
Run and train AI models with a unified local interface.
Features • Quickstart • Notebooks • Documentation • Discord
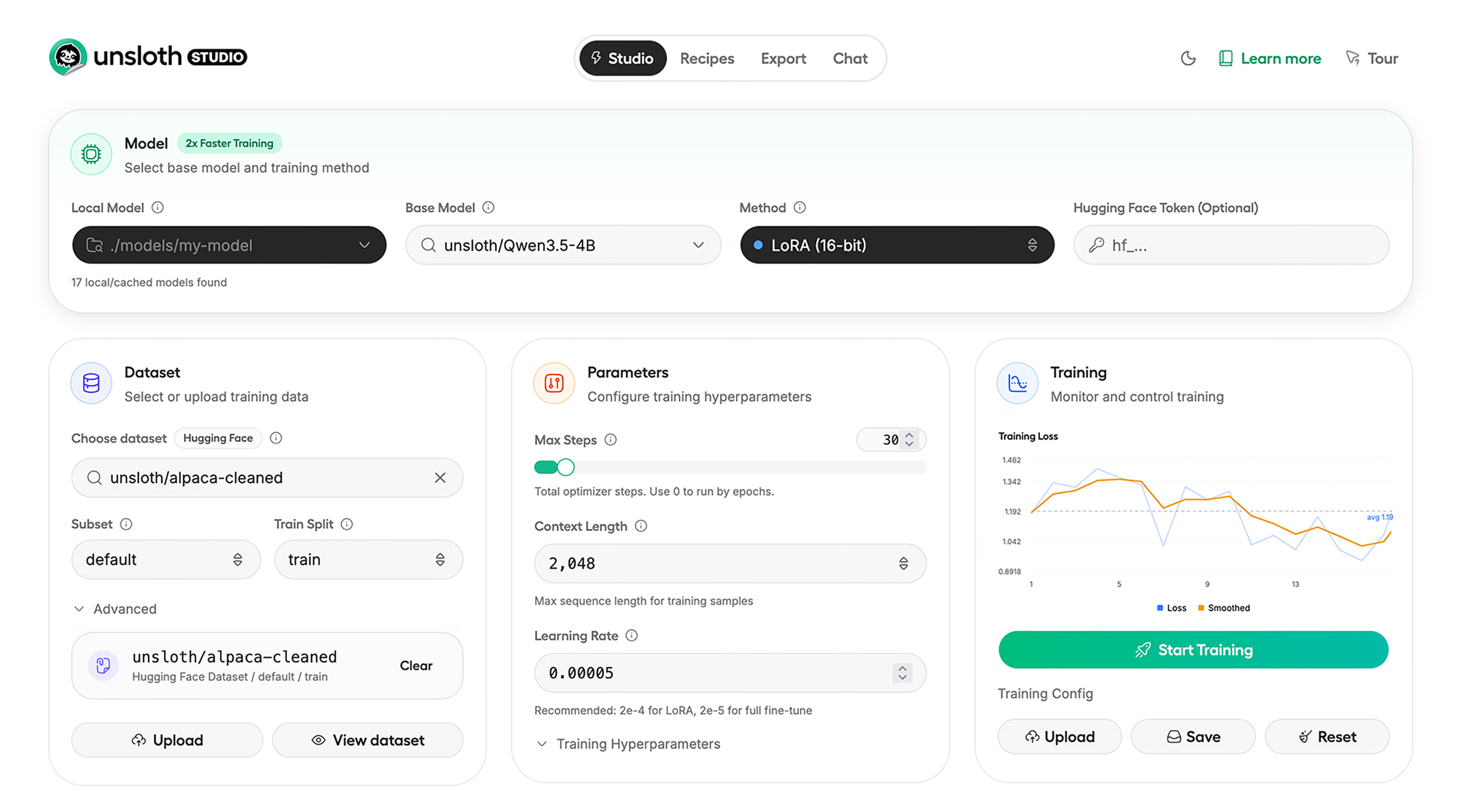 Unsloth Studio (Beta) lets you run and train text, [audio](https://unsloth.ai/docs/basics/text-to-speech-tts-fine-tuning), [embedding](https://unsloth.ai/docs/new/embedding-finetuning), [vision](https://unsloth.ai/docs/basics/vision-fine-tuning) models on Windows, Linux and macOS.
## ⭐ Features
Unsloth provides several key features for both inference and training:
### Inference
* **Search + download + run models** including GGUF, LoRA adapters, safetensors
* **Export models**: [Save or export](https://unsloth.ai/docs/new/studio/export) models to GGUF, 16-bit safetensors and other formats.
* **Tool calling**: Support for [self-healing tool calling](https://unsloth.ai/docs/new/studio/chat#auto-healing-tool-calling) and web search
* **[Code execution](https://unsloth.ai/docs/new/studio/chat#code-execution)**: lets LLMs test code in Claude artifacts and sandbox environments
* [Auto-tune inference parameters](https://unsloth.ai/docs/new/studio/chat#auto-parameter-tuning) and customize chat templates.
* Upload images, audio, PDFs, code, DOCX and more file types to chat with.
### Training
* Train **500+ models** up to **2x faster** with up to **70% less VRAM**, with no accuracy loss.
* Supports full fine-tuning, pretraining, 4-bit, 16-bit and, FP8 training.
* **Observability**: Monitor training live, track loss and GPU usage and customize graphs.
* **Data Recipes**: [Auto-create datasets](https://unsloth.ai/docs/new/studio/data-recipe) from **PDF, CSV, DOCX** etc. Edit data in a visual-node workflow.
* **Reinforcement Learning**: The most efficient [RL](https://unsloth.ai/docs/get-started/reinforcement-learning-rl-guide) library, using **80% less VRAM** for GRPO, [FP8](https://unsloth.ai/docs/get-started/reinforcement-learning-rl-guide/fp8-reinforcement-learning) etc.
* [Multi-GPU](https://unsloth.ai/docs/basics/multi-gpu-training-with-unsloth) training is supported, with major improvements coming soon.
## ⚡ Quickstart
Unsloth can be used in two ways: through **[Unsloth Studio](https://unsloth.ai/docs/new/studio/)**, the web UI, or through **Unsloth Core**, the code-based version. Each has different requirements.
### Unsloth Studio (web UI)
Unsloth Studio (Beta) works on **Windows, Linux, WSL** and **macOS**.
* **CPU:** Supported for Chat and Data Recipes currently
* **NVIDIA:** Training works on RTX 30/40/50, Blackwell, DGX Spark, Station and more
* **macOS:** Currently supports chat and Data Recipes. **MLX training** is coming very soon
* **AMD:** Chat works. Train with [Unsloth Core](#unsloth-core-code-based). Studio support is coming soon.
* **Coming soon:** Training support for Apple MLX, AMD, and Intel.
* **Multi-GPU:** Available now, with a major upgrade on the way
#### MacOS, Linux, WSL Setup:
```bash
curl -fsSL https://raw.githubusercontent.com/unslothai/unsloth/main/install.sh | sh
```
If you don't have `curl`, use `wget`. Then to launch after setup:
```bash
source unsloth_studio/bin/activate
unsloth studio -H 0.0.0.0 -p 8888
```
#### Windows PowerShell Setup:
```powershell
irm https://raw.githubusercontent.com/unslothai/unsloth/main/install.ps1 | iex
```
Then to launch after setup:
```powershell
& .\unsloth_studio\Scripts\unsloth.exe studio -H 0.0.0.0 -p 8888
```
#### MacOS, Linux, WSL developer installs:
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv unsloth_studio --python 3.13
source unsloth_studio/bin/activate
uv pip install unsloth --torch-backend=auto
unsloth studio setup
unsloth studio -H 0.0.0.0 -p 8888
```
#### Windows PowerShell developer installs:
```powershell
winget install -e --id Python.Python.3.13
winget install --id=astral-sh.uv -e
uv venv unsloth_studio --python 3.13
.\unsloth_studio\Scripts\activate
uv pip install unsloth --torch-backend=auto
unsloth studio setup
unsloth studio -H 0.0.0.0 -p 8888
```
#### Docker
Use our [Docker image](https://hub.docker.com/r/unsloth/unsloth) ```unsloth/unsloth``` container. Run:
```bash
docker run -d -e JUPYTER_PASSWORD="mypassword" \
-p 8888:8888 -p 8000:8000 -p 2222:22 \
-v $(pwd)/work:/workspace/work \
--gpus all \
unsloth/unsloth
```
#### Nightly Install - MacOS, Linux, WSL:
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
git clone --filter=blob:none https://github.com/unslothai/unsloth.git unsloth_studio
cd unsloth_studio
uv venv --python 3.13
source .venv/bin/activate
uv pip install -e . --torch-backend=auto
unsloth studio setup
unsloth studio -H 0.0.0.0 -p 8888
```
Then to launch every time:
```bash
cd unsloth_studio
source .venv/bin/activate
unsloth studio -H 0.0.0.0 -p 8888
```
#### Nightly Install - Windows:
Run in Windows Powershell:
```bash
winget install -e --id Python.Python.3.13
winget install --id=astral-sh.uv -e
git clone --filter=blob:none https://github.com/unslothai/unsloth.git unsloth_studio
cd unsloth_studio
uv venv --python 3.13
.\.venv\Scripts\activate
uv pip install -e . --torch-backend=auto
unsloth studio setup
unsloth studio -H 0.0.0.0 -p 8888
```
Then to launch every time:
```bash
cd unsloth_studio
.\.venv\Scripts\activate
unsloth studio -H 0.0.0.0 -p 8888
```
### Unsloth Core (code-based)
#### Linux, WSL
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv unsloth_env --python 3.13
source unsloth_env/bin/activate
uv pip install unsloth --torch-backend=auto
```
#### Windows Powershell
```bash
winget install -e --id Python.Python.3.13
winget install --id=astral-sh.uv -e
uv venv unsloth_env --python 3.13
.\unsloth_env\Scripts\activate
uv pip install unsloth --torch-backend=auto
```
For Windows, `pip install unsloth` works only if you have Pytorch installed. Read our [Windows Guide](https://unsloth.ai/docs/get-started/install/windows-installation).
You can use the same Docker image as Unsloth Studio.
#### AMD, Intel
For RTX 50x, B200, 6000 GPUs: `uv pip install unsloth --torch-backend=auto`. Read our guides for: [Blackwell](https://unsloth.ai/docs/blog/fine-tuning-llms-with-blackwell-rtx-50-series-and-unsloth) and [DGX Spark](https://unsloth.ai/docs/blog/fine-tuning-llms-with-nvidia-dgx-spark-and-unsloth).
Unsloth Studio (Beta) lets you run and train text, [audio](https://unsloth.ai/docs/basics/text-to-speech-tts-fine-tuning), [embedding](https://unsloth.ai/docs/new/embedding-finetuning), [vision](https://unsloth.ai/docs/basics/vision-fine-tuning) models on Windows, Linux and macOS.
## ⭐ Features
Unsloth provides several key features for both inference and training:
### Inference
* **Search + download + run models** including GGUF, LoRA adapters, safetensors
* **Export models**: [Save or export](https://unsloth.ai/docs/new/studio/export) models to GGUF, 16-bit safetensors and other formats.
* **Tool calling**: Support for [self-healing tool calling](https://unsloth.ai/docs/new/studio/chat#auto-healing-tool-calling) and web search
* **[Code execution](https://unsloth.ai/docs/new/studio/chat#code-execution)**: lets LLMs test code in Claude artifacts and sandbox environments
* [Auto-tune inference parameters](https://unsloth.ai/docs/new/studio/chat#auto-parameter-tuning) and customize chat templates.
* Upload images, audio, PDFs, code, DOCX and more file types to chat with.
### Training
* Train **500+ models** up to **2x faster** with up to **70% less VRAM**, with no accuracy loss.
* Supports full fine-tuning, pretraining, 4-bit, 16-bit and, FP8 training.
* **Observability**: Monitor training live, track loss and GPU usage and customize graphs.
* **Data Recipes**: [Auto-create datasets](https://unsloth.ai/docs/new/studio/data-recipe) from **PDF, CSV, DOCX** etc. Edit data in a visual-node workflow.
* **Reinforcement Learning**: The most efficient [RL](https://unsloth.ai/docs/get-started/reinforcement-learning-rl-guide) library, using **80% less VRAM** for GRPO, [FP8](https://unsloth.ai/docs/get-started/reinforcement-learning-rl-guide/fp8-reinforcement-learning) etc.
* [Multi-GPU](https://unsloth.ai/docs/basics/multi-gpu-training-with-unsloth) training is supported, with major improvements coming soon.
## ⚡ Quickstart
Unsloth can be used in two ways: through **[Unsloth Studio](https://unsloth.ai/docs/new/studio/)**, the web UI, or through **Unsloth Core**, the code-based version. Each has different requirements.
### Unsloth Studio (web UI)
Unsloth Studio (Beta) works on **Windows, Linux, WSL** and **macOS**.
* **CPU:** Supported for Chat and Data Recipes currently
* **NVIDIA:** Training works on RTX 30/40/50, Blackwell, DGX Spark, Station and more
* **macOS:** Currently supports chat and Data Recipes. **MLX training** is coming very soon
* **AMD:** Chat works. Train with [Unsloth Core](#unsloth-core-code-based). Studio support is coming soon.
* **Coming soon:** Training support for Apple MLX, AMD, and Intel.
* **Multi-GPU:** Available now, with a major upgrade on the way
#### MacOS, Linux, WSL Setup:
```bash
curl -fsSL https://raw.githubusercontent.com/unslothai/unsloth/main/install.sh | sh
```
If you don't have `curl`, use `wget`. Then to launch after setup:
```bash
source unsloth_studio/bin/activate
unsloth studio -H 0.0.0.0 -p 8888
```
#### Windows PowerShell Setup:
```powershell
irm https://raw.githubusercontent.com/unslothai/unsloth/main/install.ps1 | iex
```
Then to launch after setup:
```powershell
& .\unsloth_studio\Scripts\unsloth.exe studio -H 0.0.0.0 -p 8888
```
#### MacOS, Linux, WSL developer installs:
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv unsloth_studio --python 3.13
source unsloth_studio/bin/activate
uv pip install unsloth --torch-backend=auto
unsloth studio setup
unsloth studio -H 0.0.0.0 -p 8888
```
#### Windows PowerShell developer installs:
```powershell
winget install -e --id Python.Python.3.13
winget install --id=astral-sh.uv -e
uv venv unsloth_studio --python 3.13
.\unsloth_studio\Scripts\activate
uv pip install unsloth --torch-backend=auto
unsloth studio setup
unsloth studio -H 0.0.0.0 -p 8888
```
#### Docker
Use our [Docker image](https://hub.docker.com/r/unsloth/unsloth) ```unsloth/unsloth``` container. Run:
```bash
docker run -d -e JUPYTER_PASSWORD="mypassword" \
-p 8888:8888 -p 8000:8000 -p 2222:22 \
-v $(pwd)/work:/workspace/work \
--gpus all \
unsloth/unsloth
```
#### Nightly Install - MacOS, Linux, WSL:
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
git clone --filter=blob:none https://github.com/unslothai/unsloth.git unsloth_studio
cd unsloth_studio
uv venv --python 3.13
source .venv/bin/activate
uv pip install -e . --torch-backend=auto
unsloth studio setup
unsloth studio -H 0.0.0.0 -p 8888
```
Then to launch every time:
```bash
cd unsloth_studio
source .venv/bin/activate
unsloth studio -H 0.0.0.0 -p 8888
```
#### Nightly Install - Windows:
Run in Windows Powershell:
```bash
winget install -e --id Python.Python.3.13
winget install --id=astral-sh.uv -e
git clone --filter=blob:none https://github.com/unslothai/unsloth.git unsloth_studio
cd unsloth_studio
uv venv --python 3.13
.\.venv\Scripts\activate
uv pip install -e . --torch-backend=auto
unsloth studio setup
unsloth studio -H 0.0.0.0 -p 8888
```
Then to launch every time:
```bash
cd unsloth_studio
.\.venv\Scripts\activate
unsloth studio -H 0.0.0.0 -p 8888
```
### Unsloth Core (code-based)
#### Linux, WSL
```bash
curl -LsSf https://astral.sh/uv/install.sh | sh
uv venv unsloth_env --python 3.13
source unsloth_env/bin/activate
uv pip install unsloth --torch-backend=auto
```
#### Windows Powershell
```bash
winget install -e --id Python.Python.3.13
winget install --id=astral-sh.uv -e
uv venv unsloth_env --python 3.13
.\unsloth_env\Scripts\activate
uv pip install unsloth --torch-backend=auto
```
For Windows, `pip install unsloth` works only if you have Pytorch installed. Read our [Windows Guide](https://unsloth.ai/docs/get-started/install/windows-installation).
You can use the same Docker image as Unsloth Studio.
#### AMD, Intel
For RTX 50x, B200, 6000 GPUs: `uv pip install unsloth --torch-backend=auto`. Read our guides for: [Blackwell](https://unsloth.ai/docs/blog/fine-tuning-llms-with-blackwell-rtx-50-series-and-unsloth) and [DGX Spark](https://unsloth.ai/docs/blog/fine-tuning-llms-with-nvidia-dgx-spark-and-unsloth). To install Unsloth on **AMD** and **Intel** GPUs, follow our [AMD Guide](https://unsloth.ai/docs/get-started/install/amd) and [Intel Guide](https://unsloth.ai/docs/get-started/install/intel). ## ✨ Free Notebooks Train for free with our notebooks. Read our [guide](https://unsloth.ai/docs/get-started/fine-tuning-llms-guide). Add dataset, run, then deploy your trained model. | Model | Free Notebooks | Performance | Memory use | |-----------|---------|--------|----------| | **Qwen3.5 (4B)** | [▶️ Start for free](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen3_5_(4B)_Vision.ipynb) | 1.5x faster | 60% less | | **gpt-oss (20B)** | [▶️ Start for free](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/gpt-oss-(20B)-Fine-tuning.ipynb) | 2x faster | 70% less | | **gpt-oss (20B): GRPO** | [▶️ Start for free](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/gpt-oss-(20B)-GRPO.ipynb) | 2x faster | 80% less | | **Qwen3: Advanced GRPO** | [▶️ Start for free](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Qwen3_(4B)-GRPO.ipynb) | 2x faster | 50% less | | **Gemma 3 (4B) Vision** | [▶️ Start for free](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Gemma3_(4B)-Vision.ipynb) | 1.7x faster | 60% less | | **embeddinggemma (300M)** | [▶️ Start for free](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/EmbeddingGemma_(300M).ipynb) | 2x faster | 20% less | | **Mistral Ministral 3 (3B)** | [▶️ Start for free](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Ministral_3_VL_(3B)_Vision.ipynb) | 1.5x faster | 60% less | | **Llama 3.1 (8B) Alpaca** | [▶️ Start for free](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.1_(8B)-Alpaca.ipynb) | 2x faster | 70% less | | **Llama 3.2 Conversational** | [▶️ Start for free](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Llama3.2_(1B_and_3B)-Conversational.ipynb) | 2x faster | 70% less | | **Orpheus-TTS (3B)** | [▶️ Start for free](https://colab.research.google.com/github/unslothai/notebooks/blob/main/nb/Orpheus_(3B)-TTS.ipynb) | 1.5x faster | 50% less | - See all our notebooks for: [Kaggle](https://github.com/unslothai/notebooks?tab=readme-ov-file#-kaggle-notebooks), [GRPO](https://unsloth.ai/docs/get-started/unsloth-notebooks#grpo-reasoning-rl-notebooks), [TTS](https://unsloth.ai/docs/get-started/unsloth-notebooks#text-to-speech-tts-notebooks), [embedding](https://unsloth.ai/docs/new/embedding-finetuning) & [Vision](https://unsloth.ai/docs/get-started/unsloth-notebooks#vision-multimodal-notebooks) - See [all our models](https://unsloth.ai/docs/get-started/unsloth-model-catalog) and [all our notebooks](https://unsloth.ai/docs/get-started/unsloth-notebooks) - See detailed documentation for Unsloth [here](https://unsloth.ai/docs) ## 🦥 Unsloth News - **Introducing Unsloth Studio**: our new web UI for running and training LLMs. [Blog](https://unsloth.ai/docs/new/studio) - **Qwen3.5** - 0.8B, 2B, 4B, 9B, 27B, 35-A3B, 112B-A10B are now supported. [Guide + notebooks](https://unsloth.ai/docs/models/qwen3.5/fine-tune) - Train **MoE LLMs 12x faster** with 35% less VRAM - DeepSeek, GLM, Qwen and gpt-oss. [Blog](https://unsloth.ai/docs/new/faster-moe) - **Embedding models**: Unsloth now supports ~1.8-3.3x faster embedding fine-tuning. [Blog](https://unsloth.ai/docs/new/embedding-finetuning) • [Notebooks](https://unsloth.ai/docs/get-started/unsloth-notebooks#embedding-models) - New **7x longer context RL** vs. all other setups, via our new batching algorithms. [Blog](https://unsloth.ai/docs/new/grpo-long-context) - New RoPE & MLP **Triton Kernels** & **Padding Free + Packing**: 3x faster training & 30% less VRAM. [Blog](https://unsloth.ai/docs/new/3x-faster-training-packing) - **500K Context**: Training a 20B model with >500K context is now possible on an 80GB GPU. [Blog](https://unsloth.ai/docs/blog/500k-context-length-fine-tuning) - **FP8 & Vision RL**: You can now do FP8 & VLM GRPO on consumer GPUs. [FP8 Blog](https://unsloth.ai/docs/get-started/reinforcement-learning-rl-guide/fp8-reinforcement-learning) • [Vision RL](https://unsloth.ai/docs/get-started/reinforcement-learning-rl-guide/vision-reinforcement-learning-vlm-rl) - **gpt-oss** by OpenAI: Read our [RL blog](https://unsloth.ai/docs/models/gpt-oss-how-to-run-and-fine-tune/gpt-oss-reinforcement-learning), [Flex Attention](https://unsloth.ai/docs/models/gpt-oss-how-to-run-and-fine-tune/long-context-gpt-oss-training) blog and [Guide](https://unsloth.ai/docs/models/gpt-oss-how-to-run-and-fine-tune). ## 🔗 Links and Resources | Type | Links | | ----------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------ | |
 ### License
Unsloth uses a dual-licensing model of Apache 2.0 and AGPL-3.0. The core Unsloth package remains licensed under **[Apache 2.0](https://github.com/unslothai/unsloth?tab=Apache-2.0-1-ov-file)**, while certain optional components, such as the Unsloth Studio UI are licensed under the open-source license **[AGPL-3.0](https://github.com/unslothai/unsloth?tab=AGPL-3.0-2-ov-file)**.
This structure helps support ongoing Unsloth development while keeping the project open source and enabling the broader ecosystem to continue growing.
### Thank You to
- The [llama.cpp library](https://github.com/ggml-org/llama.cpp) that lets users run and save models with Unsloth
- The Hugging Face team and their libraries: [transformers](https://github.com/huggingface/transformers) and [TRL](https://github.com/huggingface/trl)
- The Pytorch and [Torch AO](https://github.com/unslothai/unsloth/pull/3391) team for their contributions
- And of course for every single person who has contributed or has used Unsloth!
================================================
FILE: build.sh
================================================
#!/usr/bin/env bash
set -euo pipefail
# 1. Build frontend (Vite outputs to dist/)
cd studio/frontend
# Clean stale dist to force a full rebuild
rm -rf dist
# Tailwind v4's oxide scanner respects .gitignore in parent directories.
# Python venvs create a .gitignore with "*" (ignore everything), which
# prevents Tailwind from scanning .tsx source files for class names.
# Temporarily hide any such .gitignore during the build, then restore it.
_HIDDEN_GITIGNORES=()
_dir="$(pwd)"
while [ "$_dir" != "/" ]; do
_dir="$(dirname "$_dir")"
if [ -f "$_dir/.gitignore" ] && grep -qx '\*' "$_dir/.gitignore" 2>/dev/null; then
mv "$_dir/.gitignore" "$_dir/.gitignore._twbuild"
_HIDDEN_GITIGNORES+=("$_dir/.gitignore")
fi
done
_restore_gitignores() {
for _gi in "${_HIDDEN_GITIGNORES[@]+"${_HIDDEN_GITIGNORES[@]}"}"; do
mv "${_gi}._twbuild" "$_gi" 2>/dev/null || true
done
}
trap _restore_gitignores EXIT
npm install
npm run build # outputs to studio/frontend/dist/
_restore_gitignores
trap - EXIT
# Validate CSS output -- catch truncated Tailwind builds before packaging
MAX_CSS_SIZE=$(find dist/assets -name '*.css' -exec wc -c {} + 2>/dev/null | sort -n | tail -1 | awk '{print $1}')
if [ -z "$MAX_CSS_SIZE" ]; then
echo "❌ ERROR: No CSS files were emitted into dist/assets."
echo " The frontend build may have failed silently."
exit 1
fi
if [ "$MAX_CSS_SIZE" -lt 100000 ]; then
echo "❌ ERROR: Largest CSS file is only $((MAX_CSS_SIZE / 1024))KB (expected >100KB)."
echo " Tailwind may not have scanned all source files."
echo " Check for .gitignore files blocking the Tailwind oxide scanner."
exit 1
fi
echo "✅ Frontend CSS validated (${MAX_CSS_SIZE} bytes)"
cd ../..
# 2. Clean old artifacts
rm -rf build dist *.egg-info
# 3. Build wheel
python -m build
# 4. Optionally publish
if [ "${1:-}" = "publish" ]; then
python -m twine upload dist/*
fi
================================================
FILE: cli.py
================================================
# SPDX-License-Identifier: AGPL-3.0-only
# Copyright 2026-present the Unsloth AI Inc. team. All rights reserved. See /studio/LICENSE.AGPL-3.0
from unsloth_cli import app
if __name__ == "__main__":
app()
================================================
FILE: install.ps1
================================================
# Unsloth Studio Installer for Windows PowerShell
# Usage: irm https://raw.githubusercontent.com/unslothai/unsloth/main/install.ps1 | iex
# Local: Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass; .\install.ps1
function Install-UnslothStudio {
$ErrorActionPreference = "Stop"
$VenvName = "unsloth_studio"
$PythonVersion = "3.13"
Write-Host ""
Write-Host "========================================="
Write-Host " Unsloth Studio Installer (Windows)"
Write-Host "========================================="
Write-Host ""
# ── Helper: refresh PATH from registry (preserving current session entries) ──
function Refresh-SessionPath {
$machine = [System.Environment]::GetEnvironmentVariable("Path", "Machine")
$user = [System.Environment]::GetEnvironmentVariable("Path", "User")
$env:Path = "$machine;$user;$env:Path"
}
# ── Check winget ──
if (-not (Get-Command winget -ErrorAction SilentlyContinue)) {
Write-Host "Error: winget is not available." -ForegroundColor Red
Write-Host " Install it from https://aka.ms/getwinget" -ForegroundColor Yellow
Write-Host " or install Python $PythonVersion and uv manually, then re-run." -ForegroundColor Yellow
return
}
# ── Install Python if no compatible version (3.11-3.13) found ──
$DetectedPythonVersion = ""
if (Get-Command python -ErrorAction SilentlyContinue) {
$pyVer = python --version 2>&1
if ($pyVer -match "Python (3\.1[1-3])\.\d+") {
Write-Host "==> Python already installed: $pyVer"
$DetectedPythonVersion = $Matches[1]
}
}
if (-not $DetectedPythonVersion) {
Write-Host "==> Installing Python ${PythonVersion}..."
winget install -e --id Python.Python.3.13 --accept-package-agreements --accept-source-agreements
Refresh-SessionPath
if ($LASTEXITCODE -ne 0) {
# winget returns non-zero for "already installed" -- only fail if python is truly missing
if (-not (Get-Command python -ErrorAction SilentlyContinue)) {
Write-Host "[ERROR] Python installation failed (exit code $LASTEXITCODE)" -ForegroundColor Red
return
}
}
$DetectedPythonVersion = $PythonVersion
}
# ── Install uv if not present ──
if (-not (Get-Command uv -ErrorAction SilentlyContinue)) {
Write-Host "==> Installing uv package manager..."
winget install --id=astral-sh.uv -e --accept-package-agreements --accept-source-agreements
Refresh-SessionPath
# Fallback: if winget didn't put uv on PATH, try the PowerShell installer
if (-not (Get-Command uv -ErrorAction SilentlyContinue)) {
Write-Host " Trying alternative uv installer..."
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
Refresh-SessionPath
}
}
if (-not (Get-Command uv -ErrorAction SilentlyContinue)) {
Write-Host "Error: uv could not be installed." -ForegroundColor Red
Write-Host " Install it from https://docs.astral.sh/uv/" -ForegroundColor Yellow
return
}
# ── Create venv (skip if it already exists and has a valid interpreter) ──
$VenvPython = Join-Path $VenvName "Scripts\python.exe"
if (-not (Test-Path $VenvPython)) {
if (Test-Path $VenvName) { Remove-Item -Recurse -Force $VenvName }
Write-Host "==> Creating Python ${DetectedPythonVersion} virtual environment (${VenvName})..."
uv venv $VenvName --python $DetectedPythonVersion
if ($LASTEXITCODE -ne 0) {
Write-Host "[ERROR] Failed to create virtual environment (exit code $LASTEXITCODE)" -ForegroundColor Red
return
}
} else {
Write-Host "==> Virtual environment ${VenvName} already exists, skipping creation."
}
# ── Install unsloth directly into the venv (no activation needed) ──
Write-Host "==> Installing unsloth (this may take a few minutes)..."
uv pip install --python $VenvPython unsloth --torch-backend=auto
if ($LASTEXITCODE -ne 0) {
Write-Host "[ERROR] Failed to install unsloth (exit code $LASTEXITCODE)" -ForegroundColor Red
return
}
# ── Run studio setup ──
# setup.ps1 will handle installing Git, CMake, Visual Studio Build Tools,
# CUDA Toolkit, Node.js, and other dependencies automatically via winget.
Write-Host "==> Running unsloth studio setup..."
$UnslothExe = Join-Path $VenvName "Scripts\unsloth.exe"
& $UnslothExe studio setup
if ($LASTEXITCODE -ne 0) {
Write-Host "[ERROR] unsloth studio setup failed (exit code $LASTEXITCODE)" -ForegroundColor Red
return
}
Write-Host ""
Write-Host "========================================="
Write-Host " Unsloth Studio installed!"
Write-Host "========================================="
Write-Host ""
Write-Host " To launch, run:"
Write-Host ""
Write-Host " .\${VenvName}\Scripts\activate"
Write-Host " unsloth studio -H 0.0.0.0 -p 8888"
Write-Host ""
}
Install-UnslothStudio
================================================
FILE: install.sh
================================================
#!/bin/sh
# Unsloth Studio Installer
# Usage (curl): curl -fsSL https://raw.githubusercontent.com/unslothai/unsloth/main/install.sh | sh
# Usage (wget): wget -qO- https://raw.githubusercontent.com/unslothai/unsloth/main/install.sh | sh
set -e
VENV_NAME="unsloth_studio"
PYTHON_VERSION="3.13"
# ── Helper: download a URL to a file (supports curl and wget) ──
download() {
if command -v curl >/dev/null 2>&1; then
curl -LsSf "$1" -o "$2"
elif command -v wget >/dev/null 2>&1; then
wget -qO "$2" "$1"
else
echo "Error: neither curl nor wget found. Install one and re-run."
exit 1
fi
}
# ── Helper: check if a single package is available on the system ──
_is_pkg_installed() {
case "$1" in
build-essential) command -v gcc >/dev/null 2>&1 ;;
libcurl4-openssl-dev)
command -v dpkg >/dev/null 2>&1 && dpkg -s "$1" >/dev/null 2>&1 ;;
pciutils)
command -v lspci >/dev/null 2>&1 ;;
*) command -v "$1" >/dev/null 2>&1 ;;
esac
}
# ── Helper: install packages via apt, escalating to sudo only if needed ──
# Usage: _smart_apt_install pkg1 pkg2 pkg3 ...
_smart_apt_install() {
_PKGS="$*"
# Step 1: Try installing without sudo (works when already root)
apt-get update -y /dev/null 2>&1 || true
apt-get install -y $_PKGS /dev/null 2>&1 || true
# Step 2: Check which packages are still missing
_STILL_MISSING=""
for _pkg in $_PKGS; do
if ! _is_pkg_installed "$_pkg"; then
_STILL_MISSING="$_STILL_MISSING $_pkg"
fi
done
_STILL_MISSING=$(echo "$_STILL_MISSING" | sed 's/^ *//')
if [ -z "$_STILL_MISSING" ]; then
return 0
fi
# Step 3: Escalate -- need elevated permissions for remaining packages
if command -v sudo >/dev/null 2>&1; then
echo ""
echo " !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!"
echo " WARNING: We require sudo elevated permissions to install:"
echo " $_STILL_MISSING"
echo " If you accept, we'll run sudo now, and it'll prompt your password."
echo " !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!"
echo ""
printf " Accept? [Y/n] "
if [ -r /dev/tty ]; then
read -r REPLY /dev/null; then
OS="wsl"
fi
echo "==> Platform: $OS"
# ── Check system dependencies ──
# cmake and git are needed by unsloth studio setup to build the GGUF inference
# engine (llama.cpp). build-essential and libcurl-dev are also needed on Linux.
MISSING=""
command -v cmake >/dev/null 2>&1 || MISSING="$MISSING cmake"
command -v git >/dev/null 2>&1 || MISSING="$MISSING git"
case "$OS" in
macos)
# Xcode Command Line Tools provide the C/C++ compiler
if ! xcode-select -p >/dev/null 2>&1; then
echo ""
echo "==> Xcode Command Line Tools are required."
echo " Installing (a system dialog will appear)..."
xcode-select --install /dev/null || true
echo " After the installation completes, please re-run this script."
exit 1
fi
;;
linux|wsl)
# curl or wget is needed for downloads; check both
if ! command -v curl >/dev/null 2>&1 && ! command -v wget >/dev/null 2>&1; then
MISSING="$MISSING curl"
fi
command -v gcc >/dev/null 2>&1 || MISSING="$MISSING build-essential"
# libcurl dev headers for llama.cpp HTTPS support
if command -v dpkg >/dev/null 2>&1; then
dpkg -s libcurl4-openssl-dev >/dev/null 2>&1 || MISSING="$MISSING libcurl4-openssl-dev"
fi
;;
esac
MISSING=$(echo "$MISSING" | sed 's/^ *//')
if [ -n "$MISSING" ]; then
echo ""
echo "==> Unsloth Studio needs these packages: $MISSING"
echo " These are needed to build the GGUF inference engine."
case "$OS" in
macos)
if ! command -v brew >/dev/null 2>&1; then
echo ""
echo " Homebrew is required to install them."
echo " Install Homebrew from https://brew.sh then re-run this script."
exit 1
fi
brew install $MISSING /dev/null 2>&1; then
_smart_apt_install $MISSING
else
echo " apt-get is not available. Please install with your package manager:"
echo " $MISSING"
echo " Then re-run Unsloth Studio setup."
exit 1
fi
;;
esac
echo ""
else
echo "==> All system dependencies found."
fi
# ── Install uv ──
if ! command -v uv >/dev/null 2>&1; then
echo "==> Installing uv package manager..."
_uv_tmp=$(mktemp)
download "https://astral.sh/uv/install.sh" "$_uv_tmp"
sh "$_uv_tmp" Creating Python ${PYTHON_VERSION} virtual environment (${VENV_NAME})..."
uv venv "$VENV_NAME" --python "$PYTHON_VERSION"
else
echo "==> Virtual environment ${VENV_NAME} already exists, skipping creation."
fi
# ── Install unsloth directly into the venv (no activation needed) ──
echo "==> Installing unsloth (this may take a few minutes)..."
uv pip install --python "$VENV_NAME/bin/python" unsloth --torch-backend=auto
# ── Run studio setup ──
# Ensure the venv's Python is on PATH for setup.sh's Python discovery.
# On macOS the system Python may be outside the 3.11-3.13 range that
# setup.sh requires, but uv already installed a compatible interpreter
# inside the venv.
VENV_ABS_BIN="$(cd "$VENV_NAME/bin" && pwd)"
if [ -n "$VENV_ABS_BIN" ]; then
export PATH="$VENV_ABS_BIN:$PATH"
fi
echo "==> Running unsloth studio setup..."
"$VENV_NAME/bin/unsloth" studio setup =3.0.0 ; ('linux' in sys_platform)",
"triton-windows ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
huggingfacenotorch = [
"wheel>=0.42.0",
"packaging",
"numpy",
"tqdm",
"psutil",
"tyro",
"protobuf",
"sentencepiece>=0.2.0",
"datasets>=3.4.1,!=4.0.*,!=4.1.0,<4.4.0",
"accelerate>=0.34.1",
"peft>=0.18.0,!=0.11.0",
"huggingface_hub>=0.34.0",
"hf_transfer",
"diffusers",
"transformers>=4.51.3,!=4.52.0,!=4.52.1,!=4.52.2,!=4.52.3,!=4.53.0,!=4.54.0,!=4.55.0,!=4.55.1,!=4.57.0,!=4.57.4,!=4.57.5,!=5.0.0,!=5.1.0,<=5.3.0",
"trl>=0.18.2,!=0.19.0,<=0.24.0",
"sentence-transformers",
]
huggingface = [
"unsloth[huggingfacenotorch]",
"unsloth_zoo>=2026.3.4",
"torchvision",
"unsloth[triton]",
]
windows = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0 ; (sys_platform == 'win32')",
"xformers>=0.0.22.post7 ; (sys_platform == 'win32')",
]
base = [
"unsloth[huggingface]",
]
cu118only = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.22.post7%2Bcu118-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.22.post7%2Bcu118-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.22.post7%2Bcu118-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu121only = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.22.post7-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.22.post7-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.22.post7-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu118onlytorch211 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.23%2Bcu118-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.23%2Bcu118-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.23%2Bcu118-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu121onlytorch211 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.23-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.23-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.23-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu118onlytorch212 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.23.post1%2Bcu118-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.23.post1%2Bcu118-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.23.post1%2Bcu118-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu121onlytorch212 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.23.post1-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.23.post1-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.23.post1-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu118onlytorch220 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.24%2Bcu118-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.24%2Bcu118-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.24%2Bcu118-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu121onlytorch220 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.24-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.24-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.24-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu118onlytorch230 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27%2Bcu118-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27%2Bcu118-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27%2Bcu118-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27%2Bcu118-cp312-cp312-manylinux2014_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu121onlytorch230 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.27-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.27-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.27-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.27-cp312-cp312-manylinux2014_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu118onlytorch240 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27.post2%2Bcu118-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27.post2%2Bcu118-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27.post2%2Bcu118-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27.post2%2Bcu118-cp312-cp312-manylinux2014_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu121onlytorch240 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post1-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post1-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post1-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post1-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu124onlytorch240 = [
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu118onlytorch250 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.28.post2-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.28.post2-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.28.post2-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.28.post2-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu121onlytorch250 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post2-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post2-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post2-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post2-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu124onlytorch250 = [
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu118onlytorch251 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post1-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post1-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post1-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post1-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu121onlytorch251 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.29.post1-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.29.post1-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.29.post1-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.29.post1-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu124onlytorch251 = [
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu118onlytorch260 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post3-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post3-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post3-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post3-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu124onlytorch260 = [
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu126onlytorch260 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu118onlytorch270 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu126onlytorch270 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu128onlytorch270 = [
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu118onlytorch271 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.31.post1-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.31.post1-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu126onlytorch271 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.31.post1-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.31.post1-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu128onlytorch271 = [
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.31.post1-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.31.post1-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu118onlytorch280 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.32.post2-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.32.post2-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu126onlytorch280 = [
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.32.post2-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.32.post2-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu128onlytorch280 = [
"xformers @ https://download.pytorch.org/whl/cu129/xformers-0.0.32.post2-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu129/xformers-0.0.32.post2-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu130onlytorch280 = [
]
cu126onlytorch290 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.33.post1-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.33.post1-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu128onlytorch290 = [
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.33.post1-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.33.post1-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu130onlytorch290 = [
"xformers @ https://download.pytorch.org/whl/cu130/xformers-0.0.33.post1-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu130/xformers-0.0.33.post1-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu126onlytorch291 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.33.post2-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.33.post2-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu128onlytorch291 = [
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.33.post2-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.33.post2-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu130onlytorch291 = [
"xformers @ https://download.pytorch.org/whl/cu130/xformers-0.0.33.post2-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu130/xformers-0.0.33.post2-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu126onlytorch2100 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.34-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.34-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu128onlytorch2100 = [
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.34-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.34-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu130onlytorch2100 = [
"xformers @ https://download.pytorch.org/whl/cu130/xformers-0.0.34-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu130/xformers-0.0.34-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu118 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118only]",
]
cu121 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121only]",
]
cu118-torch211 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu118onlytorch211]",
]
cu121-torch211 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu121onlytorch211]",
]
cu118-torch212 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu118onlytorch212]",
]
cu121-torch212 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu121onlytorch212]",
]
cu118-torch220 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch220]",
]
cu121-torch220 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch220]",
]
cu118-torch230 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch230]",
]
cu121-torch230 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch230]",
]
cu118-torch240 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch240]",
]
cu121-torch240 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch240]",
]
cu124-torch240 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch240]",
]
cu118-torch250 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch250]",
]
cu121-torch250 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch250]",
]
cu124-torch250 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch250]",
]
cu118-torch251 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch251]",
]
cu121-torch251 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch251]",
]
cu124-torch251 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch251]",
]
cu118-torch260 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch260]",
]
cu124-torch260 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch260]",
]
cu126-torch260 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch260]",
]
cu118-torch270 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch270]",
]
cu126-torch270 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch270]",
]
cu128-torch270 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch270]",
]
cu118-torch271 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch271]",
]
cu126-torch271 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch271]",
]
cu128-torch271 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch271]",
]
cu118-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch280]",
]
cu126-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch280]",
]
cu128-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch280]",
]
cu130-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch280]",
]
cu126-torch290 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch290]",
]
cu128-torch290 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch290]",
]
cu130-torch290 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch290]",
]
cu126-torch291 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch291]",
]
cu128-torch291 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch291]",
]
cu130-torch291 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch291]",
]
cu126-torch2100 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch2100]",
]
cu128-torch2100 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch2100]",
]
cu130-torch2100 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch2100]",
]
kaggle = [
"unsloth[huggingface]",
]
kaggle-new = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
]
conda = [
"unsloth[huggingface]",
]
colab-torch211 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu121onlytorch211]",
]
colab-ampere-torch211 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu121onlytorch211]",
"packaging",
"ninja",
"flash-attn>=2.6.3 ; ('linux' in sys_platform)",
]
colab-torch220 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch220]",
]
colab-ampere-torch220 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch220]",
"packaging",
"ninja",
"flash-attn>=2.6.3 ; ('linux' in sys_platform)",
]
colab-new = [
"unsloth_zoo>=2026.3.4",
"packaging",
"tyro",
"transformers>=4.51.3,!=4.52.0,!=4.52.1,!=4.52.2,!=4.52.3,!=4.53.0,!=4.54.0,!=4.55.0,!=4.55.1,!=4.57.0,!=4.57.4,!=4.57.5,!=5.0.0,!=5.1.0,<=5.3.0",
"datasets>=3.4.1,!=4.0.*,!=4.1.0,<4.4.0",
"sentencepiece>=0.2.0",
"tqdm",
"psutil",
"wheel>=0.42.0",
"numpy",
"protobuf",
"huggingface_hub>=0.34.0",
"hf_transfer",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[triton]",
"sentence-transformers",
]
colab-no-deps = [
"accelerate>=0.34.1",
"trl>=0.18.2,!=0.19.0,<=0.24.0",
"peft>=0.18.0",
"xformers ; ('linux' in sys_platform or sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"protobuf",
]
colab = [
"unsloth[cu121]",
]
flashattention = [
"packaging ; ('linux' in sys_platform)",
"ninja ; ('linux' in sys_platform)",
"flash-attn>=2.6.3 ; ('linux' in sys_platform)",
]
colab-ampere = [
"unsloth[colab-ampere-torch220]",
"unsloth[flashattention]",
]
cu118-ampere = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118only]",
"unsloth[flashattention]",
]
cu121-ampere = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121only]",
"unsloth[flashattention]",
]
cu118-ampere-torch211 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu118onlytorch211]",
"unsloth[flashattention]",
]
cu121-ampere-torch211 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu121onlytorch211]",
"unsloth[flashattention]",
]
cu118-ampere-torch220 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch220]",
"unsloth[flashattention]",
]
cu121-ampere-torch220 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch220]",
"unsloth[flashattention]",
]
cu118-ampere-torch230 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch230]",
"unsloth[flashattention]",
]
cu121-ampere-torch230 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch230]",
"unsloth[flashattention]",
]
cu118-ampere-torch240 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch240]",
"unsloth[flashattention]",
]
cu121-ampere-torch240 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch240]",
"unsloth[flashattention]",
]
cu124-ampere-torch240 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch240]",
"unsloth[flashattention]",
]
cu118-ampere-torch250 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch250]",
"unsloth[flashattention]",
]
cu121-ampere-torch250 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch250]",
"unsloth[flashattention]",
]
cu124-ampere-torch250 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch250]",
"unsloth[flashattention]",
]
cu118-ampere-torch251 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch251]",
"unsloth[flashattention]",
]
cu121-ampere-torch251 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch251]",
"unsloth[flashattention]",
]
cu124-ampere-torch251 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch251]",
"unsloth[flashattention]",
]
cu118-ampere-torch260 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch260]",
"unsloth[flashattention]",
]
cu124-ampere-torch260 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch260]",
"unsloth[flashattention]",
]
cu126-ampere-torch260 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch260]",
"unsloth[flashattention]",
]
cu118-ampere-torch270 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch270]",
"unsloth[flashattention]",
]
cu126-ampere-torch270 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch270]",
"unsloth[flashattention]",
]
cu128-ampere-torch270 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch270]",
"unsloth[flashattention]",
]
cu118-ampere-torch271 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch271]",
"unsloth[flashattention]",
]
cu126-ampere-torch271 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch271]",
"unsloth[flashattention]",
]
cu128-ampere-torch271 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch271]",
"unsloth[flashattention]",
]
cu118-ampere-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch280]",
"unsloth[flashattention]",
]
cu126-ampere-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch280]",
"unsloth[flashattention]",
]
cu128-ampere-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch280]",
"unsloth[flashattention]",
]
cu130-ampere-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch280]",
"unsloth[flashattention]",
]
cu126-ampere-torch290 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch290]",
]
cu128-ampere-torch290 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch290]",
]
cu130-ampere-torch290 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch290]",
]
cu126-ampere-torch291 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch291]",
]
cu128-ampere-torch291 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch291]",
]
cu130-ampere-torch291 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch291]",
]
cu126-ampere-torch2100 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch2100]",
]
cu128-ampere-torch2100 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch2100]",
]
cu130-ampere-torch2100 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch2100]",
]
flashattentiontorch260abiFALSEcu12x = [
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp39-cp39-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.9'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.10'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp311-cp311-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.11'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp312-cp312-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.12'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp313-cp313-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.13'",
]
flashattentiontorch260abiTRUEcu12x = [
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp39-cp39-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.9'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp310-cp310-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.10'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp311-cp311-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.11'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp312-cp312-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.12'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp313-cp313-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.13'",
]
flashattentiontorch250abiFALSEcu12x = [
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiFALSE-cp39-cp39-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.9'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiFALSE-cp310-cp310-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.10'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiFALSE-cp311-cp311-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.11'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiFALSE-cp312-cp312-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.12'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiFALSE-cp313-cp313-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.13'",
]
flashattentiontorch250abiTRUEcu12x = [
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiTRUE-cp39-cp39-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.9'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiTRUE-cp310-cp310-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.10'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiTRUE-cp311-cp311-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.11'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiTRUE-cp312-cp312-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.12'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiTRUE-cp313-cp313-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.13'",
]
flashattentiontorch240abiFALSEcu12x = [
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiFALSE-cp39-cp39-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.9'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiFALSE-cp310-cp310-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.10'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiFALSE-cp311-cp311-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.11'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiFALSE-cp312-cp312-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.12'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiFALSE-cp313-cp313-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.13'",
]
flashattentiontorch240abiTRUEcu12x = [
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiTRUE-cp39-cp39-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.9'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiTRUE-cp310-cp310-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.10'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiTRUE-cp311-cp311-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.11'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiTRUE-cp312-cp312-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.12'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiTRUE-cp313-cp313-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.13'",
]
intelgputorch260 = [
"unsloth_zoo[intelgpu]",
"unsloth[huggingfacenotorch]",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.2.0-cp39-cp39-linux_x86_64.whl#sha256=147607f190a7d7aa24ba454def5977fbbfec792fdae18e4ed278cfec29b69271 ; ('linux' in sys_platform) and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.2.0-cp310-cp310-linux_x86_64.whl#sha256=23aa423fa1542afc34f67eb3ba8ef20060f6d1b3a4697eaeab22b11c92b30f2b ; ('linux' in sys_platform) and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.2.0-cp311-cp311-linux_x86_64.whl#sha256=bcfa995229bbfd9ffd8d6c8d9f6428d393e876fa6e23ee3c20e3c0d73ca75ca5 ; ('linux' in sys_platform) and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.2.0-cp312-cp312-linux_x86_64.whl#sha256=bd340903d03470708df3442438acb8b7e08087ab9e61fbe349b2872bf9257ab0 ; ('linux' in sys_platform) and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.2.0-cp313-cp313-linux_x86_64.whl#sha256=814dccc8a07159e6eca74bed70091bc8fea2d9dd87b0d91845f9f38cde62f01c ; ('linux' in sys_platform) and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-manylinux_2_24_x86_64.whl ; ('linux' in sys_platform) and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-win_amd64.whl ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.6.0%2Bxpu-cp39-cp39-linux_x86_64.whl#sha256=6a8adf6dc4c089406e8b3a7e58ab57a463bddf9b07130d2576e76eced43e92af ; ('linux' in sys_platform) and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.6.0%2Bxpu-cp310-cp310-linux_x86_64.whl#sha256=ff4561cbf07c83bbccaa0f6e9bb0e6dcf721bacd53c9c43c4eb0e7331b4792f9 ; ('linux' in sys_platform) and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.6.0%2Bxpu-cp311-cp311-linux_x86_64.whl#sha256=12005f66b810ddd3ab93f86c4522bcfdd412cbd27fc9d189b661ff7509bc5e8a ; ('linux' in sys_platform) and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.6.0%2Bxpu-cp312-cp312-linux_x86_64.whl#sha256=c4c5c67625cdacf35765c2b94e61fe166e3c3f4a14521b1212a59ad1b3eb0f2e ; ('linux' in sys_platform) and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.6.0%2Bxpu-cp313-cp313-linux_x86_64.whl#sha256=e6864f7a60a5ecc43d5d38f59a16e5dd132384f73dfd3a697f74944026038f7b ; ('linux' in sys_platform) and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
intel-gpu-torch260 = [
"unsloth[intelgputorch260]"
]
intelgputorch270 = [
"unsloth_zoo[intelgpu]",
"unsloth[huggingfacenotorch]",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp39-cp39-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=749a7098492c6a27b356c97149a4a62973b953eae60bc1b6259260974f344913 ; ('linux' in sys_platform) and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=44362e80abd752471a08341093321955b066daa2cfb4810e73b8e3b240850f93 ; ('linux' in sys_platform) and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=faa6b8c945a837a080f641bc8ccc77a98fa66980dcd7e62e715fd853737343fd ; ('linux' in sys_platform) and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=40f6fb65b345dc9a61813abe7ac9a585f2c9808f414d140cc2a5f11f53ee063c ; ('linux' in sys_platform) and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=b22b4c02ec71b4bfc862ae3cdfd2871dc0b05d2b1802f5db2196e0f897d581e9 ; ('linux' in sys_platform) and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp39-cp39-win_amd64.whl#sha256=d4b738d7fa5100c1bd766f91614962828a4810eb57b4df92cd5214a83505a752 ; sys_platform == 'win32' and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp310-cp310-win_amd64.whl#sha256=143fe8a64d807bcdb7d81bbc062816add325570aa160448454ab6ded4a0a17a1 ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp311-cp311-win_amd64.whl#sha256=a8025459ff325d6e3532eb5cf72519db1b178155e7d60aff6c56beb5968fc758 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp312-cp312-win_amd64.whl#sha256=0dd07e6d5b872e42e48f5ee140e609d4554ca3cc509d5bf509ac232267cf358e ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp313-cp313-win_amd64.whl#sha256=a936a18182d8e065a9933afc9a3ebbffadd38604969f87c493831214539fc027 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-manylinux_2_24_x86_64.whl ; ('linux' in sys_platform) and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-win_amd64.whl ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp39-cp39-linux_x86_64.whl#sha256=f8ee75e50fcbb37ed5b498299ca2264da99ab278a93fae2358e921e4a6e28273 ; ('linux' in sys_platform) and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp310-cp310-linux_x86_64.whl#sha256=d6fdc342961d98fdcd9d03dfd491a3208bb5f7fbb435841f8f72ce9fdcd2d026 ; ('linux' in sys_platform) and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp311-cp311-linux_x86_64.whl#sha256=74d07f9357df5cf2bf223ad3c84de16346bfaa0504f988fdd5590d3e177e5e86 ; ('linux' in sys_platform) and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp312-cp312-linux_x86_64.whl#sha256=c806d44aa2ca5d225629f6fbc6c994d5deaac2d2cde449195bc8e3522ddd219a ; ('linux' in sys_platform) and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp313-cp313-linux_x86_64.whl#sha256=25d8277b7f01d42e2e014ccbab57a2692b6ec4eff8dcf894eda1b297407cf97a ; ('linux' in sys_platform) and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp39-cp39-win_amd64.whl#sha256=046e85125266ae69c1a0d083e6c092f947ab4b6b41532c16bafe40dbced845df ; sys_platform == 'win32' and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=9ebaeffb82b0b3e39b6030927d3ebe0eb62a0e9045a3b2d7b0a9e7b15222c0db ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=356ba66cee127e7e2c942880bd50e03768306a4ea08d358a0f29c6eebfc4bc81 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=94739e665d9b4d5cd7af5f517cb6103f6f9fb421c095184609653a24524040f5 ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=31df3cb674918e89bc8c532baa331dc84f4430e1f9c0ec379232db44cba78355 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
intel-gpu-torch270 = [
"unsloth[intelgputorch270]"
]
intelgputorch280 = [
"unsloth_zoo[intelgpu]",
"unsloth[huggingfacenotorch]",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp39-cp39-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=ac4d8e33986b1c3c5e48151640539272b2187e83016985853111b46fb82c3c94 ; 'linux' in sys_platform and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=999fef4c1f711092b9d3086525920545df490de476ecebe899ffc777019ae17f ; 'linux' in sys_platform and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=57b09c8c492985ff6a27cd3a22b08e8f7b96b407bd8030967b6efbb9f63b80cf ; 'linux' in sys_platform and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=df4bb3282bac9a3b90231700077110d8680b338416de03c2b7c6133c9b602649 ; 'linux' in sys_platform and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=60da63c99ca827bdcb0df28e0298bf7d066dc607454c6d6176783cb4e79d838b ; 'linux' in sys_platform and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp39-cp39-win_amd64.whl#sha256=64aea8de349f3e2e0ebf4c24b011a8122531fdffda5776edaef45829cc241cf8 ; sys_platform == 'win32' and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp310-cp310-win_amd64.whl#sha256=ae573d255b257fdbed319a3440dc9d0a721e31160ab7f6eba1b2226e6a409a1d ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp311-cp311-win_amd64.whl#sha256=8e0ea4558e5776d8ddab0264310be9b26aee5641bcac0da023537556d4317b86 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp312-cp312-win_amd64.whl#sha256=4090dde07a4fffc34aaf855701a9db28e9fccb57b368ade520f1a0f8e811c878 ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp313-cp313-win_amd64.whl#sha256=a33d0888f3c8df028a2d028842715837d0049524d6c06b9bb11869890a13601a ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp39-cp39-linux_x86_64.whl ; 'linux' in sys_platform and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp310-cp310-linux_x86_64.whl ; 'linux' in sys_platform and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp311-cp311-linux_x86_64.whl ; 'linux' in sys_platform and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp312-cp312-linux_x86_64.whl ; 'linux' in sys_platform and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp313-cp313-linux_x86_64.whl ; 'linux' in sys_platform and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp39-cp39-win_amd64.whl#sha256=f2f401276892428e4875cf1d8717c5cbab704b16fc594ccf23795e7b16549a99 ; sys_platform == 'win32' and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=125c60cd59d51b39581a7e9afcd4679bc3a6b8c1f9440b1bb502a23fdd60571e ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=47f1a57258cd460e80b38b2ed6744e31587ab77a96b4215bf59546cb4bab5cc0 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=0937d8943c145a83d9bafc6f80ef28971167817f9eda26066d33f72caf8a6646 ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=e034aab1d71760dc80a731531be43673ffe15e99033b82d24e40d2e6d41bd8bf ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-manylinux_2_24_x86_64.whl ; ('linux' in sys_platform) and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-win_amd64.whl ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp39-cp39-manylinux_2_28_x86_64.whl#sha256=6e981c192045fc249c008441179ff237bb00174d818b875b0475730b63f0eaca ; 'linux' in sys_platform and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp310-cp310-manylinux_2_28_x86_64.whl#sha256=e5ba4805969277175ebfd59cc717093528cc6e3ada89ac2725fc7a3c1fee6169 ; 'linux' in sys_platform and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp311-cp311-manylinux_2_28_x86_64.whl#sha256=74c39c144104416bc4c5ad8c26ab0c169dc5cc6be58059e01bc3665dd0ef676f ; 'linux' in sys_platform and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp312-cp312-manylinux_2_28_x86_64.whl#sha256=0acec355b80c3899841184084f365df336c508602812e34a44007b8b60d53af4 ; 'linux' in sys_platform and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp313-cp313-manylinux_2_28_x86_64.whl#sha256=e2109ae773dad27b98ca17681044b4f876563c37f2382b75de3a371399edcff8 ; 'linux' in sys_platform and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp39-cp39-win_amd64.whl#sha256=5f7904e7048d414379bc8c1167260f1e84204f105db2d0a2f9c89e87ce1cf205 ; sys_platform == 'win32' and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=005fca5e658ca8e37adb63c1a021c84f5e56dfa6cf0d601d89cfe40b9473f79f ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=c6d030f5361461550c0ff1339b5bca8585fc1e84fda2e64b6184e65a581e4f98 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=91aafd61864cdce27461cbec13ddbf28c1bc6494265a1e4b80131c64a3b7d18f ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=71dc4a6421742ed1e7f585b04a100ad53615c341fbccfbc255aefb38ea9091da ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
intel-gpu-torch280 = [
"unsloth[intelgputorch280]"
]
intelgputorch290 = [
"unsloth_zoo[intelgpu]",
"unsloth[huggingfacenotorch]",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=c169a1de14c19673b17c751290d467fa282fc90fa5da4314b2e5cdab1f553146 ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=013d9dd5d6479bd22983161f462e61c8dbe1d82e6730624a7a8d5945507eaa61 ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=afc8cabfbf7ed51fd278d1e0f88d6afc157b0201bad4b99d681e4d542f9e66d4 ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=0d24c1716088f2764d0d24c64227732195b6a42706c3c5fc89eeb4904bfa0818 ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp310-cp310-win_amd64.whl#sha256=c83ab007311d9cfb6e809ee5a4587d99a9eef4be720b90da4f1aaa68b45139a0 ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp311-cp311-win_amd64.whl#sha256=debf75348da8e8c7166b4d4a9b91d1508bb8d6581e339f79f7604b2e6746bacd ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp312-cp312-win_amd64.whl#sha256=97337a47425f1963a723475bd61037460e84ba01db4f87a1d662c3718ff6c47e ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp313-cp313-win_amd64.whl#sha256=2caf8138695f6abb023ecd02031a2611ba1bf8fff2f19802567cb2fadefe9e87 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp310-cp310-linux_x86_64.whl#sha256=5afbe860ce991825a36b75706a523601087e414b77598ef0d9d3d565741c277d ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp311-cp311-linux_x86_64.whl#sha256=607fe419c32d6e8e0556f745742e7cff1d0babce51f54be890e0c1422359c442 ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp312-cp312-linux_x86_64.whl#sha256=376bae584d89980b8e59934d248c38d5fa3b7d4687a4df1a19f4bc1d23dcc8c1 ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp313-cp313-linux_x86_64.whl#sha256=98d6a06dd7fb185874367b18bd609f05f16fdce4142a5980ca94461949965cd2 ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=47cc68f631f65bd9c84924d052cd04dec7531023caa85e80345e9c94611c887d ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=d56c44ab4818aba57e5c7b628f422d014e0d507427170a771c5be85e308b0bc6 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=18cad93aaff76a01ce73aef6935ece7cfc03344b905592ec731446c44d44592b ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=579929cdc10a76800ead41289cac191ea36d1b16f5f501d3fc25607d4375cd83 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-manylinux_2_24_x86_64.whl ; ('linux' in sys_platform) and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-win_amd64.whl ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp310-cp310-manylinux_2_28_x86_64.whl#sha256=cbfae2b79b7549fd368c2462fc8e94f8f26cc450782ee72138e908077c09a519 ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp311-cp311-manylinux_2_28_x86_64.whl#sha256=044fa36ef4b6b43edcd490b75c853fa4b3eb033c2bded29f8fbcf27734713c67 ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp312-cp312-manylinux_2_28_x86_64.whl#sha256=4b91e4bec1d740a6211f02578a79888550b73f3a4e1383035f8f6d72f587212c ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp313-cp313-manylinux_2_28_x86_64.whl#sha256=88239e73ca37254bec84f29cd5887e10ff712de7edbbda3fbb3609cd6190d99e ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=19c7da8ca767d593e13a88a12bb08d06e34a673f6f26c2f9c191d60e81c02953 ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=9bb0d1421c544ac8e2eca5b47daacaf54706dc9139c003aa5e77ee5f355c5931 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=6a5194bc736089606342d48a3f6822829b167617e9495d91d753dd1bd46fda18 ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=da47a3ce2bb7f0301a31124668b5908f9b9e92d6241443de15a310ef9632fd83 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
intel-gpu-torch290 = [
"unsloth[intelgputorch290]"
]
intelgputorch210 = [
"unsloth_zoo[intelgpu]",
"unsloth[huggingfacenotorch]",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=c169a1de14c19673b17c751290d467fa282fc90fa5da4314b2e5cdab1f553146 ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=013d9dd5d6479bd22983161f462e61c8dbe1d82e6730624a7a8d5945507eaa61 ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=afc8cabfbf7ed51fd278d1e0f88d6afc157b0201bad4b99d681e4d542f9e66d4 ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=0d24c1716088f2764d0d24c64227732195b6a42706c3c5fc89eeb4904bfa0818 ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp310-cp310-win_amd64.whl#sha256=c83ab007311d9cfb6e809ee5a4587d99a9eef4be720b90da4f1aaa68b45139a0 ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp311-cp311-win_amd64.whl#sha256=debf75348da8e8c7166b4d4a9b91d1508bb8d6581e339f79f7604b2e6746bacd ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp312-cp312-win_amd64.whl#sha256=97337a47425f1963a723475bd61037460e84ba01db4f87a1d662c3718ff6c47e ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp313-cp313-win_amd64.whl#sha256=2caf8138695f6abb023ecd02031a2611ba1bf8fff2f19802567cb2fadefe9e87 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp310-cp310-linux_x86_64.whl#sha256=abb1d1ec1ac672bac0ff35420c965f2df0c636ef9d94e2a830e34578489d0a57 ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp311-cp311-linux_x86_64.whl#sha256=71ad2f82da0f41eaec159f39fc85854e27c2391efa91b373e550648a6f4aaad3 ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp312-cp312-linux_x86_64.whl#sha256=b473571d478912f92881cc13f15fa18f8463fb0fb8a068c96ed47a7d45a4da0a ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp313-cp313-linux_x86_64.whl#sha256=3bc64a746ff25a93de140902c60c9e819d7413f5cea1e88d80999c27a5901e9c ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=ce50691ab3fb6301d9b7bb8b3834cf5fa7152a2b5f91fd24c5efdc601a25b780 ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=cb9d37f21cb9fb7df67d62863f021c3144e8d8832b9ea8e8523ac308bc620ea1 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=3ad605be4728b6d3a28a44d07dd794b1a9e45551b0057815bf25eb2a6d6a56a7 ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=2b4b56dd6c792aef82006904fa888692e3782e4ae5da27526801bad4898f05a5 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-manylinux_2_24_x86_64.whl ; ('linux' in sys_platform) and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-win_amd64.whl ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp310-cp310-manylinux_2_28_x86_64.whl#sha256=7e1e7b170fcf7161c8499b67156c5a05462243626dc0974010791a0bab4378d3 ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp311-cp311-manylinux_2_28_x86_64.whl#sha256=bd6add201bd7628af70437292e1447abb368e0b5f4ff9abd334ae435efd44792 ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp312-cp312-manylinux_2_28_x86_64.whl#sha256=6ad2543496bc29e59d3dd614a94d09aa9870318aedb66045344fffddfedd2cf8 ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp313-cp313-manylinux_2_28_x86_64.whl#sha256=80269f37865fcd8b57f20e4786efae2200bfa2b2727926c3c7acc82f0e7d3548 ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=6b9485ba85dcba4d196d6134d9c3332fb228fb2556416bf0450a64e8a472fcba ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=36cbaedf10f6412af5c89afd9aeea474e6a56a0050348ada8fabe1ecaf6b879e ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=738357d97468d75fe3d510ac37e65130f2787f81d9bbc1518898f7396dc3403f ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=1c4b44b36a557f7381e3076fb8843366742238648441d607c8d049c6da0f8886 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
intel-gpu-torch210 = [
"unsloth[intelgputorch210]"
]
intel = [
"unsloth[intelgputorch280]",
]
amd = [
"unsloth[huggingfacenotorch]",
"bitsandbytes>=0.49.1 ; ('linux' in sys_platform) and (platform_machine == 'AMD64' or platform_machine == 'x86_64' or platform_machine == 'aarch64')",
"bitsandbytes>=0.49.1 ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
rocm702-torch280 = [
"unsloth[amd]",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/triton-3.4.0%2Brocm7.0.2.gitf9e5bf54-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/triton-3.4.0%2Brocm7.0.2.gitf9e5bf54-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/triton-3.4.0%2Brocm7.0.2.gitf9e5bf54-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/torch-2.8.0%2Brocm7.0.2.lw.git245bf6ed-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/torch-2.8.0%2Brocm7.0.2.lw.git245bf6ed-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/torch-2.8.0%2Brocm7.0.2.lw.git245bf6ed-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/torchvision-0.23.0%2Brocm7.0.2.git824e8c87-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/torchvision-0.23.0%2Brocm7.0.2.git824e8c87-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/torchvision-0.23.0%2Brocm7.0.2.git824e8c87-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
]
rocm72-torch291 = [
"unsloth[amd]",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.5.1%2Brocm7.2.0.gita272dfa8-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.5.1%2Brocm7.2.0.gita272dfa8-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.5.1%2Brocm7.2.0.gita272dfa8-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.5.1%2Brocm7.2.0.gita272dfa8-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.9.1%2Brocm7.2.0.lw.git7e1940d4-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.9.1%2Brocm7.2.0.lw.git7e1940d4-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.9.1%2Brocm7.2.0.lw.git7e1940d4-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.9.1%2Brocm7.2.0.lw.git7e1940d4-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/windows/rocm-rel-7.2/torch-2.9.1%2Brocmsdk20260116-cp312-cp312-win_amd64.whl ; sys_platform == 'win32' and python_version == '3.12'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.24.0%2Brocm7.2.0.gitb919bd0c-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.24.0%2Brocm7.2.0.gitb919bd0c-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.24.0%2Brocm7.2.0.gitb919bd0c-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.24.0%2Brocm7.2.0.gitb919bd0c-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/windows/rocm-rel-7.2/torchvision-0.24.1%2Brocmsdk20260116-cp312-cp312-win_amd64.whl ; sys_platform == 'win32' and python_version == '3.12'",
]
rocm711-torch291 = [
"unsloth[amd]",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.5.1%2Brocm7.1.1.gita272dfa8-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.5.1%2Brocm7.1.1.gita272dfa8-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.5.1%2Brocm7.1.1.gita272dfa8-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.5.1%2Brocm7.1.1.gita272dfa8-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.9.1%2Brocm7.1.1.lw.git351ff442-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.9.1%2Brocm7.1.1.lw.git351ff442-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.9.1%2Brocm7.1.1.lw.git351ff442-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.9.1%2Brocm7.1.1.lw.git351ff442-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.24.0%2Brocm7.1.1.gitb919bd0c-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.24.0%2Brocm7.1.1.gitb919bd0c-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.24.0%2Brocm7.1.1.gitb919bd0c-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.24.0%2Brocm7.1.1.gitb919bd0c-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
]
rocm72-torch2100 = [
"unsloth[amd]",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.6.0%2Brocm7.2.0.gitba5c1517-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.6.0%2Brocm7.2.0.gitba5c1517-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.6.0%2Brocm7.2.0.gitba5c1517-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.6.0%2Brocm7.2.0.gitba5c1517-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.10.0%2Brocm7.2.0.lw.gitb6ee5fde-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.10.0%2Brocm7.2.0.lw.gitb6ee5fde-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.10.0%2Brocm7.2.0.lw.gitb6ee5fde-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.10.0%2Brocm7.2.0.lw.gitb6ee5fde-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.25.0%2Brocm7.2.0.git82df5f59-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.25.0%2Brocm7.2.0.git82df5f59-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.25.0%2Brocm7.2.0.git82df5f59-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.25.0%2Brocm7.2.0.git82df5f59-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
]
rocm711-torch2100 = [
"unsloth[amd]",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.6.0%2Brocm7.1.1.gitba5c1517-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.6.0%2Brocm7.1.1.gitba5c1517-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.6.0%2Brocm7.1.1.gitba5c1517-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.6.0%2Brocm7.1.1.gitba5c1517-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.10.0%2Brocm7.1.1.lw.gitd9556b05-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.10.0%2Brocm7.1.1.lw.gitd9556b05-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.10.0%2Brocm7.1.1.lw.gitd9556b05-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.10.0%2Brocm7.1.1.lw.gitd9556b05-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.25.0%2Brocm7.1.1.git82df5f59-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.25.0%2Brocm7.1.1.git82df5f59-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.25.0%2Brocm7.1.1.git82df5f59-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.25.0%2Brocm7.1.1.git82df5f59-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
]
[project.urls]
homepage = "https://unsloth.ai"
documentation = "https://unsloth.ai/docs"
repository = "https://github.com/unslothai/unsloth"
[tool.ruff]
target-version = "py311"
force-exclude = true
extend-exclude = [
"*chat_templates.py",
"*ollama_template_mappers.py",
"*_auto_install.py",
"*mapper.py",
]
[tool.ruff.lint]
select = ["E9", "F63", "F7", "F82"]
ignore = [
"E402",
"E722",
"F403",
"F405",
"F811",
"F821",
"F841",
"F401",
"E731",
"E741",
"F601",
"E712",
]
[tool.ruff.format]
================================================
FILE: scripts/enforce_kwargs_spacing.py
================================================
#!/usr/bin/env python3
"""Ensure keyword arguments use spaces around '=', prune redundant pass statements."""
from __future__ import annotations
import ast
import argparse
import io
import sys
import tokenize
from collections import defaultdict
from pathlib import Path
def enforce_spacing(text: str) -> tuple[str, bool]:
"""Return updated text with keyword '=' padded by spaces, plus change flag."""
lines = text.splitlines(keepends=True)
if not lines:
return text, False
offsets: dict[int, int] = defaultdict(int)
changed = False
reader = io.StringIO(text).readline
for token in tokenize.generate_tokens(reader):
if token.type != tokenize.OP or token.string != "=":
continue
line_index = token.start[0] - 1
col = token.start[1] + offsets[line_index]
if line_index < 0 or line_index >= len(lines):
continue
line = lines[line_index]
if col >= len(line) or line[col] != "=":
continue
line_changed = False
# Insert a space before '=' when missing and not preceded by whitespace.
if col > 0 and line[col - 1] not in {" ", "\t"}:
line = f"{line[:col]} {line[col:]}"
offsets[line_index] += 1
col += 1
line_changed = True
changed = True
# Insert a space after '=' when missing and not followed by whitespace or newline.
next_index = col + 1
if next_index < len(line) and line[next_index] not in {" ", "\t", "\n", "\r"}:
line = f"{line[:next_index]} {line[next_index:]}"
offsets[line_index] += 1
line_changed = True
changed = True
if line_changed:
lines[line_index] = line
if not changed:
return text, False
return "".join(lines), True
def remove_redundant_passes(text: str) -> tuple[str, bool]:
"""Drop pass statements that share a block with other executable code."""
try:
tree = ast.parse(text)
except SyntaxError:
return text, False
redundant: list[ast.Pass] = []
def visit(node: ast.AST) -> None:
for attr in ("body", "orelse", "finalbody"):
value = getattr(node, attr, None)
if not isinstance(value, list) or len(value) <= 1:
continue
for stmt in value:
if isinstance(stmt, ast.Pass):
redundant.append(stmt)
for stmt in value:
if isinstance(stmt, ast.AST):
visit(stmt)
handlers = getattr(node, "handlers", None)
if handlers:
for handler in handlers:
visit(handler)
visit(tree)
if not redundant:
return text, False
lines = text.splitlines(keepends=True)
changed = False
for node in sorted(
redundant, key=lambda item: (item.lineno, item.col_offset), reverse=True
):
start = node.lineno - 1
end = (node.end_lineno or node.lineno) - 1
if start >= len(lines):
continue
changed = True
if start == end:
line = lines[start]
col_start = node.col_offset
col_end = node.end_col_offset or (col_start + 4)
segment = line[:col_start] + line[col_end:]
lines[start] = segment if segment.strip() else ""
continue
# Defensive fall-back for unexpected multi-line 'pass'.
prefix = lines[start][: node.col_offset]
lines[start] = prefix if prefix.strip() else ""
for idx in range(start + 1, end):
lines[idx] = ""
suffix = lines[end][(node.end_col_offset or 0) :]
lines[end] = suffix
# Normalise to ensure lines end with newlines except at EOF.
result_lines: list[str] = []
for index, line in enumerate(lines):
if not line:
continue
if index < len(lines) - 1 and not line.endswith("\n"):
result_lines.append(f"{line}\n")
else:
result_lines.append(line)
return "".join(result_lines), changed
def process_file(path: Path) -> bool:
try:
with tokenize.open(path) as handle:
original = handle.read()
encoding = handle.encoding
except (OSError, SyntaxError) as exc: # SyntaxError from tokenize on invalid python
print(f"Failed to read {path}: {exc}", file=sys.stderr)
return False
updated, changed = enforce_spacing(original)
updated, removed = remove_redundant_passes(updated)
if changed or removed:
path.write_text(updated, encoding=encoding)
return True
return False
def main(argv: list[str]) -> int:
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument("files", nargs="+", help="Python files to fix")
args = parser.parse_args(argv)
touched: list[Path] = []
self_path = Path(__file__).resolve()
for entry in args.files:
path = Path(entry)
# Skip modifying this script to avoid self-edit loops.
if path.resolve() == self_path:
continue
if not path.exists() or path.is_dir():
continue
if process_file(path):
touched.append(path)
if touched:
for path in touched:
print(f"Adjusted kwarg spacing in {path}")
return 0
if __name__ == "__main__":
sys.exit(main(sys.argv[1:]))
================================================
FILE: scripts/run_ruff_format.py
================================================
#!/usr/bin/env python3
"""Run `ruff format` followed by kwarg spacing enforcement."""
from __future__ import annotations
import subprocess
import sys
from pathlib import Path
HERE = Path(__file__).resolve().parent
def main(argv: list[str]) -> int:
files = [arg for arg in argv if Path(arg).exists()]
if not files:
return 0
ruff_cmd = [sys.executable, "-m", "ruff", "format", *files]
ruff_proc = subprocess.run(ruff_cmd)
if ruff_proc.returncode != 0:
return ruff_proc.returncode
spacing_script = HERE / "enforce_kwargs_spacing.py"
spacing_cmd = [sys.executable, str(spacing_script), *files]
spacing_proc = subprocess.run(spacing_cmd)
return spacing_proc.returncode
if __name__ == "__main__":
raise SystemExit(main(sys.argv[1:]))
================================================
FILE: studio/LICENSE.AGPL-3.0
================================================
GNU AFFERO GENERAL PUBLIC LICENSE
Version 3, 19 November 2007
Copyright (C) 2007 Free Software Foundation, Inc.
### License
Unsloth uses a dual-licensing model of Apache 2.0 and AGPL-3.0. The core Unsloth package remains licensed under **[Apache 2.0](https://github.com/unslothai/unsloth?tab=Apache-2.0-1-ov-file)**, while certain optional components, such as the Unsloth Studio UI are licensed under the open-source license **[AGPL-3.0](https://github.com/unslothai/unsloth?tab=AGPL-3.0-2-ov-file)**.
This structure helps support ongoing Unsloth development while keeping the project open source and enabling the broader ecosystem to continue growing.
### Thank You to
- The [llama.cpp library](https://github.com/ggml-org/llama.cpp) that lets users run and save models with Unsloth
- The Hugging Face team and their libraries: [transformers](https://github.com/huggingface/transformers) and [TRL](https://github.com/huggingface/trl)
- The Pytorch and [Torch AO](https://github.com/unslothai/unsloth/pull/3391) team for their contributions
- And of course for every single person who has contributed or has used Unsloth!
================================================
FILE: build.sh
================================================
#!/usr/bin/env bash
set -euo pipefail
# 1. Build frontend (Vite outputs to dist/)
cd studio/frontend
# Clean stale dist to force a full rebuild
rm -rf dist
# Tailwind v4's oxide scanner respects .gitignore in parent directories.
# Python venvs create a .gitignore with "*" (ignore everything), which
# prevents Tailwind from scanning .tsx source files for class names.
# Temporarily hide any such .gitignore during the build, then restore it.
_HIDDEN_GITIGNORES=()
_dir="$(pwd)"
while [ "$_dir" != "/" ]; do
_dir="$(dirname "$_dir")"
if [ -f "$_dir/.gitignore" ] && grep -qx '\*' "$_dir/.gitignore" 2>/dev/null; then
mv "$_dir/.gitignore" "$_dir/.gitignore._twbuild"
_HIDDEN_GITIGNORES+=("$_dir/.gitignore")
fi
done
_restore_gitignores() {
for _gi in "${_HIDDEN_GITIGNORES[@]+"${_HIDDEN_GITIGNORES[@]}"}"; do
mv "${_gi}._twbuild" "$_gi" 2>/dev/null || true
done
}
trap _restore_gitignores EXIT
npm install
npm run build # outputs to studio/frontend/dist/
_restore_gitignores
trap - EXIT
# Validate CSS output -- catch truncated Tailwind builds before packaging
MAX_CSS_SIZE=$(find dist/assets -name '*.css' -exec wc -c {} + 2>/dev/null | sort -n | tail -1 | awk '{print $1}')
if [ -z "$MAX_CSS_SIZE" ]; then
echo "❌ ERROR: No CSS files were emitted into dist/assets."
echo " The frontend build may have failed silently."
exit 1
fi
if [ "$MAX_CSS_SIZE" -lt 100000 ]; then
echo "❌ ERROR: Largest CSS file is only $((MAX_CSS_SIZE / 1024))KB (expected >100KB)."
echo " Tailwind may not have scanned all source files."
echo " Check for .gitignore files blocking the Tailwind oxide scanner."
exit 1
fi
echo "✅ Frontend CSS validated (${MAX_CSS_SIZE} bytes)"
cd ../..
# 2. Clean old artifacts
rm -rf build dist *.egg-info
# 3. Build wheel
python -m build
# 4. Optionally publish
if [ "${1:-}" = "publish" ]; then
python -m twine upload dist/*
fi
================================================
FILE: cli.py
================================================
# SPDX-License-Identifier: AGPL-3.0-only
# Copyright 2026-present the Unsloth AI Inc. team. All rights reserved. See /studio/LICENSE.AGPL-3.0
from unsloth_cli import app
if __name__ == "__main__":
app()
================================================
FILE: install.ps1
================================================
# Unsloth Studio Installer for Windows PowerShell
# Usage: irm https://raw.githubusercontent.com/unslothai/unsloth/main/install.ps1 | iex
# Local: Set-ExecutionPolicy -Scope Process -ExecutionPolicy Bypass; .\install.ps1
function Install-UnslothStudio {
$ErrorActionPreference = "Stop"
$VenvName = "unsloth_studio"
$PythonVersion = "3.13"
Write-Host ""
Write-Host "========================================="
Write-Host " Unsloth Studio Installer (Windows)"
Write-Host "========================================="
Write-Host ""
# ── Helper: refresh PATH from registry (preserving current session entries) ──
function Refresh-SessionPath {
$machine = [System.Environment]::GetEnvironmentVariable("Path", "Machine")
$user = [System.Environment]::GetEnvironmentVariable("Path", "User")
$env:Path = "$machine;$user;$env:Path"
}
# ── Check winget ──
if (-not (Get-Command winget -ErrorAction SilentlyContinue)) {
Write-Host "Error: winget is not available." -ForegroundColor Red
Write-Host " Install it from https://aka.ms/getwinget" -ForegroundColor Yellow
Write-Host " or install Python $PythonVersion and uv manually, then re-run." -ForegroundColor Yellow
return
}
# ── Install Python if no compatible version (3.11-3.13) found ──
$DetectedPythonVersion = ""
if (Get-Command python -ErrorAction SilentlyContinue) {
$pyVer = python --version 2>&1
if ($pyVer -match "Python (3\.1[1-3])\.\d+") {
Write-Host "==> Python already installed: $pyVer"
$DetectedPythonVersion = $Matches[1]
}
}
if (-not $DetectedPythonVersion) {
Write-Host "==> Installing Python ${PythonVersion}..."
winget install -e --id Python.Python.3.13 --accept-package-agreements --accept-source-agreements
Refresh-SessionPath
if ($LASTEXITCODE -ne 0) {
# winget returns non-zero for "already installed" -- only fail if python is truly missing
if (-not (Get-Command python -ErrorAction SilentlyContinue)) {
Write-Host "[ERROR] Python installation failed (exit code $LASTEXITCODE)" -ForegroundColor Red
return
}
}
$DetectedPythonVersion = $PythonVersion
}
# ── Install uv if not present ──
if (-not (Get-Command uv -ErrorAction SilentlyContinue)) {
Write-Host "==> Installing uv package manager..."
winget install --id=astral-sh.uv -e --accept-package-agreements --accept-source-agreements
Refresh-SessionPath
# Fallback: if winget didn't put uv on PATH, try the PowerShell installer
if (-not (Get-Command uv -ErrorAction SilentlyContinue)) {
Write-Host " Trying alternative uv installer..."
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
Refresh-SessionPath
}
}
if (-not (Get-Command uv -ErrorAction SilentlyContinue)) {
Write-Host "Error: uv could not be installed." -ForegroundColor Red
Write-Host " Install it from https://docs.astral.sh/uv/" -ForegroundColor Yellow
return
}
# ── Create venv (skip if it already exists and has a valid interpreter) ──
$VenvPython = Join-Path $VenvName "Scripts\python.exe"
if (-not (Test-Path $VenvPython)) {
if (Test-Path $VenvName) { Remove-Item -Recurse -Force $VenvName }
Write-Host "==> Creating Python ${DetectedPythonVersion} virtual environment (${VenvName})..."
uv venv $VenvName --python $DetectedPythonVersion
if ($LASTEXITCODE -ne 0) {
Write-Host "[ERROR] Failed to create virtual environment (exit code $LASTEXITCODE)" -ForegroundColor Red
return
}
} else {
Write-Host "==> Virtual environment ${VenvName} already exists, skipping creation."
}
# ── Install unsloth directly into the venv (no activation needed) ──
Write-Host "==> Installing unsloth (this may take a few minutes)..."
uv pip install --python $VenvPython unsloth --torch-backend=auto
if ($LASTEXITCODE -ne 0) {
Write-Host "[ERROR] Failed to install unsloth (exit code $LASTEXITCODE)" -ForegroundColor Red
return
}
# ── Run studio setup ──
# setup.ps1 will handle installing Git, CMake, Visual Studio Build Tools,
# CUDA Toolkit, Node.js, and other dependencies automatically via winget.
Write-Host "==> Running unsloth studio setup..."
$UnslothExe = Join-Path $VenvName "Scripts\unsloth.exe"
& $UnslothExe studio setup
if ($LASTEXITCODE -ne 0) {
Write-Host "[ERROR] unsloth studio setup failed (exit code $LASTEXITCODE)" -ForegroundColor Red
return
}
Write-Host ""
Write-Host "========================================="
Write-Host " Unsloth Studio installed!"
Write-Host "========================================="
Write-Host ""
Write-Host " To launch, run:"
Write-Host ""
Write-Host " .\${VenvName}\Scripts\activate"
Write-Host " unsloth studio -H 0.0.0.0 -p 8888"
Write-Host ""
}
Install-UnslothStudio
================================================
FILE: install.sh
================================================
#!/bin/sh
# Unsloth Studio Installer
# Usage (curl): curl -fsSL https://raw.githubusercontent.com/unslothai/unsloth/main/install.sh | sh
# Usage (wget): wget -qO- https://raw.githubusercontent.com/unslothai/unsloth/main/install.sh | sh
set -e
VENV_NAME="unsloth_studio"
PYTHON_VERSION="3.13"
# ── Helper: download a URL to a file (supports curl and wget) ──
download() {
if command -v curl >/dev/null 2>&1; then
curl -LsSf "$1" -o "$2"
elif command -v wget >/dev/null 2>&1; then
wget -qO "$2" "$1"
else
echo "Error: neither curl nor wget found. Install one and re-run."
exit 1
fi
}
# ── Helper: check if a single package is available on the system ──
_is_pkg_installed() {
case "$1" in
build-essential) command -v gcc >/dev/null 2>&1 ;;
libcurl4-openssl-dev)
command -v dpkg >/dev/null 2>&1 && dpkg -s "$1" >/dev/null 2>&1 ;;
pciutils)
command -v lspci >/dev/null 2>&1 ;;
*) command -v "$1" >/dev/null 2>&1 ;;
esac
}
# ── Helper: install packages via apt, escalating to sudo only if needed ──
# Usage: _smart_apt_install pkg1 pkg2 pkg3 ...
_smart_apt_install() {
_PKGS="$*"
# Step 1: Try installing without sudo (works when already root)
apt-get update -y /dev/null 2>&1 || true
apt-get install -y $_PKGS /dev/null 2>&1 || true
# Step 2: Check which packages are still missing
_STILL_MISSING=""
for _pkg in $_PKGS; do
if ! _is_pkg_installed "$_pkg"; then
_STILL_MISSING="$_STILL_MISSING $_pkg"
fi
done
_STILL_MISSING=$(echo "$_STILL_MISSING" | sed 's/^ *//')
if [ -z "$_STILL_MISSING" ]; then
return 0
fi
# Step 3: Escalate -- need elevated permissions for remaining packages
if command -v sudo >/dev/null 2>&1; then
echo ""
echo " !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!"
echo " WARNING: We require sudo elevated permissions to install:"
echo " $_STILL_MISSING"
echo " If you accept, we'll run sudo now, and it'll prompt your password."
echo " !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!"
echo ""
printf " Accept? [Y/n] "
if [ -r /dev/tty ]; then
read -r REPLY /dev/null; then
OS="wsl"
fi
echo "==> Platform: $OS"
# ── Check system dependencies ──
# cmake and git are needed by unsloth studio setup to build the GGUF inference
# engine (llama.cpp). build-essential and libcurl-dev are also needed on Linux.
MISSING=""
command -v cmake >/dev/null 2>&1 || MISSING="$MISSING cmake"
command -v git >/dev/null 2>&1 || MISSING="$MISSING git"
case "$OS" in
macos)
# Xcode Command Line Tools provide the C/C++ compiler
if ! xcode-select -p >/dev/null 2>&1; then
echo ""
echo "==> Xcode Command Line Tools are required."
echo " Installing (a system dialog will appear)..."
xcode-select --install /dev/null || true
echo " After the installation completes, please re-run this script."
exit 1
fi
;;
linux|wsl)
# curl or wget is needed for downloads; check both
if ! command -v curl >/dev/null 2>&1 && ! command -v wget >/dev/null 2>&1; then
MISSING="$MISSING curl"
fi
command -v gcc >/dev/null 2>&1 || MISSING="$MISSING build-essential"
# libcurl dev headers for llama.cpp HTTPS support
if command -v dpkg >/dev/null 2>&1; then
dpkg -s libcurl4-openssl-dev >/dev/null 2>&1 || MISSING="$MISSING libcurl4-openssl-dev"
fi
;;
esac
MISSING=$(echo "$MISSING" | sed 's/^ *//')
if [ -n "$MISSING" ]; then
echo ""
echo "==> Unsloth Studio needs these packages: $MISSING"
echo " These are needed to build the GGUF inference engine."
case "$OS" in
macos)
if ! command -v brew >/dev/null 2>&1; then
echo ""
echo " Homebrew is required to install them."
echo " Install Homebrew from https://brew.sh then re-run this script."
exit 1
fi
brew install $MISSING /dev/null 2>&1; then
_smart_apt_install $MISSING
else
echo " apt-get is not available. Please install with your package manager:"
echo " $MISSING"
echo " Then re-run Unsloth Studio setup."
exit 1
fi
;;
esac
echo ""
else
echo "==> All system dependencies found."
fi
# ── Install uv ──
if ! command -v uv >/dev/null 2>&1; then
echo "==> Installing uv package manager..."
_uv_tmp=$(mktemp)
download "https://astral.sh/uv/install.sh" "$_uv_tmp"
sh "$_uv_tmp" Creating Python ${PYTHON_VERSION} virtual environment (${VENV_NAME})..."
uv venv "$VENV_NAME" --python "$PYTHON_VERSION"
else
echo "==> Virtual environment ${VENV_NAME} already exists, skipping creation."
fi
# ── Install unsloth directly into the venv (no activation needed) ──
echo "==> Installing unsloth (this may take a few minutes)..."
uv pip install --python "$VENV_NAME/bin/python" unsloth --torch-backend=auto
# ── Run studio setup ──
# Ensure the venv's Python is on PATH for setup.sh's Python discovery.
# On macOS the system Python may be outside the 3.11-3.13 range that
# setup.sh requires, but uv already installed a compatible interpreter
# inside the venv.
VENV_ABS_BIN="$(cd "$VENV_NAME/bin" && pwd)"
if [ -n "$VENV_ABS_BIN" ]; then
export PATH="$VENV_ABS_BIN:$PATH"
fi
echo "==> Running unsloth studio setup..."
"$VENV_NAME/bin/unsloth" studio setup =3.0.0 ; ('linux' in sys_platform)",
"triton-windows ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
huggingfacenotorch = [
"wheel>=0.42.0",
"packaging",
"numpy",
"tqdm",
"psutil",
"tyro",
"protobuf",
"sentencepiece>=0.2.0",
"datasets>=3.4.1,!=4.0.*,!=4.1.0,<4.4.0",
"accelerate>=0.34.1",
"peft>=0.18.0,!=0.11.0",
"huggingface_hub>=0.34.0",
"hf_transfer",
"diffusers",
"transformers>=4.51.3,!=4.52.0,!=4.52.1,!=4.52.2,!=4.52.3,!=4.53.0,!=4.54.0,!=4.55.0,!=4.55.1,!=4.57.0,!=4.57.4,!=4.57.5,!=5.0.0,!=5.1.0,<=5.3.0",
"trl>=0.18.2,!=0.19.0,<=0.24.0",
"sentence-transformers",
]
huggingface = [
"unsloth[huggingfacenotorch]",
"unsloth_zoo>=2026.3.4",
"torchvision",
"unsloth[triton]",
]
windows = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0 ; (sys_platform == 'win32')",
"xformers>=0.0.22.post7 ; (sys_platform == 'win32')",
]
base = [
"unsloth[huggingface]",
]
cu118only = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.22.post7%2Bcu118-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.22.post7%2Bcu118-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.22.post7%2Bcu118-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu121only = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.22.post7-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.22.post7-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.22.post7-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu118onlytorch211 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.23%2Bcu118-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.23%2Bcu118-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.23%2Bcu118-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu121onlytorch211 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.23-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.23-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.23-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu118onlytorch212 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.23.post1%2Bcu118-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.23.post1%2Bcu118-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.23.post1%2Bcu118-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu121onlytorch212 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.23.post1-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.23.post1-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.23.post1-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu118onlytorch220 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.24%2Bcu118-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.24%2Bcu118-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.24%2Bcu118-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu121onlytorch220 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.24-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.24-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.24-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
]
cu118onlytorch230 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27%2Bcu118-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27%2Bcu118-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27%2Bcu118-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27%2Bcu118-cp312-cp312-manylinux2014_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu121onlytorch230 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.27-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.27-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.27-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.27-cp312-cp312-manylinux2014_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu118onlytorch240 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27.post2%2Bcu118-cp39-cp39-manylinux2014_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27.post2%2Bcu118-cp310-cp310-manylinux2014_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27.post2%2Bcu118-cp311-cp311-manylinux2014_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.27.post2%2Bcu118-cp312-cp312-manylinux2014_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu121onlytorch240 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post1-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post1-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post1-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post1-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu124onlytorch240 = [
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post1-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu118onlytorch250 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.28.post2-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.28.post2-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.28.post2-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.28.post2-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu121onlytorch250 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post2-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post2-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post2-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.28.post2-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu124onlytorch250 = [
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.28.post2-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu118onlytorch251 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post1-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post1-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post1-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post1-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu121onlytorch251 = [
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.29.post1-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.29.post1-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.29.post1-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu121/xformers-0.0.29.post1-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu124onlytorch251 = [
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post1-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu118onlytorch260 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post3-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post3-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post3-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.29.post3-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
]
cu124onlytorch260 = [
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu124/xformers-0.0.29.post3-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu126onlytorch260 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.29.post3-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu118onlytorch270 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.30-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu126onlytorch270 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.30-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu128onlytorch270 = [
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp39-cp39-manylinux_2_28_x86_64.whl ; python_version=='3.9' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp310-cp310-manylinux_2_28_x86_64.whl ; python_version=='3.10' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp311-cp311-manylinux_2_28_x86_64.whl ; python_version=='3.11' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp312-cp312-manylinux_2_28_x86_64.whl ; python_version=='3.12' and ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp39-cp39-win_amd64.whl ; python_version=='3.9' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp310-cp310-win_amd64.whl ; python_version=='3.10' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp311-cp311-win_amd64.whl ; python_version=='3.11' and (sys_platform == 'win32')",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.30-cp312-cp312-win_amd64.whl ; python_version=='3.12' and (sys_platform == 'win32')",
]
cu118onlytorch271 = [
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.31.post1-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu118/xformers-0.0.31.post1-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu126onlytorch271 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.31.post1-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.31.post1-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu128onlytorch271 = [
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.31.post1-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.31.post1-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu118onlytorch280 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.32.post2-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.32.post2-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu126onlytorch280 = [
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.32.post2-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.32.post2-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu128onlytorch280 = [
"xformers @ https://download.pytorch.org/whl/cu129/xformers-0.0.32.post2-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu129/xformers-0.0.32.post2-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu130onlytorch280 = [
]
cu126onlytorch290 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.33.post1-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.33.post1-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu128onlytorch290 = [
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.33.post1-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.33.post1-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu130onlytorch290 = [
"xformers @ https://download.pytorch.org/whl/cu130/xformers-0.0.33.post1-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu130/xformers-0.0.33.post1-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu126onlytorch291 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.33.post2-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.33.post2-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu128onlytorch291 = [
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.33.post2-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.33.post2-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu130onlytorch291 = [
"xformers @ https://download.pytorch.org/whl/cu130/xformers-0.0.33.post2-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu130/xformers-0.0.33.post2-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu126onlytorch2100 = [
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.34-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu126/xformers-0.0.34-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu128onlytorch2100 = [
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.34-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu128/xformers-0.0.34-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu130onlytorch2100 = [
"xformers @ https://download.pytorch.org/whl/cu130/xformers-0.0.34-cp39-abi3-manylinux_2_28_x86_64.whl ; ('linux' in sys_platform)",
"xformers @ https://download.pytorch.org/whl/cu130/xformers-0.0.34-cp39-abi3-win_amd64.whl ; (sys_platform == 'win32')",
]
cu118 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118only]",
]
cu121 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121only]",
]
cu118-torch211 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu118onlytorch211]",
]
cu121-torch211 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu121onlytorch211]",
]
cu118-torch212 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu118onlytorch212]",
]
cu121-torch212 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu121onlytorch212]",
]
cu118-torch220 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch220]",
]
cu121-torch220 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch220]",
]
cu118-torch230 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch230]",
]
cu121-torch230 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch230]",
]
cu118-torch240 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch240]",
]
cu121-torch240 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch240]",
]
cu124-torch240 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch240]",
]
cu118-torch250 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch250]",
]
cu121-torch250 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch250]",
]
cu124-torch250 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch250]",
]
cu118-torch251 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch251]",
]
cu121-torch251 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch251]",
]
cu124-torch251 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch251]",
]
cu118-torch260 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch260]",
]
cu124-torch260 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch260]",
]
cu126-torch260 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch260]",
]
cu118-torch270 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch270]",
]
cu126-torch270 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch270]",
]
cu128-torch270 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch270]",
]
cu118-torch271 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch271]",
]
cu126-torch271 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch271]",
]
cu128-torch271 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch271]",
]
cu118-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch280]",
]
cu126-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch280]",
]
cu128-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch280]",
]
cu130-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch280]",
]
cu126-torch290 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch290]",
]
cu128-torch290 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch290]",
]
cu130-torch290 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch290]",
]
cu126-torch291 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch291]",
]
cu128-torch291 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch291]",
]
cu130-torch291 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch291]",
]
cu126-torch2100 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch2100]",
]
cu128-torch2100 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch2100]",
]
cu130-torch2100 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch2100]",
]
kaggle = [
"unsloth[huggingface]",
]
kaggle-new = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
]
conda = [
"unsloth[huggingface]",
]
colab-torch211 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu121onlytorch211]",
]
colab-ampere-torch211 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu121onlytorch211]",
"packaging",
"ninja",
"flash-attn>=2.6.3 ; ('linux' in sys_platform)",
]
colab-torch220 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch220]",
]
colab-ampere-torch220 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch220]",
"packaging",
"ninja",
"flash-attn>=2.6.3 ; ('linux' in sys_platform)",
]
colab-new = [
"unsloth_zoo>=2026.3.4",
"packaging",
"tyro",
"transformers>=4.51.3,!=4.52.0,!=4.52.1,!=4.52.2,!=4.52.3,!=4.53.0,!=4.54.0,!=4.55.0,!=4.55.1,!=4.57.0,!=4.57.4,!=4.57.5,!=5.0.0,!=5.1.0,<=5.3.0",
"datasets>=3.4.1,!=4.0.*,!=4.1.0,<4.4.0",
"sentencepiece>=0.2.0",
"tqdm",
"psutil",
"wheel>=0.42.0",
"numpy",
"protobuf",
"huggingface_hub>=0.34.0",
"hf_transfer",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[triton]",
"sentence-transformers",
]
colab-no-deps = [
"accelerate>=0.34.1",
"trl>=0.18.2,!=0.19.0,<=0.24.0",
"peft>=0.18.0",
"xformers ; ('linux' in sys_platform or sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"protobuf",
]
colab = [
"unsloth[cu121]",
]
flashattention = [
"packaging ; ('linux' in sys_platform)",
"ninja ; ('linux' in sys_platform)",
"flash-attn>=2.6.3 ; ('linux' in sys_platform)",
]
colab-ampere = [
"unsloth[colab-ampere-torch220]",
"unsloth[flashattention]",
]
cu118-ampere = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118only]",
"unsloth[flashattention]",
]
cu121-ampere = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121only]",
"unsloth[flashattention]",
]
cu118-ampere-torch211 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu118onlytorch211]",
"unsloth[flashattention]",
]
cu121-ampere-torch211 = [
"unsloth[huggingface]",
"bitsandbytes==0.45.5",
"unsloth[cu121onlytorch211]",
"unsloth[flashattention]",
]
cu118-ampere-torch220 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch220]",
"unsloth[flashattention]",
]
cu121-ampere-torch220 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch220]",
"unsloth[flashattention]",
]
cu118-ampere-torch230 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch230]",
"unsloth[flashattention]",
]
cu121-ampere-torch230 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch230]",
"unsloth[flashattention]",
]
cu118-ampere-torch240 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch240]",
"unsloth[flashattention]",
]
cu121-ampere-torch240 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch240]",
"unsloth[flashattention]",
]
cu124-ampere-torch240 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch240]",
"unsloth[flashattention]",
]
cu118-ampere-torch250 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch250]",
"unsloth[flashattention]",
]
cu121-ampere-torch250 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch250]",
"unsloth[flashattention]",
]
cu124-ampere-torch250 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch250]",
"unsloth[flashattention]",
]
cu118-ampere-torch251 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch251]",
"unsloth[flashattention]",
]
cu121-ampere-torch251 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu121onlytorch251]",
"unsloth[flashattention]",
]
cu124-ampere-torch251 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch251]",
"unsloth[flashattention]",
]
cu118-ampere-torch260 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch260]",
"unsloth[flashattention]",
]
cu124-ampere-torch260 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu124onlytorch260]",
"unsloth[flashattention]",
]
cu126-ampere-torch260 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch260]",
"unsloth[flashattention]",
]
cu118-ampere-torch270 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch270]",
"unsloth[flashattention]",
]
cu126-ampere-torch270 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch270]",
"unsloth[flashattention]",
]
cu128-ampere-torch270 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch270]",
"unsloth[flashattention]",
]
cu118-ampere-torch271 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch271]",
"unsloth[flashattention]",
]
cu126-ampere-torch271 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch271]",
"unsloth[flashattention]",
]
cu128-ampere-torch271 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch271]",
"unsloth[flashattention]",
]
cu118-ampere-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu118onlytorch280]",
"unsloth[flashattention]",
]
cu126-ampere-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch280]",
"unsloth[flashattention]",
]
cu128-ampere-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch280]",
"unsloth[flashattention]",
]
cu130-ampere-torch280 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch280]",
"unsloth[flashattention]",
]
cu126-ampere-torch290 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch290]",
]
cu128-ampere-torch290 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch290]",
]
cu130-ampere-torch290 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch290]",
]
cu126-ampere-torch291 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch291]",
]
cu128-ampere-torch291 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch291]",
]
cu130-ampere-torch291 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch291]",
]
cu126-ampere-torch2100 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu126onlytorch2100]",
]
cu128-ampere-torch2100 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu128onlytorch2100]",
]
cu130-ampere-torch2100 = [
"unsloth[huggingface]",
"bitsandbytes>=0.45.5,!=0.46.0,!=0.48.0",
"unsloth[cu130onlytorch2100]",
]
flashattentiontorch260abiFALSEcu12x = [
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp39-cp39-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.9'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp310-cp310-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.10'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp311-cp311-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.11'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp312-cp312-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.12'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiFALSE-cp313-cp313-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.13'",
]
flashattentiontorch260abiTRUEcu12x = [
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp39-cp39-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.9'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp310-cp310-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.10'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp311-cp311-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.11'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp312-cp312-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.12'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.6cxx11abiTRUE-cp313-cp313-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.13'",
]
flashattentiontorch250abiFALSEcu12x = [
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiFALSE-cp39-cp39-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.9'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiFALSE-cp310-cp310-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.10'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiFALSE-cp311-cp311-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.11'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiFALSE-cp312-cp312-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.12'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiFALSE-cp313-cp313-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.13'",
]
flashattentiontorch250abiTRUEcu12x = [
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiTRUE-cp39-cp39-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.9'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiTRUE-cp310-cp310-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.10'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiTRUE-cp311-cp311-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.11'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiTRUE-cp312-cp312-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.12'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.5cxx11abiTRUE-cp313-cp313-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.13'",
]
flashattentiontorch240abiFALSEcu12x = [
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiFALSE-cp39-cp39-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.9'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiFALSE-cp310-cp310-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.10'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiFALSE-cp311-cp311-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.11'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiFALSE-cp312-cp312-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.12'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiFALSE-cp313-cp313-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.13'",
]
flashattentiontorch240abiTRUEcu12x = [
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiTRUE-cp39-cp39-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.9'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiTRUE-cp310-cp310-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.10'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiTRUE-cp311-cp311-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.11'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiTRUE-cp312-cp312-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.12'",
"flash-attn @ https://github.com/Dao-AILab/flash-attention/releases/download/v2.7.4.post1/flash_attn-2.7.4.post1+cu12torch2.4cxx11abiTRUE-cp313-cp313-linux_x86_64.whl ; ('linux' in sys_platform) and python_version == '3.13'",
]
intelgputorch260 = [
"unsloth_zoo[intelgpu]",
"unsloth[huggingfacenotorch]",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.2.0-cp39-cp39-linux_x86_64.whl#sha256=147607f190a7d7aa24ba454def5977fbbfec792fdae18e4ed278cfec29b69271 ; ('linux' in sys_platform) and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.2.0-cp310-cp310-linux_x86_64.whl#sha256=23aa423fa1542afc34f67eb3ba8ef20060f6d1b3a4697eaeab22b11c92b30f2b ; ('linux' in sys_platform) and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.2.0-cp311-cp311-linux_x86_64.whl#sha256=bcfa995229bbfd9ffd8d6c8d9f6428d393e876fa6e23ee3c20e3c0d73ca75ca5 ; ('linux' in sys_platform) and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.2.0-cp312-cp312-linux_x86_64.whl#sha256=bd340903d03470708df3442438acb8b7e08087ab9e61fbe349b2872bf9257ab0 ; ('linux' in sys_platform) and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.2.0-cp313-cp313-linux_x86_64.whl#sha256=814dccc8a07159e6eca74bed70091bc8fea2d9dd87b0d91845f9f38cde62f01c ; ('linux' in sys_platform) and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-manylinux_2_24_x86_64.whl ; ('linux' in sys_platform) and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-win_amd64.whl ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.6.0%2Bxpu-cp39-cp39-linux_x86_64.whl#sha256=6a8adf6dc4c089406e8b3a7e58ab57a463bddf9b07130d2576e76eced43e92af ; ('linux' in sys_platform) and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.6.0%2Bxpu-cp310-cp310-linux_x86_64.whl#sha256=ff4561cbf07c83bbccaa0f6e9bb0e6dcf721bacd53c9c43c4eb0e7331b4792f9 ; ('linux' in sys_platform) and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.6.0%2Bxpu-cp311-cp311-linux_x86_64.whl#sha256=12005f66b810ddd3ab93f86c4522bcfdd412cbd27fc9d189b661ff7509bc5e8a ; ('linux' in sys_platform) and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.6.0%2Bxpu-cp312-cp312-linux_x86_64.whl#sha256=c4c5c67625cdacf35765c2b94e61fe166e3c3f4a14521b1212a59ad1b3eb0f2e ; ('linux' in sys_platform) and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.6.0%2Bxpu-cp313-cp313-linux_x86_64.whl#sha256=e6864f7a60a5ecc43d5d38f59a16e5dd132384f73dfd3a697f74944026038f7b ; ('linux' in sys_platform) and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
intel-gpu-torch260 = [
"unsloth[intelgputorch260]"
]
intelgputorch270 = [
"unsloth_zoo[intelgpu]",
"unsloth[huggingfacenotorch]",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp39-cp39-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=749a7098492c6a27b356c97149a4a62973b953eae60bc1b6259260974f344913 ; ('linux' in sys_platform) and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=44362e80abd752471a08341093321955b066daa2cfb4810e73b8e3b240850f93 ; ('linux' in sys_platform) and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=faa6b8c945a837a080f641bc8ccc77a98fa66980dcd7e62e715fd853737343fd ; ('linux' in sys_platform) and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=40f6fb65b345dc9a61813abe7ac9a585f2c9808f414d140cc2a5f11f53ee063c ; ('linux' in sys_platform) and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=b22b4c02ec71b4bfc862ae3cdfd2871dc0b05d2b1802f5db2196e0f897d581e9 ; ('linux' in sys_platform) and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp39-cp39-win_amd64.whl#sha256=d4b738d7fa5100c1bd766f91614962828a4810eb57b4df92cd5214a83505a752 ; sys_platform == 'win32' and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp310-cp310-win_amd64.whl#sha256=143fe8a64d807bcdb7d81bbc062816add325570aa160448454ab6ded4a0a17a1 ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp311-cp311-win_amd64.whl#sha256=a8025459ff325d6e3532eb5cf72519db1b178155e7d60aff6c56beb5968fc758 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp312-cp312-win_amd64.whl#sha256=0dd07e6d5b872e42e48f5ee140e609d4554ca3cc509d5bf509ac232267cf358e ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.3.0-cp313-cp313-win_amd64.whl#sha256=a936a18182d8e065a9933afc9a3ebbffadd38604969f87c493831214539fc027 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-manylinux_2_24_x86_64.whl ; ('linux' in sys_platform) and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-win_amd64.whl ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp39-cp39-linux_x86_64.whl#sha256=f8ee75e50fcbb37ed5b498299ca2264da99ab278a93fae2358e921e4a6e28273 ; ('linux' in sys_platform) and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp310-cp310-linux_x86_64.whl#sha256=d6fdc342961d98fdcd9d03dfd491a3208bb5f7fbb435841f8f72ce9fdcd2d026 ; ('linux' in sys_platform) and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp311-cp311-linux_x86_64.whl#sha256=74d07f9357df5cf2bf223ad3c84de16346bfaa0504f988fdd5590d3e177e5e86 ; ('linux' in sys_platform) and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp312-cp312-linux_x86_64.whl#sha256=c806d44aa2ca5d225629f6fbc6c994d5deaac2d2cde449195bc8e3522ddd219a ; ('linux' in sys_platform) and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp313-cp313-linux_x86_64.whl#sha256=25d8277b7f01d42e2e014ccbab57a2692b6ec4eff8dcf894eda1b297407cf97a ; ('linux' in sys_platform) and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp39-cp39-win_amd64.whl#sha256=046e85125266ae69c1a0d083e6c092f947ab4b6b41532c16bafe40dbced845df ; sys_platform == 'win32' and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=9ebaeffb82b0b3e39b6030927d3ebe0eb62a0e9045a3b2d7b0a9e7b15222c0db ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=356ba66cee127e7e2c942880bd50e03768306a4ea08d358a0f29c6eebfc4bc81 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=94739e665d9b4d5cd7af5f517cb6103f6f9fb421c095184609653a24524040f5 ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.7.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=31df3cb674918e89bc8c532baa331dc84f4430e1f9c0ec379232db44cba78355 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
intel-gpu-torch270 = [
"unsloth[intelgputorch270]"
]
intelgputorch280 = [
"unsloth_zoo[intelgpu]",
"unsloth[huggingfacenotorch]",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp39-cp39-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=ac4d8e33986b1c3c5e48151640539272b2187e83016985853111b46fb82c3c94 ; 'linux' in sys_platform and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=999fef4c1f711092b9d3086525920545df490de476ecebe899ffc777019ae17f ; 'linux' in sys_platform and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=57b09c8c492985ff6a27cd3a22b08e8f7b96b407bd8030967b6efbb9f63b80cf ; 'linux' in sys_platform and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=df4bb3282bac9a3b90231700077110d8680b338416de03c2b7c6133c9b602649 ; 'linux' in sys_platform and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=60da63c99ca827bdcb0df28e0298bf7d066dc607454c6d6176783cb4e79d838b ; 'linux' in sys_platform and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp39-cp39-win_amd64.whl#sha256=64aea8de349f3e2e0ebf4c24b011a8122531fdffda5776edaef45829cc241cf8 ; sys_platform == 'win32' and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp310-cp310-win_amd64.whl#sha256=ae573d255b257fdbed319a3440dc9d0a721e31160ab7f6eba1b2226e6a409a1d ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp311-cp311-win_amd64.whl#sha256=8e0ea4558e5776d8ddab0264310be9b26aee5641bcac0da023537556d4317b86 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp312-cp312-win_amd64.whl#sha256=4090dde07a4fffc34aaf855701a9db28e9fccb57b368ade520f1a0f8e811c878 ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.4.0-cp313-cp313-win_amd64.whl#sha256=a33d0888f3c8df028a2d028842715837d0049524d6c06b9bb11869890a13601a ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp39-cp39-linux_x86_64.whl ; 'linux' in sys_platform and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp310-cp310-linux_x86_64.whl ; 'linux' in sys_platform and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp311-cp311-linux_x86_64.whl ; 'linux' in sys_platform and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp312-cp312-linux_x86_64.whl ; 'linux' in sys_platform and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp313-cp313-linux_x86_64.whl ; 'linux' in sys_platform and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp39-cp39-win_amd64.whl#sha256=f2f401276892428e4875cf1d8717c5cbab704b16fc594ccf23795e7b16549a99 ; sys_platform == 'win32' and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=125c60cd59d51b39581a7e9afcd4679bc3a6b8c1f9440b1bb502a23fdd60571e ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=47f1a57258cd460e80b38b2ed6744e31587ab77a96b4215bf59546cb4bab5cc0 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=0937d8943c145a83d9bafc6f80ef28971167817f9eda26066d33f72caf8a6646 ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.8.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=e034aab1d71760dc80a731531be43673ffe15e99033b82d24e40d2e6d41bd8bf ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-manylinux_2_24_x86_64.whl ; ('linux' in sys_platform) and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-win_amd64.whl ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp39-cp39-manylinux_2_28_x86_64.whl#sha256=6e981c192045fc249c008441179ff237bb00174d818b875b0475730b63f0eaca ; 'linux' in sys_platform and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp310-cp310-manylinux_2_28_x86_64.whl#sha256=e5ba4805969277175ebfd59cc717093528cc6e3ada89ac2725fc7a3c1fee6169 ; 'linux' in sys_platform and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp311-cp311-manylinux_2_28_x86_64.whl#sha256=74c39c144104416bc4c5ad8c26ab0c169dc5cc6be58059e01bc3665dd0ef676f ; 'linux' in sys_platform and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp312-cp312-manylinux_2_28_x86_64.whl#sha256=0acec355b80c3899841184084f365df336c508602812e34a44007b8b60d53af4 ; 'linux' in sys_platform and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp313-cp313-manylinux_2_28_x86_64.whl#sha256=e2109ae773dad27b98ca17681044b4f876563c37f2382b75de3a371399edcff8 ; 'linux' in sys_platform and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp39-cp39-win_amd64.whl#sha256=5f7904e7048d414379bc8c1167260f1e84204f105db2d0a2f9c89e87ce1cf205 ; sys_platform == 'win32' and python_version == '3.9' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=005fca5e658ca8e37adb63c1a021c84f5e56dfa6cf0d601d89cfe40b9473f79f ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=c6d030f5361461550c0ff1339b5bca8585fc1e84fda2e64b6184e65a581e4f98 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=91aafd61864cdce27461cbec13ddbf28c1bc6494265a1e4b80131c64a3b7d18f ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.23.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=71dc4a6421742ed1e7f585b04a100ad53615c341fbccfbc255aefb38ea9091da ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
intel-gpu-torch280 = [
"unsloth[intelgputorch280]"
]
intelgputorch290 = [
"unsloth_zoo[intelgpu]",
"unsloth[huggingfacenotorch]",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=c169a1de14c19673b17c751290d467fa282fc90fa5da4314b2e5cdab1f553146 ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=013d9dd5d6479bd22983161f462e61c8dbe1d82e6730624a7a8d5945507eaa61 ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=afc8cabfbf7ed51fd278d1e0f88d6afc157b0201bad4b99d681e4d542f9e66d4 ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=0d24c1716088f2764d0d24c64227732195b6a42706c3c5fc89eeb4904bfa0818 ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp310-cp310-win_amd64.whl#sha256=c83ab007311d9cfb6e809ee5a4587d99a9eef4be720b90da4f1aaa68b45139a0 ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp311-cp311-win_amd64.whl#sha256=debf75348da8e8c7166b4d4a9b91d1508bb8d6581e339f79f7604b2e6746bacd ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp312-cp312-win_amd64.whl#sha256=97337a47425f1963a723475bd61037460e84ba01db4f87a1d662c3718ff6c47e ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp313-cp313-win_amd64.whl#sha256=2caf8138695f6abb023ecd02031a2611ba1bf8fff2f19802567cb2fadefe9e87 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp310-cp310-linux_x86_64.whl#sha256=5afbe860ce991825a36b75706a523601087e414b77598ef0d9d3d565741c277d ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp311-cp311-linux_x86_64.whl#sha256=607fe419c32d6e8e0556f745742e7cff1d0babce51f54be890e0c1422359c442 ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp312-cp312-linux_x86_64.whl#sha256=376bae584d89980b8e59934d248c38d5fa3b7d4687a4df1a19f4bc1d23dcc8c1 ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp313-cp313-linux_x86_64.whl#sha256=98d6a06dd7fb185874367b18bd609f05f16fdce4142a5980ca94461949965cd2 ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=47cc68f631f65bd9c84924d052cd04dec7531023caa85e80345e9c94611c887d ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=d56c44ab4818aba57e5c7b628f422d014e0d507427170a771c5be85e308b0bc6 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=18cad93aaff76a01ce73aef6935ece7cfc03344b905592ec731446c44d44592b ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.9.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=579929cdc10a76800ead41289cac191ea36d1b16f5f501d3fc25607d4375cd83 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-manylinux_2_24_x86_64.whl ; ('linux' in sys_platform) and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-win_amd64.whl ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp310-cp310-manylinux_2_28_x86_64.whl#sha256=cbfae2b79b7549fd368c2462fc8e94f8f26cc450782ee72138e908077c09a519 ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp311-cp311-manylinux_2_28_x86_64.whl#sha256=044fa36ef4b6b43edcd490b75c853fa4b3eb033c2bded29f8fbcf27734713c67 ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp312-cp312-manylinux_2_28_x86_64.whl#sha256=4b91e4bec1d740a6211f02578a79888550b73f3a4e1383035f8f6d72f587212c ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp313-cp313-manylinux_2_28_x86_64.whl#sha256=88239e73ca37254bec84f29cd5887e10ff712de7edbbda3fbb3609cd6190d99e ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=19c7da8ca767d593e13a88a12bb08d06e34a673f6f26c2f9c191d60e81c02953 ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=9bb0d1421c544ac8e2eca5b47daacaf54706dc9139c003aa5e77ee5f355c5931 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=6a5194bc736089606342d48a3f6822829b167617e9495d91d753dd1bd46fda18 ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.24.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=da47a3ce2bb7f0301a31124668b5908f9b9e92d6241443de15a310ef9632fd83 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
intel-gpu-torch290 = [
"unsloth[intelgputorch290]"
]
intelgputorch210 = [
"unsloth_zoo[intelgpu]",
"unsloth[huggingfacenotorch]",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp310-cp310-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=c169a1de14c19673b17c751290d467fa282fc90fa5da4314b2e5cdab1f553146 ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp311-cp311-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=013d9dd5d6479bd22983161f462e61c8dbe1d82e6730624a7a8d5945507eaa61 ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp312-cp312-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=afc8cabfbf7ed51fd278d1e0f88d6afc157b0201bad4b99d681e4d542f9e66d4 ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp313-cp313-manylinux_2_27_x86_64.manylinux_2_28_x86_64.whl#sha256=0d24c1716088f2764d0d24c64227732195b6a42706c3c5fc89eeb4904bfa0818 ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp310-cp310-win_amd64.whl#sha256=c83ab007311d9cfb6e809ee5a4587d99a9eef4be720b90da4f1aaa68b45139a0 ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp311-cp311-win_amd64.whl#sha256=debf75348da8e8c7166b4d4a9b91d1508bb8d6581e339f79f7604b2e6746bacd ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp312-cp312-win_amd64.whl#sha256=97337a47425f1963a723475bd61037460e84ba01db4f87a1d662c3718ff6c47e ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"pytorch_triton_xpu @ https://download.pytorch.org/whl/pytorch_triton_xpu-3.5.0-cp313-cp313-win_amd64.whl#sha256=2caf8138695f6abb023ecd02031a2611ba1bf8fff2f19802567cb2fadefe9e87 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp310-cp310-linux_x86_64.whl#sha256=abb1d1ec1ac672bac0ff35420c965f2df0c636ef9d94e2a830e34578489d0a57 ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp311-cp311-linux_x86_64.whl#sha256=71ad2f82da0f41eaec159f39fc85854e27c2391efa91b373e550648a6f4aaad3 ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp312-cp312-linux_x86_64.whl#sha256=b473571d478912f92881cc13f15fa18f8463fb0fb8a068c96ed47a7d45a4da0a ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp313-cp313-linux_x86_64.whl#sha256=3bc64a746ff25a93de140902c60c9e819d7413f5cea1e88d80999c27a5901e9c ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=ce50691ab3fb6301d9b7bb8b3834cf5fa7152a2b5f91fd24c5efdc601a25b780 ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=cb9d37f21cb9fb7df67d62863f021c3144e8d8832b9ea8e8523ac308bc620ea1 ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=3ad605be4728b6d3a28a44d07dd794b1a9e45551b0057815bf25eb2a6d6a56a7 ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torch @ https://download.pytorch.org/whl/xpu/torch-2.10.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=2b4b56dd6c792aef82006904fa888692e3782e4ae5da27526801bad4898f05a5 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-manylinux_2_24_x86_64.whl ; ('linux' in sys_platform) and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"bitsandbytes @ https://github.com/bitsandbytes-foundation/bitsandbytes/releases/download/continuous-release_main/bitsandbytes-1.33.7.preview-py3-none-win_amd64.whl ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp310-cp310-manylinux_2_28_x86_64.whl#sha256=7e1e7b170fcf7161c8499b67156c5a05462243626dc0974010791a0bab4378d3 ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp311-cp311-manylinux_2_28_x86_64.whl#sha256=bd6add201bd7628af70437292e1447abb368e0b5f4ff9abd334ae435efd44792 ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp312-cp312-manylinux_2_28_x86_64.whl#sha256=6ad2543496bc29e59d3dd614a94d09aa9870318aedb66045344fffddfedd2cf8 ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp313-cp313-manylinux_2_28_x86_64.whl#sha256=80269f37865fcd8b57f20e4786efae2200bfa2b2727926c3c7acc82f0e7d3548 ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp310-cp310-win_amd64.whl#sha256=6b9485ba85dcba4d196d6134d9c3332fb228fb2556416bf0450a64e8a472fcba ; sys_platform == 'win32' and python_version == '3.10' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp311-cp311-win_amd64.whl#sha256=36cbaedf10f6412af5c89afd9aeea474e6a56a0050348ada8fabe1ecaf6b879e ; sys_platform == 'win32' and python_version == '3.11' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp312-cp312-win_amd64.whl#sha256=738357d97468d75fe3d510ac37e65130f2787f81d9bbc1518898f7396dc3403f ; sys_platform == 'win32' and python_version == '3.12' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
"torchvision @ https://download.pytorch.org/whl/xpu/torchvision-0.25.0%2Bxpu-cp313-cp313-win_amd64.whl#sha256=1c4b44b36a557f7381e3076fb8843366742238648441d607c8d049c6da0f8886 ; sys_platform == 'win32' and python_version == '3.13' and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
intel-gpu-torch210 = [
"unsloth[intelgputorch210]"
]
intel = [
"unsloth[intelgputorch280]",
]
amd = [
"unsloth[huggingfacenotorch]",
"bitsandbytes>=0.49.1 ; ('linux' in sys_platform) and (platform_machine == 'AMD64' or platform_machine == 'x86_64' or platform_machine == 'aarch64')",
"bitsandbytes>=0.49.1 ; (sys_platform == 'win32') and (platform_machine == 'AMD64' or platform_machine == 'x86_64')",
]
rocm702-torch280 = [
"unsloth[amd]",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/triton-3.4.0%2Brocm7.0.2.gitf9e5bf54-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/triton-3.4.0%2Brocm7.0.2.gitf9e5bf54-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/triton-3.4.0%2Brocm7.0.2.gitf9e5bf54-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/torch-2.8.0%2Brocm7.0.2.lw.git245bf6ed-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/torch-2.8.0%2Brocm7.0.2.lw.git245bf6ed-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/torch-2.8.0%2Brocm7.0.2.lw.git245bf6ed-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/torchvision-0.23.0%2Brocm7.0.2.git824e8c87-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/torchvision-0.23.0%2Brocm7.0.2.git824e8c87-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.0.2/torchvision-0.23.0%2Brocm7.0.2.git824e8c87-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
]
rocm72-torch291 = [
"unsloth[amd]",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.5.1%2Brocm7.2.0.gita272dfa8-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.5.1%2Brocm7.2.0.gita272dfa8-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.5.1%2Brocm7.2.0.gita272dfa8-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.5.1%2Brocm7.2.0.gita272dfa8-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.9.1%2Brocm7.2.0.lw.git7e1940d4-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.9.1%2Brocm7.2.0.lw.git7e1940d4-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.9.1%2Brocm7.2.0.lw.git7e1940d4-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.9.1%2Brocm7.2.0.lw.git7e1940d4-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/windows/rocm-rel-7.2/torch-2.9.1%2Brocmsdk20260116-cp312-cp312-win_amd64.whl ; sys_platform == 'win32' and python_version == '3.12'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.24.0%2Brocm7.2.0.gitb919bd0c-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.24.0%2Brocm7.2.0.gitb919bd0c-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.24.0%2Brocm7.2.0.gitb919bd0c-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.24.0%2Brocm7.2.0.gitb919bd0c-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/windows/rocm-rel-7.2/torchvision-0.24.1%2Brocmsdk20260116-cp312-cp312-win_amd64.whl ; sys_platform == 'win32' and python_version == '3.12'",
]
rocm711-torch291 = [
"unsloth[amd]",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.5.1%2Brocm7.1.1.gita272dfa8-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.5.1%2Brocm7.1.1.gita272dfa8-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.5.1%2Brocm7.1.1.gita272dfa8-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.5.1%2Brocm7.1.1.gita272dfa8-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.9.1%2Brocm7.1.1.lw.git351ff442-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.9.1%2Brocm7.1.1.lw.git351ff442-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.9.1%2Brocm7.1.1.lw.git351ff442-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.9.1%2Brocm7.1.1.lw.git351ff442-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.24.0%2Brocm7.1.1.gitb919bd0c-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.24.0%2Brocm7.1.1.gitb919bd0c-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.24.0%2Brocm7.1.1.gitb919bd0c-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.24.0%2Brocm7.1.1.gitb919bd0c-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
]
rocm72-torch2100 = [
"unsloth[amd]",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.6.0%2Brocm7.2.0.gitba5c1517-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.6.0%2Brocm7.2.0.gitba5c1517-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.6.0%2Brocm7.2.0.gitba5c1517-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/triton-3.6.0%2Brocm7.2.0.gitba5c1517-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.10.0%2Brocm7.2.0.lw.gitb6ee5fde-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.10.0%2Brocm7.2.0.lw.gitb6ee5fde-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.10.0%2Brocm7.2.0.lw.gitb6ee5fde-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torch-2.10.0%2Brocm7.2.0.lw.gitb6ee5fde-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.25.0%2Brocm7.2.0.git82df5f59-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.25.0%2Brocm7.2.0.git82df5f59-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.25.0%2Brocm7.2.0.git82df5f59-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.2/torchvision-0.25.0%2Brocm7.2.0.git82df5f59-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
]
rocm711-torch2100 = [
"unsloth[amd]",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.6.0%2Brocm7.1.1.gitba5c1517-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.6.0%2Brocm7.1.1.gitba5c1517-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.6.0%2Brocm7.1.1.gitba5c1517-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"triton @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/triton-3.6.0%2Brocm7.1.1.gitba5c1517-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.10.0%2Brocm7.1.1.lw.gitd9556b05-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.10.0%2Brocm7.1.1.lw.gitd9556b05-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.10.0%2Brocm7.1.1.lw.gitd9556b05-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torch @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torch-2.10.0%2Brocm7.1.1.lw.gitd9556b05-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.25.0%2Brocm7.1.1.git82df5f59-cp310-cp310-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.10' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.25.0%2Brocm7.1.1.git82df5f59-cp311-cp311-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.11' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.25.0%2Brocm7.1.1.git82df5f59-cp312-cp312-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.12' and platform_machine == 'x86_64'",
"torchvision @ https://repo.radeon.com/rocm/manylinux/rocm-rel-7.1.1/torchvision-0.25.0%2Brocm7.1.1.git82df5f59-cp313-cp313-linux_x86_64.whl ; platform_system == 'Linux' and python_version == '3.13' and platform_machine == 'x86_64'",
]
[project.urls]
homepage = "https://unsloth.ai"
documentation = "https://unsloth.ai/docs"
repository = "https://github.com/unslothai/unsloth"
[tool.ruff]
target-version = "py311"
force-exclude = true
extend-exclude = [
"*chat_templates.py",
"*ollama_template_mappers.py",
"*_auto_install.py",
"*mapper.py",
]
[tool.ruff.lint]
select = ["E9", "F63", "F7", "F82"]
ignore = [
"E402",
"E722",
"F403",
"F405",
"F811",
"F821",
"F841",
"F401",
"E731",
"E741",
"F601",
"E712",
]
[tool.ruff.format]
================================================
FILE: scripts/enforce_kwargs_spacing.py
================================================
#!/usr/bin/env python3
"""Ensure keyword arguments use spaces around '=', prune redundant pass statements."""
from __future__ import annotations
import ast
import argparse
import io
import sys
import tokenize
from collections import defaultdict
from pathlib import Path
def enforce_spacing(text: str) -> tuple[str, bool]:
"""Return updated text with keyword '=' padded by spaces, plus change flag."""
lines = text.splitlines(keepends=True)
if not lines:
return text, False
offsets: dict[int, int] = defaultdict(int)
changed = False
reader = io.StringIO(text).readline
for token in tokenize.generate_tokens(reader):
if token.type != tokenize.OP or token.string != "=":
continue
line_index = token.start[0] - 1
col = token.start[1] + offsets[line_index]
if line_index < 0 or line_index >= len(lines):
continue
line = lines[line_index]
if col >= len(line) or line[col] != "=":
continue
line_changed = False
# Insert a space before '=' when missing and not preceded by whitespace.
if col > 0 and line[col - 1] not in {" ", "\t"}:
line = f"{line[:col]} {line[col:]}"
offsets[line_index] += 1
col += 1
line_changed = True
changed = True
# Insert a space after '=' when missing and not followed by whitespace or newline.
next_index = col + 1
if next_index < len(line) and line[next_index] not in {" ", "\t", "\n", "\r"}:
line = f"{line[:next_index]} {line[next_index:]}"
offsets[line_index] += 1
line_changed = True
changed = True
if line_changed:
lines[line_index] = line
if not changed:
return text, False
return "".join(lines), True
def remove_redundant_passes(text: str) -> tuple[str, bool]:
"""Drop pass statements that share a block with other executable code."""
try:
tree = ast.parse(text)
except SyntaxError:
return text, False
redundant: list[ast.Pass] = []
def visit(node: ast.AST) -> None:
for attr in ("body", "orelse", "finalbody"):
value = getattr(node, attr, None)
if not isinstance(value, list) or len(value) <= 1:
continue
for stmt in value:
if isinstance(stmt, ast.Pass):
redundant.append(stmt)
for stmt in value:
if isinstance(stmt, ast.AST):
visit(stmt)
handlers = getattr(node, "handlers", None)
if handlers:
for handler in handlers:
visit(handler)
visit(tree)
if not redundant:
return text, False
lines = text.splitlines(keepends=True)
changed = False
for node in sorted(
redundant, key=lambda item: (item.lineno, item.col_offset), reverse=True
):
start = node.lineno - 1
end = (node.end_lineno or node.lineno) - 1
if start >= len(lines):
continue
changed = True
if start == end:
line = lines[start]
col_start = node.col_offset
col_end = node.end_col_offset or (col_start + 4)
segment = line[:col_start] + line[col_end:]
lines[start] = segment if segment.strip() else ""
continue
# Defensive fall-back for unexpected multi-line 'pass'.
prefix = lines[start][: node.col_offset]
lines[start] = prefix if prefix.strip() else ""
for idx in range(start + 1, end):
lines[idx] = ""
suffix = lines[end][(node.end_col_offset or 0) :]
lines[end] = suffix
# Normalise to ensure lines end with newlines except at EOF.
result_lines: list[str] = []
for index, line in enumerate(lines):
if not line:
continue
if index < len(lines) - 1 and not line.endswith("\n"):
result_lines.append(f"{line}\n")
else:
result_lines.append(line)
return "".join(result_lines), changed
def process_file(path: Path) -> bool:
try:
with tokenize.open(path) as handle:
original = handle.read()
encoding = handle.encoding
except (OSError, SyntaxError) as exc: # SyntaxError from tokenize on invalid python
print(f"Failed to read {path}: {exc}", file=sys.stderr)
return False
updated, changed = enforce_spacing(original)
updated, removed = remove_redundant_passes(updated)
if changed or removed:
path.write_text(updated, encoding=encoding)
return True
return False
def main(argv: list[str]) -> int:
parser = argparse.ArgumentParser(description=__doc__)
parser.add_argument("files", nargs="+", help="Python files to fix")
args = parser.parse_args(argv)
touched: list[Path] = []
self_path = Path(__file__).resolve()
for entry in args.files:
path = Path(entry)
# Skip modifying this script to avoid self-edit loops.
if path.resolve() == self_path:
continue
if not path.exists() or path.is_dir():
continue
if process_file(path):
touched.append(path)
if touched:
for path in touched:
print(f"Adjusted kwarg spacing in {path}")
return 0
if __name__ == "__main__":
sys.exit(main(sys.argv[1:]))
================================================
FILE: scripts/run_ruff_format.py
================================================
#!/usr/bin/env python3
"""Run `ruff format` followed by kwarg spacing enforcement."""
from __future__ import annotations
import subprocess
import sys
from pathlib import Path
HERE = Path(__file__).resolve().parent
def main(argv: list[str]) -> int:
files = [arg for arg in argv if Path(arg).exists()]
if not files:
return 0
ruff_cmd = [sys.executable, "-m", "ruff", "format", *files]
ruff_proc = subprocess.run(ruff_cmd)
if ruff_proc.returncode != 0:
return ruff_proc.returncode
spacing_script = HERE / "enforce_kwargs_spacing.py"
spacing_cmd = [sys.executable, str(spacing_script), *files]
spacing_proc = subprocess.run(spacing_cmd)
return spacing_proc.returncode
if __name__ == "__main__":
raise SystemExit(main(sys.argv[1:]))
================================================
FILE: studio/LICENSE.AGPL-3.0
================================================
GNU AFFERO GENERAL PUBLIC LICENSE
Version 3, 19 November 2007
Copyright (C) 2007 Free Software Foundation, Inc. 

\n",
"  \n",
"
\n",
"  \n",
"
\n",
"  \n",
"\n",
" Join Discord if you need help + ⭐️ Star us on Github ⭐️\n",
"\n",
" This notebook is licensed AGPL-3.0\n",
"
\n",
"\n",
" Join Discord if you need help + ⭐️ Star us on Github ⭐️\n",
"\n",
" This notebook is licensed AGPL-3.0\n",
"
"
]
}
],
"metadata": {
"accelerator": "GPU",
"colab": {
"gpuType": "T4",
"include_colab_link": true,
"provenance": []
},
"kernelspec": {
"display_name": "Python 3",
"name": "python3"
},
"language_info": {
"name": "python"
}
},
"nbformat": 4,
"nbformat_minor": 5
}
================================================
FILE: studio/__init__.py
================================================
# SPDX-License-Identifier: AGPL-3.0-only
# Copyright 2026-present the Unsloth AI Inc. team. All rights reserved. See /studio/LICENSE.AGPL-3.0
================================================
FILE: studio/backend/__init__.py
================================================
# SPDX-License-Identifier: AGPL-3.0-only
# Copyright 2026-present the Unsloth AI Inc. team. All rights reserved. See /studio/LICENSE.AGPL-3.0
================================================
FILE: studio/backend/assets/__init__.py
================================================
# SPDX-License-Identifier: AGPL-3.0-only
# Copyright 2026-present the Unsloth AI Inc. team. All rights reserved. See /studio/LICENSE.AGPL-3.0
================================================
FILE: studio/backend/assets/configs/__init__.py
================================================
# SPDX-License-Identifier: AGPL-3.0-only
# Copyright 2026-present the Unsloth AI Inc. team. All rights reserved. See /studio/LICENSE.AGPL-3.0
================================================
FILE: studio/backend/assets/configs/full_finetune.yaml
================================================
model: unsloth/Qwen2.5-0.5B
data:
dataset: tatsu-lab/alpaca
format_type: auto
training:
training_type: full
max_seq_length: 2048
load_in_4bit: false
output_dir: outputs
num_epochs: 1
learning_rate: 0.0002
batch_size: 1
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 0
save_steps: 0
weight_decay: 0.01
random_seed: 3407
packing: false
train_on_completions: false
gradient_checkpointing: "unsloth"
lora:
lora_r: 64
lora_alpha: 16
lora_dropout: 0.0
target_modules: ""
vision_all_linear: false
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: unsloth-training
enable_tensorboard: false
tensorboard_dir: runs
================================================
FILE: studio/backend/assets/configs/inference_defaults.json
================================================
{
"_comment": "Per-model-family inference parameter defaults. Sources: (1) Ollama params blobs, (2) Existing Unsloth Studio YAML configs. Patterns ordered longest-match-first.",
"families": {
"qwen3.5": {
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20,
"min_p": 0.0,
"repetition_penalty": 1.0,
"presence_penalty": 1.5
},
"qwen3-coder": {
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"qwen3-next": {
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"qwen3-vl": {
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"qwen3": {
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"qwen2.5-coder": {
"temperature": 1.5,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.1,
"repetition_penalty": 1.0
},
"qwen2.5-vl": {
"temperature": 1.5,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.1,
"repetition_penalty": 1.0
},
"qwen2.5-omni": {
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"qwen2.5-math": {
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"qwen2.5": {
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"qwen2-vl": {
"temperature": 1.5,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.1,
"repetition_penalty": 1.0
},
"qwen2": {
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"qwq": {
"temperature": 0.6,
"top_p": 0.95,
"top_k": 40,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"gemma-3n": {
"temperature": 1.0,
"top_p": 0.95,
"top_k": 64,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"gemma-3": {
"temperature": 1.0,
"top_p": 0.95,
"top_k": 64,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"medgemma": {
"temperature": 1.0,
"top_p": 0.95,
"top_k": 64,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"gemma-2": {
"temperature": 1.0,
"top_p": 0.95,
"top_k": 64,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"llama-4": {
"temperature": 1.0,
"top_p": 0.9,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"llama-3.3": {
"temperature": 1.5,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.1,
"repetition_penalty": 1.0
},
"llama-3.2": {
"temperature": 1.5,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.1,
"repetition_penalty": 1.0
},
"llama-3.1": {
"temperature": 1.5,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.1,
"repetition_penalty": 1.0
},
"llama-3": {
"temperature": 1.5,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.1,
"repetition_penalty": 1.0
},
"phi-4": {
"temperature": 0.8,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.0,
"repetition_penalty": 1.0
},
"phi-3": {
"temperature": 0.7,
"top_p": 0.9,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"mistral-nemo": {
"temperature": 0.7,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"mistral-small": {
"temperature": 0.15,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"mistral-large": {
"temperature": 0.7,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"magistral": {
"temperature": 0.7,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"ministral": {
"temperature": 0.15,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"devstral": {
"temperature": 0.7,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"pixtral": {
"temperature": 1.5,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.1,
"repetition_penalty": 1.0
},
"deepseek-r1": {
"temperature": 0.6,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"deepseek-v3": {
"temperature": 0.6,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"deepseek-ocr": {
"temperature": 0.0,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"glm-5": {
"temperature": 1.0,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"glm-4": {
"temperature": 1.0,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"nemotron": {
"temperature": 1.0,
"top_p": 1.0,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"minimax-m2.5": {
"temperature": 1.0,
"top_p": 0.95,
"top_k": 40,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"minimax": {
"temperature": 1.0,
"top_p": 0.95,
"top_k": 40,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"gpt-oss": {
"temperature": 1.0,
"top_p": 1.0,
"top_k": 0,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"granite-4": {
"temperature": 0.0,
"top_p": 1.0,
"top_k": 0,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"kimi-k2": {
"temperature": 0.6,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"kimi": {
"temperature": 0.6,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"lfm2": {
"temperature": 0.1,
"top_p": 0.1,
"top_k": 50,
"min_p": 0.15,
"repetition_penalty": 1.05
},
"smollm": {
"temperature": 0.7,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"olmo": {
"temperature": 0.7,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"falcon": {
"temperature": 0.7,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"ernie": {
"temperature": 0.7,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"seed": {
"temperature": 0.7,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"grok": {
"temperature": 1.0,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
},
"mimo": {
"temperature": 0.7,
"top_p": 0.95,
"top_k": -1,
"min_p": 0.01,
"repetition_penalty": 1.0
}
},
"patterns": [
"qwen3.5",
"qwen3-coder", "qwen3-next", "qwen3-vl", "qwen3",
"qwen2.5-coder", "qwen2.5-vl", "qwen2.5-omni", "qwen2.5-math", "qwen2.5",
"qwen2-vl", "qwen2",
"qwq",
"gemma-3n", "gemma-3", "medgemma", "gemma-2",
"llama-4", "llama-3.3", "llama-3.2", "llama-3.1", "llama-3",
"phi-4", "phi-3",
"mistral-nemo", "mistral-small", "mistral-large", "magistral", "ministral",
"devstral", "pixtral",
"deepseek-r1", "deepseek-v3", "deepseek-ocr",
"glm-5", "glm-4",
"nemotron",
"minimax-m2.5", "minimax",
"gpt-oss", "granite-4",
"kimi-k2", "kimi",
"lfm2", "smollm", "olmo", "falcon", "ernie", "seed", "grok", "mimo"
]
}
================================================
FILE: studio/backend/assets/configs/lora_text.yaml
================================================
model: unsloth/Qwen2.5-0.5B
data:
dataset: tatsu-lab/alpaca
format_type: auto
training:
training_type: lora
max_seq_length: 2048
load_in_4bit: true
output_dir: outputs
num_epochs: 1
learning_rate: 0.0002
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 0
save_steps: 0
weight_decay: 0.01
random_seed: 3407
packing: false
train_on_completions: false
gradient_checkpointing: "unsloth"
lora:
lora_r: 64
lora_alpha: 16
lora_dropout: 0.0
target_modules: "q_proj,k_proj,v_proj,o_proj,gate_proj,up_proj,down_proj"
vision_all_linear: false
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: unsloth-training
enable_tensorboard: false
tensorboard_dir: runs
================================================
FILE: studio/backend/assets/configs/model_defaults/default.yaml
================================================
# Default model training parameters
# Used for models without specific configurations
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 5e-5
batch_size: 2
gradient_accumulation_steps: 4
warmup_ratio: 0.1
max_steps: 30
save_steps: 30
weight_decay: 0.01
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.7
top_p: 0.95
top_k: -1
min_p: 0.01
================================================
FILE: studio/backend/assets/configs/model_defaults/embedding/unsloth_Qwen3-Embedding-0.6B.yaml
================================================
# Model defaults for unsloth/Qwen3-Embedding-0.6B
# Based on Qwen3_Embedding_(0_6B).py embedding notebook
# Also applies to: unsloth/Qwen3-Embedding-4B
training:
max_seq_length: 512
# num_epochs: 2
num_epochs: 0
learning_rate: 3e-5
batch_size: 256
gradient_accumulation_steps: 1
warmup_ratio: 0.03
max_steps: 30
save_steps: 30
weight_decay: 0.01
random_seed: 3407
packing: false
train_on_completions: false
gradient_checkpointing: false
optim: "adamw_8bit"
lr_scheduler_type: "constant_with_warmup"
lora:
lora_r: 32
lora_alpha: 32
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "embedding-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 50
================================================
FILE: studio/backend/assets/configs/model_defaults/embedding/unsloth_all-MiniLM-L6-v2.yaml
================================================
# Model defaults for unsloth/all-MiniLM-L6-v2
# Based on All_MiniLM_L6_v2.py embedding notebook
training:
max_seq_length: 512
# num_epochs: 2
num_epochs: 0
learning_rate: 2e-4
batch_size: 256
gradient_accumulation_steps: 1
warmup_ratio: 0.03
max_steps: 30
save_steps: 30
weight_decay: 0.01
random_seed: 3407
packing: false
train_on_completions: false
gradient_checkpointing: false
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 64
lora_alpha: 128
lora_dropout: 0.0
target_modules:
- "value"
- "key"
- "dense"
- "query"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "embedding-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 50
================================================
FILE: studio/backend/assets/configs/model_defaults/embedding/unsloth_bge-m3.yaml
================================================
# Model defaults for unsloth/bge-m3
# Based on BGE_M3.py embedding notebook
training:
max_seq_length: 512
# num_epochs: 2
num_epochs: 0
learning_rate: 3e-5
batch_size: 256
gradient_accumulation_steps: 1
warmup_ratio: 0.03
max_steps: 30
save_steps: 30
weight_decay: 0.01
random_seed: 3407
packing: false
train_on_completions: false
gradient_checkpointing: false
optim: "adamw_8bit"
lr_scheduler_type: "constant_with_warmup"
lora:
lora_r: 32
lora_alpha: 64
lora_dropout: 0.0
target_modules:
- "key"
- "query"
- "dense"
- "value"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "embedding-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 50
================================================
FILE: studio/backend/assets/configs/model_defaults/embedding/unsloth_embeddinggemma-300m.yaml
================================================
# Model defaults for unsloth/embeddinggemma-300m
# Based on EmbeddingGemma_(300M).py embedding notebook
training:
max_seq_length: 1024
# num_epochs: 1
num_epochs: 0
learning_rate: 2e-5
batch_size: 64
gradient_accumulation_steps: 2
warmup_ratio: 0.03
max_steps: 30
save_steps: 30
weight_decay: 0.01
random_seed: 3407
packing: false
train_on_completions: false
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 32
lora_alpha: 64
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "embedding-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 5
================================================
FILE: studio/backend/assets/configs/model_defaults/embedding/unsloth_gte-modernbert-base.yaml
================================================
# Model defaults for unsloth/gte-modernbert-base
# Based on ModernBert.py embedding notebook
training:
max_seq_length: 512
# num_epochs: 2
num_epochs: 0
learning_rate: 3e-5
batch_size: 256
gradient_accumulation_steps: 1
warmup_ratio: 0.03
max_steps: 30
save_steps: 30
weight_decay: 0.01
random_seed: 3407
packing: false
train_on_completions: false
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "constant_with_warmup"
lora:
lora_r: 64
lora_alpha: 128
lora_dropout: 0.0
target_modules:
- "Wi"
- "Wo"
- "Wqkv"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "embedding-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 50
================================================
FILE: studio/backend/assets/configs/model_defaults/ernie/unsloth_ERNIE-4.5-21B-A3B-PT.yaml
================================================
# Model defaults for unsloth/ERNIE-4.5-21B-A3B-PT
# Based on ERNIE_4_5_21B_A3B_PT-Conversational.ipynb
# Also applies to: unsloth/ERNIE-4.5-21B-A3B-PT
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 4
gradient_accumulation_steps: 2
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 8
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/ernie/unsloth_ERNIE-4.5-VL-28B-A3B-PT.yaml
================================================
# Model defaults for unsloth/ERNIE-4.5-VL-28B-A3B-PT
# Based on ERNIE_4_5_VL_28B_A3B_PT_Vision.ipynb
# Also applies to: unsloth/ERNIE-4.5-VL-28B-A3B-PT
# added inference parameters from unsloth notebook
training:
trust_remote_code: true
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 2
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 8
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: true
temperature: 1.5
min_p: 0.1
================================================
FILE: studio/backend/assets/configs/model_defaults/falcon/tiiuae_Falcon-H1-0.5B-Instruct.yaml
================================================
# Model defaults for tiiuae/Falcon-H1-0.5B-Instruct
# Based on Falcon_H1_(0.5B)-Alpaca.ipynb
# Also applies to: tiiuae/Falcon-H1-0.5B-Instruct, unsloth/Falcon-H1-0.5B-Instruct
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 8
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.01
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: false
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.1
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/gemma/unsloth_codegemma-7b-bnb-4bit.yaml
================================================
# Model defaults for unsloth/codegemma-7b-bnb-4bit
# Based on CodeGemma_(7B)-Conversational.ipynb
# Also applies to: unsloth/codegemma-7b, google/codegemma-7b
# added inference parameters from Ollama
training:
trust_remote_code: false
max_seq_length: 4096
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 1
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0
top_p: 0.9
================================================
FILE: studio/backend/assets/configs/model_defaults/gemma/unsloth_functiongemma-270m-it.yaml
================================================
# Model defaults for unsloth/functiongemma-270m-it
# Based on FunctionGemma_(270M).ipynb
# Also applies to: unsloth/functiongemma-270m-it-unsloth-bnb-4bit, google/functiongemma-270m-it, unsloth/functiongemma-270m-it-unsloth-bnb-4bit
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 4096
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 4
gradient_accumulation_steps: 2
warmup_steps: 10
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 128
lora_alpha: 256
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.0
top_k: 64
top_p: 0.95
min_p: 0.0
================================================
FILE: studio/backend/assets/configs/model_defaults/gemma/unsloth_gemma-2-27b-bnb-4bit.yaml
================================================
# Model defaults for unsloth/gemma-2-27b-bnb-4bit
# Based on Gemma2_(9B)-Alpaca.ipynb (same defaults for larger models)
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/gemma/unsloth_gemma-2-2b.yaml
================================================
# Model defaults for unsloth/gemma-2-2b
# Based on Gemma2_(2B)-Alpaca.ipynb
# Also applies to: unsloth/gemma-2-2b-bnb-4bit, google/gemma-2-2b
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.01
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/gemma/unsloth_gemma-3-270m-it.yaml
================================================
# Model defaults for unsloth/gemma-3-270m-it
# Based on Gemma3_(270M).ipynb
# Also applies to: unsloth/gemma-3-270m-it-unsloth-bnb-4bit, google/gemma-3-270m-it, unsloth/gemma-3-270m-it-bnb-4bit
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 5e-5
batch_size: 4
gradient_accumulation_steps: 1
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 128
lora_alpha: 128
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.0
top_k: 64
top_p: 0.95
min_p: 0.0
================================================
FILE: studio/backend/assets/configs/model_defaults/gemma/unsloth_gemma-3-27b-it.yaml
================================================
# Model defaults for unsloth/gemma-3-27b-it
# Based on Gemma3_(27B)_A100-Conversational.ipynb
# Also applies to: unsloth/gemma-3-27b-it-unsloth-bnb-4bit, google/gemma-3-27b-it, unsloth/gemma-3-27b-it-bnb-4bit
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 8
lora_alpha: 8
lora_dropout: 0.0
target_modules:
- "all-linear"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.0
top_k: 64
top_p: 0.95
min_p: 0.0
================================================
FILE: studio/backend/assets/configs/model_defaults/gemma/unsloth_gemma-3-4b-it.yaml
================================================
# Model defaults for unsloth/gemma-3-4b-it
# Based on Gemma3_(4B).ipynb
# Also applies to: unsloth/gemma-3-4b-it-unsloth-bnb-4bit, google/gemma-3-4b-it, unsloth/gemma-3-4b-it-bnb-4bit
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 8
lora_alpha: 8
lora_dropout: 0.0
target_modules:
- "all-linear"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.0
top_k: 64
top_p: 0.95
min_p: 0.0
================================================
FILE: studio/backend/assets/configs/model_defaults/gemma/unsloth_gemma-3-4b-pt.yaml
================================================
# Model defaults for unsloth/gemma-3-4b-pt
# Based on Gemma3_(4B)-Vision.ipynb
# Also applies to: unsloth/gemma-3-4b-pt-unsloth-bnb-4bit, google/gemma-3-4b-pt, unsloth/gemma-3-4b-pt-bnb-4bit
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 2
num_epochs: 0
learning_rate: 2e-4
batch_size: 1
gradient_accumulation_steps: 4
warmup_ratio: 0.03
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: true
optim: "adamw_torch_fused"
lr_scheduler_type: "cosine"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "all-linear"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.0
top_k: 64
top_p: 0.95
min_p: 0.0
================================================
FILE: studio/backend/assets/configs/model_defaults/gemma/unsloth_gemma-3n-E4B-it.yaml
================================================
# Model defaults for unsloth/gemma-3n-E4B-it
# Based on Gemma3N_(4B)-Conversational.ipynb
# Also applies to: unsloth/gemma-3n-E4B-it-unsloth-bnb-4bit, google/gemma-3n-E4B-it, unsloth/gemma-3n-E4B-it-unsloth-bnb-4bit
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 1024
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 1
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 8
lora_alpha: 8
lora_dropout: 0.0
target_modules:
- "all-linear"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
audio_input: true
inference:
trust_remote_code: false
temperature: 1.0
top_k: 64
top_p: 0.95
min_p: 0.0
================================================
FILE: studio/backend/assets/configs/model_defaults/gemma/unsloth_gemma-3n-E4B.yaml
================================================
# Model defaults for unsloth/gemma-3n-E4B
# Based on Gemma3N_(4B)-Vision.ipynb
# Also applies to: unsloth/gemma-3n-E4B-unsloth-bnb-4bit, google/gemma-3n-E4B
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 2
num_epochs: 0
learning_rate: 2e-4
batch_size: 1
gradient_accumulation_steps: 4
warmup_ratio: 0.03
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: true
optim: "adamw_torch_fused"
lr_scheduler_type: "cosine"
lora:
lora_r: 32
lora_alpha: 32
lora_dropout: 0.0
target_modules:
- "all-linear"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
audio_input: true
inference:
trust_remote_code: false
temperature: 1.0
top_k: 64
top_p: 0.95
min_p: 0.0
================================================
FILE: studio/backend/assets/configs/model_defaults/gpt-oss/unsloth_gpt-oss-120b.yaml
================================================
# Model defaults for unsloth/gpt-oss-120b
# Based on gpt-oss-(120B)_A100-Fine-tuning.ipynb
# Also applies to: openai/gpt-oss-120b, unsloth/gpt-oss-120b-unsloth-bnb-4bit
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 4096
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 4
gradient_accumulation_steps: 1
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 32
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.0
top_p: 1.0
top_k: 0
================================================
FILE: studio/backend/assets/configs/model_defaults/gpt-oss/unsloth_gpt-oss-20b.yaml
================================================
# Model defaults for unsloth/gpt-oss-20b
# Based on gpt-oss-(20B)-Fine-tuning.ipynb
# Also applies to: openai/gpt-oss-20b, unsloth/gpt-oss-20b-unsloth-bnb-4bit, unsloth/gpt-oss-20b-BF16
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 1024
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 1
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 8
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.0
top_p: 1.0
top_k: 0
================================================
FILE: studio/backend/assets/configs/model_defaults/granite/unsloth_granite-4.0-350m-unsloth-bnb-4bit.yaml
================================================
# Model defaults for unsloth/granite-4.0-350m
# Based on Granite4.0_350M.ipynb
# Also applies to: ibm-granite/granite-4.0-350m, unsloth/granite-4.0-350m-bnb-4bit
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 32
lora_alpha: 32
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
- "shared_mlp.input_linear"
- "shared_mlp.output_linear"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.0
top_p: 1.0
top_k: 0
================================================
FILE: studio/backend/assets/configs/model_defaults/granite/unsloth_granite-4.0-h-micro.yaml
================================================
# Model defaults for unsloth/granite-4.0-h-micro
# Based on Granite4.0.ipynb
# Also applies to: ibm-granite/granite-4.0-h-micro, unsloth/granite-4.0-h-micro-bnb-4bit, unsloth/granite-4.0-h-micro-unsloth-bnb-4bit
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 32
lora_alpha: 32
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
- "shared_mlp.input_linear"
- "shared_mlp.output_linear"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.0
top_p: 1.0
top_k: 0
================================================
FILE: studio/backend/assets/configs/model_defaults/llama/unsloth_Llama-3.2-11B-Vision-Instruct.yaml
================================================
# Model defaults for unsloth/Llama-3.2-11B-Vision-Instruct
# Based on Llama3.2_(11B)-Vision.ipynb
# Also applies to: unsloth/Llama-3.2-11B-Vision-Instruct-unsloth-bnb-4bit, meta-llama/Llama-3.2-11B-Vision-Instruct, unsloth/Llama-3.2-11B-Vision-Instruct-bnb-4bit
# added inference parameters from unsloth notebook
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "all-linear"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.5
min_p: 0.1
================================================
FILE: studio/backend/assets/configs/model_defaults/llama/unsloth_Llama-3.2-1B-Instruct.yaml
================================================
# Model defaults for unsloth/Llama-3.2-1B-Instruct
# Based on Llama3.2_(1B)-RAFT.ipynb
# Also applies to: unsloth/Llama-3.2-1B-Instruct-unsloth-bnb-4bit, meta-llama/Llama-3.2-1B-Instruct, unsloth/Llama-3.2-1B-Instruct-bnb-4bit, RedHatAI/Llama-3.2-1B-Instruct-FP8, unsloth/Llama-3.2-1B-Instruct-FP8-Block, unsloth/Llama-3.2-1B-Instruct-FP8-Dynamic
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 5
num_epochs: 0
learning_rate: 2e-5
batch_size: 1
gradient_accumulation_steps: 8
warmup_steps: 0
max_steps: 30
save_steps: 30
weight_decay: 0.01
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: true
optim: "adamw_torch"
lr_scheduler_type: "cosine"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/llama/unsloth_Llama-3.2-3B-Instruct.yaml
================================================
# Model defaults for unsloth/Llama-3.2-3B-Instruct
# Based on Llama3.2_(1B_and_3B)-Conversational.ipynb
# Also applies to: unsloth/Llama-3.2-3B-Instruct-unsloth-bnb-4bit, meta-llama/Llama-3.2-3B-Instruct, unsloth/Llama-3.2-3B-Instruct-bnb-4bit, RedHatAI/Llama-3.2-3B-Instruct-FP8, unsloth/Llama-3.2-3B-Instruct-FP8-Block, unsloth/Llama-3.2-3B-Instruct-FP8-Dynamic
# added inference parameters from unsloth notebook
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.5
min_p: 0.1
================================================
FILE: studio/backend/assets/configs/model_defaults/llama/unsloth_Llama-3.3-70B-Instruct.yaml
================================================
# Model defaults for unsloth/Llama-3.3-70B-Instruct
# Based on Llama3.3_(70B)_A100-Conversational.ipynb
# Also applies to: unsloth/Llama-3.3-70B-Instruct-unsloth-bnb-4bit, meta-llama/Llama-3.3-70B-Instruct, unsloth/Llama-3.3-70B-Instruct-bnb-4bit, RedHatAI/Llama-3.3-70B-Instruct-FP8, unsloth/Llama-3.3-70B-Instruct-FP8-Block, unsloth/Llama-3.3-70B-Instruct-FP8-Dynamic
# added inference parameters from unsloth notebook
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.5
min_p: 0.1
================================================
FILE: studio/backend/assets/configs/model_defaults/llama/unsloth_Meta-Llama-3.1-70B-bnb-4bit.yaml
================================================
# Model defaults for unsloth/Meta-Llama-3.1-70B-bnb-4bit
# Based on Llama3.1_(8B)-Alpaca.ipynb
# Also applies to: unsloth/Meta-Llama-3.1-8B-bnb-4bit, unsloth/Meta-Llama-3.1-8B-unsloth-bnb-4bit, meta-llama/Meta-Llama-3.1-8B, unsloth/Meta-Llama-3.1-8B, unsloth/Meta-Llama-3.1-70B, meta-llama/Meta-Llama-3.1-70B, unsloth/Meta-Llama-3.1-405B-bnb-4bit, meta-llama/Meta-Llama-3.1-405B
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/llama/unsloth_Meta-Llama-3.1-8B-Instruct-bnb-4bit.yaml
================================================
# Model defaults for unsloth/Meta-Llama-3.1-8B-Instruct-bnb-4bit
# Based on Llama3.1_(8B)-Inference.ipynb
# Also applies to: "unsloth/Meta-Llama-3.1-8B-Instruct-unsloth-bnb-4bit", "meta-llama/Meta-Llama-3.1-8B-Instruct", "unsloth/Meta-Llama-3.1-8B-Instruct","RedHatAI/Llama-3.1-8B-Instruct-FP8","unsloth/Llama-3.1-8B-Instruct-FP8-Block","unsloth/Llama-3.1-8B-Instruct-FP8-Dynamic"
training:
trust_remote_code: false
max_seq_length: 8192
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/llama/unsloth_llama-3-8b-Instruct-bnb-4bit.yaml
================================================
# Model defaults for unsloth/llama-3-8b-Instruct-bnb-4bit
# Based on Llama3_(8B)-Conversational.ipynb
# Also applies to: unsloth/llama-3-8b-Instruct, meta-llama/Meta-Llama-3-8B-Instruct
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/llama/unsloth_llama-3-8b-bnb-4bit.yaml
================================================
# Model defaults for unsloth/llama-3-8b-bnb-4bit
# Based on Llama3_(8B)-Alpaca.ipynb
# Also applies to: unsloth/llama-3-8b, meta-llama/Meta-Llama-3-8B
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/llasa/unsloth_Llasa-3B.yaml
================================================
# Model defaults for unsloth/Llasa-3B
# Based on Llasa_TTS_(3B).ipynb and Llasa_TTS_(1B).ipynb
# Also applies to: HKUSTAudio/Llasa-1B
# added inference parameters from unsloth notebook
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 5e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 128
lora_alpha: 128
lora_dropout: 0.0
target_modules:
- "q_proj"
- "v_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.2
top_p: 1.2
================================================
FILE: studio/backend/assets/configs/model_defaults/mistral/unsloth_Magistral-Small-2509-unsloth-bnb-4bit.yaml
================================================
# Model defaults for unsloth/Magistral-Small-2509
# Based on Magistral_(24B)-Reasoning-Conversational.ipynb
# Also applies to: mistralai/Magistral-Small-2509, unsloth/Magistral-Small-2509-bnb-4bit
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 2
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 32
lora_alpha: 32
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.7
min_p: 0.01
top_p: 0.95
================================================
FILE: studio/backend/assets/configs/model_defaults/mistral/unsloth_Ministral-3-3B-Instruct-2512.yaml
================================================
# Model defaults for unsloth/Ministral-3-3B-Instruct-2512
# Based on Ministral_3_VL_(3B)_Vision.ipynb
# Also applies to: unsloth/Ministral-3-3B-Instruct-2512
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 4
gradient_accumulation_steps: 2
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 32
lora_alpha: 32
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.15
top_p: 0.95
================================================
FILE: studio/backend/assets/configs/model_defaults/mistral/unsloth_Mistral-Nemo-Base-2407-bnb-4bit.yaml
================================================
# Model defaults for unsloth/Mistral-Nemo-Base-2407-bnb-4bit
# Based on Mistral_Nemo_(12B)-Alpaca.ipynb
# Also applies to: "unsloth/Mistral-Nemo-Base-2407", "mistralai/Mistral-Nemo-Base-2407", "unsloth/Mistral-Nemo-Instruct-2407-bnb-4bit", "unsloth/Mistral-Nemo-Instruct-2407", "mistralai/Mistral-Nemo-Instruct-2407",
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/mistral/unsloth_Mistral-Small-Instruct-2409.yaml
================================================
# Model defaults for unsloth/Mistral-Small-Instruct-2409
# Based on Mistral_Small_(22B)-Alpaca.ipynb
# Also applies to: unsloth/Mistral-Small-Instruct-2409-bnb-4bit, mistralai/Mistral-Small-Instruct-2409
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 1
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/mistral/unsloth_Pixtral-12B-2409.yaml
================================================
# Model defaults for unsloth/Pixtral-12B-2409
# Based on Pixtral_(12B)-Vision.ipynb
# Also applies to: unsloth/Pixtral-12B-2409-unsloth-bnb-4bit, mistralai/Pixtral-12B-2409, unsloth/Pixtral-12B-2409-bnb-4bit
# added inference parameters from unsloth notebook
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 1
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "paged_adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 8
lora_alpha: 8
lora_dropout: 0.0
target_modules:
- "all-linear"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: false
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.5
min_p: 0.1
================================================
FILE: studio/backend/assets/configs/model_defaults/mistral/unsloth_mistral-7b-instruct-v0.3-bnb-4bit.yaml
================================================
# Model defaults for unsloth/mistral-7b-instruct-v0.3-bnb-4bit
# Based on Mistral_v0.3_(7B)-Conversational.ipynb
# Also applies to: unsloth/mistral-7b-instruct-v0.3, mistralai/Mistral-7B-Instruct-v0.3
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/mistral/unsloth_mistral-7b-v0.3-bnb-4bit.yaml
================================================
# Model defaults for unsloth/mistral-7b-v0.3-bnb-4bit
# Based on Mistral_v0.3_(7B)-Alpaca.ipynb
# Also applies to: "unsloth/mistral-7b-v0.3", "mistralai/Mistral-7B-v0.3",
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/other/OuteAI_Llama-OuteTTS-1.0-1B.yaml
================================================
# Model defaults for OuteAI/Llama-OuteTTS-1.0-1B
# Based on Oute_TTS_(1B).ipynb
# Also applies to: OuteAI/Llama-OuteTTS-1.0-1B
# added inference parameters from unsloth notebook
audio_type: dac
training:
trust_remote_code: false
eval_steps: 0
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 128
lora_alpha: 128
lora_dropout: 0.0
target_modules:
- "q_proj"
- "v_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.4
top_k: 40
top_p: 0.9
min_p: 0.05
================================================
FILE: studio/backend/assets/configs/model_defaults/other/Spark-TTS-0.5B_LLM.yaml
================================================
# Model defaults for Spark-TTS-0.5B/LLM
# Based on Spark_TTS_(0_5B).ipynb
# Also applies to: Spark-TTS-0.5B/LLM
# added inference parameters from unsloth notebook
audio_type: bicodec
training:
trust_remote_code: false
eval_steps: 0
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 128
lora_alpha: 128
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.8
top_k: 50
top_p: 1.0
================================================
FILE: studio/backend/assets/configs/model_defaults/other/sesame_csm-1b.yaml
================================================
# Model defaults for sesame/csm-1b
# Based on Sesame_CSM_(1B)-TTS.ipynb
# Also applies to: sesame/csm-1b
audio_type: csm
training:
trust_remote_code: false
eval_steps: 0
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 32
lora_alpha: 32
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/other/unsloth_GLM-4.7-Flash.yaml
================================================
# Model defaults for unsloth/GLM-4.7-Flash
# Based on GLM_Flash_A100(80GB).py
# Also applies to: unsloth/GLM-4.7-Flash-unsloth-bnb-4bit, unsloth/GLM-4.7-Flash-bnb-4bit, THUDM/GLM-4.7-Flash
training:
trust_remote_code: true
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 4
gradient_accumulation_steps: 2
warmup_steps: 5
max_steps: 60
save_steps: 60
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 8
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
- "out_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: true
temperature: 0.7
top_p: 0.8
top_k: 20
================================================
FILE: studio/backend/assets/configs/model_defaults/other/unsloth_LFM2-1.2B.yaml
================================================
# Model defaults for unsloth/LFM2-1.2B
# Based on Liquid_LFM2_(1.2B)-Conversational.ipynb
# Also applies to: unsloth/LFM2-1.2B
# added inference parameters from unsloth notebook
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "all-linear"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.3
min_p: 0.15
================================================
FILE: studio/backend/assets/configs/model_defaults/other/unsloth_Nemotron-3-Nano-30B-A3B.yaml
================================================
# Model defaults for unsloth/Nemotron-3-Nano-30B-A3B
# Based on Nemotron-3-Nano-30B-A3B_A100.ipynb
# Also applies to: unsloth/Nemotron-3-Nano-30B-A3B
# added inference parameters from unsloth guides
training:
trust_remote_code: true
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 4
gradient_accumulation_steps: 2
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 8
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
- "in_proj"
- "out_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: true
temperature: 1.0
top_p: 1.0
================================================
FILE: studio/backend/assets/configs/model_defaults/other/unsloth_PaddleOCR-VL.yaml
================================================
# Model defaults for unsloth/PaddleOCR-VL
# Based on Paddle_OCR_(1B)_Vision.ipynb
# Also applies to: unsloth/PaddleOCR-VL
# added inference parameters from unsloth notebook
training:
trust_remote_code: true
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 5e-5
batch_size: 4
gradient_accumulation_steps: 2
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 64
lora_alpha: 64
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: true
temperature: 1.5
min_p: 0.1
================================================
FILE: studio/backend/assets/configs/model_defaults/other/unsloth_answerdotai_ModernBERT-large.yaml
================================================
# Model defaults for answerdotai/ModernBERT-large
# Based on bert_classification.ipynb
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 1
num_epochs: 0
learning_rate: 5e-5
batch_size: 32
gradient_accumulation_steps: 1
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/other/unsloth_orpheus-3b-0.1-ft.yaml
================================================
# Model defaults for unsloth/orpheus-3b-0.1-ft
# Based on Orpheus_(3B)-TTS.ipynb
# Also applies to: unsloth/orpheus-3b-0.1-ft-unsloth-bnb-4bit, canopylabs/orpheus-3b-0.1-ft, unsloth/orpheus-3b-0.1-ft-bnb-4bit
# added inference parameters from unsloth notebook
audio_type: snac
training:
trust_remote_code: false
eval_steps: 0
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 1
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 64
lora_alpha: 64
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.6
top_p: 0.95
================================================
FILE: studio/backend/assets/configs/model_defaults/other/unsloth_tinyllama-bnb-4bit.yaml
================================================
# Model defaults for unsloth/tinyllama
# Based on TinyLlama_(1.1B)-Alpaca.ipynb
# Also applies to: TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T
training:
trust_remote_code: false
max_seq_length: 4096
# num_epochs: 1
num_epochs: 0
learning_rate: 2e-5
batch_size: 2
gradient_accumulation_steps: 4
warmup_ratio: 0.1
max_steps: 30
save_steps: 30
weight_decay: 0.1
random_seed: 3407
packing: true
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 32
lora_alpha: 32
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/other/unsloth_whisper-large-v3.yaml
================================================
# Model defaults for unsloth/whisper-large-v3
# Based on Whisper.ipynb
# Also applies to: unsloth/whisper-large-v3, openai/whisper-large-v3
audio_type: whisper
audio_input: true
training:
trust_remote_code: false
eval_steps: 5
max_seq_length: 448
# num_epochs: 4
num_epochs: 0
learning_rate: 1e-4
batch_size: 1
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 64
lora_alpha: 64
lora_dropout: 0.0
target_modules:
- "q_proj"
- "v_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/phi/unsloth_Phi-3-medium-4k-instruct.yaml
================================================
# Model defaults for unsloth/Phi-3-medium-4k-instruct
# Based on Phi_3_Medium-Conversational.ipynb
# Also applies to: "unsloth/Phi-3-medium-4k-instruct-bnb-4bit", "microsoft/Phi-3-medium-4k-instruct",
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/phi/unsloth_Phi-3.5-mini-instruct.yaml
================================================
# Model defaults for unsloth/Phi-3.5-mini-instruct
# Based on Phi_3.5_Mini-Conversational.ipynb
# Also applies to: "unsloth/Phi-3.5-mini-instruct-bnb-4bit", "microsoft/Phi-3.5-mini-instruct"
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/phi/unsloth_Phi-4.yaml
================================================
# Model defaults for unsloth/Phi-4
# Based on Phi_4-Conversational.ipynb
# Also applies to: unsloth/phi-4-unsloth-bnb-4bit, microsoft/phi-4, unsloth/phi-4-bnb-4bit
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.8
top_p: 0.95
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/imdatta0_tiny_qwen3_moe_2.8B_0.7B.yaml
================================================
# Model defaults for imdatta0/tiny_qwen3_moe_2.8B_0.7B
# Based on TinyQwen3_MoE.py
# Dummy model of qwen3moe architecture created to fit in T4
# MoE model - includes gate_up_proj for MoE layers
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 1
gradient_accumulation_steps: 1
warmup_steps: 5
max_steps: 50
save_steps: 50
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 32
lora_alpha: 64
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
- "gate_up_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.6
top_k: 20
top_p: 0.95
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen2-7B.yaml
================================================
# Model defaults for unsloth/Qwen2-7B
# Based on Qwen2_(7B)-Alpaca.ipynb
# Also applies to: unsloth/Qwen2-7B-bnb-4bit, Qwen/Qwen2-7B
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen2-VL-7B-Instruct.yaml
================================================
# Model defaults for unsloth/Qwen2-VL-7B-Instruct
# Based on Qwen2_VL_(7B)-Vision.ipynb
# Also applies to: unsloth/Qwen2-VL-7B-Instruct-unsloth-bnb-4bit, Qwen/Qwen2-VL-7B-Instruct, unsloth/Qwen2-VL-7B-Instruct-bnb-4bit
# added inference parameters from unsloth notebook
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "all-linear"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.5
min_p: 0.1
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen2.5-1.5B-Instruct.yaml
================================================
# Model defaults for unsloth/Qwen2.5-1.5B-Instruct
# Based on nemo_gym_sudoku.ipynb
# Also applies to: unsloth/Qwen2.5-1.5B-Instruct-unsloth-bnb-4bit, Qwen/Qwen2.5-1.5B-Instruct, unsloth/Qwen2.5-1.5B-Instruct-bnb-4bit
training:
trust_remote_code: false
max_seq_length: 4096
# num_epochs: 4
num_epochs: 0
learning_rate: 1e-5
batch_size: 1
gradient_accumulation_steps: 64
warmup_ratio: 0.1
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 42
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 4
lora_alpha: 8
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen2.5-7B.yaml
================================================
# Model defaults for unsloth/Qwen2.5-7B
# Based on Qwen2.5_(7B)-Alpaca.ipynb
# Also applies to: unsloth/Qwen2.5-7B-unsloth-bnb-4bit, Qwen/Qwen2.5-7B, unsloth/Qwen2.5-7B-bnb-4bit
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen2.5-Coder-1.5B-Instruct.yaml
================================================
# Model defaults for unsloth/Qwen2.5-Coder-1.5B-Instruct
# Based on Qwen2.5_Coder_(1.5B)-Tool_Calling.ipynb
# Also applies to: unsloth/Qwen2.5-Coder-1.5B-Instruct-bnb-4bit, Qwen/Qwen2.5-Coder-1.5B-Instruct
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen2.5-Coder-14B-Instruct.yaml
================================================
# Model defaults for unsloth/Qwen2.5-Coder-14B-Instruct
# Based on Qwen2.5_Coder_(14B)-Conversational.ipynb
# Also applies to: unsloth/Qwen2.5-Coder-14B-Instruct-bnb-4bit, Qwen/Qwen2.5-Coder-14B-Instruct
# added inference parameters from unsloth notebook
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 1
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "paged_adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.5
min_p: 0.1
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen2.5-Coder-7B-Instruct-bnb-4bit.yaml
================================================
# Model defaults for unsloth/Qwen2.5-Coder-7B-Instruct-bnb-4bit
# Based on CodeForces-cot-Finetune_for_Reasoning_on_CodeForces.ipynb
# Also applies to: unsloth/Qwen2.5-Coder-7B-Instruct, Qwen/Qwen2.5-Coder-7B-Instruct
training:
trust_remote_code: false
max_seq_length: 32768
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen2.5-VL-7B-Instruct-bnb-4bit.yaml
================================================
# Model defaults for unsloth/Qwen2.5-VL-7B-Instruct-bnb-4bit
# Based on Qwen2.5_VL_(7B)-Vision.ipynb
# Also applies to: unsloth/Qwen2.5-VL-7B-Instruct, Qwen/Qwen2.5-VL-7B-Instruct, unsloth/Qwen2.5-VL-7B-Instruct-unsloth-bnb-4bit
# added inference parameters from unsloth notebook
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "all-linear"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 1.5
min_p: 0.1
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen3-0.6B.yaml
================================================
# Model defaults for unsloth/Qwen3-0.6B
# Based on Qwen3_(0_6B)-Phone_Deployment.ipynb
# Also applies to: unsloth/Qwen3-0.6B-unsloth-bnb-4bit, Qwen/Qwen3-0.6B, unsloth/Qwen3-0.6B-bnb-4bit, Qwen/Qwen3-0.6B-FP8, unsloth/Qwen3-0.6B-FP8
# added inference parameters from Ollama
training:
trust_remote_code: false
max_seq_length: 1024
# num_epochs: 4
num_epochs: 0
learning_rate: 5e-5
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.6
top_k: 20
top_p: 0.95
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen3-14B-Base-unsloth-bnb-4bit.yaml
================================================
# Model defaults for unsloth/Qwen3-14B-Base
# Based on Qwen3_(14B)-Alpaca.ipynb
# Also applies to: unsloth/Qwen3-14B-Base, Qwen/Qwen3-14B-Base, unsloth/Qwen3-14B-Base-bnb-4bit
# added inference parameters from Ollama
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.6
top_k: 20
top_p: 0.95
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen3-14B.yaml
================================================
# Model defaults for unsloth/Qwen3-14B
# Based on Qwen3_(14B).ipynb
# Also applies to: unsloth/Qwen3-14B-unsloth-bnb-4bit, Qwen/Qwen3-14B, unsloth/Qwen3-14B-bnb-4bit, Qwen/Qwen3-14B-FP8, unsloth/Qwen3-14B-FP8
# added inference parameters from Ollama
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 32
lora_alpha: 32
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.6
top_k: 20
top_p: 0.95
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen3-30B-A3B-Instruct-2507.yaml
================================================
# Model defaults for unsloth/Qwen3-30B-A3B-Instruct-2507
# Based on Qwen3_MoE.py
# Also applies to: Qwen/Qwen3-30B-A3B-Instruct-2507, unsloth/Qwen3-30B-A3B-Instruct-2507-bnb-4bit
# MoE model - includes gate_up_proj for MoE layers
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 1
gradient_accumulation_steps: 1
warmup_steps: 5
max_steps: 50
save_steps: 50
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 32
lora_alpha: 64
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
- "gate_up_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.6
top_k: 20
top_p: 0.95
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen3-32B.yaml
================================================
# Model defaults for unsloth/Qwen3-32B
# Based on Qwen3_(32B)_A100-Reasoning-Conversational.ipynb
# Also applies to: unsloth/Qwen3-32B-unsloth-bnb-4bit, Qwen/Qwen3-32B, unsloth/Qwen3-32B-bnb-4bit, Qwen/Qwen3-32B-FP8, unsloth/Qwen3-32B-FP8
# added inference parameters from Ollama
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 32
lora_alpha: 32
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.6
top_k: 20
top_p: 0.95
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen3-4B-Instruct-2507.yaml
================================================
# Model defaults for unsloth/Qwen3-4B-Instruct-2507
# Based on Qwen3_(4B)-Instruct.ipynb
# Also applies to: unsloth/Qwen3-4B-Instruct-2507-unsloth-bnb-4bit, Qwen/Qwen3-4B-Instruct-2507, unsloth/Qwen3-4B-Instruct-2507-bnb-4bit, Qwen/Qwen3-4B-Instruct-2507-FP8, unsloth/Qwen3-4B-Instruct-2507-FP8
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 32
lora_alpha: 32
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.7
top_p: 0.80
top_k: 20
min_p: 0.00
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen3-4B-Thinking-2507.yaml
================================================
# Model defaults for unsloth/Qwen3-4B-Thinking-2507
# Based on Qwen3_(4B)-Thinking.ipynb
# Also applies to: unsloth/Qwen3-4B-Thinking-2507-unsloth-bnb-4bit, Qwen/Qwen3-4B-Thinking-2507, unsloth/Qwen3-4B-Thinking-2507-bnb-4bit, Qwen/Qwen3-4B-Thinking-2507-FP8, unsloth/Qwen3-4B-Thinking-2507-FP8
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 32
lora_alpha: 32
lora_dropout: 0.0
target_modules:
- "q_proj"
- "k_proj"
- "v_proj"
- "o_proj"
- "gate_proj"
- "up_proj"
- "down_proj"
use_rslora: false
use_loftq: false
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.6
top_p: 0.95
top_k: 20
min_p: 0.00
================================================
FILE: studio/backend/assets/configs/model_defaults/qwen/unsloth_Qwen3-VL-8B-Instruct-unsloth-bnb-4bit.yaml
================================================
# Model defaults for unsloth/Qwen3-VL-8B-Instruct
# Based on Qwen3_VL_(8B)-Vision.ipynb
# Also applies to: Qwen/Qwen3-VL-8B-Instruct-FP8, unsloth/Qwen3-VL-8B-Instruct-FP8, unsloth/Qwen3-VL-8B-Instruct, Qwen/Qwen3-VL-8B-Instruct, unsloth/Qwen3-VL-8B-Instruct-bnb-4bit
# added inference parameters from unsloth guides
training:
trust_remote_code: false
max_seq_length: 2048
# num_epochs: 4
num_epochs: 0
learning_rate: 2e-4
batch_size: 2
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 30
save_steps: 30
weight_decay: 0.001
random_seed: 3407
packing: false
train_on_completions: true
gradient_checkpointing: "unsloth"
optim: "adamw_8bit"
lr_scheduler_type: "linear"
lora:
lora_r: 16
lora_alpha: 16
lora_dropout: 0.0
target_modules:
- "all-linear"
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: "llm-finetuning"
enable_tensorboard: false
tensorboard_dir: "runs"
log_frequency: 10
inference:
trust_remote_code: false
temperature: 0.7
top_p: 0.8
top_k: 20
================================================
FILE: studio/backend/assets/configs/vision_lora.yaml
================================================
model: unsloth/Qwen2-VL-2B-Instruct-bnb-4bit
data:
dataset: philschmid/amazon-product-descriptions-vlm
format_type: auto
training:
training_type: lora
max_seq_length: 2048
load_in_4bit: true
output_dir: outputs
num_epochs: 1
learning_rate: 0.0002
batch_size: 1
gradient_accumulation_steps: 4
warmup_steps: 5
max_steps: 0
save_steps: 0
weight_decay: 0.01
random_seed: 3407
packing: false
train_on_completions: false
gradient_checkpointing: "unsloth"
lora:
lora_r: 64
lora_alpha: 16
lora_dropout: 0.0
target_modules: "" # vision uses vision_all_linear by default
vision_all_linear: true
use_rslora: false
use_loftq: false
finetune_vision_layers: true
finetune_language_layers: true
finetune_attention_modules: true
finetune_mlp_modules: true
logging:
enable_wandb: false
wandb_project: unsloth-training
enable_tensorboard: false
tensorboard_dir: runs
================================================
FILE: studio/backend/auth/.gitkeep
================================================
================================================
FILE: studio/backend/auth/__init__.py
================================================
# SPDX-License-Identifier: AGPL-3.0-only
# Copyright 2026-present the Unsloth AI Inc. team. All rights reserved. See /studio/LICENSE.AGPL-3.0
"""
Authentication module for JWT-based auth with SQLite storage.
"""
from .authentication import (
create_access_token,
create_refresh_token,
refresh_access_token,
get_current_subject,
get_current_subject_allow_password_change,
reload_secret,
)
from .storage import (
DEFAULT_ADMIN_USERNAME,
clear_bootstrap_password,
generate_bootstrap_password,
get_bootstrap_password,
is_initialized,
create_initial_user,
ensure_default_admin,
get_jwt_secret,
get_user_and_secret,
load_jwt_secret,
requires_password_change,
save_refresh_token,
update_password,
verify_refresh_token,
revoke_user_refresh_tokens,
)
from .hashing import hash_password, verify_password
__all__ = [
"create_access_token",
"create_refresh_token",
"refresh_access_token",
"get_current_subject",
"get_current_subject_allow_password_change",
"reload_secret",
"DEFAULT_ADMIN_USERNAME",
"clear_bootstrap_password",
"generate_bootstrap_password",
"get_bootstrap_password",
"is_initialized",
"create_initial_user",
"ensure_default_admin",
"get_jwt_secret",
"get_user_and_secret",
"load_jwt_secret",
"requires_password_change",
"save_refresh_token",
"update_password",
"verify_refresh_token",
"revoke_user_refresh_tokens",
"hash_password",
"verify_password",
]
================================================
FILE: studio/backend/auth/authentication.py
================================================
# SPDX-License-Identifier: AGPL-3.0-only
# Copyright 2026-present the Unsloth AI Inc. team. All rights reserved. See /studio/LICENSE.AGPL-3.0
import secrets
from datetime import datetime, timedelta, timezone
from typing import Optional, Tuple
from fastapi import Depends, HTTPException, status
from fastapi.security import HTTPAuthorizationCredentials, HTTPBearer
import jwt
from .storage import (
get_jwt_secret,
get_user_and_secret,
load_jwt_secret,
save_refresh_token,
verify_refresh_token,
)
ALGORITHM = "HS256"
ACCESS_TOKEN_EXPIRE_MINUTES = 60
REFRESH_TOKEN_EXPIRE_DAYS = 7
security = HTTPBearer() # Reads Authorization: Bearer \n",
" \n",
" \n",
"\n",
" Join Discord if you need help + ⭐️ Star us on Github ⭐️\n",
"\n",
" This notebook is licensed AGPL-3.0\n",
"