Repository: wangrongding/wechat-bot
Branch: main
Commit: 4b3255278c2c
Files: 39
Total size: 51.1 KB
Directory structure:
gitextract_28865r5d/
├── .dockerignore
├── .gitignore
├── .husky/
│ └── pre-commit
├── .npmrc
├── .prettierrc.cjs
├── .vscode/
│ └── settings.json
├── Dockerfile
├── Dockerfile.alpine
├── LICENSE.md
├── README.md
├── RECORD.md
├── cli.js
├── package.json
└── src/
├── 302ai/
│ ├── __test__.js
│ └── index.js
├── chatgpt/
│ └── index.js
├── claude/
│ └── index.js
├── deepseek/
│ ├── __test__.js
│ └── index.js
├── deepseek-free/
│ ├── __test__.js
│ └── index.js
├── dify/
│ ├── __test__.js
│ └── index.js
├── doubao/
│ ├── __test__.js
│ └── index.js
├── index.js
├── kimi/
│ ├── __test__.js
│ └── index.js
├── ollama/
│ ├── __test__.js
│ └── index.js
├── openai/
│ ├── __test__.js
│ └── index.js
├── tongyi/
│ └── index.js
├── wechaty/
│ ├── sendMessage.js
│ ├── serve.js
│ └── testMessage.js
└── xunfei/
├── __test__.js
├── index.js
└── xunfei.js
================================================
FILE CONTENTS
================================================
================================================
FILE: .dockerignore
================================================
node_modules/
================================================
FILE: .gitignore
================================================
node_modules
WechatEveryDay.memory-card.json
.env
test.js
package-lock.json
yarn.lock
Chromium.app
.DS_Store
.idea
================================================
FILE: .husky/pre-commit
================================================
npx lint-staged
================================================
FILE: .npmrc
================================================
# puppeteer_download_host=https://registry.npmmirror.com/-/binary/
================================================
FILE: .prettierrc.cjs
================================================
/**
* 参考 https://prettier.io/docs/en/options.html
*/
module.exports = {
tabWidth: 2, // 空格数
useTabs: false, // 是否开启tab
printWidth: 150, // 换行的宽度
semi: false, // 是否在语句末尾打印分号
singleQuote: true, // 是否使用单引号
quoteProps: 'as-needed', // 对象的key仅在需要时用引号 as-needed|consistent|preserve
trailingComma: 'all', // 多行时尽可能打印尾随逗号 |all|es5|none
rangeStart: 0, // 每个文件格式化的范围是文件的全部内容
bracketSpacing: true, // 对象文字中的括号之间打印空格
jsxSingleQuote: true, // 在JSX中是否使用单引号
bracketSameLine: false, // 将HTML元素的闭括号放在最后一行的末尾(不适用于自闭合元素)。
arrowParens: 'always', // 箭头函数,只有一个参数的时候,也需要括号 always|avoid
htmlWhitespaceSensitivity: 'ignore', // html中换行规则 css|strict|ignore,strict会强制在标签周围添加空格
vueIndentScriptAndStyle: false, // vue中script与style里的第一条语句是否空格
singleAttributePerLine: false, // 每行强制单个属性
endOfLine: 'lf', // 换行符
proseWrap: 'never', // 当超出print width时就折行 always|never|preserve .md文件?
embeddedLanguageFormatting: 'auto',
}
================================================
FILE: .vscode/settings.json
================================================
{
"cSpell.words": ["kimi", "xunfei"]
}
================================================
FILE: Dockerfile
================================================
ARG APT_SOURCE="default"
FROM node:19 as builder-default
ENV NPM_REGISTRY="https://registry.npmjs.org"
FROM node:19 as builder-aliyun
ENV NPM_REGISTRY="https://registry.npmmirror.com"
RUN sed -i s/deb.debian.org/mirrors.aliyun.com/g /etc/apt/sources.list \
&& ln -sf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime && echo 'Asia/Shanghai' >/etc/timezone
FROM builder-${APT_SOURCE} AS builder
# Instal the 'apt-utils' package to solve the error 'debconf: delaying package configuration, since apt-utils is not installed'
# https://peteris.rocks/blog/quiet-and-unattended-installation-with-apt-get/
RUN apt-get update \
&& apt-get install -y --no-install-recommends \
apt-utils \
autoconf \
automake \
bash \
build-essential \
ca-certificates \
chromium \
coreutils \
curl \
ffmpeg \
figlet \
git \
gnupg2 \
jq \
libgconf-2-4 \
libtool \
libxtst6 \
moreutils \
python-dev \
shellcheck \
sudo \
tzdata \
vim \
wget \
&& apt-get purge --auto-remove \
&& rm -rf /tmp/* /var/lib/apt/lists/*
FROM builder
ENV CHROME_BIN="/usr/bin/chromium" \
PUPPETEER_SKIP_CHROMIUM_DOWNLOAD="true"
RUN mkdir -p /app
WORKDIR /app
COPY package.json ./
RUN npm config set registry ${NPM_REGISTRY} && npm i
COPY *.js ./
COPY src/ ./src/
CMD ["npm", "run", "dev"]
================================================
FILE: Dockerfile.alpine
================================================
ARG APT_SOURCE="default"
FROM node:19-alpine as base
RUN apk update && \
apk upgrade && \
apk add --no-cache bash \
ca-certificates \
chromium-chromedriver \
chromium \
coreutils \
curl \
ffmpeg \
figlet \
jq \
moreutils \
ttf-freefont \
udev \
vim \
xauth \
xvfb \
&& rm -rf /tmp/* /var/cache/apk/*
FROM base as builder-default
ENV NPM_REGISTRY="https://registry.npmjs.org"
FROM base as builder-aliyun
ENV NPM_REGISTRY="https://registry.npmmirror.com"
FROM builder-${APT_SOURCE}
ENV CHROME_BIN="/usr/bin/chromium-browser" \
PUPPETEER_SKIP_CHROMIUM_DOWNLOAD="true"
RUN mkdir -p /app
WORKDIR /app
COPY package.json ./
RUN npm config set registry ${NPM_REGISTRY} && npm i
COPY *.js ./
COPY src/ ./src/
CMD ["npm", "run", "dev"]
================================================
FILE: LICENSE.md
================================================
MIT License
Copyright (c) 2020-present, 荣顶 and wechat-bot contributors
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
================================================
FILE: README.md
================================================
# WeChat Bot
一个 基于 `chatgpt` + `wechaty` 的微信机器人
可以用来帮助你自动回复微信消息,或者管理微信群/好友.
`简单`,`好用`,`2分钟(4 个步骤)` 就能玩起来了。🌸 如果对您有所帮助,请点个 Star ⭐️ 支持一下。
<div align='center'>
<a href="https://trendshift.io/repositories/11077" target="_blank"><img src="https://trendshift.io/api/badge/repositories/11077" alt="wangrongding%2Fwechat-bot | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a>
</div>
## 贡献者们
<a href="https://github.com/wangrongding/wechat-bot/graphs/contributors">
<img src="https://contrib.rocks/image?repo=wangrongding/wechat-bot&columns=20" />
</a>
欢迎大家提交 PR 接入更多的 ai 服务(比如扣子等...),积极贡献更好的功能实现,让 wechat-bot 变得更强!
## 注意:最近微信对此审查变得非常严格,使用默认的协议有微信警告或者封号的风险,请大家谨慎使用,关于 padlocal ,这个协议的作者没有继续维护,大家可以自行切换更稳定的协议。

## 使用前需要配置的 AI 服务(目前支持 9 种,可任选其一)
- deepseek
获取自己的 `api key`,地址戳这里 👉🏻 :[deepseek 开放平台](https://platform.deepseek.com/usage)
将获取到的`api key`填入 `.evn` 文件中的 `DEEPSEEK_FREE_TOKEN` 中。
- ChatGPT
先获取自己的 `api key`,地址戳这里 👉🏻 :[创建你的 api key](https://platform.openai.com/settings/organization/api-keys)
**注意:这个是需要去付费购买的,很多人过来问为什么请求不通,请确保终端走了代理,并且付费购买了它的服务**
```sh
# 执行下面命令,拷贝一份 .env.example 文件为 .env
cp .env.example .env
# 填写完善 .env 文件中的内容
OPENAI_API_KEY='你的key'
```
- 豆包
豆包最新的Doubao-Seed-1.6模型,支持输入图片和深度思考,而且每个模型都有 50 万的免费tokens。在火山引擎注册登录账号,可以选择最新的Doubao-Seed-1.6-thinking模型,选择“API接入” -> “获取 API Key”。
```sh
# 拷贝 .env.example 文件为 .env
cp .env.example .env
# 修改 .env 文件中的内容
DOUBAO_API_KEY='你的key'
# 简单测试API是否可用
node src/doubao/__test__.js
```
- 通义千问
通义千问是阿里云提供的 AI 服务,获取到你的 api key 之后, 填写到 .env 文件中即可
```sh
# 执行下面命令,拷贝一份 .env.example 文件为 .env
cp .env.example .env
# 填写完善 .env 文件中的内容
# 通义千问, URL 包含 uri 路径
TONGYI_URL = "https://dashscope.aliyuncs.com/compatible-mode/v1"
# 通义千问的 API_KEY
TONGYI_API_KEY = ''
# 通义千问使用的模型
TONGYI_MODEL='qwen-plus'
```
- 科大讯飞
新增科大讯飞,去这里申请一个 key:[科大讯飞](https://console.xfyun.cn/services/bm35),每个模型都有 200 万的免费 token ,感觉很难用完。
注意: 讯飞的配置文件几个 key,别填反了,很多人找到我说为什么不回复,都是填反了。
而且还有一个好处就是,接口不会像 Kimi 一样限制请求频次,相对来说稳定很多。
服务出错可参考: [issues/170](https://github.com/wangrongding/wechat-bot/issues/170), [issues/180](https://github.com/wangrongding/wechat-bot/issues/180)
- Kimi (请求限制较严重)
可以去 : [kimi apikey](https://platform.moonshot.cn/console/api-keys) 获取你的 key
最近比较忙,大家感兴趣可以提交 PR,我会尽快合并。目前 Kimi 刚刚集成,还可以实现上传文件等功能,然后有其它较好的服务也可以提交 PR 。
- dify
地址:[dify](https://dify.ai/), 创建你的应用之后, 获取到你的 api key 之后, 填写到 .env 文件中即可, 也支持私有化部署dify版本
```sh
# 执行下面命令,拷贝一份 .env.example 文件为 .env
cp .env.example .env
# 填写完善 .env 文件中的内容
DIFY_API_KEY='你的key'
# 如果需要私有化部署,请修改.env中下面的配置
# DIFY_URL='https://[你的私有化部署地址]'
```
- ollama
Ollama 是一个本地化的 AI 服务,它的 API 与 OpenAI 非常接近。配置 Ollama 的过程与各种在线服务略有不同
```sh
# 执行下面命令,拷贝一份 .env.example 文件为 .env
cp .env.example .env
# 填写完善 .env 文件中的内容
OLLAMA_URL='http://127.0.0.1:11434/api/chat'
OLLAMA_MODEL='qwen2.5:7b'
OLLAMA_SYSTEM_MESSAGE='You are a personal assistant.'
```
- 302.AI
AI聚合平台,有套壳GPT的API,也有其他模型,点这里可以[添加API](https://dash.302.ai/apis/list),添加之后把API KEY配置到.env里,如下,MODEL可以自行选择配置
```
_302AI_API_KEY = 'xxxx'
_302AI_MODEL= 'gpt-4o-mini'
```
由于openai充值需要国外信用卡,流程比较繁琐,大多需要搞国外虚拟卡,手续费也都不少,该平台可以直接支付宝,算是比较省事的,注册填问卷可领1刀额度,后续充值也有手续费,用户可自行酌情选择。
- claude
前往 [官网](https://console.anthropic.com) 注册并获取API KEY后进行配置即可
```bash
# 执行下面命令,拷贝一份 .env.example 文件为 .env,如果已存在则忽略此步
cp .env.example .env
# 编辑.env文件并添加claude相关配置
CLAUDE_API_VERSION = '2023-06-01'
CLAUDE_API_KEY = '你的API KEY'
CLAUDE_MODEL = 'claude-3-5-sonnet-latest'
# 系统人设
CLAUDE_SYSTEM = ''
```
- 其他
(待实践)理论上使用 openAI 格式的 api,都可以使用,在 env 文件中修改对应的 api_key、model、proxy_url 即可。
## API资源/平台收录
- [gpt4free](https://github.com/xtekky/gpt4free)
- [chatanywhere](https://github.com/chatanywhere/GPT_API_free)
## 赞助商
<div align="center">
<table>
<!-- Header -->
<tr>
<td align="center" width="50%">
<p align="center">
<a href="https://91api.dev/register?aff=9P6u" target="_blank">
<img src="./sponsors/91api.jpg" alt="91Api" width="300px"/>
</a>
</p>
</td>
<td align="center" width="50%">
<p align="center">
<a href="https://www.compshare.cn/model-api?ytag=GPU_YY-gh_wechatbot" target="_blank">
<img src="./sponsors/Ucloud.png" alt="UCloud" width="300px"/>
</a>
</p>
</td>
</tr>
<!-- Description -->
<tr>
<td align="left">
一站式集成 500+主流大模型中转聚合API平台,高效稳定,高并发,价格超低
<a href="https://91api.dev/register?aff=9P6u" target="_blank">产品链接</a>
</td>
<td align="left">
万卡RTX40系GPU+海内外主流模型API服务,秒级响应,按量计费,新客免费用。
<a href="https://www.compshare.cn/model-api?ytag=GPU_YY-gh_wechatbot" target="_blank">产品链接</a>
</td>
</tr>
</table>
</div>
目前该项目流量较大,已经上过 27 次 [Github Trending 榜](https://github.com/trending),如果您的公司或者产品需要推广,可以在下方二维码处联系我,我会在项目中加入您的广告,帮助您的产品获得更多的曝光。
## 开发/使用
检查好自己的开发环境,确保已经安装了 `nodejs` , 版本需要满足 Node.js >= v18.0 ,版本太低会导致运行报错,最好使用 LTS 版本。
1. 安装依赖
> 安装依赖时,大陆的朋友推荐切到 taobao 镜像源后再安装,命令:
> `npm config set registry https://registry.npmmirror.com`
> 想要灵活切换,推荐使用我的工具 👉🏻 [prm-cli](https://github.com/wangrongding/prm-cli) 快速切换。
```sh
# 安装依赖
npm i
# 推荐用 yarn 吧,npm 安装有时会遇到 wechaty 内部依赖安装失败的问题
yarn
```
2. 运行服务
```sh
# 启动服务
npm run dev # 或者 npm run start
# 启动服务
yarn dev # 或者 yarn start
```
然后就可以扫码登录了,然后根据你的需求,自己修改相关逻辑文件。
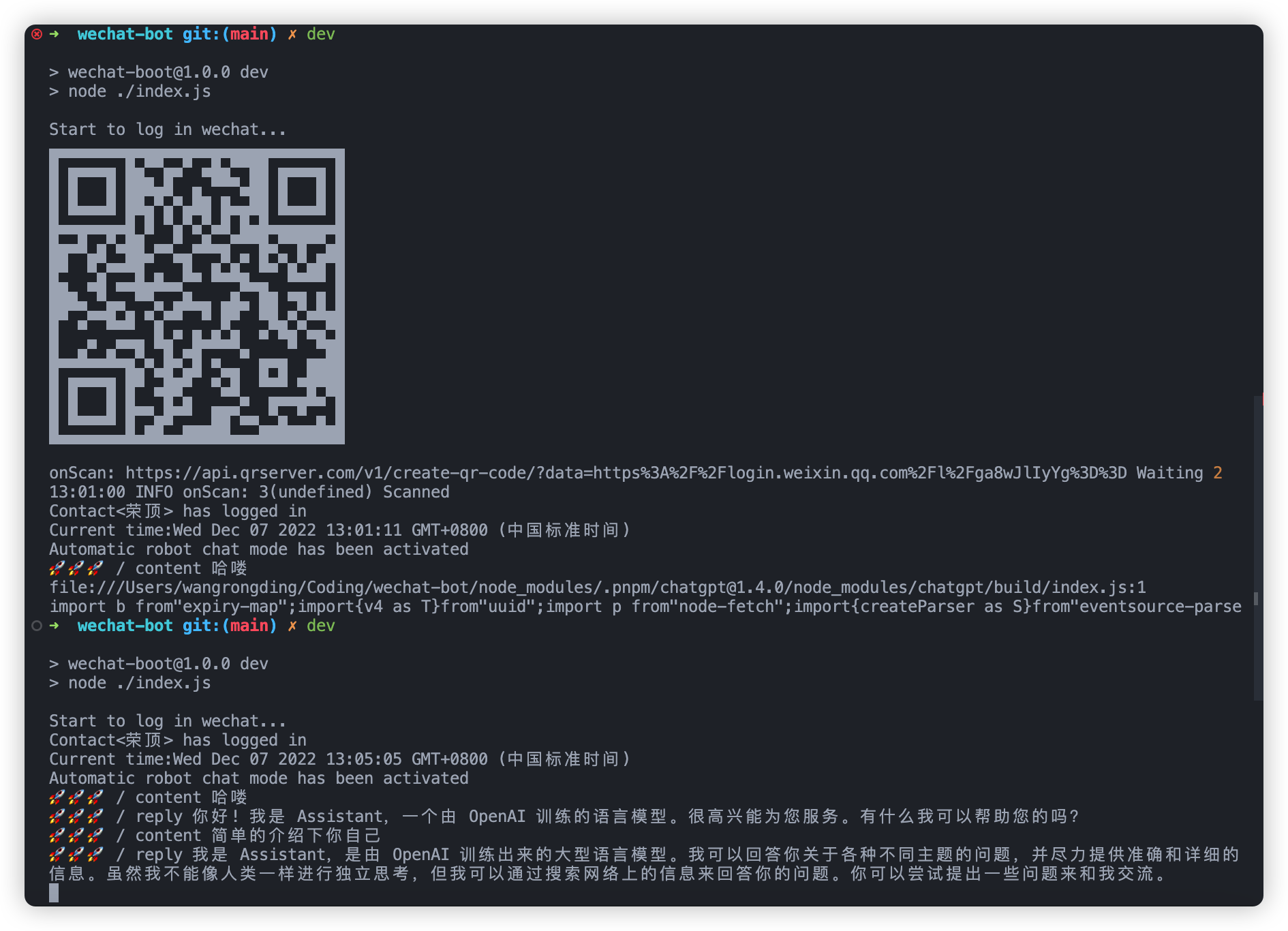
为了兼容 docker 部署,避免不必要的选择交互,新增指定服务运行
```sh
# 运行指定服务 ( 目前支持 ChatGPT | Kimi | Xunfei )
npm run start -- --serve Kimi
# 交互选择服务,仍然保持原有的逻辑
npm run start
```
3. 测试
安装完依赖后,运行 `npm run dev` 前,可以先测试下 openai 的接口是否可用,运行 `npm run test` 即可。
遇到 timeout 问题需要自行用魔法解决。(一般就是代理未成功,或者你的魔法服务限制了 openai api 的服务)
## 你要修改的
很多人说运行后不会自动收发信息,不是的哈,为了防止给每一条收到的消息都自动回复(太恐怖了),所以加了限制条件。
你要把下面提到的地方自定义修改下。
- 群聊,记得把机器人名称改成你自己微信号的名称,然后添加对应群聊的名称到白名单中,这样就可以自动回复群聊消息了。
- 私聊,记得把需要自动回复的好友名称添加到白名单中,这样就可以自动回复私聊消息了。
- 更深入的可以通过修改 `src/wechaty/sendMessage.js` 文件来满足你自己的业务场景。(大多人反馈可能无法自动回复,也可以通过调试这个文件来排查具体原因)
在.env 文件中修改你的配置即可,示例如下
```sh
# 白名单配置
#定义机器人的名称,这里是为了防止群聊消息太多,所以只有艾特机器人才会回复,
#这里不要把@去掉,在@后面加上你启动机器人账号的微信名称
BOT_NAME=@可乐
#联系人白名单
ALIAS_WHITELIST=微信名1,备注名2
#群聊白名单
ROOM_WHITELIST=XX群1,群2
#自动回复前缀匹配,文本消息匹配到指定前缀时,才会触发自动回复,不配或配空串情况下该配置不生效(适用于用大号,不期望每次被@或者私聊时都触发自动回复的人群)
#匹配规则:群聊消息去掉${BOT_NAME}并trim后进行前缀匹配,私聊消息trim后直接进行前缀匹配
AUTO_REPLY_PREFIX=''
```
可以看到,自动回复都是基于 `chatgpt` 的,记得要开代理,或者填写代理地址。

## 注意项
近期微信审查很严格,大量用户反映弹出外挂警告,由于项目内默认使用的是免费版的 web 协议,所以目前来说很容易会被微信检测到,建议使用 pad 协议,或者自行购买企业版协议,避免被封号。
修改可参考: https://github.com/wangrongding/wechat-bot/pull/263/files
自行购买 pad 协议渠道(wechaty 出的,购买仍需谨慎):http://pad-local.com
由于底层依赖的 wechaty 本身不怎么维护了,听说是被腾讯告了,所以大家购买也要谨慎,群友分享目前 pad 协议可正常使用(但频繁登录登出也会收到警告),最好别一次性买太久的。
## 常见问题
以下是我的微信和群二维码,添加的时候记得备注清楚来意。
希望可以一起交流探讨相关问题和解决方案。
| <img src="https://github.com/user-attachments/assets/902b1a20-0ea0-4348-9ac1-b9eb6645223c" width="180px"> | <img src="https://raw.githubusercontent.com/wangrongding/image-house/master/WechatIMG173.jpg" width="180px"> |
| --- | --- |
### 运行报错等问题
首先你需要做到以下几点:
- 拉取最新代码,重新安装依赖(删除 lock 文件,删除 node_modules)
- 安装依赖时最好不要设置 npm 镜像
- 遇到 puppeteer 安装失败设置环境变量:
```
# Mac
export PUPPETEER_SKIP_DOWNLOAD='true'
# Windows
SET PUPPETEER_SKIP_DOWNLOAD='true'
```
- 确保你们的终端走了代理 (开全局代理,或者手动设置终端走代理)
```sh
# 设置代理
export https_proxy=http://127.0.0.1:你的代理服务端口号;export http_proxy=http://127.0.0.1:你的代理服务端口号;export all_proxy=socks5://127.0.0.1:你的代理服务端口号
# 然后再执行 npm run test
npm run test
```

- 确保你的 openai key 有余额
- 配置好 .env 文件
- 执行 npm run test 能成功拿到 openai 的回复(设置完代理后,仍然请求不通? 可以参考: https://medium.com/@chanter2d/%E5%85%B3%E4%BA%8E%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8clash%E5%AE%9E%E7%8E%B0%E7%9C%9F%E6%AD%A3%E7%9A%84%E5%85%A8%E5%B1%80%E4%BB%A3%E7%90%86-385b2d745871)
- 执行 npm run dev 愉快的玩耍吧~ 🎉
也可以参考这条 [issue](https://github.com/wangrongding/wechat-bot/issues/54#issuecomment-1347880291)
- 怎么玩? 完成自定义修改后,群聊时,在白名单中的群,有人 @你 时会触发自动回复,私聊中,联系人白名单中的人发消息给你时会触发自动回复。
- 运行报错?检查 node 版本是否符合,如果不符合,升级 node 版本即可,检查依赖是否安装完整,如果不完整,大陆推荐切换下 npm 镜像源,然后重新安装依赖即可。(可以用我的 [prm-cli](https://github.com/wangrongding/prm-cli) 工具快速切换)
- 调整对话模式?可以修改[openai/index.js](./src/openai/index.js) ,具体可以根据官方文档给出的示例(非常多,自己对应调整参数即可) :https://beta.openai.com/examples
## 使用 Docker 部署
```sh
$ docker build . -t wechat-bot
$ docker run -d --rm --name wechat-bot -v $(pwd)/.env:/app/.env wechat-bot
```
- 如果docker build过程中node反复下载超时,可先下载nodejs镜像到本地镜像库,并将DockerFile中的'node:19'修改为本地nodejs镜像版本
## Star History Chart
该项目于 2023/2/13 日成为 Github Trending 榜首。
[](https://star-history.com/#wangrongding/wechat-bot&Date)
## License
[MIT](./LICENSE).
================================================
FILE: RECORD.md
================================================
# 使用最近很火的 OpenAi ChatGPT 配合 Wechaty 实现一个 微信聊天機器人
## 前言
使用 OpenAi ChatGPT 和 Wechaty 可以实现一个微信聊天机器人。OpenAi ChatGPT 是一个大型语言模型,能够模拟人类聊天对话,并回答用户的问题。Wechaty 是一个 Node.js 库,可以让开发者轻松地接入微信并实现聊天机器人功能。
首先,需要安装 Node.js 和 npm(Node.js 包管理器)。安装完成后,使用 npm 安装 Wechaty 和 OpenAi ChatGPT。
## 什么是 OpenAi ChatGPT
OpenAI ChatGPT 是一个语言模型,由 OpenAI 开发。它是基于 GPT-3(Generative Pretrained Transformer-3)架构的,用于对话和聊天的自然语言处理(NLP)任务。它的目的是通过模仿人类的语言方式来生成文本。
与其他语言模型不同,OpenAI ChatGPT 可以记忆之前的对话内容,并根据上下文和预先学习的知识来生成自然的回复。它可以用于支持机器人,聊天机器人和其他应用程序,以提供更加人性化和自然的对话体验。
OpenAI ChatGPT 模型使用了大量的语料数据进行预训练,并通过机器学习算法来优化其生成文本的能力。它具有出色的自然语言理解能力,可以模拟人类的语言特征,如句子结构、语法和修辞手法。
总的来说,OpenAI ChatGPT 是一个非常强大的语言模型,可以用于实现多种 NLP 应用程序,以提高对话和聊天的自然语言处理能力。
## 什么是 Wechaty
## 一些相关链接
- [OpenAI ChatGPT](https://openai.com/blog/chatting/)
- [Wechaty](https://wechaty.js.org/)
- [Wechaty Chatbot](https://wechaty.js.org/docs/examples/chatbot/)
- [Wechaty Chatbot Tutorial](https://wechaty.js.org/docs/tutorials/chatbot-tutorial/)
- https://openai.com/blog/chatgpt/
- https://download-chromium.appspot.com/?platform=Mac_Arm&type=snapshots
- https://registry.npmmirror.com/binary.html?path=chromium-browser-snapshots/Mac_Arm/
================================================
FILE: cli.js
================================================
#! /usr/bin/env node
'use strict'
import('./src/index.js')
================================================
FILE: package.json
================================================
{
"name": "wechat-bot",
"version": "1.0.2",
"description": "wechat-bot",
"main": "index.js",
"type": "module",
"scripts": {
"dev": "node ./cli.js",
"format": "prettier --write ./src",
"start": "node ./cli.js",
"test": "node ./src/wechaty/testMessage.js",
"test-openai": "node ./src/openai/__test__.js",
"test-xunfei": "node ./src/xunfei/__test__.js",
"test-kimi": "node ./src/kimi/__test__.js",
"test-dify": "node ./src/dify/__test__.js",
"prepare": "husky"
},
"lint-staged": {
"*.{js,ts,md}": [
"prettier --write"
]
},
"files": [
"src",
"./.env.example",
"./cli.js",
"./Dockerfile",
"./Dockerfile.alpine",
"./LICENSE.md",
"./README.md",
"./RECORD.md"
],
"bin": {
"wb": "./cli.js",
"wechat-bot": "./cli.js"
},
"homepage": "https://github.com/wangrongding/wechat-bot/",
"repository": {
"type": "git",
"url": "https://github.com/wangrongding/wechat-bot.git"
},
"author": "荣顶",
"license": "ISC",
"dependencies": {
"axios": "^1.6.8",
"chatgpt": "^2.5.2",
"commander": "^12.0.0",
"crypto-js": "^4.2.0",
"dotenv": "^16.4.5",
"inquirer": "^9.2.16",
"openai": "^4.52.0",
"p-timeout": "^6.0.0",
"qrcode-terminal": "^0.12.0",
"remark": "^14.0.2",
"strip-markdown": "^5.0.0",
"wechaty": "^1.20.2",
"wechaty-puppet-wechat": "^1.18.4",
"wechaty-puppet-wechat4u": "^1.14.14",
"ws": "^8.16.0"
},
"devDependencies": {
"husky": "^9.0.11",
"lint-staged": "^15.2.7",
"prettier": "^3.3.3",
"puppeteer": "13.5.1",
"puppeteer-core": "13.5.1"
}
}
================================================
FILE: src/302ai/__test__.js
================================================
import { get302AiReply } from './index.js'
// 测试 302 ai api
async function testMessage() {
const message = await get302AiReply('hello')
console.log('🌸🌸🌸 / message: ', message)
}
testMessage()
================================================
FILE: src/302ai/index.js
================================================
import axios from 'axios'
import dotenv from 'dotenv'
dotenv.config()
const env = dotenv.config().parsed
const key = env._302AI_API_KEY
const model = env._302AI_MODEL ? env._302AI_MODEL : 'gpt-4o-mini'
function setConfig(prompt) {
return {
method: 'post',
url: 'https://api.302.ai/v1/chat/completions',
headers: {
Accept: 'application/json',
Authorization: `Bearer ${key}`,
'User-Agent': 'Apifox/1.0.0 (https://apifox.com)',
'Content-Type': 'application/json',
},
data: JSON.stringify({
model: model,
messages: [
{
role: 'user',
content: prompt,
},
],
}),
}
}
export async function get302AiReply(prompt) {
try {
const config = setConfig(prompt)
const response = await axios(config)
const { choices } = response.data
return choices[0].message.content
} catch (error) {
console.error(error.code)
console.error(error.message)
}
}
================================================
FILE: src/chatgpt/index.js
================================================
import { ChatGPTAPI } from 'chatgpt'
import dotenv from 'dotenv'
const env = dotenv.config().parsed // 环境参数
// 定义ChatGPT的配置
const config = {
markdown: true, // 返回的内容是否需要markdown格式
AutoReply: true, // 是否自动回复
clearanceToken: env.CHATGPT_CLEARANCE, // ChatGPT的clearance,从cookie取值
sessionToken: env.CHATGPT_SESSION_TOKEN, // ChatGPT的sessionToken, 从cookie取值
userAgent: env.CHATGPT_USER_AGENT, // ChatGPT的user-agent,从浏览器取值,或者替换为与你的真实浏览器的User-Agent相匹配的值
accessToken: env.CHATGPT_ACCESS_TOKEN, // 在用户授权情况下,访问https://chat.openai.com/api/auth/session,获取accesstoken
}
const api = new ChatGPTAPI(config)
// 获取 chatGPT 的回复
export async function getChatGPTReply(content) {
await api.ensureAuth()
console.log('🚀🚀🚀 / content', content)
// 调用ChatGPT的接口
const reply = await api.sendMessage(content, {
// "ChatGPT 请求超时!最好开下全局代理。"
timeoutMs: 2 * 60 * 1000,
})
console.log('🚀🚀🚀 / reply', reply)
return reply
// // 如果你想要连续语境对话,可以使用下面的代码
// const conversation = api.getConversation();
// return await conversation.sendMessage(content, {
// // "ChatGPT 请求超时!最好开下全局代理。"
// timeoutMs: 2 * 60 * 1000,
// });
}
================================================
FILE: src/claude/index.js
================================================
import axios from 'axios'
import dotenv from 'dotenv'
dotenv.config()
const env = dotenv.config().parsed
/**
* 用于规整env文件中配置的url到标准格式
*/
function normalizeClaudeBaseUrl(url) {
if (!url) {
return 'https://api.anthropic.com/v1/messages'
}
let normalizedUrl = url.replace(/\/$/, '')
if (normalizedUrl.includes('/v1/messages')) {
return normalizedUrl
}
if (normalizedUrl.includes('/v1') && !normalizedUrl.includes('/messages')) {
return `${normalizedUrl}/messages`
}
if (normalizedUrl.includes('/messages') && !normalizedUrl.includes('/v1')) {
return normalizedUrl.replace('/messages', '/v1/messages')
}
return `${normalizedUrl}/v1/messages`
}
const key = env.CLAUDE_API_KEY || ''
const model = env.CLAUDE_MODEL ? env.CLAUDE_MODEL : 'claude-3-5-sonnet-latest'
const baseUrl = normalizeClaudeBaseUrl(env.CLAUDE_BASE_URL)
const system = env.CLAUDE_SYSTEM || ''
const apiVersion = env.CLAUDE_API_VERSION || '2023-06-01'
function claudeConfig(prompt) {
const body = {
model: model,
temperature: 0.4,
max_tokens: 1024,
messages: [
{
role: 'user',
content: prompt,
},
],
}
if (system !== '') {
body.system = system
}
return {
method: 'post',
url: baseUrl,
headers: {
'x-api-key': key,
'anthropic-version': apiVersion,
'Content-Type': 'application/json',
},
data: body,
}
}
export async function getClaudeReply(prompt) {
try {
const claude = claudeConfig(prompt)
const reply = await axios(claude)
return reply.data.content[0].text || ''
} catch (error) {
console.error(error)
}
}
================================================
FILE: src/deepseek/__test__.js
================================================
import { getDoubaoReply } from './index.js'
// 测试 open ai api
async function testMessage() {
const message = await getDoubaoReply('猪可以吃钛合金吗')
console.log('🌸🌸🌸 / message: ', message)
}
testMessage()
================================================
FILE: src/deepseek/index.js
================================================
import { remark } from 'remark'
import stripMarkdown from 'strip-markdown'
import OpenAI from 'openai'
import dotenv from 'dotenv'
const env = dotenv.config().parsed // 环境参数
import fs from 'fs'
import path from 'path'
const __dirname = path.resolve()
// 判断是否有 .env 文件, 没有则报错
const envPath = path.join(__dirname, '.env')
if (!fs.existsSync(envPath)) {
console.log('❌ 请先根据文档,创建并配置.env文件!')
process.exit(1)
}
let config = {
apiKey: env.DEEPSEEK_API_KEY,
}
if (env.DEEPSEEK_URL) {
config.baseURL = env.DEEPSEEK_URL
}
const openai = new OpenAI(config)
const chosen_model = env.DEEPSEEK_MODEL
export async function getDeepseekReply(prompt) {
console.log('🚀🚀🚀 / prompt', prompt)
const response = await openai.chat.completions.create({
messages: [
{ role: 'system', content: env.DEEPSEEK_SYSTEM_MESSAGE },
{ role: 'user', content: prompt },
],
model: chosen_model,
})
console.log('🚀🚀🚀 / reply', response.choices[0].message.content)
return `${response.choices[0].message.content}`
}
================================================
FILE: src/deepseek-free/__test__.js
================================================
import { getDeepSeekFreeReply } from './index.js'
// 测试 open ai api
async function testMessage() {
const message = await getDeepSeekFreeReply('hello')
console.log('🌸🌸🌸 / message: ', message)
}
testMessage()
================================================
FILE: src/deepseek-free/index.js
================================================
import axios from 'axios'
import dotenv from 'dotenv'
// 加载环境变量
dotenv.config()
const env = dotenv.config().parsed // 环境参数
const token = env.DEEPSEEK_FREE_TOKEN
const model = env.DEEPSEEK_FREE_MODEL
const url = env.DEEPSEEK_FREE_URL
const syscontent = env.DEEPSEEK_FREE_SYSTEM_MESSAGE
function setConfig(prompt) {
return {
method: 'post',
maxBodyLength: Infinity,
// url: 'https://api.deepseek.com/chat/completions',
url: url,
headers: {
'Content-Type': 'application/json',
Accept: 'application/json',
Authorization: `Bearer ${token}`,
},
data: JSON.stringify({
model: model,
messages: [
{
role: 'system',
content: syscontent,
},
{
role: 'user',
content: prompt,
},
],
stream: false,
}),
}
}
export async function getDeepSeekFreeReply(prompt) {
try {
const config = setConfig(prompt)
const response = await axios(config)
const { choices } = response.data
return choices[0].message.content
} catch (error) {
console.error(error.code)
console.error(error.message)
}
}
================================================
FILE: src/dify/__test__.js
================================================
import { getDifyReply } from './index.js'
// 测试 dify api
async function testMessage() {
const message = await getDifyReply('hello')
console.log('🌸🌸🌸 / message: ', message)
}
testMessage()
================================================
FILE: src/dify/index.js
================================================
import axios from 'axios'
import dotenv from 'dotenv'
// 加载环境变量
dotenv.config()
const env = dotenv.config().parsed // 环境参数
const token = env.DIFY_API_KEY
const url = env.DIFY_URL
const bot_name = env.BOT_NAME
function setConfig(prompt) {
return {
method: 'post',
url: `${url}/chat-messages`,
headers: {
'Content-Type': 'application/json',
Accept: 'application/json',
Authorization: `Bearer ${token}`,
},
data: JSON.stringify({
inputs: {},
query: prompt,
response_mode: 'blocking',
user: bot_name,
files: [],
}),
}
}
export async function getDifyReply(prompt) {
try {
const config = setConfig(prompt)
console.log('🌸🌸🌸 / config: ', config)
const response = await axios(config)
console.log('🌸🌸🌸 / response: ', response)
return response.data.answer
} catch (error) {
console.error(error.code)
console.error(error.message)
}
}
================================================
FILE: src/doubao/__test__.js
================================================
import { getDoubaoReply } from './index.js'
// 测试 open ai api
async function testMessage() {
let message
message = await getDoubaoReply('猪可以吃钛合金吗')
console.log('🌸🌸🌸 / message: ', message)
message = await getDoubaoReply('这是哪里?', 'https://ark-project.tos-cn-beijing.ivolces.com/images/view.jpeg')
console.log('🌸🌸🌸 / message: ', message)
}
testMessage()
================================================
FILE: src/doubao/index.js
================================================
import { remark } from 'remark'
import stripMarkdown from 'strip-markdown'
import OpenAI from 'openai'
import dotenv from 'dotenv'
const env = dotenv.config().parsed // 环境参数
import fs from 'fs'
import path from 'path'
const __dirname = path.resolve()
// 判断是否有 .env 文件, 没有则报错
const envPath = path.join(__dirname, '.env')
if (!fs.existsSync(envPath)) {
console.log('❌ 请先根据文档,创建并配置.env文件!')
process.exit(1)
}
let config = {
apiKey: env.DOUBAO_API_KEY,
baseURL: env.DOUBAO_URL,
}
const openai = new OpenAI(config)
const chosen_model = env.DOUBAO_MODEL
export async function getDoubaoReply(prompt, img_url = '') {
const only_text = img_url == ''
console.log('🚀🚀🚀 / prompt', prompt)
let response
if (only_text) {
response = await openai.chat.completions.create({
messages: [{ role: 'user', content: [{ type: 'text', text: prompt }] }],
model: chosen_model,
})
} else {
response = await openai.chat.completions.create({
messages: [
{
role: 'user',
content: [
{
type: 'image_url',
image_url: {
url: img_url,
},
},
{ type: 'text', text: prompt },
],
},
],
model: chosen_model,
})
}
console.log('🚀🚀🚀 / reply', response.choices[0].message.content)
return `${response.choices[0].message.content}`
}
================================================
FILE: src/index.js
================================================
import { Command } from 'commander'
import { WechatyBuilder, ScanStatus, log } from 'wechaty'
import inquirer from 'inquirer'
import qrTerminal from 'qrcode-terminal'
import dotenv from 'dotenv'
import fs from 'fs'
import path, { dirname } from 'path'
import { fileURLToPath } from 'url'
import { defaultMessage } from './wechaty/sendMessage.js'
const __filename = fileURLToPath(import.meta.url)
const __dirname = dirname(__filename)
const env = dotenv.config().parsed // 环境参数
const { version, name } = JSON.parse(fs.readFileSync(path.resolve(__dirname, '../package.json'), 'utf8'))
// 扫码
function onScan(qrcode, status) {
if (status === ScanStatus.Waiting || status === ScanStatus.Timeout) {
// 在控制台显示二维码
qrTerminal.generate(qrcode, { small: true })
const qrcodeImageUrl = ['https://api.qrserver.com/v1/create-qr-code/?data=', encodeURIComponent(qrcode)].join('')
console.log('onScan:', qrcodeImageUrl, ScanStatus[status], status)
} else {
log.info('onScan: %s(%s)', ScanStatus[status], status)
}
}
// 登录
function onLogin(user) {
console.log(`${user} has logged in`)
const date = new Date()
console.log(`Current time:${date}`)
console.log(`Automatic robot chat mode has been activated`)
}
// 登出
function onLogout(user) {
console.log(`${user} has logged out`)
}
// 收到好友请求
async function onFriendShip(friendship) {
const frienddShipRe = /chatgpt|chat/
if (friendship.type() === 2) {
if (frienddShipRe.test(friendship.hello())) {
await friendship.accept()
}
}
}
/**
* 消息发送
* @param msg
* @param isSharding
* @returns {Promise<void>}
*/
async function onMessage(msg) {
// 默认消息回复
await defaultMessage(msg, bot, serviceType)
// 消息分片
// await shardingMessage(msg,bot)
}
// 初始化机器人
const CHROME_BIN = process.env.CHROME_BIN ? { endpoint: process.env.CHROME_BIN } : {}
let serviceType = ''
export const bot = WechatyBuilder.build({
name: 'WechatEveryDay',
puppet: 'wechaty-puppet-wechat4u', // 如果有token,记得更换对应的puppet
// puppet: 'wechaty-puppet-wechat', // 如果 wechaty-puppet-wechat 存在问题,也可以尝试使用上面的 wechaty-puppet-wechat4u ,记得安装 wechaty-puppet-wechat4u
puppetOptions: {
uos: true,
...CHROME_BIN,
},
})
// 扫码
bot.on('scan', onScan)
// 登录
bot.on('login', onLogin)
// 登出
bot.on('logout', onLogout)
// 收到消息
bot.on('message', onMessage)
// 添加好友
bot.on('friendship', onFriendShip)
// 错误
bot.on('error', (e) => {
console.error('❌ bot error handle: ', e)
// console.log('❌ 程序退出,请重新运行程序')
// bot.stop()
// // 如果 WechatEveryDay.memory-card.json 文件存在,删除
// if (fs.existsSync('WechatEveryDay.memory-card.json')) {
// fs.unlinkSync('WechatEveryDay.memory-card.json')
// }
// process.exit()
})
// 启动微信机器人
function botStart() {
bot
.start()
.then(() => console.log('Start to log in wechat...'))
.catch((e) => console.error('❌ botStart error: ', e))
}
process.on('uncaughtException', (err) => {
if (err.code === 'ERR_ASSERTION') {
console.error('❌ uncaughtException 捕获到断言错误: ', err.message)
} else {
console.error('❌ uncaughtException 捕获到未处理的异常: ', err)
}
// if (fs.existsSync('WechatEveryDay.memory-card.json')) {
// fs.unlinkSync('WechatEveryDay.memory-card.json')
// }
})
// 控制启动
function handleStart(type) {
serviceType = type
console.log('🌸🌸🌸 / type: ', type)
switch (type) {
case 'ChatGPT':
if (env.OPENAI_API_KEY) return botStart()
console.log('❌ 请先配置.env文件中的 OPENAI_API_KEY')
break
case 'doubao':
if (env.DOUBAO_API_KEY) return botStart()
console.log('❌ 请先配置.env文件中的 DOUBAO_API_KEY')
break
case 'deepseek':
if (env.DEEPSEEK_API_KEY) return botStart()
console.log('❌ 请先配置.env文件中的 DEEPSEEK_API_KEY')
break
case 'Kimi':
if (env.KIMI_API_KEY) return botStart()
console.log('❌ 请先配置.env文件中的 KIMI_API_KEY')
break
case 'Xunfei':
if (env.XUNFEI_APP_ID && env.XUNFEI_API_KEY && env.XUNFEI_API_SECRET) {
return botStart()
}
console.log('❌ 请先配置.env文件中的 XUNFEI_APP_ID,XUNFEI_API_KEY,XUNFEI_API_SECRET')
break
case 'deepseek-free':
if (env.DEEPSEEK_FREE_URL && env.DEEPSEEK_FREE_TOKEN && env.DEEPSEEK_FREE_MODEL) {
return botStart()
}
console.log('❌ 请先配置.env文件中的 DEEPSEEK_FREE_URL,DEEPSEEK_FREE_TOKEN,DEEPSEEK_FREE_MODEL')
break
case '302AI':
if (env._302AI_API_KEY) {
return botStart()
}
console.log('❌ 请先配置.env文件中的 _302AI_API_KEY')
break
case 'dify':
if (env.DIFY_API_KEY && env.DIFY_URL) {
return botStart()
}
console.log('❌ 请先配置.env文件中的 DIFY_API_KEY')
break
case 'ollama':
if (env.OLLAMA_URL && env.OLLAMA_MODEL) {
return botStart()
}
break
case 'tongyi':
if (env.TONGYI_URL && env.TONGYI_MODEL) {
return botStart()
}
break
case 'claude':
if (env.CLAUDE_API_KEY && env.CLAUDE_MODEL) {
return botStart()
}
console.log('❌ 请先配置.env文件中的 CLAUDE_API_KEY 和 CLAUDE_MODEL')
break
default:
console.log('❌ 服务类型错误, 目前支持: ChatGPT | doubao | deepseek | Kimi | Xunfei | DIFY | OLLAMA | TONGYI')
}
}
export const serveList = [
{ name: 'ChatGPT', value: 'ChatGPT' },
{ name: 'doubao', value: 'doubao' },
{ name: 'deepseek', value: 'deepseek' },
{ name: 'Kimi', value: 'Kimi' },
{ name: 'Xunfei', value: 'Xunfei' },
{ name: 'deepseek-free', value: 'deepseek-free' },
{ name: '302AI', value: '302AI' },
{ name: 'dify', value: 'dify' },
// ... 欢迎大家接入更多的服务
{ name: 'ollama', value: 'ollama' },
{ name: 'tongyi', value: 'tongyi' },
{ name: 'claude', value: 'claude' },
]
const questions = [
{
type: 'list',
name: 'serviceType', //存储当前问题回答的变量key,
message: '请先选择服务类型',
choices: serveList,
},
]
function init() {
if (env.SERVICE_TYPE) {
// 判断env中SERVICE_TYPE是否配置和并且属于serveList数组中value的值
if (serveList.find((item) => item.value === env.SERVICE_TYPE)) {
handleStart(env.SERVICE_TYPE)
} else {
console.log('❌ 请正确配置.env文件中的 SERVICE_TYPE,或者删除该项')
}
} else {
inquirer
.prompt(questions)
.then((res) => {
handleStart(res.serviceType)
})
.catch((error) => {
console.log('❌ inquirer error:', error)
})
}
}
const program = new Command(name)
program
.alias('we')
.description('🤖一个基于 WeChaty 结合AI服务实现的微信机器人。')
.version(version, '-v, --version, -V')
.option('-s, --serve <type>', '跳过交互,直接设置启动的服务类型')
// .option('-p, --proxy <url>', 'proxy url', '')
.action(function () {
const { serve } = this.opts()
const args = this.args
if (!serve) return init()
handleStart(serve)
})
.command('start')
.option('-s, --serve <type>', '跳过交互,直接设置启动的服务类型', '')
.action(() => init())
// program
// .command('config')
// .option('-d, --depth <type>', 'Set the depth of the folder to be traversed', '10')
// .action(() => {
// // 打印当前项目的路径,而不是执行该文件时的所在路径
// console.log('请手动修改下面路径中的 config.json 文件')
// console.log(path.resolve(__dirname, '../.env'))
// })
program.parse()
================================================
FILE: src/kimi/__test__.js
================================================
import { getKimiReply } from './index.js'
// 测试 open ai api
async function test() {
const message = await getKimiReply('你好!')
console.log('🌸🌸🌸 / message: ', message)
}
test()
================================================
FILE: src/kimi/index.js
================================================
import axios from 'axios'
import dotenv from 'dotenv'
const env = dotenv.config().parsed // 环境参数
const domain = 'https://api.moonshot.cn'
const server = {
chat: `${domain}/v1/chat/completions`,
models: `${domain}/v1/models`,
files: `${domain}/v1/files`,
token: `${domain}/v1/tokenizers/estimate-token-count`,
// 这块还可以实现上传文件让 kimi 读取并交互等操作
// 具体参考文档: https://platform.moonshot.cn/docs/api-reference#api-%E8%AF%B4%E6%98%8E
// 由于我近期非常忙碌,这块欢迎感兴趣的同学提 PR ,我会很快合并
}
const configuration = {
// 参数详情请参考 https://platform.moonshot.cn/docs/api-reference#%E5%AD%97%E6%AE%B5%E8%AF%B4%E6%98%8E
/*
Model ID, 可以通过 List Models 获取
目前可选 moonshot-v1-8k | moonshot-v1-32k | moonshot-v1-128k
*/
model: 'moonshot-v1-8k',
/*
使用什么采样温度,介于 0 和 1 之间。较高的值(如 0.7)将使输出更加随机,而较低的值(如 0.2)将使其更加集中和确定性。
如果设置,值域须为 [0, 1] 我们推荐 0.3,以达到较合适的效果。
*/
temperature: 0.3,
/*
聊天完成时生成的最大 token 数。如果到生成了最大 token 数个结果仍然没有结束,finish reason 会是 "length", 否则会是 "stop"
这个值建议按需给个合理的值,如果不给的话,我们会给一个不错的整数比如 1024。特别要注意的是,这个 max_tokens 是指您期待我们返回的 token 长度,而不是输入 + 输出的总长度。
比如对一个 moonshot-v1-8k 模型,它的最大输入 + 输出总长度是 8192,当输入 messages 总长度为 4096 的时候,您最多只能设置为 4096,
否则我们服务会返回不合法的输入参数( invalid_request_error ),并拒绝回答。如果您希望获得“输入的精确 token 数”,可以使用下面的“计算 Token” API 使用我们的计算器获得计数。
*/
max_tokens: 5000,
/*
是否流式返回, 默认 false, 可选 true
*/
stream: true,
}
export async function getKimiReply(prompt) {
try {
const res = await axios.post(
server.chat,
Object.assign(configuration, {
/*
包含迄今为止对话的消息列表。
要保持对话的上下文,需要将之前的对话历史并入到该数组
这是一个结构体的列表,每个元素类似如下:{"role": "user", "content": "你好"} role 只支持 system,user,assistant 其一,content 不得为空
*/
messages: [
{
role: 'user',
content: prompt,
},
],
model: 'moonshot-v1-128k',
}),
{
timeout: 120000,
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${env.KIMI_API_KEY}`,
},
// pass a http proxy agent
// proxy: {
// host: 'localhost',
// port: 7890,
// }
},
)
if (!configuration.stream) return res.data.choices[0].message.content
let result = ''
const lines = res.data.split('\n').filter((line) => line.trim() !== '')
for (const line of lines) {
if (line.startsWith('data: ')) {
const messageObj = line.substring(6)
if (messageObj === '[DONE]') break
const message = JSON.parse(messageObj)
if (message.choices && message.choices[0].delta && message.choices[0].delta.content) {
result += message.choices[0].delta.content
}
}
}
return result
} catch (error) {
console.log('Kimi 错误对应详情可参考官网: https://platform.moonshot.cn/docs/api-reference#%E9%94%99%E8%AF%AF%E8%AF%B4%E6%98%8E')
console.log('常见的 401 一般意味着你鉴权失败, 请检查你的 API_KEY 是否正确。')
console.log('常见的 429 一般意味着你被限制了请求频次,请求频率过高,或 kimi 服务器过载,可以适当调整请求频率,或者等待一段时间再试。')
console.error(error.code)
console.error(error.message)
}
}
================================================
FILE: src/ollama/__test__.js
================================================
import { getDifyReply } from './index.js'
// 测试 dify api
async function testMessage() {
const message = await getDifyReply('hello')
console.log('🌸🌸🌸 / message: ', message)
}
testMessage()
================================================
FILE: src/ollama/index.js
================================================
import axios from 'axios'
import dotenv from 'dotenv'
// 加载环境变量
dotenv.config()
const env = dotenv.config().parsed // 环境参数
const url = env.OLLAMA_URL
const bot_name = env.BOT_NAME
const model_name = env.OLLAMA_MODEL
function createRequest(prompt) {
return {
method: 'post',
url: url,
headers: {
'Content-Type': 'application/json',
Accept: 'application/json',
},
data: JSON.stringify({
model: model_name,
messages: [
{
role: 'system',
content: env.OLLAMA_SYSTEM_MESSAGE,
},
{
role: 'user',
content: prompt,
},
],
stream: false,
}),
}
}
export async function getOllamaReply(prompt) {
try {
console.log('=============== ollama request start ======================')
const request = createRequest(prompt)
const res = await axios(request)
console.log('=============== ollama request finished ======================')
return res.data.message.content
} catch (error) {
console.error(error.code)
console.error(error.message)
}
}
================================================
FILE: src/openai/__test__.js
================================================
import { getGptReply } from './index.js'
// 测试 open ai api
async function testMessage() {
const message = await getGptReply('hello')
console.log('🌸🌸🌸 / message: ', message)
}
testMessage()
================================================
FILE: src/openai/index.js
================================================
import { remark } from 'remark'
import stripMarkdown from 'strip-markdown'
import OpenAIApi from 'openai'
import dotenv from 'dotenv'
const env = dotenv.config().parsed // 环境参数
import fs from 'fs'
import path from 'path'
const __dirname = path.resolve()
// 判断是否有 .env 文件, 没有则报错
const envPath = path.join(__dirname, '.env')
if (!fs.existsSync(envPath)) {
console.log('❌ 请先根据文档,创建并配置.env文件!')
process.exit(1)
}
let config = {
apiKey: env.OPENAI_API_KEY,
organization: '',
}
if (env.OPENAI_PROXY_URL) {
config.baseURL = env.OPENAI_PROXY_URL
}
const openai = new OpenAIApi(config)
const chosen_model = env.OPENAI_MODEL || 'gpt-4o'
export async function getGptReply(prompt) {
console.log('🚀🚀🚀 / prompt', prompt)
const response = await openai.chat.completions.create({
messages: [
{ role: 'system', content: env.OPENAI_SYSTEM_MESSAGE },
{ role: 'user', content: prompt },
],
model: chosen_model,
})
console.log('🚀🚀🚀 / reply', response.choices[0].message.content)
return `${response.choices[0].message.content}`
}
================================================
FILE: src/tongyi/index.js
================================================
import fs from 'fs'
import path from 'path'
import dotenv from 'dotenv'
import OpenAI from 'openai'
const env = dotenv.config().parsed // 环境参数
// 加载环境变量
dotenv.config()
const url = env.TONGYI_URL
const api_key = env.TONGYI_API_KEY
const model_name = env.TONGYI_MODEL || 'qwen-plus'
const openai = new OpenAI({
apiKey: api_key,
baseURL: url,
temperature: 0,
})
const __dirname = path.resolve()
// 判断是否有 .env 文件, 没有则报错
const envPath = path.join(__dirname, '.env')
if (!fs.existsSync(envPath)) {
console.log('❌ 请先根据文档,创建并配置 .env 文件!')
process.exit(1)
}
export async function getTongyiReply(prompt) {
const completion = await openai.chat.completions.create({
messages: [
{
role: 'user',
content: prompt + ' ,用中文回答',
},
],
model: model_name,
})
console.log('🚀🚀🚀 / prompt', prompt)
const Content = await completion.choices[0].message.content
console.log('🚀🚀🚀 / reply', Content)
return `${Content}`
}
================================================
FILE: src/wechaty/sendMessage.js
================================================
import dotenv from 'dotenv'
// 加载环境变量
dotenv.config()
const env = dotenv.config().parsed // 环境参数
// 从环境变量中导入机器人的名称
const botName = env.BOT_NAME
// 从环境变量中导入需要自动回复的消息前缀,默认配空串或不配置则等于无前缀
const autoReplyPrefix = env.AUTO_REPLY_PREFIX ? env.AUTO_REPLY_PREFIX : ''
// 从环境变量中导入联系人白名单
const aliasWhiteList = env.ALIAS_WHITELIST ? env.ALIAS_WHITELIST.split(',') : []
// 从环境变量中导入群聊白名单
const roomWhiteList = env.ROOM_WHITELIST ? env.ROOM_WHITELIST.split(',') : []
import { getServe } from './serve.js'
/**
* 默认消息发送
* @param msg
* @param bot
* @param ServiceType 服务类型 'GPT' | 'Kimi'
* @returns {Promise<void>}
*/
export async function defaultMessage(msg, bot, ServiceType = 'GPT') {
const getReply = getServe(ServiceType)
const contact = msg.talker() // 发消息人
const receiver = msg.to() // 消息接收人
const content = msg.text() // 消息内容
const room = msg.room() // 是否是群消息
const roomName = (await room?.topic()) || null // 群名称
const alias = (await contact.alias()) || (await contact.name()) // 发消息人昵称
const remarkName = await contact.alias() // 备注名称
const name = await contact.name() // 微信名称
const isText = msg.type() === bot.Message.Type.Text // 消息类型是否为文本
const isRoom = roomWhiteList.includes(roomName) && content.includes(`${botName}`) // 是否在群聊白名单内并且艾特了机器人
const isAlias = aliasWhiteList.includes(remarkName) || aliasWhiteList.includes(name) // 发消息的人是否在联系人白名单内
const isBotSelf = botName === `@${remarkName}` || botName === `@${name}` // 是否是机器人自己
const isBotSelfDebug = content.trimStart().startsWith('你是谁') // 是否是机器人自己的调试消息
// TODO 你们可以根据自己的需求修改这里的逻辑
if ((isBotSelf && !isBotSelfDebug) || !isText) return // 如果是机器人自己发送的消息或者消息类型不是文本则不处理
try {
// 区分群聊和私聊
// 群聊消息去掉艾特主体后,匹配自动回复前缀
if (isRoom && room && content.replace(`${botName}`, '').trimStart().startsWith(`${autoReplyPrefix}`)) {
const question = (await msg.mentionText()) || content.replace(`${botName}`, '').replace(`${autoReplyPrefix}`, '') // 去掉艾特的消息主体
console.log('🌸🌸🌸 / question: ', question)
const response = await getReply(question)
await room.say(response)
}
// 私人聊天,白名单内的直接发送
// 私人聊天直接匹配自动回复前缀
if (isAlias && !room && content.trimStart().startsWith(`${autoReplyPrefix}`)) {
const question = content.replace(`${autoReplyPrefix}`, '')
console.log('🌸🌸🌸 / content: ', question)
const response = await getReply(question)
await contact.say(response)
}
} catch (e) {
console.error(e)
}
}
/**
* 分片消息发送
* @param message
* @param bot
* @returns {Promise<void>}
*/
export async function shardingMessage(message, bot) {
const talker = message.talker()
const isText = message.type() === bot.Message.Type.Text // 消息类型是否为文本
if (talker.self() || message.type() > 10 || (talker.name() === '微信团队' && isText)) {
return
}
const text = message.text()
const room = message.room()
if (!room) {
console.log(`Chat GPT Enabled User: ${talker.name()}`)
const response = await getChatGPTReply(text)
await trySay(talker, response)
return
}
let realText = splitMessage(text)
// 如果是群聊但不是指定艾特人那么就不进行发送消息
if (text.indexOf(`${botName}`) === -1) {
return
}
realText = text.replace(`${botName}`, '')
const topic = await room.topic()
const response = await getChatGPTReply(realText)
const result = `${realText}\n ---------------- \n ${response}`
await trySay(room, result)
}
// 分片长度
const SINGLE_MESSAGE_MAX_SIZE = 500
/**
* 发送
* @param talker 发送哪个 room为群聊类 text为单人
* @param msg
* @returns {Promise<void>}
*/
async function trySay(talker, msg) {
const messages = []
let message = msg
while (message.length > SINGLE_MESSAGE_MAX_SIZE) {
messages.push(message.slice(0, SINGLE_MESSAGE_MAX_SIZE))
message = message.slice(SINGLE_MESSAGE_MAX_SIZE)
}
messages.push(message)
for (const msg of messages) {
await talker.say(msg)
}
}
/**
* 分组消息
* @param text
* @returns {Promise<*>}
*/
async function splitMessage(text) {
let realText = text
const item = text.split('- - - - - - - - - - - - - - -')
if (item.length > 1) {
realText = item[item.length - 1]
}
return realText
}
================================================
FILE: src/wechaty/serve.js
================================================
import { getGptReply } from '../openai/index.js'
import { getDoubaoReply } from '../doubao/index.js'
import { getDeepseekReply } from '../deepseek/index.js'
import { getKimiReply } from '../kimi/index.js'
import { getXunfeiReply } from '../xunfei/index.js'
import { getDeepSeekFreeReply } from '../deepseek-free/index.js'
import { get302AiReply } from '../302ai/index.js'
import { getDifyReply } from '../dify/index.js'
import { getOllamaReply } from '../ollama/index.js'
import { getTongyiReply } from '../tongyi/index.js'
import { getClaudeReply } from '../claude/index.js'
/**
* 获取ai服务
* @param serviceType 服务类型 'GPT' | 'Kimi'
* @returns {Promise<void>}
*/
export function getServe(serviceType) {
switch (serviceType) {
case 'ChatGPT':
return getGptReply
case 'doubao':
return getDoubaoReply
case 'deepseek':
return getDeepseekReply
case 'Kimi':
return getKimiReply
case 'Xunfei':
return getXunfeiReply
case 'deepseek-free':
return getDeepSeekFreeReply
case '302AI':
return get302AiReply
case 'dify':
return getDifyReply
case 'ollama':
return getOllamaReply
case 'tongyi':
return getTongyiReply
case 'claude':
return getClaudeReply
default:
return getGptReply
}
}
================================================
FILE: src/wechaty/testMessage.js
================================================
import { getGptReply } from '../openai/index.js'
import { getKimiReply } from '../kimi/index.js'
import { getXunfeiReply } from '../xunfei/index.js'
import dotenv from 'dotenv'
import inquirer from 'inquirer'
import { getDeepSeekFreeReply } from '../deepseek-free/index.js'
import { get302AiReply } from '../302ai/index.js'
import { getDifyReply } from '../dify/index.js'
import { getOllamaReply } from '../ollama/index.js'
const env = dotenv.config().parsed // 环境参数
// 控制启动
async function handleRequest(type) {
console.log('type: ', type)
switch (type) {
case 'ChatGPT':
if (env.OPENAI_API_KEY) {
const message = await getGptReply('hello')
console.log('🌸🌸🌸 / reply: ', message)
return
}
console.log('❌ 请先配置.env文件中的 OPENAI_API_KEY')
break
case 'Kimi':
if (env.KIMI_API_KEY) {
const message = await getKimiReply('你好!')
console.log('🌸🌸🌸 / reply: ', message)
return
}
console.log('❌ 请先配置.env文件中的 KIMI_API_KEY')
break
case 'Xunfei':
if (env.XUNFEI_APP_ID && env.XUNFEI_API_KEY && env.XUNFEI_API_SECRET) {
const message = await getXunfeiReply('你好!')
console.log('🌸🌸🌸 / reply: ', message)
return
}
console.log('❌ 请先配置.env文件中的 XUNFEI_APP_ID,XUNFEI_API_KEY,XUNFEI_API_SECRET')
break
case 'deepseek-free':
if (env.DEEPSEEK_FREE_URL && env.DEEPSEEK_FREE_TOKEN && env.DEEPSEEK_FREE_MODEL) {
const message = await getDeepSeekFreeReply('你好!')
console.log('🌸🌸🌸 / reply: ', message)
return
}
console.log('❌ 请先配置.env文件中的 DEEPSEEK_FREE_URL,DEEPSEEK_FREE_TOKEN,DEEPSEEK_FREE_MODEL')
break
case 'dify':
if (env.DIFY_API_KEY) {
const message = await getDifyReply('hello')
console.log('🌸🌸🌸 / reply: ', message)
return
}
console.log('❌ 请先配置.env文件中的 DIFY_API_KEY, DIFY_URL')
break
case '302AI':
if (env._302AI_API_KEY) {
const message = await get302AiReply('hello')
console.log('🌸🌸🌸 / reply: ', message)
return
}
console.log('❌ 请先配置.env文件中的 _302AI_API_KEY')
break
case 'ollama':
if (env.OLLAMA_URL) {
const message = await getOllamaReply('hello')
console.log('🌸🌸🌸 / reply: ', message)
return
}
console.log('❌ 请先配置.env文件中的 OLLAMA_URL')
break
default:
console.log('🚀服务类型错误')
}
}
const serveList = [
{ name: 'ChatGPT', value: 'ChatGPT' },
{ name: 'Kimi', value: 'Kimi' },
{ name: 'Xunfei', value: 'Xunfei' },
{ name: 'deepseek-free', value: 'deepseek-free' },
{ name: '302AI', value: '302AI' },
{ name: 'dify', value: 'dify' },
// ... 欢迎大家接入更多的服务
{ name: 'ollama', value: 'ollama' },
]
const questions = [
{
type: 'list',
name: 'serviceType', //存储当前问题回答的变量key,
message: '请先选择服务类型',
choices: serveList,
},
]
function init() {
inquirer
.prompt(questions)
.then((res) => {
handleRequest(res.serviceType)
})
.catch((error) => {
console.log('🚀error:', error)
})
}
init()
================================================
FILE: src/xunfei/__test__.js
================================================
import { getXunfeiReply } from './index.js'
// 测试 科大讯飞 api
async function testMessage() {
const message = await getXunfeiReply('秦始皇的儿子是谁?')
console.log('🌸🌸🌸 / message: ', message)
}
testMessage()
================================================
FILE: src/xunfei/index.js
================================================
import { xunfeiSendMsg } from './xunfei.js'
export async function getXunfeiReply(prompt, name) {
console.log('🚀🚀🚀 / prompt', prompt)
let reply = await xunfeiSendMsg(prompt)
if (typeof name != 'undefined') reply = `@${name}\n ${reply}`
return `${reply}`
}
================================================
FILE: src/xunfei/xunfei.js
================================================
import CryptoJS from "crypto-js";
import dotenv from "dotenv";
import WebSocket from "ws";
const env = dotenv.config().parsed; // 环境参数
// APPID,APISecret,APIKey在 https://console.xfyun.cn/services/cbm 获取
const appID = env.XUNFEI_APP_ID;
const apiKey = env.XUNFEI_API_KEY;
const apiSecret = env.XUNFEI_API_SECRET;
// 地址必须填写,代表着大模型的版本号
const modelVersion = env.XUNFEI_MODEL_VERSION || "v4.0"; // 默认值 "v4.0"
const httpUrl = new URL(`https://spark-api.xf-yun.com/${modelVersion}/chat`);
// 判断 prompt 是否存在,如果不存在则使用默认值
const prompt = env.XUNFEI_PROMPT || "你是一个专业的智能助手";
// 动态映射模型版本到 domain 的逻辑
const modelVersionMap = {
"v1.1": "general",
"v2.1": "generalv2",
"v3.1": "generalv3",
"v3.5": "generalv3.5",
"pro-128k": "pro-128k",
"max-32k": "max-32k",
"v4.0": "4.0Ultra",
};
// 获取模型域名
function getModelDomain(httpUrl) {
try {
const modelPath = httpUrl.pathname.split("/")[1]; // 提取版本号或模型路径
return modelVersionMap[modelPath] || "unknown"; // 如果没有匹配,返回 "unknown"
} catch (error) {
console.error("获取模型域名失败:", error);
return "unknown";
}
}
let modelDomain = getModelDomain(httpUrl);
// 签名生成逻辑(可复用)
function generateSignature(httpUrl, apiKey, apiSecret) {
const host = "localhost:8080";
const date = new Date().toGMTString();
const algorithm = "hmac-sha256";
const headers = "host date request-line";
const signatureOrigin = `host: ${host}\ndate: ${date}\nGET ${httpUrl.pathname} HTTP/1.1`;
const signatureSha = CryptoJS.HmacSHA256(signatureOrigin, apiSecret);
const signature = CryptoJS.enc.Base64.stringify(signatureSha);
const authorizationOrigin = `api_key="${apiKey}", algorithm="${algorithm}", headers="${headers}", signature="${signature}"`;
const authorization = btoa(authorizationOrigin);
const url = `wss://${httpUrl.host}${httpUrl.pathname}?authorization=${authorization}&date=${date}&host=${host}`;
return url;
}
// 获取 WebSocket 地址
function authenticate() {
return new Promise((resolve, reject) => {
try {
const url = generateSignature(httpUrl, apiKey, apiSecret);
resolve(url);
} catch (error) {
console.error("认证失败:", error);
reject(error);
}
});
}
// 发送消息并处理 WebSocket 逻辑
export async function xunfeiSendMsg(inputVal) {
// 获取请求地址
let myUrl = await authenticate();
let socket = new WebSocket(String(myUrl));
let total_res = ""; // 清空回答历史
// 创建一个Promise
let messagePromise = new Promise((resolve, reject) => {
socket.addEventListener("open", () => {
const params = {
header: {
app_id: appID,
uid: "fd3f47e4-d",
},
parameter: {
chat: {
domain: modelDomain,
temperature: 0.8,
max_tokens: 1024,
},
},
payload: {
message: {
text: [
{ role: "system", content: prompt },
{ role: "user", content: inputVal }, // 最新的问题
],
},
},
};
socket.send(JSON.stringify(params));
});
socket.addEventListener("message", (event) => {
const data = JSON.parse(String(event.data));
if (data.header.code !== 0) {
console.error("Socket 出错:", data.header.code, data.header.message);
socket.close();
reject("");
} else if (data.payload.choices.text && data.header.status === 2) {
total_res += data.payload.choices.text[0].content;
setTimeout(() => {
socket.close();
}, 1000);
}
});
socket.addEventListener("close", () => {
resolve(total_res);
});
socket.addEventListener("error", (event) => {
console.error("Socket 连接错误:", event);
reject("");
});
});
return await messagePromise;
}
gitextract_28865r5d/
├── .dockerignore
├── .gitignore
├── .husky/
│ └── pre-commit
├── .npmrc
├── .prettierrc.cjs
├── .vscode/
│ └── settings.json
├── Dockerfile
├── Dockerfile.alpine
├── LICENSE.md
├── README.md
├── RECORD.md
├── cli.js
├── package.json
└── src/
├── 302ai/
│ ├── __test__.js
│ └── index.js
├── chatgpt/
│ └── index.js
├── claude/
│ └── index.js
├── deepseek/
│ ├── __test__.js
│ └── index.js
├── deepseek-free/
│ ├── __test__.js
│ └── index.js
├── dify/
│ ├── __test__.js
│ └── index.js
├── doubao/
│ ├── __test__.js
│ └── index.js
├── index.js
├── kimi/
│ ├── __test__.js
│ └── index.js
├── ollama/
│ ├── __test__.js
│ └── index.js
├── openai/
│ ├── __test__.js
│ └── index.js
├── tongyi/
│ └── index.js
├── wechaty/
│ ├── sendMessage.js
│ ├── serve.js
│ └── testMessage.js
└── xunfei/
├── __test__.js
├── index.js
└── xunfei.js
SYMBOL INDEX (48 symbols across 26 files)
FILE: src/302ai/__test__.js
function testMessage (line 4) | async function testMessage() {
FILE: src/302ai/index.js
function setConfig (line 9) | function setConfig(prompt) {
function get302AiReply (line 31) | async function get302AiReply(prompt) {
FILE: src/chatgpt/index.js
function getChatGPTReply (line 18) | async function getChatGPTReply(content) {
FILE: src/claude/index.js
function normalizeClaudeBaseUrl (line 10) | function normalizeClaudeBaseUrl(url) {
function claudeConfig (line 38) | function claudeConfig(prompt) {
function getClaudeReply (line 64) | async function getClaudeReply(prompt) {
FILE: src/deepseek-free/__test__.js
function testMessage (line 4) | async function testMessage() {
FILE: src/deepseek-free/index.js
function setConfig (line 11) | function setConfig(prompt) {
function getDeepSeekFreeReply (line 39) | async function getDeepSeekFreeReply(prompt) {
FILE: src/deepseek/__test__.js
function testMessage (line 4) | async function testMessage() {
FILE: src/deepseek/index.js
function getDeepseekReply (line 25) | async function getDeepseekReply(prompt) {
FILE: src/dify/__test__.js
function testMessage (line 4) | async function testMessage() {
FILE: src/dify/index.js
function setConfig (line 9) | function setConfig(prompt) {
function getDifyReply (line 28) | async function getDifyReply(prompt) {
FILE: src/doubao/__test__.js
function testMessage (line 4) | async function testMessage() {
FILE: src/doubao/index.js
function getDoubaoReply (line 23) | async function getDoubaoReply(prompt, img_url = '') {
FILE: src/index.js
function onScan (line 18) | function onScan(qrcode, status) {
function onLogin (line 30) | function onLogin(user) {
function onLogout (line 38) | function onLogout(user) {
function onFriendShip (line 43) | async function onFriendShip(friendship) {
function onMessage (line 58) | async function onMessage(msg) {
constant CHROME_BIN (line 66) | const CHROME_BIN = process.env.CHROME_BIN ? { endpoint: process.env.CHRO...
function botStart (line 102) | function botStart() {
function handleStart (line 121) | function handleStart(type) {
function init (line 209) | function init() {
FILE: src/kimi/__test__.js
function test (line 4) | async function test() {
FILE: src/kimi/index.js
function getKimiReply (line 41) | async function getKimiReply(prompt) {
FILE: src/ollama/__test__.js
function testMessage (line 4) | async function testMessage() {
FILE: src/ollama/index.js
function createRequest (line 9) | function createRequest(prompt) {
function getOllamaReply (line 34) | async function getOllamaReply(prompt) {
FILE: src/openai/__test__.js
function testMessage (line 4) | async function testMessage() {
FILE: src/openai/index.js
function getGptReply (line 26) | async function getGptReply(prompt) {
FILE: src/tongyi/index.js
function getTongyiReply (line 27) | async function getTongyiReply(prompt) {
FILE: src/wechaty/sendMessage.js
function defaultMessage (line 27) | async function defaultMessage(msg, bot, ServiceType = 'GPT') {
function shardingMessage (line 72) | async function shardingMessage(message, bot) {
constant SINGLE_MESSAGE_MAX_SIZE (line 99) | const SINGLE_MESSAGE_MAX_SIZE = 500
function trySay (line 107) | async function trySay(talker, msg) {
function splitMessage (line 125) | async function splitMessage(text) {
FILE: src/wechaty/serve.js
function getServe (line 18) | function getServe(serviceType) {
FILE: src/wechaty/testMessage.js
function handleRequest (line 13) | async function handleRequest(type) {
function init (line 95) | function init() {
FILE: src/xunfei/__test__.js
function testMessage (line 4) | async function testMessage() {
FILE: src/xunfei/index.js
function getXunfeiReply (line 3) | async function getXunfeiReply(prompt, name) {
FILE: src/xunfei/xunfei.js
function getModelDomain (line 31) | function getModelDomain(httpUrl) {
function generateSignature (line 44) | function generateSignature(httpUrl, apiKey, apiSecret) {
function authenticate (line 62) | function authenticate() {
function xunfeiSendMsg (line 75) | async function xunfeiSendMsg(inputVal) {
Condensed preview — 39 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (57K chars).
[
{
"path": ".dockerignore",
"chars": 14,
"preview": "\nnode_modules/"
},
{
"path": ".gitignore",
"chars": 115,
"preview": "node_modules\nWechatEveryDay.memory-card.json\n.env\ntest.js\npackage-lock.json\nyarn.lock\nChromium.app\n\n.DS_Store\n.idea"
},
{
"path": ".husky/pre-commit",
"chars": 15,
"preview": "npx lint-staged"
},
{
"path": ".npmrc",
"chars": 66,
"preview": "# puppeteer_download_host=https://registry.npmmirror.com/-/binary/"
},
{
"path": ".prettierrc.cjs",
"chars": 927,
"preview": "/**\n * 参考 https://prettier.io/docs/en/options.html\n */\nmodule.exports = {\n tabWidth: 2, // 空格数\n useTabs: false, // 是否开"
},
{
"path": ".vscode/settings.json",
"chars": 41,
"preview": "{\n \"cSpell.words\": [\"kimi\", \"xunfei\"]\n}\n"
},
{
"path": "Dockerfile",
"chars": 1357,
"preview": "ARG APT_SOURCE=\"default\"\n\nFROM node:19 as builder-default\nENV NPM_REGISTRY=\"https://registry.npmjs.org\"\n\nFROM node:19 as"
},
{
"path": "Dockerfile.alpine",
"chars": 837,
"preview": "ARG APT_SOURCE=\"default\"\n\nFROM node:19-alpine as base\nRUN apk update && \\\n apk upgrade && \\\n apk add --no-cache ba"
},
{
"path": "LICENSE.md",
"chars": 1096,
"preview": "MIT License\n\nCopyright (c) 2020-present, 荣顶 and wechat-bot contributors\n\nPermission is hereby granted, free of charge, t"
},
{
"path": "README.md",
"chars": 9060,
"preview": "# WeChat Bot\n\n一个 基于 `chatgpt` + `wechaty` 的微信机器人\n\n可以用来帮助你自动回复微信消息,或者管理微信群/好友.\n\n`简单`,`好用`,`2分钟(4 个步骤)` 就能玩起来了。🌸 如果对您有所帮助,"
},
{
"path": "RECORD.md",
"chars": 1163,
"preview": "# 使用最近很火的 OpenAi ChatGPT 配合 Wechaty 实现一个 微信聊天機器人\n\n## 前言\n\n使用 OpenAi ChatGPT 和 Wechaty 可以实现一个微信聊天机器人。OpenAi ChatGPT 是一个大型语"
},
{
"path": "cli.js",
"chars": 60,
"preview": "#! /usr/bin/env node\n\n'use strict'\nimport('./src/index.js')\n"
},
{
"path": "package.json",
"chars": 1646,
"preview": "{\n \"name\": \"wechat-bot\",\n \"version\": \"1.0.2\",\n \"description\": \"wechat-bot\",\n \"main\": \"index.js\",\n \"type\": \"module\","
},
{
"path": "src/302ai/__test__.js",
"chars": 198,
"preview": "import { get302AiReply } from './index.js'\n\n// 测试 302 ai api\nasync function testMessage() {\n const message = await get3"
},
{
"path": "src/302ai/index.js",
"chars": 966,
"preview": "import axios from 'axios'\nimport dotenv from 'dotenv'\n\ndotenv.config()\nconst env = dotenv.config().parsed\nconst key = en"
},
{
"path": "src/chatgpt/index.js",
"chars": 1139,
"preview": "import { ChatGPTAPI } from 'chatgpt'\nimport dotenv from 'dotenv'\n\nconst env = dotenv.config().parsed // 环境参数\n\n// 定义ChatG"
},
{
"path": "src/claude/index.js",
"chars": 1651,
"preview": "import axios from 'axios'\nimport dotenv from 'dotenv'\n\ndotenv.config()\nconst env = dotenv.config().parsed\n\n/**\n * 用于规整en"
},
{
"path": "src/deepseek/__test__.js",
"chars": 204,
"preview": "import { getDoubaoReply } from './index.js'\n\n// 测试 open ai api\nasync function testMessage() {\n const message = await ge"
},
{
"path": "src/deepseek/index.js",
"chars": 1018,
"preview": "import { remark } from 'remark'\nimport stripMarkdown from 'strip-markdown'\nimport OpenAI from 'openai'\nimport dotenv fro"
},
{
"path": "src/deepseek-free/__test__.js",
"chars": 213,
"preview": "import { getDeepSeekFreeReply } from './index.js'\n\n// 测试 open ai api\nasync function testMessage() {\n const message = aw"
},
{
"path": "src/deepseek-free/index.js",
"chars": 1148,
"preview": "import axios from 'axios'\nimport dotenv from 'dotenv'\n// 加载环境变量\ndotenv.config()\nconst env = dotenv.config().parsed // 环境"
},
{
"path": "src/dify/__test__.js",
"chars": 194,
"preview": "import { getDifyReply } from './index.js'\n\n// 测试 dify api\nasync function testMessage() {\n const message = await getDify"
},
{
"path": "src/dify/index.js",
"chars": 933,
"preview": "import axios from 'axios'\nimport dotenv from 'dotenv'\n// 加载环境变量\ndotenv.config()\nconst env = dotenv.config().parsed // 环境"
},
{
"path": "src/doubao/__test__.js",
"chars": 363,
"preview": "import { getDoubaoReply } from './index.js'\n\n// 测试 open ai api\nasync function testMessage() {\n let message\n message = "
},
{
"path": "src/doubao/index.js",
"chars": 1399,
"preview": "import { remark } from 'remark'\nimport stripMarkdown from 'strip-markdown'\nimport OpenAI from 'openai'\nimport dotenv fro"
},
{
"path": "src/index.js",
"chars": 7074,
"preview": "import { Command } from 'commander'\nimport { WechatyBuilder, ScanStatus, log } from 'wechaty'\nimport inquirer from 'inqu"
},
{
"path": "src/kimi/__test__.js",
"chars": 180,
"preview": "import { getKimiReply } from './index.js'\n\n// 测试 open ai api\nasync function test() {\n const message = await getKimiRepl"
},
{
"path": "src/kimi/index.js",
"chars": 3069,
"preview": "import axios from 'axios'\nimport dotenv from 'dotenv'\nconst env = dotenv.config().parsed // 环境参数\n\nconst domain = 'https:"
},
{
"path": "src/ollama/__test__.js",
"chars": 194,
"preview": "import { getDifyReply } from './index.js'\n\n// 测试 dify api\nasync function testMessage() {\n const message = await getDify"
},
{
"path": "src/ollama/index.js",
"chars": 1092,
"preview": "import axios from 'axios'\nimport dotenv from 'dotenv'\n// 加载环境变量\ndotenv.config()\nconst env = dotenv.config().parsed // 环境"
},
{
"path": "src/openai/__test__.js",
"chars": 195,
"preview": "import { getGptReply } from './index.js'\n\n// 测试 open ai api\nasync function testMessage() {\n const message = await getGp"
},
{
"path": "src/openai/index.js",
"chars": 1053,
"preview": "import { remark } from 'remark'\nimport stripMarkdown from 'strip-markdown'\nimport OpenAIApi from 'openai'\nimport dotenv "
},
{
"path": "src/tongyi/index.js",
"chars": 961,
"preview": "import fs from 'fs'\nimport path from 'path'\nimport dotenv from 'dotenv'\nimport OpenAI from 'openai'\n\nconst env = dotenv."
},
{
"path": "src/wechaty/sendMessage.js",
"chars": 4118,
"preview": "import dotenv from 'dotenv'\n// 加载环境变量\ndotenv.config()\nconst env = dotenv.config().parsed // 环境参数\n\n// 从环境变量中导入机器人的名称\ncons"
},
{
"path": "src/wechaty/serve.js",
"chars": 1296,
"preview": "import { getGptReply } from '../openai/index.js'\nimport { getDoubaoReply } from '../doubao/index.js'\nimport { getDeepsee"
},
{
"path": "src/wechaty/testMessage.js",
"chars": 3092,
"preview": "import { getGptReply } from '../openai/index.js'\nimport { getKimiReply } from '../kimi/index.js'\nimport { getXunfeiReply"
},
{
"path": "src/xunfei/__test__.js",
"chars": 202,
"preview": "import { getXunfeiReply } from './index.js'\n\n// 测试 科大讯飞 api\nasync function testMessage() {\n const message = await getXu"
},
{
"path": "src/xunfei/index.js",
"chars": 265,
"preview": "import { xunfeiSendMsg } from './xunfei.js'\n\nexport async function getXunfeiReply(prompt, name) {\n console.log('🚀🚀🚀 / p"
},
{
"path": "src/xunfei/xunfei.js",
"chars": 3730,
"preview": "import CryptoJS from \"crypto-js\";\nimport dotenv from \"dotenv\";\nimport WebSocket from \"ws\";\n\nconst env = dotenv.config()."
}
]
About this extraction
This page contains the full source code of the wangrongding/wechat-bot GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 39 files (51.1 KB), approximately 18.3k tokens, and a symbol index with 48 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.