![]()
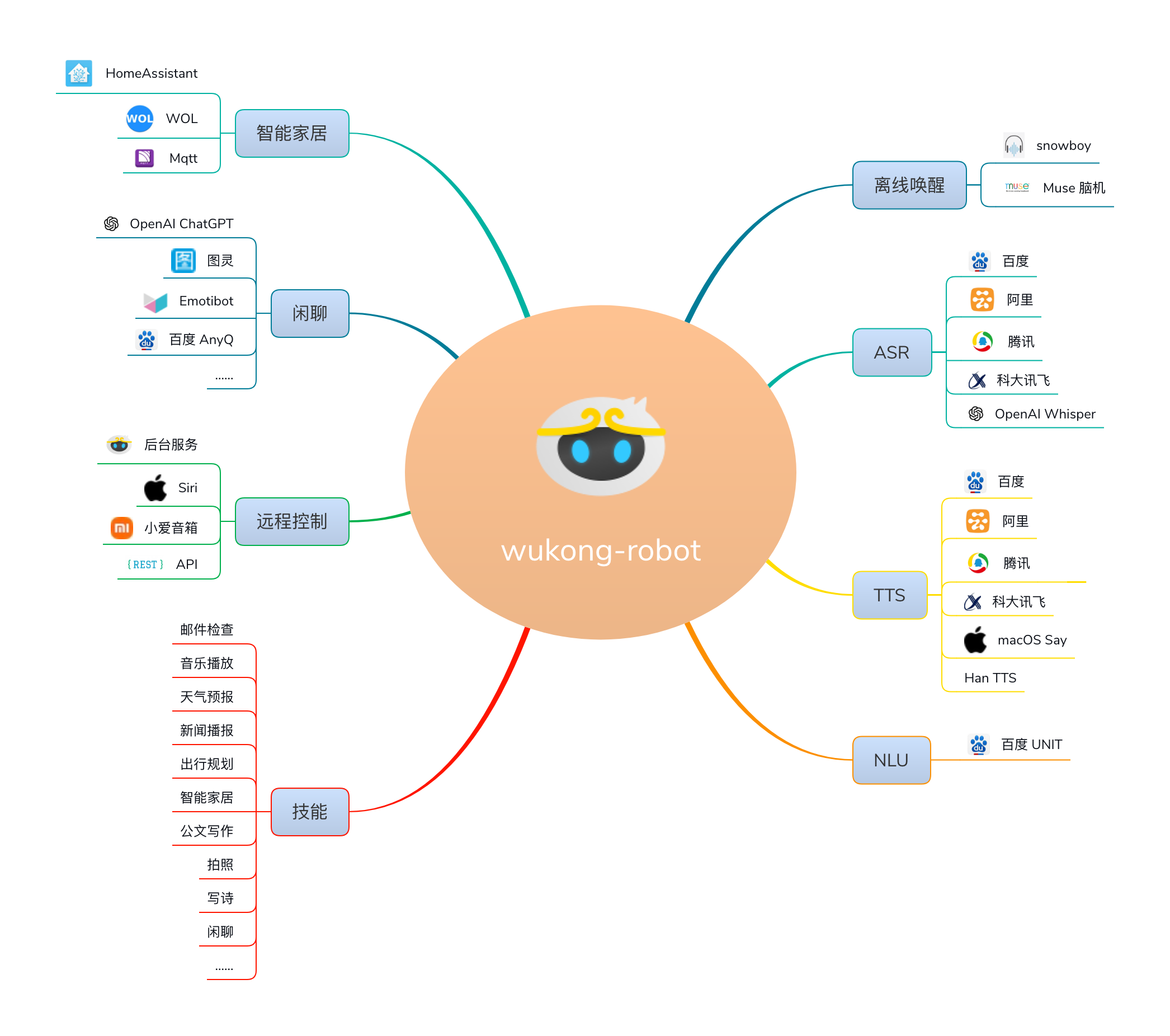
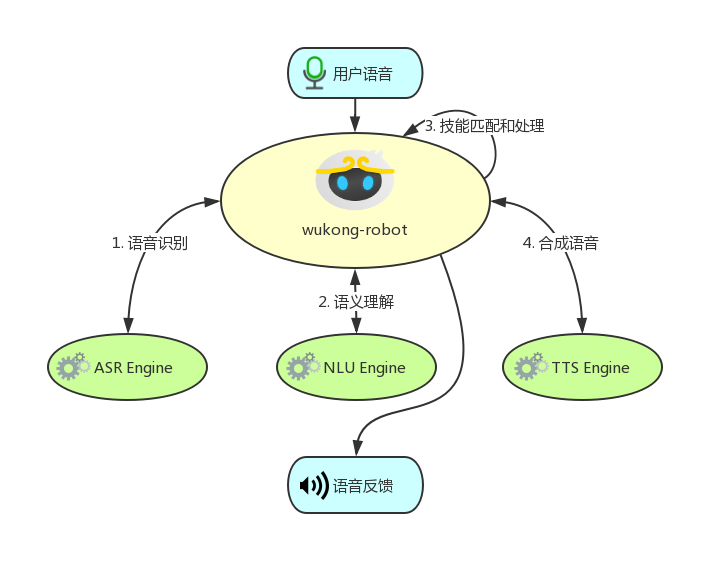
wukong-robot 是一个简单、灵活、优雅的中文语音对话机器人/智能音箱项目,目的是让中国的 Maker 和 Haker 们也能快速打造个性化的智能音箱。wukong-robot 还可能是第一个开源的脑机唤醒智能音箱。
截至 2023 年 3 月 31 日,wukong-robot 的安装设备数已超过 13,000 台,唤醒次数累积超过了 700,000 次。
![]()
![]()
![]()

![]()


 |
|  |
如果以上的图裂了,可以下载图片([支付宝](http://hahack.com/images/misc/alipay.png) | [微信](http://hahack.com/images/misc/wechatpay.jpeg))到本地进行扫描。
* 对于企业用户,建议[成为这个项目的 backer](https://opencollective.com/wukong-robot/contribute/tier/8131-sponsor),您将可以把一个带链接的 logo 放在 wukong-robot 后台管理端的首页、捐赠页面以及 Github 项目首页中。
|
如果以上的图裂了,可以下载图片([支付宝](http://hahack.com/images/misc/alipay.png) | [微信](http://hahack.com/images/misc/wechatpay.jpeg))到本地进行扫描。
* 对于企业用户,建议[成为这个项目的 backer](https://opencollective.com/wukong-robot/contribute/tier/8131-sponsor),您将可以把一个带链接的 logo 放在 wukong-robot 后台管理端的首页、捐赠页面以及 Github 项目首页中。
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
| |
如果以上的图裂了,可以下载图片([支付宝](http://hahack.com/images/misc/alipay.png) | [微信](http://hahack.com/images/misc/wechatpay.jpeg))到本地进行扫描。
## 感谢
* 悟空的前身是 [dingdang-robot](https://github.com/dingdang-robot/dingdang-robot) 项目和 [jasper-client](https://github.com/jasperproject/jasper-client) 项目。感谢 [Shubhro Saha](http://www.shubhro.com/), [Charles Marsh](http://www.crmarsh.com/) and [Jan Holthuis](http://homepage.ruhr-uni-bochum.de/Jan.Holthuis/) 在 Jasper 项目上做出的优秀贡献;
* 感谢三咲智子提供了备选的后台管理端 Demo 体验地址。
* 感谢 aliciacai 贡献的 wukong-robot 图标。
* 感谢所有为[本项目](https://github.com/wzpan/wukong-robot/graphs/contributors)、 [wukong-contrib](https://github.com/wzpan/wukong-contrib/graphs/contributors) 项目以及[dingdang-robot](https://github.com/dingdang-robot/dingdang-robot/graphs/contributors) 项目做出过贡献的人!
## Star 历史
[](https://star-history.com/#wzpan/wukong-robot&Date)
## 免责声明
* wukong-robot 只用作个人学习研究,如因使用 wukong-robot 导致任何损失,本人概不负责。
* 本开源项目与腾讯叮当助手及优必选悟空项目没有任何关系。
================================================
FILE: VERSION
================================================
3.5.3
================================================
FILE: docker/Dockerfile
================================================
# 使用官方 Python 3.8 基础镜像
FROM python:3.8-slim
# 设置工作目录
WORKDIR /app
# 安装依赖库
RUN apt-get update && apt-get install -y \
git \
portaudio19-dev \
python3-pyaudio \
sox \
pulseaudio \
libsox-fmt-all \
ffmpeg \
wget \
swig \
libpcre3 \
libpcre3-dev \
libatlas-base-dev \
build-essential \
&& rm -rf /var/lib/apt/lists/*
# 克隆项目仓库
RUN git clone https://github.com/wzpan/wukong-robot.git .
# 安装 PyAudio
RUN pip install pyaudio
# 安装 Python 依赖
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# 安装 wukong-contrib
RUN mkdir -p $HOME/.wukong \
&& cd $HOME/.wukong \
&& git clone http://github.com/wzpan/wukong-contrib.git contrib \
&& pip install -r contrib/requirements.txt
# 下载并编译 snowboy
RUN wget https://wzpan-1253537070.cos.ap-guangzhou.myqcloud.com/misc/snowboy.tar.bz2 \
&& tar -xvjf snowboy.tar.bz2 \
&& cd snowboy/swig/Python3 \
&& make \
&& cp _snowboydetect.so /app/snowboy/
# 暴露端口
EXPOSE 5001
# 设置 ENTRYPOINT
ENTRYPOINT ["python", "wukong.py"]
================================================
FILE: docker/DockerfileArm
================================================
# 使用官方 Python 3.8 基于 ARM 的镜像
FROM arm32v7/python:3.8-slim
MAINTAINER wzpan
# 设置工作目录
WORKDIR /app
# 安装依赖库
RUN apt-get update && apt-get install -y \
git \
portaudio19-dev \
python3-pyaudio \
sox \
pulseaudio \
libsox-fmt-all \
ffmpeg \
wget \
swig \
libpcre3 \
libpcre3-dev \
libatlas-base-dev \
libffi-dev \
build-essential \
&& rm -rf /var/lib/apt/lists/*
# 克隆项目仓库
RUN git clone https://github.com/wzpan/wukong-robot.git .
# 安装 PyAudio
RUN pip install pyaudio
# 安装 Python 依赖
RUN pip install --trusted-host pypi.python.org -r requirements.txt
# 安装 wukong-contrib
RUN mkdir -p $HOME/.wukong \
&& cd $HOME/.wukong \
&& git clone http://github.com/wzpan/wukong-contrib.git contrib \
&& pip install -r contrib/requirements.txt
# 下载并编译 snowboy
RUN wget https://wzpan-1253537070.cos.ap-guangzhou.myqcloud.com/misc/snowboy.tar.bz2 \
&& tar -xvjf snowboy.tar.bz2 \
&& cd snowboy/swig/Python3 \
&& make \
&& cp _snowboydetect.so /app/snowboy/
# 暴露端口
EXPOSE 5001
# 设置 ENTRYPOINT
ENTRYPOINT ["python", "wukong.py"]
================================================
FILE: docs/.buildinfo
================================================
# Sphinx build info version 1
# This file hashes the configuration used when building these files. When it is not found, a full rebuild will be done.
config: bed81550a26bd552fac818a5876d05a1
tags: 645f666f9bcd5a90fca523b33c5a78b7
================================================
FILE: docs/.nojekyll
================================================
================================================
FILE: docs/AI.html
================================================
# Copyright 2001-2016 by Vinay Sajip. All Rights Reserved.
#
# Permission to use, copy, modify, and distribute this software and its
# documentation for any purpose and without fee is hereby granted,
# provided that the above copyright notice appear in all copies and that
# both that copyright notice and this permission notice appear in
# supporting documentation, and that the name of Vinay Sajip
# not be used in advertising or publicity pertaining to distribution
# of the software without specific, written prior permission.
# VINAY SAJIP DISCLAIMS ALL WARRANTIES WITH REGARD TO THIS SOFTWARE, INCLUDING
# ALL IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL
# VINAY SAJIP BE LIABLE FOR ANY SPECIAL, INDIRECT OR CONSEQUENTIAL DAMAGES OR
# ANY DAMAGES WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER
# IN AN ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT
# OF OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.
"""
Logging package for Python. Based on PEP 282 and comments thereto in
comp.lang.python.
Copyright (C) 2001-2016 Vinay Sajip. All Rights Reserved.
To use, simply 'import logging' and log away!
"""
import sys, os, time, io, traceback, warnings, weakref, collections
from string import Template
__all__ = ['BASIC_FORMAT', 'BufferingFormatter', 'CRITICAL', 'DEBUG', 'ERROR',
'FATAL', 'FileHandler', 'Filter', 'Formatter', 'Handler', 'INFO',
'LogRecord', 'Logger', 'LoggerAdapter', 'NOTSET', 'NullHandler',
'StreamHandler', 'WARN', 'WARNING', 'addLevelName', 'basicConfig',
'captureWarnings', 'critical', 'debug', 'disable', 'error',
'exception', 'fatal', 'getLevelName', 'getLogger', 'getLoggerClass',
'info', 'log', 'makeLogRecord', 'setLoggerClass', 'warn', 'warning',
'getLogRecordFactory', 'setLogRecordFactory', 'lastResort']
try:
import threading
except ImportError: #pragma: no cover
threading = None
__author__ = "Vinay Sajip <vinay_sajip@red-dove.com>"
__status__ = "production"
# The following module attributes are no longer updated.
__version__ = "0.5.1.2"
__date__ = "07 February 2010"
#---------------------------------------------------------------------------
# Miscellaneous module data
#---------------------------------------------------------------------------
#
#_startTime is used as the base when calculating the relative time of events
#
_startTime = time.time()
#
#raiseExceptions is used to see if exceptions during handling should be
#propagated
#
raiseExceptions = True
#
# If you don't want threading information in the log, set this to zero
#
logThreads = True
#
# If you don't want multiprocessing information in the log, set this to zero
#
logMultiprocessing = True
#
# If you don't want process information in the log, set this to zero
#
logProcesses = True
#---------------------------------------------------------------------------
# Level related stuff
#---------------------------------------------------------------------------
#
# Default levels and level names, these can be replaced with any positive set
# of values having corresponding names. There is a pseudo-level, NOTSET, which
# is only really there as a lower limit for user-defined levels. Handlers and
# loggers are initialized with NOTSET so that they will log all messages, even
# at user-defined levels.
#
CRITICAL = 50
FATAL = CRITICAL
ERROR = 40
WARNING = 30
WARN = WARNING
INFO = 20
DEBUG = 10
NOTSET = 0
_levelToName = {
CRITICAL: 'CRITICAL',
ERROR: 'ERROR',
WARNING: 'WARNING',
INFO: 'INFO',
DEBUG: 'DEBUG',
NOTSET: 'NOTSET',
}
_nameToLevel = {
'CRITICAL': CRITICAL,
'ERROR': ERROR,
'WARN': WARNING,
'WARNING': WARNING,
'INFO': INFO,
'DEBUG': DEBUG,
'NOTSET': NOTSET,
}
[文档]def getLevelName(level):
"""
Return the textual representation of logging level 'level'.
If the level is one of the predefined levels (CRITICAL, ERROR, WARNING,
INFO, DEBUG) then you get the corresponding string. If you have
associated levels with names using addLevelName then the name you have
associated with 'level' is returned.
If a numeric value corresponding to one of the defined levels is passed
in, the corresponding string representation is returned.
Otherwise, the string "Level %s" % level is returned.
"""
# See Issues #22386 and #27937 for why it's this way
return (_levelToName.get(level) or _nameToLevel.get(level) or
"Level %s" % level)
[文档]def addLevelName(level, levelName):
"""
Associate 'levelName' with 'level'.
This is used when converting levels to text during message formatting.
"""
_acquireLock()
try: #unlikely to cause an exception, but you never know...
_levelToName[level] = levelName
_nameToLevel[levelName] = level
finally:
_releaseLock()
if hasattr(sys, '_getframe'):
currentframe = lambda: sys._getframe(3)
else: #pragma: no cover
def currentframe():
"""Return the frame object for the caller's stack frame."""
try:
raise Exception
except Exception:
return sys.exc_info()[2].tb_frame.f_back
#
# _srcfile is used when walking the stack to check when we've got the first
# caller stack frame, by skipping frames whose filename is that of this
# module's source. It therefore should contain the filename of this module's
# source file.
#
# Ordinarily we would use __file__ for this, but frozen modules don't always
# have __file__ set, for some reason (see Issue #21736). Thus, we get the
# filename from a handy code object from a function defined in this module.
# (There's no particular reason for picking addLevelName.)
#
_srcfile = os.path.normcase(addLevelName.__code__.co_filename)
# _srcfile is only used in conjunction with sys._getframe().
# To provide compatibility with older versions of Python, set _srcfile
# to None if _getframe() is not available; this value will prevent
# findCaller() from being called. You can also do this if you want to avoid
# the overhead of fetching caller information, even when _getframe() is
# available.
#if not hasattr(sys, '_getframe'):
# _srcfile = None
def _checkLevel(level):
if isinstance(level, int):
rv = level
elif str(level) == level:
if level not in _nameToLevel:
raise ValueError("Unknown level: %r" % level)
rv = _nameToLevel[level]
else:
raise TypeError("Level not an integer or a valid string: %r" % level)
return rv
#---------------------------------------------------------------------------
# Thread-related stuff
#---------------------------------------------------------------------------
#
#_lock is used to serialize access to shared data structures in this module.
#This needs to be an RLock because fileConfig() creates and configures
#Handlers, and so might arbitrary user threads. Since Handler code updates the
#shared dictionary _handlers, it needs to acquire the lock. But if configuring,
#the lock would already have been acquired - so we need an RLock.
#The same argument applies to Loggers and Manager.loggerDict.
#
if threading:
_lock = threading.RLock()
else: #pragma: no cover
_lock = None
def _acquireLock():
"""
Acquire the module-level lock for serializing access to shared data.
This should be released with _releaseLock().
"""
if _lock:
_lock.acquire()
def _releaseLock():
"""
Release the module-level lock acquired by calling _acquireLock().
"""
if _lock:
_lock.release()
#---------------------------------------------------------------------------
# The logging record
#---------------------------------------------------------------------------
[文档]class LogRecord(object):
"""
A LogRecord instance represents an event being logged.
LogRecord instances are created every time something is logged. They
contain all the information pertinent to the event being logged. The
main information passed in is in msg and args, which are combined
using str(msg) % args to create the message field of the record. The
record also includes information such as when the record was created,
the source line where the logging call was made, and any exception
information to be logged.
"""
def __init__(self, name, level, pathname, lineno,
msg, args, exc_info, func=None, sinfo=None, **kwargs):
"""
Initialize a logging record with interesting information.
"""
ct = time.time()
self.name = name
self.msg = msg
#
# The following statement allows passing of a dictionary as a sole
# argument, so that you can do something like
# logging.debug("a %(a)d b %(b)s", {'a':1, 'b':2})
# Suggested by Stefan Behnel.
# Note that without the test for args[0], we get a problem because
# during formatting, we test to see if the arg is present using
# 'if self.args:'. If the event being logged is e.g. 'Value is %d'
# and if the passed arg fails 'if self.args:' then no formatting
# is done. For example, logger.warning('Value is %d', 0) would log
# 'Value is %d' instead of 'Value is 0'.
# For the use case of passing a dictionary, this should not be a
# problem.
# Issue #21172: a request was made to relax the isinstance check
# to hasattr(args[0], '__getitem__'). However, the docs on string
# formatting still seem to suggest a mapping object is required.
# Thus, while not removing the isinstance check, it does now look
# for collections.Mapping rather than, as before, dict.
if (args and len(args) == 1 and isinstance(args[0], collections.Mapping)
and args[0]):
args = args[0]
self.args = args
self.levelname = getLevelName(level)
self.levelno = level
self.pathname = pathname
try:
self.filename = os.path.basename(pathname)
self.module = os.path.splitext(self.filename)[0]
except (TypeError, ValueError, AttributeError):
self.filename = pathname
self.module = "Unknown module"
self.exc_info = exc_info
self.exc_text = None # used to cache the traceback text
self.stack_info = sinfo
self.lineno = lineno
self.funcName = func
self.created = ct
self.msecs = (ct - int(ct)) * 1000
self.relativeCreated = (self.created - _startTime) * 1000
if logThreads and threading:
self.thread = threading.get_ident()
self.threadName = threading.current_thread().name
else: # pragma: no cover
self.thread = None
self.threadName = None
if not logMultiprocessing: # pragma: no cover
self.processName = None
else:
self.processName = 'MainProcess'
mp = sys.modules.get('multiprocessing')
if mp is not None:
# Errors may occur if multiprocessing has not finished loading
# yet - e.g. if a custom import hook causes third-party code
# to run when multiprocessing calls import. See issue 8200
# for an example
try:
self.processName = mp.current_process().name
except Exception: #pragma: no cover
pass
if logProcesses and hasattr(os, 'getpid'):
self.process = os.getpid()
else:
self.process = None
def __str__(self):
return '<LogRecord: %s, %s, %s, %s, "%s">'%(self.name, self.levelno,
self.pathname, self.lineno, self.msg)
__repr__ = __str__
[文档] def getMessage(self):
"""
Return the message for this LogRecord.
Return the message for this LogRecord after merging any user-supplied
arguments with the message.
"""
msg = str(self.msg)
if self.args:
msg = msg % self.args
return msg
#
# Determine which class to use when instantiating log records.
#
_logRecordFactory = LogRecord
[文档]def setLogRecordFactory(factory):
"""
Set the factory to be used when instantiating a log record.
:param factory: A callable which will be called to instantiate
a log record.
"""
global _logRecordFactory
_logRecordFactory = factory
[文档]def getLogRecordFactory():
"""
Return the factory to be used when instantiating a log record.
"""
return _logRecordFactory
[文档]def makeLogRecord(dict):
"""
Make a LogRecord whose attributes are defined by the specified dictionary,
This function is useful for converting a logging event received over
a socket connection (which is sent as a dictionary) into a LogRecord
instance.
"""
rv = _logRecordFactory(None, None, "", 0, "", (), None, None)
rv.__dict__.update(dict)
return rv
#---------------------------------------------------------------------------
# Formatter classes and functions
#---------------------------------------------------------------------------
class PercentStyle(object):
default_format = '%(message)s'
asctime_format = '%(asctime)s'
asctime_search = '%(asctime)'
def __init__(self, fmt):
self._fmt = fmt or self.default_format
def usesTime(self):
return self._fmt.find(self.asctime_search) >= 0
def format(self, record):
return self._fmt % record.__dict__
class StrFormatStyle(PercentStyle):
default_format = '{message}'
asctime_format = '{asctime}'
asctime_search = '{asctime'
def format(self, record):
return self._fmt.format(**record.__dict__)
class StringTemplateStyle(PercentStyle):
default_format = '${message}'
asctime_format = '${asctime}'
asctime_search = '${asctime}'
def __init__(self, fmt):
self._fmt = fmt or self.default_format
self._tpl = Template(self._fmt)
def usesTime(self):
fmt = self._fmt
return fmt.find('$asctime') >= 0 or fmt.find(self.asctime_format) >= 0
def format(self, record):
return self._tpl.substitute(**record.__dict__)
BASIC_FORMAT = "%(levelname)s:%(name)s:%(message)s"
_STYLES = {
'%': (PercentStyle, BASIC_FORMAT),
'{': (StrFormatStyle, '{levelname}:{name}:{message}'),
'$': (StringTemplateStyle, '${levelname}:${name}:${message}'),
}
[文档]class Formatter(object):
"""
Formatter instances are used to convert a LogRecord to text.
Formatters need to know how a LogRecord is constructed. They are
responsible for converting a LogRecord to (usually) a string which can
be interpreted by either a human or an external system. The base Formatter
allows a formatting string to be specified. If none is supplied, the
default value of "%s(message)" is used.
The Formatter can be initialized with a format string which makes use of
knowledge of the LogRecord attributes - e.g. the default value mentioned
above makes use of the fact that the user's message and arguments are pre-
formatted into a LogRecord's message attribute. Currently, the useful
attributes in a LogRecord are described by:
%(name)s Name of the logger (logging channel)
%(levelno)s Numeric logging level for the message (DEBUG, INFO,
WARNING, ERROR, CRITICAL)
%(levelname)s Text logging level for the message ("DEBUG", "INFO",
"WARNING", "ERROR", "CRITICAL")
%(pathname)s Full pathname of the source file where the logging
call was issued (if available)
%(filename)s Filename portion of pathname
%(module)s Module (name portion of filename)
%(lineno)d Source line number where the logging call was issued
(if available)
%(funcName)s Function name
%(created)f Time when the LogRecord was created (time.time()
return value)
%(asctime)s Textual time when the LogRecord was created
%(msecs)d Millisecond portion of the creation time
%(relativeCreated)d Time in milliseconds when the LogRecord was created,
relative to the time the logging module was loaded
(typically at application startup time)
%(thread)d Thread ID (if available)
%(threadName)s Thread name (if available)
%(process)d Process ID (if available)
%(message)s The result of record.getMessage(), computed just as
the record is emitted
"""
converter = time.localtime
def __init__(self, fmt=None, datefmt=None, style='%'):
"""
Initialize the formatter with specified format strings.
Initialize the formatter either with the specified format string, or a
default as described above. Allow for specialized date formatting with
the optional datefmt argument (if omitted, you get the ISO8601 format).
Use a style parameter of '%', '{' or '$' to specify that you want to
use one of %-formatting, :meth:`str.format` (``{}``) formatting or
:class:`string.Template` formatting in your format string.
.. versionchanged:: 3.2
Added the ``style`` parameter.
"""
if style not in _STYLES:
raise ValueError('Style must be one of: %s' % ','.join(
_STYLES.keys()))
self._style = _STYLES[style][0](fmt)
self._fmt = self._style._fmt
self.datefmt = datefmt
default_time_format = '%Y-%m-%d %H:%M:%S'
default_msec_format = '%s,%03d'
[文档] def formatTime(self, record, datefmt=None):
"""
Return the creation time of the specified LogRecord as formatted text.
This method should be called from format() by a formatter which
wants to make use of a formatted time. This method can be overridden
in formatters to provide for any specific requirement, but the
basic behaviour is as follows: if datefmt (a string) is specified,
it is used with time.strftime() to format the creation time of the
record. Otherwise, the ISO8601 format is used. The resulting
string is returned. This function uses a user-configurable function
to convert the creation time to a tuple. By default, time.localtime()
is used; to change this for a particular formatter instance, set the
'converter' attribute to a function with the same signature as
time.localtime() or time.gmtime(). To change it for all formatters,
for example if you want all logging times to be shown in GMT,
set the 'converter' attribute in the Formatter class.
"""
ct = self.converter(record.created)
if datefmt:
s = time.strftime(datefmt, ct)
else:
t = time.strftime(self.default_time_format, ct)
s = self.default_msec_format % (t, record.msecs)
return s
[文档] def formatException(self, ei):
"""
Format and return the specified exception information as a string.
This default implementation just uses
traceback.print_exception()
"""
sio = io.StringIO()
tb = ei[2]
# See issues #9427, #1553375. Commented out for now.
#if getattr(self, 'fullstack', False):
# traceback.print_stack(tb.tb_frame.f_back, file=sio)
traceback.print_exception(ei[0], ei[1], tb, None, sio)
s = sio.getvalue()
sio.close()
if s[-1:] == "\n":
s = s[:-1]
return s
[文档] def usesTime(self):
"""
Check if the format uses the creation time of the record.
"""
return self._style.usesTime()
[文档] def formatStack(self, stack_info):
"""
This method is provided as an extension point for specialized
formatting of stack information.
The input data is a string as returned from a call to
:func:`traceback.print_stack`, but with the last trailing newline
removed.
The base implementation just returns the value passed in.
"""
return stack_info
[文档] def format(self, record):
"""
Format the specified record as text.
The record's attribute dictionary is used as the operand to a
string formatting operation which yields the returned string.
Before formatting the dictionary, a couple of preparatory steps
are carried out. The message attribute of the record is computed
using LogRecord.getMessage(). If the formatting string uses the
time (as determined by a call to usesTime(), formatTime() is
called to format the event time. If there is exception information,
it is formatted using formatException() and appended to the message.
"""
record.message = record.getMessage()
if self.usesTime():
record.asctime = self.formatTime(record, self.datefmt)
s = self.formatMessage(record)
if record.exc_info:
# Cache the traceback text to avoid converting it multiple times
# (it's constant anyway)
if not record.exc_text:
record.exc_text = self.formatException(record.exc_info)
if record.exc_text:
if s[-1:] != "\n":
s = s + "\n"
s = s + record.exc_text
if record.stack_info:
if s[-1:] != "\n":
s = s + "\n"
s = s + self.formatStack(record.stack_info)
return s
#
# The default formatter to use when no other is specified
#
_defaultFormatter = Formatter()
[文档]class BufferingFormatter(object):
"""
A formatter suitable for formatting a number of records.
"""
def __init__(self, linefmt=None):
"""
Optionally specify a formatter which will be used to format each
individual record.
"""
if linefmt:
self.linefmt = linefmt
else:
self.linefmt = _defaultFormatter
[文档] def formatHeader(self, records):
"""
Return the header string for the specified records.
"""
return ""
[文档] def format(self, records):
"""
Format the specified records and return the result as a string.
"""
rv = ""
if len(records) > 0:
rv = rv + self.formatHeader(records)
for record in records:
rv = rv + self.linefmt.format(record)
rv = rv + self.formatFooter(records)
return rv
#---------------------------------------------------------------------------
# Filter classes and functions
#---------------------------------------------------------------------------
[文档]class Filter(object):
"""
Filter instances are used to perform arbitrary filtering of LogRecords.
Loggers and Handlers can optionally use Filter instances to filter
records as desired. The base filter class only allows events which are
below a certain point in the logger hierarchy. For example, a filter
initialized with "A.B" will allow events logged by loggers "A.B",
"A.B.C", "A.B.C.D", "A.B.D" etc. but not "A.BB", "B.A.B" etc. If
initialized with the empty string, all events are passed.
"""
def __init__(self, name=''):
"""
Initialize a filter.
Initialize with the name of the logger which, together with its
children, will have its events allowed through the filter. If no
name is specified, allow every event.
"""
self.name = name
self.nlen = len(name)
[文档] def filter(self, record):
"""
Determine if the specified record is to be logged.
Is the specified record to be logged? Returns 0 for no, nonzero for
yes. If deemed appropriate, the record may be modified in-place.
"""
if self.nlen == 0:
return True
elif self.name == record.name:
return True
elif record.name.find(self.name, 0, self.nlen) != 0:
return False
return (record.name[self.nlen] == ".")
class Filterer(object):
"""
A base class for loggers and handlers which allows them to share
common code.
"""
def __init__(self):
"""
Initialize the list of filters to be an empty list.
"""
self.filters = []
def addFilter(self, filter):
"""
Add the specified filter to this handler.
"""
if not (filter in self.filters):
self.filters.append(filter)
def removeFilter(self, filter):
"""
Remove the specified filter from this handler.
"""
if filter in self.filters:
self.filters.remove(filter)
def filter(self, record):
"""
Determine if a record is loggable by consulting all the filters.
The default is to allow the record to be logged; any filter can veto
this and the record is then dropped. Returns a zero value if a record
is to be dropped, else non-zero.
.. versionchanged:: 3.2
Allow filters to be just callables.
"""
rv = True
for f in self.filters:
if hasattr(f, 'filter'):
result = f.filter(record)
else:
result = f(record) # assume callable - will raise if not
if not result:
rv = False
break
return rv
#---------------------------------------------------------------------------
# Handler classes and functions
#---------------------------------------------------------------------------
_handlers = weakref.WeakValueDictionary() #map of handler names to handlers
_handlerList = [] # added to allow handlers to be removed in reverse of order initialized
def _removeHandlerRef(wr):
"""
Remove a handler reference from the internal cleanup list.
"""
# This function can be called during module teardown, when globals are
# set to None. It can also be called from another thread. So we need to
# pre-emptively grab the necessary globals and check if they're None,
# to prevent race conditions and failures during interpreter shutdown.
acquire, release, handlers = _acquireLock, _releaseLock, _handlerList
if acquire and release and handlers:
acquire()
try:
if wr in handlers:
handlers.remove(wr)
finally:
release()
def _addHandlerRef(handler):
"""
Add a handler to the internal cleanup list using a weak reference.
"""
_acquireLock()
try:
_handlerList.append(weakref.ref(handler, _removeHandlerRef))
finally:
_releaseLock()
[文档]class Handler(Filterer):
"""
Handler instances dispatch logging events to specific destinations.
The base handler class. Acts as a placeholder which defines the Handler
interface. Handlers can optionally use Formatter instances to format
records as desired. By default, no formatter is specified; in this case,
the 'raw' message as determined by record.message is logged.
"""
def __init__(self, level=NOTSET):
"""
Initializes the instance - basically setting the formatter to None
and the filter list to empty.
"""
Filterer.__init__(self)
self._name = None
self.level = _checkLevel(level)
self.formatter = None
# Add the handler to the global _handlerList (for cleanup on shutdown)
_addHandlerRef(self)
self.createLock()
[文档] def set_name(self, name):
_acquireLock()
try:
if self._name in _handlers:
del _handlers[self._name]
self._name = name
if name:
_handlers[name] = self
finally:
_releaseLock()
name = property(get_name, set_name)
[文档] def createLock(self):
"""
Acquire a thread lock for serializing access to the underlying I/O.
"""
if threading:
self.lock = threading.RLock()
else: #pragma: no cover
self.lock = None
[文档] def setLevel(self, level):
"""
Set the logging level of this handler. level must be an int or a str.
"""
self.level = _checkLevel(level)
[文档] def format(self, record):
"""
Format the specified record.
If a formatter is set, use it. Otherwise, use the default formatter
for the module.
"""
if self.formatter:
fmt = self.formatter
else:
fmt = _defaultFormatter
return fmt.format(record)
[文档] def emit(self, record):
"""
Do whatever it takes to actually log the specified logging record.
This version is intended to be implemented by subclasses and so
raises a NotImplementedError.
"""
raise NotImplementedError('emit must be implemented '
'by Handler subclasses')
[文档] def handle(self, record):
"""
Conditionally emit the specified logging record.
Emission depends on filters which may have been added to the handler.
Wrap the actual emission of the record with acquisition/release of
the I/O thread lock. Returns whether the filter passed the record for
emission.
"""
rv = self.filter(record)
if rv:
self.acquire()
try:
self.emit(record)
finally:
self.release()
return rv
[文档] def flush(self):
"""
Ensure all logging output has been flushed.
This version does nothing and is intended to be implemented by
subclasses.
"""
pass
[文档] def close(self):
"""
Tidy up any resources used by the handler.
This version removes the handler from an internal map of handlers,
_handlers, which is used for handler lookup by name. Subclasses
should ensure that this gets called from overridden close()
methods.
"""
#get the module data lock, as we're updating a shared structure.
_acquireLock()
try: #unlikely to raise an exception, but you never know...
if self._name and self._name in _handlers:
del _handlers[self._name]
finally:
_releaseLock()
[文档] def handleError(self, record):
"""
Handle errors which occur during an emit() call.
This method should be called from handlers when an exception is
encountered during an emit() call. If raiseExceptions is false,
exceptions get silently ignored. This is what is mostly wanted
for a logging system - most users will not care about errors in
the logging system, they are more interested in application errors.
You could, however, replace this with a custom handler if you wish.
The record which was being processed is passed in to this method.
"""
if raiseExceptions and sys.stderr: # see issue 13807
t, v, tb = sys.exc_info()
try:
sys.stderr.write('--- Logging error ---\n')
traceback.print_exception(t, v, tb, None, sys.stderr)
sys.stderr.write('Call stack:\n')
# Walk the stack frame up until we're out of logging,
# so as to print the calling context.
frame = tb.tb_frame
while (frame and os.path.dirname(frame.f_code.co_filename) ==
__path__[0]):
frame = frame.f_back
if frame:
traceback.print_stack(frame, file=sys.stderr)
else:
# couldn't find the right stack frame, for some reason
sys.stderr.write('Logged from file %s, line %s\n' % (
record.filename, record.lineno))
# Issue 18671: output logging message and arguments
try:
sys.stderr.write('Message: %r\n'
'Arguments: %s\n' % (record.msg,
record.args))
except Exception:
sys.stderr.write('Unable to print the message and arguments'
' - possible formatting error.\nUse the'
' traceback above to help find the error.\n'
)
except OSError: #pragma: no cover
pass # see issue 5971
finally:
del t, v, tb
[文档]class StreamHandler(Handler):
"""
A handler class which writes logging records, appropriately formatted,
to a stream. Note that this class does not close the stream, as
sys.stdout or sys.stderr may be used.
"""
terminator = '\n'
def __init__(self, stream=None):
"""
Initialize the handler.
If stream is not specified, sys.stderr is used.
"""
Handler.__init__(self)
if stream is None:
stream = sys.stderr
self.stream = stream
[文档] def flush(self):
"""
Flushes the stream.
"""
self.acquire()
try:
if self.stream and hasattr(self.stream, "flush"):
self.stream.flush()
finally:
self.release()
[文档] def emit(self, record):
"""
Emit a record.
If a formatter is specified, it is used to format the record.
The record is then written to the stream with a trailing newline. If
exception information is present, it is formatted using
traceback.print_exception and appended to the stream. If the stream
has an 'encoding' attribute, it is used to determine how to do the
output to the stream.
"""
try:
msg = self.format(record)
stream = self.stream
stream.write(msg)
stream.write(self.terminator)
self.flush()
except Exception:
self.handleError(record)
[文档]class FileHandler(StreamHandler):
"""
A handler class which writes formatted logging records to disk files.
"""
def __init__(self, filename, mode='a', encoding=None, delay=False):
"""
Open the specified file and use it as the stream for logging.
"""
#keep the absolute path, otherwise derived classes which use this
#may come a cropper when the current directory changes
self.baseFilename = os.path.abspath(filename)
self.mode = mode
self.encoding = encoding
self.delay = delay
if delay:
#We don't open the stream, but we still need to call the
#Handler constructor to set level, formatter, lock etc.
Handler.__init__(self)
self.stream = None
else:
StreamHandler.__init__(self, self._open())
[文档] def close(self):
"""
Closes the stream.
"""
self.acquire()
try:
try:
if self.stream:
try:
self.flush()
finally:
stream = self.stream
self.stream = None
if hasattr(stream, "close"):
stream.close()
finally:
# Issue #19523: call unconditionally to
# prevent a handler leak when delay is set
StreamHandler.close(self)
finally:
self.release()
def _open(self):
"""
Open the current base file with the (original) mode and encoding.
Return the resulting stream.
"""
return open(self.baseFilename, self.mode, encoding=self.encoding)
[文档] def emit(self, record):
"""
Emit a record.
If the stream was not opened because 'delay' was specified in the
constructor, open it before calling the superclass's emit.
"""
if self.stream is None:
self.stream = self._open()
StreamHandler.emit(self, record)
class _StderrHandler(StreamHandler):
"""
This class is like a StreamHandler using sys.stderr, but always uses
whatever sys.stderr is currently set to rather than the value of
sys.stderr at handler construction time.
"""
def __init__(self, level=NOTSET):
"""
Initialize the handler.
"""
Handler.__init__(self, level)
@property
def stream(self):
return sys.stderr
_defaultLastResort = _StderrHandler(WARNING)
lastResort = _defaultLastResort
#---------------------------------------------------------------------------
# Manager classes and functions
#---------------------------------------------------------------------------
class PlaceHolder(object):
"""
PlaceHolder instances are used in the Manager logger hierarchy to take
the place of nodes for which no loggers have been defined. This class is
intended for internal use only and not as part of the public API.
"""
def __init__(self, alogger):
"""
Initialize with the specified logger being a child of this placeholder.
"""
self.loggerMap = { alogger : None }
def append(self, alogger):
"""
Add the specified logger as a child of this placeholder.
"""
if alogger not in self.loggerMap:
self.loggerMap[alogger] = None
#
# Determine which class to use when instantiating loggers.
#
[文档]def setLoggerClass(klass):
"""
Set the class to be used when instantiating a logger. The class should
define __init__() such that only a name argument is required, and the
__init__() should call Logger.__init__()
"""
if klass != Logger:
if not issubclass(klass, Logger):
raise TypeError("logger not derived from logging.Logger: "
+ klass.__name__)
global _loggerClass
_loggerClass = klass
[文档]def getLoggerClass():
"""
Return the class to be used when instantiating a logger.
"""
return _loggerClass
class Manager(object):
"""
There is [under normal circumstances] just one Manager instance, which
holds the hierarchy of loggers.
"""
def __init__(self, rootnode):
"""
Initialize the manager with the root node of the logger hierarchy.
"""
self.root = rootnode
self.disable = 0
self.emittedNoHandlerWarning = False
self.loggerDict = {}
self.loggerClass = None
self.logRecordFactory = None
def getLogger(self, name):
"""
Get a logger with the specified name (channel name), creating it
if it doesn't yet exist. This name is a dot-separated hierarchical
name, such as "a", "a.b", "a.b.c" or similar.
If a PlaceHolder existed for the specified name [i.e. the logger
didn't exist but a child of it did], replace it with the created
logger and fix up the parent/child references which pointed to the
placeholder to now point to the logger.
"""
rv = None
if not isinstance(name, str):
raise TypeError('A logger name must be a string')
_acquireLock()
try:
if name in self.loggerDict:
rv = self.loggerDict[name]
if isinstance(rv, PlaceHolder):
ph = rv
rv = (self.loggerClass or _loggerClass)(name)
rv.manager = self
self.loggerDict[name] = rv
self._fixupChildren(ph, rv)
self._fixupParents(rv)
else:
rv = (self.loggerClass or _loggerClass)(name)
rv.manager = self
self.loggerDict[name] = rv
self._fixupParents(rv)
finally:
_releaseLock()
return rv
def setLoggerClass(self, klass):
"""
Set the class to be used when instantiating a logger with this Manager.
"""
if klass != Logger:
if not issubclass(klass, Logger):
raise TypeError("logger not derived from logging.Logger: "
+ klass.__name__)
self.loggerClass = klass
def setLogRecordFactory(self, factory):
"""
Set the factory to be used when instantiating a log record with this
Manager.
"""
self.logRecordFactory = factory
def _fixupParents(self, alogger):
"""
Ensure that there are either loggers or placeholders all the way
from the specified logger to the root of the logger hierarchy.
"""
name = alogger.name
i = name.rfind(".")
rv = None
while (i > 0) and not rv:
substr = name[:i]
if substr not in self.loggerDict:
self.loggerDict[substr] = PlaceHolder(alogger)
else:
obj = self.loggerDict[substr]
if isinstance(obj, Logger):
rv = obj
else:
assert isinstance(obj, PlaceHolder)
obj.append(alogger)
i = name.rfind(".", 0, i - 1)
if not rv:
rv = self.root
alogger.parent = rv
def _fixupChildren(self, ph, alogger):
"""
Ensure that children of the placeholder ph are connected to the
specified logger.
"""
name = alogger.name
namelen = len(name)
for c in ph.loggerMap.keys():
#The if means ... if not c.parent.name.startswith(nm)
if c.parent.name[:namelen] != name:
alogger.parent = c.parent
c.parent = alogger
#---------------------------------------------------------------------------
# Logger classes and functions
#---------------------------------------------------------------------------
[文档]class Logger(Filterer):
"""
Instances of the Logger class represent a single logging channel. A
"logging channel" indicates an area of an application. Exactly how an
"area" is defined is up to the application developer. Since an
application can have any number of areas, logging channels are identified
by a unique string. Application areas can be nested (e.g. an area
of "input processing" might include sub-areas "read CSV files", "read
XLS files" and "read Gnumeric files"). To cater for this natural nesting,
channel names are organized into a namespace hierarchy where levels are
separated by periods, much like the Java or Python package namespace. So
in the instance given above, channel names might be "input" for the upper
level, and "input.csv", "input.xls" and "input.gnu" for the sub-levels.
There is no arbitrary limit to the depth of nesting.
"""
def __init__(self, name, level=NOTSET):
"""
Initialize the logger with a name and an optional level.
"""
Filterer.__init__(self)
self.name = name
self.level = _checkLevel(level)
self.parent = None
self.propagate = True
self.handlers = []
self.disabled = False
[文档] def setLevel(self, level):
"""
Set the logging level of this logger. level must be an int or a str.
"""
self.level = _checkLevel(level)
[文档] def debug(self, msg, *args, **kwargs):
"""
Log 'msg % args' with severity 'DEBUG'.
To pass exception information, use the keyword argument exc_info with
a true value, e.g.
logger.debug("Houston, we have a %s", "thorny problem", exc_info=1)
"""
if self.isEnabledFor(DEBUG):
self._log(DEBUG, msg, args, **kwargs)
[文档] def info(self, msg, *args, **kwargs):
"""
Log 'msg % args' with severity 'INFO'.
To pass exception information, use the keyword argument exc_info with
a true value, e.g.
logger.info("Houston, we have a %s", "interesting problem", exc_info=1)
"""
if self.isEnabledFor(INFO):
self._log(INFO, msg, args, **kwargs)
[文档] def warning(self, msg, *args, **kwargs):
"""
Log 'msg % args' with severity 'WARNING'.
To pass exception information, use the keyword argument exc_info with
a true value, e.g.
logger.warning("Houston, we have a %s", "bit of a problem", exc_info=1)
"""
if self.isEnabledFor(WARNING):
self._log(WARNING, msg, args, **kwargs)
[文档] def warn(self, msg, *args, **kwargs):
warnings.warn("The 'warn' method is deprecated, "
"use 'warning' instead", DeprecationWarning, 2)
self.warning(msg, *args, **kwargs)
[文档] def error(self, msg, *args, **kwargs):
"""
Log 'msg % args' with severity 'ERROR'.
To pass exception information, use the keyword argument exc_info with
a true value, e.g.
logger.error("Houston, we have a %s", "major problem", exc_info=1)
"""
if self.isEnabledFor(ERROR):
self._log(ERROR, msg, args, **kwargs)
[文档] def exception(self, msg, *args, exc_info=True, **kwargs):
"""
Convenience method for logging an ERROR with exception information.
"""
self.error(msg, *args, exc_info=exc_info, **kwargs)
[文档] def critical(self, msg, *args, **kwargs):
"""
Log 'msg % args' with severity 'CRITICAL'.
To pass exception information, use the keyword argument exc_info with
a true value, e.g.
logger.critical("Houston, we have a %s", "major disaster", exc_info=1)
"""
if self.isEnabledFor(CRITICAL):
self._log(CRITICAL, msg, args, **kwargs)
fatal = critical
[文档] def log(self, level, msg, *args, **kwargs):
"""
Log 'msg % args' with the integer severity 'level'.
To pass exception information, use the keyword argument exc_info with
a true value, e.g.
logger.log(level, "We have a %s", "mysterious problem", exc_info=1)
"""
if not isinstance(level, int):
if raiseExceptions:
raise TypeError("level must be an integer")
else:
return
if self.isEnabledFor(level):
self._log(level, msg, args, **kwargs)
[文档] def findCaller(self, stack_info=False):
"""
Find the stack frame of the caller so that we can note the source
file name, line number and function name.
"""
f = currentframe()
#On some versions of IronPython, currentframe() returns None if
#IronPython isn't run with -X:Frames.
if f is not None:
f = f.f_back
rv = "(unknown file)", 0, "(unknown function)", None
while hasattr(f, "f_code"):
co = f.f_code
filename = os.path.normcase(co.co_filename)
if filename == _srcfile:
f = f.f_back
continue
sinfo = None
if stack_info:
sio = io.StringIO()
sio.write('Stack (most recent call last):\n')
traceback.print_stack(f, file=sio)
sinfo = sio.getvalue()
if sinfo[-1] == '\n':
sinfo = sinfo[:-1]
sio.close()
rv = (co.co_filename, f.f_lineno, co.co_name, sinfo)
break
return rv
[文档] def makeRecord(self, name, level, fn, lno, msg, args, exc_info,
func=None, extra=None, sinfo=None):
"""
A factory method which can be overridden in subclasses to create
specialized LogRecords.
"""
rv = _logRecordFactory(name, level, fn, lno, msg, args, exc_info, func,
sinfo)
if extra is not None:
for key in extra:
if (key in ["message", "asctime"]) or (key in rv.__dict__):
raise KeyError("Attempt to overwrite %r in LogRecord" % key)
rv.__dict__[key] = extra[key]
return rv
def _log(self, level, msg, args, exc_info=None, extra=None, stack_info=False):
"""
Low-level logging routine which creates a LogRecord and then calls
all the handlers of this logger to handle the record.
"""
sinfo = None
if _srcfile:
#IronPython doesn't track Python frames, so findCaller raises an
#exception on some versions of IronPython. We trap it here so that
#IronPython can use logging.
try:
fn, lno, func, sinfo = self.findCaller(stack_info)
except ValueError: # pragma: no cover
fn, lno, func = "(unknown file)", 0, "(unknown function)"
else: # pragma: no cover
fn, lno, func = "(unknown file)", 0, "(unknown function)"
if exc_info:
if isinstance(exc_info, BaseException):
exc_info = (type(exc_info), exc_info, exc_info.__traceback__)
elif not isinstance(exc_info, tuple):
exc_info = sys.exc_info()
record = self.makeRecord(self.name, level, fn, lno, msg, args,
exc_info, func, extra, sinfo)
self.handle(record)
[文档] def handle(self, record):
"""
Call the handlers for the specified record.
This method is used for unpickled records received from a socket, as
well as those created locally. Logger-level filtering is applied.
"""
if (not self.disabled) and self.filter(record):
self.callHandlers(record)
[文档] def addHandler(self, hdlr):
"""
Add the specified handler to this logger.
"""
_acquireLock()
try:
if not (hdlr in self.handlers):
self.handlers.append(hdlr)
finally:
_releaseLock()
[文档] def removeHandler(self, hdlr):
"""
Remove the specified handler from this logger.
"""
_acquireLock()
try:
if hdlr in self.handlers:
self.handlers.remove(hdlr)
finally:
_releaseLock()
[文档] def hasHandlers(self):
"""
See if this logger has any handlers configured.
Loop through all handlers for this logger and its parents in the
logger hierarchy. Return True if a handler was found, else False.
Stop searching up the hierarchy whenever a logger with the "propagate"
attribute set to zero is found - that will be the last logger which
is checked for the existence of handlers.
"""
c = self
rv = False
while c:
if c.handlers:
rv = True
break
if not c.propagate:
break
else:
c = c.parent
return rv
[文档] def callHandlers(self, record):
"""
Pass a record to all relevant handlers.
Loop through all handlers for this logger and its parents in the
logger hierarchy. If no handler was found, output a one-off error
message to sys.stderr. Stop searching up the hierarchy whenever a
logger with the "propagate" attribute set to zero is found - that
will be the last logger whose handlers are called.
"""
c = self
found = 0
while c:
for hdlr in c.handlers:
found = found + 1
if record.levelno >= hdlr.level:
hdlr.handle(record)
if not c.propagate:
c = None #break out
else:
c = c.parent
if (found == 0):
if lastResort:
if record.levelno >= lastResort.level:
lastResort.handle(record)
elif raiseExceptions and not self.manager.emittedNoHandlerWarning:
sys.stderr.write("No handlers could be found for logger"
" \"%s\"\n" % self.name)
self.manager.emittedNoHandlerWarning = True
[文档] def getEffectiveLevel(self):
"""
Get the effective level for this logger.
Loop through this logger and its parents in the logger hierarchy,
looking for a non-zero logging level. Return the first one found.
"""
logger = self
while logger:
if logger.level:
return logger.level
logger = logger.parent
return NOTSET
[文档] def isEnabledFor(self, level):
"""
Is this logger enabled for level 'level'?
"""
if self.manager.disable >= level:
return False
return level >= self.getEffectiveLevel()
[文档] def getChild(self, suffix):
"""
Get a logger which is a descendant to this one.
This is a convenience method, such that
logging.getLogger('abc').getChild('def.ghi')
is the same as
logging.getLogger('abc.def.ghi')
It's useful, for example, when the parent logger is named using
__name__ rather than a literal string.
"""
if self.root is not self:
suffix = '.'.join((self.name, suffix))
return self.manager.getLogger(suffix)
class RootLogger(Logger):
"""
A root logger is not that different to any other logger, except that
it must have a logging level and there is only one instance of it in
the hierarchy.
"""
def __init__(self, level):
"""
Initialize the logger with the name "root".
"""
Logger.__init__(self, "root", level)
_loggerClass = Logger
[文档]class LoggerAdapter(object):
"""
An adapter for loggers which makes it easier to specify contextual
information in logging output.
"""
def __init__(self, logger, extra):
"""
Initialize the adapter with a logger and a dict-like object which
provides contextual information. This constructor signature allows
easy stacking of LoggerAdapters, if so desired.
You can effectively pass keyword arguments as shown in the
following example:
adapter = LoggerAdapter(someLogger, dict(p1=v1, p2="v2"))
"""
self.logger = logger
self.extra = extra
[文档] def process(self, msg, kwargs):
"""
Process the logging message and keyword arguments passed in to
a logging call to insert contextual information. You can either
manipulate the message itself, the keyword args or both. Return
the message and kwargs modified (or not) to suit your needs.
Normally, you'll only need to override this one method in a
LoggerAdapter subclass for your specific needs.
"""
kwargs["extra"] = self.extra
return msg, kwargs
#
# Boilerplate convenience methods
#
[文档] def debug(self, msg, *args, **kwargs):
"""
Delegate a debug call to the underlying logger.
"""
self.log(DEBUG, msg, *args, **kwargs)
[文档] def info(self, msg, *args, **kwargs):
"""
Delegate an info call to the underlying logger.
"""
self.log(INFO, msg, *args, **kwargs)
[文档] def warning(self, msg, *args, **kwargs):
"""
Delegate a warning call to the underlying logger.
"""
self.log(WARNING, msg, *args, **kwargs)
[文档] def warn(self, msg, *args, **kwargs):
warnings.warn("The 'warn' method is deprecated, "
"use 'warning' instead", DeprecationWarning, 2)
self.warning(msg, *args, **kwargs)
[文档] def error(self, msg, *args, **kwargs):
"""
Delegate an error call to the underlying logger.
"""
self.log(ERROR, msg, *args, **kwargs)
[文档] def exception(self, msg, *args, exc_info=True, **kwargs):
"""
Delegate an exception call to the underlying logger.
"""
self.log(ERROR, msg, *args, exc_info=exc_info, **kwargs)
[文档] def critical(self, msg, *args, **kwargs):
"""
Delegate a critical call to the underlying logger.
"""
self.log(CRITICAL, msg, *args, **kwargs)
[文档] def log(self, level, msg, *args, **kwargs):
"""
Delegate a log call to the underlying logger, after adding
contextual information from this adapter instance.
"""
if self.isEnabledFor(level):
msg, kwargs = self.process(msg, kwargs)
self.logger._log(level, msg, args, **kwargs)
[文档] def isEnabledFor(self, level):
"""
Is this logger enabled for level 'level'?
"""
if self.logger.manager.disable >= level:
return False
return level >= self.getEffectiveLevel()
[文档] def setLevel(self, level):
"""
Set the specified level on the underlying logger.
"""
self.logger.setLevel(level)
[文档] def getEffectiveLevel(self):
"""
Get the effective level for the underlying logger.
"""
return self.logger.getEffectiveLevel()
[文档] def hasHandlers(self):
"""
See if the underlying logger has any handlers.
"""
return self.logger.hasHandlers()
root = RootLogger(WARNING)
Logger.root = root
Logger.manager = Manager(Logger.root)
#---------------------------------------------------------------------------
# Configuration classes and functions
#---------------------------------------------------------------------------
[文档]def basicConfig(**kwargs):
"""
Do basic configuration for the logging system.
This function does nothing if the root logger already has handlers
configured. It is a convenience method intended for use by simple scripts
to do one-shot configuration of the logging package.
The default behaviour is to create a StreamHandler which writes to
sys.stderr, set a formatter using the BASIC_FORMAT format string, and
add the handler to the root logger.
A number of optional keyword arguments may be specified, which can alter
the default behaviour.
filename Specifies that a FileHandler be created, using the specified
filename, rather than a StreamHandler.
filemode Specifies the mode to open the file, if filename is specified
(if filemode is unspecified, it defaults to 'a').
format Use the specified format string for the handler.
datefmt Use the specified date/time format.
style If a format string is specified, use this to specify the
type of format string (possible values '%', '{', '$', for
%-formatting, :meth:`str.format` and :class:`string.Template`
- defaults to '%').
level Set the root logger level to the specified level.
stream Use the specified stream to initialize the StreamHandler. Note
that this argument is incompatible with 'filename' - if both
are present, 'stream' is ignored.
handlers If specified, this should be an iterable of already created
handlers, which will be added to the root handler. Any handler
in the list which does not have a formatter assigned will be
assigned the formatter created in this function.
Note that you could specify a stream created using open(filename, mode)
rather than passing the filename and mode in. However, it should be
remembered that StreamHandler does not close its stream (since it may be
using sys.stdout or sys.stderr), whereas FileHandler closes its stream
when the handler is closed.
.. versionchanged:: 3.2
Added the ``style`` parameter.
.. versionchanged:: 3.3
Added the ``handlers`` parameter. A ``ValueError`` is now thrown for
incompatible arguments (e.g. ``handlers`` specified together with
``filename``/``filemode``, or ``filename``/``filemode`` specified
together with ``stream``, or ``handlers`` specified together with
``stream``.
"""
# Add thread safety in case someone mistakenly calls
# basicConfig() from multiple threads
_acquireLock()
try:
if len(root.handlers) == 0:
handlers = kwargs.pop("handlers", None)
if handlers is None:
if "stream" in kwargs and "filename" in kwargs:
raise ValueError("'stream' and 'filename' should not be "
"specified together")
else:
if "stream" in kwargs or "filename" in kwargs:
raise ValueError("'stream' or 'filename' should not be "
"specified together with 'handlers'")
if handlers is None:
filename = kwargs.pop("filename", None)
mode = kwargs.pop("filemode", 'a')
if filename:
h = FileHandler(filename, mode)
else:
stream = kwargs.pop("stream", None)
h = StreamHandler(stream)
handlers = [h]
dfs = kwargs.pop("datefmt", None)
style = kwargs.pop("style", '%')
if style not in _STYLES:
raise ValueError('Style must be one of: %s' % ','.join(
_STYLES.keys()))
fs = kwargs.pop("format", _STYLES[style][1])
fmt = Formatter(fs, dfs, style)
for h in handlers:
if h.formatter is None:
h.setFormatter(fmt)
root.addHandler(h)
level = kwargs.pop("level", None)
if level is not None:
root.setLevel(level)
if kwargs:
keys = ', '.join(kwargs.keys())
raise ValueError('Unrecognised argument(s): %s' % keys)
finally:
_releaseLock()
#---------------------------------------------------------------------------
# Utility functions at module level.
# Basically delegate everything to the root logger.
#---------------------------------------------------------------------------
[文档]def getLogger(name=None):
"""
Return a logger with the specified name, creating it if necessary.
If no name is specified, return the root logger.
"""
if name:
return Logger.manager.getLogger(name)
else:
return root
[文档]def critical(msg, *args, **kwargs):
"""
Log a message with severity 'CRITICAL' on the root logger. If the logger
has no handlers, call basicConfig() to add a console handler with a
pre-defined format.
"""
if len(root.handlers) == 0:
basicConfig()
root.critical(msg, *args, **kwargs)
fatal = critical
[文档]def error(msg, *args, **kwargs):
"""
Log a message with severity 'ERROR' on the root logger. If the logger has
no handlers, call basicConfig() to add a console handler with a pre-defined
format.
"""
if len(root.handlers) == 0:
basicConfig()
root.error(msg, *args, **kwargs)
[文档]def exception(msg, *args, exc_info=True, **kwargs):
"""
Log a message with severity 'ERROR' on the root logger, with exception
information. If the logger has no handlers, basicConfig() is called to add
a console handler with a pre-defined format.
"""
error(msg, *args, exc_info=exc_info, **kwargs)
[文档]def warning(msg, *args, **kwargs):
"""
Log a message with severity 'WARNING' on the root logger. If the logger has
no handlers, call basicConfig() to add a console handler with a pre-defined
format.
"""
if len(root.handlers) == 0:
basicConfig()
root.warning(msg, *args, **kwargs)
[文档]def warn(msg, *args, **kwargs):
warnings.warn("The 'warn' function is deprecated, "
"use 'warning' instead", DeprecationWarning, 2)
warning(msg, *args, **kwargs)
[文档]def info(msg, *args, **kwargs):
"""
Log a message with severity 'INFO' on the root logger. If the logger has
no handlers, call basicConfig() to add a console handler with a pre-defined
format.
"""
if len(root.handlers) == 0:
basicConfig()
root.info(msg, *args, **kwargs)
[文档]def debug(msg, *args, **kwargs):
"""
Log a message with severity 'DEBUG' on the root logger. If the logger has
no handlers, call basicConfig() to add a console handler with a pre-defined
format.
"""
if len(root.handlers) == 0:
basicConfig()
root.debug(msg, *args, **kwargs)
[文档]def log(level, msg, *args, **kwargs):
"""
Log 'msg % args' with the integer severity 'level' on the root logger. If
the logger has no handlers, call basicConfig() to add a console handler
with a pre-defined format.
"""
if len(root.handlers) == 0:
basicConfig()
root.log(level, msg, *args, **kwargs)
[文档]def disable(level):
"""
Disable all logging calls of severity 'level' and below.
"""
root.manager.disable = level
def shutdown(handlerList=_handlerList):
"""
Perform any cleanup actions in the logging system (e.g. flushing
buffers).
Should be called at application exit.
"""
for wr in reversed(handlerList[:]):
#errors might occur, for example, if files are locked
#we just ignore them if raiseExceptions is not set
try:
h = wr()
if h:
try:
h.acquire()
h.flush()
h.close()
except (OSError, ValueError):
# Ignore errors which might be caused
# because handlers have been closed but
# references to them are still around at
# application exit.
pass
finally:
h.release()
except: # ignore everything, as we're shutting down
if raiseExceptions:
raise
#else, swallow
#Let's try and shutdown automatically on application exit...
import atexit
atexit.register(shutdown)
# Null handler
[文档]class NullHandler(Handler):
"""
This handler does nothing. It's intended to be used to avoid the
"No handlers could be found for logger XXX" one-off warning. This is
important for library code, which may contain code to log events. If a user
of the library does not configure logging, the one-off warning might be
produced; to avoid this, the library developer simply needs to instantiate
a NullHandler and add it to the top-level logger of the library module or
package.
"""
# Warnings integration
_warnings_showwarning = None
def _showwarning(message, category, filename, lineno, file=None, line=None):
"""
Implementation of showwarnings which redirects to logging, which will first
check to see if the file parameter is None. If a file is specified, it will
delegate to the original warnings implementation of showwarning. Otherwise,
it will call warnings.formatwarning and will log the resulting string to a
warnings logger named "py.warnings" with level logging.WARNING.
"""
if file is not None:
if _warnings_showwarning is not None:
_warnings_showwarning(message, category, filename, lineno, file, line)
else:
s = warnings.formatwarning(message, category, filename, lineno, line)
logger = getLogger("py.warnings")
if not logger.handlers:
logger.addHandler(NullHandler())
logger.warning("%s", s)
[文档]def captureWarnings(capture):
"""
If capture is true, redirect all warnings to the logging package.
If capture is False, ensure that warnings are not redirected to logging
but to their original destinations.
"""
global _warnings_showwarning
if capture:
if _warnings_showwarning is None:
_warnings_showwarning = warnings.showwarning
warnings.showwarning = _showwarning
else:
if _warnings_showwarning is not None:
warnings.showwarning = _warnings_showwarning
_warnings_showwarning = None
# -*- coding: utf-8-*-
import os
import subprocess
import time
from robot import config, constants, logging
from robot.sdk.AbstractPlugin import AbstractPlugin
logger = logging.getLogger(__name__)
[文档]class Plugin(AbstractPlugin):
SLUG = "camera"
[文档] def handle(self, text, parsed):
quality = config.get('/camera/quality', 100)
count_down = config.get('/camera/count_down', 3)
dest_path = config.get('/camera/dest_path', os.path.expanduser('~/pictures'))
device = config.get('/camera/device', '/dev/video0')
vertical_flip = config.get('/camera/verical_flip', False)
horizontal_flip = config.get('/camera/horizontal_flip', False)
sound = config.get('/camera/sound', True)
camera_type = config.get('/camera/type', 0)
if config.has('/camera/usb_camera') and config.get('/camera/usb_camera'):
camera_type = 0
if any(word in text for word in [u"安静", u"偷偷", u"悄悄"]):
sound = False
try:
if not os.path.exists(dest_path):
os.makedirs(dest_path)
except Exception:
self.say(u"抱歉,照片目录创建失败", cache=True)
return
dest_file = os.path.join(dest_path, "%s.jpg" % time.time())
if camera_type == 0:
# usb camera
logger.info('usb camera')
command = ['fswebcam', '--no-banner', '-r', '1024x765', '-q', '-d', device]
if vertical_flip:
command.extend(['-s', 'v'])
if horizontal_flip:
command.extend(['-s', 'h'])
command.append(dest_file)
elif camera_type == 1:
# Raspberry Pi 5MP
logger.info('Raspberry Pi 5MP camera')
command = ['raspistill', '-o', dest_file, '-q', str(quality)]
if count_down > 0 and sound:
command.extend(['-t', str(count_down*1000)])
if vertical_flip:
command.append('-vf')
if horizontal_flip:
command.append('-hf')
else:
# notebook camera
logger.info('notebook camera')
command = ['imagesnap', dest_file]
if count_down > 0 and sound:
command.extend(['-w', str(count_down)])
if sound and count_down > 0:
self.say(u"收到,%d秒后启动拍照" % (count_down), cache=True)
if camera_type == 0:
time.sleep(count_down)
try:
subprocess.run(command, shell=False, check=True)
if sound:
self.play(constants.getData('camera.wav'))
photo_url = 'http://{}:{}/photo/{}'.format(config.get('/server/host'), config.get('/server/port'), os.path.basename(dest_file))
self.say(u'拍照成功:{}'.format(photo_url), cache=True)
except subprocess.CalledProcessError as e:
logger.error(e)
if sound:
self.say(u"拍照失败,请检查相机是否连接正确", cache=True)
# -*- coding: utf-8-*-
import os
from robot import constants, utils
from robot.sdk.AbstractPlugin import AbstractPlugin
[文档]class Plugin(AbstractPlugin):
SLUG = 'cleancache'
[文档] def handle(self, text, parsed):
temp = constants.TEMP_PATH
for f in os.listdir(temp):
if f != 'DIR':
utils.check_and_delete(os.path.join(temp, f))
self.say(u'缓存目录已清空', cache=True)
[文档] def isValid(self, text, parsed):
return any(word in text.lower() for word in ["清除缓存", u"清空缓存", u"清缓存"])
# -*- coding: utf-8-*-
# author: wzpan
# 写诗
import logging
from robot.sdk.AbstractPlugin import AbstractPlugin
logger = logging.getLogger(__name__)
# -*- coding: utf-8-*-
import imaplib
import email
import time
import datetime
from robot import logging
from dateutil import parser
from robot import config
from robot.sdk.AbstractPlugin import AbstractPlugin
[文档]class Plugin(AbstractPlugin):
SLUG = 'email'
[文档] def getSender(self, msg):
"""
Returns the best-guess sender of an email.
Arguments:
msg -- the email whose sender is desired
Returns:
Sender of the sender.
"""
fromstr = str(msg["From"])
ls = fromstr.split(' ')
if(len(ls) == 2):
fromname = email.header.decode_header(str(ls[0]).strip('\"'))
sender = fromname[0][0]
elif(len(ls) > 2):
fromname = email.header.decode_header(str(fromstr[:fromstr.find('<')])
.strip('\"'))
sender = fromname[0][0]
else:
sender = msg['From']
if isinstance(sender, bytes):
try:
return sender.decode('utf-8')
except UnicodeDecodeError:
return sender.decode('gbk')
else:
return sender
[文档] def isSelfEmail(self, msg):
""" Whether the email is sent by the user """
fromstr = str(msg["From"])
addr = (fromstr[fromstr.find('<')+1:fromstr.find('>')]).strip('\"')
address = config.get()[self.SLUG]['address'].strip()
return addr == address
[文档] def getSubject(self, msg):
"""
Returns the title of an email
Arguments:
msg -- the email
Returns:
Title of the email.
"""
subject = email.header.decode_header(msg['subject'])
if isinstance(subject[0][0], bytes):
try:
sub = subject[0][0].decode('utf-8')
except UnicodeDecodeError:
sub = subject[0][0].decode('gbk')
else:
sub = subject[0][0]
to_read = False
if sub.strip() == '':
return ''
to_read = config.get('/email/read_email_title', True)
if to_read:
return '邮件标题为 %s' % sub
return ''
[文档] def isNewEmail(msg):
""" Wether an email is a new email """
date = str(msg['Date'])
dtext = date.split(',')[1].split('+')[0].strip()
dtime = time.strptime(dtext, '%d %b %Y %H:%M:%S')
current = time.localtime()
dt = datetime.datetime(*dtime[:6])
cr = datetime.datetime(*current[:6])
return (cr - dt).days == 0
[文档] def getMostRecentDate(self, emails):
"""
Returns the most recent date of any email in the list provided.
Arguments:
emails -- a list of emails to check
Returns:
Date of the most recent email.
"""
dates = [self.getDate(e) for e in emails]
dates.sort(reverse=True)
if dates:
return dates[0]
return None
[文档] def fetchUnreadEmails(self, since=None, markRead=False, limit=None):
"""
Fetches a list of unread email objects from a user's email inbox.
Arguments:
since -- if provided, no emails before this date will be returned
markRead -- if True, marks all returned emails as read in target inbox
Returns:
A list of unread email objects.
"""
logger = logging.getLogger(__name__)
profile = config.get()
conn = imaplib.IMAP4(profile[self.SLUG]['imap_server'],
profile[self.SLUG]['imap_port'])
conn.debug = 0
msgs = []
try:
conn.login(profile[self.SLUG]['address'], profile[self.SLUG]['password'])
conn.select(readonly=(not markRead))
(retcode, messages) = conn.search(None, '(UNSEEN)')
except Exception:
logger.warning("抱歉,您的邮箱账户验证失败了,请检查下配置")
return None
if retcode == 'OK' and messages != [b'']:
numUnread = len(messages[0].split(b' '))
if limit and numUnread > limit:
return numUnread
for num in messages[0].split(b' '):
# parse email RFC822 format
ret, data = conn.fetch(num, '(RFC822)')
if data is None:
continue
msg = email.message_from_string(data[0][1].decode('utf-8'))
if not since or self.getDate(msg) > since:
msgs.append(msg)
conn.close()
conn.logout()
return msgs
[文档] def handle(self, text, parsed):
msgs = self.fetchUnreadEmails(limit=5)
if msgs is None:
self.say(
u"抱歉,您的邮箱账户验证失败了", cache=True)
return
if isinstance(msgs, int):
response = "您有 %d 封未读邮件" % msgs
self.say(response, cache=True)
return
senders = [str(self.getSender(e)) for e in msgs]
if not senders:
self.say(u"您没有未读邮件,真棒!", cache=True)
elif len(senders) == 1:
self.say(u"您有来自 {} 的未读邮件。{}".format(senders[0], self.getSubject(msgs[0])))
else:
response = u"您有 %d 封未读邮件" % len(
senders)
unique_senders = list(set(senders))
if len(unique_senders) > 1:
unique_senders[-1] = ', ' + unique_senders[-1]
response += "。这些邮件的发件人包括:"
response += ' 和 '.join(senders)
else:
response += ",邮件都来自 " + unique_senders[0]
self.say(response)
# -*- coding: utf-8-*-
from robot import logging
from robot.sdk.AbstractPlugin import AbstractPlugin
logger = logging.getLogger(__name__)
[文档]class Plugin(AbstractPlugin):
IS_IMMERSIVE = True # 这是个沉浸式技能
def __init__(self, con):
super(Plugin, self).__init__(con)
self.silent_count = 0
[文档] def handle(self, text, parsed):
if any (word in text for word in ['开启', '激活', '开始', '进入', '打开']):
self.silent_count = 0
self.say('进入极客模式', cache=True, onCompleted=lambda: self.onAsk(self.activeListen(silent=True)))
else:
self.say('退出极客模式', cache=True)
[文档] def onAsk(self, input):
if input:
logger.debug('input: {}'.format(input))
self.silent_count = 0
self.con.doResponse(input)
else:
self.silent_count += 1
if self.silent_count >= 5:
self.say('退出极客模式', cache=True)
self.clearImmersive()
else:
self.onAsk(self.activeListen(silent=True))
[文档] def isValidImmersive(self, text, parsed):
return '模式' in text and \
any(word in text for word in ['即刻', '即可', '极客', '即客', '集团', '集客']) and \
any(word in text for word in ['退出', '结束', '停止'])
[文档] def isValid(self, text, parsed):
return '模式' in text and \
any(word in text for word in ['即刻', '即可', '即客', '集团', '极客', '集客']) and \
any (word in text for word in ['开启', '激活', '开始', '进入', '打开'])
# -*- coding: utf-8-*-
import os
from robot import config, logging
from robot.Player import MusicPlayer
from robot.sdk.AbstractPlugin import AbstractPlugin
logger = logging.getLogger(__name__)
[文档]class Plugin(AbstractPlugin):
IS_IMMERSIVE = True # 这是个沉浸式技能
def __init__(self, con):
super(Plugin, self).__init__(con)
self.player = None
self.song_list = None
[文档] def get_song_list(self, path):
if not os.path.exists(path) or \
not os.path.isdir(path):
return []
song_list = list(filter(lambda d: d.endswith('.mp3'), os.listdir(path)))
return [os.path.join(path, song) for song in song_list]
[文档] def init_music_player(self):
self.song_list = self.get_song_list(config.get('/LocalPlayer/path'))
if self.song_list == None:
logger.error('{} 插件配置有误'.format(self.SLUG))
logger.info('本地音乐列表:{}'.format(self.song_list))
return MusicPlayer(self.song_list, self)
[文档] def handle(self, text, parsed):
if not self.player:
self.player = self.init_music_player()
if len(self.song_list) == 0:
self.clearImmersive() # 去掉沉浸式
self.say('本地音乐目录并没有音乐文件,播放失败')
return
if self.nlu.hasIntent(parsed, 'MUSICRANK'):
self.player.play()
elif self.nlu.hasIntent(parsed, 'CHANGE_TO_NEXT'):
self.player.next()
elif self.nlu.hasIntent(parsed, 'CHANGE_TO_LAST'):
self.player.prev()
elif self.nlu.hasIntent(parsed, 'CHANGE_VOL'):
slots = self.nlu.getSlots(parsed, 'CHANGE_VOL')
for slot in slots:
if slot['name'] == 'user_d':
word = self.nlu.getSlotWords(parsed, 'CHANGE_VOL', 'user_d')[0]
if word == '--HIGHER--':
self.player.turnUp()
else:
self.player.turnDown()
return
elif slot['name'] == 'user_vd':
word = self.nlu.getSlotWords(parsed, 'CHANGE_VOL', 'user_vd')[0]
if word == '--LOUDER--':
self.player.turnUp()
else:
self.player.turnDown()
elif self.nlu.hasIntent(parsed, 'PAUSE'):
self.player.pause()
elif self.nlu.hasIntent(parsed, 'CONTINUE'):
self.player.resume()
elif self.nlu.hasIntent(parsed, 'CLOSE_MUSIC'):
self.player.stop()
self.clearImmersive() # 去掉沉浸式
else:
self.say('没听懂你的意思呢,要停止播放,请说停止播放', wait=True)
self.player.resume()
[文档] def isValidImmersive(self, text, parsed):
return any(self.nlu.hasIntent(parsed, intent) for intent in ['CHANGE_TO_LAST', 'CHANGE_TO_NEXT', 'CHANGE_VOL', 'CLOSE_MUSIC', 'PAUSE', 'CONTINUE'])
# -*- coding: utf-8-*-
# author: wzpan
# 写诗
import logging
from robot.sdk.AbstractPlugin import AbstractPlugin
INTENT = "BUILT_POEM"
logger = logging.getLogger(__name__)
[文档]class Plugin(AbstractPlugin):
SLUG = "poem"
[文档] def handle(self, text, parsed):
try:
responds = self.nlu.getSay(parsed, INTENT)
self.say(responds, cache=True)
except Exception as e:
logger.error(e)
self.say('抱歉,写诗插件出问题了,请稍后再试', cache=True)
[文档] def isValid(self, text, parsed):
return self.nlu.hasIntent(parsed, INTENT) and '写' in text and '诗' in text
# -*- coding: utf-8-*-
import requests
import json
from robot import logging
from robot import config
from uuid import getnode as get_mac
from abc import ABCMeta, abstractmethod
logger = logging.getLogger(__name__)
[文档]class AbstractRobot(object):
__metaclass__ = ABCMeta
[文档] @classmethod
def get_instance(cls):
profile = cls.get_config()
instance = cls(**profile)
return instance
def __init__(self, **kwargs):
pass
[文档]class TulingRobot(AbstractRobot):
SLUG = "tuling"
def __init__(self, tuling_key):
"""
图灵机器人
"""
super(self.__class__, self).__init__()
self.tuling_key = tuling_key
[文档] @classmethod
def get_config(cls):
# Try to get ali_yuyin config from config
return config.get('tuling', {})
[文档] def chat(self, texts):
"""
使用图灵机器人聊天
Arguments:
texts -- user input, typically speech, to be parsed by a module
"""
msg = ''.join(texts)
try:
url = "http://www.tuling123.com/openapi/api"
userid = str(get_mac())[:32]
body = {'key': self.tuling_key, 'info': msg, 'userid': userid}
r = requests.post(url, data=body)
respond = json.loads(r.text)
result = ''
if respond['code'] == 100000:
result = respond['text'].replace('<br>', ' ')
result = result.replace(u'\xa0', u' ')
elif respond['code'] == 200000:
result = respond['url']
elif respond['code'] == 302000:
for k in respond['list']:
result = result + u"【" + k['source'] + u"】 " +\
k['article'] + "\t" + k['detailurl'] + "\n"
else:
result = respond['text'].replace('<br>', ' ')
result = result.replace(u'\xa0', u' ')
logger.info('{} 回答:{}'.format(self.SLUG, result))
return result
except Exception:
logger.critical("Tuling robot failed to responsed for %r",
msg, exc_info=True)
return "抱歉, 我的大脑短路了,请稍后再试试."
[文档]class Emotibot(AbstractRobot):
SLUG = "emotibot"
def __init__(self, appid, location, more):
"""
Emotibot机器人
"""
super(self.__class__, self).__init__()
self.appid, self.location, self.more = appid, location, more
[文档] @classmethod
def get_config(self):
appid = config.get('/emotibot/appid', '')
location = config.get('location', '深圳')
more = config.get('active_mode', False)
return {
'appid': appid,
'location': location,
'more': more
}
[文档] def chat(self, texts):
"""
使用Emotibot机器人聊天
Arguments:
texts -- user input, typically speech, to be parsed by a module
"""
msg = ''.join(texts)
try:
url = "http://idc.emotibot.com/api/ApiKey/openapi.php"
userid = str(get_mac())[:32]
register_data = {
"cmd": "chat",
"appid": self.appid,
"userid": userid,
"text": msg,
"location": self.location
}
r = requests.post(url, params=register_data)
jsondata = json.loads(r.text)
result = ''
responds = []
if jsondata['return'] == 0:
if self.more:
datas = jsondata.get('data')
for data in datas:
if data.get('type') == 'text':
responds.append(data.get('value'))
else:
responds.append(jsondata.get('data')[0].get('value'))
result = '\n'.join(responds)
else:
result = "抱歉, 我的大脑短路了,请稍后再试试."
logger.info('{} 回答:{}'.format(self.SLUG, result))
return result
except Exception:
logger.critical("Emotibot failed to responsed for %r",
msg, exc_info=True)
return "抱歉, 我的大脑短路了,请稍后再试试."
[文档]def get_robot_by_slug(slug):
"""
Returns:
A robot implementation available on the current platform
"""
if not slug or type(slug) is not str:
raise TypeError("Invalid slug '%s'", slug)
selected_robots = list(filter(lambda robot: hasattr(robot, "SLUG") and
robot.SLUG == slug, get_robots()))
if len(selected_robots) == 0:
raise ValueError("No robot found for slug '%s'" % slug)
else:
if len(selected_robots) > 1:
logger.warning("WARNING: Multiple robots found for slug '%s'. " +
"This is most certainly a bug." % slug)
robot = selected_robots[0]
logger.info("使用 {} 对话机器人".format(robot.SLUG))
return robot.get_instance()
[文档]def get_robots():
def get_subclasses(cls):
subclasses = set()
for subclass in cls.__subclasses__():
subclasses.add(subclass)
subclasses.update(get_subclasses(subclass))
return subclasses
return [robot for robot in
list(get_subclasses(AbstractRobot))
if hasattr(robot, 'SLUG') and robot.SLUG]
# -*- coding: utf-8-*-
import json
from aip import AipSpeech
from .sdk import TencentSpeech, AliSpeech, XunfeiSpeech
from . import utils, config
from robot import logging
from abc import ABCMeta, abstractmethod
logger = logging.getLogger(__name__)
[文档]class AbstractASR(object):
"""
Generic parent class for all ASR engines
"""
__metaclass__ = ABCMeta
[文档] @classmethod
def get_instance(cls):
profile = cls.get_config()
instance = cls(**profile)
return instance
[文档]class BaiduASR(AbstractASR):
"""
百度的语音识别API.
dev_pid:
- 1936: 普通话远场
- 1536:普通话(支持简单的英文识别)
- 1537:普通话(纯中文识别)
- 1737:英语
- 1637:粤语
- 1837:四川话
要使用本模块, 首先到 yuyin.baidu.com 注册一个开发者账号,
之后创建一个新应用, 然后在应用管理的"查看key"中获得 API Key 和 Secret Key
填入 config.xml 中.
...
baidu_yuyin:
appid: '9670645'
api_key: 'qg4haN8b2bGvFtCbBGqhrmZy'
secret_key: '585d4eccb50d306c401d7df138bb02e7'
...
"""
SLUG = "baidu-asr"
def __init__(self, appid, api_key, secret_key, dev_pid=1936, **args):
super(self.__class__, self).__init__()
self.client = AipSpeech(appid, api_key, secret_key)
self.dev_pid = dev_pid
[文档] @classmethod
def get_config(cls):
# Try to get baidu_yuyin config from config
return config.get('baidu_yuyin', {})
[文档] def transcribe(self, fp):
# 识别本地文件
pcm = utils.get_pcm_from_wav(fp)
res = self.client.asr(pcm, 'pcm', 16000, {
'dev_pid': self.dev_pid,
})
if res['err_no'] == 0:
logger.info('{} 语音识别到了:{}'.format(self.SLUG, res['result']))
return ''.join(res['result'])
else:
logger.info('{} 语音识别出错了: {}'.format(self.SLUG, res['err_msg']))
return ''
[文档]class TencentASR(AbstractASR):
"""
腾讯的语音识别API.
"""
SLUG = "tencent-asr"
def __init__(self, appid, secretid, secret_key, region='ap-guangzhou', **args):
super(self.__class__, self).__init__()
self.engine = TencentSpeech.tencentSpeech(secret_key, secretid)
self.region = region
[文档] @classmethod
def get_config(cls):
# Try to get tencent_yuyin config from config
return config.get('tencent_yuyin', {})
[文档] def transcribe(self, fp):
mp3_path = utils.convert_wav_to_mp3(fp)
r = self.engine.ASR(mp3_path, 'mp3', '1', self.region)
utils.check_and_delete(mp3_path)
res = json.loads(r)
if 'Response' in res and 'Result' in res['Response']:
logger.info('{} 语音识别到了:{}'.format(self.SLUG, res['Response']['Result']))
return res['Response']['Result']
else:
logger.critical('{} 语音识别出错了'.format(self.SLUG), exc_info=True)
return ''
[文档]class XunfeiASR(AbstractASR):
"""
科大讯飞的语音识别API.
外网ip查询:https://ip.51240.com/
"""
SLUG = "xunfei-asr"
def __init__(self, appid, asr_api_key, asr_api_secret, tts_api_key, voice='xiaoyan'):
super(self.__class__, self).__init__()
self.appid = appid
self.api_key = asr_api_key
self.api_secret = asr_api_secret
[文档] @classmethod
def get_config(cls):
# Try to get xunfei_yuyin config from config
return config.get('xunfei_yuyin', {})
[文档] def transcribe(self, fp):
return XunfeiSpeech.transcribe(fp, self.appid, self.api_key, self.api_secret)
[文档]class AliASR(AbstractASR):
"""
阿里的语音识别API.
"""
SLUG = "ali-asr"
def __init__(self, appKey, token, **args):
super(self.__class__, self).__init__()
self.appKey, self.token = appKey, token
[文档] @classmethod
def get_config(cls):
# Try to get ali_yuyin config from config
return config.get('ali_yuyin', {})
[文档] def transcribe(self, fp):
result = AliSpeech.asr(self.appKey, self.token, fp)
if result is not None:
logger.info('{} 语音识别到了:{}'.format(self.SLUG, result))
return result
else:
logger.critical('{} 语音识别出错了'.format(self.SLUG), exc_info=True)
return ''
[文档]def get_engine_by_slug(slug=None):
"""
Returns:
An ASR Engine implementation available on the current platform
Raises:
ValueError if no speaker implementation is supported on this platform
"""
if not slug or type(slug) is not str:
raise TypeError("无效的 ASR slug '%s'", slug)
selected_engines = list(filter(lambda engine: hasattr(engine, "SLUG") and
engine.SLUG == slug, get_engines()))
if len(selected_engines) == 0:
raise ValueError("错误:找不到名为 {} 的 ASR 引擎".format(slug))
else:
if len(selected_engines) > 1:
logger.warning("注意: 有多个 ASR 名称与指定的引擎名 {} 匹配").format(slug)
engine = selected_engines[0]
logger.info("使用 {} ASR 引擎".format(engine.SLUG))
return engine.get_instance()
[文档]def get_engines():
def get_subclasses(cls):
subclasses = set()
for subclass in cls.__subclasses__():
subclasses.add(subclass)
subclasses.update(get_subclasses(subclass))
return subclasses
return [engine for engine in
list(get_subclasses(AbstractASR))
if hasattr(engine, 'SLUG') and engine.SLUG]
# -*- coding: utf-8-*-
from robot import logging
from . import plugin_loader
logger = logging.getLogger(__name__)
[文档]class Brain(object):
def __init__(self, conversation):
"""
大脑模块,负责处理技能的匹配和响应
参数:
conversation -- 管理对话
"""
self.conversation = conversation
self.plugins = plugin_loader.get_plugins(self.conversation)
self.handling = False
[文档] def isImmersive(self, plugin, text, parsed):
return self.conversation.getImmersiveMode() == plugin.SLUG and \
plugin.isValidImmersive(text, parsed)
[文档] def printPlugins(self):
plugin_list = []
for plugin in self.plugins:
plugin_list.append(plugin.SLUG)
logger.info('已激活插件:{}'.format(plugin_list))
[文档] def query(self, text):
"""
query 模块
Arguments:
text -- 用户输入
"""
args = {
"service_id": "S13442",
"api_key": 'w5v7gUV3iPGsGntcM84PtOOM',
"secret_key": 'KffXwW6E1alcGplcabcNs63Li6GvvnfL'
}
parsed = self.conversation.doParse(text, **args)
for plugin in self.plugins:
if not plugin.isValid(text, parsed) and not self.isImmersive(plugin, text, parsed):
continue
logger.info("'{}' 命中技能 {}".format(text, plugin.SLUG))
self.conversation.matchPlugin = plugin.SLUG
if plugin.IS_IMMERSIVE:
self.conversation.setImmersiveMode(plugin.SLUG)
continueHandle = False
try:
self.handling = True
continueHandle = plugin.handle(text, parsed)
self.handling = False
except Exception:
logger.critical('Failed to execute plugin',
exc_info=True)
reply = u"抱歉,插件{}出故障了,晚点再试试吧".format(plugin.SLUG)
self.conversation.say(reply, plugin=plugin.SLUG)
else:
logger.debug("Handling of phrase '%s' by " +
"plugin '%s' completed", text,
plugin.SLUG)
finally:
if not continueHandle:
return True
logger.debug("No plugin was able to handle phrase {} ".format(text))
return False
[文档] def restore(self):
""" 恢复某个技能的处理 """
if not self.conversation.immersiveMode:
return
for plugin in self.plugins:
if plugin.SLUG == self.conversation.immersiveMode and plugin.restore:
plugin.restore()
[文档] def pause(self):
""" 暂停某个技能的处理 """
if not self.conversation.immersiveMode:
return
for plugin in self.plugins:
if plugin.SLUG == self.conversation.immersiveMode and plugin.pause:
plugin.pause()
[文档] def understand(self, fp):
if self.conversation and self.conversation.asr:
return self.conversation.asr.transcribe(fp)
return None
[文档] def say(self, msg, cache=False):
if self.conversation and self.conversation.tts:
self.conversation.tts.say(msg, cache)
# -*- coding: utf-8-*-
from robot import config
from watchdog.events import FileSystemEventHandler
# -*- coding: utf-8-*-
import time
import uuid
import cProfile
import pstats
import io
import re
import os
from robot.Brain import Brain
from snowboy import snowboydecoder
from robot import logging, ASR, TTS, NLU, AI, Player, config, constants, utils, statistic
logger = logging.getLogger(__name__)
[文档]class Conversation(object):
def __init__(self, profiling=False):
self.reload()
# 历史会话消息
self.history = []
# 沉浸模式,处于这个模式下,被打断后将自动恢复这个技能
self.matchPlugin = None
self.immersiveMode = None
self.isRecording = False
self.profiling = profiling
self.onSay = None
self.hasPardon = False
[文档] def interrupt(self):
if self.player is not None and self.player.is_playing():
self.player.stop()
self.player = None
if self.immersiveMode:
self.brain.pause()
[文档] def reload(self):
""" 重新初始化 """
try:
self.asr = ASR.get_engine_by_slug(config.get('asr_engine', 'tencent-asr'))
self.ai = AI.get_robot_by_slug(config.get('robot', 'tuling'))
self.tts = TTS.get_engine_by_slug(config.get('tts_engine', 'baidu-tts'))
self.nlu = NLU.get_engine_by_slug(config.get('nlu_engine', 'unit'))
self.player = None
self.brain = Brain(self)
self.brain.printPlugins()
except Exception as e:
logger.critical("对话初始化失败:{}".format(e))
[文档] def doResponse(self, query, UUID='', onSay=None):
statistic.report(1)
self.interrupt()
self.appendHistory(0, query, UUID)
if onSay:
self.onSay = onSay
if query.strip() == '':
self.pardon()
return
lastImmersiveMode = self.immersiveMode
if not self.brain.query(query):
# 没命中技能,使用机器人回复
msg = self.ai.chat(query)
self.say(msg, True, onCompleted=self.checkRestore)
else:
if lastImmersiveMode is not None and lastImmersiveMode != self.matchPlugin:
time.sleep(1)
if self.player is not None and self.player.is_playing():
logger.debug('等说完再checkRestore')
self.player.appendOnCompleted(lambda: self.checkRestore())
else:
logger.debug('checkRestore')
self.checkRestore()
[文档] def converse(self, fp, callback=None):
""" 核心对话逻辑 """
Player.play(constants.getData('beep_lo.wav'))
logger.info('结束录音')
self.isRecording = False
if self.profiling:
logger.info('性能调试已打开')
pr = cProfile.Profile()
pr.enable()
self.doConverse(fp, callback)
pr.disable()
s = io.StringIO()
sortby = 'cumulative'
ps = pstats.Stats(pr, stream=s).sort_stats(sortby)
ps.print_stats()
print(s.getvalue())
else:
self.doConverse(fp, callback)
[文档] def doConverse(self, fp, callback=None, onSay=None):
try:
self.interrupt()
query = self.asr.transcribe(fp)
utils.check_and_delete(fp)
self.doResponse(query, callback, onSay)
except Exception as e:
logger.critical(e)
utils.clean()
[文档] def appendHistory(self, t, text, UUID=''):
""" 将会话历史加进历史记录 """
if t in (0, 1) and text is not None and text != '':
if text.endswith(',') or text.endswith(','):
text = text[:-1]
if UUID == '' or UUID == None or UUID == 'null':
UUID = str(uuid.uuid1())
# 将图片处理成HTML
pattern = r'https?://.+\.(?:png|jpg|jpeg|bmp|gif|JPG|PNG|JPEG|BMP|GIF)'
url_pattern = r'^https?://.+'
imgs = re.findall(pattern, text)
for img in imgs:
text = text.replace(img, '<img src={} class="img"/>'.format(img))
urls = re.findall(url_pattern, text)
for url in urls:
text = text.replace(url, '<a href={} target="_blank">{}</a>'.format(url, url))
self.history.append({'type': t, 'text': text, 'time': time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(time.time())), 'uuid': UUID})
def _onCompleted(self, msg):
if config.get('active_mode', False) and \
(
msg.endswith('?') or
msg.endswith(u'?') or
u'告诉我' in msg or u'请回答' in msg
):
query = self.activeListen()
self.doResponse(query)
[文档] def pardon(self):
if not self.hasPardon:
self.say("抱歉,刚刚没听清,能再说一遍吗?", onCompleted=lambda: self.doResponse(self.activeListen()))
self.hasPardon = True
else:
self.say("没听清呢")
self.hasPardon = False
[文档] def say(self, msg, cache=False, plugin='', onCompleted=None, wait=False):
"""
说一句话
:param msg: 内容
:param cache: 是否缓存这句话的音频
:param plugin: 来自哪个插件的消息(将带上插件的说明)
:param onCompleted: 完成的回调
:param wait: 是否要等待说完(为True将阻塞主线程直至说完这句话)
"""
if plugin != '':
self.appendHistory(1, "[{}] {}".format(plugin, msg))
else:
self.appendHistory(1, msg)
pattern = r'^https?://.+'
if re.match(pattern, msg):
logger.info("内容包含URL,所以不读出来")
return
voice = ''
cache_path = ''
if utils.getCache(msg):
logger.info("命中缓存,播放缓存语音")
voice = utils.getCache(msg)
cache_path = utils.getCache(msg)
else:
try:
voice = self.tts.get_speech(msg)
cache_path = utils.saveCache(voice, msg)
except Exception as e:
logger.error('保存缓存失败:{}'.format(e))
if self.onSay:
logger.info(cache)
audio = 'http://{}:{}/audio/{}'.format(config.get('/server/host'), config.get('/server/port'), os.path.basename(cache_path))
logger.info('onSay: {}, {}'.format(msg, audio))
if plugin != '':
self.onSay("[{}] {}".format(plugin, msg), audio)
else:
self.onSay(msg, audio)
self.onSay = None
if onCompleted is None:
onCompleted = lambda: self._onCompleted(msg)
self.player = Player.SoxPlayer()
self.player.play(voice, not cache, onCompleted, wait)
if not cache:
utils.check_and_delete(cache_path, 60) # 60秒后将自动清理不缓存的音频
utils.lruCache() # 清理缓存
[文档] def activeListen(self, silent=False):
""" 主动问一个问题(适用于多轮对话) """
logger.debug('activeListen')
try:
if not silent:
time.sleep(1)
Player.play(constants.getData('beep_hi.wav'))
listener = snowboydecoder.ActiveListener([constants.getHotwordModel(config.get('hotword', 'wukong.pmdl'))])
voice = listener.listen(
silent_count_threshold=config.get('silent_threshold', 15),
recording_timeout=config.get('recording_timeout', 5) * 4
)
if not silent:
Player.play(constants.getData('beep_lo.wav'))
if voice:
query = self.asr.transcribe(voice)
utils.check_and_delete(voice)
return query
return ''
except Exception as e:
logger.error(e)
return ''
[文档] def play(self, src, delete=False, onCompleted=None, volume=1):
""" 播放一个音频 """
if self.player:
self.interrupt()
self.player = Player.SoxPlayer()
self.player.play(src, delete, onCompleted=onCompleted, volume=volume)
# -*- coding: utf-8-*-
from .sdk import unit
from robot import logging
from abc import ABCMeta, abstractmethod
logger = logging.getLogger(__name__)
[文档]class AbstractNLU(object):
"""
Generic parent class for all NLU engines
"""
__metaclass__ = ABCMeta
[文档] @classmethod
def get_instance(cls):
profile = cls.get_config()
instance = cls(**profile)
return instance
[文档] @abstractmethod
def parse(self, query, **args):
"""
进行 NLU 解析
:param query: 用户的指令字符串
:param **args: 可选的参数
"""
return None
[文档] @abstractmethod
def getIntent(self, parsed):
"""
提取意图
:param parsed: 解析结果
:returns: 意图数组
"""
return None
[文档] @abstractmethod
def hasIntent(self, parsed, intent):
"""
判断是否包含某个意图
:param parsed: 解析结果
:param intent: 意图的名称
:returns: True: 包含; False: 不包含
"""
return False
[文档] @abstractmethod
def getSlots(self, parsed, intent):
"""
提取某个意图的所有词槽
:param parsed: 解析结果
:param intent: 意图的名称
:returns: 词槽列表。你可以通过 name 属性筛选词槽,
再通过 normalized_word 属性取出相应的值
"""
return None
[文档] @abstractmethod
def getSlotWords(self, parsed, intent, name):
"""
找出命中某个词槽的内容
:param parsed: 解析结果
:param intent: 意图的名称
:param name: 词槽名
:returns: 命中该词槽的值的列表。
"""
return None
[文档] @abstractmethod
def getSay(self, parsed, intent):
"""
提取回复文本
:param parsed: 解析结果
:param intent: 意图的名称
:returns: 回复文本
"""
return ""
[文档]class UnitNLU(AbstractNLU):
"""
百度UNIT的NLU API.
"""
SLUG = "unit"
def __init__(self):
super(self.__class__, self).__init__()
[文档] def parse(self, query, **args):
"""
使用百度 UNIT 进行 NLU 解析
:param query: 用户的指令字符串
:param **args: UNIT 的相关参数
- service_id: UNIT 的 service_id
- api_key: UNIT apk_key
- secret_key: UNIT secret_key
:returns: UNIT 解析结果。如果解析失败,返回 None
"""
if 'service_id' not in args or \
'api_key' not in args or \
'secret_key' not in args:
logger.critical('{} NLU 失败:参数错误!'.format(self.SLUG))
return None
return unit.getUnit(query,
args['service_id'],
args['api_key'],
args['secret_key'])
[文档] def getIntent(self, parsed):
"""
提取意图
:param parsed: 解析结果
:returns: 意图数组
"""
return unit.getIntent(parsed)
[文档] def hasIntent(self, parsed, intent):
"""
判断是否包含某个意图
:param parsed: UNIT 解析结果
:param intent: 意图的名称
:returns: True: 包含; False: 不包含
"""
return unit.hasIntent(parsed, intent)
[文档] def getSlots(self, parsed, intent):
"""
提取某个意图的所有词槽
:param parsed: UNIT 解析结果
:param intent: 意图的名称
:returns: 词槽列表。你可以通过 name 属性筛选词槽,
再通过 normalized_word 属性取出相应的值
"""
return unit.getSlots(parsed, intent)
[文档] def getSlotWords(self, parsed, intent, name):
"""
找出命中某个词槽的内容
:param parsed: UNIT 解析结果
:param intent: 意图的名称
:param name: 词槽名
:returns: 命中该词槽的值的列表。
"""
return unit.getSlotWords(parsed, intent, name)
[文档] def getSay(self, parsed, intent):
"""
提取 UNIT 的回复文本
:param parsed: UNIT 解析结果
:param intent: 意图的名称
:returns: UNIT 的回复文本
"""
return unit.getSay(parsed, intent)
[文档]def get_engine_by_slug(slug=None):
"""
Returns:
An NLU Engine implementation available on the current platform
Raises:
ValueError if no speaker implementation is supported on this platform
"""
if not slug or type(slug) is not str:
raise TypeError("无效的 NLU slug '%s'", slug)
selected_engines = list(filter(lambda engine: hasattr(engine, "SLUG") and
engine.SLUG == slug, get_engines()))
if len(selected_engines) == 0:
raise ValueError("错误:找不到名为 {} 的 NLU 引擎".format(slug))
else:
if len(selected_engines) > 1:
logger.warning("注意: 有多个 NLU 名称与指定的引擎名 {} 匹配").format(slug)
engine = selected_engines[0]
logger.info("使用 {} NLU 引擎".format(engine.SLUG))
return engine.get_instance()
[文档]def get_engines():
def get_subclasses(cls):
subclasses = set()
for subclass in cls.__subclasses__():
subclasses.add(subclass)
subclasses.update(get_subclasses(subclass))
return subclasses
return [engine for engine in
list(get_subclasses(AbstractNLU))
if hasattr(engine, 'SLUG') and engine.SLUG]
# -*- coding: utf-8-*-
import subprocess
import os
import platform
from . import utils
import _thread as thread
from robot import logging
from ctypes import CFUNCTYPE, c_char_p, c_int, cdll
from contextlib import contextmanager
logger = logging.getLogger(__name__)
ERROR_HANDLER_FUNC = CFUNCTYPE(None, c_char_p, c_int, c_char_p, c_int, c_char_p)
c_error_handler = ERROR_HANDLER_FUNC(py_error_handler)
[文档]@contextmanager
def no_alsa_error():
try:
asound = cdll.LoadLibrary('libasound.so')
asound.snd_lib_error_set_handler(c_error_handler)
yield
asound.snd_lib_error_set_handler(None)
except:
yield
pass
[文档]def play(fname, onCompleted=None):
player = getPlayerByFileName(fname)
player.play(fname, onCompleted)
[文档]def getPlayerByFileName(fname):
foo, ext = os.path.splitext(fname)
if ext in ['.mp3', '.wav']:
return SoxPlayer()
[文档]class AbstractPlayer(object):
def __init__(self, **kwargs):
super(AbstractPlayer, self).__init__()
[文档]class SoxPlayer(AbstractPlayer):
SLUG = 'SoxPlayer'
def __init__(self, **kwargs):
super(SoxPlayer, self).__init__(**kwargs)
self.playing = False
self.proc = None
self.delete = False
self.onCompleteds = []
[文档] def doPlay(self):
cmd = ['play', str(self.src)]
logger.debug('Executing %s', ' '.join(cmd))
self.proc = subprocess.Popen(cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)
self.playing = True
self.proc.wait()
self.playing = False
if self.delete:
utils.check_and_delete(self.src)
logger.debug('play completed')
if self.proc.returncode == 0:
for onCompleted in self.onCompleteds:
if onCompleted:
onCompleted()
self.onCompleteds = []
[文档] def play(self, src, delete=False, onCompleted=None, wait=False):
if (os.path.exists(src)):
self.src = src
self.delete = delete
self.onCompleteds.append(onCompleted)
if not wait:
thread.start_new_thread(self.doPlay, ())
else:
self.doPlay()
else:
logger.critical('path not exists: {}'.format(src))
[文档] def appendOnCompleted(self, onCompleted):
if onCompleted:
self.onCompleteds.append(onCompleted)
[文档] def stop(self):
if self.proc:
self.onCompleteds = []
self.proc.terminate()
if self.delete:
utils.check_and_delete(self.src)
[文档]class MusicPlayer(SoxPlayer):
"""
给音乐播放器插件使用的,
在 SOXPlayer 的基础上增加了列表的支持,
并支持暂停和恢复播放
"""
SLUG = 'MusicPlayer'
def __init__(self, playlist, plugin, **kwargs):
super(MusicPlayer, self).__init__(**kwargs)
self.playlist = playlist
self.plugin = plugin
self.idx = 0
self.pausing = False
self.last_paused = None
[文档] def update_playlist(self, playlist):
super().stop()
self.playlist = playlist
self.idx = 0
self.play()
[文档] def play(self):
logger.debug('MusicPlayer play')
path = self.playlist[self.idx]
super().stop()
super().play(path, False, self.next)
[文档] def next(self):
logger.debug('MusicPlayer next')
super().stop()
self.idx = (self.idx+1) % len(self.playlist)
self.play()
[文档] def prev(self):
logger.debug('MusicPlayer prev')
super().stop()
self.idx = (self.idx-1) % len(self.playlist)
self.play()
[文档] def stop(self):
if self.proc:
logger.debug('MusicPlayer stop')
# STOP current play process
self.last_paused = utils.write_temp_file(str(self.proc.pid), 'pid', 'w')
self.onCompleteds = []
subprocess.run(['pkill', '-STOP', '-F', self.last_paused])
[文档] def resume(self):
logger.debug('MusicPlayer resume')
self.pausing = False
self.onCompleteds = [self.next]
if self.last_paused is not None:
print(self.last_paused)
subprocess.run(['pkill', '-CONT', '-F', self.last_paused])
[文档] def turnUp(self):
system = platform.system()
if system == 'Darwin':
res = subprocess.run(['osascript', '-e', 'output volume of (get volume settings)'], shell=False, capture_output=True, text=True)
volume = int(res.stdout.strip())
volume += 20
if volume >= 100:
volume = 100
self.plugin.say('音量已经最大啦', wait=True)
subprocess.run(['osascript', '-e', 'set volume output volume {}'.format(volume)])
elif system == 'Linux':
res = subprocess.run(["amixer sget Master | grep 'Mono:' | awk -F'[][]' '{ print $2 }'"], shell=True, capture_output=True, text=True)
print(res.stdout)
if res.stdout != '' and res.stdout.strip().endswith('%'):
volume = int(res.stdout.strip().replace('%', ''))
volume += 20
if volume >= 100:
volume = 100
self.plugin.say('音量已经最大啦', wait=True)
subprocess.run(['amixer', 'set', 'Master', '{}%'.format(volume)])
else:
subprocess.run(['amixer', 'set', 'Master', '20%+'])
else:
self.plugin.say('当前系统不支持调节音量')
self.resume()
[文档] def turnDown(self):
system = platform.system()
if system == 'Darwin':
res = subprocess.run(['osascript', '-e', 'output volume of (get volume settings)'], shell=False, capture_output=True, text=True)
volume = int(res.stdout.strip())
volume -= 20
if volume <= 20:
volume = 20
self.plugin.say('音量已经很小啦', wait=True)
subprocess.run(['osascript', '-e', 'set volume output volume {}'.format(volume)])
elif system == 'Linux':
res = subprocess.run(["amixer sget Master | grep 'Mono:' | awk -F'[][]' '{ print $2 }'"], shell=True, capture_output=True, text=True)
if res.stdout != '' and res.stdout.endswith('%'):
volume = int(res.stdout.replace('%', '').strip())
volume -= 20
if volume <= 20:
volume = 20
self.plugin.say('音量已经最小啦', wait=True)
subprocess.run(['amixer', 'set', 'Master', '{}%'.format(volume)])
else:
subprocess.run(['amixer', 'set', 'Master', '20%-'])
else:
self.plugin.say('当前系统不支持调节音量')
self.resume()
# -*- coding: utf-8-*-
from aip import AipSpeech
from .sdk import TencentSpeech, AliSpeech
from . import utils, config
from robot import logging
import base64
import time
import requests
import hashlib
from abc import ABCMeta, abstractmethod
logger = logging.getLogger(__name__)
[文档]class AbstractTTS(object):
"""
Generic parent class for all TTS engines
"""
__metaclass__ = ABCMeta
[文档] @classmethod
def get_instance(cls):
profile = cls.get_config()
instance = cls(**profile)
return instance
[文档]class BaiduTTS(AbstractTTS):
"""
使用百度语音合成技术
要使用本模块, 首先到 yuyin.baidu.com 注册一个开发者账号,
之后创建一个新应用, 然后在应用管理的"查看key"中获得 API Key 和 Secret Key
填入 config.yml 中.
...
baidu_yuyin:
appid: '9670645'
api_key: 'qg4haN8b2bGvFtCbBGqhrmZy'
secret_key: '585d4eccb50d306c401d7df138bb02e7'
dev_pid: 1936
per: 1
lan: 'zh'
...
"""
SLUG = "baidu-tts"
def __init__(self, appid, api_key, secret_key, per=1, lan='zh', **args):
super(self.__class__, self).__init__()
self.client = AipSpeech(appid, api_key, secret_key)
self.per, self.lan = str(per), lan
[文档] @classmethod
def get_config(cls):
# Try to get baidu_yuyin config from config
return config.get('baidu_yuyin', {})
[文档] def get_speech(self, phrase):
result = self.client.synthesis(phrase, self.lan, 1, {'per': self.per});
# 识别正确返回语音二进制 错误则返回dict 参照下面错误码
if not isinstance(result, dict):
tmpfile = utils.write_temp_file(result, '.mp3')
logger.info('{} 语音合成成功,合成路径:{}'.format(self.SLUG, tmpfile))
return tmpfile
else:
logger.critical('{} 合成失败!'.format(self.SLUG), exc_info=True)
[文档]class TencentTTS(AbstractTTS):
"""
腾讯的语音合成
region: 服务地域,挑个离自己最近的区域有助于提升速度。
有效值:https://cloud.tencent.com/document/api/441/17365#.E5.9C.B0.E5.9F.9F.E5.88.97.E8.A1.A8
voiceType:
- 0:女声1,亲和风格(默认)
- 1:男声1,成熟风格
- 2:男声2,成熟风格
language:
- 1: 中文,最大100个汉字(标点符号算一个汉子)
- 2: 英文,最大支持400个字母(标点符号算一个字母)
"""
SLUG = "tencent-tts"
def __init__(self, appid, secretid, secret_key, region='ap-guangzhou', voiceType=0, language=1, **args):
super(self.__class__, self).__init__()
self.engine = TencentSpeech.tencentSpeech(secret_key, secretid)
self.region, self.voiceType, self.language = region, voiceType, language
[文档] @classmethod
def get_config(cls):
# Try to get tencent_yuyin config from config
return config.get('tencent_yuyin', {})
[文档] def get_speech(self, phrase):
result = self.engine.TTS(phrase, self.voiceType, self.language, self.region)
if 'Response' in result and 'Audio' in result['Response']:
audio = result['Response']['Audio']
data = base64.b64decode(audio)
tmpfile = utils.write_temp_file(data, '.wav')
logger.info('{} 语音合成成功,合成路径:{}'.format(self.SLUG, tmpfile))
return tmpfile
else:
logger.critical('{} 合成失败!'.format(self.SLUG), exc_info=True)
[文档]class XunfeiTTS(AbstractTTS):
"""
科大讯飞的语音识别API.
外网ip查询:https://ip.51240.com/
voice_name: https://www.xfyun.cn/services/online_tts
"""
SLUG = "xunfei-tts"
def __init__(self, appid, asr_api_key, asr_api_secret, tts_api_key, voice='xiaoyan'):
super(self.__class__, self).__init__()
self.appid, self.api_key, self.voice_name = appid, tts_api_key, voice
[文档] @classmethod
def get_config(cls):
# Try to get xunfei_yuyin config from config
return config.get('xunfei_yuyin', {})
[文档] def getHeader(self, aue):
curTime = str(int(time.time()))
# curTime = '1526542623'
param = "{\"aue\":\""+aue+"\",\"auf\":\"audio/L16;rate=16000\",\"voice_name\":\"" + self.voice_name + "\",\"engine_type\":\"intp65\"}"
logger.debug("param:{}".format(param))
paramBase64 = str(base64.b64encode(param.encode('utf-8')), 'utf-8')
logger.debug("x_param:{}".format(paramBase64))
m2 = hashlib.md5()
m2.update((self.api_key + curTime + paramBase64).encode('utf-8'))
checkSum = m2.hexdigest()
header = {
'X-CurTime': curTime,
'X-Param': paramBase64,
'X-Appid': self.appid,
'X-CheckSum': checkSum,
'X-Real-Ip':'127.0.0.1',
'Content-Type': 'application/x-www-form-urlencoded; charset=utf-8',
}
return header
[文档] def get_speech(self, phrase):
URL = "http://api.xfyun.cn/v1/service/v1/tts"
r = requests.post(URL, headers=self.getHeader('lame'), data=self.getBody(phrase))
contentType = r.headers['Content-Type']
if contentType == "audio/mpeg":
tmpfile = utils.write_temp_file(r.content, '.mp3')
logger.info('{} 语音合成成功,合成路径:{}'.format(self.SLUG, tmpfile))
return tmpfile
else :
logger.critical('{} 合成失败!{}'.format(self.SLUG, r.text), exc_info=True)
[文档]class AliTTS(AbstractTTS):
"""
阿里的TTS
voice: 发音人,默认是 xiaoyun
全部发音人列表:https://help.aliyun.com/document_detail/84435.html?spm=a2c4g.11186623.2.24.67ce5275q2RGsT
"""
SLUG = "ali-tts"
def __init__(self, appKey, token, voice='xiaoyun', **args):
super(self.__class__, self).__init__()
self.appKey, self.token, self.voice = appKey, token, voice
[文档] @classmethod
def get_config(cls):
# Try to get ali_yuyin config from config
return config.get('ali_yuyin', {})
[文档] def get_speech(self, phrase):
tmpfile = AliSpeech.tts(self.appKey, self.token, self.voice, phrase)
if tmpfile is not None:
logger.info('{} 语音合成成功,合成路径:{}'.format(self.SLUG, tmpfile))
return tmpfile
else:
logger.critical('{} 合成失败!'.format(self.SLUG), exc_info=True)
[文档]def get_engine_by_slug(slug=None):
"""
Returns:
A TTS Engine implementation available on the current platform
Raises:
ValueError if no speaker implementation is supported on this platform
"""
if not slug or type(slug) is not str:
raise TypeError("无效的 TTS slug '%s'", slug)
selected_engines = list(filter(lambda engine: hasattr(engine, "SLUG") and
engine.SLUG == slug, get_engines()))
if len(selected_engines) == 0:
raise ValueError("错误:找不到名为 {} 的 TTS 引擎".format(slug))
else:
if len(selected_engines) > 1:
logger.warning("注意: 有多个 TTS 名称与指定的引擎名 {} 匹配").format(slug)
engine = selected_engines[0]
logger.info("使用 {} TTS 引擎".format(engine.SLUG))
return engine.get_instance()
[文档]def get_engines():
def get_subclasses(cls):
subclasses = set()
for subclass in cls.__subclasses__():
subclasses.add(subclass)
subclasses.update(get_subclasses(subclass))
return subclasses
return [engine for engine in
list(get_subclasses(AbstractTTS))
if hasattr(engine, 'SLUG') and engine.SLUG]
import os
import requests
import json
import semver
from subprocess import call
from robot import constants, logging
from datetime import datetime, timedelta
logger = logging.getLogger(__name__)
logger.setLevel(level=logging.INFO)
_updater = None
URL = 'https://service-e32kknxi-1253537070.ap-hongkong.apigateway.myqcloud.com/release/wukong'
DEV_URL = 'https://service-e32kknxi-1253537070.ap-hongkong.apigateway.myqcloud.com/release/wukong-dev'
[文档]class Updater(object):
def __init__(self):
self.last_check = datetime.now() - timedelta(days=1.5)
self.update_info = {}
def _pull(self, cwd, tag):
if os.path.exists(cwd):
return call(['git checkout master && git pull && git checkout {}'.format(tag, tag, tag)], cwd=cwd, shell=True) == 0
else:
logger.error("目录 {} 不存在".format(cwd))
return False
def _pip(self, cwd):
if os.path.exists(cwd):
return call(['pip3', 'install', '-r', 'requirements.txt'], cwd=cwd, shell=False) == 0
else:
logger.error("目录 {} 不存在".format(cwd))
return False
[文档] def update(self):
update_info = self.fetch()
success = True
if update_info == {}:
logger.info('恭喜你,wukong-robot 已经是最新!')
if 'main' in update_info:
if self._pull(constants.APP_PATH, update_info['main']['version']) and self._pip(constants.APP_PATH):
logger.info('wukong-robot 更新成功!')
self.update_info.pop('main')
else:
logger.info('wukong-robot 更新失败!')
success = False
if 'contrib' in update_info:
if self._pull(constants.CONTRIB_PATH, update_info['contrib']['version']) and self._pip(constants.CONTRIB_PATH):
logger.info('wukong-contrib 更新成功!')
self.update_info.pop('contrib')
else:
logger.info('wukong-contrib 更新失败!')
success = False
return success
def _get_version(self, path, current):
if os.path.exists(os.path.join(path, 'VERSION')):
with open(os.path.join(path, 'VERSION'), 'r') as f:
return f.read().strip()
else:
return current
[文档] def fetch(self, dev=False):
global URL, DEV_URL
url = URL
if dev:
url = DEV_URL
now = datetime.now()
if (now - self.last_check).seconds <= 1800:
logger.debug('30 分钟内已检查过更新,使用上次的检查结果:{}'.format(self.update_info))
return self.update_info
try:
self.last_check = now
r = requests.get(url, timeout=3)
info = json.loads(r.text)
main_version = info['main']['version']
contrib_version = info['contrib']['version']
# 检查主仓库
current_main_version = self._get_version(constants.APP_PATH, main_version)
current_contrib_version = self._get_version(constants.CONTRIB_PATH, contrib_version)
if semver.compare(main_version, current_main_version) > 0:
logger.info('主仓库检查到更新:{}'.format(info['main']))
self.update_info['main'] = info['main']
if semver.compare(contrib_version, current_contrib_version) > 0:
logger.info('插件库检查到更新:{}'.format(info['contrib']))
self.update_info['contrib'] = info['contrib']
if 'notices' in info:
self.update_info['notices'] = info['notices']
return self.update_info
except Exception as e:
logger.error("检查更新失败:", e)
return {}
[文档]def fetch(dev):
global _updater
if not _updater:
_updater = Updater()
return _updater.fetch(dev)
if __name__ == '__main__':
fetch()
# -*- coding: utf-8-*-
import yaml
import logging
import os
from . import constants
logger = logging.getLogger(__name__)
_config = {}
has_init = False
[文档]def init():
global has_init
if os.path.isfile(constants.CONFIG_PATH):
logger.critical("错误:{} 应该是个目录,而不应该是个文件".format(constants.CONFIG_PATH))
if not os.path.exists(constants.CONFIG_PATH):
os.makedirs(constants.CONFIG_PATH)
if not os.path.exists(constants.getConfigPath()):
yes_no = input("配置文件{}不存在,要创建吗?(y/n)".format(constants.getConfigPath()))
if yes_no.lower() == 'y':
constants.newConfig()
doInit(constants.getConfigPath())
else:
doInit(constants.getDefaultConfigPath())
else:
doInit(constants.getConfigPath())
has_init = True
[文档]def doInit(config_file=constants.getDefaultConfigPath()):
# Create config dir if it does not exist yet
if not os.path.exists(constants.CONFIG_PATH):
try:
os.makedirs(constants.CONFIG_PATH)
except OSError:
logger.error("Could not create config dir: '%s'",
constants.CONFIG_PATH, exc_info=True)
raise
# Check if config dir is writable
if not os.access(constants.CONFIG_PATH, os.W_OK):
logger.critical("Config dir %s is not writable. Dingdang " +
"won't work correctly.",
constants.CONFIG_PATH)
global _config
# Read config
logger.debug("Trying to read config file: '%s'", config_file)
try:
with open(config_file, "r") as f:
_config = yaml.safe_load(f)
except Exception as e:
logger.error("配置文件 {} 读取失败: {}".format(config_file, e))
raise
[文档]def get_path(items, default=None):
global _config
curConfig = _config
if isinstance(items, str) and items[0] == '/':
items = items.split('/')[1:]
for key in items:
if key in curConfig:
curConfig = curConfig[key]
else:
logger.warning("/%s not specified in profile, defaulting to "
"'%s'", '/'.join(items), default)
return default
return curConfig
[文档]def has_path(items):
global _config
curConfig = _config
if isinstance(items, str) and items[0] == '/':
items = items.split('/')[1:]
else:
items = [items]
for key in items:
if key in curConfig:
curConfig = curConfig[key]
else:
return False
return True
[文档]def has(item):
"""
判断配置里是否包含某个配置项
:param item: 配置项名
:returns: True: 包含; False: 不包含
"""
return has_path(item)
[文档]def get(item='', default=None):
"""
获取某个配置的值
:param item: 配置项名。如果是多级配置,则以 "/a/b" 的形式提供
:param default: 默认值(可选)
:returns: 这个配置的值。如果没有该配置,则提供一个默认值
"""
global has_init
if not has_init:
init()
if not item:
return _config
if item[0] == '/':
return get_path(item, default)
try:
return _config[item]
except KeyError:
logger.warning("%s not specified in profile, defaulting to '%s'",
item, default)
return default
[文档]def getText():
if os.path.exists(constants.getConfigPath()):
with open(constants.getConfigPath(), 'r') as f:
return f.read()
return ''
# -*- coding: utf-8-*-
import os
import shutil
# Wukong main directory
APP_PATH = os.path.normpath(os.path.join(
os.path.dirname(os.path.abspath(__file__)), os.pardir))
LIB_PATH = os.path.join(APP_PATH, "robot")
DATA_PATH = os.path.join(APP_PATH, "static")
TEMP_PATH = os.path.join(APP_PATH, "temp")
TEMPLATE_PATH = os.path.join(APP_PATH, "server", "templates")
PLUGIN_PATH = os.path.join(APP_PATH, "plugins")
DEFAULT_CONFIG_NAME = 'default.yml'
CUSTOM_CONFIG_NAME = 'config.yml'
CONFIG_PATH = os.path.expanduser(
os.getenv('WUKONG_CONFIG', '~/.wukong')
)
CONTRIB_PATH = os.path.expanduser(
os.getenv('WUKONG_CONFIG', '~/.wukong/contrib')
)
CUSTOM_PATH = os.path.expanduser(
os.getenv('WUKONG_CONFIG', '~/.wukong/custom')
)
[文档]def getConfigPath():
"""
获取配置文件的路径
returns: 配置文件的存储路径
"""
return os.path.join(CONFIG_PATH, CUSTOM_CONFIG_NAME)
[文档]def getConfigData(*fname):
"""
获取配置目录下的指定文件的路径
:param *fname: 指定文件名。如果传多个,则自动拼接
:returns: 配置目录下的某个文件的存储路径
"""
return os.path.join(CONFIG_PATH, *fname)
[文档]def getData(*fname):
"""
获取资源目录下指定文件的路径
:param *fname: 指定文件名。如果传多个,则自动拼接
:returns: 配置文件的存储路径
"""
return os.path.join(DATA_PATH, *fname)
[文档]def getHotwordModel(fname):
if os.path.exists(getData(fname)):
return getData(fname)
else:
return getConfigData(fname)
"""
from https://github.com/tinue/APA102_Pi
This is the main driver module for APA102 LEDs
"""
import spidev
from math import ceil
RGB_MAP = { 'rgb': [3, 2, 1], 'rbg': [3, 1, 2], 'grb': [2, 3, 1],
'gbr': [2, 1, 3], 'brg': [1, 3, 2], 'bgr': [1, 2, 3] }
[文档]class APA102:
"""
Driver for APA102 LEDS (aka "DotStar").
(c) Martin Erzberger 2016-2017
My very first Python code, so I am sure there is a lot to be optimized ;)
Public methods are:
- set_pixel
- set_pixel_rgb
- show
- clear_strip
- cleanup
Helper methods for color manipulation are:
- combine_color
- wheel
The rest of the methods are used internally and should not be used by the
user of the library.
Very brief overview of APA102: An APA102 LED is addressed with SPI. The bits
are shifted in one by one, starting with the least significant bit.
An LED usually just forwards everything that is sent to its data-in to
data-out. While doing this, it remembers its own color and keeps glowing
with that color as long as there is power.
An LED can be switched to not forward the data, but instead use the data
to change it's own color. This is done by sending (at least) 32 bits of
zeroes to data-in. The LED then accepts the next correct 32 bit LED
frame (with color information) as its new color setting.
After having received the 32 bit color frame, the LED changes color,
and then resumes to just copying data-in to data-out.
The really clever bit is this: While receiving the 32 bit LED frame,
the LED sends zeroes on its data-out line. Because a color frame is
32 bits, the LED sends 32 bits of zeroes to the next LED.
As we have seen above, this means that the next LED is now ready
to accept a color frame and update its color.
So that's really the entire protocol:
- Start by sending 32 bits of zeroes. This prepares LED 1 to update
its color.
- Send color information one by one, starting with the color for LED 1,
then LED 2 etc.
- Finish off by cycling the clock line a few times to get all data
to the very last LED on the strip
The last step is necessary, because each LED delays forwarding the data
a bit. Imagine ten people in a row. When you yell the last color
information, i.e. the one for person ten, to the first person in
the line, then you are not finished yet. Person one has to turn around
and yell it to person 2, and so on. So it takes ten additional "dummy"
cycles until person ten knows the color. When you look closer,
you will see that not even person 9 knows its own color yet. This
information is still with person 2. Essentially the driver sends additional
zeroes to LED 1 as long as it takes for the last color frame to make it
down the line to the last LED.
"""
# Constants
MAX_BRIGHTNESS = 31 # Safeguard: Set to a value appropriate for your setup
LED_START = 0b11100000 # Three "1" bits, followed by 5 brightness bits
def __init__(self, num_led, global_brightness=MAX_BRIGHTNESS,
order='rgb', bus=0, device=1, max_speed_hz=8000000):
self.num_led = num_led # The number of LEDs in the Strip
order = order.lower()
self.rgb = RGB_MAP.get(order, RGB_MAP['rgb'])
# Limit the brightness to the maximum if it's set higher
if global_brightness > self.MAX_BRIGHTNESS:
self.global_brightness = self.MAX_BRIGHTNESS
else:
self.global_brightness = global_brightness
self.leds = [self.LED_START,0,0,0] * self.num_led # Pixel buffer
self.spi = spidev.SpiDev() # Init the SPI device
self.spi.open(bus, device) # Open SPI port 0, slave device (CS) 1
# Up the speed a bit, so that the LEDs are painted faster
if max_speed_hz:
self.spi.max_speed_hz = max_speed_hz
[文档] def clock_start_frame(self):
"""Sends a start frame to the LED strip.
This method clocks out a start frame, telling the receiving LED
that it must update its own color now.
"""
self.spi.xfer2([0] * 4) # Start frame, 32 zero bits
[文档] def clock_end_frame(self):
"""Sends an end frame to the LED strip.
As explained above, dummy data must be sent after the last real colour
information so that all of the data can reach its destination down the line.
The delay is not as bad as with the human example above.
It is only 1/2 bit per LED. This is because the SPI clock line
needs to be inverted.
Say a bit is ready on the SPI data line. The sender communicates
this by toggling the clock line. The bit is read by the LED
and immediately forwarded to the output data line. When the clock goes
down again on the input side, the LED will toggle the clock up
on the output to tell the next LED that the bit is ready.
After one LED the clock is inverted, and after two LEDs it is in sync
again, but one cycle behind. Therefore, for every two LEDs, one bit
of delay gets accumulated. For 300 LEDs, 150 additional bits must be fed to
the input of LED one so that the data can reach the last LED.
Ultimately, we need to send additional numLEDs/2 arbitrary data bits,
in order to trigger numLEDs/2 additional clock changes. This driver
sends zeroes, which has the benefit of getting LED one partially or
fully ready for the next update to the strip. An optimized version
of the driver could omit the "clockStartFrame" method if enough zeroes have
been sent as part of "clockEndFrame".
"""
# Round up num_led/2 bits (or num_led/16 bytes)
for _ in range((self.num_led + 15) // 16):
self.spi.xfer2([0x00])
[文档] def clear_strip(self):
""" Turns off the strip and shows the result right away."""
for led in range(self.num_led):
self.set_pixel(led, 0, 0, 0)
self.show()
[文档] def set_pixel(self, led_num, red, green, blue, bright_percent=100):
"""Sets the color of one pixel in the LED stripe.
The changed pixel is not shown yet on the Stripe, it is only
written to the pixel buffer. Colors are passed individually.
If brightness is not set the global brightness setting is used.
"""
if led_num < 0:
return # Pixel is invisible, so ignore
if led_num >= self.num_led:
return # again, invisible
# Calculate pixel brightness as a percentage of the
# defined global_brightness. Round up to nearest integer
# as we expect some brightness unless set to 0
brightness = ceil(bright_percent*self.global_brightness/100.0)
brightness = int(brightness)
# LED startframe is three "1" bits, followed by 5 brightness bits
ledstart = (brightness & 0b00011111) | self.LED_START
start_index = 4 * led_num
self.leds[start_index] = ledstart
self.leds[start_index + self.rgb[0]] = red
self.leds[start_index + self.rgb[1]] = green
self.leds[start_index + self.rgb[2]] = blue
[文档] def set_pixel_rgb(self, led_num, rgb_color, bright_percent=100):
"""Sets the color of one pixel in the LED stripe.
The changed pixel is not shown yet on the Stripe, it is only
written to the pixel buffer.
Colors are passed combined (3 bytes concatenated)
If brightness is not set the global brightness setting is used.
"""
self.set_pixel(led_num, (rgb_color & 0xFF0000) >> 16,
(rgb_color & 0x00FF00) >> 8, rgb_color & 0x0000FF,
bright_percent)
[文档] def rotate(self, positions=1):
""" Rotate the LEDs by the specified number of positions.
Treating the internal LED array as a circular buffer, rotate it by
the specified number of positions. The number could be negative,
which means rotating in the opposite direction.
"""
cutoff = 4 * (positions % self.num_led)
self.leds = self.leds[cutoff:] + self.leds[:cutoff]
[文档] def show(self):
"""Sends the content of the pixel buffer to the strip.
Todo: More than 1024 LEDs requires more than one xfer operation.
"""
self.clock_start_frame()
# xfer2 kills the list, unfortunately. So it must be copied first
# SPI takes up to 4096 Integers. So we are fine for up to 1024 LEDs.
self.spi.xfer2(list(self.leds))
self.clock_end_frame()
[文档] def cleanup(self):
"""Release the SPI device; Call this method at the end"""
self.spi.close() # Close SPI port
[文档] @staticmethod
def combine_color(red, green, blue):
"""Make one 3*8 byte color value."""
return (red << 16) + (green << 8) + blue
[文档] def wheel(self, wheel_pos):
"""Get a color from a color wheel; Green -> Red -> Blue -> Green"""
if wheel_pos > 255:
wheel_pos = 255 # Safeguard
if wheel_pos < 85: # Green -> Red
return self.combine_color(wheel_pos * 3, 255 - wheel_pos * 3, 0)
if wheel_pos < 170: # Red -> Blue
wheel_pos -= 85
return self.combine_color(255 - wheel_pos * 3, 0, wheel_pos * 3)
# Blue -> Green
wheel_pos -= 170
return self.combine_color(0, wheel_pos * 3, 255 - wheel_pos * 3)
[文档] def dump_array(self):
"""For debug purposes: Dump the LED array onto the console."""
print(self.leds)
from . import apa102
import time
import threading
try:
import queue as Queue
except ImportError:
import Queue as Queue
[文档]class Pixels:
PIXELS_N = 3
def __init__(self):
self.basis = [0] * 3 * self.PIXELS_N
self.basis[0] = 1
self.basis[4] = 1
self.basis[8] = 2
self.colors = [0] * 3 * self.PIXELS_N
self.dev = apa102.APA102(num_led=self.PIXELS_N)
self.next = threading.Event()
self.queue = Queue.Queue()
self.thread = threading.Thread(target=self._run)
self.thread.daemon = True
self.thread.start()
[文档] def wakeup(self, direction=0):
def f():
self._wakeup(direction)
self.next.set()
self.queue.put(f)
def _run(self):
while True:
func = self.queue.get()
func()
def _wakeup(self, direction=0):
for i in range(1, 25):
colors = [i * v for v in self.basis]
self.write(colors)
time.sleep(0.01)
self.colors = colors
def _listen(self):
for i in range(1, 25):
colors = [i * v for v in self.basis]
self.write(colors)
time.sleep(0.01)
self.colors = colors
def _think(self):
colors = self.colors
self.next.clear()
while not self.next.is_set():
colors = colors[3:] + colors[:3]
self.write(colors)
time.sleep(0.2)
t = 0.1
for i in range(0, 5):
colors = colors[3:] + colors[:3]
self.write([(v * (4 - i) / 4) for v in colors])
time.sleep(t)
t /= 2
# time.sleep(0.5)
self.colors = colors
def _speak(self):
colors = self.colors
self.next.clear()
while not self.next.is_set():
for i in range(5, 25):
colors = [(v * i / 24) for v in colors]
self.write(colors)
time.sleep(0.01)
time.sleep(0.3)
for i in range(24, 4, -1):
colors = [(v * i / 24) for v in colors]
self.write(colors)
time.sleep(0.01)
time.sleep(0.3)
self._off()
def _off(self):
self.write([0] * 3 * self.PIXELS_N)
[文档] def write(self, colors):
for i in range(self.PIXELS_N):
self.dev.set_pixel(i, int(colors[3*i]), int(colors[3*i + 1]), int(colors[3*i + 2]))
self.dev.show()
pixels = Pixels()
if __name__ == '__main__':
while True:
try:
pixels.wakeup()
time.sleep(3)
pixels.think()
time.sleep(3)
pixels.speak()
time.sleep(3)
pixels.off()
time.sleep(3)
except KeyboardInterrupt:
break
pixels.off()
time.sleep(1)
import logging
import os
from robot import constants
from logging.handlers import RotatingFileHandler
PAGE = 4096
DEBUG = logging.DEBUG
INFO = logging.INFO
WARNING = logging.WARNING
ERROR = logging.ERROR
[文档]def tail(filepath, n=10):
"""
实现 tail -n
"""
res = ""
with open(filepath, 'rb') as f:
f_len = f.seek(0, 2)
rem = f_len % PAGE
page_n = f_len // PAGE
r_len = rem if rem else PAGE
while True:
# 如果读取的页大小>=文件大小,直接读取数据输出
if r_len >= f_len:
f.seek(0)
lines = f.readlines()[::-1]
break
f.seek(-r_len, 2)
# print('f_len: {}, rem: {}, page_n: {}, r_len: {}'.format(f_len, rem, page_n, r_len))
lines = f.readlines()[::-1]
count = len(lines) -1 # 末行可能不完整,减一行,加大读取量
if count >= n: # 如果读取到的行数>=指定行数,则退出循环读取数据
break
else: # 如果读取行数不够,载入更多的页大小读取数据
r_len += PAGE
page_n -= 1
for line in lines[:n][::-1]:
res += line.decode('utf-8')
return res
[文档]def getLogger(name):
"""
作用同标准模块 logging.getLogger(name)
:returns: logger
"""
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
logger = logging.getLogger(name)
logger.setLevel(logging.INFO)
# FileHandler
file_handler = RotatingFileHandler(os.path.join(constants.TEMP_PATH, 'wukong.log'), maxBytes=1024*1024,backupCount=5)
file_handler.setLevel(level=logging.DEBUG)
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
return logger
[文档]def readLog(lines=200):
"""
获取最新的指定行数的 log
:param lines: 最大的行数
:returns: 最新指定行数的 log
"""
log_path = os.path.join(constants.TEMP_PATH, 'wukong.log')
if os.path.exists(log_path):
return tail(log_path, lines)
return ''
# -*- coding: utf-8-*-
import pkgutil
from . import constants
from . import config
from robot import logging
from robot.sdk.AbstractPlugin import AbstractPlugin
logger = logging.getLogger(__name__)
_has_init = False
# plugins run at query
_plugins_query = []
[文档]def init_plugins(con):
"""
动态加载技能插件
参数:
con -- 会话模块
"""
global _has_init
locations = [
constants.PLUGIN_PATH,
constants.CONTRIB_PATH,
constants.CUSTOM_PATH
]
logger.debug("检查插件目录:{}".format(locations))
global _plugins_query
nameSet = set()
for finder, name, ispkg in pkgutil.walk_packages(locations):
try:
loader = finder.find_module(name)
mod = loader.load_module(name)
except Exception:
logger.warning("插件 {} 加载出错,跳过".format(name),
exc_info=True)
continue
if not hasattr(mod, 'Plugin'):
logger.debug("模块 {} 非插件,跳过".format(name))
continue
# plugins run at query
plugin = mod.Plugin(con)
if plugin.SLUG == 'AbstractPlugin':
plugin.SLUG = name
# check conflict
if plugin.SLUG in nameSet:
logger.warning("插件 {} SLUG({}) 重复,跳过".format(name,
plugin.SLUG))
continue
nameSet.add(plugin.SLUG)
# whether a plugin is enabled
if config.has(plugin.SLUG) and 'enable' in config.get(plugin.SLUG):
if not config.get(plugin.SLUG)['enable']:
logger.info("插件 {} 已被禁用".format(name))
continue
if issubclass(mod.Plugin, AbstractPlugin):
logger.info("插件 {} 加载成功 ".format(name))
_plugins_query.append(plugin)
def sort_priority(m):
if hasattr(m, 'PRIORITY'):
return m.PRIORITY
return 0
_plugins_query.sort(key=sort_priority, reverse=True)
_has_init = True
[文档]def get_plugins(con):
global _plugins_query
_plugins_query = []
init_plugins(con)
return _plugins_query
from abc import ABCMeta, abstractmethod
from robot import constants
from robot import logging
import sys
logger = logging.getLogger(__name__)
try:
sys.path.append(constants.CONTRIB_PATH)
except Exception as e:
logger.debug("未检测到插件目录,Error:{}".format(e))
[文档]class AbstractPlugin(metaclass=ABCMeta):
""" 技能插件基类 """
SLUG = 'AbstractPlugin'
IS_IMMERSIVE = False
def __init__(self, con):
if self.IS_IMMERSIVE is not None:
self.isImmersive = self.IS_IMMERSIVE
else:
self.isImmersive = False
self.priority = 0
self.con = con
self.nlu = self.con.nlu
[文档] def play(self, src, delete=False, onCompleted=None, volume=1):
self.con.play(src, delete, onCompleted, volume)
[文档] def say(self, text, cache=False, onCompleted=None, wait=False):
self.con.say(text, cache=cache, plugin=self.SLUG, onCompleted=onCompleted, wait=wait)
[文档] @abstractmethod
def isValid(self, query, parsed):
"""
是否适合由该插件处理
参数:
query -- 用户的指令字符串
parsed -- 用户指令经过 NLU 解析后的结果
返回:
True: 适合由该插件处理
False: 不适合由该插件处理
"""
return False
[文档] @abstractmethod
def handle(self, query, parsed):
"""
处理逻辑
参数:
query -- 用户的指令字符串
parsed -- 用户指令经过 NLU 解析后的结果
"""
pass
[文档] def isValidImmersive(self, query, parsed):
"""
是否适合在沉浸模式下处理,
仅适用于有沉浸模式的插件(如音乐等)
当用户唤醒时,可以响应更多指令集。
例如:“"上一首"、"下一首" 等
"""
return False
# -*- coding: UTF-8 -*-
import http.client
import urllib.parse
import json
from robot import utils
from robot import logging
logger = logging.getLogger(__name__)
[文档]def processGETRequest(appKey, token, voice, text, format, sampleRate) :
host = 'nls-gateway.cn-shanghai.aliyuncs.com'
url = 'https://' + host + '/stream/v1/tts'
# 设置URL请求参数
url = url + '?appkey=' + appKey
url = url + '&token=' + token
url = url + '&text=' + text
url = url + '&format=' + format
url = url + '&sample_rate=' + str(sampleRate)
url = url + '&voice=' + voice
logger.debug(url)
conn = http.client.HTTPSConnection(host)
conn.request(method='GET', url=url)
# 处理服务端返回的响应
response = conn.getresponse()
logger.debug('Response status and response reason:')
logger.debug(response.status ,response.reason)
contentType = response.getheader('Content-Type')
logger.debug(contentType)
body = response.read()
if 'audio/mpeg' == contentType :
logger.debug('The GET request succeed!')
tmpfile = utils.write_temp_file(body, '.mp3')
conn.close()
return tmpfile
else :
logger.debug('The GET request failed: ' + str(body))
conn.close()
return None
[文档]def processPOSTRequest(appKey, token, voice, text, format, sampleRate) :
host = 'nls-gateway.cn-shanghai.aliyuncs.com'
url = 'https://' + host + '/stream/v1/tts'
# 设置HTTPS Headers
httpHeaders = {
'Content-Type': 'application/json'
}
# 设置HTTPS Body
body = {'appkey': appKey, 'token': token, 'text': text, 'format': format, 'sample_rate': sampleRate, 'voice': voice}
body = json.dumps(body)
logger.debug('The POST request body content: ' + body)
# Python 2.x 请使用httplib
# conn = httplib.HTTPSConnection(host)
# Python 3.x 请使用http.client
conn = http.client.HTTPSConnection(host)
conn.request(method='POST', url=url, body=body, headers=httpHeaders)
# 处理服务端返回的响应
response = conn.getresponse()
logger.debug('Response status and response reason:')
logger.debug(response.status ,response.reason)
contentType = response.getheader('Content-Type')
logger.debug(contentType)
body = response.read()
if 'audio/mpeg' == contentType :
logger.debug('The POST request succeed!')
tmpfile = utils.write_temp_file(body, '.mp3')
conn.close()
return tmpfile
else :
logger.critical('The POST request failed: ' + str(body))
conn.close()
return None
[文档]def process(request, token, audioContent) :
# 读取音频文件
host = 'nls-gateway.cn-shanghai.aliyuncs.com'
# 设置HTTP请求头部
httpHeaders = {
'X-NLS-Token': token,
'Content-type': 'application/octet-stream',
'Content-Length': len(audioContent)
}
conn = http.client.HTTPConnection(host)
conn.request(method='POST', url=request, body=audioContent, headers=httpHeaders)
response = conn.getresponse()
logger.debug('Response status and response reason:')
logger.debug(response.status ,response.reason)
body = response.read()
try:
logger.debug('Recognize response is:')
body = json.loads(body)
logger.debug(body)
status = body['status']
if status == 20000000 :
result = body['result']
logger.debug('Recognize result: ' + result)
conn.close()
return result
else :
logger.critical('Recognizer failed!')
conn.close()
return None
except ValueError:
logger.debug('The response is not json format string')
conn.close()
return None
[文档]def tts(appKey, token, voice, text):
# 采用RFC 3986规范进行urlencode编码
textUrlencode = text
textUrlencode = urllib.parse.quote_plus(textUrlencode)
textUrlencode = textUrlencode.replace("+", "%20")
textUrlencode = textUrlencode.replace("*", "%2A")
textUrlencode = textUrlencode.replace("%7E", "~")
format = 'mp3'
sampleRate = 16000
return processPOSTRequest(appKey, token, voice, text, format, sampleRate)
[文档]def asr(appKey, token, wave_file):
# 服务请求地址
url = 'http://nls-gateway.cn-shanghai.aliyuncs.com/stream/v1/asr'
pcm = utils.get_pcm_from_wav(wave_file)
# 音频文件
format = 'pcm'
sampleRate = 16000
enablePunctuationPrediction = True
enableInverseTextNormalization = True
enableVoiceDetection = False
# 设置RESTful请求参数
request = url + '?appkey=' + appKey
request = request + '&format=' + format
request = request + '&sample_rate=' + str(sampleRate)
if enablePunctuationPrediction :
request = request + '&enable_punctuation_prediction=' + 'true'
if enableInverseTextNormalization :
request = request + '&enable_inverse_text_normalization=' + 'true'
if enableVoiceDetection :
request = request + '&enable_voice_detection=' + 'true'
logger.debug('Request: ' + request)
return process(request, token, pcm)
# -*- coding:utf-8 -*-
import urllib.request
import hmac
import hashlib
import base64
import time
import random
import os
import json
[文档]def formatSignString(param):
signstr = "POSTaai.qcloud.com/asr/v1/"
for t in param:
if 'appid' in t:
signstr += str(t[1])
break
signstr += "?"
for x in param:
tmp = x
if 'appid' in x:
continue
for t in tmp:
signstr += str(t)
signstr += "="
signstr = signstr[:-1]
signstr += "&"
signstr = signstr[:-1]
# print 'signstr',signstr
return signstr
[文档]def sign(signstr, secret_key):
sign_bytes= bytes(signstr , 'utf-8')
secret_bytes = bytes(secret_key, 'utf-8')
hmacstr = hmac.new(secret_bytes, sign_bytes, hashlib.sha1).digest()
s = base64.b64encode(hmacstr).decode('utf-8')
return s
[文档]def randstr(n):
seed = "1234567890abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ"
sa = []
for i in range(n):
sa.append(random.choice(seed))
salt = ''.join(sa)
# print salt
return salt
[文档]def sendVoice(secret_key, secretid, appid, engine_model_type, res_type, result_text_format, voice_format, filepath, cutlength, template_name=""):
if len(str(secret_key)) == 0:
print('secretKey can not empty')
return
if len(str(secretid)) == 0:
print('secretid can not empty')
return
if len(str(appid)) == 0:
print('appid can not empty')
return
if len(str(engine_model_type)) == 0 or (
str(engine_model_type) != '8k_0' and str(engine_model_type) != '16k_0' and str(
engine_model_type) != '16k_en'):
print('engine_model_type is not right')
return
if len(str(res_type)) == 0 or (str(res_type) != '0' and str(res_type) != '1'):
print('res_type is not right')
return
if len(str(result_text_format)) == 0 or (str(result_text_format) != '0' and str(result_text_format) != '1' and str(
result_text_format) != '2' and str(result_text_format) != '3'):
print('result_text_format is not right')
return
if len(str(voice_format)) == 0 or (
str(voice_format) != '1' and str(voice_format) != '4' and str(voice_format) != '6'):
print('voice_format is not right')
return
if len(str(filepath)) == 0:
print('filepath can not empty')
return
if len(str(cutlength)) == 0 or str(cutlength).isdigit() == False or cutlength > 200000:
print('cutlength can not empty')
return
# secret_key = "oaYWFO70LGDmcpfwo8uF1IInayysGtgZ"
query_arr = dict()
query_arr['appid'] = appid
query_arr['projectid'] = 1013976
if len(template_name) > 0:
query_arr['template_name'] = template_name
query_arr['sub_service_type'] = 1
query_arr['engine_model_type'] = engine_model_type
query_arr['res_type'] = res_type
query_arr['result_text_format'] = result_text_format
query_arr['voice_id'] = randstr(16)
query_arr['timeout'] = 100
query_arr['source'] = 0
query_arr['secretid'] = secretid
query_arr['timestamp'] = str(int(time.time()))
query_arr['expired'] = int(time.time()) + 24 * 60 * 60
query_arr['nonce'] = query_arr['timestamp'][0:4]
query_arr['voice_format'] = voice_format
file_object = open(filepath, 'rb')
file_object.seek(0, os.SEEK_END)
datalen = file_object.tell()
file_object.seek(0, os.SEEK_SET)
seq = 0
response = []
while (datalen > 0):
end = 0
if (datalen < cutlength):
end = 1
query_arr['end'] = end
query_arr['seq'] = seq
query = sorted(query_arr.items(), key=lambda d: d[0])
signstr = formatSignString(query)
autho = sign(signstr, secret_key)
if (datalen < cutlength):
content = file_object.read(datalen)
else:
content = file_object.read(cutlength)
seq = seq + 1
datalen = datalen - cutlength
headers = dict()
headers['Authorization'] = autho
headers['Content-Length'] = len(content)
requrl = "http://"
requrl += signstr[4::]
req = urllib.request.Request(requrl, data=content, headers=headers)
res_data = urllib.request.urlopen(req)
r = res_data.read().decode('utf-8')
res = json.loads(r)
if res['code'] == 0:
response.append(res['text'])
file_object.close()
return response[len(response)-1]
# coding: utf-8
#!/usr/bin/env python3
'Tencent ASR && TTS API'
__author__ = 'Charles Li, Joseph Pan'
import time
import uuid
import json
import random
import requests
import hmac
import base64
import urllib
#腾讯web API一句话识别请求
[文档]class tencentSpeech(object):
__slots__ = 'SECRET_ID', 'SECRET_KEY', 'SourceType', 'URL', 'VoiceFormat', 'PrimaryLanguage', 'Text', 'VoiceType', 'Region'
def __init__(self, SECRET_KEY, SECRET_ID):
self.SECRET_KEY, self.SECRET_ID = SECRET_KEY, SECRET_ID
@property
def secret_id(self):
return self.SECRET_ID
@secret_id.setter
def secret_id(self, SECRET_ID):
if not isinstance(SECRET_ID, str):
raise ValueError('SecretId must be a string!')
if len(SECRET_ID)==0:
raise ValueError('SecretId can not be empty!')
self.SECRET_ID = SECRET_ID
@property
def secret_key(self):
return self.SECRET_KEY
@secret_key.setter
def secret_key(self, SECRET_KEY):
if not isinstance(SECRET_KEY, str):
raise ValueError('SecretKey must be a string!')
if len(SECRET_KEY)==0:
raise ValueError('SecretKey can not be empty!')
self.SECRET_KEY = SECRET_KEY
@property
def source_type(self):
return self.sourcetype
@source_type.setter
def source_type(self, SourceType):
if not isinstance(SourceType, str):
raise ValueError('SecretType must be an string!')
if len(SourceType)==0:
raise ValueError('SourceType can not be empty!')
self.SourceType = SourceType
@property
def url(self):
return self.URL
@url.setter
def url(self, URL):
if not isinstance(URL, str):
raise ValueError('url must be an string!')
if len(URL)==0:
raise ValueError('url can not be empty!')
self.URL = URL
@property
def voiceformat(self):
return self.VoiceFormat
@voiceformat.setter
def voiceformat(self, VoiceFormat):
if not isinstance(VoiceFormat, str):
raise ValueError('voiceformat must be an string!')
if len(VoiceFormat)==0:
raise ValueError('voiceformat can not be empty!')
self.VoiceFormat = VoiceFormat
@property
def text(self):
return self.Text
@text.setter
def text(self, Text):
if not isinstance(Text, str):
raise ValueError('text must be an string!')
if len(Text)==0:
raise ValueError('text can not be empty!')
self.Text = Text
@property
def region(self):
return self.Region
@region.setter
def region(self, Region):
if not isinstance(Region, str):
raise ValueError('region must be an string!')
if len(Region)==0:
raise ValueError('region can not be empty!')
self.Region = Region
@property
def primarylanguage(self):
return self.PrimaryLanguage
@primarylanguage.setter
def primarylanguage(self, PrimaryLanguage):
self.PrimaryLanguage = PrimaryLanguage
@property
def voicetype(self):
return self.VoiceType
@voicetype.setter
def voicetype(self, VoiceType):
self.VoiceType = VoiceType
[文档] def TTS(self, text, voicetype, primarylanguage, region):
self.text, self.voicetype, self.primarylanguage, self.region = text, voicetype, primarylanguage, region
return self.textToSpeech()
[文档] def textToSpeech(self):
#生成body
def make_body(config_dict, sign_encode):
##注意URL编码的时候分str编码,整段编码会丢data
body = ''
for a, b in config_dict:
body += urllib.parse.quote(a) + '=' + urllib.parse.quote(str(b)) + '&'
return body + 'Signature=' + sign_encode
HOST = 'aai.tencentcloudapi.com'
config_dict= {
'Action' : 'TextToVoice',
'Version' : '2018-05-22',
'ProjectId' : 0,
'Region' : self.Region,
'VoiceType' : self.VoiceType,
'Timestamp' : int(time.time()),
'Nonce' : random.randint(100000, 200000),
'SecretId' : self.SECRET_ID,
'Text' : self.Text,
'PrimaryLanguage': self.PrimaryLanguage,
'ModelType' : 1,
'SessionId' : uuid.uuid1()
}
#按key排序
config_dict = sorted(config_dict.items())
signstr = self.formatSignString(config_dict)
sign_encode = urllib.parse.quote(self.encode_sign(signstr, self.SECRET_KEY))
body = make_body(config_dict, sign_encode)
#Get URL
req_url = "https://aai.tencentcloudapi.com"
header = {
'Host' : HOST,
'Content-Type' : 'application/x-www-form-urlencoded',
'Charset' : 'UTF-8'
}
request = requests.post(req_url, headers = header, data = body)
#有些音频utf8解码失败,存在编码错误
s = request.content.decode("utf8","ignore")
return json.loads(s)
[文档] def ASR(self, URL, voiceformat, sourcetype, region):
self.url, self.voiceformat, self.source_type, self.region = URL, voiceformat, sourcetype, region
return self.oneSentenceRecognition()
[文档] def oneSentenceRecognition(self):
#生成body
def make_body(config_dict, sign_encode):
##注意URL编码的时候分str编码,整段编码会丢data
body = ''
for a, b in config_dict:
body += urllib.parse.quote(a) + '=' + urllib.parse.quote(str(b)) + '&'
return body + 'Signature=' + sign_encode
HOST = 'aai.tencentcloudapi.com'
config_dict= {
'Action' : 'SentenceRecognition',
'Version' : '2018-05-22',
'Region' : self.Region,
'ProjectId' : 0,
'SubServiceType' : 2,
'EngSerViceType' : '16k',
'VoiceFormat' : self.VoiceFormat,
'UsrAudioKey' : random.randint(0, 20),
'Timestamp' : int(time.time()),
'Nonce' : random.randint(100000, 200000),
'SecretId' : self.SECRET_ID,
'SourceType' : self.SourceType
}
if self.SourceType == '0':
config_dict['Url'] = urllib.parse.quote(str(self.url))
else:
#不能大于1M
file_path = self.URL
file = open(file_path, 'rb')
content = file.read()
config_dict['DataLen'] = len(content)
config_dict['Data'] = base64.b64encode(content).decode()
#config_dict['Data'] = content
file.close()
#按key排序
config_dict = sorted(config_dict.items())
signstr = self.formatSignString(config_dict)
sign_encode = urllib.parse.quote(self.encode_sign(signstr, self.SECRET_KEY))
body = make_body(config_dict, sign_encode)
#Get URL
req_url = "https://aai.tencentcloudapi.com"
header = {
'Host' : HOST,
'Content-Type' : 'application/x-www-form-urlencoded',
'Charset' : 'UTF-8'
}
request = requests.post(req_url, headers = header, data = body)
#有些音频utf8解码失败,存在编码错误
s = request.content.decode("utf8","ignore")
return s
#拼接url和参数
[文档] def formatSignString(self, config_dict):
signstr="POSTaai.tencentcloudapi.com/?"
argArr = []
for a, b in config_dict:
argArr.append(a + "=" + str(b))
config_str = "&".join(argArr)
return signstr + config_str
#生成签名
[文档] def encode_sign(self, signstr, SECRET_KEY):
myhmac = hmac.new(SECRET_KEY.encode(), signstr.encode(), digestmod = 'sha1')
code = myhmac.digest()
#hmac() 完一定要decode()和 python 2 hmac不一样
signature = base64.b64encode(code).decode()
return signature
import websocket
import hashlib
import base64
import hmac
import json
from urllib.parse import urlencode
import time
import ssl
from wsgiref.handlers import format_date_time
from datetime import datetime
from time import mktime
import _thread as thread
from robot import logging
logger = logging.getLogger(__name__)
STATUS_FIRST_FRAME = 0 # 第一帧的标识
STATUS_CONTINUE_FRAME = 1 # 中间帧标识
STATUS_LAST_FRAME = 2 # 最后一帧的标识
wsParam = None
gResult = ''
[文档]class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret, AudioFile):
# 控制台鉴权信息
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
# 固定参数,可不用修改
self.Host = "iat-api.xfyun.cn/v2/iat"
self.HttpProto = "HTTP/1.1"
self.HttpMethod = "GET"
self.RequestUri = "/v2/iat"
self.Algorithm = "hmac-sha256"
self.url = "wss://" + self.Host + self.RequestUri
# 设置测试音频文件
self.AudioFile = AudioFile
# 公共参数(common)
self.CommonArgs = {"app_id": self.APPID}
# 业务参数(business),更多个性化参数可在官网查看
self.BusinessArgs = {"domain": "iat", "language": "zh_cn", "accent": "mandarin"}
# 生成url
[文档] def create_url(self):
url = 'wss://ws-api.xfyun.cn/v2/iat'
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + "/v2/iat " + "HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": "ws-api.xfyun.cn"
}
# 拼接鉴权参数,生成url
url = url + '?' + urlencode(v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
logger.debug('websocket url :', url)
return url
# 收到websocket消息的处理
[文档]def on_message(ws, message):
global gResult
try:
code = json.loads(message)["code"]
sid = json.loads(message)["sid"]
if code != 0:
errMsg = json.loads(message)["message"]
logger.critical("xunfei-asr 识别出错了:sid:%s call error:%s code is:%s" % (sid, errMsg, code))
else:
data = json.loads(message)["data"]["result"]["ws"]
result = ""
for i in data:
for w in i["cw"]:
result += w["w"]
gResult = gResult + result
logger.info("sid:%s call success!,data is:%s" % (sid, json.dumps(data, ensure_ascii=False)))
except Exception as e:
logger.critical("xunfei-asr 识别出错了:", e)
# 收到websocket错误的处理
# 收到websocket关闭的处理
# 收到websocket连接建立的处理
[文档]def on_open(ws):
global wsParam
def run(*args):
frameSize = 1220 # 每一帧的音频大小
intervel = 0.04 # 发送音频间隔(单位:s)
status = STATUS_FIRST_FRAME # 音频的状态信息,标识音频是第一帧,还是中间帧、最后一帧
with open(wsParam.AudioFile, "rb") as fp:
while True:
buf = fp.read(frameSize)
# 文件结束
if not buf:
status = STATUS_LAST_FRAME
# 第一帧处理
# 发送第一帧音频,带business 参数
# appid 必须带上,只需第一帧发送
if status == STATUS_FIRST_FRAME:
d = {"common": wsParam.CommonArgs,
"business": wsParam.BusinessArgs,
"data": {"status": 0, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
d = json.dumps(d)
ws.send(d)
status = STATUS_CONTINUE_FRAME
# 中间帧处理
elif status == STATUS_CONTINUE_FRAME:
d = {"data": {"status": 1, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
ws.send(json.dumps(d))
# 最后一帧处理
elif status == STATUS_LAST_FRAME:
d = {"data": {"status": 2, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
ws.send(json.dumps(d))
time.sleep(1)
break
# 模拟音频采样间隔
time.sleep(intervel)
ws.close()
thread.start_new_thread(run, ())
[文档]def transcribe(fpath, appid, api_key, api_secret):
"""
科大讯飞ASR
"""
global wsParam, gResult
gResult = ''
wsParam = Ws_Param(appid, api_key, APISecret=api_secret, AudioFile=fpath)
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
return gResult
# encoding:utf-8
import requests
import datetime
import uuid
import json
import os
from dateutil import parser as dparser
from robot import constants, logging
logger = logging.getLogger(__name__)
[文档]def get_token(api_key, secret_key):
cache = open(os.path.join(constants.TEMP_PATH, 'baidustt.ini'), 'a+')
try:
pms = cache.readlines()
if len(pms) > 0:
time = pms[0]
tk = pms[1]
# 计算token是否过期 官方说明一个月,这里保守29天
time = dparser.parse(time)
endtime = datetime.datetime.now()
if (endtime - time).days <= 29:
return tk
finally:
cache.close()
URL = 'http://openapi.baidu.com/oauth/2.0/token'
params = {'grant_type': 'client_credentials',
'client_id': api_key,
'client_secret': secret_key}
r = requests.get(URL, params=params)
try:
r.raise_for_status()
token = r.json()['access_token']
return token
except requests.exceptions.HTTPError:
return ''
[文档]def getUnit(query, service_id, api_key, secret_key):
"""
NLU 解析
:param query: 用户的指令字符串
:param service_id: UNIT 的 service_id
:param api_key: UNIT apk_key
:param secret_key: UNIT secret_key
:returns: UNIT 解析结果。如果解析失败,返回 None
"""
access_token = get_token(api_key, secret_key)
url = 'https://aip.baidubce.com/rpc/2.0/unit/service/chat?access_token=' + access_token
request={
"query":query,
"user_id":"888888",
}
body={
"log_id": str(uuid.uuid1()),
"version":"2.0",
"service_id": service_id,
"session_id": str(uuid.uuid1()),
"request":request
}
try:
headers = {'Content-Type': 'application/json'}
request = requests.post(url, json=body, headers=headers)
return json.loads(request.text)
except Exception:
return None
[文档]def getIntent(parsed):
"""
提取意图
:param parsed: UNIT 解析结果
:returns: 意图数组
"""
if parsed is not None and 'result' in parsed and \
'response_list' in parsed['result']:
return parsed['result']['response_list'][0]['schema']['intent']
else:
return ''
[文档]def hasIntent(parsed, intent):
"""
判断是否包含某个意图
:param parsed: UNIT 解析结果
:param intent: 意图的名称
:returns: True: 包含; False: 不包含
"""
if parsed is not None and 'result' in parsed and \
'response_list' in parsed['result']:
response_list = parsed['result']['response_list']
for response in response_list:
if response['schema']['intent'] == intent:
return True
return False
else:
return False
[文档]def getSlots(parsed, intent=''):
"""
提取某个意图的所有词槽
:param parsed: UNIT 解析结果
:param intent: 意图的名称
:returns: 词槽列表。你可以通过 name 属性筛选词槽,
再通过 normalized_word 属性取出相应的值
"""
if parsed is not None and 'result' in parsed and \
'response_list' in parsed['result']:
response_list = parsed['result']['response_list']
if intent == '':
return parsed['result']['response_list'][0]['schema']['slots']
for response in response_list:
if response['schema']['intent'] == intent:
return response['schema']['slots']
else:
return []
[文档]def getSlotWords(parsed, intent, name):
"""
找出命中某个词槽的内容
:param parsed: UNIT 解析结果
:param intent: 意图的名称
:param name: 词槽名
:returns: 命中该词槽的值的列表。
"""
slots = getSlots(parsed, intent)
words = []
for slot in slots:
if slot['name'] == name:
words.append(slot['normalized_word'])
return words
[文档]def getSay(parsed, intent=''):
"""
提取 UNIT 的回复文本
:param parsed: UNIT 解析结果
:param intent: 意图的名称
:returns: UNIT 的回复文本
"""
if parsed is not None and 'result' in parsed and \
'response_list' in parsed['result']:
response_list = parsed['result']['response_list']
if intent == '':
return response_list[0]['action_list'][0]['say']
for response in response_list:
if response['schema']['intent'] == intent:
return response['action_list'][0]['say']
return ''
else:
return ''
if __name__ == '__main__':
parsed = getUnit('今天的天气', "S13442", 'w5v7gUV3iPGsGntcM84PtOOM', 'KffXwW6E1alcGplcabcNs63Li6GvvnfL')
print(parsed)
# -*- coding: utf-8-*-
from . import config
import uuid
import requests
import threading
[文档]def getUUID():
mac = uuid.UUID(int=uuid.getnode()).hex[-12:]
return ":".join([mac[e:e+2] for e in range(0, 11, 2)])
[文档]class ReportThread (threading.Thread):
def __init__(self, t):
# 需要执行父类的初始化方法
threading.Thread.__init__(self)
self.t = t
[文档] def run(self):
to_report = config.get('statistic', True)
if to_report:
try:
persona = config.get("robot_name_cn", '孙悟空')
url = 'http://livecv.hahack.com:8022/statistic'
payload = {'type': str(self.t), 'uuid': getUUID(), 'name': persona, 'project': 'wukong'}
requests.post(url, data=payload, timeout=3)
except Exception:
return
# -*- coding: utf-8-*-
import os
import tempfile
import wave
import shutil
import re
import time
import hashlib
import subprocess
from . import constants, config
from robot import logging
from pydub import AudioSegment
from pytz import timezone
import _thread as thread
import smtplib
from email.mime.text import MIMEText
from email.mime.multipart import MIMEMultipart
logger = logging.getLogger(__name__)
do_not_bother = False
[文档]def sendEmail(SUBJECT, BODY, ATTACH_LIST, TO, FROM, SENDER,
PASSWORD, SMTP_SERVER, SMTP_PORT):
"""
发送邮件
:param SUBJECT: 邮件标题
:param BODY: 邮件正文
:param ATTACH_LIST: 附件
:param TO: 收件人
:param FROM: 发件人
:param SENDER: 发件人信息
:param PASSWORD: 密码
:param SMTP_SERVER: smtp 服务器
:param SMTP_PORT: smtp 端口号
:returns: True: 发送成功; False: 发送失败
"""
txt = MIMEText(BODY.encode('utf-8'), 'html', 'utf-8')
msg = MIMEMultipart()
msg.attach(txt)
for attach in ATTACH_LIST:
try:
att = MIMEText(open(attach, 'rb').read(), 'base64', 'utf-8')
filename = os.path.basename(attach)
att["Content-Type"] = 'application/octet-stream'
att["Content-Disposition"] = 'attachment; filename="%s"' % filename
msg.attach(att)
except Exception:
logger.error(u'附件 %s 发送失败!' % attach)
continue
msg['From'] = SENDER
msg['To'] = TO
msg['Subject'] = SUBJECT
try:
session = smtplib.SMTP()
session.connect(SMTP_SERVER, SMTP_PORT)
session.starttls()
session.login(FROM, PASSWORD)
session.sendmail(SENDER, TO, msg.as_string())
session.close()
return True
except Exception as e:
logger.error(e)
return False
[文档]def emailUser(SUBJECT="", BODY="", ATTACH_LIST=[]):
"""
给用户发送邮件
:param SUBJECT: subject line of the email
:param BODY: body text of the email
:returns: True: 发送成功; False: 发送失败
"""
# add footer
if BODY:
BODY = u"%s,<br><br>这是您要的内容:<br>%s<br>" % (config['first_name'], BODY)
recipient = config.get('/email/address', '')
robot_name = config.get('robot_name_cn', 'wukong-robot')
recipient = robot_name + " <%s>" % recipient
user = config.get('/email/address', '')
password = config.get('/email/password', '')
server = config.get('/email/smtp_server', '')
port = config.get('/email/smtp_port', '')
if not recipient or not user or not password or not server or not port:
return False
try:
sendEmail(SUBJECT, BODY, ATTACH_LIST, user, user,
recipient, password, server, port)
return True
except Exception as e:
logger.error(e)
return False
[文档]def get_file_content(filePath):
"""
读取文件内容并返回
:param filePath: 文件路径
:returns: 文件内容
:raises IOError: 读取失败则抛出 IOError
"""
with open(filePath, 'rb') as fp:
return fp.read()
[文档]def check_and_delete(fp, wait=0):
"""
检查并删除文件/文件夹
:param fp: 文件路径
"""
def run():
if wait > 0:
time.sleep(wait)
if isinstance(fp, str) and os.path.exists(fp):
if os.path.isfile(fp):
os.remove(fp)
else:
shutil.rmtree(fp)
thread.start_new_thread(run, ())
[文档]def write_temp_file(data, suffix, mode='w+b'):
"""
写入临时文件
:param data: 数据
:param suffix: 后缀名
:param mode: 写入模式,默认为 w+b
:returns: 文件保存后的路径
"""
with tempfile.NamedTemporaryFile(mode=mode, suffix=suffix, delete=False) as f:
f.write(data)
tmpfile = f.name
return tmpfile
[文档]def get_pcm_from_wav(wav_path):
"""
从 wav 文件中读取 pcm
:param wav_path: wav 文件路径
:returns: pcm 数据
"""
wav = wave.open(wav_path, 'rb')
return wav.readframes(wav.getnframes())
[文档]def convert_wav_to_mp3(wav_path):
"""
将 wav 文件转成 mp3
:param wav_path: wav 文件路径
:returns: mp3 文件路径
"""
if not os.path.exists(wav_path):
logger.critical("文件错误 {}".format(wav_path))
return None
mp3_path = wav_path.replace('.wav', '.mp3')
AudioSegment.from_wav(wav_path).export(mp3_path, format="mp3")
return mp3_path
[文档]def convert_mp3_to_wav(mp3_path):
"""
将 mp3 文件转成 wav
:param mp3_path: mp3 文件路径
:returns: wav 文件路径
"""
target = mp3_path.replace(".mp3", ".wav")
if not os.path.exists(mp3_path):
logger.critical("文件错误 {}".format(mp3_path))
return None
AudioSegment.from_mp3(mp3_path).export(target, format="wav")
return target
[文档]def clean():
""" 清理垃圾数据 """
temp = constants.TEMP_PATH
temp_files = os.listdir(temp)
for f in temp_files:
if os.path.isfile(os.path.join(temp, f)) and re.match(r'output[\d]*\.wav', os.path.basename(f)):
os.remove(os.path.join(temp, f))
[文档]def is_proper_time():
""" 是否合适时间 """
if do_not_bother == True:
return False
if not config.has('do_not_bother'):
return True
bother_profile = config.get('do_not_bother')
if not bother_profile['enable']:
return True
if 'since' not in bother_profile or 'till' not in bother_profile:
return True
since = bother_profile['since']
till = bother_profile['till']
current = time.localtime(time.time()).tm_hour
if till > since:
return current not in range(since, till)
else:
return not (current in range(since, 25) or
current in range(-1, till))
[文档]def get_do_not_bother_on_hotword():
""" 打开勿扰模式唤醒词 """
return config.get('/do_not_bother/on_hotword', '悟空别吵.pmdl')
[文档]def get_do_not_bother_off_hotword():
""" 关闭勿扰模式唤醒词 """
return config.get('/do_not_bother/off_hotword', '悟空醒醒.pmdl')
[文档]def getCache(msg):
""" 获取缓存的语音 """
md5 = hashlib.md5(msg.encode('utf-8')).hexdigest()
mp3_cache = os.path.join(constants.TEMP_PATH, md5 + '.mp3')
wav_cache = os.path.join(constants.TEMP_PATH, md5 + '.wav')
if os.path.exists(mp3_cache):
return mp3_cache
elif os.path.exists(wav_cache):
return wav_cache
return None
[文档]def saveCache(voice, msg):
""" 获取缓存的语音 """
foo, ext = os.path.splitext(voice)
md5 = hashlib.md5(msg.encode('utf-8')).hexdigest()
target = os.path.join(constants.TEMP_PATH, md5+ext)
shutil.copyfile(voice, target)
return target
[文档]def lruCache():
""" 清理最近未使用的缓存 """
def run(*args):
if config.get('/lru_cache/enable', True):
days = config.get('/lru_cache/days', 7)
subprocess.run('find . -name "*.mp3" -atime +%d -exec rm {} \;' % days, cwd=constants.TEMP_PATH, shell=True)
thread.start_new_thread(run, ())
#!/usr/bin/env python
import collections
import pyaudio
from . import snowboydetect
from robot import utils, logging
import time
import wave
import os
from ctypes import CFUNCTYPE, c_char_p, c_int, cdll
from contextlib import contextmanager
from robot import constants
logger = logging.getLogger("snowboy")
TOP_DIR = os.path.dirname(os.path.abspath(__file__))
RESOURCE_FILE = os.path.join(TOP_DIR, "resources/common.res")
DETECT_DING = os.path.join(TOP_DIR, "resources/ding.wav")
DETECT_DONG = os.path.join(TOP_DIR, "resources/dong.wav")
ERROR_HANDLER_FUNC = CFUNCTYPE(None, c_char_p, c_int, c_char_p, c_int, c_char_p)
c_error_handler = ERROR_HANDLER_FUNC(py_error_handler)
[文档]@contextmanager
def no_alsa_error():
try:
asound = cdll.LoadLibrary('libasound.so')
asound.snd_lib_error_set_handler(c_error_handler)
yield
asound.snd_lib_error_set_handler(None)
except:
yield
pass
[文档]class RingBuffer(object):
"""Ring buffer to hold audio from PortAudio"""
def __init__(self, size=4096):
self._buf = collections.deque(maxlen=size)
[文档] def get(self):
"""Retrieves data from the beginning of buffer and clears it"""
tmp = bytes(bytearray(self._buf))
self._buf.clear()
return tmp
[文档]def play_audio_file(fname=DETECT_DING):
"""Simple callback function to play a wave file. By default it plays
a Ding sound.
:param str fname: wave file name
:return: None
"""
ding_wav = wave.open(fname, 'rb')
ding_data = ding_wav.readframes(ding_wav.getnframes())
with no_alsa_error():
audio = pyaudio.PyAudio()
stream_out = audio.open(
format=audio.get_format_from_width(ding_wav.getsampwidth()),
channels=ding_wav.getnchannels(),
rate=ding_wav.getframerate(), input=False, output=True)
stream_out.start_stream()
stream_out.write(ding_data)
time.sleep(0.2)
stream_out.stop_stream()
stream_out.close()
audio.terminate()
[文档]class ActiveListener(object):
""" Active Listening with VAD """
def __init__(self, decoder_model,
resource=RESOURCE_FILE):
logger.debug("activeListen __init__()")
self.recordedData = []
model_str = ",".join(decoder_model)
self.detector = snowboydetect.SnowboyDetect(
resource_filename=resource.encode(), model_str=model_str.encode())
self.ring_buffer = RingBuffer(
self.detector.NumChannels() * self.detector.SampleRate() * 5)
[文档] def listen(self, interrupt_check=lambda: False, sleep_time=0.03, silent_count_threshold=15, recording_timeout=100):
"""
:param interrupt_check: a function that returns True if the main loop
needs to stop.
:param silent_count_threshold: indicates how long silence must be heard
to mark the end of a phrase that is
being recorded.
:param float sleep_time: how much time in second every loop waits.
:param recording_timeout: limits the maximum length of a recording.
:return: recorded file path
"""
logger.debug("activeListen listen()")
self._running = True
def audio_callback(in_data, frame_count, time_info, status):
self.ring_buffer.extend(in_data)
play_data = chr(0) * len(in_data)
return play_data, pyaudio.paContinue
with no_alsa_error():
self.audio = pyaudio.PyAudio()
logger.debug('opening audio stream')
try:
self.stream_in = self.audio.open(
input=True, output=False,
format=self.audio.get_format_from_width(
self.detector.BitsPerSample() / 8),
channels=self.detector.NumChannels(),
rate=self.detector.SampleRate(),
frames_per_buffer=2048,
stream_callback=audio_callback)
except Exception as e:
logger.critical(e)
return
logger.debug('audio stream opened')
if interrupt_check():
logger.debug("detect voice return")
return
silentCount = 0
recordingCount = 0
logger.debug("begin activeListen loop")
while self._running is True:
if interrupt_check():
logger.debug("detect voice break")
break
data = self.ring_buffer.get()
if len(data) == 0:
time.sleep(sleep_time)
continue
status = self.detector.RunDetection(data)
if status == -1:
logger.warning("Error initializing streams or reading audio data")
stopRecording = False
if recordingCount > recording_timeout:
stopRecording = True
elif status == -2: #silence found
if silentCount > silent_count_threshold:
stopRecording = True
else:
silentCount = silentCount + 1
elif status == 0: #voice found
silentCount = 0
if stopRecording == True:
return self.saveMessage()
recordingCount = recordingCount + 1
self.recordedData.append(data)
logger.debug("finished.")
[文档] def saveMessage(self):
"""
Save the message stored in self.recordedData to a timestamped file.
"""
filename = os.path.join(constants.TEMP_PATH, 'output' + str(int(time.time())) + '.wav')
data = b''.join(self.recordedData)
#use wave to save data
wf = wave.open(filename, 'wb')
wf.setnchannels(self.detector.NumChannels())
wf.setsampwidth(self.audio.get_sample_size(
self.audio.get_format_from_width(self.detector.BitsPerSample() / 8)))
wf.setframerate(self.detector.SampleRate())
wf.writeframes(data)
wf.close()
logger.debug("finished saving: " + filename)
self.stream_in.stop_stream()
self.stream_in.close()
self.audio.terminate()
return filename
[文档]class HotwordDetector(object):
"""
Snowboy decoder to detect whether a keyword specified by `decoder_model`
exists in a microphone input stream.
:param decoder_model: decoder model file path, a string or a list of strings
:param resource: resource file path.
:param sensitivity: decoder sensitivity, a float of a list of floats.
The bigger the value, the more senstive the
decoder. If an empty list is provided, then the
default sensitivity in the model will be used.
:param audio_gain: multiply input volume by this factor.
:param apply_frontend: applies the frontend processing algorithm if True.
"""
def __init__(self, decoder_model,
resource=RESOURCE_FILE,
sensitivity=[],
audio_gain=1,
apply_frontend=False):
self._running = False
tm = type(decoder_model)
ts = type(sensitivity)
if tm is not list:
decoder_model = [decoder_model]
if ts is not list:
sensitivity = [sensitivity]
model_str = ",".join(decoder_model)
self.detector = snowboydetect.SnowboyDetect(
resource_filename=resource.encode(), model_str=model_str.encode())
self.detector.SetAudioGain(audio_gain)
self.detector.ApplyFrontend(apply_frontend)
self.num_hotwords = self.detector.NumHotwords()
if len(decoder_model) > 1 and len(sensitivity) == 1:
sensitivity = sensitivity * self.num_hotwords
if len(sensitivity) != 0:
assert self.num_hotwords == len(sensitivity), \
"number of hotwords in decoder_model (%d) and sensitivity " \
"(%d) does not match" % (self.num_hotwords, len(sensitivity))
sensitivity_str = ",".join([str(t) for t in sensitivity])
if len(sensitivity) != 0:
self.detector.SetSensitivity(sensitivity_str.encode())
self.ring_buffer = RingBuffer(
self.detector.NumChannels() * self.detector.SampleRate() * 5)
[文档] def start(self, detected_callback=play_audio_file,
interrupt_check=lambda: False,
sleep_time=0.03,
audio_recorder_callback=None,
silent_count_threshold=15,
recording_timeout=100):
"""
Start the voice detector. For every `sleep_time` second it checks the
audio buffer for triggering keywords. If detected, then call
corresponding function in `detected_callback`, which can be a single
function (single model) or a list of callback functions (multiple
models). Every loop it also calls `interrupt_check` -- if it returns
True, then breaks from the loop and return.
:param detected_callback: a function or list of functions. The number of
items must match the number of models in
`decoder_model`.
:param interrupt_check: a function that returns True if the main loop
needs to stop.
:param float sleep_time: how much time in second every loop waits.
:param audio_recorder_callback: if specified, this will be called after
a keyword has been spoken and after the
phrase immediately after the keyword has
been recorded. The function will be
passed the name of the file where the
phrase was recorded.
:param silent_count_threshold: indicates how long silence must be heard
to mark the end of a phrase that is
being recorded.
:param recording_timeout: limits the maximum length of a recording.
:return: None
"""
self._running = True
def audio_callback(in_data, frame_count, time_info, status):
self.ring_buffer.extend(in_data)
play_data = chr(0) * len(in_data)
return play_data, pyaudio.paContinue
with no_alsa_error():
self.audio = pyaudio.PyAudio()
self.stream_in = self.audio.open(
input=True, output=False,
format=self.audio.get_format_from_width(
self.detector.BitsPerSample() / 8),
channels=self.detector.NumChannels(),
rate=self.detector.SampleRate(),
frames_per_buffer=2048,
stream_callback=audio_callback)
if interrupt_check():
logger.debug("detect voice return")
return
tc = type(detected_callback)
if tc is not list:
detected_callback = [detected_callback]
if len(detected_callback) == 1 and self.num_hotwords > 1:
detected_callback *= self.num_hotwords
assert self.num_hotwords == len(detected_callback), \
"Error: hotwords in your models (%d) do not match the number of " \
"callbacks (%d)" % (self.num_hotwords, len(detected_callback))
logger.debug("detecting...")
state = "PASSIVE"
while self._running is True:
if interrupt_check():
logger.debug("detect voice break")
break
data = self.ring_buffer.get()
if len(data) == 0:
time.sleep(sleep_time)
continue
status = self.detector.RunDetection(data)
if status == -1:
logger.warning("Error initializing streams or reading audio data")
#small state machine to handle recording of phrase after keyword
if state == "PASSIVE":
if status > 0: #key word found
self.recordedData = []
self.recordedData.append(data)
silentCount = 0
recordingCount = 0
message = "Keyword " + str(status) + " detected at time: "
message += time.strftime("%Y-%m-%d %H:%M:%S",
time.localtime(time.time()))
logger.info(message)
callback = detected_callback[status-1]
if callback is not None:
callback()
if audio_recorder_callback is not None and status == 1 and utils.is_proper_time():
state = "ACTIVE"
continue
elif state == "ACTIVE":
stopRecording = False
if recordingCount > recording_timeout:
stopRecording = True
elif status == -2: #silence found
if silentCount > silent_count_threshold:
stopRecording = True
else:
silentCount = silentCount + 1
elif status == 0: #voice found
silentCount = 0
if stopRecording == True:
fname = self.saveMessage()
audio_recorder_callback(fname)
state = "PASSIVE"
continue
recordingCount = recordingCount + 1
self.recordedData.append(data)
logger.debug("finished.")
[文档] def saveMessage(self):
"""
Save the message stored in self.recordedData to a timestamped file.
"""
filename = os.path.join(constants.TEMP_PATH, 'output' + str(int(time.time())) + '.wav')
data = b''.join(self.recordedData)
#use wave to save data
wf = wave.open(filename, 'wb')
wf.setnchannels(self.detector.NumChannels())
wf.setsampwidth(self.audio.get_sample_size(
self.audio.get_format_from_width(
self.detector.BitsPerSample() / 8)))
wf.setframerate(self.detector.SampleRate())
wf.writeframes(data)
wf.close()
logger.debug("finished saving: " + filename)
return filename
[文档] def terminate(self):
"""
Terminate audio stream. Users can call start() again to detect.
:return: None
"""
if self._running:
self.stream_in.stop_stream()
self.stream_in.close()
self.audio.terminate()
self._running = False
# This file was automatically generated by SWIG (http://www.swig.org).
# Version 3.0.12
#
# Do not make changes to this file unless you know what you are doing--modify
# the SWIG interface file instead.
from sys import version_info as _swig_python_version_info
if _swig_python_version_info >= (2, 7, 0):
def swig_import_helper():
import importlib
pkg = __name__.rpartition('.')[0]
mname = '.'.join((pkg, '_snowboydetect')).lstrip('.')
try:
return importlib.import_module(mname)
except ImportError:
return importlib.import_module('_snowboydetect')
_snowboydetect = swig_import_helper()
del swig_import_helper
elif _swig_python_version_info >= (2, 6, 0):
def swig_import_helper():
from os.path import dirname
import imp
fp = None
try:
fp, pathname, description = imp.find_module('_snowboydetect', [dirname(__file__)])
except ImportError:
import _snowboydetect
return _snowboydetect
try:
_mod = imp.load_module('_snowboydetect', fp, pathname, description)
finally:
if fp is not None:
fp.close()
return _mod
_snowboydetect = swig_import_helper()
del swig_import_helper
else:
import _snowboydetect
del _swig_python_version_info
try:
_swig_property = property
except NameError:
pass # Python < 2.2 doesn't have 'property'.
try:
import builtins as __builtin__
except ImportError:
import __builtin__
def _swig_setattr_nondynamic(self, class_type, name, value, static=1):
if (name == "thisown"):
return self.this.own(value)
if (name == "this"):
if type(value).__name__ == 'SwigPyObject':
self.__dict__[name] = value
return
method = class_type.__swig_setmethods__.get(name, None)
if method:
return method(self, value)
if (not static):
if _newclass:
object.__setattr__(self, name, value)
else:
self.__dict__[name] = value
else:
raise AttributeError("You cannot add attributes to %s" % self)
def _swig_setattr(self, class_type, name, value):
return _swig_setattr_nondynamic(self, class_type, name, value, 0)
def _swig_getattr(self, class_type, name):
if (name == "thisown"):
return self.this.own()
method = class_type.__swig_getmethods__.get(name, None)
if method:
return method(self)
raise AttributeError("'%s' object has no attribute '%s'" % (class_type.__name__, name))
def _swig_repr(self):
try:
strthis = "proxy of " + self.this.__repr__()
except __builtin__.Exception:
strthis = ""
return "<%s.%s; %s >" % (self.__class__.__module__, self.__class__.__name__, strthis,)
try:
_object = object
_newclass = 1
except __builtin__.Exception:
class _object:
pass
_newclass = 0
[文档]class SnowboyDetect(_object):
__swig_setmethods__ = {}
__setattr__ = lambda self, name, value: _swig_setattr(self, SnowboyDetect, name, value)
__swig_getmethods__ = {}
__getattr__ = lambda self, name: _swig_getattr(self, SnowboyDetect, name)
__repr__ = _swig_repr
def __init__(self, resource_filename, model_str):
this = _snowboydetect.new_SnowboyDetect(resource_filename, model_str)
try:
self.this.append(this)
except __builtin__.Exception:
self.this = this
[文档] def SetSensitivity(self, sensitivity_str):
return _snowboydetect.SnowboyDetect_SetSensitivity(self, sensitivity_str)
[文档] def SetHighSensitivity(self, high_sensitivity_str):
return _snowboydetect.SnowboyDetect_SetHighSensitivity(self, high_sensitivity_str)
[文档] def SetAudioGain(self, audio_gain):
return _snowboydetect.SnowboyDetect_SetAudioGain(self, audio_gain)
[文档] def ApplyFrontend(self, apply_frontend):
return _snowboydetect.SnowboyDetect_ApplyFrontend(self, apply_frontend)
__swig_destroy__ = _snowboydetect.delete_SnowboyDetect
__del__ = lambda self: None
SnowboyDetect_swigregister = _snowboydetect.SnowboyDetect_swigregister
SnowboyDetect_swigregister(SnowboyDetect)
[文档]class SnowboyVad(_object):
__swig_setmethods__ = {}
__setattr__ = lambda self, name, value: _swig_setattr(self, SnowboyVad, name, value)
__swig_getmethods__ = {}
__getattr__ = lambda self, name: _swig_getattr(self, SnowboyVad, name)
__repr__ = _swig_repr
def __init__(self, resource_filename):
this = _snowboydetect.new_SnowboyVad(resource_filename)
try:
self.this.append(this)
except __builtin__.Exception:
self.this = this
[文档] def SetAudioGain(self, audio_gain):
return _snowboydetect.SnowboyVad_SetAudioGain(self, audio_gain)
[文档] def ApplyFrontend(self, apply_frontend):
return _snowboydetect.SnowboyVad_ApplyFrontend(self, apply_frontend)
__swig_destroy__ = _snowboydetect.delete_SnowboyVad
__del__ = lambda self: None
SnowboyVad_swigregister = _snowboydetect.SnowboyVad_swigregister
SnowboyVad_swigregister(SnowboyVad)
# This file is compatible with both classic and new-style classes.
# -*- coding: utf-8-*-
from snowboy import snowboydecoder
from robot import config, utils, constants, logging, statistic, Player
from robot.Updater import Updater
from robot.ConfigMonitor import ConfigMonitor
from robot.Conversation import Conversation
from server import server
from watchdog.observers import Observer
import sys
import os
import signal
import hashlib
import fire
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
logger = logging.getLogger(__name__)
[文档]class Wukong(object):
_profiling = False
_dev = False
[文档] def init(self):
global conversation
self.detector = None
self._interrupted = False
print('''
********************************************************
* wukong-robot - 中文语音对话机器人 *
* (c) 2019 潘伟洲 <m@hahack.com> *
* https://github.com/wzpan/wukong-robot.git *
********************************************************
如需退出,可以按 Ctrl-4 组合键。
''')
config.init()
self._conversation = Conversation(self._profiling)
self._conversation.say('{} 你好!试试对我喊唤醒词叫醒我吧'.format(config.get('first_name', '主人')), True)
self._observer = Observer()
event_handler = ConfigMonitor(self._conversation)
self._observer.schedule(event_handler, constants.CONFIG_PATH, False)
self._observer.schedule(event_handler, constants.DATA_PATH, False)
self._observer.start()
def _signal_handler(self, signal, frame):
self._interrupted = True
utils.clean()
self._observer.stop()
def _detected_callback(self):
if not utils.is_proper_time():
logger.warning('勿扰模式开启中')
return
if self._conversation.isRecording:
logger.warning('正在录音中,跳过')
return
Player.play(constants.getData('beep_hi.wav'))
logger.info('开始录音')
self._conversation.interrupt()
self._conversation.isRecording = True;
def _do_not_bother_on_callback(self):
if config.get('/do_not_bother/hotword_switch', False):
utils.do_not_bother = True
Player.play(constants.getData('off.wav'))
logger.info('勿扰模式打开')
def _do_not_bother_off_callback(self):
if config.get('/do_not_bother/hotword_switch', False):
utils.do_not_bother = False
Player.play(constants.getData('on.wav'))
logger.info('勿扰模式关闭')
def _interrupt_callback(self):
return self._interrupted
[文档] def run(self):
self.init()
# capture SIGINT signal, e.g., Ctrl+C
signal.signal(signal.SIGINT, self._signal_handler)
# site
server.run(self._conversation, self)
statistic.report(0)
try:
self.initDetector()
except AttributeError:
logger.error('初始化离线唤醒功能失败')
pass
[文档] def initDetector(self):
if self.detector is not None:
self.detector.terminate()
if config.get('/do_not_bother/hotword_switch', False):
models = [
constants.getHotwordModel(config.get('hotword', 'wukong.pmdl')),
constants.getHotwordModel(utils.get_do_not_bother_on_hotword()),
constants.getHotwordModel(utils.get_do_not_bother_off_hotword())
]
else:
models = constants.getHotwordModel(config.get('hotword', 'wukong.pmdl'))
self.detector = snowboydecoder.HotwordDetector(models, sensitivity=config.get('sensitivity', 0.5))
# main loop
try:
if config.get('/do_not_bother/hotword_switch', False):
callbacks = [self._detected_callback,
self._do_not_bother_on_callback,
self._do_not_bother_off_callback]
else:
callbacks = self._detected_callback
self.detector.start(detected_callback=callbacks,
audio_recorder_callback=self._conversation.converse,
interrupt_check=self._interrupt_callback,
silent_count_threshold=config.get('silent_threshold', 15),
recording_timeout=config.get('recording_timeout', 5) * 4,
sleep_time=0.03)
self.detector.terminate()
except Exception as e:
logger.critical('离线唤醒机制初始化失败:{}'.format(e))
[文档] def restart(self):
logger.critical('程序重启...')
try:
self.detector.terminate()
except AttributeError:
pass
python = sys.executable
os.execl(python, python, * sys.argv)
if __name__ == '__main__':
if len(sys.argv) == 1:
wukong = Wukong()
wukong.run()
else:
fire.Fire(Wukong)
' + _('Hide Search Matches') + '
') .appendTo($('#searchbox')); } }, /** * init the domain index toggle buttons */ initIndexTable : function() { var togglers = $('img.toggler').click(function() { var src = $(this).attr('src'); var idnum = $(this).attr('id').substr(7); $('tr.cg-' + idnum).toggle(); if (src.substr(-9) === 'minus.png') $(this).attr('src', src.substr(0, src.length-9) + 'plus.png'); else $(this).attr('src', src.substr(0, src.length-8) + 'minus.png'); }).css('display', ''); if (DOCUMENTATION_OPTIONS.COLLAPSE_INDEX) { togglers.click(); } }, /** * helper function to hide the search marks again */ hideSearchWords : function() { $('#searchbox .highlight-link').fadeOut(300); $('span.highlighted').removeClass('highlighted'); }, /** * make the url absolute */ makeURL : function(relativeURL) { return DOCUMENTATION_OPTIONS.URL_ROOT + '/' + relativeURL; }, /** * get the current relative url */ getCurrentURL : function() { var path = document.location.pathname; var parts = path.split(/\//); $.each(DOCUMENTATION_OPTIONS.URL_ROOT.split(/\//), function() { if (this === '..') parts.pop(); }); var url = parts.join('/'); return path.substring(url.lastIndexOf('/') + 1, path.length - 1); }, initOnKeyListeners: function() { $(document).keyup(function(event) { var activeElementType = document.activeElement.tagName; // don't navigate when in search box or textarea if (activeElementType !== 'TEXTAREA' && activeElementType !== 'INPUT' && activeElementType !== 'SELECT') { switch (event.keyCode) { case 37: // left var prevHref = $('link[rel="prev"]').prop('href'); if (prevHref) { window.location.href = prevHref; return false; } case 39: // right var nextHref = $('link[rel="next"]').prop('href'); if (nextHref) { window.location.href = nextHref; return false; } } } }); } }; // quick alias for translations _ = Documentation.gettext; $(document).ready(function() { Documentation.init(); }); ================================================ FILE: docs/_static/documentation_options.js ================================================ var DOCUMENTATION_OPTIONS = { URL_ROOT: document.getElementById("documentation_options").getAttribute('data-url_root'), VERSION: '1.2.0', LANGUAGE: 'zh_CN', COLLAPSE_INDEX: false, FILE_SUFFIX: '.html', HAS_SOURCE: true, SOURCELINK_SUFFIX: '.txt', NAVIGATION_WITH_KEYS: false, }; ================================================ FILE: docs/_static/jquery-3.2.1.js ================================================ /*! * jQuery JavaScript Library v3.2.1 * https://jquery.com/ * * Includes Sizzle.js * https://sizzlejs.com/ * * Copyright JS Foundation and other contributors * Released under the MIT license * https://jquery.org/license * * Date: 2017-03-20T18:59Z */ ( function( global, factory ) { "use strict"; if ( typeof module === "object" && typeof module.exports === "object" ) { // For CommonJS and CommonJS-like environments where a proper `window` // is present, execute the factory and get jQuery. // For environments that do not have a `window` with a `document` // (such as Node.js), expose a factory as module.exports. // This accentuates the need for the creation of a real `window`. // e.g. var jQuery = require("jquery")(window); // See ticket #14549 for more info. module.exports = global.document ? factory( global, true ) : function( w ) { if ( !w.document ) { throw new Error( "jQuery requires a window with a document" ); } return factory( w ); }; } else { factory( global ); } // Pass this if window is not defined yet } )( typeof window !== "undefined" ? window : this, function( window, noGlobal ) { // Edge <= 12 - 13+, Firefox <=18 - 45+, IE 10 - 11, Safari 5.1 - 9+, iOS 6 - 9.1 // throw exceptions when non-strict code (e.g., ASP.NET 4.5) accesses strict mode // arguments.callee.caller (trac-13335). But as of jQuery 3.0 (2016), strict mode should be common // enough that all such attempts are guarded in a try block. "use strict"; var arr = []; var document = window.document; var getProto = Object.getPrototypeOf; var slice = arr.slice; var concat = arr.concat; var push = arr.push; var indexOf = arr.indexOf; var class2type = {}; var toString = class2type.toString; var hasOwn = class2type.hasOwnProperty; var fnToString = hasOwn.toString; var ObjectFunctionString = fnToString.call( Object ); var support = {}; function DOMEval( code, doc ) { doc = doc || document; var script = doc.createElement( "script" ); script.text = code; doc.head.appendChild( script ).parentNode.removeChild( script ); } /* global Symbol */ // Defining this global in .eslintrc.json would create a danger of using the global // unguarded in another place, it seems safer to define global only for this module var version = "3.2.1", // Define a local copy of jQuery jQuery = function( selector, context ) { // The jQuery object is actually just the init constructor 'enhanced' // Need init if jQuery is called (just allow error to be thrown if not included) return new jQuery.fn.init( selector, context ); }, // Support: Android <=4.0 only // Make sure we trim BOM and NBSP rtrim = /^[\s\uFEFF\xA0]+|[\s\uFEFF\xA0]+$/g, // Matches dashed string for camelizing rmsPrefix = /^-ms-/, rdashAlpha = /-([a-z])/g, // Used by jQuery.camelCase as callback to replace() fcamelCase = function( all, letter ) { return letter.toUpperCase(); }; jQuery.fn = jQuery.prototype = { // The current version of jQuery being used jquery: version, constructor: jQuery, // The default length of a jQuery object is 0 length: 0, toArray: function() { return slice.call( this ); }, // Get the Nth element in the matched element set OR // Get the whole matched element set as a clean array get: function( num ) { // Return all the elements in a clean array if ( num == null ) { return slice.call( this ); } // Return just the one element from the set return num < 0 ? this[ num + this.length ] : this[ num ]; }, // Take an array of elements and push it onto the stack // (returning the new matched element set) pushStack: function( elems ) { // Build a new jQuery matched element set var ret = jQuery.merge( this.constructor(), elems ); // Add the old object onto the stack (as a reference) ret.prevObject = this; // Return the newly-formed element set return ret; }, // Execute a callback for every element in the matched set. each: function( callback ) { return jQuery.each( this, callback ); }, map: function( callback ) { return this.pushStack( jQuery.map( this, function( elem, i ) { return callback.call( elem, i, elem ); } ) ); }, slice: function() { return this.pushStack( slice.apply( this, arguments ) ); }, first: function() { return this.eq( 0 ); }, last: function() { return this.eq( -1 ); }, eq: function( i ) { var len = this.length, j = +i + ( i < 0 ? len : 0 ); return this.pushStack( j >= 0 && j < len ? [ this[ j ] ] : [] ); }, end: function() { return this.prevObject || this.constructor(); }, // For internal use only. // Behaves like an Array's method, not like a jQuery method. push: push, sort: arr.sort, splice: arr.splice }; jQuery.extend = jQuery.fn.extend = function() { var options, name, src, copy, copyIsArray, clone, target = arguments[ 0 ] || {}, i = 1, length = arguments.length, deep = false; // Handle a deep copy situation if ( typeof target === "boolean" ) { deep = target; // Skip the boolean and the target target = arguments[ i ] || {}; i++; } // Handle case when target is a string or something (possible in deep copy) if ( typeof target !== "object" && !jQuery.isFunction( target ) ) { target = {}; } // Extend jQuery itself if only one argument is passed if ( i === length ) { target = this; i--; } for ( ; i < length; i++ ) { // Only deal with non-null/undefined values if ( ( options = arguments[ i ] ) != null ) { // Extend the base object for ( name in options ) { src = target[ name ]; copy = options[ name ]; // Prevent never-ending loop if ( target === copy ) { continue; } // Recurse if we're merging plain objects or arrays if ( deep && copy && ( jQuery.isPlainObject( copy ) || ( copyIsArray = Array.isArray( copy ) ) ) ) { if ( copyIsArray ) { copyIsArray = false; clone = src && Array.isArray( src ) ? src : []; } else { clone = src && jQuery.isPlainObject( src ) ? src : {}; } // Never move original objects, clone them target[ name ] = jQuery.extend( deep, clone, copy ); // Don't bring in undefined values } else if ( copy !== undefined ) { target[ name ] = copy; } } } } // Return the modified object return target; }; jQuery.extend( { // Unique for each copy of jQuery on the page expando: "jQuery" + ( version + Math.random() ).replace( /\D/g, "" ), // Assume jQuery is ready without the ready module isReady: true, error: function( msg ) { throw new Error( msg ); }, noop: function() {}, isFunction: function( obj ) { return jQuery.type( obj ) === "function"; }, isWindow: function( obj ) { return obj != null && obj === obj.window; }, isNumeric: function( obj ) { // As of jQuery 3.0, isNumeric is limited to // strings and numbers (primitives or objects) // that can be coerced to finite numbers (gh-2662) var type = jQuery.type( obj ); return ( type === "number" || type === "string" ) && // parseFloat NaNs numeric-cast false positives ("") // ...but misinterprets leading-number strings, particularly hex literals ("0x...") // subtraction forces infinities to NaN !isNaN( obj - parseFloat( obj ) ); }, isPlainObject: function( obj ) { var proto, Ctor; // Detect obvious negatives // Use toString instead of jQuery.type to catch host objects if ( !obj || toString.call( obj ) !== "[object Object]" ) { return false; } proto = getProto( obj ); // Objects with no prototype (e.g., `Object.create( null )`) are plain if ( !proto ) { return true; } // Objects with prototype are plain iff they were constructed by a global Object function Ctor = hasOwn.call( proto, "constructor" ) && proto.constructor; return typeof Ctor === "function" && fnToString.call( Ctor ) === ObjectFunctionString; }, isEmptyObject: function( obj ) { /* eslint-disable no-unused-vars */ // See https://github.com/eslint/eslint/issues/6125 var name; for ( name in obj ) { return false; } return true; }, type: function( obj ) { if ( obj == null ) { return obj + ""; } // Support: Android <=2.3 only (functionish RegExp) return typeof obj === "object" || typeof obj === "function" ? class2type[ toString.call( obj ) ] || "object" : typeof obj; }, // Evaluates a script in a global context globalEval: function( code ) { DOMEval( code ); }, // Convert dashed to camelCase; used by the css and data modules // Support: IE <=9 - 11, Edge 12 - 13 // Microsoft forgot to hump their vendor prefix (#9572) camelCase: function( string ) { return string.replace( rmsPrefix, "ms-" ).replace( rdashAlpha, fcamelCase ); }, each: function( obj, callback ) { var length, i = 0; if ( isArrayLike( obj ) ) { length = obj.length; for ( ; i < length; i++ ) { if ( callback.call( obj[ i ], i, obj[ i ] ) === false ) { break; } } } else { for ( i in obj ) { if ( callback.call( obj[ i ], i, obj[ i ] ) === false ) { break; } } } return obj; }, // Support: Android <=4.0 only trim: function( text ) { return text == null ? "" : ( text + "" ).replace( rtrim, "" ); }, // results is for internal usage only makeArray: function( arr, results ) { var ret = results || []; if ( arr != null ) { if ( isArrayLike( Object( arr ) ) ) { jQuery.merge( ret, typeof arr === "string" ? [ arr ] : arr ); } else { push.call( ret, arr ); } } return ret; }, inArray: function( elem, arr, i ) { return arr == null ? -1 : indexOf.call( arr, elem, i ); }, // Support: Android <=4.0 only, PhantomJS 1 only // push.apply(_, arraylike) throws on ancient WebKit merge: function( first, second ) { var len = +second.length, j = 0, i = first.length; for ( ; j < len; j++ ) { first[ i++ ] = second[ j ]; } first.length = i; return first; }, grep: function( elems, callback, invert ) { var callbackInverse, matches = [], i = 0, length = elems.length, callbackExpect = !invert; // Go through the array, only saving the items // that pass the validator function for ( ; i < length; i++ ) { callbackInverse = !callback( elems[ i ], i ); if ( callbackInverse !== callbackExpect ) { matches.push( elems[ i ] ); } } return matches; }, // arg is for internal usage only map: function( elems, callback, arg ) { var length, value, i = 0, ret = []; // Go through the array, translating each of the items to their new values if ( isArrayLike( elems ) ) { length = elems.length; for ( ; i < length; i++ ) { value = callback( elems[ i ], i, arg ); if ( value != null ) { ret.push( value ); } } // Go through every key on the object, } else { for ( i in elems ) { value = callback( elems[ i ], i, arg ); if ( value != null ) { ret.push( value ); } } } // Flatten any nested arrays return concat.apply( [], ret ); }, // A global GUID counter for objects guid: 1, // Bind a function to a context, optionally partially applying any // arguments. proxy: function( fn, context ) { var tmp, args, proxy; if ( typeof context === "string" ) { tmp = fn[ context ]; context = fn; fn = tmp; } // Quick check to determine if target is callable, in the spec // this throws a TypeError, but we will just return undefined. if ( !jQuery.isFunction( fn ) ) { return undefined; } // Simulated bind args = slice.call( arguments, 2 ); proxy = function() { return fn.apply( context || this, args.concat( slice.call( arguments ) ) ); }; // Set the guid of unique handler to the same of original handler, so it can be removed proxy.guid = fn.guid = fn.guid || jQuery.guid++; return proxy; }, now: Date.now, // jQuery.support is not used in Core but other projects attach their // properties to it so it needs to exist. support: support } ); if ( typeof Symbol === "function" ) { jQuery.fn[ Symbol.iterator ] = arr[ Symbol.iterator ]; } // Populate the class2type map jQuery.each( "Boolean Number String Function Array Date RegExp Object Error Symbol".split( " " ), function( i, name ) { class2type[ "[object " + name + "]" ] = name.toLowerCase(); } ); function isArrayLike( obj ) { // Support: real iOS 8.2 only (not reproducible in simulator) // `in` check used to prevent JIT error (gh-2145) // hasOwn isn't used here due to false negatives // regarding Nodelist length in IE var length = !!obj && "length" in obj && obj.length, type = jQuery.type( obj ); if ( type === "function" || jQuery.isWindow( obj ) ) { return false; } return type === "array" || length === 0 || typeof length === "number" && length > 0 && ( length - 1 ) in obj; } var Sizzle = /*! * Sizzle CSS Selector Engine v2.3.3 * https://sizzlejs.com/ * * Copyright jQuery Foundation and other contributors * Released under the MIT license * http://jquery.org/license * * Date: 2016-08-08 */ (function( window ) { var i, support, Expr, getText, isXML, tokenize, compile, select, outermostContext, sortInput, hasDuplicate, // Local document vars setDocument, document, docElem, documentIsHTML, rbuggyQSA, rbuggyMatches, matches, contains, // Instance-specific data expando = "sizzle" + 1 * new Date(), preferredDoc = window.document, dirruns = 0, done = 0, classCache = createCache(), tokenCache = createCache(), compilerCache = createCache(), sortOrder = function( a, b ) { if ( a === b ) { hasDuplicate = true; } return 0; }, // Instance methods hasOwn = ({}).hasOwnProperty, arr = [], pop = arr.pop, push_native = arr.push, push = arr.push, slice = arr.slice, // Use a stripped-down indexOf as it's faster than native // https://jsperf.com/thor-indexof-vs-for/5 indexOf = function( list, elem ) { var i = 0, len = list.length; for ( ; i < len; i++ ) { if ( list[i] === elem ) { return i; } } return -1; }, booleans = "checked|selected|async|autofocus|autoplay|controls|defer|disabled|hidden|ismap|loop|multiple|open|readonly|required|scoped", // Regular expressions // http://www.w3.org/TR/css3-selectors/#whitespace whitespace = "[\\x20\\t\\r\\n\\f]", // http://www.w3.org/TR/CSS21/syndata.html#value-def-identifier identifier = "(?:\\\\.|[\\w-]|[^\0-\\xa0])+", // Attribute selectors: http://www.w3.org/TR/selectors/#attribute-selectors attributes = "\\[" + whitespace + "*(" + identifier + ")(?:" + whitespace + // Operator (capture 2) "*([*^$|!~]?=)" + whitespace + // "Attribute values must be CSS identifiers [capture 5] or strings [capture 3 or capture 4]" "*(?:'((?:\\\\.|[^\\\\'])*)'|\"((?:\\\\.|[^\\\\\"])*)\"|(" + identifier + "))|)" + whitespace + "*\\]", pseudos = ":(" + identifier + ")(?:\\((" + // To reduce the number of selectors needing tokenize in the preFilter, prefer arguments: // 1. quoted (capture 3; capture 4 or capture 5) "('((?:\\\\.|[^\\\\'])*)'|\"((?:\\\\.|[^\\\\\"])*)\")|" + // 2. simple (capture 6) "((?:\\\\.|[^\\\\()[\\]]|" + attributes + ")*)|" + // 3. anything else (capture 2) ".*" + ")\\)|)", // Leading and non-escaped trailing whitespace, capturing some non-whitespace characters preceding the latter rwhitespace = new RegExp( whitespace + "+", "g" ), rtrim = new RegExp( "^" + whitespace + "+|((?:^|[^\\\\])(?:\\\\.)*)" + whitespace + "+$", "g" ), rcomma = new RegExp( "^" + whitespace + "*," + whitespace + "*" ), rcombinators = new RegExp( "^" + whitespace + "*([>+~]|" + whitespace + ")" + whitespace + "*" ), rattributeQuotes = new RegExp( "=" + whitespace + "*([^\\]'\"]*?)" + whitespace + "*\\]", "g" ), rpseudo = new RegExp( pseudos ), ridentifier = new RegExp( "^" + identifier + "$" ), matchExpr = { "ID": new RegExp( "^#(" + identifier + ")" ), "CLASS": new RegExp( "^\\.(" + identifier + ")" ), "TAG": new RegExp( "^(" + identifier + "|[*])" ), "ATTR": new RegExp( "^" + attributes ), "PSEUDO": new RegExp( "^" + pseudos ), "CHILD": new RegExp( "^:(only|first|last|nth|nth-last)-(child|of-type)(?:\\(" + whitespace + "*(even|odd|(([+-]|)(\\d*)n|)" + whitespace + "*(?:([+-]|)" + whitespace + "*(\\d+)|))" + whitespace + "*\\)|)", "i" ), "bool": new RegExp( "^(?:" + booleans + ")$", "i" ), // For use in libraries implementing .is() // We use this for POS matching in `select` "needsContext": new RegExp( "^" + whitespace + "*[>+~]|:(even|odd|eq|gt|lt|nth|first|last)(?:\\(" + whitespace + "*((?:-\\d)?\\d*)" + whitespace + "*\\)|)(?=[^-]|$)", "i" ) }, rinputs = /^(?:input|select|textarea|button)$/i, rheader = /^h\d$/i, rnative = /^[^{]+\{\s*\[native \w/, // Easily-parseable/retrievable ID or TAG or CLASS selectors rquickExpr = /^(?:#([\w-]+)|(\w+)|\.([\w-]+))$/, rsibling = /[+~]/, // CSS escapes // http://www.w3.org/TR/CSS21/syndata.html#escaped-characters runescape = new RegExp( "\\\\([\\da-f]{1,6}" + whitespace + "?|(" + whitespace + ")|.)", "ig" ), funescape = function( _, escaped, escapedWhitespace ) { var high = "0x" + escaped - 0x10000; // NaN means non-codepoint // Support: Firefox<24 // Workaround erroneous numeric interpretation of +"0x" return high !== high || escapedWhitespace ? escaped : high < 0 ? // BMP codepoint String.fromCharCode( high + 0x10000 ) : // Supplemental Plane codepoint (surrogate pair) String.fromCharCode( high >> 10 | 0xD800, high & 0x3FF | 0xDC00 ); }, // CSS string/identifier serialization // https://drafts.csswg.org/cssom/#common-serializing-idioms rcssescape = /([\0-\x1f\x7f]|^-?\d)|^-$|[^\0-\x1f\x7f-\uFFFF\w-]/g, fcssescape = function( ch, asCodePoint ) { if ( asCodePoint ) { // U+0000 NULL becomes U+FFFD REPLACEMENT CHARACTER if ( ch === "\0" ) { return "\uFFFD"; } // Control characters and (dependent upon position) numbers get escaped as code points return ch.slice( 0, -1 ) + "\\" + ch.charCodeAt( ch.length - 1 ).toString( 16 ) + " "; } // Other potentially-special ASCII characters get backslash-escaped return "\\" + ch; }, // Used for iframes // See setDocument() // Removing the function wrapper causes a "Permission Denied" // error in IE unloadHandler = function() { setDocument(); }, disabledAncestor = addCombinator( function( elem ) { return elem.disabled === true && ("form" in elem || "label" in elem); }, { dir: "parentNode", next: "legend" } ); // Optimize for push.apply( _, NodeList ) try { push.apply( (arr = slice.call( preferredDoc.childNodes )), preferredDoc.childNodes ); // Support: Android<4.0 // Detect silently failing push.apply arr[ preferredDoc.childNodes.length ].nodeType; } catch ( e ) { push = { apply: arr.length ? // Leverage slice if possible function( target, els ) { push_native.apply( target, slice.call(els) ); } : // Support: IE<9 // Otherwise append directly function( target, els ) { var j = target.length, i = 0; // Can't trust NodeList.length while ( (target[j++] = els[i++]) ) {} target.length = j - 1; } }; } function Sizzle( selector, context, results, seed ) { var m, i, elem, nid, match, groups, newSelector, newContext = context && context.ownerDocument, // nodeType defaults to 9, since context defaults to document nodeType = context ? context.nodeType : 9; results = results || []; // Return early from calls with invalid selector or context if ( typeof selector !== "string" || !selector || nodeType !== 1 && nodeType !== 9 && nodeType !== 11 ) { return results; } // Try to shortcut find operations (as opposed to filters) in HTML documents if ( !seed ) { if ( ( context ? context.ownerDocument || context : preferredDoc ) !== document ) { setDocument( context ); } context = context || document; if ( documentIsHTML ) { // If the selector is sufficiently simple, try using a "get*By*" DOM method // (excepting DocumentFragment context, where the methods don't exist) if ( nodeType !== 11 && (match = rquickExpr.exec( selector )) ) { // ID selector if ( (m = match[1]) ) { // Document context if ( nodeType === 9 ) { if ( (elem = context.getElementById( m )) ) { // Support: IE, Opera, Webkit // TODO: identify versions // getElementById can match elements by name instead of ID if ( elem.id === m ) { results.push( elem ); return results; } } else { return results; } // Element context } else { // Support: IE, Opera, Webkit // TODO: identify versions // getElementById can match elements by name instead of ID if ( newContext && (elem = newContext.getElementById( m )) && contains( context, elem ) && elem.id === m ) { results.push( elem ); return results; } } // Type selector } else if ( match[2] ) { push.apply( results, context.getElementsByTagName( selector ) ); return results; // Class selector } else if ( (m = match[3]) && support.getElementsByClassName && context.getElementsByClassName ) { push.apply( results, context.getElementsByClassName( m ) ); return results; } } // Take advantage of querySelectorAll if ( support.qsa && !compilerCache[ selector + " " ] && (!rbuggyQSA || !rbuggyQSA.test( selector )) ) { if ( nodeType !== 1 ) { newContext = context; newSelector = selector; // qSA looks outside Element context, which is not what we want // Thanks to Andrew Dupont for this workaround technique // Support: IE <=8 // Exclude object elements } else if ( context.nodeName.toLowerCase() !== "object" ) { // Capture the context ID, setting it first if necessary if ( (nid = context.getAttribute( "id" )) ) { nid = nid.replace( rcssescape, fcssescape ); } else { context.setAttribute( "id", (nid = expando) ); } // Prefix every selector in the list groups = tokenize( selector ); i = groups.length; while ( i-- ) { groups[i] = "#" + nid + " " + toSelector( groups[i] ); } newSelector = groups.join( "," ); // Expand context for sibling selectors newContext = rsibling.test( selector ) && testContext( context.parentNode ) || context; } if ( newSelector ) { try { push.apply( results, newContext.querySelectorAll( newSelector ) ); return results; } catch ( qsaError ) { } finally { if ( nid === expando ) { context.removeAttribute( "id" ); } } } } } } // All others return select( selector.replace( rtrim, "$1" ), context, results, seed ); } /** * Create key-value caches of limited size * @returns {function(string, object)} Returns the Object data after storing it on itself with * property name the (space-suffixed) string and (if the cache is larger than Expr.cacheLength) * deleting the oldest entry */ function createCache() { var keys = []; function cache( key, value ) { // Use (key + " ") to avoid collision with native prototype properties (see Issue #157) if ( keys.push( key + " " ) > Expr.cacheLength ) { // Only keep the most recent entries delete cache[ keys.shift() ]; } return (cache[ key + " " ] = value); } return cache; } /** * Mark a function for special use by Sizzle * @param {Function} fn The function to mark */ function markFunction( fn ) { fn[ expando ] = true; return fn; } /** * Support testing using an element * @param {Function} fn Passed the created element and returns a boolean result */ function assert( fn ) { var el = document.createElement("fieldset"); try { return !!fn( el ); } catch (e) { return false; } finally { // Remove from its parent by default if ( el.parentNode ) { el.parentNode.removeChild( el ); } // release memory in IE el = null; } } /** * Adds the same handler for all of the specified attrs * @param {String} attrs Pipe-separated list of attributes * @param {Function} handler The method that will be applied */ function addHandle( attrs, handler ) { var arr = attrs.split("|"), i = arr.length; while ( i-- ) { Expr.attrHandle[ arr[i] ] = handler; } } /** * Checks document order of two siblings * @param {Element} a * @param {Element} b * @returns {Number} Returns less than 0 if a precedes b, greater than 0 if a follows b */ function siblingCheck( a, b ) { var cur = b && a, diff = cur && a.nodeType === 1 && b.nodeType === 1 && a.sourceIndex - b.sourceIndex; // Use IE sourceIndex if available on both nodes if ( diff ) { return diff; } // Check if b follows a if ( cur ) { while ( (cur = cur.nextSibling) ) { if ( cur === b ) { return -1; } } } return a ? 1 : -1; } /** * Returns a function to use in pseudos for input types * @param {String} type */ function createInputPseudo( type ) { return function( elem ) { var name = elem.nodeName.toLowerCase(); return name === "input" && elem.type === type; }; } /** * Returns a function to use in pseudos for buttons * @param {String} type */ function createButtonPseudo( type ) { return function( elem ) { var name = elem.nodeName.toLowerCase(); return (name === "input" || name === "button") && elem.type === type; }; } /** * Returns a function to use in pseudos for :enabled/:disabled * @param {Boolean} disabled true for :disabled; false for :enabled */ function createDisabledPseudo( disabled ) { // Known :disabled false positives: fieldset[disabled] > legend:nth-of-type(n+2) :can-disable return function( elem ) { // Only certain elements can match :enabled or :disabled // https://html.spec.whatwg.org/multipage/scripting.html#selector-enabled // https://html.spec.whatwg.org/multipage/scripting.html#selector-disabled if ( "form" in elem ) { // Check for inherited disabledness on relevant non-disabled elements: // * listed form-associated elements in a disabled fieldset // https://html.spec.whatwg.org/multipage/forms.html#category-listed // https://html.spec.whatwg.org/multipage/forms.html#concept-fe-disabled // * option elements in a disabled optgroup // https://html.spec.whatwg.org/multipage/forms.html#concept-option-disabled // All such elements have a "form" property. if ( elem.parentNode && elem.disabled === false ) { // Option elements defer to a parent optgroup if present if ( "label" in elem ) { if ( "label" in elem.parentNode ) { return elem.parentNode.disabled === disabled; } else { return elem.disabled === disabled; } } // Support: IE 6 - 11 // Use the isDisabled shortcut property to check for disabled fieldset ancestors return elem.isDisabled === disabled || // Where there is no isDisabled, check manually /* jshint -W018 */ elem.isDisabled !== !disabled && disabledAncestor( elem ) === disabled; } return elem.disabled === disabled; // Try to winnow out elements that can't be disabled before trusting the disabled property. // Some victims get caught in our net (label, legend, menu, track), but it shouldn't // even exist on them, let alone have a boolean value. } else if ( "label" in elem ) { return elem.disabled === disabled; } // Remaining elements are neither :enabled nor :disabled return false; }; } /** * Returns a function to use in pseudos for positionals * @param {Function} fn */ function createPositionalPseudo( fn ) { return markFunction(function( argument ) { argument = +argument; return markFunction(function( seed, matches ) { var j, matchIndexes = fn( [], seed.length, argument ), i = matchIndexes.length; // Match elements found at the specified indexes while ( i-- ) { if ( seed[ (j = matchIndexes[i]) ] ) { seed[j] = !(matches[j] = seed[j]); } } }); }); } /** * Checks a node for validity as a Sizzle context * @param {Element|Object=} context * @returns {Element|Object|Boolean} The input node if acceptable, otherwise a falsy value */ function testContext( context ) { return context && typeof context.getElementsByTagName !== "undefined" && context; } // Expose support vars for convenience support = Sizzle.support = {}; /** * Detects XML nodes * @param {Element|Object} elem An element or a document * @returns {Boolean} True iff elem is a non-HTML XML node */ isXML = Sizzle.isXML = function( elem ) { // documentElement is verified for cases where it doesn't yet exist // (such as loading iframes in IE - #4833) var documentElement = elem && (elem.ownerDocument || elem).documentElement; return documentElement ? documentElement.nodeName !== "HTML" : false; }; /** * Sets document-related variables once based on the current document * @param {Element|Object} [doc] An element or document object to use to set the document * @returns {Object} Returns the current document */ setDocument = Sizzle.setDocument = function( node ) { var hasCompare, subWindow, doc = node ? node.ownerDocument || node : preferredDoc; // Return early if doc is invalid or already selected if ( doc === document || doc.nodeType !== 9 || !doc.documentElement ) { return document; } // Update global variables document = doc; docElem = document.documentElement; documentIsHTML = !isXML( document ); // Support: IE 9-11, Edge // Accessing iframe documents after unload throws "permission denied" errors (jQuery #13936) if ( preferredDoc !== document && (subWindow = document.defaultView) && subWindow.top !== subWindow ) { // Support: IE 11, Edge if ( subWindow.addEventListener ) { subWindow.addEventListener( "unload", unloadHandler, false ); // Support: IE 9 - 10 only } else if ( subWindow.attachEvent ) { subWindow.attachEvent( "onunload", unloadHandler ); } } /* Attributes ---------------------------------------------------------------------- */ // Support: IE<8 // Verify that getAttribute really returns attributes and not properties // (excepting IE8 booleans) support.attributes = assert(function( el ) { el.className = "i"; return !el.getAttribute("className"); }); /* getElement(s)By* ---------------------------------------------------------------------- */ // Check if getElementsByTagName("*") returns only elements support.getElementsByTagName = assert(function( el ) { el.appendChild( document.createComment("") ); return !el.getElementsByTagName("*").length; }); // Support: IE<9 support.getElementsByClassName = rnative.test( document.getElementsByClassName ); // Support: IE<10 // Check if getElementById returns elements by name // The broken getElementById methods don't pick up programmatically-set names, // so use a roundabout getElementsByName test support.getById = assert(function( el ) { docElem.appendChild( el ).id = expando; return !document.getElementsByName || !document.getElementsByName( expando ).length; }); // ID filter and find if ( support.getById ) { Expr.filter["ID"] = function( id ) { var attrId = id.replace( runescape, funescape ); return function( elem ) { return elem.getAttribute("id") === attrId; }; }; Expr.find["ID"] = function( id, context ) { if ( typeof context.getElementById !== "undefined" && documentIsHTML ) { var elem = context.getElementById( id ); return elem ? [ elem ] : []; } }; } else { Expr.filter["ID"] = function( id ) { var attrId = id.replace( runescape, funescape ); return function( elem ) { var node = typeof elem.getAttributeNode !== "undefined" && elem.getAttributeNode("id"); return node && node.value === attrId; }; }; // Support: IE 6 - 7 only // getElementById is not reliable as a find shortcut Expr.find["ID"] = function( id, context ) { if ( typeof context.getElementById !== "undefined" && documentIsHTML ) { var node, i, elems, elem = context.getElementById( id ); if ( elem ) { // Verify the id attribute node = elem.getAttributeNode("id"); if ( node && node.value === id ) { return [ elem ]; } // Fall back on getElementsByName elems = context.getElementsByName( id ); i = 0; while ( (elem = elems[i++]) ) { node = elem.getAttributeNode("id"); if ( node && node.value === id ) { return [ elem ]; } } } return []; } }; } // Tag Expr.find["TAG"] = support.getElementsByTagName ? function( tag, context ) { if ( typeof context.getElementsByTagName !== "undefined" ) { return context.getElementsByTagName( tag ); // DocumentFragment nodes don't have gEBTN } else if ( support.qsa ) { return context.querySelectorAll( tag ); } } : function( tag, context ) { var elem, tmp = [], i = 0, // By happy coincidence, a (broken) gEBTN appears on DocumentFragment nodes too results = context.getElementsByTagName( tag ); // Filter out possible comments if ( tag === "*" ) { while ( (elem = results[i++]) ) { if ( elem.nodeType === 1 ) { tmp.push( elem ); } } return tmp; } return results; }; // Class Expr.find["CLASS"] = support.getElementsByClassName && function( className, context ) { if ( typeof context.getElementsByClassName !== "undefined" && documentIsHTML ) { return context.getElementsByClassName( className ); } }; /* QSA/matchesSelector ---------------------------------------------------------------------- */ // QSA and matchesSelector support // matchesSelector(:active) reports false when true (IE9/Opera 11.5) rbuggyMatches = []; // qSa(:focus) reports false when true (Chrome 21) // We allow this because of a bug in IE8/9 that throws an error // whenever `document.activeElement` is accessed on an iframe // So, we allow :focus to pass through QSA all the time to avoid the IE error // See https://bugs.jquery.com/ticket/13378 rbuggyQSA = []; if ( (support.qsa = rnative.test( document.querySelectorAll )) ) { // Build QSA regex // Regex strategy adopted from Diego Perini assert(function( el ) { // Select is set to empty string on purpose // This is to test IE's treatment of not explicitly // setting a boolean content attribute, // since its presence should be enough // https://bugs.jquery.com/ticket/12359 docElem.appendChild( el ).innerHTML = "" + ""; // Support: IE8, Opera 11-12.16 // Nothing should be selected when empty strings follow ^= or $= or *= // The test attribute must be unknown in Opera but "safe" for WinRT // https://msdn.microsoft.com/en-us/library/ie/hh465388.aspx#attribute_section if ( el.querySelectorAll("[msallowcapture^='']").length ) { rbuggyQSA.push( "[*^$]=" + whitespace + "*(?:''|\"\")" ); } // Support: IE8 // Boolean attributes and "value" are not treated correctly if ( !el.querySelectorAll("[selected]").length ) { rbuggyQSA.push( "\\[" + whitespace + "*(?:value|" + booleans + ")" ); } // Support: Chrome<29, Android<4.4, Safari<7.0+, iOS<7.0+, PhantomJS<1.9.8+ if ( !el.querySelectorAll( "[id~=" + expando + "-]" ).length ) { rbuggyQSA.push("~="); } // Webkit/Opera - :checked should return selected option elements // http://www.w3.org/TR/2011/REC-css3-selectors-20110929/#checked // IE8 throws error here and will not see later tests if ( !el.querySelectorAll(":checked").length ) { rbuggyQSA.push(":checked"); } // Support: Safari 8+, iOS 8+ // https://bugs.webkit.org/show_bug.cgi?id=136851 // In-page `selector#id sibling-combinator selector` fails if ( !el.querySelectorAll( "a#" + expando + "+*" ).length ) { rbuggyQSA.push(".#.+[+~]"); } }); assert(function( el ) { el.innerHTML = "" + ""; // Support: Windows 8 Native Apps // The type and name attributes are restricted during .innerHTML assignment var input = document.createElement("input"); input.setAttribute( "type", "hidden" ); el.appendChild( input ).setAttribute( "name", "D" ); // Support: IE8 // Enforce case-sensitivity of name attribute if ( el.querySelectorAll("[name=d]").length ) { rbuggyQSA.push( "name" + whitespace + "*[*^$|!~]?=" ); } // FF 3.5 - :enabled/:disabled and hidden elements (hidden elements are still enabled) // IE8 throws error here and will not see later tests if ( el.querySelectorAll(":enabled").length !== 2 ) { rbuggyQSA.push( ":enabled", ":disabled" ); } // Support: IE9-11+ // IE's :disabled selector does not pick up the children of disabled fieldsets docElem.appendChild( el ).disabled = true; if ( el.querySelectorAll(":disabled").length !== 2 ) { rbuggyQSA.push( ":enabled", ":disabled" ); } // Opera 10-11 does not throw on post-comma invalid pseudos el.querySelectorAll("*,:x"); rbuggyQSA.push(",.*:"); }); } if ( (support.matchesSelector = rnative.test( (matches = docElem.matches || docElem.webkitMatchesSelector || docElem.mozMatchesSelector || docElem.oMatchesSelector || docElem.msMatchesSelector) )) ) { assert(function( el ) { // Check to see if it's possible to do matchesSelector // on a disconnected node (IE 9) support.disconnectedMatch = matches.call( el, "*" ); // This should fail with an exception // Gecko does not error, returns false instead matches.call( el, "[s!='']:x" ); rbuggyMatches.push( "!=", pseudos ); }); } rbuggyQSA = rbuggyQSA.length && new RegExp( rbuggyQSA.join("|") ); rbuggyMatches = rbuggyMatches.length && new RegExp( rbuggyMatches.join("|") ); /* Contains ---------------------------------------------------------------------- */ hasCompare = rnative.test( docElem.compareDocumentPosition ); // Element contains another // Purposefully self-exclusive // As in, an element does not contain itself contains = hasCompare || rnative.test( docElem.contains ) ? function( a, b ) { var adown = a.nodeType === 9 ? a.documentElement : a, bup = b && b.parentNode; return a === bup || !!( bup && bup.nodeType === 1 && ( adown.contains ? adown.contains( bup ) : a.compareDocumentPosition && a.compareDocumentPosition( bup ) & 16 )); } : function( a, b ) { if ( b ) { while ( (b = b.parentNode) ) { if ( b === a ) { return true; } } } return false; }; /* Sorting ---------------------------------------------------------------------- */ // Document order sorting sortOrder = hasCompare ? function( a, b ) { // Flag for duplicate removal if ( a === b ) { hasDuplicate = true; return 0; } // Sort on method existence if only one input has compareDocumentPosition var compare = !a.compareDocumentPosition - !b.compareDocumentPosition; if ( compare ) { return compare; } // Calculate position if both inputs belong to the same document compare = ( a.ownerDocument || a ) === ( b.ownerDocument || b ) ? a.compareDocumentPosition( b ) : // Otherwise we know they are disconnected 1; // Disconnected nodes if ( compare & 1 || (!support.sortDetached && b.compareDocumentPosition( a ) === compare) ) { // Choose the first element that is related to our preferred document if ( a === document || a.ownerDocument === preferredDoc && contains(preferredDoc, a) ) { return -1; } if ( b === document || b.ownerDocument === preferredDoc && contains(preferredDoc, b) ) { return 1; } // Maintain original order return sortInput ? ( indexOf( sortInput, a ) - indexOf( sortInput, b ) ) : 0; } return compare & 4 ? -1 : 1; } : function( a, b ) { // Exit early if the nodes are identical if ( a === b ) { hasDuplicate = true; return 0; } var cur, i = 0, aup = a.parentNode, bup = b.parentNode, ap = [ a ], bp = [ b ]; // Parentless nodes are either documents or disconnected if ( !aup || !bup ) { return a === document ? -1 : b === document ? 1 : aup ? -1 : bup ? 1 : sortInput ? ( indexOf( sortInput, a ) - indexOf( sortInput, b ) ) : 0; // If the nodes are siblings, we can do a quick check } else if ( aup === bup ) { return siblingCheck( a, b ); } // Otherwise we need full lists of their ancestors for comparison cur = a; while ( (cur = cur.parentNode) ) { ap.unshift( cur ); } cur = b; while ( (cur = cur.parentNode) ) { bp.unshift( cur ); } // Walk down the tree looking for a discrepancy while ( ap[i] === bp[i] ) { i++; } return i ? // Do a sibling check if the nodes have a common ancestor siblingCheck( ap[i], bp[i] ) : // Otherwise nodes in our document sort first ap[i] === preferredDoc ? -1 : bp[i] === preferredDoc ? 1 : 0; }; return document; }; Sizzle.matches = function( expr, elements ) { return Sizzle( expr, null, null, elements ); }; Sizzle.matchesSelector = function( elem, expr ) { // Set document vars if needed if ( ( elem.ownerDocument || elem ) !== document ) { setDocument( elem ); } // Make sure that attribute selectors are quoted expr = expr.replace( rattributeQuotes, "='$1']" ); if ( support.matchesSelector && documentIsHTML && !compilerCache[ expr + " " ] && ( !rbuggyMatches || !rbuggyMatches.test( expr ) ) && ( !rbuggyQSA || !rbuggyQSA.test( expr ) ) ) { try { var ret = matches.call( elem, expr ); // IE 9's matchesSelector returns false on disconnected nodes if ( ret || support.disconnectedMatch || // As well, disconnected nodes are said to be in a document // fragment in IE 9 elem.document && elem.document.nodeType !== 11 ) { return ret; } } catch (e) {} } return Sizzle( expr, document, null, [ elem ] ).length > 0; }; Sizzle.contains = function( context, elem ) { // Set document vars if needed if ( ( context.ownerDocument || context ) !== document ) { setDocument( context ); } return contains( context, elem ); }; Sizzle.attr = function( elem, name ) { // Set document vars if needed if ( ( elem.ownerDocument || elem ) !== document ) { setDocument( elem ); } var fn = Expr.attrHandle[ name.toLowerCase() ], // Don't get fooled by Object.prototype properties (jQuery #13807) val = fn && hasOwn.call( Expr.attrHandle, name.toLowerCase() ) ? fn( elem, name, !documentIsHTML ) : undefined; return val !== undefined ? val : support.attributes || !documentIsHTML ? elem.getAttribute( name ) : (val = elem.getAttributeNode(name)) && val.specified ? val.value : null; }; Sizzle.escape = function( sel ) { return (sel + "").replace( rcssescape, fcssescape ); }; Sizzle.error = function( msg ) { throw new Error( "Syntax error, unrecognized expression: " + msg ); }; /** * Document sorting and removing duplicates * @param {ArrayLike} results */ Sizzle.uniqueSort = function( results ) { var elem, duplicates = [], j = 0, i = 0; // Unless we *know* we can detect duplicates, assume their presence hasDuplicate = !support.detectDuplicates; sortInput = !support.sortStable && results.slice( 0 ); results.sort( sortOrder ); if ( hasDuplicate ) { while ( (elem = results[i++]) ) { if ( elem === results[ i ] ) { j = duplicates.push( i ); } } while ( j-- ) { results.splice( duplicates[ j ], 1 ); } } // Clear input after sorting to release objects // See https://github.com/jquery/sizzle/pull/225 sortInput = null; return results; }; /** * Utility function for retrieving the text value of an array of DOM nodes * @param {Array|Element} elem */ getText = Sizzle.getText = function( elem ) { var node, ret = "", i = 0, nodeType = elem.nodeType; if ( !nodeType ) { // If no nodeType, this is expected to be an array while ( (node = elem[i++]) ) { // Do not traverse comment nodes ret += getText( node ); } } else if ( nodeType === 1 || nodeType === 9 || nodeType === 11 ) { // Use textContent for elements // innerText usage removed for consistency of new lines (jQuery #11153) if ( typeof elem.textContent === "string" ) { return elem.textContent; } else { // Traverse its children for ( elem = elem.firstChild; elem; elem = elem.nextSibling ) { ret += getText( elem ); } } } else if ( nodeType === 3 || nodeType === 4 ) { return elem.nodeValue; } // Do not include comment or processing instruction nodes return ret; }; Expr = Sizzle.selectors = { // Can be adjusted by the user cacheLength: 50, createPseudo: markFunction, match: matchExpr, attrHandle: {}, find: {}, relative: { ">": { dir: "parentNode", first: true }, " ": { dir: "parentNode" }, "+": { dir: "previousSibling", first: true }, "~": { dir: "previousSibling" } }, preFilter: { "ATTR": function( match ) { match[1] = match[1].replace( runescape, funescape ); // Move the given value to match[3] whether quoted or unquoted match[3] = ( match[3] || match[4] || match[5] || "" ).replace( runescape, funescape ); if ( match[2] === "~=" ) { match[3] = " " + match[3] + " "; } return match.slice( 0, 4 ); }, "CHILD": function( match ) { /* matches from matchExpr["CHILD"] 1 type (only|nth|...) 2 what (child|of-type) 3 argument (even|odd|\d*|\d*n([+-]\d+)?|...) 4 xn-component of xn+y argument ([+-]?\d*n|) 5 sign of xn-component 6 x of xn-component 7 sign of y-component 8 y of y-component */ match[1] = match[1].toLowerCase(); if ( match[1].slice( 0, 3 ) === "nth" ) { // nth-* requires argument if ( !match[3] ) { Sizzle.error( match[0] ); } // numeric x and y parameters for Expr.filter.CHILD // remember that false/true cast respectively to 0/1 match[4] = +( match[4] ? match[5] + (match[6] || 1) : 2 * ( match[3] === "even" || match[3] === "odd" ) ); match[5] = +( ( match[7] + match[8] ) || match[3] === "odd" ); // other types prohibit arguments } else if ( match[3] ) { Sizzle.error( match[0] ); } return match; }, "PSEUDO": function( match ) { var excess, unquoted = !match[6] && match[2]; if ( matchExpr["CHILD"].test( match[0] ) ) { return null; } // Accept quoted arguments as-is if ( match[3] ) { match[2] = match[4] || match[5] || ""; // Strip excess characters from unquoted arguments } else if ( unquoted && rpseudo.test( unquoted ) && // Get excess from tokenize (recursively) (excess = tokenize( unquoted, true )) && // advance to the next closing parenthesis (excess = unquoted.indexOf( ")", unquoted.length - excess ) - unquoted.length) ) { // excess is a negative index match[0] = match[0].slice( 0, excess ); match[2] = unquoted.slice( 0, excess ); } // Return only captures needed by the pseudo filter method (type and argument) return match.slice( 0, 3 ); } }, filter: { "TAG": function( nodeNameSelector ) { var nodeName = nodeNameSelector.replace( runescape, funescape ).toLowerCase(); return nodeNameSelector === "*" ? function() { return true; } : function( elem ) { return elem.nodeName && elem.nodeName.toLowerCase() === nodeName; }; }, "CLASS": function( className ) { var pattern = classCache[ className + " " ]; return pattern || (pattern = new RegExp( "(^|" + whitespace + ")" + className + "(" + whitespace + "|$)" )) && classCache( className, function( elem ) { return pattern.test( typeof elem.className === "string" && elem.className || typeof elem.getAttribute !== "undefined" && elem.getAttribute("class") || "" ); }); }, "ATTR": function( name, operator, check ) { return function( elem ) { var result = Sizzle.attr( elem, name ); if ( result == null ) { return operator === "!="; } if ( !operator ) { return true; } result += ""; return operator === "=" ? result === check : operator === "!=" ? result !== check : operator === "^=" ? check && result.indexOf( check ) === 0 : operator === "*=" ? check && result.indexOf( check ) > -1 : operator === "$=" ? check && result.slice( -check.length ) === check : operator === "~=" ? ( " " + result.replace( rwhitespace, " " ) + " " ).indexOf( check ) > -1 : operator === "|=" ? result === check || result.slice( 0, check.length + 1 ) === check + "-" : false; }; }, "CHILD": function( type, what, argument, first, last ) { var simple = type.slice( 0, 3 ) !== "nth", forward = type.slice( -4 ) !== "last", ofType = what === "of-type"; return first === 1 && last === 0 ? // Shortcut for :nth-*(n) function( elem ) { return !!elem.parentNode; } : function( elem, context, xml ) { var cache, uniqueCache, outerCache, node, nodeIndex, start, dir = simple !== forward ? "nextSibling" : "previousSibling", parent = elem.parentNode, name = ofType && elem.nodeName.toLowerCase(), useCache = !xml && !ofType, diff = false; if ( parent ) { // :(first|last|only)-(child|of-type) if ( simple ) { while ( dir ) { node = elem; while ( (node = node[ dir ]) ) { if ( ofType ? node.nodeName.toLowerCase() === name : node.nodeType === 1 ) { return false; } } // Reverse direction for :only-* (if we haven't yet done so) start = dir = type === "only" && !start && "nextSibling"; } return true; } start = [ forward ? parent.firstChild : parent.lastChild ]; // non-xml :nth-child(...) stores cache data on `parent` if ( forward && useCache ) { // Seek `elem` from a previously-cached index // ...in a gzip-friendly way node = parent; outerCache = node[ expando ] || (node[ expando ] = {}); // Support: IE <9 only // Defend against cloned attroperties (jQuery gh-1709) uniqueCache = outerCache[ node.uniqueID ] || (outerCache[ node.uniqueID ] = {}); cache = uniqueCache[ type ] || []; nodeIndex = cache[ 0 ] === dirruns && cache[ 1 ]; diff = nodeIndex && cache[ 2 ]; node = nodeIndex && parent.childNodes[ nodeIndex ]; while ( (node = ++nodeIndex && node && node[ dir ] || // Fallback to seeking `elem` from the start (diff = nodeIndex = 0) || start.pop()) ) { // When found, cache indexes on `parent` and break if ( node.nodeType === 1 && ++diff && node === elem ) { uniqueCache[ type ] = [ dirruns, nodeIndex, diff ]; break; } } } else { // Use previously-cached element index if available if ( useCache ) { // ...in a gzip-friendly way node = elem; outerCache = node[ expando ] || (node[ expando ] = {}); // Support: IE <9 only // Defend against cloned attroperties (jQuery gh-1709) uniqueCache = outerCache[ node.uniqueID ] || (outerCache[ node.uniqueID ] = {}); cache = uniqueCache[ type ] || []; nodeIndex = cache[ 0 ] === dirruns && cache[ 1 ]; diff = nodeIndex; } // xml :nth-child(...) // or :nth-last-child(...) or :nth(-last)?-of-type(...) if ( diff === false ) { // Use the same loop as above to seek `elem` from the start while ( (node = ++nodeIndex && node && node[ dir ] || (diff = nodeIndex = 0) || start.pop()) ) { if ( ( ofType ? node.nodeName.toLowerCase() === name : node.nodeType === 1 ) && ++diff ) { // Cache the index of each encountered element if ( useCache ) { outerCache = node[ expando ] || (node[ expando ] = {}); // Support: IE <9 only // Defend against cloned attroperties (jQuery gh-1709) uniqueCache = outerCache[ node.uniqueID ] || (outerCache[ node.uniqueID ] = {}); uniqueCache[ type ] = [ dirruns, diff ]; } if ( node === elem ) { break; } } } } } // Incorporate the offset, then check against cycle size diff -= last; return diff === first || ( diff % first === 0 && diff / first >= 0 ); } }; }, "PSEUDO": function( pseudo, argument ) { // pseudo-class names are case-insensitive // http://www.w3.org/TR/selectors/#pseudo-classes // Prioritize by case sensitivity in case custom pseudos are added with uppercase letters // Remember that setFilters inherits from pseudos var args, fn = Expr.pseudos[ pseudo ] || Expr.setFilters[ pseudo.toLowerCase() ] || Sizzle.error( "unsupported pseudo: " + pseudo ); // The user may use createPseudo to indicate that // arguments are needed to create the filter function // just as Sizzle does if ( fn[ expando ] ) { return fn( argument ); } // But maintain support for old signatures if ( fn.length > 1 ) { args = [ pseudo, pseudo, "", argument ]; return Expr.setFilters.hasOwnProperty( pseudo.toLowerCase() ) ? markFunction(function( seed, matches ) { var idx, matched = fn( seed, argument ), i = matched.length; while ( i-- ) { idx = indexOf( seed, matched[i] ); seed[ idx ] = !( matches[ idx ] = matched[i] ); } }) : function( elem ) { return fn( elem, 0, args ); }; } return fn; } }, pseudos: { // Potentially complex pseudos "not": markFunction(function( selector ) { // Trim the selector passed to compile // to avoid treating leading and trailing // spaces as combinators var input = [], results = [], matcher = compile( selector.replace( rtrim, "$1" ) ); return matcher[ expando ] ? markFunction(function( seed, matches, context, xml ) { var elem, unmatched = matcher( seed, null, xml, [] ), i = seed.length; // Match elements unmatched by `matcher` while ( i-- ) { if ( (elem = unmatched[i]) ) { seed[i] = !(matches[i] = elem); } } }) : function( elem, context, xml ) { input[0] = elem; matcher( input, null, xml, results ); // Don't keep the element (issue #299) input[0] = null; return !results.pop(); }; }), "has": markFunction(function( selector ) { return function( elem ) { return Sizzle( selector, elem ).length > 0; }; }), "contains": markFunction(function( text ) { text = text.replace( runescape, funescape ); return function( elem ) { return ( elem.textContent || elem.innerText || getText( elem ) ).indexOf( text ) > -1; }; }), // "Whether an element is represented by a :lang() selector // is based solely on the element's language value // being equal to the identifier C, // or beginning with the identifier C immediately followed by "-". // The matching of C against the element's language value is performed case-insensitively. // The identifier C does not have to be a valid language name." // http://www.w3.org/TR/selectors/#lang-pseudo "lang": markFunction( function( lang ) { // lang value must be a valid identifier if ( !ridentifier.test(lang || "") ) { Sizzle.error( "unsupported lang: " + lang ); } lang = lang.replace( runescape, funescape ).toLowerCase(); return function( elem ) { var elemLang; do { if ( (elemLang = documentIsHTML ? elem.lang : elem.getAttribute("xml:lang") || elem.getAttribute("lang")) ) { elemLang = elemLang.toLowerCase(); return elemLang === lang || elemLang.indexOf( lang + "-" ) === 0; } } while ( (elem = elem.parentNode) && elem.nodeType === 1 ); return false; }; }), // Miscellaneous "target": function( elem ) { var hash = window.location && window.location.hash; return hash && hash.slice( 1 ) === elem.id; }, "root": function( elem ) { return elem === docElem; }, "focus": function( elem ) { return elem === document.activeElement && (!document.hasFocus || document.hasFocus()) && !!(elem.type || elem.href || ~elem.tabIndex); }, // Boolean properties "enabled": createDisabledPseudo( false ), "disabled": createDisabledPseudo( true ), "checked": function( elem ) { // In CSS3, :checked should return both checked and selected elements // http://www.w3.org/TR/2011/REC-css3-selectors-20110929/#checked var nodeName = elem.nodeName.toLowerCase(); return (nodeName === "input" && !!elem.checked) || (nodeName === "option" && !!elem.selected); }, "selected": function( elem ) { // Accessing this property makes selected-by-default // options in Safari work properly if ( elem.parentNode ) { elem.parentNode.selectedIndex; } return elem.selected === true; }, // Contents "empty": function( elem ) { // http://www.w3.org/TR/selectors/#empty-pseudo // :empty is negated by element (1) or content nodes (text: 3; cdata: 4; entity ref: 5), // but not by others (comment: 8; processing instruction: 7; etc.) // nodeType < 6 works because attributes (2) do not appear as children for ( elem = elem.firstChild; elem; elem = elem.nextSibling ) { if ( elem.nodeType < 6 ) { return false; } } return true; }, "parent": function( elem ) { return !Expr.pseudos["empty"]( elem ); }, // Element/input types "header": function( elem ) { return rheader.test( elem.nodeName ); }, "input": function( elem ) { return rinputs.test( elem.nodeName ); }, "button": function( elem ) { var name = elem.nodeName.toLowerCase(); return name === "input" && elem.type === "button" || name === "button"; }, "text": function( elem ) { var attr; return elem.nodeName.toLowerCase() === "input" && elem.type === "text" && // Support: IE<8 // New HTML5 attribute values (e.g., "search") appear with elem.type === "text" ( (attr = elem.getAttribute("type")) == null || attr.toLowerCase() === "text" ); }, // Position-in-collection "first": createPositionalPseudo(function() { return [ 0 ]; }), "last": createPositionalPseudo(function( matchIndexes, length ) { return [ length - 1 ]; }), "eq": createPositionalPseudo(function( matchIndexes, length, argument ) { return [ argument < 0 ? argument + length : argument ]; }), "even": createPositionalPseudo(function( matchIndexes, length ) { var i = 0; for ( ; i < length; i += 2 ) { matchIndexes.push( i ); } return matchIndexes; }), "odd": createPositionalPseudo(function( matchIndexes, length ) { var i = 1; for ( ; i < length; i += 2 ) { matchIndexes.push( i ); } return matchIndexes; }), "lt": createPositionalPseudo(function( matchIndexes, length, argument ) { var i = argument < 0 ? argument + length : argument; for ( ; --i >= 0; ) { matchIndexes.push( i ); } return matchIndexes; }), "gt": createPositionalPseudo(function( matchIndexes, length, argument ) { var i = argument < 0 ? argument + length : argument; for ( ; ++i < length; ) { matchIndexes.push( i ); } return matchIndexes; }) } }; Expr.pseudos["nth"] = Expr.pseudos["eq"]; // Add button/input type pseudos for ( i in { radio: true, checkbox: true, file: true, password: true, image: true } ) { Expr.pseudos[ i ] = createInputPseudo( i ); } for ( i in { submit: true, reset: true } ) { Expr.pseudos[ i ] = createButtonPseudo( i ); } // Easy API for creating new setFilters function setFilters() {} setFilters.prototype = Expr.filters = Expr.pseudos; Expr.setFilters = new setFilters(); tokenize = Sizzle.tokenize = function( selector, parseOnly ) { var matched, match, tokens, type, soFar, groups, preFilters, cached = tokenCache[ selector + " " ]; if ( cached ) { return parseOnly ? 0 : cached.slice( 0 ); } soFar = selector; groups = []; preFilters = Expr.preFilter; while ( soFar ) { // Comma and first run if ( !matched || (match = rcomma.exec( soFar )) ) { if ( match ) { // Don't consume trailing commas as valid soFar = soFar.slice( match[0].length ) || soFar; } groups.push( (tokens = []) ); } matched = false; // Combinators if ( (match = rcombinators.exec( soFar )) ) { matched = match.shift(); tokens.push({ value: matched, // Cast descendant combinators to space type: match[0].replace( rtrim, " " ) }); soFar = soFar.slice( matched.length ); } // Filters for ( type in Expr.filter ) { if ( (match = matchExpr[ type ].exec( soFar )) && (!preFilters[ type ] || (match = preFilters[ type ]( match ))) ) { matched = match.shift(); tokens.push({ value: matched, type: type, matches: match }); soFar = soFar.slice( matched.length ); } } if ( !matched ) { break; } } // Return the length of the invalid excess // if we're just parsing // Otherwise, throw an error or return tokens return parseOnly ? soFar.length : soFar ? Sizzle.error( selector ) : // Cache the tokens tokenCache( selector, groups ).slice( 0 ); }; function toSelector( tokens ) { var i = 0, len = tokens.length, selector = ""; for ( ; i < len; i++ ) { selector += tokens[i].value; } return selector; } function addCombinator( matcher, combinator, base ) { var dir = combinator.dir, skip = combinator.next, key = skip || dir, checkNonElements = base && key === "parentNode", doneName = done++; return combinator.first ? // Check against closest ancestor/preceding element function( elem, context, xml ) { while ( (elem = elem[ dir ]) ) { if ( elem.nodeType === 1 || checkNonElements ) { return matcher( elem, context, xml ); } } return false; } : // Check against all ancestor/preceding elements function( elem, context, xml ) { var oldCache, uniqueCache, outerCache, newCache = [ dirruns, doneName ]; // We can't set arbitrary data on XML nodes, so they don't benefit from combinator caching if ( xml ) { while ( (elem = elem[ dir ]) ) { if ( elem.nodeType === 1 || checkNonElements ) { if ( matcher( elem, context, xml ) ) { return true; } } } } else { while ( (elem = elem[ dir ]) ) { if ( elem.nodeType === 1 || checkNonElements ) { outerCache = elem[ expando ] || (elem[ expando ] = {}); // Support: IE <9 only // Defend against cloned attroperties (jQuery gh-1709) uniqueCache = outerCache[ elem.uniqueID ] || (outerCache[ elem.uniqueID ] = {}); if ( skip && skip === elem.nodeName.toLowerCase() ) { elem = elem[ dir ] || elem; } else if ( (oldCache = uniqueCache[ key ]) && oldCache[ 0 ] === dirruns && oldCache[ 1 ] === doneName ) { // Assign to newCache so results back-propagate to previous elements return (newCache[ 2 ] = oldCache[ 2 ]); } else { // Reuse newcache so results back-propagate to previous elements uniqueCache[ key ] = newCache; // A match means we're done; a fail means we have to keep checking if ( (newCache[ 2 ] = matcher( elem, context, xml )) ) { return true; } } } } } return false; }; } function elementMatcher( matchers ) { return matchers.length > 1 ? function( elem, context, xml ) { var i = matchers.length; while ( i-- ) { if ( !matchers[i]( elem, context, xml ) ) { return false; } } return true; } : matchers[0]; } function multipleContexts( selector, contexts, results ) { var i = 0, len = contexts.length; for ( ; i < len; i++ ) { Sizzle( selector, contexts[i], results ); } return results; } function condense( unmatched, map, filter, context, xml ) { var elem, newUnmatched = [], i = 0, len = unmatched.length, mapped = map != null; for ( ; i < len; i++ ) { if ( (elem = unmatched[i]) ) { if ( !filter || filter( elem, context, xml ) ) { newUnmatched.push( elem ); if ( mapped ) { map.push( i ); } } } } return newUnmatched; } function setMatcher( preFilter, selector, matcher, postFilter, postFinder, postSelector ) { if ( postFilter && !postFilter[ expando ] ) { postFilter = setMatcher( postFilter ); } if ( postFinder && !postFinder[ expando ] ) { postFinder = setMatcher( postFinder, postSelector ); } return markFunction(function( seed, results, context, xml ) { var temp, i, elem, preMap = [], postMap = [], preexisting = results.length, // Get initial elements from seed or context elems = seed || multipleContexts( selector || "*", context.nodeType ? [ context ] : context, [] ), // Prefilter to get matcher input, preserving a map for seed-results synchronization matcherIn = preFilter && ( seed || !selector ) ? condense( elems, preMap, preFilter, context, xml ) : elems, matcherOut = matcher ? // If we have a postFinder, or filtered seed, or non-seed postFilter or preexisting results, postFinder || ( seed ? preFilter : preexisting || postFilter ) ? // ...intermediate processing is necessary [] : // ...otherwise use results directly results : matcherIn; // Find primary matches if ( matcher ) { matcher( matcherIn, matcherOut, context, xml ); } // Apply postFilter if ( postFilter ) { temp = condense( matcherOut, postMap ); postFilter( temp, [], context, xml ); // Un-match failing elements by moving them back to matcherIn i = temp.length; while ( i-- ) { if ( (elem = temp[i]) ) { matcherOut[ postMap[i] ] = !(matcherIn[ postMap[i] ] = elem); } } } if ( seed ) { if ( postFinder || preFilter ) { if ( postFinder ) { // Get the final matcherOut by condensing this intermediate into postFinder contexts temp = []; i = matcherOut.length; while ( i-- ) { if ( (elem = matcherOut[i]) ) { // Restore matcherIn since elem is not yet a final match temp.push( (matcherIn[i] = elem) ); } } postFinder( null, (matcherOut = []), temp, xml ); } // Move matched elements from seed to results to keep them synchronized i = matcherOut.length; while ( i-- ) { if ( (elem = matcherOut[i]) && (temp = postFinder ? indexOf( seed, elem ) : preMap[i]) > -1 ) { seed[temp] = !(results[temp] = elem); } } } // Add elements to results, through postFinder if defined } else { matcherOut = condense( matcherOut === results ? matcherOut.splice( preexisting, matcherOut.length ) : matcherOut ); if ( postFinder ) { postFinder( null, results, matcherOut, xml ); } else { push.apply( results, matcherOut ); } } }); } function matcherFromTokens( tokens ) { var checkContext, matcher, j, len = tokens.length, leadingRelative = Expr.relative[ tokens[0].type ], implicitRelative = leadingRelative || Expr.relative[" "], i = leadingRelative ? 1 : 0, // The foundational matcher ensures that elements are reachable from top-level context(s) matchContext = addCombinator( function( elem ) { return elem === checkContext; }, implicitRelative, true ), matchAnyContext = addCombinator( function( elem ) { return indexOf( checkContext, elem ) > -1; }, implicitRelative, true ), matchers = [ function( elem, context, xml ) { var ret = ( !leadingRelative && ( xml || context !== outermostContext ) ) || ( (checkContext = context).nodeType ? matchContext( elem, context, xml ) : matchAnyContext( elem, context, xml ) ); // Avoid hanging onto element (issue #299) checkContext = null; return ret; } ]; for ( ; i < len; i++ ) { if ( (matcher = Expr.relative[ tokens[i].type ]) ) { matchers = [ addCombinator(elementMatcher( matchers ), matcher) ]; } else { matcher = Expr.filter[ tokens[i].type ].apply( null, tokens[i].matches ); // Return special upon seeing a positional matcher if ( matcher[ expando ] ) { // Find the next relative operator (if any) for proper handling j = ++i; for ( ; j < len; j++ ) { if ( Expr.relative[ tokens[j].type ] ) { break; } } return setMatcher( i > 1 && elementMatcher( matchers ), i > 1 && toSelector( // If the preceding token was a descendant combinator, insert an implicit any-element `*` tokens.slice( 0, i - 1 ).concat({ value: tokens[ i - 2 ].type === " " ? "*" : "" }) ).replace( rtrim, "$1" ), matcher, i < j && matcherFromTokens( tokens.slice( i, j ) ), j < len && matcherFromTokens( (tokens = tokens.slice( j )) ), j < len && toSelector( tokens ) ); } matchers.push( matcher ); } } return elementMatcher( matchers ); } function matcherFromGroupMatchers( elementMatchers, setMatchers ) { var bySet = setMatchers.length > 0, byElement = elementMatchers.length > 0, superMatcher = function( seed, context, xml, results, outermost ) { var elem, j, matcher, matchedCount = 0, i = "0", unmatched = seed && [], setMatched = [], contextBackup = outermostContext, // We must always have either seed elements or outermost context elems = seed || byElement && Expr.find["TAG"]( "*", outermost ), // Use integer dirruns iff this is the outermost matcher dirrunsUnique = (dirruns += contextBackup == null ? 1 : Math.random() || 0.1), len = elems.length; if ( outermost ) { outermostContext = context === document || context || outermost; } // Add elements passing elementMatchers directly to results // Support: IE<9, Safari // Tolerate NodeList properties (IE: "length"; Safari: