conds[0], noise_conds[0]): (model_paths[noise_conds[0]], [modules0, modules1]),
'%s_%s' % (noise_conds[0], noise_conds[1]): ([model_paths[noise_conds[0]][0], model_paths[noise_conds[1]][0]], [modules0, modules1]),
'orig_'+noise_conds[1]: (model_paths[noise_conds[1]][0], None),
'%s_%s' % (noise_conds[1], noise_conds[1]): (model_paths[noise_conds[1]], [modules0, modules1]),
'%s_%s' % (noise_conds[1], noise_conds[0]): ([model_paths[noise_conds[1]][0], model_paths[noise_conds[0]][0]], [modules0, modules1]),
}.items():
print('!!! %s %s %s' % (variant, path, module))
run_experiment(get_experiment_params, get_train_data_and_eval_iterator, base_path='../', exp_name=exp_name+'/'+variant, id_extra='', load_from_model_path=path, load_modules=module)
def get_all_logs(path, file_ending):
return [os.path.join(path, filename) for filename in os.listdir(path)
if os.path.isfile(os.path.join(path, filename))
# and filename.endswith(file_ending)]
and file_ending in filename]
def cross_lc2pl(method):
# for f in get_all_logs('../log/lc', 'nav02_'+method+'_1000'):
for f in get_all_logs('../log/lc', 'nav02_'+method+'_'):
cross(f, learning_curve_exp, 'lc2lc1')
cross(f, planner_agent_exp, 'lc2pl1')
def cross_pl2lc(method):
# for f in get_all_logs('../log/pl', 'nav02_'+method+'_1000'):
for f in get_all_logs('../log/pl', 'nav02_'+method):
cross(f, learning_curve_exp, 'pl2lc1')
cross(f, planner_agent_exp, 'pl2pl1')
def cross_mx(method):
for f in get_all_logs('../log/mx', 'nav02_'+method+'_1000'):
# for f in get_all_logs('../log/mx', 'nav02_'+method):
cross(f, learning_curve_exp, 'mx2lc')
cross(f, planner_agent_exp, 'mx2pl')
def swap_motion(method):
noise_conds = ['odom5_imgTG', 'odom10_imgTG']
logs = dict()
for c in noise_conds:
logs[c] = [f for f in get_all_logs('../log/nt', 'nav02_'+method+'_1000_'+c)]
i, j = np.random.choice(len(logs[c]), 2, False)
logs[c] = [logs[c][i], logs[c][j]]
swapmodels(logs, noise_conds, 'swapmo')
def swap_measurement(method):
noise_conds = ['odom10_imgG', 'odom10_imgTG']
logs = dict()
for c in noise_conds:
logs[c] = [f for f in get_all_logs('../log/nt', 'nav02_'+method+'_1000_'+c)][:2]
i, j = np.random.choice(len(logs[c]), 2, False)
logs[c] = [logs[c][i], logs[c][j]]
swapmodels(logs, noise_conds, 'swapme', flipmodules=True)
# if __name__ == '__main__':
================================================
FILE: experiments/cross_validation_kitti.py
================================================
from utils.data_utils_kitti import load_kitti_sequences
import tensorflow as tf
from methods.dpf_kitti import DPF
from utils.exp_utils_kitti import get_default_hyperparams
import numpy as np
def run_cross_validation(i):
print('RUNNING CROSS VALIDATION TRAINING FOR TESTING {}'.format(i))
model_path = '../models/tmp/cross_validation_ind_e2e/model_trained_ex_{}'.format(i)
training_subsequences = [j for j in range(11) if j not in [i]]
# Load all subsequences
data = load_kitti_sequences(training_subsequences)
# Assign weights to all subsequences based on the length of the subsequence
weights = np.zeros((data['seq_num'].shape[0],))
weights[0] = data['seq_num'][0]
weights[1:] = data['seq_num'][1:] - data['seq_num'][:-1]
weights = weights/data['seq_num'][-1]
data['weights'] = weights
# reset tensorflow graph
tf.reset_default_graph()
# instantiate method
hyperparams = get_default_hyperparams()
hyperparams['train']['split_ratio'] = 0.9 # -> 18/2 split
method = DPF(**hyperparams['global'])
with tf.Session() as session:
# train method and save result in model_path
method.fit(session, data, model_path, plot=False, **hyperparams['train'])
if __name__ == '__main__':
for i in range(11):
run_cross_validation(i)
================================================
FILE: experiments/distributed_experiments.py
================================================
import tensorflow as tf
import numpy as np
import pickle
import os
import time
import itertools
from utils.exp_utils import get_default_hyperparams, add_to_log, exp_variables_to_name, print_msg_and_dict, sample_exp_variables
from utils.data_utils import load_data, noisify_data_condition, compute_staticstics, make_batch_iterator, reduce_data, shuffle_data
from utils.method_utils import compute_sq_distance
from methods.dpf import DPF
from methods.rnn import RNN
from methods.odom import OdometryBaseline
def meta_exp(base_path, id_extra):
min_counts = []
exp_names = ['lc', 'tr', 'nt', 'ab', 'pl', 'mx']
funcs = [learning_curve_exp, tracking_exp, noise_test_exp, ablation_test_exp, planner_agent_exp, mix_agent_exp]
for exp_name, f in zip(exp_names, funcs):
get_experiment_params, get_train_data_and_eval_iterator = f(base_path, run=False)
# check progress for that experiment
log_base_path = os.path.join(base_path, 'log', exp_name)
min_counts.append(get_experiment_params(log_base_path)[-1])
print('Experiment', exp_name, 'has min_count', min_counts[-1])
min_min_count = np.min(min_counts)
sample_list = []
for i in range(len(exp_names)):
sample_list += [i] * max(0, (min_min_count + 2) - min_counts[i]) * (3 if 'lc' in exp_names[i] else 1)
if sample_list == []:
sample_list = range(len(exp_names))
i = sample_list[np.random.choice(len(sample_list))]
exp_name = exp_names[i]
f = funcs[i]
print('--> META EXPERIMENT CHOOSES ', exp_name)
f(base_path, exp_name, id_extra)
def learning_curve_exp(base_path='', exp_name='lc', id_extra='', tracking=False,
tasks=('nav01', 'nav02', 'nav03'),
methods=('pf_ind', 'pf_e2e', 'pf_ind_e2e', 'lstm', 'ff'),
episodes = (16, 32, 64, 125, 250, 500, 1000), data_dir='100s',
num_test_episodes=20000, run=True):
def get_experiment_params(base_path):
variables, min_count = sample_exp_variables(base_path, [tasks, methods, episodes])
task, method, num_episodes = variables
exp_params = {
'exp': exp_name,
'task': task,
'method': method,
'num_episodes': num_episodes,
'noise_condition': 'odom10_imgTG',
'tracking': tracking,
'computer': os.uname()[1],
'num_test_episodes': num_test_episodes,
'eval_batch_size': 16,
'eval_seq_len': 50,
'data_dir': data_dir,
'file_ending': exp_variables_to_name(variables)
}
# match sequence length to task
if exp_params['task'] == 'nav01':
exp_params['seq_len'] = 20
elif exp_params['task'] == 'nav02':
exp_params['seq_len'] = 20
elif exp_params['task'] == 'nav03':
exp_params['seq_len'] = 30
return exp_params, get_default_hyperparams(), min_count
def get_train_data_and_eval_iterator(data, exp_params):
# noisify
for k in ['train', 'test']:
data[k] = noisify_data_condition(data[k], exp_params['noise_condition'])
# form batches
eval_batch_iterators = {k: make_batch_iterator(data[k], batch_size=exp_params['eval_batch_size'], seq_len=exp_params['eval_seq_len']) for k in ['test']}
return data['train'], eval_batch_iterators
if run:
# run an experiment with these two functions
return run_experiment(get_experiment_params, get_train_data_and_eval_iterator, base_path, exp_name, id_extra)
else:
return get_experiment_params, get_train_data_and_eval_iterator
def tracking_exp(base_path='', exp_name='tr', id_extra='',
tasks=('nav02',),
methods=('pf_ind', 'pf_e2e', 'pf_ind_e2e', 'lstm', 'odom'),
episodes = (16, 32, 64, 125, 250, 500, 1000), data_dir='100s', num_test_episodes=20000, run=True):
return learning_curve_exp(base_path, exp_name, id_extra, True, tasks, methods, episodes, data_dir, num_test_episodes, run)
def planner_agent_exp(base_path='', exp_name='pl', id_extra='',
tasks=('nav02',),
methods=('pf_ind', 'pf_e2e', 'pf_ind_e2e', 'lstm'),
episodes = (16, 32, 64, 125, 250, 500, 1000), data_dir='100s_astar', num_test_episodes=20000, run=True):
return learning_curve_exp(base_path, exp_name, id_extra, False, tasks, methods, episodes, data_dir, num_test_episodes, run)
def mix_agent_exp(base_path='', exp_name='mx', id_extra='',
tasks=('nav02',),
methods=('pf_ind', 'pf_e2e', 'pf_ind_e2e', 'lstm'),
episodes = (16, 32, 64, 125, 250, 500, 1000), data_dir='100s_mix', num_test_episodes=1000, run=True):
return learning_curve_exp(base_path, exp_name, id_extra, False, tasks, methods, episodes, data_dir, num_test_episodes, run)
def noise_test_exp(base_path='', exp_name='nt', id_extra='', tracking=False,
tasks=('nav02',),
methods=('pf_ind', 'pf_e2e', 'pf_ind_e2e', 'lstm'),
episodes = (16, 125, 1000),
noise_conds=('odom0_imgTG', 'odom5_imgTG', 'odom10_imgTG', 'odom20_imgTG', 'odomX_imgTG',
'odom10_imgC', 'odom10_imgG', 'odom10_imgT', 'odom10_imgX'),
data_dir='100s', num_test_episodes=1000,
run=True,
):
def get_experiment_params(base_path):
variables, min_count = sample_exp_variables(base_path, [tasks, methods, episodes, noise_conds])
task, method, num_episodes, noise_cond = variables
exp_params = {
'exp': exp_name,
'task': task,
'method': method,
'num_episodes': num_episodes,
'noise_condition': noise_cond,
'tracking': tracking,
'computer': os.uname()[1],
'num_test_episodes': num_test_episodes,
'eval_batch_size': 16,
'eval_seq_len': 50,
'data_dir': data_dir,
'file_ending': exp_variables_to_name(variables),
'seq_len': 20,
}
return exp_params, get_default_hyperparams(), min_count
def get_train_data_and_eval_iterator(data, exp_params):
# noisify training data according to sampled noise condition
data['train'] = noisify_data_condition(data['train'], exp_params['noise_condition'])
# create eval batch iterators for every noise condition
eval_batch_iterators = dict()
for condition in noise_conds:
key = 'test' + '_' + condition
data[key] = noisify_data_condition(data['test'], condition)
eval_batch_iterators[key] = make_batch_iterator(data[key], batch_size=exp_params['eval_batch_size'], seq_len=exp_params['eval_seq_len'])
return data['train'], eval_batch_iterators
if run:
# run an experiment with these two functions
return run_experiment(get_experiment_params, get_train_data_and_eval_iterator, base_path, exp_name, id_extra)
else:
return get_experiment_params, get_train_data_and_eval_iterator
def ablation_test_exp(base_path='', exp_name='ab', id_extra='', tracking=False,
tasks=('nav02',),
methods=('pf_ind', 'pf_e2e', 'pf_ind_e2e'),
episodes=(16, 125, 1000),
ab_conds=('full', 'learn_odom', 'no_proposer', 'no_inject'),
data_dir='100s',
run=True
):
def get_experiment_params(base_path):
variables, min_count = sample_exp_variables(base_path, [tasks, methods, episodes, ab_conds])
task, method, num_episodes, ab_cond = variables
exp_params = {
'exp': exp_name,
'task': task,
'method': method,
'num_episodes': num_episodes,
'noise_condition': 'odom10_imgTG',
'tracking': tracking,
'computer': os.uname()[1],
'num_test_episodes': 20000,
'eval_batch_size': 16,
'eval_seq_len': 50,
'data_dir': data_dir,
'file_ending': exp_variables_to_name(variables),
'seq_len': 20,
}
hyper_params = get_default_hyperparams()
if ab_cond == 'learn_odom':
hyper_params['global']['learn_odom'] = True
elif ab_cond == 'no_proposer':
hyper_params['global']['use_proposer'] = False
hyper_params['global']['propose_ratio'] = 0.0
elif ab_cond == 'no_inject':
hyper_params['global']['propose_ratio'] = 0.0
return exp_params, hyper_params, min_count
def get_train_data_and_eval_iterator(data, exp_params):
# noisify
for k in ['train', 'test']:
data[k] = noisify_data_condition(data[k], exp_params['noise_condition'])
# form batches
eval_batch_iterators = {k: make_batch_iterator(data[k], batch_size=exp_params['eval_batch_size'], seq_len=exp_params['eval_seq_len']) for k in ['test']}
return data['train'], eval_batch_iterators
if run:
# run an experiment with these two functions
return run_experiment(get_experiment_params, get_train_data_and_eval_iterator, base_path, exp_name, id_extra)
else:
return get_experiment_params, get_train_data_and_eval_iterator
def run_experiment(get_experiment_params, get_train_data_and_eval_iterator, base_path, exp_name, id_extra='',
load_from_model_path=None, load_modules=None):
# construct base paths
log_base_path = os.path.join(base_path, 'log', exp_name)
if not os.path.exists(log_base_path):
os.makedirs(log_base_path)
model_base_path = os.path.join(base_path, 'models', exp_name)
# sample experiment parameters by checking the log for what is most urgent right now
exp_params, hyperparams, min_count = get_experiment_params(log_base_path)
data_path = os.path.join(base_path, 'data', exp_params['data_dir'])
id = exp_params['id'] = time.strftime('%Y-%m-%d_%H:%M:%S_') + exp_params['computer'] + str(id_extra) + '_' + exp_params['file_ending']
log_path = os.path.join(log_base_path, id)
model_path = exp_params['model_path'] = os.path.join(model_base_path, id)
if not os.path.exists(model_path):
os.makedirs(model_path)
# load data
data = {k: load_data(data_path=data_path, filename=exp_params['task'] + '_' + k) for k in ['train', 'test']}
means, stds, state_step_sizes, state_mins, state_maxs = compute_staticstics(data['train'])
data['train'] = shuffle_data(data['train'])
data['train'] = reduce_data(data['train'], exp_params['num_episodes'])
data['train'], eval_batch_iterators = get_train_data_and_eval_iterator(data, exp_params)
log = dict()
# SET THINGS UP
tf.reset_default_graph()
print_msg_and_dict('STARTING EXPERIMENT', exp_params)
hyperparams['global']['init_with_true_state'] = exp_params['tracking']
if 'pf' in exp_params['method']:
method = DPF(**hyperparams['global'])
hyperparams['train']['train_e2e'] = 'e2e' in exp_params['method']
hyperparams['train']['train_individually'] = 'ind' in exp_params['method']
elif 'lstm' in exp_params['method']:
method = RNN(**hyperparams['global'])
elif 'ff' in exp_params['method']:
method = RNN(model='ff', **hyperparams)
elif 'odom' in exp_params['method']:
method = OdometryBaseline(**hyperparams)
else:
print('I DONT KNOW THIS METHOD', exp_params['method'])
with tf.Session() as session:
t0 = time.time()
if load_from_model_path is None:
training_log = method.fit(session, data['train'], model_path, **hyperparams['train'])
elif type(load_from_model_path) == type([]):
for i, (path, modules) in enumerate(zip(load_from_model_path, load_modules)):
print('Loading %s from %s' % (modules, path))
method.load(session, path, modules=modules, connect_and_initialize=(i==0))
training_log = None
else:
print('Loading model')
if load_modules is None:
method.load(session, load_from_model_path)
else:
method.load(session, load_from_model_path, modules=load_modules)
training_log = None
t1 = time.time()
add_to_log(log, {'training_duration': t1 - t0})
print_msg_and_dict('RESULTS after {}s'.format(log['training_duration'][-1]), exp_params)
for k in sorted(eval_batch_iterators.keys()):
results = {'mse': []}
result_hist = dict()
for i in range(0, exp_params['eval_seq_len'], 10):
result_hist[i] = np.zeros(100)
for eval_batch in eval_batch_iterators[k]:
predicted_states = method.predict(session, eval_batch, **hyperparams['test'])
squared_errors = compute_sq_distance(predicted_states, eval_batch['s'], state_step_sizes)
for i in result_hist.keys():
result_hist[i] += np.histogram(squared_errors[:, i], bins=100, range=[0.0, 10.0])[0]
results['mse'].append(np.mean(squared_errors, axis=0))
if len(results['mse']) * exp_params['eval_batch_size'] >= exp_params['num_test_episodes']:
break
for i in result_hist.keys():
result_hist[i] /= len(results['mse']) * exp_params['eval_batch_size']
mse = np.stack(results['mse'], axis=0)
add_to_log(log, {k + '_hist': result_hist,
k + '_mse': np.mean(mse, axis=0),
k + '_mse_se': np.std(mse, ddof=1, axis=0) / np.sqrt(len(mse))})
for i in range(0, len(log[k+'_mse'][-1]), 5):
print('{:>10} step {} !! mse: {:.4f}+-{:.4f}'.format(k, i, log[k+'_mse'][-1][i], log[k+'_mse_se'][-1][i]))
add_to_log(log, {'hyper_params': hyperparams})
add_to_log(log, {'exp_params': exp_params})
add_to_log(log, {'training': training_log})
# save result
print('Saved log as ', log_path)
with open(log_path, 'wb') as f: # Just use 'w' mode in 3.x
pickle.dump(log, f)
================================================
FILE: experiments/evaluation_kitti.py
================================================
import tensorflow as tf
from methods.dpf_kitti import DPF
from methods.odom import OdometryBaseline
from utils.data_utils_kitti import load_data, noisyfy_data, make_batch_iterator, remove_state, split_data, load_kitti_sequences, make_batch_iterator_for_evaluation, wrap_angle, plot_video
from utils.exp_utils_kitti import get_default_hyperparams
import matplotlib.pyplot as plt
import numpy as np
def get_evaluation_stats(model_path='../models/tmp/', test_trajectories=[11], seq_lengths = [100, 200, 400, 800], plot_results=False):
data = load_kitti_sequences(test_trajectories)
# reset tensorflow graph
tf.reset_default_graph()
# instantiate method
hyperparams = get_default_hyperparams()
method = DPF(**hyperparams['global'])
with tf.Session() as session:
# load method and apply to new data
method.load(session, model_path)
errors = dict()
for i, test_traj in enumerate(test_trajectories):
s_test_traj = data['s'][0:data['seq_num'][i*2]] # take care of duplicated trajectories (left and right camera)
distance = compute_distance_for_trajectory(s_test_traj)
errors[test_traj] = dict()
for seq_len in seq_lengths:
errors[test_traj][seq_len] = {'trans': [], 'rot': []}
for start_step in range(0, distance.shape[0], 1):
end_step, dist = find_end_step(distance, start_step, seq_len, use_meters=False) #--> Put use_meters = True for official KITTI benchmark results
if end_step == -1:
continue
# test_batch_iterator = make_batch_iterator(test_data, seq_len=50)
test_batch_iterator = make_batch_iterator_for_evaluation(data, start_step, trajectory=i, batch_size=1, seq_len=end_step-start_step)
batch = next(test_batch_iterator)
batch_input = remove_state(batch, provide_initial_state=True)
prediction, particle_list, particle_prob_list = method.predict(session, batch_input, return_particles=True)
error_x = batch['s'][0, -1, 0] - prediction[0, -1, 0]
error_y = batch['s'][0, -1, 1] - prediction[0, -1, 1]
error_trans = np.sqrt(error_x ** 2 + error_y ** 2) / dist
error_rot = abs(wrap_angle(batch['s'][0, -1, 2] - prediction[0, -1, 2]))/dist * 180 / np.pi
errors[test_traj][seq_len]['trans'].append(error_trans)
errors[test_traj][seq_len]['rot'].append(error_rot)
if plot_results:
dim_names = ['pos', 'theta', 'vel_f', 'vel_th']
fig = plt.figure()
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(223)
ax4 = fig.add_subplot(224)
for t in range(particle_list.shape[1]):
dim = 0
ax1.scatter(particle_list[0, t, :, dim], particle_list[0, t, :, dim+1], c=particle_prob_list[0, t, :], cmap='viridis_r', marker='o', s=15, alpha=0.1,
linewidths=0.05,
vmin=0.0,
vmax=0.02)
ax1.plot([prediction[0, t, dim]], [prediction[0, t, dim+1]], 'o', markerfacecolor='None', markeredgecolor='b',
markersize=0.5)
ax1.plot([batch['s'][0, t, dim]], [batch['s'][0, t, dim+1]], '+', markerfacecolor='None', markeredgecolor='r',
markersize=0.5)
ax1.set_aspect('equal')
dim = 2
ax2.scatter(t * np.ones_like(particle_list[0, t, :, dim]), particle_list[0, t, :, dim], c=particle_prob_list[0, t, :], cmap='viridis_r', marker='o', s=15, alpha=0.1,
linewidths=0.05,
vmin=0.0,
vmax=0.02)
#np.max(
#s_add_probs_list[s, i, :, 0])) # , vmin=-1/filter.num_particles,)
current_state = prediction[0, t, dim]
ax2.plot([t], [current_state], 'o', markerfacecolor='None', markeredgecolor='k',
markersize=2.5)
true = batch['s'][0, t, dim]
ax2.plot([t], [true], '+', markerfacecolor='None', markeredgecolor='r',
markersize=2.5)
dim = 3
ax3.scatter(t * np.ones_like(particle_list[0, t, :, dim]), particle_list[0, t, :, dim], c=particle_prob_list[0, t, :], cmap='viridis_r', marker='o', s=15, alpha=0.1,
linewidths=0.05,
vmin=0.0,
vmax=0.02)
#np.max(
#s_add_probs_list[s, i, :, 0])) # , vmin=-1/filter.num_particles,)
current_state = prediction[0, t, dim]
ax3.plot([t], [current_state], 'o', markerfacecolor='None', markeredgecolor='k',
markersize=2.5)
true = batch['s'][0, t, dim]
ax3.plot([t], [true], '+', markerfacecolor='None', markeredgecolor='r',
markersize=2.5)
dim = 4
ax4.scatter(t * np.ones_like(particle_list[0, t, :, dim]), particle_list[0, t, :, dim], c=particle_prob_list[0, t, :], cmap='viridis_r', marker='o', s=15, alpha=0.1,
linewidths=0.05,
vmin=0.0,
vmax=0.02)
current_state = prediction[0, t, dim]
ax4.plot([t], [current_state], 'o', markerfacecolor='None', markeredgecolor='k',
markersize=2.5)
true = batch['s'][0, t, dim]
ax4.plot([t], [true], '+', markerfacecolor='None', markeredgecolor='r',
markersize=2.5)
plt.pause(0.05)
ax1.set_title(dim_names[0])
ax2.set_title(dim_names[1])
ax3.set_title(dim_names[2])
ax4.set_title(dim_names[3])
return errors
def compute_distance_for_trajectory(s):
# for ii in range(len(output_oxts_file)):
distance = [0]
for i in range(1, s.shape[0]):
diff_x = s[i, 0, 0] - s[i-1, 0, 0]
diff_y = s[i, 0, 1] - s[i-1, 0, 1]
dist = distance[-1] + np.sqrt(diff_x ** 2 + diff_y ** 2)
distance.append(dist)
distance = np.asarray(distance)
return distance
def find_end_step(distance, start_step, length, use_meters=True):
for i in range(start_step, distance.shape[0]):
if (use_meters and distance[i] > (distance[start_step] + length)) or \
(not use_meters and (i - start_step) >= length):
return i, distance[i] - distance[start_step]
return -1, 0
def find_all_cross_val_models(model_path):
import os
models = ([name for name in os.listdir(model_path) if not os.path.isfile(os.path.join(model_path, name))])
trajs = [int(name.split('_')[3]) for name in models]
return zip(models, trajs)
def main():
plt.ion()
errors = dict()
average_errors = {'trans': {i: [] for i in [100, 200, 400, 800]},
'rot': {i: [] for i in [100, 200, 400, 800]}}
model_path = '../models/tmp/cross_validation_ind_e2e/'
for model, traj in find_all_cross_val_models(model_path):
print('!!! Evaluatng model {} on trajectory {}'.format(model, traj))
new_errors = get_evaluation_stats(model_path=model_path+model, test_trajectories=[traj], plot_results=False)
errors.update(new_errors)
print('')
print('Trajectory {}'.format(traj))
for seq_len in sorted(errors[traj].keys()):
for measure in ['trans', 'rot']:
e = errors[traj][seq_len][measure]
mean_error = np.mean(e)
se_error = np.std(e, ddof=1) / np.sqrt(len(e))
average_errors[measure][seq_len].append(mean_error)
print('{:>5} error for seq_len {}: {:.4f} +- {:.4f}'.format(measure, seq_len, mean_error, se_error))
print('Averaged errors:')
for measure in ['trans', 'rot']:
e_means = []
e_ses = []
for seq_len in sorted(average_errors[measure].keys()):
e = np.array(average_errors[measure][seq_len])
e = e[~np.isnan(e)]
mean_error = np.mean(e)
e_means.append(mean_error)
se_error = np.std(e, ddof=1) / np.sqrt(len(e))
e_ses.append(se_error)
print('{:>5} error for seq_len {}: {:.4f} +- {:.4f}'.format(measure, seq_len, mean_error, se_error))
print('{:>5} error averaged over seq_lens: {:.4f} +- {:.4f}'.format(measure, np.mean(e_means), np.std(e_means, ddof=1) / np.sqrt(len(e_means))))
if __name__ == '__main__':
main()
================================================
FILE: experiments/simple.py
================================================
import tensorflow as tf
from methods.dpf import DPF
from utils.data_utils import load_data, noisyfy_data, make_batch_iterator, remove_state
from utils.exp_utils import get_default_hyperparams
def train_dpf(task='nav01', data_path='../data/100s', model_path='../models/tmp', plot=False):
# load training data and add noise
train_data = load_data(data_path=data_path, filename=task + '_train')
noisy_train_data = noisyfy_data(train_data)
# reset tensorflow graph
tf.reset_default_graph()
# instantiate method
hyperparams = get_default_hyperparams()
method = DPF(**hyperparams['global'])
with tf.Session() as session:
# train method and save result in model_path
method.fit(session, noisy_train_data, model_path, **hyperparams['train'], plot_task=task, plot=plot)
def test_dpf(task='nav01', data_path='../data/100s', model_path='../models/tmp'):
# load test data
test_data = load_data(data_path=data_path, filename=task + '_test')
noisy_test_data = noisyfy_data(test_data)
test_batch_iterator = make_batch_iterator(noisy_test_data, seq_len=50)
# reset tensorflow graph
tf.reset_default_graph()
# instantiate method
hyperparams = get_default_hyperparams()
method = DPF(**hyperparams['global'])
with tf.Session() as session:
# load method and apply to new data
method.load(session, model_path)
for i in range(10):
test_batch = next(test_batch_iterator)
test_batch_input = remove_state(test_batch, provide_initial_state=False)
result = method.predict(session, test_batch_input, **hyperparams['test'])
if __name__ == '__main__':
train_dpf(plot=True)
test_dpf()
================================================
FILE: methods/__init__.py
================================================
================================================
FILE: methods/dpf.py
================================================
import os
import numpy as np
import sonnet as snt
import tensorflow as tf
import matplotlib.pyplot as plt
from utils.data_utils import wrap_angle, compute_staticstics, split_data, make_batch_iterator, make_repeating_batch_iterator
from utils.method_utils import atan2, compute_sq_distance
from utils.plotting_utils import plot_maze, show_pause
if tf.__version__ == '1.1.0-rc1' or tf.__version__ == '1.3.0':
from tensorflow.python.framework import ops
@ops.RegisterGradient("FloorMod")
def _mod_grad(op, grad):
x, y = op.inputs
gz = grad
x_grad = gz
y_grad = None # tf.reduce_mean(-(x // y) * gz, axis=[0], keep_dims=True)[0]
return x_grad, y_grad
class DPF():
def __init__(self, init_with_true_state, learn_odom, use_proposer, propose_ratio, proposer_keep_ratio, min_obs_likelihood):
"""
:param init_with_true_state:
:param learn_odom:
:param use_proposer:
:param propose_ratio:
:param particle_std:
:param proposer_keep_ratio:
:param min_obs_likelihood:
"""
# store hyperparameters which are needed later
self.init_with_true_state = init_with_true_state
self.learn_odom = learn_odom
self.use_proposer = use_proposer and not init_with_true_state # only use proposer if we do not initializet with true state
self.propose_ratio = propose_ratio if not self.init_with_true_state else 0.0
# define some more parameters and placeholders
self.state_dim = 3
self.placeholders = {'o': tf.placeholder('float32', [None, None, 24, 24, 3], 'observations'),
'a': tf.placeholder('float32', [None, None, 3], 'actions'),
's': tf.placeholder('float32', [None, None, 3], 'states'),
'num_particles': tf.placeholder('float32'),
'keep_prob': tf.placeholder_with_default(tf.constant(1.0), []),
}
self.num_particles_float = self.placeholders['num_particles']
self.num_particles = tf.to_int32(self.num_particles_float)
# build learnable modules
self.build_modules(min_obs_likelihood, proposer_keep_ratio)
def build_modules(self, min_obs_likelihood, proposer_keep_ratio):
"""
:param min_obs_likelihood:
:param proposer_keep_ratio:
:return: None
"""
# MEASUREMENT MODEL
# conv net for encoding the image
self.encoder = snt.Sequential([
snt.nets.ConvNet2D([16, 32, 64], [[3, 3]], [2], [snt.SAME], activate_final=True, name='encoder/convnet'),
snt.BatchFlatten(),
lambda x: tf.nn.dropout(x, self.placeholders['keep_prob']),
snt.Linear(128, name='encoder/linear'),
tf.nn.relu
])
# observation likelihood estimator that maps states and image encodings to probabilities
self.obs_like_estimator = snt.Sequential([
snt.Linear(128, name='obs_like_estimator/linear'),
tf.nn.relu,
snt.Linear(128, name='obs_like_estimator/linear'),
tf.nn.relu,
snt.Linear(1, name='obs_like_estimator/linear'),
tf.nn.sigmoid,
lambda x: x * (1 - min_obs_likelihood) + min_obs_likelihood
], name='obs_like_estimator')
# motion noise generator used for motion sampling
self.mo_noise_generator = snt.nets.MLP([32, 32, self.state_dim], activate_final=False, name='mo_noise_generator')
# odometry model (if we want to learn it)
if self.learn_odom:
self.mo_transition_model = snt.nets.MLP([128, 128, 128, self.state_dim], activate_final=False, name='mo_transition_model')
# particle proposer that maps encodings to particles (if we want to use it)
if self.use_proposer:
self.particle_proposer = snt.Sequential([
snt.Linear(128, name='particle_proposer/linear'),
tf.nn.relu,
lambda x: tf.nn.dropout(x, proposer_keep_ratio),
snt.Linear(128, name='particle_proposer/linear'),
tf.nn.relu,
snt.Linear(128, name='particle_proposer/linear'),
tf.nn.relu,
snt.Linear(128, name='particle_proposer/linear'),
tf.nn.relu,
snt.Linear(4, name='particle_proposer/linear'),
tf.nn.tanh,
])
def measurement_update(self, encoding, particles, means, stds):
"""
Compute the likelihood of the encoded observation for each particle.
:param encoding: encoding of the observation
:param particles:
:param means:
:param stds:
:return: observation likelihood
"""
# prepare input (normalize particles poses and repeat encoding per particle)
particle_input = self.transform_particles_as_input(particles, means, stds)
encoding_input = tf.tile(encoding[:, tf.newaxis, :], [1, tf.shape(particles)[1], 1])
input = tf.concat([encoding_input, particle_input], axis=-1)
# estimate the likelihood of the encoded observation for each particle, remove last dimension
obs_likelihood = snt.BatchApply(self.obs_like_estimator)(input)[:, :, 0]
return obs_likelihood
def transform_particles_as_input(self, particles, means, stds):
return tf.concat([
(particles[:, :, :2] - means['s'][:, :, :2]) / stds['s'][:, :, :2], # normalized pos
tf.cos(particles[:, :, 2:3]), # cos
tf.sin(particles[:, :, 2:3])], # sin
axis=-1)
def propose_particles(self, encoding, num_particles, state_mins, state_maxs):
duplicated_encoding = tf.tile(encoding[:, tf.newaxis, :], [1, num_particles, 1])
proposed_particles = snt.BatchApply(self.particle_proposer)(duplicated_encoding)
proposed_particles = tf.concat([
proposed_particles[:,:,:1] * (state_maxs[0] - state_mins[0]) / 2.0 + (state_maxs[0] + state_mins[0]) / 2.0,
proposed_particles[:,:,1:2] * (state_maxs[1] - state_mins[1]) / 2.0 + (state_maxs[1] + state_mins[1]) / 2.0,
atan2(proposed_particles[:,:,2:3], proposed_particles[:,:,3:4])], axis=2)
return proposed_particles
def motion_update(self, actions, particles, means, stds, state_step_sizes, stop_sampling_gradient=False):
"""
Move particles according to odometry info in actions. Add learned noise.
:param actions:
:param particles:
:param means:
:param stds:
:param state_step_sizes:
:param stop_sampling_gradient:
:return: moved particles
"""
# 1. SAMPLE NOISY ACTIONS
# add dimension for particles
actions = actions[:, tf.newaxis, :]
# prepare input (normalize actions and repeat per particle)
action_input = tf.tile(actions / stds['a'], [1, tf.shape(particles)[1], 1])
random_input = tf.random_normal(tf.shape(action_input))
input = tf.concat([action_input, random_input], axis=-1)
# estimate action noise
delta = snt.BatchApply(self.mo_noise_generator)(input)
if stop_sampling_gradient:
delta = tf.stop_gradient(delta)
# zero-mean the action noise and add to actions
delta -= tf.reduce_mean(delta, axis=1, keep_dims=True)
noisy_actions = actions + delta
# 2. APPLY NOISY ACTIONS
if self.learn_odom:
# prepare input (normalize states and actions)
state_input = self.transform_particles_as_input(particles, means, stds)
action_input = noisy_actions / stds['a']
input = tf.concat([state_input, action_input], axis=-1)
# estimate state delta, scale it, and apply it
state_delta = snt.BatchApply(self.mo_transition_model)(input)
new_states = [particles[:, :, i:i+1] + state_delta[:, :, i:i+1] * state_step_sizes[i] for i in range(3)]
moved_particles = tf.concat(new_states[:2] + [wrap_angle(new_states[2])], axis=-1)
else:
# compute sin and cos of the particles
theta = particles[:, :, 2:3]
sin_theta = tf.sin(theta)
cos_theta = tf.cos(theta)
# move the particles using the noisy actions
new_x = particles[:, :, 0:1] + (noisy_actions[:, :, 0:1] * cos_theta + noisy_actions[:, :, 1:2] * sin_theta)
new_y = particles[:, :, 1:2] + (noisy_actions[:, :, 0:1] * sin_theta - noisy_actions[:, :, 1:2] * cos_theta)
new_theta = wrap_angle(particles[:, :, 2:3] + noisy_actions[:, :, 2:3])
moved_particles = tf.concat([new_x, new_y, new_theta], axis=-1)
return moved_particles
def compile_training_stages(self, sess, batch_iterators, particle_list, particle_probs_list, encodings, means, stds, state_step_sizes, state_mins, state_maxs, learning_rate, plot_task):
# TRAINING!
losses = dict()
train_stages = dict()
# TRAIN ODOMETRY
if self.learn_odom:
# apply model
motion_samples = self.motion_update(self.placeholders['a'][:,1],
self.placeholders['s'][:, :1],
means, stds, state_step_sizes,
stop_sampling_gradient=True)
# define loss and optimizer
sq_distance = compute_sq_distance(motion_samples, self.placeholders['s'][:, 1:2], state_step_sizes)
losses['motion_mse'] = tf.reduce_mean(sq_distance, name='loss')
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
var_list = [v for v in tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES) if 'mo_transition_model' in v.name]
# put everything together
train_stages['train_odom'] = {
'train_op': optimizer.minimize(losses['motion_mse'], var_list=var_list),
'batch_iterator_names': {'train': 'train1', 'val': 'val1'},
'monitor_losses': ['motion_mse'],
'validation_loss': 'motion_mse',
'plot': lambda e: self.plot_motion_model(sess, next(batch_iterators['val1']), motion_samples, plot_task) if e % 10 == 0 else None
}
# TRAIN MOTION MODEL
# apply model
motion_samples = self.motion_update(self.placeholders['a'][:,1],
tf.tile(self.placeholders['s'][:, :1], [1, self.num_particles, 1]),
means, stds, state_step_sizes)
# define loss and optimizer
std = 0.01
sq_distance = compute_sq_distance(motion_samples, self.placeholders['s'][:, 1:2], state_step_sizes)
activations_sample = (1 / self.num_particles_float) / tf.sqrt(2 * np.pi * std ** 2) * tf.exp(
-sq_distance / (2.0 * std ** 2))
losses['motion_mle'] = tf.reduce_mean(-tf.log(1e-16 + tf.reduce_sum(activations_sample, axis=-1, name='loss')))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
var_list = [v for v in tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES) if 'mo_noise_generator' in v.name]
# put everything together
train_stages['train_motion_sampling'] = {
'train_op': optimizer.minimize(losses['motion_mle'], var_list=var_list),
'batch_iterator_names': {'train': 'train1', 'val': 'val1'},
'monitor_losses': ['motion_mle'],
'validation_loss': 'motion_mle',
'plot': lambda e: self.plot_motion_model(sess, next(batch_iterators['val1']), motion_samples, plot_task) if e % 10 == 0 else None
}
# TRAIN MEASUREMENT MODEL
# apply model for all pairs of observations and states in that batch
test_particles = tf.tile(self.placeholders['s'][tf.newaxis, :, 0], [self.batch_size, 1, 1])
measurement_model_out = self.measurement_update(encodings[:, 0], test_particles, means, stds)
# define loss (correct -> 1, incorrect -> 0) and optimizer
correct_samples = tf.diag_part(measurement_model_out)
incorrect_samples = measurement_model_out - tf.diag(tf.diag_part(measurement_model_out))
losses['measurement_heuristic'] = tf.reduce_sum(-tf.log(correct_samples)) / tf.cast(self.batch_size, tf.float32) \
+ tf.reduce_sum(-tf.log(1.0 - incorrect_samples)) / tf.cast(self.batch_size * (self.batch_size - 1), tf.float32)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
var_list = [v for v in tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES) if 'encoder' in v.name or 'obs_like_estimator' in v.name]
# put everything together
train_stages['train_measurement_model'] = {
'train_op': optimizer.minimize(losses['measurement_heuristic'], var_list=var_list),
'batch_iterator_names': {'train': 'train1', 'val': 'val1'},
'monitor_losses': ['measurement_heuristic'],
'validation_loss': 'measurement_heuristic',
'plot': lambda e: self.plot_measurement_model(sess, batch_iterators['val1'], measurement_model_out) if e % 10 == 0 else None
}
# TRAIN PARTICLE PROPOSER
if self.use_proposer:
# apply model (but only compute gradients until the encoding,
# otherwise we would unlearn it and the observation likelihood wouldn't work anymore)
proposed_particles = self.propose_particles(tf.stop_gradient(encodings[:, 0]), self.num_particles, state_mins, state_maxs)
# define loss and optimizer
std = 0.2
sq_distance = compute_sq_distance(proposed_particles, self.placeholders['s'][:, :1], state_step_sizes)
activations = (1 / self.num_particles_float) / tf.sqrt(2 * np.pi * std ** 2) * tf.exp(
-sq_distance / (2.0 * std ** 2))
losses['proposed_mle'] = tf.reduce_mean(-tf.log(1e-16 + tf.reduce_sum(activations, axis=-1)))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
var_list = [v for v in tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES) if 'particle_proposer' in v.name]
# put everything together
train_stages['train_particle_proposer'] = {
'train_op': optimizer.minimize(losses['proposed_mle'], var_list=var_list),
'batch_iterator_names': {'train': 'train1', 'val': 'val1'},
'monitor_losses': ['proposed_mle'],
'validation_loss': 'proposed_mle',
'plot': lambda e: self.plot_particle_proposer(sess, next(batch_iterators['val1']), proposed_particles, plot_task) if e % 10 == 0 else None
}
# END-TO-END TRAINING
# model was already applyed further up -> particle_list, particle_probs_list
# define losses and optimizer
# first loss (which is being optimized)
sq_distance = compute_sq_distance(particle_list, self.placeholders['s'][:, :, tf.newaxis, :], state_step_sizes)
activations = particle_probs_list[:, :] / tf.sqrt(2 * np.pi * std ** 2) * tf.exp(
-sq_distance / (2.0 * self.particle_std ** 2))
losses['mle'] = tf.reduce_mean(-tf.log(1e-16 + tf.reduce_sum(activations, axis=2, name='loss')))
# second loss (which we will monitor during execution)
pred = self.particles_to_state(particle_list, particle_probs_list)
sq_distance = compute_sq_distance(pred[:, -1, :], self.placeholders['s'][:, -1, :], state_step_sizes)
losses['mse_last'] = tf.reduce_mean(sq_distance)
# optimizer
optimizer = tf.train.AdamOptimizer(learning_rate)
# put everything together
train_stages['train_e2e'] = {
'train_op': optimizer.minimize(losses['mle']),
'batch_iterator_names': {'train': 'train', 'val': 'val'},
'monitor_losses': ['mse_last', 'mle'],
'validation_loss': 'mse_last',
'plot': lambda e: self.plot_particle_filter(sess, next(batch_iterators['val_ex']), particle_list,
particle_probs_list, self.num_particles, state_step_sizes, plot_task) if e % 1 == 0 else None
}
return losses, train_stages
def load(self, sess, model_path, model_file='best_validation', statistics_file='statistics.npz', connect_and_initialize=True, modules=('encoder', 'mo_noise_generator', 'mo_transition_model', 'obs_like_estimator', 'particle_proposer')):
if type(modules) not in [type(list()), type(tuple())]:
raise Exception('modules must be a list or tuple, not a ' + str(type(modules)))
# build the tensorflow graph
if connect_and_initialize:
# load training data statistics (which are needed to build the tf graph)
statistics = dict(np.load(os.path.join(model_path, statistics_file)))
for key in statistics.keys():
if statistics[key].shape == ():
statistics[key] = statistics[key].item() # convert 0d array of dictionary back to a normal dictionary
# connect all modules into the particle filter
self.connect_modules(**statistics)
init = tf.global_variables_initializer()
sess.run(init)
else:
statistics = None
# load variables
all_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES)
vars_to_load = []
loaded_modules = set()
for v in all_vars:
for m in modules:
if m in v.name:
vars_to_load.append(v)
loaded_modules.add(m)
print('Loading these modules:', loaded_modules)
print('%s %s' % (model_path, model_file))
print('%r %r' % (model_path, model_file))
# restore variable values
saver = tf.train.Saver(vars_to_load) # <- var list goes in here
saver.restore(sess, os.path.join(model_path, model_file))
print('Loaded the following variables:')
for v in vars_to_load:
print(v.name)
return statistics
def fit(self, sess, data, model_path, train_individually, train_e2e, split_ratio, seq_len, batch_size, epoch_length, num_epochs, patience, learning_rate, dropout_keep_ratio, num_particles, particle_std, plot_task=None, plot=False):
self.particle_std = particle_std
# preprocess data
data = split_data(data, ratio=split_ratio)
epoch_lengths = {'train': epoch_length, 'val': epoch_length*2}
batch_iterators = {'train': make_batch_iterator(data['train'], seq_len=seq_len, batch_size=batch_size),
'val': make_repeating_batch_iterator(data['val'], epoch_lengths['val'], batch_size=batch_size, seq_len=seq_len),
'train_ex': make_batch_iterator(data['train'], batch_size=batch_size, seq_len=seq_len),
'val_ex': make_batch_iterator(data['val'], batch_size=batch_size, seq_len=seq_len),
'train1': make_batch_iterator(data['train'], batch_size=batch_size, seq_len=2),
'val1': make_repeating_batch_iterator(data['val'], epoch_lengths['val'], batch_size=batch_size, seq_len=2),
}
# compute some statistics of the training data
means, stds, state_step_sizes, state_mins, state_maxs = compute_staticstics(data['train'])
# build the tensorflow graph by connecting all modules in the particles filter
particles, particle_probs, encodings, particle_list, particle_probs_list = self.connect_modules(means, stds, state_mins, state_maxs, state_step_sizes)
# define losses and train stages for different ways of training (e.g. training individual models and e2e training)
losses, train_stages = self.compile_training_stages(sess, batch_iterators, particle_list, particle_probs_list,
encodings, means, stds, state_step_sizes, state_mins,
state_maxs, learning_rate, plot_task)
# initialize variables
init = tf.global_variables_initializer()
sess.run(init)
# save statistics and prepare saving variables
if not os.path.exists(model_path):
os.makedirs(model_path)
np.savez(os.path.join(model_path, 'statistics'), means=means, stds=stds, state_step_sizes=state_step_sizes,
state_mins=state_mins, state_maxs=state_maxs)
saver = tf.train.Saver()
save_path = os.path.join(model_path, 'best_validation')
# define the training curriculum
curriculum = []
if train_individually:
if self.learn_odom:
curriculum += ['train_odom']
curriculum += ['train_motion_sampling']
curriculum += ['train_measurement_model']
if self.use_proposer:
curriculum += ['train_particle_proposer']
if train_e2e:
curriculum += ['train_e2e']
# split data for early stopping
data_keys = ['train']
if split_ratio < 1.0:
data_keys.append('val')
# define log dict
log = {c: {dk: {lk: {'mean': [], 'se': []} for lk in train_stages[c]['monitor_losses']} for dk in data_keys} for c in curriculum}
# go through curriculum
for c in curriculum:
stage = train_stages[c]
best_val_loss = np.inf
best_epoch = 0
epoch = 0
while epoch < num_epochs and epoch - best_epoch < patience:
# training
for dk in data_keys:
# don't train in the first epoch, just evaluate the initial parameters
if dk == 'train' and epoch == 0:
continue
# set up loss lists which will be filled during the epoch
loss_lists = {lk: [] for lk in stage['monitor_losses']}
for e in range(epoch_lengths[dk]):
# t0 = time.time()
# pick a batch from the right iterator
batch = next(batch_iterators[stage['batch_iterator_names'][dk]])
# define the inputs and train/run the model
input_dict = {**{self.placeholders[key]: batch[key] for key in 'osa'},
**{self.placeholders['num_particles']: num_particles},
}
if dk == 'train':
input_dict[self.placeholders['keep_prob']] = dropout_keep_ratio
monitor_losses = {l: losses[l] for l in stage['monitor_losses']}
if dk == 'train':
s_losses, _ = sess.run([monitor_losses, stage['train_op']], input_dict)
else:
s_losses = sess.run(monitor_losses, input_dict)
for lk in stage['monitor_losses']:
loss_lists[lk].append(s_losses[lk])
# after each epoch, compute and log statistics
for lk in stage['monitor_losses']:
log[c][dk][lk]['mean'].append(np.mean(loss_lists[lk]))
log[c][dk][lk]['se'].append(np.std(loss_lists[lk], ddof=1) / np.sqrt(len(loss_lists[lk])))
# check whether the current model is better than all previous models
if 'val' in data_keys:
current_val_loss = log[c]['val'][stage['validation_loss']]['mean'][-1]
if current_val_loss < best_val_loss:
best_val_loss = current_val_loss
best_epoch = epoch
# save current model
saver.save(sess, save_path)
txt = 'epoch {:>3} >> '.format(epoch)
else:
txt = 'epoch {:>3} == '.format(epoch)
else:
best_epoch = epoch
saver.save(sess, save_path)
txt = 'epoch {:>3} >> '.format(epoch)
# after going through all data sets, do a print out of the current result
for lk in stage['monitor_losses']:
txt += '{}: '.format(lk)
for dk in data_keys:
if len(log[c][dk][lk]['mean']) > 0:
txt += '{:.2f}+-{:.2f}/'.format(log[c][dk][lk]['mean'][-1], log[c][dk][lk]['se'][-1])
txt = txt[:-1] + ' -- '
print(txt)
# t1 = time.time()
# time_deltas.append(t1 - t0)
if plot:
stage['plot'](epoch)
epoch += 1
# after running out of patience, restore the model with lowest validation loss
saver.restore(sess, save_path)
return log
def predict(self, sess, batch, num_particles, return_particles=False, **kwargs):
# define input dict, use the first state only if we do tracking
input_dict = {self.placeholders['o']: batch['o'],
self.placeholders['a']: batch['a'],
self.placeholders['num_particles']: num_particles}
if self.init_with_true_state:
input_dict[self.placeholders['s']] = batch['s'][:, :1]
if return_particles:
return sess.run([self.pred_states, self.particle_list, self.particle_probs_list], input_dict)
else:
return sess.run(self.pred_states, input_dict)
def connect_modules(self, means, stds, state_mins, state_maxs, state_step_sizes):
# get shapes
self.batch_size = tf.shape(self.placeholders['o'])[0]
self.seq_len = tf.shape(self.placeholders['o'])[1]
# we use the static shape here because we need it to build the graph
self.action_dim = self.placeholders['a'].get_shape()[-1].value
encodings = snt.BatchApply(self.encoder)((self.placeholders['o'] - means['o']) / stds['o'])
self.encodings = encodings
# initialize particles
if self.init_with_true_state:
# tracking with known initial state
initial_particles = tf.tile(self.placeholders['s'][:, 0, tf.newaxis, :], [1, self.num_particles, 1])
else:
# global localization
if self.use_proposer:
# propose particles from observations
initial_particles = self.propose_particles(encodings[:, 0], self.num_particles, state_mins, state_maxs)
else:
# sample particles randomly
initial_particles = tf.concat(
[tf.random_uniform([self.batch_size, self.num_particles, 1], state_mins[d], state_maxs[d]) for d in
range(self.state_dim)], axis=-1, name='particles')
initial_particle_probs = tf.ones([self.batch_size, self.num_particles],
name='particle_probs') / self.num_particles_float
# assumes that samples has the correct size
def permute_batch(x, samples):
# get shapes
batch_size = tf.shape(x)[0]
num_particles = tf.shape(x)[1]
sample_size = tf.shape(samples)[1]
# compute 1D indices into the 2D array
idx = samples + num_particles * tf.tile(
tf.reshape(tf.range(batch_size), [batch_size, 1]),
[1, sample_size])
# index using the 1D indices and reshape again
result = tf.gather(tf.reshape(x, [batch_size * num_particles, -1]), idx)
result = tf.reshape(result, tf.shape(x[:,:sample_size]))
return result
def loop(particles, particle_probs, particle_list, particle_probs_list, additional_probs_list, i):
num_proposed_float = tf.round((self.propose_ratio ** tf.cast(i, tf.float32)) * self.num_particles_float)
num_proposed = tf.cast(num_proposed_float, tf.int32)
num_resampled_float = self.num_particles_float - num_proposed_float
num_resampled = tf.cast(num_resampled_float, tf.int32)
if self.propose_ratio < 1.0:
# resampling
basic_markers = tf.linspace(0.0, (num_resampled_float - 1.0) / num_resampled_float, num_resampled)
random_offset = tf.random_uniform([self.batch_size], 0.0, 1.0 / num_resampled_float)
markers = random_offset[:, None] + basic_markers[None, :] # shape: batch_size x num_resampled
cum_probs = tf.cumsum(particle_probs, axis=1)
marker_matching = markers[:, :, None] < cum_probs[:, None, :] # shape: batch_size x num_resampled x num_particles
samples = tf.cast(tf.argmax(tf.cast(marker_matching, 'int32'), dimension=2), 'int32')
standard_particles = permute_batch(particles, samples)
standard_particle_probs = tf.ones([self.batch_size, num_resampled])
standard_particles = tf.stop_gradient(standard_particles)
standard_particle_probs = tf.stop_gradient(standard_particle_probs)
# motion update
standard_particles = self.motion_update(self.placeholders['a'][:, i], standard_particles, means, stds, state_step_sizes)
# measurement update
standard_particle_probs *= self.measurement_update(encodings[:, i], standard_particles, means, stds)
if self.propose_ratio > 0.0:
# proposed particles
proposed_particles = self.propose_particles(encodings[:, i], num_proposed, state_mins, state_maxs)
proposed_particle_probs = tf.ones([self.batch_size, num_proposed])
# NORMALIZE AND COMBINE PARTICLES
if self.propose_ratio == 1.0:
particles = proposed_particles
particle_probs = proposed_particle_probs
elif self.propose_ratio == 0.0:
particles = standard_particles
particle_probs = standard_particle_probs
else:
standard_particle_probs *= (num_resampled_float / self.num_particles_float) / tf.reduce_sum(standard_particle_probs, axis=1, keep_dims=True)
proposed_particle_probs *= (num_proposed_float / self.num_particles_float) / tf.reduce_sum(proposed_particle_probs, axis=1, keep_dims=True)
particles = tf.concat([standard_particles, proposed_particles], axis=1)
particle_probs = tf.concat([standard_particle_probs, proposed_particle_probs], axis=1)
# NORMALIZE PROBABILITIES
particle_probs /= tf.reduce_sum(particle_probs, axis=1, keep_dims=True)
particle_list = tf.concat([particle_list, particles[:, tf.newaxis]], axis=1)
particle_probs_list = tf.concat([particle_probs_list, particle_probs[:, tf.newaxis]], axis=1)
return particles, particle_probs, particle_list, particle_probs_list, additional_probs_list, i + 1
# reshapes and sets the first shape sizes to None (which is necessary to keep the shape consistent in while loop)
particle_list = tf.reshape(initial_particles,
shape=[self.batch_size, -1, self.num_particles, self.state_dim])
particle_probs_list = tf.reshape(initial_particle_probs, shape=[self.batch_size, -1, self.num_particles])
additional_probs_list = tf.reshape(tf.ones([self.batch_size, self.num_particles, 4]), shape=[self.batch_size, -1, self.num_particles, 4])
# run the filtering process
particles, particle_probs, particle_list, particle_probs_list, additional_probs_list, i = tf.while_loop(
lambda *x: x[-1] < self.seq_len, loop,
[initial_particles, initial_particle_probs, particle_list, particle_probs_list, additional_probs_list,
tf.constant(1, dtype='int32')], name='loop')
# compute mean of particles
self.pred_states = self.particles_to_state(particle_list, particle_probs_list)
self.particle_list = particle_list
self.particle_probs_list = particle_probs_list
return particles, particle_probs, encodings, particle_list, particle_probs_list
def particles_to_state(self, particle_list, particle_probs_list):
mean_position = tf.reduce_sum(particle_probs_list[:, :, :, tf.newaxis] * particle_list[:, :, :, :2], axis=2)
mean_orientation = atan2(
tf.reduce_sum(particle_probs_list[:, :, :, tf.newaxis] * tf.cos(particle_list[:, :, :, 2:]), axis=2),
tf.reduce_sum(particle_probs_list[:, :, :, tf.newaxis] * tf.sin(particle_list[:, :, :, 2:]), axis=2))
return tf.concat([mean_position, mean_orientation], axis=2)
def plot_motion_model(self, sess, batch, motion_samples, task):
# define the inputs and train/run the model
input_dict = {**{self.placeholders[key]: batch[key] for key in 'osa'},
**{self.placeholders['num_particles']: 100},
}
s_motion_samples = sess.run(motion_samples, input_dict)
plt.figure('Motion Model')
plt.gca().clear()
plot_maze(task)
for i in range(min(len(s_motion_samples), 10)):
plt.quiver(s_motion_samples[i, :, 0], s_motion_samples[i, :, 1], np.cos(s_motion_samples[i, :, 2]), np.sin(s_motion_samples[i, :, 2]), color='blue', width=0.001, scale=100)
plt.quiver(batch['s'][i, 0, 0], batch['s'][i, 0, 1], np.cos(batch['s'][i, 0, 2]), np.sin(batch['s'][i, 0, 2]), color='black', scale=50, width=0.003)
plt.quiver(batch['s'][i, 1, 0], batch['s'][i, 1, 1], np.cos(batch['s'][i, 1, 2]), np.sin(batch['s'][i, 1, 2]), color='red', scale=50, width=0.003)
plt.gca().set_aspect('equal')
plt.pause(0.01)
def plot_measurement_model(self, sess, batch_iterator, measurement_model_out):
batch = next(batch_iterator)
# define the inputs and train/run the model
input_dict = {**{self.placeholders[key]: batch[key] for key in 'osa'},
**{self.placeholders['num_particles']: 100},
}
s_measurement_model_out = sess.run(measurement_model_out, input_dict)
plt.figure('Measurement Model Output')
plt.gca().clear()
plt.imshow(s_measurement_model_out, interpolation="nearest", cmap="coolwarm")
plt.pause(0.01)
def plot_particle_proposer(self, sess, batch, proposed_particles, task):
# define the inputs and train/run the model
input_dict = {**{self.placeholders[key]: batch[key] for key in 'osa'},
**{self.placeholders['num_particles']: 100},
}
s_samples = sess.run(proposed_particles, input_dict)
plt.figure('Particle Proposer')
plt.gca().clear()
plot_maze(task)
for i in range(min(len(s_samples), 10)):
color = np.random.uniform(0.0, 1.0, 3)
plt.quiver(s_samples[i, :, 0], s_samples[i, :, 1], np.cos(s_samples[i, :, 2]), np.sin(s_samples[i, :, 2]), color=color, width=0.001, scale=100)
plt.quiver(batch['s'][i, 0, 0], batch['s'][i, 0, 1], np.cos(batch['s'][i, 0, 2]), np.sin(batch['s'][i, 0, 2]), color=color, scale=50, width=0.003)
plt.pause(0.01)
def plot_particle_filter(self, sess, batch, particle_list,
particle_probs_list, num_particles, state_step_sizes, task):
num_particles = 1000
head_scale = 1.5
quiv_kwargs = {'scale_units': 'xy', 'scale': 1. / 40., 'width': 0.003, 'headlength': 5 * head_scale,
'headwidth': 3 * head_scale, 'headaxislength': 4.5 * head_scale}
marker_kwargs = {'markersize': 4.5, 'markerfacecolor': 'None', 'markeredgewidth': 0.5}
color_list = plt.cm.tab10(np.linspace(0, 1, 10))
colors = {'lstm': color_list[0], 'pf_e2e': color_list[1], 'pf_ind_e2e': color_list[2], 'pf_ind': color_list[3],
'ff': color_list[4], 'odom': color_list[4]}
pred, s_particle_list, s_particle_probs_list = self.predict(sess, batch, num_particles,
return_particles=True)
num_steps = 20 # s_particle_list.shape[1]
for s in range(1):
plt.figure("example {}".format(s), figsize=[12, 5.15])
plt.gca().clear()
for i in range(num_steps):
ax = plt.subplot(4, 5, i + 1, frameon=False)
plt.gca().clear()
plot_maze(task, margin=5, linewidth=0.5)
if i < num_steps - 1:
ax.quiver(s_particle_list[s, i, :, 0], s_particle_list[s, i, :, 1],
np.cos(s_particle_list[s, i, :, 2]), np.sin(s_particle_list[s, i, :, 2]),
s_particle_probs_list[s, i, :], cmap='viridis_r', clim=[.0, 2.0 / num_particles],
alpha=1.0,
**quiv_kwargs
)
current_state = batch['s'][s, i, :]
plt.quiver(current_state[0], current_state[1], np.cos(current_state[2]),
np.sin(current_state[2]), color="red", **quiv_kwargs)
plt.plot(current_state[0], current_state[1], 'or', **marker_kwargs)
else:
ax.plot(batch['s'][s, :num_steps, 0], batch['s'][s, :num_steps, 1], '-', linewidth=0.6, color='red')
ax.plot(pred[s, :num_steps, 0], pred[s, :num_steps, 1], '-', linewidth=0.6,
color=colors['pf_ind_e2e'])
ax.plot(batch['s'][s, :1, 0], batch['s'][s, :1, 1], '.', linewidth=0.6, color='red', markersize=3)
ax.plot(pred[s, :1, 0], pred[s, :1, 1], '.', linewidth=0.6, markersize=3,
color=colors['pf_ind_e2e'])
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.0, wspace=0.001, hspace=0.1)
plt.gca().set_aspect('equal')
plt.xticks([])
plt.yticks([])
show_pause(pause=0.01)
================================================
FILE: methods/dpf_kitti.py
================================================
import os
import numpy as np
import sonnet as snt
import tensorflow as tf
import matplotlib.pyplot as plt
from utils.data_utils_kitti import wrap_angle, compute_statistics, split_data, make_batch_iterator, make_repeating_batch_iterator, rotation_matrix, load_data_for_stats
from utils.method_utils import atan2, compute_sq_distance
from utils.plotting_utils import plot_maze, show_pause
from datetime import datetime
if tf.__version__ == '1.1.0-rc1' or tf.__version__ == '1.2.0':
from tensorflow.python.framework import ops
@ops.RegisterGradient("FloorMod")
def _mod_grad(op, grad):
x, y = op.inputs
gz = grad
x_grad = gz
y_grad = None # tf.reduce_mean(-(x // y) * gz, axis=[0], keep_dims=True)[0]
return x_grad, y_grad
class DPF():
def __init__(self, init_with_true_state, learn_odom, use_proposer, propose_ratio, proposer_keep_ratio, min_obs_likelihood, learn_gaussian_mle):
"""
:param init_with_true_state:
:param learn_odom:
:param use_proposer:
:param propose_ratio:
:param particle_std:
:param proposer_keep_ratio:
:param min_obs_likelihood:
"""
# store hyperparameters which are needed later
self.init_with_true_state = init_with_true_state
self.learn_odom = learn_odom
self.use_proposer = use_proposer and not init_with_true_state # only use proposer if we do not initializet with true state
self.propose_ratio = propose_ratio if not self.init_with_true_state else 0.0
# define some more parameters and placeholders
self.state_dim = 5
self.action_dim = 3
self.observation_dim = 6
self.placeholders = {'o': tf.placeholder('float32', [None, None, 50, 150, self.observation_dim], 'observations'),
'a': tf.placeholder('float32', [None, None, 3], 'actions'),
's': tf.placeholder('float32', [None, None, 5], 'states'),
'num_particles': tf.placeholder('float32'),
'keep_prob': tf.placeholder_with_default(tf.constant(1.0), []),
'is_training': tf.placeholder_with_default(tf.constant(False), [])
}
self.num_particles_float = self.placeholders['num_particles']
self.num_particles = tf.to_int32(self.num_particles_float)
# build learnable modules
self.build_modules(min_obs_likelihood, proposer_keep_ratio, learn_gaussian_mle)
def build_modules(self, min_obs_likelihood, proposer_keep_ratio, learn_gaussian_mle):
"""
:param min_obs_likelihood:
:param proposer_keep_ratio:
:return: None
"""
# MEASUREMENT MODEL
# conv net for encoding the image
self.encoder = snt.Sequential([
snt.nets.ConvNet2D([16, 16, 16, 16], [[7, 7], [5, 5], [5, 5], [5, 5]], [[1,1], [1, 2], [1, 2], [2, 2]], [snt.SAME], activate_final=True, name='encoder/convnet'),
snt.BatchFlatten(),
lambda x: tf.nn.dropout(x, self.placeholders['keep_prob']),
snt.Linear(128, name='encoder/linear'),
tf.nn.relu
])
# observation likelihood estimator that maps states and image encodings to probabilities
self.obs_like_estimator = snt.Sequential([
snt.Linear(128, name='obs_like_estimator/linear'),
tf.nn.relu,
snt.Linear(128, name='obs_like_estimator/linear'),
tf.nn.relu,
snt.Linear(1, name='obs_like_estimator/linear'),
tf.nn.sigmoid,
lambda x: x * (1 - min_obs_likelihood) + min_obs_likelihood
], name='obs_like_estimator')
# motion noise generator used for motion sampling
if learn_gaussian_mle:
self.mo_noise_generator = snt.nets.MLP([32, 32, 4], activate_final=False, name='mo_noise_generator')
else:
self.mo_noise_generator = snt.nets.MLP([32, 32, 2], activate_final=False, name='mo_noise_generator')
# odometry model (if we want to learn it)
if self.learn_odom:
self.mo_transition_model = snt.nets.MLP([128, 128, 128, self.state_dim], activate_final=False, name='mo_transition_model')
# particle proposer that maps encodings to particles (if we want to use it)
if self.use_proposer:
self.particle_proposer = snt.Sequential([
snt.Linear(128, name='particle_proposer/linear'),
tf.nn.relu,
lambda x: tf.nn.dropout(x, proposer_keep_ratio),
snt.Linear(128, name='particle_proposer/linear'),
tf.nn.relu,
snt.Linear(128, name='particle_proposer/linear'),
tf.nn.relu,
snt.Linear(128, name='particle_proposer/linear'),
tf.nn.relu,
snt.Linear(4, name='particle_proposer/linear'),
tf.nn.tanh,
])
self.noise_scaler1 = snt.Module(lambda x: x * tf.exp(10 * tf.get_variable('motion_sampler/noise_scaler1', initializer=np.array(0.0, dtype='float32'))))
self.noise_scaler2 = snt.Module(lambda x: x * tf.exp(10 * tf.get_variable('motion_sampler/noise_scaler2', initializer=np.array(0.0, dtype='float32'))))
def custom_build(self, inputs):
"""A custom build method to wrap into a sonnet Module."""
outputs = snt.Conv2D(output_channels=16, kernel_shape=[7, 7], stride=[1, 1])(inputs)
outputs = tf.nn.relu(outputs)
outputs = snt.Conv2D(output_channels=16, kernel_shape=[5, 5], stride=[1, 2])(outputs)
outputs = tf.nn.relu(outputs)
outputs = snt.Conv2D(output_channels=16, kernel_shape=[5, 5], stride=[1, 2])(outputs)
outputs = tf.nn.relu(outputs)
outputs = snt.Conv2D(output_channels=16, kernel_shape=[5, 5], stride=[2, 2])(outputs)
outputs = tf.nn.relu(outputs)
outputs = tf.nn.dropout(outputs, self.placeholders['keep_prob'])
outputs = snt.BatchFlatten()(outputs)
outputs = snt.Linear(128)(outputs)
outputs = tf.nn.relu(outputs)
return outputs
def measurement_update(self, encoding, particles, means, stds):
"""
Compute the likelihood of the encoded observation for each particle.
:param encoding: encoding of the observation
:param particles:
:param means:
:param stds:
:return: observation likelihood
"""
# prepare input (normalize particles poses and repeat encoding per particle)
particle_input = self.transform_particles_as_input(particles, means, stds)
encoding_input = tf.tile(encoding[:, tf.newaxis, :], [1, tf.shape(particles)[1], 1])
input = tf.concat([encoding_input, particle_input], axis=-1)
# estimate the likelihood of the encoded observation for each particle, remove last dimension
obs_likelihood = snt.BatchApply(self.obs_like_estimator)(input)[:, :, 0]
return obs_likelihood
def transform_particles_as_input(self, particles, means, stds):
return ((particles - means['s']) / stds['s'])[..., 3:5]
def propose_particles(self, encoding, num_particles, state_mins, state_maxs):
duplicated_encoding = tf.tile(encoding[:, tf.newaxis, :], [1, num_particles, 1])
proposed_particles = snt.BatchApply(self.particle_proposer)(duplicated_encoding)
proposed_particles = tf.concat([
proposed_particles[:,:,:1] * (state_maxs[0] - state_mins[0]) / 2.0 + (state_maxs[0] + state_mins[0]) / 2.0,
proposed_particles[:,:,1:2] * (state_maxs[1] - state_mins[1]) / 2.0 + (state_maxs[1] + state_mins[1]) / 2.0,
atan2(proposed_particles[:,:,2:3], proposed_particles[:,:,3:4])], axis=2)
return proposed_particles
def motion_update(self, actions, particles, means, stds, state_step_sizes, learn_gaussian_mle, stop_sampling_gradient=False):
"""
Move particles according to odometry info in actions. Add learned noise.
:param actions:
:param particles:
:param means:
:param stds:
:param state_step_sizes:
:param stop_sampling_gradient:
:return: moved particles
"""
# 1. SAMPLE NOISY ACTIONS
# add dimension for particles
time_step = 0.103
if learn_gaussian_mle:
actions = tf.concat([particles[:, :, 3:4] - means['s'][:, :, 3:4], particles[:, :, 4:5] - means['s'][:, :, 4:5]], axis=-1)
# prepare input (normalize actions and repeat per particle)
action_input = actions / stds['s'][:, :, 3:5]
input = action_input
# estimate action noise
delta = snt.BatchApply(self.mo_noise_generator)(input)
delta = tf.concat([delta[:, :, 0:2] * state_step_sizes[3], delta[:, :, 2:4] * state_step_sizes[4]], axis=-1)
if stop_sampling_gradient:
delta = tf.stop_gradient(delta)
action_vel_f = tf.random_normal(tf.shape(particles[:, :, 3:4]), mean = delta[:, :, 0:1], stddev = delta[:, :, 1:2])
action_vel_rot = tf.random_normal(tf.shape(particles[:, :, 4:5]), mean = delta[:, :, 2:3], stddev = delta[:, :, 3:4])
heading = particles[:, :, 2:3]
sin_heading = tf.sin(heading)
cos_heading = tf.cos(heading)
new_x = particles[:, :, 0:1] + cos_heading * particles[:, :, 3:4] * time_step
new_y = particles[:, :, 1:2] + sin_heading * particles[:, :, 3:4] * time_step
new_theta = particles[:, :, 2:3] + particles[:, :, 4:5] * time_step
wrap_angle(new_theta)
new_v = particles[:, :, 3:4] + action_vel_f
new_theta_dot = particles[:, :, 4:5] + action_vel_rot
moved_particles = tf.concat([new_x, new_y, new_theta, new_v, new_theta_dot], axis=-1)
return moved_particles, delta
else:
heading = particles[:, :, 2:3]
sin_heading = tf.sin(heading)
cos_heading = tf.cos(heading)
random_input = tf.random_normal(tf.shape(particles[:, :, 3:5]))
noise = snt.BatchApply(self.mo_noise_generator)(random_input)
noise = noise - tf.reduce_mean(noise, axis=1, keep_dims=True)
new_z = particles[:, :, 0:1] + cos_heading * particles[:, :, 3:4] * time_step
new_x = particles[:, :, 1:2] + sin_heading * particles[:, :, 3:4] * time_step
new_theta = wrap_angle(particles[:, :, 2:3] + particles[:, :, 4:5] * time_step)
new_v = particles[:, :, 3:4] + noise[:, :, :1] * state_step_sizes[3]
new_theta_dot = particles[:, :, 4:5] + noise[:, :, 1:] * state_step_sizes[4]
moved_particles = tf.concat([new_z, new_x, new_theta, new_v, new_theta_dot], axis=-1)
return moved_particles
def compile_training_stages(self, sess, batch_iterators, particle_list, particle_probs_list, encodings, means, stds, state_step_sizes, state_mins, state_maxs, learn_gaussian_mle, learning_rate, plot_task):
# TRAINING!
losses = dict()
train_stages = dict()
std = 0.25
# TRAIN ODOMETRY
if self.learn_odom:
# apply model
motion_samples = self.motion_update(self.placeholders['a'][:,0],
self.placeholders['s'][:, :1],
means, stds, state_step_sizes,
stop_sampling_gradient=True)
# define loss and optimizer
sq_distance = compute_sq_distance(motion_samples, self.placeholders['s'][:, 1:2], state_step_sizes)
losses['motion_mse'] = tf.reduce_mean(sq_distance, name='loss')
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
# put everything together
train_stages['train_odom'] = {
'train_op': optimizer.minimize(losses['motion_mse']),
'batch_iterator_names': {'train': 'train1', 'val': 'val1'},
'monitor_losses': ['motion_mse'],
'validation_loss': 'motion_mse',
'plot': lambda e: self.plot_motion_model(sess, next(batch_iterators['val2']), motion_samples, plot_task, state_step_sizes) if e % 1 == 0 else None
}
# TRAIN MOTION MODEL
if learn_gaussian_mle:
motion_samples, motion_params = self.motion_update(self.placeholders['a'][:,1],
tf.tile(self.placeholders['s'][:, :1], [1, 1, 1]),
means, stds, state_step_sizes, learn_gaussian_mle)
# define loss and optimizer
diff_in_states = self.placeholders['s'][:, 1:2] - self.placeholders['s'][:, :1]
activations_vel_f = (1 / 32) / tf.sqrt(2 * np.pi * motion_params[:, :, 1] ** 2) * tf.exp(
-(diff_in_states[:, :, 3] - motion_params[:, :, 0]) ** 2 / (2.0 * motion_params[:, :, 1] ** 2))
activations_vel_rot = (1 / 32) / tf.sqrt(2 * np.pi * motion_params[:, :, 3] ** 2) * tf.exp(
-(diff_in_states[:, :, 4] - motion_params[:, :, 2]) ** 2 / (2.0 * motion_params[:, :, 3] ** 2))
losses['motion_mle'] = tf.reduce_mean(-tf.log(1e-16 + (tf.reduce_sum(activations_vel_f, axis=-1, name='loss1') * tf.reduce_sum(activations_vel_rot, axis=-1, name='loss2'))))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
# put everything together
train_stages['train_motion_sampling'] = {
'train_op': optimizer.minimize(losses['motion_mle']),
'batch_iterator_names': {'train': 'train2', 'val': 'val2'},
'monitor_losses': ['motion_mle'],
'validation_loss': 'motion_mle',
'plot': lambda e: self.plot_motion_model(sess, next(batch_iterators['val2']), motion_samples, plot_task, state_step_sizes) if e % 1 == 0 else None
}
else:
motion_samples = self.motion_update(self.placeholders['a'][:,1],
tf.tile(self.placeholders['s'][:, :1], [1, self.num_particles, 1]),
means, stds, state_step_sizes, learn_gaussian_mle)
# define loss and optimizer
sq_distance = compute_sq_distance(motion_samples, self.placeholders['s'][:, 1:2], state_step_sizes)
activations_sample = (1 / self.num_particles_float) / tf.sqrt(2 * np.pi * std ** 2) * tf.exp(
-sq_distance / (2.0 * std ** 2))
losses['motion_mle'] = tf.reduce_mean(-tf.log(1e-16 + tf.reduce_sum(activations_sample, axis=-1, name='loss')))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
# put everything together
train_stages['train_motion_sampling'] = {
'train_op': optimizer.minimize(losses['motion_mle']),
'batch_iterator_names': {'train': 'train2', 'val': 'val2'},
'monitor_losses': ['motion_mle'],
'validation_loss': 'motion_mle',
'plot': lambda e: self.plot_motion_model(sess, next(batch_iterators['val2']), motion_samples, plot_task, state_step_sizes) if e % 1 == 0 else None
}
# TRAIN MEASUREMENT MODEL
# apply model for all pairs of observations and states in that batch
test_particles = tf.tile(self.placeholders['s'][tf.newaxis, :, 0], [self.batch_size, 1, 1])
measurement_model_out = self.measurement_update(encodings[:, 0], test_particles, means, stds)
# define loss (correct -> 1, incorrect -> 0) and optimizer
correct_samples = tf.diag_part(measurement_model_out)
incorrect_samples = measurement_model_out - tf.diag(tf.diag_part(measurement_model_out))
losses['measurement_heuristic'] = tf.reduce_sum(-tf.log(correct_samples)) / tf.cast(self.batch_size, tf.float32) \
+ tf.reduce_sum(-tf.log(1.0 - incorrect_samples)) / tf.cast(self.batch_size * (self.batch_size - 1), tf.float32)
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
# put everything together
train_stages['train_measurement_model'] = {
'train_op': optimizer.minimize(losses['measurement_heuristic']),
'batch_iterator_names': {'train': 'train1', 'val': 'val1'},
'monitor_losses': ['measurement_heuristic'],
'validation_loss': 'measurement_heuristic',
'plot': lambda e: self.plot_measurement_model(sess, batch_iterators['val1'], measurement_model_out) if e % 1 == 0 else None
}
# TRAIN PARTICLE PROPOSER
if self.use_proposer:
# apply model (but only compute gradients until the encoding,
# otherwise we would unlearn it and the observation likelihood wouldn't work anymore)
proposed_particles = self.propose_particles(tf.stop_gradient(encodings[:, 0]), self.num_particles, state_mins, state_maxs)
# define loss and optimizer
std = 0.2
sq_distance = compute_sq_distance(proposed_particles, self.placeholders['s'][:, :1], state_step_sizes)
activations = (1 / self.num_particles_float) / tf.sqrt(2 * np.pi * std ** 2) * tf.exp(
-sq_distance / (2.0 * std ** 2))
losses['proposed_mle'] = tf.reduce_mean(-tf.log(1e-16 + tf.reduce_sum(activations, axis=-1)))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
# put everything together
train_stages['train_particle_proposer'] = {
'train_op': optimizer.minimize(losses['proposed_mle']),
'batch_iterator_names': {'train': 'train1', 'val': 'val1'},
'monitor_losses': ['proposed_mle'],
'validation_loss': 'proposed_mle',
'plot': lambda e: self.plot_particle_proposer(sess, next(batch_iterators['val1']), proposed_particles, plot_task) if e % 10 == 0 else None
}
# END-TO-END TRAINING
# model was already applied further up -> particle_list, particle_probs_list
# define losses and optimizer
# first loss (which is being optimized)
sq_distance = compute_sq_distance(particle_list[:, :, :, 3:5], self.placeholders['s'][:, :, tf.newaxis, 3:5], state_step_sizes[3:5])
activations = particle_probs_list[:, :] / tf.sqrt(2 * np.pi * self.particle_std ** 2) * tf.exp(
-sq_distance / (2.0 * self.particle_std ** 2))
losses['mle'] = tf.reduce_mean(-tf.log(1e-16 + tf.reduce_sum(activations, axis=2, name='loss')))
# second loss (which we will monitor during execution)
pred = self.particles_to_state(particle_list, particle_probs_list)
sq_error = compute_sq_distance(pred[:, -1, 0:2], self.placeholders['s'][:, -1, 0:2], [1., 1.])
sq_dist = compute_sq_distance(self.placeholders['s'][:, 0, 0:2], self.placeholders['s'][:, -1, 0:2], [1., 1.])
losses['m/m'] = tf.reduce_mean(sq_error**0.5/sq_dist**0.5)
sq_error = compute_sq_distance(pred[:, -1, 2:3], self.placeholders['s'][:, -1, 2:3], [np.pi/180.0])
losses['deg/m'] = tf.reduce_mean(sq_error ** 0.5 / sq_dist ** 0.5)
# optimizer
optimizer = tf.train.AdamOptimizer(learning_rate)
# put everything together
train_stages['train_e2e'] = {
'train_op': optimizer.minimize(losses['mle']),
'batch_iterator_names': {'train': 'train', 'val': 'val'},
'monitor_losses': ['m/m', 'deg/m', 'mle'],
'validation_loss': 'deg/m',
'plot': lambda e: self.plot_particle_filter(sess, next(batch_iterators['val_ex']), particle_list,
particle_probs_list, state_step_sizes, plot_task) if e % 1 == 0 else None
}
return losses, train_stages
def load(self, sess, model_path, model_file='best_validation', statistics_file='statistics.npz', connect_and_initialize=True, modules=('encoder', 'mo_noise_generator', 'mo_transition_model', 'obs_like_estimator', 'particle_proposer')):
if type(modules) not in [type(list()), type(tuple())]:
raise Exception('modules must be a list or tuple, not a ' + str(type(modules)))
# build the tensorflow graph
if connect_and_initialize:
# load training data statistics (which are needed to build the tf graph)
statistics = dict(np.load(os.path.join(model_path, statistics_file)))
for key in statistics.keys():
if statistics[key].shape == ():
statistics[key] = statistics[key].item() # convert 0d array of dictionary back to a normal dictionary
# connect all modules into the particle filter
self.connect_modules(**statistics)
init = tf.global_variables_initializer()
sess.run(init)
# load variables
all_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES)
vars_to_load = []
loaded_modules = set()
for v in all_vars:
for m in modules:
if m in v.name:
vars_to_load.append(v)
loaded_modules.add(m)
print('Loading all modules')
saver = tf.train.Saver()
saver.restore(sess, os.path.join(model_path, model_file))
# def fit(self, sess, data, model_path, train_individually, train_e2e, split_ratio, seq_len, batch_size, epoch_length, num_epochs, patience, learning_rate, dropout_keep_ratio, num_particles, particle_std, plot_task=None, plot=False):
def fit(self, sess, data, model_path, train_individually, train_e2e, split_ratio, seq_len, batch_size, epoch_length, num_epochs, patience, learning_rate, dropout_keep_ratio, num_particles, particle_std, learn_gaussian_mle, plot_task=None, plot=False):
if plot:
plt.ion()
self.particle_std = particle_std
mean_loss_for_plot = np.zeros((1,))
means, stds, state_step_sizes, state_mins, state_maxs = compute_statistics(data)
data = split_data(data, ratio=split_ratio)
epoch_lengths = {'train': epoch_length, 'val': epoch_length*2}
batch_iterators = {'train': make_batch_iterator(data['train'], seq_len=seq_len, batch_size=batch_size),
'val': make_repeating_batch_iterator(data['val'], epoch_lengths['val'], batch_size=batch_size, seq_len=seq_len),
'train_ex': make_batch_iterator(data['train'], batch_size=batch_size, seq_len=seq_len),
'val_ex': make_batch_iterator(data['val'], batch_size=batch_size, seq_len=seq_len),
'train1': make_batch_iterator(data['train'], batch_size=batch_size, seq_len=1),
'train2': make_batch_iterator(data['train'], batch_size=batch_size, seq_len=2),
'val1': make_repeating_batch_iterator(data['val'], epoch_lengths['val'], batch_size=batch_size, seq_len=1),
'val2': make_repeating_batch_iterator(data['val'], epoch_lengths['val'], batch_size=batch_size, seq_len=2),
}
# build the tensorflow graph by connecting all modules in the particles filter
particles, particle_probs, encodings, particle_list, particle_probs_list = self.connect_modules(means, stds, state_mins, state_maxs, state_step_sizes, learn_gaussian_mle)
# define losses and train stages for different ways of training (e.g. training individual models and e2e training)
losses, train_stages = self.compile_training_stages(sess, batch_iterators, particle_list, particle_probs_list,
encodings, means, stds, state_step_sizes, state_mins,
state_maxs, learn_gaussian_mle, learning_rate, plot_task)
# initialize variables
init = tf.global_variables_initializer()
sess.run(init)
# save statistics and prepare saving variables
if not os.path.exists(model_path):
os.makedirs(model_path)
np.savez(os.path.join(model_path, 'statistics'), means=means, stds=stds, state_step_sizes=state_step_sizes,
state_mins=state_mins, state_maxs=state_maxs)
saver = tf.train.Saver()
save_path = os.path.join(model_path, 'best_validation')
# define the training curriculum
curriculum = []
if train_individually:
if self.learn_odom:
curriculum += ['train_odom']
curriculum += ['train_measurement_model']
curriculum += ['train_motion_sampling']
if self.use_proposer:
curriculum += ['train_particle_proposer']
if train_e2e:
curriculum += ['train_e2e']
# split data for early stopping
data_keys = ['train']
if split_ratio < 1.0:
data_keys.append('val')
# define log dict
log = {c: {dk: {lk: {'mean': [], 'se': []} for lk in train_stages[c]['monitor_losses']} for dk in data_keys} for c in curriculum}
# go through curriculum
for c in curriculum:
stage = train_stages[c]
best_val_loss = np.inf
best_epoch = 0
epoch = 0
if c == 'train_e2e':
saver.save(sess, os.path.join(model_path, 'before_e2e/best_validation'))
np.savez(os.path.join(model_path, 'before_e2e/statistics'), means=means, stds=stds, state_step_sizes=state_step_sizes,
state_mins=state_mins, state_maxs=state_maxs)
while epoch < num_epochs and epoch - best_epoch < patience:
# training
for dk in data_keys:
# don't train in the first epoch, just evaluate the initial parameters
if dk == 'train' and epoch == 0:
continue
# set up loss lists which will be filled during the epoch
loss_lists = {lk: [] for lk in stage['monitor_losses']}
for e in range(epoch_lengths[dk]):
# t0 = time.time()
# pick a batch from the right iterator
batch = next(batch_iterators[stage['batch_iterator_names'][dk]])
# define the inputs and train/run the model
input_dict = {**{self.placeholders[key]: batch[key] for key in 'osa'},
**{self.placeholders['num_particles']: num_particles},
}
if dk == 'train':
input_dict[self.placeholders['keep_prob']] = dropout_keep_ratio
input_dict[self.placeholders['is_training']] = True
monitor_losses = {l: losses[l] for l in stage['monitor_losses']}
if dk == 'train':
s_losses, _ = sess.run([monitor_losses, stage['train_op']], input_dict)
else:
s_losses = sess.run(monitor_losses, input_dict)
for lk in stage['monitor_losses']:
loss_lists[lk].append(s_losses[lk])
# after each epoch, compute and log statistics
for lk in stage['monitor_losses']:
log[c][dk][lk]['mean'].append(np.mean(loss_lists[lk]))
log[c][dk][lk]['se'].append(np.std(loss_lists[lk], ddof=1) / np.sqrt(len(loss_lists[lk])))
# check whether the current model is better than all previous models
if 'val' in data_keys:
current_val_loss = log[c]['val'][stage['validation_loss']]['mean'][-1]
mean_loss_for_plot = np.append(mean_loss_for_plot,current_val_loss)
if current_val_loss < best_val_loss:
best_val_loss = current_val_loss
best_epoch = epoch
# save current model
saver.save(sess, save_path)
txt = 'epoch {:>3} >> '.format(epoch)
else:
txt = 'epoch {:>3} == '.format(epoch)
else:
best_epoch = epoch
saver.save(sess, save_path)
txt = 'epoch {:>3} >> '.format(epoch)
# after going through all data sets, do a print out of the current result
for lk in stage['monitor_losses']:
txt += '{}: '.format(lk)
for dk in data_keys:
if len(log[c][dk][lk]['mean']) > 0:
txt += '{:.2f}+-{:.2f}/'.format(log[c][dk][lk]['mean'][-1], log[c][dk][lk]['se'][-1])
txt = txt[:-1] + ' -- '
print(txt)
if plot:
stage['plot'](epoch)
epoch += 1
# after running out of patience, restore the model with lowest validation loss
saver.restore(sess, save_path)
return log
def predict(self, sess, batch, return_particles=False, **kwargs):
# define input dict, use the first state only if we do tracking
input_dict = {self.placeholders['o']: batch['o'],
self.placeholders['a']: batch['a'],
self.placeholders['num_particles']: 100}
if self.init_with_true_state:
input_dict[self.placeholders['s']] = batch['s'][:, :1]
if return_particles:
return sess.run([self.pred_states, self.particle_list, self.particle_probs_list], input_dict)
else:
return sess.run(self.pred_states, input_dict)
def connect_modules(self, means, stds, state_mins, state_maxs, state_step_sizes, learn_gaussian_mle=False):
# get shapes
self.batch_size = tf.shape(self.placeholders['o'])[0]
self.seq_len = tf.shape(self.placeholders['o'])[1]
# we use the static shape here because we need it to build the graph
self.action_dim = self.placeholders['a'].get_shape()[-1].value
encodings = snt.BatchApply(self.encoder)((self.placeholders['o'] - means['o']) / stds['o'])
# initialize particles
if self.init_with_true_state:
# tracking with known initial state
initial_particles = tf.tile(self.placeholders['s'][:, 0, tf.newaxis, :], [1, self.num_particles, 1])
else:
# global localization
if self.use_proposer:
# propose particles from observations
initial_particles = self.propose_particles(encodings[:, 0], self.num_particles, state_mins, state_maxs)
else:
# sample particles randomly
initial_particles = tf.concat(
[tf.random_uniform([self.batch_size, self.num_particles, 1], state_mins[d], state_maxs[d]) for d in
range(self.state_dim)], axis=-1, name='particles')
initial_particle_probs = tf.ones([self.batch_size, self.num_particles],
name='particle_probs') / self.num_particles_float
# assumes that samples has the correct size
def permute_batch(x, samples):
# get shapes
batch_size = tf.shape(x)[0]
num_particles = tf.shape(x)[1]
sample_size = tf.shape(samples)[1]
# compute 1D indices into the 2D array
idx = samples + num_particles * tf.tile(
tf.reshape(tf.range(batch_size), [batch_size, 1]),
[1, sample_size])
# index using the 1D indices and reshape again
result = tf.gather(tf.reshape(x, [batch_size * num_particles, -1]), idx)
result = tf.reshape(result, tf.shape(x[:,:sample_size]))
return result
def loop(particles, particle_probs, particle_list, particle_probs_list, additional_probs_list, i):
num_proposed_float = tf.round((self.propose_ratio ** tf.cast(i, tf.float32)) * self.num_particles_float)
num_proposed = tf.cast(num_proposed_float, tf.int32)
num_resampled_float = self.num_particles_float - num_proposed_float
num_resampled = tf.cast(num_resampled_float, tf.int32)
if self.propose_ratio < 1.0:
# resampling
basic_markers = tf.linspace(0.0, (num_resampled_float - 1.0) / num_resampled_float, num_resampled)
random_offset = tf.random_uniform([self.batch_size], 0.0, 1.0 / num_resampled_float)
markers = random_offset[:, None] + basic_markers[None, :] # shape: batch_size x num_resampled
cum_probs = tf.cumsum(particle_probs, axis=1)
marker_matching = markers[:, :, None] < cum_probs[:, None, :] # shape: batch_size x num_resampled x num_particles
samples = tf.cast(tf.argmax(tf.cast(marker_matching, 'int32'), dimension=2), 'int32')
standard_particles = permute_batch(particles, samples)
standard_particle_probs = tf.ones([self.batch_size, num_resampled])
standard_particles = tf.stop_gradient(standard_particles)
standard_particle_probs = tf.stop_gradient(standard_particle_probs)
# motion update
if learn_gaussian_mle:
standard_particles, _ = self.motion_update(self.placeholders['a'][:, i], standard_particles, means, stds, state_step_sizes, learn_gaussian_mle)
else:
standard_particles = self.motion_update(self.placeholders['a'][:, i], standard_particles, means, stds, state_step_sizes, learn_gaussian_mle)
# measurement update
standard_particle_probs *= self.measurement_update(encodings[:, i], standard_particles, means, stds)
if self.propose_ratio > 0.0:
# proposed particles
proposed_particles = self.propose_particles(encodings[:, i], num_proposed, state_mins, state_maxs)
proposed_particle_probs = tf.ones([self.batch_size, num_proposed])
# NORMALIZE AND COMBINE PARTICLES
if self.propose_ratio == 1.0:
particles = proposed_particles
particle_probs = proposed_particle_probs
elif self.propose_ratio == 0.0:
particles = standard_particles
particle_probs = standard_particle_probs
else:
standard_particle_probs *= (num_resampled_float / self.num_particles_float) / tf.reduce_sum(standard_particle_probs, axis=1, keep_dims=True)
proposed_particle_probs *= (num_proposed_float / self.num_particles_float) / tf.reduce_sum(proposed_particle_probs, axis=1, keep_dims=True)
particles = tf.concat([standard_particles, proposed_particles], axis=1)
particle_probs = tf.concat([standard_particle_probs, proposed_particle_probs], axis=1)
# NORMALIZE PROBABILITIES
particle_probs /= tf.reduce_sum(particle_probs, axis=1, keep_dims=True)
particle_list = tf.concat([particle_list, particles[:, tf.newaxis]], axis=1)
particle_probs_list = tf.concat([particle_probs_list, particle_probs[:, tf.newaxis]], axis=1)
return particles, particle_probs, particle_list, particle_probs_list, additional_probs_list, i + 1
# reshapes and sets the first shape sizes to None (which is necessary to keep the shape consistent in while loop)
particle_list = tf.reshape(initial_particles,
shape=[self.batch_size, -1, self.num_particles, self.state_dim])
particle_probs_list = tf.reshape(initial_particle_probs, shape=[self.batch_size, -1, self.num_particles])
additional_probs_list = tf.reshape(tf.ones([self.batch_size, self.num_particles, 4]), shape=[self.batch_size, -1, self.num_particles, 4])
# run the filtering process
particles, particle_probs, particle_list, particle_probs_list, additional_probs_list, i = tf.while_loop(
lambda *x: x[-1] < self.seq_len, loop,
[initial_particles, initial_particle_probs, particle_list, particle_probs_list, additional_probs_list,
tf.constant(1, dtype='int32')], name='loop')
# compute mean of particles
self.pred_states = self.particles_to_state(particle_list, particle_probs_list)
self.particle_list = particle_list
self.particle_probs_list = particle_probs_list
return particles, particle_probs, encodings, particle_list, particle_probs_list
def particles_to_state(self, particle_list, particle_probs_list):
mean_position = tf.reduce_sum(particle_probs_list[:, :, :, tf.newaxis] * particle_list[:, :, :, :2], axis=2)
mean_orientation = atan2(
tf.reduce_sum(particle_probs_list[:, :, :, tf.newaxis] * tf.cos(particle_list[:, :, :, 2:3]), axis=2),
tf.reduce_sum(particle_probs_list[:, :, :, tf.newaxis] * tf.sin(particle_list[:, :, :, 2:3]), axis=2))
mean_velocity = tf.reduce_sum(particle_probs_list[:, :, :, tf.newaxis] * particle_list[:, :, :, 3:5], axis=2)
return tf.concat([mean_position, mean_orientation, mean_velocity], axis=2)
def plot_motion_model(self, sess, batch, motion_samples, task, state_step_sizes):
# define the inputs and train/run the model
input_dict = {**{self.placeholders[key]: batch[key] for key in 'osa'},
**{self.placeholders['num_particles']: 100},
}
s_motion_samples = sess.run(motion_samples, input_dict)
plt.figure('Motion Model')
plt.gca().clear()
for i in range(min(len(s_motion_samples), 10)):
plt.scatter(s_motion_samples[i, :, 3] / state_step_sizes[3], s_motion_samples[i, :, 4] / state_step_sizes[4], color='blue', s=1)
plt.scatter(batch['s'][i, 0, 3] / state_step_sizes[3], batch['s'][i, 0, 4] / state_step_sizes[4], color='black', s=1)
plt.scatter(batch['s'][i, 1, 3] / state_step_sizes[3], batch['s'][i, 1, 4] / state_step_sizes[4], color='red', s=3)
plt.plot(batch['s'][i, :2, 3] / state_step_sizes[3], batch['s'][i, :2, 4] / state_step_sizes[4], color='black')
plt.xlim([0, 200])
plt.ylim([-50, 50])
plt.xlabel('translational vel')
plt.ylabel('angular vel')
plt.gca().set_aspect('equal')
plt.pause(0.01)
def plot_measurement_model(self, sess, batch_iterator, measurement_model_out):
batch = next(batch_iterator)
# define the inputs and train/run the model
input_dict = {**{self.placeholders[key]: batch[key] for key in 'osa'},
**{self.placeholders['num_particles']: 100},
}
s_measurement_model_out = sess.run([measurement_model_out], input_dict)
plt.figure('Measurement Model Output')
plt.gca().clear()
plt.imshow(s_measurement_model_out[0], interpolation="nearest", cmap="viridis_r", vmin=0.0, vmax=1.0)
plt.figure('Measurement Model Input')
plt.clf()
plt.scatter(batch['s'][:1, 0, 3], batch['s'][:1, 0, 4], marker='x', c=s_measurement_model_out[0][0,:1], vmin=0, vmax=1.0, cmap='viridis_r')
plt.scatter(batch['s'][1:, 0, 3], batch['s'][1:, 0, 4], marker='o', c=s_measurement_model_out[0][0,1:], vmin=0, vmax=1.0, cmap='viridis_r')
plt.xlabel('x_dot')
plt.ylabel('theta_dot')
plt.pause(0.01)
def plot_particle_proposer(self, sess, batch, proposed_particles, task):
# define the inputs and train/run the model
input_dict = {**{self.placeholders[key]: batch[key] for key in 'osa'},
**{self.placeholders['num_particles']: 100},
}
s_samples = sess.run(proposed_particles, input_dict)
plt.figure('Particle Proposer')
plt.gca().clear()
plot_maze(task)
for i in range(min(len(s_samples), 10)):
color = np.random.uniform(0.0, 1.0, 3)
plt.quiver(s_samples[i, :, 0], s_samples[i, :, 1], np.cos(s_samples[i, :, 2]), np.sin(s_samples[i, :, 2]), color=color, width=0.001, scale=100)
plt.quiver(batch['s'][i, 0, 0], batch['s'][i, 0, 1], np.cos(batch['s'][i, 0, 2]), np.sin(batch['s'][i, 0, 2]), color=color, scale=50, width=0.003)
plt.pause(0.01)
def plot_particle_filter(self, sess, batch, particle_list,
particle_probs_list, state_step_sizes, task):
s_states, s_particle_list, s_particle_probs_list, \
= sess.run([self.placeholders['s'], particle_list,
particle_probs_list], #self.noise_scaler1(1.0), self.noise_scaler2(2.0)],
{**{self.placeholders[key]: batch[key] for key in 'osa'},
**{self.placeholders['num_particles']: 20},
})
# print('learned motion noise factors {:.2f}/{:.2f}'.format(n1, n2))
num_steps = s_particle_list.shape[1]
for s in range(3):
plt.figure('particle_evolution, example {}'.format(s))
plt.clf()
for d in range(5):
plt.subplot(3, 2, [1, 3, 5, 2, 4][d])
for i in range(num_steps):
plt.scatter(i * np.ones_like(s_particle_list[s, i, :, d]),
s_particle_list[s, i, :, d] / (1 if s == 0 else state_step_sizes[d]),
c=s_particle_probs_list[s, i, :], cmap='viridis_r', marker='o', s=6, alpha=0.5,
linewidths=0.05,
vmin=0.0,
vmax=0.1)
current_state = batch['s'][s, i, d] / (1 if s == 0 else state_step_sizes[d])
plt.plot([i], [current_state], 'o', markerfacecolor='None', markeredgecolor='k',
markersize=2.5)
plt.xlabel('Time')
plt.ylabel('State {}'.format(d))
show_pause(pause=0.01)
================================================
FILE: methods/odom.py
================================================
import numpy as np
from utils.data_utils_kitti import wrap_angle
class OdometryBaseline():
def __init__(self, *args, **kwargs):
pass
def fit(self, *args, **kwargs):
pass
def predict(self, sess, batch, **kwargs):
seq_len = batch['s'].shape[1]
prediction = np.zeros_like(batch['s'])
state = batch['s'][:, 0, :]
# print('shape:', batch['s'].shape)
prediction[:, 0, :] = state
for i in range(1, seq_len):
action = batch['a'][:, i, :]
theta = state[:, 2:3]
sin_theta = np.sin(theta)
cos_theta = np.cos(theta)
new_x = state[:, 0:1] + (action[:, 0:1] * cos_theta + action[:, 1:2] * sin_theta)
new_y = state[:, 1:2] + (action[:, 0:1] * sin_theta - action[:, 1:2] * cos_theta)
new_theta = wrap_angle(state[:, 2:3] + action[:, 2:3])
# copy old and set new particles
state = np.concatenate([new_x, new_y, new_theta], axis=-1)
prediction[:, i, :] = state
return prediction
def predict_kitti(self, sess, batch, **kwargs):
seq_len = batch['s'].shape[1]
prediction = np.zeros_like(batch['s'])
state = batch['s'][:, 0, :]
# print('shape:', batch['s'].shape)
prediction[:, 0, :] = state
for i in range(1, seq_len):
time = 0.103
action = batch['a'][:, i, :]
heading = state[:, 2:3]
wrap_angle(heading)
sin_heading = np.sin(heading)
cos_heading = np.cos(heading)
# ang_acc = (noisy_actions[:, :, 1:2] * noisy_actions[:, :, 2:3])/(noisy_actions[:, :, 0:1] ** 2)
acc_north = action[:, 0:1] * sin_heading + action[:, 1:2] * cos_heading
acc_east = - action[:, 1:2] * sin_heading + action[:, 0:1] * cos_heading
new_north = state[:, 0:1] + state[:, 3:4] * time
new_east = state[:, 1:2] + state[:, 4:5] * time
new_theta = state[:, 2:3] + state[:, 5:6] * time
wrap_angle(new_theta)
new_vn = state[:, 3:4] + acc_north * time
new_ve = state[:, 4:5] + acc_east * time
new_theta_dot = state[:, 5:6] + action[:, 2:3] * time
state = np.concatenate([new_north, new_east, new_theta, new_vn, new_ve, new_theta_dot], axis=-1)
prediction[:, i, :] = state
return prediction
================================================
FILE: methods/rnn.py
================================================
import tensorflow as tf
import sonnet as snt
from utils.data_utils import *
from utils.method_utils import compute_sq_distance
class RNN():
def __init__(self, init_with_true_state=False, model='2lstm', **unused_kwargs):
self.placeholders = {'o': tf.placeholder('float32', [None, None, 24, 24, 3], 'observations'),
'a': tf.placeholder('float32', [None, None, 3], 'actions'),
's': tf.placeholder('float32', [None, None, 3], 'states'),
'keep_prob': tf.placeholder('float32')}
self.pred_states = None
self.init_with_true_state = init_with_true_state
self.model = model
# build models
# <-- observation
self.encoder = snt.Sequential([
snt.nets.ConvNet2D([16, 32, 64], [[3, 3]], [2], [snt.SAME], activate_final=True, name='encoder/convnet'),
snt.BatchFlatten(),
lambda x: tf.nn.dropout(x, self.placeholders['keep_prob']),
snt.Linear(128, name='encoder/Linear'),
tf.nn.relu,
])
# <-- action
if self.model == '2lstm':
self.rnn1 = snt.LSTM(512)
self.rnn2 = snt.LSTM(512)
if self.model == '2gru':
self.rnn1 = snt.GRU(512)
self.rnn2 = snt.GRU(512)
elif self.model == 'ff':
self.ff_lstm_replacement = snt.Sequential([
snt.Linear(512),
tf.nn.relu,
snt.Linear(512),
tf.nn.relu])
self.belief_decoder = snt.Sequential([
snt.Linear(256),
tf.nn.relu,
snt.Linear(256),
tf.nn.relu,
snt.Linear(3)
])
def fit(self, sess, data, model_path, split_ratio, seq_len, batch_size, epoch_length, num_epochs, patience, learning_rate, dropout_keep_ratio, **unused_kwargs):
# preprocess data
data = split_data(data, ratio=split_ratio)
epoch_lengths = {'train': epoch_length, 'val': epoch_length*2}
batch_iterators = {'train': make_batch_iterator(data['train'], batch_size=batch_size, seq_len=seq_len),
'val': make_repeating_batch_iterator(data['val'], epoch_lengths['val'], batch_size=batch_size, seq_len=seq_len),
'train_ex': make_batch_iterator(data['train'], batch_size=batch_size, seq_len=seq_len),
'val_ex': make_batch_iterator(data['val'], batch_size=batch_size, seq_len=seq_len)}
means, stds, state_step_sizes, state_mins, state_maxs = compute_staticstics(data['train'])
self.connect_modules(means, stds, state_mins, state_maxs, state_step_sizes)
# training
sq_dist = compute_sq_distance(self.pred_states, self.placeholders['s'], state_step_sizes)
losses = {'mse': tf.reduce_mean(sq_dist),
'mse_last': tf.reduce_mean(sq_dist[:, -1])}
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
gradients = optimizer.compute_gradients(losses['mse'])
# clipped_gradients = [(tf.clip_by_value(grad, -1., 1.), var) for grad, var in gradients]
train_op = optimizer.apply_gradients(gradients)
init = tf.global_variables_initializer()
sess.run(init)
# save statistics and prepare saving variables
if not os.path.exists(model_path):
os.makedirs(model_path)
np.savez(os.path.join(model_path, 'statistics'), means=means, stds=stds, state_step_sizes=state_step_sizes,
state_mins=state_mins, state_maxs=state_maxs)
saver = tf.train.Saver()
save_path = model_path + '/best_validation'
loss_keys = ['mse_last', 'mse']
if split_ratio < 1.0:
data_keys = ['train', 'val']
else:
data_keys = ['train']
log = {dk: {lk: {'mean': [], 'se': []} for lk in loss_keys} for dk in data_keys}
best_val_loss = np.inf
best_epoch = 0
i = 0
while i < num_epochs and i - best_epoch < patience:
# training
loss_lists = dict()
for dk in data_keys:
loss_lists = {lk: [] for lk in loss_keys}
for e in range(epoch_lengths[dk]):
batch = next(batch_iterators[dk])
if dk == 'train':
s_losses, _ = sess.run([losses, train_op], {**{self.placeholders[key]: batch[key] for key in 'osa'},
**{self.placeholders['keep_prob']: dropout_keep_ratio}})
else:
s_losses = sess.run(losses, {**{self.placeholders[key]: batch[key] for key in 'osa'},
**{self.placeholders['keep_prob']: 1.0}})
for lk in loss_keys:
loss_lists[lk].append(s_losses[lk])
# after each epoch, compute and log statistics
for lk in loss_keys:
log[dk][lk]['mean'].append(np.mean(loss_lists[lk]))
log[dk][lk]['se'].append(np.std(loss_lists[lk], ddof=1) / np.sqrt(epoch_lengths[dk]))
# check whether the current model is better than all previous models
if 'val' in data_keys:
if log['val']['mse_last']['mean'][-1] < best_val_loss:
best_val_loss = log['val']['mse_last']['mean'][-1]
best_epoch = i
# save current model
saver.save(sess, save_path)
txt = 'epoch {:>3} >> '.format(i)
else:
txt = 'epoch {:>3} == '.format(i)
else:
best_epoch = i
saver.save(sess, save_path)
txt = 'epoch {:>3} >> '.format(i)
# after going through all data sets, do a print out of the current result
for lk in loss_keys:
txt += '{}: '.format(lk)
for dk in data_keys:
txt += '{:.2f}+-{:.2f}/'.format(log[dk][lk]['mean'][-1], log[dk][lk]['se'][-1])
txt = txt[:-1] + ' -- '
print(txt)
i += 1
# for key in ['train', 'val']:
# batch = next(batch_iterators[key + '_ex'])
# s_states, s_pred_states = sess.run([self.placeholders['s'], self.pred_states], {**{self.placeholders[key]: batch[key] for key in 'osa'},
# **{self.placeholders['keep_prob']: 1.0}})
#
# # s_pred_states = np.argmax(np.reshape(s_pred_states, list(s_pred_states.shape[:2]) + [10,5,8]), axis=2) * 100
#
# plt.figure('Example: ' + key)
# plt.gca().clear()
# plot_maze('nav01')
# s_states = np.reshape(s_states, [-1, 3])
# s_pred_states = np.reshape(s_pred_states, [-1, 3])
# plt.plot(s_states[:, 0], s_states[:, 1], 'xb')
# plt.plot(s_pred_states[:, 0], s_pred_states[:, 1], 'xg' if key == 'val' else 'xr')
# errors = np.concatenate([s_states[:, np.newaxis, :], s_pred_states[:, np.newaxis, :]], axis=1)
# plt.plot(errors[:, :, 0].T, errors[:, :, 1].T, '-k')
#
# # plt.plot(np.argmax(np.amax(np.amax(np.reshape(s_belief, list(s_belief.shape[:2]) + [10, 5, 8]), axis=4), axis=3), axis=2) * 100 + 50,
# # np.argmax(np.amax(np.amax(np.reshape(s_belief, list(s_belief.shape[:2]) + [10, 5, 8]), axis=4), axis=2), axis=2) * 100 + 50, 'xg' if key == 'val' else 'xr')
# # plt.plot(s_pred_states[:, :, 0], s_pred_states[:, :, 1], 'xg' if key == 'val' else 'xr')
#
# show_pause(pause=0.01)
# else:
# print('epoch {} -- mse: {:.4f}'.format(e, log['train']['mse'][-1]))
# # plt.figure('Learning curve: {}'.format(key))
# # plt.gca().clear()
# # plt.plot(log['train'][key], '--k')
# # plt.plot(log['val'][key], '-k')
# # plt.ylim([0, max(log['val'][key])])
saver.restore(sess, save_path)
return log
def connect_modules(self, means, stds, state_mins, state_maxs, state_step_sizes):
# tracking_info_full = tf.tile(((self.placeholders['s'] - means['s']) / stds['s'])[:, :1, :], [1, tf.shape(self.placeholders['s'])[1], 1])
tracking_info = tf.concat([((self.placeholders['s'] - means['s']) / stds['s'])[:, :1, :], tf.zeros_like(self.placeholders['s'][:,1:,:])], axis=1)
flag = tf.concat([tf.ones_like(self.placeholders['s'][:,:1,:1]), tf.zeros_like(self.placeholders['s'][:,1:,:1])], axis=1)
preproc_o = snt.BatchApply(self.encoder)((self.placeholders['o'] - means['o']) / stds['o'])
# include tracking info
if self.init_with_true_state:
# preproc_o = tf.concat([preproc_o, tracking_info, flag], axis=2)
preproc_o = tf.concat([preproc_o, tracking_info, flag], axis=2)
# preproc_o = tf.concat([preproc_o, tracking_info_full], axis=2)
preproc_a = snt.BatchApply(snt.BatchFlatten())(self.placeholders['a'] / stds['a'])
preproc_ao = tf.concat([preproc_o, preproc_a], axis=-1)
if self.model == '2lstm' or self.model == '2gru':
lstm1_out, lstm1_final_state = tf.nn.dynamic_rnn(self.rnn1, preproc_ao, dtype=tf.float32)
lstm2_out, lstm2_final_state = tf.nn.dynamic_rnn(self.rnn2, lstm1_out, dtype=tf.float32)
belief_list = lstm2_out
elif self.model == 'ff':
belief_list = snt.BatchApply(self.ff_lstm_replacement)(preproc_ao)
self.pred_states = snt.BatchApply(self.belief_decoder)(belief_list)
self.pred_states = self.pred_states * stds['s'] + means['s']
def predict(self, sess, batch, **unused_kwargs):
return sess.run(self.pred_states, {**{self.placeholders[key]: batch[key] for key in 'osa'},
**{self.placeholders['keep_prob']: 1.0}})
def load(self, sess, model_path, model_file='best_validation', statistics_file='statistics.npz', connect_and_initialize=True):
# build the tensorflow graph
if connect_and_initialize:
# load training data statistics (which are needed to build the tf graph)
statistics = dict(np.load(os.path.join(model_path, statistics_file)))
for key in statistics.keys():
if statistics[key].shape == ():
statistics[key] = statistics[key].item() # convert 0d array of dictionary back to a normal dictionary
# connect all modules into the particle filter
self.connect_modules(**statistics)
init = tf.global_variables_initializer()
sess.run(init)
# load variables
all_vars = tf.get_collection(tf.GraphKeys.GLOBAL_VARIABLES)
for v in all_vars:
print("%s %r %s" % (v, v, v.shape))
# restore variable values
saver = tf.train.Saver() # <- var list goes in here
saver.restore(sess, os.path.join(model_path, model_file))
# print('Loaded the following variables:')
# for v in all_vars:
# print(v.name)
================================================
FILE: plotting/__init__.py
================================================
================================================
FILE: plotting/ab_plot.py
================================================
import pickle
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import itertools
import os
results = None
# matplotlib.rcParams.update({'font.size': 12})
color_list = plt.cm.tab10(np.linspace(0, 1, 10))
colors = {'lstm': color_list[0], 'pf_e2e': color_list[1], 'pf_ind_e2e': color_list[2], 'pf_ind': color_list[3]}
labels = {'lstm': 'LSTM', 'pf_e2e': 'e2e', 'pf_ind_e2e': 'ind+e2e', 'pf_ind': 'ind'}
# conditions = ['normal', 'no_motion_likelihood', 'learn_odom', 'no_proposer']
# conditions = ['normal', 'learn_odom', 'no_inject']
# clabels = {'normal': 'Default', 'no_motion_likelihood': 'W/o motion likelihood', 'learn_odom': 'Learned odometry', 'no_proposer': 'W/o particle proposer', 'no_inject': "No inject"}
conditions = ['full', 'learn_odom', 'no_inject', 'no_proposer']
clabels = {'full': 'Full', 'learn_odom': 'Learned\nodometry', 'no_proposer': 'No particle\nproposer', 'no_inject': "No particle\ninjection"}
tasks = ['nav02']
methods = ['pf_ind', 'pf_e2e', 'pf_ind_e2e']
# load results
results = dict()
count = 0
for task in tasks:
# log_path = '/home/rbo/Desktop/log/'+task+'_ab1'
log_path = '../log/ab'
for filename in [f for f in os.listdir(log_path) if os.path.isfile(os.path.join(log_path, f))]:
full_filename = os.path.join(log_path, filename)
print('loading {}:'.format(count) + full_filename + ' ...')
try:
# if 'DeepThought' not in filename:
# if 'DeepThought' in filename:
with open(full_filename, 'rb') as f:
result = pickle.load(f)
# result_name = result['task'][0] + '/' + result['method'][0] + '/' + str(result['num_episodes'][0]) + '/' + result['condition'][0]
result_name = result['exp_params'][0]['file_ending'] #result['exp_params'][0]['task'] + '/' + result['exp_params'][0]['method'] + '/' + str(result['exp_params'][0]['num_episodes']) + '/' + result['exp_params'][0]['ab_cond']
for ab_cond in conditions:
if result_name.endswith(ab_cond):
result['exp_params'][0]['ab_cond'] = ab_cond
print(result_name)
if result_name not in results.keys():
results[result_name] = result
else:
for key in result.keys():
if key in results[result_name].keys():
results[result_name][key] += result[key]
else:
results[result_name][key] = result[key]
# print(result_name, key)
count += 1
except Exception as e:
print(e)
print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!')
for result_name in results.keys():
print(result_name, len(results[result_name]['exp_params'][0]['task']))
print('Loaded {} results'.format(count))
# print(results['test_errors'].shape, np.mean(results['test_errors']**2, axis=1))
#print('SHAPE', results['test_mse'].shape)
# plt.figure(1)
# plt.gca().set_color_cycle(None)
# for method in set(results['method']):
task = 'nav02'
# step = 30
step = 2
episodes = [16, 125, 1000]
# episodes = [1000]
fig_names = []
max_1 = 0
max_2 = {n: 0 for n in episodes}
means = dict()
ses = dict()
fig_name = 'abcolorbar'
plt.figure(fig_name, [0.8,2.5])
fig_names.append(fig_name)
vmax=1.0
a = np.array([[0.0, 1.0]])
img = plt.imshow(a, cmap="viridis_r", vmin=-0.33*vmax, vmax=vmax)
plt.gca().set_visible(False)
cax = plt.axes([0.0, 0.2, 0.1, 0.65])
plt.colorbar(orientation="vertical", cax=cax, label='Error rate', boundaries=np.linspace(0,1.0,100), ticks=np.linspace(0.0, 1.0, 11))
for num_episodes in episodes:
means[num_episodes] = dict()
ses[num_episodes] = dict()
for method in methods:
means[num_episodes][method] = np.zeros([len(conditions), 5])
# means[num_episodes][method] = np.zeros([len(conditions), 50])
ses[num_episodes][method] = np.zeros([len(conditions), 5])
# ses[num_episodes][method] = np.zeros([len(conditions), 50])
for c, condition in enumerate(conditions):
result_name = task + '_' + method + '_' + str(num_episodes) + '_' + condition
if result_name in results.keys():
result = results[result_name]
# means[num_episodes][method][c] = np.mean(result['test_mse'], axis=0)
# std = np.std(result['test_mse'], axis=0, ddof=1)
# ses[num_episodes][method][c] = std / np.sqrt(len(result['test_mse']))
hist = np.array([[h[i] for i in range(0, 50, 10)] for h in result['test_hist']]) # result x time x sqe [.0, 0.1, .., 10.0]
err = 1. - np.sum(hist[:,:,:10], axis=-1) # sqe < 1.0
means[num_episodes][method][c] = np.mean(err, axis=0)
print(result_name)
print(err[:, step])
print(np.mean(err, axis=0)[step])
print(np.std(err, axis=0, ddof=1)[step], np.sqrt(len(err)))
ses[num_episodes][method][c] = np.std(err, axis=0, ddof=1) / np.sqrt(len(err))
else:
# print(result_name, 0)
means[num_episodes][method][c] *= np.nan
ses[num_episodes][method][c] *= np.nan
means[num_episodes]['min'] = np.stack([means[num_episodes][method] for method in methods], axis=0).min(axis=1)
fig_name = 'ab1_{}'.format(num_episodes)
plt.figure(fig_name, [3,2.5])
fig_names.append(fig_name)
# m = means[num_episodes][method][:,step-1]
m = np.stack([means[num_episodes][method][:, step] for method in methods], axis=0)
s = np.stack([ses[num_episodes][method][:, step] for method in methods], axis=0)
is_min = m == means[num_episodes]['min'][:, None, step]
# plt.imshow((means[:,:,30-1])**0.5, interpolation='nearest', vmin=0, vmax=15)
# plt.imshow(np.log(m.T), interpolation='nearest', vmin=-2.5, vmax=2.5, cmap='viridis')
plt.imshow(m.T, interpolation='nearest', vmin=-0.33, vmax=1.0, cmap='viridis_r')
# data = np.reshape(np.arange(len(conditions)*len(conditions)), [len(conditions), len(conditions)])
# plt.imshow(data, interpolation='nearest', vmin=0, vmax=10)
plt.yticks(np.arange(len(conditions)), [clabels[c] for c in conditions])
plt.xticks(np.arange(len(methods)), [labels[m] for m in methods])
# plt.xlabel('Test {}{} noise'.format(noise_in, '.' if noise_in == 'odom' else ''))
# plt.ylabel('Training {}{} noise'.format(noise_in, '.' if noise_in == 'odom' else ''))
# plt.colorbar()
#text portion
# min_val, max_val, diff = 0., len(conditions), 1.
# N_points = (max_val - min_val) / diff
ind_array_y = np.arange(0., len(methods), 1.)
ind_array_x = np.arange(0., len(conditions), 1.)
x, y = np.meshgrid(ind_array_x, ind_array_y)
for x_val, y_val in zip(x.flatten(), y.flatten()):
value = m[int(y_val),int(x_val)]
s_value = s[int(y_val),int(x_val)]
text = '{:.4s}\n+-{:.4s}'.format('{:.3f}'.format(value)[1:],'{:.2f}'.format(s_value)[1:])
plt.text(y_val, x_val, text, va='center', ha='center', color='white', fontweight='bold' if is_min[int(y_val), int(x_val)] else 'normal')
# plt.text(y_val, x_val, text, va='center', ha='center', color='white', fontweight='normal')
# fig_name = 'nt_diag_{}'.format(num_episodes)
# plt.figure(fig_name, [3,2.5])
# fig_names.append(fig_name)
#
# x = np.arange(len(conditions))
# m = means[num_episodes][method][:,:,step-1]
# s = ses[num_episodes][method][:,:,step-1]
# plt.plot(x[:-1], np.diag(m)[:-1], '-', color=colors[method], label=labels[method])
# ind = -3 if noise_in == 'odom' else -2
# plt.plot(x[ind], np.diag(m)[ind], 'x', color=colors[method])
# plt.fill_between(x[:-1], np.diag(m-s)[:-1], np.diag(m+s)[:-1], color=colors[method], alpha=0.5, linewidth=0.0)
# plt.xticks(np.arange(len(conditions)-1), [clabels[c] for c in conditions[:-1]])
# if noise_in == 'odom':
# plt.xlabel('Gaussian odometry noise in %')
# else:
# plt.xlabel('Image noise')
# plt.legend()
#
# plt.ylabel('Test MSE ({} episodes)'.format(num_episodes))
# plt.ylim([0, 2.5])
#
# fig_name = 'nt_shuffle_{}'.format(num_episodes)
# plt.figure(fig_name, [3,2.5])
# fig_names.append(fig_name)
#
# if noise_in == 'odom':
# plt.bar(0.0 - 0.5 + (methods.index(method)+1)/len(methods)*0.8,
# np.diag(m)[-2],
# 0.8/len(methods),
# yerr=np.diag(s)[-2],
# color=colors[method], label=labels[method])
# plt.bar((1.0 if noise_in == 'odom' else 2.0) - 0.5 + (methods.index(method)+1)/len(methods)*0.8,
# np.diag(m)[-1], 0.8/len(methods),
# yerr=np.diag(s)[-1],
# color=colors[method])
# relative = np.diag(m)[-1] / np.diag(m)[-2]
# textpos = np.diag(m)[-1] + np.diag(s)[-1] + 2
# if num_episodes == 1000:
# if textpos > 10:
# textpos = 3
# elif textpos > 80:
# textpos = 10
# plt.text((1.0 if noise_in == 'odom' else 2.0) - 0.5 + (methods.index(method)+1)/len(methods)*0.8,
# textpos, '×{:.0f}'.format(relative), va='bottom', ha='center',color='black', rotation=90)
# plt.xticks([0, 1, 2], ['Both', 'Image', 'Odom.'])
# plt.ylim([0,60])
# plt.xlabel('Input')
# plt.ylabel('Test MSE ({} episodes)'.format(num_episodes))
# # plt.legend()
for fn in fig_names:
plt.figure(fn)
plt.tight_layout()
plt.savefig('../plots/ab/{}.pdf'.format(fn), bbox_inches="tight", transparent=True, dpi=600, frameon=True, facecolor='w', pad_inches=0.01)
# plt.savefig('../plots/ab/{}.png'.format(fn), bbox_inches="tight", transparent=True, dpi=600, frameon=True, facecolor='w', pad_inches=0.01)
# plt.bar(np.arange(len(conditions)) + (methods.index(method)+1)/len(methods)*0.8 - 0.5, np.diag(means[:,:,30-1])/np.diag(means[:,:,30-1])[0], 0.8/len(methods), color=colors[method])
plt.show()
================================================
FILE: plotting/cross_plot.py
================================================
import pickle
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import itertools
import os
results = None
# matplotlib.rcParams.update({'font.size': 12})
color_list = plt.cm.tab10(np.linspace(0, 1, 10))
colors = {'lstm': color_list[0], 'pf_e2e': color_list[1], 'pf_ind_e2e': color_list[2], 'pf_ind': color_list[3]}
labels = {'lstm': 'LSTM', 'pf_e2e': 'DPF (e2e)', 'pf_ind_e2e': 'DPF (ind+e2e)', 'pf_ind': 'DPF (ind)', 'ff': 'FF', 'odom': 'Odom. baseline'}
# conditions = ['normal', 'no_motion_likelihood', 'learn_odom', 'no_proposer']
# conditions = ['normal', 'learn_odom', 'no_inject']
# clabels = {'normal': 'Default', 'no_motion_likelihood': 'W/o motion likelihood', 'learn_odom': 'Learned odometry', 'no_proposer': 'W/o particle proposer', 'no_inject': "No inject"}
conditions = ['lc2lc', 'pl2lc', 'mx2lc', 'lc2pl', 'pl2pl', 'mx2pl']
clabels = {'lc2lc':'lc2lc', 'lc2pl':'lc2pl', 'pl2lc':'pl2lc', 'pl2pl':'pl2pl', 'mx2lc': 'mx2lc', 'mx2pl': 'mx2pl'}
task = 'nav02'
methods = ['pf_ind', 'pf_e2e', 'pf_ind_e2e', 'lstm']
# methods = ['pf_ind_e2e', 'lstm']
# load results
results = dict()
count = 0
for cond in conditions:
# log_path = '/home/rbo/Desktop/log/'+task+'_ab1'
log_path = '../log/'+cond
for filename in [f for f in os.listdir(log_path) if os.path.isfile(os.path.join(log_path, f))]:
full_filename = os.path.join(log_path, filename)
print('loading {}:'.format(count) + full_filename + ' ...')
try:
# if 'DeepThought' not in filename:
# if 'DeepThought' in filename:
with open(full_filename, 'rb') as f:
result = pickle.load(f)
# result_name = result['task'][0] + '/' + result['method'][0] + '/' + str(result['num_episodes'][0]) + '/' + result['condition'][0]
result_name = cond + '_' + result['exp_params'][0]['file_ending'] #result['exp_params'][0]['task'] + '/' + result['exp_params'][0]['method'] + '/' + str(result['exp_params'][0]['num_episodes']) + '/' + result['exp_params'][0]['ab_cond']
print(result_name)
if result_name not in results.keys():
results[result_name] = result
else:
for key in result.keys():
if key in results[result_name].keys():
results[result_name][key] += result[key]
else:
results[result_name][key] = result[key]
# print(result_name, key)
count += 1
except Exception as e:
print(e)
print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!')
print()
for result_name in results.keys():
print(result_name, len(results[result_name]['test_mse']))
print('Loaded {} results'.format(count))
# print(results['test_errors'].shape, np.mean(results['test_errors']**2, axis=1))
#print('SHAPE', results['test_mse'].shape)
# plt.figure(1)
# plt.gca().set_color_cycle(None)
# for method in set(results['method']):
task = 'nav02'
# step = 30
step = 3
episodes = [1000]
# episodes = [1000]
fig_names = []
max_1 = 0
max_2 = {n: 0 for n in episodes}
means = dict()
ses = dict()
for num_episodes in episodes:
means[num_episodes] = dict()
ses[num_episodes] = dict()
for method in methods:
means[num_episodes][method] = np.zeros([len(conditions), 5])
# means[num_episodes][method] = np.zeros([len(conditions), 50])
ses[num_episodes][method] = np.zeros([len(conditions), 5])
# ses[num_episodes][method] = np.zeros([len(conditions), 50])
for c, condition in enumerate(conditions):
result_name = condition + '_' + task + '_' + method + '_' + str(num_episodes)
if result_name in results.keys():
result = results[result_name]
# means[num_episodes][method][c] = np.mean(result['test_mse'], axis=0)
# std = np.std(result['test_mse'], axis=0, ddof=1)
# ses[num_episodes][method][c] = std / np.sqrt(len(result['test_mse']))
hist = np.array([[h[i] for i in range(0, 50, 10)] for h in result['test_hist']]) # result x time x sqe [.0, 0.1, .., 10.0]
err = 1. - np.sum(hist[:,:,:10], axis=-1) # sqe < 1.0
# err = np.sum(hist[:,:,:10], axis=-1) # sqe < 1.0
print(result_name, err)
means[num_episodes][method][c] = np.mean(err, axis=0)
ses[num_episodes][method][c] = np.std(err, axis=0, ddof=1) / np.sqrt(len(err))
print(means[num_episodes][method][c])
else:
# print(result_name, 0)
means[num_episodes][method][c] *= np.nan
ses[num_episodes][method][c] *= np.nan
means[num_episodes]['min'] = np.stack([means[num_episodes][method] for method in methods], axis=0).min(axis=1)
fig_name = 'ab1_{}'.format(num_episodes)
fig = plt.figure(fig_name, [6, 3.5])
fig_names.append(fig_name)
ax = fig.add_subplot(111)
# Turn off axis lines and ticks of the big subplot
ax.spines['top'].set_color('none')
ax.spines['bottom'].set_color('none')
ax.spines['left'].set_color('none')
ax.spines['right'].set_color('none')
ax.tick_params(labelcolor='w', top='off', bottom='off', left='off', right='off')
for c, condition in enumerate(conditions):
sax = fig.add_subplot(2, 3, c+1)
for m, method in enumerate(methods):
sax.bar(0.0 - 0.5 + (m+1)/len(methods)*0.8,
means[num_episodes][method][c, step],
0.8/len(methods),
yerr=ses[num_episodes][method][c, step],
color=colors[method], label=labels[method])
text = '{:.3s}'.format('{:.2f}'.format(means[num_episodes][method][c, step])[1:])
plt.text(0.0 - 0.5 + (m+1)/len(methods)*0.8, means[num_episodes][method][c, step] + ses[num_episodes][method][c, step] + 0.05, text, va='center', ha='center', color=colors[method], fontweight='normal')
# sax.set_ylim([0.0, 1.05])
sax.set_ylim([0.0, 1.0])
sax.set_xticks([])
sax.set_yticks([])
# if c % 2 == 0:
# if c >= 2:
if 'lc2' in condition:
xlabel = 'A'
sax.set_ylabel(('A' if '2lc' in condition else 'B'), fontweight = 'bold')
elif 'pl2' in condition:
xlabel = 'B'
elif 'mx2' in condition:
xlabel = 'A+B'
if '2pl' in condition:
sax.set_xlabel(xlabel, fontweight = 'bold')
if c == 0:
plt.legend()
ax.set_xlabel('Trained with policy')
ax.set_ylabel('Error rate in test with policy\n')
plt.tight_layout(h_pad=0.0, w_pad=0.0, pad=0.0)
plt.savefig('../plots/cr/policy.pdf', bbox_inches="tight", transparent=True, dpi=600, frameon=True, facecolor='w', pad_inches=0.01)
plt.show()
================================================
FILE: plotting/lc_plot.py
================================================
import pickle
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
#from mpl_toolkits.mplot3d import Axes3D
import itertools
from collections import namedtuple
import os
results = None
# matplotlib.rcParams.update({'font.size': 12})
color_list = plt.cm.tab10(np.linspace(0, 1, 10))
colors = {'lstm': color_list[0], 'pf_e2e': color_list[1], 'pf_ind_e2e': color_list[2], 'pf_ind': color_list[3], 'ff': color_list[4], 'odom': color_list[4]}
labels = {'lstm': 'LSTM', 'pf_e2e': 'DPF (e2e)', 'pf_ind_e2e': 'DPF (ind+e2e)', 'pf_ind': 'DPF (ind)', 'ff': 'FF', 'odom': 'Odom. baseline'}
def load_results(base_path='../log/', exp='lc'):
results = dict()
count = 0
log_path = os.path.join(base_path, exp)
listdir = os.listdir(log_path)
for i, filename in enumerate(listdir):
full_filename = os.path.join(log_path, filename)
# if 'DeepThought' not in full_filename:
print('loading ' + full_filename + ' ...')
# try:
with open(full_filename, 'rb') as f:
result = pickle.load(f)
print(result['exp_params'][0].keys())
result_name = result['exp_params'][0]['task'] + '/' + result['exp_params'][0]['method'] + '/' + str(result['exp_params'][0]['num_episodes'])
if result_name not in results.keys():
results[result_name] = result
else:
for key in result.keys():
results[result_name][key] += result[key]
count += 1
# except Exception as e:
# print(e)
for task in tasks:
for method in methods:
for num_episodes in episodes:
result_name = task + '/' + method + '/' + str(num_episodes)
if result_name in results.keys():
print(result_name, len(results[result_name]['exp_params']))
else:
print(result_name, 0)
print('Loaded {} results'.format(count))
return results
# print(results['test_errors'].shape, np.mean(results['test_errors']**2, axis=1))
#print('SHAPE', results['test_mse'].shape)
# plt.figure(1)
# plt.gca().set_color_cycle(None)
# for method in set(results['method']):
# step = {'nav01': 20, 'nav02': 20, 'nav03': 20}
# COMPUTE STATISTICS
def compute_statistics(results):
sqe_means = dict()
sqe_ses = dict()
acc_means = dict()
acc_ses = dict()
for task in tasks:
sqe_means[task] = dict()
sqe_ses[task] = dict()
acc_means[task] = dict()
acc_ses[task] = dict()
for method in methods:
sqe_means[task][method] = []
sqe_ses[task][method] = []
acc_means[task][method] = []
acc_ses[task][method] = []
# hist[task][method] = dict()
# hist_ses[task][method] = dict()
for num_episodes in episodes:
result_name = task + '/' + method + '/' + str(num_episodes)
if result_name in results.keys():
result = results[result_name]
# hist[task][method][num_episodes] = np.mean([h[step[task]] for h in result['test_hist']], axis=0)
# hist_ses[task][method][num_episodes] = np.std([h[step[task]] for h in result['test_hist']], axis=0, ddof=1) / np.sqrt(len(result['test_hist']))
sqe_means[task][method].append(np.mean(result['test_mse'], axis=0))
sqe_ses[task][method].append(np.std(result['test_mse'], axis=0, ddof=1) / np.sqrt(len(result['test_mse'])))
# hist = np.array([h[step[task]] for h in result['test_hist']]) # result x time x sqe [.0, 0.1]
hist = np.array([[h[i] for i in range(0, 50, 10)] for h in result['test_hist']]) # result x time x sqe [.0, 0.1, .., 10.0]
acc = 1. - np.sum(hist[:,:,:10], axis=-1) # sqe < 1.0
acc_means[task][method].append(np.mean(acc, axis=0))
acc_ses[task][method].append(np.std(acc, axis=0, ddof=1) / np.sqrt(len(acc)))
else:
sqe_means[task][method].append([np.nan]*max_steps)
sqe_ses[task][method].append([np.nan]*max_steps)
print(num_episodes)
acc_means[task][method].append([np.nan] * (max_steps // 10))
acc_ses[task][method].append([np.nan] * (max_steps // 10))
sqe_means[task][method] = np.array(sqe_means[task][method])
sqe_ses[task][method] = np.nan_to_num(sqe_ses[task][method])
acc_means[task][method] = np.array(acc_means[task][method])
acc_ses[task][method] = np.nan_to_num(acc_ses[task][method])
return sqe_means, sqe_ses, acc_means, acc_ses
def plot_learning_curve(means, ses, step, f=lambda x:x, ylabel_func=lambda x: '', ylim_func=None, show_legend=None, divide_by=None, save_extra=''):
for task in tasks:
plt.figure('lc'+ save_extra + ' for ' + task, [4,2.5])
# plt.plot([125, 125], [0, 1000], ':', color='gray', linewidth=1)
# plt.plot([1000, 1000], [0, 1000], ':', color='gray', linewidth=1)
for method in methods:
# valid = np.isnan(means[:,step-1]) == False
# eps = np.array(episodes)
if divide_by is None:
plt.fill_between(episodes, (f(means[task][method])-np.array(ses[task][method]))[:,step[task]], (f(means[task][method])+np.array(ses[task][method]))[:,step[task]], color=colors[method], alpha=0.3, linewidth=0.0)
else:
plt.fill_between(episodes,
(f(means[task][method])-np.array(ses[task][method]))[:,step[task]] / f(means[task][divide_by][:, step[task]]),
(f(means[task][method])+np.array(ses[task][method]))[:,step[task]] / f(means[task][divide_by][:, step[task]]),
color=colors[method], alpha=0.3, linewidth=0.0)
# plt.plot(125, means[task][method][episodes.index(125), step[task]], 'o', color=colors[method], markersize=3, linewidth=1)
# plt.plot(1000, means[task][method][episodes.index(1000), step[task]], 'x', color=colors[method], markersize=4, linewidth=1)
for method in methods:
if divide_by is None:
plt.plot(episodes, f(means[task][method][:, step[task]]), '.-' if method != 'odom' else '--', color=colors[method], label=labels[method], markersize=2, linewidth=1)
else:
plt.plot(episodes, f(means[task][method][:, step[task]]) / f(means[task][divide_by][:, step[task]]), '.-' if method != 'odom' else '--', color=colors[method], label=labels[method], markersize=2, linewidth=1)
plt.gca().set_xscale("log", nonposx='clip')
if ylim_func is not None:
plt.ylim(ylim_func(task))
# plt.ylim([0, max_1])
# plt.ylim([0, 1.0])
plt.xticks(episodes)
plt.gca().get_xaxis().set_major_formatter(matplotlib.ticker.ScalarFormatter())
plt.gca().get_xaxis().set_tick_params(which='minor', size=0)
plt.gca().get_xaxis().set_tick_params(which='minor', width=0)
plt.xlabel('Training episodes (log. scale)')
plt.ylabel(ylabel_func(step[task]))
# plt.tight_layout()
if show_legend is None or show_legend[task]:
plt.legend(loc='upper right')
# plt.figure(task + " " + str(step) + " steps")
extra = 'lc' + save_extra
plt.savefig('../plots/' + exp + '/'+exp+'_'+task+'_'+extra+'.pdf', bbox_inches="tight", transparent=True, dpi=600, frameon=True, facecolor='w', pad_inches=0.01)
plt.savefig('../plots/' + exp + '/'+exp+'_'+task+'_'+extra+'.png', bbox_inches="tight", transparent=True, dpi=600, frameon=True, facecolor='w', pad_inches=0.01)
# PLOT FILTER CONVERGENCE
def plot_filter_convergence(means, ses, step, ylabel_func, ylim_func=None, save_extra=''):
for task in tasks:
max_2 = {n: 0 for n in episodes}
for num_episodes in [1000]:
i = episodes.index(num_episodes)
plt.figure(task + " " + str(num_episodes) + " training episodes " + save_extra, [2,2.5])
for method in methods:
n = means[task][method].shape[1]
# if num_episodes == 125:
# plt.plot([step[task]], means[task][method][i, step[task]], 'o', color=colors[method], markersize=3, linewidth=1) # label=labels[method]
# elif num_episodes == 1000:
# plt.plot([step[task]], means[task][method][i, step[task]], 'x', color=colors[method], markersize=4, linewidth=1) # label=labels[method]
plt.fill_between(np.arange(n), (np.array(means[task][method])-np.array(ses[task][method]))[i,:], (np.array(means[task][method])+np.array(ses[task][method]))[i,:], color=colors[method], alpha=0.3, linewidth=0.0)
if method is not 'pf_ind':
max_2[num_episodes] = max(means[task][method][i, -1], max_2[num_episodes])
for method in methods:
n = means[task][method].shape[1]
# plt.plot(np.arange(1, 20+1), means[task][method][i, :20], '--', color=colors[method], markersize=3, linewidth=1)
# plt.plot(np.arange(20, max_steps+1), means[task][method][i, 19:], '-', color=colors[method], markersize=3, linewidth=1) # label=labels[method]
plt.plot(means[task][method][i, :], '-' if method != 'odom' else '--', color=colors[method], markersize=3, linewidth=1) # label=labels[method]
# plt.plot([step], [0], 'w', label=' ', linewidth=0)
# plt.plot([step[task]], [0], '--', color='gray', label='Steps optimized during training', linewidth=1)
# plt.plot([step[task], step[task]], [0, 5*max_2[num_episodes]], ':', color='gray', label='Step tested in learning curve', linewidth=1)
if ylim_func is not None:
plt.ylim(ylim_func(task))
plt.xticks([0, 20, 40])
plt.xlabel('Tested at step')
plt.ylabel(ylabel_func(step[task]))
plt.ylabel('MSE ({} episodes)'.format(num_episodes))
plt.tight_layout()
# if task == 'nav01':
# plt.legend()
# plt.figure(task + " " + str(num_episodes) + " training episodes")
extra = 'convrg' + save_extra
plt.savefig('../plots/'+exp+'/'+exp+'_'+task+'_steps_'+str(num_episodes)+'_'+extra+'.pdf', bbox_inches="tight", transparent=True, dpi=600, frameon=True, facecolor='w', pad_inches=0.01)
plt.savefig('../plots/'+exp+'/'+exp+'_'+task+'_steps_'+str(num_episodes)+'_'+extra+'.png', bbox_inches="tight", transparent=True, dpi=600, frameon=True, facecolor='w', pad_inches=0.01)
methods = ['lstm', 'pf_ind', 'pf_e2e', 'pf_ind_e2e']
episodes = [16, 32, 64, 125, 250, 500, 1000]
exp = 'lc'; tasks = ['nav01', 'nav02', 'nav03']; max_steps = 50
# exp = 'pl'; tasks = ['nav02']; max_steps = 50; #methods = ['lstm', 'pf_ind_e2e']
# exp = 'mx'; tasks = ['nav02']; max_steps = 50; #methods = ['lstm', 'pf_ind_e2e']
# exp = 'tr'; tasks = ['nav02']; methods = ['lstm', 'pf_ind', 'pf_e2e', 'pf_ind_e2e', 'odom']; max_steps = 50
plot_path = '../plots/' + exp
if not os.path.exists(plot_path):
os.makedirs(plot_path)
results = load_results(exp=exp)
sqe_means, sqe_ses, acc_means, acc_ses = compute_statistics(results)
# print(acc_means['nav01']['lstm'].shape)
if exp == 'lc':
plot_learning_curve(sqe_means, sqe_ses, step = {'nav01': 20, 'nav02': 20, 'nav03': 30},
ylabel_func=lambda step: 'MSE (at step {})'.format(step),
ylim_func=lambda task: {'nav01':[0,25], 'nav02':[0,55], 'nav03':[0,110]}[task],
save_extra='_mse', show_legend={'nav01': True, 'nav02': False, 'nav03': False})
plot_learning_curve(acc_means, acc_ses, f=lambda x: x, step = {'nav01': 2, 'nav02': 2, 'nav03': 3},
ylabel_func=lambda step: 'Error rate',
ylim_func=lambda task: [0.0,1.0],
save_extra='_er', show_legend={'nav01': True, 'nav02': False, 'nav03': False})
plot_learning_curve(sqe_means, sqe_ses, step = {'nav01': 20, 'nav02': 20, 'nav03': 30},
ylabel_func=lambda step: 'MSE relative to LSTM',
ylim_func=lambda task: [0.0, 1.2],
save_extra='_mse_div', show_legend={'nav01': False, 'nav02': False, 'nav03': False}, divide_by='lstm')
plot_learning_curve(acc_means, acc_ses, f=lambda x: x, step = {'nav01': 2, 'nav02': 2, 'nav03': 3},
ylabel_func=lambda step: 'Error rate relative to LSTM',
ylim_func=lambda task: [0.0, 1.2],
save_extra='_er_div', show_legend={'nav01': False, 'nav02': False, 'nav03': False}, divide_by='lstm')
# plot_filter_convergence(sqe_means, sqe_ses, step = {'nav01': 40, 'nav02': 40, 'nav03': 40},
# ylabel_func=lambda step: 'Test MSE (at step {})'.format(step),
# ylim_func=lambda task: {'nav01':[0,25], 'nav02':[0,55], 'nav03':[0,110]}[task],
# save_extra='_mse')
#
# plot_filter_convergence(acc_means, acc_ses, step = {'nav01': 2, 'nav02': 2, 'nav03': 3},
# ylabel_func=lambda step: 'Test Accuracy (at step {})'.format(step*10),
# ylim_func=lambda task: [0.0,1.0],
# save_extra='_acc')
# plot_filter_convergence(sqe_means, sqe_ses, step = {'nav01': 40, 'nav02': 40, 'nav03': 40},
# ylabel_func=lambda step: 'Test MSE (at step {})'.format(step),
# ylim_func=lambda task: {'nav01':[0,25], 'nav02':[0,1.0], 'nav03':[0,110]}[task],
# save_extra='_mse')
elif exp == 'tr':
plot_learning_curve(sqe_means, sqe_ses, step = {'nav01': 20, 'nav02': 20, 'nav03': 30},
ylabel_func=lambda step: 'MSE (at step {})'.format(step),
ylim_func=lambda task: {'nav01':[0,25], 'nav02':[0,55], 'nav03':[0,110]}[task],
save_extra='_mse', show_legend={'nav01': True, 'nav02': True, 'nav03': False})
plot_learning_curve(acc_means, acc_ses, f=lambda x: x, step = {'nav01': 2, 'nav02': 2, 'nav03': 3},
ylabel_func=lambda step: 'Error rate',
ylim_func=lambda task: [0.0,1.0],
save_extra='_er', show_legend={'nav01': True, 'nav02': True, 'nav03': False})
#
# plot_learning_curve(sqe_means, sqe_ses, step = {'nav01': 20, 'nav02': 20, 'nav03': 30},
# ylabel_func=lambda step: 'MSE relative to LSTM',
# ylim_func=lambda task: [0.0, 1.2],
# save_extra='_mse_div', show_legend={'nav01': False, 'nav02': False, 'nav03': False}, divide_by='lstm')
#
# plot_learning_curve(acc_means, acc_ses, f=lambda x: x, step = {'nav01': 2, 'nav02': 2, 'nav03': 3},
# ylabel_func=lambda step: 'Error rate relative to LSTM',
# ylim_func=lambda task: [0.0, 1.2],
# save_extra='_er_div', show_legend={'nav01': False, 'nav02': False, 'nav03': False}, divide_by='lstm')
plot_filter_convergence(sqe_means, sqe_ses, step = {'nav01': 40, 'nav02': 40, 'nav03': 40},
ylabel_func=lambda step: 'MSE (at step {})'.format(step),
ylim_func=lambda task: {'nav01':[0,25], 'nav02':[0,1.0], 'nav03':[0,110]}[task],
save_extra='_mse')
#
# plot_filter_convergence(acc_means, acc_ses, step = {'nav01': 2, 'nav02': 2, 'nav03': 3},
# ylabel_func=lambda step: 'Test Accuracy (at step {})'.format(step*10),
# ylim_func=lambda task: [0.0,1.0],
# save_extra='_acc')
else:
plot_learning_curve(sqe_means, sqe_ses, step = {'nav01': 20, 'nav02': 20, 'nav03': 30},
ylabel_func=lambda step: 'MSE (at step {})'.format(step),
ylim_func=lambda task: {'nav01':[0,25], 'nav02':[0,55], 'nav03':[0,110]}[task],
save_extra='_mse', show_legend={'nav01': True, 'nav02': False, 'nav03': False})
plot_learning_curve(acc_means, acc_ses, f=lambda x: x, step = {'nav01': 2, 'nav02': 2, 'nav03': 3},
ylabel_func=lambda step: 'Error rate',
ylim_func=lambda task: [0.0,1.0],
save_extra='_er', show_legend={'nav01': True, 'nav02': False, 'nav03': False})
plot_learning_curve(sqe_means, sqe_ses, step = {'nav01': 20, 'nav02': 20, 'nav03': 30},
ylabel_func=lambda step: 'MSE relative to LSTM',
ylim_func=lambda task: [0.0, 1.2],
save_extra='_mse_div', show_legend={'nav01': False, 'nav02': False, 'nav03': False}, divide_by='lstm')
plot_learning_curve(acc_means, acc_ses, f=lambda x: x, step = {'nav01': 2, 'nav02': 2, 'nav03': 3},
ylabel_func=lambda step: 'Error rate relative to LSTM',
ylim_func=lambda task: [0.0, 1.2],
save_extra='_er_div', show_legend={'nav01': False, 'nav02': False, 'nav03': False}, divide_by='lstm')
# plot_filter_convergence(sqe_means, sqe_ses, step = {'nav01': 40, 'nav02': 40, 'nav03': 40},
# ylabel_func=lambda step: 'Test MSE (at step {})'.format(step),
# ylim_func=lambda task: {'nav01':[0,25], 'nav02':[0,55], 'nav03':[0,110]}[task],
# save_extra='_mse')
#
# plot_filter_convergence(acc_means, acc_ses, step = {'nav01': 2, 'nav02': 2, 'nav03': 3},
# ylabel_func=lambda step: 'Test Accuracy (at step {})'.format(step*10),
# ylim_func=lambda task: [0.0,1.0],
# save_extra='_acc')
# plot_filter_convergence(sqe_means, sqe_ses, step = {'nav01': 40, 'nav02': 40, 'nav03': 40},
# ylabel_func=lambda step: 'Test MSE (at step {})'.format(step),
# ylim_func=lambda task: {'nav01':[0,25], 'nav02':[0,1.0], 'nav03':[0,110]}[task],
# save_extra='_mse')
plt.show()
================================================
FILE: plotting/nt_plot.py
================================================
import pickle
import numpy as np
import matplotlib.pyplot as plt
import os
results = None
# matplotlib.rcParams.update({'font.size': 12})
color_list = plt.cm.tab10(np.linspace(0, 1, 10))
colors = {'lstm': color_list[0], 'pf_e2e': color_list[1], 'pf_ind_e2e': color_list[2], 'pf_ind': color_list[3]}
labels = {'lstm': 'LSTM', 'pf_e2e': 'DPF (e2e)', 'pf_ind_e2e': 'DPF (ind+e2e)', 'pf_ind': 'DPF (ind)'}
tasks = ['nav02']
methods = ['lstm', 'pf_ind', 'pf_e2e', 'pf_ind_e2e']
# load results
results = dict()
count = 0
for task in tasks:
log_path = '../log/nt'
for filename in [f for f in os.listdir(log_path) if os.path.isfile(os.path.join(log_path, f))]:
full_filename = os.path.join(log_path, filename)
print('loading {}:'.format(count) + full_filename + ' ...')
try:
# if 'DeepThought' not in filename:
# if 'DeepThought' in filename:
with open(full_filename, 'rb') as f:
result = pickle.load(f)
result_name = result['exp_params'][0]['task'] + '/' + result['exp_params'][0]['method'] + '/' + str(result['exp_params'][0]['num_episodes']) + '/' + result['exp_params'][0]['noise_condition']
print(result_name)
if result_name not in results.keys():
results[result_name] = result
else:
for key in result.keys():
if key in results[result_name].keys():
results[result_name][key] += result[key]
else:
results[result_name][key] = result[key]
# print(result_name, key)
count += 1
except Exception as e:
print('%r' % e)
# raise e
print('!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!')
for result_name in results.keys():
print(result_name, len(results[result_name]['exp_params']))
print('Loaded {} results'.format(count))
# print(results['test_errors'].shape, np.mean(results['test_errors']**2, axis=1))
#print('SHAPE', results['test_mse'].shape)
# plt.figure(1)
# plt.gca().set_color_cycle(None)
# for method in set(results['method']):
task = 'nav02'
metric = 'err'; step = 2 # err or mse
# metric = 'mse'; step = 20 # err or mse
# episodes = [125, 1000]
episodes = [1000]
fig_names = []
for noise_in in ['odom', 'image']:
if noise_in == 'odom':
conditions = ['odom0_imgTG', 'odom5_imgTG', 'odom10_imgTG', 'odom20_imgTG', 'odomX_imgTG']; clabels = {'odom0_imgTG': '0', 'odom5_imgTG': '5', 'odom10_imgTG': '10', 'odom20_imgTG': '20', 'odomX_imgTG': 'X'}
# conditions = ['odom0_imgTG', 'odom5_imgTG', 'odom10_imgTG', 'odomX_imgTG']; clabels = {'odom0_imgTG': '0', 'odom5_imgTG': '5', 'odom10_imgTG': '10', 'odomX_imgTG': 'X'}
else:
conditions = ['odom10_imgC', 'odom10_imgG', 'odom10_imgT', 'odom10_imgTG', 'odom10_imgX']; clabels = {'odom10_imgC': 'N', 'odom10_imgG': 'G', 'odom10_imgT': 'S', 'odom10_imgTG': 'G+S', 'odom10_imgX': 'X'}
max_1 = 0
max_2 = {n: 0 for n in episodes}
means = dict()
ses = dict()
for num_episodes in episodes:
means[num_episodes] = dict()
ses[num_episodes] = dict()
for method in methods:
if metric == 'mse':
means[num_episodes][method] = np.zeros([len(conditions), len(conditions), 50])
ses[num_episodes][method] = np.zeros([len(conditions), len(conditions), 50])
elif metric == 'err':
means[num_episodes][method] = np.zeros([len(conditions), len(conditions), 5])
ses[num_episodes][method] = np.zeros([len(conditions), len(conditions), 5])
for c, condition in enumerate(conditions):
result_name = task + '/' + method + '/' + str(num_episodes) + '/' + condition
if result_name in results.keys():
result = results[result_name]
for ct, test_condition in enumerate(conditions):
if 'test_'+test_condition+'_mse' not in result.keys():
means[num_episodes][method][c, ct] *= np.nan
ses[num_episodes][method][c, ct] *= np.nan
else:
if noise_in != "odom" and num_episodes == 1000 and c == 1 and ct == 1:
print(method,
np.array(result['test_'+test_condition+'_mse'])[:, 30])
if metric == 'mse':
means[num_episodes][method][c, ct] = np.mean(result['test_'+test_condition+'_mse'], axis=0)
std = np.std(result['test_'+test_condition+'_mse'], axis=0, ddof=1)
ses[num_episodes][method][c, ct] = std / np.sqrt(len(result['test_'+test_condition+'_mse']))
elif metric == 'err':
hist = np.array([[h[i] for i in range(0, 50, 10)] for h in result['test_'+test_condition+'_hist']]) # result x time x sqe [.0, 0.1, .., 10.0]
err = 1. - np.sum(hist[:,:,:10], axis=-1) # sqe < 1.0
means[num_episodes][method][c, ct] = np.mean(err, axis=0)
ses[num_episodes][method][c, ct] = np.std(err, axis=0, ddof=1) / np.sqrt(len(err))
else:
# print(result_name, 0)
for test_condition in conditions:
means[num_episodes][method][c, :] *= np.nan
# if noise_in != 'odom':
# print(means[1000]['pf_ind'][1,1,30])
means[num_episodes]['min'] = np.stack([means[num_episodes][method] for method in methods], axis=0).min(axis=0)
for method in methods:
fig_name = 'nt_{}_{}_{}'.format(noise_in,num_episodes,method)
plt.figure(fig_name, [3,2.5])
fig_names.append(fig_name)
min_val, max_val, diff = 0., len(conditions), 1.
#imshow portion
N_points = (max_val - min_val) / diff
m = means[num_episodes][method][:,:,step].T
is_min = m == means[num_episodes]['min'][:,:,step].T
# plt.imshow((means[:,:,30-1])**0.5, interpolation='nearest', vmin=0, vmax=15)
if metric == 'mse':
plt.imshow(np.log(m), interpolation='nearest', vmin=-3, vmax=6, cmap='viridis')
elif metric == 'err':
plt.imshow(m, interpolation='nearest', vmin=-0.33, vmax=1.0, cmap='viridis_r')
# data = np.reshape(np.arange(len(conditions)*len(conditions)), [len(conditions), len(conditions)])
# plt.imshow(data, interpolation='nearest', vmin=0, vmax=10)
plt.xticks(np.arange(len(conditions)), [clabels[c] for c in conditions])
plt.yticks(np.arange(len(conditions)), [clabels[c] for c in conditions])
plt.ylabel('Test {}{} noise'.format(noise_in, '.' if noise_in == 'odom' else ''))
plt.xlabel('Training {}{} noise'.format(noise_in, '.' if noise_in == 'odom' else ''))
# plt.colorbar()
#text portion
ind_array = np.arange(min_val, max_val, diff)
x, y = np.meshgrid(ind_array, ind_array)
for x_val, y_val in zip(x.flatten(), y.flatten()):
value = m[int(y_val),int(x_val)]
if metric == 'err':
text = '{:.4s}'.format('{:.3f}'.format(value)[1:])
else:
text = '{:.4s}'.format('{:.2f}'.format(value))
if x_val == y_val:
if x_val == 3 and noise_in == 'image' or x_val == 2 and noise_in == 'odom':
style = '-w'
else:
style = '--w'
plt.plot(np.array([x_val, x_val+1, x_val+1, x_val, x_val])-0.5, np.array([y_val, y_val, y_val+1, y_val+1, y_val])-0.5, style, linewidth=1.5)
# if value > 0.9:
# color = 'black'
# else:
# color = 'white'
plt.text(x_val, y_val, text, va='center', ha='center', color='white', fontweight='bold' if is_min[int(y_val), int(x_val)] else 'normal')
fig_name = 'nt_diag_{}_{}'.format(noise_in,num_episodes)
# plt.figure(fig_name, [3,2.5])
plt.figure(fig_name, [2,2.5])
fig_names.append(fig_name)
if noise_in == 'odom':
x = np.array([int(clabels[c]) for c in conditions[:-1]])
else:
x = np.arange(len(conditions)-1)
m = means[num_episodes][method][:,:,step]
s = ses[num_episodes][method][:,:,step]
plt.plot(x, np.diag(m)[:-1], '.-', color=colors[method], label=labels[method], markersize=2)
ind = 2 if noise_in == 'odom' else 3
plt.plot(x[ind], np.diag(m)[ind], 'x', color=colors[method], markersize=4)
plt.fill_between(x, np.diag(m-s)[:-1], np.diag(m+s)[:-1], color=colors[method], alpha=0.5, linewidth=0.0)
plt.xticks(x, [clabels[c] for c in conditions[:-1]])
if noise_in == 'odom':
plt.xlabel('Odometry noise (%)')
else:
plt.xlabel('Image noise')
plt.legend()
if metric == 'mse':
plt.ylabel('MSE ({} episodes)'.format(num_episodes))
else:
plt.ylabel('Error rate ({} episodes)'.format(num_episodes))
plt.ylim([0, 0.3])
plt.yticks([0.0, 0.1, 0.2, 0.3])
fig_name = 'nt_shuffle_{}'.format(num_episodes)
# plt.figure(fig_name, [3,2.5])
plt.figure(fig_name, [2,2.5])
fig_names.append(fig_name)
if noise_in == 'odom':
plt.bar(0.0 - 0.5 + (methods.index(method)+1)/len(methods)*0.8,
np.diag(m)[-3],
0.8/len(methods),
yerr=np.diag(s)[-3],
color=colors[method], label=labels[method])
plt.bar((1.0 if noise_in == 'odom' else 2.0) - 0.5 + (methods.index(method)+1)/len(methods)*0.8,
np.diag(m)[-1], 0.8/len(methods),
yerr=np.diag(s)[-1],
color=colors[method])
if noise_in == 'odom':
relative = np.diag(m)[-1] / np.diag(m)[-3]
else:
relative = np.diag(m)[-1] / np.diag(m)[-2]
textpos = np.diag(m)[-1] + np.diag(s)[-1] + 2
if num_episodes == 1000:
if textpos > 10:
textpos = 3
elif textpos > 80:
textpos = 10
color = 'black'
if metric == 'err':
textpos = 0.05
color = 'white'
# plt.text((1.0 if noise_in == 'odom' else 2.0) - 0.5 + (methods.index(method)+1)/len(methods)*0.8,
# textpos, '×{:.0f}'.format(relative), va='bottom', ha='center',color=color, rotation=90)
plt.xticks([0, 1, 2], ['Both', 'Image', 'Odom.'])
plt.ylim([0,1.05])
plt.xlabel('Input')
if metric == 'mse':
plt.ylabel('MSE ({} episodes)'.format(num_episodes))
else:
plt.ylabel('Error rate ({} episodes)'.format(num_episodes))
# plt.legend()
for fn in fig_names:
plt.figure(fn)
# plt.tight_layout()
plt.savefig('../plots/nt/{}.pdf'.format(fn), bbox_inches="tight", transparent=True, dpi=600, frameon=True, facecolor='w', pad_inches=0.01)
# plt.savefig('../plots/nt/{}.png'.format(fn), bbox_inches="tight", transparent=True, dpi=600, frameon=True, facecolor='w', pad_inches=0.01)
# plt.bar(np.arange(len(conditions)) + (methods.index(method)+1)/len(methods)*0.8 - 0.5, np.diag(means[:,:,30-1])/np.diag(means[:,:,30-1])[0], 0.8/len(methods), color=colors[method])
plt.show()
================================================
FILE: plotting/plot_models.py
================================================
import tensorflow as tf
import pickle
from methods.dpf import DPF
from methods.rnn import RNN
from utils.data_utils import load_data, noisyfy_data, make_batch_iterator, reduce_data
from utils.exp_utils import get_default_hyperparams
from utils.method_utils import compute_sq_distance
from utils.plotting_utils import plot_maze, plot_observations
from methods.odom import OdometryBaseline
import numpy as np
import matplotlib.pyplot as plt
# from mpl_toolkits.axes_grid1 import make_axes_locatable
head_scale = 1.5
quiv_kwargs = {'scale_units':'xy', 'scale':1./40., 'width': 0.003, 'headlength': 5*head_scale, 'headwidth': 3*head_scale, 'headaxislength': 4.5*head_scale}
marker_kwargs = {'markersize': 4.5, 'markerfacecolor':'None', 'markeredgewidth':0.5}
def plot_measurement_model(session, method, statistics, batch, task, num_examples, variant):
batch_size = len(batch['o'])
x = np.linspace(100.0 / 4, 1000.0 - 100.0 / 4, 20)
y = np.linspace(100.0 / 4, 500.0 - 100.0 / 4, 10)
theta = np.linspace(-np.pi, np.pi, 12 + 1)[1:]
g = np.meshgrid(x, y, theta)
poses = np.vstack([np.ravel(x) for x in g]).transpose([1, 0])
test_poses = tf.tile(tf.constant(poses, dtype='float32')[None, :, :], [batch_size, 1, 1])
measurement_model_out = method.measurement_update(method.encodings[0, :], test_poses, statistics['means'],
statistics['stds'])
# define the inputs and train/run the model
input_dict = {**{method.placeholders[key]: batch[key] for key in 'osa'},
}
obs_likelihood = session.run(measurement_model_out, input_dict)
print(obs_likelihood.shape)
for i in range(num_examples):
# plt.figure("%s likelihood" % i)
fig, (ax, cax) = plt.subplots(1, 2, figsize=(2.4 / 0.83 / 0.95 / 0.97, 1.29 / 0.9),
gridspec_kw={"width_ratios": [0.97, 0.03]}, num="%s %s likelihood" % (variant, i))
# plt.gca().clear()
plot_maze(task, margin=5, linewidth=0.5, ax=ax)
idx = obs_likelihood[i,:] > 1*np.mean(obs_likelihood[i,:])
# idx = obs_likelihood[i, :] > 0 * np.mean(obs_likelihood[i, :])
max = np.max(obs_likelihood[i, :])
# ax.scatter([poses[:, 0]], [poses[:, 1]], s=[0.001], c=[(0.8, 0.8, 0.8)], marker='.')
quiv = ax.quiver(poses[idx, 0] + 0 * np.cos(poses[idx, 2]), poses[idx, 1] + 0* np.sin(poses[idx, 2]), np.cos(poses[idx, 2]),
np.sin(poses[idx, 2]), obs_likelihood[i, idx],
cmap='viridis_r',
clim=[0.0, max],
**quiv_kwargs
)
ax.plot([batch['s'][0, i, 0]], [batch['s'][0, i, 1]], 'or', **marker_kwargs)
ax.quiver([batch['s'][0, i, 0]], [batch['s'][0, i, 1]], np.cos([batch['s'][0, i, 2]]),
np.sin([batch['s'][0, i, 2]]), color='red',
**quiv_kwargs
)
ax.axis('off')
fig.colorbar(quiv, cax=cax, orientation="vertical", label='Obs. likelihood', ticks=[0.0, 0.2, 0.4, 0.6, 0.8, 1.0])
plt.subplots_adjust(left=0.0, bottom=0.05, right=0.83, top=0.95, wspace=0.05, hspace=0.00)
plt.savefig('../plots/models/measurement_model{}.pdf'.format(i), transparent=True, dpi=600, frameon=False, facecolor='w', pad_inches=0.01)
def plot_proposer(session, method, statistics, batch, task, num_examples, variant):
num_particles = 1000
proposer_out = method.propose_particles(method.encodings[0, :], num_particles, statistics['state_mins'], statistics['state_maxs'])
# define the inputs and train/run the model
input_dict = {**{method.placeholders[key]: batch[key] for key in 'osa'},
}
particles = session.run(proposer_out, input_dict)
for i in range(num_examples):
fig = plt.figure(figsize=(2.4, 1.29/0.9), num="%s %s proposer" % (variant, i))
# plt.gca().clear()
plot_maze(task, margin=5, linewidth=0.5)
quiv = plt.quiver(particles[i, :, 0], particles[i, :, 1], np.cos(particles[i, :, 2]),
np.sin(particles[i, :, 2]), np.ones([num_particles]), cmap='viridis_r', clim=[0, 2], alpha=1.0,
**quiv_kwargs
)
plt.quiver([batch['s'][0, i, 0]], [batch['s'][0, i, 1]], np.cos([batch['s'][0,i, 2]]),
np.sin([batch['s'][0, i, 2]]), color='red',
**quiv_kwargs) # width=0.01, scale=100
plt.plot([batch['s'][0, i, 0]], [batch['s'][0, i, 1]], 'or', **marker_kwargs)
plt.gca().axis('off')
plt.subplots_adjust(left=0.0, bottom=0.05, right=1.0, top=0.95, wspace=0.0, hspace=0.00)
# plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.0, wspace=0.001, hspace=0.1)
plt.savefig('../plots/models/prop{}.pdf'.format(i), transparent=True, dpi=600, frameon=False, facecolor='w', pad_inches=0.01)
def plot_motion_model(session, method, statistics, batch, task, num_examples, num_particles, variant):
motion_samples = method.motion_update(method.placeholders['a'][:, 1],
tf.tile(method.placeholders['s'][:, :1], [1, num_particles, 1]),
statistics['means'], statistics['stds'], statistics['state_step_sizes'])
# define the inputs and train/run the model
input_dict = {**{method.placeholders[key]: batch[key] for key in 'osa'},
}
particles = session.run(motion_samples, input_dict)
fig = plt.figure(figsize=(2.4, 1.29), num="%s motion model" % (variant))
# plt.gca().clear()
plot_maze(task, margin=5, linewidth=0.5)
for i in range(num_examples):
plt.quiver(particles[i, :, 0], particles[i, :, 1], np.cos(particles[i, :, 2]),
np.sin(particles[i, :, 2]), np.ones([num_particles]), cmap='viridis_r',
**quiv_kwargs,
alpha=1.0, clim=[0, 2]) # width=0.01, scale=100
plt.quiver([batch['s'][i, 0, 0]], [batch['s'][i, 0, 1]], np.cos([batch['s'][i, 0, 2]]),
np.sin([batch['s'][i, 0, 2]]), color='black',
**quiv_kwargs,
) # width=0.01, scale=100
plt.plot(batch['s'][i, :2, 0], batch['s'][i, :2, 1], '--', color='black', linewidth=0.3)
plt.plot(batch['s'][i, :1, 0], batch['s'][i, :1, 1], 'o', color='black', linewidth=0.3, **marker_kwargs)
plt.plot(batch['s'][i, 1:2, 0], batch['s'][i, 1:2, 1], 'o', color='red', linewidth=0.3, **marker_kwargs)
plt.quiver([batch['s'][i, 1, 0]], [batch['s'][i, 1, 1]], np.cos([batch['s'][i, 1, 2]]),
np.sin([batch['s'][i, 1, 2]]), color='red',
**quiv_kwargs) # width=0.01, scale=100
plt.gca().axis('off')
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.0, wspace=0.001, hspace=0.1)
plt.savefig('../plots/models/motion_model{}.pdf'.format(i), transparent=True, dpi=600, frameon=False, facecolor='w', pad_inches=0.01)
def plot_particle_filter(session, method, statistics, batch, task, num_examples, num_particles, variant):
color_list = plt.cm.tab10(np.linspace(0, 1, 10))
colors = {'lstm': color_list[0], 'pf_e2e': color_list[1], 'pf_ind_e2e': color_list[2], 'pf_ind': color_list[3],
'ff': color_list[4], 'odom': color_list[4]}
pred, s_particle_list, s_particle_probs_list = method.predict(session, batch, num_particles, return_particles=True)
num_steps = 20 # s_particle_list.shape[1]
for s in range(num_examples):
plt.figure("example {}, vartiant: {}".format(s, variant), figsize=[12, 5.15])
plt.gca().clear()
for i in range(num_steps):
ax = plt.subplot(4, 5, i + 1, frameon=False)
plt.gca().clear()
plot_maze(task, margin=5, linewidth=0.5)
if i < num_steps - 1:
ax.quiver(s_particle_list[s, i, :, 0], s_particle_list[s, i, :, 1],
np.cos(s_particle_list[s, i, :, 2]), np.sin(s_particle_list[s, i, :, 2]),
s_particle_probs_list[s, i, :], cmap='viridis_r', clim=[.0, 2.0/num_particles], alpha=1.0,
**quiv_kwargs
)
current_state = batch['s'][s, i, :]
plt.quiver(current_state[0], current_state[1], np.cos(current_state[2]),
np.sin(current_state[2]), color="red", **quiv_kwargs)
plt.plot(current_state[0], current_state[1], 'or', **marker_kwargs)
else:
ax.plot(batch['s'][s, :num_steps, 0], batch['s'][s, :num_steps, 1], '-', linewidth=0.6, color='red')
ax.plot(pred[s, :num_steps, 0], pred[s, :num_steps, 1], '-', linewidth=0.6,
color=colors['pf_ind_e2e'])
ax.plot(batch['s'][s, :1, 0], batch['s'][s, :1, 1], '.', linewidth=0.6, color='red', markersize=3)
ax.plot(pred[s, :1, 0], pred[s, :1, 1], '.', linewidth=0.6, markersize=3,
color=colors['pf_ind_e2e'])
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.0, wspace=0.001, hspace=0.1)
plt.gca().set_aspect('equal')
plt.xticks([])
plt.yticks([])
plt.savefig('../plots/models/pf{}.pdf'.format(s), transparent=True, dpi=600, frameon=False, facecolor='w', pad_inches=0.01)
plt.figure('colorbar', (12, 0.6))
a = np.array([[0, 2.0/num_particles]])
img = plt.imshow(a, cmap="viridis_r")
plt.gca().set_visible(False)
cax = plt.axes([0.25, 0.75, 0.50, 0.2])
plt.colorbar(orientation="horizontal", cax=cax, label='Particle weight', ticks=[0, 0.001, 0.002])
plt.savefig('../plots/models/colorbar.pdf'.format(s), transparent=True, dpi=600, frameon=False, facecolor='w', pad_inches=0.01)
def plot_prediction(pred1, pred2, statistics, batch, task, num_examples, variant):
color_list = plt.cm.tab10(np.linspace(0, 1, 10))
colors = {'lstm': color_list[0], 'pf_e2e': color_list[1], 'pf_ind_e2e': color_list[2], 'pf_ind': color_list[3],
'ff': color_list[4], 'odom': color_list[4]}
num_steps = 50
init_steps = 20
for s in range(num_examples):
fig = plt.figure(figsize=(2.4, 1.29), num="%s prediction %s" % (variant, s))
# plt.figure("example {}, vartiant: {}".format(s, variant), figsize=[12, 5.15])
plt.gca().clear()
plot_maze(task, margin=5, linewidth=0.5)
plt.plot(batch['s'][s, :num_steps, 0], batch['s'][s, :num_steps, 1], '-', linewidth=0.3, color='gray')
plt.plot(pred1[s, :init_steps, 0], pred1[s, :init_steps, 1], '--', linewidth=0.3, color=colors['pf_ind_e2e'])
plt.plot(pred1[s, init_steps-1:num_steps, 0], pred1[s, init_steps-1:num_steps, 1], '-', linewidth=0.3, color=colors['pf_ind_e2e'])
plt.plot(pred2[s, :init_steps, 0], pred2[s, :init_steps, 1], '--', linewidth=0.3, color=colors['lstm'])
plt.plot(pred2[s, init_steps-1:num_steps, 0], pred2[s, init_steps-1:num_steps, 1], '-', color=colors['lstm'], linewidth=0.3)
# for i in range(init_steps, num_steps):
#
# p = pred1[s, i, :]
# plt.quiver(p[0], p[1], np.cos(p[2]),
# np.sin(p[2]), color=colors['pf_ind_e2e'], **quiv_kwargs)
# p = pred2[s, i, :]
# plt.quiver(p[0], p[1], np.cos(p[2]),
# np.sin(p[2]), color=colors['lstm'], **quiv_kwargs)
# # plt.plot(p[0], p[1], 'og', **marker_kwargs)
#
# current_state = batch['s'][s, i, :]
# plt.quiver(current_state[0], current_state[1], np.cos(current_state[2]),
# np.sin(current_state[2]), color="black", **quiv_kwargs)
# # plt.plot(current_state[0], current_state[1], 'or', **marker_kwargs)
plt.gca().set_aspect('equal')
plt.xticks([])
plt.yticks([])
plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.0, wspace=0.001, hspace=0.1)
plt.savefig('../plots/models/pred{}.pdf'.format(s), transparent=True, dpi=600, frameon=False, facecolor='w', pad_inches=0.01)
def plot_observation(batch, i, t=0):
plt.figure('%r obs' % i, (2, 2))
plt.imshow(np.clip(batch['o'][i, t, :, :, :] / 255.0, 0.0, 1.0), interpolation='nearest')
plt.axis('off')
# plt.subplots_adjust(left=0.0, bottom=0.0, right=1.0, top=1.0, wspace=0.001, hspace=0.001)
plt.subplots_adjust(left=0.0, bottom=0.15, right=1.0, top=0.85, wspace=0.0, hspace=0.00)
plt.savefig('../plots/models/obs{}.png'.format(i+t), transparent=True, dpi=600, frameon=False, facecolor='w', pad_inches=0.01)
def plot_measurement_statistics(session, method, statistics, batch_iterator, batch_size, variant):
color_list = plt.cm.tab10(np.linspace(0, 1, 10))
colors = {'lstm': color_list[0], 'e2e': color_list[1], 'ind_e2e': color_list[2], 'ind': color_list[3], 'ff': color_list[4], 'odom': color_list[4]}
labels = {'e2e': 'DPF(e2e)', 'ind_e2e': 'DPF(ind+e2e)', 'ind': 'DPF(ind)'}
x = np.linspace(100.0 / 4, 1500.0 - 100.0 / 4, 30)
y = np.linspace(100.0 / 4, 900.0 - 100.0 / 4, 18)
theta = np.linspace(-np.pi, np.pi, 12 + 1)[1:]
g = np.meshgrid(x, y, theta)
poses = np.vstack([np.ravel(x) for x in g]).transpose([1, 0])
test_poses = tf.tile(tf.constant(poses, dtype='float32')[None, :, :], [batch_size, 1, 1])
measurement_model_out = method.measurement_update(method.encodings[:, 0], test_poses, statistics['means'],
statistics['stds'])
true_measurement_model_out = method.measurement_update(method.encodings[:, 0], method.placeholders['s'][:, 0, None, :], statistics['means'],
statistics['stds'])
hist = 0.0
true_hist = 0.0
for i in range(1000000): # 1000000
# define the inputs and train/run the model
batch = next(batch_iterator)
input_dict = {**{method.placeholders[key]: batch[key] for key in 'osa'},
}
if i < 100:
obs_likelihood, true_obs_likelihood = session.run([measurement_model_out, true_measurement_model_out], input_dict)
h, bins = np.histogram(obs_likelihood, 50, [0,1])
hist += h
else:
true_obs_likelihood = session.run(true_measurement_model_out, input_dict)
h, true_bins = np.histogram(true_obs_likelihood, 20, [0,1])
true_hist += h
true_hist = true_hist / np.sum(true_hist) * len(true_hist)
hist = hist / np.sum(hist) * len(hist)
plt.figure('Observation likelihood statistics', [3.3,2.5])
plt.plot(bins[1:] - (bins[1]-bins[0])/2, hist, '--', color=colors[variant])
plt.plot(true_bins[1:] - (true_bins[1]-true_bins[0])/2, true_hist, '-', color=colors[variant], label=labels[variant])
plt.legend(loc='upper center')
plt.yticks([0, 1, 2, 3])
plt.ylim([0,3])
plt.xlabel('Estimated observation likelihood')
plt.ylabel('Density')
# plt.gca().set_yscale("log", nonposx='clip')
plt.tight_layout()
plt.savefig('../plots/models/measurement_statistics.pdf', transparent=True, dpi=600, frameon=False, facecolor='w', pad_inches=0.01)
def plot_motion_statistics(session, method, statistics, batch_iterator, task, variant):
color_list = plt.cm.tab10(np.linspace(0, 1, 10))
colors = {'lstm': color_list[0], 'e2e': color_list[1], 'ind_e2e': color_list[2], 'ind': color_list[3], 'ff': color_list[4], 'odom': color_list[4]}
labels = {'e2e': 'DPF(e2e)', 'ind_e2e': 'DPF(ind+e2e)', 'ind': 'DPF(ind)'}
num_particles = 100
motion_samples = method.motion_update(method.placeholders['a'][:, 1],
tf.tile(method.placeholders['s'][:, :1], [1, num_particles, 1]),
gitextract_3zu9lda8/
├── LICENSE
├── README.md
├── experiments/
│ ├── __init__.py
│ ├── cross_evaluation.py
│ ├── cross_validation_kitti.py
│ ├── distributed_experiments.py
│ ├── evaluation_kitti.py
│ └── simple.py
├── methods/
│ ├── __init__.py
│ ├── dpf.py
│ ├── dpf_kitti.py
│ ├── odom.py
│ └── rnn.py
├── plotting/
│ ├── __init__.py
│ ├── ab_plot.py
│ ├── cross_plot.py
│ ├── lc_plot.py
│ ├── nt_plot.py
│ ├── plot_models.py
│ ├── plotting_kitti.py
│ └── swap_plot.py
├── setup.sh
└── utils/
├── __init__.py
├── data_utils.py
├── data_utils_kitti.py
├── exp_utils.py
├── exp_utils_kitti.py
├── method_utils.py
└── plotting_utils.py
SYMBOL INDEX (142 symbols across 18 files)
FILE: experiments/cross_evaluation.py
function cross (line 6) | def cross(logfile, cross_exp, exp_name='cr'):
function swapmodels (line 28) | def swapmodels(logfiles, noise_conds, exp_name='swap', flipmodules=False):
function get_all_logs (line 73) | def get_all_logs(path, file_ending):
function cross_lc2pl (line 79) | def cross_lc2pl(method):
function cross_pl2lc (line 85) | def cross_pl2lc(method):
function cross_mx (line 91) | def cross_mx(method):
function swap_motion (line 97) | def swap_motion(method):
function swap_measurement (line 106) | def swap_measurement(method):
FILE: experiments/cross_validation_kitti.py
function run_cross_validation (line 7) | def run_cross_validation(i):
FILE: experiments/distributed_experiments.py
function meta_exp (line 15) | def meta_exp(base_path, id_extra):
function learning_curve_exp (line 44) | def learning_curve_exp(base_path='', exp_name='lc', id_extra='', trackin...
function tracking_exp (line 98) | def tracking_exp(base_path='', exp_name='tr', id_extra='',
function planner_agent_exp (line 105) | def planner_agent_exp(base_path='', exp_name='pl', id_extra='',
function mix_agent_exp (line 113) | def mix_agent_exp(base_path='', exp_name='mx', id_extra='',
function noise_test_exp (line 121) | def noise_test_exp(base_path='', exp_name='nt', id_extra='', tracking=Fa...
function ablation_test_exp (line 175) | def ablation_test_exp(base_path='', exp_name='ab', id_extra='', tracking...
function run_experiment (line 232) | def run_experiment(get_experiment_params, get_train_data_and_eval_iterat...
FILE: experiments/evaluation_kitti.py
function get_evaluation_stats (line 10) | def get_evaluation_stats(model_path='../models/tmp/', test_trajectories=...
function compute_distance_for_trajectory (line 136) | def compute_distance_for_trajectory(s):
function find_end_step (line 148) | def find_end_step(distance, start_step, length, use_meters=True):
function find_all_cross_val_models (line 156) | def find_all_cross_val_models(model_path):
function main (line 162) | def main():
FILE: experiments/simple.py
function train_dpf (line 8) | def train_dpf(task='nav01', data_path='../data/100s', model_path='../mod...
function test_dpf (line 26) | def test_dpf(task='nav01', data_path='../data/100s', model_path='../mode...
FILE: methods/dpf.py
function _mod_grad (line 14) | def _mod_grad(op, grad):
class DPF (line 22) | class DPF():
method __init__ (line 24) | def __init__(self, init_with_true_state, learn_odom, use_proposer, pro...
method build_modules (line 56) | def build_modules(self, min_obs_likelihood, proposer_keep_ratio):
method measurement_update (line 109) | def measurement_update(self, encoding, particles, means, stds):
method transform_particles_as_input (line 131) | def transform_particles_as_input(self, particles, means, stds):
method propose_particles (line 139) | def propose_particles(self, encoding, num_particles, state_mins, state...
method motion_update (line 149) | def motion_update(self, actions, particles, means, stds, state_step_si...
method compile_training_stages (line 208) | def compile_training_stages(self, sess, batch_iterators, particle_list...
method load (line 344) | def load(self, sess, model_path, model_file='best_validation', statist...
method fit (line 390) | def fit(self, sess, data, model_path, train_individually, train_e2e, s...
method predict (line 528) | def predict(self, sess, batch, num_particles, return_particles=False, ...
method connect_modules (line 542) | def connect_modules(self, means, stds, state_mins, state_maxs, state_s...
method particles_to_state (line 663) | def particles_to_state(self, particle_list, particle_probs_list):
method plot_motion_model (line 671) | def plot_motion_model(self, sess, batch, motion_samples, task):
method plot_measurement_model (line 692) | def plot_measurement_model(self, sess, batch_iterator, measurement_mod...
method plot_particle_proposer (line 710) | def plot_particle_proposer(self, sess, batch, proposed_particles, task):
method plot_particle_filter (line 731) | def plot_particle_filter(self, sess, batch, particle_list,
FILE: methods/dpf_kitti.py
function _mod_grad (line 15) | def _mod_grad(op, grad):
class DPF (line 23) | class DPF():
method __init__ (line 25) | def __init__(self, init_with_true_state, learn_odom, use_proposer, pro...
method build_modules (line 60) | def build_modules(self, min_obs_likelihood, proposer_keep_ratio, learn...
method custom_build (line 119) | def custom_build(self, inputs):
method measurement_update (line 136) | def measurement_update(self, encoding, particles, means, stds):
method transform_particles_as_input (line 158) | def transform_particles_as_input(self, particles, means, stds):
method propose_particles (line 162) | def propose_particles(self, encoding, num_particles, state_mins, state...
method motion_update (line 172) | def motion_update(self, actions, particles, means, stds, state_step_si...
method compile_training_stages (line 243) | def compile_training_stages(self, sess, batch_iterators, particle_list...
method load (line 405) | def load(self, sess, model_path, model_file='best_validation', statist...
method fit (line 439) | def fit(self, sess, data, model_path, train_individually, train_e2e, s...
method predict (line 587) | def predict(self, sess, batch, return_particles=False, **kwargs):
method connect_modules (line 601) | def connect_modules(self, means, stds, state_mins, state_maxs, state_s...
method particles_to_state (line 725) | def particles_to_state(self, particle_list, particle_probs_list):
method plot_motion_model (line 734) | def plot_motion_model(self, sess, batch, motion_samples, task, state_s...
method plot_measurement_model (line 759) | def plot_measurement_model(self, sess, batch_iterator, measurement_mod...
method plot_particle_proposer (line 783) | def plot_particle_proposer(self, sess, batch, proposed_particles, task):
method plot_particle_filter (line 804) | def plot_particle_filter(self, sess, batch, particle_list,
FILE: methods/odom.py
class OdometryBaseline (line 5) | class OdometryBaseline():
method __init__ (line 7) | def __init__(self, *args, **kwargs):
method fit (line 10) | def fit(self, *args, **kwargs):
method predict (line 13) | def predict(self, sess, batch, **kwargs):
method predict_kitti (line 34) | def predict_kitti(self, sess, batch, **kwargs):
FILE: methods/rnn.py
class RNN (line 7) | class RNN():
method __init__ (line 8) | def __init__(self, init_with_true_state=False, model='2lstm', **unused...
method fit (line 51) | def fit(self, sess, data, model_path, split_ratio, seq_len, batch_size...
method connect_modules (line 177) | def connect_modules(self, means, stds, state_mins, state_maxs, state_s...
method predict (line 205) | def predict(self, sess, batch, **unused_kwargs):
method load (line 209) | def load(self, sess, model_path, model_file='best_validation', statist...
FILE: plotting/lc_plot.py
function load_results (line 18) | def load_results(base_path='../log/', exp='lc'):
function compute_statistics (line 65) | def compute_statistics(results):
function plot_learning_curve (line 113) | def plot_learning_curve(means, ses, step, f=lambda x:x, ylabel_func=lamb...
function plot_filter_convergence (line 166) | def plot_filter_convergence(means, ses, step, ylabel_func, ylim_func=Non...
FILE: plotting/plot_models.py
function plot_measurement_model (line 18) | def plot_measurement_model(session, method, statistics, batch, task, num...
function plot_proposer (line 71) | def plot_proposer(session, method, statistics, batch, task, num_examples...
function plot_motion_model (line 104) | def plot_motion_model(session, method, statistics, batch, task, num_exam...
function plot_particle_filter (line 145) | def plot_particle_filter(session, method, statistics, batch, task, num_e...
function plot_prediction (line 204) | def plot_prediction(pred1, pred2, statistics, batch, task, num_examples,...
function plot_observation (line 248) | def plot_observation(batch, i, t=0):
function plot_measurement_statistics (line 258) | def plot_measurement_statistics(session, method, statistics, batch_itera...
function plot_motion_statistics (line 309) | def plot_motion_statistics(session, method, statistics, batch_iterator, ...
function plot_models (line 366) | def plot_models():
function plot_statistics (line 421) | def plot_statistics():
FILE: plotting/plotting_kitti.py
function get_evaluation_stats (line 10) | def get_evaluation_stats(model_path='../models/tmp/', test_trajectories=...
function compute_distance_for_trajectory (line 142) | def compute_distance_for_trajectory(s):
function find_end_step (line 154) | def find_end_step(distance, start_step, length, use_meters=True):
function find_all_cross_val_models (line 162) | def find_all_cross_val_models(model_path):
FILE: utils/data_utils.py
function wrap_angle (line 7) | def wrap_angle(angle):
function mix_data (line 10) | def mix_data(file_in1, file_in2, file_out, steps_per_episode=100, num_ep...
function average_nn (line 20) | def average_nn(states_from, states_to, step_sizes, num_from=10, num_to=1...
function load_data (line 37) | def load_data(data_path='../data/100s', filename='nav01_train', steps_pe...
function compute_staticstics (line 72) | def compute_staticstics(data):
function split_data (line 115) | def split_data(data, ratio=0.8, categories=['train', 'val']):
function reduce_data (line 127) | def reduce_data(data, num_episodes):
function shuffle_data (line 133) | def shuffle_data(data):
function remove_state (line 140) | def remove_state(data, provide_initial_state=False):
function noisify_data_condition (line 148) | def noisify_data_condition(data, condition):
function noisyfy_data (line 181) | def noisyfy_data(data, odom_noise_factor=1.0, img_noise_factor=1.0, img_...
function make_batch_iterator (line 206) | def make_batch_iterator(data, batch_size=32, seq_len=10):
function make_repeating_batch_iterator (line 214) | def make_repeating_batch_iterator(data, epoch_len, batch_size=32, seq_le...
function make_complete_batch_iterator (line 223) | def make_complete_batch_iterator(data, batch_size=1000, seq_len=10):
function compare_data_coverage (line 233) | def compare_data_coverage():
FILE: utils/data_utils_kitti.py
function wrap_angle (line 10) | def wrap_angle(angle):
function rotation_matrix (line 13) | def rotation_matrix(x):
function read_oxts_data (line 20) | def read_oxts_data(oxts, oxts_prev, oxts_init):
function load_image (line 39) | def load_image(img_file):
function image_input (line 42) | def image_input(img1, img2):
function load_data_for_stats (line 45) | def load_data_for_stats(oxts_data, images, diff_images, seq_num, base_fr...
function load_kitti_sequences (line 80) | def load_kitti_sequences(sequence_list=None):
function load_data (line 206) | def load_data(data_path='data/100s', filename='nav01_train', steps_per_e...
function compute_statistics (line 239) | def compute_statistics(data):
function split_data (line 278) | def split_data(data, ratio=0.8, categories=['train', 'val']):
function reduce_data (line 299) | def reduce_data(data, num_episodes):
function shuffle_data (line 305) | def shuffle_data(data):
function remove_state (line 312) | def remove_state(data, provide_initial_state=False):
function noisify_data_condition (line 321) | def noisify_data_condition(data, condition):
function noisyfy_data (line 354) | def noisyfy_data(data, odom_noise_factor=1.0, img_noise_factor=1.0, img_...
function make_batch_iterator (line 363) | def make_batch_iterator(data, batch_size=32, seq_len=10, use_mirrored_da...
function make_repeating_batch_iterator (line 382) | def make_repeating_batch_iterator(data, epoch_len, batch_size=32, seq_le...
function make_complete_batch_iterator (line 408) | def make_complete_batch_iterator(data, batch_size=1000, seq_len=10):
function make_batch_iterator_for_evaluation (line 418) | def make_batch_iterator_for_evaluation(data, start_step, trajectory, bat...
function plot_observation_check (line 437) | def plot_observation_check(data, means, stds):
function plot_video (line 473) | def plot_video(data):
function plot_sequences (line 488) | def plot_sequences(data, means, stds, state_step_sizes):
function add_mirrored_data (line 534) | def add_mirrored_data(data):
FILE: utils/exp_utils.py
function get_default_hyperparams (line 5) | def get_default_hyperparams():
function exp_variables_to_name (line 36) | def exp_variables_to_name(x):
function sample_exp_variables (line 40) | def sample_exp_variables(path, exp_variables):
function print_msg_and_dict (line 73) | def print_msg_and_dict(msg, d):
function add_to_log (line 83) | def add_to_log(log, d):
FILE: utils/exp_utils_kitti.py
function get_default_hyperparams (line 1) | def get_default_hyperparams():
FILE: utils/method_utils.py
function compute_sq_distance (line 7) | def compute_sq_distance(a, b, state_step_sizes):
function atan2 (line 20) | def atan2(x, y, epsilon=1.0e-12):
FILE: utils/plotting_utils.py
function show_pause (line 10) | def show_pause(show=False, pause=0.0):
function plot_maze (line 20) | def plot_maze(maze='nav01', margin=1, means=None, stds=None, figure_name...
function plot_trajectories (line 237) | def plot_trajectories(data, figure_name=None, show=False, pause=False, e...
function plot_trajectory (line 271) | def plot_trajectory(data, figure_name=None, show=False, pause=False, emp...
function plot_observations (line 291) | def plot_observations(data, n=20, figure_name=None, show=False, pause=Fa...
function view_data (line 316) | def view_data(data):
Condensed preview — 29 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (285K chars).
[
{
"path": "LICENSE",
"chars": 1099,
"preview": "MIT License\n\nCopyright (c) 2018 Robotics and Biology Laboratory, TU Berlin\n\nPermission is hereby granted, free of charge"
},
{
"path": "README.md",
"chars": 3584,
"preview": "Differentiable Particle Filters\n==================================================\n\nContact\n------------------\n\nRico Jon"
},
{
"path": "experiments/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "experiments/cross_evaluation.py",
"chars": 5740,
"preview": "import pickle\nimport os\nimport numpy as np\nfrom experiments.distributed_experiments import run_experiment, tracking_exp,"
},
{
"path": "experiments/cross_validation_kitti.py",
"chars": 1326,
"preview": "from utils.data_utils_kitti import load_kitti_sequences\nimport tensorflow as tf\nfrom methods.dpf_kitti import DPF\nfrom u"
},
{
"path": "experiments/distributed_experiments.py",
"chars": 14434,
"preview": "import tensorflow as tf\nimport numpy as np\nimport pickle\nimport os\nimport time\nimport itertools\n\nfrom utils.exp_utils im"
},
{
"path": "experiments/evaluation_kitti.py",
"chars": 9895,
"preview": "import tensorflow as tf\n\nfrom methods.dpf_kitti import DPF\nfrom methods.odom import OdometryBaseline\nfrom utils.data_uti"
},
{
"path": "experiments/simple.py",
"chars": 1729,
"preview": "import tensorflow as tf\n\nfrom methods.dpf import DPF\nfrom utils.data_utils import load_data, noisyfy_data, make_batch_it"
},
{
"path": "methods/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "methods/dpf.py",
"chars": 39079,
"preview": "import os\nimport numpy as np\nimport sonnet as snt\nimport tensorflow as tf\nimport matplotlib.pyplot as plt\n\nfrom utils.da"
},
{
"path": "methods/dpf_kitti.py",
"chars": 43029,
"preview": "import os\nimport numpy as np\nimport sonnet as snt\nimport tensorflow as tf\nimport matplotlib.pyplot as plt\n\nfrom utils.da"
},
{
"path": "methods/odom.py",
"chars": 2430,
"preview": "import numpy as np\n\nfrom utils.data_utils_kitti import wrap_angle\n\nclass OdometryBaseline():\n\n def __init__(self, *ar"
},
{
"path": "methods/rnn.py",
"chars": 11383,
"preview": "import tensorflow as tf\nimport sonnet as snt\n\nfrom utils.data_utils import *\nfrom utils.method_utils import compute_sq_d"
},
{
"path": "plotting/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "plotting/ab_plot.py",
"chars": 10332,
"preview": "import pickle\nimport numpy as np\nimport matplotlib\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes"
},
{
"path": "plotting/cross_plot.py",
"chars": 7024,
"preview": "import pickle\nimport numpy as np\nimport matplotlib\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes"
},
{
"path": "plotting/lc_plot.py",
"chars": 18450,
"preview": "import pickle\nimport numpy as np\nimport matplotlib\nimport matplotlib.pyplot as plt\n#from mpl_toolkits.mplot3d import Axe"
},
{
"path": "plotting/nt_plot.py",
"chars": 12085,
"preview": "import pickle\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport os\n\nresults = None\n\n\n\n# matplotlib.rcParams.upda"
},
{
"path": "plotting/plot_models.py",
"chars": 22631,
"preview": "import tensorflow as tf\nimport pickle\nfrom methods.dpf import DPF\nfrom methods.rnn import RNN\nfrom utils.data_utils impo"
},
{
"path": "plotting/plotting_kitti.py",
"chars": 10270,
"preview": "import tensorflow as tf\n\nfrom methods.dpf_kitti import DPF\nfrom methods.odom import OdometryBaseline\nfrom utils.data_uti"
},
{
"path": "plotting/swap_plot.py",
"chars": 8068,
"preview": "import pickle\nimport numpy as np\nimport matplotlib\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes"
},
{
"path": "setup.sh",
"chars": 319,
"preview": "#!/bin/bash\necho\necho 'Creating additional folders .. '\necho \nmkdir models\nmkdir log\nmkdir plots\necho 'Downloading data "
},
{
"path": "utils/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "utils/data_utils.py",
"chars": 13250,
"preview": "import numpy as np\nimport matplotlib.pyplot as plt\nimport os\n\nfrom utils.plotting_utils import plot_trajectories, plot_m"
},
{
"path": "utils/data_utils_kitti.py",
"chars": 22284,
"preview": "import numpy as np\nimport matplotlib.pyplot as plt\nimport os\nimport math\nimport glob\nfrom time import time\nfrom PIL impo"
},
{
"path": "utils/exp_utils.py",
"chars": 2556,
"preview": "import os\nimport itertools\nimport numpy as np\n\ndef get_default_hyperparams():\n\n # default hyperparams\n return {\n "
},
{
"path": "utils/exp_utils_kitti.py",
"chars": 904,
"preview": "def get_default_hyperparams():\n\n # default hyperparams\n return {\n 'global': {\n 'init_with_true_s"
},
{
"path": "utils/method_utils.py",
"chars": 1463,
"preview": "import numpy as np\nimport tensorflow as tf\n\nfrom utils.data_utils_kitti import wrap_angle\n\n\ndef compute_sq_distance(a, b"
},
{
"path": "utils/plotting_utils.py",
"chars": 13447,
"preview": "import matplotlib.pyplot as plt\nfrom matplotlib.patches import Rectangle\nimport numpy as np\n\nhead_scale = 3.0 # 1.5\n# h"
}
]
About this extraction
This page contains the full source code of the tu-rbo/differentiable-particle-filters GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 29 files (270.3 KB), approximately 73.8k tokens, and a symbol index with 142 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.