Repository: uzh-rpg/ssms_event_cameras
Branch: master
Commit: 7c871b55a0c5
Files: 162
Total size: 623.9 KB
Directory structure:
gitextract_9qf3l4ub/
├── .gitignore
├── README.md
├── RVT/
│ ├── .gitignore
│ ├── LICENSE
│ ├── README.md
│ ├── callbacks/
│ │ ├── custom.py
│ │ ├── detection.py
│ │ ├── gradflow.py
│ │ ├── utils/
│ │ │ └── visualization.py
│ │ └── viz_base.py
│ ├── config/
│ │ ├── dataset/
│ │ │ ├── base.yaml
│ │ │ ├── gen1.yaml
│ │ │ └── gen4.yaml
│ │ ├── experiment/
│ │ │ ├── gen1/
│ │ │ │ ├── base.yaml
│ │ │ │ ├── default.yaml
│ │ │ │ └── small.yaml
│ │ │ └── gen4/
│ │ │ ├── base.yaml
│ │ │ ├── default.yaml
│ │ │ └── small.yaml
│ │ ├── general.yaml
│ │ ├── model/
│ │ │ ├── base.yaml
│ │ │ ├── maxvit_yolox/
│ │ │ │ └── default.yaml
│ │ │ └── rnndet.yaml
│ │ ├── modifier.py
│ │ ├── train.yaml
│ │ └── val.yaml
│ ├── data/
│ │ ├── genx_utils/
│ │ │ ├── collate.py
│ │ │ ├── collate_from_pytorch.py
│ │ │ ├── dataset_rnd.py
│ │ │ ├── dataset_streaming.py
│ │ │ ├── labels.py
│ │ │ ├── sequence_base.py
│ │ │ ├── sequence_for_streaming.py
│ │ │ └── sequence_rnd.py
│ │ └── utils/
│ │ ├── augmentor.py
│ │ ├── representations.py
│ │ ├── spatial.py
│ │ ├── stream_concat_datapipe.py
│ │ ├── stream_sharded_datapipe.py
│ │ └── types.py
│ ├── loggers/
│ │ ├── utils.py
│ │ └── wandb_logger.py
│ ├── models/
│ │ ├── detection/
│ │ │ ├── __init_.py
│ │ │ ├── recurrent_backbone/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── base.py
│ │ │ │ └── maxvit_rnn.py
│ │ │ ├── yolox/
│ │ │ │ ├── models/
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── losses.py
│ │ │ │ │ ├── network_blocks.py
│ │ │ │ │ └── yolo_head.py
│ │ │ │ └── utils/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── boxes.py
│ │ │ │ └── compat.py
│ │ │ └── yolox_extension/
│ │ │ └── models/
│ │ │ ├── __init__.py
│ │ │ ├── build.py
│ │ │ ├── detector.py
│ │ │ └── yolo_pafpn.py
│ │ └── layers/
│ │ ├── maxvit/
│ │ │ ├── __init__.py
│ │ │ ├── layers/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── activations.py
│ │ │ │ ├── activations_jit.py
│ │ │ │ ├── activations_me.py
│ │ │ │ ├── adaptive_avgmax_pool.py
│ │ │ │ ├── attention_pool2d.py
│ │ │ │ ├── blur_pool.py
│ │ │ │ ├── bottleneck_attn.py
│ │ │ │ ├── cbam.py
│ │ │ │ ├── classifier.py
│ │ │ │ ├── cond_conv2d.py
│ │ │ │ ├── config.py
│ │ │ │ ├── conv2d_same.py
│ │ │ │ ├── conv_bn_act.py
│ │ │ │ ├── create_act.py
│ │ │ │ ├── create_attn.py
│ │ │ │ ├── create_conv2d.py
│ │ │ │ ├── create_norm.py
│ │ │ │ ├── create_norm_act.py
│ │ │ │ ├── drop.py
│ │ │ │ ├── eca.py
│ │ │ │ ├── evo_norm.py
│ │ │ │ ├── fast_norm.py
│ │ │ │ ├── filter_response_norm.py
│ │ │ │ ├── gather_excite.py
│ │ │ │ ├── global_context.py
│ │ │ │ ├── halo_attn.py
│ │ │ │ ├── helpers.py
│ │ │ │ ├── inplace_abn.py
│ │ │ │ ├── lambda_layer.py
│ │ │ │ ├── linear.py
│ │ │ │ ├── median_pool.py
│ │ │ │ ├── mixed_conv2d.py
│ │ │ │ ├── ml_decoder.py
│ │ │ │ ├── mlp.py
│ │ │ │ ├── non_local_attn.py
│ │ │ │ ├── norm.py
│ │ │ │ ├── norm_act.py
│ │ │ │ ├── padding.py
│ │ │ │ ├── patch_embed.py
│ │ │ │ ├── pool2d_same.py
│ │ │ │ ├── pos_embed.py
│ │ │ │ ├── selective_kernel.py
│ │ │ │ ├── separable_conv.py
│ │ │ │ ├── space_to_depth.py
│ │ │ │ ├── split_attn.py
│ │ │ │ ├── split_batchnorm.py
│ │ │ │ ├── squeeze_excite.py
│ │ │ │ ├── std_conv.py
│ │ │ │ ├── test_time_pool.py
│ │ │ │ ├── trace_utils.py
│ │ │ │ └── weight_init.py
│ │ │ └── maxvit.py
│ │ ├── rnn.py
│ │ └── s5/
│ │ ├── __init__.py
│ │ ├── jax_func.py
│ │ ├── s5_init.py
│ │ ├── s5_model.py
│ │ └── triton_comparison.py
│ ├── modules/
│ │ ├── __init__.py
│ │ ├── data/
│ │ │ └── genx.py
│ │ ├── detection.py
│ │ └── utils/
│ │ ├── detection.py
│ │ └── fetch.py
│ ├── scripts/
│ │ ├── genx/
│ │ │ ├── README.md
│ │ │ ├── conf_preprocess/
│ │ │ │ ├── extraction/
│ │ │ │ │ ├── const_count.yaml
│ │ │ │ │ ├── const_duration.yaml
│ │ │ │ │ └── frequencies/
│ │ │ │ │ ├── const_duration_100hz.yaml
│ │ │ │ │ ├── const_duration_200hz.yaml
│ │ │ │ │ ├── const_duration_40hz.yaml
│ │ │ │ │ └── const_duration_80hz.yaml
│ │ │ │ ├── filter_gen1.yaml
│ │ │ │ ├── filter_gen4.yaml
│ │ │ │ └── representation/
│ │ │ │ ├── mixeddensity_stack.yaml
│ │ │ │ └── stacked_hist.yaml
│ │ │ ├── preprocess_dataset.py
│ │ │ └── preprocess_dataset.sh
│ │ └── viz/
│ │ └── viz_gt.py
│ ├── train.py
│ ├── utils/
│ │ ├── evaluation/
│ │ │ └── prophesee/
│ │ │ ├── __init__.py
│ │ │ ├── evaluation.py
│ │ │ ├── evaluator.py
│ │ │ ├── io/
│ │ │ │ ├── __init__.py
│ │ │ │ ├── box_filtering.py
│ │ │ │ ├── box_loading.py
│ │ │ │ ├── dat_events_tools.py
│ │ │ │ ├── npy_events_tools.py
│ │ │ │ └── psee_loader.py
│ │ │ ├── metrics/
│ │ │ │ ├── __init__.py
│ │ │ │ └── coco_eval.py
│ │ │ └── visualize/
│ │ │ ├── __init__.py
│ │ │ └── vis_utils.py
│ │ ├── helpers.py
│ │ ├── padding.py
│ │ ├── preprocessing.py
│ │ └── timers.py
│ └── validation.py
├── installation_details.txt
└── scripts/
├── 1mpx/
│ ├── onempx_base.bash
│ ├── onempx_base.job
│ ├── onempx_small.bash
│ └── onempx_small.job
└── gen1/
├── base.txt
└── small.txt
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
cover/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
.pybuilder/
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
# For a library or package, you might want to ignore these files since the code is
# intended to run in multiple environments; otherwise, check them in:
# .python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# poetry
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
# This is especially recommended for binary packages to ensure reproducibility, and is more
# commonly ignored for libraries.
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
#poetry.lock
# pdm
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
#pdm.lock
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
# in version control.
# https://pdm.fming.dev/#use-with-ide
.pdm.toml
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
# pytype static type analyzer
.pytype/
# Cython debug symbols
cython_debug/
# PyCharm
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
# and can be added to the global gitignore or merged into this file. For a more nuclear
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
.idea/
*.pyc
*.iml
# Specific stuff
wandb/
cache_dir/
raw_datasets/
raw_data/
final_outputs/
outputs/
validation_logs/
apex/
*.ckpt
.vscode/
================================================
FILE: README.md
================================================
# [CVPR'24 Spotlight] State Space Models for Event Cameras

This is the official PyTorch implementation of the CVPR 2024 paper [State Space Models for Event Cameras](https://arxiv.org/abs/2402.15584).
### 🖼️ Check Out Our Poster! 🖼️ [here](https://download.ifi.uzh.ch/rpg/CVPR24_Zubic/Zubic_CVPR24_poster.pdf)
## :white_check_mark: Updates
* **` June. 14th, 2024`**: Everything is updated! Poster released! Check it above.
* **` June. 6st, 2024`**: Video released! To watch our video, simply click on the YouTube play button above.
* **` June. 1st, 2024`**: Our CVPR conference paper has also been accepted as a Spotlight presentation at "The 3rd Workshop on Transformers for Vision (T4V)."
* **` April. 19th, 2024`**: The code along with the best checkpoints is released! The poster and video will be released shortly before CVPR 2024.
## Citation
If you find this work and/or code useful, please cite our paper:
```bibtex
@InProceedings{Zubic_2024_CVPR,
author = {Zubic, Nikola and Gehrig, Mathias and Scaramuzza, Davide},
title = {State Space Models for Event Cameras},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2024},
pages = {5819-5828}
}
```
## SSM-ViT
- S5 model used in our SSM-ViT pipeline can be seen [here](https://github.com/uzh-rpg/ssms_event_cameras/tree/master/RVT/models/layers/s5).
- In particular, S5 is used instead of RNN in a 4-stage hierarchical ViT backbone, and its forward function is exposed [here](https://github.com/uzh-rpg/ssms_event_cameras/blob/master/RVT/models/detection/recurrent_backbone/maxvit_rnn.py#L245). What is nice about this approach is that we do not need a 'for' loop over sequence dimension, but instead we employ a parallel scanning algorithm. This model assumes that a hidden state is being carried over.
- For a model that is standalone, and can be used for any sequence modeling problem, one does not use by default this formulation where we carry on the hidden state. The implementation is the same as the original JAX implementation and can be downloaded in zip format from [ssms_event_cameras/RVT/models/s5.zip](https://github.com/uzh-rpg/ssms_event_cameras/raw/master/RVT/models/s5.zip).
## Installation
### Conda
We highly recommend using [Mambaforge](https://github.com/conda-forge/miniforge#mambaforge) to reduce the installation time.
```Bash
conda create -y -n events_signals python=3.11
conda activate events_signals
conda install pytorch==2.2.1 torchvision==0.17.1 torchaudio==2.2.1 pytorch-cuda=11.8 -c pytorch -c nvidia
pip install lightning wandb pandas plotly opencv-python tabulate pycocotools bbox-visualizer StrEnum hydra-core einops torchdata tqdm numba h5py hdf5plugin lovely-tensors tensorboardX pykeops scikit-learn
```
## Required Data
To evaluate or train the S5-ViT model, you will need to download the required preprocessed datasets:
You may also pre-process the dataset yourself by following the [instructions](https://github.com/NikolaZubic/ssms_event_cameras/blob/master/RVT/scripts/genx/README.md).
## Pre-trained Checkpoints
### 1 Mpx
### Gen1
## Evaluation
- Evaluation scripts with concrete parameters that we trained our models can be seen [here](https://github.com/uzh-rpg/ssms_event_cameras/tree/master/scripts).
- Set `DATA_DIR` as the path to either the 1 Mpx or Gen1 dataset directory
- Set `CKPT_PATH` to the path of the *correct* checkpoint matching the choice of the model and dataset
- Set
- `MDL_CFG=base` or
- `MDL_CFG=small`
to load either the base or small model configuration.
- Set `GPU_ID` to the PCI BUS ID of the GPU that you want to use. e.g. `GPU_ID=0`.
Only a single GPU is supported for evaluation
### 1 Mpx
```Bash
python RVT/validation.py dataset=gen4 dataset.path=${DATA_DIR} checkpoint=${CKPT_PATH} \
use_test_set=1 hardware.gpus=${GPU_ID} +experiment/gen4="${MDL_CFG}.yaml" \
batch_size.eval=12 model.postprocess.confidence_threshold=0.001
```
### Gen1
```Bash
python RVT/validation.py dataset=gen1 dataset.path=${DATA_DIR} checkpoint=${CKPT_PATH} \
use_test_set=1 hardware.gpus=${GPU_ID} +experiment/gen1="${MDL_CFG}.yaml" \
batch_size.eval=8 model.postprocess.confidence_threshold=0.001
```
We set the same batch size for the evaluation and training: 12 for the 1 Mpx dataset, and 8 for the Gen1 dataset.
## Evaluation results
Evaluation should give the same results as shown below:
- 47.7 and 47.8 mAP on Gen1 and 1 Mpx datasets for the base model, and
- 46.6 and 46.5 mAP on Gen1 and 1 Mpx datasets for the small model.

## Training
- Set `DATA_DIR` as the path to either the 1 Mpx or Gen1 dataset directory
- Set
- `MDL_CFG=base` or
- `MDL_CFG=small`
to load either the base or the small configuration.
- Set `GPU_IDS` to the PCI BUS IDs of the GPUs that you want to use. e.g. `GPU_IDS=[0,1]` for using GPU 0 and 1.
**Using a list of IDS will enable single-node multi-GPU training.**
Pay attention to the batch size which is defined per GPU.
- Set `BATCH_SIZE_PER_GPU` such that the effective batch size is matching the parameters below.
The **effective batch size** is (batch size per GPU)*(number of GPUs).
- If you would like to change the effective batch size, we found the following learning rate scaling to work well for
all models on both datasets:
`lr = 2e-4 * sqrt(effective_batch_size/8)`.
- The training code uses [W&B](https://wandb.ai/) for logging during the training.
Hence, we assume that you have a W&B account.
- The training script below will create a new project called `ssms_event_cameras`. Adapt the project name and group name if necessary.
### 1 Mpx
- The effective batch size for the 1 Mpx training is 12.
- For training the model on 1 Mpx dataset, we need 2x A100 80 GB GPUs and we use 12 workers per GPU for training and 4 workers per GPU for evaluation:
```Bash
GPU_IDS=[0,1]
BATCH_SIZE_PER_GPU=6
TRAIN_WORKERS_PER_GPU=12
EVAL_WORKERS_PER_GPU=4
python RVT/train.py model=rnndet dataset=gen4 dataset.path=${DATA_DIR} wandb.project_name=ssms_event_cameras \
wandb.group_name=1mpx +experiment/gen4="${MDL_CFG}.yaml" hardware.gpus=${GPU_IDS} \
batch_size.train=${BATCH_SIZE_PER_GPU} batch_size.eval=${BATCH_SIZE_PER_GPU} \
hardware.num_workers.train=${TRAIN_WORKERS_PER_GPU} hardware.num_workers.eval=${EVAL_WORKERS_PER_GPU}
```
If you for example want to execute the training on 4 GPUs simply adapt `GPU_IDS` and `BATCH_SIZE_PER_GPU` accordingly:
```Bash
GPU_IDS=[0,1,2,3]
BATCH_SIZE_PER_GPU=3
```
### Gen1
- The effective batch size for the Gen1 training is 8.
- For training the model on the Gen1 dataset, we need 1x A100 80 GPU using 24 workers for training and 8 workers for evaluation:
```Bash
GPU_IDS=0
BATCH_SIZE_PER_GPU=8
TRAIN_WORKERS_PER_GPU=24
EVAL_WORKERS_PER_GPU=8
python RVT/train.py model=rnndet dataset=gen1 dataset.path=${DATA_DIR} wandb.project_name=ssms_event_cameras \
wandb.group_name=gen1 +experiment/gen1="${MDL_CFG}.yaml" hardware.gpus=${GPU_IDS} \
batch_size.train=${BATCH_SIZE_PER_GPU} batch_size.eval=${BATCH_SIZE_PER_GPU} \
hardware.num_workers.train=${TRAIN_WORKERS_PER_GPU} hardware.num_workers.eval=${EVAL_WORKERS_PER_GPU}
```
## Code Acknowledgments
This project has used code from the following projects:
- [RVT](https://github.com/uzh-rpg/RVT) - Recurrent Vision Transformers for Object Detection with Event Cameras in PyTorch
- [S4](https://github.com/state-spaces/s4) - Structured State Spaces for Sequence Modeling, in particular S4 and S4D models in PyTorch
- [S5](https://github.com/lindermanlab/S5) - Simplified State Space Layers for Sequence Modeling in JAX
- [S5 PyTorch](https://github.com/i404788/s5-pytorch) - S5 model in PyTorch
================================================
FILE: RVT/.gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
pip-wheel-metadata/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
*.py,cover
.hypothesis/
.pytest_cache/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
db.sqlite3-journal
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
.python-version
# pipenv
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
# However, in case of collaboration, if having platform-specific dependencies or dependencies
# having no cross-platform support, pipenv may install dependencies that don't work, or not
# install all needed dependencies.
#Pipfile.lock
# PEP 582; used by e.g. github.com/David-OConnor/pyflow
__pypackages__/
# Celery stuff
celerybeat-schedule
celerybeat.pid
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
================================================
FILE: RVT/LICENSE
================================================
MIT License
Copyright (c) 2023 Mathias Gehrig
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: RVT/README.md
================================================
# RVT: Recurrent Vision Transformers for Object Detection with Event Cameras
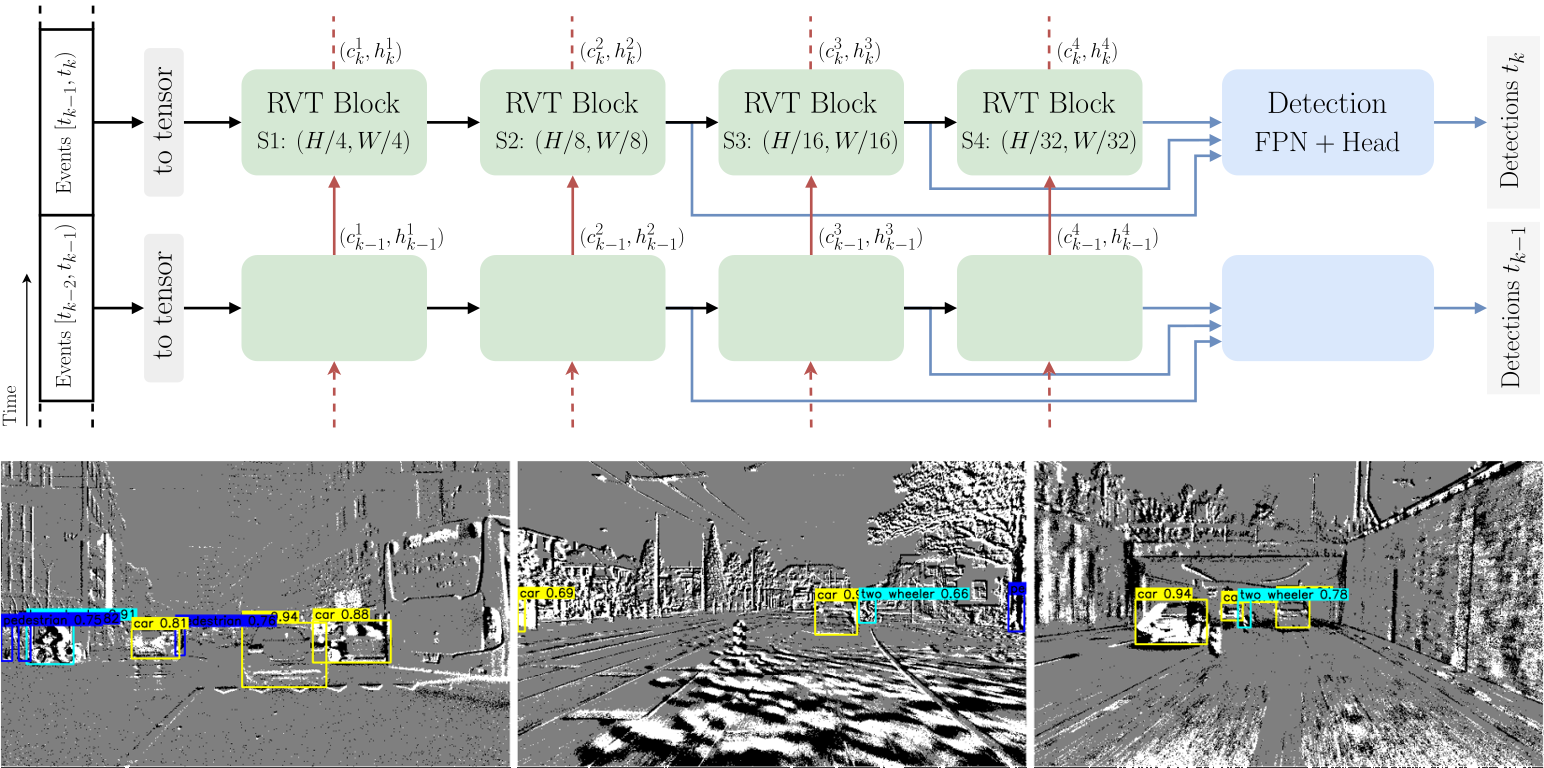
This is the official Pytorch implementation of the CVPR 2023 paper [Recurrent Vision Transformers for Object Detection with Event Cameras](https://arxiv.org/abs/2212.05598).
Watch the [**video**](https://youtu.be/xZ-pNwHxHgY) for a quick overview.
```bibtex
@InProceedings{Gehrig_2023_CVPR,
author = {Mathias Gehrig and Davide Scaramuzza},
title = {Recurrent Vision Transformers for Object Detection with Event Cameras},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023},
}
```
## Conda Installation
We highly recommend to use [Mambaforge](https://github.com/conda-forge/miniforge#mambaforge) to reduce the installation time.
```Bash
conda create -y -n rvt python=3.9 pip
conda activate rvt
conda config --set channel_priority flexible
CUDA_VERSION=11.8
conda install -y h5py=3.8.0 blosc-hdf5-plugin=1.0.0 \
hydra-core=1.3.2 einops=0.6.0 torchdata=0.6.0 tqdm numba \
pytorch=2.0.0 torchvision=0.15.0 pytorch-cuda=$CUDA_VERSION \
-c pytorch -c nvidia -c conda-forge
python -m pip install pytorch-lightning==1.8.6 wandb==0.14.0 \
pandas==1.5.3 plotly==5.13.1 opencv-python==4.6.0.66 tabulate==0.9.0 \
pycocotools==2.0.6 bbox-visualizer==0.1.0 StrEnum==0.4.10
python -m pip install 'git+https://github.com/facebookresearch/detectron2.git'
```
Detectron2 is not strictly required but speeds up the evaluation.
## Required Data
To evaluate or train RVT you will need to download the required preprocessed datasets:
You may also pre-process the dataset yourself by following the [instructions](scripts/genx/README.md).
## Pre-trained Checkpoints
### 1 Mpx
### Gen1
## Evaluation
- Set `DATA_DIR` as the path to either the 1 Mpx or Gen1 dataset directory
- Set `CKPT_PATH` to the path of the *correct* checkpoint matching the choice of the model and dataset.
- Set
- `MDL_CFG=base`, or
- `MDL_CFG=small`, or
- `MDL_CFG=tiny`
to load either the base, small, or tiny model configuration
- Set
- `USE_TEST=1` to evaluate on the test set, or
- `USE_TEST=0` to evaluate on the validation set
- Set `GPU_ID` to the PCI BUS ID of the GPU that you want to use. e.g. `GPU_ID=0`.
Only a single GPU is supported for evaluation
### 1 Mpx
```Bash
python validation.py dataset=gen4 dataset.path=${DATA_DIR} checkpoint=${CKPT_PATH} \
use_test_set=${USE_TEST} hardware.gpus=${GPU_ID} +experiment/gen4="${MDL_CFG}.yaml" \
batch_size.eval=8 model.postprocess.confidence_threshold=0.001
```
### Gen1
```Bash
python validation.py dataset=gen1 dataset.path=${DATA_DIR} checkpoint=${CKPT_PATH} \
use_test_set=${USE_TEST} hardware.gpus=${GPU_ID} +experiment/gen1="${MDL_CFG}.yaml" \
batch_size.eval=8 model.postprocess.confidence_threshold=0.001
```
## Training
- Set `DATA_DIR` as the path to either the 1 Mpx or Gen1 dataset directory
- Set
- `MDL_CFG=base`, or
- `MDL_CFG=small`, or
- `MDL_CFG=tiny`
to load either the base, small, or tiny model configuration
- Set `GPU_IDS` to the PCI BUS IDs of the GPUs that you want to use. e.g. `GPU_IDS=[0,1]` for using GPU 0 and 1.
**Using a list of IDS will enable single-node multi-GPU training.**
Pay attention to the batch size which is defined per GPU:
- Set `BATCH_SIZE_PER_GPU` such that the effective batch size is matching the parameters below.
The **effective batch size** is (batch size per gpu)*(number of GPUs).
- If you would like to change the effective batch size, we found the following learning rate scaling to work well for
all models on both datasets:
`lr = 2e-4 * sqrt(effective_batch_size/8)`.
- The training code uses [W&B](https://wandb.ai/) for logging during the training.
Hence, we assume that you have a W&B account.
- The training script below will create a new project called `RVT`. Adapt the project name and group name if necessary.
### 1 Mpx
- The effective batch size for the 1 Mpx training is 24.
- To train on 2 GPUs using 6 workers per GPU for training and 2 workers per GPU for evaluation:
```Bash
GPU_IDS=[0,1]
BATCH_SIZE_PER_GPU=12
TRAIN_WORKERS_PER_GPU=6
EVAL_WORKERS_PER_GPU=2
python train.py model=rnndet dataset=gen4 dataset.path=${DATA_DIR} wandb.project_name=RVT \
wandb.group_name=1mpx +experiment/gen4="${MDL_CFG}.yaml" hardware.gpus=${GPU_IDS} \
batch_size.train=${BATCH_SIZE_PER_GPU} batch_size.eval=${BATCH_SIZE_PER_GPU} \
hardware.num_workers.train=${TRAIN_WORKERS_PER_GPU} hardware.num_workers.eval=${EVAL_WORKERS_PER_GPU}
```
If you instead want to execute the training on 4 GPUs simply adapt `GPU_IDS` and `BATCH_SIZE_PER_GPU` accordingly:
```Bash
GPU_IDS=[0,1,2,3]
BATCH_SIZE_PER_GPU=6
```
### Gen1
- The effective batch size for the Gen1 training is 8.
- To train on 1 GPU using 6 workers for training and 2 workers for evaluation:
```Bash
GPU_IDS=0
BATCH_SIZE_PER_GPU=8
TRAIN_WORKERS_PER_GPU=6
EVAL_WORKERS_PER_GPU=2
python train.py model=rnndet dataset=gen1 dataset.path=${DATA_DIR} wandb.project_name=RVT \
wandb.group_name=gen1 +experiment/gen1="${MDL_CFG}.yaml" hardware.gpus=${GPU_IDS} \
batch_size.train=${BATCH_SIZE_PER_GPU} batch_size.eval=${BATCH_SIZE_PER_GPU} \
hardware.num_workers.train=${TRAIN_WORKERS_PER_GPU} hardware.num_workers.eval=${EVAL_WORKERS_PER_GPU}
```
## Code Acknowledgments
This project has used code from the following projects:
- [timm](https://github.com/huggingface/pytorch-image-models) for the MaxViT layer implementation in Pytorch
- [YOLOX](https://github.com/Megvii-BaseDetection/YOLOX) for the detection PAFPN/head
================================================
FILE: RVT/callbacks/custom.py
================================================
from omegaconf import DictConfig
from lightning.pytorch.callbacks import Callback
from lightning.pytorch.callbacks import ModelCheckpoint
from callbacks.detection import DetectionVizCallback
def get_ckpt_callback(config: DictConfig) -> ModelCheckpoint:
model_name = config.model.name
prefix = "val"
if model_name == "rnndet":
metric = "AP"
mode = "max"
else:
raise NotImplementedError
ckpt_callback_monitor = prefix + "/" + metric
filename_monitor_str = prefix + "_" + metric
ckpt_filename = (
"epoch={epoch:03d}-step={step}-"
+ filename_monitor_str
+ "={"
+ ckpt_callback_monitor
+ ":.2f}"
)
cktp_callback = ModelCheckpoint(
monitor=ckpt_callback_monitor,
filename=ckpt_filename,
auto_insert_metric_name=False, # because backslash would create a directory
save_top_k=1,
mode=mode,
every_n_epochs=config.logging.ckpt_every_n_epochs,
save_last=True,
verbose=True,
)
cktp_callback.CHECKPOINT_NAME_LAST = "last_epoch={epoch:03d}-step={step}"
return cktp_callback
def get_viz_callback(config: DictConfig) -> Callback:
model_name = config.model.name
if model_name == "rnndet":
return DetectionVizCallback(config=config)
raise NotImplementedError
================================================
FILE: RVT/callbacks/detection.py
================================================
from enum import Enum, auto
from typing import Any
import torch
from einops import rearrange
from omegaconf import DictConfig
from data.utils.types import ObjDetOutput
from loggers.wandb_logger import WandbLogger
from utils.evaluation.prophesee.visualize.vis_utils import (
LABELMAP_GEN1,
LABELMAP_GEN4_SHORT,
draw_bboxes,
)
from .viz_base import VizCallbackBase
class DetectionVizEnum(Enum):
EV_IMG = auto()
LABEL_IMG_PROPH = auto()
PRED_IMG_PROPH = auto()
class DetectionVizCallback(VizCallbackBase):
def __init__(self, config: DictConfig):
super().__init__(config=config, buffer_entries=DetectionVizEnum)
dataset_name = config.dataset.name
if dataset_name == "gen1":
self.label_map = LABELMAP_GEN1
elif dataset_name == "gen4":
self.label_map = LABELMAP_GEN4_SHORT
else:
raise NotImplementedError
def on_train_batch_end_custom(
self,
logger: WandbLogger,
outputs: Any,
batch: Any,
log_n_samples: int,
global_step: int,
) -> None:
if outputs is None:
# If we tried to skip the training step (not supported in DDP in PL, atm)
return
ev_tensors = outputs[ObjDetOutput.EV_REPR]
num_samples = len(ev_tensors)
assert num_samples > 0
log_n_samples = min(num_samples, log_n_samples)
merged_img = []
captions = []
start_idx = num_samples - 1
end_idx = start_idx - log_n_samples
# for sample_idx in range(log_n_samples):
for sample_idx in range(start_idx, end_idx, -1):
ev_img = self.ev_repr_to_img(ev_tensors[sample_idx].cpu().numpy())
predictions_proph = outputs[ObjDetOutput.PRED_PROPH][sample_idx]
prediction_img = ev_img.copy()
draw_bboxes(prediction_img, predictions_proph, labelmap=self.label_map)
labels_proph = outputs[ObjDetOutput.LABELS_PROPH][sample_idx]
label_img = ev_img.copy()
draw_bboxes(label_img, labels_proph, labelmap=self.label_map)
merged_img.append(
rearrange(
[prediction_img, label_img], "pl H W C -> (pl H) W C", pl=2, C=3
)
)
captions.append(f"sample_{sample_idx}")
logger.log_images(
key="train/predictions",
images=merged_img,
caption=captions,
step=global_step,
)
def on_validation_batch_end_custom(self, batch: Any, outputs: Any):
if outputs[ObjDetOutput.SKIP_VIZ]:
return
ev_tensor = outputs[ObjDetOutput.EV_REPR]
assert isinstance(ev_tensor, torch.Tensor)
ev_img = self.ev_repr_to_img(ev_tensor.cpu().numpy())
predictions_proph = outputs[ObjDetOutput.PRED_PROPH]
prediction_img = ev_img.copy()
draw_bboxes(prediction_img, predictions_proph, labelmap=self.label_map)
self.add_to_buffer(DetectionVizEnum.PRED_IMG_PROPH, prediction_img)
labels_proph = outputs[ObjDetOutput.LABELS_PROPH]
label_img = ev_img.copy()
draw_bboxes(label_img, labels_proph, labelmap=self.label_map)
self.add_to_buffer(DetectionVizEnum.LABEL_IMG_PROPH, label_img)
def on_validation_epoch_end_custom(self, logger: WandbLogger):
pred_imgs = self.get_from_buffer(DetectionVizEnum.PRED_IMG_PROPH)
label_imgs = self.get_from_buffer(DetectionVizEnum.LABEL_IMG_PROPH)
assert len(pred_imgs) == len(label_imgs)
merged_img = []
captions = []
for idx, (pred_img, label_img) in enumerate(zip(pred_imgs, label_imgs)):
merged_img.append(
rearrange([pred_img, label_img], "pl H W C -> (pl H) W C", pl=2, C=3)
)
captions.append(f"sample_{idx}")
logger.log_images(key="val/predictions", images=merged_img, caption=captions)
================================================
FILE: RVT/callbacks/gradflow.py
================================================
from typing import Any
import lightning.pytorch as pl
from lightning.pytorch.callbacks import Callback
from lightning.pytorch.utilities.rank_zero import rank_zero_only
from callbacks.utils.visualization import get_grad_flow_figure
class GradFlowLogCallback(Callback):
def __init__(self, log_every_n_train_steps: int):
super().__init__()
assert log_every_n_train_steps > 0
self.log_every_n_train_steps = log_every_n_train_steps
@rank_zero_only
def on_before_zero_grad(
self, trainer: pl.Trainer, pl_module: pl.LightningModule, optimizer: Any
) -> None:
# NOTE: before we had this in the on_after_backward callback.
# This was fine for fp32 but showed unscaled gradients for fp16.
# That is why we move it to on_before_zero_grad where gradients are scaled.
global_step = trainer.global_step
if global_step % self.log_every_n_train_steps != 0:
return
named_parameters = pl_module.named_parameters()
figure = get_grad_flow_figure(named_parameters)
trainer.logger.log_metrics({"train/gradients": figure}, step=global_step)
================================================
FILE: RVT/callbacks/utils/visualization.py
================================================
import pandas as pd
import plotly.express as px
def get_grad_flow_figure(named_params):
"""Creates figure to visualize gradients flowing through different layers in the net during training.
Can be used for checking for possible gradient vanishing / exploding problems.
Usage: Use this function after loss.backwards()
"""
data_dict = {
"name": list(),
"grad_abs": list(),
}
for name, param in named_params:
if param.requires_grad and param.grad is not None:
grad_abs = param.grad.abs()
data_dict["name"].append(name)
data_dict["grad_abs"].append(grad_abs.mean().cpu().item())
data_frame = pd.DataFrame.from_dict(data_dict)
fig = px.bar(data_frame, x="name", y="grad_abs")
return fig
================================================
FILE: RVT/callbacks/viz_base.py
================================================
import random
from enum import Enum
from typing import Any, List, Optional, Type, Union
import numpy as np
import pytorch_lightning as pl
import torch as th
from einops import rearrange, reduce
from omegaconf import DictConfig
from lightning.pytorch.callbacks import Callback
from lightning.pytorch.utilities.rank_zero import rank_zero_only
from loggers.wandb_logger import WandbLogger
class VizCallbackBase(Callback):
def __init__(self, config: DictConfig, buffer_entries: Type[Enum]):
super().__init__()
self.log_config = config.logging
self._training_has_started = False
self._selected_val_batches = False
self.buffer_entries = buffer_entries
self._val_batch_indices = list()
self._buffer = None
self._reset_buffer()
def _reset_buffer(self):
self._buffer = {entry: [] for entry in self.buffer_entries}
# Functions to be USED in the base class ---------------------------------------------------------------------------
def add_to_buffer(self, key: Enum, value: Union[np.ndarray, th.Tensor]):
if isinstance(value, th.Tensor):
assert not value.requires_grad
value = value.cpu()
else:
assert isinstance(value, np.ndarray)
assert type(key) == self.buffer_entries
assert key in self._buffer
self._buffer[key].append(value)
def get_from_buffer(self, key: Enum) -> List[th.Tensor]:
assert type(key) == self.buffer_entries
return self._buffer[key]
# Functions to be IMPLEMENTED in the base class --------------------------------------------------------------------
def on_train_batch_end_custom(
self,
logger: WandbLogger,
outputs: Any,
batch: Any,
log_n_samples: int,
global_step: int,
) -> None:
raise NotImplementedError
def on_validation_batch_end_custom(self, batch: Any, outputs: Any) -> None:
raise NotImplementedError
def on_validation_epoch_end_custom(self, logger: WandbLogger) -> None:
raise NotImplementedError
# ------------------------------------------------------------------------------------------------------------------
def on_train_batch_end(
self,
trainer: pl.Trainer,
pl_module: pl.LightningModule,
outputs: Any,
batch: Any,
batch_idx: int,
unused: int = 0,
) -> None:
log_train_hd = self.log_config.train.high_dim
if not log_train_hd.enable:
return
step = trainer.global_step
assert log_train_hd.every_n_steps > 0
if step % log_train_hd.every_n_steps != 0:
return
n_samples = log_train_hd.n_samples
logger: Optional[WandbLogger] = trainer.logger
assert isinstance(logger, WandbLogger)
global_step = trainer.global_step
self.on_train_batch_end_custom(
logger=logger,
outputs=outputs,
batch=batch,
log_n_samples=n_samples,
global_step=global_step,
)
@rank_zero_only
def on_validation_batch_end(
self,
trainer: pl.Trainer,
pl_module: pl.LightningModule,
outputs: Optional[Any],
batch: Any,
batch_idx: int,
dataloader_idx: int = 0,
) -> None:
log_val_hd = self.log_config.validation.high_dim
log_freq_val_epochs = log_val_hd.every_n_epochs
if not log_val_hd.enable:
return
if dataloader_idx > 0:
raise NotImplementedError
if not self._training_has_started:
# PL has a short sanity check for validation. Hence, we have to make sure that one training run is done.
return
if not self._selected_val_batches:
# We only want to add validation batch indices during the first true validation run.
self._val_batch_indices.append(batch_idx)
return
assert len(self._val_batch_indices) > 0
if batch_idx not in self._val_batch_indices:
return
if trainer.current_epoch % log_freq_val_epochs != 0:
return
self.on_validation_batch_end_custom(batch, outputs)
def on_validation_epoch_start(
self, trainer: pl.Trainer, pl_module: pl.LightningModule
) -> None:
self._reset_buffer()
@rank_zero_only
def on_validation_epoch_end(
self, trainer: pl.Trainer, pl_module: pl.LightningModule
) -> None:
log_val_hd = self.log_config.validation.high_dim
log_n_samples = log_val_hd.n_samples
log_freq_val_epochs = log_val_hd.every_n_epochs
if len(self._val_batch_indices) == 0:
return
if not self._selected_val_batches:
random.seed(0)
num_samples = min(len(self._val_batch_indices), log_n_samples)
# draw without replacement
sampled_indices = random.sample(self._val_batch_indices, num_samples)
self._val_batch_indices = sampled_indices
self._selected_val_batches = True
return
if trainer.current_epoch % log_freq_val_epochs != 0:
return
logger: Optional[WandbLogger] = trainer.logger
assert isinstance(logger, WandbLogger)
self.on_validation_epoch_end_custom(logger)
def on_train_batch_start(
self,
trainer: "pl.Trainer",
pl_module: "pl.LightningModule",
batch: Any,
batch_idx: int,
) -> None:
self._training_has_started = True
@staticmethod
def ev_repr_to_img(x: np.ndarray):
ch, ht, wd = x.shape[-3:]
assert ch > 1 and ch % 2 == 0
ev_repr_reshaped = rearrange(x, "(posneg C) H W -> posneg C H W", posneg=2)
img_neg = np.asarray(
reduce(ev_repr_reshaped[0], "C H W -> H W", "sum"), dtype="int32"
)
img_pos = np.asarray(
reduce(ev_repr_reshaped[1], "C H W -> H W", "sum"), dtype="int32"
)
img_diff = img_pos - img_neg
img = 127 * np.ones((ht, wd, 3), dtype=np.uint8)
img[img_diff > 0] = 255
img[img_diff < 0] = 0
return img
================================================
FILE: RVT/config/dataset/base.yaml
================================================
name: ???
path: ???
train:
sampling: 'mixed' # ('random', 'stream', 'mixed')
random:
weighted_sampling: False
mixed:
w_stream: 1
w_random: 1
eval:
sampling: 'stream'
data_augmentation:
random:
prob_hflip: 0.5
rotate:
prob: 0
min_angle_deg: 2
max_angle_deg: 6
zoom:
prob: 0.8
zoom_in:
weight: 8
factor:
min: 1
max: 1.5
zoom_out:
weight: 2
factor:
min: 1
max: 1.2
stream:
prob_hflip: 0.5
rotate:
prob: 0
min_angle_deg: 2
max_angle_deg: 6
zoom:
prob: 0.5
zoom_out:
factor:
min: 1
max: 1.2
================================================
FILE: RVT/config/dataset/gen1.yaml
================================================
defaults:
- base
name: gen1
ev_repr_name: 'stacked_histogram_dt=50_nbins=10'
sequence_length: 21
resolution_hw: [240, 304]
downsample_by_factor_2: False
only_load_end_labels: False
================================================
FILE: RVT/config/dataset/gen4.yaml
================================================
defaults:
- base
name: gen4
ev_repr_name: 'stacked_histogram_dt=50_nbins=10'
sequence_length: 10
resolution_hw: [720, 1280]
downsample_by_factor_2: True
only_load_end_labels: False
================================================
FILE: RVT/config/experiment/gen1/base.yaml
================================================
# @package _global_
defaults:
- default
model:
backbone:
embed_dim: 64
fpn:
depth: 0.67
================================================
FILE: RVT/config/experiment/gen1/default.yaml
================================================
# @package _global_
defaults:
- /model/maxvit_yolox: default
training:
precision: 32
max_epochs: 10000
max_steps: 400000
learning_rate: 0.0002
lr_scheduler:
use: True
total_steps: ${..max_steps}
pct_start: 0.005
div_factor: 20
final_div_factor: 10000
validation:
val_check_interval: 10000
check_val_every_n_epoch: null
batch_size:
train: 8
eval: 8
hardware:
num_workers:
train: 6
eval: 2
dataset:
train:
sampling: 'mixed'
random:
weighted_sampling: False
mixed:
w_stream: 1
w_random: 1
eval:
sampling: 'stream'
ev_repr_name: 'stacked_histogram_dt=50_nbins=10'
sequence_length: 21
downsample_by_factor_2: False
only_load_end_labels: False
model:
backbone:
partition_split_32: 1
================================================
FILE: RVT/config/experiment/gen1/small.yaml
================================================
# @package _global_
defaults:
- default
model:
backbone:
embed_dim: 48
stage:
attention:
dim_head: 24
fpn:
depth: 0.33
================================================
FILE: RVT/config/experiment/gen4/base.yaml
================================================
# @package _global_
defaults:
- default
model:
backbone:
embed_dim: 64
fpn:
depth: 0.67
================================================
FILE: RVT/config/experiment/gen4/default.yaml
================================================
# @package _global_
defaults:
- /model/maxvit_yolox: default
training:
precision: 32
max_epochs: 10000
max_steps: 400000
learning_rate: 0.0002449489742783178 # 2e-4 * sqrt(effective_batch_size/8) = 2e-4 * sqrt(12/8)
lr_scheduler:
use: True
total_steps: ${..max_steps}
pct_start: 0.005
div_factor: 20
final_div_factor: 10000
validation:
val_check_interval: 10000
check_val_every_n_epoch: null
batch_size:
train: 12
eval: 12
hardware:
num_workers:
train: 6
eval: 2
dataset:
train:
sampling: 'mixed'
random:
weighted_sampling: False
mixed:
w_stream: 1
w_random: 1
eval:
sampling: 'stream'
ev_repr_name: 'stacked_histogram_dt=50_nbins=10'
sequence_length: 10
downsample_by_factor_2: True
only_load_end_labels: False
================================================
FILE: RVT/config/experiment/gen4/small.yaml
================================================
# @package _global_
defaults:
- default
model:
backbone:
embed_dim: 48
stage:
attention:
dim_head: 24
fpn:
depth: 0.33
================================================
FILE: RVT/config/general.yaml
================================================
reproduce:
seed_everything: null # Union[int, null]
deterministic_flag: False # Must be true for fully deterministic behaviour (slows down training)
benchmark: False # Should be set to false for fully deterministic behaviour. Could potentially speed up training.
training:
precision: 16
max_epochs: 10000
max_steps: 400000
learning_rate: 0.0002
weight_decay: 0
gradient_clip_val: 1.0
limit_train_batches: 1.0
lr_scheduler:
use: True
total_steps: ${..max_steps}
pct_start: 0.005
div_factor: 25 # init_lr = max_lr / div_factor
final_div_factor: 10000 # final_lr = max_lr / final_div_factor (this is different from Pytorch' OneCycleLR param)
validation:
limit_val_batches: 1.0
val_check_interval: null # Optional[int]
check_val_every_n_epoch: 1 # Optional[int]
batch_size:
train: 8
eval: 8
hardware:
num_workers:
train: 6
eval: 2
gpus: 0 # Either a single integer (e.g. 3) or a list of integers (e.g. [3,5,6])
dist_backend: "nccl"
logging:
ckpt_every_n_epochs: 1
train:
metrics:
compute: false
detection_metrics_every_n_steps: null # Optional[int] -> null: every train epoch, int: every N steps
log_model_every_n_steps: 5000
log_every_n_steps: 500
high_dim:
enable: True
every_n_steps: 5000
n_samples: 4
validation:
high_dim:
enable: True
every_n_epochs: 1
n_samples: 8
wandb:
# How to use:
# 1) resume existing wandb run: set artifact_name & wandb_runpath
# 2) resume full training state in new wandb run: set artifact_name
# 3) resume only model weights of checkpoint in new wandb run: set artifact_name & resume_only_weights=True
#
# In addition: you can specify artifact_local_file to load the checkpoint from disk.
# This is for example required for resuming training with DDP.
wandb_runpath: null # WandB run path. E.g. USERNAME/PROJECTNAME/1grv5kg6
artifact_name: null # Name of checkpoint/artifact. Required for resuming. E.g. USERNAME/PROJECTNAME/checkpoint-1grv5kg6-last:v15
artifact_local_file: null # If specified, will use the provided local filepath instead of downloading it. Required if resuming with DDP.
resume_only_weights: False
group_name: ??? # Specify group name of the run
project_name: RVT
================================================
FILE: RVT/config/model/base.yaml
================================================
name: ???
================================================
FILE: RVT/config/model/maxvit_yolox/default.yaml
================================================
# @package _global_
defaults:
- override /model: rnndet
model:
backbone:
name: MaxViTRNN
compile:
enable: False
args:
mode: reduce-overhead
input_channels: 20
enable_masking: False
partition_split_32: 2
embed_dim: 64
dim_multiplier: [1, 2, 4, 8]
num_blocks: [1, 1, 1, 1]
T_max_chrono_init: [4, 8, 16, 32]
stem:
patch_size: 4
stage:
downsample:
type: patch
overlap: True
norm_affine: True
attention:
use_torch_mha: False
partition_size: ???
dim_head: 32
attention_bias: True
mlp_activation: gelu
mlp_gated: False
mlp_bias: True
mlp_ratio: 4
drop_mlp: 0
drop_path: 0
ls_init_value: 1e-5
lstm:
dws_conv: False
dws_conv_only_hidden: True
dws_conv_kernel_size: 3
drop_cell_update: 0
s5:
dim: 80
state_dim: 80
s4:
dim: 80
state_dim: 80
fpn:
name: PAFPN
compile:
enable: False
args:
mode: reduce-overhead
depth: 0.67 # round(depth * 3) == num bottleneck blocks
# stage 1 is the first and len(num_layers) is the last
in_stages: [2, 3, 4]
depthwise: False
act: "silu"
head:
name: YoloX
compile:
enable: False
args:
mode: reduce-overhead
depthwise: False
act: "silu"
postprocess:
confidence_threshold: 0.1
nms_threshold: 0.45
================================================
FILE: RVT/config/model/rnndet.yaml
================================================
defaults:
- base
name: rnndet
backbone:
name: ???
fpn:
name: ???
head:
name: ???
postprocess:
confidence_threshold: 0.1
nms_threshold: 0.45
================================================
FILE: RVT/config/modifier.py
================================================
import os
from typing import Tuple
import math
from omegaconf import DictConfig, open_dict
from data.utils.spatial import get_dataloading_hw
def dynamically_modify_train_config(config: DictConfig):
with open_dict(config):
slurm_job_id = os.environ.get("SLURM_JOB_ID")
if slurm_job_id and slurm_job_id != "":
config.slurm_job_id = int(slurm_job_id)
dataset_cfg = config.dataset
dataset_name = dataset_cfg.name
assert dataset_name in {"gen1", "gen4"}
dataset_hw = get_dataloading_hw(dataset_config=dataset_cfg)
mdl_cfg = config.model
mdl_name = mdl_cfg.name
if mdl_name == "rnndet":
backbone_cfg = mdl_cfg.backbone
backbone_name = backbone_cfg.name
if backbone_name == "MaxViTRNN":
partition_split_32 = backbone_cfg.partition_split_32
assert partition_split_32 in (1, 2, 4)
multiple_of = 32 * partition_split_32
mdl_hw = _get_modified_hw_multiple_of(
hw=dataset_hw, multiple_of=multiple_of
)
print(f"Set {backbone_name} backbone (height, width) to {mdl_hw}")
backbone_cfg.in_res_hw = mdl_hw
attention_cfg = backbone_cfg.stage.attention
partition_size = tuple(x // (32 * partition_split_32) for x in mdl_hw)
assert (mdl_hw[0] // 32) % partition_size[
0
] == 0, f"{mdl_hw[0]=}, {partition_size[0]=}"
assert (mdl_hw[1] // 32) % partition_size[
1
] == 0, f"{mdl_hw[1]=}, {partition_size[1]=}"
print(f"Set partition sizes: {partition_size}")
attention_cfg.partition_size = partition_size
else:
print(f"{backbone_name=} not available")
raise NotImplementedError
num_classes = 2 if dataset_name == "gen1" else 3
mdl_cfg.head.num_classes = num_classes
print(f"Set {num_classes=} for detection head")
else:
print(f"{mdl_name=} not available")
raise NotImplementedError
def _get_modified_hw_multiple_of(
hw: Tuple[int, int], multiple_of: int
) -> Tuple[int, ...]:
assert isinstance(hw, tuple), f"{type(hw)=}, {hw=}"
assert len(hw) == 2
assert isinstance(multiple_of, int)
assert multiple_of >= 1
if multiple_of == 1:
return hw
new_hw = tuple(math.ceil(x / multiple_of) * multiple_of for x in hw)
return new_hw
================================================
FILE: RVT/config/train.yaml
================================================
defaults:
- general
- dataset: ???
- model: rnndet
- optional model/dataset: ${model}_${dataset}
================================================
FILE: RVT/config/val.yaml
================================================
defaults:
- dataset: ???
- model: rnndet
- _self_
checkpoint: ???
use_test_set: False
hardware:
num_workers:
eval: 4
gpus: 0 # GPU idx (multi-gpu not supported for validation)
batch_size:
eval: 8
training:
precision: 16
================================================
FILE: RVT/data/genx_utils/collate.py
================================================
from copy import deepcopy
from typing import Any, Callable, Dict, Optional, Type, Tuple, Union
import torch
from data.genx_utils.collate_from_pytorch import collate, default_collate_fn_map
from data.genx_utils.labels import ObjectLabels, SparselyBatchedObjectLabels
def collate_object_labels(
batch,
*,
collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None
):
return batch
def collate_sparsely_batched_object_labels(
batch,
*,
collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None
):
return SparselyBatchedObjectLabels.transpose_list(batch)
custom_collate_fn_map = deepcopy(default_collate_fn_map)
custom_collate_fn_map[ObjectLabels] = collate_object_labels
custom_collate_fn_map[SparselyBatchedObjectLabels] = (
collate_sparsely_batched_object_labels
)
def custom_collate(batch: Any):
return collate(batch, collate_fn_map=custom_collate_fn_map)
def custom_collate_rnd(batch: Any):
samples = batch
# NOTE: We do not really need the worker id for map style datasets (rnd) but we still provide the id for consistency
worker_info = torch.utils.data.get_worker_info()
local_worker_id = 0 if worker_info is None else worker_info.id
return {
"data": custom_collate(samples),
"worker_id": local_worker_id,
}
def custom_collate_streaming(batch: Any):
"""We assume that we receive a batch collected by a worker of our streaming datapipe"""
samples = batch[0]
worker_id = batch[1]
assert isinstance(worker_id, int)
return {
"data": custom_collate(samples),
"worker_id": worker_id,
}
================================================
FILE: RVT/data/genx_utils/collate_from_pytorch.py
================================================
import collections
import contextlib
import re
import torch
torch_is_version_1 = int(torch.__version__.split(".")[0]) == 1
from typing import Callable, Dict, Optional, Tuple, Type, Union
np_str_obj_array_pattern = re.compile(r"[SaUO]")
default_collate_err_msg_format = (
"default_collate: batch must contain tensors, numpy arrays, numbers, "
"dicts or lists; found {}"
)
def collate(
batch,
*,
collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None
):
r"""
General collate function that handles collection type of element within each batch
and opens function registry to deal with specific element types. `default_collate_fn_map`
provides default collate functions for tensors, numpy arrays, numbers and strings.
Args:
batch: a single batch to be collated
collate_fn_map: Optional dictionary mapping from element type to the corresponding collate function.
If the element type isn't present in this dictionary,
this function will go through each key of the dictionary in the insertion order to
invoke the corresponding collate function if the element type is a subclass of the key.
Examples:
>>> # Extend this function to handle batch of tensors
>>> def collate_tensor_fn(batch, *, collate_fn_map):
... return torch.stack(batch, 0)
>>> def custom_collate(batch):
... collate_map = {torch.Tensor: collate_tensor_fn}
... return collate(batch, collate_fn_map=collate_map)
>>> # Extend `default_collate` by in-place modifying `default_collate_fn_map`
>>> default_collate_fn_map.update({torch.Tensor: collate_tensor_fn})
Note:
Each collate function requires a positional argument for batch and a keyword argument
for the dictionary of collate functions as `collate_fn_map`.
"""
elem = batch[0]
elem_type = type(elem)
if collate_fn_map is not None:
if elem_type in collate_fn_map:
return collate_fn_map[elem_type](batch, collate_fn_map=collate_fn_map)
for collate_type in collate_fn_map:
if isinstance(elem, collate_type):
return collate_fn_map[collate_type](
batch, collate_fn_map=collate_fn_map
)
if isinstance(elem, collections.abc.Mapping):
try:
return elem_type(
{
key: collate([d[key] for d in batch], collate_fn_map=collate_fn_map)
for key in elem
}
)
except TypeError:
# The mapping type may not support `__init__(iterable)`.
return {
key: collate([d[key] for d in batch], collate_fn_map=collate_fn_map)
for key in elem
}
elif isinstance(elem, tuple) and hasattr(elem, "_fields"): # namedtuple
return elem_type(
*(
collate(samples, collate_fn_map=collate_fn_map)
for samples in zip(*batch)
)
)
elif isinstance(elem, collections.abc.Sequence):
# check to make sure that the elements in batch have consistent size
it = iter(batch)
elem_size = len(next(it))
if not all(len(elem) == elem_size for elem in it):
raise RuntimeError("each element in list of batch should be of equal size")
transposed = list(zip(*batch)) # It may be accessed twice, so we use a list.
if isinstance(elem, tuple):
return [
collate(samples, collate_fn_map=collate_fn_map)
for samples in transposed
] # Backwards compatibility.
else:
try:
return elem_type(
[
collate(samples, collate_fn_map=collate_fn_map)
for samples in transposed
]
)
except TypeError:
# The sequence type may not support `__init__(iterable)` (e.g., `range`).
return [
collate(samples, collate_fn_map=collate_fn_map)
for samples in transposed
]
raise TypeError(default_collate_err_msg_format.format(elem_type))
if torch_is_version_1:
def collate_tensor_fn(
batch,
*,
collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None
):
elem = batch[0]
out = None
if torch.utils.data.get_worker_info() is not None:
# If we're in a background process, concatenate directly into a
# shared memory tensor to avoid an extra copy
numel = sum(x.numel() for x in batch)
storage = elem.storage()._new_shared(numel, device=elem.device)
out = elem.new(storage).resize_(len(batch), *list(elem.size()))
return torch.stack(batch, 0, out=out)
else:
def collate_tensor_fn(
batch,
*,
collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None
):
elem = batch[0]
out = None
if torch.utils.data.get_worker_info() is not None:
# If we're in a background process, concatenate directly into a
# shared memory tensor to avoid an extra copy
numel = sum(x.numel() for x in batch)
storage = elem._typed_storage()._new_shared(numel, device=elem.device)
out = elem.new(storage).resize_(len(batch), *list(elem.size()))
return torch.stack(batch, 0, out=out)
def collate_numpy_array_fn(
batch,
*,
collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None
):
elem = batch[0]
# array of string classes and object
if np_str_obj_array_pattern.search(elem.dtype.str) is not None:
raise TypeError(default_collate_err_msg_format.format(elem.dtype))
return collate([torch.as_tensor(b) for b in batch], collate_fn_map=collate_fn_map)
def collate_numpy_scalar_fn(
batch,
*,
collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None
):
return torch.as_tensor(batch)
def collate_float_fn(
batch,
*,
collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None
):
return torch.tensor(batch, dtype=torch.float64)
def collate_int_fn(
batch,
*,
collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None
):
return torch.tensor(batch)
def collate_str_fn(
batch,
*,
collate_fn_map: Optional[Dict[Union[Type, Tuple[Type, ...]], Callable]] = None
):
return batch
default_collate_fn_map: Dict[Union[Type, Tuple[Type, ...]], Callable] = {
torch.Tensor: collate_tensor_fn
}
with contextlib.suppress(ImportError):
import numpy as np
# For both ndarray and memmap (subclass of ndarray)
default_collate_fn_map[np.ndarray] = collate_numpy_array_fn
# See scalars hierarchy: https://numpy.org/doc/stable/reference/arrays.scalars.html
# Skip string scalars
default_collate_fn_map[(np.bool_, np.number, np.object_)] = collate_numpy_scalar_fn
default_collate_fn_map[float] = collate_float_fn
default_collate_fn_map[int] = collate_int_fn
default_collate_fn_map[str] = collate_str_fn
================================================
FILE: RVT/data/genx_utils/dataset_rnd.py
================================================
from collections import namedtuple
from collections.abc import Iterable
from pathlib import Path
from typing import List
import numpy as np
from omegaconf import DictConfig
from torch.utils.data import ConcatDataset, Dataset
from torch.utils.data.sampler import WeightedRandomSampler
from tqdm import tqdm
from data.genx_utils.labels import SparselyBatchedObjectLabels
from data.genx_utils.sequence_rnd import SequenceForRandomAccess
from data.utils.augmentor import RandomSpatialAugmentorGenX
from data.utils.types import DatasetMode, LoaderDataDictGenX, DatasetType, DataType
class SequenceDataset(Dataset):
def __init__(
self, path: Path, dataset_mode: DatasetMode, dataset_config: DictConfig
):
assert path.is_dir()
### extract settings from config ###
sequence_length = dataset_config.sequence_length
assert isinstance(sequence_length, int)
assert sequence_length > 0
self.output_seq_len = sequence_length
ev_representation_name = dataset_config.ev_repr_name
downsample_by_factor_2 = dataset_config.downsample_by_factor_2
only_load_end_labels = dataset_config.only_load_end_labels
augm_config = dataset_config.data_augmentation
####################################
if dataset_config.name == "gen1":
dataset_type = DatasetType.GEN1
elif dataset_config.name == "gen4":
dataset_type = DatasetType.GEN4
else:
raise NotImplementedError
self.sequence = SequenceForRandomAccess(
path=path,
ev_representation_name=ev_representation_name,
sequence_length=sequence_length,
dataset_type=dataset_type,
downsample_by_factor_2=downsample_by_factor_2,
only_load_end_labels=only_load_end_labels,
)
self.spatial_augmentor = None
if dataset_mode == DatasetMode.TRAIN:
resolution_hw = tuple(dataset_config.resolution_hw)
assert len(resolution_hw) == 2
ds_by_factor_2 = dataset_config.downsample_by_factor_2
if ds_by_factor_2:
resolution_hw = tuple(x // 2 for x in resolution_hw)
self.spatial_augmentor = RandomSpatialAugmentorGenX(
dataset_hw=resolution_hw,
automatic_randomization=True,
augm_config=augm_config.random,
)
def only_load_labels(self):
self.sequence.only_load_labels()
def load_everything(self):
self.sequence.load_everything()
def __len__(self):
return len(self.sequence)
def __getitem__(self, index: int) -> LoaderDataDictGenX:
item = self.sequence[index]
if (
self.spatial_augmentor is not None
and not self.sequence.is_only_loading_labels()
):
item = self.spatial_augmentor(item)
return item
class CustomConcatDataset(ConcatDataset):
datasets: List[SequenceDataset]
def __init__(self, datasets: Iterable[SequenceDataset]):
super().__init__(datasets=datasets)
def only_load_labels(self):
for idx, dataset in enumerate(self.datasets):
self.datasets[idx].only_load_labels()
def load_everything(self):
for idx, dataset in enumerate(self.datasets):
self.datasets[idx].load_everything()
def build_random_access_dataset(
dataset_mode: DatasetMode, dataset_config: DictConfig
) -> CustomConcatDataset:
dataset_path = Path(dataset_config.path)
assert dataset_path.is_dir(), f"{str(dataset_path)}"
mode2str = {
DatasetMode.TRAIN: "train",
DatasetMode.VALIDATION: "val",
DatasetMode.TESTING: "test",
}
split_path = dataset_path / mode2str[dataset_mode]
assert split_path.is_dir()
seq_datasets = list()
for entry in tqdm(
split_path.iterdir(),
desc=f"creating rnd access {mode2str[dataset_mode]} datasets",
):
seq_datasets.append(
SequenceDataset(
path=entry, dataset_mode=dataset_mode, dataset_config=dataset_config
)
)
return CustomConcatDataset(seq_datasets)
def get_weighted_random_sampler(dataset: CustomConcatDataset) -> WeightedRandomSampler:
class2count = dict()
ClassAndCount = namedtuple("ClassAndCount", ["class_ids", "counts"])
classandcount_list = list()
print("--- START generating weighted random sampler ---")
dataset.only_load_labels()
for idx, data in enumerate(tqdm(dataset, desc="iterate through dataset")):
labels: SparselyBatchedObjectLabels = data[DataType.OBJLABELS_SEQ]
label_list, valid_batch_indices = labels.get_valid_labels_and_batch_indices()
class_ids_seq = list()
for label in label_list:
class_ids_numpy = np.asarray(label.class_id.numpy(), dtype="int32")
class_ids_seq.append(class_ids_numpy)
class_ids_seq, counts_seq = np.unique(
np.concatenate(class_ids_seq), return_counts=True
)
for class_id, count in zip(class_ids_seq, counts_seq):
class2count[class_id] = class2count.get(class_id, 0) + count
classandcount_list.append(
ClassAndCount(class_ids=class_ids_seq, counts=counts_seq)
)
dataset.load_everything()
class2weight = {}
for class_id, count in class2count.items():
count = max(count, 1)
class2weight[class_id] = 1 / count
weights = []
for classandcount in classandcount_list:
weight = 0
for class_id, count in zip(classandcount.class_ids, classandcount.counts):
# Not only weight depending on class but also depending on number of occurrences.
# This will bias towards sampling "frames" with more bounding boxes.
weight += class2weight[class_id] * count
weights.append(weight)
print("--- DONE generating weighted random sampler ---")
return WeightedRandomSampler(
weights=weights, num_samples=len(weights), replacement=True
)
================================================
FILE: RVT/data/genx_utils/dataset_streaming.py
================================================
from functools import partialmethod
from pathlib import Path
from typing import List, Union
from omegaconf import DictConfig
from torchdata.datapipes.map import MapDataPipe
from tqdm import tqdm
from data.genx_utils.sequence_for_streaming import (
SequenceForIter,
RandAugmentIterDataPipe,
)
from data.utils.stream_concat_datapipe import ConcatStreamingDataPipe
from data.utils.stream_sharded_datapipe import ShardedStreamingDataPipe
from data.utils.types import DatasetMode, DatasetType
def build_streaming_dataset(
dataset_mode: DatasetMode,
dataset_config: DictConfig,
batch_size: int,
num_workers: int,
) -> Union[ConcatStreamingDataPipe, ShardedStreamingDataPipe]:
dataset_path = Path(dataset_config.path)
assert dataset_path.is_dir(), f"{str(dataset_path)}"
mode2str = {
DatasetMode.TRAIN: "train",
DatasetMode.VALIDATION: "val",
DatasetMode.TESTING: "test",
}
split_path = dataset_path / mode2str[dataset_mode]
assert split_path.is_dir()
datapipes = list()
num_full_sequences = 0
num_splits = 0
num_split_sequences = 0
guarantee_labels = dataset_mode == DatasetMode.TRAIN
for entry in tqdm(
split_path.iterdir(),
desc=f"creating streaming {mode2str[dataset_mode]} datasets",
):
new_datapipes = get_sequences(
path=entry, dataset_config=dataset_config, guarantee_labels=guarantee_labels
)
if len(new_datapipes) == 1:
num_full_sequences += 1
else:
num_splits += 1
num_split_sequences += len(new_datapipes)
datapipes.extend(new_datapipes)
print(f"{num_full_sequences=}\n{num_splits=}\n{num_split_sequences=}")
if dataset_mode == DatasetMode.TRAIN:
return build_streaming_train_dataset(
datapipes=datapipes,
dataset_config=dataset_config,
batch_size=batch_size,
num_workers=num_workers,
)
elif dataset_mode in (DatasetMode.VALIDATION, DatasetMode.TESTING):
return build_streaming_evaluation_dataset(
datapipes=datapipes, batch_size=batch_size
)
else:
raise NotImplementedError
def get_sequences(
path: Path, dataset_config: DictConfig, guarantee_labels: bool
) -> List[SequenceForIter]:
assert path.is_dir()
### extract settings from config ###
sequence_length = dataset_config.sequence_length
ev_representation_name = dataset_config.ev_repr_name
downsample_by_factor_2 = dataset_config.downsample_by_factor_2
if dataset_config.name == "gen1":
dataset_type = DatasetType.GEN1
elif dataset_config.name == "gen4":
dataset_type = DatasetType.GEN4
else:
raise NotImplementedError
####################################
if guarantee_labels:
return SequenceForIter.get_sequences_with_guaranteed_labels(
path=path,
ev_representation_name=ev_representation_name,
sequence_length=sequence_length,
dataset_type=dataset_type,
downsample_by_factor_2=downsample_by_factor_2,
)
return [
SequenceForIter(
path=path,
ev_representation_name=ev_representation_name,
sequence_length=sequence_length,
dataset_type=dataset_type,
downsample_by_factor_2=downsample_by_factor_2,
)
]
def partialclass(cls, *args, **kwargs):
class NewCls(cls):
__init__ = partialmethod(cls.__init__, *args, **kwargs)
return NewCls
def build_streaming_train_dataset(
datapipes: List[MapDataPipe],
dataset_config: DictConfig,
batch_size: int,
num_workers: int,
) -> ConcatStreamingDataPipe:
assert len(datapipes) > 0
augmentation_datapipe_type = partialclass(
RandAugmentIterDataPipe, dataset_config=dataset_config
)
streaming_dataset = ConcatStreamingDataPipe(
datapipe_list=datapipes,
batch_size=batch_size,
num_workers=num_workers,
augmentation_pipeline=augmentation_datapipe_type,
print_seed_debug=False,
)
return streaming_dataset
def build_streaming_evaluation_dataset(
datapipes: List[MapDataPipe], batch_size: int
) -> ShardedStreamingDataPipe:
assert len(datapipes) > 0
fill_value = datapipes[0].get_fully_padded_sample()
streaming_dataset = ShardedStreamingDataPipe(
datapipe_list=datapipes, batch_size=batch_size, fill_value=fill_value
)
return streaming_dataset
================================================
FILE: RVT/data/genx_utils/labels.py
================================================
from __future__ import annotations
from typing import List, Tuple, Union, Optional
import math
import numpy as np
import torch as th
from einops import rearrange
from torch.nn.functional import pad
class ObjectLabelBase:
_str2idx = {
"t": 0,
"x": 1,
"y": 2,
"w": 3,
"h": 4,
"class_id": 5,
"class_confidence": 6,
}
def __init__(self, object_labels: th.Tensor, input_size_hw: Tuple[int, int]):
assert isinstance(object_labels, th.Tensor)
assert object_labels.dtype in {th.float32, th.float64}
assert object_labels.ndim == 2
assert object_labels.shape[-1] == len(self._str2idx)
assert isinstance(input_size_hw, tuple)
assert len(input_size_hw) == 2
self.object_labels = object_labels
self._input_size_hw = input_size_hw
self._is_numpy = False
def clamp_to_frame_(self):
ht, wd = self.input_size_hw
x0 = th.clamp(self.x, min=0, max=wd - 1)
y0 = th.clamp(self.y, min=0, max=ht - 1)
x1 = th.clamp(self.x + self.w, min=0, max=wd - 1)
y1 = th.clamp(self.y + self.h, min=0, max=ht - 1)
w = x1 - x0
h = y1 - y0
assert th.all(w > 0)
assert th.all(h > 0)
self.x = x0
self.y = y0
self.w = w
self.h = h
def remove_flat_labels_(self):
keep = (self.w > 0) & (self.h > 0)
self.object_labels = self.object_labels[keep]
@classmethod
def create_empty(cls):
# This is useful to represent cases where no labels are available.
return ObjectLabelBase(
object_labels=th.empty((0, len(cls._str2idx))), input_size_hw=(0, 0)
)
def _assert_not_numpy(self):
assert (
not self._is_numpy
), "Labels have been converted numpy. \
Numpy is not supported for the intended operations."
def to(self, *args, **kwargs):
# This function executes torch.to on self tensors and returns self.
self._assert_not_numpy()
# This will be used by Pytorch Lightning to transfer to the relevant device
self.object_labels = self.object_labels.to(*args, **kwargs)
return self
def numpy_(self) -> None:
"""
In place conversion to numpy (detach + to cpu + to numpy).
Cannot be undone.
"""
self._is_numpy = True
self.object_labels = self.object_labels.detach().cpu().numpy()
@property
def input_size_hw(self) -> Tuple[int, int]:
return self._input_size_hw
@input_size_hw.setter
def input_size_hw(self, height_width: Tuple[int, int]):
assert isinstance(height_width, tuple)
assert len(height_width) == 2
assert height_width[0] > 0
assert height_width[1] > 0
self._input_size_hw = height_width
def get(self, request: str):
assert request in self._str2idx
return self.object_labels[:, self._str2idx[request]]
@property
def t(self):
return self.object_labels[:, self._str2idx["t"]]
@property
def x(self):
return self.object_labels[:, self._str2idx["x"]]
@x.setter
def x(self, value: Union[th.Tensor, np.ndarray]):
self.object_labels[:, self._str2idx["x"]] = value
@property
def y(self):
return self.object_labels[:, self._str2idx["y"]]
@y.setter
def y(self, value: Union[th.Tensor, np.ndarray]):
self.object_labels[:, self._str2idx["y"]] = value
@property
def w(self):
return self.object_labels[:, self._str2idx["w"]]
@w.setter
def w(self, value: Union[th.Tensor, np.ndarray]):
self.object_labels[:, self._str2idx["w"]] = value
@property
def h(self):
return self.object_labels[:, self._str2idx["h"]]
@h.setter
def h(self, value: Union[th.Tensor, np.ndarray]):
self.object_labels[:, self._str2idx["h"]] = value
@property
def class_id(self):
return self.object_labels[:, self._str2idx["class_id"]]
@property
def class_confidence(self):
return self.object_labels[:, self._str2idx["class_confidence"]]
@property
def dtype(self):
return self.object_labels.dtype
@property
def device(self):
return self.object_labels.device
class ObjectLabelFactory(ObjectLabelBase):
def __init__(
self,
object_labels: th.Tensor,
objframe_idx_2_label_idx: th.Tensor,
input_size_hw: Tuple[int, int],
downsample_factor: Optional[float] = None,
):
super().__init__(object_labels=object_labels, input_size_hw=input_size_hw)
assert objframe_idx_2_label_idx.dtype == th.int64
assert objframe_idx_2_label_idx.dim() == 1
self.objframe_idx_2_label_idx = objframe_idx_2_label_idx
self.downsample_factor = downsample_factor
if self.downsample_factor is not None:
assert self.downsample_factor > 1
self.clamp_to_frame_()
@staticmethod
def from_structured_array(
object_labels: np.ndarray,
objframe_idx_2_label_idx: np.ndarray,
input_size_hw: Tuple[int, int],
downsample_factor: Optional[float] = None,
) -> ObjectLabelFactory:
np_labels = [
object_labels[key].astype("float32") for key in ObjectLabels._str2idx.keys()
]
np_labels = rearrange(np_labels, "fields L -> L fields")
torch_labels = th.from_numpy(np_labels)
objframe_idx_2_label_idx = th.from_numpy(
objframe_idx_2_label_idx.astype("int64")
)
assert objframe_idx_2_label_idx.numel() == np.unique(object_labels["t"]).size
return ObjectLabelFactory(
object_labels=torch_labels,
objframe_idx_2_label_idx=objframe_idx_2_label_idx,
input_size_hw=input_size_hw,
downsample_factor=downsample_factor,
)
def __len__(self):
return len(self.objframe_idx_2_label_idx)
def __getitem__(self, item: int) -> ObjectLabels:
assert item >= 0
length = len(self)
assert length > 0
assert item < length
is_last_item = item == length - 1
from_idx = self.objframe_idx_2_label_idx[item]
to_idx = (
self.object_labels.shape[0]
if is_last_item
else self.objframe_idx_2_label_idx[item + 1]
)
assert to_idx > from_idx
object_labels = ObjectLabels(
object_labels=self.object_labels[from_idx:to_idx].clone(),
input_size_hw=self.input_size_hw,
)
if self.downsample_factor is not None:
object_labels.scale_(scaling_multiplier=1 / self.downsample_factor)
return object_labels
class ObjectLabels(ObjectLabelBase):
def __init__(self, object_labels: th.Tensor, input_size_hw: Tuple[int, int]):
super().__init__(object_labels=object_labels, input_size_hw=input_size_hw)
def __len__(self) -> int:
return self.object_labels.shape[0]
def rotate_(self, angle_deg: float):
if len(self) == 0:
return
# (x0,y0)---(x1,y0) p00---p10
# | | | |
# | | | |
# (x0,y1)---(x1,y1) p01---p11
p00 = th.stack((self.x, self.y), dim=1)
p10 = th.stack((self.x + self.w, self.y), dim=1)
p01 = th.stack((self.x, self.y + self.h), dim=1)
p11 = th.stack((self.x + self.w, self.y + self.h), dim=1)
# points: 4 x N x 2
points = th.stack((p00, p10, p01, p11), dim=0)
cx = self._input_size_hw[1] // 2
cy = self._input_size_hw[0] // 2
center = th.tensor([cx, cy], device=self.device)
angle_rad = angle_deg / 180 * math.pi
# counter-clockwise rotation
rot_matrix = th.tensor(
[
[math.cos(angle_rad), math.sin(angle_rad)],
[-math.sin(angle_rad), math.cos(angle_rad)],
],
device=self.device,
)
points = points - center
points = th.einsum("ij,pnj->pni", rot_matrix, points)
points = points + center
height, width = self.input_size_hw
x0 = th.clamp(th.min(points[..., 0], dim=0)[0], min=0, max=width - 1)
y0 = th.clamp(th.min(points[..., 1], dim=0)[0], min=0, max=height - 1)
x1 = th.clamp(th.max(points[..., 0], dim=0)[0], min=0, max=width - 1)
y1 = th.clamp(th.max(points[..., 1], dim=0)[0], min=0, max=height - 1)
self.x = x0
self.y = y0
self.w = x1 - x0
self.h = y1 - y0
self.remove_flat_labels_()
assert th.all(self.x >= 0)
assert th.all(self.y >= 0)
assert th.all(self.x + self.w <= self.input_size_hw[1] - 1)
assert th.all(self.y + self.h <= self.input_size_hw[0] - 1)
def zoom_in_and_rescale_(
self, zoom_coordinates_x0y0: Tuple[int, int], zoom_in_factor: float
):
"""
1) Computes a new smaller canvas size: original canvas scaled by a factor of 1/zoom_in_factor (downscaling)
2) Places the smaller canvas inside the original canvas at the top-left coordinates zoom_coordinates_x0y0
3) Extract the smaller canvas and rescale it back to the original resolution
"""
if len(self) == 0:
return
assert len(zoom_coordinates_x0y0) == 2
assert zoom_in_factor >= 1
if zoom_in_factor == 1:
return
z_x0, z_y0 = zoom_coordinates_x0y0
h_orig, w_orig = self.input_size_hw
assert 0 <= z_x0 <= w_orig - 1
assert 0 <= z_y0 <= h_orig - 1
zoom_window_h, zoom_window_w = tuple(
x / zoom_in_factor for x in self.input_size_hw
)
z_x1 = min(z_x0 + zoom_window_w, w_orig - 1)
assert z_x1 <= w_orig - 1, f"{z_x1=} is larger than {w_orig-1=}"
z_y1 = min(z_y0 + zoom_window_h, h_orig - 1)
assert z_y1 <= h_orig - 1, f"{z_y1=} is larger than {h_orig-1=}"
x0 = th.clamp(self.x, min=z_x0, max=z_x1 - 1)
y0 = th.clamp(self.y, min=z_y0, max=z_y1 - 1)
x1 = th.clamp(self.x + self.w, min=z_x0, max=z_x1 - 1)
y1 = th.clamp(self.y + self.h, min=z_y0, max=z_y1 - 1)
self.x = x0 - z_x0
self.y = y0 - z_y0
self.w = x1 - x0
self.h = y1 - y0
self.input_size_hw = (zoom_window_h, zoom_window_w)
self.remove_flat_labels_()
self.scale_(scaling_multiplier=zoom_in_factor)
def zoom_out_and_rescale_(
self, zoom_coordinates_x0y0: Tuple[int, int], zoom_out_factor: float
):
"""
1) Scales the input by a factor of 1/zoom_out_factor (i.e. reduces the canvas size)
2) Places the downscaled canvas into the original canvas at the top-left coordinates zoom_coordinates_x0y0
"""
if len(self) == 0:
return
assert len(zoom_coordinates_x0y0) == 2
assert zoom_out_factor >= 1
if zoom_out_factor == 1:
return
h_orig, w_orig = self.input_size_hw
self.scale_(scaling_multiplier=1 / zoom_out_factor)
self.input_size_hw = (h_orig, w_orig)
z_x0, z_y0 = zoom_coordinates_x0y0
assert 0 <= z_x0 <= w_orig - 1
assert 0 <= z_y0 <= h_orig - 1
self.x = self.x + z_x0
self.y = self.y + z_y0
def scale_(self, scaling_multiplier: float):
if len(self) == 0:
return
assert scaling_multiplier > 0
if scaling_multiplier == 1:
return
img_ht, img_wd = self.input_size_hw
new_img_ht = scaling_multiplier * img_ht
new_img_wd = scaling_multiplier * img_wd
self.input_size_hw = (new_img_ht, new_img_wd)
x1 = th.clamp((self.x + self.w) * scaling_multiplier, max=new_img_wd - 1)
y1 = th.clamp((self.y + self.h) * scaling_multiplier, max=new_img_ht - 1)
self.x = self.x * scaling_multiplier
self.y = self.y * scaling_multiplier
self.w = x1 - self.x
self.h = y1 - self.y
self.remove_flat_labels_()
def flip_lr_(self) -> None:
if len(self) == 0:
return
self.x = self.input_size_hw[1] - 1 - self.x - self.w
def get_labels_as_tensors(self, format_: str = "yolox") -> th.Tensor:
self._assert_not_numpy()
if format_ == "yolox":
out = th.zeros((len(self), 5), dtype=th.float32, device=self.device)
if len(self) == 0:
return out
out[:, 0] = self.class_id
out[:, 1] = self.x + 0.5 * self.w
out[:, 2] = self.y + 0.5 * self.h
out[:, 3] = self.w
out[:, 4] = self.h
return out
else:
raise NotImplementedError
@staticmethod
def get_labels_as_batched_tensor(
obj_label_list: List[ObjectLabels], format_: str = "yolox"
) -> th.Tensor:
num_object_frames = len(obj_label_list)
assert num_object_frames > 0
max_num_labels_per_object_frame = max([len(x) for x in obj_label_list])
assert max_num_labels_per_object_frame > 0
if format_ == "yolox":
tensor_labels = []
for labels in obj_label_list:
obj_labels_tensor = labels.get_labels_as_tensors(format_=format_)
num_to_pad = max_num_labels_per_object_frame - len(labels)
padded_labels = pad(
obj_labels_tensor, (0, 0, 0, num_to_pad), mode="constant", value=0
)
tensor_labels.append(padded_labels)
tensor_labels = th.stack(tensors=tensor_labels, dim=0)
return tensor_labels
else:
raise NotImplementedError
class SparselyBatchedObjectLabels:
def __init__(self, sparse_object_labels_batch: List[Optional[ObjectLabels]]):
# Can contain None elements that indicate missing labels.
for entry in sparse_object_labels_batch:
assert isinstance(entry, ObjectLabels) or entry is None
self.sparse_object_labels_batch = sparse_object_labels_batch
self.set_empty_labels_to_none_()
def __len__(self) -> int:
return len(self.sparse_object_labels_batch)
def __iter__(self):
return iter(self.sparse_object_labels_batch)
def __getitem__(self, item: int) -> Optional[ObjectLabels]:
if item < 0 or item >= len(self):
raise IndexError(f"Index ({item}) out of range (0, {len(self) - 1})")
return self.sparse_object_labels_batch[item]
def __add__(self, other: SparselyBatchedObjectLabels):
sparse_object_labels_batch = (
self.sparse_object_labels_batch + other.sparse_object_labels_batch
)
return SparselyBatchedObjectLabels(
sparse_object_labels_batch=sparse_object_labels_batch
)
def set_empty_labels_to_none_(self):
for idx, obj_label in enumerate(self.sparse_object_labels_batch):
if obj_label is not None and len(obj_label) == 0:
self.sparse_object_labels_batch[idx] = None
@property
def input_size_hw(self) -> Optional[Union[Tuple[int, int], Tuple[float, float]]]:
for obj_labels in self.sparse_object_labels_batch:
if obj_labels is not None:
return obj_labels.input_size_hw
return None
def zoom_in_and_rescale_(self, *args, **kwargs):
for idx, entry in enumerate(self.sparse_object_labels_batch):
if entry is not None:
self.sparse_object_labels_batch[idx].zoom_in_and_rescale_(
*args, **kwargs
)
# We may have deleted labels. If no labels are left, set the object to None
self.set_empty_labels_to_none_()
def zoom_out_and_rescale_(self, *args, **kwargs):
for idx, entry in enumerate(self.sparse_object_labels_batch):
if entry is not None:
self.sparse_object_labels_batch[idx].zoom_out_and_rescale_(
*args, **kwargs
)
def rotate_(self, *args, **kwargs):
for idx, entry in enumerate(self.sparse_object_labels_batch):
if entry is not None:
self.sparse_object_labels_batch[idx].rotate_(*args, **kwargs)
def scale_(self, *args, **kwargs):
for idx, entry in enumerate(self.sparse_object_labels_batch):
if entry is not None:
self.sparse_object_labels_batch[idx].scale_(*args, **kwargs)
# We may have deleted labels. If no labels are left, set the object to None
self.set_empty_labels_to_none_()
def flip_lr_(self):
for idx, entry in enumerate(self.sparse_object_labels_batch):
if entry is not None:
self.sparse_object_labels_batch[idx].flip_lr_()
def to(self, *args, **kwargs):
for idx, entry in enumerate(self.sparse_object_labels_batch):
if entry is not None:
self.sparse_object_labels_batch[idx].to(*args, **kwargs)
return self
def get_valid_labels_and_batch_indices(
self,
) -> Tuple[List[ObjectLabels], List[int]]:
out = list()
valid_indices = list()
for idx, label in enumerate(self.sparse_object_labels_batch):
if label is not None:
out.append(label)
valid_indices.append(idx)
return out, valid_indices
@staticmethod
def transpose_list(
list_of_sparsely_batched_object_labels: List[SparselyBatchedObjectLabels],
) -> List[SparselyBatchedObjectLabels]:
return [
SparselyBatchedObjectLabels(list(labels_as_tuple))
for labels_as_tuple in zip(*list_of_sparsely_batched_object_labels)
]
================================================
FILE: RVT/data/genx_utils/sequence_base.py
================================================
from pathlib import Path
from typing import Any, List, Optional
import h5py
import numpy as np
import torch
from torchdata.datapipes.map import MapDataPipe
from data.genx_utils.labels import ObjectLabelFactory, ObjectLabels
from data.utils.spatial import get_original_hw
from data.utils.types import DatasetType
from utils.timers import TimerDummy as Timer
def get_event_representation_dir(path: Path, ev_representation_name: str) -> Path:
ev_repr_dir = path / "event_representations_v2" / ev_representation_name
assert ev_repr_dir.is_dir(), f"{ev_repr_dir}"
return ev_repr_dir
def get_objframe_idx_2_repr_idx(path: Path, ev_representation_name: str) -> np.ndarray:
ev_repr_dir = get_event_representation_dir(
path=path, ev_representation_name=ev_representation_name
)
objframe_idx_2_repr_idx = np.load(str(ev_repr_dir / "objframe_idx_2_repr_idx.npy"))
return objframe_idx_2_repr_idx
class SequenceBase(MapDataPipe):
"""
Structure example of a sequence:
.
├── event_representations_v2
│ └── ev_representation_name
│ ├── event_representations.h5
│ ├── objframe_idx_2_repr_idx.npy
│ └── timestamps_us.npy
└── labels_v2
├── labels.npz
└── timestamps_us.npy
"""
def __init__(
self,
path: Path,
ev_representation_name: str,
sequence_length: int,
dataset_type: DatasetType,
downsample_by_factor_2: bool,
only_load_end_labels: bool,
):
assert sequence_length >= 1
assert path.is_dir()
assert dataset_type in {
DatasetType.GEN1,
DatasetType.GEN4,
}, f"{dataset_type} not implemented"
self.only_load_end_labels = only_load_end_labels
ev_repr_dir = get_event_representation_dir(
path=path, ev_representation_name=ev_representation_name
)
labels_dir = path / "labels_v2"
assert labels_dir.is_dir()
height, width = get_original_hw(dataset_type)
self.seq_len = sequence_length
ds_factor_str = "_ds2_nearest" if downsample_by_factor_2 else ""
self.ev_repr_file = ev_repr_dir / f"event_representations{ds_factor_str}.h5"
assert self.ev_repr_file.exists(), f"{str(self.ev_repr_file)=}"
with Timer(timer_name="prepare labels"):
label_data = np.load(str(labels_dir / "labels.npz"))
objframe_idx_2_label_idx = label_data["objframe_idx_2_label_idx"]
labels = label_data["labels"]
label_factory = ObjectLabelFactory.from_structured_array(
object_labels=labels,
objframe_idx_2_label_idx=objframe_idx_2_label_idx,
input_size_hw=(height, width),
downsample_factor=2 if downsample_by_factor_2 else None,
)
self.label_factory = label_factory
with Timer(timer_name="load objframe_idx_2_repr_idx"):
self.objframe_idx_2_repr_idx = get_objframe_idx_2_repr_idx(
path=path, ev_representation_name=ev_representation_name
)
with Timer(timer_name="construct repr_idx_2_objframe_idx"):
self.repr_idx_2_objframe_idx = dict(
zip(
self.objframe_idx_2_repr_idx,
range(len(self.objframe_idx_2_repr_idx)),
)
)
def _get_labels_from_repr_idx(self, repr_idx: int) -> Optional[ObjectLabels]:
objframe_idx = self.repr_idx_2_objframe_idx.get(repr_idx, None)
return None if objframe_idx is None else self.label_factory[objframe_idx]
def _get_event_repr_torch(self, start_idx: int, end_idx: int) -> List[torch.Tensor]:
assert end_idx > start_idx
with h5py.File(str(self.ev_repr_file), "r") as h5f:
ev_repr = h5f["data"][start_idx:end_idx]
ev_repr = torch.from_numpy(ev_repr)
if ev_repr.dtype != torch.uint8:
ev_repr = torch.asarray(ev_repr, dtype=torch.float32)
ev_repr = torch.split(ev_repr, 1, dim=0)
# remove first dim that is always 1 due to how torch.split works
ev_repr = [x[0] for x in ev_repr]
return ev_repr
def __len__(self) -> int:
raise NotImplementedError
def __getitem__(self, index: int) -> Any:
raise NotImplementedError
================================================
FILE: RVT/data/genx_utils/sequence_for_streaming.py
================================================
from pathlib import Path
from typing import List, Optional, Union, Tuple
import h5py
import numpy as np
import torch
from omegaconf import DictConfig
from torchdata.datapipes.iter import IterDataPipe
from data.genx_utils.labels import SparselyBatchedObjectLabels
from data.genx_utils.sequence_base import SequenceBase, get_objframe_idx_2_repr_idx
from data.utils.augmentor import RandomSpatialAugmentorGenX
from data.utils.types import DataType, DatasetType, LoaderDataDictGenX
from utils.timers import TimerDummy as Timer
def _scalar_as_1d_array(scalar: Union[int, float]):
return np.atleast_1d(scalar)
def _get_ev_repr_range_indices(
indices: np.ndarray, max_len: int
) -> List[Tuple[int, int]]:
"""
Computes a list of index ranges based on the input array of indices and a maximum length.
The index ranges are computed such that the difference between consecutive indices
should not exceed the maximum length (max_len).
Parameters:
-----------
indices : np.ndarray
A NumPy array of indices, where the indices are sorted in ascending order.
max_len : int
The maximum allowed length between consecutive indices.
Returns:
--------
out : List[Tuple[int, int]]
A list of tuples, where each tuple contains two integers representing the start and
stop indices of the range.
"""
meta_indices_stop = np.flatnonzero(np.diff(indices) > max_len)
meta_indices_start = np.concatenate((np.atleast_1d(0), meta_indices_stop + 1))
meta_indices_stop = np.concatenate(
(meta_indices_stop, np.atleast_1d(len(indices) - 1))
)
out = list()
for meta_idx_start, meta_idx_stop in zip(meta_indices_start, meta_indices_stop):
idx_start = max(indices[meta_idx_start] - max_len + 1, 0)
idx_stop = indices[meta_idx_stop] + 1
out.append((idx_start, idx_stop))
return out
class SequenceForIter(SequenceBase):
def __init__(
self,
path: Path,
ev_representation_name: str,
sequence_length: int,
dataset_type: DatasetType,
downsample_by_factor_2: bool,
range_indices: Optional[Tuple[int, int]] = None,
):
super().__init__(
path=path,
ev_representation_name=ev_representation_name,
sequence_length=sequence_length,
dataset_type=dataset_type,
downsample_by_factor_2=downsample_by_factor_2,
only_load_end_labels=False,
)
with h5py.File(str(self.ev_repr_file), "r") as h5f:
num_ev_repr = h5f["data"].shape[0]
if range_indices is None:
repr_idx_start = max(
self.objframe_idx_2_repr_idx[0] - sequence_length + 1, 0
)
repr_idx_stop = num_ev_repr
else:
repr_idx_start, repr_idx_stop = range_indices
# Set start idx such that the first label is no further than the last timestamp of the first sample sub-sequence
min_start_repr_idx = max(
self.objframe_idx_2_repr_idx[0] - sequence_length + 1, 0
)
assert (
0 <= min_start_repr_idx <= repr_idx_start < repr_idx_stop <= num_ev_repr
), f"{min_start_repr_idx=}, {repr_idx_start=}, {repr_idx_stop=}, {num_ev_repr=}, {path=}"
self.start_indices = list(range(repr_idx_start, repr_idx_stop, sequence_length))
self.stop_indices = self.start_indices[1:] + [repr_idx_stop]
self.length = len(self.start_indices)
self._padding_representation = None
@staticmethod
def get_sequences_with_guaranteed_labels(
path: Path,
ev_representation_name: str,
sequence_length: int,
dataset_type: DatasetType,
downsample_by_factor_2: bool,
) -> List["SequenceForIter"]:
"""Generate sequences such that we do always have labels within each sample of the sequence
This is required for training such that we are guaranteed to always have labels in the training step.
However, for validation we don't require this if we catch the special case.
"""
objframe_idx_2_repr_idx = get_objframe_idx_2_repr_idx(
path=path, ev_representation_name=ev_representation_name
)
# max diff for repr idx is sequence length
range_indices_list = _get_ev_repr_range_indices(
indices=objframe_idx_2_repr_idx, max_len=sequence_length
)
sequence_list = list()
for range_indices in range_indices_list:
sequence_list.append(
SequenceForIter(
path=path,
ev_representation_name=ev_representation_name,
sequence_length=sequence_length,
dataset_type=dataset_type,
downsample_by_factor_2=downsample_by_factor_2,
range_indices=range_indices,
)
)
return sequence_list
@property
def padding_representation(self) -> torch.Tensor:
if self._padding_representation is None:
ev_repr = self._get_event_repr_torch(start_idx=0, end_idx=1)[0]
self._padding_representation = torch.zeros_like(ev_repr)
return self._padding_representation
def get_fully_padded_sample(self) -> LoaderDataDictGenX:
is_first_sample = False
is_padded_mask = [True] * self.seq_len
ev_repr = [self.padding_representation] * self.seq_len
labels = [None] * self.seq_len
sparse_labels = SparselyBatchedObjectLabels(sparse_object_labels_batch=labels)
out = {
DataType.EV_REPR: ev_repr,
DataType.OBJLABELS_SEQ: sparse_labels,
DataType.IS_FIRST_SAMPLE: is_first_sample,
DataType.IS_PADDED_MASK: is_padded_mask,
}
return out
def __len__(self):
return self.length
def __getitem__(self, index: int) -> LoaderDataDictGenX:
start_idx = self.start_indices[index]
end_idx = self.stop_indices[index]
# sequence info ###
sample_len = end_idx - start_idx
assert self.seq_len >= sample_len > 0, (
f"{self.seq_len=}, {sample_len=}, {start_idx=}, {end_idx=}, "
f"\n{self.start_indices=}\n{self.stop_indices=}"
)
is_first_sample = True if index == 0 else False
is_padded_mask = [False] * sample_len
###################
# event representations ###
with Timer(timer_name="read ev reprs"):
ev_repr = self._get_event_repr_torch(start_idx=start_idx, end_idx=end_idx)
assert len(ev_repr) == sample_len
###########################
# labels ###
labels = list()
for repr_idx in range(start_idx, end_idx):
labels.append(self._get_labels_from_repr_idx(repr_idx))
assert len(labels) == len(ev_repr)
############
# apply padding (if necessary) ###
if sample_len < self.seq_len:
padding_len = self.seq_len - sample_len
is_padded_mask.extend([True] * padding_len)
ev_repr.extend([self.padding_representation] * padding_len)
labels.extend([None] * padding_len)
##################################
# convert labels to sparse labels for datapipes and dataloader
sparse_labels = SparselyBatchedObjectLabels(sparse_object_labels_batch=labels)
out = {
DataType.EV_REPR: ev_repr,
DataType.OBJLABELS_SEQ: sparse_labels,
DataType.IS_FIRST_SAMPLE: is_first_sample,
DataType.IS_PADDED_MASK: is_padded_mask,
}
return out
class RandAugmentIterDataPipe(IterDataPipe):
def __init__(self, source_dp: IterDataPipe, dataset_config: DictConfig):
super().__init__()
self.source_dp = source_dp
resolution_hw = tuple(dataset_config.resolution_hw)
assert len(resolution_hw) == 2
ds_by_factor_2 = dataset_config.downsample_by_factor_2
if ds_by_factor_2:
resolution_hw = tuple(x // 2 for x in resolution_hw)
augm_config = dataset_config.data_augmentation
self.spatial_augmentor = RandomSpatialAugmentorGenX(
dataset_hw=resolution_hw,
automatic_randomization=False,
augm_config=augm_config.stream,
)
def __iter__(self):
self.spatial_augmentor.randomize_augmentation()
for x in self.source_dp:
yield self.spatial_augmentor(x)
================================================
FILE: RVT/data/genx_utils/sequence_rnd.py
================================================
from pathlib import Path
from data.genx_utils.labels import SparselyBatchedObjectLabels
from data.genx_utils.sequence_base import SequenceBase
from data.utils.types import DataType, DatasetType, LoaderDataDictGenX
from utils.timers import TimerDummy as Timer
class SequenceForRandomAccess(SequenceBase):
def __init__(
self,
path: Path,
ev_representation_name: str,
sequence_length: int,
dataset_type: DatasetType,
downsample_by_factor_2: bool,
only_load_end_labels: bool,
):
super().__init__(
path=path,
ev_representation_name=ev_representation_name,
sequence_length=sequence_length,
dataset_type=dataset_type,
downsample_by_factor_2=downsample_by_factor_2,
only_load_end_labels=only_load_end_labels,
)
self.start_idx_offset = None
for objframe_idx, repr_idx in enumerate(self.objframe_idx_2_repr_idx):
if repr_idx - self.seq_len + 1 >= 0:
# We can fit the sequence length to the label
self.start_idx_offset = objframe_idx
break
if self.start_idx_offset is None:
# This leads to actual length of 0:
self.start_idx_offset = len(self.label_factory)
self.length = len(self.label_factory) - self.start_idx_offset
assert len(self.label_factory) == len(self.objframe_idx_2_repr_idx)
# Useful for weighted sampler that is based on label statistics:
self._only_load_labels = False
def __len__(self):
return self.length
def __getitem__(self, index: int) -> LoaderDataDictGenX:
corrected_idx = index + self.start_idx_offset
labels_repr_idx = self.objframe_idx_2_repr_idx[corrected_idx]
end_idx = labels_repr_idx + 1
start_idx = end_idx - self.seq_len
assert_msg = (
f"{self.ev_repr_file=}, {self.start_idx_offset=}, {start_idx=}, {end_idx=}"
)
assert start_idx >= 0, assert_msg
labels = list()
for repr_idx in range(start_idx, end_idx):
if self.only_load_end_labels and repr_idx < end_idx - 1:
labels.append(None)
else:
labels.append(self._get_labels_from_repr_idx(repr_idx))
sparse_labels = SparselyBatchedObjectLabels(sparse_object_labels_batch=labels)
if self._only_load_labels:
return {DataType.OBJLABELS_SEQ: sparse_labels}
with Timer(timer_name="read ev reprs"):
ev_repr = self._get_event_repr_torch(start_idx=start_idx, end_idx=end_idx)
assert len(sparse_labels) == len(ev_repr)
is_first_sample = True # Due to random loading
is_padded_mask = [False] * len(ev_repr)
out = {
DataType.EV_REPR: ev_repr,
DataType.OBJLABELS_SEQ: sparse_labels,
DataType.IS_FIRST_SAMPLE: is_first_sample,
DataType.IS_PADDED_MASK: is_padded_mask,
}
return out
def is_only_loading_labels(self) -> bool:
return self._only_load_labels
def only_load_labels(self):
self._only_load_labels = True
def load_everything(self):
self._only_load_labels = False
================================================
FILE: RVT/data/utils/augmentor.py
================================================
import collections.abc as abc
from dataclasses import dataclass
from typing import Any, Optional, Tuple, Union
from warnings import filterwarnings, warn
import torch as th
import torch.distributions.categorical
from omegaconf import DictConfig
from torch.nn.functional import interpolate
from torchvision.transforms import InterpolationMode
from torchvision.transforms.functional import rotate
from data.genx_utils.labels import ObjectLabels, SparselyBatchedObjectLabels
from data.utils.types import DataType, LoaderDataDictGenX
from utils.helpers import torch_uniform_sample_scalar
NO_LABEL_WARN_MSG = (
"No Labels found. This can lead to a crash and should not happen often."
)
filterwarnings("always", message=NO_LABEL_WARN_MSG)
@dataclass
class ZoomOutState:
active: bool
x0: int
y0: int
zoom_out_factor: float
@dataclass
class RotationState:
active: bool
angle_deg: float
@dataclass
class AugmentationState:
apply_h_flip: bool
rotation: RotationState
apply_zoom_in: bool
zoom_out: ZoomOutState
class RandomSpatialAugmentorGenX:
def __init__(
self,
dataset_hw: Tuple[int, int],
automatic_randomization: bool,
augm_config: DictConfig,
):
assert isinstance(dataset_hw, tuple)
assert len(dataset_hw) == 2
assert all(x > 0 for x in dataset_hw)
assert isinstance(automatic_randomization, bool)
self.hw_tuple = dataset_hw
self.automatic_randomization = automatic_randomization
self.h_flip_prob = augm_config.prob_hflip
self.rot_prob = augm_config.rotate.prob
self.rot_min_angle_deg = augm_config.rotate.get("min_angle_deg", 0)
self.rot_max_angle_deg = augm_config.rotate.max_angle_deg
self.zoom_prob = augm_config.zoom.prob
zoom_out_weight = augm_config.zoom.zoom_out.get("weight", 1)
self.min_zoom_out_factor = augm_config.zoom.zoom_out.factor.min
self.max_zoom_out_factor = augm_config.zoom.zoom_out.factor.max
has_zoom_in = "zoom_in" in augm_config.zoom
zoom_in_weight = augm_config.zoom.zoom_in.weight if has_zoom_in else 0
self.min_zoom_in_factor = (
augm_config.zoom.zoom_in.factor.min if has_zoom_in else 1
)
self.max_zoom_in_factor = (
augm_config.zoom.zoom_in.factor.max if has_zoom_in else 1
)
assert 0 <= self.h_flip_prob <= 1
assert 0 <= self.rot_prob <= 1
assert 0 <= self.rot_min_angle_deg <= self.rot_max_angle_deg
assert 0 <= self.zoom_prob <= 1
assert 0 <= zoom_in_weight
assert self.max_zoom_in_factor >= self.min_zoom_in_factor >= 1
assert 0 <= zoom_out_weight
assert self.max_zoom_out_factor >= self.min_zoom_out_factor >= 1
if not automatic_randomization:
# We are probably applying augmentation to a streaming dataset for which zoom in augm is not supported.
assert zoom_in_weight == 0, f"{zoom_in_weight=}"
self.zoom_in_or_out_distribution = torch.distributions.categorical.Categorical(
probs=th.tensor([zoom_in_weight, zoom_out_weight])
)
self.augm_state = AugmentationState(
apply_h_flip=False,
rotation=RotationState(active=False, angle_deg=0.0),
apply_zoom_in=False,
zoom_out=ZoomOutState(active=False, x0=0, y0=0, zoom_out_factor=1.0),
)
def randomize_augmentation(self):
"""Sample new augmentation parameters that will be consistently applied among the items.
This function only works with augmentations that are input-independent.
E.g. The zoom-in augmentation parameters depend on the labels and cannot be sampled in this function.
For the same reason, it is not a very reasonable augmentation for the streaming scenario.
"""
self.augm_state.apply_h_flip = self.h_flip_prob > th.rand(1).item()
self.augm_state.rotation.active = self.rot_prob > th.rand(1).item()
if self.augm_state.rotation.active:
sign = 1 if th.randn(1).item() >= 0 else -1
self.augm_state.rotation.angle_deg = sign * torch_uniform_sample_scalar(
min_value=self.rot_min_angle_deg, max_value=self.rot_max_angle_deg
)
# Zoom in and zoom out is mutually exclusive.
do_zoom = self.zoom_prob > th.rand(1).item()
do_zoom_in = self.zoom_in_or_out_distribution.sample().item() == 0
do_zoom_out = not do_zoom_in
do_zoom_in &= do_zoom
do_zoom_out &= do_zoom
self.augm_state.apply_zoom_in = do_zoom_in
self.augm_state.zoom_out.active = do_zoom_out
if do_zoom_out:
rand_zoom_out_factor = torch_uniform_sample_scalar(
min_value=self.min_zoom_out_factor, max_value=self.max_zoom_out_factor
)
height, width = self.hw_tuple
zoom_window_h, zoom_window_w = int(height / rand_zoom_out_factor), int(
width / rand_zoom_out_factor
)
x0_sampled = int(
torch_uniform_sample_scalar(
min_value=0, max_value=width - zoom_window_w
)
)
y0_sampled = int(
torch_uniform_sample_scalar(
min_value=0, max_value=height - zoom_window_h
)
)
self.augm_state.zoom_out.x0 = x0_sampled
self.augm_state.zoom_out.y0 = y0_sampled
self.augm_state.zoom_out.zoom_out_factor = rand_zoom_out_factor
def _zoom_out_and_rescale(
self, data_dict: LoaderDataDictGenX
) -> LoaderDataDictGenX:
zoom_out_state = self.augm_state.zoom_out
zoom_out_factor = zoom_out_state.zoom_out_factor
if zoom_out_factor == 1:
return data_dict
return {
k: RandomSpatialAugmentorGenX._zoom_out_and_rescale_recursive(
v,
zoom_coordinates_x0y0=(zoom_out_state.x0, zoom_out_state.y0),
zoom_out_factor=zoom_out_factor,
datatype=k,
)
for k, v in data_dict.items()
}
@staticmethod
def _zoom_out_and_rescale_tensor(
input_: th.Tensor,
zoom_coordinates_x0y0: Tuple[int, int],
zoom_out_factor: float,
datatype: DataType,
) -> th.Tensor:
assert len(zoom_coordinates_x0y0) == 2
assert isinstance(input_, th.Tensor)
if datatype == DataType.IMAGE or datatype == DataType.EV_REPR:
assert input_.ndim == 3, f"{input_.shape=}"
height, width = input_.shape[-2:]
zoom_window_h, zoom_window_w = int(height / zoom_out_factor), int(
width / zoom_out_factor
)
zoom_window = interpolate(
input_.unsqueeze(0),
size=(zoom_window_h, zoom_window_w),
mode="nearest-exact",
)[0]
output = th.zeros_like(input_)
x0, y0 = zoom_coordinates_x0y0
assert x0 >= 0
assert y0 >= 0
output[:, y0 : y0 + zoom_window_h, x0 : x0 + zoom_window_w] = zoom_window
return output
raise NotImplementedError
@classmethod
def _zoom_out_and_rescale_recursive(
cls,
input_: Any,
zoom_coordinates_x0y0: Tuple[int, int],
zoom_out_factor: float,
datatype: DataType,
):
if datatype in (DataType.IS_PADDED_MASK, DataType.IS_FIRST_SAMPLE):
return input_
if isinstance(input_, th.Tensor):
return cls._zoom_out_and_rescale_tensor(
input_=input_,
zoom_coordinates_x0y0=zoom_coordinates_x0y0,
zoom_out_factor=zoom_out_factor,
datatype=datatype,
)
if isinstance(input_, ObjectLabels) or isinstance(
input_, SparselyBatchedObjectLabels
):
assert datatype == DataType.OBJLABELS or datatype == DataType.OBJLABELS_SEQ
input_.zoom_out_and_rescale_(
zoom_coordinates_x0y0=zoom_coordinates_x0y0,
zoom_out_factor=zoom_out_factor,
)
return input_
if isinstance(input_, abc.Sequence):
return [
RandomSpatialAugmentorGenX._zoom_out_and_rescale_recursive(
x,
zoom_coordinates_x0y0=zoom_coordinates_x0y0,
zoom_out_factor=zoom_out_factor,
datatype=datatype,
)
for x in input_
]
if isinstance(input_, abc.Mapping):
return {
key: RandomSpatialAugmentorGenX._zoom_out_and_rescale_recursive(
value,
zoom_coordinates_x0y0=zoom_coordinates_x0y0,
zoom_out_factor=zoom_out_factor,
datatype=datatype,
)
for key, value in input_.items()
}
raise NotImplementedError
def _zoom_in_and_rescale(self, data_dict: LoaderDataDictGenX) -> LoaderDataDictGenX:
rand_zoom_in_factor = torch_uniform_sample_scalar(
min_value=self.min_zoom_in_factor, max_value=self.max_zoom_in_factor
)
if rand_zoom_in_factor == 1:
return data_dict
height, width = RandomSpatialAugmentorGenX._hw_from_data(data_dict=data_dict)
assert (height, width) == self.hw_tuple
zoom_window_h, zoom_window_w = int(height / rand_zoom_in_factor), int(
width / rand_zoom_in_factor
)
latest_objframe = get_most_recent_objframe(
data_dict=data_dict, check_if_nonempty=True
)
if latest_objframe is None:
warn(message=NO_LABEL_WARN_MSG, category=UserWarning, stacklevel=2)
return data_dict
x0_sampled, y0_sampled = randomly_sample_zoom_window_from_objframe(
objframe=latest_objframe,
zoom_window_height=zoom_window_h,
zoom_window_width=zoom_window_w,
)
return {
k: RandomSpatialAugmentorGenX._zoom_in_and_rescale_recursive(
v,
zoom_coordinates_x0y0=(x0_sampled, y0_sampled),
zoom_in_factor=rand_zoom_in_factor,
datatype=k,
)
for k, v in data_dict.items()
}
@staticmethod
def _zoom_in_and_rescale_tensor(
input_: th.Tensor,
zoom_coordinates_x0y0: Tuple[int, int],
zoom_in_factor: float,
datatype: DataType,
) -> th.Tensor:
assert len(zoom_coordinates_x0y0) == 2
assert isinstance(input_, th.Tensor)
if datatype == DataType.IMAGE or datatype == DataType.EV_REPR:
assert input_.ndim == 3, f"{input_.shape=}"
height, width = input_.shape[-2:]
zoom_window_h, zoom_window_w = int(height / zoom_in_factor), int(
width / zoom_in_factor
)
x0, y0 = zoom_coordinates_x0y0
assert x0 >= 0
assert y0 >= 0
zoom_canvas = input_[
..., y0 : y0 + zoom_window_h, x0 : x0 + zoom_window_w
].unsqueeze(0)
output = interpolate(
zoom_canvas, size=(height, width), mode="nearest-exact"
)
output = output[0]
return output
raise NotImplementedError
@classmethod
def _zoom_in_and_rescale_recursive(
cls,
input_: Any,
zoom_coordinates_x0y0: Tuple[int, int],
zoom_in_factor: float,
datatype: DataType,
):
if datatype in (DataType.IS_PADDED_MASK, DataType.IS_FIRST_SAMPLE):
return input_
if isinstance(input_, th.Tensor):
return cls._zoom_in_and_rescale_tensor(
input_=input_,
zoom_coordinates_x0y0=zoom_coordinates_x0y0,
zoom_in_factor=zoom_in_factor,
datatype=datatype,
)
if isinstance(input_, ObjectLabels) or isinstance(
input_, SparselyBatchedObjectLabels
):
assert datatype == DataType.OBJLABELS or datatype == DataType.OBJLABELS_SEQ
input_.zoom_in_and_rescale_(
zoom_coordinates_x0y0=zoom_coordinates_x0y0,
zoom_in_factor=zoom_in_factor,
)
return input_
if isinstance(input_, abc.Sequence):
return [
RandomSpatialAugmentorGenX._zoom_in_and_rescale_recursive(
x,
zoom_coordinates_x0y0=zoom_coordinates_x0y0,
zoom_in_factor=zoom_in_factor,
datatype=datatype,
)
for x in input_
]
if isinstance(input_, abc.Mapping):
return {
key: RandomSpatialAugmentorGenX._zoom_in_and_rescale_recursive(
value,
zoom_coordinates_x0y0=zoom_coordinates_x0y0,
zoom_in_factor=zoom_in_factor,
datatype=datatype,
)
for key, value in input_.items()
}
raise NotImplementedError
def _rotate(self, data_dict: LoaderDataDictGenX) -> LoaderDataDictGenX:
angle_deg = self.augm_state.rotation.angle_deg
return {
k: RandomSpatialAugmentorGenX._rotate_recursive(
v, angle_deg=angle_deg, datatype=k
)
for k, v in data_dict.items()
}
@staticmethod
def _rotate_tensor(input_: Any, angle_deg: float, datatype: DataType):
assert isinstance(input_, th.Tensor)
if datatype == DataType.IMAGE or datatype == DataType.EV_REPR:
return rotate(
input_, angle=angle_deg, interpolation=InterpolationMode.NEAREST
)
raise NotImplementedError
@classmethod
def _rotate_recursive(cls, input_: Any, angle_deg: float, datatype: DataType):
if datatype in (DataType.IS_PADDED_MASK, DataType.IS_FIRST_SAMPLE):
return input_
if isinstance(input_, th.Tensor):
return cls._rotate_tensor(
input_=input_, angle_deg=angle_deg, datatype=datatype
)
if isinstance(input_, ObjectLabels) or isinstance(
input_, SparselyBatchedObjectLabels
):
assert datatype == DataType.OBJLABELS or datatype == DataType.OBJLABELS_SEQ
input_.rotate_(angle_deg=angle_deg)
return input_
if isinstance(input_, abc.Sequence):
return [
RandomSpatialAugmentorGenX._rotate_recursive(
x, angle_deg=angle_deg, datatype=datatype
)
for x in input_
]
if isinstance(input_, abc.Mapping):
return {
key: RandomSpatialAugmentorGenX._rotate_recursive(
value, angle_deg=angle_deg, datatype=datatype
)
for key, value in input_.items()
}
raise NotImplementedError
@staticmethod
def _flip(data_dict: LoaderDataDictGenX, type_: str) -> LoaderDataDictGenX:
assert type_ in {"h", "v"}
return {
k: RandomSpatialAugmentorGenX._flip_recursive(
v, flip_type=type_, datatype=k
)
for k, v in data_dict.items()
}
@staticmethod
def _flip_tensor(input_: Any, flip_type: str, datatype: DataType):
assert isinstance(input_, th.Tensor)
flip_axis = -1 if flip_type == "h" else -2
if datatype == DataType.IMAGE or datatype == DataType.EV_REPR:
return th.flip(input_, dims=[flip_axis])
if datatype == DataType.FLOW:
assert input_.shape[-3] == 2
flow_idx = 0 if flip_type == "h" else 1
input_ = th.flip(input_, dims=[flip_axis])
# Also flip the sign of the x (horizontal) or y (vertical) component of the flow.
input_[..., flow_idx, :, :] = -1 * input_[..., flow_idx, :, :]
return input_
raise NotImplementedError
@classmethod
def _flip_recursive(cls, input_: Any, flip_type: str, datatype: DataType):
if datatype in (DataType.IS_PADDED_MASK, DataType.IS_FIRST_SAMPLE):
return input_
if isinstance(input_, th.Tensor):
return cls._flip_tensor(
input_=input_, flip_type=flip_type, datatype=datatype
)
if isinstance(input_, ObjectLabels) or isinstance(
input_, SparselyBatchedObjectLabels
):
assert datatype == DataType.OBJLABELS or datatype == DataType.OBJLABELS_SEQ
if flip_type == "h":
# in-place modification
input_.flip_lr_()
return input_
else:
raise NotImplementedError
if isinstance(input_, abc.Sequence):
return [
RandomSpatialAugmentorGenX._flip_recursive(
x, flip_type=flip_type, datatype=datatype
)
for x in input_
]
if isinstance(input_, abc.Mapping):
return {
key: RandomSpatialAugmentorGenX._flip_recursive(
value, flip_type=flip_type, datatype=datatype
)
for key, value in input_.items()
}
raise NotImplementedError
@staticmethod
def _hw_from_data(data_dict: LoaderDataDictGenX) -> Tuple[int, int]:
height = None
width = None
for k, v in data_dict.items():
_hw = None
if k == DataType.OBJLABELS or k == DataType.OBJLABELS_SEQ:
hw = v.input_size_hw
if hw is not None:
_hw = v.input_size_hw
elif k in (DataType.IMAGE, DataType.FLOW, DataType.EV_REPR):
_hw = v[0].shape[-2:]
if _hw is not None:
_height, _width = _hw
if height is None:
assert width is None
height, width = _height, _width
else:
assert height == _height and width == _width
assert height is not None
assert width is not None
return height, width
def __call__(self, data_dict: LoaderDataDictGenX):
"""
:param data_dict: LoaderDataDictGenX type, image-based tensors must have (*, h, w) shape.
:return: map with same keys but spatially augmented values.
"""
if self.automatic_randomization:
self.randomize_augmentation()
if self.augm_state.apply_h_flip:
data_dict = self._flip(data_dict, type_="h")
if self.augm_state.rotation.active:
data_dict = self._rotate(data_dict)
if self.augm_state.apply_zoom_in:
data_dict = self._zoom_in_and_rescale(data_dict=data_dict)
if self.augm_state.zoom_out.active:
assert not self.augm_state.apply_zoom_in
data_dict = self._zoom_out_and_rescale(data_dict=data_dict)
return data_dict
def get_most_recent_objframe(
data_dict: LoaderDataDictGenX, check_if_nonempty: bool = True
) -> Optional[ObjectLabels]:
assert (
DataType.OBJLABELS_SEQ in data_dict
), f"Requires datatype {DataType.OBJLABELS_SEQ} to be present"
sparse_obj_labels = data_dict[DataType.OBJLABELS_SEQ]
sparse_obj_labels: SparselyBatchedObjectLabels
for obj_label in reversed(sparse_obj_labels):
if obj_label is not None:
return_label = True if not check_if_nonempty else len(obj_label) > 0
if return_label:
return obj_label
# no labels found
return None
def randomly_sample_zoom_window_from_objframe(
objframe: ObjectLabels,
zoom_window_height: Union[int, float],
zoom_window_width: Union[int, float],
) -> Tuple[int, int]:
input_height, input_width = objframe.input_size_hw
possible_samples = []
for idx in range(len(objframe)):
label_xywh = (
objframe.x[idx],
objframe.y[idx],
objframe.w[idx],
objframe.h[idx],
)
possible_samples.append(
randomly_sample_zoom_window_from_label_rectangle(
label_xywh=label_xywh,
input_height=input_height,
input_width=input_width,
zoom_window_height=zoom_window_height,
zoom_window_width=zoom_window_width,
)
)
assert len(possible_samples) > 0
# Using torch to sample, to avoid potential problems with multiprocessing.
sample_idx = (
0
if len(possible_samples) == 1
else th.randint(low=0, high=len(possible_samples) - 1, size=(1,)).item()
)
x0_sample, y0_sample = possible_samples[sample_idx]
assert input_width > x0_sample >= 0, f"{x0_sample=}"
assert input_height > y0_sample >= 0, f"{y0_sample=}"
return x0_sample, y0_sample
def randomly_sample_zoom_window_from_label_rectangle(
label_xywh: Tuple[Union[int, float, th.Tensor], ...],
input_height: Union[int, float],
input_width: Union[int, float],
zoom_window_height: Union[int, float],
zoom_window_width: Union[int, float],
) -> Tuple[int, int]:
"""Computes a set of top-left coordinates from which the top-left corner of the zoom window
can be sampled such that the zoom window is guaranteed to contain the whole (rectangular) label.
Return a random sample from this set.
Notation:
(x0,y0)---(x1,y0)
| |
| |
(x0,y1)---(x1,y1)
"""
assert input_height >= zoom_window_height
assert input_width >= zoom_window_width
label_xywh = tuple(x.item() if isinstance(x, th.Tensor) else x for x in label_xywh)
x0_l, y0_l, w_l, h_l = label_xywh
x1_l = x0_l + w_l
y1_l = y0_l + h_l
assert x0_l >= 0
assert y0_l >= 0
assert w_l > 0
assert h_l > 0
assert x1_l <= input_width + 1e-2 - 1
assert y1_l <= input_height + 1e-2 - 1
x0_valid_region = max(x1_l - max(zoom_window_width, w_l), 0)
y0_valid_region = max(y1_l - max(zoom_window_height, h_l), 0)
x1_valid_region = min(x0_l + max(zoom_window_width, w_l), input_width - 1)
y1_valid_region = min(y0_l + max(zoom_window_height, h_l), input_height - 1)
x1_valid_region = max(x1_valid_region - zoom_window_width, x0_valid_region)
y1_valid_region = max(y1_valid_region - zoom_window_height, y0_valid_region)
x_topleft_sample = int(
torch_uniform_sample_scalar(
min_value=x0_valid_region, max_value=x1_valid_region
)
)
assert 0 <= x_topleft_sample < input_width
y_topleft_sample = int(
torch_uniform_sample_scalar(
min_value=y0_valid_region, max_value=y1_valid_region
)
)
assert 0 <= y_topleft_sample < input_height
return x_topleft_sample, y_topleft_sample
================================================
FILE: RVT/data/utils/representations.py
================================================
from abc import ABC, abstractmethod
from typing import Optional, Tuple
import math
import numpy as np
import torch as th
class RepresentationBase(ABC):
@abstractmethod
def construct(
self, x: th.Tensor, y: th.Tensor, pol: th.Tensor, time: th.Tensor
) -> th.Tensor: ...
@abstractmethod
def get_shape(self) -> Tuple[int, int, int]: ...
@staticmethod
@abstractmethod
def get_numpy_dtype() -> np.dtype: ...
@staticmethod
@abstractmethod
def get_torch_dtype() -> th.dtype: ...
@property
def dtype(self) -> th.dtype:
return self.get_torch_dtype()
@staticmethod
def _is_int_tensor(tensor: th.Tensor) -> bool:
return not th.is_floating_point(tensor) and not th.is_complex(tensor)
class StackedHistogram(RepresentationBase):
def __init__(
self,
bins: int,
height: int,
width: int,
count_cutoff: Optional[int] = None,
fastmode: bool = True,
):
"""
In case of fastmode == True: use uint8 to construct the representation, but could lead to overflow.
In case of fastmode == False: use int16 to construct the representation, and convert to uint8 after clipping.
Note: Overflow should not be a big problem because it happens only for hot pixels. In case of overflow,
the value will just start accumulating from 0 again.
"""
assert bins >= 1
self.bins = bins
assert height >= 1
self.height = height
assert width >= 1
self.width = width
self.count_cutoff = count_cutoff
if self.count_cutoff is None:
self.count_cutoff = 255
else:
assert count_cutoff >= 1
self.count_cutoff = min(count_cutoff, 255)
self.fastmode = fastmode
self.channels = 2
@staticmethod
def get_numpy_dtype() -> np.dtype:
return np.dtype("uint8")
@staticmethod
def get_torch_dtype() -> th.dtype:
return th.uint8
def merge_channel_and_bins(self, representation: th.Tensor):
assert representation.dim() == 4
return th.reshape(representation, (-1, self.height, self.width))
def get_shape(self) -> Tuple[int, int, int]:
return 2 * self.bins, self.height, self.width
def construct(
self, x: th.Tensor, y: th.Tensor, pol: th.Tensor, time: th.Tensor
) -> th.Tensor:
device = x.device
assert y.device == pol.device == time.device == device
assert self._is_int_tensor(x)
assert self._is_int_tensor(y)
assert self._is_int_tensor(pol)
assert self._is_int_tensor(time)
dtype = th.uint8 if self.fastmode else th.int16
representation = th.zeros(
(self.channels, self.bins, self.height, self.width),
dtype=dtype,
device=device,
requires_grad=False,
)
if x.numel() == 0:
assert y.numel() == 0
assert pol.numel() == 0
assert time.numel() == 0
return self.merge_channel_and_bins(representation.to(th.uint8))
assert x.numel() == y.numel() == pol.numel() == time.numel()
assert pol.min() >= 0
assert pol.max() <= 1
bn, ch, ht, wd = self.bins, self.channels, self.height, self.width
# NOTE: assume sorted time
t0_int = time[0]
t1_int = time[-1]
assert t1_int >= t0_int
t_norm = time - t0_int
t_norm = t_norm / max((t1_int - t0_int), 1)
t_norm = t_norm * bn
t_idx = t_norm.floor()
t_idx = th.clamp(t_idx, max=bn - 1)
indices = (
x.long()
+ wd * y.long()
+ ht * wd * t_idx.long()
+ bn * ht * wd * pol.long()
)
values = th.ones_like(indices, dtype=dtype, device=device)
representation.put_(indices, values, accumulate=True)
representation = th.clamp(representation, min=0, max=self.count_cutoff)
if not self.fastmode:
representation = representation.to(th.uint8)
return self.merge_channel_and_bins(representation)
def cumsum_channel(x: th.Tensor, num_channels: int):
for i in reversed(range(num_channels)):
x[i] = th.sum(input=x[: i + 1], dim=0)
return x
class MixedDensityEventStack(RepresentationBase):
def __init__(
self,
bins: int,
height: int,
width: int,
count_cutoff: Optional[int] = None,
allow_compilation: bool = False,
):
assert bins >= 1
self.bins = bins
assert height >= 1
self.height = height
assert width >= 1
self.width = width
self.count_cutoff = count_cutoff
if self.count_cutoff is not None:
assert isinstance(count_cutoff, int)
assert 0 <= self.count_cutoff <= 2**7 - 1
self.cumsum_ch_opt = cumsum_channel
if allow_compilation:
# Will most likely not work with multiprocessing.
try:
self.cumsum_ch_opt = th.compile(cumsum_channel)
except AttributeError:
...
@staticmethod
def get_numpy_dtype() -> np.dtype:
return np.dtype("int8")
@staticmethod
def get_torch_dtype() -> th.dtype:
return th.int8
def get_shape(self) -> Tuple[int, int, int]:
return self.bins, self.height, self.width
def construct(
self, x: th.Tensor, y: th.Tensor, pol: th.Tensor, time: th.Tensor
) -> th.Tensor:
device = x.device
assert y.device == pol.device == time.device == device
assert self._is_int_tensor(x)
assert self._is_int_tensor(y)
assert self._is_int_tensor(pol)
assert self._is_int_tensor(time)
dtype = th.int8
representation = th.zeros(
(self.bins, self.height, self.width),
dtype=dtype,
device=device,
requires_grad=False,
)
if x.numel() == 0:
assert y.numel() == 0
assert pol.numel() == 0
assert time.numel() == 0
return representation
assert x.numel() == y.numel() == pol.numel() == time.numel()
assert pol.min() >= 0 # maybe remove because too costly
assert pol.max() <= 1 # maybe remove because too costly
pol = pol * 2 - 1
bn, ht, wd = self.bins, self.height, self.width
# NOTE: assume sorted time
t0_int = time[0]
t1_int = time[-1]
assert t1_int >= t0_int
t_norm = (time - t0_int) / max((t1_int - t0_int), 1)
t_norm = th.clamp(t_norm, min=1e-6, max=1 - 1e-6)
# Let N be the number of bins. I.e. bin \in [0, N):
# Let f(bin) = t_norm, model the relationship between bin and normalized time \in [0, 1]
# f(bin=N) = 1
# f(bin=N-1) = 1/2
# f(bin=N-2) = 1/2*1/2
# -> f(bin=N-i) = (1/2)^i
# Also: f(bin) = t_norm
#
# Hence, (1/2)^(N-bin) = t_norm
# And, bin = N - log(t_norm, base=1/2) = N - log(t_norm)/log(1/2)
bin_float = self.bins - th.log(t_norm) / math.log(1 / 2)
# Can go below 0 for t_norm close to 0 -> clamp to 0
bin_float = th.clamp(bin_float, min=0)
t_idx = bin_float.floor()
indices = x.long() + wd * y.long() + ht * wd * t_idx.long()
values = th.asarray(pol, dtype=dtype, device=device)
representation.put_(indices, values, accumulate=True)
representation = self.cumsum_ch_opt(representation, num_channels=self.bins)
if self.count_cutoff is not None:
representation = th.clamp(
representation, min=-self.count_cutoff, max=self.count_cutoff
)
return representation
================================================
FILE: RVT/data/utils/spatial.py
================================================
from omegaconf import DictConfig
from data.utils.types import DatasetType
_type_2_hw = {
DatasetType.GEN1: (240, 304),
DatasetType.GEN4: (720, 1280),
}
_str_2_type = {
"gen1": DatasetType.GEN1,
"gen4": DatasetType.GEN4,
}
def get_original_hw(dataset_type: DatasetType):
return _type_2_hw[dataset_type]
def get_dataloading_hw(dataset_config: DictConfig):
dataset_name = dataset_config.name
hw = get_original_hw(dataset_type=_str_2_type[dataset_name])
downsample_by_factor_2 = dataset_config.downsample_by_factor_2
if downsample_by_factor_2:
hw = tuple(x // 2 for x in hw)
return hw
================================================
FILE: RVT/data/utils/stream_concat_datapipe.py
================================================
from typing import Any, Iterator, List, Optional, Type
import torch as th
import torch.distributed as dist
from torch.utils.data import DataLoader
from torchdata.datapipes.iter import (
Concater,
IterableWrapper,
IterDataPipe,
Zipper,
)
from torchdata.datapipes.map import MapDataPipe
class DummyIterDataPipe(IterDataPipe):
def __init__(self, source_dp: IterDataPipe):
super().__init__()
assert isinstance(source_dp, IterDataPipe)
self.source_dp = source_dp
def __iter__(self):
yield from self.source_dp
class ConcatStreamingDataPipe(IterDataPipe):
"""This Dataset avoids the sharding problem by instantiating randomized stream concatenation at the batch and
worker level.
Pros:
- Every single batch has valid samples. Consequently, the batch size is always constant.
Cons:
- There might be repeated samples in a batch. Although they should be different because of data augmentation.
- Cannot be used for validation or testing because we repeat the dataset multiple times in an epoch.
TLDR: preferred approach for training but not useful for validation or testing.
"""
def __init__(
self,
datapipe_list: List[MapDataPipe],
batch_size: int,
num_workers: int,
augmentation_pipeline: Optional[Type[IterDataPipe]] = None,
print_seed_debug: bool = False,
):
super().__init__()
assert batch_size > 0
if augmentation_pipeline is not None:
self.augmentation_dp = augmentation_pipeline
else:
self.augmentation_dp = DummyIterDataPipe
# We require MapDataPipes instead of IterDataPipes because IterDataPipes must be deepcopied in each worker.
# Instead, MapDataPipes can be converted to IterDataPipes in each worker without requiring a deepcopy.
self.datapipe_list = datapipe_list
self.batch_size = batch_size
self.print_seed_debug = print_seed_debug
@staticmethod
def random_torch_shuffle_list(data: List[Any]) -> Iterator[Any]:
assert isinstance(data, List)
return (data[idx] for idx in th.randperm(len(data)).tolist())
def _get_zipped_streams(self, datapipe_list: List[MapDataPipe], batch_size: int):
"""Use it only in the iter function of this class!!!
Reason: randomized shuffling must happen within each worker. Otherwise, the same random order will be used
for all workers.
"""
assert isinstance(datapipe_list, List)
assert batch_size > 0
streams = Zipper(
*(
Concater(
*(
self.augmentation_dp(x.to_iter_datapipe())
for x in self.random_torch_shuffle_list(datapipe_list)
)
)
for _ in range(batch_size)
)
)
return streams
def _print_seed_debug_info(self):
worker_info = th.utils.data.get_worker_info()
local_worker_id = 0 if worker_info is None else worker_info.id
worker_torch_seed = worker_info.seed
local_num_workers = 1 if worker_info is None else worker_info.num_workers
if dist.is_available() and dist.is_initialized():
global_rank = dist.get_rank()
else:
global_rank = 0
global_worker_id = global_rank * local_num_workers + local_worker_id
rnd_number = th.randn(1)
print(
f"{worker_torch_seed=},\t{global_worker_id=},\t{global_rank=},\t{local_worker_id=},\t{rnd_number=}",
flush=True,
)
def _get_zipped_streams_with_worker_id(self):
"""Use it only in the iter function of this class!!!"""
worker_info = th.utils.data.get_worker_info()
local_worker_id = 0 if worker_info is None else worker_info.id
worker_id_stream = IterableWrapper([local_worker_id]).cycle(count=None)
zipped_stream = self._get_zipped_streams(
datapipe_list=self.datapipe_list, batch_size=self.batch_size
)
return zipped_stream.zip(worker_id_stream)
def __iter__(self):
if self.print_seed_debug:
self._print_seed_debug_info()
return iter(self._get_zipped_streams_with_worker_id())
================================================
FILE: RVT/data/utils/stream_sharded_datapipe.py
================================================
from typing import Any, List, Optional
import torch
import torch.distributed as dist
from torch.utils.data import DataLoader
from torchdata.datapipes.iter import (
Concater,
IterableWrapper,
IterDataPipe,
ZipperLongest,
)
from torchdata.datapipes.map import MapDataPipe
class ShardedStreamingDataPipe(IterDataPipe):
def __init__(
self,
datapipe_list: List[MapDataPipe],
batch_size: int,
fill_value: Optional[Any] = None,
):
super().__init__()
assert batch_size > 0
# We require MapDataPipes instead of IterDataPipes because IterDataPipes must be deepcopied in each worker.
# Instead, MapDataPipes can be converted to IterDataPipes in each worker without requiring a deepcopy.
# Note: Sorting is a heuristic to get potentially better distribution of workloads than taking the data as is.
# Sort iterators from long to short.
self.datapipe_list = sorted(datapipe_list, key=lambda x: len(x), reverse=True)
self.batch_size = batch_size
self.fill_value = fill_value
@staticmethod
def yield_pyramid_indices(start_idx: int, end_idx: int):
while True:
for idx in range(start_idx, end_idx):
yield idx
for idx in range(end_idx - 1, start_idx - 1, -1):
yield idx
@classmethod
def assign_datapipes_to_worker(
cls,
sorted_datapipe_list: List[MapDataPipe],
total_num_workers: int,
global_worker_id: int,
) -> List[MapDataPipe]:
num_datapipes = len(sorted_datapipe_list)
assert (
num_datapipes >= total_num_workers > global_worker_id
), f"{num_datapipes=}, {total_num_workers=}, {global_worker_id=}"
datapipes = []
# Assumes sorted datapipes from long to short.
global_worker_id_generator = cls.yield_pyramid_indices(
start_idx=0, end_idx=total_num_workers
)
for idx, dp in enumerate(sorted_datapipe_list):
generated_global_worker_id = next(global_worker_id_generator)
if generated_global_worker_id == global_worker_id:
datapipes.append(dp)
assert len(sorted_datapipe_list) > 0
return datapipes
def get_zipped_stream_from_worker_datapipes(
self, datapipe_list: List[MapDataPipe], batch_size: int
) -> ZipperLongest:
num_datapipes = len(datapipe_list)
assert num_datapipes > 0
assert batch_size > 0
assert num_datapipes >= batch_size, (
"Each worker must at least get 'batch_size' number of datapipes. "
"Otherwise, we would have to support dynamic batch sizes. "
"As a workaround, decrease the number of workers."
)
# Sort datapipe_list from long to short.
datapipe_list = sorted(datapipe_list, key=lambda x: len(x), reverse=True)
zipped_streams = [[] for _ in range(batch_size)]
batch_id_generator = self.yield_pyramid_indices(start_idx=0, end_idx=batch_size)
for datapipe in datapipe_list:
batch_idx = next(batch_id_generator)
zipped_streams[batch_idx].append(datapipe)
for idx, streams in enumerate(zipped_streams):
zipped_streams[idx] = Concater(
*(stream.to_iter_datapipe() for stream in streams)
)
zipped_streams = ZipperLongest(*zipped_streams, fill_value=self.fill_value)
return zipped_streams
def __iter__(self):
worker_info = torch.utils.data.get_worker_info()
local_worker_id = 0 if worker_info is None else worker_info.id
local_num_workers = 1 if worker_info is None else worker_info.num_workers
if dist.is_available() and dist.is_initialized():
world_size = dist.get_world_size()
global_rank = dist.get_rank()
else:
world_size = 1
global_rank = 0
total_num_workers = local_num_workers * world_size
global_worker_id = global_rank * local_num_workers + local_worker_id
local_datapipes = self.assign_datapipes_to_worker(
sorted_datapipe_list=self.datapipe_list,
total_num_workers=total_num_workers,
global_worker_id=global_worker_id,
)
zipped_stream = self.get_zipped_stream_from_worker_datapipes(
datapipe_list=local_datapipes, batch_size=self.batch_size
)
# We also stream the local worker id for the use-case where we have a recurrent neural network that saves
# its state based on the local worker id. We don't need the global worker id for that because the states
# are saved in each DDP process (per GPU) separately and do not to communicate with each other.
worker_id_stream = IterableWrapper([local_worker_id]).cycle(count=None)
zipped_stream = zipped_stream.zip(worker_id_stream)
return iter(zipped_stream)
================================================
FILE: RVT/data/utils/types.py
================================================
from enum import auto, Enum
try:
from enum import StrEnum
except ImportError:
from strenum import StrEnum
from typing import Dict, List, Optional, Tuple, Union
import torch as th
from data.genx_utils.labels import ObjectLabels, SparselyBatchedObjectLabels
class DataType(Enum):
EV_REPR = auto()
FLOW = auto()
IMAGE = auto()
OBJLABELS = auto()
OBJLABELS_SEQ = auto()
IS_PADDED_MASK = auto()
IS_FIRST_SAMPLE = auto()
TOKEN_MASK = auto()
class DatasetType(Enum):
GEN1 = auto()
GEN4 = auto()
class DatasetMode(Enum):
TRAIN = auto()
VALIDATION = auto()
TESTING = auto()
class DatasetSamplingMode(StrEnum):
RANDOM = "random"
STREAM = "stream"
MIXED = "mixed"
class ObjDetOutput(Enum):
LABELS_PROPH = auto()
PRED_PROPH = auto()
EV_REPR = auto()
SKIP_VIZ = auto()
LoaderDataDictGenX = Dict[
DataType,
Union[List[th.Tensor], ObjectLabels, SparselyBatchedObjectLabels, List[bool]],
]
LstmState = Optional[Tuple[th.Tensor]]
LstmStates = List[LstmState]
FeatureMap = th.Tensor
BackboneFeatures = Dict[int, th.Tensor]
================================================
FILE: RVT/loggers/utils.py
================================================
from pathlib import Path
from typing import Union
import wandb
from omegaconf import DictConfig, OmegaConf
from loggers.wandb_logger import WandbLogger
def get_wandb_logger(full_config: DictConfig) -> WandbLogger:
wandb_config = full_config.wandb
wandb_runpath = wandb_config.wandb_runpath
if wandb_runpath is None:
wandb_id = wandb.util.generate_id()
print(f"new run: generating id {wandb_id}")
else:
wandb_id = Path(wandb_runpath).name
print(f"using provided id {wandb_id}")
full_config_dict = OmegaConf.to_container(
full_config, resolve=True, throw_on_missing=True
)
logger = WandbLogger(
project=wandb_config.project_name,
group=wandb_config.group_name,
wandb_id=wandb_id,
log_model=True,
save_last_only_final=False,
save_code=True,
config_args=full_config_dict,
)
return logger
def get_ckpt_path(logger: WandbLogger, wandb_config: DictConfig) -> Union[Path, None]:
cfg = wandb_config
artifact_name = cfg.artifact_name
assert (
artifact_name is not None
), "Artifact name is required to resume from checkpoint."
print(f"resuming checkpoint from artifact {artifact_name}")
artifact_local_file = cfg.artifact_local_file
if artifact_local_file is not None:
artifact_local_file = Path(artifact_local_file)
if isinstance(logger, WandbLogger):
resume_path = logger.get_checkpoint(
artifact_name=artifact_name, artifact_filepath=artifact_local_file
)
else:
resume_path = artifact_local_file
assert resume_path.exists()
assert resume_path.suffix == ".ckpt", resume_path.suffix
return resume_path
================================================
FILE: RVT/loggers/wandb_logger.py
================================================
"""
This is a modified version of the Pytorch Lightning logger
"""
import time
from argparse import Namespace
from pathlib import Path
from typing import Any, Dict, List, Optional, Union
from weakref import ReferenceType
import numpy as np
import lightning.pytorch as pl
import torch
import torch.nn as nn
pl_is_ge_1_6 = float(pl.__version__[:3]) >= 1.6
assert pl_is_ge_1_6
from lightning.pytorch.callbacks.model_checkpoint import ModelCheckpoint
from lightning.pytorch.loggers.logger import rank_zero_experiment, Logger
from lightning.pytorch.utilities.rank_zero import rank_zero_only, rank_zero_warn
from lightning.fabric.utilities.logger import (
_add_prefix,
_convert_params,
_flatten_dict,
_sanitize_callable_params,
)
import wandb
from wandb.sdk.lib import RunDisabled
from wandb.wandb_run import Run
class WandbLogger(Logger):
LOGGER_JOIN_CHAR = "-"
STEP_METRIC = "trainer/global_step"
def __init__(
self,
name: Optional[str] = None,
project: Optional[str] = None,
group: Optional[str] = None,
wandb_id: Optional[str] = None,
prefix: Optional[str] = "",
log_model: Optional[bool] = True,
save_last_only_final: Optional[bool] = False,
config_args: Optional[Dict[str, Any]] = None,
**kwargs,
):
super().__init__()
self._experiment = None
self._log_model = log_model
self._prefix = prefix
self._logged_model_time = {}
self._checkpoint_callback = None
# Save last is determined by the checkpoint callback argument
self._save_last = None
# Whether to save the last checkpoint continuously (more storage) or only when the run is aborted
self._save_last_only_final = save_last_only_final
# Save the configuration args (e.g. parsed arguments) and log it in wandb
self._config_args = config_args
# set wandb init arguments
self._wandb_init = dict(
name=name,
project=project,
group=group,
id=wandb_id,
resume="allow",
save_code=True,
)
self._wandb_init.update(**kwargs)
# extract parameters
self._name = self._wandb_init.get("name")
self._id = self._wandb_init.get("id")
# for save_top_k
self._public_run = None
# start wandb run (to create an attach_id for distributed modes)
wandb.require("service")
_ = self.experiment
def get_checkpoint(
self, artifact_name: str, artifact_filepath: Optional[Path] = None
) -> Path:
artifact = self.experiment.use_artifact(artifact_name)
if artifact_filepath is None:
assert artifact is not None, (
"You are probably using DDP, "
"in which case you should provide an artifact filepath."
)
# TODO: specify download directory
artifact_dir = artifact.download()
artifact_filepath = next(Path(artifact_dir).iterdir())
assert artifact_filepath.exists()
assert artifact_filepath.suffix == ".ckpt"
return artifact_filepath
def __getstate__(self) -> Dict[str, Any]:
state = self.__dict__.copy()
# args needed to reload correct experiment
if self._experiment is not None:
state["_id"] = getattr(self._experiment, "id", None)
state["_attach_id"] = getattr(self._experiment, "_attach_id", None)
state["_name"] = self._experiment.name
# cannot be pickled
state["_experiment"] = None
return state
@property
@rank_zero_experiment
def experiment(self) -> Run:
if self._experiment is None:
attach_id = getattr(self, "_attach_id", None)
if wandb.run is not None:
# wandb process already created in this instance
rank_zero_warn(
"There is a wandb run already in progress and newly created instances of `WandbLogger` will reuse"
" this run. If this is not desired, call `wandb.finish()` before instantiating `WandbLogger`."
)
self._experiment = wandb.run
elif attach_id is not None and hasattr(wandb, "_attach"):
# attach to wandb process referenced
self._experiment = wandb._attach(attach_id)
else:
# create new wandb process
self._experiment = wandb.init(**self._wandb_init)
if self._config_args is not None:
self._experiment.config.update(
self._config_args, allow_val_change=True
)
# define default x-axis
if isinstance(self._experiment, (Run, RunDisabled)) and getattr(
self._experiment, "define_metric", None
):
self._experiment.define_metric(self.STEP_METRIC)
self._experiment.define_metric(
"*", step_metric=self.STEP_METRIC, step_sync=True
)
assert isinstance(self._experiment, (Run, RunDisabled))
return self._experiment
def watch(
self,
model: nn.Module,
log: str = "all",
log_freq: int = 100,
log_graph: bool = True,
):
self.experiment.watch(model, log=log, log_freq=log_freq, log_graph=log_graph)
def add_step_metric(self, input_dict: dict, step: int) -> None:
input_dict.update({self.STEP_METRIC: step})
@rank_zero_only
def log_hyperparams(self, params: Union[Dict[str, Any], Namespace]) -> None:
params = _convert_params(params)
params = _flatten_dict(params)
params = _sanitize_callable_params(params)
self.experiment.config.update(params, allow_val_change=True)
@rank_zero_only
def log_metrics(self, metrics: Dict[str, Any], step: Optional[int] = None) -> None:
assert rank_zero_only.rank == 0, "experiment tried to log from global_rank != 0"
metrics = _add_prefix(metrics, self._prefix, self.LOGGER_JOIN_CHAR)
if step is not None:
self.add_step_metric(metrics, step)
self.experiment.log({**metrics}, step=step)
else:
self.experiment.log(metrics)
@rank_zero_only
def log_images(
self, key: str, images: List[Any], step: Optional[int] = None, **kwargs: str
) -> None:
"""Log images (tensors, numpy arrays, PIL Images or file paths).
Optional kwargs are lists passed to each image (ex: caption, masks, boxes).
How to use: https://pytorch-lightning.readthedocs.io/en/latest/api/pytorch_lightning.loggers.wandb.html#weights-and-biases-logger
Taken from: https://github.com/PyTorchLightning/pytorch-lightning/blob/11e289ad9f95f5fe23af147fa4edcc9794f9b9a7/pytorch_lightning/loggers/wandb.py#L420
"""
if not isinstance(images, list):
raise TypeError(f'Expected a list as "images", found {type(images)}')
n = len(images)
for k, v in kwargs.items():
if len(v) != n:
raise ValueError(f"Expected {n} items but only found {len(v)} for {k}")
kwarg_list = [{k: kwargs[k][i] for k in kwargs.keys()} for i in range(n)]
metrics = {
key: [wandb.Image(img, **kwarg) for img, kwarg in zip(images, kwarg_list)]
}
self.log_metrics(metrics, step)
@rank_zero_only
def log_videos(
self,
key: str,
videos: List[Union[np.ndarray, str]],
step: Optional[int] = None,
captions: Optional[List[str]] = None,
fps: int = 4,
format_: Optional[str] = None,
):
"""
:param video: List[(T,C,H,W)] or List[(N,T,C,H,W)]
:param captions: List[str] or None
More info: https://docs.wandb.ai/ref/python/data-types/video and
https://docs.wandb.ai/guides/track/log/media#other-media
"""
assert isinstance(videos, list)
if captions is not None:
assert isinstance(captions, list)
assert len(captions) == len(videos)
wandb_videos = list()
for idx, video in enumerate(videos):
caption = captions[idx] if captions is not None else None
wandb_videos.append(
wandb.Video(
data_or_path=video, caption=caption, fps=fps, format=format_
)
)
self.log_metrics(metrics={key: wandb_videos}, step=step)
@property
def name(self) -> Optional[str]:
# This function seems to be only relevant if LoggerCollection is used.
# don't create an experiment if we don't have one
return self._experiment.project_name() if self._experiment else self._name
@property
def version(self) -> Optional[str]:
# This function seems to be only relevant if LoggerCollection is used.
# don't create an experiment if we don't have one
return self._experiment.id if self._experiment else self._id
@rank_zero_only
def after_save_checkpoint(
self, checkpoint_callback: "ReferenceType[ModelCheckpoint]"
) -> None:
# log checkpoints as artifacts
if self._checkpoint_callback is None:
self._checkpoint_callback = checkpoint_callback
self._save_last = checkpoint_callback.save_last
if self._log_model:
self._scan_and_log_checkpoints(
checkpoint_callback, self._save_last and not self._save_last_only_final
)
@rank_zero_only
def finalize(self, status: str) -> None:
# log checkpoints as artifacts
if self._checkpoint_callback and self._log_model:
self._scan_and_log_checkpoints(self._checkpoint_callback, self._save_last)
def _get_public_run(self):
if self._public_run is None:
experiment = self.experiment
runpath = (
experiment._entity
+ "/"
+ experiment._project
+ "/"
+ experiment._run_id
)
api = wandb.Api()
self._public_run = api.run(path=runpath)
return self._public_run
def _num_logged_artifact(self):
public_run = self._get_public_run()
return len(public_run.logged_artifacts())
def _scan_and_log_checkpoints(
self, checkpoint_callback: "ReferenceType[ModelCheckpoint]", save_last: bool
) -> None:
assert self._log_model
if self._checkpoint_callback is None:
self._checkpoint_callback = checkpoint_callback
self._save_last = checkpoint_callback.save_last
checkpoints = {
checkpoint_callback.best_model_path: checkpoint_callback.best_model_score,
**checkpoint_callback.best_k_models,
}
assert len(checkpoints) <= max(checkpoint_callback.save_top_k, 0)
if save_last:
last_model_path = Path(checkpoint_callback.last_model_path)
if last_model_path.exists():
checkpoints.update(
{
checkpoint_callback.last_model_path: checkpoint_callback.current_score
}
)
else:
print(
f"last model checkpoint not found at {checkpoint_callback.last_model_path}"
)
checkpoints = sorted(
(
(Path(path).stat().st_mtime, path, score)
for path, score in checkpoints.items()
if Path(path).is_file()
),
key=lambda x: x[0],
)
# Retain only checkpoints that we have not logged before with one exception:
# If the name is the same (e.g. last checkpoint which should be overwritten),
# make sure that they are newer than the previously saved checkpoint by checking their modification time
checkpoints = [
ckpt
for ckpt in checkpoints
if ckpt[1] not in self._logged_model_time.keys()
or self._logged_model_time[ckpt[1]] < ckpt[0]
]
# remove checkpoints with undefined (None) score
checkpoints = [x for x in checkpoints if x[2] is not None]
num_ckpt_logged_before = self._num_logged_artifact()
num_new_cktps = len(checkpoints)
if num_new_cktps == 0:
return
# log iteratively all new checkpoints
for time_, path, score in checkpoints:
score = score.item() if isinstance(score, torch.Tensor) else score
is_best = path == checkpoint_callback.best_model_path
is_last = path == checkpoint_callback.last_model_path
metadata = {
"score": score,
"original_filename": Path(path).name,
"ModelCheckpoint": {
k: getattr(checkpoint_callback, k)
for k in [
"monitor",
"mode",
"save_last",
"save_top_k",
"save_weights_only",
]
# ensure it does not break if `ModelCheckpoint` args change
if hasattr(checkpoint_callback, k)
},
}
aliases = []
if is_best:
aliases.append("best")
if is_last:
aliases.append("last")
artifact_name = f"checkpoint-{self.experiment.id}-" + (
"last" if is_last else "topK"
)
artifact = wandb.Artifact(
name=artifact_name, type="model", metadata=metadata
)
assert Path(path).exists()
artifact.add_file(path, name=f"{self.experiment.id}.ckpt")
self.experiment.log_artifact(artifact, aliases=aliases)
# remember logged models - timestamp needed in case filename didn't change (last.ckpt or custom name)
self._logged_model_time[path] = time_
timeout = 20
time_spent = 0
while self._num_logged_artifact() < num_ckpt_logged_before + num_new_cktps:
time.sleep(1)
time_spent += 1
if time_spent >= timeout:
rank_zero_warn(
"Timeout: Num logged artifacts never reached expected value."
)
print(f"self._num_logged_artifact() = {self._num_logged_artifact()}")
print(f"num_ckpt_logged_before = {num_ckpt_logged_before}")
print(f"num_new_cktps = {num_new_cktps}")
break
try:
self._rm_but_top_k(checkpoint_callback.save_top_k)
except KeyError:
pass
def _rm_but_top_k(self, top_k: int):
# top_k == -1: save all models
# top_k == 0: no models saved at all. The checkpoint callback does not return checkpoints.
# top_k > 0: keep only top k models (last and best will not be deleted)
def is_last(artifact):
return "last" in artifact.aliases
def is_best(artifact):
return "best" in artifact.aliases
def try_delete(artifact):
try:
artifact.delete(delete_aliases=True)
except wandb.errors.CommError:
print(
f"Failed to delete artifact {artifact.name} due to wandb.errors.CommError"
)
public_run = self._get_public_run()
score2art = list()
for artifact in public_run.logged_artifacts():
score = artifact.metadata["score"]
original_filename = artifact.metadata["original_filename"]
if score == "Infinity":
print(
f"removing INF artifact (name, score, original_filename): ({artifact.name}, {score}, {original_filename})"
)
try_delete(artifact)
continue
if score is None:
print(
f"removing None artifact (name, score, original_filename): ({artifact.name}, {score}, {original_filename})"
)
try_delete(artifact)
continue
score2art.append((score, artifact))
# From high score to low score
score2art.sort(key=lambda x: x[0], reverse=True)
count = 0
for score, artifact in score2art:
original_filename = artifact.metadata["original_filename"]
if "last" in original_filename and not is_last(artifact):
try_delete(artifact)
continue
if is_last(artifact):
continue
count += 1
if is_best(artifact):
continue
# if top_k == -1, we do not delete anything
if 0 <= top_k < count:
try_delete(artifact)
================================================
FILE: RVT/models/detection/__init_.py
================================================
================================================
FILE: RVT/models/detection/recurrent_backbone/__init__.py
================================================
from omegaconf import DictConfig
from .maxvit_rnn import RNNDetector as MaxViTRNNDetector
def build_recurrent_backbone(backbone_cfg: DictConfig):
name = backbone_cfg.name
if name == "MaxViTRNN":
return MaxViTRNNDetector(backbone_cfg)
else:
raise NotImplementedError
================================================
FILE: RVT/models/detection/recurrent_backbone/base.py
================================================
from typing import Tuple
import torch.nn as nn
class BaseDetector(nn.Module):
def get_stage_dims(self, stages: Tuple[int, ...]) -> Tuple[int, ...]:
raise NotImplementedError
def get_strides(self, stages: Tuple[int, ...]) -> Tuple[int, ...]:
raise NotImplementedError
================================================
FILE: RVT/models/detection/recurrent_backbone/maxvit_rnn.py
================================================
from typing import Dict, Optional, Tuple
import torch as th
import torch.nn as nn
from omegaconf import DictConfig, OmegaConf
from einops import rearrange
try:
from torch import compile as th_compile
except ImportError:
th_compile = None
from data.utils.types import FeatureMap, BackboneFeatures, LstmState, LstmStates
# from models.layers.rnn import DWSConvLSTM2d
from models.layers.s5.s5_model import S5Block
from models.layers.maxvit.maxvit import (
PartitionAttentionCl,
nhwC_2_nChw,
get_downsample_layer_Cf2Cl,
PartitionType,
)
from .base import BaseDetector
class RNNDetector(BaseDetector):
def __init__(self, mdl_config: DictConfig):
super().__init__()
###### Config ######
in_channels = mdl_config.input_channels
embed_dim = mdl_config.embed_dim
dim_multiplier_per_stage = tuple(mdl_config.dim_multiplier)
num_blocks_per_stage = tuple(mdl_config.num_blocks)
T_max_chrono_init_per_stage = tuple(mdl_config.T_max_chrono_init)
enable_masking = mdl_config.enable_masking
num_stages = len(num_blocks_per_stage)
assert num_stages == 4
assert isinstance(embed_dim, int)
assert num_stages == len(dim_multiplier_per_stage)
assert num_stages == len(num_blocks_per_stage)
assert num_stages == len(T_max_chrono_init_per_stage)
###### Compile if requested ######
compile_cfg = mdl_config.get("compile", None)
if compile_cfg is not None:
compile_mdl = compile_cfg.enable
if compile_mdl and th_compile is not None:
compile_args = OmegaConf.to_container(
compile_cfg.args, resolve=True, throw_on_missing=True
)
self.forward = th_compile(self.forward, **compile_args)
elif compile_mdl:
print(
"Could not compile backbone because torch.compile is not available"
)
##################################
input_dim = in_channels
patch_size = mdl_config.stem.patch_size
stride = 1
self.stage_dims = [embed_dim * x for x in dim_multiplier_per_stage]
self.stages = nn.ModuleList()
self.strides = []
for stage_idx, (num_blocks, T_max_chrono_init_stage) in enumerate(
zip(num_blocks_per_stage, T_max_chrono_init_per_stage)
):
spatial_downsample_factor = patch_size if stage_idx == 0 else 2
stage_dim = self.stage_dims[stage_idx]
enable_masking_in_stage = enable_masking and stage_idx == 0
stage = RNNDetectorStage(
dim_in=input_dim,
stage_dim=stage_dim,
spatial_downsample_factor=spatial_downsample_factor,
num_blocks=num_blocks,
enable_token_masking=enable_masking_in_stage,
T_max_chrono_init=T_max_chrono_init_stage,
stage_cfg=mdl_config.stage,
)
stride = stride * spatial_downsample_factor
self.strides.append(stride)
input_dim = stage_dim
self.stages.append(stage)
self.num_stages = num_stages
def get_stage_dims(self, stages: Tuple[int, ...]) -> Tuple[int, ...]:
stage_indices = [x - 1 for x in stages]
assert min(stage_indices) >= 0, stage_indices
assert max(stage_indices) < len(self.stages), stage_indices
return tuple(self.stage_dims[stage_idx] for stage_idx in stage_indices)
def get_strides(self, stages: Tuple[int, ...]) -> Tuple[int, ...]:
stage_indices = [x - 1 for x in stages]
assert min(stage_indices) >= 0, stage_indices
assert max(stage_indices) < len(self.stages), stage_indices
return tuple(self.strides[stage_idx] for stage_idx in stage_indices)
def forward(
self,
x: th.Tensor,
prev_states: Optional[LstmStates] = None,
token_mask: Optional[th.Tensor] = None,
train_step: bool = True,
) -> Tuple[BackboneFeatures, LstmStates]:
if prev_states is None:
prev_states = [None] * self.num_stages
assert len(prev_states) == self.num_stages
states: LstmStates = list()
output: Dict[int, FeatureMap] = {}
for stage_idx, stage in enumerate(self.stages):
x, state = stage(
x,
prev_states[stage_idx],
token_mask if stage_idx == 0 else None,
train_step,
)
states.append(state)
stage_number = stage_idx + 1
output[stage_number] = x
return output, states
class MaxVitAttentionPairCl(nn.Module):
def __init__(self, dim: int, skip_first_norm: bool, attention_cfg: DictConfig):
super().__init__()
self.att_window = PartitionAttentionCl(
dim=dim,
partition_type=PartitionType.WINDOW,
attention_cfg=attention_cfg,
skip_first_norm=skip_first_norm,
)
self.att_grid = PartitionAttentionCl(
dim=dim,
partition_type=PartitionType.GRID,
attention_cfg=attention_cfg,
skip_first_norm=False,
)
def forward(self, x):
x = self.att_window(x)
x = self.att_grid(x)
return x
class RNNDetectorStage(nn.Module):
"""Operates with NCHW [channel-first] format as input and output."""
def __init__(
self,
dim_in: int,
stage_dim: int,
spatial_downsample_factor: int,
num_blocks: int,
enable_token_masking: bool,
T_max_chrono_init: Optional[int],
stage_cfg: DictConfig,
):
super().__init__()
assert isinstance(num_blocks, int) and num_blocks > 0
downsample_cfg = stage_cfg.downsample
lstm_cfg = stage_cfg.lstm
attention_cfg = stage_cfg.attention
self.downsample_cf2cl = get_downsample_layer_Cf2Cl(
dim_in=dim_in,
dim_out=stage_dim,
downsample_factor=spatial_downsample_factor,
downsample_cfg=downsample_cfg,
)
blocks = [
MaxVitAttentionPairCl(
dim=stage_dim,
skip_first_norm=i == 0 and self.downsample_cf2cl.output_is_normed(),
attention_cfg=attention_cfg,
)
for i in range(num_blocks)
]
self.att_blocks = nn.ModuleList(blocks)
self.s5_block = S5Block(
dim=stage_dim, state_dim=stage_dim, bidir=False, bandlimit=0.5
)
"""
self.lstm = DWSConvLSTM2d(
dim=stage_dim,
dws_conv=lstm_cfg.dws_conv,
dws_conv_only_hidden=lstm_cfg.dws_conv_only_hidden,
dws_conv_kernel_size=lstm_cfg.dws_conv_kernel_size,
cell_update_dropout=lstm_cfg.get("drop_cell_update", 0),
)
"""
###### Mask Token ################
self.mask_token = (
nn.Parameter(th.zeros(1, 1, 1, stage_dim), requires_grad=True)
if enable_token_masking
else None
)
if self.mask_token is not None:
th.nn.init.normal_(self.mask_token, std=0.02)
##################################
def forward(
self,
x: th.Tensor,
states: Optional[LstmState] = None,
token_mask: Optional[th.Tensor] = None,
train_step: bool = True,
) -> Tuple[FeatureMap, LstmState]:
sequence_length = x.shape[0]
batch_size = x.shape[1]
x = rearrange(
x, "L B C H W -> (L B) C H W"
) # where B' = (L B) is the new batch size
x = self.downsample_cf2cl(x) # B' C H W -> B' H W C
if token_mask is not None:
assert self.mask_token is not None, "No mask token present in this stage"
x[token_mask] = self.mask_token
for blk in self.att_blocks:
x = blk(x)
x = nhwC_2_nChw(x) # B' H W C -> B' C H W
new_h, new_w = x.shape[2], x.shape[3]
x = rearrange(x, "(L B) C H W -> (B H W) L C", L=sequence_length)
if states is None:
states = self.s5_block.s5.initial_state(
batch_size=batch_size * new_h * new_w
).to(x.device)
else:
states = rearrange(states, "B C H W -> (B H W) C")
x, states = self.s5_block(x, states)
x = rearrange(
x, "(B H W) L C -> L B C H W", B=batch_size, H=int(new_h), W=int(new_w)
)
states = rearrange(states, "(B H W) C -> B C H W", H=new_h, W=new_w)
return x, states
================================================
FILE: RVT/models/detection/yolox/models/__init__.py
================================================
================================================
FILE: RVT/models/detection/yolox/models/losses.py
================================================
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Copyright (c) Megvii Inc. All rights reserved.
import torch
import torch.nn as nn
class IOUloss(nn.Module):
def __init__(self, reduction="none", loss_type="iou"):
super(IOUloss, self).__init__()
self.reduction = reduction
self.loss_type = loss_type
def forward(self, pred, target):
assert pred.shape[0] == target.shape[0]
pred = pred.view(-1, 4)
target = target.view(-1, 4)
tl = torch.max(
(pred[:, :2] - pred[:, 2:] / 2), (target[:, :2] - target[:, 2:] / 2)
)
br = torch.min(
(pred[:, :2] + pred[:, 2:] / 2), (target[:, :2] + target[:, 2:] / 2)
)
area_p = torch.prod(pred[:, 2:], 1)
area_g = torch.prod(target[:, 2:], 1)
en = (tl < br).type(tl.type()).prod(dim=1)
area_i = torch.prod(br - tl, 1) * en
area_u = area_p + area_g - area_i
iou = (area_i) / (area_u + 1e-16)
if self.loss_type == "iou":
loss = 1 - iou**2
elif self.loss_type == "giou":
c_tl = torch.min(
(pred[:, :2] - pred[:, 2:] / 2), (target[:, :2] - target[:, 2:] / 2)
)
c_br = torch.max(
(pred[:, :2] + pred[:, 2:] / 2), (target[:, :2] + target[:, 2:] / 2)
)
area_c = torch.prod(c_br - c_tl, 1)
giou = iou - (area_c - area_u) / area_c.clamp(1e-16)
loss = 1 - giou.clamp(min=-1.0, max=1.0)
else:
raise NotImplementedError
if self.reduction == "mean":
loss = loss.mean()
elif self.reduction == "sum":
loss = loss.sum()
return loss
================================================
FILE: RVT/models/detection/yolox/models/network_blocks.py
================================================
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Copyright (c) Megvii Inc. All rights reserved.
import torch
import torch.nn as nn
class SiLU(nn.Module):
"""export-friendly version of nn.SiLU()"""
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
def get_activation(name="silu", inplace=True):
if name == "silu":
module = nn.SiLU(inplace=inplace)
elif name == "relu":
module = nn.ReLU(inplace=inplace)
elif name == "lrelu":
module = nn.LeakyReLU(0.1, inplace=inplace)
else:
raise AttributeError("Unsupported act type: {}".format(name))
return module
class BaseConv(nn.Module):
"""A Conv2d -> Batchnorm -> silu/leaky relu block"""
def __init__(
self, in_channels, out_channels, ksize, stride, groups=1, bias=False, act="silu"
):
super().__init__()
# same padding
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=ksize,
stride=stride,
padding=pad,
groups=groups,
bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = get_activation(act, inplace=True)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class DWConv(nn.Module):
"""Depthwise Conv + Conv"""
def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):
super().__init__()
self.dconv = BaseConv(
in_channels,
in_channels,
ksize=ksize,
stride=stride,
groups=in_channels,
act=act,
)
self.pconv = BaseConv(
in_channels, out_channels, ksize=1, stride=1, groups=1, act=act
)
def forward(self, x):
x = self.dconv(x)
return self.pconv(x)
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(
self,
in_channels,
out_channels,
shortcut=True,
expansion=0.5,
depthwise=False,
act="silu",
):
super().__init__()
hidden_channels = int(out_channels * expansion)
Conv = DWConv if depthwise else BaseConv
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv2 = Conv(hidden_channels, out_channels, 3, stride=1, act=act)
self.use_add = shortcut and in_channels == out_channels
def forward(self, x):
y = self.conv2(self.conv1(x))
if self.use_add:
y = y + x
return y
class CSPLayer(nn.Module):
"""C3 in yolov5, CSP Bottleneck with 3 convolutions"""
def __init__(
self,
in_channels,
out_channels,
n=1,
shortcut=True,
expansion=0.5,
depthwise=False,
act="silu",
):
"""
Args:
in_channels (int): input channels.
out_channels (int): output channels.
n (int): number of Bottlenecks. Default value: 1.
"""
# ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
hidden_channels = int(out_channels * expansion) # hidden channels
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv2 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv3 = BaseConv(2 * hidden_channels, out_channels, 1, stride=1, act=act)
module_list = [
Bottleneck(
hidden_channels, hidden_channels, shortcut, 1.0, depthwise, act=act
)
for _ in range(n)
]
self.m = nn.Sequential(*module_list)
def forward(self, x):
x_1 = self.conv1(x)
x_2 = self.conv2(x)
x_1 = self.m(x_1)
x = torch.cat((x_1, x_2), dim=1)
return self.conv3(x)
================================================
FILE: RVT/models/detection/yolox/models/yolo_head.py
================================================
"""
Original Yolox Head code with slight modifications
"""
import math
from typing import Dict, Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
try:
from torch import compile as th_compile
except ImportError:
th_compile = None
from models.detection.yolox.utils import bboxes_iou
from .losses import IOUloss
from .network_blocks import BaseConv, DWConv
class YOLOXHead(nn.Module):
def __init__(
self,
num_classes=80,
strides=(8, 16, 32),
in_channels=(256, 512, 1024),
act="silu",
depthwise=False,
compile_cfg: Optional[Dict] = None,
):
super().__init__()
self.num_classes = num_classes
self.decode_in_inference = True # for deploy, set to False
self.cls_convs = nn.ModuleList()
self.reg_convs = nn.ModuleList()
self.cls_preds = nn.ModuleList()
self.reg_preds = nn.ModuleList()
self.obj_preds = nn.ModuleList()
self.stems = nn.ModuleList()
Conv = DWConv if depthwise else BaseConv
self.output_strides = None
self.output_grids = None
# Automatic width scaling according to original YoloX channel dims.
# in[-1]/out = 4/1
# out = in[-1]/4 = 256 * width
# -> width = in[-1]/1024
largest_base_dim_yolox = 1024
largest_base_dim_from_input = in_channels[-1]
width = largest_base_dim_from_input / largest_base_dim_yolox
hidden_dim = int(256 * width)
for i in range(len(in_channels)):
self.stems.append(
BaseConv(
in_channels=in_channels[i],
out_channels=hidden_dim,
ksize=1,
stride=1,
act=act,
)
)
self.cls_convs.append(
nn.Sequential(
*[
Conv(
in_channels=hidden_dim,
out_channels=hidden_dim,
ksize=3,
stride=1,
act=act,
),
Conv(
in_channels=hidden_dim,
out_channels=hidden_dim,
ksize=3,
stride=1,
act=act,
),
]
)
)
self.reg_convs.append(
nn.Sequential(
*[
Conv(
in_channels=hidden_dim,
out_channels=hidden_dim,
ksize=3,
stride=1,
act=act,
),
Conv(
in_channels=hidden_dim,
out_channels=hidden_dim,
ksize=3,
stride=1,
act=act,
),
]
)
)
self.cls_preds.append(
nn.Conv2d(
in_channels=hidden_dim,
out_channels=self.num_classes,
kernel_size=1,
stride=1,
padding=0,
)
)
self.reg_preds.append(
nn.Conv2d(
in_channels=hidden_dim,
out_channels=4,
kernel_size=1,
stride=1,
padding=0,
)
)
self.obj_preds.append(
nn.Conv2d(
in_channels=hidden_dim,
out_channels=1,
kernel_size=1,
stride=1,
padding=0,
)
)
self.use_l1 = False
self.l1_loss = nn.L1Loss(reduction="none")
self.bcewithlog_loss = nn.BCEWithLogitsLoss(reduction="none")
self.iou_loss = IOUloss(reduction="none")
self.strides = strides
self.grids = [torch.zeros(1)] * len(in_channels)
# According to Focal Loss paper:
self.initialize_biases(prior_prob=0.01)
###### Compile if requested ######
if compile_cfg is not None:
compile_mdl = compile_cfg["enable"]
if compile_mdl and th_compile is not None:
self.forward = th_compile(self.forward, **compile_cfg["args"])
elif compile_mdl:
print(
"Could not compile YOLOXHead because torch.compile is not available"
)
##################################
def initialize_biases(self, prior_prob):
for conv in self.cls_preds:
b = conv.bias.view(1, -1)
b.data.fill_(-math.log((1 - prior_prob) / prior_prob))
conv.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
for conv in self.obj_preds:
b = conv.bias.view(1, -1)
b.data.fill_(-math.log((1 - prior_prob) / prior_prob))
conv.bias = torch.nn.Parameter(b.view(-1), requires_grad=True)
def forward(self, xin, labels=None):
train_outputs = []
inference_outputs = []
origin_preds = []
x_shifts = []
y_shifts = []
expanded_strides = []
for k, (cls_conv, reg_conv, stride_this_level, x) in enumerate(
zip(self.cls_convs, self.reg_convs, self.strides, xin)
):
x = self.stems[k](x)
cls_x = x
reg_x = x
cls_feat = cls_conv(cls_x)
cls_output = self.cls_preds[k](cls_feat)
reg_feat = reg_conv(reg_x)
reg_output = self.reg_preds[k](reg_feat)
obj_output = self.obj_preds[k](reg_feat)
if self.training:
output = torch.cat([reg_output, obj_output, cls_output], 1)
output, grid = self.get_output_and_grid(
output, k, stride_this_level, xin[0].type()
)
x_shifts.append(grid[:, :, 0])
y_shifts.append(grid[:, :, 1])
expanded_strides.append(
torch.zeros(1, grid.shape[1])
.fill_(stride_this_level)
.type_as(xin[0])
)
if self.use_l1:
batch_size = reg_output.shape[0]
hsize, wsize = reg_output.shape[-2:]
reg_output = reg_output.view(batch_size, 1, 4, hsize, wsize)
reg_output = reg_output.permute(0, 1, 3, 4, 2).reshape(
batch_size, -1, 4
)
origin_preds.append(reg_output.clone())
train_outputs.append(output)
inference_output = torch.cat(
[reg_output, obj_output.sigmoid(), cls_output.sigmoid()], 1
)
inference_outputs.append(inference_output)
# --------------------------------------------------------
# Modification: return decoded output also during training
# --------------------------------------------------------
losses = None
if self.training:
losses = self.get_losses(
x_shifts,
y_shifts,
expanded_strides,
labels,
torch.cat(train_outputs, 1),
origin_preds,
dtype=xin[0].dtype,
)
assert len(losses) == 6
losses = {
"loss": losses[0],
"iou_loss": losses[1],
"conf_loss": losses[2], # object-ness
"cls_loss": losses[3], # predicted class
"l1_loss": losses[4],
"num_fg": losses[5],
}
self.hw = [x.shape[-2:] for x in inference_outputs]
# [batch, n_anchors_all, 85]
outputs = torch.cat(
[x.flatten(start_dim=2) for x in inference_outputs], dim=2
).permute(0, 2, 1)
if self.decode_in_inference:
return self.decode_outputs(outputs), losses
else:
return outputs, losses
def get_output_and_grid(self, output, k, stride, dtype):
grid = self.grids[k]
batch_size = output.shape[0]
n_ch = 5 + self.num_classes
hsize, wsize = output.shape[-2:]
if grid.shape[2:4] != output.shape[2:4]:
yv, xv = torch.meshgrid([torch.arange(hsize), torch.arange(wsize)])
grid = torch.stack((xv, yv), 2).view(1, 1, hsize, wsize, 2).type(dtype)
self.grids[k] = grid
output = output.view(batch_size, 1, n_ch, hsize, wsize)
output = output.permute(0, 1, 3, 4, 2).reshape(batch_size, hsize * wsize, -1)
grid = grid.view(1, -1, 2)
output[..., :2] = (output[..., :2] + grid) * stride
output[..., 2:4] = torch.exp(output[..., 2:4]) * stride
return output, grid
def decode_outputs(self, outputs):
if self.output_grids is None:
assert self.output_strides is None
dtype = outputs.dtype
device = outputs.device
grids = []
strides = []
for (hsize, wsize), stride in zip(self.hw, self.strides):
yv, xv = torch.meshgrid(
[
torch.arange(hsize, device=device, dtype=dtype),
torch.arange(wsize, device=device, dtype=dtype),
]
)
grid = torch.stack((xv, yv), 2).view(1, -1, 2)
grids.append(grid)
shape = grid.shape[:2]
strides.append(
torch.full((*shape, 1), stride, device=device, dtype=dtype)
)
self.output_grids = torch.cat(grids, dim=1)
self.output_strides = torch.cat(strides, dim=1)
outputs = torch.cat(
[
(outputs[..., 0:2] + self.output_grids) * self.output_strides,
torch.exp(outputs[..., 2:4]) * self.output_strides,
outputs[..., 4:],
],
dim=-1,
)
return outputs
def get_losses(
self,
x_shifts,
y_shifts,
expanded_strides,
labels,
outputs,
origin_preds,
dtype,
):
bbox_preds = outputs[:, :, :4] # [batch, n_anchors_all, 4]
obj_preds = outputs[:, :, 4:5] # [batch, n_anchors_all, 1]
cls_preds = outputs[:, :, 5:] # [batch, n_anchors_all, n_cls]
# calculate targets
nlabel = (labels.sum(dim=2) > 0).sum(dim=1) # number of objects
total_num_anchors = outputs.shape[1]
x_shifts = torch.cat(x_shifts, 1) # [1, n_anchors_all]
y_shifts = torch.cat(y_shifts, 1) # [1, n_anchors_all]
expanded_strides = torch.cat(expanded_strides, 1)
if self.use_l1:
origin_preds = torch.cat(origin_preds, 1)
cls_targets = []
reg_targets = []
l1_targets = []
obj_targets = []
fg_masks = []
num_fg = 0.0
num_gts = 0.0
for batch_idx in range(outputs.shape[0]):
num_gt = int(nlabel[batch_idx])
num_gts += num_gt
if num_gt == 0:
cls_target = outputs.new_zeros((0, self.num_classes))
reg_target = outputs.new_zeros((0, 4))
l1_target = outputs.new_zeros((0, 4))
obj_target = outputs.new_zeros((total_num_anchors, 1))
fg_mask = outputs.new_zeros(total_num_anchors).bool()
else:
gt_bboxes_per_image = labels[batch_idx, :num_gt, 1:5]
gt_classes = labels[batch_idx, :num_gt, 0]
bboxes_preds_per_image = bbox_preds[batch_idx]
try:
(
gt_matched_classes,
fg_mask,
pred_ious_this_matching,
matched_gt_inds,
num_fg_img,
) = self.get_assignments( # noqa
batch_idx,
num_gt,
gt_bboxes_per_image,
gt_classes,
bboxes_preds_per_image,
expanded_strides,
x_shifts,
y_shifts,
cls_preds,
obj_preds,
)
except RuntimeError as e:
# TODO: the string might change, consider a better way
if "CUDA out of memory. " not in str(e):
raise
torch.cuda.empty_cache()
(
gt_matched_classes,
fg_mask,
pred_ious_this_matching,
matched_gt_inds,
num_fg_img,
) = self.get_assignments( # noqa
batch_idx,
num_gt,
gt_bboxes_per_image,
gt_classes,
bboxes_preds_per_image,
expanded_strides,
x_shifts,
y_shifts,
cls_preds,
obj_preds,
"cpu",
)
torch.cuda.empty_cache()
num_fg += num_fg_img
cls_target = F.one_hot(
gt_matched_classes.to(torch.int64), self.num_classes
) * pred_ious_this_matching.unsqueeze(-1)
obj_target = fg_mask.unsqueeze(-1)
reg_target = gt_bboxes_per_image[matched_gt_inds]
if self.use_l1:
l1_target = self.get_l1_target(
outputs.new_zeros((num_fg_img, 4)),
gt_bboxes_per_image[matched_gt_inds],
expanded_strides[0][fg_mask],
x_shifts=x_shifts[0][fg_mask],
y_shifts=y_shifts[0][fg_mask],
)
cls_targets.append(cls_target)
reg_targets.append(reg_target)
obj_targets.append(obj_target.to(dtype))
fg_masks.append(fg_mask)
if self.use_l1:
l1_targets.append(l1_target)
cls_targets = torch.cat(cls_targets, 0)
reg_targets = torch.cat(reg_targets, 0)
obj_targets = torch.cat(obj_targets, 0)
fg_masks = torch.cat(fg_masks, 0)
if self.use_l1:
l1_targets = torch.cat(l1_targets, 0)
num_fg = max(num_fg, 1)
loss_iou = (
self.iou_loss(bbox_preds.view(-1, 4)[fg_masks], reg_targets)
).sum() / num_fg
loss_obj = (
self.bcewithlog_loss(obj_preds.view(-1, 1), obj_targets)
).sum() / num_fg
loss_cls = (
self.bcewithlog_loss(
cls_preds.view(-1, self.num_classes)[fg_masks], cls_targets
)
).sum() / num_fg
if self.use_l1:
loss_l1 = (
self.l1_loss(origin_preds.view(-1, 4)[fg_masks], l1_targets)
).sum() / num_fg
else:
loss_l1 = 0.0
reg_weight = 5.0
loss = reg_weight * loss_iou + loss_obj + loss_cls + loss_l1
return (
loss,
reg_weight * loss_iou,
loss_obj,
loss_cls,
loss_l1,
num_fg / max(num_gts, 1),
)
def get_l1_target(self, l1_target, gt, stride, x_shifts, y_shifts, eps=1e-8):
l1_target[:, 0] = gt[:, 0] / stride - x_shifts
l1_target[:, 1] = gt[:, 1] / stride - y_shifts
l1_target[:, 2] = torch.log(gt[:, 2] / stride + eps)
l1_target[:, 3] = torch.log(gt[:, 3] / stride + eps)
return l1_target
@torch.no_grad()
def get_assignments(
self,
batch_idx,
num_gt,
gt_bboxes_per_image,
gt_classes,
bboxes_preds_per_image,
expanded_strides,
x_shifts,
y_shifts,
cls_preds,
obj_preds,
mode="gpu",
):
if mode == "cpu":
print("-----------Using CPU for the Current Batch-------------")
gt_bboxes_per_image = gt_bboxes_per_image.cpu().float()
bboxes_preds_per_image = bboxes_preds_per_image.cpu().float()
gt_classes = gt_classes.cpu().float()
expanded_strides = expanded_strides.cpu().float()
x_shifts = x_shifts.cpu()
y_shifts = y_shifts.cpu()
fg_mask, geometry_relation = self.get_geometry_constraint(
gt_bboxes_per_image,
expanded_strides,
x_shifts,
y_shifts,
)
bboxes_preds_per_image = bboxes_preds_per_image[fg_mask]
cls_preds_ = cls_preds[batch_idx][fg_mask]
obj_preds_ = obj_preds[batch_idx][fg_mask]
num_in_boxes_anchor = bboxes_preds_per_image.shape[0]
if mode == "cpu":
gt_bboxes_per_image = gt_bboxes_per_image.cpu()
bboxes_preds_per_image = bboxes_preds_per_image.cpu()
pair_wise_ious = bboxes_iou(gt_bboxes_per_image, bboxes_preds_per_image, False)
gt_cls_per_image = F.one_hot(
gt_classes.to(torch.int64), self.num_classes
).float()
pair_wise_ious_loss = -torch.log(pair_wise_ious + 1e-8)
if mode == "cpu":
cls_preds_, obj_preds_ = cls_preds_.cpu(), obj_preds_.cpu()
with torch.cuda.amp.autocast(enabled=False):
cls_preds_ = (
cls_preds_.float().sigmoid_() * obj_preds_.float().sigmoid_()
).sqrt()
pair_wise_cls_loss = F.binary_cross_entropy(
cls_preds_.unsqueeze(0).repeat(num_gt, 1, 1),
gt_cls_per_image.unsqueeze(1).repeat(1, num_in_boxes_anchor, 1),
reduction="none",
).sum(-1)
del cls_preds_
cost = (
pair_wise_cls_loss
+ 3.0 * pair_wise_ious_loss
+ float(1e6) * (~geometry_relation)
)
(
num_fg,
gt_matched_classes,
pred_ious_this_matching,
matched_gt_inds,
) = self.simota_matching(cost, pair_wise_ious, gt_classes, num_gt, fg_mask)
del pair_wise_cls_loss, cost, pair_wise_ious, pair_wise_ious_loss
if mode == "cpu":
gt_matched_classes = gt_matched_classes.cuda()
fg_mask = fg_mask.cuda()
pred_ious_this_matching = pred_ious_this_matching.cuda()
matched_gt_inds = matched_gt_inds.cuda()
return (
gt_matched_classes,
fg_mask,
pred_ious_this_matching,
matched_gt_inds,
num_fg,
)
def get_geometry_constraint(
self,
gt_bboxes_per_image,
expanded_strides,
x_shifts,
y_shifts,
):
"""
Calculate whether the center of an object is located in a fixed range of
an anchor. This is used to avert inappropriate matching. It can also reduce
the number of candidate anchors so that the GPU memory is saved.
"""
expanded_strides_per_image = expanded_strides[0]
x_centers_per_image = (
(x_shifts[0] + 0.5) * expanded_strides_per_image
).unsqueeze(0)
y_centers_per_image = (
(y_shifts[0] + 0.5) * expanded_strides_per_image
).unsqueeze(0)
# in fixed center
center_radius = 1.5
center_dist = expanded_strides_per_image.unsqueeze(0) * center_radius
gt_bboxes_per_image_l = (gt_bboxes_per_image[:, 0:1]) - center_dist
gt_bboxes_per_image_r = (gt_bboxes_per_image[:, 0:1]) + center_dist
gt_bboxes_per_image_t = (gt_bboxes_per_image[:, 1:2]) - center_dist
gt_bboxes_per_image_b = (gt_bboxes_per_image[:, 1:2]) + center_dist
c_l = x_centers_per_image - gt_bboxes_per_image_l
c_r = gt_bboxes_per_image_r - x_centers_per_image
c_t = y_centers_per_image - gt_bboxes_per_image_t
c_b = gt_bboxes_per_image_b - y_centers_per_image
center_deltas = torch.stack([c_l, c_t, c_r, c_b], 2)
is_in_centers = center_deltas.min(dim=-1).values > 0.0
anchor_filter = is_in_centers.sum(dim=0) > 0
geometry_relation = is_in_centers[:, anchor_filter]
return anchor_filter, geometry_relation
def simota_matching(self, cost, pair_wise_ious, gt_classes, num_gt, fg_mask):
matching_matrix = torch.zeros_like(cost, dtype=torch.uint8)
n_candidate_k = min(10, pair_wise_ious.size(1))
topk_ious, _ = torch.topk(pair_wise_ious, n_candidate_k, dim=1)
dynamic_ks = torch.clamp(topk_ious.sum(1).int(), min=1)
for gt_idx in range(num_gt):
_, pos_idx = torch.topk(cost[gt_idx], k=dynamic_ks[gt_idx], largest=False)
matching_matrix[gt_idx][pos_idx] = 1
del topk_ious, dynamic_ks, pos_idx
anchor_matching_gt = matching_matrix.sum(0)
# deal with the case that one anchor matches multiple ground-truths
if anchor_matching_gt.max() > 1:
multiple_match_mask = anchor_matching_gt > 1
_, cost_argmin = torch.min(cost[:, multiple_match_mask], dim=0)
matching_matrix[:, multiple_match_mask] *= 0
matching_matrix[cost_argmin, multiple_match_mask] = 1
fg_mask_inboxes = anchor_matching_gt > 0
num_fg = fg_mask_inboxes.sum().item()
fg_mask[fg_mask.clone()] = fg_mask_inboxes
matched_gt_inds = matching_matrix[:, fg_mask_inboxes].argmax(0)
gt_matched_classes = gt_classes[matched_gt_inds]
pred_ious_this_matching = (matching_matrix * pair_wise_ious).sum(0)[
fg_mask_inboxes
]
return num_fg, gt_matched_classes, pred_ious_this_matching, matched_gt_inds
================================================
FILE: RVT/models/detection/yolox/utils/__init__.py
================================================
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Copyright (c) Megvii Inc. All rights reserved.
from .boxes import *
from .compat import meshgrid
================================================
FILE: RVT/models/detection/yolox/utils/boxes.py
================================================
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
# Copyright (c) Megvii Inc. All rights reserved.
import numpy as np
import torch
import torchvision
__all__ = [
"filter_box",
"postprocess",
"bboxes_iou",
"matrix_iou",
"adjust_box_anns",
"xyxy2xywh",
"xyxy2cxcywh",
]
def filter_box(output, scale_range):
"""
output: (N, 5+class) shape
"""
min_scale, max_scale = scale_range
w = output[:, 2] - output[:, 0]
h = output[:, 3] - output[:, 1]
keep = (w * h > min_scale * min_scale) & (w * h < max_scale * max_scale)
return output[keep]
def postprocess(
prediction, num_classes, conf_thre=0.7, nms_thre=0.45, class_agnostic=False
):
box_corner = prediction.new(prediction.shape)
box_corner[:, :, 0] = prediction[:, :, 0] - prediction[:, :, 2] / 2
box_corner[:, :, 1] = prediction[:, :, 1] - prediction[:, :, 3] / 2
box_corner[:, :, 2] = prediction[:, :, 0] + prediction[:, :, 2] / 2
box_corner[:, :, 3] = prediction[:, :, 1] + prediction[:, :, 3] / 2
prediction[:, :, :4] = box_corner[:, :, :4]
output = [None for _ in range(len(prediction))]
for i, image_pred in enumerate(prediction):
# If none are remaining => process next image
if not image_pred.size(0):
continue
# Get score and class with highest confidence
class_conf, class_pred = torch.max(
image_pred[:, 5 : 5 + num_classes], 1, keepdim=True
)
conf_mask = (image_pred[:, 4] * class_conf.squeeze() >= conf_thre).squeeze()
# Detections ordered as (x1, y1, x2, y2, obj_conf, class_conf, class_pred)
detections = torch.cat((image_pred[:, :5], class_conf, class_pred.float()), 1)
detections = detections[conf_mask]
if not detections.size(0):
continue
if class_agnostic:
nms_out_index = torchvision.ops.nms(
detections[:, :4],
detections[:, 4] * detections[:, 5],
nms_thre,
)
else:
nms_out_index = torchvision.ops.batched_nms(
detections[:, :4],
detections[:, 4] * detections[:, 5],
detections[:, 6],
nms_thre,
)
detections = detections[nms_out_index]
if output[i] is None:
output[i] = detections
else:
output[i] = torch.cat((output[i], detections))
return output
def bboxes_iou(bboxes_a, bboxes_b, xyxy=True):
if bboxes_a.shape[1] != 4 or bboxes_b.shape[1] != 4:
raise IndexError
if xyxy:
tl = torch.max(bboxes_a[:, None, :2], bboxes_b[:, :2])
br = torch.min(bboxes_a[:, None, 2:], bboxes_b[:, 2:])
area_a = torch.prod(bboxes_a[:, 2:] - bboxes_a[:, :2], 1)
area_b = torch.prod(bboxes_b[:, 2:] - bboxes_b[:, :2], 1)
else:
tl = torch.max(
(bboxes_a[:, None, :2] - bboxes_a[:, None, 2:] / 2),
(bboxes_b[:, :2] - bboxes_b[:, 2:] / 2),
)
br = torch.min(
(bboxes_a[:, None, :2] + bboxes_a[:, None, 2:] / 2),
(bboxes_b[:, :2] + bboxes_b[:, 2:] / 2),
)
area_a = torch.prod(bboxes_a[:, 2:], 1)
area_b = torch.prod(bboxes_b[:, 2:], 1)
en = (tl < br).type(tl.type()).prod(dim=2)
area_i = torch.prod(br - tl, 2) * en # * ((tl < br).all())
return area_i / (area_a[:, None] + area_b - area_i)
def matrix_iou(a, b):
"""
return iou of a and b, numpy version for data augenmentation
"""
lt = np.maximum(a[:, np.newaxis, :2], b[:, :2])
rb = np.minimum(a[:, np.newaxis, 2:], b[:, 2:])
area_i = np.prod(rb - lt, axis=2) * (lt < rb).all(axis=2)
area_a = np.prod(a[:, 2:] - a[:, :2], axis=1)
area_b = np.prod(b[:, 2:] - b[:, :2], axis=1)
return area_i / (area_a[:, np.newaxis] + area_b - area_i + 1e-12)
def adjust_box_anns(bbox, scale_ratio, padw, padh, w_max, h_max):
bbox[:, 0::2] = np.clip(bbox[:, 0::2] * scale_ratio + padw, 0, w_max)
bbox[:, 1::2] = np.clip(bbox[:, 1::2] * scale_ratio + padh, 0, h_max)
return bbox
def xyxy2xywh(bboxes):
bboxes[:, 2] = bboxes[:, 2] - bboxes[:, 0]
bboxes[:, 3] = bboxes[:, 3] - bboxes[:, 1]
return bboxes
def xyxy2cxcywh(bboxes):
bboxes[:, 2] = bboxes[:, 2] - bboxes[:, 0]
bboxes[:, 3] = bboxes[:, 3] - bboxes[:, 1]
bboxes[:, 0] = bboxes[:, 0] + bboxes[:, 2] * 0.5
bboxes[:, 1] = bboxes[:, 1] + bboxes[:, 3] * 0.5
return bboxes
================================================
FILE: RVT/models/detection/yolox/utils/compat.py
================================================
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
import torch
_TORCH_VER = [int(x) for x in torch.__version__.split(".")[:2]]
__all__ = ["meshgrid"]
def meshgrid(*tensors):
if _TORCH_VER >= [1, 10]:
return torch.meshgrid(*tensors, indexing="ij")
else:
return torch.meshgrid(*tensors)
================================================
FILE: RVT/models/detection/yolox_extension/models/__init__.py
================================================
================================================
FILE: RVT/models/detection/yolox_extension/models/build.py
================================================
from typing import Tuple
from omegaconf import OmegaConf, DictConfig
from .yolo_pafpn import YOLOPAFPN
from ...yolox.models.yolo_head import YOLOXHead
def build_yolox_head(
head_cfg: DictConfig, in_channels: Tuple[int, ...], strides: Tuple[int, ...]
):
head_cfg_dict = OmegaConf.to_container(
head_cfg, resolve=True, throw_on_missing=True
)
head_cfg_dict.pop("name")
head_cfg_dict.pop("version", None)
head_cfg_dict.update({"in_channels": in_channels})
head_cfg_dict.update({"strides": strides})
compile_cfg = head_cfg_dict.pop("compile", None)
head_cfg_dict.update({"compile_cfg": compile_cfg})
return YOLOXHead(**head_cfg_dict)
def build_yolox_fpn(fpn_cfg: DictConfig, in_channels: Tuple[int, ...]):
fpn_cfg_dict = OmegaConf.to_container(fpn_cfg, resolve=True, throw_on_missing=True)
fpn_name = fpn_cfg_dict.pop("name")
fpn_cfg_dict.update({"in_channels": in_channels})
if fpn_name in {"PAFPN", "pafpn"}:
compile_cfg = fpn_cfg_dict.pop("compile", None)
fpn_cfg_dict.update({"compile_cfg": compile_cfg})
return YOLOPAFPN(**fpn_cfg_dict)
raise NotImplementedError
================================================
FILE: RVT/models/detection/yolox_extension/models/detector.py
================================================
from typing import Dict, Optional, Tuple, Union
import torch as th
from omegaconf import DictConfig
try:
from torch import compile as th_compile
except ImportError:
th_compile = None
from ...recurrent_backbone import build_recurrent_backbone
from .build import build_yolox_fpn, build_yolox_head
from utils.timers import TimerDummy as CudaTimer
from data.utils.types import BackboneFeatures, LstmStates
class YoloXDetector(th.nn.Module):
def __init__(self, model_cfg: DictConfig):
super().__init__()
backbone_cfg = model_cfg.backbone
fpn_cfg = model_cfg.fpn
head_cfg = model_cfg.head
self.backbone = build_recurrent_backbone(backbone_cfg)
in_channels = self.backbone.get_stage_dims(fpn_cfg.in_stages)
self.fpn = build_yolox_fpn(fpn_cfg, in_channels=in_channels)
strides = self.backbone.get_strides(fpn_cfg.in_stages)
self.yolox_head = build_yolox_head(
head_cfg, in_channels=in_channels, strides=strides
)
def forward_backbone(
self,
x: th.Tensor,
previous_states: Optional[LstmStates] = None,
token_mask: Optional[th.Tensor] = None,
train_step: bool = True,
) -> Tuple[BackboneFeatures, LstmStates]:
with CudaTimer(device=x.device, timer_name="Backbone"):
backbone_features, states = self.backbone(
x, previous_states, token_mask, train_step
)
return backbone_features, states
def forward_detect(
self, backbone_features: BackboneFeatures, targets: Optional[th.Tensor] = None
) -> Tuple[th.Tensor, Union[Dict[str, th.Tensor], None]]:
device = next(iter(backbone_features.values())).device
with CudaTimer(device=device, timer_name="FPN"):
fpn_features = self.fpn(backbone_features)
if self.training:
assert targets is not None
with CudaTimer(device=device, timer_name="HEAD + Loss"):
outputs, losses = self.yolox_head(fpn_features, targets)
return outputs, losses
with CudaTimer(device=device, timer_name="HEAD"):
outputs, losses = self.yolox_head(fpn_features)
assert losses is None
return outputs, losses
def forward(
self,
x: th.Tensor,
previous_states: Optional[LstmStates] = None,
retrieve_detections: bool = True,
targets: Optional[th.Tensor] = None,
) -> Tuple[Union[th.Tensor, None], Union[Dict[str, th.Tensor], None], LstmStates]:
backbone_features, states = self.forward_backbone(x, previous_states)
outputs, losses = None, None
if not retrieve_detections:
assert targets is None
return outputs, losses, states
outputs, losses = self.forward_detect(
backbone_features=backbone_features, targets=targets
)
return outputs, losses, states
================================================
FILE: RVT/models/detection/yolox_extension/models/yolo_pafpn.py
================================================
"""
Original Yolox PAFPN code with slight modifications
"""
from typing import Dict, Optional, Tuple
import torch as th
import torch.nn as nn
try:
from torch import compile as th_compile
except ImportError:
th_compile = None
from ...yolox.models.network_blocks import BaseConv, CSPLayer, DWConv
from data.utils.types import BackboneFeatures
class YOLOPAFPN(nn.Module):
"""
Removed the direct dependency on the backbone.
"""
def __init__(
self,
depth: float = 1.0,
in_stages: Tuple[int, ...] = (2, 3, 4),
in_channels: Tuple[int, ...] = (256, 512, 1024),
depthwise: bool = False,
act: str = "silu",
compile_cfg: Optional[Dict] = None,
):
super().__init__()
assert len(in_stages) == len(in_channels)
assert len(in_channels) == 3, "Current implementation only for 3 feature maps"
self.in_features = in_stages
self.in_channels = in_channels
Conv = DWConv if depthwise else BaseConv
###### Compile if requested ######
if compile_cfg is not None:
compile_mdl = compile_cfg["enable"]
if compile_mdl and th_compile is not None:
self.forward = th_compile(self.forward, **compile_cfg["args"])
elif compile_mdl:
print("Could not compile PAFPN because torch.compile is not available")
##################################
self.upsample = lambda x: nn.functional.interpolate(
x, scale_factor=2, mode="nearest-exact"
)
self.lateral_conv0 = BaseConv(in_channels[2], in_channels[1], 1, 1, act=act)
self.C3_p4 = CSPLayer(
2 * in_channels[1],
in_channels[1],
round(3 * depth),
False,
depthwise=depthwise,
act=act,
) # cat
self.reduce_conv1 = BaseConv(in_channels[1], in_channels[0], 1, 1, act=act)
self.C3_p3 = CSPLayer(
2 * in_channels[0],
in_channels[0],
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
# bottom-up conv
self.bu_conv2 = Conv(in_channels[0], in_channels[0], 3, 2, act=act)
self.C3_n3 = CSPLayer(
2 * in_channels[0],
in_channels[1],
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
# bottom-up conv
self.bu_conv1 = Conv(in_channels[1], in_channels[1], 3, 2, act=act)
self.C3_n4 = CSPLayer(
2 * in_channels[1],
in_channels[2],
round(3 * depth),
False,
depthwise=depthwise,
act=act,
)
###### Compile if requested ######
if compile_cfg is not None:
compile_mdl = compile_cfg["enable"]
if compile_mdl and th_compile is not None:
self.forward = th_compile(self.forward, **compile_cfg["args"])
elif compile_mdl:
print("Could not compile PAFPN because torch.compile is not available")
##################################
def forward(self, input: BackboneFeatures):
"""
Args:
inputs: Feature maps from backbone
Returns:
Tuple[Tensor]: FPN feature.
"""
features = [input[f] for f in self.in_features]
x2, x1, x0 = features
fpn_out0 = self.lateral_conv0(x0) # 1024->512/32
f_out0 = self.upsample(fpn_out0) # 512/16
f_out0 = th.cat([f_out0, x1], 1) # 512->1024/16
f_out0 = self.C3_p4(f_out0) # 1024->512/16
fpn_out1 = self.reduce_conv1(f_out0) # 512->256/16
f_out1 = self.upsample(fpn_out1) # 256/8
f_out1 = th.cat([f_out1, x2], 1) # 256->512/8
pan_out2 = self.C3_p3(f_out1) # 512->256/8
p_out1 = self.bu_conv2(pan_out2) # 256->256/16
p_out1 = th.cat([p_out1, fpn_out1], 1) # 256->512/16
pan_out1 = self.C3_n3(p_out1) # 512->512/16
p_out0 = self.bu_conv1(pan_out1) # 512->512/32
p_out0 = th.cat([p_out0, fpn_out0], 1) # 512->1024/32
pan_out0 = self.C3_n4(p_out0) # 1024->1024/32
outputs = (pan_out2, pan_out1, pan_out0)
return outputs
================================================
FILE: RVT/models/layers/maxvit/__init__.py
================================================
================================================
FILE: RVT/models/layers/maxvit/layers/__init__.py
================================================
from .activations import *
from .adaptive_avgmax_pool import (
adaptive_avgmax_pool2d,
select_adaptive_pool2d,
AdaptiveAvgMaxPool2d,
SelectAdaptivePool2d,
)
from .blur_pool import BlurPool2d
from .classifier import ClassifierHead, create_classifier
from .cond_conv2d import CondConv2d, get_condconv_initializer
from .config import (
is_exportable,
is_scriptable,
is_no_jit,
set_exportable,
set_scriptable,
set_no_jit,
set_layer_config,
)
from .conv2d_same import Conv2dSame, conv2d_same
from .conv_bn_act import ConvNormAct, ConvNormActAa, ConvBnAct
from .create_act import create_act_layer, get_act_layer, get_act_fn
from .create_attn import get_attn, create_attn
from .create_conv2d import create_conv2d
from .create_norm import get_norm_layer, create_norm_layer
from .create_norm_act import (
get_norm_act_layer,
create_norm_act_layer,
get_norm_act_layer,
)
from .drop import DropBlock2d, DropPath, drop_block_2d, drop_path
from .eca import (
EcaModule,
CecaModule,
EfficientChannelAttn,
CircularEfficientChannelAttn,
)
from .evo_norm import (
EvoNorm2dB0,
EvoNorm2dB1,
EvoNorm2dB2,
EvoNorm2dS0,
EvoNorm2dS0a,
EvoNorm2dS1,
EvoNorm2dS1a,
EvoNorm2dS2,
EvoNorm2dS2a,
)
from .fast_norm import is_fast_norm, set_fast_norm, fast_group_norm, fast_layer_norm
from .filter_response_norm import FilterResponseNormTlu2d, FilterResponseNormAct2d
from .gather_excite import GatherExcite
from .global_context import GlobalContext
from .helpers import (
to_ntuple,
to_2tuple,
to_3tuple,
to_4tuple,
make_divisible,
extend_tuple,
)
from .inplace_abn import InplaceAbn
from .linear import Linear
from .mixed_conv2d import MixedConv2d
from .mlp import Mlp, GluMlp, GatedMlp, ConvMlp
from .non_local_attn import NonLocalAttn, BatNonLocalAttn
from .norm import GroupNorm, GroupNorm1, LayerNorm, LayerNorm2d
from .norm_act import BatchNormAct2d, GroupNormAct, convert_sync_batchnorm
from .padding import get_padding, get_same_padding, pad_same
from .patch_embed import PatchEmbed
from .pool2d_same import AvgPool2dSame, create_pool2d
from .squeeze_excite import (
SEModule,
SqueezeExcite,
EffectiveSEModule,
EffectiveSqueezeExcite,
)
from .selective_kernel import SelectiveKernel
from .separable_conv import SeparableConv2d, SeparableConvNormAct
from .space_to_depth import SpaceToDepthModule
from .split_attn import SplitAttn
from .split_batchnorm import SplitBatchNorm2d, convert_splitbn_model
from .std_conv import StdConv2d, StdConv2dSame, ScaledStdConv2d, ScaledStdConv2dSame
from .test_time_pool import TestTimePoolHead, apply_test_time_pool
from .trace_utils import _assert, _float_to_int
from .weight_init import (
trunc_normal_,
trunc_normal_tf_,
variance_scaling_,
lecun_normal_,
)
================================================
FILE: RVT/models/layers/maxvit/layers/activations.py
================================================
""" Activations
A collection of activations fn and modules with a common interface so that they can
easily be swapped. All have an `inplace` arg even if not used.
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch
from torch import nn as nn
from torch.nn import functional as F
def swish(x, inplace: bool = False):
"""Swish - Described in: https://arxiv.org/abs/1710.05941"""
return x.mul_(x.sigmoid()) if inplace else x.mul(x.sigmoid())
class Swish(nn.Module):
def __init__(self, inplace: bool = False):
super(Swish, self).__init__()
self.inplace = inplace
def forward(self, x):
return swish(x, self.inplace)
def mish(x, inplace: bool = False):
"""Mish: A Self Regularized Non-Monotonic Neural Activation Function - https://arxiv.org/abs/1908.08681
NOTE: I don't have a working inplace variant
"""
return x.mul(F.softplus(x).tanh())
class Mish(nn.Module):
"""Mish: A Self Regularized Non-Monotonic Neural Activation Function - https://arxiv.org/abs/1908.08681"""
def __init__(self, inplace: bool = False):
super(Mish, self).__init__()
def forward(self, x):
return mish(x)
def sigmoid(x, inplace: bool = False):
return x.sigmoid_() if inplace else x.sigmoid()
# PyTorch has this, but not with a consistent inplace argmument interface
class Sigmoid(nn.Module):
def __init__(self, inplace: bool = False):
super(Sigmoid, self).__init__()
self.inplace = inplace
def forward(self, x):
return x.sigmoid_() if self.inplace else x.sigmoid()
def tanh(x, inplace: bool = False):
return x.tanh_() if inplace else x.tanh()
# PyTorch has this, but not with a consistent inplace argmument interface
class Tanh(nn.Module):
def __init__(self, inplace: bool = False):
super(Tanh, self).__init__()
self.inplace = inplace
def forward(self, x):
return x.tanh_() if self.inplace else x.tanh()
def hard_swish(x, inplace: bool = False):
inner = F.relu6(x + 3.0).div_(6.0)
return x.mul_(inner) if inplace else x.mul(inner)
class HardSwish(nn.Module):
def __init__(self, inplace: bool = False):
super(HardSwish, self).__init__()
self.inplace = inplace
def forward(self, x):
return hard_swish(x, self.inplace)
def hard_sigmoid(x, inplace: bool = False):
if inplace:
return x.add_(3.0).clamp_(0.0, 6.0).div_(6.0)
else:
return F.relu6(x + 3.0) / 6.0
class HardSigmoid(nn.Module):
def __init__(self, inplace: bool = False):
super(HardSigmoid, self).__init__()
self.inplace = inplace
def forward(self, x):
return hard_sigmoid(x, self.inplace)
def hard_mish(x, inplace: bool = False):
"""Hard Mish
Experimental, based on notes by Mish author Diganta Misra at
https://github.com/digantamisra98/H-Mish/blob/0da20d4bc58e696b6803f2523c58d3c8a82782d0/README.md
"""
if inplace:
return x.mul_(0.5 * (x + 2).clamp(min=0, max=2))
else:
return 0.5 * x * (x + 2).clamp(min=0, max=2)
class HardMish(nn.Module):
def __init__(self, inplace: bool = False):
super(HardMish, self).__init__()
self.inplace = inplace
def forward(self, x):
return hard_mish(x, self.inplace)
class PReLU(nn.PReLU):
"""Applies PReLU (w/ dummy inplace arg)"""
def __init__(
self, num_parameters: int = 1, init: float = 0.25, inplace: bool = False
) -> None:
super(PReLU, self).__init__(num_parameters=num_parameters, init=init)
def forward(self, input: torch.Tensor) -> torch.Tensor:
return F.prelu(input, self.weight)
def gelu(x: torch.Tensor, inplace: bool = False) -> torch.Tensor:
return F.gelu(x)
class GELU(nn.Module):
"""Applies the Gaussian Error Linear Units function (w/ dummy inplace arg)"""
def __init__(self, inplace: bool = False):
super(GELU, self).__init__()
def forward(self, input: torch.Tensor) -> torch.Tensor:
return F.gelu(input)
================================================
FILE: RVT/models/layers/maxvit/layers/activations_jit.py
================================================
""" Activations
A collection of jit-scripted activations fn and modules with a common interface so that they can
easily be swapped. All have an `inplace` arg even if not used.
All jit scripted activations are lacking in-place variations on purpose, scripted kernel fusion does not
currently work across in-place op boundaries, thus performance is equal to or less than the non-scripted
versions if they contain in-place ops.
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch
from torch import nn as nn
from torch.nn import functional as F
@torch.jit.script
def swish_jit(x, inplace: bool = False):
"""Swish - Described in: https://arxiv.org/abs/1710.05941"""
return x.mul(x.sigmoid())
@torch.jit.script
def mish_jit(x, _inplace: bool = False):
"""Mish: A Self Regularized Non-Monotonic Neural Activation Function - https://arxiv.org/abs/1908.08681"""
return x.mul(F.softplus(x).tanh())
class SwishJit(nn.Module):
def __init__(self, inplace: bool = False):
super(SwishJit, self).__init__()
def forward(self, x):
return swish_jit(x)
class MishJit(nn.Module):
def __init__(self, inplace: bool = False):
super(MishJit, self).__init__()
def forward(self, x):
return mish_jit(x)
@torch.jit.script
def hard_sigmoid_jit(x, inplace: bool = False):
# return F.relu6(x + 3.) / 6.
return (x + 3).clamp(min=0, max=6).div(6.0) # clamp seems ever so slightly faster?
class HardSigmoidJit(nn.Module):
def __init__(self, inplace: bool = False):
super(HardSigmoidJit, self).__init__()
def forward(self, x):
return hard_sigmoid_jit(x)
@torch.jit.script
def hard_swish_jit(x, inplace: bool = False):
# return x * (F.relu6(x + 3.) / 6)
return x * (x + 3).clamp(min=0, max=6).div(
6.0
) # clamp seems ever so slightly faster?
class HardSwishJit(nn.Module):
def __init__(self, inplace: bool = False):
super(HardSwishJit, self).__init__()
def forward(self, x):
return hard_swish_jit(x)
@torch.jit.script
def hard_mish_jit(x, inplace: bool = False):
"""Hard Mish
Experimental, based on notes by Mish author Diganta Misra at
https://github.com/digantamisra98/H-Mish/blob/0da20d4bc58e696b6803f2523c58d3c8a82782d0/README.md
"""
return 0.5 * x * (x + 2).clamp(min=0, max=2)
class HardMishJit(nn.Module):
def __init__(self, inplace: bool = False):
super(HardMishJit, self).__init__()
def forward(self, x):
return hard_mish_jit(x)
================================================
FILE: RVT/models/layers/maxvit/layers/activations_me.py
================================================
""" Activations (memory-efficient w/ custom autograd)
A collection of activations fn and modules with a common interface so that they can
easily be swapped. All have an `inplace` arg even if not used.
These activations are not compatible with jit scripting or ONNX export of the model, please use either
the JIT or basic versions of the activations.
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch
from torch import nn as nn
from torch.nn import functional as F
@torch.jit.script
def swish_jit_fwd(x):
return x.mul(torch.sigmoid(x))
@torch.jit.script
def swish_jit_bwd(x, grad_output):
x_sigmoid = torch.sigmoid(x)
return grad_output * (x_sigmoid * (1 + x * (1 - x_sigmoid)))
class SwishJitAutoFn(torch.autograd.Function):
"""torch.jit.script optimised Swish w/ memory-efficient checkpoint
Inspired by conversation btw Jeremy Howard & Adam Pazske
https://twitter.com/jeremyphoward/status/1188251041835315200
"""
@staticmethod
def symbolic(g, x):
return g.op("Mul", x, g.op("Sigmoid", x))
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
return swish_jit_fwd(x)
@staticmethod
def backward(ctx, grad_output):
x = ctx.saved_tensors[0]
return swish_jit_bwd(x, grad_output)
def swish_me(x, inplace=False):
return SwishJitAutoFn.apply(x)
class SwishMe(nn.Module):
def __init__(self, inplace: bool = False):
super(SwishMe, self).__init__()
def forward(self, x):
return SwishJitAutoFn.apply(x)
@torch.jit.script
def mish_jit_fwd(x):
return x.mul(torch.tanh(F.softplus(x)))
@torch.jit.script
def mish_jit_bwd(x, grad_output):
x_sigmoid = torch.sigmoid(x)
x_tanh_sp = F.softplus(x).tanh()
return grad_output.mul(x_tanh_sp + x * x_sigmoid * (1 - x_tanh_sp * x_tanh_sp))
class MishJitAutoFn(torch.autograd.Function):
"""Mish: A Self Regularized Non-Monotonic Neural Activation Function - https://arxiv.org/abs/1908.08681
A memory efficient, jit scripted variant of Mish
"""
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
return mish_jit_fwd(x)
@staticmethod
def backward(ctx, grad_output):
x = ctx.saved_tensors[0]
return mish_jit_bwd(x, grad_output)
def mish_me(x, inplace=False):
return MishJitAutoFn.apply(x)
class MishMe(nn.Module):
def __init__(self, inplace: bool = False):
super(MishMe, self).__init__()
def forward(self, x):
return MishJitAutoFn.apply(x)
@torch.jit.script
def hard_sigmoid_jit_fwd(x, inplace: bool = False):
return (x + 3).clamp(min=0, max=6).div(6.0)
@torch.jit.script
def hard_sigmoid_jit_bwd(x, grad_output):
m = torch.ones_like(x) * ((x >= -3.0) & (x <= 3.0)) / 6.0
return grad_output * m
class HardSigmoidJitAutoFn(torch.autograd.Function):
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
return hard_sigmoid_jit_fwd(x)
@staticmethod
def backward(ctx, grad_output):
x = ctx.saved_tensors[0]
return hard_sigmoid_jit_bwd(x, grad_output)
def hard_sigmoid_me(x, inplace: bool = False):
return HardSigmoidJitAutoFn.apply(x)
class HardSigmoidMe(nn.Module):
def __init__(self, inplace: bool = False):
super(HardSigmoidMe, self).__init__()
def forward(self, x):
return HardSigmoidJitAutoFn.apply(x)
@torch.jit.script
def hard_swish_jit_fwd(x):
return x * (x + 3).clamp(min=0, max=6).div(6.0)
@torch.jit.script
def hard_swish_jit_bwd(x, grad_output):
m = torch.ones_like(x) * (x >= 3.0)
m = torch.where((x >= -3.0) & (x <= 3.0), x / 3.0 + 0.5, m)
return grad_output * m
class HardSwishJitAutoFn(torch.autograd.Function):
"""A memory efficient, jit-scripted HardSwish activation"""
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
return hard_swish_jit_fwd(x)
@staticmethod
def backward(ctx, grad_output):
x = ctx.saved_tensors[0]
return hard_swish_jit_bwd(x, grad_output)
@staticmethod
def symbolic(g, self):
input = g.op(
"Add", self, g.op("Constant", value_t=torch.tensor(3, dtype=torch.float))
)
hardtanh_ = g.op(
"Clip",
input,
g.op("Constant", value_t=torch.tensor(0, dtype=torch.float)),
g.op("Constant", value_t=torch.tensor(6, dtype=torch.float)),
)
hardtanh_ = g.op(
"Div",
hardtanh_,
g.op("Constant", value_t=torch.tensor(6, dtype=torch.float)),
)
return g.op("Mul", self, hardtanh_)
def hard_swish_me(x, inplace=False):
return HardSwishJitAutoFn.apply(x)
class HardSwishMe(nn.Module):
def __init__(self, inplace: bool = False):
super(HardSwishMe, self).__init__()
def forward(self, x):
return HardSwishJitAutoFn.apply(x)
@torch.jit.script
def hard_mish_jit_fwd(x):
return 0.5 * x * (x + 2).clamp(min=0, max=2)
@torch.jit.script
def hard_mish_jit_bwd(x, grad_output):
m = torch.ones_like(x) * (x >= -2.0)
m = torch.where((x >= -2.0) & (x <= 0.0), x + 1.0, m)
return grad_output * m
class HardMishJitAutoFn(torch.autograd.Function):
"""A memory efficient, jit scripted variant of Hard Mish
Experimental, based on notes by Mish author Diganta Misra at
https://github.com/digantamisra98/H-Mish/blob/0da20d4bc58e696b6803f2523c58d3c8a82782d0/README.md
"""
@staticmethod
def forward(ctx, x):
ctx.save_for_backward(x)
return hard_mish_jit_fwd(x)
@staticmethod
def backward(ctx, grad_output):
x = ctx.saved_tensors[0]
return hard_mish_jit_bwd(x, grad_output)
def hard_mish_me(x, inplace: bool = False):
return HardMishJitAutoFn.apply(x)
class HardMishMe(nn.Module):
def __init__(self, inplace: bool = False):
super(HardMishMe, self).__init__()
def forward(self, x):
return HardMishJitAutoFn.apply(x)
================================================
FILE: RVT/models/layers/maxvit/layers/adaptive_avgmax_pool.py
================================================
""" PyTorch selectable adaptive pooling
Adaptive pooling with the ability to select the type of pooling from:
* 'avg' - Average pooling
* 'max' - Max pooling
* 'avgmax' - Sum of average and max pooling re-scaled by 0.5
* 'avgmaxc' - Concatenation of average and max pooling along feature dim, doubles feature dim
Both a functional and a nn.Module version of the pooling is provided.
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
def adaptive_pool_feat_mult(pool_type="avg"):
if pool_type == "catavgmax":
return 2
else:
return 1
def adaptive_avgmax_pool2d(x, output_size=1):
x_avg = F.adaptive_avg_pool2d(x, output_size)
x_max = F.adaptive_max_pool2d(x, output_size)
return 0.5 * (x_avg + x_max)
def adaptive_catavgmax_pool2d(x, output_size=1):
x_avg = F.adaptive_avg_pool2d(x, output_size)
x_max = F.adaptive_max_pool2d(x, output_size)
return torch.cat((x_avg, x_max), 1)
def select_adaptive_pool2d(x, pool_type="avg", output_size=1):
"""Selectable global pooling function with dynamic input kernel size"""
if pool_type == "avg":
x = F.adaptive_avg_pool2d(x, output_size)
elif pool_type == "avgmax":
x = adaptive_avgmax_pool2d(x, output_size)
elif pool_type == "catavgmax":
x = adaptive_catavgmax_pool2d(x, output_size)
elif pool_type == "max":
x = F.adaptive_max_pool2d(x, output_size)
else:
assert False, "Invalid pool type: %s" % pool_type
return x
class FastAdaptiveAvgPool2d(nn.Module):
def __init__(self, flatten=False):
super(FastAdaptiveAvgPool2d, self).__init__()
self.flatten = flatten
def forward(self, x):
return x.mean((2, 3), keepdim=not self.flatten)
class AdaptiveAvgMaxPool2d(nn.Module):
def __init__(self, output_size=1):
super(AdaptiveAvgMaxPool2d, self).__init__()
self.output_size = output_size
def forward(self, x):
return adaptive_avgmax_pool2d(x, self.output_size)
class AdaptiveCatAvgMaxPool2d(nn.Module):
def __init__(self, output_size=1):
super(AdaptiveCatAvgMaxPool2d, self).__init__()
self.output_size = output_size
def forward(self, x):
return adaptive_catavgmax_pool2d(x, self.output_size)
class SelectAdaptivePool2d(nn.Module):
"""Selectable global pooling layer with dynamic input kernel size"""
def __init__(self, output_size=1, pool_type="fast", flatten=False):
super(SelectAdaptivePool2d, self).__init__()
self.pool_type = (
pool_type or ""
) # convert other falsy values to empty string for consistent TS typing
self.flatten = nn.Flatten(1) if flatten else nn.Identity()
if pool_type == "":
self.pool = nn.Identity() # pass through
elif pool_type == "fast":
assert output_size == 1
self.pool = FastAdaptiveAvgPool2d(flatten)
self.flatten = nn.Identity()
elif pool_type == "avg":
self.pool = nn.AdaptiveAvgPool2d(output_size)
elif pool_type == "avgmax":
self.pool = AdaptiveAvgMaxPool2d(output_size)
elif pool_type == "catavgmax":
self.pool = AdaptiveCatAvgMaxPool2d(output_size)
elif pool_type == "max":
self.pool = nn.AdaptiveMaxPool2d(output_size)
else:
assert False, "Invalid pool type: %s" % pool_type
def is_identity(self):
return not self.pool_type
def forward(self, x):
x = self.pool(x)
x = self.flatten(x)
return x
def feat_mult(self):
return adaptive_pool_feat_mult(self.pool_type)
def __repr__(self):
return (
self.__class__.__name__
+ " ("
+ "pool_type="
+ self.pool_type
+ ", flatten="
+ str(self.flatten)
+ ")"
)
================================================
FILE: RVT/models/layers/maxvit/layers/attention_pool2d.py
================================================
""" Attention Pool 2D
Implementations of 2D spatial feature pooling using multi-head attention instead of average pool.
Based on idea in CLIP by OpenAI, licensed Apache 2.0
https://github.com/openai/CLIP/blob/3b473b0e682c091a9e53623eebc1ca1657385717/clip/model.py
Hacked together by / Copyright 2021 Ross Wightman
"""
from typing import Union, Tuple
import torch
import torch.nn as nn
from .helpers import to_2tuple
from .pos_embed import apply_rot_embed, RotaryEmbedding
from .weight_init import trunc_normal_
class RotAttentionPool2d(nn.Module):
"""Attention based 2D feature pooling w/ rotary (relative) pos embedding.
This is a multi-head attention based replacement for (spatial) average pooling in NN architectures.
Adapted from the AttentionPool2d in CLIP w/ rotary embedding instead of learned embed.
https://github.com/openai/CLIP/blob/3b473b0e682c091a9e53623eebc1ca1657385717/clip/model.py
NOTE: While this impl does not require a fixed feature size, performance at differeing resolutions from
train varies widely and falls off dramatically. I'm not sure if there is a way around this... -RW
"""
def __init__(
self,
in_features: int,
out_features: int = None,
embed_dim: int = None,
num_heads: int = 4,
qkv_bias: bool = True,
):
super().__init__()
embed_dim = embed_dim or in_features
out_features = out_features or in_features
self.qkv = nn.Linear(in_features, embed_dim * 3, bias=qkv_bias)
self.proj = nn.Linear(embed_dim, out_features)
self.num_heads = num_heads
assert embed_dim % num_heads == 0
self.head_dim = embed_dim // num_heads
self.scale = self.head_dim**-0.5
self.pos_embed = RotaryEmbedding(self.head_dim)
trunc_normal_(self.qkv.weight, std=in_features**-0.5)
nn.init.zeros_(self.qkv.bias)
def forward(self, x):
B, _, H, W = x.shape
N = H * W
x = x.reshape(B, -1, N).permute(0, 2, 1)
x = torch.cat([x.mean(1, keepdim=True), x], dim=1)
x = (
self.qkv(x)
.reshape(B, N + 1, 3, self.num_heads, self.head_dim)
.permute(2, 0, 3, 1, 4)
)
q, k, v = x[0], x[1], x[2]
qc, q = q[:, :, :1], q[:, :, 1:]
sin_emb, cos_emb = self.pos_embed.get_embed((H, W))
q = apply_rot_embed(q, sin_emb, cos_emb)
q = torch.cat([qc, q], dim=2)
kc, k = k[:, :, :1], k[:, :, 1:]
k = apply_rot_embed(k, sin_emb, cos_emb)
k = torch.cat([kc, k], dim=2)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N + 1, -1)
x = self.proj(x)
return x[:, 0]
class AttentionPool2d(nn.Module):
"""Attention based 2D feature pooling w/ learned (absolute) pos embedding.
This is a multi-head attention based replacement for (spatial) average pooling in NN architectures.
It was based on impl in CLIP by OpenAI
https://github.com/openai/CLIP/blob/3b473b0e682c091a9e53623eebc1ca1657385717/clip/model.py
NOTE: This requires feature size upon construction and well prevent adaptive sizing of the network.
"""
def __init__(
self,
in_features: int,
feat_size: Union[int, Tuple[int, int]],
out_features: int = None,
embed_dim: int = None,
num_heads: int = 4,
qkv_bias: bool = True,
):
super().__init__()
embed_dim = embed_dim or in_features
out_features = out_features or in_features
assert embed_dim % num_heads == 0
self.feat_size = to_2tuple(feat_size)
self.qkv = nn.Linear(in_features, embed_dim * 3, bias=qkv_bias)
self.proj = nn.Linear(embed_dim, out_features)
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.scale = self.head_dim**-0.5
spatial_dim = self.feat_size[0] * self.feat_size[1]
self.pos_embed = nn.Parameter(torch.zeros(spatial_dim + 1, in_features))
trunc_normal_(self.pos_embed, std=in_features**-0.5)
trunc_normal_(self.qkv.weight, std=in_features**-0.5)
nn.init.zeros_(self.qkv.bias)
def forward(self, x):
B, _, H, W = x.shape
N = H * W
assert self.feat_size[0] == H
assert self.feat_size[1] == W
x = x.reshape(B, -1, N).permute(0, 2, 1)
x = torch.cat([x.mean(1, keepdim=True), x], dim=1)
x = x + self.pos_embed.unsqueeze(0).to(x.dtype)
x = (
self.qkv(x)
.reshape(B, N + 1, 3, self.num_heads, self.head_dim)
.permute(2, 0, 3, 1, 4)
)
q, k, v = x[0], x[1], x[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N + 1, -1)
x = self.proj(x)
return x[:, 0]
================================================
FILE: RVT/models/layers/maxvit/layers/blur_pool.py
================================================
"""
BlurPool layer inspired by
- Kornia's Max_BlurPool2d
- Making Convolutional Networks Shift-Invariant Again :cite:`zhang2019shiftinvar`
Hacked together by Chris Ha and Ross Wightman
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from .padding import get_padding
class BlurPool2d(nn.Module):
r"""Creates a module that computes blurs and downsample a given feature map.
See :cite:`zhang2019shiftinvar` for more details.
Corresponds to the Downsample class, which does blurring and subsampling
Args:
channels = Number of input channels
filt_size (int): binomial filter size for blurring. currently supports 3 (default) and 5.
stride (int): downsampling filter stride
Returns:
torch.Tensor: the transformed tensor.
"""
def __init__(self, channels, filt_size=3, stride=2) -> None:
super(BlurPool2d, self).__init__()
assert filt_size > 1
self.channels = channels
self.filt_size = filt_size
self.stride = stride
self.padding = [get_padding(filt_size, stride, dilation=1)] * 4
coeffs = torch.tensor(
(np.poly1d((0.5, 0.5)) ** (self.filt_size - 1)).coeffs.astype(np.float32)
)
blur_filter = (coeffs[:, None] * coeffs[None, :])[None, None, :, :].repeat(
self.channels, 1, 1, 1
)
self.register_buffer("filt", blur_filter, persistent=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = F.pad(x, self.padding, "reflect")
return F.conv2d(x, self.filt, stride=self.stride, groups=self.channels)
================================================
FILE: RVT/models/layers/maxvit/layers/bottleneck_attn.py
================================================
""" Bottleneck Self Attention (Bottleneck Transformers)
Paper: `Bottleneck Transformers for Visual Recognition` - https://arxiv.org/abs/2101.11605
@misc{2101.11605,
Author = {Aravind Srinivas and Tsung-Yi Lin and Niki Parmar and Jonathon Shlens and Pieter Abbeel and Ashish Vaswani},
Title = {Bottleneck Transformers for Visual Recognition},
Year = {2021},
}
Based on ref gist at: https://gist.github.com/aravindsrinivas/56359b79f0ce4449bcb04ab4b56a57a2
This impl is a WIP but given that it is based on the ref gist likely not too far off.
Hacked together by / Copyright 2021 Ross Wightman
"""
from typing import List
import torch
import torch.nn as nn
import torch.nn.functional as F
from .helpers import to_2tuple, make_divisible
from .weight_init import trunc_normal_
from .trace_utils import _assert
def rel_logits_1d(q, rel_k, permute_mask: List[int]):
"""Compute relative logits along one dimension
As per: https://gist.github.com/aravindsrinivas/56359b79f0ce4449bcb04ab4b56a57a2
Originally from: `Attention Augmented Convolutional Networks` - https://arxiv.org/abs/1904.09925
Args:
q: (batch, heads, height, width, dim)
rel_k: (2 * width - 1, dim)
permute_mask: permute output dim according to this
"""
B, H, W, dim = q.shape
x = q @ rel_k.transpose(-1, -2)
x = x.reshape(-1, W, 2 * W - 1)
# pad to shift from relative to absolute indexing
x_pad = F.pad(x, [0, 1]).flatten(1)
x_pad = F.pad(x_pad, [0, W - 1])
# reshape and slice out the padded elements
x_pad = x_pad.reshape(-1, W + 1, 2 * W - 1)
x = x_pad[:, :W, W - 1 :]
# reshape and tile
x = x.reshape(B, H, 1, W, W).expand(-1, -1, H, -1, -1)
return x.permute(permute_mask)
class PosEmbedRel(nn.Module):
"""Relative Position Embedding
As per: https://gist.github.com/aravindsrinivas/56359b79f0ce4449bcb04ab4b56a57a2
Originally from: `Attention Augmented Convolutional Networks` - https://arxiv.org/abs/1904.09925
"""
def __init__(self, feat_size, dim_head, scale):
super().__init__()
self.height, self.width = to_2tuple(feat_size)
self.dim_head = dim_head
self.height_rel = nn.Parameter(
torch.randn(self.height * 2 - 1, dim_head) * scale
)
self.width_rel = nn.Parameter(torch.randn(self.width * 2 - 1, dim_head) * scale)
def forward(self, q):
B, HW, _ = q.shape
# relative logits in width dimension.
q = q.reshape(B, self.height, self.width, -1)
rel_logits_w = rel_logits_1d(q, self.width_rel, permute_mask=(0, 1, 3, 2, 4))
# relative logits in height dimension.
q = q.transpose(1, 2)
rel_logits_h = rel_logits_1d(q, self.height_rel, permute_mask=(0, 3, 1, 4, 2))
rel_logits = rel_logits_h + rel_logits_w
rel_logits = rel_logits.reshape(B, HW, HW)
return rel_logits
class BottleneckAttn(nn.Module):
"""Bottleneck Attention
Paper: `Bottleneck Transformers for Visual Recognition` - https://arxiv.org/abs/2101.11605
The internal dimensions of the attention module are controlled by the interaction of several arguments.
* the output dimension of the module is specified by dim_out, which falls back to input dim if not set
* the value (v) dimension is set to dim_out // num_heads, the v projection determines the output dim
* the query and key (qk) dimensions are determined by
* num_heads * dim_head if dim_head is not None
* num_heads * (dim_out * attn_ratio // num_heads) if dim_head is None
* as seen above, attn_ratio determines the ratio of q and k relative to the output if dim_head not used
Args:
dim (int): input dimension to the module
dim_out (int): output dimension of the module, same as dim if not set
stride (int): output stride of the module, avg pool used if stride == 2 (default: 1).
num_heads (int): parallel attention heads (default: 4)
dim_head (int): dimension of query and key heads, calculated from dim_out * attn_ratio // num_heads if not set
qk_ratio (float): ratio of q and k dimensions to output dimension when dim_head not set. (default: 1.0)
qkv_bias (bool): add bias to q, k, and v projections
scale_pos_embed (bool): scale the position embedding as well as Q @ K
"""
def __init__(
self,
dim,
dim_out=None,
feat_size=None,
stride=1,
num_heads=4,
dim_head=None,
qk_ratio=1.0,
qkv_bias=False,
scale_pos_embed=False,
):
super().__init__()
assert (
feat_size is not None
), "A concrete feature size matching expected input (H, W) is required"
dim_out = dim_out or dim
assert dim_out % num_heads == 0
self.num_heads = num_heads
self.dim_head_qk = (
dim_head or make_divisible(dim_out * qk_ratio, divisor=8) // num_heads
)
self.dim_head_v = dim_out // self.num_heads
self.dim_out_qk = num_heads * self.dim_head_qk
self.dim_out_v = num_heads * self.dim_head_v
self.scale = self.dim_head_qk**-0.5
self.scale_pos_embed = scale_pos_embed
self.qkv = nn.Conv2d(
dim, self.dim_out_qk * 2 + self.dim_out_v, 1, bias=qkv_bias
)
# NOTE I'm only supporting relative pos embedding for now
self.pos_embed = PosEmbedRel(
feat_size, dim_head=self.dim_head_qk, scale=self.scale
)
self.pool = nn.AvgPool2d(2, 2) if stride == 2 else nn.Identity()
self.reset_parameters()
def reset_parameters(self):
trunc_normal_(self.qkv.weight, std=self.qkv.weight.shape[1] ** -0.5) # fan-in
trunc_normal_(self.pos_embed.height_rel, std=self.scale)
trunc_normal_(self.pos_embed.width_rel, std=self.scale)
def forward(self, x):
B, C, H, W = x.shape
_assert(H == self.pos_embed.height, "")
_assert(W == self.pos_embed.width, "")
x = self.qkv(x) # B, (2 * dim_head_qk + dim_head_v) * num_heads, H, W
# NOTE head vs channel split ordering in qkv projection was decided before I allowed qk to differ from v
# So, this is more verbose than if heads were before qkv splits, but throughput is not impacted.
q, k, v = torch.split(
x, [self.dim_out_qk, self.dim_out_qk, self.dim_out_v], dim=1
)
q = q.reshape(B * self.num_heads, self.dim_head_qk, -1).transpose(-1, -2)
k = k.reshape(
B * self.num_heads, self.dim_head_qk, -1
) # no transpose, for q @ k
v = v.reshape(B * self.num_heads, self.dim_head_v, -1).transpose(-1, -2)
if self.scale_pos_embed:
attn = (
q @ k + self.pos_embed(q)
) * self.scale # B * num_heads, H * W, H * W
else:
attn = (q @ k) * self.scale + self.pos_embed(q)
attn = attn.softmax(dim=-1)
out = (
(attn @ v).transpose(-1, -2).reshape(B, self.dim_out_v, H, W)
) # B, dim_out, H, W
out = self.pool(out)
return out
================================================
FILE: RVT/models/layers/maxvit/layers/cbam.py
================================================
""" CBAM (sort-of) Attention
Experimental impl of CBAM: Convolutional Block Attention Module: https://arxiv.org/abs/1807.06521
WARNING: Results with these attention layers have been mixed. They can significantly reduce performance on
some tasks, especially fine-grained it seems. I may end up removing this impl.
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch
from torch import nn as nn
import torch.nn.functional as F
from .conv_bn_act import ConvNormAct
from .create_act import create_act_layer, get_act_layer
from .helpers import make_divisible
class ChannelAttn(nn.Module):
"""Original CBAM channel attention module, currently avg + max pool variant only."""
def __init__(
self,
channels,
rd_ratio=1.0 / 16,
rd_channels=None,
rd_divisor=1,
act_layer=nn.ReLU,
gate_layer="sigmoid",
mlp_bias=False,
):
super(ChannelAttn, self).__init__()
if not rd_channels:
rd_channels = make_divisible(
channels * rd_ratio, rd_divisor, round_limit=0.0
)
self.fc1 = nn.Conv2d(channels, rd_channels, 1, bias=mlp_bias)
self.act = act_layer(inplace=True)
self.fc2 = nn.Conv2d(rd_channels, channels, 1, bias=mlp_bias)
self.gate = create_act_layer(gate_layer)
def forward(self, x):
x_avg = self.fc2(self.act(self.fc1(x.mean((2, 3), keepdim=True))))
x_max = self.fc2(self.act(self.fc1(x.amax((2, 3), keepdim=True))))
return x * self.gate(x_avg + x_max)
class LightChannelAttn(ChannelAttn):
"""An experimental 'lightweight' that sums avg + max pool first"""
def __init__(
self,
channels,
rd_ratio=1.0 / 16,
rd_channels=None,
rd_divisor=1,
act_layer=nn.ReLU,
gate_layer="sigmoid",
mlp_bias=False,
):
super(LightChannelAttn, self).__init__(
channels, rd_ratio, rd_channels, rd_divisor, act_layer, gate_layer, mlp_bias
)
def forward(self, x):
x_pool = 0.5 * x.mean((2, 3), keepdim=True) + 0.5 * x.amax((2, 3), keepdim=True)
x_attn = self.fc2(self.act(self.fc1(x_pool)))
return x * F.sigmoid(x_attn)
class SpatialAttn(nn.Module):
"""Original CBAM spatial attention module"""
def __init__(self, kernel_size=7, gate_layer="sigmoid"):
super(SpatialAttn, self).__init__()
self.conv = ConvNormAct(2, 1, kernel_size, apply_act=False)
self.gate = create_act_layer(gate_layer)
def forward(self, x):
x_attn = torch.cat(
[x.mean(dim=1, keepdim=True), x.amax(dim=1, keepdim=True)], dim=1
)
x_attn = self.conv(x_attn)
return x * self.gate(x_attn)
class LightSpatialAttn(nn.Module):
"""An experimental 'lightweight' variant that sums avg_pool and max_pool results."""
def __init__(self, kernel_size=7, gate_layer="sigmoid"):
super(LightSpatialAttn, self).__init__()
self.conv = ConvNormAct(1, 1, kernel_size, apply_act=False)
self.gate = create_act_layer(gate_layer)
def forward(self, x):
x_attn = 0.5 * x.mean(dim=1, keepdim=True) + 0.5 * x.amax(dim=1, keepdim=True)
x_attn = self.conv(x_attn)
return x * self.gate(x_attn)
class CbamModule(nn.Module):
def __init__(
self,
channels,
rd_ratio=1.0 / 16,
rd_channels=None,
rd_divisor=1,
spatial_kernel_size=7,
act_layer=nn.ReLU,
gate_layer="sigmoid",
mlp_bias=False,
):
super(CbamModule, self).__init__()
self.channel = ChannelAttn(
channels,
rd_ratio=rd_ratio,
rd_channels=rd_channels,
rd_divisor=rd_divisor,
act_layer=act_layer,
gate_layer=gate_layer,
mlp_bias=mlp_bias,
)
self.spatial = SpatialAttn(spatial_kernel_size, gate_layer=gate_layer)
def forward(self, x):
x = self.channel(x)
x = self.spatial(x)
return x
class LightCbamModule(nn.Module):
def __init__(
self,
channels,
rd_ratio=1.0 / 16,
rd_channels=None,
rd_divisor=1,
spatial_kernel_size=7,
act_layer=nn.ReLU,
gate_layer="sigmoid",
mlp_bias=False,
):
super(LightCbamModule, self).__init__()
self.channel = LightChannelAttn(
channels,
rd_ratio=rd_ratio,
rd_channels=rd_channels,
rd_divisor=rd_divisor,
act_layer=act_layer,
gate_layer=gate_layer,
mlp_bias=mlp_bias,
)
self.spatial = LightSpatialAttn(spatial_kernel_size)
def forward(self, x):
x = self.channel(x)
x = self.spatial(x)
return x
================================================
FILE: RVT/models/layers/maxvit/layers/classifier.py
================================================
""" Classifier head and layer factory
Hacked together by / Copyright 2020 Ross Wightman
"""
from torch import nn as nn
from torch.nn import functional as F
from .adaptive_avgmax_pool import SelectAdaptivePool2d
def _create_pool(num_features, num_classes, pool_type="avg", use_conv=False):
flatten_in_pool = not use_conv # flatten when we use a Linear layer after pooling
if not pool_type:
assert (
num_classes == 0 or use_conv
), "Pooling can only be disabled if classifier is also removed or conv classifier is used"
flatten_in_pool = (
False # disable flattening if pooling is pass-through (no pooling)
)
global_pool = SelectAdaptivePool2d(pool_type=pool_type, flatten=flatten_in_pool)
num_pooled_features = num_features * global_pool.feat_mult()
return global_pool, num_pooled_features
def _create_fc(num_features, num_classes, use_conv=False):
if num_classes <= 0:
fc = nn.Identity() # pass-through (no classifier)
elif use_conv:
fc = nn.Conv2d(num_features, num_classes, 1, bias=True)
else:
fc = nn.Linear(num_features, num_classes, bias=True)
return fc
def create_classifier(num_features, num_classes, pool_type="avg", use_conv=False):
global_pool, num_pooled_features = _create_pool(
num_features, num_classes, pool_type, use_conv=use_conv
)
fc = _create_fc(num_pooled_features, num_classes, use_conv=use_conv)
return global_pool, fc
class ClassifierHead(nn.Module):
"""Classifier head w/ configurable global pooling and dropout."""
def __init__(
self, in_chs, num_classes, pool_type="avg", drop_rate=0.0, use_conv=False
):
super(ClassifierHead, self).__init__()
self.drop_rate = drop_rate
self.global_pool, num_pooled_features = _create_pool(
in_chs, num_classes, pool_type, use_conv=use_conv
)
self.fc = _create_fc(num_pooled_features, num_classes, use_conv=use_conv)
self.flatten = nn.Flatten(1) if use_conv and pool_type else nn.Identity()
def forward(self, x, pre_logits: bool = False):
x = self.global_pool(x)
if self.drop_rate:
x = F.dropout(x, p=float(self.drop_rate), training=self.training)
if pre_logits:
return x.flatten(1)
else:
x = self.fc(x)
return self.flatten(x)
================================================
FILE: RVT/models/layers/maxvit/layers/cond_conv2d.py
================================================
""" PyTorch Conditionally Parameterized Convolution (CondConv)
Paper: CondConv: Conditionally Parameterized Convolutions for Efficient Inference
(https://arxiv.org/abs/1904.04971)
Hacked together by / Copyright 2020 Ross Wightman
"""
import math
from functools import partial
import numpy as np
import torch
from torch import nn as nn
from torch.nn import functional as F
from .helpers import to_2tuple
from .conv2d_same import conv2d_same
from .padding import get_padding_value
def get_condconv_initializer(initializer, num_experts, expert_shape):
def condconv_initializer(weight):
"""CondConv initializer function."""
num_params = np.prod(expert_shape)
if (
len(weight.shape) != 2
or weight.shape[0] != num_experts
or weight.shape[1] != num_params
):
raise (
ValueError(
"CondConv variables must have shape [num_experts, num_params]"
)
)
for i in range(num_experts):
initializer(weight[i].view(expert_shape))
return condconv_initializer
class CondConv2d(nn.Module):
"""Conditionally Parameterized Convolution
Inspired by: https://github.com/tensorflow/tpu/blob/master/models/official/efficientnet/condconv/condconv_layers.py
Grouped convolution hackery for parallel execution of the per-sample kernel filters inspired by this discussion:
https://github.com/pytorch/pytorch/issues/17983
"""
__constants__ = ["in_channels", "out_channels", "dynamic_padding"]
def __init__(
self,
in_channels,
out_channels,
kernel_size=3,
stride=1,
padding="",
dilation=1,
groups=1,
bias=False,
num_experts=4,
):
super(CondConv2d, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = to_2tuple(kernel_size)
self.stride = to_2tuple(stride)
padding_val, is_padding_dynamic = get_padding_value(
padding, kernel_size, stride=stride, dilation=dilation
)
self.dynamic_padding = (
is_padding_dynamic # if in forward to work with torchscript
)
self.padding = to_2tuple(padding_val)
self.dilation = to_2tuple(dilation)
self.groups = groups
self.num_experts = num_experts
self.weight_shape = (
self.out_channels,
self.in_channels // self.groups,
) + self.kernel_size
weight_num_param = 1
for wd in self.weight_shape:
weight_num_param *= wd
self.weight = torch.nn.Parameter(
torch.Tensor(self.num_experts, weight_num_param)
)
if bias:
self.bias_shape = (self.out_channels,)
self.bias = torch.nn.Parameter(
torch.Tensor(self.num_experts, self.out_channels)
)
else:
self.register_parameter("bias", None)
self.reset_parameters()
def reset_parameters(self):
init_weight = get_condconv_initializer(
partial(nn.init.kaiming_uniform_, a=math.sqrt(5)),
self.num_experts,
self.weight_shape,
)
init_weight(self.weight)
if self.bias is not None:
fan_in = np.prod(self.weight_shape[1:])
bound = 1 / math.sqrt(fan_in)
init_bias = get_condconv_initializer(
partial(nn.init.uniform_, a=-bound, b=bound),
self.num_experts,
self.bias_shape,
)
init_bias(self.bias)
def forward(self, x, routing_weights):
B, C, H, W = x.shape
weight = torch.matmul(routing_weights, self.weight)
new_weight_shape = (
B * self.out_channels,
self.in_channels // self.groups,
) + self.kernel_size
weight = weight.view(new_weight_shape)
bias = None
if self.bias is not None:
bias = torch.matmul(routing_weights, self.bias)
bias = bias.view(B * self.out_channels)
# move batch elements with channels so each batch element can be efficiently convolved with separate kernel
# reshape instead of view to work with channels_last input
x = x.reshape(1, B * C, H, W)
if self.dynamic_padding:
out = conv2d_same(
x,
weight,
bias,
stride=self.stride,
padding=self.padding,
dilation=self.dilation,
groups=self.groups * B,
)
else:
out = F.conv2d(
x,
weight,
bias,
stride=self.stride,
padding=self.padding,
dilation=self.dilation,
groups=self.groups * B,
)
out = out.permute([1, 0, 2, 3]).view(
B, self.out_channels, out.shape[-2], out.shape[-1]
)
# Literal port (from TF definition)
# x = torch.split(x, 1, 0)
# weight = torch.split(weight, 1, 0)
# if self.bias is not None:
# bias = torch.matmul(routing_weights, self.bias)
# bias = torch.split(bias, 1, 0)
# else:
# bias = [None] * B
# out = []
# for xi, wi, bi in zip(x, weight, bias):
# wi = wi.view(*self.weight_shape)
# if bi is not None:
# bi = bi.view(*self.bias_shape)
# out.append(self.conv_fn(
# xi, wi, bi, stride=self.stride, padding=self.padding,
# dilation=self.dilation, groups=self.groups))
# out = torch.cat(out, 0)
return out
================================================
FILE: RVT/models/layers/maxvit/layers/config.py
================================================
""" Model / Layer Config singleton state
"""
from typing import Any, Optional
__all__ = [
"is_exportable",
"is_scriptable",
"is_no_jit",
"set_exportable",
"set_scriptable",
"set_no_jit",
"set_layer_config",
]
# Set to True if prefer to have layers with no jit optimization (includes activations)
_NO_JIT = False
# Set to True if prefer to have activation layers with no jit optimization
# NOTE not currently used as no difference between no_jit and no_activation jit as only layers obeying
# the jit flags so far are activations. This will change as more layers are updated and/or added.
_NO_ACTIVATION_JIT = False
# Set to True if exporting a model with Same padding via ONNX
_EXPORTABLE = False
# Set to True if wanting to use torch.jit.script on a model
_SCRIPTABLE = False
def is_no_jit():
return _NO_JIT
class set_no_jit:
def __init__(self, mode: bool) -> None:
global _NO_JIT
self.prev = _NO_JIT
_NO_JIT = mode
def __enter__(self) -> None:
pass
def __exit__(self, *args: Any) -> bool:
global _NO_JIT
_NO_JIT = self.prev
return False
def is_exportable():
return _EXPORTABLE
class set_exportable:
def __init__(self, mode: bool) -> None:
global _EXPORTABLE
self.prev = _EXPORTABLE
_EXPORTABLE = mode
def __enter__(self) -> None:
pass
def __exit__(self, *args: Any) -> bool:
global _EXPORTABLE
_EXPORTABLE = self.prev
return False
def is_scriptable():
return _SCRIPTABLE
class set_scriptable:
def __init__(self, mode: bool) -> None:
global _SCRIPTABLE
self.prev = _SCRIPTABLE
_SCRIPTABLE = mode
def __enter__(self) -> None:
pass
def __exit__(self, *args: Any) -> bool:
global _SCRIPTABLE
_SCRIPTABLE = self.prev
return False
class set_layer_config:
"""Layer config context manager that allows setting all layer config flags at once.
If a flag arg is None, it will not change the current value.
"""
def __init__(
self,
scriptable: Optional[bool] = None,
exportable: Optional[bool] = None,
no_jit: Optional[bool] = None,
no_activation_jit: Optional[bool] = None,
):
global _SCRIPTABLE
global _EXPORTABLE
global _NO_JIT
global _NO_ACTIVATION_JIT
self.prev = _SCRIPTABLE, _EXPORTABLE, _NO_JIT, _NO_ACTIVATION_JIT
if scriptable is not None:
_SCRIPTABLE = scriptable
if exportable is not None:
_EXPORTABLE = exportable
if no_jit is not None:
_NO_JIT = no_jit
if no_activation_jit is not None:
_NO_ACTIVATION_JIT = no_activation_jit
def __enter__(self) -> None:
pass
def __exit__(self, *args: Any) -> bool:
global _SCRIPTABLE
global _EXPORTABLE
global _NO_JIT
global _NO_ACTIVATION_JIT
_SCRIPTABLE, _EXPORTABLE, _NO_JIT, _NO_ACTIVATION_JIT = self.prev
return False
================================================
FILE: RVT/models/layers/maxvit/layers/conv2d_same.py
================================================
""" Conv2d w/ Same Padding
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Tuple, Optional
from .padding import pad_same, get_padding_value
def conv2d_same(
x,
weight: torch.Tensor,
bias: Optional[torch.Tensor] = None,
stride: Tuple[int, int] = (1, 1),
padding: Tuple[int, int] = (0, 0),
dilation: Tuple[int, int] = (1, 1),
groups: int = 1,
):
x = pad_same(x, weight.shape[-2:], stride, dilation)
return F.conv2d(x, weight, bias, stride, (0, 0), dilation, groups)
class Conv2dSame(nn.Conv2d):
"""Tensorflow like 'SAME' convolution wrapper for 2D convolutions"""
def __init__(
self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=0,
dilation=1,
groups=1,
bias=True,
):
super(Conv2dSame, self).__init__(
in_channels, out_channels, kernel_size, stride, 0, dilation, groups, bias
)
def forward(self, x):
return conv2d_same(
x,
self.weight,
self.bias,
self.stride,
self.padding,
self.dilation,
self.groups,
)
def create_conv2d_pad(in_chs, out_chs, kernel_size, **kwargs):
padding = kwargs.pop("padding", "")
kwargs.setdefault("bias", False)
padding, is_dynamic = get_padding_value(padding, kernel_size, **kwargs)
if is_dynamic:
return Conv2dSame(in_chs, out_chs, kernel_size, **kwargs)
else:
return nn.Conv2d(in_chs, out_chs, kernel_size, padding=padding, **kwargs)
================================================
FILE: RVT/models/layers/maxvit/layers/conv_bn_act.py
================================================
""" Conv2d + BN + Act
Hacked together by / Copyright 2020 Ross Wightman
"""
import functools
from torch import nn as nn
from .create_conv2d import create_conv2d
from .create_norm_act import get_norm_act_layer
class ConvNormAct(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size=1,
stride=1,
padding="",
dilation=1,
groups=1,
bias=False,
apply_act=True,
norm_layer=nn.BatchNorm2d,
act_layer=nn.ReLU,
drop_layer=None,
):
super(ConvNormAct, self).__init__()
self.conv = create_conv2d(
in_channels,
out_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
)
# NOTE for backwards compatibility with models that use separate norm and act layer definitions
norm_act_layer = get_norm_act_layer(norm_layer, act_layer)
# NOTE for backwards (weight) compatibility, norm layer name remains `.bn`
norm_kwargs = dict(drop_layer=drop_layer) if drop_layer is not None else {}
self.bn = norm_act_layer(out_channels, apply_act=apply_act, **norm_kwargs)
@property
def in_channels(self):
return self.conv.in_channels
@property
def out_channels(self):
return self.conv.out_channels
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
return x
ConvBnAct = ConvNormAct
def create_aa(aa_layer, channels, stride=2, enable=True):
if not aa_layer or not enable:
return nn.Identity()
if isinstance(aa_layer, functools.partial):
if issubclass(aa_layer.func, nn.AvgPool2d):
return aa_layer()
else:
return aa_layer(channels)
elif issubclass(aa_layer, nn.AvgPool2d):
return aa_layer(stride)
else:
return aa_layer(channels=channels, stride=stride)
class ConvNormActAa(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel_size=1,
stride=1,
padding="",
dilation=1,
groups=1,
bias=False,
apply_act=True,
norm_layer=nn.BatchNorm2d,
act_layer=nn.ReLU,
aa_layer=None,
drop_layer=None,
):
super(ConvNormActAa, self).__init__()
use_aa = aa_layer is not None and stride == 2
self.conv = create_conv2d(
in_channels,
out_channels,
kernel_size,
stride=1 if use_aa else stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
)
# NOTE for backwards compatibility with models that use separate norm and act layer definitions
norm_act_layer = get_norm_act_layer(norm_layer, act_layer)
# NOTE for backwards (weight) compatibility, norm layer name remains `.bn`
norm_kwargs = dict(drop_layer=drop_layer) if drop_layer is not None else {}
self.bn = norm_act_layer(out_channels, apply_act=apply_act, **norm_kwargs)
self.aa = create_aa(aa_layer, out_channels, stride=stride, enable=use_aa)
@property
def in_channels(self):
return self.conv.in_channels
@property
def out_channels(self):
return self.conv.out_channels
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.aa(x)
return x
================================================
FILE: RVT/models/layers/maxvit/layers/create_act.py
================================================
""" Activation Factory
Hacked together by / Copyright 2020 Ross Wightman
"""
from typing import Union, Callable, Type
from .activations import *
from .activations_jit import *
from .activations_me import *
from .config import is_exportable, is_scriptable, is_no_jit
# PyTorch has an optimized, native 'silu' (aka 'swish') operator as of PyTorch 1.7.
# Also hardsigmoid, hardswish, and soon mish. This code will use native version if present.
# Eventually, the custom SiLU, Mish, Hard*, layers will be removed and only native variants will be used.
_has_silu = "silu" in dir(torch.nn.functional)
_has_hardswish = "hardswish" in dir(torch.nn.functional)
_has_hardsigmoid = "hardsigmoid" in dir(torch.nn.functional)
_has_mish = "mish" in dir(torch.nn.functional)
_ACT_FN_DEFAULT = dict(
silu=F.silu if _has_silu else swish,
swish=F.silu if _has_silu else swish,
mish=F.mish if _has_mish else mish,
relu=F.relu,
relu6=F.relu6,
leaky_relu=F.leaky_relu,
elu=F.elu,
celu=F.celu,
selu=F.selu,
gelu=gelu,
sigmoid=sigmoid,
tanh=tanh,
hard_sigmoid=F.hardsigmoid if _has_hardsigmoid else hard_sigmoid,
hard_swish=F.hardswish if _has_hardswish else hard_swish,
hard_mish=hard_mish,
)
_ACT_FN_JIT = dict(
silu=F.silu if _has_silu else swish_jit,
swish=F.silu if _has_silu else swish_jit,
mish=F.mish if _has_mish else mish_jit,
hard_sigmoid=F.hardsigmoid if _has_hardsigmoid else hard_sigmoid_jit,
hard_swish=F.hardswish if _has_hardswish else hard_swish_jit,
hard_mish=hard_mish_jit,
)
_ACT_FN_ME = dict(
silu=F.silu if _has_silu else swish_me,
swish=F.silu if _has_silu else swish_me,
mish=F.mish if _has_mish else mish_me,
hard_sigmoid=F.hardsigmoid if _has_hardsigmoid else hard_sigmoid_me,
hard_swish=F.hardswish if _has_hardswish else hard_swish_me,
hard_mish=hard_mish_me,
)
_ACT_FNS = (_ACT_FN_ME, _ACT_FN_JIT, _ACT_FN_DEFAULT)
for a in _ACT_FNS:
a.setdefault("hardsigmoid", a.get("hard_sigmoid"))
a.setdefault("hardswish", a.get("hard_swish"))
_ACT_LAYER_DEFAULT = dict(
silu=nn.SiLU if _has_silu else Swish,
swish=nn.SiLU if _has_silu else Swish,
mish=nn.Mish if _has_mish else Mish,
relu=nn.ReLU,
relu6=nn.ReLU6,
leaky_relu=nn.LeakyReLU,
elu=nn.ELU,
prelu=PReLU,
celu=nn.CELU,
selu=nn.SELU,
gelu=GELU,
sigmoid=Sigmoid,
tanh=Tanh,
hard_sigmoid=nn.Hardsigmoid if _has_hardsigmoid else HardSigmoid,
hard_swish=nn.Hardswish if _has_hardswish else HardSwish,
hard_mish=HardMish,
)
_ACT_LAYER_JIT = dict(
silu=nn.SiLU if _has_silu else SwishJit,
swish=nn.SiLU if _has_silu else SwishJit,
mish=nn.Mish if _has_mish else MishJit,
hard_sigmoid=nn.Hardsigmoid if _has_hardsigmoid else HardSigmoidJit,
hard_swish=nn.Hardswish if _has_hardswish else HardSwishJit,
hard_mish=HardMishJit,
)
_ACT_LAYER_ME = dict(
silu=nn.SiLU if _has_silu else SwishMe,
swish=nn.SiLU if _has_silu else SwishMe,
mish=nn.Mish if _has_mish else MishMe,
hard_sigmoid=nn.Hardsigmoid if _has_hardsigmoid else HardSigmoidMe,
hard_swish=nn.Hardswish if _has_hardswish else HardSwishMe,
hard_mish=HardMishMe,
)
_ACT_LAYERS = (_ACT_LAYER_ME, _ACT_LAYER_JIT, _ACT_LAYER_DEFAULT)
for a in _ACT_LAYERS:
a.setdefault("hardsigmoid", a.get("hard_sigmoid"))
a.setdefault("hardswish", a.get("hard_swish"))
def get_act_fn(name: Union[Callable, str] = "relu"):
"""Activation Function Factory
Fetching activation fns by name with this function allows export or torch script friendly
functions to be returned dynamically based on current config.
"""
if not name:
return None
if isinstance(name, Callable):
return name
if not (is_no_jit() or is_exportable() or is_scriptable()):
# If not exporting or scripting the model, first look for a memory-efficient version with
# custom autograd, then fallback
if name in _ACT_FN_ME:
return _ACT_FN_ME[name]
if not (is_no_jit() or is_exportable()):
if name in _ACT_FN_JIT:
return _ACT_FN_JIT[name]
return _ACT_FN_DEFAULT[name]
def get_act_layer(name: Union[Type[nn.Module], str] = "relu"):
"""Activation Layer Factory
Fetching activation layers by name with this function allows export or torch script friendly
functions to be returned dynamically based on current config.
"""
if not name:
return None
if not isinstance(name, str):
# callable, module, etc
return name
if not (is_no_jit() or is_exportable() or is_scriptable()):
if name in _ACT_LAYER_ME:
return _ACT_LAYER_ME[name]
if not (is_no_jit() or is_exportable()):
if name in _ACT_LAYER_JIT:
return _ACT_LAYER_JIT[name]
return _ACT_LAYER_DEFAULT[name]
def create_act_layer(name: Union[nn.Module, str], inplace=None, **kwargs):
act_layer = get_act_layer(name)
if act_layer is None:
return None
if inplace is None:
return act_layer(**kwargs)
try:
return act_layer(inplace=inplace, **kwargs)
except TypeError:
# recover if act layer doesn't have inplace arg
return act_layer(**kwargs)
================================================
FILE: RVT/models/layers/maxvit/layers/create_attn.py
================================================
""" Attention Factory
Hacked together by / Copyright 2021 Ross Wightman
"""
import torch
from functools import partial
from .bottleneck_attn import BottleneckAttn
from .cbam import CbamModule, LightCbamModule
from .eca import EcaModule, CecaModule
from .gather_excite import GatherExcite
from .global_context import GlobalContext
from .halo_attn import HaloAttn
from .lambda_layer import LambdaLayer
from .non_local_attn import NonLocalAttn, BatNonLocalAttn
from .selective_kernel import SelectiveKernel
from .split_attn import SplitAttn
from .squeeze_excite import SEModule, EffectiveSEModule
def get_attn(attn_type):
if isinstance(attn_type, torch.nn.Module):
return attn_type
module_cls = None
if attn_type:
if isinstance(attn_type, str):
attn_type = attn_type.lower()
# Lightweight attention modules (channel and/or coarse spatial).
# Typically added to existing network architecture blocks in addition to existing convolutions.
if attn_type == "se":
module_cls = SEModule
elif attn_type == "ese":
module_cls = EffectiveSEModule
elif attn_type == "eca":
module_cls = EcaModule
elif attn_type == "ecam":
module_cls = partial(EcaModule, use_mlp=True)
elif attn_type == "ceca":
module_cls = CecaModule
elif attn_type == "ge":
module_cls = GatherExcite
elif attn_type == "gc":
module_cls = GlobalContext
elif attn_type == "gca":
module_cls = partial(GlobalContext, fuse_add=True, fuse_scale=False)
elif attn_type == "cbam":
module_cls = CbamModule
elif attn_type == "lcbam":
module_cls = LightCbamModule
# Attention / attention-like modules w/ significant params
# Typically replace some of the existing workhorse convs in a network architecture.
# All of these accept a stride argument and can spatially downsample the input.
elif attn_type == "sk":
module_cls = SelectiveKernel
elif attn_type == "splat":
module_cls = SplitAttn
# Self-attention / attention-like modules w/ significant compute and/or params
# Typically replace some of the existing workhorse convs in a network architecture.
# All of these accept a stride argument and can spatially downsample the input.
elif attn_type == "lambda":
return LambdaLayer
elif attn_type == "bottleneck":
return BottleneckAttn
elif attn_type == "halo":
return HaloAttn
elif attn_type == "nl":
module_cls = NonLocalAttn
elif attn_type == "bat":
module_cls = BatNonLocalAttn
# Woops!
else:
assert False, "Invalid attn module (%s)" % attn_type
elif isinstance(attn_type, bool):
if attn_type:
module_cls = SEModule
else:
module_cls = attn_type
return module_cls
def create_attn(attn_type, channels, **kwargs):
module_cls = get_attn(attn_type)
if module_cls is not None:
# NOTE: it's expected the first (positional) argument of all attention layers is the # input channels
return module_cls(channels, **kwargs)
return None
================================================
FILE: RVT/models/layers/maxvit/layers/create_conv2d.py
================================================
""" Create Conv2d Factory Method
Hacked together by / Copyright 2020 Ross Wightman
"""
from .mixed_conv2d import MixedConv2d
from .cond_conv2d import CondConv2d
from .conv2d_same import create_conv2d_pad
def create_conv2d(in_channels, out_channels, kernel_size, **kwargs):
"""Select a 2d convolution implementation based on arguments
Creates and returns one of torch.nn.Conv2d, Conv2dSame, MixedConv2d, or CondConv2d.
Used extensively by EfficientNet, MobileNetv3 and related networks.
"""
if isinstance(kernel_size, list):
assert (
"num_experts" not in kwargs
) # MixNet + CondConv combo not supported currently
if "groups" in kwargs:
groups = kwargs.pop("groups")
if groups == in_channels:
kwargs["depthwise"] = True
else:
assert groups == 1
# We're going to use only lists for defining the MixedConv2d kernel groups,
# ints, tuples, other iterables will continue to pass to normal conv and specify h, w.
m = MixedConv2d(in_channels, out_channels, kernel_size, **kwargs)
else:
depthwise = kwargs.pop("depthwise", False)
# for DW out_channels must be multiple of in_channels as must have out_channels % groups == 0
groups = in_channels if depthwise else kwargs.pop("groups", 1)
if "num_experts" in kwargs and kwargs["num_experts"] > 0:
m = CondConv2d(
in_channels, out_channels, kernel_size, groups=groups, **kwargs
)
else:
m = create_conv2d_pad(
in_channels, out_channels, kernel_size, groups=groups, **kwargs
)
return m
================================================
FILE: RVT/models/layers/maxvit/layers/create_norm.py
================================================
""" Norm Layer Factory
Create norm modules by string (to mirror create_act and creat_norm-act fns)
Copyright 2022 Ross Wightman
"""
import types
import functools
import torch.nn as nn
from .norm import GroupNorm, GroupNorm1, LayerNorm, LayerNorm2d
_NORM_MAP = dict(
batchnorm=nn.BatchNorm2d,
batchnorm2d=nn.BatchNorm2d,
batchnorm1d=nn.BatchNorm1d,
groupnorm=GroupNorm,
groupnorm1=GroupNorm1,
layernorm=LayerNorm,
layernorm2d=LayerNorm2d,
)
_NORM_TYPES = {m for n, m in _NORM_MAP.items()}
def create_norm_layer(
layer_name, num_features, act_layer=None, apply_act=True, **kwargs
):
layer = get_norm_layer(layer_name, act_layer=act_layer)
layer_instance = layer(num_features, apply_act=apply_act, **kwargs)
return layer_instance
def get_norm_layer(norm_layer):
assert isinstance(norm_layer, (type, str, types.FunctionType, functools.partial))
norm_kwargs = {}
# unbind partial fn, so args can be rebound later
if isinstance(norm_layer, functools.partial):
norm_kwargs.update(norm_layer.keywords)
norm_layer = norm_layer.func
if isinstance(norm_layer, str):
layer_name = norm_layer.replace("_", "")
norm_layer = _NORM_MAP.get(layer_name, None)
elif norm_layer in _NORM_TYPES:
norm_layer = norm_layer
elif isinstance(norm_layer, types.FunctionType):
# if function type, assume it is a lambda/fn that creates a norm layer
norm_layer = norm_layer
else:
type_name = norm_layer.__name__.lower().replace("_", "")
norm_layer = _NORM_MAP.get(type_name, None)
assert norm_layer is not None, f"No equivalent norm layer for {type_name}"
if norm_kwargs:
norm_layer = functools.partial(norm_layer, **norm_kwargs) # bind/rebind args
return norm_layer
================================================
FILE: RVT/models/layers/maxvit/layers/create_norm_act.py
================================================
""" NormAct (Normalizaiton + Activation Layer) Factory
Create norm + act combo modules that attempt to be backwards compatible with separate norm + act
isntances in models. Where these are used it will be possible to swap separate BN + act layers with
combined modules like IABN or EvoNorms.
Hacked together by / Copyright 2020 Ross Wightman
"""
import types
import functools
from .evo_norm import *
from .filter_response_norm import FilterResponseNormAct2d, FilterResponseNormTlu2d
from .norm_act import BatchNormAct2d, GroupNormAct, LayerNormAct, LayerNormAct2d
from .inplace_abn import InplaceAbn
_NORM_ACT_MAP = dict(
batchnorm=BatchNormAct2d,
batchnorm2d=BatchNormAct2d,
groupnorm=GroupNormAct,
groupnorm1=functools.partial(GroupNormAct, num_groups=1),
layernorm=LayerNormAct,
layernorm2d=LayerNormAct2d,
evonormb0=EvoNorm2dB0,
evonormb1=EvoNorm2dB1,
evonormb2=EvoNorm2dB2,
evonorms0=EvoNorm2dS0,
evonorms0a=EvoNorm2dS0a,
evonorms1=EvoNorm2dS1,
evonorms1a=EvoNorm2dS1a,
evonorms2=EvoNorm2dS2,
evonorms2a=EvoNorm2dS2a,
frn=FilterResponseNormAct2d,
frntlu=FilterResponseNormTlu2d,
inplaceabn=InplaceAbn,
iabn=InplaceAbn,
)
_NORM_ACT_TYPES = {m for n, m in _NORM_ACT_MAP.items()}
# has act_layer arg to define act type
_NORM_ACT_REQUIRES_ARG = {
BatchNormAct2d,
GroupNormAct,
LayerNormAct,
LayerNormAct2d,
FilterResponseNormAct2d,
InplaceAbn,
}
def create_norm_act_layer(
layer_name, num_features, act_layer=None, apply_act=True, jit=False, **kwargs
):
layer = get_norm_act_layer(layer_name, act_layer=act_layer)
layer_instance = layer(num_features, apply_act=apply_act, **kwargs)
if jit:
layer_instance = torch.jit.script(layer_instance)
return layer_instance
def get_norm_act_layer(norm_layer, act_layer=None):
assert isinstance(norm_layer, (type, str, types.FunctionType, functools.partial))
assert act_layer is None or isinstance(
act_layer, (type, str, types.FunctionType, functools.partial)
)
norm_act_kwargs = {}
# unbind partial fn, so args can be rebound later
if isinstance(norm_layer, functools.partial):
norm_act_kwargs.update(norm_layer.keywords)
norm_layer = norm_layer.func
if isinstance(norm_layer, str):
layer_name = norm_layer.replace("_", "").lower().split("-")[0]
norm_act_layer = _NORM_ACT_MAP.get(layer_name, None)
elif norm_layer in _NORM_ACT_TYPES:
norm_act_layer = norm_layer
elif isinstance(norm_layer, types.FunctionType):
# if function type, must be a lambda/fn that creates a norm_act layer
norm_act_layer = norm_layer
else:
type_name = norm_layer.__name__.lower()
if type_name.startswith("batchnorm"):
norm_act_layer = BatchNormAct2d
elif type_name.startswith("groupnorm"):
norm_act_layer = GroupNormAct
elif type_name.startswith("groupnorm1"):
norm_act_layer = functools.partial(GroupNormAct, num_groups=1)
elif type_name.startswith("layernorm2d"):
norm_act_layer = LayerNormAct2d
elif type_name.startswith("layernorm"):
norm_act_layer = LayerNormAct
else:
assert False, f"No equivalent norm_act layer for {type_name}"
if norm_act_layer in _NORM_ACT_REQUIRES_ARG:
# pass `act_layer` through for backwards compat where `act_layer=None` implies no activation.
# In the future, may force use of `apply_act` with `act_layer` arg bound to relevant NormAct types
norm_act_kwargs.setdefault("act_layer", act_layer)
if norm_act_kwargs:
norm_act_layer = functools.partial(
norm_act_layer, **norm_act_kwargs
) # bind/rebind args
return norm_act_layer
================================================
FILE: RVT/models/layers/maxvit/layers/drop.py
================================================
""" DropBlock, DropPath
PyTorch implementations of DropBlock and DropPath (Stochastic Depth) regularization layers.
Papers:
DropBlock: A regularization method for convolutional networks (https://arxiv.org/abs/1810.12890)
Deep Networks with Stochastic Depth (https://arxiv.org/abs/1603.09382)
Code:
DropBlock impl inspired by two Tensorflow impl that I liked:
- https://github.com/tensorflow/tpu/blob/master/models/official/resnet/resnet_model.py#L74
- https://github.com/clovaai/assembled-cnn/blob/master/nets/blocks.py
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
def drop_block_2d(
x,
drop_prob: float = 0.1,
block_size: int = 7,
gamma_scale: float = 1.0,
with_noise: bool = False,
inplace: bool = False,
batchwise: bool = False,
):
"""DropBlock. See https://arxiv.org/pdf/1810.12890.pdf
DropBlock with an experimental gaussian noise option. This layer has been tested on a few training
runs with success, but needs further validation and possibly optimization for lower runtime impact.
"""
B, C, H, W = x.shape
total_size = W * H
clipped_block_size = min(block_size, min(W, H))
# seed_drop_rate, the gamma parameter
gamma = (
gamma_scale
* drop_prob
* total_size
/ clipped_block_size**2
/ ((W - block_size + 1) * (H - block_size + 1))
)
# Forces the block to be inside the feature map.
w_i, h_i = torch.meshgrid(
torch.arange(W).to(x.device), torch.arange(H).to(x.device)
)
valid_block = (
(w_i >= clipped_block_size // 2) & (w_i < W - (clipped_block_size - 1) // 2)
) & ((h_i >= clipped_block_size // 2) & (h_i < H - (clipped_block_size - 1) // 2))
valid_block = torch.reshape(valid_block, (1, 1, H, W)).to(dtype=x.dtype)
if batchwise:
# one mask for whole batch, quite a bit faster
uniform_noise = torch.rand((1, C, H, W), dtype=x.dtype, device=x.device)
else:
uniform_noise = torch.rand_like(x)
block_mask = ((2 - gamma - valid_block + uniform_noise) >= 1).to(dtype=x.dtype)
block_mask = -F.max_pool2d(
-block_mask,
kernel_size=clipped_block_size, # block_size,
stride=1,
padding=clipped_block_size // 2,
)
if with_noise:
normal_noise = (
torch.randn((1, C, H, W), dtype=x.dtype, device=x.device)
if batchwise
else torch.randn_like(x)
)
if inplace:
x.mul_(block_mask).add_(normal_noise * (1 - block_mask))
else:
x = x * block_mask + normal_noise * (1 - block_mask)
else:
normalize_scale = (
block_mask.numel() / block_mask.to(dtype=torch.float32).sum().add(1e-7)
).to(x.dtype)
if inplace:
x.mul_(block_mask * normalize_scale)
else:
x = x * block_mask * normalize_scale
return x
def drop_block_fast_2d(
x: torch.Tensor,
drop_prob: float = 0.1,
block_size: int = 7,
gamma_scale: float = 1.0,
with_noise: bool = False,
inplace: bool = False,
):
"""DropBlock. See https://arxiv.org/pdf/1810.12890.pdf
DropBlock with an experimental gaussian noise option. Simplied from above without concern for valid
block mask at edges.
"""
B, C, H, W = x.shape
total_size = W * H
clipped_block_size = min(block_size, min(W, H))
gamma = (
gamma_scale
* drop_prob
* total_size
/ clipped_block_size**2
/ ((W - block_size + 1) * (H - block_size + 1))
)
block_mask = torch.empty_like(x).bernoulli_(gamma)
block_mask = F.max_pool2d(
block_mask.to(x.dtype),
kernel_size=clipped_block_size,
stride=1,
padding=clipped_block_size // 2,
)
if with_noise:
normal_noise = torch.empty_like(x).normal_()
if inplace:
x.mul_(1.0 - block_mask).add_(normal_noise * block_mask)
else:
x = x * (1.0 - block_mask) + normal_noise * block_mask
else:
block_mask = 1 - block_mask
normalize_scale = (
block_mask.numel() / block_mask.to(dtype=torch.float32).sum().add(1e-6)
).to(dtype=x.dtype)
if inplace:
x.mul_(block_mask * normalize_scale)
else:
x = x * block_mask * normalize_scale
return x
class DropBlock2d(nn.Module):
"""DropBlock. See https://arxiv.org/pdf/1810.12890.pdf"""
def __init__(
self,
drop_prob: float = 0.1,
block_size: int = 7,
gamma_scale: float = 1.0,
with_noise: bool = False,
inplace: bool = False,
batchwise: bool = False,
fast: bool = True,
):
super(DropBlock2d, self).__init__()
self.drop_prob = drop_prob
self.gamma_scale = gamma_scale
self.block_size = block_size
self.with_noise = with_noise
self.inplace = inplace
self.batchwise = batchwise
self.fast = fast # FIXME finish comparisons of fast vs not
def forward(self, x):
if not self.training or not self.drop_prob:
return x
if self.fast:
return drop_block_fast_2d(
x,
self.drop_prob,
self.block_size,
self.gamma_scale,
self.with_noise,
self.inplace,
)
else:
return drop_block_2d(
x,
self.drop_prob,
self.block_size,
self.gamma_scale,
self.with_noise,
self.inplace,
self.batchwise,
)
def drop_path(
x, drop_prob: float = 0.0, training: bool = False, scale_by_keep: bool = True
):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,
the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...
See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted for
changing the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use
'survival rate' as the argument.
"""
if drop_prob == 0.0 or not training:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (
x.ndim - 1
) # work with diff dim tensors, not just 2D ConvNets
random_tensor = x.new_empty(shape).bernoulli_(keep_prob)
if keep_prob > 0.0 and scale_by_keep:
random_tensor.div_(keep_prob)
return x * random_tensor
class DropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""
def __init__(self, drop_prob: float = 0.0, scale_by_keep: bool = True):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
self.scale_by_keep = scale_by_keep
def forward(self, x):
return drop_path(x, self.drop_prob, self.training, self.scale_by_keep)
def extra_repr(self):
return f"drop_prob={round(self.drop_prob,3):0.3f}"
================================================
FILE: RVT/models/layers/maxvit/layers/eca.py
================================================
"""
ECA module from ECAnet
paper: ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
https://arxiv.org/abs/1910.03151
Original ECA model borrowed from https://github.com/BangguWu/ECANet
Modified circular ECA implementation and adaption for use in timm package
by Chris Ha https://github.com/VRandme
Original License:
MIT License
Copyright (c) 2019 BangguWu, Qilong Wang
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
"""
import math
from torch import nn
import torch.nn.functional as F
from .create_act import create_act_layer
from .helpers import make_divisible
class EcaModule(nn.Module):
"""Constructs an ECA module.
Args:
channels: Number of channels of the input feature map for use in adaptive kernel sizes
for actual calculations according to channel.
gamma, beta: when channel is given parameters of mapping function
refer to original paper https://arxiv.org/pdf/1910.03151.pdf
(default=None. if channel size not given, use k_size given for kernel size.)
kernel_size: Adaptive selection of kernel size (default=3)
gamm: used in kernel_size calc, see above
beta: used in kernel_size calc, see above
act_layer: optional non-linearity after conv, enables conv bias, this is an experiment
gate_layer: gating non-linearity to use
"""
def __init__(
self,
channels=None,
kernel_size=3,
gamma=2,
beta=1,
act_layer=None,
gate_layer="sigmoid",
rd_ratio=1 / 8,
rd_channels=None,
rd_divisor=8,
use_mlp=False,
):
super(EcaModule, self).__init__()
if channels is not None:
t = int(abs(math.log(channels, 2) + beta) / gamma)
kernel_size = max(t if t % 2 else t + 1, 3)
assert kernel_size % 2 == 1
padding = (kernel_size - 1) // 2
if use_mlp:
# NOTE 'mlp' mode is a timm experiment, not in paper
assert channels is not None
if rd_channels is None:
rd_channels = make_divisible(channels * rd_ratio, divisor=rd_divisor)
act_layer = act_layer or nn.ReLU
self.conv = nn.Conv1d(1, rd_channels, kernel_size=1, padding=0, bias=True)
self.act = create_act_layer(act_layer)
self.conv2 = nn.Conv1d(
rd_channels, 1, kernel_size=kernel_size, padding=padding, bias=True
)
else:
self.conv = nn.Conv1d(
1, 1, kernel_size=kernel_size, padding=padding, bias=False
)
self.act = None
self.conv2 = None
self.gate = create_act_layer(gate_layer)
def forward(self, x):
y = x.mean((2, 3)).view(x.shape[0], 1, -1) # view for 1d conv
y = self.conv(y)
if self.conv2 is not None:
y = self.act(y)
y = self.conv2(y)
y = self.gate(y).view(x.shape[0], -1, 1, 1)
return x * y.expand_as(x)
EfficientChannelAttn = EcaModule # alias
class CecaModule(nn.Module):
"""Constructs a circular ECA module.
ECA module where the conv uses circular padding rather than zero padding.
Unlike the spatial dimension, the channels do not have inherent ordering nor
locality. Although this module in essence, applies such an assumption, it is unnecessary
to limit the channels on either "edge" from being circularly adapted to each other.
This will fundamentally increase connectivity and possibly increase performance metrics
(accuracy, robustness), without significantly impacting resource metrics
(parameter size, throughput,latency, etc)
Args:
channels: Number of channels of the input feature map for use in adaptive kernel sizes
for actual calculations according to channel.
gamma, beta: when channel is given parameters of mapping function
refer to original paper https://arxiv.org/pdf/1910.03151.pdf
(default=None. if channel size not given, use k_size given for kernel size.)
kernel_size: Adaptive selection of kernel size (default=3)
gamm: used in kernel_size calc, see above
beta: used in kernel_size calc, see above
act_layer: optional non-linearity after conv, enables conv bias, this is an experiment
gate_layer: gating non-linearity to use
"""
def __init__(
self,
channels=None,
kernel_size=3,
gamma=2,
beta=1,
act_layer=None,
gate_layer="sigmoid",
):
super(CecaModule, self).__init__()
if channels is not None:
t = int(abs(math.log(channels, 2) + beta) / gamma)
kernel_size = max(t if t % 2 else t + 1, 3)
has_act = act_layer is not None
assert kernel_size % 2 == 1
# PyTorch circular padding mode is buggy as of pytorch 1.4
# see https://github.com/pytorch/pytorch/pull/17240
# implement manual circular padding
self.padding = (kernel_size - 1) // 2
self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=0, bias=has_act)
self.gate = create_act_layer(gate_layer)
def forward(self, x):
y = x.mean((2, 3)).view(x.shape[0], 1, -1)
# Manually implement circular padding, F.pad does not seemed to be bugged
y = F.pad(y, (self.padding, self.padding), mode="circular")
y = self.conv(y)
y = self.gate(y).view(x.shape[0], -1, 1, 1)
return x * y.expand_as(x)
CircularEfficientChannelAttn = CecaModule
================================================
FILE: RVT/models/layers/maxvit/layers/evo_norm.py
================================================
""" EvoNorm in PyTorch
Based on `Evolving Normalization-Activation Layers` - https://arxiv.org/abs/2004.02967
@inproceedings{NEURIPS2020,
author = {Liu, Hanxiao and Brock, Andy and Simonyan, Karen and Le, Quoc},
booktitle = {Advances in Neural Information Processing Systems},
editor = {H. Larochelle and M. Ranzato and R. Hadsell and M. F. Balcan and H. Lin},
pages = {13539--13550},
publisher = {Curran Associates, Inc.},
title = {Evolving Normalization-Activation Layers},
url = {https://proceedings.neurips.cc/paper/2020/file/9d4c03631b8b0c85ae08bf05eda37d0f-Paper.pdf},
volume = {33},
year = {2020}
}
An attempt at getting decent performing EvoNorms running in PyTorch.
While faster than other PyTorch impl, still quite a ways off the built-in BatchNorm
in terms of memory usage and throughput on GPUs.
I'm testing these modules on TPU w/ PyTorch XLA. Promising start but
currently working around some issues with builtin torch/tensor.var/std. Unlike
GPU, similar train speeds for EvoNormS variants and BatchNorm.
Hacked together by / Copyright 2020 Ross Wightman
"""
from typing import Sequence, Union
import torch
import torch.nn as nn
import torch.nn.functional as F
from .create_act import create_act_layer
from .trace_utils import _assert
def instance_std(x, eps: float = 1e-5):
std = (
x.float()
.var(dim=(2, 3), unbiased=False, keepdim=True)
.add(eps)
.sqrt()
.to(x.dtype)
)
return std.expand(x.shape)
def instance_std_tpu(x, eps: float = 1e-5):
std = manual_var(x, dim=(2, 3)).add(eps).sqrt()
return std.expand(x.shape)
# instance_std = instance_std_tpu
def instance_rms(x, eps: float = 1e-5):
rms = x.float().square().mean(dim=(2, 3), keepdim=True).add(eps).sqrt().to(x.dtype)
return rms.expand(x.shape)
def manual_var(x, dim: Union[int, Sequence[int]], diff_sqm: bool = False):
xm = x.mean(dim=dim, keepdim=True)
if diff_sqm:
# difference of squared mean and mean squared, faster on TPU can be less stable
var = ((x * x).mean(dim=dim, keepdim=True) - (xm * xm)).clamp(0)
else:
var = ((x - xm) * (x - xm)).mean(dim=dim, keepdim=True)
return var
def group_std(x, groups: int = 32, eps: float = 1e-5, flatten: bool = False):
B, C, H, W = x.shape
x_dtype = x.dtype
_assert(C % groups == 0, "")
if flatten:
x = x.reshape(B, groups, -1) # FIXME simpler shape causing TPU / XLA issues
std = (
x.float()
.var(dim=2, unbiased=False, keepdim=True)
.add(eps)
.sqrt()
.to(x_dtype)
)
else:
x = x.reshape(B, groups, C // groups, H, W)
std = (
x.float()
.var(dim=(2, 3, 4), unbiased=False, keepdim=True)
.add(eps)
.sqrt()
.to(x_dtype)
)
return std.expand(x.shape).reshape(B, C, H, W)
def group_std_tpu(
x,
groups: int = 32,
eps: float = 1e-5,
diff_sqm: bool = False,
flatten: bool = False,
):
# This is a workaround for some stability / odd behaviour of .var and .std
# running on PyTorch XLA w/ TPUs. These manual var impl are producing much better results
B, C, H, W = x.shape
_assert(C % groups == 0, "")
if flatten:
x = x.reshape(B, groups, -1) # FIXME simpler shape causing TPU / XLA issues
var = manual_var(x, dim=-1, diff_sqm=diff_sqm)
else:
x = x.reshape(B, groups, C // groups, H, W)
var = manual_var(x, dim=(2, 3, 4), diff_sqm=diff_sqm)
return var.add(eps).sqrt().expand(x.shape).reshape(B, C, H, W)
# group_std = group_std_tpu # FIXME TPU temporary
def group_rms(x, groups: int = 32, eps: float = 1e-5):
B, C, H, W = x.shape
_assert(C % groups == 0, "")
x_dtype = x.dtype
x = x.reshape(B, groups, C // groups, H, W)
rms = (
x.float()
.square()
.mean(dim=(2, 3, 4), keepdim=True)
.add(eps)
.sqrt_()
.to(x_dtype)
)
return rms.expand(x.shape).reshape(B, C, H, W)
class EvoNorm2dB0(nn.Module):
def __init__(self, num_features, apply_act=True, momentum=0.1, eps=1e-3, **_):
super().__init__()
self.apply_act = apply_act # apply activation (non-linearity)
self.momentum = momentum
self.eps = eps
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
self.v = nn.Parameter(torch.ones(num_features)) if apply_act else None
self.register_buffer("running_var", torch.ones(num_features))
self.reset_parameters()
def reset_parameters(self):
nn.init.ones_(self.weight)
nn.init.zeros_(self.bias)
if self.v is not None:
nn.init.ones_(self.v)
def forward(self, x):
_assert(x.dim() == 4, "expected 4D input")
x_dtype = x.dtype
v_shape = (1, -1, 1, 1)
if self.v is not None:
if self.training:
var = x.float().var(dim=(0, 2, 3), unbiased=False)
# var = manual_var(x, dim=(0, 2, 3)).squeeze()
n = x.numel() / x.shape[1]
self.running_var.copy_(
self.running_var * (1 - self.momentum)
+ var.detach() * self.momentum * (n / (n - 1))
)
else:
var = self.running_var
left = var.add(self.eps).sqrt_().to(x_dtype).view(v_shape).expand_as(x)
v = self.v.to(x_dtype).view(v_shape)
right = x * v + instance_std(x, self.eps)
x = x / left.max(right)
return x * self.weight.to(x_dtype).view(v_shape) + self.bias.to(x_dtype).view(
v_shape
)
class EvoNorm2dB1(nn.Module):
def __init__(self, num_features, apply_act=True, momentum=0.1, eps=1e-5, **_):
super().__init__()
self.apply_act = apply_act # apply activation (non-linearity)
self.momentum = momentum
self.eps = eps
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
self.register_buffer("running_var", torch.ones(num_features))
self.reset_parameters()
def reset_parameters(self):
nn.init.ones_(self.weight)
nn.init.zeros_(self.bias)
def forward(self, x):
_assert(x.dim() == 4, "expected 4D input")
x_dtype = x.dtype
v_shape = (1, -1, 1, 1)
if self.apply_act:
if self.training:
var = x.float().var(dim=(0, 2, 3), unbiased=False)
n = x.numel() / x.shape[1]
self.running_var.copy_(
self.running_var * (1 - self.momentum)
+ var.detach().to(self.running_var.dtype)
* self.momentum
* (n / (n - 1))
)
else:
var = self.running_var
var = var.to(x_dtype).view(v_shape)
left = var.add(self.eps).sqrt_()
right = (x + 1) * instance_rms(x, self.eps)
x = x / left.max(right)
return x * self.weight.view(v_shape).to(x_dtype) + self.bias.view(v_shape).to(
x_dtype
)
class EvoNorm2dB2(nn.Module):
def __init__(self, num_features, apply_act=True, momentum=0.1, eps=1e-5, **_):
super().__init__()
self.apply_act = apply_act # apply activation (non-linearity)
self.momentum = momentum
self.eps = eps
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
self.register_buffer("running_var", torch.ones(num_features))
self.reset_parameters()
def reset_parameters(self):
nn.init.ones_(self.weight)
nn.init.zeros_(self.bias)
def forward(self, x):
_assert(x.dim() == 4, "expected 4D input")
x_dtype = x.dtype
v_shape = (1, -1, 1, 1)
if self.apply_act:
if self.training:
var = x.float().var(dim=(0, 2, 3), unbiased=False)
n = x.numel() / x.shape[1]
self.running_var.copy_(
self.running_var * (1 - self.momentum)
+ var.detach().to(self.running_var.dtype)
* self.momentum
* (n / (n - 1))
)
else:
var = self.running_var
var = var.to(x_dtype).view(v_shape)
left = var.add(self.eps).sqrt_()
right = instance_rms(x, self.eps) - x
x = x / left.max(right)
return x * self.weight.view(v_shape).to(x_dtype) + self.bias.view(v_shape).to(
x_dtype
)
class EvoNorm2dS0(nn.Module):
def __init__(
self, num_features, groups=32, group_size=None, apply_act=True, eps=1e-5, **_
):
super().__init__()
self.apply_act = apply_act # apply activation (non-linearity)
if group_size:
assert num_features % group_size == 0
self.groups = num_features // group_size
else:
self.groups = groups
self.eps = eps
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
self.v = nn.Parameter(torch.ones(num_features)) if apply_act else None
self.reset_parameters()
def reset_parameters(self):
nn.init.ones_(self.weight)
nn.init.zeros_(self.bias)
if self.v is not None:
nn.init.ones_(self.v)
def forward(self, x):
_assert(x.dim() == 4, "expected 4D input")
x_dtype = x.dtype
v_shape = (1, -1, 1, 1)
if self.v is not None:
v = self.v.view(v_shape).to(x_dtype)
x = x * (x * v).sigmoid() / group_std(x, self.groups, self.eps)
return x * self.weight.view(v_shape).to(x_dtype) + self.bias.view(v_shape).to(
x_dtype
)
class EvoNorm2dS0a(EvoNorm2dS0):
def __init__(
self, num_features, groups=32, group_size=None, apply_act=True, eps=1e-3, **_
):
super().__init__(
num_features,
groups=groups,
group_size=group_size,
apply_act=apply_act,
eps=eps,
)
def forward(self, x):
_assert(x.dim() == 4, "expected 4D input")
x_dtype = x.dtype
v_shape = (1, -1, 1, 1)
d = group_std(x, self.groups, self.eps)
if self.v is not None:
v = self.v.view(v_shape).to(x_dtype)
x = x * (x * v).sigmoid()
x = x / d
return x * self.weight.view(v_shape).to(x_dtype) + self.bias.view(v_shape).to(
x_dtype
)
class EvoNorm2dS1(nn.Module):
def __init__(
self,
num_features,
groups=32,
group_size=None,
apply_act=True,
act_layer=None,
eps=1e-5,
**_
):
super().__init__()
act_layer = act_layer or nn.SiLU
self.apply_act = apply_act # apply activation (non-linearity)
if act_layer is not None and apply_act:
self.act = create_act_layer(act_layer)
else:
self.act = nn.Identity()
if group_size:
assert num_features % group_size == 0
self.groups = num_features // group_size
else:
self.groups = groups
self.eps = eps
self.pre_act_norm = False
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
self.reset_parameters()
def reset_parameters(self):
nn.init.ones_(self.weight)
nn.init.zeros_(self.bias)
def forward(self, x):
_assert(x.dim() == 4, "expected 4D input")
x_dtype = x.dtype
v_shape = (1, -1, 1, 1)
if self.apply_act:
x = self.act(x) / group_std(x, self.groups, self.eps)
return x * self.weight.view(v_shape).to(x_dtype) + self.bias.view(v_shape).to(
x_dtype
)
class EvoNorm2dS1a(EvoNorm2dS1):
def __init__(
self,
num_features,
groups=32,
group_size=None,
apply_act=True,
act_layer=None,
eps=1e-3,
**_
):
super().__init__(
num_features,
groups=groups,
group_size=group_size,
apply_act=apply_act,
act_layer=act_layer,
eps=eps,
)
def forward(self, x):
_assert(x.dim() == 4, "expected 4D input")
x_dtype = x.dtype
v_shape = (1, -1, 1, 1)
x = self.act(x) / group_std(x, self.groups, self.eps)
return x * self.weight.view(v_shape).to(x_dtype) + self.bias.view(v_shape).to(
x_dtype
)
class EvoNorm2dS2(nn.Module):
def __init__(
self,
num_features,
groups=32,
group_size=None,
apply_act=True,
act_layer=None,
eps=1e-5,
**_
):
super().__init__()
act_layer = act_layer or nn.SiLU
self.apply_act = apply_act # apply activation (non-linearity)
if act_layer is not None and apply_act:
self.act = create_act_layer(act_layer)
else:
self.act = nn.Identity()
if group_size:
assert num_features % group_size == 0
self.groups = num_features // group_size
else:
self.groups = groups
self.eps = eps
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
self.reset_parameters()
def reset_parameters(self):
nn.init.ones_(self.weight)
nn.init.zeros_(self.bias)
def forward(self, x):
_assert(x.dim() == 4, "expected 4D input")
x_dtype = x.dtype
v_shape = (1, -1, 1, 1)
if self.apply_act:
x = self.act(x) / group_rms(x, self.groups, self.eps)
return x * self.weight.view(v_shape).to(x_dtype) + self.bias.view(v_shape).to(
x_dtype
)
class EvoNorm2dS2a(EvoNorm2dS2):
def __init__(
self,
num_features,
groups=32,
group_size=None,
apply_act=True,
act_layer=None,
eps=1e-3,
**_
):
super().__init__(
num_features,
groups=groups,
group_size=group_size,
apply_act=apply_act,
act_layer=act_layer,
eps=eps,
)
def forward(self, x):
_assert(x.dim() == 4, "expected 4D input")
x_dtype = x.dtype
v_shape = (1, -1, 1, 1)
x = self.act(x) / group_rms(x, self.groups, self.eps)
return x * self.weight.view(v_shape).to(x_dtype) + self.bias.view(v_shape).to(
x_dtype
)
================================================
FILE: RVT/models/layers/maxvit/layers/fast_norm.py
================================================
""" 'Fast' Normalization Functions
For GroupNorm and LayerNorm these functions bypass typical AMP upcast to float32.
Additionally, for LayerNorm, the APEX fused LN is used if available (which also does not upcast)
Hacked together by / Copyright 2022 Ross Wightman
"""
from typing import List, Optional
import torch
from torch.nn import functional as F
try:
from apex.normalization.fused_layer_norm import fused_layer_norm_affine
has_apex = True
except ImportError:
has_apex = False
# fast (ie lower precision LN) can be disabled with this flag if issues crop up
_USE_FAST_NORM = False # defaulting to False for now
def is_fast_norm():
return _USE_FAST_NORM
def set_fast_norm(enable=True):
global _USE_FAST_NORM
_USE_FAST_NORM = enable
def fast_group_norm(
x: torch.Tensor,
num_groups: int,
weight: Optional[torch.Tensor] = None,
bias: Optional[torch.Tensor] = None,
eps: float = 1e-5,
) -> torch.Tensor:
if torch.jit.is_scripting():
# currently cannot use is_autocast_enabled within torchscript
return F.group_norm(x, num_groups, weight, bias, eps)
if torch.is_autocast_enabled():
# normally native AMP casts GN inputs to float32
# here we use the low precision autocast dtype
# FIXME what to do re CPU autocast?
dt = torch.get_autocast_gpu_dtype()
x, weight, bias = x.to(dt), weight.to(dt), bias.to(dt)
with torch.cuda.amp.autocast(enabled=False):
return F.group_norm(x, num_groups, weight, bias, eps)
def fast_layer_norm(
x: torch.Tensor,
normalized_shape: List[int],
weight: Optional[torch.Tensor] = None,
bias: Optional[torch.Tensor] = None,
eps: float = 1e-5,
) -> torch.Tensor:
if torch.jit.is_scripting():
# currently cannot use is_autocast_enabled within torchscript
return F.layer_norm(x, normalized_shape, weight, bias, eps)
if has_apex:
return fused_layer_norm_affine(x, weight, bias, normalized_shape, eps)
if torch.is_autocast_enabled():
# normally native AMP casts LN inputs to float32
# apex LN does not, this is behaving like Apex
dt = torch.get_autocast_gpu_dtype()
# FIXME what to do re CPU autocast?
x, weight, bias = x.to(dt), weight.to(dt), bias.to(dt)
with torch.cuda.amp.autocast(enabled=False):
return F.layer_norm(x, normalized_shape, weight, bias, eps)
================================================
FILE: RVT/models/layers/maxvit/layers/filter_response_norm.py
================================================
""" Filter Response Norm in PyTorch
Based on `Filter Response Normalization Layer` - https://arxiv.org/abs/1911.09737
Hacked together by / Copyright 2021 Ross Wightman
"""
import torch
import torch.nn as nn
from .create_act import create_act_layer
from .trace_utils import _assert
def inv_instance_rms(x, eps: float = 1e-5):
rms = x.square().float().mean(dim=(2, 3), keepdim=True).add(eps).rsqrt().to(x.dtype)
return rms.expand(x.shape)
class FilterResponseNormTlu2d(nn.Module):
def __init__(self, num_features, apply_act=True, eps=1e-5, rms=True, **_):
super(FilterResponseNormTlu2d, self).__init__()
self.apply_act = apply_act # apply activation (non-linearity)
self.rms = rms
self.eps = eps
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
self.tau = nn.Parameter(torch.zeros(num_features)) if apply_act else None
self.reset_parameters()
def reset_parameters(self):
nn.init.ones_(self.weight)
nn.init.zeros_(self.bias)
if self.tau is not None:
nn.init.zeros_(self.tau)
def forward(self, x):
_assert(x.dim() == 4, "expected 4D input")
x_dtype = x.dtype
v_shape = (1, -1, 1, 1)
x = x * inv_instance_rms(x, self.eps)
x = x * self.weight.view(v_shape).to(dtype=x_dtype) + self.bias.view(
v_shape
).to(dtype=x_dtype)
return (
torch.maximum(x, self.tau.reshape(v_shape).to(dtype=x_dtype))
if self.tau is not None
else x
)
class FilterResponseNormAct2d(nn.Module):
def __init__(
self,
num_features,
apply_act=True,
act_layer=nn.ReLU,
inplace=None,
rms=True,
eps=1e-5,
**_
):
super(FilterResponseNormAct2d, self).__init__()
if act_layer is not None and apply_act:
self.act = create_act_layer(act_layer, inplace=inplace)
else:
self.act = nn.Identity()
self.rms = rms
self.eps = eps
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
self.reset_parameters()
def reset_parameters(self):
nn.init.ones_(self.weight)
nn.init.zeros_(self.bias)
def forward(self, x):
_assert(x.dim() == 4, "expected 4D input")
x_dtype = x.dtype
v_shape = (1, -1, 1, 1)
x = x * inv_instance_rms(x, self.eps)
x = x * self.weight.view(v_shape).to(dtype=x_dtype) + self.bias.view(
v_shape
).to(dtype=x_dtype)
return self.act(x)
================================================
FILE: RVT/models/layers/maxvit/layers/gather_excite.py
================================================
""" Gather-Excite Attention Block
Paper: `Gather-Excite: Exploiting Feature Context in CNNs` - https://arxiv.org/abs/1810.12348
Official code here, but it's only partial impl in Caffe: https://github.com/hujie-frank/GENet
I've tried to support all of the extent both w/ and w/o params. I don't believe I've seen another
impl that covers all of the cases.
NOTE: extent=0 + extra_params=False is equivalent to Squeeze-and-Excitation
Hacked together by / Copyright 2021 Ross Wightman
"""
import math
from torch import nn as nn
import torch.nn.functional as F
from .create_act import create_act_layer, get_act_layer
from .create_conv2d import create_conv2d
from .helpers import make_divisible
from .mlp import ConvMlp
class GatherExcite(nn.Module):
"""Gather-Excite Attention Module"""
def __init__(
self,
channels,
feat_size=None,
extra_params=False,
extent=0,
use_mlp=True,
rd_ratio=1.0 / 16,
rd_channels=None,
rd_divisor=1,
add_maxpool=False,
act_layer=nn.ReLU,
norm_layer=nn.BatchNorm2d,
gate_layer="sigmoid",
):
super(GatherExcite, self).__init__()
self.add_maxpool = add_maxpool
act_layer = get_act_layer(act_layer)
self.extent = extent
if extra_params:
self.gather = nn.Sequential()
if extent == 0:
assert (
feat_size is not None
), "spatial feature size must be specified for global extent w/ params"
self.gather.add_module(
"conv1",
create_conv2d(
channels,
channels,
kernel_size=feat_size,
stride=1,
depthwise=True,
),
)
if norm_layer:
self.gather.add_module(f"norm1", nn.BatchNorm2d(channels))
else:
assert extent % 2 == 0
num_conv = int(math.log2(extent))
for i in range(num_conv):
self.gather.add_module(
f"conv{i + 1}",
create_conv2d(
channels, channels, kernel_size=3, stride=2, depthwise=True
),
)
if norm_layer:
self.gather.add_module(f"norm{i + 1}", nn.BatchNorm2d(channels))
if i != num_conv - 1:
self.gather.add_module(f"act{i + 1}", act_layer(inplace=True))
else:
self.gather = None
if self.extent == 0:
self.gk = 0
self.gs = 0
else:
assert extent % 2 == 0
self.gk = self.extent * 2 - 1
self.gs = self.extent
if not rd_channels:
rd_channels = make_divisible(
channels * rd_ratio, rd_divisor, round_limit=0.0
)
self.mlp = (
ConvMlp(channels, rd_channels, act_layer=act_layer)
if use_mlp
else nn.Identity()
)
self.gate = create_act_layer(gate_layer)
def forward(self, x):
size = x.shape[-2:]
if self.gather is not None:
x_ge = self.gather(x)
else:
if self.extent == 0:
# global extent
x_ge = x.mean(dim=(2, 3), keepdims=True)
if self.add_maxpool:
# experimental codepath, may remove or change
x_ge = 0.5 * x_ge + 0.5 * x.amax((2, 3), keepdim=True)
else:
x_ge = F.avg_pool2d(
x,
kernel_size=self.gk,
stride=self.gs,
padding=self.gk // 2,
count_include_pad=False,
)
if self.add_maxpool:
# experimental codepath, may remove or change
x_ge = 0.5 * x_ge + 0.5 * F.max_pool2d(
x, kernel_size=self.gk, stride=self.gs, padding=self.gk // 2
)
x_ge = self.mlp(x_ge)
if x_ge.shape[-1] != 1 or x_ge.shape[-2] != 1:
x_ge = F.interpolate(x_ge, size=size)
return x * self.gate(x_ge)
================================================
FILE: RVT/models/layers/maxvit/layers/global_context.py
================================================
""" Global Context Attention Block
Paper: `GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond`
- https://arxiv.org/abs/1904.11492
Official code consulted as reference: https://github.com/xvjiarui/GCNet
Hacked together by / Copyright 2021 Ross Wightman
"""
from torch import nn as nn
import torch.nn.functional as F
from .create_act import create_act_layer, get_act_layer
from .helpers import make_divisible
from .mlp import ConvMlp
from .norm import LayerNorm2d
class GlobalContext(nn.Module):
def __init__(
self,
channels,
use_attn=True,
fuse_add=False,
fuse_scale=True,
init_last_zero=False,
rd_ratio=1.0 / 8,
rd_channels=None,
rd_divisor=1,
act_layer=nn.ReLU,
gate_layer="sigmoid",
):
super(GlobalContext, self).__init__()
act_layer = get_act_layer(act_layer)
self.conv_attn = (
nn.Conv2d(channels, 1, kernel_size=1, bias=True) if use_attn else None
)
if rd_channels is None:
rd_channels = make_divisible(
channels * rd_ratio, rd_divisor, round_limit=0.0
)
if fuse_add:
self.mlp_add = ConvMlp(
channels, rd_channels, act_layer=act_layer, norm_layer=LayerNorm2d
)
else:
self.mlp_add = None
if fuse_scale:
self.mlp_scale = ConvMlp(
channels, rd_channels, act_layer=act_layer, norm_layer=LayerNorm2d
)
else:
self.mlp_scale = None
self.gate = create_act_layer(gate_layer)
self.init_last_zero = init_last_zero
self.reset_parameters()
def reset_parameters(self):
if self.conv_attn is not None:
nn.init.kaiming_normal_(
self.conv_attn.weight, mode="fan_in", nonlinearity="relu"
)
if self.mlp_add is not None:
nn.init.zeros_(self.mlp_add.fc2.weight)
def forward(self, x):
B, C, H, W = x.shape
if self.conv_attn is not None:
attn = self.conv_attn(x).reshape(B, 1, H * W) # (B, 1, H * W)
attn = F.softmax(attn, dim=-1).unsqueeze(3) # (B, 1, H * W, 1)
context = x.reshape(B, C, H * W).unsqueeze(1) @ attn
context = context.view(B, C, 1, 1)
else:
context = x.mean(dim=(2, 3), keepdim=True)
if self.mlp_scale is not None:
mlp_x = self.mlp_scale(context)
x = x * self.gate(mlp_x)
if self.mlp_add is not None:
mlp_x = self.mlp_add(context)
x = x + mlp_x
return x
================================================
FILE: RVT/models/layers/maxvit/layers/halo_attn.py
================================================
""" Halo Self Attention
Paper: `Scaling Local Self-Attention for Parameter Efficient Visual Backbones`
- https://arxiv.org/abs/2103.12731
@misc{2103.12731,
Author = {Ashish Vaswani and Prajit Ramachandran and Aravind Srinivas and Niki Parmar and Blake Hechtman and
Jonathon Shlens},
Title = {Scaling Local Self-Attention for Parameter Efficient Visual Backbones},
Year = {2021},
}
Status:
This impl is a WIP, there is no official ref impl and some details in paper weren't clear to me.
The attention mechanism works but it's slow as implemented.
Hacked together by / Copyright 2021 Ross Wightman
"""
from typing import List
import torch
from torch import nn
import torch.nn.functional as F
from .helpers import make_divisible
from .weight_init import trunc_normal_
from .trace_utils import _assert
def rel_logits_1d(q, rel_k, permute_mask: List[int]):
"""Compute relative logits along one dimension
As per: https://gist.github.com/aravindsrinivas/56359b79f0ce4449bcb04ab4b56a57a2
Originally from: `Attention Augmented Convolutional Networks` - https://arxiv.org/abs/1904.09925
Args:
q: (batch, height, width, dim)
rel_k: (2 * window - 1, dim)
permute_mask: permute output dim according to this
"""
B, H, W, dim = q.shape
rel_size = rel_k.shape[0]
win_size = (rel_size + 1) // 2
x = q @ rel_k.transpose(-1, -2)
x = x.reshape(-1, W, rel_size)
# pad to shift from relative to absolute indexing
x_pad = F.pad(x, [0, 1]).flatten(1)
x_pad = F.pad(x_pad, [0, rel_size - W])
# reshape and slice out the padded elements
x_pad = x_pad.reshape(-1, W + 1, rel_size)
x = x_pad[:, :W, win_size - 1 :]
# reshape and tile
x = x.reshape(B, H, 1, W, win_size).expand(-1, -1, win_size, -1, -1)
return x.permute(permute_mask)
class PosEmbedRel(nn.Module):
"""Relative Position Embedding
As per: https://gist.github.com/aravindsrinivas/56359b79f0ce4449bcb04ab4b56a57a2
Originally from: `Attention Augmented Convolutional Networks` - https://arxiv.org/abs/1904.09925
"""
def __init__(self, block_size, win_size, dim_head, scale):
"""
Args:
block_size (int): block size
win_size (int): neighbourhood window size
dim_head (int): attention head dim
scale (float): scale factor (for init)
"""
super().__init__()
self.block_size = block_size
self.dim_head = dim_head
self.height_rel = nn.Parameter(torch.randn(win_size * 2 - 1, dim_head) * scale)
self.width_rel = nn.Parameter(torch.randn(win_size * 2 - 1, dim_head) * scale)
def forward(self, q):
B, BB, HW, _ = q.shape
# relative logits in width dimension.
q = q.reshape(-1, self.block_size, self.block_size, self.dim_head)
rel_logits_w = rel_logits_1d(q, self.width_rel, permute_mask=(0, 1, 3, 2, 4))
# relative logits in height dimension.
q = q.transpose(1, 2)
rel_logits_h = rel_logits_1d(q, self.height_rel, permute_mask=(0, 3, 1, 4, 2))
rel_logits = rel_logits_h + rel_logits_w
rel_logits = rel_logits.reshape(B, BB, HW, -1)
return rel_logits
class HaloAttn(nn.Module):
"""Halo Attention
Paper: `Scaling Local Self-Attention for Parameter Efficient Visual Backbones`
- https://arxiv.org/abs/2103.12731
The internal dimensions of the attention module are controlled by the interaction of several arguments.
* the output dimension of the module is specified by dim_out, which falls back to input dim if not set
* the value (v) dimension is set to dim_out // num_heads, the v projection determines the output dim
* the query and key (qk) dimensions are determined by
* num_heads * dim_head if dim_head is not None
* num_heads * (dim_out * attn_ratio // num_heads) if dim_head is None
* as seen above, attn_ratio determines the ratio of q and k relative to the output if dim_head not used
Args:
dim (int): input dimension to the module
dim_out (int): output dimension of the module, same as dim if not set
feat_size (Tuple[int, int]): size of input feature_map (not used, for arg compat with bottle/lambda)
stride: output stride of the module, query downscaled if > 1 (default: 1).
num_heads: parallel attention heads (default: 8).
dim_head: dimension of query and key heads, calculated from dim_out * attn_ratio // num_heads if not set
block_size (int): size of blocks. (default: 8)
halo_size (int): size of halo overlap. (default: 3)
qk_ratio (float): ratio of q and k dimensions to output dimension when dim_head not set. (default: 1.0)
qkv_bias (bool) : add bias to q, k, and v projections
avg_down (bool): use average pool downsample instead of strided query blocks
scale_pos_embed (bool): scale the position embedding as well as Q @ K
"""
def __init__(
self,
dim,
dim_out=None,
feat_size=None,
stride=1,
num_heads=8,
dim_head=None,
block_size=8,
halo_size=3,
qk_ratio=1.0,
qkv_bias=False,
avg_down=False,
scale_pos_embed=False,
):
super().__init__()
dim_out = dim_out or dim
assert dim_out % num_heads == 0
assert stride in (1, 2)
self.num_heads = num_heads
self.dim_head_qk = (
dim_head or make_divisible(dim_out * qk_ratio, divisor=8) // num_heads
)
self.dim_head_v = dim_out // self.num_heads
self.dim_out_qk = num_heads * self.dim_head_qk
self.dim_out_v = num_heads * self.dim_head_v
self.scale = self.dim_head_qk**-0.5
self.scale_pos_embed = scale_pos_embed
self.block_size = self.block_size_ds = block_size
self.halo_size = halo_size
self.win_size = block_size + halo_size * 2 # neighbourhood window size
self.block_stride = 1
use_avg_pool = False
if stride > 1:
use_avg_pool = avg_down or block_size % stride != 0
self.block_stride = 1 if use_avg_pool else stride
self.block_size_ds = self.block_size // self.block_stride
# FIXME not clear if this stride behaviour is what the paper intended
# Also, the paper mentions using a 3D conv for dealing with the blocking/gather, and leaving
# data in unfolded block form. I haven't wrapped my head around how that'd look.
self.q = nn.Conv2d(
dim, self.dim_out_qk, 1, stride=self.block_stride, bias=qkv_bias
)
self.kv = nn.Conv2d(dim, self.dim_out_qk + self.dim_out_v, 1, bias=qkv_bias)
self.pos_embed = PosEmbedRel(
block_size=self.block_size_ds,
win_size=self.win_size,
dim_head=self.dim_head_qk,
scale=self.scale,
)
self.pool = nn.AvgPool2d(2, 2) if use_avg_pool else nn.Identity()
self.reset_parameters()
def reset_parameters(self):
std = self.q.weight.shape[1] ** -0.5 # fan-in
trunc_normal_(self.q.weight, std=std)
trunc_normal_(self.kv.weight, std=std)
trunc_normal_(self.pos_embed.height_rel, std=self.scale)
trunc_normal_(self.pos_embed.width_rel, std=self.scale)
def forward(self, x):
B, C, H, W = x.shape
_assert(H % self.block_size == 0, "")
_assert(W % self.block_size == 0, "")
num_h_blocks = H // self.block_size
num_w_blocks = W // self.block_size
num_blocks = num_h_blocks * num_w_blocks
q = self.q(x)
# unfold
q = q.reshape(
-1,
self.dim_head_qk,
num_h_blocks,
self.block_size_ds,
num_w_blocks,
self.block_size_ds,
).permute(0, 1, 3, 5, 2, 4)
# B, num_heads * dim_head * block_size ** 2, num_blocks
q = q.reshape(B * self.num_heads, self.dim_head_qk, -1, num_blocks).transpose(
1, 3
)
# B * num_heads, num_blocks, block_size ** 2, dim_head
kv = self.kv(x)
# Generate overlapping windows for kv. This approach is good for GPU and CPU. However, unfold() is not
# lowered for PyTorch XLA so it will be very slow. See code at bottom of file for XLA friendly approach.
# FIXME figure out how to switch impl between this and conv2d if XLA being used.
kv = F.pad(kv, [self.halo_size, self.halo_size, self.halo_size, self.halo_size])
kv = (
kv.unfold(2, self.win_size, self.block_size)
.unfold(3, self.win_size, self.block_size)
.reshape(
B * self.num_heads, self.dim_head_qk + self.dim_head_v, num_blocks, -1
)
.permute(0, 2, 3, 1)
)
k, v = torch.split(kv, [self.dim_head_qk, self.dim_head_v], dim=-1)
# B * num_heads, num_blocks, win_size ** 2, dim_head_qk or dim_head_v
if self.scale_pos_embed:
attn = (q @ k.transpose(-1, -2) + self.pos_embed(q)) * self.scale
else:
attn = (q @ k.transpose(-1, -2)) * self.scale + self.pos_embed(q)
# B * num_heads, num_blocks, block_size ** 2, win_size ** 2
attn = attn.softmax(dim=-1)
out = (attn @ v).transpose(
1, 3
) # B * num_heads, dim_head_v, block_size ** 2, num_blocks
# fold
out = out.reshape(
-1, self.block_size_ds, self.block_size_ds, num_h_blocks, num_w_blocks
)
out = (
out.permute(0, 3, 1, 4, 2)
.contiguous()
.view(B, self.dim_out_v, H // self.block_stride, W // self.block_stride)
)
# B, dim_out, H // block_stride, W // block_stride
out = self.pool(out)
return out
""" Three alternatives for overlapping windows.
`.unfold().unfold()` is same speed as stride tricks with similar clarity as F.unfold()
if is_xla:
# This code achieves haloing on PyTorch XLA with reasonable runtime trade-off, it is
# EXTREMELY slow for backward on a GPU though so I need a way of selecting based on environment.
WW = self.win_size ** 2
pw = torch.eye(WW, dtype=x.dtype, device=x.device).reshape(WW, 1, self.win_size, self.win_size)
kv = F.conv2d(kv.reshape(-1, 1, H, W), pw, stride=self.block_size, padding=self.halo_size)
elif self.stride_tricks:
kv = F.pad(kv, [self.halo_size, self.halo_size, self.halo_size, self.halo_size]).contiguous()
kv = kv.as_strided((
B, self.dim_out_qk + self.dim_out_v, self.win_size, self.win_size, num_h_blocks, num_w_blocks),
stride=(kv.stride(0), kv.stride(1), kv.shape[-1], 1, self.block_size * kv.shape[-1], self.block_size))
else:
kv = F.unfold(kv, kernel_size=self.win_size, stride=self.block_size, padding=self.halo_size)
kv = kv.reshape(
B * self.num_heads, self.dim_head_qk + self.dim_head_v, -1, num_blocks).transpose(1, 3)
"""
================================================
FILE: RVT/models/layers/maxvit/layers/helpers.py
================================================
""" Layer/Module Helpers
Hacked together by / Copyright 2020 Ross Wightman
"""
from itertools import repeat
import collections.abc
# From PyTorch internals
def _ntuple(n):
def parse(x):
if isinstance(x, collections.abc.Iterable) and not isinstance(x, str):
return x
return tuple(repeat(x, n))
return parse
to_1tuple = _ntuple(1)
to_2tuple = _ntuple(2)
to_3tuple = _ntuple(3)
to_4tuple = _ntuple(4)
to_ntuple = _ntuple
def make_divisible(v, divisor=8, min_value=None, round_limit=0.9):
min_value = min_value or divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < round_limit * v:
new_v += divisor
return new_v
def extend_tuple(x, n):
# pdas a tuple to specified n by padding with last value
if not isinstance(x, (tuple, list)):
x = (x,)
else:
x = tuple(x)
pad_n = n - len(x)
if pad_n <= 0:
return x[:n]
return x + (x[-1],) * pad_n
================================================
FILE: RVT/models/layers/maxvit/layers/inplace_abn.py
================================================
import torch
from torch import nn as nn
try:
from inplace_abn.functions import inplace_abn, inplace_abn_sync
has_iabn = True
except ImportError:
has_iabn = False
def inplace_abn(
x,
weight,
bias,
running_mean,
running_var,
training=True,
momentum=0.1,
eps=1e-05,
activation="leaky_relu",
activation_param=0.01,
):
raise ImportError(
"Please install InplaceABN:'pip install git+https://github.com/mapillary/inplace_abn.git@v1.0.12'"
)
def inplace_abn_sync(**kwargs):
inplace_abn(**kwargs)
class InplaceAbn(nn.Module):
"""Activated Batch Normalization
This gathers a BatchNorm and an activation function in a single module
Parameters
----------
num_features : int
Number of feature channels in the input and output.
eps : float
Small constant to prevent numerical issues.
momentum : float
Momentum factor applied to compute running statistics.
affine : bool
If `True` apply learned scale and shift transformation after normalization.
act_layer : str or nn.Module type
Name or type of the activation functions, one of: `leaky_relu`, `elu`
act_param : float
Negative slope for the `leaky_relu` activation.
"""
def __init__(
self,
num_features,
eps=1e-5,
momentum=0.1,
affine=True,
apply_act=True,
act_layer="leaky_relu",
act_param=0.01,
drop_layer=None,
):
super(InplaceAbn, self).__init__()
self.num_features = num_features
self.affine = affine
self.eps = eps
self.momentum = momentum
if apply_act:
if isinstance(act_layer, str):
assert act_layer in ("leaky_relu", "elu", "identity", "")
self.act_name = act_layer if act_layer else "identity"
else:
# convert act layer passed as type to string
if act_layer == nn.ELU:
self.act_name = "elu"
elif act_layer == nn.LeakyReLU:
self.act_name = "leaky_relu"
elif act_layer is None or act_layer == nn.Identity:
self.act_name = "identity"
else:
assert False, f"Invalid act layer {act_layer.__name__} for IABN"
else:
self.act_name = "identity"
self.act_param = act_param
if self.affine:
self.weight = nn.Parameter(torch.ones(num_features))
self.bias = nn.Parameter(torch.zeros(num_features))
else:
self.register_parameter("weight", None)
self.register_parameter("bias", None)
self.register_buffer("running_mean", torch.zeros(num_features))
self.register_buffer("running_var", torch.ones(num_features))
self.reset_parameters()
def reset_parameters(self):
nn.init.constant_(self.running_mean, 0)
nn.init.constant_(self.running_var, 1)
if self.affine:
nn.init.constant_(self.weight, 1)
nn.init.constant_(self.bias, 0)
def forward(self, x):
output = inplace_abn(
x,
self.weight,
self.bias,
self.running_mean,
self.running_var,
self.training,
self.momentum,
self.eps,
self.act_name,
self.act_param,
)
if isinstance(output, tuple):
output = output[0]
return output
================================================
FILE: RVT/models/layers/maxvit/layers/lambda_layer.py
================================================
""" Lambda Layer
Paper: `LambdaNetworks: Modeling Long-Range Interactions Without Attention`
- https://arxiv.org/abs/2102.08602
@misc{2102.08602,
Author = {Irwan Bello},
Title = {LambdaNetworks: Modeling Long-Range Interactions Without Attention},
Year = {2021},
}
Status:
This impl is a WIP. Code snippets in the paper were used as reference but
good chance some details are missing/wrong.
I've only implemented local lambda conv based pos embeddings.
For a PyTorch impl that includes other embedding options checkout
https://github.com/lucidrains/lambda-networks
Hacked together by / Copyright 2021 Ross Wightman
"""
import torch
from torch import nn
import torch.nn.functional as F
from .helpers import to_2tuple, make_divisible
from .weight_init import trunc_normal_
def rel_pos_indices(size):
size = to_2tuple(size)
pos = torch.stack(
torch.meshgrid(torch.arange(size[0]), torch.arange(size[1]))
).flatten(1)
rel_pos = pos[:, None, :] - pos[:, :, None]
rel_pos[0] += size[0] - 1
rel_pos[1] += size[1] - 1
return rel_pos # 2, H * W, H * W
class LambdaLayer(nn.Module):
"""Lambda Layer
Paper: `LambdaNetworks: Modeling Long-Range Interactions Without Attention`
- https://arxiv.org/abs/2102.08602
NOTE: intra-depth parameter 'u' is fixed at 1. It did not appear worth the complexity to add.
The internal dimensions of the lambda module are controlled via the interaction of several arguments.
* the output dimension of the module is specified by dim_out, which falls back to input dim if not set
* the value (v) dimension is set to dim_out // num_heads, the v projection determines the output dim
* the query (q) and key (k) dimension are determined by
* dim_head = (dim_out * attn_ratio // num_heads) if dim_head is None
* q = num_heads * dim_head, k = dim_head
* as seen above, attn_ratio determines the ratio of q and k relative to the output if dim_head not set
Args:
dim (int): input dimension to the module
dim_out (int): output dimension of the module, same as dim if not set
feat_size (Tuple[int, int]): size of input feature_map for relative pos variant H, W
stride (int): output stride of the module, avg pool used if stride == 2
num_heads (int): parallel attention heads.
dim_head (int): dimension of query and key heads, calculated from dim_out * attn_ratio // num_heads if not set
r (int): local lambda convolution radius. Use lambda conv if set, else relative pos if not. (default: 9)
qk_ratio (float): ratio of q and k dimensions to output dimension when dim_head not set. (default: 1.0)
qkv_bias (bool): add bias to q, k, and v projections
"""
def __init__(
self,
dim,
dim_out=None,
feat_size=None,
stride=1,
num_heads=4,
dim_head=16,
r=9,
qk_ratio=1.0,
qkv_bias=False,
):
super().__init__()
dim_out = dim_out or dim
assert dim_out % num_heads == 0, " should be divided by num_heads"
self.dim_qk = (
dim_head or make_divisible(dim_out * qk_ratio, divisor=8) // num_heads
)
self.num_heads = num_heads
self.dim_v = dim_out // num_heads
self.qkv = nn.Conv2d(
dim,
num_heads * self.dim_qk + self.dim_qk + self.dim_v,
kernel_size=1,
bias=qkv_bias,
)
self.norm_q = nn.BatchNorm2d(num_heads * self.dim_qk)
self.norm_v = nn.BatchNorm2d(self.dim_v)
if r is not None:
# local lambda convolution for pos
self.conv_lambda = nn.Conv3d(
1, self.dim_qk, (r, r, 1), padding=(r // 2, r // 2, 0)
)
self.pos_emb = None
self.rel_pos_indices = None
else:
# relative pos embedding
assert feat_size is not None
feat_size = to_2tuple(feat_size)
rel_size = [2 * s - 1 for s in feat_size]
self.conv_lambda = None
self.pos_emb = nn.Parameter(
torch.zeros(rel_size[0], rel_size[1], self.dim_qk)
)
self.register_buffer(
"rel_pos_indices", rel_pos_indices(feat_size), persistent=False
)
self.pool = nn.AvgPool2d(2, 2) if stride == 2 else nn.Identity()
self.reset_parameters()
def reset_parameters(self):
trunc_normal_(self.qkv.weight, std=self.qkv.weight.shape[1] ** -0.5) # fan-in
if self.conv_lambda is not None:
trunc_normal_(self.conv_lambda.weight, std=self.dim_qk**-0.5)
if self.pos_emb is not None:
trunc_normal_(self.pos_emb, std=0.02)
def forward(self, x):
B, C, H, W = x.shape
M = H * W
qkv = self.qkv(x)
q, k, v = torch.split(
qkv, [self.num_heads * self.dim_qk, self.dim_qk, self.dim_v], dim=1
)
q = (
self.norm_q(q).reshape(B, self.num_heads, self.dim_qk, M).transpose(-1, -2)
) # B, num_heads, M, K
v = self.norm_v(v).reshape(B, self.dim_v, M).transpose(-1, -2) # B, M, V
k = F.softmax(k.reshape(B, self.dim_qk, M), dim=-1) # B, K, M
content_lam = k @ v # B, K, V
content_out = q @ content_lam.unsqueeze(1) # B, num_heads, M, V
if self.pos_emb is None:
position_lam = self.conv_lambda(
v.reshape(B, 1, H, W, self.dim_v)
) # B, H, W, V, K
position_lam = position_lam.reshape(
B, 1, self.dim_qk, H * W, self.dim_v
).transpose(
2, 3
) # B, 1, M, K, V
else:
# FIXME relative pos embedding path not fully verified
pos_emb = self.pos_emb[
self.rel_pos_indices[0], self.rel_pos_indices[1]
].expand(B, -1, -1, -1)
position_lam = (pos_emb.transpose(-1, -2) @ v.unsqueeze(1)).unsqueeze(
1
) # B, 1, M, K, V
position_out = (q.unsqueeze(-2) @ position_lam).squeeze(
-2
) # B, num_heads, M, V
out = (
(content_out + position_out).transpose(-1, -2).reshape(B, C, H, W)
) # B, C (num_heads * V), H, W
out = self.pool(out)
return out
================================================
FILE: RVT/models/layers/maxvit/layers/linear.py
================================================
""" Linear layer (alternate definition)
"""
import torch
import torch.nn.functional as F
from torch import nn as nn
class Linear(nn.Linear):
r"""Applies a linear transformation to the incoming data: :math:`y = xA^T + b`
Wraps torch.nn.Linear to support AMP + torchscript usage by manually casting
weight & bias to input.dtype to work around an issue w/ torch.addmm in this use case.
"""
def forward(self, input: torch.Tensor) -> torch.Tensor:
if torch.jit.is_scripting():
bias = self.bias.to(dtype=input.dtype) if self.bias is not None else None
return F.linear(input, self.weight.to(dtype=input.dtype), bias=bias)
else:
return F.linear(input, self.weight, self.bias)
================================================
FILE: RVT/models/layers/maxvit/layers/median_pool.py
================================================
""" Median Pool
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch.nn as nn
import torch.nn.functional as F
from .helpers import to_2tuple, to_4tuple
class MedianPool2d(nn.Module):
"""Median pool (usable as median filter when stride=1) module.
Args:
kernel_size: size of pooling kernel, int or 2-tuple
stride: pool stride, int or 2-tuple
padding: pool padding, int or 4-tuple (l, r, t, b) as in pytorch F.pad
same: override padding and enforce same padding, boolean
"""
def __init__(self, kernel_size=3, stride=1, padding=0, same=False):
super(MedianPool2d, self).__init__()
self.k = to_2tuple(kernel_size)
self.stride = to_2tuple(stride)
self.padding = to_4tuple(padding) # convert to l, r, t, b
self.same = same
def _padding(self, x):
if self.same:
ih, iw = x.size()[2:]
if ih % self.stride[0] == 0:
ph = max(self.k[0] - self.stride[0], 0)
else:
ph = max(self.k[0] - (ih % self.stride[0]), 0)
if iw % self.stride[1] == 0:
pw = max(self.k[1] - self.stride[1], 0)
else:
pw = max(self.k[1] - (iw % self.stride[1]), 0)
pl = pw // 2
pr = pw - pl
pt = ph // 2
pb = ph - pt
padding = (pl, pr, pt, pb)
else:
padding = self.padding
return padding
def forward(self, x):
x = F.pad(x, self._padding(x), mode="reflect")
x = x.unfold(2, self.k[0], self.stride[0]).unfold(3, self.k[1], self.stride[1])
x = x.contiguous().view(x.size()[:4] + (-1,)).median(dim=-1)[0]
return x
================================================
FILE: RVT/models/layers/maxvit/layers/mixed_conv2d.py
================================================
""" PyTorch Mixed Convolution
Paper: MixConv: Mixed Depthwise Convolutional Kernels (https://arxiv.org/abs/1907.09595)
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch
from torch import nn as nn
from .conv2d_same import create_conv2d_pad
def _split_channels(num_chan, num_groups):
split = [num_chan // num_groups for _ in range(num_groups)]
split[0] += num_chan - sum(split)
return split
class MixedConv2d(nn.ModuleDict):
"""Mixed Grouped Convolution
Based on MDConv and GroupedConv in MixNet impl:
https://github.com/tensorflow/tpu/blob/master/models/official/mnasnet/mixnet/custom_layers.py
"""
def __init__(
self,
in_channels,
out_channels,
kernel_size=3,
stride=1,
padding="",
dilation=1,
depthwise=False,
**kwargs
):
super(MixedConv2d, self).__init__()
kernel_size = kernel_size if isinstance(kernel_size, list) else [kernel_size]
num_groups = len(kernel_size)
in_splits = _split_channels(in_channels, num_groups)
out_splits = _split_channels(out_channels, num_groups)
self.in_channels = sum(in_splits)
self.out_channels = sum(out_splits)
for idx, (k, in_ch, out_ch) in enumerate(
zip(kernel_size, in_splits, out_splits)
):
conv_groups = in_ch if depthwise else 1
# use add_module to keep key space clean
self.add_module(
str(idx),
create_conv2d_pad(
in_ch,
out_ch,
k,
stride=stride,
padding=padding,
dilation=dilation,
groups=conv_groups,
**kwargs
),
)
self.splits = in_splits
def forward(self, x):
x_split = torch.split(x, self.splits, 1)
x_out = [c(x_split[i]) for i, c in enumerate(self.values())]
x = torch.cat(x_out, 1)
return x
================================================
FILE: RVT/models/layers/maxvit/layers/ml_decoder.py
================================================
from typing import Optional
import torch
from torch import nn
from torch import nn, Tensor
from torch.nn.modules.transformer import _get_activation_fn
def add_ml_decoder_head(model):
if hasattr(model, "global_pool") and hasattr(
model, "fc"
): # most CNN models, like Resnet50
model.global_pool = nn.Identity()
del model.fc
num_classes = model.num_classes
num_features = model.num_features
model.fc = MLDecoder(num_classes=num_classes, initial_num_features=num_features)
elif hasattr(model, "global_pool") and hasattr(model, "classifier"): # EfficientNet
model.global_pool = nn.Identity()
del model.classifier
num_classes = model.num_classes
num_features = model.num_features
model.classifier = MLDecoder(
num_classes=num_classes, initial_num_features=num_features
)
elif (
"RegNet" in model._get_name() or "TResNet" in model._get_name()
): # hasattr(model, 'head')
del model.head
num_classes = model.num_classes
num_features = model.num_features
model.head = MLDecoder(
num_classes=num_classes, initial_num_features=num_features
)
else:
print("Model code-writing is not aligned currently with ml-decoder")
exit(-1)
if hasattr(model, "drop_rate"): # Ml-Decoder has inner dropout
model.drop_rate = 0
return model
class TransformerDecoderLayerOptimal(nn.Module):
def __init__(
self,
d_model,
nhead=8,
dim_feedforward=2048,
dropout=0.1,
activation="relu",
layer_norm_eps=1e-5,
) -> None:
super(TransformerDecoderLayerOptimal, self).__init__()
self.norm1 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.dropout = nn.Dropout(dropout)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm2 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm3 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.activation = _get_activation_fn(activation)
def __setstate__(self, state):
if "activation" not in state:
state["activation"] = torch.nn.functional.relu
super(TransformerDecoderLayerOptimal, self).__setstate__(state)
def forward(
self,
tgt: Tensor,
memory: Tensor,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
) -> Tensor:
tgt = tgt + self.dropout1(tgt)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(tgt, memory, memory)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
# @torch.jit.script
# class ExtrapClasses(object):
# def __init__(self, num_queries: int, group_size: int):
# self.num_queries = num_queries
# self.group_size = group_size
#
# def __call__(self, h: torch.Tensor, class_embed_w: torch.Tensor, class_embed_b: torch.Tensor, out_extrap:
# torch.Tensor):
# # h = h.unsqueeze(-1).expand(-1, -1, -1, self.group_size)
# h = h[..., None].repeat(1, 1, 1, self.group_size) # torch.Size([bs, 5, 768, groups])
# w = class_embed_w.view((self.num_queries, h.shape[2], self.group_size))
# out = (h * w).sum(dim=2) + class_embed_b
# out = out.view((h.shape[0], self.group_size * self.num_queries))
# return out
@torch.jit.script
class GroupFC(object):
def __init__(self, embed_len_decoder: int):
self.embed_len_decoder = embed_len_decoder
def __call__(
self, h: torch.Tensor, duplicate_pooling: torch.Tensor, out_extrap: torch.Tensor
):
for i in range(self.embed_len_decoder):
h_i = h[:, i, :]
w_i = duplicate_pooling[i, :, :]
out_extrap[:, i, :] = torch.matmul(h_i, w_i)
class MLDecoder(nn.Module):
def __init__(
self,
num_classes,
num_of_groups=-1,
decoder_embedding=768,
initial_num_features=2048,
):
super(MLDecoder, self).__init__()
embed_len_decoder = 100 if num_of_groups < 0 else num_of_groups
if embed_len_decoder > num_classes:
embed_len_decoder = num_classes
# switching to 768 initial embeddings
decoder_embedding = 768 if decoder_embedding < 0 else decoder_embedding
self.embed_standart = nn.Linear(initial_num_features, decoder_embedding)
# decoder
decoder_dropout = 0.1
num_layers_decoder = 1
dim_feedforward = 2048
layer_decode = TransformerDecoderLayerOptimal(
d_model=decoder_embedding,
dim_feedforward=dim_feedforward,
dropout=decoder_dropout,
)
self.decoder = nn.TransformerDecoder(
layer_decode, num_layers=num_layers_decoder
)
# non-learnable queries
self.query_embed = nn.Embedding(embed_len_decoder, decoder_embedding)
self.query_embed.requires_grad_(False)
# group fully-connected
self.num_classes = num_classes
self.duplicate_factor = int(num_classes / embed_len_decoder + 0.999)
self.duplicate_pooling = torch.nn.Parameter(
torch.Tensor(embed_len_decoder, decoder_embedding, self.duplicate_factor)
)
self.duplicate_pooling_bias = torch.nn.Parameter(torch.Tensor(num_classes))
torch.nn.init.xavier_normal_(self.duplicate_pooling)
torch.nn.init.constant_(self.duplicate_pooling_bias, 0)
self.group_fc = GroupFC(embed_len_decoder)
def forward(self, x):
if len(x.shape) == 4: # [bs,2048, 7,7]
embedding_spatial = x.flatten(2).transpose(1, 2)
else: # [bs, 197,468]
embedding_spatial = x
embedding_spatial_786 = self.embed_standart(embedding_spatial)
embedding_spatial_786 = torch.nn.functional.relu(
embedding_spatial_786, inplace=True
)
bs = embedding_spatial_786.shape[0]
query_embed = self.query_embed.weight
# tgt = query_embed.unsqueeze(1).repeat(1, bs, 1)
tgt = query_embed.unsqueeze(1).expand(
-1, bs, -1
) # no allocation of memory with expand
h = self.decoder(
tgt, embedding_spatial_786.transpose(0, 1)
) # [embed_len_decoder, batch, 768]
h = h.transpose(0, 1)
out_extrap = torch.zeros(
h.shape[0],
h.shape[1],
self.duplicate_factor,
device=h.device,
dtype=h.dtype,
)
self.group_fc(h, self.duplicate_pooling, out_extrap)
h_out = out_extrap.flatten(1)[:, : self.num_classes]
h_out += self.duplicate_pooling_bias
logits = h_out
return logits
================================================
FILE: RVT/models/layers/maxvit/layers/mlp.py
================================================
""" MLP module w/ dropout and configurable activation layer
Hacked together by / Copyright 2020 Ross Wightman
"""
from torch import nn as nn
from .helpers import to_2tuple
class Mlp(nn.Module):
"""MLP as used in Vision Transformer, MLP-Mixer and related networks"""
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU,
bias=True,
drop=0.0,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
bias = to_2tuple(bias)
drop_probs = to_2tuple(drop)
self.fc1 = nn.Linear(in_features, hidden_features, bias=bias[0])
self.act = act_layer()
self.drop1 = nn.Dropout(drop_probs[0])
self.fc2 = nn.Linear(hidden_features, out_features, bias=bias[1])
self.drop2 = nn.Dropout(drop_probs[1])
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class GluMlp(nn.Module):
"""MLP w/ GLU style gating
See: https://arxiv.org/abs/1612.08083, https://arxiv.org/abs/2002.05202
"""
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.Sigmoid,
bias=True,
drop=0.0,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
assert hidden_features % 2 == 0
bias = to_2tuple(bias)
drop_probs = to_2tuple(drop)
self.fc1 = nn.Linear(in_features, hidden_features, bias=bias[0])
self.act = act_layer()
self.drop1 = nn.Dropout(drop_probs[0])
self.fc2 = nn.Linear(hidden_features // 2, out_features, bias=bias[1])
self.drop2 = nn.Dropout(drop_probs[1])
def init_weights(self):
# override init of fc1 w/ gate portion set to weight near zero, bias=1
fc1_mid = self.fc1.bias.shape[0] // 2
nn.init.ones_(self.fc1.bias[fc1_mid:])
nn.init.normal_(self.fc1.weight[fc1_mid:], std=1e-6)
def forward(self, x):
x = self.fc1(x)
x, gates = x.chunk(2, dim=-1)
x = x * self.act(gates)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class GatedMlp(nn.Module):
"""MLP as used in gMLP"""
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.GELU,
gate_layer=None,
bias=True,
drop=0.0,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
bias = to_2tuple(bias)
drop_probs = to_2tuple(drop)
self.fc1 = nn.Linear(in_features, hidden_features, bias=bias[0])
self.act = act_layer()
self.drop1 = nn.Dropout(drop_probs[0])
if gate_layer is not None:
assert hidden_features % 2 == 0
self.gate = gate_layer(hidden_features)
hidden_features = (
hidden_features // 2
) # FIXME base reduction on gate property?
else:
self.gate = nn.Identity()
self.fc2 = nn.Linear(hidden_features, out_features, bias=bias[1])
self.drop2 = nn.Dropout(drop_probs[1])
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.gate(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class ConvMlp(nn.Module):
"""MLP using 1x1 convs that keeps spatial dims"""
def __init__(
self,
in_features,
hidden_features=None,
out_features=None,
act_layer=nn.ReLU,
norm_layer=None,
bias=True,
drop=0.0,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
bias = to_2tuple(bias)
self.fc1 = nn.Conv2d(in_features, hidden_features, kernel_size=1, bias=bias[0])
self.norm = norm_layer(hidden_features) if norm_layer else nn.Identity()
self.act = act_layer()
self.drop = nn.Dropout(drop)
self.fc2 = nn.Conv2d(hidden_features, out_features, kernel_size=1, bias=bias[1])
def forward(self, x):
x = self.fc1(x)
x = self.norm(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
return x
================================================
FILE: RVT/models/layers/maxvit/layers/non_local_attn.py
================================================
""" Bilinear-Attention-Transform and Non-Local Attention
Paper: `Non-Local Neural Networks With Grouped Bilinear Attentional Transforms`
- https://openaccess.thecvf.com/content_CVPR_2020/html/Chi_Non-Local_Neural_Networks_With_Grouped_Bilinear_Attentional_Transforms_CVPR_2020_paper.html
Adapted from original code: https://github.com/BA-Transform/BAT-Image-Classification
"""
import torch
from torch import nn
from torch.nn import functional as F
from .conv_bn_act import ConvNormAct
from .helpers import make_divisible
from .trace_utils import _assert
class NonLocalAttn(nn.Module):
"""Spatial NL block for image classification.
This was adapted from https://github.com/BA-Transform/BAT-Image-Classification
Their NonLocal impl inspired by https://github.com/facebookresearch/video-nonlocal-net.
"""
def __init__(
self,
in_channels,
use_scale=True,
rd_ratio=1 / 8,
rd_channels=None,
rd_divisor=8,
**kwargs
):
super(NonLocalAttn, self).__init__()
if rd_channels is None:
rd_channels = make_divisible(in_channels * rd_ratio, divisor=rd_divisor)
self.scale = in_channels**-0.5 if use_scale else 1.0
self.t = nn.Conv2d(in_channels, rd_channels, kernel_size=1, stride=1, bias=True)
self.p = nn.Conv2d(in_channels, rd_channels, kernel_size=1, stride=1, bias=True)
self.g = nn.Conv2d(in_channels, rd_channels, kernel_size=1, stride=1, bias=True)
self.z = nn.Conv2d(rd_channels, in_channels, kernel_size=1, stride=1, bias=True)
self.norm = nn.BatchNorm2d(in_channels)
self.reset_parameters()
def forward(self, x):
shortcut = x
t = self.t(x)
p = self.p(x)
g = self.g(x)
B, C, H, W = t.size()
t = t.view(B, C, -1).permute(0, 2, 1)
p = p.view(B, C, -1)
g = g.view(B, C, -1).permute(0, 2, 1)
att = torch.bmm(t, p) * self.scale
att = F.softmax(att, dim=2)
x = torch.bmm(att, g)
x = x.permute(0, 2, 1).reshape(B, C, H, W)
x = self.z(x)
x = self.norm(x) + shortcut
return x
def reset_parameters(self):
for name, m in self.named_modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
if len(list(m.parameters())) > 1:
nn.init.constant_(m.bias, 0.0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 0)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.GroupNorm):
nn.init.constant_(m.weight, 0)
nn.init.constant_(m.bias, 0)
class BilinearAttnTransform(nn.Module):
def __init__(
self,
in_channels,
block_size,
groups,
act_layer=nn.ReLU,
norm_layer=nn.BatchNorm2d,
):
super(BilinearAttnTransform, self).__init__()
self.conv1 = ConvNormAct(
in_channels, groups, 1, act_layer=act_layer, norm_layer=norm_layer
)
self.conv_p = nn.Conv2d(
groups, block_size * block_size * groups, kernel_size=(block_size, 1)
)
self.conv_q = nn.Conv2d(
groups, block_size * block_size * groups, kernel_size=(1, block_size)
)
self.conv2 = ConvNormAct(
in_channels, in_channels, 1, act_layer=act_layer, norm_layer=norm_layer
)
self.block_size = block_size
self.groups = groups
self.in_channels = in_channels
def resize_mat(self, x, t: int):
B, C, block_size, block_size1 = x.shape
_assert(block_size == block_size1, "")
if t <= 1:
return x
x = x.view(B * C, -1, 1, 1)
x = x * torch.eye(t, t, dtype=x.dtype, device=x.device)
x = x.view(B * C, block_size, block_size, t, t)
x = torch.cat(torch.split(x, 1, dim=1), dim=3)
x = torch.cat(torch.split(x, 1, dim=2), dim=4)
x = x.view(B, C, block_size * t, block_size * t)
return x
def forward(self, x):
_assert(x.shape[-1] % self.block_size == 0, "")
_assert(x.shape[-2] % self.block_size == 0, "")
B, C, H, W = x.shape
out = self.conv1(x)
rp = F.adaptive_max_pool2d(out, (self.block_size, 1))
cp = F.adaptive_max_pool2d(out, (1, self.block_size))
p = (
self.conv_p(rp)
.view(B, self.groups, self.block_size, self.block_size)
.sigmoid()
)
q = (
self.conv_q(cp)
.view(B, self.groups, self.block_size, self.block_size)
.sigmoid()
)
p = p / p.sum(dim=3, keepdim=True)
q = q / q.sum(dim=2, keepdim=True)
p = (
p.view(B, self.groups, 1, self.block_size, self.block_size)
.expand(
x.size(0),
self.groups,
C // self.groups,
self.block_size,
self.block_size,
)
.contiguous()
)
p = p.view(B, C, self.block_size, self.block_size)
q = (
q.view(B, self.groups, 1, self.block_size, self.block_size)
.expand(
x.size(0),
self.groups,
C // self.groups,
self.block_size,
self.block_size,
)
.contiguous()
)
q = q.view(B, C, self.block_size, self.block_size)
p = self.resize_mat(p, H // self.block_size)
q = self.resize_mat(q, W // self.block_size)
y = p.matmul(x)
y = y.matmul(q)
y = self.conv2(y)
return y
class BatNonLocalAttn(nn.Module):
"""BAT
Adapted from: https://github.com/BA-Transform/BAT-Image-Classification
"""
def __init__(
self,
in_channels,
block_size=7,
groups=2,
rd_ratio=0.25,
rd_channels=None,
rd_divisor=8,
drop_rate=0.2,
act_layer=nn.ReLU,
norm_layer=nn.BatchNorm2d,
**_
):
super().__init__()
if rd_channels is None:
rd_channels = make_divisible(in_channels * rd_ratio, divisor=rd_divisor)
self.conv1 = ConvNormAct(
in_channels, rd_channels, 1, act_layer=act_layer, norm_layer=norm_layer
)
self.ba = BilinearAttnTransform(
rd_channels, block_size, groups, act_layer=act_layer, norm_layer=norm_layer
)
self.conv2 = ConvNormAct(
rd_channels, in_channels, 1, act_layer=act_layer, norm_layer=norm_layer
)
self.dropout = nn.Dropout2d(p=drop_rate)
def forward(self, x):
xl = self.conv1(x)
y = self.ba(xl)
y = self.conv2(y)
y = self.dropout(y)
return y + x
================================================
FILE: RVT/models/layers/maxvit/layers/norm.py
================================================
""" Normalization layers and wrappers
Norm layer definitions that support fast norm and consistent channel arg order (always first arg).
Hacked together by / Copyright 2022 Ross Wightman
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from .fast_norm import is_fast_norm, fast_group_norm, fast_layer_norm
class GroupNorm(nn.GroupNorm):
def __init__(self, num_channels, num_groups=32, eps=1e-5, affine=True):
# NOTE num_channels is swapped to first arg for consistency in swapping norm layers with BN
super().__init__(num_groups, num_channels, eps=eps, affine=affine)
self.fast_norm = (
is_fast_norm()
) # can't script unless we have these flags here (no globals)
def forward(self, x):
if self.fast_norm:
return fast_group_norm(x, self.num_groups, self.weight, self.bias, self.eps)
else:
return F.group_norm(x, self.num_groups, self.weight, self.bias, self.eps)
class GroupNorm1(nn.GroupNorm):
"""Group Normalization with 1 group.
Input: tensor in shape [B, C, *]
"""
def __init__(self, num_channels, **kwargs):
super().__init__(1, num_channels, **kwargs)
self.fast_norm = (
is_fast_norm()
) # can't script unless we have these flags here (no globals)
def forward(self, x: torch.Tensor) -> torch.Tensor:
if self.fast_norm:
return fast_group_norm(x, self.num_groups, self.weight, self.bias, self.eps)
else:
return F.group_norm(x, self.num_groups, self.weight, self.bias, self.eps)
class LayerNorm(nn.LayerNorm):
"""LayerNorm w/ fast norm option"""
def __init__(self, num_channels, eps=1e-6, affine=True):
super().__init__(num_channels, eps=eps, elementwise_affine=affine)
self._fast_norm = (
is_fast_norm()
) # can't script unless we have these flags here (no globals)
def forward(self, x: torch.Tensor) -> torch.Tensor:
if self._fast_norm:
x = fast_layer_norm(
x, self.normalized_shape, self.weight, self.bias, self.eps
)
else:
x = F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
return x
class LayerNorm2d(nn.LayerNorm):
"""LayerNorm for channels of '2D' spatial NCHW tensors"""
def __init__(self, num_channels, eps=1e-6, affine=True):
super().__init__(num_channels, eps=eps, elementwise_affine=affine)
self._fast_norm = (
is_fast_norm()
) # can't script unless we have these flags here (no globals)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = x.permute(0, 2, 3, 1)
if self._fast_norm:
x = fast_layer_norm(
x, self.normalized_shape, self.weight, self.bias, self.eps
)
else:
x = F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
x = x.permute(0, 3, 1, 2)
return x
def _is_contiguous(tensor: torch.Tensor) -> bool:
# jit is oh so lovely :/
if torch.jit.is_scripting():
return tensor.is_contiguous()
else:
return tensor.is_contiguous(memory_format=torch.contiguous_format)
@torch.jit.script
def _layer_norm_cf(
x: torch.Tensor, weight: torch.Tensor, bias: torch.Tensor, eps: float
):
s, u = torch.var_mean(x, dim=1, unbiased=False, keepdim=True)
x = (x - u) * torch.rsqrt(s + eps)
x = x * weight[:, None, None] + bias[:, None, None]
return x
def _layer_norm_cf_sqm(
x: torch.Tensor, weight: torch.Tensor, bias: torch.Tensor, eps: float
):
u = x.mean(dim=1, keepdim=True)
s = ((x * x).mean(dim=1, keepdim=True) - (u * u)).clamp(0)
x = (x - u) * torch.rsqrt(s + eps)
x = x * weight.view(1, -1, 1, 1) + bias.view(1, -1, 1, 1)
return x
class LayerNormExp2d(nn.LayerNorm):
"""LayerNorm for channels_first tensors with 2d spatial dimensions (ie N, C, H, W).
Experimental implementation w/ manual norm for tensors non-contiguous tensors.
This improves throughput in some scenarios (tested on Ampere GPU), esp w/ channels_last
layout. However, benefits are not always clear and can perform worse on other GPUs.
"""
def __init__(self, num_channels, eps=1e-6):
super().__init__(num_channels, eps=eps)
def forward(self, x) -> torch.Tensor:
if _is_contiguous(x):
x = F.layer_norm(
x.permute(0, 2, 3, 1),
self.normalized_shape,
self.weight,
self.bias,
self.eps,
).permute(0, 3, 1, 2)
else:
x = _layer_norm_cf(x, self.weight, self.bias, self.eps)
return x
================================================
FILE: RVT/models/layers/maxvit/layers/norm_act.py
================================================
""" Normalization + Activation Layers
Provides Norm+Act fns for standard PyTorch norm layers such as
* BatchNorm
* GroupNorm
* LayerNorm
This allows swapping with alternative layers that are natively both norm + act such as
* EvoNorm (evo_norm.py)
* FilterResponseNorm (filter_response_norm.py)
* InplaceABN (inplace_abn.py)
Hacked together by / Copyright 2022 Ross Wightman
"""
from typing import Union, List, Optional, Any
import torch
from torch import nn as nn
from torch.nn import functional as F
from .create_act import get_act_layer
from .fast_norm import is_fast_norm, fast_group_norm, fast_layer_norm
from .trace_utils import _assert
class BatchNormAct2d(nn.BatchNorm2d):
"""BatchNorm + Activation
This module performs BatchNorm + Activation in a manner that will remain backwards
compatible with weights trained with separate bn, act. This is why we inherit from BN
instead of composing it as a .bn member.
"""
def __init__(
self,
num_features,
eps=1e-5,
momentum=0.1,
affine=True,
track_running_stats=True,
apply_act=True,
act_layer=nn.ReLU,
inplace=True,
drop_layer=None,
device=None,
dtype=None,
):
try:
factory_kwargs = {"device": device, "dtype": dtype}
super(BatchNormAct2d, self).__init__(
num_features,
eps=eps,
momentum=momentum,
affine=affine,
track_running_stats=track_running_stats,
**factory_kwargs,
)
except TypeError:
# NOTE for backwards compat with old PyTorch w/o factory device/dtype support
super(BatchNormAct2d, self).__init__(
num_features,
eps=eps,
momentum=momentum,
affine=affine,
track_running_stats=track_running_stats,
)
self.drop = drop_layer() if drop_layer is not None else nn.Identity()
act_layer = get_act_layer(act_layer) # string -> nn.Module
if act_layer is not None and apply_act:
act_args = dict(inplace=True) if inplace else {}
self.act = act_layer(**act_args)
else:
self.act = nn.Identity()
def forward(self, x):
# cut & paste of torch.nn.BatchNorm2d.forward impl to avoid issues with torchscript and tracing
_assert(x.ndim == 4, f"expected 4D input (got {x.ndim}D input)")
# exponential_average_factor is set to self.momentum
# (when it is available) only so that it gets updated
# in ONNX graph when this node is exported to ONNX.
if self.momentum is None:
exponential_average_factor = 0.0
else:
exponential_average_factor = self.momentum
if self.training and self.track_running_stats:
# TODO: if statement only here to tell the jit to skip emitting this when it is None
if self.num_batches_tracked is not None: # type: ignore[has-type]
self.num_batches_tracked = self.num_batches_tracked + 1 # type: ignore[has-type]
if self.momentum is None: # use cumulative moving average
exponential_average_factor = 1.0 / float(self.num_batches_tracked)
else: # use exponential moving average
exponential_average_factor = self.momentum
r"""
Decide whether the mini-batch stats should be used for normalization rather than the buffers.
Mini-batch stats are used in training mode, and in eval mode when buffers are None.
"""
if self.training:
bn_training = True
else:
bn_training = (self.running_mean is None) and (self.running_var is None)
r"""
Buffers are only updated if they are to be tracked and we are in training mode. Thus they only need to be
passed when the update should occur (i.e. in training mode when they are tracked), or when buffer stats are
used for normalization (i.e. in eval mode when buffers are not None).
"""
x = F.batch_norm(
x,
# If buffers are not to be tracked, ensure that they won't be updated
(
self.running_mean
if not self.training or self.track_running_stats
else None
),
self.running_var if not self.training or self.track_running_stats else None,
self.weight,
self.bias,
bn_training,
exponential_average_factor,
self.eps,
)
x = self.drop(x)
x = self.act(x)
return x
class SyncBatchNormAct(nn.SyncBatchNorm):
# Thanks to Selim Seferbekov (https://github.com/rwightman/pytorch-image-models/issues/1254)
# This is a quick workaround to support SyncBatchNorm for timm BatchNormAct2d layers
# but ONLY when used in conjunction with the timm conversion function below.
# Do not create this module directly or use the PyTorch conversion function.
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = super().forward(
x
) # SyncBN doesn't work with torchscript anyways, so this is fine
if hasattr(self, "drop"):
x = self.drop(x)
if hasattr(self, "act"):
x = self.act(x)
return x
def convert_sync_batchnorm(module, process_group=None):
# convert both BatchNorm and BatchNormAct layers to Synchronized variants
module_output = module
if isinstance(module, torch.nn.modules.batchnorm._BatchNorm):
if isinstance(module, BatchNormAct2d):
# convert timm norm + act layer
module_output = SyncBatchNormAct(
module.num_features,
module.eps,
module.momentum,
module.affine,
module.track_running_stats,
process_group=process_group,
)
# set act and drop attr from the original module
module_output.act = module.act
module_output.drop = module.drop
else:
# convert standard BatchNorm layers
module_output = torch.nn.SyncBatchNorm(
module.num_features,
module.eps,
module.momentum,
module.affine,
module.track_running_stats,
process_group,
)
if module.affine:
with torch.no_grad():
module_output.weight = module.weight
module_output.bias = module.bias
module_output.running_mean = module.running_mean
module_output.running_var = module.running_var
module_output.num_batches_tracked = module.num_batches_tracked
if hasattr(module, "qconfig"):
module_output.qconfig = module.qconfig
for name, child in module.named_children():
module_output.add_module(name, convert_sync_batchnorm(child, process_group))
del module
return module_output
def _num_groups(num_channels, num_groups, group_size):
if group_size:
assert num_channels % group_size == 0
return num_channels // group_size
return num_groups
class GroupNormAct(nn.GroupNorm):
# NOTE num_channel and num_groups order flipped for easier layer swaps / binding of fixed args
def __init__(
self,
num_channels,
num_groups=32,
eps=1e-5,
affine=True,
group_size=None,
apply_act=True,
act_layer=nn.ReLU,
inplace=True,
drop_layer=None,
):
super(GroupNormAct, self).__init__(
_num_groups(num_channels, num_groups, group_size),
num_channels,
eps=eps,
affine=affine,
)
self.drop = drop_layer() if drop_layer is not None else nn.Identity()
act_layer = get_act_layer(act_layer) # string -> nn.Module
if act_layer is not None and apply_act:
act_args = dict(inplace=True) if inplace else {}
self.act = act_layer(**act_args)
else:
self.act = nn.Identity()
self._fast_norm = is_fast_norm()
def forward(self, x):
if self._fast_norm:
x = fast_group_norm(x, self.num_groups, self.weight, self.bias, self.eps)
else:
x = F.group_norm(x, self.num_groups, self.weight, self.bias, self.eps)
x = self.drop(x)
x = self.act(x)
return x
class LayerNormAct(nn.LayerNorm):
def __init__(
self,
normalization_shape: Union[int, List[int], torch.Size],
eps=1e-5,
affine=True,
apply_act=True,
act_layer=nn.ReLU,
inplace=True,
drop_layer=None,
):
super(LayerNormAct, self).__init__(
normalization_shape, eps=eps, elementwise_affine=affine
)
self.drop = drop_layer() if drop_layer is not None else nn.Identity()
act_layer = get_act_layer(act_layer) # string -> nn.Module
if act_layer is not None and apply_act:
act_args = dict(inplace=True) if inplace else {}
self.act = act_layer(**act_args)
else:
self.act = nn.Identity()
self._fast_norm = is_fast_norm()
def forward(self, x):
if self._fast_norm:
x = fast_layer_norm(
x, self.normalized_shape, self.weight, self.bias, self.eps
)
else:
x = F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
x = self.drop(x)
x = self.act(x)
return x
class LayerNormAct2d(nn.LayerNorm):
def __init__(
self,
num_channels,
eps=1e-5,
affine=True,
apply_act=True,
act_layer=nn.ReLU,
inplace=True,
drop_layer=None,
):
super(LayerNormAct2d, self).__init__(
num_channels, eps=eps, elementwise_affine=affine
)
self.drop = drop_layer() if drop_layer is not None else nn.Identity()
act_layer = get_act_layer(act_layer) # string -> nn.Module
if act_layer is not None and apply_act:
act_args = dict(inplace=True) if inplace else {}
self.act = act_layer(**act_args)
else:
self.act = nn.Identity()
self._fast_norm = is_fast_norm()
def forward(self, x):
x = x.permute(0, 2, 3, 1)
if self._fast_norm:
x = fast_layer_norm(
x, self.normalized_shape, self.weight, self.bias, self.eps
)
else:
x = F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
x = x.permute(0, 3, 1, 2)
x = self.drop(x)
x = self.act(x)
return x
================================================
FILE: RVT/models/layers/maxvit/layers/padding.py
================================================
""" Padding Helpers
Hacked together by / Copyright 2020 Ross Wightman
"""
import math
from typing import List, Tuple
import torch.nn.functional as F
# Calculate symmetric padding for a convolution
def get_padding(kernel_size: int, stride: int = 1, dilation: int = 1, **_) -> int:
padding = ((stride - 1) + dilation * (kernel_size - 1)) // 2
return padding
# Calculate asymmetric TensorFlow-like 'SAME' padding for a convolution
def get_same_padding(x: int, k: int, s: int, d: int):
return max((math.ceil(x / s) - 1) * s + (k - 1) * d + 1 - x, 0)
# Can SAME padding for given args be done statically?
def is_static_pad(kernel_size: int, stride: int = 1, dilation: int = 1, **_):
return stride == 1 and (dilation * (kernel_size - 1)) % 2 == 0
# Dynamically pad input x with 'SAME' padding for conv with specified args
def pad_same(x, k: List[int], s: List[int], d: List[int] = (1, 1), value: float = 0):
ih, iw = x.size()[-2:]
pad_h, pad_w = get_same_padding(ih, k[0], s[0], d[0]), get_same_padding(
iw, k[1], s[1], d[1]
)
if pad_h > 0 or pad_w > 0:
x = F.pad(
x,
[pad_w // 2, pad_w - pad_w // 2, pad_h // 2, pad_h - pad_h // 2],
value=value,
)
return x
def get_padding_value(padding, kernel_size, **kwargs) -> Tuple[Tuple, bool]:
dynamic = False
if isinstance(padding, str):
# for any string padding, the padding will be calculated for you, one of three ways
padding = padding.lower()
if padding == "same":
# TF compatible 'SAME' padding, has a performance and GPU memory allocation impact
if is_static_pad(kernel_size, **kwargs):
# static case, no extra overhead
padding = get_padding(kernel_size, **kwargs)
else:
# dynamic 'SAME' padding, has runtime/GPU memory overhead
padding = 0
dynamic = True
elif padding == "valid":
# 'VALID' padding, same as padding=0
padding = 0
else:
# Default to PyTorch style 'same'-ish symmetric padding
padding = get_padding(kernel_size, **kwargs)
return padding, dynamic
================================================
FILE: RVT/models/layers/maxvit/layers/patch_embed.py
================================================
""" Image to Patch Embedding using Conv2d
A convolution based approach to patchifying a 2D image w/ embedding projection.
Based on the impl in https://github.com/google-research/vision_transformer
Hacked together by / Copyright 2020 Ross Wightman
"""
from torch import nn as nn
from .helpers import to_2tuple
from .trace_utils import _assert
class PatchEmbed(nn.Module):
"""2D Image to Patch Embedding"""
def __init__(
self,
img_size=224,
patch_size=16,
in_chans=3,
embed_dim=768,
norm_layer=None,
flatten=True,
):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.flatten = flatten
self.proj = nn.Conv2d(
in_chans, embed_dim, kernel_size=patch_size, stride=patch_size
)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
_assert(
H == self.img_size[0],
f"Input image height ({H}) doesn't match model ({self.img_size[0]}).",
)
_assert(
W == self.img_size[1],
f"Input image width ({W}) doesn't match model ({self.img_size[1]}).",
)
x = self.proj(x)
if self.flatten:
x = x.flatten(2).transpose(1, 2) # BCHW -> BNC
x = self.norm(x)
return x
================================================
FILE: RVT/models/layers/maxvit/layers/pool2d_same.py
================================================
""" AvgPool2d w/ Same Padding
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import List, Tuple, Optional
from .helpers import to_2tuple
from .padding import pad_same, get_padding_value
def avg_pool2d_same(
x,
kernel_size: List[int],
stride: List[int],
padding: List[int] = (0, 0),
ceil_mode: bool = False,
count_include_pad: bool = True,
):
# FIXME how to deal with count_include_pad vs not for external padding?
x = pad_same(x, kernel_size, stride)
return F.avg_pool2d(x, kernel_size, stride, (0, 0), ceil_mode, count_include_pad)
class AvgPool2dSame(nn.AvgPool2d):
"""Tensorflow like 'SAME' wrapper for 2D average pooling"""
def __init__(
self,
kernel_size: int,
stride=None,
padding=0,
ceil_mode=False,
count_include_pad=True,
):
kernel_size = to_2tuple(kernel_size)
stride = to_2tuple(stride)
super(AvgPool2dSame, self).__init__(
kernel_size, stride, (0, 0), ceil_mode, count_include_pad
)
def forward(self, x):
x = pad_same(x, self.kernel_size, self.stride)
return F.avg_pool2d(
x,
self.kernel_size,
self.stride,
self.padding,
self.ceil_mode,
self.count_include_pad,
)
def max_pool2d_same(
x,
kernel_size: List[int],
stride: List[int],
padding: List[int] = (0, 0),
dilation: List[int] = (1, 1),
ceil_mode: bool = False,
):
x = pad_same(x, kernel_size, stride, value=-float("inf"))
return F.max_pool2d(x, kernel_size, stride, (0, 0), dilation, ceil_mode)
class MaxPool2dSame(nn.MaxPool2d):
"""Tensorflow like 'SAME' wrapper for 2D max pooling"""
def __init__(
self, kernel_size: int, stride=None, padding=0, dilation=1, ceil_mode=False
):
kernel_size = to_2tuple(kernel_size)
stride = to_2tuple(stride)
dilation = to_2tuple(dilation)
super(MaxPool2dSame, self).__init__(
kernel_size, stride, (0, 0), dilation, ceil_mode
)
def forward(self, x):
x = pad_same(x, self.kernel_size, self.stride, value=-float("inf"))
return F.max_pool2d(
x, self.kernel_size, self.stride, (0, 0), self.dilation, self.ceil_mode
)
def create_pool2d(pool_type, kernel_size, stride=None, **kwargs):
stride = stride or kernel_size
padding = kwargs.pop("padding", "")
padding, is_dynamic = get_padding_value(
padding, kernel_size, stride=stride, **kwargs
)
if is_dynamic:
if pool_type == "avg":
return AvgPool2dSame(kernel_size, stride=stride, **kwargs)
elif pool_type == "max":
return MaxPool2dSame(kernel_size, stride=stride, **kwargs)
else:
assert False, f"Unsupported pool type {pool_type}"
else:
if pool_type == "avg":
return nn.AvgPool2d(kernel_size, stride=stride, padding=padding, **kwargs)
elif pool_type == "max":
return nn.MaxPool2d(kernel_size, stride=stride, padding=padding, **kwargs)
else:
assert False, f"Unsupported pool type {pool_type}"
================================================
FILE: RVT/models/layers/maxvit/layers/pos_embed.py
================================================
import math
from typing import List, Tuple, Optional, Union
import torch
from torch import nn as nn
def pixel_freq_bands(
num_bands: int,
max_freq: float = 224.0,
linear_bands: bool = True,
dtype: torch.dtype = torch.float32,
device: Optional[torch.device] = None,
):
if linear_bands:
bands = torch.linspace(1.0, max_freq / 2, num_bands, dtype=dtype, device=device)
else:
bands = 2 ** torch.linspace(
0, math.log(max_freq, 2) - 1, num_bands, dtype=dtype, device=device
)
return bands * torch.pi
def inv_freq_bands(
num_bands: int,
temperature: float = 100000.0,
step: int = 2,
dtype: torch.dtype = torch.float32,
device: Optional[torch.device] = None,
) -> torch.Tensor:
inv_freq = 1.0 / (
temperature
** (torch.arange(0, num_bands, step, dtype=dtype, device=device) / num_bands)
)
return inv_freq
def build_sincos2d_pos_embed(
feat_shape: List[int],
dim: int = 64,
temperature: float = 10000.0,
reverse_coord: bool = False,
interleave_sin_cos: bool = False,
dtype: torch.dtype = torch.float32,
device: Optional[torch.device] = None,
) -> torch.Tensor:
"""
Args:
feat_shape:
dim:
temperature:
reverse_coord: stack grid order W, H instead of H, W
interleave_sin_cos: sin, cos, sin, cos stack instead of sin, sin, cos, cos
dtype:
device:
Returns:
"""
assert (
dim % 4 == 0
), "Embed dimension must be divisible by 4 for sin-cos 2D position embedding"
pos_dim = dim // 4
bands = inv_freq_bands(
pos_dim, temperature=temperature, step=1, dtype=dtype, device=device
)
if reverse_coord:
feat_shape = feat_shape[::-1] # stack W, H instead of H, W
grid = (
torch.stack(
torch.meshgrid(
[torch.arange(s, device=device, dtype=dtype) for s in feat_shape]
)
)
.flatten(1)
.transpose(0, 1)
)
pos2 = grid.unsqueeze(-1) * bands.unsqueeze(0)
# FIXME add support for unflattened spatial dim?
stack_dim = (
2 if interleave_sin_cos else 1
) # stack sin, cos, sin, cos instead of sin sin cos cos
pos_emb = torch.stack([torch.sin(pos2), torch.cos(pos2)], dim=stack_dim).flatten(1)
return pos_emb
def build_fourier_pos_embed(
feat_shape: List[int],
bands: Optional[torch.Tensor] = None,
num_bands: int = 64,
max_res: int = 224,
linear_bands: bool = False,
include_grid: bool = False,
concat_out: bool = True,
in_pixels: bool = True,
dtype: torch.dtype = torch.float32,
device: Optional[torch.device] = None,
) -> List[torch.Tensor]:
if bands is None:
if in_pixels:
bands = pixel_freq_bands(
num_bands,
float(max_res),
linear_bands=linear_bands,
dtype=dtype,
device=device,
)
else:
bands = inv_freq_bands(num_bands, step=1, dtype=dtype, device=device)
else:
if device is None:
device = bands.device
if dtype is None:
dtype = bands.dtype
if in_pixels:
grid = torch.stack(
torch.meshgrid(
[
torch.linspace(-1.0, 1.0, steps=s, device=device, dtype=dtype)
for s in feat_shape
]
),
dim=-1,
)
else:
grid = torch.stack(
torch.meshgrid(
[torch.arange(s, device=device, dtype=dtype) for s in feat_shape]
),
dim=-1,
)
grid = grid.unsqueeze(-1)
pos = grid * bands
pos_sin, pos_cos = pos.sin(), pos.cos()
out = (grid, pos_sin, pos_cos) if include_grid else (pos_sin, pos_cos)
# FIXME torchscript doesn't like multiple return types, probably need to always cat?
if concat_out:
out = torch.cat(out, dim=-1)
return out
class FourierEmbed(nn.Module):
def __init__(
self,
max_res: int = 224,
num_bands: int = 64,
concat_grid=True,
keep_spatial=False,
):
super().__init__()
self.max_res = max_res
self.num_bands = num_bands
self.concat_grid = concat_grid
self.keep_spatial = keep_spatial
self.register_buffer(
"bands", pixel_freq_bands(max_res, num_bands), persistent=False
)
def forward(self, x):
B, C = x.shape[:2]
feat_shape = x.shape[2:]
emb = build_fourier_pos_embed(
feat_shape,
self.bands,
include_grid=self.concat_grid,
dtype=x.dtype,
device=x.device,
)
emb = emb.transpose(-1, -2).flatten(len(feat_shape))
batch_expand = (B,) + (-1,) * (x.ndim - 1)
# FIXME support nD
if self.keep_spatial:
x = torch.cat(
[x, emb.unsqueeze(0).expand(batch_expand).permute(0, 3, 1, 2)], dim=1
)
else:
x = torch.cat(
[x.permute(0, 2, 3, 1), emb.unsqueeze(0).expand(batch_expand)], dim=-1
)
x = x.reshape(B, feat_shape.numel(), -1)
return x
def rot(x):
return torch.stack([-x[..., 1::2], x[..., ::2]], -1).reshape(x.shape)
def apply_rot_embed(x: torch.Tensor, sin_emb, cos_emb):
return x * cos_emb + rot(x) * sin_emb
def apply_rot_embed_list(x: List[torch.Tensor], sin_emb, cos_emb):
if isinstance(x, torch.Tensor):
x = [x]
return [t * cos_emb + rot(t) * sin_emb for t in x]
def apply_rot_embed_split(x: torch.Tensor, emb):
split = emb.shape[-1] // 2
return x * emb[:, :split] + rot(x) * emb[:, split:]
def build_rotary_pos_embed(
feat_shape: List[int],
bands: Optional[torch.Tensor] = None,
dim: int = 64,
max_freq: float = 224,
linear_bands: bool = False,
dtype: torch.dtype = torch.float32,
device: Optional[torch.device] = None,
):
"""
NOTE: shape arg should include spatial dim only
"""
feat_shape = torch.Size(feat_shape)
sin_emb, cos_emb = build_fourier_pos_embed(
feat_shape,
bands=bands,
num_bands=dim // 4,
max_res=max_freq,
linear_bands=linear_bands,
concat_out=False,
device=device,
dtype=dtype,
)
N = feat_shape.numel()
sin_emb = sin_emb.reshape(N, -1).repeat_interleave(2, -1)
cos_emb = cos_emb.reshape(N, -1).repeat_interleave(2, -1)
return sin_emb, cos_emb
class RotaryEmbedding(nn.Module):
"""Rotary position embedding
NOTE: This is my initial attempt at impl rotary embedding for spatial use, it has not
been well tested, and will likely change. It will be moved to its own file.
The following impl/resources were referenced for this impl:
* https://github.com/lucidrains/vit-pytorch/blob/6f3a5fcf0bca1c5ec33a35ef48d97213709df4ba/vit_pytorch/rvt.py
* https://blog.eleuther.ai/rotary-embeddings/
"""
def __init__(self, dim, max_res=224, linear_bands: bool = False):
super().__init__()
self.dim = dim
self.register_buffer(
"bands",
pixel_freq_bands(dim // 4, max_res, linear_bands=linear_bands),
persistent=False,
)
def get_embed(self, shape: List[int]):
return build_rotary_pos_embed(shape, self.bands)
def forward(self, x):
# assuming channel-first tensor where spatial dim are >= 2
sin_emb, cos_emb = self.get_embed(x.shape[2:])
return apply_rot_embed(x, sin_emb, cos_emb)
================================================
FILE: RVT/models/layers/maxvit/layers/selective_kernel.py
================================================
""" Selective Kernel Convolution/Attention
Paper: Selective Kernel Networks (https://arxiv.org/abs/1903.06586)
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch
from torch import nn as nn
from .conv_bn_act import ConvNormActAa
from .helpers import make_divisible
from .trace_utils import _assert
def _kernel_valid(k):
if isinstance(k, (list, tuple)):
for ki in k:
return _kernel_valid(ki)
assert k >= 3 and k % 2
class SelectiveKernelAttn(nn.Module):
def __init__(
self,
channels,
num_paths=2,
attn_channels=32,
act_layer=nn.ReLU,
norm_layer=nn.BatchNorm2d,
):
"""Selective Kernel Attention Module
Selective Kernel attention mechanism factored out into its own module.
"""
super(SelectiveKernelAttn, self).__init__()
self.num_paths = num_paths
self.fc_reduce = nn.Conv2d(channels, attn_channels, kernel_size=1, bias=False)
self.bn = norm_layer(attn_channels)
self.act = act_layer(inplace=True)
self.fc_select = nn.Conv2d(
attn_channels, channels * num_paths, kernel_size=1, bias=False
)
def forward(self, x):
_assert(x.shape[1] == self.num_paths, "")
x = x.sum(1).mean((2, 3), keepdim=True)
x = self.fc_reduce(x)
x = self.bn(x)
x = self.act(x)
x = self.fc_select(x)
B, C, H, W = x.shape
x = x.view(B, self.num_paths, C // self.num_paths, H, W)
x = torch.softmax(x, dim=1)
return x
class SelectiveKernel(nn.Module):
def __init__(
self,
in_channels,
out_channels=None,
kernel_size=None,
stride=1,
dilation=1,
groups=1,
rd_ratio=1.0 / 16,
rd_channels=None,
rd_divisor=8,
keep_3x3=True,
split_input=True,
act_layer=nn.ReLU,
norm_layer=nn.BatchNorm2d,
aa_layer=None,
drop_layer=None,
):
"""Selective Kernel Convolution Module
As described in Selective Kernel Networks (https://arxiv.org/abs/1903.06586) with some modifications.
Largest change is the input split, which divides the input channels across each convolution path, this can
be viewed as a grouping of sorts, but the output channel counts expand to the module level value. This keeps
the parameter count from ballooning when the convolutions themselves don't have groups, but still provides
a noteworthy increase in performance over similar param count models without this attention layer. -Ross W
Args:
in_channels (int): module input (feature) channel count
out_channels (int): module output (feature) channel count
kernel_size (int, list): kernel size for each convolution branch
stride (int): stride for convolutions
dilation (int): dilation for module as a whole, impacts dilation of each branch
groups (int): number of groups for each branch
rd_ratio (int, float): reduction factor for attention features
keep_3x3 (bool): keep all branch convolution kernels as 3x3, changing larger kernels for dilations
split_input (bool): split input channels evenly across each convolution branch, keeps param count lower,
can be viewed as grouping by path, output expands to module out_channels count
act_layer (nn.Module): activation layer to use
norm_layer (nn.Module): batchnorm/norm layer to use
aa_layer (nn.Module): anti-aliasing module
drop_layer (nn.Module): spatial drop module in convs (drop block, etc)
"""
super(SelectiveKernel, self).__init__()
out_channels = out_channels or in_channels
kernel_size = kernel_size or [
3,
5,
] # default to one 3x3 and one 5x5 branch. 5x5 -> 3x3 + dilation
_kernel_valid(kernel_size)
if not isinstance(kernel_size, list):
kernel_size = [kernel_size] * 2
if keep_3x3:
dilation = [dilation * (k - 1) // 2 for k in kernel_size]
kernel_size = [3] * len(kernel_size)
else:
dilation = [dilation] * len(kernel_size)
self.num_paths = len(kernel_size)
self.in_channels = in_channels
self.out_channels = out_channels
self.split_input = split_input
if self.split_input:
assert in_channels % self.num_paths == 0
in_channels = in_channels // self.num_paths
groups = min(out_channels, groups)
conv_kwargs = dict(
stride=stride,
groups=groups,
act_layer=act_layer,
norm_layer=norm_layer,
aa_layer=aa_layer,
drop_layer=drop_layer,
)
self.paths = nn.ModuleList(
[
ConvNormActAa(
in_channels, out_channels, kernel_size=k, dilation=d, **conv_kwargs
)
for k, d in zip(kernel_size, dilation)
]
)
attn_channels = rd_channels or make_divisible(
out_channels * rd_ratio, divisor=rd_divisor
)
self.attn = SelectiveKernelAttn(out_channels, self.num_paths, attn_channels)
def forward(self, x):
if self.split_input:
x_split = torch.split(x, self.in_channels // self.num_paths, 1)
x_paths = [op(x_split[i]) for i, op in enumerate(self.paths)]
else:
x_paths = [op(x) for op in self.paths]
x = torch.stack(x_paths, dim=1)
x_attn = self.attn(x)
x = x * x_attn
x = torch.sum(x, dim=1)
return x
================================================
FILE: RVT/models/layers/maxvit/layers/separable_conv.py
================================================
""" Depthwise Separable Conv Modules
Basic DWS convs. Other variations of DWS exist with batch norm or activations between the
DW and PW convs such as the Depthwise modules in MobileNetV2 / EfficientNet and Xception.
Hacked together by / Copyright 2020 Ross Wightman
"""
from torch import nn as nn
from .create_conv2d import create_conv2d
from .create_norm_act import get_norm_act_layer
class SeparableConvNormAct(nn.Module):
"""Separable Conv w/ trailing Norm and Activation"""
def __init__(
self,
in_channels,
out_channels,
kernel_size=3,
stride=1,
dilation=1,
padding="",
bias=False,
channel_multiplier=1.0,
pw_kernel_size=1,
norm_layer=nn.BatchNorm2d,
act_layer=nn.ReLU,
apply_act=True,
drop_layer=None,
):
super(SeparableConvNormAct, self).__init__()
self.conv_dw = create_conv2d(
in_channels,
int(in_channels * channel_multiplier),
kernel_size,
stride=stride,
dilation=dilation,
padding=padding,
depthwise=True,
)
self.conv_pw = create_conv2d(
int(in_channels * channel_multiplier),
out_channels,
pw_kernel_size,
padding=padding,
bias=bias,
)
norm_act_layer = get_norm_act_layer(norm_layer, act_layer)
norm_kwargs = dict(drop_layer=drop_layer) if drop_layer is not None else {}
self.bn = norm_act_layer(out_channels, apply_act=apply_act, **norm_kwargs)
@property
def in_channels(self):
return self.conv_dw.in_channels
@property
def out_channels(self):
return self.conv_pw.out_channels
def forward(self, x):
x = self.conv_dw(x)
x = self.conv_pw(x)
x = self.bn(x)
return x
SeparableConvBnAct = SeparableConvNormAct
class SeparableConv2d(nn.Module):
"""Separable Conv"""
def __init__(
self,
in_channels,
out_channels,
kernel_size=3,
stride=1,
dilation=1,
padding="",
bias=False,
channel_multiplier=1.0,
pw_kernel_size=1,
):
super(SeparableConv2d, self).__init__()
self.conv_dw = create_conv2d(
in_channels,
int(in_channels * channel_multiplier),
kernel_size,
stride=stride,
dilation=dilation,
padding=padding,
depthwise=True,
)
self.conv_pw = create_conv2d(
int(in_channels * channel_multiplier),
out_channels,
pw_kernel_size,
padding=padding,
bias=bias,
)
@property
def in_channels(self):
return self.conv_dw.in_channels
@property
def out_channels(self):
return self.conv_pw.out_channels
def forward(self, x):
x = self.conv_dw(x)
x = self.conv_pw(x)
return x
================================================
FILE: RVT/models/layers/maxvit/layers/space_to_depth.py
================================================
import torch
import torch.nn as nn
class SpaceToDepth(nn.Module):
def __init__(self, block_size=4):
super().__init__()
assert block_size == 4
self.bs = block_size
def forward(self, x):
N, C, H, W = x.size()
x = x.view(
N, C, H // self.bs, self.bs, W // self.bs, self.bs
) # (N, C, H//bs, bs, W//bs, bs)
x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # (N, bs, bs, C, H//bs, W//bs)
x = x.view(
N, C * (self.bs**2), H // self.bs, W // self.bs
) # (N, C*bs^2, H//bs, W//bs)
return x
@torch.jit.script
class SpaceToDepthJit(object):
def __call__(self, x: torch.Tensor):
# assuming hard-coded that block_size==4 for acceleration
N, C, H, W = x.size()
x = x.view(N, C, H // 4, 4, W // 4, 4) # (N, C, H//bs, bs, W//bs, bs)
x = x.permute(0, 3, 5, 1, 2, 4).contiguous() # (N, bs, bs, C, H//bs, W//bs)
x = x.view(N, C * 16, H // 4, W // 4) # (N, C*bs^2, H//bs, W//bs)
return x
class SpaceToDepthModule(nn.Module):
def __init__(self, no_jit=False):
super().__init__()
if not no_jit:
self.op = SpaceToDepthJit()
else:
self.op = SpaceToDepth()
def forward(self, x):
return self.op(x)
class DepthToSpace(nn.Module):
def __init__(self, block_size):
super().__init__()
self.bs = block_size
def forward(self, x):
N, C, H, W = x.size()
x = x.view(
N, self.bs, self.bs, C // (self.bs**2), H, W
) # (N, bs, bs, C//bs^2, H, W)
x = x.permute(0, 3, 4, 1, 5, 2).contiguous() # (N, C//bs^2, H, bs, W, bs)
x = x.view(
N, C // (self.bs**2), H * self.bs, W * self.bs
) # (N, C//bs^2, H * bs, W * bs)
return x
================================================
FILE: RVT/models/layers/maxvit/layers/split_attn.py
================================================
""" Split Attention Conv2d (for ResNeSt Models)
Paper: `ResNeSt: Split-Attention Networks` - /https://arxiv.org/abs/2004.08955
Adapted from original PyTorch impl at https://github.com/zhanghang1989/ResNeSt
Modified for torchscript compat, performance, and consistency with timm by Ross Wightman
"""
import torch
import torch.nn.functional as F
from torch import nn
from .helpers import make_divisible
class RadixSoftmax(nn.Module):
def __init__(self, radix, cardinality):
super(RadixSoftmax, self).__init__()
self.radix = radix
self.cardinality = cardinality
def forward(self, x):
batch = x.size(0)
if self.radix > 1:
x = x.view(batch, self.cardinality, self.radix, -1).transpose(1, 2)
x = F.softmax(x, dim=1)
x = x.reshape(batch, -1)
else:
x = torch.sigmoid(x)
return x
class SplitAttn(nn.Module):
"""Split-Attention (aka Splat)"""
def __init__(
self,
in_channels,
out_channels=None,
kernel_size=3,
stride=1,
padding=None,
dilation=1,
groups=1,
bias=False,
radix=2,
rd_ratio=0.25,
rd_channels=None,
rd_divisor=8,
act_layer=nn.ReLU,
norm_layer=None,
drop_layer=None,
**kwargs
):
super(SplitAttn, self).__init__()
out_channels = out_channels or in_channels
self.radix = radix
mid_chs = out_channels * radix
if rd_channels is None:
attn_chs = make_divisible(
in_channels * radix * rd_ratio, min_value=32, divisor=rd_divisor
)
else:
attn_chs = rd_channels * radix
padding = kernel_size // 2 if padding is None else padding
self.conv = nn.Conv2d(
in_channels,
mid_chs,
kernel_size,
stride,
padding,
dilation,
groups=groups * radix,
bias=bias,
**kwargs
)
self.bn0 = norm_layer(mid_chs) if norm_layer else nn.Identity()
self.drop = drop_layer() if drop_layer is not None else nn.Identity()
self.act0 = act_layer(inplace=True)
self.fc1 = nn.Conv2d(out_channels, attn_chs, 1, groups=groups)
self.bn1 = norm_layer(attn_chs) if norm_layer else nn.Identity()
self.act1 = act_layer(inplace=True)
self.fc2 = nn.Conv2d(attn_chs, mid_chs, 1, groups=groups)
self.rsoftmax = RadixSoftmax(radix, groups)
def forward(self, x):
x = self.conv(x)
x = self.bn0(x)
x = self.drop(x)
x = self.act0(x)
B, RC, H, W = x.shape
if self.radix > 1:
x = x.reshape((B, self.radix, RC // self.radix, H, W))
x_gap = x.sum(dim=1)
else:
x_gap = x
x_gap = x_gap.mean((2, 3), keepdim=True)
x_gap = self.fc1(x_gap)
x_gap = self.bn1(x_gap)
x_gap = self.act1(x_gap)
x_attn = self.fc2(x_gap)
x_attn = self.rsoftmax(x_attn).view(B, -1, 1, 1)
if self.radix > 1:
out = (x * x_attn.reshape((B, self.radix, RC // self.radix, 1, 1))).sum(
dim=1
)
else:
out = x * x_attn
return out.contiguous()
================================================
FILE: RVT/models/layers/maxvit/layers/split_batchnorm.py
================================================
""" Split BatchNorm
A PyTorch BatchNorm layer that splits input batch into N equal parts and passes each through
a separate BN layer. The first split is passed through the parent BN layers with weight/bias
keys the same as the original BN. All other splits pass through BN sub-layers under the '.aux_bn'
namespace.
This allows easily removing the auxiliary BN layers after training to efficiently
achieve the 'Auxiliary BatchNorm' as described in the AdvProp Paper, section 4.2,
'Disentangled Learning via An Auxiliary BN'
Hacked together by / Copyright 2020 Ross Wightman
"""
import torch
import torch.nn as nn
class SplitBatchNorm2d(torch.nn.BatchNorm2d):
def __init__(
self,
num_features,
eps=1e-5,
momentum=0.1,
affine=True,
track_running_stats=True,
num_splits=2,
):
super().__init__(num_features, eps, momentum, affine, track_running_stats)
assert (
num_splits > 1
), "Should have at least one aux BN layer (num_splits at least 2)"
self.num_splits = num_splits
self.aux_bn = nn.ModuleList(
[
nn.BatchNorm2d(num_features, eps, momentum, affine, track_running_stats)
for _ in range(num_splits - 1)
]
)
def forward(self, input: torch.Tensor):
if self.training: # aux BN only relevant while training
split_size = input.shape[0] // self.num_splits
assert (
input.shape[0] == split_size * self.num_splits
), "batch size must be evenly divisible by num_splits"
split_input = input.split(split_size)
x = [super().forward(split_input[0])]
for i, a in enumerate(self.aux_bn):
x.append(a(split_input[i + 1]))
return torch.cat(x, dim=0)
else:
return super().forward(input)
def convert_splitbn_model(module, num_splits=2):
"""
Recursively traverse module and its children to replace all instances of
``torch.nn.modules.batchnorm._BatchNorm`` with `SplitBatchnorm2d`.
Args:
module (torch.nn.Module): input module
num_splits: number of separate batchnorm layers to split input across
Example::
>>> # model is an instance of torch.nn.Module
>>> model = timm.models.convert_splitbn_model(model, num_splits=2)
"""
mod = module
if isinstance(module, torch.nn.modules.instancenorm._InstanceNorm):
return module
if isinstance(module, torch.nn.modules.batchnorm._BatchNorm):
mod = SplitBatchNorm2d(
module.num_features,
module.eps,
module.momentum,
module.affine,
module.track_running_stats,
num_splits=num_splits,
)
mod.running_mean = module.running_mean
mod.running_var = module.running_var
mod.num_batches_tracked = module.num_batches_tracked
if module.affine:
mod.weight.data = module.weight.data.clone().detach()
mod.bias.data = module.bias.data.clone().detach()
for aux in mod.aux_bn:
aux.running_mean = module.running_mean.clone()
aux.running_var = module.running_var.clone()
aux.num_batches_tracked = module.num_batches_tracked.clone()
if module.affine:
aux.weight.data = module.weight.data.clone().detach()
aux.bias.data = module.bias.data.clone().detach()
for name, child in module.named_children():
mod.add_module(name, convert_splitbn_model(child, num_splits=num_splits))
del module
return mod
================================================
FILE: RVT/models/layers/maxvit/layers/squeeze_excite.py
================================================
""" Squeeze-and-Excitation Channel Attention
An SE implementation originally based on PyTorch SE-Net impl.
Has since evolved with additional functionality / configuration.
Paper: `Squeeze-and-Excitation Networks` - https://arxiv.org/abs/1709.01507
Also included is Effective Squeeze-Excitation (ESE).
Paper: `CenterMask : Real-Time Anchor-Free Instance Segmentation` - https://arxiv.org/abs/1911.06667
Hacked together by / Copyright 2021 Ross Wightman
"""
from torch import nn as nn
from .create_act import create_act_layer
from .helpers import make_divisible
class SEModule(nn.Module):
"""SE Module as defined in original SE-Nets with a few additions
Additions include:
* divisor can be specified to keep channels % div == 0 (default: 8)
* reduction channels can be specified directly by arg (if rd_channels is set)
* reduction channels can be specified by float rd_ratio (default: 1/16)
* global max pooling can be added to the squeeze aggregation
* customizable activation, normalization, and gate layer
"""
def __init__(
self,
channels,
rd_ratio=1.0 / 16,
rd_channels=None,
rd_divisor=8,
add_maxpool=False,
bias=True,
act_layer=nn.ReLU,
norm_layer=None,
gate_layer="sigmoid",
):
super(SEModule, self).__init__()
self.add_maxpool = add_maxpool
if not rd_channels:
rd_channels = make_divisible(
channels * rd_ratio, rd_divisor, round_limit=0.0
)
self.fc1 = nn.Conv2d(channels, rd_channels, kernel_size=1, bias=bias)
self.bn = norm_layer(rd_channels) if norm_layer else nn.Identity()
self.act = create_act_layer(act_layer, inplace=True)
self.fc2 = nn.Conv2d(rd_channels, channels, kernel_size=1, bias=bias)
self.gate = create_act_layer(gate_layer)
def forward(self, x):
x_se = x.mean((2, 3), keepdim=True)
if self.add_maxpool:
# experimental codepath, may remove or change
x_se = 0.5 * x_se + 0.5 * x.amax((2, 3), keepdim=True)
x_se = self.fc1(x_se)
x_se = self.act(self.bn(x_se))
x_se = self.fc2(x_se)
return x * self.gate(x_se)
SqueezeExcite = SEModule # alias
class EffectiveSEModule(nn.Module):
"""'Effective Squeeze-Excitation
From `CenterMask : Real-Time Anchor-Free Instance Segmentation` - https://arxiv.org/abs/1911.06667
"""
def __init__(self, channels, add_maxpool=False, gate_layer="hard_sigmoid", **_):
super(EffectiveSEModule, self).__init__()
self.add_maxpool = add_maxpool
self.fc = nn.Conv2d(channels, channels, kernel_size=1, padding=0)
self.gate = create_act_layer(gate_layer)
def forward(self, x):
x_se = x.mean((2, 3), keepdim=True)
if self.add_maxpool:
# experimental codepath, may remove or change
x_se = 0.5 * x_se + 0.5 * x.amax((2, 3), keepdim=True)
x_se = self.fc(x_se)
return x * self.gate(x_se)
EffectiveSqueezeExcite = EffectiveSEModule # alias
================================================
FILE: RVT/models/layers/maxvit/layers/std_conv.py
================================================
""" Convolution with Weight Standardization (StdConv and ScaledStdConv)
StdConv:
@article{weightstandardization,
author = {Siyuan Qiao and Huiyu Wang and Chenxi Liu and Wei Shen and Alan Yuille},
title = {Weight Standardization},
journal = {arXiv preprint arXiv:1903.10520},
year = {2019},
}
Code: https://github.com/joe-siyuan-qiao/WeightStandardization
ScaledStdConv:
Paper: `Characterizing signal propagation to close the performance gap in unnormalized ResNets`
- https://arxiv.org/abs/2101.08692
Official Deepmind JAX code: https://github.com/deepmind/deepmind-research/tree/master/nfnets
Hacked together by / copyright Ross Wightman, 2021.
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from .padding import get_padding, get_padding_value, pad_same
class StdConv2d(nn.Conv2d):
"""Conv2d with Weight Standardization. Used for BiT ResNet-V2 models.
Paper: `Micro-Batch Training with Batch-Channel Normalization and Weight Standardization` -
https://arxiv.org/abs/1903.10520v2
"""
def __init__(
self,
in_channel,
out_channels,
kernel_size,
stride=1,
padding=None,
dilation=1,
groups=1,
bias=False,
eps=1e-6,
):
if padding is None:
padding = get_padding(kernel_size, stride, dilation)
super().__init__(
in_channel,
out_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
)
self.eps = eps
def forward(self, x):
weight = F.batch_norm(
self.weight.reshape(1, self.out_channels, -1),
None,
None,
training=True,
momentum=0.0,
eps=self.eps,
).reshape_as(self.weight)
x = F.conv2d(
x, weight, self.bias, self.stride, self.padding, self.dilation, self.groups
)
return x
class StdConv2dSame(nn.Conv2d):
"""Conv2d with Weight Standardization. TF compatible SAME padding. Used for ViT Hybrid model.
Paper: `Micro-Batch Training with Batch-Channel Normalization and Weight Standardization` -
https://arxiv.org/abs/1903.10520v2
"""
def __init__(
self,
in_channel,
out_channels,
kernel_size,
stride=1,
padding="SAME",
dilation=1,
groups=1,
bias=False,
eps=1e-6,
):
padding, is_dynamic = get_padding_value(
padding, kernel_size, stride=stride, dilation=dilation
)
super().__init__(
in_channel,
out_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
)
self.same_pad = is_dynamic
self.eps = eps
def forward(self, x):
if self.same_pad:
x = pad_same(x, self.kernel_size, self.stride, self.dilation)
weight = F.batch_norm(
self.weight.reshape(1, self.out_channels, -1),
None,
None,
training=True,
momentum=0.0,
eps=self.eps,
).reshape_as(self.weight)
x = F.conv2d(
x, weight, self.bias, self.stride, self.padding, self.dilation, self.groups
)
return x
class ScaledStdConv2d(nn.Conv2d):
"""Conv2d layer with Scaled Weight Standardization.
Paper: `Characterizing signal propagation to close the performance gap in unnormalized ResNets` -
https://arxiv.org/abs/2101.08692
NOTE: the operations used in this impl differ slightly from the DeepMind Haiku impl. The impact is minor.
"""
def __init__(
self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding=None,
dilation=1,
groups=1,
bias=True,
gamma=1.0,
eps=1e-6,
gain_init=1.0,
):
if padding is None:
padding = get_padding(kernel_size, stride, dilation)
super().__init__(
in_channels,
out_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
)
self.gain = nn.Parameter(torch.full((self.out_channels, 1, 1, 1), gain_init))
self.scale = gamma * self.weight[0].numel() ** -0.5 # gamma * 1 / sqrt(fan-in)
self.eps = eps
def forward(self, x):
weight = F.batch_norm(
self.weight.reshape(1, self.out_channels, -1),
None,
None,
weight=(self.gain * self.scale).view(-1),
training=True,
momentum=0.0,
eps=self.eps,
).reshape_as(self.weight)
return F.conv2d(
x, weight, self.bias, self.stride, self.padding, self.dilation, self.groups
)
class ScaledStdConv2dSame(nn.Conv2d):
"""Conv2d layer with Scaled Weight Standardization and Tensorflow-like SAME padding support
Paper: `Characterizing signal propagation to close the performance gap in unnormalized ResNets` -
https://arxiv.org/abs/2101.08692
NOTE: the operations used in this impl differ slightly from the DeepMind Haiku impl. The impact is minor.
"""
def __init__(
self,
in_channels,
out_channels,
kernel_size,
stride=1,
padding="SAME",
dilation=1,
groups=1,
bias=True,
gamma=1.0,
eps=1e-6,
gain_init=1.0,
):
padding, is_dynamic = get_padding_value(
padding, kernel_size, stride=stride, dilation=dilation
)
super().__init__(
in_channels,
out_channels,
kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=bias,
)
self.gain = nn.Parameter(torch.full((self.out_channels, 1, 1, 1), gain_init))
self.scale = gamma * self.weight[0].numel() ** -0.5
self.same_pad = is_dynamic
self.eps = eps
def forward(self, x):
if self.same_pad:
x = pad_same(x, self.kernel_size, self.stride, self.dilation)
weight = F.batch_norm(
self.weight.reshape(1, self.out_channels, -1),
None,
None,
weight=(self.gain * self.scale).view(-1),
training=True,
momentum=0.0,
eps=self.eps,
).reshape_as(self.weight)
return F.conv2d(
x, weight, self.bias, self.stride, self.padding, self.dilation, self.groups
)
================================================
FILE: RVT/models/layers/maxvit/layers/test_time_pool.py
================================================
""" Test Time Pooling (Average-Max Pool)
Hacked together by / Copyright 2020 Ross Wightman
"""
import logging
from torch import nn
import torch.nn.functional as F
from .adaptive_avgmax_pool import adaptive_avgmax_pool2d
_logger = logging.getLogger(__name__)
class TestTimePoolHead(nn.Module):
def __init__(self, base, original_pool=7):
super(TestTimePoolHead, self).__init__()
self.base = base
self.original_pool = original_pool
base_fc = self.base.get_classifier()
if isinstance(base_fc, nn.Conv2d):
self.fc = base_fc
else:
self.fc = nn.Conv2d(
self.base.num_features, self.base.num_classes, kernel_size=1, bias=True
)
self.fc.weight.data.copy_(base_fc.weight.data.view(self.fc.weight.size()))
self.fc.bias.data.copy_(base_fc.bias.data.view(self.fc.bias.size()))
self.base.reset_classifier(0) # delete original fc layer
def forward(self, x):
x = self.base.forward_features(x)
x = F.avg_pool2d(x, kernel_size=self.original_pool, stride=1)
x = self.fc(x)
x = adaptive_avgmax_pool2d(x, 1)
return x.view(x.size(0), -1)
def apply_test_time_pool(model, config, use_test_size=False):
test_time_pool = False
if not hasattr(model, "default_cfg") or not model.default_cfg:
return model, False
if use_test_size and "test_input_size" in model.default_cfg:
df_input_size = model.default_cfg["test_input_size"]
else:
df_input_size = model.default_cfg["input_size"]
if (
config["input_size"][-1] > df_input_size[-1]
and config["input_size"][-2] > df_input_size[-2]
):
_logger.info(
"Target input size %s > pretrained default %s, using test time pooling"
% (str(config["input_size"][-2:]), str(df_input_size[-2:]))
)
model = TestTimePoolHead(model, original_pool=model.default_cfg["pool_size"])
test_time_pool = True
return model, test_time_pool
================================================
FILE: RVT/models/layers/maxvit/layers/trace_utils.py
================================================
try:
from torch import _assert
except ImportError:
def _assert(condition: bool, message: str):
assert condition, message
def _float_to_int(x: float) -> int:
"""
Symbolic tracing helper to substitute for inbuilt `int`.
Hint: Inbuilt `int` can't accept an argument of type `Proxy`
"""
return int(x)
================================================
FILE: RVT/models/layers/maxvit/layers/weight_init.py
================================================
import torch
import math
import warnings
from torch.nn.init import _calculate_fan_in_and_fan_out
def _trunc_normal_(tensor, mean, std, a, b):
# Cut & paste from PyTorch official master until it's in a few official releases - RW
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
def norm_cdf(x):
# Computes standard normal cumulative distribution function
return (1.0 + math.erf(x / math.sqrt(2.0))) / 2.0
if (mean < a - 2 * std) or (mean > b + 2 * std):
warnings.warn(
"mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
"The distribution of values may be incorrect.",
stacklevel=2,
)
# Values are generated by using a truncated uniform distribution and
# then using the inverse CDF for the normal distribution.
# Get upper and lower cdf values
l = norm_cdf((a - mean) / std)
u = norm_cdf((b - mean) / std)
# Uniformly fill tensor with values from [l, u], then translate to
# [2l-1, 2u-1].
tensor.uniform_(2 * l - 1, 2 * u - 1)
# Use inverse cdf transform for normal distribution to get truncated
# standard normal
tensor.erfinv_()
# Transform to proper mean, std
tensor.mul_(std * math.sqrt(2.0))
tensor.add_(mean)
# Clamp to ensure it's in the proper range
tensor.clamp_(min=a, max=b)
return tensor
def trunc_normal_(tensor, mean=0.0, std=1.0, a=-2.0, b=2.0):
# type: (Tensor, float, float, float, float) -> Tensor
r"""Fills the input Tensor with values drawn from a truncated
normal distribution. The values are effectively drawn from the
normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
with values outside :math:`[a, b]` redrawn until they are within
the bounds. The method used for generating the random values works
best when :math:`a \leq \text{mean} \leq b`.
NOTE: this impl is similar to the PyTorch trunc_normal_, the bounds [a, b] are
applied while sampling the normal with mean/std applied, therefore a, b args
should be adjusted to match the range of mean, std args.
Args:
tensor: an n-dimensional `torch.Tensor`
mean: the mean of the normal distribution
std: the standard deviation of the normal distribution
a: the minimum cutoff value
b: the maximum cutoff value
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.trunc_normal_(w)
"""
with torch.no_grad():
return _trunc_normal_(tensor, mean, std, a, b)
def trunc_normal_tf_(tensor, mean=0.0, std=1.0, a=-2.0, b=2.0):
# type: (Tensor, float, float, float, float) -> Tensor
r"""Fills the input Tensor with values drawn from a truncated
normal distribution. The values are effectively drawn from the
normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
with values outside :math:`[a, b]` redrawn until they are within
the bounds. The method used for generating the random values works
best when :math:`a \leq \text{mean} \leq b`.
NOTE: this 'tf' variant behaves closer to Tensorflow / JAX impl where the
bounds [a, b] are applied when sampling the normal distribution with mean=0, std=1.0
and the result is subsquently scaled and shifted by the mean and std args.
Args:
tensor: an n-dimensional `torch.Tensor`
mean: the mean of the normal distribution
std: the standard deviation of the normal distribution
a: the minimum cutoff value
b: the maximum cutoff value
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.trunc_normal_(w)
"""
with torch.no_grad():
_trunc_normal_(tensor, 0, 1.0, a, b)
tensor.mul_(std).add_(mean)
return tensor
def variance_scaling_(tensor, scale=1.0, mode="fan_in", distribution="normal"):
fan_in, fan_out = _calculate_fan_in_and_fan_out(tensor)
if mode == "fan_in":
denom = fan_in
elif mode == "fan_out":
denom = fan_out
elif mode == "fan_avg":
denom = (fan_in + fan_out) / 2
variance = scale / denom
if distribution == "truncated_normal":
# constant is stddev of standard normal truncated to (-2, 2)
trunc_normal_tf_(tensor, std=math.sqrt(variance) / 0.87962566103423978)
elif distribution == "normal":
with torch.no_grad():
tensor.normal_(std=math.sqrt(variance))
elif distribution == "uniform":
bound = math.sqrt(3 * variance)
with torch.no_grad():
tensor.uniform_(-bound, bound)
else:
raise ValueError(f"invalid distribution {distribution}")
def lecun_normal_(tensor):
variance_scaling_(tensor, mode="fan_in", distribution="truncated_normal")
================================================
FILE: RVT/models/layers/maxvit/maxvit.py
================================================
"""
Part of this code stems from rwightman's MaxVit implementation:
https://github.com/huggingface/pytorch-image-models/blob/1885bdc4318cc3be459981ea1a26cd862220864d/timm/models/maxxvit.py
that is:
- LayerScale
- PartitionAttentionCl
- window*
- grid*
- SelfAttentionCl
"""
from enum import Enum, auto
from functools import partial
from typing import Optional, Union, Tuple, List, Type
import math
import torch
from omegaconf import DictConfig
from torch import nn
from .layers import DropPath, LayerNorm
from .layers import get_act_layer, get_norm_layer
from .layers import to_2tuple, _assert
class PartitionType(Enum):
WINDOW = auto()
GRID = auto()
def nChw_2_nhwC(x: torch.Tensor):
"""N C H W -> N H W C"""
assert x.ndim == 4
return x.permute(0, 2, 3, 1)
def nhwC_2_nChw(x: torch.Tensor):
"""N H W C -> N C H W"""
assert x.ndim == 4
return x.permute(0, 3, 1, 2)
class LayerScale(nn.Module):
def __init__(self, dim: int, init_values: float = 1e-5, inplace: bool = False):
super().__init__()
self.inplace = inplace
self.gamma = nn.Parameter(init_values * torch.ones(dim))
def forward(self, x):
gamma = self.gamma
return x.mul_(gamma) if self.inplace else x * gamma
class GLU(nn.Module):
def __init__(
self,
dim_in: int,
dim_out: int,
channel_last: bool,
act_layer: Type[nn.Module],
bias: bool = True,
):
super().__init__()
# Different activation functions / versions of the gated linear unit:
# - ReGLU: Relu
# - SwiGLU: Swish/SiLU
# - GeGLU: GELU
# - GLU: Sigmoid
# seem to be the most promising once.
# Extensive quantitative eval in table 1: https://arxiv.org/abs/2102.11972
# Section 2 for explanation and implementation details: https://arxiv.org/abs/2002.05202
# NOTE: Pytorch has a native GLU implementation: https://pytorch.org/docs/stable/generated/torch.nn.GLU.html?highlight=glu#torch.nn.GLU
proj_out_dim = dim_out * 2
self.proj = (
nn.Linear(dim_in, proj_out_dim, bias=bias)
if channel_last
else nn.Conv2d(dim_in, proj_out_dim, kernel_size=1, stride=1, bias=bias)
)
self.channel_dim = -1 if channel_last else 1
self.act_layer = act_layer()
def forward(self, x: torch.Tensor):
x, gate = torch.tensor_split(self.proj(x), 2, dim=self.channel_dim)
return x * self.act_layer(gate)
class MLP(nn.Module):
def __init__(
self,
dim: int,
channel_last: bool,
expansion_ratio: int,
act_layer: Type[nn.Module],
gated: bool = True,
bias: bool = True,
drop_prob: float = 0.0,
):
super().__init__()
inner_dim = int(dim * expansion_ratio)
if gated:
# To keep the number of parameters (approx) constant regardless of whether glu == True
# Section 2 for explanation: https://arxiv.org/abs/2002.05202
# inner_dim = round(inner_dim * 2 / 3)
# inner_dim = math.ceil(inner_dim * 2 / 3 / 32) * 32 # multiple of 32
# inner_dim = round(inner_dim * 2 / 3 / 32) * 32 # multiple of 32
inner_dim = math.floor(inner_dim * 2 / 3 / 32) * 32 # multiple of 32
proj_in = GLU(
dim_in=dim,
dim_out=inner_dim,
channel_last=channel_last,
act_layer=act_layer,
bias=bias,
)
else:
proj_in = nn.Sequential(
(
nn.Linear(in_features=dim, out_features=inner_dim, bias=bias)
if channel_last
else nn.Conv2d(
in_channels=dim,
out_channels=inner_dim,
kernel_size=1,
stride=1,
bias=bias,
)
),
act_layer(),
)
self.net = nn.Sequential(
proj_in,
nn.Dropout(p=drop_prob),
(
nn.Linear(in_features=inner_dim, out_features=dim, bias=bias)
if channel_last
else nn.Conv2d(
in_channels=inner_dim,
out_channels=dim,
kernel_size=1,
stride=1,
bias=bias,
)
),
)
def forward(self, x):
return self.net(x)
class DownsampleBase(nn.Module):
def __init__(self):
super().__init__()
@staticmethod
def output_is_normed():
raise NotImplementedError
def get_downsample_layer_Cf2Cl(
dim_in: int, dim_out: int, downsample_factor: int, downsample_cfg: DictConfig
) -> DownsampleBase:
type = downsample_cfg.type
if type == "patch":
return ConvDownsampling_Cf2Cl(
dim_in=dim_in,
dim_out=dim_out,
downsample_factor=downsample_factor,
downsample_cfg=downsample_cfg,
)
raise NotImplementedError
class ConvDownsampling_Cf2Cl(DownsampleBase):
"""Downsample with input in NCHW [channel-first] format.
Output in NHWC [channel-last] format.
"""
def __init__(
self,
dim_in: int,
dim_out: int,
downsample_factor: int,
downsample_cfg: DictConfig,
):
super().__init__()
assert isinstance(dim_out, int)
assert isinstance(dim_in, int)
assert downsample_factor in (2, 4, 8)
norm_affine = downsample_cfg.get("norm_affine", True)
overlap = downsample_cfg.get("overlap", True)
if overlap:
kernel_size = (downsample_factor - 1) * 2 + 1
padding = kernel_size // 2
else:
kernel_size = downsample_factor
padding = 0
self.conv = nn.Conv2d(
in_channels=dim_in,
out_channels=dim_out,
kernel_size=kernel_size,
padding=padding,
stride=downsample_factor,
bias=False,
)
self.norm = LayerNorm(num_channels=dim_out, eps=1e-5, affine=norm_affine)
def forward(self, x: torch.Tensor):
x = self.conv(x)
x = nChw_2_nhwC(x)
x = self.norm(x)
return x
@staticmethod
def output_is_normed():
return True
class PartitionAttentionCl(nn.Module):
"""Grid or Block partition + Attn + FFN.
NxC 'channels last' tensor layout.
According to RW, NHWC attention is a few percent faster on GPUs (but slower on TPUs)
https://github.com/rwightman/pytorch-image-models/blob/4f72bae43be26d9764a08d83b88f8bd4ec3dbe43/timm/models/maxxvit.py#L1258
"""
def __init__(
self,
dim: int,
partition_type: PartitionType,
attention_cfg: DictConfig,
skip_first_norm: bool = False,
):
super().__init__()
norm_eps = attention_cfg.get("norm_eps", 1e-5)
partition_size = attention_cfg.partition_size
use_torch_mha = attention_cfg.use_torch_mha
dim_head = attention_cfg.get("dim_head", 32)
attention_bias = attention_cfg.get("attention_bias", True)
mlp_act_string = attention_cfg.mlp_activation
mlp_gated = attention_cfg.mlp_gated
mlp_bias = attention_cfg.get("mlp_bias", True)
mlp_expand_ratio = attention_cfg.get("mlp_ratio", 4)
drop_path = attention_cfg.get("drop_path", 0.0)
drop_mlp = attention_cfg.get("drop_mlp", 0.0)
ls_init_value = attention_cfg.get("ls_init_value", 1e-5)
assert isinstance(use_torch_mha, bool)
assert isinstance(mlp_gated, bool)
assert_activation_string(activation_string=mlp_act_string)
mlp_act_layer = get_act_layer(mlp_act_string)
self_attn_module = TorchMHSAWrapperCl if use_torch_mha else SelfAttentionCl
if isinstance(partition_size, int):
partition_size = to_2tuple(partition_size)
else:
partition_size = tuple(partition_size)
assert len(partition_size) == 2
self.partition_size = partition_size
norm_layer = partial(
get_norm_layer("layernorm"), eps=norm_eps
) # NOTE this block is channels-last
assert isinstance(partition_type, PartitionType)
self.partition_window = partition_type == PartitionType.WINDOW
self.norm1 = nn.Identity() if skip_first_norm else norm_layer(dim)
self.self_attn = self_attn_module(dim, dim_head=dim_head, bias=attention_bias)
self.ls1 = (
LayerScale(dim=dim, init_values=ls_init_value)
if ls_init_value > 0
else nn.Identity()
)
self.drop_path1 = (
DropPath(drop_prob=drop_path) if drop_path > 0 else nn.Identity()
)
self.norm2 = norm_layer(dim)
self.mlp = MLP(
dim=dim,
channel_last=True,
expansion_ratio=mlp_expand_ratio,
act_layer=mlp_act_layer,
gated=mlp_gated,
bias=mlp_bias,
drop_prob=drop_mlp,
)
self.ls2 = (
LayerScale(dim=dim, init_values=ls_init_value)
if ls_init_value > 0
else nn.Identity()
)
self.drop_path2 = (
DropPath(drop_prob=drop_path) if drop_path > 0 else nn.Identity()
)
def _partition_attn(self, x):
img_size = x.shape[1:3]
if self.partition_window:
partitioned = window_partition(x, self.partition_size)
else:
partitioned = grid_partition(x, self.partition_size)
partitioned = self.self_attn(partitioned)
if self.partition_window:
x = window_reverse(
partitioned, self.partition_size, (img_size[0], img_size[1])
)
else:
x = grid_reverse(
partitioned, self.partition_size, (img_size[0], img_size[1])
)
return x
def forward(self, x):
x = x + self.drop_path1(self.ls1(self._partition_attn(self.norm1(x))))
x = x + self.drop_path2(self.ls2(self.mlp(self.norm2(x))))
return x
def window_partition(x, window_size: Tuple[int, int]):
B, H, W, C = x.shape
_assert(
H % window_size[0] == 0,
f"height ({H}) must be divisible by window ({window_size[0]})",
)
_assert(
W % window_size[1] == 0,
f"width ({W}) must be divisible by window ({window_size[1]})",
)
x = x.view(
B, H // window_size[0], window_size[0], W // window_size[1], window_size[1], C
)
windows = (
x.permute(0, 1, 3, 2, 4, 5)
.contiguous()
.view(-1, window_size[0], window_size[1], C)
)
return windows
def window_reverse(windows, window_size: Tuple[int, int], img_size: Tuple[int, int]):
H, W = img_size
C = windows.shape[-1]
x = windows.view(
-1, H // window_size[0], W // window_size[1], window_size[0], window_size[1], C
)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, H, W, C)
return x
def grid_partition(x, grid_size: Tuple[int, int]):
B, H, W, C = x.shape
_assert(
H % grid_size[0] == 0, f"height {H} must be divisible by grid {grid_size[0]}"
)
_assert(
W % grid_size[1] == 0, f"width {W} must be divisible by grid {grid_size[1]}"
)
x = x.view(B, grid_size[0], H // grid_size[0], grid_size[1], W // grid_size[1], C)
windows = (
x.permute(0, 2, 4, 1, 3, 5).contiguous().view(-1, grid_size[0], grid_size[1], C)
)
return windows
def grid_reverse(windows, grid_size: Tuple[int, int], img_size: Tuple[int, int]):
H, W = img_size
C = windows.shape[-1]
x = windows.view(
-1, H // grid_size[0], W // grid_size[1], grid_size[0], grid_size[1], C
)
x = x.permute(0, 3, 1, 4, 2, 5).contiguous().view(-1, H, W, C)
return x
class TorchMHSAWrapperCl(nn.Module):
"""Channels-last multi-head self-attention (B, ..., C)"""
def __init__(self, dim: int, dim_head: int = 32, bias: bool = True):
super().__init__()
assert dim % dim_head == 0
num_heads = dim // dim_head
self.mha = nn.MultiheadAttention(
embed_dim=dim, num_heads=num_heads, bias=bias, batch_first=True
)
def forward(self, x: torch.Tensor):
restore_shape = x.shape
B, C = restore_shape[0], restore_shape[-1]
x = x.view(B, -1, C)
attn_output, attn_output_weights = self.mha(query=x, key=x, value=x)
attn_output = attn_output.reshape(restore_shape)
return attn_output
class SelfAttentionCl(nn.Module):
"""Channels-last multi-head self-attention (B, ..., C)"""
def __init__(self, dim: int, dim_head: int = 32, bias: bool = True):
super().__init__()
self.num_heads = dim // dim_head
self.dim_head = dim_head
self.scale = dim_head**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias=bias)
self.proj = nn.Linear(dim, dim, bias=bias)
def forward(self, x: torch.Tensor):
B = x.shape[0]
restore_shape = x.shape[:-1]
q, k, v = (
self.qkv(x)
.view(B, -1, self.num_heads, self.dim_head * 3)
.transpose(1, 2)
.chunk(3, dim=3)
)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(restore_shape + (-1,))
x = self.proj(x)
return x
def assert_activation_string(
activation_string: Optional[Union[str, Tuple[str, ...], List[str]]]
) -> None:
# Serves as a hacky documentation and sanity check.
# List of possible activation layer strings that are reasonable:
# https://github.com/rwightman/pytorch-image-models/blob/a520da9b495422bc773fb5dfe10819acb8bd7c5c/timm/models/layers/create_act.py#L62
if activation_string is None:
return
if isinstance(activation_string, str):
assert activation_string in (
"silu",
"swish",
"mish",
"relu",
"relu6",
"leaky_relu",
"elu",
"prelu",
"celu",
"selu",
"gelu",
"sigmoid",
"tanh",
"hard_sigmoid",
"hard_swish",
"hard_mish",
)
elif isinstance(activation_string, (tuple, list)):
for entry in activation_string:
assert_activation_string(activation_string=entry)
else:
raise NotImplementedError
def assert_norm2d_layer_string(
norm_layer: Optional[Union[str, Tuple[str, ...], List[str]]]
) -> None:
# Serves as a hacky documentation and sanity check.
# List of possible norm layer strings that are reasonable:
# https://github.com/rwightman/pytorch-image-models/blob/4f72bae43be26d9764a08d83b88f8bd4ec3dbe43/timm/models/layers/create_norm.py#L14
if norm_layer is None:
return
if isinstance(norm_layer, str):
assert norm_layer in ("batchnorm", "batchnorm2d", "groupnorm", "layernorm2d")
elif isinstance(norm_layer, (tuple, list)):
for entry in norm_layer:
assert_norm2d_layer_string(norm_layer=entry)
else:
raise NotImplementedError
================================================
FILE: RVT/models/layers/rnn.py
================================================
from typing import Optional, Tuple
import torch as th
import torch.nn as nn
class DWSConvLSTM2d(nn.Module):
"""LSTM with (depthwise-separable) Conv option in NCHW [channel-first] format."""
def __init__(
self,
dim: int,
dws_conv: bool = True,
dws_conv_only_hidden: bool = True,
dws_conv_kernel_size: int = 3,
cell_update_dropout: float = 0.0,
):
super().__init__()
assert isinstance(dws_conv, bool)
assert isinstance(dws_conv_only_hidden, bool)
self.dim = dim
xh_dim = dim * 2
gates_dim = dim * 4
conv3x3_dws_dim = dim if dws_conv_only_hidden else xh_dim
self.conv3x3_dws = (
nn.Conv2d(
in_channels=conv3x3_dws_dim,
out_channels=conv3x3_dws_dim,
kernel_size=dws_conv_kernel_size,
padding=dws_conv_kernel_size // 2,
groups=conv3x3_dws_dim,
)
if dws_conv
else nn.Identity()
)
self.conv1x1 = nn.Conv2d(
in_channels=xh_dim, out_channels=gates_dim, kernel_size=1
)
self.conv_only_hidden = dws_conv_only_hidden
self.cell_update_dropout = nn.Dropout(p=cell_update_dropout)
def forward(
self,
x: th.Tensor,
h_and_c_previous: Optional[Tuple[th.Tensor, th.Tensor]] = None,
) -> Tuple[th.Tensor, th.Tensor]:
"""
:param x: (N C H W)
:param h_and_c_previous: ((N C H W), (N C H W))
:return: ((N C H W), (N C H W))
"""
if h_and_c_previous is None:
# generate zero states
hidden = th.zeros_like(x)
cell = th.zeros_like(x)
h_and_c_previous = (hidden, cell)
h_tm1, c_tm1 = h_and_c_previous
if self.conv_only_hidden:
h_tm1 = self.conv3x3_dws(h_tm1)
xh = th.cat((x, h_tm1), dim=1)
if not self.conv_only_hidden:
xh = self.conv3x3_dws(xh)
mix = self.conv1x1(xh)
gates, cell_input = th.tensor_split(mix, [self.dim * 3], dim=1)
assert gates.shape[1] == cell_input.shape[1] * 3
gates = th.sigmoid(gates)
forget_gate, input_gate, output_gate = th.tensor_split(gates, 3, dim=1)
assert forget_gate.shape == input_gate.shape == output_gate.shape
cell_input = self.cell_update_dropout(th.tanh(cell_input))
c_t = forget_gate * c_tm1 + input_gate * cell_input
h_t = output_gate * th.tanh(c_t)
return h_t, c_t
================================================
FILE: RVT/models/layers/s5/__init__.py
================================================
from .s5_model import *
================================================
FILE: RVT/models/layers/s5/jax_func.py
================================================
import torch
import numpy as np
from torch.utils._pytree import tree_flatten, tree_unflatten
from typing import (
overload,
Callable,
Iterable,
List,
TypeVar,
Any,
Literal,
Sequence,
Optional,
)
from functools import partial
import math
"""
Jax-Pytorch ported functions, mostly interfaces are kept the same but unsupported features are removed:
* Jax-Keyed RNGs are sampled from global RNG
* Canonical/Named shapes/dtypes/etc are now regular shapes,dtypes
"""
T = TypeVar("T")
T1 = TypeVar("T1")
T2 = TypeVar("T2")
T3 = TypeVar("T3")
@overload
def safe_map(f: Callable[[T1], T], __arg1: Iterable[T1]) -> List[T]: ...
@overload
def safe_map(
f: Callable[[T1, T2], T], __arg1: Iterable[T1], __arg2: Iterable[T2]
) -> List[T]: ...
@overload
def safe_map(
f: Callable[[T1, T2, T3], T],
__arg1: Iterable[T1],
__arg2: Iterable[T2],
__arg3: Iterable[T3],
) -> List[T]: ...
@overload
def safe_map(
f: Callable[..., T],
__arg1: Iterable[Any],
__arg2: Iterable[Any],
__arg3: Iterable[Any],
__arg4: Iterable[Any],
*args,
) -> List[T]: ...
def safe_map(f, *args):
args = list(map(list, args))
n = len(args[0])
for arg in args[1:]:
assert len(arg) == n, f"length mismatch: {list(map(len, args))}"
return list(map(f, *args))
def combine(tree, operator, a_flat, b_flat):
# Lower `fn` to operate on flattened sequences of elems.
a = tree_unflatten(a_flat, tree)
b = tree_unflatten(b_flat, tree)
c = operator(a, b)
c_flat, _ = tree_flatten(c)
return c_flat
def _scan(tree, operator, elems, axis: int):
"""Perform scan on `elems`."""
num_elems = elems[0].shape[axis]
if num_elems < 2:
return elems
# Combine adjacent pairs of elements.
reduced_elems = combine(
tree,
operator,
[torch.ops.aten.slice(elem, axis, 0, -1, 2) for elem in elems],
[torch.ops.aten.slice(elem, axis, 1, None, 2) for elem in elems],
)
# Recursively compute scan for partially reduced tensors.
odd_elems = _scan(tree, operator, reduced_elems, axis)
if num_elems % 2 == 0:
even_elems = combine(
tree,
operator,
[torch.ops.aten.slice(e, axis, 0, -1) for e in odd_elems],
[torch.ops.aten.slice(e, axis, 2, None, 2) for e in elems],
)
else:
even_elems = combine(
tree,
operator,
odd_elems,
[torch.ops.aten.slice(e, axis, 2, None, 2) for e in elems],
)
# The first element of a scan is the same as the first element
# of the original `elems`.
even_elems = [
(
torch.cat([torch.ops.aten.slice(elem, axis, 0, 1), result], dim=axis)
if result.shape.numel() > 0 and elem.shape[axis] > 0
else (
result
if result.shape.numel() > 0
else torch.ops.aten.slice(elem, axis, 0, 1)
)
) # Jax allows/ignores concat with 0-dim, Pytorch does not
for (elem, result) in zip(elems, even_elems)
]
return list(safe_map(partial(_interleave, axis=axis), even_elems, odd_elems))
# Pytorch impl. of jax.lax.associative_scan
def associative_scan(operator: Callable, elems, axis: int = 0, reverse: bool = False):
# if not callable(operator):
# raise TypeError("lax.associative_scan: fn argument should be callable.")
elems_flat, tree = tree_flatten(elems)
if reverse:
elems_flat = [torch.flip(elem, [axis]) for elem in elems_flat]
assert (
axis >= 0 or axis < elems_flat[0].ndim
), "Axis should be within bounds of input"
num_elems = int(elems_flat[0].shape[axis])
if not all(int(elem.shape[axis]) == num_elems for elem in elems_flat[1:]):
raise ValueError(
"Array inputs to associative_scan must have the same "
"first dimension. (saw: {})".format([elem.shape for elem in elems_flat])
)
scans = _scan(tree, operator, elems_flat, axis)
if reverse:
scans = [torch.flip(scanned, [axis]) for scanned in scans]
return tree_unflatten(scans, tree)
def test_associative_scan(shape=(1, 24, 24)):
import jax.lax
import jax
x = np.random.randn(*shape)
jx = jax.numpy.array(x)
tx = torch.tensor(x, dtype=torch.float32)
def nested_func(a, b):
a_i, b_i = a
a_j, b_j = b
return a_j * a_i, a_j * b_i + b_j
jy1, jy2 = jax.lax.associative_scan(nested_func, (jx, jx))
ty1, ty2 = associative_scan(nested_func, (tx, tx))
assert (
np.isclose(ty1.numpy(), np.array(jy1)).all()
and np.isclose(ty2.numpy(), np.array(jy2)).all()
), "Expected jax & pytorch impl to be close"
jy1, jy2 = jax.lax.associative_scan(nested_func, (jx, jx), reverse=True)
ty1, ty2 = associative_scan(nested_func, (tx, tx), reverse=True)
assert (
np.isclose(ty1.numpy(), np.array(jy1)).all()
and np.isclose(ty2.numpy(), np.array(jy2)).all()
), "Expected jax & pytorch reverse impl to be close"
print("Associative scan working as expected!")
def _interleave(a, b, axis: int):
# https://stackoverflow.com/questions/60869537/how-can-i-interleave-5-pytorch-tensors
b_trunc = a.shape[axis] == b.shape[axis] + 1
if b_trunc:
pad = [0, 0] * b.ndim
pad[(b.ndim - axis - 1) * 2 + 1] = (
1 # +1=always end of dim, pad-order is reversed so start is at end
)
b = torch.nn.functional.pad(b, pad)
stacked = torch.stack([a, b], dim=axis + 1)
interleaved = torch.flatten(stacked, start_dim=axis, end_dim=axis + 1)
if b_trunc:
# TODO: find torch alternative for slice_along axis for torch.jit.script to work
interleaved = torch.ops.aten.slice(
interleaved, axis, 0, b.shape[axis] + a.shape[axis] - 1
)
return interleaved
def test_interleave():
x, y = torch.randn(1, 32, 32), torch.randn(1, 32, 32)
v = _interleave(x, y, axis=1)
assert v.shape == (1, 64, 32)
assert (v[:, 0] == x[:, 0]).all()
assert (v[:, 1] == y[:, 0]).all()
assert (v[:, 2] == x[:, 1]).all()
assert (v[:, 3] == y[:, 1]).all()
assert (v[:, 4] == x[:, 2]).all()
v = _interleave(x, y, axis=2)
assert v.shape == (1, 32, 64)
assert (v[..., 0] == x[..., 0]).all()
assert (v[..., 1] == y[..., 0]).all()
assert (v[..., 2] == x[..., 1]).all()
assert (v[..., 3] == y[..., 1]).all()
assert (v[..., 4] == x[..., 2]).all()
x, y = torch.randn(1, 24, 24), torch.randn(1, 24, 24)
assert _interleave(x, y, axis=1).shape == (1, 48, 24)
assert _interleave(x, y, axis=2).shape == (1, 24, 48)
x, y = torch.randn(3, 96), torch.randn(2, 96)
v = _interleave(x, y, axis=0)
assert v.shape == (5, 96)
assert (v[0] == x[0]).all()
assert (v[1] == y[0]).all()
assert (v[2] == x[1]).all()
assert (v[3] == y[1]).all()
assert (v[4] == x[2]).all()
print("Interleave working as expected!")
def _compute_fans(shape, fan_in_axes=None):
"""Computes the number of input and output units for a weight shape."""
if len(shape) < 1:
fan_in = fan_out = 1
elif len(shape) == 1:
fan_in = fan_out = shape[0]
elif len(shape) == 2:
fan_in, fan_out = shape
else:
if fan_in_axes is not None:
# Compute fan-in using user-specified fan-in axes.
fan_in = np.prod([shape[i] for i in fan_in_axes])
fan_out = np.prod([s for i, s in enumerate(shape) if i not in fan_in_axes])
else:
# If no axes specified, assume convolution kernels (2D, 3D, or more.)
# kernel_shape: (..., input_depth, depth)
receptive_field_size = np.prod(shape[:-2])
fan_in = shape[-2] * receptive_field_size
fan_out = shape[-1] * receptive_field_size
return fan_in, fan_out
def uniform(shape, dtype=torch.float, minval=0.0, maxval=1.0, device=None):
src = torch.rand(shape, dtype=dtype, device=device)
if minval == 0 and maxval == 1.0:
return src
else:
return (src * (maxval - minval)) + minval
def _complex_uniform(shape: Sequence[int], dtype, device=None) -> torch.Tensor:
"""
Sample uniform random values within a disk on the complex plane,
with zero mean and unit variance.
"""
r = torch.sqrt(2 * torch.rand(shape, dtype=dtype, device=device))
theta = 2 * torch.pi * torch.rand(shape, dtype=dtype, device=device)
return r * torch.exp(1j * theta)
def complex_as_float_dtype(dtype):
match dtype:
case torch.complex32:
return torch.float32 # NOTE: complexe32 is not wel supported yet
case torch.complex64:
return torch.float32
case torch.complex128:
return torch.float64
case _:
return dtype
def _complex_truncated_normal(
upper: float, shape: Sequence[int], dtype, device=None
) -> torch.Tensor:
"""
Sample random values from a centered normal distribution on the complex plane,
whose modulus is truncated to `upper`, and the variance before the truncation
is one.
"""
real_dtype = torch.tensor(0, dtype=dtype).real.dtype
t = (
1 - torch.exp(torch.tensor(-(upper**2), dtype=dtype, device=device))
) * torch.rand(shape, dtype=real_dtype, device=device).type(dtype)
r = torch.sqrt(-torch.log(1 - t))
theta = (
2 * torch.pi * torch.rand(shape, dtype=real_dtype, device=device).type(dtype)
)
return r * torch.exp(1j * theta)
def _truncated_normal(lower, upper, shape, dtype=torch.float):
if shape is None:
shape = torch.broadcast_shapes(np.shape(lower), np.shape(upper))
sqrt2 = math.sqrt(2)
a = math.erf(lower / sqrt2)
b = math.erf(upper / sqrt2)
# a>> import jax, jax.numpy as jnp
>>> initializer = jax.nn.initializers.lecun_normal()
>>> initializer(jax.random.PRNGKey(42), (2, 3), jnp.float32) # doctest: +SKIP
Array([[ 0.46700746, 0.8414632 , 0.8518669 ],
[-0.61677957, -0.67402434, 0.09683388]], dtype=float32)
.. _Lecun normal initializer: https://arxiv.org/abs/1706.02515
"""
return variance_scaling(
1.0, "fan_in", "truncated_normal", fan_in_axes=fan_in_axes, dtype=dtype
)
def test_variance_scaling():
v = variance_scaling(1.0, distribution="normal")
n_f32 = v((1, 10000), dtype=torch.float)
assert np.isclose(
n_f32.std().item(), 1.0, rtol=0.015, atol=0.015
), f"std for f32 normal[0,1.0] is {n_f32.std()} != 1.0"
del n_f32
# NOTE: this is used in the original as `complex_normal` (but with stddev=0.5**0.5)
n_c64 = v((1, 10000), dtype=torch.complex64)
assert np.isclose(
n_c64.std().item(), 1.0, rtol=0.015, atol=0.015
), f"std for c64 normal[0,1.0] is {n_c64.std()} != 1.0"
del n_c64
# Truncated normal
v = variance_scaling(1.0, distribution="truncated_normal")
tn_f32 = v((1, 10000), dtype=torch.float)
assert np.isclose(
tn_f32.std().item(), 0.775, rtol=0.015, atol=0.015
), f"std for f32 truncated normal[0,1.0] is {tn_f32.std()} != 0.775"
del tn_f32
# NOTE: this is used in the original (both trunc_standard_normal & lecun_normal it seems),
# seems that they are using the fan-in/out feature to 'hide the low variance initialization'
# The actual std observed is np.sqrt(2/shape[1]/(2*shape[0])); shape[2] has no impact
v = variance_scaling(1.0, distribution="truncated_normal")
tn_f32 = v((1, 10000, 2), dtype=torch.float)
tn_c32 = torch.complex(tn_f32[..., 0], tn_f32[..., 1])
expected_std = np.sqrt(2 / tn_f32.shape[1] / (2 * tn_f32.shape[0]))
print(tn_c32.shape)
assert np.isclose(
tn_c32.std().item(), expected_std, rtol=0.015, atol=0.015
), f"std for f32 truncated normal[0,1.0] is {tn_c32.std()} != {expected_std}"
del tn_f32
del tn_c32
print("Variance scaling working as expected!")
if __name__ == "__main__":
test_variance_scaling()
test_interleave()
test_associative_scan()
test_associative_scan(shape=(2, 256, 24))
test_associative_scan(shape=(360, 96))
================================================
FILE: RVT/models/layers/s5/s5_init.py
================================================
import torch
import numpy as np
from .jax_func import variance_scaling, lecun_normal, uniform
import scipy.linalg
# Initialization Functions
def make_HiPPO(N):
"""Create a HiPPO-LegS matrix.
From https://github.com/srush/annotated-s4/blob/main/s4/s4.py
Args:
N (int32): state size
Returns:
N x N HiPPO LegS matrix
"""
P = np.sqrt(1 + 2 * np.arange(N))
A = P[:, np.newaxis] * P[np.newaxis, :]
A = np.tril(A) - np.diag(np.arange(N))
return -A
def make_NPLR_HiPPO(N):
"""
Makes components needed for NPLR representation of HiPPO-LegS
From https://github.com/srush/annotated-s4/blob/main/s4/s4.py
Args:
N (int32): state size
Returns:
N x N HiPPO LegS matrix, low-rank factor P, HiPPO input matrix B
"""
# Make -HiPPO
hippo = make_HiPPO(N)
# Add in a rank 1 term. Makes it Normal.
P = np.sqrt(np.arange(N) + 0.5)
# HiPPO also specifies the B matrix
B = np.sqrt(2 * np.arange(N) + 1.0)
return hippo, P, B
def make_DPLR_HiPPO(N):
"""
Makes components needed for DPLR representation of HiPPO-LegS
From https://github.com/srush/annotated-s4/blob/main/s4/s4.py
Note, we will only use the diagonal part
Args:
N:
Returns:
eigenvalues Lambda, low-rank term P, conjugated HiPPO input matrix B,
eigenvectors V, HiPPO B pre-conjugation
"""
A, P, B = make_NPLR_HiPPO(N)
S = A + P[:, np.newaxis] * P[np.newaxis, :]
S_diag = np.diagonal(S)
Lambda_real = np.mean(S_diag) * np.ones_like(S_diag)
# Diagonalize S to V \Lambda V^*
Lambda_imag, V = np.linalg.eigh(S * -1j)
P = V.conj().T @ P
B_orig = B
B = V.conj().T @ B
return Lambda_real + 1j * Lambda_imag, P, B, V, B_orig
def make_Normal_S(N):
nhippo = make_HiPPO(N)
# Add in a rank 1 term. Makes it Normal.
p = 0.5 * np.sqrt(2 * np.arange(1, N + 1) + 1.0)
q = 2 * p
S = nhippo + p[:, np.newaxis] * q[np.newaxis, :]
return S
def make_Normal_HiPPO(N, B=1):
"""Create a normal approximation to HiPPO-LegS matrix.
For HiPPO matrix A, A=S+pqT is normal plus low-rank for
a certain normal matrix S and low rank terms p and q.
We are going to approximate the HiPPO matrix with the normal matrix S.
Note we use original numpy instead of jax.numpy first to use the
onp.linalg.eig function. This is because Jax's linalg.eig function does not run
on GPU for non-symmetric matrices. This creates tracing issues.
So we instead use onp.linalg eig and then cast to a jax array
(since we only have to do this once in the beginning to initialize).
Args:
N (int32): state size
B (int32): diagonal blocks
Returns:
Lambda (complex64): eigenvalues of S (N,)
V (complex64): eigenvectors of S (N,N)
"""
assert N % B == 0, "N must divide blocks"
S = (make_Normal_S(N // B),) * B
S = scipy.linalg.block_diag(*S)
# Diagonalize S to V \Lambda V^*
Lambda, V = np.linalg.eig(S)
# Convert to jax array
return torch.tensor(Lambda), torch.tensor(V)
def log_step_initializer(dt_min=0.001, dt_max=0.1):
"""Initialize the learnable timescale Delta by sampling
uniformly between dt_min and dt_max.
Args:
dt_min (float32): minimum value
dt_max (float32): maximum value
Returns:
init function
"""
def init(shape):
"""Init function
Args:
key: jax random key
shape tuple: desired shape
Returns:
sampled log_step (float32)
"""
return uniform(shape, minval=np.log(dt_min), maxval=np.log(dt_max))
# return torch.rand(shape) * (np.log(dt_max) - np.log(dt_min)) + np.log(dt_min)
return init
def init_log_steps(H, dt_min, dt_max):
"""Initialize an array of learnable timescale parameters
Args:
key: jax random key
input: tuple containing the array shape H and
dt_min and dt_max
Returns:
initialized array of timescales (float32): (H,)
"""
log_steps = []
for i in range(H):
log_step = log_step_initializer(dt_min=dt_min, dt_max=dt_max)(shape=(1,))
log_steps.append(log_step)
return torch.tensor(log_steps)
def init_VinvB(init_fun, Vinv):
"""Initialize B_tilde=V^{-1}B. First samples B. Then compute V^{-1}B.
Note we will parameterize this with two different matrices for complex
numbers.
Args:
init_fun: the initialization function to use, e.g. lecun_normal()
shape (tuple): desired shape (P,H)
Vinv: (complex64) the inverse eigenvectors used for initialization
Returns:
B_tilde (complex64) of shape (P,H,2)
"""
def init(shape, dtype):
B = init_fun(shape, dtype)
VinvB = Vinv @ B.type(Vinv.dtype)
VinvB_real = VinvB.real
VinvB_imag = VinvB.imag
return torch.cat((VinvB_real[..., None], VinvB_imag[..., None]), axis=-1)
return init
def trunc_standard_normal(shape):
"""Sample C with a truncated normal distribution with standard deviation 1.
Args:
key: jax random key
shape (tuple): desired shape, of length 3, (H,P,_)
Returns:
sampled C matrix (float32) of shape (H,P,2) (for complex parameterization)
"""
H, P, _ = shape
Cs = []
for i in range(H):
C = lecun_normal()(shape=(1, P, 2))
Cs.append(C)
return torch.tensor(Cs)[:, 0]
def init_CV(init_fun, shape, V) -> torch.Tensor:
"""Initialize C_tilde=CV. First sample C. Then compute CV.
Note we will parameterize this with two different matrices for complex
numbers.
Args:
init_fun: the initialization function to use, e.g. lecun_normal()
shape (tuple): desired shape (H,P)
V: (complex64) the eigenvectors used for initialization
Returns:
C_tilde (complex64) of shape (H,P,2)
"""
C_ = init_fun(shape + (2,))
C = C_[..., 0] + 1j * C_[..., 1]
CV = C @ V
return CV
def init_columnwise_B(shape, dtype):
"""Initialize B matrix in columnwise fashion.
We will sample each column of B from a lecun_normal distribution.
This gives a different fan-in size then if we sample the entire
matrix B at once. We found this approach to be helpful for PathX
It appears to be related to the point in
https://arxiv.org/abs/2206.12037 regarding the initialization of
the C matrix in S4, so potentially more important for the
C initialization than for B.
Args:
key: jax random key
shape (tuple): desired shape, either of length 3, (P,H,_), or
of length 2 (N,H) depending on if the function is called
from the low-rank factorization initialization or a dense
initialization
Returns:
sampled B matrix (float32), either of shape (H,P) or
shape (H,P,2) (for complex parameterization)
"""
shape = shape[:2] + ((2,) if len(shape) == 3 else ())
lecun = variance_scaling(0.5 if len(shape) == 3 else 1.0, fan_in_axes=(0,))
return lecun(shape, dtype)
def init_columnwise_VinvB(init_fun, Vinv):
"""Same function as above, but with transpose applied to prevent shape mismatch
when using the columnwise initialization. In general this is unnecessary
and will be removed in future versions, but is left for now consistency with
certain random seeds until we rerun experiments."""
def init(shape, dtype):
B = init_fun(shape[:2], dtype)
VinvB = Vinv @ B
VinvB_real = VinvB.real
VinvB_imag = VinvB.imag
return torch.cat((VinvB_real[..., None], VinvB_imag[..., None]), axis=-1)
return init
def init_rowwise_C(shape, dtype):
"""Initialize C matrix in rowwise fashion. Analogous to init_columnwise_B function above.
We will sample each row of C from a lecun_normal distribution.
This gives a different fan-in size then if we sample the entire
matrix B at once. We found this approach to be helpful for PathX.
It appears to be related to the point in
https://arxiv.org/abs/2206.12037 regarding the initialization of
the C matrix in S4.
Args:
shape (tuple): desired shape, of length 3, (H,P,_)
Returns:
sampled C matrix (float32) of shape (H,P,2) (for complex parameterization)
"""
shape = shape[:2] + ((2,) if len(shape) == 3 else ())
lecun = variance_scaling(0.5, fan_in_axes=(0,))
return lecun(shape, dtype)
================================================
FILE: RVT/models/layers/s5/s5_model.py
================================================
import torch
import torch.nn.functional as F
from typing import Literal, Tuple, Optional
import os, sys
import math
ROOT = os.getcwd()
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT))
sys.path.append(os.path.join(ROOT, "RVT"))
from models.layers.s5.jax_func import associative_scan
from models.layers.s5.s5_init import *
# Runtime functions
@torch.jit.script
def binary_operator(
q_i: Tuple[torch.Tensor, torch.Tensor], q_j: Tuple[torch.Tensor, torch.Tensor]
):
"""Binary operator for parallel scan of linear recurrence. Assumes a diagonal matrix A.
Args:
q_i: tuple containing A_i and Bu_i at position i (P,), (P,)
q_j: tuple containing A_j and Bu_j at position j (P,), (P,)
Returns:
new element ( A_out, Bu_out )
"""
A_i, b_i = q_i
A_j, b_j = q_j
# return A_j * A_i, A_j * b_i + b_j
return A_j * A_i, torch.addcmul(b_j, A_j, b_i)
def apply_ssm(
Lambda_bars: torch.Tensor,
B_bars,
C_tilde,
D,
input_sequence,
prev_state,
bidir: bool = False,
):
B_bars = as_complex(B_bars)
C_tilde = as_complex(C_tilde)
Lambda_bars = as_complex(Lambda_bars)
cinput_sequence = input_sequence.type(
Lambda_bars.dtype
) # Cast to correct complex type
if B_bars.ndim == 3:
# Dynamic timesteps (significantly more expensive)
Bu_elements = torch.vmap(lambda B_bar, u: B_bar @ u)(B_bars, cinput_sequence)
else:
# Static timesteps
Bu_elements = torch.vmap(lambda u: B_bars @ u)(cinput_sequence)
if Lambda_bars.ndim == 1: # Repeat for associative_scan
Lambda_bars = Lambda_bars.tile(input_sequence.shape[0], 1)
Lambda_bars[0] = Lambda_bars[0] * prev_state
_, xs = associative_scan(binary_operator, (Lambda_bars, Bu_elements))
if bidir:
_, xs2 = associative_scan(
binary_operator, (Lambda_bars, Bu_elements), reverse=True
)
xs = torch.cat((xs, xs2), axis=-1)
Du = torch.vmap(lambda u: D * u)(input_sequence)
# TODO: the last element of xs (non-bidir) is the hidden state, allow returning it
return torch.vmap(lambda x: (C_tilde @ x).real)(xs) + Du, xs[-1]
def apply_ssm_liquid(
Lambda_bars, B_bars, C_tilde, D, input_sequence, bidir: bool = False
):
"""Liquid time constant SSM \u00e1 la dynamical systems given in Eq. 8 of
https://arxiv.org/abs/2209.12951"""
cinput_sequence = input_sequence.type(
Lambda_bars.dtype
) # Cast to correct complex type
if B_bars.ndim == 3:
# Dynamic timesteps (significantly more expensive)
Bu_elements = torch.vmap(lambda B_bar, u: B_bar @ u)(B_bars, cinput_sequence)
else:
# Static timesteps
Bu_elements = torch.vmap(lambda u: B_bars @ u)(cinput_sequence)
if Lambda_bars.ndim == 1: # Repeat for associative_scan
Lambda_bars = Lambda_bars.tile(input_sequence.shape[0], 1)
_, xs = associative_scan(binary_operator, (Lambda_bars + Bu_elements, Bu_elements))
if bidir:
_, xs2 = associative_scan(
binary_operator, (Lambda_bars, Bu_elements), reverse=True
)
xs = torch.cat((xs, xs2), axis=-1)
Du = torch.vmap(lambda u: D * u)(input_sequence)
return torch.vmap(lambda x: (C_tilde @ x).real)(xs) + Du
# Discretization functions
def discretize_bilinear(Lambda, B_tilde, Delta):
"""Discretize a diagonalized, continuous-time linear SSM
using bilinear transform method.
Args:
Lambda (complex64): diagonal state matrix (P,)
B_tilde (complex64): input matrix (P, H)
Delta (float32): discretization step sizes (P,)
Returns:
discretized Lambda_bar (complex64), B_bar (complex64) (P,), (P,H)
"""
Lambda = torch.view_as_complex(Lambda)
Identity = torch.ones(Lambda.shape[0], device=Lambda.device)
BL = 1 / (Identity - (Delta / 2.0) * Lambda)
Lambda_bar = BL * (Identity + (Delta / 2.0) * Lambda)
B_bar = (BL * Delta)[..., None] * B_tilde
Lambda_bar = torch.view_as_real(Lambda_bar)
B_bar = torch.view_as_real(B_bar)
return Lambda_bar, B_bar
def discretize_zoh(Lambda, B_tilde, Delta):
"""Discretize a diagonalized, continuous-time linear SSM
using zero-order hold method.
Args:
Lambda (complex64): diagonal state matrix (P,)
B_tilde (complex64): input matrix (P, H)
Delta (float32): discretization step sizes (P,)
Returns:
discretized Lambda_bar (complex64), B_bar (complex64) (P,), (P,H)
"""
# Identity = torch.ones(Lambda.shape[0], device=Lambda.device) # (replaced by -1)
Lambda_bar = torch.exp(Lambda * Delta)
B_bar = (1 / Lambda * (Lambda_bar - 1))[..., None] * B_tilde
return Lambda_bar, B_bar
def as_complex(t: torch.Tensor, dtype=torch.complex64):
assert t.shape[-1] == 2, "as_complex can only be done on tensors with shape=(...,2)"
nt = torch.complex(t[..., 0], t[..., 1])
if nt.dtype != dtype:
nt = nt.type(dtype)
return nt
Initialization = Literal["dense_columns", "dense", "factorized"]
class S5SSM(torch.nn.Module):
def __init__(
self,
lambdaInit: torch.Tensor,
V: torch.Tensor,
Vinv: torch.Tensor,
h: int,
p: int,
dt_min: float,
dt_max: float,
liquid: bool = False,
factor_rank: Optional[int] = None,
discretization: Literal["zoh", "bilinear"] = "bilinear",
bcInit: Initialization = "factorized",
degree: int = 1,
bidir: bool = False,
step_scale: float = 1.0,
bandlimit: Optional[float] = None,
):
"""The S5 SSM
Args:
lambdaInit (complex64): Initial diagonal state matrix (P,)
V (complex64): Eigenvectors used for init (P,P)
Vinv (complex64): Inverse eigenvectors used for init (P,P)
h (int32): Number of features of input seq
p (int32): state size
k (int32): rank of low-rank factorization (if used)
bcInit (string): Specifies How B and C are initialized
Options: [factorized: low-rank factorization,
dense: dense matrix drawn from Lecun_normal]
dense_columns: dense matrix where the columns
of B and the rows of C are each drawn from Lecun_normal
separately (i.e. different fan-in then the dense option).
We found this initialization to be helpful for Pathx.
discretization: (string) Specifies discretization method
options: [zoh: zero-order hold method,
bilinear: bilinear transform]
liquid: (bool): use liquid_ssm from LiquidS4
dt_min: (float32): minimum value to draw timescale values from when
initializing log_step
dt_max: (float32): maximum value to draw timescale values from when
initializing log_step
step_scale: (float32): allows for changing the step size, e.g. after training
on a different resolution for the speech commands benchmark
"""
super().__init__()
self.Lambda = torch.nn.Parameter(torch.view_as_real(lambdaInit))
self.degree = degree
self.liquid = liquid
self.bcInit = bcInit
self.bidir = bidir
self.bandlimit = bandlimit
cp = p
if self.bidir:
cp *= 2
match bcInit:
case "complex_normal":
self.C = torch.nn.Parameter(
torch.normal(0, 0.5**0.5, (h, cp), dtype=torch.complex64)
)
self.B = torch.nn.Parameter(
init_VinvB(lecun_normal(), Vinv)((p, h), torch.float)
)
case "dense_columns" | "dense":
if bcInit == "dense_columns":
B_eigen_init = init_columnwise_VinvB
B_init = init_columnwise_B
C_init = init_rowwise_C
elif bcInit == "dense":
B_eigen_init = init_VinvB
B_init = C_init = lecun_normal()
# TODO: make init_*VinvB all a the same interface
self.B = torch.nn.Parameter(
B_eigen_init(B_init, Vinv)((p, h), torch.float)
)
if self.bidir:
C = torch.cat(
[init_CV(C_init, (h, p), V), init_CV(C_init, (h, p), V)],
axis=-1,
)
else:
C = init_CV(C_init, (h, p), V)
self.C = torch.nn.Parameter(torch.view_as_real(C))
case _:
raise NotImplementedError(f"BC_init method {bcInit} not implemented")
# Initialize feedthrough (D) matrix
self.D = torch.nn.Parameter(
torch.rand(
h,
)
)
self.log_step = torch.nn.Parameter(init_log_steps(p, dt_min, dt_max))
match discretization:
case "zoh":
self.discretize = discretize_zoh
case "bilinear":
self.discretize = discretize_bilinear
case _:
raise ValueError(f"Unknown discretization {discretization}")
if self.bandlimit is not None:
step = step_scale * torch.exp(self.log_step)
freqs = step / step_scale * self.Lambda[:, 1].abs() / (2 * math.pi)
mask = torch.where(freqs < bandlimit * 0.5, 1, 0) # (64, )
self.C = torch.nn.Parameter(
torch.view_as_real(torch.view_as_complex(self.C) * mask)
)
def initial_state(self, batch_size: Optional[int]):
batch_shape = (batch_size,) if batch_size is not None else ()
_, C_tilde = self.get_BC_tilde()
return torch.zeros((*batch_shape, C_tilde.shape[-2]))
def get_BC_tilde(self):
match self.bcInit:
case "dense_columns" | "dense" | "complex_normal":
B_tilde = as_complex(self.B)
C_tilde = self.C
case "factorized":
B_tilde = self.BP @ self.BH.T
C_tilde = self.CH.T @ self.CP
return B_tilde, C_tilde
def forward_rnn(self, signal, prev_state, step_scale: float | torch.Tensor = 1.0):
assert not self.bidir, "Can't use bidirectional when manually stepping"
B_tilde, C_tilde = self.get_BC_tilde()
step = step_scale * torch.exp(self.log_step)
Lambda_bar, B_bar = self.discretize(self.Lambda, B_tilde, step)
if self.degree != 1:
assert (
B_bar.shape[-2] == B_bar.shape[-1]
), "higher-order input operators must be full-rank"
B_bar **= self.degree
if not torch.is_tensor(step_scale) or step_scale.ndim == 0:
step_scale = torch.ones(signal.shape[-2], device=signal.device) * step_scale
step = step_scale[:, None] * torch.exp(self.log_step)
# https://arxiv.org/abs/2209.12951v1, Eq. 9
Bu = B_bar @ signal
if self.liquid:
Lambda_bar += Bu
# https://arxiv.org/abs/2208.04933v2, Eq. 2
x = Lambda_bar * prev_state + Bu
y = (C_tilde @ x + self.D * signal).real
return y, x
# NOTE: can only be used as RNN OR S5(MIMO) (no mixing)
def forward(self, signal, prev_state, step_scale: float | torch.Tensor = 1.0):
B_tilde, C_tilde = self.get_BC_tilde()
if self.degree != 1:
assert (
B_bar.shape[-2] == B_bar.shape[-1]
), "higher-order input operators must be full-rank"
B_bar **= self.degree
if not torch.is_tensor(step_scale) or step_scale.ndim == 0:
# step_scale = torch.ones(signal.shape[-2], device=signal.device) * step_scale
step = step_scale * torch.exp(self.log_step)
else:
# TODO: This is very expensive due to individual steps being multiplied by B_tilde in self.discretize
step = step_scale[:, None] * torch.exp(self.log_step)
Lambda_bars, B_bars = self.discretize(self.Lambda, B_tilde, step)
# Lambda_bars, B_bars = torch.vmap(self.discretize, (None, None, 0))(self.Lambda, B_tilde, step)
forward = apply_ssm_liquid if self.liquid else apply_ssm
return forward(
Lambda_bars, B_bars, C_tilde, self.D, signal, prev_state, bidir=self.bidir
)
class S5(torch.nn.Module):
def __init__(
self,
width: int,
state_width: Optional[int] = None,
factor_rank: Optional[int] = None,
block_count: int = 1,
dt_min: float = 0.001,
dt_max: float = 0.1,
liquid: bool = False,
degree: int = 1,
bidir: bool = False,
bcInit: Optional[Initialization] = None,
bandlimit: Optional[float] = None,
):
super().__init__()
state_width = state_width or width
assert (
state_width % block_count == 0
), "block_count should be a factor of state_width"
block_size = state_width // block_count
Lambda, _, B, V, B_orig = make_DPLR_HiPPO(block_size)
Vinv = V.conj().T
Lambda, B, V, B_orig, Vinv = map(
lambda v: torch.tensor(v, dtype=torch.complex64),
(Lambda, B, V, B_orig, Vinv),
)
if block_count > 1:
Lambda = Lambda[:block_size]
V = V[:, :block_size]
Lambda = (Lambda * torch.ones((block_count, block_size))).ravel()
V = torch.block_diag(*([V] * block_count))
Vinv = torch.block_diag(*([Vinv] * block_count))
assert bool(factor_rank) != bool(
bcInit != "factorized"
), "Can't have `bcInit != factorized` and `factor_rank` defined"
bc_init = "factorized" if factor_rank is not None else (bcInit or "dense")
self.width = width
self.seq = S5SSM(
Lambda,
V,
Vinv,
width,
state_width,
dt_min,
dt_max,
factor_rank=factor_rank,
bcInit=bc_init,
liquid=liquid,
degree=degree,
bidir=bidir,
bandlimit=bandlimit,
)
def initial_state(self, batch_size: Optional[int] = None):
return self.seq.initial_state(batch_size)
def forward(self, signal, prev_state, step_scale: float | torch.Tensor = 1.0):
# NOTE: step_scale can be float | Tensor[batch] | Tensor[batch, seq]
if not torch.is_tensor(step_scale):
# Duplicate across batchdim
step_scale = torch.ones(signal.shape[0], device=signal.device) * step_scale
return torch.vmap(lambda s, ps, ss: self.seq(s, prev_state=ps, step_scale=ss))(
signal, prev_state, step_scale
)
class GEGLU(torch.nn.Module):
def forward(self, x):
x, gates = x.chunk(2, dim=-1)
return x * F.gelu(gates)
class S5Block(torch.nn.Module):
def __init__(
self,
dim: int,
state_dim: int,
bidir: bool,
block_count: int = 1,
liquid: bool = False,
degree: int = 1,
factor_rank: int | None = None,
bcInit: Optional[Initialization] = None,
ff_mult: float = 1.0,
glu: bool = True,
ff_dropout: float = 0.0,
attn_dropout: float = 0.0,
bandlimit: Optional[float] = None,
):
super().__init__()
self.s5 = S5(
dim,
state_width=state_dim,
bidir=bidir,
block_count=block_count,
liquid=liquid,
degree=degree,
factor_rank=factor_rank,
bcInit=bcInit,
bandlimit=bandlimit,
)
self.attn_norm = torch.nn.LayerNorm(dim)
self.attn_dropout = torch.nn.Dropout(p=attn_dropout)
self.geglu = GEGLU() if glu else None
self.ff_enc = torch.nn.Linear(dim, int(dim * ff_mult) * (1 + glu), bias=False)
self.ff_dec = torch.nn.Linear(int(dim * ff_mult), dim, bias=False)
self.ff_norm = torch.nn.LayerNorm(dim)
self.ff_dropout = torch.nn.Dropout(p=ff_dropout)
def forward(self, x, states):
# Standard transfomer-style block with GEGLU/Pre-LayerNorm
fx = self.attn_norm(x)
res = fx.clone()
x, new_state = self.s5(fx, states)
x = F.gelu(x) + res
x = self.attn_dropout(x)
fx = self.ff_norm(x)
res = fx.clone()
x = self.ff_enc(fx)
if self.geglu is not None:
x = self.geglu(x)
x = self.ff_dec(x) + res
x = self.ff_dropout(
x
) # TODO: test if should be placed inbetween ff or after ff
return x, new_state
if __name__ == "__main__":
import lovely_tensors as lt
lt.monkey_patch()
def tensor_stats(t: torch.Tensor): # Clone of lovely_tensors for complex support
return f"tensor[{t.shape}] n={t.shape.numel()}, u={t.mean()}, s={round(t.std().item(), 3)} var={round(t.var().item(), 3)}\n"
x = torch.rand([2, 256, 32]).cuda()
model = S5(32, 32, factor_rank=None).cuda()
print("B", tensor_stats(model.seq.B.data))
print("C", tensor_stats(model.seq.C.data))
# print('B', tensor_stats(model.seq.BH.data), tensor_stats(model.seq.BP.data))
# print('C', tensor_stats(model.seq.CH.data), tensor_stats(model.seq.CP.data))
# FIXME: unstable initialization
# state = model.initial_state(256)
# res = model(x, prev_state=state)
# print(res.shape, res.dtype, res)
res = model(x) # warm-up
print(res.shape, res.dtype, res)
# Example 2: (B, L, H) inputs
x = torch.rand([2, 256, 32]).cuda()
model = S5Block(32, 32, False).cuda()
res = model(x)
print(res.shape, res.dtype, res)
================================================
FILE: RVT/models/layers/s5/triton_comparison.py
================================================
import torch
import numpy as np
import time
import triton
import triton.language as tl
from triton.runtime.jit import TensorWrapper, reinterpret
from jax_func import associative_scan
int_dtypes = ["int8", "int16", "int32", "int64"]
uint_dtypes = ["uint8", "uint16", "uint32", "uint64"]
float_dtypes = ["float16", "float32", "float64"]
dtypes = int_dtypes + uint_dtypes + float_dtypes
dtypes_with_bfloat16 = dtypes + ["bfloat16"]
torch_dtypes = ["bool"] + int_dtypes + ["uint8"] + float_dtypes + ["bfloat16"]
def to_triton(x: np.ndarray, device="cuda", dst_type=None):
t = x.dtype.name
if t in uint_dtypes:
signed_type_name = t.lstrip("u") # e.g. "uint16" -> "int16"
x_signed = x.astype(getattr(np, signed_type_name))
return reinterpret(
torch.tensor(x_signed, device=device).contiguous(), getattr(tl, t)
)
else:
if dst_type and "float8" in dst_type:
return reinterpret(
torch.tensor(x, device=device).contiguous(), getattr(tl, dst_type)
)
if t == "float32" and dst_type == "bfloat16":
return torch.tensor(x, device=device).contiguous().bfloat16()
return torch.tensor(x, device=device).contiguous()
def to_numpy(x):
if isinstance(x, TensorWrapper):
# FIXME: torch_dtype_name doesn't exist
return x.base.cpu().numpy().astype(getattr(np, torch_dtype_name(x.dtype)))
elif isinstance(x, torch.Tensor):
if x.dtype is torch.bfloat16:
return x.cpu().float().numpy()
return x.cpu().numpy()
else:
raise ValueError(f"Not a triton-compatible tensor: {x}")
if __name__ == "__main__":
use_gpu = True
if use_gpu:
device = torch.device("cuda:0")
else:
device = None
triton_times = []
loop_times = []
loop_comp_times = []
jax_compat_times = []
print("Initializing")
op = "cumsum"
num_warps = 16
dim = 1
seq_len = 2048
batch = 4
dtype_str = "float32"
axis = 0
shape = (batch, seq_len, dim)
n_timings = 10000
x = np.random.rand(*shape).astype(dtype=np.float32)
inp = torch.tensor(x, device=device, requires_grad=True, dtype=torch.float32)
init = torch.zeros(shape[1], 1, device=device, requires_grad=True)
inp_scan = inp
@triton.jit
def sum_op(a, b):
return a + b
@triton.jit
def kernel(X, Z, BLOCK_M: tl.constexpr, BLOCK_N: tl.constexpr, AXIS: tl.constexpr):
range_m = tl.arange(0, BLOCK_M)
range_n = tl.arange(0, BLOCK_N)
x = tl.load(X + range_m[:, None] * BLOCK_N + range_n[None, :])
# tl.device_print("z", x)
z = tl.associative_scan(x, 0, sum_op)
# tl.device_print("z", z)
tl.store(Z + range_m[:, None] * BLOCK_N + range_n[None, :], z)
print("Triton")
z = np.empty_like(x)
x_tri = to_triton(x, device=device)
numpy_op = np.cumsum
z_dtype_str = dtype_str
z_ref = numpy_op(x, axis=axis).astype(getattr(np, z_dtype_str))
# triton result
z_tri = to_triton(z, device=device)
val = kernel[(1,)](
x_tri, z_tri, BLOCK_M=shape[0], BLOCK_N=shape[1], AXIS=axis, num_warps=num_warps
)
out_triton = to_numpy(z_tri)
for _ in range(n_timings):
# print('.', end='', flush=True)
start = time.monotonic_ns()
kernel[(1,)](
x_tri,
z_tri,
BLOCK_M=shape[0],
BLOCK_N=shape[1],
AXIS=axis,
num_warps=num_warps,
)
stop = time.monotonic_ns()
triton_times.append((stop - start) / (10**9))
print("\nFake scan")
def f(carry, x):
return carry + x, carry + x
def _fake_scan(f, init, x):
zs = []
carry = init
for xp in x:
carry, out = f(carry, xp)
zs.append(out)
return carry, torch.stack(zs)
expected_carry_out, expected_ys = _fake_scan(f, init, inp_scan)
for _ in range(n_timings):
# print('.', end='', flush=True)
start = time.monotonic_ns()
expected_carry_out, expected_ys = _fake_scan(f, init, inp_scan)
stop = time.monotonic_ns()
loop_times.append((stop - start) / (10**9))
# _fake_scan_comp = torch.compile(_fake_scan, mode='reduce-overhead', fullgraph=True, dynamic=False)
# # Warm-up cycles
# print("\nFake scan-compiled")
# for _ in range(5):
# expected_carry_out_comp, expected_ys_comp = _fake_scan_comp(f, init, inp_scan)
# for _ in range(n_timings):
# print('.', end='', flush=True)
# start = time.monotonic_ns()
# expected_carry_out_comp, expected_ys_comp = _fake_scan_comp(f, init, inp_scan)
# stop = time.monotonic_ns()
# loop_comp_times.append((stop - start) / (10 ** 9))
def sum_op2(a, b):
return a + b, a + b
# Warm-up
print("\njax_compat")
for _ in range(5):
expected_ys_comp = associative_scan(sum_op2, inp_scan, axis=-1)
for _ in range(n_timings):
# print('.', end='', flush=True)
start = time.monotonic_ns()
expected_ys_comp = associative_scan(sum_op2, inp_scan, axis=-1)
stop = time.monotonic_ns()
jax_compat_times.append((stop - start) / (10**9))
print()
print("Times regular loop " + str(np.array(loop_times).mean()))
# print('Times compiled loop ' + str(np.array(loop_comp_times).mean()))
print("Times triton " + str(np.array(triton_times).mean()))
print("Times jax_compat " + str(np.array(jax_compat_times).mean()))
print("Script ended")
================================================
FILE: RVT/modules/__init__.py
================================================
================================================
FILE: RVT/modules/data/genx.py
================================================
from functools import partial
from typing import Any, Dict, Optional, Union
import math
import lightning.pytorch as pl
from omegaconf import DictConfig
from torch.utils.data import DataLoader, Dataset
from data.genx_utils.collate import custom_collate_rnd, custom_collate_streaming
from data.genx_utils.dataset_rnd import (
build_random_access_dataset,
get_weighted_random_sampler,
CustomConcatDataset,
)
from data.genx_utils.dataset_streaming import build_streaming_dataset
from data.utils.spatial import get_dataloading_hw
from data.utils.types import DatasetMode, DatasetSamplingMode
def get_dataloader_kwargs(
dataset: Union[Dataset, CustomConcatDataset],
sampling_mode: DatasetSamplingMode,
dataset_mode: DatasetMode,
dataset_config: DictConfig,
batch_size: int,
num_workers: int,
) -> Dict[str, Any]:
if dataset_mode == DatasetMode.TRAIN:
if sampling_mode == DatasetSamplingMode.STREAM:
return dict(
dataset=dataset,
batch_size=None,
shuffle=False, # Done already in the streaming datapipe
num_workers=num_workers,
pin_memory=False,
drop_last=False, # Cannot be done with streaming datapipes
collate_fn=custom_collate_streaming,
)
if sampling_mode == DatasetSamplingMode.RANDOM:
use_weighted_rnd_sampling = dataset_config.train.random.weighted_sampling
sampler = (
get_weighted_random_sampler(dataset)
if use_weighted_rnd_sampling
else None
)
return dict(
dataset=dataset,
batch_size=batch_size,
shuffle=sampler is None,
sampler=sampler,
num_workers=num_workers,
pin_memory=False,
drop_last=True, # Maintain the same batch size for logging
collate_fn=custom_collate_rnd,
)
raise NotImplementedError
elif dataset_mode in (DatasetMode.VALIDATION, DatasetMode.TESTING):
if sampling_mode == DatasetSamplingMode.STREAM:
return dict(
dataset=dataset,
batch_size=None,
shuffle=False,
num_workers=num_workers,
pin_memory=False,
drop_last=False, # Cannot be done with streaming datapipes
collate_fn=custom_collate_streaming,
)
if sampling_mode == DatasetSamplingMode.RANDOM:
return dict(
dataset=dataset,
batch_size=batch_size,
shuffle=False,
num_workers=num_workers,
pin_memory=False,
drop_last=True, # Maintain the same batch size for logging
collate_fn=custom_collate_rnd,
)
raise NotImplementedError
raise NotImplementedError
class DataModule(pl.LightningDataModule):
def __init__(
self,
dataset_config: DictConfig,
num_workers_train: int,
num_workers_eval: int,
batch_size_train: int,
batch_size_eval: int,
):
super().__init__()
assert num_workers_train >= 0
assert num_workers_eval >= 0
assert batch_size_train >= 1
assert batch_size_eval >= 1
self.dataset_config = dataset_config
self.train_sampling_mode = dataset_config.train.sampling
self.eval_sampling_mode = dataset_config.eval.sampling
assert self.train_sampling_mode in iter(DatasetSamplingMode)
assert self.eval_sampling_mode in (
DatasetSamplingMode.STREAM,
DatasetSamplingMode.RANDOM,
)
# In DDP all configs are per process/GPU (num_workers, batch_size, ...).
self.overall_batch_size_train = batch_size_train
self.overall_batch_size_eval = batch_size_eval
self.overall_num_workers_train = num_workers_train
self.overall_num_workers_eval = num_workers_eval
if self.eval_sampling_mode == DatasetSamplingMode.STREAM:
self.build_eval_dataset = partial(
build_streaming_dataset,
batch_size=self.overall_batch_size_eval,
num_workers=self.overall_num_workers_eval,
)
elif self.eval_sampling_mode == DatasetSamplingMode.RANDOM:
self.build_eval_dataset = build_random_access_dataset
else:
raise NotImplementedError
self.sampling_mode_2_dataset = dict()
self.sampling_mode_2_train_workers = dict()
self.sampling_mode_2_train_batch_size = dict()
self.validation_dataset = None
self.test_dataset = None
def get_dataloading_hw(self):
return get_dataloading_hw(dataset_config=self.dataset_config)
def set_mixed_sampling_mode_variables_for_train(self):
assert (
self.overall_batch_size_train >= 2
), "Cannot use mixed mode with batch size smaller than 2"
assert (
self.overall_num_workers_train >= 2
), "Cannot use mixed mode with num workers smaller than 2"
weight_random = self.dataset_config.train.mixed.w_random
weight_stream = self.dataset_config.train.mixed.w_stream
assert weight_random > 0
assert weight_stream > 0
# Set batch size according to weights.
bs_rnd = min(
round(
self.overall_batch_size_train
* weight_random
/ (weight_stream + weight_random)
),
self.overall_batch_size_train - 1,
)
bs_str = self.overall_batch_size_train - bs_rnd
self.sampling_mode_2_train_batch_size[DatasetSamplingMode.RANDOM] = bs_rnd
self.sampling_mode_2_train_batch_size[DatasetSamplingMode.STREAM] = bs_str
# Set num workers according to batch size. Random sampling typically takes longer than stream sampling!
workers_rnd = min(
math.ceil(
self.overall_num_workers_train * bs_rnd / self.overall_batch_size_train
),
self.overall_num_workers_train - 1,
)
workers_str = self.overall_num_workers_train - workers_rnd
self.sampling_mode_2_train_workers[DatasetSamplingMode.RANDOM] = workers_rnd
self.sampling_mode_2_train_workers[DatasetSamplingMode.STREAM] = workers_str
print(
f"[Train] Local batch size for:\nstream sampling:\t{bs_str}\nrandom sampling:\t{bs_rnd}\n"
f"[Train] Local num workers for:\nstream sampling:\t{workers_str}\nrandom sampling:\t{workers_rnd}"
)
def setup(self, stage: Optional[str] = None) -> None:
if stage == "fit":
if self.train_sampling_mode == DatasetSamplingMode.MIXED:
self.set_mixed_sampling_mode_variables_for_train()
else:
self.sampling_mode_2_train_workers[self.train_sampling_mode] = (
self.overall_num_workers_train
)
self.sampling_mode_2_train_batch_size[self.train_sampling_mode] = (
self.overall_batch_size_train
)
# This code is a bit hacky because at this point we not use DatasetSamplingMode.MIXED anymore
# because we split it up into random and streaming. DatasetSamplingMode.MIXED was just used to determine
# whether we use both or not.
if self.train_sampling_mode in (
DatasetSamplingMode.RANDOM,
DatasetSamplingMode.MIXED,
):
self.sampling_mode_2_dataset[DatasetSamplingMode.RANDOM] = (
build_random_access_dataset(
dataset_mode=DatasetMode.TRAIN,
dataset_config=self.dataset_config,
)
)
if self.train_sampling_mode in (
DatasetSamplingMode.STREAM,
DatasetSamplingMode.MIXED,
):
self.sampling_mode_2_dataset[DatasetSamplingMode.STREAM] = (
build_streaming_dataset(
dataset_mode=DatasetMode.TRAIN,
dataset_config=self.dataset_config,
batch_size=self.sampling_mode_2_train_batch_size[
DatasetSamplingMode.STREAM
],
num_workers=self.sampling_mode_2_train_workers[
DatasetSamplingMode.STREAM
],
)
)
self.validation_dataset = self.build_eval_dataset(
dataset_mode=DatasetMode.VALIDATION, dataset_config=self.dataset_config
)
elif stage == "validate":
self.validation_dataset = self.build_eval_dataset(
dataset_mode=DatasetMode.VALIDATION, dataset_config=self.dataset_config
)
elif stage == "test":
self.test_dataset = self.build_eval_dataset(
dataset_mode=DatasetMode.TESTING, dataset_config=self.dataset_config
)
else:
raise NotImplementedError
def train_dataloader(self):
train_loaders = dict()
for sampling_mode, dataset in self.sampling_mode_2_dataset.items():
train_loaders[sampling_mode] = DataLoader(
**get_dataloader_kwargs(
dataset=dataset,
sampling_mode=sampling_mode,
dataset_mode=DatasetMode.TRAIN,
dataset_config=self.dataset_config,
batch_size=self.sampling_mode_2_train_batch_size[sampling_mode],
num_workers=self.sampling_mode_2_train_workers[sampling_mode],
)
)
if len(train_loaders) == 1:
train_loaders = next(iter(train_loaders.values()))
# Returns a single dataloader.
return train_loaders
assert len(train_loaders) == 2
# Returns a mapping from dataset sampling modes to dataloader.
return train_loaders
def val_dataloader(self):
return DataLoader(
**get_dataloader_kwargs(
dataset=self.validation_dataset,
sampling_mode=self.eval_sampling_mode,
dataset_mode=DatasetMode.VALIDATION,
dataset_config=self.dataset_config,
batch_size=self.overall_batch_size_eval,
num_workers=self.overall_num_workers_eval,
)
)
def test_dataloader(self):
return DataLoader(
**get_dataloader_kwargs(
dataset=self.test_dataset,
sampling_mode=self.eval_sampling_mode,
dataset_mode=DatasetMode.TESTING,
dataset_config=self.dataset_config,
batch_size=self.overall_batch_size_eval,
num_workers=self.overall_num_workers_eval,
)
)
================================================
FILE: RVT/modules/detection.py
================================================
from typing import Any, Optional, Tuple, Union, Dict
from warnings import warn
import numpy as np
import lightning.pytorch as pl
import torch
import torch as th
import torch.distributed as dist
from omegaconf import DictConfig
from lightning.pytorch.utilities.types import STEP_OUTPUT
from einops import rearrange
from data.genx_utils.labels import ObjectLabels
from data.utils.types import DataType, LstmStates, ObjDetOutput, DatasetSamplingMode
from models.detection.yolox.utils.boxes import postprocess
from models.detection.yolox_extension.models.detector import YoloXDetector
from utils.evaluation.prophesee.evaluator import PropheseeEvaluator
from utils.evaluation.prophesee.io.box_loading import to_prophesee
from utils.padding import InputPadderFromShape
from .utils.detection import (
BackboneFeatureSelector,
EventReprSelector,
RNNStates,
Mode,
mode_2_string,
merge_mixed_batches,
)
class Module(pl.LightningModule):
def __init__(self, full_config: DictConfig):
super().__init__()
self.full_config = full_config
self.mdl_config = full_config.model
in_res_hw = tuple(self.mdl_config.backbone.in_res_hw)
self.input_padder = InputPadderFromShape(desired_hw=in_res_hw)
self.mdl = YoloXDetector(self.mdl_config)
self.mode_2_rnn_states: Dict[Mode, RNNStates] = {
Mode.TRAIN: RNNStates(),
Mode.VAL: RNNStates(),
Mode.TEST: RNNStates(),
}
def setup(self, stage: Optional[str] = None) -> None:
dataset_name = self.full_config.dataset.name
self.mode_2_hw: Dict[Mode, Optional[Tuple[int, int]]] = {}
self.mode_2_batch_size: Dict[Mode, Optional[int]] = {}
self.mode_2_psee_evaluator: Dict[Mode, Optional[PropheseeEvaluator]] = {}
self.mode_2_sampling_mode: Dict[Mode, DatasetSamplingMode] = {}
self.started_training = True
dataset_train_sampling = self.full_config.dataset.train.sampling
dataset_eval_sampling = self.full_config.dataset.eval.sampling
assert dataset_train_sampling in iter(DatasetSamplingMode)
assert dataset_eval_sampling in (
DatasetSamplingMode.STREAM,
DatasetSamplingMode.RANDOM,
)
if stage == "fit": # train + val
self.train_config = self.full_config.training
self.train_metrics_config = self.full_config.logging.train.metrics
if self.train_metrics_config.compute:
self.mode_2_psee_evaluator[Mode.TRAIN] = PropheseeEvaluator(
dataset=dataset_name,
downsample_by_2=self.full_config.dataset.downsample_by_factor_2,
)
self.mode_2_psee_evaluator[Mode.VAL] = PropheseeEvaluator(
dataset=dataset_name,
downsample_by_2=self.full_config.dataset.downsample_by_factor_2,
)
self.mode_2_sampling_mode[Mode.TRAIN] = dataset_train_sampling
self.mode_2_sampling_mode[Mode.VAL] = dataset_eval_sampling
for mode in (Mode.TRAIN, Mode.VAL):
self.mode_2_hw[mode] = None
self.mode_2_batch_size[mode] = None
self.started_training = False
elif stage == "validate":
mode = Mode.VAL
self.mode_2_psee_evaluator[mode] = PropheseeEvaluator(
dataset=dataset_name,
downsample_by_2=self.full_config.dataset.downsample_by_factor_2,
)
self.mode_2_sampling_mode[Mode.VAL] = dataset_eval_sampling
self.mode_2_hw[mode] = None
self.mode_2_batch_size[mode] = None
elif stage == "test":
mode = Mode.TEST
self.mode_2_psee_evaluator[mode] = PropheseeEvaluator(
dataset=dataset_name,
downsample_by_2=self.full_config.dataset.downsample_by_factor_2,
)
self.mode_2_sampling_mode[Mode.TEST] = dataset_eval_sampling
self.mode_2_hw[mode] = None
self.mode_2_batch_size[mode] = None
else:
raise NotImplementedError
def forward(
self,
event_tensor: th.Tensor,
previous_states: Optional[LstmStates] = None,
retrieve_detections: bool = True,
targets=None,
) -> Tuple[Union[th.Tensor, None], Union[Dict[str, th.Tensor], None], LstmStates]:
return self.mdl(
x=event_tensor,
previous_states=previous_states,
retrieve_detections=retrieve_detections,
targets=targets,
)
def get_worker_id_from_batch(self, batch: Any) -> int:
return batch["worker_id"]
def get_data_from_batch(self, batch: Any):
return batch["data"]
def training_step(self, batch: Any, batch_idx: int) -> STEP_OUTPUT:
batch = merge_mixed_batches(batch)
data = self.get_data_from_batch(batch)
worker_id = self.get_worker_id_from_batch(batch)
mode = Mode.TRAIN
self.started_training = True
step = self.trainer.global_step
ev_tensor_sequence = data[DataType.EV_REPR]
sparse_obj_labels = data[DataType.OBJLABELS_SEQ]
is_first_sample = data[DataType.IS_FIRST_SAMPLE]
token_mask_sequence = data.get(DataType.TOKEN_MASK, None)
self.mode_2_rnn_states[mode].reset(
worker_id=worker_id, indices_or_bool_tensor=is_first_sample
)
sequence_len = len(ev_tensor_sequence)
assert sequence_len > 0
batch_size = len(sparse_obj_labels[0])
if self.mode_2_batch_size[mode] is None:
self.mode_2_batch_size[mode] = batch_size
else:
assert self.mode_2_batch_size[mode] == batch_size
prev_states = self.mode_2_rnn_states[mode].get_states(worker_id=worker_id)
backbone_feature_selector = BackboneFeatureSelector()
ev_repr_selector = EventReprSelector()
obj_labels = list()
ev_tensor_sequence = torch.stack(
ev_tensor_sequence
) # shape: (sequence_len, batch_size, channels, height, width) = (L, B, C, H, W)
ev_tensor_sequence = ev_tensor_sequence.to(dtype=self.dtype)
ev_tensor_sequence = self.input_padder.pad_tensor_ev_repr(ev_tensor_sequence)
if token_mask_sequence is not None:
token_mask_sequence = torch.stack(token_mask_sequence)
token_mask_sequence = token_mask_sequence.to(dtype=self.dtype)
token_mask_sequence = self.input_padder.pad_token_mask(
token_mask=token_mask_sequence
)
else:
token_mask_sequence = None
if self.mode_2_hw[mode] is None:
self.mode_2_hw[mode] = tuple(ev_tensor_sequence.shape[-2:])
else:
assert self.mode_2_hw[mode] == ev_tensor_sequence.shape[-2:]
backbone_features, states = self.mdl.forward_backbone(
x=ev_tensor_sequence,
previous_states=prev_states,
token_mask=token_mask_sequence,
train_step=True,
)
prev_states = states
for tidx, curr_labels in enumerate(sparse_obj_labels):
(
current_labels,
valid_batch_indices,
) = curr_labels.get_valid_labels_and_batch_indices()
# Store backbone features that correspond to the available labels.
if len(current_labels) > 0:
backbone_feature_selector.add_backbone_features(
backbone_features={
k: v[tidx] for k, v in backbone_features.items()
},
selected_indices=valid_batch_indices,
)
obj_labels.extend(current_labels)
ev_repr_selector.add_event_representations(
event_representations=ev_tensor_sequence[tidx],
selected_indices=valid_batch_indices,
)
self.mode_2_rnn_states[mode].save_states_and_detach(
worker_id=worker_id, states=prev_states
)
assert len(obj_labels) > 0
# Batch the backbone features and labels to parallelize the detection code.
selected_backbone_features = (
backbone_feature_selector.get_batched_backbone_features()
)
labels_yolox = ObjectLabels.get_labels_as_batched_tensor(
obj_label_list=obj_labels, format_="yolox"
)
labels_yolox = labels_yolox.to(dtype=self.dtype)
predictions, losses = self.mdl.forward_detect(
backbone_features=selected_backbone_features, targets=labels_yolox
)
if self.mode_2_sampling_mode[mode] in (
DatasetSamplingMode.MIXED,
DatasetSamplingMode.RANDOM,
):
# We only want to evaluate the last batch_size samples if we use random sampling (or mixed).
# This is because otherwise we would mostly evaluate the init phase of the sequence.
predictions = predictions[-batch_size:]
obj_labels = obj_labels[-batch_size:]
pred_processed = postprocess(
prediction=predictions,
num_classes=self.mdl_config.head.num_classes,
conf_thre=self.mdl_config.postprocess.confidence_threshold,
nms_thre=self.mdl_config.postprocess.nms_threshold,
)
loaded_labels_proph, yolox_preds_proph = to_prophesee(
obj_labels, pred_processed
)
assert losses is not None
assert "loss" in losses
# For visualization, we only use the last batch_size items.
output = {
ObjDetOutput.LABELS_PROPH: loaded_labels_proph[-batch_size:],
ObjDetOutput.PRED_PROPH: yolox_preds_proph[-batch_size:],
ObjDetOutput.EV_REPR: ev_repr_selector.get_event_representations_as_list(
start_idx=-batch_size
),
ObjDetOutput.SKIP_VIZ: False,
"loss": losses["loss"],
}
# Logging
prefix = f"{mode_2_string[mode]}/"
log_dict = {f"{prefix}{k}": v for k, v in losses.items()}
self.log_dict(
log_dict, on_step=True, on_epoch=True, batch_size=batch_size, sync_dist=True
)
if mode in self.mode_2_psee_evaluator:
self.mode_2_psee_evaluator[mode].add_labels(loaded_labels_proph)
self.mode_2_psee_evaluator[mode].add_predictions(yolox_preds_proph)
if (
self.train_metrics_config.detection_metrics_every_n_steps is not None
and step > 0
and step % self.train_metrics_config.detection_metrics_every_n_steps
== 0
):
self.run_psee_evaluator(mode=mode)
return output
def _val_test_step_impl(self, batch: Any, mode: Mode) -> Optional[STEP_OUTPUT]:
data = self.get_data_from_batch(batch)
worker_id = self.get_worker_id_from_batch(batch)
assert mode in (Mode.VAL, Mode.TEST)
ev_tensor_sequence = data[DataType.EV_REPR]
sparse_obj_labels = data[DataType.OBJLABELS_SEQ]
is_first_sample = data[DataType.IS_FIRST_SAMPLE]
self.mode_2_rnn_states[mode].reset(
worker_id=worker_id, indices_or_bool_tensor=is_first_sample
)
sequence_len = len(ev_tensor_sequence)
assert sequence_len > 0
batch_size = len(sparse_obj_labels[0])
if self.mode_2_batch_size[mode] is None:
self.mode_2_batch_size[mode] = batch_size
else:
assert self.mode_2_batch_size[mode] == batch_size
prev_states = self.mode_2_rnn_states[mode].get_states(worker_id=worker_id)
backbone_feature_selector = BackboneFeatureSelector()
ev_repr_selector = EventReprSelector()
obj_labels = list()
ev_tensor_sequence = torch.stack(
ev_tensor_sequence
) # shape: (sequence_len, batch_size, channels, height, width) = (L, B, C, H, W)
ev_tensor_sequence = ev_tensor_sequence.to(dtype=self.dtype)
ev_tensor_sequence = self.input_padder.pad_tensor_ev_repr(ev_tensor_sequence)
if self.mode_2_hw[mode] is None:
self.mode_2_hw[mode] = tuple(ev_tensor_sequence.shape[-2:])
else:
assert self.mode_2_hw[mode] == ev_tensor_sequence.shape[-2:]
backbone_features, states = self.mdl.forward_backbone(
x=ev_tensor_sequence,
previous_states=prev_states,
train_step=False,
)
prev_states = states
for tidx in range(sequence_len):
collect_predictions = (tidx == sequence_len - 1) or (
self.mode_2_sampling_mode[mode] == DatasetSamplingMode.STREAM
)
if collect_predictions:
current_labels, valid_batch_indices = sparse_obj_labels[
tidx
].get_valid_labels_and_batch_indices()
# Store backbone features that correspond to the available labels.
if len(current_labels) > 0:
backbone_feature_selector.add_backbone_features(
backbone_features={
k: v[tidx] for k, v in backbone_features.items()
},
selected_indices=valid_batch_indices,
)
obj_labels.extend(current_labels)
ev_repr_selector.add_event_representations(
event_representations=ev_tensor_sequence[tidx],
selected_indices=valid_batch_indices,
)
self.mode_2_rnn_states[mode].save_states_and_detach(
worker_id=worker_id, states=prev_states
)
if len(obj_labels) == 0:
return {ObjDetOutput.SKIP_VIZ: True}
selected_backbone_features = (
backbone_feature_selector.get_batched_backbone_features()
)
predictions, _ = self.mdl.forward_detect(
backbone_features=selected_backbone_features
)
pred_processed = postprocess(
prediction=predictions,
num_classes=self.mdl_config.head.num_classes,
conf_thre=self.mdl_config.postprocess.confidence_threshold,
nms_thre=self.mdl_config.postprocess.nms_threshold,
)
loaded_labels_proph, yolox_preds_proph = to_prophesee(
obj_labels, pred_processed
)
# For visualization, we only use the last item (per batch).
output = {
ObjDetOutput.LABELS_PROPH: loaded_labels_proph[-1],
ObjDetOutput.PRED_PROPH: yolox_preds_proph[-1],
ObjDetOutput.EV_REPR: ev_repr_selector.get_event_representations_as_list(
start_idx=-1
)[0],
ObjDetOutput.SKIP_VIZ: False,
}
if self.started_training:
self.mode_2_psee_evaluator[mode].add_labels(loaded_labels_proph)
self.mode_2_psee_evaluator[mode].add_predictions(yolox_preds_proph)
return output
def validation_step(self, batch: Any, batch_idx: int) -> Optional[STEP_OUTPUT]:
return self._val_test_step_impl(batch=batch, mode=Mode.VAL)
def test_step(self, batch: Any, batch_idx: int) -> Optional[STEP_OUTPUT]:
return self._val_test_step_impl(batch=batch, mode=Mode.TEST)
def run_psee_evaluator(self, mode: Mode):
psee_evaluator = self.mode_2_psee_evaluator[mode]
batch_size = self.mode_2_batch_size[mode]
hw_tuple = self.mode_2_hw[mode]
if psee_evaluator is None:
warn(f"psee_evaluator is None in {mode=}", UserWarning, stacklevel=2)
return
assert batch_size is not None
assert hw_tuple is not None
if psee_evaluator.has_data():
metrics = psee_evaluator.evaluate_buffer(
img_height=hw_tuple[0], img_width=hw_tuple[1]
)
assert metrics is not None
prefix = f"{mode_2_string[mode]}/"
step = self.trainer.global_step
log_dict = {}
for k, v in metrics.items():
if isinstance(v, (int, float)):
value = torch.tensor(v)
elif isinstance(v, np.ndarray):
value = torch.from_numpy(v)
elif isinstance(v, torch.Tensor):
value = v
else:
raise NotImplementedError
assert (
value.ndim == 0
), f"tensor must be a scalar.\n{v=}\n{type(v)=}\n{value=}\n{type(value)=}"
# put them on the current device to avoid this error: https://github.com/Lightning-AI/lightning/discussions/2529
log_dict[f"{prefix}{k}"] = value.to(self.device)
# Somehow self.log does not work when we eval during the training epoch.
self.log_dict(
log_dict,
on_step=False,
on_epoch=True,
batch_size=batch_size,
sync_dist=True,
)
if dist.is_available() and dist.is_initialized():
# We now have to manually sync (average the metrics) across processes in case of distributed training.
# NOTE: This is necessary to ensure that we have the same numbers for the checkpoint metric (metadata)
# and wandb metric:
# - checkpoint callback is using the self.log function which uses global sync (avg across ranks)
# - wandb uses log_metrics that we reduce manually to global rank 0
dist.barrier()
for k, v in log_dict.items():
dist.reduce(log_dict[k], dst=0, op=dist.ReduceOp.SUM)
if dist.get_rank() == 0:
log_dict[k] /= dist.get_world_size()
if self.trainer.is_global_zero:
# For some reason we need to increase the step by 2 to enable consistent logging in wandb here.
# I might not understand wandb login correctly. This works reasonably well for now.
add_hack = 2
self.logger.log_metrics(metrics=log_dict, step=step + add_hack)
psee_evaluator.reset_buffer()
else:
warn(f"psee_evaluator has not data in {mode=}", UserWarning, stacklevel=2)
def on_train_epoch_end(self) -> None:
mode = Mode.TRAIN
if (
mode in self.mode_2_psee_evaluator
and self.train_metrics_config.detection_metrics_every_n_steps is None
and self.mode_2_hw[mode] is not None
):
# For some reason PL calls this function when resuming.
# We don't know yet the value of train_height_width, so we skip this
self.run_psee_evaluator(mode=mode)
def on_validation_epoch_end(self) -> None:
mode = Mode.VAL
if self.started_training:
assert self.mode_2_psee_evaluator[mode].has_data()
self.run_psee_evaluator(mode=mode)
def on_test_epoch_end(self) -> None:
mode = Mode.TEST
assert self.mode_2_psee_evaluator[mode].has_data()
self.run_psee_evaluator(mode=mode)
def configure_optimizers(self) -> Any:
lr = self.train_config.learning_rate
weight_decay = self.train_config.weight_decay
optimizer = th.optim.AdamW(
self.mdl.parameters(), lr=lr, weight_decay=weight_decay
)
scheduler_params = self.train_config.lr_scheduler
if not scheduler_params.use:
return optimizer
total_steps = scheduler_params.total_steps
assert total_steps is not None
assert total_steps > 0
# Here we interpret the final lr as max_lr/final_div_factor.
# Note that Pytorch OneCycleLR interprets it as initial_lr/final_div_factor:
final_div_factor_pytorch = (
scheduler_params.final_div_factor / scheduler_params.div_factor
)
lr_scheduler = torch.optim.lr_scheduler.OneCycleLR(
optimizer=optimizer,
max_lr=lr,
div_factor=scheduler_params.div_factor,
final_div_factor=final_div_factor_pytorch,
total_steps=total_steps,
pct_start=scheduler_params.pct_start,
cycle_momentum=False,
anneal_strategy="linear",
)
lr_scheduler_config = {
"scheduler": lr_scheduler,
"interval": "step",
"frequency": 1,
"strict": True,
"name": "learning_rate",
}
return {"optimizer": optimizer, "lr_scheduler": lr_scheduler_config}
================================================
FILE: RVT/modules/utils/detection.py
================================================
from enum import Enum, auto
from typing import List, Optional, Union, Tuple, Dict, Any
import torch
import torch as th
from data.genx_utils.labels import SparselyBatchedObjectLabels
from data.utils.types import BackboneFeatures, LstmStates, DatasetSamplingMode
class Mode(Enum):
TRAIN = auto()
VAL = auto()
TEST = auto()
mode_2_string = {
Mode.TRAIN: "train",
Mode.VAL: "val",
Mode.TEST: "test",
}
class BackboneFeatureSelector:
def __init__(self):
self.features = None
self.reset()
def reset(self):
self.features = dict()
def add_backbone_features(
self,
backbone_features: BackboneFeatures,
selected_indices: Optional[List[int]] = None,
) -> None:
if selected_indices is not None:
assert len(selected_indices) > 0
for k, v in backbone_features.items():
if k not in self.features:
self.features[k] = (
[v[selected_indices]] if selected_indices is not None else [v]
)
else:
self.features[k].append(
v[selected_indices] if selected_indices is not None else v
)
def get_batched_backbone_features(self) -> Optional[BackboneFeatures]:
if len(self.features) == 0:
return None
return {k: th.cat(v, dim=0) for k, v in self.features.items()}
class EventReprSelector:
def __init__(self):
self.repr_list = None
self.reset()
def reset(self):
self.repr_list = list()
def __len__(self):
return len(self.repr_list)
def add_event_representations(
self,
event_representations: th.Tensor,
selected_indices: Optional[List[int]] = None,
) -> None:
if selected_indices is not None:
assert len(selected_indices) > 0
self.repr_list.extend(
x[0] for x in event_representations[selected_indices].split(1)
)
def get_event_representations_as_list(
self, start_idx: int = 0, end_idx: Optional[int] = None
) -> Optional[List[th.Tensor]]:
if len(self) == 0:
return None
if end_idx is None:
end_idx = len(self)
assert start_idx < end_idx, f"{start_idx=}, {end_idx=}"
return self.repr_list[start_idx:end_idx]
class RNNStates:
def __init__(self):
self.states = {}
def _has_states(self):
return len(self.states) > 0
@classmethod
def recursive_detach(cls, inp: Union[th.Tensor, List, Tuple, Dict]):
if isinstance(inp, th.Tensor):
return inp.detach()
if isinstance(inp, list):
return [cls.recursive_detach(x) for x in inp]
if isinstance(inp, tuple):
return tuple(cls.recursive_detach(x) for x in inp)
if isinstance(inp, dict):
return {k: cls.recursive_detach(v) for k, v in inp.items()}
raise NotImplementedError
@classmethod
def recursive_reset(
cls,
inp: Union[th.Tensor, List, Tuple, Dict],
indices_or_bool_tensor: Optional[Union[List[int], torch.Tensor]] = None,
):
if isinstance(inp, th.Tensor):
assert (
inp.requires_grad is False
), "Not assumed here but should be the case."
if indices_or_bool_tensor is None:
inp[:] = 0
else:
assert len(indices_or_bool_tensor) > 0
inp[indices_or_bool_tensor] = 0
return inp
if isinstance(inp, list):
return [
cls.recursive_reset(x, indices_or_bool_tensor=indices_or_bool_tensor)
for x in inp
]
if isinstance(inp, tuple):
return tuple(
cls.recursive_reset(x, indices_or_bool_tensor=indices_or_bool_tensor)
for x in inp
)
if isinstance(inp, dict):
return {
k: cls.recursive_reset(v, indices_or_bool_tensor=indices_or_bool_tensor)
for k, v in inp.items()
}
raise NotImplementedError
def save_states_and_detach(self, worker_id: int, states: LstmStates) -> None:
self.states[worker_id] = self.recursive_detach(states)
def get_states(self, worker_id: int) -> Optional[LstmStates]:
if not self._has_states():
return None
if worker_id not in self.states:
return None
return self.states[worker_id]
def reset(
self,
worker_id: int,
indices_or_bool_tensor: Optional[Union[List[int], torch.Tensor]] = None,
):
if not self._has_states():
return
if worker_id in self.states:
self.states[worker_id] = self.recursive_reset(
self.states[worker_id], indices_or_bool_tensor=indices_or_bool_tensor
)
def mixed_collate_fn(
x1: Union[th.Tensor, List[th.Tensor]], x2: Union[th.Tensor, List[th.Tensor]]
):
if isinstance(x1, th.Tensor):
assert isinstance(x2, th.Tensor)
return th.cat((x1, x2))
if isinstance(x1, SparselyBatchedObjectLabels):
assert isinstance(x2, SparselyBatchedObjectLabels)
return x1 + x2
if isinstance(x1, list):
assert isinstance(x2, list)
assert len(x1) == len(x2)
return [mixed_collate_fn(x1=el_1, x2=el_2) for el_1, el_2 in zip(x1, x2)]
raise NotImplementedError
def merge_mixed_batches(batch: Dict[str, Any]):
if "data" in batch:
return batch
rnd_data = batch[DatasetSamplingMode.RANDOM]["data"]
stream_batch = batch[DatasetSamplingMode.STREAM]
# We only care about the worker id of the streaming dataloader because the states will be anyway reset for the
# random dataloader batch.
out = {"worker_id": stream_batch["worker_id"]}
stream_data = stream_batch["data"]
assert (
rnd_data.keys() == stream_data.keys()
), f"{rnd_data.keys()=}, {stream_data.keys()=}"
data_out = dict()
for key in rnd_data.keys():
data_out[key] = mixed_collate_fn(stream_data[key], rnd_data[key])
out.update({"data": data_out})
return out
================================================
FILE: RVT/modules/utils/fetch.py
================================================
import lightning.pytorch as pl
from omegaconf import DictConfig
from modules.data.genx import DataModule as genx_data_module
from modules.detection import Module as rnn_det_module
def fetch_model_module(config: DictConfig) -> pl.LightningModule:
model_str = config.model.name
if model_str == "rnndet":
return rnn_det_module(config)
raise NotImplementedError
def fetch_data_module(config: DictConfig) -> pl.LightningDataModule:
batch_size_train = config.batch_size.train
batch_size_eval = config.batch_size.eval
num_workers_generic = config.hardware.get("num_workers", None)
num_workers_train = config.hardware.num_workers.get("train", num_workers_generic)
num_workers_eval = config.hardware.num_workers.get("eval", num_workers_generic)
dataset_str = config.dataset.name
if dataset_str in {"gen1", "gen4"}:
return genx_data_module(
config.dataset,
num_workers_train=num_workers_train,
num_workers_eval=num_workers_eval,
batch_size_train=batch_size_train,
batch_size_eval=batch_size_eval,
)
raise NotImplementedError
================================================
FILE: RVT/scripts/genx/README.md
================================================
# Pre-Processing the Original Dataset
### 1. Download the data
### 2. Extract the tar files
The following directory structure is assumed:
```
data_dir
├── test
│ ├── ..._bbox.npy
│ ├── ..._td.dat.h5
│ ...
│
├── train
│ ├── ....npy
│ ├── ..._td.dat.h5
│ ...
│
└── val
├── ..._bbox.npy
├── ..._td.dat.h5
...
```
### 3. Run the pre-processing script
`${DATA_DIR}` should point to the directory structure mentioned above.
`${DEST_DIR}` should point to the directory to which the data will be written.
For the 1 Mpx dataset:
```Bash
NUM_PROCESSES=20 # set to the number of parallel processes to use
python preprocess_dataset.py ${DATA_DIR} ${DEST_DIR} conf_preprocess/representation/stacked_hist.yaml \
conf_preprocess/extraction/const_duration.yaml conf_preprocess/filter_gen4.yaml -ds gen4 -np ${NUM_PROCESSES}
```
For the Gen1 dataset:
```Bash
NUM_PROCESSES=20 # set to the number of parallel processes to use
python preprocess_dataset.py ${DATA_DIR} ${DEST_DIR} conf_preprocess/representation/stacked_hist.yaml \
conf_preprocess/extraction/const_duration.yaml conf_preprocess/filter_gen1.yaml -ds gen1 -np ${NUM_PROCESSES}
```
================================================
FILE: RVT/scripts/genx/conf_preprocess/extraction/const_count.yaml
================================================
method: COUNT
value: 50000
================================================
FILE: RVT/scripts/genx/conf_preprocess/extraction/const_duration.yaml
================================================
method: DURATION
# value is in milliseconds!
value: 50
================================================
FILE: RVT/scripts/genx/conf_preprocess/extraction/frequencies/const_duration_100hz.yaml
================================================
method: DURATION
# value is in milliseconds!
value: 10
================================================
FILE: RVT/scripts/genx/conf_preprocess/extraction/frequencies/const_duration_200hz.yaml
================================================
method: DURATION
# value is in milliseconds!
value: 5
================================================
FILE: RVT/scripts/genx/conf_preprocess/extraction/frequencies/const_duration_40hz.yaml
================================================
method: DURATION
# value is in milliseconds!
value: 25
================================================
FILE: RVT/scripts/genx/conf_preprocess/extraction/frequencies/const_duration_80hz.yaml
================================================
method: DURATION
# value is in milliseconds!
value: 12
================================================
FILE: RVT/scripts/genx/conf_preprocess/filter_gen1.yaml
================================================
apply_psee_bbox_filter: True
apply_faulty_bbox_filter: True
================================================
FILE: RVT/scripts/genx/conf_preprocess/filter_gen4.yaml
================================================
apply_psee_bbox_filter: False
apply_faulty_bbox_filter: True
================================================
FILE: RVT/scripts/genx/conf_preprocess/representation/mixeddensity_stack.yaml
================================================
name: "mixeddensity_stack"
nbins: 10
count_cutoff: 32
================================================
FILE: RVT/scripts/genx/conf_preprocess/representation/stacked_hist.yaml
================================================
name: "stacked_histogram"
nbins: 10
count_cutoff: 10
================================================
FILE: RVT/scripts/genx/preprocess_dataset.py
================================================
import os
os.environ["OMP_NUM_THREADS"] = "1"
os.environ["OPENBLAS_NUM_THREADS"] = "1"
os.environ["MKL_NUM_THREADS"] = "1"
os.environ["VECLIB_MAXIMUM_THREADS"] = "1"
os.environ["NUMEXPR_NUM_THREADS"] = "1"
from abc import ABC, abstractmethod
import argparse
from dataclasses import dataclass, field
from enum import Enum, auto
from functools import partial
from multiprocessing import get_context
from pathlib import Path
import shutil
import sys
sys.path.append("../..")
from typing import Any, Dict, List, Optional, Tuple, Union
import weakref
import h5py
import hdf5plugin
from numba import jit
import numpy as np
from omegaconf import OmegaConf, DictConfig, MISSING
import torch
from tqdm import tqdm
from utils.preprocessing import _blosc_opts
from data.utils.representations import (
MixedDensityEventStack,
StackedHistogram,
RepresentationBase,
)
class DataKeys(Enum):
InNPY = auto()
InH5 = auto()
OutLabelDir = auto()
OutEvReprDir = auto()
SplitType = auto()
class SplitType(Enum):
TRAIN = auto()
VAL = auto()
TEST = auto()
split_name_2_type = {
"train": SplitType.TRAIN,
"val": SplitType.VAL,
"test": SplitType.TEST,
}
dataset_2_height = {"gen1": 240, "gen4": 720}
dataset_2_width = {"gen1": 304, "gen4": 1280}
# The following sequences would be discarded because all the labels would be removed after filtering:
dirs_to_ignore = {
"gen1": (
"17-04-06_09-57-37_6344500000_6404500000",
"17-04-13_19-17-27_976500000_1036500000",
"17-04-06_15-14-36_1159500000_1219500000",
"17-04-11_15-13-23_122500000_182500000",
),
"gen4": (),
}
class NoLabelsException(Exception):
# Raised when no labels are present anymore in the sequence after filtering
...
class H5Writer:
def __init__(
self, outfile: Path, key: str, ev_repr_shape: Tuple, numpy_dtype: np.dtype
):
assert len(ev_repr_shape) == 3
self.h5f = h5py.File(str(outfile), "w")
# Sets a finalizer that ensures the file gets closed when the object is garbage collected
self._finalizer = weakref.finalize(self, self.close_callback, self.h5f)
self.key = key # The dataset name/key inside the HDF5 file
self.numpy_dtype = numpy_dtype
# create hdf5 datasets
maxshape = (None,) + ev_repr_shape
chunkshape = (1,) + ev_repr_shape
self.maxshape = maxshape
self.h5f.create_dataset(
key,
dtype=self.numpy_dtype.name,
shape=chunkshape,
chunks=chunkshape,
maxshape=maxshape,
**_blosc_opts(complevel=1, shuffle="byte"),
)
self.t_idx = 0
# enter and exit alllow to use the class as a context manager
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self._finalizer()
@staticmethod
def close_callback(h5f: h5py.File):
h5f.close()
def close(self):
self.h5f.close()
def get_current_length(self):
return self.t_idx
def add_data(self, data: np.ndarray):
# append new data into the already initialized HDF5 dataset
assert data.dtype == self.numpy_dtype, f"{data.dtype=}, {self.numpy_dtype=}"
assert data.shape == self.maxshape[1:]
new_size = self.t_idx + 1
self.h5f[self.key].resize(new_size, axis=0)
self.h5f[self.key][
self.t_idx : new_size
] = data # it writes the new data to the last position of the first dimension
self.t_idx = new_size # It updates the internal index (self.t_idx) to point to the next empty slot in the dataset
class H5Reader:
def __init__(self, h5_file: Path, dataset: str = "gen4"):
assert h5_file.exists()
assert h5_file.suffix == ".h5"
assert dataset in {"gen1", "gen4"}
self.h5f = h5py.File(str(h5_file), "r")
self._finalizer = weakref.finalize(self, self._close_callback, self.h5f)
self.is_open = True
try:
self.height = self.h5f["events"]["height"][()].item()
self.width = self.h5f["events"]["width"][()].item()
except KeyError:
self.height = dataset_2_height[dataset]
self.width = dataset_2_width[dataset]
self.all_times = None
def __enter__(self):
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self._finalizer()
@staticmethod
def _close_callback(h5f: h5py.File):
h5f.close()
def close(self):
self.h5f.close()
self.is_open = False
def get_height_and_width(self) -> Tuple[int, int]:
return self.height, self.width
@property
def time(self) -> np.ndarray:
# We need to lazy load time because it is typically not sorted everywhere.
# - Set timestamps of events such they are not decreasing.
assert self.is_open
if self.all_times is None:
self.all_times = np.asarray(self.h5f["events"]["t"])
self._correct_time(self.all_times)
return self.all_times
@staticmethod
@jit(nopython=True)
def _correct_time(time_array: np.ndarray):
assert time_array[0] >= 0
time_last = 0
for idx, time in enumerate(time_array):
if time < time_last:
time_array[idx] = time_last
else:
time_last = time
def get_event_slice(
self, idx_start: int, idx_end: int, convert_2_torch: bool = True
):
assert self.is_open
assert idx_end >= idx_start
ev_data = self.h5f["events"]
x_array = np.asarray(ev_data["x"][idx_start:idx_end], dtype="int64")
y_array = np.asarray(ev_data["y"][idx_start:idx_end], dtype="int64")
p_array = np.asarray(ev_data["p"][idx_start:idx_end], dtype="int64")
p_array = np.clip(p_array, a_min=0, a_max=None)
t_array = np.asarray(self.time[idx_start:idx_end], dtype="int64")
assert np.all(t_array[:-1] <= t_array[1:])
ev_data = dict(
x=x_array if not convert_2_torch else torch.from_numpy(x_array),
y=y_array if not convert_2_torch else torch.from_numpy(y_array),
p=p_array if not convert_2_torch else torch.from_numpy(p_array),
t=t_array if not convert_2_torch else torch.from_numpy(t_array),
height=self.height,
width=self.width,
)
return ev_data
def prophesee_bbox_filter(labels: np.ndarray, dataset_type: str) -> np.ndarray:
assert dataset_type in {"gen1", "gen4"}
# Default values taken from: https://github.com/prophesee-ai/prophesee-automotive-dataset-toolbox/blob/0393adea2bf22d833893c8cb1d986fcbe4e6f82d/src/psee_evaluator.py#L23-L24
min_box_diag = 60 if dataset_type == "gen4" else 30
# Corrected values from supplementary mat from paper for min_box_side!
min_box_side = 20 if dataset_type == "gen4" else 10
w_lbl = labels["w"]
h_lbl = labels["h"]
diag_ok = w_lbl**2 + h_lbl**2 >= min_box_diag**2
side_ok = (w_lbl >= min_box_side) & (h_lbl >= min_box_side)
keep = diag_ok & side_ok
labels = labels[keep]
return labels
def conservative_bbox_filter(labels: np.ndarray) -> np.ndarray:
w_lbl = labels["w"]
h_lbl = labels["h"]
min_box_side = 5
side_ok = (w_lbl >= min_box_side) & (h_lbl >= min_box_side)
labels = labels[side_ok]
return labels
def remove_faulty_huge_bbox_filter(labels: np.ndarray, dataset_type: str) -> np.ndarray:
"""There are some labels which span the frame horizontally without actually covering an object."""
assert dataset_type in {"gen1", "gen4"}
w_lbl = labels["w"]
max_width = (9 * dataset_2_width[dataset_type]) // 10
side_ok = w_lbl <= max_width
labels = labels[side_ok]
return labels
def crop_to_fov_filter(labels: np.ndarray, dataset_type: str) -> np.ndarray:
assert dataset_type in {"gen1", "gen4"}, f"{dataset_type=}"
# In the gen1 and gen4 datasets the bounding box can be partially or completely outside the frame.
# We fix this labeling error by cropping to the FOV.
frame_height = dataset_2_height[dataset_type]
frame_width = dataset_2_width[dataset_type]
x_left = labels["x"]
y_top = labels["y"]
x_right = x_left + labels["w"]
y_bottom = y_top + labels["h"]
x_left_cropped = np.clip(x_left, a_min=0, a_max=frame_width - 1)
y_top_cropped = np.clip(y_top, a_min=0, a_max=frame_height - 1)
x_right_cropped = np.clip(x_right, a_min=0, a_max=frame_width - 1)
y_bottom_cropped = np.clip(y_bottom, a_min=0, a_max=frame_height - 1)
w_cropped = x_right_cropped - x_left_cropped
assert np.all(w_cropped >= 0)
h_cropped = y_bottom_cropped - y_top_cropped
assert np.all(h_cropped >= 0)
labels["x"] = x_left_cropped
labels["y"] = y_top_cropped
labels["w"] = w_cropped
labels["h"] = h_cropped
# Remove bboxes that have 0 height or width
keep = (labels["w"] > 0) & (labels["h"] > 0)
labels = labels[keep]
return labels
def prophesee_remove_labels_filter_gen4(labels: np.ndarray) -> np.ndarray:
# Original gen4 labels: pedestrian, two wheeler, car, truck, bus, traffic sign, traffic light
# gen4 labels to keep: pedestrian, two wheeler, car
# gen4 labels to remove: truck, bus, traffic sign, traffic light
#
# class_id in {0, 1, 2, 3, 4, 5, 6} in the order mentioned above
keep = labels["class_id"] <= 2
labels = labels[keep]
return labels
def apply_filters(
labels: np.ndarray,
split_type: SplitType,
filter_cfg: DictConfig,
dataset_type: str = "gen1",
) -> np.ndarray:
assert isinstance(dataset_type, str)
if dataset_type == "gen4":
labels = prophesee_remove_labels_filter_gen4(labels=labels)
labels = crop_to_fov_filter(labels=labels, dataset_type=dataset_type)
if filter_cfg.apply_psee_bbox_filter:
labels = prophesee_bbox_filter(labels=labels, dataset_type=dataset_type)
else:
labels = conservative_bbox_filter(labels=labels)
if split_type == SplitType.TRAIN and filter_cfg.apply_faulty_bbox_filter:
labels = remove_faulty_huge_bbox_filter(
labels=labels, dataset_type=dataset_type
)
return labels
def get_base_delta_ts_for_labels_us(
unique_label_ts_us: np.ndarray, dataset_type: str = "gen1"
) -> int:
if dataset_type == "gen1":
delta_t_us_4hz = 250000
return delta_t_us_4hz
assert dataset_type == "gen4"
diff_us = np.diff(unique_label_ts_us)
median_diff_us = np.median(diff_us)
hz = int(np.rint(10**6 / median_diff_us))
assert hz in {30, 60}, f"{hz=} but should be either 30 or 60"
delta_t_us_approx_10hz = int(6 * median_diff_us if hz == 60 else 3 * median_diff_us)
return delta_t_us_approx_10hz
def save_labels(
out_labels_dir: Path,
labels_per_frame: List[np.ndarray],
frame_timestamps_us: np.ndarray,
match_if_exists: bool = True,
) -> None:
assert len(labels_per_frame) == len(frame_timestamps_us)
assert len(labels_per_frame) > 0
labels_v2 = list()
objframe_idx_2_label_idx = list()
start_idx = 0
for labels, timestamp in zip(labels_per_frame, frame_timestamps_us):
objframe_idx_2_label_idx.append(start_idx)
labels_v2.append(labels)
start_idx += len(labels)
assert len(labels_v2) == len(objframe_idx_2_label_idx)
labels_v2 = np.concatenate(labels_v2)
outfile_labels = out_labels_dir / "labels.npz"
if outfile_labels.exists() and match_if_exists:
data_existing = np.load(str(outfile_labels))
labels_existing = data_existing["labels"]
assert np.array_equal(labels_existing, labels_v2)
oi_2_li_existing = data_existing["objframe_idx_2_label_idx"]
assert np.array_equal(oi_2_li_existing, objframe_idx_2_label_idx)
else:
np.savez(
str(outfile_labels),
labels=labels_v2,
objframe_idx_2_label_idx=objframe_idx_2_label_idx,
)
out_labels_ts_file = out_labels_dir / "timestamps_us.npy"
if out_labels_ts_file.exists() and match_if_exists:
frame_timestamps_us_existing = np.load(str(out_labels_ts_file))
assert np.array_equal(frame_timestamps_us_existing, frame_timestamps_us)
else:
np.save(str(out_labels_ts_file), frame_timestamps_us)
def labels_and_ev_repr_timestamps(
npy_file: Path,
split_type: SplitType,
filter_cfg: DictConfig,
align_t_ms: int,
ts_step_ev_repr_ms: int,
dataset_type: str,
):
assert npy_file.exists()
assert npy_file.suffix == ".npy"
ts_step_frame_ms = 100
assert ts_step_frame_ms >= ts_step_ev_repr_ms
assert ts_step_frame_ms % ts_step_ev_repr_ms == 0 and ts_step_ev_repr_ms > 0
align_t_us = align_t_ms * 1000
delta_t_us = ts_step_ev_repr_ms * 1000
sequence_labels = np.load(str(npy_file))
assert len(sequence_labels) > 0
sequence_labels = apply_filters(
labels=sequence_labels,
split_type=split_type,
filter_cfg=filter_cfg,
dataset_type=dataset_type,
)
if sequence_labels.size == 0:
raise NoLabelsException
unique_ts_us = np.unique(np.asarray(sequence_labels["t"], dtype="int64"))
base_delta_ts_labels_us = get_base_delta_ts_for_labels_us(
unique_label_ts_us=unique_ts_us, dataset_type=dataset_type
)
# We extract the first label at or after align_t_us to keep it as the reference for the label extraction.
unique_ts_idx_first = np.searchsorted(unique_ts_us, align_t_us, side="left")
# Extract "frame" timestamps from labels and prepare ev repr ts computation
num_ev_reprs_between_frame_ts = []
frame_timestamps_us = [unique_ts_us[unique_ts_idx_first]]
for unique_ts_idx in range(unique_ts_idx_first + 1, len(unique_ts_us)):
reference_time = frame_timestamps_us[-1]
ts = unique_ts_us[unique_ts_idx]
diff_to_ref = ts - reference_time
base_delta_count = round(diff_to_ref / base_delta_ts_labels_us)
diff_to_ref_rounded = base_delta_count * base_delta_ts_labels_us
if np.abs(diff_to_ref - diff_to_ref_rounded) <= 2000:
assert base_delta_count > 0
# We accept up to 2 millisecond of jitter
frame_timestamps_us.append(ts)
num_ev_reprs_between_frame_ts.append(
base_delta_count * (ts_step_frame_ms // ts_step_ev_repr_ms)
)
frame_timestamps_us = np.asarray(frame_timestamps_us, dtype="int64")
assert len(frame_timestamps_us) > 0, f"{npy_file=}"
start_indices_per_label = np.searchsorted(
sequence_labels["t"], frame_timestamps_us, side="left"
)
end_indices_per_label = np.searchsorted(
sequence_labels["t"], frame_timestamps_us, side="right"
)
# Create labels per "frame"
labels_per_frame = []
for idx_start, idx_end in zip(start_indices_per_label, end_indices_per_label):
labels = sequence_labels[idx_start:idx_end]
label_time_us = labels["t"][0]
assert np.all(labels["t"] == label_time_us)
labels_per_frame.append(labels)
if len(frame_timestamps_us) > 1:
assert (
np.diff(frame_timestamps_us).min() > 98000
), f"{np.diff(frame_timestamps_us).min()=}"
# Event repr timestamps generation
ev_repr_timestamps_us_end = list(
reversed(range(frame_timestamps_us[0], 0, -delta_t_us))
)[1:-1]
assert (
len(num_ev_reprs_between_frame_ts) == len(frame_timestamps_us) - 1
), f"{len(num_ev_reprs_between_frame_ts)=}, {len(frame_timestamps_us)=}"
for idx, (num_ev_repr_between, frame_ts_us_start, frame_ts_us_end) in enumerate(
zip(
num_ev_reprs_between_frame_ts,
frame_timestamps_us[:-1],
frame_timestamps_us[1:],
)
):
new_edge_timestamps = np.asarray(
np.linspace(frame_ts_us_start, frame_ts_us_end, num_ev_repr_between + 1),
dtype="int64",
).tolist()
is_last_iter = idx == len(num_ev_reprs_between_frame_ts) - 1
if not is_last_iter:
new_edge_timestamps = new_edge_timestamps[:-1]
ev_repr_timestamps_us_end.extend(new_edge_timestamps)
if len(frame_timestamps_us) == 1:
# special case not handled in above for loop (no iter in this case)
# yes, it's hacky ...
ev_repr_timestamps_us_end.append(frame_timestamps_us[0])
ev_repr_timestamps_us_end = np.asarray(ev_repr_timestamps_us_end, dtype="int64")
frameidx_2_repridx = np.searchsorted(
ev_repr_timestamps_us_end, frame_timestamps_us, side="left"
)
assert len(frameidx_2_repridx) == len(frame_timestamps_us)
# Some sanity checks:
assert len(labels_per_frame) == len(frame_timestamps_us)
assert len(frame_timestamps_us) == len(frameidx_2_repridx)
for label, frame_ts_us, repr_idx in zip(
labels_per_frame, frame_timestamps_us, frameidx_2_repridx
):
assert label["t"][0] == frame_ts_us
assert frame_ts_us == ev_repr_timestamps_us_end[repr_idx]
return (
labels_per_frame,
frame_timestamps_us,
ev_repr_timestamps_us_end,
frameidx_2_repridx,
)
def write_event_data(
in_h5_file: Path,
ev_out_dir: Path,
dataset: str,
event_representation: RepresentationBase,
ev_repr_num_events: Optional[int],
ev_repr_delta_ts_ms: Optional[int],
ev_repr_timestamps_us: np.ndarray,
downsample_by_2: bool,
frameidx2repridx: np.ndarray,
) -> None:
frameidx2repridx_file = ev_out_dir / "objframe_idx_2_repr_idx.npy"
if frameidx2repridx_file.exists():
frameidx2repridx_loaded = np.load(str(frameidx2repridx_file))
assert np.array_equal(frameidx2repridx_loaded, frameidx2repridx)
else:
np.save(str(frameidx2repridx_file), frameidx2repridx)
timestamps_file = ev_out_dir / "timestamps_us.npy"
if timestamps_file.exists():
timestamps_loaded = np.load(str(timestamps_file))
assert np.array_equal(timestamps_loaded, ev_repr_timestamps_us)
else:
np.save(str(timestamps_file), ev_repr_timestamps_us)
write_event_representations(
in_h5_file=in_h5_file,
ev_out_dir=ev_out_dir,
dataset=dataset,
event_representation=event_representation,
ev_repr_num_events=ev_repr_num_events,
ev_repr_delta_ts_ms=ev_repr_delta_ts_ms,
ev_repr_timestamps_us=ev_repr_timestamps_us,
downsample_by_2=downsample_by_2,
overwrite_if_exists=False,
)
def downsample_ev_repr(x: torch.Tensor, scale_factor: float):
assert 0 < scale_factor < 1
orig_dtype = x.dtype
if orig_dtype == torch.int8:
x = torch.asarray(x, dtype=torch.int16)
x = torch.asarray(x + 128, dtype=torch.uint8)
x = torch.nn.functional.interpolate(
x, scale_factor=scale_factor, mode="nearest-exact"
)
if orig_dtype == torch.int8:
x = torch.asarray(x, dtype=torch.int16)
x = torch.asarray(x - 128, dtype=torch.int8)
return x
def write_event_representations(
in_h5_file: Path,
ev_out_dir: Path,
dataset: str,
event_representation: RepresentationBase,
ev_repr_num_events: Optional[int],
ev_repr_delta_ts_ms: Optional[int],
ev_repr_timestamps_us: np.ndarray,
downsample_by_2: bool,
overwrite_if_exists: bool = False,
) -> None:
ev_outfile = (
ev_out_dir
/ f"event_representations{'_ds2_nearest' if downsample_by_2 else ''}.h5"
)
if ev_outfile.exists() and not overwrite_if_exists:
return
ev_outfile_in_progress = ev_outfile.parent / (
ev_outfile.stem + "_in_progress" + ev_outfile.suffix
)
if ev_outfile_in_progress.exists():
os.remove(ev_outfile_in_progress)
ev_repr_shape = tuple(event_representation.get_shape())
if downsample_by_2:
ev_repr_shape = ev_repr_shape[0], ev_repr_shape[1] // 2, ev_repr_shape[2] // 2
ev_repr_dtype = event_representation.get_numpy_dtype()
with H5Reader(in_h5_file, dataset=dataset) as h5_reader, H5Writer(
ev_outfile_in_progress,
key="data",
ev_repr_shape=ev_repr_shape,
numpy_dtype=ev_repr_dtype,
) as h5_writer:
height, width = h5_reader.get_height_and_width()
if downsample_by_2:
assert (height // 2, width // 2) == ev_repr_shape[-2:]
else:
assert (height, width) == ev_repr_shape[-2:]
ev_ts_us = h5_reader.time
end_indices = np.searchsorted(ev_ts_us, ev_repr_timestamps_us, side="right")
if ev_repr_num_events is not None:
start_indices = np.maximum(end_indices - ev_repr_num_events, 0)
else:
assert ev_repr_delta_ts_ms is not None
start_indices = np.searchsorted(
ev_ts_us,
ev_repr_timestamps_us - ev_repr_delta_ts_ms * 1000,
side="left",
)
for idx_start, idx_end in zip(start_indices, end_indices):
ev_window = h5_reader.get_event_slice(idx_start=idx_start, idx_end=idx_end)
ev_repr = event_representation.construct(
x=ev_window["x"],
y=ev_window["y"],
pol=ev_window["p"],
time=ev_window["t"],
)
if downsample_by_2:
ev_repr = ev_repr.unsqueeze(0)
ev_repr = downsample_ev_repr(x=ev_repr, scale_factor=0.5)
ev_repr_numpy = ev_repr.numpy()[0]
else:
ev_repr_numpy = ev_repr.numpy()
h5_writer.add_data(ev_repr_numpy)
num_written_ev_repr = h5_writer.get_current_length()
assert num_written_ev_repr == len(ev_repr_timestamps_us)
os.rename(ev_outfile_in_progress, ev_outfile)
def process_sequence(
dataset: str,
filter_cfg: DictConfig,
event_representation: RepresentationBase,
ev_repr_num_events: Optional[int],
ev_repr_delta_ts_ms: Optional[int],
ts_step_ev_repr_ms: int,
downsample_by_2: bool,
sequence_data: Dict[DataKeys, Union[Path, SplitType]],
):
in_npy_file = sequence_data[DataKeys.InNPY]
in_h5_file = sequence_data[DataKeys.InH5]
out_labels_dir = sequence_data[DataKeys.OutLabelDir]
out_ev_repr_dir = sequence_data[DataKeys.OutEvReprDir]
split_type = sequence_data[DataKeys.SplitType]
assert out_labels_dir.is_dir()
assert ts_step_ev_repr_ms > 0
assert bool(ev_repr_num_events is not None) ^ bool(
ev_repr_delta_ts_ms is not None
), f"{ev_repr_num_events=}, {ev_repr_delta_ts_ms=}"
# 1) extract: labels_per_frame, frame_timestamps_us, ev_repr_timestamps_us, frameidx2repridx
align_t_ms = 100
try:
(
labels_per_frame,
frame_timestamps_us,
ev_repr_timestamps_us,
frameidx2repridx,
) = labels_and_ev_repr_timestamps(
npy_file=in_npy_file,
split_type=split_type,
filter_cfg=filter_cfg,
align_t_ms=align_t_ms,
ts_step_ev_repr_ms=ts_step_ev_repr_ms,
dataset_type=dataset,
)
except NoLabelsException:
parent_dir = out_labels_dir.parent
print(f"No labels after filtering. Deleting {str(parent_dir)}")
shutil.rmtree(parent_dir)
return
# 2) save: labels_per_frame, frame_timestamps_us
save_labels(
out_labels_dir=out_labels_dir,
labels_per_frame=labels_per_frame,
frame_timestamps_us=frame_timestamps_us,
)
# 3) retrieve event data, compute event representations and save them
write_event_data(
in_h5_file=in_h5_file,
ev_out_dir=out_ev_repr_dir,
dataset=dataset,
event_representation=event_representation,
ev_repr_num_events=ev_repr_num_events,
ev_repr_delta_ts_ms=ev_repr_delta_ts_ms,
ev_repr_timestamps_us=ev_repr_timestamps_us,
downsample_by_2=downsample_by_2,
frameidx2repridx=frameidx2repridx,
)
class AggregationType(Enum):
COUNT = auto()
DURATION = auto()
aggregation_2_string = {
AggregationType.DURATION: "dt",
AggregationType.COUNT: "ne",
}
@dataclass
class FilterConf:
apply_psee_bbox_filter: bool = MISSING
apply_faulty_bbox_filter: bool = MISSING
@dataclass
class EventWindowExtractionConf:
method: AggregationType = MISSING
value: int = MISSING
@dataclass
class StackedHistogramConf:
name: str = MISSING
nbins: int = MISSING
count_cutoff: Optional[int] = MISSING
event_window_extraction: EventWindowExtractionConf = field(
default_factory=EventWindowExtractionConf
)
fastmode: bool = True
@dataclass
class MixedDensityEventStackConf:
name: str = MISSING
nbins: int = MISSING
count_cutoff: Optional[int] = MISSING
event_window_extraction: EventWindowExtractionConf = field(
default_factory=EventWindowExtractionConf
)
name_2_structured_config = {
"stacked_histogram": StackedHistogramConf,
"mixeddensity_stack": MixedDensityEventStackConf,
}
class EventRepresentationFactory(ABC):
def __init__(self, config: DictConfig):
self.config = config
@property
@abstractmethod
def name(self) -> str: ...
@abstractmethod
def create(self, height: int, width: int) -> Any: ...
class StackedHistogramFactory(EventRepresentationFactory):
@property
def name(self) -> str:
extraction = self.config.event_window_extraction
return f"{self.config.name}_{aggregation_2_string[extraction.method]}={extraction.value}_nbins={self.config.nbins}"
def create(self, height: int, width: int) -> StackedHistogram:
return StackedHistogram(
bins=self.config.nbins,
height=height,
width=width,
count_cutoff=self.config.count_cutoff,
fastmode=self.config.fastmode,
)
class MixedDensityStackFactory(EventRepresentationFactory):
@property
def name(self) -> str:
extraction = self.config.event_window_extraction
cutoff_str = (
f"_cutoff={self.config.count_cutoff}"
if self.config.count_cutoff is not None
else ""
)
return f"{self.config.name}_{aggregation_2_string[extraction.method]}={extraction.value}_nbins={self.config.nbins}{cutoff_str}"
def create(self, height: int, width: int) -> MixedDensityEventStack:
return MixedDensityEventStack(
bins=self.config.nbins,
height=height,
width=width,
count_cutoff=self.config.count_cutoff,
)
name_2_ev_repr_factory = {
"stacked_histogram": StackedHistogramFactory,
"mixeddensity_stack": MixedDensityStackFactory,
}
def get_configuration(
ev_repr_yaml_config: Path, extraction_yaml_config: Path
) -> DictConfig:
config = OmegaConf.load(ev_repr_yaml_config)
event_window_extraction_config = OmegaConf.load(extraction_yaml_config)
event_window_extraction_config = OmegaConf.merge(
OmegaConf.structured(EventWindowExtractionConf), event_window_extraction_config
)
config.event_window_extraction = event_window_extraction_config
config_schema = OmegaConf.structured(name_2_structured_config[config.name])
config = OmegaConf.merge(config_schema, config)
return config
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("input_dir")
parser.add_argument("target_dir")
parser.add_argument(
"ev_repr_yaml_config", help="Path to event representation yaml config file"
)
parser.add_argument(
"extraction_yaml_config",
help="Path to event window extraction yaml config file",
)
parser.add_argument(
"bbox_filter_yaml_config", help="Path to bbox filter yaml config file"
)
parser.add_argument("-ds", "--dataset", default="gen1", help="gen1 or gen4")
parser.add_argument(
"-np",
"--num_processes",
type=int,
default=1,
help="Num proceesses to run in parallel",
)
args = parser.parse_args()
num_processes = args.num_processes
dataset = args.dataset
assert dataset in ("gen1", "gen4")
downsample_by_2 = True if dataset == "gen4" else False
config = get_configuration(
ev_repr_yaml_config=Path(args.ev_repr_yaml_config),
extraction_yaml_config=Path(args.extraction_yaml_config),
)
bbox_filter_yaml_config = Path(args.bbox_filter_yaml_config)
assert bbox_filter_yaml_config.exists()
filter_cfg = OmegaConf.load(str(bbox_filter_yaml_config))
filter_cfg = OmegaConf.merge(OmegaConf.structured(FilterConf), filter_cfg)
print("")
print(OmegaConf.to_yaml(config))
ev_repr_factory: EventRepresentationFactory = name_2_ev_repr_factory[config.name](
config
)
height = dataset_2_height[args.dataset]
width = dataset_2_width[args.dataset]
ev_repr = ev_repr_factory.create(height=height, width=width)
ev_repr_string = ev_repr_factory.name
dataset_input_path = Path(args.input_dir)
train_path = dataset_input_path / "train"
val_path = dataset_input_path / "val"
test_path = dataset_input_path / "test"
target_dir = Path(args.target_dir)
os.makedirs(target_dir, exist_ok=True)
assert train_path.exists(), f"{train_path=}"
assert val_path.exists(), f"{val_path=}"
assert test_path.exists(), f"{test_path=}"
seq_data_list = list()
for split in [train_path, val_path, test_path]:
split_out_dir = target_dir / split.name
os.makedirs(split_out_dir, exist_ok=True)
for npy_file in split.iterdir():
if npy_file.suffix != ".npy":
continue
h5f_path = npy_file.parent / (
npy_file.stem.split("bbox")[0]
+ f"td{'.dat' if dataset == 'gen1' else ''}.h5"
)
assert h5f_path.exists(), f"{h5f_path=}"
dir_name = npy_file.stem.split("_bbox")[0]
if dir_name in dirs_to_ignore[dataset]:
continue
out_seq_path = split_out_dir / dir_name
out_labels_path = out_seq_path / "labels_v2"
os.makedirs(out_labels_path, exist_ok=True)
out_ev_repr_parent_path = out_seq_path / "event_representations_v2"
out_ev_repr_path = out_ev_repr_parent_path / ev_repr_string
os.makedirs(out_ev_repr_path, exist_ok=True)
sequence_data = {
DataKeys.InNPY: npy_file,
DataKeys.InH5: h5f_path,
DataKeys.OutLabelDir: out_labels_path,
DataKeys.OutEvReprDir: out_ev_repr_path,
DataKeys.SplitType: split_name_2_type[split.name],
}
seq_data_list.append(sequence_data)
ev_repr_num_events = None
ev_repr_delta_ts_ms = None
if config.event_window_extraction.method == AggregationType.COUNT:
ev_repr_num_events = config.event_window_extraction.value
else:
assert config.event_window_extraction.method == AggregationType.DURATION
ev_repr_delta_ts_ms = config.event_window_extraction.value
ts_step_ev_repr_ms = 50 # Could be an argument of the script.
if num_processes > 1:
chunksize = 1
func = partial(
process_sequence,
dataset,
filter_cfg,
ev_repr,
ev_repr_num_events,
ev_repr_delta_ts_ms,
ts_step_ev_repr_ms,
downsample_by_2,
)
with get_context("spawn").Pool(num_processes) as pool:
with tqdm(total=len(seq_data_list), desc="sequences") as pbar:
for _ in pool.imap_unordered(
func, iterable=seq_data_list, chunksize=chunksize
):
pbar.update()
else:
for entry in tqdm(seq_data_list, desc="sequences"):
process_sequence(
dataset=dataset,
filter_cfg=filter_cfg,
event_representation=ev_repr,
ev_repr_num_events=ev_repr_num_events,
ev_repr_delta_ts_ms=ev_repr_delta_ts_ms,
ts_step_ev_repr_ms=ts_step_ev_repr_ms,
downsample_by_2=downsample_by_2,
sequence_data=entry,
)
================================================
FILE: RVT/scripts/genx/preprocess_dataset.sh
================================================
NUM_PROCESSES=20 # set to the number of parallel processes to use
DATA_DIR=/data/scratch1/nzubic/datasets/gen1_tar/
DEST_DIR=/data/scratch1/nzubic/datasets/RVT/gen1_frequencies/gen1_200hz/
FREQUENCY=conf_preprocess/extraction/frequencies/const_duration_200hz.yaml
python preprocess_dataset.py ${DATA_DIR} ${DEST_DIR} conf_preprocess/representation/stacked_hist.yaml ${FREQUENCY} \
conf_preprocess/filter_gen1.yaml -ds gen1 -np ${NUM_PROCESSES}
================================================
FILE: RVT/scripts/viz/viz_gt.py
================================================
import os
os.environ["OMP_NUM_THREADS"] = "1" # export OMP_NUM_THREADS=1
os.environ["OPENBLAS_NUM_THREADS"] = "1" # export OPENBLAS_NUM_THREADS=1
os.environ["MKL_NUM_THREADS"] = "1" # export MKL_NUM_THREADS=1
os.environ["VECLIB_MAXIMUM_THREADS"] = "1" # export VECLIB_MAXIMUM_THREADS=1
os.environ["NUMEXPR_NUM_THREADS"] = "1" # export NUMEXPR_NUM_THREADS=1
from pathlib import Path
import sys
current_filepath = Path(os.path.realpath(__file__))
sys.path.insert(0, str(current_filepath.parent.parent.parent))
from typing import Tuple, Optional
import imageio.v3 as iio
import torch as th
from tqdm import tqdm
from data.utils.types import DataType, DatasetType
from data.genx_utils.sequence_for_streaming import SequenceForIter
from data.genx_utils.labels import ObjectLabels
from utils.evaluation.prophesee.io.box_loading import loaded_label_to_prophesee
from callbacks.viz_base import VizCallbackBase
import cv2
import numpy as np
import bbox_visualizer as bbv
import hdf5plugin
LABELMAP_GEN1 = ("car", "pedestrian")
LABELMAP_GEN4_SHORT = ("pedestrian", "two wheeler", "car")
def draw_bboxes_bbv(
img, boxes, labelmap=LABELMAP_GEN1, hd_resolution: bool = False
) -> np.ndarray:
"""
draw bboxes in the image img
"""
colors = cv2.applyColorMap(np.arange(0, 255).astype(np.uint8), cv2.COLORMAP_HSV)
colors = [tuple(*item) for item in colors.tolist()]
if labelmap == LABELMAP_GEN1:
classid2colors = {
0: (255, 255, 0), # car -> yellow (rgb)
1: (0, 0, 255), # ped -> blue (rgb)
}
scale_multiplier = 4
else:
assert labelmap == LABELMAP_GEN4_SHORT
classid2colors = {
0: (0, 0, 255), # ped -> blue (rgb)
1: (0, 255, 255), # 2-wheeler cyan (rgb)
2: (255, 255, 0), # car -> yellow (rgb)
}
scale_multiplier = 1 if hd_resolution else 2
add_score = True
ht, wd, ch = img.shape
dim_new_wh = (int(wd * scale_multiplier), int(ht * scale_multiplier))
if scale_multiplier != 1:
img = cv2.resize(img, dim_new_wh, interpolation=cv2.INTER_AREA)
for i in range(boxes.shape[0]):
pt1 = (int(boxes["x"][i]), int(boxes["y"][i]))
size = (int(boxes["w"][i]), int(boxes["h"][i]))
pt2 = (pt1[0] + size[0], pt1[1] + size[1])
bbox = (pt1[0], pt1[1], pt2[0], pt2[1])
bbox = tuple(x * scale_multiplier for x in bbox)
score = boxes["class_confidence"][i]
class_id = boxes["class_id"][i]
class_name = labelmap[class_id % len(labelmap)]
bbox_txt = class_name
if add_score:
bbox_txt += f" {score:.2f}"
color_tuple_rgb = classid2colors[class_id]
img = bbv.draw_rectangle(img, bbox, bbox_color=color_tuple_rgb)
img = bbv.add_label(
img, bbox_txt, bbox, text_bg_color=color_tuple_rgb, top=True
)
return img
def draw_predictions(
ev_repr: th.Tensor,
predictions_proph,
hd_resolution: bool = False,
labelmap=LABELMAP_GEN4_SHORT,
):
img = VizCallbackBase.ev_repr_to_img(ev_repr.cpu().numpy())
if predictions_proph is not None:
img = draw_bboxes_bbv(
img, predictions_proph, labelmap=labelmap, hd_resolution=hd_resolution
)
return img
def gen_gt_generator(
seq_path: Path,
ev_representation_name: str,
downsample_by_factor_2: bool,
dataset_type: DatasetType = DatasetType.GEN4,
) -> Tuple[th.Tensor, Optional[ObjectLabels]]:
sequence_length = 5
if dataset_type == DatasetType.GEN1:
map_dataset = SequenceForIter(
path=seq_path,
ev_representation_name=ev_representation_name,
sequence_length=sequence_length,
dataset_type=DatasetType.GEN1,
downsample_by_factor_2=downsample_by_factor_2,
)
else:
map_dataset = SequenceForIter(
path=seq_path,
ev_representation_name=ev_representation_name,
sequence_length=sequence_length,
dataset_type=DatasetType.GEN4,
downsample_by_factor_2=downsample_by_factor_2,
)
iter_dataset = map_dataset.to_iter_datapipe()
for data in iter_dataset:
seq_ev_reprs = data[DataType.EV_REPR]
seq_labels = data[DataType.OBJLABELS_SEQ]
for idx, ev_repr in enumerate(seq_ev_reprs):
labels = seq_labels[idx]
yield ev_repr, labels
if __name__ == "__main__":
SEQUENCE_PATH = "/data/scratch1/nzubic/datasets/RVT/gen1_frequencies/gen1_40hz/test/17-04-04_11-00-13_cut_15_500000_60500000/"
OUT_DIR_PATH = "/data/scratch1/nzubic/out_viz/"
DOWNSAMPLE = False
EV_REPR_NAME = "stacked_histogram_dt=25_nbins=10" # dt varies depending on different frequencies
DATASET_TYPE = DatasetType.GEN1
seq_path = Path(SEQUENCE_PATH)
out_dir = Path(OUT_DIR_PATH)
os.makedirs(out_dir, exist_ok=False)
if DATASET_TYPE == DatasetType.GEN1:
labelmap = LABELMAP_GEN1
else:
labelmap = LABELMAP_GEN4_SHORT
viz_at_hd_resolution = None
prev_img_with_labels = None
for idx, (ev_repr, labels) in enumerate(
tqdm(
gen_gt_generator(
seq_path=seq_path,
ev_representation_name=EV_REPR_NAME,
downsample_by_factor_2=DOWNSAMPLE,
dataset_type=DATASET_TYPE,
)
)
):
if viz_at_hd_resolution is None:
height, width = ev_repr.shape[-2:]
viz_at_hd_resolution = height * width > 9e5
have_labels = labels is not None
labels_proph = loaded_label_to_prophesee(labels) if have_labels else None
img = draw_predictions(
ev_repr=ev_repr,
predictions_proph=labels_proph,
hd_resolution=viz_at_hd_resolution,
labelmap=labelmap,
)
filename = f"{idx}".zfill(6) + ".png"
img_filepath = out_dir / filename
if have_labels or prev_img_with_labels is None:
img_to_write = img
else:
img_to_write = prev_img_with_labels
iio.imwrite(str(img_filepath), img_to_write)
if labels_proph is not None:
prev_img_with_labels = img
================================================
FILE: RVT/train.py
================================================
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["OMP_NUM_THREADS"] = "1"
os.environ["OPENBLAS_NUM_THREADS"] = "1"
os.environ["MKL_NUM_THREADS"] = "1"
os.environ["VECLIB_MAXIMUM_THREADS"] = "1"
os.environ["NUMEXPR_NUM_THREADS"] = "1"
import torch
torch.multiprocessing.set_sharing_strategy("file_system")
from torch.backends import cuda, cudnn
cuda.matmul.allow_tf32 = True
cudnn.allow_tf32 = True
import hydra
import hdf5plugin
from omegaconf import DictConfig, OmegaConf
import lightning.pytorch as pl
from lightning.pytorch.callbacks import LearningRateMonitor, ModelSummary
from lightning.pytorch.strategies import DDPStrategy
from callbacks.custom import get_ckpt_callback, get_viz_callback
from callbacks.gradflow import GradFlowLogCallback
from config.modifier import dynamically_modify_train_config
from data.utils.types import DatasetSamplingMode
from loggers.utils import get_wandb_logger, get_ckpt_path
from modules.utils.fetch import fetch_data_module, fetch_model_module
from modules.detection import Module
@hydra.main(config_path="config", config_name="train", version_base="1.2")
def main(config: DictConfig):
dynamically_modify_train_config(config)
# Just to check whether config can be resolved
OmegaConf.to_container(config, resolve=True, throw_on_missing=True)
print("------ Configuration ------")
print(OmegaConf.to_yaml(config))
print("---------------------------")
# ---------------------
# Reproducibility
# ---------------------
dataset_train_sampling = config.dataset.train.sampling
assert dataset_train_sampling in iter(DatasetSamplingMode)
disable_seed_everything = dataset_train_sampling in (
DatasetSamplingMode.STREAM,
DatasetSamplingMode.MIXED,
)
if disable_seed_everything:
print(
"Disabling PL seed everything because of unresolved issues with shuffling during training on streaming "
"datasets"
)
seed = config.reproduce.seed_everything
if seed is not None and not disable_seed_everything:
assert isinstance(seed, int)
print(f"USING pl.seed_everything WITH {seed=}")
pl.seed_everything(seed=seed, workers=True)
# ---------------------
# DDP
# ---------------------
gpu_config = config.hardware.gpus
gpus = (
OmegaConf.to_container(gpu_config)
if OmegaConf.is_config(gpu_config)
else gpu_config
)
gpus = gpus if isinstance(gpus, list) else [gpus]
distributed_backend = config.hardware.dist_backend
assert distributed_backend in ("nccl", "gloo"), f"{distributed_backend=}"
strategy = (
DDPStrategy(
process_group_backend=distributed_backend,
find_unused_parameters=True,
gradient_as_bucket_view=True,
)
if len(gpus) > 1
else "auto"
)
# ---------------------
# Data
# ---------------------
data_module = fetch_data_module(config=config)
# ---------------------
# Logging and Checkpoints
# ---------------------
logger = get_wandb_logger(config)
ckpt_path = None
if config.wandb.artifact_name is not None:
ckpt_path = get_ckpt_path(logger, wandb_config=config.wandb)
# ---------------------
# Model
# ---------------------
module = fetch_model_module(config=config)
if ckpt_path is not None and config.wandb.resume_only_weights:
print("Resuming only the weights instead of the full training state")
module = Module.load_from_checkpoint(
str(ckpt_path), **{"full_config": config}, strict=False
)
ckpt_path = None
# ---------------------
# Callbacks and Misc
# ---------------------
callbacks = list()
callbacks.append(get_ckpt_callback(config))
callbacks.append(GradFlowLogCallback(config.logging.train.log_model_every_n_steps))
if config.training.lr_scheduler.use:
callbacks.append(LearningRateMonitor(logging_interval="step"))
if (
config.logging.train.high_dim.enable
or config.logging.validation.high_dim.enable
):
viz_callback = get_viz_callback(config=config)
callbacks.append(viz_callback)
callbacks.append(ModelSummary(max_depth=2))
logger.watch(
model=module,
log="all",
log_freq=config.logging.train.log_model_every_n_steps,
log_graph=True,
)
# ---------------------
# Training
# ---------------------
val_check_interval = config.validation.val_check_interval
check_val_every_n_epoch = config.validation.check_val_every_n_epoch
assert val_check_interval is None or check_val_every_n_epoch is None
trainer = pl.Trainer(
accelerator="gpu",
callbacks=callbacks,
enable_checkpointing=True,
val_check_interval=val_check_interval,
check_val_every_n_epoch=check_val_every_n_epoch,
default_root_dir=None,
devices=gpus,
gradient_clip_val=config.training.gradient_clip_val,
gradient_clip_algorithm="value",
limit_train_batches=config.training.limit_train_batches,
limit_val_batches=config.validation.limit_val_batches,
logger=logger,
log_every_n_steps=config.logging.train.log_every_n_steps,
plugins=None,
precision=config.training.precision,
max_epochs=config.training.max_epochs,
max_steps=config.training.max_steps,
strategy=strategy,
sync_batchnorm=False if strategy == "auto" else True,
# move_metrics_to_cpu=False,
benchmark=config.reproduce.benchmark,
deterministic=config.reproduce.deterministic_flag,
)
trainer.fit(model=module, ckpt_path=ckpt_path, datamodule=data_module)
if __name__ == "__main__":
main()
================================================
FILE: RVT/utils/evaluation/prophesee/__init__.py
================================================
================================================
FILE: RVT/utils/evaluation/prophesee/evaluation.py
================================================
from .io.box_filtering import filter_boxes
from .metrics.coco_eval import evaluate_detection
def evaluate_list(
result_boxes_list,
gt_boxes_list,
height: int,
width: int,
camera: str = "gen1",
apply_bbox_filters: bool = True,
downsampled_by_2: bool = False,
return_aps: bool = True,
):
assert camera in {"gen1", "gen4"}
if camera == "gen1":
classes = ("car", "pedestrian")
elif camera == "gen4":
classes = ("pedestrian", "two-wheeler", "car")
else:
raise NotImplementedError
if apply_bbox_filters:
# Default values taken from: https://github.com/prophesee-ai/prophesee-automotive-dataset-toolbox/blob/0393adea2bf22d833893c8cb1d986fcbe4e6f82d/src/psee_evaluator.py#L23-L24
min_box_diag = 60 if camera == "gen4" else 30
# In the supplementary mat, they say that min_box_side is 20 for gen4.
min_box_side = 20 if camera == "gen4" else 10
if downsampled_by_2:
assert min_box_diag % 2 == 0
min_box_diag //= 2
assert min_box_side % 2 == 0
min_box_side //= 2
half_sec_us = int(5e5)
filter_boxes_fn = lambda x: filter_boxes(
x, half_sec_us, min_box_diag, min_box_side
)
gt_boxes_list = map(filter_boxes_fn, gt_boxes_list)
# NOTE: We also filter the prediction to follow the prophesee protocol of evaluation.
result_boxes_list = map(filter_boxes_fn, result_boxes_list)
return evaluate_detection(
gt_boxes_list,
result_boxes_list,
height=height,
width=width,
classes=classes,
return_aps=return_aps,
)
================================================
FILE: RVT/utils/evaluation/prophesee/evaluator.py
================================================
from typing import Any, List, Optional, Dict
from warnings import warn
import numpy as np
from utils.evaluation.prophesee.evaluation import evaluate_list
class PropheseeEvaluator:
LABELS = "lables"
PREDICTIONS = "predictions"
def __init__(self, dataset: str, downsample_by_2: bool):
super().__init__()
assert dataset in {"gen1", "gen4"}
self.dataset = dataset
self.downsample_by_2 = downsample_by_2
self._buffer = None
self._buffer_empty = True
self._reset_buffer()
def _reset_buffer(self):
self._buffer_empty = True
self._buffer = {
self.LABELS: list(),
self.PREDICTIONS: list(),
}
def _add_to_buffer(self, key: str, value: List[np.ndarray]):
assert isinstance(value, list)
for entry in value:
assert isinstance(entry, np.ndarray)
self._buffer_empty = False
assert self._buffer is not None
self._buffer[key].extend(value)
def _get_from_buffer(self, key: str) -> List[np.ndarray]:
assert not self._buffer_empty
assert self._buffer is not None
return self._buffer[key]
def add_predictions(self, predictions: List[np.ndarray]):
self._add_to_buffer(self.PREDICTIONS, predictions)
def add_labels(self, labels: List[np.ndarray]):
self._add_to_buffer(self.LABELS, labels)
def reset_buffer(self) -> None:
# E.g. call in on_validation_epoch_start
self._reset_buffer()
def has_data(self):
return not self._buffer_empty
def evaluate_buffer(
self, img_height: int, img_width: int
) -> Optional[Dict[str, Any]]:
# e.g call in on_validation_epoch_end
if self._buffer_empty:
warn(
"Attempt to use prophesee evaluation buffer, but it is empty",
UserWarning,
stacklevel=2,
)
return
labels = self._get_from_buffer(self.LABELS)
predictions = self._get_from_buffer(self.PREDICTIONS)
assert len(labels) == len(predictions)
metrics = evaluate_list(
result_boxes_list=predictions,
gt_boxes_list=labels,
height=img_height,
width=img_width,
apply_bbox_filters=True,
downsampled_by_2=self.downsample_by_2,
camera=self.dataset,
)
return metrics
================================================
FILE: RVT/utils/evaluation/prophesee/io/__init__.py
================================================
================================================
FILE: RVT/utils/evaluation/prophesee/io/box_filtering.py
================================================
"""
Define same filtering that we apply in:
"Learning to detect objects on a 1 Megapixel Event Camera" by Etienne Perot et al.
Namely we apply 2 different filters:
1. skip all boxes before 0.5s (before we assume it is unlikely you have sufficient historic)
2. filter all boxes whose diagonal <= min_box_diag**2 and whose side <= min_box_side
Copyright: (c) 2019-2020 Prophesee
"""
from __future__ import print_function
import numpy as np
def filter_boxes(boxes, skip_ts=int(5e5), min_box_diag=60, min_box_side=20):
"""Filters boxes according to the paper rule.
To note: the default represents our threshold when evaluating GEN4 resolution (1280x720)
To note: we assume the initial time of the video is always 0
Args:
boxes (np.ndarray): structured box array with fields ['t','x','y','w','h','class_id','track_id','class_confidence']
(example BBOX_DTYPE is provided in src/box_loading.py)
Returns:
boxes: filtered boxes
"""
ts = boxes["t"]
width = boxes["w"]
height = boxes["h"]
diag_square = width**2 + height**2
mask = (
(ts > skip_ts)
* (diag_square >= min_box_diag**2)
* (width >= min_box_side)
* (height >= min_box_side)
)
return boxes[mask]
================================================
FILE: RVT/utils/evaluation/prophesee/io/box_loading.py
================================================
"""
Defines some tools to handle events.
In particular :
-> defines events' types
-> defines functions to read events from binary .dat files using numpy
-> defines functions to write events to binary .dat files using numpy
Copyright: (c) 2019-2020 Prophesee
"""
from __future__ import print_function
from typing import List, Optional, Tuple
import numpy as np
import torch as th
from data.genx_utils.labels import ObjectLabels
BBOX_DTYPE = np.dtype(
{
"names": ["t", "x", "y", "w", "h", "class_id", "track_id", "class_confidence"],
"formats": [" np.ndarray:
loaded_labels.numpy_()
loaded_label_proph = np.zeros((len(loaded_labels),), dtype=BBOX_DTYPE)
for name in BBOX_DTYPE.names:
if name == "track_id":
# We don't have that and don't need it
continue
loaded_label_proph[name] = np.asarray(
loaded_labels.get(name), dtype=BBOX_DTYPE[name]
)
return loaded_label_proph
def to_prophesee(
loaded_label_list: LOADED_LABELS, yolox_pred_list: YOLOX_PRED_PROCESSED
) -> Tuple[List[np.ndarray], List[np.ndarray]]:
assert len(loaded_label_list) == len(yolox_pred_list)
loaded_label_list_proph = []
yolox_pred_list_proph = []
for loaded_labels, yolox_preds in zip(loaded_label_list, yolox_pred_list):
# TODO: use loaded_label_to_prophesee func here
time = None
# --- LOADED LABELS ---
loaded_labels.numpy_()
loaded_label_proph = np.zeros((len(loaded_labels),), dtype=BBOX_DTYPE)
for name in BBOX_DTYPE.names:
if name == "track_id":
# We don't have that and don't need it
continue
loaded_label_proph[name] = np.asarray(
loaded_labels.get(name), dtype=BBOX_DTYPE[name]
)
if name == "t":
time = np.unique(loaded_labels.get(name))
assert time.size == 1
time = time.item()
loaded_label_list_proph.append(loaded_label_proph)
# --- YOLOX PREDICTIONS ---
# Assumes batch of post-processed predictions from YoloX Head.
# See postprocessing: https://github.com/Megvii-BaseDetection/YOLOX/blob/a5bb5ab12a61b8a25a5c3c11ae6f06397eb9b296/yolox/utils/boxes.py#L32
# Detections ordered as (x1, y1, x2, y2, obj_conf, class_conf, class_pred)
num_pred = 0 if yolox_preds is None else yolox_preds.shape[0]
yolox_pred_proph = np.zeros((num_pred,), dtype=BBOX_DTYPE)
if num_pred > 0:
yolox_preds = yolox_preds.detach().cpu().numpy()
assert yolox_preds.shape == (num_pred, 7)
yolox_pred_proph["t"] = np.ones((num_pred,), dtype=BBOX_DTYPE["t"]) * time
yolox_pred_proph["x"] = np.asarray(yolox_preds[:, 0], dtype=BBOX_DTYPE["x"])
yolox_pred_proph["y"] = np.asarray(yolox_preds[:, 1], dtype=BBOX_DTYPE["y"])
yolox_pred_proph["w"] = np.asarray(
yolox_preds[:, 2] - yolox_preds[:, 0], dtype=BBOX_DTYPE["w"]
)
yolox_pred_proph["h"] = np.asarray(
yolox_preds[:, 3] - yolox_preds[:, 1], dtype=BBOX_DTYPE["h"]
)
yolox_pred_proph["class_id"] = np.asarray(
yolox_preds[:, 6], dtype=BBOX_DTYPE["class_id"]
)
yolox_pred_proph["class_confidence"] = np.asarray(
yolox_preds[:, 5], dtype=BBOX_DTYPE["class_confidence"]
)
yolox_pred_list_proph.append(yolox_pred_proph)
return loaded_label_list_proph, yolox_pred_list_proph
================================================
FILE: RVT/utils/evaluation/prophesee/io/dat_events_tools.py
================================================
"""
Defines some tools to handle events.
In particular :
-> defines events' types
-> defines functions to read events from binary .dat files using numpy
-> defines functions to write events to binary .dat files using numpy
Copyright: (c) 2019-2020 Prophesee
"""
from __future__ import print_function
import datetime
import os
import sys
import numpy as np
EV_TYPE = [("t", "u4"), ("_", "i4")] # Event2D
EV_STRING = "Event2D"
def load_td_data(filename, ev_count=-1, ev_start=0):
"""
Loads TD data from files generated by the StreamLogger consumer for Event2D
events [ts,x,y,p]. The type ID in the file header must be 0.
args :
- path to a dat file
- number of event (all if set to the default -1)
- index of the first event
return :
- dat, a dictionary like structure containing the fields ts, x, y, p
"""
with open(filename, "rb") as f:
_, ev_type, ev_size, _ = parse_header(f)
if ev_start > 0:
f.seek(ev_start * ev_size, 1)
dtype = EV_TYPE
dat = np.fromfile(f, dtype=dtype, count=ev_count)
xyp = None
if ("_", "i4") in dtype:
x = np.bitwise_and(dat["_"], 16383)
y = np.right_shift(np.bitwise_and(dat["_"], 268419072), 14)
p = np.right_shift(np.bitwise_and(dat["_"], 268435456), 28)
xyp = (x, y, p)
return _dat_transfer(dat, dtype, xyp=xyp)
def _dat_transfer(dat, dtype, xyp=None):
"""
Transfers the fields present in dtype from an old datastructure to a new datastructure
xyp should be passed as a tuple
args :
- dat vector as directly read from file
- dtype _numpy dtype_ as a list of couple of field name/ type eg [('x','i4'), ('y','f2')]
- xyp optional tuple containing x,y,p etracted from a field '_'and untangled by bitshift and masking
"""
variables = []
xyp_index = -1
for i, (name, _) in enumerate(dtype):
if name == "_":
xyp_index = i
continue
variables.append((name, dat[name]))
if xyp and xyp_index == -1:
print("Error dat didn't contain a '_' field !")
return
if xyp_index >= 0:
dtype = (
dtype[:xyp_index]
+ [("x", "i2"), ("y", "i2"), ("p", "i2")]
+ dtype[xyp_index + 1 :]
)
new_dat = np.empty(dat.shape[0], dtype=dtype)
if xyp:
new_dat["x"] = xyp[0].astype(np.uint16)
new_dat["y"] = xyp[1].astype(np.uint16)
new_dat["p"] = xyp[2].astype(np.uint16)
for name, arr in variables:
new_dat[name] = arr
return new_dat
def stream_td_data(file_handle, buffer, dtype, ev_count=-1):
"""
Streams data from opened file_handle
args :
- file_handle: file object
- buffer: pre-allocated buffer to fill with events
- dtype: expected fields
- ev_count: number of events
"""
dat = np.fromfile(file_handle, dtype=dtype, count=ev_count)
count = len(dat["t"])
for name, _ in dtype:
if name == "_":
buffer["x"][:count] = np.bitwise_and(dat["_"], 16383)
buffer["y"][:count] = np.right_shift(
np.bitwise_and(dat["_"], 268419072), 14
)
buffer["p"][:count] = np.right_shift(
np.bitwise_and(dat["_"], 268435456), 28
)
else:
buffer[name][:count] = dat[name]
def count_events(filename):
"""
Returns the number of events in a dat file
args :
- path to a dat file
"""
with open(filename, "rb") as f:
bod, _, ev_size, _ = parse_header(f)
f.seek(0, os.SEEK_END)
eod = f.tell()
if (eod - bod) % ev_size != 0:
raise Exception("unexpected format !")
return (eod - bod) // ev_size
def parse_header(f):
"""
Parses the header of a dat file
Args:
- f file handle to a dat file
return :
- int position of the file cursor after the header
- int type of event
- int size of event in bytes
- size (height, width) tuple of int or None
"""
f.seek(0, os.SEEK_SET)
bod = None
end_of_header = False
header = []
num_comment_line = 0
size = [None, None]
# parse header
while not end_of_header:
bod = f.tell()
line = f.readline()
if sys.version_info > (3, 0):
first_item = line.decode("latin-1")[:2]
else:
first_item = line[:2]
if first_item != "% ":
end_of_header = True
else:
words = line.split()
if len(words) > 1:
if words[1] == "Date":
header += ["Date", words[2] + " " + words[3]]
if (
words[1] == "Height" or words[1] == b"Height"
): # compliant with python 3 (and python2)
size[0] = int(words[2])
header += ["Height", words[2]]
if (
words[1] == "Width" or words[1] == b"Width"
): # compliant with python 3 (and python2)
size[1] = int(words[2])
header += ["Width", words[2]]
else:
header += words[1:3]
num_comment_line += 1
# parse data
f.seek(bod, os.SEEK_SET)
if num_comment_line > 0: # Ensure compatibility with previous files.
# Read event type
ev_type = np.frombuffer(f.read(1), dtype=np.uint8)[0]
# Read event size
ev_size = np.frombuffer(f.read(1), dtype=np.uint8)[0]
else:
ev_type = 0
ev_size = sum([int(n[-1]) for _, n in EV_TYPE])
bod = f.tell()
return bod, ev_type, ev_size, size
def write_header(filename, height=240, width=320, ev_type=0):
"""
write header for a dat file
"""
if max(height, width) > 2**14 - 1:
raise ValueError(
"Coordinates value exceed maximum range in"
" binary .dat file format max({:d},{:d}) vs 2^14 - 1".format(height, width)
)
f = open(filename, "w")
f.write(
"% Data file containing {:s} events.\n"
"% Version 2\n".format(EV_STRINGS[ev_type])
)
now = datetime.datetime.utcnow()
f.write(
"% Date {}-{}-{} {}:{}:{}\n".format(
now.year, now.month, now.day, now.hour, now.minute, now.second
)
)
f.write("% Height {:d}\n" "% Width {:d}\n".format(height, width))
# write type and bit size
ev_size = sum([int(b[-1]) for _, b in EV_TYPE])
np.array([ev_type, ev_size], dtype=np.uint8).tofile(f)
f.flush()
return f
def write_event_buffer(f, buffers):
"""
writes events of fields x,y,p,t into the file object f
"""
# pack data as events
dtype = EV_TYPE
data_to_write = np.empty(len(buffers["t"]), dtype=dtype)
for name, typ in buffers.dtype.fields.items():
if name == "x":
x = buffers["x"].astype("i4")
elif name == "y":
y = np.left_shift(buffers["y"].astype("i4"), 14)
elif name == "p":
buffers["p"] = (buffers["p"] == 1).astype(buffers["p"].dtype)
p = np.left_shift(buffers["p"].astype("i4"), 28)
else:
data_to_write[name] = buffers[name].astype(typ[0])
data_to_write["_"] = x + y + p
# write data
data_to_write.tofile(f)
f.flush()
================================================
FILE: RVT/utils/evaluation/prophesee/io/npy_events_tools.py
================================================
#!/usr/bin/env python
"""
Defines some tools to handle events, mimicking dat_events_tools.py.
In particular :
-> defines functions to read events from binary .npy files using numpy
-> defines functions to write events to binary .dat files using numpy (TODO later)
Copyright: (c) 2015-2019 Prophesee
"""
from __future__ import print_function
import numpy as np
def stream_td_data(file_handle, buffer, dtype, ev_count=-1):
"""
Streams data from opened file_handle
args :
- file_handle: file object
- buffer: pre-allocated buffer to fill with events
- dtype: expected fields
- ev_count: number of events
"""
dat = np.fromfile(file_handle, dtype=dtype, count=ev_count)
count = len(dat["t"])
for name, _ in dtype:
buffer[name][:count] = dat[name]
def parse_header(fhandle):
"""
Parses the header of a .npy file
Args:
- f file handle to a .npy file
return :
- int position of the file cursor after the header
- int type of event
- int size of event in bytes
- size (height, width) tuple of int or (None, None)
"""
version = np.lib.format.read_magic(fhandle)
shape, fortran, dtype = np.lib.format._read_array_header(fhandle, version)
assert not fortran, "Fortran order arrays not supported"
# Get the number of elements in one 'row' by taking
# a product over all other dimensions.
if len(shape) == 0:
count = 1
else:
count = np.multiply.reduce(shape, dtype=np.int64)
ev_size = dtype.itemsize
assert ev_size != 0
start = fhandle.tell()
# turn numpy.dtype into an iterable list
ev_type = [(x, str(dtype.fields[x][0])) for x in dtype.names]
# filter name to have only t and not ts
ev_type = [(name if name != "ts" else "t", desc) for name, desc in ev_type]
ev_type = [
(name if name != "confidence" else "class_confidence", desc)
for name, desc in ev_type
]
size = (None, None)
size = (None, None)
return start, ev_type, ev_size, size
================================================
FILE: RVT/utils/evaluation/prophesee/io/psee_loader.py
================================================
"""
This class loads events from dat or npy files
Copyright: (c) 2019-2020 Prophesee
"""
from __future__ import print_function
import os
import numpy as np
from . import dat_events_tools as dat
from . import npy_events_tools as npy_format
class PSEELoader(object):
"""
PSEELoader loads a dat or npy file and stream events
"""
def __init__(self, datfile):
"""
ctor
:param datfile: binary dat or npy file
"""
self._extension = datfile.split(".")[-1]
assert self._extension in ["dat", "npy"], "input file path = {}".format(datfile)
if self._extension == "dat":
self._binary_format = dat
elif self._extension == "npy":
self._binary_format = npy_format
self._file = open(datfile, "rb")
(
self._start,
self.ev_type,
self._ev_size,
self._size,
) = self._binary_format.parse_header(self._file)
assert self._ev_size != 0
if self._extension == "dat":
self._dtype = self._binary_format.EV_TYPE
elif self._extension == "npy":
self._dtype = self.ev_type
else:
assert False, "unsupported extension"
self._decode_dtype = []
for dtype in self._dtype:
if dtype[0] == "_":
self._decode_dtype += [("x", "u2"), ("y", "u2"), ("p", "u1")]
else:
self._decode_dtype.append(dtype)
# size
self._file.seek(0, os.SEEK_END)
self._end = self._file.tell()
self._ev_count = (self._end - self._start) // self._ev_size
self.done = False
self._file.seek(self._start)
# If the current time is t, it means that next event that will be loaded has a
# timestamp superior or equal to t (event with timestamp exactly t is not loaded yet)
self.current_time = 0
self.duration_s = self.total_time() * 1e-6
def reset(self):
"""reset at beginning of file"""
self._file.seek(self._start)
self.done = False
self.current_time = 0
def event_count(self):
"""
getter on event_count
:return:
"""
return self._ev_count
def get_size(self):
""" "(height, width) of the imager might be (None, None)"""
return self._size
def __repr__(self):
"""
prints properties
:return:
"""
wrd = ""
wrd += "PSEELoader:" + "\n"
wrd += "-----------" + "\n"
if self._extension == "dat":
wrd += "Event Type: " + str(self._binary_format.EV_STRING) + "\n"
elif self._extension == "npy":
wrd += "Event Type: numpy array element\n"
wrd += "Event Size: " + str(self._ev_size) + " bytes\n"
wrd += "Event Count: " + str(self._ev_count) + "\n"
wrd += "Duration: " + str(self.duration_s) + " s \n"
wrd += "-----------" + "\n"
return wrd
def load_n_events(self, ev_count):
"""
load batch of n events
:param ev_count: number of events that will be loaded
:return: events
Note that current time will be incremented to reach the timestamp of the first event not loaded yet
"""
event_buffer = np.empty((ev_count + 1,), dtype=self._decode_dtype)
pos = self._file.tell()
count = (self._end - pos) // self._ev_size
if ev_count >= count:
self.done = True
ev_count = count
self._binary_format.stream_td_data(
self._file, event_buffer, self._dtype, ev_count
)
self.current_time = event_buffer["t"][ev_count - 1] + 1
else:
self._binary_format.stream_td_data(
self._file, event_buffer, self._dtype, ev_count + 1
)
self.current_time = event_buffer["t"][ev_count]
self._file.seek(pos + ev_count * self._ev_size)
return event_buffer[:ev_count]
def load_delta_t(self, delta_t):
"""
loads a slice of time.
:param delta_t: (us) slice thickness
:return: events
Note that current time will be incremented by delta_t.
If an event is timestamped at exactly current_time it will not be loaded.
"""
if delta_t < 1:
raise ValueError(
"load_delta_t(): delta_t must be at least 1 micro-second: {}".format(
delta_t
)
)
if self.done or (self._file.tell() >= self._end):
self.done = True
return np.empty((0,), dtype=self._decode_dtype)
final_time = self.current_time + delta_t
tmp_time = self.current_time
start = self._file.tell()
pos = start
nevs = 0
batch = 100000
event_buffer = []
# data is read by buffers until enough events are read or until the end of the file
while tmp_time < final_time and pos < self._end:
count = (min(self._end, pos + batch * self._ev_size) - pos) // self._ev_size
buffer = np.empty((count,), dtype=self._decode_dtype)
self._binary_format.stream_td_data(self._file, buffer, self._dtype, count)
tmp_time = buffer["t"][-1]
event_buffer.append(buffer)
nevs += count
pos = self._file.tell()
if tmp_time >= final_time:
self.current_time = final_time
else:
self.current_time = tmp_time + 1
assert len(event_buffer) > 0
idx = np.searchsorted(event_buffer[-1]["t"], final_time)
event_buffer[-1] = event_buffer[-1][:idx]
event_buffer = np.concatenate(event_buffer)
idx = len(event_buffer)
self._file.seek(start + idx * self._ev_size)
self.done = self._file.tell() >= self._end
return event_buffer
def seek_event(self, ev_count):
"""
seek in the file by ev_count events
:param ev_count: seek in the file after ev_count events
Note that current time will be set to the timestamp of the next event.
"""
if ev_count <= 0:
self._file.seek(self._start)
self.current_time = 0
elif ev_count >= self._ev_count:
# we put the cursor one event before and read the last event
# which puts the file cursor at the right place
# current_time is set to the last event timestamp + 1
self._file.seek(self._start + (self._ev_count - 1) * self._ev_size)
self.current_time = (
np.fromfile(self._file, dtype=self._dtype, count=1)["t"][0] + 1
)
else:
# we put the cursor at the *ev_count*nth event
self._file.seek(self._start + (ev_count) * self._ev_size)
# we read the timestamp of the following event (this change the position in the file)
self.current_time = np.fromfile(self._file, dtype=self._dtype, count=1)[
"t"
][0]
# this is why we go back at the right position here
self._file.seek(self._start + (ev_count) * self._ev_size)
self.done = self._file.tell() >= self._end
def seek_time(self, final_time, term_criterion=100000):
"""
go to the time final_time inside the file. This is implemented using a binary search algorithm
:param final_time: expected time
:param term_cirterion: (nb event) binary search termination criterion
it will load those events in a buffer and do a numpy searchsorted so the result is always exact
"""
if final_time > self.total_time():
self._file.seek(self._end)
self.done = True
self.current_time = self.total_time() + 1
return
if final_time <= 0:
self.reset()
return
low = 0
high = self._ev_count
# binary search
while high - low > term_criterion:
middle = (low + high) // 2
self.seek_event(middle)
mid = np.fromfile(self._file, dtype=self._dtype, count=1)["t"][0]
if mid > final_time:
high = middle
elif mid < final_time:
low = middle + 1
else:
self.current_time = final_time
self.done = self._file.tell() >= self._end
return
# we now know that it is between low and high
self.seek_event(low)
final_buffer = np.fromfile(self._file, dtype=self._dtype, count=high - low)["t"]
final_index = np.searchsorted(final_buffer, final_time)
self.seek_event(low + final_index)
self.current_time = final_time
self.done = self._file.tell() >= self._end
def total_time(self):
"""
get total duration of video in mus, providing there is no overflow
:return:
"""
if not self._ev_count:
return 0
# save the state of the class
pos = self._file.tell()
current_time = self.current_time
done = self.done
# read the last event's timestamp
self.seek_event(self._ev_count - 1)
time = np.fromfile(self._file, dtype=self._dtype, count=1)["t"][0]
# restore the state
self._file.seek(pos)
self.current_time = current_time
self.done = done
return time
def __del__(self):
self._file.close()
================================================
FILE: RVT/utils/evaluation/prophesee/metrics/__init__.py
================================================
================================================
FILE: RVT/utils/evaluation/prophesee/metrics/coco_eval.py
================================================
"""
Compute the COCO metric on bounding box files by matching timestamps
Copyright: (c) 2019-2020 Prophesee
"""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import contextlib
import os
import numpy as np
from pycocotools.coco import COCO
try:
coco_eval_type = "cpp-based"
from detectron2.evaluation.fast_eval_api import COCOeval_opt as COCOeval
except ImportError:
coco_eval_type = "python-based"
from pycocotools.cocoeval import COCOeval
print(f"Using {coco_eval_type} detection evaluation")
def evaluate_detection(
gt_boxes_list,
dt_boxes_list,
classes=("car", "pedestrian"),
height=240,
width=304,
time_tol=50000,
return_aps: bool = True,
):
"""
Compute detection KPIs on list of boxes in the numpy format, using the COCO python API
https://github.com/cocodataset/cocoapi
KPIs are only computed on timestamps where there is actual at least one box
(fully empty frames are not considered)
:param gt_boxes_list: list of numpy array for GT boxes (one per file)
:param dt_boxes_list: list of numpy array for detected boxes
:param classes: iterable of classes names
:param height: int for box size statistics
:param width: int for box size statistics
:param time_tol: int size of the temporal window in micro seconds to look for a detection around a gt box
"""
flattened_gt = []
flattened_dt = []
for gt_boxes, dt_boxes in zip(gt_boxes_list, dt_boxes_list):
assert np.all(gt_boxes["t"][1:] >= gt_boxes["t"][:-1])
assert np.all(dt_boxes["t"][1:] >= dt_boxes["t"][:-1])
all_ts = np.unique(gt_boxes["t"])
n_steps = len(all_ts)
gt_win, dt_win = _match_times(all_ts, gt_boxes, dt_boxes, time_tol)
flattened_gt = flattened_gt + gt_win
flattened_dt = flattened_dt + dt_win
return _coco_eval(
flattened_gt,
flattened_dt,
height,
width,
labelmap=classes,
return_aps=return_aps,
)
def _match_times(all_ts, gt_boxes, dt_boxes, time_tol):
"""
match ground truth boxes and ground truth detections at all timestamps using a specified tolerance
return a list of boxes vectors
"""
gt_size = len(gt_boxes)
dt_size = len(dt_boxes)
windowed_gt = []
windowed_dt = []
low_gt, high_gt = 0, 0
low_dt, high_dt = 0, 0
for ts in all_ts:
while low_gt < gt_size and gt_boxes[low_gt]["t"] < ts:
low_gt += 1
# the high index is at least as big as the low one
high_gt = max(low_gt, high_gt)
while high_gt < gt_size and gt_boxes[high_gt]["t"] <= ts:
high_gt += 1
# detection are allowed to be inside a window around the right detection timestamp
low = ts - time_tol
high = ts + time_tol
while low_dt < dt_size and dt_boxes[low_dt]["t"] < low:
low_dt += 1
# the high index is at least as big as the low one
high_dt = max(low_dt, high_dt)
while high_dt < dt_size and dt_boxes[high_dt]["t"] <= high:
high_dt += 1
windowed_gt.append(gt_boxes[low_gt:high_gt])
windowed_dt.append(dt_boxes[low_dt:high_dt])
return windowed_gt, windowed_dt
def _coco_eval(
gts,
detections,
height,
width,
labelmap=("car", "pedestrian"),
return_aps: bool = True,
):
"""simple helper function wrapping around COCO's Python API
:params: gts iterable of numpy boxes for the ground truth
:params: detections iterable of numpy boxes for the detections
:params: height int
:params: width int
:params: labelmap iterable of class labels
"""
categories = [
{"id": id + 1, "name": class_name, "supercategory": "none"}
for id, class_name in enumerate(labelmap)
]
num_detections = 0
for detection in detections:
num_detections += detection.size
# Meaning: https://cocodataset.org/#detection-eval
out_keys = ("AP", "AP_50", "AP_75", "AP_S", "AP_M", "AP_L")
out_dict = {k: 0.0 for k in out_keys}
if num_detections == 0:
# Corner case at the very beginning of the training.
print("no detections for evaluation found.")
return out_dict if return_aps else None
dataset, results = _to_coco_format(
gts, detections, categories, height=height, width=width
)
coco_gt = COCO()
coco_gt.dataset = dataset
coco_gt.createIndex()
coco_pred = coco_gt.loadRes(results)
coco_eval = COCOeval(coco_gt, coco_pred, "bbox")
coco_eval.params.imgIds = np.arange(1, len(gts) + 1, dtype=int)
coco_eval.evaluate()
coco_eval.accumulate()
if return_aps:
with open(os.devnull, "w") as f, contextlib.redirect_stdout(f):
# info: https://stackoverflow.com/questions/8391411/how-to-block-calls-to-print
coco_eval.summarize()
for idx, key in enumerate(out_keys):
out_dict[key] = coco_eval.stats[idx]
return out_dict
# Print the whole summary instead without return
coco_eval.summarize()
def coco_eval_return_metrics(coco_eval: COCOeval):
pass
def _to_coco_format(gts, detections, categories, height=240, width=304):
"""
utilitary function producing our data in a COCO usable format
"""
annotations = []
results = []
images = []
# to dictionary
for image_id, (gt, pred) in enumerate(zip(gts, detections)):
im_id = image_id + 1
images.append(
{
"date_captured": "2019",
"file_name": "n.a",
"id": im_id,
"license": 1,
"url": "",
"height": height,
"width": width,
}
)
for bbox in gt:
x1, y1 = bbox["x"], bbox["y"]
w, h = bbox["w"], bbox["h"]
area = w * h
annotation = {
"area": float(area),
"iscrowd": False,
"image_id": im_id,
"bbox": [x1, y1, w, h],
"category_id": int(bbox["class_id"]) + 1,
"id": len(annotations) + 1,
}
annotations.append(annotation)
for bbox in pred:
image_result = {
"image_id": im_id,
"category_id": int(bbox["class_id"]) + 1,
"score": float(bbox["class_confidence"]),
"bbox": [bbox["x"], bbox["y"], bbox["w"], bbox["h"]],
}
results.append(image_result)
dataset = {
"info": {},
"licenses": [],
"type": "instances",
"images": images,
"annotations": annotations,
"categories": categories,
}
return dataset, results
================================================
FILE: RVT/utils/evaluation/prophesee/visualize/__init__.py
================================================
================================================
FILE: RVT/utils/evaluation/prophesee/visualize/vis_utils.py
================================================
"""
Functions to display events and boxes
Copyright: (c) 2019-2020 Prophesee
"""
from __future__ import print_function
import bbox_visualizer as bbv
import cv2
import numpy as np
LABELMAP_GEN1 = ("car", "pedestrian")
LABELMAP_GEN4 = (
"pedestrian",
"two wheeler",
"car",
"truck",
"bus",
"traffic sign",
"traffic light",
)
LABELMAP_GEN4_SHORT = ("pedestrian", "two wheeler", "car")
def make_binary_histo(events, img=None, width=304, height=240):
"""
simple display function that shows negative events as blacks dots and positive as white one
on a gray background
args :
- events structured numpy array
- img (numpy array, height x width x 3) optional array to paint event on.
- width int
- height int
return:
- img numpy array, height x width x 3)
"""
if img is None:
img = 127 * np.ones((height, width, 3), dtype=np.uint8)
else:
# if an array was already allocated just paint it grey
img[...] = 127
if events.size:
assert events["x"].max() < width, "out of bound events: x = {}, w = {}".format(
events["x"].max(), width
)
assert events["y"].max() < height, "out of bound events: y = {}, h = {}".format(
events["y"].max(), height
)
img[events["y"], events["x"], :] = 255 * events["p"][:, None]
return img
def draw_bboxes_bbv(img, boxes, labelmap=LABELMAP_GEN1) -> np.ndarray:
"""
draw bboxes in the image img
"""
colors = cv2.applyColorMap(np.arange(0, 255).astype(np.uint8), cv2.COLORMAP_HSV)
colors = [tuple(*item) for item in colors.tolist()]
if labelmap == LABELMAP_GEN1:
classid2colors = {
0: (255, 255, 0), # car -> yellow (rgb)
1: (0, 0, 255), # ped -> blue (rgb)
}
scale_multiplier = 4
else:
assert labelmap == LABELMAP_GEN4_SHORT
classid2colors = {
0: (0, 0, 255), # ped -> blue (rgb)
1: (0, 255, 255), # 2-wheeler cyan (rgb)
2: (255, 255, 0), # car -> yellow (rgb)
}
scale_multiplier = 2
add_score = True
ht, wd, ch = img.shape
dim_new_wh = (int(wd * scale_multiplier), int(ht * scale_multiplier))
if scale_multiplier != 1:
img = cv2.resize(img, dim_new_wh, interpolation=cv2.INTER_AREA)
for i in range(boxes.shape[0]):
pt1 = (int(boxes["x"][i]), int(boxes["y"][i]))
size = (int(boxes["w"][i]), int(boxes["h"][i]))
pt2 = (pt1[0] + size[0], pt1[1] + size[1])
bbox = (pt1[0], pt1[1], pt2[0], pt2[1])
bbox = tuple(x * scale_multiplier for x in bbox)
score = boxes["class_confidence"][i]
class_id = boxes["class_id"][i]
class_name = labelmap[class_id % len(labelmap)]
bbox_txt = class_name
if add_score:
bbox_txt += f" {score:.2f}"
color_tuple_rgb = classid2colors[class_id]
img = bbv.draw_rectangle(img, bbox, bbox_color=color_tuple_rgb)
img = bbv.add_label(
img, bbox_txt, bbox, text_bg_color=color_tuple_rgb, top=True
)
return img
def draw_bboxes(img, boxes, labelmap=LABELMAP_GEN1) -> None:
"""
draw bboxes in the image img
"""
colors = cv2.applyColorMap(np.arange(0, 255).astype(np.uint8), cv2.COLORMAP_HSV)
colors = [tuple(*item) for item in colors.tolist()]
for i in range(boxes.shape[0]):
pt1 = (int(boxes["x"][i]), int(boxes["y"][i]))
size = (int(boxes["w"][i]), int(boxes["h"][i]))
pt2 = (pt1[0] + size[0], pt1[1] + size[1])
score = boxes["class_confidence"][i]
class_id = boxes["class_id"][i]
class_name = labelmap[class_id % len(labelmap)]
color = colors[class_id * 60 % 255]
center = ((pt1[0] + pt2[0]) // 2, (pt1[1] + pt2[1]) // 2)
cv2.rectangle(img, pt1, pt2, color, 1)
cv2.putText(
img,
class_name,
(center[0], pt2[1] - 1),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
color,
)
cv2.putText(
img,
str(score),
(center[0], pt1[1] - 1),
cv2.FONT_HERSHEY_SIMPLEX,
0.5,
color,
)
================================================
FILE: RVT/utils/helpers.py
================================================
from typing import Union
import torch as th
def torch_uniform_sample_scalar(min_value: float, max_value: float):
assert max_value >= min_value, f"{max_value=} is smaller than {min_value=}"
if max_value == min_value:
return min_value
return min_value + (max_value - min_value) * th.rand(1).item()
def clamp(
value: Union[int, float], smallest: Union[int, float], largest: Union[int, float]
):
return max(smallest, min(value, largest))
================================================
FILE: RVT/utils/padding.py
================================================
from typing import Any, List, Tuple
import torch as th
import torch.nn.functional as F
class InputPadderFromShape:
def __init__(
self,
desired_hw: Tuple[int, int],
mode: str = "constant",
value: int = 0,
type: str = "corner",
):
"""
:param desired_hw: Desired height and width
:param mode: See torch.nn.functional.pad
:param value: See torch.nn.functional.pad
:param type: "corner": add zero to bottom and right
"""
assert isinstance(desired_hw, tuple)
assert len(desired_hw) == 2
assert desired_hw[0] % 4 == 0, "Required for token mask padding"
assert desired_hw[1] % 4 == 0, "Required for token mask padding"
assert type in {"corner"}
self.desired_hw = desired_hw
self.mode = mode
self.value = value
self.type = type
self._pad_ev_repr = None
self._pad_token_mask = None
@staticmethod
def _pad_tensor_impl(
input_tensor: th.Tensor, desired_hw: Tuple[int, int], mode: str, value: Any
) -> Tuple[th.Tensor, List[int]]:
assert isinstance(input_tensor, th.Tensor)
ht, wd = input_tensor.shape[-2:]
ht_des, wd_des = desired_hw
assert ht <= ht_des
assert wd <= wd_des
pad_left = 0
pad_right = wd_des - wd
pad_top = 0
pad_bottom = ht_des - ht
pad = [pad_left, pad_right, pad_top, pad_bottom]
return (
F.pad(
input_tensor,
pad=pad,
mode=mode,
value=value if mode == "constant" else None,
),
pad,
)
def pad_tensor_ev_repr(self, ev_repr: th.Tensor) -> th.Tensor:
padded_ev_repr, pad = self._pad_tensor_impl(
input_tensor=ev_repr,
desired_hw=self.desired_hw,
mode=self.mode,
value=self.value,
)
if self._pad_ev_repr is None:
self._pad_ev_repr = pad
else:
assert self._pad_ev_repr == pad
return padded_ev_repr
def pad_token_mask(self, token_mask: th.Tensor):
assert isinstance(token_mask, th.Tensor)
desired_hw = tuple(x // 4 for x in self.desired_hw)
padded_token_mask, pad = self._pad_tensor_impl(
input_tensor=token_mask, desired_hw=desired_hw, mode="constant", value=0
)
if self._pad_token_mask is None:
self._pad_token_mask = pad
else:
assert self._pad_token_mask == pad
return padded_token_mask
================================================
FILE: RVT/utils/preprocessing.py
================================================
def _blosc_opts(complevel=1, complib="blosc:zstd", shuffle="byte"):
shuffle = 2 if shuffle == "bit" else 1 if shuffle == "byte" else 0
compressors = ["blosclz", "lz4", "lz4hc", "snappy", "zlib", "zstd"]
complib = ["blosc:" + c for c in compressors].index(complib)
args = {
"compression": 32001,
"compression_opts": (0, 0, 0, 0, complevel, shuffle, complib),
}
if shuffle > 0:
# Do not use h5py shuffle if blosc shuffle is enabled.
args["shuffle"] = False
return args
================================================
FILE: RVT/utils/timers.py
================================================
import atexit
import time
from functools import wraps
import numpy as np
import torch
cuda_timers = {}
timers = {}
class CudaTimer:
def __init__(self, device: torch.device, timer_name: str):
assert isinstance(device, torch.device)
assert isinstance(timer_name, str)
self.timer_name = timer_name
if self.timer_name not in cuda_timers:
cuda_timers[self.timer_name] = []
self.device = device
self.start = None
self.end = None
def __enter__(self):
torch.cuda.synchronize(device=self.device)
self.start = time.time()
return self
def __exit__(self, *args):
assert self.start is not None
torch.cuda.synchronize(device=self.device)
end = time.time()
cuda_timers[self.timer_name].append(end - self.start)
def cuda_timer_decorator(device: torch.device, timer_name: str):
def decorator(func):
@wraps(func)
def wrapper(*args, **kwargs):
with CudaTimer(device=device, timer_name=timer_name):
out = func(*args, **kwargs)
return out
return wrapper
return decorator
class TimerDummy:
def __init__(self, *args, **kwargs):
pass
def __enter__(self):
pass
def __exit__(self, *args):
pass
class Timer:
def __init__(self, timer_name=""):
self.timer_name = timer_name
if self.timer_name not in timers:
timers[self.timer_name] = []
def __enter__(self):
self.start = time.time()
return self
def __exit__(self, *args):
end = time.time()
time_diff_s = end - self.start # measured in seconds
timers[self.timer_name].append(time_diff_s)
def print_timing_info():
print("== Timing statistics ==")
skip_warmup = 10
for timer_name, timing_values in [*cuda_timers.items(), *timers.items()]:
if len(timing_values) <= skip_warmup:
continue
values = timing_values[skip_warmup:]
timing_value_s_mean = np.mean(np.array(values))
timing_value_s_median = np.median(np.array(values))
timing_value_ms_mean = timing_value_s_mean * 1000
timing_value_ms_median = timing_value_s_median * 1000
if timing_value_ms_mean > 1000:
print(
"{}: mean={:.2f} s, median={:.2f} s".format(
timer_name, timing_value_s_mean, timing_value_s_median
)
)
else:
print(
"{}: mean={:.2f} ms, median={:.2f} ms".format(
timer_name, timing_value_ms_mean, timing_value_ms_median
)
)
# this will print all the timer values upon termination of any program that imported this file
atexit.register(print_timing_info)
================================================
FILE: RVT/validation.py
================================================
import os
os.environ["CUDA_DEVICE_ORDER"] = "PCI_BUS_ID"
os.environ["OMP_NUM_THREADS"] = "1"
os.environ["OPENBLAS_NUM_THREADS"] = "1"
os.environ["MKL_NUM_THREADS"] = "1"
os.environ["VECLIB_MAXIMUM_THREADS"] = "1"
os.environ["NUMEXPR_NUM_THREADS"] = "1"
from pathlib import Path
import torch
from torch.backends import cuda, cudnn
cuda.matmul.allow_tf32 = True
cudnn.allow_tf32 = True
torch.multiprocessing.set_sharing_strategy("file_system")
import hydra
import hdf5plugin
from omegaconf import DictConfig, OmegaConf
import lightning.pytorch as pl
from lightning.pytorch.loggers import CSVLogger
from lightning.pytorch.callbacks import ModelSummary
from config.modifier import dynamically_modify_train_config
from modules.utils.fetch import fetch_data_module, fetch_model_module
from modules.detection import Module
@hydra.main(config_path="config", config_name="val", version_base="1.2")
def main(config: DictConfig):
dynamically_modify_train_config(config)
# Just to check whether config can be resolved
OmegaConf.to_container(config, resolve=True, throw_on_missing=True)
print("------ Configuration ------")
print(OmegaConf.to_yaml(config))
print("---------------------------")
# ---------------------
# GPU options
# ---------------------
gpus = config.hardware.gpus
assert isinstance(gpus, int), "no more than 1 GPU supported"
gpus = [gpus]
# ---------------------
# Data
# ---------------------
data_module = fetch_data_module(config=config)
# ---------------------
# Logging and Checkpoints
# ---------------------
logger = CSVLogger(save_dir="./validation_logs")
ckpt_path = Path(config.checkpoint)
# ---------------------
# Model
# ---------------------
module = fetch_model_module(config=config)
module = Module.load_from_checkpoint(str(ckpt_path), **{"full_config": config})
# ---------------------
# Callbacks and Misc
# ---------------------
callbacks = [ModelSummary(max_depth=2)]
# ---------------------
# Validation
# ---------------------
trainer = pl.Trainer(
accelerator="gpu",
callbacks=callbacks,
default_root_dir=None,
devices=gpus,
logger=logger,
log_every_n_steps=100,
precision=config.training.precision,
# move_metrics_to_cpu=False,
)
with torch.inference_mode():
if config.use_test_set:
trainer.test(model=module, datamodule=data_module, ckpt_path=str(ckpt_path))
else:
trainer.validate(
model=module, datamodule=data_module, ckpt_path=str(ckpt_path)
)
if __name__ == "__main__":
main()
================================================
FILE: installation_details.txt
================================================
conda create -y -n events_signals python=3.11
conda activate events_signals
conda install -y pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia (Stable (2.2.1))
pip install lightning wandb pandas plotly opencv-python tabulate pycocotools bbox-visualizer StrEnum hydra-core einops torchdata tqdm numba h5py hdf5plugin lovely-tensors tensorboardX pykeops scikit-learn
================================================
FILE: scripts/1mpx/onempx_base.bash
================================================
#!/usr/bin/env bash
source activate events_signals
python RVT/train.py model=rnndet dataset=gen4 dataset.path=/shares/rpg.ifi.uzh/nzubic/datasets/RVT/gen4_new_no_psee_filter wandb.project_name=ssms_event_cameras \
wandb.group_name=1mpx +experiment/gen4=base.yaml hardware.gpus=[0,1] batch_size.train=6 batch_size.eval=6 \
hardware.num_workers.train=12 hardware.num_workers.eval=4
================================================
FILE: scripts/1mpx/onempx_base.job
================================================
#!/usr/bin/env bash
#SBATCH --ntasks-per-node=2
#SBATCH --cpus-per-task=16
#SBATCH --mem-per-cpu=8G
#SBATCH --time=86:00:00
#SBATCH --gres=gpu:2 # The GPU model is optional, you can simply specify 'gpu:1'
#SBATCH --constraint=GPUMEM80GB # This constraint is optional if you don't care about VRAM
#SBATCH --output=final_outputs/onempx_base.txt
module load gpu cuda
srun onempx_base.bash
================================================
FILE: scripts/1mpx/onempx_small.bash
================================================
#!/usr/bin/env bash
source activate events_signals
python RVT/train.py model=rnndet dataset=gen4 dataset.path=/shares/rpg.ifi.uzh/nzubic/datasets/RVT/gen4_new_no_psee_filter wandb.project_name=ssms_event_cameras \
wandb.group_name=1mpx +experiment/gen4=small.yaml hardware.gpus=[0,1] batch_size.train=6 batch_size.eval=6 \
hardware.num_workers.train=12 hardware.num_workers.eval=4
================================================
FILE: scripts/1mpx/onempx_small.job
================================================
#!/usr/bin/env bash
#SBATCH --ntasks-per-node=2
#SBATCH --cpus-per-task=16
#SBATCH --mem-per-cpu=8G
#SBATCH --time=78:00:00
#SBATCH --gres=gpu:2 # The GPU model is optional, you can simply specify 'gpu:1'
#SBATCH --constraint=GPUMEM80GB # This constraint is optional if you don't care about VRAM
#SBATCH --output=final_outputs/onempx_small_2.txt
module load gpu cuda
srun onempx_small.bash
================================================
FILE: scripts/gen1/base.txt
================================================
python RVT/train.py model=rnndet dataset=gen1 dataset.path=/data/scratch1/nzubic/datasets/RVT/gen1 wandb.project_name=ssms_event_cameras \
wandb.group_name=gen1 +experiment/gen1=base.yaml hardware.gpus=0 batch_size.train=8 batch_size.eval=8 hardware.num_workers.train=24 \
hardware.num_workers.eval=8
================================================
FILE: scripts/gen1/small.txt
================================================
python RVT/train.py model=rnndet dataset=gen1 dataset.path=/data/scratch1/nzubic/datasets/RVT/gen1 wandb.project_name=ssms_event_cameras \
wandb.group_name=gen1 +experiment/gen1=small.yaml hardware.gpus=0 batch_size.train=8 batch_size.eval=8 hardware.num_workers.train=24 \
hardware.num_workers.eval=8