
![]()
![]()
![]()
![]()
![]()












 "
"






 # 赞助商
以下排名不分先后!


================================================
FILE: docs/basics/HashMap.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> 本文 **GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 上已经收录,有一线大厂面试点思维导图,也整理了很多我的文档,欢迎Star和完善,大家面试可以参照考点复习,希望我们一起有点东西。
## 前言
作为一个在互联网公司面一次拿一次Offer的面霸,打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚(**请允许我使用一下夸张的修辞手法**)。
于是在一个寂寞难耐的夜晚,我痛定思痛,决定开始写互联网技术栈面试相关的文章,希望能帮助各位读者以后面试势如破竹,对面试官进行360°的反击,吊打问你的面试官,让一同面试的同僚瞠目结舌,疯狂收割大厂Offer!
所有文章的名字只是我的噱头,我们应该有一颗谦逊的心,所以希望大家怀着空杯心态好好学,一起进步。
### 正文
> 一个婀娜多姿,穿着衬衣的小姐姐,拿着一个精致的小笔记本,径直走过来坐在我的面前。
>
> 看着眼前这个美丽的女人,心想这不会就是Java基础系列的面试官吧,真香。
>
> 不过看样子这么年轻应该问不出什么深度的吧,嘻嘻。(哦?是么😏)

> 小伙子,听前面的面试官说了,你Redis和消息队列都回答得不错,看来还是有点东西。
美丽迷人的面试官您好,您见笑了,全靠看了敖丙的《吊打面试官》系列,不然我还真的回答不上很多原本的知识盲区,他真的有点东西。
> 面试官心想:哦,吊打面试官是么,那今天我就让你知道,吊打这两个字怎么写的吧,年轻人啊,提前为你感到惋惜。
>
> 嗯嗯小帅比,虽然前面的技术栈没啥太大的瑕疵,不过未来很长的一段时间我会用一期期的基础教你做人的,你要准备好哟!
>
> 好了我们开始今天的面试吧,小伙子你了解数据结构中的HashMap么?能跟我聊聊他的结构和底层原理么?
切,这也太看不起我了吧,居然问这种低级问题,不过还是要好好回答。
嗯嗯面试官,我知道HashMap是我们非常常用的数据结构,由**数组和链表组合构成**的数据结构。
大概如下,数组里面每个地方都存了Key-Value这样的实例,在Java7叫Entry在Java8中叫Node。

因为他本身所有的位置都为null,在put插入的时候会根据key的hash去计算一个index值。
就比如我put(”帅丙“,520),我插入了为”帅丙“的元素,这个时候我们会通过哈希函数计算出插入的位置,计算出来index是2那结果如下。
> hash(“帅丙”)= 2

> 你提到了还有链表,为啥需要链表,链表又是怎么样子的呢?
我们都知道数组长度是有限的,在有限的长度里面我们使用哈希,哈希本身就存在概率性,就是”帅丙“和”丙帅“我们都去hash有一定的概率会一样,就像上面的情况我再次哈希”丙帅“极端情况也会hash到一个值上,那就形成了链表。

每一个节点都会保存自身的hash、key、value、以及下个节点,我看看Node的源码。

> 说到链表我想问一下,你知道新的Entry节点在插入链表的时候,是怎么插入的么?
**java8之前是头插法**,就是说新来的值会取代原有的值,原有的值就顺推到链表中去,就像上面的例子一样,因为写这个代码的作者认为后来的值被查找的可能性更大一点,提升查找的效率。
但是,**在java8之后,都是所用尾部插入了。**
> 为啥改为尾部插入呢?
这!!!这个问题,面试官可真会问!!!还好我饱读诗书,不然死定了!

有人认为是作者随性而为,没啥luan用,其实不然,其中暗藏玄机
首先我们看下HashMap的扩容机制:
帅丙提到过了,数组容量是有限的,数据多次插入的,到达一定的数量就会进行扩容,也就是resize。
> 什么时候resize呢?
有两个因素:
- Capacity:HashMap当前长度。
- LoadFactor:负载因子,默认值0.75f。
怎么理解呢,就比如当前的容量大小为100,当你存进第76个的时候,判断发现需要进行resize了,那就进行扩容,但是HashMap的扩容也不是简单的扩大点容量这么简单的。
> 扩容?它是怎么扩容的呢?
分为两步
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
> 为什么要重新Hash呢,直接复制过去不香么?
卧槽这个问题!有点知识盲区呀!

1x1得 1 1x2 得 2 .... 有了,我想起来敖丙那天晚上在我耳边的话了:假如我年少有为不自卑,懂得什么是珍贵,那些美梦没给你,我一生有愧....什么鬼!
小姐姐:是因为长度扩大以后,Hash的规则也随之改变。
Hash的公式---> index = HashCode(Key) & (Length - 1)
原来长度(Length)是8你位运算出来的值是2 ,新的长度是16你位运算出来的值明显不一样了。
扩容前:

扩容后: 
> 说完扩容机制我们言归正传,为啥之前用头插法,java8之后改成尾插了呢?
卧槽,我以为她忘记了!居然还是被问到了!
我先举个例子吧,我们现在往一个容量大小为2的put两个值,负载因子是0.75是不是我们在put第二个的时候就会进行resize?
2*0.75 = 1 所以插入第二个就要resize了

现在我们要在容量为2的容器里面**用不同线程**插入A,B,C,假如我们在resize之前打个短点,那意味着数据都插入了但是还没resize那扩容前可能是这样的。
我们可以看到链表的指向A->B->C
**Tip:A的下一个指针是指向B的**

因为resize的赋值方式,也就是使用了**单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置**,在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
就可能出现下面的情况,大家发现问题没有?
B的下一个指针指向了A

一旦几个线程都调整完成,就可能出现环形链表

如果这个时候去取值,悲剧就出现了——Infinite Loop。
> 诶卧槽,小伙子难不倒他呀!
>
> 
>
> 小伙子有点东西呀,但是你都都说了头插是JDK1.7的那1.8的尾插是怎么样的呢?
因为**java8之后链表有红黑树**的部分,大家可以看到代码已经多了很多if else的逻辑判断了,红黑树的引入巧妙的将原本O(n)的时间复杂度降低到了O(logn)。
**Tip**:红黑树的知识点同样很重要,还是那句话**不打没把握的仗**,限于篇幅原因,我就不在这里过多描述了,以后写到数据结构再说吧,不过要面试的仔,还是要准备好,反正我是经常问到的。
**使用头插**会改变链表的上的顺序,但是如果**使用尾插**,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
就是说原本是A->B,在扩容后那个链表还是A->B

Java7在多线程操作HashMap时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。
Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
> 那是不是意味着Java8就可以把HashMap用在多线程中呢?
我认为即使不会出现死循环,但是通过源码看到put/get方法都没有加同步锁,多线程情况最容易出现的就是:无法保证上一秒put的值,下一秒get的时候还是原值,所以线程安全还是无法保证。
> 小伙子回答得很好嘛,这都被你回答道了,面试这么多人都不知道头插和尾插,还是被你说出来了,可以可以。
面试官谬赞啊,要不是你这样**美若天仙**的面试官面试我,我估计是想不起来了。
> 我*,你套近乎?
>
> 小姐姐抿嘴一笑,小子你offer有了,耶稣都带不走你,我说的!
>
> 
>
> 那我问你HashMap的默认初始化长度是多少?
我记得我在看源码的时候初始化大小是16
> 你那知道为啥是16么?
卧*,这叫什么问题啊?他为啥是16我怎么知道???你确定你没逗我?
我努力回忆源码,不知道有没有漏掉什么细节,以前在学校熬夜看源码的一幕幕在脑海里闪过,想起那个晚上在操场上,**跟我好了半个月的小绿**拉着我的手说:你就要当爸爸了。
等等,这都是什么鬼,哦哦哦,想起来了!!!
**在JDK1.8的 236 行有1<<4就是16**,为啥用位运算呢?直接写16不好么?

我再次陷入沉思,疯狂脑暴,叮!
有了!
面试官您好,我们在创建HashMap的时候,阿里巴巴规范插件会提醒我们最好赋初值,而且最好是2的幂。

这样是为了位运算的方便,**位与运算比算数计算的效率高了很多**,之所以选择16,是为了服务将Key映射到index的算法。
我前面说了所有的key我们都会拿到他的hash,但是我们怎么尽可能的得到一个均匀分布的hash呢?
是的我们通过Key的HashCode值去做位运算。
我打个比方,key为”帅丙“的十进制为766132那二进制就是 10111011000010110100

我们再看下index的计算公式:index = HashCode(Key) & (Length- 1)

15的的二进制是1111,那10111011000010110100 &1111 十进制就是4
之所以用位与运算效果与取模一样,性能也提高了不少!
> 那为啥用16不用别的呢?
因为在使用不是2的幂的数字的时候,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。
只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
这是为了**实现均匀分布**。
> 哟小家伙,知道的确实很多,那我问你个问题,为啥我们重写equals方法的时候需要重写hashCode方法呢?
>
> 你能用HashMap给我举个例子么?

这都能被他问到,还好我看了敖丙的系列呀,不然真的完了!!!
但是我想拖延点时间,只能**故做沉思**,仰望天空片刻,45°仰望天空的样子,说实话,我看到面试官都流口水了!可惜我是他永远得不到的男人,好了不装逼了。
我想起来了面试官!
因为在java中,所有的对象都是继承于Object类。Object类中有两个方法equals、hashCode,这两个方法都是用来比较两个对象是否相等的。
在未重写equals方法我们是继承了object的equals方法,**那里的 equals是比较两个对象的内存地址**,显然我们new了2个对象内存地址肯定不一样
- 对于值对象,==比较的是两个对象的值
- 对于引用对象,比较的是两个对象的地址
大家是否还记得我说的HashMap是通过key的hashCode去寻找index的,那index一样就形成链表了,也就是说”帅丙“和”丙帅“的index都可能是2,在一个链表上的。
我们去get的时候,他就是根据key去hash然后计算出index,找到了2,那我怎么找到具体的”帅丙“还是”丙帅“呢?
**equals**!是的,所以如果我们对equals方法进行了重写,建议一定要对hashCode方法重写,以保证相同的对象返回相同的hash值,不同的对象返回不同的hash值。
不然一个链表的对象,你哪里知道你要找的是哪个,到时候发现hashCode都一样,这不是完犊子嘛。
> 可以可以小伙子,我记得你上面说过他是线程不安全的,那你能跟我聊聊你们是怎么处理HashMap在线程安全的场景么?
面试官,在这样的场景,我们一般都会使用**HashTable**或者**ConcurrentHashMap**,但是因为前者的**并发度**的原因基本上没啥使用场景了,所以存在线程不安全的场景我们都使用的是ConcurrentHashMap。
HashTable我看过他的源码,很简单粗暴,直接在方法上锁,并发度很低,最多同时允许一个线程访问,ConcurrentHashMap就好很多了,1.7和1.8有较大的不同,不过并发度都比前者好太多了。

> 那你能跟我聊聊ConcurrentHashMap么?
好呀,不过今天天色已晚,我觉得我们要不改天再约?
再说最近敖丙好像双十二比较忙,一次怎么能怼这么多呢?
> 好吧好吧,小伙子还挺会为别人着想,而且还喜欢这么优秀的作者,你我觉得来日可期,那我们改日再约,今天表现很好,希望下次能保持住!
### 总结
**HashMap绝对是最常问的集合之一**,基本上所有点都要**烂熟于心**的那种,篇幅和时间的关系,我就不多介绍了,核心的点我基本上都讲到了,不过像红黑树这样的就没怎么聊了,但是不代表不重要。
篇幅和精力的原因我就介绍到了一部分的主要知识点,我总结了一些关于HashMap常见的面试题,大家问下自己能不能回答上来,不能的话要去查清楚哟。
HashMap常见面试题:
- HashMap的底层数据结构?
- HashMap的存取原理?
- Java7和Java8的区别?
- 为啥会线程不安全?
- 有什么线程安全的类代替么?
- 默认初始化大小是多少?为啥是这么多?为啥大小都是2的幂?
- HashMap的扩容方式?负载因子是多少?为什是这么多?
- HashMap的主要参数都有哪些?
- HashMap是怎么处理hash碰撞的?
- hash的计算规则?
## 点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇一线互联网大厂面试和常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】
如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 文章每周持续更新,可以微信搜索「 **三太子敖丙** 」第一时间阅读和催更(比博客早一到两篇哟),本文 **GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 已经收录,有一线大厂面试点思维导图,也整理了很多我的文档,欢迎Star和完善,大家面试可以参照考点复习,希望我们一起有点东西。
================================================
FILE: docs/coderLife/写作一个月在感恩节对大家说的话.md
================================================
> 所谓活着并不是单纯的呼吸,心脏跳动,也不是脑电波,而是在这个世界上留下痕迹。
>
> 要能看见自己一路走来的脚印,并确信那些都是自己留下的印记,这才叫活着。
>
>
>
> 东野圭吾 《变身》
>
> 
>
>
本来今天是没文章的,RocketMQ周末写了60%发不出来,但是感觉日子特殊嘛我就熬夜写一下。
今天敖丙我不写技术,不知道在看我文章的你知道今天是什么节日嘛?
上个月的今天我发了我在博客的第一篇文章,同时今天也是【感恩节】

我身边熟悉的我人都知道,其实帅丙我是不过西方节日的,但是最近家里出了一些事嘛,而且也是自己工作第一年的结束,晚上上班的时候就多了很多感慨,走在路上思绪转的飞快想了很多(虽然公司走到家里我只用1分钟)。
回到家跟爸妈都发了很长很长的语音,看了看窗边,外面的风在肆虐着空气,凝望着天空。
想了很多东西说就准备在这样的节日跟大家闲聊一下。
老妈他们本来在越南工作的嘛,因为外婆身体突然不好,然后回老家去了,外婆身体一切ok的,后来老妈又说要动手术,而且老爸说检查要一个周,刚得知这个消息的我其实很爆炸,因为别人手术前检查几天就好了,但是老妈为啥要一礼拜。
我没跟老爸他们说我的担心,只是在地铁站接了电话出来后,在杭师大的操场上渡步,鼻子酸酸的,是的一个大男人哭了说出来真的很丢人。
这是我在杭州第三次哭泣了,像个弱者,第一次是因为实习交不起押一付三的房租,第二次是因为代码写太差和一些压力。
这一段我删了撤回,删了撤回,觉得丢人,但是最后大家还是看到了,反正男人嘛无所谓的。
回归主题嘛,今天是感恩节嘛,虽然我才毕业一年,但是这是我来杭州的第三年了,感慨还是很多的。
先说说家庭吧,我家条件就这样,平平淡淡,贵州的小山村嘛,经常跟群里的调侃,过年发不了文章不是我不发是没网,是的还是2g泪目。

以前觉得父亲在同龄人中太平庸了,但是后来的我才知道,他付出了多少才撑起这个家,让自己读完大学,健康成长到现在。
母亲身体一直不好那种,但是她对家庭的付出跟老爸一样多,忍耐着父亲的脾气,我的幼稚,勤俭持家才有了现在的我回老家居住的环境,和我的一切。
其实在这样公开的平台说着这样的话,我觉得挺不好意思的,不过我想也没啥,我就是我,无可厚非,你就是你,也是我的朋友,不是嘛。
我就借助这样的日子把对煽情的话都说了吧哈哈,反正让我当面跟爸妈说也说不出口。
明早发了赶紧转发给他们哈哈。
友情提示:天冷了,大家记得也问候一下家人,一句话可能就让他暖得不行。
说一下我为啥写文章吧。
因为三歪的一句话吧:你真的很适合写文章。
记得是某段时间他对我经常说的,那时候回到家一直在纠结,就有了后来的系列。
其实他不说我现在应该是个B站up主吧哈哈,其实我装备都买了,视频都拍了一个了,但是没人看嘛。
因为我没啥时间拍摄,还有我上班也枯燥,剪辑也很一般般那种,就反正没人看,所以大家发现我文章里面的视频元素了么?
开头的点赞在看养成习惯,结尾的求赞,求关注,求转发,还有文章里面我会融入很多自己风格的元素,其实是相当于写文章圆了自己up主的梦吧。
还好我写了文章没继续拍下去,不然现在应该还是那个关注只有7个的小敖丙吧。
再说一下写文章一个月以来的感受吧,其实有人喷过我,有人怼过我,但是都是少数,我性格就这样怼我,表面上我也就这样吧,其实还算在意,所有有时候三歪隔着桌子看我骂空气傻*。
不过说实话谢谢大家,更多的都是鼓励我,夸奖我的,有时候我都被你们夸奖得有点飘了,觉得我是那么回事了,但是我呢这个人能经常冷静下来,我还是我,那个刚毕业一年的我,那个23岁不大不小的我。
《吊打面试官》是我最开始就定的名字,但是很多读者就问我看了是不是就能吊打面试官了,看了是不是就无敌了。
不能,不是!
我取很多标题都是为了噱头,我甚至多次想改掉了,不过写了也不少了,就没改,但是我想让大家认知正确,我刚开始学软件,我的姐就告诉我要有空杯心态,我希望大家也是一样,用一颗谦逊的心,对待每个未知事物。
面试官能面试你,肯定有人家的原因的,或许你的知识广度够但是你确定你有他深度?又或者你深度够,你能有他广度?有些东西是必须时间积累的,慢慢你们会明白的。
各个平台收获了不少粉丝,有开心也有烦恼,很多东西我可能比大家接触多点,因为电商嘛场景本身就很丰富,但是大家也不要忘记我也没工作多久,我好多技术栈的深度也不够,所以很多人的问题其实我也不是很懂,那问题就来了,我怎么做到文章的技术栈都有深度呢?
臣妾做不到。
是的短期我想我做不到,没长时间的积累我想我还是不敢写很深的东西给大家看,只能把我已知的只是点展示给大家看,写知识扫盲,趣味学东西为主的文章,这也是为啥每期我会让阿里系或者身边的大佬朋友review一遍的原因。
所以文章里面那句我们一起进步,并不是我的自谦,是我的自我认知。
Tip:这篇文章啥干货都没,所以没前言,没正文,没求赞,甚至没排版。
接下去到年底的日子,会有双十二,双旦,年会Vlog视频等一大堆事情,我有拖更的预感了,别怪我没提醒你们哟。
最后也在这样的节日,感谢大家,谢谢你们看我的文章,夜深了,我们下篇文
================================================
FILE: docs/coderLife/敖丙用20行代码拿了比赛冠军.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> [**GitHub**](https://github.com/AobingJava/JavaFamily)上已经开源[https://github.com/Java...](https://github.com/AobingJava/JavaFamily),有面试点思维导图,欢迎[**Star**](https://github.com/AobingJava/JavaFamily)和[**完善**](https://github.com/AobingJava/JavaFamily)
## 前言
这一期不算**《吊打面试官》**系列的,所有没前言我直接开始。
## 絮叨
本来应该是没有这期的,看过我上期的小伙伴应该是知道的嘛,双十一比较忙嘛,要值班又要去帮忙拍摄年会的视频素材,还得搞个程序员一天的**Vlog**,还要**写BUG**,超级忙的。
**Redis**的答案刚发,你怎么又发?这么高产?这么这么优秀!
其实这篇是我以前就写的,只是都没发出来过,而且作为**暖男**我就想着你们嘛,所以就从自己之前的文章里面水一篇给大家看一下,开始前我先回答点最近大家私聊问我的一些问题。
###知乎 阿渣a: 你为啥突然开始写面试系列了?
这个问题就算不问我也准备在某一期写出来的,因为**Java3y**的作者**三歪**哈,这个号大家在各个博客平台应该都或多或少看过,是他给的建议。
他是我基友兼同事上班的时候我们面对面坐的(昨晚在我这促膝长谈哈哈),他是一个**应届生**,但是他现在已经有**200多篇原创文章**了,知识的广度深度都挺好的。
反正就是跟我说了很多东西,我一听诶觉得这个人**有点东西**,然后有一天他说我这样的性格应该去写文章,肯定有很多人喜欢看,关注人多了,可能有点也会有点工资外的**额外收入**。
(实话实说,我也不骗你们,像我工资这么高的人 ! 跟我谈钱?真香)。
不过现实总是这样残酷,至于现在收入多少嘛,我觉得我刚开始写,我们还是不提这个好吧,我怕我把自己写哭了**o(╥﹏╥)o**!

### 掘金 Skyline7:说! 你和3y是不是同事!
是的给个图片自己感受哈哈。(左三歪,右敖丙)

###写吊打系列之后的感受?
说实话挺爽的,很多**人才**喜欢看嘛,很多人私信鼓励我写下去,还有就是因为以前跟很多博主啥的,信息都是单方面的输入的关系,就都是别人写了我看。现在自己也输出了,也有自己喜欢的博主看了,还**点赞评论加关注**了,我觉得就很开心。
特别是**CSDN**的大佬 :**梦想橡皮檫** 掘金的 :**SnailClimb( JavaGuide)**
**JavaGuide**跟**Java3y**一样都是应届生,我都是看着他们的文章长大的,这差距诶。
(不过私下确认了一下好像我和他还有三歪都是96年的哈哈)


然后有时候消息可能回不及时,但是我能回的我其实都第一时间回了,但是平时工作嘛,基本上都是晚上回家,中午吃完饭啥的看消息,但是都是这样的↓↓↓
我有点慌(其实很开心,谢谢各位的认可)!

我自己之前也面过大大小小的互联网公司,不乏阿里系腾讯系的公司,**失败过,成功过,哭过,爱过~~~~**,我知道面试的哪些点比较重要或者怎么组织话语比较重要,其实自己有在自己的本地写过一些东西。
但是都没发表过,而且本地很多好像也是我以前复制进去的,我都不知道哪些是自己写的哪些是复制的,肯定不能直接发的,所以以后应该都是自己写自己的内容,以后就**承蒙各位关注了**!

###掘金 江飞杰 :你都是在环境下写文章的呀?
一般都是周末或者下班后,孤寡老人嘛在家就坐沙发上发呆,然后写点东西,喝点闷开水,年纪大了早上也睡不着,早起也会在那写到快上班去上班。
**但凡有个女朋友都不至于这样啊!!!**

## 正文
捞一下:前几期吊打系列我们提到了**Redis**的知识,还没看的小伙伴可以回顾一下
- **[《吊打面试官》系列-Redis基础](https://juejin.im/post/5db66ed9e51d452a2f15d833)**
- **[《吊打面试官》系列-缓存雪崩、击穿、穿透](https://juejin.im/post/5dbef8306fb9a0203f6fa3e2)**
- **[《吊打面试官》系列-Redis哨兵、持久化、主从、手撕LRU](https://juejin.im/post/5dc3a9fbf265da4d3c072eab)**
- **[《吊打面试官》系列-Redis终章_凛冬将至、FPX_新王登基](https://juejin.im/post/5dc850b4e51d452c2308ee27)**
- **[《吊打面试官》系列-Redis常见面试题(带答案)](https://juejin.im/post/5dcaebea518825571f5c4ab0)**
**这期不算面试的知识点,来只看面试的小伙伴可以直接跳文末的面试技巧。**
## 公司活动
我们公司在1024当天有个活动↓

**MOGU创意代码大赛**
**参赛要求**
1.参赛作品主题鲜明,创意新颖,内容健康,适合观赏,以生活为主题;
2.充分发挥想象力和创造力,力求以独特的创意展现作品的趣味性和娱乐性。
我一看诶,我擦,这不是本渣我的强项嘛,用代码输出点啥,我第一时间就想到了用代码把一个完整的视频输出出来,我输出公司的广告不就跟公司就有强关联性了嘛。
**奖项设置**
一等奖 1名:Razer雷蛇电竞专用机械键盘
二等奖 2名:飞利浦机皇款电动牙刷
三等奖 3名:颈椎按摩器/电动理疗护颈仪
参与奖若干:国风超大电脑桌垫(哪吒闹海)
**本渣我一看居然还有奖励,不过奖励不奖励的无所谓,我主要是喜欢写代码。**
既然脑子有了想法那我也不多BB直接开搞。
#我第一时间就想起了用字符把公司的广告,输出成动画
我们都知道其实最早的动画片都是画家手动一张一张的画出来然后连起来播放,然后才成动画片的,那么原理我们也知道了,就直接开搞吧。

##那首先要做的就是把公司广告按照动画抽帧出来
**tip:这里有个注意点就是没必要一帧一帧的抽,因为肉眼最高的是60fps,要一帧一帧抽那太多了,我按照每10帧抽了,这样工作了少很多,但还是好多啊,不说了直接搞**
###我抽帧的工具是Adobe Premiere Pro cc 2019
也有批量抽帧工具,mac上我没找到,就麻烦朋友在Windows电脑抽了一下

###接下来我们要做的就是把我们抽出来的每一帧都转换为ASCII字符,将1000多帧转换好后我们可以看到已经生成1000多个txt文件了。

###转换过程用相关软件做一下就好了,谷歌百度都能查到很多,我们打开其中一个看下效果

###其实放大之后就是一个个的英文字母和数字,播放的时候我们可以把字体调小点,有点把像素调搞高点的意思。

**ps:这里有个坑,就是mac大部分的字体在txt文本中是不等宽的,就是说 i 和 o是不等宽的,你需要找到对应等宽的字体 我找了很久才找到,作为**暖男**,你不用找了我帮你找好了 !**
- Mac: Andale Mono
- Windows:宋体
我们可以看一下不等宽的样子,就会发现每一行字数一样,但是长宽不一样。

###如果你发现你还是没找到对应的字体,那么我教你两个方法:
- 去txt里面找到字体设置一个一个试,
- 用代码去拉出本地所有的字体,循环出来看效果
### 下面分别是手动查找和程序查找的代码


###接下来的事情就很简单了,我们用代码每次读取每个画面的行数每次输出一屏(我这里一屏是160行,看个人视频实际大小决定,代码里面也给了调节参数)连续输出就有动画的效果了,注意控制输出的时间间隔,我也不多BB,直接贴关键代码

##最后我们看下成片
完整版太大了gif传上来展示不出,完整版可以看我公众号,就放个一两秒的demo。

##活动结束
像我这种**天才**型的选手,你们想都不用想,拿了第二o(╥﹏╥)o,下面是hr小姐姐发奖时候的照片,为啥没拍我领奖的照片,生气!

只能感叹对手太强了,太强了。
不过还是忍不住给自己的聪明才智点个赞!
**暗示点赞,每次都看了不点赞,你们想白嫖我么?你们好坏喲,不过我喜欢**
----
## 总结
好了不逗比了,最后我来点**干货**吧,因为我发现好多读者都是**应届生**什么的,或者是明年就要出来**实习**的仔,那我给点我的建议:
**准备自我介绍!!!**
自我介绍,这个必须要准备,面试90%的套路都是**“来你先做个自我介绍吧”** ,一般自我介绍1-3分钟左右,时长看你自己的经验和经历。
**作为在校生:**
因为大家还没啥社会经验,我觉得你突出你的**大学经历**、**个人成就奖项**、**证书**、**个人成绩**等就好了。
要让面试官知道你是个人才,你没有白白荒废你的大学生活,我招你进来你是个**靠谱**的人,**肯学肯沟通能吃苦耐劳**等等,对了有**实习经历**的一定要突出出来,毕竟这是你和社会接轨的证明,
最后给个**小技巧**,大家可以把自我介绍写下来,然后说出来并且自己用手机录音听一下,联系到自己满意为止,我刚毕业就是这么做的,(每次听自己的声音都忍不住爱上自己)我印象笔记里的版本,我改掉了公司信息和学校信息,可以给你们个DEMO可以参考下,觉得不错记得**点赞**!!!

**作为已经工作的仔:**
我觉得大家,更要细心准备这1-3分钟的自我介绍。
因为这是这场面试的开始,也是面试官唯一能快速获取你经历信息的途径,多的就不说了,**公司**、**工作的内容**、**擅长的技术栈**,甚至是是否**单身**等等(有的加班严重的公司就是比较看重这个),我也准备了社招的面试Demo,你们加我公众号获取吧,算了不这么吸粉了,直接放吧(我还是心太软啊)!**点赞**!!!

**上面的学校公司都是我瞎吹的,可不能给我清华抹黑啊!**
其实我这里都是比较简单的自我介绍了,真实大家的经历可能更丰富点,而且大家也可以多多润色一下,这只是自我介绍一个环节,后面在各个**《吊打面试官》**系列里面我都会提到一些小的**贴士**大家都注意下。
有啥疑问或者需要我给建议可以去**GitHub**https://github.com/AobingJava/JavaFamily或者我公众号都有我微信。
## 下期投票!!!
下期准备了从下面两个题材中选一个写,根据你们这个篇文章的点赞是基数还是偶数决定
- 基数:Java基础
- 偶数:MQ
- 不基不偶:MySQL
## END
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇《**吊打面试官**》系列和**互联网常用技术栈**相关的文章。如果你有什么想知道的,也可以留言给我,我一有时间就会写出来,我们共同进步。
非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得**「敖丙」**我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** **求留言💬** 对暖男我来说 **非常有用**!!!
各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】
------
> **《吊打面试官》**系列每周持续更新,可以关注我的公众号**JavaFamily**第一时间阅读和催更(**公众号比博客早一到两天哟**),里面也有我个人微信有什么问题也可以直接滴滴我,我们一起进步。
================================================
FILE: docs/coderLife/教你在服务器搭建个人面试项目.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> **GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily)上已经收录有一线大厂面试点脑图、个人联系方式和人才交流群,欢迎Star和指教
## 前言
群里不知道多少次大家说自己的**项目没亮点**,在大学没项目出去后**怕找不到工作**,问敖丙我实习的时候是怎么拿的华为Offer。
其实大学的项目很简单不需要太大的难度,因为面试官知道你也没啥经验,不会很在意这个,但是你得有项目这是必要条件,再不济**增删改查你要比别人6**吧,不然找个0经验的人进去,不是给他自己挖坑?
而且如果你有个还不错的履历,或者你的项目还有一些**亮点**,那完美了,你的Offer率会拉开同行的仔一大截的。
丙帅我呢大学做过几个项目,前些天问了问学妹,还在学校稳定运行着,说实话我有点小骄傲了。

但是说实话,我拿华为Offer跟这些项目关系不大,大学时候完成的项目完全是兴趣使然,想起当初自己一个人在室友还没起床的时候去图书馆,在室友都睡觉的时候还没回去的时光,我的眼角又湿了。
**Tip**:怎么拿的Offer我会在《程序人生》系列写,过年前或者后面出个我大学到现在的心路历程哈哈。
当时在电子阅览室当管理员,甚至多次为了赶进度,在图书馆通宵达旦,好在最后还是完成了那个项目,自己一个人从前端到服务端,从研发到部署上线。
大家都知道学校选课用选课系统的时候,很多学校给第三方公司做的系统都很卡,敖丙做的项目就不卡,因为那个时候我就用到Redis了,现在想想设计思想还算前卫。
好了吹了这么多,其实就是为了引出今天的主题,**如何从0到1搭建一个可以外网访问的项目**。
很多小伙伴看到最后要说了,丙丙我要学的是**分布式**,才不要学垃圾的单机系统。
分布式不就是一个单机的服务构成的,你多起几个进行RPC通信不就好了?
## 正文
双十二阿里服务器推广,不买的小伙伴直接跳过这段,不过用来学习真的香,**比学生的9.9每月还便宜**。
**[我帮阿里云推广服务器89/年,229/3年,买来送自己,送女朋友马上过年再合适不过了,买了搭建个项目给面试官看也香,还可以熟悉技术栈,我明天会出一个服务器搭建个人项目的教程(老用户用家人的购买,我用我妈的😂)。扫码或者点击购买](https://www.aliyun.com/minisite/goods?userCode=tybhsgp5&share_source=copy_link)**

我就用自己的服务器给大家举例,怎么从0到1搭建一个学生和新手可以用来面试的项目,老手也可以回忆一下自己逝去的青春。
可能有小伙伴疑惑,丙丙为啥要服务器,本地不行么?
可以,当然不是为了推广服务器哈,大家可以不买,我只是阐述一下自己的观点,因为大家以后出去难免遇到自己操作服务器的情况,有些公司没有集成发布系统,那就需要你亲自去机器上操作了。
然后你rm -rf ,好了去财务室领下工资吧,年底了,提前回家过年可还行?

开玩笑的哈,只是很多操作大家不经常熟悉其实会都不知道,真正去操作或者面试官问你,熟悉各种操作么,你说不熟悉,好的回去等消息。
作为面试官,面试没多少经验的你,他更看重你思考的思路,还有你有没有实操过,务实么?
帅丙我大学的项目就是经常操作,所以后面很长一段时间的服务器操作,还有Linux命令啥的都还是不错的,技术栈搭建起来也是很熟悉,不过最近都是用的公司的工具,命令忘了好多了,需要反省一下了。
服务器在激活的时候会让你选系统,这个时候敖丙我个人建议,**有点基础**已经**熟悉安装过程和环境配置**的同学可以直接选择镜像,镜像市场里面有很多很适合的镜像,我选的就是带JDK8,Tomcat8,MySQL的镜像。
没搞过的同学可以尝试着选个空白机,然后下好这些东西,一步步去尝试,我想收获还是会有的,**跟你在自己电脑搭建的区别你会马上体会到**,这就是为啥建议大家去服务器操作的原因之一。
### 镜像选择

镜像**记得选不要钱的**,一般都是免费的。

选完你在**实例**就可以看到自己的服务器了,下面就是帅丙的服务器,居然跟我一样帅,天呐。

上面都是新搭建的小伙伴,已经有服务器的小伙伴,但是又想换成镜像怎么办?
大家**先把服务停掉**然后点击右边的**更换操作系统**就好了,会让你去镜像市场选的,之前你选了什么系统都可以换。

### 登录服务器
可以直接在管理界面网页登录服务器远程链接,也可以自己本地用对应的控制台工具连接。
个人推荐本地的控制台连接会好点,每次要登录服务器都要去网页很麻烦的。

远程链接的代码,记住是大家的公网ip,管理界面看得到的,要记得你购买的时候配置的密码,因为这个时候要输入。
> ssh root@123.14.123.8 -p 22 (后面的22是个端口,后面我介绍到)


到这一步的时候,很多小伙伴直接登录成功,但是之前就已经有服务器的朋友是不发现,出现下面这个页面了?

会出现这些信息是因为,第一次SSH连接时,会生成一个认证,储存在客户端(也就是用SSH连线其他电脑的那个,自己操作的那个)中的known_hosts,但是如果服务器验证过了,认证资讯当然也会更改,服务器端与客户端不同时,就会跳出错误啦~因此,只要把电脑中的认证资讯删除,连线时重新生成,就一切完美啦~要删除很简单,只要在客户端输入一个指令
> ssh-keygen -R +输入服务器的IP
接下来再次连接一次,会出现
> Are you sure you want to continue connecting (yes/no)?
输入yes!
就完成连接啦!同时,新的认证也生成了。

进去后如果是镜像的小伙伴会发现本身他准备好的东西都在了,环境都搭建起来了,大家只管直接使用就好了。
但是如果没有选择镜像的朋友,就需要自己搭建一个FTP或者使用传输命令去把你下载好的Tomcat、MySQL等传输进来安装好。

大家可以看到还**有一个默认密码文件夹**,里面就有MySQL和FTP的账号密码什么的,不同的镜像可能有差异。
这个在之后大家自己的服务写代码的时候,配置连接本地的MySQL就是需要这个的。

### 博客网站
这次教大家搭建的项目说大不大,说小吧他啥都有,反正小白和学生肯定很适合,是个个人博客网站。
我们先看看博客的效果,看看大家作为大学的项目到底合格么?
我大学做的那个项目比起这个就差点意思了,当时要是有这么好的UI就很香了!



### 项目代码
以我这种直男审美都觉得UI很不错,你以为只是UI可以?那我们看看项目!
项目的Git地址 https://github.com/halo-dev/halo.git 大家克隆一下就好了。
这个项目本身是**Gradle**的,很多小伙伴就要说了,啊帅丙我不要,我就要**Maven**项目的。

我只想告诉大家,**技多不压身**,目前很多大厂都是Maven项目Gradle项目都占有很高的比重,你怎么知道你去的公司会用啥?
你会用进去**减少多少学习的成本**啊,Leader在旁边暗自给你比一个大拇指,暗自感叹:**帅丙的读者,有点东西**。
Mac很多小伙伴安装的时候发现没有**Homebrew** 就没办法用很方便的命令行去下载安装Gradle,那简单我们安装一下,用下面的命令。(Windows的朋友直接官网下载一个就好了 [https://gradle.org/install](https://gradle.org/install/))
```java
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
```

这个安装好了,我们再用下面的命令就可以就把Gradle安装好了,是不是比你去下载方便很多?
```java
$ brew install gradle
```

接下来去项目中设置下Gradle地址,这里介绍的是IDEA的设置

### 为啥推荐个人博客项目?
很多人问我为啥推荐这个项目,这个项目看过次代码了,**没有啥语法错误**,**项目结构**完全**标准**的项目,**注释也很齐全**,**代码的风格挺不错**的,还是 **用了很多新语法和注解**。
而且他也**不难理解**,**结构很简单**,前端后端都很简单,大家看看代码,看看前后的接口,很快就能适应这个项目了。


接下来我们可以用项目去打个包,或者直接下载敖丙打包好的。(jar包还有war包随意)
### 用命令行下载最新的 Halo 安装包
```
curl -L https://github.com/halo-dev/halo/releases/download/v1.1.1/halo-1.1.1.jar --output halo-latest.jar
```
或者
```
wget https://github.com/halo-dev/halo/releases/download/v1.1.1/halo-1.1.1.jar -O halo-latest.jar
```

文件传输呢,帅丙我习惯命令行了,FTP这样的工具还是不适应,我就发下命令行是怎么把jar包从本地传输到服务器的。
```
scp -P 22 /Java/program.war root@123.456.789.987:/usr/server/tomcat7/webapps/
```

我们进入机器去看一下,文件已经传输进来了。

因为是一个SpringBoot项目,你只要有JDK直接就能跑起来了。
```bash
java -jar halo-latest.jar
```

然后大家访问下自己的 ip+端口(8090)就能看到项目了
然后很多小伙伴说,渣男,我的怎么不行?
稍等稍等,敖丙啊还正准备说呢,大家的端口默认就开通了 22 、-1、3389
22是不是很熟悉,就是开头我们链接的端口号→ ssh root@123.14.123.8 -p **22** 也是因为厂商默认给我们开通了,我们才可以直接链接的。
但是我们要访问别的端口,那就去开通嘛,**记得入口出口一样都要开通哟**!



然后重启下机器,重新启动项目,是不是!!!可以访问了???我们先注册一下

然后再登录进去。
可以看到校验的异常什么的都直接日志抛出的,项目我觉得对于学生和新手来说很香,里面的代码风格大家也多适应一下。

登录进去我们可以发现,功能很全,博客网站基本的结构都在了。
有个不成熟的猜想,还没毕业设计的朋友。。。。😂


## 絮叨
看到这里很多小伙伴可能会说你就是为了推广服务器才写的吧,我说实话有一定的成分,但是更多是因为我自己的群里,经常有很多小伙伴对**项目的整个搭建流程不是很熟悉**,所以才出这样的一篇文章的。
这里只是一个单机的项目,大家真正部署的时候要体验别的技术栈可以去Git上下载下来部署上去,体验他整个部署流程,**中间肯定很多不顺利的地方**相信我,100000%不会一次成功,但是你慢慢摸索的过程就是你学习的收获的过程。
大家经常问我那些大佬怎么成长上去的,**踩坑和付出大量实践上去的**,别无他法。
我老东家的Leader 95年的,是我们之前公司前端后端的Leader,技术深度广度,业务深度都领人发指,怎么做到的?
简单,**不断踩坑学习**咯,每天都是凌晨回去,白天开会,晚上写代码,甚至还要挤出时间学习新的业务,技术栈也是不断自己去摸索。
之前他一手带的我,我跟他太熟悉了,买了早餐刚坐下就去开会讨论业务,晚上6点回来就说:诶鸡蛋豆浆都冷了啊,然后丢垃圾桶。
学习是一条令人时而喜极若狂、时而郁郁寡欢的道路。
成长路上我们一起共勉。
## 日常求赞
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇一线互联网大厂面试和常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】 如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 文章每周持续更新,可以关注我的公众号「 **JavaFamily** 」第一时间阅读和催更(公众号比博客早一到两篇哟),本文**GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 上已经收录,有一线大厂面试点思维导图,欢迎Star和完善,里面也有我个人联系方式有什么问题也可以直接找我,也有**技术交流群**,我们一起有点东西。
================================================
FILE: docs/coderLife/记一次差点害敖丙丢工作的的线上P0事故.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> **GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily)上已经收录有一线大厂面试点脑图、个人联系方式和技术交流群,欢迎Star和指教
## 前言
这是帅丙真实事件,大家都知道很多公司都是有故障等级这么一说的,这就是敖丙在公司背的P0级故障,敖丙差点因此**被解雇**,事情经过**十分惊心动魄**,我的**心脏病都差点复发**。
> 事故等级主要针对生产环境,划分依据类似于bug等级。
>
> P0属于最高级别事故,比如崩溃,页面无法访问,主流程不通,主功能未实现,或者在影响面上影响很大(即使bug本身不严重)。
>
> P1事故属于高级别事故,一般属于主功能上的分支,支线流程,核心次功能等,后面还有P2,P3等,主要根据企业实际情况划分。
### 正文
敖丙之前也负责公司的商品搜索业务,因为业务体量增速太快了,商品表中的商品数据也很快跃入千万级别,查询的RT(response time 响应时间)也越来越高了,而且产品说需要根据**更多维度去查询商品**。
因为之前我们都是根据商品的名称去查询的,但是电商其实都会根据很多个维度去查询商品。
就比如大家去淘宝的查询的时候就会发现,你搜商品名称、颜色、标签等等多个维度都可以找到这个商品,就比如下图的搜索,我只是搜了【**帅丙**】你会发现,名字里面也没有连续的帅丙两个字,有帅和丙的出来了

大家知道的传统的关系型数据库都是用什么 name like %帅丙% 这样的方式查询的,而且查询出来的结果肯定只能是name里面带帅丙的对吧。
那你还想搜别的字段比如什么尺寸、关键词、价格等等,都能搜到帅丙,这相当于是多个维度的了,传统的关系型数据库做不到呀。
做技术选型的时候,帅丙第一时间想到了搜索引擎。
当时市面是比较流行的有:**Apache Lucene**、**Elasticsearch**、**Solr**
搜索引擎我后面会讲**ELK(Elasticsearch、Logstash、Kibana)**和**Canal**,我呀真的是太宠你们了,这样会不会把你们惯坏了。
帅丙我呀,噼里啪啦一顿操作,最后得出结论:
> 相对来讲,如果考虑静态搜索,Sorl相对更合适。
>
> 如果考虑实时,涉及到分布式,Elasticsearch相对合适。
那我们商品还是要实时的呀,你后台改了价格啥的,是不是都要实时同步出去,不然不是炸了嘛。
看到这,我想**可爱的你**和帅丙心中都有了答案:Elasticsearch这是个神一样的引擎。
我这里就做一个简单的介绍就好了,细节的点我们后面去他的章节讲,啥都写了,敖丙哪里有这么多素材写文章?
> ElasticSearch是一个基于Lucene的搜索服务器。
>
> 它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
>
> Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
>
> ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。
>
> 根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
看过敖丙之前文章的朋友都知道,我们做技术选型之前,要做什么呀,**设计**!
我们要去了解这玩意的**好处**、**坏处**、**常见的坑**、**出了问题的应急预案**等等,还有他的**数据同步机制**啊,**持久化机制啥**的,就是高可用嘛。
同样的我不大篇幅介绍了,以后都会写的嘛,我就给大家看看我当时做的设计吧。


**这个只是最初的demo,详细的终稿我就不给大家看了,因为有很多公司内部的逻辑。**
**不过大家还是可以看到敖丙真的考虑了很多,还是那句话,不打没把握的仗!**
设计做好敖丙就**卡卡卡**的用起来了。
说实话,**真香**,这玩意真的好用,学习成本也很低,查询语句分分钟掌握了,官网文档把功能介绍得清晰无比。
> https://www.elastic.co/cn/
用着用着重头戏来了,你们都知道敖丙我是做电商活动的,都是什么很高的流量打进来这样,还是如往常一样上线了一个活动。
**这是一个月飞风高的夜晚,丝丝凉风迎面吹来,敖丙悠闲的坐在椅子上,手里拿着破旧的茶杯,喝着外婆炒的苦荆茶,享受着这惬意的时光。**
突然,说时迟那时快,运维打来了紧急电话ES集群CPU打到了99%要挂了,**我的心蓦然一痛**,心里还在庆幸还是集群没崩。
然后他接着说了一句,不好集群挂了!
敖丙卒,本篇完....

开玩笑的哈,不过当时敖丙真的**要死的心真的都要有了**,就在崩掉的1分钟内,就有用户反馈搜索未响应,我第一时间想到的就是重启,于是我一个健步冲出去,开启电脑,进机器,输入了重启命令。
好了,是的好了,还好有惊无险,不过只过了10秒,集群又99%了,呐呢?

我又只能重启了,这次没挂,过了很久很久,直到活动结束,还是没挂。
### 查找问题
但是这次影响到线上,3分钟的搜索未响应,我想我估计明天是要去财务领工资,提前回家过年了。
**还好Leader说没事**,先找到问题,把他修复掉。
你们都知道敖丙天才来的,我第一时间想到的就是看日志,我登上去看es没报错,再看本身的服务,除了超时的错误啥都没有,卧槽,是的当时我脑袋嗡嗡响。
不过我继续想为啥是我的搜索挂了,**会不会是有人搜了什么奇怪的东西?**
我打开了我的搜索日志!!!
卧槽这不是吧,哪个坑爹玩意搜这么长的一串中文,差不多250个字吧。
但是我一想,搜这么长也不应该打挂服务啊,**会不会是我写了bug**!
我脸颊流下一滴汗水💦,我看了看周围,发现没人注意到我的紧张,我**故作镇定**的把它擦掉。
我仔细一想,别人查询虽然长,就算查数据库也没事啊,为啥es就报错了?会不会?

**Es有Bug!没错肯定是Es的锅。**
那为啥会这样呢,我直接跟老大这样解释也好像不行啊,**还是要被开除的吧!**
于是我去看看看代码,我在关键词使用了通配符,我当时是为了匹配更多内容才这么做的,类似数据库的like,Es的通配符就是: * 帅丙 * 这样**在关键词前后加“*”号去查询**。
后面我发现就是通配符的锅,那**柯南丙**就说一下为啥会这样的问题出现。
许多有RDBMS/SQL背景的开发者,在初次踏入ElasticSearch世界的时候,很容易就想到使用通配符(Wildcard Query)来实现模糊查询(比如用户输入补全),因为这是和SQL里like操作最相似的查询方式,用起来感觉非常舒适。
然而帅丙的故障就揭示了,**滥用Wildcard query可能带来灾难性的后果**。
我当时首先复现了问题
### 复现方法
1. 创建一个只有一条文档的索引
> POST test_index/type1/?refresh=true
>
> {
>
> "foo": "bar"
>
> }
2.使用wildcard query执行一个首尾带有通配符*的长字符串查询
> POST /test_index/_search
>
> {
>
> "query": {
>
> "wildcard": {
>
> "foo": {
>
> "value": "轻轻的我走了,正如我轻轻的来;我轻轻的招手,作别西天的云彩。那河畔的金柳,是夕阳中的新娘;波光里的艳影,在我的心头荡漾。软泥上的青荇,油油的在水底招摇;在康河的柔波里,我甘心做一条水草!那榆荫下的一潭,不是清泉,是天上虹;揉碎在浮藻间,沉淀着彩虹似的梦。寻梦?撑一支长篙,向青草更青处漫溯;满载一船星辉,在星辉斑斓里放歌。但我不能放歌,悄悄是别离的笙箫;夏虫也为我沉默,沉默是今晚的康桥!悄悄的我走了,正如我悄悄的来;我挥一挥衣袖,不带走一片云彩。"
>
> }
>
> }
>
> }
>
> }
3. 查看结果
> {
>
> "took": 3445,
>
> "timed_out": false,
>
> "_shards": {
>
> "total": 5,
>
> "successful": 5,
>
> "failed": 0
>
> },
>
> "hits": {
>
> "total": 0,
>
> "max_score": null,
>
> "hits":
>
> }
>
> }

**即使no hits**,耗时却是惊人的3.4秒 (测试机是macbook pro, i7 CPU),并且执行过程中,CPU有一个很高的尖峰。

**线上的查询比我这个范例要复杂得多**,会同时查几个字段,实际测试下来,一个查询可能会执行十几秒钟。
再有比较多长字符串查询的时候,集群可能就DOS了。
### 探查深层次根源
为什么对只有一条数据的索引做这个查询开销这么高? 直觉上应该是瞬间返回结果才对!
回答这个问题前,可以再做个测试,如果继续加大查询字符串的长度,到了一定长度后,ES直接抛异常了,服务器ES里异常给出的cause如下:
> Caused by: org.apache.lucene.util.automaton.TooComplexToDeterminizeException: Determinizing automaton with 22082 states and 34182 transitions would result in more than 10000 states. at org.apache.lucene.util.automaton.Operations.determinize(Operations.java:741) ~[lucene-core-6.4.1.jar:6.4.1
解释:该异常来自org.apache.lucene.util.automaton这个包,异常原因的字面含义是说“**自动机过于复杂而无法确定状态: 由于状态和转换太多,确定一个自动机需要生成的状态超过10000个上限**"
**柯南丙**网上查找了大量资料后,终于搞清楚了问题的来龙去脉。
为了加速通配符和正则表达式的匹配速度,Lucene4.0开始会将输入的字符串模式构建成一个DFA (Deterministic Finite Automaton),带有通配符的pattern构造出来的DFA可能会很复杂,**开销很大**。
比如a*bc构造出来的DFA就像下面这个图一样:

### Lucene构造DFA的实现
看了一下Lucene的里相关的代码,构建过程大致如下:
1. org.apache.lucene.search.WildcardQuery里的toAutomaton方法,遍历输入的通配符pattern,将每个字符变成一个自动机(automaton),然后将每个字符的自动机链接起来生成一个新的自动机。
```java
public static Automaton toAutomaton(Term wildcardquery) {
List
# 赞助商
以下排名不分先后!


================================================
FILE: docs/basics/HashMap.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> 本文 **GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 上已经收录,有一线大厂面试点思维导图,也整理了很多我的文档,欢迎Star和完善,大家面试可以参照考点复习,希望我们一起有点东西。
## 前言
作为一个在互联网公司面一次拿一次Offer的面霸,打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚(**请允许我使用一下夸张的修辞手法**)。
于是在一个寂寞难耐的夜晚,我痛定思痛,决定开始写互联网技术栈面试相关的文章,希望能帮助各位读者以后面试势如破竹,对面试官进行360°的反击,吊打问你的面试官,让一同面试的同僚瞠目结舌,疯狂收割大厂Offer!
所有文章的名字只是我的噱头,我们应该有一颗谦逊的心,所以希望大家怀着空杯心态好好学,一起进步。
### 正文
> 一个婀娜多姿,穿着衬衣的小姐姐,拿着一个精致的小笔记本,径直走过来坐在我的面前。
>
> 看着眼前这个美丽的女人,心想这不会就是Java基础系列的面试官吧,真香。
>
> 不过看样子这么年轻应该问不出什么深度的吧,嘻嘻。(哦?是么😏)

> 小伙子,听前面的面试官说了,你Redis和消息队列都回答得不错,看来还是有点东西。
美丽迷人的面试官您好,您见笑了,全靠看了敖丙的《吊打面试官》系列,不然我还真的回答不上很多原本的知识盲区,他真的有点东西。
> 面试官心想:哦,吊打面试官是么,那今天我就让你知道,吊打这两个字怎么写的吧,年轻人啊,提前为你感到惋惜。
>
> 嗯嗯小帅比,虽然前面的技术栈没啥太大的瑕疵,不过未来很长的一段时间我会用一期期的基础教你做人的,你要准备好哟!
>
> 好了我们开始今天的面试吧,小伙子你了解数据结构中的HashMap么?能跟我聊聊他的结构和底层原理么?
切,这也太看不起我了吧,居然问这种低级问题,不过还是要好好回答。
嗯嗯面试官,我知道HashMap是我们非常常用的数据结构,由**数组和链表组合构成**的数据结构。
大概如下,数组里面每个地方都存了Key-Value这样的实例,在Java7叫Entry在Java8中叫Node。

因为他本身所有的位置都为null,在put插入的时候会根据key的hash去计算一个index值。
就比如我put(”帅丙“,520),我插入了为”帅丙“的元素,这个时候我们会通过哈希函数计算出插入的位置,计算出来index是2那结果如下。
> hash(“帅丙”)= 2

> 你提到了还有链表,为啥需要链表,链表又是怎么样子的呢?
我们都知道数组长度是有限的,在有限的长度里面我们使用哈希,哈希本身就存在概率性,就是”帅丙“和”丙帅“我们都去hash有一定的概率会一样,就像上面的情况我再次哈希”丙帅“极端情况也会hash到一个值上,那就形成了链表。

每一个节点都会保存自身的hash、key、value、以及下个节点,我看看Node的源码。

> 说到链表我想问一下,你知道新的Entry节点在插入链表的时候,是怎么插入的么?
**java8之前是头插法**,就是说新来的值会取代原有的值,原有的值就顺推到链表中去,就像上面的例子一样,因为写这个代码的作者认为后来的值被查找的可能性更大一点,提升查找的效率。
但是,**在java8之后,都是所用尾部插入了。**
> 为啥改为尾部插入呢?
这!!!这个问题,面试官可真会问!!!还好我饱读诗书,不然死定了!

有人认为是作者随性而为,没啥luan用,其实不然,其中暗藏玄机
首先我们看下HashMap的扩容机制:
帅丙提到过了,数组容量是有限的,数据多次插入的,到达一定的数量就会进行扩容,也就是resize。
> 什么时候resize呢?
有两个因素:
- Capacity:HashMap当前长度。
- LoadFactor:负载因子,默认值0.75f。
怎么理解呢,就比如当前的容量大小为100,当你存进第76个的时候,判断发现需要进行resize了,那就进行扩容,但是HashMap的扩容也不是简单的扩大点容量这么简单的。
> 扩容?它是怎么扩容的呢?
分为两步
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
> 为什么要重新Hash呢,直接复制过去不香么?
卧槽这个问题!有点知识盲区呀!

1x1得 1 1x2 得 2 .... 有了,我想起来敖丙那天晚上在我耳边的话了:假如我年少有为不自卑,懂得什么是珍贵,那些美梦没给你,我一生有愧....什么鬼!
小姐姐:是因为长度扩大以后,Hash的规则也随之改变。
Hash的公式---> index = HashCode(Key) & (Length - 1)
原来长度(Length)是8你位运算出来的值是2 ,新的长度是16你位运算出来的值明显不一样了。
扩容前:

扩容后: 
> 说完扩容机制我们言归正传,为啥之前用头插法,java8之后改成尾插了呢?
卧槽,我以为她忘记了!居然还是被问到了!
我先举个例子吧,我们现在往一个容量大小为2的put两个值,负载因子是0.75是不是我们在put第二个的时候就会进行resize?
2*0.75 = 1 所以插入第二个就要resize了

现在我们要在容量为2的容器里面**用不同线程**插入A,B,C,假如我们在resize之前打个短点,那意味着数据都插入了但是还没resize那扩容前可能是这样的。
我们可以看到链表的指向A->B->C
**Tip:A的下一个指针是指向B的**

因为resize的赋值方式,也就是使用了**单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置**,在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
就可能出现下面的情况,大家发现问题没有?
B的下一个指针指向了A

一旦几个线程都调整完成,就可能出现环形链表

如果这个时候去取值,悲剧就出现了——Infinite Loop。
> 诶卧槽,小伙子难不倒他呀!
>
> 
>
> 小伙子有点东西呀,但是你都都说了头插是JDK1.7的那1.8的尾插是怎么样的呢?
因为**java8之后链表有红黑树**的部分,大家可以看到代码已经多了很多if else的逻辑判断了,红黑树的引入巧妙的将原本O(n)的时间复杂度降低到了O(logn)。
**Tip**:红黑树的知识点同样很重要,还是那句话**不打没把握的仗**,限于篇幅原因,我就不在这里过多描述了,以后写到数据结构再说吧,不过要面试的仔,还是要准备好,反正我是经常问到的。
**使用头插**会改变链表的上的顺序,但是如果**使用尾插**,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
就是说原本是A->B,在扩容后那个链表还是A->B

Java7在多线程操作HashMap时可能引起死循环,原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。
Java8在同样的前提下并不会引起死循环,原因是扩容转移后前后链表顺序不变,保持之前节点的引用关系。
> 那是不是意味着Java8就可以把HashMap用在多线程中呢?
我认为即使不会出现死循环,但是通过源码看到put/get方法都没有加同步锁,多线程情况最容易出现的就是:无法保证上一秒put的值,下一秒get的时候还是原值,所以线程安全还是无法保证。
> 小伙子回答得很好嘛,这都被你回答道了,面试这么多人都不知道头插和尾插,还是被你说出来了,可以可以。
面试官谬赞啊,要不是你这样**美若天仙**的面试官面试我,我估计是想不起来了。
> 我*,你套近乎?
>
> 小姐姐抿嘴一笑,小子你offer有了,耶稣都带不走你,我说的!
>
> 
>
> 那我问你HashMap的默认初始化长度是多少?
我记得我在看源码的时候初始化大小是16
> 你那知道为啥是16么?
卧*,这叫什么问题啊?他为啥是16我怎么知道???你确定你没逗我?
我努力回忆源码,不知道有没有漏掉什么细节,以前在学校熬夜看源码的一幕幕在脑海里闪过,想起那个晚上在操场上,**跟我好了半个月的小绿**拉着我的手说:你就要当爸爸了。
等等,这都是什么鬼,哦哦哦,想起来了!!!
**在JDK1.8的 236 行有1<<4就是16**,为啥用位运算呢?直接写16不好么?

我再次陷入沉思,疯狂脑暴,叮!
有了!
面试官您好,我们在创建HashMap的时候,阿里巴巴规范插件会提醒我们最好赋初值,而且最好是2的幂。

这样是为了位运算的方便,**位与运算比算数计算的效率高了很多**,之所以选择16,是为了服务将Key映射到index的算法。
我前面说了所有的key我们都会拿到他的hash,但是我们怎么尽可能的得到一个均匀分布的hash呢?
是的我们通过Key的HashCode值去做位运算。
我打个比方,key为”帅丙“的十进制为766132那二进制就是 10111011000010110100

我们再看下index的计算公式:index = HashCode(Key) & (Length- 1)

15的的二进制是1111,那10111011000010110100 &1111 十进制就是4
之所以用位与运算效果与取模一样,性能也提高了不少!
> 那为啥用16不用别的呢?
因为在使用不是2的幂的数字的时候,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。
只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
这是为了**实现均匀分布**。
> 哟小家伙,知道的确实很多,那我问你个问题,为啥我们重写equals方法的时候需要重写hashCode方法呢?
>
> 你能用HashMap给我举个例子么?

这都能被他问到,还好我看了敖丙的系列呀,不然真的完了!!!
但是我想拖延点时间,只能**故做沉思**,仰望天空片刻,45°仰望天空的样子,说实话,我看到面试官都流口水了!可惜我是他永远得不到的男人,好了不装逼了。
我想起来了面试官!
因为在java中,所有的对象都是继承于Object类。Object类中有两个方法equals、hashCode,这两个方法都是用来比较两个对象是否相等的。
在未重写equals方法我们是继承了object的equals方法,**那里的 equals是比较两个对象的内存地址**,显然我们new了2个对象内存地址肯定不一样
- 对于值对象,==比较的是两个对象的值
- 对于引用对象,比较的是两个对象的地址
大家是否还记得我说的HashMap是通过key的hashCode去寻找index的,那index一样就形成链表了,也就是说”帅丙“和”丙帅“的index都可能是2,在一个链表上的。
我们去get的时候,他就是根据key去hash然后计算出index,找到了2,那我怎么找到具体的”帅丙“还是”丙帅“呢?
**equals**!是的,所以如果我们对equals方法进行了重写,建议一定要对hashCode方法重写,以保证相同的对象返回相同的hash值,不同的对象返回不同的hash值。
不然一个链表的对象,你哪里知道你要找的是哪个,到时候发现hashCode都一样,这不是完犊子嘛。
> 可以可以小伙子,我记得你上面说过他是线程不安全的,那你能跟我聊聊你们是怎么处理HashMap在线程安全的场景么?
面试官,在这样的场景,我们一般都会使用**HashTable**或者**ConcurrentHashMap**,但是因为前者的**并发度**的原因基本上没啥使用场景了,所以存在线程不安全的场景我们都使用的是ConcurrentHashMap。
HashTable我看过他的源码,很简单粗暴,直接在方法上锁,并发度很低,最多同时允许一个线程访问,ConcurrentHashMap就好很多了,1.7和1.8有较大的不同,不过并发度都比前者好太多了。

> 那你能跟我聊聊ConcurrentHashMap么?
好呀,不过今天天色已晚,我觉得我们要不改天再约?
再说最近敖丙好像双十二比较忙,一次怎么能怼这么多呢?
> 好吧好吧,小伙子还挺会为别人着想,而且还喜欢这么优秀的作者,你我觉得来日可期,那我们改日再约,今天表现很好,希望下次能保持住!
### 总结
**HashMap绝对是最常问的集合之一**,基本上所有点都要**烂熟于心**的那种,篇幅和时间的关系,我就不多介绍了,核心的点我基本上都讲到了,不过像红黑树这样的就没怎么聊了,但是不代表不重要。
篇幅和精力的原因我就介绍到了一部分的主要知识点,我总结了一些关于HashMap常见的面试题,大家问下自己能不能回答上来,不能的话要去查清楚哟。
HashMap常见面试题:
- HashMap的底层数据结构?
- HashMap的存取原理?
- Java7和Java8的区别?
- 为啥会线程不安全?
- 有什么线程安全的类代替么?
- 默认初始化大小是多少?为啥是这么多?为啥大小都是2的幂?
- HashMap的扩容方式?负载因子是多少?为什是这么多?
- HashMap的主要参数都有哪些?
- HashMap是怎么处理hash碰撞的?
- hash的计算规则?
## 点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇一线互联网大厂面试和常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】
如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 文章每周持续更新,可以微信搜索「 **三太子敖丙** 」第一时间阅读和催更(比博客早一到两篇哟),本文 **GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 已经收录,有一线大厂面试点思维导图,也整理了很多我的文档,欢迎Star和完善,大家面试可以参照考点复习,希望我们一起有点东西。
================================================
FILE: docs/coderLife/写作一个月在感恩节对大家说的话.md
================================================
> 所谓活着并不是单纯的呼吸,心脏跳动,也不是脑电波,而是在这个世界上留下痕迹。
>
> 要能看见自己一路走来的脚印,并确信那些都是自己留下的印记,这才叫活着。
>
>
>
> 东野圭吾 《变身》
>
> 
>
>
本来今天是没文章的,RocketMQ周末写了60%发不出来,但是感觉日子特殊嘛我就熬夜写一下。
今天敖丙我不写技术,不知道在看我文章的你知道今天是什么节日嘛?
上个月的今天我发了我在博客的第一篇文章,同时今天也是【感恩节】

我身边熟悉的我人都知道,其实帅丙我是不过西方节日的,但是最近家里出了一些事嘛,而且也是自己工作第一年的结束,晚上上班的时候就多了很多感慨,走在路上思绪转的飞快想了很多(虽然公司走到家里我只用1分钟)。
回到家跟爸妈都发了很长很长的语音,看了看窗边,外面的风在肆虐着空气,凝望着天空。
想了很多东西说就准备在这样的节日跟大家闲聊一下。
老妈他们本来在越南工作的嘛,因为外婆身体突然不好,然后回老家去了,外婆身体一切ok的,后来老妈又说要动手术,而且老爸说检查要一个周,刚得知这个消息的我其实很爆炸,因为别人手术前检查几天就好了,但是老妈为啥要一礼拜。
我没跟老爸他们说我的担心,只是在地铁站接了电话出来后,在杭师大的操场上渡步,鼻子酸酸的,是的一个大男人哭了说出来真的很丢人。
这是我在杭州第三次哭泣了,像个弱者,第一次是因为实习交不起押一付三的房租,第二次是因为代码写太差和一些压力。
这一段我删了撤回,删了撤回,觉得丢人,但是最后大家还是看到了,反正男人嘛无所谓的。
回归主题嘛,今天是感恩节嘛,虽然我才毕业一年,但是这是我来杭州的第三年了,感慨还是很多的。
先说说家庭吧,我家条件就这样,平平淡淡,贵州的小山村嘛,经常跟群里的调侃,过年发不了文章不是我不发是没网,是的还是2g泪目。

以前觉得父亲在同龄人中太平庸了,但是后来的我才知道,他付出了多少才撑起这个家,让自己读完大学,健康成长到现在。
母亲身体一直不好那种,但是她对家庭的付出跟老爸一样多,忍耐着父亲的脾气,我的幼稚,勤俭持家才有了现在的我回老家居住的环境,和我的一切。
其实在这样公开的平台说着这样的话,我觉得挺不好意思的,不过我想也没啥,我就是我,无可厚非,你就是你,也是我的朋友,不是嘛。
我就借助这样的日子把对煽情的话都说了吧哈哈,反正让我当面跟爸妈说也说不出口。
明早发了赶紧转发给他们哈哈。
友情提示:天冷了,大家记得也问候一下家人,一句话可能就让他暖得不行。
说一下我为啥写文章吧。
因为三歪的一句话吧:你真的很适合写文章。
记得是某段时间他对我经常说的,那时候回到家一直在纠结,就有了后来的系列。
其实他不说我现在应该是个B站up主吧哈哈,其实我装备都买了,视频都拍了一个了,但是没人看嘛。
因为我没啥时间拍摄,还有我上班也枯燥,剪辑也很一般般那种,就反正没人看,所以大家发现我文章里面的视频元素了么?
开头的点赞在看养成习惯,结尾的求赞,求关注,求转发,还有文章里面我会融入很多自己风格的元素,其实是相当于写文章圆了自己up主的梦吧。
还好我写了文章没继续拍下去,不然现在应该还是那个关注只有7个的小敖丙吧。
再说一下写文章一个月以来的感受吧,其实有人喷过我,有人怼过我,但是都是少数,我性格就这样怼我,表面上我也就这样吧,其实还算在意,所有有时候三歪隔着桌子看我骂空气傻*。
不过说实话谢谢大家,更多的都是鼓励我,夸奖我的,有时候我都被你们夸奖得有点飘了,觉得我是那么回事了,但是我呢这个人能经常冷静下来,我还是我,那个刚毕业一年的我,那个23岁不大不小的我。
《吊打面试官》是我最开始就定的名字,但是很多读者就问我看了是不是就能吊打面试官了,看了是不是就无敌了。
不能,不是!
我取很多标题都是为了噱头,我甚至多次想改掉了,不过写了也不少了,就没改,但是我想让大家认知正确,我刚开始学软件,我的姐就告诉我要有空杯心态,我希望大家也是一样,用一颗谦逊的心,对待每个未知事物。
面试官能面试你,肯定有人家的原因的,或许你的知识广度够但是你确定你有他深度?又或者你深度够,你能有他广度?有些东西是必须时间积累的,慢慢你们会明白的。
各个平台收获了不少粉丝,有开心也有烦恼,很多东西我可能比大家接触多点,因为电商嘛场景本身就很丰富,但是大家也不要忘记我也没工作多久,我好多技术栈的深度也不够,所以很多人的问题其实我也不是很懂,那问题就来了,我怎么做到文章的技术栈都有深度呢?
臣妾做不到。
是的短期我想我做不到,没长时间的积累我想我还是不敢写很深的东西给大家看,只能把我已知的只是点展示给大家看,写知识扫盲,趣味学东西为主的文章,这也是为啥每期我会让阿里系或者身边的大佬朋友review一遍的原因。
所以文章里面那句我们一起进步,并不是我的自谦,是我的自我认知。
Tip:这篇文章啥干货都没,所以没前言,没正文,没求赞,甚至没排版。
接下去到年底的日子,会有双十二,双旦,年会Vlog视频等一大堆事情,我有拖更的预感了,别怪我没提醒你们哟。
最后也在这样的节日,感谢大家,谢谢你们看我的文章,夜深了,我们下篇文
================================================
FILE: docs/coderLife/敖丙用20行代码拿了比赛冠军.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> [**GitHub**](https://github.com/AobingJava/JavaFamily)上已经开源[https://github.com/Java...](https://github.com/AobingJava/JavaFamily),有面试点思维导图,欢迎[**Star**](https://github.com/AobingJava/JavaFamily)和[**完善**](https://github.com/AobingJava/JavaFamily)
## 前言
这一期不算**《吊打面试官》**系列的,所有没前言我直接开始。
## 絮叨
本来应该是没有这期的,看过我上期的小伙伴应该是知道的嘛,双十一比较忙嘛,要值班又要去帮忙拍摄年会的视频素材,还得搞个程序员一天的**Vlog**,还要**写BUG**,超级忙的。
**Redis**的答案刚发,你怎么又发?这么高产?这么这么优秀!
其实这篇是我以前就写的,只是都没发出来过,而且作为**暖男**我就想着你们嘛,所以就从自己之前的文章里面水一篇给大家看一下,开始前我先回答点最近大家私聊问我的一些问题。
###知乎 阿渣a: 你为啥突然开始写面试系列了?
这个问题就算不问我也准备在某一期写出来的,因为**Java3y**的作者**三歪**哈,这个号大家在各个博客平台应该都或多或少看过,是他给的建议。
他是我基友兼同事上班的时候我们面对面坐的(昨晚在我这促膝长谈哈哈),他是一个**应届生**,但是他现在已经有**200多篇原创文章**了,知识的广度深度都挺好的。
反正就是跟我说了很多东西,我一听诶觉得这个人**有点东西**,然后有一天他说我这样的性格应该去写文章,肯定有很多人喜欢看,关注人多了,可能有点也会有点工资外的**额外收入**。
(实话实说,我也不骗你们,像我工资这么高的人 ! 跟我谈钱?真香)。
不过现实总是这样残酷,至于现在收入多少嘛,我觉得我刚开始写,我们还是不提这个好吧,我怕我把自己写哭了**o(╥﹏╥)o**!

### 掘金 Skyline7:说! 你和3y是不是同事!
是的给个图片自己感受哈哈。(左三歪,右敖丙)

###写吊打系列之后的感受?
说实话挺爽的,很多**人才**喜欢看嘛,很多人私信鼓励我写下去,还有就是因为以前跟很多博主啥的,信息都是单方面的输入的关系,就都是别人写了我看。现在自己也输出了,也有自己喜欢的博主看了,还**点赞评论加关注**了,我觉得就很开心。
特别是**CSDN**的大佬 :**梦想橡皮檫** 掘金的 :**SnailClimb( JavaGuide)**
**JavaGuide**跟**Java3y**一样都是应届生,我都是看着他们的文章长大的,这差距诶。
(不过私下确认了一下好像我和他还有三歪都是96年的哈哈)


然后有时候消息可能回不及时,但是我能回的我其实都第一时间回了,但是平时工作嘛,基本上都是晚上回家,中午吃完饭啥的看消息,但是都是这样的↓↓↓
我有点慌(其实很开心,谢谢各位的认可)!

我自己之前也面过大大小小的互联网公司,不乏阿里系腾讯系的公司,**失败过,成功过,哭过,爱过~~~~**,我知道面试的哪些点比较重要或者怎么组织话语比较重要,其实自己有在自己的本地写过一些东西。
但是都没发表过,而且本地很多好像也是我以前复制进去的,我都不知道哪些是自己写的哪些是复制的,肯定不能直接发的,所以以后应该都是自己写自己的内容,以后就**承蒙各位关注了**!

###掘金 江飞杰 :你都是在环境下写文章的呀?
一般都是周末或者下班后,孤寡老人嘛在家就坐沙发上发呆,然后写点东西,喝点闷开水,年纪大了早上也睡不着,早起也会在那写到快上班去上班。
**但凡有个女朋友都不至于这样啊!!!**

## 正文
捞一下:前几期吊打系列我们提到了**Redis**的知识,还没看的小伙伴可以回顾一下
- **[《吊打面试官》系列-Redis基础](https://juejin.im/post/5db66ed9e51d452a2f15d833)**
- **[《吊打面试官》系列-缓存雪崩、击穿、穿透](https://juejin.im/post/5dbef8306fb9a0203f6fa3e2)**
- **[《吊打面试官》系列-Redis哨兵、持久化、主从、手撕LRU](https://juejin.im/post/5dc3a9fbf265da4d3c072eab)**
- **[《吊打面试官》系列-Redis终章_凛冬将至、FPX_新王登基](https://juejin.im/post/5dc850b4e51d452c2308ee27)**
- **[《吊打面试官》系列-Redis常见面试题(带答案)](https://juejin.im/post/5dcaebea518825571f5c4ab0)**
**这期不算面试的知识点,来只看面试的小伙伴可以直接跳文末的面试技巧。**
## 公司活动
我们公司在1024当天有个活动↓

**MOGU创意代码大赛**
**参赛要求**
1.参赛作品主题鲜明,创意新颖,内容健康,适合观赏,以生活为主题;
2.充分发挥想象力和创造力,力求以独特的创意展现作品的趣味性和娱乐性。
我一看诶,我擦,这不是本渣我的强项嘛,用代码输出点啥,我第一时间就想到了用代码把一个完整的视频输出出来,我输出公司的广告不就跟公司就有强关联性了嘛。
**奖项设置**
一等奖 1名:Razer雷蛇电竞专用机械键盘
二等奖 2名:飞利浦机皇款电动牙刷
三等奖 3名:颈椎按摩器/电动理疗护颈仪
参与奖若干:国风超大电脑桌垫(哪吒闹海)
**本渣我一看居然还有奖励,不过奖励不奖励的无所谓,我主要是喜欢写代码。**
既然脑子有了想法那我也不多BB直接开搞。
#我第一时间就想起了用字符把公司的广告,输出成动画
我们都知道其实最早的动画片都是画家手动一张一张的画出来然后连起来播放,然后才成动画片的,那么原理我们也知道了,就直接开搞吧。

##那首先要做的就是把公司广告按照动画抽帧出来
**tip:这里有个注意点就是没必要一帧一帧的抽,因为肉眼最高的是60fps,要一帧一帧抽那太多了,我按照每10帧抽了,这样工作了少很多,但还是好多啊,不说了直接搞**
###我抽帧的工具是Adobe Premiere Pro cc 2019
也有批量抽帧工具,mac上我没找到,就麻烦朋友在Windows电脑抽了一下

###接下来我们要做的就是把我们抽出来的每一帧都转换为ASCII字符,将1000多帧转换好后我们可以看到已经生成1000多个txt文件了。

###转换过程用相关软件做一下就好了,谷歌百度都能查到很多,我们打开其中一个看下效果

###其实放大之后就是一个个的英文字母和数字,播放的时候我们可以把字体调小点,有点把像素调搞高点的意思。

**ps:这里有个坑,就是mac大部分的字体在txt文本中是不等宽的,就是说 i 和 o是不等宽的,你需要找到对应等宽的字体 我找了很久才找到,作为**暖男**,你不用找了我帮你找好了 !**
- Mac: Andale Mono
- Windows:宋体
我们可以看一下不等宽的样子,就会发现每一行字数一样,但是长宽不一样。

###如果你发现你还是没找到对应的字体,那么我教你两个方法:
- 去txt里面找到字体设置一个一个试,
- 用代码去拉出本地所有的字体,循环出来看效果
### 下面分别是手动查找和程序查找的代码


###接下来的事情就很简单了,我们用代码每次读取每个画面的行数每次输出一屏(我这里一屏是160行,看个人视频实际大小决定,代码里面也给了调节参数)连续输出就有动画的效果了,注意控制输出的时间间隔,我也不多BB,直接贴关键代码

##最后我们看下成片
完整版太大了gif传上来展示不出,完整版可以看我公众号,就放个一两秒的demo。

##活动结束
像我这种**天才**型的选手,你们想都不用想,拿了第二o(╥﹏╥)o,下面是hr小姐姐发奖时候的照片,为啥没拍我领奖的照片,生气!

只能感叹对手太强了,太强了。
不过还是忍不住给自己的聪明才智点个赞!
**暗示点赞,每次都看了不点赞,你们想白嫖我么?你们好坏喲,不过我喜欢**
----
## 总结
好了不逗比了,最后我来点**干货**吧,因为我发现好多读者都是**应届生**什么的,或者是明年就要出来**实习**的仔,那我给点我的建议:
**准备自我介绍!!!**
自我介绍,这个必须要准备,面试90%的套路都是**“来你先做个自我介绍吧”** ,一般自我介绍1-3分钟左右,时长看你自己的经验和经历。
**作为在校生:**
因为大家还没啥社会经验,我觉得你突出你的**大学经历**、**个人成就奖项**、**证书**、**个人成绩**等就好了。
要让面试官知道你是个人才,你没有白白荒废你的大学生活,我招你进来你是个**靠谱**的人,**肯学肯沟通能吃苦耐劳**等等,对了有**实习经历**的一定要突出出来,毕竟这是你和社会接轨的证明,
最后给个**小技巧**,大家可以把自我介绍写下来,然后说出来并且自己用手机录音听一下,联系到自己满意为止,我刚毕业就是这么做的,(每次听自己的声音都忍不住爱上自己)我印象笔记里的版本,我改掉了公司信息和学校信息,可以给你们个DEMO可以参考下,觉得不错记得**点赞**!!!

**作为已经工作的仔:**
我觉得大家,更要细心准备这1-3分钟的自我介绍。
因为这是这场面试的开始,也是面试官唯一能快速获取你经历信息的途径,多的就不说了,**公司**、**工作的内容**、**擅长的技术栈**,甚至是是否**单身**等等(有的加班严重的公司就是比较看重这个),我也准备了社招的面试Demo,你们加我公众号获取吧,算了不这么吸粉了,直接放吧(我还是心太软啊)!**点赞**!!!

**上面的学校公司都是我瞎吹的,可不能给我清华抹黑啊!**
其实我这里都是比较简单的自我介绍了,真实大家的经历可能更丰富点,而且大家也可以多多润色一下,这只是自我介绍一个环节,后面在各个**《吊打面试官》**系列里面我都会提到一些小的**贴士**大家都注意下。
有啥疑问或者需要我给建议可以去**GitHub**https://github.com/AobingJava/JavaFamily或者我公众号都有我微信。
## 下期投票!!!
下期准备了从下面两个题材中选一个写,根据你们这个篇文章的点赞是基数还是偶数决定
- 基数:Java基础
- 偶数:MQ
- 不基不偶:MySQL
## END
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇《**吊打面试官**》系列和**互联网常用技术栈**相关的文章。如果你有什么想知道的,也可以留言给我,我一有时间就会写出来,我们共同进步。
非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得**「敖丙」**我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** **求留言💬** 对暖男我来说 **非常有用**!!!
各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】
------
> **《吊打面试官》**系列每周持续更新,可以关注我的公众号**JavaFamily**第一时间阅读和催更(**公众号比博客早一到两天哟**),里面也有我个人微信有什么问题也可以直接滴滴我,我们一起进步。
================================================
FILE: docs/coderLife/教你在服务器搭建个人面试项目.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> **GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily)上已经收录有一线大厂面试点脑图、个人联系方式和人才交流群,欢迎Star和指教
## 前言
群里不知道多少次大家说自己的**项目没亮点**,在大学没项目出去后**怕找不到工作**,问敖丙我实习的时候是怎么拿的华为Offer。
其实大学的项目很简单不需要太大的难度,因为面试官知道你也没啥经验,不会很在意这个,但是你得有项目这是必要条件,再不济**增删改查你要比别人6**吧,不然找个0经验的人进去,不是给他自己挖坑?
而且如果你有个还不错的履历,或者你的项目还有一些**亮点**,那完美了,你的Offer率会拉开同行的仔一大截的。
丙帅我呢大学做过几个项目,前些天问了问学妹,还在学校稳定运行着,说实话我有点小骄傲了。

但是说实话,我拿华为Offer跟这些项目关系不大,大学时候完成的项目完全是兴趣使然,想起当初自己一个人在室友还没起床的时候去图书馆,在室友都睡觉的时候还没回去的时光,我的眼角又湿了。
**Tip**:怎么拿的Offer我会在《程序人生》系列写,过年前或者后面出个我大学到现在的心路历程哈哈。
当时在电子阅览室当管理员,甚至多次为了赶进度,在图书馆通宵达旦,好在最后还是完成了那个项目,自己一个人从前端到服务端,从研发到部署上线。
大家都知道学校选课用选课系统的时候,很多学校给第三方公司做的系统都很卡,敖丙做的项目就不卡,因为那个时候我就用到Redis了,现在想想设计思想还算前卫。
好了吹了这么多,其实就是为了引出今天的主题,**如何从0到1搭建一个可以外网访问的项目**。
很多小伙伴看到最后要说了,丙丙我要学的是**分布式**,才不要学垃圾的单机系统。
分布式不就是一个单机的服务构成的,你多起几个进行RPC通信不就好了?
## 正文
双十二阿里服务器推广,不买的小伙伴直接跳过这段,不过用来学习真的香,**比学生的9.9每月还便宜**。
**[我帮阿里云推广服务器89/年,229/3年,买来送自己,送女朋友马上过年再合适不过了,买了搭建个项目给面试官看也香,还可以熟悉技术栈,我明天会出一个服务器搭建个人项目的教程(老用户用家人的购买,我用我妈的😂)。扫码或者点击购买](https://www.aliyun.com/minisite/goods?userCode=tybhsgp5&share_source=copy_link)**

我就用自己的服务器给大家举例,怎么从0到1搭建一个学生和新手可以用来面试的项目,老手也可以回忆一下自己逝去的青春。
可能有小伙伴疑惑,丙丙为啥要服务器,本地不行么?
可以,当然不是为了推广服务器哈,大家可以不买,我只是阐述一下自己的观点,因为大家以后出去难免遇到自己操作服务器的情况,有些公司没有集成发布系统,那就需要你亲自去机器上操作了。
然后你rm -rf ,好了去财务室领下工资吧,年底了,提前回家过年可还行?

开玩笑的哈,只是很多操作大家不经常熟悉其实会都不知道,真正去操作或者面试官问你,熟悉各种操作么,你说不熟悉,好的回去等消息。
作为面试官,面试没多少经验的你,他更看重你思考的思路,还有你有没有实操过,务实么?
帅丙我大学的项目就是经常操作,所以后面很长一段时间的服务器操作,还有Linux命令啥的都还是不错的,技术栈搭建起来也是很熟悉,不过最近都是用的公司的工具,命令忘了好多了,需要反省一下了。
服务器在激活的时候会让你选系统,这个时候敖丙我个人建议,**有点基础**已经**熟悉安装过程和环境配置**的同学可以直接选择镜像,镜像市场里面有很多很适合的镜像,我选的就是带JDK8,Tomcat8,MySQL的镜像。
没搞过的同学可以尝试着选个空白机,然后下好这些东西,一步步去尝试,我想收获还是会有的,**跟你在自己电脑搭建的区别你会马上体会到**,这就是为啥建议大家去服务器操作的原因之一。
### 镜像选择

镜像**记得选不要钱的**,一般都是免费的。

选完你在**实例**就可以看到自己的服务器了,下面就是帅丙的服务器,居然跟我一样帅,天呐。

上面都是新搭建的小伙伴,已经有服务器的小伙伴,但是又想换成镜像怎么办?
大家**先把服务停掉**然后点击右边的**更换操作系统**就好了,会让你去镜像市场选的,之前你选了什么系统都可以换。

### 登录服务器
可以直接在管理界面网页登录服务器远程链接,也可以自己本地用对应的控制台工具连接。
个人推荐本地的控制台连接会好点,每次要登录服务器都要去网页很麻烦的。

远程链接的代码,记住是大家的公网ip,管理界面看得到的,要记得你购买的时候配置的密码,因为这个时候要输入。
> ssh root@123.14.123.8 -p 22 (后面的22是个端口,后面我介绍到)


到这一步的时候,很多小伙伴直接登录成功,但是之前就已经有服务器的朋友是不发现,出现下面这个页面了?

会出现这些信息是因为,第一次SSH连接时,会生成一个认证,储存在客户端(也就是用SSH连线其他电脑的那个,自己操作的那个)中的known_hosts,但是如果服务器验证过了,认证资讯当然也会更改,服务器端与客户端不同时,就会跳出错误啦~因此,只要把电脑中的认证资讯删除,连线时重新生成,就一切完美啦~要删除很简单,只要在客户端输入一个指令
> ssh-keygen -R +输入服务器的IP
接下来再次连接一次,会出现
> Are you sure you want to continue connecting (yes/no)?
输入yes!
就完成连接啦!同时,新的认证也生成了。

进去后如果是镜像的小伙伴会发现本身他准备好的东西都在了,环境都搭建起来了,大家只管直接使用就好了。
但是如果没有选择镜像的朋友,就需要自己搭建一个FTP或者使用传输命令去把你下载好的Tomcat、MySQL等传输进来安装好。

大家可以看到还**有一个默认密码文件夹**,里面就有MySQL和FTP的账号密码什么的,不同的镜像可能有差异。
这个在之后大家自己的服务写代码的时候,配置连接本地的MySQL就是需要这个的。

### 博客网站
这次教大家搭建的项目说大不大,说小吧他啥都有,反正小白和学生肯定很适合,是个个人博客网站。
我们先看看博客的效果,看看大家作为大学的项目到底合格么?
我大学做的那个项目比起这个就差点意思了,当时要是有这么好的UI就很香了!



### 项目代码
以我这种直男审美都觉得UI很不错,你以为只是UI可以?那我们看看项目!
项目的Git地址 https://github.com/halo-dev/halo.git 大家克隆一下就好了。
这个项目本身是**Gradle**的,很多小伙伴就要说了,啊帅丙我不要,我就要**Maven**项目的。

我只想告诉大家,**技多不压身**,目前很多大厂都是Maven项目Gradle项目都占有很高的比重,你怎么知道你去的公司会用啥?
你会用进去**减少多少学习的成本**啊,Leader在旁边暗自给你比一个大拇指,暗自感叹:**帅丙的读者,有点东西**。
Mac很多小伙伴安装的时候发现没有**Homebrew** 就没办法用很方便的命令行去下载安装Gradle,那简单我们安装一下,用下面的命令。(Windows的朋友直接官网下载一个就好了 [https://gradle.org/install](https://gradle.org/install/))
```java
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
```

这个安装好了,我们再用下面的命令就可以就把Gradle安装好了,是不是比你去下载方便很多?
```java
$ brew install gradle
```

接下来去项目中设置下Gradle地址,这里介绍的是IDEA的设置

### 为啥推荐个人博客项目?
很多人问我为啥推荐这个项目,这个项目看过次代码了,**没有啥语法错误**,**项目结构**完全**标准**的项目,**注释也很齐全**,**代码的风格挺不错**的,还是 **用了很多新语法和注解**。
而且他也**不难理解**,**结构很简单**,前端后端都很简单,大家看看代码,看看前后的接口,很快就能适应这个项目了。


接下来我们可以用项目去打个包,或者直接下载敖丙打包好的。(jar包还有war包随意)
### 用命令行下载最新的 Halo 安装包
```
curl -L https://github.com/halo-dev/halo/releases/download/v1.1.1/halo-1.1.1.jar --output halo-latest.jar
```
或者
```
wget https://github.com/halo-dev/halo/releases/download/v1.1.1/halo-1.1.1.jar -O halo-latest.jar
```

文件传输呢,帅丙我习惯命令行了,FTP这样的工具还是不适应,我就发下命令行是怎么把jar包从本地传输到服务器的。
```
scp -P 22 /Java/program.war root@123.456.789.987:/usr/server/tomcat7/webapps/
```

我们进入机器去看一下,文件已经传输进来了。

因为是一个SpringBoot项目,你只要有JDK直接就能跑起来了。
```bash
java -jar halo-latest.jar
```

然后大家访问下自己的 ip+端口(8090)就能看到项目了
然后很多小伙伴说,渣男,我的怎么不行?
稍等稍等,敖丙啊还正准备说呢,大家的端口默认就开通了 22 、-1、3389
22是不是很熟悉,就是开头我们链接的端口号→ ssh root@123.14.123.8 -p **22** 也是因为厂商默认给我们开通了,我们才可以直接链接的。
但是我们要访问别的端口,那就去开通嘛,**记得入口出口一样都要开通哟**!



然后重启下机器,重新启动项目,是不是!!!可以访问了???我们先注册一下

然后再登录进去。
可以看到校验的异常什么的都直接日志抛出的,项目我觉得对于学生和新手来说很香,里面的代码风格大家也多适应一下。

登录进去我们可以发现,功能很全,博客网站基本的结构都在了。
有个不成熟的猜想,还没毕业设计的朋友。。。。😂


## 絮叨
看到这里很多小伙伴可能会说你就是为了推广服务器才写的吧,我说实话有一定的成分,但是更多是因为我自己的群里,经常有很多小伙伴对**项目的整个搭建流程不是很熟悉**,所以才出这样的一篇文章的。
这里只是一个单机的项目,大家真正部署的时候要体验别的技术栈可以去Git上下载下来部署上去,体验他整个部署流程,**中间肯定很多不顺利的地方**相信我,100000%不会一次成功,但是你慢慢摸索的过程就是你学习的收获的过程。
大家经常问我那些大佬怎么成长上去的,**踩坑和付出大量实践上去的**,别无他法。
我老东家的Leader 95年的,是我们之前公司前端后端的Leader,技术深度广度,业务深度都领人发指,怎么做到的?
简单,**不断踩坑学习**咯,每天都是凌晨回去,白天开会,晚上写代码,甚至还要挤出时间学习新的业务,技术栈也是不断自己去摸索。
之前他一手带的我,我跟他太熟悉了,买了早餐刚坐下就去开会讨论业务,晚上6点回来就说:诶鸡蛋豆浆都冷了啊,然后丢垃圾桶。
学习是一条令人时而喜极若狂、时而郁郁寡欢的道路。
成长路上我们一起共勉。
## 日常求赞
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇一线互联网大厂面试和常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】 如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 文章每周持续更新,可以关注我的公众号「 **JavaFamily** 」第一时间阅读和催更(公众号比博客早一到两篇哟),本文**GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 上已经收录,有一线大厂面试点思维导图,欢迎Star和完善,里面也有我个人联系方式有什么问题也可以直接找我,也有**技术交流群**,我们一起有点东西。
================================================
FILE: docs/coderLife/记一次差点害敖丙丢工作的的线上P0事故.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> **GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily)上已经收录有一线大厂面试点脑图、个人联系方式和技术交流群,欢迎Star和指教
## 前言
这是帅丙真实事件,大家都知道很多公司都是有故障等级这么一说的,这就是敖丙在公司背的P0级故障,敖丙差点因此**被解雇**,事情经过**十分惊心动魄**,我的**心脏病都差点复发**。
> 事故等级主要针对生产环境,划分依据类似于bug等级。
>
> P0属于最高级别事故,比如崩溃,页面无法访问,主流程不通,主功能未实现,或者在影响面上影响很大(即使bug本身不严重)。
>
> P1事故属于高级别事故,一般属于主功能上的分支,支线流程,核心次功能等,后面还有P2,P3等,主要根据企业实际情况划分。
### 正文
敖丙之前也负责公司的商品搜索业务,因为业务体量增速太快了,商品表中的商品数据也很快跃入千万级别,查询的RT(response time 响应时间)也越来越高了,而且产品说需要根据**更多维度去查询商品**。
因为之前我们都是根据商品的名称去查询的,但是电商其实都会根据很多个维度去查询商品。
就比如大家去淘宝的查询的时候就会发现,你搜商品名称、颜色、标签等等多个维度都可以找到这个商品,就比如下图的搜索,我只是搜了【**帅丙**】你会发现,名字里面也没有连续的帅丙两个字,有帅和丙的出来了

大家知道的传统的关系型数据库都是用什么 name like %帅丙% 这样的方式查询的,而且查询出来的结果肯定只能是name里面带帅丙的对吧。
那你还想搜别的字段比如什么尺寸、关键词、价格等等,都能搜到帅丙,这相当于是多个维度的了,传统的关系型数据库做不到呀。
做技术选型的时候,帅丙第一时间想到了搜索引擎。
当时市面是比较流行的有:**Apache Lucene**、**Elasticsearch**、**Solr**
搜索引擎我后面会讲**ELK(Elasticsearch、Logstash、Kibana)**和**Canal**,我呀真的是太宠你们了,这样会不会把你们惯坏了。
帅丙我呀,噼里啪啦一顿操作,最后得出结论:
> 相对来讲,如果考虑静态搜索,Sorl相对更合适。
>
> 如果考虑实时,涉及到分布式,Elasticsearch相对合适。
那我们商品还是要实时的呀,你后台改了价格啥的,是不是都要实时同步出去,不然不是炸了嘛。
看到这,我想**可爱的你**和帅丙心中都有了答案:Elasticsearch这是个神一样的引擎。
我这里就做一个简单的介绍就好了,细节的点我们后面去他的章节讲,啥都写了,敖丙哪里有这么多素材写文章?
> ElasticSearch是一个基于Lucene的搜索服务器。
>
> 它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
>
> Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
>
> ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。
>
> 根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
看过敖丙之前文章的朋友都知道,我们做技术选型之前,要做什么呀,**设计**!
我们要去了解这玩意的**好处**、**坏处**、**常见的坑**、**出了问题的应急预案**等等,还有他的**数据同步机制**啊,**持久化机制啥**的,就是高可用嘛。
同样的我不大篇幅介绍了,以后都会写的嘛,我就给大家看看我当时做的设计吧。


**这个只是最初的demo,详细的终稿我就不给大家看了,因为有很多公司内部的逻辑。**
**不过大家还是可以看到敖丙真的考虑了很多,还是那句话,不打没把握的仗!**
设计做好敖丙就**卡卡卡**的用起来了。
说实话,**真香**,这玩意真的好用,学习成本也很低,查询语句分分钟掌握了,官网文档把功能介绍得清晰无比。
> https://www.elastic.co/cn/
用着用着重头戏来了,你们都知道敖丙我是做电商活动的,都是什么很高的流量打进来这样,还是如往常一样上线了一个活动。
**这是一个月飞风高的夜晚,丝丝凉风迎面吹来,敖丙悠闲的坐在椅子上,手里拿着破旧的茶杯,喝着外婆炒的苦荆茶,享受着这惬意的时光。**
突然,说时迟那时快,运维打来了紧急电话ES集群CPU打到了99%要挂了,**我的心蓦然一痛**,心里还在庆幸还是集群没崩。
然后他接着说了一句,不好集群挂了!
敖丙卒,本篇完....

开玩笑的哈,不过当时敖丙真的**要死的心真的都要有了**,就在崩掉的1分钟内,就有用户反馈搜索未响应,我第一时间想到的就是重启,于是我一个健步冲出去,开启电脑,进机器,输入了重启命令。
好了,是的好了,还好有惊无险,不过只过了10秒,集群又99%了,呐呢?

我又只能重启了,这次没挂,过了很久很久,直到活动结束,还是没挂。
### 查找问题
但是这次影响到线上,3分钟的搜索未响应,我想我估计明天是要去财务领工资,提前回家过年了。
**还好Leader说没事**,先找到问题,把他修复掉。
你们都知道敖丙天才来的,我第一时间想到的就是看日志,我登上去看es没报错,再看本身的服务,除了超时的错误啥都没有,卧槽,是的当时我脑袋嗡嗡响。
不过我继续想为啥是我的搜索挂了,**会不会是有人搜了什么奇怪的东西?**
我打开了我的搜索日志!!!
卧槽这不是吧,哪个坑爹玩意搜这么长的一串中文,差不多250个字吧。
但是我一想,搜这么长也不应该打挂服务啊,**会不会是我写了bug**!
我脸颊流下一滴汗水💦,我看了看周围,发现没人注意到我的紧张,我**故作镇定**的把它擦掉。
我仔细一想,别人查询虽然长,就算查数据库也没事啊,为啥es就报错了?会不会?

**Es有Bug!没错肯定是Es的锅。**
那为啥会这样呢,我直接跟老大这样解释也好像不行啊,**还是要被开除的吧!**
于是我去看看看代码,我在关键词使用了通配符,我当时是为了匹配更多内容才这么做的,类似数据库的like,Es的通配符就是: * 帅丙 * 这样**在关键词前后加“*”号去查询**。
后面我发现就是通配符的锅,那**柯南丙**就说一下为啥会这样的问题出现。
许多有RDBMS/SQL背景的开发者,在初次踏入ElasticSearch世界的时候,很容易就想到使用通配符(Wildcard Query)来实现模糊查询(比如用户输入补全),因为这是和SQL里like操作最相似的查询方式,用起来感觉非常舒适。
然而帅丙的故障就揭示了,**滥用Wildcard query可能带来灾难性的后果**。
我当时首先复现了问题
### 复现方法
1. 创建一个只有一条文档的索引
> POST test_index/type1/?refresh=true
>
> {
>
> "foo": "bar"
>
> }
2.使用wildcard query执行一个首尾带有通配符*的长字符串查询
> POST /test_index/_search
>
> {
>
> "query": {
>
> "wildcard": {
>
> "foo": {
>
> "value": "轻轻的我走了,正如我轻轻的来;我轻轻的招手,作别西天的云彩。那河畔的金柳,是夕阳中的新娘;波光里的艳影,在我的心头荡漾。软泥上的青荇,油油的在水底招摇;在康河的柔波里,我甘心做一条水草!那榆荫下的一潭,不是清泉,是天上虹;揉碎在浮藻间,沉淀着彩虹似的梦。寻梦?撑一支长篙,向青草更青处漫溯;满载一船星辉,在星辉斑斓里放歌。但我不能放歌,悄悄是别离的笙箫;夏虫也为我沉默,沉默是今晚的康桥!悄悄的我走了,正如我悄悄的来;我挥一挥衣袖,不带走一片云彩。"
>
> }
>
> }
>
> }
>
> }
3. 查看结果
> {
>
> "took": 3445,
>
> "timed_out": false,
>
> "_shards": {
>
> "total": 5,
>
> "successful": 5,
>
> "failed": 0
>
> },
>
> "hits": {
>
> "total": 0,
>
> "max_score": null,
>
> "hits":
>
> }
>
> }

**即使no hits**,耗时却是惊人的3.4秒 (测试机是macbook pro, i7 CPU),并且执行过程中,CPU有一个很高的尖峰。

**线上的查询比我这个范例要复杂得多**,会同时查几个字段,实际测试下来,一个查询可能会执行十几秒钟。
再有比较多长字符串查询的时候,集群可能就DOS了。
### 探查深层次根源
为什么对只有一条数据的索引做这个查询开销这么高? 直觉上应该是瞬间返回结果才对!
回答这个问题前,可以再做个测试,如果继续加大查询字符串的长度,到了一定长度后,ES直接抛异常了,服务器ES里异常给出的cause如下:
> Caused by: org.apache.lucene.util.automaton.TooComplexToDeterminizeException: Determinizing automaton with 22082 states and 34182 transitions would result in more than 10000 states. at org.apache.lucene.util.automaton.Operations.determinize(Operations.java:741) ~[lucene-core-6.4.1.jar:6.4.1
解释:该异常来自org.apache.lucene.util.automaton这个包,异常原因的字面含义是说“**自动机过于复杂而无法确定状态: 由于状态和转换太多,确定一个自动机需要生成的状态超过10000个上限**"
**柯南丙**网上查找了大量资料后,终于搞清楚了问题的来龙去脉。
为了加速通配符和正则表达式的匹配速度,Lucene4.0开始会将输入的字符串模式构建成一个DFA (Deterministic Finite Automaton),带有通配符的pattern构造出来的DFA可能会很复杂,**开销很大**。
比如a*bc构造出来的DFA就像下面这个图一样:

### Lucene构造DFA的实现
看了一下Lucene的里相关的代码,构建过程大致如下:
1. org.apache.lucene.search.WildcardQuery里的toAutomaton方法,遍历输入的通配符pattern,将每个字符变成一个自动机(automaton),然后将每个字符的自动机链接起来生成一个新的自动机。
```java
public static Automaton toAutomaton(Term wildcardquery) {
List
\* Worst case complexity: exponential in number of states.
\* @param maxDeterminizedStates Maximum number of states created when
\* determinizing. Higher numbers allow this operation to consume more
\* memory but allow more complex automatons. Use
\* DEFAULT_MAX_DETERMINIZED_STATES as a decent default if you don't know
\* how many to allow.
\* @throws TooComplexToDeterminizeException if determinizing a creates an
\* automaton with more than maxDeterminizedStates
*/
```
代码注释里说这个过程的时间复杂度最差情况下是状态数量的指数级别!
为防止产生的状态过多,消耗过多的内存和CPU,类里面对最大状态数量做了限制
```java
/**
* Default maximum number of states that {@link Operations#determinize} should create.
*/
public static final int DEFAULT_MAX_DETERMINIZED_STATES = 10000;
```
在有首尾通配符,并且字符串很长的情况下,这个determinize过程会产生大量的state,甚至会超过上限。
至于NFA和DFA的区别是什么? 如何相互转换?
网上有很多数学层面的资料和论文,限于帅丙算法方面有限的知识,无精力去深入探究。
但是一个粗浅的理解是: NFA在输入一个条件的情况下,可以从一个状态转移到多种状态,而DFA只会有一个确定的状态可以转移,因此DFA在字符串匹配时速度更快。
**DFA虽然搜索的时候快,但是构造方面的时间复杂度可能比较高,特别是带有首部通配符+长字符串的时候。**
回想Elasticsearch官方文档里对于Wildcard query有特别说明,**要避免使用通配符开头的term**。
> " Note that this query can be slow, as it needs to iterate over many terms. In order to prevent extremely slow wildcard queries, a wildcard term should not start with one of the wildcards * or ?."
结合对上面Wildcard query底层实现的探究,也就不难理解这句话的含义了!
**小结: Wildcard query应杜绝使用通配符打头,实在不得已要这么做,就一定需要限制用户输入的字符串长度。**
最好换一种实现方式,通过在index time做文章,选用合适的分词器,比如nGram tokenizer预处理数据,然后使用更廉价的term query来实现同等的模糊搜索功能。
对于部分输入即提示的应用场景,可以考虑优先使用completion suggester, phrase/term suggeter一类性能更好,模糊程度略差的方式查询,待suggester没有匹配结果的时候,再fall back到更模糊但性能较差的wildcard, regex, fuzzy一类的查询。
**补充**: 有同学问regex, fuzzy query是否有同样的问题,答案是有,原因在于他们底层和wildcard一样,都是通过将pattern构造成DFA来加速字符串匹配速度的。
**回忆**:为啥之前挂了一次重启恢复了,马上又挂了?用户搜了两次。。。
### 解决方案
其实解决这种问题很简单,既然知道关键词长了会有问题,我就**做限制**嘛,大家可以去看看搜索引擎某度、某宝啥的,是不是都做了长度限制?
我复制了很长的一段汉字进去百度就是这个结果咯,某宝过长都返回**默认页面**了。


如果你的产品一定要给用户一点东西,简单,找出一些热词分析出来就好了,或者给点热搜商品**兜底**。
我怎么做的呢?判断字符串长度大于50我就直接返回空数组了,这样对用户体验好点,你返回个参数错误或者默认错误别人还**以为你有Bug**呢对吧。
### 总结
其实敖丙我啥事故等级都没背哈哈,这个算是事故,但是敖丙我这么可爱,领导也心疼我啊,肯定不会怪我的拉,主要是我设计都考虑了很多方案和场景了,没想到有这个坑。(yy:敖丙你个渣男,又是标题党,人家还以为你没工作了要养你呢!)
大家也可以通过这次事故体会到,技术选型的时候,**方案的重要性**了吧,就算你考虑不全,但是不至于真正的问题来了手足无措啊,并不是所有的事故都可以像这次这样重启就搞定了,**不要存有侥幸心理,心存敬畏**。
### 絮叨
敖丙啊,又有牌面了,得到**阿里云消息中间件团队**小伙伴的认可,并且发现居然是我学姐-**风云**(花名)!!!
她是个好学的小姐姐,大家多多像优秀的仔学习,学姐不是做技术的,但是都在不断学习,说实话我的眼角又湿了。

### 别跑,投票!!!
我准备把我的公众号**JavaFamily** 这个名字改了,这个名字还是差点意思,但是又不能叫敖丙了,被注册商标了,我就问了下群里的人才,目前有两个我比较喜欢的
- **帅丙**
- **三太子敖丙**
- 其他给我留言
因为这个可能会陪伴我很久,甚至直到死去,希望大家都给点建议哈哈。
别问我为啥要跟敖丙这个名字相关,**再问自杀**!
我花名就叫这个,所以😂

## 日常求赞
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇一线互联网大厂面试和常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】 如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 文章每周持续更新,可以关注我的公众号「 **JavaFamily** 」第一时间阅读和催更(公众号比博客早一到两篇哟),本文**GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 上已经收录,有一线大厂面试点思维导图,欢迎Star和完善,里面也有我个人联系方式有什么问题也可以直接找我,也有**技术交流群**,我们一起有点东西。
书三千,吾全取。
人千万,独暖你。 ---暖男敖丙
================================================
FILE: docs/coderLife/风雨十年从毕业到技术专家我做了啥.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> 本文 **GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 上已经收录,有一线大厂面试点思维导图,也整理了很多我的文档,欢迎Star和完善,大家面试可以参照考点复习,希望我们一起有点东西。
### 前言
你们都知道的,帅丙我本身肯定是达不到技术专家的地步的。
呸,敖丙你个渣男,又标题党 !

我不是但是我身边很多人是呀,字节跳动,PDD,阿里等等的大佬我认识很多,所以以下是我问了他们的成长路径的总结,还是具有一定的代表性。
身边这些朋友都是在互联网领域多年的大牛了,因为生活和个人习惯的原因,很多都没有写博客的习惯,或者没有公开出来,但是他们却遇到了帅丙,**我骚啊,我可以帮他们整理出来啊**。
目的是为了让很多跟我一样的新人,对一条完整的职业规划之路有一个清晰的认知,**青铜到王者要经历些什么**?

### 青铜-万恶之源
**《计算机基础》**,这是所有读者大学最开始都会上的课吧,我问了群里的仔,他们都说是的,我想大家也是。
在计算机基础中我们会学到计算机的历史、计算机的特点、进制转换、内存管理、线性数据结构、网络请求协议等等。
计算机基础真心很重要,无比重要,究极重要,为啥我这么说呢,里面涉及的计算机知识还有很多网络协议的知识,大家以后一定会用到,我可以负责的告诉你,面试也一定会问,什么Http、Https、Tcp/Ip、三次握手、四次挥手面试不要太常问。
**Tip**:这里有个小插曲就是我身边那个架构师团队Leader这周面试阿里p8岗位的时候,我以为问的都是什么源码,中间件的究极操作,我想大家跟我想的一样,但是大家错了,反而问的很多计算机的基础知识。
我聊天大概问了一下面试内容,有什么求二叉树的镜像,内核态和用户态的理解,计算机的缓存页等。
大家是不是惊了,这他*不是我校招的题目么?怎么P8级别的大佬还问这个?其实很好理解,大家想一下到了一定的工作年限技术的广度深度都有一定的造诣了,你写代码就这样了没办法优化了,机器配置也是最好的了,那还能优化啥?
**底层**,我们都知道所有语言到最后要运行都是变成机器语言的,最后归根究底都是要去跟机器交互的,那计算机的底层是不是最后还是要关注的东西了?
**福利**:他这周会来我们公司面试,届时我会详细问一下具体的面试内容,如果大家想看我可以到时候整理一下写出来,看看那种级别的强者的世界到底是怎么样的。

学完计算机基础你基本上对计算机的整个知识体系都一知半解了,对于编程或许还是很懵懂,但是你现在已经要踏入编程的门了。
#### 白银-编程第一课
计算机基础学了,后面就要编程的入门课程了。
想必看我这篇文章有99%的小伙伴都是以下面这段代码开始的自己的程序人生的吧:

我还记得**帅丙**我就是大一开始学习的C语言,《C语言程序设计》谭浩强老师的课本,在第27页就是第一章,**HelloWord**,现在回忆起来还历历在目,老师在黑板上写下这两个庄严的单词,同桌的她和我露出无限的求知欲......
我想所有的语言都是语法基础开始的,而且编程语言的基础语法也都是大同小异的。
If、For、While等关键字,List、Set、Map等集合,Int、float、Double等基础类型,大家第一次学的时候我想也不会知道,这些关键字将会陪伴我们走完各自的程序生涯吧?
接下去就难一点比如JDBC、IO、文件流啊什么的,帅丙依稀的记得当时还是**代码里面写SQL**然后查询,也不知道记错没有。
学到这里,你可能觉得你**JavaSE**无敌,出去可以找工作了,反正当时的帅丙,觉得自己可以闯出一片天了,不知天高地厚,四处炫技。
但是幼稚的我根本不知道,**未知的前方还有什么等着我**,我也不知道自己其实才刚入门,但是如果要往WEB方向发展,这些倒是基本足够了。
但是你到现在为止学的东西都是服务端的东西呀,怎么让你的服务端东西展示给别人看呢?
这个时候我们就应该去做个丑不拉几的页面,进行简单的交互了,你这个时候要学**HTML** 、**Servlet**、**MySQL**、 **JavaScript**、**Tomcat**、**CSS**等。
目标呢就是写出第一个动态网站,也许只是个登陆功能,只能展示下个人资料,但这是很重要的一步,你要弄清楚的是,一个用户的点击产生的请求,是从哪里发起,哪里接收,哪里处理,哪里返回,你得理解浏览器和服务器的关系和分工,**Cookie**和**Session**,**Request**和**Response**。
**Tip**:我记得我刚出来面试就有面试题是这样的,一个Http请求从网页发起到服务端产生数据返回中间经历了些什么,或者Spring做了什么?大家可以思考一下
还有有一个自己的项目真心很重要,敖丙我就是在大学期间做了项目,至今在校园内网上稳定运行着,出来实习面试的时候基本上也是一路披荆斩棘,吊打了同行面试的仔,反正大学有个项目贼加分,是读者的大学生记住了么?
### 黄金-初出茅庐
上面的只是WEB开发的学习初级阶段,这都是些JAVA诞生以来最原始的最官方的WEB开发技术,当然现在真正的项目很少直接采用这些技术了,现在都是**前后端分离了**,Vue、Node.js、React等前端的语言更新迭代速度非常快,帅丙我学了一点刚用舒服,前端的朋友告诉我又迭代了......我他*不学了!
为了不断提高技术的易用性、开发效率和可维护性、可扩展性,无数开源项目都是在这些原始技术的基础上封装、改进。
所以这个阶段**不要盲目乐观地跑去找工作或者对实习挑三拣四**,你会被打击到的,又或者找个小公司浑浑噩噩几年过去感觉跟新的技术栈脱节。
**有人跟你说小公司学的东西多,他害你的,刚开始能去多大的去多大的,越大越好,你想你去了大的你想去小的分分钟的事情,但是你小的要去大的就相对难了。**
好,初始阶段完成,开始进入WEB开发的正题,首先是传说中的框架,SSM(Spring SpringMVC Mybatis)成为熟练的增删改查程序员是必须的,在这个阶段你还要理解为什么要用这仨而不是那些Jsp、Servlet、Jdbc,你要体会到写MVC、三层架构的好处。
这个阶段不要轻易质疑框架的价值,也许刚开始你会觉得麻烦,觉得他们有时候是多此一举,我最开始这么写的时候发现,真的恶心,什么dao,service,Controller等等,分这么多干嘛。
等过一两年后回过头来你会觉得少了这些框架你已经很难干活了,没有分层清晰的系统,你反而开口大骂项目的架构师的。
你*********

不过要**提醒大家**的是,这个阶段还要避免的心态是,能熟练地增删改查了,就自认为写程序不过如此,然后往简历上填个精通,这也是新手面试被批得体无完肤的原因之一。
**浅尝即止,是新手的大忌**,为啥这么写,这么写有啥好处,有啥坏处,多问几个为什么,你**多年后会感谢敖丙**的。
如果你学得好,这会应该能熟练地写个博客啊,小论坛啊之类的WEB项目了,也就是达到了就业的基本要求。
**Tip**:而且说一下作为一个应届生,你除了基础知识,如果你有自己的技术博客,还有像样的项目能展示给面试官看,是真的很加分,搭建个简单的项目,项目流程你也知道了,技术栈也熟悉了,还可以手机访问网页给面试官现场演示,很加分的。
像我身边的朋友**Java3y**,**JavaGuide**,**我没有三颗心脏**等,就是在这个阶段就已经开始写了自己的博客,并且各自都做出了成绩,这些以后都是你面试的议价能力的一部分,也是你的加分项,和你自身的财富。
我问了一下他们,都是靠博客就已经得到不少大公司的面试邀约了,反正有项目,有不错的履历,有不错的博客,都会给你加分,如果你什么都没有,现在动手去多学点,少打两局LOL等你到我这个年纪就会发现,**索然无味**。
### 铂金-遵义会议
这会是程序员生涯的一个**转折点**,把握好了人生起飞,把握不好**全盘皆输**,所以我用在我老家遵义举办的**遵义会议**,作为这阶段的标题,我觉得,**妙啊**!

慢慢的你会发现数据库性能实在不行,出于不甘现状,或者赶时髦,你该去了解**NoSQL**了,**Memcached**、**Redis**、**Mongodb**等非关系型数据库眼花缭乱,没关系,试着用用,能很好地缓解**MySQL**、**Oracle**之类关系数据库的压力。
出于公司某些业务需要,你可能会钻研一个特定技术领域,比如全文搜索技术**ElasticSearch**(以下简称Es),那你了解了**Es**,你又要想到数据库的数据怎么同步进**Es**呢?
你可能会接触到**Logstash**,**Canal**等中间件,然后发现可视化也是个问题,那**Kibana**就应运而生,用的时候发现欧洲人的分词习惯跟我们不一样,那**Ik**中文分词器又得了解啦。
使用之后你还会发现他底层的**Lucene**有很多坑要怎避免,时间多你还可以了解**Solr**等等。
**总之知识就是一个体系**,我经常跟群里的仔说,形成知识体系,你面试说了**Es**那相关的技术栈你一样要了解的,我题目取了叫《**吊打面试官**》就是噱头,你去面试如果面试官技术深度真的很深,我想被吊打的100%是你。
你甚至会开始对系统中一些比较特殊的存在感兴趣,比如**权限系统**,**单点登陆**之类的,又或者某些特定业务领域的**算法研究**,这些是你的加分项。
你还发现服务拆分后**Http**通信有诸多弊端,就开始接触优秀的**Rpc框架**还有消息队列中间件了,如**Dubbo**、**RocketMQ**等。
再再后来你发现呀,数据量大得一批,表顶不住了,几亿数据查出来要好几秒,那**分库分表**就出来,什么**水平拆分**,**垂直拆分**,还学习了**TDDL**、**Sharding-JDBC**、**DRDS**等这样的分库分表中间件。
但是你用了发现全局的唯一id生成又是一个问题,或许中间件有自带的,但是你还是要了解原理,什么**雪花算法**,**uuid**等等也得学。
再再再后来呀,你发现分库分表也顶不住了,业务体量爆炸式增长了,你可能就需要了解动态分库分表的解决思路和解决方案了,特别是**FaceBook**开源的一些方案。
再再再再后来呀,你发现动态分库分表也不行啊,很多离线的数据也很多啊,每天几个T,公司都要被败光了,那你就要了解大数据场景的离线分析啊,数据缓存啊,数据清洗,数据可视化等等啊什么的。
那就需要学什么**ODPS**啊,**Hadoop**、**Hive**、**Hbase**等等中间件或者工具了。
再再再再再后来你开始发现你的代码很乱,久了以后自己都看不懂,重复的,难以重用的代码堆积如山,不想维护,BUG百出。
于是你要开始重视设计模式,合理地改造下自己的代码习惯,不再被僵化的SSH、MVC三层架构束缚住。
再再再再再再.....(敖丙你是不是没玩了?哈哈其实还真有我就不列举了)

到这里不知道你有没有体会到我每篇文章开头那句话的意思?敖丙就是工作之后发现自己越来越无知了,你再品一下下面这句话。
> 你知道的越多,你不知道的越多
**Google**和各种资料是你进步的动力,极少再遇到必须请教别人才能解决的问题,如果你这个阶段还老是问别人,你的技术生涯也就快到头了。
这个阶段,如果你**技术卓越**和**跟敖丙一样能吹**,你的收入将是白领水平,至少接近了,或者大幅领先同龄人了。
我觉得多数程序员在工作多年之后都能达到这个水平,有的人只需要一两年,有的人却要用上五六年,在这个阶段落伍的人,有的是出于天赋和思维所限,有的是出于对技术缺乏热情,有的是出于工作内容的制约。
**等到年近中年,再也拼不过年轻人,被淘汰出局,只能在自嘲为屌丝和码农的无奈中黯然转行。**
这是个很重要的分水龄,你能不能继续进步,能不能在30岁以后继续从事技术工作,能不能在公司里**独当一面**,我觉得就看你能不能超越这个阶段了。
很多烂公司里工作数年的项目经理,连这个层次都还没达到...
为了30岁的自己听到裁员完全不虚,为了家里的老母亲不再为了省电费不舍得开灯,为了让自己......
我想这个阶段你应该要做好准备,这也是我大篇幅介绍这个阶段的原因。
### 砖石-扬帆远航

你要读读优秀开源项目的源码,你要搞懂一些当年不懂的基础知识,你开始理解**《thinking in java》**的精髓,你能写一些底层的代码,有时还会觉得自己封装的比某些开源工具更好用更简单。
当年看不懂的《**深入分析JVM虚拟机**》现在你已经可以对里面的知识点**如数家珍**,**张口就来**,并且能够将大量知识点带入到项目中优化,并且能够看到实质性的变化(**暗示KPI**)。
WEB的难点和重点永远都在于性能、负载能力上,而现在网络的发达造成了数据量和操作密度的大大上升,硬件却没有相应的进步。
你得试着更好地运用更多的服务器来协同工作,从WEB端到服务端到数据库,全都需要集群,需要分布式,需要合理的控制数据的流向,掌握好网站上下,一大堆机器的平衡,找出性能的瓶颈,找出稳定性和安全性的瓶颈,硬件出现故障,第三方技术出现错误,将被当成家常便饭融入到你的系统和代码里仔细考虑。
你会开始觉得方案无比地重要,**一将无能累死千军**将不断应验,一个不好的设计,一个不好的方案,会让一群优秀的程序员工作成果大打折扣。
**你要关注架构知识,不能再满足于SSH三层架构到底。**
领域驱动设计,面向事件开发,敏捷开发等等一系列的思想在关键时刻能决定你项目的生死,这个阶段不再有标准范例让你照抄,你只知道思想和原理,实践却需要自己不断尝试和改进。
多关注各种杂七杂八的开源技术,有些你可能前面已经接触过了,和通信有关的,和集成开发环境有关的,和架构有关的,各个领域你都应该能信口说上几个主流技术,虽然你可能只是听说过,了解。
**但关键时刻你得知道如何去选择技术,并快速掌握它。**
你还会去考虑尝试下别的语言,这里不是说转向什么C++ C#之类的,那和JAVA程序员不相干,我说的是一些**运行于JVM之上的语言**,比如scala和groovy,初识他们时你会觉得Java真的老了。
但当你回到一个综合性的大型项目中,又会觉得Java积累下来的整个体系技术是如此完善,就像一个工业化标准一样,你可能发现光是Spring家族的东西你都受用终身,无法完全通读。
你能把这个阶段实践好,胜任项目经理,乃至中小公司的技术总监,大厂的小团队Leader都是可以的。
### 大师-登峰造极
其实写到上面这个阶段的时候我觉得,这是很多人满足的地方了,都是小公司技术总监了,那我图啥?
但是未知的人生还在那等着你呢,我问了身边顶级的大神,**为啥要走出舒适区**?去像字节、阿里等这些压力大很多的地方呢?
他们给的回答都不太一样,但是一样的就是**挑战自我**吧,**谁也不知道哪里是自己的终点**,那为啥不多做点尝试,新的环境,新的技术栈,新业务场景挑战新的自我。
这个阶段你的一举一动可能都关系一个项目的生死存亡,一个错误或者正确的决策就可能改变整个项目的命运,水能载舟亦能覆舟,我想用在这里也恰到好处。
我身边这样级别的大佬凤毛麟角,但不是没有,他们在公司都是核心人物,大型项目或者项目紧要关头都是他们带领团队**冲冲冲**,除了问题也是能最快给出解决思路和方案的。
**Tip**:我现在的老大就是这样的人,双十一大家还手忙脚乱去追数据的时候,他上来一套操作,写了几个脚本就搞定了,卧*我们当时周围一群人,**从头到尾的知识盲区**,结束了还没反应过来,只能拍手叫666。
**这就是强者的世界,我所向往的世界,当然我知道这样的世界,只有一步一个脚印才能涉足。**

### 王者-泰山之巅
最后王者其实我不会写任何内容,能到这个领域的人本身就是屈指可数了,敖丙身边有,但是我觉得大家自己体会吧,一般就是人脉,交际,能力都到了一定的高度了,这个阶段的事情我也体会不到。
能想到的就只有先祖的诗句:指点江山,挥斥方遒。
算是给大家留下无限遐想的空间吧,未来或许你就是你所在领域的王者也说不定的呢对吧。
### 总结
不知不觉写了这么多了,以上是我个人眼里的一般向JAVA 程序员的发展线路,限于篇辐也不全面,实际个人成长路线可能因为工作内容的不同差异会很大,有的人偏向了底层研究,有的人偏向了业务需求设计,有的带有浓重的行业色彩,而且技术之外,还有很多知识也很重要,做JAVA没有轻松的方向,但一个对技术抱有兴趣的人,走到这一步时,仍然会对开发抱有热情,想要写出好的项目。
**纯为了生计而工作的程序猿是走不到这一步的,这一行来都来了,大家一天都是24小时,为啥有差距,我想你我都明白的,知道为啥那就干出点名堂吧。**

### 敖丙的絮絮叨叨
上周还发起了一个投票大家记得么?就是我要修改我公众号的名字,下面是投票的结果

敖丙也是真男人来的,说改就改了,你们会发现我所有博客平台的广告,也会在周末悄无声息的被我改掉的,以后**三太子敖丙**就取代JavaFamily了。
并且也做了个很重要的决定,这一个多月来,公众号文末的广告多多少少都有点积蓄了,但是这个钱说实话我出去恰个火锅都够呛,差不多每天都是这样吧。

那我一想这个钱是大家给我的,我最后就还给大家,以后也是一样,每次到月底我就抽个奖,买十几本书送大家。
**不知道大家喜欢不喜欢呀!!!**
还有就是抽小伙伴喝咖啡了,这里好像就杭州的小伙伴我能线下约了,外地的小伙伴我就打20块吧,虽然不多但是是个心意嘛。
## 点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇一线互联网大厂面试和常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】
如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 文章每周持续更新,微信搜索「 **三太子敖丙** 」第一时间阅读和催更(比博客早一到两篇哟),本文 **GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 上已经收录,有一线大厂面试点思维导图,也整理了很多我的文档,欢迎Star和完善,大家面试可以参照考点复习,希望我们一起有点东西。
================================================
FILE: docs/creative/《吐血整理》十年风雨技术人的书单整理.md
================================================
## 《程序人生》十年风雨技术人的书单整理
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> 给岁月以文明,而不是给文明以岁月
> 本文 **GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 上已经收录,有一线大厂面试点思维导图,也整理了很多我的文档,欢迎Star和完善,大家面试可以参照考点复习,希望我们一起有点东西。
### 前言
王潇:格局决定了一个人的梦想,梦想反过来决定行为。
那格局是什么呢?
**格局是你能够看见的深度、广度和密度。**
王潇认为,格局是一本本书搭建起来的,正如她所言:“**读书让我知道世界很大,然后才知道推开门去看看这个世界。**”
之前有一篇文章我写到了几乎是一个技术人从0到1的整个生涯了,其实大家发现根本就没有终点。
[《程序人生》风雨十年-从大学到技术专家我做了啥?](https://juejin.im/post/5ded1639e51d455830350da5)
我们的一生其实也基本上都在学习,那提到学习,我第一时间想到的就是读书了。
记得帅丙在自己21岁的那个夏天,当时拿到了自己的第一笔实习工资1400块,因为是110块一天嘛,而且入职的第一个月也没上满,但是还是很开心,第一个月师傅就给了一个建议,买本书吧。
就这样我买了出社会之后的第一本技术书籍《Java核心卷一》,也是师傅推荐的,如获至宝。
到现在我的书架都茫茫当当了,但是这本书还是一直陪伴我左右,也是我印象最深刻的技术书籍,因为那感觉就像是**初恋的味道**,甜甜的。
为啥推荐大家读书呢,**书籍的作者都是几年甚至几十年的经验,最后总结为一本书,**那就算里面有错误的点,我想你花几十块,只用几个礼拜甚至几天就可以拜读人家十几年的经验,我觉得怎么算都是血赚?
## 正文
好了扯了这么多只是想要引出今天的主题,我会按照不同的类型把我知道的一些书籍,包括身边朋友推荐的书籍,都在这里列给大家,大家按需自取。
我还推荐了很多非技术的书籍,人文地理悬疑情感都会涉及,反正很多书我是真的很喜欢。
我上一篇提到的我亦师亦友的阿里技术专家朋友,他就是个很喜欢读书的人,说实话他的**学校背景不好**,刚开始出来也是在外包干活的,但是他有个习惯,就是看书,基本上闲暇时候,都能看到他看书的身影。
看他的动态也都是分享各类书籍,**口吐芬芳**,我要是个女人,估计他跑不掉了。
反正经常读书的人,你跟他说话,看他谈吐,自然就知道了,我经常说的那句:**腹有诗书气自华** 希望你能懂,不看真像网上的段子那样,看到美好的景色只能:卧*
下面是我截图的他的几条动态,这种谈吐我爱了❤



### Java
#### Java核心技术·卷 I(原书第10版)| Core Java Volume
> 讲的很全面,书中的代码示例都很好,很适合Java入门。
>
> 但是作者不太厚道的是把现在没人用的GUI编程放在了第一卷,基本上10~13章是可以不用读的。

#### Java性能权威指南|Java Performance: The Definitive Guide
> 市面上介绍Java的书有很多,但专注于Java性能的并不多,能游刃有余地展示Java性能优化难点的更是凤毛麟角,本书即是其中之一。
>
> 通过使用JVM和Java平台,以及Java语言和应用程序接口,本书详尽讲解了Java性能调优的相关知识,帮助读者深入理解Java平台性能的各个方面,最终使程序如虎添翼。

#### 实战Java高并发程序设计|葛一鸣
> 由部分段落的行文来看,搬了官方文档。
>
> 也有一些第一人称的叙述和思考,也能看出作者也是花了一点心思的。胜在比较基础,涉及到的知识点也还很全面(讲到了流水线计算和并发模型这些边边角角的),但是由于是编著,全书整体上不够统一和深入,适合作为学习高并发的第一本工具书。

#### Java 8实战
> 对Java8的新特性讲解的十分到位,尤其是lamdba表达式和流的操作。
>
> 再者对于Java8并发处理很有独到见解。对于并行数据处理和组合式异步编程还需要更深的思考才能更加掌握。
>
> 推荐给再用java8但没有去真正了解的人看,有很多你不知道的细节、原理和类库设计者的用心良苦在里面、内容没有很难,抽出几个小时就能看完,花费的时间和收获相比,性价比很高。

#### Java并发编程实战
> 先不谈本书的内容如何,光书名就足够吸引不少目光。“并发”这个词在Java世界里往往和“高级、核心”等字眼相联系起来,就冲着这两个字,都将勾起软件工程师们埋藏在心底那种对技术的探索欲和对高级API的驾驭感。
>
> 程序员嘛,多少都有点职业病。其实Java对“并发”优化从未停止过,从5.0到7.0,几乎每个版本的新特性里,都会针对前一版本在“并发”上有所改进。这种改进包括提供更丰富的API接口、JVM底层性能优化等诸多方面。

#### Thinking in Java
> 很美味的一本书,不仅有icecreamm,sundae,sandwich,还有burrito!真是越看越饿啊~

#### Effective Java中文版(第3版)|Effective Java Third Edition
> Java 高阶书籍,小白劝退。介绍了关于Java 编程的90个经验技巧。
>
> 作者功力非常强悍,导致这本书有时知识面迁移很广。总之,非常适合有一定Java开发经验的人阅读提升。

#### 深入理解Java虚拟机(第3版)| 周志明
> 浅显易懂。最重要的是开启一扇理解虚拟机的大门。
>
> 内存管理机制与Java内存模型、高效并发这三章是特别实用的。

#### Java虚拟机规范(Java SE 8版)|爱飞翔、周志明
> 整本书就觉得第二章的方法字节码执行流程,第四章的前8节和第五章能看懂一些。其他的过于细致和琐碎了。
>
> 把Java字节码讲的很清楚了,本质上Java虚拟机就是通过字节码来构建的一套体系罢了。所以字节码说的非常细致深入。

### 数据&大数据
#### 数据结构与算法分析|Data Structures and Algorithm Analysis in Java
> 数据结构是计算机的核心,这部书以java语言为基础,详细的介绍了基本数据结构、图、以及相关的排序、最短路径、最小生成树等问题。
>
> 但是有一些高级的数据结构并没有介绍,可以通过《数据结构与算法分析——C语言描述》来增加对这方面的了解。

#### MySQL必知必会
> 《MySQL必知必会》MySQL是世界上最受欢迎的数据库管理系统之一。
>
> 书中从介绍简单的数据检索开始,逐步深入一些复杂的内容,包括联结的使用、子查询、正则表达式和基于全文本的搜索、存储过程、游标、触发器、表约束,等等。通过重点突出的章节,条理清晰、系统而扼要地讲述了读者应该掌握的知识,使他们不经意间立刻功力大增。

#### 数据库系统概念|Datebase System Concepts(Fifth Edition)
> 从大学读到现在,每次拿起都有新的收获。而且这本书还是对各个数据相关领域的概览,不仅仅是数据库本身。

#### 高性能MySQL
> 对于想要了解MySQL性能提升的人来说,这是一本不可多得的书。
>
> 书中没有各种提升性能的秘籍,而是深入问题的核心,详细的解释了每种提升性能的原理,从而可以使你四两拨千斤。授之于鱼不如授之于渔,这本书做到了。

#### 高可用MySQL
> 很实用的书籍,只可惜公司现有的业务和数据量还没有达到需要实践书中知识的地步。

#### 利用Python进行数据分析|唐学韬
> 内容还是跟不上库的发展速度,建议结合里面讲的库的文档来看。
>
> 内容安排上我觉得还不错,作者是pandas的作者,所以对pandas的讲解和设计思路都讲得很清楚。除此以外,作者也是干过金融数据分析的,所以后面专门讲了时间序列和金融数据的分析。

#### HBase
> 看完影印版第一遍,开始以为会是大量讲API,实际上除了没有将HBase源代码,该讲的都讲了,CH8,9章留到最后看的,确实有点顿悟的感觉,接下来需要系统的看一遍Client API,然后深入代码,Come ON!

#### Programming Hive
> Hive工具书,Hive高级特性。

#### Hadoop in Practice| Alex Holmes
> 感觉比action那本要强 像是cookbook类型的 整个过完以后hadoop生态圈的各种都接触到了 这本书适合当参考手册用。

#### Hadoop技术内幕|董西成
> 其实国人能写这样的书,感觉还是不错的,不过感觉很多东西不太深入,感觉在深入之前,和先有整体,带着整体做深入会更好一点, jobclient,jobtracer,tasktracer之间的关系最好能系统化

#### Learning Spark
> 很不错,core的原理部分和api用途解释得很清楚,以前看文档和代码理解不了的地方豁然开朗。
>
> 不足的地方是后几章比较弱,mllib方面没有深入讲实现原理。graphx也没有涉及

#### ODPS权威指南
> 基本上还算一本不错的入门,虽然细节方面谈的不多,底层也不够深入,但毕竟是少有的ODPS书籍,且覆盖面很全,例子也还行。

#### 数据之巅|徐子沛
> 从一个新的视角(数据)切入,写美国历史,统计学的发展贯穿其中,草蛇灰线,伏脉千里,读起来波澜壮阔。

### 消息队列&Redis
#### RabbitMQ实战
> 很多年前的书了,书中的例子现在已经不适用了,推荐官方教程。
>
> 一些基础还是适用,网上也没有太多讲rab的书籍,将就看下也行,我没用过所以....

#### Apache Kafka源码剖析|徐郡明
> 虽然还没看,但知道应该不差。我是看了作者的mybatis源码分析,再来看这本的,相信作者。
>
> 作者怎么有这么多时间,把框架研究的这么透彻,佩服,佩服。

#### 深入理解Kafka:核心设计与实践原理|朱忠华
> 通俗易懂,图文并茂,用了很多图和示例讲解kafka的架构,从宏观入手,再讲到细节,比较好,值得推荐。
>
> 深入理解Kafka是市面上讲解Kafka核心原理最透彻的,全书都是挑了kafka最核心的细节在讲比如分区副本选举、分区从分配、kafka数据存储结构、时间轮、我认为是目前kafka相关书籍里最好的一本。

#### Kafka
> 认真刷了 kafka internal 那章,看了个talk,算是入了个门。
>
> 系统设计真是门艺术。

#### RocketMQ实战与原理解析|杨开元
> 对RocketMQ的脉络做了一个大概的说明吧,深入细节的东西还是需要自己看代码

#### Redis设计与实现|黄健宏
> 部分内容写得比较啰嗦,当然往好了说是对新手友好,不厌其烦地分析细节,但也让整本书变厚了😂,个人以为精炼语言可以减少20%的内容。
>
> 对于有心一窥redis实现原理的读者来说,本书展露了足够丰富的内容和细节,却不至于让冗长的实现代码吓跑读者——伪代码的意义在此。下一步是真正读源码了。

#### Redis 深度历险:核心原理与应用实践|钱文品
> 真心不错,数据结构原理+实际应用+单线程模型+集群(sentinel, codis, redis cluster), 分布式锁等等讲的都十分透彻。
>
> 一本书的作用不就是系统性梳理,为读者打开一扇窗,读者想了解更多,可以自己通过这扇窗去Google。这本书的一个瑕疵是最后一章吧,写的仓促了。不过瑕不掩瑜。

### 技术综合
#### TCP/IP详解 卷1:协议
> 读专业性书籍是一件很枯燥的事,我的建议就是把它作为一本手册,先浏览一遍,遇到问题再去详细查,高效。

#### Netty in Action
> 涉及到很多专业名词新概念看英文原版顺畅得多,第十五章 Choosing the right thread model 真是写得太好了。另外结合Ron Hitchens 写的《JAVA NIO》一起看对理解JAVA NIO和Netty还是很有帮助的

#### ZooKeeper
> 值得使用zookeeper的人员阅读, 对于zookeeper的内部机制及api进行了很详细的讲解, 后半部分深入地讲解了zookeeper中ensemble互相协作的流程, 及group等高级配置, 对zookeeper的高级应用及其它类似系统的设计都很有借鉴意义.

#### 从Paxos到Zookeeper|倪超
> 分布式入门鼻祖,开始部分深入阐述cap和base理论,所有的分布式框架都是围绕这个理论的做平衡和取舍,中间 zk的原理、特性、实战也讲的非常清晰,同时讲cap理论在zk中是如何体现,更加深你对cap的理解.

#### 深入理解Nginx(第2版)|陶辉
> 云里雾里的快速读了一遍,主要是读不懂,读完后的感受是设计的真好。
>
> 原本是抱着了解原理进而优化性能的想法来读的,却发现书中的内容都是讲源码,作者对源码的注释超级详细,非常适合开发者,但不适合使用者,给个五星好评是因为不想因为我这种菜鸡而埋没了高质量内容。
>
> 另外别人的代码写的真好看,即便是过程式语言程序也吊打我写的面向对象语言程序。
>
>
> 作者是zookeeper的活跃贡献者,而且是很资深的研究员,内容比较严谨而且较好的把握住了zk的精髓。书很薄,但是没有废话,选题是经过深思熟虑的。

#### 深入剖析Tomcat
> 本书深入剖析Tomcat 4和Tomcat 5中的每个组件,并揭示其内部工作原理。通过学习本书,你将可以自行开发Tomcat组件,或者扩展已有的组件。 Tomcat是目前比较流行的Web服务器之一。作为一个开源和小型的轻量级应用服务器,Tomcat 易于使用,便于部署,但Tomcat本身是一个非常复杂的系统,包含了很多功能模块。这些功能模块构成了Tomcat的核心结构。本书从最基本的HTTP请求开始,直至使用JMX技术管理Tomcat中的应用程序,逐一剖析Tomcat的基本功能模块,并配以示例代码,使读者可以逐步实现自己的Web服务器。

#### 深入理解计算机系统 | 布莱恩特
> 无论是内容还是纸张印刷,都是满分。计算机学科的集大成之作。引导你如何练内功的,算是高配版本的计算机导论,目的是釜底抽薪引出来操作系统、组成原理这些专业核心的课程。帮助我们按图索骥,点亮一个一个技能树。

#### 架构探险分布式服务框架 | 李业兵
> 刚看前几章的时候,心里满脑子想得都是这特么贴一整页pom文件代码上来干鸡毛,又是骗稿费的,买亏了买亏了,后来到序列化那章开始,诶?还有那么点意思啊。
>
> 到服务注册中心和服务通讯,60块钱的书钱已经赚回来了。
>
> 知识是无价的,如果能花几十块钱帮你扫了几个盲区,那就是赚了。

#### 深入分析JavaWeb技术内幕 | 许令波
> 与这本书相识大概是四年前是在老家的北方图书城里,当时看到目录的感觉是真的惊艳,对当时刚入行的自己来说,这简直就是为我量身定做的扫盲科普集啊。
>
> 但是可惜的是,这本书在后来却一直没机会读上。然后经过四年的打怪升级之后,这次的阅读体验依旧很好。
>
> 其中,java编译原理、 Servlet工作原理、 Tomcat、spring和iBatis这几章的收获很大。

### 前端
#### jQuery 技术内幕| 高云
> 非常棒的一本书,大大降低了阅读jquery源码的难度(虽然还是非常难)。

#### Head First HTML与CSS(第2版)
> 翻了非常久的时间 断断续续 其实从头翻到尾 才发现一点都不难。
>
> 可我被自己的懒惰和畏难情绪给拖累了 简单说 我成了自己往前探索的负担。网页基础的语法基本都涵盖了 限于文本形态 知识点都没法像做题一样被反复地运用和复习到。通俗易懂 这不知算是多高的评价?
>
> 作为入门真心算不错了 如果更有耐心 在翻完 HTML 后 对 CSS 部分最好是可以迅速过一遍 找案例练习估计更好 纸上得来终觉浅 总是这样。

#### JavaScript高级程序设计(第3版)
> JavaScript最基础的书籍,要看认真,慢慢地看,累计接近1000小时吧。而且对象与继承,性能优化,HTML5 api由于没有实践或缺乏代码阅读量导致看的很糊涂,不过以后可以遇到时再翻翻,或者看更专业的书。

#### 深入理解ES6
> Zakas的又一部杰作,他的作品最优秀的地方在于只是阐述,很少评价,这在帮助我们夯实基础时十分有意义,我也喜欢这种风格。
>
> 我是中英文参照阅读的,译本后半部分有一些文字上的纰漏,但是总体来说忠实原文,水平还是相当不错,希望再版时可以修复这些文字问题。

#### 高性能JavaScript
> 还是挺不错的。尤其是对初学者。总结了好多程序方面的好习惯。
>
> 不过对于老手来说,这些常识已经深入骨髓了。

#### 深入浅出Node.js|朴灵
> 本书是我看到现在对Node.JS技术原理和应用实践阐述的最深入,也最全面的一本书。鉴于作者也是淘宝的一位工程师,在技术总是国外好的大环境下,没有理由不给本书五颗星。
>
> 作者秉着授人于鱼不如授人于渔的精神,细致入微的从V8虚拟机,内存管理,字符串与Buffer的应用,异步编程的思路和原理这些基础的角度来解释Node.JS是如何工作的,比起市面上众多教你如何安装node,用几个包编写一些示例来比,本书绝对让人受益匪浅。
>
> 认真看完本书,几乎可以让你从一个Node的外行进阶到专家的水平。赞!

#### Vue跟React的技术栈的书不多,很多也是官方文档的照搬照抄,我觉得看官网吧哈哈。
### 非技术类
#### 失踪的孩子
> 整本书的能量太密集了,像一个源源不断喷发的火山,读完怅然若失。最后几页,莱农从时间中回望,生命的真相被自己毫不留情的剖白,而即使是这样的时刻,她依然能再次在对莉拉的爱和嫉妒中被激发开始进行她最为重要、最可能留在时间之中的作品的创作,如此的勇气,诚实和坚韧……反正我已经喜欢她了。
>
> 而莉拉依然是个迷。她和莱农是相反的人,莱农会攫住一切填充自己,去成为,但莉拉对任何事情的投入都不会滋养自身,而是燃烧掉自己的一部分。
>
> 她的激情,超越一切的理解和视野与她的情绪化,她的恐惧,都让人困惑。莉拉是所有人的镜子,任何人在她面前都不得不面对自己;同时,是不是没有人,或者说莉拉没有允许任何人了解她?因为她在与外界和自己的对抗中也未能真正看见自己?

#### 人生|路遥
> 想着和平凡的世界一个调子,都是乡村,都是文革的尾巴,都是那点家长里短绝对真实。
>
> 我总觉得那是作者的真实写照,一切都是从自己的记忆中提炼出来的故事。
>
> 只不过根据高加林我总在思考劳动人民是否应该有文化,有文化了以后就开始痛苦,开始怀春悲秋,开始事逼,开始怨天尤人。
>
> 知识分子那些臭毛病显露无疑。

#### 丝绸之路 | 彼得·弗兰科潘
> 书的颜值很高,厚厚的大开本,包装和纸张都不枉自己百元大洋。书名虽叫【丝绸之路】,但是读后发现其实是以中东为针,一路串起亚欧大陆各个文明两千多年间所发生的故事。
>
> 从史实、文化、宗教、政治、权力、金钱等多方面论述了以中亚和欧洲为主的发展史,信息量非常的大。每个章节的标题都用四个字直接道出当前世界的核心驱动,比如基督之路、铁蹄之路、西欧之路、纳粹之路、争霸之路。
>
> 视野广阔,大开大合,时间跨度可算是穿越千年中东。美中不足的是,中国作为丝绸之路东段上最为重要的国家,描述的篇幅却很少。

#### 我的天才女友 | 埃莱娜·费兰特
> 来自意大利作家的小说,“那不勒斯”四部曲的第1部,讲述了两个女主人公莉拉和埃莱娜的少女时代。
>
> 相比七月与安生,跨度更大,情节也要丰富很多,但是作为一个男性阅读角度似乎get不到小说所评价那样优秀的点,代入感很好,时间已经过去好久,现在留在记忆中的还是如西西里的美丽传说般暖色调的意大利小镇上有两个小女生在平淡的生活。

#### 长安十二时辰 | 马伯庸
> 开年第一单,阅读体验非常的好,完全是美国个人主义英雄大片的大唐版,而主人公张小敬身上却有着更多的坚忍和矛盾,中间有个片段,讲檀棋在元宵灯会的街上跟着张小敬,在万千盏灯笼一齐高高烛起,光彩明耀,火树银花中,看张小敬的背影显得很是落寞。
>
> 读完之后,这一幕仍然记忆犹新,靠整个故事的支撑,这一幕真的完全可以体会到落寞二字。
>
> 书中很认真的说了一些长安的城建和大唐的民俗,管制,可以看出来为了写出这本书,亲王的确是花费了不少心思的,很佩服。
>
> 一本非常非常适合改编成电影的小说(事实上也的确正在拍摄),值得推荐。
>
> ps:2019年同名电视剧已经上线了…

#### 布谷鸟的呼唤 | J·K·罗琳
> 大概三年前买的,今年回家整理新书架的时候发现了它,就带回杭州了。
>
> 故事情节比不上哈利波特,但是文笔是真的没得说,毕竟是能写出来哈利波特的人。
>
> 作为推理小说,怕是不及格,但是把它作为犯罪小说之类的非类型小说来看的话,其实阅读体验还是可以的。

#### 欧洲:1453年以来的争霸之路 | 布伦丹·西姆斯
> 自文艺复兴之后,欧洲开始渐渐的走进地球文明的舞台正中心。
>
> 读到中间德意志民族的内政被周边国家的各种干涉,感觉德国和我们的兔子一样,是个多难的民族,所以统一之后思想家才会这么多,一战二战的德国,如果用兔子的一句话概括,我们走了一些弯路。

#### 房思琪的初恋乐园 | 林奕含
> 正如文前李银河所说,林奕含属于老天爷赏口饭的那种人,非常有才华的、有灵气的一位年轻作者。我们应当感激,不用亲身经历,就可以看到世界的背面,难以想象出林每次去回忆,然后再去一步一步的描述出当时的心理活动,此间的痛苦。
>
> 最后,书中的话:忍耐不是美德,把忍耐当成美德是这个伪善的世界维持它扭曲的秩序的方式,生气才是美德。

#### 毛泽东传 | 迪克·威尔逊
> 来自英国人的传记,可以当做记事表,而且就算有一些主观评价在里面,作为外国人难免有偏差,也不可信,毛公当称之为我等民族力挽狂澜第一人。

#### 半小时漫画世界史 | 陈磊
> 和上一本中国史一样,阅读体验很轻松,如果是对这段历史毫无概念的话,真的砸墙推荐。但是如果是要有了一定的知识储备的话,那就没啥意思了,半小时也别指望能讲多深了。
>
> 巴黎和罗马真的是太值得去一次的了。

#### 欧洲现代史:从文艺复兴到现在 | 约翰·梅里曼
> 耶鲁大学历史教授的课堂讲义,采用的是国别和编年混合风格,顺着历史发展的脉络逐一展开,又不失相互关联性,而不是简简单单的说几几年发生了什么,几月几日谁谁谁死了这些。
>
> 5个世纪中葡萄牙西班牙瑞典荷兰法国轮流崛起,俄国西化,德国统一,英国宗教改革,奥地利波兰土耳其相继衰落,文艺复兴,启蒙运动,航海时代,工业革命,世界大战,美苏冷战。
>
> 维多利亚女王拿破仑一世路易十四彼得大帝叶卡捷琳娜俾斯麦希特勒丘吉尔,当称人类群星闪耀时。

#### 爱德华•巴纳德的堕落:毛姆短篇小说集1 | 毛姆
> 屯了毛姆这么多书,这次才是第一次看。
>
> 书的纸张倒是很有意思,600多页,却很轻。故事读起来倒像是个老朋友再和你讲故事,叨叨叨的从夏威夷讲到南美洲,又从西海岸讲到东南亚,讲故事的水平非常的高,几乎都是几段字下来,就把人带到了故事场景中。最喜欢的两篇是爱德华•巴纳德的堕落,赴宴之前,和最后的译后记。

#### 一句顶一万句 | 刘震云
> 第八届茅盾文学奖获奖作品,叙事架构犹如一生二二生三三生万物绵绵不绝扩散开来,薄薄三百页,前后一百年,初看时以为《平凡的世界》,结局才发现是《百年孤独》,“生活是过以后,而不是过从前”。

#### 生活的艺术家 | 李小龙
> 来自李小龙的一本散文集,是的,就是那个李小龙。
>
> 很难想到那个在电影里面喊着啊哒~的他,大学是专修哲学的。书中的文章大都是对于生活和哲学的思考,可以看到那个在大荧幕前面一秒五踢啊哒啊哒的背后,是一个冷静、理性、智慧、通达的李小龙。“我无法教你什么,只能帮助你探求你自己。除此之外,别无他法。”

#### 穷查理宝典 | 查理芒格
> 查理芒格的思想集和演讲稿编,知识面跨学科,洞察力才能足够深,包括数学、物理、生物、历史、经济等这些硬学科,从而形成一个多学科的思维框架。
>
> 致富也不只是赚了多少钱那么简单,而是在道德品质、阅读能力和个人生活上全面提升的过程。应该专注于正在做的事情,多阅读,特别是传记,来和“伟人”交朋友,减少物欲,满足自己已经拥有的,不嫉妒别人。

#### 汉密尔顿传 | 罗恩·切诺
> 我只能说汉密尔顿,这个被印在美元上的人,人生只能用精彩至极来形容了。
>
> 书中详细介绍了汉密尔顿在独立战争、费城制宪、宪法批准、首届国会以及建国初期等不同历史阶段中发挥的巨大作用,尤其是建国之初,在一切都没有先例的情况下,汉密尔顿为奠定美国联邦的政治体制、经济秩序和金融体系做出了巨大的贡献——建立美国信用体系,建立联邦银行,建立联邦税收体系,建立海关,建立海岸警卫队,以及促进制造业发展等。
>
> 在这本波澜壮阔的自传的最后,本以为能写上一大段对他的盖棺定论,然而却很平淡随意的用他写给艾丽萨的一封信作为了结尾,可能是不再需要作者去告诉书前的人他该如何评价,历史已经给出了答案。
>
> “艾丽萨,你治愈了我此生因爱而生的伤痛。”

#### 百年孤独|加西亚·马尔克斯
> 久负盛名的大作,读完只能说,果然只有这种书才配得上诺奖。
>
> 先前看《霍乱时期的爱情》,印象最深的就是华丽魔幻文笔和细腻的心理活动描写,到这本《百年孤独》,震撼的目瞪口呆,怎么能有人写得出这样的小说。
>
> 只能说,无论怎么列必读书籍,都绕不开此书。

#### 月亮与六便士
> 毛大爷名气最具盛名的一本书,很易读的文学作品。
>
> 全篇小说都是从第一人称“我”的角度,对斯特里克兰德进行了主观的描写,从斯特里克兰德开始离家出走开始渐入佳境,毛姆在环球旅行中写作,以至于场景地点的代入感都非常强,带着读者登上塔希提岛上,在酒馆里和众人逐个聊起斯特里克兰德,“我”和读者一起,在一来一去的谈话中,了解到了这个天才最后的经历。后半生穷困潦倒的他在死的时候,肯定不会知道自己在死后的一个世纪,被称之为天才,画作也被收藏在美术馆作为镇馆之宝,流传百年。但他是自由的,没有遗憾的。
>
> 最后引用一段话,“只要在我的生活中能有变迁——变迁和无法预见的刺激,**我是准备踏上怪石嶙峋的山崖,奔赴暗礁遍布的海滩的**。”

#### 股票作手回忆录|杰西·利弗莫尔
> 被誉为百年美股第一人,杰西·利弗莫尔的自传,五美元起家,到日赚一亿美金的投机之路,可以看到利弗莫尔在小的时候就对数字有着非常人的敏感和对波动线的记忆力,十多岁只身一人远走纽约,更见其杀伐果断之气。全书并没有讲操作细节,但是传主的做事风格很值得研究,时机、独立思考、判断、知错能改、以及鳄鱼般的耐心。

#### 万历十五年 | 黄仁宇
> 一本表面上写历史,却涵盖当时的政治、经济、社会民俗、当世思想的大作,对中国历史上诸多王朝暗流下那道潜规则的分析和批判。格局之大,立意之高,实属罕见。
>
> 读罢全书,我们明白明王朝的覆灭是必然的,而后的满清,只不过是改朝换代,骨子里与前朝无异,灭亡也是迟早的。
>
> 我们的身上被锁住了一个牢固的枷锁,丢在泥坑,都在挣扎,越来越烂。

#### 第五项修炼| 彼得·圣吉
> 前半部分理论,后半部分讲实战。捞干的来说,大局观的系统思考能力、增长极限和转移负担的自我超越能力、正向暗示的心智能力,拓展认知边界建立跨学科的思维架构能力。

#### 海边的卡夫卡|村上春树
> 卡夫卡,舒伯特,艾希曼,琼尼沃克,乌鸦少年,短毛猫语,竹筴鱼雨,肠子迷宫,夏目漱石,雨月物语,俄狄浦斯。在这个世界上,不单调的东西让人很快厌倦,不让人厌倦的大多是单调的东西。
>
> 我的人生可以有把玩单调的时间,但没有忍受厌倦的余地,而大部分人分不出二者的差别。
>
> 孤独因你本身而千变万化。

#### 白夜行|东野圭吾
> 把小说写成这样绝对是开挂了吧,除了连番登场的几十号人物,随处雕琢的大时代的背景也让人叹为观止。对人性的挖掘比起吉田修一还是弱一些,就是纯好看,从第一句开始吸住你逐渐往往里掉。

#### 嫌疑人X的献身|东野圭吾
> 这个社会 每一个人都是时钟上的齿轮,为了自己的意愿,也不该牺牲掉他人,哪怕那是出于爱,一个错误尚且为错,付出更大的努力用更大错误也扭转不了的,
>
> 这毕竟不是数学的负负得正,逻辑之所以没法解决罪恶的问题,只因为最初就规避了人性。

#### 追风筝的人|卡勒德·胡赛尼
> 为什么忠诚善良的人反而遭到这样的结局,面对阿米尔的污蔑,他和阿里选择离去。
>
> 当房屋需要他时,他又毅然决然的选择坚守,为了阿米尔能够得到父亲的赞许,哈桑却受到那样的凌辱,换来的却是懦弱的阿米尔的回避,身份,阶级,好可笑的头衔,生命与忠诚在那些虚无的名誉不值一提。
>
> 犹如草芥浮萍....

#### 恋情的终结 | 格雷厄姆
> 现在看的小说都不多了,而爱情小说更是少之又少,但幸运的是,这本和上一本霍乱时期的爱情一样,都是不可多得的大师之作。
>
> 小说情节简单来说就是爱上了个有妇之夫,然后阴差阳错私奔失败,接着分道扬镳直到多年之后的偶遇,最后女主患病而亡。
>
> 但文笔是真的细腻到不敢相信是个男人写的,书里穷尽了爱情中所有狂热的情感,狂热的爱,狂热的恨,狂热的猜疑,狂热的嫉妒,狂热的占有。

#### 龙族I-IV|江南
> 我十六岁的时候,看《缥缈录》,心中念着那个拿着虎牙枪的少年。
>
> 如今我二十三岁了,看《龙族》,面对一堆白烂中二的吐槽不知所措。
>
> 就像拿枪的少年穿起了风衣,救美的英雄接受了金币。我看着商业化写作对一个作者的侵蚀和改变,这让我觉得难过极了。

#### 三体I-Ⅲ|刘慈欣
> 《三体》就是那种让你在读完三部之后掩卷抬头,感觉眼中的世界都从此不一样了的书。

#### 流浪地球|刘慈欣
>觉得文笔胜于三体,且惊觉是三体之前的作品。
>
>对于其中地球变轨后的生态变化仍存在疑惑,那段地球与木星擦肩表现力强,不错的作品。

#### 全球通史
> 这种时间跨度如此之长的,有之前的《丝绸之路》和《人类简史》,但是无论是整体行文的架构、视野的宽度、以及分析思考的深度上来说,此书都要比这两本要优秀得多,尤其是到一战之前的部分。
>
> 幸亏之前大量零碎的知识点做背书,再遇此书建立整体体系,穿针引线,才有所体会到书前序中的"思接千载,视通万里"之感。

#### 程序员的自我修养|俞甲子 / 石凡 / 潘爱民
> 讲的不错,将硬件与系统、机器层与实现层整合了起来,有了一个很清晰的视角。

#### 颈椎病康复指南|董晓俊
> 出来打工不容易,大家照顾好自己。

#### 活着|余华
> 为啥安利这个,大家懂就好了

#### 我们一无所有|安东尼·马拉
> 艺术让我们不因真实而亡故,结构相当特别,像是在看电影。
>
> 讲述从苏联联邦到新俄罗斯近80年历史车轮下一些动人心魄的小人物微尘。
>
> 语言克制、平静,读来却十分疼痛,或是戏谑嘲讽像是苦中求乐,非常喜欢。

### 总结
其实我觉得在我们现在这个浮躁的社会,大家闲暇时间都是刷抖音,逛淘宝,微博......他们都在一点点吞噬你的碎片时间,如果你尝试着去用碎片的时间看看书,我想时间久了你自然能体会这样的好处。
美团技术团队甚至会奖励读完一些书本的人,很多公司都有自己的小图书馆,我觉得挺好的。

我现在也认识很多作者,像程序员小灰,老钱这样的作者,都很不错,如果未来自己能达到写作的条件的话我也想写哈哈。
至于我为啥不敢懈怠......三歪(java3y作者)在我对面我真的不敢有丝毫放松,每次闲暇之余我准备拿起手机玩耍的时候,看到他在看书,我默默的放下手机,就是这样的人在不断鞭笞着我。
### 鸣谢
自己技术群的小伙伴:很多书籍我没写进去,主要是记录被刷走太多了,我让大家私聊,结果都发群里了,我就懒得整理了,主要是没书评我没看过也不敢写。
豆瓣小伙伴:很多我没有的书籍我都是找的豆瓣书评。
阿里技术团队的小伙伴:文章有很多书评都是来自他。
博文视点:对文末抽奖的赞助
**其实很多好书我都没写到,一时想不到,大家有喜欢的也留言让更多朋友看到嘛,我有空会修改文章。**
**还有就是本文主要的目的不是安利多少书,主要是想大家放下手机翻开你在角落积灰的书籍,你会发现里面有光的。**
这周双十二有点小忙,年会的事情也紧锣密鼓的筹备着,我下周要是鸽了那......
### 抽书!!!
#### 书名:Java系统性能优化实战

个人推荐理由:
- 20多个优化技巧:说明Java性能优化的各种方法。
- 30多个具有“坏味道”的代码片段:实战演练优化技巧。
- 常用的高性能工具:以Caffeine、Jackson、HikariCP为例进行讲解,并对其高性能的原因做一定的源码解析。
- 容易阅读的代码:从代码注释、代码分解和面向对象三方面讲解如何编写容易阅读的代码。
#### 规则:
抽两本,公众号「**三太子敖丙**」这个文章下面留言点赞排名前两位送两本,截止本周我发周报之前,公众号和掘金周六我会写周报。
觉得概率不大?
**月底会有一个文章抽30本书**,至于送啥书,贫穷的我得好好想想。
## 点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇一线互联网大厂面试和常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】
如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 文章每周持续更新,可以微信搜索「 **三太子敖丙** 」第一时间阅读和催更(比博客早一到两篇哟),本文 **GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 已经收录,有一线大厂面试点思维导图,也整理了很多我的文档,欢迎Star和完善,大家面试可以参照考点复习,希望我们一起有点东西。
================================================
FILE: docs/creative/彩蛋.md
================================================
### 我定期收集一些话放在这里,大家一起共勉.
- 无论面对怎么样的失败,我决定再来一次。
- 最高级的自律,享受孤独。
- 你要悄悄拔尖,然后惊艳所有人。
- 如果父母还那么辛苦,那我们长大有什么用?
================================================
FILE: docs/creative/顶级程序员的百宝箱.md
================================================
>
>
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> **GitHub**上已经开源 [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 有一线大厂面试点脑图、个人联系方式和人才交流群,欢迎Star和指教
## 前言
这期是被人才群交流里,还有很多之前网友评论强行顶出来的一期,就是让我介绍自己常用的一些工具给他们安利一下,我一听很高兴呀,帅丙我这么乐于奉献的人是吧。
主要是能水一篇文章就很开心,不过写下来发现花的时间完全不比写技术少,**点赞**!!!
千万不要白嫖,**真香警告**⚠️。
但是我在构思这篇文章的时候发现我贴个标题,然后发下软件信息会不会太乏味了,于是创作鬼才我呀,准备用一个产品的研发流程,是的就是**用这样的一个思路**去写这个工具集的介绍文章。
因为读者很多还是学生,还有很多应届生,对一个需求的研发流程都不是很熟悉,还有可能对于以后自己需要使用到的工具都不是很熟悉,那我就一一罗列一下,帅丙我作为一个还算有点小经验的程序员都使用哪些工具呢?
那下面就跟随**暖男**的脚步,走进**顶级程序员的百宝箱**吧(我所有的标题都是噱头就为了夸大其词,我是低级程序员,大家看了也不能吊打面试官,笑笑就好了)。
**注意**:下面的软件我都是简单的介绍下是干啥的,因为太多了,真正的功能需要大家深挖的,能力允许的朋友下载正版,破解方法去Github [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 加我回复【**软件**】就好了。
## 正文
既然都说了**帅丙**是要用一个产品的研发流程角度去介绍软件,那我们先看看一个产品有哪些研发流程,帅丙就用自己接触的阿里系的研发流程举例了,这也基本上是互联网大厂的研发流程了,可能细节有出入,但是绝对大同小异。

**Tip**:我从开发的视角去介绍的话我就会**跳过一些**软件,比如提出需求这个其实一般都是文档类的,**wiki**呀这样的形式。
我就不介绍那种流程工具了,公司很多自研的,大家工作了再去熟悉也很快的。
### 概要设计:
**概要设计**,这个是大厂程序员需求下来之后基本上都会做的一步,不过看需求大小,可能很多小需求直接就**详细设计了**。
很多不了解的同学可能会问,需要设计什么呢?为什么要设计呢?
问得好,经常看我文章的都知道,**技术是把双刃剑**,你用了技术之后你是不是需要**列出他的优点缺点**,出问题之后的**解决方案**,还有**可能出现的问题**,**注意点**等等。
这么是为了让你能有把控力,比如你用了个**Es**(**Elasticsearch**)你什么都不管你就是要接入它,你把他开发好了上线了,但是有啥坑你知道么?上线崩了怎么办?
帅丙我做**Es**设计的时候设计被老大打回N次,不过成长真心大,对**Es**的了解也飞速进步。
其实远远不止这些问题,这就是我们做设计的主要原因,也是大家工作里面能成长的途径之一,你以为大佬们的经验是怎么来的?
##### 工具:Xmind/ProcessOn
- Xmind官网地址: [https://www.xmind.cn](https://www.xmind.cn/)
- ProcessOn**在线作图**地址:[https://www.processon.com](https://www.processon.com/i/5c349823e4b0db2e592c4847)
> 我这里列举了两个工具,他们两个都可以做概要设计的脑图,我给大家看看我设计过的一些脑图,都是出自这两个软件。

大家在学习,看书等等的时候做个脑图,我告诉你后面你复习还是干啥都**思路贼清晰**,而且**效率**瞬间**高**很多。
### 详细设计
小伙伴又要问了啥是详细设计呀**帅丙**?
诶呀简单,见名知意嘛,概要设计是大概的设计,详细设计是详细的设计。
我们研发的时候整个流程往往很复杂,如果你理解不对直接就写代码,最后容易造成返工,延期,加班,被骂,心情差,回家吵架,离家出走。。。
**看到不做详细设计的后果了吧**,其实大家花点时间做详细设计很有必要,你思路完全清晰了,写代码那就是分分钟的事情,不是嘛?
那再看看帅丙的一个小设计吧,之前文章中大量的流程图,时序图都来自它,**主要是这玩意还是在线的,都不用下载很方便啊。**
详细设计的工具我用的就是**在线**作图神器:**ProcessOn**
- 在线画图地址:[https://www.processon.com](https://www.processon.com/i/5c349823e4b0db2e592c4847)
> 总之一句话很香,流程图、思维导图、原型图、UML、网络拓扑图、组织结构图、BPMN等等一应俱全

### Ascilflow
- 官网地址: [http://asciiflow.com](http://asciiflow.com/)
> 进入网站后直接开画!网页上端是菜单,自行操作!

### 研发
这个关键了:**工欲善其事,必先利其器**
想必大家都知道这个谚语吧,我就说一下我写代码要用到的软件吧。
#### Intellij IDEA
- 官网地址 : [http://www.jetbrains.com/idea](http://www.jetbrains.com/idea/)
> 这个我想都不用我介绍了吧,Java的同学都耳熟能详了,有同学问为啥不用eclipse呀,我不作回答,但是我只能告诉你IDEA肯定是效率还有很多方面都要香的。
>
> 不过看个人习惯的哈,新同学还是推荐IDEA!!!

#### WebStorm
- 官网地址 : [http://www.jetbrains.com/webstorm](http://www.jetbrains.com/webstorm/)
> 有知道同学要问了,帅丙这不是前端的开发工具么,为啥你要用,帅丙我呀全才来的呀,前端偶尔也写点的嘛,主要是js,vue,jq,还有丢丢React,不过最近帮三歪改前端居然是jsx有没有大佬救救我啊。

### Visual Studio Code
- 官网地址:[https://code.visualstudio.com](https://code.visualstudio.com/)
> Visual Studio Code是一个**轻量且强大的跨平台开源**代码编辑器(IDE),支持Windows,OS X和Linux。内置JavaScript、TypeScript和Node.js支持,而且拥有丰富的插件生态系统,可通过安装插件来支持C++、C#、Python、PHP等其他语言。

#### PyCharm
- 官网地址 :[http://www.jetbrains.com/pycharm](http://www.jetbrains.com/pycharm/)
> 这个是python之前那次还记得我写代码大赛那期嘛,最开始就是用这个写的,平时学的时候也用用。

#### Navicat Premium
- 官网地址 :[https://www.navicat.com.cn](https://www.navicat.com.cn/)
> 这个呀是数据库的可视化工具很香很好用,不过我们线上的表都是网页操作的,这个只能用来看看本地的开发表了,不过也是很有必要的,你SQL怎么都得本地跑一下没问题,才向DBA申请的嘛。

#### Postman
- 官网地址 :[https://www.getpostman.com](https://www.getpostman.com/)
> 这个是接口调试的神器,单测比较繁琐的你可以试试这个嘛,不过很多接口还是只能写写单测,反正很香。
>
> 不过这个名字一看就是男生用的,那我们女生用啥呢?往下看

#### Postwoman
- 官网地址 :[https://postwoman.io](https://postwoman.io/)
> PostMan一听就是男生用的,咋妹子们肯定要用最近开源的Postwoman啊,它是一款开源的 Postman 替代品
>
>
>
> 开源没多久优点如下:
>
> - 轻盈,可直接在线访问;
> - 简约,采用简约的 UI 设计精心打造;
> - 支持 GET, HEAD, POST, PUT, DELETE, OPTIONS, PATCH 方法;
> - 支持验证;
> - 实时,发送请求即可获取响应。

#### GIt
- 官网地址 :[https://git-scm.com](https://git-scm.com/)
> 代码文档管理工具,版本控制工具,大家之后的代码基本上都是使用git做版本管理

#### Maven
- 官网地址 :[http://maven.apache.org](http://maven.apache.org/)
> 目前帅丙用到Maven的主要功能是:项目构建、项目构建、项目依赖管理、软件项目持续集成、版本管理、项目的站点描述信息管理

#### Gradle
- 官网地址 :[https://gradle.org](https://gradle.org/)
> Gradle是一个基于Apache Ant和Apache Maven概念的项目自动化构建开源工具。
>
> 它使用一种基于Groovy的特定领域语言(DSL)来声明项目设置,目前也增加了基于Kotlin语言的kotlin-based DSL,抛弃了基于XML的各种繁琐配置。
>
> 这个跟Maven功能是一样的,但是两者语法不一样,而且我觉得版本控制的时候没Maven好使,有小坑,胜在语法简洁。

#### Charles
- 官网地址 :[https://www.charlesproxy.com](https://www.charlesproxy.com/)
> 这玩意是个HTTP代理服务器,我用它的主要用法就是抓包!
>
> 都知道我是做电商的嘛,很多线上接口线上问题怎么排查呢,抓包看看数据呗。

#### JMeter
- 官网地址 :[https://jmeter.apache.org](https://jmeter.apache.org/)
> Apache JMeter是Apache组织开发的基于Java的压力测试工具
>
> 是的就是用来压测的,你怎么模拟很多请求呀,就用它就对了。

#### Dash
- 官网地址 :[https://kapeli.com/dash](https://kapeli.com/dash)
> Dash for mac是使用与Mac OS平台的软件编程文档管理工具,可以浏览API文档,以及管理代码片段工具。Dash自带了丰富的API文档,涉及各种主流的编程语言和框架。

#### Devdocs
- 官网地址:[https://devdocs.io](https://devdocs.io)
> 上面那个的兄弟,但是这个不用下载,在线的

#### DataGrip
- 官网地址 :[http://www.jetbrains.com/datagrip](http://www.jetbrains.com/datagrip/)
> DataGrip是JetBrains公司推出的管理数据库的产品,对于JetBrains公司,开发者肯定都不陌生,IDEA和ReSharper都是这个公司的产品,用户体验非常不错。
>
> 最开始我用它就单纯看同事在用很酷的界面,后面发现功能也香,高亮文本啥的,很多功能大家可以去挖。

#### JVisualVM
- 官网地址 :[http://visualvm.github.io](http://visualvm.github.io/)
> VisualVM 是Netbeans的profile子项目,已在JDK6.0 update 7 中自带,能够监控线程,内存情况,查看方法的CPU时间和内存中的对 象,已被GC的对象,反向查看分配的堆栈(如100个String对象分别由哪几个对象分配出来的)。
>
> VisualVM可以根据需要安装不同的插件,每个插件的关注点都不同,有的主要监控GC,有的主要监控内存,有的监控线程等。

#### Iterm2
- 官网地址 :https://www.iterm2.com/
> 这个是我做日志排查的客户端工具,也是支持很多配置,直接ssh上跳板机查看线上机器的状态等等,线上问题排查还是很有必要的。

#### 网*有道词典
- 官网地址 :[http://www.youdao.com](http://www.youdao.com/)
> 有朋友要疑问了帅丙这是什么情况,鬼畜乱入么?
>
> 不是的,我们研发的时候很多单词不认识,或者命名的时候这个词汇的英文不知道还是很有必要查一下的,规范的命名是你成为顶级大牛的第一步,你命名都是A,B,C你代码review的时候,你的Leader会叫hr让你提交前回家过年的,马上过年了大家不要轻易尝试。

#### Sublime Text
- 官网地址 :[http://www.sublimetext.com](http://www.sublimetext.com/)
> 这是个文本记录的工具,也可以用于写代码,但是我们有IDE了那就用来当日常琐事记录的工具,临时文档处理的工具也是可以的,反正还是很好用的。

### 刚好最近呀人才群里的人才们都叫我安利一下我做笔记还有写博客的工具,说我排版好看。(我飘了)
安排!
#### 印象笔记
- 官网地址 :[https://www.yinxiang.com](https://www.yinxiang.com/)
> 这个可以说是陪伴我大学到现在的一个工具了吧,我数了下,上千文件了,我的生活琐事的记录,还有学编程之后的很多东西,我都是收录在里面的。
>
> 这个东西我就不和别的笔记比较了,因为我最开始就用的这个一直没换过,好不好用我说了不算的,大家下一个看看就知道了。

#### Typora
- 官网地址 :[https://www.typora.io](https://www.typora.io/)
> Typora是我一直写Markdown的工具,好用到不行,还可以切换模式你敢信?打字机模式,专注模式,源码模式总有一个你的菜.

#### Ipic
- 官网地址 :[https://ipic.ca](https://ipic.ca/)
> 图床我是配合Typora一起使用的大家Markdown是不是复制图片进来都是本地的地址,发到网上就会失效的,但是跟Typora搞基的这个工具他可以在你复制进来的时候直接传到网上了,你再去任何平台发表都可以随心所欲了。
#### Md2All
- 官网地址 :[http://md.aclickall.com](http://md.aclickall.com/)
> 大家好奇我的markdown怎么这么好看呀,其实我写了markdown之后还转成了html的,用的也就是上面这个工具。
>
> 我写完也是在这里面进行排版然后发出去的,排版要花好久,忍不住给帅丙**点赞**。

### 图像处理
#### Adobe Photoshop CC 2019
- 官网地址 :[https://www.adobe.com/cn/products/photoshop](https://www.adobe.com/cn/products/photoshop.html?promoid=PC1PQQ5T&mv=other)
> Ps嘛大家都知道的,正常的图片处理啊用这个香,没事帮美女P下图,搞不好能找个女朋友(我又开始YY了)

#### Adobe Premiere Pro CC 2019
- 官网地址 :[https://www.adobe.com/products/premiere](https://www.adobe.com/products/premiere.html?promoid=PQ7SQBYQ&mv=other)
> 这个可能是大家使用得最多的视频处理软件了吧,很好用!!!
>
> 功能全到无法令人呼吸,缺点就是学习成本有点大,入门很快,想成为大神需要大量时间积累。

#### Adobe After Effects CC 2019
- 官网地址 :[https://www.adobe.com/cn/products/aftereffects](https://www.adobe.com/cn/products/aftereffects/free-trial-download.html)
> 不知道大家视频看得多么,很多视频的特效开场都是这个做的,下面也有一个我的demo。

## 
#### GIPHY CAPTURE
- 官网地址 :[https://giphy.com/apps/giphycapture](https://giphy.com/apps/giphycapture)
> 有时候大家文章不想用静态的图画去表达,想录制写代码的Gif动图,那这个软件是真的好使。

#### 视频播放 KMPlayer
- 官网地址 :[http://www.kmplayer.com](http://www.kmplayer.com/)
> 其实帅丙我心中有个播放神器的,快播。
>
> 可惜了还没用多久,播播就夭折了,我会使用下面这个播放软件去播放我自己的视频。
>
> 因为很多格式电脑自带的可能不支持,我又喜欢剪辑视频,所以一直用它了。

#### Iina
- 官网地址:[https://www.iina.io](https://www.iina.io/)
> 视频播放 同上

#### DouTu
- 官网地址 : [https://www.52doutu.cn/maker/1/?order=timedown](https://www.52doutu.cn/maker/1/?order=timedown)
>大家是不是发现我之前的文章很多表情包,其实都是在线制作的。

#### Carbon
- 官网地址 :[https://carbon.now.sh/](https://carbon.now.sh/)
> 帅丙之前的文章里面很多代码的图片都是这个网站生成的,很多样式可以选择,就很好看。

#### CodeLF
- 官网地址 :[https://unbug.github.io/codelf](https://unbug.github.io/codelf/#帅丙)
> 这个网站有意思了,写代码不知道单词怎么命名就去这里查,他是GItHub的一个爬虫工具吧,看看大神的命名总是会有思路的吧。

**注意**:上面的软件我都是简单的介绍下是干啥的,因为太多了,真正的功能需要大家深挖的,能力允许的朋友下载正版,破解方法去Github [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 加我回复【**软件**】就好了。
## 总结
其实比较香的工具还有太多了,我这里就不一一介绍了,其实有个很简单的办法,就是**问**,**学习**,**借鉴**。
我就是这样的,我看Leader用的什么工具我就问他这是啥,好用不?怎么用?
包括我写博客吧,其实才写了20多天,第一天准备写的时候我就直接问**三歪(Java3y)**,你用的什么开发工具呀,怎么用的呀,包括他主要发布的哪些平台呀,发布的时间段呀,我都直接问。
他坐我对面,**迫于我的淫威**不得不和盘托出,主要是最近有个需求需要我帮他写代码哈哈。
别人都这么多的经验下来了,软件**能差嘛**?而且使用过程中不会的**还可以问一下对方**,不香嘛。
## 絮叨
先看**人才交流群**的某个人才提的问题:

**Tip**: **GItHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 上有进群方式和个人联系方式,说实话在这个群,哪怕您不说话,光看聊天记录,都能学到东西(美团王炸,三歪(Java3y),并夕夕等的大佬都在)。
不知道大家是否还记得我之前写的幂等这样的情况?
就是下图这样的情况,我下单增减GMV先去看看这个流水有么,有就证明加过了,就直接返回,没有才继续下面的流程。

他其实提的问题很好,因为我们日常开发都是**主从同步,读写分**离的,就是说我们可能加GMV加了但是我们操作的是主库,他需要将数据同步到从库,但是这个过程中他发生了延迟。
那这个时候如果别的系统这个**订单号消息重试**了,你是不是又进来了,你去查询流水你发现没流水你以为没加,你执行加钱的操作,结果那条延迟的也好了,是不是就加了两次。
正常开发中确实会有,但是主从延迟这个应该让**DBA**(**数据库管理员 Database Administrator**)去考虑的,但是呢我说过不能写有逻辑漏洞的代码嘛,其实很简单,把他放Redis嘛,设置一个30分钟左右的时间,这期间的重复消费都可以避免,要是延迟超过30分钟了那其实问题已经很大了,DBA会知道的。
**这篇是吐血整理,大家好好食用,记得点个赞!👍**
## 日常求赞
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇《吊打面试官》系列和互联网常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】 如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 《吊打面试官》系列每周持续更新,可以关注我的公众号「 **JavaFamily** 」第一时间阅读和催更(公众号比博客早一到两篇哟),本文**GitHub**上已经收录[https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily),有一线大厂面试点思维导图,欢迎Star和完善,里面也有我个人联系方式有什么问题也可以直接找我,也有人才交流群,我们一起有点东西。
================================================
FILE: docs/idea/idea.md
================================================
> 点赞再看,养成习惯,微信搜索【**三太子敖丙**】我所有文章都在这里,本文 **GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 已收录,有一线大厂面试完整考点。
昨天群里被的人文怎么破解,晚上洗完澡睡觉正准备睡觉的时候,米豆吵醒了我,说他的idea炸了。

于是我让他搜我在公司写的破解文档,这个文档已经造福了很多同事了,我痛定思痛,觉得造福一下你们,但是我先说明,大家有能力的还是支持下正版,我只是觉得这个钱拿去洗脚香一点。
## 开始破解
今天破解的方法很简单,jar包破解的,先下载Jar包。

破解包使用方法:
0. 先下载压缩包解压后得到jetbrains-agent.jar,把它放到你认为合适的文件夹内。
公众号回复【**idea**】获取网盘链接。
1. 启动你的IDE,如果上来就需要注册,选择:试用(Evaluate for free)进入IDE
2. 点击你要注册的IDE菜单:"Configure" 或 "Help" -> "Edit Custom VM Options ..."
如果提示是否要创建文件,请点"Yes"。
3. 在打开的vmoptions编辑窗口末行添加:-javaagent:/absolute/path/to/jetbrains-agent.jar
一定要自己确认好路径(不要使用中文路径),**填错会导致IDE打不开**!!!最好使用绝对路径。
一个vmoptions内只能有一个-javaagent参数。
4. 示例:
mac: -javaagent:/Users/neo/jetbrains-agent.jar
linux: -javaagent:/home/neo/jetbrains-agent.jar
windows: -javaagent:C:\Users\neo\jetbrains-agent.jar
**注**:如果还是填错了,我帮你找到了目录:
### Windows
All the files are located under this directory by default:
- **Windows Vista, 7, 8, 10:**
```
 还有很多公司的弱校验用**token**啊什么的,反正花样很多,但是**重要的场景一定要强校验**,真正查问题的时候没有在磁盘持久化的数据,心里还是空空的,就像你和女朋友分开的时候的心里状态一样。(我单身的怎么知道这种感觉?猜的)
### 你们有接触过消息顺序消费这样的场景么?你怎么保证的?
没有!over!
乖,你肯定不能说没有啊,就是算真的没有,你看过**敖帅丙**的文章都要说有!
**Tip**:但是说实话**顺序消费**这里很难介绍,我上周到这周问了很多身边的师兄开发过程中这样的场景不多,我跟三歪也讨论了几次,网上更多的都是介绍binlog的同步,好像更多的场景就没了。
一般都是**同个业务场景下不同几个操作的消息同时过去**,本身顺序是对的,但是你发出去的时候同时发出去了,消费的时候却乱掉了,这样就有问题了。
我之前做电商活动也是有这样的例子,我们都知道数据量大的时候数据同步压力还是很大的,有时候数据量大的表需要同步几个亿的数据。(并不是主从同步,主从延迟大的话会有问题,可能是从数据库或者主数据库同步到**备库**)
这种情况我们都是怼到队列里面去,然后慢慢消费的,那问题就来了呀,我们在数据库同时对一个Id的数据进行了增、改、删三个操作,但是你消息发过去消费的时候变成了改,删、增,这样数据就不对了。
本来一条数据应该删掉了,结果在你那却还在,这不是**出大问题**!

两者的结果是不是完全不一样了 **↑**
### 那你怎么解决呢?
我简单的说一下我们使用的**RocketMQ**里面的一个简单实现吧。
**Tip**:为啥用**RocketMQ**举例呢,这玩意是阿里开源的,我问了下身边的朋友很多公司都有使用,所以读者大概率是这个的话我就用这个举例吧,具体的细节我后面会在**RocketMQ**和**Kafka**各自章节说到。
生产者消费者一般需要保证顺序消息的话,可能就是一个业务场景下的,比如订单的创建、支付、发货、收货。
那这些东西是不是一个订单号呢?一个订单的肯定是一个订单号的说,那简单了呀。
**一个topic下有多个队列**,为了保证发送有序,**RocketMQ**提供了**MessageQueueSelector**队列选择机制,他有三种实现:

我们可使用**Hash取模法**,让同一个订单发送到同一个队列中,再使用同步发送,只有同个订单的创建消息发送成功,再发送支付消息。这样,我们保证了发送有序。
**RocketMQ**的topic内的队列机制,可以保证存储满足**FIFO**(First Input First Output 简单说就是指先进先出),剩下的只需要消费者顺序消费即可。
**RocketMQ**仅保证顺序发送,顺序消费由消费者业务保证!!!
这里很好理解,一个订单你发送的时候放到一个队列里面去,你同一个的订单号Hash一下是不是还是一样的结果,那肯定是一个消费者消费,那顺序是不是就保证了?
真正的顺序消费不同的中间件都有自己的不同实现我这里就举个例子,大家思路理解下。
**Tip**:我写到这点的时候人才群里也有人问我,一个队列有序出去,一个消费者消费不就好了,我想说的是**消费者是多线程**的,你消息是有序的给他的,你能保证他是有序的处理的?还是一个消费成功了再发下一个**稳妥**。
### 你能跟我聊一下分布式事务么?
**分布式事务**在现在遍地都是分布式部署的系统中几乎是必要的。
我们先聊一下啥是**事务**?
**分布式事务**、**事务隔离级别**、**ACID**我相信大家这些东西都耳熟能详了,那什么是事务呢?
#### 概念:
> **一般是指要做的或所做的事情。**
>
> 在计算机术语中是指访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。
>
> 事务通常由高级数据库操纵语言或编程语言(如SQL,C++或Java)书写的用户程序用户程序的执行所引起,并用形如**begin transaction**和**end transaction**语句(或函数调用)来界定。
>
> 事务由事务开始(**begin transaction**)和事务结束(**end transaction**)之间执行的全体操作组成。
#### 特性:
> 事务是恢复和并发控制的基本单位。
>
> 事务应该具有4个属性:**原子性、一致性、隔离性、持久性**。这四个属性通常称为**ACID特性**。
>
> **原子性(atomicity)**:一个事务是一个不可分割的工作单位,事务中包括的操作要么都做,要么都不做。
>
> **一致性(consistency)**:事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
>
> **隔离性(isolation)**:一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
>
> **持久性(durability)**:**持久性也称永久性(permanence)**,指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
那有同学还是不理解,敖丙我总结了一下就是:**事务就是一系列操作,要么同时成功,要么同时失败。**然后会从事务的 **ACID** 特性**(原子性、一致性、隔离性、持久性)展开叙述**。
事务就是为了保证一系列操作可以正常执行,它必须同时满足 **ACID** 特性。
### 那什么是分布式事务呢?
大家可以想一下,你下单流程可能涉及到10多个环节,你下单付钱都成功了,但是你优惠券扣减失败了,积分新增失败了,前者公司会被薅羊毛,后者用户会不开心,但是**这些都在不同的服务怎么保证大家都成功呢**?
聪明,**分布式事务**,你看你都会抢答了!
**Tip**:真实的应用场景可能比我介绍的场景复杂数倍,我只是为了举例方便一下大家理解所以用了很简单的例子。
我接触和了解到的分布式事务大概分为:
- 2pc(两段式提交)
- 3pc(三段式提交)
- TCC(Try、Confirm、Cancel)
- 最大努力通知
- XA
- 本地消息表(ebay研发出的)
- 半消息/最终一致性(RocketMQ)
这里我就介绍下最简单的**2pc(两段式)**,以及大家以后可能比较常用的**半消息事务**也就是**最终一致性**,目的是让大家理解下分布式事务里面**消息中间件的作用**,别的事务都大同小异,都有很多优点。
当然也都有**种种弊端**:
例如**长时间锁定数据库资源**,导致系统的**响应不快**,**并发上不去**。
网络抖动出现**脑裂**情况,导致事物参与者,不能很好地执行协调者的指令,导致**数据不一致**。
**单点故障**:例如事物协调者,在某一时刻宕机,虽然可以通过选举机制产生新的Leader,但是这过程中,必然出现问题,而TCC,只有强悍的技术团队,才能支持开发,**成本太高**。
不多BB了,我们开始介绍这个两个事物吧。
**2pc(两段式提交)** :

**2pc(两段式提交)**可以说是分布式事务的最开始的样子了,像极了**媒婆**,就是通过消息中间件协调多个系统,在两个系统操作事务的时候都锁定资源但是不提交事务,等两者都准备好了,告诉消息中间件,然后再分别提交事务。
**但是我不知道大家看到问题所在没有?**
是的你可能已经发现了,如果A系统事务提交成功了,但是B系统在提交的时候网络波动或者各种原因提交失败了,其实还是会失败的。
**最终一致性**:

整个流程中,我们能保证是:
- 业务主动方本地事务提交失败,业务被动方不会收到消息的投递。
- 只要业务主动方本地事务执行成功,那么消息服务一定会投递消息给下游的业务被动方,并最终保证业务被动方一定能成功消费该消息(消费成功或失败,即最终一定会有一个最终态)。
不过呢技术就是这样,**各种极端的情况我们都需要考虑**,也很难有完美的方案,所以才会有这么多的方案**三段式**、**TCC**、**最大努力通知**等等分布式事务方案,大家只需要知道为啥要做,做了有啥好处,有啥坏处,在实际开发的时候都注意下就好好了,**系统都是根据业务场景设计出来的,离开业务的技术没有意义,离开技术的业务没有底气**。
还是那句话:**没有最完美的系统,只有最适合的系统。**
##面试结束
### 小伙子看不出来啊,还是有点东西的嘛,这几个点都回答的不错,明天你能跟我聊一下RocketMQ么?
敖丙这章花了这么多时间,不确定他写不写的完,心疼他。好想给他**点赞**啊,**消息回溯**也在单独介绍消息中间件的时候介绍吧,这章篇幅有点长了。
## 总结
这章其实我写的时间**比之前的秒杀还要久**,因为**顺序消息这个场景**我不知道怎么讲出来大家容易懂一点,最后就参考了网上的,顺序消息的实际应用场景没别的那么广泛,跟3y也聊了好几次,最后定了这个binlog的场景。
总之就是**这期创作源泉有点枯竭**,这章是真的难写,包括分布式事务在实际开发过程中也是很复杂的环节,需要用的时候光是做设计都要很久,反正我的流程图长得一匹。
我每次都想着写得**通俗易懂**一点,这篇即使是这样我觉得还是不够通俗易懂,但是消息的场景就是这样,还有大家加我也不要一上来就问我很多扣细节的点,**自己多点思考我觉得可能帮助比我告诉你答案好很多吧**?
## 絮叨
敖丙我呀,这周**有牌面**哟,上了**CSDN**的原力计划榜单,而且奖金高达50块!!!

钱不多但是很开心,跟老妈聊到她也觉得我出息了,刚好她生日,以前我们这一家人就是那种不过生日的,不过呀今年我工作了,而且**有牌面**的我拿了的奖金就很关键,偷偷叫表弟悄悄去给她买了蛋糕和礼物🎁,嘻嘻,开心。🎂
### DISS

这是**博客园的一个网友**在我文章下面的评论,说实话不知道**大家怎么看**的,我只想说:呵呵!傻*
我不知道这个多年的经验到底是怎么样子的多年的经验,我本来其实不准备说出来的,因为我发现我群里很多都是还没毕业的**大学生**或者**应届生**,那就假设我读者还有很多这样的学生,他们都**没社会经验**我怕他们被这样的人给误导了。
我记得我在群里说过:

我可以80%肯定的告诉大家他这个观点就是扯淡,还有那20%我是**认同他的谦虚那个观点**,但是**谦虚难道不应该是我们对待事物最基本的态度嘛?**
但是**面试装傻**这个观点?还有什么**不会要比你强的人**这个观点?技术人我相信也有面试官也在看我的文章,你们在面试的时候,我想遇到厉害的人巴不得招入麾下,为自己冲锋陷阵吧。
而且**正常面试**的时候你是1-3年的经验,面试你的基本上都是3年以上的,然后依次顺推,当然也有很多很厉害的Leader(我前东家Leader95年的,字节跳动某产品线很强的Leader96的等等)等大家工作了你就会发现有些东西**没有时间积累**是学不到的,你要做的只是一步一个脚印踏实走好就好了。
那些人不管年轻与否能坐在那面试你**肯定有他的原因**,那你有什么才华,你**尽情施展**,他没那个度量包容你的优秀,这样的公司不去也罢,但是技术人这样的真的很少,程序员是一群很崇拜能力的人。
所以**面试你有啥都秀出来,把你的才华尽情的展示出来,风就在那,你只管飞翔。**
## 鸣谢
涉及到分布式事务的环节我参考了前大神同事:**鲁班**(花名)的技术分享,很感谢他的文章给的思路,还有问题的解析!

每次写我都会在群里问大家,下次大家都在我的交流群里面也可以多给我点意见,谢谢了。

看到没,就很民主。(敖丙你个渣男,呸,自己不会就不写!)
**Tip**: **GItHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 上有进群方式和个人联系方式,说实话在这个群,哪怕您不说话,光看聊天记录,都能学到东西(美团王炸,三歪(Java3y),并夕夕等的大佬都在)。
## 日常求赞
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我每周都会更新几篇《吊打面试官》系列和互联网常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】 如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 《吊打面试官》系列每周持续更新,可以关注我的公众号「 **JavaFamily** 」第一时间阅读和催更(公众号比博客早一到两篇哟),本文**GitHub**上已经收录[https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily),有一线大厂面试点思维导图,欢迎Star和完善,里面也有我个人联系方式有什么问题也可以直接找我,也有人才交流群,我们一起有点东西。

================================================
FILE: docs/redis/Redis基础.md
================================================
>你知道的越多,你不知道的越多
>点赞再看,养成习惯
## 前言
**Redis**在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在**Redis**的使用和原理方面对小伙伴们进行360°的刁难。作为一个在互联网公司面一次拿一次offer的面霸(**请允许我使用一下夸张的修辞手法**),打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚,在一个寂寞难耐的夜晚,我痛定思痛,决定开始写《吊打面试官》系列,希望能帮助各位读者以后面试势如破竹,对面试官进行360°的反击,吊打问你的面试官,让一同面试的同僚铩羽而归,疯狂收割大厂offer!
### 面试开始
>一个大腹便便,穿着格子衬衣的中年男子,拿着一个满是划痕的mac向你走来,看着快秃顶的头发,心想着肯定是尼玛顶级架构师吧!但是我们腹有诗书气自华,虚都不虚。

### 小伙子您好,看你简历上写了你项目里面用到了Redis,你们为啥用Redis?
心里忍不住暗骂,这叫啥问题,大家不都是用的这个嘛,但是你不能说出来。
认真回答道:**帅气迷人的面试官您好**,因为传统的关系型数据库如Mysql已经不能适用所有的场景了,比如秒杀的库存扣减,APP首页的访问流量高峰等等,都很容易把数据库打崩,所以引入了缓存中间件,目前市面上比较常用的缓存中间件有Redis 和 Memcached 不过中和考虑了他们的优缺点,最后选择了Redis。
**至于更细节的对比朋友们记得查阅Redis 和 Memcached 的区别,比如两者的优缺点对比和各自的场景,后续我有时间也会写出来。**
### 那小伙子,我再问你,Redis有哪些数据结构呀?
字符串String、字典Hash、列表List、集合Set、有序集合SortedSet。
**这里我相信99%的读者都能回答上来Redis的5个基本数据类型。如果回答不出来的小伙伴我们就要加油补课哟,大家知道五种类型最适合的场景更好。**
但是,如果你是Redis中高级用户,而且你要在这次面试中突出你和其他候选人的不同,还需要加上下面几种数据结构HyperLogLog、Geo、Pub/Sub。
如果你还想加分,那你说还玩过Redis Module,像BloomFilter,RedisSearch,Redis-ML,这个时候面试官得眼睛就开始发亮了,心想这个小伙子**有点东西啊**。
******注:本人在面试回答到Redis相关的问题的时候,经常提到BloomFilter(布隆过滤器)这玩意的使用场景是真的多,而且用起来是真的香,原理也好理解,看一下文章就可以在面试官面前侃侃而谈了,不香么?下方传送门 ↓******
[避免缓存穿透的利器之BloomFilter](https://juejin.im/post/5db69365518825645656c0de)
### 如果有大量的key需要设置同一时间过期,一般需要注意什么?
如果大量的key过期时间设置的过于集中,到过期的那个时间点,redis可能会出现短暂的卡顿现象。严重的话会出现缓存雪崩,我们一般需要在时间上加一个随机值,使得过期时间分散一些。
**电商首页经常会使用定时任务刷新缓存,可能大量的数据失效时间都十分集中,如果失效时间一样,又刚好在失效的时间点大量用户涌入,就有可能造成缓存雪崩**
### 那你使用过Redis分布式锁么,它是什么回事?
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放。
### 这时候对方会告诉你说你回答得不错,然后接着问如果在setnx之后执行expire之前进程意外crash或者要重启维护了,那会怎么样?
这时候你要给予惊讶的反馈:唉,是喔,这个锁就永远得不到释放了。紧接着你需要**抓一抓自己得脑袋,故作思考片刻**,好像接下来的结果是你主动思考出来的,然后回答:我记得set指令有非常复杂的参数,这个应该是可以同时把setnx和expire合成一条指令来用的!
### 对方这时会显露笑容,心里开始默念:嗯,这小子还不错,开始有点意思了。
### 假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如何将它们全部找出来?
使用**keys**指令可以扫出指定模式的key列表。
### 对方接着追问:如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
这个时候你要回答redis关键的一个特性:redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用**scan**指令,**scan**指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
**不过,增量式迭代命令也不是没有缺点的: 举个例子, 使用 SMEMBERS 命令可以返回集合键当前包含的所有元素, 但是对于 SCAN 这类增量式迭代命令来说, 因为在对键进行增量式迭代的过程中, 键可能会被修改, 所以增量式迭代命令只能对被返回的元素提供有限的保证 。**
### 使用过Redis做异步队列么,你是怎么用的?
一般使用list结构作为队列,**rpush**生产消息,**lpop**消费消息。当lpop没有消息的时候,要适当sleep一会再重试。
### 如果对方追问可不可以不用sleep呢?
list还有个指令叫**blpop**,在没有消息的时候,它会阻塞住直到消息到来。
### 如果对方接着追问能不能生产一次消费多次呢?
使用pub/sub主题订阅者模式,可以实现 1:N 的消息队列。
### 如果对方继续追问 pub/su b有什么缺点?
在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如**RocketMQ**等。
### 如果对方究极TM追问Redis如何实现延时队列?
这一套连招下来,我估计现在你很想把面试官一棒打死(**面试官自己都想打死自己了怎么问了这么多自己都不知道的**),如果你手上有一根棒球棍的话,但是你很克制。平复一下激动的内心,然后神态自若的回答道:使用sortedset,拿时间戳作为score,消息内容作为key调用zadd来生产消息,消费者用**zrangebyscore**指令获取N秒之前的数据轮询进行处理。
**到这里,面试官暗地里已经对你竖起了大拇指。并且已经默默给了你A+,但是他不知道的是此刻你却竖起了中指,在椅子背后。**
### Redis是怎么持久化的?服务主从数据怎么交互的?
RDB做镜像全量持久化,AOF做增量持久化。因为RDB会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要AOF来配合使用。在redis实例重启时,会使用RDB持久化文件重新构建内存,再使用AOF重放近期的操作指令来实现完整恢复重启之前的状态。
**这里很好理解,把RDB理解为一整个表全量的数据,AOF理解为每次操作的日志就好了,服务器重启的时候先把表的数据全部搞进去,但是他可能不完整,你再回放一下日志,数据不就完整了嘛。不过Redis本身的机制是 AOF持久化开启且存在AOF文件时,优先加载AOF文件;AOF关闭或者AOF文件不存在时,加载RDB文件;加载AOF/RDB文件城后,Redis启动成功; AOF/RDB文件存在错误时,Redis启动失败并打印错误信息**
### 对方追问那如果突然机器掉电会怎样?
取决于AOF日志sync属性的配置,如果不要求性能,在每条写指令时都sync一下磁盘,就不会丢失数据。但是在高性能的要求下每次都sync是不现实的,一般都使用定时sync,比如1s1次,这个时候最多就会丢失1s的数据。
### 对方追问RDB的原理是什么?
你给出两个词汇就可以了,fork和cow。fork是指redis通过创建子进程来进行RDB操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
******注:回答这个问题的时候,如果你还能说出AOF和RDB的优缺点,我觉得我是面试官在这个问题上我会给你点赞,两者其实区别还是很大的,而且涉及到Redis集群的数据同步问题等等。想了解的伙伴也可以留言,我会专门写一篇来介绍的。 ******
### Pipeline有什么好处,为什么要用pipeline?
可以将多次IO往返的时间缩减为一次,前提是pipeline执行的指令之间没有因果相关性。使用redis-benchmark进行压测的时候可以发现影响redis的QPS峰值的一个重要因素是pipeline批次指令的数目。
### Redis的同步机制了解么?
Redis可以使用主从同步,从从同步。第一次同步时,主节点做一次bgsave,并同时将后续修改操作记录到内存buffer,待完成后将RDB文件全量同步到复制节点,复制节点接受完成后将RDB镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。后续的增量数据通过AOF日志同步即可,有点类似数据库的binlog。
### 是否使用过Redis集群,集群的高可用怎么保证,集群的原理是什么?
Redis Sentinal着眼于高可用,在master宕机时会自动将slave提升为master,继续提供服务。
Redis Cluster着眼于扩展性,在单个redis内存不足时,使用Cluster进行分片存储。
## 面试结束
### 小伙子你可以的,什么时候有时间来上班啊,要不明天就来吧?
你强装镇定,这么急啊我还需要租房,要不下礼拜一吧。
### 好的 心想这小子这么NB是不是很多Offer在手上,不行我得叫hr给他加钱。
能撑到最后,你自己都忍不住自己给自己点个赞了!
(**暗示点赞,每次都看了不点赞,你们想白嫖我么?你们好坏喲,不过我喜欢**)。
## 总结
**在技术面试的时候,不管是Redis还是什么问题,如果你能举出实际的例子,或者是直接说自己开发过程的问题和收获会给面试官的印象分会加很多,回答逻辑性也要强一点,不要东一点西一点,容易把自己都绕晕的。**
**还有一点就是我问你为啥用Redis你不要一上来就直接回答问题了,你可以这样回答:**
**帅气的面试官您好**,首先我们的项目DB遇到了瓶颈,特别是秒杀和热点数据这样的场景DB基本上就扛不住了,那就需要缓存中间件的加入了,目前市面上有的缓存中间件有 Redis 和 Memcached ,他们的优缺点......,综合这些然后再结合我们项目特点,最后我们在技术选型的时候选了谁。
如果你这样有条不紊,有理有据的回答了我的问题而且还说出这么多我问题外的知识点,我会觉得你不只是一个会写代码的人,你逻辑清晰,你对技术选型,对中间件对项目都有自己的理解和思考,说白了就是你的offer有戏了。
好了 以上就是这篇文章的全部内容了,我后面会不断更新《吊打面试官》系列和Java技术栈相关的文章。如果你有什么想知道的,也可以**留言**给我,我一有时间就会写出来,我们共同进步。
非常感谢您能看到这里,如果这个文章写得还不错的话 **求点赞** **求关注** **求分享** **求留言** 各位的支持和认可,就是我创作的最大动力,OK各位我们下期见!
敖丙 | 文
----
>后面会持续更新《吊打面试官》系列可以关注我的公众号第一时间阅读,也会有朋友一线大厂的内推机会不定期推出(字节跳动,阿里,网易,PDD,滴滴,蘑菇街等),就业上有什么问题也可以直接微信滴滴我,我也是个新人,不过不影响我们一起进步,作为渣男,我给不了你工作,还给不了你温暖嘛?

================================================
FILE: docs/redis/Redis常见面试题.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> [**GitHub**](https://github.com/AobingJava/JavaFamily)上已经开源[https://github.com/Java...](https://github.com/AobingJava/JavaFamily),有面试点思维导图,欢迎[**Star**](https://github.com/AobingJava/JavaFamily)和[**完善**](https://github.com/AobingJava/JavaFamily)
## 前言
**Redis**在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在**Redis**的使用和原理方面对小伙伴们进行360°的刁难。
作为一个在互联网公司面一次拿一次Offer的面霸,打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚(**请允许我使用一下夸张的修辞手法**)。
于是在一个寂寞难耐的夜晚,我痛定思痛,决定开始写**《吊打面试官》**系列,希望能帮助各位读者以后面试势如破竹,对面试官进行360°的反击,吊打问你的面试官,让一同面试的同僚瞠目结舌,疯狂收割大厂Offer!
## 絮叨
上一期因为是在双十一一直在熬夜的大环境下完成的,所以我自己觉得质量明显没之前的好,我这不一睡好就加班加点准备补偿大家,来点干货。(熬夜太容易感冒了,这次**点个赞**别白嫖了!)
顺带提一嘴,我把我准备写啥画了一个思维导图,以后总不能每篇都放个贼大的图吧,就开源到了我的**[GitHub](https://github.com/AobingJava/JavaFamily)**,大家有兴趣可以去完善和**Star**。
这篇我就先放出来大家看看,感觉还是差点意思,等大家完善了。

## 回望过去
上一期吊打系列我们提到了**Redis**相关的一些知识,还没看的小伙伴可以回顾一下
- **[《吊打面试官》系列-Redis基础](https://juejin.im/post/5db66ed9e51d452a2f15d833)**
- **[《吊打面试官》系列-缓存雪崩、击穿、穿透](https://juejin.im/post/5dbef8306fb9a0203f6fa3e2)**
- **[《吊打面试官》系列-Redis哨兵、持久化、主从、手撕LRU](https://juejin.im/post/5dc3a9fbf265da4d3c072eab)**
- **[《吊打面试官》系列-Redis终章-凛冬将至、FPX-新王登基](https://juejin.im/post/5dc850b4e51d452c2308ee27)**
这期我就从缓存到一些常见的问题讲一下,有一些我是之前提到过的,不过可能大部分仔是第一次看,我就重复发一下。
### 缓存知识点
###### 
### 缓存有哪些类型?
缓存是高并发场景下提高热点数据访问性能的一个有效手段,在开发项目时会经常使用到。
缓存的类型分为:**本地缓存**、**分布式缓存**和**多级缓存**。
#### 本地缓存:
**本地缓存**就是在进程的内存中进行缓存,比如我们的 **JVM** 堆中,可以用 **LRUMap** 来实现,也可以使用 **Ehcache** 这样的工具来实现。
本地缓存是内存访问,没有远程交互开销,性能最好,但是受限于单机容量,一般缓存较小且无法扩展。
#### 分布式缓存:
**分布式缓存**可以很好得解决这个问题。
分布式缓存一般都具有良好的水平扩展能力,对较大数据量的场景也能应付自如。缺点就是需要进行远程请求,性能不如本地缓存。
#### 多级缓存:
为了平衡这种情况,实际业务中一般采用**多级缓存**,本地缓存只保存访问频率最高的部分热点数据,其他的热点数据放在分布式缓存中。
在目前的一线大厂中,这也是最常用的缓存方案,单考单一的缓存方案往往难以撑住很多高并发的场景。
### 淘汰策略
不管是本地缓存还是分布式缓存,为了保证较高性能,都是使用内存来保存数据,由于成本和内存限制,当存储的数据超过缓存容量时,需要对缓存的数据进行剔除。
一般的剔除策略有 **FIFO** 淘汰最早数据、**LRU** 剔除最近最少使用、和 **LFU** 剔除最近使用频率最低的数据几种策略。
- **noeviction**:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
- **allkeys-lru**: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
- **volatile-lru**: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
- **allkeys-random**: 回收随机的键使得新添加的数据有空间存放。
- **volatile-random**: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
- **volatile-ttl**: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
如果没有键满足回收的前提条件的话,策略**volatile-lru**, **volatile-random**以及**volatile-ttl**就和noeviction 差不多了。
其实在大家熟悉的**LinkedHashMap**中也实现了Lru算法的,实现如下:

当容量超过100时,开始执行**LRU**策略:将最近最少未使用的 **TimeoutInfoHolder** 对象 **evict** 掉。
真实面试中会让你写LUR算法,你可别搞原始的那个,那真TM多,写不完的,你要么怼上面这个,要么怼下面这个,找一个数据结构实现下Java版本的LRU还是比较容易的,知道啥原理就好了。

### Memcache
注意后面会把 **Memcache** 简称为 MC。
先来看看 MC 的特点:
- MC 处理请求时使用多线程异步 IO 的方式,可以合理利用 CPU 多核的优势,性能非常优秀;
- MC 功能简单,使用内存存储数据;
- MC 的内存结构以及钙化问题我就不细说了,大家可以查看[官网](http://www.memcached.org/about)了解下;
- MC 对缓存的数据可以设置失效期,过期后的数据会被清除;
- 失效的策略采用延迟失效,就是当再次使用数据时检查是否失效;
- 当容量存满时,会对缓存中的数据进行剔除,剔除时除了会对过期 key 进行清理,还会按 LRU 策略对数据进行剔除。
另外,使用 MC 有一些限制,这些限制在现在的互联网场景下很致命,成为大家选择**Redis**、**MongoDB**的重要原因:
- key 不能超过 250 个字节;
- value 不能超过 1M 字节;
- key 的最大失效时间是 30 天;
- 只支持 K-V 结构,不提供持久化和主从同步功能。
### Redis
先简单说一下 **Redis** 的特点,方便和 MC 比较。
- 与 MC 不同的是,Redis 采用单线程模式处理请求。这样做的原因有 2 个:一个是因为采用了非阻塞的异步事件处理机制;另一个是缓存数据都是内存操作 IO 时间不会太长,单线程可以避免线程上下文切换产生的代价。
- **Redis** 支持持久化,所以 Redis 不仅仅可以用作缓存,也可以用作 NoSQL 数据库。
- 相比 MC,**Redis** 还有一个非常大的优势,就是除了 K-V 之外,还支持多种数据格式,例如 list、set、sorted set、hash 等。
- **Redis** 提供主从同步机制,以及 **Cluster** 集群部署能力,能够提供高可用服务。
#
### 详解 Redis
Redis 的知识点结构如下图所示。
### 功能
来看 **Redis** 提供的功能有哪些吧!
#### 我们先看基础类型:
#### **String:**
**String** 类型是 **Redis** 中最常使用的类型,内部的实现是通过 **SDS**(Simple Dynamic String )来存储的。SDS 类似于 **Java** 中的 **ArrayList**,可以通过预分配冗余空间的方式来减少内存的频繁分配。
这是最简单的类型,就是普通的 set 和 get,做简单的 KV 缓存。
但是真实的开发环境中,很多仔可能会把很多比较复杂的结构也统一转成**String**去存储使用,比如有的仔他就喜欢把对象或者**List**转换为**JSONString**进行存储,拿出来再反序列话啥的。
我在这里就不讨论这样做的对错了,但是我还是希望大家能在最合适的场景使用最合适的数据结构,对象找不到最合适的但是类型可以选最合适的嘛,之后别人接手你的代码一看这么**规范**,诶这小伙子**有点东西**呀,看到你啥都是用的**String**,**垃圾!**

好了这些都是题外话了,道理还是希望大家记在心里,习惯成自然嘛,小习惯成就你。
**String**的实际应用场景比较广泛的有:
- **缓存功能:String**字符串是最常用的数据类型,不仅仅是**Redis**,各个语言都是最基本类型,因此,利用**Redis**作为缓存,配合其它数据库作为存储层,利用**Redis**支持高并发的特点,可以大大加快系统的读写速度、以及降低后端数据库的压力。
- **计数器:**许多系统都会使用**Redis**作为系统的实时计数器,可以快速实现计数和查询的功能。而且最终的数据结果可以按照特定的时间落地到数据库或者其它存储介质当中进行永久保存。
- **共享用户Session:**用户重新刷新一次界面,可能需要访问一下数据进行重新登录,或者访问页面缓存**Cookie**,但是可以利用**Redis**将用户的**Session**集中管理,在这种模式只需要保证**Redis**的高可用,每次用户**Session**的更新和获取都可以快速完成。大大提高效率。
#### **Hash:**
这个是类似 **Map** 的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是**这个对象没嵌套其他的对象**)给缓存在 **Redis** 里,然后每次读写缓存的时候,可以就操作 **Hash** 里的**某个字段**。
但是这个的场景其实还是多少单一了一些,因为现在很多对象都是比较复杂的,比如你的商品对象可能里面就包含了很多属性,其中也有对象。我自己使用的场景用得不是那么多。
#### **List:**
**List** 是有序列表,这个还是可以玩儿出很多花样的。
比如可以通过 **List** 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的东西。
比如可以通过 **lrange** 命令,读取某个闭区间内的元素,可以基于 **List** 实现分页查询,这个是很棒的一个功能,基于 **Redis** 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西,性能高,就一页一页走。
比如可以搞个简单的消息队列,从 **List** 头怼进去,从 **List** 屁股那里弄出来。
**List**本身就是我们在开发过程中比较常用的数据结构了,热点数据更不用说了。
- **消息队列:Redis**的链表结构,可以轻松实现阻塞队列,可以使用左进右出的命令组成来完成队列的设计。比如:数据的生产者可以通过**Lpush**命令从左边插入数据,多个数据消费者,可以使用**BRpop**命令阻塞的“抢”列表尾部的数据。
- 文章列表或者数据分页展示的应用。
比如,我们常用的博客网站的文章列表,当用户量越来越多时,而且每一个用户都有自己的文章列表,而且当文章多时,都需要分页展示,这时可以考虑使用**Redis**的列表,列表不但有序同时还支持按照范围内获取元素,可以完美解决分页查询功能。大大提高查询效率。
#### **Set:**
**Set** 是无序集合,会自动去重的那种。
直接基于 **Set** 将系统里需要去重的数据扔进去,自动就给去重了,如果你需要对一些数据进行快速的全局去重,你当然也可以基于 **JVM** 内存里的 **HashSet** 进行去重,但是如果你的某个系统部署在多台机器上呢?得基于**Redis**进行全局的 **Set** 去重。
可以基于 **Set** 玩儿交集、并集、差集的操作,比如交集吧,我们可以把两个人的好友列表整一个交集,看看俩人的共同好友是谁?对吧。
反正这些场景比较多,因为对比很快,操作也简单,两个查询一个**Set**搞定。
#### **Sorted Set:**
**Sorted set** 是排序的 **Set**,去重但可以排序,写进去的时候给一个分数,自动根据分数排序。
有序集合的使用场景与集合类似,但是set集合不是自动有序的,而**Sorted set**可以利用分数进行成员间的排序,而且是插入时就排序好。所以当你需要一个有序且不重复的集合列表时,就可以选择**Sorted set**数据结构作为选择方案。
- 排行榜:有序集合经典使用场景。例如视频网站需要对用户上传的视频做排行榜,榜单维护可能是多方面:按照时间、按照播放量、按照获得的赞数等。
- 用**Sorted Sets**来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
微博热搜榜,就是有个后面的热度值,前面就是名称
### 高级用法:
#### **Bitmap** :
位图是支持按 bit 位来存储信息,可以用来实现 **布隆过滤器(BloomFilter)**;
#### **HyperLogLog:**
供不精确的去重计数功能,比较适合用来做大规模数据的去重统计,例如统计 UV;
#### **Geospatial:**
可以用来保存地理位置,并作位置距离计算或者根据半径计算位置等。有没有想过用Redis来实现附近的人?或者计算最优地图路径?
这三个其实也可以算作一种数据结构,不知道还有多少朋友记得,我在梦开始的地方,Redis基础中提到过,你如果只知道五种基础类型那只能拿60分,如果你能讲出高级用法,那就觉得你**有点东西**。
#### **pub/sub:**
功能是订阅发布功能,可以用作简单的消息队列。
#### **Pipeline:**
可以批量执行一组指令,一次性返回全部结果,可以减少频繁的请求应答。
#### **Lua:**
**Redis** 支持提交 **Lua** 脚本来执行一系列的功能。
我在前电商老东家的时候,秒杀场景经常使用这个东西,讲道理有点香,利用他的原子性。
话说你们想看秒杀的设计么?我记得我面试好像每次都问啊,想看的直接**点赞**后评论秒杀吧。
#### **事务:**
最后一个功能是事务,但 **Redis** 提供的不是严格的事务,**Redis** 只保证串行执行命令,并且能保证全部执行,但是执行命令失败时并不会回滚,而是会继续执行下去。
### 持久化
**Redis** 提供了 RDB 和 AOF 两种持久化方式,RDB 是把内存中的数据集以快照形式写入磁盘,实际操作是通过 fork 子进程执行,采用二进制压缩存储;AOF 是以文本日志的形式记录 **Redis** 处理的每一个写入或删除操作。
**RDB** 把整个 Redis 的数据保存在单一文件中,比较适合用来做灾备,但缺点是快照保存完成之前如果宕机,这段时间的数据将会丢失,另外保存快照时可能导致服务短时间不可用。
**AOF** 对日志文件的写入操作使用的追加模式,有灵活的同步策略,支持每秒同步、每次修改同步和不同步,缺点就是相同规模的数据集,AOF 要大于 RDB,AOF 在运行效率上往往会慢于 RDB。
细节的点大家去高可用这章看,特别是两者的优缺点,以及怎么抉择。
**[《吊打面试官》系列-Redis哨兵、持久化、主从、手撕LRU](https://juejin.im/post/5dc3a9fbf265da4d3c072eab)**
### 高可用
来看 Redis 的高可用。Redis 支持主从同步,提供 Cluster 集群部署模式,通过 Sentine l哨兵来监控 Redis 主服务器的状态。当主挂掉时,在从节点中根据一定策略选出新主,并调整其他从 slaveof 到新主。
选主的策略简单来说有三个:
- slave 的 priority 设置的越低,优先级越高;
- 同等情况下,slave 复制的数据越多优先级越高;
- 相同的条件下 runid 越小越容易被选中。
在 Redis 集群中,sentinel 也会进行多实例部署,sentinel 之间通过 Raft 协议来保证自身的高可用。
Redis Cluster 使用分片机制,在内部分为 16384 个 slot 插槽,分布在所有 master 节点上,每个 master 节点负责一部分 slot。数据操作时按 key 做 CRC16 来计算在哪个 slot,由哪个 master 进行处理。数据的冗余是通过 slave 节点来保障。
### 哨兵
哨兵必须用三个实例去保证自己的健壮性的,哨兵+主从并**不能保证数据不丢失**,但是可以保证集群的**高可用**。
为啥必须要三个实例呢?我们先看看两个哨兵会咋样。

master宕机了 s1和s2两个哨兵只要有一个认为你宕机了就切换了,并且会选举出一个哨兵去执行故障,但是这个时候也需要大多数哨兵都是运行的。
那这样有啥问题呢?M1宕机了,S1没挂那其实是OK的,但是整个机器都挂了呢?哨兵就只剩下S2个裸屌了,没有哨兵去允许故障转移了,虽然另外一个机器上还有R1,但是故障转移就是不执行。
经典的哨兵集群是这样的:

M1所在的机器挂了,哨兵还有两个,两个人一看他不是挂了嘛,那我们就选举一个出来执行故障转移不就好了。
暖男我,小的总结下哨兵组件的主要功能:
- 集群监控:负责监控 Redis master 和 slave 进程是否正常工作。
- 消息通知:如果某个 **Redis** 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
- 故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
- 配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
### 主从
提到这个,就跟我前面提到的数据持久化的**RDB**和**AOF**有着比密切的关系了。
我先说下为啥要用主从这样的架构模式,前面提到了单机**QPS**是有上限的,而且**Redis**的特性就是必须支撑读高并发的,那你一台机器又读又写,**这谁顶得住啊**,不当人啊!但是你让这个master机器去写,数据同步给别的slave机器,他们都拿去读,分发掉大量的请求那是不是好很多,而且扩容的时候还可以轻松实现水平扩容。
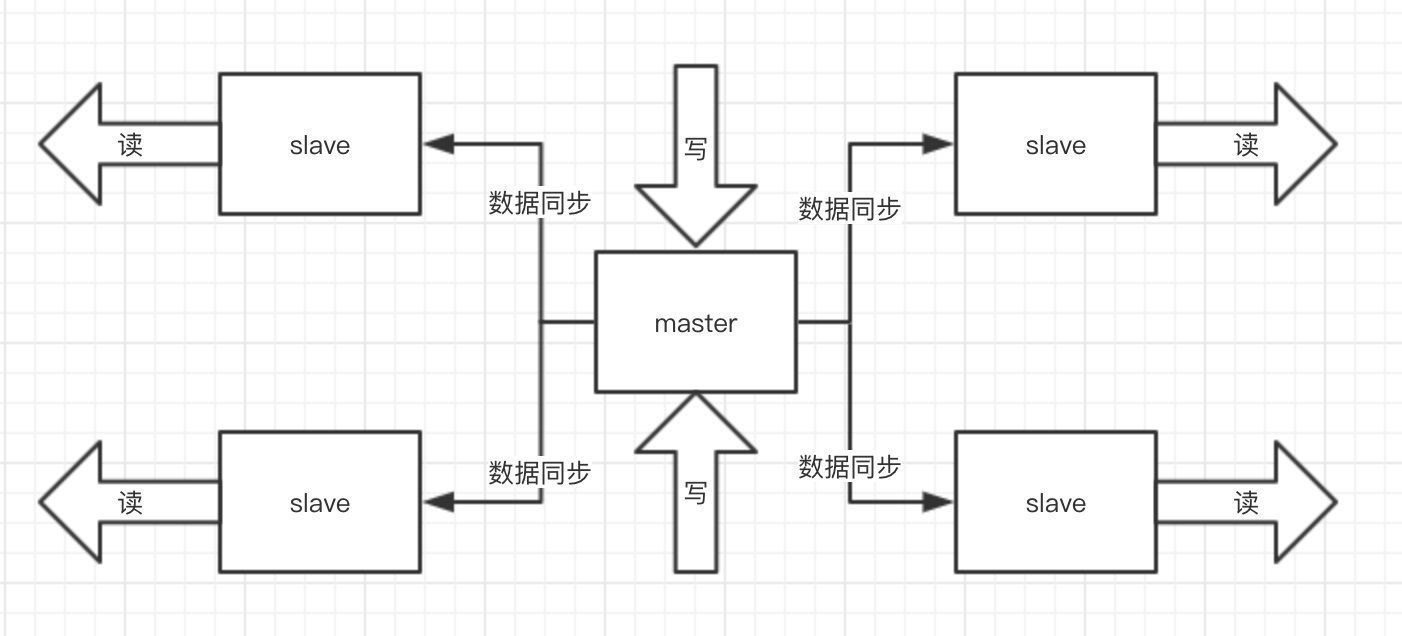
你启动一台slave 的时候,他会发送一个**psync**命令给master ,如果是这个slave第一次连接到master,他会触发一个全量复制。master就会启动一个线程,生成**RDB**快照,还会把新的写请求都缓存在内存中,**RDB**文件生成后,master会将这个**RDB**发送给slave的,slave拿到之后做的第一件事情就是写进本地的磁盘,然后加载进内存,然后master会把内存里面缓存的那些新命名都发给slave。
**我发出来之后来自CSDN的网友:Jian_Shen_Zer 问了个问题:**
主从同步的时候,新的slaver进来的时候用**RDB**,那之后的数据呢?有新的数据进入master怎么同步到slaver啊
敖丙答:笨,**AOF**嘛,增量的就像**MySQL**的**Binlog**一样,把日志增量同步给从服务就好了
#### key 失效机制
**Redis** 的 key 可以设置过期时间,过期后 Redis 采用主动和被动结合的失效机制,一个是和 MC 一样在访问时触发被动删除,另一种是定期的主动删除。
定期+惰性+内存淘汰
### 缓存常见问题
#### 缓存更新方式
这是决定在使用缓存时就该考虑的问题。
缓存的数据在数据源发生变更时需要对缓存进行更新,数据源可能是 DB,也可能是远程服务。更新的方式可以是主动更新。数据源是 DB 时,可以在更新完 DB 后就直接更新缓存。
当数据源不是 DB 而是其他远程服务,可能无法及时主动感知数据变更,这种情况下一般会选择对缓存数据设置失效期,也就是数据不一致的最大容忍时间。
这种场景下,可以选择失效更新,key 不存在或失效时先请求数据源获取最新数据,然后再次缓存,并更新失效期。
但这样做有个问题,如果依赖的远程服务在更新时出现异常,则会导致数据不可用。改进的办法是异步更新,就是当失效时先不清除数据,继续使用旧的数据,然后由异步线程去执行更新任务。这样就避免了失效瞬间的空窗期。另外还有一种纯异步更新方式,定时对数据进行分批更新。实际使用时可以根据业务场景选择更新方式。
#### 数据不一致
第二个问题是数据不一致的问题,可以说只要使用缓存,就要考虑如何面对这个问题。缓存不一致产生的原因一般是主动更新失败,例如更新 DB 后,更新 **Redis** 因为网络原因请求超时;或者是异步更新失败导致。
解决的办法是,如果服务对耗时不是特别敏感可以增加重试;如果服务对耗时敏感可以通过异步补偿任务来处理失败的更新,或者短期的数据不一致不会影响业务,那么只要下次更新时可以成功,能保证最终一致性就可以。
#### 缓存穿透
**缓存穿透**。产生这个问题的原因可能是外部的恶意攻击,例如,对用户信息进行了缓存,但恶意攻击者使用不存在的用户id频繁请求接口,导致查询缓存不命中,然后穿透 DB 查询依然不命中。这时会有大量请求穿透缓存访问到 DB。
解决的办法如下。
1. 对不存在的用户,在缓存中保存一个空对象进行标记,防止相同 ID 再次访问 DB。不过有时这个方法并不能很好解决问题,可能导致缓存中存储大量无用数据。
2. 使用 **BloomFilter** 过滤器,BloomFilter 的特点是存在性检测,如果 BloomFilter 中不存在,那么数据一定不存在;如果 BloomFilter 中存在,实际数据也有可能会不存在。非常适合解决这类的问题。
#### 缓存击穿
**缓存击穿**,就是某个热点数据失效时,大量针对这个数据的请求会穿透到数据源。
解决这个问题有如下办法。
1. 可以使用互斥锁更新,保证同一个进程中针对同一个数据不会并发请求到 DB,减小 DB 压力。
2. 使用随机退避方式,失效时随机 sleep 一个很短的时间,再次查询,如果失败再执行更新。
3. 针对多个热点 key 同时失效的问题,可以在缓存时使用固定时间加上一个小的随机数,避免大量热点 key 同一时刻失效。
#### 缓存雪崩
**缓存雪崩**,产生的原因是缓存挂掉,这时所有的请求都会穿透到 DB。
解决方法:
1. 使用快速失败的熔断策略,减少 DB 瞬间压力;
2. 使用主从模式和集群模式来尽量保证缓存服务的高可用。
实际场景中,这两种方法会结合使用。
老朋友都知道为啥我**没有大篇幅介绍**这个几个点了吧,我在之前的文章实在是写得太详细了,忍不住**点赞**那种,我这里就不做重复拷贝了。
- **[《吊打面试官》系列-Redis基础](https://juejin.im/post/5db66ed9e51d452a2f15d833)**
- **[《吊打面试官》系列-缓存雪崩、击穿、穿透](https://juejin.im/post/5dbef8306fb9a0203f6fa3e2)**
- **[《吊打面试官》系列-Redis哨兵、持久化、主从、手撕LRU](https://juejin.im/post/5dc3a9fbf265da4d3c072eab)**
- **[《吊打面试官》系列-Redis终章_凛冬将至、FPX_新王登基](https://juejin.im/post/5dc850b4e51d452c2308ee27)**
### 考点与加分项
拿笔记一下!

#### 考点
面试的时候问你缓存,主要是考察缓存特性的理解,对 **MC**、**Redis** 的特点和使用方式的掌握。
- 要知道缓存的使用场景,不同类型缓存的使用方式,例如:
1. - 对 DB 热点数据进行缓存减少 DB 压力;对依赖的服务进行缓存,提高并发性能;
2. - 单纯 K-V 缓存的场景可以使用 **MC**,而需要缓存 list、set 等特殊数据格式,可以使用 **Redis**;
3. - 需要缓存一个用户最近播放视频的列表可以使用 **Redis** 的 list 来保存、需要计算排行榜数据时,可以使用 **Redis** 的 zset 结构来保存。
- 要了解 MC 和 **Redis** 的常用命令,例如原子增减、对不同数据结构进行操作的命令等。
- 了解 MC 和 **Redis** 在内存中的存储结构,这对评估使用容量会很有帮助。
- 了解 MC 和 **Redis** 的数据失效方式和剔除策略,比如主动触发的定期剔除和被动触发延期剔除
- 要理解 **Redis** 的持久化、主从同步与 **Cluster** 部署的原理,比如 **RDB** 和 **AOF** 的实现方式与区别。
- 要知道缓存穿透、击穿、雪崩分别的异同点以及解决方案。
- 不管你有没有电商经验我觉得你都应该知道秒杀的具体实现,以及细节点。
- ........
欢迎去[GitHub](https://github.com/AobingJava/JavaFamily)补充
#### 加分项
如果想要在面试中获得更好的表现,还应了解下面这些加分项。
- 是要结合实际应用场景来介绍缓存的使用。例如调用后端服务接口获取信息时,可以使用本地+远程的多级缓存;对于动态排行榜类的场景可以考虑通过 **Redis** 的 **Sorted set** 来实现等等。
- 最好你有过分布式缓存设计和使用经验,例如项目中在什么场景使用过 **Redis**,使用了什么数据结构,解决哪类的问题;使用 MC 时根据预估值大小调整 **McSlab** 分配参数等等。
- 最好可以了解缓存使用中可能产生的问题。比如 **Redis** 是单线程处理请求,应尽量避免耗时较高的单个请求任务,防止相互影响;**Redis** 服务应避免和其他 CPU 密集型的进程部署在同一机器;或者禁用 Swap 内存交换,防止 **Redis** 的缓存数据交换到硬盘上,影响性能。再比如前面提到的 MC 钙化问题等等。
- 要了解 **Redis** 的典型应用场景,例如,使用 **Redis** 来实现分布式锁;使用 **Bitmap** 来实现 **BloomFilter**,使用 **HyperLogLog** 来进行 UV 统计等等。
- 知道 Redis4.0、5.0 中的新特性,例如支持多播的可持久化消息队列 Stream;通过 Module 系统来进行定制功能扩展等等。
- ........
还是那句话欢迎去[GitHub](https://github.com/AobingJava/JavaFamily)补充。
## 总结
这次是对我**Redis**系列的总结,这应该是**Redis**相关的最后一篇文章了,其实四篇看下来的小伙伴很多都从**一知半解**到了**一脸懵逼**,哈哈开个玩笑。
我觉得我的方式应该还好,大部分小伙伴还是比较能理解的,这篇之后我就不会写**Redis**相关的文章了(秒杀看大家想看的热度吧),有啥问题可以微信找我,**下个系列写啥**?
大家不用急,下个系列前我会发个有意思的文章,是我在公司代码创意大赛拿奖的文章,我觉得还是**有点东西**,我忍不住分享一下,顺便就在那期发起**投票**吧哈哈。
我看到很多小伙伴都有评论说想看别的,大概搜集了一下,还没留言的这期赶紧哟:
#### 掘金
**愚辛** :想看计算机基础,网络和操作系统那些(FPX牛脾)
**cherish君**:讲讲dubbo经常遇到的面试题目,太多人喜欢问dubbo😃
**Java架构养成记**:真的很香啊,下一期讲Dubbbo(重点SPI)然后讲MQ好吗
#### CSDN
**小殿下**:看完了所有的redis篇 希望可以出ssm
#### 博客园
**程然**:Dubbo Dubbo
#### 开源中国
**linshi2019**:这期明显是赶工之作啊
敖丙:这条我回一下,鞭策我,我很喜欢,不过说实话还是希望大家**理解**下,我双十一熬夜三天了,现在给你们写的时候也是值班回家2点左右了,我一天吃饭工作时间肯定是固定的,想写点东西就只有挤出睡觉时间了,这种产出肯定没周末全情投入写的来的质量高。
其实第一期看过来的小伙伴应该也知道,我在**排版**,还有很多**文案**,**配图**其实我一直都有在改进的,光是名词高亮我都要弄很久,因为怕大家看单一的黑白色调枯燥。
我是真的用心在搞,还是希望大家支持下理解下。
**知乎、简书、思否、慕课手记**没人看不知道为啥,懂行的老铁可以跟我说一下。
我只想说你们想看的肯定都在我开头和[GITHub](https://github.com/AobingJava/JavaFamily)那个图里吧,问题不大,后面都会写的。
## 鸣谢
最后感谢下,新浪微博的技术专家张雷。
他于2013年加入**新浪微博**,作为核心技术人员参与了微博服务化、混合云等多个重点项目,是微博开源的**RPC**框架**Motan**的技术负责人,同时也负责微博的**Service Mesh**方案的研发与推广,专注于高可用架构及服务中间件开发方向。
他负责的**Motan**框架每天承载着万亿级别的请求调用,是微博平台服务化的基石,每次的突发热点事件、每次的春晚流量高峰,都离不开**Motan**框架的支撑与保障。此外,他也多次应邀在**ArchSummit、WOT、GIAC**技术峰会做技术分享。
感谢他对文章部分文案提供的支持和思路。
## END
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇《**吊打面试官**》系列和**互联网常用技术栈**相关的文章。如果你有什么想知道的,也可以留言给我,我一有时间就会写出来,我们共同进步。
非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** **求留言💬** 对暖男我来说 **非常有用**!!!
各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】
------
> 《吊打面试官》系列每周持续更新,可以关注我的公众号[JavaFamily](https://github.com/AobingJava/JavaFamily#%E5%85%AC%E4%BC%97%E5%8F%B7)第一时间阅读和催更(**公众号比博客早一到两天哟**),[**GitHub**](https://github.com/AobingJava/JavaFamily)上已经开源[https://github.com/Java...](https://github.com/AobingJava/JavaFamily),有面试点思维导图,欢迎[**Star**](https://github.com/AobingJava/JavaFamily)和[**完善**](https://github.com/AobingJava/JavaFamily)里面也有我个人微信有什么问题也可以直接滴滴我,我们一起进步。

================================================
FILE: docs/redis/分布式锁、并发竞争、双写一致性.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
## 前言
**Redis**在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在**Redis**的使用和原理方面对小伙伴们进行360°的刁难。作为一个在互联网公司面一次拿一次offer的面霸(**请允许我使用一下夸张的修辞手法**),打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚,在一个寂寞难耐的夜晚,我痛定思痛,决定开始写**《吊打面试官》**系列,希望能帮助各位读者以后面试势如破竹,对面试官进行360°的反击,吊打问你的面试官,让一同面试的同僚瞠目结舌,疯狂收割大厂offer!
## 絮叨
**男儿何不带吴钩,收取关山五十州 FPX 🐂B,LPL两年连冠🏆 🐂B!**
看着金色的雨落下,我到窗边,发现天有点蓝,风有点绵,我的眼角又湿了!

最近双十一讲道理有点忙的说,直接肝爆,就是这样作为**暖男**的我,还是给你们挤出时间搞出终章,忍不住给自己**点赞**👍
放个双十一照片证明真的忙,希望别取关!!!

现在你们在看的时候,我应该还在睡觉哈哈。困🛌
之前跟你们说的,**限流**,**降级**,是不是在双十一又应验了,下单接口其实没挂,牺牲部分用户体验,保住服务器,你多点几下是可以成功的,等流量高峰过去了,所有的用户全部都恢复正常访问,服务器也没啥事。

去年退款接口被打崩了,今年阿里明显也聪明了很多。

## 正文
上几期吊打系列我们提到了Redis的很多知识,还没看的小伙伴可以回顾一下
- **[《吊打面试官》系列-Redis基础](https://juejin.im/post/5db66ed9e51d452a2f15d833)**
- **[《吊打面试官》系列-缓存雪崩、击穿、穿透](https://juejin.im/post/5dbef8306fb9a0203f6fa3e2)**
- **[《吊打面试官》系列-Redis哨兵、持久化、主从、手撕LRU](https://juejin.im/post/5dc3a9fbf265da4d3c072eab)**
那提到**Redis**我相信各位在面试,或者实际开发过程中对基本类型的使用场景,并发竞争带来的问题,以及缓存数据库双写入一致性的问题等,我们有请下一位受害者。
## 面试开始
> 一个大腹便便,穿着格子衬衣的中年男子,拿着一个满是划痕的mac向你走来,看着快秃顶的头发,心想着肯定是尼玛顶级架构师吧!但是我们腹有诗书气自华,虚都不虚。(这不是第一篇文章的面试官么?)

### 小伙子,你还记得我在第一章里面问过你,Redis有几种基础数据类型么?
嗯嗯,帅气的面试官,我肯定记得,没齿难忘!!!
我特么谢谢你,都四面了还不给Offer!

### 那你能说一下他们的特性,还有分别的使用场景么?
行吧,那我先从String说起。
**String:**
这是最简单的类型,就是普通的 set 和 get,做简单的 KV 缓存。
但是真实的开发环境中,很多仔可能会把很多比较复杂的结构也统一转成**String**去存储使用,比如有的仔他就喜欢把对象或者**List**转换为**JSONString**进行存储,拿出来再反序列话啥的。
我在这里就不讨论这样做的对错了,但是我还是希望大家能在最合适的场景使用最合适的数据结构,对象找不到最合适的但是类型可以选最合适的嘛,之后别人接手你的代码一看这么**规范**,诶这小伙子**有点东西**呀,看到你啥都是用的**String**,**垃圾!**

好了这些都是题外话了,道理还是希望大家记在心里,习惯成自然嘛,小习惯成就你。
**String**的实际应用场景比较广泛的有:
- **缓存功能:String**字符串是最常用的数据类型,不仅仅是**Redis**,各个语言都是最基本类型,因此,利用**Redis**作为缓存,配合其它数据库作为存储层,利用**Redis**支持高并发的特点,可以大大加快系统的读写速度、以及降低后端数据库的压力。
- **计数器:**许多系统都会使用**Redis**作为系统的实时计数器,可以快速实现计数和查询的功能。而且最终的数据结果可以按照特定的时间落地到数据库或者其它存储介质当中进行永久保存。
- **共享用户Session:**用户重新刷新一次界面,可能需要访问一下数据进行重新登录,或者访问页面缓存**Cookie**,但是可以利用**Redis**将用户的**Session**集中管理,在这种模式只需要保证**Redis**的高可用,每次用户**Session**的更新和获取都可以快速完成。大大提高效率。
**Hash:**
这个是类似 **Map** 的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是**这个对象没嵌套其他的对象**)给缓存在 **Redis** 里,然后每次读写缓存的时候,可以就操作 **Hash** 里的**某个字段**。
但是这个的场景其实还是多少单一了一些,因为现在很多对象都是比较复杂的,比如你的商品对象可能里面就包含了很多属性,其中也有对象。我自己使用的场景用得不是那么多。
**List:**
**List** 是有序列表,这个还是可以玩儿出很多花样的。
比如可以通过 **List** 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的东西。
比如可以通过 **lrange** 命令,读取某个闭区间内的元素,可以基于 **List** 实现分页查询,这个是很棒的一个功能,基于 **Redis** 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西,性能高,就一页一页走。
比如可以搞个简单的消息队列,从 **List** 头怼进去,从 **List** 屁股那里弄出来。
**List**本身就是我们在开发过程中比较常用的数据结构了,热点数据更不用说了。
- **消息队列:Redis**的链表结构,可以轻松实现阻塞队列,可以使用左进右出的命令组成来完成队列的设计。比如:数据的生产者可以通过**Lpush**命令从左边插入数据,多个数据消费者,可以使用**BRpop**命令阻塞的“抢”列表尾部的数据。
- 文章列表或者数据分页展示的应用。
比如,我们常用的博客网站的文章列表,当用户量越来越多时,而且每一个用户都有自己的文章列表,而且当文章多时,都需要分页展示,这时可以考虑使用**Redis**的列表,列表不但有序同时还支持按照范围内获取元素,可以完美解决分页查询功能。大大提高查询效率。
**Set:**
**Set** 是无序集合,会自动去重的那种。
直接基于 **Set** 将系统里需要去重的数据扔进去,自动就给去重了,如果你需要对一些数据进行快速的全局去重,你当然也可以基于 **JVM** 内存里的 **HashSet** 进行去重,但是如果你的某个系统部署在多台机器上呢?得基于**Redis**进行全局的 **Set** 去重。
可以基于 **Set** 玩儿交集、并集、差集的操作,比如交集吧,我们可以把两个人的好友列表整一个交集,看看俩人的共同好友是谁?对吧。
反正这些场景比较多,因为对比很快,操作也简单,两个查询一个**Set**搞定。
**Sorted Set:**
**Sorted set** 是排序的 **Set**,去重但可以排序,写进去的时候给一个分数,自动根据分数排序。
有序集合的使用场景与集合类似,但是set集合不是自动有序的,而**Sorted set**可以利用分数进行成员间的排序,而且是插入时就排序好。所以当你需要一个有序且不重复的集合列表时,就可以选择**Sorted set**数据结构作为选择方案。
- 排行榜:有序集合经典使用场景。例如视频网站需要对用户上传的视频做排行榜,榜单维护可能是多方面:按照时间、按照播放量、按照获得的赞数等。
- 用**Sorted Sets**来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
微博热搜榜,就是有个后面的热度值,前面就是名称

## 小结
**Redis**基础类型有五种,这个我在基础里面也有提到了,这个问题其实一般都是对P6以下,也就是1-3年左右的小伙伴可能是会问得比较多的问题。
能回答出来五种我想大家都可以,但是不知道大家是否知道,五种类型具体的使用场景,以及什么时候用什么类型最合适呢?
要是你回答的不好,没说出几种数据类型,也没说什么场景,你完了,面试官对你印象肯定不好,觉得你平时就是做个简单的 set 和 get。所以看似很简单的面试题实则最容易看出你的深浅了,大家都要注意**打好基础**。
###你有没有考虑过,如果你多个系统同时操作(并发)Redis带来的数据问题?
嗯嗯这个问题我以前开发的时候遇到过,其实并发过程中确实会有这样的问题,比如下面这样的情况

系统A、B、C三个系统,分别去操作**Redis**的同一个Key,本来顺序是1,2,3是正常的,但是因为系统A网络突然抖动了一下,B,C在他前面操作了**Redis**,这样数据不就错了么。
就好比下单,支付,退款三个顺序你变了,你先退款,再下单,再支付,那流程就会失败,那数据不就乱了?你订单还没生成你却支付,退款了?明显走不通了,这在线上是很恐怖的事情。
### 那这种情况怎么解决呢?
我们可以找个管家帮我们管理好数据的嘛!

某个时刻,多个系统实例都去更新某个 key。可以基于 **Zookeeper** 实现分布式锁。每个系统通过 **Zookeeper** 获取分布式锁,确保同一时间,只能有一个系统实例在操作某个 Key,别人都不允许读和写。
你要写入缓存的数据,都是从 **MySQL** 里查出来的,都得写入 **MySQL** 中,写入 **MySQL** 中的时候必须保存一个时间戳,从 **MySQL** 查出来的时候,时间戳也查出来。
每次要**写之前,先判断**一下当前这个 Value 的时间戳是否比缓存里的 Value 的时间戳要新。如果是的话,那么可以写,否则,就不能用旧的数据覆盖新的数据。
### 你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
一般来说,如果允许缓存可以稍微的跟数据库偶尔有不一致的情况,也就是说如果你的系统**不是严格要求** “缓存+数据库” 必须保持一致性的话,最好不要做这个方案,即:**读请求和写请求串行化**,串到一个**内存队列**里去。
串行化可以保证一定不会出现不一致的情况,但是它也会导致系统的吞吐量大幅度降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
把一些列的操作都放到队列里面,顺序肯定不会乱,但是并发高了,这队列很容易阻塞,反而会成为整个系统的弱点,瓶颈

### 你了解最经典的KV、DB读写模式么?
最经典的缓存+数据库读写的模式,就是 **Cache Aside Pattern**
- 读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
- 更新的时候,**先更新数据库,然后再删除缓存**。
###为什么是删除缓存,而不是更新缓存?
原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于**比较复杂的缓存数据计算的场景**,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,**这个缓存到底会不会被频繁访问到?**
举个栗子:一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有**大量的冷数据**。
实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。**用到缓存才去算缓存。**
其实删除缓存,而不是更新缓存,就是一个 Lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。
像 **Mybatis**,**Hibernate**,都有懒加载思想。查询一个部门,部门带了一个员工的 **List**,没有必要说每次查询部门,都里面的 1000 个员工的数据也同时查出来啊。80% 的情况,查这个部门,就只是要访问这个部门的信息就可以了。先查部门,同时要访问里面的员工,那么这个时候只有在你要访问里面的员工的时候,才会去数据库里面查询 1000 个员工。
###Redis 和 Memcached 有啥区别,为啥选择用Redis作为你们的缓存中间件?
**Redis** 支持复杂的数据结构:
**Redis** 相比 **Memcached** 来说,拥有更多的数据结构,能支持更丰富的数据操作。如果需要缓存能够支持更复杂的结构和操作, **Redis** 会是不错的选择。
**Redis** 原生支持集群模式:
在 redis3.x 版本中,便能支持 **Cluster** 模式,而 **Memcached** 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据。
性能对比:
由于 **Redis** 只使用单核,而 **Memcached** 可以使用多核,所以平均每一个核上 **Redis** 在存储小数据时比 **Memcached** 性能更高。而在 100k 以上的数据中,**Memcached** 性能要高于 **Redis**,虽然 **Redis** 最近也在存储大数据的性能上进行优化,但是比起 **Remcached**,还是稍有逊色。
Tip:其实面试官这么问,是想看你知道为啥用这个技术栈么?你为啥选这个技术栈,你是否做过技术选型的对比,优缺点你是否了解,你啥都不知道,只是为了用而用,那你可能就**差点意思**了。
### Redis 的线程模型了解么?
**Redis** 内部使用文件事件处理器 `file event handler`,这个文件事件处理器是单线程的,所以 **Redis** 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 **Socket**,根据 **Socket** 上的事件来选择对应的事件处理器进行处理。
文件事件处理器的结构包含 4 个部分:
- 多个 **Socket**
- IO 多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多个 **Socket** 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 **Socket**,会将 **Socket** 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
## 面试结束
### 小伙子对你面试了四轮,你说话有理有据,逻辑清晰,来公司后肯定是一把好手,我想要不你来当我的Leader吧,哈哈?
面试官别跟我开玩笑了,我跟您这样日积月累的技术专家还是有很多差距的,您的经验和技术上的深度,没有很长时间的磨练是无法达到的,我还得多跟您学习。
### 好的,小伙子有点东西,你年少有为不自卑,知道什么是珍贵,就是你了来上班吧。
好的面试官,不过我想我在Java基础,MQ,Dubbo等等领域还有好多知识点您没问我,要不下次继续面我?
强行,为吊打下一期埋伏笔哈哈,下期写啥你们定!!!
能撑到最后,你自己都忍不住自己给自己点个赞了!
(**暗示点赞,每次都看了不点赞,你们想白嫖我么?你们好坏喲,不过我喜欢**)。
----
**《吊打面试官》Redis系列 ---- 全剧终**
----
## 总结
既然都说了是**Redis**的终章我最后也做个**Redis**方面常见面试题,题目的总结,答案大家要去思考我前面的文章基本上都提到了,结果可以去我公众号回复【答案】获取,不过我还是希望大家能看到题目就能想到答案,并且记在心中,教大家怎么回答只是帮大家组织下语言,真正的场景解决方案还是要大家理解的。
(周三以后出答案,我先睡会)
- 0、在集群模式下,Redis 的 Key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 Hash 算法吗?
- 1、使用Redis有哪些好处?
- 2、Redis相比Memcached有哪些优势?
- 3、Redis常见性能问题和解决方案
- 4、MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?
- 5、Memcache与Redis的区别都有哪些?
- 6、Redis 常见的性能问题都有哪些?如何解决?
- 7、在什么样的场景下可以充分的利用Redis的特性,大大提高Redis的效率?
- 8、Redis的缓存雪崩、穿透、击穿了解么?有什么异同点?分别怎么解决?
- 9、Redis的基本类型有哪些?他们的使用场景了解么?比较高级的用法你使用过么?
- 10、Redis主从怎么同步数据的?集群的高可用怎么保证?持久化机制了解么?
- 11、为什么 redis 单线程却能支撑高并发?
- 12、如何保证缓存和数据库数据的一致性?
- 13、项目中是怎么用缓存的,用了缓存之后会带来什么问题?
## 絮叨+
最后我想说的就是,我这四章只是介绍到了一些**Redis**面试比较常见的问题,其实还有很多点我都没回答到,大家如果为了对付面试**可能**是够用了,但是我们技术人员还是要保持对技术的**敬畏心**,你不能**浅尝即止**,还是要深究的。
你永远只会用,不去考虑用了会带来的问题,以及出现问题之后的解决方案,我觉得你大概率会**停滞不前**,既然入都入了这行了,为啥不武装一下自己。
其实学习技术是个**反哺**的过程,学习的时候可能你只是感觉知识广度、深度上去了,一个知识点你这样,两个、三个知识点你都这样,最后你发现你的技术已经跟身边一样P6的仔不一样了,这样你可能在团队重大项目的贡献都上去了,那P7的晋升几率是不是大了,钱是不是上去了,女朋友是不是好看了,房子是不是大了。
## End
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**,我后面会每周都更新几篇《**吊打面试官**》系列和**Java技术栈**相关的文章。如果你有什么想知道的,也可以留言给我,或者去公众号加我微信,我一有时间就会写出来,我们共同进步。
非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得**「敖丙」**我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** **求留言💬** 对暖男我来说**非常有用**。
各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】
------
> **《吊打面试官》**系列每周持续更新,可以关注我的公众号「 **JavaFamily** 」第时间阅读和催更(公众号比博客早一到两天哟),里面也有我个人微信有什么问题也可以直接滴滴我,我也是个新人,不过不影响我们一起进步,作为渣男,我给不了你幸福,还给不了你温暖嘛?

================================================
FILE: docs/redis/布隆过滤器(BloomFilter).md
================================================
避免缓存击穿的利器之BloomFilter
# Bloom Filter 概念
布隆过滤器(英语:Bloom Filter)是1970年由一个叫布隆的小伙子提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
***面试关联:一般都会在回答缓存穿透,或者海量数据去重这个时候引出来,加分项哟***
# Bloom Filter 原理
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。

简单的说一下就是我们先把我们数据库的数据都加载到我们的过滤器中,比如数据库的id现在有:1、2、3
那就用id:1 为例子他在上图中经过三次hash之后,把三次原本值0的地方改为1
下次我进来查询如果id也是1 那我就把1拿去三次hash 发现跟上面的三个位置完全一样,那就能证明过滤器中有1的
反之如果不一样就说明不存在了
那应用的场景在哪里呢?一般我们都会用来防止缓存击穿(如果不知道缓存击穿是啥的小伙伴不要着急,我已经帮你准备好了,传送门 ↓ )
简单来说就是你数据库的id都是1开始然后自增的,那我知道你接口是通过id查询的,我就拿负数去查询,这个时候,会发现缓存里面没这个数据,我又去数据库查也没有,一个请求这样,100个,1000个,10000个呢?你的DB基本上就扛不住了,如果在缓存里面加上这个,是不是就不存在了,你判断没这个数据就不去查了,直接return一个数据为空不就好了嘛。
这玩意这么好使那有啥缺点么?有的,我们接着往下看
# Bloom Filter的缺点
bloom filter之所以能做到在时间和空间上的效率比较高,是因为牺牲了判断的准确率、删除的便利性
- 存在误判,可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。如果bloom filter中存储的是黑名单,那么可以通过建立一个白名单来存储可能会误判的元素。
- 删除困难。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。可以采用[Counting Bloom Filter](http://wiki.corp.qunar.com/confluence/download/attachments/199003276/US9740797.pdf?version=1&modificationDate=1526538500000&api=v2)
# Bloom Filter 实现
布隆过滤器有许多实现与优化,Guava中就提供了一种Bloom Filter的实现。
在使用bloom filter时,绕不过的两点是预估数据量n以及期望的误判率fpp,
在实现bloom filter时,绕不过的两点就是hash函数的选取以及bit数组的大小。
对于一个确定的场景,我们预估要存的数据量为n,期望的误判率为fpp,然后需要计算我们需要的Bit数组的大小m,以及hash函数的个数k,并选择hash函数
## (1)Bit数组大小选择
根据预估数据量n以及误判率fpp,bit数组大小的m的计算方式:
## (2)哈希函数选择
由预估数据量n以及bit数组长度m,可以得到一个hash函数的个数k:
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
哈希函数个数k、位数组大小m、加入的字符串数量n的关系可以参考[Bloom Filters - the math](http://pages.cs.wisc.edu/~cao/papers/summary-cache/node8.html),[Bloom_filter-wikipedia](https://en.wikipedia.org/wiki/Bloom_filter)
要使用BloomFilter,需要引入guava包:
```java
还有很多公司的弱校验用**token**啊什么的,反正花样很多,但是**重要的场景一定要强校验**,真正查问题的时候没有在磁盘持久化的数据,心里还是空空的,就像你和女朋友分开的时候的心里状态一样。(我单身的怎么知道这种感觉?猜的)
### 你们有接触过消息顺序消费这样的场景么?你怎么保证的?
没有!over!
乖,你肯定不能说没有啊,就是算真的没有,你看过**敖帅丙**的文章都要说有!
**Tip**:但是说实话**顺序消费**这里很难介绍,我上周到这周问了很多身边的师兄开发过程中这样的场景不多,我跟三歪也讨论了几次,网上更多的都是介绍binlog的同步,好像更多的场景就没了。
一般都是**同个业务场景下不同几个操作的消息同时过去**,本身顺序是对的,但是你发出去的时候同时发出去了,消费的时候却乱掉了,这样就有问题了。
我之前做电商活动也是有这样的例子,我们都知道数据量大的时候数据同步压力还是很大的,有时候数据量大的表需要同步几个亿的数据。(并不是主从同步,主从延迟大的话会有问题,可能是从数据库或者主数据库同步到**备库**)
这种情况我们都是怼到队列里面去,然后慢慢消费的,那问题就来了呀,我们在数据库同时对一个Id的数据进行了增、改、删三个操作,但是你消息发过去消费的时候变成了改,删、增,这样数据就不对了。
本来一条数据应该删掉了,结果在你那却还在,这不是**出大问题**!

两者的结果是不是完全不一样了 **↑**
### 那你怎么解决呢?
我简单的说一下我们使用的**RocketMQ**里面的一个简单实现吧。
**Tip**:为啥用**RocketMQ**举例呢,这玩意是阿里开源的,我问了下身边的朋友很多公司都有使用,所以读者大概率是这个的话我就用这个举例吧,具体的细节我后面会在**RocketMQ**和**Kafka**各自章节说到。
生产者消费者一般需要保证顺序消息的话,可能就是一个业务场景下的,比如订单的创建、支付、发货、收货。
那这些东西是不是一个订单号呢?一个订单的肯定是一个订单号的说,那简单了呀。
**一个topic下有多个队列**,为了保证发送有序,**RocketMQ**提供了**MessageQueueSelector**队列选择机制,他有三种实现:

我们可使用**Hash取模法**,让同一个订单发送到同一个队列中,再使用同步发送,只有同个订单的创建消息发送成功,再发送支付消息。这样,我们保证了发送有序。
**RocketMQ**的topic内的队列机制,可以保证存储满足**FIFO**(First Input First Output 简单说就是指先进先出),剩下的只需要消费者顺序消费即可。
**RocketMQ**仅保证顺序发送,顺序消费由消费者业务保证!!!
这里很好理解,一个订单你发送的时候放到一个队列里面去,你同一个的订单号Hash一下是不是还是一样的结果,那肯定是一个消费者消费,那顺序是不是就保证了?
真正的顺序消费不同的中间件都有自己的不同实现我这里就举个例子,大家思路理解下。
**Tip**:我写到这点的时候人才群里也有人问我,一个队列有序出去,一个消费者消费不就好了,我想说的是**消费者是多线程**的,你消息是有序的给他的,你能保证他是有序的处理的?还是一个消费成功了再发下一个**稳妥**。
### 你能跟我聊一下分布式事务么?
**分布式事务**在现在遍地都是分布式部署的系统中几乎是必要的。
我们先聊一下啥是**事务**?
**分布式事务**、**事务隔离级别**、**ACID**我相信大家这些东西都耳熟能详了,那什么是事务呢?
#### 概念:
> **一般是指要做的或所做的事情。**
>
> 在计算机术语中是指访问并可能更新数据库中各种数据项的一个程序执行单元(unit)。
>
> 事务通常由高级数据库操纵语言或编程语言(如SQL,C++或Java)书写的用户程序用户程序的执行所引起,并用形如**begin transaction**和**end transaction**语句(或函数调用)来界定。
>
> 事务由事务开始(**begin transaction**)和事务结束(**end transaction**)之间执行的全体操作组成。
#### 特性:
> 事务是恢复和并发控制的基本单位。
>
> 事务应该具有4个属性:**原子性、一致性、隔离性、持久性**。这四个属性通常称为**ACID特性**。
>
> **原子性(atomicity)**:一个事务是一个不可分割的工作单位,事务中包括的操作要么都做,要么都不做。
>
> **一致性(consistency)**:事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
>
> **隔离性(isolation)**:一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
>
> **持久性(durability)**:**持久性也称永久性(permanence)**,指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
那有同学还是不理解,敖丙我总结了一下就是:**事务就是一系列操作,要么同时成功,要么同时失败。**然后会从事务的 **ACID** 特性**(原子性、一致性、隔离性、持久性)展开叙述**。
事务就是为了保证一系列操作可以正常执行,它必须同时满足 **ACID** 特性。
### 那什么是分布式事务呢?
大家可以想一下,你下单流程可能涉及到10多个环节,你下单付钱都成功了,但是你优惠券扣减失败了,积分新增失败了,前者公司会被薅羊毛,后者用户会不开心,但是**这些都在不同的服务怎么保证大家都成功呢**?
聪明,**分布式事务**,你看你都会抢答了!
**Tip**:真实的应用场景可能比我介绍的场景复杂数倍,我只是为了举例方便一下大家理解所以用了很简单的例子。
我接触和了解到的分布式事务大概分为:
- 2pc(两段式提交)
- 3pc(三段式提交)
- TCC(Try、Confirm、Cancel)
- 最大努力通知
- XA
- 本地消息表(ebay研发出的)
- 半消息/最终一致性(RocketMQ)
这里我就介绍下最简单的**2pc(两段式)**,以及大家以后可能比较常用的**半消息事务**也就是**最终一致性**,目的是让大家理解下分布式事务里面**消息中间件的作用**,别的事务都大同小异,都有很多优点。
当然也都有**种种弊端**:
例如**长时间锁定数据库资源**,导致系统的**响应不快**,**并发上不去**。
网络抖动出现**脑裂**情况,导致事物参与者,不能很好地执行协调者的指令,导致**数据不一致**。
**单点故障**:例如事物协调者,在某一时刻宕机,虽然可以通过选举机制产生新的Leader,但是这过程中,必然出现问题,而TCC,只有强悍的技术团队,才能支持开发,**成本太高**。
不多BB了,我们开始介绍这个两个事物吧。
**2pc(两段式提交)** :

**2pc(两段式提交)**可以说是分布式事务的最开始的样子了,像极了**媒婆**,就是通过消息中间件协调多个系统,在两个系统操作事务的时候都锁定资源但是不提交事务,等两者都准备好了,告诉消息中间件,然后再分别提交事务。
**但是我不知道大家看到问题所在没有?**
是的你可能已经发现了,如果A系统事务提交成功了,但是B系统在提交的时候网络波动或者各种原因提交失败了,其实还是会失败的。
**最终一致性**:

整个流程中,我们能保证是:
- 业务主动方本地事务提交失败,业务被动方不会收到消息的投递。
- 只要业务主动方本地事务执行成功,那么消息服务一定会投递消息给下游的业务被动方,并最终保证业务被动方一定能成功消费该消息(消费成功或失败,即最终一定会有一个最终态)。
不过呢技术就是这样,**各种极端的情况我们都需要考虑**,也很难有完美的方案,所以才会有这么多的方案**三段式**、**TCC**、**最大努力通知**等等分布式事务方案,大家只需要知道为啥要做,做了有啥好处,有啥坏处,在实际开发的时候都注意下就好好了,**系统都是根据业务场景设计出来的,离开业务的技术没有意义,离开技术的业务没有底气**。
还是那句话:**没有最完美的系统,只有最适合的系统。**
##面试结束
### 小伙子看不出来啊,还是有点东西的嘛,这几个点都回答的不错,明天你能跟我聊一下RocketMQ么?
敖丙这章花了这么多时间,不确定他写不写的完,心疼他。好想给他**点赞**啊,**消息回溯**也在单独介绍消息中间件的时候介绍吧,这章篇幅有点长了。
## 总结
这章其实我写的时间**比之前的秒杀还要久**,因为**顺序消息这个场景**我不知道怎么讲出来大家容易懂一点,最后就参考了网上的,顺序消息的实际应用场景没别的那么广泛,跟3y也聊了好几次,最后定了这个binlog的场景。
总之就是**这期创作源泉有点枯竭**,这章是真的难写,包括分布式事务在实际开发过程中也是很复杂的环节,需要用的时候光是做设计都要很久,反正我的流程图长得一匹。
我每次都想着写得**通俗易懂**一点,这篇即使是这样我觉得还是不够通俗易懂,但是消息的场景就是这样,还有大家加我也不要一上来就问我很多扣细节的点,**自己多点思考我觉得可能帮助比我告诉你答案好很多吧**?
## 絮叨
敖丙我呀,这周**有牌面**哟,上了**CSDN**的原力计划榜单,而且奖金高达50块!!!

钱不多但是很开心,跟老妈聊到她也觉得我出息了,刚好她生日,以前我们这一家人就是那种不过生日的,不过呀今年我工作了,而且**有牌面**的我拿了的奖金就很关键,偷偷叫表弟悄悄去给她买了蛋糕和礼物🎁,嘻嘻,开心。🎂
### DISS

这是**博客园的一个网友**在我文章下面的评论,说实话不知道**大家怎么看**的,我只想说:呵呵!傻*
我不知道这个多年的经验到底是怎么样子的多年的经验,我本来其实不准备说出来的,因为我发现我群里很多都是还没毕业的**大学生**或者**应届生**,那就假设我读者还有很多这样的学生,他们都**没社会经验**我怕他们被这样的人给误导了。
我记得我在群里说过:

我可以80%肯定的告诉大家他这个观点就是扯淡,还有那20%我是**认同他的谦虚那个观点**,但是**谦虚难道不应该是我们对待事物最基本的态度嘛?**
但是**面试装傻**这个观点?还有什么**不会要比你强的人**这个观点?技术人我相信也有面试官也在看我的文章,你们在面试的时候,我想遇到厉害的人巴不得招入麾下,为自己冲锋陷阵吧。
而且**正常面试**的时候你是1-3年的经验,面试你的基本上都是3年以上的,然后依次顺推,当然也有很多很厉害的Leader(我前东家Leader95年的,字节跳动某产品线很强的Leader96的等等)等大家工作了你就会发现有些东西**没有时间积累**是学不到的,你要做的只是一步一个脚印踏实走好就好了。
那些人不管年轻与否能坐在那面试你**肯定有他的原因**,那你有什么才华,你**尽情施展**,他没那个度量包容你的优秀,这样的公司不去也罢,但是技术人这样的真的很少,程序员是一群很崇拜能力的人。
所以**面试你有啥都秀出来,把你的才华尽情的展示出来,风就在那,你只管飞翔。**
## 鸣谢
涉及到分布式事务的环节我参考了前大神同事:**鲁班**(花名)的技术分享,很感谢他的文章给的思路,还有问题的解析!

每次写我都会在群里问大家,下次大家都在我的交流群里面也可以多给我点意见,谢谢了。

看到没,就很民主。(敖丙你个渣男,呸,自己不会就不写!)
**Tip**: **GItHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 上有进群方式和个人联系方式,说实话在这个群,哪怕您不说话,光看聊天记录,都能学到东西(美团王炸,三歪(Java3y),并夕夕等的大佬都在)。
## 日常求赞
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我每周都会更新几篇《吊打面试官》系列和互联网常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】 如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 《吊打面试官》系列每周持续更新,可以关注我的公众号「 **JavaFamily** 」第一时间阅读和催更(公众号比博客早一到两篇哟),本文**GitHub**上已经收录[https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily),有一线大厂面试点思维导图,欢迎Star和完善,里面也有我个人联系方式有什么问题也可以直接找我,也有人才交流群,我们一起有点东西。

================================================
FILE: docs/redis/Redis基础.md
================================================
>你知道的越多,你不知道的越多
>点赞再看,养成习惯
## 前言
**Redis**在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在**Redis**的使用和原理方面对小伙伴们进行360°的刁难。作为一个在互联网公司面一次拿一次offer的面霸(**请允许我使用一下夸张的修辞手法**),打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚,在一个寂寞难耐的夜晚,我痛定思痛,决定开始写《吊打面试官》系列,希望能帮助各位读者以后面试势如破竹,对面试官进行360°的反击,吊打问你的面试官,让一同面试的同僚铩羽而归,疯狂收割大厂offer!
### 面试开始
>一个大腹便便,穿着格子衬衣的中年男子,拿着一个满是划痕的mac向你走来,看着快秃顶的头发,心想着肯定是尼玛顶级架构师吧!但是我们腹有诗书气自华,虚都不虚。

### 小伙子您好,看你简历上写了你项目里面用到了Redis,你们为啥用Redis?
心里忍不住暗骂,这叫啥问题,大家不都是用的这个嘛,但是你不能说出来。
认真回答道:**帅气迷人的面试官您好**,因为传统的关系型数据库如Mysql已经不能适用所有的场景了,比如秒杀的库存扣减,APP首页的访问流量高峰等等,都很容易把数据库打崩,所以引入了缓存中间件,目前市面上比较常用的缓存中间件有Redis 和 Memcached 不过中和考虑了他们的优缺点,最后选择了Redis。
**至于更细节的对比朋友们记得查阅Redis 和 Memcached 的区别,比如两者的优缺点对比和各自的场景,后续我有时间也会写出来。**
### 那小伙子,我再问你,Redis有哪些数据结构呀?
字符串String、字典Hash、列表List、集合Set、有序集合SortedSet。
**这里我相信99%的读者都能回答上来Redis的5个基本数据类型。如果回答不出来的小伙伴我们就要加油补课哟,大家知道五种类型最适合的场景更好。**
但是,如果你是Redis中高级用户,而且你要在这次面试中突出你和其他候选人的不同,还需要加上下面几种数据结构HyperLogLog、Geo、Pub/Sub。
如果你还想加分,那你说还玩过Redis Module,像BloomFilter,RedisSearch,Redis-ML,这个时候面试官得眼睛就开始发亮了,心想这个小伙子**有点东西啊**。
******注:本人在面试回答到Redis相关的问题的时候,经常提到BloomFilter(布隆过滤器)这玩意的使用场景是真的多,而且用起来是真的香,原理也好理解,看一下文章就可以在面试官面前侃侃而谈了,不香么?下方传送门 ↓******
[避免缓存穿透的利器之BloomFilter](https://juejin.im/post/5db69365518825645656c0de)
### 如果有大量的key需要设置同一时间过期,一般需要注意什么?
如果大量的key过期时间设置的过于集中,到过期的那个时间点,redis可能会出现短暂的卡顿现象。严重的话会出现缓存雪崩,我们一般需要在时间上加一个随机值,使得过期时间分散一些。
**电商首页经常会使用定时任务刷新缓存,可能大量的数据失效时间都十分集中,如果失效时间一样,又刚好在失效的时间点大量用户涌入,就有可能造成缓存雪崩**
### 那你使用过Redis分布式锁么,它是什么回事?
先拿setnx来争抢锁,抢到之后,再用expire给锁加一个过期时间防止锁忘记了释放。
### 这时候对方会告诉你说你回答得不错,然后接着问如果在setnx之后执行expire之前进程意外crash或者要重启维护了,那会怎么样?
这时候你要给予惊讶的反馈:唉,是喔,这个锁就永远得不到释放了。紧接着你需要**抓一抓自己得脑袋,故作思考片刻**,好像接下来的结果是你主动思考出来的,然后回答:我记得set指令有非常复杂的参数,这个应该是可以同时把setnx和expire合成一条指令来用的!
### 对方这时会显露笑容,心里开始默念:嗯,这小子还不错,开始有点意思了。
### 假如Redis里面有1亿个key,其中有10w个key是以某个固定的已知的前缀开头的,如何将它们全部找出来?
使用**keys**指令可以扫出指定模式的key列表。
### 对方接着追问:如果这个redis正在给线上的业务提供服务,那使用keys指令会有什么问题?
这个时候你要回答redis关键的一个特性:redis的单线程的。keys指令会导致线程阻塞一段时间,线上服务会停顿,直到指令执行完毕,服务才能恢复。这个时候可以使用**scan**指令,**scan**指令可以无阻塞的提取出指定模式的key列表,但是会有一定的重复概率,在客户端做一次去重就可以了,但是整体所花费的时间会比直接用keys指令长。
**不过,增量式迭代命令也不是没有缺点的: 举个例子, 使用 SMEMBERS 命令可以返回集合键当前包含的所有元素, 但是对于 SCAN 这类增量式迭代命令来说, 因为在对键进行增量式迭代的过程中, 键可能会被修改, 所以增量式迭代命令只能对被返回的元素提供有限的保证 。**
### 使用过Redis做异步队列么,你是怎么用的?
一般使用list结构作为队列,**rpush**生产消息,**lpop**消费消息。当lpop没有消息的时候,要适当sleep一会再重试。
### 如果对方追问可不可以不用sleep呢?
list还有个指令叫**blpop**,在没有消息的时候,它会阻塞住直到消息到来。
### 如果对方接着追问能不能生产一次消费多次呢?
使用pub/sub主题订阅者模式,可以实现 1:N 的消息队列。
### 如果对方继续追问 pub/su b有什么缺点?
在消费者下线的情况下,生产的消息会丢失,得使用专业的消息队列如**RocketMQ**等。
### 如果对方究极TM追问Redis如何实现延时队列?
这一套连招下来,我估计现在你很想把面试官一棒打死(**面试官自己都想打死自己了怎么问了这么多自己都不知道的**),如果你手上有一根棒球棍的话,但是你很克制。平复一下激动的内心,然后神态自若的回答道:使用sortedset,拿时间戳作为score,消息内容作为key调用zadd来生产消息,消费者用**zrangebyscore**指令获取N秒之前的数据轮询进行处理。
**到这里,面试官暗地里已经对你竖起了大拇指。并且已经默默给了你A+,但是他不知道的是此刻你却竖起了中指,在椅子背后。**
### Redis是怎么持久化的?服务主从数据怎么交互的?
RDB做镜像全量持久化,AOF做增量持久化。因为RDB会耗费较长时间,不够实时,在停机的时候会导致大量丢失数据,所以需要AOF来配合使用。在redis实例重启时,会使用RDB持久化文件重新构建内存,再使用AOF重放近期的操作指令来实现完整恢复重启之前的状态。
**这里很好理解,把RDB理解为一整个表全量的数据,AOF理解为每次操作的日志就好了,服务器重启的时候先把表的数据全部搞进去,但是他可能不完整,你再回放一下日志,数据不就完整了嘛。不过Redis本身的机制是 AOF持久化开启且存在AOF文件时,优先加载AOF文件;AOF关闭或者AOF文件不存在时,加载RDB文件;加载AOF/RDB文件城后,Redis启动成功; AOF/RDB文件存在错误时,Redis启动失败并打印错误信息**
### 对方追问那如果突然机器掉电会怎样?
取决于AOF日志sync属性的配置,如果不要求性能,在每条写指令时都sync一下磁盘,就不会丢失数据。但是在高性能的要求下每次都sync是不现实的,一般都使用定时sync,比如1s1次,这个时候最多就会丢失1s的数据。
### 对方追问RDB的原理是什么?
你给出两个词汇就可以了,fork和cow。fork是指redis通过创建子进程来进行RDB操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写脏的页面数据会逐渐和子进程分离开来。
******注:回答这个问题的时候,如果你还能说出AOF和RDB的优缺点,我觉得我是面试官在这个问题上我会给你点赞,两者其实区别还是很大的,而且涉及到Redis集群的数据同步问题等等。想了解的伙伴也可以留言,我会专门写一篇来介绍的。 ******
### Pipeline有什么好处,为什么要用pipeline?
可以将多次IO往返的时间缩减为一次,前提是pipeline执行的指令之间没有因果相关性。使用redis-benchmark进行压测的时候可以发现影响redis的QPS峰值的一个重要因素是pipeline批次指令的数目。
### Redis的同步机制了解么?
Redis可以使用主从同步,从从同步。第一次同步时,主节点做一次bgsave,并同时将后续修改操作记录到内存buffer,待完成后将RDB文件全量同步到复制节点,复制节点接受完成后将RDB镜像加载到内存。加载完成后,再通知主节点将期间修改的操作记录同步到复制节点进行重放就完成了同步过程。后续的增量数据通过AOF日志同步即可,有点类似数据库的binlog。
### 是否使用过Redis集群,集群的高可用怎么保证,集群的原理是什么?
Redis Sentinal着眼于高可用,在master宕机时会自动将slave提升为master,继续提供服务。
Redis Cluster着眼于扩展性,在单个redis内存不足时,使用Cluster进行分片存储。
## 面试结束
### 小伙子你可以的,什么时候有时间来上班啊,要不明天就来吧?
你强装镇定,这么急啊我还需要租房,要不下礼拜一吧。
### 好的 心想这小子这么NB是不是很多Offer在手上,不行我得叫hr给他加钱。
能撑到最后,你自己都忍不住自己给自己点个赞了!
(**暗示点赞,每次都看了不点赞,你们想白嫖我么?你们好坏喲,不过我喜欢**)。
## 总结
**在技术面试的时候,不管是Redis还是什么问题,如果你能举出实际的例子,或者是直接说自己开发过程的问题和收获会给面试官的印象分会加很多,回答逻辑性也要强一点,不要东一点西一点,容易把自己都绕晕的。**
**还有一点就是我问你为啥用Redis你不要一上来就直接回答问题了,你可以这样回答:**
**帅气的面试官您好**,首先我们的项目DB遇到了瓶颈,特别是秒杀和热点数据这样的场景DB基本上就扛不住了,那就需要缓存中间件的加入了,目前市面上有的缓存中间件有 Redis 和 Memcached ,他们的优缺点......,综合这些然后再结合我们项目特点,最后我们在技术选型的时候选了谁。
如果你这样有条不紊,有理有据的回答了我的问题而且还说出这么多我问题外的知识点,我会觉得你不只是一个会写代码的人,你逻辑清晰,你对技术选型,对中间件对项目都有自己的理解和思考,说白了就是你的offer有戏了。
好了 以上就是这篇文章的全部内容了,我后面会不断更新《吊打面试官》系列和Java技术栈相关的文章。如果你有什么想知道的,也可以**留言**给我,我一有时间就会写出来,我们共同进步。
非常感谢您能看到这里,如果这个文章写得还不错的话 **求点赞** **求关注** **求分享** **求留言** 各位的支持和认可,就是我创作的最大动力,OK各位我们下期见!
敖丙 | 文
----
>后面会持续更新《吊打面试官》系列可以关注我的公众号第一时间阅读,也会有朋友一线大厂的内推机会不定期推出(字节跳动,阿里,网易,PDD,滴滴,蘑菇街等),就业上有什么问题也可以直接微信滴滴我,我也是个新人,不过不影响我们一起进步,作为渣男,我给不了你工作,还给不了你温暖嘛?

================================================
FILE: docs/redis/Redis常见面试题.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> [**GitHub**](https://github.com/AobingJava/JavaFamily)上已经开源[https://github.com/Java...](https://github.com/AobingJava/JavaFamily),有面试点思维导图,欢迎[**Star**](https://github.com/AobingJava/JavaFamily)和[**完善**](https://github.com/AobingJava/JavaFamily)
## 前言
**Redis**在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在**Redis**的使用和原理方面对小伙伴们进行360°的刁难。
作为一个在互联网公司面一次拿一次Offer的面霸,打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚(**请允许我使用一下夸张的修辞手法**)。
于是在一个寂寞难耐的夜晚,我痛定思痛,决定开始写**《吊打面试官》**系列,希望能帮助各位读者以后面试势如破竹,对面试官进行360°的反击,吊打问你的面试官,让一同面试的同僚瞠目结舌,疯狂收割大厂Offer!
## 絮叨
上一期因为是在双十一一直在熬夜的大环境下完成的,所以我自己觉得质量明显没之前的好,我这不一睡好就加班加点准备补偿大家,来点干货。(熬夜太容易感冒了,这次**点个赞**别白嫖了!)
顺带提一嘴,我把我准备写啥画了一个思维导图,以后总不能每篇都放个贼大的图吧,就开源到了我的**[GitHub](https://github.com/AobingJava/JavaFamily)**,大家有兴趣可以去完善和**Star**。
这篇我就先放出来大家看看,感觉还是差点意思,等大家完善了。

## 回望过去
上一期吊打系列我们提到了**Redis**相关的一些知识,还没看的小伙伴可以回顾一下
- **[《吊打面试官》系列-Redis基础](https://juejin.im/post/5db66ed9e51d452a2f15d833)**
- **[《吊打面试官》系列-缓存雪崩、击穿、穿透](https://juejin.im/post/5dbef8306fb9a0203f6fa3e2)**
- **[《吊打面试官》系列-Redis哨兵、持久化、主从、手撕LRU](https://juejin.im/post/5dc3a9fbf265da4d3c072eab)**
- **[《吊打面试官》系列-Redis终章-凛冬将至、FPX-新王登基](https://juejin.im/post/5dc850b4e51d452c2308ee27)**
这期我就从缓存到一些常见的问题讲一下,有一些我是之前提到过的,不过可能大部分仔是第一次看,我就重复发一下。
### 缓存知识点
###### 
### 缓存有哪些类型?
缓存是高并发场景下提高热点数据访问性能的一个有效手段,在开发项目时会经常使用到。
缓存的类型分为:**本地缓存**、**分布式缓存**和**多级缓存**。
#### 本地缓存:
**本地缓存**就是在进程的内存中进行缓存,比如我们的 **JVM** 堆中,可以用 **LRUMap** 来实现,也可以使用 **Ehcache** 这样的工具来实现。
本地缓存是内存访问,没有远程交互开销,性能最好,但是受限于单机容量,一般缓存较小且无法扩展。
#### 分布式缓存:
**分布式缓存**可以很好得解决这个问题。
分布式缓存一般都具有良好的水平扩展能力,对较大数据量的场景也能应付自如。缺点就是需要进行远程请求,性能不如本地缓存。
#### 多级缓存:
为了平衡这种情况,实际业务中一般采用**多级缓存**,本地缓存只保存访问频率最高的部分热点数据,其他的热点数据放在分布式缓存中。
在目前的一线大厂中,这也是最常用的缓存方案,单考单一的缓存方案往往难以撑住很多高并发的场景。
### 淘汰策略
不管是本地缓存还是分布式缓存,为了保证较高性能,都是使用内存来保存数据,由于成本和内存限制,当存储的数据超过缓存容量时,需要对缓存的数据进行剔除。
一般的剔除策略有 **FIFO** 淘汰最早数据、**LRU** 剔除最近最少使用、和 **LFU** 剔除最近使用频率最低的数据几种策略。
- **noeviction**:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
- **allkeys-lru**: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
- **volatile-lru**: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
- **allkeys-random**: 回收随机的键使得新添加的数据有空间存放。
- **volatile-random**: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
- **volatile-ttl**: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
如果没有键满足回收的前提条件的话,策略**volatile-lru**, **volatile-random**以及**volatile-ttl**就和noeviction 差不多了。
其实在大家熟悉的**LinkedHashMap**中也实现了Lru算法的,实现如下:

当容量超过100时,开始执行**LRU**策略:将最近最少未使用的 **TimeoutInfoHolder** 对象 **evict** 掉。
真实面试中会让你写LUR算法,你可别搞原始的那个,那真TM多,写不完的,你要么怼上面这个,要么怼下面这个,找一个数据结构实现下Java版本的LRU还是比较容易的,知道啥原理就好了。

### Memcache
注意后面会把 **Memcache** 简称为 MC。
先来看看 MC 的特点:
- MC 处理请求时使用多线程异步 IO 的方式,可以合理利用 CPU 多核的优势,性能非常优秀;
- MC 功能简单,使用内存存储数据;
- MC 的内存结构以及钙化问题我就不细说了,大家可以查看[官网](http://www.memcached.org/about)了解下;
- MC 对缓存的数据可以设置失效期,过期后的数据会被清除;
- 失效的策略采用延迟失效,就是当再次使用数据时检查是否失效;
- 当容量存满时,会对缓存中的数据进行剔除,剔除时除了会对过期 key 进行清理,还会按 LRU 策略对数据进行剔除。
另外,使用 MC 有一些限制,这些限制在现在的互联网场景下很致命,成为大家选择**Redis**、**MongoDB**的重要原因:
- key 不能超过 250 个字节;
- value 不能超过 1M 字节;
- key 的最大失效时间是 30 天;
- 只支持 K-V 结构,不提供持久化和主从同步功能。
### Redis
先简单说一下 **Redis** 的特点,方便和 MC 比较。
- 与 MC 不同的是,Redis 采用单线程模式处理请求。这样做的原因有 2 个:一个是因为采用了非阻塞的异步事件处理机制;另一个是缓存数据都是内存操作 IO 时间不会太长,单线程可以避免线程上下文切换产生的代价。
- **Redis** 支持持久化,所以 Redis 不仅仅可以用作缓存,也可以用作 NoSQL 数据库。
- 相比 MC,**Redis** 还有一个非常大的优势,就是除了 K-V 之外,还支持多种数据格式,例如 list、set、sorted set、hash 等。
- **Redis** 提供主从同步机制,以及 **Cluster** 集群部署能力,能够提供高可用服务。
#
### 详解 Redis
Redis 的知识点结构如下图所示。

### 功能
来看 **Redis** 提供的功能有哪些吧!
#### 我们先看基础类型:
#### **String:**
**String** 类型是 **Redis** 中最常使用的类型,内部的实现是通过 **SDS**(Simple Dynamic String )来存储的。SDS 类似于 **Java** 中的 **ArrayList**,可以通过预分配冗余空间的方式来减少内存的频繁分配。
这是最简单的类型,就是普通的 set 和 get,做简单的 KV 缓存。
但是真实的开发环境中,很多仔可能会把很多比较复杂的结构也统一转成**String**去存储使用,比如有的仔他就喜欢把对象或者**List**转换为**JSONString**进行存储,拿出来再反序列话啥的。
我在这里就不讨论这样做的对错了,但是我还是希望大家能在最合适的场景使用最合适的数据结构,对象找不到最合适的但是类型可以选最合适的嘛,之后别人接手你的代码一看这么**规范**,诶这小伙子**有点东西**呀,看到你啥都是用的**String**,**垃圾!**

好了这些都是题外话了,道理还是希望大家记在心里,习惯成自然嘛,小习惯成就你。
**String**的实际应用场景比较广泛的有:
- **缓存功能:String**字符串是最常用的数据类型,不仅仅是**Redis**,各个语言都是最基本类型,因此,利用**Redis**作为缓存,配合其它数据库作为存储层,利用**Redis**支持高并发的特点,可以大大加快系统的读写速度、以及降低后端数据库的压力。
- **计数器:**许多系统都会使用**Redis**作为系统的实时计数器,可以快速实现计数和查询的功能。而且最终的数据结果可以按照特定的时间落地到数据库或者其它存储介质当中进行永久保存。
- **共享用户Session:**用户重新刷新一次界面,可能需要访问一下数据进行重新登录,或者访问页面缓存**Cookie**,但是可以利用**Redis**将用户的**Session**集中管理,在这种模式只需要保证**Redis**的高可用,每次用户**Session**的更新和获取都可以快速完成。大大提高效率。
#### **Hash:**
这个是类似 **Map** 的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是**这个对象没嵌套其他的对象**)给缓存在 **Redis** 里,然后每次读写缓存的时候,可以就操作 **Hash** 里的**某个字段**。
但是这个的场景其实还是多少单一了一些,因为现在很多对象都是比较复杂的,比如你的商品对象可能里面就包含了很多属性,其中也有对象。我自己使用的场景用得不是那么多。
#### **List:**
**List** 是有序列表,这个还是可以玩儿出很多花样的。
比如可以通过 **List** 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的东西。
比如可以通过 **lrange** 命令,读取某个闭区间内的元素,可以基于 **List** 实现分页查询,这个是很棒的一个功能,基于 **Redis** 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西,性能高,就一页一页走。
比如可以搞个简单的消息队列,从 **List** 头怼进去,从 **List** 屁股那里弄出来。
**List**本身就是我们在开发过程中比较常用的数据结构了,热点数据更不用说了。
- **消息队列:Redis**的链表结构,可以轻松实现阻塞队列,可以使用左进右出的命令组成来完成队列的设计。比如:数据的生产者可以通过**Lpush**命令从左边插入数据,多个数据消费者,可以使用**BRpop**命令阻塞的“抢”列表尾部的数据。
- 文章列表或者数据分页展示的应用。
比如,我们常用的博客网站的文章列表,当用户量越来越多时,而且每一个用户都有自己的文章列表,而且当文章多时,都需要分页展示,这时可以考虑使用**Redis**的列表,列表不但有序同时还支持按照范围内获取元素,可以完美解决分页查询功能。大大提高查询效率。
#### **Set:**
**Set** 是无序集合,会自动去重的那种。
直接基于 **Set** 将系统里需要去重的数据扔进去,自动就给去重了,如果你需要对一些数据进行快速的全局去重,你当然也可以基于 **JVM** 内存里的 **HashSet** 进行去重,但是如果你的某个系统部署在多台机器上呢?得基于**Redis**进行全局的 **Set** 去重。
可以基于 **Set** 玩儿交集、并集、差集的操作,比如交集吧,我们可以把两个人的好友列表整一个交集,看看俩人的共同好友是谁?对吧。
反正这些场景比较多,因为对比很快,操作也简单,两个查询一个**Set**搞定。
#### **Sorted Set:**
**Sorted set** 是排序的 **Set**,去重但可以排序,写进去的时候给一个分数,自动根据分数排序。
有序集合的使用场景与集合类似,但是set集合不是自动有序的,而**Sorted set**可以利用分数进行成员间的排序,而且是插入时就排序好。所以当你需要一个有序且不重复的集合列表时,就可以选择**Sorted set**数据结构作为选择方案。
- 排行榜:有序集合经典使用场景。例如视频网站需要对用户上传的视频做排行榜,榜单维护可能是多方面:按照时间、按照播放量、按照获得的赞数等。
- 用**Sorted Sets**来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
微博热搜榜,就是有个后面的热度值,前面就是名称
### 高级用法:
#### **Bitmap** :
位图是支持按 bit 位来存储信息,可以用来实现 **布隆过滤器(BloomFilter)**;
#### **HyperLogLog:**
供不精确的去重计数功能,比较适合用来做大规模数据的去重统计,例如统计 UV;
#### **Geospatial:**
可以用来保存地理位置,并作位置距离计算或者根据半径计算位置等。有没有想过用Redis来实现附近的人?或者计算最优地图路径?
这三个其实也可以算作一种数据结构,不知道还有多少朋友记得,我在梦开始的地方,Redis基础中提到过,你如果只知道五种基础类型那只能拿60分,如果你能讲出高级用法,那就觉得你**有点东西**。
#### **pub/sub:**
功能是订阅发布功能,可以用作简单的消息队列。
#### **Pipeline:**
可以批量执行一组指令,一次性返回全部结果,可以减少频繁的请求应答。
#### **Lua:**
**Redis** 支持提交 **Lua** 脚本来执行一系列的功能。
我在前电商老东家的时候,秒杀场景经常使用这个东西,讲道理有点香,利用他的原子性。
话说你们想看秒杀的设计么?我记得我面试好像每次都问啊,想看的直接**点赞**后评论秒杀吧。
#### **事务:**
最后一个功能是事务,但 **Redis** 提供的不是严格的事务,**Redis** 只保证串行执行命令,并且能保证全部执行,但是执行命令失败时并不会回滚,而是会继续执行下去。
### 持久化
**Redis** 提供了 RDB 和 AOF 两种持久化方式,RDB 是把内存中的数据集以快照形式写入磁盘,实际操作是通过 fork 子进程执行,采用二进制压缩存储;AOF 是以文本日志的形式记录 **Redis** 处理的每一个写入或删除操作。
**RDB** 把整个 Redis 的数据保存在单一文件中,比较适合用来做灾备,但缺点是快照保存完成之前如果宕机,这段时间的数据将会丢失,另外保存快照时可能导致服务短时间不可用。
**AOF** 对日志文件的写入操作使用的追加模式,有灵活的同步策略,支持每秒同步、每次修改同步和不同步,缺点就是相同规模的数据集,AOF 要大于 RDB,AOF 在运行效率上往往会慢于 RDB。
细节的点大家去高可用这章看,特别是两者的优缺点,以及怎么抉择。
**[《吊打面试官》系列-Redis哨兵、持久化、主从、手撕LRU](https://juejin.im/post/5dc3a9fbf265da4d3c072eab)**
### 高可用
来看 Redis 的高可用。Redis 支持主从同步,提供 Cluster 集群部署模式,通过 Sentine l哨兵来监控 Redis 主服务器的状态。当主挂掉时,在从节点中根据一定策略选出新主,并调整其他从 slaveof 到新主。
选主的策略简单来说有三个:
- slave 的 priority 设置的越低,优先级越高;
- 同等情况下,slave 复制的数据越多优先级越高;
- 相同的条件下 runid 越小越容易被选中。
在 Redis 集群中,sentinel 也会进行多实例部署,sentinel 之间通过 Raft 协议来保证自身的高可用。
Redis Cluster 使用分片机制,在内部分为 16384 个 slot 插槽,分布在所有 master 节点上,每个 master 节点负责一部分 slot。数据操作时按 key 做 CRC16 来计算在哪个 slot,由哪个 master 进行处理。数据的冗余是通过 slave 节点来保障。
### 哨兵
哨兵必须用三个实例去保证自己的健壮性的,哨兵+主从并**不能保证数据不丢失**,但是可以保证集群的**高可用**。
为啥必须要三个实例呢?我们先看看两个哨兵会咋样。

master宕机了 s1和s2两个哨兵只要有一个认为你宕机了就切换了,并且会选举出一个哨兵去执行故障,但是这个时候也需要大多数哨兵都是运行的。
那这样有啥问题呢?M1宕机了,S1没挂那其实是OK的,但是整个机器都挂了呢?哨兵就只剩下S2个裸屌了,没有哨兵去允许故障转移了,虽然另外一个机器上还有R1,但是故障转移就是不执行。
经典的哨兵集群是这样的:

M1所在的机器挂了,哨兵还有两个,两个人一看他不是挂了嘛,那我们就选举一个出来执行故障转移不就好了。
暖男我,小的总结下哨兵组件的主要功能:
- 集群监控:负责监控 Redis master 和 slave 进程是否正常工作。
- 消息通知:如果某个 **Redis** 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
- 故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
- 配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
### 主从
提到这个,就跟我前面提到的数据持久化的**RDB**和**AOF**有着比密切的关系了。
我先说下为啥要用主从这样的架构模式,前面提到了单机**QPS**是有上限的,而且**Redis**的特性就是必须支撑读高并发的,那你一台机器又读又写,**这谁顶得住啊**,不当人啊!但是你让这个master机器去写,数据同步给别的slave机器,他们都拿去读,分发掉大量的请求那是不是好很多,而且扩容的时候还可以轻松实现水平扩容。

你启动一台slave 的时候,他会发送一个**psync**命令给master ,如果是这个slave第一次连接到master,他会触发一个全量复制。master就会启动一个线程,生成**RDB**快照,还会把新的写请求都缓存在内存中,**RDB**文件生成后,master会将这个**RDB**发送给slave的,slave拿到之后做的第一件事情就是写进本地的磁盘,然后加载进内存,然后master会把内存里面缓存的那些新命名都发给slave。
**我发出来之后来自CSDN的网友:Jian_Shen_Zer 问了个问题:**
主从同步的时候,新的slaver进来的时候用**RDB**,那之后的数据呢?有新的数据进入master怎么同步到slaver啊
敖丙答:笨,**AOF**嘛,增量的就像**MySQL**的**Binlog**一样,把日志增量同步给从服务就好了
#### key 失效机制
**Redis** 的 key 可以设置过期时间,过期后 Redis 采用主动和被动结合的失效机制,一个是和 MC 一样在访问时触发被动删除,另一种是定期的主动删除。
定期+惰性+内存淘汰
### 缓存常见问题
#### 缓存更新方式
这是决定在使用缓存时就该考虑的问题。
缓存的数据在数据源发生变更时需要对缓存进行更新,数据源可能是 DB,也可能是远程服务。更新的方式可以是主动更新。数据源是 DB 时,可以在更新完 DB 后就直接更新缓存。
当数据源不是 DB 而是其他远程服务,可能无法及时主动感知数据变更,这种情况下一般会选择对缓存数据设置失效期,也就是数据不一致的最大容忍时间。
这种场景下,可以选择失效更新,key 不存在或失效时先请求数据源获取最新数据,然后再次缓存,并更新失效期。
但这样做有个问题,如果依赖的远程服务在更新时出现异常,则会导致数据不可用。改进的办法是异步更新,就是当失效时先不清除数据,继续使用旧的数据,然后由异步线程去执行更新任务。这样就避免了失效瞬间的空窗期。另外还有一种纯异步更新方式,定时对数据进行分批更新。实际使用时可以根据业务场景选择更新方式。
#### 数据不一致
第二个问题是数据不一致的问题,可以说只要使用缓存,就要考虑如何面对这个问题。缓存不一致产生的原因一般是主动更新失败,例如更新 DB 后,更新 **Redis** 因为网络原因请求超时;或者是异步更新失败导致。
解决的办法是,如果服务对耗时不是特别敏感可以增加重试;如果服务对耗时敏感可以通过异步补偿任务来处理失败的更新,或者短期的数据不一致不会影响业务,那么只要下次更新时可以成功,能保证最终一致性就可以。
#### 缓存穿透
**缓存穿透**。产生这个问题的原因可能是外部的恶意攻击,例如,对用户信息进行了缓存,但恶意攻击者使用不存在的用户id频繁请求接口,导致查询缓存不命中,然后穿透 DB 查询依然不命中。这时会有大量请求穿透缓存访问到 DB。
解决的办法如下。
1. 对不存在的用户,在缓存中保存一个空对象进行标记,防止相同 ID 再次访问 DB。不过有时这个方法并不能很好解决问题,可能导致缓存中存储大量无用数据。
2. 使用 **BloomFilter** 过滤器,BloomFilter 的特点是存在性检测,如果 BloomFilter 中不存在,那么数据一定不存在;如果 BloomFilter 中存在,实际数据也有可能会不存在。非常适合解决这类的问题。
#### 缓存击穿
**缓存击穿**,就是某个热点数据失效时,大量针对这个数据的请求会穿透到数据源。
解决这个问题有如下办法。
1. 可以使用互斥锁更新,保证同一个进程中针对同一个数据不会并发请求到 DB,减小 DB 压力。
2. 使用随机退避方式,失效时随机 sleep 一个很短的时间,再次查询,如果失败再执行更新。
3. 针对多个热点 key 同时失效的问题,可以在缓存时使用固定时间加上一个小的随机数,避免大量热点 key 同一时刻失效。
#### 缓存雪崩
**缓存雪崩**,产生的原因是缓存挂掉,这时所有的请求都会穿透到 DB。
解决方法:
1. 使用快速失败的熔断策略,减少 DB 瞬间压力;
2. 使用主从模式和集群模式来尽量保证缓存服务的高可用。
实际场景中,这两种方法会结合使用。
老朋友都知道为啥我**没有大篇幅介绍**这个几个点了吧,我在之前的文章实在是写得太详细了,忍不住**点赞**那种,我这里就不做重复拷贝了。
- **[《吊打面试官》系列-Redis基础](https://juejin.im/post/5db66ed9e51d452a2f15d833)**
- **[《吊打面试官》系列-缓存雪崩、击穿、穿透](https://juejin.im/post/5dbef8306fb9a0203f6fa3e2)**
- **[《吊打面试官》系列-Redis哨兵、持久化、主从、手撕LRU](https://juejin.im/post/5dc3a9fbf265da4d3c072eab)**
- **[《吊打面试官》系列-Redis终章_凛冬将至、FPX_新王登基](https://juejin.im/post/5dc850b4e51d452c2308ee27)**
### 考点与加分项
拿笔记一下!

#### 考点
面试的时候问你缓存,主要是考察缓存特性的理解,对 **MC**、**Redis** 的特点和使用方式的掌握。
- 要知道缓存的使用场景,不同类型缓存的使用方式,例如:
1. - 对 DB 热点数据进行缓存减少 DB 压力;对依赖的服务进行缓存,提高并发性能;
2. - 单纯 K-V 缓存的场景可以使用 **MC**,而需要缓存 list、set 等特殊数据格式,可以使用 **Redis**;
3. - 需要缓存一个用户最近播放视频的列表可以使用 **Redis** 的 list 来保存、需要计算排行榜数据时,可以使用 **Redis** 的 zset 结构来保存。
- 要了解 MC 和 **Redis** 的常用命令,例如原子增减、对不同数据结构进行操作的命令等。
- 了解 MC 和 **Redis** 在内存中的存储结构,这对评估使用容量会很有帮助。
- 了解 MC 和 **Redis** 的数据失效方式和剔除策略,比如主动触发的定期剔除和被动触发延期剔除
- 要理解 **Redis** 的持久化、主从同步与 **Cluster** 部署的原理,比如 **RDB** 和 **AOF** 的实现方式与区别。
- 要知道缓存穿透、击穿、雪崩分别的异同点以及解决方案。
- 不管你有没有电商经验我觉得你都应该知道秒杀的具体实现,以及细节点。
- ........
欢迎去[GitHub](https://github.com/AobingJava/JavaFamily)补充
#### 加分项
如果想要在面试中获得更好的表现,还应了解下面这些加分项。
- 是要结合实际应用场景来介绍缓存的使用。例如调用后端服务接口获取信息时,可以使用本地+远程的多级缓存;对于动态排行榜类的场景可以考虑通过 **Redis** 的 **Sorted set** 来实现等等。
- 最好你有过分布式缓存设计和使用经验,例如项目中在什么场景使用过 **Redis**,使用了什么数据结构,解决哪类的问题;使用 MC 时根据预估值大小调整 **McSlab** 分配参数等等。
- 最好可以了解缓存使用中可能产生的问题。比如 **Redis** 是单线程处理请求,应尽量避免耗时较高的单个请求任务,防止相互影响;**Redis** 服务应避免和其他 CPU 密集型的进程部署在同一机器;或者禁用 Swap 内存交换,防止 **Redis** 的缓存数据交换到硬盘上,影响性能。再比如前面提到的 MC 钙化问题等等。
- 要了解 **Redis** 的典型应用场景,例如,使用 **Redis** 来实现分布式锁;使用 **Bitmap** 来实现 **BloomFilter**,使用 **HyperLogLog** 来进行 UV 统计等等。
- 知道 Redis4.0、5.0 中的新特性,例如支持多播的可持久化消息队列 Stream;通过 Module 系统来进行定制功能扩展等等。
- ........
还是那句话欢迎去[GitHub](https://github.com/AobingJava/JavaFamily)补充。
## 总结
这次是对我**Redis**系列的总结,这应该是**Redis**相关的最后一篇文章了,其实四篇看下来的小伙伴很多都从**一知半解**到了**一脸懵逼**,哈哈开个玩笑。
我觉得我的方式应该还好,大部分小伙伴还是比较能理解的,这篇之后我就不会写**Redis**相关的文章了(秒杀看大家想看的热度吧),有啥问题可以微信找我,**下个系列写啥**?
大家不用急,下个系列前我会发个有意思的文章,是我在公司代码创意大赛拿奖的文章,我觉得还是**有点东西**,我忍不住分享一下,顺便就在那期发起**投票**吧哈哈。
我看到很多小伙伴都有评论说想看别的,大概搜集了一下,还没留言的这期赶紧哟:
#### 掘金
**愚辛** :想看计算机基础,网络和操作系统那些(FPX牛脾)
**cherish君**:讲讲dubbo经常遇到的面试题目,太多人喜欢问dubbo😃
**Java架构养成记**:真的很香啊,下一期讲Dubbbo(重点SPI)然后讲MQ好吗
#### CSDN
**小殿下**:看完了所有的redis篇 希望可以出ssm
#### 博客园
**程然**:Dubbo Dubbo
#### 开源中国
**linshi2019**:这期明显是赶工之作啊
敖丙:这条我回一下,鞭策我,我很喜欢,不过说实话还是希望大家**理解**下,我双十一熬夜三天了,现在给你们写的时候也是值班回家2点左右了,我一天吃饭工作时间肯定是固定的,想写点东西就只有挤出睡觉时间了,这种产出肯定没周末全情投入写的来的质量高。
其实第一期看过来的小伙伴应该也知道,我在**排版**,还有很多**文案**,**配图**其实我一直都有在改进的,光是名词高亮我都要弄很久,因为怕大家看单一的黑白色调枯燥。
我是真的用心在搞,还是希望大家支持下理解下。
**知乎、简书、思否、慕课手记**没人看不知道为啥,懂行的老铁可以跟我说一下。
我只想说你们想看的肯定都在我开头和[GITHub](https://github.com/AobingJava/JavaFamily)那个图里吧,问题不大,后面都会写的。
## 鸣谢
最后感谢下,新浪微博的技术专家张雷。
他于2013年加入**新浪微博**,作为核心技术人员参与了微博服务化、混合云等多个重点项目,是微博开源的**RPC**框架**Motan**的技术负责人,同时也负责微博的**Service Mesh**方案的研发与推广,专注于高可用架构及服务中间件开发方向。
他负责的**Motan**框架每天承载着万亿级别的请求调用,是微博平台服务化的基石,每次的突发热点事件、每次的春晚流量高峰,都离不开**Motan**框架的支撑与保障。此外,他也多次应邀在**ArchSummit、WOT、GIAC**技术峰会做技术分享。
感谢他对文章部分文案提供的支持和思路。
## END
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇《**吊打面试官**》系列和**互联网常用技术栈**相关的文章。如果你有什么想知道的,也可以留言给我,我一有时间就会写出来,我们共同进步。
非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** **求留言💬** 对暖男我来说 **非常有用**!!!
各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】
------
> 《吊打面试官》系列每周持续更新,可以关注我的公众号[JavaFamily](https://github.com/AobingJava/JavaFamily#%E5%85%AC%E4%BC%97%E5%8F%B7)第一时间阅读和催更(**公众号比博客早一到两天哟**),[**GitHub**](https://github.com/AobingJava/JavaFamily)上已经开源[https://github.com/Java...](https://github.com/AobingJava/JavaFamily),有面试点思维导图,欢迎[**Star**](https://github.com/AobingJava/JavaFamily)和[**完善**](https://github.com/AobingJava/JavaFamily)里面也有我个人微信有什么问题也可以直接滴滴我,我们一起进步。

================================================
FILE: docs/redis/分布式锁、并发竞争、双写一致性.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
## 前言
**Redis**在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在**Redis**的使用和原理方面对小伙伴们进行360°的刁难。作为一个在互联网公司面一次拿一次offer的面霸(**请允许我使用一下夸张的修辞手法**),打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚,在一个寂寞难耐的夜晚,我痛定思痛,决定开始写**《吊打面试官》**系列,希望能帮助各位读者以后面试势如破竹,对面试官进行360°的反击,吊打问你的面试官,让一同面试的同僚瞠目结舌,疯狂收割大厂offer!
## 絮叨
**男儿何不带吴钩,收取关山五十州 FPX 🐂B,LPL两年连冠🏆 🐂B!**
看着金色的雨落下,我到窗边,发现天有点蓝,风有点绵,我的眼角又湿了!

最近双十一讲道理有点忙的说,直接肝爆,就是这样作为**暖男**的我,还是给你们挤出时间搞出终章,忍不住给自己**点赞**👍
放个双十一照片证明真的忙,希望别取关!!!

现在你们在看的时候,我应该还在睡觉哈哈。困🛌
之前跟你们说的,**限流**,**降级**,是不是在双十一又应验了,下单接口其实没挂,牺牲部分用户体验,保住服务器,你多点几下是可以成功的,等流量高峰过去了,所有的用户全部都恢复正常访问,服务器也没啥事。

去年退款接口被打崩了,今年阿里明显也聪明了很多。

## 正文
上几期吊打系列我们提到了Redis的很多知识,还没看的小伙伴可以回顾一下
- **[《吊打面试官》系列-Redis基础](https://juejin.im/post/5db66ed9e51d452a2f15d833)**
- **[《吊打面试官》系列-缓存雪崩、击穿、穿透](https://juejin.im/post/5dbef8306fb9a0203f6fa3e2)**
- **[《吊打面试官》系列-Redis哨兵、持久化、主从、手撕LRU](https://juejin.im/post/5dc3a9fbf265da4d3c072eab)**
那提到**Redis**我相信各位在面试,或者实际开发过程中对基本类型的使用场景,并发竞争带来的问题,以及缓存数据库双写入一致性的问题等,我们有请下一位受害者。
## 面试开始
> 一个大腹便便,穿着格子衬衣的中年男子,拿着一个满是划痕的mac向你走来,看着快秃顶的头发,心想着肯定是尼玛顶级架构师吧!但是我们腹有诗书气自华,虚都不虚。(这不是第一篇文章的面试官么?)

### 小伙子,你还记得我在第一章里面问过你,Redis有几种基础数据类型么?
嗯嗯,帅气的面试官,我肯定记得,没齿难忘!!!
我特么谢谢你,都四面了还不给Offer!

### 那你能说一下他们的特性,还有分别的使用场景么?
行吧,那我先从String说起。
**String:**
这是最简单的类型,就是普通的 set 和 get,做简单的 KV 缓存。
但是真实的开发环境中,很多仔可能会把很多比较复杂的结构也统一转成**String**去存储使用,比如有的仔他就喜欢把对象或者**List**转换为**JSONString**进行存储,拿出来再反序列话啥的。
我在这里就不讨论这样做的对错了,但是我还是希望大家能在最合适的场景使用最合适的数据结构,对象找不到最合适的但是类型可以选最合适的嘛,之后别人接手你的代码一看这么**规范**,诶这小伙子**有点东西**呀,看到你啥都是用的**String**,**垃圾!**

好了这些都是题外话了,道理还是希望大家记在心里,习惯成自然嘛,小习惯成就你。
**String**的实际应用场景比较广泛的有:
- **缓存功能:String**字符串是最常用的数据类型,不仅仅是**Redis**,各个语言都是最基本类型,因此,利用**Redis**作为缓存,配合其它数据库作为存储层,利用**Redis**支持高并发的特点,可以大大加快系统的读写速度、以及降低后端数据库的压力。
- **计数器:**许多系统都会使用**Redis**作为系统的实时计数器,可以快速实现计数和查询的功能。而且最终的数据结果可以按照特定的时间落地到数据库或者其它存储介质当中进行永久保存。
- **共享用户Session:**用户重新刷新一次界面,可能需要访问一下数据进行重新登录,或者访问页面缓存**Cookie**,但是可以利用**Redis**将用户的**Session**集中管理,在这种模式只需要保证**Redis**的高可用,每次用户**Session**的更新和获取都可以快速完成。大大提高效率。
**Hash:**
这个是类似 **Map** 的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是**这个对象没嵌套其他的对象**)给缓存在 **Redis** 里,然后每次读写缓存的时候,可以就操作 **Hash** 里的**某个字段**。
但是这个的场景其实还是多少单一了一些,因为现在很多对象都是比较复杂的,比如你的商品对象可能里面就包含了很多属性,其中也有对象。我自己使用的场景用得不是那么多。
**List:**
**List** 是有序列表,这个还是可以玩儿出很多花样的。
比如可以通过 **List** 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的东西。
比如可以通过 **lrange** 命令,读取某个闭区间内的元素,可以基于 **List** 实现分页查询,这个是很棒的一个功能,基于 **Redis** 实现简单的高性能分页,可以做类似微博那种下拉不断分页的东西,性能高,就一页一页走。
比如可以搞个简单的消息队列,从 **List** 头怼进去,从 **List** 屁股那里弄出来。
**List**本身就是我们在开发过程中比较常用的数据结构了,热点数据更不用说了。
- **消息队列:Redis**的链表结构,可以轻松实现阻塞队列,可以使用左进右出的命令组成来完成队列的设计。比如:数据的生产者可以通过**Lpush**命令从左边插入数据,多个数据消费者,可以使用**BRpop**命令阻塞的“抢”列表尾部的数据。
- 文章列表或者数据分页展示的应用。
比如,我们常用的博客网站的文章列表,当用户量越来越多时,而且每一个用户都有自己的文章列表,而且当文章多时,都需要分页展示,这时可以考虑使用**Redis**的列表,列表不但有序同时还支持按照范围内获取元素,可以完美解决分页查询功能。大大提高查询效率。
**Set:**
**Set** 是无序集合,会自动去重的那种。
直接基于 **Set** 将系统里需要去重的数据扔进去,自动就给去重了,如果你需要对一些数据进行快速的全局去重,你当然也可以基于 **JVM** 内存里的 **HashSet** 进行去重,但是如果你的某个系统部署在多台机器上呢?得基于**Redis**进行全局的 **Set** 去重。
可以基于 **Set** 玩儿交集、并集、差集的操作,比如交集吧,我们可以把两个人的好友列表整一个交集,看看俩人的共同好友是谁?对吧。
反正这些场景比较多,因为对比很快,操作也简单,两个查询一个**Set**搞定。
**Sorted Set:**
**Sorted set** 是排序的 **Set**,去重但可以排序,写进去的时候给一个分数,自动根据分数排序。
有序集合的使用场景与集合类似,但是set集合不是自动有序的,而**Sorted set**可以利用分数进行成员间的排序,而且是插入时就排序好。所以当你需要一个有序且不重复的集合列表时,就可以选择**Sorted set**数据结构作为选择方案。
- 排行榜:有序集合经典使用场景。例如视频网站需要对用户上传的视频做排行榜,榜单维护可能是多方面:按照时间、按照播放量、按照获得的赞数等。
- 用**Sorted Sets**来做带权重的队列,比如普通消息的score为1,重要消息的score为2,然后工作线程可以选择按score的倒序来获取工作任务。让重要的任务优先执行。
微博热搜榜,就是有个后面的热度值,前面就是名称

## 小结
**Redis**基础类型有五种,这个我在基础里面也有提到了,这个问题其实一般都是对P6以下,也就是1-3年左右的小伙伴可能是会问得比较多的问题。
能回答出来五种我想大家都可以,但是不知道大家是否知道,五种类型具体的使用场景,以及什么时候用什么类型最合适呢?
要是你回答的不好,没说出几种数据类型,也没说什么场景,你完了,面试官对你印象肯定不好,觉得你平时就是做个简单的 set 和 get。所以看似很简单的面试题实则最容易看出你的深浅了,大家都要注意**打好基础**。
###你有没有考虑过,如果你多个系统同时操作(并发)Redis带来的数据问题?
嗯嗯这个问题我以前开发的时候遇到过,其实并发过程中确实会有这样的问题,比如下面这样的情况

系统A、B、C三个系统,分别去操作**Redis**的同一个Key,本来顺序是1,2,3是正常的,但是因为系统A网络突然抖动了一下,B,C在他前面操作了**Redis**,这样数据不就错了么。
就好比下单,支付,退款三个顺序你变了,你先退款,再下单,再支付,那流程就会失败,那数据不就乱了?你订单还没生成你却支付,退款了?明显走不通了,这在线上是很恐怖的事情。
### 那这种情况怎么解决呢?
我们可以找个管家帮我们管理好数据的嘛!

某个时刻,多个系统实例都去更新某个 key。可以基于 **Zookeeper** 实现分布式锁。每个系统通过 **Zookeeper** 获取分布式锁,确保同一时间,只能有一个系统实例在操作某个 Key,别人都不允许读和写。
你要写入缓存的数据,都是从 **MySQL** 里查出来的,都得写入 **MySQL** 中,写入 **MySQL** 中的时候必须保存一个时间戳,从 **MySQL** 查出来的时候,时间戳也查出来。
每次要**写之前,先判断**一下当前这个 Value 的时间戳是否比缓存里的 Value 的时间戳要新。如果是的话,那么可以写,否则,就不能用旧的数据覆盖新的数据。
### 你只要用缓存,就可能会涉及到缓存与数据库双存储双写,你只要是双写,就一定会有数据一致性的问题,那么你如何解决一致性问题?
一般来说,如果允许缓存可以稍微的跟数据库偶尔有不一致的情况,也就是说如果你的系统**不是严格要求** “缓存+数据库” 必须保持一致性的话,最好不要做这个方案,即:**读请求和写请求串行化**,串到一个**内存队列**里去。
串行化可以保证一定不会出现不一致的情况,但是它也会导致系统的吞吐量大幅度降低,用比正常情况下多几倍的机器去支撑线上的一个请求。
把一些列的操作都放到队列里面,顺序肯定不会乱,但是并发高了,这队列很容易阻塞,反而会成为整个系统的弱点,瓶颈

### 你了解最经典的KV、DB读写模式么?
最经典的缓存+数据库读写的模式,就是 **Cache Aside Pattern**
- 读的时候,先读缓存,缓存没有的话,就读数据库,然后取出数据后放入缓存,同时返回响应。
- 更新的时候,**先更新数据库,然后再删除缓存**。
###为什么是删除缓存,而不是更新缓存?
原因很简单,很多时候,在复杂点的缓存场景,缓存不单单是数据库中直接取出来的值。
比如可能更新了某个表的一个字段,然后其对应的缓存,是需要查询另外两个表的数据并进行运算,才能计算出缓存最新的值的。
另外更新缓存的代价有时候是很高的。是不是说,每次修改数据库的时候,都一定要将其对应的缓存更新一份?也许有的场景是这样,但是对于**比较复杂的缓存数据计算的场景**,就不是这样了。如果你频繁修改一个缓存涉及的多个表,缓存也频繁更新。但是问题在于,**这个缓存到底会不会被频繁访问到?**
举个栗子:一个缓存涉及的表的字段,在 1 分钟内就修改了 20 次,或者是 100 次,那么缓存更新 20 次、100 次;但是这个缓存在 1 分钟内只被读取了 1 次,有**大量的冷数据**。
实际上,如果你只是删除缓存的话,那么在 1 分钟内,这个缓存不过就重新计算一次而已,开销大幅度降低。**用到缓存才去算缓存。**
其实删除缓存,而不是更新缓存,就是一个 Lazy 计算的思想,不要每次都重新做复杂的计算,不管它会不会用到,而是让它到需要被使用的时候再重新计算。
像 **Mybatis**,**Hibernate**,都有懒加载思想。查询一个部门,部门带了一个员工的 **List**,没有必要说每次查询部门,都里面的 1000 个员工的数据也同时查出来啊。80% 的情况,查这个部门,就只是要访问这个部门的信息就可以了。先查部门,同时要访问里面的员工,那么这个时候只有在你要访问里面的员工的时候,才会去数据库里面查询 1000 个员工。
###Redis 和 Memcached 有啥区别,为啥选择用Redis作为你们的缓存中间件?
**Redis** 支持复杂的数据结构:
**Redis** 相比 **Memcached** 来说,拥有更多的数据结构,能支持更丰富的数据操作。如果需要缓存能够支持更复杂的结构和操作, **Redis** 会是不错的选择。
**Redis** 原生支持集群模式:
在 redis3.x 版本中,便能支持 **Cluster** 模式,而 **Memcached** 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据。
性能对比:
由于 **Redis** 只使用单核,而 **Memcached** 可以使用多核,所以平均每一个核上 **Redis** 在存储小数据时比 **Memcached** 性能更高。而在 100k 以上的数据中,**Memcached** 性能要高于 **Redis**,虽然 **Redis** 最近也在存储大数据的性能上进行优化,但是比起 **Remcached**,还是稍有逊色。
Tip:其实面试官这么问,是想看你知道为啥用这个技术栈么?你为啥选这个技术栈,你是否做过技术选型的对比,优缺点你是否了解,你啥都不知道,只是为了用而用,那你可能就**差点意思**了。
### Redis 的线程模型了解么?
**Redis** 内部使用文件事件处理器 `file event handler`,这个文件事件处理器是单线程的,所以 **Redis** 才叫做单线程的模型。它采用 IO 多路复用机制同时监听多个 **Socket**,根据 **Socket** 上的事件来选择对应的事件处理器进行处理。
文件事件处理器的结构包含 4 个部分:
- 多个 **Socket**
- IO 多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
多个 **Socket** 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO 多路复用程序会监听多个 **Socket**,会将 **Socket** 产生的事件放入队列中排队,事件分派器每次从队列中取出一个事件,把该事件交给对应的事件处理器进行处理。
## 面试结束
### 小伙子对你面试了四轮,你说话有理有据,逻辑清晰,来公司后肯定是一把好手,我想要不你来当我的Leader吧,哈哈?
面试官别跟我开玩笑了,我跟您这样日积月累的技术专家还是有很多差距的,您的经验和技术上的深度,没有很长时间的磨练是无法达到的,我还得多跟您学习。
### 好的,小伙子有点东西,你年少有为不自卑,知道什么是珍贵,就是你了来上班吧。
好的面试官,不过我想我在Java基础,MQ,Dubbo等等领域还有好多知识点您没问我,要不下次继续面我?
强行,为吊打下一期埋伏笔哈哈,下期写啥你们定!!!
能撑到最后,你自己都忍不住自己给自己点个赞了!
(**暗示点赞,每次都看了不点赞,你们想白嫖我么?你们好坏喲,不过我喜欢**)。
----
**《吊打面试官》Redis系列 ---- 全剧终**
----
## 总结
既然都说了是**Redis**的终章我最后也做个**Redis**方面常见面试题,题目的总结,答案大家要去思考我前面的文章基本上都提到了,结果可以去我公众号回复【答案】获取,不过我还是希望大家能看到题目就能想到答案,并且记在心中,教大家怎么回答只是帮大家组织下语言,真正的场景解决方案还是要大家理解的。
(周三以后出答案,我先睡会)
- 0、在集群模式下,Redis 的 Key 是如何寻址的?分布式寻址都有哪些算法?了解一致性 Hash 算法吗?
- 1、使用Redis有哪些好处?
- 2、Redis相比Memcached有哪些优势?
- 3、Redis常见性能问题和解决方案
- 4、MySQL里有2000w数据,Redis中只存20w的数据,如何保证Redis中的数据都是热点数据?
- 5、Memcache与Redis的区别都有哪些?
- 6、Redis 常见的性能问题都有哪些?如何解决?
- 7、在什么样的场景下可以充分的利用Redis的特性,大大提高Redis的效率?
- 8、Redis的缓存雪崩、穿透、击穿了解么?有什么异同点?分别怎么解决?
- 9、Redis的基本类型有哪些?他们的使用场景了解么?比较高级的用法你使用过么?
- 10、Redis主从怎么同步数据的?集群的高可用怎么保证?持久化机制了解么?
- 11、为什么 redis 单线程却能支撑高并发?
- 12、如何保证缓存和数据库数据的一致性?
- 13、项目中是怎么用缓存的,用了缓存之后会带来什么问题?
## 絮叨+
最后我想说的就是,我这四章只是介绍到了一些**Redis**面试比较常见的问题,其实还有很多点我都没回答到,大家如果为了对付面试**可能**是够用了,但是我们技术人员还是要保持对技术的**敬畏心**,你不能**浅尝即止**,还是要深究的。
你永远只会用,不去考虑用了会带来的问题,以及出现问题之后的解决方案,我觉得你大概率会**停滞不前**,既然入都入了这行了,为啥不武装一下自己。
其实学习技术是个**反哺**的过程,学习的时候可能你只是感觉知识广度、深度上去了,一个知识点你这样,两个、三个知识点你都这样,最后你发现你的技术已经跟身边一样P6的仔不一样了,这样你可能在团队重大项目的贡献都上去了,那P7的晋升几率是不是大了,钱是不是上去了,女朋友是不是好看了,房子是不是大了。
## End
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**,我后面会每周都更新几篇《**吊打面试官**》系列和**Java技术栈**相关的文章。如果你有什么想知道的,也可以留言给我,或者去公众号加我微信,我一有时间就会写出来,我们共同进步。
非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得**「敖丙」**我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** **求留言💬** 对暖男我来说**非常有用**。
各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】
------
> **《吊打面试官》**系列每周持续更新,可以关注我的公众号「 **JavaFamily** 」第时间阅读和催更(公众号比博客早一到两天哟),里面也有我个人微信有什么问题也可以直接滴滴我,我也是个新人,不过不影响我们一起进步,作为渣男,我给不了你幸福,还给不了你温暖嘛?

================================================
FILE: docs/redis/布隆过滤器(BloomFilter).md
================================================
避免缓存击穿的利器之BloomFilter
# Bloom Filter 概念
布隆过滤器(英语:Bloom Filter)是1970年由一个叫布隆的小伙子提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
***面试关联:一般都会在回答缓存穿透,或者海量数据去重这个时候引出来,加分项哟***
# Bloom Filter 原理
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
Bloom Filter跟单哈希函数Bit-Map不同之处在于:Bloom Filter使用了k个哈希函数,每个字符串跟k个bit对应。从而降低了冲突的概率。

简单的说一下就是我们先把我们数据库的数据都加载到我们的过滤器中,比如数据库的id现在有:1、2、3
那就用id:1 为例子他在上图中经过三次hash之后,把三次原本值0的地方改为1
下次我进来查询如果id也是1 那我就把1拿去三次hash 发现跟上面的三个位置完全一样,那就能证明过滤器中有1的
反之如果不一样就说明不存在了
那应用的场景在哪里呢?一般我们都会用来防止缓存击穿(如果不知道缓存击穿是啥的小伙伴不要着急,我已经帮你准备好了,传送门 ↓ )
简单来说就是你数据库的id都是1开始然后自增的,那我知道你接口是通过id查询的,我就拿负数去查询,这个时候,会发现缓存里面没这个数据,我又去数据库查也没有,一个请求这样,100个,1000个,10000个呢?你的DB基本上就扛不住了,如果在缓存里面加上这个,是不是就不存在了,你判断没这个数据就不去查了,直接return一个数据为空不就好了嘛。
这玩意这么好使那有啥缺点么?有的,我们接着往下看
# Bloom Filter的缺点
bloom filter之所以能做到在时间和空间上的效率比较高,是因为牺牲了判断的准确率、删除的便利性
- 存在误判,可能要查到的元素并没有在容器中,但是hash之后得到的k个位置上值都是1。如果bloom filter中存储的是黑名单,那么可以通过建立一个白名单来存储可能会误判的元素。
- 删除困难。一个放入容器的元素映射到bit数组的k个位置上是1,删除的时候不能简单的直接置为0,可能会影响其他元素的判断。可以采用[Counting Bloom Filter](http://wiki.corp.qunar.com/confluence/download/attachments/199003276/US9740797.pdf?version=1&modificationDate=1526538500000&api=v2)
# Bloom Filter 实现
布隆过滤器有许多实现与优化,Guava中就提供了一种Bloom Filter的实现。
在使用bloom filter时,绕不过的两点是预估数据量n以及期望的误判率fpp,
在实现bloom filter时,绕不过的两点就是hash函数的选取以及bit数组的大小。
对于一个确定的场景,我们预估要存的数据量为n,期望的误判率为fpp,然后需要计算我们需要的Bit数组的大小m,以及hash函数的个数k,并选择hash函数
## (1)Bit数组大小选择
根据预估数据量n以及误判率fpp,bit数组大小的m的计算方式:
## (2)哈希函数选择
由预估数据量n以及bit数组长度m,可以得到一个hash函数的个数k:
哈希函数的选择对性能的影响应该是很大的,一个好的哈希函数要能近似等概率的将字符串映射到各个Bit。选择k个不同的哈希函数比较麻烦,一种简单的方法是选择一个哈希函数,然后送入k个不同的参数。
哈希函数个数k、位数组大小m、加入的字符串数量n的关系可以参考[Bloom Filters - the math](http://pages.cs.wisc.edu/~cao/papers/summary-cache/node8.html),[Bloom_filter-wikipedia](https://en.wikipedia.org/wiki/Bloom_filter)
要使用BloomFilter,需要引入guava包:
```java
#### 超卖:
但凡是个秒杀,都怕**超卖**,我这里举例的只是尿不湿,要是换成100个华为MatePro30,商家的预算经费卖100个可以赚点还可以造势,结果你写错程序多卖出去200个,你不发货用户**投诉你**,平台**封你店**,你发货就**血亏**,你怎么办?
(没事看了敖丙的文章直接不怕)
那最后只能**杀个开发祭天**解气了,秒杀的价格本来就低了,基本上都是不怎么赚钱的,超卖了就恐怖了呀,所以超卖也是很关键的一个点。

#### 恶意请求:
你这么低的价格,假如我抢到了,我转手卖掉我不是**血赚**?就算我不卖我也不亏啊,那用户知道,你知道,别的别有用心的人(黑客、黄牛...)肯定也知道的。
那简单啊,我知道你什么时候抢,我搞个几十台机器搞点脚本,我也模拟出来十几万个人左右的请求,那我是不是意味着我基本上有80%的成功率了。
真实情况可能远远不止,因为机器请求的速度比人的手速往往快太多了,在贵州的敖丙我每年回家抢高铁票都是**秒光**的,我也不知道有没有黄牛的功劳,我要Diss你,黄牛。杰伦演唱会门票抢不到,我也Diss你。
Tip:科普下,小道消息了解到的,黄牛的抢票系统,比国内很多小公司的系统还吊很多,架构设计都是顶级的,我用**顶配的服务**加上**顶配的架构设计**,你还想看演唱会?还想回家?
不过不用黄牛我回家都难,我们云贵川跟我一样要回家过年的仔太多了555!
#### 链接暴露:
前面几个问题大家可能都很好理解,一看到这个有的小伙伴可能会比较疑惑,啥是**链接暴露**呀?
 相信是个开发同学都对这个画面一点都不陌生吧,懂点行的仔都可以打开谷歌的**开发者模式**,然后看看你的网页代码,有的就有URL,但是我写VUE的时候是事件触发然后去调用文件里面的接口看源码看不到,但是我可以点击一下**查看你的请求地址**啊,不过你好像可以对按钮在秒杀前置灰。
不管怎么样子都有危险,撇开外面的所有的东西你都挡住了,你卖这个东西实在便宜得过分,有诱惑力,你能保证**开发不动心**?开发知道地址,在秒杀的时候自己提前请求。。。(开发:怎么TM又是我)

#### 数据库:
每秒上万甚至十几万的**QPS**(每秒请求数)直接打到**数据库**,基本上都要把库打挂掉,而且你服务不单单是做秒杀的还涉及其他的业务,你没做**降级、限流、熔断**啥的,别的一起挂,小公司的话可能**全站崩溃404**。
反正不管你秒杀怎么挂,你别把别的搞挂了对吧,搞挂了就不是杀一个程序员能搞定的。
程序员:我TM好难啊!
### 问题都列出来了,那怎么设计,怎么解决这些问题就是接下去要考虑的了,我们对症下药。
#### 服务单一职责:
设计个能抗住高并发的系统,我觉得还是得**单一职责**。
什么意思呢,大家都知道现在设计都是**微服务的设计思想**,然后再用**分布式的部署方式**
也就是我们下单是有个订单服务,用户登录管理等有个用户服务等等,那为啥我们不给秒杀也开个服务,我们把秒杀的代码业务逻辑放一起。
单独给他建立一个数据库,现在的互联网架构部署都是**分库**的,一样的就是订单服务对应订单库,秒杀我们也给他建立自己的秒杀库。
至于表就看大家怎么设计了,该设置索引的地方还是要设置索引的,建完后记得用**explain**看看**SQL**的执行计划。(不了解的小伙伴也没事,MySQL章节我会说的)
单一职责的好处就是就算秒杀没抗住,秒杀库崩了,服务挂了,也不会影响到其他的服务。(强行高可用)
#### 秒杀链接加盐:
我们上面说了链接要是提前暴露出去可能有人直接访问url就提前秒杀了,那又有小伙伴要说了我做个时间的校验就好了呀,那我告诉你,知道链接的地址比起页面人工点击的还是有**很大优势**。
我知道url了,那我通过程序不断获取最新的北京时间,可以达到**毫秒级别**的,我就在00毫秒的时候请求,我敢说绝对比你人工点的成功率大太多了,而且我可以一毫秒发送N次请求,搞不好你卖100个产品我全拿了。
相信是个开发同学都对这个画面一点都不陌生吧,懂点行的仔都可以打开谷歌的**开发者模式**,然后看看你的网页代码,有的就有URL,但是我写VUE的时候是事件触发然后去调用文件里面的接口看源码看不到,但是我可以点击一下**查看你的请求地址**啊,不过你好像可以对按钮在秒杀前置灰。
不管怎么样子都有危险,撇开外面的所有的东西你都挡住了,你卖这个东西实在便宜得过分,有诱惑力,你能保证**开发不动心**?开发知道地址,在秒杀的时候自己提前请求。。。(开发:怎么TM又是我)

#### 数据库:
每秒上万甚至十几万的**QPS**(每秒请求数)直接打到**数据库**,基本上都要把库打挂掉,而且你服务不单单是做秒杀的还涉及其他的业务,你没做**降级、限流、熔断**啥的,别的一起挂,小公司的话可能**全站崩溃404**。
反正不管你秒杀怎么挂,你别把别的搞挂了对吧,搞挂了就不是杀一个程序员能搞定的。
程序员:我TM好难啊!
### 问题都列出来了,那怎么设计,怎么解决这些问题就是接下去要考虑的了,我们对症下药。
#### 服务单一职责:
设计个能抗住高并发的系统,我觉得还是得**单一职责**。
什么意思呢,大家都知道现在设计都是**微服务的设计思想**,然后再用**分布式的部署方式**
也就是我们下单是有个订单服务,用户登录管理等有个用户服务等等,那为啥我们不给秒杀也开个服务,我们把秒杀的代码业务逻辑放一起。
单独给他建立一个数据库,现在的互联网架构部署都是**分库**的,一样的就是订单服务对应订单库,秒杀我们也给他建立自己的秒杀库。
至于表就看大家怎么设计了,该设置索引的地方还是要设置索引的,建完后记得用**explain**看看**SQL**的执行计划。(不了解的小伙伴也没事,MySQL章节我会说的)
单一职责的好处就是就算秒杀没抗住,秒杀库崩了,服务挂了,也不会影响到其他的服务。(强行高可用)
#### 秒杀链接加盐:
我们上面说了链接要是提前暴露出去可能有人直接访问url就提前秒杀了,那又有小伙伴要说了我做个时间的校验就好了呀,那我告诉你,知道链接的地址比起页面人工点击的还是有**很大优势**。
我知道url了,那我通过程序不断获取最新的北京时间,可以达到**毫秒级别**的,我就在00毫秒的时候请求,我敢说绝对比你人工点的成功率大太多了,而且我可以一毫秒发送N次请求,搞不好你卖100个产品我全拿了。
 **那这种情况怎么避免?**
简单,把**URL动态化**,就连写代码的人都不知道,你就通过MD5之类的加密算法加密随机的字符串去做url,然后通过前端代码获取url后台校验才能通过。
暖男我呢,又准备了一个简单的url加密给大家尝尝鲜,还不**点个赞**?
**那这种情况怎么避免?**
简单,把**URL动态化**,就连写代码的人都不知道,你就通过MD5之类的加密算法加密随机的字符串去做url,然后通过前端代码获取url后台校验才能通过。
暖男我呢,又准备了一个简单的url加密给大家尝尝鲜,还不**点个赞**?
#### Redis集群:
之前不是说单机的**Redis**顶不住嘛,那简单多找几个兄弟啊,秒杀本来就是读多写少,那你们是不是瞬间想起来我之前跟你们提到过的,**Redis集群**,**主从同步**、**读写分离**,我们还搞点**哨兵**,开启**持久化**直接无敌高可用!
 #### Nginx:
**Nginx**大家想必都不陌生了吧,这玩意是**高性能的web服务器**,并发也随便顶几万不是梦,但是我们的**Tomcat**只能顶几百的并发呀,那简单呀**负载均衡**嘛,一台服务几百,那就多搞点,在秒杀的时候多租点**流量机**。
Tip:据我所知国内某大厂就是在去年春节活动期间租光了亚洲所有的服务器,小公司也很喜欢在双十一期间买流量机来顶住压力。
#### Nginx:
**Nginx**大家想必都不陌生了吧,这玩意是**高性能的web服务器**,并发也随便顶几万不是梦,但是我们的**Tomcat**只能顶几百的并发呀,那简单呀**负载均衡**嘛,一台服务几百,那就多搞点,在秒杀的时候多租点**流量机**。
Tip:据我所知国内某大厂就是在去年春节活动期间租光了亚洲所有的服务器,小公司也很喜欢在双十一期间买流量机来顶住压力。
 **这样一对比是不是觉得你的集群能顶很多了。**
**恶意请求拦截**也需要用到它,一般单个用户请求次数太夸张,不像人为的请求在网关那一层就得拦截掉了,不然请求多了他抢不抢得到是一回事,服务器压力上去了,可能占用网络带宽或者把**服务器打崩、缓存击穿**等等。
#### 资源静态化:
秒杀一般都是特定的商品还有页面模板,现在一般都是前后端分离的,所以页面一般都是不会经过后端的,但是前端也要自己的服务器啊,那就把能提前放入**cdn服务器**的东西都放进去,反正把所有能提升效率的步骤都做一下,减少真正秒杀时候服务器的压力。
#### 按钮控制:
大家有没有发现没到秒杀前,一般按钮都是**置灰**的,只有时间到了,才能点击。
这是因为怕大家在时间快到的最后几秒秒疯狂请求服务器,然后还没到秒杀的时候基本上服务器就挂了。
这个时候就需要前端的配合,定时去请求你的后端服务器,获取最新的北京时间,到时间点再给按钮可用状态。
按钮可以点击之后也得给他置灰几秒,不然他一样在开始之后一直点的。**你敢说你们秒杀的时候不是这样的?**
#### 限流:
限流这里我觉得应该分为**前端限流**和**后端限流**。
**前端限流**:这个很简单,一般秒杀不会让你一直点的,一般都是点击一下或者两下然后几秒之后才可以继续点击,这也是保护服务器的一种手段。
**后端限流**:秒杀的时候肯定是涉及到后续的订单生成和支付等操作,但是都只是成功的幸运儿才会走到那一步,那一旦100个产品卖光了,return了一个false,前端直接秒杀结束,然后你后端也关闭后续无效请求的介入了。
Tip:真正的限流还会有限流组件的加入例如:阿里的Sentinel、Hystrix等。我这里就不展开了,就说一下物理的限流。
#### 库存预热:
**秒杀的本质,就是对库存的抢夺**,每个秒杀的用户来你都去数据库查询库存校验库存,然后扣减库存,撇开性能因数,你不觉得这样好繁琐,对业务开发人员都不友好,而且数据库顶不住啊。
**开发:你tm总算为我着想一次了。**

#### 那怎么办?
我们都知道数据库顶不住但是他的兄弟非关系型的数据库**Redis**能顶啊!
那不简单了,我们要开始秒杀前你通过定时任务或者运维同学**提前把商品的库存加载到Redis中**去,让整个流程都在Redis里面去做,然后等秒杀介绍了,再异步的去修改库存就好了。
但是用了Redis就有一个问题了,我们上面说了我们采用**主从**,就是我们会去读取库存然后再判断然后有库存才去减库存,正常情况没问题,但是高并发的情况问题就很大了。
这里我就不画图了,我本来想画图的,想了半天我觉得语言可能更好表达一点。
**多品几遍!!!**就比如现在库存只剩下1个了,我们高并发嘛,4个服务器一起查询了发现都是还有1个,那大家都觉得是自己抢到了,就都去扣库存,那结果就变成了-3,是的只有一个是真的抢到了,别的都是超卖的。咋办?
### Lua:
之前的文章就简单的提到了他,我今天就多一定点篇幅说一下吧。
> **Lua** 脚本功能是 Reids在 2.6 版本的最大亮点, 通过内嵌对 Lua 环境的支持, Redis 解决了长久以来不能高效地处理 **CAS** (check-and-set)命令的缺点, 并且可以通过组合使用多个命令, 轻松实现以前很难实现或者不能高效实现的模式。
**Lua脚本是类似Redis事务,有一定的原子性,不会被其他命令插队,可以完成一些Redis事务性的操作。**这点是关键。
知道原理了,我们就写一个脚本把判断库存扣减库存的操作都写在一个脚本丢给Redis去做,那到0了后面的都Return False了是吧,一个失败了你修改一个开关,直接挡住所有的请求,然后再做后面的事情嘛。
#### 限流&降级&熔断&隔离:
这个为啥要做呢,不怕一万就怕万一,万一你真的顶不住了,**限流**,顶不住就挡一部分出去但是不能说不行,**降级**,降级了还是被打挂了,**熔断**,至少不要影响别的系统,**隔离**,你本身就独立的,但是你会调用其他的系统嘛,你快不行了你别拖累兄弟们啊。

#### 削峰填谷:
一说到这个名词,很多小伙伴就知道了,对的**MQ**,你买东西少了你直接100个请求改库我觉得没问题,但是万一秒杀一万个,10万个呢?服务器挂了,**程序员又要背锅的**。
Tip:**可能小伙伴说我们业务达不到这个量级,没必要。但是我想说我们写代码,就不应该写出有逻辑漏洞的代码,至少以后公司体量上去了,别人一看居然不用改代码,一看代码作者是敖丙?有点东西!**
你可以把它放消息队列,然后一点点消费去改库存就好了嘛,不过单个商品其实一次修改就够了,我这里说的是**某个点多个商品**一起秒杀的场景,像极了双十一零点。
## 总结
到这里我想我已经基本上把该考虑的点还有对应的解决方案也都说了一下,不知道还有没有没考虑到的,但是就算没考虑到我想我这个设计,应该也能撑住一个完整的秒杀流程。
(有大佬的话给敖丙点多的思路,去GitHub [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 上给我提,也有我的联系)
最后我就画个完整的流程图给大家收个尾吧!

Tip:这个链路还是比较简单的,很多细节的点全部画出来就太复杂了,我上面已经提到了所有的注意点了,大家都看看,真正的秒杀有比我这个简单的,也有比我这个复杂N倍的,之前的电商老东家就做的很高级,有机会也可以跟你们探讨,不过是面试嘛,我就给思路,让你理解比较关键的点。
秒杀这章我脑细胞死了很多,考虑了很多个点,最后还是出来了,忍不住给自己**点赞**!
(**这章是真的不要白嫖,每次都看了不点赞,你们想白嫖我么?你们好坏喲,不过我好喜欢**)
## 总结
我们玩归玩,闹归闹,别拿面试开玩笑。
秒杀不一定是每个同学都会问到的,至少肯定没**Redis基础**那样常问,但是一旦问到,大家一定要回答到点上。
至少你得说出**可能出现的情况**,**需要注意的情况**,以及对于的**解决思路和方案**。
最后就是需要对整个链路比较熟悉,注意是一个完整的链路,前端怎么设计的呀,网关的作用呀,怎么**解决Redis的并发竞争**啊,**数据的同步方式**呀,**MQ的作用**啊。
(提到MQ又是一整条的知识链路,什么异步、削峰、解耦等等,所以面试,我们还是不打没有把握的胜仗)
### 流着泪说再见
**Redis系列**到此是真的要跟大家说再见了,写了7篇文章,其实很多大佬的思路和片段真心赞,其实大家看出来了我的文章个人风格色彩特别浓厚,我个人在生活中就是这么说话的,也希望用这种风格把原本枯燥乏味的知识点让大家都像看小说一样津津有味的看下去,不知道大家什么感受,好的不好的都请给我留言。
我这个系列的我会写到我**GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 图中所有的知识点,以后就麻烦大家多多关照了,我写作的时间都是业余时间,基本上周末和晚上的时间都贡献出来了,我也是个新人很多点也没接触到,也要看书看资料才能写出来,所以有时候还是希望大家多多包涵。
那我们下期见!
下期写________________?
不告诉你,哈哈!
## 日常求赞
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇《吊打面试官》系列和互联网常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】 如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 《吊打面试官》系列每周持续更新,可以关注我的公众号「**JavaFamily**」第一时间阅读和催更(公众号比博客早一到两篇哟),本文**GitHub**上已经收录[https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily),有一线大厂面试点思维导图,欢迎Star和完善,里面也有我个人联系方式有什么问题也可以直接找我,也有人才交流群,我们一起有点东西。

================================================
FILE: docs/redis/缓存击穿、雪崩、穿透.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
## 前言
**Redis**在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在**Redis**的使用和原理方面对小伙伴们进行360°的刁难。作为一个在互联网公司面一次拿一次offer的面霸(**请允许我使用一下夸张的修辞手法**),打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚,在一个寂寞难耐的夜晚,我痛定思痛,决定开始写**《吊打面试官》**系列,希望能帮助各位读者以后面试势如破竹,对面试官进行360°的反击,吊打问你的面试官,让一同面试的同僚瞠目结舌,疯狂收割大厂offer!
## 一点感慨
本来都把稿子放到公众号保存了,洗澡的时候想了一下晚上的比赛,觉得还是打开电脑写点东西,跟文章内容没关系,只是一点个人的感慨,不知道多少小伙伴看了昨天**SKT VS G2**的比赛,又不知道多少小伙伴还记得**Faker**手抖的那一幕。

不知道你们看了是什么感受,我看到他手抖的时候我内心也抖了,世界赛我支持的都是**LPL**的队伍,但是我喜欢李哥这个人,那种对胜利的执著,这么多年了那种坚持自己的坚持,这么多利益诱惑在面前却只想要胜利,这样的人我好喜欢啊,我想很多人也喜欢。

可能就像很多网友说的那样,英雄迟暮,但是我觉得他还是有点东西,就像很多人说我们程序员只能吃年轻饭一样,但是如果你坚持自己的坚持,做个腹有诗书气自华的仔,我想最后肯定会得到自己的得到。
好了我也不煽情了,我们开始讲技术吧。
## 正文
上一期吊打系列我们提到了Redis的基础知识,还没看的小伙伴可以回顾一下
[《吊打面试官》系列-Redis基础](https://juejin.im/post/5db66ed9e51d452a2f15d833)
那提到**Redis**我相信各位在面试,或者实际开发过程中对缓存**雪崩**,**穿透**,**击穿**也不陌生吧,就算没遇到过但是你肯定听过,那三者到底有什么区别,我们又应该怎么去防止这样的情况发生呢,我们有请下一位受害者。
## 面试开始
> 一个大腹便便,穿着格子衬衣的中年男子,拿着一个满是划痕的mac向你走来,看着快秃顶的头发,心想着肯定是尼玛顶级架构师吧!但是我们腹有诗书气自华,虚都不虚。

### 小伙子我看你的简历上写到了Redis,那么我们直接开门见山,直接怼常见的几个大问题,Redis雪崩了解么?
帅气迷人的面试官您好,我了解的,目前电商首页以及热点数据都会去做缓存 ,一般缓存都是定时任务去刷新,或者是查不到之后去更新的,定时任务刷新就有一个问题。
**举个简单的例子**:如果所有首页的Key失效时间都是12小时,中午12点刷新的,我零点有个秒杀活动大量用户涌入,假设当时每秒 6000 个请求,本来缓存在可以扛住每秒 5000 个请求,但是缓存当时所有的Key都失效了。此时 1 秒 6000 个请求全部落数据库,数据库必然扛不住,它会报一下警,真实情况可能DBA都没反应过来就直接挂了。此时,如果没用什么特别的方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被新的流量给打死了。这就是我理解的缓存雪崩。
**我刻意看了下我做过的项目感觉再吊的都不允许这么大的QPS直接打DB去,不过没慢SQL加上分库,大表分表可能还还算能顶,但是跟用了Redis的差距还是很大**

**同一时间大面积失效,那一瞬间Redis跟没有一样,那这个数量级别的请求直接打到数据库几乎是灾难性的,你想想如果打挂的是一个用户服务的库,那其他依赖他的库所有的接口几乎都会报错,如果没做熔断等策略基本上就是瞬间挂一片的节奏,你怎么重启用户都会把你打挂,等你能重启的时候,用户早就睡觉去了,并且对你的产品失去了信心,什么垃圾产品。**
### 面试官摸了摸自己的头发,嗯还不错,那这种情况咋整?你都是怎么去应对的?
处理缓存雪崩简单,在批量往**Redis**存数据的时候,把每个Key的失效时间都加个随机值就好了,这样可以保证数据不会在同一时间大面积失效,我相信,Redis这点流量还是顶得住的。
```java
setRedis(Key,value,time + Math.random() * 10000);
```
如果**Redis**是集群部署,将热点数据均匀分布在不同的**Redis**库中也能避免全部失效的问题,不过本渣我在生产环境中操作集群的时候,单个服务都是对应的单个**Redis**分片,是为了方便数据的管理,但是也同样有了可能会失效这样的弊端,失效时间随机是个好策略。
或者设置热点数据永远不过期,有更新操作就更新缓存就好了(比如运维更新了首页商品,那你刷下缓存就完事了,不要设置过期时间),电商首页的数据也可以用这个操作,保险。
### 那你了解缓存穿透和击穿么,可以说说他们跟雪崩的区别么?
嗯,了解,我先说一下缓存穿透吧,缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,我们数据库的 id 都是1开始自增上去的,如发起为id值为 -1 的数据或 id 为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大,严重会击垮数据库。
**小点的单机系统,基本上用postman就能搞死,比如我自己买的阿里云服务**

**像这种你如果不对参数做校验,数据库id都是大于0的,我一直用小于0的参数去请求你,每次都能绕开Redis直接打到数据库,数据库也查不到,每次都这样,并发高点就容易崩掉了。**
至于**缓存击穿**嘛,这个跟**缓存雪崩**有点像,但是又有一点不一样,缓存雪崩是因为大面积的缓存失效,打崩了DB,而缓存击穿不同的是**缓存击穿**是指一个Key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个完好无损的桶上凿开了一个洞。

### 面试官露出欣慰的眼光,那他们分别怎么解决
**缓存穿透**我会在接口层增加校验,比如用户鉴权校验,参数做校验,不合法的参数直接代码Return,比如:id 做基础校验,id <=0的直接拦截等。
**这里我想提的一点就是,我们在开发程序的时候都要有一颗“不信任”的心,就是不要相信任何调用方,比如你提供了API接口出去,你有这几个参数,那我觉得作为被调用方,任何可能的参数情况都应该被考虑到,做校验,因为你不相信调用你的人,你不知道他会传什么参数给你。**
**举个简单的例子,你这个接口是分页查询的,但是你没对分页参数的大小做限制,调用的人万一一口气查 Integer.MAX_VALUE 一次请求就要你几秒,多几个并发你不就挂了么?是公司同事调用还好大不了发现了改掉,但是如果是黑客或者竞争对手呢?在你双十一当天就调你这个接口会发生什么,就不用我说了吧。这是之前的Leader跟我说的,我觉得大家也都应该了解下。**
从缓存取不到的数据,在数据库中也没有取到,这时也可以将对应Key的Value对写为null、位置错误、稍后重试这样的值具体取啥问产品,或者看具体的场景,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。
这样可以防止攻击用户反复用同一个id暴力攻击,但是我们要知道正常用户是不会在单秒内发起这么多次请求的,那网关层**Nginx**本渣我也记得有配置项,可以让运维大大对单个IP每秒访问次数超出阈值的IP都拉黑。
### 那你还有别的办法么?
还有我记得**Redis**还有一个高级用法**布隆过滤器(Bloom Filter)**这个也能很好的防止缓存穿透的发生,他的原理也很简单就是利用高效的数据结构和算法快速判断出你这个Key是否在数据库中存在,不存在你return就好了,存在你就去查了DB刷新KV再return。
那又有小伙伴说了如果黑客有很多个IP同时发起攻击呢?这点我一直也不是很想得通,但是一般级别的黑客没这么多肉鸡,再者正常级别的**Redis**集群都能抗住这种级别的访问的,小公司我想他们不会感兴趣的。把系统的高可用做好了,集群还是很能顶的。
**缓存击穿**的话,设置热点数据永远不过期。或者加上互斥锁就能搞定了
**作为暖男,代码我肯定帮你们准备好了**

##面试结束
### 嗯嗯还不错,三个点都回答得很好,今天也不早了,面试就先到这里,明天你再过来二面我继续问一下你关于Redis集群高可用,主从同步,哨兵等知识点的问题。
晕居然还有下一轮面试!(强行下一期的伏笔哈哈)但是为了offer还是得舔,嗯嗯,好的帅气面试官。
能回答得这么全面这么细节还是忍不住点赞
(**暗示点赞,每次都看了不点赞,你们想白嫖我么?你们好坏喲,不过我喜欢**)
## 总结
我们玩归玩,闹归闹,别拿面试开玩笑。
本文简单的介绍了,**Redis**的**雪崩**,**击穿**,**穿透**,三者其实都差不多,但是又有一些区别,在面试中其实这是问到缓存必问的,大家不要把三者搞混了,因为缓存雪崩、穿透和击穿,是缓存最大的问题,要么不出现,一旦出现就是致命性的问题,所以面试官一定会问你。
大家一定要理解是**怎么发生的**,以及是怎么去**避免**的,发生之后又怎么去**抢救**,你可以不是知道很深入,但是你不能一点都不去想,面试有时候不一定是对知识面的拷问,或许是对你的态度的拷问,如果你思路清晰,然后**知其然还知其所以然**那就很赞,还知道怎么预防那来上班吧。
### 最后暖男我继续给你们做个小的技术总结:
一般避免以上情况发生我们从三个时间段去分析下:
- 事前:**Redis** 高可用,主从+哨兵,**Redis cluster**,避免全盘崩溃。
- 事中:本地 **ehcache** 缓存 + **Hystrix** 限流+降级,避免** MySQL** 被打死。
- 事后:**Redis** 持久化 **RDB**+**AOF**,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
上面的几点我会在吊打系列Redis篇全部讲一下这个月应该可以吧Redis更完,限流组件,可以设置每秒的请求,有多少能通过组件,剩余的未通过的请求,怎么办?**走降级**!可以返回一些默认的值,或者友情提示,或者空白的值。
**好处:**
数据库绝对不会死,限流组件确保了每秒只有多少个请求能通过。 只要数据库不死,就是说,对用户来说,3/5 的请求都是可以被处理的。 只要有 3/5 的请求可以被处理,就意味着你的系统没死,对用户来说,可能就是点击几次刷不出来页面,但是多点几次,就可以刷出来一次。
**这个在目前主流的互联网大厂里面是最常见的,你是不是好奇,某明星爆出什么事情,你发现你去微博怎么刷都空白界面,但是有的人又直接进了,你多刷几次也出来了,现在知道了吧,那是做了降级,牺牲部分用户的体验换来服务器的安全,可还行?**
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**,我后面会每周都更新几篇《**吊打面试官**》系列和Java技术栈相关的文章。如果你有什么想知道的,也可以留言给我,我一有时间就会写出来,我们共同进步。
非常感谢**靓仔/靓女**您能看到这里,如果这个文章写得还不错的话 **求点赞** **求关注** **求分享** **求留言** **(对我非常有用)**各位的支持和认可,就是我创作的最大动力,我们下篇文章见,拜了个拜!
敖丙 | 文 【原创】
------
> 每周都会持续更新《吊打面试官》系列可以关注我的公众号第一时间阅读和催更,也可以在公众号回复【人才】加入人才交流群一起讨论面试题,就业和工作上有什么问题也可以直接滴滴我,我也是个新人,不过不影响我们一起进步,作为渣男,我给不了你工作,还给不了你温暖嘛?

================================================
FILE: docs/redis/课代表总结.md
================================================
>
>
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> **GitHub**上已经开源 [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 有一线大厂面试点脑图、个人联系方式和人才交流群,欢迎Star和指教
## 絮叨
本来是没这期的,按道理更新也应该是在周一更新**消息队列**的幂等,分布式事务相关的文章,但是这篇**暖男**我**实在忍不住了**,不是发自己的文章,是帮**课代表**发一下,她本科是**北京交通大学**,也是**电子科技大学**的研究生。
**她**看了我的系列,做了个**笔记**📒,我一看,**偶买噶 !**。
**这是什么仙女啊**,这是我**第一次**有这种感觉,这笔记有着前**所未有的新鲜感**,细节的勾勒,让整个笔记更显出**奥妙.**...有些**不太成熟的话语**,跟我文章的**骚气**十分搭配,将**Redis**的性能衬托的更为出色,这才呈现出完美的**课代表笔记**。
这也是我第一次看到看个渣男的文章都做笔记的,这笔记让我有了初恋的味道,这我以后可得好好写了,不然**辜负**了**课代表这样认真的妹子**,到时候到杭州来找我:敖丙你个**渣男**乱写,害我没拿Offer! **我要杀了你**!
我也不多BB了不影响大家食用了,**课代表**说了以后我写的**其他技术栈的笔记**一样会贡献出来,代价就是要嫁给我,呸呸呸,代价就是我以后帮他介绍大厂朋友内推下,看看简历呀,解答下职场问题啊什么的。(根本就是举手之劳啊,我血赚?)
我一听我不能忍啊,我**气得拍桌子**,不行你以后不懂的知识点我包了,我也不懂的咳咳我看完书再包?
哈哈开玩笑的,总之**课代表的精神**大家包括我都应该好好学学,这种人活该她拿**SSP**的Offer。
**Tip**:SSP (Special Offer 优秀生源Offer渠道 )

能总结得这么全面连我都忍不住**点赞**了!
## 总结
里面很多细节的点还是需要完善的,课代表最近上课很忙帅丙我呢除了周末也没时间,不过会不断完善到GIt的,大家也可以去公众号回复「**课代表**」获取思维导图原稿。
其实我真的很欣赏课代表这样的精神的,她这样的举动**触动了我**,想想自己大学时候的样子,我忍不住给了自己两嘴巴子,我但凡有课代表一半的努力都不至于沦落到今天这样,等我冷静下来,走到了窗边,眺望头上若影若现的月亮,**我的眼角又湿了**!
## 花絮
人才群里的人才真的都是**人才**,一周两更**高产似母猪**了我都,还天天**催更**不过我也认了,**课代表**进去差点把人家吓走,**这么好的课代表**吓走了我哪里找第二个?
**GitHub**上有我联系方式和入群方式 [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily)


## 日常求赞
这期本来不想求赞的,但是我一想是**课代表**写的大家是给她赞,不是给我赞呀。
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇《吊打面试官》系列和互联网常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「课代表」**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙&**课代表** | 文 【原创】【转载请联系本人】 如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 《吊打面试官》系列每周持续更新,可以关注我的公众号「 **JavaFamily** 」第一时间阅读和催更(公众号比博客早一到两篇哟),本文**GitHub**上已经收录[https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily),有一线大厂面试点思维导图,欢迎Star和完善,里面也有我个人联系方式有什么问题也可以直接找我,也有人才交流群,我们一起有点东西。

================================================
FILE: docs/redis/集群高可用、哨兵、持久化、LRU.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
## 前言
**Redis**在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在**Redis**的使用和原理方面对小伙伴们进行360°的刁难。作为一个在互联网公司面一次拿一次offer的面霸(**请允许我使用一下夸张的修辞手法**),打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚,在一个寂寞难耐的夜晚,我痛定思痛,决定开始写**《吊打面试官》**系列,希望能帮助各位读者以后面试势如破竹,对面试官进行360°的反击,吊打问你的面试官,让一同面试的同僚瞠目结舌,疯狂收割大厂**Offer**!
## 絮叨
写这期其实比较纠结,我之前的写的比较通俗易懂,一是我都知道这些点,二是之前我在所在的电商公司对雪崩,击穿啥的还算有场景去接触。但是线上的Redis集群我实际操作经验很少,总不能在公司线上环境实践那些操作吧,所以最后看了下官网,还有一些资料(文章后面我都会贴出来),强行怼了这么篇出来。
最近双十一小忙,周末双十一值班目测没时间写,那我是暖男呀,我不能鸽啊,就有了这一篇,下一篇迟到你们不要喷我哈,而且下一篇还是**Redis**的终章还是得构思下,不熟悉的知识点我怕漏洞多,特意让以前的大牛同事看了下,所以有啥不对的地方大家及时留言**Diss**我,写这篇是真的难,诺下面就是我本人某天凌晨两点的拍的视频,多动症的仔。

之前说过系列第二篇到300赞我就发第三篇


咋样没骗你们吧,就很枯竭,不BB了,开搞。
**不点个赞对不起我,这次不要白嫖我!**
----
##正文
上几期**《吊打面试官》**还没看的小伙伴可以回顾一下(明明就写了两期说的好像很多一样)!
- [《吊打面试官》系列-Redis基础](https://juejin.im/post/5db66ed9e51d452a2f15d833)
- [《吊打面试官》系列-缓存雪崩、击穿、穿透](https://juejin.im/post/5dbef8306fb9a0203f6fa3e2)
大家都知道一个技术的引入方便了开发,解决了各种问题,但是也会带来对应的问题,**技术是把双刃剑**嘛,集群的引入也会带来很多问题,如:集群的高可用怎么保证,数据怎么同步等等,我们话不多说,有请下一位受害者为我们展示。
### 面试开始
> 三个大腹便便,穿着格子衬衣的中年男子,拿着三个满是划痕的mac向你走来,看着快秃顶的头发,心想着肯定是尼玛顶级架构师吧!而且还是三个,但是还好我看过敖丙写的《吊打面试官》系列,腹有诗书气自华,根本虚都不虚好伐。

#### 小伙子你好,之前问过了你基础知识以及一些缓存的常见几个大问题了,那你能跟我聊聊为啥Redis那么快么?
哦,帅气迷人的面试官您好,我们可以先看一下关系型数据库跟Redis本质上的区别。

**Redis**采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,由C语言编写,官方提供的数据是可以达到100000+的**QPS(每秒内查询次数)**。
- 完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。它的,数据存在内存中,类似于**HashMap**,**HashMap**的优势就是查找和操作的时间复杂度都是O(1);
- 数据结构简单,对数据操作也简单,**Redis**中的数据结构是专门进行设计的;
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 **CPU**,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
- 使用多路I/O复用模型,非阻塞IO;
- 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,**Redis**直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
### 我可以问一下啥是上下文切换么?
我可以打个比方么:我记得有过一个小伙伴微信问过我上下文切换是啥,为啥可能会线程不安全,我是这么说的,就好比你看一本英文书,你看到第十页发现有个单词不会读,你加了个书签,然后去查字典,过了一会你又回来继续从书签那里读,ok到目前为止没啥问题。
如果是你一个人读肯定没啥问题,但是你去查的时候,别的小伙伴好奇你在看啥他就翻了一下你的书,然后溜了,哦豁,你再看的时候就发现书不是你看的那一页了。不知道到这里为止我有没有解释清楚,以及为啥会线程不安全,就是因为你一个人怎么看都没事,但是人多了换来换去的操作一本书数据就乱了。可能我的解释很粗糙,但是道理应该是一样的。
### 那他是单线程的,我们现在服务器都是多核的,那不是很浪费?
是的他是单线程的,但是,我们可以通过在单机开多个**Redis实例**嘛。
### 既然提到了单机会有瓶颈,那你们是怎么解决这个瓶颈的?
我们用到了集群的部署方式也就是**Redis cluster**,并且是主从同步读写分离,类似**Mysql**的主从同步,**Redis cluster** 支撑 N 个 **Redis master node**,每个**master node**都可以挂载多个 **slave node**。
这样整个 **Redis** 就可以横向扩容了。如果你要支撑更大数据量的缓存,那就横向扩容更多的 **master** 节点,每个 **master** 节点就能存放更多的数据了。
### 哦?那问题就来了,他们之间是怎么进行数据交互的?以及Redis是怎么进行持久化的?Redis数据都在内存中,一断电或者重启不就木有了嘛?
是的,持久化的话是**Redis**高可用中比较重要的一个环节,因为**Redis**数据在内存的特性,持久化必须得有,我了解到的持久化是有两种方式的。
- RDB:**RDB** 持久化机制,是对 **Redis** 中的数据执行**周期性**的持久化。
- AOF:**AOF** 机制对每条写入命令作为日志,以 **append-only** 的模式写入一个日志文件中,因为这个模式是只追加的方式,所以没有任何磁盘寻址的开销,所以很快,有点像Mysql中的**binlog**。
两种方式都可以把**Redis**内存中的数据持久化到磁盘上,然后再将这些数据备份到别的地方去,**RDB**更适合做**冷备**,**AOF**更适合做**热备**,比如我杭州的某电商公司有这两个数据,我备份一份到我杭州的节点,再备份一个到上海的,就算发生无法避免的自然灾害,也不会两个地方都一起挂吧,这**灾备**也就是**异地容灾**,地球毁灭他没办法。
**tip:两种机制全部开启的时候,Redis在重启的时候会默认使用AOF去重新构建数据,因为AOF的数据是比RDB更完整的。**
### 那这两种机制各自优缺点是啥?
我先说**RDB**吧
#### 优点:
他会生成多个数据文件,每个数据文件分别都代表了某一时刻**Redis**里面的数据,这种方式,有没有觉得很适合做**冷备**,完整的数据运维设置定时任务,定时同步到远端的服务器,比如阿里的云服务,这样一旦线上挂了,你想恢复多少分钟之前的数据,就去远端拷贝一份之前的数据就好了。
**RDB**对**Redis**的性能影响非常小,是因为在同步数据的时候他只是**fork**了一个子进程去做持久化的,而且他在数据恢复的时候速度比**AOF**来的快。
#### 缺点:
**RDB**都是快照文件,都是默认五分钟甚至更久的时间才会生成一次,这意味着你这次同步到下次同步这中间五分钟的数据都很可能全部丢失掉。**AOF**则最多丢一秒的数据,**数据完整性**上高下立判。
还有就是**RDB**在生成数据快照的时候,如果文件很大,客户端可能会暂停几毫秒甚至几秒,你公司在做秒杀的时候他刚好在这个时候**fork**了一个子进程去生成一个大快照,哦豁,出大问题。
我们再来说说**AOF**
####优点:
上面提到了,**RDB**五分钟一次生成快照,但是**AOF**是一秒一次去通过一个后台的线程`fsync`操作,那最多丢这一秒的数据。
**AOF**在对日志文件进行操作的时候是以`append-only`的方式去写的,他只是追加的方式写数据,自然就少了很多磁盘寻址的开销了,写入性能惊人,文件也不容易破损。
**AOF**的日志是通过一个叫**非常可读**的方式记录的,这样的特性就适合做**灾难性数据误删除**的紧急恢复了,比如公司的实习生通过**flushall**清空了所有的数据,只要这个时候后台重写还没发生,你马上拷贝一份**AOF**日志文件,把最后一条**flushall**命令删了就完事了。
**tip:我说的命令你们别真去线上系统操作啊,想试去自己买的服务器上装个Redis试,别到时候来说,敖丙真是个渣男,害我把服务器搞崩了,Redis官网上的命令都去看看,不要乱试!!!**
####缺点:
一样的数据,**AOF**文件比**RDB**还要大。
**AOF**开启后,**Redis**支持写的**QPS**会比**RDB**支持写的要低,他不是每秒都要去异步刷新一次日志嘛**fsync**,当然即使这样性能还是很高,我记得**ElasticSearch**也是这样的,异步刷新缓存区的数据去持久化,为啥这么做呢,不直接来一条怼一条呢,那我会告诉你这样性能可能低到没办法用的,大家可以思考下为啥哟。
###那两者怎么选择?

小孩子才做选择,**我全都要**,你单独用**RDB**你会丢失很多数据,你单独用**AOF**,你数据恢复没**RDB**来的快,真出什么时候第一时间用**RDB**恢复,然后**AOF**做数据补全,真香!冷备热备一起上,才是互联网时代一个高健壮性系统的王道。
### 看不出来年纪轻轻有点东西的呀,对了我听你提到了高可用,Redis还有其他保证集群高可用的方式么?
!!!晕 自己给自己埋个坑(其实是明早就准备好了,故意抛出这个词等他问,就怕他不问)。
假装思考一会(**不要太久,免得以为你真的不会**),哦我想起来了,还有哨兵集群**sentinel**。
哨兵必须用三个实例去保证自己的健壮性的,哨兵+主从并**不能保证数据不丢失**,但是可以保证集群的**高可用**。
为啥必须要三个实例呢?我们先看看两个哨兵会咋样。

master宕机了 s1和s2两个哨兵只要有一个认为你宕机了就切换了,并且会选举出一个哨兵去执行故障,但是这个时候也需要大多数哨兵都是运行的。
那这样有啥问题呢?M1宕机了,S1没挂那其实是OK的,但是整个机器都挂了呢?哨兵就只剩下S2个裸屌了,没有哨兵去允许故障转移了,虽然另外一个机器上还有R1,但是故障转移就是不执行。
经典的哨兵集群是这样的:

M1所在的机器挂了,哨兵还有两个,两个人一看他不是挂了嘛,那我们就选举一个出来执行故障转移不就好了。
暖男我,小的总结下哨兵组件的主要功能:
- 集群监控:负责监控 Redis master 和 slave 进程是否正常工作。
- 消息通知:如果某个 **Redis** 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
- 故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
- 配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
### 我记得你还提到了主从同步,能说一下主从之间的数据怎么同步的么?
面试官您的记性可真是一级棒呢,我都要忘了你还记得,我特么谢谢你,提到这个,就跟我前面提到的数据持久化的**RDB**和**AOF**有着比密切的关系了。
我先说下为啥要用主从这样的架构模式,前面提到了单机**QPS**是有上限的,而且**Redis**的特性就是必须支撑读高并发的,那你一台机器又读又写,**这谁顶得住啊**,不当人啊!但是你让这个master机器去写,数据同步给别的slave机器,他们都拿去读,分发掉大量的请求那是不是好很多,而且扩容的时候还可以轻松实现水平扩容。

**回归正题,他们数据怎么同步的呢?**
你启动一台slave 的时候,他会发送一个**psync**命令给master ,如果是这个slave第一次连接到master,他会触发一个全量复制。master就会启动一个线程,生成**RDB**快照,还会把新的写请求都缓存在内存中,**RDB**文件生成后,master会将这个**RDB**发送给slave的,slave拿到之后做的第一件事情就是写进本地的磁盘,然后加载进内存,然后master会把内存里面缓存的那些新命名都发给slave。
###数据传输的时候断网了或者服务器挂了怎么办啊?
传输过程中有什么网络问题啥的,会自动重连的,并且连接之后会把缺少的数据补上的。
**大家需要记得的就是,RDB快照的数据生成的时候,缓存区也必须同时开始接受新请求,不然你旧的数据过去了,你在同步期间的增量数据咋办?是吧?**
### 那说了这么多你能说一下他的内存淘汰机制么,来手写一下LRU代码?

#### 手写LRU?你是不是想直接跳起来说一句:Are U F**k Kidding me?
这个问题是我在蚂蚁金服三面的时候亲身被问过的问题,不知道大家有没有被怼到过这个问题。
**Redis**的过期策略,是有**定期删除+惰性删除**两种。
定期好理解,默认100s就随机抽一些设置了过期时间的key,去检查是否过期,过期了就删了。
### 为啥不扫描全部设置了过期时间的key呢?
假如Redis里面所有的key都有过期时间,都扫描一遍?那太恐怖了,而且我们线上基本上也都是会设置一定的过期时间的。全扫描跟你去查数据库不带where条件不走索引全表扫描一样,100s一次,Redis累都累死了。
###如果一直没随机到很多key,里面不就存在大量的无效key了?
好问题,**惰性删除**,见名知意,惰性嘛,我不主动删,我懒,我等你来查询了我看看你过期没,过期就删了还不给你返回,没过期该怎么样就怎么样。
### 最后就是如果的如果,定期没删,我也没查询,那可咋整?
**内存淘汰机制**!
官网上给到的内存淘汰机制是以下几个:
- **noeviction**:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
- **allkeys-lru**: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
- **volatile-lru**: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
- **allkeys-random**: 回收随机的键使得新添加的数据有空间存放。
- **volatile-random**: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
- **volatile-ttl**: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
如果没有键满足回收的前提条件的话,策略**volatile-lru**, **volatile-random**以及**volatile-ttl**就和noeviction 差不多了。
至于**LRU**我也简单提一下,手写实在是太长了,大家可以去**Redis官网**看看,我把**近视LUR**效果给大家看看
**tip:Redis为什么不使用真实的LRU实现是因为这需要太多的内存。不过近似的LRU算法对于应用而言应该是等价的。使用真实的LRU算法与近似的算法可以通过下面的图像对比。**

你可以看到三种点在图片中, 形成了三种带.
- 浅灰色带是已经被回收的对象。
- 灰色带是没有被回收的对象。
- 绿色带是被添加的对象。
- 在**LRU**实现的理论中,我们希望的是,在旧键中的第一半将会过期。**Redis**的**LRU**算法则是概率的过期旧的键。
你可以看到,在都是五个采样的时候Redis 3.0比Redis 2.8要好,Redis2.8中在最后一次访问之间的大多数的对象依然保留着。使用10个采样大小的Redis 3.0的近似值已经非常接近理论的性能。
注意LRU只是个预测键将如何被访问的模型。另外,如果你的数据访问模式非常接近幂定律,大部分的访问将集中在一个键的集合中,LRU的近似算法将处理得很好。
其实在大家熟悉的**LinkedHashMap**中也实现了Lru算法的,实现如下:

当容量超过100时,开始执行**LRU**策略:将最近最少未使用的 **TimeoutInfoHolder** 对象 **evict** 掉。
真实面试中会让你写LUR算法,你可别搞原始的那个,那真TM多,写不完的,你要么怼上面这个,要么怼下面这个,找一个数据结构实现下Java版本的LRU还是比较容易的,知道啥原理就好了。

## 面试结束
### 小伙子,你确实有点东西,HRBP会联系你的,请务必保持你的手机畅通好么?
好的谢谢面试官,面试官真好,我还想再面几次,噗此。
能回答得这么全面这么细节还是忍不住点赞
**(暗示点赞,每次都看了不点赞,你们想白嫖我么?你们好坏喲,不过我好喜欢)**
## 总结
好了,我们玩归玩,闹归闹,别拿面试开玩笑,我这么写是为了节目效果,大家面试请认真对待。
这一期是这期没前面好理解了对吧,我就在自己的服务器上启动了,然后再去官网看看命令一顿瞎操作的,查阅了部分资料,这里给大家推荐几本经典的Redis入门的书籍和我参考的资料。
- [Redis中文官网](http://www.redis.cn/)
- 《Redis入门指南(第2版)》
- 《Redis实战》
- 《Redis设计与实现》
- 《[大型网站技术架构](https://github.com/doocs/technical-books#architecture)——李智慧》
- 《[Redis 设计与实现](https://github.com/doocs/technical-books#database)——黄健宏》
- 《[Redis 深度历险](https://github.com/doocs/technical-books#database)——钱文品》
- 《[亿级流量网站架构核心技术](https://github.com/doocs/technical-books#architecture)——张开涛》
- 《[中华石杉](https://github.com/doocs/advanced-java)——石杉》
不出意外的话这是Redis的倒数第二期,最后一期不知道写啥还没想好,我得好好想想,加上最近不是双十一嘛得加加班,**你看看开头的我,多可怜,那还不点个赞?买个服务器**?不确定下一期多久出,想早点看到更新的小伙伴可以去公众号**催更**,公众号提前一到两天更新。
### END
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**,我后面会每周都更新几篇《**吊打面试官**》系列和**Java技术栈**相关的文章。如果你有什么想知道的,也可以**留言**给我,我一有时间就会写出来,我们共同进步。
非常感谢**靓仔/靓女**您能看到这里,如果这个文章写得还不错,觉得敖丙有点东西 **求点赞** **求关注** **求分享** **求留言** **(对我非常有用)**各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】
------
> 每周都会持续更新《吊打面试官》系列可以关注我的公众号第一时间阅读和催更,公众号比博客提前一到两天更新,也可以在公众号回复【人才】加入人才交流群,里面都是人才长得好看说话还好听,进去就像回家了一样,就业和工作上有什么问题也可以直接滴滴我,我也是个新人,不过不影响我们一起进步。

**这样一对比是不是觉得你的集群能顶很多了。**
**恶意请求拦截**也需要用到它,一般单个用户请求次数太夸张,不像人为的请求在网关那一层就得拦截掉了,不然请求多了他抢不抢得到是一回事,服务器压力上去了,可能占用网络带宽或者把**服务器打崩、缓存击穿**等等。
#### 资源静态化:
秒杀一般都是特定的商品还有页面模板,现在一般都是前后端分离的,所以页面一般都是不会经过后端的,但是前端也要自己的服务器啊,那就把能提前放入**cdn服务器**的东西都放进去,反正把所有能提升效率的步骤都做一下,减少真正秒杀时候服务器的压力。
#### 按钮控制:
大家有没有发现没到秒杀前,一般按钮都是**置灰**的,只有时间到了,才能点击。
这是因为怕大家在时间快到的最后几秒秒疯狂请求服务器,然后还没到秒杀的时候基本上服务器就挂了。
这个时候就需要前端的配合,定时去请求你的后端服务器,获取最新的北京时间,到时间点再给按钮可用状态。
按钮可以点击之后也得给他置灰几秒,不然他一样在开始之后一直点的。**你敢说你们秒杀的时候不是这样的?**
#### 限流:
限流这里我觉得应该分为**前端限流**和**后端限流**。
**前端限流**:这个很简单,一般秒杀不会让你一直点的,一般都是点击一下或者两下然后几秒之后才可以继续点击,这也是保护服务器的一种手段。
**后端限流**:秒杀的时候肯定是涉及到后续的订单生成和支付等操作,但是都只是成功的幸运儿才会走到那一步,那一旦100个产品卖光了,return了一个false,前端直接秒杀结束,然后你后端也关闭后续无效请求的介入了。
Tip:真正的限流还会有限流组件的加入例如:阿里的Sentinel、Hystrix等。我这里就不展开了,就说一下物理的限流。
#### 库存预热:
**秒杀的本质,就是对库存的抢夺**,每个秒杀的用户来你都去数据库查询库存校验库存,然后扣减库存,撇开性能因数,你不觉得这样好繁琐,对业务开发人员都不友好,而且数据库顶不住啊。
**开发:你tm总算为我着想一次了。**

#### 那怎么办?
我们都知道数据库顶不住但是他的兄弟非关系型的数据库**Redis**能顶啊!
那不简单了,我们要开始秒杀前你通过定时任务或者运维同学**提前把商品的库存加载到Redis中**去,让整个流程都在Redis里面去做,然后等秒杀介绍了,再异步的去修改库存就好了。
但是用了Redis就有一个问题了,我们上面说了我们采用**主从**,就是我们会去读取库存然后再判断然后有库存才去减库存,正常情况没问题,但是高并发的情况问题就很大了。
这里我就不画图了,我本来想画图的,想了半天我觉得语言可能更好表达一点。
**多品几遍!!!**就比如现在库存只剩下1个了,我们高并发嘛,4个服务器一起查询了发现都是还有1个,那大家都觉得是自己抢到了,就都去扣库存,那结果就变成了-3,是的只有一个是真的抢到了,别的都是超卖的。咋办?
### Lua:
之前的文章就简单的提到了他,我今天就多一定点篇幅说一下吧。
> **Lua** 脚本功能是 Reids在 2.6 版本的最大亮点, 通过内嵌对 Lua 环境的支持, Redis 解决了长久以来不能高效地处理 **CAS** (check-and-set)命令的缺点, 并且可以通过组合使用多个命令, 轻松实现以前很难实现或者不能高效实现的模式。
**Lua脚本是类似Redis事务,有一定的原子性,不会被其他命令插队,可以完成一些Redis事务性的操作。**这点是关键。
知道原理了,我们就写一个脚本把判断库存扣减库存的操作都写在一个脚本丢给Redis去做,那到0了后面的都Return False了是吧,一个失败了你修改一个开关,直接挡住所有的请求,然后再做后面的事情嘛。
#### 限流&降级&熔断&隔离:
这个为啥要做呢,不怕一万就怕万一,万一你真的顶不住了,**限流**,顶不住就挡一部分出去但是不能说不行,**降级**,降级了还是被打挂了,**熔断**,至少不要影响别的系统,**隔离**,你本身就独立的,但是你会调用其他的系统嘛,你快不行了你别拖累兄弟们啊。

#### 削峰填谷:
一说到这个名词,很多小伙伴就知道了,对的**MQ**,你买东西少了你直接100个请求改库我觉得没问题,但是万一秒杀一万个,10万个呢?服务器挂了,**程序员又要背锅的**。
Tip:**可能小伙伴说我们业务达不到这个量级,没必要。但是我想说我们写代码,就不应该写出有逻辑漏洞的代码,至少以后公司体量上去了,别人一看居然不用改代码,一看代码作者是敖丙?有点东西!**
你可以把它放消息队列,然后一点点消费去改库存就好了嘛,不过单个商品其实一次修改就够了,我这里说的是**某个点多个商品**一起秒杀的场景,像极了双十一零点。
## 总结
到这里我想我已经基本上把该考虑的点还有对应的解决方案也都说了一下,不知道还有没有没考虑到的,但是就算没考虑到我想我这个设计,应该也能撑住一个完整的秒杀流程。
(有大佬的话给敖丙点多的思路,去GitHub [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 上给我提,也有我的联系)
最后我就画个完整的流程图给大家收个尾吧!

Tip:这个链路还是比较简单的,很多细节的点全部画出来就太复杂了,我上面已经提到了所有的注意点了,大家都看看,真正的秒杀有比我这个简单的,也有比我这个复杂N倍的,之前的电商老东家就做的很高级,有机会也可以跟你们探讨,不过是面试嘛,我就给思路,让你理解比较关键的点。
秒杀这章我脑细胞死了很多,考虑了很多个点,最后还是出来了,忍不住给自己**点赞**!
(**这章是真的不要白嫖,每次都看了不点赞,你们想白嫖我么?你们好坏喲,不过我好喜欢**)
## 总结
我们玩归玩,闹归闹,别拿面试开玩笑。
秒杀不一定是每个同学都会问到的,至少肯定没**Redis基础**那样常问,但是一旦问到,大家一定要回答到点上。
至少你得说出**可能出现的情况**,**需要注意的情况**,以及对于的**解决思路和方案**。
最后就是需要对整个链路比较熟悉,注意是一个完整的链路,前端怎么设计的呀,网关的作用呀,怎么**解决Redis的并发竞争**啊,**数据的同步方式**呀,**MQ的作用**啊。
(提到MQ又是一整条的知识链路,什么异步、削峰、解耦等等,所以面试,我们还是不打没有把握的胜仗)
### 流着泪说再见
**Redis系列**到此是真的要跟大家说再见了,写了7篇文章,其实很多大佬的思路和片段真心赞,其实大家看出来了我的文章个人风格色彩特别浓厚,我个人在生活中就是这么说话的,也希望用这种风格把原本枯燥乏味的知识点让大家都像看小说一样津津有味的看下去,不知道大家什么感受,好的不好的都请给我留言。
我这个系列的我会写到我**GitHub** [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 图中所有的知识点,以后就麻烦大家多多关照了,我写作的时间都是业余时间,基本上周末和晚上的时间都贡献出来了,我也是个新人很多点也没接触到,也要看书看资料才能写出来,所以有时候还是希望大家多多包涵。
那我们下期见!
下期写________________?
不告诉你,哈哈!
## 日常求赞
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇《吊打面试官》系列和互联网常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「敖丙」我**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】【转载请联系本人】 如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 《吊打面试官》系列每周持续更新,可以关注我的公众号「**JavaFamily**」第一时间阅读和催更(公众号比博客早一到两篇哟),本文**GitHub**上已经收录[https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily),有一线大厂面试点思维导图,欢迎Star和完善,里面也有我个人联系方式有什么问题也可以直接找我,也有人才交流群,我们一起有点东西。

================================================
FILE: docs/redis/缓存击穿、雪崩、穿透.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
## 前言
**Redis**在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在**Redis**的使用和原理方面对小伙伴们进行360°的刁难。作为一个在互联网公司面一次拿一次offer的面霸(**请允许我使用一下夸张的修辞手法**),打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚,在一个寂寞难耐的夜晚,我痛定思痛,决定开始写**《吊打面试官》**系列,希望能帮助各位读者以后面试势如破竹,对面试官进行360°的反击,吊打问你的面试官,让一同面试的同僚瞠目结舌,疯狂收割大厂offer!
## 一点感慨
本来都把稿子放到公众号保存了,洗澡的时候想了一下晚上的比赛,觉得还是打开电脑写点东西,跟文章内容没关系,只是一点个人的感慨,不知道多少小伙伴看了昨天**SKT VS G2**的比赛,又不知道多少小伙伴还记得**Faker**手抖的那一幕。

不知道你们看了是什么感受,我看到他手抖的时候我内心也抖了,世界赛我支持的都是**LPL**的队伍,但是我喜欢李哥这个人,那种对胜利的执著,这么多年了那种坚持自己的坚持,这么多利益诱惑在面前却只想要胜利,这样的人我好喜欢啊,我想很多人也喜欢。

可能就像很多网友说的那样,英雄迟暮,但是我觉得他还是有点东西,就像很多人说我们程序员只能吃年轻饭一样,但是如果你坚持自己的坚持,做个腹有诗书气自华的仔,我想最后肯定会得到自己的得到。
好了我也不煽情了,我们开始讲技术吧。
## 正文
上一期吊打系列我们提到了Redis的基础知识,还没看的小伙伴可以回顾一下
[《吊打面试官》系列-Redis基础](https://juejin.im/post/5db66ed9e51d452a2f15d833)
那提到**Redis**我相信各位在面试,或者实际开发过程中对缓存**雪崩**,**穿透**,**击穿**也不陌生吧,就算没遇到过但是你肯定听过,那三者到底有什么区别,我们又应该怎么去防止这样的情况发生呢,我们有请下一位受害者。
## 面试开始
> 一个大腹便便,穿着格子衬衣的中年男子,拿着一个满是划痕的mac向你走来,看着快秃顶的头发,心想着肯定是尼玛顶级架构师吧!但是我们腹有诗书气自华,虚都不虚。

### 小伙子我看你的简历上写到了Redis,那么我们直接开门见山,直接怼常见的几个大问题,Redis雪崩了解么?
帅气迷人的面试官您好,我了解的,目前电商首页以及热点数据都会去做缓存 ,一般缓存都是定时任务去刷新,或者是查不到之后去更新的,定时任务刷新就有一个问题。
**举个简单的例子**:如果所有首页的Key失效时间都是12小时,中午12点刷新的,我零点有个秒杀活动大量用户涌入,假设当时每秒 6000 个请求,本来缓存在可以扛住每秒 5000 个请求,但是缓存当时所有的Key都失效了。此时 1 秒 6000 个请求全部落数据库,数据库必然扛不住,它会报一下警,真实情况可能DBA都没反应过来就直接挂了。此时,如果没用什么特别的方案来处理这个故障,DBA 很着急,重启数据库,但是数据库立马又被新的流量给打死了。这就是我理解的缓存雪崩。
**我刻意看了下我做过的项目感觉再吊的都不允许这么大的QPS直接打DB去,不过没慢SQL加上分库,大表分表可能还还算能顶,但是跟用了Redis的差距还是很大**

**同一时间大面积失效,那一瞬间Redis跟没有一样,那这个数量级别的请求直接打到数据库几乎是灾难性的,你想想如果打挂的是一个用户服务的库,那其他依赖他的库所有的接口几乎都会报错,如果没做熔断等策略基本上就是瞬间挂一片的节奏,你怎么重启用户都会把你打挂,等你能重启的时候,用户早就睡觉去了,并且对你的产品失去了信心,什么垃圾产品。**
### 面试官摸了摸自己的头发,嗯还不错,那这种情况咋整?你都是怎么去应对的?
处理缓存雪崩简单,在批量往**Redis**存数据的时候,把每个Key的失效时间都加个随机值就好了,这样可以保证数据不会在同一时间大面积失效,我相信,Redis这点流量还是顶得住的。
```java
setRedis(Key,value,time + Math.random() * 10000);
```
如果**Redis**是集群部署,将热点数据均匀分布在不同的**Redis**库中也能避免全部失效的问题,不过本渣我在生产环境中操作集群的时候,单个服务都是对应的单个**Redis**分片,是为了方便数据的管理,但是也同样有了可能会失效这样的弊端,失效时间随机是个好策略。
或者设置热点数据永远不过期,有更新操作就更新缓存就好了(比如运维更新了首页商品,那你刷下缓存就完事了,不要设置过期时间),电商首页的数据也可以用这个操作,保险。
### 那你了解缓存穿透和击穿么,可以说说他们跟雪崩的区别么?
嗯,了解,我先说一下缓存穿透吧,缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,我们数据库的 id 都是1开始自增上去的,如发起为id值为 -1 的数据或 id 为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大,严重会击垮数据库。
**小点的单机系统,基本上用postman就能搞死,比如我自己买的阿里云服务**

**像这种你如果不对参数做校验,数据库id都是大于0的,我一直用小于0的参数去请求你,每次都能绕开Redis直接打到数据库,数据库也查不到,每次都这样,并发高点就容易崩掉了。**
至于**缓存击穿**嘛,这个跟**缓存雪崩**有点像,但是又有一点不一样,缓存雪崩是因为大面积的缓存失效,打崩了DB,而缓存击穿不同的是**缓存击穿**是指一个Key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个完好无损的桶上凿开了一个洞。

### 面试官露出欣慰的眼光,那他们分别怎么解决
**缓存穿透**我会在接口层增加校验,比如用户鉴权校验,参数做校验,不合法的参数直接代码Return,比如:id 做基础校验,id <=0的直接拦截等。
**这里我想提的一点就是,我们在开发程序的时候都要有一颗“不信任”的心,就是不要相信任何调用方,比如你提供了API接口出去,你有这几个参数,那我觉得作为被调用方,任何可能的参数情况都应该被考虑到,做校验,因为你不相信调用你的人,你不知道他会传什么参数给你。**
**举个简单的例子,你这个接口是分页查询的,但是你没对分页参数的大小做限制,调用的人万一一口气查 Integer.MAX_VALUE 一次请求就要你几秒,多几个并发你不就挂了么?是公司同事调用还好大不了发现了改掉,但是如果是黑客或者竞争对手呢?在你双十一当天就调你这个接口会发生什么,就不用我说了吧。这是之前的Leader跟我说的,我觉得大家也都应该了解下。**
从缓存取不到的数据,在数据库中也没有取到,这时也可以将对应Key的Value对写为null、位置错误、稍后重试这样的值具体取啥问产品,或者看具体的场景,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。
这样可以防止攻击用户反复用同一个id暴力攻击,但是我们要知道正常用户是不会在单秒内发起这么多次请求的,那网关层**Nginx**本渣我也记得有配置项,可以让运维大大对单个IP每秒访问次数超出阈值的IP都拉黑。
### 那你还有别的办法么?
还有我记得**Redis**还有一个高级用法**布隆过滤器(Bloom Filter)**这个也能很好的防止缓存穿透的发生,他的原理也很简单就是利用高效的数据结构和算法快速判断出你这个Key是否在数据库中存在,不存在你return就好了,存在你就去查了DB刷新KV再return。
那又有小伙伴说了如果黑客有很多个IP同时发起攻击呢?这点我一直也不是很想得通,但是一般级别的黑客没这么多肉鸡,再者正常级别的**Redis**集群都能抗住这种级别的访问的,小公司我想他们不会感兴趣的。把系统的高可用做好了,集群还是很能顶的。
**缓存击穿**的话,设置热点数据永远不过期。或者加上互斥锁就能搞定了
**作为暖男,代码我肯定帮你们准备好了**

##面试结束
### 嗯嗯还不错,三个点都回答得很好,今天也不早了,面试就先到这里,明天你再过来二面我继续问一下你关于Redis集群高可用,主从同步,哨兵等知识点的问题。
晕居然还有下一轮面试!(强行下一期的伏笔哈哈)但是为了offer还是得舔,嗯嗯,好的帅气面试官。
能回答得这么全面这么细节还是忍不住点赞
(**暗示点赞,每次都看了不点赞,你们想白嫖我么?你们好坏喲,不过我喜欢**)
## 总结
我们玩归玩,闹归闹,别拿面试开玩笑。
本文简单的介绍了,**Redis**的**雪崩**,**击穿**,**穿透**,三者其实都差不多,但是又有一些区别,在面试中其实这是问到缓存必问的,大家不要把三者搞混了,因为缓存雪崩、穿透和击穿,是缓存最大的问题,要么不出现,一旦出现就是致命性的问题,所以面试官一定会问你。
大家一定要理解是**怎么发生的**,以及是怎么去**避免**的,发生之后又怎么去**抢救**,你可以不是知道很深入,但是你不能一点都不去想,面试有时候不一定是对知识面的拷问,或许是对你的态度的拷问,如果你思路清晰,然后**知其然还知其所以然**那就很赞,还知道怎么预防那来上班吧。
### 最后暖男我继续给你们做个小的技术总结:
一般避免以上情况发生我们从三个时间段去分析下:
- 事前:**Redis** 高可用,主从+哨兵,**Redis cluster**,避免全盘崩溃。
- 事中:本地 **ehcache** 缓存 + **Hystrix** 限流+降级,避免** MySQL** 被打死。
- 事后:**Redis** 持久化 **RDB**+**AOF**,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
上面的几点我会在吊打系列Redis篇全部讲一下这个月应该可以吧Redis更完,限流组件,可以设置每秒的请求,有多少能通过组件,剩余的未通过的请求,怎么办?**走降级**!可以返回一些默认的值,或者友情提示,或者空白的值。
**好处:**
数据库绝对不会死,限流组件确保了每秒只有多少个请求能通过。 只要数据库不死,就是说,对用户来说,3/5 的请求都是可以被处理的。 只要有 3/5 的请求可以被处理,就意味着你的系统没死,对用户来说,可能就是点击几次刷不出来页面,但是多点几次,就可以刷出来一次。
**这个在目前主流的互联网大厂里面是最常见的,你是不是好奇,某明星爆出什么事情,你发现你去微博怎么刷都空白界面,但是有的人又直接进了,你多刷几次也出来了,现在知道了吧,那是做了降级,牺牲部分用户的体验换来服务器的安全,可还行?**
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**,我后面会每周都更新几篇《**吊打面试官**》系列和Java技术栈相关的文章。如果你有什么想知道的,也可以留言给我,我一有时间就会写出来,我们共同进步。
非常感谢**靓仔/靓女**您能看到这里,如果这个文章写得还不错的话 **求点赞** **求关注** **求分享** **求留言** **(对我非常有用)**各位的支持和认可,就是我创作的最大动力,我们下篇文章见,拜了个拜!
敖丙 | 文 【原创】
------
> 每周都会持续更新《吊打面试官》系列可以关注我的公众号第一时间阅读和催更,也可以在公众号回复【人才】加入人才交流群一起讨论面试题,就业和工作上有什么问题也可以直接滴滴我,我也是个新人,不过不影响我们一起进步,作为渣男,我给不了你工作,还给不了你温暖嘛?

================================================
FILE: docs/redis/课代表总结.md
================================================
>
>
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
> **GitHub**上已经开源 [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily) 有一线大厂面试点脑图、个人联系方式和人才交流群,欢迎Star和指教
## 絮叨
本来是没这期的,按道理更新也应该是在周一更新**消息队列**的幂等,分布式事务相关的文章,但是这篇**暖男**我**实在忍不住了**,不是发自己的文章,是帮**课代表**发一下,她本科是**北京交通大学**,也是**电子科技大学**的研究生。
**她**看了我的系列,做了个**笔记**📒,我一看,**偶买噶 !**。
**这是什么仙女啊**,这是我**第一次**有这种感觉,这笔记有着前**所未有的新鲜感**,细节的勾勒,让整个笔记更显出**奥妙.**...有些**不太成熟的话语**,跟我文章的**骚气**十分搭配,将**Redis**的性能衬托的更为出色,这才呈现出完美的**课代表笔记**。
这也是我第一次看到看个渣男的文章都做笔记的,这笔记让我有了初恋的味道,这我以后可得好好写了,不然**辜负**了**课代表这样认真的妹子**,到时候到杭州来找我:敖丙你个**渣男**乱写,害我没拿Offer! **我要杀了你**!
我也不多BB了不影响大家食用了,**课代表**说了以后我写的**其他技术栈的笔记**一样会贡献出来,代价就是要嫁给我,呸呸呸,代价就是我以后帮他介绍大厂朋友内推下,看看简历呀,解答下职场问题啊什么的。(根本就是举手之劳啊,我血赚?)
我一听我不能忍啊,我**气得拍桌子**,不行你以后不懂的知识点我包了,我也不懂的咳咳我看完书再包?
哈哈开玩笑的,总之**课代表的精神**大家包括我都应该好好学学,这种人活该她拿**SSP**的Offer。
**Tip**:SSP (Special Offer 优秀生源Offer渠道 )

能总结得这么全面连我都忍不住**点赞**了!
## 总结
里面很多细节的点还是需要完善的,课代表最近上课很忙帅丙我呢除了周末也没时间,不过会不断完善到GIt的,大家也可以去公众号回复「**课代表**」获取思维导图原稿。
其实我真的很欣赏课代表这样的精神的,她这样的举动**触动了我**,想想自己大学时候的样子,我忍不住给了自己两嘴巴子,我但凡有课代表一半的努力都不至于沦落到今天这样,等我冷静下来,走到了窗边,眺望头上若影若现的月亮,**我的眼角又湿了**!
## 花絮
人才群里的人才真的都是**人才**,一周两更**高产似母猪**了我都,还天天**催更**不过我也认了,**课代表**进去差点把人家吓走,**这么好的课代表**吓走了我哪里找第二个?
**GitHub**上有我联系方式和入群方式 [https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily)


## 日常求赞
这期本来不想求赞的,但是我一想是**课代表**写的大家是给她赞,不是给我赞呀。
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**。
我后面会每周都更新几篇《吊打面试官》系列和互联网常用技术栈相关的文章,非常感谢**人才**们能看到这里,如果这个文章写得还不错,觉得「课代表」**有点东西**的话 **求点赞👍** **求关注❤️** **求分享👥** 对暖男我来说真的 **非常有用**!!!
创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙&**课代表** | 文 【原创】【转载请联系本人】 如果本篇博客有任何错误,请批评指教,不胜感激 !
------
> 《吊打面试官》系列每周持续更新,可以关注我的公众号「 **JavaFamily** 」第一时间阅读和催更(公众号比博客早一到两篇哟),本文**GitHub**上已经收录[https://github.com/JavaFamily](https://github.com/AobingJava/JavaFamily),有一线大厂面试点思维导图,欢迎Star和完善,里面也有我个人联系方式有什么问题也可以直接找我,也有人才交流群,我们一起有点东西。

================================================
FILE: docs/redis/集群高可用、哨兵、持久化、LRU.md
================================================
> 你知道的越多,你不知道的越多
> 点赞再看,养成习惯
## 前言
**Redis**在互联网技术存储方面使用如此广泛,几乎所有的后端技术面试官都要在**Redis**的使用和原理方面对小伙伴们进行360°的刁难。作为一个在互联网公司面一次拿一次offer的面霸(**请允许我使用一下夸张的修辞手法**),打败了无数竞争对手,每次都只能看到无数落寞的身影失望的离开,略感愧疚,在一个寂寞难耐的夜晚,我痛定思痛,决定开始写**《吊打面试官》**系列,希望能帮助各位读者以后面试势如破竹,对面试官进行360°的反击,吊打问你的面试官,让一同面试的同僚瞠目结舌,疯狂收割大厂**Offer**!
## 絮叨
写这期其实比较纠结,我之前的写的比较通俗易懂,一是我都知道这些点,二是之前我在所在的电商公司对雪崩,击穿啥的还算有场景去接触。但是线上的Redis集群我实际操作经验很少,总不能在公司线上环境实践那些操作吧,所以最后看了下官网,还有一些资料(文章后面我都会贴出来),强行怼了这么篇出来。
最近双十一小忙,周末双十一值班目测没时间写,那我是暖男呀,我不能鸽啊,就有了这一篇,下一篇迟到你们不要喷我哈,而且下一篇还是**Redis**的终章还是得构思下,不熟悉的知识点我怕漏洞多,特意让以前的大牛同事看了下,所以有啥不对的地方大家及时留言**Diss**我,写这篇是真的难,诺下面就是我本人某天凌晨两点的拍的视频,多动症的仔。

之前说过系列第二篇到300赞我就发第三篇


咋样没骗你们吧,就很枯竭,不BB了,开搞。
**不点个赞对不起我,这次不要白嫖我!**
----
##正文
上几期**《吊打面试官》**还没看的小伙伴可以回顾一下(明明就写了两期说的好像很多一样)!
- [《吊打面试官》系列-Redis基础](https://juejin.im/post/5db66ed9e51d452a2f15d833)
- [《吊打面试官》系列-缓存雪崩、击穿、穿透](https://juejin.im/post/5dbef8306fb9a0203f6fa3e2)
大家都知道一个技术的引入方便了开发,解决了各种问题,但是也会带来对应的问题,**技术是把双刃剑**嘛,集群的引入也会带来很多问题,如:集群的高可用怎么保证,数据怎么同步等等,我们话不多说,有请下一位受害者为我们展示。
### 面试开始
> 三个大腹便便,穿着格子衬衣的中年男子,拿着三个满是划痕的mac向你走来,看着快秃顶的头发,心想着肯定是尼玛顶级架构师吧!而且还是三个,但是还好我看过敖丙写的《吊打面试官》系列,腹有诗书气自华,根本虚都不虚好伐。

#### 小伙子你好,之前问过了你基础知识以及一些缓存的常见几个大问题了,那你能跟我聊聊为啥Redis那么快么?
哦,帅气迷人的面试官您好,我们可以先看一下关系型数据库跟Redis本质上的区别。

**Redis**采用的是基于内存的采用的是单进程单线程模型的 KV 数据库,由C语言编写,官方提供的数据是可以达到100000+的**QPS(每秒内查询次数)**。
- 完全基于内存,绝大部分请求是纯粹的内存操作,非常快速。它的,数据存在内存中,类似于**HashMap**,**HashMap**的优势就是查找和操作的时间复杂度都是O(1);
- 数据结构简单,对数据操作也简单,**Redis**中的数据结构是专门进行设计的;
- 采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 **CPU**,不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗;
- 使用多路I/O复用模型,非阻塞IO;
- 使用底层模型不同,它们之间底层实现方式以及与客户端之间通信的应用协议不一样,**Redis**直接自己构建了VM 机制 ,因为一般的系统调用系统函数的话,会浪费一定的时间去移动和请求;
### 我可以问一下啥是上下文切换么?
我可以打个比方么:我记得有过一个小伙伴微信问过我上下文切换是啥,为啥可能会线程不安全,我是这么说的,就好比你看一本英文书,你看到第十页发现有个单词不会读,你加了个书签,然后去查字典,过了一会你又回来继续从书签那里读,ok到目前为止没啥问题。
如果是你一个人读肯定没啥问题,但是你去查的时候,别的小伙伴好奇你在看啥他就翻了一下你的书,然后溜了,哦豁,你再看的时候就发现书不是你看的那一页了。不知道到这里为止我有没有解释清楚,以及为啥会线程不安全,就是因为你一个人怎么看都没事,但是人多了换来换去的操作一本书数据就乱了。可能我的解释很粗糙,但是道理应该是一样的。
### 那他是单线程的,我们现在服务器都是多核的,那不是很浪费?
是的他是单线程的,但是,我们可以通过在单机开多个**Redis实例**嘛。
### 既然提到了单机会有瓶颈,那你们是怎么解决这个瓶颈的?
我们用到了集群的部署方式也就是**Redis cluster**,并且是主从同步读写分离,类似**Mysql**的主从同步,**Redis cluster** 支撑 N 个 **Redis master node**,每个**master node**都可以挂载多个 **slave node**。
这样整个 **Redis** 就可以横向扩容了。如果你要支撑更大数据量的缓存,那就横向扩容更多的 **master** 节点,每个 **master** 节点就能存放更多的数据了。
### 哦?那问题就来了,他们之间是怎么进行数据交互的?以及Redis是怎么进行持久化的?Redis数据都在内存中,一断电或者重启不就木有了嘛?
是的,持久化的话是**Redis**高可用中比较重要的一个环节,因为**Redis**数据在内存的特性,持久化必须得有,我了解到的持久化是有两种方式的。
- RDB:**RDB** 持久化机制,是对 **Redis** 中的数据执行**周期性**的持久化。
- AOF:**AOF** 机制对每条写入命令作为日志,以 **append-only** 的模式写入一个日志文件中,因为这个模式是只追加的方式,所以没有任何磁盘寻址的开销,所以很快,有点像Mysql中的**binlog**。
两种方式都可以把**Redis**内存中的数据持久化到磁盘上,然后再将这些数据备份到别的地方去,**RDB**更适合做**冷备**,**AOF**更适合做**热备**,比如我杭州的某电商公司有这两个数据,我备份一份到我杭州的节点,再备份一个到上海的,就算发生无法避免的自然灾害,也不会两个地方都一起挂吧,这**灾备**也就是**异地容灾**,地球毁灭他没办法。
**tip:两种机制全部开启的时候,Redis在重启的时候会默认使用AOF去重新构建数据,因为AOF的数据是比RDB更完整的。**
### 那这两种机制各自优缺点是啥?
我先说**RDB**吧
#### 优点:
他会生成多个数据文件,每个数据文件分别都代表了某一时刻**Redis**里面的数据,这种方式,有没有觉得很适合做**冷备**,完整的数据运维设置定时任务,定时同步到远端的服务器,比如阿里的云服务,这样一旦线上挂了,你想恢复多少分钟之前的数据,就去远端拷贝一份之前的数据就好了。
**RDB**对**Redis**的性能影响非常小,是因为在同步数据的时候他只是**fork**了一个子进程去做持久化的,而且他在数据恢复的时候速度比**AOF**来的快。
#### 缺点:
**RDB**都是快照文件,都是默认五分钟甚至更久的时间才会生成一次,这意味着你这次同步到下次同步这中间五分钟的数据都很可能全部丢失掉。**AOF**则最多丢一秒的数据,**数据完整性**上高下立判。
还有就是**RDB**在生成数据快照的时候,如果文件很大,客户端可能会暂停几毫秒甚至几秒,你公司在做秒杀的时候他刚好在这个时候**fork**了一个子进程去生成一个大快照,哦豁,出大问题。
我们再来说说**AOF**
####优点:
上面提到了,**RDB**五分钟一次生成快照,但是**AOF**是一秒一次去通过一个后台的线程`fsync`操作,那最多丢这一秒的数据。
**AOF**在对日志文件进行操作的时候是以`append-only`的方式去写的,他只是追加的方式写数据,自然就少了很多磁盘寻址的开销了,写入性能惊人,文件也不容易破损。
**AOF**的日志是通过一个叫**非常可读**的方式记录的,这样的特性就适合做**灾难性数据误删除**的紧急恢复了,比如公司的实习生通过**flushall**清空了所有的数据,只要这个时候后台重写还没发生,你马上拷贝一份**AOF**日志文件,把最后一条**flushall**命令删了就完事了。
**tip:我说的命令你们别真去线上系统操作啊,想试去自己买的服务器上装个Redis试,别到时候来说,敖丙真是个渣男,害我把服务器搞崩了,Redis官网上的命令都去看看,不要乱试!!!**
####缺点:
一样的数据,**AOF**文件比**RDB**还要大。
**AOF**开启后,**Redis**支持写的**QPS**会比**RDB**支持写的要低,他不是每秒都要去异步刷新一次日志嘛**fsync**,当然即使这样性能还是很高,我记得**ElasticSearch**也是这样的,异步刷新缓存区的数据去持久化,为啥这么做呢,不直接来一条怼一条呢,那我会告诉你这样性能可能低到没办法用的,大家可以思考下为啥哟。
###那两者怎么选择?

小孩子才做选择,**我全都要**,你单独用**RDB**你会丢失很多数据,你单独用**AOF**,你数据恢复没**RDB**来的快,真出什么时候第一时间用**RDB**恢复,然后**AOF**做数据补全,真香!冷备热备一起上,才是互联网时代一个高健壮性系统的王道。
### 看不出来年纪轻轻有点东西的呀,对了我听你提到了高可用,Redis还有其他保证集群高可用的方式么?
!!!晕 自己给自己埋个坑(其实是明早就准备好了,故意抛出这个词等他问,就怕他不问)。
假装思考一会(**不要太久,免得以为你真的不会**),哦我想起来了,还有哨兵集群**sentinel**。
哨兵必须用三个实例去保证自己的健壮性的,哨兵+主从并**不能保证数据不丢失**,但是可以保证集群的**高可用**。
为啥必须要三个实例呢?我们先看看两个哨兵会咋样。

master宕机了 s1和s2两个哨兵只要有一个认为你宕机了就切换了,并且会选举出一个哨兵去执行故障,但是这个时候也需要大多数哨兵都是运行的。
那这样有啥问题呢?M1宕机了,S1没挂那其实是OK的,但是整个机器都挂了呢?哨兵就只剩下S2个裸屌了,没有哨兵去允许故障转移了,虽然另外一个机器上还有R1,但是故障转移就是不执行。
经典的哨兵集群是这样的:

M1所在的机器挂了,哨兵还有两个,两个人一看他不是挂了嘛,那我们就选举一个出来执行故障转移不就好了。
暖男我,小的总结下哨兵组件的主要功能:
- 集群监控:负责监控 Redis master 和 slave 进程是否正常工作。
- 消息通知:如果某个 **Redis** 实例有故障,那么哨兵负责发送消息作为报警通知给管理员。
- 故障转移:如果 master node 挂掉了,会自动转移到 slave node 上。
- 配置中心:如果故障转移发生了,通知 client 客户端新的 master 地址。
### 我记得你还提到了主从同步,能说一下主从之间的数据怎么同步的么?
面试官您的记性可真是一级棒呢,我都要忘了你还记得,我特么谢谢你,提到这个,就跟我前面提到的数据持久化的**RDB**和**AOF**有着比密切的关系了。
我先说下为啥要用主从这样的架构模式,前面提到了单机**QPS**是有上限的,而且**Redis**的特性就是必须支撑读高并发的,那你一台机器又读又写,**这谁顶得住啊**,不当人啊!但是你让这个master机器去写,数据同步给别的slave机器,他们都拿去读,分发掉大量的请求那是不是好很多,而且扩容的时候还可以轻松实现水平扩容。

**回归正题,他们数据怎么同步的呢?**
你启动一台slave 的时候,他会发送一个**psync**命令给master ,如果是这个slave第一次连接到master,他会触发一个全量复制。master就会启动一个线程,生成**RDB**快照,还会把新的写请求都缓存在内存中,**RDB**文件生成后,master会将这个**RDB**发送给slave的,slave拿到之后做的第一件事情就是写进本地的磁盘,然后加载进内存,然后master会把内存里面缓存的那些新命名都发给slave。
###数据传输的时候断网了或者服务器挂了怎么办啊?
传输过程中有什么网络问题啥的,会自动重连的,并且连接之后会把缺少的数据补上的。
**大家需要记得的就是,RDB快照的数据生成的时候,缓存区也必须同时开始接受新请求,不然你旧的数据过去了,你在同步期间的增量数据咋办?是吧?**
### 那说了这么多你能说一下他的内存淘汰机制么,来手写一下LRU代码?

#### 手写LRU?你是不是想直接跳起来说一句:Are U F**k Kidding me?
这个问题是我在蚂蚁金服三面的时候亲身被问过的问题,不知道大家有没有被怼到过这个问题。
**Redis**的过期策略,是有**定期删除+惰性删除**两种。
定期好理解,默认100s就随机抽一些设置了过期时间的key,去检查是否过期,过期了就删了。
### 为啥不扫描全部设置了过期时间的key呢?
假如Redis里面所有的key都有过期时间,都扫描一遍?那太恐怖了,而且我们线上基本上也都是会设置一定的过期时间的。全扫描跟你去查数据库不带where条件不走索引全表扫描一样,100s一次,Redis累都累死了。
###如果一直没随机到很多key,里面不就存在大量的无效key了?
好问题,**惰性删除**,见名知意,惰性嘛,我不主动删,我懒,我等你来查询了我看看你过期没,过期就删了还不给你返回,没过期该怎么样就怎么样。
### 最后就是如果的如果,定期没删,我也没查询,那可咋整?
**内存淘汰机制**!
官网上给到的内存淘汰机制是以下几个:
- **noeviction**:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
- **allkeys-lru**: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
- **volatile-lru**: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
- **allkeys-random**: 回收随机的键使得新添加的数据有空间存放。
- **volatile-random**: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
- **volatile-ttl**: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
如果没有键满足回收的前提条件的话,策略**volatile-lru**, **volatile-random**以及**volatile-ttl**就和noeviction 差不多了。
至于**LRU**我也简单提一下,手写实在是太长了,大家可以去**Redis官网**看看,我把**近视LUR**效果给大家看看
**tip:Redis为什么不使用真实的LRU实现是因为这需要太多的内存。不过近似的LRU算法对于应用而言应该是等价的。使用真实的LRU算法与近似的算法可以通过下面的图像对比。**

你可以看到三种点在图片中, 形成了三种带.
- 浅灰色带是已经被回收的对象。
- 灰色带是没有被回收的对象。
- 绿色带是被添加的对象。
- 在**LRU**实现的理论中,我们希望的是,在旧键中的第一半将会过期。**Redis**的**LRU**算法则是概率的过期旧的键。
你可以看到,在都是五个采样的时候Redis 3.0比Redis 2.8要好,Redis2.8中在最后一次访问之间的大多数的对象依然保留着。使用10个采样大小的Redis 3.0的近似值已经非常接近理论的性能。
注意LRU只是个预测键将如何被访问的模型。另外,如果你的数据访问模式非常接近幂定律,大部分的访问将集中在一个键的集合中,LRU的近似算法将处理得很好。
其实在大家熟悉的**LinkedHashMap**中也实现了Lru算法的,实现如下:

当容量超过100时,开始执行**LRU**策略:将最近最少未使用的 **TimeoutInfoHolder** 对象 **evict** 掉。
真实面试中会让你写LUR算法,你可别搞原始的那个,那真TM多,写不完的,你要么怼上面这个,要么怼下面这个,找一个数据结构实现下Java版本的LRU还是比较容易的,知道啥原理就好了。

## 面试结束
### 小伙子,你确实有点东西,HRBP会联系你的,请务必保持你的手机畅通好么?
好的谢谢面试官,面试官真好,我还想再面几次,噗此。
能回答得这么全面这么细节还是忍不住点赞
**(暗示点赞,每次都看了不点赞,你们想白嫖我么?你们好坏喲,不过我好喜欢)**
## 总结
好了,我们玩归玩,闹归闹,别拿面试开玩笑,我这么写是为了节目效果,大家面试请认真对待。
这一期是这期没前面好理解了对吧,我就在自己的服务器上启动了,然后再去官网看看命令一顿瞎操作的,查阅了部分资料,这里给大家推荐几本经典的Redis入门的书籍和我参考的资料。
- [Redis中文官网](http://www.redis.cn/)
- 《Redis入门指南(第2版)》
- 《Redis实战》
- 《Redis设计与实现》
- 《[大型网站技术架构](https://github.com/doocs/technical-books#architecture)——李智慧》
- 《[Redis 设计与实现](https://github.com/doocs/technical-books#database)——黄健宏》
- 《[Redis 深度历险](https://github.com/doocs/technical-books#database)——钱文品》
- 《[亿级流量网站架构核心技术](https://github.com/doocs/technical-books#architecture)——张开涛》
- 《[中华石杉](https://github.com/doocs/advanced-java)——石杉》
不出意外的话这是Redis的倒数第二期,最后一期不知道写啥还没想好,我得好好想想,加上最近不是双十一嘛得加加班,**你看看开头的我,多可怜,那还不点个赞?买个服务器**?不确定下一期多久出,想早点看到更新的小伙伴可以去公众号**催更**,公众号提前一到两天更新。
### END
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是**人才**,我后面会每周都更新几篇《**吊打面试官**》系列和**Java技术栈**相关的文章。如果你有什么想知道的,也可以**留言**给我,我一有时间就会写出来,我们共同进步。
非常感谢**靓仔/靓女**您能看到这里,如果这个文章写得还不错,觉得敖丙有点东西 **求点赞** **求关注** **求分享** **求留言** **(对我非常有用)**各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
敖丙 | 文 【原创】
------
> 每周都会持续更新《吊打面试官》系列可以关注我的公众号第一时间阅读和催更,公众号比博客提前一到两天更新,也可以在公众号回复【人才】加入人才交流群,里面都是人才长得好看说话还好听,进去就像回家了一样,就业和工作上有什么问题也可以直接滴滴我,我也是个新人,不过不影响我们一起进步。
