[
{
"path": ".all-contributorsrc",
"content": "{\n \"projectName\": \"so-vits-svc-fork\",\n \"projectOwner\": \"voicepaw\",\n \"repoType\": \"github\",\n \"repoHost\": \"https://github.com\",\n \"files\": [\"README.md\"],\n \"imageSize\": 80,\n \"commit\": true,\n \"commitConvention\": \"angular\",\n \"contributors\": [\n {\n \"login\": \"34j\",\n \"name\": \"34j\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/55338215?v=4\",\n \"profile\": \"https://github.com/34j\",\n \"contributions\": [\n \"code\",\n \"ideas\",\n \"doc\",\n \"example\",\n \"infra\",\n \"maintenance\",\n \"review\",\n \"test\",\n \"tutorial\",\n \"promotion\",\n \"bug\"\n ]\n },\n {\n \"login\": \"GarrettConway\",\n \"name\": \"GarrettConway\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/22782004?v=4\",\n \"profile\": \"https://github.com/GarrettConway\",\n \"contributions\": [\"code\", \"bug\", \"doc\", \"review\"]\n },\n {\n \"login\": \"BlueAmulet\",\n \"name\": \"BlueAmulet\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/43395286?v=4\",\n \"profile\": \"https://github.com/BlueAmulet\",\n \"contributions\": [\"ideas\", \"question\", \"code\", \"maintenance\"]\n },\n {\n \"login\": \"ThrowawayAccount01\",\n \"name\": \"ThrowawayAccount01\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/125531852?v=4\",\n \"profile\": \"https://github.com/ThrowawayAccount01\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"MashiroSA\",\n \"name\": \"緋\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/40637516?v=4\",\n \"profile\": \"https://github.com/MashiroSA\",\n \"contributions\": [\"doc\", \"bug\"]\n },\n {\n \"login\": \"Lordmau5\",\n \"name\": \"Lordmau5\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/1345036?v=4\",\n \"profile\": \"https://github.com/Lordmau5\",\n \"contributions\": [\n \"bug\",\n \"code\",\n \"ideas\",\n \"maintenance\",\n \"question\",\n \"userTesting\"\n ]\n },\n {\n \"login\": \"DL909\",\n \"name\": \"DL909\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/71912115?v=4\",\n \"profile\": \"https://github.com/DL909\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"Satisfy256\",\n \"name\": \"Satisfy256\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/101394399?v=4\",\n \"profile\": \"https://github.com/Satisfy256\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"pierluigizagaria\",\n \"name\": \"Pierluigi Zagaria\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/57801386?v=4\",\n \"profile\": \"https://github.com/pierluigizagaria\",\n \"contributions\": [\"userTesting\"]\n },\n {\n \"login\": \"ruckusmattster\",\n \"name\": \"ruckusmattster\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/77196088?v=4\",\n \"profile\": \"https://github.com/ruckusmattster\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"Desuka-art\",\n \"name\": \"Desuka-art\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/111822082?v=4\",\n \"profile\": \"https://github.com/Desuka-art\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"heyfixit\",\n \"name\": \"heyfixit\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/41658450?v=4\",\n \"profile\": \"https://github.com/heyfixit\",\n \"contributions\": [\"doc\"]\n },\n {\n \"login\": \"nerdyrodent\",\n \"name\": \"Nerdy Rodent\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/74688049?v=4\",\n \"profile\": \"https://www.youtube.com/c/NerdyRodent\",\n \"contributions\": [\"video\"]\n },\n {\n \"login\": \"xieyumc\",\n \"name\": \"谢宇\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/47858007?v=4\",\n \"profile\": \"https://github.com/xieyumc\",\n \"contributions\": [\"doc\"]\n },\n {\n \"login\": \"ColdCawfee\",\n \"name\": \"ColdCawfee\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/79474598?v=4\",\n \"profile\": \"https://github.com/ColdCawfee\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"sbersier\",\n \"name\": \"sbersier\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/34165937?v=4\",\n \"profile\": \"https://github.com/sbersier\",\n \"contributions\": [\"ideas\", \"userTesting\", \"bug\"]\n },\n {\n \"login\": \"Meldoner\",\n \"name\": \"Meldoner\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/43951115?v=4\",\n \"profile\": \"https://github.com/Meldoner\",\n \"contributions\": [\"bug\", \"ideas\", \"code\"]\n },\n {\n \"login\": \"mmodeusher\",\n \"name\": \"mmodeusher\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/46575920?v=4\",\n \"profile\": \"https://github.com/mmodeusher\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"AlonDan\",\n \"name\": \"AlonDan\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/21152334?v=4\",\n \"profile\": \"https://github.com/AlonDan\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"Likkkez\",\n \"name\": \"Likkkez\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/44336181?v=4\",\n \"profile\": \"https://github.com/Likkkez\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"DuctTapeGames\",\n \"name\": \"Duct Tape Games\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/84365142?v=4\",\n \"profile\": \"https://github.com/DuctTapeGames\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"hxl9654\",\n \"name\": \"Xianglong He\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/6624983?v=4\",\n \"profile\": \"https://tec.hxlxz.com/\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"75aosu\",\n \"name\": \"75aosu\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/79185331?v=4\",\n \"profile\": \"https://github.com/75aosu\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"tonyco82\",\n \"name\": \"tonyco82\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/56610534?v=4\",\n \"profile\": \"https://github.com/tonyco82\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"yxlllc\",\n \"name\": \"yxlllc\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/33565655?v=4\",\n \"profile\": \"https://github.com/yxlllc\",\n \"contributions\": [\"ideas\", \"code\"]\n },\n {\n \"login\": \"outhipped\",\n \"name\": \"outhipped\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/116147475?v=4\",\n \"profile\": \"https://github.com/outhipped\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"escoolioinglesias\",\n \"name\": \"escoolioinglesias\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/73505402?v=4\",\n \"profile\": \"https://github.com/escoolioinglesias\",\n \"contributions\": [\"bug\", \"userTesting\", \"video\"]\n },\n {\n \"login\": \"Blacksingh\",\n \"name\": \"Blacksingh\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/130872856?v=4\",\n \"profile\": \"https://github.com/Blacksingh\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"tybantarnusa\",\n \"name\": \"Mgs. M. Thoyib Antarnusa\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/9532857?v=4\",\n \"profile\": \"http://tybantarnusa.com\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"ZeroHackz\",\n \"name\": \"Exosfeer\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/15729496?v=4\",\n \"profile\": \"https://github.com/ZeroHackz\",\n \"contributions\": [\"bug\", \"code\"]\n },\n {\n \"login\": \"guranon\",\n \"name\": \"guranon\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/130421189?v=4\",\n \"profile\": \"https://github.com/guranon\",\n \"contributions\": [\"bug\", \"ideas\", \"code\"]\n },\n {\n \"login\": \"alexanderkoumis\",\n \"name\": \"Alexander Koumis\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/5108856?v=4\",\n \"profile\": \"https://github.com/alexanderkoumis\",\n \"contributions\": [\"code\"]\n },\n {\n \"login\": \"acekagami\",\n \"name\": \"acekagami\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/127201056?v=4\",\n \"profile\": \"https://github.com/acekagami\",\n \"contributions\": [\"translation\"]\n },\n {\n \"login\": \"Highupech\",\n \"name\": \"Highupech\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/114140670?v=4\",\n \"profile\": \"https://github.com/Highupech\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"Scorpi\",\n \"name\": \"Scorpi\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/969654?v=4\",\n \"profile\": \"https://github.com/Scorpi\",\n \"contributions\": [\"code\"]\n },\n {\n \"login\": \"maximxlss\",\n \"name\": \"Maximxls\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/29152154?v=4\",\n \"profile\": \"http://maximxlss.github.io\",\n \"contributions\": [\"code\"]\n },\n {\n \"login\": \"Star3Lord\",\n \"name\": \"Star3Lord\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/57606931?v=4\",\n \"profile\": \"https://github.com/Star3Lord\",\n \"contributions\": [\"bug\", \"code\"]\n },\n {\n \"login\": \"Ph0rk0z\",\n \"name\": \"Forkoz\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/59298527?v=4\",\n \"profile\": \"https://github.com/Ph0rk0z\",\n \"contributions\": [\"bug\", \"code\"]\n },\n {\n \"login\": \"Zerui18\",\n \"name\": \"Zerui Chen\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/34794550?v=4\",\n \"profile\": \"https://github.com/Zerui18\",\n \"contributions\": [\"code\", \"ideas\"]\n },\n {\n \"login\": \"shenberg\",\n \"name\": \"Roee Shenberg\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/653972?v=4\",\n \"profile\": \"https://www.meimadix.com\",\n \"contributions\": [\"userTesting\", \"ideas\", \"code\"]\n },\n {\n \"login\": \"ShinyJustyZ\",\n \"name\": \"Justas\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/65282440?v=4\",\n \"profile\": \"https://github.com/ShinyJustyZ\",\n \"contributions\": [\"bug\", \"code\"]\n },\n {\n \"login\": \"Onako2\",\n \"name\": \"Onako2\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/79749977?v=4\",\n \"profile\": \"https://onako2.github.io/\",\n \"contributions\": [\"doc\"]\n },\n {\n \"login\": \"4ll0w3v1l\",\n \"name\": \"4ll0w3v1l\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/53517147?v=4\",\n \"profile\": \"https://github.com/4ll0w3v1l\",\n \"contributions\": [\"code\"]\n },\n {\n \"login\": \"SamuelSwartzberg\",\n \"name\": \"j5y0V6b\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/16353439?v=4\",\n \"profile\": \"https://github.com/SamuelSwartzberg\",\n \"contributions\": [\"security\"]\n },\n {\n \"login\": \"marcellocirelli\",\n \"name\": \"marcellocirelli\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/51972090?v=4\",\n \"profile\": \"https://github.com/marcellocirelli\",\n \"contributions\": [\"bug\"]\n },\n {\n \"login\": \"Priyanshu-hawk\",\n \"name\": \"Priyanshu Patel\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/76026651?v=4\",\n \"profile\": \"https://github.com/Priyanshu-hawk\",\n \"contributions\": [\"code\"]\n },\n {\n \"login\": \"annagorshunova\",\n \"name\": \"Anna Gorshunova\",\n \"avatar_url\": \"https://avatars.githubusercontent.com/u/5199204?v=4\",\n \"profile\": \"https://github.com/annagorshunova\",\n \"contributions\": [\"bug\", \"code\"]\n }\n ],\n \"contributorsPerLine\": 7,\n \"skipCi\": true,\n \"commitType\": \"docs\"\n}\n"
},
{
"path": ".codespellrc",
"content": "[codespell]\nignore-words-list = socio-economic\n"
},
{
"path": ".copier-answers.yml",
"content": "# Changes here will be overwritten by Copier\n_commit: 2e4f7d0\n_src_path: gh:34j/pypackage-template\ncopyright_year: '2023'\ndocumentation: true\nemail: 34j.95a2p@simplelogin.com\nfull_name: 34j\ngithub_username: voicepaw\nhas_cli: false\ninitial_commit: false\nis_django_package: false\nopen_source_license: MIT\nopen_with_editor: false\npackage_name: so_vits_svc_fork\nproject_name: SoftVC VITS Singing Voice Conversion Fork\nproject_short_description: A fork of so-vits-svc.\nproject_slug: so-vits-svc-fork\nrun_uv_sync: false\nsetup_pre_commit: false\n\n"
},
{
"path": ".dockerignore",
"content": "# Ignore everything\n*\n"
},
{
"path": ".editorconfig",
"content": "# http://editorconfig.org\n\nroot = true\n\n[*]\nindent_style = space\nindent_size = 4\ntrim_trailing_whitespace = true\ninsert_final_newline = true\ncharset = utf-8\nend_of_line = lf\n\n[*.bat]\nindent_style = tab\nend_of_line = crlf\n\n[LICENSE]\ninsert_final_newline = false\n\n[Makefile]\nindent_style = tab\n"
},
{
"path": ".flake8",
"content": "[flake8]\nexclude = docs\nmax-line-length = 88\nignore = E203, E501, E741, E402, E712, W503, E731, E711, E226\n"
},
{
"path": ".github/CODE_OF_CONDUCT.md",
"content": "# Contributor Covenant Code of Conduct\n\n## Our Pledge\n\nWe as members, contributors, and leaders pledge to make participation in our\ncommunity a harassment-free experience for everyone, regardless of age, body\nsize, visible or invisible disability, ethnicity, sex characteristics, gender\nidentity and expression, level of experience, education, socio-economic status,\nnationality, personal appearance, race, religion, or sexual identity\nand orientation.\n\nWe pledge to act and interact in ways that contribute to an open, welcoming,\ndiverse, inclusive, and healthy community.\n\n## Our Standards\n\nExamples of behavior that contributes to a positive environment for our\ncommunity include:\n\n- Demonstrating empathy and kindness toward other people\n- Being respectful of differing opinions, viewpoints, and experiences\n- Giving and gracefully accepting constructive feedback\n- Accepting responsibility and apologizing to those affected by our mistakes,\n and learning from the experience\n- Focusing on what is best not just for us as individuals, but for the\n overall community\n\nExamples of unacceptable behavior include:\n\n- The use of sexualized language or imagery, and sexual attention or\n advances of any kind\n- Trolling, insulting or derogatory comments, and personal or political attacks\n- Public or private harassment\n- Publishing others' private information, such as a physical or email\n address, without their explicit permission\n- Other conduct which could reasonably be considered inappropriate in a\n professional setting\n\n## Enforcement Responsibilities\n\nCommunity leaders are responsible for clarifying and enforcing our standards of\nacceptable behavior and will take appropriate and fair corrective action in\nresponse to any behavior that they deem inappropriate, threatening, offensive,\nor harmful.\n\nCommunity leaders have the right and responsibility to remove, edit, or reject\ncomments, commits, code, wiki edits, issues, and other contributions that are\nnot aligned to this Code of Conduct, and will communicate reasons for moderation\ndecisions when appropriate.\n\n## Scope\n\nThis Code of Conduct applies within all community spaces, and also applies when\nan individual is officially representing the community in public spaces.\nExamples of representing our community include using an official e-mail address,\nposting via an official social media account, or acting as an appointed\nrepresentative at an online or offline event.\n\n## Enforcement\n\nInstances of abusive, harassing, or otherwise unacceptable behavior may be\nreported by contacting @voicepaw. All complaints will be reviewed and\ninvestigated promptly and fairly.\n\nAll community leaders are obligated to respect the privacy and security of the\nreporter of any incident.\n\n## Enforcement Guidelines\n\nCommunity leaders will follow these Community Impact Guidelines in determining\nthe consequences for any action they deem in violation of this Code of Conduct:\n\n### 1. Correction\n\n**Community Impact**: Use of inappropriate language or other behavior deemed\nunprofessional or unwelcome in the community.\n\n**Consequence**: A private, written warning from community leaders, providing\nclarity around the nature of the violation and an explanation of why the\nbehavior was inappropriate. A public apology may be requested.\n\n### 2. Warning\n\n**Community Impact**: A violation through a single incident or series\nof actions.\n\n**Consequence**: A warning with consequences for continued behavior. No\ninteraction with the people involved, including unsolicited interaction with\nthose enforcing the Code of Conduct, for a specified period of time. This\nincludes avoiding interactions in community spaces as well as external channels\nlike social media. Violating these terms may lead to a temporary or\npermanent ban.\n\n### 3. Temporary Ban\n\n**Community Impact**: A serious violation of community standards, including\nsustained inappropriate behavior.\n\n**Consequence**: A temporary ban from any sort of interaction or public\ncommunication with the community for a specified period of time. No public or\nprivate interaction with the people involved, including unsolicited interaction\nwith those enforcing the Code of Conduct, is allowed during this period.\nViolating these terms may lead to a permanent ban.\n\n### 4. Permanent Ban\n\n**Community Impact**: Demonstrating a pattern of violation of community\nstandards, including sustained inappropriate behavior, harassment of an\nindividual, or aggression toward or disparagement of classes of individuals.\n\n**Consequence**: A permanent ban from any sort of public interaction within\nthe community.\n\n## Attribution\n\nThis Code of Conduct is adapted from the [Contributor Covenant][homepage],\nversion 2.0, available at\nhttps://www.contributor-covenant.org/version/2/0/code_of_conduct.html.\n\nCommunity Impact Guidelines were inspired by [Mozilla's code of conduct\nenforcement ladder](https://github.com/mozilla/diversity).\n\n[homepage]: https://www.contributor-covenant.org\n\nFor answers to common questions about this code of conduct, see the FAQ at\nhttps://www.contributor-covenant.org/faq. Translations are available at\nhttps://www.contributor-covenant.org/translations.\n"
},
{
"path": ".github/FUNDING.yml",
"content": "github: [\"voicepaw\"]\n"
},
{
"path": ".github/ISSUE_TEMPLATE/1-bug-report.yml",
"content": "name: Bug report\ndescription: Create a report to help us improve\nlabels: [bug]\nbody:\n - type: textarea\n id: description\n attributes:\n label: Describe the bug\n description: A clear and concise description of what the bug is.\n placeholder: Describe the bug\n validations:\n required: true\n - type: textarea\n id: reproduce\n attributes:\n label: To Reproduce\n description: Steps to reproduce the behavior.\n placeholder: To Reproduce\n validations:\n required: true\n - type: textarea\n id: context\n attributes:\n label: Additional context\n description: Add any other context about the problem here.\n placeholder: Additional context\n - type: input\n id: version\n attributes:\n label: Version\n description: Version of the project.\n placeholder: Version\n validations:\n required: true\n - type: input\n id: platform\n attributes:\n label: Platform\n description: Platform where the bug was found.\n placeholder: \"Example: Windows 11 / macOS 12.0.1 / Ubuntu 20.04\"\n validations:\n required: true\n - type: checkboxes\n id: terms\n attributes:\n label: Code of Conduct\n description: By submitting this issue, you agree to follow our\n [Code of Conduct](https://github.com/voicepaw/so-vits-svc-fork/blob/main/.github/CODE_OF_CONDUCT.md).\n options:\n - label: I agree to follow this project's Code of Conduct.\n required: true\n - type: checkboxes\n id: no-duplicate\n attributes:\n label: No Duplicate\n description: Please check [existing issues](https://github.com/voicepaw/so-vits-svc-fork/issues) to avoid duplicates.\n options:\n - label: I have checked existing issues to avoid duplicates.\n required: true\n - type: markdown\n attributes:\n value: 👋 Have a great day and thank you for the bug report!\n"
},
{
"path": ".github/ISSUE_TEMPLATE/1-bug_report.yml",
"content": "name: Bug report\ndescription: Create a report to help us improve\nlabels: [bug]\nbody:\n - type: textarea\n id: description\n attributes:\n label: Describe the bug\n description: A clear and concise description of what the bug is.\n placeholder: Describe the bug\n validations:\n required: true\n - type: textarea\n id: reproduce\n attributes:\n label: To Reproduce\n description: Steps to reproduce the behavior.\n placeholder: To Reproduce\n validations:\n required: true\n - type: textarea\n id: context\n attributes:\n label: Additional context\n description: Add any other context about the problem here.\n placeholder: Additional context\n - type: input\n id: version\n attributes:\n label: Version\n description: Version of the project.\n placeholder: Version\n validations:\n required: true\n - type: input\n id: platform\n attributes:\n label: Platform\n description: Platform where the bug was found.\n placeholder: \"Example: Windows 11 / macOS 12.0.1 / Ubuntu 20.04\"\n validations:\n required: true\n - type: checkboxes\n id: terms\n attributes:\n label: Code of Conduct\n description: By submitting this issue, you agree to follow our\n [Code of Conduct](https://github.com/34j/so-vits-svc-fork/blob/main/CODE_OF_CONDUCT.md).\n options:\n - label: I agree to follow this project's Code of Conduct.\n required: true\n - type: checkboxes\n id: no-duplicate\n attributes:\n label: No Duplicate\n description: Please check [existing issues](https://github.com/34j/so-vits-svc-fork/issues) to avoid duplicates.\n options:\n - label: I have checked existing issues to avoid duplicates.\n required: true\n"
},
{
"path": ".github/ISSUE_TEMPLATE/2-feature-request.yml",
"content": "name: Feature request\ndescription: Suggest an idea for this project\nlabels: [enhancement]\nbody:\n - type: textarea\n id: description\n attributes:\n label: Is your feature request related to a problem? Please describe.\n description: A clear and concise description of what the problem is.\n value: I'm always frustrated when\n validations:\n required: true\n - type: textarea\n id: solution\n attributes:\n label: Describe alternatives you've considered\n description: A clear and concise description of any alternative solutions or features you've considered.\n placeholder: Describe alternatives you've considered\n validations:\n required: true\n - type: textarea\n id: context\n attributes:\n label: Additional context\n description: Add any other context or screenshots about the feature request here.\n placeholder: Additional context\n - type: checkboxes\n id: terms\n attributes:\n label: Code of Conduct\n description: By submitting this issue, you agree to follow our\n [Code of Conduct](https://github.com/voicepaw/so-vits-svc-fork/blob/main/.github/CODE_OF_CONDUCT.md).\n options:\n - label: I agree to follow this project's Code of Conduct\n required: true\n - type: checkboxes\n id: willing\n attributes:\n label: Are you willing to resolve this issue by submitting a Pull Request?\n description: Remember that first-time contributors are welcome! 🙌\n options:\n - label: Yes, I have the time, and I know how to start.\n - label: Yes, I have the time, but I don't know how to start. I would need guidance.\n - label: No, I don't have the time, although I believe I could do it if I had the time...\n - label: No, I don't have the time and I wouldn't even know how to start.\n - type: markdown\n attributes:\n value: 👋 Have a great day and thank you for the feature request!\n"
},
{
"path": ".github/ISSUE_TEMPLATE/config.yml",
"content": "# Disabling blank issues to ensure all necessary information is provided\n# Users should use the provided templates for specific issues\n# For general questions, please refer to the contact links section\nblank_issues_enabled: false\ncontact_links:\n - name: Questions\n url: https://github.com/voicepaw/so-vits-svc-fork/discussions/categories/q-a\n about: Please ask and answer questions here.\n"
},
{
"path": ".github/PULL_REQUEST_TEMPLATE.md",
"content": "\n\n### Description of change\n\n\n\n### Pull-Request Checklist\n\n\n\n- [ ] Code is up-to-date with the `main` branch\n- [ ] This pull request follows the [contributing guidelines](https://github.com/voicepaw/so-vits-svc-fork/blob/main/CONTRIBUTING.md).\n- [ ] This pull request links relevant issues as `Fixes #0000`\n- [ ] There are new or updated unit tests validating the change\n- [ ] Documentation has been updated to reflect this change\n- [ ] The new commits follow conventions outlined in the [conventional commit spec](https://www.conventionalcommits.org/en/v1.0.0/), such as \"fix(api): prevent racing of requests\".\n\n> - If pre-commit.ci is failing, try `pre-commit run -a` for further information.\n> - If CI / test is failing, try `uv run pytest` for further information.\n\n\n"
},
{
"path": ".github/labels.toml",
"content": "[breaking]\ncolor = \"ffcc00\"\nname = \"breaking\"\ndescription = \"Breaking change.\"\n\n[bug]\ncolor = \"d73a4a\"\nname = \"bug\"\ndescription = \"Something isn't working\"\n\n[dependencies]\ncolor = \"0366d6\"\nname = \"dependencies\"\ndescription = \"Pull requests that update a dependency file\"\n\n[github_actions]\ncolor = \"000000\"\nname = \"github_actions\"\ndescription = \"Update of github actions\"\n\n[documentation]\ncolor = \"1bc4a5\"\nname = \"documentation\"\ndescription = \"Improvements or additions to documentation\"\n\n[duplicate]\ncolor = \"cfd3d7\"\nname = \"duplicate\"\ndescription = \"This issue or pull request already exists\"\n\n[enhancement]\ncolor = \"a2eeef\"\nname = \"enhancement\"\ndescription = \"New feature or request\"\n\n[\"good first issue\"]\ncolor = \"7057ff\"\nname = \"good first issue\"\ndescription = \"Good for newcomers\"\n\n[\"help wanted\"]\ncolor = \"008672\"\nname = \"help wanted\"\ndescription = \"Extra attention is needed\"\n\n[invalid]\ncolor = \"e4e669\"\nname = \"invalid\"\ndescription = \"This doesn't seem right\"\n\n[nochangelog]\ncolor = \"555555\"\nname = \"nochangelog\"\ndescription = \"Exclude pull requests from changelog\"\n\n[question]\ncolor = \"d876e3\"\nname = \"question\"\ndescription = \"Further information is requested\"\n\n[removed]\ncolor = \"e99695\"\nname = \"removed\"\ndescription = \"Removed piece of functionalities.\"\n\n[tests]\ncolor = \"bfd4f2\"\nname = \"tests\"\ndescription = \"CI, CD and testing related changes\"\n\n[wontfix]\ncolor = \"ffffff\"\nname = \"wontfix\"\ndescription = \"This will not be worked on\"\n\n[discussion]\ncolor = \"c2e0c6\"\nname = \"discussion\"\ndescription = \"Some discussion around the project\"\n\n[hacktoberfest]\ncolor = \"ffa663\"\nname = \"hacktoberfest\"\ndescription = \"Good issues for Hacktoberfest\"\n\n[answered]\ncolor = \"0ee2b6\"\nname = \"answered\"\ndescription = \"Automatically closes as answered after a delay\"\n\n[waiting]\ncolor = \"5f7972\"\nname = \"waiting\"\ndescription = \"Automatically closes if no answer after a delay\"\n\n[fund]\ncolor = \"0E8A16\"\nname = \"fund\"\ndescription = \"Add a section linking to polar.sh for funding the issue.\"\n"
},
{
"path": ".github/workflows/ci.yml",
"content": "name: CI\n\non:\n push:\n branches:\n - main\n pull_request:\n\nconcurrency:\n group: ${{ github.head_ref || github.run_id }}\n cancel-in-progress: true\n\njobs:\n lint:\n runs-on: ubuntu-latest\n steps:\n - uses: actions/checkout@de0fac2e4500dabe0009e67214ff5f5447ce83dd # v6\n - uses: actions/setup-python@a309ff8b426b58ec0e2a45f0f869d46889d02405 # v6\n with:\n python-version: 3.x\n - uses: pre-commit/action@2c7b3805fd2a0fd8c1884dcaebf91fc102a13ecd # v3.0.1\n\n # Make sure commit messages follow the conventional commits convention:\n # https://www.conventionalcommits.org\n commitlint:\n name: Lint Commit Messages\n runs-on: ubuntu-latest\n steps:\n - uses: actions/checkout@de0fac2e4500dabe0009e67214ff5f5447ce83dd # v6\n with:\n fetch-depth: 0\n - uses: wagoid/commitlint-github-action@b948419dd99f3fd78a6548d48f94e3df7f6bf3ed # v6.2.1\n\n test:\n strategy:\n fail-fast: false\n matrix:\n python-version:\n # - \"3.9\"\n - \"3.10\"\n - \"3.11\"\n - \"3.12\"\n - \"3.13\"\n os:\n - ubuntu-latest\n # - windows-latest\n # - macOS-latest\n runs-on: ${{ matrix.os }}\n steps:\n - uses: actions/checkout@de0fac2e4500dabe0009e67214ff5f5447ce83dd # v6\n - uses: actions/setup-python@a309ff8b426b58ec0e2a45f0f869d46889d02405 # v6\n id: setup-python\n with:\n python-version: ${{ matrix.python-version }}\n - uses: astral-sh/setup-uv@37802adc94f370d6bfd71619e3f0bf239e1f3b78 # v7\n - run: uv sync --no-python-downloads\n shell: bash\n - run: uv run pytest\n shell: bash\n - uses: codecov/codecov-action@1af58845a975a7985b0beb0cbe6fbbb71a41dbad # v5\n with:\n token: ${{ secrets.CODECOV_TOKEN }}\n\n release:\n needs:\n - test\n - lint\n - commitlint\n\n runs-on: ubuntu-latest\n environment: release\n concurrency: release\n permissions:\n id-token: write\n attestations: write\n contents: write\n\n steps:\n - uses: actions/checkout@de0fac2e4500dabe0009e67214ff5f5447ce83dd # v6\n with:\n fetch-depth: 0\n ref: ${{ github.sha }}\n\n - name: Checkout commit for release\n run: |\n git checkout -B ${{ github.ref_name }} ${{ github.sha }}\n\n # Do a dry run of PSR\n - name: Test release\n uses: python-semantic-release/python-semantic-release@350c48fcb3ffcdfd2e0a235206bc2ecea6b69df0 # v10\n if: github.ref_name != 'main'\n with:\n root_options: --noop\n github_token: noop\n\n # On main branch: actual PSR + upload to PyPI & GitHub\n - name: Release\n uses: python-semantic-release/python-semantic-release@350c48fcb3ffcdfd2e0a235206bc2ecea6b69df0 # v10\n id: release\n if: github.ref_name == 'main'\n with:\n github_token: ${{ secrets.GITHUB_TOKEN }}\n\n - name: Attest build provenance\n uses: actions/attest-build-provenance@a2bbfa25375fe432b6a289bc6b6cd05ecd0c4c32 # v4\n if: steps.release.outputs.released == 'true'\n with:\n subject-path: \"dist/*\"\n\n - name: Publish package distributions to PyPI\n uses: pypa/gh-action-pypi-publish@release/v1\n if: steps.release.outputs.released == 'true'\n\n - name: Publish package distributions to GitHub Releases\n uses: python-semantic-release/publish-action@310a9983a0ae878b29f3aac778d7c77c1db27378 # v10\n if: steps.release.outputs.released == 'true'\n with:\n github_token: ${{ secrets.GITHUB_TOKEN }}\n tag: ${{ steps.release.outputs.tag }}\n"
},
{
"path": ".github/workflows/hacktoberfest.yml",
"content": "name: Hacktoberfest\n\non:\n schedule:\n # Run every day in October\n - cron: \"0 0 * 10 *\"\n # Run on the 1st of November to revert\n - cron: \"0 13 1 11 *\"\n\njobs:\n hacktoberfest:\n runs-on: ubuntu-latest\n\n steps:\n - uses: browniebroke/hacktoberfest-labeler-action@72564cc2b8f1cd239fb6880cca150a1b8b6b027b # v2.6.0\n with:\n github_token: ${{ secrets.GH_PAT }}\n"
},
{
"path": ".github/workflows/issue-manager.yml",
"content": "name: Issue Manager\n\non:\n schedule:\n - cron: \"0 0 * * *\"\n issue_comment:\n types:\n - created\n issues:\n types:\n - labeled\n pull_request_target:\n types:\n - labeled\n workflow_dispatch:\n\njobs:\n issue-manager:\n runs-on: ubuntu-latest\n steps:\n - uses: tiangolo/issue-manager@2fb3484ec9279485df8659e8ec73de262431737d # 0.6.0\n with:\n token: ${{ secrets.GITHUB_TOKEN }}\n config: >\n {\n \"answered\": {\n \"message\": \"Assuming the original issue was solved, it will be automatically closed now.\"\n },\n \"waiting\": {\n \"message\": \"Automatically closing. To re-open, please provide the additional information requested.\"\n }\n }\n"
},
{
"path": ".github/workflows/labels.yml",
"content": "name: Sync Github labels\n\non:\n push:\n branches:\n - main\n paths:\n - \".github/**\"\n\njobs:\n labels:\n runs-on: ubuntu-latest\n steps:\n - uses: actions/checkout@de0fac2e4500dabe0009e67214ff5f5447ce83dd # v6\n - name: Set up Python\n uses: actions/setup-python@a309ff8b426b58ec0e2a45f0f869d46889d02405 # v6\n with:\n python-version: 3.x\n - name: Install labels\n run: pip install labels\n - name: Sync config with Github\n run: labels -u ${{ github.repository_owner }} -t ${{ secrets.GH_PAT }} sync -f .github/labels.toml\n"
},
{
"path": ".github/workflows/poetry-upgrade.yml",
"content": "name: Upgrader\n\non:\n workflow_dispatch:\n schedule:\n - cron: \"29 23 16 * *\"\n\njobs:\n upgrade:\n uses: browniebroke/github-actions/.github/workflows/poetry-upgrade.yml@a4a8428c6f76ab8848c94c5a649fa809aacf8688 # v1\n secrets:\n gh_pat: ${{ secrets.GH_PAT }}\n"
},
{
"path": ".github/workflows/upgrader.yml",
"content": "name: Upgrader\n\non:\n workflow_dispatch:\n schedule:\n - cron: \"15 11 3 1-9,11-12 *\"\n\njobs:\n upgrade:\n uses: browniebroke/github-actions/.github/workflows/uv-upgrade.yml@a4a8428c6f76ab8848c94c5a649fa809aacf8688 # v1\n secrets:\n gh_pat: ${{ secrets.GH_PAT }}\n"
},
{
"path": ".gitignore",
"content": "# Created by .ignore support plugin (hsz.mobi)\n### Python template\n# Byte-compiled / optimized / DLL files\n__pycache__/\n*.py[cod]\n*$py.class\n\n# C extensions\n*.so\n\n# Distribution / packaging\n.Python\nbuild/\ndevelop-eggs/\ndist/\ndownloads/\neggs/\n.eggs/\nlib/\nlib64/\nparts/\nsdist/\nvar/\nwheels/\nshare/python-wheels/\n*.egg-info/\n.installed.cfg\n*.egg\nMANIFEST\n\n# PyInstaller\n# Usually these files are written by a python script from a template\n# before PyInstaller builds the exe, so as to inject date/other infos into it.\n*.manifest\n*.spec\n\n# Installer logs\npip-log.txt\npip-delete-this-directory.txt\n\n# Unit test / coverage reports\nhtmlcov/\n.tox/\n.nox/\n.coverage\n.coverage.*\n.cache\nnosetests.xml\ncoverage.xml\n*.cover\n*.py,cover\n.hypothesis/\n.pytest_cache/\ncover/\n\n# Translations\n*.mo\n*.pot\n\n# Django stuff:\n*.log\nlocal_settings.py\ndb.sqlite3\ndb.sqlite3-journal\n\n# Flask stuff:\ninstance/\n.webassets-cache\n\n# Scrapy stuff:\n.scrapy\n\n# Sphinx documentation\ndocs/_build/\n\n# PyBuilder\n.pybuilder/\ntarget/\n\n# Jupyter Notebook\n.ipynb_checkpoints\n\n# IPython\nprofile_default/\nipython_config.py\n\n# pyenv\n# For a library or package, you might want to ignore these files since the code is\n# intended to run in multiple environments; otherwise, check them in:\n# .python-version\n\n# pipenv\n# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.\n# However, in case of collaboration, if having platform-specific dependencies or dependencies\n# having no cross-platform support, pipenv may install dependencies that don't work, or not\n# install all needed dependencies.\n#Pipfile.lock\n\n# PEP 582; used by e.g. github.com/David-OConnor/pyflow\n__pypackages__/\n\n# Celery stuff\ncelerybeat-schedule\ncelerybeat.pid\n\n# SageMath parsed files\n*.sage.py\n\n# Environments\n.env\n.venv\nenv/\nvenv/\nENV/\nenv.bak/\nvenv.bak/\n\n# Spyder {{package_name}} settings\n.spyderproject\n.spyproject\n\n# Rope {{package_name}} settings\n.ropeproject\n\n# mkdocs documentation\n/site\n\n# mypy\n.mypy_cache/\n.dmypy.json\ndmypy.json\n\n# Pyre type checker\n.pyre/\n\n# pytype static type analyzer\n.pytype/\n\n# Cython debug symbols\ncython_debug/\n\n# additional files\ntests/**/*.wav\n!tests/dataset_raw/test/**/*.wav\ntests/**/*.npy\ntests/**/*.pt\ntests/**/*.txt\ntests/**/*.json\ntests/**/*.pth\ntests/**/*.download\ntests/**/*.lab\ntests/**/*.pdf\ntests/**/*.csv\ntests/**/*.ckpt\ntests/**/*.yaml\n*.tfevents.*\n*.pt\nuser_gui_presets.json\nlogs\ndataset\ndataset_raw\nconfigs\nfilelists\n"
},
{
"path": ".gitpod.yml",
"content": "tasks:\n - command: |\n pip install uv\n PIP_USER=false uv sync\n - command: |\n pip install pre-commit\n pre-commit install\n PIP_USER=false pre-commit install-hooks\n"
},
{
"path": ".pre-commit-config.yaml",
"content": "# See https://pre-commit.com for more information\n# See https://pre-commit.com/hooks.html for more hooks\nexclude: \"CHANGELOG.md|.copier-answers.yml|.all-contributorsrc|project\"\ndefault_stages: [pre-commit]\n\nci:\n autofix_commit_msg: \"chore(pre-commit.ci): auto fixes\"\n autoupdate_commit_msg: \"chore(pre-commit.ci): pre-commit autoupdate\"\n\nrepos:\n - repo: https://github.com/commitizen-tools/commitizen\n rev: v4.13.9\n hooks:\n - id: commitizen\n stages: [commit-msg]\n - repo: https://github.com/pre-commit/pre-commit-hooks\n rev: v6.0.0\n hooks:\n - id: debug-statements\n - id: check-builtin-literals\n - id: check-case-conflict\n - id: check-docstring-first\n - id: check-json\n - id: check-toml\n - id: check-xml\n - id: check-yaml\n - id: detect-private-key\n - id: end-of-file-fixer\n - id: trailing-whitespace\n - repo: https://github.com/tox-dev/pyproject-fmt\n rev: \"v2.20.0\"\n hooks:\n - id: pyproject-fmt\n - repo: https://github.com/astral-sh/uv-pre-commit\n rev: 0.10.12\n hooks:\n - id: uv-lock\n - repo: https://github.com/pre-commit/mirrors-prettier\n rev: v3.1.0\n hooks:\n - id: prettier\n args: [\"--tab-width\", \"2\"]\n - repo: https://github.com/astral-sh/ruff-pre-commit\n rev: v0.14.14\n hooks:\n - id: ruff\n args: [--fix, --exit-non-zero-on-fix]\n - id: ruff-format\n - repo: https://github.com/codespell-project/codespell\n rev: v2.4.2\n hooks:\n - id: codespell\n # - repo: https://github.com/pre-commit/mirrors-mypy\n # rev: v1.15.0\n # hooks:\n # - id: mypy\n # additional_dependencies: []\n"
},
{
"path": ".readthedocs.yml",
"content": "# Read the Docs configuration file\n# See https://docs.readthedocs.io/en/stable/config-file/v2.html for details\n\n# Required\nversion: 2\n\n# Set the version of Python and other tools you might need\nbuild:\n os: ubuntu-22.04\n tools:\n python: \"3.12\"\n commands:\n - asdf plugin add uv\n - asdf install uv latest\n - asdf global uv latest\n - uv sync --only-group docs --frozen\n - uv run -m sphinx -T -b html -d docs/_build/doctrees -D language=en docs $READTHEDOCS_OUTPUT/html\n\n# Build documentation in the docs directory with Sphinx\nsphinx:\n configuration: docs/conf.py\n"
},
{
"path": "CHANGELOG.md",
"content": "# Changelog\n\n## v4.2.30 (2026-02-02)\n\n### Bug fixes\n\n- Fix `.json` files not included ([`922beed`](https://github.com/voicepaw/so-vits-svc-fork/commit/922beedff7d1efd7d54c75d92f2e090e18c58369))\n\n## v4.2.29 (2025-10-27)\n\n### Bug fixes\n\n- Fix train not working ([`f90cc40`](https://github.com/voicepaw/so-vits-svc-fork/commit/f90cc40802a56ebb3a8ba1f1493ff8d6008fa57b))\n\n### Documentation\n\n- Better notebook ([`a80a296`](https://github.com/voicepaw/so-vits-svc-fork/commit/a80a296166ed0a872f93fc30f504b3a504e11f9e))\n\n## v4.2.28 (2025-10-26)\n\n### Documentation\n\n- Better notebook ([`b3e9fe3`](https://github.com/voicepaw/so-vits-svc-fork/commit/b3e9fe3b6069ee0846701111c4dbc9c69924fbc6))\n\n### Bug fixes\n\n- Fix config templates not included ([`319ba6e`](https://github.com/voicepaw/so-vits-svc-fork/commit/319ba6e0ef2ee61c3f096e3e8e2c58665da42c8c))\n\n## v4.2.27 (2025-09-10)\n\n### Bug fixes\n\n- Run copier recopy ([`b806ddb`](https://github.com/voicepaw/so-vits-svc-fork/commit/b806ddb4e14f2e82ad9349596d776bfdbd3ce4b7))\n- Remove onnx deps ([`021c959`](https://github.com/voicepaw/so-vits-svc-fork/commit/021c95936ca1b459e79fc14e4d801ffccb48346a))\n\n### Documentation\n\n- Update civitai model url ([`0f015e3`](https://github.com/voicepaw/so-vits-svc-fork/commit/0f015e32aada5cf7481f91bbe6758e574c9c5f39))\n\n## v4.2.26 (2024-07-29)\n\n### Bug fixes\n\n- Update dependency transformers to v4.43.3 ([`bd9262f`](https://github.com/voicepaw/so-vits-svc-fork/commit/bd9262f546eb9aaa8d9f9641f2d1faa361cf8ea8))\n\n## v4.2.25 (2024-07-29)\n\n### Bug fixes\n\n- Update dependency torch to v2.4.0 ([`20549f6`](https://github.com/voicepaw/so-vits-svc-fork/commit/20549f6f4e1f59090d6bbfe45c43f62613effa0e))\n\n## v4.2.24 (2024-07-18)\n\n### Bug fixes\n\n- Update dependency transformers to v4.42.4 ([`f949a07`](https://github.com/voicepaw/so-vits-svc-fork/commit/f949a071b542b4b699aaa39cf4cfb39d0b53950b))\n\n## v4.2.23 (2024-07-18)\n\n### Bug fixes\n\n- Update dependency lightning to v2.3.3 ([`31edf05`](https://github.com/voicepaw/so-vits-svc-fork/commit/31edf05234d72401db02d994f27d611c4015a65b))\n\n## v4.2.22 (2024-07-18)\n\n### Bug fixes\n\n- Update dependency fastapi to v0.111.1 ([`59ed5f3`](https://github.com/voicepaw/so-vits-svc-fork/commit/59ed5f32e67d4bb96fdd7b2bb606d1ce9e4bb9f0))\n\n## v4.2.21 (2024-07-04)\n\n### Bug fixes\n\n- Update dependency transformers to v4.42.3 ([`b9c031c`](https://github.com/voicepaw/so-vits-svc-fork/commit/b9c031c6814c12c9d5e04ea19745b67f41f8e9ae))\n\n## v4.2.20 (2024-07-04)\n\n### Bug fixes\n\n- Update dependency tensorboard to v2.17.0 ([`e5f3c13`](https://github.com/voicepaw/so-vits-svc-fork/commit/e5f3c1354dcda41c1fa3e518d0d5bc204800f03c))\n\n## v4.2.19 (2024-07-04)\n\n### Bug fixes\n\n- Update dependency lightning to v2.3.2 ([`a7e299f`](https://github.com/voicepaw/so-vits-svc-fork/commit/a7e299ff882c5854ac4be88d21fe95ed1a159711))\n\n## v4.2.18 (2024-07-04)\n\n### Bug fixes\n\n- Update dependency matplotlib to v3.9.1 ([`df6adf4`](https://github.com/voicepaw/so-vits-svc-fork/commit/df6adf461d2174b92ccc0aa6ee4b02a1c9e4634e))\n\n## v4.2.17 (2024-07-04)\n\n### Bug fixes\n\n- Update dependency lightning to v2.3.1 ([`89da16b`](https://github.com/voicepaw/so-vits-svc-fork/commit/89da16bd89ac08c07334156d28ab7dac29a0f01e))\n\n## v4.2.16 (2024-07-04)\n\n### Bug fixes\n\n- Update dependency scipy to v1.14.0 ([`45a1167`](https://github.com/voicepaw/so-vits-svc-fork/commit/45a1167f9d09a822e9dca2b497bed08edca6e919))\n\n## v4.2.15 (2024-07-03)\n\n### Bug fixes\n\n- Update dependency torchcrepe to v0.0.23 ([`2d76d82`](https://github.com/voicepaw/so-vits-svc-fork/commit/2d76d82df14afc3ec6b89770997f267237f98d53))\n\n## v4.2.14 (2024-07-03)\n\n### Bug fixes\n\n- Update dependency torch to v2.3.1 ([`cc51418`](https://github.com/voicepaw/so-vits-svc-fork/commit/cc514182b48a133ed2da249f3d3dc65b28870e74))\n\n## v4.2.13 (2024-07-03)\n\n### Bug fixes\n\n- Update dependency sounddevice to v0.4.7 ([`4df53c2`](https://github.com/voicepaw/so-vits-svc-fork/commit/4df53c22579c9bfe236953bfe238dde0179cfaca))\n\n## v4.2.12 (2024-07-03)\n\n### Bug fixes\n\n- Update dependency requests to v2.32.3 ([`e60876a`](https://github.com/voicepaw/so-vits-svc-fork/commit/e60876ab2c883ca1accb9488a5ee17232d4e4ce7))\n\n## v4.2.11 (2024-07-02)\n\n### Bug fixes\n\n- Update dependency onnx to v1.16.1 ([`0d7ed17`](https://github.com/voicepaw/so-vits-svc-fork/commit/0d7ed171011bdcdf4ec701d1df53573ced09ddbf))\n\n### Documentation\n\n- Update docs ([`94b2412`](https://github.com/voicepaw/so-vits-svc-fork/commit/94b2412f95ee6cb194c37ae558c9ca03b23402db))\n- Update docs ([`94b2412`](https://github.com/voicepaw/so-vits-svc-fork/commit/94b2412f95ee6cb194c37ae558c9ca03b23402db))\n- Update docs ([`94b2412`](https://github.com/voicepaw/so-vits-svc-fork/commit/94b2412f95ee6cb194c37ae558c9ca03b23402db))\n- Update docs ([`94b2412`](https://github.com/voicepaw/so-vits-svc-fork/commit/94b2412f95ee6cb194c37ae558c9ca03b23402db))\n\n## v4.2.10 (2024-07-02)\n\n### Bug fixes\n\n- Replace pysimplegui with pysimplegui-4-foss ([`34e2e77`](https://github.com/voicepaw/so-vits-svc-fork/commit/34e2e77a7f258e09f4661a96645a5f79d761cbed))\n\n## v4.2.9 (2024-05-23)\n\n### Bug fixes\n\n- Update dependency transformers to v4.41.1 ([`42c69fd`](https://github.com/voicepaw/so-vits-svc-fork/commit/42c69fd48146f6b43f9dbfac53339ad573d61acd))\n\n## v4.2.8 (2024-05-22)\n\n### Bug fixes\n\n- Update dependency lightning to v2.2.5 ([`6a457dc`](https://github.com/voicepaw/so-vits-svc-fork/commit/6a457dc4996220cebe0ce54d7f116873f1cf94f3))\n\n## v4.2.7 (2024-05-22)\n\n### Bug fixes\n\n- Update dependency requests to v2.32.2 ([`28e1be1`](https://github.com/voicepaw/so-vits-svc-fork/commit/28e1be1ef191badbe314cf232e932646fd6811d1))\n\n## v4.2.6 (2024-05-18)\n\n### Bug fixes\n\n- Update dependency transformers to v4.41.0 ([`9d20b50`](https://github.com/voicepaw/so-vits-svc-fork/commit/9d20b509e210d20cb7005a58c6408830522b94cf))\n\n## v4.2.5 (2024-05-16)\n\n### Bug fixes\n\n- Update dependency matplotlib to v3.9.0 ([`ed95519`](https://github.com/voicepaw/so-vits-svc-fork/commit/ed9551956bbae36164f9404bad87ac78d7a326c5))\n\n## v4.2.4 (2024-05-16)\n\n### Bug fixes\n\n- Update dependency tqdm-joblib to ^0.0.4 ([`06ea73c`](https://github.com/voicepaw/so-vits-svc-fork/commit/06ea73cd3a82cc058df5b5973aa6edf97d4d708e))\n\n## v4.2.3 (2024-05-10)\n\n### Bug fixes\n\n- Update dependency fastapi to v0.111.0 ([`ee70d52`](https://github.com/voicepaw/so-vits-svc-fork/commit/ee70d522ab1943513517d5068e17c1e5578b09ce))\n\n## v4.2.2 (2024-05-10)\n\n### Bug fixes\n\n- Fix format selection for the input audio in non-windows ([`8168cb4`](https://github.com/voicepaw/so-vits-svc-fork/commit/8168cb404648c23e3ac5f3d2418bf38a606710e4))\n- Fix format selection for the input audio in non-windows ([`8168cb4`](https://github.com/voicepaw/so-vits-svc-fork/commit/8168cb404648c23e3ac5f3d2418bf38a606710e4))\n\n## v4.2.1 (2024-05-10)\n\n### Bug fixes\n\n- Support python 3.12, end support for python 3.8, explicitly specify click as a dependency, update deps ([`a7ceffa`](https://github.com/voicepaw/so-vits-svc-fork/commit/a7ceffa57566082f2a4ce9842be236505681d629))\n\n### Documentation\n\n- Replace 3.10 with 3.11 ([`a7ceffa`](https://github.com/voicepaw/so-vits-svc-fork/commit/a7ceffa57566082f2a4ce9842be236505681d629))\n\n## v4.2.0 (2024-04-11)\n\n### Features\n\n- Add leading zeros for 4-digit width of the output file name's numeric part #1154 ([`41b147f`](https://github.com/voicepaw/so-vits-svc-fork/commit/41b147f6c20873fc1cfeaae50d27b7b80d5fdeb6))\n\n### Documentation\n\n- Add annagorshunova as a contributor for bug, and code ([`50f6d79`](https://github.com/voicepaw/so-vits-svc-fork/commit/50f6d79f81d443c3dea9a4de3c65dca6988080ac))\n- Update readme.md [skip ci] ([`50f6d79`](https://github.com/voicepaw/so-vits-svc-fork/commit/50f6d79f81d443c3dea9a4de3c65dca6988080ac))\n- Update .all-contributorsrc [skip ci] ([`50f6d79`](https://github.com/voicepaw/so-vits-svc-fork/commit/50f6d79f81d443c3dea9a4de3c65dca6988080ac))\n\n### Bug fixes\n\n- Set speaker-diarization version to 3.1 for pyannote.audio 3.1.1 compatibility ([`9bd3089`](https://github.com/voicepaw/so-vits-svc-fork/commit/9bd3089d87be0c4e7bd0fbed51c06c203ad55474))\n\n## v4.1.61 (2024-04-06)\n\n### Bug fixes\n\n- Update dependency fastapi to v0.110.1 ([`eab647c`](https://github.com/voicepaw/so-vits-svc-fork/commit/eab647c8e21b954aa082b8319f084ae080105180))\n\n### Documentation\n\n- Add priyanshu-hawk as a contributor for code ([`d6888db`](https://github.com/voicepaw/so-vits-svc-fork/commit/d6888db4204f87b7075d41371edf08c050179912))\n- Update readme.md [skip ci] ([`d6888db`](https://github.com/voicepaw/so-vits-svc-fork/commit/d6888db4204f87b7075d41371edf08c050179912))\n- Update .all-contributorsrc [skip ci] ([`d6888db`](https://github.com/voicepaw/so-vits-svc-fork/commit/d6888db4204f87b7075d41371edf08c050179912))\n- Add marcellocirelli as a contributor for bug ([`8795709`](https://github.com/voicepaw/so-vits-svc-fork/commit/879570933831cdee3f325c94fc5b4e3fd172990f))\n- Update readme.md [skip ci] ([`8795709`](https://github.com/voicepaw/so-vits-svc-fork/commit/879570933831cdee3f325c94fc5b4e3fd172990f))\n- Update .all-contributorsrc [skip ci] ([`8795709`](https://github.com/voicepaw/so-vits-svc-fork/commit/879570933831cdee3f325c94fc5b4e3fd172990f))\n\n## v4.1.60 (2024-04-06)\n\n### Documentation\n\n- Add description of repository maintenance status ([`3f537b0`](https://github.com/voicepaw/so-vits-svc-fork/commit/3f537b0919c0e651297c190ede9eb3c03782f319))\n- Add samuelswartzberg as a contributor for security ([`cddb722`](https://github.com/voicepaw/so-vits-svc-fork/commit/cddb72236f00d00a566a27a0243b71abbd615c64))\n- Update readme.md [skip ci] ([`cddb722`](https://github.com/voicepaw/so-vits-svc-fork/commit/cddb72236f00d00a566a27a0243b71abbd615c64))\n- Update .all-contributorsrc [skip ci] ([`cddb722`](https://github.com/voicepaw/so-vits-svc-fork/commit/cddb72236f00d00a566a27a0243b71abbd615c64))\n- Update pytorch urls ([`c0c5376`](https://github.com/voicepaw/so-vits-svc-fork/commit/c0c537639c72455328f98d147c06bd8f86030399))\n- Add 4ll0w3v1l as a contributor for code ([`df699c7`](https://github.com/voicepaw/so-vits-svc-fork/commit/df699c7284149f79238b783f530d058b2a272447))\n- Update readme.md [skip ci] ([`df699c7`](https://github.com/voicepaw/so-vits-svc-fork/commit/df699c7284149f79238b783f530d058b2a272447))\n- Update .all-contributorsrc [skip ci] ([`df699c7`](https://github.com/voicepaw/so-vits-svc-fork/commit/df699c7284149f79238b783f530d058b2a272447))\n\n### Bug fixes\n\n- Disallow pysimplegui>=5, update deps, update pytorch urls in readme.md ([`c0c5376`](https://github.com/voicepaw/so-vits-svc-fork/commit/c0c537639c72455328f98d147c06bd8f86030399))\n- Disallow pysimplegui>=5 ([`c0c5376`](https://github.com/voicepaw/so-vits-svc-fork/commit/c0c537639c72455328f98d147c06bd8f86030399))\n\n## v4.1.59 (2024-04-06)\n\n### Bug fixes\n\n- Fix broken scipy imports in _pqmf.py ([`b7639ca`](https://github.com/voicepaw/so-vits-svc-fork/commit/b7639ca3a2b283f371a14ce176fe5d0e1d74581e))\n\n## v4.1.58 (2024-03-25)\n\n### Bug fixes\n\n- Update dependency transformers to v4.39.1 ([`a274333`](https://github.com/voicepaw/so-vits-svc-fork/commit/a274333e764ea56aa099033de24279619b4f2210))\n\n## v4.1.57 (2024-03-25)\n\n### Bug fixes\n\n- Update dependency pebble to v5.0.7 ([`e14b62f`](https://github.com/voicepaw/so-vits-svc-fork/commit/e14b62f11f8ed245a05c663381b086e92f76f2c6))\n\n## v4.1.56 (2024-03-05)\n\n### Bug fixes\n\n- Update dependency lightning to v2.2.1 ([`a84d26b`](https://github.com/voicepaw/so-vits-svc-fork/commit/a84d26ba6614c3cf1ca3415ee5131e77867f5d10))\n\n## v4.1.55 (2024-03-04)\n\n### Bug fixes\n\n- Update dependency onnxsim to v0.4.36 ([`12761e8`](https://github.com/voicepaw/so-vits-svc-fork/commit/12761e8989f43864b9f35f1dc144f5bc4dea1ac0))\n\n## v4.1.54 (2024-03-03)\n\n### Bug fixes\n\n- Update dependency transformers to v4.38.2 ([`cfc4edb`](https://github.com/voicepaw/so-vits-svc-fork/commit/cfc4edb570d5381f044cc9db51f291744c118f87))\n\n## v4.1.53 (2024-02-28)\n\n### Bug fixes\n\n- Update dependency rich to v13.7.1 ([`21f33d6`](https://github.com/voicepaw/so-vits-svc-fork/commit/21f33d6494f09b62e2b97ceb356be7d6fa6560bc))\n\n## v4.1.52 (2024-02-25)\n\n### Bug fixes\n\n- Update dependency fastapi to v0.110.0 ([`29fc759`](https://github.com/voicepaw/so-vits-svc-fork/commit/29fc7592dae3a16c310a159ebe94df5f64ac2271))\n\n## v4.1.51 (2024-02-23)\n\n### Bug fixes\n\n- Update dependency torch to v2.2.1 ([`bbc73c1`](https://github.com/voicepaw/so-vits-svc-fork/commit/bbc73c1b15608a8d4b1cf564ac2183044a94bdc6))\n\n## v4.1.50 (2024-02-22)\n\n### Bug fixes\n\n- Update dependency transformers to v4.38.1 ([`c90cfee`](https://github.com/voicepaw/so-vits-svc-fork/commit/c90cfee4dbcd29f6fd54193d506232c4a1ab0fe7))\n\n## v4.1.49 (2024-02-21)\n\n### Bug fixes\n\n- Update dependency transformers to v4.38.0 ([`4dec304`](https://github.com/voicepaw/so-vits-svc-fork/commit/4dec3048ed3fd208ed9b24dfe2e17338adcc8253))\n\n## v4.1.48 (2024-02-16)\n\n### Bug fixes\n\n- Update dependency matplotlib to v3.8.3 ([`e8eab7f`](https://github.com/voicepaw/so-vits-svc-fork/commit/e8eab7f9fc47c1ddc7c2753705abfdbafbc53f69))\n\n## v4.1.47 (2024-02-10)\n\n### Bug fixes\n\n- Update dependency tqdm to v4.66.2 ([`4516483`](https://github.com/voicepaw/so-vits-svc-fork/commit/451648353d5d473dfa058d75ce4953db67422506))\n\n## v4.1.46 (2024-02-08)\n\n### Bug fixes\n\n- Update dependency lightning to v2.2.0 ([`f7b2a42`](https://github.com/voicepaw/so-vits-svc-fork/commit/f7b2a427f11cab439b03ec6ec87a5794b184aa57))\n\n## v4.1.45 (2024-02-05)\n\n### Bug fixes\n\n- Update dependency fastapi to v0.109.2 ([`c570f8e`](https://github.com/voicepaw/so-vits-svc-fork/commit/c570f8e37b7c1b9ab0faada3c4f7f37a7e8fe896))\n\n## v4.1.44 (2024-02-03)\n\n### Bug fixes\n\n- Update dependency fastapi to v0.109.1 ([`6ee83d5`](https://github.com/voicepaw/so-vits-svc-fork/commit/6ee83d5931c2e2f5f3658ce96a83bec53e6e1d73))\n\n## v4.1.43 (2024-02-02)\n\n### Bug fixes\n\n- Update dependency lightning to v2.1.4 ([`33334fd`](https://github.com/voicepaw/so-vits-svc-fork/commit/33334fd9a0e112a811b5ad90cedc0e1929f10e89))\n\n## v4.1.42 (2024-01-30)\n\n### Bug fixes\n\n- Update dependency torch to v2.2.0 ([`8750059`](https://github.com/voicepaw/so-vits-svc-fork/commit/875005917101170e755b4dca7fe223436fb3e41e))\n\n## v4.1.41 (2024-01-29)\n\n### Bug fixes\n\n- Update dependency transformers to v4.37.2 ([`69c59b8`](https://github.com/voicepaw/so-vits-svc-fork/commit/69c59b8180cd489f30b5f13bc037c9928e1e65ba))\n\n### Documentation\n\n- Add onako2 as a contributor for doc ([`b204663`](https://github.com/voicepaw/so-vits-svc-fork/commit/b204663d36a1bf1ed5a2af23866824ed9c5dce43))\n- Update readme.md [skip ci] ([`b204663`](https://github.com/voicepaw/so-vits-svc-fork/commit/b204663d36a1bf1ed5a2af23866824ed9c5dce43))\n- Update .all-contributorsrc [skip ci] ([`b204663`](https://github.com/voicepaw/so-vits-svc-fork/commit/b204663d36a1bf1ed5a2af23866824ed9c5dce43))\n\n## v4.1.40 (2024-01-24)\n\n### Bug fixes\n\n- Update dependency transformers to v4.37.1 ([`d8be0d0`](https://github.com/voicepaw/so-vits-svc-fork/commit/d8be0d01361a00fb71477daab666a75a33d0fd49))\n\n## v4.1.39 (2024-01-22)\n\n### Bug fixes\n\n- Update dependency transformers to v4.37.0 ([`7b405c6`](https://github.com/voicepaw/so-vits-svc-fork/commit/7b405c6daff500c4f60f37cc430cbf364e95bd26))\n\n## v4.1.38 (2024-01-11)\n\n### Bug fixes\n\n- Update dependency fastapi to v0.109.0 ([`565be56`](https://github.com/voicepaw/so-vits-svc-fork/commit/565be56fcc4c62e4f2099db8108bb2c982326411))\n\n## v4.1.37 (2024-01-03)\n\n### Bug fixes\n\n- Update dependency transformers to v4.36.2 ([`7e18425`](https://github.com/voicepaw/so-vits-svc-fork/commit/7e18425b8d1c29820fff30df0bb7c6ee6d24e22d))\n\n## v4.1.36 (2024-01-03)\n\n### Bug fixes\n\n- Update dependency fastapi to v0.108.0 ([`091805c`](https://github.com/voicepaw/so-vits-svc-fork/commit/091805c1d070922318ef10389ab225788db89dd7))\n\n## v4.1.35 (2024-01-03)\n\n### Bug fixes\n\n- Update dependency torch to v2.1.2 ([`77586fd`](https://github.com/voicepaw/so-vits-svc-fork/commit/77586fd8d1eded848cc334aac46be35202da2e0a))\n\n## v4.1.34 (2024-01-03)\n\n### Bug fixes\n\n- Update dependency pebble to v5.0.6 ([`546db40`](https://github.com/voicepaw/so-vits-svc-fork/commit/546db40768114fcfab4a15a8c9b28398a8075446))\n\n## v4.1.33 (2024-01-02)\n\n### Bug fixes\n\n- Update dependency lightning to v2.1.3 ([`47b15e6`](https://github.com/voicepaw/so-vits-svc-fork/commit/47b15e6ba439239ea5459f01321e7a8d2c681ae4))\n\n## v4.1.32 (2023-11-21)\n\n### Bug fixes\n\n- Update dependency pebble to v5.0.4 ([`a8dc5d7`](https://github.com/voicepaw/so-vits-svc-fork/commit/a8dc5d7f88f0117291ba90fce23e3b1eebc52902))\n\n## v4.1.31 (2023-11-18)\n\n### Bug fixes\n\n- Update dependency matplotlib to v3.8.2 ([`68eb536`](https://github.com/voicepaw/so-vits-svc-fork/commit/68eb536b4a45a61803ffbab57a1a5c932b2dedcb))\n\n## v4.1.30 (2023-11-16)\n\n### Bug fixes\n\n- Update dependency torch to v2.1.1 ([`1911035`](https://github.com/voicepaw/so-vits-svc-fork/commit/19110358c12306b087af11837b43baf7d626e500))\n\n## v4.1.29 (2023-11-16)\n\n### Bug fixes\n\n- Update dependency lightning to v2.1.2 ([`58c8d5a`](https://github.com/voicepaw/so-vits-svc-fork/commit/58c8d5aa65dc55b53ed9dce25b7f08280fff5fba))\n\n## v4.1.28 (2023-11-16)\n\n### Bug fixes\n\n- Update dependency rich to v13.7.0 ([`1be5442`](https://github.com/voicepaw/so-vits-svc-fork/commit/1be54422e5383900fac818f7b9d33b31eac4ee92))\n\n## v4.1.27 (2023-11-15)\n\n### Bug fixes\n\n- Update dependency transformers to v4.35.2 ([`77ee0c0`](https://github.com/voicepaw/so-vits-svc-fork/commit/77ee0c0384c02c34c85ec77a8b8e1cfad2f94caf))\n\n## v4.1.26 (2023-11-14)\n\n### Bug fixes\n\n- Update dependency transformers to v4.35.1 ([`fa503ce`](https://github.com/voicepaw/so-vits-svc-fork/commit/fa503ce412d6afcd859375255fb128b33a648465))\n\n### Documentation\n\n- Add shinyjustyz as a contributor for bug, and code ([`acd6a8e`](https://github.com/voicepaw/so-vits-svc-fork/commit/acd6a8e4733ad1dbe94f118599aafa87f23ce89f))\n- Update readme.md [skip ci] ([`acd6a8e`](https://github.com/voicepaw/so-vits-svc-fork/commit/acd6a8e4733ad1dbe94f118599aafa87f23ce89f))\n- Update .all-contributorsrc [skip ci] ([`acd6a8e`](https://github.com/voicepaw/so-vits-svc-fork/commit/acd6a8e4733ad1dbe94f118599aafa87f23ce89f))\n\n## v4.1.25 (2023-11-09)\n\n### Bug fixes\n\n- Make pyanote.audio use gpu ([`c9d49ca`](https://github.com/voicepaw/so-vits-svc-fork/commit/c9d49ca8a903e1bf6e8a6ac9c6a8365077bedad4))\n\n## v4.1.24 (2023-11-08)\n\n### Bug fixes\n\n- Update dependency lightning to v2.1.1 ([`ce8efce`](https://github.com/voicepaw/so-vits-svc-fork/commit/ce8efcefb8df2601941cae0d63e843e49ffbdfb6))\n\n## v4.1.23 (2023-11-02)\n\n### Bug fixes\n\n- Update dependency transformers to v4.35.0 ([`bb05569`](https://github.com/voicepaw/so-vits-svc-fork/commit/bb055692363677cf48f22baef2b72b255fc74182))\n\n## v4.1.22 (2023-10-30)\n\n### Bug fixes\n\n- Update dependency fastapi to v0.104.1 ([`dbd4490`](https://github.com/voicepaw/so-vits-svc-fork/commit/dbd44909e3aabb2787e136036c1e2ca9ab6b9316))\n\n## v4.1.21 (2023-10-26)\n\n### Bug fixes\n\n- Update dependency onnx to v1.15.0 ([`5736bf7`](https://github.com/voicepaw/so-vits-svc-fork/commit/5736bf7e257dbd39c64ac73f3593ffebaa559def))\n\n## v4.1.20 (2023-10-26)\n\n### Bug fixes\n\n- Update python to >=3.8,<3.13 ([`031712a`](https://github.com/voicepaw/so-vits-svc-fork/commit/031712a70177f20610f8fefd20f49036dfe15721))\n\n## v4.1.19 (2023-10-21)\n\n### Bug fixes\n\n- Update dependency onnxsim to v0.4.35 ([`dd89347`](https://github.com/voicepaw/so-vits-svc-fork/commit/dd89347e863fd7a40683447463dfb665522a1d10))\n\n## v4.1.18 (2023-10-21)\n\n### Bug fixes\n\n- Update dependency onnxsim to v0.4.34 ([`3d2d4af`](https://github.com/voicepaw/so-vits-svc-fork/commit/3d2d4af65221ded497e3e805dfb48792ab20640f))\n\n## v4.1.17 (2023-10-19)\n\n### Bug fixes\n\n- Update dependency transformers to v4.34.1 ([`78c2d4c`](https://github.com/voicepaw/so-vits-svc-fork/commit/78c2d4c850c7cee2e58dc7e0ad10243e55247f64))\n\n## v4.1.16 (2023-10-18)\n\n### Bug fixes\n\n- Update dependency fastapi to v0.104.0 ([`6440667`](https://github.com/voicepaw/so-vits-svc-fork/commit/6440667b03cc79519b9e83aa08757c21d17bcf99))\n\n## v4.1.15 (2023-10-13)\n\n### Bug fixes\n\n- Update dependency rich to v13.6.0 ([`9ae0737`](https://github.com/voicepaw/so-vits-svc-fork/commit/9ae073700058ff17ab5a8a0a781fb3fe942e1994))\n\n## v4.1.14 (2023-10-13)\n\n### Bug fixes\n\n- Update dependency lightning to v2.1.0 ([`4637f69`](https://github.com/voicepaw/so-vits-svc-fork/commit/4637f693ea994c5180ec7a517bea6e5ddd8445aa))\n- Update dependency transformers to v4.34.0 ([`6bb2555`](https://github.com/voicepaw/so-vits-svc-fork/commit/6bb2555ace79487a4252a23ba7915a5b3676629e))\n\n## v4.1.13 (2023-10-13)\n\n### Bug fixes\n\n- Update dependency librosa to v0.10.1 ([`3ae20b7`](https://github.com/voicepaw/so-vits-svc-fork/commit/3ae20b7cbcc2fbfc72a2c8cb73a653bb7ee863a1))\n- Update dependency torchcrepe to v0.0.22 ([`ad7b2bf`](https://github.com/voicepaw/so-vits-svc-fork/commit/ad7b2bfa23e9e669b46976b796fb58d6b4829ce3))\n\n## v4.1.12 (2023-10-13)\n\n### Bug fixes\n\n- Update dependency fastapi to v0.103.2 ([`02cea64`](https://github.com/voicepaw/so-vits-svc-fork/commit/02cea643631e2c39265c7f4f58e40cea18e707e6))\n\n## v4.1.11 (2023-09-23)\n\n### Documentation\n\n- Replace \"34j\" with \"voicepaw\" ([`c1e6c0c`](https://github.com/voicepaw/so-vits-svc-fork/commit/c1e6c0c0c61d4a99eb1a19e8ca0f619d9a07146a))\n\n### Bug fixes\n\n- Update python to >=3.11,<3.12 ([`a5455b9`](https://github.com/voicepaw/so-vits-svc-fork/commit/a5455b92f7228fc01d51cdbfb7da6e9241c7fcca))\n\n## v4.1.10 (2023-09-17)\n\n### Bug fixes\n\n- Update dependency rich to v13.5.3 ([`e692e8c`](https://github.com/voicepaw/so-vits-svc-fork/commit/e692e8cd81dc648edcd60503a52274a8b9738dab))\n\n## v4.1.9 (2023-09-16)\n\n### Bug fixes\n\n- Update dependency transformers to v4.33.2 ([`7a8e54f`](https://github.com/voicepaw/so-vits-svc-fork/commit/7a8e54f10d0679df8419cc1cf934434f9f08e9b9))\n\n## v4.1.8 (2023-09-15)\n\n### Bug fixes\n\n- Update dependency lightning to v2.0.9 ([`dcde3d1`](https://github.com/voicepaw/so-vits-svc-fork/commit/dcde3d1a0b67e4825a709d19f5708b086b6c35e7))\n\n## v4.1.7 (2023-09-12)\n\n### Bug fixes\n\n- Update dependency matplotlib to v3.7.3 ([`302d5a7`](https://github.com/voicepaw/so-vits-svc-fork/commit/302d5a7dd0f0578d9f126c898b1c871f22987742))\n\n## v4.1.6 (2023-09-06)\n\n### Bug fixes\n\n- Update dependency transformers to v4.33.1 ([`f3e3b68`](https://github.com/voicepaw/so-vits-svc-fork/commit/f3e3b689d416f7191b8c5a25976afb0b11b4a3c7))\n\n## v4.1.5 (2023-09-05)\n\n### Bug fixes\n\n- Update dependency transformers to v4.33.0 ([`146d3ae`](https://github.com/voicepaw/so-vits-svc-fork/commit/146d3ae33aeb7b7440b47a89f286ec2dfe4c689f))\n\n## v4.1.4 (2023-09-02)\n\n### Bug fixes\n\n- Update dependency fastapi to v0.103.1 ([`f7473aa`](https://github.com/voicepaw/so-vits-svc-fork/commit/f7473aa1226c8aed89b44f6d08bea05dba68e882))\n\n## v4.1.3 (2023-08-30)\n\n### Bug fixes\n\n- Update dependency lightning to v2.0.8 ([`825fa44`](https://github.com/voicepaw/so-vits-svc-fork/commit/825fa44279bd7c3c2812efafe4f9757803f04519))\n\n## v4.1.2 (2023-08-28)\n\n### Bug fixes\n\n- Update dependency transformers to v4.32.1 ([`da7a72f`](https://github.com/voicepaw/so-vits-svc-fork/commit/da7a72ff0b11231793e48ac5fcb38a1b022fa26b))\n\n### Documentation\n\n- Add instructions for pipx installation, update torch urls ([`0b02c49`](https://github.com/voicepaw/so-vits-svc-fork/commit/0b02c49edb5701becfe141645f0e3fc00c241944))\n- Add shenberg as a contributor for usertesting, ideas, and code ([`319ddf3`](https://github.com/voicepaw/so-vits-svc-fork/commit/319ddf35e2f7e915bbf786fa785ec2734f4b0c00))\n\n## v4.1.1 (2023-07-02)\n\n### Bug fixes\n\n- Remove weight norm on inference so metal backend will work without cpu fallback ([`39ea0bc`](https://github.com/voicepaw/so-vits-svc-fork/commit/39ea0bc57f39fdbbcf07c92fab310474d95d1d39))\n\n## v4.1.0 (2023-06-25)\n\n### Documentation\n\n- Add zerui18 as a contributor for code, and ideas ([`4e74fc4`](https://github.com/voicepaw/so-vits-svc-fork/commit/4e74fc4f2f9165a48d75565ae5d0910b6b77dbaf))\n- Add ph0rk0z as a contributor for bug, and code ([`8dc25c7`](https://github.com/voicepaw/so-vits-svc-fork/commit/8dc25c793a8a92985ac589b31cc863768a9ba6a7))\n\n### Features\n\n- Add batched loading to clustering & max length per clip to split ([`4179ec9`](https://github.com/voicepaw/so-vits-svc-fork/commit/4179ec9e1d1ac20cffc9e66f522b5f865828f7fe))\n\n## v4.0.3 (2023-06-25)\n\n### Documentation\n\n- Add star3lord as a contributor for bug, and code ([`b3e2cfe`](https://github.com/voicepaw/so-vits-svc-fork/commit/b3e2cfe1294e7b64f76cd34c5b527a080ede2e87))\n\n### Bug fixes\n\n- Pass str instead of path in sf.load() and sf.write() ([`561cbfe`](https://github.com/voicepaw/so-vits-svc-fork/commit/561cbfe64927371ea68c0be70b4bc5007f6514b4))\n\n## v4.0.2 (2023-06-14)\n\n### Bug fixes\n\n- Fix typo in core.py ([`6a87d32`](https://github.com/voicepaw/so-vits-svc-fork/commit/6a87d323ec7716f09062e4846c31e58758a27e33))\n\n## v4.0.1 (2023-05-29)\n\n### Bug fixes\n\n- Fix window scaling ([`9cd720c`](https://github.com/voicepaw/so-vits-svc-fork/commit/9cd720c60d7baa6a945610f674820e14c4833917))\n\n## v4.0.0 (2023-05-29)\n\n### Features\n\n- Update pretrained model url, raise error if there are no files to preprocess, shuffle files consistently ([`c4c719c`](https://github.com/voicepaw/so-vits-svc-fork/commit/c4c719cdddd0e8f7703a02474208451729ab6d18))\n- Update urls for pretrained models ([`c4c719c`](https://github.com/voicepaw/so-vits-svc-fork/commit/c4c719cdddd0e8f7703a02474208451729ab6d18))\n\n## v3.15.0 (2023-05-22)\n\n### Features\n\n- Add gui command for module root entrypoint ([`3940a4c`](https://github.com/voicepaw/so-vits-svc-fork/commit/3940a4c0f51943dc3caec0832850f110b0f27961))\n- Add gui command to __main__ ([`3940a4c`](https://github.com/voicepaw/so-vits-svc-fork/commit/3940a4c0f51943dc3caec0832850f110b0f27961))\n- Add gui command to __main__ ([`3940a4c`](https://github.com/voicepaw/so-vits-svc-fork/commit/3940a4c0f51943dc3caec0832850f110b0f27961))\n- Add gui cli command ([`3940a4c`](https://github.com/voicepaw/so-vits-svc-fork/commit/3940a4c0f51943dc3caec0832850f110b0f27961))\n\n## v3.14.1 (2023-05-07)\n\n### Bug fixes\n\n- Replace pyinputplus with normal input ([`2b507da`](https://github.com/voicepaw/so-vits-svc-fork/commit/2b507da7da68f6baf00e5b0437d2d08e2d4f1246))\n\n## v3.14.0 (2023-05-06)\n\n### Features\n\n- Add batch inference, enhance gui, add custom theme ([`3ce110b`](https://github.com/voicepaw/so-vits-svc-fork/commit/3ce110be72aa2c614f24249ee26f00cba03f16a8))\n\n## v3.13.3 (2023-05-06)\n\n### Documentation\n\n- Add meldoner as a contributor for ideas, and code ([`880fea8`](https://github.com/voicepaw/so-vits-svc-fork/commit/880fea84696938b6636332d8c5d88664adae4004))\n\n### Bug fixes\n\n- Complete removal of ckpts in colab ([`e8964c6`](https://github.com/voicepaw/so-vits-svc-fork/commit/e8964c604bba31a9a8fa0a27bb5ea72a49a5fa5b))\n\n## v3.13.2 (2023-05-06)\n\n### Bug fixes\n\n- Always refresh output path if input path changed ([`f79de0c`](https://github.com/voicepaw/so-vits-svc-fork/commit/f79de0c81b6e748f8aa87ab94895c738f1808fcf))\n\n### Documentation\n\n- Fix minor issues in readme.md ([`139ed18`](https://github.com/voicepaw/so-vits-svc-fork/commit/139ed182a39a779d8cbdcefc8022a0ed7ff604cd))\n- Add notes about minimum requirements ([`ae9aece`](https://github.com/voicepaw/so-vits-svc-fork/commit/ae9aece9529145ed76aec24febdc77c07522a110))\n\n## v3.13.1 (2023-05-04)\n\n### Bug fixes\n\n- Remove filehandler to avoid permissionerror ([`38e0c4e`](https://github.com/voicepaw/so-vits-svc-fork/commit/38e0c4ed471c4520571a1585d868e325ea1a57e3))\n\n## v3.13.0 (2023-05-04)\n\n### Documentation\n\n- Add maximxlss as a contributor for code ([`435ca3c`](https://github.com/voicepaw/so-vits-svc-fork/commit/435ca3c58ab48934622c3d192cc11fd130a4a6f7))\n\n### Features\n\n- Add max_chunk_seconds option ([`101b948`](https://github.com/voicepaw/so-vits-svc-fork/commit/101b9484a86cce634a71054e5b8110998566197b))\n\n## v3.12.1 (2023-04-30)\n\n### Documentation\n\n- Add scorpi as a contributor for code ([`542d3a8`](https://github.com/voicepaw/so-vits-svc-fork/commit/542d3a8382d97064f13c1dcc4ba11107614dec3f))\n\n### Bug fixes\n\n- Fix epoch variable name to log in checkpoint save/load functions ([`0530ea3`](https://github.com/voicepaw/so-vits-svc-fork/commit/0530ea34fa42d9af51c73872b02d6453427c5a00))\n\n## v3.12.0 (2023-04-30)\n\n### Features\n\n- Add pre-classify command to manually classify files ([`7a0319c`](https://github.com/voicepaw/so-vits-svc-fork/commit/7a0319c65f42b0cc54d1d86ae5945d4a356b507a))\n\n## v3.11.2 (2023-04-30)\n\n### Bug fixes\n\n- Decouple lf0 predictor from speaker embeddings ([`7ab47f4`](https://github.com/voicepaw/so-vits-svc-fork/commit/7ab47f44e2ec77aa8c9e36b2e322d2dca0f94fb0))\n\n## v3.11.1 (2023-04-30)\n\n### Documentation\n\n- Add highupech as a contributor for bug ([`8eedc24`](https://github.com/voicepaw/so-vits-svc-fork/commit/8eedc2439b6987f70c94033c3f375ea330498a64))\n- Fix typo in readme.md ([`1773940`](https://github.com/voicepaw/so-vits-svc-fork/commit/1773940ae4a17a522ebc9fe6c1c70c3e02728341))\n- Add acekagami as a contributor for translation ([`958b9fd`](https://github.com/voicepaw/so-vits-svc-fork/commit/958b9fdf5fd1d527b63ac488ad21db2ce90539aa))\n- Update readme.md [skip ci] ([`958b9fd`](https://github.com/voicepaw/so-vits-svc-fork/commit/958b9fdf5fd1d527b63ac488ad21db2ce90539aa))\n- Update .all-contributorsrc [skip ci] ([`958b9fd`](https://github.com/voicepaw/so-vits-svc-fork/commit/958b9fdf5fd1d527b63ac488ad21db2ce90539aa))\n- Update readme_zh_cn.md ([`1ccd594`](https://github.com/voicepaw/so-vits-svc-fork/commit/1ccd5941e5f17a273dad681301a287aafb7973d9))\n\n### Bug fixes\n\n- Specify encoding to utf-8 in read_text() and write_text() ([`e947336`](https://github.com/voicepaw/so-vits-svc-fork/commit/e94733678955430f4e0c8ee5a26627077c0ffad9))\n\n## v3.11.0 (2023-04-23)\n\n### Documentation\n\n- Add alexanderkoumis as a contributor for code ([`5e032a3`](https://github.com/voicepaw/so-vits-svc-fork/commit/5e032a3e1eb36b0a7f99fd440b3e2a82f2345747))\n- Update readme.md [skip ci] ([`5e032a3`](https://github.com/voicepaw/so-vits-svc-fork/commit/5e032a3e1eb36b0a7f99fd440b3e2a82f2345747))\n- Update .all-contributorsrc [skip ci] ([`5e032a3`](https://github.com/voicepaw/so-vits-svc-fork/commit/5e032a3e1eb36b0a7f99fd440b3e2a82f2345747))\n\n### Features\n\n- Configurable output file (#452) ([`d2e3596`](https://github.com/voicepaw/so-vits-svc-fork/commit/d2e3596d5c0874918712488765e068f4010d62b9))\n\n## v3.10.5 (2023-04-22)\n\n### Bug fixes\n\n- Fix so-vits-svc style contentvec usage ([`6d35139`](https://github.com/voicepaw/so-vits-svc-fork/commit/6d351390354b17a2cd004bc9572d7dc1202f236c))\n\n## v3.10.4 (2023-04-21)\n\n### Bug fixes\n\n- Only save checkpoints on main device ([`1aaaac6`](https://github.com/voicepaw/so-vits-svc-fork/commit/1aaaac6328476249371799b92ced3edcbaac8d18))\n\n### Documentation\n\n- Add sbersier as a contributor for bug ([`58b936d`](https://github.com/voicepaw/so-vits-svc-fork/commit/58b936d669fbf5156f1ae1381393762994dd7414))\n- Add escoolioinglesias as a contributor for video ([`69f097f`](https://github.com/voicepaw/so-vits-svc-fork/commit/69f097f388447d64b7807cf554a5c310c34b7ef0))\n- Add garrettconway as a contributor for review ([`c1e4ada`](https://github.com/voicepaw/so-vits-svc-fork/commit/c1e4ada97739bf0b360295335475fef7029fbe49))\n- Add blueamulet as a contributor for maintenance ([`514ed84`](https://github.com/voicepaw/so-vits-svc-fork/commit/514ed84ffda901243c1bd6f39677eb020257f11f))\n- Add guranon as a contributor for bug, ideas, and code ([`b9eb3fd`](https://github.com/voicepaw/so-vits-svc-fork/commit/b9eb3fdc350588b9528a74d5b7be8e80b2bfbd51))\n- Add zerohackz as a contributor for bug, and code ([`66d5adc`](https://github.com/voicepaw/so-vits-svc-fork/commit/66d5adcf6dbb60fd6b6800162e3e16570a8dac1c))\n- Add tybantarnusa as a contributor for bug ([`e6e57b3`](https://github.com/voicepaw/so-vits-svc-fork/commit/e6e57b3e0d97ac91cadde45d5f080ced873df959))\n- Add blacksingh as a contributor for bug ([`7bc76ba`](https://github.com/voicepaw/so-vits-svc-fork/commit/7bc76ba9355089ab94fce9231f5dbbdd54e849ee))\n- Add escoolioinglesias as a contributor for bug, and usertesting ([`f00fe6e`](https://github.com/voicepaw/so-vits-svc-fork/commit/f00fe6e15cd12085cd01ae3c2676c195e7924429))\n- Add outhipped as a contributor for bug ([`7497175`](https://github.com/voicepaw/so-vits-svc-fork/commit/74971752821a852154bbfc35c318bb05e7b1169c))\n- Add yxlllc as a contributor for ideas, and code ([`42e35d2`](https://github.com/voicepaw/so-vits-svc-fork/commit/42e35d2a1f83be25e3fb0318e694163b0e936c59))\n- Add lordmau5 as a contributor for ideas, maintenance, and 2 more ([`352451c`](https://github.com/voicepaw/so-vits-svc-fork/commit/352451ccc9c1e1f800dc7697d5c705c0b9707c96))\n- Add tonyco82 as a contributor for bug ([`036ce90`](https://github.com/voicepaw/so-vits-svc-fork/commit/036ce9052f145cf047434d472f775b563e503946))\n- Add 75aosu as a contributor for bug ([`5afc28b`](https://github.com/voicepaw/so-vits-svc-fork/commit/5afc28bf918e1a62343f445a72487c1d932dc7b4))\n- Add hxl9654 as a contributor for bug ([`0953f1f`](https://github.com/voicepaw/so-vits-svc-fork/commit/0953f1fd0dfbfa557f639eb8d917805f8891d7b0))\n- Add ducttapegames as a contributor for bug ([`b0f4d39`](https://github.com/voicepaw/so-vits-svc-fork/commit/b0f4d39371ed2913ad792a46754469eb68c8c72d))\n- Add likkkez as a contributor for bug ([`4a12109`](https://github.com/voicepaw/so-vits-svc-fork/commit/4a12109b6a0b3cd2741f10d6e9027204603b0f27))\n- Add alondan as a contributor for bug ([`662ec4b`](https://github.com/voicepaw/so-vits-svc-fork/commit/662ec4b39816b1a1311d56e3edaca31fb442bb8d))\n- Add mmodeusher as a contributor for bug ([`6a78df9`](https://github.com/voicepaw/so-vits-svc-fork/commit/6a78df97d8191b62a04c9ec48b74cf1f00e47c30))\n- Add meldoner as a contributor for bug ([`5586bec`](https://github.com/voicepaw/so-vits-svc-fork/commit/5586becd35b456523cec1e1aa8c601cd1039dd1c))\n\n## v3.10.3 (2023-04-19)\n\n### Bug fixes\n\n- Don't save model when tuning for auto batch size ([`2311a35`](https://github.com/voicepaw/so-vits-svc-fork/commit/2311a35c36315123c87b7f20dde3c4dda723bea3))\n\n## v3.10.2 (2023-04-19)\n\n### Bug fixes\n\n- Properly stop training after `epochs` has been reached ([`f9bb3d8`](https://github.com/voicepaw/so-vits-svc-fork/commit/f9bb3d86605321288f11387bc853143378c3284e))\n\n## v3.10.1 (2023-04-19)\n\n### Bug fixes\n\n- Support ddp in windows (gloo backend) ([`bcb0507`](https://github.com/voicepaw/so-vits-svc-fork/commit/bcb05078d8ca7a6ac681de919552b3a190b2cd9b))\n\n## v3.10.0 (2023-04-18)\n\n### Features\n\n- Replace `fairseq` with `transformers` ([`a2fe0f3`](https://github.com/voicepaw/so-vits-svc-fork/commit/a2fe0f376d33f02987c91a57bd90a794de90a0e1))\n\n## v3.9.5 (2023-04-18)\n\n### Bug fixes\n\n- Set persistent_workers = true in dataloader for performance, do not save checkpoints, fix logging issue and multiple warning issues, do not do validation when global_step == 0 ([`6cab9af`](https://github.com/voicepaw/so-vits-svc-fork/commit/6cab9af86e3a96e79243fa890eb1c6c51fae4476))\n\n## v3.9.4 (2023-04-18)\n\n### Bug fixes\n\n- Always use \"spawn\" context in processpool ([`5d7fb77`](https://github.com/voicepaw/so-vits-svc-fork/commit/5d7fb774e8d5e97a9a31dbc891892e9f934f3884))\n\n## v3.9.3 (2023-04-16)\n\n### Bug fixes\n\n- Fix subprocess errors in linux and fix wrong error logging ([`fd67db6`](https://github.com/voicepaw/so-vits-svc-fork/commit/fd67db6312944557c09afd7b1ccbb97987a03489))\n\n## v3.9.2 (2023-04-16)\n\n### Bug fixes\n\n- Fix y_mel length ([`2d71992`](https://github.com/voicepaw/so-vits-svc-fork/commit/2d71992d80ba4142d2d5a5df17c69c2f2ac553fd))\n\n## v3.9.1 (2023-04-16)\n\n### Bug fixes\n\n- Allow higher segment size ([`09d5a52`](https://github.com/voicepaw/so-vits-svc-fork/commit/09d5a52b9bfc8eba8857f2b6c804ecdb39b4b38b))\n- Do not use weights_only in get_cluster_model() ([`24c05d1`](https://github.com/voicepaw/so-vits-svc-fork/commit/24c05d16c3b55f664699400496a7e0fd2fd84353))\n\n## v3.9.0 (2023-04-16)\n\n### Features\n\n- Add option to name ckpts by epochs ([`bba24c4`](https://github.com/voicepaw/so-vits-svc-fork/commit/bba24c4a62b935ed29572aa2c2c437d1b54aa2e2))\n\n## v3.8.1 (2023-04-16)\n\n### Bug fixes\n\n- Patch stft and add mps to get_optimal_device() ([`da928aa`](https://github.com/voicepaw/so-vits-svc-fork/commit/da928aa0bb1399bf5780526f8a7e9b674476a000))\n\n## v3.8.0 (2023-04-15)\n\n### Features\n\n- Automatically decide batch_size ([`8ffa128`](https://github.com/voicepaw/so-vits-svc-fork/commit/8ffa128aa209787fde8fb1f0e4ae5c96dfe31217))\n\n## v3.7.3 (2023-04-15)\n\n### Bug fixes\n\n- Show errors raised in inference ([`99833c5`](https://github.com/voicepaw/so-vits-svc-fork/commit/99833c55045647b9a766042765b454cb3d7d18ce))\n\n## v3.7.2 (2023-04-15)\n\n### Bug fixes\n\n- Suppress pytorch logs for deprecated typedstorage ([`e67ac62`](https://github.com/voicepaw/so-vits-svc-fork/commit/e67ac621296cf6667d05b51f23ce8cb9ef8a0855))\n\n## v3.7.1 (2023-04-15)\n\n### Bug fixes\n\n- Fix check for notebook / colab ([`7f69814`](https://github.com/voicepaw/so-vits-svc-fork/commit/7f698141e1b65e901579a5dbbabf28bfae5cc91f))\n\n## v3.7.0 (2023-04-14)\n\n### Features\n\n- Add option to specify tensorboardlogger version parameter support ([`a685123`](https://github.com/voicepaw/so-vits-svc-fork/commit/a685123a4063e08e0b021a1ad51098d3154b75de))\n\n## v3.6.2 (2023-04-14)\n\n### Bug fixes\n\n- Fix torch.load and save to use file objects and weights_only and remove unidecode ([`4aad701`](https://github.com/voicepaw/so-vits-svc-fork/commit/4aad701badc1eae5195e874dec40f9ed8dd40ee6))\n\n## v3.6.1 (2023-04-14)\n\n### Bug fixes\n\n- Fix gradient logging ([`73ef3dc`](https://github.com/voicepaw/so-vits-svc-fork/commit/73ef3dc94ccd4c0514ab33b0c5a65edf8b356484))\n\n## v3.6.0 (2023-04-13)\n\n### Features\n\n- Support sola algorithm ([`0fcbf99`](https://github.com/voicepaw/so-vits-svc-fork/commit/0fcbf9979862e945ca2427612a92549db2d627d0))\n\n## v3.5.1 (2023-04-13)\n\n### Bug fixes\n\n- Do not use rich in notebook ([`03c8240`](https://github.com/voicepaw/so-vits-svc-fork/commit/03c824015872e3d7e4e5795b9d65fad4116d54e4))\n\n## v3.5.0 (2023-04-13)\n\n### Features\n\n- Run inference in thread and disable button ([`c55caa8`](https://github.com/voicepaw/so-vits-svc-fork/commit/c55caa8019cc06fc6bd8851b0fd895b73cf926a4))\n\n## v3.4.0 (2023-04-13)\n\n### Features\n\n- Make num_workers configurable ([`e8df714`](https://github.com/voicepaw/so-vits-svc-fork/commit/e8df7146b0d1d3ee32af576c251f47d8fdd80bb3))\n\n## v3.3.1 (2023-04-13)\n\n### Performance improvements\n\n- Specify num_workers in dataloader ([`6042164`](https://github.com/voicepaw/so-vits-svc-fork/commit/6042164a60f9990eb0636e37dd650bb0cdff032b))\n\n## v3.3.0 (2023-04-13)\n\n### Features\n\n- Use richprogressbar ([`17e937a`](https://github.com/voicepaw/so-vits-svc-fork/commit/17e937aae9c90b513e4b7674f442a60161c84e83))\n\n## v3.2.0 (2023-04-13)\n\n### Features\n\n- Add optional `accumulate_grad_batches` config param ([`1172b23`](https://github.com/voicepaw/so-vits-svc-fork/commit/1172b2385cfe5239da3222cf93916436395e0f1a))\n- Add accumulate_grad_batches hparam ([`1172b23`](https://github.com/voicepaw/so-vits-svc-fork/commit/1172b2385cfe5239da3222cf93916436395e0f1a))\n\n### Bug fixes\n\n- Normalize loss when using gradient accumulation ([`1172b23`](https://github.com/voicepaw/so-vits-svc-fork/commit/1172b2385cfe5239da3222cf93916436395e0f1a))\n\n## v3.1.13 (2023-04-12)\n\n### Bug fixes\n\n- Fix too noisy logger ([`bd0eb33`](https://github.com/voicepaw/so-vits-svc-fork/commit/bd0eb33a66d77afff8328d08008f2643651c712a))\n- Fix cli() not called in __main__ ([`11f2d24`](https://github.com/voicepaw/so-vits-svc-fork/commit/11f2d245137da240f5e8214e4b6ce4330d726143))\n\n## v3.1.12 (2023-04-12)\n\n### Bug fixes\n\n- Fix ddp not working ([`bec43fc`](https://github.com/voicepaw/so-vits-svc-fork/commit/bec43fcbedf6b16260411655b19cf780ddbafe8e))\n\n## v3.1.11 (2023-04-12)\n\n### Bug fixes\n\n- Fix init_logger not showing debug messages in certain conditions as intended ([`d3ab7d6`](https://github.com/voicepaw/so-vits-svc-fork/commit/d3ab7d667c391ba1d8d1b34e2b66992256b3989d))\n\n## v3.1.10 (2023-04-11)\n\n### Bug fixes\n\n- Improves inference ([`d3228df`](https://github.com/voicepaw/so-vits-svc-fork/commit/d3228df704b2e6a0746b3f842ca5f2240890d829))\n- Improves and nb_clean ([`d3228df`](https://github.com/voicepaw/so-vits-svc-fork/commit/d3228df704b2e6a0746b3f842ca5f2240890d829))\n- Improves inference ([`d3228df`](https://github.com/voicepaw/so-vits-svc-fork/commit/d3228df704b2e6a0746b3f842ca5f2240890d829))\n- Improves inference ([`d3228df`](https://github.com/voicepaw/so-vits-svc-fork/commit/d3228df704b2e6a0746b3f842ca5f2240890d829))\n- Unix formatting ([`d3228df`](https://github.com/voicepaw/so-vits-svc-fork/commit/d3228df704b2e6a0746b3f842ca5f2240890d829))\n- Step lr schedulers at end of epoch ([`3af223e`](https://github.com/voicepaw/so-vits-svc-fork/commit/3af223eeb5146abcbb8198d4c11e2c1895ece130))\n\n## v3.1.9 (2023-04-10)\n\n### Bug fixes\n\n- Fix fp16_run not being mix precision and fix bf16 errors ([`b0dd0ed`](https://github.com/voicepaw/so-vits-svc-fork/commit/b0dd0ed4014d32e9f19e335ec603bdab92c52039))\n\n## v3.1.8 (2023-04-10)\n\n### Bug fixes\n\n- Fix wrong commands in \"before training\" ([`e056ad9`](https://github.com/voicepaw/so-vits-svc-fork/commit/e056ad9ec22cbaa119f7c93cb60b5b8851e80a7e))\n\n## v3.1.7 (2023-04-09)\n\n### Bug fixes\n\n- Improve quality of training ([`7ed71d6`](https://github.com/voicepaw/so-vits-svc-fork/commit/7ed71d6fd89ca8bf2c4aefbb280e705b1d7ae6b8))\n- Initialize `_temp_epoch` variable ([`7ed71d6`](https://github.com/voicepaw/so-vits-svc-fork/commit/7ed71d6fd89ca8bf2c4aefbb280e705b1d7ae6b8))\n- Fix order of optimizer as per lightning.ai documentation ([`7ed71d6`](https://github.com/voicepaw/so-vits-svc-fork/commit/7ed71d6fd89ca8bf2c4aefbb280e705b1d7ae6b8))\n- Remove `with torch.no_grad():` call for generator loss ([`7ed71d6`](https://github.com/voicepaw/so-vits-svc-fork/commit/7ed71d6fd89ca8bf2c4aefbb280e705b1d7ae6b8))\n- Ensure `log_audio_dict` uses correct `total_batch_idx` ([`7ed71d6`](https://github.com/voicepaw/so-vits-svc-fork/commit/7ed71d6fd89ca8bf2c4aefbb280e705b1d7ae6b8))\n- Only save checkpoints for first `batch_idx` ([`7ed71d6`](https://github.com/voicepaw/so-vits-svc-fork/commit/7ed71d6fd89ca8bf2c4aefbb280e705b1d7ae6b8))\n\n## v3.1.6 (2023-04-09)\n\n### Bug fixes\n\n- Fix checkpoint not properly loaded ([`0979147`](https://github.com/voicepaw/so-vits-svc-fork/commit/0979147a234e08999a19dba4988a53886f61dade))\n\n## v3.1.5 (2023-04-09)\n\n### Bug fixes\n\n- Fix optim_d functions called in wrong order ([`13d6346`](https://github.com/voicepaw/so-vits-svc-fork/commit/13d63469b0a84ace0dc8848df47dc20538b98770))\n\n## v3.1.4 (2023-04-09)\n\n### Bug fixes\n\n- Add bf16 and fp16 support ([`4229fd8`](https://github.com/voicepaw/so-vits-svc-fork/commit/4229fd8ead64cf03caad9acd3d8f7f0fec3a7fee))\n\n## v3.1.3 (2023-04-09)\n\n### Bug fixes\n\n- Update dependency starlette to v0.26.1 ([`5eb574b`](https://github.com/voicepaw/so-vits-svc-fork/commit/5eb574bec01430399df48e90e6112cef85e21945))\n\n## v3.1.2 (2023-04-09)\n\n### Bug fixes\n\n- Remove wrong test and trigger release ([`9ea77e4`](https://github.com/voicepaw/so-vits-svc-fork/commit/9ea77e4c5c6575844685998e237994d54be84bb9))\n- Remove pydantic constraints ([`f446e3b`](https://github.com/voicepaw/so-vits-svc-fork/commit/f446e3bbd62205b9c847e9ecdc46f519417b572a))\n- Fix fastapi version to 0.88 ([`a26f387`](https://github.com/voicepaw/so-vits-svc-fork/commit/a26f387abea585c300cd1ed0c36c6b9afc731764))\n- Fix get_optimal_device ([`79e4b5a`](https://github.com/voicepaw/so-vits-svc-fork/commit/79e4b5a0abe20789335eaaf4a359880c099aaa35))\n\n## v3.1.1 (2023-04-08)\n\n### Bug fixes\n\n- Update dependency fastapi to <0.96 ([`29c8cc0`](https://github.com/voicepaw/so-vits-svc-fork/commit/29c8cc05b7e5180058e03f2dc1f681e58cc67f09))\n\n## v3.1.0 (2023-04-08)\n\n### Features\n\n- Migrate to lightning ([`824ecbd`](https://github.com/voicepaw/so-vits-svc-fork/commit/824ecbd7222b9b9ada77c4fbbd7ae7f491049f21))\n\n## v3.0.5 (2023-04-08)\n\n### Bug fixes\n\n- Fix train_cluster ([`b0c93e4`](https://github.com/voicepaw/so-vits-svc-fork/commit/b0c93e49f9cdfdcd714575fc27011bf56ce4493d))\n\n## v3.0.4 (2023-04-06)\n\n### Bug fixes\n\n- Fix default config type to revert breaking changes ([`e05c0b5`](https://github.com/voicepaw/so-vits-svc-fork/commit/e05c0b52b6affac5e4483c0938e04584e1bd8d98))\n\n## v3.0.3 (2023-04-05)\n\n### Bug fixes\n\n- Fix issues when loading legacy checkpoint and fix pre-hubert n_jobs ([`15f1e7f`](https://github.com/voicepaw/so-vits-svc-fork/commit/15f1e7ffca80cb551316affae546ea72e8cccb34))\n\n## v3.0.2 (2023-04-04)\n\n### Performance improvements\n\n- Move methods from dataloader to pre-hubert ([`d5a4456`](https://github.com/voicepaw/so-vits-svc-fork/commit/d5a4456ebd5b6659ca037ee2f43480a00d7915f6))\n\n## v3.0.1 (2023-04-03)\n\n### Bug fixes\n\n- Remove possible leak in unused code ([`e921c3d`](https://github.com/voicepaw/so-vits-svc-fork/commit/e921c3dc018ea783b4c26375a04f499a45ad9df0))\n\n### Performance improvements\n\n- Better implementation of repeat_expand_2d ([`ef30a9d`](https://github.com/voicepaw/so-vits-svc-fork/commit/ef30a9d5ae60fdde5f6b44d6cea8cee0a40dd3e9))\n\n## v3.0.0 (2023-04-03)\n\n### Features\n\n- Add quickvc, fix usage of contentvec, remove onnx support ([`1a6c021`](https://github.com/voicepaw/so-vits-svc-fork/commit/1a6c021cd102b48b44e006decebc165062df8a95))\n\n### Documentation\n\n- Update allcontributors link for @mashirosa ([`650524b`](https://github.com/voicepaw/so-vits-svc-fork/commit/650524bb37997326e924814632c6202b76660f77))\n- Add paperspace referral ([`7280012`](https://github.com/voicepaw/so-vits-svc-fork/commit/7280012df66b5ea71291e5a80bb22451f0ca236e))\n- Add paperspace link and add more description, add a link for zh-cn docs ([`bc4b122`](https://github.com/voicepaw/so-vits-svc-fork/commit/bc4b1229e4ad9c046fda38334c4c6d22548356c2))\n\n## v2.1.5 (2023-04-01)\n\n### Bug fixes\n\n- Update dependency tensorboard to v2.12.1 ([`0ccda1c`](https://github.com/voicepaw/so-vits-svc-fork/commit/0ccda1ccb34b8125abe369f738b06de7b77c8efc))\n\n## v2.1.4 (2023-03-31)\n\n### Bug fixes\n\n- Update dependency gradio to v3.24.1 ([`4fa141b`](https://github.com/voicepaw/so-vits-svc-fork/commit/4fa141b210cb9b80bc7f75176fb01b18352c91cd))\n\n## v2.1.3 (2023-03-31)\n\n### Bug fixes\n\n- Update dependency gradio to v3.24.0 ([`4e441cb`](https://github.com/voicepaw/so-vits-svc-fork/commit/4e441cb30429e4a47afd261d69e32ec5f86564c9))\n\n### Documentation\n\n- Add sbersier as a contributor for ideas, and usertesting ([`a655bf4`](https://github.com/voicepaw/so-vits-svc-fork/commit/a655bf47dde4ad2506283997987bce3a09229c57))\n- Add coldcawfee as a contributor for bug ([`87a09e6`](https://github.com/voicepaw/so-vits-svc-fork/commit/87a09e654a0e8f064293750779b743abf2897ebb))\n\n## v2.1.2 (2023-03-28)\n\n### Bug fixes\n\n- Fix wrong devices set as default ([`6265f8f`](https://github.com/voicepaw/so-vits-svc-fork/commit/6265f8f93e8facd4f58aab906bfcb23e05d4032b))\n- Fix -h option overridden ([`52f1cfe`](https://github.com/voicepaw/so-vits-svc-fork/commit/52f1cfe1f08bd63966b0d1d7c025abed17cb36a6))\n\n### Documentation\n\n- Add xieyumc as a contributor for doc ([`29474d9`](https://github.com/voicepaw/so-vits-svc-fork/commit/29474d9dc77555fe5a55427278d44dfea7ece5ef))\n- Update readme_zh_cn.md ([`f94a14c`](https://github.com/voicepaw/so-vits-svc-fork/commit/f94a14cb63e2afd40cba3e94f84077643d9a7560))\n\n## v2.1.1 (2023-03-27)\n\n### Bug fixes\n\n- Update dependency rich to v13.3.3 ([`8bdefa9`](https://github.com/voicepaw/so-vits-svc-fork/commit/8bdefa9636e13fb0a24058a589675a20655357f4))\n\n### Documentation\n\n- Add nerdyrodent as a contributor for video ([`78ab661`](https://github.com/voicepaw/so-vits-svc-fork/commit/78ab661af198d87ce2ca5525fa262c639ed03cdc))\n- Add heyfixit as a contributor for doc ([`32a2a63`](https://github.com/voicepaw/so-vits-svc-fork/commit/32a2a63b375300be6d67be56035005956003bdfd))\n- Add desuka-art as a contributor for bug ([`fe3c6bf`](https://github.com/voicepaw/so-vits-svc-fork/commit/fe3c6bf8270fc219cdaeef05b7deacdbfc4df313))\n- Add ruckusmattster as a contributor for bug ([`2b971db`](https://github.com/voicepaw/so-vits-svc-fork/commit/2b971db5c7a332c8321e99bd77bb956a0ee3ec88))\n- Add pierluigizagaria as a contributor for usertesting ([`6fabe8d`](https://github.com/voicepaw/so-vits-svc-fork/commit/6fabe8d10b684caa236331a157455db1da686f8f))\n- Add satisfy256 as a contributor for bug ([`ee72aee`](https://github.com/voicepaw/so-vits-svc-fork/commit/ee72aee12f23fee458599b8b7fa4f0ed27d33b1c))\n- Add dl909 as a contributor for bug ([`a5e6651`](https://github.com/voicepaw/so-vits-svc-fork/commit/a5e6651a8f537961caf53adbb8bc52c1412c0762))\n\n## v2.1.0 (2023-03-27)\n\n### Features\n\n- Add an option to launch tensorboard in `train` command ([`ef22cce`](https://github.com/voicepaw/so-vits-svc-fork/commit/ef22cceaeb7f06ea53b2151ef9c962d1040de20d))\n\n## v2.0.0 (2023-03-27)\n\n### Bug fixes\n\n- Fix preprocessing and convert bool options to flags, use `unidecode` to decode non-ascii filenames in `pre-resample` ([`98d7ee2`](https://github.com/voicepaw/so-vits-svc-fork/commit/98d7ee22a40104468285324cc6ec21c707c30d54))\n\n### Documentation\n\n- Add yt tutorial vid link ([`1694f44`](https://github.com/voicepaw/so-vits-svc-fork/commit/1694f449e5a9f7b9da71e9a4c2764830c5268de3))\n\n## v1.4.3 (2023-03-26)\n\n### Performance improvements\n\n- Specify samplerate to reduce memory usage ([`6217eda`](https://github.com/voicepaw/so-vits-svc-fork/commit/6217eda0ec3bac27e408fcd0466a6b658cf718c5))\n\n## v1.4.2 (2023-03-26)\n\n### Bug fixes\n\n- Initialize logging in logger file and move version log ([`441d51f`](https://github.com/voicepaw/so-vits-svc-fork/commit/441d51f8efa84144d8a9f8fa02f2adaaf15295c0))\n- Fix dtype in sf.read() to save memory and fix preprocess_resample ([`0af1e13`](https://github.com/voicepaw/so-vits-svc-fork/commit/0af1e13a468ad282266a595b8d3c77d62aa938dc))\n- Fix audio resampled to 22khz ([`4203f37`](https://github.com/voicepaw/so-vits-svc-fork/commit/4203f374c5625369518063888e1ca70d1af4f694))\n\n### Documentation\n\n- Update notebook and readme.md ([`38d9744`](https://github.com/voicepaw/so-vits-svc-fork/commit/38d97449d5b443167926f409f904f4b40c6e0f03))\n\n## v1.4.1 (2023-03-26)\n\n### Bug fixes\n\n- Fix some parameters not passed ([`6cfe3d3`](https://github.com/voicepaw/so-vits-svc-fork/commit/6cfe3d3f567c03e1c59065ff827f564a13a7aaaf))\n\n## v1.4.0 (2023-03-26)\n\n### Features\n\n- Add 2 more preprocessing commands ([`45eba0f`](https://github.com/voicepaw/so-vits-svc-fork/commit/45eba0f25db1346757fcd9134ccb3a62125a05a9))\n\n### Documentation\n\n- Add blueamulet as a contributor for code ([`6a7e8ba`](https://github.com/voicepaw/so-vits-svc-fork/commit/6a7e8ba827ee69f1ceca60b83dfbae437bbe6667))\n\n## v1.3.5 (2023-03-26)\n\n### Bug fixes\n\n- Allow float32 audio to be processed properly ([`13943b6`](https://github.com/voicepaw/so-vits-svc-fork/commit/13943b693d177cf5417127647a3280a9e5ff9ca5))\n\n## v1.3.4 (2023-03-25)\n\n### Bug fixes\n\n- Change default f0 method from crepe to dio ([`baf58d2`](https://github.com/voicepaw/so-vits-svc-fork/commit/baf58d286c286c0064fd015e0e8f0b9e690021f7))\n\n## v1.3.3 (2023-03-25)\n\n### Documentation\n\n- Add lordmau5 as a contributor for bug, and code ([`4df46ee`](https://github.com/voicepaw/so-vits-svc-fork/commit/4df46eed47378f41d76c7637f540779db3bb54a3))\n- Update readme.md [skip ci] ([`4df46ee`](https://github.com/voicepaw/so-vits-svc-fork/commit/4df46eed47378f41d76c7637f540779db3bb54a3))\n- Update .all-contributorsrc [skip ci] ([`4df46ee`](https://github.com/voicepaw/so-vits-svc-fork/commit/4df46eed47378f41d76c7637f540779db3bb54a3))\n\n### Bug fixes\n\n- Fix old checkpoint deletion by sorting the models properly (#65) ([`287dc94`](https://github.com/voicepaw/so-vits-svc-fork/commit/287dc94be719147023af0ecfe7e92b16a8e98fc5))\n\n## v1.3.2 (2023-03-24)\n\n### Bug fixes\n\n- Fix devices list and fix tqdm error in gui ([`59724cd`](https://github.com/voicepaw/so-vits-svc-fork/commit/59724cd2afc6a8d5ef6ea4b7fa8c012e21fc4af6))\n\n### Documentation\n\n- Add mashirosa as a contributor for doc, and bug ([`495b7cb`](https://github.com/voicepaw/so-vits-svc-fork/commit/495b7cbfc9f9468d49bc3f57efe6c5c076dcb0d3))\n- Fix cluster inference command and improve cluster training command ([`7642594`](https://github.com/voicepaw/so-vits-svc-fork/commit/7642594472bd660fe046c45909f0475398af199e))\n\n## v1.3.1 (2023-03-24)\n\n### Bug fixes\n\n- Fix defaut for auto_play ([`07920a4`](https://github.com/voicepaw/so-vits-svc-fork/commit/07920a4954e1a14d47fcb2687f050d49d03da415))\n- Fix speaker not automaticlly set to the first one if not found in cluster inference ([`a643e4f`](https://github.com/voicepaw/so-vits-svc-fork/commit/a643e4f26b59f12f00b316467edad876467dad49))\n\n### Documentation\n\n- Add cluster training and inference ([`9ffb621`](https://github.com/voicepaw/so-vits-svc-fork/commit/9ffb6216f418d8c5a4a9f1bdd79fc2cebb885db1))\n\n## v1.3.0 (2023-03-23)\n\n### Features\n\n- Better error handling ([`985704b`](https://github.com/voicepaw/so-vits-svc-fork/commit/985704b1afa8af15fe8eab5e3fc838465f5162c8))\n\n## v1.2.11 (2023-03-23)\n\n### Bug fixes\n\n- Fix onnx export and fix gui ([`3e9a47d`](https://github.com/voicepaw/so-vits-svc-fork/commit/3e9a47dd4faa938a6aaebf2d7c1c0b9d68cc97d3))\n\n## v1.2.10 (2023-03-23)\n\n### Bug fixes\n\n- Fix cluster not working ([`29b209c`](https://github.com/voicepaw/so-vits-svc-fork/commit/29b209cf7060deb7f15ae28fe2e520bb20a236f4))\n\n## v1.2.9 (2023-03-23)\n\n### Bug fixes\n\n- Fix speakers and devices not updated and fix default presets ([`a851150`](https://github.com/voicepaw/so-vits-svc-fork/commit/a8511508b0d2b3a62e7b77833280e4264997d9ed))\n\n## v1.2.8 (2023-03-22)\n\n### Bug fixes\n\n- Update dependency torchcrepe to v0.0.18 ([`4fda479`](https://github.com/voicepaw/so-vits-svc-fork/commit/4fda4799f017e7de57de36c95cd8d64ab6f9b446))\n\n### Documentation\n\n- Shorten docs ([`e0c1572`](https://github.com/voicepaw/so-vits-svc-fork/commit/e0c1572d057032735c3118e9137be8e4399c6251))\n\n## v1.2.7 (2023-03-22)\n\n### Bug fixes\n\n- Fix clean_checkpoints ([`e5169bf`](https://github.com/voicepaw/so-vits-svc-fork/commit/e5169bf8121578a6cc3ed1bccd1b47a6281cafe4))\n\n## v1.2.6 (2023-03-22)\n\n### Documentation\n\n- Add blueamulet as a contributor for question ([`8d073e3`](https://github.com/voicepaw/so-vits-svc-fork/commit/8d073e3e0798a0739cea5b979cf6cfd361f3e6d3))\n- Add garrettconway as a contributor for doc ([`6c6cbc6`](https://github.com/voicepaw/so-vits-svc-fork/commit/6c6cbc6ac8a97ecb71d789a5782bb8db2c4c52f8))\n- Update readme.md regarding installation, update. wsl audio support ([`4f1323b`](https://github.com/voicepaw/so-vits-svc-fork/commit/4f1323b3d12a080f38a195bf494db7086dbfa7e4))\n\n### Bug fixes\n\n- Disable checkbox if cuda is not available and show errors for vc ([`3fdd983`](https://github.com/voicepaw/so-vits-svc-fork/commit/3fdd9836c3b60d2e737fc7e40efe42a9cc84888e))\n\n## v1.2.5 (2023-03-22)\n\n### Bug fixes\n\n- Fix rtf calculation ([`fb25500`](https://github.com/voicepaw/so-vits-svc-fork/commit/fb25500f4e3e70e5d71462715b83fb3bedcf8bd5))\n\n## v1.2.4 (2023-03-22)\n\n### Bug fixes\n\n- Fix latest_checkpoint_path ([`00b9f4a`](https://github.com/voicepaw/so-vits-svc-fork/commit/00b9f4acd005cdb801b3f41df6e25b0b8799d631))\n\n## v1.2.3 (2023-03-21)\n\n### Bug fixes\n\n- Update dependency onnxsim to v0.4.19 ([`f8a4cf6`](https://github.com/voicepaw/so-vits-svc-fork/commit/f8a4cf61bad5d0d55a7334af8f022114605e7038))\n\n## v1.2.2 (2023-03-21)\n\n### Bug fixes\n\n- Update dependency onnxoptimizer to v0.3.10 ([`d0137f9`](https://github.com/voicepaw/so-vits-svc-fork/commit/d0137f920083a08173d58e35492b9b9fb925e41f))\n\n### Documentation\n\n- Add links for pretrained models and fix gui pic height ([`34ac39f`](https://github.com/voicepaw/so-vits-svc-fork/commit/34ac39f0c9ce89f2effdd18f3fc4ab91e72b3f82))\n- Add more explanation to notebook ([`9b3c483`](https://github.com/voicepaw/so-vits-svc-fork/commit/9b3c4835e063d26d1e66d172cf592e69e30d59b8))\n\n## v1.2.1 (2023-03-21)\n\n### Bug fixes\n\n- Use librosa.load() instead of soundfile.read() ([`b343106`](https://github.com/voicepaw/so-vits-svc-fork/commit/b34310662b2bac53884df396932f72366132ea01))\n- Fix window too big to show in a fhd environment ([`259e6e6`](https://github.com/voicepaw/so-vits-svc-fork/commit/259e6e6eb6ebfd9027b1813756d67d1a516e0214))\n\n## v1.2.0 (2023-03-21)\n\n### Features\n\n- Add presets ([`e8adcc6`](https://github.com/voicepaw/so-vits-svc-fork/commit/e8adcc621f6caf5f4b20846575b3559c032ed47f))\n\n## v1.1.1 (2023-03-21)\n\n### Bug fixes\n\n- Update dependency gradio to v3.23.0 ([`a2bdb48`](https://github.com/voicepaw/so-vits-svc-fork/commit/a2bdb48b436d206b30bb72409852c0b30d6811e9))\n\n## v1.1.0 (2023-03-21)\n\n### Documentation\n\n- Update gui screenshot ([`58d06aa`](https://github.com/voicepaw/so-vits-svc-fork/commit/58d06aa7460dd75ef793da295bf7651ae9940814))\n\n### Features\n\n- Enhance realtimevc ([`81551ce`](https://github.com/voicepaw/so-vits-svc-fork/commit/81551ce9c6fb7924d184c3c5a4cf9035168b28d2))\n\n## v1.0.2 (2023-03-21)\n\n### Bug fixes\n\n- Update dependency scipy to v1.10.1 ([`e0253bf`](https://github.com/voicepaw/so-vits-svc-fork/commit/e0253bf1e655f86be605395a18f343763d975101))\n\n## v1.0.1 (2023-03-20)\n\n### Documentation\n\n- Add throwawayaccount01 as a contributor for bug ([`15e31fa`](https://github.com/voicepaw/so-vits-svc-fork/commit/15e31fa806249d45235918fa62a48a86c43538cb))\n- Add blueamulet as a contributor for ideas ([`a3bcb2b`](https://github.com/voicepaw/so-vits-svc-fork/commit/a3bcb2be2992c98bcc2485082c19009c74cb3194))\n\n### Performance improvements\n\n- Do dummy inference before running vc ([`4066c43`](https://github.com/voicepaw/so-vits-svc-fork/commit/4066c4334b107062d2daa7c9dc00600a56c6e553))\n\n## v1.0.0 (2023-03-20)\n\n### Bug fixes\n\n- Fix default dataset path ([`ac47fed`](https://github.com/voicepaw/so-vits-svc-fork/commit/ac47fede2581d375c2be9c28102961f19f5a9aa1))\n\n## v0.8.2 (2023-03-20)\n\n### Bug fixes\n\n- Fix compute_f0_crepe returning wrong length ([`afb42b0`](https://github.com/voicepaw/so-vits-svc-fork/commit/afb42b019ccd133876a2c55cf01007950a733d8c))\n\n## v0.8.1 (2023-03-20)\n\n### Bug fixes\n\n- Update dependency librosa to v0.10.0 ([`8e92f71`](https://github.com/voicepaw/so-vits-svc-fork/commit/8e92f71b2820628f0f8583e6bc455d8f753f4302))\n\n## v0.8.0 (2023-03-20)\n\n### Features\n\n- Add more f0 calculation methods ([`6b3b20d`](https://github.com/voicepaw/so-vits-svc-fork/commit/6b3b20dfd609d81cb1184b7c8e8865a58f8d45f9))\n\n## v0.7.1 (2023-03-20)\n\n### Bug fixes\n\n- Update dependency gradio to v3.22.1 ([`f09fc23`](https://github.com/voicepaw/so-vits-svc-fork/commit/f09fc23ca82519cc095509d4d4760561424a17ec))\n\n### Features\n\n- Allow nested dataset ([`0433151`](https://github.com/voicepaw/so-vits-svc-fork/commit/0433151d94c4da8e84a0183bdd47f1e08ea3c462))\n\n## v0.6.3 (2023-03-20)\n\n### Bug fixes\n\n- Update dependency torch to v1.13.1 ([`8826d68`](https://github.com/voicepaw/so-vits-svc-fork/commit/8826d6870e223e7969baa069bf12235e0deec0b7))\n- Update dependency torchaudio to v0.13.1 ([`989f5d9`](https://github.com/voicepaw/so-vits-svc-fork/commit/989f5d903b47ba9b0ea1d0fe37cbfe76edf0a811))\n\n### Documentation\n\n- Update notes about vram caps ([`0a245f4`](https://github.com/voicepaw/so-vits-svc-fork/commit/0a245f4ee69bd0d4371836367becf0fe409431e2))\n\n## v0.6.2 (2023-03-19)\n\n### Documentation\n\n- Add garrettconway as a contributor for bug ([`31d9671`](https://github.com/voicepaw/so-vits-svc-fork/commit/31d9671207143fd06b8db148802d1e27874151ce))\n- Launch tensorboard ([`52229ba`](https://github.com/voicepaw/so-vits-svc-fork/commit/52229ba0fe9458e37b45287c0a716c7cd36adbd6))\n- Add 34j as a contributor for example, infra, and 6 more ([`1b90378`](https://github.com/voicepaw/so-vits-svc-fork/commit/1b903783b4b89f2f5a4fc2e1b47f3eade0c0402f))\n- Add garrettconway as a contributor for code ([`716813f`](https://github.com/voicepaw/so-vits-svc-fork/commit/716813fbff85ab4609d8ec3f374b78c6551877e5))\n\n### Bug fixes\n\n- Use hubert preprocess force_rebuild argument ([`87cf807`](https://github.com/voicepaw/so-vits-svc-fork/commit/87cf807496248e2c7b859069f81aa040e86aec59))\n\n## v0.6.1 (2023-03-19)\n\n### Performance improvements\n\n- Better performance ([`668c8e1`](https://github.com/voicepaw/so-vits-svc-fork/commit/668c8e1f18cefb0ebd2fb2f1d6572ce4d37d1102))\n\n## v0.6.0 (2023-03-18)\n\n### Features\n\n- Configurable input and output devices ([`a822a60`](https://github.com/voicepaw/so-vits-svc-fork/commit/a822a6098d322ff37725eee19d17758f72a6db49))\n\n### Documentation\n\n- Fix notebook ([`427b4c1`](https://github.com/voicepaw/so-vits-svc-fork/commit/427b4c1c6e0482345b17fedb018f7a18db68ccc5))\n- Update notebook ([`ae3e471`](https://github.com/voicepaw/so-vits-svc-fork/commit/ae3e4710aac41555f00ddcdfbcf5a5e925afb718))\n\n## v0.5.0 (2023-03-18)\n\n### Features\n\n- Remember last directory (misc) ([`92558da`](https://github.com/voicepaw/so-vits-svc-fork/commit/92558da2f0e4eb24a8de412fb7e22dc3530b648a))\n- Show defaults ([`3d298df`](https://github.com/voicepaw/so-vits-svc-fork/commit/3d298df91bdfca230959603da74331b5eef4d487))\n\n### Bug fixes\n\n- Fix option names ([`7ff34fe`](https://github.com/voicepaw/so-vits-svc-fork/commit/7ff34fe623dde6b0a684c45cf33dc54118f9a800))\n\n### Documentation\n\n- Update readme.md ([`b988101`](https://github.com/voicepaw/so-vits-svc-fork/commit/b98810194703b6bb0ede03a00c460eeecdab5131))\n\n## v0.4.1 (2023-03-18)\n\n### Bug fixes\n\n- Call init_logger() ([`e6378f1`](https://github.com/voicepaw/so-vits-svc-fork/commit/e6378f12e747e618ff90ece1552d09c0d0714d41))\n\n## v0.4.0 (2023-03-18)\n\n### Features\n\n- Enhance realtime algorythm ([`d789a12`](https://github.com/voicepaw/so-vits-svc-fork/commit/d789a12308784473ae5d09e0b73fa15bf7554de1))\n\n## v0.3.0 (2023-03-17)\n\n### Features\n\n- Add gui ([`34aec2b`](https://github.com/voicepaw/so-vits-svc-fork/commit/34aec2b98ee4ef82ef488129b61a7952af5226a3))\n\n### Documentation\n\n- Update notebook ([`7b74606`](https://github.com/voicepaw/so-vits-svc-fork/commit/7b74606508cfb7e45224cbd76f3de9c43c8b4309))\n\n## v0.2.1 (2023-03-17)\n\n### Bug fixes\n\n- Fix notebook ([`3ed00cc`](https://github.com/voicepaw/so-vits-svc-fork/commit/3ed00cc66d4f66e045f61fc14937cb9160eee556))\n\n## v0.2.0 (2023-03-17)\n\n### Features\n\n- Realtime inference ([`4dea1ae`](https://github.com/voicepaw/so-vits-svc-fork/commit/4dea1ae51fe2e47a3f41556bdbe3fefd033d729a))\n\n## v0.1.0 (2023-03-17)\n\n### Features\n\n- Main feat ([`faa990c`](https://github.com/voicepaw/so-vits-svc-fork/commit/faa990ce6411d8b4e8b3d2d48c4b532b76ff7800))\n"
},
{
"path": "CONTRIBUTING.md",
"content": "# Contributing\n\nContributions are welcome, and they are greatly appreciated! Every little helps, and credit will always be given.\n\nYou can contribute in many ways:\n\n## Types of Contributions\n\n### Report Bugs\n\nReport bugs to [our issue page][gh-issues]. If you are reporting a bug, please include:\n\n- Your operating system name and version.\n- Any details about your local setup that might be helpful in troubleshooting.\n- Detailed steps to reproduce the bug.\n\n### Fix Bugs\n\nLook through the GitHub issues for bugs. Anything tagged with \"bug\" and \"help wanted\" is open to whoever wants to implement it.\n\n### Implement Features\n\nLook through the GitHub issues for features. Anything tagged with \"enhancement\" and \"help wanted\" is open to whoever wants to implement it.\n\n### Write Documentation\n\nSoftVC VITS Singing Voice Conversion Fork could always use more documentation, whether as part of the official SoftVC VITS Singing Voice Conversion Fork docs, in docstrings, or even on the web in blog posts, articles, and such.\n\n### Submit Feedback\n\nThe best way to send feedback [our issue page][gh-issues] on GitHub. If you are proposing a feature:\n\n- Explain in detail how it would work.\n- Keep the scope as narrow as possible, to make it easier to implement.\n- Remember that this is a volunteer-driven project, and that contributions are welcome 😊\n\n## Get Started!\n\nReady to contribute? Here's how to set yourself up for local development.\n\n1. Fork the repo on GitHub.\n\n2. Clone your fork locally:\n\n ```shell\n $ git clone git@github.com:your_name_here/so-vits-svc-fork.git\n ```\n\n3. Install the project dependencies with [uv](https://docs.astral.sh/uv/):\n\n ```shell\n $ uv sync\n ```\n\n4. Create a branch for local development:\n\n ```shell\n $ git checkout -b name-of-your-bugfix-or-feature\n ```\n\n Now you can make your changes locally.\n\n5. When you're done making changes, check that your changes pass our tests:\n\n ```shell\n $ uv run pytest\n ```\n\n6. Linting is done through [pre-commit](https://pre-commit.com). Provided you have the tool installed globally, you can run them all as one-off:\n\n ```shell\n $ pre-commit run -a\n ```\n\n Or better, install the hooks once and have them run automatically each time you commit:\n\n ```shell\n $ pre-commit install\n ```\n\n7. Commit your changes and push your branch to GitHub:\n\n ```shell\n $ git add .\n $ git commit -m \"feat(something): your detailed description of your changes\"\n $ git push origin name-of-your-bugfix-or-feature\n ```\n\n Note: the commit message should follow [the conventional commits](https://www.conventionalcommits.org). We run [`commitlint` on CI](https://github.com/marketplace/actions/commit-linter) to validate it, and if you've installed pre-commit hooks at the previous step, the message will be checked at commit time.\n\n8. Submit a pull request through the GitHub website or using the GitHub CLI (if you have it installed):\n\n ```shell\n $ gh pr create --fill\n ```\n\n## Pull Request Guidelines\n\nWe like to have the pull request open as soon as possible, that's a great place to discuss any piece of work, even unfinished. You can use draft pull request if it's still a work in progress. Here are a few guidelines to follow:\n\n1. Include tests for feature or bug fixes.\n2. Update the documentation for significant features.\n3. Ensure tests are passing on CI.\n\n## Tips\n\nTo run a subset of tests:\n\n```shell\n$ pytest tests\n```\n\n## Making a new release\n\nThe deployment should be automated and can be triggered from the Semantic Release workflow in GitHub. The next version will be based on [the commit logs](https://python-semantic-release.readthedocs.io/en/latest/commit-log-parsing.html#commit-log-parsing). This is done by [python-semantic-release](https://python-semantic-release.readthedocs.io/en/latest/index.html) via a GitHub action.\n\n[gh-issues]: https://github.com/voicepaw/so-vits-svc-fork/issues\n"
},
{
"path": "Dockerfile",
"content": "FROM pytorch/pytorch:2.0.1-cuda11.7-cudnn8-runtime@sha256:82e0d379a5dedd6303c89eda57bcc434c40be11f249ddfadfd5673b84351e806\nRUN [\"apt\", \"update\"]\nRUN [\"apt\", \"install\", \"-y\", \"build-essential\"]\nRUN [\"pip\", \"install\", \"-U\", \"pip\", \"setuptools\", \"wheel\"]\nRUN [\"pip\", \"install\", \"-U\", \"so-vits-svc-fork\"]\nENTRYPOINT [ \"svcg\" ]\n"
},
{
"path": "LICENSE",
"content": "MIT License\n\nCopyright (c) 2023 34j and contributors\nCopyright (c) 2021 Jingyi Li\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof this software and associated documentation files (the \"Software\"), to deal\nin the Software without restriction, including without limitation the rights\nto use, copy, modify, merge, publish, distribute, sublicense, and/or sell\ncopies of the Software, and to permit persons to whom the Software is\nfurnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in all\ncopies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\nIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\nOUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\nSOFTWARE.\n Apache License\n Version 2.0, January 2004\n http://www.apache.org/licenses/\n\n TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION\n\n 1. Definitions.\n\n \"License\" shall mean the terms and conditions for use, reproduction,\n and distribution as defined by Sections 1 through 9 of this document.\n\n \"Licensor\" shall mean the copyright owner or entity authorized by\n the copyright owner that is granting the License.\n\n \"Legal Entity\" shall mean the union of the acting entity and all\n other entities that control, are controlled by, or are under common\n control with that entity. For the purposes of this definition,\n \"control\" means (i) the power, direct or indirect, to cause the\n direction or management of such entity, whether by contract or\n otherwise, or (ii) ownership of fifty percent (50%) or more of the\n outstanding shares, or (iii) beneficial ownership of such entity.\n\n \"You\" (or \"Your\") shall mean an individual or Legal Entity\n exercising permissions granted by this License.\n\n \"Source\" form shall mean the preferred form for making modifications,\n including but not limited to software source code, documentation\n source, and configuration files.\n\n \"Object\" form shall mean any form resulting from mechanical\n transformation or translation of a Source form, including but\n not limited to compiled object code, generated documentation,\n and conversions to other media types.\n\n \"Work\" shall mean the work of authorship, whether in Source or\n Object form, made available under the License, as indicated by a\n copyright notice that is included in or attached to the work\n (an example is provided in the Appendix below).\n\n \"Derivative Works\" shall mean any work, whether in Source or Object\n form, that is based on (or derived from) the Work and for which the\n editorial revisions, annotations, elaborations, or other modifications\n represent, as a whole, an original work of authorship. For the purposes\n of this License, Derivative Works shall not include works that remain\n separable from, or merely link (or bind by name) to the interfaces of,\n the Work and Derivative Works thereof.\n\n \"Contribution\" shall mean any work of authorship, including\n the original version of the Work and any modifications or additions\n to that Work or Derivative Works thereof, that is intentionally\n submitted to Licensor for inclusion in the Work by the copyright owner\n or by an individual or Legal Entity authorized to submit on behalf of\n the copyright owner. For the purposes of this definition, \"submitted\"\n means any form of electronic, verbal, or written communication sent\n to the Licensor or its representatives, including but not limited to\n communication on electronic mailing lists, source code control systems,\n and issue tracking systems that are managed by, or on behalf of, the\n Licensor for the purpose of discussing and improving the Work, but\n excluding communication that is conspicuously marked or otherwise\n designated in writing by the copyright owner as \"Not a Contribution.\"\n\n \"Contributor\" shall mean Licensor and any individual or Legal Entity\n on behalf of whom a Contribution has been received by Licensor and\n subsequently incorporated within the Work.\n\n 2. Grant of Copyright License. Subject to the terms and conditions of\n this License, each Contributor hereby grants to You a perpetual,\n worldwide, non-exclusive, no-charge, royalty-free, irrevocable\n copyright license to reproduce, prepare Derivative Works of,\n publicly display, publicly perform, sublicense, and distribute the\n Work and such Derivative Works in Source or Object form.\n\n 3. Grant of Patent License. Subject to the terms and conditions of\n this License, each Contributor hereby grants to You a perpetual,\n worldwide, non-exclusive, no-charge, royalty-free, irrevocable\n (except as stated in this section) patent license to make, have made,\n use, offer to sell, sell, import, and otherwise transfer the Work,\n where such license applies only to those patent claims licensable\n by such Contributor that are necessarily infringed by their\n Contribution(s) alone or by combination of their Contribution(s)\n with the Work to which such Contribution(s) was submitted. If You\n institute patent litigation against any entity (including a\n cross-claim or counterclaim in a lawsuit) alleging that the Work\n or a Contribution incorporated within the Work constitutes direct\n or contributory patent infringement, then any patent licenses\n granted to You under this License for that Work shall terminate\n as of the date such litigation is filed.\n\n 4. Redistribution. You may reproduce and distribute copies of the\n Work or Derivative Works thereof in any medium, with or without\n modifications, and in Source or Object form, provided that You\n meet the following conditions:\n\n (a) You must give any other recipients of the Work or\n Derivative Works a copy of this License; and\n\n (b) You must cause any modified files to carry prominent notices\n stating that You changed the files; and\n\n (c) You must retain, in the Source form of any Derivative Works\n that You distribute, all copyright, patent, trademark, and\n attribution notices from the Source form of the Work,\n excluding those notices that do not pertain to any part of\n the Derivative Works; and\n\n (d) If the Work includes a \"NOTICE\" text file as part of its\n distribution, then any Derivative Works that You distribute must\n include a readable copy of the attribution notices contained\n within such NOTICE file, excluding those notices that do not\n pertain to any part of the Derivative Works, in at least one\n of the following places: within a NOTICE text file distributed\n as part of the Derivative Works; within the Source form or\n documentation, if provided along with the Derivative Works; or,\n within a display generated by the Derivative Works, if and\n wherever such third-party notices normally appear. The contents\n of the NOTICE file are for informational purposes only and\n do not modify the License. You may add Your own attribution\n notices within Derivative Works that You distribute, alongside\n or as an addendum to the NOTICE text from the Work, provided\n that such additional attribution notices cannot be construed\n as modifying the License.\n\n You may add Your own copyright statement to Your modifications and\n may provide additional or different license terms and conditions\n for use, reproduction, or distribution of Your modifications, or\n for any such Derivative Works as a whole, provided Your use,\n reproduction, and distribution of the Work otherwise complies with\n the conditions stated in this License.\n\n 5. Submission of Contributions. Unless You explicitly state otherwise,\n any Contribution intentionally submitted for inclusion in the Work\n by You to the Licensor shall be under the terms and conditions of\n this License, without any additional terms or conditions.\n Notwithstanding the above, nothing herein shall supersede or modify\n the terms of any separate license agreement you may have executed\n with Licensor regarding such Contributions.\n\n 6. Trademarks. This License does not grant permission to use the trade\n names, trademarks, service marks, or product names of the Licensor,\n except as required for reasonable and customary use in describing the\n origin of the Work and reproducing the content of the NOTICE file.\n\n 7. Disclaimer of Warranty. Unless required by applicable law or\n agreed to in writing, Licensor provides the Work (and each\n Contributor provides its Contributions) on an \"AS IS\" BASIS,\n WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\n implied, including, without limitation, any warranties or conditions\n of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A\n PARTICULAR PURPOSE. You are solely responsible for determining the\n appropriateness of using or redistributing the Work and assume any\n risks associated with Your exercise of permissions under this License.\n\n 8. Limitation of Liability. In no event and under no legal theory,\n whether in tort (including negligence), contract, or otherwise,\n unless required by applicable law (such as deliberate and grossly\n negligent acts) or agreed to in writing, shall any Contributor be\n liable to You for damages, including any direct, indirect, special,\n incidental, or consequential damages of any character arising as a\n result of this License or out of the use or inability to use the\n Work (including but not limited to damages for loss of goodwill,\n work stoppage, computer failure or malfunction, or any and all\n other commercial damages or losses), even if such Contributor\n has been advised of the possibility of such damages.\n\n 9. Accepting Warranty or Additional Liability. While redistributing\n the Work or Derivative Works thereof, You may choose to offer,\n and charge a fee for, acceptance of support, warranty, indemnity,\n or other liability obligations and/or rights consistent with this\n License. However, in accepting such obligations, You may act only\n on Your own behalf and on Your sole responsibility, not on behalf\n of any other Contributor, and only if You agree to indemnify,\n defend, and hold each Contributor harmless for any liability\n incurred by, or claims asserted against, such Contributor by reason\n of your accepting any such warranty or additional liability.\n\n END OF TERMS AND CONDITIONS\n\n APPENDIX: How to apply the Apache License to your work.\n\n To apply the Apache License to your work, attach the following\n boilerplate notice, with the fields enclosed by brackets \"[]\"\n replaced with your own identifying information. (Don't include\n the brackets!) The text should be enclosed in the appropriate\n comment syntax for the file format. We also recommend that a\n file or class name and description of purpose be included on the\n same \"printed page\" as the copyright notice for easier\n identification within third-party archives.\n\n Copyright [yyyy] [name of copyright owner]\n\n Licensed under the Apache License, Version 2.0 (the \"License\");\n you may not use this file except in compliance with the License.\n You may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\n Unless required by applicable law or agreed to in writing, software\n distributed under the License is distributed on an \"AS IS\" BASIS,\n WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n See the License for the specific language governing permissions and\n limitations under the License.\n"
},
{
"path": "README.md",
"content": "# SoftVC VITS Singing Voice Conversion Fork\n\n[简体中文](README_zh_CN.md)\n\n\n \n  \n \n \n
\n \n \n  \n \n \n
\n \n \n  \n \n
\n \n
\n\n \n  \n \n \n
\n \n \n  \n \n \n
\n \n \n  \n \n
\n \n
\n\n \n  \n \n
\n \n  \n
\n  \n
\n
\n\nA fork of [`so-vits-svc`](https://github.com/svc-develop-team/so-vits-svc) with **realtime support** and **greatly improved interface**. Based on branch `4.0` (v1) (or `4.1`) and the models are compatible. `4.1` models are not supported. Other models are also not supported.\n\n## No Longer Maintained\n\n### Reasons\n\n- Within a year, the technology has evolved enormously and there are many better alternatives\n- Was hoping to create a more Modular, easy-to-install repository, but didn't have the skills, time, money to do so\n- PySimpleGUI is no longer LGPL\n- Using Typer is getting more popular than directly using Click\n\n### Alternatives\n\nAlways beware of the very few influencers who are **quite overly surprised** about any new project/technology. You need to take every social networking post with semi-doubt.\n\nThe voice changer boom that occurred in 2023 has come to an end, and many developers, not just those in this repository, have been not very active for a while.\n\nThere are too many alternatives to list here but:\n\n- RVC family: [IAHispano/Applio](https://github.com/IAHispano/Applio) (MIT) (actively maintained), [fumiama's RVC](https://github.com/fumiama/Retrieval-based-Voice-Conversion-WebUI) (AGPL) and [original RVC](https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI) (MIT) (no longer maintained)\n- [VCClient](https://github.com/w-okada/voice-changer) (MIT etc.) offers web-based GUI for real-time conversion but not quite actively maintained.\n- [fish-diffusion](https://github.com/fishaudio/fish-diffusion/commits/main/) tried to be quite modular but not actively maintained.\n- [yxlllc/DDSP\\-SVC](https://github.com/yxlllc/DDSP-SVC) - new releases are issued occasionally. [yxlllc/ReFlow\\-VAE\\-SVC](https://github.com/yxlllc/ReFlow-VAE-SVC)\n- [coqui\\-ai/TTS](https://github.com/coqui-ai/TTS) was for TTS but was partially modular. However, it is not maintained anymore, unfortunately.\n\nElsewhere, several start-ups have improved and marketed voice changers (probably for profit).\n\n> Updates to this repository have been limited to maintenance since Spring 2023.\n> ~~It is difficult to narrow the list of alternatives here, but please consider trying other projects if you are looking for a voice changer with even better performance (especially in terms of latency other than quality).~~ > ~~However, this project may be ideal for those who want to try out voice conversion for the moment (because it is easy to install).~~\n\n## Features not available in the original repo\n\n- **Realtime voice conversion** (enhanced in v1.1.0)\n- Partially integrates [`QuickVC`](https://github.com/quickvc/QuickVC-VoiceConversion)\n- Fixed misuse of [`ContentVec`](https://github.com/auspicious3000/contentvec) in the original repository.[^c]\n- More accurate pitch estimation using [`CREPE`](https://github.com/marl/crepe/).\n- GUI and unified CLI available\n- ~2x faster training\n- Ready to use just by installing with `pip`.\n- Automatically download pretrained models. No need to install `fairseq`.\n- Code completely formatted with black, isort, autoflake etc.\n\n[^c]: [#206](https://github.com/voicepaw/so-vits-svc-fork/issues/206)\n\n## Installation\n\n### Option 1. One click easy installation\n\n\n  \n\n\nThis BAT file will automatically perform the steps described below.\n\n### Option 2. Manual installation (using pipx, experimental)\n\n#### 1. Installing pipx\n\nWindows (development version required due to [pypa/pipx#940](https://github.com/pypa/pipx/issues/940)):\n\n```shell\npy -3 -m pip install --user git+https://github.com/pypa/pipx.git\npy -3 -m pipx ensurepath\n```\n\nLinux/MacOS:\n\n```shell\npython -m pip install --user pipx\npython -m pipx ensurepath\n```\n\n#### 2. Installing so-vits-svc-fork\n\n```shell\npipx install so-vits-svc-fork --python=3.11\npipx inject so-vits-svc-fork torch torchaudio --pip-args=\"--upgrade\" --index-url=https://download.pytorch.org/whl/cu121 # https://download.pytorch.org/whl/nightly/cu121\n```\n\n### Option 3. Manual installation\n\n
\n\n\nThis BAT file will automatically perform the steps described below.\n\n### Option 2. Manual installation (using pipx, experimental)\n\n#### 1. Installing pipx\n\nWindows (development version required due to [pypa/pipx#940](https://github.com/pypa/pipx/issues/940)):\n\n```shell\npy -3 -m pip install --user git+https://github.com/pypa/pipx.git\npy -3 -m pipx ensurepath\n```\n\nLinux/MacOS:\n\n```shell\npython -m pip install --user pipx\npython -m pipx ensurepath\n```\n\n#### 2. Installing so-vits-svc-fork\n\n```shell\npipx install so-vits-svc-fork --python=3.11\npipx inject so-vits-svc-fork torch torchaudio --pip-args=\"--upgrade\" --index-url=https://download.pytorch.org/whl/cu121 # https://download.pytorch.org/whl/nightly/cu121\n```\n\n### Option 3. Manual installation\n\n\n Creating a virtual environment
\n\nWindows:\n\n```shell\npy -3.11 -m venv venv\nvenv\\Scripts\\activate\n```\n\nLinux/MacOS:\n\n```shell\npython3.11 -m venv venv\nsource venv/bin/activate\n```\n\nAnaconda:\n\n```shell\nconda create -n so-vits-svc-fork python=3.11 pip\nconda activate so-vits-svc-fork\n```\n\nInstalling without creating a virtual environment may cause a `PermissionError` if Python is installed in Program Files, etc.\n\n \n\nInstall this via pip (or your favourite package manager that uses pip):\n\n```shell\npython -m pip install -U pip setuptools wheel\npip install -U torch torchaudio --index-url https://download.pytorch.org/whl/cu121 # https://download.pytorch.org/whl/nightly/cu121\npip install -U so-vits-svc-fork\n```\n\n\n Notes
\n\n- If no GPU is available or using MacOS, simply remove `pip install -U torch torchaudio --index-url https://download.pytorch.org/whl/cu121`. MPS is probably supported.\n- If you are using an AMD GPU on Linux, replace `--index-url https://download.pytorch.org/whl/cu121` with `--index-url https://download.pytorch.org/whl/nightly/rocm5.7`. AMD GPUs are not supported on Windows ([#120](https://github.com/voicepaw/so-vits-svc-fork/issues/120)).\n \n\n### Update\n\nPlease update this package regularly to get the latest features and bug fixes.\n\n```shell\npip install -U so-vits-svc-fork\n# pipx upgrade so-vits-svc-fork\n```\n\n## Usage\n\n### Inference\n\n#### GUI\n\n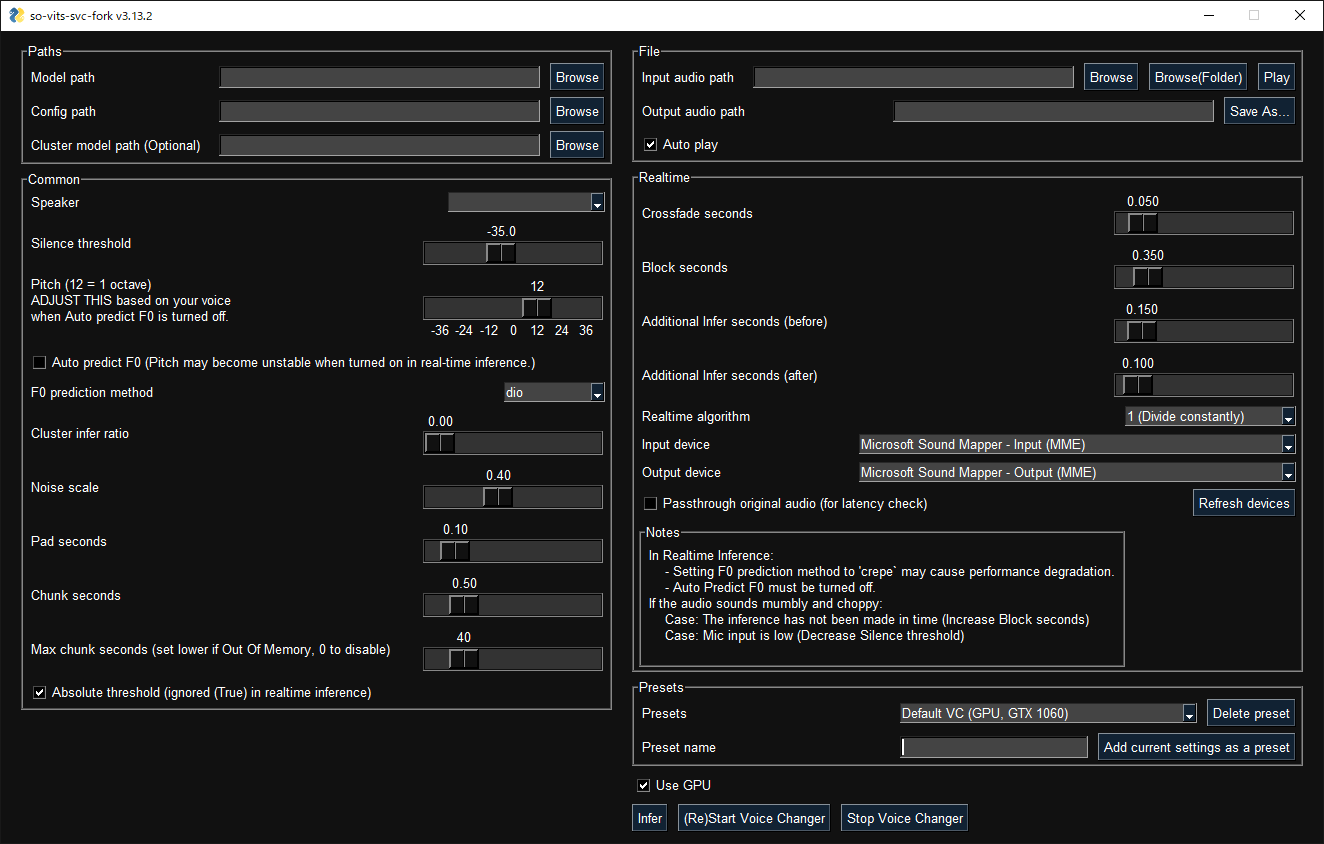\n\nGUI launches with the following command:\n\n```shell\nsvcg\n```\n\n#### CLI\n\n- Realtime (from microphone)\n\n```shell\nsvc vc\n```\n\n- File\n\n```shell\nsvc infer source.wav\n```\n\nPretrained models are available on [Hugging Face](https://huggingface.co/models?search=so-vits-svc) or [CIVITAI](https://civitai.com/tag/so-vits-svc-fork).\n\n#### Notes\n\n- If using WSL, please note that WSL requires additional setup to handle audio and the GUI will not work without finding an audio device.\n- In real-time inference, if there is noise on the inputs, the HuBERT model will react to those as well. Consider using realtime noise reduction applications such as [RTX Voice](https://www.nvidia.com/en-us/geforce/guides/nvidia-rtx-voice-setup-guide/) in this case.\n- Models other than for 4.0v1 or this repository are not supported.\n- GPU inference requires at least 4 GB of VRAM. If it does not work, try CPU inference as it is fast enough. [^r-inference]\n\n[^r-inference]: [#469](https://github.com/voicepaw/so-vits-svc-fork/issues/469)\n\n### Training\n\n#### Before training\n\n- If your dataset has BGM, please remove the BGM using software such as [Ultimate Vocal Remover](https://ultimatevocalremover.com/). `3_HP-Vocal-UVR.pth` or `UVR-MDX-NET Main` is recommended. [^1]\n- If your dataset is a long audio file with a single speaker, use `svc pre-split` to split the dataset into multiple files (using `librosa`).\n- If your dataset is a long audio file with multiple speakers, use `svc pre-sd` to split the dataset into multiple files (using `pyannote.audio`). Further manual classification may be necessary due to accuracy issues. If speakers speak with a variety of speech styles, set --min-speakers larger than the actual number of speakers. Due to unresolved dependencies, please install `pyannote.audio` manually: `pip install pyannote-audio`.\n- To manually classify audio files, `svc pre-classify` is available. Up and down arrow keys can be used to change the playback speed.\n\n[^1]: https://ytpmv.info/how-to-use-uvr/\n\n#### Cloud\n\n[](https://colab.research.google.com/github/voicepaw/so-vits-svc-fork/blob/main/notebooks/so-vits-svc-fork-4.0.ipynb)\n[](https://console.paperspace.com/github/voicepaw/so-vits-svc-fork-paperspace/blob/main/so-vits-svc-fork-4.0-paperspace.ipynb)\n[![Paperspace Referral]()](https://www.paperspace.com/?r=9VJN74I)[^p]\n\nIf you do not have access to a GPU with more than 10 GB of VRAM, the free plan of Google Colab is recommended for light users and the Pro/Growth plan of Paperspace is recommended for heavy users. Conversely, if you have access to a high-end GPU, the use of cloud services is not recommended.\n\n[^p]: If you register a referral code and then add a payment method, you may save about $5 on your first month's monthly billing. Note that both referral rewards are Paperspace credits and not cash. It was a tough decision but inserted because debugging and training the initial model requires a large amount of computing power and the developer is a student.\n\n#### Local\n\nPlace your dataset like `dataset_raw/{speaker_id}/**/{wav_file}.{any_format}` (subfolders and non-ASCII filenames are acceptable) and run:\n\n```shell\nsvc pre-resample\nsvc pre-config\nsvc pre-hubert\nsvc train -t\n```\n\n#### Notes\n\n- Dataset audio duration per file should be <~ 10s.\n- Need at least 4GB of VRAM. [^r-training]\n- It is recommended to increase the `batch_size` as much as possible in `config.json` before the `train` command to match the VRAM capacity. Setting `batch_size` to `auto-{init_batch_size}-{max_n_trials}` (or simply `auto`) will automatically increase `batch_size` until OOM error occurs, but may not be useful in some cases.\n- To use `CREPE`, replace `svc pre-hubert` with `svc pre-hubert -fm crepe`.\n- To use `ContentVec` correctly, replace `svc pre-config` with `-t so-vits-svc-4.0v1`. Training may take slightly longer because some weights are reset due to reusing legacy initial generator weights.\n- To use `MS-iSTFT Decoder`, replace `svc pre-config` with `svc pre-config -t quickvc`.\n- Silence removal and volume normalization are automatically performed (as in the upstream repo) and are not required.\n- If you have trained on a large, copyright-free dataset, consider releasing it as an initial model.\n- For further details (e.g. parameters, etc.), you can see the [Wiki](https://github.com/voicepaw/so-vits-svc-fork/wiki) or [Discussions](https://github.com/voicepaw/so-vits-svc-fork/discussions).\n\n[^r-training]: [#456](https://github.com/voicepaw/so-vits-svc-fork/issues/456)\n\n### Further help\n\nFor more details, run `svc -h` or `svc -h`.\n\n```shell\n> svc -h\nUsage: svc [OPTIONS] COMMAND [ARGS]...\n\n so-vits-svc allows any folder structure for training data.\n However, the following folder structure is recommended.\n When training: dataset_raw/{speaker_name}/**/{wav_name}.{any_format}\n When inference: configs/44k/config.json, logs/44k/G_XXXX.pth\n If the folder structure is followed, you DO NOT NEED TO SPECIFY model path, config path, etc.\n (The latest model will be automatically loaded.)\n To train a model, run pre-resample, pre-config, pre-hubert, train.\n To infer a model, run infer.\n\nOptions:\n -h, --help Show this message and exit.\n\nCommands:\n clean Clean up files, only useful if you are using the default file structure\n infer Inference\n onnx Export model to onnx (currently not working)\n pre-classify Classify multiple audio files into multiple files\n pre-config Preprocessing part 2: config\n pre-hubert Preprocessing part 3: hubert If the HuBERT model is not found, it will be...\n pre-resample Preprocessing part 1: resample\n pre-sd Speech diarization using pyannote.audio\n pre-split Split audio files into multiple files\n train Train model If D_0.pth or G_0.pth not found, automatically download from hub.\n train-cluster Train k-means clustering\n vc Realtime inference from microphone\n```\n\n#### External Links\n\n[Video Tutorial](https://www.youtube.com/watch?v=tZn0lcGO5OQ)\n\n## Contributors ✨\n\nThanks goes to these wonderful people ([emoji key](https://allcontributors.org/docs/en/emoji-key)):\n\n\n\n\n\n\n\n\n\n\n\n\nThis project follows the [all-contributors](https://github.com/all-contributors/all-contributors) specification. Contributions of any kind welcome!\n\n## Credits\n\n[](https://github.com/copier-org/copier)\n\nThis package was created with\n[Copier](https://copier.readthedocs.io/) and the\n[browniebroke/pypackage-template](https://github.com/browniebroke/pypackage-template)\nproject template.\n"
},
{
"path": "README_zh_CN.md",
"content": "# SoftVC VITS Singing Voice Conversion\n\n\n \n  \n \n \n \n \n \n
\n \n \n \n \n \n  \n \n
\n \n
\n\n \n  \n \n \n
\n \n \n  \n \n \n \n \n
\n \n \n \n \n
\n\n \n \n \n \n \n
\n\n基于 [`so-vits-svc4.0(V1)`](https://github.com/svc-develop-team/so-vits-svc)的一个分支,支持实时推理和图形化推理界面,且兼容其模型。\n\n## 新功能\n\n- **实时语音转换** (增强版本 v1.1.0)\n- 与[`QuickVC`](https://github.com/quickvc/QuickVC-VoiceConversion)相结合\n- 修复了原始版本中对 [`ContentVec`](https://github.com/auspicious3000/contentvec) 的误用[^c]\n- 使用 CREPE 进行更准确的音高推测\n- 图形化界面和统一命令行界面\n- 相比之前双倍的训练速度\n- 只需使用 `pip` 安装即可使用,不需要安装 `fairseq`\n- 自动下载预训练模型和 HuBERT 模型\n- 使用 black、isort、autoflake 等完全格式化的代码\n\n[^c]: [#206](https://github.com/34j/so-vits-svc-fork/issues/206)\n\n## 安装教程\n\n### 可以使用 bat 一键安装\n\n\n \n\n\n### 本 bat 汉化基于英文版,对原版进行了一些本地工作和优化,如安装过程有问题,可以尝试安装原版\n\n\n \n\n\n### 手动安装\n\n\n 创建一个虚拟环境
\n\nWindows:\n\n```shell\npy -3.10 -m venv venv\nvenv\\Scripts\\activate\n```\n\nLinux/MacOS:\n\n```shell\npython3.10 -m venv venv\nsource venv/bin/activate\n```\n\nAnaconda:\n\n```shell\nconda create -n so-vits-svc-fork python=3.10 pip\nconda activate so-vits-svc-fork\n```\n\n如果 Python 安装在 Program Files,在安装时未创造虚拟环境可能会导致`PermissionError`\n\n \n\n### 安装\n\n通过 pip 安装 (或者通过包管理器使用 pip 安装):\n\n```shell\npython -m pip install -U pip setuptools wheel\npip install -U torch torchaudio --index-url https://download.pytorch.org/whl/cu118\npip install -U so-vits-svc-fork\n```\n\n- 如果没有可用 GPU 或使用 MacOS, 不需要执行 `pip install -U torch torchaudio --index-url https://download.pytorch.org/whl/cu118`. MPS 可能已经安装了.\n- 如果在 Linux 下使用 AMD GPU, 请使用此命令 `--index-url https://download.pytorch.org/whl/rocm5.4.2`\n 替换掉 `--index-url https://download.pytorch.org/whl/cu118` . Windows 下不支持 AMD GPUs (#120).\n\n### 更新\n\n请经常更新以获取最新功能和修复错误:\n\n```shell\npip install -U so-vits-svc-fork\n```\n\n## 使用教程\n\n### 推理\n\n#### 图形化界面\n\n\n\n请使用以下命令运行图形化界面:\n\n```shell\nsvcg\n```\n\n#### 命令行界面\n\n- 实时转换 (输入源为麦克风)\n\n```shell\nsvc vc\n```\n\n- 从文件转换\n\n```shell\nsvc infer source.wav\n```\n\n[预训练模型](https://huggingface.co/models?search=so-vits-svc-4.0) 可以在 HuggingFace 获得。\n\n#### 注意\n\n- 如果使用 WSL, 请注意 WSL 需要额外设置来处理音频,如果 GUI 找不到音频设备将不能正常工作。\n- 在实时语音转换中, 如果输入源有杂音, HuBERT\n 模型依然会把杂音进行推理.可以考虑使用实时噪音减弱程序比如 [RTX Voice](https://www.nvidia.com/en-us/geforce/guides/nvidia-rtx-voice-setup-guide/)\n 来解决.\n\n### 训练\n\n#### 预处理\n\n- 如果数据集有 BGM,请用例如[Ultimate Vocal Remover](https://ultimatevocalremover.com/)等软件去除 BGM.\n 推荐使用`3_HP-Vocal-UVR.pth` 或者 `UVR-MDX-NET Main` . [^1]\n- 如果数据集是包含单个歌手的长音频文件, 使用 `svc pre-split` 将数据集拆分为多个文件 (使用 `librosa`).\n- 如果数据集是包含多个歌手的长音频文件, 使用 `svc pre-sd` 将数据集拆分为多个文件 (使用 `pyannote.audio`)\n 。为了提高准确率,可能需要手动进行分类。如果歌手的声线多样,请把 --min-speakers 设置为大于实际说话者数量. 如果出现依赖未安装,\n 请通过 `pip install pyannote-audio`来安装 `pyannote.audio`。\n\n[^1]: https://ytpmv.info/how-to-use-uvr/\n\n#### 云端\n\n[](https://colab.research.google.com/github/34j/so-vits-svc-fork/blob/main/notebooks/so-vits-svc-fork-4.0.ipynb)\n[](https://console.paperspace.com/github/34j/so-vits-svc-fork-paperspace/blob/main/so-vits-svc-fork-4.0-paperspace.ipynb)\n[![Paperspace Referral]()](https://www.paperspace.com/?r=9VJN74I)[^p]\n\n如果你无法获取 10GB 显存以上的显卡,对于轻量用户,推荐使用 Google Colab 的免费方案;而重度用户,则建议使用 Paperspace 的 Pro/Growth Plan。当然,如果你有高端的显卡,就没必要使用云服务了。\n\n[^p]: If you register a referral code and then add a payment method, you may save about $5 on your first month's monthly billing. Note that both referral rewards are Paperspace credits and not cash. It was a tough decision but inserted because debugging and training the initial model requires a large amount of computing power and the developer is a student.\n\n#### 本地\n\n将数据集处理成 `dataset_raw/{speaker_id}/**/{wav_file}.{any_format}` 的格式(可以使用子文件夹和非 ASCII 文件名)然后运行:\n\n```shell\nsvc pre-resample\nsvc pre-config\nsvc pre-hubert\nsvc train -t\n```\n\n#### 注意\n\n- 数据集的每个文件应该小于 10s,不然显存会爆。\n- 建议在执行 `train` 命令之前提高 `config.json` 中的 `batch_size` 以匹配显存容量。 将`batch_size`设为`auto-{init_batch_size}-{max_n_trials}`(或者只需设为`auto`)就会自动提高`batch_size`,直到爆显存为止(不过自动调高 batch_size 有概率失效)\n- 如果想要 f0 的推理方式为 `CREPE`, 用 `svc pre-hubert -fm crepe` 替换 `svc pre-hubert`.\n- 若想正确使用`ContentVec`,用 `-t so-vits-svc-4.0v1`替换`svc pre-config`。由于复用 generator weights,一些 weights 会被重置而导致训练时间稍微延长.\n- 若要使用`MS-iSTFT Decoder`,用 `svc pre-config -t quickvc`替换 `svc pre-config`.\n- 在原始仓库中,会自动移除静音和进行音量平衡,且这个操作并不是必须要处理的。\n- 倘若你已经大规模训练了一个免费公开版权的数据集,可以考虑将其作为底模发布。\n- 对于更多细节(比如参数等),详见[Wiki](https://github.com/34j/so-vits-svc-fork/wiki) 或 [Discussions](https://github.com/34j/so-vits-svc-fork/discussions).\n\n### 帮助\n\n更多命令, 运行 `svc -h` 或者 `svc -h`\n\n```shell\n> svc -h\n用法: svc [OPTIONS] COMMAND [ARGS]...\n\n so-vits-svc 允许任何文件夹结构用于训练数据\n 但是, 建议使用以下文件夹结构\n 训练: dataset_raw/{speaker_name}/**/{wav_name}.{any_format}\n 推理: configs/44k/config.json, logs/44k/G_XXXX.pth\n 如果遵循文件夹结构,则无需指定模型路径,配置路径等,将自动加载最新模型\n 若要要训练模型, 运行 pre-resample, pre-config, pre-hubert, train.\n 若要要推理模型, 运行 infer.\n\n可选:\n -h, --help 显示信息并退出\n\n命令:\n clean 清理文件,仅在使用默认文件结构时有用\n infer 推理\n onnx 导出模型到onnx\n pre-config 预处理第 2 部分: config\n pre-hubert 预处理第 3 部分: 如果没有找到 HuBERT 模型,则会...\n pre-resample 预处理第 1 部分: resample\n pre-sd Speech diarization 使用 pyannote.audio\n pre-split 将音频文件拆分为多个文件\n train 训练模型 如果 D_0.pth 或 G_0.pth 没有找到,自动从集线器下载.\n train-cluster 训练 k-means 聚类模型\n vc 麦克风实时推理\n```\n\n#### 补充链接\n\n[视频教程](https://www.youtube.com/watch?v=tZn0lcGO5OQ)\n\n## Contributors ✨\n\nThanks goes to these wonderful people ([emoji key](https://allcontributors.org/docs/en/emoji-key)):\n\n\n\n\n\n\n\n\n\n\n\n\n\nThis project follows the [all-contributors](https://github.com/all-contributors/all-contributors) specification. Contributions of any kind welcome!\n"
},
{
"path": "commitlint.config.js",
"content": "module.exports = {\n extends: [\"@commitlint/config-conventional\"],\n rules: {\n \"header-max-length\": [0, \"always\", Infinity],\n \"body-max-line-length\": [0, \"always\", Infinity],\n \"footer-max-line-length\": [0, \"always\", Infinity],\n },\n};\n"
},
{
"path": "commitlint.config.mjs",
"content": "export default {\n extends: [\"@commitlint/config-conventional\"],\n rules: {\n \"header-max-length\": [0, \"always\", Infinity],\n \"body-max-line-length\": [0, \"always\", Infinity],\n \"footer-max-line-length\": [0, \"always\", Infinity],\n },\n};\n"
},
{
"path": "docs/Makefile",
"content": "# Minimal makefile for Sphinx documentation\n#\n\n# You can set these variables from the command line, and also\n# from the environment for the first two.\nSPHINXOPTS ?=\nSPHINXBUILD ?= sphinx-build\nSOURCEDIR = .\nBUILDDIR = _build\n\n.PHONY: help livehtml Makefile\n\n# Put it first so that \"make\" without argument is like \"make help\".\nhelp:\n\t@$(SPHINXBUILD) -M help \"$(SOURCEDIR)\" \"$(BUILDDIR)\" $(SPHINXOPTS) $(O)\n\n# Build, watch and serve docs with live reload\nlivehtml:\n\tsphinx-autobuild -b html -c . $(SOURCEDIR) $(BUILDDIR)/html\n\n# Catch-all target: route all unknown targets to Sphinx using the new\n# \"make mode\" option. $(O) is meant as a shortcut for $(SPHINXOPTS).\n%: Makefile\n\t@$(SPHINXBUILD) -M $@ \"$(SOURCEDIR)\" \"$(BUILDDIR)\" $(SPHINXOPTS) $(O)\n"
},
{
"path": "docs/_static/.gitkeep",
"content": ""
},
{
"path": "docs/changelog.md",
"content": "(changelog)=\n\n```{include} ../CHANGELOG.md\n\n```\n"
},
{
"path": "docs/conf.py",
"content": "# Configuration file for the Sphinx documentation builder.\n#\n# This file only contains a selection of the most common options. For a full\n# list see the documentation:\n# https://www.sphinx-doc.org/en/master/usage/configuration.html\nfrom pathlib import Path\nfrom typing import Any\n\nfrom sphinx.application import Sphinx\nfrom sphinx.ext import apidoc\n\n# -- Project information -----------------------------------------------------\n# https://www.sphinx-doc.org/en/master/usage/configuration.html#project-information\n\nproject = \"SoftVC VITS Singing Voice Conversion Fork\"\ncopyright = \"2023, 34j\"\nauthor = \"34j\"\nrelease = \"4.2.30\"\n\n# -- General configuration ---------------------------------------------------\n# https://www.sphinx-doc.org/en/master/usage/configuration.html#general-configuration\n\n# Add any Sphinx extension module names here, as strings. They can be\n# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom\n# ones.\nextensions = [\n \"myst_parser\",\n \"sphinx.ext.napoleon\",\n \"sphinx.ext.autodoc\",\n \"sphinx.ext.viewcode\",\n]\nnapoleon_google_docstring = False\n\n# The suffix of source filenames.\nsource_suffix = [\n \".rst\",\n \".md\",\n]\n\n# Add any paths that contain templates here, relative to this directory.\ntemplates_path = [\n \"_templates\",\n]\n\n# List of patterns, relative to source directory, that match files and\n# directories to ignore when looking for source files.\n# This pattern also affects html_static_path and html_extra_path.\nexclude_patterns = [\n \"_build\",\n \"Thumbs.db\",\n \".DS_Store\",\n]\n\n\n# -- Options for HTML output -------------------------------------------------\n\n# The theme to use for HTML and HTML Help pages. See the documentation for\n# a list of builtin themes.\n#\nhtml_theme = \"furo\"\n\n# Add any paths that contain custom static files (such as style sheets) here,\n# relative to this directory. They are copied after the builtin static files,\n# so a file named \"default.css\" will overwrite the builtin \"default.css\".\nhtml_static_path = [\"_static\"]\n\n\n# -- Automatically run sphinx-apidoc -----------------------------------------\n\n\ndef run_apidoc(_: Any) -> None:\n \"\"\"Run sphinx-apidoc.\"\"\"\n docs_path = Path(__file__).parent\n module_path = docs_path.parent / \"src\" / \"so_vits_svc_fork\"\n\n apidoc.main(\n [\n \"--force\",\n \"--module-first\",\n \"-o\",\n docs_path.as_posix(),\n module_path.as_posix(),\n ]\n )\n\n\ndef setup(app: Sphinx) -> None:\n \"\"\"Setup sphinx.\"\"\"\n app.connect(\"builder-inited\", run_apidoc)\n"
},
{
"path": "docs/contributing.md",
"content": "(contributing)=\n\n```{include} ../CONTRIBUTING.md\n\n```\n"
},
{
"path": "docs/index.md",
"content": "# Welcome to SoftVC VITS Singing Voice Conversion Fork documentation!\n\n```{toctree}\n:caption: Installation & Usage\n:maxdepth: 2\n\ninstallation\nusage\n```\n\n```{toctree}\n:caption: Project Info\n:maxdepth: 2\n\nchangelog\ncontributing\n```\n\n```{toctree}\n:caption: API Reference\n:maxdepth: 2\n\nso_vits_svc_fork\n```\n\n```{include} ../README.md\n\n```\n"
},
{
"path": "docs/installation.md",
"content": "(installation)=\n\n# Installation\n\nThe package is published on [PyPI](https://pypi.org/project/so-vits-svc-fork/) and can be installed with `pip` (or any equivalent):\n\n```bash\npip install so-vits-svc-fork\n```\n\nNext, see the {ref}`section about usage ` to see how to use it.\n"
},
{
"path": "docs/make.bat",
"content": "@ECHO OFF\n\npushd %~dp0\n\nREM Command file for Sphinx documentation\n\nif \"%SPHINXBUILD%\" == \"\" (\n\tset SPHINXBUILD=sphinx-build\n)\nset SOURCEDIR=.\nset BUILDDIR=_build\n\n%SPHINXBUILD% >NUL 2>NUL\nif errorlevel 9009 (\n\techo.\n\techo.The 'sphinx-build' command was not found. Make sure you have Sphinx\n\techo.installed, then set the SPHINXBUILD environment variable to point\n\techo.to the full path of the 'sphinx-build' executable. Alternatively you\n\techo.may add the Sphinx directory to PATH.\n\techo.\n\techo.If you don't have Sphinx installed, grab it from\n\techo.https://www.sphinx-doc.org/\n\texit /b 1\n)\n\nif \"%1\" == \"\" goto help\n\n%SPHINXBUILD% -M %1 %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%\ngoto end\n\n:help\n%SPHINXBUILD% -M help %SOURCEDIR% %BUILDDIR% %SPHINXOPTS% %O%\n\n:end\npopd\n"
},
{
"path": "docs/usage.md",
"content": "(usage)=\n\n# Usage\n\nAssuming that you've followed the {ref}`installations steps `, you're now ready to use this package.\n\nStart by importing it:\n\n```python\nimport so_vits_svc_fork\n```\n\nTODO: Document usage\n"
},
{
"path": "easy-installation/install-cn.bat",
"content": "@echo off\r\n\r\necho batӢİ棬ԭһЩعŻ簲װ⣬Գװԭ\r\necho.\r\n\r\necho.\r\necho Python 汾 3.10...\r\necho.\r\n\r\npy -3.10 --version >nul 2>&1\r\nif %errorlevel%==0 (\r\n echo Python 3.10 Ѿװ\r\n\techo.\r\n) else (\r\n echo Python 3.10 δװʼ...\r\n\techo.\r\n curl https://www.python.org/ftp/python/3.10.10/python-3.10.10-amd64.exe -o python-3.10.10-amd64.exe\r\n\r\n echo װ Python 3.10...\r\n\techo.\r\n python-3.10.10-amd64.exe /quiet InstallAllUsers=1 PrependPath=1\r\n\r\n echo װ...\r\n\techo.\r\n del python-3.10.10-amd64.exe\r\n)\r\necho.\r\necho GPU...\r\necho.\r\nnvidia-smi >nul 2>&1\r\nif %errorlevel%==0 (\r\n echo ҵGPU\r\n\techo.\r\n) else (\r\n echo δҵfound\r\n\techo.\r\n)\r\n\r\nnvidia-smi >nul 2>&1\r\nif %errorlevel%==0 (\r\n\r\n\techo.\r\n echo CUDA...\r\n\techo.\r\n\r\n if %errorlevel%==0 (\r\n echo CUDA Ѿװ\r\n\t\techo.\r\n ) else (\r\n echo δCUDAֶװCUDAװб\r\n\t\techo https://developer.nvidia.com/cuda-11-8-0-download-archive?target_os=Windows\r\n\t\techo.\r\n\t\techo ѾȷװCUDAdzǿƼִУرձװCUDA\r\n\t\techo.\r\n\t\tPause\r\n )\r\n\r\n echo cuDNN...\r\n if exist \"C:\\Program Files\\NVIDIA GPU Computing Toolkit\\CUDA\\v11.8\\bin\\cudnn64_8.dll\" (\r\n echo cuDNN Ѿװ\r\n\t\techo.\r\n ) else (\r\n echo δcuDNNֶװCUDAװб\r\n\t\techo https://developer.nvidia.com/cudnn (https://developer.nvidia.com/downloads/compute/cudnn/secure/8.8.1/local_installers/11.8/cudnn-windows-x86_64-8.8.1.3_cuda11-archive.zip/)\r\n\t\techo.\r\n\t\techo ѾȷװcuDNNdzǿƼִУرձװCUDA\r\n\t\techo.\r\n\t\tPause\r\n )\r\n)\r\necho.\r\necho ڴҪһʱ䣬ĵȴ...\r\necho.\r\npy -3.10 -m venv venv\r\necho.\r\necho pip wheel...\r\necho.\r\nvenv\\Scripts\\python.exe -m pip install --upgrade pip wheel\r\necho.\r\nnvidia-smi >nul 2>&1\r\nif %errorlevel%==0 (\r\necho װ PyTorch GPU汾...\r\necho.\r\nvenv\\Scripts\\pip.exe install torch torchvision torchaudio --index-url https://mirror.sjtu.edu.cn/pytorch-wheels\r\n echo װ PyTorch CPU汾...\r\n\techo.\r\n venv\\Scripts\\pip.exe install torch torchaudio -i https://pypi.tuna.tsinghua.edu.cn/simple pyspider\r\n)\r\necho.\r\necho ϰǷɹװȷɹװʼװso-vits-svc-fork\r\necho.\r\nPause\r\necho װ so-vits-svc-fork...\r\necho.\r\nvenv\\Scripts\\pip.exe install so-vits-svc-fork\r\necho.\r\necho so-vits-svc-fork ͼλ...\r\necho.\r\nvenv\\Scripts\\svcg.exe\r\n\r\nPause\r\n"
},
{
"path": "easy-installation/install.bat",
"content": "@echo off\n\necho You can rerun this script to update the installation.\n\necho Moving to AppData\\Roaming\\so-vits-svc-fork...\nmkdir \"%APPDATA%\\so-vits-svc-fork\" >nul 2>&1\ncd \"%APPDATA%\\so-vits-svc-fork\"\n\necho Checking for Python 3.10...\n\npy -3.10 --version >nul 2>&1\nif %errorlevel%==0 (\n echo Python 3.10 is already installed.\n) else (\n echo Python 3.10 is not installed. Downloading installer...\n curl https://www.python.org/ftp/python/3.10.10/python-3.10.10-amd64.exe -o python-3.10.10-amd64.exe\n\n echo Installing Python 3.10...\n python-3.10.10-amd64.exe /quiet InstallAllUsers=1 PrependPath=1\n\n echo Cleaning up installer...\n del python-3.10.10-amd64.exe\n)\n\necho Creating virtual environment...\npy -3.10 -m venv venv\n\necho Updating pip and wheel...\nvenv\\Scripts\\python.exe -m pip install --upgrade pip wheel\n\nnvidia-smi >nul 2>&1\nif %errorlevel%==0 (\n echo Installing PyTorch with GPU support...\nvenv\\Scripts\\pip.exe install torch torchaudio --index-url https://download.pytorch.org/whl/cu118\n) else (\n echo Installing PyTorch without GPU support...\n venv\\Scripts\\pip.exe install torch torchaudio\n)\n\necho Installing so-vits-svc-fork...\nvenv\\Scripts\\pip.exe install so-vits-svc-fork\n\nrem echo Creating shortcut...\nrem powershell \"$s=(New-Object -COM WScript.Shell).CreateShortcut('%USDRPROFILE%\\Desktop\\so-vits-svc-fork.lnk');$s.TargetPath='%APPDATA%\\so-vits-svc-fork\\venv\\Scripts\\svcg.exe';$s.Save()\"\n\necho Creating shortcut to the start menu...\npowershell \"$s=(New-Object -COM WScript.Shell).CreateShortcut('%APPDATA%\\Microsoft\\Windows\\Start Menu\\Programs\\so-vits-svc-fork.lnk');$s.TargetPath='%APPDATA%\\so-vits-svc-fork\\venv\\Scripts\\svcg.exe';$s.Save()\"\n\necho Launching so-vits-svc-fork GUI...\nvenv\\Scripts\\svcg.exe\n"
},
{
"path": "flake.nix",
"content": "{\n description = \"A flake providing a dev shell for Numba with CUDA without installing Numba via nix. Also supports PyTorch yet being minimal for Numba with CUDA.\";\n\n inputs = {\n nixpkgs.url = \"github:NixOS/nixpkgs/nixos-unstable\";\n };\n\n outputs =\n { self, nixpkgs }:\n let\n system = \"x86_64-linux\"; # Adjust if needed\n pkgs = import nixpkgs {\n system = system;\n config.allowUnfree = true;\n };\n cudatookit-with-cudart-to-lib64 = pkgs.symlinkJoin {\n name = \"cudatoolkit\";\n paths = with pkgs.cudaPackages; [\n cudatoolkit\n (pkgs.lib.getStatic cuda_cudart)\n ];\n postBuild = ''\n ln -s $out/lib $out/lib64\n '';\n };\n in\n {\n devShells.${system}.default = pkgs.mkShell {\n shellHook = ''\n # Required for both PyTorch and Numba to find CUDA\n export CUDA_PATH=${cudatookit-with-cudart-to-lib64}\n\n # Required for both PyTorch and Numba, adds necessary paths for dynamic linking\n export LD_LIBRARY_PATH=${\n pkgs.lib.makeLibraryPath [\n \"/run/opengl-driver\" # Needed to find libGL.so, required by both PyTorch and Numba\n ]\n }:$LD_LIBRARY_PATH\n\n export LIBRARY_PATH=${\n pkgs.lib.makeLibraryPath [\n pkgs.graphviz\n ]\n }:$LIBRARY_PATH\n\n export C_INCLUDE_PATH=${\n pkgs.lib.makeIncludePath [\n pkgs.graphviz\n ]\n }:$C_INCLUDE_PATH\n '';\n };\n };\n}\n"
},
{
"path": "notebooks/so-vits-svc-fork-4.0.ipynb",
"content": "{\n \"cells\": [\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## Before training\\n\",\n \"\\n\",\n \"This program saves the last 3 generations of models to Google Drive. Since 1 generation of models is >1GB, you should have at least 3GB of free space in Google Drive. If you do not have such free space, it is recommended to create another Google Account.\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## Installation\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# @title Check GPU\\n\",\n \"!nvidia-smi\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# @title Mount Google Drive\\n\",\n \"from google.colab import drive\\n\",\n \"\\n\",\n \"drive.mount(\\\"/content/drive\\\")\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# @title Install dependencies\\n\",\n \"# @markdown pip may fail to resolve dependencies and raise ERROR, but it can be ignored.\\n\",\n \"!python -m pip install -U pip wheel\\n\",\n \"%pip install -U ipython\\n\",\n \"\\n\",\n \"# @markdown Branch (for development)\\n\",\n \"BRANCH = \\\"none\\\" # @param {\\\"type\\\": \\\"string\\\"}\\n\",\n \"if BRANCH == \\\"none\\\":\\n\",\n \" %pip install -U so-vits-svc-fork\\n\",\n \"else:\\n\",\n \" %pip install -U git+https://github.com/34j/so-vits-svc-fork.git@{BRANCH}\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## Training\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# @title Make dataset directory\\n\",\n \"!mkdir -p \\\"dataset_raw\\\"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# @title Copy your dataset\\n\",\n \"# @markdown **We assume that your dataset is in your Google Drive's `so-vits-svc-fork/dataset/(speaker_name)` directory.**\\n\",\n \"DATASET_NAME = \\\"kiritan\\\" # @param {type: \\\"string\\\"}\\n\",\n \"!cp -R /content/drive/MyDrive/so-vits-svc-fork/dataset/{DATASET_NAME}/ -t \\\"dataset_raw/\\\"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# @title Download dataset (Tsukuyomi-chan JVS)\\n\",\n \"# @markdown You can download this dataset if you don't have your own dataset.\\n\",\n \"# @markdown Make sure you agree to the license when using this dataset.\\n\",\n \"# @markdown https://tyc.rei-yumesaki.net/material/corpus/#toc6\\n\",\n \"# !wget -N https://tyc.rei-yumesaki.net/files/voice/tyc-corpus1.zip\\n\",\n \"# !unzip -O sjis tyc-corpus1.zip\\n\",\n \"# !mv \\\"/content/つくよみちゃんコーパス Vol.1 声優統計コーパス(JVSコーパス準拠)/おまけ:WAV(+12dB増幅&高音域削減)/WAV(+12dB増幅&高音域削減)\\\" \\\"dataset_raw/tsukuyomi\\\"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# @title Automatic preprocessing\\n\",\n \"!svc pre-resample\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"!svc pre-config\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"F0_METHOD = \\\"dio\\\" # @param [\\\"crepe\\\", \\\"crepe-tiny\\\", \\\"parselmouth\\\", \\\"dio\\\", \\\"harvest\\\"]\\n\",\n \"!svc pre-hubert -fm {F0_METHOD}\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# @title Train\\n\",\n \"%load_ext tensorboard\\n\",\n \"%tensorboard --logdir drive/MyDrive/so-vits-svc-fork/logs/44k\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"!svc train --model-path drive/MyDrive/so-vits-svc-fork/logs/44k\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## Training Cluster model\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"!svc train-cluster --output-path drive/MyDrive/so-vits-svc-fork/logs/44k/kmeans.pt\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"## Inference\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# @title Get the author's voice as a source\\n\",\n \"import random\\n\",\n \"\\n\",\n \"NAME = str(random.randint(1, 49))\\n\",\n \"TYPE = \\\"fsd50k\\\" # @param [\\\"\\\", \\\"digit\\\", \\\"dog\\\", \\\"fsd50k\\\"]\\n\",\n \"CUSTOM_FILEPATH = \\\"\\\" # @param {type: \\\"string\\\"}\\n\",\n \"if CUSTOM_FILEPATH != \\\"\\\":\\n\",\n \" NAME = CUSTOM_FILEPATH\\n\",\n \"else:\\n\",\n \" # it is extremely difficult to find a voice that can download from the internet directly\\n\",\n \" if TYPE == \\\"dog\\\":\\n\",\n \" !wget -N f\\\"https://huggingface.co/datasets/437aewuh/dog-dataset/resolve/main/dogs/dogs_{NAME:.0000}.wav\\\" -O {NAME}.wav\\n\",\n \" elif TYPE == \\\"digit\\\":\\n\",\n \" # george, jackson, lucas, nicolas, ...\\n\",\n \" !wget -N f\\\"https://github.com/Jakobovski/free-spoken-digit-dataset/raw/master/recordings/0_george_{NAME}.wav\\\" -O {NAME}.wav\\n\",\n \" elif TYPE == \\\"fsd50k\\\":\\n\",\n \" !wget -N f\\\"https://huggingface.co/datasets/Fhrozen/FSD50k/blob/main/clips/dev/{10000+int(NAME)}.wav\\\" -O {NAME}.wav\\n\",\n \" else:\\n\",\n \" !wget -N f\\\"https://zunko.jp/sozai/utau/voice_{\\\"kiritan\\\" if NAME < 25 else \\\"itako\\\"}{NAME % 5 + 1}.wav\\\" -O {NAME}.wav\\n\",\n \"from IPython.display import Audio, display\\n\",\n \"\\n\",\n \"display(Audio(f\\\"{NAME}.wav\\\"))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# @title Use trained model\\n\",\n \"# @markdown **Put your .wav file in `so-vits-svc-fork/audio` directory**\\n\",\n \"from IPython.display import Audio, display\\n\",\n \"\\n\",\n \"!svc infer drive/MyDrive/so-vits-svc-fork/audio/{NAME}.wav -m drive/MyDrive/so-vits-svc-fork/logs/44k/ -c drive/MyDrive/so-vits-svc-fork/logs/44k/config.json\\n\",\n \"display(Audio(f\\\"drive/MyDrive/so-vits-svc-fork/audio/{NAME}.out.wav\\\", autoplay=True))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"##@title Use trained model (with cluster)\\n\",\n \"!svc infer {NAME}.wav -s speaker -r 0.1 -m drive/MyDrive/so-vits-svc-fork/logs/44k/ -c drive/MyDrive/so-vits-svc-fork/logs/44k/config.json -k drive/MyDrive/so-vits-svc-fork/logs/44k/kmeans.pt\\n\",\n \"display(Audio(f\\\"{NAME}.out.wav\\\", autoplay=True))\"\n ]\n },\n {\n \"cell_type\": \"markdown\",\n \"metadata\": {},\n \"source\": [\n \"### Pretrained models\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# @title https://huggingface.co/TachibanaKimika/so-vits-svc-4.0-models/tree/main\\n\",\n \"!wget -N \\\"https://huggingface.co/TachibanaKimika/so-vits-svc-4.0-models/resolve/main/riri/G_riri_220.pth\\\"\\n\",\n \"!wget -N \\\"https://huggingface.co/TachibanaKimika/so-vits-svc-4.0-models/resolve/main/riri/config.json\\\"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"!svc infer {NAME}.wav -c config.json -m G_riri_220.pth\\n\",\n \"display(Audio(f\\\"{NAME}.out.wav\\\", autoplay=True))\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"# @title https://huggingface.co/therealvul/so-vits-svc-4.0/tree/main\\n\",\n \"!wget -N \\\"https://huggingface.co/therealvul/so-vits-svc-4.0/resolve/main/Pinkie%20(speaking%20sep)/G_166400.pth\\\"\\n\",\n \"!wget -N \\\"https://huggingface.co/therealvul/so-vits-svc-4.0/resolve/main/Pinkie%20(speaking%20sep)/config.json\\\"\"\n ]\n },\n {\n \"cell_type\": \"code\",\n \"execution_count\": null,\n \"metadata\": {},\n \"outputs\": [],\n \"source\": [\n \"!svc infer {NAME}.wav --speaker \\\"Pinkie {neutral}\\\" -c config.json -m G_166400.pth\\n\",\n \"display(Audio(f\\\"{NAME}.out.wav\\\", autoplay=True))\"\n ]\n }\n ],\n \"metadata\": {\n \"accelerator\": \"GPU\",\n \"colab\": {\n \"provenance\": []\n },\n \"gpuClass\": \"standard\",\n \"kernelspec\": {\n \"display_name\": \"Python 3\",\n \"name\": \"python3\"\n },\n \"language_info\": {\n \"codemirror_mode\": {\n \"name\": \"ipython\",\n \"version\": 3\n },\n \"file_extension\": \".py\",\n \"mimetype\": \"text/x-python\",\n \"name\": \"python\",\n \"nbconvert_exporter\": \"python\",\n \"pygments_lexer\": \"ipython3\"\n }\n },\n \"nbformat\": 4,\n \"nbformat_minor\": 0\n}\n"
},
{
"path": "pyproject.toml",
"content": "[build-system]\nbuild-backend = \"setuptools.build_meta\"\nrequires = [ \"setuptools\" ]\n\n[project]\nname = \"so-vits-svc-fork\"\nversion = \"4.2.30\"\ndescription = \"A fork of so-vits-svc.\"\nreadme = \"README.md\"\nlicense = { text = \"MIT\" }\nauthors = [\n { name = \"34j\", email = \"34j.95a2p@simplelogin.com\" },\n]\nrequires-python = \">=3.9\"\nclassifiers = [\n \"Development Status :: 2 - Pre-Alpha\",\n \"Intended Audience :: Developers\",\n \"Natural Language :: English\",\n \"Operating System :: OS Independent\",\n \"Programming Language :: Python :: 3.9\",\n \"Programming Language :: Python :: 3.10\",\n \"Programming Language :: Python :: 3.11\",\n \"Programming Language :: Python :: 3.12\",\n \"Programming Language :: Python :: 3.13\",\n \"Topic :: Software Development :: Libraries\",\n]\n\ndependencies = [\n \"click>=8.1.8\",\n \"cm-time>=0.1.2\",\n \"fastapi>=0.116.1\",\n \"librosa>=0.11.0\",\n \"lightning>=2.5.5\",\n \"matplotlib>=3.9.4\",\n \"numpy>=2.0.2\",\n \"pebble>=5.1.3\",\n \"praat-parselmouth>=0.4.6\",\n \"psutil>=7.1.2\",\n \"pysimplegui-4-foss>=4.60.4.1\",\n \"pyworld>=0.3.5\",\n \"requests>=2.32.5\",\n \"rich>=14.1.0\",\n \"scipy>=1.13.1\",\n \"sounddevice>=0.5.2\",\n \"soundfile>=0.13.1\",\n \"tensorboard>=2.20.0\",\n \"tensorboardx>=2.6.4\",\n \"torch>=2.8.0\",\n \"torchaudio>=2.8.0\",\n \"torchcrepe>=0.0.24\",\n \"tqdm>=4.67.1\",\n \"tqdm-joblib>=0.0.4\",\n \"transformers>=4.56.1\",\n]\nurls.\"Bug Tracker\" = \"https://github.com/voicepaw/so-vits-svc-fork/issues\"\nurls.Changelog = \"https://github.com/voicepaw/so-vits-svc-fork/blob/main/CHANGELOG.md\"\nurls.documentation = \"https://so-vits-svc-fork.readthedocs.io\"\nurls.repository = \"https://github.com/voicepaw/so-vits-svc-fork\"\nscripts.svc = \"so_vits_svc_fork.__main__:cli\"\nscripts.svcg = \"so_vits_svc_fork.gui:main\"\n\n[dependency-groups]\ndev = [\n \"pytest>=8,<9\",\n \"pytest-cov>=7,<8\",\n]\ndocs = [\n \"furo>=2023.5.20; python_version>='3.11'\",\n \"myst-parser>=0.16; python_version>='3.11'\",\n \"sphinx>=4; python_version>='3.11'\",\n \"sphinx-autobuild>=2025,<2026; python_version>='3.11'\",\n]\n\n[tool.setuptools.package-data]\n\"so_vits_svc_fork\" = [\"**/*.json\"]\n\n[tool.ruff]\nline-length = 150\nlint.select = [\n # \"B\", # flake8-bugbear\n # \"D\", # flake8-docstrings\n # \"C4\", # flake8-comprehensions\n # \"S\", # flake8-bandit\n \"F\", # pyflake\n # \"E\", # pycodestyle\n \"W\", # pycodestyle\n # \"UP\", # pyupgrade\n \"I\", # isort\n # \"RUF\", # ruff specific\n]\nlint.ignore = [\n \"D203\", # 1 blank line required before class docstring\n \"D212\", # Multi-line docstring summary should start at the first line\n \"D100\", # Missing docstring in public module\n \"D104\", # Missing docstring in public package\n \"D107\", # Missing docstring in `__init__`\n \"D401\", # First line of docstring should be in imperative mood\n]\nlint.per-file-ignores.\"conftest.py\" = [ \"D100\" ]\nlint.per-file-ignores.\"docs/conf.py\" = [ \"D100\" ]\nlint.per-file-ignores.\"setup.py\" = [ \"D100\" ]\nlint.per-file-ignores.\"tests/**/*\" = [\n \"D100\",\n \"D101\",\n \"D102\",\n \"D103\",\n \"D104\",\n \"S101\",\n]\nlint.isort.known-first-party = [ \"so_vits_svc_fork\", \"tests\" ]\n\n[tool.pytest.ini_options]\naddopts = \"\"\"\\\n -v\n -Wdefault\n --cov=so_vits_svc_fork\n --cov-report=term\n --cov-report=xml\n \"\"\"\npythonpath = [ \"src\" ]\n\n[tool.coverage.run]\nbranch = true\n\n[tool.coverage.report]\nexclude_lines = [\n \"pragma: no cover\",\n \"@overload\",\n \"if TYPE_CHECKING\",\n \"raise NotImplementedError\",\n 'if __name__ == \"__main__\":',\n]\n\n[tool.mypy]\ncheck_untyped_defs = true\ndisallow_any_generics = true\ndisallow_incomplete_defs = true\ndisallow_untyped_defs = true\nmypy_path = \"src/\"\nno_implicit_optional = true\nshow_error_codes = true\nwarn_unreachable = true\nwarn_unused_ignores = true\nexclude = [\n 'docs/.*',\n 'setup.py',\n]\n\n[[tool.mypy.overrides]]\nmodule = \"tests.*\"\nallow_untyped_defs = true\n\n[[tool.mypy.overrides]]\nmodule = \"docs.*\"\nignore_errors = true\n\n[tool.semantic_release]\nversion_toml = [ \"pyproject.toml:project.version\" ]\nversion_variables = [\n \"src/so_vits_svc_fork/__init__.py:__version__\",\n \"docs/conf.py:release\",\n]\nbuild_command = \"\"\"\npip install uv\nuv lock\ngit add uv.lock\nuv build\n\"\"\"\n\n[tool.semantic_release.changelog]\nexclude_commit_patterns = [\n '''chore(?:\\([^)]*?\\))?: .+''',\n '''ci(?:\\([^)]*?\\))?: .+''',\n '''refactor(?:\\([^)]*?\\))?: .+''',\n '''style(?:\\([^)]*?\\))?: .+''',\n '''test(?:\\([^)]*?\\))?: .+''',\n '''build\\((?!deps\\): .+)''',\n '''Merged? .*''',\n '''Initial [Cc]ommit.*''', # codespell:ignore\n]\n\n[tool.semantic_release.changelog.environment]\nkeep_trailing_newline = true\n\n[tool.semantic_release.branches.main]\nmatch = \"main\"\n\n[tool.semantic_release.branches.noop]\nmatch = \"(?!main$)\"\nprerelease = true\n"
},
{
"path": "renovate.json",
"content": "{\n \"extends\": [\n \"config:best-practices\",\n \":pinOnlyDevDependencies\",\n \":automergeAll\",\n \":enablePreCommit\"\n ],\n \"packageRules\": [\n {\n \"matchPackageNames\": [\"python\"],\n \"rangeStrategy\": \"widen\",\n \"separateMultipleMinor\": true\n }\n ]\n}\n"
},
{
"path": "setup.py",
"content": "#!/usr/bin/env python\n\n# This is a shim to allow GitHub to detect the package, build is done with uv\n# Taken from https://github.com/Textualize/rich\n\nimport setuptools\n\nif __name__ == \"__main__\":\n setuptools.setup(name=\"so-vits-svc-fork\")\n"
},
{
"path": "src/so_vits_svc_fork/__init__.py",
"content": "__version__ = \"4.2.30\"\n\nfrom .logger import init_logger\n\ninit_logger()\n"
},
{
"path": "src/so_vits_svc_fork/__main__.py",
"content": "from __future__ import annotations\n\nimport os\nfrom logging import getLogger\nfrom multiprocessing import freeze_support\nfrom pathlib import Path\nfrom typing import Literal\n\nimport click\nimport torch\n\nfrom so_vits_svc_fork import __version__\nfrom so_vits_svc_fork.utils import get_optimal_device\n\nLOG = getLogger(__name__)\n\nIS_TEST = \"test\" in Path(__file__).parent.stem\nif IS_TEST:\n LOG.debug(\"Test mode is on.\")\n\n\nclass RichHelpFormatter(click.HelpFormatter):\n def __init__(\n self,\n indent_increment: int = 2,\n width: int | None = None,\n max_width: int | None = None,\n ) -> None:\n width = 100\n super().__init__(indent_increment, width, max_width)\n LOG.info(f\"Version: {__version__}\")\n\n\ndef patch_wrap_text():\n orig_wrap_text = click.formatting.wrap_text\n\n def wrap_text(\n text,\n width=78,\n initial_indent=\"\",\n subsequent_indent=\"\",\n preserve_paragraphs=False,\n ):\n return orig_wrap_text(\n text.replace(\"\\n\", \"\\n\\n\"),\n width=width,\n initial_indent=initial_indent,\n subsequent_indent=subsequent_indent,\n preserve_paragraphs=True,\n ).replace(\"\\n\\n\", \"\\n\")\n\n click.formatting.wrap_text = wrap_text\n\n\npatch_wrap_text()\n\nCONTEXT_SETTINGS = dict(help_option_names=[\"-h\", \"--help\"], show_default=True)\nclick.Context.formatter_class = RichHelpFormatter\n\n\n@click.group(context_settings=CONTEXT_SETTINGS)\ndef cli():\n \"\"\"\n so-vits-svc allows any folder structure for training data.\n However, the following folder structure is recommended.\\n\n When training: dataset_raw/{speaker_name}/**/{wav_name}.{any_format}\\n\n When inference: configs/44k/config.json, logs/44k/G_XXXX.pth\\n\n If the folder structure is followed, you DO NOT NEED TO SPECIFY model path, config path, etc.\n (The latest model will be automatically loaded.)\\n\n To train a model, run pre-resample, pre-config, pre-hubert, train.\\n\n To infer a model, run infer.\n \"\"\"\n\n\n@cli.command()\n@click.option(\n \"-c\",\n \"--config-path\",\n type=click.Path(exists=True),\n help=\"path to config\",\n default=Path(\"./configs/44k/config.json\"),\n)\n@click.option(\n \"-m\",\n \"--model-path\",\n type=click.Path(),\n help=\"path to output dir\",\n default=Path(\"./logs/44k\"),\n)\n@click.option(\n \"-t/-nt\",\n \"--tensorboard/--no-tensorboard\",\n default=False,\n type=bool,\n help=\"launch tensorboard\",\n)\n@click.option(\n \"-r\",\n \"--reset-optimizer\",\n default=False,\n type=bool,\n help=\"reset optimizer\",\n is_flag=True,\n)\ndef train(\n config_path: Path,\n model_path: Path,\n tensorboard: bool = False,\n reset_optimizer: bool = False,\n):\n \"\"\"\n Train model\n If D_0.pth or G_0.pth not found, automatically download from hub.\n \"\"\"\n from .train import train\n\n config_path = Path(config_path)\n model_path = Path(model_path)\n\n if tensorboard:\n import webbrowser\n\n from tensorboard import program\n\n getLogger(\"tensorboard\").setLevel(30)\n tb = program.TensorBoard()\n tb.configure(argv=[None, \"--logdir\", model_path.as_posix()])\n url = tb.launch()\n webbrowser.open(url)\n\n train(config_path=config_path, model_path=model_path, reset_optimizer=reset_optimizer)\n\n\n@cli.command()\ndef gui():\n \"\"\"\n Opens GUI\n for conversion and realtime inference\n \"\"\"\n from .gui import main\n\n main()\n\n\n@cli.command()\n@click.argument(\n \"input-path\",\n type=click.Path(exists=True),\n)\n@click.option(\n \"-o\",\n \"--output-path\",\n type=click.Path(),\n help=\"path to output dir\",\n)\n@click.option(\"-s\", \"--speaker\", type=str, default=None, help=\"speaker name\")\n@click.option(\n \"-m\",\n \"--model-path\",\n type=click.Path(exists=True),\n default=Path(\"./logs/44k/\"),\n help=\"path to model\",\n)\n@click.option(\n \"-c\",\n \"--config-path\",\n type=click.Path(exists=True),\n default=Path(\"./configs/44k/config.json\"),\n help=\"path to config\",\n)\n@click.option(\n \"-k\",\n \"--cluster-model-path\",\n type=click.Path(exists=True),\n default=None,\n help=\"path to cluster model\",\n)\n@click.option(\n \"-re\",\n \"--recursive\",\n type=bool,\n default=False,\n help=\"Search recursively\",\n is_flag=True,\n)\n@click.option(\"-t\", \"--transpose\", type=int, default=0, help=\"transpose\")\n@click.option(\"-db\", \"--db-thresh\", type=int, default=-20, help=\"threshold (DB) (RELATIVE)\")\n@click.option(\n \"-fm\",\n \"--f0-method\",\n type=click.Choice([\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"]),\n default=\"dio\",\n help=\"f0 prediction method\",\n)\n@click.option(\n \"-a/-na\",\n \"--auto-predict-f0/--no-auto-predict-f0\",\n type=bool,\n default=True,\n help=\"auto predict f0\",\n)\n@click.option(\"-r\", \"--cluster-infer-ratio\", type=float, default=0, help=\"cluster infer ratio\")\n@click.option(\"-n\", \"--noise-scale\", type=float, default=0.4, help=\"noise scale\")\n@click.option(\"-p\", \"--pad-seconds\", type=float, default=0.5, help=\"pad seconds\")\n@click.option(\n \"-d\",\n \"--device\",\n type=str,\n default=get_optimal_device(),\n help=\"device\",\n)\n@click.option(\"-ch\", \"--chunk-seconds\", type=float, default=0.5, help=\"chunk seconds\")\n@click.option(\n \"-ab/-nab\",\n \"--absolute-thresh/--no-absolute-thresh\",\n type=bool,\n default=False,\n help=\"absolute thresh\",\n)\n@click.option(\n \"-mc\",\n \"--max-chunk-seconds\",\n type=float,\n default=40,\n help=\"maximum allowed single chunk length, set lower if you get out of memory (0 to disable)\",\n)\ndef infer(\n # paths\n input_path: Path,\n output_path: Path,\n model_path: Path,\n config_path: Path,\n recursive: bool,\n # svc config\n speaker: str,\n cluster_model_path: Path | None = None,\n transpose: int = 0,\n auto_predict_f0: bool = False,\n cluster_infer_ratio: float = 0,\n noise_scale: float = 0.4,\n f0_method: Literal[\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"] = \"dio\",\n # slice config\n db_thresh: int = -40,\n pad_seconds: float = 0.5,\n chunk_seconds: float = 0.5,\n absolute_thresh: bool = False,\n max_chunk_seconds: float = 40,\n device: str | torch.device = get_optimal_device(),\n):\n \"\"\"Inference\"\"\"\n from so_vits_svc_fork.inference.main import infer\n\n if not auto_predict_f0:\n LOG.warning(\n f\"auto_predict_f0 = False, transpose = {transpose}. If you want to change the pitch, please set transpose.\"\n \"Generally transpose = 0 does not work because your voice pitch and target voice pitch are different.\"\n )\n\n input_path = Path(input_path)\n if output_path is None:\n output_path = input_path.parent / f\"{input_path.stem}.out{input_path.suffix}\"\n output_path = Path(output_path)\n if input_path.is_dir() and not recursive:\n raise ValueError(\"input_path is a directory. Use 0re or --recursive to infer recursively.\")\n model_path = Path(model_path)\n if model_path.is_dir():\n model_path = sorted(model_path.glob(\"G_*.pth\"), key=lambda x: x.stat().st_mtime)[-1]\n LOG.info(f\"Since model_path is a directory, use {model_path}\")\n config_path = Path(config_path)\n if cluster_model_path is not None:\n cluster_model_path = Path(cluster_model_path)\n infer(\n # paths\n input_path=input_path,\n output_path=output_path,\n model_path=model_path,\n config_path=config_path,\n recursive=recursive,\n # svc config\n speaker=speaker,\n cluster_model_path=cluster_model_path,\n transpose=transpose,\n auto_predict_f0=auto_predict_f0,\n cluster_infer_ratio=cluster_infer_ratio,\n noise_scale=noise_scale,\n f0_method=f0_method,\n # slice config\n db_thresh=db_thresh,\n pad_seconds=pad_seconds,\n chunk_seconds=chunk_seconds,\n absolute_thresh=absolute_thresh,\n max_chunk_seconds=max_chunk_seconds,\n device=device,\n )\n\n\n@cli.command()\n@click.option(\n \"-m\",\n \"--model-path\",\n type=click.Path(exists=True),\n default=Path(\"./logs/44k/\"),\n help=\"path to model\",\n)\n@click.option(\n \"-c\",\n \"--config-path\",\n type=click.Path(exists=True),\n default=Path(\"./configs/44k/config.json\"),\n help=\"path to config\",\n)\n@click.option(\n \"-k\",\n \"--cluster-model-path\",\n type=click.Path(exists=True),\n default=None,\n help=\"path to cluster model\",\n)\n@click.option(\"-t\", \"--transpose\", type=int, default=12, help=\"transpose\")\n@click.option(\n \"-a/-na\",\n \"--auto-predict-f0/--no-auto-predict-f0\",\n type=bool,\n default=True,\n help=\"auto predict f0 (not recommended for realtime since voice pitch will not be stable)\",\n)\n@click.option(\"-r\", \"--cluster-infer-ratio\", type=float, default=0, help=\"cluster infer ratio\")\n@click.option(\"-n\", \"--noise-scale\", type=float, default=0.4, help=\"noise scale\")\n@click.option(\"-db\", \"--db-thresh\", type=int, default=-30, help=\"threshold (DB) (ABSOLUTE)\")\n@click.option(\n \"-fm\",\n \"--f0-method\",\n type=click.Choice([\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"]),\n default=\"dio\",\n help=\"f0 prediction method\",\n)\n@click.option(\"-p\", \"--pad-seconds\", type=float, default=0.02, help=\"pad seconds\")\n@click.option(\"-ch\", \"--chunk-seconds\", type=float, default=0.5, help=\"chunk seconds\")\n@click.option(\n \"-cr\",\n \"--crossfade-seconds\",\n type=float,\n default=0.01,\n help=\"crossfade seconds\",\n)\n@click.option(\n \"-ab\",\n \"--additional-infer-before-seconds\",\n type=float,\n default=0.2,\n help=\"additional infer before seconds\",\n)\n@click.option(\n \"-aa\",\n \"--additional-infer-after-seconds\",\n type=float,\n default=0.1,\n help=\"additional infer after seconds\",\n)\n@click.option(\"-b\", \"--block-seconds\", type=float, default=0.5, help=\"block seconds\")\n@click.option(\n \"-d\",\n \"--device\",\n type=str,\n default=get_optimal_device(),\n help=\"device\",\n)\n@click.option(\"-s\", \"--speaker\", type=str, default=None, help=\"speaker name\")\n@click.option(\"-v\", \"--version\", type=int, default=2, help=\"version\")\n@click.option(\"-i\", \"--input-device\", type=int, default=None, help=\"input device\")\n@click.option(\"-o\", \"--output-device\", type=int, default=None, help=\"output device\")\n@click.option(\n \"-po\",\n \"--passthrough-original\",\n type=bool,\n default=False,\n is_flag=True,\n help=\"passthrough original (for latency check)\",\n)\ndef vc(\n # paths\n model_path: Path,\n config_path: Path,\n # svc config\n speaker: str,\n cluster_model_path: Path | None,\n transpose: int,\n auto_predict_f0: bool,\n cluster_infer_ratio: float,\n noise_scale: float,\n f0_method: Literal[\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"],\n # slice config\n db_thresh: int,\n pad_seconds: float,\n chunk_seconds: float,\n # realtime config\n crossfade_seconds: float,\n additional_infer_before_seconds: float,\n additional_infer_after_seconds: float,\n block_seconds: float,\n version: int,\n input_device: int | str | None,\n output_device: int | str | None,\n device: torch.device,\n passthrough_original: bool = False,\n) -> None:\n \"\"\"Realtime inference from microphone\"\"\"\n from so_vits_svc_fork.inference.main import realtime\n\n if auto_predict_f0:\n LOG.warning(\"auto_predict_f0 = True in realtime inference will cause unstable voice pitch, use with caution\")\n else:\n LOG.warning(\n f\"auto_predict_f0 = False, transpose = {transpose}. If you want to change the pitch, please change the transpose value.\"\n \"Generally transpose = 0 does not work because your voice pitch and target voice pitch are different.\"\n )\n model_path = Path(model_path)\n config_path = Path(config_path)\n if cluster_model_path is not None:\n cluster_model_path = Path(cluster_model_path)\n if model_path.is_dir():\n model_path = sorted(model_path.glob(\"G_*.pth\"), key=lambda x: x.stat().st_mtime)[-1]\n LOG.info(f\"Since model_path is a directory, use {model_path}\")\n\n realtime(\n # paths\n model_path=model_path,\n config_path=config_path,\n # svc config\n speaker=speaker,\n cluster_model_path=cluster_model_path,\n transpose=transpose,\n auto_predict_f0=auto_predict_f0,\n cluster_infer_ratio=cluster_infer_ratio,\n noise_scale=noise_scale,\n f0_method=f0_method,\n # slice config\n db_thresh=db_thresh,\n pad_seconds=pad_seconds,\n chunk_seconds=chunk_seconds,\n # realtime config\n crossfade_seconds=crossfade_seconds,\n additional_infer_before_seconds=additional_infer_before_seconds,\n additional_infer_after_seconds=additional_infer_after_seconds,\n block_seconds=block_seconds,\n version=version,\n input_device=input_device,\n output_device=output_device,\n device=device,\n passthrough_original=passthrough_original,\n )\n\n\n@cli.command()\n@click.option(\n \"-i\",\n \"--input-dir\",\n type=click.Path(exists=True),\n default=Path(\"./dataset_raw\"),\n help=\"path to source dir\",\n)\n@click.option(\n \"-o\",\n \"--output-dir\",\n type=click.Path(),\n default=Path(\"./dataset/44k\"),\n help=\"path to output dir\",\n)\n@click.option(\"-s\", \"--sampling-rate\", type=int, default=44100, help=\"sampling rate\")\n@click.option(\n \"-n\",\n \"--n-jobs\",\n type=int,\n default=-1,\n help=\"number of jobs (optimal value may depend on your RAM capacity and audio duration per file)\",\n)\n@click.option(\"-d\", \"--top-db\", type=float, default=30, help=\"top db\")\n@click.option(\"-f\", \"--frame-seconds\", type=float, default=1, help=\"frame seconds\")\n@click.option(\"-ho\", \"-hop\", \"--hop-seconds\", type=float, default=0.3, help=\"hop seconds\")\ndef pre_resample(\n input_dir: Path,\n output_dir: Path,\n sampling_rate: int,\n n_jobs: int,\n top_db: int,\n frame_seconds: float,\n hop_seconds: float,\n) -> None:\n \"\"\"Preprocessing part 1: resample\"\"\"\n from so_vits_svc_fork.preprocessing.preprocess_resample import preprocess_resample\n\n input_dir = Path(input_dir)\n output_dir = Path(output_dir)\n preprocess_resample(\n input_dir=input_dir,\n output_dir=output_dir,\n sampling_rate=sampling_rate,\n n_jobs=n_jobs,\n top_db=top_db,\n frame_seconds=frame_seconds,\n hop_seconds=hop_seconds,\n )\n\n\nfrom so_vits_svc_fork.preprocessing.preprocess_flist_config import CONFIG_TEMPLATE_DIR\n\n\n@cli.command()\n@click.option(\n \"-i\",\n \"--input-dir\",\n type=click.Path(exists=True),\n default=Path(\"./dataset/44k\"),\n help=\"path to source dir\",\n)\n@click.option(\n \"-f\",\n \"--filelist-path\",\n type=click.Path(),\n default=Path(\"./filelists/44k\"),\n help=\"path to filelist dir\",\n)\n@click.option(\n \"-c\",\n \"--config-path\",\n type=click.Path(),\n default=Path(\"./configs/44k/config.json\"),\n help=\"path to config\",\n)\n@click.option(\n \"-t\",\n \"--config-type\",\n type=click.Choice([x.stem for x in CONFIG_TEMPLATE_DIR.rglob(\"*.json\")]),\n default=\"so-vits-svc-4.0v1\",\n help=\"config type\",\n)\ndef pre_config(\n input_dir: Path,\n filelist_path: Path,\n config_path: Path,\n config_type: str,\n):\n \"\"\"Preprocessing part 2: config\"\"\"\n from so_vits_svc_fork.preprocessing.preprocess_flist_config import preprocess_config\n\n input_dir = Path(input_dir)\n filelist_path = Path(filelist_path)\n config_path = Path(config_path)\n preprocess_config(\n input_dir=input_dir,\n train_list_path=filelist_path / \"train.txt\",\n val_list_path=filelist_path / \"val.txt\",\n test_list_path=filelist_path / \"test.txt\",\n config_path=config_path,\n config_name=config_type,\n )\n\n\n@cli.command()\n@click.option(\n \"-i\",\n \"--input-dir\",\n type=click.Path(exists=True),\n default=Path(\"./dataset/44k\"),\n help=\"path to source dir\",\n)\n@click.option(\n \"-c\",\n \"--config-path\",\n type=click.Path(exists=True),\n help=\"path to config\",\n default=Path(\"./configs/44k/config.json\"),\n)\n@click.option(\n \"-n\",\n \"--n-jobs\",\n type=int,\n default=None,\n help=\"number of jobs (optimal value may depend on your VRAM capacity and audio duration per file)\",\n)\n@click.option(\n \"-f/-nf\",\n \"--force-rebuild/--no-force-rebuild\",\n type=bool,\n default=True,\n help=\"force rebuild existing preprocessed files\",\n)\n@click.option(\n \"-fm\",\n \"--f0-method\",\n type=click.Choice([\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"]),\n default=\"dio\",\n)\ndef pre_hubert(\n input_dir: Path,\n config_path: Path,\n n_jobs: bool,\n force_rebuild: bool,\n f0_method: Literal[\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"],\n) -> None:\n \"\"\"\n Preprocessing part 3: hubert\n If the HuBERT model is not found, it will be downloaded automatically.\n \"\"\"\n from so_vits_svc_fork.preprocessing.preprocess_hubert_f0 import preprocess_hubert_f0\n\n input_dir = Path(input_dir)\n config_path = Path(config_path)\n preprocess_hubert_f0(\n input_dir=input_dir,\n config_path=config_path,\n n_jobs=n_jobs,\n force_rebuild=force_rebuild,\n f0_method=f0_method,\n )\n\n\n@cli.command()\n@click.option(\n \"-i\",\n \"--input-dir\",\n type=click.Path(exists=True),\n default=Path(\"./dataset_raw_raw/\"),\n help=\"path to source dir\",\n)\n@click.option(\n \"-o\",\n \"--output-dir\",\n type=click.Path(),\n default=Path(\"./dataset_raw/\"),\n help=\"path to output dir\",\n)\n@click.option(\n \"-n\",\n \"--n-jobs\",\n type=int,\n default=-1,\n help=\"number of jobs (optimal value may depend on your VRAM capacity and audio duration per file)\",\n)\n@click.option(\"-min\", \"--min-speakers\", type=int, default=2, help=\"min speakers\")\n@click.option(\"-max\", \"--max-speakers\", type=int, default=2, help=\"max speakers\")\n@click.option(\"-t\", \"--huggingface-token\", type=str, default=None, help=\"huggingface token\")\n@click.option(\"-s\", \"--sr\", type=int, default=44100, help=\"sampling rate\")\ndef pre_sd(\n input_dir: Path | str,\n output_dir: Path | str,\n min_speakers: int,\n max_speakers: int,\n huggingface_token: str | None,\n n_jobs: int,\n sr: int,\n):\n \"\"\"Speech diarization using pyannote.audio\"\"\"\n if huggingface_token is None:\n huggingface_token = os.environ.get(\"HUGGINGFACE_TOKEN\", None)\n if huggingface_token is None:\n huggingface_token = click.prompt(\"Please enter your HuggingFace token\", hide_input=True)\n if os.environ.get(\"HUGGINGFACE_TOKEN\", None) is None:\n LOG.info(\"You can also set the HUGGINGFACE_TOKEN environment variable.\")\n assert huggingface_token is not None\n huggingface_token = huggingface_token.rstrip(\" \\n\\r\\t\\0\")\n if len(huggingface_token) <= 1:\n raise ValueError(\"HuggingFace token is empty: \" + huggingface_token)\n\n if max_speakers == 1:\n LOG.warning(\"Consider using pre-split if max_speakers == 1\")\n from so_vits_svc_fork.preprocessing.preprocess_speaker_diarization import (\n preprocess_speaker_diarization,\n )\n\n preprocess_speaker_diarization(\n input_dir=input_dir,\n output_dir=output_dir,\n min_speakers=min_speakers,\n max_speakers=max_speakers,\n huggingface_token=huggingface_token,\n n_jobs=n_jobs,\n sr=sr,\n )\n\n\n@cli.command()\n@click.option(\n \"-i\",\n \"--input-dir\",\n type=click.Path(exists=True),\n default=Path(\"./dataset_raw_raw/\"),\n help=\"path to source dir\",\n)\n@click.option(\n \"-o\",\n \"--output-dir\",\n type=click.Path(),\n default=Path(\"./dataset_raw/\"),\n help=\"path to output dir\",\n)\n@click.option(\n \"-n\",\n \"--n-jobs\",\n type=int,\n default=-1,\n help=\"number of jobs (optimal value may depend on your RAM capacity and audio duration per file)\",\n)\n@click.option(\n \"-l\",\n \"--max-length\",\n type=float,\n default=10,\n help=\"max length of each split in seconds\",\n)\n@click.option(\"-d\", \"--top-db\", type=float, default=30, help=\"top db\")\n@click.option(\"-f\", \"--frame-seconds\", type=float, default=1, help=\"frame seconds\")\n@click.option(\"-ho\", \"-hop\", \"--hop-seconds\", type=float, default=0.3, help=\"hop seconds\")\n@click.option(\"-s\", \"--sr\", type=int, default=44100, help=\"sample rate\")\ndef pre_split(\n input_dir: Path | str,\n output_dir: Path | str,\n max_length: float,\n top_db: int,\n frame_seconds: float,\n hop_seconds: float,\n n_jobs: int,\n sr: int,\n):\n \"\"\"Split audio files into multiple files\"\"\"\n from so_vits_svc_fork.preprocessing.preprocess_split import preprocess_split\n\n preprocess_split(\n input_dir=input_dir,\n output_dir=output_dir,\n max_length=max_length,\n top_db=top_db,\n frame_seconds=frame_seconds,\n hop_seconds=hop_seconds,\n n_jobs=n_jobs,\n sr=sr,\n )\n\n\n@cli.command()\n@click.option(\n \"-i\",\n \"--input-dir\",\n type=click.Path(exists=True),\n required=True,\n help=\"path to source dir\",\n)\n@click.option(\n \"-o\",\n \"--output-dir\",\n type=click.Path(),\n default=None,\n help=\"path to output dir\",\n)\n@click.option(\n \"-c/-nc\",\n \"--create-new/--no-create-new\",\n type=bool,\n default=True,\n help=\"create a new folder for the speaker if not exist\",\n)\ndef pre_classify(\n input_dir: Path | str,\n output_dir: Path | str | None,\n create_new: bool,\n) -> None:\n \"\"\"Classify multiple audio files into multiple files\"\"\"\n from so_vits_svc_fork.preprocessing.preprocess_classify import preprocess_classify\n\n if output_dir is None:\n output_dir = input_dir\n preprocess_classify(\n input_dir=input_dir,\n output_dir=output_dir,\n create_new=create_new,\n )\n\n\n@cli.command\ndef clean():\n \"\"\"Clean up files, only useful if you are using the default file structure\"\"\"\n import shutil\n\n folders = [\"dataset\", \"filelists\", \"logs\"]\n # if pyip.inputYesNo(f\"Are you sure you want to delete files in {folders}?\") == \"yes\":\n if input(\"Are you sure you want to delete files in {folders}?\") in [\"yes\", \"y\"]:\n for folder in folders:\n if Path(folder).exists():\n shutil.rmtree(folder)\n LOG.info(\"Cleaned up files\")\n else:\n LOG.info(\"Aborted\")\n\n\n@cli.command\n@click.option(\n \"-i\",\n \"--input-path\",\n type=click.Path(exists=True),\n help=\"model path\",\n default=Path(\"./logs/44k/\"),\n)\n@click.option(\n \"-o\",\n \"--output-path\",\n type=click.Path(),\n help=\"onnx model path to save\",\n default=None,\n)\n@click.option(\n \"-c\",\n \"--config-path\",\n type=click.Path(),\n help=\"config path\",\n default=Path(\"./configs/44k/config.json\"),\n)\n@click.option(\n \"-d\",\n \"--device\",\n type=str,\n default=\"cpu\",\n help=\"device to use\",\n)\ndef onnx(input_path: Path, output_path: Path, config_path: Path, device: torch.device | str) -> None:\n \"\"\"Export model to onnx (currently not working)\"\"\"\n raise NotImplementedError(\"ONNX export is not yet supported\")\n input_path = Path(input_path)\n if input_path.is_dir():\n input_path = list(input_path.glob(\"*.pth\"))[0]\n if output_path is None:\n output_path = input_path.with_suffix(\".onnx\")\n output_path = Path(output_path)\n if output_path.is_dir():\n output_path = output_path / (input_path.stem + \".onnx\")\n config_path = Path(config_path)\n device_ = torch.device(device)\n from so_vits_svc_fork.modules.onnx._export import onnx_export\n\n onnx_export(\n input_path=input_path,\n output_path=output_path,\n config_path=config_path,\n device=device_,\n )\n\n\n@cli.command\n@click.option(\n \"-i\",\n \"--input-dir\",\n type=click.Path(exists=True),\n help=\"dataset directory\",\n default=Path(\"./dataset/44k\"),\n)\n@click.option(\n \"-o\",\n \"--output-path\",\n type=click.Path(),\n help=\"model path to save\",\n default=Path(\"./logs/44k/kmeans.pt\"),\n)\n@click.option(\"-n\", \"--n-clusters\", type=int, help=\"number of clusters\", default=2000)\n@click.option(\"-m/-nm\", \"--minibatch/--no-minibatch\", default=True, help=\"use minibatch k-means\")\n@click.option(\"-b\", \"--batch-size\", type=int, default=4096, help=\"batch size for minibatch kmeans\")\n@click.option(\"-p/-np\", \"--partial-fit\", default=False, help=\"use partial fit (only use with -m)\")\ndef train_cluster(\n input_dir: Path,\n output_path: Path,\n n_clusters: int,\n minibatch: bool,\n batch_size: int,\n partial_fit: bool,\n) -> None:\n \"\"\"Train k-means clustering\"\"\"\n from .cluster.train_cluster import main\n\n main(\n input_dir=input_dir,\n output_path=output_path,\n n_clusters=n_clusters,\n verbose=True,\n use_minibatch=minibatch,\n batch_size=batch_size,\n partial_fit=partial_fit,\n )\n\n\nif __name__ == \"__main__\":\n freeze_support()\n cli()\n"
},
{
"path": "src/so_vits_svc_fork/cluster/__init__.py",
"content": "from __future__ import annotations\n\nfrom pathlib import Path\nfrom typing import Any\n\nimport torch\nfrom sklearn.cluster import KMeans\n\n\ndef get_cluster_model(ckpt_path: Path | str):\n with Path(ckpt_path).open(\"rb\") as f:\n checkpoint = torch.load(f, map_location=\"cpu\") # Danger of arbitrary code execution\n kmeans_dict = {}\n for spk, ckpt in checkpoint.items():\n km = KMeans(ckpt[\"n_features_in_\"])\n km.__dict__[\"n_features_in_\"] = ckpt[\"n_features_in_\"]\n km.__dict__[\"_n_threads\"] = ckpt[\"_n_threads\"]\n km.__dict__[\"cluster_centers_\"] = ckpt[\"cluster_centers_\"]\n kmeans_dict[spk] = km\n return kmeans_dict\n\n\ndef check_speaker(model: Any, speaker: Any):\n if speaker not in model:\n raise ValueError(f\"Speaker {speaker} not in {list(model.keys())}\")\n\n\ndef get_cluster_result(model: Any, x: Any, speaker: Any):\n \"\"\"\n x: np.array [t, 256]\n return cluster class result\n \"\"\"\n check_speaker(model, speaker)\n return model[speaker].predict(x)\n\n\ndef get_cluster_center_result(model: Any, x: Any, speaker: Any):\n \"\"\"x: np.array [t, 256]\"\"\"\n check_speaker(model, speaker)\n predict = model[speaker].predict(x)\n return model[speaker].cluster_centers_[predict]\n\n\ndef get_center(model: Any, x: Any, speaker: Any):\n check_speaker(model, speaker)\n return model[speaker].cluster_centers_[x]\n"
},
{
"path": "src/so_vits_svc_fork/cluster/train_cluster.py",
"content": "from __future__ import annotations\n\nimport math\nfrom logging import getLogger\nfrom pathlib import Path\nfrom typing import Any\n\nimport numpy as np\nimport torch\nfrom cm_time import timer\nfrom joblib import Parallel, delayed\nfrom sklearn.cluster import KMeans, MiniBatchKMeans\nfrom tqdm_joblib import tqdm_joblib\n\nLOG = getLogger(__name__)\n\n\ndef train_cluster(\n input_dir: Path | str,\n n_clusters: int,\n use_minibatch: bool = True,\n batch_size: int = 4096,\n partial_fit: bool = False,\n verbose: bool = False,\n) -> dict:\n input_dir = Path(input_dir)\n if not partial_fit:\n LOG.info(f\"Loading features from {input_dir}\")\n features = []\n for path in input_dir.rglob(\"*.data.pt\"):\n with path.open(\"rb\") as f:\n features.append(torch.load(f, weights_only=True)[\"content\"].squeeze(0).numpy().T)\n if not features:\n raise ValueError(f\"No features found in {input_dir}\")\n features = np.concatenate(features, axis=0).astype(np.float32)\n if features.shape[0] < n_clusters:\n raise ValueError(\"Too few HuBERT features to cluster. Consider using a smaller number of clusters.\")\n LOG.info(f\"shape: {features.shape}, size: {features.nbytes / 1024**2:.2f} MB, dtype: {features.dtype}\")\n with timer() as t:\n if use_minibatch:\n kmeans = MiniBatchKMeans(\n n_clusters=n_clusters,\n verbose=verbose,\n batch_size=batch_size,\n max_iter=80,\n n_init=\"auto\",\n ).fit(features)\n else:\n kmeans = KMeans(n_clusters=n_clusters, verbose=verbose, n_init=\"auto\").fit(features)\n LOG.info(f\"Clustering took {t.elapsed:.2f} seconds\")\n\n x = {\n \"n_features_in_\": kmeans.n_features_in_,\n \"_n_threads\": kmeans._n_threads,\n \"cluster_centers_\": kmeans.cluster_centers_,\n }\n return x\n else:\n # minibatch partial fit\n paths = list(input_dir.rglob(\"*.data.pt\"))\n if len(paths) == 0:\n raise ValueError(f\"No features found in {input_dir}\")\n LOG.info(f\"Found {len(paths)} features in {input_dir}\")\n n_batches = math.ceil(len(paths) / batch_size)\n LOG.info(f\"Splitting into {n_batches} batches\")\n with timer() as t:\n kmeans = MiniBatchKMeans(\n n_clusters=n_clusters,\n verbose=verbose,\n batch_size=batch_size,\n max_iter=80,\n n_init=\"auto\",\n )\n for i in range(0, len(paths), batch_size):\n LOG.info(f\"Processing batch {i // batch_size + 1}/{n_batches} for speaker {input_dir.stem}\")\n features = []\n for path in paths[i : i + batch_size]:\n with path.open(\"rb\") as f:\n features.append(torch.load(f, weights_only=True)[\"content\"].squeeze(0).numpy().T)\n features = np.concatenate(features, axis=0).astype(np.float32)\n kmeans.partial_fit(features)\n LOG.info(f\"Clustering took {t.elapsed:.2f} seconds\")\n\n x = {\n \"n_features_in_\": kmeans.n_features_in_,\n \"_n_threads\": kmeans._n_threads,\n \"cluster_centers_\": kmeans.cluster_centers_,\n }\n return x\n\n\ndef main(\n input_dir: Path | str,\n output_path: Path | str,\n n_clusters: int = 10000,\n use_minibatch: bool = True,\n batch_size: int = 4096,\n partial_fit: bool = False,\n verbose: bool = False,\n) -> None:\n input_dir = Path(input_dir)\n output_path = Path(output_path)\n\n if not (use_minibatch or not partial_fit):\n raise ValueError(\"partial_fit requires use_minibatch\")\n\n def train_cluster_(input_path: Path, **kwargs: Any) -> tuple[str, dict]:\n return input_path.stem, train_cluster(input_path, **kwargs)\n\n with tqdm_joblib(desc=\"Training clusters\", total=len(list(input_dir.iterdir()))):\n parallel_result = Parallel(n_jobs=-1)(\n delayed(train_cluster_)(\n speaker_name,\n n_clusters=n_clusters,\n use_minibatch=use_minibatch,\n batch_size=batch_size,\n partial_fit=partial_fit,\n verbose=verbose,\n )\n for speaker_name in input_dir.iterdir()\n )\n assert parallel_result is not None\n checkpoint = dict(parallel_result)\n output_path.parent.mkdir(exist_ok=True, parents=True)\n with output_path.open(\"wb\") as f:\n torch.save(checkpoint, f)\n"
},
{
"path": "src/so_vits_svc_fork/dataset.py",
"content": "from __future__ import annotations\n\nfrom collections.abc import Sequence\nfrom pathlib import Path\nfrom random import Random\n\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom torch.utils.data import Dataset\n\nfrom .hparams import HParams\n\n\nclass TextAudioDataset(Dataset):\n def __init__(self, hps: HParams, is_validation: bool = False):\n self.datapaths = [\n Path(x).parent / (Path(x).name + \".data.pt\")\n for x in Path(hps.data.validation_files if is_validation else hps.data.training_files).read_text(\"utf-8\").splitlines()\n ]\n self.hps = hps\n self.random = Random(hps.train.seed)\n self.random.shuffle(self.datapaths)\n self.max_spec_len = 800\n\n def __getitem__(self, index: int) -> dict[str, torch.Tensor]:\n with Path(self.datapaths[index]).open(\"rb\") as f:\n data = torch.load(f, weights_only=True, map_location=\"cpu\")\n\n # cut long data randomly\n spec_len = data[\"mel_spec\"].shape[1]\n hop_len = self.hps.data.hop_length\n if spec_len > self.max_spec_len:\n start = self.random.randint(0, spec_len - self.max_spec_len)\n end = start + self.max_spec_len - 10\n for key in data.keys():\n if key == \"audio\":\n data[key] = data[key][:, start * hop_len : end * hop_len]\n elif key == \"spk\":\n continue\n else:\n data[key] = data[key][..., start:end]\n torch.cuda.empty_cache()\n return data\n\n def __len__(self) -> int:\n return len(self.datapaths)\n\n\ndef _pad_stack(array: Sequence[torch.Tensor]) -> torch.Tensor:\n max_idx = torch.argmax(torch.tensor([x_.shape[-1] for x_ in array]))\n max_x = array[max_idx]\n x_padded = [F.pad(x_, (0, max_x.shape[-1] - x_.shape[-1]), mode=\"constant\", value=0) for x_ in array]\n return torch.stack(x_padded)\n\n\nclass TextAudioCollate(nn.Module):\n def forward(self, batch: Sequence[dict[str, torch.Tensor]]) -> tuple[torch.Tensor, ...]:\n batch = [b for b in batch if b is not None]\n batch = sorted(batch, key=lambda x: x[\"mel_spec\"].shape[1], reverse=True)\n lengths = torch.tensor([b[\"mel_spec\"].shape[1] for b in batch]).long()\n results = {}\n for key in batch[0].keys():\n if key not in [\"spk\"]:\n results[key] = _pad_stack([b[key] for b in batch]).cpu()\n else:\n results[key] = torch.tensor([[b[key]] for b in batch]).cpu()\n\n return (\n results[\"content\"],\n results[\"f0\"],\n results[\"spec\"],\n results[\"mel_spec\"],\n results[\"audio\"],\n results[\"spk\"],\n lengths,\n results[\"uv\"],\n )\n"
},
{
"path": "src/so_vits_svc_fork/default_gui_presets.json",
"content": "{\n \"Default VC (GPU, GTX 1060)\": {\n \"silence_threshold\": -35.0,\n \"transpose\": 12.0,\n \"auto_predict_f0\": false,\n \"f0_method\": \"dio\",\n \"cluster_infer_ratio\": 0.0,\n \"noise_scale\": 0.4,\n \"pad_seconds\": 0.1,\n \"chunk_seconds\": 0.5,\n \"absolute_thresh\": true,\n \"max_chunk_seconds\": 40,\n \"crossfade_seconds\": 0.05,\n \"block_seconds\": 0.35,\n \"additional_infer_before_seconds\": 0.15,\n \"additional_infer_after_seconds\": 0.1,\n \"realtime_algorithm\": \"1 (Divide constantly)\",\n \"passthrough_original\": false,\n \"use_gpu\": true\n },\n \"Default VC (CPU)\": {\n \"silence_threshold\": -35.0,\n \"transpose\": 12.0,\n \"auto_predict_f0\": false,\n \"f0_method\": \"dio\",\n \"cluster_infer_ratio\": 0.0,\n \"noise_scale\": 0.4,\n \"pad_seconds\": 0.1,\n \"chunk_seconds\": 0.5,\n \"absolute_thresh\": true,\n \"max_chunk_seconds\": 40,\n \"crossfade_seconds\": 0.05,\n \"block_seconds\": 1.5,\n \"additional_infer_before_seconds\": 0.01,\n \"additional_infer_after_seconds\": 0.01,\n \"realtime_algorithm\": \"1 (Divide constantly)\",\n \"passthrough_original\": false,\n \"use_gpu\": false\n },\n \"Default VC (Mobile CPU)\": {\n \"silence_threshold\": -35.0,\n \"transpose\": 12.0,\n \"auto_predict_f0\": false,\n \"f0_method\": \"dio\",\n \"cluster_infer_ratio\": 0.0,\n \"noise_scale\": 0.4,\n \"pad_seconds\": 0.1,\n \"chunk_seconds\": 0.5,\n \"absolute_thresh\": true,\n \"max_chunk_seconds\": 40,\n \"crossfade_seconds\": 0.05,\n \"block_seconds\": 2.5,\n \"additional_infer_before_seconds\": 0.01,\n \"additional_infer_after_seconds\": 0.01,\n \"realtime_algorithm\": \"1 (Divide constantly)\",\n \"passthrough_original\": false,\n \"use_gpu\": false\n },\n \"Default VC (Crooning)\": {\n \"silence_threshold\": -35.0,\n \"transpose\": 12.0,\n \"auto_predict_f0\": false,\n \"f0_method\": \"dio\",\n \"cluster_infer_ratio\": 0.0,\n \"noise_scale\": 0.4,\n \"pad_seconds\": 0.1,\n \"chunk_seconds\": 0.5,\n \"absolute_thresh\": true,\n \"max_chunk_seconds\": 40,\n \"crossfade_seconds\": 0.04,\n \"block_seconds\": 0.15,\n \"additional_infer_before_seconds\": 0.05,\n \"additional_infer_after_seconds\": 0.05,\n \"realtime_algorithm\": \"1 (Divide constantly)\",\n \"passthrough_original\": false,\n \"use_gpu\": true\n },\n \"Default File\": {\n \"silence_threshold\": -35.0,\n \"transpose\": 0.0,\n \"auto_predict_f0\": true,\n \"f0_method\": \"crepe\",\n \"cluster_infer_ratio\": 0.0,\n \"noise_scale\": 0.4,\n \"pad_seconds\": 0.1,\n \"chunk_seconds\": 0.5,\n \"absolute_thresh\": true,\n \"max_chunk_seconds\": 40,\n \"auto_play\": true,\n \"passthrough_original\": false\n }\n}\n"
},
{
"path": "src/so_vits_svc_fork/f0.py",
"content": "from __future__ import annotations\n\nfrom logging import getLogger\nfrom typing import Any, Literal\n\nimport numpy as np\nimport torch\nimport torchcrepe\nfrom cm_time import timer\nfrom numpy import dtype, float32, ndarray\nfrom torch import FloatTensor, Tensor\n\nfrom so_vits_svc_fork.utils import get_optimal_device\n\nLOG = getLogger(__name__)\n\n\ndef normalize_f0(f0: FloatTensor, x_mask: FloatTensor, uv: FloatTensor, random_scale=True) -> FloatTensor:\n # calculate means based on x_mask\n uv_sum = torch.sum(uv, dim=1, keepdim=True)\n uv_sum[uv_sum == 0] = 9999\n means = torch.sum(f0[:, 0, :] * uv, dim=1, keepdim=True) / uv_sum\n\n if random_scale:\n factor = torch.Tensor(f0.shape[0], 1).uniform_(0.8, 1.2).to(f0.device)\n else:\n factor = torch.ones(f0.shape[0], 1).to(f0.device)\n # normalize f0 based on means and factor\n f0_norm = (f0 - means.unsqueeze(-1)) * factor.unsqueeze(-1)\n if torch.isnan(f0_norm).any():\n exit(0)\n return f0_norm * x_mask\n\n\ndef interpolate_f0(\n f0: ndarray[Any, dtype[float32]],\n) -> tuple[ndarray[Any, dtype[float32]], ndarray[Any, dtype[float32]]]:\n data = np.reshape(f0, (f0.size, 1))\n\n vuv_vector = np.zeros((data.size, 1), dtype=np.float32)\n vuv_vector[data > 0.0] = 1.0\n vuv_vector[data <= 0.0] = 0.0\n\n ip_data = data\n\n frame_number = data.size\n last_value = 0.0\n for i in range(frame_number):\n if data[i] <= 0.0:\n j = i + 1\n for j in range(i + 1, frame_number):\n if data[j] > 0.0:\n break\n if j < frame_number - 1:\n if last_value > 0.0:\n step = (data[j] - data[i - 1]) / float(j - i)\n for k in range(i, j):\n ip_data[k] = data[i - 1] + step * (k - i + 1)\n else:\n for k in range(i, j):\n ip_data[k] = data[j]\n else:\n for k in range(i, frame_number):\n ip_data[k] = last_value\n else:\n ip_data[i] = data[i]\n last_value = data[i]\n\n return ip_data[:, 0], vuv_vector[:, 0]\n\n\ndef compute_f0_parselmouth(\n wav_numpy: ndarray[Any, dtype[float32]],\n p_len: None | int = None,\n sampling_rate: int = 44100,\n hop_length: int = 512,\n):\n import parselmouth\n\n x = wav_numpy\n if p_len is None:\n p_len = x.shape[0] // hop_length\n else:\n assert abs(p_len - x.shape[0] // hop_length) < 4, \"pad length error\"\n time_step = hop_length / sampling_rate * 1000\n f0_min = 50\n f0_max = 1100\n f0 = (\n parselmouth.Sound(x, sampling_rate)\n .to_pitch_ac(\n time_step=time_step / 1000,\n voicing_threshold=0.6,\n pitch_floor=f0_min,\n pitch_ceiling=f0_max,\n )\n .selected_array[\"frequency\"]\n )\n\n pad_size = (p_len - len(f0) + 1) // 2\n if pad_size > 0 or p_len - len(f0) - pad_size > 0:\n f0 = np.pad(f0, [[pad_size, p_len - len(f0) - pad_size]], mode=\"constant\")\n return f0\n\n\ndef _resize_f0(x: ndarray[Any, dtype[float32]], target_len: int) -> ndarray[Any, dtype[float32]]:\n source = np.array(x)\n source[source < 0.001] = np.nan\n target = np.interp(\n np.arange(0, len(source) * target_len, len(source)) / target_len,\n np.arange(0, len(source)),\n source,\n )\n res = np.nan_to_num(target)\n return res\n\n\ndef compute_f0_pyworld(\n wav_numpy: ndarray[Any, dtype[float32]],\n p_len: None | int = None,\n sampling_rate: int = 44100,\n hop_length: int = 512,\n type_: Literal[\"dio\", \"harvest\"] = \"dio\",\n):\n import pyworld\n\n if p_len is None:\n p_len = wav_numpy.shape[0] // hop_length\n if type_ == \"dio\":\n f0, t = pyworld.dio(\n wav_numpy.astype(np.double),\n fs=sampling_rate,\n f0_ceil=f0_max,\n f0_floor=f0_min,\n frame_period=1000 * hop_length / sampling_rate,\n )\n elif type_ == \"harvest\":\n f0, t = pyworld.harvest(\n wav_numpy.astype(np.double),\n fs=sampling_rate,\n f0_ceil=f0_max,\n f0_floor=f0_min,\n frame_period=1000 * hop_length / sampling_rate,\n )\n f0 = pyworld.stonemask(wav_numpy.astype(np.double), f0, t, sampling_rate)\n for index, pitch in enumerate(f0):\n f0[index] = round(pitch, 1)\n return _resize_f0(f0, p_len)\n\n\ndef compute_f0_crepe(\n wav_numpy: ndarray[Any, dtype[float32]],\n p_len: None | int = None,\n sampling_rate: int = 44100,\n hop_length: int = 512,\n device: str | torch.device = get_optimal_device(),\n model: Literal[\"full\", \"tiny\"] = \"full\",\n):\n audio = torch.from_numpy(wav_numpy).to(device, copy=True)\n audio = torch.unsqueeze(audio, dim=0)\n\n if audio.ndim == 2 and audio.shape[0] > 1:\n audio = torch.mean(audio, dim=0, keepdim=True).detach()\n # (T) -> (1, T)\n audio = audio.detach()\n\n pitch: Tensor = torchcrepe.predict(\n audio,\n sampling_rate,\n hop_length,\n f0_min,\n f0_max,\n model,\n batch_size=hop_length * 2,\n device=device,\n pad=True,\n )\n\n f0 = pitch.squeeze(0).cpu().float().numpy()\n p_len = p_len or wav_numpy.shape[0] // hop_length\n f0 = _resize_f0(f0, p_len)\n return f0\n\n\ndef compute_f0(\n wav_numpy: ndarray[Any, dtype[float32]],\n p_len: None | int = None,\n sampling_rate: int = 44100,\n hop_length: int = 512,\n method: Literal[\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"] = \"dio\",\n **kwargs,\n):\n with timer() as t:\n wav_numpy = wav_numpy.astype(np.float32)\n wav_numpy /= np.quantile(np.abs(wav_numpy), 0.999)\n if method in [\"dio\", \"harvest\"]:\n f0 = compute_f0_pyworld(wav_numpy, p_len, sampling_rate, hop_length, method)\n elif method == \"crepe\":\n f0 = compute_f0_crepe(wav_numpy, p_len, sampling_rate, hop_length, **kwargs)\n elif method == \"crepe-tiny\":\n f0 = compute_f0_crepe(wav_numpy, p_len, sampling_rate, hop_length, model=\"tiny\", **kwargs)\n elif method == \"parselmouth\":\n f0 = compute_f0_parselmouth(wav_numpy, p_len, sampling_rate, hop_length)\n else:\n raise ValueError(\"type must be dio, crepe, crepe-tiny, harvest or parselmouth\")\n rtf = t.elapsed / (len(wav_numpy) / sampling_rate)\n LOG.info(f\"F0 inference time: {t.elapsed:.3f}s, RTF: {rtf:.3f}\")\n return f0\n\n\ndef f0_to_coarse(f0: torch.Tensor | float):\n is_torch = isinstance(f0, torch.Tensor)\n f0_mel = 1127 * (1 + f0 / 700).log() if is_torch else 1127 * np.log(1 + f0 / 700)\n f0_mel[f0_mel > 0] = (f0_mel[f0_mel > 0] - f0_mel_min) * (f0_bin - 2) / (f0_mel_max - f0_mel_min) + 1\n\n f0_mel[f0_mel <= 1] = 1\n f0_mel[f0_mel > f0_bin - 1] = f0_bin - 1\n f0_coarse = (f0_mel + 0.5).long() if is_torch else np.rint(f0_mel).astype(np.int)\n assert f0_coarse.max() <= 255 and f0_coarse.min() >= 1, (\n f0_coarse.max(),\n f0_coarse.min(),\n )\n return f0_coarse\n\n\nf0_bin = 256\nf0_max = 1100.0\nf0_min = 50.0\nf0_mel_min = 1127 * np.log(1 + f0_min / 700)\nf0_mel_max = 1127 * np.log(1 + f0_max / 700)\n"
},
{
"path": "src/so_vits_svc_fork/gui.py",
"content": "from __future__ import annotations\n\nimport json\nimport multiprocessing\nimport os\nfrom copy import copy\nfrom logging import getLogger\nfrom pathlib import Path\n\nimport PySimpleGUI as sg\nimport sounddevice as sd\nimport soundfile as sf\nimport torch\nfrom pebble import ProcessFuture, ProcessPool\n\nfrom . import __version__\nfrom .utils import get_optimal_device\n\nGUI_DEFAULT_PRESETS_PATH = Path(__file__).parent / \"default_gui_presets.json\"\nGUI_PRESETS_PATH = Path(\"./user_gui_presets.json\").absolute()\n\nLOG = getLogger(__name__)\n\n\ndef play_audio(path: Path | str):\n if isinstance(path, Path):\n path = path.as_posix()\n data, sr = sf.read(path)\n sd.play(data, sr)\n\n\ndef load_presets() -> dict:\n defaults = json.loads(GUI_DEFAULT_PRESETS_PATH.read_text(\"utf-8\"))\n users = json.loads(GUI_PRESETS_PATH.read_text(\"utf-8\")) if GUI_PRESETS_PATH.exists() else {}\n # prioriy: defaults > users\n # order: defaults -> users\n return {**defaults, **users, **defaults}\n\n\ndef add_preset(name: str, preset: dict) -> dict:\n presets = load_presets()\n presets[name] = preset\n with GUI_PRESETS_PATH.open(\"w\") as f:\n json.dump(presets, f, indent=2)\n return load_presets()\n\n\ndef delete_preset(name: str) -> dict:\n presets = load_presets()\n if name in presets:\n del presets[name]\n else:\n LOG.warning(f\"Cannot delete preset {name} because it does not exist.\")\n with GUI_PRESETS_PATH.open(\"w\") as f:\n json.dump(presets, f, indent=2)\n return load_presets()\n\n\ndef get_output_path(input_path: Path) -> Path:\n # Default output path\n output_path = input_path.parent / f\"{input_path.stem}.out{input_path.suffix}\"\n\n # Increment file number in path if output file already exists\n file_num = 1\n while output_path.exists():\n output_path = input_path.parent / f\"{input_path.stem}.out_{file_num}{input_path.suffix}\"\n file_num += 1\n return output_path\n\n\ndef get_supported_file_types() -> tuple[tuple[str, str], ...]:\n res = tuple([(extension, f\".{extension.lower()}\") for extension in sf.available_formats().keys()])\n\n # Sort by popularity\n common_file_types = [\"WAV\", \"MP3\", \"FLAC\", \"OGG\", \"M4A\", \"WMA\"]\n res = sorted(\n res,\n key=lambda x: (common_file_types.index(x[0]) if x[0] in common_file_types else len(common_file_types)),\n )\n return res\n\n\ndef get_supported_file_types_concat() -> tuple[tuple[str, str], ...]:\n return ((\"Audio\", \" \".join(sf.available_formats().keys())),)\n\n\ndef validate_output_file_type(output_path: Path) -> bool:\n supported_file_types = sorted([f\".{extension.lower()}\" for extension in sf.available_formats().keys()])\n if not output_path.suffix:\n sg.popup_ok(\"Error: Output path missing file type extension, enter \" + \"one of the following manually:\\n\\n\" + \"\\n\".join(supported_file_types))\n return False\n if output_path.suffix.lower() not in supported_file_types:\n sg.popup_ok(\n f\"Error: {output_path.suffix.lower()} is not a supported \" + \"extension; use one of the following:\\n\\n\" + \"\\n\".join(supported_file_types)\n )\n return False\n return True\n\n\ndef get_devices(\n update: bool = True,\n) -> tuple[list[str], list[str], list[int], list[int]]:\n if update:\n sd._terminate()\n sd._initialize()\n devices = sd.query_devices()\n hostapis = sd.query_hostapis()\n for hostapi in hostapis:\n for device_idx in hostapi[\"devices\"]:\n devices[device_idx][\"hostapi_name\"] = hostapi[\"name\"]\n input_devices = [f\"{d['name']} ({d['hostapi_name']})\" for d in devices if d[\"max_input_channels\"] > 0]\n output_devices = [f\"{d['name']} ({d['hostapi_name']})\" for d in devices if d[\"max_output_channels\"] > 0]\n input_devices_indices = [d[\"index\"] for d in devices if d[\"max_input_channels\"] > 0]\n output_devices_indices = [d[\"index\"] for d in devices if d[\"max_output_channels\"] > 0]\n return input_devices, output_devices, input_devices_indices, output_devices_indices\n\n\ndef after_inference(window: sg.Window, path: Path, auto_play: bool, output_path: Path):\n try:\n LOG.info(f\"Finished inference for {path.stem}{path.suffix}\")\n window[\"infer\"].update(disabled=False)\n\n if auto_play:\n play_audio(output_path)\n except Exception as e:\n LOG.exception(e)\n\n\ndef main():\n LOG.info(f\"version: {__version__}\")\n\n # sg.theme(\"Dark\")\n sg.theme_add_new(\n \"Very Dark\",\n {\n \"BACKGROUND\": \"#111111\",\n \"TEXT\": \"#FFFFFF\",\n \"INPUT\": \"#444444\",\n \"TEXT_INPUT\": \"#FFFFFF\",\n \"SCROLL\": \"#333333\",\n \"BUTTON\": (\"white\", \"#112233\"),\n \"PROGRESS\": (\"#111111\", \"#333333\"),\n \"BORDER\": 2,\n \"SLIDER_DEPTH\": 2,\n \"PROGRESS_DEPTH\": 2,\n },\n )\n sg.theme(\"Very Dark\")\n\n model_candidates = sorted(Path(\"./logs/44k/\").glob(\"G_*.pth\"))\n\n frame_contents = {\n \"Paths\": [\n [\n sg.Text(\"Model path\"),\n sg.Push(),\n sg.InputText(\n key=\"model_path\",\n default_text=(model_candidates[-1].absolute().as_posix() if model_candidates else \"\"),\n enable_events=True,\n ),\n sg.FileBrowse(\n initial_folder=(Path(\"./logs/44k/\").absolute if Path(\"./logs/44k/\").exists() else Path(\".\").absolute().as_posix()),\n key=\"model_path_browse\",\n file_types=(\n (\"PyTorch\", \"G_*.pth G_*.pt\"),\n (\"Pytorch\", \"*.pth *.pt\"),\n ),\n ),\n ],\n [\n sg.Text(\"Config path\"),\n sg.Push(),\n sg.InputText(\n key=\"config_path\",\n default_text=(Path(\"./configs/44k/config.json\").absolute().as_posix() if Path(\"./configs/44k/config.json\").exists() else \"\"),\n enable_events=True,\n ),\n sg.FileBrowse(\n initial_folder=(Path(\"./configs/44k/\").as_posix() if Path(\"./configs/44k/\").exists() else Path(\".\").absolute().as_posix()),\n key=\"config_path_browse\",\n file_types=((\"JSON\", \"*.json\"),),\n ),\n ],\n [\n sg.Text(\"Cluster model path (Optional)\"),\n sg.Push(),\n sg.InputText(\n key=\"cluster_model_path\",\n default_text=(Path(\"./logs/44k/kmeans.pt\").absolute().as_posix() if Path(\"./logs/44k/kmeans.pt\").exists() else \"\"),\n enable_events=True,\n ),\n sg.FileBrowse(\n initial_folder=(\"./logs/44k/\" if Path(\"./logs/44k/\").exists() else \".\"),\n key=\"cluster_model_path_browse\",\n file_types=((\"PyTorch\", \"*.pt\"), (\"Pickle\", \"*.pt *.pth *.pkl\")),\n ),\n ],\n ],\n \"Common\": [\n [\n sg.Text(\"Speaker\"),\n sg.Push(),\n sg.Combo(values=[], key=\"speaker\", size=(20, 1)),\n ],\n [\n sg.Text(\"Silence threshold\"),\n sg.Push(),\n sg.Slider(\n range=(-60.0, 0),\n orientation=\"h\",\n key=\"silence_threshold\",\n resolution=0.1,\n ),\n ],\n [\n sg.Text(\n \"Pitch (12 = 1 octave)\\nADJUST THIS based on your voice\\nwhen Auto predict F0 is turned off.\",\n size=(None, 4),\n ),\n sg.Push(),\n sg.Slider(\n range=(-36, 36),\n orientation=\"h\",\n key=\"transpose\",\n tick_interval=12,\n ),\n ],\n [\n sg.Checkbox(\n key=\"auto_predict_f0\",\n text=\"Auto predict F0 (Pitch may become unstable when turned on in real-time inference.)\",\n )\n ],\n [\n sg.Text(\"F0 prediction method\"),\n sg.Push(),\n sg.Combo(\n [\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"],\n key=\"f0_method\",\n ),\n ],\n [\n sg.Text(\"Cluster infer ratio\"),\n sg.Push(),\n sg.Slider(\n range=(0, 1.0),\n orientation=\"h\",\n key=\"cluster_infer_ratio\",\n resolution=0.01,\n ),\n ],\n [\n sg.Text(\"Noise scale\"),\n sg.Push(),\n sg.Slider(\n range=(0.0, 1.0),\n orientation=\"h\",\n key=\"noise_scale\",\n resolution=0.01,\n ),\n ],\n [\n sg.Text(\"Pad seconds\"),\n sg.Push(),\n sg.Slider(\n range=(0.0, 1.0),\n orientation=\"h\",\n key=\"pad_seconds\",\n resolution=0.01,\n ),\n ],\n [\n sg.Text(\"Chunk seconds\"),\n sg.Push(),\n sg.Slider(\n range=(0.0, 3.0),\n orientation=\"h\",\n key=\"chunk_seconds\",\n resolution=0.01,\n ),\n ],\n [\n sg.Text(\"Max chunk seconds (set lower if Out Of Memory, 0 to disable)\"),\n sg.Push(),\n sg.Slider(\n range=(0.0, 240.0),\n orientation=\"h\",\n key=\"max_chunk_seconds\",\n resolution=1.0,\n ),\n ],\n [\n sg.Checkbox(\n key=\"absolute_thresh\",\n text=\"Absolute threshold (ignored (True) in realtime inference)\",\n )\n ],\n ],\n \"File\": [\n [\n sg.Text(\"Input audio path\"),\n sg.Push(),\n sg.InputText(key=\"input_path\", enable_events=True),\n sg.FileBrowse(\n initial_folder=\".\",\n key=\"input_path_browse\",\n file_types=(get_supported_file_types_concat() if os.name == \"nt\" else get_supported_file_types()),\n ),\n sg.FolderBrowse(\n button_text=\"Browse(Folder)\",\n initial_folder=\".\",\n key=\"input_path_folder_browse\",\n target=\"input_path\",\n ),\n sg.Button(\"Play\", key=\"play_input\"),\n ],\n [\n sg.Text(\"Output audio path\"),\n sg.Push(),\n sg.InputText(key=\"output_path\"),\n sg.FileSaveAs(\n initial_folder=\".\",\n key=\"output_path_browse\",\n file_types=get_supported_file_types(),\n ),\n ],\n [sg.Checkbox(key=\"auto_play\", text=\"Auto play\", default=True)],\n ],\n \"Realtime\": [\n [\n sg.Text(\"Crossfade seconds\"),\n sg.Push(),\n sg.Slider(\n range=(0, 0.6),\n orientation=\"h\",\n key=\"crossfade_seconds\",\n resolution=0.001,\n ),\n ],\n [\n sg.Text(\n \"Block seconds\", # \\n(big -> more robust, slower, (the same) latency)\"\n tooltip=\"Big -> more robust, slower, (the same) latency\",\n ),\n sg.Push(),\n sg.Slider(\n range=(0, 3.0),\n orientation=\"h\",\n key=\"block_seconds\",\n resolution=0.001,\n ),\n ],\n [\n sg.Text(\n \"Additional Infer seconds (before)\", # \\n(big -> more robust, slower)\"\n tooltip=\"Big -> more robust, slower, additional latency\",\n ),\n sg.Push(),\n sg.Slider(\n range=(0, 2.0),\n orientation=\"h\",\n key=\"additional_infer_before_seconds\",\n resolution=0.001,\n ),\n ],\n [\n sg.Text(\n \"Additional Infer seconds (after)\", # \\n(big -> more robust, slower, additional latency)\"\n tooltip=\"Big -> more robust, slower, additional latency\",\n ),\n sg.Push(),\n sg.Slider(\n range=(0, 2.0),\n orientation=\"h\",\n key=\"additional_infer_after_seconds\",\n resolution=0.001,\n ),\n ],\n [\n sg.Text(\"Realtime algorithm\"),\n sg.Push(),\n sg.Combo(\n [\"2 (Divide by speech)\", \"1 (Divide constantly)\"],\n default_value=\"1 (Divide constantly)\",\n key=\"realtime_algorithm\",\n ),\n ],\n [\n sg.Text(\"Input device\"),\n sg.Push(),\n sg.Combo(\n key=\"input_device\",\n values=[],\n size=(60, 1),\n ),\n ],\n [\n sg.Text(\"Output device\"),\n sg.Push(),\n sg.Combo(\n key=\"output_device\",\n values=[],\n size=(60, 1),\n ),\n ],\n [\n sg.Checkbox(\n \"Passthrough original audio (for latency check)\",\n key=\"passthrough_original\",\n default=False,\n ),\n sg.Push(),\n sg.Button(\"Refresh devices\", key=\"refresh_devices\"),\n ],\n [\n sg.Frame(\n \"Notes\",\n [\n [\n sg.Text(\n \"In Realtime Inference:\\n\"\n \" - Setting F0 prediction method to 'crepe` may cause performance degradation.\\n\"\n \" - Auto Predict F0 must be turned off.\\n\"\n \"If the audio sounds mumbly and choppy:\\n\"\n \" Case: The inference has not been made in time (Increase Block seconds)\\n\"\n \" Case: Mic input is low (Decrease Silence threshold)\\n\"\n )\n ]\n ],\n ),\n ],\n ],\n \"Presets\": [\n [\n sg.Text(\"Presets\"),\n sg.Push(),\n sg.Combo(\n key=\"presets\",\n values=list(load_presets().keys()),\n size=(40, 1),\n enable_events=True,\n ),\n sg.Button(\"Delete preset\", key=\"delete_preset\"),\n ],\n [\n sg.Text(\"Preset name\"),\n sg.Stretch(),\n sg.InputText(key=\"preset_name\", size=(26, 1)),\n sg.Button(\"Add current settings as a preset\", key=\"add_preset\"),\n ],\n ],\n }\n\n # frames\n frames = {}\n for name, items in frame_contents.items():\n frame = sg.Frame(name, items)\n frame.expand_x = True\n frames[name] = [frame]\n\n bottoms = [\n [\n sg.Checkbox(\n key=\"use_gpu\",\n default=get_optimal_device() != torch.device(\"cpu\"),\n text=\"Use GPU\"\n + (\n \" (not available; if your device has GPU, make sure you installed PyTorch with CUDA support)\"\n if get_optimal_device() == torch.device(\"cpu\")\n else \"\"\n ),\n disabled=get_optimal_device() == torch.device(\"cpu\"),\n )\n ],\n [\n sg.Button(\"Infer\", key=\"infer\"),\n sg.Button(\"(Re)Start Voice Changer\", key=\"start_vc\"),\n sg.Button(\"Stop Voice Changer\", key=\"stop_vc\"),\n sg.Push(),\n # sg.Button(\"ONNX Export\", key=\"onnx_export\"),\n ],\n ]\n column1 = sg.Column(\n [\n frames[\"Paths\"],\n frames[\"Common\"],\n ],\n vertical_alignment=\"top\",\n )\n column2 = sg.Column(\n [\n frames[\"File\"],\n frames[\"Realtime\"],\n frames[\"Presets\"],\n ]\n + bottoms\n )\n # columns\n layout = [[column1, column2]]\n # get screen size\n screen_width, screen_height = sg.Window.get_screen_size()\n if screen_height < 720:\n layout = [\n [\n sg.Column(\n layout,\n vertical_alignment=\"top\",\n scrollable=False,\n expand_x=True,\n expand_y=True,\n vertical_scroll_only=True,\n key=\"main_column\",\n )\n ]\n ]\n window = sg.Window(\n f\"{__name__.split('.')[0].replace('_', '-')} v{__version__}\",\n layout,\n grab_anywhere=True,\n finalize=True,\n scaling=1,\n font=(\"Yu Gothic UI\", 11) if os.name == \"nt\" else None,\n # resizable=True,\n # size=(1280, 720),\n # Below disables taskbar, which may be not useful for some users\n # use_custom_titlebar=True, no_titlebar=False\n # Keep on top\n # keep_on_top=True\n )\n\n # event, values = window.read(timeout=0.01)\n # window[\"main_column\"].Scrollable = True\n\n # make slider height smaller\n try:\n for v in window.element_list():\n if isinstance(v, sg.Slider):\n v.Widget.configure(sliderrelief=\"flat\", width=10, sliderlength=20)\n except Exception as e:\n LOG.exception(e)\n\n # for n in [\"input_device\", \"output_device\"]:\n # window[n].Widget.configure(justify=\"right\")\n event, values = window.read(timeout=0.01)\n\n def update_speaker() -> None:\n from . import utils\n\n config_path = Path(values[\"config_path\"])\n if config_path.exists() and config_path.is_file():\n hp = utils.get_hparams(values[\"config_path\"])\n LOG.debug(f\"Loaded config from {values['config_path']}\")\n window[\"speaker\"].update(values=list(hp.__dict__[\"spk\"].keys()), set_to_index=0)\n\n def update_devices() -> None:\n (\n input_devices,\n output_devices,\n input_device_indices,\n output_device_indices,\n ) = get_devices()\n input_device_indices_reversed = {v: k for k, v in enumerate(input_device_indices)}\n output_device_indices_reversed = {v: k for k, v in enumerate(output_device_indices)}\n window[\"input_device\"].update(values=input_devices, value=values[\"input_device\"])\n window[\"output_device\"].update(values=output_devices, value=values[\"output_device\"])\n input_default, output_default = sd.default.device\n if values[\"input_device\"] not in input_devices:\n window[\"input_device\"].update(\n values=input_devices,\n set_to_index=input_device_indices_reversed.get(input_default, 0),\n )\n if values[\"output_device\"] not in output_devices:\n window[\"output_device\"].update(\n values=output_devices,\n set_to_index=output_device_indices_reversed.get(output_default, 0),\n )\n\n PRESET_KEYS = [key for key in values.keys() if not any(exclude in key for exclude in [\"preset\", \"browse\"])]\n\n def apply_preset(name: str) -> None:\n for key, value in load_presets()[name].items():\n if key in PRESET_KEYS:\n window[key].update(value)\n values[key] = value\n\n default_name = list(load_presets().keys())[0]\n apply_preset(default_name)\n window[\"presets\"].update(default_name)\n del default_name\n update_speaker()\n update_devices()\n # with ProcessPool(max_workers=1) as pool:\n # to support Linux\n with ProcessPool(\n max_workers=min(2, multiprocessing.cpu_count()),\n context=multiprocessing.get_context(\"spawn\"),\n ) as pool:\n future: None | ProcessFuture = None\n infer_futures: set[ProcessFuture] = set()\n while True:\n event, values = window.read(200)\n if event == sg.WIN_CLOSED:\n break\n if not event == sg.EVENT_TIMEOUT:\n LOG.info(f\"Event {event}, values {values}\")\n if event.endswith(\"_path\"):\n for name in window.AllKeysDict:\n if str(name).endswith(\"_browse\"):\n browser = window[name]\n if isinstance(browser, sg.Button):\n LOG.info(f\"Updating browser {browser} to {Path(values[event]).parent}\")\n browser.InitialFolder = Path(values[event]).parent\n browser.update()\n else:\n LOG.warning(f\"Browser {browser} is not a FileBrowse\")\n window[\"transpose\"].update(\n disabled=values[\"auto_predict_f0\"],\n visible=not values[\"auto_predict_f0\"],\n )\n\n input_path = Path(values[\"input_path\"])\n output_path = Path(values[\"output_path\"])\n\n if event == \"add_preset\":\n presets = add_preset(values[\"preset_name\"], {key: values[key] for key in PRESET_KEYS})\n window[\"presets\"].update(values=list(presets.keys()))\n elif event == \"delete_preset\":\n presets = delete_preset(values[\"presets\"])\n window[\"presets\"].update(values=list(presets.keys()))\n elif event == \"presets\":\n apply_preset(values[\"presets\"])\n update_speaker()\n elif event == \"refresh_devices\":\n update_devices()\n elif event == \"config_path\":\n update_speaker()\n elif event == \"input_path\":\n # Don't change the output path if it's already set\n # if values[\"output_path\"]:\n # continue\n # Set a sensible default output path\n window.Element(\"output_path\").Update(str(get_output_path(input_path)))\n elif event == \"infer\":\n if \"Default VC\" in values[\"presets\"]:\n window[\"presets\"].update(set_to_index=list(load_presets().keys()).index(\"Default File\"))\n apply_preset(\"Default File\")\n if values[\"input_path\"] == \"\":\n LOG.warning(\"Input path is empty.\")\n continue\n if not input_path.exists():\n LOG.warning(f\"Input path {input_path} does not exist.\")\n continue\n # if not validate_output_file_type(output_path):\n # continue\n\n try:\n from so_vits_svc_fork.inference.main import infer\n\n LOG.info(\"Starting inference...\")\n window[\"infer\"].update(disabled=True)\n infer_future = pool.schedule(\n infer,\n kwargs=dict(\n # paths\n model_path=Path(values[\"model_path\"]),\n output_path=output_path,\n input_path=input_path,\n config_path=Path(values[\"config_path\"]),\n recursive=True,\n # svc config\n speaker=values[\"speaker\"],\n cluster_model_path=(Path(values[\"cluster_model_path\"]) if values[\"cluster_model_path\"] else None),\n transpose=values[\"transpose\"],\n auto_predict_f0=values[\"auto_predict_f0\"],\n cluster_infer_ratio=values[\"cluster_infer_ratio\"],\n noise_scale=values[\"noise_scale\"],\n f0_method=values[\"f0_method\"],\n # slice config\n db_thresh=values[\"silence_threshold\"],\n pad_seconds=values[\"pad_seconds\"],\n chunk_seconds=values[\"chunk_seconds\"],\n absolute_thresh=values[\"absolute_thresh\"],\n max_chunk_seconds=values[\"max_chunk_seconds\"],\n device=(\"cpu\" if not values[\"use_gpu\"] else get_optimal_device()),\n ),\n )\n infer_future.add_done_callback(lambda _future: after_inference(window, input_path, values[\"auto_play\"], output_path))\n infer_futures.add(infer_future)\n except Exception as e:\n LOG.exception(e)\n elif event == \"play_input\":\n if Path(values[\"input_path\"]).exists():\n pool.schedule(play_audio, args=[Path(values[\"input_path\"])])\n elif event == \"start_vc\":\n _, _, input_device_indices, output_device_indices = get_devices(update=False)\n from so_vits_svc_fork.inference.main import realtime\n\n if future:\n LOG.info(\"Canceling previous task\")\n future.cancel()\n future = pool.schedule(\n realtime,\n kwargs=dict(\n # paths\n model_path=Path(values[\"model_path\"]),\n config_path=Path(values[\"config_path\"]),\n speaker=values[\"speaker\"],\n # svc config\n cluster_model_path=(Path(values[\"cluster_model_path\"]) if values[\"cluster_model_path\"] else None),\n transpose=values[\"transpose\"],\n auto_predict_f0=values[\"auto_predict_f0\"],\n cluster_infer_ratio=values[\"cluster_infer_ratio\"],\n noise_scale=values[\"noise_scale\"],\n f0_method=values[\"f0_method\"],\n # slice config\n db_thresh=values[\"silence_threshold\"],\n pad_seconds=values[\"pad_seconds\"],\n chunk_seconds=values[\"chunk_seconds\"],\n # realtime config\n crossfade_seconds=values[\"crossfade_seconds\"],\n additional_infer_before_seconds=values[\"additional_infer_before_seconds\"],\n additional_infer_after_seconds=values[\"additional_infer_after_seconds\"],\n block_seconds=values[\"block_seconds\"],\n version=int(values[\"realtime_algorithm\"][0]),\n input_device=input_device_indices[window[\"input_device\"].widget.current()],\n output_device=output_device_indices[window[\"output_device\"].widget.current()],\n device=get_optimal_device() if values[\"use_gpu\"] else \"cpu\",\n passthrough_original=values[\"passthrough_original\"],\n ),\n )\n elif event == \"stop_vc\":\n if future:\n future.cancel()\n future = None\n elif event == \"onnx_export\":\n try:\n raise NotImplementedError(\"ONNX export is not implemented yet.\")\n from so_vits_svc_fork.modules.onnx._export import onnx_export\n\n onnx_export(\n input_path=Path(values[\"model_path\"]),\n output_path=Path(values[\"model_path\"]).with_suffix(\".onnx\"),\n config_path=Path(values[\"config_path\"]),\n device=\"cpu\",\n )\n except Exception as e:\n LOG.exception(e)\n if future is not None and future.done():\n try:\n future.result()\n except Exception as e:\n LOG.error(\"Error in realtime: \")\n LOG.exception(e)\n future = None\n for future in copy(infer_futures):\n if future.done():\n try:\n future.result()\n except Exception as e:\n LOG.error(\"Error in inference: \")\n LOG.exception(e)\n infer_futures.remove(future)\n if future:\n future.cancel()\n window.close()\n"
},
{
"path": "src/so_vits_svc_fork/hparams.py",
"content": "from __future__ import annotations\n\nfrom typing import Any\n\n\nclass HParams:\n def __init__(self, **kwargs: Any) -> None:\n for k, v in kwargs.items():\n if type(v) == dict: # noqa\n v = HParams(**v)\n self[k] = v\n\n def keys(self):\n return self.__dict__.keys()\n\n def items(self):\n return self.__dict__.items()\n\n def values(self):\n return self.__dict__.values()\n\n def get(self, key: str, default: Any = None):\n return self.__dict__.get(key, default)\n\n def __len__(self):\n return len(self.__dict__)\n\n def __getitem__(self, key):\n return getattr(self, key)\n\n def __setitem__(self, key, value):\n return setattr(self, key, value)\n\n def __contains__(self, key):\n return key in self.__dict__\n\n def __repr__(self):\n return self.__dict__.__repr__()\n"
},
{
"path": "src/so_vits_svc_fork/inference/__init__.py",
"content": ""
},
{
"path": "src/so_vits_svc_fork/inference/core.py",
"content": "from __future__ import annotations\n\nfrom collections.abc import Iterable\nfrom copy import deepcopy\nfrom logging import getLogger\nfrom pathlib import Path\nfrom typing import Any, Callable, Literal\n\nimport attrs\nimport librosa\nimport numpy as np\nimport torch\nfrom cm_time import timer\nfrom numpy import dtype, float32, ndarray\n\nimport so_vits_svc_fork.f0\nfrom so_vits_svc_fork import cluster, utils\n\nfrom ..modules.synthesizers import SynthesizerTrn\nfrom ..utils import get_optimal_device\n\nLOG = getLogger(__name__)\n\n\ndef pad_array(array_, target_length: int):\n current_length = array_.shape[0]\n if current_length >= target_length:\n return array_[\n (current_length - target_length) // 2 : (current_length - target_length) // 2 + target_length,\n ...,\n ]\n else:\n pad_width = target_length - current_length\n pad_left = pad_width // 2\n pad_right = pad_width - pad_left\n padded_arr = np.pad(array_, (pad_left, pad_right), \"constant\", constant_values=(0, 0))\n return padded_arr\n\n\n@attrs.frozen(kw_only=True)\nclass Chunk:\n is_speech: bool\n audio: ndarray[Any, dtype[float32]]\n start: int\n end: int\n\n @property\n def duration(self) -> float32:\n # return self.end - self.start\n return float32(self.audio.shape[0])\n\n def __repr__(self) -> str:\n return f\"Chunk(Speech: {self.is_speech}, {self.duration})\"\n\n\ndef split_silence(\n audio: ndarray[Any, dtype[float32]],\n top_db: int = 40,\n ref: float | Callable[[ndarray[Any, dtype[float32]]], float] = 1,\n frame_length: int = 2048,\n hop_length: int = 512,\n aggregate: Callable[[ndarray[Any, dtype[float32]]], float] = np.mean,\n max_chunk_length: int = 0,\n) -> Iterable[Chunk]:\n non_silence_indices = librosa.effects.split(\n audio,\n top_db=top_db,\n ref=ref,\n frame_length=frame_length,\n hop_length=hop_length,\n aggregate=aggregate,\n )\n last_end = 0\n for start, end in non_silence_indices:\n if start != last_end:\n yield Chunk(is_speech=False, audio=audio[last_end:start], start=last_end, end=start)\n while max_chunk_length > 0 and end - start > max_chunk_length:\n yield Chunk(\n is_speech=True,\n audio=audio[start : start + max_chunk_length],\n start=start,\n end=start + max_chunk_length,\n )\n start += max_chunk_length\n if end - start > 0:\n yield Chunk(is_speech=True, audio=audio[start:end], start=start, end=end)\n last_end = end\n if last_end != len(audio):\n yield Chunk(is_speech=False, audio=audio[last_end:], start=last_end, end=len(audio))\n\n\nclass Svc:\n def __init__(\n self,\n *,\n net_g_path: Path | str,\n config_path: Path | str,\n device: torch.device | str | None = None,\n cluster_model_path: Path | str | None = None,\n half: bool = False,\n ):\n self.net_g_path = net_g_path\n if device is None:\n self.device = (get_optimal_device(),)\n else:\n self.device = torch.device(device)\n self.hps = utils.get_hparams(config_path)\n self.target_sample = self.hps.data.sampling_rate\n self.hop_size = self.hps.data.hop_length\n self.spk2id = self.hps.spk\n self.hubert_model = utils.get_hubert_model(self.device, self.hps.data.get(\"contentvec_final_proj\", True))\n self.dtype = torch.float16 if half else torch.float32\n self.contentvec_final_proj = self.hps.data.__dict__.get(\"contentvec_final_proj\", True)\n self.load_model()\n if cluster_model_path is not None and Path(cluster_model_path).exists():\n self.cluster_model = cluster.get_cluster_model(cluster_model_path)\n\n def load_model(self):\n self.net_g = SynthesizerTrn(\n self.hps.data.filter_length // 2 + 1,\n self.hps.train.segment_size // self.hps.data.hop_length,\n **self.hps.model,\n )\n _ = utils.load_checkpoint(self.net_g_path, self.net_g, None)\n _ = self.net_g.eval()\n for m in self.net_g.modules():\n utils.remove_weight_norm_if_exists(m)\n _ = self.net_g.to(self.device, dtype=self.dtype)\n self.net_g = self.net_g\n\n def get_unit_f0(\n self,\n audio: ndarray[Any, dtype[float32]],\n tran: int,\n cluster_infer_ratio: float,\n speaker: int | str,\n f0_method: Literal[\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"] = \"dio\",\n ):\n f0 = so_vits_svc_fork.f0.compute_f0(\n audio,\n sampling_rate=self.target_sample,\n hop_length=self.hop_size,\n method=f0_method,\n )\n f0, uv = so_vits_svc_fork.f0.interpolate_f0(f0)\n f0 = torch.as_tensor(f0, dtype=self.dtype, device=self.device)\n uv = torch.as_tensor(uv, dtype=self.dtype, device=self.device)\n f0 = f0 * 2 ** (tran / 12)\n f0 = f0.unsqueeze(0)\n uv = uv.unsqueeze(0)\n\n c = utils.get_content(\n self.hubert_model,\n audio,\n self.device,\n self.target_sample,\n self.contentvec_final_proj,\n ).to(self.dtype)\n c = utils.repeat_expand_2d(c.squeeze(0), f0.shape[1])\n\n if cluster_infer_ratio != 0:\n cluster_c = cluster.get_cluster_center_result(self.cluster_model, c.cpu().numpy().T, speaker).T\n cluster_c = torch.FloatTensor(cluster_c).to(self.device)\n c = cluster_infer_ratio * cluster_c + (1 - cluster_infer_ratio) * c\n\n c = c.unsqueeze(0)\n return c, f0, uv\n\n def infer(\n self,\n speaker: int | str,\n transpose: int,\n audio: ndarray[Any, dtype[float32]],\n cluster_infer_ratio: float = 0,\n auto_predict_f0: bool = False,\n noise_scale: float = 0.4,\n f0_method: Literal[\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"] = \"dio\",\n ) -> tuple[torch.Tensor, int]:\n audio = audio.astype(np.float32)\n # get speaker id\n if isinstance(speaker, int):\n if len(self.spk2id.__dict__) >= speaker:\n speaker_id = speaker\n else:\n raise ValueError(f\"Speaker id {speaker} >= number of speakers {len(self.spk2id.__dict__)}\")\n else:\n if speaker in self.spk2id.__dict__:\n speaker_id = self.spk2id.__dict__[speaker]\n else:\n LOG.warning(f\"Speaker {speaker} is not found. Use speaker 0 instead.\")\n speaker_id = 0\n speaker_candidates = list(filter(lambda x: x[1] == speaker_id, self.spk2id.__dict__.items()))\n if len(speaker_candidates) > 1:\n raise ValueError(f\"Speaker_id {speaker_id} is not unique. Candidates: {speaker_candidates}\")\n elif len(speaker_candidates) == 0:\n raise ValueError(f\"Speaker_id {speaker_id} is not found.\")\n speaker = speaker_candidates[0][0]\n sid = torch.LongTensor([int(speaker_id)]).to(self.device).unsqueeze(0)\n\n # get unit f0\n c, f0, uv = self.get_unit_f0(audio, transpose, cluster_infer_ratio, speaker, f0_method)\n\n # inference\n with torch.no_grad():\n with timer() as t:\n audio = self.net_g.infer(\n c,\n f0=f0,\n g=sid,\n uv=uv,\n predict_f0=auto_predict_f0,\n noice_scale=noise_scale,\n )[0, 0].data.float()\n audio_duration = audio.shape[-1] / self.target_sample\n LOG.info(f\"Inference time: {t.elapsed:.2f}s, RTF: {t.elapsed / audio_duration:.2f}\")\n torch.cuda.empty_cache()\n return audio, audio.shape[-1]\n\n def infer_silence(\n self,\n audio: np.ndarray[Any, np.dtype[np.float32]],\n *,\n # svc config\n speaker: int | str,\n transpose: int = 0,\n auto_predict_f0: bool = False,\n cluster_infer_ratio: float = 0,\n noise_scale: float = 0.4,\n f0_method: Literal[\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"] = \"dio\",\n # slice config\n db_thresh: int = -40,\n pad_seconds: float = 0.5,\n chunk_seconds: float = 0.5,\n absolute_thresh: bool = False,\n max_chunk_seconds: float = 40,\n # fade_seconds: float = 0.0,\n ) -> np.ndarray[Any, np.dtype[np.float32]]:\n sr = self.target_sample\n result_audio = np.array([], dtype=np.float32)\n chunk_length_min = chunk_length_min = (\n int(\n min(\n sr / so_vits_svc_fork.f0.f0_min * 20 + 1,\n chunk_seconds * sr,\n )\n )\n // 2\n )\n for chunk in split_silence(\n audio,\n top_db=-db_thresh,\n frame_length=chunk_length_min * 2,\n hop_length=chunk_length_min,\n ref=1 if absolute_thresh else np.max,\n max_chunk_length=int(max_chunk_seconds * sr),\n ):\n LOG.info(f\"Chunk: {chunk}\")\n if not chunk.is_speech:\n audio_chunk_infer = np.zeros_like(chunk.audio)\n else:\n # pad\n pad_len = int(sr * pad_seconds)\n audio_chunk_pad = np.concatenate(\n [\n np.zeros([pad_len], dtype=np.float32),\n chunk.audio,\n np.zeros([pad_len], dtype=np.float32),\n ]\n )\n audio_chunk_pad_infer_tensor, _ = self.infer(\n speaker,\n transpose,\n audio_chunk_pad,\n cluster_infer_ratio=cluster_infer_ratio,\n auto_predict_f0=auto_predict_f0,\n noise_scale=noise_scale,\n f0_method=f0_method,\n )\n audio_chunk_pad_infer = audio_chunk_pad_infer_tensor.cpu().numpy()\n pad_len = int(self.target_sample * pad_seconds)\n cut_len_2 = (len(audio_chunk_pad_infer) - len(chunk.audio)) // 2\n audio_chunk_infer = audio_chunk_pad_infer[cut_len_2 : cut_len_2 + len(chunk.audio)]\n\n # add fade\n # fade_len = int(self.target_sample * fade_seconds)\n # _audio[:fade_len] = _audio[:fade_len] * np.linspace(0, 1, fade_len)\n # _audio[-fade_len:] = _audio[-fade_len:] * np.linspace(1, 0, fade_len)\n\n # empty cache\n torch.cuda.empty_cache()\n result_audio = np.concatenate([result_audio, audio_chunk_infer])\n result_audio = result_audio[: audio.shape[0]]\n return result_audio\n\n\ndef sola_crossfade(\n first: ndarray[Any, dtype[float32]],\n second: ndarray[Any, dtype[float32]],\n crossfade_len: int,\n sola_search_len: int,\n) -> ndarray[Any, dtype[float32]]:\n cor_nom = np.convolve(\n second[: sola_search_len + crossfade_len],\n np.flip(first[-crossfade_len:]),\n \"valid\",\n )\n cor_den = np.sqrt(\n np.convolve(\n second[: sola_search_len + crossfade_len] ** 2,\n np.ones(crossfade_len),\n \"valid\",\n )\n + 1e-8\n )\n sola_shift = np.argmax(cor_nom / cor_den)\n LOG.info(f\"SOLA shift: {sola_shift}\")\n second = second[sola_shift : sola_shift + len(second) - sola_search_len]\n return np.concatenate(\n [\n first[:-crossfade_len],\n first[-crossfade_len:] * np.linspace(1, 0, crossfade_len) + second[:crossfade_len] * np.linspace(0, 1, crossfade_len),\n second[crossfade_len:],\n ]\n )\n\n\nclass Crossfader:\n def __init__(\n self,\n *,\n additional_infer_before_len: int,\n additional_infer_after_len: int,\n crossfade_len: int,\n sola_search_len: int = 384,\n ) -> None:\n if additional_infer_before_len < 0:\n raise ValueError(\"additional_infer_len must be >= 0\")\n if crossfade_len < 0:\n raise ValueError(\"crossfade_len must be >= 0\")\n if additional_infer_after_len < 0:\n raise ValueError(\"additional_infer_len must be >= 0\")\n if additional_infer_before_len < 0:\n raise ValueError(\"additional_infer_len must be >= 0\")\n self.additional_infer_before_len = additional_infer_before_len\n self.additional_infer_after_len = additional_infer_after_len\n self.crossfade_len = crossfade_len\n self.sola_search_len = sola_search_len\n self.last_input_left = np.zeros(\n sola_search_len + crossfade_len + additional_infer_before_len + additional_infer_after_len,\n dtype=np.float32,\n )\n self.last_infered_left = np.zeros(crossfade_len, dtype=np.float32)\n\n def process(self, input_audio: ndarray[Any, dtype[float32]], *args, **kwargs: Any) -> ndarray[Any, dtype[float32]]:\n \"\"\"\n Chunks : ■■■■■■□□□□□□\n add last input:□■■■■■■\n ■□□□□□□\n infer :□■■■■■■\n ■□□□□□□\n crossfade :▲■■■■■\n ▲□□□□□\n \"\"\"\n # check input\n if input_audio.ndim != 1:\n raise ValueError(\"Input audio must be 1-dimensional.\")\n if input_audio.shape[0] + self.additional_infer_before_len <= self.crossfade_len:\n raise ValueError(\n f\"Input audio length ({input_audio.shape[0]}) + additional_infer_len ({self.additional_infer_before_len}) must be greater than crossfade_len ({self.crossfade_len}).\"\n )\n input_audio = input_audio.astype(np.float32)\n input_audio_len = len(input_audio)\n\n # concat last input and infer\n input_audio_concat = np.concatenate([self.last_input_left, input_audio])\n del input_audio\n pad_len = 0\n if pad_len:\n infer_audio_concat = self.infer(\n np.pad(input_audio_concat, (pad_len, pad_len), mode=\"reflect\"),\n *args,\n **kwargs,\n )[pad_len:-pad_len]\n else:\n infer_audio_concat = self.infer(input_audio_concat, *args, **kwargs)\n\n # debug SOLA (using copy synthesis with a random shift)\n \"\"\"\n rs = int(np.random.uniform(-200,200))\n LOG.info(f\"Debug random shift: {rs}\")\n infer_audio_concat = np.roll(input_audio_concat, rs)\n \"\"\"\n\n if len(infer_audio_concat) != len(input_audio_concat):\n raise ValueError(f\"Inferred audio length ({len(infer_audio_concat)}) should be equal to input audio length ({len(input_audio_concat)}).\")\n infer_audio_to_use = infer_audio_concat[\n -(self.sola_search_len + self.crossfade_len + input_audio_len + self.additional_infer_after_len) : -self.additional_infer_after_len\n ]\n assert len(infer_audio_to_use) == input_audio_len + self.sola_search_len + self.crossfade_len, (\n f\"{len(infer_audio_to_use)} != {input_audio_len + self.sola_search_len + self.cross_fade_len}\"\n )\n _audio = sola_crossfade(\n self.last_infered_left,\n infer_audio_to_use,\n self.crossfade_len,\n self.sola_search_len,\n )\n result_audio = _audio[: -self.crossfade_len]\n assert len(result_audio) == input_audio_len, f\"{len(result_audio)} != {input_audio_len}\"\n\n # update last input and inferred\n self.last_input_left = input_audio_concat[\n -(self.sola_search_len + self.crossfade_len + self.additional_infer_before_len + self.additional_infer_after_len) :\n ]\n self.last_infered_left = _audio[-self.crossfade_len :]\n return result_audio\n\n def infer(self, input_audio: ndarray[Any, dtype[float32]]) -> ndarray[Any, dtype[float32]]:\n return input_audio\n\n\nclass RealtimeVC(Crossfader):\n def __init__(\n self,\n *,\n svc_model: Svc,\n crossfade_len: int = 3840,\n additional_infer_before_len: int = 7680,\n additional_infer_after_len: int = 7680,\n split: bool = True,\n ) -> None:\n self.svc_model = svc_model\n self.split = split\n super().__init__(\n crossfade_len=crossfade_len,\n additional_infer_before_len=additional_infer_before_len,\n additional_infer_after_len=additional_infer_after_len,\n )\n\n def process(\n self,\n input_audio: ndarray[Any, dtype[float32]],\n *args: Any,\n **kwargs: Any,\n ) -> ndarray[Any, dtype[float32]]:\n return super().process(input_audio, *args, **kwargs)\n\n def infer(\n self,\n input_audio: np.ndarray[Any, np.dtype[np.float32]],\n # svc config\n speaker: int | str,\n transpose: int,\n cluster_infer_ratio: float = 0,\n auto_predict_f0: bool = False,\n noise_scale: float = 0.4,\n f0_method: Literal[\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"] = \"dio\",\n # slice config\n db_thresh: int = -40,\n pad_seconds: float = 0.5,\n chunk_seconds: float = 0.5,\n ) -> ndarray[Any, dtype[float32]]:\n # infer\n if self.split:\n return self.svc_model.infer_silence(\n audio=input_audio,\n speaker=speaker,\n transpose=transpose,\n cluster_infer_ratio=cluster_infer_ratio,\n auto_predict_f0=auto_predict_f0,\n noise_scale=noise_scale,\n f0_method=f0_method,\n db_thresh=db_thresh,\n pad_seconds=pad_seconds,\n chunk_seconds=chunk_seconds,\n absolute_thresh=True,\n )\n else:\n rms = np.sqrt(np.mean(input_audio**2))\n min_rms = 10 ** (db_thresh / 20)\n if rms < min_rms:\n LOG.info(f\"Skip silence: RMS={rms:.2f} < {min_rms:.2f}\")\n return np.zeros_like(input_audio)\n else:\n LOG.info(f\"Start inference: RMS={rms:.2f} >= {min_rms:.2f}\")\n infered_audio_c, _ = self.svc_model.infer(\n speaker=speaker,\n transpose=transpose,\n audio=input_audio,\n cluster_infer_ratio=cluster_infer_ratio,\n auto_predict_f0=auto_predict_f0,\n noise_scale=noise_scale,\n f0_method=f0_method,\n )\n return infered_audio_c.cpu().numpy()\n\n\nclass RealtimeVC2:\n chunk_store: list[Chunk]\n\n def __init__(self, svc_model: Svc) -> None:\n self.input_audio_store = np.array([], dtype=np.float32)\n self.chunk_store = []\n self.svc_model = svc_model\n\n def process(\n self,\n input_audio: np.ndarray[Any, np.dtype[np.float32]],\n # svc config\n speaker: int | str,\n transpose: int,\n cluster_infer_ratio: float = 0,\n auto_predict_f0: bool = False,\n noise_scale: float = 0.4,\n f0_method: Literal[\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"] = \"dio\",\n # slice config\n db_thresh: int = -40,\n chunk_seconds: float = 0.5,\n ) -> ndarray[Any, dtype[float32]]:\n def infer(audio: ndarray[Any, dtype[float32]]) -> ndarray[Any, dtype[float32]]:\n infered_audio_c, _ = self.svc_model.infer(\n speaker=speaker,\n transpose=transpose,\n audio=audio,\n cluster_infer_ratio=cluster_infer_ratio,\n auto_predict_f0=auto_predict_f0,\n noise_scale=noise_scale,\n f0_method=f0_method,\n )\n return infered_audio_c.cpu().numpy()\n\n self.input_audio_store = np.concatenate([self.input_audio_store, input_audio])\n LOG.info(f\"input_audio_store: {self.input_audio_store.shape}\")\n sr = self.svc_model.target_sample\n chunk_length_min = int(min(sr / so_vits_svc_fork.f0.f0_min * 20 + 1, chunk_seconds * sr)) // 2\n LOG.info(f\"Chunk length min: {chunk_length_min}\")\n chunk_list = list(\n split_silence(\n self.input_audio_store,\n -db_thresh,\n frame_length=chunk_length_min * 2,\n hop_length=chunk_length_min,\n ref=1, # use absolute threshold\n )\n )\n assert len(chunk_list) > 0\n LOG.info(f\"Chunk list: {chunk_list}\")\n # do not infer LAST incomplete is_speech chunk and save to store\n if chunk_list[-1].is_speech:\n self.input_audio_store = chunk_list.pop().audio\n else:\n self.input_audio_store = np.array([], dtype=np.float32)\n\n # infer complete is_speech chunk and save to store\n self.chunk_store.extend([attrs.evolve(c, audio=infer(c.audio) if c.is_speech else c.audio) for c in chunk_list])\n\n # calculate lengths and determine compress rate\n total_speech_len = sum([c.duration if c.is_speech else 0 for c in self.chunk_store])\n total_silence_len = sum([c.duration if not c.is_speech else 0 for c in self.chunk_store])\n input_audio_len = input_audio.shape[0]\n silence_compress_rate = total_silence_len / max(0, input_audio_len - total_speech_len)\n LOG.info(f\"Total speech len: {total_speech_len}, silence len: {total_silence_len}, silence compress rate: {silence_compress_rate}\")\n\n # generate output audio\n output_audio = np.array([], dtype=np.float32)\n break_flag = False\n LOG.info(f\"Chunk store: {self.chunk_store}\")\n for chunk in deepcopy(self.chunk_store):\n compress_rate = 1 if chunk.is_speech else silence_compress_rate\n left_len = input_audio_len - output_audio.shape[0]\n # calculate chunk duration\n chunk_duration_output = int(min(chunk.duration / compress_rate, left_len))\n chunk_duration_input = int(min(chunk.duration, left_len * compress_rate))\n LOG.info(f\"Chunk duration output: {chunk_duration_output}, input: {chunk_duration_input}, left len: {left_len}\")\n\n # remove chunk from store\n self.chunk_store.pop(0)\n if chunk.duration > chunk_duration_input:\n left_chunk = attrs.evolve(chunk, audio=chunk.audio[chunk_duration_input:])\n chunk = attrs.evolve(chunk, audio=chunk.audio[:chunk_duration_input])\n\n self.chunk_store.insert(0, left_chunk)\n break_flag = True\n\n if chunk.is_speech:\n # if is_speech, just concat\n output_audio = np.concatenate([output_audio, chunk.audio])\n else:\n # if is_silence, concat with zeros and compress with silence_compress_rate\n output_audio = np.concatenate(\n [\n output_audio,\n np.zeros(\n chunk_duration_output,\n dtype=np.float32,\n ),\n ]\n )\n\n if break_flag:\n break\n LOG.info(f\"Chunk store: {self.chunk_store}, output_audio: {output_audio.shape}\")\n # make same length (errors)\n output_audio = output_audio[:input_audio_len]\n output_audio = np.concatenate(\n [\n output_audio,\n np.zeros(input_audio_len - output_audio.shape[0], dtype=np.float32),\n ]\n )\n return output_audio\n"
},
{
"path": "src/so_vits_svc_fork/inference/main.py",
"content": "from __future__ import annotations\n\nfrom collections.abc import Sequence\nfrom logging import getLogger\nfrom pathlib import Path\nfrom typing import Literal\n\nimport librosa\nimport numpy as np\nimport soundfile\nimport torch\nfrom cm_time import timer\nfrom tqdm import tqdm\n\nfrom so_vits_svc_fork.inference.core import RealtimeVC, RealtimeVC2, Svc\nfrom so_vits_svc_fork.utils import get_optimal_device\n\nLOG = getLogger(__name__)\n\n\ndef infer(\n *,\n # paths\n input_path: Path | str | Sequence[Path | str],\n output_path: Path | str | Sequence[Path | str],\n model_path: Path | str,\n config_path: Path | str,\n recursive: bool = False,\n # svc config\n speaker: int | str,\n cluster_model_path: Path | str | None = None,\n transpose: int = 0,\n auto_predict_f0: bool = False,\n cluster_infer_ratio: float = 0,\n noise_scale: float = 0.4,\n f0_method: Literal[\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"] = \"dio\",\n # slice config\n db_thresh: int = -40,\n pad_seconds: float = 0.5,\n chunk_seconds: float = 0.5,\n absolute_thresh: bool = False,\n max_chunk_seconds: float = 40,\n device: str | torch.device = get_optimal_device(),\n):\n if isinstance(input_path, (str, Path)):\n input_path = [input_path]\n if isinstance(output_path, (str, Path)):\n output_path = [output_path]\n if len(input_path) != len(output_path):\n raise ValueError(f\"input_path and output_path must have same length, but got {len(input_path)} and {len(output_path)}\")\n\n model_path = Path(model_path)\n config_path = Path(config_path)\n output_path = [Path(p) for p in output_path]\n input_path = [Path(p) for p in input_path]\n output_paths = []\n input_paths = []\n\n for input_path, output_path in zip(input_path, output_path):\n if input_path.is_dir():\n if not recursive:\n raise ValueError(f\"input_path is a directory, but recursive is False: {input_path}\")\n input_paths.extend(list(input_path.rglob(\"*.*\")))\n output_paths.extend([output_path / p.relative_to(input_path) for p in input_paths])\n continue\n input_paths.append(input_path)\n output_paths.append(output_path)\n\n cluster_model_path = Path(cluster_model_path) if cluster_model_path else None\n svc_model = Svc(\n net_g_path=model_path.as_posix(),\n config_path=config_path.as_posix(),\n cluster_model_path=(cluster_model_path.as_posix() if cluster_model_path else None),\n device=device,\n )\n\n try:\n pbar = tqdm(list(zip(input_paths, output_paths)), disable=len(input_paths) == 1)\n for input_path, output_path in pbar:\n pbar.set_description(f\"{input_path}\")\n try:\n audio, _ = librosa.load(str(input_path), sr=svc_model.target_sample)\n except Exception as e:\n LOG.error(f\"Failed to load {input_path}\")\n LOG.exception(e)\n continue\n output_path.parent.mkdir(parents=True, exist_ok=True)\n audio = svc_model.infer_silence(\n audio.astype(np.float32),\n speaker=speaker,\n transpose=transpose,\n auto_predict_f0=auto_predict_f0,\n cluster_infer_ratio=cluster_infer_ratio,\n noise_scale=noise_scale,\n f0_method=f0_method,\n db_thresh=db_thresh,\n pad_seconds=pad_seconds,\n chunk_seconds=chunk_seconds,\n absolute_thresh=absolute_thresh,\n max_chunk_seconds=max_chunk_seconds,\n )\n soundfile.write(str(output_path), audio, svc_model.target_sample)\n finally:\n del svc_model\n torch.cuda.empty_cache()\n\n\ndef realtime(\n *,\n # paths\n model_path: Path | str,\n config_path: Path | str,\n # svc config\n speaker: str,\n cluster_model_path: Path | str | None = None,\n transpose: int = 0,\n auto_predict_f0: bool = False,\n cluster_infer_ratio: float = 0,\n noise_scale: float = 0.4,\n f0_method: Literal[\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"] = \"dio\",\n # slice config\n db_thresh: int = -40,\n pad_seconds: float = 0.5,\n chunk_seconds: float = 0.5,\n # realtime config\n crossfade_seconds: float = 0.05,\n additional_infer_before_seconds: float = 0.2,\n additional_infer_after_seconds: float = 0.1,\n block_seconds: float = 0.5,\n version: int = 2,\n input_device: int | str | None = None,\n output_device: int | str | None = None,\n device: str | torch.device = get_optimal_device(),\n passthrough_original: bool = False,\n):\n import sounddevice as sd\n\n model_path = Path(model_path)\n config_path = Path(config_path)\n cluster_model_path = Path(cluster_model_path) if cluster_model_path else None\n svc_model = Svc(\n net_g_path=model_path.as_posix(),\n config_path=config_path.as_posix(),\n cluster_model_path=(cluster_model_path.as_posix() if cluster_model_path else None),\n device=device,\n )\n\n LOG.info(\"Creating realtime model...\")\n if version == 1:\n model = RealtimeVC(\n svc_model=svc_model,\n crossfade_len=int(crossfade_seconds * svc_model.target_sample),\n additional_infer_before_len=int(additional_infer_before_seconds * svc_model.target_sample),\n additional_infer_after_len=int(additional_infer_after_seconds * svc_model.target_sample),\n )\n else:\n model = RealtimeVC2(\n svc_model=svc_model,\n )\n\n # LOG all device info\n devices = sd.query_devices()\n LOG.info(f\"Device: {devices}\")\n if isinstance(input_device, str):\n input_device_candidates = [i for i, d in enumerate(devices) if d[\"name\"] == input_device]\n if len(input_device_candidates) == 0:\n LOG.warning(f\"Input device {input_device} not found, using default\")\n input_device = None\n else:\n input_device = input_device_candidates[0]\n if isinstance(output_device, str):\n output_device_candidates = [i for i, d in enumerate(devices) if d[\"name\"] == output_device]\n if len(output_device_candidates) == 0:\n LOG.warning(f\"Output device {output_device} not found, using default\")\n output_device = None\n else:\n output_device = output_device_candidates[0]\n if input_device is None or input_device >= len(devices):\n input_device = sd.default.device[0]\n if output_device is None or output_device >= len(devices):\n output_device = sd.default.device[1]\n LOG.info(f\"Input Device: {devices[input_device]['name']}, Output Device: {devices[output_device]['name']}\")\n\n # the model RTL is somewhat significantly high only in the first inference\n # there could be no better way to warm up the model than to do a dummy inference\n # (there are not differences in the behavior of the model between the first and the later inferences)\n # so we do a dummy inference to warm up the model (1 second of audio)\n LOG.info(\"Warming up the model...\")\n svc_model.infer(\n speaker=speaker,\n transpose=transpose,\n auto_predict_f0=auto_predict_f0,\n cluster_infer_ratio=cluster_infer_ratio,\n noise_scale=noise_scale,\n f0_method=f0_method,\n audio=np.zeros(svc_model.target_sample, dtype=np.float32),\n )\n\n def callback(\n indata: np.ndarray,\n outdata: np.ndarray,\n frames: int,\n time: int,\n status: sd.CallbackFlags,\n ) -> None:\n LOG.debug(f\"Frames: {frames}, Status: {status}, Shape: {indata.shape}, Time: {time}\")\n\n kwargs = dict(\n input_audio=indata.mean(axis=1).astype(np.float32),\n # svc config\n speaker=speaker,\n transpose=transpose,\n auto_predict_f0=auto_predict_f0,\n cluster_infer_ratio=cluster_infer_ratio,\n noise_scale=noise_scale,\n f0_method=f0_method,\n # slice config\n db_thresh=db_thresh,\n # pad_seconds=pad_seconds,\n chunk_seconds=chunk_seconds,\n )\n if version == 1:\n kwargs[\"pad_seconds\"] = pad_seconds\n with timer() as t:\n inference = model.process(\n **kwargs,\n ).reshape(-1, 1)\n if passthrough_original:\n outdata[:] = (indata + inference) / 2\n else:\n outdata[:] = inference\n rtf = t.elapsed / block_seconds\n LOG.info(f\"Realtime inference time: {t.elapsed:.3f}s, RTF: {rtf:.3f}\")\n if rtf > 1:\n LOG.warning(\"RTF is too high, consider increasing block_seconds\")\n\n try:\n with sd.Stream(\n device=(input_device, output_device),\n channels=1,\n callback=callback,\n samplerate=svc_model.target_sample,\n blocksize=int(block_seconds * svc_model.target_sample),\n latency=\"low\",\n ) as stream:\n LOG.info(f\"Latency: {stream.latency}\")\n while True:\n sd.sleep(1000)\n finally:\n # del model, svc_model\n torch.cuda.empty_cache()\n"
},
{
"path": "src/so_vits_svc_fork/logger.py",
"content": "import os\nimport sys\nfrom logging import DEBUG, INFO, StreamHandler, basicConfig, captureWarnings, getLogger\nfrom pathlib import Path\n\nfrom rich.logging import RichHandler\n\nLOGGER_INIT = False\n\n\ndef init_logger() -> None:\n global LOGGER_INIT\n if LOGGER_INIT:\n return\n\n IS_TEST = \"test\" in Path.cwd().stem\n package_name = sys.modules[__name__].__package__\n basicConfig(\n level=INFO,\n format=\"%(asctime)s %(message)s\",\n datefmt=\"[%X]\",\n handlers=[\n StreamHandler() if is_notebook() else RichHandler(),\n # FileHandler(f\"{package_name}.log\"),\n ],\n )\n if IS_TEST:\n getLogger(package_name).setLevel(DEBUG)\n captureWarnings(True)\n LOGGER_INIT = True\n\n\ndef is_notebook():\n try:\n from IPython import get_ipython\n\n if \"IPKernelApp\" not in get_ipython().config: # pragma: no cover\n raise ImportError(\"console\")\n return False\n if \"VSCODE_PID\" in os.environ: # pragma: no cover\n raise ImportError(\"vscode\")\n return False\n except Exception:\n return False\n else: # pragma: no cover\n return True\n"
},
{
"path": "src/so_vits_svc_fork/modules/__init__.py",
"content": ""
},
{
"path": "src/so_vits_svc_fork/modules/attentions.py",
"content": "import math\n\nimport torch\nfrom torch import nn\nfrom torch.nn import functional as F\n\nfrom so_vits_svc_fork.modules import commons\nfrom so_vits_svc_fork.modules.modules import LayerNorm\n\n\nclass FFT(nn.Module):\n def __init__(\n self,\n hidden_channels,\n filter_channels,\n n_heads,\n n_layers=1,\n kernel_size=1,\n p_dropout=0.0,\n proximal_bias=False,\n proximal_init=True,\n **kwargs,\n ):\n super().__init__()\n self.hidden_channels = hidden_channels\n self.filter_channels = filter_channels\n self.n_heads = n_heads\n self.n_layers = n_layers\n self.kernel_size = kernel_size\n self.p_dropout = p_dropout\n self.proximal_bias = proximal_bias\n self.proximal_init = proximal_init\n\n self.drop = nn.Dropout(p_dropout)\n self.self_attn_layers = nn.ModuleList()\n self.norm_layers_0 = nn.ModuleList()\n self.ffn_layers = nn.ModuleList()\n self.norm_layers_1 = nn.ModuleList()\n for i in range(self.n_layers):\n self.self_attn_layers.append(\n MultiHeadAttention(\n hidden_channels,\n hidden_channels,\n n_heads,\n p_dropout=p_dropout,\n proximal_bias=proximal_bias,\n proximal_init=proximal_init,\n )\n )\n self.norm_layers_0.append(LayerNorm(hidden_channels))\n self.ffn_layers.append(\n FFN(\n hidden_channels,\n hidden_channels,\n filter_channels,\n kernel_size,\n p_dropout=p_dropout,\n causal=True,\n )\n )\n self.norm_layers_1.append(LayerNorm(hidden_channels))\n\n def forward(self, x, x_mask):\n \"\"\"\n x: decoder input\n h: encoder output\n \"\"\"\n self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(device=x.device, dtype=x.dtype)\n x = x * x_mask\n for i in range(self.n_layers):\n y = self.self_attn_layers[i](x, x, self_attn_mask)\n y = self.drop(y)\n x = self.norm_layers_0[i](x + y)\n\n y = self.ffn_layers[i](x, x_mask)\n y = self.drop(y)\n x = self.norm_layers_1[i](x + y)\n x = x * x_mask\n return x\n\n\nclass Encoder(nn.Module):\n def __init__(\n self,\n hidden_channels,\n filter_channels,\n n_heads,\n n_layers,\n kernel_size=1,\n p_dropout=0.0,\n window_size=4,\n **kwargs,\n ):\n super().__init__()\n self.hidden_channels = hidden_channels\n self.filter_channels = filter_channels\n self.n_heads = n_heads\n self.n_layers = n_layers\n self.kernel_size = kernel_size\n self.p_dropout = p_dropout\n self.window_size = window_size\n\n self.drop = nn.Dropout(p_dropout)\n self.attn_layers = nn.ModuleList()\n self.norm_layers_1 = nn.ModuleList()\n self.ffn_layers = nn.ModuleList()\n self.norm_layers_2 = nn.ModuleList()\n for i in range(self.n_layers):\n self.attn_layers.append(\n MultiHeadAttention(\n hidden_channels,\n hidden_channels,\n n_heads,\n p_dropout=p_dropout,\n window_size=window_size,\n )\n )\n self.norm_layers_1.append(LayerNorm(hidden_channels))\n self.ffn_layers.append(\n FFN(\n hidden_channels,\n hidden_channels,\n filter_channels,\n kernel_size,\n p_dropout=p_dropout,\n )\n )\n self.norm_layers_2.append(LayerNorm(hidden_channels))\n\n def forward(self, x, x_mask):\n attn_mask = x_mask.unsqueeze(2) * x_mask.unsqueeze(-1)\n x = x * x_mask\n for i in range(self.n_layers):\n y = self.attn_layers[i](x, x, attn_mask)\n y = self.drop(y)\n x = self.norm_layers_1[i](x + y)\n\n y = self.ffn_layers[i](x, x_mask)\n y = self.drop(y)\n x = self.norm_layers_2[i](x + y)\n x = x * x_mask\n return x\n\n\nclass Decoder(nn.Module):\n def __init__(\n self,\n hidden_channels,\n filter_channels,\n n_heads,\n n_layers,\n kernel_size=1,\n p_dropout=0.0,\n proximal_bias=False,\n proximal_init=True,\n **kwargs,\n ):\n super().__init__()\n self.hidden_channels = hidden_channels\n self.filter_channels = filter_channels\n self.n_heads = n_heads\n self.n_layers = n_layers\n self.kernel_size = kernel_size\n self.p_dropout = p_dropout\n self.proximal_bias = proximal_bias\n self.proximal_init = proximal_init\n\n self.drop = nn.Dropout(p_dropout)\n self.self_attn_layers = nn.ModuleList()\n self.norm_layers_0 = nn.ModuleList()\n self.encdec_attn_layers = nn.ModuleList()\n self.norm_layers_1 = nn.ModuleList()\n self.ffn_layers = nn.ModuleList()\n self.norm_layers_2 = nn.ModuleList()\n for i in range(self.n_layers):\n self.self_attn_layers.append(\n MultiHeadAttention(\n hidden_channels,\n hidden_channels,\n n_heads,\n p_dropout=p_dropout,\n proximal_bias=proximal_bias,\n proximal_init=proximal_init,\n )\n )\n self.norm_layers_0.append(LayerNorm(hidden_channels))\n self.encdec_attn_layers.append(MultiHeadAttention(hidden_channels, hidden_channels, n_heads, p_dropout=p_dropout))\n self.norm_layers_1.append(LayerNorm(hidden_channels))\n self.ffn_layers.append(\n FFN(\n hidden_channels,\n hidden_channels,\n filter_channels,\n kernel_size,\n p_dropout=p_dropout,\n causal=True,\n )\n )\n self.norm_layers_2.append(LayerNorm(hidden_channels))\n\n def forward(self, x, x_mask, h, h_mask):\n \"\"\"\n x: decoder input\n h: encoder output\n \"\"\"\n self_attn_mask = commons.subsequent_mask(x_mask.size(2)).to(device=x.device, dtype=x.dtype)\n encdec_attn_mask = h_mask.unsqueeze(2) * x_mask.unsqueeze(-1)\n x = x * x_mask\n for i in range(self.n_layers):\n y = self.self_attn_layers[i](x, x, self_attn_mask)\n y = self.drop(y)\n x = self.norm_layers_0[i](x + y)\n\n y = self.encdec_attn_layers[i](x, h, encdec_attn_mask)\n y = self.drop(y)\n x = self.norm_layers_1[i](x + y)\n\n y = self.ffn_layers[i](x, x_mask)\n y = self.drop(y)\n x = self.norm_layers_2[i](x + y)\n x = x * x_mask\n return x\n\n\nclass MultiHeadAttention(nn.Module):\n def __init__(\n self,\n channels,\n out_channels,\n n_heads,\n p_dropout=0.0,\n window_size=None,\n heads_share=True,\n block_length=None,\n proximal_bias=False,\n proximal_init=False,\n ):\n super().__init__()\n assert channels % n_heads == 0\n\n self.channels = channels\n self.out_channels = out_channels\n self.n_heads = n_heads\n self.p_dropout = p_dropout\n self.window_size = window_size\n self.heads_share = heads_share\n self.block_length = block_length\n self.proximal_bias = proximal_bias\n self.proximal_init = proximal_init\n self.attn = None\n\n self.k_channels = channels // n_heads\n self.conv_q = nn.Conv1d(channels, channels, 1)\n self.conv_k = nn.Conv1d(channels, channels, 1)\n self.conv_v = nn.Conv1d(channels, channels, 1)\n self.conv_o = nn.Conv1d(channels, out_channels, 1)\n self.drop = nn.Dropout(p_dropout)\n\n if window_size is not None:\n n_heads_rel = 1 if heads_share else n_heads\n rel_stddev = self.k_channels**-0.5\n self.emb_rel_k = nn.Parameter(torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) * rel_stddev)\n self.emb_rel_v = nn.Parameter(torch.randn(n_heads_rel, window_size * 2 + 1, self.k_channels) * rel_stddev)\n\n nn.init.xavier_uniform_(self.conv_q.weight)\n nn.init.xavier_uniform_(self.conv_k.weight)\n nn.init.xavier_uniform_(self.conv_v.weight)\n if proximal_init:\n with torch.no_grad():\n self.conv_k.weight.copy_(self.conv_q.weight)\n self.conv_k.bias.copy_(self.conv_q.bias)\n\n def forward(self, x, c, attn_mask=None):\n q = self.conv_q(x)\n k = self.conv_k(c)\n v = self.conv_v(c)\n\n x, self.attn = self.attention(q, k, v, mask=attn_mask)\n\n x = self.conv_o(x)\n return x\n\n def attention(self, query, key, value, mask=None):\n # reshape [b, d, t] -> [b, n_h, t, d_k]\n b, d, t_s, t_t = (*key.size(), query.size(2))\n query = query.view(b, self.n_heads, self.k_channels, t_t).transpose(2, 3)\n key = key.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)\n value = value.view(b, self.n_heads, self.k_channels, t_s).transpose(2, 3)\n\n scores = torch.matmul(query / math.sqrt(self.k_channels), key.transpose(-2, -1))\n if self.window_size is not None:\n assert t_s == t_t, \"Relative attention is only available for self-attention.\"\n key_relative_embeddings = self._get_relative_embeddings(self.emb_rel_k, t_s)\n rel_logits = self._matmul_with_relative_keys(query / math.sqrt(self.k_channels), key_relative_embeddings)\n scores_local = self._relative_position_to_absolute_position(rel_logits)\n scores = scores + scores_local\n if self.proximal_bias:\n assert t_s == t_t, \"Proximal bias is only available for self-attention.\"\n scores = scores + self._attention_bias_proximal(t_s).to(device=scores.device, dtype=scores.dtype)\n if mask is not None:\n scores = scores.masked_fill(mask == 0, -1e4)\n if self.block_length is not None:\n assert t_s == t_t, \"Local attention is only available for self-attention.\"\n block_mask = torch.ones_like(scores).triu(-self.block_length).tril(self.block_length)\n scores = scores.masked_fill(block_mask == 0, -1e4)\n p_attn = F.softmax(scores, dim=-1) # [b, n_h, t_t, t_s]\n p_attn = self.drop(p_attn)\n output = torch.matmul(p_attn, value)\n if self.window_size is not None:\n relative_weights = self._absolute_position_to_relative_position(p_attn)\n value_relative_embeddings = self._get_relative_embeddings(self.emb_rel_v, t_s)\n output = output + self._matmul_with_relative_values(relative_weights, value_relative_embeddings)\n output = output.transpose(2, 3).contiguous().view(b, d, t_t) # [b, n_h, t_t, d_k] -> [b, d, t_t]\n return output, p_attn\n\n def _matmul_with_relative_values(self, x, y):\n \"\"\"\n x: [b, h, l, m]\n y: [h or 1, m, d]\n ret: [b, h, l, d]\n \"\"\"\n ret = torch.matmul(x, y.unsqueeze(0))\n return ret\n\n def _matmul_with_relative_keys(self, x, y):\n \"\"\"\n x: [b, h, l, d]\n y: [h or 1, m, d]\n ret: [b, h, l, m]\n \"\"\"\n ret = torch.matmul(x, y.unsqueeze(0).transpose(-2, -1))\n return ret\n\n def _get_relative_embeddings(self, relative_embeddings, length):\n 2 * self.window_size + 1\n # Pad first before slice to avoid using cond ops.\n pad_length = max(length - (self.window_size + 1), 0)\n slice_start_position = max((self.window_size + 1) - length, 0)\n slice_end_position = slice_start_position + 2 * length - 1\n if pad_length > 0:\n padded_relative_embeddings = F.pad(\n relative_embeddings,\n commons.convert_pad_shape([[0, 0], [pad_length, pad_length], [0, 0]]),\n )\n else:\n padded_relative_embeddings = relative_embeddings\n used_relative_embeddings = padded_relative_embeddings[:, slice_start_position:slice_end_position]\n return used_relative_embeddings\n\n def _relative_position_to_absolute_position(self, x):\n \"\"\"\n x: [b, h, l, 2*l-1]\n ret: [b, h, l, l]\n \"\"\"\n batch, heads, length, _ = x.size()\n # Concat columns of pad to shift from relative to absolute indexing.\n x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, 1]]))\n\n # Concat extra elements so to add up to shape (len+1, 2*len-1).\n x_flat = x.view([batch, heads, length * 2 * length])\n x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [0, length - 1]]))\n\n # Reshape and slice out the padded elements.\n x_final = x_flat.view([batch, heads, length + 1, 2 * length - 1])[:, :, :length, length - 1 :]\n return x_final\n\n def _absolute_position_to_relative_position(self, x):\n \"\"\"\n x: [b, h, l, l]\n ret: [b, h, l, 2*l-1]\n \"\"\"\n batch, heads, length, _ = x.size()\n # pad along column\n x = F.pad(x, commons.convert_pad_shape([[0, 0], [0, 0], [0, 0], [0, length - 1]]))\n x_flat = x.view([batch, heads, length**2 + length * (length - 1)])\n # add 0's in the beginning that will skew the elements after reshape\n x_flat = F.pad(x_flat, commons.convert_pad_shape([[0, 0], [0, 0], [length, 0]]))\n x_final = x_flat.view([batch, heads, length, 2 * length])[:, :, :, 1:]\n return x_final\n\n def _attention_bias_proximal(self, length):\n \"\"\"\n Bias for self-attention to encourage attention to close positions.\n\n Args:\n length: an integer scalar.\n\n Returns:\n a Tensor with shape [1, 1, length, length]\n\n \"\"\"\n r = torch.arange(length, dtype=torch.float32)\n diff = torch.unsqueeze(r, 0) - torch.unsqueeze(r, 1)\n return torch.unsqueeze(torch.unsqueeze(-torch.log1p(torch.abs(diff)), 0), 0)\n\n\nclass FFN(nn.Module):\n def __init__(\n self,\n in_channels,\n out_channels,\n filter_channels,\n kernel_size,\n p_dropout=0.0,\n activation=None,\n causal=False,\n ):\n super().__init__()\n self.in_channels = in_channels\n self.out_channels = out_channels\n self.filter_channels = filter_channels\n self.kernel_size = kernel_size\n self.p_dropout = p_dropout\n self.activation = activation\n self.causal = causal\n\n if causal:\n self.padding = self._causal_padding\n else:\n self.padding = self._same_padding\n\n self.conv_1 = nn.Conv1d(in_channels, filter_channels, kernel_size)\n self.conv_2 = nn.Conv1d(filter_channels, out_channels, kernel_size)\n self.drop = nn.Dropout(p_dropout)\n\n def forward(self, x, x_mask):\n x = self.conv_1(self.padding(x * x_mask))\n if self.activation == \"gelu\":\n x = x * torch.sigmoid(1.702 * x)\n else:\n x = torch.relu(x)\n x = self.drop(x)\n x = self.conv_2(self.padding(x * x_mask))\n return x * x_mask\n\n def _causal_padding(self, x):\n if self.kernel_size == 1:\n return x\n pad_l = self.kernel_size - 1\n pad_r = 0\n padding = [[0, 0], [0, 0], [pad_l, pad_r]]\n x = F.pad(x, commons.convert_pad_shape(padding))\n return x\n\n def _same_padding(self, x):\n if self.kernel_size == 1:\n return x\n pad_l = (self.kernel_size - 1) // 2\n pad_r = self.kernel_size // 2\n padding = [[0, 0], [0, 0], [pad_l, pad_r]]\n x = F.pad(x, commons.convert_pad_shape(padding))\n return x\n"
},
{
"path": "src/so_vits_svc_fork/modules/commons.py",
"content": "from __future__ import annotations\n\nimport torch\nimport torch.nn.functional as F\nfrom torch import Tensor\n\n\ndef slice_segments(x: Tensor, starts: Tensor, length: int) -> Tensor:\n if length is None:\n return x\n length = min(length, x.size(-1))\n x_slice = torch.zeros((x.size()[:-1] + (length,)), dtype=x.dtype, device=x.device)\n ends = starts + length\n for i, (start, end) in enumerate(zip(starts, ends)):\n # LOG.debug(i, start, end, x.size(), x[i, ..., start:end].size(), x_slice.size())\n # x_slice[i, ...] = x[i, ..., start:end] need to pad\n # x_slice[i, ..., :end - start] = x[i, ..., start:end] this does not work\n x_slice[i, ...] = F.pad(x[i, ..., start:end], (0, max(0, length - x.size(-1))))\n return x_slice\n\n\ndef rand_slice_segments_with_pitch(x: Tensor, f0: Tensor, x_lengths: Tensor | int | None, segment_size: int | None):\n if segment_size is None:\n return x, f0, torch.arange(x.size(0), device=x.device)\n if x_lengths is None:\n x_lengths = x.size(-1) * torch.ones(x.size(0), dtype=torch.long, device=x.device)\n # slice_starts = (torch.rand(z.size(0), device=z.device) * (z_lengths - segment_size)).long()\n slice_starts = (torch.rand(x.size(0), device=x.device) * torch.max(x_lengths - segment_size, torch.zeros_like(x_lengths, device=x.device))).long()\n z_slice = slice_segments(x, slice_starts, segment_size)\n f0_slice = slice_segments(f0, slice_starts, segment_size)\n return z_slice, f0_slice, slice_starts\n\n\ndef slice_2d_segments(x: Tensor, starts: Tensor, length: int) -> Tensor:\n batch_size, num_features, seq_len = x.shape\n ends = starts + length\n idxs = torch.arange(seq_len, device=x.device).unsqueeze(0).unsqueeze(1).repeat(batch_size, num_features, 1)\n mask = (idxs >= starts.unsqueeze(-1).unsqueeze(-1)) & (idxs < ends.unsqueeze(-1).unsqueeze(-1))\n return x[mask].reshape(batch_size, num_features, length)\n\n\ndef slice_1d_segments(x: Tensor, starts: Tensor, length: int) -> Tensor:\n batch_size, seq_len = x.shape\n ends = starts + length\n idxs = torch.arange(seq_len, device=x.device).unsqueeze(0).repeat(batch_size, 1)\n mask = (idxs >= starts.unsqueeze(-1)) & (idxs < ends.unsqueeze(-1))\n return x[mask].reshape(batch_size, length)\n\n\ndef _slice_segments_v3(x: Tensor, starts: Tensor, length: int) -> Tensor:\n shape = x.shape[:-1] + (length,)\n ends = starts + length\n idxs = torch.arange(x.shape[-1], device=x.device).unsqueeze(0).unsqueeze(0)\n unsqueeze_dims = len(shape) - len(x.shape) # calculate number of dimensions to unsqueeze\n starts = starts.reshape(starts.shape + (1,) * unsqueeze_dims)\n ends = ends.reshape(ends.shape + (1,) * unsqueeze_dims)\n mask = (idxs >= starts) & (idxs < ends)\n return x[mask].reshape(shape)\n\n\ndef init_weights(m, mean=0.0, std=0.01):\n classname = m.__class__.__name__\n if classname.find(\"Conv\") != -1:\n m.weight.data.normal_(mean, std)\n\n\ndef get_padding(kernel_size, dilation=1):\n return int((kernel_size * dilation - dilation) / 2)\n\n\ndef convert_pad_shape(pad_shape):\n l = pad_shape[::-1]\n pad_shape = [item for sublist in l for item in sublist]\n return pad_shape\n\n\ndef subsequent_mask(length):\n mask = torch.tril(torch.ones(length, length)).unsqueeze(0).unsqueeze(0)\n return mask\n\n\n@torch.jit.script\ndef fused_add_tanh_sigmoid_multiply(input_a, input_b, n_channels):\n n_channels_int = n_channels[0]\n in_act = input_a + input_b\n t_act = torch.tanh(in_act[:, :n_channels_int, :])\n s_act = torch.sigmoid(in_act[:, n_channels_int:, :])\n acts = t_act * s_act\n return acts\n\n\ndef sequence_mask(length, max_length=None):\n if max_length is None:\n max_length = length.max()\n x = torch.arange(max_length, dtype=length.dtype, device=length.device)\n return x.unsqueeze(0) < length.unsqueeze(1)\n\n\ndef clip_grad_value_(parameters, clip_value, norm_type=2):\n if isinstance(parameters, torch.Tensor):\n parameters = [parameters]\n parameters = list(filter(lambda p: p.grad is not None, parameters))\n norm_type = float(norm_type)\n if clip_value is not None:\n clip_value = float(clip_value)\n\n total_norm = 0\n for p in parameters:\n param_norm = p.grad.data.norm(norm_type)\n total_norm += param_norm.item() ** norm_type\n if clip_value is not None:\n p.grad.data.clamp_(min=-clip_value, max=clip_value)\n total_norm = total_norm ** (1.0 / norm_type)\n return total_norm\n"
},
{
"path": "src/so_vits_svc_fork/modules/decoders/__init__.py",
"content": ""
},
{
"path": "src/so_vits_svc_fork/modules/decoders/f0.py",
"content": "import torch\nfrom torch import nn\n\nfrom so_vits_svc_fork.modules import attentions as attentions\n\n\nclass F0Decoder(nn.Module):\n def __init__(\n self,\n out_channels,\n hidden_channels,\n filter_channels,\n n_heads,\n n_layers,\n kernel_size,\n p_dropout,\n spk_channels=0,\n ):\n super().__init__()\n self.out_channels = out_channels\n self.hidden_channels = hidden_channels\n self.filter_channels = filter_channels\n self.n_heads = n_heads\n self.n_layers = n_layers\n self.kernel_size = kernel_size\n self.p_dropout = p_dropout\n self.spk_channels = spk_channels\n\n self.prenet = nn.Conv1d(hidden_channels, hidden_channels, 3, padding=1)\n self.decoder = attentions.FFT(hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout)\n self.proj = nn.Conv1d(hidden_channels, out_channels, 1)\n self.f0_prenet = nn.Conv1d(1, hidden_channels, 3, padding=1)\n self.cond = nn.Conv1d(spk_channels, hidden_channels, 1)\n\n def forward(self, x, norm_f0, x_mask, spk_emb=None):\n x = torch.detach(x)\n if spk_emb is not None:\n spk_emb = torch.detach(spk_emb)\n x = x + self.cond(spk_emb)\n x += self.f0_prenet(norm_f0)\n x = self.prenet(x) * x_mask\n x = self.decoder(x * x_mask, x_mask)\n x = self.proj(x) * x_mask\n return x\n"
},
{
"path": "src/so_vits_svc_fork/modules/decoders/hifigan/__init__.py",
"content": "from ._models import NSFHifiGANGenerator\n\n__all__ = [\"NSFHifiGANGenerator\"]\n"
},
{
"path": "src/so_vits_svc_fork/modules/decoders/hifigan/_models.py",
"content": "from logging import getLogger\n\nimport numpy as np\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nfrom torch.nn import Conv1d, ConvTranspose1d\nfrom torch.nn.utils import remove_weight_norm, weight_norm\n\nfrom ...modules import ResBlock1, ResBlock2\nfrom ._utils import init_weights\n\nLOG = getLogger(__name__)\n\nLRELU_SLOPE = 0.1\n\n\ndef padDiff(x):\n return F.pad(F.pad(x, (0, 0, -1, 1), \"constant\", 0) - x, (0, 0, 0, -1), \"constant\", 0)\n\n\nclass SineGen(torch.nn.Module):\n \"\"\"\n Definition of sine generator\n SineGen(samp_rate, harmonic_num = 0,\n sine_amp = 0.1, noise_std = 0.003,\n voiced_threshold = 0,\n flag_for_pulse=False)\n samp_rate: sampling rate in Hz\n harmonic_num: number of harmonic overtones (default 0)\n sine_amp: amplitude of sine-wavefrom (default 0.1)\n noise_std: std of Gaussian noise (default 0.003)\n voiced_thoreshold: F0 threshold for U/V classification (default 0)\n flag_for_pulse: this SinGen is used inside PulseGen (default False)\n Note: when flag_for_pulse is True, the first time step of a voiced\n segment is always sin(np.pi) or cos(0)\n \"\"\"\n\n def __init__(\n self,\n samp_rate,\n harmonic_num=0,\n sine_amp=0.1,\n noise_std=0.003,\n voiced_threshold=0,\n flag_for_pulse=False,\n ):\n super().__init__()\n self.sine_amp = sine_amp\n self.noise_std = noise_std\n self.harmonic_num = harmonic_num\n self.dim = self.harmonic_num + 1\n self.sampling_rate = samp_rate\n self.voiced_threshold = voiced_threshold\n self.flag_for_pulse = flag_for_pulse\n\n def _f02uv(self, f0):\n # generate uv signal\n uv = (f0 > self.voiced_threshold).type(torch.float32)\n return uv\n\n def _f02sine(self, f0_values):\n \"\"\"\n f0_values: (batchsize, length, dim)\n where dim indicates fundamental tone and overtones\n \"\"\"\n # convert to F0 in rad. The integer part n can be ignored\n # because 2 * np.pi * n doesn't affect phase\n rad_values = (f0_values / self.sampling_rate) % 1\n\n # initial phase noise (no noise for fundamental component)\n rand_ini = torch.rand(f0_values.shape[0], f0_values.shape[2], device=f0_values.device)\n rand_ini[:, 0] = 0\n rad_values[:, 0, :] = rad_values[:, 0, :] + rand_ini\n\n # instantanouse phase sine[t] = sin(2*pi \\sum_i=1 ^{t} rad)\n if not self.flag_for_pulse:\n # for normal case\n\n # To prevent torch.cumsum numerical overflow,\n # it is necessary to add -1 whenever \\sum_k=1^n rad_value_k > 1.\n # Buffer tmp_over_one_idx indicates the time step to add -1.\n # This will not change F0 of sine because (x-1) * 2*pi = x * 2*pi\n tmp_over_one = torch.cumsum(rad_values, 1) % 1\n tmp_over_one_idx = (padDiff(tmp_over_one)) < 0\n cumsum_shift = torch.zeros_like(rad_values)\n cumsum_shift[:, 1:, :] = tmp_over_one_idx * -1.0\n\n sines = torch.sin(torch.cumsum(rad_values + cumsum_shift, dim=1) * 2 * np.pi)\n else:\n # If necessary, make sure that the first time step of every\n # voiced segments is sin(pi) or cos(0)\n # This is used for pulse-train generation\n\n # identify the last time step in unvoiced segments\n uv = self._f02uv(f0_values)\n uv_1 = torch.roll(uv, shifts=-1, dims=1)\n uv_1[:, -1, :] = 1\n u_loc = (uv < 1) * (uv_1 > 0)\n\n # get the instantanouse phase\n tmp_cumsum = torch.cumsum(rad_values, dim=1)\n # different batch needs to be processed differently\n for idx in range(f0_values.shape[0]):\n temp_sum = tmp_cumsum[idx, u_loc[idx, :, 0], :]\n temp_sum[1:, :] = temp_sum[1:, :] - temp_sum[0:-1, :]\n # stores the accumulation of i.phase within\n # each voiced segments\n tmp_cumsum[idx, :, :] = 0\n tmp_cumsum[idx, u_loc[idx, :, 0], :] = temp_sum\n\n # rad_values - tmp_cumsum: remove the accumulation of i.phase\n # within the previous voiced segment.\n i_phase = torch.cumsum(rad_values - tmp_cumsum, dim=1)\n\n # get the sines\n sines = torch.cos(i_phase * 2 * np.pi)\n return sines\n\n def forward(self, f0):\n \"\"\"\n sine_tensor, uv = forward(f0)\n input F0: tensor(batchsize=1, length, dim=1)\n f0 for unvoiced steps should be 0\n output sine_tensor: tensor(batchsize=1, length, dim)\n output uv: tensor(batchsize=1, length, 1)\n \"\"\"\n with torch.no_grad():\n # f0_buf = torch.zeros(f0.shape[0], f0.shape[1], self.dim, device=f0.device)\n # fundamental component\n # fn = torch.multiply(\n # f0, torch.FloatTensor([[range(1, self.harmonic_num + 2)]]).to(f0.device)\n # )\n fn = torch.multiply(f0, torch.arange(1, self.harmonic_num + 2).to(f0.device).to(f0.dtype))\n\n # generate sine waveforms\n sine_waves = self._f02sine(fn) * self.sine_amp\n\n # generate uv signal\n # uv = torch.ones(f0.shape)\n # uv = uv * (f0 > self.voiced_threshold)\n uv = self._f02uv(f0)\n\n # noise: for unvoiced should be similar to sine_amp\n # std = self.sine_amp/3 -> max value ~ self.sine_amp\n # . for voiced regions is self.noise_std\n noise_amp = uv * self.noise_std + (1 - uv) * self.sine_amp / 3\n noise = noise_amp * torch.randn_like(sine_waves)\n\n # first: set the unvoiced part to 0 by uv\n # then: additive noise\n sine_waves = sine_waves * uv + noise\n return sine_waves, uv, noise\n\n\nclass SourceModuleHnNSF(torch.nn.Module):\n \"\"\"\n SourceModule for hn-nsf\n SourceModule(sampling_rate, harmonic_num=0, sine_amp=0.1,\n add_noise_std=0.003, voiced_threshod=0)\n sampling_rate: sampling_rate in Hz\n harmonic_num: number of harmonic above F0 (default: 0)\n sine_amp: amplitude of sine source signal (default: 0.1)\n add_noise_std: std of additive Gaussian noise (default: 0.003)\n note that amplitude of noise in unvoiced is decided\n by sine_amp\n voiced_threshold: threshold to set U/V given F0 (default: 0)\n Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)\n F0_sampled (batchsize, length, 1)\n Sine_source (batchsize, length, 1)\n noise_source (batchsize, length 1)\n uv (batchsize, length, 1)\n \"\"\"\n\n def __init__(\n self,\n sampling_rate,\n harmonic_num=0,\n sine_amp=0.1,\n add_noise_std=0.003,\n voiced_threshod=0,\n ):\n super().__init__()\n\n self.sine_amp = sine_amp\n self.noise_std = add_noise_std\n\n # to produce sine waveforms\n self.l_sin_gen = SineGen(sampling_rate, harmonic_num, sine_amp, add_noise_std, voiced_threshod)\n\n # to merge source harmonics into a single excitation\n self.l_linear = torch.nn.Linear(harmonic_num + 1, 1)\n self.l_tanh = torch.nn.Tanh()\n\n def forward(self, x):\n \"\"\"\n Sine_source, noise_source = SourceModuleHnNSF(F0_sampled)\n F0_sampled (batchsize, length, 1)\n Sine_source (batchsize, length, 1)\n noise_source (batchsize, length 1)\n \"\"\"\n # source for harmonic branch\n sine_wavs, uv, _ = self.l_sin_gen(x)\n sine_merge = self.l_tanh(self.l_linear(sine_wavs))\n\n # source for noise branch, in the same shape as uv\n noise = torch.randn_like(uv) * self.sine_amp / 3\n return sine_merge, noise, uv\n\n\nclass NSFHifiGANGenerator(torch.nn.Module):\n def __init__(self, h):\n super().__init__()\n self.h = h\n\n self.num_kernels = len(h[\"resblock_kernel_sizes\"])\n self.num_upsamples = len(h[\"upsample_rates\"])\n self.f0_upsamp = torch.nn.Upsample(scale_factor=np.prod(h[\"upsample_rates\"]))\n self.m_source = SourceModuleHnNSF(sampling_rate=h[\"sampling_rate\"], harmonic_num=8)\n self.noise_convs = nn.ModuleList()\n self.conv_pre = weight_norm(Conv1d(h[\"inter_channels\"], h[\"upsample_initial_channel\"], 7, 1, padding=3))\n resblock = ResBlock1 if h[\"resblock\"] == \"1\" else ResBlock2\n self.ups = nn.ModuleList()\n for i, (u, k) in enumerate(zip(h[\"upsample_rates\"], h[\"upsample_kernel_sizes\"])):\n c_cur = h[\"upsample_initial_channel\"] // (2 ** (i + 1))\n self.ups.append(\n weight_norm(\n ConvTranspose1d(\n h[\"upsample_initial_channel\"] // (2**i),\n h[\"upsample_initial_channel\"] // (2 ** (i + 1)),\n k,\n u,\n padding=(k - u) // 2,\n )\n )\n )\n if i + 1 < len(h[\"upsample_rates\"]): #\n stride_f0 = np.prod(h[\"upsample_rates\"][i + 1 :])\n self.noise_convs.append(\n Conv1d(\n 1,\n c_cur,\n kernel_size=stride_f0 * 2,\n stride=stride_f0,\n padding=stride_f0 // 2,\n )\n )\n else:\n self.noise_convs.append(Conv1d(1, c_cur, kernel_size=1))\n self.resblocks = nn.ModuleList()\n for i in range(len(self.ups)):\n ch = h[\"upsample_initial_channel\"] // (2 ** (i + 1))\n for j, (k, d) in enumerate(zip(h[\"resblock_kernel_sizes\"], h[\"resblock_dilation_sizes\"])):\n self.resblocks.append(resblock(ch, k, d))\n\n self.conv_post = weight_norm(Conv1d(ch, 1, 7, 1, padding=3))\n self.ups.apply(init_weights)\n self.conv_post.apply(init_weights)\n self.cond = nn.Conv1d(h[\"gin_channels\"], h[\"upsample_initial_channel\"], 1)\n\n def forward(self, x, f0, g=None):\n # LOG.info(1,x.shape,f0.shape,f0[:, None].shape)\n f0 = self.f0_upsamp(f0[:, None]).transpose(1, 2) # bs,n,t\n # LOG.info(2,f0.shape)\n har_source, noi_source, uv = self.m_source(f0)\n har_source = har_source.transpose(1, 2)\n x = self.conv_pre(x)\n x = x + self.cond(g)\n # LOG.info(124,x.shape,har_source.shape)\n for i in range(self.num_upsamples):\n x = F.leaky_relu(x, LRELU_SLOPE)\n # LOG.info(3,x.shape)\n x = self.ups[i](x)\n x_source = self.noise_convs[i](har_source)\n # LOG.info(4,x_source.shape,har_source.shape,x.shape)\n x = x + x_source\n xs = None\n for j in range(self.num_kernels):\n if xs is None:\n xs = self.resblocks[i * self.num_kernels + j](x)\n else:\n xs += self.resblocks[i * self.num_kernels + j](x)\n x = xs / self.num_kernels\n x = F.leaky_relu(x)\n x = self.conv_post(x)\n x = torch.tanh(x)\n\n return x\n\n def remove_weight_norm(self):\n LOG.info(\"Removing weight norm...\")\n for l in self.ups:\n remove_weight_norm(l)\n for l in self.resblocks:\n l.remove_weight_norm()\n remove_weight_norm(self.conv_pre)\n remove_weight_norm(self.conv_post)\n"
},
{
"path": "src/so_vits_svc_fork/modules/decoders/hifigan/_utils.py",
"content": "from logging import getLogger\n\n# matplotlib.use(\"Agg\")\n\nLOG = getLogger(__name__)\n\n\ndef init_weights(m, mean=0.0, std=0.01):\n classname = m.__class__.__name__\n if classname.find(\"Conv\") != -1:\n m.weight.data.normal_(mean, std)\n\n\ndef get_padding(kernel_size, dilation=1):\n return int((kernel_size * dilation - dilation) / 2)\n"
},
{
"path": "src/so_vits_svc_fork/modules/decoders/mb_istft/__init__.py",
"content": "from ._generators import (\n Multiband_iSTFT_Generator,\n Multistream_iSTFT_Generator,\n iSTFT_Generator,\n)\nfrom ._loss import subband_stft_loss\nfrom ._pqmf import PQMF\n\n__all__ = [\n \"PQMF\",\n \"Multiband_iSTFT_Generator\",\n \"Multistream_iSTFT_Generator\",\n \"iSTFT_Generator\",\n \"subband_stft_loss\",\n]\n"
},
{
"path": "src/so_vits_svc_fork/modules/decoders/mb_istft/_generators.py",
"content": "import math\n\nimport torch\nfrom torch import nn\nfrom torch.nn import Conv1d, ConvTranspose1d\nfrom torch.nn import functional as F\nfrom torch.nn.utils import remove_weight_norm, weight_norm\n\nfrom ....modules import modules\nfrom ....modules.commons import get_padding, init_weights\nfrom ._pqmf import PQMF\nfrom ._stft import TorchSTFT\n\n\nclass iSTFT_Generator(torch.nn.Module):\n def __init__(\n self,\n initial_channel,\n resblock,\n resblock_kernel_sizes,\n resblock_dilation_sizes,\n upsample_rates,\n upsample_initial_channel,\n upsample_kernel_sizes,\n gen_istft_n_fft,\n gen_istft_hop_size,\n gin_channels=0,\n ):\n super().__init__()\n # self.h = h\n self.gen_istft_n_fft = gen_istft_n_fft\n self.gen_istft_hop_size = gen_istft_hop_size\n\n self.num_kernels = len(resblock_kernel_sizes)\n self.num_upsamples = len(upsample_rates)\n self.conv_pre = weight_norm(Conv1d(initial_channel, upsample_initial_channel, 7, 1, padding=3))\n resblock = modules.ResBlock1 if resblock == \"1\" else modules.ResBlock2\n\n self.ups = nn.ModuleList()\n for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):\n self.ups.append(\n weight_norm(\n ConvTranspose1d(\n upsample_initial_channel // (2**i),\n upsample_initial_channel // (2 ** (i + 1)),\n k,\n u,\n padding=(k - u) // 2,\n )\n )\n )\n\n self.resblocks = nn.ModuleList()\n for i in range(len(self.ups)):\n ch = upsample_initial_channel // (2 ** (i + 1))\n for j, (k, d) in enumerate(zip(resblock_kernel_sizes, resblock_dilation_sizes)):\n self.resblocks.append(resblock(ch, k, d))\n\n self.post_n_fft = self.gen_istft_n_fft\n self.conv_post = weight_norm(Conv1d(ch, self.post_n_fft + 2, 7, 1, padding=3))\n self.ups.apply(init_weights)\n self.conv_post.apply(init_weights)\n self.reflection_pad = torch.nn.ReflectionPad1d((1, 0))\n self.stft = TorchSTFT(\n filter_length=self.gen_istft_n_fft,\n hop_length=self.gen_istft_hop_size,\n win_length=self.gen_istft_n_fft,\n )\n\n def forward(self, x, g=None):\n x = self.conv_pre(x)\n for i in range(self.num_upsamples):\n x = F.leaky_relu(x, modules.LRELU_SLOPE)\n x = self.ups[i](x)\n xs = None\n for j in range(self.num_kernels):\n if xs is None:\n xs = self.resblocks[i * self.num_kernels + j](x)\n else:\n xs += self.resblocks[i * self.num_kernels + j](x)\n x = xs / self.num_kernels\n x = F.leaky_relu(x)\n x = self.reflection_pad(x)\n x = self.conv_post(x)\n spec = torch.exp(x[:, : self.post_n_fft // 2 + 1, :])\n phase = math.pi * torch.sin(x[:, self.post_n_fft // 2 + 1 :, :])\n out = self.stft.inverse(spec, phase).to(x.device)\n return out, None\n\n def remove_weight_norm(self):\n print(\"Removing weight norm...\")\n for l in self.ups:\n remove_weight_norm(l)\n for l in self.resblocks:\n l.remove_weight_norm()\n remove_weight_norm(self.conv_pre)\n remove_weight_norm(self.conv_post)\n\n\nclass Multiband_iSTFT_Generator(torch.nn.Module):\n def __init__(\n self,\n initial_channel,\n resblock,\n resblock_kernel_sizes,\n resblock_dilation_sizes,\n upsample_rates,\n upsample_initial_channel,\n upsample_kernel_sizes,\n gen_istft_n_fft,\n gen_istft_hop_size,\n subbands,\n gin_channels=0,\n ):\n super().__init__()\n # self.h = h\n self.subbands = subbands\n self.num_kernels = len(resblock_kernel_sizes)\n self.num_upsamples = len(upsample_rates)\n self.conv_pre = weight_norm(Conv1d(initial_channel, upsample_initial_channel, 7, 1, padding=3))\n resblock = modules.ResBlock1 if resblock == \"1\" else modules.ResBlock2\n\n self.ups = nn.ModuleList()\n for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):\n self.ups.append(\n weight_norm(\n ConvTranspose1d(\n upsample_initial_channel // (2**i),\n upsample_initial_channel // (2 ** (i + 1)),\n k,\n u,\n padding=(k - u) // 2,\n )\n )\n )\n\n self.resblocks = nn.ModuleList()\n for i in range(len(self.ups)):\n ch = upsample_initial_channel // (2 ** (i + 1))\n for j, (k, d) in enumerate(zip(resblock_kernel_sizes, resblock_dilation_sizes)):\n self.resblocks.append(resblock(ch, k, d))\n\n self.post_n_fft = gen_istft_n_fft\n self.ups.apply(init_weights)\n self.reflection_pad = torch.nn.ReflectionPad1d((1, 0))\n self.reshape_pixelshuffle = []\n\n self.subband_conv_post = weight_norm(Conv1d(ch, self.subbands * (self.post_n_fft + 2), 7, 1, padding=3))\n\n self.subband_conv_post.apply(init_weights)\n\n self.gen_istft_n_fft = gen_istft_n_fft\n self.gen_istft_hop_size = gen_istft_hop_size\n\n def forward(self, x, g=None):\n stft = TorchSTFT(\n filter_length=self.gen_istft_n_fft,\n hop_length=self.gen_istft_hop_size,\n win_length=self.gen_istft_n_fft,\n ).to(x.device)\n pqmf = PQMF(x.device, subbands=self.subbands).to(x.device, dtype=x.dtype)\n\n x = self.conv_pre(x) # [B, ch, length]\n\n for i in range(self.num_upsamples):\n x = F.leaky_relu(x, modules.LRELU_SLOPE)\n x = self.ups[i](x)\n\n xs = None\n for j in range(self.num_kernels):\n if xs is None:\n xs = self.resblocks[i * self.num_kernels + j](x)\n else:\n xs += self.resblocks[i * self.num_kernels + j](x)\n x = xs / self.num_kernels\n\n x = F.leaky_relu(x)\n x = self.reflection_pad(x)\n x = self.subband_conv_post(x)\n x = torch.reshape(x, (x.shape[0], self.subbands, x.shape[1] // self.subbands, x.shape[-1]))\n\n spec = torch.exp(x[:, :, : self.post_n_fft // 2 + 1, :])\n phase = math.pi * torch.sin(x[:, :, self.post_n_fft // 2 + 1 :, :])\n\n y_mb_hat = stft.inverse(\n torch.reshape(\n spec,\n (\n spec.shape[0] * self.subbands,\n self.gen_istft_n_fft // 2 + 1,\n spec.shape[-1],\n ),\n ),\n torch.reshape(\n phase,\n (\n phase.shape[0] * self.subbands,\n self.gen_istft_n_fft // 2 + 1,\n phase.shape[-1],\n ),\n ),\n )\n y_mb_hat = torch.reshape(y_mb_hat, (x.shape[0], self.subbands, 1, y_mb_hat.shape[-1]))\n y_mb_hat = y_mb_hat.squeeze(-2)\n\n y_g_hat = pqmf.synthesis(y_mb_hat)\n\n return y_g_hat, y_mb_hat\n\n def remove_weight_norm(self):\n print(\"Removing weight norm...\")\n for l in self.ups:\n remove_weight_norm(l)\n for l in self.resblocks:\n l.remove_weight_norm()\n\n\nclass Multistream_iSTFT_Generator(torch.nn.Module):\n def __init__(\n self,\n initial_channel,\n resblock,\n resblock_kernel_sizes,\n resblock_dilation_sizes,\n upsample_rates,\n upsample_initial_channel,\n upsample_kernel_sizes,\n gen_istft_n_fft,\n gen_istft_hop_size,\n subbands,\n gin_channels=0,\n ):\n super().__init__()\n # self.h = h\n self.subbands = subbands\n self.num_kernels = len(resblock_kernel_sizes)\n self.num_upsamples = len(upsample_rates)\n self.conv_pre = weight_norm(Conv1d(initial_channel, upsample_initial_channel, 7, 1, padding=3))\n resblock = modules.ResBlock1 if resblock == \"1\" else modules.ResBlock2\n\n self.ups = nn.ModuleList()\n for i, (u, k) in enumerate(zip(upsample_rates, upsample_kernel_sizes)):\n self.ups.append(\n weight_norm(\n ConvTranspose1d(\n upsample_initial_channel // (2**i),\n upsample_initial_channel // (2 ** (i + 1)),\n k,\n u,\n padding=(k - u) // 2,\n )\n )\n )\n\n self.resblocks = nn.ModuleList()\n for i in range(len(self.ups)):\n ch = upsample_initial_channel // (2 ** (i + 1))\n for j, (k, d) in enumerate(zip(resblock_kernel_sizes, resblock_dilation_sizes)):\n self.resblocks.append(resblock(ch, k, d))\n\n self.post_n_fft = gen_istft_n_fft\n self.ups.apply(init_weights)\n self.reflection_pad = torch.nn.ReflectionPad1d((1, 0))\n self.reshape_pixelshuffle = []\n\n self.subband_conv_post = weight_norm(Conv1d(ch, self.subbands * (self.post_n_fft + 2), 7, 1, padding=3))\n\n self.subband_conv_post.apply(init_weights)\n\n self.gen_istft_n_fft = gen_istft_n_fft\n self.gen_istft_hop_size = gen_istft_hop_size\n\n updown_filter = torch.zeros((self.subbands, self.subbands, self.subbands)).float()\n for k in range(self.subbands):\n updown_filter[k, k, 0] = 1.0\n self.register_buffer(\"updown_filter\", updown_filter)\n self.multistream_conv_post = weight_norm(Conv1d(self.subbands, 1, kernel_size=63, bias=False, padding=get_padding(63, 1)))\n self.multistream_conv_post.apply(init_weights)\n\n def forward(self, x, g=None):\n stft = TorchSTFT(\n filter_length=self.gen_istft_n_fft,\n hop_length=self.gen_istft_hop_size,\n win_length=self.gen_istft_n_fft,\n ).to(x.device)\n # pqmf = PQMF(x.device)\n\n x = self.conv_pre(x) # [B, ch, length]\n\n for i in range(self.num_upsamples):\n x = F.leaky_relu(x, modules.LRELU_SLOPE)\n x = self.ups[i](x)\n\n xs = None\n for j in range(self.num_kernels):\n if xs is None:\n xs = self.resblocks[i * self.num_kernels + j](x)\n else:\n xs += self.resblocks[i * self.num_kernels + j](x)\n x = xs / self.num_kernels\n\n x = F.leaky_relu(x)\n x = self.reflection_pad(x)\n x = self.subband_conv_post(x)\n x = torch.reshape(x, (x.shape[0], self.subbands, x.shape[1] // self.subbands, x.shape[-1]))\n\n spec = torch.exp(x[:, :, : self.post_n_fft // 2 + 1, :])\n phase = math.pi * torch.sin(x[:, :, self.post_n_fft // 2 + 1 :, :])\n\n y_mb_hat = stft.inverse(\n torch.reshape(\n spec,\n (\n spec.shape[0] * self.subbands,\n self.gen_istft_n_fft // 2 + 1,\n spec.shape[-1],\n ),\n ),\n torch.reshape(\n phase,\n (\n phase.shape[0] * self.subbands,\n self.gen_istft_n_fft // 2 + 1,\n phase.shape[-1],\n ),\n ),\n )\n y_mb_hat = torch.reshape(y_mb_hat, (x.shape[0], self.subbands, 1, y_mb_hat.shape[-1]))\n y_mb_hat = y_mb_hat.squeeze(-2)\n\n y_mb_hat = F.conv_transpose1d(\n y_mb_hat,\n self.updown_filter.to(x.device) * self.subbands,\n stride=self.subbands,\n )\n\n y_g_hat = self.multistream_conv_post(y_mb_hat)\n\n return y_g_hat, y_mb_hat\n\n def remove_weight_norm(self):\n print(\"Removing weight norm...\")\n for l in self.ups:\n remove_weight_norm(l)\n for l in self.resblocks:\n l.remove_weight_norm()\n"
},
{
"path": "src/so_vits_svc_fork/modules/decoders/mb_istft/_loss.py",
"content": "from ._stft_loss import MultiResolutionSTFTLoss\n\n\ndef subband_stft_loss(h, y_mb, y_hat_mb):\n sub_stft_loss = MultiResolutionSTFTLoss(h.train.fft_sizes, h.train.hop_sizes, h.train.win_lengths)\n y_mb = y_mb.view(-1, y_mb.size(2))\n y_hat_mb = y_hat_mb.view(-1, y_hat_mb.size(2))\n sub_sc_loss, sub_mag_loss = sub_stft_loss(y_hat_mb[:, : y_mb.size(-1)], y_mb)\n return sub_sc_loss + sub_mag_loss\n"
},
{
"path": "src/so_vits_svc_fork/modules/decoders/mb_istft/_pqmf.py",
"content": "# Copyright 2020 Tomoki Hayashi\n# MIT License (https://opensource.org/licenses/MIT)\n\n\"\"\"Pseudo QMF modules.\"\"\"\n\nimport numpy as np\nimport torch\nimport torch.nn.functional as F\nfrom scipy.signal.windows import kaiser\n\n\ndef design_prototype_filter(taps=62, cutoff_ratio=0.15, beta=9.0):\n \"\"\"\n Design prototype filter for PQMF.\n This method is based on `A Kaiser window approach for the design of prototype\n filters of cosine modulated filterbanks`_.\n\n Args:\n taps (int): The number of filter taps.\n cutoff_ratio (float): Cut-off frequency ratio.\n beta (float): Beta coefficient for kaiser window.\n\n Returns:\n ndarray: Impluse response of prototype filter (taps + 1,).\n .. _`A Kaiser window approach for the design of prototype filters of cosine modulated filterbanks`:\n https://ieeexplore.ieee.org/abstract/document/681427\n\n \"\"\"\n # check the arguments are valid\n assert taps % 2 == 0, \"The number of taps mush be even number.\"\n assert 0.0 < cutoff_ratio < 1.0, \"Cutoff ratio must be > 0.0 and < 1.0.\"\n\n # make initial filter\n omega_c = np.pi * cutoff_ratio\n with np.errstate(invalid=\"ignore\"):\n h_i = np.sin(omega_c * (np.arange(taps + 1) - 0.5 * taps)) / (np.pi * (np.arange(taps + 1) - 0.5 * taps))\n h_i[taps // 2] = np.cos(0) * cutoff_ratio # fix nan due to indeterminate form\n\n # apply kaiser window\n w = kaiser(taps + 1, beta)\n h = h_i * w\n\n return h\n\n\nclass PQMF(torch.nn.Module):\n \"\"\"\n PQMF module.\n This module is based on `Near-perfect-reconstruction pseudo-QMF banks`_.\n .. _`Near-perfect-reconstruction pseudo-QMF banks`:\n https://ieeexplore.ieee.org/document/258122\n \"\"\"\n\n def __init__(self, device, subbands=8, taps=62, cutoff_ratio=0.15, beta=9.0):\n \"\"\"\n Initialize PQMF module.\n\n Args:\n subbands (int): The number of subbands.\n taps (int): The number of filter taps.\n cutoff_ratio (float): Cut-off frequency ratio.\n beta (float): Beta coefficient for kaiser window.\n\n \"\"\"\n super().__init__()\n\n # define filter coefficient\n h_proto = design_prototype_filter(taps, cutoff_ratio, beta)\n h_analysis = np.zeros((subbands, len(h_proto)))\n h_synthesis = np.zeros((subbands, len(h_proto)))\n for k in range(subbands):\n h_analysis[k] = (\n 2 * h_proto * np.cos((2 * k + 1) * (np.pi / (2 * subbands)) * (np.arange(taps + 1) - ((taps - 1) / 2)) + (-1) ** k * np.pi / 4)\n )\n h_synthesis[k] = (\n 2 * h_proto * np.cos((2 * k + 1) * (np.pi / (2 * subbands)) * (np.arange(taps + 1) - ((taps - 1) / 2)) - (-1) ** k * np.pi / 4)\n )\n\n # convert to tensor\n analysis_filter = torch.from_numpy(h_analysis).float().unsqueeze(1).to(device)\n synthesis_filter = torch.from_numpy(h_synthesis).float().unsqueeze(0).to(device)\n\n # register coefficients as buffer\n self.register_buffer(\"analysis_filter\", analysis_filter)\n self.register_buffer(\"synthesis_filter\", synthesis_filter)\n\n # filter for downsampling & upsampling\n updown_filter = torch.zeros((subbands, subbands, subbands)).float().to(device)\n for k in range(subbands):\n updown_filter[k, k, 0] = 1.0\n self.register_buffer(\"updown_filter\", updown_filter)\n self.subbands = subbands\n\n # keep padding info\n self.pad_fn = torch.nn.ConstantPad1d(taps // 2, 0.0)\n\n def analysis(self, x):\n \"\"\"\n Analysis with PQMF.\n\n Args:\n x (Tensor): Input tensor (B, 1, T).\n\n Returns:\n Tensor: Output tensor (B, subbands, T // subbands).\n\n \"\"\"\n x = F.conv1d(self.pad_fn(x), self.analysis_filter)\n return F.conv1d(x, self.updown_filter, stride=self.subbands)\n\n def synthesis(self, x):\n \"\"\"\n Synthesis with PQMF.\n\n Args:\n x (Tensor): Input tensor (B, subbands, T // subbands).\n\n Returns:\n Tensor: Output tensor (B, 1, T).\n\n \"\"\"\n # NOTE(kan-bayashi): Power will be dreased so here multiply by # subbands.\n # Not sure this is the correct way, it is better to check again.\n # TODO(kan-bayashi): Understand the reconstruction procedure\n x = F.conv_transpose1d(x, self.updown_filter * self.subbands, stride=self.subbands)\n return F.conv1d(self.pad_fn(x), self.synthesis_filter)\n"
},
{
"path": "src/so_vits_svc_fork/modules/decoders/mb_istft/_stft.py",
"content": "\"\"\"\nBSD 3-Clause License\nCopyright (c) 2017, Prem Seetharaman\nAll rights reserved.\n* Redistribution and use in source and binary forms, with or without\n modification, are permitted provided that the following conditions are met:\n* Redistributions of source code must retain the above copyright notice,\n this list of conditions and the following disclaimer.\n* Redistributions in binary form must reproduce the above copyright notice, this\n list of conditions and the following disclaimer in the\n documentation and/or other materials provided with the distribution.\n* Neither the name of the copyright holder nor the names of its\n contributors may be used to endorse or promote products derived from this\n software without specific prior written permission.\nTHIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS \"AS IS\" AND\nANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED\nWARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\nDISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR\nANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES\n(INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES;\nLOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON\nANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT\n(INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS\nSOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n\"\"\"\n\nimport librosa.util as librosa_util\nimport numpy as np\nimport torch\nimport torch.nn.functional as F\nfrom librosa.util import pad_center, tiny\nfrom scipy.signal import get_window\nfrom torch.autograd import Variable\n\n\ndef window_sumsquare(\n window,\n n_frames,\n hop_length=200,\n win_length=800,\n n_fft=800,\n dtype=np.float32,\n norm=None,\n):\n \"\"\"\n # from librosa 0.6\n Compute the sum-square envelope of a window function at a given hop length.\n This is used to estimate modulation effects induced by windowing\n observations in short-time fourier transforms.\n\n Parameters\n ----------\n window : string, tuple, number, callable, or list-like\n Window specification, as in `get_window`\n n_frames : int > 0\n The number of analysis frames\n hop_length : int > 0\n The number of samples to advance between frames\n win_length : [optional]\n The length of the window function. By default, this matches `n_fft`.\n n_fft : int > 0\n The length of each analysis frame.\n dtype : np.dtype\n The data type of the output\n\n Returns\n -------\n wss : np.ndarray, shape=`(n_fft + hop_length * (n_frames - 1))`\n The sum-squared envelope of the window function\n\n \"\"\"\n if win_length is None:\n win_length = n_fft\n\n n = n_fft + hop_length * (n_frames - 1)\n x = np.zeros(n, dtype=dtype)\n\n # Compute the squared window at the desired length\n win_sq = get_window(window, win_length, fftbins=True)\n win_sq = librosa_util.normalize(win_sq, norm=norm) ** 2\n win_sq = librosa_util.pad_center(win_sq, n_fft)\n\n # Fill the envelope\n for i in range(n_frames):\n sample = i * hop_length\n x[sample : min(n, sample + n_fft)] += win_sq[: max(0, min(n_fft, n - sample))]\n return x\n\n\nclass STFT(torch.nn.Module):\n \"\"\"adapted from Prem Seetharaman's https://github.com/pseeth/pytorch-stft\"\"\"\n\n def __init__(self, filter_length=800, hop_length=200, win_length=800, window=\"hann\"):\n super().__init__()\n self.filter_length = filter_length\n self.hop_length = hop_length\n self.win_length = win_length\n self.window = window\n self.forward_transform = None\n scale = self.filter_length / self.hop_length\n fourier_basis = np.fft.fft(np.eye(self.filter_length))\n\n cutoff = int(self.filter_length / 2 + 1)\n fourier_basis = np.vstack([np.real(fourier_basis[:cutoff, :]), np.imag(fourier_basis[:cutoff, :])])\n\n forward_basis = torch.FloatTensor(fourier_basis[:, None, :])\n inverse_basis = torch.FloatTensor(np.linalg.pinv(scale * fourier_basis).T[:, None, :])\n\n if window is not None:\n assert filter_length >= win_length\n # get window and zero center pad it to filter_length\n fft_window = get_window(window, win_length, fftbins=True)\n fft_window = pad_center(fft_window, filter_length)\n fft_window = torch.from_numpy(fft_window).float()\n\n # window the bases\n forward_basis *= fft_window\n inverse_basis *= fft_window\n\n self.register_buffer(\"forward_basis\", forward_basis.float())\n self.register_buffer(\"inverse_basis\", inverse_basis.float())\n\n def transform(self, input_data):\n num_batches = input_data.size(0)\n num_samples = input_data.size(1)\n\n self.num_samples = num_samples\n\n # similar to librosa, reflect-pad the input\n input_data = input_data.view(num_batches, 1, num_samples)\n input_data = F.pad(\n input_data.unsqueeze(1),\n (int(self.filter_length / 2), int(self.filter_length / 2), 0, 0),\n mode=\"reflect\",\n )\n input_data = input_data.squeeze(1)\n\n forward_transform = F.conv1d(\n input_data,\n Variable(self.forward_basis, requires_grad=False),\n stride=self.hop_length,\n padding=0,\n )\n\n cutoff = int((self.filter_length / 2) + 1)\n real_part = forward_transform[:, :cutoff, :]\n imag_part = forward_transform[:, cutoff:, :]\n\n magnitude = torch.sqrt(real_part**2 + imag_part**2)\n phase = torch.autograd.Variable(torch.atan2(imag_part.data, real_part.data))\n\n return magnitude, phase\n\n def inverse(self, magnitude, phase):\n recombine_magnitude_phase = torch.cat([magnitude * torch.cos(phase), magnitude * torch.sin(phase)], dim=1)\n\n inverse_transform = F.conv_transpose1d(\n recombine_magnitude_phase,\n Variable(self.inverse_basis, requires_grad=False),\n stride=self.hop_length,\n padding=0,\n )\n\n if self.window is not None:\n window_sum = window_sumsquare(\n self.window,\n magnitude.size(-1),\n hop_length=self.hop_length,\n win_length=self.win_length,\n n_fft=self.filter_length,\n dtype=np.float32,\n )\n # remove modulation effects\n approx_nonzero_indices = torch.from_numpy(np.where(window_sum > tiny(window_sum))[0])\n window_sum = torch.autograd.Variable(torch.from_numpy(window_sum), requires_grad=False)\n window_sum = window_sum.to(inverse_transform.device())\n inverse_transform[:, :, approx_nonzero_indices] /= window_sum[approx_nonzero_indices]\n\n # scale by hop ratio\n inverse_transform *= float(self.filter_length) / self.hop_length\n\n inverse_transform = inverse_transform[:, :, int(self.filter_length / 2) :]\n inverse_transform = inverse_transform[:, :, : -int(self.filter_length / 2) :]\n\n return inverse_transform\n\n def forward(self, input_data):\n self.magnitude, self.phase = self.transform(input_data)\n reconstruction = self.inverse(self.magnitude, self.phase)\n return reconstruction\n\n\nclass TorchSTFT(torch.nn.Module):\n def __init__(self, filter_length=800, hop_length=200, win_length=800, window=\"hann\"):\n super().__init__()\n self.filter_length = filter_length\n self.hop_length = hop_length\n self.win_length = win_length\n self.window = torch.from_numpy(get_window(window, win_length, fftbins=True).astype(np.float32))\n\n def transform(self, input_data):\n forward_transform = torch.stft(\n input_data,\n self.filter_length,\n self.hop_length,\n self.win_length,\n window=self.window,\n return_complex=True,\n )\n\n return torch.abs(forward_transform), torch.angle(forward_transform)\n\n def inverse(self, magnitude, phase):\n inverse_transform = torch.istft(\n magnitude * torch.exp(phase * 1j),\n self.filter_length,\n self.hop_length,\n self.win_length,\n window=self.window.to(magnitude.device),\n )\n\n return inverse_transform.unsqueeze(-2) # unsqueeze to stay consistent with conv_transpose1d implementation\n\n def forward(self, input_data):\n self.magnitude, self.phase = self.transform(input_data)\n reconstruction = self.inverse(self.magnitude, self.phase)\n return reconstruction\n"
},
{
"path": "src/so_vits_svc_fork/modules/decoders/mb_istft/_stft_loss.py",
"content": "# Copyright 2019 Tomoki Hayashi\n# MIT License (https://opensource.org/licenses/MIT)\n\n\"\"\"STFT-based Loss modules.\"\"\"\n\nimport torch\nimport torch.nn.functional as F\n\n\ndef stft(x, fft_size, hop_size, win_length, window):\n \"\"\"\n Perform STFT and convert to magnitude spectrogram.\n\n Args:\n x (Tensor): Input signal tensor (B, T).\n fft_size (int): FFT size.\n hop_size (int): Hop size.\n win_length (int): Window length.\n window (str): Window function type.\n\n Returns:\n Tensor: Magnitude spectrogram (B, #frames, fft_size // 2 + 1).\n\n \"\"\"\n x_stft = torch.stft(x, fft_size, hop_size, win_length, window.to(x.device), return_complex=False)\n real = x_stft[..., 0]\n imag = x_stft[..., 1]\n\n # NOTE(kan-bayashi): clamp is needed to avoid nan or inf\n return torch.sqrt(torch.clamp(real**2 + imag**2, min=1e-7)).transpose(2, 1)\n\n\nclass SpectralConvergengeLoss(torch.nn.Module):\n \"\"\"Spectral convergence loss module.\"\"\"\n\n def __init__(self):\n \"\"\"Initialize spectral convergence loss module.\"\"\"\n super().__init__()\n\n def forward(self, x_mag, y_mag):\n \"\"\"\n Calculate forward propagation.\n\n Args:\n x_mag (Tensor): Magnitude spectrogram of predicted signal (B, #frames, #freq_bins).\n y_mag (Tensor): Magnitude spectrogram of groundtruth signal (B, #frames, #freq_bins).\n\n Returns:\n Tensor: Spectral convergence loss value.\n\n \"\"\"\n return torch.norm(y_mag - x_mag) / torch.norm(y_mag) # MB-iSTFT-VITS changed here due to codespell\n\n\nclass LogSTFTMagnitudeLoss(torch.nn.Module):\n \"\"\"Log STFT magnitude loss module.\"\"\"\n\n def __init__(self):\n \"\"\"Initialize los STFT magnitude loss module.\"\"\"\n super().__init__()\n\n def forward(self, x_mag, y_mag):\n \"\"\"\n Calculate forward propagation.\n\n Args:\n x_mag (Tensor): Magnitude spectrogram of predicted signal (B, #frames, #freq_bins).\n y_mag (Tensor): Magnitude spectrogram of groundtruth signal (B, #frames, #freq_bins).\n\n Returns:\n Tensor: Log STFT magnitude loss value.\n\n \"\"\"\n return F.l1_loss(torch.log(y_mag), torch.log(x_mag))\n\n\nclass STFTLoss(torch.nn.Module):\n \"\"\"STFT loss module.\"\"\"\n\n def __init__(self, fft_size=1024, shift_size=120, win_length=600, window=\"hann_window\"):\n \"\"\"Initialize STFT loss module.\"\"\"\n super().__init__()\n self.fft_size = fft_size\n self.shift_size = shift_size\n self.win_length = win_length\n self.window = getattr(torch, window)(win_length)\n self.spectral_convergenge_loss = SpectralConvergengeLoss()\n self.log_stft_magnitude_loss = LogSTFTMagnitudeLoss()\n\n def forward(self, x, y):\n \"\"\"\n Calculate forward propagation.\n\n Args:\n x (Tensor): Predicted signal (B, T).\n y (Tensor): Groundtruth signal (B, T).\n\n Returns:\n Tensor: Spectral convergence loss value.\n Tensor: Log STFT magnitude loss value.\n\n \"\"\"\n x_mag = stft(x, self.fft_size, self.shift_size, self.win_length, self.window)\n y_mag = stft(y, self.fft_size, self.shift_size, self.win_length, self.window)\n sc_loss = self.spectral_convergenge_loss(x_mag, y_mag)\n mag_loss = self.log_stft_magnitude_loss(x_mag, y_mag)\n\n return sc_loss, mag_loss\n\n\nclass MultiResolutionSTFTLoss(torch.nn.Module):\n \"\"\"Multi resolution STFT loss module.\"\"\"\n\n def __init__(\n self,\n fft_sizes=[1024, 2048, 512],\n hop_sizes=[120, 240, 50],\n win_lengths=[600, 1200, 240],\n window=\"hann_window\",\n ):\n \"\"\"\n Initialize Multi resolution STFT loss module.\n\n Args:\n fft_sizes (list): List of FFT sizes.\n hop_sizes (list): List of hop sizes.\n win_lengths (list): List of window lengths.\n window (str): Window function type.\n\n \"\"\"\n super().__init__()\n assert len(fft_sizes) == len(hop_sizes) == len(win_lengths)\n self.stft_losses = torch.nn.ModuleList()\n for fs, ss, wl in zip(fft_sizes, hop_sizes, win_lengths):\n self.stft_losses += [STFTLoss(fs, ss, wl, window)]\n\n def forward(self, x, y):\n \"\"\"\n Calculate forward propagation.\n\n Args:\n x (Tensor): Predicted signal (B, T).\n y (Tensor): Groundtruth signal (B, T).\n\n Returns:\n Tensor: Multi resolution spectral convergence loss value.\n Tensor: Multi resolution log STFT magnitude loss value.\n\n \"\"\"\n sc_loss = 0.0\n mag_loss = 0.0\n for f in self.stft_losses:\n sc_l, mag_l = f(x, y)\n sc_loss += sc_l\n mag_loss += mag_l\n sc_loss /= len(self.stft_losses)\n mag_loss /= len(self.stft_losses)\n\n return sc_loss, mag_loss\n"
},
{
"path": "src/so_vits_svc_fork/modules/descriminators.py",
"content": "import torch\nfrom torch import nn\nfrom torch.nn import AvgPool1d, Conv1d, Conv2d\nfrom torch.nn import functional as F\nfrom torch.nn.utils import spectral_norm, weight_norm\n\nfrom so_vits_svc_fork.modules import modules as modules\nfrom so_vits_svc_fork.modules.commons import get_padding\n\n\nclass DiscriminatorP(torch.nn.Module):\n def __init__(self, period, kernel_size=5, stride=3, use_spectral_norm=False):\n super().__init__()\n self.period = period\n self.use_spectral_norm = use_spectral_norm\n norm_f = weight_norm if use_spectral_norm == False else spectral_norm\n self.convs = nn.ModuleList(\n [\n norm_f(\n Conv2d(\n 1,\n 32,\n (kernel_size, 1),\n (stride, 1),\n padding=(get_padding(kernel_size, 1), 0),\n )\n ),\n norm_f(\n Conv2d(\n 32,\n 128,\n (kernel_size, 1),\n (stride, 1),\n padding=(get_padding(kernel_size, 1), 0),\n )\n ),\n norm_f(\n Conv2d(\n 128,\n 512,\n (kernel_size, 1),\n (stride, 1),\n padding=(get_padding(kernel_size, 1), 0),\n )\n ),\n norm_f(\n Conv2d(\n 512,\n 1024,\n (kernel_size, 1),\n (stride, 1),\n padding=(get_padding(kernel_size, 1), 0),\n )\n ),\n norm_f(\n Conv2d(\n 1024,\n 1024,\n (kernel_size, 1),\n 1,\n padding=(get_padding(kernel_size, 1), 0),\n )\n ),\n ]\n )\n self.conv_post = norm_f(Conv2d(1024, 1, (3, 1), 1, padding=(1, 0)))\n\n def forward(self, x):\n fmap = []\n\n # 1d to 2d\n b, c, t = x.shape\n if t % self.period != 0: # pad first\n n_pad = self.period - (t % self.period)\n x = F.pad(x, (0, n_pad), \"reflect\")\n t = t + n_pad\n x = x.view(b, c, t // self.period, self.period)\n\n for l in self.convs:\n x = l(x)\n x = F.leaky_relu(x, modules.LRELU_SLOPE)\n fmap.append(x)\n x = self.conv_post(x)\n fmap.append(x)\n x = torch.flatten(x, 1, -1)\n\n return x, fmap\n\n\nclass DiscriminatorS(torch.nn.Module):\n def __init__(self, use_spectral_norm=False):\n super().__init__()\n norm_f = weight_norm if use_spectral_norm == False else spectral_norm\n self.convs = nn.ModuleList(\n [\n norm_f(Conv1d(1, 16, 15, 1, padding=7)),\n norm_f(Conv1d(16, 64, 41, 4, groups=4, padding=20)),\n norm_f(Conv1d(64, 256, 41, 4, groups=16, padding=20)),\n norm_f(Conv1d(256, 1024, 41, 4, groups=64, padding=20)),\n norm_f(Conv1d(1024, 1024, 41, 4, groups=256, padding=20)),\n norm_f(Conv1d(1024, 1024, 5, 1, padding=2)),\n ]\n )\n self.conv_post = norm_f(Conv1d(1024, 1, 3, 1, padding=1))\n\n def forward(self, x):\n fmap = []\n\n for l in self.convs:\n x = l(x)\n x = F.leaky_relu(x, modules.LRELU_SLOPE)\n fmap.append(x)\n x = self.conv_post(x)\n fmap.append(x)\n x = torch.flatten(x, 1, -1)\n\n return x, fmap\n\n\nclass MultiPeriodDiscriminator(torch.nn.Module):\n def __init__(self, use_spectral_norm=False):\n super().__init__()\n periods = [2, 3, 5, 7, 11]\n\n discs = [DiscriminatorS(use_spectral_norm=use_spectral_norm)]\n discs = discs + [DiscriminatorP(i, use_spectral_norm=use_spectral_norm) for i in periods]\n self.discriminators = nn.ModuleList(discs)\n\n def forward(self, y, y_hat):\n y_d_rs = []\n y_d_gs = []\n fmap_rs = []\n fmap_gs = []\n for i, d in enumerate(self.discriminators):\n y_d_r, fmap_r = d(y)\n y_d_g, fmap_g = d(y_hat)\n y_d_rs.append(y_d_r)\n y_d_gs.append(y_d_g)\n fmap_rs.append(fmap_r)\n fmap_gs.append(fmap_g)\n\n return y_d_rs, y_d_gs, fmap_rs, fmap_gs\n\n\nclass MultiScaleDiscriminator(torch.nn.Module):\n def __init__(self):\n super().__init__()\n self.discriminators = nn.ModuleList(\n [\n DiscriminatorS(use_spectral_norm=True),\n DiscriminatorS(),\n DiscriminatorS(),\n ]\n )\n self.meanpools = nn.ModuleList([AvgPool1d(4, 2, padding=2), AvgPool1d(4, 2, padding=2)])\n\n def forward(self, y, y_hat):\n y_d_rs = []\n y_d_gs = []\n fmap_rs = []\n fmap_gs = []\n for i, d in enumerate(self.discriminators):\n if i != 0:\n y = self.meanpools[i - 1](y)\n y_hat = self.meanpools[i - 1](y_hat)\n y_d_r, fmap_r = d(y)\n y_d_g, fmap_g = d(y_hat)\n y_d_rs.append(y_d_r)\n fmap_rs.append(fmap_r)\n y_d_gs.append(y_d_g)\n fmap_gs.append(fmap_g)\n\n return y_d_rs, y_d_gs, fmap_rs, fmap_gs\n"
},
{
"path": "src/so_vits_svc_fork/modules/encoders.py",
"content": "import torch\nfrom torch import nn\n\nfrom so_vits_svc_fork.modules import attentions as attentions\nfrom so_vits_svc_fork.modules import commons as commons\nfrom so_vits_svc_fork.modules import modules as modules\n\n\nclass SpeakerEncoder(torch.nn.Module):\n def __init__(\n self,\n mel_n_channels=80,\n model_num_layers=3,\n model_hidden_size=256,\n model_embedding_size=256,\n ):\n super().__init__()\n self.lstm = nn.LSTM(mel_n_channels, model_hidden_size, model_num_layers, batch_first=True)\n self.linear = nn.Linear(model_hidden_size, model_embedding_size)\n self.relu = nn.ReLU()\n\n def forward(self, mels):\n self.lstm.flatten_parameters()\n _, (hidden, _) = self.lstm(mels)\n embeds_raw = self.relu(self.linear(hidden[-1]))\n return embeds_raw / torch.norm(embeds_raw, dim=1, keepdim=True)\n\n def compute_partial_slices(self, total_frames, partial_frames, partial_hop):\n mel_slices = []\n for i in range(0, total_frames - partial_frames, partial_hop):\n mel_range = torch.arange(i, i + partial_frames)\n mel_slices.append(mel_range)\n\n return mel_slices\n\n def embed_utterance(self, mel, partial_frames=128, partial_hop=64):\n mel_len = mel.size(1)\n last_mel = mel[:, -partial_frames:]\n\n if mel_len > partial_frames:\n mel_slices = self.compute_partial_slices(mel_len, partial_frames, partial_hop)\n mels = list(mel[:, s] for s in mel_slices)\n mels.append(last_mel)\n mels = torch.stack(tuple(mels), 0).squeeze(1)\n\n with torch.no_grad():\n partial_embeds = self(mels)\n embed = torch.mean(partial_embeds, axis=0).unsqueeze(0)\n # embed = embed / torch.linalg.norm(embed, 2)\n else:\n with torch.no_grad():\n embed = self(last_mel)\n\n return embed\n\n\nclass Encoder(nn.Module):\n def __init__(\n self,\n in_channels,\n out_channels,\n hidden_channels,\n kernel_size,\n dilation_rate,\n n_layers,\n gin_channels=0,\n ):\n super().__init__()\n self.in_channels = in_channels\n self.out_channels = out_channels\n self.hidden_channels = hidden_channels\n self.kernel_size = kernel_size\n self.dilation_rate = dilation_rate\n self.n_layers = n_layers\n self.gin_channels = gin_channels\n\n self.pre = nn.Conv1d(in_channels, hidden_channels, 1)\n self.enc = modules.WN(\n hidden_channels,\n kernel_size,\n dilation_rate,\n n_layers,\n gin_channels=gin_channels,\n )\n self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)\n\n def forward(self, x, x_lengths, g=None):\n # print(x.shape,x_lengths.shape)\n x_mask = torch.unsqueeze(commons.sequence_mask(x_lengths, x.size(2)), 1).to(x.dtype)\n x = self.pre(x) * x_mask\n x = self.enc(x, x_mask, g=g)\n stats = self.proj(x) * x_mask\n m, logs = torch.split(stats, self.out_channels, dim=1)\n z = (m + torch.randn_like(m) * torch.exp(logs)) * x_mask\n return z, m, logs, x_mask\n\n\nclass TextEncoder(nn.Module):\n def __init__(\n self,\n out_channels,\n hidden_channels,\n kernel_size,\n n_layers,\n gin_channels=0,\n filter_channels=None,\n n_heads=None,\n p_dropout=None,\n ):\n super().__init__()\n self.out_channels = out_channels\n self.hidden_channels = hidden_channels\n self.kernel_size = kernel_size\n self.n_layers = n_layers\n self.gin_channels = gin_channels\n self.proj = nn.Conv1d(hidden_channels, out_channels * 2, 1)\n self.f0_emb = nn.Embedding(256, hidden_channels)\n\n self.enc_ = attentions.Encoder(hidden_channels, filter_channels, n_heads, n_layers, kernel_size, p_dropout)\n\n def forward(self, x, x_mask, f0=None, noice_scale=1):\n x = x + self.f0_emb(f0).transpose(1, 2)\n x = self.enc_(x * x_mask, x_mask)\n stats = self.proj(x) * x_mask\n m, logs = torch.split(stats, self.out_channels, dim=1)\n z = (m + torch.randn_like(m) * torch.exp(logs) * noice_scale) * x_mask\n\n return z, m, logs, x_mask\n"
},
{
"path": "src/so_vits_svc_fork/modules/flows.py",
"content": "from torch import nn\n\nfrom so_vits_svc_fork.modules import modules as modules\n\n\nclass ResidualCouplingBlock(nn.Module):\n def __init__(\n self,\n channels,\n hidden_channels,\n kernel_size,\n dilation_rate,\n n_layers,\n n_flows=4,\n gin_channels=0,\n ):\n super().__init__()\n self.channels = channels\n self.hidden_channels = hidden_channels\n self.kernel_size = kernel_size\n self.dilation_rate = dilation_rate\n self.n_layers = n_layers\n self.n_flows = n_flows\n self.gin_channels = gin_channels\n\n self.flows = nn.ModuleList()\n for i in range(n_flows):\n self.flows.append(\n modules.ResidualCouplingLayer(\n channels,\n hidden_channels,\n kernel_size,\n dilation_rate,\n n_layers,\n gin_channels=gin_channels,\n mean_only=True,\n )\n )\n self.flows.append(modules.Flip())\n\n def forward(self, x, x_mask, g=None, reverse=False):\n if not reverse:\n for flow in self.flows:\n x, _ = flow(x, x_mask, g=g, reverse=reverse)\n else:\n for flow in reversed(self.flows):\n x = flow(x, x_mask, g=g, reverse=reverse)\n return x\n"
},
{
"path": "src/so_vits_svc_fork/modules/losses.py",
"content": "import torch\n\n\ndef feature_loss(fmap_r, fmap_g):\n loss = 0\n for dr, dg in zip(fmap_r, fmap_g):\n for rl, gl in zip(dr, dg):\n rl = rl.float().detach()\n gl = gl.float()\n loss += torch.mean(torch.abs(rl - gl))\n\n return loss * 2\n\n\ndef discriminator_loss(disc_real_outputs, disc_generated_outputs):\n loss = 0\n r_losses = []\n g_losses = []\n for dr, dg in zip(disc_real_outputs, disc_generated_outputs):\n dr = dr.float()\n dg = dg.float()\n r_loss = torch.mean((1 - dr) ** 2)\n g_loss = torch.mean(dg**2)\n loss += r_loss + g_loss\n r_losses.append(r_loss.item())\n g_losses.append(g_loss.item())\n\n return loss, r_losses, g_losses\n\n\ndef generator_loss(disc_outputs):\n loss = 0\n gen_losses = []\n for dg in disc_outputs:\n dg = dg.float()\n l = torch.mean((1 - dg) ** 2)\n gen_losses.append(l)\n loss += l\n\n return loss, gen_losses\n\n\ndef kl_loss(z_p, logs_q, m_p, logs_p, z_mask):\n \"\"\"\n z_p, logs_q: [b, h, t_t]\n m_p, logs_p: [b, h, t_t]\n \"\"\"\n z_p = z_p.float()\n logs_q = logs_q.float()\n m_p = m_p.float()\n logs_p = logs_p.float()\n z_mask = z_mask.float()\n # print(logs_p)\n kl = logs_p - logs_q - 0.5\n kl += 0.5 * ((z_p - m_p) ** 2) * torch.exp(-2.0 * logs_p)\n kl = torch.sum(kl * z_mask)\n l = kl / torch.sum(z_mask)\n return l\n"
},
{
"path": "src/so_vits_svc_fork/modules/mel_processing.py",
"content": "\"\"\"\nfrom logging import getLogger\n\nimport torch\nimport torch.utils.data\nimport torchaudio\n\nLOG = getLogger(__name__)\n\n\nfrom ..hparams import HParams\n\n\ndef spectrogram_torch(audio: torch.Tensor, hps: HParams) -> torch.Tensor:\n return torchaudio.transforms.Spectrogram(\n n_fft=hps.data.filter_length,\n win_length=hps.data.win_length,\n hop_length=hps.data.hop_length,\n power=1.0,\n window_fn=torch.hann_window,\n normalized=False,\n ).to(audio.device)(audio)\n\n\ndef spec_to_mel_torch(spec: torch.Tensor, hps: HParams) -> torch.Tensor:\n return torchaudio.transforms.MelScale(\n n_mels=hps.data.n_mel_channels,\n sample_rate=hps.data.sampling_rate,\n f_min=hps.data.mel_fmin,\n f_max=hps.data.mel_fmax,\n ).to(spec.device)(spec)\n\n\ndef mel_spectrogram_torch(audio: torch.Tensor, hps: HParams) -> torch.Tensor:\n return torchaudio.transforms.MelSpectrogram(\n sample_rate=hps.data.sampling_rate,\n n_fft=hps.data.filter_length,\n n_mels=hps.data.n_mel_channels,\n win_length=hps.data.win_length,\n hop_length=hps.data.hop_length,\n f_min=hps.data.mel_fmin,\n f_max=hps.data.mel_fmax,\n power=1.0,\n window_fn=torch.hann_window,\n normalized=False,\n ).to(audio.device)(audio)\n\"\"\"\n\nfrom logging import getLogger\n\nimport torch\nimport torch.utils.data\nfrom librosa.filters import mel as librosa_mel_fn\n\nLOG = getLogger(__name__)\n\nMAX_WAV_VALUE = 32768.0\n\n\ndef dynamic_range_compression_torch(x, C=1, clip_val=1e-5):\n \"\"\"\n PARAMS\n ------\n C: compression factor\n \"\"\"\n return torch.log(torch.clamp(x, min=clip_val) * C)\n\n\ndef dynamic_range_decompression_torch(x, C=1):\n \"\"\"\n PARAMS\n ------\n C: compression factor used to compress\n \"\"\"\n return torch.exp(x) / C\n\n\ndef spectral_normalize_torch(magnitudes):\n output = dynamic_range_compression_torch(magnitudes)\n return output\n\n\ndef spectral_de_normalize_torch(magnitudes):\n output = dynamic_range_decompression_torch(magnitudes)\n return output\n\n\nmel_basis = {}\nhann_window = {}\n\n\ndef spectrogram_torch(y, hps, center=False):\n if torch.min(y) < -1.0:\n LOG.info(\"min value is \", torch.min(y))\n if torch.max(y) > 1.0:\n LOG.info(\"max value is \", torch.max(y))\n n_fft = hps.data.filter_length\n hop_size = hps.data.hop_length\n win_size = hps.data.win_length\n global hann_window\n dtype_device = str(y.dtype) + \"_\" + str(y.device)\n wnsize_dtype_device = str(win_size) + \"_\" + dtype_device\n if wnsize_dtype_device not in hann_window:\n hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)\n\n y = torch.nn.functional.pad(\n y.unsqueeze(1),\n (int((n_fft - hop_size) / 2), int((n_fft - hop_size) / 2)),\n mode=\"reflect\",\n )\n y = y.squeeze(1)\n\n spec = torch.stft(\n y,\n n_fft,\n hop_length=hop_size,\n win_length=win_size,\n window=hann_window[wnsize_dtype_device],\n center=center,\n pad_mode=\"reflect\",\n normalized=False,\n onesided=True,\n return_complex=False,\n )\n\n spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)\n return spec\n\n\ndef spec_to_mel_torch(spec, hps):\n sampling_rate = hps.data.sampling_rate\n n_fft = hps.data.filter_length\n num_mels = hps.data.n_mel_channels\n fmin = hps.data.mel_fmin\n fmax = hps.data.mel_fmax\n global mel_basis\n dtype_device = str(spec.dtype) + \"_\" + str(spec.device)\n fmax_dtype_device = str(fmax) + \"_\" + dtype_device\n if fmax_dtype_device not in mel_basis:\n mel = librosa_mel_fn(sr=sampling_rate, n_fft=n_fft, n_mels=num_mels, fmin=fmin, fmax=fmax)\n mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=spec.dtype, device=spec.device)\n spec = torch.matmul(mel_basis[fmax_dtype_device], spec)\n spec = spectral_normalize_torch(spec)\n return spec\n\n\ndef mel_spectrogram_torch(y, hps, center=False):\n sampling_rate = hps.data.sampling_rate\n n_fft = hps.data.filter_length\n num_mels = hps.data.n_mel_channels\n fmin = hps.data.mel_fmin\n fmax = hps.data.mel_fmax\n hop_size = hps.data.hop_length\n win_size = hps.data.win_length\n if torch.min(y) < -1.0:\n LOG.info(f\"min value is {torch.min(y)}\")\n if torch.max(y) > 1.0:\n LOG.info(f\"max value is {torch.max(y)}\")\n\n global mel_basis, hann_window\n dtype_device = str(y.dtype) + \"_\" + str(y.device)\n fmax_dtype_device = str(fmax) + \"_\" + dtype_device\n wnsize_dtype_device = str(win_size) + \"_\" + dtype_device\n if fmax_dtype_device not in mel_basis:\n mel = librosa_mel_fn(sr=sampling_rate, n_fft=n_fft, n_mels=num_mels, fmin=fmin, fmax=fmax)\n mel_basis[fmax_dtype_device] = torch.from_numpy(mel).to(dtype=y.dtype, device=y.device)\n if wnsize_dtype_device not in hann_window:\n hann_window[wnsize_dtype_device] = torch.hann_window(win_size).to(dtype=y.dtype, device=y.device)\n\n y = torch.nn.functional.pad(\n y.unsqueeze(1),\n (int((n_fft - hop_size) / 2), int((n_fft - hop_size) / 2)),\n mode=\"reflect\",\n )\n y = y.squeeze(1)\n\n spec = torch.stft(\n y,\n n_fft,\n hop_length=hop_size,\n win_length=win_size,\n window=hann_window[wnsize_dtype_device],\n center=center,\n pad_mode=\"reflect\",\n normalized=False,\n onesided=True,\n return_complex=False,\n )\n\n spec = torch.sqrt(spec.pow(2).sum(-1) + 1e-6)\n\n spec = torch.matmul(mel_basis[fmax_dtype_device], spec)\n spec = spectral_normalize_torch(spec)\n\n return spec\n"
},
{
"path": "src/so_vits_svc_fork/modules/modules.py",
"content": "import torch\nfrom torch import nn\nfrom torch.nn import Conv1d\nfrom torch.nn import functional as F\nfrom torch.nn.utils import remove_weight_norm, weight_norm\n\nfrom so_vits_svc_fork.modules import commons\nfrom so_vits_svc_fork.modules.commons import get_padding, init_weights\n\nLRELU_SLOPE = 0.1\n\n\nclass LayerNorm(nn.Module):\n def __init__(self, channels, eps=1e-5):\n super().__init__()\n self.channels = channels\n self.eps = eps\n\n self.gamma = nn.Parameter(torch.ones(channels))\n self.beta = nn.Parameter(torch.zeros(channels))\n\n def forward(self, x):\n x = x.transpose(1, -1)\n x = F.layer_norm(x, (self.channels,), self.gamma, self.beta, self.eps)\n return x.transpose(1, -1)\n\n\nclass ConvReluNorm(nn.Module):\n def __init__(\n self,\n in_channels,\n hidden_channels,\n out_channels,\n kernel_size,\n n_layers,\n p_dropout,\n ):\n super().__init__()\n self.in_channels = in_channels\n self.hidden_channels = hidden_channels\n self.out_channels = out_channels\n self.kernel_size = kernel_size\n self.n_layers = n_layers\n self.p_dropout = p_dropout\n assert n_layers > 1, \"Number of layers should be larger than 0.\"\n\n self.conv_layers = nn.ModuleList()\n self.norm_layers = nn.ModuleList()\n self.conv_layers.append(nn.Conv1d(in_channels, hidden_channels, kernel_size, padding=kernel_size // 2))\n self.norm_layers.append(LayerNorm(hidden_channels))\n self.relu_drop = nn.Sequential(nn.ReLU(), nn.Dropout(p_dropout))\n for _ in range(n_layers - 1):\n self.conv_layers.append(\n nn.Conv1d(\n hidden_channels,\n hidden_channels,\n kernel_size,\n padding=kernel_size // 2,\n )\n )\n self.norm_layers.append(LayerNorm(hidden_channels))\n self.proj = nn.Conv1d(hidden_channels, out_channels, 1)\n self.proj.weight.data.zero_()\n self.proj.bias.data.zero_()\n\n def forward(self, x, x_mask):\n x_org = x\n for i in range(self.n_layers):\n x = self.conv_layers[i](x * x_mask)\n x = self.norm_layers[i](x)\n x = self.relu_drop(x)\n x = x_org + self.proj(x)\n return x * x_mask\n\n\nclass DDSConv(nn.Module):\n \"\"\"\n Dialted and Depth-Separable Convolution\n \"\"\"\n\n def __init__(self, channels, kernel_size, n_layers, p_dropout=0.0):\n super().__init__()\n self.channels = channels\n self.kernel_size = kernel_size\n self.n_layers = n_layers\n self.p_dropout = p_dropout\n\n self.drop = nn.Dropout(p_dropout)\n self.convs_sep = nn.ModuleList()\n self.convs_1x1 = nn.ModuleList()\n self.norms_1 = nn.ModuleList()\n self.norms_2 = nn.ModuleList()\n for i in range(n_layers):\n dilation = kernel_size**i\n padding = (kernel_size * dilation - dilation) // 2\n self.convs_sep.append(\n nn.Conv1d(\n channels,\n channels,\n kernel_size,\n groups=channels,\n dilation=dilation,\n padding=padding,\n )\n )\n self.convs_1x1.append(nn.Conv1d(channels, channels, 1))\n self.norms_1.append(LayerNorm(channels))\n self.norms_2.append(LayerNorm(channels))\n\n def forward(self, x, x_mask, g=None):\n if g is not None:\n x = x + g\n for i in range(self.n_layers):\n y = self.convs_sep[i](x * x_mask)\n y = self.norms_1[i](y)\n y = F.gelu(y)\n y = self.convs_1x1[i](y)\n y = self.norms_2[i](y)\n y = F.gelu(y)\n y = self.drop(y)\n x = x + y\n return x * x_mask\n\n\nclass WN(torch.nn.Module):\n def __init__(\n self,\n hidden_channels,\n kernel_size,\n dilation_rate,\n n_layers,\n gin_channels=0,\n p_dropout=0,\n ):\n super().__init__()\n assert kernel_size % 2 == 1\n self.hidden_channels = hidden_channels\n self.kernel_size = (kernel_size,)\n self.dilation_rate = dilation_rate\n self.n_layers = n_layers\n self.gin_channels = gin_channels\n self.p_dropout = p_dropout\n\n self.in_layers = torch.nn.ModuleList()\n self.res_skip_layers = torch.nn.ModuleList()\n self.drop = nn.Dropout(p_dropout)\n\n if gin_channels != 0:\n cond_layer = torch.nn.Conv1d(gin_channels, 2 * hidden_channels * n_layers, 1)\n self.cond_layer = torch.nn.utils.weight_norm(cond_layer, name=\"weight\")\n\n for i in range(n_layers):\n dilation = dilation_rate**i\n padding = int((kernel_size * dilation - dilation) / 2)\n in_layer = torch.nn.Conv1d(\n hidden_channels,\n 2 * hidden_channels,\n kernel_size,\n dilation=dilation,\n padding=padding,\n )\n in_layer = torch.nn.utils.weight_norm(in_layer, name=\"weight\")\n self.in_layers.append(in_layer)\n\n # last one is not necessary\n if i < n_layers - 1:\n res_skip_channels = 2 * hidden_channels\n else:\n res_skip_channels = hidden_channels\n\n res_skip_layer = torch.nn.Conv1d(hidden_channels, res_skip_channels, 1)\n res_skip_layer = torch.nn.utils.weight_norm(res_skip_layer, name=\"weight\")\n self.res_skip_layers.append(res_skip_layer)\n\n def forward(self, x, x_mask, g=None, **kwargs):\n output = torch.zeros_like(x)\n n_channels_tensor = torch.IntTensor([self.hidden_channels])\n\n if g is not None:\n g = self.cond_layer(g)\n\n for i in range(self.n_layers):\n x_in = self.in_layers[i](x)\n if g is not None:\n cond_offset = i * 2 * self.hidden_channels\n g_l = g[:, cond_offset : cond_offset + 2 * self.hidden_channels, :]\n else:\n g_l = torch.zeros_like(x_in)\n\n acts = commons.fused_add_tanh_sigmoid_multiply(x_in, g_l, n_channels_tensor)\n acts = self.drop(acts)\n\n res_skip_acts = self.res_skip_layers[i](acts)\n if i < self.n_layers - 1:\n res_acts = res_skip_acts[:, : self.hidden_channels, :]\n x = (x + res_acts) * x_mask\n output = output + res_skip_acts[:, self.hidden_channels :, :]\n else:\n output = output + res_skip_acts\n return output * x_mask\n\n def remove_weight_norm(self):\n if self.gin_channels != 0:\n torch.nn.utils.remove_weight_norm(self.cond_layer)\n for l in self.in_layers:\n torch.nn.utils.remove_weight_norm(l)\n for l in self.res_skip_layers:\n torch.nn.utils.remove_weight_norm(l)\n\n\nclass ResBlock1(torch.nn.Module):\n def __init__(self, channels, kernel_size=3, dilation=(1, 3, 5)):\n super().__init__()\n self.convs1 = nn.ModuleList(\n [\n weight_norm(\n Conv1d(\n channels,\n channels,\n kernel_size,\n 1,\n dilation=dilation[0],\n padding=get_padding(kernel_size, dilation[0]),\n )\n ),\n weight_norm(\n Conv1d(\n channels,\n channels,\n kernel_size,\n 1,\n dilation=dilation[1],\n padding=get_padding(kernel_size, dilation[1]),\n )\n ),\n weight_norm(\n Conv1d(\n channels,\n channels,\n kernel_size,\n 1,\n dilation=dilation[2],\n padding=get_padding(kernel_size, dilation[2]),\n )\n ),\n ]\n )\n self.convs1.apply(init_weights)\n\n self.convs2 = nn.ModuleList(\n [\n weight_norm(\n Conv1d(\n channels,\n channels,\n kernel_size,\n 1,\n dilation=1,\n padding=get_padding(kernel_size, 1),\n )\n ),\n weight_norm(\n Conv1d(\n channels,\n channels,\n kernel_size,\n 1,\n dilation=1,\n padding=get_padding(kernel_size, 1),\n )\n ),\n weight_norm(\n Conv1d(\n channels,\n channels,\n kernel_size,\n 1,\n dilation=1,\n padding=get_padding(kernel_size, 1),\n )\n ),\n ]\n )\n self.convs2.apply(init_weights)\n\n def forward(self, x, x_mask=None):\n for c1, c2 in zip(self.convs1, self.convs2):\n xt = F.leaky_relu(x, LRELU_SLOPE)\n if x_mask is not None:\n xt = xt * x_mask\n xt = c1(xt)\n xt = F.leaky_relu(xt, LRELU_SLOPE)\n if x_mask is not None:\n xt = xt * x_mask\n xt = c2(xt)\n x = xt + x\n if x_mask is not None:\n x = x * x_mask\n return x\n\n def remove_weight_norm(self):\n for l in self.convs1:\n remove_weight_norm(l)\n for l in self.convs2:\n remove_weight_norm(l)\n\n\nclass ResBlock2(torch.nn.Module):\n def __init__(self, channels, kernel_size=3, dilation=(1, 3)):\n super().__init__()\n self.convs = nn.ModuleList(\n [\n weight_norm(\n Conv1d(\n channels,\n channels,\n kernel_size,\n 1,\n dilation=dilation[0],\n padding=get_padding(kernel_size, dilation[0]),\n )\n ),\n weight_norm(\n Conv1d(\n channels,\n channels,\n kernel_size,\n 1,\n dilation=dilation[1],\n padding=get_padding(kernel_size, dilation[1]),\n )\n ),\n ]\n )\n self.convs.apply(init_weights)\n\n def forward(self, x, x_mask=None):\n for c in self.convs:\n xt = F.leaky_relu(x, LRELU_SLOPE)\n if x_mask is not None:\n xt = xt * x_mask\n xt = c(xt)\n x = xt + x\n if x_mask is not None:\n x = x * x_mask\n return x\n\n def remove_weight_norm(self):\n for l in self.convs:\n remove_weight_norm(l)\n\n\nclass Log(nn.Module):\n def forward(self, x, x_mask, reverse=False, **kwargs):\n if not reverse:\n y = torch.log(torch.clamp_min(x, 1e-5)) * x_mask\n logdet = torch.sum(-y, [1, 2])\n return y, logdet\n else:\n x = torch.exp(x) * x_mask\n return x\n\n\nclass Flip(nn.Module):\n def forward(self, x, *args, reverse=False, **kwargs):\n x = torch.flip(x, [1])\n if not reverse:\n logdet = torch.zeros(x.size(0)).to(dtype=x.dtype, device=x.device)\n return x, logdet\n else:\n return x\n\n\nclass ElementwiseAffine(nn.Module):\n def __init__(self, channels):\n super().__init__()\n self.channels = channels\n self.m = nn.Parameter(torch.zeros(channels, 1))\n self.logs = nn.Parameter(torch.zeros(channels, 1))\n\n def forward(self, x, x_mask, reverse=False, **kwargs):\n if not reverse:\n y = self.m + torch.exp(self.logs) * x\n y = y * x_mask\n logdet = torch.sum(self.logs * x_mask, [1, 2])\n return y, logdet\n else:\n x = (x - self.m) * torch.exp(-self.logs) * x_mask\n return x\n\n\nclass ResidualCouplingLayer(nn.Module):\n def __init__(\n self,\n channels,\n hidden_channels,\n kernel_size,\n dilation_rate,\n n_layers,\n p_dropout=0,\n gin_channels=0,\n mean_only=False,\n ):\n assert channels % 2 == 0, \"channels should be divisible by 2\"\n super().__init__()\n self.channels = channels\n self.hidden_channels = hidden_channels\n self.kernel_size = kernel_size\n self.dilation_rate = dilation_rate\n self.n_layers = n_layers\n self.half_channels = channels // 2\n self.mean_only = mean_only\n\n self.pre = nn.Conv1d(self.half_channels, hidden_channels, 1)\n self.enc = WN(\n hidden_channels,\n kernel_size,\n dilation_rate,\n n_layers,\n p_dropout=p_dropout,\n gin_channels=gin_channels,\n )\n self.post = nn.Conv1d(hidden_channels, self.half_channels * (2 - mean_only), 1)\n self.post.weight.data.zero_()\n self.post.bias.data.zero_()\n\n def forward(self, x, x_mask, g=None, reverse=False):\n x0, x1 = torch.split(x, [self.half_channels] * 2, 1)\n h = self.pre(x0) * x_mask\n h = self.enc(h, x_mask, g=g)\n stats = self.post(h) * x_mask\n if not self.mean_only:\n m, logs = torch.split(stats, [self.half_channels] * 2, 1)\n else:\n m = stats\n logs = torch.zeros_like(m)\n\n if not reverse:\n x1 = m + x1 * torch.exp(logs) * x_mask\n x = torch.cat([x0, x1], 1)\n logdet = torch.sum(logs, [1, 2])\n return x, logdet\n else:\n x1 = (x1 - m) * torch.exp(-logs) * x_mask\n x = torch.cat([x0, x1], 1)\n return x\n"
},
{
"path": "src/so_vits_svc_fork/modules/synthesizers.py",
"content": "import warnings\nfrom collections.abc import Sequence\nfrom logging import getLogger\nfrom typing import Any, Literal\n\nimport torch\nfrom torch import nn\n\nimport so_vits_svc_fork.f0\nfrom so_vits_svc_fork.f0 import f0_to_coarse\nfrom so_vits_svc_fork.modules import commons as commons\nfrom so_vits_svc_fork.modules.decoders.f0 import F0Decoder\nfrom so_vits_svc_fork.modules.decoders.hifigan import NSFHifiGANGenerator\nfrom so_vits_svc_fork.modules.decoders.mb_istft import (\n Multiband_iSTFT_Generator,\n Multistream_iSTFT_Generator,\n iSTFT_Generator,\n)\nfrom so_vits_svc_fork.modules.encoders import Encoder, TextEncoder\nfrom so_vits_svc_fork.modules.flows import ResidualCouplingBlock\n\nLOG = getLogger(__name__)\n\n\nclass SynthesizerTrn(nn.Module):\n \"\"\"\n Synthesizer for Training\n \"\"\"\n\n def __init__(\n self,\n spec_channels: int,\n segment_size: int,\n inter_channels: int,\n hidden_channels: int,\n filter_channels: int,\n n_heads: int,\n n_layers: int,\n kernel_size: int,\n p_dropout: int,\n resblock: str,\n resblock_kernel_sizes: Sequence[int],\n resblock_dilation_sizes: Sequence[Sequence[int]],\n upsample_rates: Sequence[int],\n upsample_initial_channel: int,\n upsample_kernel_sizes: Sequence[int],\n gin_channels: int,\n ssl_dim: int,\n n_speakers: int,\n sampling_rate: int = 44100,\n type_: Literal[\"hifi-gan\", \"istft\", \"ms-istft\", \"mb-istft\"] = \"hifi-gan\",\n gen_istft_n_fft: int = 16,\n gen_istft_hop_size: int = 4,\n subbands: int = 4,\n **kwargs: Any,\n ):\n super().__init__()\n self.spec_channels = spec_channels\n self.inter_channels = inter_channels\n self.hidden_channels = hidden_channels\n self.filter_channels = filter_channels\n self.n_heads = n_heads\n self.n_layers = n_layers\n self.kernel_size = kernel_size\n self.p_dropout = p_dropout\n self.resblock = resblock\n self.resblock_kernel_sizes = resblock_kernel_sizes\n self.resblock_dilation_sizes = resblock_dilation_sizes\n self.upsample_rates = upsample_rates\n self.upsample_initial_channel = upsample_initial_channel\n self.upsample_kernel_sizes = upsample_kernel_sizes\n self.segment_size = segment_size\n self.gin_channels = gin_channels\n self.ssl_dim = ssl_dim\n self.n_speakers = n_speakers\n self.sampling_rate = sampling_rate\n self.type_ = type_\n self.gen_istft_n_fft = gen_istft_n_fft\n self.gen_istft_hop_size = gen_istft_hop_size\n self.subbands = subbands\n if kwargs:\n warnings.warn(f\"Unused arguments: {kwargs}\")\n\n self.emb_g = nn.Embedding(n_speakers, gin_channels)\n\n if ssl_dim is None:\n self.pre = nn.LazyConv1d(hidden_channels, kernel_size=5, padding=2)\n else:\n self.pre = nn.Conv1d(ssl_dim, hidden_channels, kernel_size=5, padding=2)\n\n self.enc_p = TextEncoder(\n inter_channels,\n hidden_channels,\n filter_channels=filter_channels,\n n_heads=n_heads,\n n_layers=n_layers,\n kernel_size=kernel_size,\n p_dropout=p_dropout,\n )\n\n LOG.info(f\"Decoder type: {type_}\")\n if type_ == \"hifi-gan\":\n hps = {\n \"sampling_rate\": sampling_rate,\n \"inter_channels\": inter_channels,\n \"resblock\": resblock,\n \"resblock_kernel_sizes\": resblock_kernel_sizes,\n \"resblock_dilation_sizes\": resblock_dilation_sizes,\n \"upsample_rates\": upsample_rates,\n \"upsample_initial_channel\": upsample_initial_channel,\n \"upsample_kernel_sizes\": upsample_kernel_sizes,\n \"gin_channels\": gin_channels,\n }\n self.dec = NSFHifiGANGenerator(h=hps)\n self.mb = False\n else:\n hps = {\n \"initial_channel\": inter_channels,\n \"resblock\": resblock,\n \"resblock_kernel_sizes\": resblock_kernel_sizes,\n \"resblock_dilation_sizes\": resblock_dilation_sizes,\n \"upsample_rates\": upsample_rates,\n \"upsample_initial_channel\": upsample_initial_channel,\n \"upsample_kernel_sizes\": upsample_kernel_sizes,\n \"gin_channels\": gin_channels,\n \"gen_istft_n_fft\": gen_istft_n_fft,\n \"gen_istft_hop_size\": gen_istft_hop_size,\n \"subbands\": subbands,\n }\n\n # gen_istft_n_fft, gen_istft_hop_size, subbands\n if type_ == \"istft\":\n del hps[\"subbands\"]\n self.dec = iSTFT_Generator(**hps)\n elif type_ == \"ms-istft\":\n self.dec = Multistream_iSTFT_Generator(**hps)\n elif type_ == \"mb-istft\":\n self.dec = Multiband_iSTFT_Generator(**hps)\n else:\n raise ValueError(f\"Unknown type: {type_}\")\n self.mb = True\n\n self.enc_q = Encoder(\n spec_channels,\n inter_channels,\n hidden_channels,\n 5,\n 1,\n 16,\n gin_channels=gin_channels,\n )\n self.flow = ResidualCouplingBlock(inter_channels, hidden_channels, 5, 1, 4, gin_channels=gin_channels)\n self.f0_decoder = F0Decoder(\n 1,\n hidden_channels,\n filter_channels,\n n_heads,\n n_layers,\n kernel_size,\n p_dropout,\n spk_channels=gin_channels,\n )\n self.emb_uv = nn.Embedding(2, hidden_channels)\n\n def forward(self, c, f0, uv, spec, g=None, c_lengths=None, spec_lengths=None):\n g = self.emb_g(g).transpose(1, 2)\n # ssl prenet\n x_mask = torch.unsqueeze(commons.sequence_mask(c_lengths, c.size(2)), 1).to(c.dtype)\n x = self.pre(c) * x_mask + self.emb_uv(uv.long()).transpose(1, 2)\n\n # f0 predict\n lf0 = 2595.0 * torch.log10(1.0 + f0.unsqueeze(1) / 700.0) / 500\n norm_lf0 = so_vits_svc_fork.f0.normalize_f0(lf0, x_mask, uv)\n pred_lf0 = self.f0_decoder(x, norm_lf0, x_mask, spk_emb=g)\n\n # encoder\n z_ptemp, m_p, logs_p, _ = self.enc_p(x, x_mask, f0=f0_to_coarse(f0))\n z, m_q, logs_q, spec_mask = self.enc_q(spec, spec_lengths, g=g)\n\n # flow\n z_p = self.flow(z, spec_mask, g=g)\n z_slice, pitch_slice, ids_slice = commons.rand_slice_segments_with_pitch(z, f0, spec_lengths, self.segment_size)\n\n # MB-iSTFT-VITS\n if self.mb:\n o, o_mb = self.dec(z_slice, g=g)\n # HiFi-GAN\n else:\n o = self.dec(z_slice, g=g, f0=pitch_slice)\n o_mb = None\n return (\n o,\n o_mb,\n ids_slice,\n spec_mask,\n (z, z_p, m_p, logs_p, m_q, logs_q),\n pred_lf0,\n norm_lf0,\n lf0,\n )\n\n def infer(self, c, f0, uv, g=None, noice_scale=0.35, predict_f0=False):\n c_lengths = (torch.ones(c.size(0)) * c.size(-1)).to(c.device)\n g = self.emb_g(g).transpose(1, 2)\n x_mask = torch.unsqueeze(commons.sequence_mask(c_lengths, c.size(2)), 1).to(c.dtype)\n x = self.pre(c) * x_mask + self.emb_uv(uv.long()).transpose(1, 2)\n\n if predict_f0:\n lf0 = 2595.0 * torch.log10(1.0 + f0.unsqueeze(1) / 700.0) / 500\n norm_lf0 = so_vits_svc_fork.f0.normalize_f0(lf0, x_mask, uv, random_scale=False)\n pred_lf0 = self.f0_decoder(x, norm_lf0, x_mask, spk_emb=g)\n f0 = (700 * (torch.pow(10, pred_lf0 * 500 / 2595) - 1)).squeeze(1)\n\n z_p, m_p, logs_p, c_mask = self.enc_p(x, x_mask, f0=f0_to_coarse(f0), noice_scale=noice_scale)\n z = self.flow(z_p, c_mask, g=g, reverse=True)\n\n # MB-iSTFT-VITS\n if self.mb:\n o, o_mb = self.dec(z * c_mask, g=g)\n else:\n o = self.dec(z * c_mask, g=g, f0=f0)\n return o\n"
},
{
"path": "src/so_vits_svc_fork/preprocessing/__init__.py",
"content": ""
},
{
"path": "src/so_vits_svc_fork/preprocessing/config_templates/__init__.py",
"content": ""
},
{
"path": "src/so_vits_svc_fork/preprocessing/config_templates/quickvc.json",
"content": "{\n \"train\": {\n \"log_interval\": 100,\n \"eval_interval\": 200,\n \"seed\": 1234,\n \"epochs\": 10000,\n \"learning_rate\": 0.0001,\n \"betas\": [0.8, 0.99],\n \"eps\": 1e-9,\n \"batch_size\": 16,\n \"fp16_run\": false,\n \"bf16_run\": false,\n \"lr_decay\": 0.999875,\n \"segment_size\": 10240,\n \"init_lr_ratio\": 1,\n \"warmup_epochs\": 0,\n \"c_mel\": 45,\n \"c_kl\": 1.0,\n \"use_sr\": true,\n \"max_speclen\": 512,\n \"port\": \"8001\",\n \"keep_ckpts\": 3,\n \"fft_sizes\": [768, 1366, 342],\n \"hop_sizes\": [60, 120, 20],\n \"win_lengths\": [300, 600, 120],\n \"window\": \"hann_window\",\n \"num_workers\": 4,\n \"log_version\": 0,\n \"ckpt_name_by_step\": false,\n \"accumulate_grad_batches\": 1\n },\n \"data\": {\n \"training_files\": \"filelists/44k/train.txt\",\n \"validation_files\": \"filelists/44k/val.txt\",\n \"max_wav_value\": 32768.0,\n \"sampling_rate\": 44100,\n \"filter_length\": 2048,\n \"hop_length\": 512,\n \"win_length\": 2048,\n \"n_mel_channels\": 80,\n \"mel_fmin\": 0.0,\n \"mel_fmax\": 22050,\n \"contentvec_final_proj\": false\n },\n \"model\": {\n \"inter_channels\": 192,\n \"hidden_channels\": 192,\n \"filter_channels\": 768,\n \"n_heads\": 2,\n \"n_layers\": 6,\n \"kernel_size\": 3,\n \"p_dropout\": 0.1,\n \"resblock\": \"1\",\n \"resblock_kernel_sizes\": [3, 7, 11],\n \"resblock_dilation_sizes\": [\n [1, 3, 5],\n [1, 3, 5],\n [1, 3, 5]\n ],\n \"upsample_rates\": [8, 4],\n \"upsample_initial_channel\": 512,\n \"upsample_kernel_sizes\": [32, 16],\n \"n_layers_q\": 3,\n \"use_spectral_norm\": false,\n \"gin_channels\": 256,\n \"ssl_dim\": 768,\n \"n_speakers\": 200,\n \"type_\": \"ms-istft\",\n \"gen_istft_n_fft\": 16,\n \"gen_istft_hop_size\": 4,\n \"subbands\": 4,\n \"pretrained\": {\n \"D_0.pth\": \"https://huggingface.co/datasets/ms903/sovits4.0-768vec-layer12/resolve/main/sovits_768l12_pre_large_320k/clean_D_320000.pth\",\n \"G_0.pth\": \"https://huggingface.co/datasets/ms903/sovits4.0-768vec-layer12/resolve/main/sovits_768l12_pre_large_320k/clean_G_320000.pth\"\n }\n },\n \"spk\": {}\n}\n"
},
{
"path": "src/so_vits_svc_fork/preprocessing/config_templates/so-vits-svc-4.0v1-legacy.json",
"content": "{\n \"train\": {\n \"log_interval\": 200,\n \"eval_interval\": 800,\n \"seed\": 1234,\n \"epochs\": 10000,\n \"learning_rate\": 0.0001,\n \"betas\": [0.8, 0.99],\n \"eps\": 1e-9,\n \"batch_size\": 16,\n \"fp16_run\": false,\n \"bf16_run\": false,\n \"lr_decay\": 0.999875,\n \"segment_size\": 10240,\n \"init_lr_ratio\": 1,\n \"warmup_epochs\": 0,\n \"c_mel\": 45,\n \"c_kl\": 1.0,\n \"use_sr\": true,\n \"max_speclen\": 512,\n \"port\": \"8001\",\n \"keep_ckpts\": 3,\n \"num_workers\": 4,\n \"log_version\": 0,\n \"ckpt_name_by_step\": false,\n \"accumulate_grad_batches\": 1\n },\n \"data\": {\n \"training_files\": \"filelists/44k/train.txt\",\n \"validation_files\": \"filelists/44k/val.txt\",\n \"max_wav_value\": 32768.0,\n \"sampling_rate\": 44100,\n \"filter_length\": 2048,\n \"hop_length\": 512,\n \"win_length\": 2048,\n \"n_mel_channels\": 80,\n \"mel_fmin\": 0.0,\n \"mel_fmax\": 22050\n },\n \"model\": {\n \"inter_channels\": 192,\n \"hidden_channels\": 192,\n \"filter_channels\": 768,\n \"n_heads\": 2,\n \"n_layers\": 6,\n \"kernel_size\": 3,\n \"p_dropout\": 0.1,\n \"resblock\": \"1\",\n \"resblock_kernel_sizes\": [3, 7, 11],\n \"resblock_dilation_sizes\": [\n [1, 3, 5],\n [1, 3, 5],\n [1, 3, 5]\n ],\n \"upsample_rates\": [8, 8, 2, 2, 2],\n \"upsample_initial_channel\": 512,\n \"upsample_kernel_sizes\": [16, 16, 4, 4, 4],\n \"n_layers_q\": 3,\n \"use_spectral_norm\": false,\n \"gin_channels\": 256,\n \"ssl_dim\": 256,\n \"n_speakers\": 200,\n \"pretrained\": {\n \"D_0.pth\": \"https://huggingface.co/therealvul/so-vits-svc-4.0-init/resolve/main/D_0.pth\",\n \"G_0.pth\": \"https://huggingface.co/therealvul/so-vits-svc-4.0-init/resolve/main/G_0.pth\"\n }\n },\n \"spk\": {}\n}\n"
},
{
"path": "src/so_vits_svc_fork/preprocessing/config_templates/so-vits-svc-4.0v1.json",
"content": "{\n \"train\": {\n \"log_interval\": 100,\n \"eval_interval\": 200,\n \"seed\": 1234,\n \"epochs\": 10000,\n \"learning_rate\": 0.0001,\n \"betas\": [0.8, 0.99],\n \"eps\": 1e-9,\n \"batch_size\": 16,\n \"fp16_run\": false,\n \"bf16_run\": false,\n \"lr_decay\": 0.999875,\n \"segment_size\": 10240,\n \"init_lr_ratio\": 1,\n \"warmup_epochs\": 0,\n \"c_mel\": 45,\n \"c_kl\": 1.0,\n \"use_sr\": true,\n \"max_speclen\": 512,\n \"port\": \"8001\",\n \"keep_ckpts\": 3,\n \"num_workers\": 4,\n \"log_version\": 0,\n \"ckpt_name_by_step\": false,\n \"accumulate_grad_batches\": 1\n },\n \"data\": {\n \"training_files\": \"filelists/44k/train.txt\",\n \"validation_files\": \"filelists/44k/val.txt\",\n \"max_wav_value\": 32768.0,\n \"sampling_rate\": 44100,\n \"filter_length\": 2048,\n \"hop_length\": 512,\n \"win_length\": 2048,\n \"n_mel_channels\": 80,\n \"mel_fmin\": 0.0,\n \"mel_fmax\": 22050,\n \"contentvec_final_proj\": false\n },\n \"model\": {\n \"inter_channels\": 192,\n \"hidden_channels\": 192,\n \"filter_channels\": 768,\n \"n_heads\": 2,\n \"n_layers\": 6,\n \"kernel_size\": 3,\n \"p_dropout\": 0.1,\n \"resblock\": \"1\",\n \"resblock_kernel_sizes\": [3, 7, 11],\n \"resblock_dilation_sizes\": [\n [1, 3, 5],\n [1, 3, 5],\n [1, 3, 5]\n ],\n \"upsample_rates\": [8, 8, 2, 2, 2],\n \"upsample_initial_channel\": 512,\n \"upsample_kernel_sizes\": [16, 16, 4, 4, 4],\n \"n_layers_q\": 3,\n \"use_spectral_norm\": false,\n \"gin_channels\": 256,\n \"ssl_dim\": 768,\n \"n_speakers\": 200,\n \"type_\": \"hifi-gan\",\n \"pretrained\": {\n \"D_0.pth\": \"https://huggingface.co/datasets/ms903/sovits4.0-768vec-layer12/resolve/main/sovits_768l12_pre_large_320k/clean_D_320000.pth\",\n \"G_0.pth\": \"https://huggingface.co/datasets/ms903/sovits4.0-768vec-layer12/resolve/main/sovits_768l12_pre_large_320k/clean_G_320000.pth\"\n }\n },\n \"spk\": {}\n}\n"
},
{
"path": "src/so_vits_svc_fork/preprocessing/preprocess_classify.py",
"content": "from __future__ import annotations\n\nfrom logging import getLogger\nfrom pathlib import Path\n\nimport keyboard\nimport librosa\nimport sounddevice as sd\nimport soundfile as sf\nfrom rich.console import Console\nfrom tqdm.rich import tqdm\n\nLOG = getLogger(__name__)\n\n\ndef preprocess_classify(input_dir: Path | str, output_dir: Path | str, create_new: bool = True) -> None:\n # paths\n input_dir_ = Path(input_dir)\n output_dir_ = Path(output_dir)\n speed = 1\n if not input_dir_.is_dir():\n raise ValueError(f\"{input_dir} is not a directory.\")\n output_dir_.mkdir(exist_ok=True)\n\n console = Console()\n # get audio paths and folders\n audio_paths = list(input_dir_.glob(\"*.*\"))\n last_folders = [x for x in output_dir_.glob(\"*\") if x.is_dir()]\n console.print(\"Press ↑ or ↓ to change speed. Press any other key to classify.\")\n console.print(f\"Folders: {[x.name for x in last_folders]}\")\n\n pbar_description = \"\"\n\n pbar = tqdm(audio_paths)\n for audio_path in pbar:\n # read file\n audio, sr = sf.read(audio_path)\n\n # update description\n duration = librosa.get_duration(y=audio, sr=sr)\n pbar_description = f\"{duration:.1f} {pbar_description}\"\n pbar.set_description(pbar_description)\n\n while True:\n # start playing\n sd.play(librosa.effects.time_stretch(audio, rate=speed), sr, loop=True)\n\n # wait for key press\n key = str(keyboard.read_key())\n if key == \"down\":\n speed /= 1.1\n console.print(f\"Speed: {speed:.2f}\")\n elif key == \"up\":\n speed *= 1.1\n console.print(f\"Speed: {speed:.2f}\")\n else:\n break\n\n # stop playing\n sd.stop()\n\n # print if folder changed\n folders = [x for x in output_dir_.glob(\"*\") if x.is_dir()]\n if folders != last_folders:\n console.print(f\"Folders updated: {[x.name for x in folders]}\")\n last_folders = folders\n\n # get folder\n folder_candidates = [x for x in folders if x.name.startswith(key)]\n if len(folder_candidates) == 0:\n if create_new:\n folder = output_dir_ / key\n else:\n console.print(f\"No folder starts with {key}.\")\n continue\n else:\n if len(folder_candidates) > 1:\n LOG.warning(\n f\"Multiple folders ({[x.name for x in folder_candidates]}) start with {key}. Using first one ({folder_candidates[0].name}).\"\n )\n folder = folder_candidates[0]\n folder.mkdir(exist_ok=True)\n\n # move file\n new_path = folder / audio_path.name\n audio_path.rename(new_path)\n\n # update description\n pbar_description = f\"Last: {audio_path.name} -> {folder.name}\"\n\n # yield result\n # yield audio_path, key, folder, new_path\n"
},
{
"path": "src/so_vits_svc_fork/preprocessing/preprocess_flist_config.py",
"content": "from __future__ import annotations\n\nimport json\nimport os\nfrom copy import deepcopy\nfrom logging import getLogger\nfrom pathlib import Path\n\nimport numpy as np\nfrom librosa import get_duration\nfrom tqdm import tqdm\n\nLOG = getLogger(__name__)\nCONFIG_TEMPLATE_DIR = Path(__file__).parent / \"config_templates\"\n\n\ndef preprocess_config(\n input_dir: Path | str,\n train_list_path: Path | str,\n val_list_path: Path | str,\n test_list_path: Path | str,\n config_path: Path | str,\n config_name: str,\n):\n input_dir = Path(input_dir)\n train_list_path = Path(train_list_path)\n val_list_path = Path(val_list_path)\n test_list_path = Path(test_list_path)\n config_path = Path(config_path)\n train = []\n val = []\n test = []\n spk_dict = {}\n spk_id = 0\n random = np.random.RandomState(1234)\n for speaker in os.listdir(input_dir):\n spk_dict[speaker] = spk_id\n spk_id += 1\n paths = []\n for path in tqdm(list((input_dir / speaker).rglob(\"*.wav\"))):\n if get_duration(filename=path) < 0.3:\n LOG.warning(f\"skip {path} because it is too short.\")\n continue\n paths.append(path)\n random.shuffle(paths)\n if len(paths) <= 4:\n raise ValueError(f\"too few files in {input_dir / speaker} (expected at least 5).\")\n train += paths[2:-2]\n val += paths[:2]\n test += paths[-2:]\n\n LOG.info(f\"Writing {train_list_path}\")\n train_list_path.parent.mkdir(parents=True, exist_ok=True)\n train_list_path.write_text(\"\\n\".join([x.as_posix() for x in train]), encoding=\"utf-8\")\n\n LOG.info(f\"Writing {val_list_path}\")\n val_list_path.parent.mkdir(parents=True, exist_ok=True)\n val_list_path.write_text(\"\\n\".join([x.as_posix() for x in val]), encoding=\"utf-8\")\n\n LOG.info(f\"Writing {test_list_path}\")\n test_list_path.parent.mkdir(parents=True, exist_ok=True)\n test_list_path.write_text(\"\\n\".join([x.as_posix() for x in test]), encoding=\"utf-8\")\n\n config = deepcopy(\n json.loads((CONFIG_TEMPLATE_DIR / (config_name if config_name.endswith(\".json\") else config_name + \".json\")).read_text(encoding=\"utf-8\"))\n )\n config[\"spk\"] = spk_dict\n config[\"data\"][\"training_files\"] = train_list_path.as_posix()\n config[\"data\"][\"validation_files\"] = val_list_path.as_posix()\n LOG.info(f\"Writing {config_path}\")\n config_path.parent.mkdir(parents=True, exist_ok=True)\n with config_path.open(\"w\", encoding=\"utf-8\") as f:\n json.dump(config, f, indent=2)\n"
},
{
"path": "src/so_vits_svc_fork/preprocessing/preprocess_hubert_f0.py",
"content": "from __future__ import annotations\n\nfrom collections.abc import Iterable\nfrom logging import getLogger\nfrom pathlib import Path\nfrom random import shuffle\nfrom typing import Literal\n\nimport librosa\nimport numpy as np\nimport torch\nimport torchaudio\nfrom joblib import Parallel, cpu_count, delayed\nfrom tqdm import tqdm\nfrom transformers import HubertModel\n\nimport so_vits_svc_fork.f0\nfrom so_vits_svc_fork import utils\n\nfrom ..hparams import HParams\nfrom ..modules.mel_processing import spec_to_mel_torch, spectrogram_torch\nfrom ..utils import get_optimal_device, get_total_gpu_memory\nfrom .preprocess_utils import check_hubert_min_duration\n\nLOG = getLogger(__name__)\nHUBERT_MEMORY = 2900\nHUBERT_MEMORY_CREPE = 3900\n\n\ndef _process_one(\n *,\n filepath: Path,\n content_model: HubertModel,\n device: torch.device | str = get_optimal_device(),\n f0_method: Literal[\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"] = \"dio\",\n force_rebuild: bool = False,\n hps: HParams,\n):\n audio, sr = librosa.load(filepath, sr=hps.data.sampling_rate, mono=True)\n\n if not check_hubert_min_duration(audio, sr):\n LOG.info(f\"Skip {filepath} because it is too short.\")\n return\n\n data_path = filepath.parent / (filepath.name + \".data.pt\")\n if data_path.exists() and not force_rebuild:\n return\n\n # Compute f0\n f0 = so_vits_svc_fork.f0.compute_f0(audio, sampling_rate=sr, hop_length=hps.data.hop_length, method=f0_method)\n f0, uv = so_vits_svc_fork.f0.interpolate_f0(f0)\n f0 = torch.from_numpy(f0).float()\n uv = torch.from_numpy(uv).float()\n\n # Compute HuBERT content\n audio = torch.from_numpy(audio).float().to(device)\n c = utils.get_content(\n content_model,\n audio,\n device,\n sr=sr,\n legacy_final_proj=hps.data.get(\"contentvec_final_proj\", True),\n )\n c = utils.repeat_expand_2d(c.squeeze(0), f0.shape[0])\n torch.cuda.empty_cache()\n\n # Compute spectrogram\n audio, sr = torchaudio.load(filepath)\n spec = spectrogram_torch(audio, hps).squeeze(0)\n mel_spec = spec_to_mel_torch(spec, hps)\n torch.cuda.empty_cache()\n\n # fix lengths\n lmin = min(spec.shape[1], mel_spec.shape[1], f0.shape[0], uv.shape[0], c.shape[1])\n spec, mel_spec, f0, uv, c = (\n spec[:, :lmin],\n mel_spec[:, :lmin],\n f0[:lmin],\n uv[:lmin],\n c[:, :lmin],\n )\n\n # get speaker id\n spk_name = filepath.parent.name\n spk = hps.spk.__dict__[spk_name]\n spk = torch.tensor(spk).long()\n assert spec.shape[1] == mel_spec.shape[1] == f0.shape[0] == uv.shape[0] == c.shape[1], (\n spec.shape,\n mel_spec.shape,\n f0.shape,\n uv.shape,\n c.shape,\n )\n data = {\n \"spec\": spec,\n \"mel_spec\": mel_spec,\n \"f0\": f0,\n \"uv\": uv,\n \"content\": c,\n \"audio\": audio,\n \"spk\": spk,\n }\n data = {k: v.cpu() for k, v in data.items()}\n with data_path.open(\"wb\") as f:\n torch.save(data, f)\n\n\ndef _process_batch(filepaths: Iterable[Path], pbar_position: int, **kwargs):\n hps = kwargs[\"hps\"]\n content_model = utils.get_hubert_model(get_optimal_device(), hps.data.get(\"contentvec_final_proj\", True))\n\n for filepath in tqdm(filepaths, position=pbar_position):\n _process_one(\n content_model=content_model,\n filepath=filepath,\n **kwargs,\n )\n\n\ndef preprocess_hubert_f0(\n input_dir: Path | str,\n config_path: Path | str,\n n_jobs: int | None = None,\n f0_method: Literal[\"crepe\", \"crepe-tiny\", \"parselmouth\", \"dio\", \"harvest\"] = \"dio\",\n force_rebuild: bool = False,\n):\n input_dir = Path(input_dir)\n config_path = Path(config_path)\n hps = utils.get_hparams(config_path)\n if n_jobs is None:\n # add cpu_count() to avoid SIGKILL\n memory = get_total_gpu_memory(\"total\")\n n_jobs = min(\n max(\n (memory // (HUBERT_MEMORY_CREPE if f0_method == \"crepe\" else HUBERT_MEMORY) if memory is not None else 1),\n 1,\n ),\n cpu_count(),\n )\n LOG.info(f\"n_jobs automatically set to {n_jobs}, memory: {memory} MiB\")\n\n filepaths = list(input_dir.rglob(\"*.wav\"))\n n_jobs = min(len(filepaths) // 16 + 1, n_jobs)\n shuffle(filepaths)\n filepath_chunks = np.array_split(filepaths, n_jobs)\n Parallel(n_jobs=n_jobs)(\n delayed(_process_batch)(\n filepaths=chunk,\n pbar_position=pbar_position,\n f0_method=f0_method,\n force_rebuild=force_rebuild,\n hps=hps,\n )\n for (pbar_position, chunk) in enumerate(filepath_chunks)\n )\n"
},
{
"path": "src/so_vits_svc_fork/preprocessing/preprocess_resample.py",
"content": "from __future__ import annotations\n\nimport warnings\nfrom collections.abc import Iterable\nfrom logging import getLogger\nfrom pathlib import Path\n\nimport librosa\nimport soundfile\nfrom joblib import Parallel, delayed\nfrom tqdm_joblib import tqdm_joblib\n\nfrom .preprocess_utils import check_hubert_min_duration\n\nLOG = getLogger(__name__)\n\n# input_dir and output_dir exists.\n# write code to convert input dir audio files to output dir audio files,\n# without changing folder structure. Use joblib to parallelize.\n# Converting audio files includes:\n# - resampling to specified sampling rate\n# - trim silence\n# - adjust volume in a smart way\n# - save as 16-bit wav file\n\n\ndef _get_unique_filename(path: Path, existing_paths: Iterable[Path]) -> Path:\n \"\"\"Return a unique path by appending a number to the original path.\"\"\"\n if path not in existing_paths:\n return path\n i = 1\n while True:\n new_path = path.parent / f\"{path.stem}_{i}{path.suffix}\"\n if new_path not in existing_paths:\n return new_path\n i += 1\n\n\ndef is_relative_to(path: Path, *other):\n \"\"\"\n Return True if the path is relative to another path or False.\n Python 3.9+ has Path.is_relative_to() method, but we need to support Python 3.8.\n \"\"\"\n try:\n path.relative_to(*other)\n return True\n except ValueError:\n return False\n\n\ndef _preprocess_one(\n input_path: Path,\n output_path: Path,\n sr: int,\n *,\n top_db: int,\n frame_seconds: float,\n hop_seconds: float,\n) -> None:\n \"\"\"Preprocess one audio file.\"\"\"\n try:\n audio, sr = librosa.load(input_path, sr=sr, mono=True)\n\n # Audioread is the last backend it will attempt, so this is the exception thrown on failure\n except Exception as e:\n # Failure due to attempting to load a file that is not audio, so return early\n LOG.warning(f\"Failed to load {input_path} due to {e}\")\n return\n\n if not check_hubert_min_duration(audio, sr):\n LOG.info(f\"Skip {input_path} because it is too short.\")\n return\n\n # Adjust volume\n audio /= max(audio.max(), -audio.min())\n\n # Trim silence\n audio, _ = librosa.effects.trim(\n audio,\n top_db=top_db,\n frame_length=int(frame_seconds * sr),\n hop_length=int(hop_seconds * sr),\n )\n\n if not check_hubert_min_duration(audio, sr):\n LOG.info(f\"Skip {input_path} because it is too short.\")\n return\n\n soundfile.write(output_path, audio, samplerate=sr, subtype=\"PCM_16\")\n\n\ndef preprocess_resample(\n input_dir: Path | str,\n output_dir: Path | str,\n sampling_rate: int,\n n_jobs: int = -1,\n *,\n top_db: int = 30,\n frame_seconds: float = 0.1,\n hop_seconds: float = 0.05,\n) -> None:\n input_dir = Path(input_dir)\n output_dir = Path(output_dir)\n \"\"\"Preprocess audio files in input_dir and save them to output_dir.\"\"\"\n\n out_paths = []\n in_paths = list(input_dir.rglob(\"*.*\"))\n if not in_paths:\n raise ValueError(f\"No audio files found in {input_dir}\")\n for in_path in in_paths:\n in_path_relative = in_path.relative_to(input_dir)\n if not in_path.is_absolute() and is_relative_to(in_path, Path(\"dataset_raw\") / \"44k\"):\n new_in_path_relative = in_path_relative.relative_to(\"44k\")\n warnings.warn(\n f\"Recommended folder structure has changed since v1.0.0. \"\n \"Please move your dataset directly under dataset_raw folder. \"\n f\"Recognized {in_path_relative} as {new_in_path_relative}\"\n )\n in_path_relative = new_in_path_relative\n\n if len(in_path_relative.parts) < 2:\n continue\n speaker_name = in_path_relative.parts[0]\n file_name = in_path_relative.with_suffix(\".wav\").name\n out_path = output_dir / speaker_name / file_name\n out_path = _get_unique_filename(out_path, out_paths)\n out_path.parent.mkdir(parents=True, exist_ok=True)\n out_paths.append(out_path)\n\n in_and_out_paths = list(zip(in_paths, out_paths))\n\n with tqdm_joblib(desc=\"Preprocessing\", total=len(in_and_out_paths)):\n Parallel(n_jobs=n_jobs)(\n delayed(_preprocess_one)(\n *args,\n sr=sampling_rate,\n top_db=top_db,\n frame_seconds=frame_seconds,\n hop_seconds=hop_seconds,\n )\n for args in in_and_out_paths\n )\n"
},
{
"path": "src/so_vits_svc_fork/preprocessing/preprocess_speaker_diarization.py",
"content": "from __future__ import annotations\n\nfrom collections import defaultdict\nfrom logging import getLogger\nfrom pathlib import Path\n\nimport librosa\nimport soundfile as sf\nimport torch\nfrom joblib import Parallel, delayed\nfrom pyannote.audio import Pipeline\nfrom tqdm import tqdm\nfrom tqdm_joblib import tqdm_joblib\n\nLOG = getLogger(__name__)\n\n\ndef _process_one(\n input_path: Path,\n output_dir: Path,\n sr: int,\n *,\n min_speakers: int = 1,\n max_speakers: int = 1,\n huggingface_token: str | None = None,\n) -> None:\n try:\n audio, sr = librosa.load(input_path, sr=sr, mono=True)\n except Exception as e:\n LOG.warning(f\"Failed to read {input_path}: {e}\")\n return\n pipeline = Pipeline.from_pretrained(\"pyannote/speaker-diarization-3.1\", use_auth_token=huggingface_token)\n if pipeline is None:\n raise ValueError(\"Failed to load pipeline\")\n pipeline = pipeline.to(torch.device(\"cuda\"))\n LOG.info(f\"Processing {input_path}. This may take a while...\")\n diarization = pipeline(input_path, min_speakers=min_speakers, max_speakers=max_speakers)\n\n LOG.info(f\"Found {len(diarization)} tracks, writing to {output_dir}\")\n speaker_count = defaultdict(int)\n\n output_dir.mkdir(parents=True, exist_ok=True)\n for segment, track, speaker in tqdm(list(diarization.itertracks(yield_label=True)), desc=f\"Writing {input_path}\"):\n if segment.end - segment.start < 1:\n continue\n speaker_count[speaker] += 1\n audio_cut = audio[int(segment.start * sr) : int(segment.end * sr)]\n sf.write(\n (output_dir / f\"{speaker}_{speaker_count[speaker]:04d}.wav\"),\n audio_cut,\n sr,\n )\n\n LOG.info(f\"Speaker count: {speaker_count}\")\n\n\ndef preprocess_speaker_diarization(\n input_dir: Path | str,\n output_dir: Path | str,\n sr: int,\n *,\n min_speakers: int = 1,\n max_speakers: int = 1,\n huggingface_token: str | None = None,\n n_jobs: int = -1,\n) -> None:\n if huggingface_token is not None and not huggingface_token.startswith(\"hf_\"):\n LOG.warning(\"Huggingface token probably should start with hf_\")\n if not torch.cuda.is_available():\n LOG.warning(\"CUDA is not available. This will be extremely slow.\")\n input_dir = Path(input_dir)\n output_dir = Path(output_dir)\n input_dir.mkdir(parents=True, exist_ok=True)\n output_dir.mkdir(parents=True, exist_ok=True)\n input_paths = list(input_dir.rglob(\"*.*\"))\n with tqdm_joblib(desc=\"Preprocessing speaker diarization\", total=len(input_paths)):\n Parallel(n_jobs=n_jobs)(\n delayed(_process_one)(\n input_path,\n output_dir / input_path.relative_to(input_dir).parent / input_path.stem,\n sr,\n max_speakers=max_speakers,\n min_speakers=min_speakers,\n huggingface_token=huggingface_token,\n )\n for input_path in input_paths\n )\n"
},
{
"path": "src/so_vits_svc_fork/preprocessing/preprocess_split.py",
"content": "from __future__ import annotations\n\nfrom logging import getLogger\nfrom pathlib import Path\n\nimport librosa\nimport soundfile as sf\nfrom joblib import Parallel, delayed\nfrom tqdm import tqdm\nfrom tqdm_joblib import tqdm_joblib\n\nLOG = getLogger(__name__)\n\n\ndef _process_one(\n input_path: Path,\n output_dir: Path,\n sr: int,\n *,\n max_length: float = 10.0,\n top_db: int = 30,\n frame_seconds: float = 0.5,\n hop_seconds: float = 0.1,\n):\n try:\n audio, sr = librosa.load(input_path, sr=sr, mono=True)\n except Exception as e:\n LOG.warning(f\"Failed to read {input_path}: {e}\")\n return\n intervals = librosa.effects.split(\n audio,\n top_db=top_db,\n frame_length=int(sr * frame_seconds),\n hop_length=int(sr * hop_seconds),\n )\n output_dir.mkdir(parents=True, exist_ok=True)\n for start, end in tqdm(intervals, desc=f\"Writing {input_path}\"):\n for sub_start in range(start, end, int(sr * max_length)):\n sub_end = min(sub_start + int(sr * max_length), end)\n audio_cut = audio[sub_start:sub_end]\n sf.write(\n (output_dir / f\"{input_path.stem}_{sub_start / sr:.3f}_{sub_end / sr:.3f}.wav\"),\n audio_cut,\n sr,\n )\n\n\ndef preprocess_split(\n input_dir: Path | str,\n output_dir: Path | str,\n sr: int,\n *,\n max_length: float = 10.0,\n top_db: int = 30,\n frame_seconds: float = 0.5,\n hop_seconds: float = 0.1,\n n_jobs: int = -1,\n):\n input_dir = Path(input_dir)\n output_dir = Path(output_dir)\n output_dir.mkdir(parents=True, exist_ok=True)\n input_paths = list(input_dir.rglob(\"*.*\"))\n with tqdm_joblib(desc=\"Splitting\", total=len(input_paths)):\n Parallel(n_jobs=n_jobs)(\n delayed(_process_one)(\n input_path,\n output_dir / input_path.relative_to(input_dir).parent,\n sr,\n max_length=max_length,\n top_db=top_db,\n frame_seconds=frame_seconds,\n hop_seconds=hop_seconds,\n )\n for input_path in input_paths\n )\n"
},
{
"path": "src/so_vits_svc_fork/preprocessing/preprocess_utils.py",
"content": "from numpy import ndarray\n\n\ndef check_hubert_min_duration(audio: ndarray, sr: int) -> bool:\n return len(audio) / sr >= 0.3\n"
},
{
"path": "src/so_vits_svc_fork/py.typed",
"content": ""
},
{
"path": "src/so_vits_svc_fork/train.py",
"content": "from __future__ import annotations\n\nimport os\nimport warnings\nfrom logging import getLogger\nfrom multiprocessing import cpu_count\nfrom pathlib import Path\nfrom typing import Any\n\nimport lightning.pytorch as pl\nimport torch\nfrom lightning.pytorch.accelerators import MPSAccelerator, TPUAccelerator\nfrom lightning.pytorch.callbacks import DeviceStatsMonitor\nfrom lightning.pytorch.loggers import TensorBoardLogger\nfrom lightning.pytorch.strategies.ddp import DDPStrategy\nfrom lightning.pytorch.tuner import Tuner\nfrom torch.cuda.amp import autocast\nfrom torch.nn import functional as F\nfrom torch.utils.data import DataLoader\nfrom torch.utils.tensorboard.writer import SummaryWriter\n\nimport so_vits_svc_fork.f0\nimport so_vits_svc_fork.modules.commons as commons\nimport so_vits_svc_fork.utils\n\nfrom . import utils\nfrom .dataset import TextAudioCollate, TextAudioDataset\nfrom .logger import is_notebook\nfrom .modules.descriminators import MultiPeriodDiscriminator\nfrom .modules.losses import discriminator_loss, feature_loss, generator_loss, kl_loss\nfrom .modules.mel_processing import mel_spectrogram_torch\nfrom .modules.synthesizers import SynthesizerTrn\n\nLOG = getLogger(__name__)\ntorch.set_float32_matmul_precision(\"high\")\n\n\nclass VCDataModule(pl.LightningDataModule):\n batch_size: int\n\n def __init__(self, hparams: Any):\n super().__init__()\n self.__hparams = hparams\n self.batch_size = hparams.train.batch_size\n if not isinstance(self.batch_size, int):\n self.batch_size = 1\n self.collate_fn = TextAudioCollate()\n\n # these should be called in setup(), but we need to calculate check_val_every_n_epoch\n self.train_dataset = TextAudioDataset(self.__hparams, is_validation=False)\n self.val_dataset = TextAudioDataset(self.__hparams, is_validation=True)\n\n def train_dataloader(self):\n return DataLoader(\n self.train_dataset,\n num_workers=min(cpu_count(), self.__hparams.train.get(\"num_workers\", 8)),\n batch_size=self.batch_size,\n collate_fn=self.collate_fn,\n persistent_workers=True,\n )\n\n def val_dataloader(self):\n return DataLoader(\n self.val_dataset,\n batch_size=1,\n collate_fn=self.collate_fn,\n )\n\n\ndef train(config_path: Path | str, model_path: Path | str, reset_optimizer: bool = False):\n config_path = Path(config_path)\n model_path = Path(model_path)\n\n hparams = utils.get_backup_hparams(config_path, model_path)\n utils.ensure_pretrained_model(\n model_path,\n hparams.model.get(\n \"pretrained\",\n {\n \"D_0.pth\": \"https://huggingface.co/therealvul/so-vits-svc-4.0-init/resolve/main/D_0.pth\",\n \"G_0.pth\": \"https://huggingface.co/therealvul/so-vits-svc-4.0-init/resolve/main/G_0.pth\",\n },\n ),\n )\n\n datamodule = VCDataModule(hparams)\n strategy = (\n (\"ddp_find_unused_parameters_true\" if os.name != \"nt\" else DDPStrategy(find_unused_parameters=True, process_group_backend=\"gloo\"))\n if torch.cuda.device_count() > 1\n else \"auto\"\n )\n LOG.info(f\"Using strategy: {strategy}\")\n trainer = pl.Trainer(\n logger=TensorBoardLogger(model_path, \"lightning_logs\", hparams.train.get(\"log_version\", 0)),\n # profiler=\"simple\",\n val_check_interval=hparams.train.eval_interval,\n max_epochs=hparams.train.epochs,\n check_val_every_n_epoch=None,\n precision=(\"16-mixed\" if hparams.train.fp16_run else \"bf16-mixed\" if hparams.train.get(\"bf16_run\", False) else 32),\n strategy=strategy,\n callbacks=([pl.callbacks.RichProgressBar()] if not is_notebook() else []) + [DeviceStatsMonitor()],\n benchmark=True,\n enable_checkpointing=False,\n )\n tuner = Tuner(trainer)\n model = VitsLightning(reset_optimizer=reset_optimizer, **hparams)\n\n # automatic batch size scaling\n batch_size = hparams.train.batch_size\n batch_split = str(batch_size).split(\"-\")\n batch_size = batch_split[0]\n init_val = 2 if len(batch_split) <= 1 else int(batch_split[1])\n max_trials = 25 if len(batch_split) <= 2 else int(batch_split[2])\n if batch_size == \"auto\":\n batch_size = \"binsearch\"\n if batch_size in [\"power\", \"binsearch\"]:\n model.tuning = True\n tuner.scale_batch_size(\n model,\n mode=batch_size,\n datamodule=datamodule,\n steps_per_trial=1,\n init_val=init_val,\n max_trials=max_trials,\n )\n model.tuning = False\n else:\n batch_size = int(batch_size)\n # automatic learning rate scaling is not supported for multiple optimizers\n \"\"\"if hparams.train.learning_rate == \"auto\":\n lr_finder = tuner.lr_find(model)\n LOG.info(lr_finder.results)\n fig = lr_finder.plot(suggest=True)\n fig.savefig(model_path / \"lr_finder.png\")\"\"\"\n\n trainer.fit(model, datamodule=datamodule)\n\n\nclass VitsLightning(pl.LightningModule):\n def __init__(self, reset_optimizer: bool = False, **hparams: Any):\n super().__init__()\n self._temp_epoch = 0 # Add this line to initialize the _temp_epoch attribute\n self.save_hyperparameters(\"reset_optimizer\")\n self.save_hyperparameters(*[k for k in hparams.keys()])\n torch.manual_seed(self.hparams.train.seed)\n self.net_g = SynthesizerTrn(\n self.hparams.data.filter_length // 2 + 1,\n self.hparams.train.segment_size // self.hparams.data.hop_length,\n **self.hparams.model,\n )\n self.net_d = MultiPeriodDiscriminator(self.hparams.model.use_spectral_norm)\n self.automatic_optimization = False\n self.learning_rate = self.hparams.train.learning_rate\n self.optim_g = torch.optim.AdamW(\n self.net_g.parameters(),\n self.learning_rate,\n betas=self.hparams.train.betas,\n eps=self.hparams.train.eps,\n )\n self.optim_d = torch.optim.AdamW(\n self.net_d.parameters(),\n self.learning_rate,\n betas=self.hparams.train.betas,\n eps=self.hparams.train.eps,\n )\n self.scheduler_g = torch.optim.lr_scheduler.ExponentialLR(self.optim_g, gamma=self.hparams.train.lr_decay)\n self.scheduler_d = torch.optim.lr_scheduler.ExponentialLR(self.optim_d, gamma=self.hparams.train.lr_decay)\n self.optimizers_count = 2\n self.load(reset_optimizer)\n self.tuning = False\n\n def on_train_start(self) -> None:\n if not self.tuning:\n self.set_current_epoch(self._temp_epoch)\n total_batch_idx = self._temp_epoch * len(self.trainer.train_dataloader)\n self.set_total_batch_idx(total_batch_idx)\n global_step = total_batch_idx * self.optimizers_count\n self.set_global_step(global_step)\n\n # check if using tpu or mps\n if isinstance(self.trainer.accelerator, (TPUAccelerator, MPSAccelerator)):\n # patch torch.stft to use cpu\n LOG.warning(\"Using TPU/MPS. Patching torch.stft to use cpu.\")\n\n def stft(\n input: torch.Tensor,\n n_fft: int,\n hop_length: int | None = None,\n win_length: int | None = None,\n window: torch.Tensor | None = None,\n center: bool = True,\n pad_mode: str = \"reflect\",\n normalized: bool = False,\n onesided: bool | None = None,\n return_complex: bool | None = None,\n ) -> torch.Tensor:\n device = input.device\n input = input.cpu()\n if window is not None:\n window = window.cpu()\n return torch.functional.stft(\n input,\n n_fft,\n hop_length,\n win_length,\n window,\n center,\n pad_mode,\n normalized,\n onesided,\n return_complex,\n ).to(device)\n\n torch.stft = stft\n\n elif \"bf\" in self.trainer.precision:\n LOG.warning(\"Using bf. Patching torch.stft to use fp32.\")\n\n def stft(\n input: torch.Tensor,\n n_fft: int,\n hop_length: int | None = None,\n win_length: int | None = None,\n window: torch.Tensor | None = None,\n center: bool = True,\n pad_mode: str = \"reflect\",\n normalized: bool = False,\n onesided: bool | None = None,\n return_complex: bool | None = None,\n ) -> torch.Tensor:\n dtype = input.dtype\n input = input.float()\n if window is not None:\n window = window.float()\n return torch.functional.stft(\n input,\n n_fft,\n hop_length,\n win_length,\n window,\n center,\n pad_mode,\n normalized,\n onesided,\n return_complex,\n ).to(dtype)\n\n torch.stft = stft\n\n def on_train_end(self) -> None:\n self.save_checkpoints(adjust=0)\n\n def save_checkpoints(self, adjust=1):\n if self.tuning or self.trainer.sanity_checking:\n return\n\n # only save checkpoints if we are on the main device\n if hasattr(self.device, \"index\") and self.device.index != None and self.device.index != 0:\n return\n\n # `on_train_end` will be the actual epoch, not a -1, so we have to call it with `adjust = 0`\n current_epoch = self.current_epoch + adjust\n total_batch_idx = self.total_batch_idx - 1 + adjust\n\n utils.save_checkpoint(\n self.net_g,\n self.optim_g,\n self.learning_rate,\n current_epoch,\n Path(self.hparams.model_dir) / f\"G_{total_batch_idx if self.hparams.train.get('ckpt_name_by_step', False) else current_epoch}.pth\",\n )\n utils.save_checkpoint(\n self.net_d,\n self.optim_d,\n self.learning_rate,\n current_epoch,\n Path(self.hparams.model_dir) / f\"D_{total_batch_idx if self.hparams.train.get('ckpt_name_by_step', False) else current_epoch}.pth\",\n )\n keep_ckpts = self.hparams.train.get(\"keep_ckpts\", 0)\n if keep_ckpts > 0:\n utils.clean_checkpoints(\n path_to_models=self.hparams.model_dir,\n n_ckpts_to_keep=keep_ckpts,\n sort_by_time=True,\n )\n\n def set_current_epoch(self, epoch: int):\n LOG.info(f\"Setting current epoch to {epoch}\")\n self.trainer.fit_loop.epoch_progress.current.completed = epoch\n self.trainer.fit_loop.epoch_progress.current.processed = epoch\n assert self.current_epoch == epoch, f\"{self.current_epoch} != {epoch}\"\n\n def set_global_step(self, global_step: int):\n LOG.info(f\"Setting global step to {global_step}\")\n self.trainer.fit_loop.epoch_loop.manual_optimization.optim_step_progress.total.completed = global_step\n self.trainer.fit_loop.epoch_loop.automatic_optimization.optim_progress.optimizer.step.total.completed = global_step\n assert self.global_step == global_step, f\"{self.global_step} != {global_step}\"\n\n def set_total_batch_idx(self, total_batch_idx: int):\n LOG.info(f\"Setting total batch idx to {total_batch_idx}\")\n self.trainer.fit_loop.epoch_loop.batch_progress.total.ready = total_batch_idx + 1\n self.trainer.fit_loop.epoch_loop.batch_progress.total.completed = total_batch_idx\n assert self.total_batch_idx == total_batch_idx + 1, f\"{self.total_batch_idx} != {total_batch_idx + 1}\"\n\n @property\n def total_batch_idx(self) -> int:\n return self.trainer.fit_loop.epoch_loop.total_batch_idx + 1\n\n def load(self, reset_optimizer: bool = False):\n latest_g_path = utils.latest_checkpoint_path(self.hparams.model_dir, \"G_*.pth\")\n latest_d_path = utils.latest_checkpoint_path(self.hparams.model_dir, \"D_*.pth\")\n if latest_g_path is not None and latest_d_path is not None:\n try:\n _, _, _, epoch = utils.load_checkpoint(\n latest_g_path,\n self.net_g,\n self.optim_g,\n reset_optimizer,\n )\n _, _, _, epoch = utils.load_checkpoint(\n latest_d_path,\n self.net_d,\n self.optim_d,\n reset_optimizer,\n )\n self._temp_epoch = epoch\n self.scheduler_g.last_epoch = epoch - 1\n self.scheduler_d.last_epoch = epoch - 1\n except Exception as e:\n raise RuntimeError(\"Failed to load checkpoint\") from e\n else:\n LOG.warning(\"No checkpoint found. Start from scratch.\")\n\n def configure_optimizers(self):\n return [self.optim_g, self.optim_d], [self.scheduler_g, self.scheduler_d]\n\n def log_image_dict(self, image_dict: dict[str, Any], dataformats: str = \"HWC\") -> None:\n if not isinstance(self.logger, TensorBoardLogger):\n warnings.warn(\"Image logging is only supported with TensorBoardLogger.\")\n return\n writer: SummaryWriter = self.logger.experiment\n for k, v in image_dict.items():\n try:\n writer.add_image(k, v, self.total_batch_idx, dataformats=dataformats)\n except Exception as e:\n warnings.warn(f\"Failed to log image {k}: {e}\")\n\n def log_audio_dict(self, audio_dict: dict[str, Any]) -> None:\n if not isinstance(self.logger, TensorBoardLogger):\n warnings.warn(\"Audio logging is only supported with TensorBoardLogger.\")\n return\n writer: SummaryWriter = self.logger.experiment\n for k, v in audio_dict.items():\n writer.add_audio(\n k,\n v.float(),\n self.total_batch_idx,\n sample_rate=self.hparams.data.sampling_rate,\n )\n\n def log_dict_(self, log_dict: dict[str, Any], **kwargs) -> None:\n if not isinstance(self.logger, TensorBoardLogger):\n warnings.warn(\"Logging is only supported with TensorBoardLogger.\")\n return\n writer: SummaryWriter = self.logger.experiment\n for k, v in log_dict.items():\n writer.add_scalar(k, v, self.total_batch_idx)\n kwargs[\"logger\"] = False\n self.log_dict(log_dict, **kwargs)\n\n def log_(self, key: str, value: Any, **kwargs) -> None:\n self.log_dict_({key: value}, **kwargs)\n\n def training_step(self, batch: dict[str, torch.Tensor], batch_idx: int) -> None:\n self.net_g.train()\n self.net_d.train()\n\n # get optims\n optim_g, optim_d = self.optimizers()\n\n # Generator\n # train\n self.toggle_optimizer(optim_g)\n c, f0, spec, mel, y, g, lengths, uv = batch\n (\n y_hat,\n y_hat_mb,\n ids_slice,\n z_mask,\n (z, z_p, m_p, logs_p, m_q, logs_q),\n pred_lf0,\n norm_lf0,\n lf0,\n ) = self.net_g(c, f0, uv, spec, g=g, c_lengths=lengths, spec_lengths=lengths)\n y_mel = commons.slice_segments(\n mel,\n ids_slice,\n self.hparams.train.segment_size // self.hparams.data.hop_length,\n )\n y_hat_mel = mel_spectrogram_torch(y_hat.squeeze(1), self.hparams)\n y_mel = y_mel[..., : y_hat_mel.shape[-1]]\n y = commons.slice_segments(\n y,\n ids_slice * self.hparams.data.hop_length,\n self.hparams.train.segment_size,\n )\n y = y[..., : y_hat.shape[-1]]\n\n # generator loss\n y_d_hat_r, y_d_hat_g, fmap_r, fmap_g = self.net_d(y, y_hat)\n\n with autocast(enabled=False):\n loss_mel = F.l1_loss(y_mel, y_hat_mel) * self.hparams.train.c_mel\n loss_kl = kl_loss(z_p, logs_q, m_p, logs_p, z_mask) * self.hparams.train.c_kl\n loss_fm = feature_loss(fmap_r, fmap_g)\n loss_gen, losses_gen = generator_loss(y_d_hat_g)\n loss_lf0 = F.mse_loss(pred_lf0, lf0)\n loss_gen_all = loss_gen + loss_fm + loss_mel + loss_kl + loss_lf0\n\n # MB-iSTFT-VITS\n loss_subband = torch.tensor(0.0)\n if self.hparams.model.get(\"type_\") == \"mb-istft\":\n from .modules.decoders.mb_istft import PQMF, subband_stft_loss\n\n y_mb = PQMF(y.device, self.hparams.model.subbands).analysis(y)\n loss_subband = subband_stft_loss(self.hparams, y_mb, y_hat_mb)\n loss_gen_all += loss_subband\n\n # log loss\n self.log_(\"lr\", self.optim_g.param_groups[0][\"lr\"])\n self.log_dict_(\n {\n \"loss/g/total\": loss_gen_all,\n \"loss/g/fm\": loss_fm,\n \"loss/g/mel\": loss_mel,\n \"loss/g/kl\": loss_kl,\n \"loss/g/lf0\": loss_lf0,\n },\n prog_bar=True,\n )\n if self.hparams.model.get(\"type_\") == \"mb-istft\":\n self.log_(\"loss/g/subband\", loss_subband)\n if self.total_batch_idx % self.hparams.train.log_interval == 0:\n self.log_image_dict(\n {\n \"slice/mel_org\": utils.plot_spectrogram_to_numpy(y_mel[0].data.cpu().float().numpy()),\n \"slice/mel_gen\": utils.plot_spectrogram_to_numpy(y_hat_mel[0].data.cpu().float().numpy()),\n \"all/mel\": utils.plot_spectrogram_to_numpy(mel[0].data.cpu().float().numpy()),\n \"all/lf0\": so_vits_svc_fork.utils.plot_data_to_numpy(\n lf0[0, 0, :].cpu().float().numpy(),\n pred_lf0[0, 0, :].detach().cpu().float().numpy(),\n ),\n \"all/norm_lf0\": so_vits_svc_fork.utils.plot_data_to_numpy(\n lf0[0, 0, :].cpu().float().numpy(),\n norm_lf0[0, 0, :].detach().cpu().float().numpy(),\n ),\n }\n )\n\n accumulate_grad_batches = self.hparams.train.get(\"accumulate_grad_batches\", 1)\n should_update = (batch_idx + 1) % accumulate_grad_batches == 0 or self.trainer.is_last_batch\n # optimizer\n self.manual_backward(loss_gen_all / accumulate_grad_batches)\n if should_update:\n self.log_(\"grad_norm_g\", commons.clip_grad_value_(self.net_g.parameters(), None))\n optim_g.step()\n optim_g.zero_grad()\n self.untoggle_optimizer(optim_g)\n\n # Discriminator\n # train\n self.toggle_optimizer(optim_d)\n y_d_hat_r, y_d_hat_g, _, _ = self.net_d(y, y_hat.detach())\n\n # discriminator loss\n with autocast(enabled=False):\n loss_disc, losses_disc_r, losses_disc_g = discriminator_loss(y_d_hat_r, y_d_hat_g)\n loss_disc_all = loss_disc\n\n # log loss\n self.log_(\"loss/d/total\", loss_disc_all, prog_bar=True)\n\n # optimizer\n self.manual_backward(loss_disc_all / accumulate_grad_batches)\n if should_update:\n self.log_(\"grad_norm_d\", commons.clip_grad_value_(self.net_d.parameters(), None))\n optim_d.step()\n optim_d.zero_grad()\n self.untoggle_optimizer(optim_d)\n\n # end of epoch\n if self.trainer.is_last_batch:\n self.scheduler_g.step()\n self.scheduler_d.step()\n\n def validation_step(self, batch, batch_idx):\n # avoid logging with wrong global step\n if self.global_step == 0:\n return\n with torch.no_grad():\n self.net_g.eval()\n c, f0, _, mel, y, g, _, uv = batch\n y_hat = self.net_g.infer(c, f0, uv, g=g)\n y_hat_mel = mel_spectrogram_torch(y_hat.squeeze(1).float(), self.hparams)\n self.log_audio_dict({f\"gen/audio_{batch_idx}\": y_hat[0], f\"gt/audio_{batch_idx}\": y[0]})\n self.log_image_dict(\n {\n \"gen/mel\": utils.plot_spectrogram_to_numpy(y_hat_mel[0].cpu().float().numpy()),\n \"gt/mel\": utils.plot_spectrogram_to_numpy(mel[0].cpu().float().numpy()),\n }\n )\n\n def on_validation_end(self) -> None:\n self.save_checkpoints()\n"
},
{
"path": "src/so_vits_svc_fork/utils.py",
"content": "from __future__ import annotations\n\nimport json\nimport os\nimport re\nimport subprocess\nimport warnings\nfrom collections.abc import Sequence\nfrom itertools import groupby\nfrom logging import getLogger\nfrom pathlib import Path\nfrom typing import Any, Literal\n\nimport matplotlib\nimport matplotlib.pylab as plt\nimport numpy as np\nimport requests\nimport torch\nimport torch.backends.mps\nimport torch.nn as nn\nimport torchaudio\nfrom cm_time import timer\nfrom numpy import ndarray\nfrom tqdm import tqdm\nfrom transformers import HubertModel\n\nfrom so_vits_svc_fork.hparams import HParams\n\nLOG = getLogger(__name__)\nHUBERT_SAMPLING_RATE = 16000\nIS_COLAB = os.getenv(\"COLAB_RELEASE_TAG\", False)\n\n\ndef get_optimal_device(index: int = 0) -> torch.device:\n if torch.cuda.is_available():\n return torch.device(f\"cuda:{index % torch.cuda.device_count()}\")\n elif torch.backends.mps.is_available():\n return torch.device(\"mps\")\n else:\n try:\n import torch_xla.core.xla_model as xm\n\n if xm.xrt_world_size() > 0:\n return torch.device(\"xla\")\n # return xm.xla_device()\n except ImportError:\n pass\n return torch.device(\"cpu\")\n\n\ndef download_file(\n url: str,\n filepath: Path | str,\n chunk_size: int = 64 * 1024,\n tqdm_cls: type = tqdm,\n skip_if_exists: bool = False,\n overwrite: bool = False,\n **tqdm_kwargs: Any,\n):\n if skip_if_exists is True and overwrite is True:\n raise ValueError(\"skip_if_exists and overwrite cannot be both True\")\n filepath = Path(filepath)\n filepath.parent.mkdir(parents=True, exist_ok=True)\n temppath = filepath.parent / f\"{filepath.name}.download\"\n if filepath.exists():\n if skip_if_exists:\n return\n elif not overwrite:\n filepath.unlink()\n else:\n raise FileExistsError(f\"{filepath} already exists\")\n temppath.unlink(missing_ok=True)\n resp = requests.get(url, stream=True)\n total = int(resp.headers.get(\"content-length\", 0))\n kwargs = dict(\n total=total,\n unit=\"iB\",\n unit_scale=True,\n unit_divisor=1024,\n desc=f\"Downloading {filepath.name}\",\n )\n kwargs.update(tqdm_kwargs)\n with temppath.open(\"wb\") as f, tqdm_cls(**kwargs) as pbar:\n for data in resp.iter_content(chunk_size=chunk_size):\n size = f.write(data)\n pbar.update(size)\n temppath.rename(filepath)\n\n\nPRETRAINED_MODEL_URLS = {\n \"hifi-gan\": [\n [\n \"https://huggingface.co/therealvul/so-vits-svc-4.0-init/resolve/main/D_0.pth\",\n \"https://huggingface.co/therealvul/so-vits-svc-4.0-init/resolve/main/G_0.pth\",\n ],\n [\n \"https://huggingface.co/Himawari00/so-vits-svc4.0-pretrain-models/resolve/main/D_0.pth\",\n \"https://huggingface.co/Himawari00/so-vits-svc4.0-pretrain-models/resolve/main/G_0.pth\",\n ],\n ],\n \"contentvec\": [\n [\"https://huggingface.co/therealvul/so-vits-svc-4.0-init/resolve/main/checkpoint_best_legacy_500.pt\"],\n [\"https://huggingface.co/Himawari00/so-vits-svc4.0-pretrain-models/resolve/main/checkpoint_best_legacy_500.pt\"],\n [\"http://obs.cstcloud.cn/share/obs/sankagenkeshi/checkpoint_best_legacy_500.pt\"],\n ],\n}\nfrom joblib import Parallel, delayed\n\n\ndef ensure_pretrained_model(folder_path: Path | str, type_: str | dict[str, str], **tqdm_kwargs: Any) -> tuple[Path, ...] | None:\n folder_path = Path(folder_path)\n\n # new code\n if not isinstance(type_, str):\n try:\n Parallel(n_jobs=len(type_))(\n [\n delayed(download_file)(\n url,\n folder_path / filename,\n position=i,\n skip_if_exists=True,\n **tqdm_kwargs,\n )\n for i, (filename, url) in enumerate(type_.items())\n ]\n )\n return tuple(folder_path / filename for filename in type_.values())\n except Exception as e:\n LOG.error(f\"Failed to download {type_}\")\n LOG.exception(e)\n\n # old code\n models_candidates = PRETRAINED_MODEL_URLS.get(type_, None)\n if models_candidates is None:\n LOG.warning(f\"Unknown pretrained model type: {type_}\")\n return\n for model_urls in models_candidates:\n paths = [folder_path / model_url.split(\"/\")[-1] for model_url in model_urls]\n try:\n Parallel(n_jobs=len(paths))(\n [\n delayed(download_file)(url, path, position=i, skip_if_exists=True, **tqdm_kwargs)\n for i, (url, path) in enumerate(zip(model_urls, paths))\n ]\n )\n return tuple(paths)\n except Exception as e:\n LOG.error(f\"Failed to download {model_urls}\")\n LOG.exception(e)\n\n\nclass HubertModelWithFinalProj(HubertModel):\n def __init__(self, config):\n super().__init__(config)\n\n # The final projection layer is only used for backward compatibility.\n # Following https://github.com/auspicious3000/contentvec/issues/6\n # Remove this layer is necessary to achieve the desired outcome.\n self.final_proj = nn.Linear(config.hidden_size, config.classifier_proj_size)\n\n\ndef remove_weight_norm_if_exists(module, name: str = \"weight\"):\n r\"\"\"\n Removes the weight normalization reparameterization from a module.\n\n Args:\n module (Module): containing module\n name (str, optional): name of weight parameter\n\n Example:\n >>> m = weight_norm(nn.Linear(20, 40))\n >>> remove_weight_norm(m)\n\n \"\"\"\n from torch.nn.utils.weight_norm import WeightNorm\n\n for k, hook in module._forward_pre_hooks.items():\n if isinstance(hook, WeightNorm) and hook.name == name:\n hook.remove(module)\n del module._forward_pre_hooks[k]\n return module\n\n\ndef get_hubert_model(device: str | torch.device, final_proj: bool = True) -> HubertModel:\n if final_proj:\n model = HubertModelWithFinalProj.from_pretrained(\"lengyue233/content-vec-best\")\n else:\n model = HubertModel.from_pretrained(\"lengyue233/content-vec-best\")\n # Hubert is always used in inference mode, we can safely remove weight-norms\n for m in model.modules():\n if isinstance(m, (nn.Conv2d, nn.Conv1d)):\n remove_weight_norm_if_exists(m)\n\n return model.to(device)\n\n\ndef get_content(\n cmodel: HubertModel,\n audio: torch.Tensor | ndarray[Any, Any],\n device: torch.device | str,\n sr: int,\n legacy_final_proj: bool = False,\n) -> torch.Tensor:\n audio = torch.as_tensor(audio)\n if sr != HUBERT_SAMPLING_RATE:\n audio = torchaudio.transforms.Resample(sr, HUBERT_SAMPLING_RATE).to(audio.device)(audio).to(device)\n if audio.ndim == 1:\n audio = audio.unsqueeze(0)\n with torch.no_grad(), timer() as t:\n if legacy_final_proj:\n warnings.warn(\"legacy_final_proj is deprecated\")\n if not hasattr(cmodel, \"final_proj\"):\n raise ValueError(\"HubertModel does not have final_proj\")\n c = cmodel(audio, output_hidden_states=True)[\"hidden_states\"][9]\n c = cmodel.final_proj(c)\n else:\n c = cmodel(audio)[\"last_hidden_state\"]\n c = c.transpose(1, 2)\n wav_len = audio.shape[-1] / HUBERT_SAMPLING_RATE\n LOG.info(f\"HuBERT inference time : {t.elapsed:.3f}s, RTF: {t.elapsed / wav_len:.3f}\")\n return c\n\n\ndef _substitute_if_same_shape(to_: dict[str, Any], from_: dict[str, Any]) -> None:\n not_in_to = list(filter(lambda x: x not in to_, from_.keys()))\n not_in_from = list(filter(lambda x: x not in from_, to_.keys()))\n if not_in_to:\n warnings.warn(f\"Keys not found in model state dict:{not_in_to}\")\n if not_in_from:\n warnings.warn(f\"Keys not found in checkpoint state dict:{not_in_from}\")\n shape_missmatch = []\n for k, v in from_.items():\n if k not in to_:\n pass\n elif hasattr(v, \"shape\"):\n if not hasattr(to_[k], \"shape\"):\n raise ValueError(f\"Key {k} is not a tensor\")\n if to_[k].shape == v.shape:\n to_[k] = v\n else:\n shape_missmatch.append((k, to_[k].shape, v.shape))\n elif isinstance(v, dict):\n assert isinstance(to_[k], dict)\n _substitute_if_same_shape(to_[k], v)\n else:\n to_[k] = v\n if shape_missmatch:\n warnings.warn(f\"Shape mismatch: {[f'{k}: {v1} -> {v2}' for k, v1, v2 in shape_missmatch]}\")\n\n\ndef safe_load(model: torch.nn.Module, state_dict: dict[str, Any]) -> None:\n model_state_dict = model.state_dict()\n _substitute_if_same_shape(model_state_dict, state_dict)\n model.load_state_dict(model_state_dict)\n\n\ndef load_checkpoint(\n checkpoint_path: Path | str,\n model: torch.nn.Module,\n optimizer: torch.optim.Optimizer | None = None,\n skip_optimizer: bool = False,\n) -> tuple[torch.nn.Module, torch.optim.Optimizer | None, float, int]:\n if not Path(checkpoint_path).is_file():\n raise FileNotFoundError(f\"File {checkpoint_path} not found\")\n with Path(checkpoint_path).open(\"rb\") as f:\n with warnings.catch_warnings():\n warnings.filterwarnings(\"ignore\", category=UserWarning, message=\"TypedStorage is deprecated\")\n checkpoint_dict = torch.load(f, map_location=\"cpu\", weights_only=True)\n iteration = checkpoint_dict[\"iteration\"]\n learning_rate = checkpoint_dict[\"learning_rate\"]\n\n # safe load module\n if hasattr(model, \"module\"):\n safe_load(model.module, checkpoint_dict[\"model\"])\n else:\n safe_load(model, checkpoint_dict[\"model\"])\n # safe load optim\n if optimizer is not None and not skip_optimizer and checkpoint_dict[\"optimizer\"] is not None:\n with warnings.catch_warnings():\n warnings.simplefilter(\"ignore\")\n safe_load(optimizer, checkpoint_dict[\"optimizer\"])\n\n LOG.info(f\"Loaded checkpoint '{checkpoint_path}' (epoch {iteration})\")\n return model, optimizer, learning_rate, iteration\n\n\ndef save_checkpoint(\n model: torch.nn.Module,\n optimizer: torch.optim.Optimizer,\n learning_rate: float,\n iteration: int,\n checkpoint_path: Path | str,\n) -> None:\n LOG.info(f\"Saving model and optimizer state at epoch {iteration} to {checkpoint_path}\")\n if hasattr(model, \"module\"):\n state_dict = model.module.state_dict()\n else:\n state_dict = model.state_dict()\n with Path(checkpoint_path).open(\"wb\") as f:\n torch.save(\n {\n \"model\": state_dict,\n \"iteration\": iteration,\n \"optimizer\": optimizer.state_dict(),\n \"learning_rate\": learning_rate,\n },\n f,\n )\n\n\ndef clean_checkpoints(path_to_models: Path | str, n_ckpts_to_keep: int = 2, sort_by_time: bool = True) -> None:\n \"\"\"\n Freeing up space by deleting saved ckpts\n\n Arguments:\n path_to_models -- Path to the model directory\n n_ckpts_to_keep -- Number of ckpts to keep, excluding G_0.pth and D_0.pth\n sort_by_time -- True -> chronologically delete ckpts\n False -> lexicographically delete ckpts\n\n \"\"\"\n LOG.info(\"Cleaning old checkpoints...\")\n path_to_models = Path(path_to_models)\n\n # Define sort key functions\n name_key = lambda p: int(re.match(r\"[GD]_(\\d+)\", p.stem).group(1))\n time_key = lambda p: p.stat().st_mtime\n path_key = lambda p: (p.stem[0], time_key(p) if sort_by_time else name_key(p))\n\n models = list(\n filter(\n lambda p: (p.is_file() and re.match(r\"[GD]_\\d+\", p.stem) and not p.stem.endswith(\"_0\")),\n path_to_models.glob(\"*.pth\"),\n )\n )\n\n models_sorted = sorted(models, key=path_key)\n\n models_sorted_grouped = groupby(models_sorted, lambda p: p.stem[0])\n\n for group_name, group_items in models_sorted_grouped:\n to_delete_list = list(group_items)[:-n_ckpts_to_keep]\n\n for to_delete in to_delete_list:\n if to_delete.exists():\n LOG.info(f\"Removing {to_delete}\")\n if IS_COLAB:\n to_delete.write_text(\"\")\n to_delete.unlink()\n\n\ndef latest_checkpoint_path(dir_path: Path | str, regex: str = \"G_*.pth\") -> Path | None:\n dir_path = Path(dir_path)\n name_key = lambda p: int(re.match(r\"._(\\d+)\\.pth\", p.name).group(1))\n paths = sorted(dir_path.glob(regex), key=name_key)\n if len(paths) == 0:\n return None\n return paths[-1]\n\n\ndef plot_spectrogram_to_numpy(spectrogram: ndarray) -> ndarray:\n matplotlib.use(\"Agg\")\n fig, ax = plt.subplots(figsize=(10, 2))\n im = ax.imshow(spectrogram, aspect=\"auto\", origin=\"lower\", interpolation=\"none\")\n plt.colorbar(im, ax=ax)\n plt.xlabel(\"Frames\")\n plt.ylabel(\"Channels\")\n plt.tight_layout()\n\n fig.canvas.draw()\n data = np.fromstring(fig.canvas.tostring_argb(), dtype=np.uint8, sep=\"\")\n data = data.reshape(fig.canvas.get_width_height()[::-1] + (4,))\n plt.close()\n return data\n\n\ndef get_backup_hparams(config_path: Path, model_path: Path, init: bool = True) -> HParams:\n model_path.mkdir(parents=True, exist_ok=True)\n config_save_path = model_path / \"config.json\"\n if init:\n with config_path.open() as f:\n data = f.read()\n with config_save_path.open(\"w\") as f:\n f.write(data)\n else:\n with config_save_path.open() as f:\n data = f.read()\n config = json.loads(data)\n\n hparams = HParams(**config)\n hparams.model_dir = model_path.as_posix()\n return hparams\n\n\ndef get_hparams(config_path: Path | str) -> HParams:\n config = json.loads(Path(config_path).read_text(\"utf-8\"))\n hparams = HParams(**config)\n return hparams\n\n\ndef repeat_expand_2d(content: torch.Tensor, target_len: int) -> torch.Tensor:\n # content : [h, t]\n src_len = content.shape[-1]\n if target_len < src_len:\n return content[:, :target_len]\n else:\n return torch.nn.functional.interpolate(content.unsqueeze(0), size=target_len, mode=\"nearest\").squeeze(0)\n\n\ndef plot_data_to_numpy(x: ndarray, y: ndarray) -> ndarray:\n matplotlib.use(\"Agg\")\n fig, ax = plt.subplots(figsize=(10, 2))\n plt.plot(x)\n plt.plot(y)\n plt.tight_layout()\n\n fig.canvas.draw()\n data = np.fromstring(fig.canvas.tostring_argb(), dtype=np.uint8, sep=\"\")\n data = data.reshape(fig.canvas.get_width_height()[::-1] + (4,))\n plt.close()\n return data\n\n\ndef get_gpu_memory(type_: Literal[\"total\", \"free\", \"used\"]) -> Sequence[int] | None:\n command = f\"nvidia-smi --query-gpu=memory.{type_} --format=csv\"\n try:\n memory_free_info = subprocess.check_output(command.split()).decode(\"ascii\").split(\"\\n\")[:-1][1:]\n memory_free_values = [int(x.split()[0]) for i, x in enumerate(memory_free_info)]\n return memory_free_values\n except Exception:\n return\n\n\ndef get_total_gpu_memory(type_: Literal[\"total\", \"free\", \"used\"]) -> int | None:\n memories = get_gpu_memory(type_)\n if memories is None:\n return\n return sum(memories)\n"
},
{
"path": "templates/CHANGELOG.md.j2",
"content": "# Changelog\n\n{%- for version, release in context.history.released.items() %}\n\n## {{ version.as_tag() }} ({{ release.tagged_date.strftime(\"%Y-%m-%d\") }})\n\n{%- for category, commits in release[\"elements\"].items() %}{% if category != \"unknown\" %}\n{# Category title: Breaking, Fix, Documentation #}\n### {{ category | capitalize }}\n{# List actual changes in the category #}\n{%- for commit in commits %}\n- {{ commit.descriptions[0] | capitalize }} ([`{{ commit.short_hash }}`]({{ commit.hexsha | commit_hash_url }}))\n{%- endfor %}{# for commit #}\n\n{%- endif %}{% endfor %}{# for category, commits #}\n\n{%- endfor %}{# for version, release #}\n"
},
{
"path": "tests/__init__.py",
"content": ""
},
{
"path": "tests/test_main.py",
"content": "import json\nimport os\nfrom pathlib import Path\nfrom unittest import SkipTest, TestCase\n\nIS_CI = os.environ.get(\"GITHUB_ACTIONS\", False)\nIS_COLAB = os.getenv(\"COLAB_RELEASE_TAG\", False)\n\n\nclass TestMain(TestCase):\n def test_import(self):\n import so_vits_svc_fork.cluster.train_cluster\n import so_vits_svc_fork.inference.main\n\n # import so_vits_svc_fork.modules.onnx._export\n import so_vits_svc_fork.preprocessing.preprocess_flist_config\n import so_vits_svc_fork.preprocessing.preprocess_hubert_f0\n import so_vits_svc_fork.preprocessing.preprocess_resample\n import so_vits_svc_fork.preprocessing.preprocess_split\n import so_vits_svc_fork.train # noqa\n\n def test_infer(self):\n if IS_CI:\n raise SkipTest(\"Skip inference test on CI\")\n from so_vits_svc_fork.inference.main import infer # noqa\n\n # infer(\"tests/dataset_raw/34j/1.wav\", \"tests/configs/config.json\", \"tests/logs/44k\")\n\n def test_preprocess(self):\n from so_vits_svc_fork.preprocessing.preprocess_resample import (\n preprocess_resample,\n )\n\n preprocess_resample(\"tests/dataset_raw\", \"tests/dataset/44k\", 44100, n_jobs=1 if IS_CI else -1)\n\n from so_vits_svc_fork.preprocessing.preprocess_flist_config import (\n preprocess_config,\n )\n\n preprocess_config(\n \"tests/dataset/44k\",\n \"tests/filelists/train.txt\",\n \"tests/filelists/val.txt\",\n \"tests/filelists/test.txt\",\n \"tests/configs/44k/config.json\",\n \"so-vits-svc-4.0v1\",\n )\n\n if IS_CI:\n raise SkipTest(\"Skip hubert and f0 test on CI\")\n from so_vits_svc_fork.preprocessing.preprocess_hubert_f0 import (\n preprocess_hubert_f0,\n )\n\n preprocess_hubert_f0(\"tests/dataset/44k\", \"tests/configs/44k/config.json\")\n\n def test_train(self):\n if not IS_COLAB:\n raise SkipTest(\"Skip training test on non-colab\")\n # requires >10GB of GPU memory, can be only tested on colab\n from so_vits_svc_fork.train import train\n\n config_path = Path(\"tests/logs/44k/config.json\")\n config_json = json.loads(config_path.read_text(\"utf-8\"))\n config_json[\"train\"][\"epochs\"] = 1\n config_path.write_text(json.dumps(config_json), \"utf-8\")\n train(config_path, \"tests/logs/44k\")\n"
}
] 













































