Showing preview only (469K chars total). Download the full file or copy to clipboard to get everything.
Repository: waditu/tushare
Branch: master
Commit: 093856995af0
Files: 77
Total size: 446.5 KB
Directory structure:
gitextract_rwiezwpg/
├── .gitignore
├── .travis.yml
├── LICENSE
├── MANIFEST
├── README.md
├── issues/
│ ├── from_email.txt
│ └── from_sns.txt
├── requirements.txt
├── setup.py
├── test/
│ ├── __init__.py
│ ├── bar_test.py
│ ├── billboard_test.py
│ ├── classifying_test.py
│ ├── dateu_test.py
│ ├── fund_test.py
│ ├── indictor_test.py
│ ├── macro_test.py
│ ├── nav_test.py
│ ├── news_test.py
│ ├── ref_test.py
│ ├── shibor_test.py
│ ├── storing_test.py
│ └── trading_test.py
├── test_unittest.py
├── tushare/
│ ├── VERSION.txt
│ ├── __init__.py
│ ├── bond/
│ │ ├── __init__.py
│ │ └── bonds.py
│ ├── coins/
│ │ ├── __init__.py
│ │ └── market.py
│ ├── data/
│ │ └── __init__.py
│ ├── fund/
│ │ ├── __init__.py
│ │ ├── cons.py
│ │ └── nav.py
│ ├── futures/
│ │ ├── __init__.py
│ │ ├── cons.py
│ │ ├── domestic.py
│ │ ├── domestic_cons.py
│ │ └── intlfutures.py
│ ├── internet/
│ │ ├── __init__.py
│ │ ├── boxoffice.py
│ │ ├── caixinnews.py
│ │ └── indexes.py
│ ├── pro/
│ │ ├── __init__.py
│ │ ├── client.py
│ │ └── data_pro.py
│ ├── stock/
│ │ ├── __init__.py
│ │ ├── billboard.py
│ │ ├── classifying.py
│ │ ├── cons.py
│ │ ├── fundamental.py
│ │ ├── globals.py
│ │ ├── indictor.py
│ │ ├── macro.py
│ │ ├── macro_vars.py
│ │ ├── news_vars.py
│ │ ├── newsevent.py
│ │ ├── ref_vars.py
│ │ ├── reference.py
│ │ ├── shibor.py
│ │ ├── trading.py
│ │ └── trendline.py
│ ├── trader/
│ │ ├── __init__.py
│ │ ├── trader.py
│ │ ├── utils.py
│ │ └── vars.py
│ └── util/
│ ├── __init__.py
│ ├── common.py
│ ├── conns.py
│ ├── dateu.py
│ ├── formula.py
│ ├── mailmerge.py
│ ├── netbase.py
│ ├── store.py
│ ├── upass.py
│ └── vars.py
└── whats_new.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
# Byte-compiled / optimized / DLL files
*.log
*.swp
*.pdb
.project
.pydevproject
.settings
__pycache__/
*.py[cod]
# C extensions
*.so
# Distribution / packaging
.Python
env/
build/
develop-eggs/
dist/
downloads/
eggs/
source/
baks/
lib/
lib64/
parts/
sdist/
var/
docs/
*.egg-info/
.installed.cfg
*.egg
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.coverage
.cache
nosetests.xml
coverage.xml
# Translations
*.mo
*.pot
# Django stuff:
*.log
# Sphinx documentation
docs/_build/
docs/*.md
docs/bin
.idea/
# PyBuilder
target/
#Visual Studio Environment
*.pyproj
*.sln
.vs/
#Vim Environment
tags
*~
================================================
FILE: .travis.yml
================================================
language: python
python:
# We don't actually use the Travis Python, but this keeps it organized.
- "2.7"
# "3.3"
- "3.4"
install:
- sudo apt-get update
# We do this conditionally because it saves us some downloading if the
# version is the same.
- if [[ "$TRAVIS_PYTHON_VERSION" == "2.7" ]]; then
wget https://repo.continuum.io/miniconda/Miniconda-latest-Linux-x86_64.sh -O miniconda.sh;
else
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh -O miniconda.sh;
fi
- bash miniconda.sh -b -p $HOME/miniconda
- export PATH="$HOME/miniconda/bin:$PATH"
- hash -r
- conda config --set always_yes yes --set changeps1 no
- conda update -q conda
# Useful for debugging any issues with conda
- conda info -a
before_script:
- conda install --yes python=$TRAVIS_PYTHON_VERSION numpy scipy pandas matplotlib lxml pytesseract
- python setup.py install
script:
- python test_unittest.py
================================================
FILE: LICENSE
================================================
Copyright (c) 2015, 挖地兔
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions are met:
* Redistributions of source code must retain the above copyright notice, this
list of conditions and the following disclaimer.
* Redistributions in binary form must reproduce the above copyright notice,
this list of conditions and the following disclaimer in the documentation
and/or other materials provided with the distribution.
* Neither the name of tushare nor the names of its
contributors may be used to endorse or promote products derived from
this software without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
================================================
FILE: MANIFEST
================================================
# file GENERATED by distutils, do NOT edit
setup.py
test\test.py
tushare\__init__.py
tushare\data\__init__.py
tushare\data\all.csv
tushare\stock\__init__.py
tushare\stock\cons.py
tushare\stock\fundamental.py
tushare\stock\trading.py
================================================
FILE: README.md
================================================
TuShare
Tushare Pro版已发布,请访问新的官网了解和查询数据接口! [https://tushare.pro](https://tushare.pro)
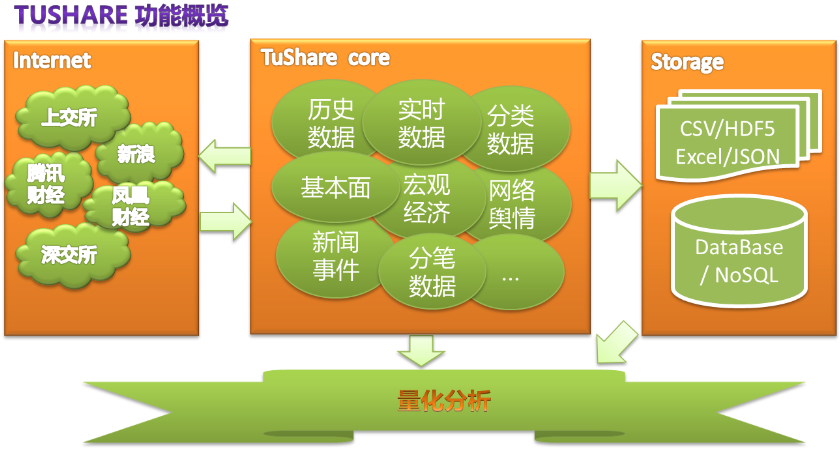
TuShare是实现对股票/期货等金融数据从**数据采集**、**清洗加工** 到 **数据存储**过程的工具,满足金融量化分析师和学习数据分析的人在数据获取方面的需求,它的特点是数据覆盖范围广,接口调用简单,响应快速。
欢迎关注扫描TuShare的微信公众号“挖地兔”,更多资源和信息与您分享。另外,由于tushare官网在重新设计和开发,最新接口的使用文档都会在挖地兔公众号发布,所以,请扫码关注,谢谢!

QQ交流群:
- 一群(已满):14934432
- 二群(付费高级用户群,可获得更多支持及参与圈子活动):658562506
- 三群(免费):665480579
- 四群 (免费) :527416821
Dependencies
=========
python 2.x/3.x
[pandas](http://pandas.pydata.org/ "pandas")
Installation
====
- 方式1:pip install tushare
- 方式2:python setup.py install
- 方式3:访问[https://pypi.python.org/pypi/tushare/](https://pypi.python.org/pypi/tushare/)下载安装
Upgrade
=======
pip install tushare --upgrade
Quick Start
======
**Example 1.** 获取个股历史交易数据(包括均线数据):
import tushare as ts
ts.get_hist_data('600848') #一次性获取全部数据
另外,参考get_k_data函数
结果显示:
> 日期 ,开盘价, 最高价, 收盘价, 最低价, 成交量, 价格变动 ,涨跌幅,5日均价,10日均价,20日均价,5日均量,10日均量,20日均量,换手率
open high close low volume p_change ma5 \
date
2012-01-11 6.880 7.380 7.060 6.880 14129.96 2.62 7.060
2012-01-12 7.050 7.100 6.980 6.900 7895.19 -1.13 7.020
2012-01-13 6.950 7.000 6.700 6.690 6611.87 -4.01 6.913
2012-01-16 6.680 6.750 6.510 6.480 2941.63 -2.84 6.813
2012-01-17 6.660 6.880 6.860 6.460 8642.57 5.38 6.822
2012-01-18 7.000 7.300 6.890 6.880 13075.40 0.44 6.788
2012-01-19 6.690 6.950 6.890 6.680 6117.32 0.00 6.770
2012-01-20 6.870 7.080 7.010 6.870 6813.09 1.74 6.832
ma10 ma20 v_ma5 v_ma10 v_ma20 turnover
date
2012-01-11 7.060 7.060 14129.96 14129.96 14129.96 0.48
2012-01-12 7.020 7.020 11012.58 11012.58 11012.58 0.27
2012-01-13 6.913 6.913 9545.67 9545.67 9545.67 0.23
2012-01-16 6.813 6.813 7894.66 7894.66 7894.66 0.10
2012-01-17 6.822 6.822 8044.24 8044.24 8044.24 0.30
2012-01-18 6.833 6.833 7833.33 8882.77 8882.77 0.45
2012-01-19 6.841 6.841 7477.76 8487.71 8487.71 0.21
2012-01-20 6.863 6.863 7518.00 8278.38 8278.38 0.23
设定历史数据的时间:
ts.get_hist_data('600848',start='2015-01-05',end='2015-01-09')
open high close low volume p_change ma5 ma10 \
date
2015-01-05 11.160 11.390 11.260 10.890 46383.57 1.26 11.156 11.212
2015-01-06 11.130 11.660 11.610 11.030 59199.93 3.11 11.182 11.155
2015-01-07 11.580 11.990 11.920 11.480 86681.38 2.67 11.366 11.251
2015-01-08 11.700 11.920 11.670 11.640 56845.71 -2.10 11.516 11.349
2015-01-09 11.680 11.710 11.230 11.190 44851.56 -3.77 11.538 11.363
ma20 v_ma5 v_ma10 v_ma20 turnover
date
2015-01-05 11.198 58648.75 68429.87 97141.81 1.59
2015-01-06 11.382 54854.38 63401.05 98686.98 2.03
2015-01-07 11.543 55049.74 61628.07 103010.58 2.97
2015-01-08 11.647 57268.99 61376.00 105823.50 1.95
2015-01-09 11.682 58792.43 60665.93 107924.27 1.54
**复权历史数据**
获取历史复权数据,分为前复权和后复权数据,接口提供股票上市以来所有历史数据,默认为前复权。如果不设定开始和结束日期,则返回近一年的复权数据,从性能上考虑,推荐设定开始日期和结束日期,而且最好不要超过一年以上,获取到数据后,请及时在本地存储。
ts.get_h_data('002337') #前复权
ts.get_h_data('002337',autype='hfq') #后复权
ts.get_h_data('002337',autype=None) #不复权
ts.get_h_data('002337',start='2015-01-01',end='2015-03-16') #两个日期之间的前复权数据
**Example 2.** 一次性获取最近一个日交易日所有股票的交易数据(结果显示速度取决于网速)
ts.get_today_all()
结果显示:
> 代码,名称,涨跌幅,现价,开盘价,最高价,最低价,最日收盘价,成交量,换手率
code name changepercent trade open high low settlement \
0 002738 中矿资源 10.023 19.32 19.32 19.32 19.32 17.56
1 300410 正业科技 10.022 25.03 25.03 25.03 25.03 22.75
2 002736 国信证券 10.013 16.37 16.37 16.37 16.37 14.88
3 300412 迦南科技 10.010 31.54 31.54 31.54 31.54 28.67
4 300411 金盾股份 10.007 29.68 29.68 29.68 29.68 26.98
5 603636 南威软件 10.006 38.15 38.15 38.15 38.15 34.68
6 002664 信质电机 10.004 30.68 29.00 30.68 28.30 27.89
7 300367 东方网力 10.004 86.76 78.00 86.76 77.87 78.87
8 601299 中国北车 10.000 11.44 11.44 11.44 11.29 10.40
9 601880 大连港 10.000 5.72 5.34 5.72 5.22 5.20
10 000856 冀东装备 10.000 8.91 8.18 8.91 8.18 8.10
volume turnoverratio
0 375100 1.25033
1 85800 0.57200
2 1058925 0.08824
3 69400 0.51791
4 252220 1.26110
5 1374630 5.49852
6 6448748 9.32700
7 2025030 6.88669
8 433453523 4.28056
9 323469835 9.61735
10 25768152 19.51090
**Example 3.** 获取历史分笔数据
import tushare as ts
df = ts.get_tick_data('600848',date='2014-01-09')
df.head(10)
结果显示:
>成交时间、成交价格、价格变动,成交手、成交金额(元),买卖类型
Out[3]:
time price change volume amount type
0 15:00:00 6.05 -- 8 4840 卖盘
1 14:59:55 6.05 -- 50 30250 卖盘
2 14:59:35 6.05 -- 20 12100 卖盘
3 14:59:30 6.05 -0.01 165 99825 卖盘
4 14:59:20 6.06 0.01 4 2424 买盘
5 14:59:05 6.05 -0.01 2 1210 卖盘
6 14:58:55 6.06 -- 4 2424 买盘
7 14:58:45 6.06 -- 2 1212 买盘
8 14:58:35 6.06 0.01 2 1212 买盘
9 14:58:25 6.05 -0.01 20 12100 卖盘
10 14:58:05 6.06 -- 5 3030 买盘
**Example 4.** 获取实时交易数据(Realtime Quotes Data)
df = ts.get_realtime_quotes('000581') #Single stock symbol
df[['code','name','price','bid','ask','volume','amount','time']]
结果显示:
>名称、开盘价、昨价、现价、最高、最低、买入价、卖出价、成交量、成交金额...more in docs
code name price bid ask volume amount time
0 000581 威孚高科 31.15 31.14 31.15 8183020 253494991.16 11:30:36
请求多个股票方法(一次最好不要超过30个):
ts.get_realtime_quotes(['600848','000980','000981']) #symbols from a list
ts.get_realtime_quotes(df['code'].tail(10)) #from a Series
更多文档
========
[https://tushare.pro](https://tushare.pro)
[http://tushare.org/](http://tushare.org/ "TuShare Docs")
Change Logs
-----------
1.2.17 2018/11/24
======
- Pro版增加期货数据
- Pro版增加A股周/月数据
- Pro版增加通用行情pro_bar接口股票/基金/期货/数据货币行情的支持,同时支持股票的复权行情
1.2.15 2018/10/15
====
- 增加通用行情pro_bar接口
- 优化set_token功能
1.2.12 2018/08/10
====
- 发布Pro版第一稿
- 发布Pro网站,[https://tushare.pro](https://tushare.pro)
1.0.5 2017/11/12
======
- 新增可转债数据
- 增加长连接关闭函数
- 修复部分bug
1.0.2 2017/10/29
==========
- 新增bar接口,支持更稳定的股票、ETF、期货期权、港股、中概股等品种
- 新增tick接口,支持以上品种的成交数据
- 新增沪深港通每日资金流向数据
- 修复了部分bug
0.9.2 2017/09/13
===========
- 新增数据货币行情数据接口,同时支持火币、okcoin、中国比特币
- 部分bug修复
0.8.8 2017/08/29
===========
- 新增分红送股数据(包含历史)
- 新增get_day_all接口
- 新增BDI接口
0.8.0 2017/06/05
===========
- 新增期货行情数据6个接口,感谢debugo贡献代码
- 修复部分bug
0.7.6 2017/05/16
=============
- get\_today\_all接口数据补齐
- forecast\_data mac下编码问题修复
0.7.0 2017/03/12
=============
- get\_today\_all接口提速
- 版本累积更新
0.6.2 2016/12/03
==========
- 新增十大股东和十大流通股接口 top10_holders
- 新增全球实时指数列表接口 global_realtime
- 修复部分bug
0.6.1 2016/11/22
===========
- 修正get_k_databug
- 修正实盘交易登录问题
0.5.6 2016/11/06
=============
- 新增全新行情数据接口get_k_data(请关注tushare公众号“挖地兔”后查看历史文章《全新的免费行情数据接口》)
- 修复程序和文档bug
0.5.1 2016/10/16
=============
- 新增实盘交易接口
- 修复bug
0.4.9 2016/03/26
=============
- 新增申万行业分类get_industry_classified(standard='sw')
- 新增交易日历trade_cal()
- 修复bug
0.4.3 2015/12/24
============
- 新增电影票房数据
- 修复部分bug
0.4.1 2015/11/27
==============
- 新增sina大单数据
- 修改当日分笔bug
- 深市融资融券数据修复
0.3.9 2015/10/13
============
- 新增期权隐含波动率数据
- 修复指数成份及权重接口问题
0.3.8 2015/09/19
============
- 沪深300成份股和权重接口问题修复
- 其它bug的修复
0.3.5 2015/07/27
==========
- 部分代码修正
0.3.4 2015/06/15
===========
- 新增‘龙虎榜’模块
1. 每日龙虎榜列表
1. 个股上榜统计
1. 营业部上榜统计
1. 龙虎榜机构席位追踪
1. 龙虎榜机构席位成交明细
- 修改get\_h\_data数据类型为float
- 修改get_index接口遗漏的open列
- 合并GitHub上提交的bug修复
0.2.8 2015/04/28
============
- 新增大盘指数实时行情列表
- 新增大盘指数历史行情数据(全部)
- 新增终止上市公司列表(退市)
- 新增暂停上市公司列表
- 修正融资融券明细无日期的缺陷
- 修正get\_h\_data部分bug
0.2.6
========
- 新增沪市融资融券列表
- 新增沪市融资融券明细列表
- 新增深市融资融券列表
- 新增深市融资融券明细列表
- 修正复权数据数据源出现null造成异常问题(对大约300个股票有影响)
0.2.5 2015/04/16
===========
- 完成python2.x和python3.x兼容性支持
- 部分算法优化和代码重构
- 新增中证500成份股
- 新增当日分笔交易明细
- 修正分配预案(高送转)bug
0.2.3 2015/04/11
===========
- 新增“新浪股吧”消息和热度
- 新增新股上市数据
- 修正“基本面”模块中数据重复的问题
- 修正历史数据缺少一列column(数据来源问题)的bug
0.2.0 2015/03/17
=======
- 新增历史复权数据接口
- 新增即时滚动新闻、信息地雷数据
- 新增沪深300指数成股份及动态权重、
- 新增上证50指数成份股
- 修改历史行情数据类型为float
0.1.9 2015/02/06
========
- 增加分类数据
- 增加数据存储示例
0.1.6 2015/01/27
========
- 增加了重点指数的历史和实时行情
- 更新docs
0.1.5 2015/01/26
=====
- 增加基本面数据接口
- 发布一版使用手册,开通[TuShare docs](http://tushare.waditu.com)网站
0.1.3 2015/01/13
===
- 增加实时交易数据的获取
- Done for crawling Realtime Quotes data
0.1.1 2015/01/11
===
- 增加tick数据的获取
0.1.0 2014/12/01
===
- 创建第一个版本
- 实现个股历史数据的获取
================================================
FILE: issues/from_email.txt
================================================
2015-2-10
------------
ASK:Stupidinsect:ϣӻ
REP:
2015-2-26
------------
ASK:Allisnoneproblem with python keywords
REP:н
2015-3-1
------------
ASK:: get_hist_dataMySQLdate(index)
REP:ʱͨdf['date'] = df.indexto_sqlòindex=Falseһ汾ȡindex
2015-3-23
--------------
chendonghui1987:ȡǰȨݱTypeError: cannot convert the series to <type 'float'>
from v0.2.1
2015-04-05
-------------------
̹:
JimmyTuã
ȸлṩôõһ⣬Һܾõ⣬
ύһbugع˾걨ݣreport = ts.get_report_data(2014, 1)
⣺
1ȱ˾ƽУ000001
2˾ظ總ˢ
ϣлָ
2015-04-18
---------------
huhaook:ijЩɵĸȨ쳣ʵԴΪnullҪij(418)
2015-04-28
----------------
Ԭͨget_hist_dataȡ600102ʱ600102йƱݷأֱӷNone
2015-06-13
Tales Yuantushareprofit_dataȡ2015Ԥʧܡ61423ʱ25
================================================
FILE: issues/from_sns.txt
================================================
2015-02-12
-----------
QQȺ297882961kݸȨ۵⡢ݲ
2015-03-01
-----------
QQȺ275882700@ kߴ⣬ȷʵǷ˲ƾԴ⣨ɸget_h_data()ӿڣ
2015-03-02
-----------
QQȺ275882700@װ˹̹ ϣṩָijɷݹɺȨ
2015-03-20
QQȺ297882961:@x ֤100֤800ָk
2015-04-09
-------------
QQȺ297882961:@㽭-QT002738Ʊʷݱget_hist_data飬ԭǷ˲ƾĽӿһлʵݡʽжһcolumnsöԵȵcolumsб
2015-04-10
-------------
־ȨݵΪobject
2015-04-16
-------------
@ariestigerget_h_data()ijɽƴд
2015-05-01
------------------
QQȺ297882961:@Koffʹget_today_tickӿڵʱUnboundLocalError: local variable 'data' referenced before assignment쳣̺ϵõģ
2015-05-05
QQ Mr.OKӹ˾ɶĽӿ
PHENXI-ڻ
--------------------
http://vip.stock.finance.sina.com.cn/mkt/#hqIndex
ҳбȽȫгϢ
http://blog.sina.com.cn/s/blog_7ed3ed3d0101gphj.html
ƪгһЩݽṹ
http://quote.hexun.com/futures/newfutures.aspx?market=9&type=all&n=%C8%AB%B2%BF
http://webcffex.hermes.hexun.com/cffex/kline?code=CFFEXIH1606&start=20160206091500&number=-1000&type=5
PHENXI 2016/2/15 8:57:44
http://webftcn.hermes.hexun.com/
http://webcffex.hermes.hexun.com/cffex/quotelist?code=CFFEXIH1606,CFFEXIF1609,CFFEXIC1603,dceA1611,CFFEXIC1512,&column=code,name,price,priceweight,updownrate,high,low,updown,lastclose,open&callback=getdata1&callback=jQuery111107492109271895186_1455497884413&_=1455497884414
================================================
FILE: requirements.txt
================================================
pandas>=0.18.0
requests>=2.0.0
lxml>=3.8.0
simplejson>=3.16.0
bs4>=0.0.1
beautfulsoup4>=4.5.1
================================================
FILE: setup.py
================================================
from setuptools import setup, find_packages
import codecs
import os
def read(fname):
return codecs.open(os.path.join(os.path.dirname(__file__), fname)).read()
long_desc = """
TuShare
===============
.. image:: https://api.travis-ci.org/waditu/tushare.png?branch=master
:target: https://travis-ci.org/waditu/tushare
.. image:: https://badge.fury.io/py/tushare.png
:target: http://badge.fury.io/py/tushare
* easy to use as most of the data returned are pandas DataFrame objects
* can be easily saved as csv, excel or json files
* can be inserted into MySQL or Mongodb
Target Users
--------------
* financial market analyst of China
* learners of financial data analysis with pandas/NumPy
* people who are interested in China financial data
Installation
--------------
pip install tushare
Upgrade
---------------
pip install tushare --upgrade
Quick Start
--------------
::
import tushare as ts
ts.get_hist_data('600848')
return::
open high close low volume p_change ma5 \
date
2012-01-11 6.880 7.380 7.060 6.880 14129.96 2.62 7.060
2012-01-12 7.050 7.100 6.980 6.900 7895.19 -1.13 7.020
2012-01-13 6.950 7.000 6.700 6.690 6611.87 -4.01 6.913
2012-01-16 6.680 6.750 6.510 6.480 2941.63 -2.84 6.813
2012-01-17 6.660 6.880 6.860 6.460 8642.57 5.38 6.822
2012-01-18 7.000 7.300 6.890 6.880 13075.40 0.44 6.788
2012-01-19 6.690 6.950 6.890 6.680 6117.32 0.00 6.770
2012-01-20 6.870 7.080 7.010 6.870 6813.09 1.74 6.832
"""
def read_install_requires():
reqs = [
'pandas>=0.18.0',
'requests>=2.0.0',
'lxml>=3.8.0',
'simplejson>=3.16.0',
'msgpack>=0.5.6',
'pyzmq>=16.0.0'
]
return reqs
setup(
name='tushare',
version=read('tushare/VERSION.txt'),
description='A utility for crawling historical and Real-time Quotes data of China stocks',
# long_description=read("READM.rst"),
long_description = long_desc,
author='Jimmy Liu',
author_email='jimmysoa@sina.cn',
license='BSD',
url='http://tushare.org',
install_requires=read_install_requires(),
keywords='Global Financial Data',
classifiers=['Development Status :: 4 - Beta',
'Programming Language :: Python :: 2.6',
'Programming Language :: Python :: 2.7',
'Programming Language :: Python :: 3.2',
'Programming Language :: Python :: 3.3',
'Programming Language :: Python :: 3.4',
'Programming Language :: Python :: 3.5',
'License :: OSI Approved :: BSD License'],
packages=find_packages(),
include_package_data=True,
package_data={'': ['*.csv', '*.txt']},
)
================================================
FILE: test/__init__.py
================================================
================================================
FILE: test/bar_test.py
================================================
# -*- coding:utf-8 -*-
'''
Created on 2017/9/24
@author: Jimmy Liu
'''
import unittest
import tushare.stock.trading as fd
class Test(unittest.TestCase):
def set_data(self):
self.code = '600848'
self.start = ''
self.end = ''
def test_bar_data(self):
self.set_data()
print(fd.bar(self.code, self.start, self.end))
if __name__ == "__main__":
#import sys;sys.argv = ['', 'Test.testName']
unittest.main()
================================================
FILE: test/billboard_test.py
================================================
# -*- coding:utf-8 -*-
'''
Created on 2015/3/14
@author: Jimmy Liu
'''
import unittest
import tushare.stock.billboard as fd
class Test(unittest.TestCase):
def set_data(self):
self.date = '2015-06-12'
self.days = 5
def test_top_list(self):
self.set_data()
print(fd.top_list(self.date))
def test_cap_tops(self):
self.set_data()
print(fd.cap_tops(self.days))
def test_broker_tops(self):
self.set_data()
print(fd.broker_tops(self.days))
def test_inst_tops(self):
self.set_data()
print(fd.inst_tops(self.days))
def test_inst_detail(self):
print(fd.inst_detail())
if __name__ == "__main__":
unittest.main()
================================================
FILE: test/classifying_test.py
================================================
# -*- coding:utf-8 -*-
'''
Created on 2015/3/14
@author: Jimmy Liu
'''
import unittest
import tushare.stock.classifying as fd
class Test(unittest.TestCase):
def set_data(self):
self.code = '600848'
self.start = '2015-01-03'
self.end = '2015-04-07'
self.year = 2014
self.quarter = 4
def test_get_industry_classified(self):
print(fd.get_industry_classified())
def test_get_concept_classified(self):
print(fd.get_concept_classified())
def test_get_area_classified(self):
print(fd.get_area_classified())
def test_get_gem_classified(self):
print(fd.get_gem_classified())
def test_get_sme_classified(self):
print(fd.get_sme_classified())
def test_get_st_classified(self):
print(fd.get_st_classified())
def test_get_hs300s(self):
print(fd.get_hs300s())
def test_get_sz50s(self):
print(fd.get_sz50s())
def test_get_zz500s(self):
print(fd.get_zz500s())
if __name__ == "__main__":
unittest.main()
# suite = unittest.TestSuite()
# suite.addTest(Test('test_get_gem_classified'))
# unittest.TextTestRunner(verbosity=2).run(suite)
================================================
FILE: test/dateu_test.py
================================================
# -*- coding:utf-8 -*-
"""
@author: ZackZK
"""
from unittest import TestCase
from tushare.util import dateu
from tushare.util.dateu import is_holiday
class Test_Is_holiday(TestCase):
def test_is_holiday(self):
dateu.holiday = ['2016-01-04'] # holiday stub for later test
self.assertTrue(is_holiday('2016-01-04')) # holiday
self.assertFalse(is_holiday('2016-01-01')) # not holiday
self.assertTrue(is_holiday('2016-01-09')) # Saturday
self.assertTrue(is_holiday('2016-01-10')) # Sunday
================================================
FILE: test/fund_test.py
================================================
# -*- coding:utf-8 -*-
import unittest
import tushare.stock.fundamental as fd
class Test(unittest.TestCase):
def set_data(self):
self.code = '600848'
self.start = '2015-01-03'
self.end = '2015-04-07'
self.year = 2014
self.quarter = 4
def test_get_stock_basics(self):
print(fd.get_stock_basics())
# def test_get_report_data(self):
# self.set_data()
# print(fd.get_report_data(self.year, self.quarter))
#
# def test_get_profit_data(self):
# self.set_data()
# print(fd.get_profit_data(self.year, self.quarter))
#
# def test_get_operation_data(self):
# self.set_data()
# print(fd.get_operation_data(self.year, self.quarter))
#
# def test_get_growth_data(self):
# self.set_data()
# print(fd.get_growth_data(self.year, self.quarter))
#
# def test_get_debtpaying_data(self):
# self.set_data()
# print(fd.get_debtpaying_data(self.year, self.quarter))
#
# def test_get_cashflow_data(self):
# self.set_data()
# print(fd.get_cashflow_data(self.year, self.quarter))
if __name__ == '__main__':
unittest.main()
================================================
FILE: test/indictor_test.py
================================================
# -*- coding:utf-8 -*-
'''
Created on 2018/05/26
@author: Jackie Liao
'''
import unittest
import tushare.stock.indictor as idx
import tushare as ts
class Test(unittest.TestCase):
def test_plot_all(self):
data = ts.get_k_data("601398", start="2018-01-01", end="2018-05-27")
data = data.sort_values(by=["date"], ascending=True)
idx.plot_all(data, is_show=True, output=None)
if __name__ == "__main__":
# import sys;sys.argv = ['', 'Test.testName']
unittest.main()
================================================
FILE: test/macro_test.py
================================================
# -*- coding:utf-8 -*-
'''
Created on 2015/3/14
@author: Jimmy Liu
'''
import unittest
import tushare.stock.macro as fd
class Test(unittest.TestCase):
def test_get_gdp_year(self):
print(fd.get_gdp_year())
def test_get_gdp_quarter(self):
print(fd.get_gdp_quarter())
def test_get_gdp_for(self):
print(fd.get_gdp_for())
def test_get_gdp_pull(self):
print(fd.get_gdp_pull())
def test_get_gdp_contrib(self):
print(fd.get_gdp_contrib())
def test_get_cpi(self):
print(fd.get_cpi())
def test_get_ppi(self):
print(fd.get_ppi())
def test_get_deposit_rate(self):
print(fd.get_deposit_rate())
def test_get_loan_rate(self):
print(fd.get_loan_rate())
def test_get_rrr(self):
print(fd.get_rrr())
def test_get_money_supply(self):
print(fd.get_money_supply())
def test_get_money_supply_bal(self):
print(fd.get_money_supply_bal())
if __name__ == "__main__":
#import sys;sys.argv = ['', 'Test.testName']
unittest.main()
================================================
FILE: test/nav_test.py
================================================
# -*- coding:utf-8 -*-
'''
Created on 2016/5/26
@author: leo
'''
import unittest
import tushare.fund.nav as nav
class Test(unittest.TestCase):
def set_data(self):
self.symbol = '600848'
self.start = '2014-11-24'
self.end = '2016-02-29'
self.disp = 5
def test_get_nav_open(self):
self.set_data()
lst = ['all', 'equity', 'mix', 'bond', 'monetary', 'qdii']
print('get nav open................\n')
for item in lst:
print('=============\nget %s nav\n=============' % item)
fund_df = nav.get_nav_open(item)
print('\nnums=%d' % len(fund_df))
print(fund_df[:self.disp])
def test_get_nav_close(self):
self.set_data()
type2 = ['all', 'fbqy', 'fbzq']
qy_t3 = ['all', 'ct', 'cx']
zq_t3 = ['all', 'wj', 'jj', 'cz']
print('\nget nav closed................\n')
fund_df = None
for item in type2:
if item == 'fbqy':
for t3i in qy_t3:
print('\n=============\nget %s-%s nav\n=============' %
(item, t3i))
fund_df = nav.get_nav_close(item, t3i)
print('\nnums=%d' % len(fund_df))
print(fund_df[:self.disp])
elif item == 'fbzq':
for t3i in zq_t3:
print('\n=============\nget %s-%s nav\n=============' %
(item, t3i))
fund_df = nav.get_nav_close(item, t3i)
print('\nnums=%d' % len(fund_df))
print(fund_df[:self.disp])
else:
print('\n=============\nget %s nav\n=============' % item)
fund_df = nav.get_nav_close(item)
print('\nnums=%d' % len(fund_df))
print(fund_df[:self.disp])
def test_get_nav_grading(self):
self.set_data()
t2 = ['all', 'fjgs', 'fjgg']
t3 = {'all': '0', 'wjzq': '13', 'gp': '14',
'zs': '15', 'czzq': '16', 'jjzq': '17'}
print('\nget nav grading................\n')
fund_df = None
for item in t2:
if item == 'all':
print('\n=============\nget %s nav\n=============' % item)
fund_df = nav.get_nav_grading(item)
print('\nnums=%d' % len(fund_df))
print(fund_df[:self.disp])
else:
for t3i in t3.keys():
print('\n=============\nget %s-%s nav\n=============' %
(item, t3i))
fund_df = nav.get_nav_grading(item, t3i)
print('\nnums=%d' % len(fund_df))
print(fund_df[:self.disp])
def test_nav_history(self):
self.set_data()
lst = ['164905', '161005', '380007', '000733', '159920', '164902',
'184721', '165519', '164302', '519749', '150275', '150305',
'150248']
for _, item in enumerate(lst):
print('\n=============\nget %s nav\n=============' % item)
fund_df = nav.get_nav_history(item, self.start, self.end)
if fund_df is not None:
print('\nnums=%d' % len(fund_df))
print(fund_df[:self.disp])
def test_get_fund_info(self):
self.set_data()
lst = ['164905', '161005', '380007', '000733', '159920', '164902',
'184721', '165519', '164302', '519749', '150275', '150305',
'150248']
for item in lst:
print('\n=============\nget %s nav\n=============' % item)
fund_df = nav.get_fund_info(item)
if fund_df is not None:
print('%s fund info' % item)
print(fund_df)
if __name__ == '__main__':
unittest.main()
================================================
FILE: test/news_test.py
================================================
# -*- coding:utf-8 -*-
'''
Created on 2015/3/14
@author: Jimmy Liu
'''
import unittest
import tushare.stock.newsevent as fd
class Test(unittest.TestCase):
def set_data(self):
self.code = '600848'
self.start = '2015-01-03'
self.end = '2015-04-07'
self.year = 2014
self.quarter = 4
self.top = 60
self.show_content = True
def test_get_latest_news(self):
self.set_data()
print(fd.get_latest_news(self.top, self.show_content))
def test_get_notices(self):
self.set_data()
df = fd.get_notices(self.code)
print(fd.notice_content(df.ix[0]['url']))
def test_guba_sina(self):
self.set_data()
print(fd.guba_sina(self.show_content))
if __name__ == "__main__":
unittest.main()
================================================
FILE: test/ref_test.py
================================================
# -*- coding:utf-8 -*-
'''
Created on 2015/3/14
@author: Jimmy Liu
'''
import unittest
from tushare.stock import reference as fd
class Test(unittest.TestCase):
def set_data(self):
self.code = '600848'
self.start = '2015-01-03'
self.end = '2015-04-07'
self.year = 2014
self.quarter = 4
self.top = 60
self.show_content = True
def test_profit_data(self):
self.set_data()
print(fd.profit_data(top=self.top))
def test_forecast_data(self):
self.set_data()
print(fd.forecast_data(self.year, self.quarter))
def test_xsg_data(self):
print(fd.xsg_data())
def test_fund_holdings(self):
self.set_data()
print(fd.fund_holdings(self.year, self.quarter))
def test_new_stocksa(self):
print(fd.new_stocks())
def test_sh_margin_details(self):
self.set_data()
print(fd.sh_margin_details(self.start, self.end, self.code))
def test_sh_margins(self):
self.set_data()
print(fd.sh_margins(self.start, self.end))
def test_sz_margins(self):
self.set_data()
print(fd.sz_margins(self.start, self.end))
def test_sz_margin_details(self):
self.set_data()
print(fd.sz_margin_details(self.end))
if __name__ == "__main__":
unittest.main()
================================================
FILE: test/shibor_test.py
================================================
# -*- coding:utf-8 -*-
import unittest
import tushare.stock.shibor as fd
class Test(unittest.TestCase):
def set_data(self):
self.year = 2014
# self.year = None
def test_shibor_data(self):
self.set_data()
fd.shibor_data(self.year)
def test_shibor_quote_data(self):
self.set_data()
fd.shibor_quote_data(self.year)
def test_shibor_ma_data(self):
self.set_data()
fd.shibor_ma_data(self.year)
def test_lpr_data(self):
self.set_data()
fd.lpr_data(self.year)
def test_lpr_ma_data(self):
self.set_data()
fd.lpr_ma_data(self.year)
if __name__ == '__main__':
unittest.main()
================================================
FILE: test/storing_test.py
================================================
# -*- coding:utf-8 -*-
import os
from sqlalchemy import create_engine
from pandas.io.pytables import HDFStore
import tushare as ts
def csv():
df = ts.get_hist_data('000875')
df.to_csv('c:/day/000875.csv',columns=['open','high','low','close'])
def xls():
df = ts.get_hist_data('000875')
#直接保存
df.to_excel('c:/day/000875.xlsx', startrow=2,startcol=5)
def hdf():
df = ts.get_hist_data('000875')
# df.to_hdf('c:/day/store.h5','table')
store = HDFStore('c:/day/store.h5')
store['000875'] = df
store.close()
def json():
df = ts.get_hist_data('000875')
df.to_json('c:/day/000875.json',orient='records')
#或者直接使用
print(df.to_json(orient='records'))
def appends():
filename = 'c:/day/bigfile.csv'
for code in ['000875', '600848', '000981']:
df = ts.get_hist_data(code)
if os.path.exists(filename):
df.to_csv(filename, mode='a', header=None)
else:
df.to_csv(filename)
def db():
df = ts.get_tick_data('600848',date='2014-12-22')
engine = create_engine('mysql://root:jimmy1@127.0.0.1/mystock?charset=utf8')
# db = MySQLdb.connect(host='127.0.0.1',user='root',passwd='jimmy1',db="mystock",charset="utf8")
# df.to_sql('TICK_DATA',con=db,flavor='mysql')
# db.close()
df.to_sql('tick_data',engine,if_exists='append')
def nosql():
import pymongo
import json
conn = pymongo.Connection('127.0.0.1', port=27017)
df = ts.get_tick_data('600848',date='2014-12-22')
print(df.to_json(orient='records'))
conn.db.tickdata.insert(json.loads(df.to_json(orient='records')))
# print conn.db.tickdata.find()
if __name__ == '__main__':
nosql()
================================================
FILE: test/trading_test.py
================================================
# -*- coding:utf-8 -*-
'''
Created on 2015/3/14
@author: Jimmy Liu
'''
import unittest
import tushare.stock.trading as fd
class Test(unittest.TestCase):
def set_data(self):
self.code = '600848'
self.start = '2015-01-03'
self.end = '2015-04-07'
self.year = 2014
self.quarter = 4
def test_get_hist_data(self):
self.set_data()
print(fd.get_hist_data(self.code, self.start))
def test_get_tick_data(self):
self.set_data()
print(fd.get_tick_data(self.code, self.end))
def test_get_today_all(self):
print(fd.get_today_all())
def test_get_realtime_quotesa(self):
self.set_data()
print(fd.get_realtime_quotes(self.code))
def test_get_h_data(self):
self.set_data()
print(fd.get_h_data(self.code, self.start, self.end))
def test_get_today_ticks(self):
self.set_data()
print(fd.get_today_ticks(self.code))
if __name__ == "__main__":
#import sys;sys.argv = ['', 'Test.testName']
unittest.main()
================================================
FILE: test_unittest.py
================================================
'''
UnitTest for API
@author: Jimmy
'''
import unittest
import tushare.stock.trading as td
class TestTrading(unittest.TestCase):
def set_data(self):
self.code = '600848'
self.start = '2014-11-03'
self.end = '2014-11-07'
def test_tickData(self):
self.set_data()
td.get_tick_data(self.code, date=self.start)
# def test_histData(self):
# self.set_data()
# td.get_hist_data(self.code, start=self.start, end=self.end)
if __name__ == "__main__":
#import sys;sys.argv = ['', 'Test.testName']
unittest.main()
================================================
FILE: tushare/VERSION.txt
================================================
1.2.18
================================================
FILE: tushare/__init__.py
================================================
# -*- coding:utf-8 -*-
import codecs
import os
__version__ = codecs.open(os.path.join(os.path.dirname(__file__), 'VERSION.txt')).read()
__author__ = 'Jimmy Liu'
"""
for trading data
"""
from tushare.stock.trading import (get_hist_data, get_tick_data,
get_today_all, get_realtime_quotes,
get_h_data, get_today_ticks,
get_index, get_hists,
get_k_data, get_day_all,
get_sina_dd, bar, tick,
get_markets, quotes,
get_instrument, reset_instrument)
"""
for trading data
"""
from tushare.stock.fundamental import (get_stock_basics, get_report_data,
get_profit_data,
get_operation_data, get_growth_data,
get_debtpaying_data, get_cashflow_data,
get_balance_sheet, get_profit_statement, get_cash_flow)
"""
for macro data
"""
from tushare.stock.macro import (get_gdp_year, get_gdp_quarter,
get_gdp_for, get_gdp_pull,
get_gdp_contrib, get_cpi,
get_ppi, get_deposit_rate,
get_loan_rate, get_rrr,
get_money_supply, get_money_supply_bal,
get_gold_and_foreign_reserves)
"""
for classifying data
"""
from tushare.stock.classifying import (get_industry_classified, get_concept_classified,
get_area_classified, get_gem_classified,
get_sme_classified, get_st_classified,
get_hs300s, get_sz50s, get_zz500s,
get_terminated, get_suspended)
"""
for macro data
"""
from tushare.stock.newsevent import (get_latest_news, latest_content,
get_notices, notice_content,
guba_sina)
"""
for reference
moneyflow_hsgt:沪深港通资金流向
"""
from tushare.stock.reference import (profit_data, forecast_data,
xsg_data, fund_holdings,
new_stocks, new_cbonds, sh_margins,
sh_margin_details,
sz_margins, sz_margin_details,
top10_holders, profit_divis,
moneyflow_hsgt, margin_detail,
margin_target, margin_offset,
margin_zsl, stock_issuance,
stock_pledged, pledged_detail)
"""
for shibor
"""
from tushare.stock.shibor import (shibor_data, shibor_quote_data,
shibor_ma_data, lpr_data,
lpr_ma_data)
"""
for tushare pro api
"""
from tushare.pro.data_pro import (pro_api, pro_bar)
"""
for LHB
"""
from tushare.stock.billboard import (top_list, cap_tops, broker_tops,
inst_tops, inst_detail)
"""
for utils
"""
from tushare.util.dateu import (trade_cal, is_holiday)
from tushare.internet.boxoffice import (realtime_boxoffice, day_boxoffice,
day_cinema, month_boxoffice)
from tushare.internet.indexes import (bdi)
"""
for fund data
"""
from tushare.fund.nav import (get_nav_open, get_nav_close, get_nav_grading,
get_nav_history, get_fund_info)
"""
for trader API
"""
from tushare.trader.trader import TraderAPI
"""
for futures API
"""
from tushare.futures.intlfutures import (get_intlfuture)
from tushare.stock.globals import (global_realtime)
from tushare.util.mailmerge import (MailMerge)
"""
for futures API
"""
from tushare.futures.domestic import (get_cffex_daily, get_czce_daily,
get_dce_daily, get_future_daily,
get_shfe_daily, get_shfe_vwap)
from tushare.coins.market import (coins_tick, coins_bar,
coins_snapshot, coins_trade)
from tushare.util.conns import (get_apis, close_apis)
from tushare.util.upass import (get_token, set_token)
================================================
FILE: tushare/bond/__init__.py
================================================
================================================
FILE: tushare/bond/bonds.py
================================================
# -*- coding:utf-8 -*-
"""
投资参考数据接口
Created on 2017/10/01
@author: Jimmy Liu
@group : waditu
@contact: jimmysoa@sina.cn
"""
def get_bond_info(code):
pass
if __name__ == '__main__':
pass
================================================
FILE: tushare/coins/__init__.py
================================================
================================================
FILE: tushare/coins/market.py
================================================
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
数字货币行情数据
Created on 2017年9月9日
@author: Jimmy Liu
@group : waditu
@contact: jimmysoa@sina.cn
"""
import pandas as pd
import traceback
import time
import json
try:
from urllib.request import urlopen, Request
except ImportError:
from urllib2 import urlopen, Request
URL = {
"hb": {
"rt" : 'http://api.huobi.com/staticmarket/ticker_%s_json.js',
"kline" : 'http://api.huobi.com/staticmarket/%s_kline_%s_json.js?length=%s',
"snapshot" : 'http://api.huobi.com/staticmarket/depth_%s_%s.js',
"tick" : 'http://api.huobi.com/staticmarket/detail_%s_json.js',
},
"ok": {
"rt" : 'https://www.okcoin.cn/api/v1/ticker.do?symbol=%s_cny',
"kline" : 'https://www.okcoin.cn/api/v1/kline.do?symbol=%s_cny&type=%s&size=%s',
"snapshot" : 'https://www.okcoin.cn/api/v1/depth.do?symbol=%s_cny&merge=&size=%s',
"tick" : 'https://www.okcoin.cn/api/v1/trades.do?symbol=%s_cny',
},
'chbtc': {
"rt" : 'http://api.chbtc.com/data/v1/ticker?currency=%s_cny',
"kline" : 'http://api.chbtc.com/data/v1/kline?currency=%s_cny&type=%s&size=%s',
"snapshot" : 'http://api.chbtc.com/data/v1/depth?currency=%s_cny&size=%s&merge=',
"tick" : 'http://api.chbtc.com/data/v1/trades?currency=%s_cny',
}
}
KTYPES = {
"D": {
"hb" : '100',
'ok' : '1day',
'chbtc' : '1day',
},
"W": {
"hb" : '200',
'ok' : '1week',
'chbtc' : '1week',
},
"M": {
"hb" : '300',
"ok" : '',
"chbtc" : '',
},
"1MIN": {
"hb" : '001',
'ok' : '1min',
'chbtc' : '1min',
},
"5MIN": {
"hb" : '005',
'ok' : '5min',
'chbtc' : '5min',
},
"15MIN": {
"hb" : '015',
'ok' : '15min',
'chbtc' : '15min',
},
"30MIN": {
"hb" : '030',
'ok' : '30min',
'chbtc' : '30min',
},
"60MIN": {
"hb" : '060',
'ok' : '1hour',
'chbtc' : '1hour',
},
}
def coins_tick(broker='hb', code='btc'):
"""
实时tick行情
params:
---------------
broker: hb:火币
ok:okCoin
chbtc:中国比特币
code: hb:btc,ltc
----okcoin---
btc_cny:比特币 ltc_cny:莱特币 eth_cny :以太坊 etc_cny :以太经典 bcc_cny :比特现金
----chbtc----
btc_cny:BTC/CNY
ltc_cny :LTC/CNY
eth_cny :以太币/CNY
etc_cny :ETC币/CNY
bts_cny :BTS币/CNY
eos_cny :EOS币/CNY
bcc_cny :BCC币/CNY
qtum_cny :量子链/CNY
hsr_cny :HSR币/CNY
return:json
---------------
hb:
{
"time":"1504713534",
"ticker":{
"symbol":"btccny",
"open":26010.90,
"last":28789.00,
"low":26000.00,
"high":28810.00,
"vol":17426.2198,
"buy":28750.000000,
"sell":28789.000000
}
}
ok:
{
"date":"1504713864",
"ticker":{
"buy":"28743.0",
"high":"28886.99",
"last":"28743.0",
"low":"26040.0",
"sell":"28745.0",
"vol":"20767.734"
}
}
chbtc:
{
u'date': u'1504794151878',
u'ticker': {
u'sell': u'28859.56',
u'buy': u'28822.89',
u'last': u'28859.56',
u'vol': u'2702.71',
u'high': u'29132',
u'low': u'27929'
}
}
"""
return _get_data(URL[broker]['rt'] % (code))
def coins_bar(broker='hb', code='btc', ktype='D', size='2000'):
"""
获取各类k线数据
params:
broker:hb,ok,chbtc
code:btc,ltc,eth,etc,bcc
ktype:D,W,M,1min,5min,15min,30min,60min
size:<2000
return DataFrame: 日期时间,开盘价,最高价,最低价,收盘价,成交量
"""
try:
js = _get_data(URL[broker]['kline'] % (code, KTYPES[ktype.strip().upper()][broker], size))
if js is None:
return js
if broker == 'chbtc':
js = js['data']
df = pd.DataFrame(js, columns=['DATE', 'OPEN', 'HIGH', 'LOW', 'CLOSE', 'VOL'])
if broker == 'hb':
if ktype.strip().upper() in ['D', 'W', 'M']:
df['DATE'] = df['DATE'].apply(lambda x: x[0:8])
else:
df['DATE'] = df['DATE'].apply(lambda x: x[0:12])
else:
df['DATE'] = df['DATE'].apply(lambda x: int2time(x / 1000))
if ktype.strip().upper() in ['D', 'W', 'M']:
df['DATE'] = df['DATE'].apply(lambda x: str(x)[0:10])
df['DATE'] = pd.to_datetime(df['DATE'])
return df
except Exception:
print(traceback.print_exc())
def coins_snapshot(broker='hb', code='btc', size='5'):
"""
获取实时快照数据
params:
broker:hb,ok,chbtc
code:btc,ltc,eth,etc,bcc
size:<150
return Panel: asks,bids
"""
try:
js = _get_data(URL[broker]['snapshot'] % (code, size))
if js is None:
return js
if broker == 'hb':
timestr = js['ts']
timestr = int2time(timestr / 1000)
if broker == 'ok':
timestr = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
if broker == 'chbtc':
timestr = js['timestamp']
timestr = int2time(timestr)
asks = pd.DataFrame(js['asks'], columns = ['price', 'vol'])
bids = pd.DataFrame(js['bids'], columns = ['price', 'vol'])
asks['time'] = timestr
bids['time'] = timestr
djs = {"asks": asks, "bids": bids}
pf = pd.Panel(djs)
return pf
except Exception:
print(traceback.print_exc())
def coins_trade(broker='hb', code='btc'):
"""
获取实时交易数据
params:
-------------
broker: hb,ok,chbtc
code:btc,ltc,eth,etc,bcc
return:
---------------
DataFrame
'tid':order id
'datetime', date time
'price' : trade price
'amount' : trade amount
'type' : buy or sell
"""
js = _get_data(URL[broker]['tick'] % code)
if js is None:
return js
if broker == 'hb':
df = pd.DataFrame(js['trades'])
df = df[['id', 'ts', 'price', 'amount', 'direction']]
df['ts'] = df['ts'].apply(lambda x: int2time(x / 1000))
if broker == 'ok':
df = pd.DataFrame(js)
df = df[['tid', 'date_ms', 'price', 'amount', 'type']]
df['date_ms'] = df['date_ms'].apply(lambda x: int2time(x / 1000))
if broker == 'chbtc':
df = pd.DataFrame(js)
df = df[['tid', 'date', 'price', 'amount', 'type']]
df['date'] = df['date'].apply(lambda x: int2time(x))
df.columns = ['tid', 'datetime', 'price', 'amount', 'type']
return df
def _get_data(url):
try:
request = Request(url)
lines = urlopen(request, timeout = 10).read()
if len(lines) < 50: #no data
return None
js = json.loads(lines.decode('GBK'))
return js
except Exception:
print(traceback.print_exc())
def int2time(timestamp):
value = time.localtime(timestamp)
dt = time.strftime('%Y-%m-%d %H:%M:%S', value)
return dt
================================================
FILE: tushare/data/__init__.py
================================================
__version__ = "0.0.1"
================================================
FILE: tushare/fund/__init__.py
================================================
================================================
FILE: tushare/fund/cons.py
================================================
# -*- coding:utf-8 -*-
"""
Created on 2016/04/03
@author: Leo
@group : lazytech
@contact: lazytech@sina.cn
"""
VERSION = '0.0.1'
P_TYPE = {'http': 'http://', 'ftp': 'ftp://'}
FORMAT = lambda x: '%.2f' % x
FORMAT4 = lambda x: '%.4f' % x
DOMAINS = {'sina': 'sina.com.cn', 'sinahq': 'sinajs.cn',
'ifeng': 'ifeng.com', 'sf': 'finance.sina.com.cn',
'ssf': 'stock.finance.sina.com.cn',
'vsf': 'vip.stock.finance.sina.com.cn',
'idx': 'www.csindex.com.cn', '163': 'money.163.com',
'em': 'eastmoney.com', 'sseq': 'query.sse.com.cn',
'sse': 'www.sse.com.cn', 'szse': 'www.szse.cn',
'oss': '218.244.146.57',
'shibor': 'www.shibor.org'}
NAV_OPEN_API = {'all': 'getNetValueOpen', 'equity': 'getNetValueOpen',
'mix': 'getNetValueOpen', 'bond': 'getNetValueOpen',
'monetary': 'getNetValueMoney', 'qdii': 'getNetValueOpen'}
NAV_OPEN_KEY = {'all': '6XxbX6h4CED0ATvW', 'equity': 'Gb3sH5uawH5WCUZ9',
'mix': '6XxbX6h4CED0ATvW', 'bond': 'Gb3sH5uawH5WCUZ9',
'monetary': 'uGo5qniFnmT5eQjp', 'qdii': 'pTYExKwRmqrSaP0P'}
NAV_OPEN_T2 = {'all': '0', 'equity': '2', 'mix': '1',
'bond': '3', 'monetary': '0', 'qdii': '6'}
NAV_OPEN_T3 = ''
NAV_CLOSE_API = 'getNetValueClose'
NAV_CLOSE_KEY = ''
NAV_CLOSE_T2 = {'all': '0', 'fbqy': '4', 'fbzq': '9'}
NAV_CLOSE_T3 = {'all': '0', 'ct': '10',
'cx': '11', 'wj': '3', 'jj': '5', 'cz': '12'}
NAV_GRADING_API = 'getNetValueCX'
NAV_GRADING_KEY = ''
NAV_GRADING_T2 = {'all': '0', 'fjgs': '7', 'fjgg': '8'}
NAV_GRADING_T3 = {'all': '0', 'wjzq': '13',
'gp': '14', 'zs': '15', 'czzq': '16', 'jjzq': '17'}
NAV_DEFAULT_PAGE = 1
##########################################################################
# 基金数据列名
NAV_OPEN_COLUMNS = ['symbol', 'sname', 'per_nav', 'total_nav', 'yesterday_nav',
'nav_rate', 'nav_a', 'nav_date', 'fund_manager',
'jjlx', 'jjzfe']
NAV_HIS_JJJZ = ['fbrq', 'jjjz', 'ljjz']
NAV_HIS_NHSY = ['fbrq', 'nhsyl', 'dwsy']
FUND_INFO_COLS = ['symbol', 'jjqc', 'jjjc', 'clrq', 'ssrq', 'xcr', 'ssdd',
'Type1Name', 'Type2Name', 'Type3Name', 'jjgm', 'jjfe',
'jjltfe', 'jjferq', 'quarter', 'glr', 'tgr']
NAV_CLOSE_COLUMNS = ['symbol', 'sname', 'per_nav', 'total_nav', 'nav_rate',
'discount_rate', 'nav_date', 'start_date', 'end_date',
'fund_manager', 'jjlx', 'jjzfe']
NAV_GRADING_COLUMNS = ['symbol', 'sname', 'per_nav', 'total_nav', 'nav_rate',
'discount_rate', 'nav_date', 'start_date', 'end_date',
'fund_manager', 'jjlx', 'jjzfe']
NAV_COLUMNS = {'open': NAV_OPEN_COLUMNS,
'close': NAV_CLOSE_COLUMNS, 'grading': NAV_GRADING_COLUMNS}
##########################################################################
# 数据源URL
SINA_NAV_COUNT_URL = '%s%s/fund_center/data/jsonp.php/IO.XSRV2.CallbackList[\'%s\']/NetValue_Service.%s?ccode=&type2=%s&type3=%s'
SINA_NAV_DATA_URL = '%s%s/fund_center/data/jsonp.php/IO.XSRV2.CallbackList[\'%s\']/NetValue_Service.%s?page=%s&num=%s&ccode=&type2=%s&type3=%s'
SINA_NAV_HISTROY_COUNT_URL = '%s%s/fundInfo/api/openapi.php/CaihuiFundInfoService.getNav?symbol=%s&datefrom=%s&dateto=%s'
SINA_NAV_HISTROY_DATA_URL = '%s%s/fundInfo/api/openapi.php/CaihuiFundInfoService.getNav?symbol=%s&datefrom=%s&dateto=%s&num=%s'
SINA_NAV_HISTROY_COUNT_CUR_URL = '%s%s/fundInfo/api/openapi.php/CaihuiFundInfoService.getNavcur?symbol=%s&datefrom=%s&dateto=%s'
SINA_NAV_HISTROY_DATA_CUR_URL = '%s%s/fundInfo/api/openapi.php/CaihuiFundInfoService.getNavcur?symbol=%s&datefrom=%s&dateto=%s&num=%s'
SINA_DATA_DETAIL_URL = '%s%s/quotes_service/api/%s/Market_Center.getHQNodeData?page=1&num=400&sort=symbol&asc=1&node=%s&symbol=&_s_r_a=page'
SINA_FUND_INFO_URL = '%s%s/fundInfo/api/openapi.php/FundPageInfoService.tabjjgk?symbol=%s&format=json'
##########################################################################
DATA_GETTING_TIPS = '[Getting data:]'
DATA_GETTING_FLAG = '#'
DATA_ROWS_TIPS = '%s rows data found.Please wait for a moment.'
DATA_INPUT_ERROR_MSG = 'date input error.'
NETWORK_URL_ERROR_MSG = '获取失败,请检查网络和URL'
DATE_CHK_MSG = '年度输入错误:请输入1989年以后的年份数字,格式:YYYY'
DATE_CHK_Q_MSG = '季度输入错误:请输入1、2、3或4数字'
TOP_PARAS_MSG = 'top有误,请输入整数或all.'
LHB_MSG = '周期输入有误,请输入数字5、10、30或60'
OFT_MSG = u'开放型基金类型输入有误,请输入all、equity、mix、bond、monetary、qdii'
DICT_NAV_EQUITY = {
'fbrq': 'date',
'jjjz': 'value',
'ljjz': 'total',
'change': 'change'
}
DICT_NAV_MONETARY = {
'fbrq': 'date',
'nhsyl': 'value',
'dwsy': 'total',
'change': 'change'
}
import sys
PY3 = (sys.version_info[0] >= 3)
def _write_head():
sys.stdout.write(DATA_GETTING_TIPS)
sys.stdout.flush()
def _write_console():
sys.stdout.write(DATA_GETTING_FLAG)
sys.stdout.flush()
def _write_tips(tip):
sys.stdout.write(DATA_ROWS_TIPS % tip)
sys.stdout.flush()
def _write_msg(msg):
sys.stdout.write(msg)
sys.stdout.flush()
def _check_nav_oft_input(found_type):
if found_type not in NAV_OPEN_KEY.keys():
raise TypeError(OFT_MSG)
else:
return True
def _check_input(year, quarter):
if isinstance(year, str) or year < 1989:
raise TypeError(DATE_CHK_MSG)
elif quarter is None or isinstance(quarter, str) or quarter not in [1, 2, 3, 4]:
raise TypeError(DATE_CHK_Q_MSG)
else:
return True
================================================
FILE: tushare/fund/nav.py
================================================
# -*- coding:utf-8 -*-
"""
获取基金净值数据接口
Created on 2016/04/03
@author: leo
@group : lazytech
@contact: lazytech@sina.cn
"""
from __future__ import division
import time
import json
import re
import pandas as pd
import numpy as np
from tushare.fund import cons as ct
from tushare.util import dateu as du
try:
from urllib.request import urlopen, Request
except ImportError:
from urllib2 import urlopen, Request
def get_nav_open(fund_type='all'):
"""
获取开放型基金净值数据
Parameters
------
type:string
开放基金类型:
1. all 所有开放基金
2. equity 股票型开放基金
3. mix 混合型开放基金
4. bond 债券型开放基金
5. monetary 货币型开放基金
6. qdii QDII型开放基金
return
-------
DataFrame
开放型基金净值数据(DataFrame):
symbol 基金代码
sname 基金名称
per_nav 单位净值
total_nav 累计净值
yesterday_nav 前一日净值
nav_a 涨跌额
nav_rate 增长率(%)
nav_date 净值日期
fund_manager 基金经理
jjlx 基金类型
jjzfe 基金总份额
"""
if ct._check_nav_oft_input(fund_type) is True:
ct._write_head()
nums = _get_fund_num(ct.SINA_NAV_COUNT_URL %
(ct.P_TYPE['http'], ct.DOMAINS['vsf'],
ct.NAV_OPEN_KEY[fund_type],
ct.NAV_OPEN_API[fund_type],
ct.NAV_OPEN_T2[fund_type],
ct.NAV_OPEN_T3))
pages = 2 # 分两次请求数据
limit_cnt = int(nums/pages)+1 # 每次取的数量
fund_dfs = []
for page in range(1, pages+1):
fund_dfs = _parse_fund_data(ct.SINA_NAV_DATA_URL %
(ct.P_TYPE['http'], ct.DOMAINS['vsf'],
ct.NAV_OPEN_KEY[fund_type],
ct.NAV_OPEN_API[fund_type],
page,
limit_cnt,
ct.NAV_OPEN_T2[fund_type],
ct.NAV_OPEN_T3))
return pd.concat(fund_dfs, ignore_index=True)
def get_nav_close(fund_type='all', sub_type='all'):
"""
获取封闭型基金净值数据
Parameters
------
type:string
封闭基金类型:
1. all 所有封闭型基金
2. fbqy 封闭-权益
3. fbzq 封闭债券
sub_type:string
基金子类型:
1. type=all sub_type无效
2. type=fbqy 封闭-权益
*all 全部封闭权益
*ct 传统封基
*cx 创新封基
3. type=fbzq 封闭债券
*all 全部封闭债券
*wj 稳健债券型
*jj 激进债券型
*cz 纯债债券型
return
-------
DataFrame
开放型基金净值数据(DataFrame):
symbol 基金代码
sname 基金名称
per_nav 单位净值
total_nav 累计净值
nav_rate 增长率(%)
discount_rate 折溢价率(%)
nav_date 净值日期
start_date 成立日期
end_date 到期日期
fund_manager 基金经理
jjlx 基金类型
jjzfe 基金总份额
"""
ct._write_head()
nums = _get_fund_num(ct.SINA_NAV_COUNT_URL %
(ct.P_TYPE['http'], ct.DOMAINS['vsf'],
ct.NAV_CLOSE_KEY, ct.NAV_CLOSE_API,
ct.NAV_CLOSE_T2[fund_type],
ct.NAV_CLOSE_T3[sub_type]))
fund_df = _parse_fund_data(ct.SINA_NAV_DATA_URL %
(ct.P_TYPE['http'], ct.DOMAINS['vsf'],
ct.NAV_OPEN_KEY, ct.NAV_CLOSE_API,
ct.NAV_DEFAULT_PAGE,
nums,
ct.NAV_CLOSE_T2[fund_type],
ct.NAV_CLOSE_T3[sub_type]),
'close')
return fund_df
def get_nav_grading(fund_type='all', sub_type='all'):
"""
获取分级子基金净值数据
Parameters
------
type:string
封闭基金类型:
1. all 所有分级基金
2. fjgs 分级-固收
3. fjgg 分级-杠杆
sub_type:string
基金子类型(type=all sub_type无效):
*all 全部分级债券
*wjzq 稳健债券型
*czzq 纯债债券型
*jjzq 激进债券型
*gp 股票型
*zs 指数型
return
-------
DataFrame
开放型基金净值数据(DataFrame):
symbol 基金代码
sname 基金名称
per_nav 单位净值
total_nav 累计净值
nav_rate 增长率(%)
discount_rate 折溢价率(%)
nav_date 净值日期
start_date 成立日期
end_date 到期日期
fund_manager 基金经理
jjlx 基金类型
jjzfe 基金总份额
"""
ct._write_head()
nums = _get_fund_num(ct.SINA_NAV_COUNT_URL %
(ct.P_TYPE['http'], ct.DOMAINS['vsf'],
ct.NAV_GRADING_KEY, ct.NAV_GRADING_API,
ct.NAV_GRADING_T2[fund_type],
ct.NAV_GRADING_T3[sub_type]))
fund_df = _parse_fund_data(ct.SINA_NAV_DATA_URL %
(ct.P_TYPE['http'], ct.DOMAINS['vsf'],
ct.NAV_GRADING_KEY, ct.NAV_GRADING_API,
ct.NAV_DEFAULT_PAGE,
nums,
ct.NAV_GRADING_T2[fund_type],
ct.NAV_GRADING_T3[sub_type]),
'grading')
return fund_df
def get_nav_history(code, start=None, end=None, retry_count=3, pause=0.001, timeout=10):
'''
获取历史净值数据
Parameters
------
code:string
基金代码 e.g. 000001
start:string
开始日期 format:YYYY-MM-DD 为空时取当前日期
end:string
结束日期 format:YYYY-MM-DD 为空时取去年今日
retry_count : int, 默认 3
如遇网络等问题重复执行的次数
pause : int, 默认 0
重复请求数据过程中暂停的秒数,防止请求间隔时间太短出现的问题
timeout: int 默认 10s
请求大量数据时的网络超时
return
-------
DataFrame
date 发布日期 (index)
value 基金净值(股票/混合/QDII型基金) / 年华收益(货币/债券基金)
total 累计净值(股票/混合/QDII型基金) / 万分收益(货币/债券基金)
change 净值增长率(股票/混合/QDII型基金)
'''
start = du.today_last_year() if start is None else start
end = du.today() if end is None else end
# 判断基金类型
ismonetary = False # 是否是债券型和货币型基金
df_fund = get_fund_info(code)
fund_type = df_fund.ix[0]['Type2Name']
if (fund_type.find(u'债券型') != -1) or (fund_type.find(u'货币型') != -1):
ismonetary = True
ct._write_head()
nums = _get_nav_histroy_num(code, start, end, ismonetary)
data = _parse_nav_history_data(
code, start, end, nums, ismonetary, retry_count, pause, timeout)
return data
def get_fund_info(code):
'''
获取基金基本信息
Parameters
------
code:string
基金代码 e.g. 000001
return
-------
DataFrame
jjqc 基金全称
jjjc 基金简称
symbol 基金代码
clrq 成立日期
ssrq 上市日期
xcr 存续期限
ssdd 上市地点
Type1Name 运作方式
Type2Name 基金类型
Type3Name 二级分类
jjgm 基金规模(亿元)
jjfe 基金总份额(亿份)
jjltfe 上市流通份额(亿份)
jjferq 基金份额日期
quarter 上市季度
glr 基金管理人
tgr 基金托管人
'''
request = ct.SINA_FUND_INFO_URL % (
ct.P_TYPE['http'], ct.DOMAINS['ssf'], code)
text = urlopen(request, timeout=10).read()
text = text.decode('gbk')
org_js = json.loads(text)
status_code = int(org_js['result']['status']['code'])
if status_code != 0:
status = str(org_js['result']['status']['msg'])
raise ValueError(status)
data = org_js['result']['data']
fund_df = pd.DataFrame(data, columns=ct.FUND_INFO_COLS, index=[0])
fund_df = fund_df.set_index('symbol')
return fund_df
def _parse_fund_data(url, fund_type='open'):
ct._write_console()
try:
request = Request(url)
text = urlopen(request, timeout=10).read()
if text == 'null':
return None
text = text.decode('gbk') if ct.PY3 else text
text = text.split('data:')[1].split(',exec_time')[0]
reg = re.compile(r'\,(.*?)\:')
text = reg.sub(r',"\1":', text)
text = text.replace('"{symbol', '{"symbol')
text = text.replace('{symbol', '{"symbol"')
if ct.PY3:
jstr = json.dumps(text)
else:
jstr = json.dumps(text, encoding='gbk')
org_js = json.loads(jstr)
fund_df = pd.DataFrame(pd.read_json(org_js, dtype={'symbol': object}),
columns=ct.NAV_COLUMNS[fund_type])
fund_df.fillna(0, inplace=True)
return fund_df
except Exception as er:
print(str(er))
def _get_fund_num(url):
"""
获取基金数量
"""
ct._write_console()
try:
request = Request(url)
text = urlopen(request, timeout=10).read()
text = text.decode('gbk')
if text == 'null':
raise ValueError('get fund num error')
text = text.split('((')[1].split('))')[0]
reg = re.compile(r'\,(.*?)\:')
text = reg.sub(r',"\1":', text)
text = text.replace('{total_num', '{"total_num"')
text = text.replace('null', '0')
org_js = json.loads(text)
nums = org_js["total_num"]
return int(nums)
except Exception as er:
print(str(er))
def _get_nav_histroy_num(code, start, end, ismonetary=False):
"""
获取基金历史净值数量
--------
货币和证券型基金采用的url不同,需要增加基金类型判断
"""
ct._write_console()
if ismonetary:
request = Request(ct.SINA_NAV_HISTROY_COUNT_CUR_URL %
(ct.P_TYPE['http'], ct.DOMAINS['ssf'],
code, start, end))
else:
request = Request(ct.SINA_NAV_HISTROY_COUNT_URL %
(ct.P_TYPE['http'], ct.DOMAINS['ssf'],
code, start, end))
text = urlopen(request, timeout=10).read()
text = text.decode('gbk')
org_js = json.loads(text)
status_code = int(org_js['result']['status']['code'])
if status_code != 0:
status = str(org_js['result']['status']['msg'])
raise ValueError(status)
nums = org_js['result']['data']['total_num']
return int(nums)
def _parse_nav_history_data(code, start, end, nums, ismonetary=False, retry_count=3, pause=0.01, timeout=10):
if nums == 0:
return None
for _ in range(retry_count):
time.sleep(pause)
# try:
ct._write_console()
if ismonetary:
request = Request(ct.SINA_NAV_HISTROY_DATA_CUR_URL %
(ct.P_TYPE['http'], ct.DOMAINS['ssf'],
code, start, end, nums))
else:
request = Request(ct.SINA_NAV_HISTROY_DATA_URL %
(ct.P_TYPE['http'], ct.DOMAINS['ssf'],
code, start, end, nums))
text = urlopen(request, timeout=timeout).read()
text = text.decode('gbk')
org_js = json.loads(text)
status_code = int(org_js['result']['status']['code'])
if status_code != 0:
status = str(org_js['result']['status']['msg'])
raise ValueError(status)
data = org_js['result']['data']['data']
if 'jjjz' in data[0].keys():
fund_df = pd.DataFrame(data, columns=ct.NAV_HIS_JJJZ)
fund_df['jjjz'] = fund_df['jjjz'].astype(float)
fund_df['ljjz'] = fund_df['ljjz'].astype(float)
fund_df.rename(columns=ct.DICT_NAV_EQUITY, inplace=True)
else:
fund_df = pd.DataFrame(data, columns=ct.NAV_HIS_NHSY)
fund_df['nhsyl'] = fund_df['nhsyl'].astype(float)
fund_df['dwsy'] = fund_df['dwsy'].astype(float)
fund_df.rename(columns=ct.DICT_NAV_MONETARY, inplace=True)
#fund_df.fillna(0, inplace=True)
if fund_df['date'].dtypes == np.object:
fund_df['date'] = pd.to_datetime(fund_df['date'])
fund_df = fund_df.set_index('date')
fund_df = fund_df.sort_index(ascending=False)
fund_df['pre_value'] = fund_df['value'].shift(-1)
fund_df['change'] = (fund_df['value'] / fund_df['pre_value'] - 1) * 100
fund_df = fund_df.drop('pre_value', axis=1)
return fund_df
raise IOError(ct.NETWORK_URL_ERROR_MSG)
================================================
FILE: tushare/futures/__init__.py
================================================
================================================
FILE: tushare/futures/cons.py
================================================
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''
Created on 2016年10月17日
@author: Jimmy Liu
@group : waditu
@contact: jimmysoa@sina.cn
'''
P_TYPE = {'http': 'http://', 'ftp': 'ftp://'}
DOMAINS = {
'EM': 'eastmoney.com'
}
PAGES = {'INTL_FUT': 'index.aspx'}
INTL_FUTURE_CODE = 'CONX0,GLNZ0,LCPS0,SBCX0,CRCZ0,WHCZ0,SMCZ0,SOCZ0,CTNZ0,HONV0,LALS0,LZNS0,LTNS0,LNKS0,LLDS0,RBTZ0,SBCC0,SMCC0,SOCC0,WHCC0,SGNC0,SFNC0,CTNC0,CRCC0,CCNC0,CFNC0,GLNC0,CONC0,HONC0,RBTC0,OILC0'
INTL_FUTURE_URL = '%shq2gjqh.%s/EM_Futures2010NumericApplication/%s?type=z&jsName=quote_future&sortType=A&sortRule=1&jsSort=1&ids=%s&_g=0.%s'
INTL_FUTURES_COL = ['code', 'name', 'price', 'open', 'high', 'low', 'preclose', 'vol', 'pct_count', 'pct_change', 'posi', 'b_amount', 's_amount']
================================================
FILE: tushare/futures/domestic.py
================================================
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''
Created on 2017年06月04日
@author: debugo
@contact: me@debugo.com
'''
import json
import datetime
from bs4 import BeautifulSoup
import pandas as pd
from tushare.futures import domestic_cons as ct
try:
from urllib.request import urlopen, Request
from urllib.parse import urlencode
from urllib.error import HTTPError
from http.client import IncompleteRead
except ImportError:
from urllib import urlencode
from urllib2 import urlopen, Request
from urllib2 import HTTPError
from httplib import IncompleteRead
def get_cffex_daily(date = None):
"""
获取中金所日交易数据
Parameters
------
date: 日期 format:YYYY-MM-DD 或 YYYYMMDD 或 datetime.date对象 为空时为当天
Return
-------
DataFrame
中金所日交易数据(DataFrame):
symbol 合约代码
date 日期
open 开盘价
high 最高价
low 最低价
close 收盘价
volume 成交量
open_interest 持仓量
turnover 成交额
settle 结算价
pre_settle 前结算价
variety 合约类别
或 None(给定日期没有交易数据)
"""
day = ct.convert_date(date) if date is not None else datetime.date.today()
try:
html = urlopen(Request(ct.CFFEX_DAILY_URL % (day.strftime('%Y%m'),
day.strftime('%d'), day.strftime('%Y%m%d')),
headers=ct.SIM_HAEDERS)).read().decode('gbk', 'ignore')
except HTTPError as reason:
if reason.code != 404:
print(ct.CFFEX_DAILY_URL % (day.strftime('%Y%m'), day.strftime('%d'),
day.strftime('%Y%m%d')), reason)
return
if html.find(u'网页错误') >= 0:
return
html = [i.replace(' ','').split(',') for i in html.split('\n')[:-2] if i[0][0] != u'小' ]
if html[0][0]!=u'合约代码':
return
dict_data = list()
day_const = day.strftime('%Y%m%d')
for row in html[1:]:
m = ct.FUTURE_SYMBOL_PATTERN.match(row[0])
if not m:
continue
row_dict = {'date': day_const, 'symbol': row[0], 'variety': m.group(1)}
for i,field in enumerate(ct.CFFEX_COLUMNS):
if row[i+1] == u"":
row_dict[field] = 0.0
elif field in ['volume', 'open_interest', 'oi_chg']:
row_dict[field] = int(row[i+1])
else:
row_dict[field] = float(row[i+1])
row_dict['pre_settle'] = row_dict['close'] - row_dict['change1']
dict_data.append(row_dict)
return pd.DataFrame(dict_data)[ct.OUTPUT_COLUMNS]
def get_czce_daily(date=None, type="future"):
"""
获取郑商所日交易数据
Parameters
------
date: 日期 format:YYYY-MM-DD 或 YYYYMMDD 或 datetime.date对象 为空时为当天
type: 数据类型, 为'future'期货 或 'option'期权二者之一
Return
-------
DataFrame
郑商所每日期货交易数据:
symbol 合约代码
date 日期
open 开盘价
high 最高价
low 最低价
close 收盘价
volume 成交量
open_interest 持仓量
turnover 成交额
settle 结算价
pre_settle 前结算价
variety 合约类别
或
DataFrame
郑商所每日期权交易数据
symbol 合约代码
date 日期
open 开盘价
high 最高价
low 最低价
close 收盘价
pre_settle 前结算价
settle 结算价
delta 对冲值
volume 成交量
open_interest 持仓量
oi_change 持仓变化
turnover 成交额
implied_volatility 隐含波动率
exercise_volume 行权量
variety 合约类别
None(类型错误或给定日期没有交易数据)
"""
if type == 'future':
url = ct.CZCE_DAILY_URL
listed_columns = ct.CZCE_COLUMNS
output_columns = ct.OUTPUT_COLUMNS
elif type == 'option':
url = ct.CZCE_OPTION_URL
listed_columns = ct.CZCE_OPTION_COLUMNS
output_columns = ct.OPTION_OUTPUT_COLUMNS
else:
print('invalid type :' + type + ',type should be one of "future" or "option"')
return
day = ct.convert_date(date) if date is not None else datetime.date.today()
try:
html = urlopen(Request(url % (day.strftime('%Y'),
day.strftime('%Y%m%d')),
headers=ct.SIM_HAEDERS)).read().decode('gbk', 'ignore')
except HTTPError as reason:
if reason.code != 404:
print(ct.CZCE_DAILY_URL % (day.strftime('%Y'),
day.strftime('%Y%m%d')), reason)
return
if html.find(u'您的访问出错了') >= 0 or html.find(u'无期权每日行情交易记录') >= 0:
return
html = [i.replace(' ','').split('|') for i in html.split('\n')[:-4] if i[0][0] != u'小']
if html[1][0] not in [u'品种月份', u'品种代码']:
return
dict_data = list()
day_const = int(day.strftime('%Y%m%d'))
for row in html[2:]:
m = ct.FUTURE_SYMBOL_PATTERN.match(row[0])
if not m:
continue
row_dict = {'date': day_const, 'symbol': row[0], 'variety': m.group(1)}
for i,field in enumerate(listed_columns):
if row[i+1] == "\r":
row_dict[field] = 0.0
elif field in ['volume', 'open_interest', 'oi_chg', 'exercise_volume']:
row[i+1] = row[i+1].replace(',','')
row_dict[field] = int(row[i+1])
else:
row[i+1] = row[i+1].replace(',','')
row_dict[field] = float(row[i+1])
dict_data.append(row_dict)
return pd.DataFrame(dict_data)[output_columns]
def get_shfe_vwap(date = None):
"""
获取上期所日成交均价数据
Parameters
------
date: 日期 format:YYYY-MM-DD 或 YYYYMMDD 或 datetime.date对象 为空时为当天
Return
-------
DataFrame
郑商所日交易数据(DataFrame):
symbol 合约代码
date 日期
time_range vwap时段,分09:00-10:15和09:00-15:00两类
vwap 加权平均成交均价
或 None(给定日期没有数据)
"""
day = ct.convert_date(date) if date is not None else datetime.date.today()
try:
json_data = json.loads(urlopen(Request(ct.SHFE_VWAP_URL % (day.strftime('%Y%m%d')),
headers=ct.SIM_HAEDERS)).read().decode('utf8'))
except HTTPError as reason:
if reason.code != 404:
print(ct.SHFE_DAILY_URL % (day.strftime('%Y%m%d')), reason)
return
if len(json_data['o_currefprice']) == 0:
return
df = pd.DataFrame(json_data['o_currefprice'])
df['INSTRUMENTID'] = df['INSTRUMENTID'].str.strip()
df[':B1'].astype('int16')
return df.rename(columns=ct.SHFE_VWAP_COLUMNS)[list(ct.SHFE_VWAP_COLUMNS.values())]
def get_shfe_daily(date = None):
"""
获取上期所日交易数据
Parameters
------
date: 日期 format:YYYY-MM-DD 或 YYYYMMDD 或 datetime.date对象 为空时为当天
Return
-------
DataFrame
上期所日交易数据(DataFrame):
symbol 合约代码
date 日期
open 开盘价
high 最高价
low 最低价
close 收盘价
volume 成交量
open_interest 持仓量
turnover 成交额
settle 结算价
pre_settle 前结算价
variety 合约类别
或 None(给定日期没有交易数据)
"""
day = ct.convert_date(date) if date is not None else datetime.date.today()
try:
json_data = json.loads(urlopen(Request(ct.SHFE_DAILY_URL % (day.strftime('%Y%m%d')),
headers=ct.SIM_HAEDERS)).read().decode('utf8'))
except HTTPError as reason:
if reason.code != 404:
print(ct.SHFE_DAILY_URL % (day.strftime('%Y%m%d')), reason)
return
if len(json_data['o_curinstrument']) == 0:
return
df = pd.DataFrame([row for row in json_data['o_curinstrument'] if row['DELIVERYMONTH'] != u'小计' and row['DELIVERYMONTH'] != ''])
df['variety'] = df.PRODUCTID.str.slice(0, -6).str.upper()
df['symbol'] = df['variety'] + df['DELIVERYMONTH']
df['date'] = day.strftime('%Y%m%d')
vwap_df = get_shfe_vwap(day)
if vwap_df is not None:
df = pd.merge(df, vwap_df[vwap_df.time_range == '9:00-15:00'], on=['date', 'symbol'], how='left')
df['turnover'] = df.vwap * df.VOLUME
else:
print('Failed to fetch SHFE vwap.', day.strftime('%Y%m%d'))
df['turnover'] = .0
df.rename(columns=ct.SHFE_COLUMNS, inplace=True)
return df[ct.OUTPUT_COLUMNS]
def get_dce_daily(date = None, type="future", retries=0):
"""
获取大连商品交易所日交易数据
Parameters
------
date: 日期 format:YYYY-MM-DD 或 YYYYMMDD 或 datetime.date对象 为空时为当天
type: 数据类型, 为'future'期货 或 'option'期权二者之一
retries: int, 当前重试次数,达到3次则获取数据失败
Return
-------
DataFrame
大商所日交易数据(DataFrame):
symbol 合约代码
date 日期
open 开盘价
high 最高价
low 最低价
close 收盘价
volume 成交量
open_interest 持仓量
turnover 成交额
settle 结算价
pre_settle 前结算价
variety 合约类别
或
DataFrame
郑商所每日期权交易数据
symbol 合约代码
date 日期
open 开盘价
high 最高价
low 最低价
close 收盘价
pre_settle 前结算价
settle 结算价
delta 对冲值
volume 成交量
open_interest 持仓量
oi_change 持仓变化
turnover 成交额
implied_volatility 隐含波动率
exercise_volume 行权量
variety 合约类别
或 None(给定日期没有交易数据)
"""
day = ct.convert_date(date) if date is not None else datetime.date.today()
if retries > 3:
print("maximum retires for DCE market data: ", day.strftime("%Y%m%d"))
return
if type == 'future':
url = ct.DCE_DAILY_URL + '?' + urlencode({"currDate":day.strftime('%Y%m%d'),
"year":day.strftime('%Y'),
"month": str(int(day.strftime('%m'))-1),
"day":day.strftime('%d')})
listed_columns = ct.DCE_COLUMNS
output_columns = ct.OUTPUT_COLUMNS
elif type == 'option':
url = ct.DCE_DAILY_URL + '?' + urlencode({"currDate":day.strftime('%Y%m%d'),
"year":day.strftime('%Y'),
"month": str(int(day.strftime('%m'))-1),
"day":day.strftime('%d'),
"dayQuotes.trade_type": "1"})
listed_columns = ct.DCE_OPTION_COLUMNS
output_columns = ct.OPTION_OUTPUT_COLUMNS
else:
print('invalid type :' + type + ', should be one of "future" or "option"')
return
try:
response = urlopen(Request(url, method='POST', headers=ct.DCE_HEADERS)).read().decode('utf8')
except IncompleteRead as reason:
return get_dce_daily(day, retries=retries+1)
except HTTPError as reason:
if reason.code == 504:
return get_dce_daily(day, retries=retries+1)
elif reason.code != 404:
print(ct.DCE_DAILY_URL, reason)
return
if u'错误:您所请求的网址(URL)无法获取' in response:
return get_dce_daily(day, retries=retries+1)
elif u'暂无数据' in response:
return
data = BeautifulSoup(response, 'html.parser').find_all('tr')
if len(data) == 0:
return
dict_data = list()
implied_data = list()
for idata in data[1:]:
if u'小计' in idata.text or u'总计' in idata.text:
continue
x = idata.find_all('td')
if type == 'future':
row_dict = {'variety': ct.DCE_MAP[x[0].text.strip()]}
row_dict['symbol'] = row_dict['variety'] + x[1].text.strip()
for i,field in enumerate(listed_columns):
field_content = x[i+2].text.strip()
if '-' in field_content:
row_dict[field] = 0
elif field in ['volume', 'open_interest']:
row_dict[field] = int(field_content.replace(',',''))
else:
row_dict[field] = float(field_content.replace(',',''))
dict_data.append(row_dict)
elif len(x) == 16:
m = ct.FUTURE_SYMBOL_PATTERN.match(x[1].text.strip())
if not m:
continue
row_dict = {'symbol': x[1].text.strip(), 'variety': m.group(1).upper(), 'contract_id': m.group(0)}
for i,field in enumerate(listed_columns):
field_content = x[i+2].text.strip()
if '-' in field_content:
row_dict[field] = 0
elif field in ['volume', 'open_interest']:
row_dict[field] = int(field_content.replace(',',''))
else:
row_dict[field] = float(field_content.replace(',',''))
dict_data.append(row_dict)
elif len(x) == 2:
implied_data.append({'contract_id': x[0].text.strip(), 'implied_volatility': float(x[1].text.strip())})
df = pd.DataFrame(dict_data)
df['date'] = day.strftime('%Y%m%d')
if type == 'future':
return df[output_columns]
else:
return pd.merge(df, pd.DataFrame(implied_data), on='contract_id', how='left', indicator=False)[output_columns]
def get_future_daily(start = None, end = None, market = 'CFFEX'):
"""
获取中金所日交易数据
Parameters
------
start: 开始日期 format:YYYY-MM-DD 或 YYYYMMDD 或 datetime.date对象 为空时为当天
end: 结束数据 format:YYYY-MM-DD 或 YYYYMMDD 或 datetime.date对象 为空时为当天
market: 'CFFEX' 中金所, 'CZCE' 郑商所, 'SHFE' 上期所, 'DCE' 大商所 之一。默认为中金所
Return
-------
DataFrame
中金所日交易数据(DataFrame):
symbol 合约代码
date 日期
open 开盘价
high 最高价
low 最低价
close 收盘价
volume 成交量
open_interest 持仓量
turnover 成交额
settle 结算价
pre_settle 前结算价
variety 合约类别
或 None(给定日期没有交易数据)
"""
if market.upper() == 'CFFEX':
f = get_cffex_daily
elif market.upper() == 'CZCE':
f = get_czce_daily
elif market.upper() == 'SHFE':
f = get_shfe_daily
elif market.upper() == 'DCE':
f = get_dce_daily
else:
print('Invalid market.')
return
start = ct.convert_date(start) if start is not None else datetime.date.today()
end = ct.convert_date(end) if end is not None else datetime.date.today()
df_list = list()
while start <= end:
df = f(start)
if df is not None:
df_list.append(df)
start += datetime.timedelta(days = 1)
if len(df_list) > 0:
return pd.concat(df_list)
================================================
FILE: tushare/futures/domestic_cons.py
================================================
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''
Created on 2017年06月04日
@author: debugo
@contact: me@debugo.com
'''
import re
import datetime
CFFEX_DAILY_URL = 'http://www.cffex.com.cn/fzjy/mrhq/%s/%s/%s_1.csv'
SHFE_DAILY_URL = 'http://www.shfe.com.cn/data/dailydata/kx/kx%s.dat'
SHFE_VWAP_URL = 'http://www.shfe.com.cn/data/dailydata/ck/%sdailyTimePrice.dat'
DCE_DAILY_URL = 'http://www.dce.com.cn//publicweb/quotesdata/dayQuotesCh.html'
CZCE_DAILY_URL = 'http://www.czce.com.cn/portal/DFSStaticFiles/Future/%s/%s/FutureDataDaily.txt'
CZCE_OPTION_URL = 'http://www.czce.com.cn/portal/DFSStaticFiles/Option/%s/%s/OptionDataDaily.txt'
CFFEX_COLUMNS = ['open','high','low','volume','turnover','open_interest','close','settle','change1','change2']
CZCE_COLUMNS = ['pre_settle','open','high','low','close','settle','change1','change2','volume','open_interest','oi_chg','turnover','final_settle']
CZCE_OPTION_COLUMNS = ['pre_settle', 'open', 'high', 'low', 'close', 'settle', 'change1', 'change2', 'volume', 'open_interest', 'oi_chg', 'turnover', 'delta', 'implied_volatility', 'exercise_volume']
SHFE_COLUMNS = {'CLOSEPRICE': 'close', 'HIGHESTPRICE': 'high', 'LOWESTPRICE': 'low', 'OPENINTEREST': 'open_interest', 'OPENPRICE': 'open', 'PRESETTLEMENTPRICE': 'pre_settle', 'SETTLEMENTPRICE': 'settle', 'VOLUME': 'volume'}
SHFE_VWAP_COLUMNS = {':B1': 'date', 'INSTRUMENTID': 'symbol', 'TIME': 'time_range', 'REFSETTLEMENTPRICE': 'vwap'}
DCE_COLUMNS = ['open', 'high', 'low', 'close', 'pre_settle', 'settle', 'change1','change2','volume','open_interest','oi_chg','turnover']
DCE_OPTION_COLUMNS = ['open', 'high', 'low', 'close', 'pre_settle', 'settle', 'change1', 'change2', 'delta', 'volume', 'open_interest', 'oi_chg', 'turnover', 'exercise_volume']
OUTPUT_COLUMNS = ['symbol', 'date', 'open', 'high', 'low', 'close', 'volume', 'open_interest', 'turnover', 'settle', 'pre_settle', 'variety']
OPTION_OUTPUT_COLUMNS = ['symbol', 'date', 'open', 'high', 'low', 'close', 'pre_settle', 'settle', 'delta', 'volume', 'open_interest', 'oi_chg', 'turnover', 'implied_volatility', 'exercise_volume', 'variety']
CLOSE_LOC = 5
PRE_SETTLE_LOC = 11
FUTURE_SYMBOL_PATTERN = re.compile(r'(^[A-Za-z]{1,2})[0-9]+')
DATE_PATTERN = re.compile(r'^([0-9]{4})[-/]?([0-9]{2})[-/]?([0-9]{2})')
SIM_HAEDERS = {'User-Agent': 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'}
DCE_HEADERS = {
'cache-control': "no-cache",
'postman-token': "153f42ca-148a-8f03-3302-8172cc4a5185"
}
def convert_date(date):
"""
transform a date string to datetime.date object.
:param day, string, e.g. 2016-01-01, 20160101 or 2016/01/01
:return: object of datetime.date(such as 2016-01-01) or None
"""
if isinstance(date, datetime.date):
return date
elif isinstance(date, str):
match = DATE_PATTERN.match(date)
if match:
groups = match.groups()
if len(groups) == 3:
return datetime.date(year=int(groups[0]), month=int(groups[1]), day=int(groups[2]))
return None
DCE_MAP = {
'豆一': 'A',
'豆二': 'B',
'豆粕': 'M',
'豆油': 'Y',
'棕榈油': 'P',
'玉米': 'C',
'玉米淀粉': 'CS',
'鸡蛋': 'JD',
'纤维板': 'FB',
'胶合板': 'BB',
'聚乙烯': 'L',
'聚氯乙烯': 'V',
'聚丙烯': 'PP',
'焦炭': 'J',
'焦煤': 'JM',
'铁矿石': 'I'
}
FUTURE_CODE={
'IH': ('CFFEX', '上证50指数', 300),
'IF': ('CFFEX', '沪深300指数', 300),
'IC': ('CFFEX', '中证500指数', 200),
'T': ('CFFEX', '10年期国债期货', 10000),
'TF': ('CFFEX', '5年期国债期货', 10000),
'CU': ('SHFE', '沪铜' ,5),
'AL': ('SHFE', '沪铝', 5),
'ZN': ('SHFE', '沪锌', 5),
'PB': ('SHFE', '沪铅', 5),
'NI': ('SHFE', '沪镍', 1),
'SN': ('SHFE', '沪锡', 1),
'AU': ('SHFE', '沪金', 1000),
'AG': ('SHFE', '沪银', 15),
'RB': ('SHFE', '螺纹钢', 10),
'WR': ('SHFE', '线材', 10),
'HC': ('SHFE', '热轧卷板', 10),
'FU': ('SHFE', '燃油', 50),
'BU': ('SHFE', '沥青', 10),
'RU': ('SHFE', '橡胶', 10),
'A': ('DCE', '豆一', 10),
'B': ('DCE', '豆二', 10),
'M': ('DCE', '豆粕', 10),
'Y': ('DCE', '豆油', 10),
'P': ('DCE', '棕榈油', 10),
'C': ('DCE', '玉米', 10),
'CS': ('DCE', '玉米淀粉', 10),
'JD': ('DCE', '鸡蛋', 5),
'FB': ('DCE', '纤维板', 500),
'BB': ('DCE', '胶合板', 500),
'L': ('DCE', '聚乙烯', 5),
'V': ('DCE', '聚氯乙烯', 5),
'PP': ('DCE', '聚丙烯', 5),
'J': ('DCE', '焦炭', 100),
'JM': ('DCE', '焦煤', 60),
'I': ('DCE', '铁矿石', 100),
'SR': ('CZCE', '白糖', 10),
'CF': ('CZCE', '棉花',5),
'PM': ('CZCE', '普麦',50),
'WH': ('CZCE', '强麦',20),
'OI': ('CZCE', '菜籽油',10),
'PTA': ('CZCE', 'PTA', 0),
'RI': ('CZCE', '早籼稻',20),
'LR': ('CZCE', '晚籼稻',20),
'MA': ('CZCE', '甲醇', 10),
'FG': ('CZCE', '玻璃', 20),
'RS': ('CZCE', '油菜籽', 10),
'RM': ('CZCE', '籽粕', 10),
'TC': ('CZCE', '动力煤', 200),
'ZC': ('CZCE', '动力煤', 100),
'JR': ('CZCE', '粳稻', 20),
'SF': ('CZCE', '硅铁', 5),
'SM': ('CZCE', '锰硅', 5)
}
================================================
FILE: tushare/futures/intlfutures.py
================================================
# -*- coding:utf-8 -*-
"""
国际期货
Created on 2016/10/01
@author: Jimmy Liu
@group : waditu
@contact: jimmysoa@sina.cn
"""
import json
import six
import pandas as pd
from tushare.futures import cons as ct
try:
from urllib.request import urlopen, Request
except ImportError:
from urllib2 import urlopen, Request
def get_intlfuture(symbols=None):
symbols = ct.INTL_FUTURE_CODE if symbols is None else symbols
df = _get_data(ct.INTL_FUTURE_URL%(ct.P_TYPE['http'], ct.DOMAINS['EM'],
ct.PAGES['INTL_FUT'], symbols,
_random(17)))
return df
def _get_data(url):
try:
request = Request(url)
data_str = urlopen(request, timeout=10).read()
data_str = data_str.split('=')[1]
data_str = data_str.replace('futures', '"futures"')
if six.PY3:
data_str = data_str.decode('utf-8')
data_str = json.loads(data_str)
df = pd.DataFrame([[col for col in row.split(',')] for row in data_str.values()[0]]
)
df = df[[1, 2, 5, 4, 6, 7, 13, 9, 17, 18, 16, 21, 22]]
df.columns = ct.INTL_FUTURES_COL
return df
except Exception as er:
print(str(er))
def _random(n=13):
from random import randint
start = 10**(n-1)
end = (10**n)-1
return str(randint(start, end))
================================================
FILE: tushare/internet/__init__.py
================================================
================================================
FILE: tushare/internet/boxoffice.py
================================================
# -*- coding:utf-8 -*-
"""
电影票房
Created on 2015/12/24
@author: Jimmy Liu
@group : waditu
@contact: jimmysoa@sina.cn
"""
import pandas as pd
from tushare.stock import cons as ct
from tushare.util import dateu as du
try:
from urllib.request import urlopen, Request
except ImportError:
from urllib2 import urlopen, Request
import time
import json
def realtime_boxoffice(retry_count=3,pause=0.001):
"""
获取实时电影票房数据
数据来源:EBOT艺恩票房智库
Parameters
------
retry_count : int, 默认 3
如遇网络等问题重复执行的次数
pause : int, 默认 0
重复请求数据过程中暂停的秒数,防止请求间隔时间太短出现的问题
return
-------
DataFrame
BoxOffice 实时票房(万)
Irank 排名
MovieName 影片名
boxPer 票房占比 (%)
movieDay 上映天数
sumBoxOffice 累计票房(万)
time 数据获取时间
"""
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(ct.MOVIE_BOX%(ct.P_TYPE['http'], ct.DOMAINS['mbox'],
ct.BOX, _random()))
lines = urlopen(request, timeout = 10).read()
if len(lines) < 15: #no data
return None
except Exception as e:
print(e)
else:
js = json.loads(lines.decode('utf-8') if ct.PY3 else lines)
df = pd.DataFrame(js['data2'])
df = df.drop(['MovieImg','mId'], axis=1)
df['time'] = du.get_now()
return df
def day_boxoffice(date=None, retry_count=3, pause=0.001):
"""
获取单日电影票房数据
数据来源:EBOT艺恩票房智库
Parameters
------
date:日期,默认为上一日
retry_count : int, 默认 3
如遇网络等问题重复执行的次数
pause : int, 默认 0
重复请求数据过程中暂停的秒数,防止请求间隔时间太短出现的问题
return
-------
DataFrame
AvgPrice 平均票价
AvpPeoPle 场均人次
BoxOffice 单日票房(万)
BoxOffice_Up 环比变化 (%)
IRank 排名
MovieDay 上映天数
MovieName 影片名
SumBoxOffice 累计票房(万)
WomIndex 口碑指数
"""
for _ in range(retry_count):
time.sleep(pause)
try:
if date is None:
date = 0
else:
date = int(du.diff_day(du.today(), date)) + 1
request = Request(ct.BOXOFFICE_DAY%(ct.P_TYPE['http'], ct.DOMAINS['mbox'],
ct.BOX, date, _random()))
lines = urlopen(request, timeout = 10).read()
if len(lines) < 15: #no data
return None
except Exception as e:
print(e)
else:
js = json.loads(lines.decode('utf-8') if ct.PY3 else lines)
df = pd.DataFrame(js['data1'])
df = df.drop(['MovieImg', 'BoxOffice1', 'MovieID', 'Director', 'IRank_pro'], axis=1)
return df
def month_boxoffice(date=None, retry_count=3, pause=0.001):
"""
获取单月电影票房数据
数据来源:EBOT艺恩票房智库
Parameters
------
date:日期,默认为上一月,格式YYYY-MM
retry_count : int, 默认 3
如遇网络等问题重复执行的次数
pause : int, 默认 0
重复请求数据过程中暂停的秒数,防止请求间隔时间太短出现的问题
return
-------
DataFrame
Irank 排名
MovieName 电影名称
WomIndex 口碑指数
avgboxoffice 平均票价
avgshowcount 场均人次
box_pro 月度占比
boxoffice 单月票房(万)
days 月内天数
releaseTime 上映日期
"""
if date is None:
date = du.day_last_week(-30)[0:7]
elif len(date)>8:
print(ct.BOX_INPUT_ERR_MSG)
return
date += '-01'
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(ct.BOXOFFICE_MONTH%(ct.P_TYPE['http'], ct.DOMAINS['mbox'],
ct.BOX, date))
lines = urlopen(request, timeout = 10).read()
if len(lines) < 15: #no data
return None
except Exception as e:
print(e)
else:
js = json.loads(lines.decode('utf-8') if ct.PY3 else lines)
df = pd.DataFrame(js['data1'])
df = df.drop(['defaultImage', 'EnMovieID'], axis=1)
return df
def day_cinema(date=None, retry_count=3, pause=0.001):
"""
获取影院单日票房排行数据
数据来源:EBOT艺恩票房智库
Parameters
------
date:日期,默认为上一日
retry_count : int, 默认 3
如遇网络等问题重复执行的次数
pause : int, 默认 0
重复请求数据过程中暂停的秒数,防止请求间隔时间太短出现的问题
return
-------
DataFrame
Attendance 上座率
AvgPeople 场均人次
CinemaName 影院名称
RowNum 排名
TodayAudienceCount 当日观众人数
TodayBox 当日票房
TodayShowCount 当日场次
price 场均票价(元)
"""
if date is None:
date = du.day_last_week(-1)
data = pd.DataFrame()
ct._write_head()
for x in range(1, 11):
df = _day_cinema(date, x, retry_count,
pause)
if df is not None:
data = pd.concat([data, df])
data = data.drop_duplicates()
return data.reset_index(drop=True)
def _day_cinema(date=None, pNo=1, retry_count=3, pause=0.001):
ct._write_console()
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(ct.BOXOFFICE_CBD%(ct.P_TYPE['http'], ct.DOMAINS['mbox'],
ct.BOX, pNo, date))
lines = urlopen(request, timeout = 10).read()
if len(lines) < 15: #no data
return None
except Exception as e:
print(e)
else:
js = json.loads(lines.decode('utf-8') if ct.PY3 else lines)
df = pd.DataFrame(js['data1'])
df = df.drop(['CinemaID'], axis=1)
return df
def _random(n=13):
from random import randint
start = 10**(n-1)
end = (10**n)-1
return str(randint(start, end))
================================================
FILE: tushare/internet/caixinnews.py
================================================
# -*- coding:utf-8 -*-
"""
财新网新闻数据检索下载
Created on 2017/06/09
@author: Yuan Yifan
@group : ~
@contact: tsingjyujing@163.com
"""
"""
# 测试脚本
from caixinnews import *
urls = query_news(start_date='2017-05-09',end_date='2017-05-09')
title,text = read_page(urls[0])
print(title)
print(text)
"""
import re
import datetime
from bs4 import BeautifulSoup
try:
from urllib.request import urlopen, Request
except ImportError:
from urllib2 import urlopen, Request
caixin_search_url = "http://search.caixin.com/search/search.jsp?startDate=%s&endDate=%s&keyword=%s&x=0&y=0"
default_parser = "html.parser"
#default_parser = "lxml"
UA = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "+\
"AppleWebKit/537.36 (KHTML, like Gecko) "+\
"Chrome/42.0.2311.135 "+\
"Safari/537.36 "+\
"Edge/12.10240"
req_header = {\
'User-Agent': UA,\
'Accept': '"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8"',\
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3'}
req_timeout = 10
def read_url(url):
"""
读取URL对应的内容(模拟浏览器)
Parameters
------
url string 需要读取的链接
Return
------
string 读取的内容
"""
req_header_this = req_header
req_header_this['Host'] = re.findall('://.*?/',url,re.DOTALL)[0][3:-1]
return urlopen(Request(url,None,req_header),None,req_timeout).read()
def get_soup(url):
"""
读取URL对应的内容,并解析为Soup
Parameters
url string 需要读取的链接
Return
string 读取的内容
"""
return BeautifulSoup(read_url(url), default_parser)
def query_news(keywords='*',start_date=None,end_date=None):
"""
读取某一时间段对应的新闻链接列表
Parameters
------
keywords string 关键词
start_date string 开始日期,格式yyyy-mm-dd
end_date string 结束日期,格式yyyy-mm-dd
Return
------
List<string> 读取的内容
"""
if start_date is None or end_date is None:
now_time = datetime.datetime.now()
last_day = datetime.datetime(now_time.year,now_time.month,now_time.day,12,0) - datetime.timedelta(seconds = 3600*24)
start_date = last_day.strftime("%Y-%m-%d")
end_date = start_date
url = caixin_search_url % (start_date,end_date,keywords)
soup = get_soup(url)
info_urls = []
while(True):
next_info = soup.find_all(name='a',attrs={'class','pageNavBtn2'})[0]
all_res = soup.find_all(name='div',attrs={'class','searchxt'})
for res in all_res:
info_urls.append(res.a.attrs['href'])
next_info = next_info.attrs['href']
if next_info=="javascript:void();":
break;
else:
soup = get_soup(caixin_search_url+next_info)
return info_urls
def is_blog(url):
"""
判断某一链接是否博客
Parameters
------
url string 需要判断的链接
Return
------
bool 该url是否是博客URL
"""
return len(re.findall('blog\.caixin\.com',url))>0
def read_page(url):
"""
读取链接的内容
Parameters
------
url string 需要判断的链接
Return
------
title string 文章标题
text string 文章内容
"""
if is_blog(url):
return read_blog(url)
else:
return read_normal_artical(url)
def read_normal_artical(url):
soup = get_soup(url)
title = soup.title.get_text()
ps = soup.find_all('p')
text = ''
for p in ps:
text += p.get_text() + "\n"
return title,text
def read_blog(url):
soup = get_soup(url)
title = soup.title.get_text()
bcontent = soup.find_all(name='div',attrs={'class','blog_content'})
ps = bcontent[0].find_all('p')
text = ''
for p in ps:
text += p.get_text() + "\n"
return title,text
================================================
FILE: tushare/internet/indexes.py
================================================
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
龙虎榜数据
Created on 2017年8月13日
@author: Jimmy Liu
@group : waditu
@contact: jimmysoa@sina.cn
"""
import pandas as pd
from pandas.compat import StringIO
from tushare.stock import cons as ct
import time
import re
import lxml.html
from lxml import etree
try:
from urllib.request import urlopen, Request
except ImportError:
from urllib2 import urlopen, Request
def bdi(itype='D', retry_count=3,
pause=0.001):
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(ct.BDI_URL%(ct.P_TYPE['http'], ct.DOMAINS['v500']))
lines = urlopen(request, timeout = 10).read()
if len(lines) < 100: #no data
return None
except Exception as e:
print(e)
else:
linestr = lines.decode('utf-8') if ct.PY3 else lines
if itype == 'D': # Daily
reg = re.compile(r'\"chart_data\",\"(.*?)\"\);')
lines = reg.findall(linestr)
lines = lines[0]
lines = lines.replace('chart', 'table').\
replace('</series><graphs>', '').\
replace('</graphs>', '').\
replace('series', 'tr').\
replace('value', 'td').\
replace('graph', 'tr').\
replace('graphs', 'td')
df = pd.read_html(lines, encoding='utf8')[0]
df = df.T
df.columns = ['date', 'index']
df['date'] = df['date'].map(lambda x: x.replace(u'年', '-')).\
map(lambda x: x.replace(u'月', '-')).\
map(lambda x: x.replace(u'日', ''))
df['date'] = pd.to_datetime(df['date'])
df['index'] = df['index'].astype(float)
df = df.sort_values('date', ascending=False).reset_index(drop = True)
df['change'] = df['index'].pct_change(-1)
df['change'] = df['change'] * 100
df['change'] = df['change'].map(lambda x: '%.2f' % x)
df['change'] = df['change'].astype(float)
return df
else: #Weekly
html = lxml.html.parse(StringIO(linestr))
res = html.xpath("//table[@class=\"style33\"]/tr/td/table[last()]")
if ct.PY3:
sarr = [etree.tostring(node).decode('utf-8') for node in res]
else:
sarr = [etree.tostring(node) for node in res]
sarr = ''.join(sarr)
sarr = '<table>%s</table>'%sarr
df = pd.read_html(sarr)[0][1:]
df.columns = ['month', 'index']
df['month'] = df['month'].map(lambda x: x.replace(u'年', '-')).\
map(lambda x: x.replace(u'月', ''))
df['month'] = pd.to_datetime(df['month'])
df['month'] = df['month'].map(lambda x: str(x).replace('-', '')).\
map(lambda x: x[:6])
df['index'] = df['index'].astype(float)
df['change'] = df['index'].pct_change(-1)
df['change'] = df['change'].map(lambda x: '%.2f' % x)
df['change'] = df['change'].astype(float)
return df
================================================
FILE: tushare/pro/__init__.py
================================================
================================================
FILE: tushare/pro/client.py
================================================
# !/usr/bin/env python
# -*- coding: utf-8 -*-
"""
Pro数据接口
Created on 2017/07/01
@author: polo,Jimmy
@group : tushare.pro
"""
import pandas as pd
import simplejson as json
from functools import partial
import requests
class DataApi:
__token = ''
__http_url = 'http://api.tushare.pro'
def __init__(self, token, timeout=10):
"""
Parameters
----------
token: str
API接口TOKEN,用于用户认证
"""
self.__token = token
self.__timeout = timeout
def query(self, api_name, fields='', **kwargs):
req_params = {
'api_name': api_name,
'token': self.__token,
'params': kwargs,
'fields': fields
}
res = requests.post(self.__http_url, json=req_params, timeout=self.__timeout)
result = json.loads(res.text)
if result['code'] != 0:
raise Exception(result['msg'])
data = result['data']
columns = data['fields']
items = data['items']
return pd.DataFrame(items, columns=columns)
def __getattr__(self, name):
return partial(self.query, name)
================================================
FILE: tushare/pro/data_pro.py
================================================
# -*- coding:utf-8 -*-
"""
pro init
Created on 2018/07/01
@author: Jimmy Liu
@group : tushare.pro
@contact: jimmysoa@sina.cn
"""
from tushare.pro import client
from tushare.util import upass
from tushare.util.formula import MA
PRICE_COLS = ['open', 'close', 'high', 'low', 'pre_close']
FORMAT = lambda x: '%.2f' % x
FREQS = {'D': '1DAY',
'W': '1WEEK',
'Y': '1YEAR',
}
def pro_api(token=''):
"""
初始化pro API,第一次可以通过ts.set_token('your token')来记录自己的token凭证,临时token可以通过本参数传入
"""
if token == '' or token is None:
token = upass.get_token()
if token is not None and token != '':
pro = client.DataApi(token)
return pro
else:
raise Exception('api init error.')
def pro_bar(ts_code='', pro_api=None, start_date=None, end_date=None, freq='D', asset='E',
exchange='',
adj = None,
ma = [],
factors = None,
contract_type = '',
retry_count = 3):
"""
BAR数据
Parameters:
------------
ts_code:证券代码,支持股票,ETF/LOF,期货/期权,港股,数字货币
start_date:开始日期 YYYYMMDD
end_date:结束日期 YYYYMMDD
freq:支持1/5/15/30/60分钟,周/月/季/年
asset:证券类型 E:股票和交易所基金,I:沪深指数,C:数字货币,FT:期货 FD:基金/O期权/H港股/中概美国/中证指数/国际指数
exchange:市场代码,用户数字货币行情
adj:复权类型,None不复权,qfq:前复权,hfq:后复权
ma:均线,支持自定义均线频度,如:ma5/ma10/ma20/ma60/maN
factors因子数据,目前支持以下两种:
vr:量比,默认不返回,返回需指定:factor=['vr']
tor:换手率,默认不返回,返回需指定:factor=['tor']
以上两种都需要:factor=['vr', 'tor']
retry_count:网络重试次数
Return
----------
DataFrame
code:代码
open:开盘close/high/low/vol成交量/amount成交额/maN均价/vr量比/tor换手率
期货(asset='X')
code/open/close/high/low/avg_price:均价 position:持仓量 vol:成交总量
"""
ts_code = ts_code.strip().upper() if asset != 'C' else ts_code.strip().lower()
api = pro_api if pro_api is not None else pro_api()
for _ in range(retry_count):
try:
freq = freq.strip().upper() if asset != 'C' else freq.strip().lower()
asset = asset.strip().upper()
if asset == 'E':
if freq == 'D':
df = api.daily(ts_code=ts_code, start_date=start_date, end_date=end_date)
if factors is not None and len(factors) >0 :
ds = api.daily_basic(ts_code=ts_code, start_date=start_date, end_date=end_date)[['trade_date', 'turnover_rate', 'volume_ratio']]
ds = ds.set_index('trade_date')
df = df.set_index('trade_date')
df = df.merge(ds, left_index=True, right_index=True)
df = df.reset_index()
if ('tor' in factors) and ('vr' not in factors):
df = df.drop('volume_ratio', axis=1)
if ('vr' in factors) and ('tor' not in factors):
df = df.drop('turnover_rate', axis=1)
if freq == 'W':
df = api.weekly(ts_code=ts_code, start_date=start_date, end_date=end_date)
if freq == 'M':
df = api.monthly(ts_code=ts_code, start_date=start_date, end_date=end_date)
if adj is not None:
fcts = api.adj_factor(ts_code=ts_code, start_date=start_date, end_date=end_date)[['trade_date', 'adj_factor']]
data = df.set_index('trade_date', drop=False).merge(fcts.set_index('trade_date'), left_index=True, right_index=True, how='left')
data['adj_factor'] = data['adj_factor'].fillna(method='bfill')
for col in PRICE_COLS:
if adj == 'hfq':
data[col] = data[col] * data['adj_factor']
else:
data[col] = data[col] * data['adj_factor'] / float(fcts['adj_factor'][0])
data[col] = data[col].map(FORMAT)
for col in PRICE_COLS:
data[col] = data[col].astype(float)
data = data.drop('adj_factor', axis=1)
df['change'] = df['close'] - df['pre_close']
df['pct_change'] = df['close'].pct_change() * 100
else:
data = df
elif asset == 'I':
if freq == 'D':
data = api.index_daily(ts_code=ts_code, start_date=start_date, end_date=end_date)
elif asset == 'FT':
if freq == 'D':
data = api.fut_daily(ts_code=ts_code, start_dae=start_date, end_date=end_date, exchange=exchange)
elif asset == 'O':
if freq == 'D':
data = api.opt_daily(ts_code=ts_code, start_dae=start_date, end_date=end_date, exchange=exchange)
elif asset == 'FD':
if freq == 'D':
data = api.fund_daily(ts_code=ts_code, start_dae=start_date, end_date=end_date)
if asset == 'C':
if freq == 'd':
freq = 'daily'
elif freq == 'w':
freq = 'week'
data = api.coinbar(exchange=exchange, symbol=ts_code, freq=freq, start_dae=start_date, end_date=end_date,
contract_type=contract_type)
if ma is not None and len(ma) > 0:
for a in ma:
if isinstance(a, int):
data['ma%s'%a] = MA(data['close'], a).map(FORMAT).shift(-(a-1))
data['ma%s'%a] = data['ma%s'%a].astype(float)
data['ma_v_%s'%a] = MA(data['vol'], a).map(FORMAT).shift(-(a-1))
data['ma_v_%s'%a] = data['ma_v_%s'%a].astype(float)
return data
except Exception as e:
print(e)
return None
else:
return
raise IOError('ERROR.')
if __name__ == '__main__':
# upass.set_token('your token here')
pro = pro_api()
# print(pro_bar(ts_code='000001.SZ', pro_api=pro, start_date='19990101', end_date='', adj='qfq', ma=[5, 10, 15]))
# print(pro_bar(ts_code='000905.SH', pro_api=pro, start_date='20181001', end_date='', asset='I'))
# print(pro.trade_cal(exchange_id='', start_date='20131031', end_date='', fields='pretrade_date', is_open='0'))
# print(pro_bar(ts_code='CU1811.SHF', pro_api=pro, start_date='20180101', end_date='', asset='FT', ma=[5, 10, 15]))
# print(pro_bar(ts_code='150023.SZ', pro_api=pro, start_date='20180101', end_date='', asset='FD', ma=[5, 10, 15]))
# print(pro_bar(pro_api=pro, ts_code='000528.SZ',start_date='20180101', end_date='20181121', ma=[20]))
# print(pro_bar(ts_code='000528.SZ', pro_api=pro, freq='W', start_date='20180101', end_date='20180820', adj='hfq', ma=[5, 10, 15]))
# print(pro_bar(ts_code='000528.SZ', pro_api=pro, freq='M', start_date='20180101', end_date='20180820', adj='qfq', ma=[5, 10, 15]))
# print(pro_bar(ts_code='btcusdt', pro_api=pro, exchange='huobi', freq='D', start_date='20180101', end_date='20181123', asset='C', ma=[5, 10]))
# df = pro_bar(ts_code='000001.SZ', pro_api=pro, adj='qfq', start_date='19900101', end_date='20050509')
df = pro_bar(ts_code='600862.SH', pro_api=pro, start_date='20150118', end_date='20150615', factors=['tor', 'vr'])
print(df)
================================================
FILE: tushare/stock/__init__.py
================================================
================================================
FILE: tushare/stock/billboard.py
================================================
#!/usr/bin/env python
# -*- coding:utf-8 -*-
"""
龙虎榜数据
Created on 2015年6月10日
@author: Jimmy Liu
@group : waditu
@contact: jimmysoa@sina.cn
"""
import pandas as pd
from pandas.compat import StringIO
from tushare.stock import cons as ct
import numpy as np
import time
import json
import re
import lxml.html
from lxml import etree
from tushare.util import dateu as du
from tushare.stock import ref_vars as rv
try:
from urllib.request import urlopen, Request
except ImportError:
from urllib2 import urlopen, Request
def top_list(date = None, retry_count=3, pause=0.001):
"""
获取每日龙虎榜列表
Parameters
--------
date:string
明细数据日期 format:YYYY-MM-DD 如果为空,返回最近一个交易日的数据
retry_count : int, 默认 3
如遇网络等问题重复执行的次数
pause : int, 默认 0
重复请求数据过程中暂停的秒数,防止请求间隔时间太短出现的问题
Return
------
DataFrame
code:代码
name :名称
pchange:涨跌幅
amount:龙虎榜成交额(万)
buy:买入额(万)
bratio:占总成交比例
sell:卖出额(万)
sratio :占总成交比例
reason:上榜原因
date :日期
"""
if date is None:
if du.get_hour() < 18:
date = du.last_tddate()
else:
date = du.today()
else:
if(du.is_holiday(date)):
return None
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(rv.LHB_URL%(ct.P_TYPE['http'], ct.DOMAINS['em'], date, date))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
text = text.split('_1=')[1]
text = eval(text, type('Dummy', (dict,),
dict(__getitem__ = lambda s, n:n))())
text = json.dumps(text)
text = json.loads(text)
df = pd.DataFrame(text['data'], columns=rv.LHB_TMP_COLS)
df.columns = rv.LHB_COLS
df = df.fillna(0)
df = df.replace('', 0)
df['buy'] = df['buy'].astype(float)
df['sell'] = df['sell'].astype(float)
df['amount'] = df['amount'].astype(float)
df['Turnover'] = df['Turnover'].astype(float)
df['bratio'] = df['buy'] / df['Turnover']
df['sratio'] = df['sell'] /df['Turnover']
df['bratio'] = df['bratio'].map(ct.FORMAT)
df['sratio'] = df['sratio'].map(ct.FORMAT)
df['date'] = date
for col in ['amount', 'buy', 'sell']:
df[col] = df[col].astype(float)
df[col] = df[col] / 10000
df[col] = df[col].map(ct.FORMAT)
df = df.drop('Turnover', axis=1)
except Exception as e:
print(e)
else:
return df
raise IOError(ct.NETWORK_URL_ERROR_MSG)
def cap_tops(days= 5, retry_count= 3, pause= 0.001):
"""
获取个股上榜统计数据
Parameters
--------
days:int
天数,统计n天以来上榜次数,默认为5天,其余是10、30、60
retry_count : int, 默认 3
如遇网络等问题重复执行的次数
pause : int, 默认 0
重复请求数据过程中暂停的秒数,防止请求间隔时间太短出现的问题
Return
------
DataFrame
code:代码
name:名称
count:上榜次数
bamount:累积购买额(万)
samount:累积卖出额(万)
net:净额(万)
bcount:买入席位数
scount:卖出席位数
"""
if ct._check_lhb_input(days) is True:
ct._write_head()
df = _cap_tops(days, pageNo=1, retry_count=retry_count,
pause=pause)
if df is not None:
df['code'] = df['code'].map(lambda x: str(x).zfill(6))
df = df.drop_duplicates('code')
return df
def _cap_tops(last=5, pageNo=1, retry_count=3, pause=0.001, dataArr=pd.DataFrame()):
ct._write_console()
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(rv.LHB_SINA_URL%(ct.P_TYPE['http'], ct.DOMAINS['vsf'], rv.LHB_KINDS[0],
ct.PAGES['fd'], last, pageNo))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
html = lxml.html.parse(StringIO(text))
res = html.xpath("//table[@id=\"dataTable\"]/tr")
if ct.PY3:
sarr = [etree.tostring(node).decode('utf-8') for node in res]
else:
sarr = [etree.tostring(node) for node in res]
sarr = ''.join(sarr)
sarr = '<table>%s</table>'%sarr
df = pd.read_html(sarr)[0]
df.columns = rv.LHB_GGTJ_COLS
dataArr = dataArr.append(df, ignore_index=True)
nextPage = html.xpath('//div[@class=\"pages\"]/a[last()]/@onclick')
if len(nextPage)>0:
pageNo = re.findall(r'\d+', nextPage[0])[0]
return _cap_tops(last, pageNo, retry_count, pause, dataArr)
else:
return dataArr
except Exception as e:
print(e)
def broker_tops(days= 5, retry_count= 3, pause= 0.001):
"""
获取营业部上榜统计数据
Parameters
--------
days:int
天数,统计n天以来上榜次数,默认为5天,其余是10、30、60
retry_count : int, 默认 3
如遇网络等问题重复执行的次数
pause : int, 默认 0
重复请求数据过程中暂停的秒数,防止请求间隔时间太短出现的问题
Return
---------
broker:营业部名称
count:上榜次数
bamount:累积购买额(万)
bcount:买入席位数
samount:累积卖出额(万)
scount:卖出席位数
top3:买入前三股票
"""
if ct._check_lhb_input(days) is True:
ct._write_head()
df = _broker_tops(days, pageNo=1, retry_count=retry_count,
pause=pause)
return df
def _broker_tops(last=5, pageNo=1, retry_count=3, pause=0.001, dataArr=pd.DataFrame()):
ct._write_console()
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(rv.LHB_SINA_URL%(ct.P_TYPE['http'], ct.DOMAINS['vsf'], rv.LHB_KINDS[1],
ct.PAGES['fd'], last, pageNo))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
html = lxml.html.parse(StringIO(text))
res = html.xpath("//table[@id=\"dataTable\"]/tr")
if ct.PY3:
sarr = [etree.tostring(node).decode('utf-8') for node in res]
else:
sarr = [etree.tostring(node) for node in res]
sarr = ''.join(sarr)
sarr = '<table>%s</table>'%sarr
df = pd.read_html(sarr)[0]
df.columns = rv.LHB_YYTJ_COLS
dataArr = dataArr.append(df, ignore_index=True)
nextPage = html.xpath('//div[@class=\"pages\"]/a[last()]/@onclick')
if len(nextPage)>0:
pageNo = re.findall(r'\d+', nextPage[0])[0]
return _broker_tops(last, pageNo, retry_count, pause, dataArr)
else:
return dataArr
except Exception as e:
print(e)
def inst_tops(days= 5, retry_count= 3, pause= 0.001):
"""
获取机构席位追踪统计数据
Parameters
--------
days:int
天数,统计n天以来上榜次数,默认为5天,其余是10、30、60
retry_count : int, 默认 3
如遇网络等问题重复执行的次数
pause : int, 默认 0
重复请求数据过程中暂停的秒数,防止请求间隔时间太短出现的问题
Return
--------
code:代码
name:名称
bamount:累积买入额(万)
bcount:买入次数
samount:累积卖出额(万)
scount:卖出次数
net:净额(万)
"""
if ct._check_lhb_input(days) is True:
ct._write_head()
df = _inst_tops(days, pageNo=1, retry_count=retry_count,
pause=pause)
df['code'] = df['code'].map(lambda x: str(x).zfill(6))
return df
def _inst_tops(last=5, pageNo=1, retry_count=3, pause=0.001, dataArr=pd.DataFrame()):
ct._write_console()
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(rv.LHB_SINA_URL%(ct.P_TYPE['http'], ct.DOMAINS['vsf'], rv.LHB_KINDS[2],
ct.PAGES['fd'], last, pageNo))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
html = lxml.html.parse(StringIO(text))
res = html.xpath("//table[@id=\"dataTable\"]/tr")
if ct.PY3:
sarr = [etree.tostring(node).decode('utf-8') for node in res]
else:
sarr = [etree.tostring(node) for node in res]
sarr = ''.join(sarr)
sarr = '<table>%s</table>'%sarr
df = pd.read_html(sarr)[0]
df = df.drop([2,3], axis=1)
df.columns = rv.LHB_JGZZ_COLS
dataArr = dataArr.append(df, ignore_index=True)
nextPage = html.xpath('//div[@class=\"pages\"]/a[last()]/@onclick')
if len(nextPage)>0:
pageNo = re.findall(r'\d+', nextPage[0])[0]
return _inst_tops(last, pageNo, retry_count, pause, dataArr)
else:
return dataArr
except Exception as e:
print(e)
def inst_detail(retry_count= 3, pause= 0.001):
"""
获取最近一个交易日机构席位成交明细统计数据
Parameters
--------
retry_count : int, 默认 3
如遇网络等问题重复执行的次数
pause : int, 默认 0
重复请求数据过程中暂停的秒数,防止请求间隔时间太短出现的问题
Return
----------
code:股票代码
name:股票名称
date:交易日期
bamount:机构席位买入额(万)
samount:机构席位卖出额(万)
type:类型
"""
ct._write_head()
df = _inst_detail(pageNo=1, retry_count=retry_count,
pause=pause)
if len(df)>0:
df['code'] = df['code'].map(lambda x: str(x).zfill(6))
return df
def _inst_detail(pageNo=1, retry_count=3, pause=0.001, dataArr=pd.DataFrame()):
ct._write_console()
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(rv.LHB_SINA_URL%(ct.P_TYPE['http'], ct.DOMAINS['vsf'], rv.LHB_KINDS[3],
ct.PAGES['fd'], '', pageNo))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
html = lxml.html.parse(StringIO(text))
res = html.xpath("//table[@id=\"dataTable\"]/tr")
if ct.PY3:
sarr = [etree.tostring(node).decode('utf-8') for node in res]
else:
sarr = [etree.tostring(node) for node in res]
sarr = ''.join(sarr)
sarr = '<table>%s</table>'%sarr
df = pd.read_html(sarr)[0]
df.columns = rv.LHB_JGMX_COLS
dataArr = dataArr.append(df, ignore_index=True)
nextPage = html.xpath('//div[@class=\"pages\"]/a[last()]/@onclick')
if len(nextPage)>0:
pageNo = re.findall(r'\d+', nextPage[0])[0]
return _inst_detail(pageNo, retry_count, pause, dataArr)
else:
return dataArr
except Exception as e:
print(e)
def _f_rows(x):
if '%' in x[3]:
x[11] = x[6]
for i in range(6, 11):
x[i] = x[i-5]
for i in range(1, 6):
x[i] = np.NaN
return x
================================================
FILE: tushare/stock/classifying.py
================================================
# -*- coding:utf-8 -*-
"""
获取股票分类数据接口
Created on 2015/02/01
@author: Jimmy Liu
@group : waditu
@contact: jimmysoa@sina.cn
"""
import pandas as pd
from tushare.stock import cons as ct
from tushare.stock import ref_vars as rv
import json
import re
from pandas.util.testing import _network_error_classes
import time
import tushare.stock.fundamental as fd
from tushare.util.netbase import Client
try:
from urllib.request import urlopen, Request
except ImportError:
from urllib2 import urlopen, Request
def get_industry_classified(standard='sina'):
"""
获取行业分类数据
Parameters
----------
standard
sina:新浪行业 sw:申万 行业
Returns
-------
DataFrame
code :股票代码
name :股票名称
c_name :行业名称
"""
if standard == 'sw':
# df = _get_type_data(ct.SINA_INDUSTRY_INDEX_URL%(ct.P_TYPE['http'],
# ct.DOMAINS['vsf'], ct.PAGES['ids_sw']))
df = pd.read_csv(ct.TSDATA_CLASS%(ct.P_TYPE['http'], ct.DOMAINS['oss'], 'industry_sw'),
dtype={'code':object})
else:
# df = _get_type_data(ct.SINA_INDUSTRY_INDEX_URL%(ct.P_TYPE['http'],
# ct.DOMAINS['vsf'], ct.PAGES['ids']))
df = pd.read_csv(ct.TSDATA_CLASS%(ct.P_TYPE['http'], ct.DOMAINS['oss'], 'industry'),
dtype={'code':object})
# data = []
# ct._write_head()
# for row in df.values:
# rowDf = _get_detail(row[0], retry_count=10, pause=0.01)
# rowDf['c_name'] = row[1]
# data.append(rowDf)
# data = pd.concat(data, ignore_index=True)
return df
def get_concept_classified():
"""
获取概念分类数据
Return
--------
DataFrame
code :股票代码
name :股票名称
c_name :概念名称
"""
df = pd.read_csv(ct.TSDATA_CLASS%(ct.P_TYPE['http'], ct.DOMAINS['oss'], 'concept'),
dtype={'code':object})
return df
def concetps():
ct._write_head()
df = _get_type_data(ct.SINA_CONCEPTS_INDEX_URL%(ct.P_TYPE['http'],
ct.DOMAINS['sf'], ct.PAGES['cpt']))
data = []
for row in df.values:
rowDf = _get_detail(row[0])
if rowDf is not None:
rowDf['c_name'] = row[1]
data.append(rowDf)
if len(data) > 0:
data = pd.concat(data, ignore_index=True)
data.to_csv('d:\\cpt.csv', index=False)
def get_concepts(src='dfcf'):
"""
获取概念板块行情数据
Return
--------
DataFrame
code :股票代码
name :股票名称
c_name :概念名称
"""
clt = Client(ct.ET_CONCEPTS_INDEX_URL%(ct.P_TYPE['http'],
ct.DOMAINS['dfcf'], _random(15)), ref='')
content = clt.gvalue()
content = content.decode('utf-8') if ct.PY3 else content
js = json.loads(content)
data = []
for row in js:
cols = row.split(',')
cs = cols[6].split('|')
arr = [cols[2], cols[3], cs[0], cs[2], cols[7], cols[9]]
data.append(arr)
df = pd.DataFrame(data, columns=['concept', 'change', 'up', 'down', 'top_code', 'top_name'])
return df
def get_area_classified():
"""
获取地域分类数据
Return
--------
DataFrame
code :股票代码
name :股票名称
area :地域名称
"""
df = fd.get_stock_basics()
df = df[['name', 'area']]
df.reset_index(inplace=True)
df = df.sort_values('area').reset_index(drop=True)
return df
def get_gem_classified():
"""
获取创业板股票
Return
--------
DataFrame
code :股票代码
name :股票名称
"""
df = fd.get_stock_basics()
df.reset_index(inplace=True)
df = df[ct.FOR_CLASSIFY_COLS]
df = df.ix[df.code.str[0] == '3']
df = df.sort_values('code').reset_index(drop=True)
return df
def get_sme_classified():
"""
获取中小板股票
Return
--------
DataFrame
code :股票代码
name :股票名称
"""
df = fd.get_stock_basics()
df.reset_index(inplace=True)
df = df[ct.FOR_CLASSIFY_COLS]
df = df.ix[df.code.str[0:3] == '002']
df = df.sort_values('code').reset_index(drop=True)
return df
def get_st_classified():
"""
获取风险警示板股票
Return
--------
DataFrame
code :股票代码
name :股票名称
"""
df = fd.get_stock_basics()
df.reset_index(inplace=True)
df = df[ct.FOR_CLASSIFY_COLS]
df = df.ix[df.name.str.contains('ST')]
df = df.sort_values('code').reset_index(drop=True)
return df
def _get_detail(tag, retry_count=3, pause=0.001):
dfc = pd.DataFrame()
p = 0
num_limit = 100
while(True):
p = p+1
for _ in range(retry_count):
time.sleep(pause)
try:
ct._write_console()
request = Request(ct.SINA_DATA_DETAIL_URL%(ct.P_TYPE['http'],
ct.DOMAINS['vsf'], ct.PAGES['jv'],
p,tag))
text = urlopen(request, timeout=10).read()
text = text.decode('gbk')
except _network_error_classes:
pass
else:
break
reg = re.compile(r'\,(.*?)\:')
text = reg.sub(r',"\1":', text)
text = text.replace('"{symbol', '{"symbol')
text = text.replace('{symbol', '{"symbol"')
jstr = json.dumps(text)
js = json.loads(jstr)
df = pd.DataFrame(pd.read_json(js, dtype={'code':object}), columns=ct.THE_FIELDS)
# df = df[ct.FOR_CLASSIFY_B_COLS]
df = df[['code', 'name']]
dfc = pd.concat([dfc, df])
if df.shape[0] < num_limit:
return dfc
#raise IOError(ct.NETWORK_URL_ERROR_MSG)
def _get_type_data(url):
try:
request = Request(url)
data_str = urlopen(request, timeout=10).read()
data_str = data_str.decode('GBK')
data_str = data_str.split('=')[1]
data_json = json.loads(data_str)
df = pd.DataFrame([[row.split(',')[0], row.split(',')[1]] for row in data_json.values()],
columns=['tag', 'name'])
return df
except Exception as er:
print(str(er))
def get_hs300s():
"""
获取沪深300当前成份股及所占权重
Return
--------
DataFrame
code :股票代码
name :股票名称
date :日期
weight:权重
"""
try:
wt = pd.read_excel(ct.HS300_CLASSIFY_URL_FTP%(ct.P_TYPE['http'], ct.DOMAINS['idx'],
ct.PAGES['hs300w']), usecols=[0, 4, 5, 8])
wt.columns = ct.FOR_CLASSIFY_W_COLS
wt['code'] = wt['code'].map(lambda x :str(x).zfill(6))
return wt
except Exception as er:
print(str(er))
def get_sz50s():
"""
获取上证50成份股
Return
--------
DataFrame
date :日期
code :股票代码
name :股票名称
"""
try:
df = pd.read_excel(ct.SZ_CLASSIFY_URL_FTP%(ct.P_TYPE['http'], ct.DOMAINS['idx'],
ct.PAGES['sz50b']), parse_cols=[0, 4, 5])
df.columns = ct.FOR_CLASSIFY_B_COLS
df['code'] = df['code'].map(lambda x :str(x).zfill(6))
return df
except Exception as er:
print(str(er))
def get_zz500s():
"""
获取中证500成份股
Return
--------
DataFrame
date :日期
code :股票代码
name :股票名称
weight : 权重
"""
try:
wt = pd.read_excel(ct.HS300_CLASSIFY_URL_FTP%(ct.P_TYPE['http'], ct.DOMAINS['idx'],
ct.PAGES['zz500wt']), usecols=[0, 4, 5, 8])
wt.columns = ct.FOR_CLASSIFY_W_COLS
wt['code'] = wt['code'].map(lambda x :str(x).zfill(6))
return wt
except Exception as er:
print(str(er))
def get_terminated():
"""
获取终止上市股票列表
Return
--------
DataFrame
code :股票代码
name :股票名称
oDate:上市日期
tDate:终止上市日期
"""
try:
ref = ct.SSEQ_CQ_REF_URL%(ct.P_TYPE['http'], ct.DOMAINS['sse'])
clt = Client(rv.TERMINATED_URL%(ct.P_TYPE['http'], ct.DOMAINS['sseq'],
ct.PAGES['ssecq'], _random(5),
_random()), ref=ref, cookie=rv.MAR_SH_COOKIESTR)
lines = clt.gvalue()
lines = lines.decode('utf-8') if ct.PY3 else lines
lines = lines[19:-1]
lines = json.loads(lines)
df = pd.DataFrame(lines['result'], columns=rv.TERMINATED_T_COLS)
df.columns = rv.TERMINATED_COLS
return df
except Exception as er:
print(str(er))
def get_suspended():
"""
获取暂停上市股票列表
Return
--------
DataFrame
code :股票代码
name :股票名称
oDate:上市日期
tDate:终止上市日期
"""
try:
ref = ct.SSEQ_CQ_REF_URL%(ct.P_TYPE['http'], ct.DOMAINS['sse'])
clt = Client(rv.SUSPENDED_URL%(ct.P_TYPE['http'], ct.DOMAINS['sseq'],
ct.PAGES['ssecq'], _random(5),
_random()), ref=ref, cookie=rv.MAR_SH_COOKIESTR)
lines = clt.gvalue()
lines = lines.decode('utf-8') if ct.PY3 else lines
lines = lines[19:-1]
lines = json.loads(lines)
df = pd.DataFrame(lines['result'], columns=rv.TERMINATED_T_COLS)
df.columns = rv.TERMINATED_COLS
return df
except Exception as er:
print(str(er))
def _random(n=13):
from random import randint
start = 10**(n-1)
end = (10**n)-1
return str(randint(start, end))
================================================
FILE: tushare/stock/cons.py
================================================
# -*- coding:utf-8 -*-
'''
Created on 2014/07/31
@author: Jimmy Liu
@group : waditu
@contact: jimmysoa@sina.cn
'''
VERSION = '1.0.3'
K_LABELS = ['D', 'W', 'M']
K_MIN_LABELS = ['5', '15', '30', '60']
K_TYPE = {'D': 'akdaily', 'W': 'akweekly', 'M': 'akmonthly'}
TT_K_TYPE = {'D': 'day', 'W': 'week', 'M': 'month'}
FQ_KEY = ['qfqday', 'hfqday', 'day']
INDEX_LABELS = ['sh', 'sz', 'hs300', 'sz50', 'cyb', 'zxb', 'zx300', 'zh500']
INDEX_LIST = {'sh': 'sh000001', 'sz': 'sz399001', 'hs300': 'sh000300',
'sz50': 'sh000016', 'zxb': 'sz399005', 'cyb': 'sz399006',
'zx300': 'sz399008', 'zh500':'sh000905'}
P_TYPE = {'http': 'http://', 'ftp': 'ftp://'}
PAGE_NUM = [40, 60, 80, 100]
FORMAT = lambda x: '%.2f' % x
FORMAT4 = lambda x: '%.4f' % x
DOMAINS = {'sina': 'sina.com.cn', 'sinahq': 'sinajs.cn',
'ifeng': 'ifeng.com', 'sf': 'finance.sina.com.cn',
'vsf': 'vip.stock.finance.sina.com.cn',
'idx': 'www.csindex.com.cn', '163': 'money.163.com',
'em': 'eastmoney.com', 'sseq': 'query.sse.com.cn',
'sse': 'www.sse.com.cn', 'szse': 'www.szse.cn',
'oss': 'file.tushare.org', 'idxip':'115.29.204.48',
'shibor': 'www.shibor.org', 'mbox':'www.cbooo.cn',
'tt': 'gtimg.cn', 'gw': 'gw.com.cn',
'v500': 'value500.com', 'sstar': 'stock.stockstar.com',
'dfcf': 'nufm.dfcfw.com'}
PAGES = {'fd': 'index.phtml', 'dl': 'downxls.php', 'jv': 'json_v2.php',
'cpt': 'newFLJK.php', 'ids': 'newSinaHy.php', 'lnews':'rollnews_ch_out_interface.php',
'ntinfo':'vCB_BulletinGather.php', 'hs300b':'000300cons.xls',
'hs300w':'000300closeweight.xls','sz50b':'000016cons.xls',
'dp':'all_fpya.php', '163dp':'fpyg.html',
'emxsg':'JS.aspx', '163fh':'jjcgph.php',
'newstock':'vRPD_NewStockIssue.php', 'zz500b':'000905cons.xls',
'zz500wt':'000905closeweight.xls',
't_ticks':'vMS_tradedetail.php', 'dw': 'downLoad.html',
'qmd':'queryMargin.do', 'szsefc':'ShowReport.szse',
'ssecq':'commonQuery.do', 'sinadd':'cn_bill_download.php', 'ids_sw':'SwHy.php',
'idx': 'index.php', 'index': 'index.html'}
TICK_COLUMNS = ['time', 'price', 'change', 'volume', 'amount', 'type']
TODAY_TICK_COLUMNS = ['time', 'price', 'pchange', 'change', 'volume', 'amount', 'type']
DAY_TRADING_COLUMNS = ['code', 'symbol', 'name', 'changepercent',
'trade', 'open', 'high', 'low', 'settlement', 'volume', 'turnoverratio',
'amount', 'per', 'pb', 'mktcap', 'nmc']
REPORT_COLS = ['code', 'name', 'eps', 'eps_yoy', 'bvps', 'roe',
'epcf', 'net_profits', 'profits_yoy', 'distrib', 'report_date']
FORECAST_COLS = ['code', 'name', 'type', 'report_date', 'pre_eps', 'range']
PROFIT_COLS = ['code', 'name', 'roe', 'net_profit_ratio',
'gross_profit_rate', 'net_profits', 'eps', 'business_income', 'bips']
OPERATION_COLS = ['code', 'name', 'arturnover', 'arturndays', 'inventory_turnover',
'inventory_days', 'currentasset_turnover', 'currentasset_days']
GROWTH_COLS = ['code', 'name', 'mbrg', 'nprg', 'nav', 'targ', 'epsg', 'seg']
DEBTPAYING_COLS = ['code', 'name', 'currentratio',
'quickratio', 'cashratio', 'icratio', 'sheqratio', 'adratio']
CASHFLOW_COLS = ['code', 'name', 'cf_sales', 'rateofreturn',
'cf_nm', 'cf_liabilities', 'cashflowratio']
DAY_PRICE_COLUMNS = ['date', 'open', 'high', 'close', 'low', 'volume', 'price_change', 'p_change',
'ma5', 'ma10', 'ma20', 'v_ma5', 'v_ma10', 'v_ma20', 'turnover']
INX_DAY_PRICE_COLUMNS = ['date', 'open', 'high', 'close', 'low', 'volume', 'price_change', 'p_change',
'ma5', 'ma10', 'ma20', 'v_ma5', 'v_ma10', 'v_ma20']
LIVE_DATA_COLS = ['name', 'open', 'pre_close', 'price', 'high', 'low', 'bid', 'ask', 'volume', 'amount',
'b1_v', 'b1_p', 'b2_v', 'b2_p', 'b3_v', 'b3_p', 'b4_v', 'b4_p', 'b5_v', 'b5_p',
'a1_v', 'a1_p', 'a2_v', 'a2_p', 'a3_v', 'a3_p', 'a4_v', 'a4_p', 'a5_v', 'a5_p', 'date', 'time', 's']
US_LIVE_DATA_COLS = ['name', 'price', 'change_percent', 'time', 'change', 'open', 'high', 'low', 'high_52week', 'low_52week', 'volume', 'volume_average', 'mktcap', 'eps', 'pe', 'fpe', 'beta', 'dividend', 'earnings_yield', 'totals', 'instown', 'extended_price', 'extended_change_percent', 'extended_change', 'extended_time', 'time_est', 'pre_close', 'extended_volume']
FOR_CLASSIFY_COLS = ['code','name']
FOR_CLASSIFY_B_COLS = ['date', 'code','name']
FOR_CLASSIFY_W_COLS = ['date','code', 'name', 'weight']
FOR_CLASSIFY_W5_COLS = ['date','code', 'name', 'weight']
TSDATA_CLASS = '%s%s/tsdata/industry/%s.csv'
THE_FIELDS = ['code','symbol','name','changepercent','trade','open','high','low','settlement','volume','turnoverratio']
KLINE_TT_COLS_MINS = ['date', 'open', 'close', 'high', 'low', 'volume']
KLINE_TT_COLS = ['date', 'open', 'close', 'high', 'low', 'volume', 'amount', 'turnoverratio']
TICK_PRICE_URL = '%smarket.%s/%s?date=%s&symbol=%s'
TICK_PRICE_URL_TT = '%sstock.%s/data/%s?appn=detail&action=download&c=%s&d=%s'
TICK_PRICE_URL_NT = '%squotes.%s/cjmx/%s/%s/%s.xls'
TODAY_TICKS_PAGE_URL = '%s%s/quotes_service/api/%s/CN_Transactions.getAllPageTime?date=%s&symbol=%s'
TODAY_TICKS_URL = '%s%s/quotes_service/view/%s?symbol=%s&date=%s&page=%s'
KLINE_TT_URL = '%sweb.ifzq.%s/appstock/app/%skline/get?_var=kline_day%s¶m=%s,%s,%s,%s,640,%s&r=0.%s'
KLINE_TT_MIN_URL = '%sifzq.%s/appstock/app/kline/mkline?param=%s,m%s,,640&_var=m%s_today&r=0.%s'
DAY_PRICE_URL = '%sapi.finance.%s/%s/?code=%s&type=last'
LIVE_DATA_URL = '%shq.%s/rn=%s&list=%s'
DAY_PRICE_MIN_URL = '%sapi.finance.%s/akmin?scode=%s&type=%s'
SINA_DAY_PRICE_URL = '%s%s/quotes_service/api/%s/Market_Center.getHQNodeData?num=80&sort=code&asc=0&node=%s&symbol=&_s_r_a=page&page=%s'
# SINA_DAY_PRICE_URL = '%s%s/quotes_service/api/%s/Market_Center.getHQNodeData?num=10000&node=%s'
REPORT_URL = '%s%s/q/go.php/vFinanceAnalyze/kind/mainindex/%s?s_i=&s_a=&s_c=&reportdate=%s&quarter=%s&p=%s&num=%s'
FORECAST_URL = '%s%s/q/go.php/vFinanceAnalyze/kind/performance/%s?s_i=&s_a=&s_c=&s_type=&reportdate=%s&quarter=%s&p=%s&num=%s'
PROFIT_URL = '%s%s/q/go.php/vFinanceAnalyze/kind/profit/%s?s_i=&s_a=&s_c=&reportdate=%s&quarter=%s&p=%s&num=%s'
OPERATION_URL = '%s%s/q/go.php/vFinanceAnalyze/kind/operation/%s?s_i=&s_a=&s_c=&reportdate=%s&quarter=%s&p=%s&num=%s'
GROWTH_URL = '%s%s/q/go.php/vFinanceAnalyze/kind/grow/%s?s_i=&s_a=&s_c=&reportdate=%s&quarter=%s&p=%s&num=%s'
DEBTPAYING_URL = '%s%s/q/go.php/vFinanceAnalyze/kind/debtpaying/%s?s_i=&s_a=&s_c=&reportdate=%s&quarter=%s&p=%s&num=%s'
CASHFLOW_URL = '%s%s/q/go.php/vFinanceAnalyze/kind/cashflow/%s?s_i=&s_a=&s_c=&reportdate=%s&quarter=%s&p=%s&num=%s'
SHIBOR_TYPE ={'Shibor': 'Shibor数据', 'Quote': '报价数据', 'Tendency': 'Shibor均值数据',
'LPR': 'LPR数据', 'LPR_Tendency': 'LPR均值数据'}
SHIBOR_DATA_URL = '%s%s/shibor/web/html/%s?nameNew=Historical_%s_Data_%s.xls&downLoadPath=data&nameOld=%s%s.xls&shiborSrc=http://www.shibor.org/shibor/'
ALL_STOCK_BASICS_FILE = P_TYPE['http'] + DOMAINS['oss'] + '/tsdata/%sall%s.csv'
ALL_DAY_FILE = P_TYPE['http'] + DOMAINS['oss'] + '/tsdata/h/%s%s.csv'
ALL_CAL_FILE = '%s%s/tsdata/calAll.csv'%(P_TYPE['http'], DOMAINS['oss'])
SINA_CONCEPTS_INDEX_URL = '%smoney.%s/q/view/%s?param=class'
ET_CONCEPTS_INDEX_URL = '%s%s/EM_Finance2014NumericApplication/JS.aspx?type=CT&cmd=C._BKGN&js=[(x)]&sty=FPGBKI&st=c&sr=-1&p=1&ps=5000&cb=&token=7bc05d0d4c3c22ef9fca8c2a912d779c&v=0.0%s'
SINA_INDUSTRY_INDEX_URL = '%s%s/q/view/%s'
SINA_DATA_DETAIL_URL = '%s%s/quotes_service/api/%s/Market_Center.getHQNodeData?page=%s&num=1000&sort=symbol&asc=1&node=%s&symbol=&_s_r_a=page'
SINA_BALANCESHEET_URL = 'http://money.finance.sina.com.cn/corp/go.php/vDOWN_BalanceSheet/displaytype/4/stockid/%s/ctrl/all.phtml'
SINA_PROFITSTATEMENT_URL = 'http://money.finance.sina.com.cn/corp/go.php/vDOWN_ProfitStatement/displaytype/4/stockid/%s/ctrl/all.phtml'
SINA_CASHFLOW_URL = 'http://money.finance.sina.com.cn/corp/go.php/vDOWN_CashFlow/displaytype/4/stockid/%s/ctrl/all.phtml'
INDEX_C_COMM = 'sseportal/ps/zhs/hqjt/csi'
HS300_CLASSIFY_URL_FTP = '%s%s/uploads/file/autofile/closeweight/%s'
SZ_CLASSIFY_URL_FTP = '%s%s/uploads/file/autofile/cons/%s'
HS300_CLASSIFY_URL_HTTP = '%s%s/%s/%s'
BDI_URL = '%s%s/BDI.asp'
HIST_FQ_URL = '%s%s/corp/go.php/vMS_FuQuanMarketHistory/stockid/%s.phtml?year=%s&jidu=%s'
HIST_INDEX_URL = '%s%s/corp/go.php/vMS_MarketHistory/stockid/%s/type/S.phtml?year=%s&jidu=%s'
HIST_FQ_FACTOR_URL = '%s%s/api/json.php/BasicStockSrv.getStockFuQuanData?symbol=%s&type=hfq'
ADJ_FAC_URL = '%s%s/tsdata/f/factor/%s.csv'
MG_URL = '%s%s/tsdata/rzrq/%s/%s%s.csv'
MG_ZSL_URL = '%s%s/tsdata/rzrq/%s/zsl/%s_%s.csv'
GPZY_URL = '%s%s/tsdata/gpzy/%s.csv'
GPZY_D_URL = '%s%s/tsdata/gpzy/%s.csv'
SHS_FAC_URL = '%s%s/tsdata/shares/%s.csv'
ZF = '%s%s/tsdata/%s.csv'
INDEX_HQ_URL = '''%shq.%s/rn=xppzh&list=sh000001,sh000002,sh000003,sh000008,sh000009,sh000010,sh000011,sh000012,sh000016,sh000017,sh000300,sh000905,sz399001,sz399002,sz399003,sz399004,sz399005,sz399006,sz399008,sz399100,sz399101,sz399106,sz399107,sz399108,sz399333,sz399606'''
SSEQ_CQ_REF_URL = '%s%s/assortment/stock/list/name'
ALL_STK_URL = '%s%s/all.csv'
SINA_DD = '%s%s/quotes_service/view/%s?symbol=%s&num=60&page=1&sort=ticktime&asc=0&volume=%s&amount=0&type=0&day=%s'
BOX = 'boxOffice'
MOVIE_BOX = '%s%s/%s/GetHourBoxOffice?d=%s'
BOXOFFICE_DAY = '%s%s/%s/GetDayBoxOffice?num=%s&d=%s'
BOXOFFICE_MONTH = '%s%s/%s/getMonthBox?sdate=%s'
BOXOFFICE_CBD = '%s%s/%s/getCBD?pIndex=%s&dt=%s'
SHIBOR_COLS = ['date', 'ON', '1W', '2W', '1M', '3M', '6M', '9M', '1Y']
SHIBOR_Q_COLS = ['date', 'bank', 'ON', '1W', '2W', '1M', '3M', '6M', '9M', '1Y']
QUOTE_COLS = ['date', 'bank', 'ON_B', 'ON_A', '1W_B', '1W_A', '2W_B', '2W_A', '1M_B', '1M_A',
'3M_B', '3M_A', '6M_B', '6M_A', '9M_B', '9M_A', '1Y_B', '1Y_A']
SHIBOR_MA_COLS = ['date', 'ON_5', 'ON_10', 'ON_20', '1W_5', '1W_10', '1W_20','2W_5', '2W_10', '2W_20',
'1M_5', '1M_10', '1M_20', '3M_5', '3M_10', '3M_20', '6M_5', '6M_10', '6M_20',
'9M_5', '9M_10', '9M_20','1Y_5', '1Y_10', '1Y_20']
LPR_COLS = ['date', '1Y']
KTYPE = {
'D' : 9,
'XD' : 4,
'W' : 5,
'M' : 6,
'Q' : 10,
'Y' : 11,
'1MIN' : 8,
'5MIN' : 0,
'15MIN' : 1,
'30MIN' : 2,
'60MIN' : 3,
}
ASSET = {
'E' : 'get_security_bars',
'INDEX' : 'get_index_bars',
'X' : 'get_instrument_bars',
}
KTYPE_LOW_COLS = ['D', 'XD', 'W', 'M', 'Q', 'Y']
KTYPE_ARR = ['1MIN', '5MIN', '15MIN', '30MIN', '60MIN']
BAR_E_COLS = ['code', 'open', 'close', 'high', 'low', 'vol', 'amount']
BAR_X_COLS = ['code', 'open', 'close', 'high', 'low', 'price', 'position','trade']
BAR_X_FUTURE_COLS = ['code', 'open', 'close', 'high', 'low', 'avg_price', 'position', 'vol']
BAR_X_FUTURE_RL_COLS = ['code', 'open', 'close', 'high', 'low', 'vol', 'avg_price', 'position']
BAR_X_OTHER_COLS = ['code', 'open', 'close', 'high', 'low', 'vol']
T_DROP_COLS = ['year', 'month', 'day', 'hour','minute']
LPR_MA_COLS = ['date', '1Y_5', '1Y_10', '1Y_20']
INDEX_HEADER = 'code,name,open,preclose,close,high,low,0,0,volume,amount,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,d,c,3\n'
INDEX_COLS = ['code', 'name', 'change', 'open', 'preclose', 'close', 'high', 'low', 'volume', 'amount']
HIST_FQ_COLS = ['date', 'open', 'high', 'close', 'low', 'volume', 'amount', 'factor']
SINA_DD_COLS = ['code', 'name', 'time', 'price', 'volume', 'preprice', 'type']
GLOBAL_HQ_SYMBOL = 'sh000001,hkHSI,znb_UKX,znb_DAX,znb_INDEXCF,znb_CAC,znb_SMI,znb_FTSEMIB,znb_MADX,znb_OMX,znb_SPX,znb_HEX,znb_OSEAX,znb_ISEQ,znb_AEX,znb_ICEXI,znb_NKY,znb_TWSE,znb_FSSTI,znb_KOSPI,znb_FBMKLCI,znb_SET,znb_JCI,znb_PCOMP,znb_KSE100,znb_SENSEX,znb_VNINDEX,znb_CSEALL,znb_SASEIDX,znb_SPTSX,znb_MEXBOL,znb_IBOV,znb_MERVAL,znb_AS51,znb_NZSE50FG,znb_CASE,znb_JALSH,sz399001,znb_INDU,znb_CCMP'
GLOBAL_HQ_COLS = ['symbol', 'name', 'price', 'chga', 'chgp', 'datetime']
INST_PLK_F = 'ts_instrument.plk'
PROFIT_DIVIS = ['code',
'name',
'year',
'bshares',
'incshares',
'totals',
'cash',
'plandate',
'regdate',
'exdate',
'eventproc',
'anndate']
HIST_FQ_FACTOR_COLS = ['code','value']
DATA_GETTING_TIPS = '[Getting data:]'
DATA_GETTING_FLAG = '#'
DATA_ROWS_TIPS = '%s rows data found.Please wait for a moment.'
DATA_INPUT_ERROR_MSG = 'date input error.'
MSG_NOT_CONNECTED = '服务器连接为空,请通过ts.get_apis()获取'
NETWORK_URL_ERROR_MSG = '获取失败,请检查网络.'
DATE_CHK_MSG = '年度输入错误:请输入1989年以后的年份数字,格式:YYYY'
DATE_CHK_Q_MSG = '季度输入错误:请输入1、2、3或4数字'
TOP_PARAS_MSG = 'top有误,请输入整数或all.'
LHB_MSG = '周期输入有误,请输入数字5、10、30或60'
TOKEN_F_P = 'tk.csv'
TOKEN_ERR_MSG = '请设置tushare pro的token凭证码,如果没有请访问https://tushare.pro注册申请'
BOX_INPUT_ERR_MSG = '请输入YYYY-MM格式的年月数据'
TICK_SRCS = ['sn', 'tt', 'nt']
TICK_SRC_ERROR = '数据源代码只能输入sn,tt,nt其中之一'
INDEX_SYMBOL = {'399990': 'sz399990', '000006': 'sh000006', '399998': 'sz399998',
'399436': 'sz399436', '399678': 'sz399678', '399804': 'sz399804',
'000104': 'sh000104', '000070': 'sh000070', '399613': 'sz399613',
'399690': 'sz399690', '399928': 'sz399928', '000928': 'sh000928',
'000986': 'sh000986', '399806': 'sz399806', '000032': 'sh000032',
'000005': 'sh000005', '399381': 'sz399381', '399908': 'sz399908',
'000908': 'sh000908', '399691': 'sz399691', '000139': 'sh000139',
'399427': 'sz399427', '399248': 'sz399248', '000832': 'sh000832',
'399901': 'sz399901', '399413': 'sz399413', '000901': 'sh000901',
'000078': 'sh000078', '000944': 'sh000944', '000025': 'sh000025',
'399944': 'sz399944', '399307': 'sz399307', '000052': 'sh000052',
'399680': 'sz399680', '399232': 'sz399232', '399993': 'sz399993',
'000102': 'sh000102', '000950': 'sh000950', '399950': 'sz399950',
'399244': 'sz399244', '399925': 'sz399925', '000925': 'sh000925',
'000003': 'sh000003', '000805': 'sh000805', '000133': 'sh000133',
'399677': 'sz399677', '399319': 'sz399319', '399397': 'sz399397',
'399983': 'sz399983', '399654': 'sz399654', '399440': 'sz399440',
'000043': 'sh000043', '000012': 'sh000012', '000833': 'sh000833',
'000145': 'sh000145', '000053': 'sh000053', '000013': 'sh000013',
'000022': 'sh000022', '000094': 'sh000094', '399299': 'sz399299',
'000101': 'sh000101', '399817': 'sz399817', '399481': 'sz399481',
'399434': 'sz399434', '399301': 'sz399301', '000029': 'sh000029',
'399812': 'sz399812', '399441': 'sz399441', '000098': 'sh000098',
'399557': 'sz399557', '000068': 'sh000068', '399298': 'sz399298',
'399302': 'sz399302', '000961': 'sh000961', '000959': 'sh000959',
'399961': 'sz399961', '000126': 'sh000126', '000036': 'sh000036',
'399305': 'sz399305', '000116': 'sh000116', '399359': 'sz399359',
'399810': 'sz399810', '000062': 'sh000062', '399618': 'sz399618',
'399435': 'sz399435', '000149': 'sh000149', '000819': 'sh000819',
'000020': 'sh000020', '000061': 'sh000061', '000016': 'sh000016',
'000028': 'sh000028', '399809': 'sz399809', '000999': 'sh000999',
'399238': 'sz399238', '000100': 'sh000100', '399979': 'sz399979',
'000979': 'sh000979', '399685': 'sz399685', '000152': 'sh000152',
'000153': 'sh000153', '399318': 'sz399318', '000853': 'sh000853',
'000040': 'sh000040', '399693': 'sz399693', '000076': 'sh000076',
'000017': 'sh000017', '000134': 'sh000134', '399989': 'sz399989',
'000042': 'sh000042', '000066': 'sh000066', '000008': 'sh000008',
'000002': 'sh000002', '000001': 'sh000001', '000011': 'sh000011',
'000031': 'sh000031', '399403': 'sz399403', '000951': 'sh000951',
'399951': 'sz399951', '000092': 'sh000092', '399234': 'sz399234',
'000823': 'sh000823', '399986': 'sz399986', '399647': 'sz399647',
'000050': 'sh000050', '000073': 'sh000073', '399357': 'sz399357',
'000940': 'sh000940', '000107': 'sh000107', '000048': 'sh000048',
'399411': 'sz399411', '399366': 'sz399366', '399373': 'sz399373',
'000015': 'sh000015', '000021': 'sh000021', '000151': 'sh000151',
'000851': 'sh000851', '000058': 'sh000058', '399404': 'sz399404',
'399102': 'sz399102', '399431': 'sz399431', '399971': 'sz399971',
'000125': 'sh000125', '000069': 'sh000069', '000063': 'sh000063',
'399395': 'sz399395', '000038': 'sh000038', '399240': 'sz399240',
'399903': 'sz399903', '000989': 'sh000989', '399321': 'sz399321',
'399675': 'sz399675', '399235': 'sz399235', '000057': 'sh000057',
'000056': 'sh000056', '000903': 'sh000903', '399310': 'sz399310',
'000004': 'sh000004', '000019': 'sh000019', '399919': 'sz399919',
'000974': 'sh000974', '000919': 'sh000919', '399635': 'sz399635',
'399663': 'sz399663', '399106': 'sz399106', '399107': 'sz399107',
'399555': 'sz399555', '000090': 'sh000090', '000155': 'sh000155',
'000060': 'sh000060', '399636': 'sz399636', '000816': 'sh000816',
'000010': 'sh000010', '399671': 'sz399671', '000035': 'sh000035',
'399352': 'sz399352', '399683': 'sz399683', '399554': 'sz399554',
'399409': 'sz399409', '000018': 'sh000018', '399101': 'sz399101',
'000992': 'sh000992', '399416': 'sz399416', '399918': 'sz399918',
'399379': 'sz399379', '399674': 'sz399674', '399239': 'sz399239',
'399384': 'sz399384', '399367': 'sz399367', '000918': 'sh000918',
'000914': 'sh000914', '399914': 'sz399914', '000054': 'sh000054',
'000806': 'sh000806', '399619': 'sz399619', '399015': 'sz399015',
'399393': 'sz399393', '399313': 'sz399313', '399231': 'sz399231',
'000846': 'sh000846', '000854': 'sh000854', '399010': 'sz399010',
'399666': 'sz399666', '399387': 'sz399387', '399399': 'sz399399',
'000026': 'sh000026', '399934': 'sz399934', '000150': 'sh000150',
'000934': 'sh000934', '399317': 'sz399317', '000138': 'sh000138',
'399371': 'sz399371', '399394': 'sz399394', '399659': 'sz399659',
'399665': 'sz399665', '399931': 'sz399931', '000161': 'sh000161',
'399380': 'sz399380', '000931': 'sh000931', '399704': 'sz399704',
'399616': 'sz399616', '000817': 'sh000817', '399303': 'sz399303',
'399629': 'sz399629', '399624': 'sz399624', '399009': 'sz399009',
'399233': 'sz399233', '399103': 'sz399103', '399242': 'sz399242',
'399627': 'sz399627', '000971': 'sh000971', '399679': 'sz399679',
'399912': 'sz399912', '000982': 'sh000982', '399668': 'sz399668',
'000096': 'sh000096', '399982': 'sz399982', '000849': 'sh000849',
'000148': 'sh000148', '399364': 'sz399364', '000912': 'sh000912',
'000129': 'sh000129', '000055': 'sh000055', '000047': 'sh000047', '399355': 'sz399355', '399622': 'sz399622', '000033': 'sh000033', '399640': 'sz399640', '000852': 'sh000852', '399966': 'sz399966', '399615': 'sz399615', '399802': 'sz399802', '399602': 'sz399602', '000105': 'sh000105', '399660': 'sz399660', '399672': 'sz399672',
'399913': 'sz399913', '399420': 'sz399420', '000159': 'sh000159', '399314': 'sz399314', '399652': 'sz399652',
'399369': 'sz399369', '000913': 'sh000913', '000065': 'sh000065',
'000808': 'sh000808', '399386': 'sz399386', '399100': 'sz399100',
'000997': 'sh000997', '000990': 'sh000990', '000093': 'sh000093', '399637': 'sz399637', '399439': 'sz399439', '399306': 'sz399306', '000855': 'sh000855', '000123': 'sh000123', '399623': 'sz399623',
'399312': 'sz399312', '399249': 'sz399249', '399311': 'sz399311', '399975': 'sz399975', '399356': 'sz399356',
'399400': 'sz399400', '399676': 'sz399676', '000136': 'sh000136', '399361': 'sz399361', '399974': 'sz399974', '399995': 'sz399995', '399316': 'sz399316', '399701': 'sz399701', '000300': 'sh000300', '000030': 'sh000030', '000976': 'sh000976', '399686': 'sz399686', '399108': 'sz399108', '399374': 'sz399374',
'000906': 'sh000906', '399707': 'sz399707', '000064': 'sh000064', '399633': 'sz399633', '399300': 'sz399300', '399628': 'sz399628', '399398': 'sz399398', '000034': 'sh000034',
'399644': 'sz399644', '399905': 'sz399905', '399626': 'sz399626',
'399625': 'sz399625', '000978': 'sh000978', '399664': 'sz399664', '399682': 'sz399682', '399322': 'sz399322', '000158': 'sh000158', '000842': 'sh000842', '399550': 'sz399550', '399423': 'sz399423', '399978': 'sz399978', '399996': 'sz399996', '000905': 'sh000905',
'000007': 'sh000007', '000827': 'sh000827', '399655': 'sz399655', '399401': 'sz399401', '399650': 'sz399650', '000963': 'sh000963', '399661': 'sz399661', '399922': 'sz399922', '000091': 'sh000091', '399375': 'sz399375', '000922': 'sh000922', '399702': 'sz399702', '399963': 'sz399963', '399011': 'sz399011', '399012': 'sz399012',
'399383': 'sz399383', '399657': 'sz399657', '399910': 'sz399910', '399351': 'sz399351', '000910': 'sh000910', '000051': 'sh000051', '399376': 'sz399376', '399639': 'sz399639', '000821': 'sh000821', '399360': 'sz399360', '399604': 'sz399604', '399315': 'sz399315', '399658': 'sz399658', '000135': 'sh000135',
'000059': 'sh000059', '399006': 'sz399006',
'399320': 'sz399320', '000991': 'sh000991', '399606': 'sz399606',
'399428': 'sz399428', '399406': 'sz399406', '399630': 'sz399630', '000802': 'sh000802', '399803': 'sz399803', '000071': 'sh000071', '399358': 'sz399358',
'399013': 'sz399013', '399385': 'sz399385', '399008': 'sz399008', '399649': 'sz399649',
'399673': 'sz399673', '399418': 'sz399418', '399370': 'sz399370', '000814': 'sh000814',
'399002': 'sz399002', '399814': 'sz399814', '399641': 'sz399641', '399001': 'sz399001',
'399662': 'sz399662', '399706': 'sz399706', '399932': 'sz399932', '000095': 'sh000095', '000932': 'sh000932', '399965': 'sz399965', '399363': 'sz399363', '399354': 'sz399354', '399638': 'sz399638', '399648': 'sz399648', '399608': 'sz399608', '000939': 'sh000939', '399939': 'sz399939', '399365': 'sz399365', '399382': 'sz399382', '399631': 'sz399631', '399612': 'sz399612', '399611': 'sz399611', '399645': 'sz399645',
'399324': 'sz399324', '399552': 'sz399552', '000858': 'sh000858', '000045': 'sh000045',
'000121': 'sh000121', '399703': 'sz399703', '399003': 'sz399003',
'399348': 'sz399348', '399389': 'sz399389', '399007': 'sz399007', '399391': 'sz399391', '000973': 'sh000973',
'000984': 'sh000984', '000969': 'sh000969', '000952': 'sh000952', '399332': 'sz399332', '399952': 'sz399952', '399553': 'sz399553', '000856': 'sh000856',
'399969': 'sz399969', '399643': 'sz399643', '399402': 'sz399402', '399372': 'sz399372', '399632': 'sz399632', '399344': 'sz399344', '399808': 'sz399808', '399620': 'sz399620', '000103': 'sh000103', '399911': 'sz399911', '000993': 'sh000993', '000983': 'sh000983', '399687': 'sz399687', '399933': 'sz399933', '000933': 'sh000933', '399437': 'sz399437', '399433': 'sz399433', '000046': 'sh000046', '000911': 'sh000911', '000114': 'sh000114', '000049': 'sh000049', '399392': 'sz399392', '399653': 'sz399653', '000975': 'sh000975', '000044': 'sh000044', '399378': 'sz399378', '000828': 'sh000828', '399634': 'sz399634',
'399005': 'sz399005', '000162': 'sh000162', '399333': 'sz399333', '000122': 'sh000122', '399646': 'sz399646', '000077': 'sh000077', '000074': 'sh000074', '399656': 'sz399656', '399396': 'sz399396', '399415': 'sz399415', '399408': 'sz399408', '000115': 'sh000115', '000987': 'sh000987', '399362': 'sz399362', '000841': 'sh000841', '000141': 'sh000141', '000120': 'sh000120', '399992': 'sz399992', '000807': 'sh000807', '399350': 'sz399350', '000009': 'sh000009', '000998': 'sh000998', '399390': 'sz399390', '399405': 'sz399405', '000099': 'sh000099', '399337': 'sz399337', '000142': 'sh000142', '399419': 'sz399419', '399407': 'sz399407', '000909': 'sh000909', '000119': 'sh000119', '399909': 'sz399909', '399805': 'sz399805', '000996': 'sh000996', '000847': 'sh000847', '000130': 'sh000130', '399377': 'sz399377', '399388': 'sz399388', '399610': 'sz399610', '000958': 'sh000958',
'399958': 'sz399958', '000075': 'sh000075', '399346': 'sz399346', '000147': 'sh000147', '000132': 'sh000132', '000108': 'sh000108', '399642': 'sz399642', '000977': 'sh000977', '399689': 'sz399689', '399335': 'sz399335', '399977': 'sz399977', '399972': 'sz399972', '399970': 'sz399970', '399004': 'sz399004', '399341': 'sz399341', '399330': 'sz399330', '399917': 'sz399917', '000160': 'sh000160', '399432': 'sz399432', '399429': 'sz399429', '000917': 'sh000917',
'000128': 'sh000128', '000067': 'sh000067', '000079': 'sh000079', '399236': 'sz399236', '399994': 'sz399994', '399237': 'sz399237', '000966': 'sh000966', '000957': 'sh000957', '399328': 'sz399328',
'399353': 'sz399353', '399957': 'sz399957', '399412': 'sz399412', '000904': 'sh000904', '399904': 'sz399904', '399410': 'sz399410', '000027': 'sh000027', '399667': 'sz399667', '000857': 'sh000857',
'000131': 'sh000131', '000964': 'sh000964', '399339': 'sz399339', '399964': 'sz399964', '399991': 'sz399991', '399417': 'sz399417', '000146': 'sh000146', '399551': 'sz399551', '000137': 'sh000137', '000118': 'sh000118', '399976': 'sz399976', '000109': 'sh000109', '399681': 'sz399681', '399438': 'sz399438', '000117': 'sh000117', '399614': 'sz399614', '399669': 'sz399669', '000111': 'sh000111', '399670': 'sz399670', '000097': 'sh000097', '000106': 'sh000106', '000039': 'sh000039', '399935': 'sz399935', '000935': 'sh000935', '399813': 'sz399813', '000037': 'sh000037', '399811': 'sz399811', '399705': 'sz399705', '399556': 'sz399556', '000113': 'sh000113', '000072': 'sh000072', '399651': 'sz399651', '399617': 'sz399617', '399684': 'sz399684', '000041': 'sh000041', '399807': 'sz399807', '399959': 'sz399959', '399967': 'sz399967', '399326': 'sz399326', '399688': 'sz399688', '399368': 'sz399368', '399241': 'sz399241', '399696': 'sz399696', '000850': 'sh000850', '000110': 'sh000110', '399621': 'sz399621', '399243': 'sz399243',
'399973': 'sz399973', '399987': 'sz399987', '000112': 'sh000112', '399997': 'sz399997',
'000915': 'sh000915', '000916': 'sh000916',
'hkHSI':'hkHSI'}
MKTS = {
'TP': [1, 1,'临时股'],
'OZ': [4, 12, '郑州商品期权'],
'OD': [5, 12, '大连商品期权'],
'OS': [6, 12, '上海商品期权'],
'QQ': [8, 12, '上海个股期权'],
'FH': [27, 5, '香港指数'],
'QZ': [28, 3, '郑州商品'],
'QD': [29, 3, '大连商品'],
'QS': [30, 3, '上海期货'],
'KH': [31, 2, '香港主板'],
'KR': [32, 2, '香港权证'],
'FU': [33, 8, '开放式基金'],
'FB': [34, 9, '货币型基金'],
'LC': [35, 8,'招商理财产品'],
'LB': [36, 9,'招商货币产品'],
'FW': [37, 11, '国际指数'],
'HG': [38, 10,'国内宏观指标'],
'CH': [40, 11, '中国概念股'],
'MG': [41, 11,'美股知名公司'],
'HB': [43, 1, 'B股转H股'],
'SB': [44, 1, '股份转让'],
'CZ': [47, 3, '股指期货'],
'KG': [48, 2, '香港创业板'],
'KT': [49, 2,'香港信托基金'],
'GY': [54, 6, '国债预发行'],
'MA': [60, 3,'主力期货合约'],
'ZZ': [62, 5, '中证指数'],
'GH': [71, 2, '港股通'],
'SZ': [0, 0, 'SHENZHEN'],
'SH': [1, 1, 'SHANGHAI']
}
SLIST = ['180.153.18.170', '180.153.18.171', '202.108.253.130', '202.108.253.131', '60.191.117.167', '115.238.56.198', '218.75.126.9', '115.238.90.165',
'124.160.88.183', '60.12.136.250', '218.108.98.244', '218.108.47.69', '14.17.75.71', '180.153.39.51']
XXLIST = ['61.152.107.141']
XLIST = ['121.14.110.210', '119.147.212.76', '113.105.73.86', '119.147.171.211', '119.147.164.57', '119.147.164.58', '61.49.50.180', '61.49.50.181',
'61.135.142.85', '61.135.149.181', '114.80.80.210', '222.73.49.15', '221.194.181.176']
T_PORT = 7709
X_PORT = 7727
import sys
PY3 = (sys.version_info[0] >= 3)
def _write_head():
sys.stdout.write(DATA_GETTING_TIPS)
sys.stdout.flush()
def _write_console():
sys.stdout.write(DATA_GETTING_FLAG)
sys.stdout.flush()
def _write_tips(tip):
sys.stdout.write(DATA_ROWS_TIPS%tip)
sys.stdout.flush()
def _write_msg(msg):
sys.stdout.write(msg)
sys.stdout.flush()
def _check_input(year, quarter):
if isinstance(year, str) or year < 1989 :
raise TypeError(DATE_CHK_MSG)
elif quarter is None or isinstance(quarter, str) or quarter not in [1, 2, 3, 4]:
raise TypeError(DATE_CHK_Q_MSG)
else:
return True
def _check_lhb_input(last):
if last not in [5, 10, 30, 60]:
raise TypeError(LHB_MSG)
else:
return True
def _market_code(code):
code = str(code)
if code[0] in ['5', '6', '9'] or code[:3] in ['009', '100', '110', '112', \
'113', '120', '129', '181', \
'126', '201', '202', '203', \
'204', '190', '191']:
return 1
return 0
def _idx_market_code(code):
code = str(code)
if code[0] in ['0']:
return 1
if code[:3] in ['399']:
return 0
return code
def _code_to_symbol(code):
'''
生成symbol代码标志
'''
if code in INDEX_LABELS:
return INDEX_LIST[code]
elif code[:3] == 'gb_':
return code
else:
if len(code) != 6 :
return code
else:
return 'sh%s'%code if code[:1] in ['5', '6', '9'] or code[:2] in ['11', '13'] else 'sz%s'%code
def _code_to_symbol_dgt(code):
'''
生成symbol代码标志
'''
if code in INDEX_LABELS:
return INDEX_LIST[code]
else:
if len(code) != 6 :
return code
else:
return '0%s'%code if code[:1] in ['5', '6', '9'] else '1%s'%code
def _get_server():
import random
ips = SLIST
random.shuffle(ips)
return ips[0]
def _get_xserver():
import random
ips = XLIST
random.shuffle(ips)
return ips[0]
def _get_xxserver():
import random
ips = XXLIST
random.shuffle(ips)
return ips[0]
================================================
FILE: tushare/stock/fundamental.py
================================================
# -*- coding:utf-8 -*-
"""
基本面数据接口
Created on 2015/01/18
@author: Jimmy Liu
@group : waditu
@contact: jimmysoa@sina.cn
"""
import pandas as pd
from tushare.stock import cons as ct
import lxml.html
from lxml import etree
import re
import time
from pandas.compat import StringIO
from tushare.util import dateu as du
try:
from urllib.request import urlopen, Request
except ImportError:
from urllib2 import urlopen, Request
def get_stock_basics(date=None):
"""
获取沪深上市公司基本情况
Parameters
date:日期YYYY-MM-DD,默认为上一个交易日,目前只能提供2016-08-09之后的历史数据
Return
--------
DataFrame
code,代码
name,名称
industry,细分行业
area,地区
pe,市盈率
outstanding,流通股本
totals,总股本(万)
totalAssets,总资产(万)
liquidAssets,流动资产
fixedAssets,固定资产
reserved,公积金
reservedPerShare,每股公积金
eps,每股收益
bvps,每股净资
pb,市净率
timeToMarket,上市日期
"""
wdate = du.last_tddate() if date is None else date
wdate = wdate.replace('-', '')
if wdate < '20160809':
return None
datepre = '' if date is None else wdate[0:4] + wdate[4:6] + '/'
request = Request(ct.ALL_STOCK_BASICS_FILE%(datepre, '' if date is None else wdate))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
text = text.replace('--', '')
df = pd.read_csv(StringIO(text), dtype={'code':'object'})
df = df.set_index('code')
return df
def get_report_data(year, quarter):
"""
获取业绩报表数据
Parameters
--------
year:int 年度 e.g:2014
quarter:int 季度 :1、2、3、4,只能输入这4个季度
说明:由于是从网站获取的数据,需要一页页抓取,速度取决于您当前网络速度
Return
--------
DataFrame
code,代码
name,名称
eps,每股收益
eps_yoy,每股收益同比(%)
bvps,每股净资产
roe,净资产收益率(%)
epcf,每股现金流量(元)
net_profits,净利润(万元)
profits_yoy,净利润同比(%)
distrib,分配方案
report_date,发布日期
"""
if ct._check_input(year,quarter) is True:
ct._write_head()
df = _get_report_data(year, quarter, 1, pd.DataFrame())
if df is not None:
# df = df.drop_duplicates('code')
df['code'] = df['code'].map(lambda x:str(x).zfill(6))
return df
def _get_report_data(year, quarter, pageNo, dataArr,
retry_count=3, pause=0.001):
ct._write_console()
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(ct.REPORT_URL%(ct.P_TYPE['http'], ct.DOMAINS['vsf'], ct.PAGES['fd'],
year, quarter, pageNo, ct.PAGE_NUM[1]))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
text = text.replace('--', '')
html = lxml.html.parse(StringIO(text))
res = html.xpath("//table[@class=\"list_table\"]/tr")
if ct.PY3:
sarr = [etree.tostring(node).decode('utf-8') for node in res]
else:
sarr = [etree.tostring(node) for node in res]
sarr = ''.join(sarr)
sarr = '<table>%s</table>'%sarr
df = pd.read_html(sarr)[0]
df = df.drop(11, axis=1)
df.columns = ct.REPORT_COLS
dataArr = dataArr.append(df, ignore_index=True)
nextPage = html.xpath('//div[@class=\"pages\"]/a[last()]/@onclick')
if len(nextPage)>0:
pageNo = re.findall(r'\d+', nextPage[0])[0]
return _get_report_data(year, quarter, pageNo, dataArr)
else:
return dataArr
except Exception as e:
pass
raise IOError(ct.NETWORK_URL_ERROR_MSG)
def get_profit_data(year, quarter):
"""
获取盈利能力数据
Parameters
--------
year:int 年度 e.g:2014
quarter:int 季度 :1、2、3、4,只能输入这4个季度
说明:由于是从网站获取的数据,需要一页页抓取,速度取决于您当前网络速度
Return
--------
DataFrame
code,代码
name,名称
roe,净资产收益率(%)
net_profit_ratio,净利率(%)
gross_profit_rate,毛利率(%)
net_profits,净利润(万元)
eps,每股收益
business_income,营业收入(百万元)
bips,每股主营业务收入(元)
"""
if ct._check_input(year, quarter) is True:
ct._write_head()
data = _get_profit_data(year, quarter, 1, pd.DataFrame())
if data is not None:
# data = data.drop_duplicates('code')
data['code'] = data['code'].map(lambda x:str(x).zfill(6))
return data
def _get_profit_data(year, quarter, pageNo, dataArr,
retry_count=3, pause=0.001):
ct._write_console()
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(ct.PROFIT_URL%(ct.P_TYPE['http'], ct.DOMAINS['vsf'],
ct.PAGES['fd'], year,
quarter, pageNo, ct.PAGE_NUM[1]))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
text = text.replace('--', '')
html = lxml.html.parse(StringIO(text))
res = html.xpath("//table[@class=\"list_table\"]/tr")
if ct.PY3:
sarr = [etree.tostring(node).decode('utf-8') for node in res]
else:
sarr = [etree.tostring(node) for node in res]
sarr = ''.join(sarr)
sarr = '<table>%s</table>'%sarr
df = pd.read_html(sarr)[0]
df.columns=ct.PROFIT_COLS
dataArr = dataArr.append(df, ignore_index=True)
nextPage = html.xpath('//div[@class=\"pages\"]/a[last()]/@onclick')
if len(nextPage)>0:
pageNo = re.findall(r'\d+', nextPage[0])[0]
return _get_profit_data(year, quarter, pageNo, dataArr)
else:
return dataArr
except:
pass
raise IOError(ct.NETWORK_URL_ERROR_MSG)
def get_operation_data(year, quarter):
"""
获取营运能力数据
Parameters
--------
year:int 年度 e.g:2014
quarter:int 季度 :1、2、3、4,只能输入这4个季度
说明:由于是从网站获取的数据,需要一页页抓取,速度取决于您当前网络速度
Return
--------
DataFrame
code,代码
name,名称
arturnover,应收账款周转率(次)
arturndays,应收账款周转天数(天)
inventory_turnover,存货周转率(次)
inventory_days,存货周转天数(天)
currentasset_turnover,流动资产周转率(次)
currentasset_days,流动资产周转天数(天)
"""
if ct._check_input(year, quarter) is True:
ct._write_head()
data = _get_operation_data(year, quarter, 1, pd.DataFrame())
if data is not None:
# data = data.drop_duplicates('code')
data['code'] = data['code'].map(lambda x:str(x).zfill(6))
return data
def _get_operation_data(year, quarter, pageNo, dataArr,
retry_count=3, pause=0.001):
ct._write_console()
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(ct.OPERATION_URL%(ct.P_TYPE['http'], ct.DOMAINS['vsf'],
ct.PAGES['fd'], year,
quarter, pageNo, ct.PAGE_NUM[1]))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
text = text.replace('--', '')
html = lxml.html.parse(StringIO(text))
res = html.xpath("//table[@class=\"list_table\"]/tr")
if ct.PY3:
sarr = [etree.tostring(node).decode('utf-8') for node in res]
else:
sarr = [etree.tostring(node) for node in res]
sarr = ''.join(sarr)
sarr = '<table>%s</table>'%sarr
df = pd.read_html(sarr)[0]
df.columns=ct.OPERATION_COLS
dataArr = dataArr.append(df, ignore_index=True)
nextPage = html.xpath('//div[@class=\"pages\"]/a[last()]/@onclick')
if len(nextPage)>0:
pageNo = re.findall(r'\d+', nextPage[0])[0]
return _get_operation_data(year, quarter, pageNo, dataArr)
else:
return dataArr
except Exception as e:
pass
raise IOError(ct.NETWORK_URL_ERROR_MSG)
def get_growth_data(year, quarter):
"""
获取成长能力数据
Parameters
--------
year:int 年度 e.g:2014
quarter:int 季度 :1、2、3、4,只能输入这4个季度
说明:由于是从网站获取的数据,需要一页页抓取,速度取决于您当前网络速度
Return
--------
DataFrame
code,代码
name,名称
mbrg,主营业务收入增长率(%)
nprg,净利润增长率(%)
nav,净资产增长率
targ,总资产增长率
epsg,每股收益增长率
seg,股东权益增长率
"""
if ct._check_input(year, quarter) is True:
ct._write_head()
data = _get_growth_data(year, quarter, 1, pd.DataFrame())
if data is not None:
# data = data.drop_duplicates('code')
data['code'] = data['code'].map(lambda x:str(x).zfill(6))
return data
def _get_growth_data(year, quarter, pageNo, dataArr,
retry_count=3, pause=0.001):
ct._write_console()
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(ct.GROWTH_URL%(ct.P_TYPE['http'], ct.DOMAINS['vsf'],
ct.PAGES['fd'], year,
quarter, pageNo, ct.PAGE_NUM[1]))
text = urlopen(request, timeout=50).read()
text = text.decode('GBK')
text = text.replace('--', '')
html = lxml.html.parse(StringIO(text))
res = html.xpath("//table[@class=\"list_table\"]/tr")
if ct.PY3:
sarr = [etree.tostring(node).decode('utf-8') for node in res]
else:
sarr = [etree.tostring(node) for node in res]
sarr = ''.join(sarr)
sarr = '<table>%s</table>'%sarr
df = pd.read_html(sarr)[0]
df.columns=ct.GROWTH_COLS
dataArr = dataArr.append(df, ignore_index=True)
nextPage = html.xpath('//div[@class=\"pages\"]/a[last()]/@onclick')
if len(nextPage)>0:
pageNo = re.findall(r'\d+', nextPage[0])[0]
return _get_growth_data(year, quarter, pageNo, dataArr)
else:
return dataArr
except Exception as e:
pass
raise IOError(ct.NETWORK_URL_ERROR_MSG)
def get_debtpaying_data(year, quarter):
"""
获取偿债能力数据
Parameters
--------
year:int 年度 e.g:2014
quarter:int 季度 :1、2、3、4,只能输入这4个季度
说明:由于是从网站获取的数据,需要一页页抓取,速度取决于您当前网络速度
Return
--------
DataFrame
code,代码
name,名称
currentratio,流动比率
quickratio,速动比率
cashratio,现金比率
icratio,利息支付倍数
sheqratio,股东权益比率
adratio,股东权益增长率
"""
if ct._check_input(year, quarter) is True:
ct._write_head()
df = _get_debtpaying_data(year, quarter, 1, pd.DataFrame())
if df is not None:
# df = df.drop_duplicates('code')
df['code'] = df['code'].map(lambda x:str(x).zfill(6))
return df
def _get_debtpaying_data(year, quarter, pageNo, dataArr,
retry_count=3, pause=0.001):
ct._write_console()
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(ct.DEBTPAYING_URL%(ct.P_TYPE['http'], ct.DOMAINS['vsf'],
ct.PAGES['fd'], year,
quarter, pageNo, ct.PAGE_NUM[1]))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
html = lxml.html.parse(StringIO(text))
res = html.xpath("//table[@class=\"list_table\"]/tr")
if ct.PY3:
sarr = [etree.tostring(node).decode('utf-8') for node in res]
else:
sarr = [etree.tostring(node) for node in res]
sarr = ''.join(sarr)
sarr = '<table>%s</table>'%sarr
df = pd.read_html(sarr)[0]
df.columns = ct.DEBTPAYING_COLS
dataArr = dataArr.append(df, ignore_index=True)
nextPage = html.xpath('//div[@class=\"pages\"]/a[last()]/@onclick')
if len(nextPage)>0:
pageNo = re.findall(r'\d+', nextPage[0])[0]
return _get_debtpaying_data(year, quarter, pageNo, dataArr)
else:
return dataArr
except Exception as e:
pass
raise IOError(ct.NETWORK_URL_ERROR_MSG)
def get_cashflow_data(year, quarter):
"""
获取现金流量数据
Parameters
--------
year:int 年度 e.g:2014
quarter:int 季度 :1、2、3、4,只能输入这4个季度
说明:由于是从网站获取的数据,需要一页页抓取,速度取决于您当前网络速度
Return
--------
DataFrame
code,代码
name,名称
cf_sales,经营现金净流量对销售收入比率
rateofreturn,资产的经营现金流量回报率
cf_nm,经营现金净流量与净利润的比率
cf_liabilities,经营现金净流量对负债比率
cashflowratio,现金流量比率
"""
if ct._check_input(year, quarter) is True:
ct._write_head()
df = _get_cashflow_data(year, quarter, 1, pd.DataFrame())
if df is not None:
# df = df.drop_duplicates('code')
df['code'] = df['code'].map(lambda x:str(x).zfill(6))
return df
def _get_cashflow_data(year, quarter, pageNo, dataArr,
retry_count=3, pause=0.001):
ct._write_console()
for _ in range(retry_count):
time.sleep(pause)
try:
request = Request(ct.CASHFLOW_URL%(ct.P_TYPE['http'], ct.DOMAINS['vsf'],
ct.PAGES['fd'], year,
quarter, pageNo, ct.PAGE_NUM[1]))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
text = text.replace('--', '')
html = lxml.html.parse(StringIO(text))
res = html.xpath("//table[@class=\"list_table\"]/tr")
if ct.PY3:
sarr = [etree.tostring(node).decode('utf-8') for node in res]
else:
sarr = [etree.tostring(node) for node in res]
sarr = ''.join(sarr)
sarr = '<table>%s</table>'%sarr
df = pd.read_html(sarr)[0]
df.columns = ct.CASHFLOW_COLS
dataArr = dataArr.append(df, ignore_index=True)
nextPage = html.xpath('//div[@class=\"pages\"]/a[last()]/@onclick')
if len(nextPage)>0:
pageNo = re.findall(r'\d+', nextPage[0])[0]
return _get_cashflow_data(year, quarter, pageNo, dataArr)
else:
return dataArr
except Exception as e:
pass
raise IOError(ct.NETWORK_URL_ERROR_MSG)
def _data_path():
import os
import inspect
caller_file = inspect.stack()[1][1]
pardir = os.path.abspath(os.path.join(os.path.dirname(caller_file), os.path.pardir))
return os.path.abspath(os.path.join(pardir, os.path.pardir))
def get_balance_sheet(code):
"""
获取某股票的历史所有时期资产负债表
Parameters
--------
code:str 股票代码 e.g:600518
Return
--------
DataFrame
行列名称为中文且数目较多,建议获取数据后保存到本地查看
"""
if code.isdigit():
request = Request(ct.SINA_BALANCESHEET_URL%(code))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
text = text.replace('\t\n', '\r\n')
text = text.replace('\t', ',')
df = pd.read_csv(StringIO(text), dtype={'code':'object'})
return df
def get_profit_statement(code):
"""
获取某股票的历史所有时期利润表
Parameters
--------
code:str 股票代码 e.g:600518
Return
--------
DataFrame
行列名称为中文且数目较多,建议获取数据后保存到本地查看
"""
if code.isdigit():
request = Request(ct.SINA_PROFITSTATEMENT_URL%(code))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
text = text.replace('\t\n', '\r\n')
text = text.replace('\t', ',')
df = pd.read_csv(StringIO(text), dtype={'code':'object'})
return df
def get_cash_flow(code):
"""
获取某股票的历史所有时期现金流表
Parameters
--------
code:str 股票代码 e.g:600518
Return
--------
DataFrame
行列名称为中文且数目较多,建议获取数据后保存到本地查看
"""
if code.isdigit():
request = Request(ct.SINA_CASHFLOW_URL%(code))
text = urlopen(request, timeout=10).read()
text = text.decode('GBK')
text = text.replace('\t\n', '\r\n')
text = text.replace('\t', ',')
df = pd.read_csv(StringIO(text), dtype={'code':'object'})
return df
================================================
FILE: tushare/stock/globals.py
================================================
#!/usr/bin/env python
# -*- coding:utf-8 -*-
'''
全球市场
Created on 2016/11/27
@author: Jimmy Liu
@group : waditu
@contact: jimmysoa@sina.cn
'''
import pandas as pd
from tushare.stock import cons as ct
from tushare.util import dateu as du
try:
from urllib.request import urlopen, Request
except ImportError:
from urllib2 import urlopen, Request
def global_realtime(symbols=None):
"""
全球实时指数
"""
symbols_list = ''
if symbols is None or symbols == '':
symbols_list = ct.GLOBAL_HQ_SYMBOL
else:
if isinstance(symbols, list) or isinstance(symbols, set) or isinstance(symbols, tuple) or isinstance(symbols, pd.Series):
for code in symbols:
symbols_list += 'znb_' + code + ','
else:
symbols_list = 'znb_' + symbols
symbols_list = symbols_list[:-1] if len(symbols_list) > 8 else symbols_list
request = Request(ct.LIVE_DATA_URL%(ct.P_TYPE['http'], ct.DOMAINS['sinahq'],
du._random(), symbols_list))
content = urlopen(request,timeout=10).readlines()
datalist = []
for cont in content:
arrs = []
cont = cont.decode('GBK')
cont = cont.split('=')
symbolstr = cont[0].split('_')
symbol = symbolstr[2]
vals = cont[1][1:-3]
valarr = vals.split(',')
if (symbol == 'sh000001') or (symbol == 'sz399001'):
price = float(valarr[3])
preclose = float(valarr[2])
chg = (price - preclose) / preclose * 100
arrs = [symbol, valarr[0], valarr[3], price-preclose , chg, valarr[30] + ' ' + valarr[31]]
elif symbol == 'hkHSI':
arrs = [symbol, valarr[1], valarr[6], valarr[7], valarr[8], valarr[17].replace('/', '-') + ' ' + valarr[18] + ':00']
else:
arrs = [symbolstr[3], valarr[0], valarr[1], valarr[2], valarr[3], du.int2time(int(valarr[5]))]
datalist.append(arrs)
df = pd.DataFrame(datalist, columns=ct.GLOBAL_HQ_COLS)
return df
================================================
FILE: tushare/stock/indictor.py
================================================
# -*- coding:utf-8 -*-
"""
股票技术指标接口
Created on 2018/05/26
@author: Jackie Liao
@group : **
@contact: info@liaocy.net
"""
def ma(data, n=10, val_name="close"):
import numpy as np
'''
移动平均线 Moving Average
Parameters
------
data:pandas.DataFrame
通过 get_h_data 取得的股票数据
n:int
移动平均线时长,时间单位根据data决定
val_name:string
计算哪一列的列名,默认为 close 收盘值
return
-------
list
移动平均线
'''
values = []
MA = []
for index, row in data.iterrows():
values.append(row[val_name])
if len(values) == n:
del values[0]
MA.append(np.average(values))
return np.asarray(MA)
def md(data, n=10, val_name="close"):
import numpy as np
'''
移动标准差
Parameters
------
data:pandas.DataFrame
通过 get_h_data 取得的股票数据
n:int
移动平均线时长,时间单位根据data决定
val_name:string
计算哪一列的列名,默认为 close 收盘值
return
-------
list
移动平均线
'''
values = []
MD = []
for index, row in data.iterrows():
values.append(row[val_name])
if len(values) == n:
del values[0]
MD.append(np.std(values))
return np.asarray(MD)
def _get_day_ema(prices, n):
a = 1 - 2 / (n + 1)
day_ema = 0
for index, price in enumerate(reversed(prices)):
day_ema += a ** index * price
return day_ema
def ema(data, n=12, val_name="close"):
import numpy as np
'''
指数平均数指标 Exponential Moving Average
Parameters
------
data:pandas.DataFrame
通过 get_h_data 取得的股票数据
n:int
移动平均线时长,时间单位根据data决定
val_name:string
计算哪一列的列名,默认为 close 收盘值
return
-------
EMA:numpy.ndarray<numpy.float64>
指数平均数指标
'''
prices = []
EMA = []
for index, row in data.iterrows():
if index == 0:
past_ema = row[val_name]
EMA.append(row[val_name])
else:
# Y=[2*X+(N-1)*Y’]/(N+1)
today_ema = (2 * row[val_name] + (n - 1) * past_ema) / (n + 1)
past_ema = today_ema
EMA.append(today_ema)
return np.asarray(EMA)
def macd(data, quick_n=12, slow_n=26, dem_n=9, val_name="close"):
import numpy as np
'''
指数平滑异同平均线(MACD: Moving Average Convergence Divergence)
Parameters
------
data:pandas.DataFrame
通过 get_h_data 取得的股票数据
quick_n:int
DIFF差离值中快速移动天数
slow_n:int
DIFF差离值中慢速移动天数
dem_n:int
DEM讯号线的移动天数
val_name:string
计算哪一列的列名,默认为 close 收盘值
return
-------
OSC:numpy.ndarray<numpy.float64>
MACD bar / OSC 差值柱形图 DIFF - DEM
DIFF:numpy.ndarray<numpy.float64>
差离值
DEM:numpy.ndarray<numpy.float64>
讯号线
'''
ema_quick = np.asarray(ema(data, quick_n, val_name))
ema_slow = np.asarray(ema(data, slow_n, val_name))
DIFF = ema_quick - ema_slow
data["diff"] = DIFF
DEM = ema(data, dem_n, "diff")
OSC = DIFF - DEM
return OSC, DIFF, DEM
def kdj(data):
import numpy as np
'''
随机指标KDJ
Parameters
------
data:pandas.DataFrame
通过 get_h_data 取得的股票数据
return
-------
K:numpy.ndarray<numpy.float64>
K线
D:numpy.ndarray<numpy.float64>
D线
J:numpy.ndarray<numpy.float64>
J线
'''
K, D, J = [], [], []
last_k, last_d = None, None
for index, row in data.iterrows():
if last_k is None or last_d is None:
last_k = 50
last_d = 50
c, l, h = row["close"], row["low"], row["high"]
rsv = (c - l) / (h - l) * 100
k = (2 / 3) * last_k + (1 / 3) * rsv
d = (2 / 3) * last_d + (1 / 3) * k
j = 3 * k - 2 * d
K.append(k)
D.append(d)
J.append(j)
last_k, last_d = k, d
return np.asarray(K), np.asarray(D), np.asarray(J)
def rsi(data, n=6, val_name="close"):
import numpy as np
'''
相对强弱指标RSI
Parameters
------
data:pandas.DataFrame
通过 get_h_data 取得的股票数据
n:int
统计时长,时间单位根据data决定
return
-------
RSI:numpy.ndarray<numpy.float64>
RSI线
'''
RSI = []
UP = []
DOWN = []
for index, row in data.iterrows():
if index == 0:
past_value = row[val_name]
RSI.append(0)
else:
diff = row[val_name] - past_value
if diff > 0:
UP.append(diff)
DOWN.append(0)
else:
UP.append(0)
DOWN.append(diff)
if len(UP) == n:
del UP[0]
if len(DOWN) == n:
del DOWN[0]
past_value = row[val_name]
rsi = np.sum(UP) / (-np.sum(DOWN) + np.sum(UP)) * 100
RSI.append(rsi)
return np.asarray(RSI)
def boll(data, n=10, val_name="close", k=2):
'''
布林线指标BOLL
Parameters
------
data:pandas.DataFrame
通过 get_h_data 取得的股票数据
n:int
统计时长,时间单位根据data决定
return
-------
BOLL:numpy.ndarray<numpy.float64>
中轨线
UPPER:numpy.ndarray<numpy.float64>
D线
J:numpy.ndarray<numpy.float64>
J线
'''
BOLL = ma(data, n, val_name)
MD = md(data, n, val_name)
UPPER = BOLL + k * MD
LOWER = BOLL - k * MD
return BOLL, UPPER, LOWER
def wnr(data, n=14):
'''
威廉指标 w&r
Parameters
------
data:pandas.DataFrame
通过 get_h_data 取得的股票数据
n:int
统计时长,时间单位根据data决定
return
-------
WNR:numpy.ndarray<numpy.float64>
威廉指标
'''
high_prices = []
low_prices = []
WNR = []
for index, row in data.iterrows():
high_prices.append(row["high"])
if len(high_prices) == n:
del high_prices[0]
low_prices.append(row["low"])
if len(low_prices) == n:
del low_prices[0]
highest = max(high_prices)
lowest = min(low_prices)
wnr = (highest - row["close"]) / (highest - lowest) * 100
WNR.append(wnr)
return WNR
def _get_any_ma(arr, n):
import numpy as np
MA = []
values = []
for val in arr:
values.append(val)
if len(values) == n:
del values[0]
MA.append(np.average(values))
return np.asarray(MA)
def dmi(data, n=14, m=14, k=6):
import numpy as np
'''
动向指标或趋向指标 DMI
Parameters
------
data:pandas.DataFrame
通过 get_h_data 取得的股票数据
n:int
+-DI(n): DI统计时长,默认14
m:int
ADX(m): ADX统计时常参数,默认14
k:int
ADXR(k): ADXR统计k个周期前数据,默认6
return
-------
P_DI:numpy.ndarray<numpy.float64>
+DI指标
M_DI:numpy.ndarray<numpy.float64>
-DI指标
ADX:numpy.ndarray<numpy.float64>
ADX指标
ADXR:numpy.ndarray<numpy.float64>
ADXR指标
ref.
-------
https://www.mk-mode.com/octopress/2012/03/03/03002038/
'''
# 上升动向(+DM)
P_DM = [0.]
# 下降动向(-DM)
M_DM = [0.]
# 真实波幅TR
TR = [0.]
# 动向
DX = [0.]
P_DI = [0.]
M_DI = [0.]
for index, row in data.iterrows():
if index == 0:
past_row = row
else:
p_dm = row["high"] - past_row["high"]
m_dm = past_row["low"] - row["low"]
if (p_dm < 0 and m_dm < 0) or (np.isclose(p_dm, m_dm)):
p_dm = 0
m_dm = 0
if p_dm > m_dm:
m_dm = 0
if m_dm > p_dm:
p_dm = 0
P_DM.append(p_dm)
M_DM.append(m_dm)
tr = max(row["high"] - past_row["low"], row["high"] - past_row["close"], past_row["close"] - row["low"])
TR.append(tr)
if len(P_DM) == n:
del P_DM[0]
if len(M_DM) == n:
del M_DM[0]
if len(TR) == n:
del TR[0]
# 上升方向线(+DI)
p_di = (np.average(P_DM) / np.average(TR)) * 100
P_DI.append(p_di)
# 下降方向线(-DI)
m_di = (np.average(M_DM) / np.average(TR)) * 100
M_DI.append(m_di)
# 当日+DI与-DI
# p_day_di = (p_dm / tr) * 100
# m_day_di = (m_dm / tr) * 100
# 动向DX
# dx=(di dif÷di sum) ×100
# di dif为上升指标和下降指标的价差的绝对值
# di sum为上升指标和下降指标的总和
# adx就是dx的一定周期n的移动平均值。
if (p_di + m_di) == 0:
dx = 0
else:
dx = (abs(p_di - m_di) / (p_di + m_di)) * 100
DX.append(dx)
past_row = row
ADX = _get_any_ma(DX, m)
#
# # 估计数值ADXR
ADXR = []
for index, adx in enumerate(ADX):
if index >= k:
adxr = (adx + ADX[index - k]) / 2
ADXR.append(adxr)
else:
ADXR.append(0)
return P_DI, M_DI, ADX, ADXR
def bias(data, n=5):
import numpy as np
'''
乖离率 bias
Parameters
------
data:pandas.DataFrame
通过 get_h_data 取得的股票数据
n:int
统计时长,默认5
return
-------
BIAS:numpy.ndarray<numpy.float64>
乖离率指标
'
gitextract_rwiezwpg/ ├── .gitignore ├── .travis.yml ├── LICENSE ├── MANIFEST ├── README.md ├── issues/ │ ├── from_email.txt │ └── from_sns.txt ├── requirements.txt ├── setup.py ├── test/ │ ├── __init__.py │ ├── bar_test.py │ ├── billboard_test.py │ ├── classifying_test.py │ ├── dateu_test.py │ ├── fund_test.py │ ├── indictor_test.py │ ├── macro_test.py │ ├── nav_test.py │ ├── news_test.py │ ├── ref_test.py │ ├── shibor_test.py │ ├── storing_test.py │ └── trading_test.py ├── test_unittest.py ├── tushare/ │ ├── VERSION.txt │ ├── __init__.py │ ├── bond/ │ │ ├── __init__.py │ │ └── bonds.py │ ├── coins/ │ │ ├── __init__.py │ │ └── market.py │ ├── data/ │ │ └── __init__.py │ ├── fund/ │ │ ├── __init__.py │ │ ├── cons.py │ │ └── nav.py │ ├── futures/ │ │ ├── __init__.py │ │ ├── cons.py │ │ ├── domestic.py │ │ ├── domestic_cons.py │ │ └── intlfutures.py │ ├── internet/ │ │ ├── __init__.py │ │ ├── boxoffice.py │ │ ├── caixinnews.py │ │ └── indexes.py │ ├── pro/ │ │ ├── __init__.py │ │ ├── client.py │ │ └── data_pro.py │ ├── stock/ │ │ ├── __init__.py │ │ ├── billboard.py │ │ ├── classifying.py │ │ ├── cons.py │ │ ├── fundamental.py │ │ ├── globals.py │ │ ├── indictor.py │ │ ├── macro.py │ │ ├── macro_vars.py │ │ ├── news_vars.py │ │ ├── newsevent.py │ │ ├── ref_vars.py │ │ ├── reference.py │ │ ├── shibor.py │ │ ├── trading.py │ │ └── trendline.py │ ├── trader/ │ │ ├── __init__.py │ │ ├── trader.py │ │ ├── utils.py │ │ └── vars.py │ └── util/ │ ├── __init__.py │ ├── common.py │ ├── conns.py │ ├── dateu.py │ ├── formula.py │ ├── mailmerge.py │ ├── netbase.py │ ├── store.py │ ├── upass.py │ └── vars.py └── whats_new.md
SYMBOL INDEX (476 symbols across 50 files)
FILE: setup.py
function read (line 6) | def read(fname):
function read_install_requires (line 65) | def read_install_requires():
FILE: test/bar_test.py
class Test (line 9) | class Test(unittest.TestCase):
method set_data (line 11) | def set_data(self):
method test_bar_data (line 16) | def test_bar_data(self):
FILE: test/billboard_test.py
class Test (line 9) | class Test(unittest.TestCase):
method set_data (line 11) | def set_data(self):
method test_top_list (line 15) | def test_top_list(self):
method test_cap_tops (line 19) | def test_cap_tops(self):
method test_broker_tops (line 23) | def test_broker_tops(self):
method test_inst_tops (line 27) | def test_inst_tops(self):
method test_inst_detail (line 31) | def test_inst_detail(self):
FILE: test/classifying_test.py
class Test (line 9) | class Test(unittest.TestCase):
method set_data (line 11) | def set_data(self):
method test_get_industry_classified (line 18) | def test_get_industry_classified(self):
method test_get_concept_classified (line 21) | def test_get_concept_classified(self):
method test_get_area_classified (line 24) | def test_get_area_classified(self):
method test_get_gem_classified (line 27) | def test_get_gem_classified(self):
method test_get_sme_classified (line 30) | def test_get_sme_classified(self):
method test_get_st_classified (line 33) | def test_get_st_classified(self):
method test_get_hs300s (line 36) | def test_get_hs300s(self):
method test_get_sz50s (line 39) | def test_get_sz50s(self):
method test_get_zz500s (line 42) | def test_get_zz500s(self):
FILE: test/dateu_test.py
class Test_Is_holiday (line 12) | class Test_Is_holiday(TestCase):
method test_is_holiday (line 13) | def test_is_holiday(self):
FILE: test/fund_test.py
class Test (line 6) | class Test(unittest.TestCase):
method set_data (line 8) | def set_data(self):
method test_get_stock_basics (line 15) | def test_get_stock_basics(self):
FILE: test/indictor_test.py
class Test (line 11) | class Test(unittest.TestCase):
method test_plot_all (line 13) | def test_plot_all(self):
FILE: test/macro_test.py
class Test (line 9) | class Test(unittest.TestCase):
method test_get_gdp_year (line 11) | def test_get_gdp_year(self):
method test_get_gdp_quarter (line 14) | def test_get_gdp_quarter(self):
method test_get_gdp_for (line 17) | def test_get_gdp_for(self):
method test_get_gdp_pull (line 20) | def test_get_gdp_pull(self):
method test_get_gdp_contrib (line 23) | def test_get_gdp_contrib(self):
method test_get_cpi (line 26) | def test_get_cpi(self):
method test_get_ppi (line 29) | def test_get_ppi(self):
method test_get_deposit_rate (line 32) | def test_get_deposit_rate(self):
method test_get_loan_rate (line 35) | def test_get_loan_rate(self):
method test_get_rrr (line 38) | def test_get_rrr(self):
method test_get_money_supply (line 41) | def test_get_money_supply(self):
method test_get_money_supply_bal (line 44) | def test_get_money_supply_bal(self):
FILE: test/nav_test.py
class Test (line 10) | class Test(unittest.TestCase):
method set_data (line 12) | def set_data(self):
method test_get_nav_open (line 18) | def test_get_nav_open(self):
method test_get_nav_close (line 28) | def test_get_nav_close(self):
method test_get_nav_grading (line 57) | def test_get_nav_grading(self):
method test_nav_history (line 79) | def test_nav_history(self):
method test_get_fund_info (line 91) | def test_get_fund_info(self):
FILE: test/news_test.py
class Test (line 9) | class Test(unittest.TestCase):
method set_data (line 11) | def set_data(self):
method test_get_latest_news (line 21) | def test_get_latest_news(self):
method test_get_notices (line 26) | def test_get_notices(self):
method test_guba_sina (line 32) | def test_guba_sina(self):
FILE: test/ref_test.py
class Test (line 9) | class Test(unittest.TestCase):
method set_data (line 11) | def set_data(self):
method test_profit_data (line 20) | def test_profit_data(self):
method test_forecast_data (line 24) | def test_forecast_data(self):
method test_xsg_data (line 28) | def test_xsg_data(self):
method test_fund_holdings (line 31) | def test_fund_holdings(self):
method test_new_stocksa (line 35) | def test_new_stocksa(self):
method test_sh_margin_details (line 39) | def test_sh_margin_details(self):
method test_sh_margins (line 43) | def test_sh_margins(self):
method test_sz_margins (line 47) | def test_sz_margins(self):
method test_sz_margin_details (line 51) | def test_sz_margin_details(self):
FILE: test/shibor_test.py
class Test (line 6) | class Test(unittest.TestCase):
method set_data (line 8) | def set_data(self):
method test_shibor_data (line 12) | def test_shibor_data(self):
method test_shibor_quote_data (line 16) | def test_shibor_quote_data(self):
method test_shibor_ma_data (line 20) | def test_shibor_ma_data(self):
method test_lpr_data (line 24) | def test_lpr_data(self):
method test_lpr_ma_data (line 28) | def test_lpr_ma_data(self):
FILE: test/storing_test.py
function csv (line 8) | def csv():
function xls (line 12) | def xls():
function hdf (line 17) | def hdf():
function json (line 25) | def json():
function appends (line 32) | def appends():
function db (line 41) | def db():
function nosql (line 49) | def nosql():
FILE: test/trading_test.py
class Test (line 9) | class Test(unittest.TestCase):
method set_data (line 11) | def set_data(self):
method test_get_hist_data (line 18) | def test_get_hist_data(self):
method test_get_tick_data (line 22) | def test_get_tick_data(self):
method test_get_today_all (line 26) | def test_get_today_all(self):
method test_get_realtime_quotesa (line 29) | def test_get_realtime_quotesa(self):
method test_get_h_data (line 33) | def test_get_h_data(self):
method test_get_today_ticks (line 37) | def test_get_today_ticks(self):
FILE: test_unittest.py
class TestTrading (line 8) | class TestTrading(unittest.TestCase):
method set_data (line 10) | def set_data(self):
method test_tickData (line 15) | def test_tickData(self):
FILE: tushare/bond/bonds.py
function get_bond_info (line 11) | def get_bond_info(code):
FILE: tushare/coins/market.py
function coins_tick (line 86) | def coins_tick(broker='hb', code='btc'):
function coins_bar (line 152) | def coins_bar(broker='hb', code='btc', ktype='D', size='2000'):
function coins_snapshot (line 184) | def coins_snapshot(broker='hb', code='btc', size='5'):
function coins_trade (line 216) | def coins_trade(broker='hb', code='btc'):
function _get_data (line 252) | def _get_data(url):
function int2time (line 264) | def int2time(timestamp):
FILE: tushare/fund/cons.py
function _write_head (line 125) | def _write_head():
function _write_console (line 130) | def _write_console():
function _write_tips (line 135) | def _write_tips(tip):
function _write_msg (line 140) | def _write_msg(msg):
function _check_nav_oft_input (line 145) | def _check_nav_oft_input(found_type):
function _check_input (line 152) | def _check_input(year, quarter):
FILE: tushare/fund/nav.py
function get_nav_open (line 25) | def get_nav_open(fund_type='all'):
function get_nav_close (line 79) | def get_nav_close(fund_type='all', sub_type='all'):
function get_nav_grading (line 139) | def get_nav_grading(fund_type='all', sub_type='all'):
function get_nav_history (line 193) | def get_nav_history(code, start=None, end=None, retry_count=3, pause=0.0...
function get_fund_info (line 236) | def get_fund_info(code):
function _parse_fund_data (line 281) | def _parse_fund_data(url, fund_type='open'):
function _get_fund_num (line 310) | def _get_fund_num(url):
function _get_nav_histroy_num (line 335) | def _get_nav_histroy_num(code, start, end, ismonetary=False):
function _parse_nav_history_data (line 366) | def _parse_nav_history_data(code, start, end, nums, ismonetary=False, re...
FILE: tushare/futures/domestic.py
function get_cffex_daily (line 26) | def get_cffex_daily(date = None):
function get_czce_daily (line 89) | def get_czce_daily(date=None, type="future"):
function get_shfe_vwap (line 183) | def get_shfe_vwap(date = None):
function get_shfe_daily (line 218) | def get_shfe_daily(date = None):
function get_dce_daily (line 270) | def get_dce_daily(date = None, type="future", retries=0):
function get_future_daily (line 401) | def get_future_daily(start = None, end = None, market = 'CFFEX'):
FILE: tushare/futures/domestic_cons.py
function convert_date (line 37) | def convert_date(date):
FILE: tushare/futures/intlfutures.py
function get_intlfuture (line 22) | def get_intlfuture(symbols=None):
function _get_data (line 29) | def _get_data(url):
function _random (line 47) | def _random(n=13):
FILE: tushare/internet/boxoffice.py
function realtime_boxoffice (line 19) | def realtime_boxoffice(retry_count=3,pause=0.001):
function day_boxoffice (line 58) | def day_boxoffice(date=None, retry_count=3, pause=0.001):
function month_boxoffice (line 104) | def month_boxoffice(date=None, retry_count=3, pause=0.001):
function day_cinema (line 151) | def day_cinema(date=None, retry_count=3, pause=0.001):
function _day_cinema (line 187) | def _day_cinema(date=None, pNo=1, retry_count=3, pause=0.001):
function _random (line 206) | def _random(n=13):
FILE: tushare/internet/caixinnews.py
function read_url (line 45) | def read_url(url):
function get_soup (line 59) | def get_soup(url):
function query_news (line 69) | def query_news(keywords='*',start_date=None,end_date=None):
function is_blog (line 102) | def is_blog(url):
function read_page (line 114) | def read_page(url):
function read_normal_artical (line 130) | def read_normal_artical(url):
function read_blog (line 139) | def read_blog(url):
FILE: tushare/internet/indexes.py
function bdi (line 23) | def bdi(itype='D', retry_count=3,
FILE: tushare/pro/client.py
class DataApi (line 17) | class DataApi:
method __init__ (line 22) | def __init__(self, token, timeout=10):
method query (line 32) | def query(self, api_name, fields='', **kwargs):
method __getattr__ (line 50) | def __getattr__(self, name):
FILE: tushare/pro/data_pro.py
function pro_api (line 21) | def pro_api(token=''):
function pro_bar (line 34) | def pro_bar(ts_code='', pro_api=None, start_date=None, end_date=None, fr...
FILE: tushare/stock/billboard.py
function top_list (line 28) | def top_list(date = None, retry_count=3, pause=0.001):
function cap_tops (line 98) | def cap_tops(days= 5, retry_count= 3, pause= 0.001):
function _cap_tops (line 132) | def _cap_tops(last=5, pageNo=1, retry_count=3, pause=0.001, dataArr=pd.D...
function broker_tops (line 162) | def broker_tops(days= 5, retry_count= 3, pause= 0.001):
function _broker_tops (line 190) | def _broker_tops(last=5, pageNo=1, retry_count=3, pause=0.001, dataArr=p...
function inst_tops (line 220) | def inst_tops(days= 5, retry_count= 3, pause= 0.001):
function _inst_tops (line 250) | def _inst_tops(last=5, pageNo=1, retry_count=3, pause=0.001, dataArr=pd....
function inst_detail (line 281) | def inst_detail(retry_count= 3, pause= 0.001):
function _inst_detail (line 308) | def _inst_detail(pageNo=1, retry_count=3, pause=0.001, dataArr=pd.DataFr...
function _f_rows (line 338) | def _f_rows(x):
FILE: tushare/stock/classifying.py
function get_industry_classified (line 27) | def get_industry_classified(standard='sina'):
function get_concept_classified (line 62) | def get_concept_classified():
function concetps (line 77) | def concetps():
function get_concepts (line 93) | def get_concepts(src='dfcf'):
function get_area_classified (line 118) | def get_area_classified():
function get_gem_classified (line 135) | def get_gem_classified():
function get_sme_classified (line 152) | def get_sme_classified():
function get_st_classified (line 168) | def get_st_classified():
function _get_detail (line 185) | def _get_detail(tag, retry_count=3, pause=0.001):
function _get_type_data (line 219) | def _get_type_data(url):
function get_hs300s (line 233) | def get_hs300s():
function get_sz50s (line 254) | def get_sz50s():
function get_zz500s (line 274) | def get_zz500s():
function get_terminated (line 295) | def get_terminated():
function get_suspended (line 323) | def get_suspended():
function _random (line 352) | def _random(n=13):
FILE: tushare/stock/cons.py
function _write_head (line 359) | def _write_head():
function _write_console (line 363) | def _write_console():
function _write_tips (line 367) | def _write_tips(tip):
function _write_msg (line 371) | def _write_msg(msg):
function _check_input (line 375) | def _check_input(year, quarter):
function _check_lhb_input (line 383) | def _check_lhb_input(last):
function _market_code (line 391) | def _market_code(code):
function _idx_market_code (line 400) | def _idx_market_code(code):
function _code_to_symbol (line 409) | def _code_to_symbol(code):
function _code_to_symbol_dgt (line 424) | def _code_to_symbol_dgt(code):
function _get_server (line 437) | def _get_server():
function _get_xserver (line 443) | def _get_xserver():
function _get_xxserver (line 449) | def _get_xxserver():
FILE: tushare/stock/fundamental.py
function get_stock_basics (line 22) | def get_stock_basics(date=None):
function get_report_data (line 62) | def get_report_data(year, quarter):
function _get_report_data (line 95) | def _get_report_data(year, quarter, pageNo, dataArr,
function get_profit_data (line 129) | def get_profit_data(year, quarter):
function _get_profit_data (line 160) | def _get_profit_data(year, quarter, pageNo, dataArr,
function get_operation_data (line 194) | def get_operation_data(year, quarter):
function _get_operation_data (line 224) | def _get_operation_data(year, quarter, pageNo, dataArr,
function get_growth_data (line 258) | def get_growth_data(year, quarter):
function _get_growth_data (line 288) | def _get_growth_data(year, quarter, pageNo, dataArr,
function get_debtpaying_data (line 322) | def get_debtpaying_data(year, quarter):
function _get_debtpaying_data (line 352) | def _get_debtpaying_data(year, quarter, pageNo, dataArr,
function get_cashflow_data (line 385) | def get_cashflow_data(year, quarter):
function _get_cashflow_data (line 414) | def _get_cashflow_data(year, quarter, pageNo, dataArr,
function _data_path (line 448) | def _data_path():
function get_balance_sheet (line 456) | def get_balance_sheet(code):
function get_profit_statement (line 477) | def get_profit_statement(code):
function get_cash_flow (line 499) | def get_cash_flow(code):
FILE: tushare/stock/globals.py
function global_realtime (line 19) | def global_realtime(symbols=None):
FILE: tushare/stock/indictor.py
function ma (line 12) | def ma(data, n=10, val_name="close"):
function md (line 45) | def md(data, n=10, val_name="close"):
function _get_day_ema (line 78) | def _get_day_ema(prices, n):
function ema (line 88) | def ema(data, n=12, val_name="close"):
function macd (line 125) | def macd(data, quick_n=12, slow_n=26, dem_n=9, val_name="close"):
function kdj (line 161) | def kdj(data):
function rsi (line 203) | def rsi(data, n=6, val_name="close"):
function boll (line 250) | def boll(data, n=10, val_name="close", k=2):
function wnr (line 280) | def wnr(data, n=14):
function _get_any_ma (line 316) | def _get_any_ma(arr, n):
function dmi (line 328) | def dmi(data, n=14, m=14, k=6):
function bias (line 439) | def bias(data, n=5):
function asi (line 462) | def asi(data, n=5):
function vr (line 517) | def vr(data, n=26):
function arbr (line 566) | def arbr(data, n=26):
function dpo (line 623) | def dpo(data, n=20, m=6):
function trix (line 649) | def trix(data, n=12, m=20):
function bbi (line 695) | def bbi(data):
function mtm (line 725) | def mtm(data, n=6):
function obv (line 754) | def obv(data):
function sar (line 775) | def sar(data, n=4):
function plot_all (line 779) | def plot_all(data, is_show=True, output=None):
FILE: tushare/stock/macro.py
function get_gdp_year (line 23) | def get_gdp_year():
function get_gdp_quarter (line 58) | def get_gdp_quarter():
function get_gdp_for (line 92) | def get_gdp_for():
function get_gdp_pull (line 122) | def get_gdp_pull():
function get_gdp_contrib (line 151) | def get_gdp_contrib():
function get_cpi (line 179) | def get_cpi():
function get_ppi (line 204) | def get_ppi():
function get_deposit_rate (line 241) | def get_deposit_rate():
function get_loan_rate (line 268) | def get_loan_rate():
function get_rrr (line 295) | def get_rrr():
function get_money_supply (line 323) | def get_money_supply():
function get_money_supply_bal (line 364) | def get_money_supply_bal():
function get_gold_and_foreign_reserves (line 397) | def get_gold_and_foreign_reserves():
FILE: tushare/stock/macro_vars.py
function random (line 21) | def random(n=13):
FILE: tushare/stock/newsevent.py
function get_latest_news (line 26) | def get_latest_news(top=None, show_content=False):
function latest_content (line 71) | def latest_content(url):
function get_notices (line 97) | def get_notices(code=None, date=None):
function notice_content (line 132) | def notice_content(url):
function guba_sina (line 151) | def guba_sina(show_content=False):
function _guba_content (line 195) | def _guba_content(url):
function _random (line 215) | def _random(n=16):
FILE: tushare/stock/reference.py
function profit_data (line 28) | def profit_data(year=2017, top=25,
function _fun_divi (line 77) | def _fun_divi(x):
function _fun_into (line 93) | def _fun_into(x):
function _dist_cotent (line 118) | def _dist_cotent(year, pageNo, retry_count, pause):
function profit_divis (line 156) | def profit_divis():
function _profit_divis (line 184) | def _profit_divis(pageNo, dataArr, nextPage):
function forecast_data (line 205) | def forecast_data(year, quarter):
function _get_forecast_data (line 233) | def _get_forecast_data(year, quarter, pageNo, dataArr):
function xsg_data (line 263) | def xsg_data(year=None, month=None,
function fund_holdings (line 314) | def fund_holdings(year, quarter,
function _holding_cotent (line 354) | def _holding_cotent(start, end, pageNo, retry_count, pause):
function new_stocks (line 394) | def new_stocks(retry_count=3, pause=0.001):
function _newstocks (line 427) | def _newstocks(data, pageNo, retry_count, pause):
function new_cbonds (line 462) | def new_cbonds(default=1, retry_count=3, pause=0.001):
function _newcbonds (line 506) | def _newcbonds(pageNo, retry_count, pause):
function sh_margins (line 538) | def sh_margins(start=None, end=None, retry_count=3, pause=0.001):
function _sh_hz (line 576) | def _sh_hz(data, start=None, end=None,
function sh_margin_details (line 619) | def sh_margin_details(date='', symbol='',
function _sh_mx (line 666) | def _sh_mx(data, date='', start='', end='',
function sz_margins (line 713) | def sz_margins(start=None, end=None, retry_count=3, pause=0.001):
function _sz_hz (line 759) | def _sz_hz(date='', retry_count=3, pause=0.001):
function sz_margin_details (line 779) | def sz_margin_details(date='', retry_count=3, pause=0.001):
function top10_holders (line 823) | def top10_holders(code=None, year=None, quarter=None, gdtype='0',
function moneyflow_hsgt (line 874) | def moneyflow_hsgt():
function margin_detail (line 902) | def margin_detail(date=''):
function margin_target (line 931) | def margin_target(date=''):
function margin_offset (line 954) | def margin_offset(date):
function stock_pledged (line 975) | def stock_pledged():
function pledged_detail (line 995) | def pledged_detail():
function margin_zsl (line 1019) | def margin_zsl(date='', broker=''):
function stock_issuance (line 1050) | def stock_issuance(start_date='', end_date=''):
function _random (line 1085) | def _random(n=13):
FILE: tushare/stock/shibor.py
function shibor_data (line 16) | def shibor_data(year=None):
function shibor_quote_data (line 55) | def shibor_quote_data(year=None):
function shibor_ma_data (line 105) | def shibor_ma_data(year=None):
function lpr_data (line 138) | def lpr_data(year=None):
function lpr_ma_data (line 171) | def lpr_ma_data(year=None):
FILE: tushare/stock/trading.py
function get_hist_data (line 32) | def get_hist_data(code=None, start=None, end=None,
function _parsing_dayprice_json (line 103) | def _parsing_dayprice_json(types=None, page=1):
function get_tick_data (line 135) | def get_tick_data(code=None, date=None, retry_count=3, pause=0.001,
function get_sina_dd (line 190) | def get_sina_dd(code=None, date=None, vol=400, retry_count=3, pause=0.001):
function get_today_ticks (line 232) | def get_today_ticks(code=None, retry_count=3, pause=0.001):
function _today_ticks (line 278) | def _today_ticks(symbol, tdate, pageNo, retry_count, pause):
function get_today_all (line 305) | def get_today_all():
function get_realtime_quotes (line 324) | def get_realtime_quotes(symbols=None):
function get_h_data (line 397) | def get_h_data(code, start=None, end=None, autype='qfq',
function _parase_fq_factor (line 512) | def _parase_fq_factor(code, start, end):
function _fun_except (line 535) | def _fun_except(x):
function _parse_fq_data (line 542) | def _parse_fq_data(url, index, retry_count, pause):
function get_index (line 578) | def get_index():
function _get_index_url (line 614) | def _get_index_url(index, code, qt):
function get_k_data (line 624) | def get_k_data(code=None, start='', end='',
function _get_k_data (line 710) | def _get_k_data(url, dataflag='',
function get_hists (line 750) | def get_hists(symbols, start=None, end=None,
function get_day_all (line 769) | def get_day_all(date=None):
function get_dt_time (line 801) | def get_dt_time(t):
function bar2h5 (line 807) | def bar2h5(market='', date='', freq='D', asset='E', filepath=''):
function bar (line 900) | def bar(code, conn=None, start_date=None, end_date=None, freq='D', asset...
function _get_mkcode (line 1040) | def _get_mkcode(code='', asset='E', xapi=None):
function tick (line 1056) | def tick(code, conn=None, date='', asset='E', market='', retry_count = 3):
function quotes (line 1142) | def quotes(symbols, conn=None, asset='E', market=[], retry_count = 3):
function get_security (line 1197) | def get_security(api):
function reset_instrument (line 1211) | def reset_instrument(xapi=None):
function get_instrument (line 1229) | def get_instrument(xapi=None):
function get_markets (line 1248) | def get_markets(xapi=None):
function factor_adj (line 1260) | def factor_adj(code):
function factor_shares (line 1267) | def factor_shares(code):
function _random (line 1274) | def _random(n=13):
FILE: tushare/stock/trendline.py
function ma (line 17) | def ma(df, n=10):
function _ma (line 28) | def _ma(series, n):
function md (line 35) | def md(df, n=10):
function _md (line 46) | def _md(series, n):
function ema (line 53) | def ema(df, n=12):
function _ema (line 65) | def _ema(series, n):
function macd (line 72) | def macd(df, n=12, m=26, k=9):
function kdj (line 92) | def kdj(df, n=9):
function rsi (line 109) | def rsi(df, n=6):
function vrsi (line 130) | def vrsi(df, n=6):
function boll (line 143) | def boll(df, n=26, k=2):
function bbiboll (line 159) | def bbiboll(df, n=10, k=3):
function wr (line 177) | def wr(df, n=14):
function bias (line 190) | def bias(df, n=12):
function asi (line 203) | def asi(df, n=5):
function vr_rate (line 224) | def vr_rate(df, n=26):
function vr (line 246) | def vr(df, n=5):
function arbr (line 261) | def arbr(df, n=26):
function dpo (line 276) | def dpo(df, n=20, m=6):
function trix (line 289) | def trix(df, n=12, m=20):
function bbi (line 304) | def bbi(df):
function mtm (line 315) | def mtm(df, n=6, m=5):
function obv (line 329) | def obv(df):
function cci (line 353) | def cci(df, n=14):
function priceosc (line 368) | def priceosc(df, n=12, m=26):
function sma (line 380) | def sma(a, n, m=1):
function dbcd (line 412) | def dbcd(df, n=5, m=16, t=76):
function roc (line 430) | def roc(df, n=12, m=6):
function vroc (line 445) | def vroc(df, n=12):
function cr (line 456) | def cr(df, n=26):
function psy (line 471) | def psy(df, n=12):
function wad (line 486) | def wad(df, n=30):
function mfi (line 517) | def mfi(df, n=14):
function pvt (line 540) | def pvt(df):
function wvad (line 554) | def wvad(df, n=24, m=6):
function cdp (line 568) | def cdp(df):
function env (line 588) | def env(df, n=14):
function mike (line 601) | def mike(df, n=12):
function vma (line 628) | def vma(df, n=5):
function vmacd (line 639) | def vmacd(df, qn=12, sn=26, m=9):
function vosc (line 655) | def vosc(df, n=12, m=26):
function tapi (line 666) | def tapi(df, n=6):
function vstd (line 678) | def vstd(df, n=10):
function adtm (line 689) | def adtm(df, n=23, m=8):
function mi (line 719) | def mi(df, n=12):
function micd (line 731) | def micd(df, n=3, m=10, k=20):
function rc (line 747) | def rc(df, n=50):
function rccd (line 760) | def rccd(df, n=59, m=21, k=28):
function srmi (line 777) | def srmi(df, n=9):
function dptb (line 794) | def dptb(df, n=7):
function jdqs (line 814) | def jdqs(df, n=20):
function jdrs (line 836) | def jdrs(df, n=20):
function zdzb (line 858) | def zdzb(df, n=125, m=5, k=20):
function atr (line 877) | def atr(df, n=14):
function mass (line 892) | def mass(df, n=9, m=25):
function vhf (line 908) | def vhf(df, n=28):
function cvlt (line 919) | def cvlt(df, n=10):
function up_n (line 931) | def up_n(df):
function down_n (line 954) | def down_n(df):
function join_frame (line 976) | def join_frame(d1, d2, column='date'):
FILE: tushare/trader/trader.py
class TraderAPI (line 20) | class TraderAPI(object):
method __init__ (line 27) | def __init__(self, broker = ''):
method login (line 44) | def login(self):
method _login (line 56) | def _login(self, v_code):
method keepalive (line 78) | def keepalive(self):
method send_heartbeat (line 85) | def send_heartbeat(self):
method heartbeat (line 98) | def heartbeat(self):
method exit (line 102) | def exit(self):
method buy (line 106) | def buy(self, stkcode, price=0, count=0, amount=0):
method sell (line 122) | def sell(self, stkcode, price=0, count=0, amount=0):
method _trading (line 138) | def _trading(self, stkcode, price, count, amount, tradeflag, tradetype):
method position (line 176) | def position(self):
method _get_position (line 192) | def _get_position(self):
method entrust_list (line 202) | def entrust_list(self):
method deal_list (line 228) | def deal_list(self, begin=None, end=None):
method cancel (line 267) | def cancel(self, ordersno='', orderdate=''):
method baseinfo (line 292) | def baseinfo(self):
method _get_baseinfo (line 309) | def _get_baseinfo(self):
method check_login_status (line 318) | def check_login_status(self, return_data):
class NotLoginError (line 323) | class NotLoginError(Exception):
method __init__ (line 324) | def __init__(self, result=None):
method heartbeat (line 327) | def heartbeat(self):
FILE: tushare/trader/utils.py
function nowtime_str (line 16) | def nowtime_str():
function get_jdata (line 20) | def get_jdata(txtdata):
function get_vcode (line 28) | def get_vcode(broker, res):
FILE: tushare/util/common.py
class Client (line 18) | class Client:
method __init__ (line 20) | def __init__(self , token):
method __del__ (line 25) | def __del__( self ):
method encodepath (line 30) | def encodepath(self, path):
method init (line 64) | def init(self, token):
method getData (line 68) | def getData(self, path):
FILE: tushare/util/conns.py
function api (line 14) | def api(retry_count=3):
function xapi (line 26) | def xapi(retry_count=3):
function xapi_x (line 38) | def xapi_x(retry_count=3):
function get_apis (line 50) | def get_apis():
function close_apis (line 54) | def close_apis(conn):
FILE: tushare/util/dateu.py
function year_qua (line 8) | def year_qua(date):
function _quar (line 14) | def _quar(mon):
function today (line 27) | def today():
function get_year (line 32) | def get_year():
function get_month (line 37) | def get_month():
function get_hour (line 41) | def get_hour():
function today_last_year (line 45) | def today_last_year():
function day_last_week (line 50) | def day_last_week(days=-7):
function get_now (line 55) | def get_now():
function int2time (line 59) | def int2time(timestamp):
function diff_day (line 65) | def diff_day(start=None, end=None):
function get_quarts (line 72) | def get_quarts(start, end):
function trade_cal (line 78) | def trade_cal():
function is_holiday (line 87) | def is_holiday(date):
function last_tddate (line 102) | def last_tddate():
function tt_dates (line 111) | def tt_dates(start='', end=''):
function _random (line 118) | def _random(n=13):
function get_q_date (line 124) | def get_q_date(year=None, quarter=None):
FILE: tushare/util/formula.py
function EMA (line 8) | def EMA(DF, N):
function MA (line 12) | def MA(DF, N):
function SMA (line 16) | def SMA(DF, N, M):
function ATR (line 28) | def ATR(DF, N):
function HHV (line 37) | def HHV(DF, N):
function LLV (line 41) | def LLV(DF, N):
function SUM (line 45) | def SUM(DF, N):
function ABS (line 49) | def ABS(DF):
function MAX (line 53) | def MAX(A, B):
function MIN (line 58) | def MIN(A, B):
function IF (line 63) | def IF(COND, V1, V2):
function REF (line 70) | def REF(DF, N):
function STD (line 76) | def STD(DF, N):
function MACD (line 80) | def MACD(DF, FAST, SLOW, MID):
function KDJ (line 91) | def KDJ(DF, N, M1, M2):
function OSC (line 104) | def OSC(DF, N, M): # 变动速率线
function BBI (line 113) | def BBI(DF, N1, N2, N3, N4): # 多空指标
function BBIBOLL (line 121) | def BBIBOLL(DF, N1, N2, N3, N4, N, M): # 多空布林线
function PBX (line 130) | def PBX(DF, N1, N2, N3, N4, N5, N6): # 瀑布线
function BOLL (line 144) | def BOLL(DF, N): # 布林线
function ROC (line 154) | def ROC(DF, N, M): # 变动率指标
function MTM (line 163) | def MTM(DF, N, M): # 动量线
function MFI (line 172) | def MFI(DF, N): # 资金指标
function SKDJ (line 186) | def SKDJ(DF, N, M):
function WR (line 198) | def WR(DF, N, N1): # 威廉指标
function BIAS (line 209) | def BIAS(DF, N1, N2, N3): # 乖离率
function RSI (line 219) | def RSI(DF, N1, N2, N3): # 相对强弱指标RSI1:SMA(MAX(CLOSE-LC,0),N1,1)/SMA(ABS...
function ADTM (line 230) | def ADTM(DF, N, M): # 动态买卖气指标
function DDI (line 247) | def DDI(DF, N, N1, M, M1): # 方向标准离差指数
FILE: tushare/util/mailmerge.py
class MailMerge (line 22) | class MailMerge(object):
method __init__ (line 23) | def __init__(self, file, remove_empty_tables=False):
method __get_tree_of_file (line 90) | def __get_tree_of_file(self, file):
method write (line 95) | def write(self, file):
method get_merge_fields (line 112) | def get_merge_fields(self, parts=None):
method merge_pages (line 121) | def merge_pages(self, replacements):
method merge (line 152) | def merge(self, parts=None, **replacements):
method __merge_field (line 163) | def __merge_field(self, part, field, text):
method merge_rows (line 194) | def merge_rows(self, anchor, rows):
method __find_row_anchor (line 210) | def __find_row_anchor(self, field, parts=None):
FILE: tushare/util/netbase.py
class Client (line 9) | class Client(object):
method __init__ (line 10) | def __init__(self, url=None, ref=None, cookie=None):
method _setOpener (line 16) | def _setOpener(self):
method gvalue (line 26) | def gvalue(self):
FILE: tushare/util/store.py
class Store (line 14) | class Store(object):
method __init__ (line 16) | def __init__(self, data=None, name=None, path=None):
method save_as (line 24) | def save_as(self, name, path, to='csv'):
FILE: tushare/util/upass.py
function set_token (line 16) | def set_token(token):
function get_token (line 23) | def get_token():
function set_broker (line 34) | def set_broker(broker='', user='', passwd=''):
function get_broker (line 48) | def get_broker(broker=''):
function remove_broker (line 59) | def remove_broker():
Condensed preview — 77 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (481K chars).
[
{
"path": ".gitignore",
"chars": 848,
"preview": "# Byte-compiled / optimized / DLL files\n*.log\n*.swp\n*.pdb\n.project\n.pydevproject\n.settings\n__pycache__/\n*.py[cod]\n\n# C e"
},
{
"path": ".travis.yml",
"chars": 965,
"preview": "language: python\n\npython:\n # We don't actually use the Travis Python, but this keeps it organized.\n - \"2.7\"\n # \"3.3\"\n"
},
{
"path": "LICENSE",
"chars": 1469,
"preview": "Copyright (c) 2015, 挖地兔\nAll rights reserved.\n\nRedistribution and use in source and binary forms, with or without\nmodific"
},
{
"path": "MANIFEST",
"chars": 233,
"preview": "# file GENERATED by distutils, do NOT edit\nsetup.py\ntest\\test.py\ntushare\\__init__.py\ntushare\\data\\__init__.py\ntushare\\da"
},
{
"path": "README.md",
"chars": 9874,
"preview": "TuShare\r\n\r\n\r\nTushare Pro版已发布,请访问新的官网了解和查询数据接口! [https://tushare.pro](https://tushare.pro)\r\n\r\nTuShare是实现对股票/期货等金融数据从**数据采"
},
{
"path": "issues/from_email.txt",
"chars": 698,
"preview": "2015-2-10\r\n------------\r\nASK:Stupidinsect:ϣӻ\r\nREP:\r\n\r\n2015-2-26\r\n------------\r\nASK:Allisnoneproblem with python keywords"
},
{
"path": "issues/from_sns.txt",
"chars": 1221,
"preview": "2015-02-12\n-----------\nQQȺ297882961kݸȨ۵⡢ݲ\n\n2015-03-01\n-----------\nQQȺ275882700@ kߴ⣬ȷʵǷ˲ƾԴ⣨ɸget_h_data()ӿڣ\n\n2015-03-02\n--"
},
{
"path": "requirements.txt",
"chars": 93,
"preview": "pandas>=0.18.0\nrequests>=2.0.0\nlxml>=3.8.0\nsimplejson>=3.16.0\nbs4>=0.0.1\nbeautfulsoup4>=4.5.1"
},
{
"path": "setup.py",
"chars": 2947,
"preview": "from setuptools import setup, find_packages\r\nimport codecs\r\nimport os\r\n\r\n\r\ndef read(fname):\r\n return codecs.open(os.p"
},
{
"path": "test/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "test/bar_test.py",
"chars": 477,
"preview": "# -*- coding:utf-8 -*- \n'''\nCreated on 2017/9/24\n@author: Jimmy Liu\n'''\nimport unittest\nimport tushare.stock.trading as "
},
{
"path": "test/billboard_test.py",
"chars": 811,
"preview": "# -*- coding:utf-8 -*- \r\n'''\r\nCreated on 2015/3/14\r\n@author: Jimmy Liu\r\n'''\r\nimport unittest\r\nimport tushare.stock.billb"
},
{
"path": "test/classifying_test.py",
"chars": 1288,
"preview": "# -*- coding:utf-8 -*- \n'''\nCreated on 2015/3/14\n@author: Jimmy Liu\n'''\nimport unittest\nimport tushare.stock.classifying"
},
{
"path": "test/dateu_test.py",
"chars": 538,
"preview": "# -*- coding:utf-8 -*-\n\"\"\"\n@author: ZackZK\n\"\"\"\n\nfrom unittest import TestCase\n\nfrom tushare.util import dateu\nfrom tusha"
},
{
"path": "test/fund_test.py",
"chars": 1232,
"preview": "# -*- coding:utf-8 -*- \n\nimport unittest\nimport tushare.stock.fundamental as fd\n\nclass Test(unittest.TestCase):\n\n def"
},
{
"path": "test/indictor_test.py",
"chars": 505,
"preview": "# -*- coding:utf-8 -*- \n'''\nCreated on 2018/05/26\n@author: Jackie Liao\n'''\nimport unittest\nimport tushare.stock.indictor"
},
{
"path": "test/macro_test.py",
"chars": 1185,
"preview": "# -*- coding:utf-8 -*- \n'''\nCreated on 2015/3/14\n@author: Jimmy Liu\n'''\nimport unittest\nimport tushare.stock.macro as fd"
},
{
"path": "test/nav_test.py",
"chars": 3849,
"preview": "# -*- coding:utf-8 -*-\n'''\nCreated on 2016/5/26\n@author: leo\n'''\nimport unittest\nimport tushare.fund.nav as nav\n\n\nclass "
},
{
"path": "test/news_test.py",
"chars": 864,
"preview": "# -*- coding:utf-8 -*- \n'''\nCreated on 2015/3/14\n@author: Jimmy Liu\n'''\nimport unittest\nimport tushare.stock.newsevent a"
},
{
"path": "test/ref_test.py",
"chars": 1507,
"preview": "# -*- coding:utf-8 -*- \r\n'''\r\nCreated on 2015/3/14\r\n@author: Jimmy Liu\r\n'''\r\nimport unittest\r\nfrom tushare.stock import "
},
{
"path": "test/shibor_test.py",
"chars": 762,
"preview": "# -*- coding:utf-8 -*- \r\n\r\nimport unittest\r\nimport tushare.stock.shibor as fd\r\n\r\nclass Test(unittest.TestCase):\r\n\r\n d"
},
{
"path": "test/storing_test.py",
"chars": 1709,
"preview": "# -*- coding:utf-8 -*- \n\nimport os\nfrom sqlalchemy import create_engine\nfrom pandas.io.pytables import HDFStore\nimport t"
},
{
"path": "test/trading_test.py",
"chars": 1105,
"preview": "# -*- coding:utf-8 -*- \n'''\nCreated on 2015/3/14\n@author: Jimmy Liu\n'''\nimport unittest\nimport tushare.stock.trading as "
},
{
"path": "test_unittest.py",
"chars": 597,
"preview": "'''\nUnitTest for API\n@author: Jimmy\n'''\nimport unittest\nimport tushare.stock.trading as td\n\nclass TestTrading(unittest.T"
},
{
"path": "tushare/VERSION.txt",
"chars": 6,
"preview": "1.2.18"
},
{
"path": "tushare/__init__.py",
"chars": 4601,
"preview": "# -*- coding:utf-8 -*- \r\nimport codecs\r\nimport os\r\n\r\n__version__ = codecs.open(os.path.join(os.path.dirname(__file__), '"
},
{
"path": "tushare/bond/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "tushare/bond/bonds.py",
"chars": 200,
"preview": "# -*- coding:utf-8 -*- \n\"\"\"\n投资参考数据接口 \nCreated on 2017/10/01\n@author: Jimmy Liu\n@group : waditu\n@contact: jimmysoa@sina.c"
},
{
"path": "tushare/coins/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "tushare/coins/market.py",
"chars": 7800,
"preview": "#!/usr/bin/env python\n# -*- coding:utf-8 -*- \n\"\"\"\n数字货币行情数据\nCreated on 2017年9月9日\n@author: Jimmy Liu\n@group : waditu\n@cont"
},
{
"path": "tushare/data/__init__.py",
"chars": 21,
"preview": "__version__ = \"0.0.1\""
},
{
"path": "tushare/fund/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "tushare/fund/cons.py",
"chars": 5494,
"preview": "# -*- coding:utf-8 -*-\n\"\"\"\nCreated on 2016/04/03\n@author: Leo\n@group : lazytech\n@contact: lazytech@sina.cn\n\"\"\"\n\nVERSION "
},
{
"path": "tushare/fund/nav.py",
"chars": 13015,
"preview": "# -*- coding:utf-8 -*-\n\n\"\"\"\n获取基金净值数据接口 \nCreated on 2016/04/03\n@author: leo\n@group : lazytech\n@contact: lazytech@sina.cn\n"
},
{
"path": "tushare/futures/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "tushare/futures/cons.py",
"chars": 775,
"preview": "#!/usr/bin/env python\n# -*- coding:utf-8 -*- \n\n'''\nCreated on 2016年10月17日\n@author: Jimmy Liu\n@group : waditu\n@contact: j"
},
{
"path": "tushare/futures/domestic.py",
"chars": 16013,
"preview": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n'''\nCreated on 2017年06月04日\n@author: debugo\n@contact: me@debugo.com\n'''\n\nimp"
},
{
"path": "tushare/futures/domestic_cons.py",
"chars": 4940,
"preview": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n'''\nCreated on 2017年06月04日\n@author: debugo\n@contact: me@debugo.com\n'''\nimpo"
},
{
"path": "tushare/futures/intlfutures.py",
"chars": 1371,
"preview": "# -*- coding:utf-8 -*-\n\n\"\"\"\n国际期货\nCreated on 2016/10/01\n@author: Jimmy Liu\n@group : waditu\n@contact: jimmysoa@sina.cn\n\"\"\""
},
{
"path": "tushare/internet/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "tushare/internet/boxoffice.py",
"chars": 6291,
"preview": "# -*- coding:utf-8 -*- \n\"\"\"\n电影票房 \nCreated on 2015/12/24\n@author: Jimmy Liu\n@group : waditu\n@contact: jimmysoa@sina.cn\n\"\""
},
{
"path": "tushare/internet/caixinnews.py",
"chars": 3733,
"preview": "# -*- coding:utf-8 -*- \n\"\"\"\n财新网新闻数据检索下载\nCreated on 2017/06/09\n@author: Yuan Yifan\n@group : ~\n@contact: tsingjyujing@163"
},
{
"path": "tushare/internet/indexes.py",
"chars": 3366,
"preview": "#!/usr/bin/env python\n# -*- coding:utf-8 -*- \n\"\"\"\n龙虎榜数据\nCreated on 2017年8月13日\n@author: Jimmy Liu\n@group : waditu\n@contac"
},
{
"path": "tushare/pro/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "tushare/pro/client.py",
"chars": 1150,
"preview": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\nPro数据接口 \nCreated on 2017/07/01\n@author: polo,Jimmy\n@group : tushare."
},
{
"path": "tushare/pro/data_pro.py",
"chars": 7391,
"preview": "# -*- coding:utf-8 -*- \n\"\"\"\npro init \nCreated on 2018/07/01\n@author: Jimmy Liu\n@group : tushare.pro\n@contact: jimmysoa@s"
},
{
"path": "tushare/stock/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "tushare/stock/billboard.py",
"chars": 11174,
"preview": "#!/usr/bin/env python\n# -*- coding:utf-8 -*- \n\"\"\"\n龙虎榜数据\nCreated on 2015年6月10日\n@author: Jimmy Liu\n@group : waditu\n@contac"
},
{
"path": "tushare/stock/classifying.py",
"chars": 10083,
"preview": "# -*- coding:utf-8 -*-\r\n\r\n\"\"\"\r\n获取股票分类数据接口 \r\nCreated on 2015/02/01\r\n@author: Jimmy Liu\r\n@group : waditu\r\n@contact: jimmys"
},
{
"path": "tushare/stock/cons.py",
"chars": 31653,
"preview": "# -*- coding:utf-8 -*-\r\n'''\r\nCreated on 2014/07/31\r\n@author: Jimmy Liu\r\n@group : waditu\r\n@contact: jimmysoa@sina.cn\r\n'''"
},
{
"path": "tushare/stock/fundamental.py",
"chars": 17373,
"preview": "# -*- coding:utf-8 -*- \r\n\"\"\"\r\n基本面数据接口 \r\nCreated on 2015/01/18\r\n@author: Jimmy Liu\r\n@group : waditu\r\n@contact: jimmysoa@s"
},
{
"path": "tushare/stock/globals.py",
"chars": 2041,
"preview": "#!/usr/bin/env python\n# -*- coding:utf-8 -*- \n\n'''\n全球市场\nCreated on 2016/11/27\n@author: Jimmy Liu\n@group : waditu\n@contac"
},
{
"path": "tushare/stock/indictor.py",
"chars": 22817,
"preview": "# -*- coding:utf-8 -*-\n\n\"\"\"\n股票技术指标接口\nCreated on 2018/05/26\n@author: Jackie Liao\n@group : **\n@contact: info@liaocy.net\n\"\""
},
{
"path": "tushare/stock/macro.py",
"chars": 12009,
"preview": "# -*- coding:utf-8 -*- \n\n\"\"\"\n宏观经济数据接口 \nCreated on 2015/01/24\n@author: Jimmy Liu\n@group : waditu\n@contact: jimmysoa@sina."
},
{
"path": "tushare/stock/macro_vars.py",
"chars": 1429,
"preview": "# -*- coding:utf-8 -*- \n\nP_TYPE = {'http':'http://','ftp':'ftp://'}\nDOMAINS = {'sina':'sina.com.cn','sinahq':'sinajs.cn'"
},
{
"path": "tushare/stock/news_vars.py",
"chars": 445,
"preview": "# -*- coding:utf-8 -*- \n\nLATEST_URL = '%sroll.news.%s/interface/%s?col=43&spec=&type=&ch=03&k=&offset_page=0&offset_num="
},
{
"path": "tushare/stock/newsevent.py",
"chars": 6334,
"preview": "# -*- coding:utf-8 -*-\n\n\"\"\"\n新闻事件数据接口 \nCreated on 2015/02/07\n@author: Jimmy Liu\n@group : waditu\n@contact: jimmysoa@sina.c"
},
{
"path": "tushare/stock/ref_vars.py",
"chars": 4449,
"preview": "# -*- coding:utf-8 -*- \r\n\r\nDP_URL = '%sapp.finance.%s/data/stock/%s?day=&page=%s'\r\nDP_163_URL = '%squotes.%s/data/caibao"
},
{
"path": "tushare/stock/reference.py",
"chars": 34549,
"preview": "# -*- coding:utf-8 -*- \r\n\"\"\"\r\n投资参考数据接口 \r\nCreated on 2015/03/21\r\n@author: Jimmy Liu\r\n@group : waditu\r\n@contact: jimmysoa@"
},
{
"path": "tushare/stock/shibor.py",
"chars": 5661,
"preview": "# -*- coding:utf-8 -*-\n\"\"\"\n上海银行间同业拆放利率(Shibor)数据接口\nCreated on 2014/07/31\n@author: Jimmy Liu\n@group : waditu\n@contact: ji"
},
{
"path": "tushare/stock/trading.py",
"chars": 48824,
"preview": "# -*- coding:utf-8 -*- \r\n\"\"\"\r\n交易数据接口 \r\nCreated on 2014/07/31\r\n@author: Jimmy Liu\r\n@group : waditu\r\n@contact: jimmysoa@si"
},
{
"path": "tushare/stock/trendline.py",
"chars": 28313,
"preview": "# -*- coding:utf-8 -*-\n\n\"\"\"\n股票技术指标接口\nCreated on 2018/07/26\n@author: Wangzili\n@group : **\n@contact: 446406177@qq.com\n\n所有指"
},
{
"path": "tushare/trader/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "tushare/trader/trader.py",
"chars": 10228,
"preview": "#!/usr/bin/env python\n# -*- coding:utf-8 -*- \n\n'''\nCreated on 2016年9月25日\n@author: Jimmy Liu\n@group : waditu\n@contact: ji"
},
{
"path": "tushare/trader/utils.py",
"chars": 710,
"preview": "#!/usr/bin/env python\n# -*- coding:utf-8 -*- \n\n'''\nCreated on 2016年10月1日\n@author: Jimmy Liu\n@group : waditu\n@contact: ji"
},
{
"path": "tushare/trader/vars.py",
"chars": 1738,
"preview": "# -*- coding:utf-8 -*-\n\"\"\"\nCreated on 2016/09/31\n@author: Jimmy Liu\n@group : waditu\n@contact: jimmysoa@sina.cn\n\"\"\"\n\nP_TY"
},
{
"path": "tushare/util/__init__.py",
"chars": 0,
"preview": ""
},
{
"path": "tushare/util/common.py",
"chars": 2490,
"preview": "#!/usr/bin/env python\n# -*- coding:utf-8 -*- \n\"\"\"\nCreated on 2015年7月31日\n@author: Jimmy Liu\n@group: DataYes Data.dept\n@QQ"
},
{
"path": "tushare/util/conns.py",
"chars": 1348,
"preview": "# -*- coding:utf-8 -*- \n\"\"\"\nconnection for api \nCreated on 2017/09/23\n@author: Jimmy Liu\n@group : waditu\n@contact: jimmy"
},
{
"path": "tushare/util/dateu.py",
"chars": 2885,
"preview": "# -*- coding:utf-8 -*-\r\n\r\nimport datetime\r\nimport time\r\nimport pandas as pd\r\nfrom tushare.stock import cons as ct\r\n\r\ndef"
},
{
"path": "tushare/util/formula.py",
"chars": 6484,
"preview": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport numpy as np\nimport pandas as pd\n\n\ndef EMA(DF, N):\n return pd.Series"
},
{
"path": "tushare/util/mailmerge.py",
"chars": 8762,
"preview": "from copy import deepcopy\nimport re\nfrom lxml.etree import Element\nfrom lxml import etree\nfrom zipfile import ZipFile, Z"
},
{
"path": "tushare/util/netbase.py",
"chars": 914,
"preview": "# -*- coding:utf-8 -*- \n\ntry:\n from urllib.request import urlopen, Request\nexcept ImportError:\n from urllib2 impor"
},
{
"path": "tushare/util/store.py",
"chars": 1124,
"preview": "# -*- coding:utf-8 -*-\n\"\"\"\nCreated on 2015/02/04\n@author: Jimmy Liu\n@group : waditu\n@contact: jimmysoa@sina.cn\n\"\"\"\nimpor"
},
{
"path": "tushare/util/upass.py",
"chars": 1453,
"preview": "# -*- coding:utf-8 -*- \n\n\"\"\"\nCreated on 2015/08/24\n@author: Jimmy Liu\n@group : waditu\n@contact: jimmysoa@sina.cn\n\"\"\"\n\nim"
},
{
"path": "tushare/util/vars.py",
"chars": 69349,
"preview": "# -*- coding:utf-8 -*- \nimport sys\nPY3 = (sys.version_info[0] >= 3)\nHTTP_OK = 200\nHTTP_AUTHORIZATION_ERROR = 401\nHTTP_UR"
},
{
"path": "whats_new.md",
"chars": 1592,
"preview": "0.4.5\n-------\n\r\n- get_today_all接口增加实时PE、PB和流通市值等\n- 修改财务数据问题\r\n- get_h_data前复权数据bug修复(白天获取)\n\n0.4.2\n--------\n\n- 新增电影票房数据\r\n-"
}
]
About this extraction
This page contains the full source code of the waditu/tushare GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 77 files (446.5 KB), approximately 146.6k tokens, and a symbol index with 476 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.