Showing preview only (1,105K chars total). Download the full file or copy to clipboard to get everything.
Repository: windstormeye/iOS-Course
Branch: master
Commit: caa019bf38e8
Files: 151
Total size: 612.8 KB
Directory structure:
gitextract_3vegyaaq/
├── .github/
│ └── workflows/
│ └── jekyll-gh-pages.yml
├── .gitignore
├── AI/
│ └── basic.md
├── Android/
│ ├── Java.md
│ ├── Kotlin.md
│ ├── feature.md
│ ├── 内存.md
│ ├── 基础知识.md
│ └── 问题汇总.md
├── Back-end/
│ ├── DB.md
│ ├── Docker.md
│ ├── RESTful.md
│ ├── Vapor.md
│ ├── django.md
│ ├── jwt.md
│ ├── mysql.md
│ ├── nginx.md
│ ├── web服务器.md
│ └── 后端学习.md
├── Base/
│ ├── C++.md
│ ├── UML.md
│ ├── algorithm-java.md
│ ├── leetCode.md
│ ├── leetcode/
│ │ ├── 两个排序数组的中位数.md
│ │ ├── 两数之和.md
│ │ ├── 两数相加.md
│ │ ├── 无重复字符的最长子串.md
│ │ └── 最长回文子串.md
│ ├── nowCode.md
│ ├── python.md
│ ├── 操作系统.md
│ └── 网络相关知识.md
├── Blockchain/
│ └── basic.md
├── Books/
│ └── iOS面试之道.md
├── CV/
│ └── basic.md
├── Flutter/
│ ├── Dart.md
│ ├── Flutter_2.md
│ ├── Flutter_3.md
│ └── Flutter问题汇总.md
├── Front-end/
│ ├── CSS.md
│ ├── FCC.md
│ ├── JavaScript.md
│ ├── Vue.md
│ ├── basic.md
│ ├── vue-context-mune.md
│ ├── 前端学习.md
│ └── 图解HTTP学习笔记.md
├── Game/
│ └── Cocos/
│ └── basic.md
├── Graphics/
│ ├── app.md
│ └── metal.md
├── History/
│ ├── 2_Apple_History.md
│ ├── 3_Mac_OS_X.md
│ └── 4_iOS.md
├── LICENSE
├── Media/
│ ├── basic.md
│ └── feature.md
├── MiniProgram/
│ ├── 小程序初探.md
│ └── 小程序初探(二).md
├── NLP/
│ └── NLP.md
├── Others/
│ ├── myinterview.md
│ ├── 招一个靠谱的iOS实习生(附参考答案).md
│ ├── 简介.md
│ └── 面试准备.md
├── Product/
│ └── Map.md
├── Project/
│ ├── Bonfire.md
│ ├── CocosCreator——方块弹球.md
│ ├── ONEUIKit-ONEProgressHUD.md
│ ├── PFollow.md
│ ├── PLook.md
│ ├── coding-interview-university学习笔记.md
│ ├── iBistu4-0(先导篇).md
│ ├── iBistu4-0(地图).md
│ ├── iBistu4-0(失物).md
│ ├── iBistu4-0(新闻).md
│ ├── iBistu4-0(黄页).md
│ ├── 上架.md
│ ├── 第三方库管理.md
│ └── 翻译——ViewsprogrammingGuideforiOS.md
├── Qt/
│ ├── C++.md
│ ├── UI.md
│ ├── base.md
│ ├── crossPlatform.md
│ ├── opt.md
│ └── project.md
├── README.md
├── React-Native/
│ ├── React-Native记〇.md
│ ├── React-Native记(一).md
│ └── React-Native记(二).md
├── Test/
│ └── 单元测试.md
├── Tools/
│ ├── 2_百家汇.md
│ ├── 3_GitHub.md
│ ├── 4_Xcode.md
│ ├── 5_Xcode.md
│ ├── Playerground.md
│ ├── Xcode.md
│ ├── XcodeGuide.md
│ └── 开发中可能会用到的内容.md
├── Toturial/
│ └── 剪刀石头布.md
├── UI/
│ └── 3_StoryBoard.md
├── Weex/
│ └── Weex新手记.md
├── Win/
│ └── basic.md
├── iOS/
│ ├── Layout.md
│ ├── More-弹幕.md
│ ├── Objective-C/
│ │ ├── More-Audio.md
│ │ ├── More-DesignPattern.md
│ │ ├── More-iOS上的相机.md
│ │ ├── More-iOS国际化一站式解决方案.md
│ │ ├── More-视频相关.md
│ │ ├── More-页面传值.md
│ │ ├── Objective-C注意点.md
│ │ ├── ping.md
│ │ ├── runtime.md
│ │ ├── tips-自定义tabBar大加号引发的思考.md
│ │ ├── 并发编程.md
│ │ └── 系统相关.md
│ ├── Swift/
│ │ ├── Cache.md
│ │ ├── CoreData.md
│ │ ├── OC转Swift.md
│ │ ├── PFollow.md
│ │ ├── PJPickerView开发总结.md
│ │ ├── PJPickerView开发总结.md).md
│ │ ├── PhotosKit开发总结(一).md
│ │ ├── Playgrounds.md
│ │ ├── SpriteKit.md
│ │ ├── SwiftUI.md
│ │ ├── Swift注意点.md
│ │ ├── UIDynamic.md
│ │ ├── code.md
│ │ ├── debug.md
│ │ ├── landscapeandportrait.md
│ │ ├── tips.md
│ │ ├── 七牛图片上传助手.md
│ │ ├── 品种选择器总结.md
│ │ └── 自定义NavigationBar.md
│ ├── Today_Extension.md
│ ├── UI.md
│ ├── UICollectionView.md
│ ├── UITableView.md
│ ├── basic.md
│ ├── code.md
│ ├── debug.md
│ └── system.md
├── macOS/
│ ├── TranslateP.md
│ ├── basic.md
│ ├── crash.md
│ ├── kindle.md
│ ├── macOS开发(词法分析器).md
│ ├── performance.md
│ ├── playground.md
│ └── 一台设备多个git账号.md
└── ruby/
└── basic.md
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/workflows/jekyll-gh-pages.yml
================================================
# Sample workflow for building and deploying a Jekyll site to GitHub Pages
name: Deploy Jekyll with GitHub Pages dependencies preinstalled
on:
# Runs on pushes targeting the default branch
push:
branches: ["master"]
# Allows you to run this workflow manually from the Actions tab
workflow_dispatch:
# Sets permissions of the GITHUB_TOKEN to allow deployment to GitHub Pages
permissions:
contents: read
pages: write
id-token: write
# Allow only one concurrent deployment, skipping runs queued between the run in-progress and latest queued.
# However, do NOT cancel in-progress runs as we want to allow these production deployments to complete.
concurrency:
group: "pages"
cancel-in-progress: false
jobs:
# Build job
build:
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v4
- name: Setup Pages
uses: actions/configure-pages@v4
- name: Build with Jekyll
uses: actions/jekyll-build-pages@v1
with:
source: ./
destination: ./_site
- name: Upload artifact
uses: actions/upload-pages-artifact@v3
# Deployment job
deploy:
environment:
name: github-pages
url: ${{ steps.deployment.outputs.page_url }}
runs-on: ubuntu-latest
needs: build
steps:
- name: Deploy to GitHub Pages
id: deployment
uses: actions/deploy-pages@v4
================================================
FILE: .gitignore
================================================
.vscode
================================================
FILE: AI/basic.md
================================================
# AI
## 各种原则
### 金发姑娘原则
* [相关链接](https://en.wikipedia.org/wiki/Goldilocks_principle)
* 解释“金发姑娘原则”指出,凡事都必须有度,而不能超越极限。按照这一原则行事产生的效应就称为“金发姑娘效应”。
### 学习速率
* 通过一个图来解释
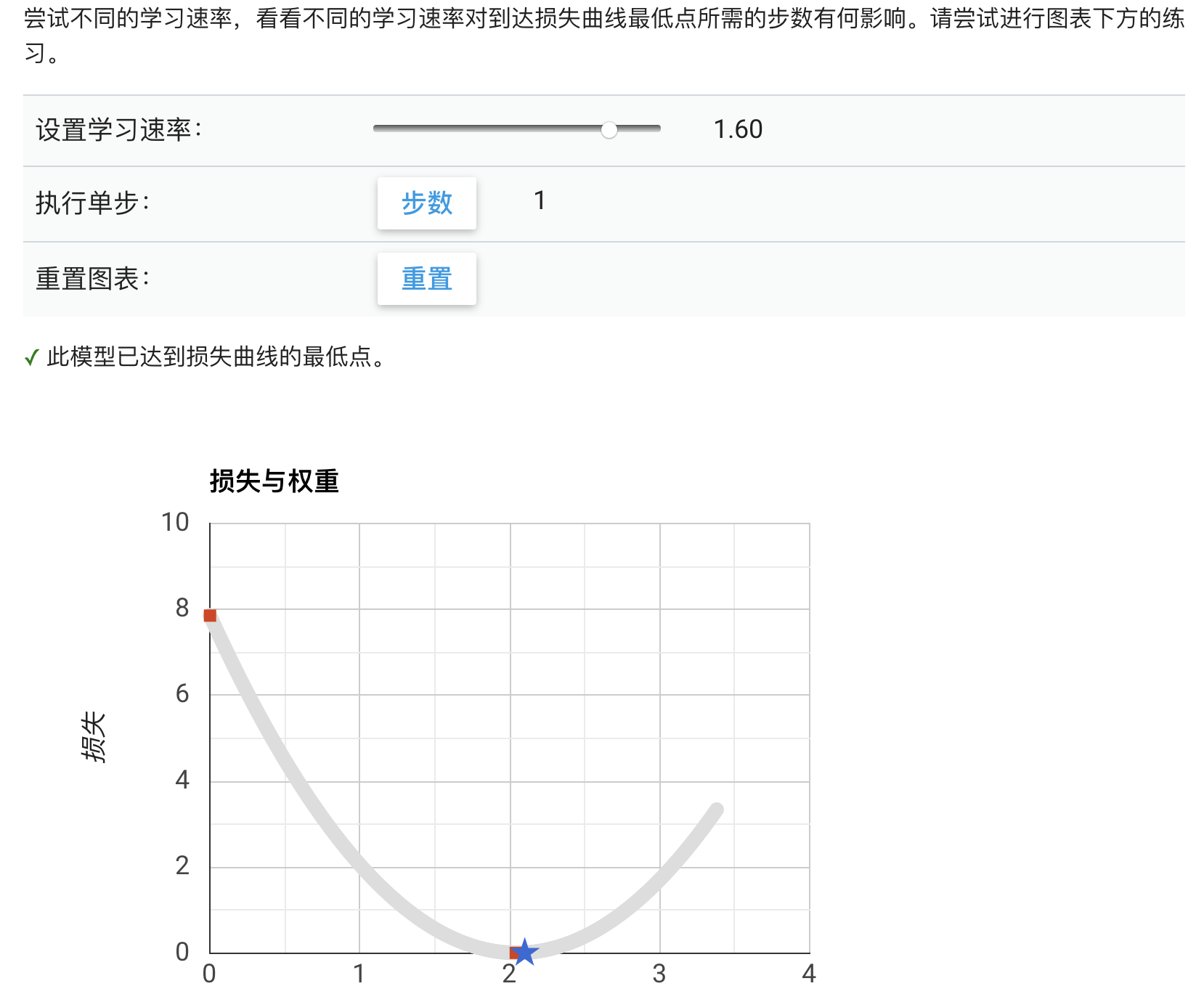
* 当「学习速率」过高,容易导致每一步都在曲线上进行跳跃,沿着曲线向上爬,而不是降到底部。
### 随机梯度下降法/ SGD
### 小批量随机梯度下降法/小批量 SGD
### 协同过滤
* 基于用户的协同过滤算法 UserCF
* 统计两个用户的相似度。两个用户阅读过的内容 ID 列表如果重合度越高,说明越相似。
* 适合用在个性化需求不强,热点很明显的领域,比如新闻,电影推荐。
* 基于物品的协同过滤算法 ItemCF
* 适合用在个性化需求比较强,长尾比较长的领域,比如书、电商的推荐。
### 如何判断用户会不会点一个物品:特征
* 用户特征
* 历史上点击的文章列表
* 历史上点击的文章的关键词分布
* 历史上点击的文章的作者分布
* 文章特征
* 文章的作者,关键词
* 用户和文章的交叉特征
* 用户历史上有没有点过这篇文章的作者发表的其他文章
* 用户历史上有没有点击过和这篇文章关键词类似的其他文章
### 文章冷启动
* 推荐系统是所有的文章在一个候选池互相 PK,找到对当前用户兴趣最好的
* 新文章因为展现少,在 PK 中往往落在下风
* 要做一个专门的冷启动机制,保证新文章在展现小于 X 前在 PK 中取得更大的获胜概率,直到充分展现,可以在 PK 中公平竞争
================================================
FILE: Android/Java.md
================================================
## Java
### 注解 `@`
提到注解就要带上注释,注释是给开发者看的,而注解就是给程序自己看的。比较类似做一些小方法检查,压缩代码量,本质上与 Swift 5.5 引入的 `@PropertyWrapper` 作用一致。
注解分位编译期注解和运行时注解,作用范围不同。运行时注解可以通过反射进行获取使用,但反射本身有性能损耗。
================================================
FILE: Android/Kotlin.md
================================================
# Kotlin 问题汇总
## 语法
### `var` 和 `val` 的区别
`var` 与我们之前见到的 `var` 概念一致,但 `val` 取代了以往 `let` 作用。kotlin 中 `let` 另有他用。
```kotlin
var a: String = "initial" // 1
println(a)
val b: Int = 1 // 2
b = 2
// 报错:Val cannot be reassigned
```
### `vararg`
本质上是个 `Array<String>` 的语法糖,但可以用“逗号”分隔开参数。在保证参数类型一致的情况下可以这么传参:
```kotlin
class MutableStack<E>(vararg items: E) { // 1
private val elements = items.toMutableList()
fun push(element: E) = elements.add(element) // 2
fun peek(): E = elements.last() // 3
fun pop(): E = elements.removeAt(elements.size - 1)
fun isEmpty() = elements.isEmpty()
fun size() = elements.size
override fun toString() = "MutableStack(${elements.joinToString()})"
}
fun <E> mutableStackOf(vararg elements: E) = MutableStack(*elements)
fun main() {
val stack = mutableStackOf(0.62, 3.14, 2.7)
println(stack)
}
```
### class
```kotlin
// 可以声明一个没有任何属性的 class,kotlin 会自动创建一个无参构造函数
class Customer
```
* kotlin 的类默认是 `final`,如果该类想要被继承,需要用 `open` 进行修饰;
* kotlin 的方法默认同样也是 `final`,在类中,如果想要的该方法可以被重载,需要用 `open` 进行修饰,并且在重载方法前加上 `override` 修饰;
```kotlin
open class Dog { // 1
open fun sayHello() { // 2
println("wow wow!")
}
}
class Yorkshire : Dog() { // 3
override fun sayHello() { // 4
println("wif wif!")
}
}
fun main() {
val dog: Dog = Yorkshire()
dog.sayHello()
}
```
#### 继承有参构造类
不得不说,这种写法真是太奇特了。
```kotlin
open class Tiger(val origin: String) {
fun sayHello() {
println("A tiger from $origin says: grrhhh!")
}
}
class SiberianTiger : Tiger("Siberia") // 1
fun main() {
val tiger: Tiger = SiberianTiger()
tiger.sayHello()
}
```
================================================
FILE: Android/feature.md
================================================
## feature 思考
### 拼多多自动拉起 app
android 的四大基础组件中,只有 activity 是完整的用户可见应用程序入口,剩下的三大基础组件用户都不可见,可以通过 Service 来注册一个不可见的服务,在某些条件下唤起主 activity。
还有另外一种做法是 app 间互相拉起,接入一个中间层 SDK,目前猜测可能是友盟有类似的服务,在接入友盟后某个 app 被杀掉后,可以由另外的 app 拉起。
================================================
FILE: Android/内存.md
================================================
## 内存知识
### Java GC
大概流程详见:[https://zhuanlan.zhihu.com/p/23102625]()
Java堆内存不足时,GC会被调用。当应用线程在运行,并在运行过程中创建新对象,若这时内存空间不足,JVM就会强制地调用GC线程,以便回收内存用于新的分配。若GC一次之后仍不能满足内存分配的要求,JVM会再进行两次GC作进一步的尝试,若仍无法满足要求,则 JVM将报 OOM(out of memory)的错误,Java应用将停止。
================================================
FILE: Android/基础知识.md
================================================
# Android 基础
## 名词解释
* APK:Android application package,Android 应用程序包;
*
## APK 基础
应用安装到设备后,每个 APK 都运行在自己的**安全沙箱**中(这点与 ipa 一致):
* Android 是一种多用户的 `Linux` 系统,其中每个应用都是一个不同的用户;
* 默认情况下,系统会为每个应用分配一个**唯一的 Linux 用户 ID**(应用不知晓)。系统为应用中的所有文件设置权限,使得只有分配给该应用的用户 ID 才能访问这些文件;
* 每个进程都具有自己的虚拟机,因此应用之间被隔离;
* 默认情况下,每个应用都在自己的 Linux 进程内运行。 Android 会在需要执行任何应用组件时启动该进程,然后在不需要时将该进程或系统必须为其它应用程序恢复内存时杀掉该进程;
Android 系统通过这种方式实现**最小权限原则**。默认情况下,每个英语都只能访问其工作所需的组件,而不能访问其它组件,在这个非常安全的环境中,应用无法访问系统中未获得权限的部分。但应用仍然可以通过一些途径与其它应用共享数据以及访问系统服务:
* 可以让两个应用共享同一个 Linux 用户 ID,它们可以相互访问彼此的文件。为了节省资源,可以让具有**相同用户 ID **、**相同签名证书**的应用在同一 Linux 进程中运行,并共享同一虚拟机
* 应用可以请求访问设备数据权限(联系人、相机、蓝牙等),用户必须明确授予这些权限。
## 应用组件(应用的基本构建基块)
系统都可以通过这些组件直接进入应用,但并非所以组件都是用户的实际入口。共有**四种不同的应用组件类型**,每种类型服务于不同的目的,并且具有定义组件创建和销毁方式的不同生命周期。
* **`Activity`**:`Activity` 表示具有用户界面的单一屏幕。每一个 `Activity` 都独立于其它 `Activity` 而存在,其它应用可以启动其中任何一个 `Activity`。例如,相机应用可以启动 email 应用内用于撰写新电子邮件的 `Activity`,以共享图片。
* **服务(`Service`)**:服务是一种在后台运行的组件,用于执行长时间运行的操作或为远程进程执行作业,且不提供用户界面。当用户设备前台处于其它应用时,服务可能在后台播放音乐或正在通过网络获取数据,此时并不会阻碍与 `Activity` 的交互。 `Activity` 等其它组件可以启动服务。
* **内容提供程序(`ContentProvider`)**:内容提供程序管理一组共享的应用数据,您可以将数据存储在文件系统、SQLite 数据库、网络或其它可以被应用访问到的地方。其它应用可以通过内容提供程序查询、修改数据。任何具有适当权限的应用都可以查询内容提供程序的某一部分。
* **广播接收器(`BroadcastReceiver`)**:广播接收器时一种用于响应系统范围广播通知的组件。许多广播都是由系统发起的,如通知屏幕已关闭、电池电量不足等,应用也可以发起广播,如其它应用某些数据已下载至该设备。同样,广播接收器也没有用户界面,但它们可以创建**状态栏通知**。
当系统启动某个组件时,会启动该应用的进程(如果还未运行),并实例化该组件所需的类。如果应用启动相机应用中拍摄照片的 `Activity` ,则该 `Activity` 会在属于相机应用的进程,而不是我们应用的进程中运行。所以,Android 应用并没有单一入口点(`main()` 函数)。
由于系统在单独的进程中运行每个应用,且其文件权限会限制对其它应用的访问,故我们的应用无法直接启动其它应用中的组件,但可通过 Android 系统传递消息,说明我们想要启动特定组件的 `intent`,系统随后便会启动。
### 启动组件
`Activity` 、服务和广播接收器通过 `intent` 的异步消息进行启动。 `intent` 会在运行时将各个组件相互绑定(可将 `intent` 视为从其它组件请求操作的信使),无论该组件是否为我们的应用。 `intent` 可以是显式的也可以是隐式的。对 `Activity` 和服务, `intent` 定义要执行的操作,并且可以指定要执行操作数据的 URI。
`intent` 不会启动内容提供程序组件,它会在成为 `ContentResolver` 的请求目标时启动,内容解析程序通过内容提供程序处理所有直接事物,使得通过提供程序执行事物的组件可以无需执行事物,而是改为在 `ContentResolver` 对象上调用方法,已留出一个抽象层确保安全。
每种类型的组件有不同的启动方法:
* 可以通过将 `Intent` 传递到 `startActivity()` 或 `startActivityForResult()`(当您想让 `Activity` 返回结果时)来启动 `Activity`(或为其安排新任务)。
* 可以通过将 `Intent` 传递到 `startService()` 来启动服务(或对执行中的服务下达新指令)。 或者,您也可以通过将 `Intent` 传递到 `bindService()` 来绑定到该服务。
* 可以通过将 `Intent` 传递到 `sendBroadcast()`、`sendOrderedBroadcast()` 或 `sendStickyBroadcast()` 等方法来发起广播;
* 可以通过在 `ContentResolver` 上调用 `query()` 来对内容提供程序执行查询。
## 清单文件
在 Android 系统启动应用组件之前,系统必须通过读取应用的 `AndroidManifest.xml` 文件(清单文件)来确认组件存在,应用必须在此文件中声明所有组件,该文件必须位于应用项目目录的根目录中。清单文件还有以下作用:
* 确定应用需要的任何用户权限,如互联网访问权限或对用户联系人的读取权限;
* 根据应用使用的 API,声明应用所需的最低 API 级别;
* 声明应用使用或需要的硬件和软件功能,如相机、蓝牙服务;
* 应用需要链接的 API 库(系统 API 除外);
通过以下方式声明所有应用组件:
* Activity 的 `<activity>` 元素
* 服务的 `<service>` 元素
* 广播接收器的 `<receiver>` 元素
* 内容提供程序的 `<provider>` 元素
如果在源码中写明的组件,但未再清单文件中声明的 `Activity`、服务和内容提供程序将对系统不可见且永远不会运行。不过广播接收器可以在清单文件中声明或在代码中动态创建,并在系统中注册即可。
### 声明组件功能
当在应用的清单文件中声明 `Activity` 时,可以选择性加入声明 `Activity` 功能的 `Intent` 过滤器,以便响应来自其它应用的 `Intent`,可以使用 `<intent-filter>` 元素作为组件声明元素的子项进行添加来为您的组件声明 `intent` 过滤器。
例如,电子邮件应用包含一个用于撰写新电子邮件的 `Activity`,则可以像下面这样声明一个 `Intent` 过滤器来响应“send” Intent(以发送新电子邮件):
```xml
<manifest ... >
...
<application ... >
<activity android:name="com.example.project.ComposeEmailActivity">
<intent-filter>
<action android:name="android.intent.action.SEND" />
<data android:type="*/*" />
<category android:name="android.intent.category.DEFAULT" />
</intent-filter>
</activity>
</application>
</manifest>
```
如果另一个应用创建了一个包含 `ACTION_SEND` 操作的 `Intent`,并将其传递到 `startActivity()`,则系统可能会启动您的 `Activity`,以便用户能够草拟并发送电子邮件。
### 声明应用要求
例如,如果您的应用需要相机,并使用 Android 2.1(API 级别 7)中引入的 API,您应该像下面这样在清单文件中以要求形式声明这些信息:
```xml
<manifest ... >
<uses-feature android:name="android.hardware.camera.any"
android:required="true" />
<uses-sdk android:minSdkVersion="7" android:targetSdkVersion="19" />
...
</manifest>
```
现在,没有相机且 Android 版本低于 2.1 的设备将无法从 Google Play 安装您的应用。
不过,您也可以声明您的应用使用相机,但并不要求必须使用。 在这种情况下,您的应用必须将 `required` 属性设置为 "false",并在运行时检查设备是否具有相机,然后根据需要停用任何相机功能。
## 应用资源
如果应用包含一个名为 `logo.png` 的图像文件(保存在 `res/drawable/` 目录中),则 SDK 工具会生成一个名为 `R.drawable.logo` 的资源 ID,可以利用它来引用该图像并将其插入用户界面。
================================================
FILE: Android/问题汇总.md
================================================
# Andriod 问题汇总
## 设备
新购了一台开发机 meizu 15。之前有考虑过小米6,但京东和淘宝上都没有找到靠谱的卖家,接着看了华为和三星,华为的低端机的外观实在是不敢恭维,三星的 A9 让我惊艳了一番,但价格有些稍贵,最后逛了 meizu,发现居然有了我当初高一高二时火爆的 meizu MX2 外观类似的机型!由于情怀因素,就购置了 meizu 15。
## 开发者模式
Andriod 与 iOS 不一致的地方在于设备默认是“不可调试”的,必须打开“开发者模式”后才能进行调试,在 meizu 15 上,打开开发者模式的流程如下:
* 设置-关于手机。滑动到最底下,找到“Andriod 版本”,连续点击 7 下,即可看到“已经打开开发者模式”的 toast 提示;
* 设置-辅助功能-开发者选项(上一步未完成是看不到的)。开启开发者选型,且启动“USB 调试”。
================================================
FILE: Back-end/DB.md
================================================
# 数据库相关知识点
## 备份
* 先写日志,再写 SQL。这样可以保证当 SQL 写入出现问题时,可以查到日志。
### 备份策略
周日 | 周一 | 周二 | 周三 | 周四 | 周五 | 周六 |
--- | --- | --- | --- | --- | --- | --- |
完全备份|增量备份|增量备份|增量备份|差量备份|增量备份|增量备份|
周四差量备份可以保证当周五或周六出现问题时,不用一次次的反复回复一二三的增量备份。
================================================
FILE: Back-end/Docker.md
================================================
# Docker
## 虚拟化和容器化技术
### 虚拟化技术
虚拟化技术是一种将计算机物理资源进行抽象、转换为虚拟的计算机资源提供给程序使用的技术。这些资源包括了 CPU 提供的运算控制资源,硬盘提供的数据存储资源,网卡提供的网络传输资源等。
#### 跨平台
保证程序跨平台兼容,也就是要保证操作系统或物理硬件所提供的接口调用方式一致,程序便不需要兼容不同硬件平台的接口。此时突然想到,使用 `Swift` 编写 iOS app 时,构建出包后总是会带上 `Swift` 的整个运行时,以保证随着 iOS 系统版本的升级 app 的正常运行,因其 `ABI` 并未稳定,还不能内置在操作系统中。
#### 资源管理
可将虚拟化技术运用于计算机资源的管理,其中最实用的就是“虚拟内存”虚拟化技术能够提高计算机资源的使用率,是指利用虚拟化,可以将原来程序用不到的一些资源拿出来,分享给另外一些程序,让计算机资源不被浪费。
### 虚拟化技术的分类
主要分为两大类:**硬件虚拟化**和**软件虚拟化**。
* 硬件虚拟化:比如假设 iOS 基于的 arm 架构 CPU 能够运行基于 x86 架构的 macOS 应用程序,这是因为 CPU 能够将另外一个平台的指令集转换为自身的指令集执行(但实际上并不可能)。
* 软件虚拟化:在 2018 WWDC 中,宣布可以在 `UIKit` 层面提供一部分把 iOS app 转移到 macOS app 中的特性,可以理解为是 Apple 在 Xcode 层面协助开发者构建了迁移代码,帮开发者解决了不同平台指令的转换。也就是说,软件虚拟化实际上是通过一层夹杂在应用程序和硬件平台上的虚拟化实现软件来进行指令的转换。
其它虚拟化技术的分类:
* **平台虚拟化**:在操作系统和硬件平台间搭建虚拟化设施,使得整个操作系统都运行在虚拟后的环境中。类似 `VMware`、`PD`;
* **应用程序虚拟化**:在操作系统和应用程序间实现虚拟化,只让应用程序运行在虚拟化环境中。类似 `Python` 的虚拟环境;
* **内存虚拟化**:将不相邻的内存区,甚至硬盘空间虚拟成统一连续的内存地址,即虚拟内存;
* **桌面虚拟化**:让本地桌面程序利用远程计算机资源运行,达到控制远程计算机的目的。类似华为云的云桌面以及各种远程桌面控制软件,如 Teamviewer。
* ......
### 虚拟机
虚拟机通常说法是通过一个**虚拟机监视器( Virtual Machine Monitor )** 的设施来隔离操作系统与硬件或应用程序和操作系统,以达到虚拟化的目的。这个虚拟机监视器,通常被称为:**`Hypervisor`**。
虚拟机有一个永远都逃不掉的问题:性能低下。这种效率的低下有时候是无法容忍的,故真实的虚拟机程序常常不完全遵守 `Hypervisor` 的设计结构,而是引入一些其它技术来解决效率低下问题,比如解释执行、即时编译(Just In Time)运行机制,但这些技术的引入已不属于虚拟化的范畴了。
### 容器技术
按分类或者实现方式来说,容器技术应该属于**操作系统虚拟化**,也就是在由操作系统提供虚拟化的支持。总的来说,容器技术指的是操作系统自身支持一些接口,能够让应用程序间可以互不干扰的独立运行,并能够对其在运行中所使用的资源进行干预。
那这也不应该被称为“容器”呀?是的,这里所谓的容器指的是由于应用程序的运行被隔离在了一个独立的运行环境之中,这个独立的运行环境就好似一个容器,包裹了应用程序。
容器这么火爆,火到一心扑在 iOS 上的我都要好好梳理一番,很重要的一个原因是其在运行性能上远超虚拟机等其它虚拟化实现,甚至在运行效率上与真实运行在物理平台的应用程序不相上下。但注意,容器技术并没有进行指令转换,运行爱容器中的应用程序自身必须支持在真实操作系统上运行,也就是必须遵守硬件平台的指令规则。
曾经看到一篇文章说 `linux` **内核命名空间**的改进,直接推动了容器的最大化发展。
> 利用内核命名空间,从进程 ID 到网络名称,一切都可在 Linux 内核中实现虚拟化。新增的用户命名空间“使得用户和组 ID 可以按命名空间进行映射。对于容器而言,这意味着用户和组可以在容器内部拥有执行某些操作的特权,而在容器外部则没有这种特权。”Linux 容器项目 (LXC) 还添加了用户亟需的一些工具、模板、库和语言绑定,从而推动了进步,改善了使用容器的用户体验。LXC 使得用户能够通过简单的命令行界面轻松地启动容器。(来源 `redhat` 官网)
容器由于没有虚拟操作系统和虚拟机监视器这两个层次,大幅减少了应用程序带来的额外消耗。所以在容器中的应用程序其实完全运行在了宿主操作系统中,与其它真实运行在其中的应用程序在指令运行层面是完全没有任何区别的。
## `Docker` 的核心组成
### 四大组成对象
#### 镜像
可以理解为一个只读的文件包,其中包含了虚拟环境运行的最原始文件系统的内容。
因为 `Docker` 采用 `AUFS` 作为底层文件系统的实现,实现了一种**增量式**的镜像结构。每次对镜像内容修改,`Docker` 都会将这些修改铸造成一个镜像层,而一个镜像本质上是由其下层所有的镜像层所组成的,而每一个镜像层单独拿出来,都可以与它之下的镜像层组成一个镜像。正是由于这种结构,`Docker` 的镜像本质上是无法被修改的,因为所以的镜像修改只会产生新的镜像,而不是更新原有的镜像。
#### 容器
在容器技术中,容器是用来隔离虚拟环境的基础设施,但在 `Docker` 中,被引申为隔离出来的虚拟环境。如果我们把镜像理解为类,则容器为实例对象。镜像内存放的是不可变化的东西,当以他们为基础的容器启动后,容器内也就成为类一个“活”的空间。
`Docker` 的容器应该有三项内容组成:
* 一个 `Docker` 镜像;
* 一个程序运行环境;
* 一个指令集合。
#### 网络
在 `Docker` 中可对每个容器进行单独的网络配置,也可对各个容器间建立虚拟网络,将数个容器包裹其中,同时与其它网络环境隔离,并且 `Docker` 还能在容器中构造独立的 `DNS`,我们可以在不修改代码和配置的前提下直接迁移容器。
#### 数据卷
在以往的虚拟机中,大部分情况下都直接使用虚拟机的文件系统作为应用数据等文件的存储位置,但并未是完全安全的,当虚拟机或容器出现问题导致文件系统无法使用时,虽可直接通过快速的镜像进行重制文件系统以至于恢复,但数据也就丢失了。
为保证数据的独立性,通常会单独挂在一个文件系统来存放数据,得意与 `Docker` 底层的 `Union File System` 技术,我们可以不用管类似于搞定挂载在不同宿主机中实现的方法、考虑挂载文件系统兼容性、虚拟机操作系统配置等问题。
## 镜像与容器
### `Docker` 镜像
所有的 `Docker` 镜像都是按照 `Docker` 所设定的逻辑打包的,也是收到 `Docker Engine` 所控制。常见的虚拟机镜像都是由其它用户通过各自熟悉的方式打包成镜像文件,公布到网上再被其它用户所下载后,恢复到虚拟机中的文件系统中,但 `Docker` 的镜像必须通过 `Docker` 来打包,也必须通过 `Docker` 下载或导入后使用,不能单独直接恢复成容器中的文件系统。这样,我们就可以直接在服务器之间传递 `Docker` 镜像,并配合 `Docker` 自身对镜像的管理功能,使得在不同的机器中传递和共享变得非常方便。
每一个记录文件系统修改的镜像层 `Docker` 都会根据它们的信息生产一个64位的 `hash` 码,正是因为这个编码,可以能够区分不同的镜像层并保证内容和编码是一致的,我们可以在镜像之间共享镜像层。当 `A` 镜像依赖了 `C` 镜像,且 `B` 镜像也依赖了 `C` 镜像,在实际使用过程中,`A` 和 `B` 两个镜像是可以公用 `C` 镜像内部的镜像层的。
#### 查看镜像
```
$ docker images
```
#### 镜像命名
可以分为三部分:
* **username**:一般都是镜像创作者,但如果不写则是由官方进行维护。
* **repository**:一般都是该镜像中所包含的软件名。但镜像名归镜像名,镜像归镜像,`Docker` 对容器的设计和定义是微型容器而不是庞大臃肿的完整环境,所有通常只会在一个容器中运行一个应用程序,能够大幅降低程序之间互相的影响,利用容器技术控制每个程序所使用的资源。
* **tag**:
#### 主进程
在 `Docker` 的设计中,容器的生命周期与容器中 `PID` 为 1 这个进程由密切的关系,容器的启动本质上可以理解为这个进程的启动,而容器的停止也就意味着这个进程的停止。
### 写时复制
通过镜像运行容器时并不是立即把镜像里所有内容拷贝到容器所运行的沙盒文件系统中,而是利用 `UnionFS` 将镜像以只读方式挂载到沙盒文件系统中,只有在容器对文件的修改时,修改才会体现到沙盒环境上。
## 从镜像仓库获得镜像
### 获取镜像
```
docker pull ubuntu
```
### 获取镜像更详细的信息
```
docker inspect ubuntu
```
### 搜索镜像
```
docker search django
```
### 删除镜像
```
docker rmi ubuntu
```
## 运行和管理容器
### 容器的生命周期
* **Created**
* **Running**
* **Paused**
* **Stopped**:容器的停止状态下,占用的资源和沙盒环境都存在,只是容器中的应用程序均已停止
* **Deleted**
#### 创建容器
```
$ docker create ubuntu
```
如果我们之前选择的 `docker pull` 容器并不是默认的 `latest` 版本,而是手动选择了一个版本,那镜像的名字将会比如 `nginx:1.12`,对于后续的操作都十分的不方便,对此,我们可以采用 `--name` 进行重命名:
```
$ docker create --name nginx nginx:1.12
```
#### 启动容器
```
$ docker start ubuntu
```
通过 `docker run` 可将上述两个命令进行合并:
```
$ docker run --name nginx nginx:1.12
```
以上命令跑起来的容器运行都是运行在前台,如果我们想要容器运行在后台,可以通过 `-d`,其是 `-detach` 的简称,告诉 `Docker` 在启动后将程序和控制进行分离。:
```
$ docker run -d ubuntu
```
#### 管理容器
列出运行中的所有容器
```
$ docker ps
```
列出所有容器
```
$ docker ps -a/-all
```
其中打印出的列表需要注意的是 **STATUS** 字段,常见的状态表示有三种:
* **Create**:容器已创建,没有启动过;
* **Up[ Time ]**:容器正在运行,[ Time ] 代表从开始运行到查看时的时间;
* **Exited([ Code ]) [ Time ]**:容器已结束运行,[ Code ] 表示容器结束运行时,主程序返回的程序退出码,而 [ Time ] 则表示容器结束到查看时的时间。
#### 停止和删除容器
```
$ docker stop ubuntu
```
容器停止后,其维持的文件系统沙盒环境会一直保存,内部被修改的内容也会被保留。通过 `docker start` 将容器继续启动。
当需要把容器完全删除容器,可以使用:
```
$ docker rm ubuntu
```
但在运行中的容器默认情况下是不能被删除的,但我们可以通过以下命令进行删除:
```
$ docker rm -f ubuntu
```
#### 随时删除容器
`Docker` 与其它虚拟机不同,其所定位的轻量级设计讲究随用随开,随关随删,当我们短时间内不需要使用容器时,最佳的做法是删除它而不是仅仅停止它。
如果我们要对程序做一些环境配置,完全可以直接将这些配置打包至一个新的镜像中,下次直接使用该镜像创建容器即可。对于一些重要的文件资料,不能随着容器的删除而删除,可以使用 `Docker` 中的**数据卷**来单独存放。
### 进入容器
#### 直接创建,进入
```
$ docker run -it --name ubuntu ubuntu
```
#### 已经创建完成,进入
```
$ docker exec -it ubuntu /bin/bash
```
* `-i` 表示保持我们的输入流;
* `-t` 表示启用一个伪终端,形成我们与 bash 的交互。
当容器运行在后台,想要在将当前的输入输出流连接到指定的容器上,可以这么做:
```
$ docker attach ubuntu
```
通过 `docker attach` 启动的容器,可以理解为与 `docker run -d` 做了相反的事情,把当前容器从后台拉回了前台。
## 为容器配置网络
### 容器网络
在 `Docker` 网络中,有三个比较核心的概念,形成了 `Docker` 的网络核心模型,即**容器网络模型(Container Network Model)**:
* 沙盒:提供容器的虚拟网络栈。比如端口套接、`IP` 路由表、防火墙等;
* 网络:`Docker` 内部的虚拟子网,网络内的参与者相互可见并能够进行通讯。需要注意的是,这种虚拟网络与宿主机存在隔离关系。
* 端点:主要目的是形成一个可以控制的突破封闭网络环境的出入口,当容器的端点与网络的端点形成配对后,就如同在这两者之间搭建了桥梁,可进行数据传输。
### `Docker` 的网络实现
目前官方提供了五种网络驱动:
* Bridge Driver(default):通过基于硬件或软件的网桥来实现通讯
* Host Driver
* Overlay Driver:借助 `Docker` 的集群模块 `Docker Swarm` 来搭建的跨 `Docker Daemon` 网络,可以通过它搭建跨物理主机的虚拟网络,从而让不同物理机中运行的容器感知不到多个物理机的存在。
* MacLan Driver
* None Driver
### 容器互联
让一个容器连接到另外一个容器,可以通过 `docker create` 或 `docker run` 创建时通过 `--link` 选项进行配置。例如,创建一个 `Mysql` 容器,将运行的 `web` 容器连接到这个 `Mysql` 容器中:
```shell
$ sudo docker run -d --name PJMysql -e MYSQL_RANDOM_ROOT_PASSWORD=yes mysql
$ sudo docker run -d --name webapp --link mysql webapp:latest
```
网络已经打通,在 `web` 应用程序中连接到 `Mysql` 数据库可以使用 `Docker` 提供的简便方式,只需要通过**容器的网络命名**填入到连接地址中即可访问需要连接的容器,连接地址中的 `PJMysql` 类似于域名解析,`Docker` 会将其指向 `Mysql` 容器的 `IP` 地址,从此映射 `IP` 的工作就交给 `Docker` 完成了!以 `Django` 配置文件为例:
```python
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'pigpen',
'USER': 'pigpen',
'PASSWORD': 'pigpen_2018',
# 在此次填入 mysql 容器的网络命名,我的是 PJMysql
'HOST': 'PJMysql',
'PORT': '3306',
'ATOMIC_REQUESTS': True,
}
}
```
#### 暴露端口
容器与容器间的网络打通了,但我们还是不能访问已经连接容器中的任何服务。`Docker` 为容器网络增加了一套**安全机制**,只有容器自身允许的端口,才能被其它容器所访问。这个容器自我标记端口可被访问的过程,通常称为`暴露端口`。通过 `docker ps` 命令可以看到容器暴露给其它容器访问的端口(`PORTS` 字段下将会列出):
```shell
PJ@localhost:~$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e1c348025713 ubuntu "/bin/bash" 6 days ago Up 6 days ubuntu
```
如果想增加容器对外暴露的端口,可以在容器创建时使用 `--expose` 选项进行增加:
```shell
$ sudo docker run -d --name mysql -e MYSQL_RANDOM_ROOT_PASSWORD=yes --expose 13306 --expose 23306 mysql:5.7
```
但还需要注意的是,容器中所暴露出的端口可以认为我们只是打开了容器的防火墙,能否通过这个端口去访问容器中的服务还需要容器中的应用监听并处理来自这个端口的请求,比如我们虽然打开了 `Nginx` 容器的 `443` 端口,并不意味着该容器能够直接对来自 `443` 端口的数据进行处理,需要在 `Nginx` 容器中的对应文件中进行配置处理。
#### 别名连接
`Docker` 还支持连接时使用别名来摆脱对容器名的限制:
```shell
$ sudo docker run -d --name webapp --link mysql:database webapp:latest
```
以使用 `JDBC`进行数据库连接的配置为例,对 `Mysql` 容器进行别名设置后,可以改为:
```java
String url = "jdbc:mysql://database:3306/webapp";
```
### 网络管理
容器之间能够相互连接的前提是两者处于同一个网络之中,这里网络概念可以理解为 `Docker` 所处的虚拟子网,而容器网络沙盒可以看作是虚拟的主机,只有当多个主机在同一个子网里时,才能互相看到并进行网络数据的交换。
当我们启动一个 `Docker` 服务时,默认会给我们创建一个 `bridge` 网络,而我们创建的容器如果不显式指定网络的情况下都会连接到这个网络上。通过 `docker inspect` 命令查看容器,可以在打印出的信息中看到容器网络相关的信息:
```shell
$ PJ@localhost:~$ docker inspect ubuntu
"NetworkSettings": {
"Bridge": "",
"SandboxID": "a70241c1c304d46e60ca2ee4e95df7474cf1318e316ef104abe87d22b68588bb",
"HairpinMode": false,
"LinkLocalIPv6Address": "",
"LinkLocalIPv6PrefixLen": 0,
"Ports": {},
"SandboxKey": "/var/run/docker/netns/a70241c1c304",
"SecondaryIPAddresses": null,
"SecondaryIPv6Addresses": null,
"EndpointID": "41e89e7a31382f5a28e9c0e5618ab37cc6427430e6b83f24936c263f74a81381",
"Gateway": "172.17.0.1",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"IPAddress": "172.17.0.2",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"MacAddress": "02:42:ac:11:00:02",
"Networks": {
"bridge": {
"IPAMConfig": null,
"Links": null,
"Aliases": null,
"NetworkID": "482a88e80b5585ef83a0b5bcd41eb3550aa4056bd22fd49884ded618be9bbe80",
"EndpointID": "41e89e7a31382f5a28e9c0e5618ab37cc6427430e6b83f24936c263f74a81381",
"Gateway": "172.17.0.1",
"IPAddress": "172.17.0.2",
"IPPrefixLen": 16,
"IPv6Gateway": "",
"GlobalIPv6Address": "",
"GlobalIPv6PrefixLen": 0,
"MacAddress": "02:42:ac:11:00:02",
"DriverOpts": null
}
}
}
```
在打印出的信息中,我们可以看到该容器在 `bridge` 网络中所分配的 `IP` 地址、自身的端点、`Mac` 地址、`bridge` 网络的网关地址等信息。
#### 创建网络
`Docker` 也能够创建网络,形成自己定义虚拟子网的目的。`Docker` 里与网络相关的命令都以 `docker network` 开头,使用 `docker network create` 来创建网络:
```shell
sudo docker network create -d bridge PJNetwork
```
通过添加 `-d` 选项可以为新的网络指定驱动类型,可以是之前所提及的 `bridge`、`host`、`overlay`、`maclan`、`none`,也可以是其它网络驱动插件所定义的类型,当我们不指定网络驱动时,`Docker` 也会默认采用 `Bridge Driver` 作为网络驱动。
通过 `docker network ls/list` 可以查看 `Docker` 中已存在的网络,我的如下所示:
```shell
PJ@localhost:~$ docker network ls
NETWORK ID NAME DRIVER SCOPE
482a88e80b55 bridge bridge local
4a3f4ba8daf8 host host local
2f6f7bb9f46e none null local
```
在创建容器时,可以通过 `--network` 来指定容器所加入的网络,一旦该选项参数被指定,容器则不会再加入到 `bridge` 该网络中,但后续仍可通过 `--network bridge` 使其加入:
```shell
$ sudo docker run -d --name mysql -e MYSQL_RANDOM_ROOT_PASSWORD=yes --network PJNetwork mysql:5.7
```
### 端口映射
如果我们需要在容器外通过网络访问容器中的应用,比如提供了 `web` 服务,那就需要提供一种方式访问运行在容器中的 `web` 应用。在 `Docker` 中,提供了**端口映射**的功能来实现。
通过 `Docker` 的端口映射功能,可以把容器的端口映射到宿主操作系统的端口上,当从外部访问宿主操作系统的端口时,数据请求就会自动发送给与之关联的容器端口。在创建容器时,可以使用 `-p/--publish` 选项来指定映射端口。
```shell
$ sudo docker run -d --name nginx -p 80:80 -p 443:443 nginx:1.12
```
使用端口映射选项的格式是 `-p <ip>:<host-port>:<container-port>`,其中 `ip` 是宿主操作系统的监听 `ip`,可以用来控制监听的网卡,默认为 `0.0.0.0`,也就是监听所有网卡。`host-port` 和 `container-port` 分别表示映射到宿主操作系统的端口和容器的端口,这两者是可以不一样的,我们可以将容器的 `80` 端口映射到宿主操作系统的 `8080` 端口,传入 `-p 8080:80` 即可。
## 管理和存储数据
#### 挂载方式
基于底层存储实现,`Docker` 提供了三种适用于不同场景的文件系统挂载方式:
* **Bind Mount**:将宿主操作系统中的目录和文件挂载到容器内的文件系统中,通过指定容器外的路径和容器内的路径,形成挂载映射关系,在容器内外对文件的读写,都是相互可见的。
* **Volume**:
* **Tmpfs Mount**
================================================
FILE: Back-end/RESTful.md
================================================
# REST
`HTTP` 是一种**应用层**协议,能从 `HTTP` 基础设施中获取多少收益,主要取决于把它用做应用层协议用得有多好。
`HTTP` 实际上是为 `REST` 而生的,它能够表达状态和状态转移,者就是它位于应用层而非传输层的原因。
## 使用统一接口
### 如何保持交互的可见性
可见性是 `HTTP` 的一个核心特征。可见性是“一个组件能够对其他两个组件之间的交互进行监视或仲裁的能了”。当协议是可见的时,缓存、代理、防火墙等组件就可以监视甚至参与其中。
`HTTP` 通过一下途径来实现可见性:
* `HTTP` 的交互是无状态的,任何 `HTTP` 中介都可以推断出给定请求和响应的意义,而无须关联过去或将来的请求和响应。
* `HTTP` 使用一个统一接口,包括有 `OPTIONS`,`GET`,`HEAD`,`POST`,`DELETE` 和 `TRACE` 方法。接口中的每一个方法操作一个且仅有一个资源。每个方法的语法和含义不会因应用程序或资源的不同而发生改变。
* `HTTP` 使用一种与 [`MIME`](https://developer.mozilla.org/zh-CN/docs/Web/HTTP/Basics_of_HTTP/MIME_types) 类似的信封格式进行表述编码。这种格式明确区分标头和内容。标头时可见的,除了创建、处理消息的部分,软件的其他部分都可以不用关心消息的内容。
对于 `RESTful web` 服务,主要目标是尽可能保持可见性。保持可见性非常简单,使用 `HTTP` 方法时,其语义要与 `HTTP` 所规定的语义保持一致,并添加适当的标头来描述请求和响应。
## HTTP 方法的安全性和幂等性
### 安全性
安全性并不意味着服务器每次都必须返回同一结果。它只是表明客户端可以发送请求,并指导它不会改变资源的状态。
### 幂等性
幂等性保证客户的发起多次请求获取到的结果和一次请求获取到的结果一致。
================================================
FILE: Back-end/Vapor.md
================================================
# Vapor
在这里将记录使用 Vapor 的过程中遇到的问题。感觉特别一些设计模式的 tips 杂糅在一起后,就特别像 `Django`。
## 如何快速开始
### 下载 `vapor`
[详见官网](https://docs.vapor.codes/3.0/install/macos/)。
### 运行 `Hello, world!`
* `vapor new yourProjectName`。创建模版工程,当然可以加上 `--template=api` 来创建提供对应服务的模版工程,但我测试了一下好像没什么区别。
* `vapor xcode`。创建 Xcode 工程,特别特别慢,而且会有一定几率失败。
### MVC
`Vapor` 默认是 `SQLite` 的**内存**数据库。我原本想看看 `Vapor` 自带的 `SQLite` 数据库中的表,但没翻着,最后想了一下,这是内存数据库啊,也就是说,每次 `Run` 数据都会被清空。可以从 `config.swift` 中看出:
```swift
// ...
let sqlite = try SQLiteDatabase(storage: .memory)
// ...
```
在 `Vapor` 文档中写了推荐使用 `Fluent` ORM 框架进行数据库表结构的管理,刚开始我们并不了解关于 `Fluent` 的任何内容,可以查看模版文件中的 `Todo.swift`:
```swift
import FluentSQLite
import Vapor
final class Todo: SQLiteModel {
/// 唯一标识符
var id: Int?
var title: String
init(id: Int? = nil, title: String) {
self.id = id
self.title = title
}
}
/// 实现数据库操作。如增加表字段,更新表结构
extension Todo: Migration { }
/// 允许从 HTTP 消息中编解码出对应数据
extension Todo: Content { }
/// 允许使用动态的使用在路由中定义的参数
extension Todo: Parameter { }
```
从模版文件中的 `Model` 可以看出来创建一张表结构相当于是**描述一个类**,之前有使用过 `Django` 的经验,看到 `Vapor` 的这种 ORM 这么 `Swifty` 确实眼前一亮。`Vapor` 同样可以遵循 `MVC` 设计模式进行构建,在生成的模版文件中确实是基于 `MVC` 去做的。
#################### 没写完
### 从 `SQLite` 到 `Mysql`
这部分 `Vapor` 官方文档讲的不够系统,虽然都点到了但是过于分散,而且我感觉 `Vapor` 的文档是不是跟 Apple 学了一套,细节都不展开,遇到一些字段问题得亲自写下代码,然后看实现和注释,不写之前你是很难知道在描述什么。
#### `Package.swift`
在 `Package.swift` 中写下对应的依赖,
```swift
import PackageDescription
let package = Package(
name: "Unicorn-Server",
products: [
.library(name: "Unicorn-Server", targets: ["App"]),
],
dependencies: [
.package(url: "https://github.com/vapor/vapor.git", from: "3.0.0"),
// here
.package(url: "https://github.com/vapor/fluent-mysql.git", from: "3.0.0"),
],
targets: [
.target(name: "App",
dependencies: [
"Vapor",
"FluentMySQL"
]),
.target(name: "Run", dependencies: ["App"]),
.testTarget(name: "AppTests", dependencies: ["App"])
]
)
```
触发更新
```shell
vapor xcode
```
`Vapor` 搞了我几次,更新依赖的时候特别慢,而且还更新失败,导致我现在每次更新时都要去确认一遍依赖是否更新成功。
#### 更新 ORM
更新成功后,我们就可以根据之前生成的模版文件 `Todo.swift` 的样式改成 `MySQL` 版本的 ORM:
```swift
import FluentMySQL
import Vapor
/// A simple user.
final class User: MySQLModel {
/// The unique identifier for this user.
var id: Int?
/// The user's full name.
var name: String
/// The user's current age in years.
var age: Int
/// Creates a new user.
init(id: Int? = nil, name: String, age: Int) {
self.id = id
self.name = name
self.age = age
}
}
/// Allows `User` to be used as a dynamic migration.
extension User: Migration { }
/// Allows `User` to be encoded to and decoded from HTTP messages.
extension User: Content { }
/// Allows `User` to be used as a dynamic parameter in route definitions.
extension User: Parameter { }
```
其实改动的地方只有两个,`import FluentMySQL` 和继承自 `MySQLModel`。
#### 修改 `config.swift`
```swift
import FluentMySQL
import Vapor
/// 应用初始化完会被调用
public func configure(_ config: inout Config, _ env: inout Environment, _ services: inout Services) throws {
// === mysql ===
// 首先注册数据库
try services.register(FluentMySQLProvider())
// 注册路由到路由器中进行管理
let router = EngineRouter.default()
try routes(router)
services.register(router, as: Router.self)
// 注册中间件
// 创建一个中间件配置文件
var middlewares = MiddlewareConfig()
// 错误中间件。捕获错误并转化到 HTTP 返回体中
middlewares.use(ErrorMiddleware.self)
services.register(middlewares)
// === mysql ===
// 配置 MySQL 数据库
let mysql = MySQLDatabase(config: MySQLDatabaseConfig(hostname: "", port: 3306, username: "", password: "", database: "", capabilities: .default, characterSet: .utf8mb4_unicode_ci, transport: .unverifiedTLS))
// 注册 SQLite 数据库配置文件到数据库配置中心
var databases = DatabasesConfig()
// === mysql ===
databases.add(database: mysql, as: .mysql)
services.register(databases)
// 配置迁移文件。相当于注册表
var migrations = MigrationConfig()
// === mysql ===
migrations.add(model: User.self, database: .mysql)
services.register(migrations)
}
```
注意 `MySQLDatabaseConfig` 的配置信息。如果我们的 mysql 版本在 **8** 以上,目前只能选择 `unverifiedTLS` 进行验证连接MySQL容器时使用的安全连接选项,也即 `transport` 字段。在代码中用 `// === mysql ===` 进行标记的代码块是跟模版文件中使用 `SQLite` 所不同的地方。
#### 运行
运行工程,打开 mysql 进行查看。
```shell
mysql> show tables;
+----------------------+
| Tables_in_unicorn_db |
+----------------------+
| fluent |
| Sticker |
| User |
+----------------------+
3 rows in set (0.01 sec)
mysql> desc User;
+-------+--------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+--------------+------+-----+---------+----------------+
| id | bigint(20) | NO | PRI | NULL | auto_increment |
| name | varchar(255) | NO | | NULL | |
| age | bigint(20) | NO | | NULL | |
+-------+--------------+------+-----+---------+----------------+
3 rows in set (0.01 sec)
```
`Vapor` 不像 `Django` 那般在生成的表加上前缀,而是你 ORM 类名是什么,最终生成的表名就是什么,这点很喜欢!
### 对表字段的修改
`Vapor` 没有像 `Django` 那么强大的工作流,很多人都说 `Perfect` 像 `Django`,我自己的认为 `Vapor` 像 `Flask`。
对 `Vapor` 修改表字段,不仅仅只是修改 `Model` 属性这么简单,同样也不像 `Django` 中修改完后,执行 `python manage.py makemigrations` 和 `python manage.py migrate` 就结束了,我们需要自己创建迁移文件,自己写清楚此次表结构到底发生了什么改变。
在泊学的[这篇文章](https://boxueio.com/series/vapor-fluent/ebook/473)中推荐在 `App` 目录下创建一个 `Migrations group`,方便操作。但我思考了一下,这么做势必会造成 `Model` 和对应的迁移文件割裂,然后在另外一个上级文件夹中又要对不同迁移文件所属的 `Model` 做切分,这很显然是有一些问题的。最后,我脑子冒出了一个非常可怕的想法:“`Django` 是一个非常强大、架构非常良好的框架!”。
所以,最后我的目录是这样的:
```shell
Models
└── User
├── Migrations
│ ├── 19-04-30-AddUserCreatedTime.swift
│ └── 19-04-30-DeleteUserNickname.swift
├── UserController.swift
└── User.swift
```
这是 `Django` 中的一个 `app` 文件树:
```shell
user_avatar
├── __init__.py
├── admin.py
├── apps.py
├── migrations
│ ├── 0001_initial.py
│ ├── 0002_auto_20190303_2154.py
│ ├── 0002_auto_20190303_2209.py
│ ├── 0003_auto_20190303_2154.py
│ ├── 0003_auto_20190322_1638.py
│ ├── 0004_merge_20190408_2131.py
│ └── __init__.py
├── models.py
├── tests.py
├── urls.py
└── views.py
```
已经删除掉了一些非重要信息。可以看到,`Django` 的 `app` 文件夹结构非常好!注意看 `migrations` 文件夹下的迁移文件命名。如果开发能力不错的话,我们是可以做到与业务无关的 `app` 发布供他人直接导入到工程中。
不过关于工程文件的管理,这是一个智者见智的事情啦~对于我个人来说,我反而更加喜欢 `Vapor`/`Flask` 一系,因为需要什么再加什么,整个设计模式也可以按照自己的喜好来做。
#### 删除一个表字段
使用 `Swift` 开发服务端很容易受到使用 `Swift` 做其它开发的影响。刚开始时我确实认为在 `Model` 中把需要删除的字段删除就好了,然而运行工程后去查数据库发现并不是这么一回事。
首先,我们需要先创建一个文件来写 `Model` 的迁移代码,但这不是必须的,你可以把该 `Model` 后续需要进行表字段的 CURD 都写在同一个文件中,因为没一个迁移都是一个 `struct`。我的做法是像上文所说,对每一个迁移都做新文件,并且每一个迁移文件都写上“时间”和“做了什么”。
```swift
import FluentMySQL
struct DeleteUserNickname: MySQLMigration {
static func prepare(on conn: MySQLConnection) -> EventLoopFuture<Void> {
return MySQLDatabase.create(User.self, on: conn, closure: {
$0.field(for: \.id, isIdentifier: true)
$0.field(for: \.nickname)
})
}
static func revert(on conn: MySQLConnection) -> EventLoopFuture<Void> {
return MySQLDatabase.delete(User.self, on: conn)
}
}
```
发现了一个问题,如果我们从 `Model` 中已经提前删除掉了需要移除的字段,那么在 `migrations` 中,这个字段就没法被索引,因为已经被移除了,那么就无法被 `deleteField`。最终我的解决办法是,因为这个字段已经不需要了,那么直接写 SQL 删除掉这个字段。
隐约觉得,这不是 `Vapor` 的最佳实践。
#### 增加/修改一个表字段
```swift
import FluentMySQL
struct AddUserCreatedTime: MySQLMigration {
static func prepare(on conn: MySQLConnection) -> EventLoopFuture<Void> {
return MySQLDatabase.update(User.self, on: conn, closure: {
$0.field(for: \.fluentCreatedAt)
})
}
static func revert(on conn: MySQLConnection) -> EventLoopFuture<Void> {
return MySQLDatabase.delete(User.self, on: conn)
}
}
```
需要注意的是,不管你是要做 CURD 中的任何一个功能,你都需要实现 `prepare` 和 `revert` 两个方法,`revert` 方法的作用是用于撤销 `prepare` 方法中的逻辑。
### Auth
在 `Vapor` 中有两种对用户鉴权的方式。一为适用 `API` 服务的 `Stateless` 方式,二为适用于 `Web` 的 `Sessions`,
#### 添加依赖
```swift
// swift-tools-version:4.0
import PackageDescription
let package = Package(
name: "Unicorn-Server",
products: [
.library(name: "Unicorn-Server", targets: ["App"]),
],
dependencies: [
.package(url: "https://github.com/vapor/vapor.git", from: "3.0.0"),
.package(url: "https://github.com/SwiftyJSON/SwiftyJSON.git", from: "4.0.0"),
.package(url: "https://github.com/vapor/fluent-mysql.git", from: "3.0.0"),
// 添加 auth
.package(url: "https://github.com/vapor/auth.git", from: "2.0.0"),
],
targets: [
.target(name: "App",
dependencies: [
"Vapor",
"SwiftyJSON",
"FluentMySQL",
// 添加 auth
"Authentication"
]),
.target(name: "Run", dependencies: ["App"]),
.testTarget(name: "AppTests", dependencies: ["App"])
]
)
```
执行 `vapor xcode` 拉取依赖并重新生成 `Xcode` 工程。
#### 注册
在 `config.swift` 中增加:
```swift
public func configure(_ config: inout Config, _ env: inout Environment, _ services: inout Services) throws {
// ...
try services.register(AuthenticationProvider())
// ...
}
```
#### Basic Authorization
简单来说,该方式就是验证密码。我们需要维护一个做 `Basic Authorization` 方式进行鉴权的 `Path` 集合。请求属于该集合中的 `Path` 时,都需要把用户名和密码用 `:` 进行连接成新的字符串,且做 `base64` 加密,例如,`username` 为 `pjhubs`,`password` 为 `pjhubs123`,则,拼接后的结果为 `pjhubs:pjhubs123`,加密完的结果为 `cGpodWJzOnBqaHViczEyMw==`。按照如下格式添加到每次发起 `HTTP` 请求的 `header` 中:
```
Authorization: Basic cGpodWJzOnBqaHViczEyMw==
```
#### Bearer Authorization
当用户登录成功后,我们应该返回一个完整的 `token` 用于标识该用户已经在我们系统中登录且验证成功,并让该 `token` 和用户进行关联。使用 `Bearer Authorization` 方式进行权限验证,我们需要自行生成 `token`,可以使用任何方法进行生成,`Vapor` 官方并没有提供对应的生成工具,只要能够保持全局唯一即可。每次进行 `HTTP` 请求时,把 `token` 按照如下格式直接添加到 `HTTP request` 中,假设此次请求的 `token` 为 `pxoGJUtBVn7MXWoajWH+iw==`,则完整的 `HTTP header` 为:
```
Authorization: Bearer pxoGJUtBVn7MXWoajWH+iw==
```
#### 创建 `Token` Model
```swift
import Foundation
import Vapor
import FluentMySQL
import Authentication
final class Token: MySQLModel {
var id: Int?
var userId: User.ID
var token: String
var fluentCreatedAt: Date?
init(token: String, userId: User.ID) {
self.token = token
self.userId = userId
}
}
extension Token {
var user: Parent<Token, User> {
return parent(\.userId)
}
}
// 实现 `BearerAuthenticatable` 协议,并返回绑定的 `tokenKey` 以告知使用 `Token` Model 的哪个属性作为真正的 `token`
extension Token: BearerAuthenticatable {
static var tokenKey: WritableKeyPath<Token, String> { return \Token.token }
}
extension Token: Migration { }
extension Token: Content { }
extension Token: Parameter { }
// 实现 `Authentication.Token` 协议,使 `Token` 成为 `Authentication.Token`
extension Token: Authentication.Token {
// 指定协议中的 `UserType` 为自定义的 `User`
typealias UserType = User
// 置顶协议中的 `UserIDType` 为自定义的 `User.ID`
typealias UserIDType = User.ID
// `token` 与 `user` 进行绑定
static var userIDKey: WritableKeyPath<Token, User.ID> {
return \Token.userId
}
}
extension Token {
/// `token` 生成
static func generate(for user: User) throws -> Token {
let random = try CryptoRandom().generateData(count: 16)
return try Token(token: random.base64EncodedString(), userId: user.requireID())
}
}
```
#### 添加配置
在 `config.swift` 中写下 `Token` 的配置信息。
```swift
migrations.add(model: Token.self, database: .mysql)
```
#### 修改 `User` Model
让 `User` 和 `Token` 进行关联。
```Swift
import Vapor
import FluentMySQL
import Authentication
final class User: MySQLModel {
var id: Int?
var phoneNumber: String
var nickname: String
var password: String
init(id: Int? = nil,
phoneNumber: String,
password: String,
nickname: String) {
self.id = id
self.nickname = nickname
self.password = password
self.phoneNumber = phoneNumber
}
}
extension User: Migration { }
extension User: Content { }
extension User: Parameter { }
// 实现 `TokenAuthenticatable`。当 `User` 中的方法需要进行 `token` 验证时,需要关联哪个 Model
extension User: TokenAuthenticatable {
typealias TokenType = Token
}
extension User {
func toPublic() -> User.Public {
return User.Public(id: self.id!, nickname: self.nickname)
}
}
extension User {
/// User 对外输出信息,因为并不想把整个 `User` 实体的所有属性都暴露出去
struct Public: Content {
let id: Int
let nickname: String
}
}
extension Future where T: User {
func toPublic() -> Future<User.Public> {
return map(to: User.Public.self) { (user) in
return user.toPublic()
}
}
}
```
#### 路由方法
使用 `Basic Authorization` 方式做用户鉴权后,我们就可以把需要使用鉴权的方法和非鉴权的方法按照如下方式在 `UserController.swift` 文件分开进行路由,如果这个文件你没有,需要新建一个。
```swift
import Vapor
import Authentication
final class UserController: RouteCollection {
// 重载 `boot` 方法,在控制器中定义路由
func boot(router: Router) throws {
let userRouter = router.grouped("api", "user")
// 正常路由
let userController = UserController()
router.post("register", use: userController.register)
router.post("login", use: userController.login)
// `tokenAuthMiddleware` 该中间件能够自行寻找当前 `HTTP header` 的 `Authorization` 字段中的值,并取出与该 `token` 对应的 `user`,并把结果缓存到请求缓存中供后续其它方法使用
// 需要进行 `token` 鉴权的路由
let tokenAuthenticationMiddleware = User.tokenAuthMiddleware()
let authedRoutes = userRouter.grouped(tokenAuthenticationMiddleware)
authedRoutes.get("profile", use: userController.profile)
authedRoutes.get("logout", use: userController.logout)
authedRoutes.get("", use: userController.all)
authedRoutes.get("delete", use: userController.delete)
authedRoutes.get("update", use: userController.update)
}
func logout(_ req: Request) throws -> Future<HTTPResponse> {
let user = try req.requireAuthenticated(User.self)
return try Token
.query(on: req)
.filter(\Token.userId, .equal, user.requireID())
.delete()
.transform(to: HTTPResponse(status: .ok))
}
func profile(_ req: Request) throws -> Future<User.Public> {
let user = try req.requireAuthenticated(User.self)
return req.future(user.toPublic())
}
func all(_ req: Request) throws -> Future<[User.Public]> {
return User.query(on: req).decode(data: User.Public.self).all()
}
func register(_ req: Request) throws -> Future<User.Public> {
return try req.content.decode(User.self).flatMap({
return $0.save(on: req).toPublic()
})
}
func delete(_ req: Request) throws -> Future<HTTPStatus> {
return try req.parameters.next(User.self).flatMap { todo in
return todo.delete(on: req)
}.transform(to: .ok)
}
func update(_ req: Request) throws -> Future<User.Public> {
return try flatMap(to: User.Public.self, req.parameters.next(User.self), req.content.decode(User.self)) { (user, updatedUser) in
user.nickname = updatedUser.nickname
user.password = updatedUser.password
return user.save(on: req).toPublic()
}
}
}
```
需要注意的是,如果某个路由方法需要从 `token` 关联的用户取信息才需要 `let user = try req.requireAuthenticated(User.self)` 这行代码取用户,否则如果我们仅仅只是需要对某个路由方法进行鉴权,只需要加入到 `tokenAuthenticationMiddleware` 的路由组中即可。
#### 修改 `config.swift`
最后,把我们实现了 `RouteCollection` 协议的 `userController` 加入到 `config.swift` 中进行路由注册即可。
```swift
import Vapor
public func routes(_ router: Router) throws {
// 用户路由
let usersController = UserController()
try router.register(collection: usersController)
}
```
================================================
FILE: Back-end/django.md
================================================
这个文章主要是记录我在学习django过程中所遇到的问题,为后续其它个人项目做铺垫,之前陆陆续续的在使用djano,但是一直都没有好好的去记录一些内容,借此机会完整的记录下学习过程遇到的问题和注意点。django最适合用于做网站,从django官网上的slogan看的出来了。至于django有多适合进行网站开发估计得要接着后续的学习才能知道了,不过我用django主要还是用与做api服务,在考虑之中的还有flask,flask比django更加简单,其中[这个repo](https://github.com/windstormeye/watchDog)是基于flask做的api服务。
### 创建一个django项目
```django-admin startproject <项目名称>```
### __init__.py文件
python包文件必须包含的,只要有这个文件,说明该Python文件目录下的所有文件都是一个包。
### 启动本地服务
```python manage.py runserver```
### 通过域名访问(dev environment)
```python manager.py runserver 0.0.0.0:8000```并且需要把域名在setting.py中的`ALLOWED_HOSTS`字段中。
### 创建超级管理员
忘记命令`manage.py`提供的命令,可以采用`python manage.py help`进行查看。
可以通过`python manage.py createsuperuser`创建创建超级管理员
### 创建一个django app
```django-admin startproject <项目名称>```
### 同步数据库
制造迁移(迁移数据库可以只保存这个)```python manage.py makemigrations```
迁移```python manage.py migrate```
### path
写url时最好是通过path方式,而不是用正则走`re_path/url`的方式,因为会更加直观一些。
### 异常
eg:
```python
try:
article = Artcle.objects.get(id=article_id)
except Artcle.DoesNotExist:
return HttpResponse("不存在”)
```
### 模板
前端页面和后端代码进行分离,降低耦合性。django中规定了模板文件(html)的存放位置和格式,在project下的setting.py文件中的`TEMPLATES`可以看到且修改,如果采用默认配置,需要在app中新建`templates`文件夹,在其中写好对应的模板文件,
eg:这是循环打印文章列表的模板例子,
```html
<html>
<head>
</head>
<body>
{% for article in articles %}
<a href="{% url 'article_details' article.pk %}">{{ article.title }}</a>
{% endfor %}
<h2>{{article_obj.title}}</h2>
<p>{{article_obj.content}}</p>
</body>
</html>
```
### 模板渲染
使用`django.shortcuts`app中的`render/render_to_response/get_objects_or_404`都可以进行模板渲染和调起。
### response的部分写法
这是一种返回数据的写法:
```python
def article_details(request, article_id):
try:
article = Artcle.objects.get(id=article_id)
context = {}
context['article_obj'] = article
return render(request, "article_details.html", context)
except Artcle.DoesNotExist:
raise Http404("not exist")
return HttpResponse("文章标题:%s
文章内容:%s" % (article.title, article.content))
```
这是另外一种,使用from django.shortcuts import get_object_or_404
```python
def article_details(request, article_id):
article = get_object_or_404(Artcle, pk=article_id)
context = {}
context['article_obj'] = article
return render(request, "article_details.html", context)
```
这样做会简洁很多,这也是django所推崇的做法。
### 模板中列出所有文章
列出所有文章。模板中可以采用`{/article/{{ article.pk }}`或者`{% url ‘article_list’ article.pk %}`,用第二种方法需要在对应的`urls.py`文件中添加对应的path.name。
### 分离url
很多时候我们不应该把所有的路由设置都放在project下的`urls.py`文件中,最佳的做法应该是把对应的url放在各自的app`urls.py`文件中(需新建),做法如下所示:
```python
# project `urls.py`
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('article/', include('artcle.urls'))
]
```
```python
# article `urls.py`
from django.urls import path, include
from . import views
urlpatterns = [
path('', views.article_list, name="article_list"),
path('<int:article_id>', views.article_details, name="article_details"),
]
```
千万要注意对应文件的路径!!!
### Python定制类
通过使用定制类中的__str__给用户定制显示内容,当然python中的定制类不止只有这些,详情可以参考[廖雪峰](https://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000/0013946328809098c1be08a2c7e4319bd60269f62be04fa000)
```python
def __str__(self):
return "Article: %s" % self.title
```
### 在admin页面中显示字段
想要在admin管理页面中显示字段,可以在对应app的`admin.py`中这么做:
```py
class ArticleAdmin(admin.ModelAdmin):
list_display = ("title", "content”)
# admin注册(其中的一种方法)
admin.site.register(Artcle, ArticleAdmin)
```
### 给admin管理页面某个字段排序
```py
class ArticleAdmin(admin.ModelAdmin):
list_display = ("id", "title", "content")
ordering = ("id", )
```
ordering默认是升序,改为-id,则为降序排序
### 给现有模型添加时间字段。
`from django.utils import timezone`,第一第二种需要这个库。
1. 如果是直接写。`created_time = models.DateTimeField()`并在对应app中的models.py文件中添加进了新字段,运行时会告知模型和数据库匹配不上,需要去同步数据库,当同步数据库的时候,系统添加默认值,两种方法,第一种在terminal中直接添加,第二种退出然后再添加默认值。
2. 同上第二种,退出后再添加默认值。`created_time = models.DateTimeField(default=timezone.now)`
3.
```py
created_time = models.DateTimeField(auto_now_add=True)
last_updated_time = models.DateTimeField(auto_now=True)
```
### 修改时间类型。
在project的`setting.py`文件中找到`TIME_ZONE`字段,`TIME_ZONE = 'Asia/Shanghai’`(不知道为啥没有北京时间
### 使用自带用户类型。
导入`from django.contrib.auth.models import User`。给每篇文章添加作者信息,外键。 `author = models.ForeignKey(User, on_delete=models.DO_NOTHING, default=1)`
### 文章删除。
最好不要真的删除,而是作为用户不可见。文章模型添加字段`is_deleted = models.BooleanField(default=False)`。文章`views.py`的添加数据筛选
```py
def article_list(request):
articles = Artcle.objects.filter(is_deleted=False)
context = {}
context['articles'] = articles
return render_to_response("article_list.html", context)
```
### 下载virtualenv
`pip install virtualenv`
下载过程中若出现如下信息:
```shell
Traceback (most recent call last):
File "/usr/bin/pip3", line 11, in <module>
sys.exit(main())
File "/usr/lib/python3/dist-packages/pip/__init__.py", line 215, in main
locale.setlocale(locale.LC_ALL, '')
File "/usr/lib/python3.5/locale.py", line 594, in setlocale
return _setlocale(category, locale)
locale.Error: unsupported locale setting
```
则是因为语言配置所导致的,执行如下命令即可:
```shell
$ export LC_ALL=C
```
目的是为了去除所有本地化的设置,让命令能够正确执行。`LC_ALL` 它是一个宏,如果该值设置了,则该值会覆盖所有LC_*的设置值。注意,LANG的值不受该宏影响。`C` 是系统默认的locale,"POSIX"是"C"的别名。所以当我们新安装完一个系统时,默认的locale就是C或POSIX。
### 创建虚拟环境
```py
$ cd env
$ source ./bin/activate
```
### 内容显示截断。
`<p>{{ blog.content|truncatechars:30 }}</p>`,也可以使用`truncatewords`,但是要求词和词中间要有空格,针对的是一个个的词,英文可以直接用。
### 模板文件
模板文件(一般都是html)如果是跟着项目走,那就应该放到全局模板文件里,如果是跟着app走应该放到app的模板文件里。
### html中标签的id一般写在class前面
### django的命名空间
在app中新建的static文件夹中再新建一个跟app名字一样的文件夹,然后把需要的静态文件放进行。注意:要重启服务器(CSS没效果也可以重启)
### 加载静态文件的声明
{% load staticfiles %}要放在需要用到的静态文件之前,而不是拆开。
```python
{% load staticfiles %}
{% block header_extends %}
<link rel="stylesheet" href="{% static 'blog/blog.css' %}">
{% endblock %}
```
### bootstrap和jquery最好都down下来,毕竟也不是特别大。使用bootstrap推荐直接上官网查资料。www.bootcss.com
### python2的range()出来后是个list,而python3得到的是个生成器
### filter筛选符合条件,exclude筛选不符合条件。
### 条件中的双下划线:字段查询类型、外键拓展(以博客分类为例)、日期拓展(以月份分类为例)、支持链式查询:可以一直链接下去
### 去除该段文本中的h5比标签内容,只保留文本
`<p>{{ blog.content|striptags|truncatechars:120 }}</p>。`
### 过滤器safa显示h5标签内容
`<div class="blog-content">{{ blog.content|safe }}</div>`
### 富文本编辑库。django-ckeditor
### admin中文简体——zh-hans
### django2.0后url的设置可以直接用path
### pypi.org。可以查到相关的pip库
### 框架引用顺序:先是python自带,后是django自带,最后才是自己写的
----
## 事物
`Django` 中实现事物主要有两种方式:一是通过 `Django ORM` 框架的事物处理;另外一种是基于原生执行 `SQL` 语句的 `transaction` 处理。
至于为什么需要做事物管理,简单来说就是需要对用户提交的本次操作做完整性保证,有可能用户提交的本次操作涉及10多条 `SQL` 语句,但如果执行到其中第七第八条时出现问题后,之前执行的却已经被写入数据库中了,按道理说,如果中途出现错误,应该把之前的以及执行完的语句全都撤回。具体细节可参考我的[另一篇文章](http://pjhubs.com/2018/03/25/软件开发项目实践(一)/)
据官方文档中所描述的内容[https://docs.djangoproject.com/zh-hans/2.0/topics/db/transactions/](https://docs.djangoproject.com/zh-hans/2.0/topics/db/transactions/) ,`Django` 中的默认事物级别为 `auto-commit` ,用文档中举的例子来说,当我们在 `Django` 中做的 `model().save()` 和 `model().delete` 操作所有的改动都会立即提交,没有 `rollback` 。
<!-- 通过这种配置,django在调每个view方法之前会开始一个事务,当且仅当该响应没有任何问题,django才会提交这个事务;如果view中出现了异常,则django会回滚该事务。这样做的好处显而易见,就是安全简便,但是随着网站的流量变大,如果每个view被调用时都打开一个事务就会变得有点繁重,从而会降低网站的效率。它对性能的影响取决于你的应用的查询效率以及你的数据库处理锁的能力。此外,使用这种方式,回退的只是数据库的状态,而不包括其他非数据库项的操作,例如发送email等。 -->
### `Django ORM` 框架的事物处理
1. **将 `http request` 数据库操作全都包括。** 这种做法相当的简单粗暴,具体配置如下:
```json
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': '',
'USER': '',
'PASSWORD': '',
'HOST': '',
'PORT': '',
'ATOMIC_REQUESTS': True, // !!!
}
}
```
这种方法是在 `django` 调用每个视图方法前都启动一个事物,并且要保证该响应没有任何问题, `django` 最终才会提交这个事物;如果在这其中出现了其它问题, `django` 会自动的回滚该事物。 这样会非常的简单,但不适合流量大的服务,因为这要对每个视图函数都要开启事物,而且回滚的只是数据库操作,如果本次操作中途涉及到了一些其它操作,比如执行了到了一半发送了邮件,但是下一步操作后发现有错误要回滚,但邮件此时已经发送出去了,没法回滚除了数据库之外的操作。
2. **中间件拦截。** 这个办法是我最开始采用的,但无奈一直 `Run` 不起来,需要添加上这个中间件 `django.middleware.transaction.TransactionMiddleware` 。我在 django 官方文档中一直没找到这个中间件,估计在 2.0 被丢弃了吧。
3. **手动通过装饰器进行管理。** 这是官方文档中描述最清楚的内容,也是最方便的内容,具体的细节可以直接去看[文档](https://docs.djangoproject.com/zh-hans/2.0/topics/db/transactions/)。因为现在项目还有很多变化的地方,等后续业务逻辑稳定了再使用该方法。
### 原生 SQL 语句的处理
使用这种方法基本上就是存粹的手写 `SQL` 语句了,如果我们需要做更多细致的东西可以直接采用这种做法。通过连接定义一个游标 `cursor`,通过 `cursor` 执行sql语句,最后通过 `transaction.commit_unless_managed()` 来提交事务。
## 其它
需要注意的地方是,使用原生 SQL 处理事物和使用 django ORM 框架进行处理的区别在于,如果视图函数中出现的问题是视图函数本身而不是数据库的问题,那么使用 django ORM 框架也会回滚,而使用原生 SQL 处理却不会。
### 数据库表生成
写完 model 后,需要把对应的 app 放到 setting 配置文件中。
### 重新生成表结构
很多时候当我们在修改 django 的 model 结构时,会因为某些“特殊”情况(搞不懂为啥)没有更新数据库表结构,这个时候可以参考如下做法:
1. 把数据库中对应的表删除;
2. 把 `django_migrations` 表中 `app` 对应字段中的 model 删除;
3. 重新执行 `makemigrations` 和 `migrate` 。
### 让媒体文件(图片)可被访问
按照正常的 django 流程做图片(或其它资源文件)上传即可,如最终生成的 json 格式如下:
```json
{
avatar = "/media/avatar/pjhubs.jpg";
"masuser_id" = 7028492784;
}
```
此时在浏览器中直接访问 `http://hostname/media/avatar/pjhubs.jpg` ,是访问不到资源文件的,需要这么做:
1. 在 project app 下(与 settings.py 同级别)的 url.py 文件中添加:
```py
from . import settings
from django.conf.urls.static import static
```
2. 在末尾添加上:
```py
urlpatterns += static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)
```
可根据自己的要去进行设置,此时就可通过 `http://hostname/media/avatar/pjhubs.jpg` 访问到资源文件了。
### request.POST 接收不到客户端发送的参数
Django 的 `request.POST` 方法获取到的 POST 方法参数只支持 `Content-Type` 类型为:
* `multipart/form-dat`
* `application/x-www-form-urlencoded`
其它类型的 `Content-Type` 通过 `request.POST` 方法获取到的参数列表均为空。但一般来说我们都希望在 POST 请求中参数类型为 `json`,所以我们需要让客户端同学把 POST 请求的 `Content-Type` 设置为 `application/json` 类型。
在 iOS 的一个常用网络请求框架 `AFNetworking` 中,默认的 `POST` 请求 `Content-type` 就是为 `application/json`。
### Django 如何做 `OR` 查询
使用 `Q` 对象,不可使用 `filter`,因为 Django 默认为 `AND` 关系。
**注意:**
* 如果涉及到多参数时,`Q` 对象应该在前,其它参数在后。
### 搜索
原本是想基于 `ES` 来一套搜索全家桶的,但无奈 `ES` 太重了,基于 `django-haystack` 最后完成了需求,相关配置如下:
* 下载相关依赖
```shell
pip install django-haystack whoosh
```
* 创建相关文件
- `settings.py`
添加 `app`
```python
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'haystack',
# 在所有自定义 app 之上
]
```
```python
# 配置全文搜索
# 指定搜索引擎
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.whoosh_backend.WhooshEngine',
'PATH': os.path.join(BASE_DIR, 'whoosh_index'),
},
}
# 指定如何对搜索结果分页,这里设置为每 10 项结果为一页,默认是 20 项为一页
HAYSTACK_SEARCH_RESULTS_PER_PAGE = 20
# 添加此项,当数据库改变时,会自动更新索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'
```
**注意:** 需要给 `settings.py` 中设置好 `templates` 文件夹目录
```python
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
# 重点
'DIRS': [os.path.join(BASE_DIR, 'templates')],
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
```
- `tempaltes` 文件夹。估计要新建,最终创建出的目录层级为:
```shell
├── templates
└── search
└── indexes
└── user
└── xxx_text.txt
```
xxx 即为需要创建搜索索引的 `app` 名称,若有大小写,则全小写即可。该 `txt` 文件写下需要进行被索引的字段即可,`objct` 即为 `xxx` 的传入对象实体,不需要修改。
```python
{{ object.nick_name }}
```
- `models.py` 需要做索引 `app`。在 `app` 的目录下创建新文件 `search_indexes.py`,作为索引类
```python
from .models import MasUser
from haystack import indexes
class MasUserIndex(indexes.SearchIndex, indexes.Indexable):
text = indexes.CharField(document=True,
use_template=True)
# 需要搜索的字段
nick_name = indexes.CharField(model_attr='nick_name')
def get_model(self):
return MasUser
def index_queryset(self, using=None):
return self.get_model().objects.all()
```
- `views.py` 中的使用。
```python
@decorator.request_methon('GET')
@decorator.request_check_args(['s_nick_name'])
def searchFriend(request):
nick_name = request.GET.get('s_nick_name')
users = SearchQuerySet().models(MasUser).filter(nick_name__contains=nick_name)
f_users = []
for user in users:
f_users.append(user.object.toJSON())
json = {
'users': f_users
}
return utils.SuccessResponse(json, request)
```
- 建立索引
```shell
python manage.py rebuild_index
```
最后自己配置一下路由即可。
### uwsgi 安装失败
`sudo apt-get install python3.6-dev`
### `python manage.py makemigrations` 的触发
使用 `python manage.py makemigrations` 命令来触发数据库表的生成和更新,需要保证在 app 目录下有 `migrations` 这个包。注意,这里说的是包!包!包!!!
### 如何给 `DecimalField` 类型的模型字段赋值
```python
from decimal import Decimal
current_drink_score.score = Decimal(str(10))
```
### 在同一局域网下,如何让其他电脑连接上自己的 `django` 服务器
* 查找到自己的 ip 地址。
* 在 django 的 `ALLOWED_HOSTS` 中添加上该 ip 。
* 通过 `python runserver ip:port` 允许项目即可。
或者直接修改 pyCharm 中的 web 服务器工程配置:
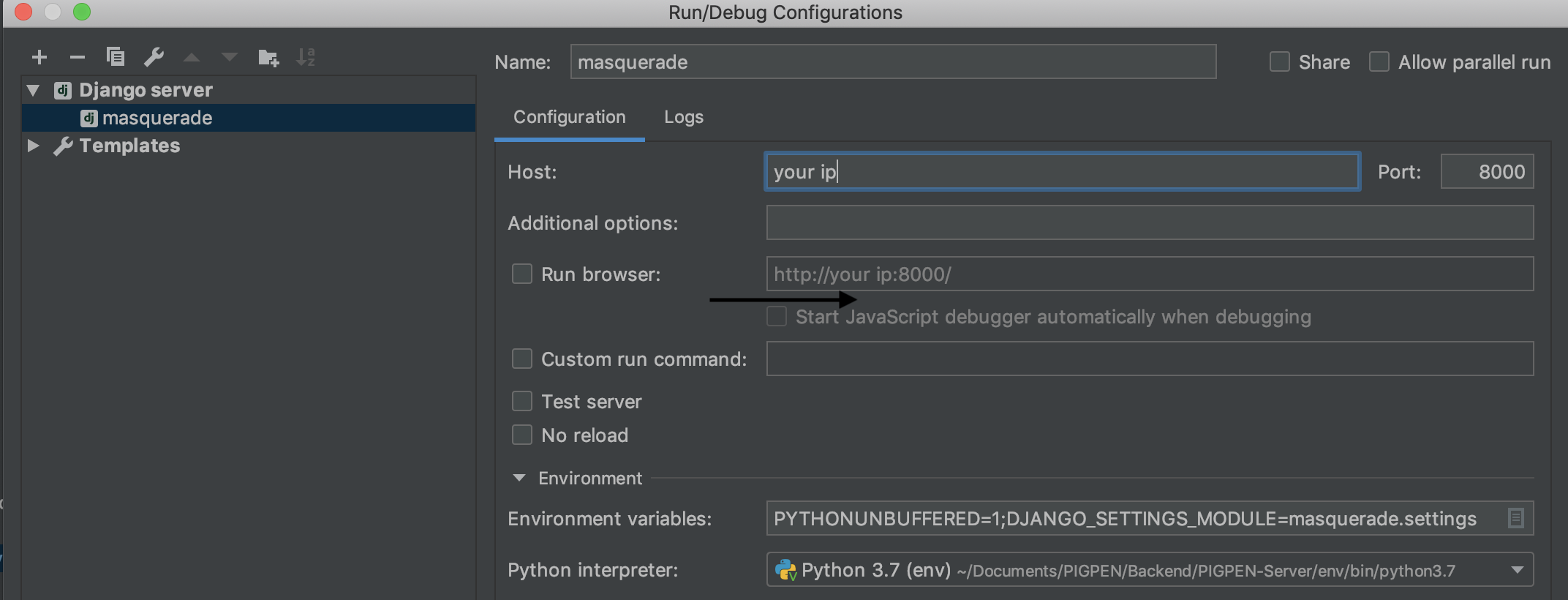
### 如何做「不包含」/「不等于」操作
```python
from django.db.models import Q
myapps = App.objects.filter(~Q(name= ''))
```
### 如果出现了本地的 `django_migrations` 和服务器的 `django_migrations` 记录不一致
导致执行 `migrate` 时各个 app 的上下游依赖出现问题,报错:
```shell
django.db.migrations.exceptions.InconsistentMigrationHistory: Migration user_avatar.0001_initial is applied before its dependency user.0002_auto_20190705_2356 on database 'default'.
```
这是因为在 `django_migrations` 表中有可能因为 `user_avatar.0001_initial` 已经有记录了,且依赖 `user.0002_auto_20190705_2356`,但此时 `user.0002_auto_20190705_2356` 并未生成。
解决办法:把 `user_avatar.0001_initial` 这条记录删掉,但非常不好。
### 直接 copy 别人的 django 文件夹
如果是直接 copy 了别人的 django 文件夹,可能会出现它的 env 与本机的各种不匹配问题,需要删除重新生成
================================================
FILE: Back-end/jwt.md
================================================
# JWT
这里将会记录我在学习 JWT 的过程中遇到的问题、思考和总结。
## JWT 简介
全称为 **J**SON **W**eb **T**oken。
## 彩虹表
================================================
FILE: Back-end/mysql.md
================================================
# Mysql
## Mysql 的客户端/服务器架构
`mysql` 的服务器进程默认名称为 `mysqld`,常用的 `mysql` 客户端进程的默认名称为 `mysql`。
## 启动
`mysql -h主机名 -u用户名 -p密码`
* `-h/--host=主机名`:后可跟服务器域名或 IP 地址,若 mysql 服务器进程运行在本机则可以省略;
* `-u/--user=用户名`;
* `-p/--password=密码`。
### 如果 mysql 默认端口号 3306 被占用
在启动 `mysql` 服务器时使用 `mysqld -P3307`,启动 `mysql` 客户端程序时使用 `mysql -u root -P3307 -p`,打写的 `-P` 代表选择
## 服务器处理客户端请求
### 连接管理
每当有一个客户端连接到 `mysql` 服务器进程时,服务器进程都会创建一个线程来处理与客户端的交互。当该客户端与服务器断开连接时,服务器并不会立即把该线程销毁,而是缓存起来供下一次使用。但线程开辟太多会影响系统性能,需要限制同时连接服务器的客户端数量。
### 查询缓存
`mysql` 服务器会把已经处理过的查询请求和结果缓存起来,若下一次有相同的请求时,则从缓存中直接返回。但如果两个查询请求在任何自负上的不同,都会导致缓存不会命中。
`mysql` 缓存系统会检测当前缓存中设计到的每张表,只要该表的结果或者数据被修改,则该表的所有高速缓存都将变为无效并删除。**从 mysql 8.0 中已移除**。
## 存储引擎
表,是有一行一行的记录组成的,但这只是逻辑上的概念,在物理上如何表示记录,怎么从表中读取数据,怎么把数据写入具体的物理存储器上,这都是存储引擎做的事情。我常用的 mysql 存储引擎为具备外键支持的事务存储引擎 **`InnoDB`** 。
其它常见的 `mysql` 存储引擎有:
存储引擎 | 描述
---- | ---- s
MEMORY | 置于内存的表
MyISAM | 主要的非事务处理存储引擎
### 设置表的存储引擎
存储引擎负责对表中的数据进行提取和写入工作的,可以**为不同的表设置白虎通你的存储引擎**,不同的表可以有不同的物理存储结构,不同的提取和写入方式。
## 启动选项和配置文件
* mysql 服务器默认的客户端连接数量为:151;
* 表的默认存储引擎为:`InnoDB`;
* 通过 `-h` 方式来启动服务器程序时,客户端和服务器进程之间使用 `TCP/IP` 网络进行通信,如果想要禁止这种方式,可以在启动服务器命令选项中加上 `--skip_networking` 来禁止使用 `TCP/IP` 方式来进行连接。
================================================
FILE: Back-end/nginx.md
================================================
# nginx
## 错误日志地址
`etc/log/nginx`
##
================================================
FILE: Back-end/web服务器.md
================================================
# 浅析 Web 服务器的工作原理(Java)
## 什么是 Web 服务器,应用服务器和 web 容器?
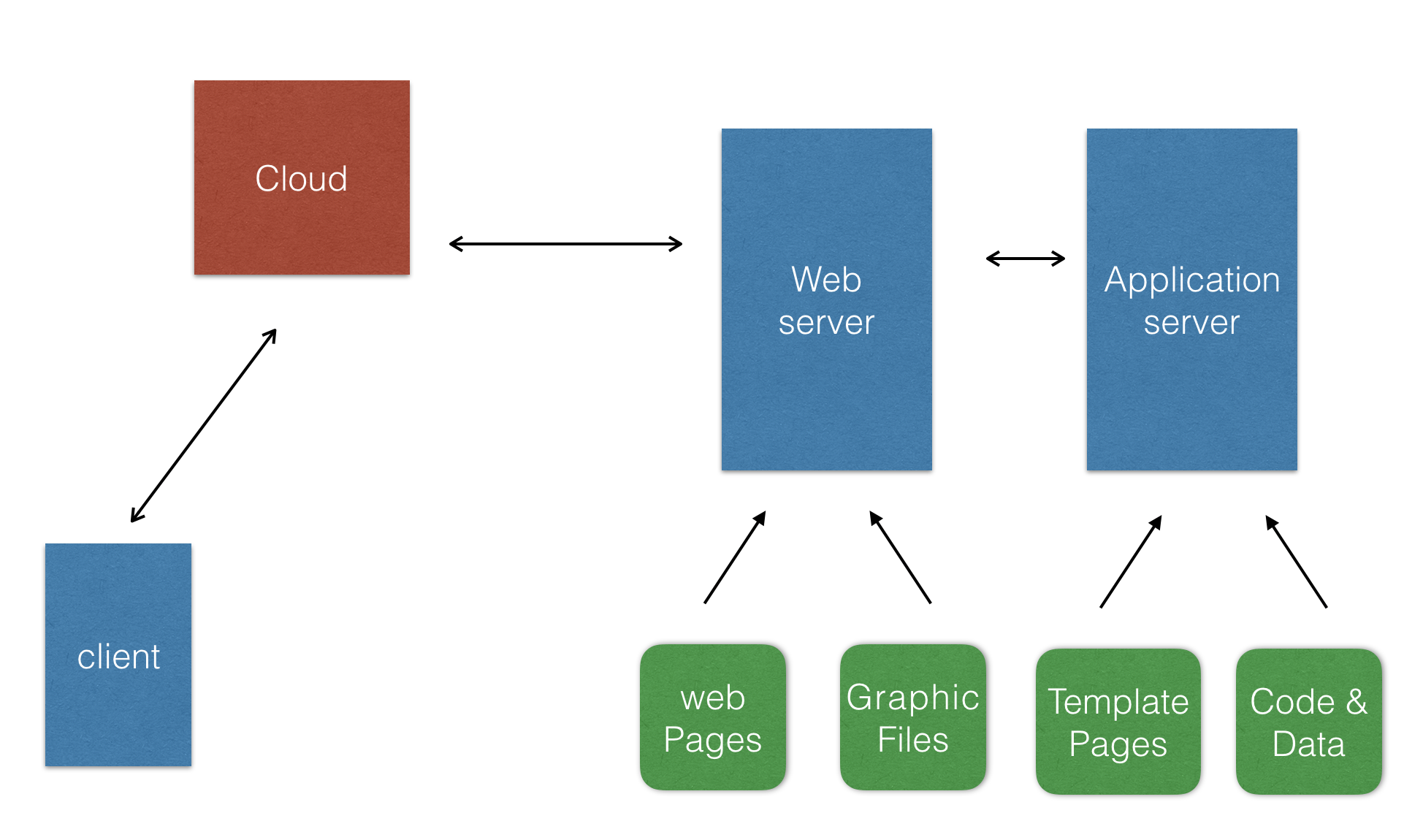
### web 服务器
在过去很长的一段时间中,它们是有区别的,但是这两个分类慢慢的合并了,而如今在大多情况下可以把它们看成一个整体。在早期,引发出“ web 服务器”的概念是因为通过了 HTTP 协议来提供静态页面内容和图片的服务,当时大部分内容都是静态的,并且 HTTP 1.0 只是一种传送文件的方式,但在不久后 web 服务器提供了 CGI 功能,意味着我们能够为每一个 web 请求启动一个进程来产生动态内容。现在 HTTP 协议已经非常成熟了并且 web 服务器变得更加复杂,拥有了例如缓存、安全和 session 管理等这些附加功能。
### 应用服务器
在同一时期,应用服务器已经存在并发展了很长一段时间了,大部分产品都指定了“封闭的”产品专用通信协议来互连胖客户端和服务器,在 90 年代,传统的应用服务器产品开始嵌入了 HTTP 通信功能,准备利用网关来实现。不久之后这两者的界限开始变得模糊。同时,web 服务器变得越来越成熟,可以处理更高的负载、更多的并发和拥有更好的特性;应用服务器开始添加越来越多的机遇 HTTP 的通信功能。所有的这些导致了 web 服务器与应用服务器的界线变得更窄了。
目前,应用服务器和 web 服务器之间的界线已经变得模糊不清了,但是人们还把这两个术语分开来。当有人说到 web 服务器时,我们通常要把它认为是以 HTTP 为核心、web UI 为向导的应用。当有人说到应用服务器时,你可能想到“高负载、企业级特性、事物和队列、多通道通行(HTTP 和更多的协议)”,但现在提供这些需求的基本上都是同一个产品。
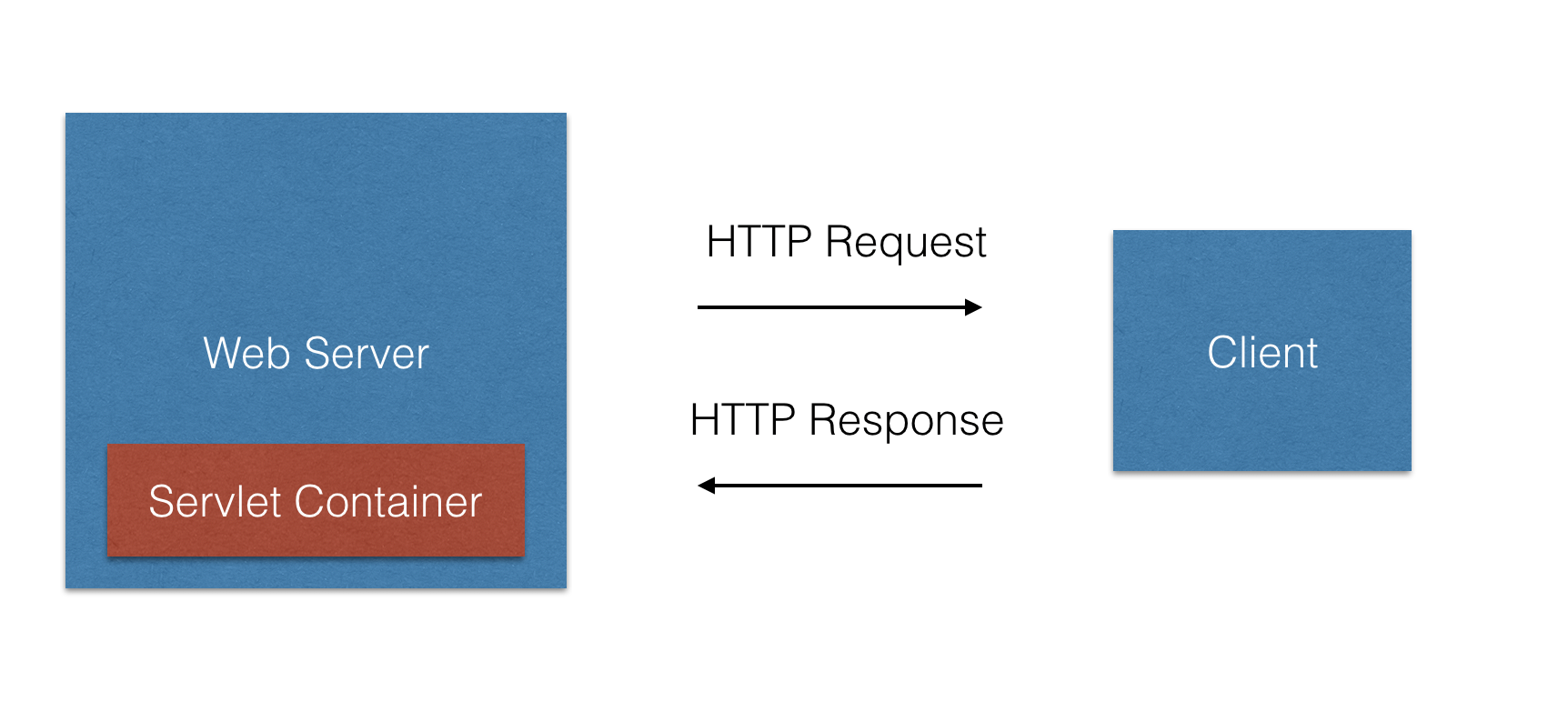
### web 容器
在 java 中,web 容器一般就是指 Servlet 容器。Servlet 容器是与 Java Servlet 交互的 web 容器的组件。web 容器负责管理 Servlet 的生命周期、把 URL 映射到特定的 Servlet 、确保 URL 请求拥有正确的访问权限和更多类似的服务。综合来看,Servlet 容器就是用来运行你的 Servlet 和维护它的生命周期的运行环境。
### 什么是 Servlet?它们有什么用?
在 java 中,Servlet 使你能够编写根据请求动态生成内容的服务端组件。事实上,Servlet 是一个在 javax.servlet 包里定义的接口。它为 Servlet 的生命周期声明里三个基本方法 —— init()、service() 和 destroy() 。每个 Servlet 都要实现这些方法(在 SDK 里定义或者用户定义)并在它们的生命周期的特定时间由服务器来调用这些方法。
类加载器通过懒加载或者预加载自动地把 Service 类加载到容器里,每个请求都拥有自己的线程,而一个 Service 对象可以同时为多个线程服务。当 Service 对象不再被使用时,它就会被 JVM 当作垃圾回收掉。
### 什么是 ServletContext?它由谁创建
当 Servlet 容器启动时,它会部署并加载所有的 web 应用。当 web 应用被加载时,Servlet 容器会一次性为每个应用创建 Servlet 上下文(ServletContext)并把它保存在内存里。Servlet 容器会处理 web 应用的 web.xml 文件,并且一次性创建在 web.xml 文件里定义的 Servlet、Filter 和 Listener ,同样也会把它们保存在内存里。当 Servlet 容器关闭时,它会卸载所有的 web 应用和 ServletContext ,所有的 Servlet、Filter 和 Listener 实例都会被销毁。
从 java 的文档中可知,ServletContext 定义了一组方法,Servlet 使用这些方法来与它的 Servlet 容器进行通信。例如,用来获取文件的 MIME 类型、转发请求或编写日志文件。在 web 应用的部署文件(deployment describtor)标明“分布式”的情况下,web 应用的每一个虚拟机都拥有一个上下文实例。在这种情况下,不能把 Servlet 上下文当作共享全局信息的变量(因为它的信息已经不具有全局性了)。可以使用外部资源来代替,比如数据库。
### ServletRequest 和 ServletResponse 从哪里进入生命周期?
Servlet 容器包含在 web 服务器中,web 服务器监听来自特定端口的 HTTP 请求,这个端口通常是 80 。当客户端发送一个 HTTP 请求时,Servlet 容器会创建新的 HttpServletRequest 和 HttpServletResponse 对象,并且把它们传递给已经创建的 Filter 和 URL 模式与请求 URL 匹配的 Servlet 实例的方法,所有的这些都使用同一个线程。
request 对象提供了获取 HTTP 请求的所有信息的入口,比如请求头和请求实体。response 对象提供了控制和发送 HTTP 响应的便利方法,比如设置请求头和请求实体。response 对象提供了控制和发送 HTTP 响应的便利方法,比如设置响应头和响应实体(通常是 JSP 生成的 HTML 内容)。当 HTTP 响应被提交并结束后,request 和 response 对象都会被销毁。
### 如何管理 Session?cookie 呢?
当客户端第一次访问 web 应用或第一次使用 request.getSession() 获取 HttpSession 时,Servlet 容器会创建 Session,生成一个 long 类型的唯一 ID (可以使用 session.getId() 获取它)并把它保存在服务器的内存里。Servlet 容器同样会在 HTTP 响应里设置一个 Cookie ,cookie 的名字是 JSESSIONID 并且 cookie 的值是 session 的唯一 ID 。
根据 HTTP cookie 规范(正规的 web 浏览器和 web 服务器必须遵守的约定),在 cookie 的有效期间,客户端(浏览器)之后的每个请求都要把该 cookie 返回给服务器,Servlet 容器会利用带有名为 JSESSIONID 的 cookie 检测每一个到来的 HTTP 请求头,并使用 cookie 的值从服务器内容里获取相关的 HttpSession 。
HttpSession 会一直存活着,除非超过一段时间没使用。可以在 web.xml 文件中设置该时间段,默认时间段是 30 分钟。因此,如果客户端已经超过 30 分钟没有访问 web 应用的话,Servlet 容器就会销毁 Session 。之后的每一个请求,即使带有特定的 cookie ,都再也不会访问到同一个 Session 了,ServletContainer 会创建一个新的 Session 。
另外,在客户端的 session cookie 拥有一个默认的存活时间,这个时间与浏览器的运行时间相同,因此,当用户关闭浏览器后(所以的标签或窗口),客户端的 Session 就会被销毁,重新打开浏览器后,与之前的 Session 关联的 cookie 就再也不会被发送出去了。再次使用 request.getSession() 会返回一个全新的 HttpSession 并且使用一个全新的 session ID 来设置 cookie 。
### 如何确保线程安全?
我们现在已经知道了所有的请求都在共享 Servlet 和 Filter 。它是多线程的并且不同的线程(HTTP 请求)可以使用同一个实例。否则,对每一个请求都重新创建一个实体会耗费很多的资源。同样也要知道,不应该使用 Servlet 或者 Filter 的实例变量来存放任何的请求或者会话范围内的数据,这些数据会被其它 Session 的所有请求共享,这是非线程安全的。
================================================
FILE: Back-end/后端学习.md
================================================
## 用户态与核心态
### 用户态与核心态是什么?
将内核程序和基于内核程序之上构建的用户程序分开处理,使其分别运行在用户态和核心态
### 为什么需要用户态和核心态?
在CPU的所有指令中,有一些指令是非常危险的(不是`rm -rf`这种),如果错用,将导致整个系统奔溃,比如:清空内存,修改时钟等。如果所有的程序代码都能够直接使用这些指令,那么很有可能我们的系统一天将会死n次。
所以,CPU将指令分为 **特权指令** 和 **非特权指令** ,对于较为危险的指令,只允许操作系统本身及其相关模块进行调用,普通的、用户自行编写的应用程序只能使用那些不会造成危险的指令。intel的CPU将指令级别分为了4个等级,分别是:`RING0`, `RING1`, `RING2`, `RING3`。
当一个程序或一个任务(进程)执行系统调用而陷入内核代码中执行时,我们就称该程序、该任务处于内核态,此时处理器处于特权级别最高的`RING0`内核代码中执行,当进程处于内核态时,执行的内核代码将会使用该进程的内核栈,每个进程都拥有自己的内核栈。
当程序、进程在执行用户自己的代码时,我们就称该程序、该进程处在用户态,此时处理器处在特权级别最低的`RING3`用户代码中运行。
当正在执行用户程序而突然被中断程序(被打断了),此时用户程序也可以象征性的称为处于核心态,因为中断处理程序将使用当前进程的内核栈。
CPU总是处于以下状态中的一种:
* 内核态:运行于进程上下文,内核代表进程运行于内核空间;
* 内核态:运行于中断上下文,内核代表硬件运行于内核空间;
* 用户态:运行于用户空间。
### 什么是系统调用?
处在用户空间的应用程序,通过系统调用,进入内核空间。此时用户空间的进程要传递很多变量、参数给内核,内核态运行的时候也要保存用户进程的一些寄存器值、变量等等。所谓的“进程上下文”,就是用户进程传递给内核的参数以及内核要保存的那一整套变量、寄存器值和当时的环境等。比如`fork()`开启一个新的进程。
### 什么是中断程序?
硬件通过触发信号,导致内核调用中断处理程序,进入内核的空间。在这个过程中,硬件的一些变量和参数也要传递给内核,内核通过这些参数进行中断处理。所谓的“中断上下文”,其实也可以看做就是硬件传递的参数和内核需要保存的一些其它环境信息(被打断执行的进程环境)。
### 什么是内核?
操作系统大致经历了无结构操作系统(第一代)、模块化操作系统(第二代)、分层式操作系统(第三代),它们操作系统被称为“传统操作系统结构”,而单内核和微内核是目前“线代操作系统结构”中最重要的两个。比如Linux是单内核,windows和macOS都是微内核的。
操作系统的内核作用是对软件、硬件资源的管理。内核的最重要的一个作用就是实现任务调度,让计算机的资源被均衡的调度。如果一个操作系统没有内核,那么所有的任务(进程)都是完全独占计算机的,聊天的同时不能刷浏览器。
没有操作系统的内核,内存的动态管理也不存在了,后果就是可能没有虚拟内存,也就是说,如果此时运行的程序需要占用内存2G,但此时计算机只有1G内存,这个程序就跑不起来了。同时,设备的管理功能也就不存在了,比如动态设备的插拔(U盘)等等,而且计算机启动的时间会将会非常漫长,因为需要检测并加载各种驱动。
没有操作系统内核,多线程的操作都不能支持,因为信号量、消息队列这些都是操作系统提供的,所以如果真的把操作系统的内核剔除掉,现在大部分应用程序都要彻底重写来支持无内核的操作系统。并且多核CPU也发挥不了作用。
早期的操作系统有些游戏和软件就是直接拿软盘启动,是因为那时操作系统很小、功能弱、系统资源紧缺,没有什么内核也是OK的,但是现在计算机的硬件资源非常丰富,操作系统很庞大,没有内核进行统一管理的话,要么太浪费要么这个应用程序的负担(要处理的事情)会很重。
### 什么是虚拟内存?
以下内容摘自wiki,我没理解好虚拟内存的大概实现思路,先把wiki的结果放在着:
```
虚拟内存是电脑系统内存管理的一种技术。它使得应用程序认为它拥有连续可用的内存(一个连续完整的地址空间),而实际上,它通常是被分隔成多个物理内存碎片,还有部分暂时存储在外部磁盘存储器上,在需要时进行数据交换。与没有使用虚拟内存技术的系统相比,使用这种技术的系统使得大型程序的编写变得更容易,对真正的物理内存(例如RAM)的使用也更有效率。
注意:虚拟内存不只是“用磁盘空间来扩展物理内存”的意思——这只是扩充内存级别以使其包含硬盘驱动器而已。把内存扩展到磁盘只是使用虚拟内存技术的一个结果,它的作用也可以通过覆盖或者把处于不活动状态的程序以及它们的数据全部交换到磁盘上等方式来实现。对虚拟内存的定义是基于对地址空间的重定义的,即把地址空间定义为“连续的虚拟内存地址”,以借此“欺骗”程序,使它们以为自己正在使用一大块的“连续”地址。
现代所有用于一般应用的操作系统都对普通的应用程序使用虚拟内存技术,例如文字处理软件,电子制表软件,多媒体播放器等等。老一些的操作系统,如DOS和1980年代的Windows,或者那些1960年代的大型机,一般都没有虚拟内存的功能——但是Atlas,B5000和苹果公司的Lisa都是很值得注意的例外。[1]
那些需要快速访问或者反应时间非常一致的嵌入式系统,和其他的具有特殊应用的电脑系统,可能会为了避免让运算结果的可预测性降低,而选择不使用虚拟内存。
```
在Linux中用户进程空间和内核进程控件占用的虚拟内存比例为3:1。32位机虚拟内存最高2^32 = 4 GB,64位机虚拟内存最高2^64 ≈ 16000 PB。
### 计算机启动,检测并加载各种驱动
差一篇讲计算器启动全流程的讲解。
### 中间件
中间件的概念挺容易理解,就是整体来看要把分布式集群之间联系起来,业界一直在发布新的轮子,知乎这篇文章供参考:[https://www.zhihu.com/question/19730582](https://www.zhihu.com/question/19730582)
### 并发和并行
引用:[https://www.zhihu.com/question/33515481](https://www.zhihu.com/question/33515481)
```
你吃饭吃到一半,电话来了,你一直到吃完了以后才去接,这就说明你不支持并发也不支持并行。
你吃饭吃到一半,电话来了,你停了下来接了电话,接完后继续吃饭,这说明你支持并发。
你吃饭吃到一半,电话来了,你一边打电话一边吃饭,这说明你支持并行。
并发的关键是你有处理多个任务的能力,不一定要同时。并行的关键是你有同时处理多个任务的能力。所以我认为它们最关键的点就是:是否是『同时』。
```
* 并发在于「发生」
* 并行在于「运行」
### 生产者消费者模式
找到一篇讲解得比较细致的文章,但是文章本身内容太长,不易于总结,但实际上前后语义又通畅,就不做摘要了,原文链接:[https://www.jianshu.com/p/0d1c950e6614](https://www.jianshu.com/p/0d1c950e6614)
### C10K问题
留给自己以后看,这个问题不是目前自己需要考虑的。[https://blog.csdn.net/yeasy/article/details/43152115](https://blog.csdn.net/yeasy/article/details/43152115)
### kill 掉对应端口信息
以 `8000` 端口为例:
```shell
lsof -i tcp:8000
```
================================================
FILE: Base/C++.md
================================================
### ends 的差异
ends 在 windows 和类 unix 系统下有差异,[http://www.cplusplus.com/reference/ostream/ends/](http://www.cplusplus.com/reference/ostream/ends/)上说的是加入了一个 '\0' ,而不是空格,之所以是空格是因为操作系统的原因
* Qt 的信号槽机制是动态插入代码
================================================
FILE: Base/UML.md
================================================
# UML
## 面向对象技术概述
面向对象的基本建模原则:抽象、封装、继承和分类。
面向对象的基本软件工程:OOA(面向对象的分析)、OOD(面向对象的设计)、OOP(面向对象的编程)和OOSM(面向对象的软件维护)
对象的概念是:对问题域中某个实体的抽象;类的概念是:对具有项目属性和行为的一个或多个对象的描述
属性的定义:描述对象静态特征的数据项;服务的定义:描述对象的动态特征(行为)的一个操作序列。
类的定义要包括:名称、属性和操作三要素。
面向对象呈现设计的三大特性:封装、继承和多态。
面向对象的系统分析要确立 3 个系统模型是对象模型、功能模型和动态模型。
## 用例图
### 参与者
**参与者**是指系统以外的、需要使用系统或与系统交互的外部实体,包括**人、设备、外部系统**等。
### 用例
用例是对一个活动者使用系统的一项功能时所进行的交互过程的一个文字描述序列。可以说,软件开发的过程是**用例驱动**的。
用例是对系统行为的动态描述,属于 UML 的动态建模部分。UML 中的建模机制包括**静态建模**和**动态建模**两部分,其中静态建模机制包括类图、对象图、构件图和部署图;动态建模机制包括用例图、顺序图、协作图、状态图和活动图。
理论上可以把一个软件系统的所有用例都画出来,但实际开发过程中,进行用例分析时只需把那些**重要的、交互过程复杂的用例**找出来。不要试图把所有的需求都以用例的方式表示出来。需求有两种基本形式:功能性需求和非功能性需求。用例描述的只是功能性方面的需求,那些难以用 UML 表示的需求很多是非功能性需求。
#### 泛化关系
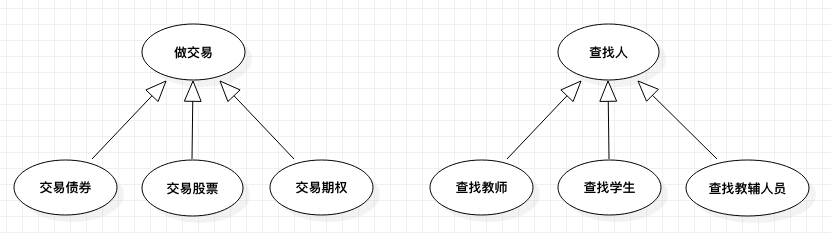
官方解释:泛化代表一般的与特殊的关系,在用例之间的泛化关系中,子用例继承了父用例的行为和含义,子用例也可以增加新的行为和含义或覆盖父用例中的行为和含义。
PJ 的解释:子类和父类的关系。
#### 包含关系
官方解释:包含关系指的是两个用例之间的关系,其中一个用例(基本用例)的行为包含了另一个用例(包含用例)的行为。
PJ 的解释:把某一个功能进行重用。
【例 1】银行的 ATM 系统中,有“存款”、“取款”、“账户余额查询”和“转账”四个用例,都要求用户必须登录了 ATM 机。也就是说,它们都包含了用户登录系统的行为。因此,用户登录系统的行为是这些用例中相同的动作,可以将它提取出来,单独的作为一个包含用例。
“存款”、“取款”、“查询用户余额”和“转账”是基本用例,“登录”是包含用例,如下图所示:
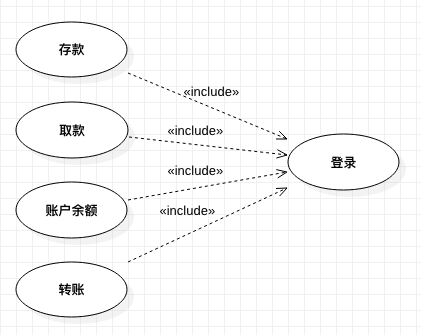
由于将共同的用户登录系统行为提取出来,“存款”、“取款”、“查询用户余额”和“转账”四个基本用例都不再含有用户登录系统的行为。
【例 2】网上购物系统,当注册会员在线购物时,网上购物系统需要对顾客的信用卡进行检查,检查输入的信用卡号是否有效,信用卡是否有足够的资金进行支付。
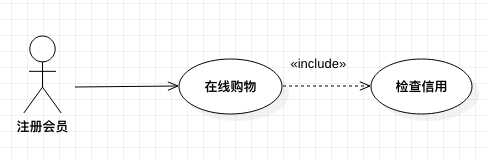
上图中有没有必要将检查信用的行为提取出来,单独构成一个用例(作为包含用例),当信用检查的行为只发生在“在线购物”活动中时,可以不用提取出来。当信用检查的行为还发生在其它活动中时,应该提取出来,以便实现软件重用。
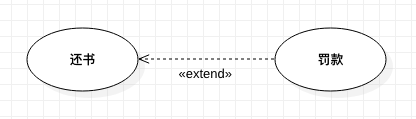
#### 拓展关系
官方解释:在拓展关系中,对于拓展用例的执行有更多的规则限制,基本用例必须声明若干个“拓展点”,而拓展用例只能在这些拓展点上增加新的行为和含义。
PJ 的解释:基本用例在满足一定条件后可进行选择执行拓展用例。
【例 3】图书借阅系统。当读者还书时,如果借书时间超期,则需要缴纳一定的滞纳金,作为罚款。
#### 综合
【例 4】 网上购物系统,当注册会员浏览网站时,他可能临时决定购买商品,当他决定购买商品后,就必须将商品放进购物车,然后下订单。

如果网上购物系统的需求改为了:注册会员即可以直接在线购物,又可以浏览商品后临时决定在线购物,则可以改为下图所示:
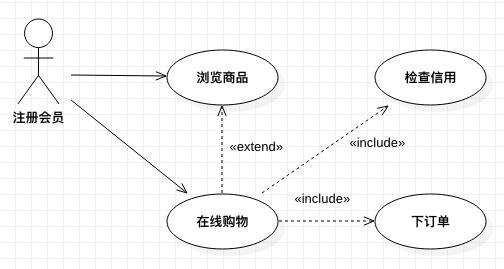
### 用例描述
> 没有描述的用例就像是一本书的目录,人们只知道该目录的标题,但并不知道该目录的具体内容是什么,仅用图形符号表示的用例本身并不能提供该用例所具备的全部信息,必须通过文本的方式描述该用例的完整功能。实际上,用例的描述才是用例的主要部分,是后续的交互图分析和类图分析必不可少的部分。
用例描述了参与者和软件系统进行交互时,系统所执行的一系列动作序列,因此这些动作序列应该包含正常使用的各种动作序列(主事件流),而且还包含对非正常使用时软件系统的动作序列(子事件流)。
【例 1】 在银行 ATM 系统的 ATM 机上“取款”用例一个简单用例描述可以采取如下格式
描述项 | 说明
--- | ---
用例名称 | 取款。
用例描述 | 在储户账户有足够金额的情况下,为储户提供现金,并从储户账户中减去所取金额。
参与者 | 储户。
前置条件 | 储户正确登录系统。
后置条件 | 储户账户余额被调整。
主事件流 | (1)储户在主界面选择“取款”选项,**开始用例**(这个词的出现很重要)。(2)ATM 机提示储户输入欲取金额。(3)储户输入欲取金额。(4)ATM 确认该储户账户是否有足够的金额。如果金额不够,则执行子事件流 `b` 。**如果与主机连接有问题,则执行异常事件流 `e`**。(5)ATM 机从储户帐号中减去所取金额。(6)ATM 机向储户提供要取的现金。(7)ATM 机打印取款凭证。(8)进入主界面。ATM 机提供以下选项:存款、取款、查询和转账。**用例结束**(这个词的出现同样很重要)。
子事件流 `b` | b1. 提示储户余额不够。b2. 返回主界面,等待储户重新选择选项。
异常事件流 `e` | e1. 提示储户主机连接不上。e2. 系统自动关闭,退出储户银行卡,用例结束。
一个复杂用例主要体现在基本操作流程和可选操作流程的步骤和分之过多,此时,可以采用“场景(或称脚本)”的技术来描述用例,而不是用大量的分之和附属流来描述用例。
### 用例建模
用例模型主要应用在需求分析时使用。
#### 步骤
* 找出**系统外部**的参与者和外部系统,确定系统的边界和范围;
* 确定每一个参与者所期望的系统行为,参与者对系统的基本业务需求;
* 把这些**系统行为作为基本用例**;
* 区分用例的优先级;
* 细化用例。使用泛化、包含、拓展等关系进行处理;
* 编写每个用例的用例描述;
* 绘制用例图;
* 编写项目词汇表。
#### 确定系统边界
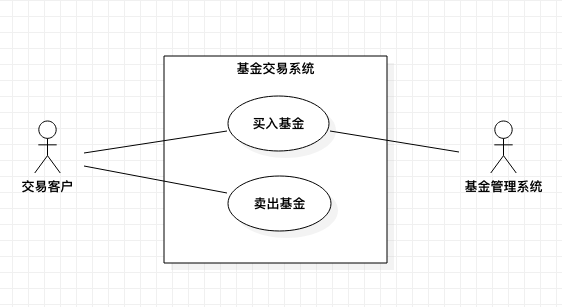
系统边界是指系统与系统之间的界限。系统可以认为是一系列的相互作用的元素形成的具有特定功能的有机整体。不属于这个有机整体的部分可以认为是**外部系统**。因此系统边界定义了**油谁或什么参与者来使用系统**,系统能够为参与者提供什么特定服务。**系统边界决定了参与者**。
【例 1】在一个仅为交易客户提供买卖基金的基金交易系统中,**参与者**为交易客户,交易客户能够操作的系统功能有买入基金和卖出基金。因此,系统有两个用例:买入基金和卖出基金。
进一步分析发现,基金的品种应该存在与该系统中,否则交易客户无法进行基金的买卖。但系统已存的两个用例都不能完成基金品种的管理,所以可以确认基金品种的管理应该在别的系统中完成。
所以,我们需要开发这个系统,仅存在两个用例:买入基金、卖出基金。
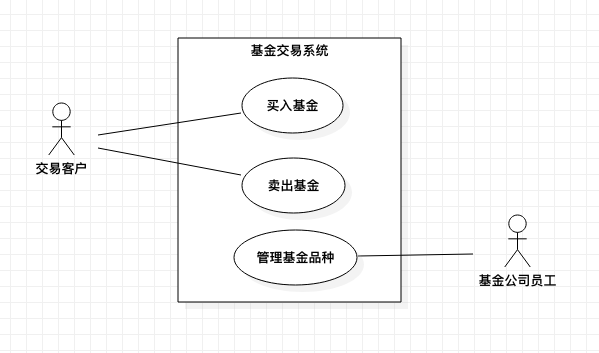
【例 2】对例 1 做个调整。在一个既提供基金买卖又提供基金品种录入的基金交易系统中,交易客户,能够进行基金的买入和卖出。因为还需要对基金品种进行管理(录入、修改、删除和查询),由基金公司员工进行操作。所以该系统的参与者有交易客户和基金公司员工。系统边界可以改为下图所示:
#### 如何确定参与者
* 谁将使用系统的主要功能?
* 谁将需要系统的支持来完成她们的日常工作?
* 谁将必须维护、管理和确保系统正常工作?
* 谁将给系统提供信息、使用信息和维护信息?
* 系统需要处理哪些硬件设备?
* 系统使用外部资源吗?
* 系统需要与其他系统交互吗?
* 谁对系统产生的结果感兴趣?
需要注意的问题:
* 只要是参与者,对于子系统而言都是外部的;
* 参与者直接与系统进行交互;
* 参与者指的与系统直接交互时所扮演的角色,而不是特定的人或事物。比如,不是 PJ 与教务系统产生交互而是学生与教务系统产生交互;
#### 如何确定用例
识别用例可以从列出的参与者列表中从头开始寻找,考虑每个参与者如何使用系统,需要系统提供什么样的服务。
* 参与者要向系统请求什么功能?
* 每个参与者的特定任务是什么?
* 参与者需要读取、创建、撤销、修改和存储系统的某些信息吗?
* 参与者是否有需要通知系统的事件?系统是否有需要通知参与者的事件?
* 这些事件代表了哪些功能?
* 系统需要哪些输入输出功能?
* 是否所有的功能需求都被用例使用了?
需要注意以下问题:
* 每个用例至少有一个参与者;
* 每个参与者至少一个用例;
* 如果存在没有参与者的用例,再三检查后,还是没有参与者,可以考虑把该用例并入其他用例中;
* 如果存在没有用例的参与者,再三检查后,该参与者还是没有用例,可以考虑该参与者是如何与系统产生交互的,或由该参与者确定一个新的用例,或实际上该参与者本身就是多余的。
#### 项目词汇表
这什么鬼,没见过,没听说过......
### 其他问题
#### 需求应该有层次的组织
系统的高层需求一版用不超过 12 个左右的用例进行表示,在其下的层次中,用例的数量不应超过当前用例的 5~10 倍。可以将用例划分为**业务用例**、**系统用例**和**组件用例**等。
#### 不要从用例直接推导设计
用例应该描述参与者使用系统所遵循的顺序,但用例绝不说明系统内部采用什么步骤来响应参与者的刺激。
### 用例包
#### 用例模型的调整
如果两个用例总是以同样的顺序被激活,可能需要将它们合并为一个用例。
#### 不要过于详细
在进行用例描述时还没有考虑系统的设计方案,那么也不会涉及用户界面。
================================================
FILE: Base/algorithm-java.md
================================================
1. `public static void`和`public void`的区别:`public static void`所标明的静态方法能够用类名直接调用,但是静态方法不能够调用非静态方法。
2. final关键字浅析:[https://www.cnblogs.com/dolphin0520/p/3736238.html](https://www.cnblogs.com/dolphin0520/p/3736238.html)
3. `const`和`static`关键词:
* [http://blog.sina.com.cn/s/blog_668aae780101m4ex.html](http://blog.sina.com.cn/s/blog_668aae780101m4ex.html)
* [https://www.jianshu.com/p/1598004e8215](https://www.jianshu.com/p/1598004e8215)
`const` 修饰为只读常量,只能初始化一次,`static` 修饰的变量和函数只能在当前模块或文件中可见。
4. 如何才能将一个`double`变量初始化为无穷大?使用java内置常数,`Double.POSITIVE_INFINITY`和`Double.NEGATIVE_INFINITY`
5. 能够将`double`类型的值和`int`类型的值相互比较吗?不通过类型转换不行!但是java一般会自动进行所需的类型转换,例如,如果`int x = 3`,则`(x < 3.1)`为`true`,java会在比较前将x转换为`double`类型(因为3.1为`double`类型的字面量)
6. java二维数组表示:`int[][] arr = { {1,2,3}, {4,5,6} };`
================================================
FILE: Base/leetCode.md
================================================
- [x][两数相加](./leetcode/两数相加.md)
- [x][两数之和](./leetcode/两数之和.md)
- [x][无重复字符的最长子串](./leetcode/无重复字符的最长子串.md)
- [x][两个排序数组的中位数](./leetcode/两个排序数组的中位数.md)
- [ ][最长回文子串](./leetcode/最长回文子串.md)
================================================
FILE: Base/leetcode/两个排序数组的中位数.md
================================================
## 两个排序数组的中位数
惊呆了,用自己最初的想法居然直接一把 AC 掉了困难题目,真不知道这困难是不是放错了哈哈哈,总之很开心就是了。刚开始想的巨多,一直在纠结怎么把两个有序的数组用一个较好的方法直接合并,然后又考虑到了题目是个有序数组,接着想到了用二分balabala,总之就是题还没开始写,我就已经想得乱七八糟,最后差点被自己吓屎去翻参考答案了,这又给了我一个提醒,做题之前确实是要好好的构思题目怎么来,但是要注意不要想太多,因为其实很多东西都是水到渠成的hhhh
```swift
func findMedianSortedArrays(_ nums1: [Int], _ nums2: [Int]) -> Double {
var finalArray: Array<Int> = []
var i = 0, j = 0
// 合并两个有序数组
while (i < nums1.count && j < nums2.count) {
if (nums1[i] < nums2[j]) {
finalArray.append(nums1[i])
i += 1
} else {
finalArray.append(nums2[j])
j += 1
}
}
// 添加剩余内容
while true {1`
if i < nums1.count {
finalArray.append(nums1[i])
i += 1
}
if j < nums2.count {
finalArray.append(nums2[j])
j += 1
}
if i >= nums1.count && j >= nums2.count {
break
}
}
// 返回中位数
if finalArray.count % 2 != 0 {
return Double(finalArray[finalArray.count / 2])
} else {
let v = (finalArray[finalArray.count / 2] + finalArray[finalArray.count / 2 - 1])
if v % 2 != 0 {
return Double(v / 2) + 0.5
}
return Double(v / 2)
}
}
```
================================================
FILE: Base/leetcode/两数之和.md
================================================
## TwoSum
Given an array of integers, return indices of the two numbers such that they add up to a specific target.
You may assume that each input would have exactly one solution, and you may not use the same element twice.
```
Example:
Given nums = [2, 7, 11, 15], target = 9,
Because nums[0] + nums[1] = 2 + 7 = 9,
return [0, 1].
```
### AC Code
```swift
class Solution {
func twoSum(_ nums: [Int], _ target: Int) -> [Int] {
var final: [Int] = [0, 0]
var index: Int = 0
for _ in nums {
var index_i:Int = index+1
for _ in index+1..<nums.count {
if target == nums[index] + nums[index_i] {
final = [index, index_i]
}
index_i = index_i + 1
}
index = index + 1
}
return final
}
}
```
题意非常简单,在LeetCode上也是Easy,可能是太久没被OJ虐过了,以为它说的Easy和我自己想的Easy是一个层面。🙂。最开始我的想法是用target遍历nums,对每一个item做差值temp,然后再nums中直接contains(temp),这就是我认为的Easy。😔。
然后事实上我却忘了最简单的重复对象没考虑上,当出现([3, 2, 4], 6)的测试集wa就直打脸,最后加上判重方法后,再submit,居然这回给我wa的是因为含有负数的测试集没过。
这时才想起来,原来Easy的套路这么多。此时,我的做法变为了把nums先abs后为Nums,Nums再重复之前的工作,此时负数的测试集过了,但是尼玛居然还出了比如负数和正数凑一块的测试集([-3, 2, 3], 0),这回print出来的final就成了(0, 0),因为abs后导致了做了差值的temp去找了第一次出现的3,而不是第二次出现的3。
最后受不了了,仔细的再梳理了一遍思路,很多时候啊一些被别人标上Easy的事情,没经过自己手也私以为是Easy,殊不知那是人家磕磕碰碰后的“得道”Easy,最后一拍脑瓜子才傻愣愣的发现完全不需要abs,直接用target见遍历后的item拿到temp后,直接contains即可,但是!!!submit居然woc的又time out!!!我只记得当初自己踏坑的时候每遇到time out就GG。
此时隐约的觉得会不会是while的问题导致的time out,但实际上while和for的时间复杂度都是O(n)哇,但是我没查到关于contains函数的复杂度到底是多少,我觉得Swift的Array实际上跟C++中的Vector差不多,虽然肯定是不会直接干find,但至少我认为应该是有参考过find的,而且还是觉得哪里不太对劲,但是又说不出来,我觉得不管是find还是contains会不会就是个hash_map呢?如果就是hash_map,那就游离在O(1)和O(n)之间了。所以那最差也就是O(n^2),我就没搞懂这是为啥老给我time out。
没办法,死磕也不是个办法,这出门不顺一下子就遇到了坎,看了solution,原来就是把contains换成了两个for,修改成了Swift版本后,这尼玛就AC了。
我是没搞懂为啥,只能日后再探了或者希望有识之士能给我提个醒🙏。
====== 2018-8-13 更新 ======
哈哈,最近又开始做 LeetCode 主要是想用剩下的时间给明年春招的优势更大一些(我是真的不想秋招),所以又开始二刷 2Sum 哈哈。不过第二次再去思考这道题的时候又给了我很多不一样的思考,直接看代码吧。
### AC Code
```Swift
func twoSum(_ nums: [Int], _ target: Int) -> [Int] {
var index = 0
var final:[Int] = [0 ,0]
for num in nums {
let tempNum = target - num
let tempNums = nums[index+1..<nums.count]
// contains 为一次遍历
if tempNums.contains(tempNum) {
// 这里的 index 多了一次遍历
let tempIndex:Int = tempNums.index(of: tempNum)!
final = [index, tempIndex]
}
index += 1
}
return final
}
```
这是第一遍提交的超时代码,给我报超时了以后其实我就知道个差不多了,首先有个 for 已经是 O(n) 了,用到了 `num[index+1..<nums.count]` 这已经是 O(n^2) 了,然后还有个 `contains` 这就 O(n^3) 了,后边还有个 `index` ,emmm,确实该超时了。
接下来又优化了一下,代码如下:
```Swift
var index = 0
var final:[Int] = [0 ,0]
for num in nums {
var n_index = index + 1
for n in nums[n_index..<nums.count] {
if n + num == target {
final = [index, n_index]
}
n_index += 1
}
index += 1
}
return final
```
提交后还是超时,后边想了一下,时间复杂度还是 O(n^2) ,因为 `nums[n_index..<nums.count]` 还在。此时我没法了,看了之前写的代码,用的是 for(index) 套了 for(index - 1) ,这样复杂度是 O(logn)。随后在网上又看到了一个解法利用上了 Dictionary ,直接就是 O(n),我自己认为应该是最优解了哈哈,代码如下:
```Swift
func twoSum(_ nums: [Int], _ target: Int) -> [Int] {
var final = [Int]()
var dict = [Int: Int]()
for index in 0..<nums.count {
guard let lastIndex = dict[target - nums[index]] else {
dict[nums[index]] = index
continue
}
final.append(index)
final.append(lastIndex)
}
return final
}
```
================================================
FILE: Base/leetcode/两数相加.md
================================================
## 两数相加
这道题难度是 medium ,AC 后我觉得完全没有昨天的 Easy 好做,开始怀疑 LeetCode 是不是搞错了哈哈。做的过程没有感觉到有多困难,但是最后输出 finalNode 的时候只丢出来了最后一个节点,突然想起来这是因为一直都在让 finalNode = finalNode.next ,然后开始陷入纠结中,稍微找到了点思路,肯定要用一个中间 node 去记录当前链,然后把每次生成的新节点添加到中间 node 上去,最后再把中间 node 每次都赋值给 finalNode 。但是这样也有问题,维护这几个 node 的成本太大,差点没绕晕我。
最后还是看了参考答案,整体框架跟我写的都是一致的,只不过在我最纠结的地方,参考答案居然用的是一个新 node 等于了 finalNode,最后直接 return finalNode , finalNode 根本就不参与这其中的计算,突然觉得这个方法好棒!因为 finalNode 始终都是新 node 的头,不管后续新 node 怎么去变换都不会改变,因为链表头已经被 finalNode 抓住了!
### AC Code
```swift
/**
* Definition for singly-linked list.
* public class ListNode {
* public var val: Int
* public var next: ListNode?
* public init(_ val: Int) {
* self.val = val
* self.next = nil
* }
* }
*/
class Solution {
func addTwoNumbers(_ l1: ListNode?, _ l2: ListNode?) -> ListNode? {
// 判断是否为空
if l1 == nil && l2 != nil {
return l2
} else if l1 != nil && l2 == nil {
return l1
} else if (l1 == nil && l2 == nil) {
return nil
} else {
var finalNode = ListNode(0)
var tempNode = l1
var otherNode = l2
var currentNode = finalNode
while true {
// 判断当前是否为空
if tempNode != nil {
currentNode.val += (tempNode?.val)!
}
if otherNode != nil {
currentNode.val += (otherNode?.val)!
}
tempNode = tempNode?.next
otherNode = otherNode?.next
if currentNode.val - 10 >= 0 {
currentNode.val = currentNode.val - 10
currentNode.next = ListNode(1)
currentNode = currentNode.next!
} else {
if tempNode == nil && otherNode == nil {
break
}
currentNode.next = ListNode(0)
currentNode = currentNode.next!
}
}
return finalNode
}
}
}
```
================================================
FILE: Base/leetcode/无重复字符的最长子串.md
================================================
## 无重复字符的最长子串
啊哈哈,这道题真有趣,刚开始没看懂题意中为什么要指出 "pwke" 是 子序列 而不是子串 这句话,然后自己用 k-v 过了前两个样例后到这个样例才恍然大悟,原来是这么个意思哈哈。
<img src="https://i.loli.net/2018/08/20/5b7ac7b203866.png" />
### 搞笑的code
```swift
func lengthOfLongestSubstring(_ s: String) -> Int {
var dict = [Character: Character]()
for c in s {
guard dict[c] != nil else {
dict[c] = c
continue
}
}
print(dict.values)
return dict.keys.count
}
```
### 一次超时的代码
```Swift
class Solution {
func lengthOfLongestSubstring(_ s: String) -> Int {
var dict = [Character: Character]()
var longestSubStringLength = 0
for c in s {
if dict[c] != nil {
if longestSubStringLength < dict.keys.count {
longestSubStringLength = dict.keys.count
}
dict.removeValue(forKey: c)
}
dict[c] = c
}
if longestSubStringLength < dict.keys.count {
longestSubStringLength = dict.keys.count
}
return longestSubStringLength
}
}
```
### AC 代码
```swift
func lengthOfLongestSubstring(_ s: String) -> Int {
var longestSubStringLength = 0
var finalString = ""
var index = 0
for c in s {
if finalString.contains(c) {
longestSubStringLength = max(longestSubStringLength, finalString.count)
let endIndex = finalString.index(of: c)
let stringRange = finalString.startIndex...endIndex!
finalString.removeSubrange(stringRange)
}
finalString.append(c)
index += 1
}
return max(longestSubStringLength, finalString.count)
}
```
其实挺惭愧的,看了官方题解没看懂哈哈哈,不过官方题解倒是给了三个大的解题方向,直接字符串暴力遍历、滑动窗口、Set 和 HashMap 三种。刚开始我受到了昨天(应该是前天)的结题思路影响,因为这道题的核心是返回“最长不重复子串”的长度,只需要知道个数就行,所以我就想到了直接刚 dictionary ,不过这也就给我后续的挖了一个巨大的坑,知道第二天早上(也就是今天)才解决掉,之前做的时候漏掉了一个问题,dictionary 没法删掉从某一个下标开始之前的所有字符,都是离散的,之前一直绕在这个里边,但是 dictionary 的解法是 O(1) 的,非常诱人。不过最后实在没绕出这个圈,又换了字符串再刚了一次,换了字符串直接暴力思路就非常顺畅了。
没错,因为受到了题解给的思路,就直接字符串做了,确实也 AC 了。AC 后我在想字符串按照我之前的经验不管是只要是遍历都是 O(n) 这一趟趟又 index(of:) 又 subRange 的早就 O(n^3) 了吧,岂能不超时?但实际上就是没超时 😑 。查阅了一波资料后才发现,原来 Apple 对 Swift 的 String 居然花了如此大的力气进行打磨,详见[这篇文章](https://github.com/apple/swift/blob/master/docs/StringManifesto.md#string-should-be-a-collection-of-characters-again),总结来说是 Swift 1.0 的时候只是字符的集合,相当于就是HashSet 了,Swift 2.0 后又把它移除掉了,一直到 Swift 4.0 又加了回来,在刚给出的那篇文章中,Apple 的开发团队写了不少为什么要加回来的思考,推荐阅读。
知道了 String 是 collection 后还是翻 collection 的文档,没想到不管是 index(of:) 还是 subRange() 等等得这些居然统统都是 O(1) !所以我写出了一个 O(n) 的解法 😑 。这还真是令人惊讶呢!(其实我觉得应该还是 O(n^2))
================================================
FILE: Base/leetcode/最长回文子串.md
================================================
## 最长回文子串
刚开始做的时候直接按照了自己的思路去搞,这一弄问题就出来了,因为没有考虑好回文字符串最重要的特点,导致最开始就想错了,大概的思路是这样的,还是一个字符一个字符的从目标字符串中读取,然后以当前读取到的字符出发,再起一个循环往后接着读取,一直读到下一个字符与当前字符相等,然后把从当前字符到下一个相等字符之间的字符串进行翻转,判断翻转前和翻转后是否相等,如果相等就记录下此时字符串和长度,然后接着循环。
好吧,其实看到这大家也都知道这种做法是一定会超时的,但是刚开始的时候因为我并不知道要考虑哪些测试样例,题目给的和自己想的一些简单样例都过了,交了一发,没报超时,只是一些边界条件没考虑好,加上这些边界条件后再交一发,好吧,从此一 wa 到底,统统超时。
### 超时代码1
```Swift
func longestPalindrome(_ s: String) -> String {
var stringindex = 0
var finalString = ""
var finalStringMaxLength = 0
while true {
if stringindex == s.count {
break
}
var tempString = ""
let currentStringStart = s.index(s.startIndex, offsetBy: stringindex)
for c in s[currentStringStart..<s.endIndex] {
tempString.append(c)
if tempString == String(tempString.reversed()) {
finalStringMaxLength = max(finalStringMaxLength, tempString.count)
guard finalStringMaxLength > tempString.count else {
finalString = tempString
continue
}
}
}
stringindex += 1
}
return finalString
}
```
### 超时代码2
```Swift
func longestPalindrome(_ s: String) -> String {
var stringindex = 0
var finalString = ""
var finalStringMaxLength = 0
while true {
if stringindex == s.count {
break
}
var tempString = ""
let currentStringStart = s.index(s.startIndex, offsetBy: stringindex)
for c in s[currentStringStart..<s.endIndex] {
if !tempString.isEmpty {
if c == tempString[tempString.startIndex] {
tempString.append(c)
if tempString == String(tempString.reversed()) {
finalStringMaxLength = max(finalStringMaxLength, tempString.count)
guard finalStringMaxLength > tempString.count else {
finalString = tempString
continue
}
continue
}
if tempString.count < s.count - stringindex {
continue
}
tempString = ""
break
}
}
tempString.append(c)
}
stringindex += 1
}
if finalString == "" {
if s == "" {
return ""
}
return String(s[s.startIndex])
}
return finalString
}
```
思考了一下,我的做法就是循环太多,而且循环的次数也很多,赶紧试着调了一下,发现问题还是没解决,但是又不想看答案,接着再纠结了一波,还是超时。翻了参考的思路,才意识到自己的出发点出了,应该要从当前字符两侧同时出发,同时判断左右两个字符,但是一直没写起来。
看了道长写的一个答案,看上去是打表做的,但是这思路自己完全看不懂 🙄 ,真是不明白这种题是怎么打表做的hhh,等以后能力够了再去回味一番吧。[repo 在此](https://github.com/soapyigu/LeetCode-Swift/blob/master/DP/LongestPalindromicSubstring.swift)
今天下午又在 github 上翻到了一个自己能够看懂的方法,用的就是官方题解的思路,但实际上却是超时代码。😓 ,[repo 在此](https://github.com/lexrus/LeetCode.swift/blob/swift4/Tests/5.swift)
超时的样例实在是太好玩了。hhhh
```
"bbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbbb"
```
================================================
FILE: Base/nowCode.md
================================================
## 有一棵二叉树,请设计一个算法,按照层次打印这棵二叉树
给定二叉树的根结点root,请返回打印结果,结果按照每一层一个数组进行储存,所有数组的顺序按照层数从上往下,且每一层的数组内元素按照从左往右排列。保证结点数小于等于500。
### AC code
```c++
#include <iostream>
#include <vector>
#include <queue>
struct TreeNode {
int val;
struct TreeNode *left;
struct TreeNode *right;
TreeNode(int x) :
val(x), left(NULL), right(NULL) {}
};
class TreePrinter {
public:
std::vector<std::vector<int> > printTree(TreeNode* root) {
std::queue<TreeNode *> queue;
std::vector<std::vector<int> > finalVec;
if (root) {
queue.push(root);
queue.push(NULL);
std::vector<int> layerVec;
while (!queue.empty()) {
TreeNode *frontNode = queue.front();
queue.pop();
if (frontNode) {
layerVec.push_back(frontNode->val);
if (frontNode->left != NULL) {
queue.push(frontNode->left);
}
if (frontNode->right != NULL) {
queue.push(frontNode->right);
}
} else {
finalVec.push_back(layerVec);
layerVec.clear();
if (!queue.empty()) {
queue.push(NULL);
}
}
}
}
return finalVec;
}
};
int main(int argc, const char * argv[]) {
TreeNode *rootNode = new TreeNode(1);
TreeNode *node1 = new TreeNode(2);
rootNode->left = node1;
TreeNode *node2 = new TreeNode(3);
rootNode->right = node2;
TreeNode *node3 = new TreeNode(4);
node1->left = node3;
TreeNode *node4 = new TreeNode(5);
node1->right = node4;
TreeNode *node5 = new TreeNode(6);
node2->left = node5;
TreeNode *node6 = new TreeNode(7);
node2->right = node6;
TreePrinter *printer = new TreePrinter();
printer->printTree(rootNode);
std::vector<std::vector<int>> finalVec = printer->printTree(rootNode);
for (std::vector<std::vector<int> >::iterator vec = finalVec.begin(); vec != finalVec.end(); vec ++) {
std::vector<int> tempVec = *vec;
for (std::vector<int>::iterator instance = tempVec.begin(); instance != tempVec.end(); instance ++) {
std::cout << *instance << std::ends;
}
std::cout << std::endl;
}
return 0;
}
```
## 总结
刚开始一点思路都没有,可能是太久没有摸算法了吧,而且也不知道要用上队列,更别说要考虑的一些细节了。总之这道题让我反思了很多,确实是不应该让自己的目光一直放在工程上了。
因为这道题十分经典,网上已经有了大量的题解,左神讲的意思是用一个队列 Q 去管理且用两个变量 last 和 nlash 去做记录,last 作为当前层级的最右节点,nlast 为当前下一层级的最右节点。刚开始先让 last 等于 rootNode ,然后 rootNode push() 入队,接着再让 rootNode pop() 出队,让 nlast 等于 rootNode->leftNode 入队,接着让 nlast 等于 rootNode->rightNode 且入队,此时发现 last 所代表的节点和 出队的 rootNode 相等,换行。继续用 last 等于 root->rightNode ,重复以上过程。
刚开始我觉得云里雾里的,虽然自己也确实没有思路,但是总感觉怪怪的。于是先来纠结一番如何进行按层遍历,也就是宽度优先遍历,当初自己前中后序遍历“嗖嗖”的就写出来了,现如今还得缓好久才知道应该怎么动手,😔。刚开始根本就不知道要用到队列,一直在纠结怎么递归。翻了翻网上的题解,一看到大家都在使用队列思路就开始活跃起来了。
经过一番修整,代码撸出来了,但是跟左神的做法不太一样,没有用到任何标记变量,当前层级如果要结束了直接在 push 进一个 NULL ,后边再去遍历的时候遇到 NULL 就标记着当前层级已经结束了,开始进行下一层级的宽度优先遍历。
再调整一下,代码也撸出来了,但是格式不对,研究了一下,发现是因为 push 进 finalVec 的时机不对,又调整了一下才得以 AC 。
## 二叉树的序列化
没有题意,意思就是要让我们把二叉树进行序列化,做二叉树的序列化左神讲到了一个重点,要进行区分节点的孩子,尤其对于 BFS 来说,需要标识清楚层级关系。
### BFS
```C++
bool serializationBinaryTree(std::vector<std::vector<int> > finalVec) {
std::ofstream fileOut;
fileOut.open("traversalOfBinaryTree.txt");
if (!fileOut) {
return false;
}
for (std::vector<std::vector<int> >::iterator vec = finalVec.begin(); vec != finalVec.end(); vec ++) {
std::vector<int> tempVec = *vec;
for (std::vector<int>::iterator instance = tempVec.begin(); instance != tempVec.end(); instance ++) {
fileOut << *instance;
}
fileOut << std::endl;
}
fileOut.close();
return true;
}
```
### 总结
直接用上了上一题的输出的二维 vector 。
### 二叉树的序列化
二叉树的反序列化相对于序列化来说考虑的事情更多一些。同样,我也将实现二叉树的前中后序以及 BFS 反序列化。
### BFS
```C++
TreeNode* deserializationBinaryTree() {
std::ifstream fileIn;
fileIn.open("traversalOfBinaryTree.txt");
std::vector<std::vector<int>> finalVec;
if (!fileIn) {
return nullptr;
}
TreeNode *rootNode = nullptr, *currentNode = nullptr;
std::queue<int> queue;
std::queue<TreeNode *> nodeQueue;
while(!fileIn.eof()) {
std::string tmpString;
std::getline(fileIn, tmpString);
for (int i = 0; i < tmpString.length(); i ++) {
queue.push(tmpString[i] - 48);
}
// int queue don't accept nullptr, becauese of it's real null pointer
queue.push(-1);
}
while (!queue.empty()) {
if (!rootNode) {
rootNode = new TreeNode(queue.front());
nodeQueue.push(rootNode);
queue.pop();
currentNode = rootNode;
} else {
if (queue.front() == -1) {
queue.pop();
} else {
if (!currentNode->left) {
currentNode->left = new TreeNode(queue.front());
nodeQueue.push(currentNode->left);
queue.pop();
} else if (!currentNode->right) {
currentNode->right = new TreeNode(queue.front());
nodeQueue.push(currentNode->right);
queue.pop();
} else {
currentNode = nodeQueue.front();
nodeQueue.pop();
}
}
}
}
fileIn.close();
return rootNode;
}
```
### 总结
做 BFS 的反序列化纠结得有些久,刚开始也没想到用队列去存 getline 切割出来的内容,到最后想起了左神说的用什么方法进行序列化就用什么方法进行反序列化后,才点醒了我,撸完了第一波代码后,又卡住了,又掉进了死胡同,currentNode 无法和 parentNode 进行交互,也就说到了 rootNode 后,没法再进行循环建树了,差点又要放弃。在去刷牙的过程中,脑子活了一下,发现可以再用一个 nodeQueue 去 push queue pop 出来的当前层 node,遂搞定。
================================================
FILE: Base/python.md
================================================
## 模块
每个 `.py` 文件的主文件就是模块名称,想要导入模块时必须使用 `import` 关键词来制定模块名称。若要引用模块中定义的名称,则必须在名称前加上模块名称与一个 “`.`" 符号。
## __pycache__
CPython 将 .py 文件编译后的字节码文件,如果之后再次导入同一个模块,检测到源码文件没有更改过,就不会再对源码重头开始进行语义和语法解析等操作。
## 获取命令行参数
可通过 `sys` 模块中的 `argv` 列表,argv[0] 保存的是源码的文件名:
```python
import sys
print('hello', sys.argv[1])
```
## 包
文件夹中一定要有一个 `__init__.py` 文件,该文件夹才会被视为一个软件包,并且软件包名称会成为命名空间的一部分。
## python 中所有数据都是对象
## python3 之后,整数类型为 `int`,不再区分 `int` 和 `long`
## type()
想知道某个数据的类型可以使用 `type()` 函数:
```python
>>>type(10)
<class 'int'>
```
## python 支持复数的直接表示法
```python
>>> a = 3 + 2j
>>> b = 5 + 3j
>>> a + b
(8 + 5j)
```
## 格式化字符串
### 旧方式
```python
>>> 'hello, %s!' % 'world'
```
### 新方式
```python
>>> 'hello, {}!'.format('world')
```
## 字典
当从字典中通过某个 key 取值时,当 key 不存在,则会报 `KeyError` 的错误,此时可以通过 `in` 来判断:
```python
>>> nums = {'aha': 2333}
>>> 'wow' in nums
False
>>> nums['wow']
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
KeyError: 'wow'
```
## 需要处理小数且还需要精确的结果
`import decimal`,其它细节查资料
## 指数运算
```python
>>> 2 ** 10
1024
```
## 比较与赋值
`== != < >` 等符号用来比较值,`is, is not` 用来比较两个对象的引用是否相等
## * 与 **
### `*`
如果事先无法预期要传入的自变量个数,可以在定义函数的参数时使用 `*`,表示该参数接受不定长度的自变量:
```python
def sum(*numbers):
total = 0
for number in numbers:
total += number
return total
```
### `**`
让指定的关键词自变量收集为一个字典:
```python
def ahaha(**user_settings):
methon = user_settings.get('methon', 'GET')
contents = user_settings.get('contents', '')
```
================================================
FILE: Base/操作系统.md
================================================
# 第一章 计算机操作系统概述
## 第一节
时间 | 硬件 | 语言 | 用途
--------- | --------- | --------- | -------- |
1945 | 电子真空管 | 机器语言 | 应用于科学计算
1956 | 晶体管 批处理控制 | Fortran/COBOL | 数据处理领域
1959 | 集成电路 多道程序 | 操作系统/数据库/高级语言 | 应用领域得到了进一步的拓展
1976 | 大规模/超大规模集成电路 | | 向快速化/小型化/系统化/网络化/智能化等方面发展
1980 | 微机出现 | | 廉价化促使应用领域快速膨胀 |
1990 | 图形化人机交互技术 | | 友善化推动了应用人群的快速扩展
2003 | 移动计算 | | |
### 计算机系统组成
* 硬件子系统和软件子系统
* 硬件:CPU、I/O控制系统等
* 软件:操作系统等
### 计算机系统的用户视图
<img src="https://i.loli.net/2018/09/10/5b96747ba3f16.jpg" width="70%" />
## 第二节
### 计算机硬件系统
* 中央处理器:运算单元,用于执行机器指令的运算;控制单元:解义机器指令。
* 主存储器:存储正在执行的指令和数据。
* 外围设备:显示器等输出设备,键盘鼠标等输入设备,硬盘等存储设备,机机网络设备。
* 总线:连接
### 冯诺依曼模型
存储程序计算机在体系结构上主要特点:
1. 以运算单元为中心,控制流由指令流产生;
2. 采用存储程序原理,面向主存组织数据流;
3. 主存是按地址访问、线形编址的空间;
4. 指令由操作码和地址码组成;
5. 数据以二进制编码。
### 总线
* 总线(Bus)是计算机各种功能部件之间传送信息的公共通信干线,它是 CPU 、内存、输入输出设备传递信息的公用通道。
* 计算机的各个部件通过总线相连接,外围设备通过相应的接口电路再与总线相连接,从而形成了计算机硬件系统
* 按照所传输的信息种类,总线包括一组控制线、一组数据线和一组地址线。
### 总线类型
* 内部总线:用于 CPU 芯片内部连接各元件;
* 系统总线:用于连接 CPU 、存储器和各种 I/O 模块等主要部件
* 通信总线:用于计算机系统之间通信。
### 中央处理器(CPU)
是计算机运算核心(Core)和控制单元(Control Unit),主要包括:
* 运算逻辑部件:一个或多个运算器;
* 寄存器部件:包括通用寄存器、控制与状态寄存器,以及高速缓冲存储器(Cache)
* 控制部件:
* 实现各部件间联系的数据、控制及状态的内部总线
* 负责对指令译码、发出为完成每条指令所要执行操作的控制信号、实现数据传输等功能的部件。
### 存储器的组织结构
<img src="https://i.loli.net/2018/09/10/5b9674a17ff9f.jpg" width="70%" />
L0 ~ L4 :挥发性存储器,断电数据消失。
### 外围设备及其控制
设备类型:
* 输入设备
* 输出设备
* 存储设备
* 机机通信设备:不同网络设备块大小不一致,以字节、以包等进行数据传输
设备控制方式:
* 轮询方式:CPU 忙式控制,CPU 执行内存数据交换;
* 中断方式:CPU 启动外设,外设中断 CPU ,CPU 执行内存数据交换。
* DMA (直接内存存取)方式:CPU 启动 DMA ,DMA 执行输入输出与内存数据交换,DMA 中断 CPU 。举个例子,移动一个外部内存的区块到芯片内部更快的内存区,这样的操作并没有让处理器工作拖延,反而可以重新排程处理其它工作。
## 第三节
### 计算机软件系统的组成
* 系统软件:操作系统、实用程序、语言处理程序和数据库管理系统。操作系统为实施对各种软硬件资源的管理控制;实用程序为方便用户所设,如文本编辑;语言处理程序把用汇编语言/高级语言编写的程序,翻译成可执行的机器语言程序。
* 支撑软件:有接口软件、工具软件、环境数据库,支持用户使用计算机的环境,提供开发工具。(也可以认为是系统软件的一部分)
* 应用软件:是用户按其需要自行编写的专用程序。
### 软件开发的不同层次
* 计算机硬件系统:机器语言;
* 操作系统之资源管理:机器语言 + 广义指令(拓充了硬件资源管理);
* 操作系统之文件系统:机器语言 + 系统调用(扩充了信息资源管理);
* 数据库管理系统:+ 数据库语言(扩充了功能更强的信息资源管理);
* 语言处理程序:面向问题的语言。
## 第四节
### 计算机的手工操作
哈哈,跟之前上计算机组成原理一样,做个大实验手指疼两天。
### 装入程序的引进
* 引入卡片和纸带描述程序指令与数据
* 引入装入程序(Loader)。自动化执行程序装入,必要时进行地址转换;通常存放在 ROM 中。
### 引入汇编语言后的计算机控制
* 计算机操作变成:汇编和执行两个阶段。
### 高级语言之后
* 计算机操作变成:编译、**连接**和执行三步骤。
### 简单批处理系统的操作
* 原先,手工操作与计算机速度严重不匹配的问题。现在,引入**作业控制语言**,用户编写作业说明书,描述对一次计算机求解(作业)的控制;
* 操作员控制计算机成批输入作业,成批执行作业;
* 这一方式明显缩短了手工操作时间,提高了计算机系利用率;
* 这一阶段,磁带的出现,使得卡片与纸带等机械输入方式得以进一步提高。
只是一个简单的批处理系统,谈不上是操作系统,只提供了一个半自动化操作方式,并没有解决与中央处理器电子速度不匹配的矛盾,要让多个程序同时进入计算机系统,而想要多道程序同时进行,就需要进行程序的切换,而该切换的解决需要更加高速的外存储设备的支撑。
### 操作系统与自动化系统
磁盘的出现,计算机操作系统从此出现,实现了真正的自动化控制。
## 第五节
### 操作系统概念
* 操作系统简称:OS
* OS 是计算机系统最基础的系统软件,管理软硬件资源、控制程序执行,改善人机界面,合理组织计算机工作流程,为用户使用计算机提供良好运行环境。
### 操作系统
操作系统是方便用户、管理和控制计算机软硬件资源的系统程序集合。
* 从用户角度看,OS 管理计算机系统的各种资源,扩充硬件的功能,控制程序的执行;
* 从人机交互看,OS 是用户与机器的接口,提高良好的人机界面,方便用户使用计算机;
* 从系统结构看,OS 是一个大型软件系统,其功能复杂,体系庞大,采用层次式、模块化的程序结构。
### 操作系统的组成
* 进程调度子系统;
* 进程通信子系统;
* 内存管理子系统;
* 设备管理子系统;
* 文件管理子系统;
* 网络通信子系统;
* 作业控制子系统;
### 操作系统的类型
* **从操作方式看**
* 多道批处理操作系统,采用脱机控制方式;
* 分时操作系统,采用交互控制方式;
* 实时操作系统。
* **从应用领域看**
* 服务器操作系统、并行操作系统;
* 网络操作系统、分布式操作系统;
* 个人机操作系统、手机操作系统;
* 嵌入式操作系统、传感器操作系统。
## 第六节
### 操作系统的资源
* 硬件资源:处理器、内存、外设。
* 信息资源:数据、程序。
### 管理计算机系统的软硬件资源
* 处理器资源:哪个程序占有处理器运行?
* 内存资源:程序/数据在内存中如何分布?
* 设备管理:如何分配、去配和使用设备?
* 信息资源管理:如何访问文件信息?
* 信号量资源:如何管理进程之间的通信?
### 屏蔽资源使用的底层细节
* **驱动程序**:最底层的、直接控制和监视各类硬件(或文件)资源的部分;
* 职责是隐藏底层硬件的具体细节,并向其它部分提供一个抽象的通用的接口;
* 比如说:打印一段文字或一个文件,既不需要知道文件信息存储在硬盘上的细节,也不必知道具体打印机类型和控制细节。
### 资源的共享与分配方式
* 资源共享方式:独占使用方式、并发使用方式;
* 资源分配策略:静态分配方式(无死锁)、动态分配方式(注意死锁)、资源抢占方式(无死锁)。
## 第七节
### 多道程序同时计算
* CPU 速度与 I/O 速度不匹配的矛盾,非常突出。
* 只有让多道程序同时进入内存争抢 CPU 运行,才能够使得 CPU 和外围设备充分并行,从而提高计算机系统的使用效率。
### 多道程序设计
* 多道程序设计:指让多个程序同时进入计算机的主存储器进行计算;
* 多道程序设计的特点
* CPU 与外部设备充分并行;
* 外部设备之间充分并行;
* 发挥 CPU 的使用效率;
* 提高单位时间的算题量。
### 多道程序系统的实现
* 为进入内存执行的程序建立管理实体:**进程**
* OS 应能管理与控制进程程序的执行;
* OS 协调管理各类资源在进程间的使用
* 处理器的管理和调度;
* 主存储器的管理和调度;
* 其它资源的管理和调度。
### 多道程序系统的实现要点:
* 如何使用资源:调用操作系统提供的服务例程(如何陷入操作系统);
* 如何复用 CPU :调度程序(在 CPU 空闲时让其他程序运行);
* 如何使 CPU 与 I/O 设备充分并行:设备控制器与通道(专用的 I/O 处理器)
* 如何让正在运行的程序让出 CPU :中断(中断正在执行的程序,引入 OS 处理)
## 第八节
### 计算机系统操作方式
* OS 规定了合理操作计算机的工作流程;
* OS 的操作接口 —— 系统程序;
* OS 提供给用户的功能级接口,为用户提供的解决操作计算机和计算共性问题所有服务的集合。
* OS 的两类作业级接口:
* 脱机作业控制方式:作业控制语言;
* 联机作业控制方式:操作控制命令。
### 脱机作业控制方式
* OS : 提供作业说明语言包;
* 用户:编写作业说明书,确定作业加工控制步骤,并与程序数据一并提交;
* 操作员:通过控制台输入作业;
* OS :通过作业控制程序自动控制作业的执行;
* 例如:批处理 OS 的作业控制方式,UNIX 的 shell 程序,DOS 的 bat 文件。
### 联机作业控制方式
* 计算机:提供终端(键盘/显示器);
* 用户:登录系统;
* OS :提供命令解释程序;
* 用户:联机输入命令,直接控制作业步的执行;
* 例如:分时 OS 的交互控制方式。
### 命令解释程序
* 命令解释程序:接受和执行一条用户提出的对作业的加工处理命令;
* 当一个新的批作业被启动,或新的交互型用户登录进系统时,系统就自动地执行命令解释程序,负责读入控制卡或命令行,作出相应解释,并予以执行;
* 会话语言:可编程的命令解释程序;
* 图形化的命令控制方式;
* 多通道交互的命令控制方式。
### 命令解释程序的处理过程
* OS 启动命令解释程序,输出命令提示符,等待键盘中断/鼠标点击/多通道识别;
* 每当用户输入一条命令(暂存在命令缓冲区)并按回车换行时,申请中断;
* CPU 响应后,将控制权交给命令解释程序,接着读入命令缓冲区内容,分析命令、接受参数,执行处理代码;
* 前台命令执行结束后,再次输出命令提示符,等待下一条命令;
* 后台命令处理启动后,即可接收下条命令。
## 第九节
### 操作系统的人机交互部分
* OS 改善人机界面,为用户使用计算机提供良好的环境;
* 人机交互设备包括传统的终端设备和新型的模式识别设备;
* OS 的人机交互部分用于控制有关设备运行和理解执行设备传来的命令;
* 人机交互功能是决定计算机系统友善性的重要因素,是当今 OS 研发热点。
### 人机交互的初期发展
* 交互式控制方式:
* 行命令控制方式:1960 年代开始使用;
* 全屏幕控制方式:1970 年代开始使用;
* 斯坦福研究所提出的发展计划:
* 始于 1960 年代,1980 年代广泛应用;
* 强调人而不是技术是人机交互的中心;
* 代表性成果:鼠标、菜单与窗口控制。
### 人机交互发展 —— WIMP 界面
* 缘起:70年代后期施乐的原型机 Star;
* 特征:窗口(Windows)、图标(Icons)、菜单(Menu)和指示装置(Pointing Devices)为基础的图形用户界面 WIMP 。
* 得益:Apple 最初采用并大力推动;
* 时间:1990 年代开始广泛使用;
* 不足:不能运行同时使用多个交互通道,从而产生人-机交互的不平衡。
### 人机交互发展 —— 多媒体计算机
* 缘起:1985年的 MPC
* 把音视频、图形图像和人机交互控制结合起来,进行综合处理的计算机系统;
* 构成:多媒体硬件平台、多媒体 OS 、图形用户接口、多媒体数据开发工具。
* 提供与时间有关的时变媒体界面,既控制信息呈现,也控制何时呈现/如何呈现;
* 人机交互界面需要使用多种媒体,同时支持多通道交互整合,改善用户体验。
### 人机交互发展 —— 虚拟现实系统
* 缘起:1980年代的虚拟现实新型用户界面;
* VR 通过计算机模拟三位虚拟世界,根据观察点、观察点改变的导航和对周围对象的操作,来模拟临境体验;
* 支持多通道交互整合,提供良好用户体验;
* 支持用户主动参与的高度自然三位 HCI ,以及语音识别、头部跟踪、视觉跟踪、姿势识别等新型 HCI 。
## 第十节
### 操作系统的程序接口
* 操作系统功能的程序接口 —— 系统调用;
* 操作系统实现的完成某种特定功能的过程;为所有运行程序提供访问操作系统的接口。
### 系统调用的实现机制
* 陷入处理机制:计算机系统中控制和实现系统调用的机制;
* 陷入指令:也称访管指令,或异常中断指令;
* 每个系统调用都事先规定了编号,并在约定寄存器中规定了传递给内部处理程序的参数。
### 系统调用的实现要点
* 编写系统调用处理程序;
* 设计一张系统调用入口地址表,每个入口地址指向一个系统调用的处理程序,并包含系统调用自带参数的个数;
* 陷入处理机制需要开辟现场保护区,以保持发生系统调用时的处理器现场。
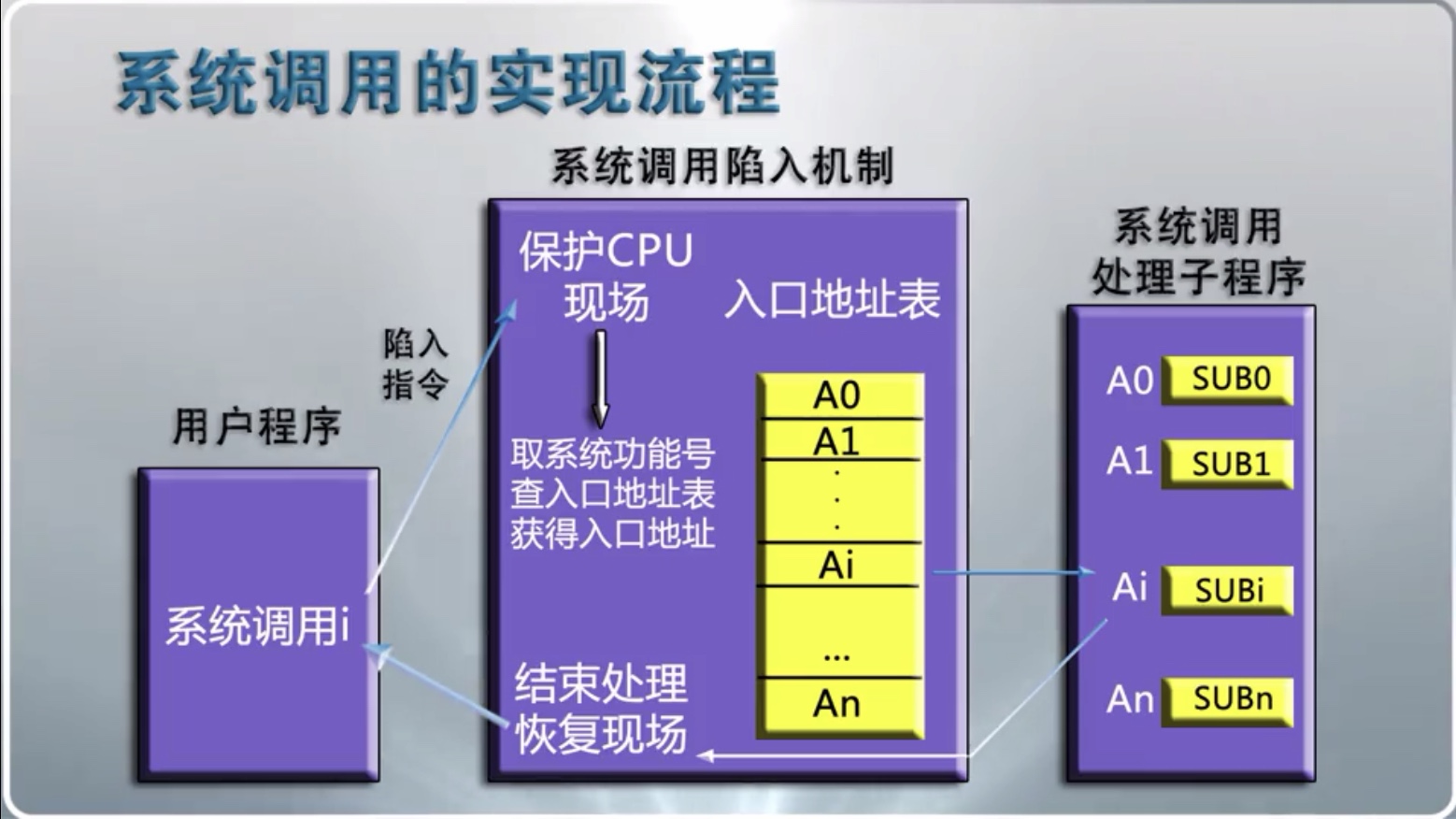
## 第十一节
### 操作系统软件的规模
* 在计算机软件发展史上, OS 是第一个大规模的软件系统;
* 1960 年代,由 OS 开发所衍生的体系结构、模块化开发、测试与验证、演化与维护等研究直接催生了软件工程这一新兴研究领域(另一个催生来源是 DB 应用引发的需求与规格)
### 操作系统软件的结构设计
* OS 构件:内核、进程、线程、管程等;
* 设计概念:模块化、层次式、虚拟化。
### 操作系统内核
* 单内核:内核中各部件杂然混居的形态,始于1960年代,广泛使用。如 Unix/Linux ,及 Windows (官方称为混合内核的 CS 结构);
* 微内核:1980 年代开始,强调结构性部件与功能性部件的分离,大部分 OS 研究都集中在此;
* 混合内核:微内核和单内核的折中,较多组件在核心态中运行;
* 外内核:尽可能减少内核的软件抽象化和传统微内核的消息传递机制,使得开发者专注于硬件的抽象化(部分嵌入式系统使用)


# 第二章 处理器管理
## 第一节 处理器与寄存器
操作系统是对计算机硬件的第一次扩充,操作系统在设计的实话贯彻了软硬件协同的概念,操作系统对硬件设计提出了一系列要求。
### 处理器部件的简单示意
### 用户可见寄存器
* 可以使程序员减少访问主存储器的次数,提高指令执行的效率;
* 所有程序可使用,包括应用呈现和系统程序:
* 数据寄存器:又称通用寄存器(AX、BX、CX、DX);
* 地址寄存器:索引寄存器(SI、DI)、栈指针寄存器(SP、BP)、段地址寄存器(CS、DS、SS、ES)等;
### 控制与状态寄存器
* 用于控制处理器的操作。主要被具有特权的操作系统程序使用,以控制程序的执行。
* 程序计数器 PC :存储将取指令的地址;
* 指令寄存器 IR :存储最近使用的指令;
* 条件码 CC :CPU 为指令操作结果设置的位,标志正/负/零/溢出等结果;
* 标志位:中断位、中断允许位、中断屏蔽位、处理器模式位、内存保护位等。
### 程序状态字 PSW
* PSW 即是操作系统的概念,指记录当前程序运行的动态信息,通常包含:
* 程序计数器,指令寄存器,条件码;
* 中断字,中断运行/禁止,中断屏蔽,处理器模式,内存包含,调试控制。
* PSW 也是计算机系统的寄存器
* 通常设置一组控制与状态寄存器;
* 也可以专设一个 PSW 寄存器。
## 第二节 指令与处理器模式
### 机器指令
* 机器指令是 **计算机系统执行** 的基本命令,是 **中央处理器执行** 的基本单位;
* 指令由一个或多个字节组成,包括操作码字段、一个或多个操作数地址字段以及一些表征机器状态的状态字或特征码;
* 指令完成各种算术逻辑运算、数据传输、控制流跳转特征码。
### 指令执行过程
* CPU 根据 PC (程序计数器)取出指令,放入 IR (指令暂存器),并对指令译码,然后发出各种控制命令,执行微操作系列,从而完成一条指令的执行。
* 一种指令执行步骤如下:
* 取指:根据 PC 从存储器或高速缓冲存储器中取指令到 IR ;
* 解码:解译 IR 中的指令来决定其执行行为;
* 执行:连接到 CPU 部件,执行运算,产生结果并写回,同时在 CC 里设置运算结论标志;跳转指令操作 PC ,其它指令递增 PC 值。
### 特权指令与非特权指令
* 用户程序并非能够使用全部机器指令,那些与计算机核心资源相关的特殊指令会被保护。
* 如:启动 I/O 指令、置 PC 指令等
* 核心资源相关的指令只能被操作系统程序使用;
* 特权指令:只能被操作系统内核使用的指令;
* 非特权指令:能够被所有程序使用的指令。
### 处理器模式
* 计算机通过设置处理器模式实现特权指令管理;
* 计算机一般设置 0 、 1 、2 、 3 等四种运行模式,建议分别对应:
值 | 保护级别
--- | ---
0 | 操作系统内核
1 | 系统调用
2 | 共享库程序
3 | 用户程序
* 一般来说,现代操作系统只使用 0 和 3 两种模式,对应与内核模式和用户模式。
### 模式的切换
* 简称模式切换,包括“用户模式 -> 内核模式”和“内核模式 -> 用户模式”的转换;
* 中断、异常或系统异常等事件导致用户程序向 OS 内核切换,触发:用户模式 -> 内核模式;
* 程序运行时发生并响应中断
* 程序运行时发生异常
* 程序请求操作系统服务
* OS 内核处理完成后,调用中断返回指令触发:内核模式 -> 用户模式。
## 中断
### 中断的概念
* 中断是指程序执行过程中,遇到急需处理的事件时,暂时中止 CPU 上现行程序的运行,转去执行相应的事件处理程序,待处理完成后再返回原程序被中断处或调度其他程序执行的过程。
* **操作系统时“中断驱动”的**;换言之,中断时激活操作系统的唯一方式。
* 中断有广义和狭义之分,上述中断是广义的中断。
### 中断、异常与系统异常
* 狭义的中断指来源于处理器之外的中断事件,即与当前运行指令无关的中断事件,如 I/O 中断、时钟中断、外部信号中断等。
* 异常指当前运行指令引起的中断事件,如地址异常、算数异常、处理器硬件故障等。
* 系统异常指执行陷入指令而触发系统调用引起的中断事件,如请求设备、请求 I/O 、创建进程等。
================================================
FILE: Base/网络相关知识.md
================================================
# HTTPS 通信原理剖析
## 基本概念
### 公钥密码体制(public-key cryptography)
公钥密码体制分为三个部分:**公钥**、**私钥**和**加密解密算法**。它的加密解密过程如下:
* 加密:通过加密算法和公钥对内容(或明文)进行加密,得到密文。加密过程需要用到公钥;
* 解密:通过解密算法和私钥对密文进行解密,得到明文。解密过程需要用到解密算法和私钥。注意,由公钥加密的内容,只能由私钥进行解密。
公钥密码体制的公钥和算法都是公开的,私钥是保密的。大家都使用公钥进行加密,但只有私钥的持有者才能进行解密,在实际的使用中,有需要的人会生成一对公钥和私钥,把公钥发布出去,私钥自己留着。
### 对称加密算法(symmetric key algorithms)
在对称加密算法中,加密使用的密钥和解密使用的密钥是相同的,因此对称加密算法要保证安全性的话,密钥要做好保密,只能让使用的人知道,不能对外公开。与上文中国呢的公钥密码体制有所不同,公钥密码体制中加密是用公钥,解密是用私钥,而对称加密算法中,加密和解密都是使用同一个密钥,不区分公钥和私钥。
### 非对称加密算法(asymmetric key algorithms)
在非对称加密算法中,加密使用的密钥和解密使用的密钥是不相同的。前面所说的公钥密码体制就是一种非对称加密算法,它的公钥和私钥是不能相同的。
### RSA 简介
RSA 密码体制是一种公钥密码体制,公钥公开,私钥保密,它的加密解密算法是公开的,由公钥加密的内容可以并且只能由私钥进行解密,并且由私钥加密的内容可以并且只能由公钥进行解密。
### 签名和加密
加密,是指对某个内容加密,加密后的内容还可以通过解密进行还原。比如我们把电子邮件进行加密,在网络上传输给对方,对方通过解密后可以还原电子邮件的真实内容。
签名,是指在信息后面再加上一段内容,可以证明信息没有被修改过。一般是对信息做一个 hash 计算得到一个 hash 值(总之要不可逆),在把信息发出去后,把这个 hash 值作为一个签名和信息一块发出去。接收方在收到信息后,会重新计算信息的 hash 值,并和信息所附带的 hash 值(解密完)进行对比,如果一致,就说明信息的内容没有被修改过。当然,这么做还是有可能会让 hacker 在修改真实内容的同时修改 hash 值,为了防止这种情况,签名一般会加密后再和真实内容一起发送出去,保证该签名不被修改。(如何解密该签名,涉及到数字证书,后文讲解)
## 练练
### 一
假设服务器和客户端要在网络上通信,并且打算使用 RSA 来对通信进行加密以保证内容传输的安全,由于是使用 RSA 这种公钥密码体制,服务器需要对外发布公钥(算法不需要公布,RSA 算法大家都知道),自己留着私钥,客户端通过某些途径拿到了服务器发布的公钥,客户端并不知道私钥。
如果有人 hack ,则会出现:
故客户端在接收到消息后,并不能肯定这个该消息就是由真实服务器发出的,可以被第三者冒充真实服务器发出该消息。那该如何确定该信息是由真实服务器发送过来的呢?我们知道,因为只有服务器才有私钥,所以能够确认只有对方才拥有私钥,那对方就是真实服务器,因此可为:
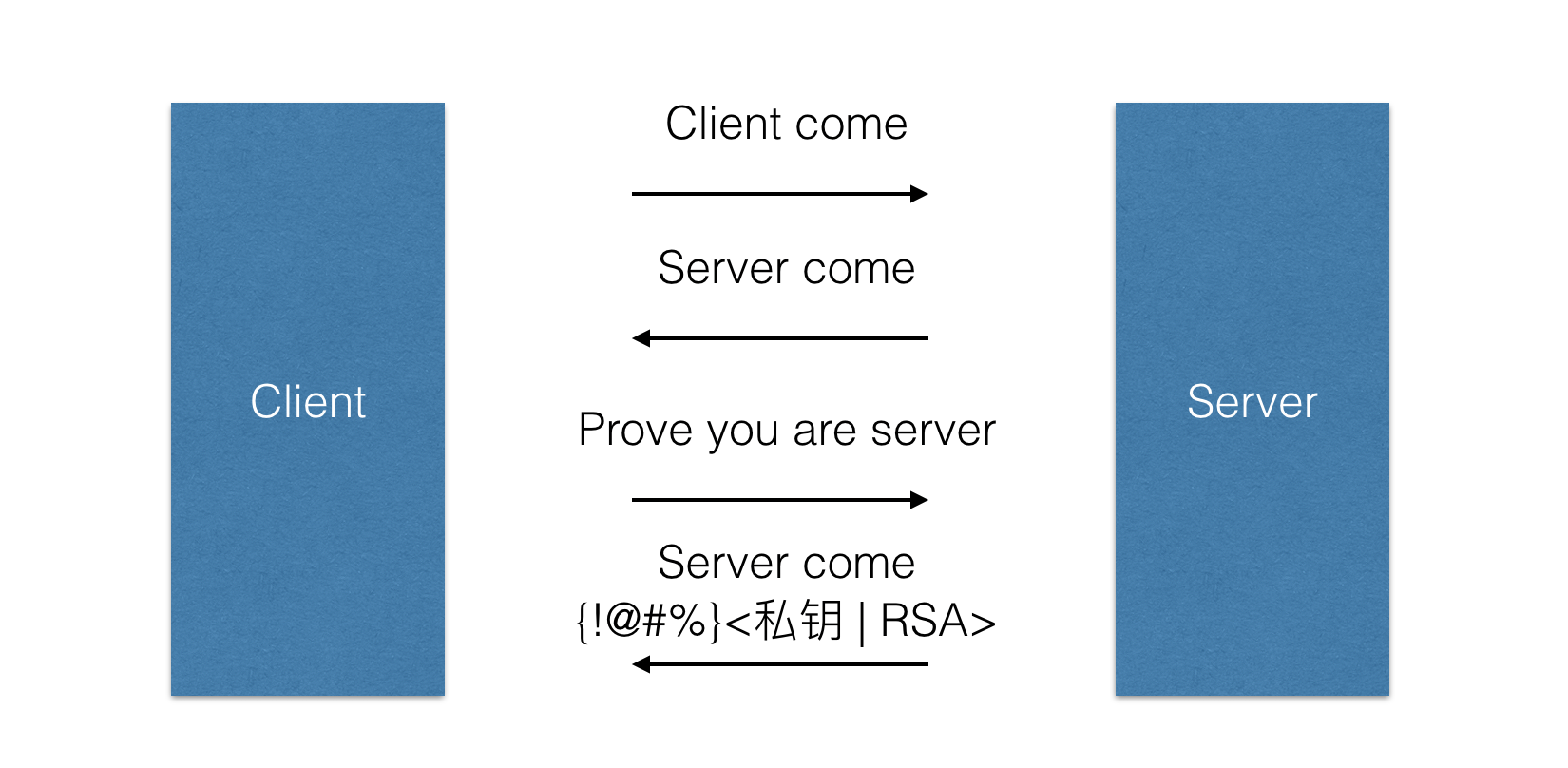
* {!@#%} 为 RSA 加密后的内容;
* < a | b > 为用 a 密钥和 b 算法进行加密。
* {!@#%}<私钥 | RSA> 表示为用 私钥 对 “Server come” 进行加密后的结果。
为了向客户端证明自己是服务器,服务器先把一个字符串(Server come)用自己的私钥加密,把明文和加密后的密文一起发给客户端。客户端收到消息后,用自己的公钥解密密文,和明文进行比较,如果一致,说明信息的确是由服务器发过来的。因为由服务器用私钥加密后的内容由且只能由公钥进行解密,私钥只有服务器持有,所以如果解密出来的内容是能够对得上,那说明信息一定是从服务器发送过来的。
如果想 hack 服务器,
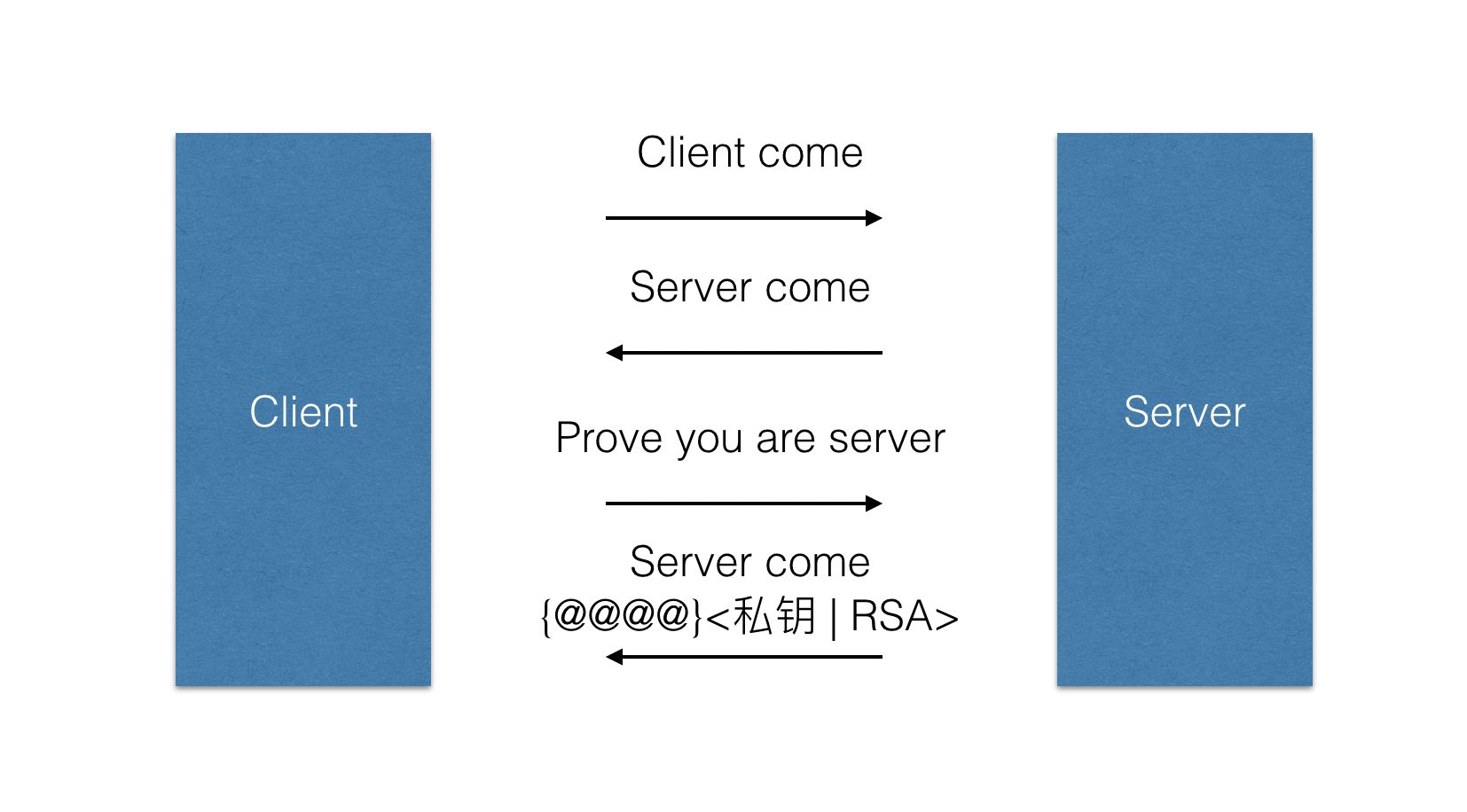
在上图中的第四步{@@@@}<私钥 | RSA> ,这块是无法 hack 的,因为不知道私钥,无法用私钥加密,可以认定对方是个假货。
到这里,客户端可以确认服务器的身份了,可以放心的和服务器进行通信,但还有个问题,通信的内容在网络上还是无法保密,
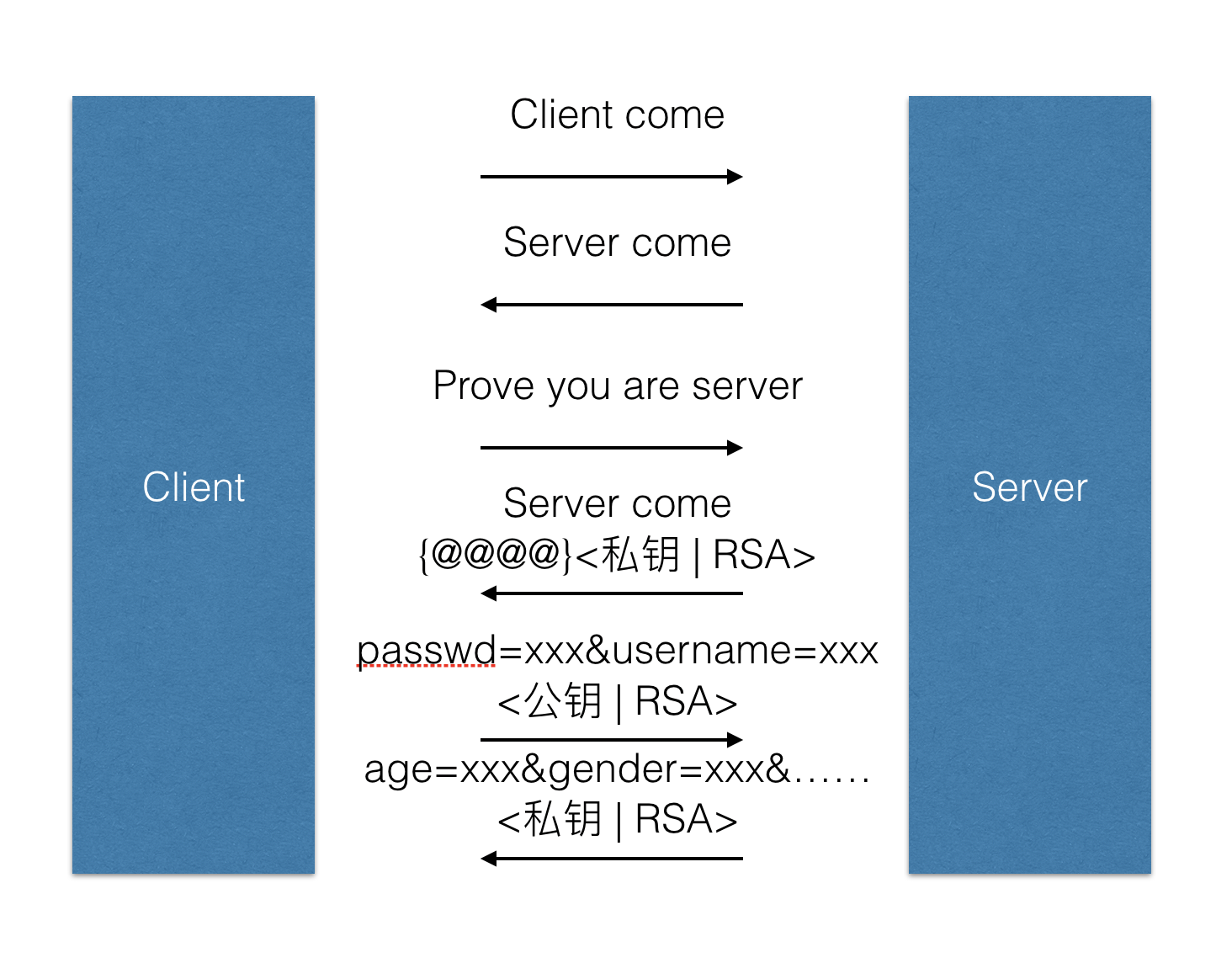
最后一步把用户的个人信息通过私钥加密发送出去了,因为公钥是所有人都知道的,除了这一个客户端,其它拥有公钥的客户端也能够对该条使用私钥进行加密的消息进行解密。一般会采用对称加密来解决这个问题。

在上图所示的通信过程中,客户端在确认了服务器身份后,自己选择一个对称加密算法和密钥,把选择的加密算法和密钥通过公钥进行加密发送给服务端。这个过程如果被 hack 了,但因为没有私钥也无法解密使用公钥加密后的内容。
RSA 加密算法在这个通信过程中所起到的作用主要有两个:
* 私钥只在服务器上,客户端可通过判断对方是有拥有私钥来保证是否为“真”服务器;
* 客户端通过 RSA 的掩护,安全的和服务器商量好一个对称加密算法和密钥来保证后续通信过程内容的安全。
这引发出了一个新的问题,服务器要对外发布公钥,服务器如何把公钥发送给客户端呢?可能会想到:
* 把公钥放到网络上的某个地址,都去这拿;
* 每次通信开始都下发公钥。
第一个方法的问题出在下载地址会被伪造,第二个方法的容易被中间人伪造,因为我们都可以生成公钥和私钥,无法确认公钥到底是谁的,如果能够确认公钥到底是谁的即可解决。
为了解决这个问题,数字证书出现了。一个证书包含了以下内容:
* 证书的发布机构
* 证书的有效期
* 公钥
* 证书的所有者
* 签名所使用的算法
* 指纹及指纹算法
这样,通信流程就变成了:
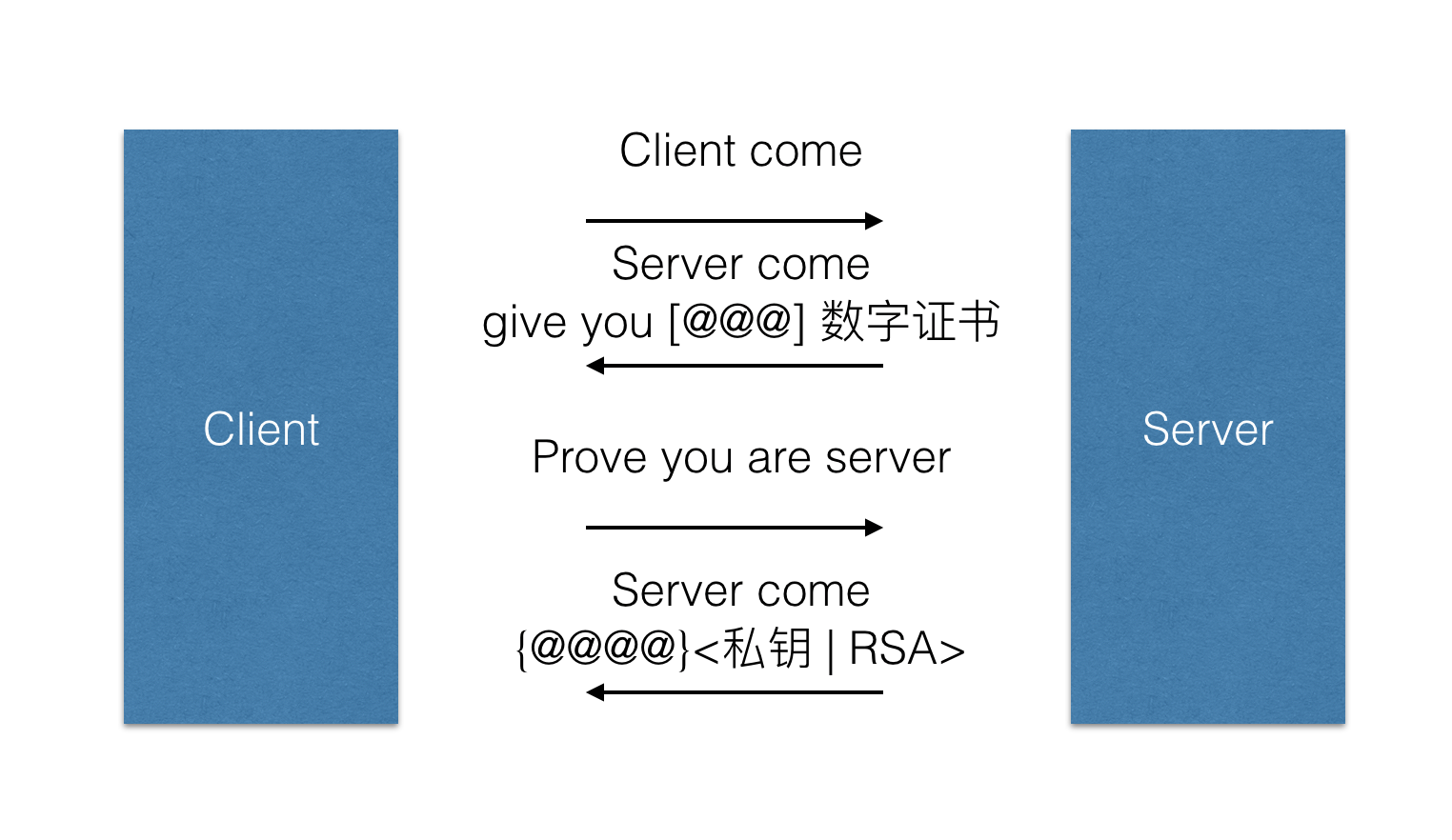
上图中的第二次通信,服务器把自己的证书发给了客户端而不是公钥。客户端根据证书校验来确认证书是否为服务器的,后续操作都是一致的。
为了保证安全,在证书的发布机构发布证书时,证书的指纹和指纹算法都会加密后再和证书放到一起发布,以防有人修改指纹后伪造相应的数字证书。那证书的指纹和指纹算法用什么加密呢?答案是用那个证书发布机构的私钥进行加密的,也就是说,证书发布机构除了给别人发布证书外,自己本身也有自己的证书(一般由自己生成)。在 OS 安装好时,这些证书发布机构的数字证书就已经被安装在其中了,操作系统厂商会根据一些权威安全机构的评估选取一些信誉很好并且通过一定安全认证的证书发布机构,把这些证书发布机构的证书默认安装在 OS 中,且设置为 OS 信任的数字证书。这些证书发布机构自己持有与自己的数字证书对应的私钥,会用这个私钥加密所有发布证书的指纹作为数字签名。
-----
## 初涉 HTTPS (超文本传输安全协议,也被称为 HTTP over TLS,HTTP over SSL 或 HTTP Secure )
首先明确一个概念,HTTPS 并没有推翻之前的 HTTP 协议,而是一个安全的 HTTP 。
> HTTPS 开发的主要目的,是提供对网络服务器的认证,保证交换信息的机密性和完整性。
末尾的 S 指的是 SSL ( Secure Sockets Layer 安全套接层), /TLS (传输层安全性协议,英语:Transport Layer Security,缩写为 TLS )。该层协议位于 HTTP 协议和 TCP/IP 协议的中间
所谓的信息传输安全指的是:
1. 客户端和服务器传输信息只有双方才能看懂。
2. 为了防止第三方就算看不懂数据也会瞎改的情况,客户端和服务器要有能力去验证数据是否被修改过;
3. 客户端必须要防止避免中间人攻击,除了真正要建立连接的服务器外,任何第三方都无法冒充真实服务器。
对于信息的加密,可以通过对称和非对称加密。简单来说,对称加密是客户端和服务器双方都约定俗成了一套加密规则,当然这套规则可以是客户端和服务器开始建立连接之前就已经规定好,也可以在已经建立连接时,向服务器先请求加密规则。
此时的 HTTPS 握手流程多了两步:
> 客户端:服务器,我需要发起一个 HTTPS 请求
> 服务器:客户端,你的秘钥是 xxxx
而非对称加密也可以简单得认为是客户端有自己的一套加解密规则(公钥),服务器有自己的一套加解密规则(私钥),经过服务器的加解密规则(私钥)加密后的数据只有客户端的加解密规则(公钥)才能解析,经过客户端加解密规则(公钥)只有服务器的加解密规则(私钥)才能解析。
由此可见,用对称加密进行数据传输肯定比非对称加密快得多。当然,私钥是服务器自己留着的,不对外公开的,而公钥是可对外公开获取的。
那么现在又引入了一个问题,对称加密的秘钥怎么传输?服务器直接明文返回对称加密的秘钥肯定是不科学的,而且我们还不能直接用一个新的对称加密算法去加密原来的对称秘钥,因为这又涉及了新的对称加密秘钥如何传输的问题,这是个悖论。
OK,为了解决这个问题,就用上了之前我们说的非对称加密方式,从上文我们所讲的非对称加密特点,服务器用私钥加密的数据实际上并不是真正意义上的加密,因为只要有私钥与之对应的公钥即可解密,更何况公钥谁都可以有,谁都可是是客户端,所有服务器的密码能被所有人进行解析,但私钥只存在服务器上,这就说明了:
1. 服务器下发的内容不可被伪造,因为私钥唯一,如果第三方 **强行二次加密** 则客户端的公钥无法解密;
2. 任何用公钥加密的内容都是 **绝对安全** 的,因为私钥唯一,只有拥有私钥的真正服务器才可进行解密。
故解决了我们之前的问题,秘钥并不是服务器生成,而是客户端自行用公钥生成且主动告诉服务器的,此时 HTTPS 的握手流程就变成了:
> 客户端:服务器,我要发起一个 HTTPS 请求,这是我用你下发的公钥生成的秘钥。
> 服务器:我知道了,以后咱们用这个秘钥进行验证。
OK,现在进入下一个问题,那这个公钥如何下发给客户端?啊哈,其实之前用“下发”这个词是为了好理解,实际上应该是每个使用了 HTTPS 协议的服务器都应该去一个专门的证书机构注册一个证书,这个证书中保存了权威证书机构私钥加密的公钥,客户端就用这个权威证书机构的公钥作为其的 HTTPS 公钥即可。
因此,HTTPS 握手流程就变为了:
> 客户端:服务器!我要发起一个 HTTPS 请求,给我公钥!
> 服务器:好的,我给你个证书,自己从里边拿。
> 客户端:(解密成功后)这是我解密完后的秘钥
> 服务器:我知道了,以后咱们用这个秘钥(公钥)进行验证。
实际上 `HTTPS` 并不是重新构建了一套传输协议,而是与上文中所说的一样,只是在原有传输协议的应用层和传输层之间多添加了一个安全层(会话层),如下图所示:
<img src="https://i.loli.net/2018/06/01/5b11446f898ae.png" width = "70%" height = "70%" align=center />
emmm,其实我弄到这也懵逼了,这所谓的权威证书机构公钥又如何传输?查了相关资料后发现,其实就是内置在了 OS 或者浏览器中,但是这有个问题,我们不可能穷举所有权威证书机构服务器,太多了根本存不完,而且 OS 会对其产生怀疑,凭啥你说这证书可靠就是可靠?
故,我们可以认为全世界上的权威认证机构只有一个(实践上并不),其它的想搞证书这门生意的公司得去这个唯一权威认证机构去取得认证,所以 OS 或浏览器只需要维护这一个权威认证机构的公钥即可。每次客户端只需要获取这个公钥即可。
到现在算是把我的 HTTPS 的疑惑解决得差不多了,但是还有个问题,现在证书也有个唯一的机构去做认证了,但是我们却没法知道这个证书是否真的可靠,就好像我们都知道人民币都是中国人民银行唯一认证和发行的,但是没人保证每张人民币都是真币,紫外线验证是一种人民币有效性验证的手段,那对于证书来说,如何做有效性验证呢?
又查了一波资料,每份证书会有各自对应的 hash 值,在传输证书的时候也会同时传输对应证书的 hash 值。如果此时有中间人进行攻击,因为公钥不唯一,谁都可以进行解密,但是其伪造的数据经过中间人的私钥加密后,无法正确加密,再次返回给客户端的数据经过客户端公钥解密后是乱码,如果凑巧对上了,但是也无法通过 hash 校验(至于如何校验,我还没查到)
从以上观点我们可以看出,貌似 HTTPS 坚不可破啊,它真的是无敌了么?其实从某种意义上来看,它还真的就无敌了,但也不是万无一失,因为如果我们第一次请求的就不是真的服务器,而是一个攻击者,这就完全有机会进行所谓的中间人攻击。正常的流程是在第一次握手时,服务器会下发给客户端证明自己身份的证书,客户端再用预设在设备上的公钥来解密。
但是如果我们不小心在自己的设备上安装了非权威认证机构的根证书,比如 Charles 的私有根证书,那么我们的设备上就多了一个预设的公钥,那通过Charles的私钥加密的证书就能够被正常解析出来,Charles对于我们的设备来说相当于是设备的服务器,对真的服务器来说,Charles是客户端,所以相当于Charles既拿到了私钥又拿到了公钥,能够解析并修改数据也就不在话下了,不过也不要觉得 Charles 是啥恐怖的东西,我们之所以使用 Charles 进行抓包,是因为我们信任它,你都信任了还有啥欺骗不欺骗的,中间人攻击也就不存在了,但如果你的 Charles 是个盗版的,很有可能下发这个盗版 Charles 的开发者就已经给你开了个后门。支持正版,从我做起。
### 更进一步
#### TLS协议做了什么?
正如上文所说, `HTTPS` 只是比 `HTTP` 多了一个安全层,那么这个传输层安全协议到底是怎么一回事呢?在此做了一张图分享如下, `TLS` 运行在一个可靠的 `TCP` 协议上。
1. 客户端和服务器还是跟原来一样进行 `TCP` 三次握手,握手完后,客户端和服务器建立起了连接;
2. 客户端像服务器发送一系列说明,比如客户端使用的 `TLS` 协议版本,支持的加密算法等等;
3. 服务器拿到了客户端发送而来的说明,从中获取到客户端支持的 `TLS` 协议版本和支持的加密算法列表,从列表中选择一个合适的加密算法,将选择的加密算法和证书一同发送给客户端;
4. 客户端拿到确定的 `TLS` 版本和加密算法,并检测服务端的证书,通过后使用公钥进行加密某个数据(例如:“完成”);
5. 服务器使用私钥解密客户端公钥加密过的消息,并验证 `MAC` ( Message Authentication Code ,消息认证码)把解密出的消息(例如:“完成”)使用私钥加密发送给客户端;
6. 客户端使用公钥解密消息,并验证 `MAC` ,通过后加密通道建立,以后在该加密通道进行的数据传输都采用对称秘钥对数据加密。
由此可见,是先经过了非对称加密,最后再进行对称加密,也即——对称加密的密钥使用非对称加密的公钥进行加密,然后发送出去,服务器使用私钥进行解密得到对称加密的密钥,然后双方可以使用对称加密来进行数据传输。流程如下图所示:
<img src="https://i.loli.net/2018/06/01/5b114aeb7e009.png" width = "70%" height = "70%" align=center />
## iOS 中的 HTTPS
`AFSecurityPolicy` 这个类为 AFN 设置 SSL 钢钉的类,有 3 种验证方式:
1. `AFSSLPinningModeNone`:这个模式表示不做 SSL pining ,跟浏览器一样在系统的信任机构列表里验证服务端返回的证书。如果证书是信任机构签发的就会通过,如果是自己服务器生成的证书,就不会通过。(注意:该模式是不安全的,HTTPS API 能正常访问,但没有校验证书,失去了 HTTPS 的意义)
2. `AFSSLPinningModePublicKey`:代表客户端回将服务器端返回的证书与本地保存的证书中的 `PublickKey` 部分进行校验,校验通过后才继续进行。
3. `AFSSLPinningModeCertificate`:代表客户端会将服务器端返回的证书和本地保存的证书中的所有内容进行匹配,全部进行校验,如果正确,才继续进行通信。
2 和 3 都需要把证书内置在 app bundle 中。
## 超文本链接
原来超文本链接可以用指针去理解,指针是指向了一块内存地址,那超文本链接实际上就是指向了服务器上的一个资源位置哇!!!
## `HTTP` 协议特点
优点:解放了服务器,每一次请求“点到为止”,不会造成不必要的连接占用。
缺点:每次请求会传输大量的重复内容信息。
* 支持客户端/服务器模式
* 简单快捷
* 灵活
* 无连接
* 无状态
**无连接**:服务端处理完客户端一次请求,等到客户端作出回应之后(确定收到)便断开连接。这种方式节省传输时间,但随着业务量的庞大,如果还采用原来的方式,会在建立和断开连接上话费大部分时间。`HTTP` 借助底层的 `TCP` 虚拟连接(并不是真实的电路连接),`HTTP` 协议无需连接,比如 A 和 B 打电话,A 和 B 两者并没有进行“连接”,而是借助了电话简化了连接从而进行交换信息。
**无状态**:服务端对客户端每次发送的请求都认为是一个新的请求,上一次会话和下一次会话之间没有联系。之所以这么设计,也是为了让 http 变得简单,可以处理大量事物。但无状态的特效,也导致了一些问题,比如说一个用户登录一家网站后,跳到另一个页面,应该还保持着登录状态,所以后面就推出了 cookie 状态管理技术。
**请求只能从客户端开始**:客户端不可以接收除响应之外的指令,服务器必须等待客户端的请求,才能给客户端发送响应数据,服务器时不能主动给客户端推送数据的,对于一些实时监控的功能,常用 websocket 来代替。
**没有用户认证,任何人都可以发起请求**:不存在确认通信方的处理步骤,任何人都可以发起请求,且服务器只要收到请求,无论是谁,都会返回一个响应,所以会存在伪装的隐患,https 可以解决这个问题。
**通信使用的是明文**
**无法验证报文完整性**
**可任意选择数据压缩格式,非强制性压缩发送**
**HTTP 0.9**:短连接。每个 `HTTP` 请求都要经历一次 `DNS` 解析,三次握手,传输和四次挥手。
**HTTP 1.0**:持久连接(长连接)被提出来。在此之前,每次连接只处理一个请求,且每个连接的获取都需要创建一个独立的 `TCP` 连接,因为 `HTTP` 是基于 `TCP/IP` 协议的,创建一个 `TCP` 连接需要经过三个步骤,有一定的开销,如果每次通讯如果每次都需要重新建立连接,对性能有影响,所以最好是需要维护一个长连接。当一个 `TCP` 连接对服务器做了多次请求:客户端可以在 `request header` 中携带 `Connection: Keep-Alive` 字段向服务器请求持久连接,若服务器允许就会在 `response header` 中加上相同字段。
双方都确认后,客户端便可继续使用同一个 `TCP` 连接发送接下来若干请求。`Keep-Alive` 默认是 `[timeput=5, max=100]` ,即每一个 `TCP` 连接可以服务最多 5 秒内的 100 次请求。当服务端主动切断一个长连接时(或不支持),则会在 `response header` 中携带 `Connection:Close` ,要求客户端停止使用这一连接。
长连接机制仍然是串行的,如果某个请求出现网络阻塞等问题,会导致同一条连接上的后续请求被阻塞。
**HTTP 1.1**:提出 `piplining` (管线化)机制,且默认支持长连接,就算客户端 `request header` 中未携带 `Connection:Keep-Alive` ,传输也会默认支持。客户端发起一次请求时不必等待响应便直接发起第二个请求;服务端根据请求顺序一次放回结果。该机制基于长连接完成,且只有 `GET` 和 `HEAD` 请求可进行 `piplining` , `POST` 请求会有所限制。第一次建立连接时服务器不一定支持 `HTTP 1.1` 协议。
该机制可将 `HTTP` 请求大批量提交,将多个请求同时塞入一个 `TCP` 分组中,达到只提交一个分组即可同时发出多个要求,大幅缩短页面加载时间(特别是在传输延迟较高的情况下),减少网络上多余的分组并降低线路负载。
支持只发送 `header` 信息( `HEAD` 方法),如果服务器认为客户端有权限请求,则返回 100 ,否则返回 401 。客户端如果接受到 100 ,才开始把请求 `body` 发送到服务器,并且还支持传送内容的一部分,当客户端已经有了一部分资源后,只需要跟服务器请求另外部分资源即可(断点续传的基础)
**HTTP 2.0**:多路复用技术出现。能够让多个 `request` 和 `response` 杂糅在一起,通过 `streamID` 区别。
## TCP
* `TCP` 提供一种面向连接的、可靠的字节流服务;
* 在一个 `TCP` 连接中,仅有双方进行彼此通信。广播和多播不能用于 `TCP`;
* `TCP` 使用校验和、确认和重传机制来保证可靠传输;
* `TCP` 给数据分节进行排序,并使用累积确认保证数据的顺序不变和非重复;
* `TCP` 使用滑动窗口机制来实现流量控制,通过动态改变窗口的大小进行拥塞控制。(🧐 没搞懂)
`TCP` 连接有一个“预热”过程,先检查数据是否传输成功,一旦传输成功过,则慢慢加大传输速度。如果对应瞬时并发的连接,服务器的响应就会变慢。
### 三次握手
三次握手(Three-way Handshake),是指建立一个 TCP 连接时,需要客户端和服务器总共发送 **3** 个包。三次握手的目的是为了连接服务器制定端口,建立 TCP 连接,并同步连接双方的 **序列号** 和 **确认号** ,交换 TCP 窗口大小信息。
* 第一次握手:客户端发送一个位码 SYN = 1 ,以及随机产生的 seq number = x 。发送完毕后,客户端进入 `SYN_SEND` 状态。服务器由 syn = 1 得知客户端需要建立连接。
* 第二次握手:服务器要确认连接信息,向客户端发送 ack number = y ( x + 1 ), syn = 1 , ack = 1 ,并随机产生 seq = y。发送完毕后,服务器进入 `SYN_RCVD` 状态。
* 第三次握手:客户端收到数据包后,验证 y == x + 1 ,位码 ack == 1 。验证通过后,客户端发送 ack number = z(y + 1) , ack = 1 ,发送完毕后,客户端进入 `ESTABLISHED` 状态,服务器收到后验证 z == y + 1 ,ack == 1 ,验证通过后,建立连接,服务器进入 `ESTABLISHED` 状态,TCP 三次握手建立连接结束。
## ARP
ARP 协议 `OSI` 五层模型中的数据链路层,是把 IP 地址转化成 MAC 地址的一个 `TCP/IP` 协议。
## 负载均衡
客户端将请求发送至服务端,单一服务器无法承受过高并发量,可将请求转发到其它服务器,但真正的负载均衡架构并不是一台 server 转发到另一台 server ,而是在客户端和服务器中间加入一个专门**负责分配请求**的负载均衡硬件(软件)
### DNS(Domain Name System)
是客户端发送请求中一个非常重要的中转,它的作用是讲用户请求的 URL 地址映射为具体的 IP 地址,全世界有 13 台根服务器,但通常对我们做域名解析的并不是根服务器,而是直接访问我们的 LDNS (Local DNS Server),通常由 ISP 维护。
最开始的负载均衡就是利用搭建本地 DNS 服务器实现的,实现的方式简单易懂,为同一个主机名分配多个映射,可采用轮询、随机等方式分配请求。
但在使用过程中会发现,如果其中一个地址宕机,我们无法及时发现。若有用户被分配到了该主机则会出现访问失败的状况,同时我们也无法判断每个 server 的负载,可能会出现某个 server 几乎闲置,另外一个 server 负载压力极高的情况。
### 负载均衡器(Load Balancer)
负载均衡器通常作为独立的硬件置于客户端和服务器之间。其拥有非常好的负载均衡性能,用户众多的负载均衡策略,如权重、动态比率、最快模式、最小连接数等,可以保证以相对较优的方式分配请求,但价格过高。
### 反向代理
一般使用 `Nginx` ,其高性能、轻量级已经成了人们对 Nginx 的第一印象。 Nginx 可作为 HTTP 服务器,在处理高并发请求时拥有比现在主流 Apach 服务器更高的性能,同时它也是一个优秀的反向代理服务器。
正向代理通常由客户端主动链接,比如科学上网。反向代理在服务器端,无需主动连接,当我们访问拥有反代的网站时,实际上访问的是其反代服务器,而非真正的服务器,当请求到达反代服务器时,其再将请求转发至服务器。
## CDN(Content Delivery Network)
简单来说其为存储一些静态文件的一台或多台服务器,通过复制、缓存等方式,将文件保存其中。
### 哪些属于静态文件?
CSS,HTML,图片等多媒体都属于静态文件,用户发送的请求不会影响静态文件的内容,而 JSP、PHP 等文件不属于静态文件,因为内容会随着用户的请求而改变。
### CDN 如何实现加速?
一般情况下,我们要获取的数据都在主服务器中,但用户若在北方,主服务器在南方,访问速度就会变慢,而变慢的原因有很多,如传输距离,运营商,带宽等等因素。而使用 CDN 技术,我们会将 CDN 节点分布在各地,当用户发送请求到达服务器时,服务器会根据用户的区域信息,为用户分配最近的 CDN 服务器。
### CDN 数据从哪里来?
复制、缓存、CDN 服务器可以在用户请求后缓存文件,也可以主动抓取主服务器内容。
## 从输入一个 url 到返回数据,中间到底发生了什么?
### 浏览器解析出主机名
例如从搜索框中拿到的域名为:`http://pjhubs.com`
### 浏览器查询这个主机名的 ip 地址(DNS)
DNS 解析的作用就是把域名解析成 ip 地址,这样才能在广域网路由器转发报文给目标 ip ,不然路由器不知道要把报文发给谁。
* 浏览器启动时,首先会从 OS 获取 DNS 服务器地址,然后把地址缓存下来,同时浏览器还会去读取和解析 hosts 文件,同样进行缓存。浏览器对解析过的域名和 ip 地址都会保存着这两者的映射关系(存到 cache 中)。
* 当解析域名时,首先浏览器回去 cache 中查找有没有缓存好的映射关系;如果没有,则去 hosts 文件中查找;如果没有,浏览器则会发起请求去 DNS 服务器缓存查询;如果没有,最后则去 DNS 服务器查询。
假设 pjhubs.com 的 ip 地址为:123.123.123.123
### 浏览器获取端口号
假设为 123.123.123.123:80
### 浏览器向目标 ip 发起一条 123.123.123.123:80 的 tcp 连接
为了传输的可靠性,tcp 协议要有“三次握手”的过程(细节上文):
* 浏览器向服务器发起一个连接请求;
* 服务器对请求作出响应,表示同意建立连接;
* 浏览器收到响应后,再告知对方,它知道服务器同意它建立连接了。
### 数据包在 ip 层传输,通过多台计算机和网络设备中转,在中转时利用中转设备的 mac 地址搜索下一个中转目标(采用 `ARP` 协议,根据通信方的 ip 地址就可反查出对应的 mac 地址),直到目标 ip 地址。
### 数据链路层处理网络连接的硬件部分,比如找到服务器的网卡
### 浏览器向服务器发送一条 http 报文
每一条 http 报文的组成:起始行 + 首部 + 主体(可选)
* **起始行**:http/1.1 200 OK (一般包括 http 版本、状态码、状态码信息)
* **首部**:Content-Type:text/plain Content-Length:19
* **主体**:请求字段数据
### 服务器接受客户端请求,进行一些处理,返回响应报文
web 服务器接收到请求之后,实际上会做:
* 建立连接:如果接受一个客户端连接,就建立连接,如果不同意,就将其关闭;
* 接收请求:读取 http 请求报文;
* 访问资源:访问报文中制定的资源;
* 构建响应:创建带有首部的 http 响应报文;
* 发送响应:将响应回送给客户端。
### 浏览器读取 http 响应报文
### 浏览器关闭连接
### `0.0.0.0` 和 `255.255.255.255`
计算机的 `ip` 获取方式有**静态ip** 和 **动态ip** 两种获取方式,但大部分的设置都是动态 ip 获取方式,除非我们能保证的 ip 地址的唯一性,否则会不小心配置了一个已经
被别人使用过的 ip 地址(还包括 DNS、网关等)。
那什么是动态获取 ip 地址呢?如果计算机重启之后,此时啥 ip 也没有,需要找到 `DHCP 服务器` 发送一个报文来动态获取 ip,但此时计算机并不知道谁是 `DHCP 服务器`,
需要发送一个**广播**告诉当前局域网内的所有设备,该报文的**目的ip**部分填入 `255.255.255.255`,代表这是一个**广播报文**。直到真正的 `DHCP 服务器`收到这个报
文,但是 `DHCP 服务器`并不知道这个报文是要要**获取ip**,所以在计算机发出这个报文之前,要在这个报文的**源ip**地址部分填入 `0.0.0.0`,借此来标记出 `DHCP 服务器`
此时收到的该报文是要获取ip。
但是 `DHCP 服务器` 怎么知道是当前局域网中的哪台计算机需要获取 ip 呢?利用 `Mac` 地址。所以 `255.255.255.255` 该地址一般用来**广播**时使用,而 `0.0.0.0` 可以
代表这是一个还没有分配 ip 的主机。当然 `0.0.0.0` 还有其它作用,用到了再更。s
================================================
FILE: Blockchain/basic.md
================================================
## 区块链技术综述
1. 区块链是从比特币中脱离出来的。
2. 加密货币
3. 分布式共识
* 想要生成一个加密货币,还要所有人去承认它
4. ecash 盲签名技术
5. hashcash 解决邮件系统中 DoS 攻击问题
* 提出使用「工作量证明」(POW Proof of Work)机制来获取额度
6. B-money 引入数字货币生成过程。
7. 比特币
* 加密基础理论发展:RSA 算法 & 公钥私钥加密体系 PPKC
* P2P 技术开发成熟
* hash 现金解决双重支付问题(痛点)
8. 量子计算机对 RSA 有破坏性
9. 分布式数据库存储
* 没有中心系统
10. 如何保证每个节点的数据一致性问题?
* 如果有中心系统的话,只需要保证中心系统这一个节点的数据一致性就好了。
* 为什么要引入分布式?
* 高可用、稳定性问题
* 一致性 hash
* 冗余存储
* 强一致性、弱一致性、最终一致性。根据业务特征去选择
* FLP 不可能性原理
* 在一个分布式系统中不可能在同一个时刻保证数据一致性(强一致性
* 通过「共识算法」解决
* 拜占庭问题。打不打这个仗,需要五个将军来投票,超过 1/2 就打,而不是让一个将军自己去决定,防止被策反。
* 通过 POW 算法进行优化
* POW:工作量证明,通过计算来猜测一个数值,得以解决规定的 hash 问题。保证在一段时间内,系统中只能出现少数合法提案。
11. hash 算法
12. 加解密算法
* 解决我发给你的消息,只有你才能知道
13. 数字签名
* 解决大家都知道这个消息是我发的
14. 密钥、地址和钱包
* 密钥 => 私钥,不需要在网络上进行传播
* LevelDB
* 钱包不存钱,钱包存的是交易记录,谁给你转了钱,你给谁转了钱
* 基于椭圆曲线的公钥、私钥
* 私钥丢了就是丢了!!!没人知道这个私钥是你的私钥
15. 交易
* 创建一个交易
* 在网络上广播这个交易
* 比特币找零:别人给我输入了 15 个比特币,我给别人输出 13 个比特币,还剩 2 个比特币再输入给自己。产生三笔交易
* 交易的确认
* 确认 A 是 A,通过 A 的签名
*
16. 挖矿
* 把交易写入区块链,就是挖矿
* 交易不产生比特币,挖矿产生比特币
* 挖矿的过程中,回去监听比特币网络,正在挖 78 这个块时监听到其它矿工已经挖完了 78 这个块,自己必须要立马放弃,因为要让自己利益最大化,去挖 79 这个块。
* 博弈论。
17. 贪心算法
18. 哈希二叉树。用作快速归纳和椒盐大规模数据完整性的数据结构,包含加密哈希值。
19. 图灵不完备系统
20. 智能合约
================================================
FILE: Books/iOS面试之道.md
================================================
## 第一天
### 字典和集合
一般的字典和集合都要求它们的 Key 都必须实现 Hashable 协议,Cocoa中的基本数据类型都满足这一点。
### 字符串
Swift 中的字符串为值类型,而不是 OC 中的引用类型。
#### 判断字符串是否由数字构成
```Swift
var str1 = "123ws"
// nil
Int(str1)
var str2 = "123"
// not nil
Int(str2)
```
### Swift 的访问修饰符
`private`: 当前类内使用
`fileprivate`:当前文件内使用
`internal`:(默认访问级别)整个 module 里使用
`public`:可被任何地方使用,但除了 ·mudule 外不可以被继承和 override
`open`:可被任何地方使用
### 如何检测一个链表中是否有环?
用 **快行指针** 的做法,一个指针在前,一个在后,两个指针的间隔一般为 2 ,循环终止条件为链表尾,如果有快指针和慢指针走到一起了,则该链表成环。
### 栈和队列的转化
用栈实现队列(腾讯一面):
先写一个转换函数,把栈 A 的元素都 pop 到 栈 B 中,进队相当于给栈 A push ,出队之前先执行转换函数,然后再 pop 栈 B 元素。
用队列实现栈(腾讯一面):
先写一个转换函数,这个函数把队列 A 中的除了队尾元素外的所有元素都入队到队列 B 中,那么经过这个转换函数转换之后队列 A 中剩下的就是栈顶元素。
再写一个函数,把队列 B 和队列 A 进行对调,此时因为队列 A 已经全部出队,所以队列 B 为空,队列 A 为少了之前的队尾元素队列
---
## 第二天
### 二叉树的遍历
因为二叉树本身是由递归定义的,从原理上讲,所有二叉树的题目都可以用递归来解。二叉树的遍历主要由 `BFS` (前中后序遍历)和 `DFS` (层级遍历)两种组成,需要注意的是,广度优先遍历需要用队列进行搭配
### 排序算法
动画和代码展示:[https://www.cnblogs.com/onepixel/articles/7674659.html](https://www.cnblogs.com/onepixel/articles/7674659.html)
## 第三天
### 几乎都是算法
比如 排序、动态规划、二分查找等等。慢慢总结吧
---
## 第四天
### inout 关键字
使用 `inout` 关键字可以修改传入参数的原始值,调用的时候需要在对应的参数前加上符号 `&` ,类似 `C/C++` 中的指针。
### protocol
在转 `Swift` 将近三四个月的过程中,我居然一点都没有感到在写 `protocol` 时代理对象居然不加 `weak` 关键字感到奇怪。
举个例子,之前我是这么粗暴的写 `protocol` :
```Swift
protocol PjhubsDelegate {
func pjhubsDeleagteFunction()
}
class Pjhubs: UIView {
var viewDelegate: PjhubsDelegate?
}
```
就这么写了三四个月,看书看着看着才猛的发现,为啥我要把 `weak` 去掉,遂改成了以下代码:
```swift
weak var viewDelegate: PjhubsDelegate?
```
此时,`Xcode` 给我报了个错,
`'weak' must not be applied to non-class-bound 'PjhubsDelegate'; consider adding a protocol conformance that has a class bound`
也就是说:`weak` 只能能添加到非类绑定的 `PjhubsDelegate` 上,考虑给其添加上一个类绑定。根据提示,代码修改为:
```Swift
protocol PjhubsDelegate: class {
func pjhubsDeleagteFunction()
}
class Pjhubs: UIView {
weak var viewDelegate: PjhubsDelegate?
}
```
总的来说, `weak` 修饰引用类型,而上文中我所定义的 `protocol` 为值类型,所以 `Xcode` 报了错。如果不加 `weak` 修饰,则表明我们的 `protocol` 可为枚举、结构体所使用,所以当我们使用 `weak` 修饰了代理对象,那么就要求代理(协议)为 `class-only` (只类使用)
### copy-on-write
值类型在复制时,新对象和原对象实际上在内存中指向同一块区域,只有当新对象发生改变时(增加或删除一个对象),才会给新对象开辟新内存区域。
### 属性观察
最开始的时候,我直接在 `Swift` 中拿了 `OC` 的思想做了 `setter & getter` ,但是当我想只要 `setter` 时,一定要把 `getter` 写上,就算 `getter` 什么也不做,只是返回一个存储属性的值而已。
后边理解到了 `Swift` 中的属性观察,即 `willSet & didSet` ,意思就是方法名所代表的意思。需要注意的是,在初始化器中对属性的设定,以及在 `willSet & didSet` 方法中对属性的再次设定,都会出发调用属性观察。
### @autoclosure
[http://swifter.tips/autoclosure/](http://swifter.tips/autoclosure/)
---
## 第五天
### 柯里化(Curring)
[http://swifter.tips/currying/](http://swifter.tips/currying/)。说实话,书中和喵神的这篇 blog 描述的代码都很简单,主要是这种神奇的写法根本没见过,书中的例子是这样的,要求写一个函数满足只传入一个整数参数,返回该整数 +2 的值,这很简单对吧,但是实际的要求是只写这么一个函数,然后满足 +2、+3、+4 等,其实我内心直接就冒出多态、模版、范型啦这些东西,但仔细一想,不对啊,只能有一个参数,瞬间缓过神来,柯里化牛逼啊。😂。
```Swift
func add(_ num: Int) -> (Int) -> Int {
return { val in
return num + val
}
}
let number2 = add(2)
print(number2(2))
```
### 实现一个函数:求 0 ~ 100 (包括 0 和 100)中为偶数并且恰好是其他数字平方的数字
```Swift
(0...100).map { $0 * $0 }.filter { $0 % 2 == 0 }
```
Swift 函数式编程的一些资料:[https://www.jianshu.com/p/7233f140e6c3](https://www.jianshu.com/p/7233f140e6c3)
### ARC
ARC 和 Garbage Collection 的区别在于:Garbage Collection 在运行时管理内存,可以解决 retain cycle, 而 ARC 在编译时管理内存
### @property 关键字
在 OC 中基本数据类型的默认关键字是 `atomic`、`readwrite` 和 `assign`,普通属性的默认关键字为 `atomic`,`readwrite` 和 `strong`
### 关键字 automic 和 nonatomic
* automic : 修饰的对象保证 setter 和 getter 的完整性,任何线程访问它都可以的哦大一个完整的初始化对象。正是因为要保证操作的完整性,所以速度较慢。automic 比 nonatomic 安全,但也不是绝对的线程安全,当多个线程同时调用 set 和 get 时,会导致获得的对象值不一样。想要获得线程绝对安全,使用 @synchronized (个人觉得 @synchronized 的做法也不好,这是 iOS 中最垃圾的锁哈哈)
* nonatomic : 修饰的对象不保证 set 和 get 的完整性,所以当多个线程访问它时可能会返回未初始化的对象,故其速度会比 atomic 快,但线程也不是安全的。
### runloop 和 线程的关系
runloop 是每一个线程一直运行的一个对象,它主要用来负责响应需要处理的各种事件和消息。每一个线程都有且仅有一个 runloop 与之对应,没有线程,就没有 runloop 。在所有线程中,只有主线程的 runloop 是默认启动的,main 函数会设置一个 NSRunLoop 对象,而其它线程的 runLoop 默认是没有启动的,可以通过 `[NSRunLoop currentRunLoop]` 启动。
### code show
```objc
NSString *firstStr = @"helloworld";
NSString *secondStr = @"helloworld";
if (firstString == secondStr) {
NSLog(@"Equal");
} else {
NSLong(@"Not Equal");
}
```
最终将打印出 "Equal",`==` 该符号是判断着两个指针是否指向同一个对象。上段代码尽管指向不同对象,但它们的值相同,iOS 编译器优化了内存分配,当两个指针指向两个值一样的 `NSString` 时,两者指向同一个内存地址。
## 后续内容已分门别类进行了归档。
================================================
FILE: CV/basic.md
================================================
# 图形学 & 视觉
## 基础概念
### OpenGL
OpenGL 本身不提供源码实现,其只是定义了一堆协议接口,各个平台自行根据统一规范好的协议,去实现各自平台上 OpenGL 协议接口,几乎没有不支持 OpenGL 协议的硬件平台。
## 微软的 Direct3D
一开始各家系统厂商都提供了 OpenGL 的实现,微软也实现了一份,但在当时的时代北京下,PC 无法良好的运行 OpenGL 相关的能力,单是跑起来事例程序就已经很慢了。再加上当时微软看上了 video game 的市场,想要做 3D 相关的事情,顺带收购了一家做 3D 渲染框架的公司,其中 Direct3D 就是这套框架的 API 集合。
在同时支持 OpenGL 时微软也在持续完善 D3D 的能力,使其成为 win 平台上的最佳图形 API,最终 OpenGL 的版本更新停滞在了 1.1,后续在 win 平台上都是通过 D3D 来完成图形操作。
## 一些小 case
### 如何去除视频封面的黑边?
* 逐行检测去黑边,设置黑边的阈值为 <10 都是黑边
* 如果遇到有水印的视频,做「腐蚀」
### 反转视频检测
* 通过「人脸检测」去做这个事情;
* 设原视频的人脸检测数据为 `face`,旋转 90 度之后视频的人脸检测为数据为 `face_r`;
* 如果 `face` > `face_r` 说明原视频是反转的。
注意前提:人脸检测不经过调整的情况下只能检测正常角度。
================================================
FILE: Flutter/Dart.md
================================================
# Dart
## 语言
### 私有变量
变量以下划线(_)开头,在 `Dart` 语言中使用下划线前缀标识符,会强制其变成私有的。
### null
dart 中任何类型变量都可以判 `null`。
================================================
FILE: Flutter/Flutter_2.md
================================================
原文地址:[PJHubs](http://pjhubs.com/2019/01/14/flutter-2/)
> 在上篇文章中,已经大致的描述出为什么要接触 Flutter 以及对 Flutter 初体验的一些总结,整体上 Flutter 给我的第一印象是不太好的,但这次不一样了!这篇文章主要描述了我在使用 Flutter 实现的豆瓣电影 Top250 demo 过程,让我领略到了 Flutter 在 UI 层面的魅力!
## 前言
目前只完成了 demo 的 **UI 部分**,主要体验了 Flutter 在基本 UI 层面上友好度。从整体来看,在一些细节的地方确实没有原生(iOS & Android)有太大的优势,在某些 UI 上的实现还比较麻烦。如果仅仅从跨端开发这一点上看,优势就相当明显了,如[上篇文章](http://pjhubs.com/2019/01/11/Flutter-1/)中所说,Flutter 在 SDK 层面直接替换掉了整个与原生相关的框架,采用了 `Skia` 替换,在跨端上能够很好的保证 UI 最终渲染出来的结果统一。 demo 如下:
### 数据来源
原本想直接使用公司 API 进行测试,这样能够快速验证在接触到实际数据的过程中,Flutter 在 UI 层面上和原生的优劣,但因保密等原因,只能另寻它路。最终从[历史上的今天](http://www.ipip5.com/today/api.php?type=json)和[豆瓣电影 Top250 ](https://api.douban.com/v2/movie/top250)两个 API 中选择了后者,原本只是想验证在长列表的展示上的优劣,但后来又考虑到了豆瓣电影 Top250 的 API 所提供的资源较丰富、数据格式也够复杂,算是比较贴合生产环境。


### 涉及 Flutter 知识点
* HTTP;
* JSON 数据格式解析和模型转换;
* `Row` 、 `Column` 、 `Padding` 、 布局;
* `ListView`、`Text` 等基本 `Widget` 使用;
* `Container` 设置图片圆角、阴影等属性设置。
## 实践
有了数据源,就可以准备上手搭建 UI 了。因为是豆瓣电影 Top250 的数据源,就直接 copy 了官方 App 的设计,同时也为了保证后续做性能验证时各种跨端和原生技术互相对比时遵循“单一变量”原则,但中途还是因为数据源的关系,有些数据并未暴露出来,导致没法 100% 的 copy 。
### 数据处理
Flutter 中进行 `RESTful` web API 请求是一件比较流畅的事情。在 flutter 中使用 http 拉取豆瓣电影 Top250 的数据,我是这么做的:
```Dart
import 'dart:io';
import 'dart:convert';
import 'package:movie_top_250/movieModel.dart';
class MovieAPI {
Future<MovieEnvelope> getMovieList(int start) async {
var client = HttpClient();
var request = await client.getUrl(Uri.parse(
'https://api.douban.com/v2/movie/top250?start=$start&count=100'));
var response = await request.close();
var responseBody = await response.transform(utf8.decoder).join();
Map data = json.decode(responseBody);
return MovieEnvelope.fromJSON(data);
}
}
```
对 API 数据请求方法做了简单的封装,并返回 `Future` 类型数据。flutter 中进行异步操作,返回的都是“懒加载”数据,上文我们也说到,豆瓣电影 Top250 API 返回的数据格式较复杂,直接使用 response 中的数据成本很大,所以在此又封装了两个 Model ,分别为 `Movies` 和 `Movie`。
```Dart
class Movie {
String id;
String rating;
String stars;
String title;
String director;
String year;
String poster;
List<String> genres;
Movie({
this.id,
this.rating,
this.title,
this.director,
this.year,
this.stars,
this.poster,
this.genres
});
Movie.fromJSON(Map<String, dynamic> json) {
this.id = json['id'];
this.rating = json['rating']['average'].toString();
this.stars = json['rating']['stars'];
this.title = json['title'];
this.director = json['directors'][0]['name'];
this.year = json['year'];
this.poster = json['images']['small'];
this.genres = new List<String>.from(json['genres']);
}
}
class Movies {
int count;
int start;
int total;
List<Movie> movies;
Movies({this.count, this.start, this.total, this.movies});
Movies.fromJSON(Map data) {
this.count = data['count'];
this.start = data['start'];
this.total = data['total'];
List<Movie> movies = [];
(data['subjects'] as List).forEach((item) {
Movie movie = Movie.fromJSON(item);
movies.add(movie);
});
this.movies = movies;
}
}
```
### UI
UI 部分在上篇文章中快速入门了一下,但比较 `Dart` 对于我来说是一门全新的语言,光是在“数据处理”环节中就耗费了一部分精力(虽然最后的代码较精简),原本打算就将就的写写就完事了,但睡了一觉醒来后,告诉自己并不能放弃!继续开始对豆瓣电影 Top250 App 页面的布局进行分析。
因为本来就没打算把这个 demo 做得多么完美,只想尽可能的做到贴近 app 的展示,所以没有采用其它更适合的布局 `Widget`,经过分析后发现只用简单的 `Row` 和 `Column` 布局几乎可以完成大部分工作。
#### 主体
```Dart
import 'package:flutter/material.dart';
import 'package:movie_top_250/movieApi.dart';
import 'package:movie_top_250/movieModel.dart';
void main() => runApp(MyApp(movies: MovieAPI().getMovieList(0)));
class MyApp extends StatelessWidget {
final Future<Movies> movies;
var page = 0;
MyApp({Key key, this.movies}) : super(key: key);
@override
Widget build(BuildContext context) {
return MaterialApp(
title: '豆瓣电影 Top250',
theme: ThemeData(
primaryColor: Colors.black,
),
home: Scaffold(
appBar: AppBar(
title: Text('豆瓣电影 Top250'),
),
body: _buildList(),
),
);
}
}
```
排除掉其它 `Widget` 组件后,整个 demo 的骨架如上图所示,整体来看还算清晰,而且与 HTML 的骨架也基本类似,可以说 `Dart` 当初的为了替换 JS 目的的影子还是十分明显的。
#### ListView Widget
在 `_buildList()` 方法中主要利用了 `ListView Widget` 进行搭建。令我感到意外的是,`ListView Widget` 居然没有属性进行设置分割线!当然,在 `Weex` 和 `React-Native` 中同样也是没有的,这两个框架本质上就是写的 HTML ,接着我又想到 `Dart` 不也是要替换前端三剑客霸主的么?这么一想就没啥问题了。
```Dart
// body List Widget
Widget _buildList() {
return FutureBuilder<Movies>(
future: movies,
builder: (context, snapshot) {
if (snapshot.hasData) {
return ListView.builder(
// 加了分割线,长度需要为两倍
itemCount: snapshot.data.movies.length * 2,
itemBuilder: (context, index) {
if (snapshot.data.movies.length - index < 10) {
MovieAPI().getMovieList(++page);
}
if (index.isOdd) {
//是奇数
return new Divider();
} else {
index = index ~/ 2;
return _buildListRow(snapshot.data.movies[index]);
}
});
} else if (snapshot.hasError) {
return Text("${snapshot.error}");
}
return new Center(
child: new CircularProgressIndicator(
backgroundColor: Colors.black
)
);
},
);
}
```
分割线的设置利用了 `Divider Widget` 进行设置,而且还不能直接添加到单一 `item` 的渲染节点树中,必须重新起一个 `item` ,单独占据 `ListView` 的一个索引。上文这段代码的核心来自官方 demo,但写完后,个人觉得这么做有点不妥,总是担心后续在使用 `ListView` 树节点进行某些“特殊”操作时引发一些问题。
需要注意的地方是 `ListView` 渲染的 `cell` 条数会因为分割线的加入而减少一半,所以我们要对 `itemCount` 属性值变为模型列表的两倍长,以此来恢复正确需要渲染的 `cell` 数据。
#### ListViewRowPoster Widget
`_buildListRow(movie)` 方法主要是用来搭建 `cell widget` 而进行的简单封装。不得不说在编写该 `widget` 时,整体给我一种以为是在写 `CSS` 布局的错觉,这点给有一些 web 基础的同学上手会十分快!
```Dart
Widget _buildListRow(Movie movie) {
return Padding(
padding: EdgeInsets.all(10),
child: new Row(
mainAxisAlignment: MainAxisAlignment.start,
crossAxisAlignment: CrossAxisAlignment.start,
children: <Widget>[
new Container(
width: 100,
height: 150,
decoration: new BoxDecoration(
image: DecorationImage(image: NetworkImage(movie.poster)),
boxShadow: <BoxShadow>[
new BoxShadow(
color: Colors.grey,
offset: new Offset(0.0, 2.0),
blurRadius: 4.0,
)
],
borderRadius: new BorderRadius.all(
const Radius.circular(8.0),
),
),
),
_buildTextContent(movie),
]),
);
}
```
刚开始使用 `Image widget` 进行图片的加载,非常顺畅的就把图片资源加载出来了,等到后边开始统一美化数据时被“圆角”和“阴影”坑惨了,本以为给 `Image widget` 添加这两个属性是非常容易的事情,就像在 iOS 中给 `UIImageView` 或者 `UIView` 那般简单粗暴,但后来磕磕碰碰的查阅资料写出了“圆角”和“阴影”效果后才恍然大悟!
在 iOS 中之所以能够简单粗暴快速的给 `UIView` 和 `UIImageView` 添加上“圆角”和“阴影”属性,是因为二者都父类之一是 `UIView`,`UIView` 实现了 `CALayerDelegate` 协议,所谓的“圆角”和“阴影”都是 `CALayer` 的属性,所以设置的时候通常都是这么写:
```Swift
yourIamgeView.layer.cornerRadius = 8
yourIamgeView.layer.shadowColor = .black
```
但是在 flutter 中的 `Image widget` 只是继承自 `StatefulWidget` ,而 `StatefulWidget` 是继承自 `Widget` ,并不具备绘图能力,所以为什么没有“圆角”和“阴影”属性也就水落石出了。最后的做法是通过利用 `Container widget` 的 `decoration` 属性来添加相关修饰。
#### ListViewRowTextContent Widget
`ListViewRow Widget` 的左侧部分已经完成了,接下来就到了稍微复杂的右侧部分。在文章开头部分,我们已经看到了相关相关的设计图,主要是个整体纵向布局和几块小部分的横向布局。
```Dart
Widget _buildTextContent(Movie movie) {
return new Padding(
padding: EdgeInsets.fromLTRB(10, 0, 0, 0),
child: new Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: <Widget>[
_buildTitle(movie),
_buildRatingStar(movie),
_buildDetails(movie),
],
),
);
}
Widget _buildTitle(Movie movie) {
return new Row(
children: <Widget>[
new Text(
movie.title,
style: new TextStyle(
fontSize: 18,
fontWeight: FontWeight.w600,
),
),
new Text(
' (' + movie.year + ')',
style: new TextStyle(
color: Color.fromRGBO(150, 150, 150, 1),
fontWeight: FontWeight.w600,
fontSize: 18,
),
)
],
);
}
Widget _buildRatingStar(Movie movie) {
List<Widget> icons = [];
int fS = int.parse(movie.stars) ~/ 10;
int f = 0;
while (f < fS) {
icons.add(new Icon(Icons.star, color: Colors.orange, size: 13));
f++;
}
while (icons.length != 5) {
icons.add(new Icon(Icons.star,
color: Color.fromRGBO(220, 220, 220, 1), size: 13));
}
icons.add(new Padding(
padding: EdgeInsets.fromLTRB(5, 0, 0, 0),
child: new Text(
movie.rating,
style: new TextStyle(
fontSize: 12,
fontWeight: FontWeight.w600,
color: Color.fromRGBO(180, 180, 180, 1),
),
),
));
return new Padding(
padding: EdgeInsets.fromLTRB(0, 10, 0, 10),
child: new Row(children: icons),
);
}
Widget _buildDetails(Movie movie) {
var detailsString = '';
detailsString = movie.director;
detailsString += '/';
for (String name in movie.genres) {
detailsString += ' ' + name;
}
return new Container(
width: 230.0,
child: new Text(detailsString,
softWrap: true,
)
);
}
```
在这部分中,稍微费劲点的地方是 `_buildRatingStar()` 方法所构造的“评分组件”,在豆瓣 App 中浏览了好一会儿“评分组件”的星星是怎么个显示规则,琢磨了一会儿得出了一个结论:
* **9.2+**:五星;
* **8.1~9.1+**:四星半;
正准备拍手叫好接入数据时,突然发现了一个令人尴尬的事情,
其实 API 中已经给出了具体的评分,根本不需要我们自己去算!当时还奇怪怎么翻了前面几条数据的 `star` 字段数据都是 `"50"`,实际上是五星的意思......经过这样一番折腾后,后续的重点就转移到了星星的显示上,好在 flutter 提供了 `star` 这个 icon,但是却没有半个星星的 icon。权衡了一下决定就先这样吧,没有半星就没有了。
## 总结
因为时间和内容消化等因素,豆瓣电影 Top250 demo 将在下篇文章中完成:
* 下拉刷新;
* 上拉加载;
* 跳转页面,查看影片详情;
* 性能测试。
经过本次对 Flutter 在 UI 层面上的学习,对 flutter 的认识又更深了一步,反驳掉了自己在上篇文章中说 flutter 要凉的一部分。
================================================
FILE: Flutter/Flutter_3.md
================================================
## Flutter 三探
> 历时一个星期对 Flutter 一期调研在这篇文章中就告一段落了,这篇文章中继续完善上篇文章中利用豆瓣电影 Top250 公开 API demo。
## 前言
在这两三天的继续完善 demo 的时间中,首先是对 Flutter 在基本 UI 视觉方面的实现表示赞赏,有些地方的 UI 布局的代码编写习惯了 Flutter 的思维后,会有一个非常快速的反应。下面是具体 demo 具体的完成图:
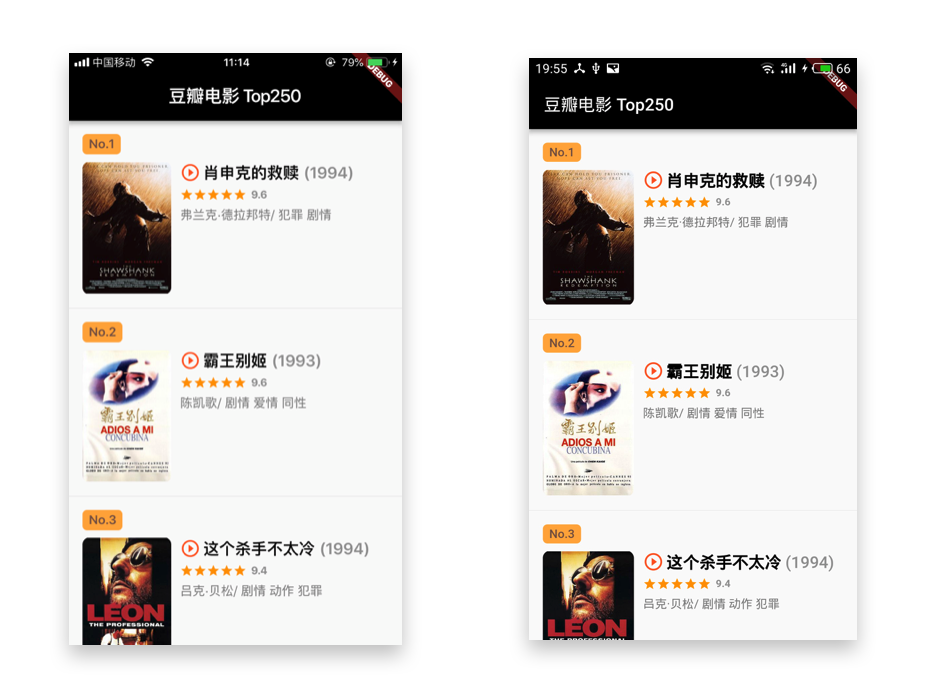
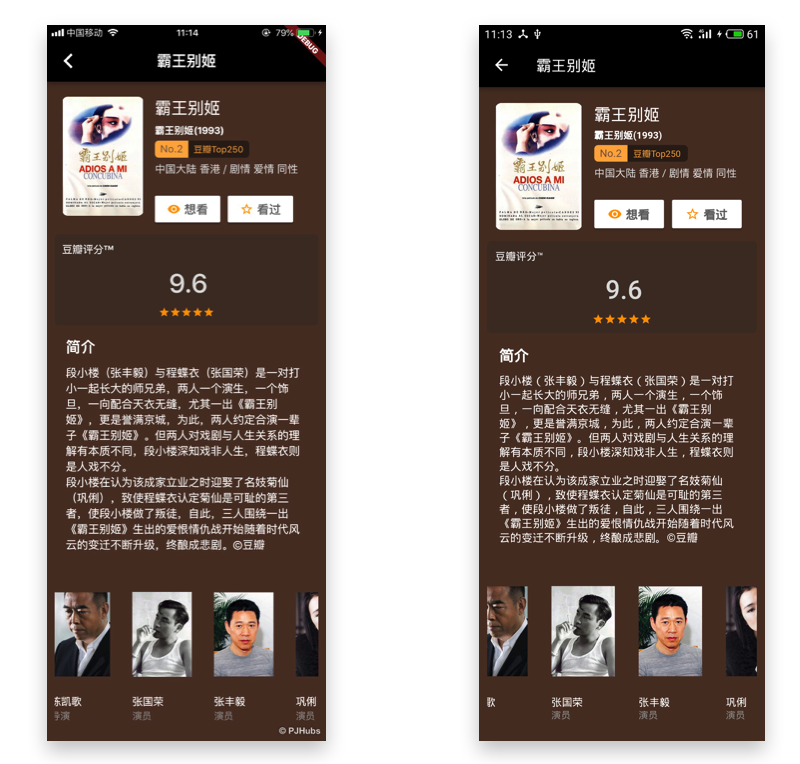
整体 demo 做完后,全程都是在使用 meizu 15 这台开发机进行调试,在 flutter 的 IDE 选择上一直都在使用 `Android Studio`,在断点调试、查看渲染节点、性能对比等活动上都非常方便的解决了,依然强推!但整体没有遵循 Flutter 官方推荐的[ `BloC` ](https://cloud.tencent.com/developer/article/1345645) 设计模式,还是采用“设计模式之王”的 `MVC`,同样是考虑到了后续在对比其它跨段方案时尽可能的保证一致性。
### 数据来源
[豆瓣电影详情 API ](https://api.douban.com/v2/movie/subject/26942674)同样不需要做验证,传入对应电影的 id 即可,但会限制同一 IP 在一定间隔时间内的访问次数,如果在一定间隔时间内容访问 API 的速度过于频繁,则会拒绝服务,不过得益于 Flutter 的 `hot reload` 技术,可以不需要每次都重新拉去数据。该详情 API 多了一些更具体的数据,但依然没有达到豆瓣 App 本身那般丰富。

### 涉及 Flutter 知识点
* 下拉刷新;
* 上拉加载;
* 利用 `GestureDetector Widget` 进行页面跳转(动态路由方式);
* 利用 `SingleChildScrollView Widget` 进行滚动视图的构建;
* 简单性能分析。
## 实践
### 目录结构
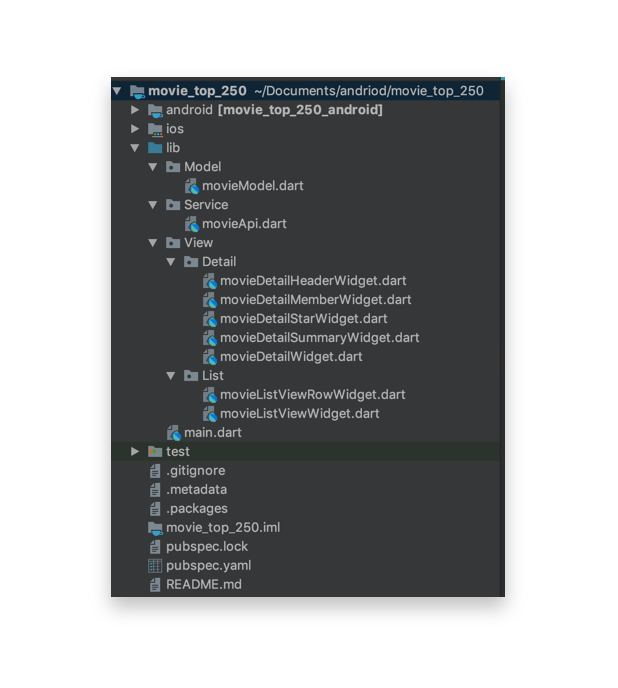
### 数据处理
电影详情 API 返回的字段更多,同样可以确认的是 Model 也一定要从网络数据源中进行抛离,这同样也为后续构建子组件回填数据时提供方便,我的电影详情 Model 如下所示:
```Dart
class MovieMember {
String id;
// 成员姓名
String name;
// 详情 URL
String detailUrl;
// 中清晰度头像
String avatarUrl;
MovieMember({
this.name,
this.detailUrl,
this.avatarUrl,
});
MovieMember.fromJSON(Map<String, dynamic> json) {
this.id = json['id'];
this.avatarUrl = json['avatars']['medium'];
this.detailUrl = json['alt'];
this.name = json['name'];
}
}
class MovieDetail {
// 标题
String title;
// 上映年份
String year;
// 原名
String originalTitle;
// 所属国家或地区
List<String> countries;
// 评分
String rating;
// "想看"人数
String wishCount;
// 星星
String stars;
// 高清晰度海报
String poster;
// 电影类型
List<String> genres;
// 评分人数
int ratingsCount;
// 主要导演
List<MovieMember> director;
// 主要演员
List<MovieMember> casts;
// 简介
String summary;
MovieDetail({
this.title,
this.year,
this.countries,
this.rating,
this.stars,
this.poster,
this.genres,
this.ratingsCount,
this.director,
this.casts,
this.summary,
this.wishCount,
});
MovieDetail.fromJSON(Map<String, dynamic> json) {
this.title = json['title'];
this.year = json['year'];
this.summary = json['summary'];
this.poster = json['images']['large'];
this.ratingsCount = json['ratings_count'];
this.originalTitle = json['original_title'];
this.wishCount = json['wish_count'].toString();
this.rating = json['rating']['average'].toString();
this.stars = json['rating']['stars'].toString();
this.countries = new List<String>.from(json['countries']);
this.genres = new List<String>.from(json['genres']);
List<MovieMember> castsMembers = [];
(json['directors'] as List).forEach((item) {
MovieMember movieMember = MovieMember.fromJSON(item);
castsMembers.add(movieMember);
});
this.director = castsMembers;
List<MovieMember> directorMembers = [];
(json['casts'] as List).forEach((item) {
MovieMember movieMember = MovieMember.fromJSON(item);
directorMembers.add(movieMember);
});
this.casts = directorMembers;
}
}
```
在写 `MovieDetail` Model 时发现电影详情 API 返回数据源中的“演员”数据存在多字段必要数据,为了后续方便调用同样也抽离了一个 `MovieMember` Model(二期调研估计会继续做演员详情)。
网络数据的获取因为有了上篇文章的铺垫,这次再写一个速度明显快了很多,一期调研完整的网络层方法如下:
```Dart
import 'dart:io';
import 'dart:convert';
import 'package:movie_top_250/Model/movieModel.dart';
class MovieAPI {
Future<Movies> getMovieList(int start) async {
var client = HttpClient();
int page = start * 50;
var request = await client.getUrl(Uri.parse(
'https://api.douban.com/v2/movie/top250?start=$page&count=50'));
var response = await request.close();
var responseBody = await response.transform(utf8.decoder).join();
Map data = json.decode(responseBody);
return Movies.fromJSON(data);
}
Future<MovieDetail> getMovieDetail(String movieId) async {
var client = HttpClient();
var request = await client.getUrl(Uri.parse(
'https://api.douban.com/v2/movie/subject/$movieId'));
var response = await request.close();
var responseBody = await response.transform(utf8.decoder).join();
Map data = json.decode(responseBody);
return MovieDetail.fromJSON(data);
}
}
```
### 下拉刷新与上拉加载
下拉刷新的整体与 Native 开发思路一致。上拉加载有根据业务有很多种实现方案,因为只是为了做验证性 demo ,直接采取了使用“静默加载”的思路,当然因为一次加载数据量太大(一页 50 条),所以在快速滑动列表时会导致下一页数据未载入等待的体验。如果不考虑过多的定制化操作,直接使用 flutter 系统组件是一件非常舒服的事情。完整代码如下:
```Dart
import 'package:flutter/material.dart';
import 'package:movie_top_250/Service/movieApi.dart';
import 'package:movie_top_250/Model/movieModel.dart';
import 'package:movie_top_250/View/List/movieListViewRowWidget.dart';
class MovieWidget extends StatefulWidget {
@override
State<StatefulWidget> createState() {
return _DouBanMovieState();
}
}
class _DouBanMovieState extends State<MovieWidget> {
// 数据源
List<Movie> movies = [];
// 分页
int page = 0;
@override
void initState() {
super.initState();
_requestData();
}
@override
Widget build(BuildContext context) {
return Scaffold(
appBar: AppBar(
title: Text('豆瓣电影 Top250'),
),
body: new RefreshIndicator(
child: _buildList(context),
onRefresh: _requestData,
color: Colors.black,
),
);
}
// 下拉刷新
Future<Null> _requestData() async {
movies.clear();
await MovieAPI().getMovieList(0).then((moviesData) {
setState(() {
movies = moviesData.movies;
});
});
return;
}
// 上拉加载
_requestMoreData(int page) {
print('page = $page');
MovieAPI().getMovieList(page).then((moviesData) {
setState(() {
movies += moviesData.movies;
});
});
}
// body List Widget
Widget _buildList(BuildContext context) {
var screenWidth = MediaQuery.of(context).size.width;
if (movies.length != 0) {
return ListView.separated(
itemBuilder: (context, index) {
// 还剩 15 条数据的时去拉取新数据
if (movies.length - index == 15) {
_requestMoreData(++page);
}
return new Container(
width: screenWidth,
child: buildListRow(index, movies[index], context),
);
},
separatorBuilder: (context, index) => Divider(
height: 1,
),
itemCount: movies.length);
} else {
return Center(
child: CircularProgressIndicator(),
);
}
}
}
```
### UI 分析
上文中也已经说到,因为豆瓣电影详情公开 API 所暴露出的数据有限,导致未能 100% 的重写。经过分析后主要将页面分为了以下几部分:
#### 第一部分
第一部分与上篇文章中所讲述的布局编写思路大部分一致,对于我自己来说有个需要注意的地方,在第一部分中有个“豆瓣电影排名”的 `badge`,原本打算是用 `RichText Widget` 进行实现的,但翻完属性后发现并没有提供 `decoration` 字段进行修饰,最后直接使用了两个 `DecoratedBox Widget` 作为父容器,在其 `decoration` 属性下使用 `BoxDecoration Widget` 完成“一左一右”圆角的 `badge` 组件编写,flutter 在组件“半圆角”的实现过程比 iOS 原生实现的代码量上少太多了(不封装的话),实现代码如下:
```Dart
Widget _buildBadge(int index, MovieDetail movieDetail) {
index++;
return new Row(
children: <Widget>[
DecoratedBox(
child: Padding(
padding: EdgeInsets.fromLTRB(7, 3, 7, 3),
child: Text('No.$index',
style: TextStyle(color: Colors.brown, fontSize: 14))),
decoration: new BoxDecoration(
color: Colors.orangeAccent,
borderRadius: BorderRadius.only(
topLeft: Radius.circular(5),
bottomLeft: Radius.circular(5)))),
DecoratedBox(
child: Padding(
padding: EdgeInsets.fromLTRB(7, 3, 7, 3),
child: Text('豆瓣Top250',
style: TextStyle(color: Colors.orangeAccent, fontSize: 12))),
decoration: new BoxDecoration(
color: Colors.black45,
borderRadius: BorderRadius.only(
topRight: Radius.circular(5),
bottomRight: Radius.circular(5)))),
],
);
}
```
在实现“想看”和“看过”两个按钮组件时,我使用了 `RaisedButton Widget` 。一开始是这么写的:
```Dart
new RaisedButton(
onPressed: null,
color: Colors.white,
child: new Text('B'),
textColor: Colors.black,
)
```
当显示出来后,不管怎么调整样式、修改颜色、文字等都不管用。最后带着郁闷的心情浏览官方文档,居然发现了这么一段话:

嗯,就算我们并不想让这个 Button 响应任何点击事件也不能给这个属性置空,并且也不能删除,因为这是个必须参数......这点需要注意。让同样也没想到的是 `RaisedButton` 没有 `text` 或类似设置按钮文本的属性,而是给了一个 `child` 属性,被 `UIButton` 虐过几次后在 `Flutter` 中看到某个组件提供了 `child` 属性现在就两眼放光!完成的代码如下:
```Dart
Widget _buildButton() {
return new Padding(
padding: EdgeInsets.fromLTRB(0, 20, 0, 0),
child: new Row(
children: <Widget>[
new Padding(
padding: EdgeInsets.fromLTRB(0, 0, 10, 0),
child: new RaisedButton(
onPressed: () {},
color: Colors.white,
child: new Row(
children: <Widget>[
new Padding(
padding: EdgeInsets.fromLTRB(0, 0, 5, 0),
child: new Icon(
Icons.remove_red_eye,
size: 18,
color: Colors.orange,
)
),
new Text('想看',
style: new TextStyle(
color: Color.fromRGBO(100, 100, 100, 1),
fontSize: 16,
fontWeight: FontWeight.w700,
),
),
],
),
textColor: Colors.black,
),
),
new RaisedButton(
onPressed: () {},
color: Colors.white,
child: new Row(
children: <Widget>[
new Padding(
padding: EdgeInsets.fromLTRB(0, 0, 5, 0),
child: new Icon(
Icons.star_border,
size: 18,
color: Colors.orange,
)
),
new Text('看过',
style: new TextStyle(
color: Color.fromRGBO(100, 100, 100, 1),
fontSize: 16,
fontWeight: FontWeight.w700,
),
),
],
),
textColor: Colors.black,
),
],
),
);
}
```
#### 第二部分
这部分布局与上篇文章所讲述的内容都是一致的。并且我也偷懒了,主要是没有太多值得花费心思的地方,都是常规的布局.本来想实现下“进度条”,但无奈并没有真实数据,也就懒得弄了。完整代码如下:
```Dart
import 'package:flutter/material.dart';
import 'package:movie_top_250/Model/movieModel.dart';
Widget movieDetailStarWidget(MovieDetail movieDetail) {
return new DecoratedBox(
decoration: new BoxDecoration(
color: Color.fromRGBO(65, 46, 37, 1),
borderRadius: BorderRadius.all(Radius.circular(5))),
child: new Column(
mainAxisAlignment: MainAxisAlignment.center,
children: <Widget>[
new Row(
crossAxisAlignment: CrossAxisAlignment.start,
children: <Widget>[
new Padding(
padding: EdgeInsets.all(10),
child: new Text(
'豆瓣评分™',
style: TextStyle(color: Colors.white),
)
)
],
),
_buildRatingStar(movieDetail),
],
)
);
}
Widget _buildRatingStar(MovieDetail movieDetail) {
List<Widget> icons = [];
int fS = int.parse(movieDetail.stars) ~/ 10;
int f = 0;
while (f < fS) {
icons.add(new Icon(Icons.star, color: Colors.orange, size: 15));
f++;
}
while (icons.length != 5) {
icons.add(new Icon(Icons.star,
color: Color.fromRGBO(220, 220, 220, 1), size: 15));
}
return new Padding(
padding: EdgeInsets.fromLTRB(0, 5, 0, 10),
child: new Column(children: <Widget>[
new Padding(
padding: EdgeInsets.fromLTRB(5, 0, 0, 10),
child: new Text(
movieDetail.rating,
style: new TextStyle(
fontSize: 35,
fontWeight: FontWeight.w500,
color: Color.fromRGBO(220, 220, 220, 1),
),
),
),
new Row(
mainAxisAlignment: MainAxisAlignment.center,
children: icons
),
]),
);
}
```
#### 第三部分
这部分涉及到了长文本,flutter 中同样也没有提供长文本显示组件,但好在 flutter 的 `Text Widget` 本身就适用于长文本展示的组件,默认开启 `softWrap` 属性(自动换行)。`Text Widget` 会从自身节点树里一直向上寻找能够提供宽度约束的父组件,并以此作为单行文本最长显示宽度,这点还是比较惊讶的,省了非常多的事情。完整的代码如下:
```Dart
import 'package:flutter/material.dart';
import 'package:movie_top_250/Model/movieModel.dart';
Widget movieDetailSummaryWidget(MovieDetail movieDetail) {
return new Padding(
padding: EdgeInsets.all(15),
child: new Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: <Widget>[
new Padding(
padding: EdgeInsets.fromLTRB(0, 0, 0, 10),
child: new Text(
'简介',
style: new TextStyle(
fontSize: 20,
color: Colors.white,
fontWeight: FontWeight.w600,
),
)
),
new Text(
movieDetail.summary,
style: new TextStyle(
color: Colors.white,
fontSize: 15,
)
)
],
)
);
}
```
当数据展示出来后,发现超出当前页面的显示范围了,这也是意料之中。按照之前的做法,会把 `UIScrollView` 作为当前页面所有原始的父容器,等所有 UI 元素都回填数据重新渲染完后,再把位于最底部的 UI 组件 bottom 值赋给 `scrollView.contentSize`。
翻了 flutter 文档后,发现了提供常规滑动视图能力的 Widget 不只一个,最后选择了 `SingleChildScrollView`。本以为设置滑动区域的步骤也会向在 Native 中那般麻烦,但实际上只需要把需要滑动视图组件的父节点赋给 `child` 属性即可,`SingleChildScrollView` 同样会自动的拓展自己的滑动区域进行适配,如下所示:
```Dart
Widget _buildBody(BuildContext context) {
// 数据源没来时展示 loading
if (movieDetail == null) {
return new Center(
child: new CircularProgressIndicator(),
);
} else {
return new SingleChildScrollView(
child: new Padding(
padding: EdgeInsets.all(10),
child: new Column(children: <Widget>[
movieDetailHeaderWidget(rankIndex, movieDetail, context),
movieDetailStarWidget(movieDetail),
movieDetailSummaryWidget(movieDetail),
movieDetailMemberWidget(movieDetail),
])
),
);
}
}
```
#### 第四部分
这部分是整体比较纠结的地方,到底是基于 `GridView Widget` 还是 `SingleChildScrollView Widget` 配合着其它布局 Widget 去做呢?如果这在 iOS 中,我会毫不犹豫的选择 `UICollectionView` 进行构建,因为又快又好~
最后还是抱着“又快又好”目的出发,选择了 `SingleChildScrollView Widget` 配合着其它布局 Widget 去做。需要注意是的 `SingleChildScrollView Widget` 默认是纵向滚动,该部分豆瓣 App 进行的横行滚动,需要改变滚动视图方式。完整代码如下:
```Dart
import 'package:flutter/material.dart';
import 'package:movie_top_250/Model/movieModel.dart';
Widget movieDetailMemberWidget(MovieDetail movieDetail) {
List<Widget> memberWidgets = [];
for (MovieMember member in movieDetail.director) {
memberWidgets.add(_buildMemberWidget(member, true));
}
for (MovieMember member in movieDetail.casts) {
memberWidgets.add(_buildMemberWidget(member, false));
}
return new SingleChildScrollView(
scrollDirection: Axis.horizontal,
child: new Row(
children: memberWidgets,
),
);
}
Widget _buildMemberWidget(MovieMember member, bool isDirector) {
var col = new Column(
crossAxisAlignment: CrossAxisAlignment.start,
children: <Widget>[
new Container(
width: 110,
height: 160,
decoration: new BoxDecoration(
image: DecorationImage(image: NetworkImage(member.avatarUrl)),
borderRadius: new BorderRadius.all(
const Radius.circular(8.0),
),
),
),
new Text(member.name,
style: new TextStyle(
color: Colors.white,
),
),
],
);
if (isDirector) {
col.children.add(
new Text(
'导演',
style: new TextStyle(
fontSize: 13,
color: Color.fromRGBO(150, 150, 150, 1)
),
)
);
} else {
col.children.add(
new Text(
'演员',
style: new TextStyle(
fontSize: 13,
color: Color.fromRGBO(150, 150, 150, 1)
),
)
);
}
return new Container(
width: 110,
child: new Padding(
padding: EdgeInsets.all(15),
child: col,
),
);
}
```
## 分析工具
在本 demo 中的 `ListView Widget` 未做太多优化的地方,所以会导致在启动 App 完成后直接开始上拉页面会体验到卡顿,但实际上的做法是先把当前页数据源的条数给 `ListView` 设置上,当用户停止滑动页面后,再开始 load 当前在可视区域范围内的 `ListViewRow Widget` 相关子组件数据。这一点优化在 iOS 上通过 `UITableView` 配合 `RunLoop` 就可以解决,但在对 flutter 的一期调研中并未打算开始此项调优工作。
使用各种跨平台工具最令人感到窒息的莫过于调试了,基于 `JSCore` 比如 `Weex`、`React-Native` 等框架还行,能够利用 web 开发者工具搭配进行。但比如 `Xamarin`、`Qt` 等框架想要进行调试基本上就比较费劲了,如果框架开发者不提供一些功能完备的 IDE 或插件,调试几乎等于噩梦。好在 `Android Stuido` 对 flutter 的支持是相当丰富,具体见下图:
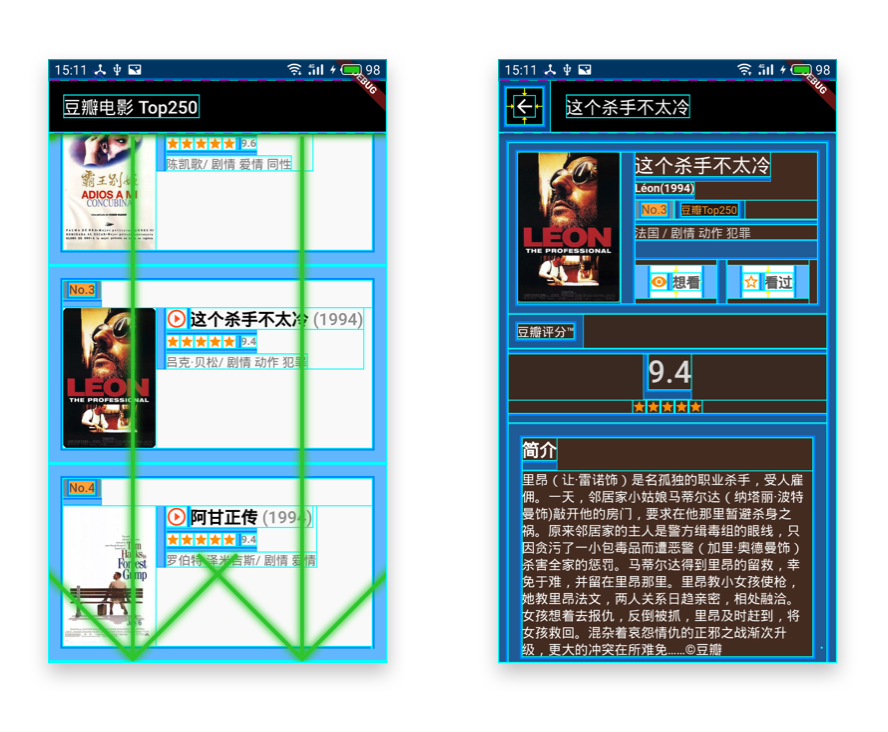
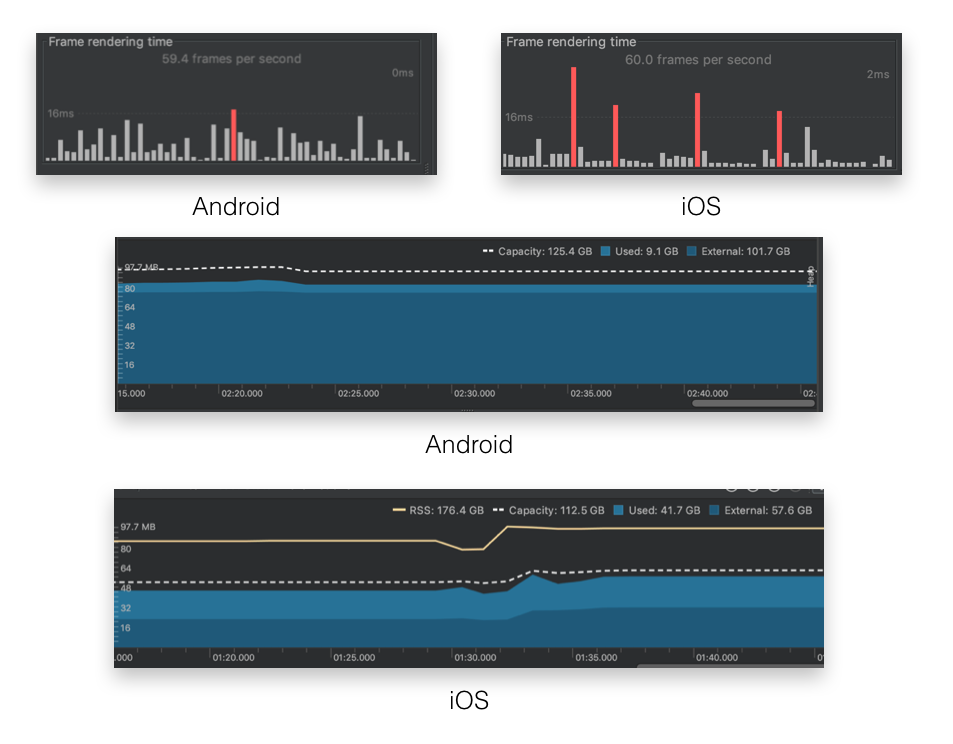
## 其它
### webView
今天原本还想做跳转 `webView`,以为也只是直接调个 `webView Widget`,填入 `requestUrl` 属性就完事了。但当我输入 web ,IDE 并未提示任何相关信息时,开始发觉有点不太对劲,不会 flutter 没有提供 `webView Widget` 吧?仔细浏览后,确认 flutter 还真的没有提供官方 `webView` 组件,但在 Pub 上已经有了对应的插件。
接着去掘金的 flutter 交流群里咨询,讨论在 flutter 中 `webView` 以及 `JSBridge` 最佳思路,最后讨论出了两个插件:
* webView 插件(带 JSBridge):[https://pub.flutter-io.cn/packages/interactive_webview](https://pub.flutter-io.cn/packages/interactive_webview)
* webView 插件:[https://pub.dartlang.org/packages/flutter_webview_plugin](https://pub.dartlang.org/packages/flutter_webview_plugin)
对于 `webView` 这块不是特别满意,而且看了 flutter 在 github 上的 issue,推荐自己做一个 `webView plugin`,暴露给 flutter 进行调用,这样可以最大程度上的降低基础组件重写成本。仔细一想,其实还是不满意,所以这部分内容也延后到二期调研中了。
### `StatefulWidget` 和 `StatelessWidget` 的选择
对于开发一个新的组件时,到底是基于 `StatefulWidget` 还是 `StatelessWidget` ,我认为只需要明确两个概念即可:
* 是否需要更新组件数据源;
* 是否需要利用组件各种生命周期;
如果以上两个条件都符合,那就选择 `StatefulWidget`。
## 总结
### 源码地址
本次 flutter 一期调研学习产出的豆瓣电影 Top250 demo 链接地址:[movie_top_250](https://github.com/windstormeye/flutter-practices/tree/master/movie_top_250)
flutter 的这种“声明式”编码体验,我认为对于第一次接触的新手来说,肯定有需要一定的学习成本,当逼迫自己去熟悉开发思路后,就会觉得真的很过瘾。在一期调研的学习中,没有涉及到的方面有:
* 设计模式;
* `webView` 及 `JSBridge`;
* flutter 与 native 的交互;
* 复杂 UI 的构建;
* 音视频处理(这还是得通过 native 进行暴露);
以上几块是构建一个 App 所需要具备的基本组件。经过一期学习后,对 flutter 也有了自己的理解,给我最大的感受是因为不用像 `React-Native`、`Weex` 等需要回调节点树给中间层通知 native 利用原生 UI 框架进行渲染,首先在 UI 绘制速度上已经远超其它框架,这点是毋庸置疑的。但因为 flutter 还太年轻,一些基础设施和社区都做得不算太好。所以如果非要选择一个跨端技术投入实际开发中,我还是会选择 `React-Native`,所以将重新捡起来 `React-Native`, 对其同样重新进行一期调研。
================================================
FILE: Flutter/Flutter问题汇总.md
================================================
# Flutter 问题汇总
## 环境配置
根据[ `flutter` 中文官网](https://flutterchina.club)上所引导的步骤进行配置,中途可以根据 `flutter doctor` 命令进行检查相关依赖是否配置完成。
### 设备
* iOS: iPhone 7, iOS 12.1.2
* Android: meizu 15, Andriod 7.1.1
### 遇到的问题
* 在环境配置中,官方推荐使用 `Andriod Studio` 进行开发,因为体验是最好的,当然同时也支持 `VS Code` 和 `IntelliJ`。因为开发机“常年”连接公司内网,导致无法在 `Andriod Studio` 中下载 `Dart` 和 `Flutter` 插件,尝试好几次,网上的资料都翻遍了,突然灵光一闪!我特么这是在内网啊!切回外网后,一切顺畅......
## 初体验
Flutter 官方上说的优势之一为“热重载”,新建 flutter 测试项目分别运行在 iOS 和 Andriod 两台测试设备上,iOS 的热重载只要每次 `cmd + s` 即可,但 Andriod 需要执行两次,看第一次打印出来的信息提示已经完成 `hot reload`,但设备上什么都没出现,必须执行第二次 `cmd + s` 操作后,才能看到真正的 `hot reload` 的效果。
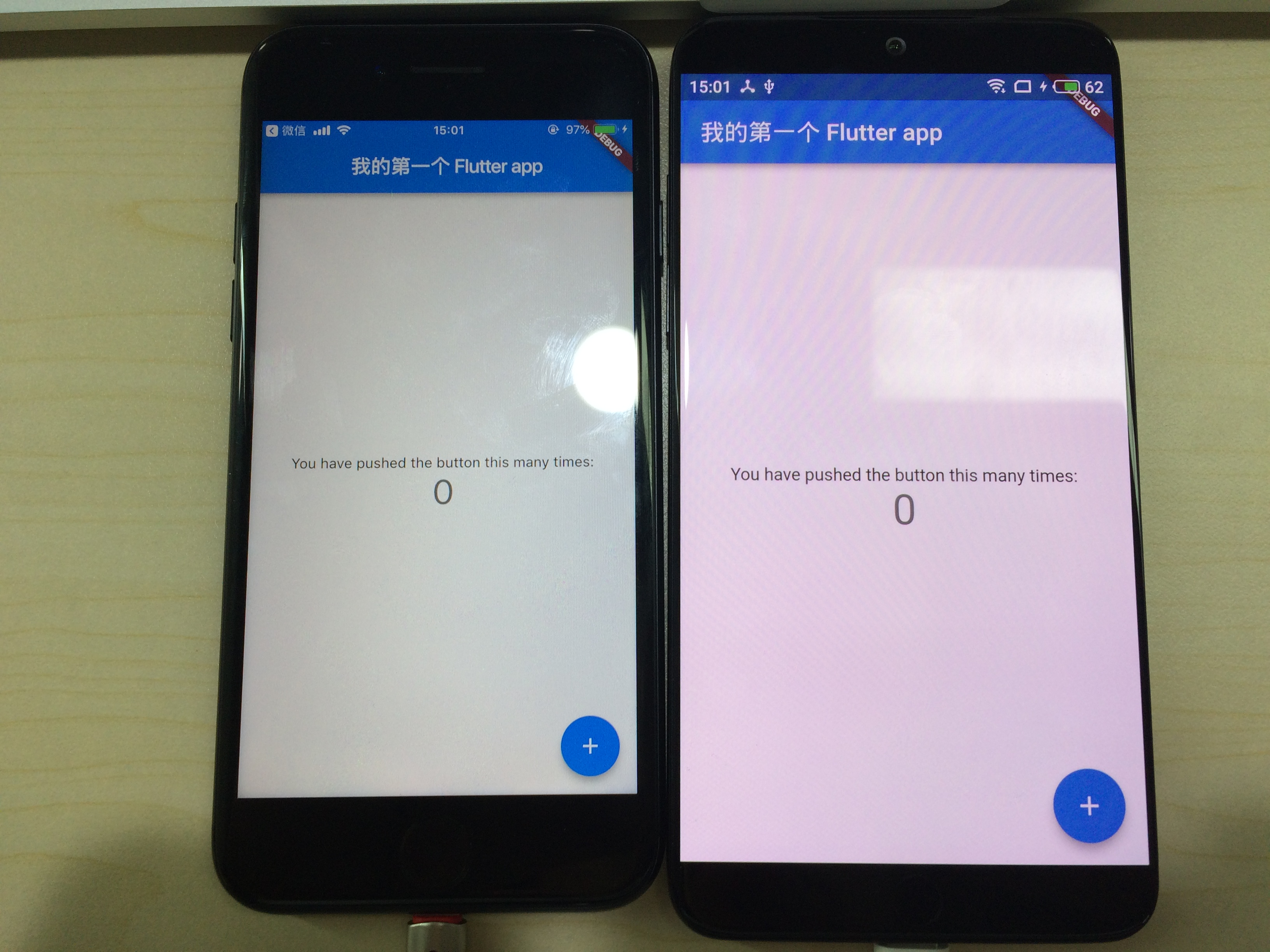
flutter 官网上对于“热重载”是这么描述的:
> 通过将更新后的源代码文件注入正在运行的 `Dart` 虚拟机(VM)中来实现热重载。在虚拟机使用新的的字段和函数更新类后,`Flutter` 框架会自动重新构建 `widget` 树,以便您快速查看更改的效果。
所以对于在 meizu 15 上需要执行两次保存操作才能触发“热重载”后的效果展示,我的推测是,在第一次执行保存操作时要么没有把新更新后的代码注入进 `Dart` 虚拟机中,要么就是注入了但未触发重新自动构建 `widget` 树。
### 渲染
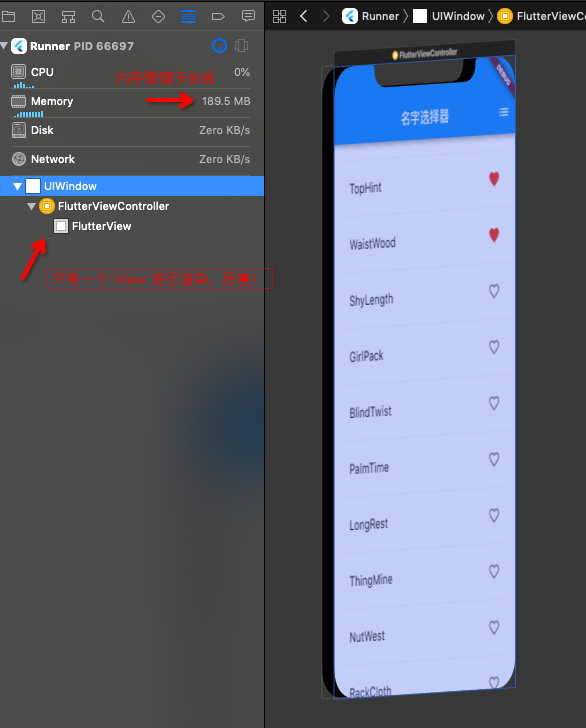
### 差异点
* 入口的 Main 函数入口使用了 `=>` 语法糖,官方说是“这是 `Dart` 中单行函数或方法的简写”:
```Dart
void main() => runApp(new MyApp());
// 我的推测:上下两者相等,论简洁性,确实是好看一丢丢
void main() { runApp(new MyApp()) }
```
* 每一个 `Widget` 都会有一个 `build()` 方法,用于描述如何根据其他较低级别的 `widget` 来显示自己。我的理解就是 `initView` 方法;
* 在 `Dart` 中“万物”(包括布局)都是 `Widget`,这点就类似与 `Objective-C` 中的“万物”都是 `NSObject`;
* `Scaffold Widget` 是 `Material library` 中的一个 `Widget`,提供了 `Material` 风格的基本组件。
* Flutter 中并没有类似 iOS 中的 `UITableViewCell`,直接在 `ListView Widget` 中构建了 `cell`,正是因为没有 `cell` 的概念,所以原本每个 `cell` 之间的“分割线”也需要手动使用 `Divider Widget` 进行索引模拟。推荐一篇关于 `Scaffold Widget` 的[内容介绍](http://flutter.link/2018/03/20/Scaffold/)
* Flutter 的 `Widget` 分为 `StatefulWidget(有状态)` 和 `StatelessWidget(无状态)` 两种,这跟在 iOS 中只要是继承了 `UIResponder` 就具备与用户产生交互进行状态的改变不一样。在 flutter 中如果我们需要实现设计要这个组件是否需要有状态的改变。
### 一些简单操作
#### 当打开一个工程时
`flutter packages get` 来下载工程中所依赖的库。
#### 格式化代码
`Dart` 疯狂嵌套的代码风格已经被吐槽烂了,好在可以在写完代码后,利用 `Android Studio` 中提供的 `Dart` 格式化代码工具:选择任何一个 `Dart` 代码文件,右键选择“Reformat Code with dartfmt”,代码格式立马变得好看了许多。
### 总结
经过这次对 Flutter 的初体验,对其惊叹的地方有:
* 真的做到了一套代码可以“无脑”运行在 iOS 和 Android 两个平台上,使用 `Andriod Studio` 编写完主体代码后,完全不需要做任何平台差异化设置,直接选择不同平台设备直接运行即可,在加上真的脱离了 `JS Core` 的“热重载”技术,在 iOS 上的开发体验非常流畅和方便!
* 在 iOS 上真的抛弃了 `UIKit` 的所有内容,全都基于 `Skia` 自己渲染,这点跟 `Texture` 在 UI 渲染上有异曲同工之处。
* `Dart` 这门语言本身有着与 `JSX` 类似的代码风格痕迹,尤其是对 `Widget` 做属性的定义时,但从整体上来看因为前身是准备要替代 `JS`,所以在很多地方也有 `JS` 痕迹,在一些细节上又透露着 `Java` 的微小细节,所以从语言本身的上手难度不算大,并没有在语法层面上做出太多的革新。
* 强烈推荐使用 `Android Studio` 进行开发!!!
* 创建 Flutter 工程下的 iOS 平台工程居然主体基于 `Swift`,这点让我十分意外!
目前来看不满意的地方只有一个:
* 在 iOS 上的长列表滑动卡顿十分严重!!!在快速滑动下,估计只有两三帧,而且每一个 `ListTitle Widget` 上只放了一个 `Text Widget` 啊!太辣眼睛了......[视频在此](https://www.bilibili.com/video/av40402669/)
## 二探 Flutter
### 一些细节
* `MaterialApp` 下的 `title` 属性代表的是在 Android 任务管理器中的名称(iOS 下只看 app name),`home` 属性下的 `appBar` 中所返回的 `AppBar` 中 `title` 属性才是定义 app 当前页面的标题;
### http
想要在 `Flutter` 中使用 `http` 请求,需要先在 `pubspec.yaml` 文件中加入对应依赖:
```yaml
dependencies:
# ...
http: ^0.12.0+1
```
随后可在对应 `dart` 文件中进行引入:
```dart
import 'package:http/http.dart' as http;
```
## HTTP 相关
### 刷新数据
因为 Flutter 对数据和视图已经进行了绑定,如果想要在网络请求完成后刷新视图所绑定的数据源,需要使用 `setState` 方法进行数据源状态的刷新。当然,使用 `setState` 方法的前提得是我们的 `Widget` 得是一个 `StatefulWidget` ,具备“状态改变的能力”。
### 异步加载后获取数据
通过 flutter 的自带 HTTP 请求库开启异步获取数据后,要求把数据为 `Future` 类型格式,以便在组件中进行“懒加载”,对于 `Future` 类型数据的解析可以采用如下方法():
```Dart
class MovieAPI {
Future<Movies> getMovieList(int start) async {
var client = HttpClient();
var request = await client.getUrl(Uri.parse(
'https://api.douban.com/v2/movie/top250?start=$start&count=100'));
var response = await request.close();
var responseBody = await response.transform(utf8.decoder).join();
Map data = json.decode(responseBody);
return Movies.fromJSON(data);
}
}
// 上拉加载
_requestMoreData(int page) {
MovieAPI().getMovieList(page).then((moviesData) {
setState(() {
movies = moviesData.movies;
});
});
}
```
### 点击事件
在 iOS 和 Android 中所有的 `View` 都可以添加点击或其它多手势事件,但在 Flutter 中除了少数几个自带 `onPress` 或 `onTap` 事件的 `Widget` ,剩下绝大部分 `Widget` 都不带事件,需要我们自己使用 `GestureDetector Widget` 作为父组件进行包裹。
```Dart
return GestureDetector(
onTap: () {
// 写下单机后触发的内容,当然还有双击、长按等事件
},
child: yourWidget,
);
```
### Flutter Widget Inspector
### 关于 `RaisedButton` 问题
```Dart
new RaisedButton(
onPressed: null,
color: Colors.white,
child: new Text('B'),
textColor: Colors.black,
)
```
如果不对 `onPressed` 设置处理事件,则对 `RaisedButton` 设置的所有修饰都不生效。
================================================
FILE: Front-end/CSS.md
================================================
# CSS
## 基本
### `<ul>` 实现 `<li>` 等分
```html
<ul id="father">
<li class="children">第一个</li>
<li class="children">第二个</li>
<li class="children">第三个</li>
</ul>
```
```css
#father{
display:flex;
width:100%;
height:10rem;
}
.children{
flex:1;
text-align:center;
}
```
### 横向布局
1. 使用 `float` 进行浮动;
2. 使用 `inline-block` 行块标签;
3. 使用 `flex` 布局。
### 使用 `div` 还算 `button` 设置按钮呢?
考虑语义化时尽量都按照标准来,但做个性化定制时,需要修改 `button` 的默认属性。考虑兼容性等适配问题时,直接上 `div`,且更容易定制化。
### `float: right`
当多个 `div` 进行右浮动时,顺序会颠倒,可以让颠倒的 `div` 再嵌套一个容器 `div`,对容器 `div` 设置 `float: right`,对容器内部的 `div` 做 `float: left` 即可。
### `div` 如何设置背景图片
```css
.more-button {
float: left;
width: 30px;
height: 30px;
background: url(../../../static/images/normal-report/more.png) no-repeat;
background-size: 30px 30px;
}
```
### 设置 `padding` 再设置 `width: 100%` 后超出父节点宽度
> 在 CSS 盒子模型的默认定义里,你对一个元素所设置的 width 与 height 只会应用到这个元素的内容区。如果这个元素有任何的 border 或 padding ,绘制到屏幕上时的盒子宽度和高度会加上设置的边框和内边距值。——来源 MDN
此时可以使用 `box-sizing` 属性进行调整:
* `content-box`:默认值,如果设置 `width: 100px`,此时再设置 `padding` 或者 `margin` 都会进行叠加;
* `border-box`:设置 `padding` 或者 `margin` 将会包括在 `width` 中,不会进行叠加。
### `let` 和 `var`
在 ES6 之后,使用 `let` 修饰变量在代码块中有效。
### 跨域问题
#### 什么是跨域
#### 浏览器层防护
1. 同源策略
#### 解决
1. 让本地的 node 服务器代理前端发出去的请求,服务器之间的请求是没有跨域一说的。
### 页面跳转
方式 | 解释
--- | ---
`self.location.href` | 当前页面打开URL页面
`window.location.href` | 当前页面打开URL页面
`this.location.href` | 当前页面打开URL页面
`location.href` | 当前页面打开URL页面
`parent.location.href` | 在父页面打开新页面
`top.location.href` | 在顶层页面打开新页面
#### 单页面
如果构建的是一个单页面应用,可以使用 `vue-router`。
单页面应用一次性载入所有资源,按需加载。页面中部分模块的更新,例如 `div1` 到 `div2` 只是插入而已~
#### 多页面
如果构建的是一个多页面应用,则应该使用以上描述的方法进行页面跳转。
多页面按需加载对应资源。
### 本地测试没法获取 cookie 怎么办?
可以在 chrome 的 console 中通过 `document.cookie` 进行设置暂时 cookie。
### 修改特定 index 元素 css
给单数 `li` 添加右边框
```css
li {
&:nth-of-type(2n + 1) {
border-right: 1px solid #ddd;
}
}
```
### 边框
```css
border: 1px solid rgb(253, 185, 152);
```
### 文字水平居中
设置 `line-height` 为父视图高度
================================================
FILE: Front-end/FCC.md
================================================
# FCC 学习笔记
这是我在 [freecodecamp.one](http://freecodecamp.one) 上学习遇到的问题以及值得记录的点。
## `<main>` 标签
该标签用与在 `<body>` 标签内标识出“内容主体”,因为同时还会有 `<nav>、<header>、<footer>` 等标签,把页面主体内容写在 `<main>` 标签中,有这样搜索引擎进行检索,它只应包含与页面中心主题相关的信息,而不应包含如导航连接、网页横幅等可以在多个页面中重复出现的内容。
`main` 标签的语义化特性可以使辅助技术快速定位到页面的主体。有些页面中有 “跳转到主要内容” 的链接,使用 `main` 标签可以使辅助设备自动获得这个功能。例子如下:
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>Using main</title>
</head>
<body>
<header>My page</header>
<nav>
[url=#]Home[/url]
</nav>
<main>
<article>
<h1>My article</h1>
Content
</article>
<aside>
More information
</aside>
</main>
<footer>Copyright 2013</footer>
</body>
</html>
```
## HTML 5 `<a>` 标签的 `target` 属性
target 属性规定在何处打开被链接文档。只能在 href 属性存在时使用。
`<a href="http://www.w3school.com.cn" target="_blank">Visit W3School</a>`
值 | 描述
---- | ----
_blank | 在新窗口中打开被链接文档。
_self | 在被点击时的同一框架中打开被链接文档(默认)。
_parent | 在父框架中打开被链接文档。
_top | 在窗口主体中打开被链接文档。
## `<br>`
`<br>` 标签是空标签(意味着它没有结束标签,因此这是错误的:`<br></br>`)。在 XHTML 中,把结束标签放在开始标签中,也就是 `<br />`。
## HTML `<meta>` 标签
`<meta>` 元素可提供有关页面的元信息(meta-information),比如针对搜索引擎和更新频度的描述和关键词。
## `class` 选择器
在 `<style></style>` 区域,这么写:
```html
<style>
.red-text {
color: red;
}
</style>
```
在 `<body></body>` 区域,这么写:
```html
<body>
<h2 class="red-text"> 2333 </h2>
</body>
```
### 其它
在 `<style>` 标签里面声明的 `class` 顺序十分重要。第二个声明始终优于第一个声明。因为 `.blue-text` 在 `.pink-text` 的后面声明,所以 `.blue-text` 会覆盖 `.pink-text` 的样式。
## 更换字体
在 `<style>` 标签之前(或者顶部),写下:
```html
<link href="https://fonts.googleapis.com/css?family=Lobster" rel="stylesheet" type="text/css">
```
可以去 [Google 免费字体库](https://fonts.google.com/) 中找一些自己需要的字体。
## 字体降级
所有浏览器都有几种默认的字体,包括但不限于:`monospace`, `serif`, `sans-serif`, `Helvetica` 等。
当我们引用外部字体却因为某些原因导致字体加载失败时,可以采用“字体降级”:
```css
p {
font-family: Lobster, sans-serif;
}
```
当找不到 `Lobster` 字体时,将自动降级为 `sans-serif`,但如果设备中已经安装了 `Lobster` 字体,则不会降级,因为浏览器会找到这个字体(目前暂不知道浏览器怎么寻找字体)。
## CSS 设置圆形
```css
.image {
border-radius: 50%;
}
```
## id 属性(id 选择器)
在 CSS 里,`id` 不可以重用,只应用于一个元素上且`id` 的优先级要高于 `class`,如果一个元素同时应用了 `class` 和 `id`,并设置样式有冲突,会优先应用`id` 的样式。
```css
#cat-photo-element {
background-color: green;
}
```
## padding(内边距),margin(外边距)和border(边框)
* `padding` 控制着元素内容与border之间的空隙大小。
* `margin`(外边距)控制元素的边框与其他元素之间的距离。
## 属性选择器
```css
[type='checkbox'] {
margin: 10px 0 15px 0px
}
```
这样就把 `type` 类型为 `checkbox` 的复选框一同进行设置了。
```html
<form action="/submit-cat-photo" id="cat-photo-form">
<label><input type="radio" name="indoor-outdoor">室内</label>
<label><input type="radio" name="indoor-outdoor">室外</label><br>
<label><input type="checkbox" name="personality">忠诚</label>
<label><input type="checkbox" name="personality">懒惰</label>
<label><input type="checkbox" name="personality">积极</label><br>
<input type="text" placeholder="猫咪图片地址" required>
<button type="submit">提交</button>
</form>
```
## 内联样式的优先级高于 id 选择器
## !important
在很多时候,你使用 CSS 库,有时候它们声明的样式会意外的覆盖你的 CSS 样式。当你需要保证你的 CSS 样式不受影响,你可以使用 `!important`:
```css
.pink-text {
color: pink !important;
}
```
## 绝对单位和相对单位
单位长度的类型可以分成 2 种,一种是相对的,一种是绝对的。例如,`in` 和 `mm` 分别代表着英寸和毫米。绝对长度单位会接近屏幕上的实际测量值,不过不同屏幕的分辨率会存在差异,可能会导致一些误差。
相对单位长度,就像 `em` 和 `rem`,它们会依赖其他长度的值。就好像 `em` 的大小基于元素的字体的 `font-size` 值,如果你使用 `em` 单位来设置 `font-size` 值,它的值会跟随父元素的 `font-size` 值来改变。
## 每一个 HTML 页面都含有 body 元素
## 定义并使用自己的 CSS 变量
### 定义
创建一个 CSS 变量,你只需要在变量名前添加两个破折号,并为其赋值,例子如下:
```css
--penguin-skin: gray;
```
这样会创建一个 `--penguin-skin` 变量并赋值为 `gray`(灰色)。
### 使用
创建变量后,CSS 属性可以通过引用变量名来使用它的值。
```css
background: var(--penguin-skin);
```
### 其它
使用变量来作为 CSS 属性值的时候,可以设置一个备用值来防止由于某些原因导致变量不生效的情况。
或许有些人正在使用着不支持 CSS 变量的旧浏览器,又或者,设备不支持你设置的变量值。为了防止这种情况出现,那么你可以这样写:
`background: var(--penguin-skin, black);`
这样,当你的变量有问题的时候,它会设置你的背景颜色为黑色。
## `:root` 变量
就像 `html` 是 `body` 的容器一样,你也可以认为 `:root` 元素是你整个 `HTML` 文档的容器。在 `:root` 创建的变量,在整个网页里面都能生效。
```css
<style>
:root {
/* add code below */
--penguin-belly: pink;
/* add code above */
}
</style>
```
当你在:root里创建变量时,这些变量的作用域是整个页面。如果在元素里创建相同的变量,会重写:root变量设置的值。
## 使用媒体查询更改变量
CSS 变量可以简化媒体查询的方式。例如,当屏幕小于或大于媒体查询所设置的值,通过改变变量的值,那么应用了变量的元素样式都会得到响应修改:
```css
@media (max-width: 350px) {
:root {
/* add code below */
--penguin-size: 200px;
--penguin-skin: black;
/* add code above */
}
}
```
## `text-align`
* `text-align: justify;` 可以让除最后一行之外的文字两端对齐,即每行的左右两端都紧贴行的边缘。
* `text-align: center;` 可以让文本居中对齐。
* `text-align: right;` 可以让文本右对齐。
* `text-align: left;` 是 `text-align` 的默认值,它可以让文本左对齐。
## `strong` 标签加粗文本
你可以使用 `strong` 标签来加粗文字。添加了 `strong` 标签后,浏览器会自动给元素应用 `font-weight:bold;` 。
## `u` 标签
你可以使用u标签来给文字添加下划线。添加了 `u` 标签后,浏览器会自动给元素应用 `text-decoration: underline;` 。
## `em` 标签
你可以使用 `em` 标签来强调文本。由于浏览器会自动给元素应用 `font-style: italic;`,所以文本会显示为斜体。
## `s` 标签
你可以用 `s` 标签来给文字添加删除线,它代表着这段文字不再有效。添加了 `s` 标签后,浏览器会自动给元素应用`text-decoration: line-through;`。
## `hr` 标签
你可以用 `hr` 标签来创建一条宽度撑满父元素的水平线。它一般用来表示文档主题的改变,在视觉上将文档分隔成几个部分。在 `HTML` 里,`hr` 是自关闭标签,所以不需要一个单独的关闭标签。
## `text-transform` 给文本添加大小写效果
`CSS` 里面的 `text-transform` 属性来改变英文中字母的大小写。它通常用来统一页面里英文的显示,且无需直接改变 `HTML` 元素中的文本。下面的表格展示了 `text-transform` 的不同值对文字 “Transform me” 的影响。
Value | Result
--- | ---
lowercase | "transform me"
uppercase | "TRANSFORM ME"
capitalize | "Transform Me"
initial | 使用默认值
inherit | 使用父元素的text-transform值。
none | Default:不改变文字。
## `font-weight`
`font-weight` 属性用于设置文本中所用的字体的粗细。
## `line-height`
CSS 提供 `line-height` 属性来设置行间的距离。行高,顾名思义,用来设置每行文字所占据的垂直空间。
## 伪类
比如,超链接可以使用 `:hover` **伪类选择器**定义它的悬停状态样式。下面是悬停超链接时改变超链接颜色的 CSS:
```css
a:hover {
color: red;
}
```
## 更改元素的相对位置——`position`
在 CSS 里一切 HTML 元素皆为盒子,也就是通常所说的 **盒模型**。块级元素自动从新的一行开始(比如标题、段落以及 div),行内元素(也称:内联元素)排列在上一个元素后(比如图片以及 span)。元素默认按照这种方式布局称为文档的**普通流**,同时 CSS 提供了 `position` 属性来覆盖它。
```css
p {
position: relative;
bottom: 10px;
}
```
## 更改元素的绝对位置——`absolute`
CSS `position` 属性的取值选项 `absolute`,`absolute` 相对于其包含块定位。和 `relative` 定位不一样,`absolute` 定位会将元素从当前的文档流里面移除,周围的元素会忽略它。可以用 CSS 的 `top`、`bottom`、`left `和 `right` 属性来调整元素的位置。
`absolute` 定位比较特殊的一点是元素的定位参照于最近的已定位祖先元素。如果它的父元素没有添加定位规则(默认是`position:relative;`),浏览器会继续寻找直到默认的 `body` 标签。
## `fixed` 定位
`fixed` 定位,它是一种特殊的绝对(absolute)定位,区别是其包含块是浏览器窗口。和绝对定位类似,`fixed` 定位使用 `top`、`bottom`、`left` 和 `right` 属性来调整元素的位置,并且会将元素从当前的文档流里面移除,其它元素会忽略它的存在。
`fixed` 定位和 `absolute` 定位的最明显的区别是 `fixed` 定位元素不会随着屏幕滚动而移动。
## 元素浮动
浮动元素不在文档流中,它向左或向右浮动,直到它的外边缘碰到包含框或另一个浮动框的边框为止。通常需要用 `width` 属性来指定浮动元素占据的水平空间。
## `z-index` 属性更改重叠元素的位置
在 HTML 里后出现的元素会默认显示在更早出现的元素的上面。你可以使用 `z-index` 属性指定元素的堆叠次序。`z-index` 的取值是整数,数值大的元素优先于数值小的元素显示。
## 让元素水平居中
一种常见的实现方式是把块级元素的 `margin` 值设置为 `auto`。同样的,这个方法也对图片奏效。图片默认是**内联元素**,但是可以通过设置其 `display` 属性为 `block` 来把它变成**块级元素**。
## 线性渐变器
`background: linear-gradient(45deg, #CCFFFF, #FFCCCC);`
## 重复线性渐变器
```css
background: repeating-linear-gradient(
45deg,
yellow 0px,
yellow 40px,
black 40px,
black 80px
);
```
## 通过添加细微图案作为背景图像来创建纹理
终于明白了公司内网上标记名字的背景图像是怎么做的了
`background: url(https://i.imgur.com/MJAkxbh.png);`
## 更改元素大小
`transform: scale(1.5);`
## 鼠标悬停时缩放元素
```css
div:hover {
transform: scale(1.1);
}
```
## 倾斜
```css
transform: skewX(24deg);
transform: skewY(-10deg);
```
## 画一个月亮 🌛
`blur-radius` => 模糊半径,`spread-radius` => 辐射半径,`transparent` => 透明的,`border-radius` => 圆角边框
```css
background-color: transparent;
border-radius: 50%;
box-shadow: 25px 10px 0px 0px green;
```
## 画一个爱心 ❤️
```css
<style>
<!-- 先画一个正方形 -->
.heart {
position: absolute;
margin: auto;
top: 0;
right: 0;
bottom: 0;
left: 0;
background-color: pink;
height: 50px;
width: 50px;
transform: rotate(-45deg);
}
<!-- 再画一个圆形在左上角 -->
.heart:after {
background-color: pink;
content: "";
border-radius: 50%;
position: absolute;
width: 50px;
height: 50px;
top: 0px;
left: 25px;
}
<!-- 再画一个圆形右上角 -->
.heart:before {
content: "";
background-color: pink;
border-radius: 50%;
position: absolute;
width: 50px;
height: 50px;
top: -25px;
left: 0px;
}
</style>
<div class = "heart"></div>
```
## 动画
```css
#anim {
animation-name: colorful;
animation-duration: 3s;
}
@keyframes colorful {
0% {
background-color: blue;
}
100% {
background-color: yellow;
}
}
```
## 修改动画的填充模式
动画在持续时间之后重置了,所以按钮又变成了之前的颜色。如果我们想要的效果是按钮在悬停时始终高亮。
`animation-fill-mode: forwards;`
## 动画次数
`animation-iteration-count: infinite;`
## 使用关键字更改动画定时器
`animation-timing-function: ease-out;`
## 当图片无法读取或需要提供描述信息时
`<img src="samuraiSwords.jpeg" alt="这里填写图片描述信息">`
## 每个页面应该只有一个h1标签,用来说明页面主要内容。h1标签和其他的标题标签可以让搜索引擎获取页面的大纲
## 音频播放
```css
<audio controls>
<source src="https://s3.amazonaws.com/freecodecamp/screen-reader.mp3" type="audio/mpeg" />
</audio>
```
## `label` 标签的 `for` 属性
`label` 元素不会向用户呈现任何特殊效果。不过,它为鼠标用户改进了可用性。如果您在 `label` 元素内点击文本,就会触发此控件。就是说,当用户选择该标签时,浏览器就会自动将焦点转到和标签相关的表单控件上。前提得跟表单内的输入组件 id 相同,例如:
```html
<form>
<label for="name">Name:</label>
<input type="text" id="name" name="name">
</form>
```
## `<sub>` 标签
`<sup>` 标签可定义上标文本。
包含在 `<sup>` 标签和其结束标签 `</sup>` 中的内容将会以当前文本流中字符高度的一半来显示,但是与当前文本流中文字的字体和字号都是一样的。
## 将键盘焦点添加到元素中
```html
<p tabindex = "0">Instructions: Fill in ALL your information then click <b>Submit</b></p>
```
这样就会当用户使用 `tab` 键进行切换时,会把键盘焦点聚集在该标签上。
# 响应式 Web 设计原则
## 创建一个媒介查询
设备的高度小于或等于 `800p`x 时,`p` 标签的 `font-size` 为 `12px` 的媒体查询:
```css
@media (min-height: 800px) {
p {
font-size: 12px;
}
}
@media (max-height: 800px) {
p {
font-size: 12px;
}
}
```
## 使排版根据设备尺寸自如响应
视窗单位相对于设备的视窗尺寸 (宽度或高度) ,百分比是相对于父级元素的大小。
四个不同的视窗单位分别是:
* vw:如 10vw 的意思是视窗宽度的 10%。
* vh: 如 3vh 的意思是视窗高度的 3%。
* vmin: 如 70vmin 的意思是视窗中较小尺寸的 70% (高度 VS 宽度)。
* vmax: 如 100vmax 的意思是视窗中较大尺寸的 100% (高度 VS 宽度)。
================================================
FILE: Front-end/JavaScript.md
================================================
# JavaScript
## 指定 `Array` 的元素类型
不好意思做不到!js 是弱类型语言,我们不能真正的做到指定元素类型,但是可以先指定元素长度,然后再循环赋值哈哈哈~
## `HttpOnly`
产品上出现了一个奇怪的问题,一个 H5 页面在测试环境下(hostName 为 xxx-test.xxx.com)完全没有任何问题,`Cookie` 可以取到所有信息,但是发布到线上后,发现了一个十分捉鸡的问题,线上环境(xxx.xxx.com)居然取不到 `Cookie` 中的 `xxx_ticket` 信息!!!
刚开始吭哧吭哧的整了一波后,始终在怀疑是自己写的逻辑有问题,查来查去,还是没啥头绪,没办法只能去请教下前辈。一波操作后,发现了如下情况:
线上环境:
测试环境:
原因就在这个 `HttpOnly` 上,关于 `HttpOnly` 的解释如下:
>>> HttpOnly: HttpOnly is an additional flag included in a Set-Cookie HTTP response header. Using the HttpOnly flag when generating a cookie helps mitigate the risk of client side script accessing the protected cookie (if the browser supports it).
换句话说,客户端/浏览器是无法对 `Cookie` 中的这个 `key` 进行操作的,并且不可见。
## 连接两个数组
不可使用 `+=`,而是 `concat`。
## 基础语法
### ES6
#### 数组展开
可用使用 `...` 对一维数组下另外塞入的完整一维数组进行进行展开,防止变为二维数组。
```js
ES6 扩展运算符...可以将两重数组转换为单层数组:
[].concat(...[1, [2, 3, [4]], "a", "b", ["c", "d"], [["d"],"e"], "f"]); // [1, 2, 3, Array(1), "a", "b", "c", "d", Array(1), "e", "f"]
// 利用 some 方法,我们可以实现多重转换为单层:
function flatten(origin) { while(origin.some(item=> Array.isArray(item))) {
origin = [].concat(...origin);
} return origin;
}
var arr = [1, [2, 3, [4]], "a", "b", ["c", "d"], [["d"],"e"], "f"];
console.log(flatten(arr)) // [1, 2, 3, 4, "a", "b", "c", "d", "d", "e", "f"]
```
================================================
FILE: Front-end/Vue.md
================================================
# Vue
## 基础知识
### MVVM 数据绑定
在学习 `Vue` 的过程中,非常好奇 `Vue` 自身的数据绑定模式是否与我之前在 iOS 上接触到的数据绑定认识一致,然后又在资料中发现了 `Object.defineProperty()` 和 `Object.defineProperties` 方法,相当于对一个属性进行了 `setter` 和 `getter` 的监听,然后根据监听结果重新更新元素,大致如下所示:
```html
<html>
<head>
</head>
<body>
<span id="span"></span>
<script>
var obj = {
pwd: "123123"
};
Object.defineProperty(obj, "userName", {
get: function () {
console.log("get init")
},
set: function (newValue) {
console.log("set init")
document.getElementById("span").innerText = newValue
}
});
</script>
</body>
</html>
```
看到这段代码后,瞬间就大彻大悟!其实也不是什么特别高深的内容(当然还是有其它值得学习的地方~),而且这么做耦合度十分的高,就目前的学习内容来看,`Vue` 中对 **组件化** 的核心思路跟之前在 iOS 中流程还是一致的~
## 构建
### 生成 package.json 文件(需要手动选择配置)
`npm init`
### 生成 package.json 文件(使用默认配置)
`npm init -y`
### 一键安装 package.json 下的依赖包
`npm i`
### 在项目中安装包名为 xxx 的依赖包(配置在 dependencies 下)
`npm i xxx`
### 在项目中安装包名为 xxx 的依赖包(配置在 dependencies 下)
`npm i xxx --save`
### 在项目中安装包名为 xxx 的依赖包(配置在 devDependencies 下)
`npm i xxx --save-dev`
### 全局安装包名为 xxx 的依赖包
`npm i -g xxx...`
### 自定义执行命令
也就是会运行 `package.json` 中 `scripts` 下的命令:
```shell
npm run xxx
```
## 懒加载
H5 页面也可以像之前原生中的“懒加载”思想一致,等到需要真的需要使用这个组件时,再对其进行渲染,如果你跟我一样使用 `vue-router`,则可以这么写:
```js
import Vue from 'vue'
import Router from 'vue-router'
import Home from './views/Home.vue'
Vue.use(Router)
export default new Router({
routes: [
{
// 该页面为直接加载
path: '/',
name: 'home',
component: Home
},
{
// 该页面为懒加载
path: '/about',
name: 'about',
// route level code-splitting
// this generates a separate chunk (about.[hash].js) for this route
// which is lazy-loaded when the route is visited.
component: function () {
return import(/* webpackChunkName: "about" */ './views/About.vue')
}
}
]
})
```
## Vue 的一些属性描述
### `name`
只有作为**组件选项**时起作用。允许组件模版递归地调用自身,注意,组件在全局用 `Vue.component()` 注册时,全局 ID 自动作为组件的 name;指定 `name` 选项的另一个好处是便于调试。有名字的组件有更友好的警告信息。另外,当在有 `vue-devtools`,未命名组件将显示成 `<AnonymousComponent>`,这很没有语义。通过提供 `name` 选项,可以获得更有语义信息的组件树。
## Props
### `Array`
如果我们要传递一个字符串数组给子组件,错误的传递方式:
```html
<nav-header item-names="['笔记', '海洋', '书写', '通知', '我']"></nav-header>
```
正确的传递方式:
```html
<nav-header v-bind:item-names="['笔记', '海洋', '书写', '通知', '我']"></nav-header>
```
vue 官网上是这么说的,
> 即便数组是静态的,我们仍然需要 `v-bind` 来告诉 Vue,这是一个 `JavaScript` 表达式而不是一个字符串。
###m mint-UI 是怎么实现下拉刷新的呢?
简单来说获取下拉手势后通过 `transform` 来做动画偏移。
================================================
FILE: Front-end/basic.md
================================================
# Basic HTML and HTML5
* 作为惯例,所有的 HTML 标签都是小写,比如是 <p></p>,而不是<P></P>
* 所有的 img 标签都必须有 alt 修饰。该标签可被用户读屏和如果图片加载不出来时进行文本展示。
* 使用 a 标签通过 href 进行跳转时,增加 target="_blank" 可以在新的标签页打开。
* 一般来说我们在 <a> 标签中通过 href 进行跳转,但如果在 href 中使用 #about 等类似的标识符,这将会挑战到当前页面对于的 id 的标签上,如果此时只给了 #,则只会刷新当前页面。
* <input> 如果为必填框,可以设置 required 标记
* 每一个 <input> type 为 radio 的标签都应该内嵌在各自独立的 <label> 标签中。
* <label> 标签作用在 <input> 类型标签的作用在于 accessibility,供读屏软件定位到输入区域时给用户提示
# Basic CSS
* CSS 下的 font-family 设置字体时,先在编辑器最顶部导入字体源,然后再写入对应的字体名字,若当前字体不可用时,可以多写一个浏览器自带字体,做个捞底。
* Id 修饰有助于JS 调用,而且应该全局唯一。浏览器虽然不会强制要求,但这是一个最佳实践。
* Id 不可被服用,且应该只对一个元素生效。当 id 和 class 所挂载的 css 发生冲突时,id 的优先级大于 class。
* 类似 <input> 标签给了 type 后,想要针对不同的 type 做 CSS,可以通过这种方式
[type = ‘checkbox’] = {
}
* Class 中修饰的内容大于 body 中修饰的内容,后边更新的属性会覆盖前一个属性
* 写在同一个元素中的不同 class,第二个 class 修饰的内容会复写第一个修饰的 class 中修饰的内容
* 不管 class 修饰了多少次,id 再去修饰同一个属性的优先级是最高的
* 当比较难重写 CSS 时,可以使用 !important 进行强制使用
* 十六进制颜色值是按照 #RRGGBB 的格式进行排布,0 为最低色值,F 为最高。
* 如果涉及到一个 CSS 属性很多地方都有用到,可以使用 CSS 变量进行统一处理:
```css
.penguin {
--penguin-skin: black;
}
.penguin-top {
background: var(--pengiun-skin);
}
```
* CSS 变量有些浏览器并不支持,为了提升可用性,可以重复定义一个相同的 CSS 属性。
```css
.red-box {
background: red;
background: var(--red-color);
}
```
* CSS 变量可以被重写
* 媒体查询
```css
:root {
--penguin-size: 300px;
--penguin-skin: gray;
--penguin-belly: white;
--penguin-beak: orange;
}
@media (max-width: 350px) {
:root {
--penguin-skin: black;
--penguin-size: 200px;
}
}
```
* CSS :root 伪类选择器?
* :root 这个 CSS 伪类匹配文档树的根元素。对于 HTML 来说,:root 表示 <html> 元素,除了优先级更高之外,与 html 选择器相同。
* CSS 伪类 是添加到选择器的关键字,指定要选择的元素的特殊状态。例如,:hover 可被用于在用户将鼠标悬停在按钮上时改变按钮的颜色。
# Applied Visual Design
* text-align: justify;
* 文字向两侧对齐,对最后一行无效。
* text-align: justify-all;
* 同上,但强制最后一行两端对齐。
* <strong> 标签可以替代 CSS 属性 font-weight: bold; 作用。
* <u> 标签加下划线
* <em> 加斜体
* <hr> 加横线
* 所有的 CSS 属性设置后都必须添加分号。
* position: relative
* 让元素脱离当前的文档流,但盒子原先占据的位置还在,适合做微调。
* float 属性把当前元素推出文档流。
* z-index 属性可以调整元素和元素之间在 z 轴上的位置
================================================
FILE: Front-end/vue-context-mune.md
================================================
# 使用 Vue 实现 Context-Menu 的思考与总结
## 简介
先来看最终成果:
操作逻辑为:
* 点击 `...` 弹出 `context-menu`;
* 点击非 `context-menu` 区域,隐藏 `context-menu`;
* 点击 `context-menu` 中的任何一个选项,隐藏 `context-menu`;
## 思考
项目是基于 `vux` 做的,本想着偷懒直接在 `vux` 库翻组件用,但看了一圈下来,居然这么通用的组件在 `vuex` 中没有!接着又去翻开源的解决方案,看了几个库还算 ok,但此时前端小哥来了,说实现这个菜单不需要用到这么重的东西,直接写就行了。
当时我的脑海中在思考了把 `context-menu` 封装成一个 `component`,通过数据配置的方式动态拓展菜单选项。但没想到前端小哥直接给我干了回来,没必要进行封装,这个组件对页面依赖性太强,就算封装完了下次也不一定能直接用,PM 的思路十分清奇。
所以,最后的做法就直接硬上了。
## 实现
### 调整操作逻辑
该页面是一个通俗意义上的列表展示页,使用了 `vux` 的 `swipeout` 表单组件,给用户提供了侧滑操作,需要把原先写好的侧滑功能删除。
### 调整 UI
在调整 UI 的过程中我感到了 CSS 满满的恶意,当然说是这么说,但实际上还是因为太久没有用而导致的不够熟悉。非常费劲的终于调整了好了新 UI,此时已经过去了整整一天了,非常怀念 `autoLayout`。
### context-mune
在正式开始写之前,上文已经说了我一直在翻开源库,主要是不懂得如何下手去,因为距离上一次写 `vue` 已经过去了快两个月了,而且也没搞清楚如何写一个组件,所以中间也有一段时间浪费在了这个上。最后的解决思路让我感到意外:
```vue
<div class="more-menu-wrapper">
<ul v-show="item.showOption">
<li>更换分类</li>
<li>向上移动</li>
<li>移至顶部</li>
<li>取消收藏</li>
</ul>
</div>
```
没想到使用无序列表就可以完成了~在 iOS 中,我会在 `UITableView` 和 `UIStackView` 中纠结。当然只有这样是不行的,当又调整了 UI 后,发现 `...` 和 `context-menu` “融合”在一起了,没有设计图中的“悬浮”效果,最后的解决方法是:
```css
.more-wrapper {
/* ... */
position: absolute;
.more-menu-wrapper {
position: relative;
/* ... */
}
}
```
当继续调整 CSS 时又发现 `context-menu` 的会被其父组件挡住,`context-menu` 的显示范围会限制与其父组件的显示高度,最后得知是 `overflow` 这个属性在最底层的父组件中设置了 `overflow: hidden;`,删除掉,使其为默认的 `visible` 即可显示为 `context-menu` 高度溢出的效果。
### 事件绑定
UI 都调整完后开始绑定事件。因为只是改造 UI,并没有涉及到多少的新逻辑,所以很快的就写出了以下代码:
```vue
<ul v-show="item.showOption">
<li @click="moveItem(item)">更换分类</li>
<li @click="moveUp(item)">向上移动</li>
<li @click="setTop(item)">移至顶部</li>
<li @click="deleteItem(item)">取消收藏</li>
</ul>
```
`context-menu` 的显示依赖 `v-show`,当页面首次拉取到网络数据时,`data` 中对每个 `listData` 的 `item` 新增了 `context-menu` 显示隐藏的初始化标志位 `item.showOption = false`,且在这四个入口方法中都控制了 `item.showOption` 的改变:
```js
//...
moveUp(item) {
item.showOption = false;
// ...
}
//...
```
刷新页面,很愉快的看到了 `context-menu` 的显示,但在点击菜单选项时没有任何反应!一开始以为是标识位的问题,但看来看去没有任何问题哇~本来想去找前端小哥看一眼,但一直不在工位上,最后问了下同组的前端实习生,他认为是 `item.showOption` 字段在数据更新时没有加上,导致后续直接读取时不存在。
但我其实一直纳闷如果 `item.showOption` 字段数据不存在的话,那第一次的页面渲染实际上是有错误的。我们两个人看了一会也没发现具体是哪有问题,最后只能四处寻找前端小哥,没想到他已经被封闭起来做商业化了,我说怎么四处找不到人。
前端小哥在文件中加上了 `debugger` 进行调试,发现进入到 `moveUp` 等一类事件时虽然 `item.showOption` 被修改成功了,一旦出去事件周期外,又被改回去了。
最后发现,问题出在被**冒泡**到了父组件中,调用了 `...` 所绑定的 `onMore` 事件中,而在 `onMore` 事件中 `item.showOption = true`,所以实际上是执行了 `context-menu` 和 `...` 的两者所绑定的事件。解决的方法是:
```vue
<ul v-show="item.showOption">
<li @click.stop="moveItem(item)">更换分类</li>
<li @click.stop="moveUp(item)">向上移动</li>
<li @click.stop="setTop(item)">移至顶部</li>
<li @click.stop="deleteItem(item)">取消收藏</li>
</ul>
```
使用 `@click.stop` 来阻止冒泡事件。解决完问题后,前端小哥还好奇我做 iOS 怎么会不知道冒泡事件的问题,但实际上在 iOS 中跟前端的思路完全是反过来的。iOS 的事件响应链是逐级传递到子组件中,也就是向下传递,而不是像前端中的向上传递。所以在遇到这个问题时也就完全没有往冒泡的方面去思考。
### 触摸其它区域消失 `context-menu`
在 iOS 中,我会直接封装出一个带有 `UIWindow` 的组件。与 `context-menu` 有关的所有操作与主 `window` 没有任何关系,更别说事件穿透了。所以最终我的做法是多加了一个遮罩层,显示和隐藏的时机与 `context-menu` 的时机保持一致。
最后在我拿着最终的成果去找前端小哥复查时,他对这个做法不满意,还是觉得要使用 `outside-click` 的做法。也就是使用 js 中的事件代理,通过 `e.targe` 去判断。最后找到了可以使用 [`v-outside-click`](https://github.com/ndelvalle/v-click-outside) 进行。`v-outside-click` 有两种引入的方式,为了简洁,我选择了“指令”的方式引入。
在使用 `v-outside-click` 这个库的过程中遇到了一个比较大的问题。`v-outside-click` 此库给我的感觉是用于单个组件,而不适用于多个组件。列表中的每一个 `cell` 都需要带上一个单独的 `context-menu`,如果给每一个 `context-menu` 都绑上一个单独的 `outside-click` 事件,一旦用户的触摸范围不在 `context-menu` 中,则视图上的所有 `context-menu` 都会响应这个 `outside-click` 事件,列表数据一旦多起来,事件响应次数将线性增长。
这个问题跟前端小哥说过后,他说问题不大,那就这样吧~接下来的问题就到了怎么在 `outside-click` 事件中标识出是哪个 `context-menu` 需要隐藏呢?刚开始就按照了以往的套路,直接使用了如下所示的方式:
```html
<div v-click-outside="onClickOutside(item)">
<!-- ... -->
</div>
```
然后开心看到了报错 `Binding value must be a function or an object`。提示需要传入一个方法?!翻了源码后发现了这么一段:
```js
function processDirectiveArguments(bindingValue) {
const isFunction = typeof bindingValue === 'function'
if (!isFunction && typeof bindingValue !== 'object') {
throw new Error('v-click-outside: Binding value must be a function or an object')
}
// ...
}
```
回过头去看之前写的代码,没有问题啊!思来想去还是没弄明白,又去找了前端小哥请求帮忙,经过了一番折腾了,他的结论是这个库应该是有问题的。最后采取的解决方法是:
```html
<div v-click-outside="onClickOutside">
<p>…</p>
<!-- 重点 -->
<div :id="item.metricId" v-show="item.showOption">
<ul>
<li>更换分类</li>
<!-- ... -->
</ul>
</div>
</div>
```
```js
onClickOutside (event, el) {
let queryInstance = el.querySelector('.more-menu-wrapper')
if (queryInstance) {
let metricId = el.querySelector('.more-menu-wrapper').id;
if (metricId != "") {
this.listData.some((item) => {
if (item.metricId == metricId) {
item.showOption = false;
return true;
}
});
}
}
}
```
通过设置 `context-menu` 的 `id` 作为标识,然后在 `v-outside-click` 的指令方法中获取 `id`,通过这个 `id` 去数据源中找到对应的 `item`,从而设置 `item.showOption = false` 来隐藏 `context-menu`。
## 总结
这算是转大前端完成的第一个功能吧,因为不熟悉导致中间出现了一些好玩的事情。客户端和前端的开发流程说大也不大,但要是说没有是绝对不可能的。在一些小的问题上,没有踩过坑或者没有大佬带一带,真的会爬不起来或者就弃坑了,说到底其实还是需要多加学习啊!前端有时候真的挺香的。
================================================
FILE: Front-end/前端学习.md
================================================
## https协议的主要作用是:建立一个信息安全通道,来确保数据的传输,确保网站的真实性。
## TCP和UDP的区别
* TCP是面向连接的,UDP是无连接的即发送数据前不需要先建立链接。
面向连接基于电话系统模型,而面向无连接则基于邮政系统模型。相对于面向连接的建立连接的三个过程,面向无连接只有“传送数据”的过程。
* TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付。 并且因为tcp可靠,面向连接,不会丢失数据因此适合大数据量的交换。
* TCP是面向字节流,UDP面向报文,并且网络出现拥塞不会使得发送速率降低(因此会出现丢包,对实时的应用比如IP电话和视频会议等)。
* TCP只能是1对1的,UDP支持1对1,1对多。
* TCP的首部较大为20字节,而UDP只有8字节。
* TCP是面向连接的可靠性传输,而UDP是不可靠的。
## 一个图片url访问后直接下载怎样实现
浏览器会通过头信息进行判断,一旦没有找到头信息浏览器则根据自己的既定规则进行解析。如果浏览器能识别该文件,则会以相应的方式显示该文件;如果浏览器不能识别该文件,则会弹出下载保存窗口供用户进行下载保存。
参考文章:[https://blog.csdn.net/qq_39759115/article/details/78611732](https://blog.csdn.net/qq_39759115/article/details/78611732)、[https://scarletsky.github.io/2016/07/03/download-file-using-javascript/](https://scarletsky.github.io/2016/07/03/download-file-using-javascript/)
## 一句话概括RESTFUL
就是用URL定位资源,用HTTP描述操作
## COOKIE和SESSION有什么区别?
Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
1,session 在服务器端,cookie 在客户端(浏览器)
2,session 默认被存在在服务器的一个文件里(不是内存)
3,session 的运行依赖 session id,而 session id 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,同时 session 也会失效(但是可以通过其它方式实现,比如在 url 中传递 session_id)
4,session 可以放在 文件、数据库、或内存中都可以。
5,用户验证这种场合一般会用 session 因此,维持一个会话的核心就是客户端的唯一标识,即 session id
参考文章:[https://www.zhihu.com/question/19786827](https://www.zhihu.com/question/19786827)
## click在ios上有300ms延迟,原因及如何解决?
* 粗暴型,禁用缩放
`<meta name="viewport" content="width=device-width, user-scalable=no"> `
* 利用FastClick,其原理是:
检测到touchend事件后,立刻出发模拟click事件,并且把浏览器300毫秒之后真正出发的事件给阻断掉
## `<span>` 的妙用
因为 `<span>` 标签是内联元素不是块级元素,不会破坏文档流,可以做一些 JS hook。
================================================
FILE: Front-end/图解HTTP学习笔记.md
================================================
这是我在学习《图解HTTP》这本书时做的笔记,可能有些凌乱,会加入自己的一些思考和之前计网课上已习得的内容。
### 第一章:了解Web及网络基础
1. 通过发送请求获取服务器资源的Web浏览器等,都可称为客户端。
2. **CGI**:通用网关接口,用于处理动态请求内容,根据参数找程序显示出内容。
3. 通常使用的网络(包括互联网)是在 TCP/IP 协议的基础上运作 的。而 **HTTP属于它内部的一个子集**。
4. **应用层**:应用层决定了向用户提供应用服务时通信的活动。
**传输层**:传输层对上层应用层,提供处于网络连接中的两台计算机之间的数据传输。
**网络层(又名网络互连层)**:网络层用来处理在网络上流动的数据包。数据包的网络传输的最小数据单元。该层规定了通过怎样的路径到达对方计算机,并把数据包传送给对方。与对方计算机之间通过多台计算机或网络设备进行传输时,网络层所起的作用就是在众多的选项内选择一条传输线路。
**链路层(又名数据链路层,网络接口层)**:用来处理连接网络的硬件部分。包括控制操作系统、硬件的设备驱动、NIC(网卡)及光纤等物理可见部分(还包括连接器等一切传输媒介)。硬件上的范畴均在链路层的作用范围之内。
5. 利用TCP/IP协议族进行网络通信时,发送端从应用层往下走,接收端则从应用层往上走。
6. 传输层把从应用层处接收到的数据(HTTP请求报文)进行**分割**,并在各个报文上打上标记序号及端口号后转发给网络层。
7. 在网络层(IP协议),增加作为通信目的地的**MAC地址**后转发给链路层。
8. 发送端在层与层之间传输数据时,每经过一层时必定会被打上一个该层所属的首部信息。反之,接收端在层与层传输数据时,每经过一层时会把对应的首部消去。这种把数据信息包装起来的做法称为**封装**。
9. 负责传输的IP协议。IP协议的作用是把各种数据包传送给对方,其中两个重要的条件是**IP地址**和**MAC地址**。IP地址指明了节点被分配到的地址,MAC地址是指网卡所属的固定地址。IP地址可以和MAC地址进行配对。**IP地址可以变换,但MAC地址基本上不会更改**。
10. 使用ARP协议凭借MAC地址进行通信。IP间的通信依赖MAC地址。在进行中转时,会利用下一站中转设备的MAC地址来搜索下一个中转目标,此时会采用ARP协议,ARP协议是一种解析地址的协议,根据通信方的IP地址就可以反查出对应的MAC地址。
11. 确保可靠性的TCP协议。TCP位于传输层,提供可靠的字节流服务。字节流服务是指,为了方便传输,将大块数据分割以报文段为单位的数据包进行管理,而且TCP协议能够确认数据最终是否送达到对方。采用**三次握手**。
12. 负责域名解析的DNS服务。它提供域名到IP地址之间的解析服务,通过域名查找IP地址,或逆向从IP地址反查域名。
================================================
FILE: Game/Cocos/basic.md
================================================
# Cocos 基础知识点
## 布局
### 约束
之前在做“方块弹球”时没考虑好多屏幕适配的问题,导致在 Android 上玩时会出现黑边。如果想要对的组件进行约束,可以选择**像素值**或**百分比**进行约束,如下图所示:
================================================
FILE: Graphics/app.md
================================================
## 多媒体工具
### Pr
通过 Creative Creator 下载的 pr 版本需要跟随购买时所选择的国家授权,中国大陆只认简体中文,选择英文后下载的 pr 授权无法获取,太操蛋了。
### Ae
同上,需要在系统设置中手动修改 app 语言为简体中文后才可打开。
================================================
FILE: Graphics/metal.md
================================================
## Metal
* 标准化:提供面向 3D 图像和数据并行化计算范式。
* 更底层:提供更底层的 API 访问 GPU。
* 低开销:通过提供多线程计算和预编译资源来降低运行时消耗。
除了以上所说,Metal 不但使用了大量的 GPU 并行计算的能力来进行数据可视化或做数学计算,还可定制化于机器学习、图片和视频处理或图形图像渲染。
WWDC14 推出基于 C++11 的 MSL(Metal Shading Language)。
GPU 的优化方向是“在单位时间内可以处理多少数据”,而 CPU 的优化方向是“处理单个数据需要花费多少时间”。
### 基础知识
#### 渲染流程
**什么是渲染?**
在 3D 计算机图形学下,把一堆点汇集在一起创建出一副图像,这个图像就被称为渲染。

### 文章链接
- [Metal - Apple](https://developer.apple.com/documentation/metal)
- [Metal 语法说明](https://xiaozhuanlan.com/star)
- [iOS 图像处理](https://xiaozhuanlan.com/colin)
### 代码链接
- [LearnMetal](https://github.com/loyinglin/LearnMetal)
- [Metal-Practice](https://github.com/colin1994/Metal-Practice)
================================================
FILE: History/2_Apple_History.md
================================================
# Apple history
苹果公司,截止到2017年5月25日为止,市值首次突破8000亿美元大关,达历史最高位。笔者估计乔帮主一定不会想到当初他和沃兹尼亚克一同在家里的车库创造出来的苹果会达到今天这种高度。
苹果公司可以说是一个极具传奇色彩的企业,不但创始人乔帮主是奇葩,整个公司上下都充满了奇葩的气氛。为什么要说乔帮主是个奇葩呢,关于奇葩的定义大家各有所见,但是笔者在此所说奇葩绝对是个褒义词。如果大家有阅读过一些关于乔帮主的书,那么或多或少都会知道关于乔帮主为人处世的一些东西,一千个读者就会一千个哈姆雷特,所以很多人在阅读这类书籍时,很容易就会产生误解。市面上的很多书籍为了达到宣传的效果,把乔帮主宣传得上天入地无所不能,与乔帮主一起开创苹果公司的沃兹尼亚克前段时间出来澄清了,他和乔帮主其实并未在位于洛思阿图斯的车库里进行创业,在接受《外电》采访时,沃兹尼亚克称:“外界对那间车库知之甚少,而媒体对它也过分渲染了。那个车库虽然最能够代表我们的初期创业,但是我们在那没做任何设计工作。我们将已组装好的产品运到车库,确保它们能用,然后我们再把这些电脑运到商店拿钱。”
沃兹尼亚克解释称,羽翼丰满的苹果很快就离开那间车库了。他还补充,“那个车库很少同时有超过两个人,并且大多数情况是,他们呆在那闲晃,什么也不做。”,不过人们都希望听到些附有传奇色彩的创业故事,最好是能够拍成电影那种,尽管这会有些失真
微软和苹果真的是对欢喜冤家。乔帮主一直都很憎恨盖茨盗取了他在Lisa OS上的图形界面设计,不过乔帮主的这种图形界面的人机交互操作方式好像也是在参观施乐的帕洛阿尔托研究中心时看到了一款早期的操作系统版本,之后产生了图形用户界面的创意。关于谁才是图形界面的发明者,微软、苹果和施乐打了近六年的官司,最后法院把这场官司给打回原告了,具体原因笔者一直没找到确切的相关资料,不过现有的一种说法是,最高法院也无法做出谁才是最终的图形界面发明者。
还有这么一件趣事,乔帮主一直都对Android怀恨在心,曾经落下狠话:“如果有必要的话,我愿意耗尽最后一口气,花掉苹果公司存在银行里的400亿美元,一定要纠正这个错误……我要毁掉安卓,因为它是一件剽窃产品,我将为此发动热核战争。”。Android之父Andy Rubin原本可是想把Android用在数码相机上的,直到iPhone的出现,才让Andy Rubin意识到移动设备的潮流已经非常清晰,数码相机的市场还不够大。
其实对于乔帮主这种独特的性格和气质,很多人如果不能理解的话,是非常痛苦的。比如在苹果公司工作的工程师们,很多次都向公司高层管理人员抱怨过乔帮主那奇怪的性格,他是那种喜欢直接指挥的管理者,他经常直接过问员工的具体工作,而且又总是朝令夕改,让员工感到无所适从,不少人跑去和高管们抱怨。但正是因为乔帮主这种独特的性格,才让苹果公司推出了这么多激动人心的产品。关于乔帮主在1985年因为他特立独行的性格导致了被公司董事会集体卸下CEO的职务,关于这方面的内容网上有非常多的资料,大家可以自行网上查找。
苹果公司董事会看不惯乔帮主的这种挥霍资金的做法,强烈要求他交出管理权力,由“更具经验”的职业经理人来操盘苹果公司,而乔帮主唯一争取到的权力,就是这个信任CEO的候选名单可以由他来提供。这个CEO候选人就是当时被乔布斯一语“Do you prefer to sell sugar water for the rest of your life or come with me and change the world?”击中要害的约翰·斯卡利。
斯卡利在乔帮主离开苹果公司后的担任CEO期间,为了增收营业额,还做了很多悲剧的事情。他曾一度让苹果公司进入了服装、家居、生活甚至是玩具市场,并且生产制造出了大量的商品成品。
公允的说,约翰·斯卡利并非一无是处的蠢货,只是这个不太适合苹果的家伙,被阴差阳错的放到了苹果公司掌舵人的位置上——事实上,除了乔布斯以外,可能全世界都没剩下几个人能够挽救当时的苹果——如今,约翰·斯卡利创办并经营着一家情况不错的投资公司,主要关注于可穿戴设备领域,我们也祝他一切顺利。
<div align="center">
<img src="images/斯卡利.jpg" width = "50%" height = "50%" align=center />
</div>
// 上图就是约翰·斯卡利在对着镜头演示其最新投产的智能手环产品Misfit,只支持连接iOS系统。“Misfit”这个名称就来自乔布斯及苹果公司最著名的广告《不同凡响》中:“Here’s to the crazy ones. The misfits(致那些疯狂的人们,那些与众不同的人)”。
推荐大家几个关于苹果公司和乔布斯的资料,仅供参考:
1、[乔布斯传](http://list.youku.com/show/id_z1eaf3b7c404c11e2b16f.html?tpa=dW5pb25faWQ9MTAzNzUzXzEwMDAwMV8wMV8wMQ)
2、[成为乔布斯(Kindle)](http://pan.baidu.com/s/1jIKEM7k)
**以上内容部分来自网络**
================================================
FILE: History/3_Mac_OS_X.md
================================================
# macOS(Mac OS X)
关于macOS系统笔者认为除了计算机相关或者工作需要的小部分同学外,剩下的大部分人还是对它不是很了解。估计这个不了解也是来源于macOS目前在全球市场份额太小的原因所致,因其高昂的价格挡住了非常多的人购买它的欲望。反观国内,说起Windows大家就一点都不陌生了,上个世纪首先打入国内个人电脑市场的操作系统就是Windows(DOS是最早进入中国市场,而不是进入国内个人电脑市场),毕竟先入为主的优势让很多人习惯了去使用Windows。习惯了Windows系统的操作习惯后,再去切换另外一个新的操作系统使用的话,这成本有点高,而且大家想想,Windows操作系统在上个时间80年代引入中国,那段时间能使用上个人电脑的现在都已经快四十岁了,快四十岁的人,如果不是从事计算机专业的相关工作,他已经很难去学习一种新的操作方式了(macOS和Windows的使用习惯上还确实是有很多不一样的地方),当然不可否认,也确实是因为有了Windows的授权安装在各种品牌的电脑上,才让全国甚至全世界快速的迈进了信息时代。
**一.最早期Mac OS**
**1. System 1-6**
<div align="center">
<img src="images/macOS1.jpg" width = "70%" height = "70%" align=center />
</div>
1984年的苹果发布了其第一台Mac个人电脑,与其一起发布的操作系统当时被简单的称为System Software,第一代System 1打破了字符终端的模式,最早使用图形界面和用户交互设计:基于窗口操作并使用了图标,鼠标可以在屏幕上进行移动,并可以通过拖拽来拷贝文件及文件夹。这让它成为图形界面设计的先驱,但后续直到System 7界面始终没有大改变。
**2. System 7**
<div align="center">
<img src="images/macOS2.jpg" width = "70%" height = "70%" align=center />
</div>
1991年的System 7开始引入彩色,图标也增加了隐约的灰色,蓝色和黄色阴影。但Mac OS整体界面却始终没有显著的变化。与此同时微软家的Windows从黑屏的DOS到全屏幕的Windows 1,再到成熟的Windows 3,最后演变到奠定当今Windows界面基础的炫丽多彩的Windows 95。用当时的眼光来看,这个变化是相当惊人的。而Mac OS因为因循守旧,在界面设计上从领先掉到了最后。
另外从System 7的7.6版本开始被苹果公司改名为Mac OS ,这一年是1997年。
**3. Mac OS 8**
<div align="center">
<img src="images/macOS3.jpg" width = "70%" height = "70%" align=center />
</div>
1997年,苹果发布的Mac OS 8开始加入更多的颜色,默认支持256色的图标,并较早的采用了等距风格图标,也称伪3D图标,但整体界面变化依旧不大。
**二. NeXT附体**
<div align="center">
<img src="images/macOS4.jpg" width = "70%" height = "70%" align=center />
</div>
已经有十年历史的Mac OS已经遇到了瓶颈限制,为了让Mac OS现代化内部做了一番尝试和舍弃后,最后决定收购NeXT,因为不仅可以带来用户界面的变化,还可以使整个系统设计的全盘革新。
买完NeXT后,乔布斯回来了,“你们就是一群白痴!”他把所有团队的人叫到一个房间里以乔布斯风格把所有地方都骂了一遍,之后包括拉茨拉夫在内的设计师们的日子便越来越难熬了。
注:拉茨拉夫,当时Mac OS人机界面设计负责人
**三. 过渡OS X**
**1. Rhapsody**
<div align="center">
<img src="images/macOS5.jpg" width = "70%" height = "70%" align=center />
</div>
1997年苹果发布了过渡时代的Rhapsody,整合了Mac OS 8的外观与NeXT-based界面,它是介于NeXT以及Mac OS X之间的操作系统,也可以理解为是套了壳的NeXT操作系统。
而代号Rhapsody是依循苹果在1990年代以音乐名词作为操作系统代号的模式所命名的,其他代号包括Harmony \(Mac OS 7.6\),Tempo \(Mac OS 8\),Allegro \(Mac OS 8.5\)及Sonata \(Mac OS 9\)。
**2. Mac OS 9**
<div align="center">
<img src="images/macOS6.jpg" width = "70%" height = "70%" align=center />
</div>
1999年发布,是乔布斯宣布过渡到Mac OS X阶段路线上最后一个Mac OS系列。
**3. Mac OS X Server 1.0**
<div align="center">
<img src="images/macOS7.jpg" width = "70%" height = "70%" align=center />
</div>
1999年3月苹果发布Mac OS X Server 1.0,即第一个版本的Mac OS X开发者预览版,它是苹果第一个真正基于NeXT的操作系统,和Rhapsody很像。
**四. 早期Mac OS X**
**1. OS X公开测试版**
<div align="center">
<img src="images/macOS8.jpg" width = "70%" height = "70%" align=center />
</div>
2000年9月发布,在这个版本中全新的用户界面Aqua初次亮相。另外它也是所有Mac OS中惟一一个将苹果菜单置于屏幕顶部中央的版本,这个修改因饱受用家诟病而在Mac OS X 10.0中被恢复。
注:Aqua是Mac OS X的GUI商标名称。
**2.OS X 10.0 Cheetah猎豹**
<div align="center">
<img src="images/macOS9.jpg" width = "70%" height = "70%" align=center />
</div>
2001年3月,经历了四个开发者预览版和一个公共测试版之后的Aqua界面终于跟随10.0正式发布,发布后改变了人们对计算机界面的印象,在随后的10年里苹果一直沿用这套界面风格。
另外伴随Aqua一起来的还有苹果一整堪称经典的套拟物化的图标,也是一直基本持续沿用到现在,以及一个全新的方式组织Mac OS X应用程序的用户界面:Dock栏,以及组成Aqua界面的那些细节:菜单、按钮、进度条、滚动条等等,其中一根看似简单得不能再简单的滚动条,就耗费了苹果设计组整整六个月。这些都影响了整整一代图形界面设计者。
One more thing,从Mac OS X苹果开启了以猫科动物系列为代号的命名史。
**3. OS X 10.1 Puma美洲狮**
<div align="center">
<img src="images/macOS10.jpg" width = "70%" height = "70%" align=center />
</div>
OS X 10.0半年后即2001年9月,苹果就推出了OS X 10.1美洲狮,没有新增太多功能,主要聚焦于改善系统表现。
**4. OS X 10.2 Jaguar美洲豹**
<div align="center">
<img src="images/macOS11.jpg" width = "70%" height = "70%" align=center />
</div>
2002年8月发布,在这一版本中Aqua界面的装饰风格达到新高峰:窗口背景底纹,非活动窗口标题栏半透明、滚动条的抽空效果。另外也是从这个版本有了新的起始画面和新的苹果标志,过往Happy Mac的标志不再出现,取而代之的是如今那颗被偷咬了一口的苹果。
**五. 进化Mac OS X**
Aqua的衰退,这种变化事实上从OS X 10.3 Panther就开始了。
**1. OS X 10.3 Panther黑豹**
<div align="center">
<img src="images/macOS12.jpg" width = "70%" height = "70%" align=center />
</div>
2003年10月发布,在这一版本Aqua界面引入了新的Brush风格,即金属拉丝质感,并在最常用的Finder上使用。
**2. OS X 10.4 Tiger老虎**
<div align="center">
<img src="images/macOS13.jpg" width = "70%" height = "70%" align=center />
</div>
2005年4月发布,顶栏最右侧新增了一个蓝色的Spotlight搜索按钮。
**3. OS X 10.5 Leopard豹**
<div align="center">
<img src="images/macOS14.jpg" width = "70%" height = "70%" align=center />
</div>
2007年10月发布,用户界面上改进幅度比较大的一个版本,虽然基本的界面仍为Aqua和其糖果滚动条,但新加入了一些铂灰色和蓝色,另外重新设计的3D Dock和更多的动画交互使得新界面看上去3D效果更强,此外还改进了Finder、半透明菜单条并新增了最初只用于iTunes的Cover Flow界面。
整体来说这一版本的界面相比之前有了翻天覆地的变化。
**4. OS X 10.6 Snow Leopard雪豹**
<div align="center">
<img src="images/macOS15.jpg" width = "70%" height = "70%" align=center />
</div>
2009年8月发布,就像雪豹的名字,只比豹多了个雪字,它是以OS X 10.5的版本为基础跟进开发的,不过OS X 10.6还跑去向iOS偷师,引进了Mac App Store即应用商店。
**六. 现代Mac OS X**
**1. OS X 10.7 Lion狮子**
<div align="center">
<img src="images/macOS16.jpg" width = "70%" height = "70%" align=center />
</div>
2011年7月发布,重新设计了Aqua GUI元素、按钮、进度条、滚动条(不使用时会自动隐藏)以及“滑动切换”的选项卡,全新设计了拟物化iCal界面,新的通信录和邮件应用都使用了类似iPad的界面。此外还引进了像iOS那样的应用启动器Lauchpad界面。
**2. OS X 10.8 Mountain Lion美洲狮**
<div align="center">
<img src="images/macOS17.jpg" width = "70%" height = "70%" align=center />
</div>
2012年7月发布,和Lion同样的的风格,更多类iPad及iOS的功能界面被引入(一些内置应用程序甚至被更名以与iOS保持一致),整体界面变化不大。
**3. OS X 10.9 Mavericks**
<div align="center">
<img src="images/macOS18.jpg" width = "70%" height = "70%" align=center />
</div>
2013年10月发布,可以说是近期苹果的突破之作,界面上它看起来则更像是OS X 10.6的继承者,OS X 10.7和OS X 10.8里面的拟物化设计在OS X 10.9中被移除。
另外从这一版本苹果不再以动物命名Mac OS X,取而代之的是加州地名,如Mavericks就是加州某个冲浪景点。
**4. OS X 10.10 Yosemite优胜美地**
<div align="center">
<img src="images/macOS19.jpg" width = "70%" height = "70%" align=center />
</div>
2014年10月发布,苹果历年来变化最大的操作系统,包括趋于扁平化的界面风格、类似iOS7的图标设计、半透明导航栏及全新字体设计等。
**5、至今**
在去年的WWDC大会上Mac OS X正式更名为macOS,同时也在当年的WWDC上把所有的平台的名字都变成了统一的风格。进入到macOS后界面上还是没有多大的变化,不过,比界面上的变化更大的变化那就是苹果把文件管理系统换成了APFS,升级成功后就多了好几个G。这不得不说是一个很大的进步,非常大的进步。
推荐一本关于macOS的书:[Mac OS X背后的故事](http://pan.baidu.com/s/1bp1Wn9P)
**以上内容部分来自网络**
================================================
FILE: History/4_iOS.md
================================================
# iOS(iPhone OS)
iOS,经历了十年的发展,现在已经发展为移动操作系统家族中不可或缺的一员。从当初iPhone Runs OS X到现在最新的iOS 10,乔帮主改变了世界,改变了我们对移动设备的看法。说实话,在iOS发展到现在的这十年间,曾经无比辉煌的功能机厂商一个接着一个倒在了移动浪潮之中,就算是有微软这个好爹的Windows phone也即将与我们告别。
先不说这是否合情合理,但就从市场占有率上来说,Android和iOS两家已经把整个移动设备的操作系统占了绝大部分,留给后来者的份额微乎其微,相当于没有。但是就算这样,当初的Windows phone最高全球市场占有率也没达到3%,黑莓更不用说了,在全球每一个国家,黑莓的占有率都不足0.5%,翻身是基本不可能的了。
通过Android和iOS这几年的发展,双方互相吸收优点,互相成长。现在基本上已经不可能有任何一个操作系统能够达到这种高度。前段时间,Android全球设备拥有量正式超过Windows,成为全球用户量最大的操作系统,可见当前的移动操作系统是多么受人们欢迎。
在这十年中,iOS不断的向前发展,不断的推陈出新。App Store 2.0已经把与开发者原先三七分成的比例改成了1.5:8.5,这对我们开发者来说是一个巨大的好处。iOS的生态环境正在变得越来越好,用户的操作习惯这几年被逐渐的固化下来,这对我们来说是一个好消息,因为这不会像iPhone刚推出那会儿,所有厂商并且好包括大部分消费者都在嘲笑iPhone的操作方式,但是iOS和iPhone相辅相成发展到今天,已经给世人一份最好的答卷。苹果在完成这份答卷的过程中,苹果公司做出了很多不为人知的努力,相关内容可以参考[这篇文章](https://www.zhihu.com/question/39684892)。
接下来,我们来看看在iOS发展的这十年中都经历了哪些变化
**iPhone Runs OS X——革命的开始**
2007年1月的MacWorld大会上乔布斯发布了苹果的第一款手机,当时iOS系统还没有一个正式的名称,只是被叫做iPhone Runs OS X。全世界的同行都觉得这是一个笑话,一个不能更换铃声和壁纸,不能运行后台程序,甚至根本没有第三方应用的手机,怎么好意思被称作“智能手机”?
<div align="center">
<img src="images/iOS1.png" width = "50%" height = "50%" align=center />
</div>
但一向擅长创新的苹果公司还是让我们见到了许多新奇的玩法,像3.5英寸480\*320分辨率的大屏幕、多点触控的交互方式以及从未见过的简洁UI,都颠覆了人们对于传统意义上手机的认识。尽管iPhone的出现起初只是为了挽救在当时急剧萎缩的iPod市场,但苹果也许自己都没有想到,这一部手机将会引起巨大的行业革命,颠覆整个市场的格局。
**iPhone OS 2.0——生态坏境初建成**
在iPhone OS诞生初期,还没有应用商店可供下载第三方的应用程序。乔布斯在当时鼓励开发者开发网页应用而不是原生应用,导致在当时应用程序质量不高,功能有限。直到几个月后,苹果改变了主意,并在2008年3月发布了第一款iOS软件开发包。并在当年7月推出App Store,这是iOS历史上的一个重要里程碑,它的出现开启了iOS和整个移动应用时代。
<div align="center">
<img src="images/iOS2.png" width = "50%" height = "50%" align=center />
</div>
收入三七分成的制度和良好的生态环境迅速吸引了大量开发者。很快,iPhone几乎变成了一款“万能”的手机:量角器,水平仪,游戏机,其中还不乏一些相当具有逼格的“喝啤酒”,“吹蜡烛”等游戏。并且在此后的几年中苹果不停地完善App Store的功能。直到现在,App Store里的应用数量都是苹果自己最值得骄傲的地方之一。
**iPhone OS 3.0——再度完善**
iPhone OS 3.0更像是填补前两代系统的空白。例如键盘的横向模式、新邮件和短信的推送通知、彩信、数字杂志,以及最初的语音控制功能,能够帮助用户寻找/播放音乐以及调用联系人,还有最重要的复制粘贴功能。实际上在前两代系统中,人们在用惯比较成熟的塞班系统后,iPhone OS系统还是存在诸多差异或者不便,尽管在当时人们看来iPhone提供了一种新奇的使用体验。
<div align="center">
<img src="images/iOS3.png" width = "50%" height = "50%" align=center />
</div>
但在3.0版本中对着些缺失的功能进行补齐之后,iPhone的实用性也大大增强了。随后,在2010年4月,苹果发布了iOS 3.2。iOS 3.2是一次划时代的演变,因为这是第一款针对“大屏”iPad平板优化的移动系统。
**iOS4——高颜值模式开启**
iPhone OS操作系统在这一代正式更名为iOS。iOS 4是前四代iOS系统中外观改善最大的一代操作系统,乔布斯及其设计团队为界面上的图标设计了复杂的光影效果,让让界面看上去更加漂亮。
<div align="center">
<img src="images/iOS4.png" width = "50%" height = "50%" align=center />
</div>
Game Center是我们看到的第一个变化很大的例子。它的界面颜色丰富,绿色、酒红色、黄色等,上下底部则是类实木设计。正是在这一版系统中,“skeuomorphic(仿真拟物风格)”开始完善起来。不仅如此,界面可切换壁纸终于被带进了iOS。苹果还在iOS 4中加入了文件夹功能,全新亚麻质地背景的文件夹中,用户可以存放相关应用内容。
甚至还可把这个图标放入底部的Dock,不失为一个非常实用的功能。此外还带来全新的多任务处理新功能。通过双击Home键,用户会在屏幕底部看到一排常用应用程序列表。有了它,用户无需翻页,便能快速地在应用间切换。当然除了操作系统之外,与iOS4同期的iPhone4也是前所未有的漂亮,首次引入了前后双玻璃的设计,厚度也仅有9.2mm,创下了全球最薄智能手机的记录。
iPhone4被认为是乔布斯最经典的杰作之一,也是乔帮主临终前最后一部杰作。至少在大众审美的角度,iPhone4在当初的市场上当之无愧的成为颜值最高的手机,供不应求的现象屡见不鲜。
**iOS5——你好,Siri**
界面与iOS 4基本相同的iOS 5,为苹果用户带来了一项非常重要的新功能:Siri。尽管最初被批功能有限,但这是苹果第一次尝试让用户以不同的方式使用自己的iOS设备,并将Siri打造成为iOS中的个人助理服务,从此以后,调戏Siri就成了iPhone 4S用户的一大乐趣。
<div align="center">
<img src="images/iOS5.png" width = "50%" height = "50%" align=center />
</div>
仿真拟物设计在iOS 5中可谓达到了极致,苹果的软件界面中大量模仿现实世界中的实物纹理,例如,黄色纸张背景的“备忘录”和亚麻纹理的“提醒”应用。通知中心也在此版本中被引入了,用户从此不再需要从icon的角标中寻找通知了。iOS5时代还有一项重大的改变:App Store终于支持人民币支付了。
在App Store必须使用VISA和万事达信用卡的时候,越狱成了很多用户安装收费软件的唯一办法。而这一状况终于在iOS5时代得到改善,App Store支持网银转账充值了,我不知道有多少人为此踏上了正版App之路,但笔者就是其中之一。
**iOS6——扭曲的世界**
在这一版本中,苹果采用了全新设计的地图软件,放弃已经合作了多个版本的谷歌地图。地图元素基于矢量,即使你放大画面,图形和文字的细节仍然存在。3D模式可以让你用倾斜和旋转的角度查看一个区域。然而这一全新的地图软件并未受到广大用户的喜爱,不少用户抱怨新的地图软件是iPhone5上最大的倒退。
<div align="center">
<img src="images/iOS6.png" width = "50%" height = "50%" align=center />
</div>
其地图数据并不完善,还存在大量图形扭曲现象,可以说是“一致差评”。然而在中国地区得到的评价则大不相同,由于中国地区的地图数据由高德提供,不少地方要比谷歌做得更好。除了地图之外,苹果也添加了诸多功能,Passbook,全景相机,蜂窝数据状态下的FaceTime,丢失模式等等都在iOS6中加入。
**iOS7——扁平化or拟物化?**
乔纳森带领的设计团队这一次彻头彻尾重新设计了iOS系统。如果说这是iOS系统诞生以来变化最大的一次那绝对不为过。这一次更新引发了人们对扁平和拟物两种设计风格的强烈探讨。它采用全新的图标界面设计,总计有上百项改动,其中包括控制中心、通知中心、多任务处理能力等等。
<div align="center">
<img src="images/iOS7.png" width = "50%" height = "50%" align=center />
</div>
除了UI的巨大变化之外,笔者认为iOS7也不乏很多非常实用的功能,像控制中心的出现很大程度上简化了iOS系统的操作繁杂之处,我们不必为了开一个Wi-Fi而进入设置打开开关了。在这个版本中还添加了中国人较为喜爱的九宫格输入法,用户也因此少了一个越狱的理由。
**iOS8——强大的生态环境**
经过了iOS7这样翻天覆地的变化,很多用户认为iOS8的改动相对而言就小了许多。但事实上笔者认为iOS8最出彩的地方不在于这个系统本身,而是苹果对旗下所有平台进行了整合,使其生态环境愈发完善。Continuity功能的加入使苹果旗下的产品联系更紧密了,利用iOS 8中新增的Continuity,可以继续在另一台iOS设备上未做完的事情了。
<div align="center">
<img src="images/iOS8.png" width = "50%" height = "50%" align=center />
</div>
比如写了一半的电子邮件或读了一半的网页等等。只要你的Mac或iPad与iPhone使用的是同一个WiFi网络,你就可以直接在Mac或iPad上接电话。这样的设计很大程度上加大了用户对苹果产品的依赖,但不得不说确实能够加强用户体验。在这一版本中苹果还为开发者带来了一些新玩具,新的编程语言Swift和Metal渲染接口,还开放了Touch ID的API,开发者还能编写额外的通知中心控件,总而言之iOS8比以往的iOS系统要更开放了。联想起在当年Symbian系统对开发者严格的约束,这样的待遇确实是非常吸引开发者的。
**iOS9——大幅降低的升级门槛**
在WWDC2015中,苹果公布了最新一代的iOS9系统,除了功能上的各种升级,最令人意外的是苹果这次把iOS 9的升级门槛控制在与上一代的iOS8相同,支持的升级设备与iOS 8相同,也就是说连iPhone4s也可以取得升级,iPhone 4s作为历史最受欢迎的iPhone手机之一,这无疑是一个天大的好消息。
<div align="center">
<img src="images/iOS9.png" width = "50%" height = "50%" align=center />
</div>
与此同时iPad 2平板和第五代iPod Touch相同可以享受iOS 9升级服务。同时苹果也大幅度降低了iOS 9升级安装所需的存储空间,从原来的4.6GB下降到现在的1.3GB,对于广大16GB内存空间的iPhone用户来说又少了一个不升级的理由了。在系统上的一些功能完善也很有看点,原生地图支持公交查询,新的News新闻软件,iPad的分屏模式等等,都是一些比较实用的功能。最重要的当然是3D Touch了!随着iOS9一同发布的还有iPhone 6S & Plus,新设备的推出也就是意味着新的交互方式产生。3D Touch直接把以往横向上的二维操作变为了横向和纵向上的三维操作,大大加强了用户和设备的交互性。
**iOS10——迄今为止最好用的iOS系统**
<div align="center">
<img src="images/iOS10.png" width = "50%" height = "50%" align=center />
</div>
北京时间2016年6月14日凌晨一点,苹果开发者大会WWDC2016在旧金山召开,苹果系统iOS10正式亮相,苹果为iOS 10带来了十大项更新。关于iOS10是自iOS由拟物化风格变为扁平化风格以来界面变化最大的一次系统升级,新的通知中心和新的推送界面设计,融入了卡片式风格,更加的贴合了3D Touch的操作,给用户一种直观上的反馈,同时在这一次的系统版本更新中,苹果把文件管理系统换成了更为先进的APFS,让小存储容量设备空闲出了几个G空间,同时也大大的减小了零碎文件的整理,不得不说这才是最为iOS 10中最激动人心的升级!
**iOS 11——带来的众多新功能为 iPad 注入了强大新动力,也让 iPhone 进一步成为你日常必备。**
<div align="center">
<img src="images/iOS11.png" width = "50%" height = "50%" align=center />
</div>
iOS11中,苹果增加了对AR增强现实的支持,为开发者提供ARKit。该功能使用iPhone传感器来确定平面,照明,尺度估计等,用户可以加入不同的物品, AR应用能够实现更加真实的效果,光影效果更出色。苹果表示,ARKit将使iOS成为世界上最大的AR平台。iOS 11采用HEVC视频压缩标准和HEIF照片压缩标准,它们可以在保留视频和照片高质量的同时,有效地缩小这些多媒体文件的大小。并且还重点优化了相机的功能,包括样张质量、低光拍摄、光学稳定和HDR模式等方面的改善。更新了控制界面,并加入了更多选项。新的控制中心变为了一整页,所有功能都集中到了这一页,包括锁屏、3D Touch等。在锁屏界面,iOS 11更加重视一体化,用户可以通过滑动实现所有的事情。
**以上内容部分来自网络**
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2018 PJHubs
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: Media/basic.md
================================================
## Windows 系统知识
### 注册表
注册表确实是 windows 所特有的东西,早期用于解决繁杂的系统配置,类 unix 直接选择了以文件为最下单位进行管理,但大量琐碎的文件对 windwos 这种 FAT 文件管理系统是噩梦,而如 Linux 所采用的 EXT 文件系统则可以较好的处理这个问题,所以为了避免零碎文件过多而放大当时 win 文件系统的缺点,引入注册表来提高性能是非常重要的。
注册表本身是一个数据库,具备数据库的特性。
### UAC 提权
UAC(User Account Control)用户账户控制,是 Windows Vista 及以上版本中引入。以下是会导致 UAC 提权才能进行的操作:
* 配置Windows Update
* 增加、删除账户;更改账户类型
* 更改UAC的设置
* 安装ActiveX;安装、卸载程序
* **安装设备驱动程序**
* **将文件移动/复制到ProgramFiles或Windows目录下**
* 查看其它用户的文件夹
## 多媒体
### 基础知识
#### 框架
WebGL 是 OpenGL ES 的 js 封装。
OpenGL 并不是库,只是一组规范不包括实现,类似菜单。每家饭馆都有京酱肉丝,顾客可以去不同的饭馆都点京酱肉丝,不同的饭馆都有自己实现的一份京酱肉丝。一般做 OpenGL 接口实现都是 GPU 厂商去做,做完的东西被称为“驱动”,也可以不依赖 GPU 厂商提供的“硬实现”,比如 Windows 就提供了一份脱离硬件的“软实现”系统库。
================================================
FILE: Media/feature.md
================================================
## feature
### 视频变速

变速的本质:就是修改视频帧的时间戳。比如2倍速,就是 视频帧的pts(Presentation Time Stamp/显示时间戳)=原始帧pts/2,0.5倍速,就是 视频视频帧的pts=原始帧pts/0.5;外部取帧逻辑这些是不变的。
普通变速和曲线变速的区别
* 普通变速:速度是恒定的,整个视频的帧的pts计算方法是固定的,只需要除以一个固定的速度。
* 曲线变速:曲线变速的速度不是固定的,具体的计算公式根据不同的曲线类型而不同
逆变速也是一样的道理,但稍微麻烦一些。
================================================
FILE: MiniProgram/小程序初探.md
================================================
近期筹备期末考试,但每天晚上还是有些空闲时间的,想着今年要好好经营一番GitHub,因为今年给自己定下了一个“宏大”的计划——打满小绿点!当然在执行这个计划的过程中可能会由于某些突发情况导致“断点”,但梦想还是要有的嘛。
因此,啃下小程序就成为了我今年的第二件事情(第一件事为iBistu 4.0),完成这个去年就十分想踏入的“坑”。在去年也就是上个学期的某一天得知小程序面向个人开发者后,就一直按捺不住自己,总想着试一试,但因为当时开始了第一份实习工作,导致这个计划迟迟未能展开。最难受的是没想到在上学期末总共收到了两份小程序开发的外包需求,一咬牙用了大概一晚上加一个白天的时间吭吭哧哧的摸索了一番,最后的结果是——放弃。🙂把这个外包需求移交给其它同学后,草草了事。
但是现在不一样了啊,当时是因为动机不纯,现在有大把的时间可以快活~也就把这个事情提上了日程。小程序,张小龙同学给微信生态又注入的一个新成员,用张小龙同学的话来说,之所以要推出小程序,初衷是因为,“让信息触手可及,改变应用程序需要下载、安装的繁琐过程”。🙄,俗话说的好,话不能说的太满,后续发生的事情大家想必都已经了解。
在小程序推出至今也用了大大小小不下十几个小程序,不得不说确实是达到了张小龙同学所说的“用完即走”的概念,而且依托于微信开发团队强大的封装能力,为小程序提供了调用非常简单的API,使用起来难度比Native降了不止一个层级。在此给大家推荐两本书,
</div>
<div align="center">
<img src="http://7xszq8.com1.
gitextract_3vegyaaq/
├── .github/
│ └── workflows/
│ └── jekyll-gh-pages.yml
├── .gitignore
├── AI/
│ └── basic.md
├── Android/
│ ├── Java.md
│ ├── Kotlin.md
│ ├── feature.md
│ ├── 内存.md
│ ├── 基础知识.md
│ └── 问题汇总.md
├── Back-end/
│ ├── DB.md
│ ├── Docker.md
│ ├── RESTful.md
│ ├── Vapor.md
│ ├── django.md
│ ├── jwt.md
│ ├── mysql.md
│ ├── nginx.md
│ ├── web服务器.md
│ └── 后端学习.md
├── Base/
│ ├── C++.md
│ ├── UML.md
│ ├── algorithm-java.md
│ ├── leetCode.md
│ ├── leetcode/
│ │ ├── 两个排序数组的中位数.md
│ │ ├── 两数之和.md
│ │ ├── 两数相加.md
│ │ ├── 无重复字符的最长子串.md
│ │ └── 最长回文子串.md
│ ├── nowCode.md
│ ├── python.md
│ ├── 操作系统.md
│ └── 网络相关知识.md
├── Blockchain/
│ └── basic.md
├── Books/
│ └── iOS面试之道.md
├── CV/
│ └── basic.md
├── Flutter/
│ ├── Dart.md
│ ├── Flutter_2.md
│ ├── Flutter_3.md
│ └── Flutter问题汇总.md
├── Front-end/
│ ├── CSS.md
│ ├── FCC.md
│ ├── JavaScript.md
│ ├── Vue.md
│ ├── basic.md
│ ├── vue-context-mune.md
│ ├── 前端学习.md
│ └── 图解HTTP学习笔记.md
├── Game/
│ └── Cocos/
│ └── basic.md
├── Graphics/
│ ├── app.md
│ └── metal.md
├── History/
│ ├── 2_Apple_History.md
│ ├── 3_Mac_OS_X.md
│ └── 4_iOS.md
├── LICENSE
├── Media/
│ ├── basic.md
│ └── feature.md
├── MiniProgram/
│ ├── 小程序初探.md
│ └── 小程序初探(二).md
├── NLP/
│ └── NLP.md
├── Others/
│ ├── myinterview.md
│ ├── 招一个靠谱的iOS实习生(附参考答案).md
│ ├── 简介.md
│ └── 面试准备.md
├── Product/
│ └── Map.md
├── Project/
│ ├── Bonfire.md
│ ├── CocosCreator——方块弹球.md
│ ├── ONEUIKit-ONEProgressHUD.md
│ ├── PFollow.md
│ ├── PLook.md
│ ├── coding-interview-university学习笔记.md
│ ├── iBistu4-0(先导篇).md
│ ├── iBistu4-0(地图).md
│ ├── iBistu4-0(失物).md
│ ├── iBistu4-0(新闻).md
│ ├── iBistu4-0(黄页).md
│ ├── 上架.md
│ ├── 第三方库管理.md
│ └── 翻译——ViewsprogrammingGuideforiOS.md
├── Qt/
│ ├── C++.md
│ ├── UI.md
│ ├── base.md
│ ├── crossPlatform.md
│ ├── opt.md
│ └── project.md
├── README.md
├── React-Native/
│ ├── React-Native记〇.md
│ ├── React-Native记(一).md
│ └── React-Native记(二).md
├── Test/
│ └── 单元测试.md
├── Tools/
│ ├── 2_百家汇.md
│ ├── 3_GitHub.md
│ ├── 4_Xcode.md
│ ├── 5_Xcode.md
│ ├── Playerground.md
│ ├── Xcode.md
│ ├── XcodeGuide.md
│ └── 开发中可能会用到的内容.md
├── Toturial/
│ └── 剪刀石头布.md
├── UI/
│ └── 3_StoryBoard.md
├── Weex/
│ └── Weex新手记.md
├── Win/
│ └── basic.md
├── iOS/
│ ├── Layout.md
│ ├── More-弹幕.md
│ ├── Objective-C/
│ │ ├── More-Audio.md
│ │ ├── More-DesignPattern.md
│ │ ├── More-iOS上的相机.md
│ │ ├── More-iOS国际化一站式解决方案.md
│ │ ├── More-视频相关.md
│ │ ├── More-页面传值.md
│ │ ├── Objective-C注意点.md
│ │ ├── ping.md
│ │ ├── runtime.md
│ │ ├── tips-自定义tabBar大加号引发的思考.md
│ │ ├── 并发编程.md
│ │ └── 系统相关.md
│ ├── Swift/
│ │ ├── Cache.md
│ │ ├── CoreData.md
│ │ ├── OC转Swift.md
│ │ ├── PFollow.md
│ │ ├── PJPickerView开发总结.md
│ │ ├── PJPickerView开发总结.md).md
│ │ ├── PhotosKit开发总结(一).md
│ │ ├── Playgrounds.md
│ │ ├── SpriteKit.md
│ │ ├── SwiftUI.md
│ │ ├── Swift注意点.md
│ │ ├── UIDynamic.md
│ │ ├── code.md
│ │ ├── debug.md
│ │ ├── landscapeandportrait.md
│ │ ├── tips.md
│ │ ├── 七牛图片上传助手.md
│ │ ├── 品种选择器总结.md
│ │ └── 自定义NavigationBar.md
│ ├── Today_Extension.md
│ ├── UI.md
│ ├── UICollectionView.md
│ ├── UITableView.md
│ ├── basic.md
│ ├── code.md
│ ├── debug.md
│ └── system.md
├── macOS/
│ ├── TranslateP.md
│ ├── basic.md
│ ├── crash.md
│ ├── kindle.md
│ ├── macOS开发(词法分析器).md
│ ├── performance.md
│ ├── playground.md
│ └── 一台设备多个git账号.md
└── ruby/
└── basic.md
Condensed preview — 151 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (1,111K chars).
[
{
"path": ".github/workflows/jekyll-gh-pages.yml",
"chars": 1411,
"preview": "# Sample workflow for building and deploying a Jekyll site to GitHub Pages\nname: Deploy Jekyll with GitHub Pages depende"
},
{
"path": ".gitignore",
"chars": 8,
"preview": ".vscode\n"
},
{
"path": "AI/basic.md",
"chars": 823,
"preview": "# AI\n\n## 各种原则\n### 金发姑娘原则\n* [相关链接](https://en.wikipedia.org/wiki/Goldilocks_principle)\n* 解释“金发姑娘原则”指出,凡事都必须有度,而不能超越极限。按照这"
},
{
"path": "Android/Java.md",
"chars": 170,
"preview": "## Java\n\n### 注解 `@`\n提到注解就要带上注释,注释是给开发者看的,而注解就是给程序自己看的。比较类似做一些小方法检查,压缩代码量,本质上与 Swift 5.5 引入的 `@PropertyWrapper` 作用一致。\n\n注解"
},
{
"path": "Android/Kotlin.md",
"chars": 1756,
"preview": "# Kotlin 问题汇总\n\n## 语法\n### `var` 和 `val` 的区别\n`var` 与我们之前见到的 `var` 概念一致,但 `val` 取代了以往 `let` 作用。kotlin 中 `let` 另有他用。\n```kotl"
},
{
"path": "Android/feature.md",
"chars": 217,
"preview": "## feature 思考\n\n### 拼多多自动拉起 app\nandroid 的四大基础组件中,只有 activity 是完整的用户可见应用程序入口,剩下的三大基础组件用户都不可见,可以通过 Service 来注册一个不可见的服务,在某些条"
},
{
"path": "Android/内存.md",
"chars": 236,
"preview": "## 内存知识\n\n### Java GC\n大概流程详见:[https://zhuanlan.zhihu.com/p/23102625]()\nJava堆内存不足时,GC会被调用。当应用线程在运行,并在运行过程中创建新对象,若这时内存空间不足,"
},
{
"path": "Android/基础知识.md",
"chars": 4246,
"preview": "# Android 基础\n\n\n## 名词解释\n* APK:Android application package,Android 应用程序包;\n* \n\n## APK 基础\n应用安装到设备后,每个 APK 都运行在自己的**安全沙箱**中(这"
},
{
"path": "Android/问题汇总.md",
"chars": 395,
"preview": "# Andriod 问题汇总\n## 设备\n新购了一台开发机 meizu 15。之前有考虑过小米6,但京东和淘宝上都没有找到靠谱的卖家,接着看了华为和三星,华为的低端机的外观实在是不敢恭维,三星的 A9 让我惊艳了一番,但价格有些稍贵,最后逛"
},
{
"path": "Back-end/DB.md",
"chars": 226,
"preview": "# 数据库相关知识点\n\n## 备份\n* 先写日志,再写 SQL。这样可以保证当 SQL 写入出现问题时,可以查到日志。\n\n### 备份策略\n\n周日 | 周一 | 周二 | 周三 | 周四 | 周五 | 周六 |\n--- | --- | --"
},
{
"path": "Back-end/Docker.md",
"chars": 11300,
"preview": "# Docker\n## 虚拟化和容器化技术\n### 虚拟化技术\n虚拟化技术是一种将计算机物理资源进行抽象、转换为虚拟的计算机资源提供给程序使用的技术。这些资源包括了 CPU 提供的运算控制资源,硬盘提供的数据存储资源,网卡提供的网络传输资源"
},
{
"path": "Back-end/RESTful.md",
"chars": 852,
"preview": "# REST\n`HTTP` 是一种**应用层**协议,能从 `HTTP` 基础设施中获取多少收益,主要取决于把它用做应用层协议用得有多好。\n\n`HTTP` 实际上是为 `REST` 而生的,它能够表达状态和状态转移,者就是它位于应用层而非传"
},
{
"path": "Back-end/Vapor.md",
"chars": 15785,
"preview": "# Vapor\n在这里将记录使用 Vapor 的过程中遇到的问题。感觉特别一些设计模式的 tips 杂糅在一起后,就特别像 `Django`。\n\n## 如何快速开始\n### 下载 `vapor`\n[详见官网](https://docs.va"
},
{
"path": "Back-end/django.md",
"chars": 14411,
"preview": "这个文章主要是记录我在学习django过程中所遇到的问题,为后续其它个人项目做铺垫,之前陆陆续续的在使用djano,但是一直都没有好好的去记录一些内容,借此机会完整的记录下学习过程遇到的问题和注意点。django最适合用于做网站,从djan"
},
{
"path": "Back-end/jwt.md",
"chars": 88,
"preview": "# JWT\n这里将会记录我在学习 JWT 的过程中遇到的问题、思考和总结。\n\n## JWT 简介\n全称为 **J**SON **W**eb **T**oken。\n\n## 彩虹表"
},
{
"path": "Back-end/mysql.md",
"chars": 1176,
"preview": "# Mysql\n## Mysql 的客户端/服务器架构\n`mysql` 的服务器进程默认名称为 `mysqld`,常用的 `mysql` 客户端进程的默认名称为 `mysql`。\n\n## 启动\n`mysql -h主机名 -u用户名 -p密码"
},
{
"path": "Back-end/nginx.md",
"chars": 40,
"preview": "# nginx \n\n## 错误日志地址\n`etc/log/nginx`\n\n## "
},
{
"path": "Back-end/web服务器.md",
"chars": 3536,
"preview": "# 浅析 Web 服务器的工作原理(Java)\n## 什么是 Web 服务器,应用服务器和 web 容器?\n### web 服务器\n在过去很长的一段时间中,它们是有区别的,但是这两个分类慢慢的合并了,而如今在大多情况下可以把它们看成一个整体"
},
{
"path": "Back-end/后端学习.md",
"chars": 3243,
"preview": "## 用户态与核心态\n\n### 用户态与核心态是什么?\n将内核程序和基于内核程序之上构建的用户程序分开处理,使其分别运行在用户态和核心态\n\n### 为什么需要用户态和核心态?\n在CPU的所有指令中,有一些指令是非常危险的(不是`rm -rf"
},
{
"path": "Base/C++.md",
"chars": 201,
"preview": "### ends 的差异\nends 在 windows 和类 unix 系统下有差异,[http://www.cplusplus.com/reference/ostream/ends/](http://www.cplusplus.com/r"
},
{
"path": "Base/UML.md",
"chars": 4738,
"preview": "# UML\n## 面向对象技术概述\n面向对象的基本建模原则:抽象、封装、继承和分类。\n\n面向对象的基本软件工程:OOA(面向对象的分析)、OOD(面向对象的设计)、OOP(面向对象的编程)和OOSM(面向对象的软件维护)\n\n对象的概念是:对"
},
{
"path": "Base/algorithm-java.md",
"chars": 790,
"preview": "1. `public static void`和`public void`的区别:`public static void`所标明的静态方法能够用类名直接调用,但是静态方法不能够调用非静态方法。\n\n2. final关键字浅析:[https:/"
},
{
"path": "Base/leetCode.md",
"chars": 191,
"preview": "- [x][两数相加](./leetcode/两数相加.md)\n- [x][两数之和](./leetcode/两数之和.md)\n- [x][无重复字符的最长子串](./leetcode/无重复字符的最长子串.md)\n- [x][两个排序数组"
},
{
"path": "Base/leetcode/两个排序数组的中位数.md",
"chars": 1436,
"preview": "## 两个排序数组的中位数\n惊呆了,用自己最初的想法居然直接一把 AC 掉了困难题目,真不知道这困难是不是放错了哈哈哈,总之很开心就是了。刚开始想的巨多,一直在纠结怎么把两个有序的数组用一个较好的方法直接合并,然后又考虑到了题目是个有序数组"
},
{
"path": "Base/leetcode/两数之和.md",
"chars": 3552,
"preview": "## TwoSum\n\nGiven an array of integers, return indices of the two numbers such that they add up to a specific target.\n\nYo"
},
{
"path": "Base/leetcode/两数相加.md",
"chars": 2170,
"preview": "## 两数相加\n这道题难度是 medium ,AC 后我觉得完全没有昨天的 Easy 好做,开始怀疑 LeetCode 是不是搞错了哈哈。做的过程没有感觉到有多困难,但是最后输出 finalNode 的时候只丢出来了最后一个节点,突然想起来"
},
{
"path": "Base/leetcode/无重复字符的最长子串.md",
"chars": 2609,
"preview": "## 无重复字符的最长子串\n\n啊哈哈,这道题真有趣,刚开始没看懂题意中为什么要指出 \"pwke\" 是 子序列 而不是子串 这句话,然后自己用 k-v 过了前两个样例后到这个样例才恍然大悟,原来是这么个意思哈哈。\n\n<img src=\"ht"
},
{
"path": "Base/leetcode/最长回文子串.md",
"chars": 3998,
"preview": "## 最长回文子串\n\n刚开始做的时候直接按照了自己的思路去搞,这一弄问题就出来了,因为没有考虑好回文字符串最重要的特点,导致最开始就想错了,大概的思路是这样的,还是一个字符一个字符的从目标字符串中读取,然后以当前读取到的字符出发,再起一个循"
},
{
"path": "Base/nowCode.md",
"chars": 6237,
"preview": "## 有一棵二叉树,请设计一个算法,按照层次打印这棵二叉树\n给定二叉树的根结点root,请返回打印结果,结果按照每一层一个数组进行储存,所有数组的顺序按照层数从上往下,且每一层的数组内元素按照从左往右排列。保证结点数小于等于500。\n\n\n#"
},
{
"path": "Base/python.md",
"chars": 1464,
"preview": "## 模块\n每个 `.py` 文件的主文件就是模块名称,想要导入模块时必须使用 `import` 关键词来制定模块名称。若要引用模块中定义的名称,则必须在名称前加上模块名称与一个 “`.`\" 符号。\n\n## __pycache__\nCPyt"
},
{
"path": "Base/操作系统.md",
"chars": 8932,
"preview": "# 第一章 计算机操作系统概述\n## 第一节\n时间 | 硬件 | 语言 | 用途 \n--------- | --------- | --------- | -------- |\n1945 | 电子真空管 | 机器语言 | 应用于科学计算 \n"
},
{
"path": "Base/网络相关知识.md",
"chars": 13294,
"preview": "# HTTPS 通信原理剖析\n## 基本概念\n### 公钥密码体制(public-key cryptography)\n公钥密码体制分为三个部分:**公钥**、**私钥**和**加密解密算法**。它的加密解密过程如下:\n* 加密:通过加密算法"
},
{
"path": "Blockchain/basic.md",
"chars": 1299,
"preview": "## 区块链技术综述\n\n1. 区块链是从比特币中脱离出来的。\n2. 加密货币\n3. 分布式共识\n * 想要生成一个加密货币,还要所有人去承认它\n4. ecash 盲签名技术\n5. hashcash 解决邮件系统中 DoS 攻击问题\n "
},
{
"path": "Books/iOS面试之道.md",
"chars": 4240,
"preview": "## 第一天\n\n### 字典和集合\n一般的字典和集合都要求它们的 Key 都必须实现 Hashable 协议,Cocoa中的基本数据类型都满足这一点。\n\n### 字符串\nSwift 中的字符串为值类型,而不是 OC 中的引用类型。\n\n###"
},
{
"path": "CV/basic.md",
"chars": 646,
"preview": "# 图形学 & 视觉\n\n## 基础概念\n\n### OpenGL\nOpenGL 本身不提供源码实现,其只是定义了一堆协议接口,各个平台自行根据统一规范好的协议,去实现各自平台上 OpenGL 协议接口,几乎没有不支持 OpenGL 协议的硬件"
},
{
"path": "Flutter/Dart.md",
"chars": 102,
"preview": "# Dart\n## 语言\n### 私有变量\n变量以下划线(_)开头,在 `Dart` 语言中使用下划线前缀标识符,会强制其变成私有的。\n\n### null\ndart 中任何类型变量都可以判 `null`。"
},
{
"path": "Flutter/Flutter_2.md",
"chars": 10090,
"preview": "原文地址:[PJHubs](http://pjhubs.com/2019/01/14/flutter-2/)\n\n\n> 在上篇文章中,已经大致的描述出为什么要接触 Flutter 以及对 Flutter 初体验的一些总结,整体上 Flutte"
},
{
"path": "Flutter/Flutter_3.md",
"chars": 18670,
"preview": "## Flutter 三探\n> 历时一个星期对 Flutter 一期调研在这篇文章中就告一段落了,这篇文章中继续完善上篇文章中利用豆瓣电影 Top250 公开 API demo。\n\n## 前言\n在这两三天的继续完善 demo 的时间中,首先"
},
{
"path": "Flutter/Flutter问题汇总.md",
"chars": 4473,
"preview": "# Flutter 问题汇总\n## 环境配置\n根据[ `flutter` 中文官网](https://flutterchina.club)上所引导的步骤进行配置,中途可以根据 `flutter doctor` 命令进行检查相关依赖是否配置完"
},
{
"path": "Front-end/CSS.md",
"chars": 1971,
"preview": "# CSS\n## 基本\n### `<ul>` 实现 `<li>` 等分\n```html\n<ul id=\"father\">\n <li class=\"children\">第一个</li>\n <li class=\"children\">第二个<"
},
{
"path": "Front-end/FCC.md",
"chars": 9770,
"preview": "# FCC 学习笔记\n这是我在 [freecodecamp.one](http://freecodecamp.one) 上学习遇到的问题以及值得记录的点。\n\n## `<main>` 标签\n该标签用与在 `<body>` 标签内标识出“内容主"
},
{
"path": "Front-end/JavaScript.md",
"chars": 1418,
"preview": "# JavaScript\n## 指定 `Array` 的元素类型\n不好意思做不到!js 是弱类型语言,我们不能真正的做到指定元素类型,但是可以先指定元素长度,然后再循环赋值哈哈哈~\n\n## `HttpOnly`\n产品上出现了一个奇怪的问题,"
},
{
"path": "Front-end/Vue.md",
"chars": 2524,
"preview": "# Vue\n## 基础知识\n### MVVM 数据绑定\n在学习 `Vue` 的过程中,非常好奇 `Vue` 自身的数据绑定模式是否与我之前在 iOS 上接触到的数据绑定认识一致,然后又在资料中发现了 `Object.defineProper"
},
{
"path": "Front-end/basic.md",
"chars": 2035,
"preview": "# Basic HTML and HTML5\n\n* 作为惯例,所有的 HTML 标签都是小写,比如是 <p></p>,而不是<P></P>\n* 所有的 img 标签都必须有 alt 修饰。该标签可被用户读屏和如果图片加载不出来时进行文本展示"
},
{
"path": "Front-end/vue-context-mune.md",
"chars": 5237,
"preview": "# 使用 Vue 实现 Context-Menu 的思考与总结\n## 简介\n先来看最终成果:\n\n\n\n操作"
},
{
"path": "Front-end/前端学习.md",
"chars": 1619,
"preview": "## https协议的主要作用是:建立一个信息安全通道,来确保数据的传输,确保网站的真实性。\n\n## TCP和UDP的区别\n* TCP是面向连接的,UDP是无连接的即发送数据前不需要先建立链接。\n面向连接基于电话系统模型,而面向无连接则基于"
},
{
"path": "Front-end/图解HTTP学习笔记.md",
"chars": 1237,
"preview": "这是我在学习《图解HTTP》这本书时做的笔记,可能有些凌乱,会加入自己的一些思考和之前计网课上已习得的内容。\n\n### 第一章:了解Web及网络基础\n\n1. 通过发送请求获取服务器资源的Web浏览器等,都可称为客户端。\n\n2. **CGI*"
},
{
"path": "Game/Cocos/basic.md",
"chars": 177,
"preview": "# Cocos 基础知识点\n\n## 布局\n### 约束\n之前在做“方块弹球”时没考虑好多屏幕适配的问题,导致在 Android 上玩时会出现黑边。如果想要对的组件进行约束,可以选择**像素值**或**百分比**进行约束,如下图所示:\n\n\n\n变速的本质:就是修改视频帧的时间戳。比如2倍速,就是 视频帧的pts(Presentation Time Stamp/显示时间戳)=原始帧pts/2,"
},
{
"path": "MiniProgram/小程序初探.md",
"chars": 3125,
"preview": "近期筹备期末考试,但每天晚上还是有些空闲时间的,想着今年要好好经营一番GitHub,因为今年给自己定下了一个“宏大”的计划——打满小绿点!当然在执行这个计划的过程中可能会由于某些突发情况导致“断点”,但梦想还是要有的嘛。\n\n因此,啃下小程序"
},
{
"path": "MiniProgram/小程序初探(二).md",
"chars": 15187,
"preview": "iBistu 4.0终于在几位同学的努力下正式推出,我也没想到iBistu怎么就发展到了4.0,四年多过去了,还能“隐约”看到学长们的代码,这种“恍如隔世”的感觉每写下一行代码就会冒出。\n\n在学习开发微信小程序的过程中,一直在苦于追求到底哪"
},
{
"path": "NLP/NLP.md",
"chars": 1795,
"preview": "# 基础知识\n* 单词边界界定\n * 中文缺少词和词之间的界限符(中文自动分词)\n* 上下文关联\n* 基于统计学习的分词工具优于人工规则的分词工具。\n* 未登录词造成的分词精度下降至少比分词歧义大 5 倍。\n* 字标注统计学习方法能够"
},
{
"path": "Others/myinterview.md",
"chars": 4988,
"preview": "# 我的大学——实习生涯\n\n> 去年暑假旅行回来后,开始萌生要着手用在大学最后一年的时间来写完自己的大学回忆录。可在网易云音乐中搜索电台《PJHubs》收听语音版。此篇文章为第三篇,主要讲述了大学四年中,我所经历的工作。\n\n## 简介\n很多"
},
{
"path": "Others/招一个靠谱的iOS实习生(附参考答案).md",
"chars": 6639,
"preview": "以下是我列出来的能够帮助大家招到一个 **靠谱的iOS实习生** 需要掌握的点,再次说明下情况:\n\n1. 此份题适用于电面和face to face,更加偏向于电面;\n2. 能够较为流畅的说到每道题的点上,基本上可以认为是掌握了;\n3. 考"
},
{
"path": "Others/简介.md",
"chars": 2201,
"preview": "# 前言\n\n## 关于自己\n\n笔者为[北京信息科技大学网络实践创新联盟](http://iflab.org)(以下简称ifLab)iOS副组长,目前为我校计算机学院软件工程系大二学生。\n\n这是笔者的[GitHub](https://gith"
},
{
"path": "Others/面试准备.md",
"chars": 6906,
"preview": "# 面试准备\n这篇文章是结合了《iOS 面试之道》的第一章“iOS 工程师的面试”部分以及自己的所掌握的知识内容所得,主要用于提醒自己和帮助其它同学。\n\n## 简历的准备\n### 页数\n简历通常最好是两页,一页的简历会显得过于简洁,正常来说"
},
{
"path": "Product/Map.md",
"chars": 212,
"preview": "## 地图 SDK\n\n几乎所有的地图 SDK 都是基于 OpenGL 自行绘制。其中提供给 Qt 的插件基本也是通过提供 JS API 间接 webView 渲染完成,剩余的 Android、iOS 下是基于同一套渲染接口的 OpenGL "
},
{
"path": "Project/Bonfire.md",
"chars": 693,
"preview": "这篇文章主要记录我在开发Bonfire的过程中遇到的问题。\n\n1. [CAShapeLayer的相关属性介绍](https://www.jianshu.com/p/98ff8012362a) \n2. 出现`dyld: Library not"
},
{
"path": "Project/CocosCreator——方块弹球.md",
"chars": 3500,
"preview": "## 简介\n这是我的游戏开发系列第一讲,我会在拥有下一个大串空闲的时间中持续开展此系列内容。这其中可能会涉及Cocos、Unity、白鹭、虚幻、LayaBox等游戏引擎。\n\n先说明一点,方块弹珠这个名字我是直接拿微信小游戏上一块名为《方块弹"
},
{
"path": "Project/ONEUIKit-ONEProgressHUD.md",
"chars": 686,
"preview": "## ONEUIKit/ONEProgressHUD\nONEUIKit/ONEProgressHUD为当前滴滴出行App中的HUD,我们先来看看其的样式,\n\n<img src=\"https://i.loli.net/2018/04/09/5"
},
{
"path": "Project/PFollow.md",
"chars": 1889,
"preview": "## PFollow\n在这一系列文章中主要记录了我在开发 PFollow 过程中遇到的问题和总结。\n\n### 解决点击用户定位蓝点出现 callout 的问题:\nfunc mapView(_ mapView: MAMapView!, did"
},
{
"path": "Project/PLook.md",
"chars": 2707,
"preview": "这篇文章主要记录我在开发PLook的过程中遇到的问题。\n\n1. UIButton的各种状态参考文章:[https://www.jianshu.com/p/57b2c41448bf](https://www.jianshu.com/p/57b"
},
{
"path": "Project/coding-interview-university学习笔记.md",
"chars": 810,
"preview": "这是我在学习一套完整的学习手册帮助自己准备 Google 的面试的笔记,其想通过这种方式去提升自己姿势水平,链接在此,欢迎大家一块学习。[https://github.com/jwasham/coding-interview-univers"
},
{
"path": "Project/iBistu4-0(先导篇).md",
"chars": 5003,
"preview": "最开始我知道iBistu的时候非常憧憬,那会应该是大一,得知咱们社团有给学校做了一个移动校园App,这无疑给当时正在学习iOS开发的我打了一剂强心针,为啥?那个时候社团还没现在这般“自由”,只有每周日晚上的小组活动时间才能和各位学长和同学交"
},
{
"path": "Project/iBistu4-0(地图).md",
"chars": 8135,
"preview": "# 数据源\n\n## 获取校区位置数据\n**接口: **http://api.iflab.org/api/v2/ibistu/_table/module_map\n**请求方法:**get\n**参数:**无\n**示例请求成功返回值:**\n```"
},
{
"path": "Project/iBistu4-0(失物).md",
"chars": 6027,
"preview": "本系列文章为记录iBistu 4.0各个模块开发中进行的思考、设计和编码总结,供同学们参考。\n\n---\n\n# 数据源\n## 获取失物招领列表数据\n**接口:**http://api.iflab.org/api/v2/ibistu/_tabl"
},
{
"path": "Project/iBistu4-0(新闻).md",
"chars": 5778,
"preview": "# 数据源\n\n## 获取新闻列表数据\n\n**接口:** http://api.iflab.org/api/v2/newsapi/newslist\n\n**请求方法:** get\n\n**参数:**\n\n`category`:必需参数,新闻分类,可"
},
{
"path": "Project/iBistu4-0(黄页).md",
"chars": 3374,
"preview": "本系列文章为记录iBistu 4.0各个模块开发中进行的思考、设计和编码总结,供同学们参考。\n\n---\n\n# 数据源\n\n## 获取黄页部门列表数据\n**接口:**\nibistu/_table/module_yellowpage?filter"
},
{
"path": "Project/上架.md",
"chars": 598,
"preview": "1. iOS开发账号区别于联系。说起来容易懵逼,以之前做的一张图说明,如下所示:\n <img src=\"https://i.loli.net/2018/04/21/5adb51cc3bd7a.jpeg\" width = \"100%\" he"
},
{
"path": "Project/第三方库管理.md",
"chars": 3755,
"preview": "## 背景\n\n在iOS开发中,我们很多时候都会去使用到其它人写好的功能、函数甚至组件,在刚开始学习iOS开发时,我想用别人写好的代码怎么办呢?当时我是真的一点都不知道有第三方库管理工具这么个东西,只能去GitHub、CSDN、OSChina"
},
{
"path": "Project/翻译——ViewsprogrammingGuideforiOS.md",
"chars": 11747,
"preview": "原文地址:[https://developer.apple.com/library/content/documentation/WindowsViews/Conceptual/ViewPG_iPhoneOS/Introduction/Int"
},
{
"path": "Qt/C++.md",
"chars": 4009,
"preview": "## C++ 拾遗\n\n## 为什么 main 函数要 return 0?\n在大多数系统中,main 的返回值被用来指示状态。返回值 0 表明成功,非 0 的返回值的含义由系统定义,通常用来指出错误类型。\n\n## do {...} while"
},
{
"path": "Qt/UI.md",
"chars": 619,
"preview": "\n## 鼠标\n\n## onActivChanged\n\n该事件只要鼠标光标在非目标 `Item` 区按下即可收到信号,与之前的 `onClicked` 这种鼠标光标按下再抬起才接收到信号的事件不同。\n\n\n### 悬浮\n```qml\nMouse"
},
{
"path": "Qt/base.md",
"chars": 1531,
"preview": "## 内存管理\n\n### Qt 对象树内存管理机制\nQt 是一个基于 C++ 的跨平台 GUI 框架,C++ 本身是没有自动垃圾回收机制的,但 Qt 为了解决 C++ 中大量重复性的 `new` 和 `delete`,引入了“对象树”的“半"
},
{
"path": "Qt/crossPlatform.md",
"chars": 743,
"preview": "## 本地构建 Qt\n去 [download.qt.io](https://download.qt.io/archive/qt/) 下载对应的 Qt 源码后,可用通过该[文档中的方式](https://wiki.qt.io/Building"
},
{
"path": "Qt/opt.md",
"chars": 331,
"preview": "## processEvents\n`QCoreApplication::processEvents()` 可以解决 `while(1)` 这种卡死当前线程的事情\n\n有些情况下,我们并不想卡死 UI 线程的操作,但又必须等待某件事的完成,用户"
},
{
"path": "Qt/project.md",
"chars": 1336,
"preview": "## 工程配置\n\n### 使用 VS 进行开发\n\n#### 设置 Qt 版本路径\n如果默认使用 Qt Creator 进行开发毫无问题,但都已经使用 win 了不好好利用上 vs 实在是浪费。在 vs 中下载好对于的 qt 拓展插件后,ex"
},
{
"path": "README.md",
"chars": 6153,
"preview": "<img src=\"./Others/header.png\" width = \"100%\" height = \"100%\" align=center />\n\n## 前言\n\n这是我在学习iOS开发相关内容过程中的总结,包括在日常coding、"
},
{
"path": "React-Native/React-Native记〇.md",
"chars": 4360,
"preview": "emmm,这是我今年的第三件事。微信小程序的学习告一段落,开始正式进入RN的学习,RN到现在发展了将近三年,业界有对其有非常大的赞誉,而且现目前不管是整体架构成熟度还是社区的活跃度都非常靠前,可以说是杀入的好时机(其实已经很晚了。)正适合我"
},
{
"path": "React-Native/React-Native记(一).md",
"chars": 4150,
"preview": "期末考完了,RN的学习一直在进行着,这段时间初步的学习了RN的一些基本组件、触摸事件及相关的生命周期等,整体给我的感觉与之前的微信小程序开发流程非常相似,甚至某些地方如出一辙,不能说微信小程序抄了RN,反而微信小程序的开发体验上会给人一种“"
},
{
"path": "React-Native/React-Native记(二).md",
"chars": 12072,
"preview": "停了一段时间后RN的学习又持续了💪。在停止的这段时间中主要是去做了关于iOS的一些细节加强,这部分内容也是自己之前一直想去总结出来容易遗忘和出错的地方。\n\n随后跟进的RN学习主要是学习`ScrollView相关使用`、`手撸轮播图`、`Li"
},
{
"path": "Test/单元测试.md",
"chars": 2367,
"preview": "# 单元测试\n## 前言\n这小半年的几次发版本把自己搞累得不行,可以说这一方面来源于留给测试的时间不多,大致也就一周时间左右,其二是因为很多功能在不停的重构,因为 `pv`、 `uv` 都上去了,承载的业务量也慢慢的变大,从 UI 层面上看"
},
{
"path": "Tools/2_百家汇.md",
"chars": 6400,
"preview": "# 百家汇\n\n在这一节内容中,笔者将向大家介绍一些在iOS开发中可能会用到的工具,并且还会提供部分工具的下载链接。这些工具都是在开发过程中遇到了部分瓶颈后发现的工具。笔者会在介绍部分工具的时候附带上一些使用教程。\n\n---\n\n<div a"
},
{
"path": "Tools/3_GitHub.md",
"chars": 3395,
"preview": "# **GitHub**\n\n<div align=\"center\"> \n<img src=\"images/GitHub.png\" width = \"20%\" height = \"20%\" align=center />\n</div>"
},
{
"path": "Tools/4_Xcode.md",
"chars": 8299,
"preview": "# Xcode\n\n<div align=\"center\"> \n<img src=\"images/Xcode1.jpg\" width = \"10%\" height = \"10%\" align=center />\n</div>\n\nXcod"
},
{
"path": "Tools/5_Xcode.md",
"chars": 8299,
"preview": "# Xcode\n\n<div align=\"center\"> \n<img src=\"images/Xcode1.jpg\" width = \"10%\" height = \"10%\" align=center />\n</div>\n\nXcod"
},
{
"path": "Tools/Playerground.md",
"chars": 1128,
"preview": "## Playground\n在这篇文章中将记录我在使用 `Playground` 中遇到的问题。\n\n### 让 Playground 具备多线程调试功能\n记得之前用 Playgound 做了一些关于 UI 方面的练习,涉及到了回归主线程的操"
},
{
"path": "Tools/Xcode.md",
"chars": 1378,
"preview": "## Xcode\n在这篇文章中主要讲述了我在使用 `Xcode` 过程中遇到的问题\n\n### Xcode 简单入门\n[Xcode 简单入门](./4_Xcode.md)\n\n### 观察 App 启动时间\nApp 的启动时间分为“ `main"
},
{
"path": "Tools/XcodeGuide.md",
"chars": 428,
"preview": "# Xcode\n\n## `liveView`\n在Xcode 11 中推出了针对 `SwiftUI` 的 `liveView` 功能。前提是需要 macOS 10.15 及 Xcode 11。\n\n在安装好以上两个必须的条件后,此时如果出现了"
},
{
"path": "Tools/开发中可能会用到的内容.md",
"chars": 5969,
"preview": "* [iOS--再也不用担心数组越界](https://mp.weixin.qq.com/s/RYHquy5r33NzQNgWfbnMdA):文章主要用了给 NSArray 等集合类型添加分类,或者用 runtime 做方法替换,判断出如果"
},
{
"path": "Toturial/剪刀石头布.md",
"chars": 6587,
"preview": "## 剪刀石头布\n\n该项目为[ifLab](https://iflab.org)的iOS方向新生练习项目之一,为接触了Objective-C语言后的第一个UI小练习。\n\n主要涉及的内容有:\n1. Objective-C语言初等语法实践;\n2"
},
{
"path": "UI/3_StoryBoard.md",
"chars": 445,
"preview": "# **StoryBoard**\n\nStoryboard是苹果官方主推的一个代替xib的策略。下图为StoryBoard整体的一个介绍(来源网络),当然,我们不会在本节内容中把每个知识点都讲清楚,笔者将会以几集视频为主,告诉大家如何使用St"
},
{
"path": "Weex/Weex新手记.md",
"chars": 4645,
"preview": "# Weex 新手记\n## 前言\n上周五 leader 跟我说了一下,想让我转大前端,周一让前端组长跟我聊一下,当时我内心还是比较兴奋的,因为这跟我最开始对自己的定位是完全一致的,但后续做了一些后端的东西后,发现自己对后端也有感觉,不过实话"
},
{
"path": "Win/basic.md",
"chars": 245,
"preview": "## win\n\n### 程序包\n\n#### exe\n\n#### WPF\nWindows Presentation Foundation\n\n#### UWP\nUniversal Windows Platform,该类型应用本质上也是一个 ex"
},
{
"path": "iOS/Layout.md",
"chars": 1181,
"preview": "# Layout\n这篇文章中将记录 iOS 中 `Layout` 相关的内容。\n\n## `Auto Layout` 介绍\n### 有歧义的布局\n想要测试一个 `UIVIew/NSView` 的布局约束是否充分,可以在 `loadView` "
},
{
"path": "iOS/More-弹幕.md",
"chars": 6035,
"preview": "这是iOS开发More系列的弹幕练习总结。关于弹幕的实现在GitHub上已经有一堆的实现了,国内外都有大量的第三方库,并且做的都不错,但是给我的感觉弹幕的简单实现并不需要多少精力,遂有了这次练习。\n\n先来看整体实现(可能有些丑😓),\n\n<i"
},
{
"path": "iOS/Objective-C/More-Audio.md",
"chars": 9395,
"preview": "这段时间陆陆续续的在做一些关于iOS开发细节的东西,先是跟进了音频部分(以下简称为Audio),主要分为以下几大部分:\n1. Audio的架构和框架\n2. 编解码/文件封装格式\n3. 播放系统声音/震动/提示声音\n4. 综合demo\n5. "
},
{
"path": "iOS/Objective-C/More-DesignPattern.md",
"chars": 19881,
"preview": "设计模式,这是一个可以持续投入研究的问题,当初我一直不能理解学长们口中谈论的设计模式到底是什么意思,什么是MVC、MVP、MVVM甚至CDD呢?以及现在层出不穷的MVX等等🙄。有人这么跟我说,“架构,其实是一个设计上的东西,它可以小到类与类"
},
{
"path": "iOS/Objective-C/More-iOS上的相机.md",
"chars": 6158,
"preview": "这篇文章主要是用于记录我在使用iOS上进行相机开发的过程中的相关内容总结,因为多媒体是iOS中很大的一块内容,因此不太能够用一篇完整的文章进行描述,因此这篇文章将会持续更新。\n\n在iOS中启用相机功能可以使用`UIImagePickerCo"
},
{
"path": "iOS/Objective-C/More-iOS国际化一站式解决方案.md",
"chars": 11756,
"preview": "关于iOS开发中的国际化(也可称为多语言)在网上的文章多如牛毛,不过总结起来就那么一回事,不是说他们写的不好我写的多好,而是说过于零散。\n\n现在,我将结合实际场景需求进行国际化做法详解。可以肯定的是,Android的国际化做法大同小异,无非"
},
{
"path": "iOS/Objective-C/More-视频相关.md",
"chars": 166,
"preview": "## 简介\n\n在iOS开发中的视频相关内容简介,用一张图说明,如下所示:\n\n<img src=\"https://i.loli.net/2018/04/22/5adc39aa3a220.png\" width = \"100%\" height ="
},
{
"path": "iOS/Objective-C/More-页面传值.md",
"chars": 5995,
"preview": "这篇文章来梳理一番在iOS页面间的传值方式,说到页面传值,不管在任何平台开发中都是一个非常的重要的事情,这就让我想起了当初大一那会儿对Qt\u001e还不够熟悉,居然对两个Window之间的传值用了一个全局变量来实现,然后在其它Window中显式声明"
},
{
"path": "iOS/Objective-C/Objective-C注意点.md",
"chars": 29703,
"preview": "本篇文章为我在日常coding过程中使用OC进行了一些骚操作或者被虐得很惨的记录,可能会记得比较乱,因为有时候我也不知道应该怎么分类,但是我会努力哒!(๑•̀ㅂ•́)و✧\n\n1. 实例对象所属的类成为类对象,而类对象所属的类被成为元类`Me"
},
{
"path": "iOS/Objective-C/ping.md",
"chars": 10412,
"preview": "**这篇文章是我在项目中需要判断内外网环境根据网上的资料及自己的改造所得结果,有些不足之处望指出。**\n\n使用`ping`命令来检测数据包(ICMP,Internet Control Message Protocol,互联网控制报文协议)能"
},
{
"path": "iOS/Objective-C/runtime.md",
"chars": 3633,
"preview": "# Runtime\n我终于来啃这个大骨头了,从开始学 iOS 开发起,`runtime` 和 `runloop` 一直挥之不去,网络上的各种资料写的关于这两个方向的内容也十分庞大,弄得我一直不敢碰(梳理)。趁着最近时间较充裕,学习学习 `r"
},
{
"path": "iOS/Objective-C/tips-自定义tabBar大加号引发的思考.md",
"chars": 10075,
"preview": "## 前言\n最近在琢磨一些之前非常想玩的点,最让我感到有趣的是天朝才有的 tabBar 中间大加号,而且我还发现好像咸鱼的没做好,如果我们去点击咸鱼中间的加号上边部分,会发现其实是没有响应的,必须要点进 tabBar 里边才能被响应到。其实"
},
{
"path": "iOS/Objective-C/并发编程.md",
"chars": 1299,
"preview": "## 简介\n明确几个概念:\n\n* **进程**:进程是资源拥有单位,同一个进程内的线程共享进程里的资源。\n\n* **线程**:线程是资源分配的最小单元,CPU调度的基本\n\n* **多线程** 多线程是针对单核CPU设计的,目的是是为了让CP"
},
{
"path": "iOS/Objective-C/系统相关.md",
"chars": 15424,
"preview": "# 系统相关\n在这里记录了跟 Apple 相关操作系统中遇到的问题和记录。\n\n### iOS中的内存区域划分,如下图所示:\n<img src=\"https://i.loli.net/2018/04/08/5aca1d572b81b.jpeg"
},
{
"path": "iOS/Swift/Cache.md",
"chars": 207,
"preview": "# Cache\n缓存相关内容\n\n1. CPU 接收到指令后,它会最先像 CPU 中的一级缓存(L1 Cache)去寻找相关的数据,虽然一级缓存是与 CPU 同频运行的,但由于容量小,所有不可能每次都命中。这是 CPU 会继续向下一级的二级缓"
},
{
"path": "iOS/Swift/CoreData.md",
"chars": 4481,
"preview": "# CoreData\n\n* 要把 `Core Data` 作为一个对象图管理系统来使用,而不是关系型数据库\n\n* `Core Data` 的架构图:\n.md",
"chars": 8391,
"preview": "> 这个组件做的实在是太久了,最近终于从一大堆事儿中慢慢的恢复过来了,继续肝!\n\n## 前言\n\n这次的组件开发换了个思路继续精进,也还是 `MVC` 的模式,前段时间自己非常纠结到底哪种模式才是“最佳”设计模式?翻阅了大量资料,后来在[这篇"
},
{
"path": "iOS/Swift/PhotosKit开发总结(一).md",
"chars": 8391,
"preview": "> 这个组件做的实在是太久了,最近终于从一大堆事儿中慢慢的恢复过来了,继续肝!\n\n## 前言\n\n这次的组件开发换了个思路继续精进,也还是 `MVC` 的模式,前段时间自己非常纠结到底哪种模式才是“最佳”设计模式?翻阅了大量资料,后来在[这篇"
},
{
"path": "iOS/Swift/Playgrounds.md",
"chars": 167,
"preview": "这里汇集了我感兴趣的各种 Playgrounds repo 合集,在 mac 或 iPad Swift Playgrounds 上做出一些不同的东西是一件非常有特殊意义的事情。\n\n* [Pwnground](https://github.c"
},
{
"path": "iOS/Swift/SpriteKit.md",
"chars": 2278,
"preview": "## Sprite Kit\n这篇文章将记录我在使用 `Sprite Kit` 过程中遇到的问题和解决方法。\n\n### 初始化一个场景\n\n```Swift\nprivate func initScene() {\n let scnV"
},
{
"path": "iOS/Swift/SwiftUI.md",
"chars": 14449,
"preview": "# SwiftUI 注意点\n\n## 前言\n`SwiftUI` 让我找到了初学 iOS 开发时的乐趣。强烈推荐:[SWIFTUI BY EXAMPLE](https://www.hackingwithswift.com/quick-start"
},
{
"path": "iOS/Swift/Swift注意点.md",
"chars": 28373,
"preview": "# Swift\n\n这篇文章主要记录我在学习Swift的一些记录、Swift是14年的WWDC上苹果推出的一门新语言,这是一门非常新的语言,而且在不停的发展当中,对新手非常的友好,可以断定的是Swift将来一定是苹果推的主流开发语言。Obje"
},
{
"path": "iOS/Swift/UIDynamic.md",
"chars": 1234,
"preview": "## UI Dynamic\n这篇文章中将记录我在使用 UI Dynamic 功能进行编码时遇到的问题。\n\n### 简介\n在使用 UIDynamic 时需要有一个全局的动画者,把我们需要发生的动态行为 `UIGravityBehavior` "
},
{
"path": "iOS/Swift/code.md",
"chars": 534,
"preview": "# 有趣的代码段\n\n### `Bool` 怎么转 `Int`\n```swift\nreturn boolValue ? 1 : 0\n```\n\n### `Int` 怎么转 `Bool`\n```swift\nreturn intValue != 0"
},
{
"path": "iOS/Swift/debug.md",
"chars": 395,
"preview": "## Swift 调试\n\n## lldb\nOC 代码中可以很方便的直接通过发消息的方式调用私有方法,但 Swift 中却因为静态语言的原因无法直接通过类似 OC 中发消息的方式调用私有方法,但 apple 对 Swift 保留了通过 `pe"
},
{
"path": "iOS/Swift/landscapeandportrait.md",
"chars": 976,
"preview": "# 横竖屏切换的一些思考\n最近在优化负责产品中的横竖屏切换功能,这部分是最开始接手这个产品时的第一个功能,过去了一年多了,有很多架构上不完整的地方,其中最忍受不了的是在 `Notification` 中使用中文作为 `value`。下文将详"
},
{
"path": "iOS/Swift/tips.md",
"chars": 1004,
"preview": "## 小功能实现细节\n\n## 悬浮窗口\n类似网易云桌面悬浮单词,本质上都是基于画中画做的,第一种方案是把 view 转视频,按时塞帧,第二种方案是直接获取 pip window 贴自定义 view。\n\n可见:[https://github."
},
{
"path": "iOS/Swift/七牛图片上传助手.md",
"chars": 276,
"preview": "# 七牛图片上传助手\n\npodfile 中需要使用 `use_frameworks!`\n\n```ruby\nplatform :ios, '10.0'\ntarget 'PIGPEN' do\n use_frameworks!\n\n p"
},
{
"path": "iOS/Swift/品种选择器总结.md",
"chars": 6081,
"preview": "# 品种选择器组件开发历程\n这是我另外一个项目其中一个组件——品种选择器,因为今天是周六,磨磨唧唧的造出了它。一眼看过去跟现有的通讯录样式和操作方式基本一致,但大家也知道我的尿性,从最开始能用三方组件就用三方到现在能自己写就自己写。\n\n因为"
},
{
"path": "iOS/Swift/自定义NavigationBar.md",
"chars": 1339,
"preview": "## 自定义 NavigationBar\n自定义 NavigationBar 几乎已经存在 99% app 中,也可以说差不多的 app 或多或少都对原生 NavigationBar 做了一些改造工作。在这篇文章中我将总结我在项目中遇到的需"
},
{
"path": "iOS/Today_Extension.md",
"chars": 784,
"preview": "## 这篇文章将记录我在进行 Today Extension 开发时遇到的问题\n\n### 自定义视图\n一般来说,我们都不会去使用 SB 来搭建界面,几乎都是纯代码的方式直接手撸,因为这样会更加直观一些,而且也更加易于协作,虽然效率上确实会确"
},
{
"path": "iOS/UI.md",
"chars": 2836,
"preview": "# UI\n\n### UIKit 架构图\n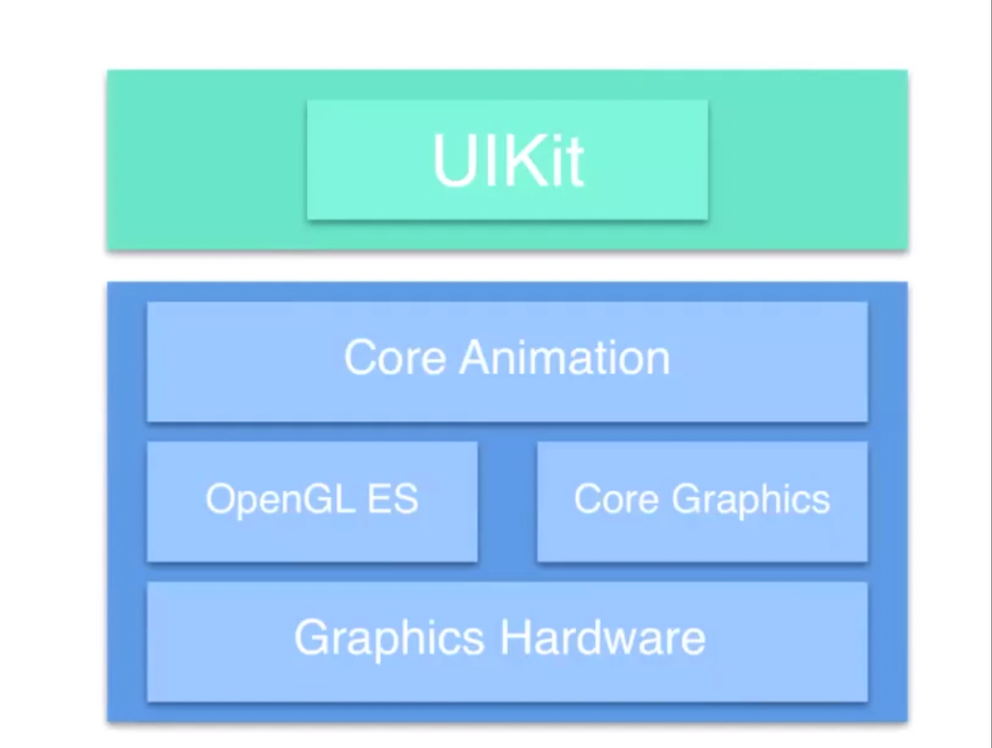\n\n## 布局\n### 界面布局(frame)\n* `setNeed"
},
{
"path": "iOS/UICollectionView.md",
"chars": 1607,
"preview": "# UICollectionView 的使用、注意点和优化\n\n## 让 UICollectionView 进行滚动\n这是我今天刚遇到的问题,虽然 `UICollectionView` 是继承 `UIScrollView` 的,而且也有 `c"
},
{
"path": "iOS/UITableView.md",
"chars": 3661,
"preview": "本文主要总结在日常撸码中,遇到`UITableView`的各种需求demo及各种问题和骚操作集合。持续更新中......\n\n## 差异\n\n### Android\n\n如果你有做过Android,那么`UITableView`就是`ListVi"
},
{
"path": "iOS/basic.md",
"chars": 1397,
"preview": "# iOS 基础\n强推 [Apple Developer Documentation](https://developer.apple.com/documentation/)\n\n## 名词解释\n* ipa:iPhone applicatio"
},
{
"path": "iOS/code.md",
"chars": 1616,
"preview": "# iOS 短代码集合\n\n## 查询当前最上层 VC\n\n```objc\n+ (UIViewController *)currentViewController {\n UIViewController* viewController ="
},
{
"path": "iOS/debug.md",
"chars": 50,
"preview": "## debug 技巧\n\n### `_shortMethodDescription`\n动态打印类信息"
},
{
"path": "iOS/system.md",
"chars": 160,
"preview": "## 系统架构\n\n### mach-O 文件\n macOS 和 iOS 和可执行文件。主要分为了三大块,Header、Load Command 和 Section。Header 的作用是配置和说明,Load Command 说明了需要加载的"
},
{
"path": "macOS/TranslateP.md",
"chars": 421,
"preview": "## TranslateP 开发过程\n\n## 选型\n使用 SwiftUI,因为 AppKit 实在是太难用了,痛苦。并且作为一个无主界面的 app,运行后只有菜单栏程序,使用[`MenuBarExtra`](https://develope"
},
{
"path": "macOS/basic.md",
"chars": 404,
"preview": "## 基础知识\n\n### 窗体\nmacOS 的窗体大小由内容决定,只需要限制窗体其中内容最小 size 即可。\n\n### 如何判断是否能引入一个库/平台类型\n\n```swift\n#if canImport(UIKit)\nimport UIK"
},
{
"path": "macOS/crash.md",
"chars": 3487,
"preview": "# 解析 crash log(一)\n## 前言\n在负责的产品中有最近一段时间有极个别用户老是反馈有偶尔闪退的情况,而且就这几个用户反复出现,其它用户,甚至就坐在他边上的用户进行了一样的操作都没有任何问题。\n\n刚开始丢了个重现构建的新包给这几"
},
{
"path": "macOS/kindle.md",
"chars": 274,
"preview": "# kindle\n\n以后可能会做个 kindle 管理的小工具吧,这里记录一下提前了解到的知识和思考的内容。\n\n## 如何读取 kindle 标注?\n有很多管理 kindle 标注的处理软件,几乎都需要在 mac 上使用 USB 连接 ki"
},
{
"path": "macOS/macOS开发(词法分析器).md",
"chars": 12584,
"preview": "这是我的第一个存粹基于Swift的project,重点是用Swift进行macOS的开发,而不是词法分析器。\n\n对于开发桌面应用来说,目前可供参考的框有windows原生“古老的”MFC、常规的跨平台Qt、目前最火的跨平台[electron"
},
{
"path": "macOS/performance.md",
"chars": 2270,
"preview": "# iOS 和 macOS 性能优化\n\n## 命令行工具\n### `top`\n`top` 命令能够连续动态地更新显示大量有关系统性能的参数。`top -u` 能够把 CPU 当前的占用比排序,置顶最活跃的进程。\n\n### `time`\n使用"
},
{
"path": "macOS/playground.md",
"chars": 3461,
"preview": "# 来一次完整的使用 Playground(一)\n## 简介\n在使用 `Xcode Playground` 进行 WWDC 2019 scholarship 项目的开发时,原本以为 apple 指定的 Xcode 10.1 版本上会有不错的"
},
{
"path": "macOS/一台设备多个git账号.md",
"chars": 1019,
"preview": "# 一台设备多个 git 账号\n## 取消全局用户信息\n```shell\n# 通过以下语句查看设置的账户信息\n$ git config --global user.name\n$ git config --global user.email\n"
},
{
"path": "ruby/basic.md",
"chars": 1375,
"preview": "# Ruby\n\n## 概念\n### 使用 `irb` 进入交互式终端环境\n\n### 单引号和双引号的区别\n单引号可以直接把包括的特殊字符进行输出。\n\n### `print`、`puts` 和 `p` 的区别\n* 使用 `p` 进行输出,特殊"
}
]
About this extraction
This page contains the full source code of the windstormeye/iOS-Course GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 151 files (612.8 KB), approximately 284.7k tokens. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.