//...
```
从这里可以看出已经可以更新元素的内容,事实上也就是替换它。那么真正的行为是怎样的呢,其实它会生成一个“配置对象”并且其配置的动作会被相应地应用。在我们的场景下这个文字的更新操作可能形如:
```javascript
{
afterNode: null,
content: "click state message",
fromIndex: null,
fromNode: null,
toIndex: null,
type: "TEXT_CONTENT"
}
```
我们可以看到很多字段是空,因为文字更新是比较简单的。但是它有很多属性字段,因为当你移动节点就会比仅仅更新字符串要复杂得多。我们来看这部分的源码加深理解。
```javascript
//src\renderers\dom\client\utils\DOMChildrenOperations.js#172
processUpdates: function(parentNode, updates) {
for (var k = 0; k < updates.length; k++) {
var update = updates[k];
switch (update.type) {
case 'INSERT_MARKUP':
insertLazyTreeChildAt(
parentNode,
update.content,
getNodeAfter(parentNode, update.afterNode)
);
break;
case 'MOVE_EXISTING':
moveChild(
parentNode,
update.fromNode,
getNodeAfter(parentNode, update.afterNode)
);
break;
case 'SET_MARKUP':
setInnerHTML(
parentNode,
update.content
);
break;
case 'TEXT_CONTENT':
setTextContent(
parentNode,
update.content
);
break;
case 'REMOVE_NODE':
removeChild(parentNode, update.fromNode);
break;
}
}
}
```
在我们的情况下,更新类型是 `TEXT_CONTENT`,因此实际上这是最后一步,我们调用步骤 (3) 的 `setTextContent` 方法并且更新 HTML 节点(从真实 DOM 中操作)。
非常好!内容已经被更新,界面上也做了重绘。我们还有什么遗忘的吗?让我们结束更新!这些事都做完了,我们的组件生命周期钩子函数 `componentDidUpdate` 会被调用。这样的延迟回调是怎么调用的呢?实际上就是通过事务的封装器。如果你还记得,脏组件的更新会被 `ReactUpdatesFlushTransaction` 封装器修饰,并且其中的一个封装器实际上包含了 `this.callbackQueue.notifyAll()` 逻辑,所以它回调用 `componentDidUpdate`。很好,现在看上去我们已经讲完了全部内容。
### 好, 第 14 部分我们讲完了
我们来回顾一下我们学到的。我们再看一下这种模式,然后去掉冗余的部分:
[](https://rawgit.com/Bogdan-Lyashenko/Under-the-hood-ReactJS/master/stack/images/14/part-14-A.svg)
14.2 第 14 部分简化板 (点击查看大图)
然后我们适当再调整一下:
[](https://rawgit.com/Bogdan-Lyashenko/Under-the-hood-ReactJS/master/stack/images/14/part-14-B.svg)
14.3 第 14 简化和重构 (点击查看大图)
很好,实际上,下面的示意图就是我们所讲的。因此,我们可以理解**第 14 部分**的本质,并将其用于最终的 `updating` 方案:
[](https://rawgit.com/Bogdan-Lyashenko/Under-the-hood-ReactJS/master/stack/images/14/part-14-C.svg)
14.4 第 14 部分 本质 (点击查看大图)
我们已经完成了更新操作的学习,让我们重头整理一下。
[](https://rawgit.com/Bogdan-Lyashenko/Under-the-hood-ReactJS/master/stack/images/14/updating-parts-C.svg)
14.5 更新 (点击查看大图)
================================================
FILE: TODO/Understanding-code-signing-for-iOS-apps.md
================================================
> * 原文地址:[Understanding code signing for iOS apps](https://engineering.nodesagency.com/articles/iOS/Understanding-code-signing-for-iOS-apps/)
* 原文作者:[MariusConstantinescu](https://twitter.com/marius_const)
* 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
* 译者: [Nicolas(Yifei) Li](https://github.com/yifili09)
* 校对者: [Tuccuay](https://github.com/Tuccuay), [fengzhihao123](https://github.com/fengzhihao123)
# 理解 `iOS` 应用程序的代码签名机制
如果你是一位 `iOS` 应用程序开发者,你有可能已经使用过代码签名了。如果你是一位初级的 `iOS` 应用程序开发者,你可能对开发者网站上那些有关 "Certificates,Identifiers & Profiles" 的部分感到不知所措。

本文的目的是帮助初级 `iOS` 应用程序开发者从宏观角度理解代码签名是什么。这不是一个如何按部就班地对你的应用程序进行代码签名的操作手册。理想化来说,在你阅读完这篇文章后,你能够对应用程序进行代码签名而不需要按照任何操作手册。
我不准备对底层细节进行讨论,但是我们将讨论一些非对称加密技术的内容。
### [](#Asymmetric-cryptography "Asymmetric cryptography")非对称加密技术
你至少要知道的是,非对称加密技术使用一个**公钥**和一个**私钥**。用户需要保留自己的私钥,但是他们能把公钥分享出去。并且使用这些公钥和私钥,用户就能证明那确实就是他自己。
[这里](https://blog.vrypan.net/2013/08/28/public-key-cryptography-for-non-geeks/) 有一篇浅显易懂地解释什么是非对称加密技术的文章。如果你想知道实现这个技术的细节或者背后用到了哪些数学算法原理,在网络上有很多这样的文章。
### [](#App-ID "App ID")App ID
`App ID` 是你应用程序的唯一识别符。它由苹果为你创建的 `team id (团队 id)`(你无法插手) 和你应用程序的 `bundle id (程序包 id)` (比如,`com.youcompany.yourapp`)组成。
也有通配符形式的 `App ID`: `com.yourcompany.*`。它们会匹配多个 `bundle id`。
总而言之,你的应用程序会有一个明确的 `App ID`,而不是一个通配符形式的。
### [](#Certificates "Certificates")Certificates / 证书
你可能已经注意到,为了在苹果开发者网站上创建一个证书 / certificate,你需要上传一个签名证书申请 (Certificate Signing Request)。你能通过 `Keychain` 创建这个 `CSR` 文件,并且这个 `CSR` 文件包含一个私钥。
之后在开发者网站上,你能使用这个 `CSR` 文件创建一个证书 (certificate)。
证书 (certificates) 的类型有很多种。最常见的是:
* 应用程序开发证书 (`iOS` 应用程序开发) - 你需要使用这些证书才能让 `XCode` 中的应用程序运行在设备上。
* 应用程序分发证书 (苹果应用市场和内部分发渠道) - 你需要使用这些证书,它能让你把应用程序提交到苹果应用市场或者内部分发渠道。
* `APNS` (Apple Push Notification Service / 苹果推送通知服务系统) - 你需要使用这些证书,它能让你推送内容到你的应用程序中。与应用程序的开发证书和分发证书不同,`APNS` 与 `APP ID` 有关。`APNS` 有两种证书,对于开发环境来说 - Apple Push Notification Service / 苹果推送通知服务 SSL (适用于沙盒环境),对生产环境来说 - Apple Push Notification Service / 苹果推送通知服务 `SSL` (适用于沙盒和生产环境)。如果你想让推送服务在调试和分发程序上都能使用,你需要创建这两个证书。
### [](#Devices "Devices")Devices / 设备
在你账户每年的会员期内,你能为每个产品添加最多 100 个设备。100 个 iPhone, 100 个 iPad, 100 个 iPod Touch, 100 个 Apple Watche 和 100 个 Apple TV。为了把设备添加到你的账户下,你需要添加该设备的唯一识别码。你能在 `Xcode` 中方便地找到它,或在 `iTunes` 中(可能会稍微麻烦点儿)。[这里](https://developer.apple.com/library/content/documentation/IDEs/Conceptual/AppDistributionGuide/MaintainingProfiles/MaintainingProfiles.html#//apple_ref/doc/uid/TP40012582-CH30-SW10) 有一份详细的指导手册教你如何添加设备到你的账户下。
### [](#Provisioning-profiles "Provisioning profiles")Provisioning profiles / 配置文件
配置文件将 `App ID`,开发者或者内部分发证书和一些设备联系起来。你在苹果开发者网站上创建这些配置文件,然后在 `Xcode` 内下载它们。
### [](#Usage "Usage")使用方法
在你创建了这些以后,回到 `Xcode` 页面,添加你的证书,更新你的配置文件,之后选择你想要的那个配置文件。从这些配置文件中,你能选择需要的签名身份(这取决于联系到它的证书)。
### [](#F-A-Q "F.A.Q.")常见问题解答
多年来在 `iOS` 开发的过程中,我问过也被很多人问过有关代码签名的问题。比如下面的这些。
* **问题**: 我已经从开发者网站上下载了配置文件和证书,但是我还是不能对应用程序签名。
**解答**: 是的,因为你没有私钥,就是那个在证书签名申请中使用的那个。可能是之前其他团队的成员创建了这些证书和配置文件。你能从原来的开发者那里获得这些私钥,重新激活这个证书并且创建一个新的 (和这个证书有联系的所有配置文件都会失效,但是不会对任何应用市场上使用这些证书的应用程序造成问题) 或者如果可能的话,创建一个全新的证书。(目前,每一个开发者账户最多申请 3 个应用程序分发证书。)
* **问题**: 那有关推送服务的证书呢?我想让应用程序能接收推送通知。难道我不应该使用 `APNS` 证书创建一个配置文件么?
**解答**: 不是这样的。当你创建一个 `APNS` (Apple Push Notification Service / 苹果推送通知服务) 证书的时候,你把 `APP ID` 联系到这个证书上。所以,首先要有 `CSR` 文件,之后通过这个 `CSR` 文件创建一个新的 `APNS`,下载后在 `Keychain` 中打开它,并以 `.p12` 文件格式导出,之后把这个文件上传到你的推送服务提供商处。这个 `.p12` 文件知道它是和那个应用程序联系的,并且它会只推送内容到这个应用程序。这也是为什么你不能把一个 `APNS` 证书联系到通配符形式的 `APP ID` (com.youcompany.*)。推送通知的服务器需要知道,它需要推送内容到哪个应用程序。
* **问题**: 我买了一个新的 `mac` 计算机,为了代码签名能正常工作,我应该从旧的 `mac` 计算机上 `keychain` 中导出什么到新的 `mac` 计算机中?
**解答**: 你可能想把所有 `keychain` 中的内容导出到新的 `mac` 计算机中。你可以通过 [这些步骤](https://support.apple.com/kb/PH20120?locale=en_US) 完成。但是如果你想导出一个证书,确保你也能导出这个私钥。在 `Keychain` 中,你应该可以通过点击证书旁边的三角选项展开它的内容,之后你就会看到这个私钥。这些证书都能以 `.p12` 文件格式导出。否则,他们会以 `.cer` 格式导出,没有私钥,这个文件是没用的。
* **问题**: 我的 `iOS` 应用程序分发证书过期了,我的应用程序还能继续工作么?
**解答**: 当你的证书过期了,使用这个证书的配置文件就会失效了。在应用程序市场(`App Store`)上,只要你的开发者账号还有效,这个应用程序还是能正常使用的。但是通过这个证书在内部渠道分发的应用程序就不能继续使用了。
* **问题**: 我的 `APNS` 证书过期了,现在会发生什么?
**解答**: 你不能再发送推送通知给应用程序。通过创建一个与 `App ID` 联系的 新的 `APNS` 证书,下载并导出这个 `.p12` 文件,之后把它上上传给你的推送通知服务提供商。并且不需要为此而更新应用程序。
### [](#Summary "Summary")总结
我想再次强调有关代码签名的是:
* 每一个应用程序都有一个 `App ID`
* 对所有使用中的证书,你都必须存有相关的**私钥**
* 一个**调试版本的配置文件**把 `APP ID`,调试设备和应用程序开发证书联系在一起。
* 一个**内部分发渠道的配置文件**把 `App ID`,调试设备和应用程序分发证书联系在一起。
* 一个**应用程序市场 (`App Store`)的配置文件**把 `App ID` 和你的应用程序分发证书联系在一起。
* 对于推送通知,创建一个 **APNS 证书**,它和 `App ID` 联系在一起,下载并以 `.p12` 文件格式导出,并上传这个文件到推送通知服务供应商处;如果你想要这个推送通知在调试和生产环境下都起作用,你不得不分别为开发调试和生产环境创建 2 个 `APNS` 证书。
通晓这些能帮助你更好的理解代码签名机制,并且最终省去了很多时间。

### [](#Further-reading "Further reading")延伸阅读
* [深入理解代码签名机制](https://www.objc.io/issues/17-security/inside-code-signing/)
* [官方指南 - 代码签名](https://developer.apple.com/support/code-signing/)
* [从入门到放弃 - `iOS` 代码签名和配置文件](https://medium.com/ios-os-x-development/ios-code-signing-provisioning-in-a-nutshell-d5b247760bef)
================================================
FILE: TODO/Unit-tests-with-Mockito.md
================================================
> * 原文链接 : [Unit tests with Mockito - Tutorial](http://www.vogella.com/tutorials/Mockito/article.html)
> * 原文作者 : [vogella](http://www.vogella.com/)
> * 译文出自 : [掘金翻译计划](https://github.com/xitu/gold-miner)
> * 译者 : [edvardhua](https://github.com/edvardHua/)
> * 校对者: [hackerkevin](https://github.com/hackerkevin), [futureshine](https://github.com/futureshine)
# 使用强大的 Mockito 测试框架来测试你的代码
>这篇教程介绍了如何使用 Mockito 框架来给软件写测试用例
## 1\. 预备知识
如果需要往下学习,你需要先理解 Junit 框架中的单元测试。
如果你不熟悉 JUnit,请查看下面的教程:
[http://www.vogella.com/tutorials/JUnit/article.html](http://www.vogella.com/tutorials/JUnit/article.html)
## 2\. 使用mock对象来进行测试
### 2.1\. 单元测试的目标和挑战
单元测试的思路是在不涉及依赖关系的情况下测试代码(隔离性),所以测试代码与其他类或者系统的关系应该尽量被消除。一个可行的消除方法是替换掉依赖类(测试替换),也就是说我们可以使用替身来替换掉真正的依赖对象。
### 2.2\. 测试类的分类
_dummy object_ 做为参数传递给方法但是绝对不会被使用。譬如说,这种测试类内部的方法不会被调用,或者是用来填充某个方法的参数。
_Fake_ 是真正接口或抽象类的实现体,但给对象内部实现很简单。譬如说,它存在内存中而不是真正的数据库中。(译者注:_Fake_ 实现了真正的逻辑,但它的存在只是为了测试,而不适合于用在产品中。)
_stub_ 类是依赖类的部分方法实现,而这些方法在你测试类和接口的时候会被用到,也就是说 _stub_ 类在测试中会被实例化。_stub_ 类会回应任何外部测试的调用。_stub_ 类有时候还会记录调用的一些信息。
_mock object_ 是指类或者接口的模拟实现,你可以自定义这个对象中某个方法的输出结果。
测试替代技术能够在测试中模拟测试类以外对象。因此你可以验证测试类是否响应正常。譬如说,你可以验证在 Mock 对象的某一个方法是否被调用。这可以确保隔离了外部依赖的干扰只测试测试类。
我们选择 Mock 对象的原因是因为 Mock 对象只需要少量代码的配置。
### 2.3\. Mock 对象的产生
你可以手动创建一个 Mock 对象或者使用 Mock 框架来模拟这些类,Mock 框架允许你在运行时创建 Mock 对象并且定义它的行为。
一个典型的例子是把 Mock 对象模拟成数据的提供者。在正式的生产环境中它会被实现用来连接数据源。但是我们在测试的时候 Mock 对象将会模拟成数据提供者来确保我们的测试环境始终是相同的。
Mock 对象可以被提供来进行测试。因此,我们测试的类应该避免任何外部数据的强依赖。
通过 Mock 对象或者 Mock 框架,我们可以测试代码中期望的行为。譬如说,验证只有某个存在 Mock 对象的方法是否被调用了。
### 2.4\. 使用 Mockito 生成 Mock 对象
_Mockito_ 是一个流行 mock 框架,可以和JUnit结合起来使用。Mockito 允许你创建和配置 mock 对象。使用Mockito可以明显的简化对外部依赖的测试类的开发。
一般使用 Mockito 需要执行下面三步
* 模拟并替换测试代码中外部依赖。
* 执行测试代码
* 验证测试代码是否被正确的执行

## 3\. 为自己的项目添加 Mockito 依赖
### 3.1\. 在 Gradle 添加 Mockito 依赖
如果你的项目使用 Gradle 构建,将下面代码加入 Gradle 的构建文件中为自己项目添加 Mockito 依赖
repositories { jcenter() }
dependencies { testCompile "org.mockito:mockito-core:2.0.57-beta" }
### 3.2\. 在 Maven 添加 Mockito 依赖
需要在 Maven 声明依赖,您可以在 [http://search.maven.org](http://search.maven.org) 网站中搜索 g:"org.mockito", a:"mockito-core" 来得到具体的声明方式。
### 3.3\. 在 Eclipse IDE 使用 Mockito
Eclipse IDE 支持 Gradle 和 Maven 两种构建工具,所以在 Eclipse IDE 添加依赖取决你使用的是哪一个构建工具。
### 3.4\. 以 OSGi 或者 Eclipse 插件形式添加 Mockito 依赖
在 Eclipse RCP 应用依赖通常可以在 p2 update 上得到。Orbit 是一个很好的第三方仓库,我们可以在里面寻找能在 Eclipse 上使用的应用和插件。
Orbit 仓库地址 [http://download.eclipse.org/tools/orbit/downloads](http://download.eclipse.org/tools/orbit/downloads)

## 4\. 使用Mockito API
### 4.1\. 静态引用
如果在代码中静态引用了`org.mockito.Mockito.*;`,那你你就可以直接调用静态方法和静态变量而不用创建对象,譬如直接调用 mock() 方法。
### 4.2\. 使用 Mockito 创建和配置 mock 对象
除了上面所说的使用 mock() 静态方法外,Mockito 还支持通过 `@Mock` 注解的方式来创建 mock 对象。
如果你使用注解,那么必须要实例化 mock 对象。Mockito 在遇到使用注解的字段的时候,会调用`MockitoAnnotations.initMocks(this)` 来初始化该 mock 对象。另外也可以通过使用`@RunWith(MockitoJUnitRunner.class)`来达到相同的效果。
通过下面的例子我们可以了解到使用`@Mock` 的方法和`MockitoRule`规则。
import static org.mockito.Mockito.*;
public class MockitoTest {
@Mock
MyDatabase databaseMock; (1)
@Rule public MockitoRule mockitoRule = MockitoJUnit.rule(); (2)
@Test
public void testQuery() {
ClassToTest t = new ClassToTest(databaseMock); (3)
boolean check = t.query("* from t"); (4)
assertTrue(check); (5)
verify(databaseMock).query("* from t"); (6)
}
}
1. 告诉 Mockito 模拟 databaseMock 实例
2. Mockito 通过 @mock 注解创建 mock 对象
3. 使用已经创建的mock初始化这个类
4. 在测试环境下,执行测试类中的代码
5. 使用断言确保调用的方法返回值为 true
6. 验证 query 方法是否被 `MyDatabase` 的 mock 对象调用
### 4.3\. 配置 mock
当我们需要配置某个方法的返回值的时候,Mockito 提供了链式的 API 供我们方便的调用
`when(….).thenReturn(….)`可以被用来定义当条件满足时函数的返回值,如果你需要定义多个返回值,可以多次定义。当你多次调用函数的时候,Mockito 会根据你定义的先后顺序来返回返回值。Mocks 还可以根据传入参数的不同来定义不同的返回值。譬如说你的函数可以将`anyString` 或者 `anyInt`作为输入参数,然后定义其特定的放回值。
import static org.mockito.Mockito.*;
import static org.junit.Assert.*;
@Test
public void test1() {
// 创建 mock
MyClass test = Mockito.mock(MyClass.class);
// 自定义 getUniqueId() 的返回值
when(test.getUniqueId()).thenReturn(43);
// 在测试中使用mock对象
assertEquals(test.getUniqueId(), 43);
}
// 返回多个值
@Test
public void testMoreThanOneReturnValue() {
Iterator i= mock(Iterator.class);
when(i.next()).thenReturn("Mockito").thenReturn("rocks");
String result=i.next()+" "+i.next();
// 断言
assertEquals("Mockito rocks", result);
}
// 如何根据输入来返回值
@Test
public void testReturnValueDependentOnMethodParameter() {
Comparable c= mock(Comparable.class);
when(c.compareTo("Mockito")).thenReturn(1);
when(c.compareTo("Eclipse")).thenReturn(2);
// 断言
assertEquals(1,c.compareTo("Mockito"));
}
// 如何让返回值不依赖于输入
@Test
public void testReturnValueInDependentOnMethodParameter() {
Comparable c= mock(Comparable.class);
when(c.compareTo(anyInt())).thenReturn(-1);
// 断言
assertEquals(-1 ,c.compareTo(9));
}
// 根据参数类型来返回值
@Test
public void testReturnValueInDependentOnMethodParameter() {
Comparable c= mock(Comparable.class);
when(c.compareTo(isA(Todo.class))).thenReturn(0);
// 断言
Todo todo = new Todo(5);
assertEquals(todo ,c.compareTo(new Todo(1)));
}
对于无返回值的函数,我们可以使用`doReturn(…).when(…).methodCall`来获得类似的效果。例如我们想在调用某些无返回值函数的时候抛出异常,那么可以使用`doThrow` 方法。如下面代码片段所示
import static org.mockito.Mockito.*;
import static org.junit.Assert.*;
// 下面测试用例描述了如何使用doThrow()方法
@Test(expected=IOException.class)
public void testForIOException() {
// 创建并配置 mock 对象
OutputStream mockStream = mock(OutputStream.class);
doThrow(new IOException()).when(mockStream).close();
// 使用 mock
OutputStreamWriter streamWriter= new OutputStreamWriter(mockStream);
streamWriter.close();
}
### 4.4\. 验证 mock 对象方法是否被调用
Mockito 会跟踪 mock 对象里面所有的方法和变量。所以我们可以用来验证函数在传入特定参数的时候是否被调用。这种方式的测试称行为测试,行为测试并不会检查函数的返回值,而是检查在传入正确参数时候函数是否被调用。
import static org.mockito.Mockito.*;
@Test
public void testVerify() {
// 创建并配置 mock 对象
MyClass test = Mockito.mock(MyClass.class);
when(test.getUniqueId()).thenReturn(43);
// 调用mock对象里面的方法并传入参数为12
test.testing(12);
test.getUniqueId();
test.getUniqueId();
// 查看在传入参数为12的时候方法是否被调用
verify(test).testing(Matchers.eq(12));
// 方法是否被调用两次
verify(test, times(2)).getUniqueId();
// 其他用来验证函数是否被调用的方法
verify(mock, never()).someMethod("never called");
verify(mock, atLeastOnce()).someMethod("called at least once");
verify(mock, atLeast(2)).someMethod("called at least twice");
verify(mock, times(5)).someMethod("called five times");
verify(mock, atMost(3)).someMethod("called at most 3 times");
}
### 4.5\. 使用 Spy 封装 java 对象
@Spy或者`spy()`方法可以被用来封装 java 对象。被封装后,除非特殊声明(打桩 _stub_),否则都会真正的调用对象里面的每一个方法
import static org.mockito.Mockito.*;
// Lets mock a LinkedList
List list = new LinkedList();
List spy = spy(list);
// 可用 doReturn() 来打桩
doReturn("foo").when(spy).get(0);
// 下面代码不生效
// 真正的方法会被调用
// 将会抛出 IndexOutOfBoundsException 的异常,因为 List 为空
when(spy.get(0)).thenReturn("foo");
方法`verifyNoMoreInteractions()`允许你检查没有其他的方法被调用了。
### 4.6\. 使用 @InjectMocks 在 Mockito 中进行依赖注入
我们也可以使用`@InjectMocks` 注解来创建对象,它会根据类型来注入对象里面的成员方法和变量。假定我们有 ArticleManager 类
public class ArticleManager {
private User user;
private ArticleDatabase database;
ArticleManager(User user) {
this.user = user;
}
void setDatabase(ArticleDatabase database) { }
}
这个类会被 Mockito 构造,而类的成员方法和变量都会被 mock 对象所代替,正如下面的代码片段所示:
@RunWith(MockitoJUnitRunner.class)
public class ArticleManagerTest {
@Mock ArticleCalculator calculator;
@Mock ArticleDatabase database;
@Most User user;
@Spy private UserProvider userProvider = new ConsumerUserProvider();
@InjectMocks private ArticleManager manager; (1)
@Test public void shouldDoSomething() {
// 假定 ArticleManager 有一个叫 initialize() 的方法被调用了
// 使用 ArticleListener 来调用 addListener 方法
manager.initialize();
// 验证 addListener 方法被调用
verify(database).addListener(any(ArticleListener.class));
}
}
1. 创建ArticleManager实例并注入Mock对象
更多的详情可以查看
[http://docs.mockito.googlecode.com/hg/1.9.5/org/mockito/InjectMocks.html](http://docs.mockito.googlecode.com/hg/1.9.5/org/mockito/InjectMocks.html).
### 4.7\. 捕捉参数
`ArgumentCaptor`类允许我们在verification期间访问方法的参数。得到方法的参数后我们可以使用它进行测试。
```
import static org.hamcrest.Matchers.hasItem;
import static org.junit.Assert.assertThat;
import static org.mockito.Mockito.mock;
import static org.mockito.Mockito.verify;
import java.util.Arrays;
import java.util.List;
import org.junit.Rule;
import org.junit.Test;
import org.mockito.ArgumentCaptor;
import org.mockito.Captor;
import org.mockito.junit.MockitoJUnit;
import org.mockito.junit.MockitoRule;
public class MockitoTests {
@Rule
public MockitoRule rule = MockitoJUnit.rule();
@Captor
private ArgumentCaptor
> captor;
@Test
public final void shouldContainCertainListItem() {
List asList = Arrays.asList("someElement_test", "someElement");
final List mockedList = mock(List.class);
mockedList.addAll(asList);
verify(mockedList).addAll(captor.capture());
final List capturedArgument = captor.getValue();
assertThat(capturedArgument, hasItem("someElement"));
}
}
```
### 4.8\. Mockito的限制
Mockito当然也有一定的限制。而下面三种数据类型则不能够被测试
* final classes
* anonymous classes
* primitive types
## 5\. 在Android中使用Mockito
在 Android 中的 Gradle 构建文件中加入 Mockito 依赖后就可以直接使用 Mockito 了。若想使用 Android Instrumented tests 的话,还需要添加 dexmaker 和 dexmaker-mockito 依赖到 Gradle 的构建文件中。(需要 Mockito 1.9.5版本以上)
dependencies {
testCompile 'junit:junit:4.12'
// Mockito unit test 的依赖
testCompile 'org.mockito:mockito-core:1.+'
// Mockito Android instrumentation tests 的依赖
androidTestCompile 'org.mockito:mockito-core:1.+'
androidTestCompile "com.google.dexmaker:dexmaker:1.2"
androidTestCompile "com.google.dexmaker:dexmaker-mockito:1.2"
}
## 6\. 实例:使用Mockito写一个Instrumented Unit Test
### 6.1\. 创建一个测试的Android 应用
创建一个包名为`com.vogella.android.testing.mockito.contextmock`的Android应用,添加一个静态方法
,方法里面创建一个包含参数的Intent,如下代码所示:
public static Intent createQuery(Context context, String query, String value) {
// 简单起见,重用MainActivity
Intent i = new Intent(context, MainActivity.class);
i.putExtra("QUERY", query);
i.putExtra("VALUE", value);
return i;
}
### 6.2\. 在app/build.gradle文件中添加Mockito依赖
dependencies {
// Mockito 和 JUnit 的依赖
// instrumentation unit tests on the JVM
androidTestCompile 'junit:junit:4.12'
androidTestCompile 'org.mockito:mockito-core:2.0.57-beta'
androidTestCompile 'com.android.support.test:runner:0.3'
androidTestCompile "com.google.dexmaker:dexmaker:1.2"
androidTestCompile "com.google.dexmaker:dexmaker-mockito:1.2"
// Mockito 和 JUnit 的依赖
// tests on the JVM
testCompile 'junit:junit:4.12'
testCompile 'org.mockito:mockito-core:1.+'
}
### 6.3\. 创建测试
使用 Mockito 创建一个单元测试来验证在传递正确 extra data 的情况下,intent 是否被触发。
因此我们需要使用 Mockito 来 mock 一个`Context`对象,如下代码所示:
package com.vogella.android.testing.mockitocontextmock;
import android.content.Context;
import android.content.Intent;
import android.os.Bundle;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.mockito.Mockito;
import static org.junit.Assert.assertEquals;
import static org.junit.Assert.assertNotNull;
public class TextIntentCreation {
@Test
public void testIntentShouldBeCreated() {
Context context = Mockito.mock(Context.class);
Intent intent = MainActivity.createQuery(context, "query", "value");
assertNotNull(intent);
Bundle extras = intent.getExtras();
assertNotNull(extras);
assertEquals("query", extras.getString("QUERY"));
assertEquals("value", extras.getString("VALUE"));
}
}
## 7\. 实例:使用 Mockito 创建一个 mock 对象
### 7.1\. 目标
创建一个 Api,它可以被 Mockito 来模拟并做一些工作
### 7.2\. 创建一个Twitter API 的例子
实现 `TwitterClient`类,它内部使用到了 `ITweet` 的实现。但是`ITweet`实例很难得到,譬如说他需要启动一个很复杂的服务来得到。
public interface ITweet {
String getMessage();
}
public class TwitterClient {
public void sendTweet(ITweet tweet) {
String message = tweet.getMessage();
// send the message to Twitter
}
}
### 7.3\. 模拟 ITweet 的实例
为了能够不启动复杂的服务来得到 `ITweet`,我们可以使用 Mockito 来模拟得到该实例。
@Test
public void testSendingTweet() {
TwitterClient twitterClient = new TwitterClient();
ITweet iTweet = mock(ITweet.class);
when(iTweet.getMessage()).thenReturn("Using mockito is great");
twitterClient.sendTweet(iTweet);
}
现在 `TwitterClient` 可以使用 `ITweet` 接口的实现,当调用 `getMessage()` 方法的时候将会打印 "Using Mockito is great" 信息。
### 7.4\. 验证方法调用
确保 getMessage() 方法至少调用一次。
@Test
public void testSendingTweet() {
TwitterClient twitterClient = new TwitterClient();
ITweet iTweet = mock(ITweet.class);
when(iTweet.getMessage()).thenReturn("Using mockito is great");
twitterClient.sendTweet(iTweet);
verify(iTweet, atLeastOnce()).getMessage();
}
### 7.5\. 验证
运行测试,查看代码是否测试通过。
## 8\. 模拟静态方法
### 8.1\. 使用 Powermock 来模拟静态方法
因为 Mockito 不能够 mock 静态方法,因此我们可以使用 `Powermock`。
import java.net.InetAddress;
import java.net.UnknownHostException;
public final class NetworkReader {
public static String getLocalHostname() {
String hostname = "";
try {
InetAddress addr = InetAddress.getLocalHost();
// Get hostname
hostname = addr.getHostName();
} catch ( UnknownHostException e ) {
}
return hostname;
}
}
我们模拟了 NetworkReader 的依赖,如下代码所示:
import org.junit.runner.RunWith;
import org.powermock.core.classloader.annotations.PrepareForTest;
@RunWith( PowerMockRunner.class )
@PrepareForTest( NetworkReader.class )
public class MyTest {
// 测试代码
@Test
public void testSomething() {
mockStatic( NetworkUtil.class );
when( NetworkReader.getLocalHostname() ).andReturn( "localhost" );
// 与 NetworkReader 协作的测试
}
### 8.2\.用封装的方法代替Powermock
有时候我们可以在静态方法周围包含非静态的方法来达到和 Powermock 同样的效果。
class FooWraper {
void someMethod() {
Foo.someStaticMethod()
}
}
### 9\. Mockito 参考资料
http://site.mockito.org - Mockito 官网
https://github.com/mockito/mockito- Mockito Github
https://github.com/mockito/mockito/blob/master/doc/release-notes/official.md - Mockito 发行说明
http://martinfowler.com/articles/mocksArentStubs.html 与Mocks,Stub有关的文章
http://chiuki.github.io/advanced-android-espresso/ 高级android教程(竟然是个妹子)
================================================
FILE: TODO/Using-Flutter-in-China.md
================================================
> * 原文地址:[Using Flutter in China](https://github.com/flutter/flutter/wiki/Using-Flutter-in-China)
> * 原文作者:[Flutter](https://github.com/flutter)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/Using-Flutter-in-China.md](https://github.com/xitu/gold-miner/blob/master/TODO/Using-Flutter-in-China.md)
> * 译者:[mysterytony](https://github.com/mysterytony)
> * 校对者:[hanliuxin5](https://github.com/hanliuxin5), [Starriers](https://github.com/Starriers)
# 在中国使用 Flutter
如果你在中国安装或使用 Flutter ,可以用一个可信的本地镜像来托管 Flutter 的依赖关系。为了让 Flutter 能使用一个备用的在线访问地址,你需要在运行 `flutter` 指令之前设置两个环境变量:`PUB_HOSTED_URL` 和 `FLUTTER_STORAGE_BASE_URL`。
比如说,在 MacOS 或 Linux 上,为了让你能使用镜像站点,下面是首先需要进行的一系列设置步骤。在你想要存储克隆下来的 Flutter 文件夹下运行下面的 Bash 命令:
```source-shell
export PUB_HOSTED_URL=https://pub.flutter-io.cn
export FLUTTER_STORAGE_BASE_URL=https://storage.flutter-io.cn
git clone -b dev https://github.com/flutter/flutter.git
export PATH="$PWD/flutter/bin:$PATH"
cd ./flutter
flutter doctor
```
然后,你就应该可以继续正常地 [配置 Flutter](https://flutter.io/setup/)。从现在开始,在有 `PUB_HOSTED_URL` 和 `FLUTTER_STORAGE_BASE_URL` 环境变量的控制台用 `flutter packages get` 下载的包将会从 `flutter-io.cn` 下载。
`flutter-io.cn` 服务器是 Flutter 一个由 [GDG China](http://www.chinagdg.com/) 维护的依赖和包的临时镜像。Flutter 团队不能保证这个服务的长期可用性。你可以自由使用其他可用的镜像。如果你对在中国建立你自己的镜像感兴趣,请联系 [flutter-dev@googlegroups.com](mailto:flutter-dev@googlegroups.com) 以获得协助。
已知问题:
* 从源码运行 Flutter Gallery 程序需要的资源目前托管在这个解决方案暂不支持的域名。你可以订阅 [这个问题](https://github.com/flutter/flutter/issues/13763) 的更新。同时,你也可以在 Google Play 或者你信任的第三方商店看看 Flutter Gallery。
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
================================================
FILE: TODO/What-would-be-your-advice-to-a-software-engineer-who-wants-to-learn-machine-learning.md
================================================
> * 原文地址:[What would be your advice to a software engineer who wants to learn machine learning?](https://www.quora.com/What-would-be-your-advice-to-a-software-engineer-who-wants-to-learn-machine-learning-3/answer/Alex-Smola-1)
> * 原文作者:[Alex Smola](https://www.quora.com/profile/Alex-Smola-1)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/What-would-be-your-advice-to-a-software-engineer-who-wants-to-learn-machine-learning.md](https://github.com/xitu/gold-miner/blob/master/TODO/What-would-be-your-advice-to-a-software-engineer-who-wants-to-learn-machine-learning.md)
> * 译者:[lsvih](https://github.com/lsvih)
> * 校对者:[吃土小2叉](https://github.com/xunge0613),[Tina92](https://github.com/Tina92)
# 你会给想学习机器学习的软件工程师提出什么建议?
这很大一部分都取决于这名软件工程师的背景,以及他希望掌握机器学习的哪一部分。为了具体讨论,现在假设这是一名初级工程师,他读了 4 年本科,从业 2 年,现在想从事计算广告学(CA)、自然语言处理(NLP)、图像分析、社交网络分析、搜索、推荐排名相关领域。现在,让我们从机器学习的必要课程开始讨论(声明:下面的清单很不完整,如果您的论文没有被包括在内,提前向您抱歉)。
- 线性代数
很多的机器学习算法、统计学原理、模型优化都依赖线性代数。这也解释了为何在深度学习领域 GPU 要优于 CPU。在线性代数方面,你至少得熟练掌握以下内容:
- 标量、向量、矩阵、张量。你可以将它们看成零维、一维、二维、三维与更高维的对象,可以对它们进行各种组合、变换,就像乐高玩具一样。它们为数据变换提供了最基础的处理方法。
- 特征向量、标准化、矩阵近似、分解。实质上这些方法都是为了方便线性代数的运算。如果你想分析一个矩阵是如何运算的(例如检查神经网络中梯度消失问题,或者检查强化学习算法发散的问题),你得了解矩阵与向量应用了多少种缩放方法。而低阶矩阵近似与 Cholesky 分解可以帮你写出性能更好、稳定性更强的代码。
- 数值线性代数
如果你想进一步优化算法的话,这是必修课。它对于理解核方法与深度学习很有帮助,不过对于图模型及采样来说它并不重要。
- 推荐书籍
[《Serge Lang, Linear Algebra》](http://www.amazon.com/Linear-Algebra-Undergraduate-Texts-Mathematics/dp/0387964126)
很基础的线代书籍,很适合在校学生。
[《Bela Bolobas, Linear Analysis》](http://www.amazon.com/Linear-Analysis-Introductory-Cambridge-Mathematical/dp/0521655773)
这本书目标人群是那些想做数学分析、泛函分析的人。当然它的内容更加晦涩难懂,但更有意义。如果你攻读 PhD,值得一读。
[《Lloyd Trefethen and David Bau, Numerical Linear Algebra》](http://www.amazon.com/Numerical-Linear-Algebra-Lloyd-Trefethen/dp/0898713617)
这本书是同类书籍中较为推荐的一本。[《Numerical Recipes》](http://www.amazon.com/Numerical-Recipes-Scientific-Computing-Second/dp/0521431085/)也是一本不错的书,但是里面的算法略为过时了。另外,推荐 Golub 和 van Loan 合著的书[《Matrix Computations》](http://www.amazon.com/Computations-Hopkins-Studies-Mathematical-Sciences/dp/1421407949/)。
- 优化与基础运算
大多数时候提出问题是很简单的,而解答问题则是很困难的。例如,你想对一组数据使用线性回归(即线性拟合),那么你应该希望数据点与拟合线的距离平方和最小;又或者,你想做一个良好的点击预测模型,那么你应该希望最大程度地提高用户点击广告概率估计的准确性。也就是说,在一般情况下,我们会得到一个客观问题、一些参数、一堆数据,我们要做的就是找到通过它们解决问题的方法。找到这种方法是很重要的,因为我们一般得不到闭式解。
- 凸优化
在大多情况下,优化问题不会存在太多的局部最优解,因此这类问题会比较好解决。这种“局部最优即全局最优”的问题就是凸优化问题。
(如果你在集合的任意两点间画一条直线,整条线始终在集合范围内,则这个集合是一个凸集合;如果你在一条函数曲线的任意两点间画一条直线,这两点间的函数曲线始终在这条直线之下,则这个函数是一个凸函数)
Steven Boyd 与 Lieven Vandenberghe [合著的书](http://stanford.edu/~boyd/cvxbook/)可以说是这个领域的规范书籍了,这本书非常棒,而且是免费的,值得一读;此外,你可以在 [Boyd 的课程](http://web.stanford.edu/~boyd/)中找到很多很棒的幻灯片;[Dimitri Bertsekas](http://www.mit.edu/~dimitrib/home.html) 写了一系列关于优化、控制方面的书籍。读通这些书足以让任何一个人在这个领域立足。
- 随机梯度下降(SGD)
大多数问题其实最开始都是凸优化问题的特殊情况(至少早期定理如此),但是随着数据的增加,凸优化问题的占比会逐渐减少。因此,假设你现在得到了一些数据,你的算法将会需要在每一个更新步骤前将所有的数据都检查一遍。
现在,我不怀好意地给了你 10 份相同的数据,你将不得不重复 10 次没有任何帮助的工作。不过在现实中并不会这么糟糕,你可以设置很小的更新迭代步长,每次更新前都将所有的数据检查一遍,这种方法将会帮你解决这类问题。小步长计算在机器学习中已经有了很大的转型,配合上一些相关的算法会使得解决问题更加地简单。
不过,这样的做法对并行化计算提出了挑战。我们于 2009 年发表的[《Slow Learners are Fast》](http://arxiv.org/abs/0911.0491)论文可能就是这个方向的先导者之一。2013 年牛峰等人发表的[《Hogwild》](https://www.eecs.berkeley.edu/~brecht/papers/hogwildTR.pdf)论文给出了一种相当优雅的无锁版本变体。简而言之,这类各种各样的算法都是通过在单机计算局部梯度,并异步更新共有的参数集实现并行快速迭代运算。
随机梯度下降的另一个难题就是如何控制过拟合(例如可以通过正则化加以控制)。另外还有一种解决凸优化的惩罚方式叫近端梯度算法(PGD)。最流行的当属 Amir Beck 和 Marc Teboulle 提出的 [FISTA 算法](http://people.rennes.inria.fr/Cedric.Herzet/Cedric.Herzet/Sparse_Seminar/Entrees/2012/11/12_A_Fast_Iterative_Shrinkage-Thresholding_Algorithmfor_Linear_Inverse_Problems_(A._Beck,_M._Teboulle)_files/Breck_2009.pdf)了。相关代码可以参考 Francis Bach 的 [SPAM toolbox](http://spams-devel.gforge.inria.fr/)。
- 非凸优化方法
许多的机器学习问题是非凸的。尤其是与深度学习相关的问题几乎都是非凸的,聚类、主题模型(topic model)、潜变量方法(latent variable method)等各种有趣的机器学习方法也是如此。一些最新的加速技术将对此有所帮助。例如我的学生 [Sashank Reddy](http://www.cs.cmu.edu/~sjakkamr/) 最近展示了如何在这种情况下得到良好的[收敛](http://arxiv.org/abs/1603.06160)[速率](http://arxiv.org/abs/1603.06159)。
也可以用一种叫做谱学习算法(Spectral Method)的技术。[Anima Anandkumar](http://newport.eecs.uci.edu/anandkumar/) 在最近的 [Quora session](/profile/Anima-Anandkumar-1) 中详细地描述了这项技术的细节。请仔细阅读她的文章,因为里面干货满满。简而言之,凸优化问题并不是唯一能够可靠解决的问题。在某些情况中你可以试着找出其问题的数学等价形式,通过这样找到能够真正反映数据中聚类、主题、相关维度、神经元等一切信息的参数。如果你愿意且能够将一切托付给数学解决,那是一件无比伟大的事。
最近,在深度神经网络训练方面涌现出了各种各样的新技巧。我将会在下面介绍它们,但是在一些情况中,我们的目标不仅仅是优化模型,而是找到一种特定的解决方案(就好像旅途的重点其实是过程一样)。
- (分布式)系统
机器学习之所以现在成为了人类、测量学、传感器及数据相关领域几乎是最常用的工具,和过去 10 年规模化算法的发展密不可分。[Jeff Dean](http://research.google.com/pubs/jeff.html) 过去的一年发了 6 篇机器学习教程并不是巧合。在此简单介绍一下他:[点击查看](http://www.informatika.bg/jeffdean),他是 MapReduce、GFS 及 BigTable 等技术背后的创造者,正是这些技术让 Google 成为了伟大的公司。
言归正传,(分布式)系统研究为我们提供了分布式、异步、容错、规模化、简单(Simplicity)的宝贵工具。最后一条“简单”是机器学习研究者们常常忽视的一件事。简单(Simplicity)不是 bug,而是一种特征。下面这些技术会让你受益良多:
- 分布式哈希表
它是 [memcached](https://memcached.org/)、[dynamo](http://www.allthingsdistributed.com/files/amazon-dynamo-sosp2007.pdf)、[pastry](http://research.microsoft.com/en-us/um/people/antr/PAST/pastry.pdf) 以及 [ceph](http://docs.ceph.com/docs/hammer/rados/) 等的技术基础。它们所解决的都是同一件事情 —— 如何将对象分发到多台机器上,从而避免向中央存储区提出请求。为了达到这个目的,你必须将数据位置进行随机但确定的编码(即哈希)。另外,你需要考虑到当有机器出现故障时的处理方式。
我们自己的参数服务器就是使用这种[数据布局](https://www.cs.cmu.edu/~dga/papers/osdi14-paper-li_mu.pdf)。这个项目的幕后大脑是我的学生 [Mu Li](http://www.cs.cmu.edu/~muli/) 。请参阅 [DMLC](http://dmlc.ml/) 查看相关的工具集。
- 一致性与通信
这一切的基础都是 Leslie Lamport 的 [PAXOS](http://research.microsoft.com/en-us/um/people/lamport/pubs/paxos-simple.pdf) 协议。它解决了不同机器(甚至部分机器不可用)的一致性问题。如果你曾经使用过版本控制工具,你应该可以直观地明白它是如何运行的——比如你有很多机器(或者很多开发者)都在进行数据更新(或更新代码),在它们(他们)不随时进行交流的情况下,你会如何将它们(他们)结合起来(不靠反复地求 diff)?
在(分布式)系统中,解决方案是一个叫做向量时钟的东西(请参考 Google 的 [Chubby](http://blogoscoped.com/archive/2008-07-24-n69.html))。我们也在参数服务器上使用了这种向量时钟的变体,这个变体与本体的区别就是我们仅使用向量时钟来限制参数的范围(Mu Li 做的),这样可以确保内存不会被无限增长的向量时钟时间戳给撑爆,正如文件系统不需要给每个字节都打上时间戳。
- 容错机制、规模化与云
学习这些内容最简单的方法就是在云服务器上运行各种算法,至于云服务可以找 [Amazon AWS](http://aws.amazon.com)、[Google GWC](http://console.google.com)、[Microsoft Azure](http://azure.microsoft.com) 或者 [其它各种各样的服务商](http://serverbear.com/)。一次性启动 1,000 台服务器,意识到自己坐拥如此之大的合法“僵尸网络”是多么的让人兴奋!之前我在 Google 工作,曾在欧洲某处接手 5,000 余台高端主机作为主题模型计算终端,它们是我们通过能源法案获益的核电厂相当可观的一部分资源。我的经理把我带到一旁,偷偷告诉我这个实验是多么的昂贵……
可能入门这块最简单的方法就是去了解 [docker](http://www.docker.com) 了吧。现在 docker 团队已经开发了大量的规模化工具。特别是他们最近加上的 [Docker Machine](https://docs.docker.com/machine/) 和 [Docker Cloud](https://docs.docker.com/cloud/),可以让你就像使用打印机驱动一样连接云服务。
- 硬件
说道硬件可能会让人迷惑,但是如果你了解你的算法会在什么硬件上运行,对优化算法是很有帮助的。这可以让你知道你的算法是否能在任何条件下保持巅峰性能。我认为每个入门者都应该看看 Jeff Dean 的 [《每个工程师都需要记住的数值》](https://gist.github.com/jboner/2841832)。我在面试时最喜欢的问题(至少现在最喜欢)就是“请问你的笔记本电脑有多快”。了解是什么限制了算法的性能是很有用的:是缓存?是内存带宽?延迟?还是磁盘?或者别的什么?[Anandtech](http://www.anandtech.com) 在微处理器架构与相关方面写了很多很好的文章与评论,在 Intel、ARM、AMD 发布新硬件的时候不妨去看一看他的评论。
- 统计学
我故意把这块内容放在文章的末尾,因为几乎所有人都认为它是(它的确是)机器学习的关键因而忽视了其它内容。统计学可以帮你问出好的问题,也能帮你理解你的建模与实际数据有多接近。
大多数图模型、核方法、深度学习等都能从“问一个好的问题”得到改进,或者说能够定义一个合理的可优化的目标函数。
- 统计学相关资料
[Larry Wasserman](http://www.stat.cmu.edu/~larry/) 的书[《All of Statistics》](http://www.stat.cmu.edu/~larry/all-of-statistics/)很好地介绍了统计学。或者你也可以看看 David McKay 的 [《Machine Learning》](http://www.inference.phy.cam.ac.uk/itprnn/book.pdf)一书,它是免费的,内容丰富而全面。此外还有很多好书值得一看,例如 [Kevin Murphy](https://mitpress.mit.edu/books/machine-learning-0) 的、[Chris Bishop](http://research.microsoft.com/en-us/um/people/cmbishop/prml/) 的、以及 [Trevor Hastie、Rob Tibshirani 与 Jerome Friedman](http://statweb.stanford.edu/~tibs/ElemStatLearn/) 合著的书。还有,Bernhard Scholkopf 和我也[写了一本](https://mitpress.mit.edu/books/learning-kernels)。
- 随机算法与概率计算
统计学算法本质上也是个计算机科学方面的问题。但是统计学的算法与计算机科学的最大区别在于,统计学是将计算机作为一个工具来设计算法,而不是作为一个黑箱进行调参。我很喜欢[这本 Michael Mitzenmacher 与 Eli Upfal 合著的书](http://www.amazon.com/Probability-Computing-Randomized-Algorithms-Probabilistic/dp/0521835402),它涵盖了很多方面的问题,并且很容易读懂。另外如果你想更深入地了解这个“工具”,请阅读[这本 Rajeev Motwani 和 Prabhakar Raghavan 合著的书籍](http://www.amazon.com/Randomized-Algorithms-Rajeev-Motwani/dp/0521474655)。这本书写的很棒,但是没有统计学背景很难理解它。
这篇文章已经写的够久了,不知道有没有人能读到这里,我要去休息啦。现在网上有很多很棒的视频内容可以帮助你学习,许多教师现在都开通了他们的 Youtube 频道,上传他们的上课内容。这些课程有时可以帮你解决一些复杂的问题。这儿是[我的 Youtube 频道](https://www.youtube.com/user/smolix/playlists)欢迎订阅。顺便推荐 [Nando de Freitas 的 Youtube 频道](https://www.youtube.com/user/ProfNandoDF),他比我讲得好多了。
最后推荐一个非常好用的工具:[DMLC](http://www.dmlc.ml)。它很适合入门,包含了大量的分布式、规模化的机器学习算法,还包括了通过 MXNET 实现的神经网络。
虽然本文还有很多方面没有提到(例如编程语言、数据来源等),但是这篇文章已经太长了,这些内容请参考其他文章吧~
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)。
================================================
FILE: TODO/Yarn-A-new-package-manager-for-JavaScript.md
================================================
>* 原文链接 : [Yarn: A new package manager for JavaScript](https://code.facebook.com/posts/1840075619545360)
* 原文作者 : [SEBASTIAN MCKENZIE](https://www.facebook.com/sebmck),[CHRISTOPH POJER](https://www.facebook.com/cpojer),[JAMES KYLE](https://www.facebook.com/thejameskyle)
* 译文出自 : [掘金翻译计划](https://github.com/xitu/gold-miner)
* 译者 : [达仔](https://github.com/Zhangjd)
* 校对者: [根号三](https://github.com/sqrthree)
在 JavaScript 社区中,工程师们互相分享成千上万的代码,帮助我们节省大量编写基础组件、类库或框架的时间。每个代码包可能都依赖于其他代码,而代码间的依赖关系则由包管理器负责维护。目前最流行的 JavaScript 包管理器是 `npm` 客户端,在 `npm` 仓库中提供了多达 30 万的软件包。据统计,已有超过 500 万的工程师使用 `npm` 仓库,其软件包下载量达到了 50 亿次/月。
在 Facebook 中,我们多年来一直在使用 `npm` 客户端并取得了成功,但随着代码仓库与团队人数的增长,我们在一致性、安全性以及性能方面遇到了挑战。在尝试解决每个方面的问题后,我们最终决定着手打造一套新的客户端解决方案,以帮助我们更可靠地管理依赖。我们把这个客户端工具称为 `Yarn` —— 更加快速、可靠、安全的 `npm` 客户端的替代品。
我们在此荣幸地宣布,我们与 Exponent、 Google 和 Tilde 进行了合作,并开源 `Yarn` 项目。工程师在使用 `Yarn` 时,依然可以访问 `npm` 仓库,但 `Yarn` 能够更快速地安装软件包和管理依赖关系,并且可以在跨机器或者无网络的安全环境中保持代码的一致性。`Yarn` 提高了开发效率,并解决了共享代码时面临的一些问题,使得工程师们可以专注在构建新产品以及新特性上。
## JavaScript 包管理方式在 Facebook 的演变
在包管理工具出现之前,JavaScript 工程师们通常依赖的项目并不多,因此会把依赖直接存储在工程目录或上传到 CDN 上。在 Node.js 出现后不久,第一个主流的 JavaScript 包管理工具 `npm` 被引入进来,并很快成为了最受欢迎的包管理工具之一。从此,新的开源项目不断涌现,工程师们比起以前更加乐于分享代码了。
在 Facebook 中,我们有很多项目都要依赖 `npm` 仓库上的代码,比如 React。但随着内部规模的扩大,我们面临着以下挑战:在跨平台与跨用户之间安装依赖时的代码一致性问题、在安装依赖时花费太长时间、以及 `npm` 客户端自动执行某些依赖库的代码所导致的安全性问题。我们尝试过寻找这些问题的解决方案,但在这个过程中通常又会引起一些新的问题。
### 尝试修改 npm 客户端
在开始阶段,我们遵循了最佳实践,在代码仓库中只跟踪了 `package.json` 文件的变化,并要求工程师手动运行 `npm install` 命令安装依赖。这种模式在开发人员的电脑上没有问题,但在持续集成环境中遇到了困难,因为出于安全与可靠性的考虑,持续集成环境需要进行沙箱隔离,不能进行联网,因此也无法安装依赖。
接下来,我们尝试在代码仓库中跟踪整个 `node_modules` 目录的文件变化。虽然这种方式有效,却使得一些简单操作变得复杂化了。比如,对 [babel](https://babeljs.io/) 更新一个次要版本号时,会产生多达 800,000 行的提交记录,此外由于 lint 规则的存在,引起无效的 utf-8 字节序列、windows 换行符、非 png 压缩图片等问题时,将会导致工程师经常需要花费一整天的时间合并 `node_modules` 目录的文件。而我们负责源码控制的团队也指出,跟踪 `node_modules` 目录会引入过多的元数据。比如 React Native 的 `package.json` 文件目前只列出了68项依赖,但在运行 `npm install` 后,`node_modules` 目录整整包含了 121,358 个文件。
最后,为了有效组织 Facebook 逐渐增长的工程师人数以及管理需要安装的代码量,我们尝试修改 `npm` 客户端。我们决定压缩整个 `node_modules` 目录,并上传到内部 CDN,然后我们的工程师与持续集成系统都能从 CDN 上下载并解压文件,从而保证了代码一致性。这样我们就可以从源码控制系统中删除数以万计的文件了,但不足之处是工程师现在不仅在拉代码时需要联网了,构建也同样需要联网。
我们还试图为 `npm` 的 [shrinkwrap](https://docs.npmjs.com/cli/shrinkwrap) 功能寻求优化方案,这个工具是用来锁定依赖版本号的。但 `Shrinkwrap` 功能的文件默认不会生成,如果开发者忘记了生成这一步骤,文件就不会被同步更新,因此我们编写了一个工具,以确定 `Shrinkwrap` 的文件内容和 `node_modules` 目录中的文件相符。这些文件由大量的 JSON 块组成,并且键名是无序的,因此每次更改通常会导致 `Shrinkwrap` 文件的内容大幅变化,难以进行代码审查。为减缓这一问题,我们还需要借助一个额外的脚本,对所有条目进行排序。
最后,通过 `npm` 升级单个依赖包时,基于 [语义化版本号](http://semver.org/) 规则,`npm` 通常会连同其他无关依赖一起更新。这使得每次更新都会比预期产生更多的变化,工程师们认为这样把 `node_modules` 提交上传到 CDN 的过程,难以达到预期的效果。
### 构建新客户端
与其围绕 `npm` 客户端继续构建基础设施,不如从整体上再次回顾这些问题。伦敦办公室的 Sebastian McKenzie 提出,如果我们建立一个新客户端工具以代替 `npm` 客户端,从而解决我们的核心问题呢?这一构思很快得到了我们的认同,团队对于这个主意也感到非常兴奋。
在开发过程中,我们与业界的工程师们进行了交流讨论,发现他们也面临着类似的问题,也尝试过许多类似的解决方案,通常只能把这些问题逐一解决。很明显,有必要把整个 JavaScript 社区正在面临的问题集合起来,然后我们就可以开发一个主流的解决方案了。在此感谢 Exponent、 Google 与 Tilde 的工程师们的协助,我们共同建立了 `Yarn` 客户端,并在每一个主流 JS 框架以及 Facebook 外的使用场景中测试验证了 Yarn 的性能。今天(2016-10-11),我们很荣幸把这个工具开源分享到社区中。
## 介绍 Yarn
`Yarn` 是一个新的包管理器,用于替代现有的 `npm` 客户端或者其他兼容 `npm` 仓库的包管理工具。`Yarn` 保留了现有工作流的特性,优点是更快、更安全、更可靠。
任何包管理器的主要功能都是安装某些软件包,软件包即用于特定功能的某段代码,通常是从一个全局的仓库安装到工程师的本地环境。每个软件包可以依赖于其他包,也可以不依赖。一个典型的项目结构的依赖树通常会包含数十个、数百个甚至上千个软件包。
这些依赖包通常是带版本号的,通过语义化版本控制(semver)安装。Semver 定义的版本号反映了每个新版本更改的类型,到底是进行了不兼容的API改动(MAJOR),还是添加了向后兼容的新特性(MINOR),还是进行了向后兼容的 bug 修复(PATCH)。然而,semver 依赖于软件包的开发者不能犯错误——如果依赖关系没有加锁,可能会引入一些破坏性更改或者产生新的 bug。
### 结构
在 Node 生态系统中,依赖通常安装在项目的 `node_modules` 文件夹中。然而,这个文件的结构和实际依赖树可能有所区别,因为重复的依赖可以合并到一起。`npm` 客户端把依赖安装到 `node_modules` 目录的过程具有不确定性。这意味着当依赖的安装顺序不同时,`node_modules` 目录的结构可能会发生变化。这种差异可能会导致类似“我的机子上可以运行,别的机子不行”的情况,并且通常要花费大量时间定位与解决。
`Yarn` 通过 lockfiles 文件以及一个确定性的、可靠的安装算法,解决了版本问题和 `npm` 的不确定性问题。Lockfile 文件把安装的软件包版本锁定在某个特定版本,并保证 `node_modules` 目录在所有机器上的安装结果都是相同的。Lockfile 还使用简洁的有序键名的格式,保证了每次的文件变化最小化,进行代码审查也更为简单。
安装过程分为以下三个步骤:
1. **处理:** `Yarn` 通过向代码仓库发送请求,并递归查找每个依赖项,从而解决依赖关系。
2. **抓取:** 接下来,`Yarn` 会查找全局的缓存目录,检查所需的软件包是否已被下载。如果没有,Yarn 会抓取对应的压缩包,并放置在全局的缓存目录中,因此 `Yarn` 支持离线安装,同一个安装包不需要下载多次。依赖也可以通过 tarball 的压缩形式放置在源码控制系统中,以支持完整的离线安装。
3. **生成:** 最后,`Yarn` 从全局缓存中把需要用到的所有文件复制到本地的 `node_modules` 目录中。
通过清晰地细分这些步骤,以及确定性的算法支持,使得 `Yarn` 支持并行操作,从而最大化地利用资源,并加速安装进程。在一些 Facebook 的项目上,`Yarn` 甚至可以把安装过程降低一个数量级,从几分钟到只需几秒钟。`Yarn` 还使用了互斥锁,以确保多个 CLI 实例同时运行时不会互相冲突与影响。
纵观整个过程,`Yarn` 对于软件包安装加上了严格的限制。你可以对哪个生命周期脚本作用于哪个软件包进行控制。软件包的 checksum 也会存储在 lockfile 中,以确保每一次安装都可以得到同一个包。
### 特性
`Yarn` 除了让安装过程变得更快与更可靠,还添加了一些额外的特性,从而进一步简化依赖管理的工作流。
* 同时兼容 `npm` 与 [bower](https://bower.io/) 工作流,并支持两种软件仓库混合使用
* 可以限制已安装模块的协议,并提供方法输出协议信息
* 提供一套稳定的公有 JS API,用于记录构建工具的输出信息
* 可读、最小化、美观的 CLI 输出信息
### Yarn 用于生产环境
我们已经在 Facebook 中把 `Yarn` 用于生产环境,并且效果非常理想。`Yarn` 有效地管理了许多 JavaScript 项目的包依赖关系。在每次迁移时,构建都可以离线进行,因此加速了工作流程。我们基于 React Native 在不同条件下进行安装时间测试,比较了 `Yarn` 与 `npm` 的性能,[具体参见这里](https://yarnpkg.com/en/compare)。

## 起步
最简单的起步方法是:
npm install -g yarnpkg
yarn
`yarn` CLI 代替了原有开发工作流中 `npm` CLI 的作用,用法可能是单纯的替代,也可能是一个新的、相似的命令:
* `npm install` → `yarn`
不需要带参数,`yarn` 命令会读取 `package.json` 文件,然后从 npm 仓库中抓取软件包,并放置到 `node_modules` 目录中。等价于运行 `npm install`。
* `npm install --save ` → `yarn add `
我们避免了 `npm install ` 命令中安装“不可见的依赖”的行为,并分离出一个新命令。运行 `yarn add ` 等价于运行 `npm install --save `。
### 未来
目前已经有许多成员一起参与到 `Yarn` 的构建中,以解决我们的共同问题,我们也希望 `Yarn` 未来能真正成为一个大众化的社区项目。`Yarn` 目前已经 [在 GitHub 开源](https://github.com/yarnpkg/yarn) ,我们也已经准备好向 Node 社区进行推广:使用 `Yarn`、分享构思、编写文档、互相支持,并帮助构建一个很棒的社区来进行长期维护。我们相信 `Yarn` 已经拥有一个良好的开局,如果有你的帮助,`Yarn` 的未来将会更加美好。
================================================
FILE: TODO/a-5-minute-intro-to-styled-components.md
================================================
> * 原文地址:[A 5-minute Intro to Styled Components](https://medium.freecodecamp.com/a-5-minute-intro-to-styled-components-41f40eb7cd55#.z1nrxe1zr)
* 原文作者:[Sacha Greif](https://medium.freecodecamp.com/@sachagreif)
* 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
* 译者:[根号三](https://github.com/sqrthree)
* 校对者:[Tina92](https://github.com/Tina92)、[lovelyCiTY](https://github.com/lovelyCiTY)
# 一个关于 Styled Components 的五分钟介绍
CSS 是一个很神奇的语言,你可以在 15 分钟之内就学会一些基础部分,但是如果你要找到一个好的方式来组织你的样式,将会花费数年时间。
这主要是由于语言本身很奇葩。不合常规的是, CSS 是相当有限的,没有变量、循环或者函数。与此同时,它又是相当自由的,你可以随意使用元素、Class、ID 或它们的任意组合。
### 混乱的样式表
正如你自己所经历过的那样,CSS 通常是很混乱的。虽然有诸如 SASS 和 LESS 这样的预处理器添加了大量有用的特性,但是它们仍然不能阻止 CSS 的这种混乱状态。
组织工作留给了像 [BEM](http://getbem.com/) 这样的方法,这些方法虽然很有用但是完全是自选方案,不能在语言或工具级别强制实施。
### CSS 的新浪潮
最近一两年,新一波基于 JavaScript 的工具正试图通过改变编写 CSS 的方式来从根本上解决这些问题。
[Styled Components](https://github.com/styled-components/styled-components) 就是那些工具库之一,因为兼顾创新和传统的优势,它很快就吸引了大量的关注。因此,如果你是 React 使用者(如果你不是的话,可以看看 [我的 JavaScript 学习计划](https://medium.freecodecamp.com/a-study-plan-to-cure-javascript-fatigue-8ad3a54f2eb1) 和我写的 [React 简介](https://medium.freecodecamp.com/the-5-things-you-need-to-know-to-understand-react-a1dbd5d114a3)),就绝对值得看看这个新的 CSS 替代者。
最近我用它 [重新设计了我的个人网站](http://sachagreif.com/),今天我想分享下我在这个过程中所学到的一些东西。
### 组件, 样式化
关于 Styled Components 你需要理解的最主要的事情就是其名称应该采取字面意思。你不再根据他们的 Class 或者 HTML 元素来对 HTML 元素或组件进行样式化了。
Hello World
h1.title {
font-size: 1.5em;
color: purple;
}
相反,你可以定义一个拥有它们自己的封装风格的 styled Components。然后你就可以在你的代码中自由的使用它们了。
import styled from 'styled-components';
const Title = styled.h1`
font-size: 1.5em;
color: purple;
`;
Hello World
这两段代码看起来有一些细微的差别,事实上两者语法是非常相似的。但是它们的关键区别在于样式现在是这些组件的一部分啦。
换句话说,我们正在摆脱 CSS class 作为组件和其样式的中间步骤这种情况。
styled-components 的联合创造者 Max Stoiber 说:
> styled-components 的基本思想就是通过移除样式和组件之间的映射关系来达到最佳实践。
### 减少复杂性
这首先是反直觉的,因为使用 CSS 而不是直接定义 HTML 元素的关键点(还记得 `` 标签吗?)是引入 class 这个中间层来解耦样式和标签。
但是这层解耦也创造了很多复杂性。有这样一个的观点:相比于 CSS,诸如 Javascript 这类『真正』的编程语言具备了更好的处理这种复杂性的能力。
### 类(Class)上的 Props
为了遵循 『无类(no-class)』的理念,当涉及到自定义一个组件的行为时,styled-components 使用了类上的 props(props over classes)。所以呢,代码不是这样的:
Hello World
// will be blue
h1.title{
font-size: 1.5em;
color: purple;
&.primary{
color: blue;
}
}
你需要这样写:
const Title = styled.h1`
font-size: 1.5em;
color: ${props => props.primary ? 'blue' : 'purple'};
`;
Hello World // will be blue
正如你所看到的那样,styled-components 通过将所有的 CSS 和 HTML 之间的相关实现细节(从组件中)分离出来使你的 React 组件更干净。
也就是说,styled-components 的 CSS 仍然还是 CSS。所以像下面这样的代码也是完全有效的(尽管略微不常用)。
const Title = styled.h1`
font-size: 1.5em;
color: purple;
&.primary{
color: blue;
}
`;
Hello World // will be blue
这是让 styled-components 很容易就被接受的一个特性:当存在疑惑时,你总是可以倒退回你所熟悉的领域。
### 警告
需要提到的很重要的一点是 styled-components 仍然是一个很年轻的项目。有一些特性到目前为止还没有完全支持。例如,如果你想 [从父组件中样式化一个子组件](https://github.com/styled-components/styled-components/issues/142) 时,目前你仍不得不依靠 CSS class 来实现(至少要持续到 styled-components 版本 2 发布)。
目前也有一个非官方的方法来实现 [服务端预渲染你的 CSS](https://github.com/styled-components/styled-components/issues/124),虽然它是通过手动注入样式来实现的。
事实上,styled-components 生成它自己的随机 class 名会使你很难通过浏览器的开发工具来确定你的样式最初是在哪里定义的。
但是鼓舞人心的是,styled-components 核心团队已经意识到了这些问题,并且努力地一个又一个的攻克它们。[版本 2 很快就要来啦]((https://github.com/styled-components/styled-components/tree/v2)),我真的很期待它呢。
### 了解更多一点吧
我这篇文章的目的不是向你详细解释 styled-components 是如何生效的,更多的是给你一个小瞥。所以你可以自己决定是否值得一试。
如果我的文章让你感到好奇的话,这里有一些链接你可以了解更多关于 styled-components 的知识。
- Max Stoiber 最近给 [Smashing Magazine](https://www.smashingmagazine.com/2017/01/styled-components-enforcing-best-practices-component-based-systems/) 写了一篇文章有关创建 styled-components 的原因的文章。
- [styled-components repo](https://github.com/styled-components/styled-components) 它自己就有一个很丰富的文档.
- [Jamie Dixon 写的这篇文章](https://medium.com/@jamiedixon/styled-components-production-patterns-c22e24b1d896#.tfxr5bws2) 讲述了切换到 styled-components 的几个好处.
- 如果你想了解更多关于这个库实际上是如何实现的,可以阅读 Max 的 [这篇文章](http://mxstbr.blog/2016/11/styled-components-magic-explained/)。
如果你想更进一步,也可以了解下 [Glamor](https://github.com/threepointone/glamor) —— 一个完全不同的 CSS 新浪潮。
================================================
FILE: TODO/a-beginners-guide-to-making-progressive-web-apps.md
================================================
> * 原文地址:[A beginner’s guide to making Progressive Web Apps](https://medium.com/samsung-internet-dev/a-beginners-guide-to-making-progressive-web-apps-beb56224948e)
> * 原文作者:[uve](https://medium.com/@uveavanto)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/a-beginners-guide-to-making-progressive-web-apps.md](https://github.com/xitu/gold-miner/blob/master/TODO/a-beginners-guide-to-making-progressive-web-apps.md)
> * 译者:[Haichao Jiang](https://github.com/AceLeeWinnie)
> * 校对者:[sun](https://github.com/sunui) [leviding](https://github.com/leviding)
# 构建渐进式 Web 应用入门指南
你可能已经听过渐进式 Web 应用或 PWA 的大名,然而我并不打算深入 PWA 的构建和工作细节。这篇文章的目的在于说明 **PWA 是一个可以添加到手机主屏幕的网页**,并且它还能够离线运行。
我知道一些 HTML、CSS、JavaScript 的知识并且了解如何使用 GitHub。
我是 web 开发新手,当下也不想学习 Web 开发的原理和工作机制。我希望有一个简单、基础的方式做出一些东西,而不用连篇累牍地阅读文档和教程。**希望通过这篇文章你会学到所有在开始构建 PWA 时需要的知识。**
要做 PWA 首先要有一个网站。当然,本文假定你已经可以制作多端适配的网站。幸运的是我们不需要通过 scratch 才能做到,我们可以使用模板。我喜欢使用 [HTML5 UP](https://html5up.net/) 和 [Start Bootstrap](https://startbootstrap.com/)。
选择并下载主题,把 index.html 中的所有内容替换成你自己的。如果你对编辑 CSS 有把握的话,你甚至可以更改颜色。
在这个项目里,我为 Web Community Leads UK and IE 组织制作了一个登录页。你可以通过阅读 [Daniel](https://medium.com/@torgo) 的[相关博客](https://medium.com/samsung-internet-dev/web-communities-for-the-people-6440e0c8e543)读到更多内容,或者访问我做的网站 [https://webcommunityukie.github.io/](https://webcommunityukie.github.io/)。
把这个网站做成 PWA 并没有为大多数用户带来更多体验,同时我也不希望每个人都把它加入主屏幕,但是它仍然优化了体验。我只是想要一个小网站来开启自己制作 PWA 之旅。
我真的想要一个简单的网站,我喜欢 [Hacksmiths](http://goldsmiths.tech/) 并且知道它是开源的,所以我下载下来并且消化了源码。我保留了一个链接在下方,指向原网页和源码,人们可以 folk 出一个新网站。
现在我们有个网站了,可以把它变成一个渐进式 web 应用。为了达到目的,我们需要添加一系列东西,待会我会说明为什么我们需要他们。
### 测试你的 PWA
要检查你的网站是否是 PWA,你可以用 [Lighthouse](https://developers.google.com/web/tools/lighthouse/)。Lighthouse 是一个 chrome 插件,可以告诉你访问的网站是不是支持 PWA,如果不支持应该如何优化。
安装插件后打开网站点击浏览器右上角的 Lighthouse 图标然后点击 Generate Report。对网站检测后会打开一个新的 tab 页展示结果,你可以浏览全文或者关注顶部的数字,忽略其他部分。

我开始处理网站的 PWA 部分前 Lighthouse 的检测结果。
鉴于还没有对网站开始进行 PWA 改造,36/100 不是一个悲观的数字。
### 制作 app icon
你的网站要放在主屏幕,你需要图标来展示它。
你不需要设计一个专业的 logo。对于大多数小项目来说,通过 [the noun project](https://thenounproject.com/),找到一至两个喜欢的 icon,用 GIMP 把他们放在一起。然后在图层后面添加渐变背景。当然你也可以使用别的方法来制作 icon,只要确认它是方形的。

这是我做的图标。现在回头看我本来应该再加上圆角的。
现在你有一个 app icon 了。🎉
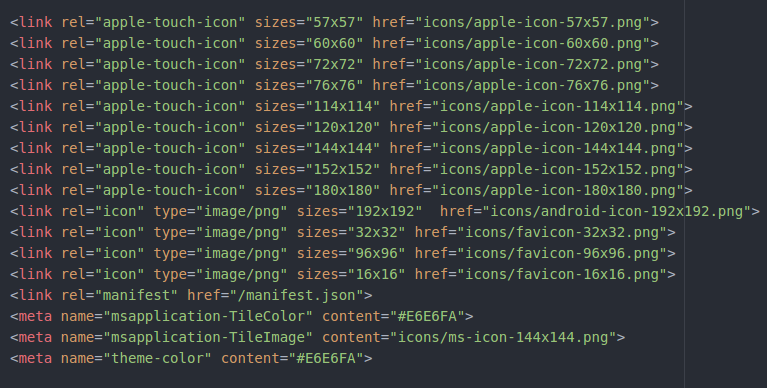
是时候把它放进你的网站里去了。我的方法是通过 [在线 icon 生成工具](http://www.favicon-generator.org/)。上传 blingbling 的新 icon,它会返回一些列不同尺寸版本和 HTML 代码。
- 下载文件并解压。
- 把 icon 放进网站文件夹。
- 把对应的代码放进 index.html 的 \ 中
- 确保 icon 的路径是正确的。我把 icon 放在子文件夹中,所以我需要添加"/icons"前缀。
### Web App Manifest
下一件要做的就是创建 manifest。manifest 是一个文件,包含了网站的数据,例如网站名字、偏好色彩和使用的 icon。
实际上,你已经有了一份 manifest,是 icon 生成工具生成的,接着我们要在上面添加更多内容。
打开 [web app manifest 生成器](https://tomitm.github.io/appmanifest/),填写网站的相关信息。对要填写的内容不确定的话,设置为默认即可。
页面右侧,有一些 JSON 数据。复制粘贴到 manifest.json 文件头部,为确保格式正确,你可能需要添加一个逗号或删除一个大括号。
我的 manifest 文件是 [这样](https://github.com/webcommunityukie/webcommunityukie.github.io/blob/master/manifest.json) 的。
再次运行 lighthouse,检测 manifest 是否正常工作。

Lighthouse 给 manifest 打分,并且 icon 也正常添加了。
### 添加 service worker
service worker 是另一个我们要加入项目的文件,它允许网站离线工作。它也是实现 PWA 的一个要求,我们需要添加。
service worker 比较复杂,相关的文档都很长,并且很混乱,整个页面充满了链接,链接内容也同样又长又乱。
幸运的是看到了 [Peter](https://medium.com/@poshaughnessy) 推荐的 sw-toolbox,他还给了我一个他自己的代码链接。
所以我拷贝了他的代码,移除额外的 JavaScript 文件,添加到 service worker, 简化后用到我自己的项目里。
#### 创建 service worker 需要做的 3 件事。
- 在 index.html 的 \ 里添加以下代码,注册 service worker:
```javascript
```
- 添加 sw-toolbox 到项目里。你只需要添加 [这个文件](https://github.com/GoogleChrome/sw-toolbox/blob/master/sw-toolbox.js) 到根目录下。
- 新建文件,命名为 "sw.js",拷贝并粘贴以下代码:
```javascript
‘use strict’;
importScripts(‘sw-toolbox.js’); toolbox.precache([“index.html”,”style/style.css”]); toolbox.router.get(‘/images/*’, toolbox.cacheFirst); toolbox.router.get(‘/*’, toolbox.networkFirst, { networkTimeoutSeconds: 5});
```
你想要检查所有文件路径是否正确,编辑预缓存和列出离线时要存储的所有文件,我的站点只用到 index.html 和 style.css,你可能需要其他文件或页面。
现在,用 Lighthouse 再次检测。

添加 service worker 之后 —— 测试 localhost
**如果你想要 service worker 做些不一样的事情,而不是仅仅是保存页面,例如网络不通时访问特定的离线页面,你可以试下 [pwabuilder](http://www.pwabuilder.com/generator) 这个 service worker 脚本。**
### 托管到 GitHub Pages 上
你完成了一个 PWA 页面,是时候和全世界分享了。
我发现最简单的分享方法就是 [GitHub Pages](https://pages.github.com/)。因为它是免费的,并且能为你处理所有安全问题。
新建一个仓库并上传代码到仓库,就可以托管你的代码了,GitHub GUI 会帮你做这些工作。
完成以上步骤后,在网站上找到你的仓库,在设置最下面可以选择 master 分支开启 GitHub Pages 功能。
它会返回访问 PWA 的在线 URL。
通过 Lighthouse 运行会得到不(更)同(好)的结果,然后把网址分享给你所有的朋友就好啦,或者只要把它下载到自己的手机主屏幕上就可以了。

在 GitHub Pages 托管网站后 Lighthouse 的结果。
**代码如下:**[https://github.com/webcommunityukie/webcommunityukie.github.io](https://github.com/webcommunityukie/webcommunityukie.github.io)
**完整网站如下:**[https://webcommunityukie.github.io/](https://webcommunityukie.github.io/)
它看起来和我开始时完全一样,但是在 Samsung Internet 上浏览时,地址栏会变成主题色,即浅紫色。会出现一个加号图标让你把它添加到你的主屏幕,允许全屏和离线使用。
还有很多 PWA 相关内容本文没有提到,你可以向他们发送推送通知告知用户你的应用有了新的内容。你可以阅读更多关于 [PWA 构成](https://www.smashingmagazine.com/2016/09/the-building-blocks-of-progressive-web-apps/) 的内容。
我希望本文能帮助你第一次体验到渐进式 web app,如果你在使用的过程中遇到困难,请给我留言或在推特 @ 我。
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)。
================================================
FILE: TODO/a-beginners-guide-to-website-optimization.md
================================================
> * 原文地址:[A beginner’s guide to website optimization](https://medium.freecodecamp.org/a-beginners-guide-to-website-optimization-2185edca0b72)
> * 原文作者:[Mario Hoyos](https://medium.freecodecamp.org/@mariohoyos?source=post_header_lockup)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/a-beginners-guide-to-website-optimization.md](https://github.com/xitu/gold-miner/blob/master/TODO/a-beginners-guide-to-website-optimization.md)
> * 译者:[Starrier](https://github.com/Starriers)
> * 校对者:[Clarence](https://github.com/ClarenceC)、[dazhi1011](https://github.com/dazhi1011)
# 网站优化初学者指南

图片由 Pexels 提供。
我是一名初学者,在 Google 优化排名中,我可以达到 99/100。如果我可以做到,那么您也可以。
如果您和我一样,喜欢证据。下面是 [Google 的 PageSpeed Insights](https://developers.google.com/speed/pagespeed/insights/) 结果。[hasslefreebeats](https://www.hasslefreebeats.com) 是我维护的网站,我最近花了一些时间进行优化。
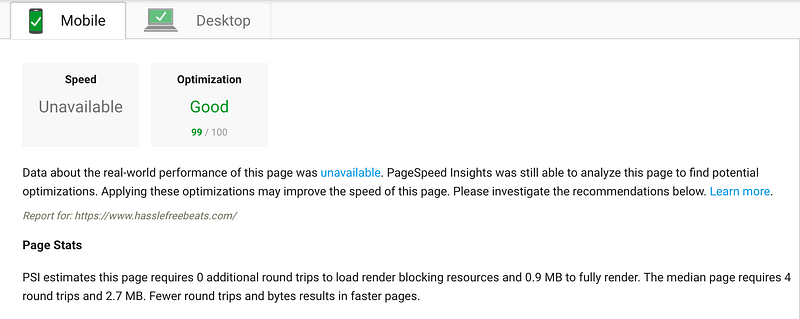
我的 PageSpeed Insights 分数截图。
我对这些结果感到非常自豪,但是我想强调的是,几周前我还不知道如何去优化一个网站。今天我要和大家分享的只是一大堆 Google 搜素和故障排除所得出的结果,我希望可以为您省去麻烦。
为了防止您想跳过,这篇文章被分成了几个小节。
我绝不是专家,但我相信如果您实施以下技术,你会看到效果!
### 图片

图片由 Pexels 提供 (Medium 已做优化).
作为一个网站开发初学者,我并没有想过图片的事情。我知道向我的网站添加高质量图片会使它看上去更专业,但是我从没有停下来考虑它们对我的网页加载时间的影响。
我为优化图像所做的事情主要是压缩它们。
回想起来,这从一开始就非常直观,只是我没有在意,可能您也一样。
我用来压缩图片的服务是 [Optimizilla](http://optimizilla.com/), 一个易于使用的网站,那您只需上传图片,选择你要压缩的级别,然后下载压缩图片。我看到一些资源的大小减少了 70% 以上,这对于更快的加载时间有很大的帮助。
Optimizilla 并不是您图片压缩需求的唯一选择。您可以使用一些独立的开源软件,Mac 环境下的 [ImageOptim](https://imageoptim.com/mac) 或者 Windows 环境下的 [FileOptimizer](https://sourceforge.net/projects/nikkhokkho/files/FileOptimizer/)。如果您更喜欢用构建工具进行压缩,那么可以使用 [Gulp](https://www.npmjs.com/package/gulp-imagemin) 和 [WebPack](https://github.com/Klathmon/imagemin-webpack-plugin) 插件。无论您怎么做,只要做了,那么即使是最小的努力,也会在性能上获取提升。
根据您的情况,可能还需要查看文件格式。一般来说,jpg 会比 png更小。我是否使用其中一个的主要区别是我是否需要图片背后的透明度:如果我需要透明度就使用 png,否则使用 jpg。您可以在 [这里](https://www.digitaltrends.com/photography/jpeg-vs-png-photo-format/)更深入地了解这两者的利弊。
此外,Google 已经推出了一种非常贴心的 webp 格式,但由于目前没有在所有浏览器被支持,所以我还在犹豫是否使用它。会留意未来是否有进一步地更新支持!
我没有在我的图片上做更多的压缩来获得以上展示的结果,但是如果您想进一步优化 [这里有一篇很棒的文章。](https://www.frontamentals.com/practical-guide-to-images)
### 视频

照片来自 Pexels 的 Terje Sollie。
尤其是我没有在我目前的任何项目中使用视频,所以我只会简单地涉及到这一点,因为我不觉得在这方面我这是最佳的解决方案。
在这种情况下我可能会让专业人士来做繁重的工作。Vimeo 为托管视频提供了一个很好的平台,在那里它们会降低视频质量,从而降低链接速度,并压缩您的视频以优化性能。
您也可以在 YouTube 上托管视频,然后使用 [youtube-dl](https://rg3.github.io/youtube-dl/) 工具从 You Tube 下载视频,同时根据您网站的需要配置视频。
至于其他可能的解决方案,请查看 [Brightcove](https://www.brightcove.com/en/), [Sprout](https://sproutvideo.com/) 或者 [Wistia](https://wistia.com/).
### Gzip 压缩

了解了么? Zip 压缩? Pexels 提供的图片。
最初部署我的网站时,我不知道 gzip 是什么。
长话短说,gzip 是一种大多数浏览器都能理解的文件压缩格式。它可以在幕后运行而不需要用户知道它正在发生。
根据您应用程序所在的位置,gzip 可能非常简单,只需打开配置开关,以指定您希望服务器在发送文件时对其进行 gzip 压缩。就我而言,托管我网站的 Heroku 不提供这个选项。
事实证明,在服务器代码中有些包可以进行显式压缩。这使得您只需几行代码即可获取 gzip 的好处。使用[这个](https://github.com/expressjs/compression)压缩中间件,[我能够将 JavaScript 和 CSS 捆绑包大小减少 75%。](https://codeburst.io/how-i-decreased-the-size-of-my-heroku-app-by-75-1a4cf329b0ab)
检查一下您的托管服务是否提供 gzip 选项是值得的。如果没有,请查看如何将 gzip 添加到服务器代码中。
### 最小化

最小化的菠萝 Pexels 提供。
最小化是在不影响代码功能(空格、换行符等)的情况下从代码中删除不必要字符的过程。这使您可以减少您正在通过互联网传输文件的大小。它也有助于混淆您的代码,这使得狡猾的黑客更难检测到安全弱点。
如今,最小化功能通常是 Webpack 或 Gulp 或者其他方法作为构建过程的一部分。但是这些构建工具有一些学习曲线,因此如果您正在寻找更简单的替代方法,Google 推荐 [HTML-Minifier for HTML](https://github.com/kangax/html-minifier)、 [CSSNano for CSS](https://github.com/ben-eb/cssnano) 和 [UglifyJS for Javascript](https://github.com/mishoo/UglifyJS2)。
### 浏览器缓存

不太清楚浏览器具体如何存储数据,但它是我所能得到的最接近的。Pexels 赞助。
将静态文件存储在浏览器的缓存中是提高网站速度的一种非常有效的方法,特别是在来自同一浏览器的回访时。直到 Google 告诉我,我的一些资源没有被适当地缓存,因为我从服务器发送的 HTTP 响应头中缺少标题,我才意识到这一点。
一旦加载了我的主页,就会向我的服务器发送一个请求,以获取一堆歌曲的数据,然后在音乐播放器中解析这些歌曲。我不经常更新这个网站上的歌曲,所以如果这会是我的页面加载速度更快一些的话,我不介意用户在我的网站上看到他们上次访问的相同歌曲。
为了提高性能,我在服务器的响应对象 (Express/Node server) 中添加了以下代码:
```
res.append("Cache-Control", "max-age=604800000");
res.status(200).json(response);
```
我在这里所做的就是在我的响应中附加一个说明超过一周(毫秒)应该重新下载资源的缓存控制头。如果您经常更新这些文件,缩短最长时间可能是个好主意。
### **内容分发网络**

现实中的 CDN 图像,Pexels 提供。
内容分发网络(CDN)是允许来自世界各地的用户在地理上更接近您的内容的网络。如果用户必须加载来自日本的大图像,但您的服务器在美国,这将比您在东京的服务器花费更长的时间。
CDN 允许您利用分布在世界各地的一组代理服务器,无论您的最终用户位于何处,都可以更快加载您的内容。
我想指出的是,实现 CDN 之前,我能够实现**上面**你所看到的结果--我只是想提及它们,因为没有网站优化的文章提及到他们。如果您计划拥有全世界的读者,那么在您的网站上有一些创新是绝对必要的。
一些流行的 CDNs 包括 [CloudFront](https://aws.amazon.com/cloudfront/) 和 [CloudFlare](https://www.cloudflare.com/lp/ddos-a/?_bt=157293179478&_bk=cloudflare&_bm=e&_bn=g&gclid=CjwKCAiA_c7UBRAjEiwApCZi8Ri3kAEt3UraYPUFUQOMTG0Xz7WGCNRUri0UNtCOUAdUMJI8osxuDRoCTx8QAvD_BwE).
### 其他方法
这里有些能让您有所收获的内容:
* 首先通过增加您网站的感知性能优先加载“首页”来优化您的网站。一种常见的方法是[延迟加载](https://en.wikipedia.org/wiki/Lazy_loading)没有显示在登录页面上的图像。
* 除非您的应用程序依赖于 JavaScript 来渲染 HTML,例如使用 Angular 或者 React 来构建网站,那么它会在你 HTML 文件的 body 底部看似安全的区域加载你的 script 标签。即使这可能会影响您的[交互时间](https://developers.google.com/web/tools/lighthouse/audits/time-to-interactive),所以我并不会对每个情况都推荐使用这种技术。
### 总结
当涉及到优化您的网站时,这都只是冰山一角。根据您接受的流量和所提供的服务数量,您可能会在许多不同的领域存在性能瓶颈。也许您需要更多的服务器,也许您需要一个拥有更多 RAM 的服务器,也许您的三重嵌套 for 循环可以使用一些重构--谁知道呢?
对于加速您的网站来说,没有一个准确无误的方法,您最终将不得不根据您的测试来做出最好的决定。不要浪费时间去优化不需要优化的东西。分析您网站的性能,找出瓶颈,然后专门解决这些瓶颈。
我希望您能在这篇文章中找到一些有用的东西!正如我所提到的,我在这个领域还有很多东西要学。如果您有任何额外的提示或者建议,请将它们留在下面的评论中!
如果您喜欢我的文章,请为我鼓掌,还有以下内容:
* [当我开始编码时,我希望我已经了解的工具](https://medium.freecodecamp.org/tools-i-wish-i-had-known-about-when-i-started-coding-57849efd9248)
* [当我开始编码时,我希望我已经了解的工具: 重新访问](https://medium.freecodecamp.org/tools-i-wish-i-had-known-about-when-i-started-coding-revisited-ffb715ffd23f)
当然,也可以关注我的 [Twitter](https://twitter.com/marioahoyos).
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
================================================
FILE: TODO/a-better-underline-for-android.md
================================================
>* 原文链接 : [A better underline for Android](https://medium.com/google-developers/a-better-underline-for-android-90ba3a2e4fb)
* 原文作者 : [Romain Guy](https://medium.com/@romainguy)
* 译文出自 : [掘金翻译计划](https://github.com/xitu/gold-miner)
* 译者 : [jamweak](https://github.com/jamweak)
* 校对者: [yifili09](https://github.com/yifili09),[whyalwaysmea](https://github.com/whyalwaysmea)
# Android 中美腻的下划线
在过去两年里,我经常发现一些尝试去如何提高有关在网页中渲染下划线文本修饰的[文章](https://medium.com/design/crafting-link-underlines-on-medium-7c03a9274f9)和[库](https://eager.io/blog/smarter-link-underlines/)。此类问题也同样发生在Android(平台):下划线的文本修饰与[降部](http://www.fontke.com/article/712)相交。比较下Android当前如何绘制下划线文本(上图)以及它的替代方案(下图):

你更喜欢哪一种?
尽管我完全认可这些努力,但是我从未喜欢过任何公开的解决方法。目前最新的技术(追求艺术般的状态)—毫无疑问地会强迫开发者们受限于CSS—似乎是通过绘制线性渐变以及多重阴影(我见过多达12层的!)来实现的。这些解决方案都具有无法否认的成效,但这种绘制如此多阴影的做法,即使没有增加模糊效果,也会使得图形开发者们足够头疼了。还有一点,这种方法仅仅在实色的背景下有效。
我今天下午一时兴起,开始着手发掘满足以下需求的其他解决方案:
* 兼容旧版本的Android系统
* 仅使用标准的View和Canvas APIs
* 不需要过度重绘或者大量的阴影开销
* 在任何背景下都有效,而不是只支持实色背景
* 不依赖绘制流水线的操作顺序(文本先于/晚于下划线的绘制是无关紧要的)
我在这里提供了两种解决方案,你可以在[GitHub](https://github.com/romainguy/elegant-underline)获取。其中一种方法适用于[API level 19](https://www.android.com/versions/kit-kat-4-4/)及以上,另外一种适用于[API level 1](http://arstechnica.com/gadgets/2014/06/building-android-a-40000-word-history-of-googles-mobile-os/6/)及以上,或者说它 _应该_ 至少支持API level 1以上,我没有完全地测试,但我相信API文档。
你可以在下面的截图中观察比较下这两种被称作 _Path_ 和 _Region_ 的方法:

在Android中更好展示下划线文本的两种可能的实现方式
### 如何实现的?
这些实现背后的思想与之前提到的CSS方法出奇地类似。我们使用一整条直线段来表示下划线,剩下所需要做的就是为降部挪出空间...
#### 使用Path类
API level 19 (叫KitKat更耳熟) 中引入了一个操作路径的新API叫做[path ops](https://developer.android.com/reference/android/graphics/Path.html#op%28android.graphics.Path,%20android.graphics.Path.Op%29)。这个API允许你为实例建立两个路径的交叉点,或是从一条路径中减去其它的路径。
使用这个API,制作我们想要的下划线就非常简单了。第一步就是为我们的文本[获取轮廓](https://developer.android.com/reference/android/graphics/Paint.html#getTextPath%28java.lang.String,%20int,%20int,%20float,%20float,%20android.graphics.Path%29):
mPaint.getTextPath(mText, 0, mText.length(), 0.0f, 0.0f, mOutline);
注意返回的path可以通过一种填充的样式来渲染原始文本,我们在这里要使用它来进行后续操作。

文本轮廓
下一步就是剪切表示下划线的矩形轮廓。这一步不完全是必要的,但是这样可以避免在下一步可能出现的近似值偏差。我们只需使用intersection path操作就能方便的实现这一功能:
mOutline.op(mUnderline, Path.Op.INTERSECT);
现在轮廓路径仅仅包含几位降部与下划线的交叉部分。

只有黑色区域表示是路径的一部分,其余的部分只是为了可视目的。
剩下要做的就是从下划线中减去那些降部位置的部分。在做这个之前,我们必须扩大原始文本的尺寸来为降部与下划线间创造出间隙。这个功能可以通过划除我们剪切的轮廓然后建立一个新的填充路径实现:
mStroke.setStyle(Paint.Style.FILL_AND_STROKE); mStroke.setStrokeWidth(UNDERLINE_CLEAR_GAP);
mStroke.getFillPath(mOutline, strokedOutline);
划掉的宽带代表着你想为降部和下划线之间留下多大的空间。

划除剪切掉的轮廓
最后一步就是使用另外一个path操作从下划线矩形轮廓中减去划除部分和剪切掉的部分:
mUnderline.op(strokedOutline, Path.Op.DIFFERENCE);
最后的下划线可以使用一个填充画笔绘制:
canvas.drawPath(mUnderline, mPaint);
#### 使用Region类
[Region](https://developer.android.com/reference/android/graphics/Region.html)是一种在屏幕上高效展示非矩形形状的方法。你可以想象一块区域是由若干对齐到渲染缓冲区的矩形集合组成的。Regions可以被看作是_栅格化_的Path。这意味着如果我们将Path转换成Region后,我们获得的是一系列像素坐标点的集合,一旦Path被绘制,它将影响到这些获得的坐标集合。
Region有趣的地方在于它[提供了与Path相同的操作](https://developer.android.com/reference/android/graphics/Region.html#op%28android.graphics.Region,%20android.graphics.Region.Op%29)。两块Regions能够互相交错、扣除重叠的部分等等。更重要的是,Region从最早的Android API中就已经存在了。
用Region实现下划线的方法几乎与用Path完全相同,主要的区别存在于轮廓何时怎样被剪切的:
Region underlineRegion = new Region(underlineRect);
// 为文本建立一个Region并且剪切掉下划线部分
Region outlineRegion = new Region();
outlineRegion.setPath(mOutline, underlineRegion);
// 提取返回的Region的Path,从而获得一份剪切后的文本轮廓的拷贝
mOutline.rewind();
outlineRegion.getBoundaryPath(mOutline);
// 划掉剪切掉的文本,将其结果转为一个填充样式的Path
mStroke.getFillPath(mOutline, strokedOutline);
// 使用划掉文本的轮廓建立一个Region对象
outlineRegion = new Region();
outlineRegion.setPath(strokedOutline, new Region(mBounds));
// 在下划线轮廓中扣除剪切掉的,划掉的文本轮廓
underlineRegion.op(outlineRegion, Region.Op.DIFFERENCE);
// 使用下划线Region建立一个Path
underlineRegion.getBoundaryPath(mUnderline);
#### 两种方法的区别
由于Path类和Region类的本质不同,两种实现间有着不易察觉的区别。因为Path类仅仅在曲线上操作,因此在我们从下划线轮廓中扣除降部时,就保留了降部轮廓的斜度,这就造成下划线空隙的边缘与降部的曲线斜度平行。这种效果或许是又或许不是所期望的。
另一方面,Region类操作的是整个像素点,它会清除下划线竖向的切割(你的下划线足够细的话)。下图是两种实现的比较:

上图: Path类. 下图: Region类. 注意到上面的斜度没?如果没有,你需要仔细看。
### 应当在产品中使用吗?
在你尝试将这些技术运用到你的应用之前,需要了解到我这次没有做任何的性能测试。请记住这些尝试很大程度上只是一种编程乐趣的挑战。所提供的代码没有根据文本的大小来适配下划线的位置,也没有适配间隙的宽度。可能在字体的适配上也有问题,我只尝试了几种Android默认的字型。就让我们将这些问题留给读者当做练习来解决吧。
如果你将尝试着在你的应用里使用这些代码,那么我必须承认我将很乐于看到关于[spans](http://flavienlaurent.com/blog/2014/01/31/spans/)的实现,我会鼓励你至少缓存一下最后的填充Path。由于它仅仅依赖于字型,字体和字符串,缓存还是比较容易实现的。
另外,文章中描述的这两种实现方法完全严格遵循开放的SDK API。如果在Android framework层直接实现的话,我有一些想法能使得这个功能变得更有效率。
比如 _Region_ 的转换能够通过渲染自身来获得优化,而不用转换回 _Path_ 了(这会造成软件的碎片化以及GPU结构化更新)。Region类本身就是一系列矩形的集合,对于渲染流水线来说,与绘制碎片化的Path相比,绘制一系列的直线或矩形变得容易多了。
你想了解更多关于Android文本的东西?学习[Android的硬件是如何加速字体渲染的?](https://medium.com/@romainguy/androids-font-renderer-c368bbde87d9#.493idqqrm)。
在GitHub上获取[演示源码](https://github.com/romainguy/elegant-underline)。
================================================
FILE: TODO/a-blurring-view-for-android.md
================================================
> * 原文链接: [A Blurring View for Android](http://developers.500px.com/2015/03/17/a-blurring-view-for-android.html)
* 原文作者 : [Jun Luo](https://500px.com/junluo)
* 译文出自 : [掘金翻译计划](https://github.com/xitu/gold-miner)
* 译者 : [Sausre](https://github.com/Sausure)
* 校对者 :[lekenny](https://github.com/lekenny),[Adam Shen](https://github.com/shenxn)
# 在 Android 下进行实时模糊渲染
## 模糊渲染
模糊渲染能生动地表达内容间的层次感。当专注于当前特定内容的时候,它允许用户维持相对的上下文,即使模糊层下面的内容发生了视差移动或者动态变化。
在IOS开发中,我们首先可以通过构造`UIVisualEffectView`获得这种模糊效果:
UIVisualEffect *blurEffect = [UIBlurEffect effectWithStyle:UIBlurEffectStyleLight];
UIVisualEffectView *visualEffectView = [[UIVisualEffectView alloc] initWithEffect:blurEffect];
接着我们可以添加`visualEffectView`到视图层中,那么在它之下的内容都会动态渲染模糊效果。
## 在Android中的现状
虽然在Android中并没有直接的方法实现模糊渲染,但我们依然能见到些十分优秀的例子比如Yahoo Weather应用,见[Nicholas Pomepuy的博文](http://nicolaspomepuy.fr/blur-effect-for-android-design/),然而,它是通过缓存一张预先渲染模糊的背景图片实现的。
虽然这种方法挺有效果,但并不是我们想要的。在[500px](https://500px.com)社区,图片并不是用作背景而是焦点内容,这意味着图片可以随意改变甚至迅速改变,即使它们被覆盖在模糊层之下。[我们的Android应用](https://play.google.com/store/apps/details?id=com.fivehundredpx.viewer)就是个十分典型的例子。比如,当用户滑到下一页时,图片会向反方向移动并淡出,通过适当地维护多个预先渲染模糊的图片是很难满足这种需求的。

## 通过自定义View的OnDraw方法
我们的需求是希望能实现一个模糊视图,它能实时动态地模糊渲染在它之下的视图。我们最终想要的代码最好能尽量简单例如直接让模糊视图拥有一份被模糊视图的引用:
```java
blurringView.setBlurredView(blurredView);
```
然后当被模糊视图改变时 - 不管是内容的改变(如显示张新的图片)、视图的移动、或者是视图动画,我们都需要刷新模糊视图:
```java
blurringView.invalidate();
```
为了实现模糊视图,我们需要继承`View`类然后重写`onDraw()`方法来渲染模糊效果:
```java
protected void onDraw(Canvas canvas) {
super.onDraw(canvas);
// 让被模糊视图的draw()方法在私有的画布上绘制
mBlurredView.draw(mBlurringCanvas);
// 模糊私有画布的位图并传递给mBlurredBitmap
blur();
// 经过转换后将mBlurredBitmap绘制在模糊视图的默认画布上
canvas.save();
canvas.translate(mBlurredView.getX() - getX(), mBlurredView.getY() - getY());
canvas.scale(DOWNSAMPLE_FACTOR, DOWNSAMPLE_FACTOR);
canvas.drawBitmap(mBlurredBitmap, 0, 0, null);
canvas.restore();
}
```
这里的关键是当模糊视图重绘的时候,我们会通过对被模糊视图的引用来调用它的`draw`方法,同时它会在我们私有的画布上绘画(译者注:对该画布的操作最终会作用到我们私有的位图上):
```java
mBlurredView.draw(mBlurringCanvas);
```
(通过这种途径访问其它的视图的`draw`方法十分有参考价值,我们也可以实现一个放大镜或者用来标注的视图,相对于模糊渲染,放大镜或者标注的区域更需要放大。)
下面的想法在[Nicholas Pomepuy的博文](http://nicolaspomepuy.fr/blur-effect-for-android-design/)中有谈到,我们结合二次抽样与[RenderScript](http://developer.android.com/guide/topics/renderscript/compute.html)进行快速处理。在我们完成模糊视图的私有画布`mBlurringCanvas`的初始化后二次抽样也设置完成:
```java
int scaledWidth = mBlurredView.getWidth() / DOWNSAMPLE_FACTOR;
int scaledHeight = mBlurredView.getHeight() / DOWNSAMPLE_FACTOR;
mBitmapToBlur = Bitmap.createBitmap(scaledWidth, scaledHeight, Bitmap.Config.ARGB_8888);
mBlurringCanvas = new Canvas(mBitmapToBlur);
```
通过了上面的设置后再适当地初始化RenderScript。那么上文`onDraw()`调用的`blur()`方法就简单多了:
```java
mBlurInput.copyFrom(mBitmapToBlur);
mBlurScript.setInput(mBlurInput);
mBlurScript.forEach(mBlurOutput);
mBlurOutput.copyTo(mBlurredBitmap);
```
注意此时`mBlurredBitmap`已经渲染好了,余下的工作是`onDraw()`方法对它适当的移动和缩放后绘制到模糊视图默认画布中。
## 实现细节
对于完全的实现,我们需要留心多个技术细节。首先,我们意识到,8个单位的缩放采样以及15个单位的模糊半径就能很好地呈现我们想要的效果。当然,或许对你来说,别的参数才能满足你的需求。
其次,在模糊位图的边缘处我们遇到了一些RenderScript的历史遗留问题,为了应对这个问题,我们对宽度和高度缩放到近似4倍。
```java
// The rounding-off here is for suppressing RenderScript artifacts at the edge.
scaledWidth = scaledWidth - (scaledWidth % 4) + 4;
scaledHeight = scaledHeight - (scaledHeight % 4) + 4;
```
第三,我们为了更好地保证性能,需要创建两张位图分别是`mBitmapToBlur`做为私有画布`mBlurringCanvas`的底图和`mBlurredBitmap`,并会在被模糊视图的大小改变时重新创建它们。同时,我们也需要重新创建RenderScript的`Allocation`对象也就是`mBlurInput`和`mBlurOutput`。
第四,为了设计的明亮程度考虑,当最上面的被模糊视图拥有属性`PorterDuff.Mode.OVERLAY`时我们也可以绘制一个统一白色半透明层。
最后,由于RenderScript仅在API版本17及以上有效,我们在较低级版本也应该有个比较优雅的降级方案。可不幸的是,正如[Nicholas Pomepuy的博文](http://nicolaspomepuy.fr/blur-effect-for-android-design/)中说的那样,通过Java来实现图片模糊渲染速度上达不到实时渲染的需求。最后我们只能决定使用个有较高透明度的半透明视图做为降级方案。
## 优缺点
我们欣赏这个视图的绘制策略因为它能做到实时模糊同时十分简单易用。它无需知道被模糊视图的内容,同时在模糊和被模糊视图的关系之间有很大的灵活性。当然,最重要的是他很好地满足了我们的需求。
然而,这种策略需要模糊视图通过适当的坐标转换来掌握被模糊视图的位置。关键是模糊视图不能是被模糊视图的子视图否则你将会收到堆栈溢出错误提示因为它们在互相调用对方的绘制方法。一个简单但又十分有效摆脱这种限制的方法是保证模糊视图是被模糊视图的姊妹视图并通过z-order来变换它们的层次关系。
还有个注意点是对于矢量图和文本,默认的位图采样并不太有效。
## 类库和演示
你可以在[我们的Android应用](https://play.google.com/store/apps/details?id=com.fivehundredpx.viewer)中看到完全的解决方案。同时我们也[在GitHub上](https://github.com/500px/500px-android-blur)推出了一个轻量级的开源类库,里面有个演示应用来展示如何在内容发生改变和视图动画时使用该类库。

================================================
FILE: TODO/a-cartoon-intro-to-webassembly.md
================================================
> * 原文地址:[A cartoon intro to WebAssembly](https://hacks.mozilla.org/2017/02/a-cartoon-intro-to-webassembly/)
> * 原文作者:本文已获作者 [Lin Clark](https://code-cartoons.com/@linclark) 授权
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 译者: [根号三](https://github.com/sqrthree)
> * 校对者:[Reid](https://github.com/reid3290)、[Tina92](https://github.com/Tina92)
# 看漫画,学 WebAssembly
WebAssembly 运行得很快,你可能已经听说过这个了。但是是什么让 WebAssembly 这么快呢?
在这个系列的文章里,我想和你解释一下为什么 WebAssembly 这么快。
## 等等,WebAssembly 究竟是什么?
WebAssembly 是一种用 JavaScript 以外的编程语言编写代码并在浏览器中运行该代码的方法。因此当人们说 WebAssembly 运行得很快的时候,通常他们都是在和 JavaScript 进行比较。
现在,我不想暗示这是一个二选一的情况 —— 你要么用 WebAssembly 或者用 JavaScript。事实上,我们期望开发者能够在同一个应用里面同时使用 WebAssembly 和 JavaScript。
但是比较一下这二者是非常有用的,你可以因此理解 WebAssembly 将会具有的潜在影响。
## 一点性能历史
JavaScript 创建于 1995 年。它不是为了快而设计的,并且在最初前十年,它并不快。
然后浏览器之间的竞争开始变得愈演愈烈。
在 2008 年,人们所谓的“性能战争”时期开始了。很多浏览器都添加了即时编译器 —— 也叫做 JIT。当 JavaScript 运行时,JIT 可以看到模式(pattern)并且基于这些模式(pattern)让代码运行得更快。
这些 JIT 的引入致使 JavaScript 的性能进入了一个转折点。JS 的执行速度快了 10 倍。

通过这种性能的改善,JavaScript 开始被用于没有人期望用它来做的一些事情上。例如使用 Node.js 进行服务端编程。性能的改善使得在一个全新的问题上使用 JavaScript 成为了可能。
伴随着 WebAssembly,我们现在可能正处于另一个转折点。

因此,让我们深入细节之中,来理解是什么使得 WebAssembly 很快。
[第二篇传送门](https://github.com/xitu/gold-miner/blob/master/TODO/a-crash-course-in-just-in-time-jit-compilers.md)
================================================
FILE: TODO/a-case-for-using-storyboards-on-ios.md
================================================
> * 原文地址:[A Case For Using Storyboards on iOS](https://medium.cobeisfresh.com/a-case-for-using-storyboards-on-ios-3bbe69efbdf4)
> * 原文作者:[Marin Benčević](https://medium.cobeisfresh.com/@marinbenc)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 译者:
> * 校对者:
# A Case For Using Storyboards on iOS #
I’ve seen a lot of articles recently that argue against using storyboards when creating iOS apps. The most commonly mentioned arguments are that storyboards are not human readable, they are slow and they cause git conflicts. These are all valid concerns, but can be avoided. I want to tell you how we use storyboards on non-trivial projects, and how you can avoid these concerns and still get the nice things storyboards give you.
#### Why use storyboards?
> A picture is worth a thousand words.
Humans are visual thinkers. The vast majority of information we receive is through our eyes, and our brains are incredibly complex visual pattern matching machines, which help us understand the world around us.
Storyboards give you an overview of a screen in your app, unmatched by code representation, whether it’s XML or plain Swift. When you open up a storyboard, you can see all views, their positions and their hierarchies in a second. For each view, you can see all the constraints that affect it, and how it interacts with other views. The efficiency of transferring information visually can’t be matched with text.
Another benefit of storyboards is that it makes auto layout more intuitive. Auto layout is an inherently visual system. It might be a set of mathematical equations under the hood, but we don’t think like that. We think in terms of “this view needs to be next to this one at all times”. Doing auto layout visually is a natural fit.

Also, doing auto layout in storyboards gives you some compile-time safety. Most missing or ambiguous constraints are caught during the creation of the layout, not when you open the app. This means less time spent on tracking down ambiguous layouts, or finding out why a view is missing from the screen.
#### How you should do it ####
**One storyboard per UIViewController**
You wouldn’t write your whole app inside a single UIViewController. The same goes for storyboards. Each view controller deserves its own storyboard. This has several advantages.
1. **Git conflicts occur only if two developers are working on the same UIViewController in a storyboard at the same time.** In my experience, this doesn’t happen often, and it’s not hard to fix when it does.
2. **The storyboard is no longer slow to load, since it only loads one UIViewController.**
3. **You are free to instantiate any UIViewController whichever way you like, just by getting the initial view controller of a storyboard.** Whether you’re using segues or pushing them through code.
When I’m creating a new screen, my first step is to create a UIViewController. Once I did that, I create a storyboard **with the same name** as the view controller I just created. This lets you do a pretty cool thing: instantiate UIViewControllers in a type safe way, without hard-coded strings.
let feed = FeedViewController.instance()
// `feed` is of type `FeedViewController`
This method works by finding a storyboard with the same name as the class name, and getting the initial view controller from that storyboard.
I know that’s how NIBs are used. But the NIB format is outdated, and some features (like creating UITableViewCells in the actual UIViewController’s nib) are not supported in the .xib editor. I have a feeling that the list of unsupported features will only grow, and that’s why I use storyboards over nibs.
**No segues**
Segues seem cool at first, but as soon as you have to transmit data from one screen to the next, it becomes a pain. You have to store the data in some temporary variable somewhere, and then set that value inside the `prepare(for segue:, sender:)` method.
class UsersViewController: UIViewController, UITableViewDelegate {
private enum SegueIdentifier {
static let showUserDetails = "showUserDetails"
}
var usernames: [String] = ["Marin"]
func tableView(_ tableView: UITableView, didSelectRowAt indexPath: IndexPath) {
usernameToSend = usernames[indexPath.row]
performSegue(withIdentifier: SegueIdentifier.showUserDetails, sender: nil)
}
private var usernameToSend: String?
override func prepare(for segue: UIStoryboardSegue, sender: Any?) {
switch segue.identifier {
case SegueIdentifier.showUserDetails?:
guard let usernameToSend = usernameToSend else {
assertionFailure("No username provided!")
return
}
let destination = segue.destination as! UserDetailViewController
destination.username = usernameToSend
default:
break
}
}
}
This code has a lot of problems. `prepare(for:sender:)` is not a pure function since it depends on the temporary variable defined above it. Even worse, that variable is optional, and it’s unclear what should happen if it’s nil.
You need to remember to manually set the *usernameToSend* property, which adds mutable state to our code. You also need to cast the segue’s destination to the type you expect. That’s lot of boilerplate and more than one point of failure.
I would much rather have a function that takes a non-optional value, and pushes the next view controller with that value. Simple and easy.
class UsersViewController: UIViewController, UITableViewDelegate {
var usernames: [String] = ["Marin"]
func tableView(_ tableView: UITableView, didSelectRowAt indexPath: IndexPath) {
let username = usernames[indexPath.row]
showDetail(withUsername: username)
}
private func showDetail(withUsername username: String) {
let detail = UserDetailViewController.instance()
detail.username = username
navigationController?.pushViewController(detail, animated: true)
}
}
This code is much safer, more readable and more concise.
**All properties are set in code**
Leave all storyboard values at their defaults. If a label needs to have a different text, or a view needs to have a background color, those things are done in code. This relates especially to all the little checkmarks in the property inspector.
The reason is that you don’t want to hard-code fonts, colors and texts. You can have constants for those, and a single place where they are kept, so you have a single place to change when you need to make a design change.
Also, scanning the code for view properties is easier than trying to find which checkmarks are checked in the storyboard.
This means you can build auto layout and views in the storyboard, but [style them in code](https://medium.cobeisfresh.com/composable-type-safe-uiview-styling-with-swift-functions-8be417da947f), which gives you complete freedom to create reusable code and a human-readable change history.
#### What storyboards are for me ####
You might be reading this article and thinking “This guy says storyboards are great, and then says he doesn’t use half of the features!”, and you’re right!
Storyboards do have problems, and these are the ways I avoid those problems. I find storyboards very useful for what I want to do with them: create the view hierarchy and constraints. Nothing more, nothing less.
My point is to not disregard a whole technology because you don’t like one aspect of it. You are free to pick and choose which parts you want to use. **It’s not all or nothing.**
So for those of you who want the benefits or storyboards, but want to minimize the downsides, this is our approach that has worked very well so far. If you have any comments, feel free to leave a response or hit me up on @marinbenc on Twitter.
*If you liked this one, check out some some other articles from my team:*
[](https://medium.cobeisfresh.com/how-to-win-a-hackathon-tips-tricks-8cd391e18705)
[](https://medium.cobeisfresh.com/accessing-types-from-extensions-in-swift-32ca87ec5190)
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)。
================================================
FILE: TODO/a-crash-course-in-assembly.md
================================================
> * 原文地址:[A crash course in assembly](https://hacks.mozilla.org/2017/02/a-crash-course-in-assembly/)
> * 原文作者:本文已获作者 [Lin Clark](https://code-cartoons.com/@linclark) 授权
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 译者:[zhouzihanntu](https://github.com/zhouzihanntu)
> * 校对者:[Tina92](https://github.com/Tina92)、[zhaochuanxing](https://github.com/zhaochuanxing)
# 汇编快速入门
**本文是 WebAssembly 系列文章的第三部分。如果你还没有阅读过前面的文章,我们建议你 [从头开始](https://github.com/xitu/gold-miner/blob/master/TODO/a-cartoon-intro-to-webassembly.md)。**
理解汇编和编译器如何生成它的有助于你后续理解 WebAssembly 的工作原理,
在 [介绍 JIT 的文章](https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/)里,我谈到了与机器交流的方式和与外星人通信是相似的。

我现在真想看看外星人大脑的思考方式——即机器大脑解析和理解通信的机制。
大脑中有一部分专门用来思考(例如做加减或其他逻辑运算),一部分提供短期记忆存储,还有一部分提供长期记忆存储。
这几个不同的部分都有各自的名称:
- 负责思维的部分称为算术逻辑单元 (ALU)。
- 短期存储由寄存器提供。
- 长期存储由随机存取存储器 (RAM) 提供。

机器码中的句子被称为指令。
当一条指令进入大脑时会发生什么?它会被分解成带不同含义的不同部分。
指令分解的方式是特定于当前大脑构造的。
例如,这种结构的大脑可能总是将前六位传送给 ALU。ALU 根据接收到的序列中 1 和 0 的排列,就会明白需要将两个东西加在一起。
这个字段称为操作码(opcode),它的作用是告诉 ALU 要执行的操作。

接下来大脑会取后续两个三位的字段来确定要相加的两个数。这两个数会存储在寄存器中。

注意这里机器码上方的注释,有助于我们理解这个过程。这就叫做汇编。这段代码称为符号机器码。符号机器码是人类理解机器码的一种方式。
你会发现汇编和这台机器的机器码有很直接的关系。因此不同的机器架构对应有不同的汇编方式。当你遇到使用不同架构的机器时,可能就得按它们自己的方式进行汇编。
因此,我们的翻译对象并不止一个。机器码不止一种语言,有许多不同种类的机器码。就像我们人类会说不同的语言一样,机器也会使用不同的语言。
随着人类和外星人之间的翻译问题解决,你也可以将英语、俄语、普通话等语言转化成外星文A、外星文B了。对编程而言,就是将 C、C++、Rust 等语言转化成 x86、ARM。
如果你想将任意一种高级语言编译成对应任意体系结构的汇编语言,一种方法是创建一整套不同语言到不同汇编的转化器。

但这样的做法非常低效。大部分编译器会在中间放置至少一个中间层。编译器接收高级编程语言并将其转化成相对底层的形式,转化结果也不能和机器码一样直接运行。这类形式称为中间表示(IR)。

这意味着编译器可以将任意一种高级编程语言翻译成一种 IR 语言。编译器的另一部分将得到的 IR 内容编译成特定于目标架构的语言。
编译器的前端部分将高级编程语言翻译成 IR 语言,再由后端将它们从 IR 语言编译成目标架构的汇编代码。

## 总结
以上就是汇编的简要说明,以及编译器将高级程序语言转成汇编的过程。在[下一篇文章](https://github.com/xitu/gold-miner/blob/master/TODO/creating-and-working-with-webassembly-modules.md)里,我们将会看到 WebAssembly 是如何实现的。
================================================
FILE: TODO/a-crash-course-in-just-in-time-jit-compilers.md
================================================
> * 原文地址:[A crash course in just-in-time (JIT) compilers](https://hacks.mozilla.org/2017/02/a-crash-course-in-just-in-time-jit-compilers/)
> * 原文作者:本文已获作者 [Lin Clark](https://code-cartoons.com/@linclark) 授权
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 译者:[zhouzihanntu](https://github.com/zhouzihanntu)
> * 校对者:[Tina92](https://github.com/Tina92)、[Germxu](https://github.com/Germxu)
# JIT 编译器快速入门 #
**本文是 WebAssembly 系列文章的第二部分。如果你还没有阅读过前面的文章,我们建议你 [从头开始](https://github.com/xitu/gold-miner/blob/master/TODO/a-cartoon-intro-to-webassembly.md)。**
JavaScript 刚面世时运行速度是很慢的,而 JIT 的出现令其性能快速提升。那么问题来了,JIT 是如何运作的呢?
## JavaScript 在浏览器中的运行机制 ##
作为一名开发者,当你向网页中添加 JavaScript 代码的时候,你有一个目标和一个问题。
目标: 你想要告诉计算机做什么。
问题: 你和计算机使用的是不同的语言。
你使用的是人类语言,而计算机使用的是机器语言。即使你不愿承认,对于计算机来说 JavaScript 甚至其他高级编程语言都是人类语言。这些语言是为人类的认知设计的,而不是机器。
所以 JavaScript 引擎的作用就是将你使用的人类语言转换成机器能够理解的东西。
我认为这就像电影 [降临](https://en.wikipedia.org/wiki/Arrival_(film)) 里人类和外星人试图互相交谈的情节一样。

在那部电影中,人类和外星人在尝试交流的过程里并不只是做逐字翻译。这两个群体对世界有不同的思考方式,人类和机器也是如此(我将在下一篇文章中详细说明)。
既然这样,那转化是如何发生的呢?
在编程中,我们通常使用解释器和编译器这两种方法将程序代码转化为机器语言。
解释器会在程序运行时对代码进行逐行转义。

相反的是,编译器会提前将代码转义并保存下来,而不是在运行时对代码进行转义。

以上两种转化方式都各有优劣。
### 解释器的优缺点 ###
解释器可以迅速开始工作。在运行代码之前,你不必等待所有的汇编步骤完成,只要开始转义第一行代码就可以运行程序了。
因此,解释器看起来自然很适用于 JavaScript 这类语言。对于 Web 开发者来说,能够快速运行代码相当重要。
这就是各浏览器在初期使用 JavaScript 解释器的原因。
但是当你重复运行同样的代码时,解释器的劣势就显现出来了。举个例子,如果在循环中,你就不得不重复对循环体进行转化。
### 编译器的优缺点 ###
编译器的优缺点恰恰和解释器相反。
使用编译器在启动时会花费多一些时间,因为它必须在启动前完成编译的所有步骤。但是在循环体中的代码运行速度更快,因为它不需要在每次循环时都进行编译。
另一个不同之处在于编译器有更多时间对代码进行查看和编辑,来让程序运行得更快。这些编辑我们称为优化。
解释器在程序运行时工作,因此它无法在转义过程中花费大量时间来确定这些优化。
## 两全其美的解决办法 —— JIT 编译器 ##
为了解决解释器在循环时重复编译导致的低效问题,浏览器开始将编译器混合进来。
不同浏览器的实现方式稍有不同,但基本思路是一致的。它们向 JavaScript 引擎添加了一个新的部件,我们称之为监视器(又名分析器)。监视器会在代码运行时监视并记录下代码的运行次数和使用到的类型。
起初,监视器只是通过解释器执行所有操作。

如果一段代码运行了几次,这段代码被称为 warm code;当这段代码运行了很多次时,它就会被称为 hot code。
### 基线编译器 ###
当一个函数运行了数次时,JIT 会将该函数发送给编译器编译,然后把编译结果保存下来。

该函数的每一行都被编译成一个“存根”,存根以行号和变量类型为索引(这很重要,我后面会解释)。如果监视器监测到程序再次使用相同类型的变量运行这段代码,它将直接抽取出对应代码的编译后版本。
这有助于加快程序的运行速度,但是像我说的,编译器可以做得更多。只要花费一些时间,它能够确定最高效的执行方式,即优化。
基线编译器可以完成一些优化(我会在后续给出示例)。不过,为了不阻拦进程过久,它并不愿意在优化上花费太多时间。
然而,如果这段代码运行次数实在太多,那就值得花费额外的时间对它做进一步优化。
### 优化编译器 ###
当一段代码运行的频率非常高时,监视器会把它发送给优化编译器。然后得到另一个运行速度更快的函数版本并保存下来。

为了得到运行速度更快的代码版本,优化编译器会做一些假设。
举例来说,如果它可以假设由特定构造函数创建的所有对象结构相同,即所有对象的属性名相同,并且这些属性的添加顺序相同,然后它就可以基于这个进行优化。
优化编译器会依据监视器监测代码运行时收集到的信息做出判断。如果在之前通过的循环中有一个值总是 true,它便假定这个值在后续的循环中也是 true。
但在 JavaScript 中没有任何情况是可以保证的。你可能会先得到 99 个结构相同的对象,但第 100 个就有可能缺少一个属性。
所以编译后的代码在运行前需要检查假设是否有效。如果有效,编译后的代码即运行。但如果无效,JIT 就认为它做了错误的假设并销毁对应的优化后代码。

进程会回退到解释器或基线编译器编译的版本。这个过程被称为去优化(或应急机制)。
通常优化编译器会加快代码运行速度,但有时它们也会导致意外的性能问题。如果你的代码被不断的优化和去优化,运行速度会比基线编译版本更慢。
为了防止这种情况发生,许多浏览器添加了限制,以便在“优化-去优化”这类循环发生时打破循环。例如,当 JIT 尝试了 10 次优化仍未成功时,就会停止当前优化。
### 优化示例: 类型专门化 ###
优化的类型有很多,但我只演示其中一种以便你理解优化是如何发生的。优化编译器最大的成功之一来自于类型专门化。
JavaScript 使用的动态类型系统在运行时需要多做一些额外的工作。例如下面这段代码:
```
function arraySum(arr) {
var sum = 0;
for (var i = 0; i < arr.length; i++) {
sum += arr[i];
}
}
```
执行循环中的 `+=` 一步似乎很简单。看起来你可以一步就得到计算结果,但由于 JavaScript 的动态类型,处理它所需要的步骤比你想象的多。
假定 `arr` 是一个存放 100 个整数的数组。在代码执行几次后,基线编译器将为函数中的每个操作创建一个存根。`sum += arr[i]` 将会有一个把 `+=` 依据整数加法处理的存根。
然而我们并不能保证 `sum` 和 `arr[i]` 一定是整数。因为在 JavaScript 中数据类型是动态的,有可能在下一次循环中的 `arr[i]` 是一个字符串。整数加法和字符串拼接是两个完全不同的操作,因此也会编译成非常不同的机器码。
JIT 处理这种情况的方法是编译多个基线存根。一段代码如果是单态的(即总被同一种类型调用),将得到一个存根。如果是多态的(即被不同类型调用),那么它将得到分别对应各类型组合操作的存根。
这意味着 JIT 在确定存根前要问许多问题。

在基线编译器中,由于每一行代码都有各自对应的存根,每次代码运行时,JIT 要不断检查该行代码的操作类型。因此在每次循环时,JIT 都要询问相同的问题。

如果 JIT 不需要重复这些检查,代码运行速度会加快很多。这就是优化编译器的工作之一了。
在优化编译器中,整个函数会被一起编译。所以类型检查可以在循环开始前完成。

一些 JIT 编译器做了进一步优化。例如,在 Firefox 中为仅包含整数的数组设立了一个特殊分类。如果 `arr` 是在这个分类下的数组,JIT 就不需要检查 `arr[i]` 是否是整数了。这意味着 JIT 可以在进入循环前完成所有类型检查。
## 总结 ##
简而言之,这就是 JIT。它通过监控代码运行确定高频代码,并进行优化,加快了 JavaScript 的运行速度,因此令大多数 JavaScript 应用程序的性能提高了数倍。
即使有了这些改进,JavaScript 的性能仍是不可预测的。为了加速代码运行,JIT 在运行时增加了以下开销:
- 优化和去优化
- 用于存储监视器纪录和应急回退时的恢复信息的内存
- 用于存储函数的基线和优化版本的内存
这里还有改进空间:除去以上的开销,提高性能的可预测性。这是 WebAssembly 实现的工作之一。
在[下一篇文章](https://github.com/xitu/gold-miner/blob/master/TODO/a-crash-course-in-assembly.md)中,我将对汇编做更多说明并解释编译器与它是如何工作的。
================================================
FILE: TODO/a-day-without-javascript.md
================================================
> * 原文地址:[A day without Javascript](https://sonniesedge.co.uk/blog/a-day-without-javascript)
> * 原文作者:[A day without Javascript](https://sonniesedge.co.uk/about/)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 译者:
> * 校对者:
# A day without Javascript
As I write this it’s raining outside, and I’m trying to avoid having to go out into the murk and watch the Germans conduct their annual [diversity maneuvers](http://www.karneval-berlin.de/en/). I’ve therefore decided to pass my time by doing the one thing that counts as a religious crime in web dev land: I’m going to turn off javascript in my browser and see what sites work and what sites don’t.
I know, I know, my life is simply too exciting.
Now, I know that because I write a lot about the universal web and progressive enhancement, people assume that I must hate javascript.
This would be an incorrect assumption.
I simply hate people relying on brittle client-side javascript when there are other alternatives. In the same way as I wouldn’t rely on some unknown minicab firm as the sole way of getting me to the airport for a wedding flight, I don’t like relying on a non-guaranteed technology as the sole way of delivering a web app.
For me it’s a matter of elegance and simplicity over unnecessary complexity.
## Too many tabs
So, for my dreary grey day experiment I restricted myself to just the things open in my browser tabs. For normal people this might be two or three sites.
Not for me. I have approximately 17 shitmillion tabs open, because I Have a Problem With Tabs.
No seriously. I can never just close a tab. I’ve tried things like [One Tab](https://www.one-tab.com/) but I just can’t get down to less than 30 in any one window (“I’ll just save that tab for later” I think, each and ever time). Let’s just agree that I need some kind of therapy, and we’ll all be able to move on.
Anyway, there’s nothing fancy to this experiment. It was a case of turning off javascript in the browser and reloading a site, nothing more. To quickly disable the browser’s JS with one click I used Chrome and the [Toggle Javascript](https://chrome.google.com/webstore/detail/toggle-javascript/cidlcjdalomndpeagkjpnefhljffbnlo) extension - available, ironically enough, via the javascript-only Chrome web store.
Oh, and for you, sweet reader, I opened these tabs in new windows, so you don’t have to see the pain of 50 tabs open at once.
## First impressions
So how was it? Well, with just a few minutes of sans-javascript life under my belt, my first impression was “Holy shit, things are *fast* without javascript”. There’s no ads. There’s no video loading at random times. There’s no sudden interrupts by “DO YOU WANT TO FUCKING SUBSCRIBE?” modals.
If this were the only manifestation of turning off javascript, I’d do this for the rest of time. However, a lot of things don’t work. Navigation is the most common failure mode. Hamburger menus fail to internally link to a nav section (come on, that’s an easy one kids). Forms die when javascript is taken away (point the form to an endpoint that accepts GET/POST queries ffs). Above the fold *images* fail to load (you do know they’re streaming by default, yes?).
## The sites
Let’s get to it. I think I’ve got a pretty representative list of sites in my open tabs (perhaps due to the aforementioned Tab Problem). Howl at me on Twitter if you feel I missed anything particularly important.
### Feedly

My very first attempt at sans-JS and I get nothing but a blank white page. Fuck you feedly.
*sighs, runs hands over face, shouts after Feedly*
Wait no, Feedly, I’m sorry. I didn’t mean that. It was the coffee talking. Can we talk this over? I like using you to keep up with blog posts.
But why do you work like this, Feedly? Your devs *could* offer the site in basic HTML and use advanced features such as, er, anchor links, to move to other articles. Then when JS is available, new content can be loaded via JS.
*Verdict:* Relationship counselling.
### Twitter

Twitter shows the normal website (with full content) for a brief moment, then redirects to [mobile.twitter.com](https://mobile.twitter.com) (the old one, not the spanky new React one, of course). This is really frustrating, as the full site would still be great to load without javascript. It could use the same navigation method as the mobile site, where it sets a query parameter to the URL “?max_id=871333359884148737” that dictates what is the latest tweet in your timeline to show. Simple and elegant.
*Verdict:* Could try harder.
### Google Chrome

The Google Chrome download page just fails completely, with no notice, only a blank white page.
*Sigh*.
*Verdict:* No Chrome for you, you dirty javascriptophobe!
### Youtube

Youtube really really wants to load. Really, reallllllly, wants to. But then it fucks things up at the last nanosecond and farts out, showing no video, no preview icons, and no comments (that last one is perhaps a positive).
Even if the site is doing some funky blob loading of video media, it wouldn’t be hard to put a basic version on the page initially (with `preload="none"`), and then have it upgrade when JS kicks in.
*Verdict:* Can’t watch My Drunk Kitchen or Superwoman. :( :( :(
### 24 ways

I’ve had this open in my tabs for the last 6 months, meaning to read it. Look, I’M SORRY, okay? But holy fuck, this site works great without javascript. All the animations are there (because they’re CSS) and the slide in navigation works (because it internally links to the static version of the menu at the bottom of the page).
*Verdict:* Class act. Smoooooth. Jazzz.
### Netflix

I’m using netflix to try and indoctrinate my girlfriend into watching Star Trek. So far she’s not convinced, mainly because “Tasha *slept with Mr Data?* But it’d be like fucking your microwave”.
Anyway, Netflix doesn’t work. Well, it loads the header, if you want to count that. I get why they don’t do things with HTML5 - DRMing all yo shit needs javascript. But still :(.
*Verdict:* JavaScript-only is the New Black
### NYtimes


Not sure why this was in my tab list, but tbh I’ve found rotting tabs from 2015 in there, so I’m not surprised.
The NY Times site loads in *561ms* and 957kb without javascript. Holy crap, that’s what it should be like normally. For reference it took 12000ms (12seconds) and 4000kb (4mb) to load *with* javascript. Oh, and as a bonus, you get a screenful of adverts.
A lot of images are lazy loaded, and so don’t work, getting replaced with funky loading icons. But hey ho, I can still read the stories.
*Verdict:* Failing… to *not* work. Sad!
### BBC News

It’s the day after the latest London terrorism attacks, and so I’ve got this open, just to see how the media intensifies and aids every terrorist action. The BBC is the inventor and poster-child for progressive enhancement via Cutting the Mustard, and it doesn’t disappoint. The non-CTM site works fully and while it doesn’t *look* the same as the full desktop site (it’s mobile-first and so is pretty much the mobile version), it still *works*.
*Verdict:* Colman’s Mustard
### Google search

Without JS, Google search still does what it’s best at: searching.
Okay, there’s no autocomplete, the layout reverts to the early 2000s again, and image search is shockingly bad looking. But, in the best progressive enhancement manner, you can still perform your core tasks.
*Verdict:* Solid.
### Wikipedia

Like a good friend, Wikipedia never disappoints. The site is indistinguishable from the JS version. Keep being beautiful, Wikipedia.
*Verdict:* BFFs.
### Amazon

The site looks a little… *off* without JS (the myriad accordions vomit their content over the page when JS isn’t there to keep them under control). But the entire site works! You can still search, you still get recommendations. You can still add items to your basket, and you can still proceed to the checkout.
*Verdict:* Amazonian warrior.
### Google Maps

Discounting Gmail, Google Maps is perhaps one of the most heavily used Single Page Applications out there. As such I expected some kind of fallback, like Gmail provides, even if it wasn’t true progressive enhancement. Maybe some kind of Streetmap style tile-by-tile navigation fallback?
But it failed completely.
*Verdict:* Cartography catastrophe.
## Overall verdict
This has made me appreciate the number of large sites that make the effort to build robust sites that work for everybody. But even on those sites that are progressively enhanced, it’s a sad indictment of things that they can be so slow on the multi-core hyperpowerful Mac that I use every day, but immediately become fast when JavaScript is disabled.
It’s even sadder when using a typical site and you realise how much Javascript it downloads. I now know why my 1GB mobile data allowance keeps burning out at least…
I maintain that it’s perfectly possible to use the web without javascript, especially on those sites that are considerate to the diversity of devices and users out there. And if I want to browse the web without javascript, well fuck, that’s my choice as a user. This is the web, not the Javascript App Store, and we should be making sure that things work on even the most basic device.
I think I’m going to be turning off javascript more, just on principle.
Haters, please tweet at me as you feel fit.
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)。
================================================
FILE: TODO/a-detailed-guide-on-developing-android-apps-using-the-clean-architecture-pattern.md
================================================
>* 原文链接 : [A detailed guide on developing Android apps using the Clean Architecture pattern](https://medium.com/@dmilicic/a-detailed-guide-on-developing-android-apps-using-the-clean-architecture-pattern-d38d71e94029#.7cz5w0dp3)
* 原文作者 : [Dario Miličić](https://medium.com/@dmilicic)
* 译文出自 : [掘金翻译计划](https://github.com/xitu/gold-miner)
* 译者 :
* 校对者:
Ever since I started developing Android apps there was this feeling that it could be done better. I’ve seen a lot of bad software design decisions during my career, some of which were my own — and Android complexity mixed with bad software design is a recipe for disaster. But it is important to learn from your mistakes and keep improving. After a lot of searching for a better way to develop apps I encountered the **Clean Architecture**. After applying it to Android, with some refinement and inspiration from similar projects, I decided that this approach is practical enough and worth sharing.
The **goal** of this article is to provide a step-by-step guide for developing Android apps in a Clean way. This whole approach is how I’ve recently been building my apps for clients with great success.
## What is Clean Architecture?
I will not go into too much detail here as there are articles that explain it much better than I can. But the next paragraph provides the **crux** of what you need to know to understand Clean.
Generally in Clean, code is separated into layers in an onion shape with one **dependency rule:** The inner layers should not know anything about the outer layers. Meaning that the **dependencies should point inwards**.
This is the previous paragraph visualized:

Awesome visual representation of the Clean Architecture. All credit for this image goes to [Uncle Bob](https://blog.8thlight.com/uncle-bob/archive.html).
Clean Architecture, as mentioned in the provided articles, makes your code:
* **Independent of Frameworks**
* **Testable.**
* **Independent of UI.**
* **Independent of Database.**
* **Independent of any external agency.**
I will hopefully make you understand how these points are achieved with examples below. For a more detailed explanation of Clean I really recommend this [article](https://blog.8thlight.com/uncle-bob/2012/08/13/the-clean-architecture.html) and this [video](https://vimeo.com/43612849).
### What this means for Android
Generally, your app can have an arbitrary amount of layers but unless you have Enterprise wide business logic that you have to apply in every Android app, you will most often have 3 layers:
* Outer: Implementation layer
* Middle: Interface adapter layer
* Inner: Business logic layer
The **implementation layer** is where everything framework specific happens. Framework specific code **includes every line of code that is not solving the problem you set to solve**, this includes all Android stuff like creating activities and fragments, sending intents, and other framework code like networking code and databases.
The purpose of the **interface adapter layer** is to act as a connector between your business logic and framework specific code.
The most important layer is the **business logic layer**. This is where you actually solve the problem you want to solve building your app. This layer does not contain any framework specific code and you **should be able to run it without an emulator**. This way you can have your business logic code that is **easy to test, develop and maintain**. That is the main benefit of the Clean Architecture.
Each layer, above the core layer, is also responsible for converting models to lower layer models before the lower layer can use them. An inner layer can not have a reference to model class that belongs to the outer layer. However, the outer layer can use and reference models from the inner layer. Again, this is due to our **dependency rule**. It does create overhead but it is necessary for making sure code is decoupled between layers.
> **Why is this model conversion necessary?** For example, your business logic models might not be appropriate for showing them to the user directly. Perhaps you need to show a combination of multiple business logic models at once. Therefore, I suggest you create a ViewModel class that makes it easier for you to display it to the UI. Then, you use a _converter_ class in the outer layer to convert your business models to the appropriate ViewModel.
> Another example might be the following: Let’s say you get a **Cursor** object from a **ContentProvider** in an outer database layer. Then the outer layer would convert it to your inner business model first, and then send it to your business logic layer to be processed.
I will add more resources to learn from at the bottom of the article. Now that we know about the basic principles of the Clean Architecture, let’s get our hands dirty with some actual code. I will show you how to build an example functionality using Clean in the next section.
## How do I start writing Clean apps?
I’ve made a [boilerplate project](https://github.com/dmilicic/Android-Clean-Boilerplate) that has all of the plumbing written for you. It acts as a **Clean starter pack** and is designed to be built upon immediately with most common tools included from the start. You are **free** to download it, modify it and build your apps with it.
You can find the starter project here: [**Android Clean Boilerplate**](https://github.com/dmilicic/Android-Clean-Boilerplate)
## Getting started writing a new use case
This section will explain all the code you need to write to create a use case using the Clean approach on top of the boilerplate provided in the previous section. A use case is just some isolated functionality of the app. A use case may (e.g. on user click) or may not be started by a user.
First let’s explain the structure and terminology of this approach. This is how I build apps but it is _not set in stone_ and you can organize it differently if you want.
### Structure
The general structure for an Android app looks like this:
* Outer layer packages: UI, Storage, Network, etc.
* Middle layer packages: Presenters, Converters
* Inner layer packages: Interactors, Models, Repositories, Executor
### Outer layer
As already mentioned, this is where the framework details go.
**UI — **This is where you put all your Activities, Fragments, Adapters and other Android code related to the user interface.
**Storage — **Database specific code that implements the interface our Interactors use for accessing data and storing data. This includes, for example, [**ContentProviders**](http://developer.android.com/guide/topics/providers/content-providers.html) or ORM-s such as [**DBFlow**](https://github.com/Raizlabs/DBFlow).
**Network — **Things like [**Retrofit**](http://square.github.io/retrofit/) go here.
### Middle layer
Glue code layer which connects the implementation details with your business logic.
**Presenters — **Presenters handle events from the UI (e.g. user click) and usually serve as callbacks from inner layers (Interactors).
**Converters — **Converter objects are responsible for converting inner models to outer models and vice versa.
### Inner layer
The core layer contains the most high-level code. **All classes here are POJOs**. Classes and objects in this layer have no knowledge that they are run in an Android app and can easily be ported to any machine running JVM.
**Interactors — **These are the classes which actually **contain your business logic code**. These are run in the background and communicate events to the upper layer using callbacks. They are also called UseCases in some projects (probably a better name). It is normal to have a lot of small Interactor classes in your projects that solve specific problems. This conforms to the [**Single Responsibility Principle**](https://en.wikipedia.org/wiki/Single_responsibility_principle)and in my opinion is easier on the brain.
**Models — **These are your business models that you manipulate in your business logic.
**Repositories — **This package only contains interfaces that the database or some other outer layer implements. These interfaces are used by Interactors to access and store data. This is also called a [repository pattern.](https://msdn.microsoft.com/en-us/library/ff649690.aspx)
**Executor — **This package contains code for making Interactors run in the background by using a worker thread executor. This package is generally not something you need to change.
### A simple example
In this example, our use case will be: **_“Greet the user with a message when the app starts where that message is stored in the database.”_** This example will showcase how to write the following three packages needed to make the use case work:
* the **presentation** package
* the **storage** package
* the **domain** package
The first two belong to the outer layer while the last one is the inner/core layer.
**Presentation** package is responsible for everything related to showing things on the screen — it includes the whole [MVP](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93presenter) stack (it means it also includes both the UI and Presenter packages even though they belong to different layers).
OK — less talk, more code.
## Writing a new Interactor (inner/core layer)
In reality you could start in any layer of the architecture, but I recommend you to start on your core business logic first. You can write it, test it and make sure it works without ever creating an activity.
So let’s start by creating an Interactor. The Interactor is where the main logic of the use case resides. **All Interactors are run in the background thread so there shouldn’t be any impact on UI performance.** Let’s create a new Interactor with a warm name of **WelcomingInteractor**.
public interface WelcomingInteractor extends Interactor {
interface Callback {
void onMessageRetrieved(String message);
void onRetrievalFailed(String error);
}
}
The **Callback** is responsible for talking to the UI on the main thread, we put it into this Interactor’s interface so we don’t have to name it a _WelcomingInteractorCallback — _to distinguish it from other callbacks. Now let’s implement our logic of retrieving a message. Let’s say we have a **MessageRepository** that can give us our welcome message.
public interface MessageRepository {
String getWelcomeMessage();
}
Now let’s implement our Interactor interface with our business logic. **It is important that the implementation extends the AbstractInteractor which takes care of running it on the background thread.**
```
public class WelcomingInteractorImpl extends AbstractInteractor implements WelcomingInteractor {
private void notifyError() {
mMainThread.post(new Runnable() {
@Override
public void run() {
mCallback.onRetrievalFailed("Nothing to welcome you with :(");
}
});
}
private void postMessage(final String msg) {
mMainThread.post(new Runnable() {
@Override
public void run() {
mCallback.onMessageRetrieved(msg);
}
});
}
@Override
public void run() {
// retrieve the message
final String message = mMessageRepository.getWelcomeMessage();
// check if we have failed to retrieve our message
if (message == null || message.length() == 0) {
// notify the failure on the main thread
notifyError();
return;
}
// we have retrieved our message, notify the UI on the main thread
postMessage(message);
}
```
This just attempts to retrieve the message and sends the message or the error to the UI to display it. We notify the UI using our Callback which is actually going to be our Presenter. **That is the crux of our business logic. Everything else we need to do is framework dependent.**
Let’s take a look which dependencies does this Interactor have:
```
import com.kodelabs.boilerplate.domain.executor.Executor;
import com.kodelabs.boilerplate.domain.executor.MainThread;
import com.kodelabs.boilerplate.domain.interactors.WelcomingInteractor;
import com.kodelabs.boilerplate.domain.interactors.base.AbstractInteractor;
import com.kodelabs.boilerplate.domain.repository.MessageRepository;
```
As you can see, there is **no mention of any Android code.** That is the **main benefit** of this approach. You can see that the **Independent of Frameworks** point holds. Also, we do not care about specifics of the UI or database, we just call interface methods that someone somewhere in the outer layer will implement. Therefore, we are **Independent of UI** and **Independent of Databases.**
## Testing our Interactor
We can now run and **test our Interactor without running an emulator**. So let’s write a simple **JUnit** test to make sure it works:
```
@Test
public void testWelcomeMessageFound() throws Exception {
String msg = "Welcome, friend!";
when(mMessageRepository.getWelcomeMessage())
.thenReturn(msg);
WelcomingInteractorImpl interactor = new WelcomingInteractorImpl(
mExecutor,
mMainThread,
mMockedCallback,
mMessageRepository
);
interactor.run();
Mockito.verify(mMessageRepository).getWelcomeMessage();
Mockito.verifyNoMoreInteractions(mMessageRepository);
Mockito.verify(mMockedCallback).onMessageRetrieved(msg);
}
```
Again, this Interactor code has no idea that it will live inside an Android app. This proves that our business logic is **Testable,** which was the second point to show.
## Writing the presentation layer
Presentation code belongs to the **outer layer** in Clean. It consists of framework dependent code to display the UI to the user. We will use the **MainActivity** class to display the welcome message to the user when the app resumes.
Let’s start by writing the interface of our **Presenter** and **View**. The only thing our view needs to do is to display the welcome message:
public interface MainPresenter extends BasePresenter {
interface View extends BaseView {
void displayWelcomeMessage(String msg);
}
}
So how and where do we start the Interactor when an app resumes? Everything that is not strictly view related should go into the Presenter class. This helps achieve [**separation of concerns**](https://en.wikipedia.org/wiki/Separation_of_concerns) and prevents the Activity classes from getting bloated. This includes all code working with Interactors.
In our **MainActivity** class we override the **_onResume()_** method:
@Override
protected void onResume() {
super.onResume();
// let's start welcome message retrieval when the app resumes
mPresenter.resume();
}
All **Presenter** objects implement the **_resume()_** method when they extend **BasePresenter**.
> **Note**: Astute readers will probably see that I have added Android lifecycle methods to the BasePresenter interface as helper methods, even though the Presenter is in a lower layer. The Presenter should not know about anything in the UI layer — e.g. that it has a lifecycle. However, I’m not specifying Android specific *_event_* here as every UI has to be shown to the user sometime. Imagine I called it **onUIShow()** instead of **onResume()**. It’s all good now, right? :)
We start the Interactor inside the **MainPresenter** class in the **_resume()_** method:
@Override
public void resume() {
mView.showProgress();
// initialize the interactor
WelcomingInteractor interactor = new WelcomingInteractorImpl(
mExecutor,
mMainThread,
this,
mMessageRepository
);
// run the interactor
interactor.execute();
}
The **_execute()_** method will just execute the **_run()_** method of the **WelcomingInteractorImpl** in a background thread. The **_run()_** method can be seen in the **_Writing a new Interactor_** section.
You may notice that the Interactor behaves similarly to the **AsyncTask** class. You supply it with all that it needs to run and execute it. You might ask why didn’t we just use AsyncTask? Because that is **Android specific code** and you would need an emulator to run it and to test it.
We provide several things to the interactor:
* The **ThreadExecutor** instance which is responsible for executing Interactors in a background thread. I usually make it a singleton. This class actually resides in the **domain** package and does not need to be implemented in an outer layer.
* The **MainThreadImpl** instance which is responsible for posting runnables on the main thread from the Interactor. Main threads are accessible using framework specific code and so we should implement it in an outer layer.
* You may also notice we provide **_this_** to the Interactor — **MainPresenter** is the Callback object the Interactor will use to notify the UI for events.
* We provide an instance of the **WelcomeMessageRepository** which implements the **MessageRepository** interface that our interactor uses. The **WelcomeMessageRepository** is covered later in the **_Writing the storage layer_** section.
> **Note**: Since there are many things you need to provide to an Interactor each time, a dependency injection framework like [Dagger 2](https://github.com/google/dagger) would be useful. But I choose not to include it here for simplicity. Implementation of such a framework is left to your own discretion.
Regarding **_this_**, the **MainPresenter** of the **MainActivity** really does implement the Callback interface:
public class MainPresenterImpl extends AbstractPresenter implements MainPresenter, WelcomingInteractor.Callback {
And that is how we listen for events from the Interactor. This is the code from the **MainPresenter**:
@Override
public void onMessageRetrieved(String message) {
mView.hideProgress();
mView.displayWelcomeMessage(message);
}
@Override
public void onRetrievalFailed(String error) {
mView.hideProgress();
onError(error);
}
The View seen in these snippets is our **MainActivity** which implements this interface:
public class MainActivity extends AppCompatActivity implements MainPresenter.View {
Which is then responsible for displaying the welcome message, as seen here:
@Override
public void displayWelcomeMessage(String msg) {
mWelcomeTextView.setText(msg);
}
And that is pretty much it for the presentation layer.
## Writing the storage layer
This is where our repository gets implemented. All the database specific code should come here. The repository pattern just abstracts where the data is coming from. Our main business logic is oblivious to the source of the data — be it from a database, a server or text files.
For complex data you can use [**ContentProviders**](http://developer.android.com/guide/topics/providers/content-providers.html) or ORM tools such as [**DBFlow**](https://github.com/Raizlabs/DBFlow). If you need to retrieve data from the web then [**Retrofit**](http://square.github.io/retrofit/) will help you. If you need simple key-value storage then you can use [**SharedPreferences**](http://developer.android.com/training/basics/data-storage/shared-preferences.html). You should use the right tool for the job.
Our database is not really a database. It is going to be a very simple class with some simulated delay:
public class WelcomeMessageRepository implements MessageRepository {
@Override
public String getWelcomeMessage() {
String msg = "Welcome, friend!"; // let's be friendly
// let's simulate some network/database lag
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return msg;
}
}
As far as our **WelcomingInteractor** is concerned, the lag might be because of the real network or any other reason. It doesn’t really care what is underneath the **MessageRepository** as long as it implements that interface.
### Summary
This example can be accessed on a git repository [here](https://github.com/dmilicic/Android-Clean-Boilerplate/tree/example). The summarized version of calls by class is as follows:
> **MainActivity ->MainPresenter -> WelcomingInteractor -> WelcomeMessageRepository -> WelcomingInteractor -> MainPresenter -> MainActivity**
It is important to note the flow of control:
> **Outer — Mid — Core — Outer — Core — Mid — Outer**
It is common to access the outer layers multiple times during a single use case. In case you need to display something, store something and access something from the web, your flow of control will access the outer layer at least three times.
## Conclusion
For me, this has been the best way to develop apps so far. Decoupled code makes it easy to focus your attention on specific issues without a lot of bloatware getting in the way. After all, I think this is a pretty [SOLID](https://en.wikipedia.org/wiki/SOLID_%28object-oriented_design%29) approach but it does take some time getting used to. That was also the reason I wrote all of this, to help people understand better with step-by-step examples. If anything remains unclear I will gladly address those concerns as your feedback is very important. I would also very much like to hear what can be improved. A healthy discussion would benefit everyone.
I have also built and open sourced a sample cost tracker app with Clean to showcase how the code would look like on a real app. It’s nothing really innovative in terms of features but I think it covers what I talked about well with a bit more complex examples. You can find it here: [**Sample Cost Tracker App**](https://github.com/dmilicic/android-clean-sample-app)
And again, that sample app was built upon the _Clean starter pack_ that can be found here: [**Android Clean Boilerplate**](https://github.com/dmilicic/Android-Clean-Boilerplate)
================================================
FILE: TODO/a-dramatic-tour-through-pythons-data-visualization-landscape-including-ggplot-and-altair.md
================================================
> * 原文地址:[A Dramatic Tour through Python’s Data Visualization Landscape (including ggplot and Altair)](https://dansaber.wordpress.com/2016/10/02/a-dramatic-tour-through-pythons-data-visualization-landscape-including-ggplot-and-altair/)
* 原文作者:[Dan Saber](https://dansaber.wordpress.com/about-me/)
* 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
* 译者:[cdpath](https://github.com/cdpath)
* 校对者:[Gran](https://github.com/Graning), [Freya Yu](https://github.com/ZiXYu)
# Python 数据可视化概览(涵盖 ggplot 和 Altair)
### 伙计,为什么还要去尝试?
* * *
我最近偶然发现了 Brian Granger 和 Jake VanderPlas 开发的 Altair,一个非常有潜力的新可视化库。Altair 似乎非常适合用来表达 Python 对 ggplot 的羡慕,而它采用了 JavaScript 的 Vega-Lite 语法,这意味着后者开发的新功能(比如提示框和缩放)都能被 Altair 所用,而且看样子是免费的!
我甚至是太喜欢 Altair 了,都想把本文的主题改成: **「嘿,用 Altair 吧。」**
不过我随后开始反思自以为更 Pythonic 的可视化习惯,在这相当痛苦的自我反思中,我发现自己错得一塌糊涂:为了应对手头的工作我用了一大堆工具还有乱七八糟的技术,通常是随便选一个第一个能完成工作的库 1。
这并不好。俗话说得好,「未经校对的绘图不值得导出 PNG 文件」。
于是我借着探索 Altair 的机会回过头来研究了 Python 可视化统计工具是如何组织在一起的。希望我的调查结果对你也有用。
### 我们从哪里开始呢?
* * *
本文用别出心裁的对比手法写成:「你需要做某事。你要怎么用 matplotlib,pandas,Seaborn,ggplot 或者 Altair 来实现呢?」通过这些不同的实现方式,我们就可以得出它们的优点,缺点,还有其他收获 —— 至少这么多代码说不定啥时候有用呢。
(警告:所有这一切都会以双幕剧的形式呈现)
### 主角们(按主观复杂性递减排列)
* * *
首先,欢迎我们的朋友们2:
**[matplotlib](http://matplotlib.org/)**
matplotlib 就像八百磅的大猩猩一样「重」,最好躲着它走,除非真的需要它的力量,比如需要定制化绘图或者提供可以出版的图像。
(我们将会看到,当谈到统计可视化时,正确的思路可能是:「尽量用熟悉的工具(比如下面要讲到的四个库)把活干完,剩下的再用 matplotlib」。)
**[pandas](http://pandas.pydata.org/pandas-docs/stable/visualization.html)**
为数据框而生;坚持使用绘图便利函数,而这可以说比被取代的 matplotlib 代码好用多了。- 被拒的 pandas 广告语。
(花边新闻:pandas 项目组肯定有些可视化迷,因为它包含了诸如 RadViz 图和 Andrews 曲线这类其他库没有的东西。)
**[Seaborn](https://stanford.edu/~mwaskom/software/seaborn/)**
Seaborn 一直是我最核心的统计可视化库,它这样自我总结的:
**如果说 matplotlib 试图让简单的更简单,让难的变得可行,那么 Seaborn 就是试图让虽难却定义精良的部分也变得简单。**
**[yhat’s ggplot](https://github.com/yhat/ggplot)**
ggplot 是出色的声明式 ggplot2 的 Python 实现。它不仅仅「逐一复刻」了 ggplot2 的特性,还有一些共有的强大特性。(对业余的 R 语言用户而言,重要的组件似乎应有尽有。)
**[Altair](https://github.com/ellisonbg/altair)**
新成员 Altair 是「声明式统计可视化库」,有着极其好用的 API。
好极了。既然大伙都到了还做了自我介绍,我们开始尴尬的晚宴对话吧。我们的演出叫……
## Python 可视化库小商店(每个库演的就是自己)
* * *
### 第一幕:线和点
* * *
(在第一场,我们要处理的是整洁数据集 `ts`。它有三列:`dt`(存日期),`value` (存值)和 `kind` (有四个不同的**水平**:A,B,C 和 D)。数据长这个样子:)
||dt|kind|value|
|---|---|---|---|
|0|2000-01-01|A|1.442521|
|1|2000-01-02|A|1.981290|
|2|2000-01-03|A|1.586494|
|3|2000-01-04|A|1.378969|
|4|2000-01-05|A|-0.277937|
#### 第一场:如何在一张图上画多个时间序列?
* * *
**matplotlib**: 哈!哈哈!不能再简单了。虽然我可以用很多复杂的方式搞定这个,不过我明白你们的笨脑子是无法理解其中的精妙的。所以我退而求其次给你们展示两个简单的方法。第一个方法,我循环使用你们虚构的矩阵,我相信你们这些人把它叫做「数据框」,取其子集传给相关的时间序列。然后调用 `plot` 方法,传入子集中的相关列。
``` python
# MATPLOTLIB
fig, ax = plt.subplots(1, 1,
figsize=(7.5, 5))
for k in ts.kind.unique():
tmp = ts[ts.kind == k]
ax.plot(tmp.dt, tmp.value, label=k)
ax.set(xlabel='Date',
ylabel='Value',
title='Random Timeseries')
ax.legend(loc=2)
fig.autofmt_xdate()
```

**MPL**: 然后我把它转换成数组(给 pandas 做手势),让他对「数据框」做轴向旋转(pivot),结果是这样的:
``` python
# the notion of a tidy dataframe matters not here
dfp = ts.pivot(index='dt', columns='kind', values='value')
dfp.head()
```
|kind|A|B|C|D|
|---|---|---|---|---|
|dt|||||
|2000-01-01|1.442521|1.808741|0.437415|0.096980|
|2000-01-02|1.981290|2.277020|0.706127|-1.523108|
|2000-01-03|1.586494|3.474392|1.358063|-3.100735|
|2000-01-04|1.378969|2.906132|0.262223|-2.660599|
|2000-01-05|-0.277937|3.489553|0.796743|-3.417402|
**MPL**: 将数据转换为有四个列的索引 —— 每一列都对应待画的线 —— 我用一步就可以搞定这一切(比如,调用一次 `plot` 函数)。
``` python
# MATPLOTLIB
fig, ax = plt.subplots(1, 1,
figsize=(7.5, 5))
ax.plot(dfp)
ax.set(xlabel='Date',
ylabel='Value',
title='Random Timeseries')
ax.legend(dfp.columns, loc=2)
fig.autofmt_xdate()
```

**pandas (看上去怯生生的):** 这很不错,Mat。真的不错。谢谢你提到我。我也能用同样的方法搞定这个 —— 希望可以同样出色(微微一笑)。
``` python
# PANDAS
fig, ax = plt.subplots(1, 1,
figsize=(7.5, 5))
dfp.plot(ax=ax)
ax.set(xlabel='Date',
ylabel='Value',
title='Random Timeseries')
ax.legend(loc=2)
fig.autofmt_xdate()
```
**pandas**: 结果看上去完全一样,所以我就不展示了。
**Seaborn(抽着烟,调整着贝雷帽)**: 唔。看上去区区一个折线图就让你们做了这么多数据处理。我是说,for 循环和轴向旋转?这不是九十年代的微软 Excel(译者注:pivot table 即 Excel 的数据透视表)。我在国外学到一个叫做 FacetGrid 的东西。你们大概从来没有听说过……
``` python
# SEABORN
g = sns.FacetGrid(ts, hue='kind', size=5, aspect=1.5)
g.map(plt.plot, 'dt', 'value').add_legend()
g.ax.set(xlabel='Date',
ylabel='Value',
title='Random Timeseries')
g.fig.autofmt_xdate()
```

**SB:** 看懂了吗?直接给 FacetGrid 传入未处理的整洁数据。在这里,将 `kind` 赋给 `hue` 参数的意思是绘出四条不同的线 —— 每条线对应 `kind` 的一个水平。而真正画出这四条线,得把 FacetGrid 映射到到庸俗的(**示意 matplotlib**) plot 函数,再传入 `x` 和 `y` 参数。显然,这些东西得牢记,就像添加图例一样,但是也不会太难。好吧,对有些人来说没有什么东西有挑战性……
**ggplot**: 哇,赞!我的方法和她差不多,但是我做起来更像我的大哥。你们听过他吗?他超级酷 ——
**SB**: 谁邀请了这个孩子?
**GG**: 快来看看!
``` python
# GGPLOT
fig, ax = plt.subplots(1, 1, figsize=(7.5, 5))
g = ggplot(ts, aes(x='dt', y='value', color='kind')) + \
geom_line(size=2.0) + \
xlab('Date') + \
ylab('Value') + \
ggtitle('Random Timeseries')
g
```

**GG (拿起 Hadley Wickham 写的 《ggplot2》读出声来)**: 每一幅图都由数据(比如 `ds`),图形映射(比如 `x`,`y` 和 `color`)和几何图形(比如 `geom_line`)组成,而后者将数据和图形映射转换成真正的可视化。
**Altair**: 没错,我也是这么做的。
``` python
# ALTAIR
c = Chart(ts).mark_line().encode(
x='dt',
y='value',
color='kind'
)
c
```

**ALT**: 给我的 Chart 类同样的数据,告诉它你要哪种可视化:这里就是 `mark_line`。然后指定想要的图形映射:x 轴是 `data`,y 轴是 `value`;因为我们想要按 `kind` 分组,所以把 `kind` 传给 `color`。就跟你一样,GG(**拨乱 GG 的头发**)。哦,这样一来,要用你们都用的配色方案也轻而易举了:
``` python
# ALTAIR
# cp corresponds to Seaborn's standard color palette
c = Chart(ts).mark_line().encode(
x='dt',
y='value',
color=Color('kind', scale=Scale(range=cp.as_hex()))
)
c
```

**MPL 害怕又惊讶地盯着**
#### 第一场的分析
* * *
除了混蛋的 matplotlib 3,还有一些要点值得注意。
* 用 matplotlib 和 pandas 的时候,要么得多次调用 `plot` 函数(比如每个 for 循环里面),要么得对数据进行处理才能更好适用于 plot 函数(比如轴向旋转)。(也就是说我们在第二场还会见到其他的技术。)
* (说实话,我从来不觉得这是个大问题,直到我遇到了 R 语言使用者。他们看到我都惊呆了。)
* 与之相反,ggplot 和 Altair 用的是类似声明式「图形语法」的方法去解决这种简单问题:给「主」函数 (ggplot 中的 `ggplot` 和 Altair 中的 `Chart`)传入整洁的数据集。然后定义一组图形映射(x,y 和 color)来说明数据该如何映射到图形上(比如视觉标记做了很多努力以便更好地传达信息)。只要使用这些图形(ggplot 的 `geom_line` 和 Altair 的 `mark_line`),数据和图形映射就会被转换成便于人类理解的视觉形象,这样一来就大功告成了。
* 聪明得话,你可以(甚至应该)透过同样的视角看待 Seaborn 的 FacetGrit;但是并不是完全一致。FacetGrid 除了数据集之外还需要**预先**提供 `hue` 参数,然后才需要 x 和 y 参数。这种映射并不是图形映射,只是函数映射:数据集中的每一个 `hue` 都会调用 matplotlib 的 plot 函数,`dt` 和 `value` 分别传给 x 和 y 参数。for 循环是不可见的底层实现。
* 也就是说,尽管图形映射需要两个独立的步骤,比起命令式的思维方式,我还是更喜欢图形映射(至少在画图时如此)。
**数据说明**
(在第二场到第四场,我们会处理著名的「鸢尾花」数据集(在代码中用 `df` 表示)。它包含了四个数字列,对应不同的测量,还有一个类别列,表明它是三种鸢尾花中的哪一种。下面是预览:
|花瓣长度|花瓣宽度|萼片长度|萼片宽度|品种|
|---|---|---|---|---|
|0|1.4|0.2|5.1|3.5|setosa|
|1|1.4|0.2|4.9|3.0|setosa|
|2|1.3|0.2|4.7|3.2|setosa|
|3|1.5|0.2|4.6|3.1|setosa|
|4|1.4|0.2|5.0|3.6|setosa|
#### 第二场:如何画散点图?
* * *
**MPL(看上去有点震惊)**: 我是说,你可以继续用 for 循环,当然了。这样也没什么问题。当然。懂了吗?(**压低声音小声说**)只要记得显式地设定好颜色变量,不然所有的点都是蓝的……
``` python
# MATPLOTLIB
fig, ax = plt.subplots(1, 1, figsize=(7.5, 7.5))
for i, s in enumerate(df.species.unique()):
tmp = df[df.species == s]
ax.scatter(tmp.petalLength, tmp.petalWidth,
label=s, color=cp[i])
ax.set(xlabel='Petal Length',
ylabel='Petal Width',
title='Petal Width v. Length -- by Species')
ax.legend(loc=2)
```

**MPL**: 可是,呃,(**假装充满自信**)我有个更好的主意!看这个:
``` python
# MATPLOTLIB
fig, ax = plt.subplots(1, 1, figsize=(7.5, 7.5))
def scatter(group):
plt.plot(group['petalLength'],
group['petalWidth'],
'o', label=group.name)
df.groupby('species').apply(scatter)
ax.set(xlabel='Petal Length',
ylabel='Petal Width',
title='Petal Width v. Length -- by Species')
ax.legend(loc=2)
```

**MPL**: 我在这定义了 `scatter` 函数。它用 pandas 的 groupby 对象得到分组,然后在 x 轴上画出花瓣长度,y 轴则是花瓣宽度。每组都如此处理一番!厉害吧!
**P**: 真不错,Mat!真不错!基本上和我的方法差不多,所以我就坐这里不展示了。
**SB (咧嘴笑)**: 这次怎么没用轴向旋转?
**P**: 嗯,这个例子里要用轴向旋转的话比较复杂。因为不像处理时序数据一样有一个通用的索引,所以……
**MPL**: 嘘!我们没必要跟她解释。
**SB**: 随便你了。不管怎样,在我看来这个问题和上一个没有什么区别。还是构建一个 FacetGrid,只是这次将 `plt.plot` 换成 `plt.scatter`。
``` python
# SEABORN
g = sns.FacetGrid(df, hue='species', size=7.5)
g.map(plt.scatter, 'petalLength', 'petalWidth').add_legend()
g.ax.set_title('Petal Width v. Length -- by Species')
```

**GG**: 对!对!就是这样!我的写法就是把 `geom_line` 换成 `geom_point`!
``` python
# GGPLOT
g = ggplot(df, aes(x='petalLength',
y='petalWidth',
color='species')) + \
geom_point(size=40.0) + \
ggtitle('Petal Width v. Length -- by Species')
g
```

**ALT (一脸茫然)**: 是的,只要把 `mark_line` 换成 `mark_point`。
``` python
# ALTAIR
c = Chart(df).mark_point(filled=True).encode(
x='petalLength',
y='petalWidth',
color='species'
)
c
```

#### 第二场的分析
* * *
* 到这儿,用数据构建 API 的潜在难题变得清晰了。尽管 pandas 的轴向旋转处理时序数据时非常方便,处理这个例子却力不从心了。
* 公平地说,`group by` 方法是可以推导出来的,而 for 循环就更容易推出来了;但是这样一来就要有更多自定义的逻辑,也就意味着更多的工作:Seaborn 已经好心帮你做好了,不然你还得自己造轮子。
* 反过来说,Seaborn,ggplot 和 Altair 都明白散点图在很多方面就是没有假设的折线图(尽管这些假设可能是无害的)。因此,第一场中的代码大都可以重用,但是得用新的几何对象(ggplot 和 Altair 分别用的是 `geom_point` 和 `mark_point`)或者新的方法(比如 Seaborn 的 `plt.scatter`)。在这个节点上,没有哪个库比其他库更方便,尽管我爱 Altair 优雅的简洁。
#### 第三场:如何画分面的散点图?
* * *
**MPL**: 那么,嗯,一旦你掌握了 for 循环 —— 显然我就掌握了 —— 只需要简单调整一下之前的代码就行了。我用 `subplot` 方法画了三个轴,而不是一个。接下来就跟以前一样遍历一遍,用类似取数据子集的方法来取相关的 Axes 对象的子集。
(**重拾自信)我敢打赌你们各位没有更简单的方法!(举起双臂,差点打到了 pandas)**
``` python
# MATPLOTLIB
fig, ax = plt.subplots(1, 3, figsize=(15, 5))
for i, s in enumerate(df.species.unique()):
tmp = df[df.species == s]
ax[i].scatter(tmp.petalLength, tmp.petalWidth, c=cp[i])
ax[i].set(xlabel='Petal Length',
ylabel='Petal Width',
title=s)
fig.tight_layout()
```

**SB 和笑起来的 ALT 交换了目光;GG 仿佛听到笑话了笑了起来**
**MPL**: 怎么啦?!
**Altair**: 老兄,看看你的 x 轴和 y 轴。所有图像的坐标轴范围都不一样。
**MPL (脸红了)**: 呃,是,当然啊。我就是想看看你们有没有注意听我说话。你当然可以在 `subplot` 函数中指定坐标轴范围,保证所有的子图坐标轴范围是统一的。
``` python
# MATPLOTLIB
fig, ax = plt.subplots(1, 3, figsize=(15, 5),
sharex=True, sharey=True)
for i, s in enumerate(df.species.unique()):
tmp = df[df.species == s]
ax[i].scatter(tmp.petalLength,
tmp.petalWidth,
c=cp[i])
ax[i].set(xlabel='Petal Length',
ylabel='Petal Width',
title=s)
fig.tight_layout()
```

**P(叹气)**: 我也是这么做的。跳过我吧。
**SB**: 改写 FacetGrid 然后用在这个例子上很简单。就像使用 `hue` 变量一样,我们可以简单加一个 `col` 变量(比如 colum)。这会告诉 FacetGrid 不仅给每个种类一个唯一的颜色,还把每个种类都画在唯一的子图上,按列排列。(只要将 `col` 变量换成 `row` 就可以按行排列。)
``` python
# SEABORN
g = sns.FacetGrid(df, col='species', hue='species', size=5)
g.map(plt.scatter, 'petalLength', 'petalWidth')
```

**GG:** 哦,这和我的做法不同(**再一次拿起《ggplot2》开始读**)。看,分面和图形映射本质上是两个不同的步骤,我们不应该一时疏忽把它们混为一谈。因此,我们接着用之前的代码这次加上 `facet_grid` 层,也就是显式地用类别进行分面。(**开心地合上书**)至少我大哥是这么说的!你们听到他了吗?在书里。他真酷啊4。
``` python
# GGPLOT
g = ggplot(df, aes(x='petalLength',
y='petalWidth',
color='species')) + \
facet_grid(y='species') + \
geom_point(size=40.0)
g
```

**ALT****:** 我这里采用更具 Seaborn 风格的方法。具体地说,我给编码函数加了一个 `column` 参数。也就是说我也做了一些新工作:第一,虽然 `column` 参数可以接受一个简单的字符串变量,实际上我传给它的是 Column 对象,如此我可以自定义标题了。第二,我用了自定义的 `configure_cell` 方法,如果不用的话子图会变得特别巨大。
``` python
# ALTAIR
c = Chart(df).mark_point().encode(
x='petalLength',
y='petalWidth',
color='species',
column=Column('species',
title='Petal Width v. Length by Species')
)
c.configure_cell(height=300, width=300)
```

#### 第三场的分析
* * *
* matplotlib 说得很清楚:这个例子中,他的代码根据分类对数据进行分面的思路和上面的其他方案是一样的;假如你的脑袋可以搞清楚那些 for 循环的话,你可以再试试下面这段代码。但是我可没有让他再搞出更复杂的东西出来,比如 2 x 3 的网格。不然他就得像下面这样干:
``` python
# MATPLOTLIB
fig, ax = plt.subplots(2, 3, figsize=(15, 10), sharex=True, sharey=True)
# this is preposterous -- don't do this
for i, s in enumerate(df.species.unique()):
for j, r in enumerate(df.random_factor.sort_values().unique()):
tmp = df[(df.species == s) & (df.random_factor == r)]
ax[j][i].scatter(tmp.petalLength,
tmp.petalWidth,
c=cp[i+j])
ax[j][i].set(xlabel='Petal Length',
ylabel='Petal Width',
title=s + '--' + r)
fig.tight_layout()
```

* 为了用正规的可视化表达式**: 呸**。如果用 Altair 的话一切都变得非常简单。
``` python
# ALTAIR
c = Chart(df).mark_point().encode(
x='petalLength',
y='petalWidth',
color='species',
column=Column('species',
title='Petal Width v. Length by Species'),
row='random_factor'
)
c.configure_cell(height=200, width=200)
```

* 只比我们刚才用过的 `encode` 函数多一个变量!
* 幸运的是,把分面构建到可视化库框架中的好处是显而易见的。
### 第二幕:分布和条形图
* * *
#### 第四场:怎么可视化分布?
* * *
**MPL (信心明显不足了)**: 好吧,如果我们要画箱线图——我们真的要箱线图吗?——我知道怎么画。不过非常愚蠢;你肯定不会喜欢。不过我给 `boxplot` 方法传入一个数组组成的数组,每个数组就都会得到一个箱线图。你可能需要手动标注 X 轴的刻度。
``` python
# MATPLOTLIB
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
ax.boxplot([df[df.species == s]['petalWidth'].values
for s in df.species.unique()])
ax.set(xticklabels=df.species.unique(),
xlabel='Species',
ylabel='Petal Width',
title='Distribution of Petal Width by Species')
```

**MPL:** 如果要画柱状图 —— 我们真的要画柱状图吗? —— 我也有个方法可以用,你可以用之前提到的 for 循环或者 `group by`。
``` python
# MATPLOTLIB
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
for i, s in enumerate(df.species.unique()):
tmp = df[df.species == s]
ax.hist(tmp.petalWidth, label=s, alpha=.8)
ax.set(xlabel='Petal Width',
ylabel='Frequency',
title='Distribution of Petal Width by Species')
ax.legend(loc=1)
```

**P (看上去不同寻常的骄傲)**: 哈!哈哈哈哈!该我大显身手了!你们都觉得我一无是处,只是 `matplotlib` 的替罪羊。虽然我目前都只是套用他的 `plot` 方法,但我也拥有一些特殊的函数可以处理箱线图**和**柱状图。用他们来可视化分布简直就是小菜一碟!你只需要提供两个列名:第一,用来分组的列名;第二,待分布统计的列名。分别把它们传给 `by` 和 `column` 参数,图马上就画好了!
``` python
# PANDAS
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
df.boxplot(column='petalWidth', by='species', ax=ax)
```

``` python
# PANDAS
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
df.hist(column='petalWidth', by='species', grid=None, ax=ax)
```

**GG和ALT举手击掌然后祝贺P;高呼「棒极了!」,「就该这样!」,「就这么干!」**
**SB (假装很热情)**: 喔喔喔。很赞。同时呢,分布对我非常重要,所以我为它准备了一些特殊方法。比如,我的 `boxplot` 方法只需要 x 变量、y 变量和数据就可以得到这个:
``` python
# SEABORN
fig, ax = plt.subplots(1, 1, figsize=(10, 10))
g = sns.boxplot('species', 'petalWidth', data=df, ax=ax)
g.set(title='Distribution of Petal Width by Species')
```

**SB:** 这个图不错吧,我是说有人这么说过…… 不管了。我还有个特殊的分布方法叫 `distplot` 远不止条形图那么简单(傲慢的看了眼 pandas)。你可以用来画条形图,KDEs 和轴须图(rugplots) —— 甚至画在一起。比如把 `displot` 和 FacedGrid 结合起来,我就可以为每一种鸢尾花都画出直方轴须图:
``` python
# SEABORN
g = sns.FacetGrid(df, hue='species', size=7.5)
g.map(sns.distplot, 'petalWidth', bins=10,
kde=False, rug=True).add_legend()
g.set(xlabel='Petal Width',
ylabel='Frequency',
title='Distribution of Petal Width by Species')
```

**SB**: 不过…… 管他呢。
**GG:** 这些只不过是新的几何对象!`GEOM_BOXPLOT` 来画箱线图,`GEOM_HISTOGRAM` 来画直方图!换用它俩就行了!(**绕着餐桌跑了起来**)
``` python
# GGPLOT
g = ggplot(df, aes(x='species',
y='petalWidth',
fill='species')) + \
geom_boxplot() + \
ggtitle('Distribution of Petal Width by Species')
g
```

``` python
# GGPLOT
g = ggplot(df, aes(x='petalWidth',
fill='species')) + \
geom_histogram() + \
ylab('Frequency') + \
ggtitle('Distribution of Petal Width by Species')
g
```

**ALT (看上去坚定又自信)**: 我要忏悔……
**四周安静了下来 —— GG停了下来,把盘子撞到了地上。**
**ALT:(沉重地喘气)** 我……我……我不会画箱线图。从来没学过怎么画,不过我相信我的源语言 JavaScript 的语法不支持箱线图肯定是有原因的。不过我会画直方图……
``` python
# ALTAIR
c = Chart(df).mark_bar(opacity=.75).encode(
x=X('petalWidth', bin=Bin(maxbins=30)),
y='count(*)',
color=Color('species', scale=Scale(range=cp.as_hex()))
)
c
```

**ALT**: 乍一看代码会觉得有点怪,但是不要担心。这里实际是在说:「嘿,直方图事实上就是条形图」。X 轴对应着 `bin`,我们可以用 `Bin` 类来定义;同时 y 轴对应到数据集里落到对应 Bin 的数据的数量。用 SQL 语言来说 y 就是 `count(*)`。
#### 第四场的分析
* * *
* 在工作中,我的确发现 pandas 的便利函数很方便,但是我得承认,脑子里总要惦记着 pandas 给箱线图和直方图提供了 `by` 参数,却没有给折线图提供该参数。
* 我把第一场和第二场分开是有原因的,其中最重要的原因是:从第二场开始 matplotlib 变得比较吓人。比如说要画箱线图还得记着用一个完全独立的界面,这根本不适合我。
* 说起第一场和第二场,有一个有趣的小细节:其实我一开始是因为 Seaborn 有丰富的「专利级」可视化函数(比如,distplot,小提琴图,回归图等等)而从 matplotlib/pandas 转移阵营的。但我后来喜欢上了 FacetGrid,我必须说这些第二场中的函数是 Seaborn 的杀手级应用。只要我还在画图我就离不开它们。
* (此外,我需要说明:Seaborn 提供了许多被小型库所忽略的优秀可视化函数;如果你碰巧需要一二,那么 Seaborn 是你唯一的选择。)
* 这些例子真的可以让你领会到 ggplot 图形对象系统的力量。用基本相同的代码(更重要的是连思路都基本相同),就可以画出截然不同的图来。还不用调用不同的函数,只是改变图形映射呈现给视图的方式就行了,比如换一下几何对象。
* 类似的,哪怕在第二场,Altair 的 API 也有非同寻常的一致性。哪怕对于那些看上去非常另类的操作,Altair 的 API 也非常简单、优雅,令人印象深刻。
**数据说明**
(在最后一幕,我们会处理「泰坦尼克」,另一个著名的整洁数据集(代码中仍然用 `df` 来表示)。下面是预览……)
|survived|pclass|sex|age|fare|class|
|---|---|---|---|---|---|
|0|0|3|male|22.0|7.2500|Third|
|1|1|1|female|38.0|71.2833|First|
|2|1|3|female|26.0|7.9250|Third|
|3|1|1|female|35.0|53.1000|First|
|4|0|3|male|35.0|8.0500|Third|
这个例子中,我们感兴趣的是看看每个客舱等级的平均费用是否和逃生率相关。显然,在 pandas 中我们可以这样写:
``` python
dfg = df.groupby(['survived', 'pclass']).agg({'fare': 'mean'})
dfg
```
|
|
fare |
| survived |
pclass |
|
| 0 |
1 |
64.684008 |
| 2 |
19.412328 |
| 3 |
13.669364 |
| 1 |
1 |
95.608029 |
| 2 |
22.055700 |
| 3 |
13.694887 |
…… 不过这有什么意思呢?我写的可是数据可视化文章,所以用条形图再试一次!
#### 第五场:如何画条形图?
* * *
**MPL (表情严肃)**: 一句话也没说。
``` python
# MATPLOTLIB
died = dfg.loc[0, :]
survived = dfg.loc[1, :]
# more or less copied from matplotlib's own
# api example
fig, ax = plt.subplots(1, 1, figsize=(12.5, 7))
N = 3
ind = np.arange(N) # the x locations for the groups
width = 0.35 # the width of the bars
rects1 = ax.bar(ind, died.fare, width, color='r')
rects2 = ax.bar(ind + width, survived.fare, width, color='y')
# add some text for labels, title and axes ticks
ax.set_ylabel('Fare')
ax.set_title('Fare by survival and class')
ax.set_xticks(ind + width)
ax.set_xticklabels(('First', 'Second', 'Third'))
ax.legend((rects1[0], rects2[0]), ('Died', 'Survived'))
def autolabel(rects):
# attach some text labels
for rect in rects:
height = rect.get_height()
ax.text(rect.get_x() + rect.get_width()/2., 1.05*height,
'%d' % int(height),
ha='center', va='bottom')
ax.set_ylim(0, 110)
autolabel(rects1)
autolabel(rects2)
plt.show()
```

**其他人都开始摇头**
**P**: 我得先对数据进行一些处理 —— 也就是 `group by` 和 `pivot` —— 处理完就可以用非常帅气的条形图方法了,比上面这些简单得多!哇,我现在自信多了,我把其他人都比下去了!5
``` python
# PANDAS
fig, ax = plt.subplots(1, 1, figsize=(12.5, 7))
# note: dfg refers to grouped by
# version of df, presented above
dfg.reset_index().\
pivot(index='pclass',
columns='survived',
values='fare').plot.bar(ax=ax)
ax.set(xlabel='Class',
ylabel='Fare',
title='Fare by survival and class')
```

**SB:** 我恰好又认为这类工作非常重要。鉴于此,我使用了特殊的 `factorplot` 函数来帮助我:
``` python
# SEABORN
g = sns.factorplot(x='class', y='fare', hue='survived',
data=df, kind='bar',
order=['First', 'Second', 'Third'],
size=7.5, aspect=1.5)
g.ax.set_title('Fare by survival and class')
```

**SB**: 跟之前一样,先将未处理过的数据传给数据框,再搞明白自己要按照什么进行分组,这里就是 `class` 和 `survived`,它们对应 `x` 和 `hue` 变量。然后搞明白要对哪个数据列进行摘要统计,这里就是 `fare`,对应到 `y` 变量。默认的摘要统计方法是求平均数,不过 `factorplot` 提供了 `estimator` 参数,可以通过它指定想要的函数,比如求和,标准差,中位数等等。而选择的函数会决定每个柱的高度。
当然,有很多方法可以可视化这个信息,条形图只有一种。同样我还提供了 `kind` 参数用来指定不同的可视化方法。
最后,**还有人**比较在意统计确定性,所以我会默认给你加上误差线,这样可以看出不同等级舱位的平均费用和生存率是否有关系。
(**压低声音说**)希望你们做得比我还好
**ggplot2 停下兰博基尼,走了进来**
**ggplo2**: 嘿,你们看到 ——
**GG**: 嘿,大哥。
**GG2**: 嘿,小家伙。我们得走了。
**GG**: 等一下,我得马上把这个条形图画好,不过遇到麻烦了。你会怎么做呢?
**GG2 (阅读手册)**_: 哦,就像这样:
``` python
# GGPLOT2
# R 语言中你得这样写
ggplot(df, aes(x=factor(survived), y=fare)) +
stat_summary_bin(aes(fill=factor(survived)),
fun.y=mean) +
facet_wrap(~class)
# 天啊,ggplot2 可真棒
```

**GG2**: 看懂了吗?你要像我之前说的一样定义好图形映射,不过得把 `y` 映射到平均费用上。这就得叫我的好兄弟 `stat_summary_bin` 帮忙了,我只要把 `mean` 传给 `fun.y` 参数就行了。
**GG (惊讶地睁大眼睛)**: 哦,呃…… 我发现我还没有 `stat_summary_bin` 呢。我想想 —— pandas 你能帮帮我吗?
**P**: 呃,当然可以。
**GG**: 好诶!
``` python
# GGPLOT
g = ggplot(df.groupby(['class', 'survived']).\
agg({'fare': 'mean'}).\
reset_index(), aes(x='class',
fill='factor(survived)',
weight='fare',
y='fare')) + \
geom_bar() + \
ylab('Avg. Fare') + \
xlab('Class') + \
ggtitle('Fare by survival and class')
g
```

**GG2**: 噢,不完全是图形式语法,不过我觉得只要 Hadley 还没有发现,这样也能用…… 特别是你不应该在可视化之前就对数据进行汇总。我也不是特别懂这个上下文中 `weight` 是什么意思……
**GG**: 是这样,我的条形图形对象默认会使用简单计数,所以如果没有 `weight` 的话所有柱子的高度都是 `1`。
**GG2**: 噢,我懂了…… 我们以后再讨论吧。
**GG 和 GG2 道别并离开了晚宴**
**ALT**: 噢,现在**这**可是我的安身立命之道。非常简单。
``` python
# ALTAIR
c = Chart(df).mark_bar().encode(
x='survived:N',
y='mean(fare)',
color='survived:N',
column='class')
c.configure_facet_cell(strokeWidth=0, height=250)
```
**ALT:** 我希望下面的解释可以让所有的变量都非常直观:我想按幸存数来画平均船费,按舱位等级进行分面。写在代码里就是 `survived` 是 x 变量,`mean(fare)` 是 y 变量,而 `class` 是 column 变量。(我还指定了 color 变量这样画面可以热闹点。)
但是,这里也有一些新东西值得注意。注意,我在 x 和 color 中的 `survivde` 字符串后面加了 `:N`。这是我给自己加的注释,意思就是「这是个名义上的变量。」我需要加这个注释是因为 `survived` 看上去像个定量变量,而定量变量有可能让绘的图变得有点丑。也不要太担心啦,这问题也不是每次都能碰到,只有个别情况下会有影响。比如,在上面的时间序列图中,如果我不知道 `dt` 是时间变量,我可能会假设它们只是名义变量,这样子就尴尬了(还好我在后面加上了 `:T`,这样就好了)。
另外我还用了 `configure_facet_cell` 协议让三个子图看上去更加统一。
#### 第五场的分析
* * *
* 这条不要想太多:我再也不用 matplotlib 画条形图了,明确地说,这不是我的个人观点!事实上 matplotlib 不会像其他的库那样对传入的数据进行推测。这有时候就意味着你得写严格的命令式代码。
* (当然,正是这种数据不可知论让 matplotlib 成了其他 Python 可视化库的基础。)
* 相对而言,在需要汇总统计和误差线的时候,我总是会用 Seaborn。
* (这样比较可能有失公允,毕竟我选的例子仿佛是为 Seaborn 的一个函数量身定制的,不过我的工作中这种事遇到的太多了,而且,嘿,这篇文章可是我写的。)
* 我不觉得 pandas 或 ggplot 的方式有什么特别的优势。
* 不过,就 pandas 而言,哪怕是简单的条形图也必须得记得用 `group by` 和 `pivot`,这看上去有点傻。
* 同样,我的确认为这是 yhat 开发的 ggplot 的一个重大缺陷,要找一个 `stat_summary` 的替代品从而让 ggplot 变得功能完善全面还有很长的路要走。
* 同时,Altair 依然让我印象深刻!我被解决这个例子的代码的直观性震惊了。哪怕你从来没有见过 Altair,我也能想象有人是可以看懂的。正是它**这种**思考,代码和可视化的一一对应让它成了我最爱的库。
### 最后的感想
* * *
你知道有时我觉得心怀感激非常重要:我们有非常多的可视化库可以选择,我痴迷于深入探索这一切!
(是啊,这只是种逃避。)
尽管我在 matplotlib 上遇到了点困难,它还是非常好玩的(每一部剧都要有搞笑的部分)。不仅仅是因为 matplotlib 是 pandas,Seaborn 和 ggplot 这些库的底层基础,而且是因为它给予你非常细粒度的控制权。虽然我没有说,但是我用 matplotlib 调整了所有非 Altair 所绘的图。但是,注意听,matplotlib 是纯声明式的,非常细节地指定可视化图像的方方面面简直是无趣的(看看条形图的例子吧)。
的确,还有这种结果:「用统计可视化能力来评价 matplotlib 是不公平的,你这个刻薄的家伙。你在用它的一种使用案例来和其他库的主要使用案例进行比较。这些方法显然应该一起使用。你可以使用自己喜欢的方便的/陈述式表达层—— pandas,Seaborn,ggplot 或者将来的 Altair(下文会详述)—— 来做基础工作。然后用 matplotlib 完成那些非基础工作。如果你穷尽了其他库所能提供的一切也找不到想要的东西,你会很高兴可以看到能力无限的 matplotlib 就在你身边,你这个不知感恩的业余绘图的。」
对于这些人我得说:是的!这很有道理,却脱离现实……,尽管只是**说**这些并不会撑起博文的大部分内容。
再说,要是我就不会骂人。
同时,轴向旋转(pivot)结合 pandas 处理时间序列图像非常好用。考虑到 pandas 的时间序列支持更加广泛,我还会接着用。此外,下一次如果要画 [RadViz](http://pandas.pydata.org/pandas-docs/stable/visualization.html#radviz) 图,我就知道该怎么做了。也就是说,尽管 pandas 的确在 matplotlib 的命令式范式的基础上提供了声明式语法(比如条形图),它仍然极具 matplotlib 风格。
接着说:如果你想要一些更偏向统计的东西,用 Seaborn 吧(她的确在国外学到了很多很酷的东西)。学习她的 API —— factorplot, regplot, displot 等等等等 —— 然后爱上她。这时间花得值。至于 faceting,我觉得 FacetGrid 是个很有用的共犯(wtf!);但是要不是我使用 Seaborn 已久,我可能更喜欢 ggplot 或 Altair。
说到声明式的优雅,我一直深爱着 ggplot2 ,而且对 Python 的 ggplot 留下了深刻印象。我肯定会持续关注这个项目。(更自私地说,我希望它可以阻止那些使用 R 语言同事取笑我。)
最后,如果你要做的事可以用 Altair 完成(抱歉了,箱线图使用者),用它吧!它提供的 API 异常简单又非常好用。如果还需要其他动力,想想这些:Altair 一个令人激动的特性是(除了即将到来的针对其底层 Vega-Lite 语法的改进之外),从技术的角度来说,它并不是可视化库。它输出符合 Vega-Lite 标准的 JSON 对象,可以用 IPython Vega 渲染得非常好。
这有什么好激动的?好吧,在底层,所有的可视化看上去都是这个样子的:

的确,看上去没什么好激动的,但是想想它的影响:如果其他的库对此感兴趣,他们可以直接开发新方法将这些 Vega-Lite JSON 对象转换成可视化结果。这就意味着可以用 Altair 搞定基本工作,然后深入底层用 matplotlib 获得更多控制。
我已经对此期待万分了。
说完这一切,再说几句告别的话:Python 可视化可比一个男人,女人或者尼斯湖水怪大多了。所以你得有选择地接受我刚才说的一切,不论是代码还是意见。记得:互联网上的一切都是谎言,该死的谎言和统计。
希望你喜欢这个书呆子气十足的疯帽匠茶会,如果学到了什么东西你可以用到自己的工作中。
照旧, 代码在 [GitHub](https://github.com/dsaber/py-viz-blog) 上。
#### _**注释**_
* * *
首先,非常感谢订阅了 /u/counters 的 reddit 用户,你们在[这个评论](https://www.reddit.com/r/Python/comments/55k4ru/a_dramatic_tour_through_pythons_data/d8bawp4)留下了非常有价值的反馈和观点。我选取了一些放在了「最后的感谢」一节;不过我的表示远没有那么清楚,也就是说,看看那个评论吧;非常不错。
其次,非常非常感谢 [Thomas Caswell](https://plus.google.com/+ThomasCaswell),他写的关于 matplotlib 的特性的评论你绝对要读一读。这样你就能一睹远比我写的优雅得多的 matplotlib 代码了。
1. 严格地说,这不是真的。我会尽量使用 Seaborn,只有在需要定制的时候才深入到 matplotlib。也就是说,我觉得这个前提是更强有力的陷阱,毕竟我们生活在后真相社会。
2. 马上解释一下,你都对我愤怒了,所以允许我解释一二:我爱 bokeh 和 plotly。真的,我在提交分析之前最爱做的一件事就是把图像传给相关的 bokeh/plotly 函数,获得自由的交互性;但是我对它俩都不是特别熟,没法做更高级的操作。(说实话,这篇文章已经够长的了。)
显然,如果你要的是交互可视化(而不是统计可视化),你可能就得找它俩了。
3. **请**注意:这只是为了好玩。我**没有**用业余的拟人化手法评价任何库。我相信显示生活中的 matplotlib 是非常可爱的。
4. 坦率地说,我不是**完全**确定单独进行分面操作是为了意识形态上的纯洁,或者只是单纯出于实用的考虑。虽然我的 ggplot 角色声称他是前者(他的理解来自匆匆读完的[这篇论文](http://vita.had.co.nz/papers/layered-grammar.pdf)),也有可能是因为(实际上) ggplot2 对分面的支持太丰富了,所以需要当作是独立的步骤。如果我描述的角色违反了任何图形语法规则,请务必告诉我,我会去找个新的。
5. 绝对不是这个故事的道德准则。
================================================
FILE: TODO/a-fairer-vue-of-react-comparing-react-to-vue-for-dynamic-tabular-data-part-2.md
================================================
>* 原文链接 : ["A fairer Vue of React" - Comparing React to Vue for dynamic tabular data, part 2.](https://engineering.footballradar.com/a-fairer-vue-of-react-comparing-react-to-vue-for-dynamic-tabular-data-part-2/)
* 原文作者 : [Max Willmott](https://engineering.footballradar.com/author/max-willmott/)
* 译文出自 : [掘金翻译计划](https://github.com/xitu/gold-miner)
* 译者 : [wildflame](https://github.com/wildflame)
* 校对者:[hikerpig](https://github.com/hikerpig), [JolsonZhu](https://github.com/JolsonZhu), [godofchina](https://github.com/godofchina)
# 较为完整的 React.js / Vue.js 的性能比较 Part 1
_有关第一部分的文章,请访问 [https://engineering.footballradar.com/from-a-react-point-of-vue-comparing-reactjs-to-vuejs-for-dynamic-tabular-data/](https://engineering.footballradar.com/from-a-react-point-of-vue-comparing-reactjs-to-vuejs-for-dynamic-tabular-data/) 。第一篇文章的实验结果已经被证明有错误,但是它为这篇文章奠定了基础。_
五月23日,周一,我们发布了一篇关于比较 React 和 Vue 的性能的文章,其实验数据比较了二者谁更适合处理频繁更新的列表数据,特别是在对性能要求非常高的情况下。比方说我们手头上的一个足球雷达(Football Radar)的项目。
最初我们对实验结果信心满满,但发现几个较为重要的错误后,才知道实验结果并非像我们预期的那样。我们非常感谢在 React 和 Vue 社区里的宝贵意见 —— 特别是 React 的核心工程师克里斯托弗(Christopher Chedeau) ([@vjeux](https://twitter.com/vjeux)),和 Vue 的创始人尤雨溪([@youyuxi](https://twitter.com/youyuxi))—— 因为你们,我们才能快速的锁定这次测试中的出现的问题,可以说是因祸得福,因为尽管错误被公开使我感到有一些小小的尴尬,但我的确学到了很多,所以衷心的感谢你们的讨论。
鉴于我们已为第一篇文章做了许多改进,不能否定还有进一步改进的余地,因此这篇文章比起来,更像是一篇游记,而不是一个全面完善的结果。
这里首先,我想重申一下这次实验的目的,然后讲一下我们所犯的错误 —— 掌声送给那些帮助我们改正错误的人 —— 最后我会公布更新的更公正的测试结果。
## 测试
这个实验的输出是一组足球比赛,每一个都一秒更新一次数据。在实验中,为了测试性能及可拓展性,我们会修改两组独立的数据:足球比赛数量和每次更新之间的延迟。

为了模拟页面加载情况及测量其可扩展性,我们分别使用 Vue 和 React 测试了50,100,500场比赛,其延迟分别是100ms,1s,然后看其可拓展性如何。
我们的第一次结果不太客观,显示 Vue 的性能表现比 React 要好很多,其实是因为测试运行在开发模式(Development Mode),而这个疏忽直接造成了结果偏差。感谢克里斯多弗(@Christopher)提出这个问题:[https://github.com/footballradar/VueReactPerf/pull/3](https://github.com/footballradar/VueReactPerf/pull/3)。在生产模式(Production Mode)运行 React 忽略了一些消耗资源较大的进程,包括了 prop-types 的检查和警告。尽管这是一个非常明显的优化,但由于 React 默认运行在开发模式,所以这个优化很容易被忽略掉。我们要强调的是 Vue 也是运行在开发模式的,二者都同样被影响到了。那篇 pull-request 里接下来的相关讨论都非常醍醐灌顶。
我们也用了一些无效的测试数据,这使得 Vue 比起 React 在同等条件下快了10倍。在我们的测试中,两个框架都具有相同的测试数据。但是 Github 上的 pull-request 里的那个版本并没有确保这点一致性,所以其他测试的人也许会看到这个具有误导性的结论。
## 与上一个测试相比的改变
* 在[生产模式](https://github.com/footballradar/VueReactPerf/pull/3)下运行。
* 添加了 `webpack.optimize.UglifyJsPlugin`
* 添加了 [babel-react-optimize preset](https://github.com/thejameskyle/babel-react-optimize)
## 新发现
以下是部分的开发者工具 timeline 的概要,在下面的这个项目里有实际的栈和 timeline 的截图:[[https://github.com/footballradar/VueReactPerf/tree/master/results/v2](https://github.com/footballradar/VueReactPerf/tree/master/results/v2)
有意思的是,Chrome 的开发工具在获取 Vue 的 500 场比赛测试结果的 30s 时间线时崩溃了,但 React 的 500 场比赛测试却没有。我们截取了 15s 的结果以取代它,但是让人不解的是,Vue 相比于 React,其实有更多的空闲时间。
所有下面的结果都共享同一个主题:由于 React 的虚拟 Dom 的实现,它的 scripting 上运行的时间更长;Vue 由于要直接更改 Dom ,所以它有关在 painting 和 rendering 工作上更耗费资源。然而,所有工作都做完以后,Vue 在大多数情况下仍然比 React 快25%。这虽然不同于我们最初的巨大区别,仍然是一个值得关注的问题。
##### 50 场比赛,100ms 的延迟
React:

Vue:

##### 50 场比赛,1s的延迟
React:

Vue:

##### 100 场比赛,100ms 的延迟
React:

Vue:

##### 100 场比赛,1s 的延迟
React:

Vue:

##### 500 场比赛,100ms 的延迟
React:

Vue:

##### 500 场比赛,1s 的延迟
React:

Vue:

## 结论
总的来说,最初那个 Vue 比 React 表现好的结论在_这个用例_上仍然是有价值的,但是明显还有很多可以优化的地方,特别是 React。一个附带的结论是,需要多少的工作和相关知识,才能提高 React 的性能,而 Vue 在开箱即用的情况下就优化的很好。但不管我们说些什么,Vue 的开发者体验毫无疑问是更棒的。
================================================
FILE: TODO/a-first-walk-into-kotlin-coroutines-on-android.md
================================================
> * 原文地址:[A first walk into Kotlin coroutines on Android](https://android.jlelse.eu/a-first-walk-into-kotlin-coroutines-on-android-fe4a6e25f46a)
> * 原文作者:[Antonio Leiva](https://android.jlelse.eu/@antoniolg)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 译者:[Feximin](https://github.com/Feximin)
> * 校对者:[wilsonandusa](https://github.com/wilsonandusa) 、[atuooo](https://github.com/atuooo)
---
# 第一次走进 Android 中的 Kotlin 协程

> 本文提取并改编自最近更新的 [Kotlin for Android Developers](https://antonioleiva.com/book) 一书。
协程是 Kotlin 1.1 引入的最牛逼的功能。他们确实很棒,不但很强大,而且社区仍然在挖掘如何使他们得到更加充分的利用。
简单来说,协程是一种按序写异步代码的方式。**你可以一行一行地写代码,而不是到处都有乱七八糟的回调**。有的还将会有暂停执行然后等待结果返回的能力。
如果你以前是 C# 程序员,async/await 是最接近的概念。但是 Kotlin 中的协程功能更强大,因为他们不是一个特定想法的实现,而是**一个语言级别的功能,可以有多种实现去解决各种问题**。
你可以编写自己的实现,或者使用一个 Kotlin 团队和其他独立开发者已经构建好的实现。
你要明白**协程在 Kotlin 1.1 中是一个实验性的功能**。这意味着当前实现在将来可能会改变,尽管旧的实现仍将被支持,但你有可能想迁移到新的定义上。如我们稍后将见,你需要去选择开启这个特性,否则在使用的时候会有警告。
这也意味着你应该将本文视为一个(协程)可以做些什么的示例而不是一个经验法则。未来几个月可能会有很大变动。
---
### 理解协程如何工作
本文旨在让你了解一些基本概念,会用一个现有的库,而不是去自己去实现一个。但我认为重要的是了解一些内部原理,这样你就不会盲目使用了。
协程基于**暂停函数**的想法:那些函数被调用之后**可以终止(程序)执行**,一旦完成他们自己的任务之后又可以让他(程序)继续执行。
暂停函数用保留关键字 `suspend` 来标记,而且只能在其他暂停函数或协程内部被调用。
这意味着你不能随便调用一个暂停函数。需要有一个包裹函数来构建协程并提供所需的上下文。类似这样的:
fun async(block: suspend () -> T)
我并不是在解释如何实现上述方法。那是一个复杂的过程,不在本文范围内,并且大多情况下已经有多种实现好的方法了。
如果你确实有兴趣实现自己的,你可以读一下 [**coroutines Github**](https://github.com/Kotlin/kotlin-coroutines/blob/master/kotlin-coroutines-informal.md) 中所写的规范。你仅需要知道的是:方法名字可以随意取,至少有一个暂停块做为参数。
然后你可以实现一个暂停函数并在块中调用:
suspend fun mySuspendingFun(x: Int) : Result {
…
}
async {
val res = mySuspendingFun(20)
print(res)
}
协程是线程吗?不完全是。他们的工作方式相似,但是(协程)更轻量、更有效。你可以有数以百万的协程运行在少量的几个线程中,这打开了一个充满可能性的世界。
使用协程功能有三种方式:
- **原始实现**:意思是创建你自己的方式去使用协程。这非常复杂并且通常不是必要的。
- **底层实现**: Kotlin 提供了一套库,解决了一些最难的部分并提供了不同场景下的具体实现,你可以在 [kotlinx.coroutines](https://github.com/Kotlin/kotlinx.coroutines) 仓库中找到这些库,比如说: [one for Android](https://github.com/Kotlin/kotlinx.coroutines/tree/master/ui/kotlinx-coroutines-android) 。
- **高级实现**:如果你只是想要**一个可以提供一切你所需的解决方案**来开始马上使用协程的话,有几个库可以使用,他们为你做了所有复杂的工作,并且(库的)数量在持续增长。我推荐 [Anko](https://github.com/Kotlin/anko),他提供了一个可以很好的工作在 Android 上的方案,有可能你已经很熟悉了。
---
### 使用 Anko 实现协程
自从 0.10 版本以来,Anko 提供了两种方法以在 Android 上使用协程。
第一种与我们在上面的例子中看到的非常相似,和其他的库所做的也类似。
首先,你需要创建**一个可以调用暂停函数的异步块**:
async(UI) {
…
}
UI参数是 `async` 块的执行上下文。
然后你可以创建**在后台线程中执行的块**,将结果返回给UI线程。那些块以 `bg` 方法定义:
async(UI) {
val r1: Deferred = bg { fetchResult1() }
val r2: Deferred = bg { fetchResult2() }
updateUI(r1.await(), r2.await())
}
`bg` 返回一个 `Deferred` 对象,这个对象**在 `await()` 方法被调用后会暂停协程**,直到有结果返回。我们将在下面的例子中采用这种方案。
正如你可能知道的,由于 Kotlin 编译器能够[推导出变量类型](https://antonioleiva.com/variables-kotlin/),因此可以更加简单:
async(UI) {
val r1 = bg { fetchResult1() }
val r2 = bg { fetchResult2() }
updateUI(r1.await(), r2.await())
}
第二种方法是利用与特定子库中提供的监听器的集成,这取决于你打算使用哪个监听器。
例如,在 `anko-sdk15-coroutines` 中有一个 `onClick` 监听器,他的 lambda 实际上是一个协程。这样你就可以在监听器代码块上立即使用暂停函数:
textView.onClick {
val r1 = bg { fetchResult1() }
val r2 = bg { fetchResult2() }
updateUI(r1.await(), r2.await())
}
如你所见,结果与之前的很相似。只是少了一些代码。
为了使用他,你需要添加一些依赖,这取决于你想要使用哪些监听器:
compile “org.jetbrains.anko:anko-sdk15-coroutines:$anko_version”
compile “org.jetbrains.anko:anko-appcompat-v7-coroutines:$anko_version”
compile “org.jetbrains.anko:anko-design-coroutines:$anko_version”
---
### 在示例中使用协程
在[这本书](https://antonioleiva.com/book)所解释的例子(你可以在[这里](https://github.com/antoniolg/Kotlin-for-Android-Developers)找到)中,我们创建了一个简单的天气应用。
为了使用 Anko 协程,我们首先需要添加这个新的依赖:
compile “org.jetbrains.anko:anko-coroutines:$anko_version”
接下来,如果你还记得,我曾经告诉过你需要选择使用这个功能,否则就会出现警告。要做到这一点(使用协程功能),只需要简单地在根文件夹下的 `gradle.properties` 文件(如果不存在就创建)中添加这一行:
kotlin.coroutines=enable
现在,你已经准备好开始使用协程了。让我们首先进入详情 activity 中。他只是使用一个特定的命令调用了数据库(用来缓存每周的天气预报数据)。
这是生成的代码:
async(UI) {
val id = intent.getLongExtra(ID, -1)
val result = bg { RequestDayForecastCommand(id)
.execute() }
bindForecast(result.await())
}
太棒了!天气预报数据是在一个后台线程中请求的,这多亏了 `bg` 方法,这个方法返回了一个延迟结果。那个延迟结果在可以返回前会一直在 `bindForecast` 调用中等待。
但并不是一切都好。发生了什么?协程有一个问题:**他们持有一个 `DetailActivity` 的引用,如果这个请求永不结束就会内存泄露**。
别担心,因为 Anko 有一个解决方案。你可以为你的 activity 创建一个弱引用,然后使用那个弱引用来代替:
val ref = asReference()
val id = intent.getLongExtra(ID, -1)
async(UI) {
val result = bg { RequestDayForecastCommand(id).execute() }
ref().bindForecast(result.await())
}
在 activity 可用时,弱引用允许访问 activity,当 activity 被杀死,协程将会取消。需要仔细确保的是所有对 activity 中的方法或属性的调用都要经过这个 `ref` 对象。
但是如果协程多次和 activity 交互的话会有点复杂。例如,在 `MainActivity` 使用这个方案将变得更加复杂。
这个 activity 将基于一个 zipCode 来调用一个端点来请求一周的天气预报数据:
private fun loadForecast() {
val ref = asReference()
val localZipCode = zipCode
async(UI) {
val result = bg { RequestForecastCommand(localZipCode).execute() }
val weekForecast = result.await()
ref().updateUI(weekForecast)
}
}
你不能在 `bg` 块中使用 `ref()` ,因为在那个块中的代码不是一个暂停上下文,因此你需要将 `zipCode` 保存在另一个本地变量中。
老实说,我认为泄露 activity 对象 1-2 秒没那么糟糕,不过有可能不能成为样板代码。因此如果你能确保你的后台处理不会永远不结束(比如,为你的服务器请求设置一个超时)的话,不使用 `asReference()` 也是安全的。
这样的话,`MainActivity` 将变得更加简单:
private fun loadForecast() = async(UI) {
val result = bg { RequestForecastCommand(zipCode).execute() }
updateUI(result.await())
}
综上,你已经可以一种非常简单的同步方式来写你的异步代码。
这些代码非常简单,但是想象一下复杂的情况:后台操作的结果被下一个后台操作使用,或者当你需要遍历列表并为每一项都执行请求的时候。
所有一切都可以写成常规的同步代码,写起来、维护起来将更加容易。
---
关于如何充分利用协程还有很多需要学习。如果你有更多相关的经验,请评论以让我们更加了解协程。
如果你刚刚开始学习 Kotlin ,你可以看看[我的博客](https://antonioleiva.com/kotlin),[这本书](https://antonioleiva.com/book),或者关注我的 [Twitter](https://twitter.com/lime_cl), [LinkedIn](https://www.linkedin.com/in/antoniolg/) 或者 [Github](https://github.com/antoniolg/) 。
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)。
================================================
FILE: TODO/a-follow-up-on-how-to-store-tokens-securely-in-android.md
================================================
> * 原文地址:[A follow-up on how to store tokens securely in Android](https://medium.com/@enriquelopezmanas/a-follow-up-on-how-to-store-tokens-securely-in-android-e84ac5f15f17)
> * 原文作者:[Enrique López Mañas](https://medium.com/@enriquelopezmanas)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 译者: [lovexiaov](https://github.com/lovexiaov)
> * 校对者:[luoqiuyu](https://github.com/luoqiuyu) [hackerkevin](https://github.com/hackerkevin)

# 再谈如何安全地在 Android 中存储令牌 #
作为本文的序言,我想对读者做一个简短的声明。下面的引言对本文的后续内容而言十分重要。
> 没有绝对的安全。所谓的安全是指利用一系列措施的堆积和组合,来试图延缓必然发生的事情。
大约 3 年前,我写了[一篇文章](http://codetalk.de/?p=86),给出了几种方法来防止潜在攻击者反编译我们 Android 应用窃取字符串令牌。为了便于回忆,也为了防止不可避免的网络瘫痪,我将会在此重新列出一些章节。
客户端应用与服务端的交互是最常见的场景之一。数据交换时的敏感度差别很大,并且登录请求、用户数据更改请求等之间交换的数据类型也变化多样。
首先要提到并应用的技术是使用 [SSL](http://info.ssl.com/article.aspx?id=10241)(安全套接层)链接客户端与服务端。再看一下文章开头的引言。尽管这样做是一个良好的开端,但这并不能确保绝对的隐私和安全。
当你使用 SSL 连接时(也就是当你看到浏览器上有一个小锁时),这意味着你与服务器之间的连接被加密了。理论上讲,没有什么能够访问到你请求里的信息(*)
(*)我说过绝对的安全不存在吧?SSL 连接仍然可以被攻破。本文不打算提供所有可能的攻击手段列表,只想让你了解几种攻击的可能性。比如,可以伪造 SSL 证书,或者进行中间人攻击。
我们继续。假设客户端正在通过加密的 SSL 通道与后台链接,它们在愉快的交换有用的数据,执行业务逻辑。但是我们还想提供一个额外的安全层。
接下来要采取的措施是在通信中使用授权令牌或 API 密钥。当后台收到一个请求时,我们如何判断该请求是来自认证的客户端而不是任意一个想要获取我们 API 数据的家伙?后台会检查该客户端是否提供了一个有效的 API 密钥。如果密钥有效,则执行请求操作,否则拒绝该请求并根据业务需求采取一些措施(当出现此情况时,我一般会纪录他们的 IP 地址和客户端 ID,看一下他们的访问频率。如果频率高于我的忍受范围,我会考虑禁止并观察一下这个无礼的家伙想要得到什么)。
让我们从头开始构建我们的城堡吧。在我们的应用中,添加一个叫做 API_KEY 的变量,该变量会自动注入到每次的请求(如果是 Android 应用,可能会是你的 Retrofit 客户端)中。
```java
private final static String API_KEY = “67a5af7f89ah3katf7m20fdj202”
```
很好,这样可以帮助我们鉴定客户端。但问题在于它本身并没有提供一个十分有效的安全保证。
如果你使用 [apktool](https://ibotpeaches.github.io/Apktool/) 反编译该应用,然后搜索该字符串,你会在其中一个 .smali 文件中发现:
```smali
const-string v1, “67a5af7f89ah3katf7m20fdj202”
```
是的,我知道。这并不能保证是一个有效的令牌,所以我们仍然需要通过一个精确的验证来决定如何找到那个字符串,和它是否可以用来通过验证。但是你知道我要表达什么:这通常只是时间和资源的问题。
Proguard 是否会能我们保证该字符串的安全呢?并不能。Proguard 在[常见问题](http://proguard.sourceforge.net/FAQ.html#encrypt)中提到了字符串的加密是完全不可能的。
那将字符串保存到 Android 提供的其他存储机制中呢,比如说 SharedPreferences?这并不是一个好方法。在模拟器或者 root 过的设备中可以轻易的访问到 SharedPreferences。几年前,一个叫 [Srinivas](http://resources.infosecinstitute.com/android-hacking-security-part-9-insecure-local-storage-shared-preferences/) 的伙计向我们证明了如何更改一个视频游戏中的得分。跑题了!
#### 原生开发工具包 (NDK) ####
我将会更新我提出的初始模型,不断迭代它,以提供更安全的替代方案。我们假设有两个函数分别负责加密和解密数据:
```java
private static byte[] encrypt(byte[] raw, byte[] clear) throws Exception {
SecretKeySpec skeySpec = new SecretKeySpec(raw, "AES");
Cipher cipher = Cipher.getInstance("AES");
cipher.init(Cipher.ENCRYPT_MODE, skeySpec);
byte[] encrypted = cipher.doFinal(clear);
return encrypted;
}
private static byte[] decrypt(byte[] raw, byte[] encrypted) throws Exception {
SecretKeySpec skeySpec = new SecretKeySpec(raw, "AES");
Cipher cipher = Cipher.getInstance("AES");
cipher.init(Cipher.DECRYPT_MODE, skeySpec);
byte[] decrypted = cipher.doFinal(encrypted);
return decrypted;
}
```
代码没啥好说的。这两个函数会使用一个密钥值和一个被用来编/解码的字符串作为入参。它们会返回相应的加密或解密过的字符串。我们会用如下方式调用它们:
```java
ByteArrayOutputStream baos = new ByteArrayOutputStream();
bm.compress(Bitmap.CompressFormat.PNG, 100, baos);
byte[] b = baos.toByteArray();
byte[] keyStart = "encryption key".getBytes();
KeyGenerator kgen = KeyGenerator.getInstance("AES");
SecureRandom sr = SecureRandom.getInstance("SHA1PRNG");
sr.setSeed(keyStart);
kgen.init(128, sr);
SecretKey skey = kgen.generateKey();
byte[] key = skey.getEncoded();
// encrypt
byte[] encryptedData = encrypt(key,b);
// decrypt
byte[] decryptedData = decrypt(key,encryptedData);
```
猜到为什么要这么做了吗?是的,我们可以根据需求来加/解密令牌。这就为我们提供了一个额外的安全层:当代码混淆后,寻找令牌不再像执行字符串搜索和检查字符串周围的环境那样简单了。但是,你能指出还有一个需要解决的问题吗?
找到了吗?
如果还没找到就多花点时间。
是的。我们仍然有一个加密密钥以字符串的形式存储。虽然这种隐晦的做法增加了更多的安全层,但不管这个令牌是用于加密或它本身就是一个令牌,我们仍然有一个以明文形式存在的令牌。
现在,我们将使用 NDK 来继续迭代我们的安全机制。
NDK 允许我们在 Android 代码中访问 C++ 代码库。首先我们来想一下要做什么。我们可以在一个 C++ 函数中存放 API 密钥或者敏感数据。该函数可以在之后的代码中调用,避免了在 Java 文件中存储字符串。这就提供了一个自动的保护机制来防止反编译技术。
C++ 函数如下:
```cpp
Java_com_example_exampleApp_ExampleClass_getSecretKey( JNIEnv* env,
jobject thiz )
{
return (*env)->NewStringUTF(env, "mySecretKey".");
}
```
在 Java 代码中调用它也很简单:
```java
static {
System.loadLibrary("library-name");
}
public native String getSecretKey();
```
在加/解密函数中会这样调用:
```java
byte[] keyStart = getSecretKey().getBytes();
```
此时我们生成 APK,混淆它,然后反编译并尝试在原生函数 getSecretKey() 中查找该字符串,无法找到!胜利了吗?
并没有!NDK 代码其实也可以被反汇编和检查。只是难度较高,需要更高级的工具和技术。虽然这样可以摆脱掉 95% 的脚本小子,但一个有充足资源和动机的团队让然可以拿到令牌。还记得这句话吗?
> 没有绝对的安全。所谓的安全是指利用一系列措施的堆积和组合,来试图延缓必然发生的事情。
你仍然可以在反汇编代码中找到该字符串字面值。[Hex Rays](https://www.hex-rays.com/products/decompiler/) 在反编译原生文件方面就做的很好。我很确信有一大堆的工具可以解构 Android 生成的任意原生代码(我跟 Hex Rays 并没有关系,也没有从他们那里拿到任何形式的资金酬劳)。
那么,我们要使用哪种方案来避免后台与客户端的通信被标记呢?
**在设备上实时生成密钥。**
你的设备不需要存储任何形式的密钥并处理各种保护字符串字面值的麻烦!这是在服务中用到的非常古老的技术,比如远程密钥验证。
1. 客户端知道有个函数会返回一个密钥。
2. 后台知道在客户端中实现的那个函数。
3. 客户端通过该函数生成一个密钥,并发送到服务器上。
4. 服务器验证密钥,并根据请求执行相应的操作。
抓到重点了吗?为什么不使用返回三个随机素数( 1~100 之间)之和的函数来代替返回一个字符串(很容易被识别)的原生函数呢?或者拿到当天的 UNIX 时间,然后给每一位数字加 1?通过设备的一些上下文相关信息(如正在使用的内存量)来提供一个更高程度的熵值?
上面这段包含了一些想法,希望读者们已经得到重点了。
### **总结** ###
1. 绝对的安全是不存在的。
2. 多种保护手段的结合是达到高安全度的关键。
3. 不要在代码中存储字符串明文。
4. 使用 NDK 来创建自生成的密钥。
还记得开头的那段话吧?
> 没有绝对的安全。所谓的安全是指利用一系列措施的堆积和组合,来试图延缓必然发生的事情。
我想再强调一次,你的目标是尽可能的保护你的代码,同时不要忘记 100% 的安全是不可能的。但是,如果你能保证解密你代码中任意的敏感信息都需要耗费大量的资源,你就能安心睡觉啦。
### 一个小小的免责声明 ###
我知道,读到此处,纵观整文,你会纳闷“这家伙怎么讲了所有麻烦的方法而没有提到 [Dexguard](https://www.guardsquare.com/en/dexguard) 呢?”。是的 Dexguard 可以混淆字符串,他们在这方面做的很好。然而 Dexguard 的售价[让人望而却步](http://thinkdiff.net/mobile/dexguard-480-eur-to-10313-eur-the-worst-software-do-not-use/)。我在之前的公司的关键安全系统中使用过 Dexguard,但这也许并不是一个适合所有人的选择。再说了,像生活一样,在软件开发中选择越多世界越丰富多彩。
愉快的编码吧!
我会在 [Twitter](https://twitter.com/eenriquelopez) 上写一些关于软件工程和生活点滴的思考。如果你喜欢此文,或者它能帮到你,请随意分享,点赞或者留言。这是业余作者写作的动力。
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)。
================================================
FILE: TODO/a-functional-programmers-introduction-to-javascript-composing-software.md
================================================
> * 原文地址:[A Functional Programmer’s Introduction to JavaScript (Composing Software)(part 3)](https://medium.com/javascript-scene/a-functional-programmers-introduction-to-javascript-composing-software-d670d14ede30)
> * 原文作者:[Eric Elliott](https://medium.com/@_ericelliott?source=post_header_lockup)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 译者:[sunui](http://suncafe.cc)
> * 校对者:[Aladdin-ADD](https://github.com/Aladdin-ADD)、[avocadowang](https://github.com/avocadowang)
# [第三篇] 函数式程序员的 JavaScript 简介(软件编写)
 烟雾艺术魔方 — MattysFlicks — (CC BY 2.0)
> 注意:这是“软件编写”系列文章的第三部分,该系列主要阐述如何在 JavaScript ES6+ 中从零开始学习函数式编程和组合化软件(compositional software)技术(译注:关于软件可组合性的概念,参见维基百科 [Composability](https://en.wikipedia.org/wiki/Composability))。后续还有更多精彩内容,敬请期待!
> [< 上一篇](https://github.com/xitu/gold-miner/blob/master/TODO/why-learn-functional-programming-in-javascript-composing-software.md) | [<<第一篇](https://github.com/xitu/gold-miner/blob/master/TODO/the-rise-and-fall-and-rise-of-functional-programming-composable-software.md) | [下一篇 >](https://github.com/xitu/gold-miner/blob/master/TODO/higher-order-functions-composing-software.md)
对于不熟悉 JavaScript 或 ES6+ 的同学,这里做一个简短的介绍。无论你是 JavaScript 开发新手还是有经验的老兵,你都可能学到一些新东西。以下内容仅是浅尝辄止,吊吊大家的兴致。如果想知道更多,还需深入学习。敬请期待吧。
学习编程最好的方法就是动手编程。我建议您使用交互式 JavaScript 编程环境(如 [CodePen](https://codepen.io/) 或 [Babel REPL](https://babeljs.io/repl/))。
或者,您也可以使用 Node 或浏览器控制台 REPL。
### 表达式和值 ###
表达式是可以求得数据值的代码块。
下面这些都是 JavaScript 中合法的表达式:
```
7;
7 + 1; // 8
7 * 2; // 14
'Hello'; // Hello
```
表达式的值可以被赋予一个名称。执行此操作时,表达式首先被计算,取得的结果值被赋值给该名称。对于这一点我们将使用 `const` 关键字。这不是唯一的方式,但这将是你使用最多的,所以目前我们就可以坚持使用 `const`。
```
const hello = 'Hello';
hello; // Hello
```
### var、let 和 const ###
JavaScript 支持另外两种变量声明关键字:`var`,还有 `let`。我喜欢根据选择的顺序来考虑它们。默认情况下,我选择最严格的声明方式:`const`。用 `const` 关键字声明的变量不能被重新赋值。最终值必须在声明时分配。这可能听起来很严格,但限制是一件好事。这是个标识在提醒你“赋给这个名称的值将不会改变”。它可以帮你全面了解这个名称的意义,而无需阅读整个函数或块级作用域。
有时,给变量重新赋值很有用。比如,如果你正在写一个手动的强制性迭代,而不是一个更具功能性的方法,你可以迭代一个用 `let` 赋值的计数器。
因为 `var` 能告诉你很少关于这个变量的信息,所以它是最无力的声明标识。自从开始用 ES6,我就再也没在实际软件项目中有意使用 `var` 作声明了。
注意一下,一个变量一旦用 `let` 或 `const` 声明,任何再次声明的尝试都将导致报错。如果你在 REPL(读取-求值-输出循环)环境中更喜欢多一些实验性和灵活性,那么建议你使用 `var` 声明变量,与 `let` 和 `const` 不同,使用 `var` 重新声明变量是合法的。
本文将使用 const 来让您习惯于为实际程序中用 `const`,而出于试验的目的自由切换回 `var`。
### 数据类型 ###
目前为止我们见到了两种数据类型:数字和字符串。JavaScript 也有布尔值(`true` 或 `false`)、数组、对象等。稍后我们再看其他类型。
数组是一系列值的有序列表。可以把它比作一个能够装很多元素的容器。这是一个数组字面量:
```
[1, 2, 3];
```
当然,它也是一个可被赋予名称的表达式:
```
const arr = [1, 2, 3];
```
在 JavaScript 中,对象是一系列键值对的集合。它也有字面量:
```
{
key: 'value'
}
```
当然,你也可以给对象赋予名称:
```
const foo = {
bar: 'bar'
}
```
如果你想将现有变量赋值给同名的对象属性,这有个捷径。你可以仅输入变量名,而不用同时提供一个键和一个值:
```
const a = 'a';
const oldA = { a: a }; // 长而冗余的写法
const oA = { a }; // 短小精悍!
```
为了好玩而已,让我们再来一次:
```
const b = 'b';
const oB = { b };
```
对象可以轻松合并到新的对象中:
```
const c = {...oA, ...oB}; // { a: 'a', b: 'b' }
```
这些点是对象扩展运算符。它迭代 `oA` 的属性并分配到新的对象中,`oB` 也是一样,在新对象中已经存在的键都会被重写。在撰写本文时,对象扩展是一个新的试验特性,可能还没有被所有主流浏览器支持,但如果你那不能用,还可以用 `Object.assign()` 替代:
```
const d = Object.assign({}, oA, oB); // { a: 'a', b: 'b' }
```
这个 `Object.assign()` 的例子代码很少,如果你想合并很多对象,它甚至可以节省一些打字。注意当你使用 `Object.assign()` 时,你必须传一个目标对象作为第一个参数。它就是那个源对象的属性将被复制过去的对象。如果你忘了传,第一个参数传递的对象将被改变。
以我的经验,改变一个已经存在的对象而不创建一个新的对象常常引发 bug。至少至少,它很容易出错。要小心使用 `Object.assign()`。
### 解构 ###
对象和数组都支持解构,这意味着你可以从中提取值分配给命过名的变量:
```
const [t, u] = ['a', 'b'];
t; // 'a'
u; // 'b'
const blep = {
blop: 'blop'
};
// 下面等同于:
// const blop = blep.blop;
const { blop } = blep;
blop; // 'blop'
```
和上面数组的例子类似,你可以一次解构多次分配。下面这行你在大量的 Redux 项目中都能见到。
```
const { type, payload } = action;
```
下面是它在一个 reducer(后面的话题再详细说) 的上下文中的使用方法。
```
const myReducer = (state = {}, action = {}) => {
const { type, payload } = action;
switch (type) {
case 'FOO': return Object.assign({}, state, payload);
default: return state;
}
};
```
如果不想为新绑定使用不同的名称,你可以分配一个新名称:
```
const { blop: bloop } = blep;
bloop; // 'blop'
```
读作:把 `blep.blop` 分配给 `bloop`。
### 比较运算符和三元表达式 ###
你可以用严格的相等操作符(有时称为“三等于”)来比较数据值:
```
3 + 1 === 4; // true
```
还有另外一种宽松的相等操作符。它正式地被称为“等于”运算符。非正式地可以叫“双等于”。双等于有一两个有效的用例,但大多数时候默认使用 `===` 操作符是更好的选择。
其它比较操作符有:
- `>` 大于
- `<` 小于
- `>=` 大于或等于
- `<=` 小于或等于
- `!=` 不等于
- `!==` 严格不等于
- `&&` 逻辑与
- `||` 逻辑或
三元表达式是一个可以让你使用一个比较器来问问题的表达式,运算出的不同答案取决于表达式是否为真:
```
14 - 7 === 7 ? 'Yep!' : 'Nope.'; // Yep!
```
### 函数 ###
JavaScript 支持函数表达式,函数可以这样分配名称:
```
const double = x => x * 2;
```
这和数学表达式 `f(x) = 2x` 是一个意思。大声说出来,这个函数读作 `x` 的 `f` 等于 `2x`。这个函数只有当你用一个具体的 `x` 的值应用它的时候才有意思。在其它方程式里面你写 `f(2)`,就等同于 `4`。
换种说话就是 `f(2) = 4`。您可以将数学函数视为从输入到输出的映射。这个例子里 `f(x)` 是输入数值 `x` 到相应的输出数值的映射,等于输入数值和 `2` 的乘积。
在 JavaScript 中,函数表达式的值是函数本身:
```
double; // [Function: double]
```
你可以使用 `.toString()` 方法看到这个函数的定义。
```
double.toString(); // 'x => x * 2'
```
如果要将函数应用于某些参数,则必须使用函数调用来调用它。函数调用会接收参数并且计算一个返回值。
你可以使用 `(argument1, argument2, ...rest)` 调用一个函数。比如调用我们的 double 函数,就加一对括号并传进去一个值:
```
double(2); // 4
```
和一些函数式语言不同,这对括号是有意义的。没有它们,函数将不会被调用。
```
double 4; // SyntaxError: Unexpected number
```
### 签名 ###
函数的签名可以包含以下内容:
1. 一个 **可选的** 函数名。
2. 在括号里的一组参数。 参数的命名是可选的。
3. 返回值的类型。
JavaScript 的签名无需指定类型。JavaScript 引擎将会在运行时断定类型。如果你提供足够的线索,签名信息也可以通过开发工具推断出来,比如一些 IDE(集成开发环境)和使用数据流分析的 [Tern.js](http://ternjs.net/)。
JavaScript 缺少它自己的函数签名语法,所以有几个竞争标准:JSDoc 在历史上非常流行,但它太过笨拙臃肿,没有人会不厌其烦地维护更新文档与代码同步,所以很多 JS 开发者都弃坑了。
TypeScript 和 Flow 是目前的大竞争者。这二者都不能让我确定地知道怎么表达我需要的一切,所以我使用 [Rtype](https://github.com/ericelliott/rtype),仅仅用于写文档。一些人倒退回 Haskell 的 curry-only [Hindley–Milner 类型系统](http://web.cs.wpi.edu/~cs4536/c12/milner-damas_principal_types.pdf)。如果仅用于文档,我很乐意看到 JavaScript 能有一个好的标记系统标准,但目前为止,我觉得当前的解决方案没有能胜任这个任务的。现在,怪异的类型标记即使和你在用的不尽相同,也就将就先用着吧。
```
functionName(param1: Type, param2: Type) => Type
```
double 函数的签名是:
```
double(x: n) => n
```
尽管事实上 JavaScript 不需要注释签名,知道何为签名和它意味着什么依然很重要,它有助于你高效地交流函数是如何使用和如何构建的。大多数可重复使用的函数构建工具都需要你传入同样类型签名的函数。
### 默认参数值 ###
JavaScript 支持默认参数值。下面这个函数类似一个恒等函数(以你传入参数为返回值的函数),一旦你用 `undefined` 调用它,或者根本不传入参数——它就会返回 0,来替代:
```
const orZero = (n = 0) => n;
```
如上,若想设置默认值,只需在传入参数时带上 `=` 操作符,比如 `n = 0`。当你用这种方式传入默认值,像 [Tern.js](http://ternjs.net/)、Flow、或者 TypeScript 这些类型检测工具可以自行推断函数的类型签名,甚至你不需要刻意声明类型注解。
结果就是这样,在你的编辑器或者 IDE 中安装正确的插件,在你输入函数调用时,你可以看见内联显示的函数签名。依据它的调用签名,函数的使用方法也一目了然。无论起不起作用,使用默认值可以让你写出更具可读性的代码。
> 注意: 使用默认值的参数不会增加函数的 `.length` 属性,比如使用依赖 `.length` 值的自动柯里化会抛出不可用异常。如果你碰上它,一些柯里化工具(比如 `lodash/curry`)允许你传入自定义参数来绕开这个限制。
### 命名参数 ###
JavaScript 函数可以传入对象字面量作为参数,并且使用对象解构来分配参数标识,这样做可以达到命名参数的同样效果。注意,你也可以使用默认参数特性传入默认值。
```
const createUser = ({
name = 'Anonymous',
avatarThumbnail = '/avatars/anonymous.png'
}) => ({
name,
avatarThumbnail
});
const george = createUser({
name: 'George',
avatarThumbnail: 'avatars/shades-emoji.png'
});
george;
/*
{
name: 'George',
avatarThumbnail: 'avatars/shades-emoji.png'
}
*/
```
### 剩余和展开 ###
JavaScript 中函数共有的一个特性是可以在函数参数中使用剩余操作符 `...` 来将一组剩余的参数聚集到一起。
例如下面这个函数简单地丢弃第一个参数,返回其余的参数:
```
const aTail = (head, ...tail) => tail;
aTail(1, 2, 3); // [2, 3]
```
剩余参数将各个元素组成一个数组。而展开操作恰恰相反:它将一个数组中的元素扩展为独立元素。研究一下这个:
```
const shiftToLast = (head, ...tail) => [...tail, head];
shiftToLast(1, 2, 3); // [2, 3, 1]
```
JavaScript 数组在使用扩展操作符的时候会调用一个迭代器,对于数组中的每一个元素,迭代器都会传递一个值。在 `[...tail, head]` 表达式中,迭代器按顺序从 `tail` 数组中拷贝到一个刚刚创建的新的数组。之前 head 已经是一个独立元素了,我们只需把它放到数组的末端,就完成了。
### 柯里化 ###
可以通过返回另一个函数来实现柯里化(Curry)和偏应用(partial application):
```
const highpass = cutoff => n => n >= cutoff;
const gt4 = highpass(4); // highpass() 返回了一个新函数
```
你可以不使用箭头函数。JavaScript 也有一个 `function` 关键字。我们使用箭头函数是因为 `function` 关键字需要打更多的字。
这种写法和上面的 `highPass()` 定义是一样的:
```
const highpass = function highpass(cutoff) {
return function (n) {
return n >= cutoff;
};
};
```
JavaScript 中箭头的大致意义就是“函数”。使用不同种的方式声明,函数行为会有一些重要的不同点(`=>` 缺少了它自己的 `this` ,不能作为构造函数),但当我们遇见那就知道不同之处了。现在,当你看见 `x => x`,想到的是 “一个携带 `x` 并且返回 `x` 的函数”。所以 `const highpass = cutoff => n => n >= cutoff;` 可以这样读:
“`highpass` 是一个携带 `cutoff` 返回一个携带 `n` 并返回结果 `n >= cutoff` 的函数的函数”
既然 `highpass()` 返回一个函数,你可以使用它创建一个更独特的函数:
```
const gt4 = highpass(4);
gt4(6); // true
gt4(3); // false
```
自动柯里化函数,有利于获得最大的灵活性。比如你有一个函数 `add3()`:
```
const add3 = curry((a, b, c) => a + b + c);
```
使用自动柯里化,你可以有很多种不同方法使用它,它将根据你传入多少个参数返回正确结果:
```
add3(1, 2, 3); // 6
add3(1, 2)(3); // 6
add3(1)(2, 3); // 6
add3(1)(2)(3); // 6
```
令 Haskell 粉遗憾的是,JavaScript 没有内置自动柯里化机制,但你可以从 Lodash 引入:
```
$ npm install --save lodash
```
然后在你的模块里:
```
import curry from 'lodash/curry';
```
或者你可以使用下面这个魔性写法:
```
// 精简的递归自动柯里化
const curry = (
f, arr = []
) => (...args) => (
a => a.length === f.length ?
f(...a) :
curry(f, a)
)([...arr, ...args]);
```
### 函数组合 ###
当然你能够开始组合函数了。组合函数是传入一个函数的返回值作为参数给另一个函数的过程。用数学符号标识:
```
f . g
```
翻译成 JavaScript:
```
f(g(x))
```
这是从内到外地求值:
1. `x` 是被求数值
2. `g()` 应用给 `x`
3. `f()` 应用给 `g(x)` 的返回值
例如:
```
const inc = n => n + 1;
inc(double(2)); // 5
```
数值 `2` 被传入 `double()`,求得 `4`。 `4` 被传入 `inc()` 求得 `5`。
你可以给函数传入任何表达式作为参数。表达式在函数应用之前被计算:
```
inc(double(2) * double(2)); // 17
```
既然 `double(2)` 求得 `4`,你可以读作 `inc(4 * 4)`,然后计算得 `inc(16)`,然后求得 `17`。
函数组合是函数式编程的核心。我们后面还会介绍很多。
### 数组 ###
数组有一些内置方法。方法是指对象关联的函数,通常是这个对象的属性:
```
const arr = [1, 2, 3];
arr.map(double); // [2, 4, 6]
```
这个例子里,`arr` 是对象,`.map()` 是一个以函数为值的对象属性。当你调用它,这个函数会被应用给参数,和一个特别的参数叫做 `this`,`this` 在方法被调用之时自动设置。这个 `this` 的存在使 `.map()` 能够访问数组的内容。
注意我们传递给 `map` 的是 `double` 函数而不是直接调用。因为 `map` 携带一个函数作为参数并将函数应用给数组的每一个元素。它返回一个包含了 `double()` 返回值的新的数组。
注意原始的 `arr` 值没有改变:
```
arr; // [1, 2, 3]
```
### 方法链 ###
你也可以链式调用方法。方法链是指在函数返回值上直接调用方法的过程,在此期间不需要给返回值命名:
```
const arr = [1, 2, 3];
arr.map(double).map(double); // [4, 8, 12]
```
返回布尔值(`true` 或 `false`)的函数叫做 **断言**(predicate)。`.filter()` 方法携带断言并返回一个新的数组,新数组中只包含传入断言函数(返回 `true`)的元素:
```
[2, 4, 6].filter(gt4); // [4, 6]
```
你常常会想要从一个列表选择一些元素,然后把这些元素序列化到一个新列表中:
```
[2, 4, 6].filter(gt4).map(double); [8, 12]
```
注意:后面的文章你将看到使用叫做 **transducer** 东西更高效地同时选择元素并序列化,不过这之前还有一些其他东西要了解。
### 总结 ###
如果你现在有点发懵,不必担心。我们仅仅概览了一下很多事情的表面,它们尚需大量的解释和总结。很快我们就会回过头来,深入探讨其中的一些话题。
[**继续阅读 “高阶函数”…**](https://github.com/xitu/gold-miner/blob/master/TODO/higher-order-functions-composing-software.md)
### 接下来 ###
想要学习更多 JavaScript 函数式编程知识?
[和 Eric Elliott 一起学习 JavaScript](http://ericelliottjs.com/product/lifetime-access-pass/)。 如果你不是其中一员,千万别错过!
[
烟雾艺术魔方 — MattysFlicks — (CC BY 2.0)
> 注意:这是“软件编写”系列文章的第三部分,该系列主要阐述如何在 JavaScript ES6+ 中从零开始学习函数式编程和组合化软件(compositional software)技术(译注:关于软件可组合性的概念,参见维基百科 [Composability](https://en.wikipedia.org/wiki/Composability))。后续还有更多精彩内容,敬请期待!
> [< 上一篇](https://github.com/xitu/gold-miner/blob/master/TODO/why-learn-functional-programming-in-javascript-composing-software.md) | [<<第一篇](https://github.com/xitu/gold-miner/blob/master/TODO/the-rise-and-fall-and-rise-of-functional-programming-composable-software.md) | [下一篇 >](https://github.com/xitu/gold-miner/blob/master/TODO/higher-order-functions-composing-software.md)
对于不熟悉 JavaScript 或 ES6+ 的同学,这里做一个简短的介绍。无论你是 JavaScript 开发新手还是有经验的老兵,你都可能学到一些新东西。以下内容仅是浅尝辄止,吊吊大家的兴致。如果想知道更多,还需深入学习。敬请期待吧。
学习编程最好的方法就是动手编程。我建议您使用交互式 JavaScript 编程环境(如 [CodePen](https://codepen.io/) 或 [Babel REPL](https://babeljs.io/repl/))。
或者,您也可以使用 Node 或浏览器控制台 REPL。
### 表达式和值 ###
表达式是可以求得数据值的代码块。
下面这些都是 JavaScript 中合法的表达式:
```
7;
7 + 1; // 8
7 * 2; // 14
'Hello'; // Hello
```
表达式的值可以被赋予一个名称。执行此操作时,表达式首先被计算,取得的结果值被赋值给该名称。对于这一点我们将使用 `const` 关键字。这不是唯一的方式,但这将是你使用最多的,所以目前我们就可以坚持使用 `const`。
```
const hello = 'Hello';
hello; // Hello
```
### var、let 和 const ###
JavaScript 支持另外两种变量声明关键字:`var`,还有 `let`。我喜欢根据选择的顺序来考虑它们。默认情况下,我选择最严格的声明方式:`const`。用 `const` 关键字声明的变量不能被重新赋值。最终值必须在声明时分配。这可能听起来很严格,但限制是一件好事。这是个标识在提醒你“赋给这个名称的值将不会改变”。它可以帮你全面了解这个名称的意义,而无需阅读整个函数或块级作用域。
有时,给变量重新赋值很有用。比如,如果你正在写一个手动的强制性迭代,而不是一个更具功能性的方法,你可以迭代一个用 `let` 赋值的计数器。
因为 `var` 能告诉你很少关于这个变量的信息,所以它是最无力的声明标识。自从开始用 ES6,我就再也没在实际软件项目中有意使用 `var` 作声明了。
注意一下,一个变量一旦用 `let` 或 `const` 声明,任何再次声明的尝试都将导致报错。如果你在 REPL(读取-求值-输出循环)环境中更喜欢多一些实验性和灵活性,那么建议你使用 `var` 声明变量,与 `let` 和 `const` 不同,使用 `var` 重新声明变量是合法的。
本文将使用 const 来让您习惯于为实际程序中用 `const`,而出于试验的目的自由切换回 `var`。
### 数据类型 ###
目前为止我们见到了两种数据类型:数字和字符串。JavaScript 也有布尔值(`true` 或 `false`)、数组、对象等。稍后我们再看其他类型。
数组是一系列值的有序列表。可以把它比作一个能够装很多元素的容器。这是一个数组字面量:
```
[1, 2, 3];
```
当然,它也是一个可被赋予名称的表达式:
```
const arr = [1, 2, 3];
```
在 JavaScript 中,对象是一系列键值对的集合。它也有字面量:
```
{
key: 'value'
}
```
当然,你也可以给对象赋予名称:
```
const foo = {
bar: 'bar'
}
```
如果你想将现有变量赋值给同名的对象属性,这有个捷径。你可以仅输入变量名,而不用同时提供一个键和一个值:
```
const a = 'a';
const oldA = { a: a }; // 长而冗余的写法
const oA = { a }; // 短小精悍!
```
为了好玩而已,让我们再来一次:
```
const b = 'b';
const oB = { b };
```
对象可以轻松合并到新的对象中:
```
const c = {...oA, ...oB}; // { a: 'a', b: 'b' }
```
这些点是对象扩展运算符。它迭代 `oA` 的属性并分配到新的对象中,`oB` 也是一样,在新对象中已经存在的键都会被重写。在撰写本文时,对象扩展是一个新的试验特性,可能还没有被所有主流浏览器支持,但如果你那不能用,还可以用 `Object.assign()` 替代:
```
const d = Object.assign({}, oA, oB); // { a: 'a', b: 'b' }
```
这个 `Object.assign()` 的例子代码很少,如果你想合并很多对象,它甚至可以节省一些打字。注意当你使用 `Object.assign()` 时,你必须传一个目标对象作为第一个参数。它就是那个源对象的属性将被复制过去的对象。如果你忘了传,第一个参数传递的对象将被改变。
以我的经验,改变一个已经存在的对象而不创建一个新的对象常常引发 bug。至少至少,它很容易出错。要小心使用 `Object.assign()`。
### 解构 ###
对象和数组都支持解构,这意味着你可以从中提取值分配给命过名的变量:
```
const [t, u] = ['a', 'b'];
t; // 'a'
u; // 'b'
const blep = {
blop: 'blop'
};
// 下面等同于:
// const blop = blep.blop;
const { blop } = blep;
blop; // 'blop'
```
和上面数组的例子类似,你可以一次解构多次分配。下面这行你在大量的 Redux 项目中都能见到。
```
const { type, payload } = action;
```
下面是它在一个 reducer(后面的话题再详细说) 的上下文中的使用方法。
```
const myReducer = (state = {}, action = {}) => {
const { type, payload } = action;
switch (type) {
case 'FOO': return Object.assign({}, state, payload);
default: return state;
}
};
```
如果不想为新绑定使用不同的名称,你可以分配一个新名称:
```
const { blop: bloop } = blep;
bloop; // 'blop'
```
读作:把 `blep.blop` 分配给 `bloop`。
### 比较运算符和三元表达式 ###
你可以用严格的相等操作符(有时称为“三等于”)来比较数据值:
```
3 + 1 === 4; // true
```
还有另外一种宽松的相等操作符。它正式地被称为“等于”运算符。非正式地可以叫“双等于”。双等于有一两个有效的用例,但大多数时候默认使用 `===` 操作符是更好的选择。
其它比较操作符有:
- `>` 大于
- `<` 小于
- `>=` 大于或等于
- `<=` 小于或等于
- `!=` 不等于
- `!==` 严格不等于
- `&&` 逻辑与
- `||` 逻辑或
三元表达式是一个可以让你使用一个比较器来问问题的表达式,运算出的不同答案取决于表达式是否为真:
```
14 - 7 === 7 ? 'Yep!' : 'Nope.'; // Yep!
```
### 函数 ###
JavaScript 支持函数表达式,函数可以这样分配名称:
```
const double = x => x * 2;
```
这和数学表达式 `f(x) = 2x` 是一个意思。大声说出来,这个函数读作 `x` 的 `f` 等于 `2x`。这个函数只有当你用一个具体的 `x` 的值应用它的时候才有意思。在其它方程式里面你写 `f(2)`,就等同于 `4`。
换种说话就是 `f(2) = 4`。您可以将数学函数视为从输入到输出的映射。这个例子里 `f(x)` 是输入数值 `x` 到相应的输出数值的映射,等于输入数值和 `2` 的乘积。
在 JavaScript 中,函数表达式的值是函数本身:
```
double; // [Function: double]
```
你可以使用 `.toString()` 方法看到这个函数的定义。
```
double.toString(); // 'x => x * 2'
```
如果要将函数应用于某些参数,则必须使用函数调用来调用它。函数调用会接收参数并且计算一个返回值。
你可以使用 `(argument1, argument2, ...rest)` 调用一个函数。比如调用我们的 double 函数,就加一对括号并传进去一个值:
```
double(2); // 4
```
和一些函数式语言不同,这对括号是有意义的。没有它们,函数将不会被调用。
```
double 4; // SyntaxError: Unexpected number
```
### 签名 ###
函数的签名可以包含以下内容:
1. 一个 **可选的** 函数名。
2. 在括号里的一组参数。 参数的命名是可选的。
3. 返回值的类型。
JavaScript 的签名无需指定类型。JavaScript 引擎将会在运行时断定类型。如果你提供足够的线索,签名信息也可以通过开发工具推断出来,比如一些 IDE(集成开发环境)和使用数据流分析的 [Tern.js](http://ternjs.net/)。
JavaScript 缺少它自己的函数签名语法,所以有几个竞争标准:JSDoc 在历史上非常流行,但它太过笨拙臃肿,没有人会不厌其烦地维护更新文档与代码同步,所以很多 JS 开发者都弃坑了。
TypeScript 和 Flow 是目前的大竞争者。这二者都不能让我确定地知道怎么表达我需要的一切,所以我使用 [Rtype](https://github.com/ericelliott/rtype),仅仅用于写文档。一些人倒退回 Haskell 的 curry-only [Hindley–Milner 类型系统](http://web.cs.wpi.edu/~cs4536/c12/milner-damas_principal_types.pdf)。如果仅用于文档,我很乐意看到 JavaScript 能有一个好的标记系统标准,但目前为止,我觉得当前的解决方案没有能胜任这个任务的。现在,怪异的类型标记即使和你在用的不尽相同,也就将就先用着吧。
```
functionName(param1: Type, param2: Type) => Type
```
double 函数的签名是:
```
double(x: n) => n
```
尽管事实上 JavaScript 不需要注释签名,知道何为签名和它意味着什么依然很重要,它有助于你高效地交流函数是如何使用和如何构建的。大多数可重复使用的函数构建工具都需要你传入同样类型签名的函数。
### 默认参数值 ###
JavaScript 支持默认参数值。下面这个函数类似一个恒等函数(以你传入参数为返回值的函数),一旦你用 `undefined` 调用它,或者根本不传入参数——它就会返回 0,来替代:
```
const orZero = (n = 0) => n;
```
如上,若想设置默认值,只需在传入参数时带上 `=` 操作符,比如 `n = 0`。当你用这种方式传入默认值,像 [Tern.js](http://ternjs.net/)、Flow、或者 TypeScript 这些类型检测工具可以自行推断函数的类型签名,甚至你不需要刻意声明类型注解。
结果就是这样,在你的编辑器或者 IDE 中安装正确的插件,在你输入函数调用时,你可以看见内联显示的函数签名。依据它的调用签名,函数的使用方法也一目了然。无论起不起作用,使用默认值可以让你写出更具可读性的代码。
> 注意: 使用默认值的参数不会增加函数的 `.length` 属性,比如使用依赖 `.length` 值的自动柯里化会抛出不可用异常。如果你碰上它,一些柯里化工具(比如 `lodash/curry`)允许你传入自定义参数来绕开这个限制。
### 命名参数 ###
JavaScript 函数可以传入对象字面量作为参数,并且使用对象解构来分配参数标识,这样做可以达到命名参数的同样效果。注意,你也可以使用默认参数特性传入默认值。
```
const createUser = ({
name = 'Anonymous',
avatarThumbnail = '/avatars/anonymous.png'
}) => ({
name,
avatarThumbnail
});
const george = createUser({
name: 'George',
avatarThumbnail: 'avatars/shades-emoji.png'
});
george;
/*
{
name: 'George',
avatarThumbnail: 'avatars/shades-emoji.png'
}
*/
```
### 剩余和展开 ###
JavaScript 中函数共有的一个特性是可以在函数参数中使用剩余操作符 `...` 来将一组剩余的参数聚集到一起。
例如下面这个函数简单地丢弃第一个参数,返回其余的参数:
```
const aTail = (head, ...tail) => tail;
aTail(1, 2, 3); // [2, 3]
```
剩余参数将各个元素组成一个数组。而展开操作恰恰相反:它将一个数组中的元素扩展为独立元素。研究一下这个:
```
const shiftToLast = (head, ...tail) => [...tail, head];
shiftToLast(1, 2, 3); // [2, 3, 1]
```
JavaScript 数组在使用扩展操作符的时候会调用一个迭代器,对于数组中的每一个元素,迭代器都会传递一个值。在 `[...tail, head]` 表达式中,迭代器按顺序从 `tail` 数组中拷贝到一个刚刚创建的新的数组。之前 head 已经是一个独立元素了,我们只需把它放到数组的末端,就完成了。
### 柯里化 ###
可以通过返回另一个函数来实现柯里化(Curry)和偏应用(partial application):
```
const highpass = cutoff => n => n >= cutoff;
const gt4 = highpass(4); // highpass() 返回了一个新函数
```
你可以不使用箭头函数。JavaScript 也有一个 `function` 关键字。我们使用箭头函数是因为 `function` 关键字需要打更多的字。
这种写法和上面的 `highPass()` 定义是一样的:
```
const highpass = function highpass(cutoff) {
return function (n) {
return n >= cutoff;
};
};
```
JavaScript 中箭头的大致意义就是“函数”。使用不同种的方式声明,函数行为会有一些重要的不同点(`=>` 缺少了它自己的 `this` ,不能作为构造函数),但当我们遇见那就知道不同之处了。现在,当你看见 `x => x`,想到的是 “一个携带 `x` 并且返回 `x` 的函数”。所以 `const highpass = cutoff => n => n >= cutoff;` 可以这样读:
“`highpass` 是一个携带 `cutoff` 返回一个携带 `n` 并返回结果 `n >= cutoff` 的函数的函数”
既然 `highpass()` 返回一个函数,你可以使用它创建一个更独特的函数:
```
const gt4 = highpass(4);
gt4(6); // true
gt4(3); // false
```
自动柯里化函数,有利于获得最大的灵活性。比如你有一个函数 `add3()`:
```
const add3 = curry((a, b, c) => a + b + c);
```
使用自动柯里化,你可以有很多种不同方法使用它,它将根据你传入多少个参数返回正确结果:
```
add3(1, 2, 3); // 6
add3(1, 2)(3); // 6
add3(1)(2, 3); // 6
add3(1)(2)(3); // 6
```
令 Haskell 粉遗憾的是,JavaScript 没有内置自动柯里化机制,但你可以从 Lodash 引入:
```
$ npm install --save lodash
```
然后在你的模块里:
```
import curry from 'lodash/curry';
```
或者你可以使用下面这个魔性写法:
```
// 精简的递归自动柯里化
const curry = (
f, arr = []
) => (...args) => (
a => a.length === f.length ?
f(...a) :
curry(f, a)
)([...arr, ...args]);
```
### 函数组合 ###
当然你能够开始组合函数了。组合函数是传入一个函数的返回值作为参数给另一个函数的过程。用数学符号标识:
```
f . g
```
翻译成 JavaScript:
```
f(g(x))
```
这是从内到外地求值:
1. `x` 是被求数值
2. `g()` 应用给 `x`
3. `f()` 应用给 `g(x)` 的返回值
例如:
```
const inc = n => n + 1;
inc(double(2)); // 5
```
数值 `2` 被传入 `double()`,求得 `4`。 `4` 被传入 `inc()` 求得 `5`。
你可以给函数传入任何表达式作为参数。表达式在函数应用之前被计算:
```
inc(double(2) * double(2)); // 17
```
既然 `double(2)` 求得 `4`,你可以读作 `inc(4 * 4)`,然后计算得 `inc(16)`,然后求得 `17`。
函数组合是函数式编程的核心。我们后面还会介绍很多。
### 数组 ###
数组有一些内置方法。方法是指对象关联的函数,通常是这个对象的属性:
```
const arr = [1, 2, 3];
arr.map(double); // [2, 4, 6]
```
这个例子里,`arr` 是对象,`.map()` 是一个以函数为值的对象属性。当你调用它,这个函数会被应用给参数,和一个特别的参数叫做 `this`,`this` 在方法被调用之时自动设置。这个 `this` 的存在使 `.map()` 能够访问数组的内容。
注意我们传递给 `map` 的是 `double` 函数而不是直接调用。因为 `map` 携带一个函数作为参数并将函数应用给数组的每一个元素。它返回一个包含了 `double()` 返回值的新的数组。
注意原始的 `arr` 值没有改变:
```
arr; // [1, 2, 3]
```
### 方法链 ###
你也可以链式调用方法。方法链是指在函数返回值上直接调用方法的过程,在此期间不需要给返回值命名:
```
const arr = [1, 2, 3];
arr.map(double).map(double); // [4, 8, 12]
```
返回布尔值(`true` 或 `false`)的函数叫做 **断言**(predicate)。`.filter()` 方法携带断言并返回一个新的数组,新数组中只包含传入断言函数(返回 `true`)的元素:
```
[2, 4, 6].filter(gt4); // [4, 6]
```
你常常会想要从一个列表选择一些元素,然后把这些元素序列化到一个新列表中:
```
[2, 4, 6].filter(gt4).map(double); [8, 12]
```
注意:后面的文章你将看到使用叫做 **transducer** 东西更高效地同时选择元素并序列化,不过这之前还有一些其他东西要了解。
### 总结 ###
如果你现在有点发懵,不必担心。我们仅仅概览了一下很多事情的表面,它们尚需大量的解释和总结。很快我们就会回过头来,深入探讨其中的一些话题。
[**继续阅读 “高阶函数”…**](https://github.com/xitu/gold-miner/blob/master/TODO/higher-order-functions-composing-software.md)
### 接下来 ###
想要学习更多 JavaScript 函数式编程知识?
[和 Eric Elliott 一起学习 JavaScript](http://ericelliottjs.com/product/lifetime-access-pass/)。 如果你不是其中一员,千万别错过!
[ ](https://ericelliottjs.com/product/lifetime-access-pass/)
***Eric Elliott*** 是 [*“JavaScript 应用程序设计”*](http://pjabook.com) (O’Reilly) 以及 [*“和 Eric Elliott 一起学习 JavaScript”*](http://ericelliottjs.com/product/lifetime-access-pass/) 的作者。 曾就职于 **Adobe Systems、Zumba Fitness、The Wall Street Journal、ESPN、BBC and top recording artists including Usher、Frank Ocean、Metallica** 等公司,具有丰富的软件实践经验。
**他大多数时间在 San Francisco By Area ,和世界上最美丽的姑娘在一起。**
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)。
================================================
FILE: TODO/a-gentle-introduction-to-self-sovereign-identity.md
================================================
> * 原文地址:[A gentle introduction to self-sovereign identity](https://bitsonblocks.net/2017/05/17/a-gentle-introduction-to-self-sovereign-identity/)
> * 原文作者:[antonylewis2015](https://bitsonblocks.net/author/antonylewis2015/)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/a-gentle-introduction-to-self-sovereign-identity.md](https://github.com/xitu/gold-miner/blob/master/TODO/a-gentle-introduction-to-self-sovereign-identity.md)
> * 译者:[foxxnuaa](https://github.com/foxxnuaa)
> * 校对者:[ryouaki](https://github.com/ryouaki)
# 自主权身份简介

2017 年 5 月,印度[互联网与社会智库中心]( http://cis-india.org/ )发布了一份[报告]( http://cis-india.org/internet-governance/information-security-practices-of-aadhaar-or-lack-thereof-a-documentation-of-public-availability-of-aadhaar-numbers-with-sensitive-personal-financial-information-1 ),详细介绍了印度国家身份数据库( [ Adahaar ]( https://uidai.gov.in/ ))泄漏可能危及个人信息的方式。这些信息涉及 1.3 亿印度国民。信息泄漏给金融诈骗创造了机会,同时对个人隐私造成不可挽回的伤害。
很明显,中心化身份存储模型存在缺陷。本文描述了一种管理数字身份的新方式:自主权身份。
自主权身份的含义是人们和企业将自己的身份数据存储在自己的设备上,并能有效地提供给需要的人进行验证,而不用依赖中心化的身份数据存储。相对如今的纸质处理,自主权身份是一种数字化方式。与手动处理和中心化存储如印度的 Aadhaar 相比,自主权身份更有益。
高效地识别过程能够促进普惠金融。通过降低小企业开设银行账户的成本,融资对银行更加有利,小企业便可以获得融资。
### 身份中有哪些重要概念?
身份包含三个部分:**声明**、**证明** 和 **认证**。
#### 声明
身份 **声明** 是由个人或企业发起的:
> “我是 Antony ,出生于 1901 年 1 月 1 日”

#### 证明
**证明** 是某种形式的文件,为声明提供证据。证明有各种格式。通常情况下,个人证明是护照、出生证和账单的复印件。对于公司来说,它是大量的公司和所有权结构文件。

#### 认证
**认证** 是第三方根据他们的记录验证声明是真实的。例如,一所大学可以证明有人在那里学习过并取得学位。来自权威机构的认证比伪造的证据更加有力。但是,由于信息是敏感的,认证对于权威机构来说是一个负担。认证意味着信息需要保持,且只有特定的人才能访问。

### 身份的问题是什么?
银行需要了解他们的新客户和商业客户以便检查资格,并向监管机构证明他们(银行)不是银行坏账。他们也需要保持客户的信息是最新的。
问题在于:
* 证明通常是图片和复印件形式的 **非结构化数据**。这意味着银行工作人员必须手动读取和扫描文档以提取相关数据,然后输入系统进行存储和处理。
* 当在现实生活中发生 **数据变化** 时(如地址变更、公司所有权结构变更),客户有义务通知与他们有关系的各种金融服务提供商。
* 某些形式的证据(如原始文件的复印件)**很容易被伪造**,这就需要采取额外的步骤来证明真实性,如经过公证的复印件,从而导致其他的矛盾和费用。
结果是昂贵、耗时且麻烦的过程,使每个人都感到烦恼。

### 技术上有哪些改进?
无论采用什么样的整体解决方案,上述三个问题都需要在技术上解决。标准化和数字签名结合运作良好。
**改进非结构化数据** 的技术解决方案是将数据以机器可读的结构化格式进行存储和传输,即将 **文本存储在标准化的标签中**。
**管理数据变化** 的技术解决方案是更新所有必要实体的通用方法。即使用 **APIs**连接、验证自身(证明是您的账户)、更新详细信息。
**证明身份真实性** 的技术解决方案是 **数字签名认证**,可能有时间限制。数字签名证明与认证一样有效,因为数字签名不能伪造。数字签名有如下两个属性,使其本质上比纸质文档更好:
1. 如果签名文档发生任何更改,数字签名将失效。换句话说,它保证文件的完整性。
2. 数字签名不能被取消,并从一个文档复制到另一个文档。
### 什么是中心化解决方案?
身份管理的常见解决方案是中心化存储。第三方拥有和控制许多人身份的存储。客户将自身信息录入到系统,并上传证据。无论谁需要,都可以访问这些数据(当然得有客户的许可),并可以系统地将这些数据存储到自己的系统中。如果细节发生变化,客户会更新一次,并将更新推送给相关的银行。

这听起来不错,当然也有一些好处。但是这个模型有些问题。
### 中心化解决方案有什么问题?
#### 1. 不良数据
运营身份存储是一把双刃剑。一方面,运营商可以通过对工具收费来赚钱。另一方面,数据对运营商是不利的:对于黑客来说,集中化的身份系统是一座金矿;而对于运营商,网络安全很是头痛。
如果黑客可以侵入系统并拷贝数据,他们可以将数字身份和书面证据出售给其他坏人。这些坏人就可以以无辜者的名义窃取身份、欺诈和犯罪。这样会而且确实破坏了无辜者的生活,并给运营商造成重大的不利。
#### 2. 司法政治
监管机构希望将个人数据存储在其管辖下的地理范围内。因此,创建国际身份存储库是很困难的,因为总是有关于哪个国家存储数据和谁可以访问数据的争论。
#### 3. 垄断倾向
对于中心化存储库运营商来说,这不是问题,但对于用户来说是一个问题。如果一个公用事业运营商获得足够的关注,网络效应会吸引更多的用户。公用事业运营商可能成为准垄断企业。垄断性运营商往往对变革产生抵触;由于缺乏竞争力,他们会过度收费和乏于创新。这对于运营商是有利的,但是却损害了用户的利益。
### 去中心化的解决方案是什么?
#### 是区块链吗?
区块链是一种分布式账簿,所有数据都可以实时复制到所有参与者。是否应该将身份数据存储在多个参与实体(比如大银行)管理的区块链中?不:
1. 将所有身份数据复制到所有各方,打破了关于将个人数据保存在管辖范围内的所有规定;只储存与业务有关的个人资料;并且只存储客户授权的数据。
2. 网络安全风险增加。如果中心化数据存储很难保证安全,那么现在您正在将这些数据复制到多个参与方,每个参与方都有自己的网络安全实践和漏洞。这使得攻击者更容易窃取数据。
如果加密身份数据会怎样?
1. 加密个人数据仍可能违反个人数据规定。
2. 为什么各方(如银行)会存储和管理一些他们看不到或不使用的身份数据?积极的一面是什么?
### 那么最终的答案是什么?
最新的解决方案是 “**自主权身份**”。这个数字概念与我们今天保管非数字身份的方式非常相似。
今天,我们自己保管护照、出生证明、家用水电费账单等,也许把他们放在一个“重要的抽屉”里,并且在需要的时候才拿出来。我们将这些纸质文件和其他东西分开存放。自主权身份等同于我们现在使用的纸质文件的数字等价物。
### 如何对用户进行自主权身份识别?
你会在智能手机或电脑上安装一个应用程序,类似于某种”身份钱包“,将身份数据存储在设备硬件上,可能备份在另一个设备上或个人备份解决方案上,但 **关键** 是不存储在中心化存储库中。
身份钱包一开始是 **空** 的,只有一个根据公钥 **生成** 的 **识别号码** 以及相应的私钥(类似密码,用于创建数字签名)。这个密钥对不同于用户名和密码,因为它是由用户通过"随机和数学运算"创建的,而不是由第三方请求用户名/密码产生的。
现阶段,**没有其他任何人** 知道这个识别号码。没有人发给你。你自己创建了它。这就是自主权。大数法则和随机数法则确保没有人会产生和你一样的识别号码。
然后你可以使用这个 **识别号码**,连同 **身份声明** 一起,从相关部门得到 **认证**。
你就可以使用这些证明作为你的身份信息。

**声明** 会被输入到标准化文本中存储,并保存照片或扫描文档。
**证明** 会通过保存扫描或者证明文件的照片来存储。 然而,这只是为了向后兼容,因为数字签名认证消除了我们今天所知道的证明的需要。
**认证** - 即有效部分,也会存储在这个钱包里。它是机器可读的,数字签名的一些信息片段,在一定时间段内有效。官方如护照机构、医院、驾照机构、警察局等需要签署这些数字签名。
**需要了解,但是无需更多**:官方可以提供“超过18”、“超过21”、“合格投资者”、“可驾驶汽车”等证明文件,供用户使用。身份所有者能够选择将哪些信息传递给请求者。例如,如果你需要证明你已经超过18岁,你不需要分享你的出生日期,你只需要一个声明说你已经超过18岁,该声明由相关部门签署。

共享这类数据对于 **身份提供者和接收者来说都更安全**。提供者不需要过度共享,而接收者不需要存储不必要的敏感数据 — 例如,如果接收者被入侵,它们只存储“超过18岁”的标志,而不是出生日期。
即使银行本身也可以证明哪些人在银行有账户。我们首先需要了解他们在创建这些认证时所承担的责任。我认为,当他们寄给你一张银行账单时,它不会比他们目前承担的责任更大,而你只是把它作为在其他地方的地址证明。
#### 数据共享
数据将存储在个人设备上(如同今天将纸质文件存储在家里),且在需要时,个人通过打开设备上的通知同意第三方收集特定数据。我们已经有一些类似的 - 如果你曾使用过“连接”你的 Facebook 或 LinkedIn 账户服务,这是相似的 - 但是,不是去 Facebook 服务器收集你的个人数据,而是从你的手机中请求它,同时你对共享的数据有粒度控制。

### 总结 - 分布式账本
谁来组织这些?也许这就是分布式账本的起源。软件、网络和工作流需要构建、运行和维护。数字签名需要管理公钥和私钥,证书需要颁发、撤销、刷新。身份数据不是静态的,它需要根据某些业务逻辑进行演化。
**非区块链分布式账本将是一个理想的平台**。R3 的 Corda (注:我在 R3 中工作)已经具备了许多必要的元素 —— 协调工作流、数字签名、数据演化规则,以及一个由 80 多个金融机构组成的联盟,他们正在尝试这种精确的自我权身份概念。
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
================================================
FILE: TODO/a-guide-to-automating-scraping-the-web-with-javascript-chrome-puppeteer-node-js.md
================================================
> * 原文地址:[A Guide to Automating & Scraping the Web with JavaScript (Chrome + Puppeteer + Node JS)](https://codeburst.io/a-guide-to-automating-scraping-the-web-with-javascript-chrome-puppeteer-node-js-b18efb9e9921)
> * 原文作者:[Brandon Morelli](https://codeburst.io/@bmorelli25?source=post_header_lockup)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/a-guide-to-automating-scraping-the-web-with-javascript-chrome-puppeteer-node-js.md](https://github.com/xitu/gold-miner/blob/master/TODO/a-guide-to-automating-scraping-the-web-with-javascript-chrome-puppeteer-node-js.md)
> * 译者:[pot-code](https://github.com/pot-code)
> * 校对者:[bambooom](https://github.com/bambooom)
# JavaScript 自动化爬虫入门指北(Chrome + Puppeteer + Node JS)
## 和 Headless Chrome 一起装逼一起飞

> [**Udemy Black Friday Sale**](https://codeburst.io/udemys-black-friday-sale-starts-today-all-web-development-courses-just-10-44966e590bd4) — Thousands of Web Development & Software Development courses are on sale for only $10 for a limited time! [**Full details and course recommendations can be found here**](https://codeburst.io/udemys-black-friday-sale-starts-today-all-web-development-courses-just-10-44966e590bd4).
#### 内容简介
本文将会教你如何用 JavaScript 自动化 web 爬虫,技术上用到了 Google 团队开发的 Puppeteer。 [__Puppeteer__](https://github.com/GoogleChrome/puppeteer) 运行在 Node 环境,可以用来操作 headless Chrome。何谓 [__Headless Chrome__](https://developers.google.com/web/updates/2017/04/headless-chrome)?通俗来讲就是在不打开 Chrome 浏览器的情况下使用提供的 API 模拟用户的浏览行为。
**如果你还是不理解,你可以想象成使用 JavaScript 全自动化操作 Chrome 浏览器。**
#### 前言
先确保你已经安装了 Node 8 及以上的版本,没有的话,可以先到 [**官网**](https://nodejs.org/en/) 里下载安装。注意,一定要选“Current”处显示的版本号大于 8 的。
如果你是第一次接触 Node,最好先看一下入门教程:[**Learn Node JS — The 3 Best Online Node JS Courses**](https://codeburst.io/learn-node-js-the-3-best-online-node-js-courses-87e5841f4c47).
安装好 Node 之后,创建一个项目文件夹,然后安装 Puppeteer。安装 Puppeteer 的过程中会附带下载匹配版本的 Chromium(译者注:国内网络环境可能会出现安装失败的问题,可以设置环境变量 `PUPPETEER_SKIP_CHROMIUM_DOWNLOAD = 1` 跳过下载,副作用是每次使用 `launch` 方法时,需要手动指定浏览器的执行路径):
```shell
npm install --save puppeteer
```
#### 例 1 —— 网页截图
Puppeteer 安装好之后,我们就可以开始写一个简单的例子。这个例子直接照搬自官方文档,它可以对给定的网站进行截图。
首先创建一个 js 文件,名字随便起,这里我们用 `test.js` 作为示例,输入以下代码:
```javascript
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://google.com');
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();
```
下面我们来逐行分析上面的代码。
* **第 1 行:** 引入依赖。
* **第 3–10 行:** 核心代码,自动化过程在这里完成。
* **第 12 行:** 执行 `getPic()` 方法。
细心的读者会发现,`getPic()` 前面有个 `async` 前缀,它表示 `getPic()` 方法是个异步方法。`async` 和 `await` 成对出现,属于 ES 2017 新特性。介于它是个异步方法,所以调用之后返回的是 `Promise` 对象。当 `async` 方法返回值时,对应的 `Promise` 对象会将这个值传递给 `resolve`(如果抛出异常,那么会将错误信息传递给 `Reject`)。
在 `async` 方法中,可以使用 `await` 表达式暂停方法的执行,直到表达式里的 `Promise` 对象完全解析之后再继续向下执行。看不懂没关系,后面我再详细讲解,到时候你就明白了。
接下来,我们将会深入分析 `getPic()` 方法:
* **第 4 行:**
```javascript
const browser = await puppeteer.launch();
```
这段代码用于启动 puppeteer,实质上打开了一个 Chrome 的实例,然后将这个实例对象赋给变量 `browser`。因为使用了 `await` 关键字,代码运行到这里会阻塞(暂停),直到 `Promise` 解析完毕(无论执行结果是否成功)
* **第 5 行:**
```javascript
const page = await browser.newPage();
```
接下来,在上文获取到的浏览器实例中新建一个页面,等到其返回之后将新建的页面对象赋给变量 `page`。
* **第 6 行:**
```javascript
await page.goto('https://google.com');
```
使用上文获取到的 `page` 对象,用它来加载我们给的 URL 地址,随后代码暂停执行,等待页面加载完毕。
* **第 7 行:**
```javascript
await page.screenshot({path: 'google.png'});
```
等到页面加载完成之后,就可以对页面进行截图了。`screenshot()` 方法接受一个对象参数,可以用来配置截图保存的路径。注意,不要忘了加上 `await` 关键字。
* **第 9 行:**
```javascript
await browser.close();
```
最后,关闭浏览器。
#### 运行示例
在命令行输入以下命令执行示例代码:
```shell
node test.js
```
以下是示例里的截图结果:

是不是很厉害?这只是热身,下面教你怎么在非 headless 环境下运行代码。
非 headless?百闻不如一见,自己先动手试一下吧,把第 4 行的代码:
```javascript
const browser = await puppeteer.launch();
```
换成这句:
```javascript
const browser = await puppeteer.launch({headless: false});
```
然后再次运行:
```shell
node test.js
```
是不是更炫酷了?当配置了 `{headless: false}` 之后,就可以直观的看到代码是怎么操控 Chrome 浏览器的。
这里还有一个小问题,之前我们的截图有点没截完整的感觉,那是因为 `page` 对象默认的截屏尺寸有点小的缘故,我们可以通过下面的代码重新设置 `page` 的视口大小,然后再截取:
```javascript
await page.setViewport({width: 1000, height: 500})
```
这下就好多了:
最终代码如下:
```javascript
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://google.com');
await page.setViewport({width: 1000, height: 500})
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();
```
#### 例 2 —— 爬取数据
通过上面的例子,你应该掌握了 Puppeteer 的基本用法,下面再来看一个稍微复杂点的例子。
开始前,不妨先看看 [官方文档](https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md#)。你会发现 Puppeteer 能干很多事,像是模拟鼠标的点击、填充表单数据、输入文字、读取页面数据等。
在接下来的教程里,我们将爬一个叫 [_Books To Scrape_](http://books.toscrape.com/) 的网站,这个网站是专门用来给开发者做爬虫练习用的。
还是在之前创建的文件夹里,新建一个 js 文件,这里用 `scrape.js` 作为示例,然后输入以下代码:
```javascript
const puppeteer = require('puppeteer');
let scrape = async () => {
// Actual Scraping goes Here...
// Return a value
};
scrape().then((value) => {
console.log(value); // Success!
});
```
有了上一个例子的经验,这段代码要看懂应该不难。如果你还是看不懂的话......那也没啥问题就是了。
首先,还是引入 `puppeteer` 依赖,然后定义一个 `scrape()` 方法,用来写爬虫代码。这个方法返回一个值,到时候我们会处理这个返回值(示例代码是直接打印出这个值)
先在 scrape 方法中添加下面这一行测试一下:
```javascript
let scrape = async () => {
return 'test';
};
```
在命令行输入 `node scrape.js`,不出问题的话,控制台会打印一个 `test` 字符串。测试通过后,我们来继续完善 `scrape` 方法。
**步骤 1:前期准备**
和例 1 一样,先获取浏览器实例,再新建一个页面,然后加载 URL:
```javascript
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.waitFor(1000);
// Scrape
browser.close();
return result;
};
```
再来分析一下上面的代码:
首先,我们创建了一个浏览器实例,将 `headless` 设置为 `false`,这样就能直接看到浏览器的操作过程:
```javascript
const browser = await puppeteer.launch({headless: false});
```
然后创建一个新标签页:
```javascript
const page = await browser.newPage();
```
访问 `books.toscrape.com`:
```javascript
await page.goto('http://books.toscrape.com/');
```
下面这一步可选,让代码暂停执行 1 秒,保证页面能完全加载完毕:
```javascript
await page.waitFor(1000);
```
任务完成之后关闭浏览器,返回执行结果。
```javascript
browser.close();
return result;
```
步骤 1 结束。
**步骤 2: 开爬**
打开 Books to Scrape 网站之后,想必你也发现了,这里面有海量的书籍,只是数据都是假的而已。先从简单的开始,我们先抓取页面里第一本书的数据,返回它的标题和价格信息(红色边框选中的那本)。
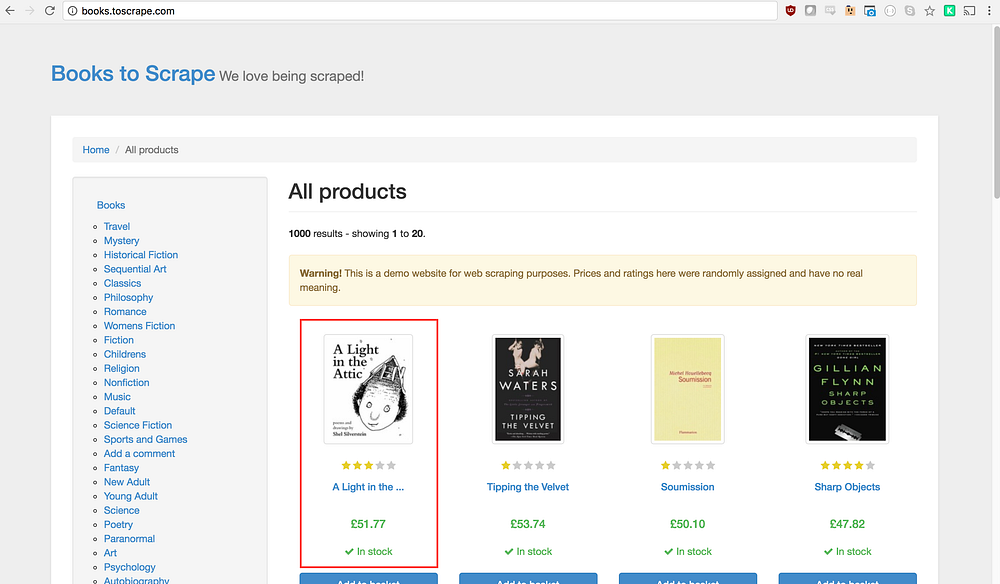
查一下文档,注意到这个方法能模拟页面点击:
**page.click(selector[, options])**
* `selector` 选择器,定位需要进行点击的元素,如果有多个元素匹配,以第一个为准。
这里可以使用开发者工具查看元素的选择器,在图片上右击选中 inspect:

上面的操作会打开开发者工具栏,之前选中的元素也会被高亮显示,这个时候点击前面的三个小点,选择 copy - copy selector:

有了元素的选择器之后,再加上之前查到的元素点击方法,得到如下代码:
```javascript
await page.click('#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img');
```
然后就会观察到浏览器点击了第一本书的图片,页面也会跳转到详情页。
在详情页里,我们只关心书的标题和价格信息 —— 见图中红框标注。

为了获取这些数据,需要用到 `page.evaluate()` 方法。这个方法可以用来执行浏览器内置 DOM API ,例如 `querySelector()`。
首先创建 `page.evaluate()` 方法,将其返回值保存在 `result` 变量中:
```javascript
const result = await page.evaluate(() => {
// return something
});
```
同样,要在方法里选择我们要用到的元素,再次打开开发者工具,选择需要 inspect 的元素:

标题是个简单的 `h1` 元素,使用下面的代码获取:
```javascript
let title = document.querySelector('h1');
```
其实我们需要的只是元素里的文字部分,可以在后面加上 `.innerText`,代码如下:
```javascript
let title = document.querySelector('h1').innerText;
```
获取价格信息同理:
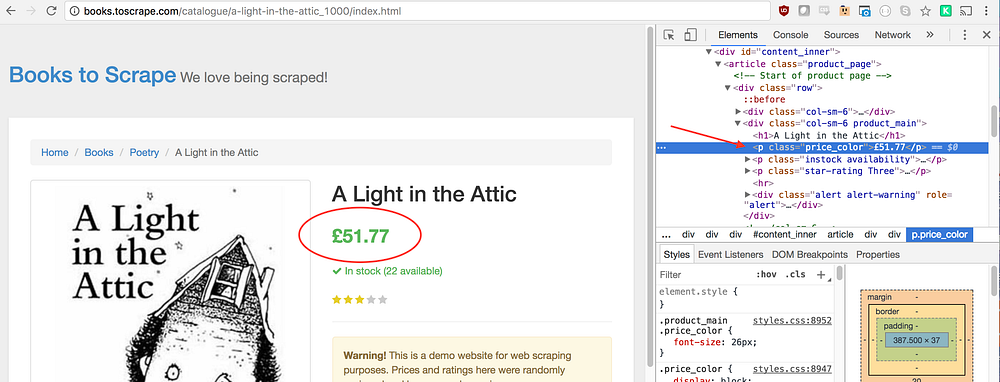
刚好价格元素上有个 `price_color` class,可以用这个 class 作为选择器获取到价格对应的元素:
```javascript
let price = document.querySelector('.price_color').innerText;
```
这样,标题和价格都有了,把它们放到一个对象里返回:
```javascript
return {
title,
price
}
```
回顾刚才的操作,我们获取到了标题和价格信息,将它们保存在一个对象里返回,返回结果赋给 `result` 变量。所以,现在你的代码应该是这样:
```javascript
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}
});
```
然后只需要将 `result` 返回即可,返回结果会打印到控制台:
```javascript
return result;
```
最后,综合起来代码如下:
```javascript
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.click('#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img');
await page.waitFor(1000);
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}
});
browser.close();
return result;
};
scrape().then((value) => {
console.log(value); // Success!
});
```
在控制台运行代码:
```javascript
node scrape.js
// { title: 'A Light in the Attic', price: '£51.77' }
```
操作正确的话,在控制台会看到正确的输出结果,到此为止,你已经完成了 web 爬虫。
#### 例 3 —— 后期完善
稍加思考一下你会发现,标题和价格信息是直接展示在首页的,所以,完全没必要进入详情页去抓取这些数据。既然这样,不妨再进一步思考,能否抓取所有书的标题和价格信息?
所以,抓取的方式其实有很多,需要你自己去发现。另外,上面提到的直接在主页抓取数据也不一定可行,因为有些标题可能会显示不全。
**拔高题**
目标 —— 抓取主页所有书籍的标题和价格信息,并且用数组的形式保存返回。正确的输出应该是这样:

开干吧,伙计,其实实现起来和上面的例子相差无几,如果你觉得实在太难,可以参考下面的提示。
* * *
**提示:**
其实最大的区别在于你需要遍历整个结果集,代码的大致结构如下:
```javascript
const result = await page.evaluate(() => {
let data = []; // 创建一个空数组
let elements = document.querySelectorAll('xxx'); // 选择所有相关元素
// 遍历所有的元素
// 提取标题信息
// 提取价格信息
data.push({title, price}); // 将数据插入到数组中
return data; // 返回数据集
});
```
* * *
如果提示了还是做不出来的话,好吧,以下是参考答案。在以后的教程中,我会在下面这段代码的基础上再做一些拓展,同时也会涉及一些更高级的爬虫技术。你可以在 [**这里**](https://docs.google.com/forms/d/e/1FAIpQLSeQYYmBCBfJF9MXFmRJ7hnwyXvMwyCtHC5wxVDh5Cq--VT6Fg/viewform) 提交你的邮箱地址进行订阅,有新的内容更新时我们会通知你。
**参考答案:**
```javascript
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
const result = await page.evaluate(() => {
let data = []; // 创建一个数组保存结果
let elements = document.querySelectorAll('.product_pod'); // 选择所有书籍
for (var element of elements){ // 遍历书籍列表
let title = element.childNodes[5].innerText; // 提取标题信息
let price = element.childNodes[7].children[0].innerText; // 提取价格信息
data.push({title, price}); // 组合数据放入数组
}
return data; // 返回数据集
});
browser.close();
return result; // 返回数据
};
scrape().then((value) => {
console.log(value); // 打印结果
});
```
### 结语:
谢谢观看!如果你有学习 NodeJS 的意向,可以移步 [**Learn Node JS — The 3 Best Online Node JS Courses**](https://codeburst.io/learn-node-js-the-3-best-online-node-js-courses-87e5841f4c47)。
每周我都会发布 4 篇有关 web 开发的技术文章,[**欢迎订阅**](https://docs.google.com/forms/d/e/1FAIpQLSeQYYmBCBfJF9MXFmRJ7hnwyXvMwyCtHC5wxVDh5Cq--VT6Fg/viewform)!或者你也可以在 Twitter 上 [**关注我**](https://twitter.com/BrandonMorelli)
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
================================================
FILE: TODO/a-guide-to-interviewing-for-product-design-internships.md
================================================
>* 原文链接 : [A Guide to Interviewing for Product Design Internships](https://medium.com/facebook-design/a-guide-to-interviewing-for-product-design-internships-d719dd4c146c#.jhgjr12c)
* 原文作者 : [Andrew Hwang](https://medium.com/@ahwng)
* 译文出自 : [掘金翻译计划](https://github.com/xitu/gold-miner)
* 译者 :
* 校对者:
> “We reviewed your portfolio, and we’d love to interview you for our product design internship. What times will you be available in the upcoming week?”
Upon seeing this email, your pulse quickens. Your eyes widen. You drool a little. You sent out so many cover letters, submitted so many applications, and — finally! A small but meaningful step on the journey to becoming a full-fledged product designer.
But what will they ask you? And how could you possibly prepare?
Breaking into the product design field as a student is hard. Some product designers stumble into the field with a graphic design or art degree. Others are self-taught. Either way the field of digital product design is so new that there are very few resources for curious students.
In high school I hadn’t yet heard of the product design industry. I dabbled in web design but quite frankly, I was terrible at it. I couldn’t imagine it going anywhere.
But over time I accumulated enough design work to find myself with a design internship at a mobile app startup. There I first got a taste of product design. And I fell in love with the problem-solving, the complexity, the collaboration with product managers and engineers and illustrators to build something from nothing. So I pursued it ruthlessly.
The following summer I ramped up my internship application game, submitting resumes to over 50 companies. Five of them responded positively. Of those five, three small tech companies interviewed me immediately. But I went into those interviews not having the faintest idea what they’d ask, so those doors shut as quickly as they had opened.
Evernote was the fourth company to respond positively. And though I had botched the previous three interviews, I had a better idea of what to expect when I hopped on the phone with the Evernote designers.
I landed the Evernote product design internship that summer. And with a bit more experience under my belt, the following summer I received an offer for Facebook’s product design internship. Now I’m a full-time product designer at Facebook.
As a student I interviewed for product design internships at many of the Silicon Valley behemoths: Google; Facebook; Mozilla; Quora; Groupon; Dropbox. And if one thing stuck with me, it was that product design interviews are quite similar across tech companies. They usually include all or some combination of the following:
1. Phone screen
2. Portfolio review
3. Design exercise
4. App critique
Let’s dig a little deeper into each step
The phone screen allows the recruiter to get to know you better, to go past the words on your resume. You might be asked:
* What’s your background like?
* How did you get into design?
* Why are you interested in working here?
* What was your favorite past project, and why?
During the phone screen, sound excited. And come prepared with questions for the recruiter. Try to ask questions specific to the company, questions that are not easily answerable with a Google search. Recruiters can tell generic questions from authentic ones, and asking canned questions may damage the strength of your candidacy.
While preparing for my first phone screen with Facebook, for instance, I [discovered](http://www.quora.com/What-do-Facebook-interns-do) the company regularly hosts intern hack-a-thons. So during the phone screen I probed further about the hack-a-thons: How do they work, exactly? Is it okay for interns to completely ignore their summer projects during the hack-a-thons? Who reviews the final projects? Questions like these show genuine interest. They tell the recruiter you’ve done your homework and care deeply about the internship opportunity.
If the recruiter thinks your background and interests might be a good fit for the internship, the next step is usually a showcase of your past work.
Here you’ll speak with a designer. Typically, the review will include a deep dive into three or four of your portfolio projects. The point of the portfolio review is for the designer to tease out your design process, to understand what types of questions you ask and what kinds of solutions you consider. In short, the interviewer wants to know how you approach design. You might be asked questions such as:
* What were the problems you were trying to solve?
* Who did you partner with?
* What kind of research did you perform, if any?
* Why did you choose that design solution over this one?
* What were the tradeoffs?
* What challenges did you face in designing X?
* If you had more time to work on Y, what would you change?
* If you got stuck on a certain design problem, how did you overcome it?
One of your main tasks in the portfolio review is to show **intentionality** in your design process, to demonstrate that you thought through each design decision carefully, from the high-level product features to the visual styling of a button.
Describe your rationale clearly. Arbitrary design decisions won’t hold up to the scrutiny of a portfolio review.
](https://ericelliottjs.com/product/lifetime-access-pass/)
***Eric Elliott*** 是 [*“JavaScript 应用程序设计”*](http://pjabook.com) (O’Reilly) 以及 [*“和 Eric Elliott 一起学习 JavaScript”*](http://ericelliottjs.com/product/lifetime-access-pass/) 的作者。 曾就职于 **Adobe Systems、Zumba Fitness、The Wall Street Journal、ESPN、BBC and top recording artists including Usher、Frank Ocean、Metallica** 等公司,具有丰富的软件实践经验。
**他大多数时间在 San Francisco By Area ,和世界上最美丽的姑娘在一起。**
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)。
================================================
FILE: TODO/a-gentle-introduction-to-self-sovereign-identity.md
================================================
> * 原文地址:[A gentle introduction to self-sovereign identity](https://bitsonblocks.net/2017/05/17/a-gentle-introduction-to-self-sovereign-identity/)
> * 原文作者:[antonylewis2015](https://bitsonblocks.net/author/antonylewis2015/)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/a-gentle-introduction-to-self-sovereign-identity.md](https://github.com/xitu/gold-miner/blob/master/TODO/a-gentle-introduction-to-self-sovereign-identity.md)
> * 译者:[foxxnuaa](https://github.com/foxxnuaa)
> * 校对者:[ryouaki](https://github.com/ryouaki)
# 自主权身份简介

2017 年 5 月,印度[互联网与社会智库中心]( http://cis-india.org/ )发布了一份[报告]( http://cis-india.org/internet-governance/information-security-practices-of-aadhaar-or-lack-thereof-a-documentation-of-public-availability-of-aadhaar-numbers-with-sensitive-personal-financial-information-1 ),详细介绍了印度国家身份数据库( [ Adahaar ]( https://uidai.gov.in/ ))泄漏可能危及个人信息的方式。这些信息涉及 1.3 亿印度国民。信息泄漏给金融诈骗创造了机会,同时对个人隐私造成不可挽回的伤害。
很明显,中心化身份存储模型存在缺陷。本文描述了一种管理数字身份的新方式:自主权身份。
自主权身份的含义是人们和企业将自己的身份数据存储在自己的设备上,并能有效地提供给需要的人进行验证,而不用依赖中心化的身份数据存储。相对如今的纸质处理,自主权身份是一种数字化方式。与手动处理和中心化存储如印度的 Aadhaar 相比,自主权身份更有益。
高效地识别过程能够促进普惠金融。通过降低小企业开设银行账户的成本,融资对银行更加有利,小企业便可以获得融资。
### 身份中有哪些重要概念?
身份包含三个部分:**声明**、**证明** 和 **认证**。
#### 声明
身份 **声明** 是由个人或企业发起的:
> “我是 Antony ,出生于 1901 年 1 月 1 日”

#### 证明
**证明** 是某种形式的文件,为声明提供证据。证明有各种格式。通常情况下,个人证明是护照、出生证和账单的复印件。对于公司来说,它是大量的公司和所有权结构文件。

#### 认证
**认证** 是第三方根据他们的记录验证声明是真实的。例如,一所大学可以证明有人在那里学习过并取得学位。来自权威机构的认证比伪造的证据更加有力。但是,由于信息是敏感的,认证对于权威机构来说是一个负担。认证意味着信息需要保持,且只有特定的人才能访问。

### 身份的问题是什么?
银行需要了解他们的新客户和商业客户以便检查资格,并向监管机构证明他们(银行)不是银行坏账。他们也需要保持客户的信息是最新的。
问题在于:
* 证明通常是图片和复印件形式的 **非结构化数据**。这意味着银行工作人员必须手动读取和扫描文档以提取相关数据,然后输入系统进行存储和处理。
* 当在现实生活中发生 **数据变化** 时(如地址变更、公司所有权结构变更),客户有义务通知与他们有关系的各种金融服务提供商。
* 某些形式的证据(如原始文件的复印件)**很容易被伪造**,这就需要采取额外的步骤来证明真实性,如经过公证的复印件,从而导致其他的矛盾和费用。
结果是昂贵、耗时且麻烦的过程,使每个人都感到烦恼。

### 技术上有哪些改进?
无论采用什么样的整体解决方案,上述三个问题都需要在技术上解决。标准化和数字签名结合运作良好。
**改进非结构化数据** 的技术解决方案是将数据以机器可读的结构化格式进行存储和传输,即将 **文本存储在标准化的标签中**。
**管理数据变化** 的技术解决方案是更新所有必要实体的通用方法。即使用 **APIs**连接、验证自身(证明是您的账户)、更新详细信息。
**证明身份真实性** 的技术解决方案是 **数字签名认证**,可能有时间限制。数字签名证明与认证一样有效,因为数字签名不能伪造。数字签名有如下两个属性,使其本质上比纸质文档更好:
1. 如果签名文档发生任何更改,数字签名将失效。换句话说,它保证文件的完整性。
2. 数字签名不能被取消,并从一个文档复制到另一个文档。
### 什么是中心化解决方案?
身份管理的常见解决方案是中心化存储。第三方拥有和控制许多人身份的存储。客户将自身信息录入到系统,并上传证据。无论谁需要,都可以访问这些数据(当然得有客户的许可),并可以系统地将这些数据存储到自己的系统中。如果细节发生变化,客户会更新一次,并将更新推送给相关的银行。

这听起来不错,当然也有一些好处。但是这个模型有些问题。
### 中心化解决方案有什么问题?
#### 1. 不良数据
运营身份存储是一把双刃剑。一方面,运营商可以通过对工具收费来赚钱。另一方面,数据对运营商是不利的:对于黑客来说,集中化的身份系统是一座金矿;而对于运营商,网络安全很是头痛。
如果黑客可以侵入系统并拷贝数据,他们可以将数字身份和书面证据出售给其他坏人。这些坏人就可以以无辜者的名义窃取身份、欺诈和犯罪。这样会而且确实破坏了无辜者的生活,并给运营商造成重大的不利。
#### 2. 司法政治
监管机构希望将个人数据存储在其管辖下的地理范围内。因此,创建国际身份存储库是很困难的,因为总是有关于哪个国家存储数据和谁可以访问数据的争论。
#### 3. 垄断倾向
对于中心化存储库运营商来说,这不是问题,但对于用户来说是一个问题。如果一个公用事业运营商获得足够的关注,网络效应会吸引更多的用户。公用事业运营商可能成为准垄断企业。垄断性运营商往往对变革产生抵触;由于缺乏竞争力,他们会过度收费和乏于创新。这对于运营商是有利的,但是却损害了用户的利益。
### 去中心化的解决方案是什么?
#### 是区块链吗?
区块链是一种分布式账簿,所有数据都可以实时复制到所有参与者。是否应该将身份数据存储在多个参与实体(比如大银行)管理的区块链中?不:
1. 将所有身份数据复制到所有各方,打破了关于将个人数据保存在管辖范围内的所有规定;只储存与业务有关的个人资料;并且只存储客户授权的数据。
2. 网络安全风险增加。如果中心化数据存储很难保证安全,那么现在您正在将这些数据复制到多个参与方,每个参与方都有自己的网络安全实践和漏洞。这使得攻击者更容易窃取数据。
如果加密身份数据会怎样?
1. 加密个人数据仍可能违反个人数据规定。
2. 为什么各方(如银行)会存储和管理一些他们看不到或不使用的身份数据?积极的一面是什么?
### 那么最终的答案是什么?
最新的解决方案是 “**自主权身份**”。这个数字概念与我们今天保管非数字身份的方式非常相似。
今天,我们自己保管护照、出生证明、家用水电费账单等,也许把他们放在一个“重要的抽屉”里,并且在需要的时候才拿出来。我们将这些纸质文件和其他东西分开存放。自主权身份等同于我们现在使用的纸质文件的数字等价物。
### 如何对用户进行自主权身份识别?
你会在智能手机或电脑上安装一个应用程序,类似于某种”身份钱包“,将身份数据存储在设备硬件上,可能备份在另一个设备上或个人备份解决方案上,但 **关键** 是不存储在中心化存储库中。
身份钱包一开始是 **空** 的,只有一个根据公钥 **生成** 的 **识别号码** 以及相应的私钥(类似密码,用于创建数字签名)。这个密钥对不同于用户名和密码,因为它是由用户通过"随机和数学运算"创建的,而不是由第三方请求用户名/密码产生的。
现阶段,**没有其他任何人** 知道这个识别号码。没有人发给你。你自己创建了它。这就是自主权。大数法则和随机数法则确保没有人会产生和你一样的识别号码。
然后你可以使用这个 **识别号码**,连同 **身份声明** 一起,从相关部门得到 **认证**。
你就可以使用这些证明作为你的身份信息。

**声明** 会被输入到标准化文本中存储,并保存照片或扫描文档。
**证明** 会通过保存扫描或者证明文件的照片来存储。 然而,这只是为了向后兼容,因为数字签名认证消除了我们今天所知道的证明的需要。
**认证** - 即有效部分,也会存储在这个钱包里。它是机器可读的,数字签名的一些信息片段,在一定时间段内有效。官方如护照机构、医院、驾照机构、警察局等需要签署这些数字签名。
**需要了解,但是无需更多**:官方可以提供“超过18”、“超过21”、“合格投资者”、“可驾驶汽车”等证明文件,供用户使用。身份所有者能够选择将哪些信息传递给请求者。例如,如果你需要证明你已经超过18岁,你不需要分享你的出生日期,你只需要一个声明说你已经超过18岁,该声明由相关部门签署。

共享这类数据对于 **身份提供者和接收者来说都更安全**。提供者不需要过度共享,而接收者不需要存储不必要的敏感数据 — 例如,如果接收者被入侵,它们只存储“超过18岁”的标志,而不是出生日期。
即使银行本身也可以证明哪些人在银行有账户。我们首先需要了解他们在创建这些认证时所承担的责任。我认为,当他们寄给你一张银行账单时,它不会比他们目前承担的责任更大,而你只是把它作为在其他地方的地址证明。
#### 数据共享
数据将存储在个人设备上(如同今天将纸质文件存储在家里),且在需要时,个人通过打开设备上的通知同意第三方收集特定数据。我们已经有一些类似的 - 如果你曾使用过“连接”你的 Facebook 或 LinkedIn 账户服务,这是相似的 - 但是,不是去 Facebook 服务器收集你的个人数据,而是从你的手机中请求它,同时你对共享的数据有粒度控制。

### 总结 - 分布式账本
谁来组织这些?也许这就是分布式账本的起源。软件、网络和工作流需要构建、运行和维护。数字签名需要管理公钥和私钥,证书需要颁发、撤销、刷新。身份数据不是静态的,它需要根据某些业务逻辑进行演化。
**非区块链分布式账本将是一个理想的平台**。R3 的 Corda (注:我在 R3 中工作)已经具备了许多必要的元素 —— 协调工作流、数字签名、数据演化规则,以及一个由 80 多个金融机构组成的联盟,他们正在尝试这种精确的自我权身份概念。
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
================================================
FILE: TODO/a-guide-to-automating-scraping-the-web-with-javascript-chrome-puppeteer-node-js.md
================================================
> * 原文地址:[A Guide to Automating & Scraping the Web with JavaScript (Chrome + Puppeteer + Node JS)](https://codeburst.io/a-guide-to-automating-scraping-the-web-with-javascript-chrome-puppeteer-node-js-b18efb9e9921)
> * 原文作者:[Brandon Morelli](https://codeburst.io/@bmorelli25?source=post_header_lockup)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/a-guide-to-automating-scraping-the-web-with-javascript-chrome-puppeteer-node-js.md](https://github.com/xitu/gold-miner/blob/master/TODO/a-guide-to-automating-scraping-the-web-with-javascript-chrome-puppeteer-node-js.md)
> * 译者:[pot-code](https://github.com/pot-code)
> * 校对者:[bambooom](https://github.com/bambooom)
# JavaScript 自动化爬虫入门指北(Chrome + Puppeteer + Node JS)
## 和 Headless Chrome 一起装逼一起飞

> [**Udemy Black Friday Sale**](https://codeburst.io/udemys-black-friday-sale-starts-today-all-web-development-courses-just-10-44966e590bd4) — Thousands of Web Development & Software Development courses are on sale for only $10 for a limited time! [**Full details and course recommendations can be found here**](https://codeburst.io/udemys-black-friday-sale-starts-today-all-web-development-courses-just-10-44966e590bd4).
#### 内容简介
本文将会教你如何用 JavaScript 自动化 web 爬虫,技术上用到了 Google 团队开发的 Puppeteer。 [__Puppeteer__](https://github.com/GoogleChrome/puppeteer) 运行在 Node 环境,可以用来操作 headless Chrome。何谓 [__Headless Chrome__](https://developers.google.com/web/updates/2017/04/headless-chrome)?通俗来讲就是在不打开 Chrome 浏览器的情况下使用提供的 API 模拟用户的浏览行为。
**如果你还是不理解,你可以想象成使用 JavaScript 全自动化操作 Chrome 浏览器。**
#### 前言
先确保你已经安装了 Node 8 及以上的版本,没有的话,可以先到 [**官网**](https://nodejs.org/en/) 里下载安装。注意,一定要选“Current”处显示的版本号大于 8 的。
如果你是第一次接触 Node,最好先看一下入门教程:[**Learn Node JS — The 3 Best Online Node JS Courses**](https://codeburst.io/learn-node-js-the-3-best-online-node-js-courses-87e5841f4c47).
安装好 Node 之后,创建一个项目文件夹,然后安装 Puppeteer。安装 Puppeteer 的过程中会附带下载匹配版本的 Chromium(译者注:国内网络环境可能会出现安装失败的问题,可以设置环境变量 `PUPPETEER_SKIP_CHROMIUM_DOWNLOAD = 1` 跳过下载,副作用是每次使用 `launch` 方法时,需要手动指定浏览器的执行路径):
```shell
npm install --save puppeteer
```
#### 例 1 —— 网页截图
Puppeteer 安装好之后,我们就可以开始写一个简单的例子。这个例子直接照搬自官方文档,它可以对给定的网站进行截图。
首先创建一个 js 文件,名字随便起,这里我们用 `test.js` 作为示例,输入以下代码:
```javascript
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://google.com');
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();
```
下面我们来逐行分析上面的代码。
* **第 1 行:** 引入依赖。
* **第 3–10 行:** 核心代码,自动化过程在这里完成。
* **第 12 行:** 执行 `getPic()` 方法。
细心的读者会发现,`getPic()` 前面有个 `async` 前缀,它表示 `getPic()` 方法是个异步方法。`async` 和 `await` 成对出现,属于 ES 2017 新特性。介于它是个异步方法,所以调用之后返回的是 `Promise` 对象。当 `async` 方法返回值时,对应的 `Promise` 对象会将这个值传递给 `resolve`(如果抛出异常,那么会将错误信息传递给 `Reject`)。
在 `async` 方法中,可以使用 `await` 表达式暂停方法的执行,直到表达式里的 `Promise` 对象完全解析之后再继续向下执行。看不懂没关系,后面我再详细讲解,到时候你就明白了。
接下来,我们将会深入分析 `getPic()` 方法:
* **第 4 行:**
```javascript
const browser = await puppeteer.launch();
```
这段代码用于启动 puppeteer,实质上打开了一个 Chrome 的实例,然后将这个实例对象赋给变量 `browser`。因为使用了 `await` 关键字,代码运行到这里会阻塞(暂停),直到 `Promise` 解析完毕(无论执行结果是否成功)
* **第 5 行:**
```javascript
const page = await browser.newPage();
```
接下来,在上文获取到的浏览器实例中新建一个页面,等到其返回之后将新建的页面对象赋给变量 `page`。
* **第 6 行:**
```javascript
await page.goto('https://google.com');
```
使用上文获取到的 `page` 对象,用它来加载我们给的 URL 地址,随后代码暂停执行,等待页面加载完毕。
* **第 7 行:**
```javascript
await page.screenshot({path: 'google.png'});
```
等到页面加载完成之后,就可以对页面进行截图了。`screenshot()` 方法接受一个对象参数,可以用来配置截图保存的路径。注意,不要忘了加上 `await` 关键字。
* **第 9 行:**
```javascript
await browser.close();
```
最后,关闭浏览器。
#### 运行示例
在命令行输入以下命令执行示例代码:
```shell
node test.js
```
以下是示例里的截图结果:

是不是很厉害?这只是热身,下面教你怎么在非 headless 环境下运行代码。
非 headless?百闻不如一见,自己先动手试一下吧,把第 4 行的代码:
```javascript
const browser = await puppeteer.launch();
```
换成这句:
```javascript
const browser = await puppeteer.launch({headless: false});
```
然后再次运行:
```shell
node test.js
```
是不是更炫酷了?当配置了 `{headless: false}` 之后,就可以直观的看到代码是怎么操控 Chrome 浏览器的。
这里还有一个小问题,之前我们的截图有点没截完整的感觉,那是因为 `page` 对象默认的截屏尺寸有点小的缘故,我们可以通过下面的代码重新设置 `page` 的视口大小,然后再截取:
```javascript
await page.setViewport({width: 1000, height: 500})
```
这下就好多了:

最终代码如下:
```javascript
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://google.com');
await page.setViewport({width: 1000, height: 500})
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();
```
#### 例 2 —— 爬取数据
通过上面的例子,你应该掌握了 Puppeteer 的基本用法,下面再来看一个稍微复杂点的例子。
开始前,不妨先看看 [官方文档](https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md#)。你会发现 Puppeteer 能干很多事,像是模拟鼠标的点击、填充表单数据、输入文字、读取页面数据等。
在接下来的教程里,我们将爬一个叫 [_Books To Scrape_](http://books.toscrape.com/) 的网站,这个网站是专门用来给开发者做爬虫练习用的。
还是在之前创建的文件夹里,新建一个 js 文件,这里用 `scrape.js` 作为示例,然后输入以下代码:
```javascript
const puppeteer = require('puppeteer');
let scrape = async () => {
// Actual Scraping goes Here...
// Return a value
};
scrape().then((value) => {
console.log(value); // Success!
});
```
有了上一个例子的经验,这段代码要看懂应该不难。如果你还是看不懂的话......那也没啥问题就是了。
首先,还是引入 `puppeteer` 依赖,然后定义一个 `scrape()` 方法,用来写爬虫代码。这个方法返回一个值,到时候我们会处理这个返回值(示例代码是直接打印出这个值)
先在 scrape 方法中添加下面这一行测试一下:
```javascript
let scrape = async () => {
return 'test';
};
```
在命令行输入 `node scrape.js`,不出问题的话,控制台会打印一个 `test` 字符串。测试通过后,我们来继续完善 `scrape` 方法。
**步骤 1:前期准备**
和例 1 一样,先获取浏览器实例,再新建一个页面,然后加载 URL:
```javascript
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.waitFor(1000);
// Scrape
browser.close();
return result;
};
```
再来分析一下上面的代码:
首先,我们创建了一个浏览器实例,将 `headless` 设置为 `false`,这样就能直接看到浏览器的操作过程:
```javascript
const browser = await puppeteer.launch({headless: false});
```
然后创建一个新标签页:
```javascript
const page = await browser.newPage();
```
访问 `books.toscrape.com`:
```javascript
await page.goto('http://books.toscrape.com/');
```
下面这一步可选,让代码暂停执行 1 秒,保证页面能完全加载完毕:
```javascript
await page.waitFor(1000);
```
任务完成之后关闭浏览器,返回执行结果。
```javascript
browser.close();
return result;
```
步骤 1 结束。
**步骤 2: 开爬**
打开 Books to Scrape 网站之后,想必你也发现了,这里面有海量的书籍,只是数据都是假的而已。先从简单的开始,我们先抓取页面里第一本书的数据,返回它的标题和价格信息(红色边框选中的那本)。

查一下文档,注意到这个方法能模拟页面点击:
**page.click(selector[, options])**
* `selector` 选择器,定位需要进行点击的元素,如果有多个元素匹配,以第一个为准。
这里可以使用开发者工具查看元素的选择器,在图片上右击选中 inspect:

上面的操作会打开开发者工具栏,之前选中的元素也会被高亮显示,这个时候点击前面的三个小点,选择 copy - copy selector:

有了元素的选择器之后,再加上之前查到的元素点击方法,得到如下代码:
```javascript
await page.click('#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img');
```
然后就会观察到浏览器点击了第一本书的图片,页面也会跳转到详情页。
在详情页里,我们只关心书的标题和价格信息 —— 见图中红框标注。

为了获取这些数据,需要用到 `page.evaluate()` 方法。这个方法可以用来执行浏览器内置 DOM API ,例如 `querySelector()`。
首先创建 `page.evaluate()` 方法,将其返回值保存在 `result` 变量中:
```javascript
const result = await page.evaluate(() => {
// return something
});
```
同样,要在方法里选择我们要用到的元素,再次打开开发者工具,选择需要 inspect 的元素:

标题是个简单的 `h1` 元素,使用下面的代码获取:
```javascript
let title = document.querySelector('h1');
```
其实我们需要的只是元素里的文字部分,可以在后面加上 `.innerText`,代码如下:
```javascript
let title = document.querySelector('h1').innerText;
```
获取价格信息同理:

刚好价格元素上有个 `price_color` class,可以用这个 class 作为选择器获取到价格对应的元素:
```javascript
let price = document.querySelector('.price_color').innerText;
```
这样,标题和价格都有了,把它们放到一个对象里返回:
```javascript
return {
title,
price
}
```
回顾刚才的操作,我们获取到了标题和价格信息,将它们保存在一个对象里返回,返回结果赋给 `result` 变量。所以,现在你的代码应该是这样:
```javascript
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}
});
```
然后只需要将 `result` 返回即可,返回结果会打印到控制台:
```javascript
return result;
```
最后,综合起来代码如下:
```javascript
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.click('#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img');
await page.waitFor(1000);
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}
});
browser.close();
return result;
};
scrape().then((value) => {
console.log(value); // Success!
});
```
在控制台运行代码:
```javascript
node scrape.js
// { title: 'A Light in the Attic', price: '£51.77' }
```
操作正确的话,在控制台会看到正确的输出结果,到此为止,你已经完成了 web 爬虫。
#### 例 3 —— 后期完善
稍加思考一下你会发现,标题和价格信息是直接展示在首页的,所以,完全没必要进入详情页去抓取这些数据。既然这样,不妨再进一步思考,能否抓取所有书的标题和价格信息?
所以,抓取的方式其实有很多,需要你自己去发现。另外,上面提到的直接在主页抓取数据也不一定可行,因为有些标题可能会显示不全。
**拔高题**
目标 —— 抓取主页所有书籍的标题和价格信息,并且用数组的形式保存返回。正确的输出应该是这样:

开干吧,伙计,其实实现起来和上面的例子相差无几,如果你觉得实在太难,可以参考下面的提示。
* * *
**提示:**
其实最大的区别在于你需要遍历整个结果集,代码的大致结构如下:
```javascript
const result = await page.evaluate(() => {
let data = []; // 创建一个空数组
let elements = document.querySelectorAll('xxx'); // 选择所有相关元素
// 遍历所有的元素
// 提取标题信息
// 提取价格信息
data.push({title, price}); // 将数据插入到数组中
return data; // 返回数据集
});
```
* * *
如果提示了还是做不出来的话,好吧,以下是参考答案。在以后的教程中,我会在下面这段代码的基础上再做一些拓展,同时也会涉及一些更高级的爬虫技术。你可以在 [**这里**](https://docs.google.com/forms/d/e/1FAIpQLSeQYYmBCBfJF9MXFmRJ7hnwyXvMwyCtHC5wxVDh5Cq--VT6Fg/viewform) 提交你的邮箱地址进行订阅,有新的内容更新时我们会通知你。
**参考答案:**
```javascript
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
const result = await page.evaluate(() => {
let data = []; // 创建一个数组保存结果
let elements = document.querySelectorAll('.product_pod'); // 选择所有书籍
for (var element of elements){ // 遍历书籍列表
let title = element.childNodes[5].innerText; // 提取标题信息
let price = element.childNodes[7].children[0].innerText; // 提取价格信息
data.push({title, price}); // 组合数据放入数组
}
return data; // 返回数据集
});
browser.close();
return result; // 返回数据
};
scrape().then((value) => {
console.log(value); // 打印结果
});
```
### 结语:
谢谢观看!如果你有学习 NodeJS 的意向,可以移步 [**Learn Node JS — The 3 Best Online Node JS Courses**](https://codeburst.io/learn-node-js-the-3-best-online-node-js-courses-87e5841f4c47)。
每周我都会发布 4 篇有关 web 开发的技术文章,[**欢迎订阅**](https://docs.google.com/forms/d/e/1FAIpQLSeQYYmBCBfJF9MXFmRJ7hnwyXvMwyCtHC5wxVDh5Cq--VT6Fg/viewform)!或者你也可以在 Twitter 上 [**关注我**](https://twitter.com/BrandonMorelli)
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
================================================
FILE: TODO/a-guide-to-interviewing-for-product-design-internships.md
================================================
>* 原文链接 : [A Guide to Interviewing for Product Design Internships](https://medium.com/facebook-design/a-guide-to-interviewing-for-product-design-internships-d719dd4c146c#.jhgjr12c)
* 原文作者 : [Andrew Hwang](https://medium.com/@ahwng)
* 译文出自 : [掘金翻译计划](https://github.com/xitu/gold-miner)
* 译者 :
* 校对者:
> “We reviewed your portfolio, and we’d love to interview you for our product design internship. What times will you be available in the upcoming week?”
Upon seeing this email, your pulse quickens. Your eyes widen. You drool a little. You sent out so many cover letters, submitted so many applications, and — finally! A small but meaningful step on the journey to becoming a full-fledged product designer.
But what will they ask you? And how could you possibly prepare?
Breaking into the product design field as a student is hard. Some product designers stumble into the field with a graphic design or art degree. Others are self-taught. Either way the field of digital product design is so new that there are very few resources for curious students.
In high school I hadn’t yet heard of the product design industry. I dabbled in web design but quite frankly, I was terrible at it. I couldn’t imagine it going anywhere.
But over time I accumulated enough design work to find myself with a design internship at a mobile app startup. There I first got a taste of product design. And I fell in love with the problem-solving, the complexity, the collaboration with product managers and engineers and illustrators to build something from nothing. So I pursued it ruthlessly.
The following summer I ramped up my internship application game, submitting resumes to over 50 companies. Five of them responded positively. Of those five, three small tech companies interviewed me immediately. But I went into those interviews not having the faintest idea what they’d ask, so those doors shut as quickly as they had opened.
Evernote was the fourth company to respond positively. And though I had botched the previous three interviews, I had a better idea of what to expect when I hopped on the phone with the Evernote designers.
I landed the Evernote product design internship that summer. And with a bit more experience under my belt, the following summer I received an offer for Facebook’s product design internship. Now I’m a full-time product designer at Facebook.
As a student I interviewed for product design internships at many of the Silicon Valley behemoths: Google; Facebook; Mozilla; Quora; Groupon; Dropbox. And if one thing stuck with me, it was that product design interviews are quite similar across tech companies. They usually include all or some combination of the following:
1. Phone screen
2. Portfolio review
3. Design exercise
4. App critique
Let’s dig a little deeper into each step
The phone screen allows the recruiter to get to know you better, to go past the words on your resume. You might be asked:
* What’s your background like?
* How did you get into design?
* Why are you interested in working here?
* What was your favorite past project, and why?
During the phone screen, sound excited. And come prepared with questions for the recruiter. Try to ask questions specific to the company, questions that are not easily answerable with a Google search. Recruiters can tell generic questions from authentic ones, and asking canned questions may damage the strength of your candidacy.
While preparing for my first phone screen with Facebook, for instance, I [discovered](http://www.quora.com/What-do-Facebook-interns-do) the company regularly hosts intern hack-a-thons. So during the phone screen I probed further about the hack-a-thons: How do they work, exactly? Is it okay for interns to completely ignore their summer projects during the hack-a-thons? Who reviews the final projects? Questions like these show genuine interest. They tell the recruiter you’ve done your homework and care deeply about the internship opportunity.
If the recruiter thinks your background and interests might be a good fit for the internship, the next step is usually a showcase of your past work.
Here you’ll speak with a designer. Typically, the review will include a deep dive into three or four of your portfolio projects. The point of the portfolio review is for the designer to tease out your design process, to understand what types of questions you ask and what kinds of solutions you consider. In short, the interviewer wants to know how you approach design. You might be asked questions such as:
* What were the problems you were trying to solve?
* Who did you partner with?
* What kind of research did you perform, if any?
* Why did you choose that design solution over this one?
* What were the tradeoffs?
* What challenges did you face in designing X?
* If you had more time to work on Y, what would you change?
* If you got stuck on a certain design problem, how did you overcome it?
One of your main tasks in the portfolio review is to show **intentionality** in your design process, to demonstrate that you thought through each design decision carefully, from the high-level product features to the visual styling of a button.
Describe your rationale clearly. Arbitrary design decisions won’t hold up to the scrutiny of a portfolio review.

Make sure you can articulate your design decisions. Comic credit: Andrew Hwang
During the portfolio review, you should also be able to **thoughtfully critique** your own designs. No design solution is perfect. Reflect on your projects and come up with suggestions for how to improve them.
Many companies think of product design as having three pillars:
1. Visual design: How polished are your designs? Do they feel well-crafted and refined? Are they aesthetically pleasing?
2. Interaction design: Can you design intuitive end-to-end user flows? Do you consider edge cases appropriately? How easy is it to get from point A to point B in an app you designed?
3. Product thinking: What problems are you trying to solve? Who are you designing for? What features should be included in your product, and why?
The portfolio review helps the interviewer gauge your strengths and weaknesses in these areas. Maybe you’re more comfortable with visual design and less so with interaction design. Maybe you’re a fantastic product thinker but can’t build a prototype to save your life. But that’s okay! You’re a student. Interviewers don’t expect you to be a rockstar in every facet of product design. Being honest about your weaknesses shows humility, a vital quality for any designer.
**Preparing for the portfolio review is key**. While interviewing I often found myself nervously rushing through each project in my portfolio. Having a list of talking points prevented me from skipping over any important items and forced me to slow down.
Your list of talking points should shed more light on the specific design process for each project, elaborating on what went wrong and what went right. Reflect deeply on each piece you plan to present. Write down everything you can remember about the design process. Ask a friend to mock interview you. Prepare, prepare, prepare!
If the portfolio review goes well, it’s on to the design exercise.
The typical design exercise follows this pattern:
_Please design an interface/object/product that does X or solves Y._
Its on-the-spot nature can make the design exercise intimidating. Where the portfolio review fleshed out your past design processes, the design exercise asks that you flex your design chops right here, right now.
Some exercises I’ve encountered:
* Design a web form that collects only high-quality phone numbers. That is, if you called the phone numbers, someone would receive the call.
* Design the homepage for a search engine.
* Brainstorm products you could design using the Kindle’s e-reader screen material.
Every designer has their own design process, so I can’t exactly tell you how to go about the design exercise. But I’d suggest thinking about who you’re designing for, quickly sketching out many different options, and analyzing the tradeoffs of each option as you go. Don’t dive too deeply into the interaction or visual details of any one option before completing a thorough high-level exploration.
I was once asked to design a mobile app that made it easy for restaurant customers to split the bill. The exercise started well. I quickly sketched one design option where the waiter enters the items on the receipt. Then another option where the customer enters the data by hand. But before finishing the high-level exploration, I became married to this option, diving too far into the details (what would the layout be? how would the typography work?)
I wasted my time on the visual details and as a result, I didn’t have enough time to explore other types of solutions (e.g. using the customer’s smartphone to take a picture of the receipt). The week after that interview I received a rejection from the recruiter. But looking back, it taught me a valuable lesson about the design exercise: the interviewer cares much more about your high-level idea explorations than your pixel-level ambitions.

Don’t get caught up in the visual design details before thinking deeply about the bigger picture. Comic credit: Andrew Hwang
In the design exercise it’s crucial to **demonstrate your idea generation skills.** So don’t be afraid to come up with some crazy blue-sky ideas. Ask your interviewer questions. Don’t assume anything. And remember, brainstorming and analyzing high-level feature ideas is much more meaningful than exploring a bunch of different button styles.
Thankfully, the high-pressure design exercise is not part of every interview loop. You might be tasked with the app critique instead.
Pick an app. Any app. Make sure it’s an app you know well.
The app critique is intended to analyze your product thinking skills. You’ll walk the interviewer through an app of your choice. Along the way, the interviewer will stop you and ask questions such as:
* What audience do you think this app was intended for?
* What problem is the app supposed to solve?
* How well does it solve the problem?
* What are your favorite features on the app, and why?
* What are your least favorite features on the app? Why?
* Why do you think the designers made decision X?
* What is the point of feature Y? What value does it add?
* How would you improve the app?
* Who are the app’s competitors?
* What does the app do better than its competitors? What does it do worse?
Strategizing for the app critique is hard because it relies so heavily on your product intuition. The best advice I can give is to practice analyzing apps at a high level. Forget about the colors, the typography, the buttons. Instead, think about **what value the app provides**. And **how features in the app align with the app’s overall value proposition**. Snapchat, for example, strives to be _the_ app for live sharing with friends. So they built awesome features like Live Snapchat stories for major events and Live Video in direct message threads.
Product design interviews are hard. They’re stressful, and open-ended, and you can receive rejection after rejection with no idea what you’re doing wrong.
But interviewing for product design internships is like any other skill. With time and practice, you improve. It never hurts to interview for a few companies you have no intention of working at, just to practice your interviewing skills.
Have notes prepared before you start each interview. Especially the portfolio review. I found it extremely helpful to write down a list of talking points for each project. This list prevents you from nervously skipping over any important items.
Last but not least, the design community is small and tight-knit and people are more than willing to help if you can just find the courage to ask.
================================================
FILE: TODO/a-guide-to-the-google-play-console.md
================================================
> * 原文地址:[A guide to the Google Play Console](https://medium.com/googleplaydev/a-guide-to-the-google-play-console-1bdc79ca956f)
> * 原文作者:[Dom Elliott](https://medium.com/@iamdom?source=post_header_lockup)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/a-guide-to-the-google-play-console.md](https://github.com/xitu/gold-miner/blob/master/TODO/a-guide-to-the-google-play-console.md)
> * 译者:[JayZhaoBoy](https://github.com/JayZhaoBoy)
> * 校对者:[hanliuxin5](https://github.com/hanliuxin5),[IllllllIIl](https://github.com/IllllllIIl)
# Google Play 控制台指南
## 无论你是企业用户还是作为技术人员,在 1 或 100 人的团队中,Play 控制台能为你做的都不仅仅是发布应用这么简单而已

你或许使用 [Google Play 控制台](http://g.co/play/console)上传过 Android 应用或者游戏,创建一个商品详情并点击上传按钮把它添加到 Google Play 上。但你可能没意识到 Play 控制台其实还有很多其他的功能,特别是对那些专注于改善其应用的质量和业务表现的人。
和我一起来学习 Play 控制台;我将向你介绍每一个功能并指出其中一些有用的资源,以充分利用它们。一旦你熟悉了这些功能,你就可以通过用户管理控制,允许团队成员使用合适的特性功能或他们所需的数据。注意:在这篇文章中我所说的「应用」通常代表的意思是「应用或者游戏」。
目录跳转到:
* [快速上手](#8b10)
* [信息中心和统计信息(Dashboard and statistics)](#a5a0)
* [Android vitals](#ed9a)
* [开发工具(Development tools)](#add5)
* [发布管理(Release management)](#4e06)
* [Store 展示(Store presence)](#c527)
* [用户获取(User acquisition)](#111b)
* [财务报告(Financial reports)](#fb37)
* [用户反馈(User feedback)](#d92a)
* [全局 Play 控制台部分](#4f14)
* [获取 Play 控制台应用](#a696)
* [保持最新状态](#eb8c)
* [疑问?](#3882)
* * *
### 快速上手
如果你受邀协助管理应用或你已经上传过一个应用,当你访问 Play 控制台时,你会看到如下所示的内容:
这是当你拥有一个应用程序或游戏时,登录 Play 控制台后的视图。
在这篇文章中我会假设你已经拥有了一个应用。如果你刚开始发布你的第一个应用,看一下[启动清单](https://developer.android.com/distribute/best-practices/launch/launch-checklist.html)。稍后我会回到全局菜单选项(游戏服务,警报和设置)。
从列表中选择一个应用,然后跳转到其信息中心。在左侧有一个导航菜单(三),可快速访问所有 Play 控制台的工具,让我们来依次的看一下。
* * *
### 信息中心和统计信息(Dashboard and statistics)
前两项是信息中心和统计信息。通过这些相关报告你可以对你的应用的表现情况做一个概览。
**信息中心**(**Dashboard**)提供了安装和卸载情况的概要,安装排名前列的国家,安装的激活量,评分的数量和值,崩溃简报,Android vitals 的概要,以及一个发布前测试报告的列表。对于每个概要,点击**查看详细信息**(**view details**)以获取更多详细的信息。你可以在 7 天,30 天,1 年以及应用程序整个生命周期之间切换视图。

应用的信息中心。
运气好的话,概要会显示出你的应用成功的获得了很高的安装率和很低的崩溃率。快速浏览信息中心是一种可以查看事情是否按照预期进行的简单的方法,要格外注意:卸载增长,崩溃增长,评分下滑,以及其他一些性能不佳的指标。如果这一切都不是你所预期的,那么你或你的工程师可以获得更多的细节来找出这些不同问题的原因。
**统计信息**(**Statistics**)让你可以构建一个对你十分重要的应用数据视图。除了查看任何日期范围内的数据外,你还可以同时绘制两个指标,并将它们与前一个期间进行比较。你可以通过图表下方的表格中选定的维度(例如设备,国家/地区,语言或应用版本)对统计信息进行全面细分。有些统计数据每小时提供一次绘图,以获取更详细的情况。事件(例如应用程序的发布或销售)显示在图表和其下面的事件时间轴中,因此你可以了解到统计信息是因为什么而变化的。

统计信息。
例如,你可能正在巴西进行新的应用推广。你就可以将报告设置为按国家显示安装情况,将国家/地区列表过滤为巴西(从维度表中),然后将数据与早期推广活动的数据进行比较,以清楚地了解你的促销活动的进展情况。
> **更多关于信息中心和统计信息的资源:**
> -[监控你的应用程序的统计信息,并查看预期之外的警报](https://developer.android.com/distribute/best-practices/launch/monitor-stats.html)
* * *
### Android vitals
> 大鱼游戏(Big Fish Games)在他们管理游戏的过程中[使用 Android vitals 减少 21% 的崩溃](https://www.youtube.com/watch?v=qRXkEQOtQ98),[Cooking Craze](https://play.google.com/store/apps/details?id=com.bigfishgames.cookingcrazegooglef2p).
**Android vitals** 主要是以性能和稳定性来衡量你应用的质量的一个工具。去年 Google 进行的一项内部研究考察了 Play Store 中的一星评论,发现 50% 的人提到了应用程序的稳定性和错误。通过解决这些问题,对影响用户满意度是有积极作用的,从而使得更多人留下正面评论并保留你的应用。Android vitals 提供了关于应用性能的三个方面的信息:稳定性,渲染(也称为 jank)和电池寿命。

Android vitals(只有 Play 有足够的关于您应用的数据时,才会显示每一项)。
前两项指标—**插入唤醒锁**(**stuck wake locks**)和**过度唤醒**(**excessive wakeups**)—表明应用是否对电池寿命产生负面影响。这些报告显示应用程序是否要求设备长时间(一小时或更长时间)保持打开状态,或者经常要求设备唤醒(设备充满电后每小时唤醒超过 10 次)。
应用程序稳定性信息采用**应用程序无响应**(**ANR**)和**崩溃率**(**crash rate**)报告的形式。正如本节中的所有概要一样,按应用版本,设备和 Android 版本提供细分。从概要中,你可以深入了解到哪些旨在帮助开发人员识别这些问题的原因的细节。最近对信息中心的改进中提供了有关 ANR 和崩溃的更多详细信息,使它们更易于诊断和修复。工程师可以从 **ANR 和崩溃**(**crashs**)部分获取更多详细信息,并通过加载**去混淆文件**(**de-obfuscation files**)来提高崩溃报告的可读性。
接下来的两项指标—**渲染速度减缓**(**slow rendering**)和**帧冻结**(**frozen frames**)—与开发人员称为 _jank_ 的内容或应用 UI 中的帧频不一致有关。每一次应用程序的 UI 抖动和卡顿都会导致糟糕的用户体验。这些统计数据会告诉你有多少用户会出现以下这些情况:
* 超过 15% 的帧需要超过 16 毫秒才能完成渲染,或者
* 1000 帧中至少有一帧的渲染时间大于 700 毫秒。
**行为阈值(Behavior thresholds)**
对于每个指标,你都会看到一个**不良行为阈值**(**bad behavior threshold**)。如果你的某个 Android vitals 超出了不良行为阈值,你会看到一个红色的错误图标。这个图标表示你的应用程序在该指标的分数上高于其他应用程序(在这里值越高代表越差!)。你应该尽快解决这个糟糕的表现,因为若如果你的受众的用户体验不好,你的应用在 Play Store 中也会有不好的表现。这是因为 Google Play 的搜索和排名算法以及包含 Google Play 奖励在内的所有促销机会都会结合应用的 vitals 来考虑。超过不良行为阈值将导致排名降低。
> **更多关于 Android vitals 的资源:**
> - [使用 Android vitals 提高你的应用的表现和稳定性](https://developer.android.com/distribute/best-practices/develop/android-vitals.html)
> - [了解如何调试和修复 Android vitals 文档中的问题](https://developer.android.com/topic/performance/vitals/index.html)
> - [在精不在多:为什么质量很重要](https://www.youtube.com/watch?v=hfpnldMBN38) (Playtime ‘17 session)
> - [用于优化 Android 应用程序的 10 个秘诀,以保持良好的用户体验](https://www.youtube.com/watch?v=ovPCRS_lEWU) (I/O ‘17 session)
> - [使用 Android 和 Play 中的工具来提高工作效率](https://www.youtube.com/watch?v=ySxCrzsKSGI) (I/O ‘17 session)
* * *
### 开发工具(Development tools)
我会略过这一部分;这是控制台为技术人员提供的一些工具。**服务和 API** 部分列出了各种服务及 API 的密钥和 ID,例如 Firebase Cloud Messaging 和 Google Play 游戏服务。而 **FCM 统计信息**会向你显示通过 Firebase Cloud Messaging 发送的与数据相关的信息。欲了解更多信息请[查看帮助中心](https://support.google.com/googleplay/android-developer/answer/2663268).
* * *
### 发布管理(Release management)
> [Zalando](https://play.google.com/store/apps/details?id=de.zalando.mobilehttps://play.google.com/store/apps/details?id=de.zalando.mobile) focused on quality and used release management tools to 每季度[减少 90% 的崩溃次数并将用户终身价值提高 15%。](https://youtu.be/Aau8LWGdBFE)。
在**发布管理**(**Release management**)部分中,你可以控制如何让你的新应用或者已更新的应用被人们来安装。这包括在发布之前测试你的应用程序,设置正确的设备定位,管理和监控测试,以及产品的实时追踪。
随着应用程序版本的发布,**发布信息中心**(**release dashboard**)将为你提供重要统计数据的整体视图。你还可以将当前版本与过去的版本进行比较。你可能还想和一个不太满意的版本做比较,以确保类似的情况不会再发生。或者与最佳的版本进行比较,看看是否能做进一步改进。
发布信息中心。
你应该在发布时使用**分阶段发布**(**staged rollouts**)。你可以选择一定比例的受众群体来接收应用更新,然后监控发布信息中心。如果事情进展不顺利— 例如崩溃持续增加,评级下降或卸载量增加—在太多用户受到影响之前,你可以点击**管理版本**(**manage release**)并暂停部署。运气好的话,希望你们的工程师能在恢复部署(如果问题不需要应用程序更新)或启动新版本(如果需要更新)之前解决这些问题。如果一切顺利的话,你可以继续提高收到更新的受众群体的百分比,直到达到 100%。
> Google Play 你将测试版本的软件发布到全球发布,并持续获取用户的反馈。这使我们能够查看到真实的数据并尽可能为我们的玩家制作最好的游戏。
> — [David Barretto, Hutch Games 的 CEO 和联合创始人](https://www.youtube.com/watch?v=jLOIwdKiSd0)
**应用程序发布(App releases)** 是应用程序包(你的 APK)上传和准备发布的地方。应用可以发布到不同的渠道:**alpha**,**beta** 和 **production**。在 alpha 和 beta 渠道上进行受信任用户的封闭测试或任何人都可以加入的公开测试。在准备发布时,你可以将其保存为草稿,这使得你有机会反复并仔细的编辑应用的详细信息,直到你准备好要发布为止。
> **[免安装应用]使用户无需额外从 Play Store 安装应用程序即可轻松获得出色的应用体验。我们已经看到我们的即时应用取得了巨大成功。**
> - [Laurie Kahn, Realtor.com 的首席产品经理](https://developer.android.com/stories/instant-apps/realtor-com.html)
**Android 免安装应用**(**Instant Apps**)部分就像应用程序发布,只不过是为了适用于免安装应用。如果你还不熟悉免安装应用,它们允许用户通过链接即时访问应用程序的部分功能,而不必花时间从 Play Store 下载完整的应用程序。查看 [Android 免安装应用](https://developer.android.com/topic/instant-apps/index.html)文档获取更多详细信息。
**工件库**(**artifact library**)是一个专门展示你为发布应用上传的所有文件集合的部分,例如 APK,假如出于某些需要,你可以回顾并从这里下载某些旧的 APK。
> 在第一次使用时,[设备目录(device catalog)]让我避免了去做出一个糟糕的,不知情的决定。我当时正打算移除一种支持设备,但后来我发现它有着很好的安装,4.6 的评分和 30 天的重要收入。在目录中有这样的数据非常棒!
> - Oliver Miao, [Pixelberry Studios](https://play.google.com/store/apps/developer?id=Pixelberry&hl=en) 的创始人和首席执行官
**设备目录**(**device catalog**)包含数千台经过 Google 认证的 Android 和 Chrome 操作系统设备,可提供搜索和查看设备规格的功能。通过精细筛选控制,你可以移除使用范围较小的问题设备,以便在你的应用能在所有支持的设备上提供最佳体验。你可以单独移除设备和/或通过性能指标(如 RAM 和芯片系统)来设置规则。该目录还显示每种设备类型的安装量,评分和收入。例如,特定设备的平均评分较低,可能是设备问题在一般测试中没有被捕捉到导致的。你可以移除这样的设备,并暂时停止新的安装,直到你完成修复。

设备目录。
**应用签名**(**App signing**)是我们为帮助你保护应用签名密钥的安全而推出的一项服务。Google Play 上的每个应用都由其开发人员签名,提供了一个可追踪的声明来让开发人员证明 “真的是我开发的这个 app”。如果用于签名应用程序的密钥丢失,这是一个严重问题。你将无法更新你的应用程序。作为替代,你需要上传一个新的应用程序,你将失去应用程序的安装历史记录,评分和评论,并且尝试切换时可能会导致用户混淆。使用应用程序签名后,你可以上传应用程序签名密钥,将其安全的存储到 Google 的云中。这与使用 Google 存储我们的应用密钥的技术是相同的,这得益于我们在业界领先的安全基础架构。上传的密钥随后可用于在你提交更新时为你的应用签名。当你第一次上传全新的应用程序时,你可以很容易注册应用程序签名。而我们将为你生成应用签名密钥。

应用签名(由 Google Play 提供的服务)。
> 应用开发语言学习者 [Erudite](https://play.google.com/store/apps/dev?id=7358092740483658893&hl=en) 因为[使用预发行报告提高了 60% 的留存率](https://www.youtube.com/watch?v=WMJR6CuPp4w&list=PLWz5rJ2EKKc9ofd2f-_-xmUi07wIGZa1c&index=17v).
本节的最后一个部分是**预发行报告**(**re-launch report**)。当你上传应用的 alpha 版或 beta 版时,我们会在 Android 的 Firebase 测试实验室中针对各种规格的流行设备进行自动化测试,并展示结果。这些测试会查找月崩溃,性能和安全漏洞相关的一些错误和问题。您可以查看在不同设备和不同语言中运行的应用的屏幕截图。你还可以设置证书,以便在登录后执行测试,以及使用 Google Play 许可服务来测试应用程序。
预启动报告(Pre-launch report)(自动生成 alpha/beta 版)。
在发行一个 app 后,有限或不完整的测试可能会使应用因为其质量问题导致低评分和负面评论,从而使得应用被推出,这种情况很难恢复。预发行报告是全面测试以及帮助你识别和修复应用中的常见问题的良好开端。然而,您仍然需要运行一套测试来全面检查您的应用。在 [**Android 的 Firebase 测试实验室**](https://firebase.google.com/docs/test-lab/)中来构建测试,该测试通过预发行报告来提供其他功能,并且测试实验室能够在多台设备上自动运行这些测试,这可能比人工测试更有效及高效。
> **更多关于发布管理的资源:**
> - [根据质量准则进行测试来满足用户期望](https://developer.android.com/distribute/best-practices/develop/quality-guidelines.html)
> - [使用预发行和崩溃报告来改进您的应用](https://developer.android.com/distribute/best-practices/launch/pre-launch-crash-reports.htmlhttps://developer.android.com/distribute/best-practices/launch/pre-launch-crash-reports.html)
> - [用 Beta 版测试你的应用程序并获取用户宝贵的早期反馈](https://developer.android.com/distribute/best-practices/launch/beta-tests.html)
> - [分段发布更新以确保获得积极的反响](https://developer.android.com/distribute/best-practices/launch/progressive-updates.html)
> - [推出手机游戏的新时代](https://medium.com/googleplaydev/a-new-era-of-launching-mobile-games-ef2453686f73) (Medium 推送)
> - [发布你的游戏](https://www.youtube.com/watch?v=rV9Q6AMdt84) (Playtime ‘17 session)
> - [新版本和设备定位工具](https://www.youtube.com/watch?v=peCWuCSIv7U) (I/O ‘17 session)
> - [注册应用签名以保护您的应用密钥](https://www.youtube.com/watch?v=PuaYhnGmeEk) (DevByte video)
* * *
### Store 展示(Store presence)
你可以在此部分管理应用在 Google Play 上的宣传文案,针对应用的内容运行实验,设置定价和市场,获取内容分级,管理应用内商品以及获取翻译。
**商品详情**(**Store listing**)部分和你想象中的一样—这是你维护应用元数据的地方,例如其标题,说明,图标,功能图片,功能视频,屏幕截图,商店分类,联系详情和隐私政策。

商品详情(Store listing)。
一个好的商品详情应该有一个醒目的图标; 一个用于展示应用程序的特别之处的功能的图形,视频和屏幕截图(支持所有设备类别和所有方向); 以及一个引人注目的描述。对于游戏,请上传视频和至少三张横屏截图,以确保您的游戏符合 Play Store 游戏部分中的视频/屏幕截图群集。了解哪些内容最适合并推动最多安装可能是一项挑战。但是,控制台的下一部分旨在回答这个问题。
> 通过利用应用程序的图标和屏幕截图进行商品详情实验后,日本房地产应用程序 [LIFULL HOME’S](https://play.google.com/store/apps/details?id=jp.co.homes.android3) [安装率增加了 188%](https://www.youtube.com/watch?v=PXW6zcm3-4c&index=7&list=PLWz5rJ2EKKc9ofd2f-_-xmUi07wIGZa1c).
**商品详情实验室**(**Store listing experiments**)使你能够测试商品详情的许多方面,例如其说明,应用图标,功能图形,屏幕截图和促销视频。你可以对图像和视频进行全局实验,以及对文本进行本地化实验。进行实验时,你最多可以指定要测试的项目的三种变体,并且你将会看到测试变体所占的 store 访问者的百分比。这个实验会一直运进行直到统计到足够多的 store 访问者为止,然后会告诉你如何去比较变体。如果你得到了具有明确优势的变体,您可以选择将该变体应用于商品详情并将其展示给所有访问者。

商品详情实验室(Store listing experiments)。
有效的实验需要从一个明确的目标开始。首先要测试你的应用程序图标,因为它是你的清单中最明显的部分,其次是其他清单内容。每个实验测试一种内容类型以获得更可靠的结果。实验应至少运行七天,尤其是在商店流量较低的情况下,以达到 store 访问者的 50%—但如果测试可能会有一些风险,请保持较低的百分比。通过反复从实验中获取表现良好的内容并针对主题进行进一步的迭代。例如,如果你的第一个测试发现一个更好的元素添加到游戏的图标中,你的下一个实验可以测试一下图标背景颜色变化所带来的影响。
**定价和分发**(**Pricing & distribution**)是你为应用设置价格的地方,并且可以限制其分发的国家/地区。你还可以在这里指出你的应用是否针对特定设备类别(如 Android Wear)进行了支持,以及你的应用是否适用于诸如 Designed for Families 之类的计划。每个设备类别和程序都有相关要求和最佳做法,我在下面添加了有关每种设备更多信息的链接。
定价和分发(Pricing & distribution)。
在设定价格时,你会看到一个本地化功能,控制台会自动将价格调整为最符合该指定国家/地区的惯例。例如,日本的结算价格为 .00。此时,你可能还想创建一个 **定价模板**(**pricing template**)。使用定价模板,你可以按国家/地区创建一组价格,然后将其应用于多个付费应用和应用内商品。对模板所做的任何更改都会自动应用于所有使用该模板设置过价格的应用或产品。在控制台的全局设置菜单中可以找到你的定价模板。
在为应用程序设置了详细信息后,最有可能重回此部分的原因是运行付费应用程序的销售,选择加入新程序或更新应用程序分发的国家列表。
> **详细了解分配设备类别和程序:**
> - [分发到 Android Wear](https://developer.android.com/distribute/best-practices/launch/distribute-wear.html)
> - [分发到 Android TV](https://developer.android.com/distribute/best-practices/launch/distribute-tv.html)
> - [分发到 Android Auto](https://developer.android.com/distribute/best-practices/launch/distribute-auto.html)
> - [优化 Chrome OS 设备](https://developer.android.com/distribute/best-practices/engage/optimize-for-chromebook.html)
> - [分发到 Daydream](https://developer.android.com/distribute/best-practices/develop/daydream-and-cardboard-vr.html)
> - [使用托管的 Google Play 分发给企业和组织](https://developer.android.com/distribute/google-play/work.html)
> - [分发以家庭或孩子为中心的应用程序和游戏](https://developer.android.com/distribute/google-play/families.html)
接下来是你的应用的**内容评级**(**content rating**)。通过回答内容评级调查问卷获得评分,完成后,你的应用将收到来自世界各地认可机构贴切的评分标记。没有内容分级的应用将从 Play Store 中删除。
**应用内商品**(**in-app products**)部分是你维护从你的应用中出售的产品和订阅目录的地方。在这里添加商品不会为你的应用或游戏增加功能,每个产品的交付或解锁或订阅都需要编码到应用中。这里的信息决定了 store 对这些商品所做的事情,比如它向用户收费的金额以及续订的时间。因此,对于应用内商品,除了说明和价格明细之外,你还可以添加其订阅时描述和价格,然后添加结算周期,试用期和未付款宽限期。项目价格可以单独设置或基于定价模板设置。如果价格是为各国单独设定的,你可以接受根据当前汇率所得的价格或手动设置每个价格。
应用内商品(in-app products)。
> Noom [国际收入增长了 80%](https://developer.android.com/stories/apps/noom-health.html) 通过将其应用在Google Play 上本地化。
本部分的最后一个选项是**翻译服务**(**translation service**)。Play 控制台让你可以通过可靠的经过审核的翻译人员,将你的应用翻译成新的语言。当你的应用程序以当地的语言提供时,这将有很大的可能提高商品详情转换率以及增加定的国家/地区的安装次数。Play 控制台中有一些工具可帮助识别要翻译成哪些合适的语言。例如,通过使用收入报告,你可以识别哪些访问商品详情较多但安装量却较低的国家/地区。如果您的技术团队正在通过此服务翻译应用的用户界面,那么你也可以得到翻译文本。通过在提交翻译之前在 strings.xml 文件中包含商店列表元数据,应用内商品名称和通用应用推广文本来实现这一点。
> **更多关于 store 展示的资源:**
> - [制作引人注目的 Google Play Store 详情以吸引更多的安装](https://developer.android.com/distribute/best-practices/launch/store-listing.html)
> - [使用引人注目的功能图形来展示你的应用](https://developer.android.com/distribute/best-practices/launch/feature-graphic.html)
> - [使用商品详情实验室将更多访问转化为安装](https://developer.android.com/distribute/best-practices/grow/store-listing-experiments.html)
> - [走向全球并在新的国家成功培养有价值的观众](https://developer.android.com/distribute/best-practices/grow/go-global.html)
* * *
### 用户获取(User acquisition)
> 相较于其他移动平台 Peak Games 在 Android 平台上[平均成本降低了 30% — 40%](https://www.youtube.com/watch?v=eNpDqYoHFZk) 。
每个开发者都希望能吸引受众,Play 控制台的这一部分是关于理解和优化用户的获取及保留的。
在**收获报告中**(**acquisition reports**),根据你是销售应用内商品还是订阅,最多可以访问三份报告(顶部的标签):
* **保留的安装程序**(**Retained Installers**)—显示应用程序在 Store 页面的访问者数量,然后显示其中有多少人安装了你的应用程序并将其保留了 30 天以上。
* **购买者**(**Buyers**)—显示应用程序在 Store 页面的访问者数量,然后有多少人安装了您的应用程序,然后继续购买一个或多个应用内商品或订阅。
* **订阅者**(**Subscribers**)—显示应用在 Store 页面的访问者数量,然后显示其中有多少人安装了您的应用,然后继续激活了应用内订阅。
每个报告都包含一个图表,显示报告期间访问你应用在商品详情页面的用户数量,其次是安装人员的数量,保留安装人员的数量以及(在购买者或订阅报告中)购买者或订阅的人数。如果我们确定没有足够的数据可显示,那么一些报告将是空白的。使用「衡量」(measured by)下拉菜单在按以下方式细分的数据之间切换:
* **获取渠道**(**Acquisition channel**)—显示访问者来自哪里的数据表格,如 Play Store,Google 搜索,AdWords 等。
* **国家/地区**(**Country**)—显示每个国家/地区访问者的总人数。
* **国家/地区**(**Country**)(**Play Store organic**)—通过过滤国家/地区总数有机地向你展示访问者通过 Google Play 上搜索和浏览来到你的商品详情页面。
在所有报告中,你可以切换选项以查看未访问商品详情页面的安装者数量,例如直接从 Google 搜索结果或 play.google.com/store 安装的安装者。
收入报告。
当通过审查收入渠道或国家/地区(Play Store organic)的报告时,如果有足够的数据,你将看到**转化率基准**(**conversion rate benchmarks**)。根据你的应用的类别和获利方式,这些基准将提供一个关于你的应用的性能与 Play Store 中的所有类似应用的比较。基准是一种方便的方法,用于检查你是否在操作安装时做得很好。

转化率基准。
增加安装量的方法之一是进行推广活动,并且你可以从 **AdWords 推广系列快速入门**。你可以在本节创建和跟踪一个通用应用推广系列。这种类型的推广系列使用 Google 的机器学习算法为你的应用程序找到最佳收入渠道以及目标每次安装费用(CPI)。为推广系列提供文字,图片和视频,其余部分则由 AdWords 完成,通过 AdMob 广告网络在 Google Play,Google Search,YouTube,其他应用以及 Google Display Network 网络中的移动网站上投放广告。
一旦你的通用应用推广系列投入运行,你将在收入报告中获得更多数据。要详细了解和跟踪情况,请查看 AdWords 帐户中的报告。
推动安装和参与的另一个选择是进行**促销**。你可以在此创建促销码并管理促销活动,以便免费赠送应用或应用内商品的副本。例如,你可以在社交媒体上的营销中或在电子邮件活动中使用促销码。
本节最后的功能是**优化建议**。这些建议是在我们检测到存在可以改善你的应用程序及其性能的更改时自动生成的。在其他建议中,优化建议可能会建议你根据你的应用受欢迎的地区的语言来翻译你的应用,识别使用了某些过时的 Google API,确定你是否从使用 Google Play 游戏服务中受益,亦或者检测你的应用还未对平板电脑进行优化。每个建议都包含了帮助你实施的说明。
> **更多关于获取和保留用户的资源:**
> - [了解具有价值的用户来自哪里并优化您的营销](https://developer.android.com/distribute/best-practices/grow/user-aquisition.html)
> - [通过通用应用推广系列增加下载量](https://developer.android.com/distribute/best-practices/grow/install-ads.html)
> - [走向全球,成功地在新的国家增加有价值的观众](https://developer.android.com/distribute/best-practices/grow/go-global.html)
> - [打消付费用户获取的疑虑](https://medium.com/googleplaydev/taking-the-guesswork-out-of-paid-user-acquisition-720d9d74882e) (来自 Medium)
> - [缩小 APK,增加安装量](https://medium.com/googleplaydev/shrinking-apks-growing-installs-5d3fcba23ce2) (来自 Medium)
> - [如何针对新兴市场优化您的 Android 应用程序](https://medium.com/googleplaydev/how-to-optimize-your-android-app-for-emerging-markets-7124c4180fc) (来自 Medium)
> - [在 Google Play上制作有帮助的数据](https://www.youtube.com/watch?v=Dr82cv6Lj0c) (I/O ‘17 大会)
* * *
### 财务报告(Financial reports)
> Play 提供的分析和测试功能无与伦比,为开发如 Hooked 这样应用的开发者们提供了帮助其发展的重要见解,对帮助我们理解和优化我们的收入至关重要。
> —Prerna Gupta, 创始人 & CEO, [HOOKED](https://play.google.com/store/apps/details?id=tv.telepathic.hooked)
如果你销售应用,应用内商品或订阅,则需要跟踪并了解你的收入进展情况。**财务报告**(**Financial reports**)部分可让你访问多个信息中心和报告。
该部分的第一份报告提供了收入和购买者的**概览**。该报告显示了与上一期报告相比,你的收入和买家购买力是如何变化的。

财务报告(Financial reports)。
单独的报告提供了**收入**(**revenue**),**购买者**(**buyers**)和**转化**(**conversions**)的详细分类,可以深入了解用户的支出模式。每个报告都允许你查看特定时段的数据,例如最后一天,7 天,30 天或在应用程序的整个生命周期。你还可以深入了解收入和买家报告中的设备以及国家/地区数据。
转化报告有助于你讲了解用户的支出模式。**转化率**表格显示了你的受众群体在你的应用中购买商品的百分比,并帮助你了解最近的更改对转化的影响。**买家平均开销**的表可以让你深入的了解用户的消费习惯是如何改变的以及付费用户的生命周期价值。
> **更多关于获利的资源:**
> - [使用 Google Play 帐单销售应用内商品](https://developer.android.com/distribute/best-practices/earn/in-app-purchases.html)
> - [设计你的应用来推动转化](https://developer.android.com/distribute/best-practices/develop/design-to-drive-conversions.html)
> - [使用针对 Firebase 的 Google 分析来提高转化次数](https://developer.android.com/distribute/best-practices/earn/improve-conversions.html)
> - [从应用程序浏览者到首次购买者](https://medium.com/googleplaydev/from-app-explorer-to-first-time-buyer-6476be50893) (来自 Medium)
> - [预测你的应用的获利的未来](https://medium.com/googleplaydev/predicting-your-apps-future-65b741999e0e) (来自 Medium)
> - [提高游戏即服务货币化的五大技巧](https://medium.com/googleplaydev/five-tips-to-improve-your-games-as-a-service-monetization-1a99cccdf21) (来自 Medium)
> - [推动 Android 应用转化](https://www.youtube.com/watch?v=P2z1CnNj6ag) (‘17 大会游戏时间)
> - [与游戏的生命周期价值一起玩耍](https://www.youtube.com/watch?v=mZIIMRbh8z8) (‘17 大会游戏时间)
> - [在 Google Play 上赚钱](https://www.youtube.com/watch?v=LQ6MsPmUa38) (DevByte)
> - [Play 应用内结算库 1.0](https://www.youtube.com/watch?v=y78ugwN4Obg) (DevByte 视屏)
> 随时可用于分析的订阅数据很有价值。能够看到订阅如何随着时间的推移而变化,许多开发人员认为这是有用的。
> —Kyle Grymonprez,[Glu](https://play.google.com/store/apps/developer?id=Glu) 跨平台和 Android 开发负责人
最后,如果你发放**订阅**,信息中心将为你提供订阅如何进行的全面视图,以帮助你可就如何增加订阅,减少取消和增加收入方面做出更好的决策。信息中心包括概述,详细的订阅获取报告,终生保留报告和取消报告。你可以使用此信息来发现优化营销和应用内消息的机会,以推动新的订阅以及减少客户流失。

订阅信息中心。
> **更多关于订阅的资源:**
> - [通过 Google Play 帐号销售订阅](https://developer.android.com/distribute/best-practices/earn/subscriptions.html)
> - [建立全天候的订阅业务](https://medium.com/googleplaydev/building-a-subscriptions-business-for-all-seasons-7ffd95b3f929) (来自 Medium)
> - [如何留住你的应用的订阅者们](https://medium.com/googleplaydev/how-to-hold-on-to-your-apps-subscribers-eebb5965e267) (来自 Medium)
> - [智对订阅难点](https://medium.com/googleplaydev/outsmarting-subscription-challenges-711216b6292c) (来自 Medium)
> - [使用行为经济学来传达价值订阅](https://medium.com/googleplaydev/using-behavioural-economics-to-convey-the-value-of-paid-app-subscriptions-cd96ca171d5b) (来自 Medium)
> - [通过 Google Play 上的订阅获得更多收益](https://www.youtube.com/watch?v=hRZPXgRhOH0) (I/O ‘17 大会)
* * *
### 用户反馈(User feedback)
> **评分和评论部分是了解你们社区的强大工具。在 Google 翻译的帮助下,我们用他们的母语回答他们。因此,我们看到用户评分有了很大提高。事实上,他们全部都是 4.4 星,甚至更高。**
> **—** [**Papumba 首席产品官员 Andres Ballone**](https://www.youtube.com/watch?v=9M9mAhYAspU)
通过评论进行评分和用户反馈非常重要。Play Store 的访问者在决定是否安装它时会考量你的应用的评分和评论。评论还提供了一种与受众群体进行互动的方式,并收集有关对你的应用有帮助的反馈。
**评分**是随着时间推移按照国家/地区,语言,应用版本,Android 版本,设备和运营商得出的所有评分的摘要。你可以深入了解这些数据,以了解你的应用的评分与其应用类别的基准评分的对比情况。
在分析这些数据时,需要注意两件关键的事情。首先是随着时间推移而变化的评分,特别是其上升或者下降时。平分的降低则表明你需要查看最近的更新。也许更新使得应用程序难以使用或引入了导致其更频繁崩溃的问题。第二种用法是寻找与评分整体水平不一致的地方。也许对某种语言的评价很低—这意味着你的翻译可能牛头不对马嘴。或者可能在特定设备上的评分较低—表明你的应用未针对该设备进行优化。如果你的评分总体上较好,那么查找并解决「挑刺儿」差评可帮助你提高评分,特别是在难以找到应用改进机会的情况下。

评分。
> **我们使用评论分析(reviews analysis)来收集用户在 Google Play 上的反馈,并使用它们来改善 Erudite 的功能。它还使我们能够直接单独的回复用户,因此我们可以提升与用户的沟通并了解他们的真实需求。**
> **—** [**Benji Chan, Erudite 的产品经理**](https://www.youtube.com/watch?v=WMJR6CuPp4w)
用户可以在不提供评论的情况下为你的应用打分,但是当评分包含评论时,通过其内容可以洞悉是什么导致了这个评分。这是**评论分析**(**reviews analysis**)部分发挥作用的地方。它提供了三种见解:更新后的评分(updated ratings),基准(benchmarks)和话题分析(topic analysis)。

评论分析(reviews analysis)。
**更新后的评分**(**updated ratings**)可帮助你了解更改评论的用户是如何更改他们提供的评分的。数据在你回复的评论和没有回复的评论之间进行了细分。你会发现报告显示,对差评进行回复(例如,如果你答复让用户知道问题已得到解决)通常会使用户返回并向上修改其评分。
**基准**(**benchmarks**)根据应用类别的常见评论话题来提供评分分析。因此,例如,你可以看到用户如何提及你的应用的注册体验以及该项的评论是如何对你的评分作出贡献的。此外,你还可以看到你的评分和评论数量与同一类别中的类似应用的比较情况。如果你想进一步了解,点击一个话题去查看构成此分析的评论。
**话题**(**Topic**)提供了有关应用评价中使用的关键字的信息及其对评分的影响。从每个单词中,你可以深入了解这些出现的评论的详细信息,以便可以更详细地了解所发生的情况。此功能为英语,印地语,意大利语,日语,韩语和西班牙语的评论提供分析。
> **它使我们可以轻松地搜索评论,并且在需要获取更多信息时联系用户,一般而言,它为我节省了大量时间,每周大约节省 5 到 10 小时。**
> **— Olivia Schafer,[Aviary](https://play.google.com/store/apps/dev?id=5644820617218674509) 的社区支持专家**
在**评论**(**reviews**)部分中,你可以查看个别评论。默认视图显示所有来源和所有语言的最新评论。使用过滤器选项来优化列表。注意**所有回复状态**(**all reply states**)选项。筛选评论以查看你未回复的内容,以及你回复的内容和用户随后更新其评论或评分的评论。回复评论很容易,在评论中只需点击**回复此评论**(**reply to this review**)。
有时候你会遇到违反[评论发布政策](https://play.google.com/about/comment-posting-policy.html)的评论,你可通过点击评论区域中的举报标志来举报这些评论。

评论(Reviews)。
> **在**[**抢先体验**](https://developer.android.com/distribute/google-play/startups.html#be-part-of-early-access)**中使用测试反馈,西班牙游戏开发者** [**Omnidrone**](https://play.google.com/store/apps/developer?id=Omnidrone&hl=en) [**提高了 41% 的保留率,50% 的参与率和 20% 的货币化**](https://www.youtube.com/watch?v=LzGC6V_YnlE&index=10&list=PLWz5rJ2EKKc9ofd2f-_-xmUi07wIGZa1c)。
有一个专门针对**测试反馈**(**beta feedback**)的部分。当你对应用进行公开测试时,测试人员提供的任何反馈都会在此处显示—它不会包含在你产品应用的评分和评论中,并且不会公开显示。这些功能类似于公众反馈:您可以过滤评论,回复评论以及查看与用户对话的历史记录。
> **更多关于用户反馈的资源:**
> - [浏览并回复应用评价以积极的与用户互动](https://developer.android.com/distribute/best-practices/engage/user-reviews.html)
> - [分析用户评论以了解关于你的应用的意见](https://developer.android.com/distribute/best-practices/grow/user-reviews.html)
* * *
### 全局 Play 控制台部分
到目前为止,我已经查看了可用于每个应用的 Play 控制台功能。完成之前,我想给你一个关于全局 Play 控制台功能的简要指南:游戏服务,订单管理,下载报告,警报和设置。
> [**Senri 实施 Play 游戏服务**](https://developer.android.com/stories/games/leos-fortune.html) **在 Leo’s Fortune(里奥的财富)及每一章的排行榜上存储游戏。Google Play 游戏服务用户在 1 天后返回的可能性增加 22%,在 2 天后增加 17%。**
**Google Play 游戏服务**提供一系列提供游戏功能以帮助推动玩家参与度的工具,例如:
* **排行榜**(**Leaderboards**)—让玩家与朋友比较他们的分数并与顶级玩家竞争的地方。
* **成就**(**Achievements**)—在游戏中设定目标,玩家获得经验值(XP)来完成。
* **游戏的保存**(**Saved Games**)—存储游戏数据并跨设备进行同步,以便玩家可以轻松恢复游戏。
* **多玩家**(**Multiplayer**)—通过实时和回合制的多人游戏来连结玩家们。
许多这些功能可以在不更改游戏代码的情况下进行更新和管理。
> **Eric Froemling 使用玩家分析在游戏** [**Bombsquad**](https://play.google.com/store/apps/details?id=net.froemling.bombsquad) **上** [**平均每位用户收入提升了 140%,平均每位付费用户收入提升了 67%**](https://www.youtube.com/watch?v=3ks0IwqLNnI)
**玩家分析**(**Player analytics**)将有关游戏性能的宝贵信息集中在一个地方,并提供一组免费报告,帮助你管理游戏业务并了解游戏中的玩家行为。当你将 Google Play 游戏服务集成到您的游戏时,它就是标准配置。

玩家分析(作为 Google Play 游戏服务的一部分)。
您可以设置玩家花费的每日目标,然后监控**目标 vs 实际**(**target vs. actual**)**图表**中的表现,并定义如何将你的玩家花费与**业务驱动**(**business drivers**)报告中类似游戏的基准相比。您可以使用**保留**(**retention**)报告追踪新用户队列中的玩家保留情况,并通过**玩家进度**(**player progression**)报告查看玩家在哪里花费时间,竞争以及变动的情况。然后通过**资源和渠道**(**sources and sinks**)报告来检查和帮助管理你的游戏内经济,例如,你不会弃用玩家正在使用中的资源。
你还可以深入了解玩家行为的细节。使用**筛选器**(**funnels**)可根据任何顺序事件(如成就,花费和自定义事件)创建图表,或使用**群组**(**cohorts**)报告通过新用户群组比较任何事件的累积事件值。通过玩家**时间系列**资源管理器,了解玩家在关键时刻会发生什么情况,并根据你的自定义 Play 游戏事件与**事件查看器**(**events viewer**)创建报告。
> **更多关于 Google Play 游戏服务的资源:**
> - [使用 Google Play 游戏服务创建更具吸引力的游戏体验](https://developer.android.com/distribute/best-practices/engage/games-services.htmlhttps://developer.android.com/distribute/best-practices/engage/games-services.html)
> - [使用玩家分析来更好地了解玩家在游戏中的表现](https://developer.android.com/distribute/best-practices/engage/player-analytics.html)
> - [通过玩家分析并提供收入目标来管理您的游戏业务](https://developer.android.com/distribute/best-practices/earn/grow-game-revenue.html)
> - [针对游戏开发者的 Medium 文章](https://medium.com/googleplaydev/tagged/game-development)
**订单管理**(**Order management**)提供访问用户所有付款的详细信息。你的客户服务团队成员将使用此部分查找和退款或取消订阅。
订单管理(Order management)。
**下载报告**(**Download reports**)会获取包括崩溃和应用程序无响应错误(ANR),评论和财务报告详细信息在内的数据。此外,还提供了用于安装,评分,崩溃,Firebase 云消息传递(FCM)和订阅的汇总数据。你可以通过工具使用这些下载报告来分析 Play 控制台捕获的数据。
**警报**(**Alerts**)涉及与崩溃,安装,评分,卸载和安全相关的问题。对于使用 Google Play 游戏服务的游戏,会出现游戏功能警报,可能是因为未正确使用游戏功能而被阻止,例如达到限制或过度的 API 调用等等。你可以在设置菜单的通知部分选择通过电子邮件接收提醒。
**设置**(**Settings**)提供各种选项来控制你的开发者帐户以及 Play 控制台的行为。
我想着重介绍**开发者帐户**(**developer account**)下的一个设置功能,**用户帐户和权限**(**user accounts & rights**)。你可以完全控制哪些人可以在控制台中访问你应用的功能和数据。你可以为每个团队成员提供对整个帐户的查看或编辑的访问权限,也可以为特定的部分提供访问权限。例如,你可以选择允许你的市场部门主管访问商品详情(store listing),评论和 AdWords 推广系列,但不能访问控制台的其他部分。访问权的另一个常见用途是使你的财务报告仅显示给那些需要查看它们的人。
你应该设置你的**开发者页面**(**developer page**),以便在用户点击你的开发者名称时在 store 中展示你的应用或游戏以及公司的品牌。你可以添加标题图片,徽标,简要说明,网站 URL 以及精选应用程序(你的应用程序的完整列表可自动显示)。
在**偏好设置**(**preferences**)中,你可以选择通过网络界面或电子邮件收到哪些 Play 控制台的通知,[注册新闻](http://g.co/play/monthlynews) 选择参与反馈并调查,告诉我们你的角色,并更改你的偏好,与我们分享你的控制台使用数据。
* * *
### 获取 Play 控制台应用程序
本文中的屏幕截图展示了浏览器中的 Play 控制台,但是你的 Android 设备也可以使用 Play 控制台应用。快速访问你应用的统计信息,评分,评论以及发布信息。获取重要更新的通知,例如你的最新版本已经上线,以及执行回复评论等快速操作。
[在 Google Play 上获取](https://play.google.com/store/apps/details?id=com.google.android.apps.playconsole&hl=en).
* * *
### 保持最新状态
有几种方法可以保持从 Google Play 获取最新最好的状态:
* 点击 Play 控制台右上角的 🔔 ,查看需了解的有关新功能和更改的通知。
* [通过电子邮件注册获取新闻和提示](http://g.co/play/monthlynews) 包括我们的月刊。
* [在 Medium 上关注我们](https://medium.com/googleplaydev)来自团队的长篇文章,包括最佳实践,商业策略,研究和行业思想。
* [在 Twitter 上联系我们](https://twitter.com/googleplaydev)或者通过 [Linkedin](https://www.linkedin.com/showcase/googleplaydev/) 与我们开始对话。
* 获取[给开发者的 Playbook 应用](https://play.google.com/store/apps/details?id=com.google.android.apps.secrets&hl=en) 以管理推送(包括我们所有的博客及 Medium 中的推送)和 YouTube 视频从而帮助你在 Google Play 上成功发展业务,并选择接收通知的内容。
* * *
**关于 Play 控制台的问题或反馈?请与我们取得联系!**
在下方评论或者使用标签 **#AskPlayDev** 向我们发送推文,我们将通过 [@GooglePlayDev](http://twitter.com/googleplaydev) 进行回复,我们会定期分享有关如何在 Google Play 上取得成功的新闻和技巧。
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
================================================
FILE: TODO/a-look-back-at-the-state-of-javascript-in-2017.md
================================================
> * 原文地址:[A Look Back at the State of JavaScript in 2017](https://medium.freecodecamp.org/a-look-back-at-the-state-of-javascript-in-2017-a5b7f562e977)
> * 原文作者:[Sacha Greif](https://medium.freecodecamp.org/@sachagreif?source=post_header_lockup)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/a-look-back-at-the-state-of-javascript-in-2017.md](https://github.com/xitu/gold-miner/blob/master/TODO/a-look-back-at-the-state-of-javascript-in-2017.md)
> * 译者:[LeviDing](https://leviding.com)
> * 校对者:[yanyixin](https://github.com/yanyixin),[zhouzihanntu](https://github.com/zhouzihanntu)
# 2017 年 JavaScript 发展状况回顾
## 在 2017 年 JavaScript 状态调查结果出来之前,我们专家小组对 JavaScript 过去一年的发展进行了回顾

[去年的 JavaScript 状况调查报告](http://stateofjs.com/2016/introduction/)的亮点之一就是,我们组建了一个专家小组对调查结果进行深入分析。
今年呢,我们决定换一种稍微不同的方法:用数据说话。
但是我仍然想知道我们之前专家组成员(以及两位新的特邀嘉宾)的看法,于是我联系了他们,问了些过去一年关于 JavaScript 的问题。
### 与专家组成员会面

* [Michael Shilman](https://medium.com/@shilman): [Testing](http://2016.stateofjs.com/2016/testing/)
* [Jennifer Wong](http://mochimachine.org): [Build Tools](http://2016.stateofjs.com/2016/buildtools/)
* [Tom Coleman](https://twitter.com/tmeasday): [State Management](http://2016.stateofjs.com/2016/statemanagement/)
* [Michael Rambeau](https://michaelrambeau.com/): [Full-Stack Frameworks](http://2016.stateofjs.com/2016/fullstack/)
* 特邀嘉宾 #1: [Wes Bos](http://wesbos.com/)
* 特邀嘉宾 #2: [Raphaël Benitte](https://twitter.com/benitteraphael) ([Nivo](http://nivo.rocks/#/) 的作者)
* * *
### 回顾下去年你写了些什么,关于这个特定领域你认为今后会如何发展
#### Michael Shilman
去年的调查报告显示,Jest 的 [NPM 下载量](https://npm-stat.com/charts.html?package=jest&package=jasmine&package=mocha&from=2016-11-10&to=2017-11-10)呈现出爆炸式增长,并且超过了 Jasmine。
Jest 支持 snapshot testing,我已经看到许多人将快照测试(snapshot testing)作为基本 input/output 单元测试的选择。这在 [Storyshots](https://github.com/storybooks/storybook/tree/master/addons/storyshots) 以及由 [Loki](https://loki.js.org/)、[Percy](https://percy.io/)、[Screener](https://screener.io/) 和 [Chromatic](https://blog.hichroma.com/introducing-chromatic-ui-testing-for-react-c5cc01a79aaa) 等工具构成的整个生态系统的 UI 领域更受欢迎。
#### Jennifer Wong
去年的调查报告也预测了 2017 年的一些发展趋势。随着各种新鲜事物的不断普及,Webpack 的发展势不可挡。Yarn 去年还不在调查对象之列,但是自从 9 月份首次发布以来,Yarn 的影响力就在不断扩大。我很好奇,看看 Yarn 和 npm 能擦出怎样的火花。
[](https://yarnpkg.com/)
Yarn
#### Tom Coleman
我不确定 Redux 真正的竞争对手是否已经出现,但或许在社区中有一种正如创建者 Dan Abramov 所说的趋势:“并不是每个应用都需要使用 Redux,而且在很多情况下使用 Redux 带来的问题的复杂性高于其所解决的问题”。
随着服务器数据管理工具(尤其是 GraphQL)的使用日益增加(请参阅 Apollo 和 Relay Modern),对复杂的客户端数据工具的需求可能会有所减少。看这些工具是如何逐步向本地数据支持发展将是一件非常有趣的事。
* * *
### 你在 2017 年用过什么新的 JavaScript 工具/库/框架等等吗?
#### Michael Shilman
我今年在测试领域发现的最好用的工具就是 [Cypress](https://www.cypress.io/),[Cypress](https://www.cypress.io/) 是一个 OSS/商业上进行端到端(End-to-End)测试的一个很好的选择。尽管它现在还不是那么完善。
另外,我正在维护 [Storybook](https://storybook.js.org/),这是 React、React Native 和 Vue 最流行的 UI 开发工具。
#### Jennifer Wong
我们正在将大部分前端代码转换为使用 React、Redux、Webpack 和 Yarn。这个过渡过程有趣也复杂,但这将会让今后的一些工作变得轻松不少。部分原因是共享设计系统和组件库的建立。
#### Tom Coleman
[Prettier](https://github.com/prettier/prettier)!没有这个工具我就写不了代码了。 我用 [Jest](https://facebook.github.io/jest/) 已经很长时间了,而且真的很好用。[Storybook](https://storybook.js.org/) 也是,使用的越来越频繁(并且开始帮助进行维护)。
[](https://prettier.io/)
Prettier
此外,我一直在开发一个名叫 [Chromatic](https://blog.hichroma.com/introducing-chromatic-ui-testing-for-react-c5cc01a79aaa) 的 Storybook 可视化回归测试(regression testing)工具。当看到一些公司(包括我自己的)使用这个工具完成前端测试,我真的是十分高兴。
#### Michael Rambeau
我在 2017 年发现的最喜欢的工具是 [Prettier](https://github.com/prettier/prettier)。它让我写代码时不用再担心代码“风格”了,节省了我大量时间。
我不再关心 tab 和代码是否整齐这类问题,只需在 IDE 中按下 Ctrl S,一切就都格式化了!此外,它还可以减少与其他团队成员在相同一个代码库上进行协作时的冲突。
#### Wes Bos
各种各样的东西 让我放弃了对 [moment.js](https://momentjs.com/) 的使用。[Next.js](https://github.com/zeit/next.js/) 对于构建服务端渲染的 React 应用越来越重要。我也在学习如何将 Apollo 与 GraphQL 一起用好。
#### Raphaël Benitte
同时服务于几个开源项目,并且要兼顾工作,提高项目的自动化程度就显得尤为重要。Prettier、ESLint、Jest、[Validate-commit-msg](https://github.com/willsoto/validate-commit) 和 [Lint-staged](https://github.com/okonet/lint-staged) 在这方面确实很有用。
我还为 React 构建了一个名叫 [Nivo](http://nivo.rocks/#/) 的数据可视化的库。
[](http://nivo.rocks/#/)
最后,随着原生的 Node.js 对 Async/Await 的支持越来越好,我也尝试使用了 [Koa](http://koajs.com/)。虽然其生态系统比 Express 更窄,但我发现它很容易上手,而且如果你熟悉 Express,那就不会有陌生感。
* * *
### 如果有人想从头开始学习 JavaScript,那么你会推荐他专注于哪三种技术呢?
#### Michael Shilman
* React for UI.
* Webpack for build.
* Apollo for networking.
#### Jennifer Wong
任意一种框架、任意一种构建工具和 Node。许多概念都是在框架和构建工具之间进行转换的,所以你仔细学习其中之一,还会对你理解其他的内容有帮助。如果必须要我选一个框架和构建工具,我应该会选 React 和 Webpack,因为它们正在趋势化,并且在业内看来,他们的发展趋势也很不错。
#### Tom Coleman
当然是 React,尽管其他前端相关的东西也很有意思,但是 React 生态系统相当庞大且完善。这是你必须掌握的技术。
GraphQL,我认为大多数有经验的前端开发都能认识到,GraphQL 所能解决的问题非常广,并且用起来也很舒服。
[](http://graphql.org/)
GraphQL
Storybook,我认为从组件构建其状态是应用程序开发的未来,而 Storybook 就是这样做的。
#### Michael Rambeau
* 前端部分:React
* 后端部分:Express
* 前后端测试部分:Jest
#### Wes Bos
如果你还在学习阶段,你需要通过一些小小的成就感来保持你对这门语言的兴趣。所以我只说些基础知识,学习 DOM API,学习 Async 和 Await,并学习新的可视化 API,如网页动画等。
#### Raphaël Benitte
* 如果你是个 JavaScript 方面的小白,那就从基础学起吧,并且 ES6 现在已经是 JavaScript 基础的一部分了。
* 当然还有 React for building UIs
* [GraphQL](http://graphql.org/)正在走向成熟,现在已经被 Facebook、GitHub、Twitter 和 [其他很多大公司](http://graphql.org/users/) 使用…
* * *
### 现在你在 JavaScript 方向最大的痛点是什么
#### Michael Shilman
最佳实践方法和怎么选 CSS-in-JS 的库。虽然有很多不错的选择,但感觉仍然碎片化,并且现在还有很多人在做 CSS-in-CSS,所以有很多痛点。
#### Jennifer Wong
不断的变化。当我学习一项新技术的时候,我们正在走向下一个。 另外,停止偷我的CSS,JavaScript!前端这块技术是日新月异,学了这个又有新的蹦出来了。喂 JavaScript 你就别来抢我 CSS 的饭碗了,中不中?
#### Tom Coleman
Webpack。卓越强大的工具在"越配置越方便"的错误观念道路下越走越远了。
要避免学习复杂的 JS 应用程序是非常困难的,但通常情况下,你不用太纠结于这些细枝末节。我仍然希望 Meteor 能够重得宝座,成为构建现代 JS 应用程序的最佳方式。
#### Michael Rambeau
缺乏标准,在开始一个新项目之前选择技术栈时,需要考虑方方面面。但是这种状况正在逐步改善。
#### Wes Bos
`checking && checking.for && checking.for.nested && checking.for.nested.properties`。我知道这里有一些实用的功能,但是看起来我们可能很快就会用到这个语言。
#### Raphaël Benitte
有太多的工具了...选择合适的工具太困难,我们必须非常小心,因为 JS 生态系统中的趋势变化速度太快。
* * *
### 你最期待 JavaScript 生态系统在 2018 年中有什么发展?
#### Michael Shilman
心愿单(不知道这些会不会在 2018 年发生):
* GraphQL 在数据同步方面的方便程度达到 Meteor 的水平。
* React Native 的通用(Web 端/移动端)稳定性得到提升。
* Cypress 或其他端到端的测试工具出现。
#### Jennifer Wong
稳定性。我掐指一算啊,JavaScript 栈和 JavaScript 社区会平静一段时间,我们会进入到一个流失度较低的新阶段。
#### Tom Coleman
Babel 的末日到了!我很喜欢 Babel,但是自从有了 Node 8,babel 就被我嫌弃了。能够再次和 interpreter 合作简直太棒了。
很显然,ES 标准将继续向前发展,但是随着 JavaScript modules 和 async/await 的很多痛点被解决掉,JS 新版本和 node 及所有现代浏览器融合度的提升,很多项目会在短时间内发展的非常好。
#### Michael Rambeau
我很想看看 GraphQL 是如何发展的。它会在发布新的 API 的时候成为标准吗?
#### Wes Bos
既然 Node 已经稳定并且所有浏览器都有了 Async 和 Await,我期待原生 promise 在众多框架、工具库和你日常编写的代码中越来越普遍。
#### Raphaël Benitte
大多数语言都有一个 专用/首选 的构建工具(例如 Java 的 Maven)。尽管在 JavaScript 方面我们有很多选择,但这些解决方案往往是专门用于前端的。我希望看到 npm(或 Yarn)添加对基本功能的支持,如文档,自动完成,脚本依赖等。否则,我可能会继续使用 GNU Make。
虽然这个问题很有争议,但是我们已经看到有人对 [TypeScript](https://www.typescriptlang.org/) (或 [Flow](https://flow.org/)) 很感兴趣。Node.js 和浏览器已经明显加快了发展速度,但是如果你想要静态类型的话,你仍要为它再添加一个编译转换层。那么原生静态类型的 Javascript 呢? 你可以在 [这儿](https://esdiscuss.org/topic/es8-proposal-optional-static-typing) 找到关于这个的讨论。
* * *
### 总结
通过上面的内容,我们的小组有几点一致性意见:React 是一个明智的选择,Prettier 是一个很好的工具,JavaScript 生态系统仍然太复杂了...
这正是我们做这个调查的时候试图找到的问题。
我们很快就会在我们的网站上将报告发布出来。 大概在 12 月 12 号之后的那周吧。
我们将举行[直播 + Q&A 环节](https://medium.com/@sachagreif/announcing-the-stateofjs-2017-launch-livestream-14e4aeeeec3a),所以大家可以在那问你想问的问题 - 或者就过来看看呗。我们还有可能为大家带来神秘嘉宾哟... :)
如果你想知道活动啥时候开始,结果是啥,你想收到及时的通知的话可以[在这留下您的 Email](http://stateofjs.com/),我们会通知你的。
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
================================================
FILE: TODO/a-map-to-modern-javascript-development.md
================================================
> * 原文地址:[A Map To Modern JavaScript Development](https://hackernoon.com/a-map-to-modern-javascript-development-2017-16d9eb86309c#.5veb58lh7)
> * 原文作者:[Santiago de León](https://hackernoon.com/@sdeleon28?source=post_header_lockup)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 译者:[gy134340](https://github.com/gy134340)
> * 校对者:[IridescentMia](https://github.com/IridescentMia),[Tina92](https://github.com/Tina92)
# 新一代 JavaScript 的开发图谱(2017)
过去 5 年里你一直使用 REST 接口。或者你一直在优化搜索公司里庞大的数据库。又或者你一直在给微波炉写嵌入式软件。自从你用 Prototype.js 来对浏览器进行面向对象编程已经过去很久了,现在你想提升一下你的前端技能,你看了一下发现情况是[这样](https://thefullfool.files.wordpress.com/2010/09/wheres-waldo1.jpg)。
当然你不是要从一堆徐峥里找出葛优,你在找 25 个连名字都不知道的人。这种情况在 JavaScript 社区特别常见,以至于存在 “JavaScript 疲劳” 这个词。当你有时间去看一些关于这个主题的有趣的东西的时候,你会看到[在2016年学习JavaScript是怎样的体验?](https://hackernoon.com/how-it-feels-to-learn-javascript-in-2016-d3a717dd577f#.c7g9ng4e7)绝妙的反映了这个现象。
但你现在没时间了,你在一个大迷宫里,你需要一张地图,所以我做了一张。
一点声明在前:这是一张可以让你快速行动,不必做自己太多决定的作弊表。基本我会给通用的前端开发制定一套工具,这将会给你一个舒服的环境而不会让你太头疼。一旦你搞定了这些问题,你就可以根据需要自信地调整技术栈。
### 地图结构
我将会将这张地图分为几个你需要解决的问题,对于每个问题,我将会:
* 描述问题或工具需求
* 决定你需要选取哪种工具
* 讨论为什么这样选
* 给一些其他选择
### 包管理
* 问题:需要管理项目和其依赖。
* 解决办法:NPM 和 Yarn
* 原因:NPM 是目前相当多的软件包管理器。Yarn 基于 NPM 但是优化了依赖的解决方案,并且维护一个锁文件(lock file),用来保存库确切的版本号(它可以集成在 NPM 中,它们是相辅相成而不是单独存在的)。
* 可选:暂时未知。
### JavaScript风格
* 问题:ECMAScript5 (老版本 JavaScript) 太烂。
* 解决办法:ES6
* 原因:这是未来的 JavaScript ,但是你可以现在就用了。结合其他多种语言有用的特性。比如说:箭头函数、模块导入/导出功能、解构、模版字符串、let 和 const、生成器、promises。如果你是写 Python 的你会感觉更舒服和习惯。
* 可选:TypeScript、CoffeeScript、PureScript、Elm
### 编译
* 问题:许多浏览器目前不支持 ES6,你需要东西来把你现代的 ES6 编译成 ES5。
* 解决办法:babel
* 原因:在服务端编译,完美的解决办法,也是事实上的标准。
* 可选:Traceur
* 注意:你需要使用 babel-loader,一个 Webpack loader (以及一些其他的),如果你计划使用任何风格的 JavaScript 你都需要编译。
### Linting
* 问题:有一万种写 JavaScript 的方式所以很难达到一致性。一些 bug 可以用 linter 检查出来。
* 解决办法:ESLint
* 原因:完美的检查和很好的可配置性。airbnb preset 值得遵循。对你熟悉新的语法绝对有帮助。
* 可选:JSLint
### 打包工具
* 问题:你不能使用分开的单独文件,依赖需要被解析和正确的加载。
* 解决办法:Webpack
* 原因:高度可配置性,可以加载所有的依赖和文件,支持热插拔。事实上,他是 React 项目的打包工具。
* 可选:Browserify
* 不利性:一开始可能很难配置
* 注意:你需要一点时间来了解这东西是怎样工作的,你还需要了解一点 babel-loader、style-loader、 css-loader、file-loader、url-loader。
### 测试
* 问题:你的应用很脆弱,很容易崩溃,所以你需要测试。
* 解决办法:mocha (测试运行),chai (断言库) 和 chai-spies (对于假的对象,你可以查询某些事件应不应该发生)。
* 原因:使用简单,功能强大。
* 可选:Jasmine、Jest、Sinon、Tape。
### UI 库/状态管理
* 问题:这是大家伙,单页应用越来越复杂,状态管理也很麻烦
* 解决办法:React 和 Redux
* 使用 React 的原因:令人兴奋的范式转变,打破许多 web 领域的教条更好的实现。关注比传统方法更好的分离:取代分离 HTML/CSS/JavaScript 而采取组件化的思想。你的交互界面只是状态的反映。
* 使用 Redux 的原因:如果你的应用不是很轻量,你需要你个东西来管理状态 (否则你疲于对于组件间的交互与数据传递,以及组件化的局限性)。网上的每一个采取抽象的 Flux 架构模式的解决办法对会让你摆脱迷惑。帮助你节省时间直接采用 Redux 就行了。 他的实现模式很精简。即使 Facebook 也使用他。另外的美妙之处:重载并保持应用状态,可测试性。
* 可选:Angular2、Vue.js。
* 警告:当你第一次看到 JSX 风格的代码你可能会很吃惊。然后找一个社区大喊,这是多年来认知的失调,事实上将 HTML、JavaScript 和 CSS 写在一起是很棒的。相信我— 不需要在一个文件里写两个蹩脚的引用。
### DOM 操作和动画
* 问题:猜猜看?当你在选择元素和执行操作 DOM 节点时你仍然需要一点权宜之计。
* 解决办法:原生 ES6 或者 jQuery。
* 原因:是的,jQuery还活着,React 和 jQuery 并不冲突,你的大多数需求都可以用 vanilla React 来实现 (和`querySelector`)。添加 jQuery 将会使你的打包速度变慢,我想说在 React 上使用 jQuery 不是很好你应当避免他。如果你被 ES6 和 React 不能解决的问题卡住了,或者你正在处理讨厌的跨浏览器问题,也许需要使用一下jQuery。
* 可选:Dojo (不知还在不?)。
### 样式
* 问题:现在你有了正确的模块,你希望他们都是独立的并且可以有组织化的重用。组件化的样式应该像组件本身一样轻便。
* 解决办法:CSS 模块化。
* 原因:我喜欢内联样式(并且广泛的使用),我必须承认他们有很多弱点。是的,在 React 内可以写行内样式,但是你不能使用伪类选择器(比如`:hover`),这将会导致很多问题。
* 可选:内联样式。我特别喜欢内联风格的原因是他们把样式看作常规的 JavaScript 对象,可以让你程序化的处理。另外,他们在你每一个的组件文件里,可以让你更好的维持。一些人仍推荐 SASS/SCSS/Less。这些语言意味着额外的构建步骤,他们并不像 CSS 模块/内联风格一样便携,但是功能强大。
### 就这样
你现在有一堆的东西来学习,但至少你不要在花费时间来做调查了。如果发现我少做了或者漏了什么东西?在 twitter 上给我留言或者评论吧 [@bug_factory](http://twitter.com/bug_factory)。
================================================
FILE: TODO/a-mindful-design-process.md
================================================
> * 原文地址:[A Mindful Design Process](https://headspace.design/a-mindful-design-process-f4a4641ee88f)
> * 原文作者:[François Chartrand](https://headspace.design/@frankchartrand)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 译者:
> * 校对者:
# A Mindful Design Process #
How integrating mindfulness techniques will help you become a stronger designer and a more engaged team member.

We all have a process we follow to get us from concept to execution. Sometimes we’ll have access to a great brief, data, insights, and an inspirational mood board but still, we get stuck: we procrastinate, get hung up, or struggle with artist’s block. Sound familiar? Read on…
I’ve outlined some easy-to-implement mindfulness techniques that you can start building into your process today. It’s about creating your best work in a meaningful and intentional way, and having fun while you’re at it.
> “Mindfulness is awareness that arises through paying attention, on purpose, in the present moment, non-judgmentally.”
> — Jon Kabat-Zinn
### **Before you begin** ###
**Just listen**
This one is so easy: just listen and pay attention. Put your phone away, close your laptop, and open your ears.
Whether you’re meeting with clients, stakeholders, or having a 1-on-1 with a colleague, practice the art of listening. Ask more questions. Talk it through. Projects get much more interesting when you feel like you have skin in the game and actually care about the outcome. Here’s a short TED Talk by [Julian Treasure](https://medium.com/@juliantreasure) on ["5 ways to listen better.”](https://www.ted.com/talks/julian_treasure_5_ways_to_listen_better)
*Pro tip:* Using simple [body language techniques](https://blog.udemy.com/positive-body-language/) can be an invaluable tool in your life and career. I know it sounds lame, but it actually works—and others will feel more comfortable around you. [Mitch Joel](https://medium.com/@mitchjoel) discusses some winning body language tips on his podcast—[ check it out](https://overcast.fm/+JjXi7iC4).

**Set realistic timelines and expectations**
Ensure you have enough time to get the task completed.
Rushing the process leads to uninspired work, so make sure you ask for enough time (or budget) to be successful. Even if you can’t get it, it’s always worth asking for what you truly believe the project requires.
Many designers accept deadlines without asking why and burn out. You’ll leave a more positive impression on your peers when you set expectations early.
**Design with intent**
Is there something about this project that excites you? Is this your specialization, or are you up for a new challenge?
Try asking yourself, is this a step in the right direction to improve my design skills? Will this help with my ideal career path? Your career is the sum of all of your work, and knowing you’re growing in the right direction can be motivating.
### Do your research ###
**Get context and re-frame the project**
Before you start, do some research. Without context, you won’t be able to do your best work. Even seemingly boring projects can be exciting if you re-frame them. Check out what the best-in-class are doing—there’s a lot you can learn from their successes and slip-ups.
[Paul Woods](https://medium.com/@paulthedesigner) wrote a great article on [turning an uninspiring brief into an awesome portfolio piece](https://medium.com/@paulthedesigner/turning-an-uninspiring-brief-into-an-awesome-portfolio-project-31b2aa871bb7#.7dclqp3w) that may be helpful for you.
Time spent researching is never time wasted. Research will help guide you toward the next step of the process with some key insights. Plus, with solid research, it’s easier to sell your ideas internally or to clients.
**Visualize with a mood board**
Use [InVision Boards](https://support.invisionapp.com/hc/en-us/articles/205249269-Introduction-to-Boards) or [Pinterest](http://www.pinterest.com) and share early on with your team. Mood boards can act as visualizations of the success you want the project to achieve. They can also help align others on the project and help, or serve as a reflection when your creative juices are running low.
**Get the tools for the task**
Look into what tools and licenses you’ll need and set yourself up with the proper stack of tools and software.
- Stickies/markers
- Whiteboard
- [Paper](https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=1&cad=rja&uact=8&ved=0ahUKEwjI-sT67ffSAhXFvLwKHQOtDtUQFggcMAA&url=https%3A%2F%2Fwww.fiftythree.com%2F&usg=AFQjCNGyxIjM39EcNUzww6FXtJw96xwKfA&sig2=ik8RiXeUi5YCI-7Ydyrx2Q) (flows, wireframes)
- [Sketch](https://www.sketchapp.com/) (app/web design)
- [Zeplin](http://www.zeplin.io) (spec’ing)
- [InVision](https://www.invisionapp.com/) (lofi prototyping)
- [Framer](https://framer.com/) (hifi prototyping)
- [Skitch](https://evernote.com/skitch/)(QA annotation)

### Set yourself up for success ###
The biggest hurdle in any creative process is *beginning*. If you’re having trouble getting started, sit quietly and take few deep breaths. If that isn’t helping, go for a walk, stretch, meditate, make yourself coffee, put on an album you enjoy—whatever you need to clear your mind.
> “Begin anywhere.”
> — John Cage
**Check your posture**
I’m no scientist, but I know that posture makes a big difference in my focus and concentration. Settle in, feel the weight of your body and ensure you’re comfortable, not slouching. Standing desks are also a great option that allow you to stretch your legs and feel weight on your toes, giving you extra mobility.
**Keep your focus**
Try [Focus](https://heyfocus.com/) (app) to block websites you find yourself visiting often—or fully disconnect from WiFi. Set your phone on Airplane mode and put it in another room.
**Stop multitasking**
Successful people know that being [fully present and committed to one task](http://www.zerotoskill.com/proven-steps-to-the-most-productive-day-youll-ever-have/) is indispensable.

### Unlocking creativity ###
**Sketch. Iterate. Simplify.**
Great designers know that your best ideas are often your last. When sketching, try not to dwell on a concept or idea for too long. Sketch out the idea or allow the thought to float away. Consider different scenarios in which people might observe this design in, whether on a mobile phone or piece of branding. Embrace and consider each thought or sensation without judging it as good or bad. Ideas will come in abundance… If your mind wanders elsewhere, notice where it has gone and gently redirect it to the present.
**Reduce, simplify, observe,** and you’ll eventually get to an iteration you can move forward with confidently.


Photos by Ian Whittlesea
*Want more? Try some breathing exercises…*
If you’re looking for more of a creative boost, you might want to consider the breathing exercises found in *Hazdaznan Health & Breath Culture*, a book exploring the relationship between Mazdaznan, Johannes Itten and the Vorkurs (Preliminary or Foundation Course) at the Bauhaus.
**Remember that design is for people**
No matter what, design is for an end-user or consumer and we should do our best to understand their needs and desires—whether that’s a subscriber, a client, or a client’s client. Be respectful and considerate of everything they’re going through when engaging with your design.
### Communication matters ###
**Share often and communicate clearly**
Keep your team in the loop often and set expectations early. Meet your deadlines, and if you’re about to miss a deadline, give your manager or client a heads up and let them know how you’ll avoid this in the future.
**Communicating with your team**
When it comes to communicating with your team, be aware of communication styles. Some people appreciate a note on Slack before you swing by their desk. Others prefer to meet in private. Everyone’s different and [increasing your self-awareness](http://www.tanveernaseer.com/increasing-self-awareness-to-improve-how-we-communicate-scott-schwertly/) will improve the way others react to your feedback.
### **Take notes** ###
**You can never take too many notes**
It’s better to take too many notes than not enough. If it helps, you can even record meetings on your phone to listen to later when you’re working on the project. This way you can be totally sure you’re checking all the boxes your manager or client shared. [Helen Tran](https://medium.com/@tranhelen) of Shopify wrote about her [bullet-journal system](http://helentran.com/two-habits)and how a system like this is a habit that changed her career.
Before completing a project, take time to jot down what went well and what didn’t so you can learn from any successes or shortcomings and be better prepared in the future. If you’re not being mindful of the process and how you felt under certain pressures, you’re bound to keep repeating the same mistakes. [Journaling](http://stronginsideout.com/journaling-techniques/)is handy as a general life practice and helps you track the progress you’re making in your life.
**Don’t take revisions or feedback personally**
Even if you think you’ve found the best solution it’s not a solution if it doesn’t work for your user or clients. Reach a good balance between your knowledge, expertise, and your client’s.
While criticism isn’t personal, you should always stand up for your decisions if you think it’ll help the end-user. You should be proud of your work, but design is, in the end, for users and customers. Sometimes people give ego-driven feedback because they feel like they have to prove their own worth (even you!), and being aware of this is helpful. Practicing deep breathing or a short meditation before meetings can help keep the ego in check.
[Julie Zhuo](https://medium.com/@joulee) wrote a post on [taking feedback impersonally](https://medium.com/the-year-of-the-looking-glass/taking-feedback-impersonally-7c0f3a8199d9) that I highly recommend.
*Pro tip:* People fear feedback because it’s usually negative. If you’re able to, try and mix it up and give more positive feedback too.
### Other thoughts ###

**Remember *why* you design**
Are you designing to build up your portfolio? To empower users? To put a roof over your head? Try keeping a memento around that reminds you why you’re doing this—whether that’s a photo on your desk or a note in your wallet. Something small that will motivate you when you’re losing steam.
**Get some rest**
Don’t forget to take a break once in a while. We often celebrate the tireless designers who hustle 24/7, and I’m not saying you shouldn’t — that’s up to you — but if you’re burning the midnight oil often, you might consider using apps like [f.lux](https://justgetflux.com/) to help with your sleep. (makes your computer screen look like the room you’re in based on time of day).
**Be humble. Give credit where it’s due.**
It takes teamwork to make the dream work. Give credit to your teammates and share that big launch or award with others—even Buzz Aldrin had hundreds of people behind him when he first stepped onto the surface of the moon.
**Keep your desk clean**
NASA astronauts clean up their stations after every use; more designers should do this, especially when it comes to meeting rooms and communal spaces. Keep your desk clean, keep your mind clean (and ready for those bursts of creativity).
**Be thankful**
We’re lucky to do what we do for a living. Design is still in its infancy, and there’s so much exciting work to do. Happy designing! 🌞
Thanks to [Alex Pompliano](https://twitter.com/alexpompliano) for editing. 🙏
*Frank is a Product Designer at [*Headspace*](http://www.headspace.com). He was previously at [*Edenspiekermann*](http://www.edenspiekermann.com) and co-founded [*Bureau*](http://www.bureau.ca).*
*You can follow him on [*Twitter*](http://www.twitter.com/frankchartrand).*
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)。
================================================
FILE: TODO/a-primer-on-android-navigation.md
================================================
> * 原文地址:[A Primer on Android navigation](https://medium.com/google-design/a-primer-on-android-navigation-75e57d9d63fe)
> * 原文作者:[Liam Spradlin](https://medium.com/@LiamSpradlin)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/a-primer-on-android-navigation.md](https://github.com/xitu/gold-miner/blob/master/TODO/a-primer-on-android-navigation.md)
> * 译者:[horizon13th](https://github.com/horizon13th)
> * 校对者:[SumiMakito](https://github.com/sumimakito), [laiyun90](https://github.com/laiyun90)
# 安卓界面导航初识
> 界面中任何引领用户跳转于页面之间的媒介 —— 这便是导航
当你的应用中的两个不同页面产生联系时,导航便由此而生。跳转链接(不论从哪跳到哪)便是页面间传递用户的媒介。创建导航相对容易,但想要把导航**做好**并不总是那么简单。这篇博文里,我们探讨一下安卓系统下最常见的导航模式,看看它们是怎样影响系统布局,以及如何为你的应用界面,用户量身打造导航栏。
---
### ✏️ 定义导航
在深入探索导航模式前,让我们先退后一步回到起点,做一个小练习,回想一下你的应用中的导航。
在 Material Design 网站中有许多 [优秀设计规范](https://material.io/guidelines/patterns/navigation.html#navigation-defining-your-navigation) 介绍了如何着手定义导航结构。但本文中我们把所有的理论归结为简单的两点:
- 基于**任务和内容**构建导航
- 基于**用户**构建导航
基于**任务和内容**构建导航意味着,将任务分步骤拆分。设想用户在完成任务的过程中应该做什么看到什么,怎样处理步骤之间的关系,决定哪一步更重要,哪些步骤是并列关系,哪些步骤是包含关系,哪些步骤常见或不常见。
至于基于**用户**构建导航,只有真正使用过你设计的界面的用户才能告诉你这适不适合他们。你所设计的导航最好能帮助他们更好地使用应用,带给他们最大化的便利。
当你搞清楚在你的应用中,多个任务怎样协同工作的,便可以着手设计。用户在完成任务的过程中可以看到什么内容,在什么时候,以什么方式来呈现。这个小练习能够让你从根本上思考什么样的设计模式能更好地服务于你的 app 体验。
📚 分解任务行为以设计导航更多内容,详见 [Material Design](https://material.io/guidelines/patterns/navigation.html)。
---
### 🗂 标签页(Tabs)
#### 定义
标签页提供了在相同父页面场景下,同级页面间的快速导航。所有的选项卡是位于同一平面的,这意味着,他们可以放置在同一可扩展的状态栏上,也可以相互改变位置。
标签页是很好的页面内容过滤、分段、分级工具。但是对于毫无关联的内容,或是层级化结构内容,也许其它的导航模式会更合适。
📚 设计标签页的更多细节 [参考此处](https://material.io/guidelines/components/tabs.html#),更多实现 [参考此处](https://developer.android.com/training/implementing-navigation/lateral.html)。
#### 标签页实例

Play Music 应用,Google+ 应用,Play Newsstand 应用
Play Music 应用(左)使用标签页增加音乐库的探索深度,以不同的方式组织大致相同的内容,为用户定制不同的探索方法。
Google+ 应用(中)使用标签页将收藏列表分块,每个类别下都是深层异构的内容。
Play Newsstand 应用(右)在媒体库页面使用标签页来呈现相同信息的不同集合 - 其中一个选项卡呈现一个整体的多层次的集合,另一个选项卡显示浓缩集合的大标题。
#### 访问记录
标签页一般为同一级别,因此它们的布局在相同的父级页面下。两个标签页间的切换不需要为系统后退键或应用的返回键新建历史记录。
---
### 🍔 侧边栏/抽屉式导航栏(Nav drawers)

#### 定义
侧边栏(抽屉式导航栏)可以理解为附于页面左部边缘的垂直面板。设计者可以将侧边栏设计在屏幕外或屏幕内可见,持续存在或者不用时隐藏,但这些不同的设计往往有相同的特点。
通常侧边栏会列出一些同级的父级页面们,尤其用于放置较重要的页面,又例如一些“设置”,“帮助”这类特殊页面。
如果你将侧边栏和另一个导航控件相组合——底部导航栏,那么侧边栏可以放置一些二级链接,或者底部导航不能直接到达的重要链接。
当使用侧边栏时,要注意链接**类别**——放过多的链接,或展示过多不同级别的链接,都会让应用的层次结构显得混乱。
还有需要注意的一点是界面的可视性。侧边栏可以很好的帮助应用减少可视性,压缩与主要内容无关的导航区。但是,这也可能成为应用的不足,取决于导航栏的目标链接在具体场景中如何呈现和被访问。
📚 设计侧边栏的更多细节[参考此处](https://material.io/guidelines/patterns/navigation-drawer.html),更多实现[参考此处](https://developer.android.com/training/implementing-navigation/nav-drawer.html)。
#### 侧边栏实例



Play Store 应用,Google Camera 应用,Inbox 应用
Play Store 应用(左上)使用侧边栏展示应用商店的不同区域,每一栏都链接到不同区域的内容。
Google Camera(中上)使用侧边栏列出其它支持功能——大部分是提升照相体验的其他应用外链,当然了还有相机设置。
Inbox(右上)邮箱应用使用了伸长版的侧边栏。顶端是电子邮箱的主要功能链接,用于展示不同类别的邮件,侧边栏的下方则为一些支持工具和扩展包。由于电子邮箱的侧边栏非常的长,“设置”和“帮助反馈”按钮固定在侧边栏底端,方便用户随时访问。
#### 访问记录
当应用程序有明显的“返回首页”功能时,侧边栏应当为系统创建“返回首页”的功能。例如,在 Play Store 应用商店中,点击“返回首页”按钮回到页面“应用程序及游戏”,展示给用户的是所有类别的精选应用。因而 Play Store 应用创建了从其它页面到主页面的返回功能。
同样的,在使用 Google Camera 相机应用时,当用户点击返回键时,返回到相机的默认拍摄界面。



“开始导航” 圆形按钮增强主地图功能。
谷歌地图(如上)也用了相同的方案,侧边栏的选项要么是在地图上加层,要么增强主地图提供辅助功能。所以当用户点击“返回”按钮时回到的也是默认地图界面。



你可能会注意到,随着你进入其他页面,Play Store 谷歌商店(上图)工具栏中的侧边栏图标并未改变。这是因为侧边栏的按钮在应用的层级结构中为同一级别。由于用户并没有深入到子级页面(例如,点击“音乐与视频”),因而侧边栏的图标并不会改变成返回上一级的样式。用户始终在最顶级的页面,只不过是在同级页面中切换而已。
---
### 🚨 底部导航(Bottom nav)

#### 定义
在安卓系统中,底部导航控件通常由三到五个目的地按钮构成。重要的一点是,“更多”按钮并不能看作一个目的地,更不是菜单或对话框。
当你的应用只有有限个数的顶级页面需要被访问时,使用底部导航栏最合适(底部导航千万不能滚动)。底栏最主要的优点在于,可以从子页面迅速跳入毫无关联的顶级页面,而无需先导航到当前页面的父页面。
值得注意的是,尽管底部导航的链接应当在应用中有相同的层级结构,但是他们和标签页截然不同,也绝不能以标签页的形式展现。
切换底部栏,暗示着两个面板是毫无关系的。每个面板是孤立的父节点,而不是其它面板的兄弟节点。如果你的应用中,两个面板有相同内容或者相同的父节点,也许用标签页是更好的选择。
📚 设计底部导航的更多细节[参考此处](https://material.io/guidelines/components/bottom-navigation.html#),更多实现[参考此处](https://developer.android.com/reference/android/support/design/widget/BottomNavigationView.html)。
#### 底部导航实例



Google Photos 相册应用
除了底部导航的基本定义,还有一些有意思的点值得考虑。也许最复杂的问题就是:底部导航栏是否要持续存在?答案和许多设计决策一样,那就是:“看情况”。
通常底部导航在整个应用中是持续存在的,但在某些情况下,导航栏是隐藏的状态。例如用户使用的应用只有很浅的层次结构,像收发短信这类单一功能的页面,又或者应用想给用户更深刻的用户体验,那底部导航或许隐藏起来更好。
在 Google Photos 相册应用中(上图),底部导航在相册中是隐藏的。相册在整个层级结构中处于第二层,比相册更深一层只有查看相片,打开它时从相册页面顶部展现。这种实现方式满足了隐藏底边导航以达到“唯一目的”的规则。当用户进入程序最顶层时,为其创造沉浸式体验。
#### 其它考虑
如果底部导航在整个应用中持续存在,那么下一个需要考虑的问题便是底部导航的跳转逻辑。假设一个用户在深层层级结构中进行跳转,从一个子页面切换到另一个子页面,再点击返回跳转到前一个子页面,那他到底应该看到哪一个页面呢?父级页面?还是他停留过的子级页面?
这个功能应该取决于应用的使用者。一般来说,点击底部按钮应该直接跳转到关联页面,而不是更深层的页面。不过话说回来还是老问题,**看情况**。
#### 访问记录
底部导航栏的点按不应该为系统“返回键”创建历史记录。不过层级结构中进入深层级可以为系统“返回键”创造系统历史记录,为应用创建“返回上级”访问记录,但是底部栏其本身便是一种具有记录历史特性的导航结构。
点按底部导航按钮,应当直接跳转到关联页面。用户再次点击按钮应当跳转到该栏的父页面,或者当用户以及在父级页面时刷新页面。
---
### 🕹 上下文导航(In-context navigation)

#### 定义
上下文导航由所有非上述导航控件间的交互组成。这些控件包括像按钮、方块、卡片,还有其它应用内跳转的内容。
通常,上下文导航和常用导航形式相比,更多是非线性操作 —— 交互行为使用户在层级结构,离散型结构之间任意跳转,甚至跳转到应用之外。
📚 设计上下文导航的更多细节[参考此处](https://material.io/guidelines/patterns/navigation.html#navigation-combined-patterns)。
#### 上下文导航实例



时钟应用,Google 搜索应用,Google 日历应用
时钟应用(左上)设计的很巧妙,有一个浮动操作按钮;Google 搜索应用(中上)主要靠下部卡片维护信息;Google 日历(右上)给每一个日历时间创建块状条目。



在时钟应用里(左上)通过点击浮动按钮,即刻查看世界时钟;在 Google 搜索应用(中上)里点击天气卡片,搜索引擎立马为你展示“天气”的搜索结果;Google 日历(右上)点击块状条目进入事件详情页。
我们也能看出来,这些截图展现了上下文导航给用户带来不一样的跳转体验。时钟应用里,用户进入应用的子级页面;Google 搜索应用使用卡片以增强主屏幕,而 Google 日历是点击打开[全屏窗口](https://material.io/guidelines/components/dialogs.html#dialogs-full-screen-dialogs)。
#### 访问记录
对于上下文导航,并没有对访问记录的硬性规定。访问记录的创建与否完全取决于使用什么形式的上下文导航,还有用户通过导航要去哪里。为了以防万一,在某些情况里应用创建什么类型的历史记录并不明确,设计者最好了解下,在通常情况点击返回键和向上键设置会产生什么操作。
---
### ↖️ 向上键、返回键、关闭键(Up, back, and close buttons)

返回键,向上键,关闭键这三个按键在安卓用户界面里都非常重要,但却常常被理解错误。实际上,从用户体验的角度,三个按钮都很简单,只要熟记下面的几条规则,保证再也不会陷入困惑。
- **向上键**往往是当用户沿着应用层级结构返回上级菜单时使用到,常出现于应用工具栏。点击向上键,窗口延时间先后顺序后退直到用户到达最顶级父页面。由于顶级父页面无法再往上跳出应用,向上键不应该出现在顶极父页面中。
- **返回键**存在于系统底部导航栏。它的导航作用是沿时间顺序后退,而非应用页面的层级关系,哪怕前一个时间节点是在其它应用中。它还用于关闭临时页面元素,比如对话框,底部表单等层叠面板。
- **关闭键**通常用于关闭界面临时层,或者放弃修改[全屏对话框](https://material.io/guidelines/components/dialogs.html#dialogs-full-screen-dialogs)。例如 Google 日历事件详情页(下图)。全屏日历事件详情页面属于很明显是临时页,设计时使用关闭键。Google 邮箱应用(下图)中,从收件箱到邮件正文的渐进效果显示,邮件正文是收件箱页面的叠加层,因此使用关闭键较合适。 而 Gmail 应用中(下图)邮件正文是作为一个独立层存在于应用中的,因此返回键更合适。



日历应用,邮箱应用,Gmail 应用
📚更多关于 后退键 vs 返回键 用户行为探讨,尽在 [Material Design](https://material.io/guidelines/patterns/navigation.html#navigation-up-back-buttons)。
### 🔄 混合模式(Combining patterns)
尽管在这份初学者指南中,我们主要分析了使用单个导航组件的成功案例。实际上,这些应用在组合运用多类导航时仍然表现出色,构建了合理的用户行为框架。在文章结尾,我们来看看几个混搭实例。


Google+
可能最显而易见的实例便是 Google+(上图),混合上述所有元素 —— 标签页、底部导航、上下文导航。
分离来看,底部导航是 Google+ 的焦点,可以访问四个顶级页面。而标签页将页面结构化增强,通过不同类别拆分内容。而侧边栏囊括了剩余其它按钮,以访问频率区分主次。



Google Play 应用商店
Google Play 应用商店(上图)使用侧边栏当作主要导航,大量使用上下文导航,局部使用标签页导航。
上图中,我们看到所有从侧边栏进入的页面中,打开侧边栏的图标始终是可点按的,因为这些页面都是最顶级父页面。在顶端工具栏下方,小椭圆片帮助细分页面内容,是典型的上下文导航。在应用下载统计页面,标签页将排列好的应用分门别类。



Google 日历应用
Google 日历应用(上图)巧妙得使用了侧边栏导航和上下文导航。此处侧边栏是一个非标准的日历增强面板。日历本身由可扩展的工具栏控制,不同颜色的色块表示用户的日历事项,点击进入详情即可查看详细日程。
📚 更多混合导航实例[参考此处](https://material.io/guidelines/patterns/navigation.html#navigation-patterns)。
### 🤔 更多问题?
导航本身是一个很复杂的话题,希望这篇导航初识能帮助到读者,对安卓导航的设计原理有一个较好的理解。如果你还有其它问题,欢迎留言或在推特 [#AskMaterial](https://twitter.com/search?q=%23AskMaterial) 话题下与 [Material Design](http://Material.io) 进行互动,当然还有我们团队账号,[猛戳这里](https://twitter.com/i/moments/884845596145836032)关注!
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[React](https://github.com/xitu/gold-miner#react)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计) 等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)。
================================================
FILE: TODO/a-quick-look-at-semaphores.md
================================================
> * 原文地址:[A Quick Look at Semaphores in Swift 🚦](https://medium.com/swiftly-swift/a-quick-look-at-semaphores-6b7b85233ddb#.61uw6lq2d)
> * 原文作者:[Federico Zanetello](https://medium.com/@zntfdr)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 译者:[Deepmissea](http://deepmissea.blue)
> * 校对者:[Gocy015](http://blog.gocy.tech),[skyar2009](https://github.com/skyar2009)
---
# 看!Swift 里竟然有红绿灯 🚦!
首先,如果你对 GCD 和 Dispatch Queue 不熟悉,请看看 [AppCoda](https://medium.com/@appcodamobile) 的[这篇文章](http://www.appcoda.com/grand-central-dispatch/)。
好了!是时候来聊聊信号量了!

### 引言
让我们想象一下,一群**作家**只能共同使用一支**笔**。显然,在任何指定的时间里,只有一名**作家**可以使用**笔**。
现在,把**作家**想象成我们的线程,把**笔**想象成我们的**共享资源**(可以是任何东西:一个文件、一个变量、做某事的权利等等)。
怎么才能确保我们的**资源**是真正[互斥](https://en.wikipedia.org/wiki/Mutual_exclusion)的呢?

### 实现我们自己的资源控制访问
有人可能会想:我只要用一个 **Bool** 类型的 **resourceIsAvailable** 变量,然后设置它为 **true** 或者 **false** 就可以互斥了。
```
if (resourceIsAvailable) {
resourceIsAvailable = false
useResource()
resourceIsAvailable = true
} else {
// resource is not available, wait or do something else
}
```
问题是出现在并发上,**不论线程之间的优先级如何,我们都没办法确切知道哪个线程会执行下一步。**
#### 例子
假设我们实现了上面的代码,我们有两个线程,**threadA** 和 **threadB**,他们会使用一个互斥的资源:
- **threadA** 读取到 if 条件语句,发现资源可用,很棒!
- 但是,在执行下一行代码(**resourceIsAvalilable = false**)之前,处理器切换到 **threadB**,然后它也读取了 if 条件语句。
- 现在我们的两个线程都确信资源是可用的,然后他们都会执行**使用资源**部分的代码块。
不用 GCD 编写线程安全的代码可不是一个容易的任务。

### 信号量是如何工作的
三步:
1. 在我们需要使用一个共享资源的时候,我们发送一个 **request** 给它的信号量;
2. 一旦信号量给出我们绿灯(see what I did here?),我们就可以假定资源是我们的并使用它;
3. 一旦不需要资源了,我们通过发送给信号量一个 **signal** 让它知道,然后它可以把资源分配给另一个的线程。
当这个资源只有一个,并且在任何给定的时间里,只有一个线程可以使用,你就可以把这些 **request/signal** 作为资源的 **lock/unlock**。

### 在幕后发生了什么
#### 结构
信号量由下面的两部分组成:
- 一个**计数器**,让信号量知道有多少个线程能使用它的资源;
- 一个 **FIFO 队列**,用来追踪这些等待资源的线程;
#### 请求资源: wait()
当信号量收到一个请求时,它会检查它的**计数器**是否大于零:
- 如果是,那信号量会减一,然后给线程放绿灯;
- 如果不是,它会把线程添加到它队列的末尾;
#### 释放资源: signal()
一旦信号量收到一个信号,它会检查它的 FIFO 队列是否有线程存在:
- 如果有,那么信号量会把第一个线程拉出来,然后给他一个绿灯;
- 如果没有,那么它会增加它的计数器;
#### 警告: 忙碌等待
当一个线程发送一个 **wait()** 资源请求给信号量时,线程会**冻结**直到信号量给线程绿灯。
⚠️️如果你在在主线程这么做,那整个应用都会冻结⚠️️

### 在 Swift 里使用信号量 (通过 GCD)
让我们写一些代码!
#### 声明
声明一个信号量很简单:
```
let semaphore = DispatchSemaphore(value: 1)
```
**value** 参数代表创建的信号量允许同时访问该资源的线程数量。
#### 资源请求
如果要**请求信号量**的资源,我们只需:
```
semaphore.wait()
```
要知道信号量并不能实质上地给我们任何东西,资源都是在线程的范围内,而我们只是在请求和释放调用之间使用资源。
一旦信号量给我们放行,那线程就会恢复正常执行,并可以放心地将资源纳为己用了。
#### 资源释放
要**释放**资源,我们这么写:
```
semaphore.signal()
```
在发送这个信号后,我们就不能接触到任何资源了,直到我们再次的请求它。
### Playgrounds 中的信号量
跟随 [AppCoda](https://medium.com/@appcodamobile) 上[这篇文章](http://www.appcoda.com/grand-central-dispatch/)的例子,让我们看看实际应用中的信号量!
> 注意:这些是 Xcode 中的 Playground,Swift Playground 还不支持日志记录。希望 WWDC17 能解决这个问题!
在这些 playground 里,我们有两个线程,一个线程的优先级比其他的略微高一些,打印 10 次表情和增加的数字。
#### 没有信号量的 Playground
```
import Foundation
import PlaygroundSupport
let higherPriority = DispatchQueue.global(qos: .userInitiated)
let lowerPriority = DispatchQueue.global(qos: .utility)
func asyncPrint(queue: DispatchQueue, symbol: String) {
queue.async {
for i in 0...10 {
print(symbol, i)
}
}
}
asyncPrint(queue: higherPriority, symbol: "🔴")
asyncPrint(queue: lowerPriority, symbol: "🔵")
PlaygroundPage.current.needsIndefiniteExecution = true
```
和你想的一样,多数情况下,高优先级的线程先完成任务:
#### 有信号量的 Playground
这次我们会使用和前面一样的代码,但是在同一时间,我们只给一个线程赋予打印**表情+数字**的权利。
为了达到这个目的,我们定义了一个信号量并且更新了我们的 **asyncPrint** 函数:
```
import Foundation
import PlaygroundSupport
let higherPriority = DispatchQueue.global(qos: .userInitiated)
let lowerPriority = DispatchQueue.global(qos: .utility)
let semaphore = DispatchSemaphore(value: 1)
func asyncPrint(queue: DispatchQueue, symbol: String) {
queue.async {
print("\(symbol) waiting")
semaphore.wait() // 请求资源
for i in 0...10 {
print(symbol, i)
}
print("\(symbol) signal")
semaphore.signal() // 释放资源
}
}
asyncPrint(queue: higherPriority, symbol: "🔴")
asyncPrint(queue: lowerPriority, symbol: "🔵")
PlaygroundPage.current.needsIndefiniteExecution = true
```
我还添加了一些 **print** 指令,以便我们看到每个线程执行中的实际状态。
就像你看到的,当一个线程开始打印队列,另一个线程必须等待,直到第一个结束,然后信号量会从第一个线程收到 **signal**。**当且仅当此后**,第二个线程才能开始打印它的队列。
第二个线程在队列的哪个点发送 **wait()** 无关紧要,它会一直处于等待状态直到另一个线程结束。
**优先级反转**
现在我们已经明白每个步骤是如何工作的,请看一下这个日志:
在这种情况下,通过上面的代码,处理器决定先执行低优先级的线程。
这时,高优先级的线程必须等待低优先级的线程完成!这是真的,它的确会发生。
问题是即使一个高优先级线程正等待它,低优先级的线程也是低优先级的:这被称为[***优先级反转***](https://en.wikipedia.org/wiki/Priority_inversion)。
在不同于信号量的其他编程概念里,当发生这种情况时,低优先级的线程会暂时**继承**等待它的最高优先级线程的优先级,这被称为:[***优先级继承***](https://en.wikipedia.org/wiki/Priority_inheritance)。
在使用信号量的时候不是这样的,实际上,谁都可以调用 **signal()** 函数(不仅是当前正使用资源的线程)。
**线程饥饿**
为了让事情变得更糟,让我们假设在我们的高优先级和低优先级线程之间还有 1000 多个中优先级的线程。
如果我们有一种像上面那样**优先级反转**的情况,高优先级的线程必须等待低优先级的线程,但是,大多数情况下,处理器会执行中优先级的线程,因为他们的优先级高于我们的低优先级线程。
这种情况下,我们的高优先级线程正被 CPU 饿的要死(于是有了[饥饿](https://en.wikipedia.org/wiki/Starvation_%28computer_science%29)的概念)。
#### 解决方案
我的观点是,在使用信号量的时候,线程之间最好都使用相同的优先级。如果这不符合你的情况,我建议你看看其他的解决方案,比如[临界区块](https://en.wikipedia.org/wiki/Critical_section)和[管程](https://en.wikipedia.org/wiki/Monitor_%28synchronization%29).
### Playground 上的死锁
现在我们有两个线程,使用两个互斥的资源,“**A**” 和 “**B**”。
如果两个资源可以分离使用,为每个资源定义一个信号量是有意义的,如果不可以,那一个信号量足以管理两者。
我想用一个用前一种情况(2 个资源, 2 个信号量)做一个例子:高优先级线程会先使用资源 “A”,然后 “B”,而低优先级的线程会先使用 “B”,然后再使用 "A"。
代码在这:
```
import Foundation
import PlaygroundSupport
let higherPriority = DispatchQueue.global(qos: .userInitiated)
let lowerPriority = DispatchQueue.global(qos: .utility)
let semaphoreA = DispatchSemaphore(value: 1)
let semaphoreB = DispatchSemaphore(value: 1)
func asyncPrint(queue: DispatchQueue, symbol: String, firstResource: String, firstSemaphore: DispatchSemaphore, secondResource: String, secondSemaphore: DispatchSemaphore) {
func requestResource(_ resource: String, with semaphore: DispatchSemaphore) {
print("\(symbol) waiting resource \(resource)")
semaphore.wait() // requesting the resource
}
queue.async {
requestResource(firstResource, with: firstSemaphore)
for i in 0...10 {
if i == 5 {
requestResource(secondResource, with: secondSemaphore)
}
print(symbol, i)
}
print("\(symbol) releasing resources")
firstSemaphore.signal() // releasing first resource
secondSemaphore.signal() // releasing second resource
}
}
asyncPrint(queue: higherPriority, symbol: "🔴", firstResource: "A", firstSemaphore: semaphoreA, secondResource: "B", secondSemaphore: semaphoreB)
asyncPrint(queue: lowerPriority, symbol: "🔵", firstResource: "B", firstSemaphore: semaphoreB, secondResource: "A", secondSemaphore: semaphoreA)
PlaygroundPage.current.needsIndefiniteExecution = true
```
如果我们幸运的话,会这样:
简单来说就是,第一个资源会先提供给高优先级线程,然后对于第二个资源,处理器只有稍后把它移动到低优先级线程。
然而,如果我们不是很幸运的话,那这种情况也会发生:
两个线程都没有完成他们的执行!让我们检查一下当前的状态:
- 高优先级的线程正在等待资源 “B”,可是被低优先级的线程持有;
- 低优先级的线程正在等待资源 “A”,可是被高优先级的线程持有;
两个线程都在等待相互的资源,谁也不能向前一步:欢迎来到[**线程死锁**](https://en.wikipedia.org/wiki/Deadlock)!
#### 解决方案
避免[死锁](https://en.wikipedia.org/wiki/Deadlock)很难。最好的解决方案是编写[不能达到这种状态](https://en.wikipedia.org/wiki/Deadlock_prevention_algorithms)的代码来防止他们。
例如,在其他的操作系统里,为了其他线程的继续执行,其中一个死锁线程可能被杀死(为了释放它的所有资源)。
...或者你可以使用[鸵鸟算法(Ostrich_Algorithm)](https://en.wikipedia.org/wiki/Ostrich_algorithm) 😆。

### 结论
信号量是一个很棒的概念,它可以在很多应用里方便的使用,只是要小心:过马路要看两边。
---
**[Federico](https://twitter.com/zntfdr) 是一名在曼谷的软件工程师,对 Swift、Minimalism、Design 和 iOS 开发有浓厚的热情。**
================================================
FILE: TODO/a-simple-object-model.md
================================================
> * 原文地址:[A Simple Object Model](http://aosabook.org/en/500L/a-simple-object-model.html)
* 原文作者:[Carl Friedrich Bolz](https://twitter.com/cfbolz)
* 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
* 译者:[Zheaoli](https://github.com/Zheaoli)
* 校对者:[Yuze Ma](https://github.com/bobmayuze), [Gran](https://github.com/Graning)
# 一个简单的对象模型
Carl Friedrich Bolz 是一位在伦敦国王大学任职的研究员,他沉迷于动态语言的实现及优化等领域而不可自拔。他是 PyPy/RPython 的核心开发者之一,于此同时,他也在为 Prolog, Racket, Smalltalk, PHP 和 Ruby 等语言贡献代码。这是他的 Twitter [@cfbolz](https://twitter.com/cfbolz) 。
## 开篇
面向对象编程是目前被广泛使用的一种编程范式,这种编程范式也被大量现代编程语言所支持。虽然大部分语言给程序猿提供了相似的面向对象的机制,但是如果深究细节的话,还是能发现它们之间还是有很多不同的。大部分的语言的共同点在于都拥有对象处理和继承机制。而对于类来说的话,并不是每种语言都完美支持它。比如对于 Self 或者 JavaScript 这样的原型继承的语言来说,是没有类这个概念的,他们的继承行为都是在对象之间所产生的。
深入了解不同语言的对象模型是一件非常有意思的事儿。这样我们可以去欣赏不同的编程语言的相似性。不得不说,这样的经历可以在我们学习新的语言的时候,利用上我们已有的经验,以便于我们快速的掌握它。
这篇文章将会带领你实现一套简单的对象模型。首先我们将实现一个简单的类与其实例,并能够通过这个实例去访问一些方法。这是被诸如 Simula 67 、Smalltalk 等早期面向对象语言所采用的面向对象模型。然后我们会一步步的扩展这个模型,你可以看到接下来两步会为你展现不同语言的模型设计思路,然后最后一步是来优化我们的对象模型的性能。最终我们所得到的模型并不是哪一门真实存在的语言所采用的模型,不过,硬是要说的话,你可以把我们得到的最终模型视为一个低配版的 Python 对象模型。
这篇文章里所展现的对象模型都是基于 Python 实现的。代码在 Python 2.7 以及 Python 3.4 上都可以完美运行。为了让大家更好的了解模型里的设计哲学,本文也为我们所设计的对象模型准备了单元测试,这些测试代码可以利用 py.test 或者 nose 来运行。
讲真,用 Python 来作为对象模型的实现语言并不是一个好的选择。一般而言,语言的虚拟机都是基于 C/C++ 这样更为贴近底层的语言来实现的,同时在实现中需要非常注意很多的细节,以保证其执行效率。不过,Python 这样非常简单的语言能让我们将主要精力都放在不同的行为表现上,而不是纠结于实现细节不可自拔。
## 基础方法模型
我们将以 Smalltalk 中的实现的非常简单的对象模型来开始讲解我们的对象模型。Smalltalk 是一门由施乐帕克研究中心下属的 Alan Kay 所带领的小组在 70 年代所开发出的一门面向对象语言。它普及了面向对象编程,同时在今天的编程语言中依然能看到当时它所包含的很多特性。在 Smalltalk 核心设计原则之一便是:“万物皆对象”。Smalltalk 最广为人知的继承者是 Ruby,一门使用类似 C 语言语法的同时保留了 Smalltalk 对象模型的语言。
在这一部分中,我们所实现的对象模型将包含类,实例,属性的调用及修改,方法的调用,同时允许子类的存在。开始前,先声明一下,这里的类都是有他们自己的属性和方法的普通的类
友情提示:在这篇文章中,“实例”代表着“不是类的对象”的含义。
一个非常好的习惯就是优先编写测试代码,以此来约束具体实现的行为。本文所编写的测试代码由两个部分组成。第一部分由常规的 Python 代码组成,可能会使用到 Python 中的类及其余一些更高级的特性。第二部分将会用我们自己建立的对象模型来替代 Python 的类。
在编写测试代码时,我们需要手动维护常规的 Python 类和我们自建类之间的映射关系。比如,在我们自定类中将会使用 `obj.read_attr("attribute")` 来作为 Python 中的 `obj.attribute` 的替代品。在现实生活中,这样的映射关系将由语言的编译器/解释器来进行实现。
在本文中,我们还对模型进行了进一步简化,这样看起来我们实现对象模型的代码和和编写对象中方法的代码看起来没什么两样。在现实生活中,这同样是基本不可能的,一般而言,这两者都是由不同的语言实现的。
首先,让我们来编写一段用于测试读取求改对象字段的代码:
~~~Python
def test_read_write_field():
# Python code
class A(object):
pass
obj = A()
obj.a = 1
assert obj.a == 1
obj.b = 5
assert obj.a == 1
assert obj.b == 5
obj.a = 2
assert obj.a == 2
assert obj.b == 5
# Object model code
A = Class(name="A", base_class=OBJECT, fields={}, metaclass=TYPE)
obj = Instance(A)
obj.write_attr("a", 1)
assert obj.read_attr("a") == 1
obj.write_attr("b", 5)
assert obj.read_attr("a") == 1
assert obj.read_attr("b") == 5
obj.write_attr("a", 2)
assert obj.read_attr("a") == 2
assert obj.read_attr("b") == 5
~~~
在上面这个测试代码中包含了我们必须实现的三个东西。`Class` 以及 `Instance` 类分别代表着我们对象中的类以及实例。同时这里有两个特殊的类的实例:`OBJECT` 和 `TYPE`。 `OBJECT` 对应的是作为 Python 继承系统起点的 `object` 类(译者注:在 Python 2.x 版本中,实际上是有两套类系统,一套被统称为 **new style class** , 一套被称为 **old style class** ,`object` 是 **new style class** 的基类)。`TYPE` 对应的是 Python 类型系统中的 `type` 。
为了给 `Class` 以及 `Instance` 类的实例提供通用操作支持,这两个类都会从 `Base` 类这样提供了一系列方法的基础类中进行继承并实现:
~~~Python
class Base(object):
""" The base class that all of the object model classes inherit from. """
def __init__(self, cls, fields):
""" Every object has a class. """
self.cls = cls
self._fields = fields
def read_attr(self, fieldname):
""" read field 'fieldname' out of the object """
return self._read_dict(fieldname)
def write_attr(self, fieldname, value):
""" write field 'fieldname' into the object """
self._write_dict(fieldname, value)
def isinstance(self, cls):
""" return True if the object is an instance of class cls """
return self.cls.issubclass(cls)
def callmethod(self, methname, *args):
""" call method 'methname' with arguments 'args' on object """
meth = self.cls._read_from_class(methname)
return meth(self, *args)
def _read_dict(self, fieldname):
""" read an field 'fieldname' out of the object's dict """
return self._fields.get(fieldname, MISSING)
def _write_dict(self, fieldname, value):
""" write a field 'fieldname' into the object's dict """
self._fields[fieldname] = value
MISSING = object()
~~~
`Base` 实现了对象类的储存,同时也使用了一个字典来保存对象字段的值。现在,我们需要去实现 `Class` 以及 `Instance` 类。在`Instance` 的构造器中将会完成类的实例化以及 `fields` 和 `dict` 初始化的操作。换句话说,`Instance` 只是 `Base` 的子类,同时并不会为其添加额外的方法。
`Class` 的构造器将会接受类名、基础类、类字典、以及元类这样几个操作。对于类来讲,上面几个变量都会在类初始化的时候由用户传递给构造器。同时构造器也会从它的基类那里获取变量的默认值。不过这个点,我们将在下一章节进行讲述。
~~~Python
class Instance(Base):
"""Instance of a user-defined class. """
def __init__(self, cls):
assert isinstance(cls, Class)
Base.__init__(self, cls, {})
class Class(Base):
""" A User-defined class. """
def __init__(self, name, base_class, fields, metaclass):
Base.__init__(self, metaclass, fields)
self.name = name
self.base_class = base_class
~~~
同时,你可能注意到这点,类依旧是一种特殊的对象,他们间接的从 `Base` 中继承。因此,类也是一个特殊类的特殊实例,这样的很特殊的类叫做:元类。
现在,我们可以顺利通过我们第一组测试。不过这里,我们还没有定义 `Type` 以及 `OBJECT` 这样两个 `Class` 的实例。对于这些东西,我们将不会按照 Smalltalk 的对象模型进行构建,因为 Smalltalk 的对象模型对于我们来说太过于复杂。作为替代品,我们将采用 ObjVlisp1 的类型系统,Python 的类型系统从这里吸收了不少东西。
在 ObjVlisp 的对象模型中,`OBJECT` 以及 `TYPE` 是交杂在一起的。`OBJECT` 是所有类的母类,意味着 `OBJECT` 没有母类。`TYPE` 是 `OBJECT` 的子类。一般而言,每一个类都是 `TYPE` 的实例。在特定情况下,`TYPE` 和 `OBJECT` 都是 `TYPE` 的实例。不过,程序猿可以从 `TYPE` 派生出一个类去作为元类:
~~~Python
# set up the base hierarchy as in Python (the ObjVLisp model)
# the ultimate base class is OBJECT
OBJECT = Class(name="object", base_class=None, fields={}, metaclass=None)
# TYPE is a subclass of OBJECT
TYPE = Class(name="type", base_class=OBJECT, fields={}, metaclass=None)
# TYPE is an instance of itself
TYPE.cls = TYPE
# OBJECT is an instance of TYPE
OBJECT.cls = TYPE
~~~
为了去编写一个新的元类,我们需要自行从 `TYPE` 进行派生。不过在本文中我们并不会这么做,我们将只会使用 `TYPE` 作为我们每个类的元类。

好了,现在第一组测试已经完全通过了。现在让我们来看看第二组测试,我们将会在这组测试中测试对象属性读写是否正常。这段代码还是很好写的。
~~~Python
def test_read_write_field_class():
# classes are objects too
# Python code
class A(object):
pass
A.a = 1
assert A.a == 1
A.a = 6
assert A.a == 6
# Object model code
A = Class(name="A", base_class=OBJECT, fields={"a": 1}, metaclass=TYPE)
assert A.read_attr("a") == 1
A.write_attr("a", 5)
assert A.read_attr("a") == 5
~~~
### `isinstance` 检查
到目前为止,我们还没有将对象有类这点特性利用起来。接下来的测试代码将会自动的实现 `isinstance` 。
~~~Python
def test_isinstance():
# Python code
class A(object):
pass
class B(A):
pass
b = B()
assert isinstance(b, B)
assert isinstance(b, A)
assert isinstance(b, object)
assert not isinstance(b, type)
# Object model code
A = Class(name="A", base_class=OBJECT, fields={}, metaclass=TYPE)
B = Class(name="B", base_class=A, fields={}, metaclass=TYPE)
b = Instance(B)
assert b.isinstance(B)
assert b.isinstance(A)
assert b.isinstance(OBJECT)
assert not b.isinstance(TYPE)
~~~
我们可以通过检查 `cls` 是不是 `obj` 类或者它自己的超类来判断 `obj` 对象是不是某些类 `cls` 的实例。通过检查一个类是否在一个超类链上工作,来判断一个类是不是另一个类的超类。如果还有其余类存在于这个超类链上,那么这些类也可以被称为是超类。这个包含了超类和类本身的链条,被称之为**方法解析顺序**(译者注:简称MRO)。它很容易以递归的方式进行计算:
~~~Python
class Class(Base):
...
def method_resolution_order(self):
""" compute the method resolution order of the class """
if self.base_class is None:
return [self]
else:
return [self] + self.base_class.method_resolution_order()
def issubclass(self, cls):
""" is self a subclass of cls? """
return cls in self.method_resolution_order()
~~~
好了,在修改代码后,测试就完全能通过了
### 方法调用
前面所建立的对象模型中还缺少了方法调用这样的重要特性。在本章我们将会建立一个简单的继承模型。
~~~Python
def test_callmethod_simple():
# Python code
class A(object):
def f(self):
return self.x + 1
obj = A()
obj.x = 1
assert obj.f() == 2
class B(A):
pass
obj = B()
obj.x = 1
assert obj.f() == 2 # works on subclass too
# Object model code
def f_A(self):
return self.read_attr("x") + 1
A = Class(name="A", base_class=OBJECT, fields={"f": f_A}, metaclass=TYPE)
obj = Instance(A)
obj.write_attr("x", 1)
assert obj.callmethod("f") == 2
B = Class(name="B", base_class=A, fields={}, metaclass=TYPE)
obj = Instance(B)
obj.write_attr("x", 2)
assert obj.callmethod("f") == 3
~~~
为了找到调用对象方法的正确实现,我们现在开始讨论类对象的方法解析顺序。在 MRO 中我们所寻找到的类对象字典中第一个方法将会被调用:
~~~Python
class Class(Base):
...
def _read_from_class(self, methname):
for cls in self.method_resolution_order():
if methname in cls._fields:
return cls._fields[methname]
return MISSING
~~~
在完成 `Base` 类中 `callmethod` 实现后,可以通过上面的测试。
为了保证函数参数传递正确,同时也确保我们事先的代码能完成方法重载的功能,我们可以编写下面这段测试代码,当然结果是完美通过测试:
~~~Python
def test_callmethod_subclassing_and_arguments():
# Python code
class A(object):
def g(self, arg):
return self.x + arg
obj = A()
obj.x = 1
assert obj.g(4) == 5
class B(A):
def g(self, arg):
return self.x + arg * 2
obj = B()
obj.x = 4
assert obj.g(4) == 12
# Object model code
def g_A(self, arg):
return self.read_attr("x") + arg
A = Class(name="A", base_class=OBJECT, fields={"g": g_A}, metaclass=TYPE)
obj = Instance(A)
obj.write_attr("x", 1)
assert obj.callmethod("g", 4) == 5
def g_B(self, arg):
return self.read_attr("x") + arg * 2
B = Class(name="B", base_class=A, fields={"g": g_B}, metaclass=TYPE)
obj = Instance(B)
obj.write_attr("x", 4)
assert obj.callmethod("g", 4) == 12
~~~
## 基础属性模型
现在最简单版本的对象模型已经可以开始工作了,不过我们还需要去不断的改进。这一部分将会介绍基础方法模型和基础属性模型之间的差异。这也是 Smalltalk 、 Ruby 、 JavaScript 、 Python 和 Lua 之间的核心差异。
基础方法模型将会按照最原始的方式去调用方法:
~~~Python
result = obj.f(arg1, arg2)
~~~
基础属性模型将会将调用过程分为两步:寻找属性,以及返回执行结果:
~~~Python
method = obj.f
result = method(arg1, arg2)
~~~
你可以在接下来的测试中体会到前文所述的差异:
~~~Python
def test_bound_method():
# Python code
class A(object):
def f(self, a):
return self.x + a + 1
obj = A()
obj.x = 2
m = obj.f
assert m(4) == 7
class B(A):
pass
obj = B()
obj.x = 1
m = obj.f
assert m(10) == 12 # works on subclass too
# Object model code
def f_A(self, a):
return self.read_attr("x") + a + 1
A = Class(name="A", base_class=OBJECT, fields={"f": f_A}, metaclass=TYPE)
obj = Instance(A)
obj.write_attr("x", 2)
m = obj.read_attr("f")
assert m(4) == 7
B = Class(name="B", base_class=A, fields={}, metaclass=TYPE)
obj = Instance(B)
obj.write_attr("x", 1)
m = obj.read_attr("f")
assert m(10) == 12
~~~
我们可以按照之前测试代码中对方法调用设置一样的步骤去设置属性调用,不过和方法调用相比,这里面发生了一些变化。首先,我们将会在对象中寻找与函数名对应的方法名。这样一个查找过程结果被称之为已绑定的方法,具体来说就是,这个结果一个绑定了方法与具体对象的特殊对象。然后这个绑定方法会在接下来的操作中被调用。
为了实现这样的操作,我们需要修改 `Base.read_attr` 的实现。如果在实例字典中没有找到对应的属性,那么我们需要去在类字典中查找。如果在类字典中查找到了这个属性,那么我们将会执行方法绑定的操作。我们可以使用一个闭包来很简单的模拟绑定方法。除了更改 `Base.read_attr` 实现以外,我们也可以修改 `Base.callmethod` 方法来确保我们代码能通过测试。
~~~Python
class Base(object):
...
def read_attr(self, fieldname):
""" read field 'fieldname' out of the object """
result = self._read_dict(fieldname)
if result is not MISSING:
return result
result = self.cls._read_from_class(fieldname)
if _is_bindable(result):
return _make_boundmethod(result, self)
if result is not MISSING:
return result
raise AttributeError(fieldname)
def callmethod(self, methname, *args):
""" call method 'methname' with arguments 'args' on object """
meth = self.read_attr(methname)
return meth(*args)
def _is_bindable(meth):
return callable(meth)
def _make_boundmethod(meth, self):
def bound(*args):
return meth(self, *args)
return bound
~~~
其余的代码并不需要修改。
## 元对象协议
除了常规的类方法之外,很多动态语言还支持特殊方法。有这样一些方法在调用时是由对象系统调用而不是使用常规调用。在 Python 中你可以看到这些方法的方法名用两个下划线作为开头和结束的,比如 `__init__` 。特殊方法可以用于重载一些常规操作,同时可以提供一些自定义的功能。因此,它们的存在可以告诉对象模型如何自动的处理不同的事情。Python 中相关特殊方法的说明可以查看这篇[文档](https://docs.python.org/2/reference/datamodel.html#special-method-names)。
元对象协议这一概念由 Smalltalk 引入,然后在诸如 CLOS 这样的通用 Lisp 的对象模型中也广泛的使用这个概念。这个概念包含特殊方法的集合(注:这里没有查到 coined3 的梗,请校者帮忙参考)。
在这一章中,我们将会为我们的对象模型添加三个元调用操作。它们将会用来对我们读取和修改对象的操作进行更为精细的控制。我们首先要添加的两个方法是 `__getattr__` 和 `__setattr__`, 这两个方法的命名看起来和我们 Python 中相同功能函数的方法名很相似。
### 自定义属性读写操作
`__getattr__` 方法将会在属性通过常规方法无法查找到的情况下被调用,换句话说,在实例字典、类字典、父类字典等等对象中都找不到对应的属性时,会触发该方法的调用。我们将传入一个被查找属性的名字作为这个方法的参数。在早期的 Smalltalk4 中这个方法被称为 `doesNotUnderstand:` 。
在 `__setattr__` 这里事情可能发生了点变化。首先我们需要明确一点的是,设置一个属性的时候通常意味着我们需要创建它,在这个时候,在设置属性的时候通常会触发 `__setattr__` 方法。为了确保 `__setattr__` 的存在,我们需要在 `OBJECT` 对象中实现 `__setattr__` 方法。这样最基础的实现完成了我们向相对应的字典里写入属性的操作。这可以使得用户可以将自己定义的 `__setattr__` 委托给 `OBJECT.__setattr__` 方法。
针对这两个特殊方法的测试用例如下所示:
~~~Python
def test_getattr():
# Python code
class A(object):
def __getattr__(self, name):
if name == "fahrenheit":
return self.celsius * 9\. / 5\. + 32
raise AttributeError(name)
def __setattr__(self, name, value):
if name == "fahrenheit":
self.celsius = (value - 32) * 5\. / 9.
else:
# call the base implementation
object.__setattr__(self, name, value)
obj = A()
obj.celsius = 30
assert obj.fahrenheit == 86 # test __getattr__
obj.celsius = 40
assert obj.fahrenheit == 104
obj.fahrenheit = 86 # test __setattr__
assert obj.celsius == 30
assert obj.fahrenheit == 86
# Object model code
def __getattr__(self, name):
if name == "fahrenheit":
return self.read_attr("celsius") * 9\. / 5\. + 32
raise AttributeError(name)
def __setattr__(self, name, value):
if name == "fahrenheit":
self.write_attr("celsius", (value - 32) * 5\. / 9.)
else:
# call the base implementation
OBJECT.read_attr("__setattr__")(self, name, value)
A = Class(name="A", base_class=OBJECT,
fields={"__getattr__": __getattr__, "__setattr__": __setattr__},
metaclass=TYPE)
obj = Instance(A)
obj.write_attr("celsius", 30)
assert obj.read_attr("fahrenheit") == 86 # test __getattr__
obj.write_attr("celsius", 40)
assert obj.read_attr("fahrenheit") == 104
obj.write_attr("fahrenheit", 86) # test __setattr__
assert obj.read_attr("celsius") == 30
assert obj.read_attr("fahrenheit") == 86
~~~
为了通过测试,我们需要修改下 `Base.read_attr` 以及 `Base.write_attr` 两个方法:
~~~Python
class Base(object):
...
def read_attr(self, fieldname):
""" read field 'fieldname' out of the object """
result = self._read_dict(fieldname)
if result is not MISSING:
return result
result = self.cls._read_from_class(fieldname)
if _is_bindable(result):
return _make_boundmethod(result, self)
if result is not MISSING:
return result
meth = self.cls._read_from_class("__getattr__")
if meth is not MISSING:
return meth(self, fieldname)
raise AttributeError(fieldname)
def write_attr(self, fieldname, value):
""" write field 'fieldname' into the object """
meth = self.cls._read_from_class("__setattr__")
return meth(self, fieldname, value)
~~~
获取属性的过程变成调用 `__getattr__` 方法并传入字段名作为参数,如果字段不存在,将会抛出一个异常。请注意 `__getattr__` 只能在类中调用(Python 中的特殊方法也是这样),同时需要避免这样的 `self.read_attr("__getattr__")` 递归调用,因为如果 `__getattr__` 方法没有定义的话,上面的调用会造成无限递归。
对属性的修改操作也会像读取一样交给 `__setattr__` 方法执行。为了保证这个方法能够正常执行,`OBJECT` 需要实现 `__setattr__` 的默认行为,比如:
~~~Python
def OBJECT__setattr__(self, fieldname, value):
self._write_dict(fieldname, value)
OBJECT = Class("object", None, {"__setattr__": OBJECT__setattr__}, None)
~~~
`OBJECT.__setattr__` 的具体实现和之前 `write_attr` 方法的实现有着相似之处。在完成这些修改后,我们可以顺利的通过我们的测试。
### 描述符协议
在上面的测试中,我们频繁的在不同的温标之间切换,不得不说,在执行修改属性操作的时候这样真的很蛋疼,所以我们需要在 `__getattr__` 和 `__setattr__` 中检查所使用的属性的名称为了解决这个问题,在 Python 中引入了**描述符协议**的概念。
我们将从 `__getattr__` 和 `__setattr__` 方法中获取具体的属性,而描述符协议则是在属性调用过程结束返回结果时触发一个特殊的方法。描述符协议可以视为一种可以绑定类与方法的特殊手段,我们可以使用描述符协议来完成将方法绑定到对象的具体操作。除了绑定方法,在 Python 中描述符最重要的几个使用场景之一就是 `staticmethod`、 `classmethod` 和 `property`。
在接下来一点文字中,我们将介绍怎么样来使用描述符进行对象绑定。我们可以通过使用 `__get__` 方法来达成这一目标,具体请看下面的测试代码:
~~~Python
def test_get():
# Python code
class FahrenheitGetter(object):
def __get__(self, inst, cls):
return inst.celsius * 9\. / 5\. + 32
class A(object):
fahrenheit = FahrenheitGetter()
obj = A()
obj.celsius = 30
assert obj.fahrenheit == 86
# Object model code
class FahrenheitGetter(object):
def __get__(self, inst, cls):
return inst.read_attr("celsius") * 9\. / 5\. + 32
A = Class(name="A", base_class=OBJECT,
fields={"fahrenheit": FahrenheitGetter()},
metaclass=TYPE)
obj = Instance(A)
obj.write_attr("celsius", 30)
assert obj.read_attr("fahrenheit") == 86
~~~
`__get__` 方法将会在属性查找完后被 `FahrenheitGetter` 实例所调用。传递给 `__get__` 的参数是查找过程结束时所处的那个实例。
实现这样的功能倒是很简单,我们可以很简单的修改 `_is_bindable` 和 `_make_boundmethod` 方法:
~~~Python
def _is_bindable(meth):
return hasattr(meth, "__get__")
def _make_boundmethod(meth, self):
return meth.__get__(self, None)
~~~
好了,这样简单的修改能保证我们通过测试了。之前关于方法绑定的测试也能通过了,在 Python 中 `__get__` 方法执行完了将会返回一个已绑定方法对象。
在实践中,描述符协议的确看起来比较复杂。它同时还包含用于设置属性的 `__set__` 方法。此外,你现在所看到我们实现的版本是经过一些简化的。请注意,前面 `_make_boundmethod` 方法调用 `__get__` 是实现级的操作,而不是使用 `meth.read_attr('__get__')` 。这是很有必要的,因为我们的对象模型只是从 Python 中借用函数和方法,而不是展示 Python 的对象模型。进一步完善模型的话可以有效解决这个问题。
## 实例优化
这个对象模型前面三个部分的建立过程中伴随着很多的行为变化,而最后一部分的优化工作并不会伴随着行为变化。这种优化方式被称为 **map** ,广泛存在在可以自举的语言虚拟机中。这是一种最为重要对象模型优化手段:在 PyPy ,诸如 V8 现代 JavaScript 虚拟机中得到应用(在 V8 中这种方法被称为 **_hidden classes_**)。
这种优化手段基于如下的观察:到目前所实现的对象模型中,所有实例都使用一个完整的字典来储存他们的属性。字典是基于哈希表进行实现的,这将会耗费大量的内存。在很多时候,同一个类的实例将会拥有同样的属性,比如,有一个类 `Point` ,它所有的实例都包含同样的属性 `x` `y`。
`Map` 优化利用了这样一个事实。它将会将每个实例的字典分割为两个部分。一部分存放可以在所有实例中共享的属性名。然后另一部分只存放对第一部分产生的 `Map` 的引用和存放具体的值。存放属性名的 **map** 将会作为值的索引。
我们将为上面所述的需求编写一些测试用例,如下所示:
~~~Python
def test_maps():
# white box test inspecting the implementation
Point = Class(name="Point", base_class=OBJECT, fields={}, metaclass=TYPE)
p1 = Instance(Point)
p1.write_attr("x", 1)
p1.write_attr("y", 2)
assert p1.storage == [1, 2]
assert p1.map.attrs == {"x": 0, "y": 1}
p2 = Instance(Point)
p2.write_attr("x", 5)
p2.write_attr("y", 6)
assert p1.map is p2.map
assert p2.storage == [5, 6]
p1.write_attr("x", -1)
p1.write_attr("y", -2)
assert p1.map is p2.map
assert p1.storage == [-1, -2]
p3 = Instance(Point)
p3.write_attr("x", 100)
p3.write_attr("z", -343)
assert p3.map is not p1.map
assert p3.map.attrs == {"x": 0, "z": 1}
~~~
注意,这里测试代码的风格和我们之前的才是代码看起不太一样。之前所有的测试只是通过已实现的接口来测试类的功能。这里的测试通过读取类的内部属性来获取实现的详细信息,并将其与预设的值进行比较。这种测试方法又被称之为白盒测试。
`p1` 的包含 `attrs` 的 `map` 存放了 `x` 和 `y` 两个属性,其在 `p1` 中存放的值分别为 0 和 1。然后创建第二个实例 `p2` ,并通过同样的方法网同样的 `map` 中添加同样的属性。 换句话说,如果不同的属性被添加了,那么其中的 `map` 是不通用的。
`Map` 类长下面这样:
~~~Python
class Map(object):
def __init__(self, attrs):
self.attrs = attrs
self.next_maps = {}
def get_index(self, fieldname):
return self.attrs.get(fieldname, -1)
def next_map(self, fieldname):
assert fieldname not in self.attrs
if fieldname in self.next_maps:
return self.next_maps[fieldname]
attrs = self.attrs.copy()
attrs[fieldname] = len(attrs)
result = self.next_maps[fieldname] = Map(attrs)
return result
EMPTY_MAP = Map({})
~~~
Map 类拥有两个方法,分别是 `get_index` 和 `next_map` 。前者用于查找对象储存空间中的索引中查找对应的属性名称。而在新的属性添加到对象中时应该使用后者。在这种情况下,不同的实例需要用 `next_map` 计算不同的映射关系。这个方法将会使用 `next_maps` 来查找已经存在的映射。这样,相似的实例将会使用相似的 `Map` 对象。

Figure 14.2 - Map transitions
使用 `map` 的 `Instance` 实现如下:
~~~Python
class Instance(Base):
"""Instance of a user-defined class. """
def __init__(self, cls):
assert isinstance(cls, Class)
Base.__init__(self, cls, None)
self.map = EMPTY_MAP
self.storage = []
def _read_dict(self, fieldname):
index = self.map.get_index(fieldname)
if index == -1:
return MISSING
return self.storage[index]
def _write_dict(self, fieldname, value):
index = self.map.get_index(fieldname)
if index != -1:
self.storage[index] = value
else:
new_map = self.map.next_map(fieldname)
self.storage.append(value)
self.map = new_map
~~~
现在这个类将给 `Base` 类传递 `None` 作为字段字典,那是因为 `Instance` 将会以另一种方式构建存储字典。因此它需要重载 `_read_dict` 和 `_write_dict` 。在实际操作中,我们将重构 `Base` 类,使其不在负责存放字段字典。不过眼下,我们传递一个 `None` 作为参数就足够了。
在一个新的实例创建之初使用的是 `EMPTY_MAP` ,这里面没有任何的对象存放着。在实现 `_read_dict` 后,我们将从实例的 `map` 中查找属性名的索引,然后映射相对应的储存表。
向字段字典写入数据分为两种情况。第一种是现有属性值的修改,那么就简单的在映射的列表中修改对应的值就好。而如果对应属性不存在,那么需要进行 `map` 变换(如上面的图所示一样),将会调用 `next_map` 方法,然后将新的值存放入储存列表中。
你肯定想问,这种优化方式到底优化了什么?一般而言,在具有很多相似结构实例的情况下能较好的优化内存。但是请记住,这不是一个通用的优化手段。有些时候代码中充斥着结构不同的实例之时,这种手段可能会耗费更大的空间。
这是动态语言优化中的常见问题。一般而言,不太可能找到一种万能的方法去优化代码,使其更快,更节省空间。因此,具体情况具体分析,我们需要根据不同的情况去选择优化方式。
在 `Map` 优化中很有意思的一点就是,虽然这里只有花了内存占用,但是在 VM 使用 JIT 技术的情况下,也能较好的提高程序的性能。为了实现这一点,JIT 技术使用映射来查找属性在存储空间中的偏移量。然后完全除去字典查找的方式。
## 潜在扩展
扩展我们的对象模型和引入不同语言的设计选择是一件非常容易的事儿。这里给出一些可能的方向:
* 最简单的是添加更多的特殊方法方法,比如一些 `__init__`, `__getattribute__`, `__set__` 这样非常容易实现和有趣的方法。
* 扩展模型支持多重继承。为了实现这一点,每一个类都需要一个父类列表。然后 `Class.method_resolution_order` 需要进行修改,以便支持方法查找。一个简单的 MRO 计算规则可以使用深度优先原则。然后更为复杂的可以采用[C3 算法](https://www.python.org/download/releases/2.3/mro/), 这种算法能更好的处理菱形继承结构所带来的一些问题。
* 一个更为疯狂的想法是切换到原型模式,这需要消除类和实例之间的差别。
## 总结
面向对象编程语言设计的核心是其对象模型的细节。编写一些简单的对象模型是一件非常简单而且有趣的事情。你可以通过这种方式来了解现有语言的工作机制,并且深入了解面向对象语言的设计原则。编写不同的对象模型验证不同对象的设计思路是一个非常棒的方法。你也不在需要将注意力放在其余一些琐碎的事情上,比如解析和执行代码。
这样编写对象模型的工作在实践中也是非常有用的。除了作为实验品以外,它们还可以被其余语言所使用。这种例子有很多:比如 GObject 模型,用 C 语言编写,在 GLib 和 其余 Gonme 中得到使用,还有就是用 JavaScript 实现的各类对象模型。
# 参考文献
1. P. Cointe, “Metaclasses are first class: The ObjVlisp Model,” SIGPLAN Not, vol. 22, no. 12, pp. 156–162, 1987.↩
2. It seems that the attribute-based model is conceptually more complex, because it needs both method lookup and call. In practice, calling something is defined by looking up and calling a special attribute `__call__`, so conceptual simplicity is regained. This won't be implemented in this chapter, however.)↩
3. G. Kiczales, J. des Rivieres, and D. G. Bobrow, The Art of the Metaobject Protocol. Cambridge, Mass: The MIT Press, 1991.↩
4. A. Goldberg, Smalltalk-80: The Language and its Implementation. Addison-Wesley, 1983, page 61.↩
5. In Python the second argument is the class where the attribute was found, though we will ignore that here.↩
6. C. Chambers, D. Ungar, and E. Lee, “An efficient implementation of SELF, a dynamically-typed object-oriented language based on prototypes,” in OOPSLA, 1989, vol. 24.↩
7. How that works is beyond the scope of this chapter. I tried to give a reasonably readable account of it in a paper I wrote a few years ago. It uses an object model that is basically a variant of the one in this chapter: C. F. Bolz, A. Cuni, M. Fijałkowski, M. Leuschel, S. Pedroni, and A. Rigo, “Runtime feedback in a meta-tracing JIT for efficient dynamic languages,” in Proceedings of the 6th Workshop on Implementation, Compilation, Optimization of Object-Oriented Languages, Programs and Systems, New York, NY, USA, 2011, pp. 9:1–9:8.↩
================================================
FILE: TODO/a-simple-web-app-in-rust-conclusion.md
================================================
> * 原文地址:[A Simple Web App in Rust, Conclusion: Putting Rust Aside for Now](http://joelmccracken.github.io/entries/a-simple-web-app-in-rust-conclusion/)
> * 原文作者:[Joel's Journal](http://joelmccracken.github.io/)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/a-simple-web-app-in-rust-conclusion.md](https://github.com/xitu/gold-miner/blob/master/TODO/a-simple-web-app-in-rust-conclusion.md)
> * 译者:[mysterytony](https://github.com/mysterytony)
> * 校对者:[pthtc](https://github.com/pthtc)
# 使用 Rust 开发一个简单的 Web 应用之总结篇:还是先把 Rust 放一边吧
**警告:这篇文章充满了主见。虽然 Rust 社区可能不会很震惊,但我还是想列出这一系列。**
多年前,我编辑过一系列以《Building a Simple Webapp in Rust》为标题的博客。我希望有一天能重新开始编辑,但是我没有,我甚至怀疑我能不能完成这一系列的创作 —— 现在来看,那个博客里几乎所有内容都是过时的。
但不可忽视的是,这个项目还是成功的,因为我学到了很多关于 Rust 的知识。
我最终还是停止了这个项目,也停止了学习 Rust 。为什么?简单来说,相比于其他互联网的领域,我开始怀疑 Rust 是否**对我来说**有足够的价值。对我来说有一点是很清楚的,那就是当需要对硬件和性能有严格控制的时候, Rust 是一个很不错的语言。如果给我一个有这些要求的项目,我肯定会重新使用 Rust 。当需要我在 Rust 和 C++ 中做出选择的话,我会选择 Rust 。
但是,在大多数我写过的软件里,硬件管理通常不是一个很重要的因素。我也从来没有写过 C++ ,因为需要权衡开发时间,简洁性和可维护性才是最重要的因素。性能问题几乎总可以等到软件能正常工作之后再来处理,例如通过一些性能测试和聪明的优化。
一个激励我继续研究 Rust 的原因是,有人说过 Rust 是对他们来说效率最高的语言,同时对一般程序员来说是也是效率最高的语言。其中的原因是,Rust 的 Ownership 机制让他们更多地思考代码,并在某些方面显著地改善着设计。但这个理由不足以让我对 Rust 倾注过多时间,还是把时间花在别的事上吧。
总而言之,我决定还是学习其他东西比较好。特别是 Haskell (最初由 Elm 演变而来)以及其他对系统有很大影响的语言。
—
系列:用 Rust 做的简单网页
* [部分 1](http://joelmccracken.github.io/entries/a-simple-web-app-in-rust-pt-1/)
* [部分 2a](http://joelmccracken.github.io/entries/a-simple-web-app-in-rust-pt-2a/)
* [部分 2b](http://joelmccracken.github.io/entries/a-simple-web-app-in-rust-pt-2b/)
* [部分 3](http://joelmccracken.github.io/entries/a-simple-web-app-in-rust-pt-3/)
* [部分 4](http://joelmccracken.github.io/entries/a-simple-web-app-in-rust-pt-4-cli-option-parsing/)
* [总结](http://joelmccracken.github.io/entries/a-simple-web-app-in-rust-conclusion/)
---
> [掘金翻译计划](https://github.com/xitu/gold-miner) 是一个翻译优质互联网技术文章的社区,文章来源为 [掘金](https://juejin.im) 上的英文分享文章。内容覆盖 [Android](https://github.com/xitu/gold-miner#android)、[iOS](https://github.com/xitu/gold-miner#ios)、[前端](https://github.com/xitu/gold-miner#前端)、[后端](https://github.com/xitu/gold-miner#后端)、[区块链](https://github.com/xitu/gold-miner#区块链)、[产品](https://github.com/xitu/gold-miner#产品)、[设计](https://github.com/xitu/gold-miner#设计)、[人工智能](https://github.com/xitu/gold-miner#人工智能)等领域,想要查看更多优质译文请持续关注 [掘金翻译计划](https://github.com/xitu/gold-miner)、[官方微博](http://weibo.com/juejinfanyi)、[知乎专栏](https://zhuanlan.zhihu.com/juejinfanyi)。
================================================
FILE: TODO/a-simple-web-app-in-rust-pt-1.md
================================================
> * 原文地址:[A Simple Web App in Rust, Part 1](http://joelmccracken.github.io/entries/a-simple-web-app-in-rust-pt-1/)
> * 原文作者:[Joel's Journal](http://joelmccracken.github.io/)
> * 译文出自:[掘金翻译计划](https://github.com/xitu/gold-miner)
> * 本文永久链接:[https://github.com/xitu/gold-miner/blob/master/TODO/a-simple-web-app-in-rust-pt-1.md](https://github.com/xitu/gold-miner/blob/master/TODO/a-simple-web-app-in-rust-pt-1.md)
> * 译者:[LeopPro](https://github.com/LeopPro)
> * 校对者:[pthtc](https://github.com/pthtc) [hippyk](https://github.com/hippyk)
# 使用 Rust 开发一个简单的 Web 应用,第 1 部分
## 1 简介 & 背景
站在一个经验丰富但刚接触本生态系统的开发者的角度,使用 Rust 开发一个小型的 Web 应用是什么感觉呢?请继续阅读。
我第一次听说 Rust 的时候就对它产生了兴趣。一个支持宏的系统级语言,并且在高级抽象方面有成长空间。真棒!
到目前为止,我只写过关于 Rust 的博客,做了一些很基础的“Hello World”级程序。所以,我估计我的观点会欠一些火候。
不久之前,我看见了关于学习 Racket 的[这篇文章](http://artyom.me/learning-racket-1),我觉得特别好。我们需要更多的人分享他们作为技术初学者时获得的经验,尤其是那些已经有相当丰富的技术经验的人[1](#fn.1)。我也非常喜欢它的“思维流”方法。我想,像这样写一个 Rust 教程,应该是一个非常好的尝试。
好了,前言说完了,我们开始吧!
## 2 应用
我想构建的应用要实现我的一个简单需求:用一种无脑的方式记录我每天服药时间。我想我点一下主屏幕上的链接,让它记录这次访问,并且这将会储存为一份我服药时间的记录。
Rust 似乎很适合这个应用。它速度快,运行一个简单的服务器消耗的资源特别少,所以它不会对我的 VPS 造成负担。我还想用 Rust 做一些更实际的事。
最小可行性版本非常小巧,但如果我想添加更多功能,它也有增长空间。听起来完美!
## 3 计划
我不得不承认一件事:我弄丢了这个项目的早期版本,这将产生以下弊端:当我重现它的时候,我并不会有几周前刚刚接触它的时候那种陌生感。然而,我想我仍然记得当时让我痛苦的地方,并且我会尽力重现这些难点。
我知道一个道理有必要在这里讲一下:对于一个独立的个人程序来说,利用现有 API 要比试着独立完成所有的工作容易得多。
为了达成目的,我制定了如下计划:
1. 构建一个简单的 Web 服务器,当我访问他的时候它能在屏幕上显示“Hello World”。
2. 构建一个小型程序,每当他运行的时候,它会按照一定格式记录当前时间。
3. 将上面两个整合到一个程序中。
4. 将此应用程序部署到我的 Digital Ocean VPS 上。
## 4 编写一个“Hello World” Web 应用
所以,我要建立一个新的 Git 仓库 & 装好 homebrew。我至少知道,我先要安装 Rust。
### 4.1 安装 Rust
```
$ brew update
...
$ brew install rust
==> Downloading https://homebrew.bintray.com/bottles/rust-1.0.0.yosemite.bottle.tar.gz
############################################################ 100.0%
==> Pouring rust-1.0.0.yosemite.bottle.tar.gz
==> Caveats
Bash completion has been installed to:
/usr/local/etc/bash_completion.d
zsh completion has been installed to:
/usr/local/share/zsh/site-functions
==> Summary
/usr/local/Cellar/rust/1.0.0: 13947 files, 353M
```
Ok,在开始之前,我们先写一个常规的“Hello World”程序。
```
$ cat > hello_world.rs
fn main() {
println!("hello world");
}
^D
$ rustc hello_world.rs
$ ./hello_world
hello world
$
```
到目前为止一切顺利。Rust 正常工作了,或者至少说,Rust 的编译器在正常工作。
有位朋友建议我尝试使用 [nickle.rs](http://nickel-org.github.io/),那是 Rust 的 一个 Web 应用框架。我觉得不错。
截止到今天,它的第一个示例是:
```
#[macro_use] extern crate nickel;
use nickel::Nickel;
fn main() {
let mut server = Nickel::new();
server.utilize(router! {
get "**" => |_req, _res| {
"Hello world!"
}
});
server.listen("127.0.0.1:6767");
}
```
我第一次做这些的时候,我有一点小分心,去学了一点 Cargo。这次我注意到了这个[入门指南](http://nickel-org.github.io/getting-started.html),所以我打算跟着它走而不是什么都靠自己误打误撞。
这里有一个脚本,我应该通过 `curl` 下载然后使用 root 权限执行。但是“患有强迫症的”我打算先把脚本下载下来检查一下。
`curl -LO https://static.rust-lang.org/rustup.sh`
Ok,这事实上并不像我预想的那样,这个脚本完成了很多工作,大部分都是我现在不想自己去做的。而我很想知道,`cargo` 是不是用 `rustc` 来安装的?
```
$ which cargo
/usr/local/bin/cargo
$ cargo -v
Rust 包管理器
用法:
cargo <命令> [<参数>...]
cargo [选项]
选项:
-h, --help 显示帮助信息
-V, --version 显示版本信息并退出
--list 安装命令列表
-v, --verbose 使用详细的输出
常见的 cargo 命令:
build 编译当前工程
clean 删除目标目录
doc 编译此工程及其依赖项文档
new 创建一个新的 cargo 工程
run 编译并执行 src/main.rs
test 运行测试
bench 运行基准测试
update 更新 Cargo.lock 中的依赖项
search 搜索注册过的 crates
执行 'cargo help 