Repository: vipstone/faceai
Branch: master
Commit: 64b9920c650b
Files: 75
Total size: 17.5 MB
Directory structure:
gitextract_iy8eplpr/
├── .gitignore
├── LICENSE
├── README.md
├── README_en.md
├── doc/
│ ├── chinese.md
│ ├── colorize.md
│ ├── compose.md
│ ├── detectionDlib.md
│ ├── detectionOpenCV.md
│ ├── emotion.md
│ ├── faceRecognition.md
│ ├── faceRecognitionMakeup.md
│ ├── faceRecognitionOutline.md
│ ├── gender.md
│ ├── hsv-opencv.md
│ ├── inpaint.md
│ ├── opencv/
│ │ ├── hsv.md
│ │ └── mouse.md
│ ├── pipChange.md
│ ├── settingup.md
│ ├── tesseractOCR.md
│ ├── ubuntuChange.md
│ ├── videoDlib.md
│ └── videoOpenCV.md
├── doc-en/
│ ├── chinese.md
│ ├── colorize.md
│ ├── compose.md
│ ├── detectionDlib.md
│ ├── detectionOpenCV.md
│ ├── emotion.md
│ ├── faceRecognition.md
│ ├── faceRecognitionMakeup.md
│ ├── faceRecognitionOutline.md
│ ├── gender.md
│ ├── hsv-opencv.md
│ ├── inpaint.md
│ ├── opencv/
│ │ ├── hsv.md
│ │ └── mouse.md
│ ├── pipChange.md
│ ├── settingup.md
│ ├── tesseractOCR.md
│ ├── ubuntuChange.md
│ ├── videoDlib.md
│ └── videoOpenCV.md
└── faceai/
├── .vscode/
│ └── launch.json
├── chineseText.py
├── classifier/
│ ├── emotion_models/
│ │ └── simple_CNN.530-0.65.hdf5
│ └── gender_models/
│ ├── gender_mini_XCEPTION.21-0.95.hdf5
│ └── simple_CNN.81-0.96.hdf5
├── colorize.py
├── compose.py
├── data/
│ └── simple_colorize.h5
├── detectionDlib.py
├── detectionOpencv.py
├── emotion.py
├── eye.py
├── eye2.py
├── faceRecognition.py
├── faceRecognitionMakeup.py
├── faceRecognitionOutline.py
├── faceswap.py
├── font/
│ └── simsun.ttc
├── gender.py
├── grabCut.py
├── opencv/
│ ├── hist.py
│ ├── hsv.py
│ ├── imgbase.py
│ ├── inpaint.py
│ ├── mouse.py
│ └── trackbar.py
├── tesseractOcr.py
├── test.py
├── versionPut.py
├── videoDlib.py
└── videoOpencv.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
env/
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
*.egg-info/
.installed.cfg
*.egg
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# pyenv
.python-version
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# dotenv
.env
# virtualenv
.venv
venv/
ENV/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2018 stone
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
[English Doc](README_en.md)
# 功能 #
1. 人脸检测、识别(图片、视频)
2. 轮廓标识
3. 头像合成(给人戴帽子)
4. 数字化妆(画口红、眉毛、眼睛等)
5. 性别识别
6. 表情识别(生气、厌恶、恐惧、开心、难过、惊喜、平静等七种情绪)
7. 视频对象提取
8. 图片修复(可用于水印去除)
9. 图片自动上色
10. 眼动追踪(待完善)
11. 换脸(待完善)
**查看功能预览↓↓↓**
# 开发环境 #
- Windows 10(x64)
- Python 3.6.4
- OpenCV 3.4.1
- Dlib 19.8.1
- face_recognition 1.2.2
- keras 2.1.6
- tensorflow 1.8.0
- Tesseract OCR 4.0.0-beta.1
# 教程 #
[OpenCV环境搭建](doc/settingup.md)
[Tesseract OCR文字识别](doc/tesseractOCR.md)
[图片人脸检测(OpenCV版)](doc/detectionOpenCV.md)
[图片人脸检测(Dlib版)](doc/detectionDlib.md)
[视频人脸检测(OpenCV版)](doc/videoOpenCV.md)
[视频人脸检测(Dlib版)](doc/videoDlib.md)
[脸部轮廓绘制](doc/faceRecognitionOutline.md)
[数字化妆](doc/faceRecognitionMakeup.md)
[视频人脸识别](doc/faceRecognition.md)
[头像特效合成](doc/compose.md)
[性别识别](doc/gender.md)
[表情识别](doc/emotion.md)
[视频对象提取](https://github.com/vipstone/faceai/blob/master/doc/hsv-opencv.md)
[图片修复](https://github.com/vipstone/faceai/blob/master/doc/inpaint.md)
# 其他教程 #
[Ubuntu apt-get和pip源更换](doc/ubuntuChange.md)
[pip/pip3更换国内源——Windows版](doc/pipChange.md)
[OpenCV添加中文](doc/chinese.md)
[使用鼠标绘图——OpenCV](https://github.com/vipstone/faceai/blob/master/doc/opencv/mouse.md)
# 功能预览 #
**绘制脸部轮廓**
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/face_recognition-outline.png" width = "250" height = "300" alt="绘制脸部轮廓" />
----------
**人脸68个关键点标识**
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/dlib68.png" width = "230" height = "300" alt="人脸68个关键点标识" />
----------
**头像特效合成**
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/compose.png" width = "200" height = "300" alt="头像特效合成" />
----------
**性别识别**
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/gender.png" width = "430" height = "220" alt="性别识别" />
----------
**表情识别**
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/emotion.png" width = "250" height = "300" alt="表情识别" />
----------
**数字化妆**
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/faceRecognitionMakeup-1.png" width = "450" height = "300" alt="视频人脸识别" />
----------
**视频人脸检测**

----------
**视频人脸识别**

----------
**视频人脸识别**
----------
**图片修复**

----------
**图片自动上色**
----------
# 技术方案 #
技术实现方案介绍
人脸识别:OpenCV / Dlib
人脸检测:face_recognition
性别识别:keras + tensorflow
文字识别:Tesseract OCR
### TODO ###
换脸——待完善
眼睛移动方向检测——待完善
Dlib性能优化方案
Dlib模型训练方法
Tesseract模型训练方法
# 贡献者名单(特别感谢)
[archersmind](https://github.com/archersmind)
[rishab-sharma](https://github.com/rishab-sharma)
# 微信打赏

================================================
FILE: README_en.md
================================================
Translation for English Documentations are Working In Progress
# Functions #
1. Face Detection and Recognition(From Image or Video)
2. Facial Landmark
3. Image compositing(e.g. Wear Hat For a Figure)
4. Face Makeup(e.g. Lipstick, Eyebrow, Eyes, etc)
5. Gender Recognition
6. Emotion Recognition(e.g. Angry, Disgust, Fear, Happy, Sad, Surprise, Neutral)
7. Video Object Extraction
8. Image Denoising(e.g. Watermark Removal)
9. Image Colorization
10. Eye Tracking(W.I.P)
11. Face Replacement(W.I.P)
# Development Environment #
- Windows 10(x64)
- Python 3.6.4
- OpenCV 3.4.1
- Dlib 19.8.1
- face_recognition 1.2.2
- keras 2.1.6
- tensorflow 1.8.0
- Tesseract OCR 4.0.0-beta.1
# Tutorials #
[OpenCV Setup](doc-en/settingup.md)
[Tesseract OCR Text Recognition](doc-en/tesseractOCR.md)
[Face Detection From Image(OpenCV based)](doc-en/detectionOpenCV.md)
[Face Detection From Image(Dlib based)](doc-en/detectionDlib.md)
[Face Detection From Video(OpenCV based)](doc-en/videoOpenCV.md)
[Face Detection From Video(Dlib based)](doc-en/videoDlib.md)
[Face Outline Recognition](doc-en/faceRecognitionOutline.md)
[Face Makeup](doc-en/faceRecognitionMakeup.md)
[Face Recognition From Video](doc-en/faceRecognition.md)
[Image Compositing](doc-en/compose.md)
[Gender Recognition](doc-en/gender.md)
[Emotion Recognition](doc-en/emotion.md)
[Video Object Extraction](doc-en/hsv-opencv.md)
[Image Denoising](doc-en/inpaint.md)
# Other Related Tutorials #
[Ubuntu Software And pip Sources Update](doc-en/ubuntuChange.md)
[pip/pip3 Update To Repository Inside China Mainland——Windows](doc-en/pipChange.md)
[Chinese Font Support In OpenCV](doc-en/chinese.md)
[Mouse Drawing——Based on OpenCV](doc-en/opencv/mouse.md)
# Preview #
**Face Outline Recognition**
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/face_recognition-outline.png" width = "250" height = "300" alt="绘制脸部轮廓" />
----------
**68-point Facial Landmark Detection**
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/dlib68.png" width = "230" height = "300" alt="人脸68个关键点标识" />
----------
**Image Compositing**
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/compose.png" width = "200" height = "300" alt="头像特效合成" />
----------
**Gender Recognition**
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/gender.png" width = "430" height = "220" alt="性别识别" />
----------
**Emotion Recognition**
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/emotion.png" width = "250" height = "300" alt="表情识别" />
----------
**Face Makeup**
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/faceRecognitionMakeup-1.png" width = "450" height = "300" alt="视频人脸识别" />
----------
**Face Detection From Video**

----------
**Face Recognition From Video**

----------
**Face Recognition From Video**

----------
**Image Denoising**

----------
**Image Colorization**

----------
# Background #
Requirements
Face Recognition :OpenCV / Dlib / face_recognition
Gender Recognition:keras + tensorflow
Text Recognition:Tesseract OCR
### TODO ###
Face Replacement——W.I.P
Eye Tracking——W.I.P
Dlib Performance Optimization
Dlib Model Training
Tesseract Model Training
# Contributor
[archersmind](https://github.com/archersmind)
[rishab-sharma](https://github.com/rishab-sharma)
================================================
FILE: doc/chinese.md
================================================
# OpenCV添加中文 #
OpenCV添加文字的方法putText(...),添加英文是没有问题的,但如果你要添加中文就会出现“???”的乱码,需要特殊处理一下。
下文提供封装好的(代码)方法,供OpenCV添加中文使用。
# 效果预览 #
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/chinese.png" width = "300" height = "200" alt="效果展示" />
# 实现思路 #
使用PIL的图片绘制添加中文,可以指定字体文件,那么也就是说使用PIL可以实现中文的输出。
有思路之后,接下来的工作就简单了。
1. OpenCV图片格式转换成PIL的图片格式;
1. 使用PIL绘制文字;
1. PIL图片格式转换成OpenCV的图片格式;
# 代码分解 #
**OpenCV图片转换为PIL图片格式**
```
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
```
**使用PIL绘制文字**
```
draw = ImageDraw.Draw(img)
fontText = ImageFont.truetype("font/simsun.ttc", textSize, encoding="utf-8")
draw.text((left, top), "文字内容", textColor, font=fontText)
```
字体文件为:simsun.ttc,Windows可以在C:\Windows\Fonts下面查找。
**PIL图片格式转换成OpenCV的图片格式**
```
cv2.cvtColor(numpy.asarray(img), cv2.COLOR_RGB2BGR)
```
# 完整代码 #
封装好的完整方法
```
#coding=utf-8
#中文乱码处理
import cv2
import numpy
from PIL import Image, ImageDraw, ImageFont
def cv2ImgAddText(img, text, left, top, textColor=(0, 255, 0), textSize=20):
if (isinstance(img, numpy.ndarray)): #判断是否OpenCV图片类型
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img)
fontText = ImageFont.truetype(
"font/simsun.ttc", textSize, encoding="utf-8")
draw.text((left, top), text, textColor, font=fontText)
return cv2.cvtColor(numpy.asarray(img), cv2.COLOR_RGB2BGR)
```
代码调用
```
img = cv2ImgAddText(img, "大家好,我是星爷", 140, 60, (255, 255, 0), 20)
```
================================================
FILE: doc/colorize.md
================================================
# 图片上色 #
安装scikit-image模块:scikit-image (a.k.a. skimage) 是一个图像处理和计算机视觉的算法集合。
>sudo pip3 install scikit-image
================================================
FILE: doc/compose.md
================================================
# 头像特效合成
实现思路:使用OpenCV检测出头部位置,向上移动20像素添加虚拟帽子,帽子的宽度等于脸的大小,高度等比缩小,需要注意的是如果高度小于脸部向上移动20像素的值,那么帽子的高度就等于最小高度=(脸部位置-20)。
为什么是20而不是30或者40,因为取得是检测的脸部和头顶的一般距离20,开发者可自己调整。
**注意事项**
图片合成元件,要是黑背景图片,透明的图片也会有问题,在ps手动处理一下透明图片,添加新图层,选中alt+Del添加黑背景,把新图层层级放到最底部即可。
# 效果图预览 #
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/compose.png" width = "200" height = "300" alt="头像特效合成" />
## 代码实现 ##
```
#coding=utf-8
import cv2
# OpenCV人脸识别分类器
classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
img = cv2.imread("img/ag-3.png") # 读取图片
imgCompose = cv2.imread("img/compose/maozi-1.png")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换灰色
color = (0, 255, 0) # 定义绘制颜色
# 调用识别人脸
faceRects = classifier.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects): # 大于0则检测到人脸
for faceRect in faceRects:
x, y, w, h = faceRect
sp = imgCompose.shape
imgComposeSizeH = int(sp[0]/sp[1]*w)
if imgComposeSizeH>(y-20):
imgComposeSizeH=(y-20)
imgComposeSize = cv2.resize(imgCompose,(w, imgComposeSizeH), interpolation=cv2.INTER_NEAREST)
top = (y-imgComposeSizeH-20)
if top<=0:
top=0
rows, cols, channels = imgComposeSize.shape
roi = img[top:top+rows,x:x+cols]
# Now create a mask of logo and create its inverse mask also
img2gray = cv2.cvtColor(imgComposeSize, cv2.COLOR_RGB2GRAY)
ret, mask = cv2.threshold(img2gray, 10, 255, cv2.THRESH_BINARY)
mask_inv = cv2.bitwise_not(mask)
# Now black-out the area of logo in ROI
img1_bg = cv2.bitwise_and(roi, roi, mask=mask_inv)
# Take only region of logo from logo image.
img2_fg = cv2.bitwise_and(imgComposeSize, imgComposeSize, mask=mask)
# Put logo in ROI and modify the main image
dst = cv2.add(img1_bg, img2_fg)
img[top:top+rows, x:x+cols] = dst
cv2.imshow("image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
================================================
FILE: doc/detectionDlib.md
================================================
# 图片人脸检测(dlib版)
上几篇给大家讲了OpenCV的图片人脸检测,而本文给大家带来的是比OpenCV更加精准的图片人脸检测Dlib库。
点击查看往期:
[《图片人脸检测(OpenCV版)》](https://github.com/vipstone/faceai/blob/master/doc/detectionOpenCV.md)
[《视频人脸检测(OpenCV版)》](https://github.com/vipstone/faceai/blob/master/doc/videoOpenCV.md)
## dlib与OpenCV对比 ##
识别精准度:Dlib >= OpenCV
Dlib更多的人脸识别模型,可以检测脸部68甚至更多的特征点
## 效果展示 ##

人脸的68个特征点

## 安装dlib ##
下载地址:[https://pypi.org/simple/dlib/](https://pypi.org/simple/dlib/) 选择适合你的版本,本人配置:
> Window 10 + Python 3.6.4
我现在的版本是:dlib-19.8.1-cp36-cp36m-win_amd64.whl
使用命令安装:
>pip3 install D:\soft\py\dlib-19.8.1-cp36-cp36m-win_amd64.whl
显示结果:
Processing d:\soft\py\dlib-19.8.1-cp36-cp36m-win_amd64.whl
Installing collected packages: dlib
Successfully installed dlib-19.8.1
为安装成功。
## 下载训练模型 ##
训练模型用于是人脸识别的关键,用于查找图片的关键点。
下载地址:[http://dlib.net/files/](http://dlib.net/files/)
下载文件:shape_predictor_68_face_landmarks.dat.bz2
当然你也可以训练自己的人脸关键点模型,这个功能会放在后面讲。
下载好的模型文件,我的存放地址是:C:\Python36\Lib\site-packages\dlib-data\shape_predictor_68_face_landmarks.dat.bz2
解压:shape_predictor_68_face_landmarks.dat.bz2得到文件:shape_predictor_68_face_landmarks.dat
## 代码实现 ##
```
#coding=utf-8
import cv2
import dlib
path = "img/meinv.png"
img = cv2.imread(path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#人脸分类器
detector = dlib.get_frontal_face_detector()
# 获取人脸检测器
predictor = dlib.shape_predictor(
"C:\\Python36\\Lib\\site-packages\\dlib-data\\shape_predictor_68_face_landmarks.dat"
)
dets = detector(gray, 1)
for face in dets:
shape = predictor(img, face) # 寻找人脸的68个标定点
# 遍历所有点,打印出其坐标,并圈出来
for pt in shape.parts():
pt_pos = (pt.x, pt.y)
cv2.circle(img, pt_pos, 2, (0, 255, 0), 1)
cv2.imshow("image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
================================================
FILE: doc/detectionOpenCV.md
================================================
# 图片人脸检测
人脸检测使用到的技术是OpenCV,上一节已经介绍了OpenCV的环境安装,[点击查看](https://github.com/vipstone/faceai/blob/master/doc/settingup.md).
## 功能展示 ##
识别一种图上的所有人的脸,并且标出人脸的位置,画出人眼以及嘴的位置,展示效果图如下:

多张脸识别效果图:
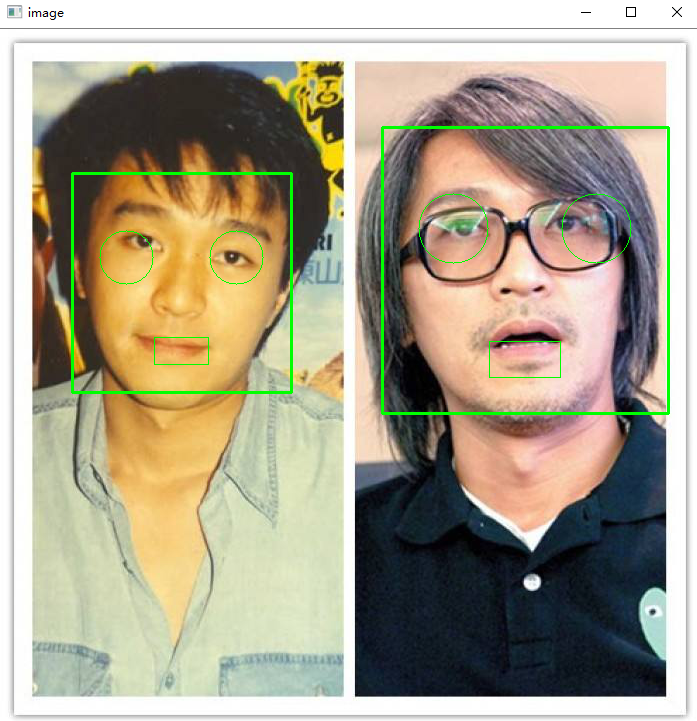
## 技术实现思路 ##
图片转换成灰色(降低为一维的灰度,减低计算强度)
图片上画矩形
使用训练分类器查找人脸
## 具体实现代码 ##
**图片转换成灰色**
使用OpenCV的cvtColor()转换图片颜色,代码如下:
```
import cv2
filepath = "img/xingye-1.png"
img = cv2.imread(filepath)
# 转换灰色
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 显示图像
cv2.imshow("Image", gray)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**图片上画矩形**
使用OpenCV的rectangle()绘制矩形,代码如下:
```
import cv2
filepath = "img/xingye-1.png"
img = cv2.imread(filepath) # 读取图片
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换灰色
x = y = 10 # 坐标
w = 100 # 矩形大小(宽、高)
color = (0, 0, 255) # 定义绘制颜色
cv2.rectangle(img, (x, y), (x + w, y + w), color, 1) # 绘制矩形
cv2.imshow("Image", img) # 显示图像
cv2.waitKey(0)
cv2.destroyAllWindows() # 释放所有的窗体资源
```
**使用训练分类器查找人脸**
在使用OpenCV的人脸检测之前,需要一个人脸训练模型,格式是xml的,我们这里使用OpenCV提供好的人脸分类模型xml,下载地址:[https://github.com/opencv/opencv/tree/master/data/haarcascades](https://github.com/opencv/opencv/tree/master/data/haarcascades) 可全部下载到本地,本人存放的路径是:C:\Python36\Lib\site-packages\opencv-master\data\haarcascades.
完整实现代码:
```
import cv2
filepath = "img/xingye-1.png"
img = cv2.imread(filepath) # 读取图片
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换灰色
# OpenCV人脸识别分类器
classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
color = (0, 255, 0) # 定义绘制颜色
# 调用识别人脸
faceRects = classifier.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects): # 大于0则检测到人脸
for faceRect in faceRects: # 单独框出每一张人脸
x, y, w, h = faceRect
# 框出人脸
cv2.rectangle(img, (x, y), (x + h, y + w), color, 2)
# 左眼
cv2.circle(img, (x + w // 4, y + h // 4 + 30), min(w // 8, h // 8),
color)
#右眼
cv2.circle(img, (x + 3 * w // 4, y + h // 4 + 30), min(w // 8, h // 8),
color)
#嘴巴
cv2.rectangle(img, (x + 3 * w // 8, y + 3 * h // 4),
(x + 5 * w // 8, y + 7 * h // 8), color)
cv2.imshow("image", img) # 显示图像
c = cv2.waitKey(10)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
分类器classifier.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))**参数说明**:
gray:转换的灰图
scaleFactor:图像缩放比例,可理解为相机的X倍镜
minNeighbors:对特征检测点周边多少有效点同时检测,这样可避免因选取的特征检测点太小而导致遗漏
minSize:特征检测点的最小尺寸
================================================
FILE: doc/emotion.md
================================================
# 表情识别 #
表情识别支持7种表情类型,生气、厌恶、恐惧、开心、难过、惊喜、平静等。
# 实现思路 #
使用OpenCV识别图片中的脸,在使用keras进行表情识别。
# 开发环境 #
- Windows10 x64
- python 3.6
- keras 2.1.6
- OpenCV 3.4.1
# 效果预览 #

# 实现代码 #
与[《性别识别》](https://github.com/vipstone/faceai/blob/master/doc/gender.md)相似,本文表情识别也是使用keras实现的,和性别识别相同,型数据使用的是[oarriaga/face_classification](https://github.com/oarriaga/face_classification)的,代码如下:
```
#coding=utf-8
#表情识别
import cv2
from keras.models import load_model
import numpy as np
import chineseText
import datetime
startTime = datetime.datetime.now()
emotion_classifier = load_model(
'classifier/emotion_models/simple_CNN.530-0.65.hdf5')
endTime = datetime.datetime.now()
print(endTime - startTime)
emotion_labels = {
0: '生气',
1: '厌恶',
2: '恐惧',
3: '开心',
4: '难过',
5: '惊喜',
6: '平静'
}
img = cv2.imread("img/emotion/emotion.png")
face_classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_classifier.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(40, 40))
color = (255, 0, 0)
for (x, y, w, h) in faces:
gray_face = gray[(y):(y + h), (x):(x + w)]
gray_face = cv2.resize(gray_face, (48, 48))
gray_face = gray_face / 255.0
gray_face = np.expand_dims(gray_face, 0)
gray_face = np.expand_dims(gray_face, -1)
emotion_label_arg = np.argmax(emotion_classifier.predict(gray_face))
emotion = emotion_labels[emotion_label_arg]
cv2.rectangle(img, (x + 10, y + 10), (x + h - 10, y + w - 10),
(255, 255, 255), 2)
img = chineseText.cv2ImgAddText(img, emotion, x + h * 0.3, y, color, 20)
cv2.imshow("Image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
================================================
FILE: doc/faceRecognition.md
================================================
# 人脸识别
人脸识别,需要使用face_recognition库做人脸对比,OpenCV获取摄像头数据。
## 环境 ##
+ Windows 10
+ OpenCV 3.4.1
+ Dlib 19.8.1
+ face_recognition 1.2.2
## 环境安装 ##
**OpenCV安装**
点击查看:[《OpenCV环境搭建》](https://github.com/vipstone/faceai/blob/master/doc/settingup.md)
**Dlib安装**
点击查看:[《图片人脸检测(dlib版)》](https://github.com/vipstone/faceai/blob/master/doc/detectionDlib.md)
**face_recognition安装**
使用命令:
>pip3 install face_recognition
此项,安装需要很长时间。
## 效果预览 ##

## 完整代码 ##
```
#coding=utf-8
#人脸识别类 - 使用face_recognition模块
import cv2
import face_recognition
import os
path = "img/face_recognition" # 模型数据图片目录
cap = cv2.VideoCapture(0)
total_image_name = []
total_face_encoding = []
for fn in os.listdir(path): #fn 表示的是文件名q
print(path + "/" + fn)
total_face_encoding.append(
face_recognition.face_encodings(
face_recognition.load_image_file(path + "/" + fn))[0])
fn = fn[:(len(fn) - 4)] #截取图片名(这里应该把images文件中的图片名命名为为人物名)
total_image_name.append(fn) #图片名字列表
while (1):
ret, frame = cap.read()
# 发现在视频帧所有的脸和face_enqcodings
face_locations = face_recognition.face_locations(frame)
face_encodings = face_recognition.face_encodings(frame, face_locations)
# 在这个视频帧中循环遍历每个人脸
for (top, right, bottom, left), face_encoding in zip(
face_locations, face_encodings):
# 看看面部是否与已知人脸相匹配。
for i, v in enumerate(total_face_encoding):
match = face_recognition.compare_faces(
[v], face_encoding, tolerance=0.5)
name = "Unknown"
if match[0]:
name = total_image_name[i]
break
# 画出一个框,框住脸
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2)
# 画出一个带名字的标签,放在框下
cv2.rectangle(frame, (left, bottom - 35), (right, bottom), (0, 0, 255),
cv2.FILLED)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, name, (left + 6, bottom - 6), font, 1.0,
(255, 255, 255), 1)
# 显示结果图像
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
```
================================================
FILE: doc/faceRecognitionMakeup.md
================================================
# 数字化妆
数字化妆,使用face_recognition实现.
## 环境 ##
+ Windows 10
+ face_recognition 1.2.2
## 环境安装 ##
**face_recognition安装**
使用命令:
>pip3 install face_recognition
此项,安装需要很长时间。
## 效果预览 ##

## 完整代码 ##
```
#coding=utf-8
#数字化妆类
import face_recognition
from PIL import Image, ImageDraw
#加载图片到numpy array
image = face_recognition.load_image_file("img/ag.png")
#标识脸部特征
face_landmarks_list = face_recognition.face_landmarks(image)
for face_landmarks in face_landmarks_list:
pil_image = Image.fromarray(image)
d = ImageDraw.Draw(pil_image, 'RGBA')
# 绘制眉毛
d.polygon(face_landmarks['left_eyebrow'], fill=(68, 54, 39, 128))
d.polygon(face_landmarks['right_eyebrow'], fill=(68, 54, 39, 128))
d.line(face_landmarks['left_eyebrow'], fill=(68, 54, 39, 150), width=5)
d.line(face_landmarks['right_eyebrow'], fill=(68, 54, 39, 150), width=5)
# 绘制嘴唇
d.polygon(face_landmarks['top_lip'], fill=(150, 0, 0, 128))
d.polygon(face_landmarks['bottom_lip'], fill=(150, 0, 0, 128))
d.line(face_landmarks['top_lip'], fill=(150, 0, 0, 64), width=8)
d.line(face_landmarks['bottom_lip'], fill=(150, 0, 0, 64), width=8)
# 绘制眼睛
d.polygon(face_landmarks['left_eye'], fill=(255, 255, 255, 30))
d.polygon(face_landmarks['right_eye'], fill=(255, 255, 255, 30))
# 绘制眼线
d.line(
face_landmarks['left_eye'] + [face_landmarks['left_eye'][0]],
fill=(0, 0, 0, 110),
width=6)
d.line(
face_landmarks['right_eye'] + [face_landmarks['right_eye'][0]],
fill=(0, 0, 0, 110),
width=6)
pil_image.show()
```
================================================
FILE: doc/faceRecognitionOutline.md
================================================
# 绘制脸部轮廓
使用face_recognition绘制脸部特征
## 环境 ##
+ Windows 10
+ face_recognition 1.2.2
## 环境安装 ##
**face_recognition安装**
使用命令:
>pip3 install face_recognition
此项,安装需要很长时间。
## 效果预览 ##

## 完整代码 ##
```
#coding=utf-8
#绘制面部轮廓
import face_recognition
from PIL import Image, ImageDraw
# 将图片文件加载到numpy 数组中
image = face_recognition.load_image_file("img/ag.png")
#查找图像中所有面部的所有面部特征
face_landmarks_list = face_recognition.face_landmarks(image)
for face_landmarks in face_landmarks_list:
facial_features = [
'chin', 'left_eyebrow', 'right_eyebrow', 'nose_bridge', 'nose_tip',
'left_eye', 'right_eye', 'top_lip', 'bottom_lip'
]
pil_image = Image.fromarray(image)
d = ImageDraw.Draw(pil_image)
for facial_feature in facial_features:
d.line(face_landmarks[facial_feature], fill=(255, 255, 255), width=3)
pil_image.show()
```
================================================
FILE: doc/gender.md
================================================
# 性别识别 #
使用keras实现性别识别,模型数据使用的是oarriaga/face_classification的模型,下文给出项目地址。
# 开发环境 #
- Windows 10
- Python 3.6.4
- keras 2.1.6
- tensorflow 1.8.0
# 效果展示 #
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/gender.png" width = "430" height = "220" alt="性别识别" />
# 准备工作 #
在开始之前先要安装keras和tensorflow,在安装模块之前先要把pip的数据源换成国内的,这样能大大提高安装速度。
点击查看:[pip/pip3更换国内源](pipChange.md)
OpenCV添加文字默认情况是乱码的,需要手动转换一下,点击查看:[OpenCV添加中文](chinese.md)
# 开始安装 #
安装keras使用命令:pip3 install keras
安装tensorflow使用命令:pip3 install tensorflow
# 编码部分 #
结合之前[图片人脸检测(OpenCV版)](detectionOpenCV.md)的项目,我们使用OpenCV先识别到人脸,然后在通过keras识别性别,具体代码如下:
```
#coding=utf-8
#性别识别
import cv2
from keras.models import load_model
import numpy as np
import ChineseText
img = cv2.imread("img/gather.png")
face_classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_classifier.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(140, 140))
gender_classifier = load_model(
"classifier/gender_models/simple_CNN.81-0.96.hdf5")
gender_labels = {0: '女', 1: '男'}
color = (255, 255, 255)
for (x, y, w, h) in faces:
face = img[(y - 60):(y + h + 60), (x - 30):(x + w + 30)]
face = cv2.resize(face, (48, 48))
face = np.expand_dims(face, 0)
face = face / 255.0
gender_label_arg = np.argmax(gender_classifier.predict(face))
gender = gender_labels[gender_label_arg]
cv2.rectangle(img, (x, y), (x + h, y + w), color, 2)
img = ChineseText.cv2ImgAddText(img, gender, x + h, y, color, 30)
cv2.imshow("Image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
更多信息:
oarriaga/face_classification项目地址:https://github.com/oarriaga/face_classification
================================================
FILE: doc/hsv-opencv.md
================================================
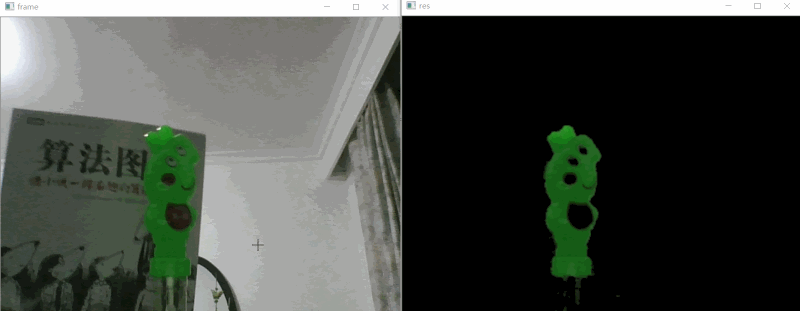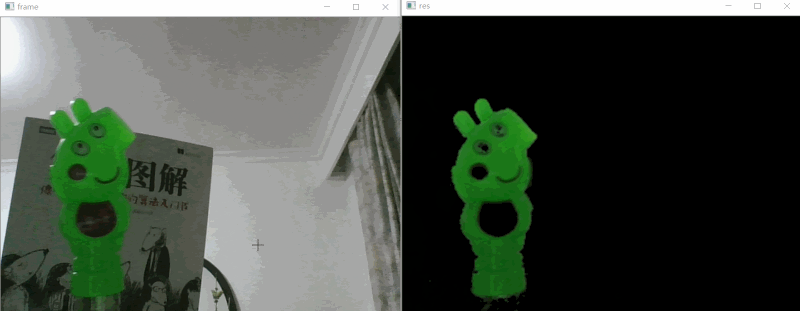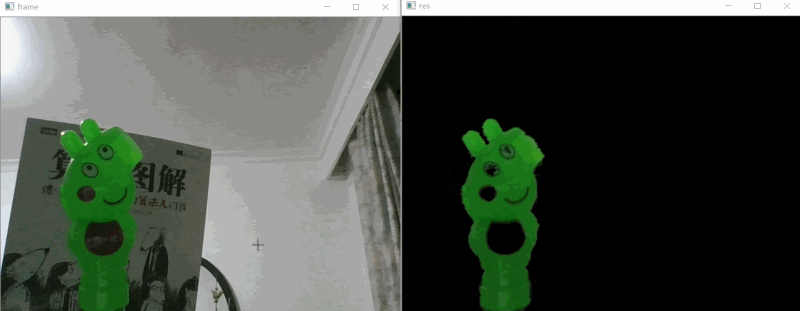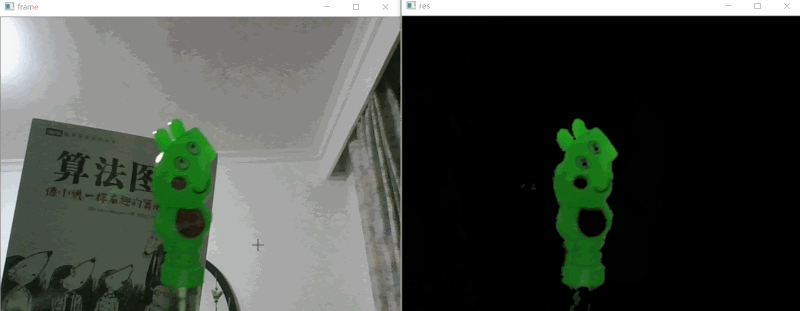
# 视频对象提取 #
与其说是视频对象提取,不如说是视频颜色提取,因为其本质还是使用了OpenCV的HSV颜色物体检测。
# HSV介绍 #
HSV分别代表,色调(H:hue),饱和度(S:saturation),亮度(V:value),由A. R. Smith在1978年创建的一种颜色空间, 也称六角锥体模型(Hexcone Model);
色调(H:hue):用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,品红为300°;(OpenCV中H的取值范围为0~180,8bit存储时);
饱和度(S:saturation):取值范围为0~255,值越大,颜色越饱和;
亮度(V:value):取值范围为0(黑色)~255(白色);

# 效果展示 #
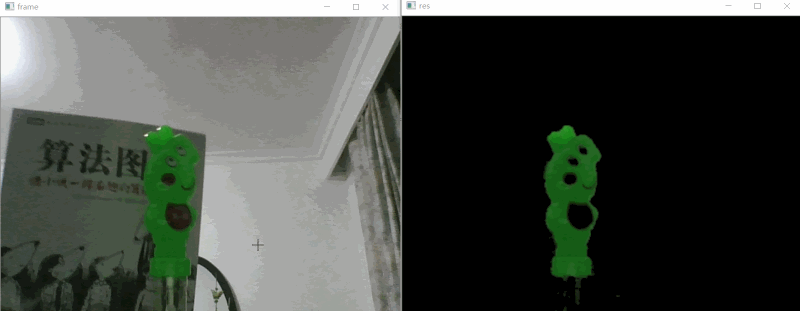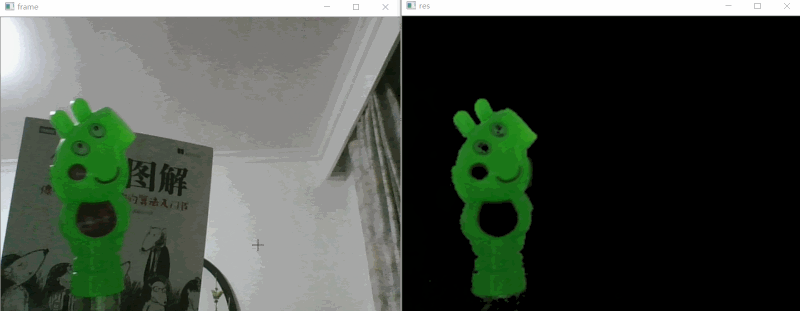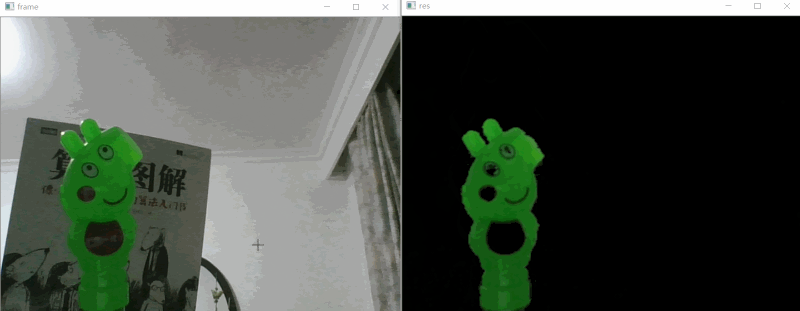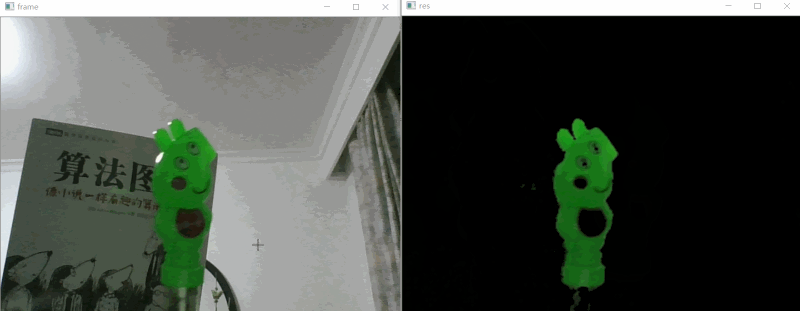
# 实现思路 #
如上效果图所示,我们要做的就是把视频中的绿色的小猪佩奇识别出来即可,下面是的识别步骤:
1. 使用PS取的小猪佩奇颜色的HSB值,相当于OpenCV的HSV,不过PS的HSV(HSB)取值是:0~360、0~1、0~1,而OpenCV的HSV是:0~180、0~255、0~255,所以要对ps的hsv进行处理,H/2、SV*255;
1. 使用OpenCV位“与运算”提取HSV的颜色部分画面;
2. 使用高斯模糊优化图片;
3. 图片展示;
PS中工具栏右侧HSB显示:
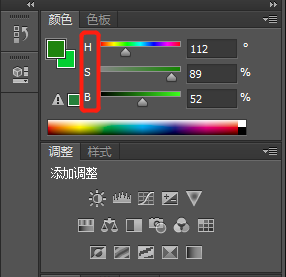
# 完整代码 #
```
#coding=utf-8
#HSV转换(颜色提取)
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while (1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
#在PS里用取色器的HSV
psHSV = [112, 89, 52]
diff = 40 #上下浮动值
#因为PS的HSV(HSB)取值是:0~360、0~1、0~1,而OpenCV的HSV是:0~180、0~255、0~255,所以要对ps的hsv进行处理,H/2、SV*255
lowerHSV = [(psHSV[0] - diff) / 2, (psHSV[1] - diff) * 255 / 100,
(psHSV[2] - diff) * 255 / 100]
upperHSV = [(psHSV[0] + diff) / 2, (psHSV[1] + diff) * 255 / 100,
(psHSV[2] + diff) * 255 / 100]
mask = cv2.inRange(hsv, np.array(lowerHSV), np.array(upperHSV))
#使用位“与运算”提取颜色部分
res = cv2.bitwise_and(frame, frame, mask=mask)
#使用高斯模式优化图片
res = cv2.GaussianBlur(res, (5, 5), 1)
cv2.imshow('frame', frame)
# cv2.imshow('mask', mask)
cv2.imshow('res', res)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
```
================================================
FILE: doc/inpaint.md
================================================
# 图片修复程序-可用于水印去除 #
在现实的生活中,我们可能会遇到一些美好的或是珍贵的图片被噪声干扰,比如旧照片的折痕,比如镜头上的灰尘或污渍,更或者是某些我们想为我所用但有讨厌水印,那么有没有一种办法可以消除这些噪声呢?
答案是肯定的,依然是被我们用了无数次的OpenCV这款优秀的框架。
# 效果预览 #

# 图片修复原理 #
那OpenCV究竟是怎么实现的,简单的来说就是开发者标定噪声的特征,在使用噪声周围的颜色特征推理出应该修复的图片的颜色,从而实现图片修复的。
# 程序实现解析 #
1. 标定噪声的特征,使用cv2.inRange二值化标识噪声对图片进行二值化处理,具体代码:cv2.inRange(img, np.array([240, 240, 240]), np.array([255, 255, 255])),把[240, 240, 240]~[255, 255, 255]以外的颜色处理为0;
1. 使用OpenCV的dilate方法,扩展特征的区域,优化图片处理效果;
2. 使用inpaint方法,把噪声的mask作为参数,推理并修复图片;
# 完整代码 #
```
#coding=utf-8
#图片修复
import cv2
import numpy as np
path = "img/inpaint.png"
img = cv2.imread(path)
hight, width, depth = img.shape[0:3]
#图片二值化处理,把[240, 240, 240]~[255, 255, 255]以外的颜色变成0
thresh = cv2.inRange(img, np.array([240, 240, 240]), np.array([255, 255, 255]))
#创建形状和尺寸的结构元素
kernel = np.ones((3, 3), np.uint8)
#扩张待修复区域
hi_mask = cv2.dilate(thresh, kernel, iterations=1)
specular = cv2.inpaint(img, hi_mask, 5, flags=cv2.INPAINT_TELEA)
cv2.namedWindow("Image", 0)
cv2.resizeWindow("Image", int(width / 2), int(hight / 2))
cv2.imshow("Image", img)
cv2.namedWindow("newImage", 0)
cv2.resizeWindow("newImage", int(width / 2), int(hight / 2))
cv2.imshow("newImage", specular)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
图片扩展与腐蚀更多资料:[http://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_morphological_ops/py_morphological_ops.html](http://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_morphological_ops/py_morphological_ops.html)
================================================
FILE: doc/opencv/hsv.md
================================================
# 视频对象提取 #
```
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while (1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
#在PS里用取色器的HSV
psHSV = [112, 89, 52]
diff = 40 #上下浮动值
#因为PS的HSV(HSB)取值是:0~360、0~1、0~1,而OpenCV的HSV是:0~180、0~255、0~255,所以要对ps的hsv进行处理,H/2、SV*255
lowerHSV = [(psHSV[0] - diff) / 2, (psHSV[1] - diff) * 255 / 100,
(psHSV[2] - diff) * 255 / 100]
upperHSV = [(psHSV[0] + diff) / 2, (psHSV[1] + diff) * 255 / 100,
(psHSV[2] + diff) * 255 / 100]
mask = cv2.inRange(hsv, np.array(lowerHSV), np.array(upperHSV))
res = cv2.bitwise_and(frame, frame, mask=mask)
res = cv2.GaussianBlur(res, (5, 5), 1)
cv2.imshow('frame', frame)
# cv2.imshow('mask', mask)
cv2.imshow('res', res)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
```
================================================
FILE: doc/opencv/mouse.md
================================================
# 使用鼠标绘图——OpenCV #
OpenCV可以使用cv2.setMouseCallback()进行简单的鼠标绘图。
# 简单示例 #
查看所有的事件
```
for i in dir(cv2):
if 'EVENT' in i:
print(i)
'''
输入如下:
EVENT_FLAG_ALTKEY #按住alt键
EVENT_FLAG_CTRLKEY #按住ctrl键
EVENT_FLAG_LBUTTON #按住鼠标左键
EVENT_FLAG_MBUTTON #按住右键点击左键
EVENT_FLAG_RBUTTON #按住鼠标右键
EVENT_FLAG_SHIFTKEY #按住shift键
EVENT_LBUTTONDBLCLK #左键双击
EVENT_LBUTTONDOWN #左键按下
EVENT_LBUTTONUP #左键抬起
EVENT_MBUTTONDBLCLK #滚轮双击
EVENT_MBUTTONDOWN #滚轮按下
EVENT_MBUTTONUP #滚轮抬起
EVENT_MOUSEMOVE #鼠标移动
EVENT_MOUSEWHEEL #鼠标滚轮滚动
EVENT_RBUTTONDBLCLK #右键双击
EVENT_RBUTTONDOWN #右键按下
EVENT_RBUTTONUP #右键抬起
'''
```
来一个简单的小示例,点击鼠标左键,在画板绘制一个圆
```
def draw_circle(event, x, y, flags, param):
if event == cv2.EVENT_FLAG_LBUTTON:
cv2.circle(img, (x, y), 20, (255, 0, 0), -1)
img = np.zeros((512, 512, 3), np.uint8) #创建一个空白的512*512的图
cv2.namedWindow('image')
cv2.setMouseCallback('image', draw_circle)
while (1):
cv2.imshow('image', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
```
效果图如下:

# 使用鼠标自由绘 #
接下来实现一个鼠标自由绘的功能。
**实现原理**
当我按下鼠标左键的时候,开始绘制一个跟随鼠标的图形,当我放开鼠标的时候停止自由绘制,效果如下:

具体代码如下:
```
drawing = False
def drawDef(event, x, y, flags, param):
global drawing
if event == cv2.EVENT_LBUTTONDOWN:
drawing = True
if event == cv2.EVENT_LBUTTONUP:
drawing = False
if event == cv2.EVENT_MOUSEMOVE and drawing == True:
cv2.circle(img, (x, y), 10, (255, 0, 0), -1)
img = np.zeros((512, 512, 3), np.uint8)
cv2.namedWindow('image')
cv2.setMouseCallback('image', drawDef)
while (1):
cv2.imshow('image', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
```
================================================
FILE: doc/pipChange.md
================================================
# pip/pip3更换国内源——Windows版 #
用途:pip更换为国内源,可以大大的提高安装成功率和速度。
# Windows更换pip/pip3源 #
1. 打开目录:%appdata%
1. 新增pip文件夹,新建pip.ini文件
1. 给pip.ini添加内容
```
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
```
这个更换的是清华的源,清华的源5分钟同步官网一次,建议使用。
注意:不管你用的是pip3还是pip,方法都是一样的,都是创建pip文件夹。
# 国内源列表 #
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
================================================
FILE: doc/settingup.md
================================================
# OpenCV环境搭建 #
本文将介绍OpenCV在Python3.x上的实现,分为Window版和Linux版。
## Windows版环境搭建 ##
> 系统环境:windows 10 + python 3.6 + OpenCV 3.4.1
### 一、安装python ###
python的安装之前在[python自学笔记](https://github.com/vipstone/python)的项目中描述了,在这不做重复说明,有需要的朋友,点击查看:[python环境安装](https://github.com/vipstone/python/blob/master/%E5%BC%80%E5%8F%91%E7%8E%AF%E5%A2%83%E6%90%AD%E5%BB%BA.md)
### 二、安装numpy模块 ###
根据上文提示,现在我们已经正确安装了python和pip(安装和管理python包的工具),在正式安装OpenCV之前,首先我们要安装numpy模块。
numpy:是一个定义了数值数组和矩阵类型和它们的基本运算的语言扩展,OpenCV引用了numpy模块,所以安装OpenCV之前必须安装numpy。
本文安装python模块使用的是.whl文件安装的。
**whl文件是什么?**
whl是一个python的压缩包,其中包含了py文件以及经过编译的pyd文件。
**whl安装命令**
> pip3 install 存放路径\xxx.whl
回到主题,我们是要安装numpy模块的。
第一步:先去网站下载对应的numpy版本,下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy 本人是64为系统python3.6所以对应的最新版本是:numpy‑1.14.2+mkl‑cp36‑cp36m‑win_amd64.whl,点击下载到D:根目录。
百度云链接:https://pan.baidu.com/s/10RefansrC4_0zsNehjyKTg
提取密码:gua3
第2步:启动命令窗体运行
> pip3 install d:\numpy‑1.14.2+mkl‑cp36‑cp36m‑win_amd64.whl
命令窗体显示:
Processing d:\numpy-1.14.2+mkl-cp36-cp36m-win_amd64.whl
Installing collected packages: numpy
Successfully installed numpy-1.14.2+mkl
说明已经安装成功。
### 三、安装OpenCV ###
同样安装OpenCV模块和numpy方式类似。
第1步:首先去网站下载OpenCV对应的.whl版本压缩包,网址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv 本人下载的版本是:opencv_python‑3.4.1‑cp36‑cp36m‑win_amd64.whl 64位系统对应python3.6的,下载到d盘根目录。
百度云链接:https://pan.baidu.com/s/10RefansrC4_0zsNehjyKTg
提取密码:gua3
第2步:启动命令窗体运行
> pip3 install d:\opencv_python-3.4.1-cp36-cp36m-win_amd64.whl
窗体显示:
Processing d:\opencv_python-3.4.1-cp36-cp36m-win_amd64.whl
Installing collected packages: opencv-python
Successfully installed opencv-python-3.4.1
说明安装成功。
### 四、运行OpenCV ###
到此,我们的环境配置已经完成了,终于到了可以撸代码的时刻了,想想还有一点小激动呢。
``` python
import cv2
print(cv2.__version__)
# 输出:3.4.1
```
上面我们简单的打印了OpenCV的版本号,如果能正常输出不报错,说明我们已经把OpenCV的python环境搭建ok了。
什么?感觉还不过瘾,那就来撸一张图,用OpenCV把它展示出来,代码如下:
``` python
import cv2
filepath = "img/meinv.png"
img = cv2.imread(filepath)
cv2.namedWindow('Image')
cv2.imshow('Image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
展示效果如图:
----------
## Linux版环境搭建 ##
>Ubuntu 18.04
>Python 3.6.5
>Pip 10.0.1
>Numpy 1.14.3
>OpenCV 3.4.0
Ubuntu有一个好处就是内置Python环境,不需要像Windows那样在为Python环境折腾了,但要注意的是Ubuntu本身自带的apt-get和安装的pip的数据源是国外的,所以使用起来都很慢,一定要把apt-get和pip的数据源更换成国内的,请移步到:[《Ubuntu apt-get和pip源更换》](http://www.cnblogs.com/vipstone/p/9038023.html)
### 正式安装 ###
根据上面的提示,你已经配置好了开发环境,现在需要正式安装了,当然Ubuntu的安装也比Windows简单很多,只需要使用pip安装包,安装相应的模块即可。
#### 安装Numpy ####
使用命令:pip3 install numpy
使用命令:python3,进入python脚本执行环境,输入代码查看numpy是否安装成功,以及numpy的安装版本:
```
import numpy
numpy.__version__
```
正常输入版本号,证明已经安装成功。
如图: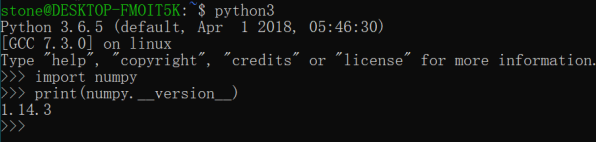
#### 安装OpenCV ####
OpenCV的安装在Ubuntu和numpy相似,使用命令:
>pip3 install opencv-python
使用命令:python3,进入python脚本执行环境,输入代码查看OpenCV版本:
```
import cv2
cv2.__version__
```
正常输出版本号,证明已经安装成功。
# 常见错误 #
错误一、python3: Relink `/lib/x86_64-linux-gnu/libudev.so.1` with `/lib/x86_64-linux-gnu/librt.so.1` for IFUNC symbol `clock_gettime`
Segmentation fault (core dumped)
解决方案:apt install python3-opencv
----------
================================================
FILE: doc/tesseractOCR.md
================================================
# Tesseract Ocr文字识别
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。Tesseract目前已作为开源项目发布在Google Project.
运行环境:
>windows10 + python 3.6 + tesseract 4.0.0-beta.1
先看效果:
一、安装python模块
>pip3 install pytesseract
二、安装tesseract orc
下载地址:https://github.com/UB-Mannheim/tesseract/wiki 点击“tesseract-ocr-w64-setup-v4.0.0-beta.1.20180414.exe”下载安装。
注意:安装的时候选中中文包。
本人安装目录:C:\Users\Administrator\AppData\Local\Tesseract-OCR
使用命令,查看版本号和支持语言:
>cd C:\Users\Administrator\AppData\Local\Tesseract-OCR
>tesseract -v
>tesseract --list-langs #查看Tesseract-OCR支持语言
三、配置tesseract运行文件
C:\Python36\Lib\site-packages\pytesseract\pytesseract.py
找到文件:
>tesseract_cmd = 'tesseract'
修改为:
>tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
四、代码识别
```
from PIL import Image
import pytesseract
path = "img\\text-img.png"
text = pytesseract.image_to_string(Image.open(path), lang='chi_sim')
print(text)
```
作为非常优秀的Ocr识别库,tesseract当然可以训练自己的数据模型,从而达到为我所用的目的,后续文章会介绍如何训练自己的文字识别库。
================================================
FILE: doc/ubuntuChange.md
================================================
# Ubuntu apt-get和pip源更换 #
更新数据源为国内,是为了加速安装包的增加速度。
# 更换apt-get数据源 #
1. 输入:sudo -s切换为root超级管理员;
2. 执行命令:vim /etc/apt/sources.list;
1. 使用命令:%d 清空所有内容;
1. 清华数据源地址:https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu/ 选择相应的版本复制内容,点击“i”键进入编辑文本模式,粘贴内容到vim编辑窗体,点击“ESC”键进入编辑模式,输入“:wq”保存离开;
2. 更新源:sudo apt-get update;
3. 更新软件:sudo apt-get upgrade;
# pip3的安装与升级 #
安装pip3:sudo apt-get install python3-pip
升级pip3:sudo pip install --upgrade pip
查看pip版本:pip -V
# pip源更换 #
1. 根目录创建.pip文件:mkdir ~/.pip;
1. 创建文件pip.conf:vim .pip/pip.conf;
1. 点击“i”键,进入编辑模式,复制信息:
```
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
```
这个更换的是清华的源,清华的源5分钟同步官网一次,建议使用。
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
1. 点击:“ESC”切换到命令行模式,输入“:wq”保存离开。
# 修改默认python版本号 #
我们也可以把Ubuntu的默认python版本号进行修改,步骤如下:
1、删除原有Python连接文件
>sudo rm /usr/bin/python
2、切换成root账户,建立指向Python3的连接
切换root账户:sudo -s
建立执行Python3的连接
>ln -s /usr/bin/python3.6 /usr/bin/python
以上操作就是完成默认Python版本号设置,使用:python -V查看默认版本号.
================================================
FILE: doc/videoDlib.md
================================================
# 视频人脸检测(dlib版)
视频人脸检测是图片识别的高级版本,图片检测详情点击查看我的上一篇[《图片人脸检测(dlib版)》](https://github.com/vipstone/faceai/blob/master/doc/detectionDlib.md)
除了人脸识别用的是Dlib外,还是用OpenCV读取摄像头和处理图片(转为灰色),所以给出相关的文档,方便理解。
[视频人脸检测(OpenCV版)](doc/videoOpenCV.md)
有了OpenCV的视频人脸检测,Dlib也大致相同除了视频识别器模型的声明和使用不同,具体的细节请参考,[视频人脸检测(OpenCV版)](doc/videoOpenCV.md) 那篇已经讲的很细致了,在这就不具体叙述了。
完整的代码如下:
```
# coding=utf-8
import cv2
import dlib
detector = dlib.get_frontal_face_detector() #使用默认的人类识别器模型
def discern(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dets = detector(gray, 1)
for face in dets:
left = face.left()
top = face.top()
right = face.right()
bottom = face.bottom()
cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0), 2)
cv2.imshow("image", img)
cap = cv2.VideoCapture(0)
while (1):
ret, img = cap.read()
discern(img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
```
那么,OpenCV和Dlib的视频识别对比,有两个地方是不同的:
1.Dlib模型识别的准确率和效果要好于OpenCV;
2.Dlib识别的性能要比OpenCV差,使用视频测试的时候Dlib有明显的卡顿,但是OpenCV就好很多,基本看不出来;
================================================
FILE: doc/videoOpenCV.md
================================================
# 视频人脸检测(OpenCV版)
视频人脸检测是图片人脸检测的高级版本,图片检测详情点击查看我的上一篇[《图片人脸检测(OpenCV版)》](https://github.com/vipstone/faceai/blob/master/doc/detectionOpenCV.md) 。
**实现思路:**
调用电脑的摄像头,把摄像的信息逐帧分解成图片,基于图片检测标识出人脸的位置,把处理的图片逐帧绘制给用户,用户看到的效果就是视频的人脸检测。
效果预览:

## 实现步骤 ##
使用OpenCV调用摄像头并展示。
**获取摄像头**
```
cap = cv2.VideoCapture(0)
```
参数0表示,获取第一个摄像头。
**显示摄像头**
逐帧显示,代码如下:
```
while (1):
ret, img = cap.read()
cv2.imshow("Image", img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release() # 释放摄像头
cv2.destroyAllWindows() # 释放窗口资源
```
cv2.waitKey(1) & 0xFF使用了“&”位元算法,含义是获取用户输入的最后一个字符的ASCII码,如果输入的是“q”,则跳出循环。
**视频的人脸识别**
这个时候,用到了上一节的[《图片人脸检测(OpenCV版)》](https://github.com/vipstone/faceai/blob/master/doc/detectionOpenCV.md) 把人脸识别的代码封装成方法,代码如下:
```
def discern(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cap = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
faceRects = cap.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(50, 50))
if len(faceRects):
for faceRect in faceRects:
x, y, w, h = faceRect
cv2.rectangle(img, (x, y), (x + h, y + w), (0, 255, 0), 2) # 框出人脸
cv2.imshow("Image", img)
```
再循环摄像头帧图片的时候,调用图片识别方法即可,代码如下:
```
# 获取摄像头0表示第一个摄像头
cap = cv2.VideoCapture(0)
while (1): # 逐帧显示
ret, img = cap.read()
# cv2.imshow("Image", img)
discern(img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release() # 释放摄像头
cv2.destroyAllWindows() # 释放窗口资源
```
完整的代码如下:
```
# -*- coding:utf-8 -*-
# OpenCV版本的视频检测
import cv2
# 图片识别方法封装
def discern(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cap = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
faceRects = cap.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(50, 50))
if len(faceRects):
for faceRect in faceRects:
x, y, w, h = faceRect
cv2.rectangle(img, (x, y), (x + h, y + w), (0, 255, 0), 2) # 框出人脸
cv2.imshow("Image", img)
# 获取摄像头0表示第一个摄像头
cap = cv2.VideoCapture(0)
while (1): # 逐帧显示
ret, img = cap.read()
# cv2.imshow("Image", img)
discern(img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release() # 释放摄像头
cv2.destroyAllWindows() # 释放窗口资源
```
================================================
FILE: doc-en/chinese.md
================================================
# OpenCV添加中文 #
OpenCV添加文字的方法putText(...),添加英文是没有问题的,但如果你要添加中文就会出现“???”的乱码,需要特殊处理一下。
下文提供封装好的(代码)方法,供OpenCV添加中文使用。
# 效果预览 #
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/chinese.png" width = "300" height = "200" alt="效果展示" />
# 实现思路 #
使用PIL的图片绘制添加中文,可以指定字体文件,那么也就是说使用PIL可以实现中文的输出。
有思路之后,接下来的工作就简单了。
1. OpenCV图片格式转换成PIL的图片格式;
1. 使用PIL绘制文字;
1. PIL图片格式转换成OpenCV的图片格式;
# 代码分解 #
**OpenCV图片转换为PIL图片格式**
```
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
```
**使用PIL绘制文字**
```
draw = ImageDraw.Draw(img)
fontText = ImageFont.truetype("font/simsun.ttc", textSize, encoding="utf-8")
draw.text((left, top), "文字内容", textColor, font=fontText)
```
字体文件为:simsun.ttc,Windows可以在C:\Windows\Fonts下面查找。
**PIL图片格式转换成OpenCV的图片格式**
```
cv2.cvtColor(numpy.asarray(img), cv2.COLOR_RGB2BGR)
```
# 完整代码 #
封装好的完整方法
```
#coding=utf-8
#中文乱码处理
import cv2
import numpy
from PIL import Image, ImageDraw, ImageFont
def cv2ImgAddText(img, text, left, top, textColor=(0, 255, 0), textSize=20):
if (isinstance(img, numpy.ndarray)): #判断是否OpenCV图片类型
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img)
fontText = ImageFont.truetype(
"font/simsun.ttc", textSize, encoding="utf-8")
draw.text((left, top), text, textColor, font=fontText)
return cv2.cvtColor(numpy.asarray(img), cv2.COLOR_RGB2BGR)
```
代码调用
```
img = cv2ImgAddText(img, "大家好,我是星爷", 140, 60, (255, 255, 0), 20)
```
================================================
FILE: doc-en/colorize.md
================================================
# 图片上色 #
安装scikit-image模块:scikit-image (a.k.a. skimage) 是一个图像处理和计算机视觉的算法集合。
>sudo pip3 install scikit-image
================================================
FILE: doc-en/compose.md
================================================
# 头像特效合成
实现思路:使用OpenCV检测出头部位置,向上移动20像素添加虚拟帽子,帽子的宽度等于脸的大小,高度等比缩小,需要注意的是如果高度小于脸部向上移动20像素的值,那么帽子的高度就等于最小高度=(脸部位置-20)。
为什么是20而不是30或者40,因为取得是检测的脸部和头顶的一般距离20,开发者可自己调整。
**注意事项**
图片合成元件,要是黑背景图片,透明的图片也会有问题,在ps手动处理一下透明图片,添加新图层,选中alt+Del添加黑背景,把新图层层级放到最底部即可。
# 效果图预览 #
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/compose.png" width = "200" height = "300" alt="头像特效合成" />
## 代码实现 ##
```
#coding=utf-8
import cv2
# OpenCV人脸识别分类器
classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
img = cv2.imread("img/ag-3.png") # 读取图片
imgCompose = cv2.imread("img/compose/maozi-1.png")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换灰色
color = (0, 255, 0) # 定义绘制颜色
# 调用识别人脸
faceRects = classifier.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects): # 大于0则检测到人脸
for faceRect in faceRects:
x, y, w, h = faceRect
sp = imgCompose.shape
imgComposeSizeH = int(sp[0]/sp[1]*w)
if imgComposeSizeH>(y-20):
imgComposeSizeH=(y-20)
imgComposeSize = cv2.resize(imgCompose,(w, imgComposeSizeH), interpolation=cv2.INTER_NEAREST)
top = (y-imgComposeSizeH-20)
if top<=0:
top=0
rows, cols, channels = imgComposeSize.shape
roi = img[top:top+rows,x:x+cols]
# Now create a mask of logo and create its inverse mask also
img2gray = cv2.cvtColor(imgComposeSize, cv2.COLOR_RGB2GRAY)
ret, mask = cv2.threshold(img2gray, 10, 255, cv2.THRESH_BINARY)
mask_inv = cv2.bitwise_not(mask)
# Now black-out the area of logo in ROI
img1_bg = cv2.bitwise_and(roi, roi, mask=mask_inv)
# Take only region of logo from logo image.
img2_fg = cv2.bitwise_and(imgComposeSize, imgComposeSize, mask=mask)
# Put logo in ROI and modify the main image
dst = cv2.add(img1_bg, img2_fg)
img[top:top+rows, x:x+cols] = dst
cv2.imshow("image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
================================================
FILE: doc-en/detectionDlib.md
================================================
# 图片人脸检测(dlib版)
上几篇给大家讲了OpenCV的图片人脸检测,而本文给大家带来的是比OpenCV更加精准的图片人脸检测Dlib库。
点击查看往期:
[《图片人脸检测(OpenCV版)》](https://github.com/vipstone/faceai/blob/master/doc/detectionOpenCV.md)
[《视频人脸检测(OpenCV版)》](https://github.com/vipstone/faceai/blob/master/doc/videoOpenCV.md)
## dlib与OpenCV对比 ##
识别精准度:Dlib >= OpenCV
Dlib更多的人脸识别模型,可以检测脸部68甚至更多的特征点
## 效果展示 ##

人脸的68个特征点

## 安装dlib ##
下载地址:[https://pypi.org/simple/dlib/](https://pypi.org/simple/dlib/) 选择适合你的版本,本人配置:
> Window 10 + Python 3.6.4
我现在的版本是:dlib-19.8.1-cp36-cp36m-win_amd64.whl
使用命令安装:
>pip3 install D:\soft\py\dlib-19.8.1-cp36-cp36m-win_amd64.whl
显示结果:
Processing d:\soft\py\dlib-19.8.1-cp36-cp36m-win_amd64.whl
Installing collected packages: dlib
Successfully installed dlib-19.8.1
为安装成功。
## 下载训练模型 ##
训练模型用于是人脸识别的关键,用于查找图片的关键点。
下载地址:[http://dlib.net/files/](http://dlib.net/files/)
下载文件:shape_predictor_68_face_landmarks.dat.bz2
当然你也可以训练自己的人脸关键点模型,这个功能会放在后面讲。
下载好的模型文件,我的存放地址是:C:\Python36\Lib\site-packages\dlib-data\shape_predictor_68_face_landmarks.dat.bz2
解压:shape_predictor_68_face_landmarks.dat.bz2得到文件:shape_predictor_68_face_landmarks.dat
## 代码实现 ##
```
#coding=utf-8
import cv2
import dlib
path = "img/meinv.png"
img = cv2.imread(path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#人脸分类器
detector = dlib.get_frontal_face_detector()
# 获取人脸检测器
predictor = dlib.shape_predictor(
"C:\\Python36\\Lib\\site-packages\\dlib-data\\shape_predictor_68_face_landmarks.dat"
)
dets = detector(gray, 1)
for face in dets:
shape = predictor(img, face) # 寻找人脸的68个标定点
# 遍历所有点,打印出其坐标,并圈出来
for pt in shape.parts():
pt_pos = (pt.x, pt.y)
cv2.circle(img, pt_pos, 2, (0, 255, 0), 1)
cv2.imshow("image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
================================================
FILE: doc-en/detectionOpenCV.md
================================================
# 图片人脸检测
人脸检测使用到的技术是OpenCV,上一节已经介绍了OpenCV的环境安装,[点击查看](https://github.com/vipstone/faceai/blob/master/doc/settingup.md).
## 功能展示 ##
识别一种图上的所有人的脸,并且标出人脸的位置,画出人眼以及嘴的位置,展示效果图如下:

多张脸识别效果图:

## 技术实现思路 ##
图片转换成灰色(降低为一维的灰度,减低计算强度)
图片上画矩形
使用训练分类器查找人脸
## 具体实现代码 ##
**图片转换成灰色**
使用OpenCV的cvtColor()转换图片颜色,代码如下:
```
import cv2
filepath = "img/xingye-1.jpg"
img = cv2.imread(filepath)
# 转换灰色
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# 显示图像
cv2.imshow("Image", gray)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
**图片上画矩形**
使用OpenCV的rectangle()绘制矩形,代码如下:
```
import cv2
filepath = "img/xingye-1.jpg"
img = cv2.imread(filepath) # 读取图片
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换灰色
x = y = 10 # 坐标
w = 100 # 矩形大小(宽、高)
color = (0, 0, 255) # 定义绘制颜色
cv2.rectangle(img, (x, y), (x + w, y + w), color, 1) # 绘制矩形
cv2.imshow("Image", img) # 显示图像
cv2.waitKey(0)
cv2.destroyAllWindows() # 释放所有的窗体资源
```
**使用训练分类器查找人脸**
在使用OpenCV的人脸检测之前,需要一个人脸训练模型,格式是xml的,我们这里使用OpenCV提供好的人脸分类模型xml,下载地址:[https://github.com/opencv/opencv/tree/master/data/haarcascades](https://github.com/opencv/opencv/tree/master/data/haarcascades) 可全部下载到本地,本人存放的路径是:C:\Python36\Lib\site-packages\opencv-master\data\haarcascades.
完整实现代码:
```
import cv2
filepath = "img/xingye-1.jpg"
img = cv2.imread(filepath) # 读取图片
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换灰色
# OpenCV人脸识别分类器
classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
color = (0, 255, 0) # 定义绘制颜色
# 调用识别人脸
faceRects = classifier.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects): # 大于0则检测到人脸
for faceRect in faceRects: # 单独框出每一张人脸
x, y, w, h = faceRect
# 框出人脸
cv2.rectangle(img, (x, y), (x + h, y + w), color, 2)
# 左眼
cv2.circle(img, (x + w // 4, y + h // 4 + 30), min(w // 8, h // 8),
color)
#右眼
cv2.circle(img, (x + 3 * w // 4, y + h // 4 + 30), min(w // 8, h // 8),
color)
#嘴巴
cv2.rectangle(img, (x + 3 * w // 8, y + 3 * h // 4),
(x + 5 * w // 8, y + 7 * h // 8), color)
cv2.imshow("image", img) # 显示图像
c = cv2.waitKey(10)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
分类器classifier.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))**参数说明**:
gray:转换的灰图
scaleFactor:图像缩放比例,可理解为相机的X倍镜
minNeighbors:对特征检测点周边多少有效点同时检测,这样可避免因选取的特征检测点太小而导致遗漏
minSize:特征检测点的最小尺寸
================================================
FILE: doc-en/emotion.md
================================================
# 表情识别 #
表情识别支持7种表情类型,生气、厌恶、恐惧、开心、难过、惊喜、平静等。
# 实现思路 #
使用OpenCV识别图片中的脸,在使用keras进行表情识别。
# 开发环境 #
- Windows10 x64
- python 3.6
- keras 2.1.6
- OpenCV 3.4.1
# 效果预览 #

# 实现代码 #
与[《性别识别》](https://github.com/vipstone/faceai/blob/master/doc/gender.md)相似,本文表情识别也是使用keras实现的,和性别识别相同,型数据使用的是[oarriaga/face_classification](https://github.com/oarriaga/face_classification)的,代码如下:
```
#coding=utf-8
#表情识别
import cv2
from keras.models import load_model
import numpy as np
import chineseText
import datetime
startTime = datetime.datetime.now()
emotion_classifier = load_model(
'classifier/emotion_models/simple_CNN.530-0.65.hdf5')
endTime = datetime.datetime.now()
print(endTime - startTime)
emotion_labels = {
0: '生气',
1: '厌恶',
2: '恐惧',
3: '开心',
4: '难过',
5: '惊喜',
6: '平静'
}
img = cv2.imread("img/emotion/emotion.png")
face_classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_classifier.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(40, 40))
color = (255, 0, 0)
for (x, y, w, h) in faces:
gray_face = gray[(y):(y + h), (x):(x + w)]
gray_face = cv2.resize(gray_face, (48, 48))
gray_face = gray_face / 255.0
gray_face = np.expand_dims(gray_face, 0)
gray_face = np.expand_dims(gray_face, -1)
emotion_label_arg = np.argmax(emotion_classifier.predict(gray_face))
emotion = emotion_labels[emotion_label_arg]
cv2.rectangle(img, (x + 10, y + 10), (x + h - 10, y + w - 10),
(255, 255, 255), 2)
img = chineseText.cv2ImgAddText(img, emotion, x + h * 0.3, y, color, 20)
cv2.imshow("Image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
================================================
FILE: doc-en/faceRecognition.md
================================================
# 人脸识别
人脸识别,需要使用face_recognition库做人脸对比,OpenCV获取摄像头数据。
## 环境 ##
+ Windows 10
+ OpenCV 3.4.1
+ Dlib 19.8.1
+ face_recognition 1.2.2
## 环境安装 ##
**OpenCV安装**
点击查看:[《OpenCV环境搭建》](https://github.com/vipstone/faceai/blob/master/doc/settingup.md)
**Dlib安装**
点击查看:[《图片人脸检测(dlib版)》](https://github.com/vipstone/faceai/blob/master/doc/detectionDlib.md)
**face_recognition安装**
使用命令:
>pip3 install face_recognition
此项,安装需要很长时间。
## 效果预览 ##

## 完整代码 ##
```
#coding=utf-8
#人脸识别类 - 使用face_recognition模块
import cv2
import face_recognition
import os
path = "img/face_recognition" # 模型数据图片目录
cap = cv2.VideoCapture(0)
total_image_name = []
total_face_encoding = []
for fn in os.listdir(path): #fn 表示的是文件名q
print(path + "/" + fn)
total_face_encoding.append(
face_recognition.face_encodings(
face_recognition.load_image_file(path + "/" + fn))[0])
fn = fn[:(len(fn) - 4)] #截取图片名(这里应该把images文件中的图片名命名为为人物名)
total_image_name.append(fn) #图片名字列表
while (1):
ret, frame = cap.read()
# 发现在视频帧所有的脸和face_enqcodings
face_locations = face_recognition.face_locations(frame)
face_encodings = face_recognition.face_encodings(frame, face_locations)
# 在这个视频帧中循环遍历每个人脸
for (top, right, bottom, left), face_encoding in zip(
face_locations, face_encodings):
# 看看面部是否与已知人脸相匹配。
for i, v in enumerate(total_face_encoding):
match = face_recognition.compare_faces(
[v], face_encoding, tolerance=0.5)
name = "Unknown"
if match[0]:
name = total_image_name[i]
break
# 画出一个框,框住脸
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2)
# 画出一个带名字的标签,放在框下
cv2.rectangle(frame, (left, bottom - 35), (right, bottom), (0, 0, 255),
cv2.FILLED)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, name, (left + 6, bottom - 6), font, 1.0,
(255, 255, 255), 1)
# 显示结果图像
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
```
================================================
FILE: doc-en/faceRecognitionMakeup.md
================================================
# 数字化妆
数字化妆,使用face_recognition实现.
## 环境 ##
+ Windows 10
+ face_recognition 1.2.2
## 环境安装 ##
**face_recognition安装**
使用命令:
>pip3 install face_recognition
此项,安装需要很长时间。
## 效果预览 ##

## 完整代码 ##
```
#coding=utf-8
#数字化妆类
import face_recognition
from PIL import Image, ImageDraw
#加载图片到numpy array
image = face_recognition.load_image_file("img/ag.png")
#标识脸部特征
face_landmarks_list = face_recognition.face_landmarks(image)
for face_landmarks in face_landmarks_list:
pil_image = Image.fromarray(image)
d = ImageDraw.Draw(pil_image, 'RGBA')
# 绘制眉毛
d.polygon(face_landmarks['left_eyebrow'], fill=(68, 54, 39, 128))
d.polygon(face_landmarks['right_eyebrow'], fill=(68, 54, 39, 128))
d.line(face_landmarks['left_eyebrow'], fill=(68, 54, 39, 150), width=5)
d.line(face_landmarks['right_eyebrow'], fill=(68, 54, 39, 150), width=5)
# 绘制嘴唇
d.polygon(face_landmarks['top_lip'], fill=(150, 0, 0, 128))
d.polygon(face_landmarks['bottom_lip'], fill=(150, 0, 0, 128))
d.line(face_landmarks['top_lip'], fill=(150, 0, 0, 64), width=8)
d.line(face_landmarks['bottom_lip'], fill=(150, 0, 0, 64), width=8)
# 绘制眼睛
d.polygon(face_landmarks['left_eye'], fill=(255, 255, 255, 30))
d.polygon(face_landmarks['right_eye'], fill=(255, 255, 255, 30))
# 绘制眼线
d.line(
face_landmarks['left_eye'] + [face_landmarks['left_eye'][0]],
fill=(0, 0, 0, 110),
width=6)
d.line(
face_landmarks['right_eye'] + [face_landmarks['right_eye'][0]],
fill=(0, 0, 0, 110),
width=6)
pil_image.show()
```
================================================
FILE: doc-en/faceRecognitionOutline.md
================================================
# 绘制脸部轮廓
使用face_recognition绘制脸部特征
## 环境 ##
+ Windows 10
+ face_recognition 1.2.2
## 环境安装 ##
**face_recognition安装**
使用命令:
>pip3 install face_recognition
此项,安装需要很长时间。
## 效果预览 ##

## 完整代码 ##
```
#coding=utf-8
#绘制面部轮廓
import face_recognition
from PIL import Image, ImageDraw
# 将图片文件加载到numpy 数组中
image = face_recognition.load_image_file("img/ag.png")
#查找图像中所有面部的所有面部特征
face_landmarks_list = face_recognition.face_landmarks(image)
for face_landmarks in face_landmarks_list:
facial_features = [
'chin', 'left_eyebrow', 'right_eyebrow', 'nose_bridge', 'nose_tip',
'left_eye', 'right_eye', 'top_lip', 'bottom_lip'
]
pil_image = Image.fromarray(image)
d = ImageDraw.Draw(pil_image)
for facial_feature in facial_features:
d.line(face_landmarks[facial_feature], fill=(255, 255, 255), width=3)
pil_image.show()
```
================================================
FILE: doc-en/gender.md
================================================
# 性别识别 #
使用keras实现性别识别,模型数据使用的是oarriaga/face_classification的模型,下文给出项目地址。
# 开发环境 #
- Windows 10
- Python 3.6.4
- keras 2.1.6
- tensorflow 1.8.0
# 效果展示 #
<img src="https://raw.githubusercontent.com/vipstone/faceai/master/res/gender.png" width = "430" height = "220" alt="性别识别" />
# 准备工作 #
在开始之前先要安装keras和tensorflow,在安装模块之前先要把pip的数据源换成国内的,这样能大大提高安装速度。
点击查看:[pip/pip3更换国内源](pipChange.md)
OpenCV添加文字默认情况是乱码的,需要手动转换一下,点击查看:[OpenCV添加中文](chinese.md)
# 开始安装 #
安装keras使用命令:pip3 install keras
安装tensorflow使用命令:pip3 install tensorflow
# 编码部分 #
结合之前[图片人脸检测(OpenCV版)](detectionOpenCV.md)的项目,我们使用OpenCV先识别到人脸,然后在通过keras识别性别,具体代码如下:
```
#coding=utf-8
#性别识别
import cv2
from keras.models import load_model
import numpy as np
import ChineseText
img = cv2.imread("img/gather.png")
face_classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_classifier.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(140, 140))
gender_classifier = load_model(
"classifier/gender_models/simple_CNN.81-0.96.hdf5")
gender_labels = {0: '女', 1: '男'}
color = (255, 255, 255)
for (x, y, w, h) in faces:
face = img[(y - 60):(y + h + 60), (x - 30):(x + w + 30)]
face = cv2.resize(face, (48, 48))
face = np.expand_dims(face, 0)
face = face / 255.0
gender_label_arg = np.argmax(gender_classifier.predict(face))
gender = gender_labels[gender_label_arg]
cv2.rectangle(img, (x, y), (x + h, y + w), color, 2)
img = ChineseText.cv2ImgAddText(img, gender, x + h, y, color, 30)
cv2.imshow("Image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
更多信息:
oarriaga/face_classification项目地址:https://github.com/oarriaga/face_classification
================================================
FILE: doc-en/hsv-opencv.md
================================================
# 视频对象提取 #
与其说是视频对象提取,不如说是视频颜色提取,因为其本质还是使用了OpenCV的HSV颜色物体检测。
# HSV介绍 #
HSV分别代表,色调(H:hue),饱和度(S:saturation),亮度(V:value),由A. R. Smith在1978年创建的一种颜色空间, 也称六角锥体模型(Hexcone Model);
色调(H:hue):用角度度量,取值范围为0°~360°,从红色开始按逆时针方向计算,红色为0°,绿色为120°,蓝色为240°。它们的补色是:黄色为60°,青色为180°,品红为300°;(OpenCV中H的取值范围为0~180,8bit存储时);
饱和度(S:saturation):取值范围为0~255,值越大,颜色越饱和;
亮度(V:value):取值范围为0(黑色)~255(白色);
# 效果展示 #

# 实现思路 #
如上效果图所示,我们要做的就是把视频中的绿色的小猪佩奇识别出来即可,下面是的识别步骤:
1. 使用PS取的小猪佩奇颜色的HSB值,相当于OpenCV的HSV,不过PS的HSV(HSB)取值是:0~360、0~1、0~1,而OpenCV的HSV是:0~180、0~255、0~255,所以要对ps的hsv进行处理,H/2、SV*255;
1. 使用OpenCV位“与运算”提取HSV的颜色部分画面;
2. 使用高斯模糊优化图片;
3. 图片展示;
PS中工具栏右侧HSB显示:

# 完整代码 #
```
#coding=utf-8
#HSV转换(颜色提取)
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while (1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
#在PS里用取色器的HSV
psHSV = [112, 89, 52]
diff = 40 #上下浮动值
#因为PS的HSV(HSB)取值是:0~360、0~1、0~1,而OpenCV的HSV是:0~180、0~255、0~255,所以要对ps的hsv进行处理,H/2、SV*255
lowerHSV = [(psHSV[0] - diff) / 2, (psHSV[1] - diff) * 255 / 100,
(psHSV[2] - diff) * 255 / 100]
upperHSV = [(psHSV[0] + diff) / 2, (psHSV[1] + diff) * 255 / 100,
(psHSV[2] + diff) * 255 / 100]
mask = cv2.inRange(hsv, np.array(lowerHSV), np.array(upperHSV))
#使用位“与运算”提取颜色部分
res = cv2.bitwise_and(frame, frame, mask=mask)
#使用高斯模式优化图片
res = cv2.GaussianBlur(res, (5, 5), 1)
cv2.imshow('frame', frame)
# cv2.imshow('mask', mask)
cv2.imshow('res', res)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
```
================================================
FILE: doc-en/inpaint.md
================================================
# 图片修复程序-可用于水印去除 #
在现实的生活中,我们可能会遇到一些美好的或是珍贵的图片被噪声干扰,比如旧照片的折痕,比如镜头上的灰尘或污渍,更或者是某些我们想为我所用但有讨厌水印,那么有没有一种办法可以消除这些噪声呢?
答案是肯定的,依然是被我们用了无数次的OpenCV这款优秀的框架。
# 效果预览 #

# 图片修复原理 #
那OpenCV究竟是怎么实现的,简单的来说就是开发者标定噪声的特征,在使用噪声周围的颜色特征推理出应该修复的图片的颜色,从而实现图片修复的。
# 程序实现解析 #
1. 标定噪声的特征,使用cv2.inRange二值化标识噪声对图片进行二值化处理,具体代码:cv2.inRange(img, np.array([240, 240, 240]), np.array([255, 255, 255])),把[240, 240, 240]~[255, 255, 255]以外的颜色处理为0;
1. 使用OpenCV的dilate方法,扩展特征的区域,优化图片处理效果;
2. 使用inpaint方法,把噪声的mask作为参数,推理并修复图片;
# 完整代码 #
```
#coding=utf-8
#图片修复
import cv2
import numpy as np
path = "img/inpaint.png"
img = cv2.imread(path)
hight, width, depth = img.shape[0:3]
#图片二值化处理,把[240, 240, 240]~[255, 255, 255]以外的颜色变成0
thresh = cv2.inRange(img, np.array([240, 240, 240]), np.array([255, 255, 255]))
#创建形状和尺寸的结构元素
kernel = np.ones((3, 3), np.uint8)
#扩张待修复区域
hi_mask = cv2.dilate(thresh, kernel, iterations=1)
specular = cv2.inpaint(img, hi_mask, 5, flags=cv2.INPAINT_TELEA)
cv2.namedWindow("Image", 0)
cv2.resizeWindow("Image", int(width / 2), int(hight / 2))
cv2.imshow("Image", img)
cv2.namedWindow("newImage", 0)
cv2.resizeWindow("newImage", int(width / 2), int(hight / 2))
cv2.imshow("newImage", specular)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
图片扩展与腐蚀更多资料:[http://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_morphological_ops/py_morphological_ops.html](http://opencv-python-tutroals.readthedocs.io/en/latest/py_tutorials/py_imgproc/py_morphological_ops/py_morphological_ops.html)
================================================
FILE: doc-en/opencv/hsv.md
================================================
# 视频对象提取 #
```
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while (1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
#在PS里用取色器的HSV
psHSV = [112, 89, 52]
diff = 40 #上下浮动值
#因为PS的HSV(HSB)取值是:0~360、0~1、0~1,而OpenCV的HSV是:0~180、0~255、0~255,所以要对ps的hsv进行处理,H/2、SV*255
lowerHSV = [(psHSV[0] - diff) / 2, (psHSV[1] - diff) * 255 / 100,
(psHSV[2] - diff) * 255 / 100]
upperHSV = [(psHSV[0] + diff) / 2, (psHSV[1] + diff) * 255 / 100,
(psHSV[2] + diff) * 255 / 100]
mask = cv2.inRange(hsv, np.array(lowerHSV), np.array(upperHSV))
res = cv2.bitwise_and(frame, frame, mask=mask)
res = cv2.GaussianBlur(res, (5, 5), 1)
cv2.imshow('frame', frame)
# cv2.imshow('mask', mask)
cv2.imshow('res', res)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
```
================================================
FILE: doc-en/opencv/mouse.md
================================================
# 使用鼠标绘图——OpenCV #
OpenCV可以使用cv2.setMouseCallback()进行简单的鼠标绘图。
# 简单示例 #
查看所有的事件
```
for i in dir(cv2):
if 'EVENT' in i:
print(i)
'''
输入如下:
EVENT_FLAG_ALTKEY #按住alt键
EVENT_FLAG_CTRLKEY #按住ctrl键
EVENT_FLAG_LBUTTON #按住鼠标左键
EVENT_FLAG_MBUTTON #按住右键点击左键
EVENT_FLAG_RBUTTON #按住鼠标右键
EVENT_FLAG_SHIFTKEY #按住shift键
EVENT_LBUTTONDBLCLK #左键双击
EVENT_LBUTTONDOWN #左键按下
EVENT_LBUTTONUP #左键抬起
EVENT_MBUTTONDBLCLK #滚轮双击
EVENT_MBUTTONDOWN #滚轮按下
EVENT_MBUTTONUP #滚轮抬起
EVENT_MOUSEMOVE #鼠标移动
EVENT_MOUSEWHEEL #鼠标滚轮滚动
EVENT_RBUTTONDBLCLK #右键双击
EVENT_RBUTTONDOWN #右键按下
EVENT_RBUTTONUP #右键抬起
'''
```
来一个简单的小示例,点击鼠标左键,在画板绘制一个圆
```
def draw_circle(event, x, y, flags, param):
if event == cv2.EVENT_FLAG_LBUTTON:
cv2.circle(img, (x, y), 20, (255, 0, 0), -1)
img = np.zeros((512, 512, 3), np.uint8) #创建一个空白的512*512的图
cv2.namedWindow('image')
cv2.setMouseCallback('image', draw_circle)
while (1):
cv2.imshow('image', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
```
效果图如下:

# 使用鼠标自由绘 #
接下来实现一个鼠标自由绘的功能。
**实现原理**
当我按下鼠标左键的时候,开始绘制一个跟随鼠标的图形,当我放开鼠标的时候停止自由绘制,效果如下:

具体代码如下:
```
drawing = False
def drawDef(event, x, y, flags, param):
global drawing
if event == cv2.EVENT_LBUTTONDOWN:
drawing = True
if event == cv2.EVENT_LBUTTONUP:
drawing = False
if event == cv2.EVENT_MOUSEMOVE and drawing == True:
cv2.circle(img, (x, y), 10, (255, 0, 0), -1)
img = np.zeros((512, 512, 3), np.uint8)
cv2.namedWindow('image')
cv2.setMouseCallback('image', drawDef)
while (1):
cv2.imshow('image', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
```
================================================
FILE: doc-en/pipChange.md
================================================
# pip/pip3更换国内源——Windows版 #
用途:pip更换为国内源,可以大大的提高安装成功率和速度。
# Windows更换pip/pip3源 #
1. 打开目录:%appdata%
1. 新增pip文件夹,新建pip.ini文件
1. 给pip.ini添加内容
```
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
```
这个更换的是清华的源,清华的源5分钟同步官网一次,建议使用。
注意:不管你用的是pip3还是pip,方法都是一样的,都是创建pip文件夹。
# 国内源列表 #
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
================================================
FILE: doc-en/settingup.md
================================================
# OpenCV Setting up and Introducation #
This tutorial is going to illustrate the installation of Python3.x on both Linux and Windows.
And introduce OpenCV on top of Python.
## OpenCV setting up in Windows ##
> Env:windows 10 + python 3.6 + OpenCV 3.4.1
### 1 Install Python ###
In this [Pthon study note](https://github.com/vipstone/python)I've elaborated the Python install instructions:[Python setup](https://github.com/vipstone/python/blob/master/%E5%BC%80%E5%8F%91%E7%8E%AF%E5%A2%83%E6%90%AD%E5%BB%BA.md)
### 2 Install Python package NumPy ###
After above step, we should have Python and pip (package management system used to install and manage software packages written in Python) installed. Before OpenCV acutal installed we should have Numpy settled, which is a fundamental package for scientific computing with Python, OpenCV depends on Numpy, so it's the prerequisite for OpenCV.
we're using .whl files to install Python packages.
**What is a whl file ?**
whl file are compressed built-package format used for Python.
**Install whl package for Python**
> pip3 install path_to\xxx.whl
Go back the Numpy installation.
Step 1:Download corresponding whl files from here:https://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy
E.g. Windows 64 with Python 3.6 should download this file: numpy‑1.14.2+mkl‑cp36‑cp36m‑win_amd64.whl
Download from Baidu Yunpan:https://pan.baidu.com/s/10RefansrC4_0zsNehjyKTg
Password:gua3
Step 2:Input Command-line in a terminal
> pip3 install d:\numpy‑1.14.2+mkl‑cp36‑cp36m‑win_amd64.whl
Output:
Processing d:\numpy-1.14.2+mkl-cp36-cp36m-win_amd64.whl
Installing collected packages: numpy
Successfully installed numpy-1.14.2+mkl
### 3 Install OpenCV as Python package ###
Similar way to install OpenCV.
Step 1:Download corresponding whl files from here:https://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv E.g Windows 64 with Python 3.6 should download this file::opencv_python‑3.4.1‑cp36‑cp36m‑win_amd64.whl
Download from Baidu Yunpan:https://pan.baidu.com/s/10RefansrC4_0zsNehjyKTg
Password:gua3
Step 2:Input Command-line in a terminal
> pip3 install d:\opencv_python-3.4.1-cp36-cp36m-win_amd64.whl
Output:
Processing d:\opencv_python-3.4.1-cp36-cp36m-win_amd64.whl
Installing collected packages: opencv-python
Successfully installed opencv-python-3.4.1
### 4 OpenCV examples ###
``` python
import cv2
print(cv2.__version__)
# Output:3.4.1
```
If the version number can be print out correctly which means OpenCV-Python is settled.
Show an image with OpenCV:
``` python
import cv2
filepath = "img/meinv.png"
img = cv2.imread(filepath)
cv2.namedWindow('Image')
cv2.imshow('Image', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
```
----------
## OpenCV setting up in Linux ##
>Ubuntu 18.04
>Python 3.6.5
>Pip 10.0.1
>Numpy 1.14.3
>OpenCV 3.4.0
Ubuntu already had Python built in which is easier for setting campare to Windows, so just using apt-get command in Ubuntu for software package installation. Please refer this [tutorial](http://www.cnblogs.com/vipstone/p/9038023.html) for software sources updating (if needed).
### Installation ###
It's easier in Ubuntu than Windows for OpenCV installation, basically we only need pip command to do all the work.
#### Install Numpy ####
CLI:pip3 install numpy
Try below Python code to see if Numpy settled
```
import numpy
numpy.__version__
```
If version number print out correctly which means Numpy installed successfully.
#### Install OpenCV ####
Similar way to install OpenCV:
>pip3 install opencv-python
Try below Python code to see if OpenCV settled
```
import cv2
cv2.__version__
```
If version number print out correctly which means OpemCV installed successfully.
# FAQ #
[1] python3: Relink `/lib/x86_64-linux-gnu/libudev.so.1` with `/lib/x86_64-linux-gnu/librt.so.1` for IFUNC symbol `clock_gettime`
Segmentation fault (core dumped)
Answer:apt install python3-opencv
----------
================================================
FILE: doc-en/tesseractOCR.md
================================================
# Tesseract Ocr文字识别
Tesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于Google对Tesseract进行改进、消除Bug、优化工作。Tesseract目前已作为开源项目发布在Google Project.
运行环境:
>windows10 + python 3.6 + tesseract 4.0.0-beta.1
先看效果:


一、安装python模块
>pip3 install pytesseract
二、安装tesseract orc
下载地址:https://github.com/UB-Mannheim/tesseract/wiki 点击“tesseract-ocr-w64-setup-v4.0.0-beta.1.20180414.exe”下载安装。
注意:安装的时候选中中文包。
本人安装目录:C:\Users\Administrator\AppData\Local\Tesseract-OCR
使用命令,查看版本号和支持语言:
>cd C:\Users\Administrator\AppData\Local\Tesseract-OCR
>tesseract -v
>tesseract --list-langs #查看Tesseract-OCR支持语言
三、配置tesseract运行文件
C:\Python36\Lib\site-packages\pytesseract\pytesseract.py
找到文件:
>tesseract_cmd = 'tesseract'
修改为:
>tesseract_cmd = 'C:/Program Files (x86)/Tesseract-OCR/tesseract.exe'
四、代码识别
```
from PIL import Image
import pytesseract
path = "img\\text-img.png"
text = pytesseract.image_to_string(Image.open(path), lang='chi_sim')
print(text)
```
作为非常优秀的Ocr识别库,tesseract当然可以训练自己的数据模型,从而达到为我所用的目的,后续文章会介绍如何训练自己的文字识别库。
================================================
FILE: doc-en/ubuntuChange.md
================================================
# Ubuntu apt-get和pip源更换 #
更新数据源为国内,是为了加速安装包的增加速度。
# 更换apt-get数据源 #
1. 输入:sudo -s切换为root超级管理员;
2. 执行命令:vim /etc/apt/sources.list;
1. 使用命令:%d 清空所有内容;
1. 清华数据源地址:https://mirrors.tuna.tsinghua.edu.cn/help/ubuntu/ 选择相应的版本复制内容,点击“i”键进入编辑文本模式,粘贴内容到vim编辑窗体,点击“ESC”键进入编辑模式,输入“:wq”保存离开;
2. 更新源:sudo apt-get update;
3. 更新软件:sudo apt-get upgrade;
# pip3的安装与升级 #
安装pip3:sudo apt-get install python3-pip
升级pip3:sudo pip install --upgrade pip
查看pip版本:pip -V
# pip源更换 #
1. 根目录创建.pip文件:mkdir ~/.pip;
1. 创建文件pip.conf:vim .pip/pip.conf;
1. 点击“i”键,进入编辑模式,复制信息:
```
[global]
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
trusted-host = pypi.tuna.tsinghua.edu.cn
```
这个更换的是清华的源,清华的源5分钟同步官网一次,建议使用。
清华大学 https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云 http://mirrors.aliyun.com/pypi/simple/
中国科技大学 https://pypi.mirrors.ustc.edu.cn/simple/
豆瓣(douban) http://pypi.douban.com/simple/
中国科学技术大学 http://pypi.mirrors.ustc.edu.cn/simple/
1. 点击:“ESC”切换到命令行模式,输入“:wq”保存离开。
# 修改默认python版本号 #
我们也可以把Ubuntu的默认python版本号进行修改,步骤如下:
1、删除原有Python连接文件
>sudo rm /usr/bin/python
2、切换成root账户,建立指向Python3的连接
切换root账户:sudo -s
建立执行Python3的连接
>ln -s /usr/bin/python3.6 /usr/bin/python
以上操作就是完成默认Python版本号设置,使用:python -V查看默认版本号.
================================================
FILE: doc-en/videoDlib.md
================================================
# 视频人脸检测(dlib版)
视频人脸检测是图片识别的高级版本,图片检测详情点击查看我的上一篇[《图片人脸检测(dlib版)》](https://github.com/vipstone/faceai/blob/master/doc/detectionDlib.md)
除了人脸识别用的是Dlib外,还是用OpenCV读取摄像头和处理图片(转为灰色),所以给出相关的文档,方便理解。
[视频人脸检测(OpenCV版)](doc/videoOpenCV.md)
有了OpenCV的视频人脸检测,Dlib也大致相同除了视频识别器模型的声明和使用不同,具体的细节请参考,[视频人脸检测(OpenCV版)](doc/videoOpenCV.md) 那篇已经讲的很细致了,在这就不具体叙述了。
完整的代码如下:
```
# coding=utf-8
import cv2
import dlib
detector = dlib.get_frontal_face_detector() #使用默认的人类识别器模型
def discern(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dets = detector(gray, 1)
for face in dets:
left = face.left()
top = face.top()
right = face.right()
bottom = face.bottom()
cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0), 2)
cv2.imshow("image", img)
cap = cv2.VideoCapture(0)
while (1):
ret, img = cap.read()
discern(img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
```
那么,OpenCV和Dlib的视频识别对比,有两个地方是不同的:
1.Dlib模型识别的准确率和效果要好于OpenCV;
2.Dlib识别的性能要比OpenCV差,使用视频测试的时候Dlib有明显的卡顿,但是OpenCV就好很多,基本看不出来;
================================================
FILE: doc-en/videoOpenCV.md
================================================
# 视频人脸检测(OpenCV版)
视频人脸检测是图片人脸检测的高级版本,图片检测详情点击查看我的上一篇[《图片人脸检测(OpenCV版)》](https://github.com/vipstone/faceai/blob/master/doc/detectionOpenCV.md) 。
**实现思路:**
调用电脑的摄像头,把摄像的信息逐帧分解成图片,基于图片检测标识出人脸的位置,把处理的图片逐帧绘制给用户,用户看到的效果就是视频的人脸检测。
效果预览:

## 实现步骤 ##
使用OpenCV调用摄像头并展示。
**获取摄像头**
```
cap = cv2.VideoCapture(0)
```
参数0表示,获取第一个摄像头。
**显示摄像头**
逐帧显示,代码如下:
```
while (1):
ret, img = cap.read()
cv2.imshow("Image", img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release() # 释放摄像头
cv2.destroyAllWindows() # 释放窗口资源
```
cv2.waitKey(1) & 0xFF使用了“&”位元算法,含义是获取用户输入的最后一个字符的ASCII码,如果输入的是“q”,则跳出循环。
**视频的人脸识别**
这个时候,用到了上一节的[《图片人脸检测(OpenCV版)》](https://github.com/vipstone/faceai/blob/master/doc/detectionOpenCV.md) 把人脸识别的代码封装成方法,代码如下:
```
def discern(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cap = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
faceRects = cap.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(50, 50))
if len(faceRects):
for faceRect in faceRects:
x, y, w, h = faceRect
cv2.rectangle(img, (x, y), (x + h, y + w), (0, 255, 0), 2) # 框出人脸
cv2.imshow("Image", img)
```
再循环摄像头帧图片的时候,调用图片识别方法即可,代码如下:
```
# 获取摄像头0表示第一个摄像头
cap = cv2.VideoCapture(0)
while (1): # 逐帧显示
ret, img = cap.read()
# cv2.imshow("Image", img)
discern(img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release() # 释放摄像头
cv2.destroyAllWindows() # 释放窗口资源
```
完整的代码如下:
```
# -*- coding:utf-8 -*-
# OpenCV版本的视频检测
import cv2
# 图片识别方法封装
def discern(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cap = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
faceRects = cap.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(50, 50))
if len(faceRects):
for faceRect in faceRects:
x, y, w, h = faceRect
cv2.rectangle(img, (x, y), (x + h, y + w), (0, 255, 0), 2) # 框出人脸
cv2.imshow("Image", img)
# 获取摄像头0表示第一个摄像头
cap = cv2.VideoCapture(0)
while (1): # 逐帧显示
ret, img = cap.read()
# cv2.imshow("Image", img)
discern(img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release() # 释放摄像头
cv2.destroyAllWindows() # 释放窗口资源
```
================================================
FILE: faceai/.vscode/launch.json
================================================
{
// 使用 IntelliSense 了解相关属性。
// 悬停以查看现有属性的描述。
// 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"name": "Python: Current File",
"type": "python",
"request": "launch",
"program": "${file}"
},
{
"name": "Python: Attach",
"type": "python",
"request": "attach",
"localRoot": "${workspaceFolder}",
"remoteRoot": "${workspaceFolder}",
"port": 3000,
"secret": "my_secret",
"host": "localhost"
},
{
"name": "Python: Terminal (integrated)",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal"
},
{
"name": "Python: Terminal (external)",
"type": "python",
"request": "launch",
"program": "${file}",
"console": "externalTerminal"
},
{
"name": "Python: Django",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/manage.py",
"args": ["runserver", "--noreload", "--nothreading"],
"debugOptions": ["RedirectOutput", "Django"]
},
{
"name": "Python: Flask (0.11.x or later)",
"type": "python",
"request": "launch",
"module": "flask",
"env": {
"FLASK_APP": "${workspaceFolder}/app.py"
},
"args": ["run", "--no-debugger", "--no-reload"]
},
{
"name": "Python: Module",
"type": "python",
"request": "launch",
"module": "module.name"
},
{
"name": "Python: Pyramid",
"type": "python",
"request": "launch",
"args": ["${workspaceFolder}/development.ini"],
"debugOptions": ["RedirectOutput", "Pyramid"]
},
{
"name": "Python: Watson",
"type": "python",
"request": "launch",
"program": "${workspaceFolder}/console.py",
"args": ["dev", "runserver", "--noreload=True"]
},
{
"name": "Python: All debug Options",
"type": "python",
"request": "launch",
"pythonPath": "${config:python.pythonPath}",
"program": "${file}",
"module": "module.name",
"env": {
"VAR1": "1",
"VAR2": "2"
},
"envFile": "${workspaceFolder}/.env",
"args": ["arg1", "arg2"],
"debugOptions": ["RedirectOutput"]
}
]
}
================================================
FILE: faceai/chineseText.py
================================================
#coding=utf-8
#中文乱码处理
import cv2
import numpy
from PIL import Image, ImageDraw, ImageFont
# img = cv2.imread("img/xingye-1.png")
def cv2ImgAddText(img, text, left, top, textColor=(0, 255, 0), textSize=20):
if (isinstance(img, numpy.ndarray)): #判断是否OpenCV图片类型
img = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
draw = ImageDraw.Draw(img)
fontText = ImageFont.truetype(
"font/simsun.ttc", textSize, encoding="utf-8")
draw.text((left, top), text, textColor, font=fontText)
return cv2.cvtColor(numpy.asarray(img), cv2.COLOR_RGB2BGR)
# img = cv2ImgAddText(img, "大家好,我是星爷", 140, 60, (255, 255, 0), 20)
# cv2.imshow("Image", img)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
================================================
FILE: faceai/colorize.py
================================================
#coding=utf-8
#图片着色
import keras
# import tensorflow as tf
from skimage.io import imread, imsave
from skimage.color import rgb2gray, gray2rgb, rgb2lab, lab2rgb
from keras.models import Sequential
from keras.layers import Conv2D, UpSampling2D, InputLayer, Conv2DTranspose
from keras.preprocessing.image import img_to_array, load_img
import numpy as np
from keras.preprocessing.image import ImageDataGenerator
import os
import cv2
def get_train_data(img_file):
image = img_to_array(load_img(img_file))
image_shape = image.shape
image = np.array(image, dtype=float)
x = rgb2lab(1.0 / 255 * image)[:, :, 0]
y = rgb2lab(1.0 / 255 * image)[:, :, 1:]
y /= 128
x = x.reshape(1, image_shape[0], image_shape[1], 1)
y = y.reshape(1, image_shape[0], image_shape[1], 2)
return x, y, image_shape
def build_model():
model = Sequential()
model.add(InputLayer(input_shape=(None, None, 1)))
model.add(Conv2D(8, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(8, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same', strides=2))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same', strides=2))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(16, (3, 3), activation='relu', padding='same'))
model.add(UpSampling2D((2, 2)))
model.add(Conv2D(2, (3, 3), activation='tanh', padding='same'))
# model.compile(optimizer='rmsprop', loss='mse')
model.compile(optimizer='adam', loss='mse')
return model
#训练数据
def train():
x, y, img_shape = get_train_data('./img/colorize/colorize-original.png')
# x2, y2, img_shape2 = get_train_data(
# './img/colorize/colorize2-original.png')
model = build_model()
num_epochs = 1000 #训练次数
batch_size = 1
model.fit(x, y, batch_size=batch_size, epochs=num_epochs)
# model.fit(x2, y2, batch_size=batch_size, epochs=num_epochs)
model.save('./data/simple_colorize.h5')
#着色
def colorize():
path = './img/colorize/colorize2.png'
# cv2.imwrite('./img/colorize3.png', cv2.imread(path, 0))
x, y, image_shape = get_train_data(path)
model = build_model()
model.load_weights('./data/simple_colorize.h5')
output = model.predict(x)
output *= 128
tmp = np.zeros((200, 200, 3))
tmp[:, :, 0] = x[0][:, :, 0]
tmp[:, :, 1:] = output[0]
colorizePath = path.replace(".png", "-res.png")
imsave(colorizePath, lab2rgb(tmp))
cv2.imshow("I", cv2.imread(path))
cv2.imshow("II", cv2.imread(colorizePath))
cv2.waitKey(0)
cv2.destroyAllWindows()
# imsave("test_image_gray.png", rgb2gray(lab2rgb(tmp)))
if __name__ == '__main__':
# train()
colorize()
================================================
FILE: faceai/compose.py
================================================
#coding=utf-8
#头像特效合成
import cv2
# OpenCV人脸识别分类器
classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
img = cv2.imread("img/ag-3.png") # 读取图片
imgCompose = cv2.imread("img/compose/maozi-1.png")
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换灰色
color = (0, 255, 0) # 定义绘制颜色
# 调用识别人脸
faceRects = classifier.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects): # 大于0则检测到人脸
for faceRect in faceRects:
x, y, w, h = faceRect
sp = imgCompose.shape
imgComposeSizeH = int(sp[0]/sp[1]*w)
if imgComposeSizeH>(y-20):
imgComposeSizeH=(y-20)
imgComposeSize = cv2.resize(imgCompose,(w, imgComposeSizeH), interpolation=cv2.INTER_NEAREST)
top = (y-imgComposeSizeH-20)
if top<=0:
top=0
rows, cols, channels = imgComposeSize.shape
roi = img[top:top+rows,x:x+cols]
# Now create a mask of logo and create its inverse mask also
img2gray = cv2.cvtColor(imgComposeSize, cv2.COLOR_RGB2GRAY)
ret, mask = cv2.threshold(img2gray, 10, 255, cv2.THRESH_BINARY)
mask_inv = cv2.bitwise_not(mask)
# Now black-out the area of logo in ROI
img1_bg = cv2.bitwise_and(roi, roi, mask=mask_inv)
# Take only region of logo from logo image.
img2_fg = cv2.bitwise_and(imgComposeSize, imgComposeSize, mask=mask)
# Put logo in ROI and modify the main image
dst = cv2.add(img1_bg, img2_fg)
img[top:top+rows, x:x+cols] = dst
cv2.imshow("image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
================================================
FILE: faceai/detectionDlib.py
================================================
#coding=utf-8
#图片检测 - Dlib版本
import cv2
import dlib
path = "img/ag.png"
img = cv2.imread(path)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
#人脸分类器
detector = dlib.get_frontal_face_detector()
# 获取人脸检测器
predictor = dlib.shape_predictor(
"C:\\Python36\\Lib\\site-packages\\dlib-data\\shape_predictor_68_face_landmarks.dat"
)
dets = detector(gray, 1)
for face in dets:
# 在图片中标注人脸,并显示
# left = face.left()
# top = face.top()
# right = face.right()
# bottom = face.bottom()
# cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0), 2)
# cv2.imshow("image", img)
shape = predictor(img, face) # 寻找人脸的68个标定点
# 遍历所有点,打印出其坐标,并圈出来
for pt in shape.parts():
pt_pos = (pt.x, pt.y)
cv2.circle(img, pt_pos, 1, (0, 255, 0), 2)
cv2.imshow("image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
================================================
FILE: faceai/detectionOpencv.py
================================================
#coding=utf-8
#图片检测 - OpenCV版本
import cv2
import datetime
import time
filepath = "img/xingye-1.png"
# OpenCV人脸识别分类器
classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
# 程序开始时间
startTime = datetime.datetime.now()
img = cv2.imread(filepath) # 读取图片
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转换灰色
color = (0, 255, 0) # 定义绘制颜色
# 调用识别人脸
faceRects = classifier.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects): # 大于0则检测到人脸
for faceRect in faceRects: # 单独框出每一张人脸
x, y, w, h = faceRect
# 框出人脸
cv2.rectangle(img, (x, y), (x + h, y + w), color, 2)
# 左眼
cv2.circle(img, (x + w // 4, y + h // 4 + 30), min(w // 8, h // 8),
color)
#右眼
cv2.circle(img, (x + 3 * w // 4, y + h // 4 + 30), min(w // 8, h // 8),
color)
#嘴巴
cv2.rectangle(img, (x + 3 * w // 8, y + 3 * h // 4),
(x + 5 * w // 8, y + 7 * h // 8), color)
# 程序结束时间
endTime = datetime.datetime.now()
print((endTime - startTime))
cv2.imshow("image", img) # 显示图像
cv2.waitKey(0)
cv2.destroyAllWindows()
================================================
FILE: faceai/emotion.py
================================================
#coding=utf-8
#表情识别
import cv2
from keras.models import load_model
import numpy as np
import chineseText
import datetime
startTime = datetime.datetime.now()
emotion_classifier = load_model(
'classifier/emotion_models/simple_CNN.530-0.65.hdf5')
endTime = datetime.datetime.now()
print(endTime - startTime)
emotion_labels = {
0: '生气',
1: '厌恶',
2: '恐惧',
3: '开心',
4: '难过',
5: '惊喜',
6: '平静'
}
img = cv2.imread("img/emotion/emotion.png")
face_classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_classifier.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(40, 40))
color = (255, 0, 0)
for (x, y, w, h) in faces:
gray_face = gray[(y):(y + h), (x):(x + w)]
gray_face = cv2.resize(gray_face, (48, 48))
gray_face = gray_face / 255.0
gray_face = np.expand_dims(gray_face, 0)
gray_face = np.expand_dims(gray_face, -1)
emotion_label_arg = np.argmax(emotion_classifier.predict(gray_face))
emotion = emotion_labels[emotion_label_arg]
cv2.rectangle(img, (x + 10, y + 10), (x + h - 10, y + w - 10),
(255, 255, 255), 2)
img = chineseText.cv2ImgAddText(img, emotion, x + h * 0.3, y, color, 20)
cv2.imshow("Image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
================================================
FILE: faceai/eye.py
================================================
#coding=utf-8
# 38x-37x 44x-43x
# 40x-39x 46x-45x
import cv2
import dlib
import numpy as np
import time
# img = cv2.imread(path)
# gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# detector = dlib.get_frontal_face_detector()
# predictor = dlib.shape_predictor(
# "C:\\Python36\\Lib\\site-packages\\dlib-data\\shape_predictor_68_face_landmarks.dat"
# )
# dets = detector(gray, 1)
# for face in dets:
# shape = predictor(img, face)
# leftDiffer1 = shape.parts()[37].x - shape.parts()[36].x
# leftDiffer2 = shape.parts()[39].x - shape.parts()[38].x
# print("leftDiffer1:{} leftDiffer2:{} ".format(leftDiffer1, leftDiffer2))
counter = 1
#获取眼球中心
def houghCircles(path, counter):
img = cv2.imread(path, 0)
# img = cv2.medianBlur(img, 5)
x = cv2.Sobel(img, -1, 1, 0, ksize=3)
y = cv2.Sobel(img, -1, 0, 1, ksize=3)
absx = cv2.convertScaleAbs(x)
absy = cv2.convertScaleAbs(y)
img = cv2.addWeighted(absx, 0.5, absy, 0.5, 0)
# ycrcb = cv2.cvtColor(img, cv2.COLOR_BGR2YCR_CB)
# channels = cv2.split(ycrcb)
# cv2.equalizeHist(channels[0], channels[0]) #输入通道、输出通道矩阵
# cv2.merge(channels, ycrcb) #合并结果通道
# cv2.cvtColor(ycrcb, cv2.COLOR_YCR_CB2BGR, img)
# img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cimg = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR)
# cv2.imshow("img2", img)
# cv2.imshow("grayimg", grayimg)
circles = cv2.HoughCircles(
img,
cv2.HOUGH_GRADIENT,
1,
50,
param1=50,
param2=10,
minRadius=2,
maxRadius=0)
circles = np.uint16(np.around(circles))
for i in circles[0, :]:
# draw the outer circle
# cv2.circle(cimg, (i[0], i[1]), i[2], (0, 255, 0), 1)
# draw the center of the circle
cv2.circle(cimg, (i[0], i[1]), 2, (0, 0, 255), 2)
# cv2.imshow("img" + str(counter), cimg)
return (i[0] + 3, i[1] + 3)
#彩色直方图均衡化
def hist(img):
ycrcb = cv2.cvtColor(img, cv2.COLOR_BGR2YCR_CB)
channels = cv2.split(ycrcb)
cv2.equalizeHist(channels[0], channels[0]) #输入通道、输出通道矩阵
cv2.merge(channels, ycrcb) #合并结果通道
cv2.cvtColor(ycrcb, cv2.COLOR_YCR_CB2BGR, img)
return img
classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_eye.xml" #haarcascade_eye_tree_eyeglasses
)
def discern(img, counter):
grayImg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
color = (0, 255, 0)
faceRects = classifier.detectMultiScale(
grayImg, scaleFactor=1.2, minNeighbors=3, minSize=(58, 58))
if len(faceRects):
for faceRect in faceRects:
x, y, w, h = faceRect
rightEyeImg = img[(y):(y + h), (x):(x + w)]
# cv2.rectangle(img, (x, y), (x + h, y + w), color, 2)
rightEyeImg = cv2.GaussianBlur(rightEyeImg, (5, 5), 1)
# rightEyeImg = hist(rightEyeImg)
cv2.imwrite("img/temp.png", rightEyeImg)
# cv2.imwrite("img/temp.png", rightEyeImg)
circleCenter = houghCircles("img/temp.png", counter) #(x,y)
cv2.circle(img, (x + circleCenter[0], y + circleCenter[1]), 2,
(128, 0, 0), 2)
counter += 1
cv2.imshow("image", img)
# path = "img/ag-3.png"
# img = cv2.imread(path)
# gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# faceRects = classifier.detectMultiScale(
# gray, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
# if len(faceRects):
# for faceRect in faceRects:
# x, y, w, h = faceRect
# # cv2.rectangle(img, (x, y), (x + h, y + w), (255, 0, 0), 2)
# rightEyeImg = img[(y):(y + h), (x):(x + w)]
# cv2.imwrite("img/temp.png", rightEyeImg)
# houghCircles("img/temp.png", counter)
# counter += 1
# # cv2.imshow("img", houghCircles("img/temp.png"))
path = "img/ag.png"
img = cv2.imread(path)
discern(img, counter)
# cap = cv2.VideoCapture(0)
# while (1):
# ret, frame = cap.read()
# # cv2.imshow('frame', gray)
# discern(frame, counter)
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
#
# cv2.imwrite('img/eye-2.png', rightEyeImg)
# eyeImg = img[(y):(y + h), (x):(x + w)]
# eyeImg = cv2.medianBlur(eyeImg, 5)
# cimg = cv2.cvtColor(eyeImg, cv2.COLOR_GRAY2BGR)
# circles = cv2.HoughCircles(
# eyeImg,
# cv2.HOUGH_GRADIENT,
# 1,
# 20,
# param1=50,
# param2=30,
# minRadius=0,
# maxRadius=0)
# circles = np.uint16(np.around(circles))
# for i in circles[0, :]:
# # draw the outer circle
# cv2.circle(cimg, (i[0], i[1]), i[2], (0, 255, 0), 2)
# # draw the center of the circle
# cv2.circle(cimg, (i[0], i[1]), 2, (0, 0, 255), 3)
# cv2.imshow('detected circles', cimg)
# cv2.imshow("image", img) # 显示图像
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# time.sleep(1)
# img = cv2.imread("img/eye-2.png")
# ycrcb = cv2.cvtColor(img, cv2.COLOR_BGR2YCR_CB)
# channels = cv2.split(ycrcb)
# cv2.equalizeHist(channels[0], channels[0]) #输入通道、输出通道矩阵
# cv2.merge(channels, ycrcb) #合并结果通道
# cv2.cvtColor(ycrcb, cv2.COLOR_YCR_CB2BGR, img)
# # cv2.imshow("old image", cv2.imread("img/hist.png"))
# # cv2.imshow("image", img)
# cv2.imwrite("img/eye-3.png", img)
# time.sleep(1)
# cv2.imshow('detected circles', cimg)
cv2.waitKey(0)
cv2.destroyAllWindows()
================================================
FILE: faceai/eye2.py
================================================
import cv2
import dlib
import numpy as np
import time
classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_eye_tree_eyeglasses.xml" # haarcascade_eye
)
#彩色直方图均衡化
def hist(img):
ycrcb = cv2.cvtColor(img, cv2.COLOR_BGR2YCR_CB)
channels = cv2.split(ycrcb)
cv2.equalizeHist(channels[0], channels[0]) #输入通道、输出通道矩阵
cv2.merge(channels, ycrcb) #合并结果通道
cv2.cvtColor(ycrcb, cv2.COLOR_YCR_CB2BGR, img)
return img
def discern(img):
grayImg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faceRects = classifier.detectMultiScale(
grayImg, scaleFactor=1.2, minNeighbors=3, minSize=(30, 30))
if len(faceRects):
for faceRect in faceRects:
x, y, w, h = faceRect
rightEyeImg = img[(y):(y + h), (x):(x + w)]
# cv2.rectangle(img, (x, y), (x + h, y + w), color, 2)
# rightEyeImg = hist(rightEyeImg)
rightEyeImg = cv2.GaussianBlur(rightEyeImg, (5, 5), 1)
cv2.imwrite("img/temp.png", rightEyeImg)
# cv2.imshow("img", rightEyeImg)
# print(len(faceRects))
# discern(cv2.imread("img/ag-2.png"))
img = cv2.imread("img/temp.png", 0)
# img = cv2.GaussianBlur(img, (3, 3), 0)
# img = cv2.Canny(img, 50, 150)
img = cv2.bilateralFilter(img, 7, 50, 50)
# x = cv2.Sobel(img, -1, 1, 0, ksize=3)
# y = cv2.Sobel(img, -1, 0, 1, ksize=3)
# absx = cv2.convertScaleAbs(x)
# absy = cv2.convertScaleAbs(y)
# dist = cv2.addWeighted(absx, 0.5, absy, 0.5, 0)
# img = cv2.GaussianBlur(img, (5, 5), 1)
# laplacian = cv2.Laplacian(img, -1, ksize=3)
# laplacian = cv2.GaussianBlur(laplacian, (3, 3), 1)
# laplacian = cv2.medianBlur(laplacian, 3)
# img = dist
# img = cv2.cvtColor(dist, cv2.COLOR_BGR2GRAY)
cimg = cv2.cvtColor(img, cv2.COLOR_GRAY2BGR) # cv2.imread("img/temp.png") #
# cv2.imshow("img2", img)
# cv2.imshow("grayimg", grayimg)
circles = cv2.HoughCircles(
img,
cv2.HOUGH_GRADIENT,
1,
100,
param1=50,
param2=10,
minRadius=2,
maxRadius=0)
circles = np.uint16(np.around(circles))
for i in circles[0, :]:
# draw the outer circle
# cv2.circle(cimg, (i[0], i[1]), i[2], (0, 255, 0), 1)
# draw the center of the circle
cv2.circle(cimg, (i[0], i[1]), 2, (0, 0, 255), 2)
cv2.imshow("img", cimg)
cv2.waitKey(0)
cv2.destroyAllWindows()
================================================
FILE: faceai/faceRecognition.py
================================================
#coding=utf-8
#人脸识别类 - 使用face_recognition模块
import cv2
import face_recognition
import os
path = "img/face_recognition" # 模型数据图片目录
cap = cv2.VideoCapture(0)
total_image_name = []
total_face_encoding = []
for fn in os.listdir(path): #fn 表示的是文件名q
print(path + "/" + fn)
total_face_encoding.append(
face_recognition.face_encodings(
face_recognition.load_image_file(path + "/" + fn))[0])
fn = fn[:(len(fn) - 4)] #截取图片名(这里应该把images文件中的图片名命名为为人物名)
total_image_name.append(fn) #图片名字列表
while (1):
ret, frame = cap.read()
# 发现在视频帧所有的脸和face_enqcodings
face_locations = face_recognition.face_locations(frame)
face_encodings = face_recognition.face_encodings(frame, face_locations)
# 在这个视频帧中循环遍历每个人脸
for (top, right, bottom, left), face_encoding in zip(
face_locations, face_encodings):
# 看看面部是否与已知人脸相匹配。
for i, v in enumerate(total_face_encoding):
match = face_recognition.compare_faces(
[v], face_encoding, tolerance=0.5)
name = "Unknown"
if match[0]:
name = total_image_name[i]
break
# 画出一个框,框住脸
cv2.rectangle(frame, (left, top), (right, bottom), (0, 0, 255), 2)
# 画出一个带名字的标签,放在框下
cv2.rectangle(frame, (left, bottom - 35), (right, bottom), (0, 0, 255),
cv2.FILLED)
font = cv2.FONT_HERSHEY_DUPLEX
cv2.putText(frame, name, (left + 6, bottom - 6), font, 1.0,
(255, 255, 255), 1)
# 显示结果图像
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
================================================
FILE: faceai/faceRecognitionMakeup.py
================================================
#coding=utf-8
#数字化妆类
import face_recognition
from PIL import Image, ImageDraw
#加载图片到numpy array
image = face_recognition.load_image_file("img/ag.png")
#标识脸部特征
face_landmarks_list = face_recognition.face_landmarks(image)
for face_landmarks in face_landmarks_list:
pil_image = Image.fromarray(image)
d = ImageDraw.Draw(pil_image, 'RGBA')
# 绘制眉毛
d.polygon(face_landmarks['left_eyebrow'], fill=(68, 54, 39, 128))
d.polygon(face_landmarks['right_eyebrow'], fill=(68, 54, 39, 128))
d.line(face_landmarks['left_eyebrow'], fill=(68, 54, 39, 150), width=5)
d.line(face_landmarks['right_eyebrow'], fill=(68, 54, 39, 150), width=5)
# 绘制嘴唇
d.polygon(face_landmarks['top_lip'], fill=(150, 0, 0, 128))
d.polygon(face_landmarks['bottom_lip'], fill=(150, 0, 0, 128))
d.line(face_landmarks['top_lip'], fill=(150, 0, 0, 64), width=8)
d.line(face_landmarks['bottom_lip'], fill=(150, 0, 0, 64), width=8)
# 绘制眼睛
d.polygon(face_landmarks['left_eye'], fill=(255, 255, 255, 30))
d.polygon(face_landmarks['right_eye'], fill=(255, 255, 255, 30))
# 绘制眼线
d.line(
face_landmarks['left_eye'] + [face_landmarks['left_eye'][0]],
fill=(0, 0, 0, 110),
width=6)
d.line(
face_landmarks['right_eye'] + [face_landmarks['right_eye'][0]],
fill=(0, 0, 0, 110),
width=6)
pil_image.show()
================================================
FILE: faceai/faceRecognitionOutline.py
================================================
#coding=utf-8
#绘制面部轮廓
import face_recognition
from PIL import Image, ImageDraw
# 将图片文件加载到numpy 数组中
image = face_recognition.load_image_file("img/ag.png")
#查找图像中所有面部的所有面部特征
face_landmarks_list = face_recognition.face_landmarks(image)
for face_landmarks in face_landmarks_list:
facial_features = [
'chin', # 下巴
'left_eyebrow', # 左眉毛
'right_eyebrow', # 右眉毛
'nose_bridge', # 鼻樑
'nose_tip', # 鼻尖
'left_eye', # 左眼
'right_eye', # 右眼
'top_lip', # 上嘴唇
'bottom_lip' # 下嘴唇
]
pil_image = Image.fromarray(image)
d = ImageDraw.Draw(pil_image)
for facial_feature in facial_features:
d.line(face_landmarks[facial_feature], fill=(255, 255, 255), width=2)
pil_image.show()
================================================
FILE: faceai/faceswap.py
================================================
#coding=utf-8
import cv2
import numpy
import dlib
modelPath = "C:\Python36\Lib\site-packages\dlib-data\shape_predictor_68_face_landmarks.dat"
SCALE_FACTOR = 1
FEATHER_AMOUNT = 11
FACE_POINTS = list(range(17, 68))
MOUTH_POINTS = list(range(48, 61))
RIGHT_BROW_POINTS = list(range(17, 22))
LEFT_BROW_POINTS = list(range(22, 27))
RIGHT_EYE_POINTS = list(range(36, 42))
LEFT_EYE_POINTS = list(range(42, 48))
NOSE_POINTS = list(range(27, 35))
JAW_POINTS = list(range(0, 17))
ALIGN_POINTS = (LEFT_BROW_POINTS + RIGHT_EYE_POINTS + LEFT_EYE_POINTS +
RIGHT_BROW_POINTS + NOSE_POINTS + MOUTH_POINTS)
OVERLAY_POINTS = [
LEFT_EYE_POINTS + RIGHT_EYE_POINTS + LEFT_BROW_POINTS + RIGHT_BROW_POINTS,
NOSE_POINTS + MOUTH_POINTS,
]
COLOUR_CORRECT_BLUR_FRAC = 0.6
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(modelPath)
class TooManyFaces(Exception):
pass
class NoFaces(Exception):
pass
def get_landmarks(im):
rects = detector(im, 1)
if len(rects) > 1:
raise TooManyFaces
if len(rects) == 0:
raise NoFaces
return numpy.matrix([[p.x, p.y] for p in predictor(im, rects[0]).parts()])
def annotate_landmarks(im, landmarks):
im = im.copy()
for idx, point in enumerate(landmarks):
pos = (point[0, 0], point[0, 1])
cv2.putText(
im,
str(idx),
pos,
fontFace=cv2.FONT_HERSHEY_SCRIPT_SIMPLEX,
fontScale=0.4,
color=(0, 0, 255))
cv2.circle(im, pos, 3, color=(0, 255, 255))
return im
def draw_convex_hull(im, points, color):
points = cv2.convexHull(points)
cv2.fillConvexPoly(im, points, color=color)
def get_face_mask(im, landmarks):
im = numpy.zeros(im.shape[:2], dtype=numpy.float64)
for group in OVERLAY_POINTS:
draw_convex_hull(im, landmarks[group], color=1)
im = numpy.array([im, im, im]).transpose((1, 2, 0))
im = (cv2.GaussianBlur(im, (FEATHER_AMOUNT, FEATHER_AMOUNT), 0) > 0) * 1.0
im = cv2.GaussianBlur(im, (FEATHER_AMOUNT, FEATHER_AMOUNT), 0)
return im
def transformation_from_points(points1, points2):
points1 = points1.astype(numpy.float64)
points2 = points2.astype(numpy.float64)
c1 = numpy.mean(points1, axis=0)
c2 = numpy.mean(points2, axis=0)
points1 -= c1
points2 -= c2
s1 = numpy.std(points1)
s2 = numpy.std(points2)
points1 /= s1
points2 /= s2
U, S, Vt = numpy.linalg.svd(points1.T * points2)
R = (U * Vt).T
return numpy.vstack([
numpy.hstack(((s2 / s1) * R, c2.T - (s2 / s1) * R * c1.T)),
numpy.matrix([0., 0., 1.])
])
def read_im_and_landmarks(fname):
im = cv2.imread(fname, cv2.IMREAD_COLOR)
im = cv2.resize(im,
(im.shape[1] * SCALE_FACTOR, im.shape[0] * SCALE_FACTOR))
s = get_landmarks(im)
return im, s
def warp_im(im, M, dshape):
output_im = numpy.zeros(dshape, dtype=im.dtype)
cv2.warpAffine(
im,
M[:2], (dshape[1], dshape[0]),
dst=output_im,
borderMode=cv2.BORDER_TRANSPARENT,
flags=cv2.WARP_INVERSE_MAP)
return output_im
def correct_colours(im1, im2, landmarks1):
blur_amount = COLOUR_CORRECT_BLUR_FRAC * numpy.linalg.norm(
numpy.mean(landmarks1[LEFT_EYE_POINTS], axis=0) -
numpy.mean(landmarks1[RIGHT_EYE_POINTS], axis=0))
blur_amount = int(blur_amount)
if blur_amount % 2 == 0:
blur_amount += 1
im1_blur = cv2.GaussianBlur(im1, (blur_amount, blur_amount), 0)
im2_blur = cv2.GaussianBlur(im2, (blur_amount, blur_amount), 0)
im2_blur += (128 * (im2_blur <= 1.0)).astype(im2_blur.dtype)
return (im2.astype(numpy.float64) * im1_blur.astype(numpy.float64) /
im2_blur.astype(numpy.float64))
im1, landmarks1 = read_im_and_landmarks("img/ag-2.png")
im2, landmarks2 = read_im_and_landmarks("img/ag.png")
M = transformation_from_points(landmarks1[ALIGN_POINTS],
landmarks2[ALIGN_POINTS])
mask = get_face_mask(im2, landmarks2)
warped_mask = warp_im(mask, M, im1.shape)
combined_mask = numpy.max(
[get_face_mask(im1, landmarks1), warped_mask], axis=0)
warped_im2 = warp_im(im2, M, im1.shape)
warped_corrected_im2 = correct_colours(im1, warped_im2, landmarks1)
output_im = im1 * (1.0 - combined_mask) + warped_corrected_im2 * combined_mask
cv2.imwrite("img/faceswap.png", output_im)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
================================================
FILE: faceai/font/simsun.ttc
================================================
[File too large to display: 17.4 MB]
================================================
FILE: faceai/gender.py
================================================
#coding=utf-8
#性别识别
import cv2
from keras.models import load_model
import numpy as np
import chineseText
img = cv2.imread("img/gather.png")
face_classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_classifier.detectMultiScale(
gray, scaleFactor=1.2, minNeighbors=3, minSize=(140, 140))
gender_classifier = load_model(
"classifier/gender_models/simple_CNN.81-0.96.hdf5")
gender_labels = {0: '女', 1: '男'}
color = (255, 255, 255)
for (x, y, w, h) in faces:
face = img[(y - 60):(y + h + 60), (x - 30):(x + w + 30)]
face = cv2.resize(face, (48, 48))
face = np.expand_dims(face, 0)
face = face / 255.0
gender_label_arg = np.argmax(gender_classifier.predict(face))
gender = gender_labels[gender_label_arg]
cv2.rectangle(img, (x, y), (x + h, y + w), color, 2)
img = chineseText.cv2ImgAddText(img, gender, x + h, y, color, 30)
cv2.imshow("Image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
================================================
FILE: faceai/grabCut.py
================================================
#coding=utf-8
#抠图
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('img/face_recognition/Gates.png')
mask = np.zeros(img.shape[:2], np.uint8)
bgdModel = np.zeros((1, 65), np.float64)
fgdModel = np.zeros((1, 65), np.float64)
rect = (0, 0, 505, 448) #划定区域
cv2.grabCut(img, mask, rect, bgdModel, fgdModel, 5,
cv2.GC_INIT_WITH_RECT) #函数返回值为mask,bgdModel,fgdModel
mask2 = np.where((mask == 2) | (mask == 0), 0, 1).astype('uint8') #0和2做背景
img = img * mask2[:, :, np.newaxis] #使用蒙板来获取前景区域
cv2.imshow('p', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
================================================
FILE: faceai/opencv/hist.py
================================================
#coding=utf-8
#直方图
import cv2
import numpy as np
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
# ut = np.zeros(256, dtype=img.dtype) #创建空的查找表
# hist = cv2.calcHist(
# [img], #计算图像的直方图
# [0], #使用的通道
# None, #没有使用mask
# [256], #it is a 1D histogram
# [0.0, 255.0])
# def calcAndDrawHist(image, color):
# hist = cv2.calcHist([image], [0], None, [256], [0.0, 255.0])
# minVal, maxVal, minLoc, maxLoc = cv2.minMaxLoc(hist)
# histImg = np.zeros([256, 256, 3], np.uint8)
# hpt = int(0.9 * 256)
# for h in range(256):
# intensity = int(hist[h] * hpt / maxVal)
# cv2.line(histImg, (h, 256), (h, 256 - intensity), color)
# return histImg
# img = cv2.imread("img/hist.png")
# b, g, r = cv2.split(img)
# print(b)
# print(g)
# print(r)
# histImgB = calcAndDrawHist(b, [255, 0, 0])
# histImgG = calcAndDrawHist(g, [0, 255, 0])
# histImgR = calcAndDrawHist(r, [0, 0, 255])
# cv2.imshow("histImgB", histImgB)
# cv2.imshow("histImgG", histImgG)
# cv2.imshow("histImgR", histImgR)
# #灰色直方图均衡化
# img = cv2.imread("img/hist.png", 0)
# equ = cv2.equalizeHist(img)
# cv2.imshow("old image", img)
# cv2.imshow("image", equ)
##彩色直方图均衡化
# img = cv2.imread("img/hist.png")
# ycrcb = cv2.cvtColor(img, cv2.COLOR_BGR2YCR_CB)
# channels = cv2.split(ycrcb)
# cv2.equalizeHist(channels[0], channels[0]) #输入通道、输出通道矩阵
# cv2.merge(channels, ycrcb) #合并结果通道
# cv2.cvtColor(ycrcb, cv2.COLOR_YCR_CB2BGR, img)
# cv2.imshow("old image", cv2.imread("img/hist.png"))
# cv2.imshow("image", img)
##绘制直方图
# img = cv2.imread("img/hist.png")
# chans = cv2.split(img)
# colors = ("b", "g", "r")
# plt.figure()
# plt.title("直方图分布")
# plt.xlabel("颜色值")
# plt.ylabel("像素点")
# for (chan, color) in zip(chans, colors):
# hist = cv2.calcHist([chan], [0], None, [256], [0, 256])
# plt.plot(hist, color=color)
# plt.xlim([0, 256])
# plt.show()
# #添加噪声
# img = cv2.imread("img/black.png")
# for k in range(0, 1000):
# xi = int(np.random.uniform(0, img.shape[1]))
# xj = int(np.random.uniform(0, img.shape[0]))
# if img.ndim == 2:
# img[xj, xi] = 255
# elif img.ndim == 3:
# img[xj, xi, 0] = 255
# img[xj, xi, 1] = 255
# img[xj, xi, 2] = 255
# cv2.imwrite("img/black-noise.png", img)
# cv2.imshow("image", img)
# #滤波器
img = cv2.imread("img/black-noise.png")
dst = cv2.blur(img, (5, 5)) #均值滤波
gaussian = cv2.GaussianBlur(img, (5, 5), 1) #高斯滤波
median = cv2.medianBlur(img, 5) #中值滤波
cv2.imshow("image", gaussian)
# #Sobel算子 —— 是一种带有方向性的滤波器
# img = cv2.imread('img/ag.png', cv2.IMREAD_COLOR)
# x = cv2.Sobel(
# img, cv2.CV_16S, 1, 0
# ) #cv2.CV_16S -- Sobel 函数求完导数后会有负值和大于255的值,而原图像是uint8(8位无符号数据),所以在建立图像时长度不够,会被截断,所以使用16位有符号数据
# y = cv2.Sobel(img, cv2.CV_16S, 0, 1)
# absx = cv2.convertScaleAbs(
# x) #convertScaleAbs() -- 转回uint8形式,否则将无法显示图像,而只是一副灰色图像
# absy = cv2.convertScaleAbs(y)
# dist = cv2.addWeighted(absx, 0.5, absy, 0.5, 0) #参数2:第1张图的权重;参数4:第2张图的权重
# # cv2.imshow('y', absy)
# # cv2.imshow('x', absx)
# cv2.imshow('dsit', dist)
# cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
================================================
FILE: faceai/opencv/hsv.py
================================================
#coding=utf-8
#HSV转换(颜色提取)
import cv2
import numpy as np
cap = cv2.VideoCapture(0)
while (1):
_, frame = cap.read()
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
#在PS里用取色器的HSV
psHSV = [112, 89, 52]
diff = 40 #上下浮动值
#因为PS的HSV(HSB)取值是:0~360、0~1、0~1,而OpenCV的HSV是:0~180、0~255、0~255,所以要对ps的hsv进行处理,H/2、SV*255
lowerHSV = [(psHSV[0] - diff) / 2, (psHSV[1] - diff) * 255 / 100,
(psHSV[2] - diff) * 255 / 100]
upperHSV = [(psHSV[0] + diff) / 2, (psHSV[1] + diff) * 255 / 100,
(psHSV[2] + diff) * 255 / 100]
mask = cv2.inRange(hsv, np.array(lowerHSV), np.array(upperHSV))
#使用位“与运算”提取颜色部分
res = cv2.bitwise_and(frame, frame, mask=mask)
#使用高斯模式优化图片
res = cv2.GaussianBlur(res, (5, 5), 1)
cv2.imshow('frame', frame)
# cv2.imshow('mask', mask)
cv2.imshow('res', res)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
================================================
FILE: faceai/opencv/imgbase.py
================================================
#coding=utf-8
#图片基础
import cv2
import numpy as np
img = cv2.imread("img/ag.png")
# shape = img.shape # 形状 (高,宽,3通道[彩色图])
# size = img.size # 像素总数
# dtype = img.dtype # uint8 图片类型
# roi = img[200:350, 300:330] # [y轴选取区域,x轴选取区域]
# img[0:150, 100:130] = roi
# cv2.imshow("image", img)
b, g, r = cv2.split(img) #分割通道
img = cv2.merge((b, g, r)) #合并通道
img = img[:, :, 0]
cv2.imshow("image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
================================================
FILE: faceai/opencv/inpaint.py
================================================
#coding=utf-8
#图片修复
import cv2
import numpy as np
path = "img/inpaint.png"
img = cv2.imread(path)
hight, width, depth = img.shape[0:3]
#图片二值化处理,把[240, 240, 240]~[255, 255, 255]以外的颜色变成0
thresh = cv2.inRange(img, np.array([240, 240, 240]), np.array([255, 255, 255]))
#创建形状和尺寸的结构元素
kernel = np.ones((3, 3), np.uint8)
#扩张待修复区域
hi_mask = cv2.dilate(thresh, kernel, iterations=1)
specular = cv2.inpaint(img, hi_mask, 5, flags=cv2.INPAINT_TELEA)
cv2.namedWindow("Image", 0)
cv2.resizeWindow("Image", int(width / 2), int(hight / 2))
cv2.imshow("Image", img)
cv2.namedWindow("newImage", 0)
cv2.resizeWindow("newImage", int(width / 2), int(hight / 2))
cv2.imshow("newImage", specular)
cv2.waitKey(0)
cv2.destroyAllWindows()
================================================
FILE: faceai/opencv/mouse.py
================================================
#coding=utf-8
#鼠标绘图
import cv2
import numpy as np
# **************** 1 ****************
# for i in dir(cv2):
# if 'EVENT' in i:
# print(i)
'''
EVENT_FLAG_ALTKEY #按住alt键
EVENT_FLAG_CTRLKEY #按住ctrl键
EVENT_FLAG_LBUTTON #按住鼠标左键
EVENT_FLAG_MBUTTON #按住右键点击左键
EVENT_FLAG_RBUTTON #按住鼠标右键
EVENT_FLAG_SHIFTKEY #按住shift键
EVENT_LBUTTONDBLCLK #左键双击
EVENT_LBUTTONDOWN #左键按下
EVENT_LBUTTONUP #左键抬起
EVENT_MBUTTONDBLCLK #滚轮双击
EVENT_MBUTTONDOWN #滚轮按下
EVENT_MBUTTONUP #滚轮抬起
EVENT_MOUSEMOVE #鼠标移动
EVENT_MOUSEWHEEL #鼠标滚轮滚动
EVENT_RBUTTONDBLCLK #右键双击
EVENT_RBUTTONDOWN #右键按下
EVENT_RBUTTONUP #右键抬起
'''
# # **************** 2 ****************
# def draw_circle(event, x, y, flags, param):
# if event == cv2.EVENT_MBUTTONDOWN:
# cv2.circle(img, (x, y), 20, (255, 0, 0), -1)
# img = np.zeros((512, 512, 3), np.uint8)
# cv2.namedWindow('image')
# cv2.setMouseCallback('image', draw_circle)
# while (1):
# cv2.imshow('image', img)
# if cv2.waitKey(1) & 0xFF == ord('q'):
# break
# **************** 3 happy的自由绘图 ****************
drawing = False
def drawDef(event, x, y, flags, param):
global drawing
if event == cv2.EVENT_LBUTTONDOWN:
drawing = True
if event == cv2.EVENT_LBUTTONUP:
drawing = False
if event == cv2.EVENT_MOUSEMOVE and drawing == True:
cv2.circle(img, (x, y), 10, (255, 0, 0), -1)
img = np.zeros((512, 512, 3), np.uint8)
cv2.namedWindow('image')
cv2.setMouseCallback('image', drawDef)
while (1):
cv2.imshow('image', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cv2.destroyAllWindows()
================================================
FILE: faceai/opencv/trackbar.py
================================================
#coding=utf-8
#调色板
import cv2
import numpy as np
img = np.zeros((300, 512, 3), np.uint8)
cv2.namedWindow('image')
def callback(x):
pass
#参数1:名称;参数2:作用窗口,参数3、4:最小值和最大值;参数5:值更改回调方法
cv2.createTrackbar('R', 'image', 0, 255, callback)
cv2.createTrackbar('G', 'image', 0, 255, callback)
cv2.createTrackbar('B', 'image', 0, 255, callback)
while (1):
cv2.imshow('image', img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
r = cv2.getTrackbarPos('R', 'image')
g = cv2.getTrackbarPos('G', 'image')
b = cv2.getTrackbarPos('B', 'image')
img[:] = [b, g, r]
cv2.destroyAllWindows()
================================================
FILE: faceai/tesseractOcr.py
================================================
#coding=utf-8
#文字识别类
from PIL import Image
import pytesseract
import cv2
path = "img\\text-img.png"
text = pytesseract.image_to_string(Image.open(path), lang='chi_sim')
print(text)
img = cv2.imread(path)
cv2.imshow("Image", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
================================================
FILE: faceai/test.py
================================================
#coding=utf-8
#练习类
import datetime
import time
#开始计时
startTime = datetime.datetime.now()
time.sleep(1)
#结束计时
endTime = datetime.datetime.now()
print(endTime - startTime)
#输出:0:00:01.000791
================================================
FILE: faceai/versionPut.py
================================================
#coding=utf-8
#版本号输出类
import cv2
import dlib
import face_recognition
import keras
import tensorflow
print(cv2.__version__) # 输出:3.4.1
print(dlib.__version__) # 输出:19.8.1
print(face_recognition.__version__) #输出:1.2.2
print(keras.__version__) # 输出:2.1.6
print(tensorflow.VERSION) # 输出:1.8.0
================================================
FILE: faceai/videoDlib.py
================================================
#coding=utf-8
#视频人脸检测类 - Dlib版本
import cv2
import dlib
detector = dlib.get_frontal_face_detector() #使用默认的人类识别器模型
def discern(img):
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
dets = detector(gray, 1)
for face in dets:
left = face.left()
top = face.top()
right = face.right()
bottom = face.bottom()
cv2.rectangle(img, (left, top), (right, bottom), (0, 255, 0), 2)
cv2.imshow("image", img)
cap = cv2.VideoCapture(0)
while (1):
ret, img = cap.read()
discern(img)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
================================================
FILE: faceai/videoOpencv.py
================================================
#coding=utf-8
#视频人脸检测类 - OpenCV版本
import cv2
# 图片识别方法
def discern(img):
grayImg = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
# OpenCV人脸识别分类器
classifier = cv2.CascadeClassifier(
"C:\Python36\Lib\site-packages\opencv-master\data\haarcascades\haarcascade_frontalface_default.xml"
)
color = (0, 255, 0) # 定义绘制颜色
# 调用识别人脸
faceRects = classifier.detectMultiScale(
grayImg, scaleFactor=1.2, minNeighbors=3, minSize=(32, 32))
if len(faceRects): # 大于0则检测到人脸
for faceRect in faceRects: # 单独框出每一张人脸
x, y, w, h = faceRect
# 框出人脸
cv2.rectangle(img, (x, y), (x + h, y + w), color, 2)
cv2.imshow("image", img) # 显示图像
cap = cv2.VideoCapture(0)
while (1):
ret, frame = cap.read()
# cv2.imshow('frame', gray)
discern(frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
gitextract_iy8eplpr/
├── .gitignore
├── LICENSE
├── README.md
├── README_en.md
├── doc/
│ ├── chinese.md
│ ├── colorize.md
│ ├── compose.md
│ ├── detectionDlib.md
│ ├── detectionOpenCV.md
│ ├── emotion.md
│ ├── faceRecognition.md
│ ├── faceRecognitionMakeup.md
│ ├── faceRecognitionOutline.md
│ ├── gender.md
│ ├── hsv-opencv.md
│ ├── inpaint.md
│ ├── opencv/
│ │ ├── hsv.md
│ │ └── mouse.md
│ ├── pipChange.md
│ ├── settingup.md
│ ├── tesseractOCR.md
│ ├── ubuntuChange.md
│ ├── videoDlib.md
│ └── videoOpenCV.md
├── doc-en/
│ ├── chinese.md
│ ├── colorize.md
│ ├── compose.md
│ ├── detectionDlib.md
│ ├── detectionOpenCV.md
│ ├── emotion.md
│ ├── faceRecognition.md
│ ├── faceRecognitionMakeup.md
│ ├── faceRecognitionOutline.md
│ ├── gender.md
│ ├── hsv-opencv.md
│ ├── inpaint.md
│ ├── opencv/
│ │ ├── hsv.md
│ │ └── mouse.md
│ ├── pipChange.md
│ ├── settingup.md
│ ├── tesseractOCR.md
│ ├── ubuntuChange.md
│ ├── videoDlib.md
│ └── videoOpenCV.md
└── faceai/
├── .vscode/
│ └── launch.json
├── chineseText.py
├── classifier/
│ ├── emotion_models/
│ │ └── simple_CNN.530-0.65.hdf5
│ └── gender_models/
│ ├── gender_mini_XCEPTION.21-0.95.hdf5
│ └── simple_CNN.81-0.96.hdf5
├── colorize.py
├── compose.py
├── data/
│ └── simple_colorize.h5
├── detectionDlib.py
├── detectionOpencv.py
├── emotion.py
├── eye.py
├── eye2.py
├── faceRecognition.py
├── faceRecognitionMakeup.py
├── faceRecognitionOutline.py
├── faceswap.py
├── font/
│ └── simsun.ttc
├── gender.py
├── grabCut.py
├── opencv/
│ ├── hist.py
│ ├── hsv.py
│ ├── imgbase.py
│ ├── inpaint.py
│ ├── mouse.py
│ └── trackbar.py
├── tesseractOcr.py
├── test.py
├── versionPut.py
├── videoDlib.py
└── videoOpencv.py
SYMBOL INDEX (24 symbols across 9 files) FILE: faceai/chineseText.py function cv2ImgAddText (line 11) | def cv2ImgAddText(img, text, left, top, textColor=(0, 255, 0), textSize=... FILE: faceai/colorize.py function get_train_data (line 16) | def get_train_data(img_file): function build_model (line 28) | def build_model(): function train (line 49) | def train(): function colorize (line 65) | def colorize(): FILE: faceai/eye.py function houghCircles (line 32) | def houghCircles(path, counter): function hist (line 76) | def hist(img): function discern (line 90) | def discern(img, counter): FILE: faceai/eye2.py function hist (line 12) | def hist(img): function discern (line 21) | def discern(img): FILE: faceai/faceswap.py class TooManyFaces (line 33) | class TooManyFaces(Exception): class NoFaces (line 37) | class NoFaces(Exception): function get_landmarks (line 41) | def get_landmarks(im): function annotate_landmarks (line 52) | def annotate_landmarks(im, landmarks): function draw_convex_hull (line 67) | def draw_convex_hull(im, points, color): function get_face_mask (line 72) | def get_face_mask(im, landmarks): function transformation_from_points (line 86) | def transformation_from_points(points1, points2): function read_im_and_landmarks (line 105) | def read_im_and_landmarks(fname): function warp_im (line 114) | def warp_im(im, M, dshape): function correct_colours (line 125) | def correct_colours(im1, im2, landmarks1): FILE: faceai/opencv/mouse.py function drawDef (line 49) | def drawDef(event, x, y, flags, param): FILE: faceai/opencv/trackbar.py function callback (line 10) | def callback(x): FILE: faceai/videoDlib.py function discern (line 9) | def discern(img): FILE: faceai/videoOpencv.py function discern (line 7) | def discern(img):
Condensed preview — 75 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (122K chars).
[
{
"path": ".gitignore",
"chars": 1157,
"preview": "# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Distribution / packagi"
},
{
"path": "LICENSE",
"chars": 1062,
"preview": "MIT License\n\nCopyright (c) 2018 stone\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof t"
},
{
"path": "README.md",
"chars": 2925,
"preview": "[English Doc](README_en.md)\n# 功能 #\n\n1. 人脸检测、识别(图片、视频)\n2. 轮廓标识\n3. 头像合成(给人戴帽子)\n4. 数字化妆(画口红、眉毛、眼睛等)\n5. 性别识别\n6. 表情识别(生气、厌恶、恐"
},
{
"path": "README_en.md",
"chars": 3697,
"preview": "Translation for English Documentations are Working In Progress\n\n# Functions #\n\n1. Face Detection and Recognition(From Im"
},
{
"path": "doc/chinese.md",
"chars": 1469,
"preview": "# OpenCV添加中文 #\nOpenCV添加文字的方法putText(...),添加英文是没有问题的,但如果你要添加中文就会出现“???”的乱码,需要特殊处理一下。\n\n下文提供封装好的(代码)方法,供OpenCV添加中文使用。\n\n# 效果"
},
{
"path": "doc/colorize.md",
"chars": 113,
"preview": "# 图片上色 #\n\n\n安装scikit-image模块:scikit-image (a.k.a. skimage) 是一个图像处理和计算机视觉的算法集合。\n>sudo pip3 install scikit-image \n\n"
},
{
"path": "doc/compose.md",
"chars": 2086,
"preview": "# 头像特效合成\n\n实现思路:使用OpenCV检测出头部位置,向上移动20像素添加虚拟帽子,帽子的宽度等于脸的大小,高度等比缩小,需要注意的是如果高度小于脸部向上移动20像素的值,那么帽子的高度就等于最小高度=(脸部位置-20)。\n为什么是"
},
{
"path": "doc/detectionDlib.md",
"chars": 1900,
"preview": "# 图片人脸检测(dlib版)\n\n上几篇给大家讲了OpenCV的图片人脸检测,而本文给大家带来的是比OpenCV更加精准的图片人脸检测Dlib库。\n\n点击查看往期:\n\n[《图片人脸检测(OpenCV版)》](https://github.c"
},
{
"path": "doc/detectionOpenCV.md",
"chars": 2669,
"preview": "# 图片人脸检测\n\n人脸检测使用到的技术是OpenCV,上一节已经介绍了OpenCV的环境安装,[点击查看](https://github.com/vipstone/faceai/blob/master/doc/settingup.md)."
},
{
"path": "doc/emotion.md",
"chars": 1859,
"preview": "# 表情识别 #\n表情识别支持7种表情类型,生气、厌恶、恐惧、开心、难过、惊喜、平静等。\n\n# 实现思路 #\n使用OpenCV识别图片中的脸,在使用keras进行表情识别。\n\n# 开发环境 #\n- Windows10 x64\n- pytho"
},
{
"path": "doc/faceRecognition.md",
"chars": 2227,
"preview": "# 人脸识别\n\n人脸识别,需要使用face_recognition库做人脸对比,OpenCV获取摄像头数据。\n\n## 环境 ##\n+ Windows 10 \n+ OpenCV 3.4.1\n+ Dlib 19.8.1\n+ fa"
},
{
"path": "doc/faceRecognitionMakeup.md",
"chars": 1684,
"preview": "# 数字化妆\n\n数字化妆,使用face_recognition实现.\n\n## 环境 ##\n+ Windows 10 \n+ face_recognition 1.2.2\n\n\n## 环境安装 ##\n\n**face_recognition"
},
{
"path": "doc/faceRecognitionOutline.md",
"chars": 964,
"preview": "# 绘制脸部轮廓\n\n使用face_recognition绘制脸部特征\n\n## 环境 ##\n+ Windows 10 \n+ face_recognition 1.2.2\n\n\n## 环境安装 ##\n\n**face_recognition"
},
{
"path": "doc/gender.md",
"chars": 1802,
"preview": "# 性别识别 #\n\n使用keras实现性别识别,模型数据使用的是oarriaga/face_classification的模型,下文给出项目地址。\n\n# 开发环境 #\n\n- Windows 10\n- Python 3.6.4\n- keras"
},
{
"path": "doc/hsv-opencv.md",
"chars": 1725,
"preview": "# 视频对象提取 #\n\n与其说是视频对象提取,不如说是视频颜色提取,因为其本质还是使用了OpenCV的HSV颜色物体检测。\n\n# HSV介绍 #\nHSV分别代表,色调(H:hue),饱和度(S:saturation),亮度(V:value)"
},
{
"path": "doc/inpaint.md",
"chars": 1539,
"preview": "# 图片修复程序-可用于水印去除 #\n\n在现实的生活中,我们可能会遇到一些美好的或是珍贵的图片被噪声干扰,比如旧照片的折痕,比如镜头上的灰尘或污渍,更或者是某些我们想为我所用但有讨厌水印,那么有没有一种办法可以消除这些噪声呢?\n\n答案是肯定"
},
{
"path": "doc/opencv/hsv.md",
"chars": 894,
"preview": "# 视频对象提取 #\n\n\n\n```\nimport cv2\nimport numpy as np\n\ncap = cv2.VideoCapture(0)\n\nwhile (1):\n _, frame = cap.read()\n hsv"
},
{
"path": "doc/opencv/mouse.md",
"chars": 1750,
"preview": "# 使用鼠标绘图——OpenCV #\nOpenCV可以使用cv2.setMouseCallback()进行简单的鼠标绘图。\n\n# 简单示例 #\n查看所有的事件\n```\nfor i in dir(cv2):\n if 'EVENT' in"
},
{
"path": "doc/pipChange.md",
"chars": 590,
"preview": "# pip/pip3更换国内源——Windows版 #\n\n用途:pip更换为国内源,可以大大的提高安装成功率和速度。\n\n\n# Windows更换pip/pip3源 #\n\n1. 打开目录:%appdata%\n1. 新增pip文件夹,新建pip"
},
{
"path": "doc/settingup.md",
"chars": 3165,
"preview": "# OpenCV环境搭建 #\n\n本文将介绍OpenCV在Python3.x上的实现,分为Window版和Linux版。\n\n## Windows版环境搭建 ##\n\n> 系统环境:windows 10 + python 3.6 + OpenCV"
},
{
"path": "doc/tesseractOCR.md",
"chars": 1226,
"preview": "# Tesseract Ocr文字识别\n\nTesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于"
},
{
"path": "doc/ubuntuChange.md",
"chars": 1208,
"preview": "# Ubuntu apt-get和pip源更换 #\n\n更新数据源为国内,是为了加速安装包的增加速度。\n\n\n# 更换apt-get数据源 #\n\n1. 输入:sudo -s切换为root超级管理员;\n2. 执行命令:vim /etc/apt/s"
},
{
"path": "doc/videoDlib.md",
"chars": 1104,
"preview": "# 视频人脸检测(dlib版)\n\n视频人脸检测是图片识别的高级版本,图片检测详情点击查看我的上一篇[《图片人脸检测(dlib版)》](https://github.com/vipstone/faceai/blob/master/doc/de"
},
{
"path": "doc/videoOpenCV.md",
"chars": 2495,
"preview": "# 视频人脸检测(OpenCV版)\n\n视频人脸检测是图片人脸检测的高级版本,图片检测详情点击查看我的上一篇[《图片人脸检测(OpenCV版)》](https://github.com/vipstone/faceai/blob/master/"
},
{
"path": "doc-en/chinese.md",
"chars": 1469,
"preview": "# OpenCV添加中文 #\nOpenCV添加文字的方法putText(...),添加英文是没有问题的,但如果你要添加中文就会出现“???”的乱码,需要特殊处理一下。\n\n下文提供封装好的(代码)方法,供OpenCV添加中文使用。\n\n# 效果"
},
{
"path": "doc-en/colorize.md",
"chars": 113,
"preview": "# 图片上色 #\n\n\n安装scikit-image模块:scikit-image (a.k.a. skimage) 是一个图像处理和计算机视觉的算法集合。\n>sudo pip3 install scikit-image \n\n"
},
{
"path": "doc-en/compose.md",
"chars": 2086,
"preview": "# 头像特效合成\n\n实现思路:使用OpenCV检测出头部位置,向上移动20像素添加虚拟帽子,帽子的宽度等于脸的大小,高度等比缩小,需要注意的是如果高度小于脸部向上移动20像素的值,那么帽子的高度就等于最小高度=(脸部位置-20)。\n为什么是"
},
{
"path": "doc-en/detectionDlib.md",
"chars": 1900,
"preview": "# 图片人脸检测(dlib版)\n\n上几篇给大家讲了OpenCV的图片人脸检测,而本文给大家带来的是比OpenCV更加精准的图片人脸检测Dlib库。\n\n点击查看往期:\n\n[《图片人脸检测(OpenCV版)》](https://github.c"
},
{
"path": "doc-en/detectionOpenCV.md",
"chars": 2669,
"preview": "# 图片人脸检测\n\n人脸检测使用到的技术是OpenCV,上一节已经介绍了OpenCV的环境安装,[点击查看](https://github.com/vipstone/faceai/blob/master/doc/settingup.md)."
},
{
"path": "doc-en/emotion.md",
"chars": 1859,
"preview": "# 表情识别 #\n表情识别支持7种表情类型,生气、厌恶、恐惧、开心、难过、惊喜、平静等。\n\n# 实现思路 #\n使用OpenCV识别图片中的脸,在使用keras进行表情识别。\n\n# 开发环境 #\n- Windows10 x64\n- pytho"
},
{
"path": "doc-en/faceRecognition.md",
"chars": 2227,
"preview": "# 人脸识别\n\n人脸识别,需要使用face_recognition库做人脸对比,OpenCV获取摄像头数据。\n\n## 环境 ##\n+ Windows 10 \n+ OpenCV 3.4.1\n+ Dlib 19.8.1\n+ fa"
},
{
"path": "doc-en/faceRecognitionMakeup.md",
"chars": 1684,
"preview": "# 数字化妆\n\n数字化妆,使用face_recognition实现.\n\n## 环境 ##\n+ Windows 10 \n+ face_recognition 1.2.2\n\n\n## 环境安装 ##\n\n**face_recognition"
},
{
"path": "doc-en/faceRecognitionOutline.md",
"chars": 964,
"preview": "# 绘制脸部轮廓\n\n使用face_recognition绘制脸部特征\n\n## 环境 ##\n+ Windows 10 \n+ face_recognition 1.2.2\n\n\n## 环境安装 ##\n\n**face_recognition"
},
{
"path": "doc-en/gender.md",
"chars": 1802,
"preview": "# 性别识别 #\n\n使用keras实现性别识别,模型数据使用的是oarriaga/face_classification的模型,下文给出项目地址。\n\n# 开发环境 #\n\n- Windows 10\n- Python 3.6.4\n- keras"
},
{
"path": "doc-en/hsv-opencv.md",
"chars": 1661,
"preview": "# 视频对象提取 #\n\n与其说是视频对象提取,不如说是视频颜色提取,因为其本质还是使用了OpenCV的HSV颜色物体检测。\n\n# HSV介绍 #\nHSV分别代表,色调(H:hue),饱和度(S:saturation),亮度(V:value)"
},
{
"path": "doc-en/inpaint.md",
"chars": 1539,
"preview": "# 图片修复程序-可用于水印去除 #\n\n在现实的生活中,我们可能会遇到一些美好的或是珍贵的图片被噪声干扰,比如旧照片的折痕,比如镜头上的灰尘或污渍,更或者是某些我们想为我所用但有讨厌水印,那么有没有一种办法可以消除这些噪声呢?\n\n答案是肯定"
},
{
"path": "doc-en/opencv/hsv.md",
"chars": 894,
"preview": "# 视频对象提取 #\n\n\n\n```\nimport cv2\nimport numpy as np\n\ncap = cv2.VideoCapture(0)\n\nwhile (1):\n _, frame = cap.read()\n hsv"
},
{
"path": "doc-en/opencv/mouse.md",
"chars": 1750,
"preview": "# 使用鼠标绘图——OpenCV #\nOpenCV可以使用cv2.setMouseCallback()进行简单的鼠标绘图。\n\n# 简单示例 #\n查看所有的事件\n```\nfor i in dir(cv2):\n if 'EVENT' in"
},
{
"path": "doc-en/pipChange.md",
"chars": 590,
"preview": "# pip/pip3更换国内源——Windows版 #\n\n用途:pip更换为国内源,可以大大的提高安装成功率和速度。\n\n\n# Windows更换pip/pip3源 #\n\n1. 打开目录:%appdata%\n1. 新增pip文件夹,新建pip"
},
{
"path": "doc-en/settingup.md",
"chars": 3914,
"preview": "# OpenCV Setting up and Introducation #\n\nThis tutorial is going to illustrate the installation of Python3.x on both Linu"
},
{
"path": "doc-en/tesseractOCR.md",
"chars": 1226,
"preview": "# Tesseract Ocr文字识别\n\nTesseract的OCR引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。2005年,Tesseract由美国内华达州信息技术研究所获得,并求诸于"
},
{
"path": "doc-en/ubuntuChange.md",
"chars": 1208,
"preview": "# Ubuntu apt-get和pip源更换 #\n\n更新数据源为国内,是为了加速安装包的增加速度。\n\n\n# 更换apt-get数据源 #\n\n1. 输入:sudo -s切换为root超级管理员;\n2. 执行命令:vim /etc/apt/s"
},
{
"path": "doc-en/videoDlib.md",
"chars": 1104,
"preview": "# 视频人脸检测(dlib版)\n\n视频人脸检测是图片识别的高级版本,图片检测详情点击查看我的上一篇[《图片人脸检测(dlib版)》](https://github.com/vipstone/faceai/blob/master/doc/de"
},
{
"path": "doc-en/videoOpenCV.md",
"chars": 2495,
"preview": "# 视频人脸检测(OpenCV版)\n\n视频人脸检测是图片人脸检测的高级版本,图片检测详情点击查看我的上一篇[《图片人脸检测(OpenCV版)》](https://github.com/vipstone/faceai/blob/master/"
},
{
"path": "faceai/.vscode/launch.json",
"chars": 2346,
"preview": "{\n // 使用 IntelliSense 了解相关属性。\n // 悬停以查看现有属性的描述。\n // 欲了解更多信息,请访问: https://go.microsoft.com/fwlink/?linkid=830387\n \"ve"
},
{
"path": "faceai/chineseText.py",
"chars": 718,
"preview": "#coding=utf-8\n#中文乱码处理\n\nimport cv2\nimport numpy\nfrom PIL import Image, ImageDraw, ImageFont\n\n# img = cv2.imread(\"img/xing"
},
{
"path": "faceai/colorize.py",
"chars": 2974,
"preview": "#coding=utf-8\n#图片着色\nimport keras\n# import tensorflow as tf\nfrom skimage.io import imread, imsave\nfrom skimage.color impo"
},
{
"path": "faceai/compose.py",
"chars": 1684,
"preview": "#coding=utf-8\n#头像特效合成\nimport cv2\n\n# OpenCV人脸识别分类器\nclassifier = cv2.CascadeClassifier(\n \"C:\\Python36\\Lib\\site-packages"
},
{
"path": "faceai/detectionDlib.py",
"chars": 848,
"preview": "#coding=utf-8\n#图片检测 - Dlib版本\nimport cv2\nimport dlib\n\npath = \"img/ag.png\"\nimg = cv2.imread(path)\ngray = cv2.cvtColor(img,"
},
{
"path": "faceai/detectionOpencv.py",
"chars": 1231,
"preview": "#coding=utf-8\n#图片检测 - OpenCV版本\nimport cv2\nimport datetime\nimport time\n\nfilepath = \"img/xingye-1.png\"\n# OpenCV人脸识别分类器\ncla"
},
{
"path": "faceai/emotion.py",
"chars": 1399,
"preview": "#coding=utf-8\n#表情识别\n\nimport cv2\nfrom keras.models import load_model\nimport numpy as np\nimport chineseText\nimport datetim"
},
{
"path": "faceai/eye.py",
"chars": 5314,
"preview": "#coding=utf-8\n# 38x-37x 44x-43x\n# 40x-39x 46x-45x\n\nimport cv2\nimport dlib\nimport numpy as np\nimport time\n\n# img = cv2.im"
},
{
"path": "faceai/eye2.py",
"chars": 2357,
"preview": "import cv2\nimport dlib\nimport numpy as np\nimport time\n\nclassifier = cv2.CascadeClassifier(\n \"C:\\Python36\\Lib\\site-pac"
},
{
"path": "faceai/faceRecognition.py",
"chars": 1672,
"preview": "#coding=utf-8\n#人脸识别类 - 使用face_recognition模块\nimport cv2\nimport face_recognition\nimport os\n\npath = \"img/face_recognition\" "
},
{
"path": "faceai/faceRecognitionMakeup.py",
"chars": 1377,
"preview": "#coding=utf-8\n#数字化妆类\nimport face_recognition\nfrom PIL import Image, ImageDraw\n\n#加载图片到numpy array\nimage = face_recognitio"
},
{
"path": "faceai/faceRecognitionOutline.py",
"chars": 771,
"preview": "#coding=utf-8\n#绘制面部轮廓\nimport face_recognition\nfrom PIL import Image, ImageDraw\n\n# 将图片文件加载到numpy 数组中\nimage = face_recogni"
},
{
"path": "faceai/faceswap.py",
"chars": 4456,
"preview": "#coding=utf-8\nimport cv2\nimport numpy\nimport dlib\n\nmodelPath = \"C:\\Python36\\Lib\\site-packages\\dlib-data\\shape_predictor_"
},
{
"path": "faceai/gender.py",
"chars": 1074,
"preview": "#coding=utf-8\n#性别识别\n\nimport cv2\nfrom keras.models import load_model\nimport numpy as np\nimport chineseText\n\nimg = cv2.imr"
},
{
"path": "faceai/grabCut.py",
"chars": 597,
"preview": "#coding=utf-8\n#抠图\n\nimport numpy as np\nimport cv2\nfrom matplotlib import pyplot as plt\n\nimg = cv2.imread('img/face_recogn"
},
{
"path": "faceai/opencv/hist.py",
"chars": 3153,
"preview": "#coding=utf-8\n#直方图\n\nimport cv2\nimport numpy as np\nfrom matplotlib import pyplot as plt\n\nplt.rcParams['font.sans-serif'] "
},
{
"path": "faceai/opencv/hsv.py",
"chars": 936,
"preview": "#coding=utf-8\n#HSV转换(颜色提取)\n\nimport cv2\nimport numpy as np\n\ncap = cv2.VideoCapture(0)\n\nwhile (1):\n _, frame = cap.read"
},
{
"path": "faceai/opencv/imgbase.py",
"chars": 442,
"preview": "#coding=utf-8\n#图片基础\nimport cv2\nimport numpy as np\n\nimg = cv2.imread(\"img/ag.png\")\n\n# shape = img.shape # 形状 (高,宽,3通道[彩色"
},
{
"path": "faceai/opencv/inpaint.py",
"chars": 721,
"preview": "#coding=utf-8\n#图片修复\n\nimport cv2\nimport numpy as np\n\npath = \"img/inpaint.png\"\n\nimg = cv2.imread(path)\nhight, width, depth"
},
{
"path": "faceai/opencv/mouse.py",
"chars": 1587,
"preview": "#coding=utf-8\n#鼠标绘图\n\nimport cv2\nimport numpy as np\n\n# **************** 1 ****************\n# for i in dir(cv2):\n# if "
},
{
"path": "faceai/opencv/trackbar.py",
"chars": 610,
"preview": "#coding=utf-8\n#调色板\nimport cv2\nimport numpy as np\n\nimg = np.zeros((300, 512, 3), np.uint8)\ncv2.namedWindow('image')\n\n\ndef"
},
{
"path": "faceai/tesseractOcr.py",
"chars": 271,
"preview": "#coding=utf-8\n#文字识别类\nfrom PIL import Image\nimport pytesseract\nimport cv2\n\npath = \"img\\\\text-img.png\"\n\ntext = pytesseract"
},
{
"path": "faceai/test.py",
"chars": 191,
"preview": "#coding=utf-8\n#练习类\nimport datetime\nimport time\n\n#开始计时\nstartTime = datetime.datetime.now()\n\ntime.sleep(1)\n\n#结束计时\nendTime "
},
{
"path": "faceai/versionPut.py",
"chars": 296,
"preview": "#coding=utf-8\n#版本号输出类\nimport cv2\nimport dlib\nimport face_recognition\nimport keras\nimport tensorflow\n\nprint(cv2.__version"
},
{
"path": "faceai/videoDlib.py",
"chars": 629,
"preview": "#coding=utf-8\n#视频人脸检测类 - Dlib版本\nimport cv2\nimport dlib\n\ndetector = dlib.get_frontal_face_detector() #使用默认的人类识别器模型\n\n\ndef"
},
{
"path": "faceai/videoOpencv.py",
"chars": 914,
"preview": "#coding=utf-8\n#视频人脸检测类 - OpenCV版本\nimport cv2\n\n\n# 图片识别方法\ndef discern(img):\n grayImg = cv2.cvtColor(img, cv2.COLOR_BGR2"
}
]
// ... and 5 more files (download for full content)
About this extraction
This page contains the full source code of the vipstone/faceai GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 75 files (17.5 MB), approximately 43.5k tokens, and a symbol index with 24 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.