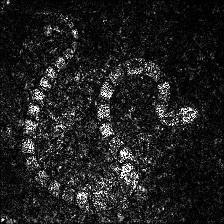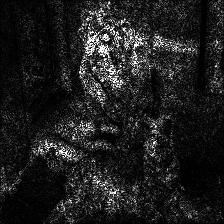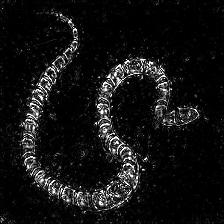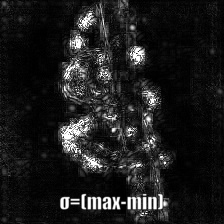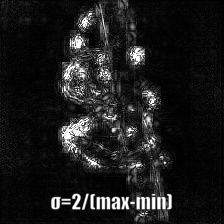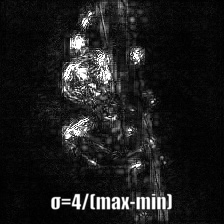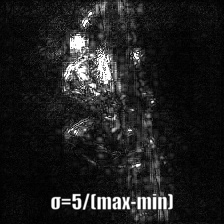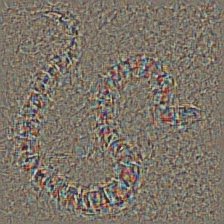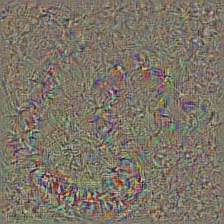| |
Target class: King Snake (56) |
Target class: Mastiff (243) |
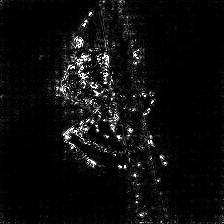
Target class: Spider (72) |
| Original Image |
 |
 |
 |
| Colored Vanilla Backpropagation |
 |
 |
 |
Vanilla Backpropagation Saliency |
 |
 |
 |
Colored Guided Backpropagation
(GB) |
 |
 |
 |
Guided Backpropagation Saliency
(GB) |
 |
 |
 |
Guided Backpropagation Negative Saliency
(GB) |
 |
 |
 |
Guided Backpropagation Positive Saliency
(GB) |
 |
 |
 |
Gradient-weighted Class Activation Map
(Grad-CAM) |
 |
 |
 |
Gradient-weighted Class Activation Heatmap
(Grad-CAM) |
 |
 |
 |
Gradient-weighted Class Activation Heatmap on Image
(Grad-CAM) |
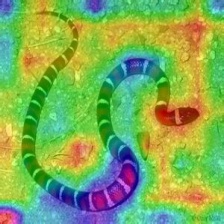 |
 |
 |
Score-weighted Class Activation Map
(Score-CAM) |
 |
 |
 |
Score-weighted Class Activation Heatmap
(Score-CAM) |
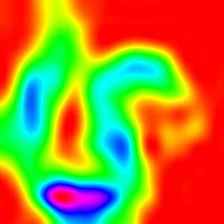 |
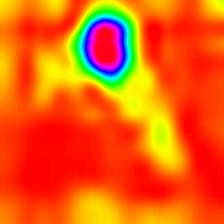 |
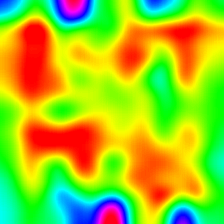 |
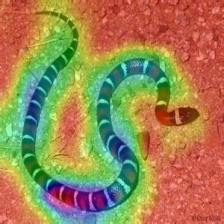
Score-weighted Class Activation Heatmap on Image
(Score-CAM) |
 |
 |
 |
Colored Guided Gradient-weighted Class Activation Map
(Guided-Grad-CAM) |
 |
 |
 |
Guided Gradient-weighted Class Activation Map Saliency
(Guided-Grad-CAM) |
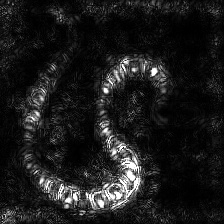 |
 |
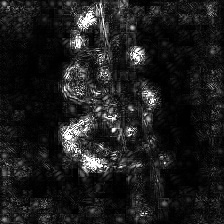 |
Integrated Gradients
(without image multiplication) |
 |
 |
 |
Layerwise Relevance
(LRP) - Layer 7 |
 |
 |
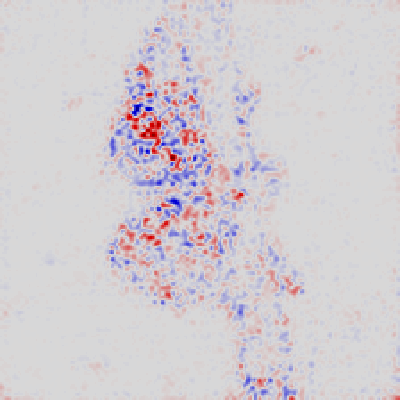 |
Layerwise Relevance
(LRP) - Layer 1 |
 |
 |
 |