Repository: vmdiff/vmdiff-prototype
Branch: main
Commit: 4e56302666ad
Files: 45
Total size: 121.4 KB
Directory structure:
gitextract_xvezqapj/
├── .dockerignore
├── .github/
│ └── ISSUE_TEMPLATE/
│ ├── bug_report.md
│ └── feature_request.md
├── .gitignore
├── CODE_OF_CONDUCT.md
├── CONTRIBUTING.md
├── Dockerfile
├── LICENSE
├── README.md
├── __init__.py
├── backend/
│ ├── Dockerfile
│ ├── __init__.py
│ ├── diff_tree.py
│ ├── diffcache.py
│ ├── diskdiff.py
│ ├── file_entry_lister.py
│ ├── memdiff.py
│ ├── pyvmdk_delta.py
│ ├── requirements.txt
│ ├── unified_diff.py
│ ├── utils.py
│ ├── vmdiff.py
│ └── vmdk_file_io.py
├── config.py
├── docker-compose.yml
├── frontend/
│ ├── .dockerignore
│ ├── .gitignore
│ ├── README.md
│ ├── package.json
│ ├── public/
│ │ ├── index.html
│ │ └── manifest.json
│ ├── src/
│ │ ├── App.css
│ │ ├── App.test.tsx
│ │ ├── App.tsx
│ │ ├── index.css
│ │ ├── index.tsx
│ │ ├── react-app-env.d.ts
│ │ ├── reportWebVitals.ts
│ │ └── setupTests.ts
│ └── tsconfig.json
├── memory-processing/
│ ├── Dockerfile
│ └── memdiff.sh
├── requirements.txt
├── server.py
└── vmdiff
================================================
FILE CONTENTS
================================================
================================================
FILE: .dockerignore
================================================
**/__pycache__
**/.venv
**/.classpath
**/.dockerignore
**/.env
**/.git
**/.gitignore
**/.project
**/.settings
**/.toolstarget
**/.vs
**/.vscode
**/*.*proj.user
**/*.dbmdl
**/*.jfm
**/bin
**/charts
**/docker-compose*
**/compose*
**/Dockerfile*
**/node_modules
**/npm-debug.log
**/obj
**/secrets.dev.yaml
**/values.dev.yaml
**/results
**/.cache
**/.changed_files_cache
**/prototyping
**/node_modules
LICENSE
README.md
================================================
FILE: .github/ISSUE_TEMPLATE/bug_report.md
================================================
---
name: Bug report
about: Create a report to help us improve
title: ''
labels: ''
assignees: ''
---
**Describe the bug**
A clear and concise description of what the bug is.
**To Reproduce**
Steps to reproduce the behavior:
1. Go to '...'
2. Click on '....'
3. Scroll down to '....'
4. See error
**Expected behavior**
A clear and concise description of what you expected to happen.
**Screenshots**
If applicable, add screenshots to help explain your problem.
**Desktop (please complete the following information):**
- OS: [e.g. iOS]
- Browser [e.g. chrome, safari]
- Version [e.g. 22]
**Smartphone (please complete the following information):**
- Device: [e.g. iPhone6]
- OS: [e.g. iOS8.1]
- Browser [e.g. stock browser, safari]
- Version [e.g. 22]
**Additional context**
Add any other context about the problem here.
================================================
FILE: .github/ISSUE_TEMPLATE/feature_request.md
================================================
---
name: Feature request
about: Suggest an idea for this project
title: ''
labels: ''
assignees: ''
---
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
================================================
FILE: .gitignore
================================================
acab
autopsy*
__pycache__
libvmdl
sleuthkit-*
.cache
.DS_Store
.vscode
*.txt
diffs/
node_modules
.changed_files_cache/
results/
frontend/yarn.lock
feedback.md
preview.sh
volatility3/
build/
*volatilitycache*
profile.pstats
volatility3
libvmdk/
frontend/public/json
frontend/build/json
!requirements.txt
================================================
FILE: CODE_OF_CONDUCT.md
================================================
# Contributor Covenant Code of Conduct
## Our Pledge
We as members, contributors, and leaders pledge to make participation in our
community a harassment-free experience for everyone, regardless of age, body
size, visible or invisible disability, ethnicity, sex characteristics, gender
identity and expression, level of experience, education, socio-economic status,
nationality, personal appearance, race, religion, or sexual identity
and orientation.
We pledge to act and interact in ways that contribute to an open, welcoming,
diverse, inclusive, and healthy community.
## Our Standards
Examples of behavior that contributes to a positive environment for our
community include:
* Demonstrating empathy and kindness toward other people
* Being respectful of differing opinions, viewpoints, and experiences
* Giving and gracefully accepting constructive feedback
* Accepting responsibility and apologizing to those affected by our mistakes,
and learning from the experience
* Focusing on what is best not just for us as individuals, but for the
overall community
Examples of unacceptable behavior include:
* The use of sexualized language or imagery, and sexual attention or
advances of any kind
* Trolling, insulting or derogatory comments, and personal or political attacks
* Public or private harassment
* Publishing others' private information, such as a physical or email
address, without their explicit permission
* Other conduct which could reasonably be considered inappropriate in a
professional setting
## Enforcement Responsibilities
Community leaders are responsible for clarifying and enforcing our standards of
acceptable behavior and will take appropriate and fair corrective action in
response to any behavior that they deem inappropriate, threatening, offensive,
or harmful.
Community leaders have the right and responsibility to remove, edit, or reject
comments, commits, code, wiki edits, issues, and other contributions that are
not aligned to this Code of Conduct, and will communicate reasons for moderation
decisions when appropriate.
## Scope
This Code of Conduct applies within all community spaces, and also applies when
an individual is officially representing the community in public spaces.
Examples of representing our community include using an official e-mail address,
posting via an official social media account, or acting as an appointed
representative at an online or offline event.
## Enforcement
Instances of abusive, harassing, or otherwise unacceptable behavior may be
reported to the community leaders responsible for enforcement at
127803604+vmdiff@users.noreply.github.com.
All complaints will be reviewed and investigated promptly and fairly.
All community leaders are obligated to respect the privacy and security of the
reporter of any incident.
## Enforcement Guidelines
Community leaders will follow these Community Impact Guidelines in determining
the consequences for any action they deem in violation of this Code of Conduct:
### 1. Correction
**Community Impact**: Use of inappropriate language or other behavior deemed
unprofessional or unwelcome in the community.
**Consequence**: A private, written warning from community leaders, providing
clarity around the nature of the violation and an explanation of why the
behavior was inappropriate. A public apology may be requested.
### 2. Warning
**Community Impact**: A violation through a single incident or series
of actions.
**Consequence**: A warning with consequences for continued behavior. No
interaction with the people involved, including unsolicited interaction with
those enforcing the Code of Conduct, for a specified period of time. This
includes avoiding interactions in community spaces as well as external channels
like social media. Violating these terms may lead to a temporary or
permanent ban.
### 3. Temporary Ban
**Community Impact**: A serious violation of community standards, including
sustained inappropriate behavior.
**Consequence**: A temporary ban from any sort of interaction or public
communication with the community for a specified period of time. No public or
private interaction with the people involved, including unsolicited interaction
with those enforcing the Code of Conduct, is allowed during this period.
Violating these terms may lead to a permanent ban.
### 4. Permanent Ban
**Community Impact**: Demonstrating a pattern of violation of community
standards, including sustained inappropriate behavior, harassment of an
individual, or aggression toward or disparagement of classes of individuals.
**Consequence**: A permanent ban from any sort of public interaction within
the community.
## Attribution
This Code of Conduct is adapted from the [Contributor Covenant][homepage],
version 2.0, available at
https://www.contributor-covenant.org/version/2/0/code_of_conduct.html.
Community Impact Guidelines were inspired by [Mozilla's code of conduct
enforcement ladder](https://github.com/mozilla/diversity).
[homepage]: https://www.contributor-covenant.org
For answers to common questions about this code of conduct, see the FAQ at
https://www.contributor-covenant.org/faq. Translations are available at
https://www.contributor-covenant.org/translations.
================================================
FILE: CONTRIBUTING.md
================================================
## Contributing
* I’m not going be working on/maintaining vmdiff for at least 12 months, maybe ever
* I’d _love_ for someone to steal this genius idea, either forking the prototype, or making their own
## Future work
* If a Windows disk has corrupted sectors, `dfvfs` can’t read those sectors. This comes up a lot, and while you can run `chkdsk` on the VM to get around it, it would be nice to not have to.
* It would be nice to be able to diff snapshots of your actual computer, not a virtual machine, but this is hard without external storage
* The two snapshots of your disk may not fit on your disk itself, to say nothing of the memory snapshots
* See the [blog post](https://community.atlassian.com/t5/Trust-Security-articles/Introducing-vmdiff-a-tool-to-find-everything-that-changes-on/ba-p/2321969) for allll the good details
================================================
FILE: Dockerfile
================================================
FROM node:lts-alpine as frontend
WORKDIR /app
ENV PATH /app/node_modules/.bin:$PATH
COPY frontend ./
RUN yarn install --production
RUN yarn build --production
# For more information, please refer to https://aka.ms/vscode-docker-python
FROM python:3.8-slim
EXPOSE 5000
# Keeps Python from generating .pyc files in the container
ENV PYTHONDONTWRITEBYTECODE=1
# Turns off buffering for easier container logging
ENV PYTHONUNBUFFERED=1
# Install pip requirements
COPY server_requirements.txt .
RUN python -m pip install -r server_requirements.txt
WORKDIR /app
COPY --from=frontend /app/build /react-build/
COPY backend/ backend/
COPY server.py .
COPY config.py .
# Creates a non-root user with an explicit UID and adds permission to access the /app folder
# For more info, please refer to https://aka.ms/vscode-docker-python-configure-containers
RUN adduser -u 5678 --disabled-password --gecos "" appuser && chown -R appuser /app
USER appuser
# During debugging, this entry point will be overridden. For more information, please refer to https://aka.ms/vscode-docker-python-debug
CMD ["gunicorn", "--bind", "0.0.0.0:5000", "server:app"]
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2023 vmdiff
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
# vmdiff

A tool to compare virtual machine snapshots, allowing you to see everything that changes on your computer.
## Blog post
There's also a delightful [companion blog post](https://community.atlassian.com/t5/Trust-Security-articles/Introducing-vmdiff-a-tool-to-find-everything-that-changes-on/ba-p/2321969) with more context :))
## Features
* Accepts two Windows or macOS virtual machine snapshots (`.vmdk` and `.vmem` files)
* Diffs all files on both disks, line-by line (including deleted files). If it’s not in the list, it didn’t happen
* Diffs memory (running processes, command lines, and environment variables) on Windows
* Diffs also available to search/process via terminal as local directories (think `grep`)
* Runs on Windows, macOS, Linux
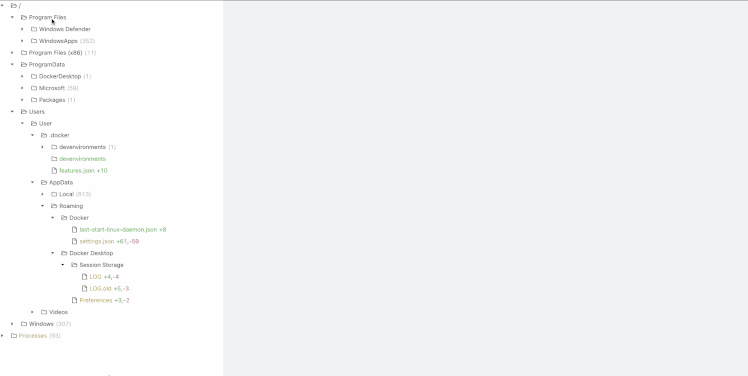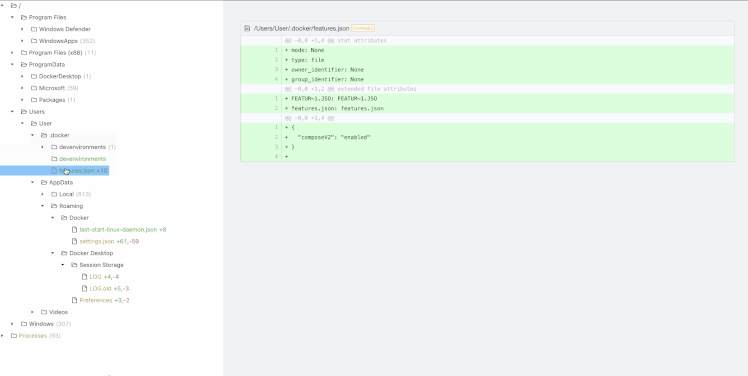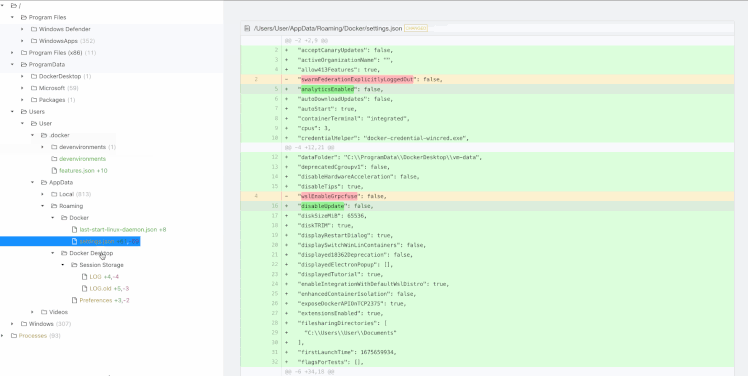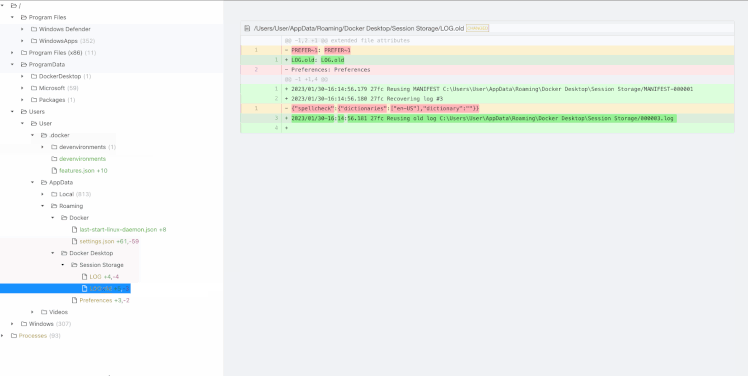
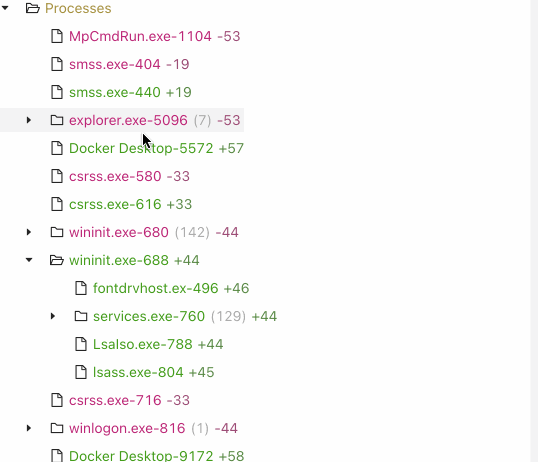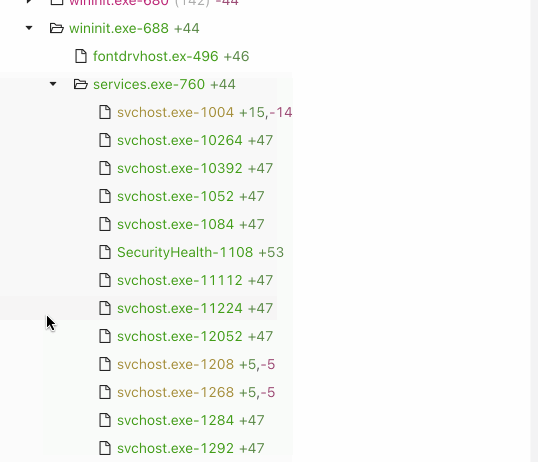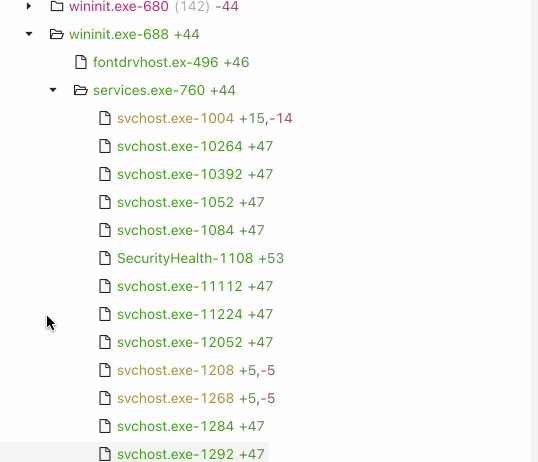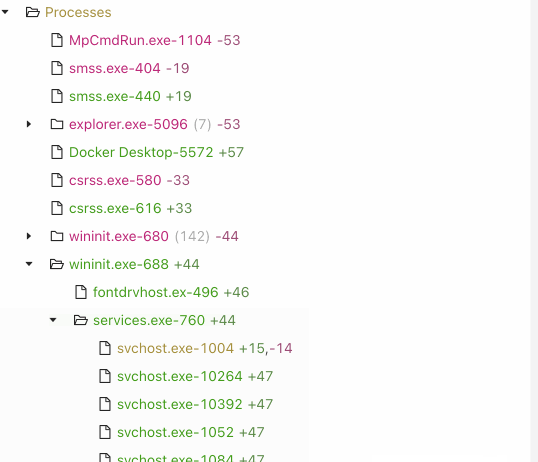
## Installation
```shell
git clone github.com/vmdiff/vmdiff-prototype
cd vmdiff-prototype
```
### Install Docker
Docker will need to be installed and running, since `vmdiff` uses `docker-compose`.
### Install dependencies for the CLI
```shell
pip install -r requirements.txt
```
## Usage
You'll need a directory in which the virtual machine snapshots (`.vmdk` and `.vmem` files) are all stored.
For [VMWare](https://kb.vmware.com/s/article/1003880), the default directories are:
* `C:\Users\<username>\My Documents\My Virtual Machines\<VM name>\` (Windows)
* `~/Virtual Machines.localized/<VM name>/` (macOS)
* `~/vmware/` (Linux)
```shell
$ ./vmdiff --help
Usage: vmdiff [OPTIONS] INPUT_DIR
Generate and view diffs for .vmdk and .vmem files.
EXAMPLES:
What snapshots do I have to choose from?
./vmdiff "~/Virtual Machines.localized/VMName/" --list-snapshots
Diff snapshots 1 and 2
./vmdiff "~/Virtual Machines.localized/VMName/" --from-snapshot 1 --to-snapshot 2
Don't prompt me for a partition, I know it's partition 4
./vmdiff "~/Virtual Machines.localized/VMName/" --from-snapshot 1 --to-snapshot 2 --partition 4
Diff generic VMDK files, not necessarily from a snapshot
./vmdiff ~/dir-with-vmdk-files/ --from-disk disk1.vmdk --to-disk disk2.vmdk --no-use-memory
Only show files that have changed in the user's home directory
./vmdiff "~/Virtual Machines.localized/VMName/" --from-snapshot 1 --to-snapshot 2 --filter-path "/home/username/"
Ignore .log and .txt files
./vmdiff "~/Virtual Machines.localized/VMName/" --from-snapshot 1 --to-snapshot 2 --filter-path "/home/username/"
--ignore-path ".*\.log" --ignore-path ".*\.txt"
╭─ Input and output ─────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ * input_dir DIRECTORY Path to virtual machine directory, or any directory containing .vmdk/.vmem files. │
│ [required] │
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ Options ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ --list-snapshots -l Show information about the VM snapshots in INPUT_DIR, e.g. the files belonging to each │
│ snapshot. │
│ --debug Enable debug logging. │
│ --help Show this message and exit. │
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ Input and output ─────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ --from-disk -fd PATH Path (or filename) of first chronological disk snapshot. │
│ --to-disk -td PATH Path (or filename) of second chronological disk snapshot. │
│ --from-memory -fm PATH Path (or filename) of first chronological memory snapshot. │
│ --to-memory -tm PATH Path (or filename) of second chronological memory snapshot. │
│ --from-snapshot -fs TEXT First chronological snapshot ID obtained via --list-snapshots. │
│ --to-snapshot -ts TEXT Second chronological snapshot ID obtained via --list-snapshots. │
│ --partition -p TEXT Disk Partition ID to use. If not set, show partitions and ask which one to use via STDIN. │
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ Configuring ──────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ --ignore-path -i TEXT List of disk path regular expressions to ignore when diffing. Multiple │
│ values accepted via e.g. "--ignore-path /path/one --ignore-path │
│ /path/two" │
│ --filter-path -f TEXT List of disk path regular expressions. Only these paths will be │
│ processed. Multiple values accepted via e.g. "--filter-path /path/one │
│ --filter-path /path/two" │
│ [default: /, \] │
│ --ignore-process -I TEXT Regular expression to ignore when diffing process names. Note that only │
│ the first 14 characters of the process name are processed (by │
│ Volatility). │
│ --cache --no-cache Whether to cache results based on input filenames and config options. │
│ [default: cache] │
│ --use-memory --no-use-memory Whether to process/diff memory. [default: use-memory] │
│ --use-disk --no-use-disk Whether to process/diff disks. [default: use-disk] │
│ --include-binary --no-include-binary Whether to also process and diff binary files. │
│ [default: no-include-binary] │
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ Display ──────────────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ --show -s Open browser and show diff viewer UI. │
╰────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
```
### Typical usage
Which snapshots do I have to choose from?
```shell
./vmdiff "~/Virtual Machines.localized/VMName/" --list-snapshots
Found snapshots in ~/Virtual Machines.localized/VirtualMachine.vmwarevm
┏━━━━┳━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ ┃ Parent ┃ ┃ ┃ ┃ ┃
┃ ID ┃ ID ┃ Creation time ┃ Disk file ┃ Memory file ┃ Description ┃
┡━━━━╇━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ 1 │ │ 2022-11-17 13:24:39 │ VirtualMachine-disk1.vmdk │ VirtualMachine-Snapshot1.… │ Initial Snapshot │
│ 2 │ 1 │ 2022-11-17 13:39:40 │ VirtualMachine-disk1-00000… │ VirtualMachine-Snapshot2.… │ Snapshot after changes made │
└────┴────────┴─────────────────────┴─────────────────────────────┴────────────────────────────┴─────────────────────────────┘
```
Let's diff snapshots 1 and 2 (this will prompt you for which partition to use on STDIN unless you use `--partition`)
```shell
./vmdiff "~/Virtual Machines.localized/VMName/" --from-snapshot 1 --to-snapshot 2
```
Now let's view the diffs in browser:
```shell
./vmdiff "~/Virtual Machines.localized/VMName/" --from-snapshot 1 --to-snapshot 2 --show
```
The UI will then be running on `http://localhost:5000`
### Browse the diffs via shell
The raw diffs are available in a directory structure mirroring the VM in the `results/` directory
## How it works

### Tech Stack
* [Typer](https://typer.tiangolo.com/) (CLI)
* docker-compose
* Volatility (to parse memory images)
* [dfvfs](https://github.com/log2timeline/dfvfs) (to parse disk images)
* Custom fork of [pyvmdk](https://github.com/libyal/libvmdk) (enables .vmdk delta disks for snapshots)
* React + TypeScript + Ant Design (frontend)
* grep (Searching diffs via command line)
## Contributing
* I’m not going be working on/maintaining vmdiff for at least 12 months, maybe ever
* I’d _love_ for someone to steal this genius idea, either forking the prototype, or making their own
## Future work
* If a Windows disk has corrupted sectors, `dfvfs` can’t read those sectors. This comes up a lot, and while you can run `chkdsk` on the VM to get around it, it would be nice to not have to.
* It would be nice to be able to diff snapshots of your actual computer, not a virtual machine, but this is hard without external storage
* The two snapshots of your disk may not fit on your disk itself, to say nothing of the memory snapshots
================================================
FILE: __init__.py
================================================
================================================
FILE: backend/Dockerfile
================================================
# For more information, please refer to https://aka.ms/vscode-docker-python
FROM ubuntu:22.04
# Keeps Python from generating .pyc files in the container
ENV PYTHONDONTWRITEBYTECODE=1
# Turns off buffering for easier container logging
ENV PYTHONUNBUFFERED=1
RUN apt-get update && apt-get install -y \
gcc \
python3 \
python3-pip
# python3-dfvfs
# Install pip requirements
COPY backend/requirements.txt .
RUN pip3 install dfvfs==20220816
# CRIME TIME
# Copy in our patched pyvmdk with delta disk support, putting it in the same directory as `vmdk_file_io.py`
COPY backend/pyvmdk_delta.py /usr/local/lib/python3.10/dist-packages/dfvfs/file_io
COPY backend/vmdk_file_io.py /usr/local/lib/python3.10/dist-packages/dfvfs/file_io
# Put config.py in the same relative location as outside the containers so it can be imported.
COPY config.py /
WORKDIR /backend
# Creates a non-root user with an explicit UID and adds permission to access the /app folder
# For more info, please refer to https://aka.ms/vscode-docker-python-configure-containers
# RUN adduser -u 5678 --disabled-password --gecos "" appuser && chown -R appuser /app
# USER appuser
# During debugging, this entry point will be overridden. For more information, please refer to https://aka.ms/vscode-docker-python-debug
CMD ["python3", "vmdiff.py"]
================================================
FILE: backend/__init__.py
================================================
================================================
FILE: backend/diff_tree.py
================================================
import utils
class DiffTree(object):
def __init__(self, differ):
self.nodes = {}
self.children_map = {}
# Parents of leaf nodes only
self.leaf_parents = {}
# Create the nested array structure that will be the tree.
self.tree = []
self.root = None
self.node_parent_ids = {}
self.differ = differ
self.create_file_tree()
def merge(self, other):
"""Combine this diff tree with another (only so it can be cached/uncached)"""
self.nodes.update(other.nodes)
self.children_map.update(other.children_map)
self.tree.extend(other.tree)
return self
def get_tree(self):
return self.tree
def get_children_map(self):
return self.children_map
def get_children(self, parent_node):
key = parent_node["key"]
if key not in self.children_map:
self.children_map[key] = []
return self.children_map[key]
def add_child(self, parent_node, child):
key = parent_node["key"]
if key not in self.children_map:
self.children_map[key] = []
self.children_map[key].append(child)
def create_node(self, path: str, is_dir=True, is_leaf=False):
"""Create a node, allowing for children to be added later."""
if path in self.nodes:
return
if self.differ.diff_type == "disk":
p = utils.ensure_posix(path)
parent_id = None if p.parent == p else str(p.parent)
if parent_id is None:
text = "/"
else:
text = p.name
key = str(p)
elif self.differ.diff_type == "process":
node_id = path
text = node_id
pid = node_id.split("-")[-1]
key = pid
# Defaults (for created parent nodes, mostly)
status = "unchanged"
lines_added = 0
lines_removed = 0
diff = self.differ.diff(path)
if diff is not None:
status = diff.status
lines_added = diff.lines_added
lines_removed = diff.lines_removed
if diff.title:
text = diff.title
# This gets fixed later.
is_leaf = not diff.is_dir
is_dir = diff.is_dir
ppid = diff.ppid
if ppid is not None:
# Save which node is this node's parent, if any.
self.node_parent_ids[pid] = ppid
node = {
"title": text,
"key": key,
"isLeaf": is_leaf,
"isDirectory": is_dir,
"children": [],
"status": status,
"linesAdded": lines_added,
"linesRemoved": lines_removed,
"numChildren": 0,
"numDirectChildren": 0,
}
self.nodes[key] = node
return node
def create_root_process_node(self):
key = "Processes"
node = {
"title": key,
"key": key,
"isLeaf": False,
"isDirectory": False,
"children": [],
"status": "modified",
"linesAdded": 0,
"linesRemoved": 0,
"numChildren": 0,
"numDirectChildren": 0,
}
self.nodes[key] = node
self.node_parent_ids[key] = key
self.root = node
return node
def get_parent(self, node):
if self.differ.diff_type == "disk":
p = utils.ensure_posix(node["key"])
parent_path = str(p.parent)
parent_node = self.nodes.get(parent_path)
return parent_node
elif self.differ.diff_type == "process":
parent_id = self.node_parent_ids.get(node["key"])
parent = self.nodes.get(parent_id)
if parent is None:
return self.root
return parent
def create_file_tree(self):
# If we're calling this function a second time, we don't need to do anything, the tree is already generated.
if len(self.tree) > 0:
return
def create_parent_nodes(path: str):
p = utils.ensure_posix(path)
parent_paths = p.parents
for parent_path in parent_paths:
parent_path = str(parent_path)
if parent_path not in self.nodes:
self.nodes[parent_path] = self.create_node(
parent_path, is_dir=True)
paths = self.differ.diffs.keys()
# Create flat node index.
for path in paths:
if self.differ.diff_type == "disk":
create_parent_nodes(path)
self.create_node(path)
if self.differ.diff_type == "process" and len(self.differ.diffs) > 0:
self.create_root_process_node()
# Link up the nodes to their parents
for path, node in sorted(self.nodes.items()):
parent_node = self.get_parent(node)
# If this node is the root, just add it.
if parent_node == node:
self.root = node
self.tree.append(node)
continue
# Otherwise, insert this node underneath the parent node.
# Sorting paths guarantees that parents are inserted first, then children.
if parent_node:
# Link this node to its parent
self.add_child(parent_node, node)
if len(self.tree) > 0:
root = self.tree[0]
else:
root = []
if len(self.tree) == 0:
return []
# Fix the tree
for node in reversed(list(self.traverse(root))):
# Directories without children should be leaves.
children = self.get_children(node)
if len(children) == 0:
node["isLeaf"] = True
else:
node["isLeaf"] = False
# Count the number of file descendants of each node.
for child in children:
num_child_children = 0
# Don't count directories as children.
if not child["isDirectory"]:
num_child_children += 1
node["numDirectChildren"] += 1
num_child_children += child["numChildren"]
node["numChildren"] += num_child_children
return
def traverse(self, node):
yield node
for child in self.get_children(node):
yield from self.traverse(child)
================================================
FILE: backend/diffcache.py
================================================
import pathlib
import os
import logging
import json
import unified_diff
import utils
DIR_META_FILENAME = ".__this_directory__"
class DiffCache(object):
def __init__(self, run_disk_path, run_tree_path, run_process_path=None):
self.run_path = pathlib.Path(run_disk_path)
self.tree_path = pathlib.Path(run_tree_path)
self.run_process_path = pathlib.Path(str(run_process_path))
if run_process_path:
os.makedirs(self.run_process_path, exist_ok=True)
def cache_results(self, results):
"""Create output directory, and write the same filesystem into it as in the results"""
os.makedirs(self.run_path, exist_ok=True)
# Sort by path, so we only create parent directories after children.
for path, diff in sorted(results.items(), key=lambda tup: tup[0]):
path = utils.ensure_posix(path)
if diff.is_dir:
path = path / pathlib.Path(DIR_META_FILENAME)
root, *relative_disk_path = path.parts
relative_disk_path = pathlib.Path(
relative_disk_path[0]).joinpath(*relative_disk_path[1:])
result_path = self.run_path / pathlib.Path(relative_disk_path)
try:
# Create the parent directories
result_path.parent.mkdir(parents=True, exist_ok=True)
except FileExistsError:
# This means a path has changed from a directory to a file.
# Whatever, tho
# Limitation: Let's keep it as a directory
result_path.parent.rename(
result_path.parent.with_suffix(".__renamed__"))
result_path.parent.mkdir(parents=True, exist_ok=True)
logging.warning(
f"Ignoring file exists error when creating parents for {str(result_path)}, overwriting parent file with directory.")
if result_path.is_dir():
result_path = result_path.with_suffix(".__directory_as_file__")
logging.warning(
f"Path has changed from directory to file (or vice versa), writing as {str(result_path)}")
# Write the diff file.
with open(result_path, "w") as f:
f.writelines(diff.diff_lines)
def ensure_posix(self, path):
if path.startswith("\\"):
# Force POSIX path so that we can create the directory structure in the Docker container, even if the path is Windows.
path = pathlib.PureWindowsPath(path).as_posix()
path = pathlib.Path(path)
return path
def cache_process_results(self, results):
for pid, diff in results.items():
filename = pid
result_path = self.run_process_path / filename
# Write the diff file.
with open(result_path, "w") as f:
f.writelines(diff.diff_lines)
def get_process_diff_from_cache(self, pid):
filename = pid
result_path = self.run_process_path / filename
try:
with open(result_path, "r") as f:
lines = f.readlines()
diff = unified_diff.UnifiedDiff(lines)
return diff
except FileNotFoundError:
print(f"Process diff cache not found: {result_path}")
return None
def get_diff_from_cache(self, vm_path):
if not self.run_path.exists:
return None
vm_path = utils.ensure_posix(vm_path)
# Slice off the root (and drive on Windows) from the vm path, so it's not an absolute path
cache_path = self.run_path.joinpath(*vm_path.parts[1:])
is_dir = False
# If this was a directory on the VM, the diff is stored in a file called DIR_META_FILENAME
if cache_path.joinpath(DIR_META_FILENAME).exists():
is_dir = True
cache_path = cache_path.joinpath(DIR_META_FILENAME)
if not cache_path.is_file():
return None
with open(cache_path) as f:
lines = f.readlines()
diff = unified_diff.UnifiedDiff(lines, is_dir)
return diff
def get_diff(self, key):
# If the key is a process ID (numeric)
if key.isdigit():
return self.get_process_diff_from_cache(key)
else:
return self.get_diff_from_cache(key)
def cache_exists(self):
return self.run_path.exists() and self.tree_cache_exists()
def process_cache_exists(self):
return self.run_process_path is not None and self.run_process_path.exists()
def get_cached_results(self):
if not self.cache_exists():
raise RuntimeError(f"Cache path {self.run_path} does not exist!")
results = {}
logging.info(f"Loading from diff cache {self.run_dir}")
for path, subdirs, files in os.walk(self.run_path):
for filename in files:
is_dir = False
if filename == DIR_META_FILENAME:
is_dir = True
filepath = os.path.join(path, filename)
with open(filepath) as f:
lines = f.readlines()
diff = unified_diff.UnifiedDiff(lines, is_dir)
relative_path = pathlib.Path(
filepath).relative_to(self.run_path)
if is_dir:
# Remove dir suffix if this is a dir
relative_path = relative_path.parent
original_path = os.path.join("/", relative_path)
results[original_path] = diff
return results
def tree_cache_exists(self):
return (self.tree_path / "tree.json").exists()
def cache_tree(self, tree):
os.makedirs(self.tree_path, exist_ok=True)
with open(self.tree_path / "tree.json", "w") as f:
json.dump(tree.get_tree(), f)
with open(self.tree_path / "children.json", "w") as f:
json.dump(tree.get_children_map(), f)
def get_tree_data_from_cache(self):
with open(self.tree_path / "tree.json", "r") as f:
tree = json.load(f)
with open(self.tree_path / "children.json", "r") as f:
children_map = json.load(f)
return tree, children_map
================================================
FILE: backend/diskdiff.py
================================================
import difflib
import hashlib
import logging
import stat as statlib
import sys
import os
import inspect
import unified_diff
# Hacks to import the config from the parent directory.
currentdir = os.path.dirname(os.path.abspath(
inspect.getfile(inspect.currentframe())))
parentdir = os.path.dirname(currentdir)
sys.path.insert(0, parentdir)
import config # noqa
class DiskDiffer(object):
# Class constant that defines the default read buffer size.
_READ_BUFFER_SIZE = 16 * 1024 * 1024
MAX_SIZE = 1024 * 1024 * 2 # 2MB
_STAT_ATTRIBUTES = set([
"type",
"owner_identifier",
"group_identifier",
"mode",
])
_TIME_ATTRIBUTES = set([
"access_time",
"added_time",
"change_time",
"creation_time",
"modification_time",
])
_ATTRIBUTE_ATTRIBUTES = set([
"name",
])
diff_type = "disk"
def __init__(self, a_file_lister, b_file_lister,
use_stat=True,
use_times=True,
use_attributes=True,
use_contents=True,
ignore_binary=True,
ignore_directories=False,
ignore_contents_unchanged=False,
show_times=False,
only_changed_files=False,
**kwargs):
"""
a: { path: str -> file_entry FileEntry }
b: { path: str -> file_entry FileEntry }
"""
# Save options for creating unique caches later.
self.init_options = locals()
self.a_file_lister = a_file_lister
self.b_file_lister = b_file_lister
self.a_file_map = {}
self.b_file_map = {}
self.use_stat = use_stat
self.use_times = use_times
self.use_attributes = use_attributes
self.use_contents = use_contents
self.ignore_binary = ignore_binary
self.ignore_directories = ignore_directories
self.ignore_contents_unchanged = ignore_contents_unchanged
self.show_times = show_times
self.only_changed_files = only_changed_files
self.changed_file_paths = set()
self.diffs = {}
def get_a_file(self, path):
file_lister_cache_hit = self.a_file_lister.file_entries.get(path)
if file_lister_cache_hit:
return file_lister_cache_hit
if path in self.a_file_map:
return self.a_file_map[path]
file_entry = self.a_file_lister.GetFileEntry(path)
self.a_file_map[path] = file_entry
return file_entry
def get_b_file(self, path):
file_lister_cache_hit = self.b_file_lister.file_entries.get(path)
if file_lister_cache_hit:
return file_lister_cache_hit
if path in self.b_file_map:
return self.b_file_map[path]
file_entry = self.b_file_lister.GetFileEntry(path)
self.b_file_map[path] = file_entry
return file_entry
def get_file(self, path):
"""Just get the file, don't care whether it's from before or after"""
b_file = self.get_b_file(path)
if b_file:
return b_file
return self.get_a_file(path)
def diff_all(self):
# Step 1, find files which are different
changed_file_paths = self.get_changed_files()
results = {}
for path in changed_file_paths:
if self._should_ignore(path):
continue
result = self.diff(path)
if result is None:
logging.debug(f"Ignoring diffing (no diff): {path}")
continue
virtual_path = path
results[virtual_path] = result
return results
def diff(self, path):
"""
Returns:
(virtual_path: str, merged_diff: list) | None
"""
if path in self.diffs:
return self.diffs[path]
if self._should_ignore(path):
return None
# Step 2, diff those files
# (Get diffable attributes, then return diff for each one)
a_file = self.get_a_file(path)
b_file = self.get_b_file(path)
stat_diff = times_diff = attribute_diff = contents_diff = []
diff_kwargs = self._make_diff_kwargs(path)
if self.use_stat:
stat_diff = list(difflib.unified_diff(
self.get_stat_sequence(
a_file), self.get_stat_sequence(b_file),
**diff_kwargs
))
if self.show_times:
times_diff = list(difflib.unified_diff(
self.get_times_sequence(
a_file), self.get_times_sequence(b_file),
**diff_kwargs
))
if self.use_attributes:
attribute_diff = list(difflib.unified_diff(
self.get_attribute_sequence(
a_file), self.get_attribute_sequence(b_file),
**diff_kwargs
))
has_contents = a_file is not None and a_file.IsFile(
) or b_file is not None and b_file.IsFile()
# We're not ignoring binary if we're here, so treat the files as if they might be binary.
if self.use_contents and has_contents:
# Don't try and diff files larger than MAX_SIZE
if (a_file and a_file.size > self.MAX_SIZE) or (b_file and b_file.size > self.MAX_SIZE):
logging.info(f"Generating generic diff: (too big): {path}")
size = b_file.size if b_file else a_file.size
contents_diff = [
f"--- {path}\n",
f"+++ {path}\n",
"@@ 0,0 +0,0 @@\n",
# Note the extra space for Unified Diff format.
f" File too large to diff ({size}B)\n"
]
# If the file is binary, diff it as binary.
elif not self.ignore_binary:
files = [a_file, b_file]
existing_files = [f for f in files if f is not None]
binary_files = [
self._is_binary(f) for f in existing_files
]
# If the files are both binary (or one is None and the other is binary), diff them as binary
if all(binary_files):
if self._compare_binaries(a_file, b_file):
contents_diff = [
f"--- {path}\n",
f"+++ {path}\n",
"@@ 0,0 +0,0 @@\n",
" Binary files differ\n"
]
else:
# If at least one file is not binary, do a real diff.
# If only one is binary, just consider it the string "Binary File"
a_contents_sequence = self.get_contents_sequence(
a_file)
b_contents_sequence = self.get_contents_sequence(
b_file)
# If both are nonbinary (😎😎😎) diff them as text
contents_diff = list(difflib.unified_diff(
a_contents_sequence,
b_contents_sequence,
**self._make_diff_kwargs(path)))
if not any((stat_diff, times_diff, attribute_diff, contents_diff)):
logging.debug(f"Ignoring (no diff): {path}")
return None
# If it's a file, and the contents are unchanged, ignore it.
# (Don't ignore directories though, because they don't have contents.)
if not self.get_file(path).IsDirectory() and not contents_diff and self.ignore_contents_unchanged:
return None
merged_diff = self.merge_diffs(
stat_diff, times_diff, attribute_diff, contents_diff)
# Add headers to conform with git diff format and look pretty for diff2html
init_header = f"diff --git {path} {path}"
added_removed_header = ""
if a_file is None:
mode = b_file.GetStatAttribute().mode
if mode is not None:
mode = format(mode, "o")
else:
mode = "<unknown>"
added_removed_header = f"new file mode {mode}"
if b_file is None:
mode = a_file.GetStatAttribute().mode
if mode is not None:
mode = format(mode, "o")
else:
mode = "<unknown>"
added_removed_header = f"deleted file mode {mode}"
self.add_header(merged_diff, added_removed_header)
self.add_header(merged_diff, init_header)
diff = unified_diff.UnifiedDiff(
merged_diff, is_dir=self.get_file(path).IsDirectory())
self.diffs[path] = diff
return diff
def _should_ignore(self, path):
if not path:
return True
a_file = self.get_a_file(path)
b_file = self.get_b_file(path)
if self.ignore_directories and (a_file and a_file.IsDirectory() or b_file and b_file.IsDirectory()):
logging.info(f"Ignoring (directory): {path}")
return True
a_is_binary = self._is_binary(a_file)
b_is_binary = self._is_binary(b_file)
# Ignore this file if it is or was binary
if self.ignore_binary and (a_is_binary or b_is_binary):
logging.info(f"Ignoring (binary): {path}")
return True
return False
def _make_diff_kwargs(self, path, pseudo_file_type=None):
kwargs = {
"n": 0
}
from_path = path
to_path = path
# Add pseudo file types (e.g. "stat", "attributes")
if pseudo_file_type:
from_path = f"{from_path}.{pseudo_file_type}"
to_path = f"{to_path}.{pseudo_file_type}"
kwargs["fromfile"] = from_path
kwargs["tofile"] = to_path
return kwargs
def add_header(self, delta, header):
"""Add an arbitrary header to a delta (sequence of diff lines)"""
if not delta or not header:
return
header_line = f"{header}\n"
delta.insert(0, header_line)
def merge_diffs(self, stat_diff, times_diff, attribute_diff, contents_diff):
"""Merge all the diffs into one, adding the metadata diffs as their own special hunks"""
stat_hunk = self.create_hunk_diff(stat_diff, "stat attributes")
times_hunk = self.create_hunk_diff(times_diff, "file times")
attribute_hunk = self.create_hunk_diff(
attribute_diff, "extended file attributes")
for diff in (stat_diff, times_diff, attribute_diff, contents_diff):
if diff:
# --- a/file
# +++ b/file
headers = diff[:2]
if contents_diff:
contents_diff_hunks = contents_diff[2:]
else:
contents_diff_hunks = []
# Insert the metadata hunks into the content diff, before everything else (even the first hunk in the content diff)
merged_diff = []
merged_diff.extend(headers)
merged_diff.extend(stat_hunk)
merged_diff.extend(times_hunk)
merged_diff.extend(attribute_hunk)
merged_diff.extend(contents_diff_hunks)
return merged_diff
def create_hunk_diff(self, diff, name):
if not diff:
return []
headers, content = self.split_diff(diff)
# --- a/file
# +++ b/file
# @@ hunk header @@
hunk_header = headers[-1].rstrip("\n")
hunk_header = [f"{hunk_header} {name}\n"]
hunk_diff = hunk_header + content
return hunk_diff
def split_diff(self, diff):
"""Return (headers: list, content: list)"""
return diff[:3], diff[3:]
def equal(self, file1, file2):
"""Compares two file_entry objects"""
if file1.size != file2.size:
return False
# Compare stat
if self.use_stat and not self._equal_stat(file1, file2):
return False
# Compare times
if self.use_times and not self._equal_times(file1, file2):
return False
# Compare attributes
if self.use_attributes and not self._equal_attributes(file1, file2):
return False
# TODO: Optionally diff hashes
return True
def _is_binary(self, file):
if file is None:
return False
textchars = bytearray({7, 8, 9, 10, 12, 13, 27}
| set(range(0x20, 0x100)) - {0x7f}) # noqa
file_obj = file.GetFileObject()
if file_obj is None:
return False
try:
header = file_obj.read(512)
file_obj.seek(0)
try:
header.decode("utf8", errors="strict")
except UnicodeDecodeError:
return True
return bool(header.translate(None, textchars))
except OSError:
logging.warning(f"Failed to read {file.path_spec.location}")
return True
def _compare_binaries(self, file1, file2):
return self._hash_file(file1) == self._hash_file(file2)
def _hash_file(self, file_entry):
"""Calculates a message digest hash of the data of the file entry.
Args:
file_entry (dfvfs.FileEntry): file entry.
Returns:
str: digest hash or None.
"""
if file_entry is None:
return None
if file_entry.IsDevice() or file_entry.IsPipe() or file_entry.IsSocket():
# Ignore devices, FIFOs/pipes and sockets.
return None
hash_context = hashlib.sha256()
try:
file_object = file_entry.GetFileObject()
except IOError as exception:
logging.warning((
'Unable to open path specification:\n{0:s}'
'with error: {1!s}').format(file_entry.path_spec.location, exception))
return None
if not file_object:
return None
try:
data = file_object.read(self._READ_BUFFER_SIZE)
while data:
hash_context.update(data)
data = file_object.read(self._READ_BUFFER_SIZE)
except IOError as exception:
logging.warning((
'Unable to read from path specification:\n{0:s}'
'with error: {1!s}').format(file_entry.path_spec.location, exception))
return None
return hash_context.hexdigest()
def get_stat_sequence(self, file):
if file is None:
return []
stat = file.GetStatAttribute()
out = []
for attr in self._STAT_ATTRIBUTES:
value = getattr(stat, attr)
if value and attr == "mode":
value = statlib.filemode(value)
line = f"{attr}: {value}\n"
out.append(line)
return out
def get_times_sequence(self, file):
if file is None:
return []
out = []
for attr in self._TIME_ATTRIBUTES:
line = f"{attr}: {getattr(file, attr).CopyToDateTimeStringISO8601()}\n"
out.append(line)
return out
def get_attribute_sequence(self, file):
def _get_attribute_value(attribute):
# macOS dfvfs
if hasattr(attribute, "read"):
attribute_value = attribute.read().decode(errors="ignore")
return attribute_value
# Windows dfvfs
elif hasattr(attribute, "name"):
attribute_value = attribute.name
return attribute_value
return None
if file is None:
return []
out = []
for attribute in file.attributes:
attribute_value = _get_attribute_value(attribute)
if attribute_value:
line = f"{attribute.name}: {attribute_value}\n"
out.append(line)
return out
def get_contents_sequence(self, file):
if file is None:
return []
if not self.ignore_binary and self._is_binary(file):
return ["<Binary file>\n"]
file_obj = file.GetFileObject()
if file_obj is None:
return []
contents = file_obj.read().decode("utf8", "ignore")
lines = []
# Make sure all lines end with newlines, to conform with diff format.
for line in contents.split("\n"):
lines.append(line + "\n")
return lines
def _equal_stat(self, file1, file2):
stat1 = file1.GetStatAttribute()
stat2 = file2.GetStatAttribute()
for attr in self._STAT_ATTRIBUTES:
if getattr(stat1, attr) != getattr(stat2, attr):
return False
return True
def _equal_times(self, file1, file2):
for attr in self._TIME_ATTRIBUTES:
if getattr(file1, attr) != getattr(file2, attr):
return False
return True
def _equal_attributes(self, file1, file2):
if file1.number_of_attributes != file2.number_of_attributes:
return False
for attr1, attr2 in zip(file1.attributes, file2.attributes):
# Only check the attributes we care about when considering equality.
# (We have literally invented prejudice today boys.)
for attr in self._ATTRIBUTE_ATTRIBUTES:
if hasattr(attr1, attr) and hasattr(attr2, attr):
if getattr(attr1, attr) != getattr(attr2, attr):
return False
return True
def get_run_id(self):
return config.RUN_ID
def get_changed_files(self):
if self.changed_file_paths:
return self.changed_file_paths
# Otherwise, we need to list the files in A and B first
# This is the slowest part.
self.a_file_lister.ListFileEntries()
self.b_file_lister.ListFileEntries()
# If path doesn't exist, consider it different
changed_file_paths = set()
a_paths_set = set(self.a_file_lister.file_entries.keys())
b_paths_set = set(self.b_file_lister.file_entries.keys())
self.added_files = b_paths_set - a_paths_set
self.deleted_files = a_paths_set - b_paths_set
if not self.only_changed_files:
changed_file_paths = changed_file_paths | self.added_files | self.deleted_files
# Get all files in A but not B (and vice versa), and consider them different
remaining_paths = a_paths_set & b_paths_set
# These paths are guaranteed to be in both A and B
for path in remaining_paths:
a_file = self.get_a_file(path)
b_file = self.get_b_file(path)
if not self.equal(a_file, b_file):
changed_file_paths.add(path)
logging.info(f"Files (from): {len(a_paths_set)}")
logging.info(f"Files (to): {len(b_paths_set)}")
logging.info(f"Files (both): {len(remaining_paths)}")
logging.info(f"Files added: {len(self.added_files)}")
logging.info(f"Files deleted: {len(self.deleted_files)}")
logging.info(
f"Files changed (including binary): {len(changed_file_paths)}")
logging.debug("Changed files: ")
logging.debug(changed_file_paths)
self.changed_file_paths = changed_file_paths
return self.changed_file_paths
================================================
FILE: backend/file_entry_lister.py
================================================
import re
import logging
from dfvfs.helpers import volume_scanner
from dfvfs.lib import definitions as dfvfs_definitions
from dfvfs.lib import errors
from dfvfs.resolver import resolver
from dfvfs.path import factory
class FileEntryLister(volume_scanner.VolumeScanner):
"""File entry lister."""
_NON_PRINTABLE_CHARACTERS = list(range(0, 0x20)) + list(range(0x7f, 0xa0))
_ESCAPE_CHARACTERS = str.maketrans({
value: '\\x{0:02x}'.format(value)
for value in _NON_PRINTABLE_CHARACTERS})
def __init__(self, source, volume_scanner_options, mediator=None, ignore_dirs=None, allow_dirs=None):
"""Initializes a file entry lister.
Args:
mediator (VolumeScannerMediator): a volume scanner mediator.
"""
super(FileEntryLister, self).__init__(mediator=mediator)
if ignore_dirs is None:
ignore_dirs = set()
if allow_dirs is None:
allow_dirs = set(["/"])
self.allow_dirs = allow_dirs
self.ignore_dirs = ignore_dirs
self._list_only_files = False
self.base_path_specs = self.GetBasePathSpecs(
source, options=volume_scanner_options)
self.source = source
if not self.base_path_specs:
raise Exception(
f'{source}: No supported file system found in source.')
# TODO: Support multiple base path specs
self.base_path_spec = self.base_path_specs[0]
self.file_system = resolver.Resolver.OpenFileSystem(
self.base_path_spec)
self.file_entries = {}
def _GetDisplayPath(self, path_spec, path_segments, data_stream_name):
"""Retrieves a path to display.
Args:
path_spec (dfvfs.PathSpec): path specification of the file entry.
path_segments (list[str]): path segments of the full path of the file
entry.
data_stream_name (str): name of the data stream.
Returns:
str: path to display.
"""
display_path = ''
if path_spec.HasParent():
parent_path_spec = path_spec.parent
if parent_path_spec and parent_path_spec.type_indicator in (
dfvfs_definitions.PARTITION_TABLE_TYPE_INDICATORS):
display_path = ''.join(
[display_path, parent_path_spec.location])
path_segments = [
segment.translate(self._ESCAPE_CHARACTERS) for segment in path_segments]
display_path = ''.join([display_path, '/'.join(path_segments)])
if data_stream_name:
data_stream_name = data_stream_name.translate(
self._ESCAPE_CHARACTERS)
display_path = ':'.join([display_path, data_stream_name])
return display_path or '/'
def _ShouldListDir(self, file_entry):
location = file_entry.path_spec.location
for allow_dir in self.allow_dirs:
if location.startswith(allow_dir) or allow_dir.startswith(location):
for ignore_dir in self.ignore_dirs:
# Convert to raw string so backslashes aren't interpreted as escapes.
ignore_dir = repr(ignore_dir).strip("'")
if re.search(ignore_dir, location):
return False
return True
return False
def _ListFileEntry(
self, file_entry):
"""Lists a file entry.
Args:
file_entry (dfvfs.FileEntry): file entry to list.
"""
def _dedup_backslashes(path):
return path.replace("\\\\", "\\")
location = file_entry.path_spec.location
if location.startswith("\\"):
location = _dedup_backslashes(location)
self.file_entries[location] = file_entry
try:
for sub_file_entry in file_entry.sub_file_entries:
if not self._ShouldListDir(sub_file_entry):
continue
self._ListFileEntry(sub_file_entry)
except OSError as e:
if "unable to read MFT entry:" in str(e):
logging.error(
f"{self.source}: Unable to list subdirectories for {location}: MFT is corrupted. Try chkdsk first?")
else:
logging.error(
f"{self.source}: Unable to list subdirectories for {location}")
logging.debug(
f"{self.source}: {e}")
def ListFileEntries(self):
"""Lists file entries in the base path specification."""
for base_path_spec in self.base_path_specs:
self.file_system = resolver.Resolver.OpenFileSystem(base_path_spec)
file_entry = resolver.Resolver.OpenFileEntry(base_path_spec)
if file_entry is None:
logging.warning(
'Unable to open base path specification:\n{0:s}'.format(
base_path_spec))
return
self._ListFileEntry(file_entry)
def GetFileEntry(self, path):
for base_path_spec in self.base_path_specs:
path_spec = factory.Factory.NewPathSpec(
base_path_spec.type_indicator, location=path, parent=self.base_path_spec.parent)
try:
file_entry = resolver.Resolver.OpenFileEntry(path_spec)
if file_entry:
return file_entry
except errors.BackEndError:
logging.warning(
f"{base_path_spec.location}: Unable to open file: {path}")
return None
================================================
FILE: backend/memdiff.py
================================================
import collections
import difflib
import json
import re
import logging
import unified_diff
class MemoryDiffer(object):
# TODO: Inherit from a shared "Differ" class
diff_type = "process"
def __init__(self, from_pslist, to_pslist, from_envars=None, to_envars=None, from_cmdline=None, to_cmdline=None, ignore_regex=""):
self.ignore_regex = ignore_regex
self.from_procs = self._list_by_id(from_pslist)
self.to_procs = self._list_by_id(to_pslist)
self.add_envars(from_envars, to_envars)
self.add_cmdline(from_cmdline, to_cmdline)
self.all_pids = set(self.from_procs.keys()) | set(self.to_procs.keys())
self.diffs = {}
def diff_all(self):
if self.diffs:
return self.diffs
for pid in self.all_pids:
diff = self.diff(pid)
if diff:
self.diffs[pid] = diff
return self.diffs
def diff(self, pid):
if pid in self.diffs:
return self.diffs[pid]
from_proc = self.from_procs.get(pid, "")
to_proc = self.to_procs.get(pid, "")
# Ignore "Required memory <address> is not valid (process exited?)" errors.
if to_proc and "is not valid (process exited?)" in to_proc["CommandLine"]:
to_proc = ""
if from_proc and "is not valid (process exited?)" in from_proc["CommandLine"]:
from_proc = ""
kwargs = {}
fromfile = self._make_title(from_proc)
tofile = self._make_title(to_proc)
from_name = fromfile.split("-")[0] if fromfile else ""
to_name = tofile.split("-")[0] if tofile else ""
if self.ignore_regex:
# Ignore this proceses if the to or from process name matches the supplied regex.
if (from_name and re.search(self.ignore_regex, from_name)):
logging.info(
f"Ignoring due to filter regex: {from_name}")
from_proc = ""
if (to_name and re.search(self.ignore_regex, to_name)):
logging.info(
f"Ignoring due to filter regex: {to_name}")
to_proc = ""
# Use the other filename if one of the filenames is empty (because this is an added or deleted file)
fromfile = fromfile or tofile
tofile = tofile or fromfile
kwargs["fromfile"] = fromfile
kwargs["tofile"] = tofile
# Number of lines of context to show (show the entire process)
kwargs["n"] = 999
result = list(difflib.unified_diff(
self._to_string(from_proc),
self._to_string(to_proc),
**kwargs
))
if not result:
return None
# Add headers to conform with git diff format and look pretty for diff2html
init_header = f"diff --git {fromfile} {tofile}"
is_added = not from_proc and to_proc
is_removed = not to_proc and from_proc
added_removed_header = ""
if is_added:
added_removed_header = "new file"
if is_removed:
added_removed_header = "deleted file"
self.add_header(result, added_removed_header)
self.add_header(result, init_header)
ppid = self.get_ppid(pid)
title = self._make_title(to_proc or from_proc)
diff = unified_diff.UnifiedDiff(result, ppid=ppid, title=title)
return diff
def add_envars(self, from_envars, to_envars):
if not from_envars and to_envars:
return
def _add_envars_to_procs(envars, procs):
# Group vars by PID
pid_vars = collections.defaultdict(dict)
for var in envars:
key = var["Variable"]
value = var["Value"]
pid = str(var["PID"])
pid_vars[pid][key] = value
# Add vars dict to PID in procs
for pid in pid_vars:
procs[pid]["EnvironmentVariables"] = pid_vars[pid]
_add_envars_to_procs(from_envars, self.from_procs)
_add_envars_to_procs(to_envars, self.to_procs)
def add_cmdline(self, from_cmdline, to_cmdline):
if not from_cmdline and to_cmdline:
return
def _add_cmdline_to_procs(cmdlines, procs):
# Group vars by PID
for cmdline in cmdlines:
args = cmdline["Args"]
pid = str(cmdline["PID"])
# Add "Args" field to existing processes by PID
procs[pid]["CommandLine"] = args
_add_cmdline_to_procs(from_cmdline, self.from_procs)
_add_cmdline_to_procs(to_cmdline, self.to_procs)
def _make_id(self, proc):
if not proc:
return ""
pid = str(proc["PID"])
return pid
def _make_title(self, proc):
if not proc:
return ""
pid = proc["PID"]
name = proc["ImageFileName"]
return f"{name}-{pid}"
def _list_by_id(self, pslist):
procs = {}
for proc in pslist:
process_id = self._make_id(proc)
# Ignore "Threads" value, since it changes a lot and isn't worth diffing on.
del proc["Threads"]
procs[process_id] = proc
return procs
def _to_string(self, proc):
if not proc:
return ""
return [line + "\n" for line in json.dumps(proc,
separators=(',', ': '),
sort_keys=True,
indent=4).split("\n")]
def get_ppid(self, pid):
from_proc = self.from_procs.get(pid)
to_proc = self.to_procs.get(pid)
# Select whichever one isn't none, defaulting to to_proc.
proc = to_proc or from_proc
ppid = str(proc.get("PPID", ""))
return ppid
def add_header(self, delta, header):
"""Add an arbitrary header to a delta (sequence of diff lines)"""
if not delta or not header:
return
header_line = f"{header}\n"
delta.insert(0, header_line)
================================================
FILE: backend/pyvmdk_delta.py
================================================
import pyvmdk
import os
class handle(object):
"""Trick dfvfs into keeping the parent handles in scope by storing them in this object, which is going to masquerade as a pyvmdk.handle"""
# The list of parent handles. Even though we never read from this list, storing parent handles in it keeps them in scope, preventing them from being deallocated.
parent_handles = []
def __init__(self):
self.parent = None
self._handle = pyvmdk.handle()
def open(self, path):
"""Open a handle to a VMDK path
AND open any parent delta files
AND open extent data files for all VMDK files"""
self._handle.open(path)
self._handle.open_extent_data_files()
parent_filename = self._handle.get_parent_filename()
# If this disk is a delta disk, set its parent.
if parent_filename:
# Delta disks contain the filename to their parent disk, not the full path,
# so we expect the parent disk to be in the same directory.
parent_path = os.path.join(os.path.dirname(path), parent_filename)
parent_handle = handle()
# The parent disk may itself be a child of another disk, so recurse.
parent_handle.open(parent_path)
self.parent_handles.append(parent_handle)
self._handle.set_parent(parent_handle._handle)
def __getattribute__(self, name):
# Hard code the list of attributes, because try/except is slow.
if name in ("__getattribute__", "_handle", "open", "parent", "__init__", "parent_handles"):
return object.__getattribute__(self, name)
else:
return getattr(self._handle, name)
================================================
FILE: backend/requirements.txt
================================================
libvmdk-python
dfvfs==20220816
================================================
FILE: backend/unified_diff.py
================================================
class UnifiedDiff(object):
def __init__(self, diff_lines, is_dir=None, ppid=None, title=None):
self.diff_lines = diff_lines
self._iter = iter(diff_lines)
self.is_dir = is_dir
self.title = title
# Parent PID if this is a process node.
self.ppid = ppid
header = diff_lines[1]
if header.startswith("new"):
self.status = "added"
elif header.startswith("deleted"):
self.status = "removed"
else:
self.status = "modified"
self.lines_added = 0
self.lines_removed = 0
for line in diff_lines:
# Ignore --- and +++ lines
if line.startswith("+") and not line.startswith("++"):
self.lines_added += 1
if line.startswith("-") and not line.startswith("--"):
self.lines_removed += 1
def __next__(self):
return next(self._iter)
================================================
FILE: backend/utils.py
================================================
import pathlib
def ensure_posix(path):
if path.startswith("\\"):
# Force POSIX path so that we can create the directory structure in the Docker container, even if the path is Windows.
path = pathlib.PureWindowsPath(path).as_posix()
path = pathlib.Path(path)
return path
================================================
FILE: backend/vmdiff.py
================================================
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""Script to list file entries."""
from dfvfs.helpers import command_line
from dfvfs.helpers import volume_scanner
import memdiff
import diff_tree
import diffcache
import diskdiff
import file_entry_lister
import logging
import sys
import os
import json
import inspect
import hashlib
# Hacks to import the config from the parent directory.
currentdir = os.path.dirname(os.path.abspath(
inspect.getfile(inspect.currentframe())))
parentdir = os.path.dirname(currentdir)
sys.path.insert(0, parentdir)
import config # noqa
logging.basicConfig(
format='[%(asctime)s]:%(levelname)s:%(message)s', level=config.LOG_LEVEL)
class CachingStdinInputReader(command_line.StdinInputReader):
"""Remembers the last input, so it can be reused."""
def __init__(self, encoding='utf-8'):
"""
Args:
encoding (Optional[str]): input encoding.
"""
super(CachingStdinInputReader, self).__init__(encoding=encoding)
self.last_input = None
def Read(self):
self.last_input = super(CachingStdinInputReader, self).Read()
return self.last_input
def load_memory_results():
memory_run_name = f"{config.FROM_MEMORY_IMAGE_FILENAME}__{config.TO_MEMORY_IMAGE_FILENAME}"
memory_run_path = os.path.join(
config.RESULTS_DIR, "memory", memory_run_name)
results = {}
for plugin in config.MEMORY_PLUGINS:
from_plugin_path = os.path.join(memory_run_path, f"from-{plugin}.json")
to_plugin_path = os.path.join(memory_run_path, f"to-{plugin}.json")
with open(from_plugin_path) as f:
from_plugin = json.load(f)
with open(to_plugin_path) as f:
to_plugin = json.load(f)
results[plugin] = (from_plugin, to_plugin)
return results
def dump_api_data(cache):
run_path = cache.tree_path
dump_dir = run_path / "json"
children_dir = dump_dir / "children"
diff_dir = dump_dir / "diff"
if config.USE_CACHE and dump_dir.exists():
return
logging.info(f"Generating API data for static site: {dump_dir}")
os.makedirs(dump_dir, exist_ok=True)
os.makedirs(children_dir, exist_ok=True)
os.makedirs(diff_dir, exist_ok=True)
logging.info(f"Dumping API data to {dump_dir}")
tree, children_map = cache.get_tree_data_from_cache()
json.dump(tree, open(dump_dir / "changed_files", "w"))
# Dump all the data with url encoded keys, so we can serve it statically later
for key, children in children_map.items():
# Make sure to also encode the "/" character.
filename = hashlib.sha1(key.encode("utf8")).hexdigest()
path = children_dir / filename
json.dump(children, open(path, "w"))
# Get the diff and dump it too.
diff = cache.get_diff(key)
if diff is None:
result = None
else:
result = diff.diff_lines
if result:
path = diff_dir / filename
json.dump(result, open(path, "w"))
def Main():
# Leave Blank or invalid for interactive prompt
partition = config.PARTITION
VOLUMES = "all"
logging.basicConfig(
level=logging.INFO, format='[%(levelname)s] %(message)s')
caching_input_reader = CachingStdinInputReader()
mediator = command_line.CLIVolumeScannerMediator(
input_reader=caching_input_reader)
volume_scanner_options = volume_scanner.VolumeScannerOptions()
volume_scanner_options.partitions = mediator.ParseVolumeIdentifiersString(
partition)
volume_scanner_options.volumes = mediator.ParseVolumeIdentifiersString(
VOLUMES)
# Init disk file listers.
parent_lister = file_entry_lister.FileEntryLister(
config.FROM_DISK_PATH, volume_scanner_options, mediator=mediator, ignore_dirs=config.ignore_dirs, allow_dirs=config.allow_dirs)
partition_input = partition
if not partition_input:
# Get the input the user gave the first time, if any.
partition_input = caching_input_reader.last_input
volume_scanner_options.partitions = list(mediator.ParseVolumeIdentifiersString(
partition_input))
delta_lister = file_entry_lister.FileEntryLister(
config.TO_DISK_PATH, volume_scanner_options, mediator=mediator, ignore_dirs=config.ignore_dirs, allow_dirs=config.allow_dirs)
# ls parition to make sure it's the right one:
if not partition:
entries = list(
parent_lister.file_system.GetRootFileEntry().sub_file_entries)
ls_root = [e.name for e in entries]
logging.info(f"Partition {partition} root files: {ls_root}")
diff_config = config.diff_config
differ = diskdiff.DiskDiffer(
parent_lister, delta_lister,
**diff_config
)
USE_CACHE = config.USE_CACHE
run_process_path = config.RUN_MEMORY_PATH if config.USE_MEMORY else None
cache = diffcache.DiffCache(
config.RUN_DISK_PATH, config.RUN_TREE_PATH, run_process_path)
if USE_CACHE and cache.cache_exists() and (not config.USE_MEMORY or (config.USE_MEMORY and cache.process_cache_exists())):
# Slice off the leading "/" and trailing "/disk"
results_dir = os.path.join(*cache.run_path.parts[1:-1])
logging.info(f"Results already cached at: {str(results_dir)}")
# The diffs can be accessed via cache.get_diff_from_cache(path)
else:
logging.info("No cache found, diffing... ")
if config.USE_DISK:
logging.info("Diffing disk... ")
# Get results and cache them.
differ.get_changed_files()
results = differ.diff_all()
if not results:
logging.info("No disk differences found.")
cache.cache_results(results)
# Now render the tree
disk_tree = diff_tree.DiffTree(differ)
if config.USE_MEMORY:
logging.info("Diffing memory... ")
plugin_results = load_memory_results()
from_pslist, to_pslist = plugin_results.get(
"windows.pslist.PsList")
from_envars, to_envars = plugin_results.get(
"windows.envars.Envars")
from_cmdline, to_cmdline = plugin_results.get(
"windows.cmdline.CmdLine")
# Load pslists already provided by memory-processing.
mem_differ = memdiff.MemoryDiffer(from_pslist,
to_pslist,
from_envars=from_envars,
to_envars=to_envars,
from_cmdline=from_cmdline,
to_cmdline=to_cmdline,
ignore_regex=config.IGNORE_PROCESSES_REGEX)
memdiffs = mem_differ.diff_all()
if not memdiffs:
logging.info("No memory differences found.")
cache.cache_process_results(memdiffs)
mem_tree = diff_tree.DiffTree(mem_differ)
if config.USE_DISK and config.USE_MEMORY:
merged_tree = disk_tree.merge(mem_tree)
elif config.USE_DISK:
merged_tree = disk_tree
elif config.USE_MEMORY:
merged_tree = mem_tree
else:
raise RuntimeError(
"Must set either USE_DISK or USE_MEMORY, otherwise what am I supposed to diff, huh wise guy")
logging.debug(merged_tree.children_map)
cache.cache_tree(merged_tree)
dump_api_data(cache)
logging.info(f"Saved results to {cache.run_path}")
return cache
if __name__ == '__main__':
Main()
================================================
FILE: backend/vmdk_file_io.py
================================================
# -*- coding: utf-8 -*-
"""The VMDK image file-like object."""
# Copy of `vmdk_file_io` we patch and copy into the docker container.
# This is the patch.
import pyvmdk_delta as pyvmdk
from dfvfs.file_io import file_object_io
from dfvfs.lib import errors
from dfvfs.path import factory as path_spec_factory
from dfvfs.resolver import resolver
class VMDKFile(file_object_io.FileObjectIO):
"""File input/output (IO) object using pyvmdk."""
def _OpenFileObject(self, path_spec):
"""Opens the file-like object defined by path specification.
Args:
path_spec (PathSpec): path specification.
Returns:
pyvmdk.handle: a file-like object.
Raises:
IOError: if the file-like object could not be opened.
OSError: if the file-like object could not be opened.
PathSpecError: if the path specification is incorrect.
"""
if not path_spec.HasParent():
raise errors.PathSpecError(
'Unsupported path specification without parent.')
parent_path_spec = path_spec.parent
parent_location = getattr(parent_path_spec, 'location', None)
if not parent_location:
raise errors.PathSpecError(
'Unsupported parent path specification without location.')
# Note that we cannot use pyvmdk's open_extent_data_files_as_file_objects
# function since it does not handle the file system abstraction dfVFS
# provides.
file_system = resolver.Resolver.OpenFileSystem(
parent_path_spec, resolver_context=self._resolver_context)
file_object = resolver.Resolver.OpenFileObject(
parent_path_spec, resolver_context=self._resolver_context)
vmdk_handle = pyvmdk.handle()
vmdk_handle.open(parent_location)
return vmdk_handle
def open_extent_data_files(self, vmdk_handle, parent_path_spec):
parent_location = getattr(parent_path_spec, 'location', None)
file_system = resolver.Resolver.OpenFileSystem(
parent_path_spec, resolver_context=self._resolver_context)
parent_location_path_segments = file_system.SplitPath(parent_location)
extent_data_files = []
for extent_descriptor in iter(vmdk_handle.extent_descriptors):
extent_data_filename = extent_descriptor.filename
_, path_separator, filename = extent_data_filename.rpartition('/')
if not path_separator:
_, path_separator, filename = extent_data_filename.rpartition(
'\\')
if not path_separator:
filename = extent_data_filename
# The last parent location path segment contains the extent data filename.
# Since we want to check if the next extent data file exists we remove
# the previous one form the path segments list and add the new filename.
# After that the path segments list can be used to create the location
# string.
parent_location_path_segments.pop()
parent_location_path_segments.append(filename)
extent_data_file_location = file_system.JoinPath(
parent_location_path_segments)
# Note that we don't want to set the keyword arguments when not used
# because the path specification base class will check for unused
# keyword arguments and raise.
kwargs = path_spec_factory.Factory.GetProperties(parent_path_spec)
kwargs['location'] = extent_data_file_location
if parent_path_spec.parent is not None:
kwargs['parent'] = parent_path_spec.parent
extent_data_file_path_spec = path_spec_factory.Factory.NewPathSpec(
parent_path_spec.type_indicator, **kwargs)
if not file_system.FileEntryExistsByPathSpec(extent_data_file_path_spec):
break
extent_data_files.append(extent_data_file_path_spec)
if len(extent_data_files) != vmdk_handle.number_of_extents:
raise IOError('Unable to locate all extent data files.')
file_objects = []
for extent_data_file_path_spec in extent_data_files:
file_object = resolver.Resolver.OpenFileObject(
extent_data_file_path_spec, resolver_context=self._resolver_context)
file_objects.append(file_object)
vmdk_handle.open_extent_data_files_as_file_objects(file_objects)
def get_size(self):
"""Retrieves the size of the file-like object.
Returns:
int: size of the file-like object data.
Raises:
IOError: if the file-like object has not been opened.
OSError: if the file-like object has not been opened.
"""
if not self._is_open:
raise IOError('Not opened.')
return self._file_object.get_media_size()
================================================
FILE: config.py
================================================
import os
import hashlib
import logging
import json
def as_bool(var):
if var is None:
return False
val = var.lower()
if val == "false":
return False
if val == "true":
return True
logging.debug(str(os.environ))
raise RuntimeError(
f"Environment variable with value {var} is neither True nor False")
# Read config vars dynamically fron environment (set in `.env`)
diff_config_keys = [key for key in os.environ if key.startswith("DIFF_")]
# Convert environment variable format (DIFF_USE_ATTRIBUTES) to variable name format for diskdiff.py (use_attributes)
diff_config = {
key[5:].lower(): as_bool(os.environ[key])
for key in diff_config_keys
}
dev = "_DEV" if os.environ.get("VMDIFF_DEV") else ""
filter_path_json = os.environ.get("FILTER_PATH_JSON")
ignore_path_json = os.environ.get("IGNORE_PATH_JSON")
allow_dirs = json.loads(filter_path_json) if filter_path_json else []
ignore_dirs = json.loads(ignore_path_json) if ignore_path_json else []
IGNORE_PROCESSES_REGEX = os.environ.get("IGNORE_PROCESSES_REGEX")
PARTITION = os.environ.get("PARTITION_IDENTIFIER")
MEMORY_PLUGINS = os.environ.get("MEMORY_PLUGINS").split()
FROM_DISK_IMAGE_FILENAME = os.environ.get(
"FROM_DISK_IMAGE_FILENAME")
TO_DISK_IMAGE_FILENAME = os.environ.get(
"TO_DISK_IMAGE_FILENAME")
USE_DISK = False
if FROM_DISK_IMAGE_FILENAME and TO_DISK_IMAGE_FILENAME and as_bool(os.environ.get("USE_DISK")):
USE_DISK = True
USE_CACHE = as_bool(os.environ.get("USE_CACHE"))
SNAPSHOT_DIR = os.environ.get(f"SNAPSHOT_DIR{dev}")
FROM_DISK_PATH = os.path.join(SNAPSHOT_DIR, FROM_DISK_IMAGE_FILENAME)
TO_DISK_PATH = os.path.join(SNAPSHOT_DIR, TO_DISK_IMAGE_FILENAME)
FROM_MEMORY_IMAGE_FILENAME = os.environ.get("FROM_MEMORY_IMAGE_FILENAME")
TO_MEMORY_IMAGE_FILENAME = os.environ.get("TO_MEMORY_IMAGE_FILENAME")
USE_MEMORY = False
if FROM_MEMORY_IMAGE_FILENAME and TO_MEMORY_IMAGE_FILENAME and as_bool(os.environ.get("USE_MEMORY")):
USE_MEMORY = True
RESULTS_DIR = os.environ[f"RESULTS_DIR{dev}"]
REACT_BUILD_DIR = os.environ[f"REACT_BUILD_DIR{dev}"]
LOG_LEVEL = logging.DEBUG if dev else logging.INFO
def get_run_id():
opts_bitfield = "".join(
["1" if opt else "0" for opt in sorted(diff_config.values())])
dir_opts = "".join(sorted(allow_dirs)) + "".join(sorted(ignore_dirs))
config_str = opts_bitfield + dir_opts
config_hash = hashlib.sha1(config_str.encode()).hexdigest()[:10]
if USE_DISK:
filename = f"{FROM_DISK_IMAGE_FILENAME}--{TO_DISK_IMAGE_FILENAME}--{config_hash}"
else:
filename = f"{FROM_MEMORY_IMAGE_FILENAME}--{TO_MEMORY_IMAGE_FILENAME}--{config_hash}"
return filename
RUN_ID = get_run_id()
RUN_PATH = os.path.join(RESULTS_DIR, RUN_ID)
RUN_DISK_PATH = os.path.join(RUN_PATH, "disk")
RUN_MEMORY_PATH = os.path.join(RUN_PATH, "memory")
RUN_TREE_PATH = os.path.join(RUN_PATH, "tree")
================================================
FILE: docker-compose.yml
================================================
version: '3.4'
services:
vmdiff:
image: vmdiff/vmdiff
build:
context: ./
dockerfile: ./backend/Dockerfile
tty: true
env_file:
- .env
volumes:
- ./backend:/backend
- ./results:$RESULTS_DIR
memdiff:
image: vmdiff/memory-processor
build:
context: ./
dockerfile: ./memory-processing/Dockerfile
env_file:
- .env
volumes:
- ./memory-processing:/memdiff
- ./memory-processing/volatilitycache:/home/unprivileged/.cache/volatility3
- ./results:$RESULTS_DIR
app:
image: vmdiff/vmdiff-app
build:
context: .
dockerfile: ./Dockerfile
env_file:
- .env
volumes:
- ./results:$RESULTS_DIR
ports:
- "5000:5000"
================================================
FILE: frontend/.dockerignore
================================================
**/.classpath
**/.dockerignore
**/.env
**/.git
**/.gitignore
**/.project
**/.settings
**/.toolstarget
**/.vs
**/.vscode
**/*.*proj.user
**/*.dbmdl
**/*.jfm
**/charts
**/docker-compose*
**/compose*
**/Dockerfile*
**/node_modules
**/npm-debug.log
**/obj
**/secrets.dev.yaml
**/values.dev.yaml
README.md
================================================
FILE: frontend/.gitignore
================================================
# See https://help.github.com/articles/ignoring-files/ for more about ignoring files.
# dependencies
/node_modules
/.pnp
.pnp.js
# testing
/coverage
# production
/build
# misc
.DS_Store
.env.local
.env.development.local
.env.test.local
.env.production.local
npm-debug.log*
yarn-debug.log*
yarn-error.log*
================================================
FILE: frontend/README.md
================================================
# Getting Started with Create React App
This project was bootstrapped with [Create React App](https://github.com/facebook/create-react-app).
## Available Scripts
In the project directory, you can run:
### `yarn start`
Runs the app in the development mode.\
Open [http://localhost:3000](http://localhost:3000) to view it in the browser.
The page will reload if you make edits.\
You will also see any lint errors in the console.
### `yarn test`
Launches the test runner in the interactive watch mode.\
See the section about [running tests](https://facebook.github.io/create-react-app/docs/running-tests) for more information.
### `yarn build`
Builds the app for production to the `build` folder.\
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.\
Your app is ready to be deployed!
See the section about [deployment](https://facebook.github.io/create-react-app/docs/deployment) for more information.
### `yarn eject`
**Note: this is a one-way operation. Once you `eject`, you can’t go back!**
If you aren’t satisfied with the build tool and configuration choices, you can `eject` at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except `eject` will still work, but they will point to the copied scripts so you can tweak them. At this point you’re on your own.
You don’t have to ever use `eject`. The curated feature set is suitable for small and middle deployments, and you shouldn’t feel obligated to use this feature. However we understand that this tool wouldn’t be useful if you couldn’t customize it when you are ready for it.
## Learn More
You can learn more in the [Create React App documentation](https://facebook.github.io/create-react-app/docs/getting-started).
To learn React, check out the [React documentation](https://reactjs.org/).
================================================
FILE: frontend/package.json
================================================
{
"name": "vmdiff-regrets",
"version": "0.1.0",
"private": true,
"homepage": ".",
"dependencies": {
"@testing-library/jest-dom": "^5.14.1",
"@testing-library/react": "^13.0.0",
"@testing-library/user-event": "^13.2.1",
"@types/jest": "^27.0.1",
"@types/react": "^18.0.0",
"@types/react-dom": "^18.0.0",
"antd": "^4.23.5",
"crypto": "^1.0.1",
"crypto-browserify": "^3.12.0",
"crypto-hash": "^2.0.1",
"diff2html": "^3.4.19",
"node-polyfill-webpack-plugin": "^2.0.1",
"react": "^18.2.0",
"react-dom": "^18.2.0",
"react-scripts": "5.0.1",
"typescript": "^4.4.2",
"web-vitals": "^2.1.0"
},
"scripts": {
"start": "GENERATE_SOURCEMAP=false react-scripts start",
"build": "GENERATE_SOURCEMAP=false react-scripts build",
"test": "react-scripts test",
"eject": "react-scripts eject"
},
"eslintConfig": {
"extends": [
"react-app",
"react-app/jest"
]
},
"browserslist": {
"production": [
">0.2%",
"not dead",
"not op_mini all"
],
"development": [
"last 1 chrome version",
"last 1 firefox version",
"last 1 safari version"
]
},
"devDependencies": {
"@types/node": "^18.11.19"
}
}
================================================
FILE: frontend/public/index.html
================================================
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<link rel="icon" href="%PUBLIC_URL%/favicon.ico" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<meta name="theme-color" content="#000000" />
<meta name="description" content="Web site created using create-react-app" />
<link rel="apple-touch-icon" href="%PUBLIC_URL%/logo192.png" />
<!--
manifest.json provides metadata used when your web app is installed on a
user's mobile device or desktop. See https://developers.google.com/web/fundamentals/web-app-manifest/
-->
<link rel="manifest" href="%PUBLIC_URL%/manifest.json" />
<!--
Notice the use of %PUBLIC_URL% in the tags above.
It will be replaced with the URL of the `public` folder during the build.
Only files inside the `public` folder can be referenced from the HTML.
Unlike "/favicon.ico" or "favicon.ico", "%PUBLIC_URL%/favicon.ico" will
work correctly both with client-side routing and a non-root public URL.
Learn how to configure a non-root public URL by running `npm run build`.
-->
<title>🔥vmdiff🔥 (beta)</title>
</head>
<body>
<noscript>You need to enable JavaScript to run this app.</noscript>
<div id="root"></div>
<!--
This HTML file is a template.
If you open it directly in the browser, you will see an empty page.
You can add webfonts, meta tags, or analytics to this file.
The build step will place the bundled scripts into the <body> tag.
To begin the development, run `npm start` or `yarn start`.
To create a production bundle, use `npm run build` or `yarn build`.
-->
</body>
</html>
================================================
FILE: frontend/public/manifest.json
================================================
{
"short_name": "vmdiff",
"name": "vmdiff",
"icons": [
{
"src": "favicon.ico",
"sizes": "64x64 32x32 24x24 16x16",
"type": "image/x-icon"
}
],
"start_url": ".",
"display": "standalone",
"theme_color": "#000000",
"background_color": "#ffffff"
}
================================================
FILE: frontend/src/App.css
================================================
@import '~antd/dist/antd.css';
div.ant-tree-treenode {
width: max-content;
}
================================================
FILE: frontend/src/App.test.tsx
================================================
import React from 'react';
import { render, screen } from '@testing-library/react';
import App from './App';
test('renders learn react link', () => {
render(<App />);
const linkElement = screen.getByText(/learn react/i);
expect(linkElement).toBeInTheDocument();
});
================================================
FILE: frontend/src/App.tsx
================================================
import React, { useEffect, useState } from 'react';
import { FolderOutlined, ExperimentOutlined } from '@ant-design/icons';
import type { DataNode } from 'antd/es/tree';
import { Tree, Layout } from 'antd';
import { Typography, Space } from 'antd';
import * as Diff2Html from "diff2html";
import "diff2html/bundles/css/diff2html.min.css";
import './App.css';
import { sha1 } from 'crypto-hash'
const { Title } = Typography;
const { Header, Content, Sider } = Layout;
const { DirectoryTree } = Tree;
type DiffNodeProps = {
status: string,
linesAdded: number,
linesRemoved: number,
numChildren: number,
numDirectChildren: number,
isDirectory: boolean
};
type DiffNode = DataNode & Partial<DiffNodeProps>;
let DEMO = !(process.env.VMDIFF_DEMO === "false")
let BASE_URL = ""
// Serve from the cached /json directory if this is a demo, otherwise from the localhost server directly.
// It's always a demo, though.
if (DEMO) {
BASE_URL = window.location.pathname + "json";
}
const colours: any = {
added: "#52c41a",
removed: "#eb2f96",
modified: "#d0b44c",
unchanged: "#333"
}
const initTreeData: DiffNode[] = [];
const getInitTreeData = (): Promise<DiffNode[]> => {
return fetch(BASE_URL + "/changed_files").then((response) => {
return response.json()
});
}
const getChildrenData = (key: React.Key): Promise<DiffNode[]> => {
if (DEMO) {
const hasher = sha1(String(key))
return hasher.then((hash) => {
return fetch(BASE_URL + `/children/` + hash).then((response) => {
return response.json()
});
});
} else {
return fetch(BASE_URL + `/children?` + new URLSearchParams({
key: String(key)
})).then((response) => {
return response.json()
});
}
}
const getDiffString = (key: React.Key): Promise<string[]> => {
if (DEMO) {
const hasher = sha1(String(key))
return hasher.then((hash) => {
return fetch(BASE_URL + `/diff/` + hash).then((response) => {
return response.json()
});
});
} else {
return fetch(BASE_URL + `/diff?` + new URLSearchParams({
key: String(key)
})).then((response) => {
return response.json()
});
}
}
const treeMap = new Map<React.Key, DiffNode>();
const cache = (nodes: DiffNode[]): void => {
nodes.map((node) => {
treeMap.set(node.key, node)
if (node.children) {
cache(node.children)
}
return null
})
}
// Cache the initial tree
cache(initTreeData);
const setIcon = (node: DiffNode): DiffNode => {
if (node.isDirectory && node.isLeaf) {
node.icon = <FolderOutlined />
}
return node
}
const iconifyAll = () => {
treeMap.forEach((value, key) => {
treeMap.set(key, setIcon(value));
})
}
// It's just a simple demo. You can use tree map to optimize update perf.
function updateTreeData(
list: DiffNode[],
key: React.Key,
children: DiffNode[]
): DiffNode[] {
iconifyAll();
return list.map((node) => {
if (node.key === key) {
return {
...node,
children,
};
} else if (node.children) {
return {
...node,
children: updateTreeData(node.children, key, children),
};
}
return node;
});
}
const getDiffHtml = (key: React.Key): Promise<string> => {
return getDiffString(key).then((diffLines) => {
const unifiedDiffString = diffLines.join("");
const diffHtml = Diff2Html.html(
unifiedDiffString,
{
drawFileList: false,
matching: "lines",
outputFormat: "line-by-line",
renderNothingWhenEmpty: false
}
);
return diffHtml
})
}
const App: React.FC = () => {
const [treeData, setTreeData] = useState<DiffNode[] | undefined>(undefined);
const [expandedKeys, setExpandedKeys] = useState<React.Key[]>([]);
const [, setLoadedKeys] = useState<React.Key[]>([]);
const [autoExpandParent, setAutoExpandParent] = useState(true);
const [diff, setDiff] = useState("");
const [collapsed, setCollapsed] = useState(true);
useEffect(() => {
getInitTreeData().then((data) => {
cache(data)
iconifyAll()
const newExpandedKeys: React.Key[] = []
const newLoadedKeys: React.Key[] = []
treeMap.forEach((value, key) => {
newLoadedKeys.push(key)
// Nodes to leave collapsed initially
if (value.children !== undefined && value.children.length > 0) {
// If all children are leaves
let allChildrenLeaves = true
for (const child of value.children) {
if (!child.isLeaf) {
allChildrenLeaves = false;
break;
}
}
if (!allChildrenLeaves && value.numDirectChildren! < 10 && newExpandedKeys.length < 1000) {
newExpandedKeys.push(key)
}
}
})
setExpandedKeys(newExpandedKeys)
setLoadedKeys(newLoadedKeys)
setTreeData(data)
})
}, []);
const onExpand = (expandedKeys: React.Key[], { node }: { expanded: boolean, node: DiffNode }): any => {
setExpandedKeys(expandedKeys)
setAutoExpandParent(false);
}
const shouldAutoExpand = (key: React.Key): boolean => {
const node = treeMap.get(key);
// Always expand if there are just empty folders underneath.
if (node?.numChildren === 0) {
return true;
}
if (node?.numDirectChildren! > 10) {
return false;
}
// Does the key have all leaf children?
if (node !== undefined && node.children?.every(child => { return child.isLeaf })) {
// TODO: Find a way to measure how many nodes are showing, not expanded
if ((treeMap.size + node.children!.length) < 20) {
console.log(`(${expandedKeys.length}) allowing expand of ${key}`)
return true;
}
console.log(` (${expandedKeys.length}) not expanding ${key}`)
}
return false;
}
const expand = (key: React.Key) => {
if (!(key in expandedKeys)) {
setExpandedKeys((prev) => [...prev, key]);
}
}
const onSelect = (selectedKeys: React.Key[]): any => {
const key = selectedKeys[0];
getDiffHtml(key).then((html) => {
setDiff(html);
});
}
const onLoadData = ({ key, children }: any) =>
new Promise<void>(resolve => {
console.log(key)
if (children != null && children.length > 0) {
// Do nothing if the node has children already somehow (double expand?)
resolve();
return;
}
setTimeout(() => {
// Load the children of this node.
getChildrenData(key).then((children) => {
cache(children)
setTreeData(origin =>
origin === undefined ? undefined :
updateTreeData(origin, key, children)
);
children.forEach((child) => {
if (!child.isLeaf && shouldAutoExpand(child.key)) {
expand(child.key);
}
})
resolve();
})
resolve();
})
});
const renderTitle = (node: DiffNode): React.ReactNode | undefined => {
const titleTextStyle = {
color: colours[node.status!],
filter: "brightness(0.8)"
}
const numChildrenStyle = {
color: "#aaa",
"marginLeft": "5px"
}
const linesAddedStyle = {
color: colours["added"],
filter: "brightness(0.55)"
}
const linesRemovedStyle = {
color: colours["removed"],
filter: "brightness(0.55)"
}
const linesChangedStyle = {
"marginLeft": "0.3rem",
opacity: "80%"
}
const showLineStats = (node.linesAdded !== 0 || node.linesRemoved !== 0) && !node.isDirectory
return <span className="node-title">
{/* {node.status === "added" ? <PlusSquareTwoTone twoToneColor={colours.added} /> : null}
{node.status === "removed" ? <MinusSquareTwoTone twoToneColor={colours.removed} /> : null}
{node.status === "modified" ? <RightSquareTwoTone twoToneColor={colours.modified} /> : null} */}
<span className="node-name" style={titleTextStyle} >{String(node.title)}</span>
{node.numChildren !== undefined && node.numChildren > 0 && !expandedKeys.includes(node.key) ? <span style={numChildrenStyle}>({node.numChildren})</span> : null}
{showLineStats ? <span style={linesChangedStyle}>
{node.linesAdded !== 0 ? <span style={linesAddedStyle}>+{node.linesAdded}</span> : null}{node.linesAdded !== 0 && node.linesRemoved !== 0 ? "," : null}
{node.linesRemoved !== 0 ? <span style={linesRemovedStyle}>-{node.linesRemoved}</span> : null}
</span>
: null}
</span>
}
return (<Layout>
<Header style={{ position: 'sticky', top: 0, zIndex: 1, width: '100%' }}>
<Space>
<Typography>
<Title level={2} style={{
color: "#fff"
}}>
<Space>
<ExperimentOutlined
size={30}
/>
🔥vmdiff🔥
</Space>
</Title>
</Typography>
</Space >
</Header >
<Layout hasSider className="site-layout" style={{}}>
<Sider collapsible collapsed={collapsed} onCollapse={value => setCollapsed(value)}
theme={"light"}
collapsedWidth={"30vw"}
width={"60vw"}
style={{
overflow: 'scroll',
height: '100vh',
marginBottom: '50px',
}}>
<div id="components-tree-demo-dynamic"
style={{
height: "100%"
}}
>
<DirectoryTree
loadData={onLoadData}
expandedKeys={expandedKeys}
treeData={treeData}
onExpand={onExpand}
onSelect={onSelect}
titleRender={renderTitle}
virtual={true}
blockNode={false}
autoExpandParent={autoExpandParent}
defaultExpandParent={true}
style={{
height: "100%"
}}
/>
</div>
</Sider>
<Content style={{ margin: '24px 16px 0', overflow: 'initial' }}>
<div className="site-layout-background" style={{ padding: 24, textAlign: 'center' }}>
<div id="code-diff" dangerouslySetInnerHTML={{ __html: diff }}>
</div>
</div>
</Content>
</Layout>
</Layout >
)
};
export default App;
================================================
FILE: frontend/src/index.css
================================================
body {
margin: 0;
font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', 'Roboto', 'Oxygen',
'Ubuntu', 'Cantarell', 'Fira Sans', 'Droid Sans', 'Helvetica Neue',
sans-serif;
-webkit-font-smoothing: antialiased;
-moz-osx-font-smoothing: grayscale;
}
code {
font-family: source-code-pro, Menlo, Monaco, Consolas, 'Courier New',
monospace;
}
================================================
FILE: frontend/src/index.tsx
================================================
import React from 'react';
import ReactDOM from 'react-dom/client';
import './index.css';
import App from './App';
import reportWebVitals from './reportWebVitals';
const root = ReactDOM.createRoot(
document.getElementById('root') as HTMLElement
);
root.render(
<React.StrictMode>
<App />
</React.StrictMode>
);
// If you want to start measuring performance in your app, pass a function
// to log results (for example: reportWebVitals(console.log))
// or send to an analytics endpoint. Learn more: https://bit.ly/CRA-vitals
reportWebVitals();
================================================
FILE: frontend/src/react-app-env.d.ts
================================================
/// <reference types="react-scripts" />
================================================
FILE: frontend/src/reportWebVitals.ts
================================================
import { ReportHandler } from 'web-vitals';
const reportWebVitals = (onPerfEntry?: ReportHandler) => {
if (onPerfEntry && onPerfEntry instanceof Function) {
import('web-vitals').then(({ getCLS, getFID, getFCP, getLCP, getTTFB }) => {
getCLS(onPerfEntry);
getFID(onPerfEntry);
getFCP(onPerfEntry);
getLCP(onPerfEntry);
getTTFB(onPerfEntry);
});
}
};
export default reportWebVitals;
================================================
FILE: frontend/src/setupTests.ts
================================================
// jest-dom adds custom jest matchers for asserting on DOM nodes.
// allows you to do things like:
// expect(element).toHaveTextContent(/react/i)
// learn more: https://github.com/testing-library/jest-dom
import '@testing-library/jest-dom';
================================================
FILE: frontend/tsconfig.json
================================================
{
"compilerOptions": {
"target": "es5",
"lib": [
"dom",
"dom.iterable",
"esnext"
],
"allowJs": true,
"skipLibCheck": true,
"esModuleInterop": true,
"allowSyntheticDefaultImports": true,
"strict": true,
"forceConsistentCasingInFileNames": true,
"noFallthroughCasesInSwitch": true,
"module": "esnext",
"moduleResolution": "node",
"resolveJsonModule": true,
"isolatedModules": true,
"noEmit": true,
"jsx": "react-jsx"
},
"include": [
"src"
]
}
================================================
FILE: memory-processing/Dockerfile
================================================
# For more information, please refer to https://aka.ms/vscode-docker-python
FROM sk4la/volatility3
# Keeps Python from generating .pyc files in the container
ENV PYTHONDONTWRITEBYTECODE=1
# Turns off buffering for easier container logging
ENV PYTHONUNBUFFERED=1
WORKDIR /memdiff
RUN mkdir -p volatilitycache
RUN mkdir -p results
COPY memory-processing/memdiff.sh .
# Creates a non-root user with an explicit UID and adds permission to access the /app folder
# For more info, please refer to https://aka.ms/vscode-docker-python-configure-containers
USER root
RUN chown -R unprivileged /memdiff
RUN chmod +x memdiff.sh
RUN mkdir -p /disk
RUN mkdir -p /memory
# RUN touch /disk/from
# RUN touch /disk/to
# RUN touch /memory/from
# RUN touch /memory/to
# USER appuser
USER unprivileged
# ENTRYPOINT [ "/usr/bin/dumb-init", "--", "volatility3" ]
ENTRYPOINT [ "/bin/sh", "memdiff.sh" ]
================================================
FILE: memory-processing/memdiff.sh
================================================
#! /bin/bash
if [ "${#FROM_MEMORY_IMAGE_FILENAME}" -lt 1 ]; then
echo "No memory image filename given by ${FROM_MEMORY_IMAGE_FILENAME}, skipping memory analysis"
exit 0
fi
PLUGINS=$MEMORY_PLUGINS
RUN_NAME="${FROM_MEMORY_IMAGE_FILENAME}__${TO_MEMORY_IMAGE_FILENAME}"
RUN_DIR="/results/memory/$RUN_NAME"
FROM_OUTPUT_PATH_TEMPLATE="$RUN_DIR/from"
TO_OUTPUT_PATH_TEMPLATE="$RUN_DIR/to"
mkdir -p "$RUN_DIR"
for plugin in $PLUGINS; do
FROM_OUTPUT_FILENAME="$FROM_OUTPUT_PATH_TEMPLATE-$plugin.json"
TO_OUTPUT_FILENAME="$TO_OUTPUT_PATH_TEMPLATE-$plugin.json"
if [ ! -s "$FROM_OUTPUT_FILENAME" ]; then
volatility3 --cache-path ./volatilitycache -o . -f "/snapshots/$FROM_MEMORY_IMAGE_FILENAME" --renderer json $plugin | tee "$FROM_OUTPUT_FILENAME"
fi
if [ ! -s "$TO_OUTPUT_FILENAME" ]; then
volatility3 --cache-path ./volatilitycache -o . -f "/snapshots/$TO_MEMORY_IMAGE_FILENAME" --renderer json $plugin | tee "$TO_OUTPUT_FILENAME"
fi
done
================================================
FILE: requirements.txt
================================================
# To ensure app dependencies are ported from your virtual environment/host machine into your container, run 'pip freeze > requirements.txt' in the terminal to overwrite this file
typer[all]==0.7.0
================================================
FILE: server.py
================================================
import inspect
import os
import sys
import time
import logging
from flask import Flask, jsonify, request, render_template, send_from_directory
import config
# Python Crimes to import from a local module
currentdir = os.path.dirname(os.path.abspath(
inspect.getfile(inspect.currentframe())))
backend_dir = os.path.join(currentdir, "backend")
sys.path.insert(0, backend_dir)
if config.dev:
from backend import vmdiff
vmdiff.Main()
try:
import diffcache # noqa
except ImportError:
from backend import diffcache
REACT_BUILD_DIR = config.REACT_BUILD_DIR
app = Flask(
__name__, static_folder=f"{REACT_BUILD_DIR}/static", template_folder=f"{REACT_BUILD_DIR}")
logging.info(f"Waiting for results at {config.RUN_TREE_PATH}....")
if not os.path.exists(config.RUN_TREE_PATH):
logging.critical(
f"No results found at {config.RUN_TREE_PATH}. Generate results first?")
sys.exit(1)
cache = diffcache.DiffCache(
config.RUN_DISK_PATH, config.RUN_TREE_PATH, config.RUN_MEMORY_PATH)
while True:
try:
tree, children_map = cache.get_tree_data_from_cache()
break
except FileNotFoundError:
time.sleep(3)
logging.debug(f"Tree: {len(tree)}, children: {len(children_map)}")
@app.route("/children")
def get_children_handler():
key = request.args.get("key")
node_children = children_map[key]
response = jsonify(node_children)
response.headers.add('Access-Control-Allow-Origin', '*')
return response
@app.route("/diff")
def get_diff():
key = request.args.get("key")
diff = cache.get_diff(key)
if diff is None:
logging.warning(f"No diff found for {key}")
result = None
else:
result = diff.diff_lines
response = jsonify(result)
response.headers.add('Access-Control-Allow-Origin', '*')
# to start with, just return the directories, and let the user expand out the files.
return response
@app.route("/changed_files")
def get_changed_files():
response = jsonify(tree)
response.headers.add('Access-Control-Allow-Origin', '*')
# To start with, just return the directories, and let the user expand out the files.
return response
@app.route("/json/<path:path>")
def json(path):
json_dir = f"{cache.tree_path}/json"
return send_from_directory(json_dir, path)
@app.route("/")
def index():
return render_template("index.html")
if __name__ == "__main__":
app.run("0.0.0.0", debug=True)
================================================
FILE: vmdiff
================================================
#! env python3
"""
vmdiff CLI
"""
__author__ = "Atlassian Icarus Labs"
__version__ = "0.1.0"
__license__ = "MIT"
from typing import Optional, List
import typer
import pathlib
import subprocess
import sys
import shlex
import os
import re
import json
from datetime import datetime
from struct import unpack, pack
from rich.table import Table
from rich import print
app = typer.Typer()
input_path_options = {
"exists": True,
"rich_help_panel": "Input and output",
"show_default": False
}
def main(
input_dir: pathlib.Path = typer.Argument(..., help="Path to virtual machine directory, or any directory containing .vmdk/.vmem files.",
file_okay=False, **input_path_options),
from_disk: pathlib.Path = typer.Option(
None, "--from-disk", "-fd", help="Path (or filename) of first chronological disk snapshot.",
**input_path_options),
to_disk: pathlib.Path = typer.Option(
None, "--to-disk", "-td", help="Path (or filename) of second chronological disk snapshot.",
**input_path_options),
from_memory: pathlib.Path = typer.Option(
None, "--from-memory", "-fm", help="Path (or filename) of first chronological memory snapshot.",
**input_path_options),
to_memory: pathlib.Path = typer.Option(
None, "--to-memory", "-tm", help="Path (or filename) of second chronological memory snapshot.",
**input_path_options),
from_snapshot: str = typer.Option(
None, "--from-snapshot", "-fs", help="First chronological snapshot ID obtained via --list-snapshots.", rich_help_panel="Input and output", show_default=False),
to_snapshot: str = typer.Option(
None, "--to-snapshot", "-ts", help="Second chronological snapshot ID obtained via --list-snapshots.", rich_help_panel="Input and output", show_default=False),
list_snapshots: bool = typer.Option(
False, "--list-snapshots", "-l", help="Show information about the VM snapshots in INPUT_DIR, e.g. the files belonging to each snapshot."),
ignore_path: Optional[List[str]] = typer.Option(
[], "--ignore-path", "-i", help="List of disk path regular expressions to ignore when diffing. Multiple values accepted via e.g. \"--ignore-path /path/one --ignore-path /path/two\"", rich_help_panel="Configuring"),
filter_path: Optional[List[str]] = typer.Option(
["/", "\\"], "--filter-path", "-f", help="List of disk path regular expressions. Only these paths will be processed. Multiple values accepted via e.g. \"--filter-path /path/one --filter-path /path/two\"", rich_help_panel="Configuring"),
ignore_processes: Optional[str] = typer.Option(
"", "--ignore-process", "-I", help="Regular expression to ignore when diffing process names. Note that only the first 14 characters of the process name are processed (by Volatility).", rich_help_panel="Configuring"),
cache: bool = typer.Option(
True, help="Whether to cache results based on input filenames and config options.", rich_help_panel="Configuring"),
partition: str = typer.Option(
"", "--partition", "-p", help="Disk Partition ID to use. If not set, show partitions and ask which one to use via STDIN.", rich_help_panel="Input and output", show_default=False),
use_memory: bool = typer.Option(
True, help="Whether to process/diff memory.", rich_help_panel="Configuring"),
use_disk: bool = typer.Option(
True, help="Whether to process/diff disks.", rich_help_panel="Configuring"),
include_binary: bool = typer.Option(
None, help="Whether to also process and diff binary files.", rich_help_panel="Configuring"),
show: bool = typer.Option(
None, "--show", "-s", help="Open browser and show diff viewer UI.", rich_help_panel="Display"),
debug: bool = typer.Option(
None, "--debug", help="Enable debug logging."),
):
"""
\b
Generate and view diffs for .vmdk and .vmem files.
\b
EXAMPLES:
\b
What snapshots do I have to choose from?
./vmdiff "~/Virtual Machines.localized/VMName/" --list-snapshots
\b
Diff snapshots 1 and 2
./vmdiff "~/Virtual Machines.localized/VMName/" --from-snapshot 1 --to-snapshot 2
\b
Don't prompt me for a partition, I know it's partition 4
./vmdiff "~/Virtual Machines.localized/VMName/" --from-snapshot 1 --to-snapshot 2 --partition 4
\b
Diff generic VMDK files, not necessarily from a snapshot
./vmdiff ~/dir-with-vmdk-files/ --from-disk disk1.vmdk --to-disk disk2.vmdk --no-use-memory
\b
Only show files that have changed in the user's home directory
./vmdiff "~/Virtual Machines.localized/VMName/" --from-snapshot 1 --to-snapshot 2 --filter-path "/home/username/"
\b
Ignore .log and .txt files
./vmdiff "~/Virtual Machines.localized/VMName/" --from-snapshot 1 --to-snapshot 2 --filter-path "/home/username/" --ignore-path ".*\.log" --ignore-path ".*\.txt"
"""
def run_command(command, description, env):
if debug:
print(command)
subprocess.run(command, stdin=sys.stdin,
stdout=sys.stdout, stderr=sys.stderr, shell=True, check=True, env=env)
file_opts = (from_disk, to_disk, from_memory, to_memory)
disk_opts = (from_disk, to_disk)
memory_opts = (from_memory, to_memory)
snapshot_opts = (from_snapshot, to_snapshot)
if list_snapshots or (from_snapshot and to_snapshot):
if any(file_opts):
raise typer.BadParameter(
"--list-snapshots and --from/to-snapshot cannot be specified with any of --from-disk, --to-disk, --from-memory, --to-memory")
if list_snapshots:
table, _ = do_list_snapshots(input_dir)
print(table)
return
# If no specific opts given, list the snapshots.
if not any(file_opts) and not any(disk_opts) and not any(memory_opts) and not any(snapshot_opts):
table, _ = do_list_snapshots(input_dir)
print(table)
return
if any(snapshot_opts):
if not all(snapshot_opts):
raise typer.BadParameter(
"Need both --to-snapshot and --from-snapshot when using one.")
_, snapshots = do_list_snapshots(input_dir)
from_disk = snapshots[from_snapshot]["disk_filename"]
to_disk = snapshots[to_snapshot]["disk_filename"]
from_memory = snapshots[from_snapshot]["memory_filename"]
to_memory = snapshots[to_snapshot]["memory_filename"]
else:
if any(disk_opts) and not all(disk_opts):
raise typer.BadParameter(
"Need both --to-disk and --from-disk.")
else:
from_disk = from_disk.name
to_disk = to_disk.name
if any(memory_opts) and not all(memory_opts):
raise typer.BadParameter(
"Need both --to-memory and --from-memory.")
else:
from_memory = from_memory.name
to_memory = to_memory.name
filter_path_json = json.dumps(filter_path)
ignore_path_json = json.dumps(ignore_path)
# Unset paths if not used, so config.py resolves USE_DISK and USE_MEMORY correctly.
if not use_disk:
from_disk = to_disk = ""
if not use_memory:
from_memory = to_memory = ""
# Convert to filenames, not file paths.
env_var_mapping = {
"FROM_DISK_IMAGE_FILENAME": from_disk,
"TO_DISK_IMAGE_FILENAME": to_disk,
"FROM_MEMORY_IMAGE_FILENAME": from_memory,
"TO_MEMORY_IMAGE_FILENAME": to_memory,
"SNAPSHOT_DIR": input_dir,
"FILTER_PATH_JSON": filter_path_json,
"IGNORE_PATH_JSON": ignore_path_json,
"IGNORE_PROCESSES_REGEX": ignore_processes,
"PARTITION_IDENTIFIER": partition,
"USE_CACHE": str(cache),
"USE_DISK": str(use_disk),
"USE_MEMORY": str(use_memory),
"DIFF_IGNORE_BINARY": str(not include_binary),
"VMDIFF_DEV": str(debug)
}
env = os.environ.copy()
env.update(env_var_mapping)
# Generate the docker compose run CLI args to mount the files.
volume_maps = [
f"{input_dir}:/snapshots"
]
volume_args_list = []
for volume_map in volume_maps:
volume_args_list.append("-v")
volume_args_list.append(shlex.quote(volume_map))
parts = "docker compose --env-file .env run -i".split(
" ")
parts.extend(volume_args_list)
parts.extend(["memdiff"])
command = " ".join(parts)
if use_memory and not show:
run_command(command, "[green] :gear: Processing memory dump...", env)
parts[-1] = "vmdiff"
command = " ".join(parts)
if not show:
if use_disk:
message = "[green] :gear: Reading and diffing virtual disks..."
else:
message = "[green] :gear: Diffing memory..."
run_command(
command, message, env)
print("Now run with --show to display results in browser")
if show:
command = "docker compose --env-file .env up app"
print("[green] :gear: Serving results on http://localhost:5000")
run_command(
command, "[green] :gear: Serving results on localhost:5000...", env)
def do_list_snapshots(snapshot_dir):
contents = os.listdir(snapshot_dir)
vmsd_filename = None
for filename in contents:
if filename.endswith(".vmsd"):
vmsd_filename = filename
if vmsd_filename is None:
raise typer.BadParameter(
"Couldn't find .vmsd file in input directory, so can't list snapshots.")
vmsd_path = os.path.join(snapshot_dir, vmsd_filename)
vmsd = parse_vmsd(vmsd_path)
table = Table(title=f"Found snapshots in {snapshot_dir}")
table.add_column("ID", style="bold")
table.add_column("Parent ID", style="bold", max_width=6)
table.add_column("Creation time", style="yellow", no_wrap=True)
table.add_column("Disk file", style="magenta", )
table.add_column("Memory file", style="magenta")
table.add_column("Description", style="green")
# Sort snapshots by create time.
for sid, snapshot in sorted(vmsd.items(), key=lambda tup: tup[1].get("create_time")):
create_time = snapshot.get("create_time")
disk_filename = snapshot.get("disk_filename")
memory_filename = snapshot.get("memory_filename")
description = snapshot.get("displayName")
table.add_row(sid, snapshot.get("parent"), create_time,
disk_filename, memory_filename, description)
return table, vmsd
def parse_vmsd(vmsd_path: os.PathLike):
def convert_time(low, high):
low = int(low)
high = int(high)
combinedTimeMsec = float(
(high * 2**32) + unpack('I', pack('i', low))[0])
combinedTimeSec = combinedTimeMsec / 1000000
timestamp = datetime.fromtimestamp(combinedTimeSec)
return timestamp.strftime('%Y-%m-%d %H:%M:%S')
with open(vmsd_path) as f:
lines = f.readlines()
sid2uid = {}
snapshots = {}
for line in lines:
# Ignore encoding.
if line.startswith(".encoding"):
continue
LINE = re.compile(r'(?P<key>(\w+\.?)+) = "(?P<value>[^"]+)"')
match = re.search(LINE, line)
key = match.group("key")
keys = key.split(".")
subkey = keys[-1]
value = match.group("value")
# Ignore "snapshot" rather than "snapshot0, snapshot1", etc.
sid_match = re.match(r"snapshot(\d+)$", keys[0])
if not sid_match:
continue
sid = sid_match.group(0)
if subkey == "uid":
uid = value
sid2uid[sid] = uid
snapshots[uid] = {}
else:
uid = sid2uid[sid]
if subkey == "fileName":
subkey = "disk_filename"
# It's fiiiiine.
if subkey == "filename":
subkey = "memory_filename"
# The .vmsd file lists memory dumps as .vmsn, but we're interested in the actual .vmem dumps.
value = value.replace(".vmsn", ".vmem")
snapshots[uid][subkey] = value
for sid, snapshot in snapshots.items():
create_time = convert_time(
snapshot["createTimeLow"], snapshot["createTimeHigh"])
snapshot["create_time"] = create_time
return snapshots
if __name__ == "__main__":
typer.run(main)
gitextract_xvezqapj/ ├── .dockerignore ├── .github/ │ └── ISSUE_TEMPLATE/ │ ├── bug_report.md │ └── feature_request.md ├── .gitignore ├── CODE_OF_CONDUCT.md ├── CONTRIBUTING.md ├── Dockerfile ├── LICENSE ├── README.md ├── __init__.py ├── backend/ │ ├── Dockerfile │ ├── __init__.py │ ├── diff_tree.py │ ├── diffcache.py │ ├── diskdiff.py │ ├── file_entry_lister.py │ ├── memdiff.py │ ├── pyvmdk_delta.py │ ├── requirements.txt │ ├── unified_diff.py │ ├── utils.py │ ├── vmdiff.py │ └── vmdk_file_io.py ├── config.py ├── docker-compose.yml ├── frontend/ │ ├── .dockerignore │ ├── .gitignore │ ├── README.md │ ├── package.json │ ├── public/ │ │ ├── index.html │ │ └── manifest.json │ ├── src/ │ │ ├── App.css │ │ ├── App.test.tsx │ │ ├── App.tsx │ │ ├── index.css │ │ ├── index.tsx │ │ ├── react-app-env.d.ts │ │ ├── reportWebVitals.ts │ │ └── setupTests.ts │ └── tsconfig.json ├── memory-processing/ │ ├── Dockerfile │ └── memdiff.sh ├── requirements.txt ├── server.py └── vmdiff
SYMBOL INDEX (101 symbols across 13 files)
FILE: backend/diff_tree.py
class DiffTree (line 4) | class DiffTree(object):
method __init__ (line 6) | def __init__(self, differ):
method merge (line 23) | def merge(self, other):
method get_tree (line 30) | def get_tree(self):
method get_children_map (line 33) | def get_children_map(self):
method get_children (line 36) | def get_children(self, parent_node):
method add_child (line 42) | def add_child(self, parent_node, child):
method create_node (line 48) | def create_node(self, path: str, is_dir=True, is_leaf=False):
method create_root_process_node (line 108) | def create_root_process_node(self):
method get_parent (line 127) | def get_parent(self, node):
method create_file_tree (line 141) | def create_file_tree(self):
method traverse (line 215) | def traverse(self, node):
FILE: backend/diffcache.py
class DiffCache (line 12) | class DiffCache(object):
method __init__ (line 14) | def __init__(self, run_disk_path, run_tree_path, run_process_path=None):
method cache_results (line 21) | def cache_results(self, results):
method ensure_posix (line 64) | def ensure_posix(self, path):
method cache_process_results (line 71) | def cache_process_results(self, results):
method get_process_diff_from_cache (line 82) | def get_process_diff_from_cache(self, pid):
method get_diff_from_cache (line 94) | def get_diff_from_cache(self, vm_path):
method get_diff (line 117) | def get_diff(self, key):
method cache_exists (line 124) | def cache_exists(self):
method process_cache_exists (line 127) | def process_cache_exists(self):
method get_cached_results (line 130) | def get_cached_results(self):
method tree_cache_exists (line 159) | def tree_cache_exists(self):
method cache_tree (line 162) | def cache_tree(self, tree):
method get_tree_data_from_cache (line 169) | def get_tree_data_from_cache(self):
FILE: backend/diskdiff.py
class DiskDiffer (line 24) | class DiskDiffer(object):
method __init__ (line 50) | def __init__(self, a_file_lister, b_file_lister,
method get_a_file (line 88) | def get_a_file(self, path):
method get_b_file (line 104) | def get_b_file(self, path):
method get_file (line 120) | def get_file(self, path):
method diff_all (line 127) | def diff_all(self):
method diff (line 148) | def diff(self, path):
method _should_ignore (line 277) | def _should_ignore(self, path):
method _make_diff_kwargs (line 299) | def _make_diff_kwargs(self, path, pseudo_file_type=None):
method add_header (line 317) | def add_header(self, delta, header):
method merge_diffs (line 327) | def merge_diffs(self, stat_diff, times_diff, attribute_diff, contents_...
method create_hunk_diff (line 355) | def create_hunk_diff(self, diff, name):
method split_diff (line 368) | def split_diff(self, diff):
method equal (line 373) | def equal(self, file1, file2):
method _is_binary (line 395) | def _is_binary(self, file):
method _compare_binaries (line 420) | def _compare_binaries(self, file1, file2):
method _hash_file (line 424) | def _hash_file(self, file_entry):
method get_stat_sequence (line 466) | def get_stat_sequence(self, file):
method get_times_sequence (line 481) | def get_times_sequence(self, file):
method get_attribute_sequence (line 490) | def get_attribute_sequence(self, file):
method get_contents_sequence (line 517) | def get_contents_sequence(self, file):
method _equal_stat (line 539) | def _equal_stat(self, file1, file2):
method _equal_times (line 549) | def _equal_times(self, file1, file2):
method _equal_attributes (line 557) | def _equal_attributes(self, file1, file2):
method get_run_id (line 574) | def get_run_id(self):
method get_changed_files (line 577) | def get_changed_files(self):
FILE: backend/file_entry_lister.py
class FileEntryLister (line 12) | class FileEntryLister(volume_scanner.VolumeScanner):
method __init__ (line 20) | def __init__(self, source, volume_scanner_options, mediator=None, igno...
method _GetDisplayPath (line 54) | def _GetDisplayPath(self, path_spec, path_segments, data_stream_name):
method _ShouldListDir (line 86) | def _ShouldListDir(self, file_entry):
method _ListFileEntry (line 101) | def _ListFileEntry(
method ListFileEntries (line 136) | def ListFileEntries(self):
method GetFileEntry (line 150) | def GetFileEntry(self, path):
FILE: backend/memdiff.py
class MemoryDiffer (line 12) | class MemoryDiffer(object):
method __init__ (line 16) | def __init__(self, from_pslist, to_pslist, from_envars=None, to_envars...
method diff_all (line 28) | def diff_all(self):
method diff (line 38) | def diff(self, pid):
method add_envars (line 110) | def add_envars(self, from_envars, to_envars):
method add_cmdline (line 132) | def add_cmdline(self, from_cmdline, to_cmdline):
method _make_id (line 150) | def _make_id(self, proc):
method _make_title (line 156) | def _make_title(self, proc):
method _list_by_id (line 163) | def _list_by_id(self, pslist):
method _to_string (line 174) | def _to_string(self, proc):
method get_ppid (line 182) | def get_ppid(self, pid):
method add_header (line 192) | def add_header(self, delta, header):
FILE: backend/pyvmdk_delta.py
class handle (line 6) | class handle(object):
method __init__ (line 13) | def __init__(self):
method open (line 17) | def open(self, path):
method __getattribute__ (line 42) | def __getattribute__(self, name):
FILE: backend/unified_diff.py
class UnifiedDiff (line 2) | class UnifiedDiff(object):
method __init__ (line 4) | def __init__(self, diff_lines, is_dir=None, ppid=None, title=None):
method __next__ (line 31) | def __next__(self):
FILE: backend/utils.py
function ensure_posix (line 3) | def ensure_posix(path):
FILE: backend/vmdiff.py
class CachingStdinInputReader (line 33) | class CachingStdinInputReader(command_line.StdinInputReader):
method __init__ (line 36) | def __init__(self, encoding='utf-8'):
method Read (line 44) | def Read(self):
function load_memory_results (line 49) | def load_memory_results():
function dump_api_data (line 68) | def dump_api_data(cache):
function Main (line 112) | def Main():
FILE: backend/vmdk_file_io.py
class VMDKFile (line 14) | class VMDKFile(file_object_io.FileObjectIO):
method _OpenFileObject (line 17) | def _OpenFileObject(self, path_spec):
method open_extent_data_files (line 57) | def open_extent_data_files(self, vmdk_handle, parent_path_spec):
method get_size (line 114) | def get_size(self):
FILE: config.py
function as_bool (line 7) | def as_bool(var):
function get_run_id (line 79) | def get_run_id():
FILE: frontend/src/App.tsx
type DiffNodeProps (line 25) | type DiffNodeProps = {
type DiffNode (line 34) | type DiffNode = DataNode & Partial<DiffNodeProps>;
constant DEMO (line 36) | let DEMO = !(process.env.VMDIFF_DEMO === "false")
constant BASE_URL (line 37) | let BASE_URL = ""
function updateTreeData (line 131) | function updateTreeData(
FILE: server.py
function get_children_handler (line 55) | def get_children_handler():
function get_diff (line 66) | def get_diff():
function get_changed_files (line 85) | def get_changed_files():
function json (line 94) | def json(path):
function index (line 100) | def index():
Condensed preview — 45 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (135K chars).
[
{
"path": ".dockerignore",
"chars": 448,
"preview": "**/__pycache__\r\n**/.venv\r\n**/.classpath\r\n**/.dockerignore\r\n**/.env\r\n**/.git\r\n**/.gitignore\r\n**/.project\r\n**/.settings\r\n*"
},
{
"path": ".github/ISSUE_TEMPLATE/bug_report.md",
"chars": 834,
"preview": "---\nname: Bug report\nabout: Create a report to help us improve\ntitle: ''\nlabels: ''\nassignees: ''\n\n---\n\n**Describe the b"
},
{
"path": ".github/ISSUE_TEMPLATE/feature_request.md",
"chars": 595,
"preview": "---\nname: Feature request\nabout: Suggest an idea for this project\ntitle: ''\nlabels: ''\nassignees: ''\n\n---\n\n**Is your fea"
},
{
"path": ".gitignore",
"chars": 303,
"preview": "acab\nautopsy*\n__pycache__\nlibvmdl\nsleuthkit-*\n.cache\n.DS_Store\n.vscode\n*.txt\ndiffs/\nnode_modules\n.changed_files_cache/\nr"
},
{
"path": "CODE_OF_CONDUCT.md",
"chars": 5243,
"preview": "# Contributor Covenant Code of Conduct\n\n## Our Pledge\n\nWe as members, contributors, and leaders pledge to make participa"
},
{
"path": "CONTRIBUTING.md",
"chars": 839,
"preview": "## Contributing\n\n* I’m not going be working on/maintaining vmdiff for at least 12 months, maybe ever\n* I’d _love_ for so"
},
{
"path": "Dockerfile",
"chars": 1181,
"preview": "FROM node:lts-alpine as frontend\r\nWORKDIR /app\r\nENV PATH /app/node_modules/.bin:$PATH\r\nCOPY frontend ./\r\nRUN yarn instal"
},
{
"path": "LICENSE",
"chars": 1063,
"preview": "MIT License\n\nCopyright (c) 2023 vmdiff\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof "
},
{
"path": "README.md",
"chars": 13175,
"preview": "# vmdiff\n\n:\n\n def __init__(self, differ):\n self.nodes = {}\n self.children_ma"
},
{
"path": "backend/diffcache.py",
"chars": 6318,
"preview": "import pathlib\nimport os\nimport logging\nimport json\n\nimport unified_diff\nimport utils\n\nDIR_META_FILENAME = \".__this_dire"
},
{
"path": "backend/diskdiff.py",
"chars": 19402,
"preview": "\nimport difflib\nimport hashlib\n\nimport logging\nimport stat as statlib\n\nimport sys\nimport os\nimport inspect\n\nimport unifi"
},
{
"path": "backend/file_entry_lister.py",
"chars": 5590,
"preview": "import re\nimport logging\n\n\nfrom dfvfs.helpers import volume_scanner\nfrom dfvfs.lib import definitions as dfvfs_definitio"
},
{
"path": "backend/memdiff.py",
"chars": 6146,
"preview": "\n\nimport collections\nimport difflib\nimport json\nimport re\nimport logging\n\nimport unified_diff\n\n\nclass MemoryDiffer(objec"
},
{
"path": "backend/pyvmdk_delta.py",
"chars": 1719,
"preview": "\nimport pyvmdk\nimport os\n\n\nclass handle(object):\n\n \"\"\"Trick dfvfs into keeping the parent handles in scope by storing"
},
{
"path": "backend/requirements.txt",
"chars": 30,
"preview": "libvmdk-python\ndfvfs==20220816"
},
{
"path": "backend/unified_diff.py",
"chars": 941,
"preview": "\nclass UnifiedDiff(object):\n\n def __init__(self, diff_lines, is_dir=None, ppid=None, title=None):\n self.diff_l"
},
{
"path": "backend/utils.py",
"chars": 299,
"preview": "import pathlib \n\ndef ensure_posix(path):\n if path.startswith(\"\\\\\"):\n # Force POSIX path so that we can create "
},
{
"path": "backend/vmdiff.py",
"chars": 7716,
"preview": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"Script to list file entries.\"\"\"\n\nfrom dfvfs.helpers import command_line"
},
{
"path": "backend/vmdk_file_io.py",
"chars": 4940,
"preview": "# -*- coding: utf-8 -*-\n\"\"\"The VMDK image file-like object.\"\"\"\n# Copy of `vmdk_file_io` we patch and copy into the docke"
},
{
"path": "config.py",
"chars": 2917,
"preview": "import os\nimport hashlib\nimport logging\nimport json\n\n\ndef as_bool(var):\n if var is None:\n return False\n\n va"
},
{
"path": "docker-compose.yml",
"chars": 788,
"preview": "version: '3.4'\r\n\r\nservices:\r\n vmdiff:\r\n image: vmdiff/vmdiff\r\n build:\r\n context: ./\r\n dockerfile: ./bac"
},
{
"path": "frontend/.dockerignore",
"chars": 324,
"preview": "**/.classpath\r\n**/.dockerignore\r\n**/.env\r\n**/.git\r\n**/.gitignore\r\n**/.project\r\n**/.settings\r\n**/.toolstarget\r\n**/.vs\r\n**"
},
{
"path": "frontend/.gitignore",
"chars": 310,
"preview": "# See https://help.github.com/articles/ignoring-files/ for more about ignoring files.\n\n# dependencies\n/node_modules\n/.pn"
},
{
"path": "frontend/README.md",
"chars": 2099,
"preview": "# Getting Started with Create React App\n\nThis project was bootstrapped with [Create React App](https://github.com/facebo"
},
{
"path": "frontend/package.json",
"chars": 1254,
"preview": "{\n \"name\": \"vmdiff-regrets\",\n \"version\": \"0.1.0\",\n \"private\": true,\n \"homepage\": \".\",\n \"dependencies\": {\n \"@test"
},
{
"path": "frontend/public/index.html",
"chars": 1679,
"preview": "<!DOCTYPE html>\n<html lang=\"en\">\n\n<head>\n <meta charset=\"utf-8\" />\n <link rel=\"icon\" href=\"%PUBLIC_URL%/favicon.ico\" /"
},
{
"path": "frontend/public/manifest.json",
"chars": 286,
"preview": "{\n \"short_name\": \"vmdiff\",\n \"name\": \"vmdiff\",\n \"icons\": [\n {\n \"src\": \"favicon.ico\",\n \"sizes\": \"64x64 32x"
},
{
"path": "frontend/src/App.css",
"chars": 82,
"preview": "@import '~antd/dist/antd.css';\n\ndiv.ant-tree-treenode {\n width: max-content;\n}\n"
},
{
"path": "frontend/src/App.test.tsx",
"chars": 273,
"preview": "import React from 'react';\nimport { render, screen } from '@testing-library/react';\nimport App from './App';\n\ntest('rend"
},
{
"path": "frontend/src/App.tsx",
"chars": 10288,
"preview": "import React, { useEffect, useState } from 'react';\n\nimport { FolderOutlined, ExperimentOutlined } from '@ant-design/ico"
},
{
"path": "frontend/src/index.css",
"chars": 365,
"preview": "body {\n margin: 0;\n font-family: -apple-system, BlinkMacSystemFont, 'Segoe UI', 'Roboto', 'Oxygen',\n 'Ubuntu', 'Can"
},
{
"path": "frontend/src/index.tsx",
"chars": 554,
"preview": "import React from 'react';\nimport ReactDOM from 'react-dom/client';\nimport './index.css';\nimport App from './App';\nimpor"
},
{
"path": "frontend/src/react-app-env.d.ts",
"chars": 40,
"preview": "/// <reference types=\"react-scripts\" />\n"
},
{
"path": "frontend/src/reportWebVitals.ts",
"chars": 425,
"preview": "import { ReportHandler } from 'web-vitals';\n\nconst reportWebVitals = (onPerfEntry?: ReportHandler) => {\n if (onPerfEntr"
},
{
"path": "frontend/src/setupTests.ts",
"chars": 241,
"preview": "// jest-dom adds custom jest matchers for asserting on DOM nodes.\n// allows you to do things like:\n// expect(element).to"
},
{
"path": "frontend/tsconfig.json",
"chars": 534,
"preview": "{\n \"compilerOptions\": {\n \"target\": \"es5\",\n \"lib\": [\n \"dom\",\n \"dom.iterable\",\n \"esnext\"\n ],\n "
},
{
"path": "memory-processing/Dockerfile",
"chars": 890,
"preview": "# For more information, please refer to https://aka.ms/vscode-docker-python\nFROM sk4la/volatility3\n\n# Keeps Python from "
},
{
"path": "memory-processing/memdiff.sh",
"chars": 986,
"preview": "#! /bin/bash\nif [ \"${#FROM_MEMORY_IMAGE_FILENAME}\" -lt 1 ]; then\n echo \"No memory image filename given by ${FROM_MEMO"
},
{
"path": "requirements.txt",
"chars": 197,
"preview": "# To ensure app dependencies are ported from your virtual environment/host machine into your container, run 'pip freeze "
},
{
"path": "server.py",
"chars": 2464,
"preview": "import inspect\nimport os\nimport sys\nimport time\n\nimport logging\n\nfrom flask import Flask, jsonify, request, render_templ"
},
{
"path": "vmdiff",
"chars": 12556,
"preview": "#! env python3\n\"\"\"\nvmdiff CLI\n\"\"\"\n\n__author__ = \"Atlassian Icarus Labs\"\n__version__ = \"0.1.0\"\n__license__ = \"MIT\"\n\nfrom "
}
]
About this extraction
This page contains the full source code of the vmdiff/vmdiff-prototype GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 45 files (121.4 KB), approximately 28.6k tokens, and a symbol index with 101 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.