Repository: xmu-xiaoma666/External-Attention-pytorch
Branch: master
Commit: c413dae1f053
Files: 106
Total size: 1.0 MB
Directory structure:
gitextract_gcvwg1wd/
├── LICENSE
├── README.md
├── README_EN.md
├── README_pip.md
├── main.py
├── model/
│ ├── .vscode/
│ │ └── settings.json
│ ├── __init__.py
│ ├── analysis/
│ │ ├── Attention.md
│ │ ├── 注意力机制.md
│ │ └── 重参数机制.md
│ ├── attention/
│ │ ├── A2Atttention.py
│ │ ├── ACmixAttention.py
│ │ ├── AFT.py
│ │ ├── Axial_attention.py
│ │ ├── BAM.py
│ │ ├── CBAM.py
│ │ ├── CoAtNet.py
│ │ ├── CoTAttention.py
│ │ ├── CoordAttention.py
│ │ ├── CrissCrossAttention.py
│ │ ├── Crossformer.py
│ │ ├── DANet.py
│ │ ├── DAT.py
│ │ ├── ECAAttention.py
│ │ ├── EMSA.py
│ │ ├── ExternalAttention.py
│ │ ├── HaloAttention.py
│ │ ├── MOATransformer.py
│ │ ├── MUSEAttention.py
│ │ ├── MobileViTAttention.py
│ │ ├── MobileViTv2Attention.py
│ │ ├── OutlookAttention.py
│ │ ├── PSA.py
│ │ ├── ParNetAttention.py
│ │ ├── PolarizedSelfAttention.py
│ │ ├── ResidualAttention.py
│ │ ├── S2Attention.py
│ │ ├── SEAttention.py
│ │ ├── SGE.py
│ │ ├── SKAttention.py
│ │ ├── SelfAttention.py
│ │ ├── ShuffleAttention.py
│ │ ├── SimAM.py
│ │ ├── SimplifiedSelfAttention.py
│ │ ├── TripletAttention.py
│ │ ├── UFOAttention.py
│ │ ├── ViP.py
│ │ └── gfnet.py
│ ├── backbone/
│ │ ├── CMT.py
│ │ ├── CPVT.py
│ │ ├── CaiT.py
│ │ ├── CeiT.py
│ │ ├── CoaT.py
│ │ ├── ConTNet.py
│ │ ├── ConViT.py
│ │ ├── Container.py
│ │ ├── ConvMixer.py
│ │ ├── CrossViT.py
│ │ ├── DViT.py
│ │ ├── DeiT.py
│ │ ├── EfficientFormer.py
│ │ ├── HATNet.py
│ │ ├── LeViT.py
│ │ ├── MobileNetV3.py
│ │ ├── MobileViT.py
│ │ ├── PIT.py
│ │ ├── PVT.py
│ │ ├── PatchConvnet.py
│ │ ├── ShuffleTransformer.py
│ │ ├── TnT.py
│ │ ├── VOLO.py
│ │ ├── convnextv2.py
│ │ ├── resnet.py
│ │ ├── resnext.py
│ │ ├── swin_transformer.py
│ │ ├── swin_transformer_v2.py
│ │ └── swin_transformer_v2_cr.py
│ ├── conv/
│ │ ├── CondConv.py
│ │ ├── DepthwiseSeparableConvolution.py
│ │ ├── DynamicConv.py
│ │ ├── HorNet.py
│ │ ├── Involution.py
│ │ └── MBConv.py
│ ├── fighingcv.egg-info/
│ │ ├── PKG-INFO
│ │ ├── SOURCES.txt
│ │ ├── dependency_links.txt
│ │ ├── entry_points.txt
│ │ ├── requires.txt
│ │ └── top_level.txt
│ ├── huggingface_hub.egg-info/
│ │ ├── PKG-INFO
│ │ ├── SOURCES.txt
│ │ ├── dependency_links.txt
│ │ ├── entry_points.txt
│ │ ├── requires.txt
│ │ └── top_level.txt
│ ├── mlp/
│ │ ├── g_mlp.py
│ │ ├── mlp_mixer.py
│ │ ├── repmlp.py
│ │ ├── resmlp.py
│ │ ├── sMLP_block.py
│ │ └── vip-mlp.py
│ └── rep/
│ ├── acnet.py
│ ├── ddb.py
│ ├── mobileone.py
│ └── repvgg.py
└── setup.py
================================================
FILE CONTENTS
================================================
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2021 xmu-xiaoma666
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
 简体中文 | [English](./README_EN.md)
# FightingCV 代码库, 包含 [***Attention***](#attention-series),[***Backbone***](#backbone-series), [***MLP***](#mlp-series), [***Re-parameter***](#re-parameter-series), [**Convolution**](#convolution-series)



## 🌟 Star History
[](https://star-history.com/#xmu-xiaoma666/External-Attention-pytorch&Date)
## 使用
### 安装
直接通过 pip 安装
```shell
pip install fightingcv-attention
```
或克隆该仓库
```shell
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorch
```
### 演示
#### 使用 pip 方式
```python
import torch
from torch import nn
from torch.nn import functional as F
# 使用 pip 方式
from fightingcv_attention.attention.MobileViTv2Attention import *
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
- pip包 内置模块使用参考: [fightingcv-attention 说明文档](./README_pip.md)
#### 使用 git 方式
```python
import torch
from torch import nn
from torch.nn import functional as F
# 与 pip方式 区别在于 将 `fightingcv_attention` 替换 `model`
from model.attention.MobileViTv2Attention import *
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
-------
# 目录
- [Attention Series](#attention-series)
- [1. External Attention Usage](#1-external-attention-usage)
- [2. Self Attention Usage](#2-self-attention-usage)
- [3. Simplified Self Attention Usage](#3-simplified-self-attention-usage)
- [4. Squeeze-and-Excitation Attention Usage](#4-squeeze-and-excitation-attention-usage)
- [5. SK Attention Usage](#5-sk-attention-usage)
- [6. CBAM Attention Usage](#6-cbam-attention-usage)
- [7. BAM Attention Usage](#7-bam-attention-usage)
- [8. ECA Attention Usage](#8-eca-attention-usage)
- [9. DANet Attention Usage](#9-danet-attention-usage)
- [10. Pyramid Split Attention (PSA) Usage](#10-Pyramid-Split-Attention-Usage)
- [11. Efficient Multi-Head Self-Attention(EMSA) Usage](#11-Efficient-Multi-Head-Self-Attention-Usage)
- [12. Shuffle Attention Usage](#12-Shuffle-Attention-Usage)
- [13. MUSE Attention Usage](#13-MUSE-Attention-Usage)
- [14. SGE Attention Usage](#14-SGE-Attention-Usage)
- [15. A2 Attention Usage](#15-A2-Attention-Usage)
- [16. AFT Attention Usage](#16-AFT-Attention-Usage)
- [17. Outlook Attention Usage](#17-Outlook-Attention-Usage)
- [18. ViP Attention Usage](#18-ViP-Attention-Usage)
- [19. CoAtNet Attention Usage](#19-CoAtNet-Attention-Usage)
- [20. HaloNet Attention Usage](#20-HaloNet-Attention-Usage)
- [21. Polarized Self-Attention Usage](#21-Polarized-Self-Attention-Usage)
- [22. CoTAttention Usage](#22-CoTAttention-Usage)
- [23. Residual Attention Usage](#23-Residual-Attention-Usage)
- [24. S2 Attention Usage](#24-S2-Attention-Usage)
- [25. GFNet Attention Usage](#25-GFNet-Attention-Usage)
- [26. Triplet Attention Usage](#26-TripletAttention-Usage)
- [27. Coordinate Attention Usage](#27-Coordinate-Attention-Usage)
- [28. MobileViT Attention Usage](#28-MobileViT-Attention-Usage)
- [29. ParNet Attention Usage](#29-ParNet-Attention-Usage)
- [30. UFO Attention Usage](#30-UFO-Attention-Usage)
- [31. ACmix Attention Usage](#31-Acmix-Attention-Usage)
- [32. MobileViTv2 Attention Usage](#32-MobileViTv2-Attention-Usage)
- [33. DAT Attention Usage](#33-DAT-Attention-Usage)
- [34. CrossFormer Attention Usage](#34-CrossFormer-Attention-Usage)
- [35. MOATransformer Attention Usage](#35-MOATransformer-Attention-Usage)
- [36. CrissCrossAttention Attention Usage](#36-CrissCrossAttention-Attention-Usage)
- [37. Axial_attention Attention Usage](#37-Axial_attention-Attention-Usage)
- [Backbone Series](#Backbone-series)
- [1. ResNet Usage](#1-ResNet-Usage)
- [2. ResNeXt Usage](#2-ResNeXt-Usage)
- [3. MobileViT Usage](#3-MobileViT-Usage)
- [4. ConvMixer Usage](#4-ConvMixer-Usage)
- [5. ShuffleTransformer Usage](#5-ShuffleTransformer-Usage)
- [6. ConTNet Usage](#6-ConTNet-Usage)
- [7. HATNet Usage](#7-HATNet-Usage)
- [8. CoaT Usage](#8-CoaT-Usage)
- [9. PVT Usage](#9-PVT-Usage)
- [10. CPVT Usage](#10-CPVT-Usage)
- [11. PIT Usage](#11-PIT-Usage)
- [12. CrossViT Usage](#12-CrossViT-Usage)
- [13. TnT Usage](#13-TnT-Usage)
- [14. DViT Usage](#14-DViT-Usage)
- [15. CeiT Usage](#15-CeiT-Usage)
- [16. ConViT Usage](#16-ConViT-Usage)
- [17. CaiT Usage](#17-CaiT-Usage)
- [18. PatchConvnet Usage](#18-PatchConvnet-Usage)
- [19. DeiT Usage](#19-DeiT-Usage)
- [20. LeViT Usage](#20-LeViT-Usage)
- [21. VOLO Usage](#21-VOLO-Usage)
- [22. Container Usage](#22-Container-Usage)
- [23. CMT Usage](#23-CMT-Usage)
- [24. EfficientFormer Usage](#24-EfficientFormer-Usage)
- [25. ConvNeXtV2 Usage](#25-ConvNeXtV2-Usage)
- [MLP Series](#mlp-series)
- [1. RepMLP Usage](#1-RepMLP-Usage)
- [2. MLP-Mixer Usage](#2-MLP-Mixer-Usage)
- [3. ResMLP Usage](#3-ResMLP-Usage)
- [4. gMLP Usage](#4-gMLP-Usage)
- [5. sMLP Usage](#5-sMLP-Usage)
- [6. vip-mlp Usage](#6-vip-mlp-Usage)
- [Re-Parameter(ReP) Series](#Re-Parameter-series)
- [1. RepVGG Usage](#1-RepVGG-Usage)
- [2. ACNet Usage](#2-ACNet-Usage)
- [3. Diverse Branch Block(DDB) Usage](#3-Diverse-Branch-Block-Usage)
- [Convolution Series](#Convolution-series)
- [1. Depthwise Separable Convolution Usage](#1-Depthwise-Separable-Convolution-Usage)
- [2. MBConv Usage](#2-MBConv-Usage)
- [3. Involution Usage](#3-Involution-Usage)
- [4. DynamicConv Usage](#4-DynamicConv-Usage)
- [5. CondConv Usage](#5-CondConv-Usage)
***
# Attention Series
- Pytorch implementation of ["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks---arXiv 2021.05.05"](https://arxiv.org/abs/2105.02358)
- Pytorch implementation of ["Attention Is All You Need---NIPS2017"](https://arxiv.org/pdf/1706.03762.pdf)
- Pytorch implementation of ["Squeeze-and-Excitation Networks---CVPR2018"](https://arxiv.org/abs/1709.01507)
- Pytorch implementation of ["Selective Kernel Networks---CVPR2019"](https://arxiv.org/pdf/1903.06586.pdf)
- Pytorch implementation of ["CBAM: Convolutional Block Attention Module---ECCV2018"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
- Pytorch implementation of ["BAM: Bottleneck Attention Module---BMCV2018"](https://arxiv.org/pdf/1807.06514.pdf)
- Pytorch implementation of ["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020"](https://arxiv.org/pdf/1910.03151.pdf)
- Pytorch implementation of ["Dual Attention Network for Scene Segmentation---CVPR2019"](https://arxiv.org/pdf/1809.02983.pdf)
- Pytorch implementation of ["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30"](https://arxiv.org/pdf/2105.14447.pdf)
- Pytorch implementation of ["ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28"](https://arxiv.org/abs/2105.13677)
- Pytorch implementation of ["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS---ICASSP 2021"](https://arxiv.org/pdf/2102.00240.pdf)
- Pytorch implementation of ["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning---arXiv 2019.11.17"](https://arxiv.org/abs/1911.09483)
- Pytorch implementation of ["Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks---arXiv 2019.05.23"](https://arxiv.org/pdf/1905.09646.pdf)
- Pytorch implementation of ["A2-Nets: Double Attention Networks---NIPS2018"](https://arxiv.org/pdf/1810.11579.pdf)
- Pytorch implementation of ["An Attention Free Transformer---ICLR2021 (Apple New Work)"](https://arxiv.org/pdf/2105.14103v1.pdf)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition---arXiv 2021.06.24"](https://arxiv.org/abs/2106.13112)
[【论文解析】](https://zhuanlan.zhihu.com/p/385561050)
- Pytorch implementation of [Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition---arXiv 2021.06.23](https://arxiv.org/abs/2106.12368)
[【论文解析】](https://mp.weixin.qq.com/s/5gonUQgBho_m2O54jyXF_Q)
- Pytorch implementation of [CoAtNet: Marrying Convolution and Attention for All Data Sizes---arXiv 2021.06.09](https://arxiv.org/abs/2106.04803)
[【论文解析】](https://zhuanlan.zhihu.com/p/385578588)
- Pytorch implementation of [Scaling Local Self-Attention for Parameter Efficient Visual Backbones---CVPR2021 Oral](https://arxiv.org/pdf/2103.12731.pdf) [【论文解析】](https://zhuanlan.zhihu.com/p/388598744)
- Pytorch implementation of [Polarized Self-Attention: Towards High-quality Pixel-wise Regression---arXiv 2021.07.02](https://arxiv.org/abs/2107.00782) [【论文解析】](https://zhuanlan.zhihu.com/p/389770482)
- Pytorch implementation of [Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292) [【论文解析】](https://zhuanlan.zhihu.com/p/394795481)
- Pytorch implementation of [Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
- Pytorch implementation of [S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072) [【论文解析】](https://zhuanlan.zhihu.com/p/397003638)
- Pytorch implementation of [Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
- Pytorch implementation of [Rotate to Attend: Convolutional Triplet Attention Module---WACV 2021](https://arxiv.org/abs/2010.03045)
- Pytorch implementation of [Coordinate Attention for Efficient Mobile Network Design ---CVPR 2021](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2110.02178)
- Pytorch implementation of [Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
- Pytorch implementation of [UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2109.14382)
- Pytorch implementation of [Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
- Pytorch implementation of [On the Integration of Self-Attention and Convolution---ArXiv 2022.03.14](https://arxiv.org/pdf/2111.14556.pdf)
- Pytorch implementation of [CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
- Pytorch implementation of [Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
- Pytorch implementation of [CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
- Pytorch implementation of [Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
***
### 1. External Attention Usage
#### 1.1. Paper
["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks"](https://arxiv.org/abs/2105.02358)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
***
### 2. Self Attention Usage
#### 2.1. Paper
["Attention Is All You Need"](https://arxiv.org/pdf/1706.03762.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 3. Simplified Self Attention Usage
#### 3.1. Paper
[None]()
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)
```
***
### 4. Squeeze-and-Excitation Attention Usage
#### 4.1. Paper
["Squeeze-and-Excitation Networks"](https://arxiv.org/abs/1709.01507)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 5. SK Attention Usage
#### 5.1. Paper
["Selective Kernel Networks"](https://arxiv.org/pdf/1903.06586.pdf)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 6. CBAM Attention Usage
#### 6.1. Paper
["CBAM: Convolutional Block Attention Module"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
#### 6.2. Overview


#### 6.3. Usage Code
```python
from model.attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
***
### 7. BAM Attention Usage
#### 7.1. Paper
["BAM: Bottleneck Attention Module"](https://arxiv.org/pdf/1807.06514.pdf)
#### 7.2. Overview

#### 7.3. Usage Code
```python
from model.attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
***
### 8. ECA Attention Usage
#### 8.1. Paper
["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks"](https://arxiv.org/pdf/1910.03151.pdf)
#### 8.2. Overview

#### 8.3. Usage Code
```python
from model.attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
***
### 9. DANet Attention Usage
#### 9.1. Paper
["Dual Attention Network for Scene Segmentation"](https://arxiv.org/pdf/1809.02983.pdf)
#### 9.2. Overview

#### 9.3. Usage Code
```python
from model.attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
***
### 10. Pyramid Split Attention Usage
#### 10.1. Paper
["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network"](https://arxiv.org/pdf/2105.14447.pdf)
#### 10.2. Overview

#### 10.3. Usage Code
```python
from model.attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
***
### 11. Efficient Multi-Head Self-Attention Usage
#### 11.1. Paper
["ResT: An Efficient Transformer for Visual Recognition"](https://arxiv.org/abs/2105.13677)
#### 11.2. Overview

#### 11.3. Usage Code
```python
from model.attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
***
### 12. Shuffle Attention Usage
#### 12.1. Paper
["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS"](https://arxiv.org/pdf/2102.00240.pdf)
#### 12.2. Overview

#### 12.3. Usage Code
```python
from model.attention.ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
```
***
### 13. MUSE Attention Usage
#### 13.1. Paper
["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning"](https://arxiv.org/abs/1911.09483)
#### 13.2. Overview

#### 13.3. Usage Code
```python
from model.attention.MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 14. SGE Attention Usage
#### 14.1. Paper
[Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks](https://arxiv.org/pdf/1905.09646.pdf)
#### 14.2. Overview

#### 14.3. Usage Code
```python
from model.attention.SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
```
***
### 15. A2 Attention Usage
#### 15.1. Paper
[A2-Nets: Double Attention Networks](https://arxiv.org/pdf/1810.11579.pdf)
#### 15.2. Overview

#### 15.3. Usage Code
```python
from model.attention.A2Atttention import DoubleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
```
### 16. AFT Attention Usage
#### 16.1. Paper
[An Attention Free Transformer](https://arxiv.org/pdf/2105.14103v1.pdf)
#### 16.2. Overview

#### 16.3. Usage Code
```python
from model.attention.AFT import AFT_FULL
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
```
### 17. Outlook Attention Usage
#### 17.1. Paper
[VOLO: Vision Outlooker for Visual Recognition"](https://arxiv.org/abs/2106.13112)
#### 17.2. Overview

#### 17.3. Usage Code
```python
from model.attention.OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)
```
***
### 18. ViP Attention Usage
#### 18.1. Paper
[Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 18.2. Overview

#### 18.3. Usage Code
```python
from model.attention.ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)
```
***
### 19. CoAtNet Attention Usage
#### 19.1. Paper
[CoAtNet: Marrying Convolution and Attention for All Data Sizes"](https://arxiv.org/abs/2106.04803)
#### 19.2. Overview
None
#### 19.3. Usage Code
```python
from model.attention.CoAtNet import CoAtNet
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=CoAtNet(in_ch=3,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 20. HaloNet Attention Usage
#### 20.1. Paper
[Scaling Local Self-Attention for Parameter Efficient Visual Backbones"](https://arxiv.org/pdf/2103.12731.pdf)
#### 20.2. Overview

#### 20.3. Usage Code
```python
from model.attention.HaloAttention import HaloAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)
```
***
### 21. Polarized Self-Attention Usage
#### 21.1. Paper
[Polarized Self-Attention: Towards High-quality Pixel-wise Regression"](https://arxiv.org/abs/2107.00782)
#### 21.2. Overview

#### 21.3. Usage Code
```python
from model.attention.PolarizedSelfAttention import ParallelPolarizedSelfAttention,SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
```
***
### 22. CoTAttention Usage
#### 22.1. Paper
[Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292)
#### 22.2. Overview

#### 22.3. Usage Code
```python
from model.attention.CoTAttention import CoTAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
```
***
### 23. Residual Attention Usage
#### 23.1. Paper
[Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
#### 23.2. Overview

#### 23.3. Usage Code
```python
from model.attention.ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
resatt = ResidualAttention(channel=512,num_class=1000,la=0.2)
output=resatt(input)
print(output.shape)
```
***
### 24. S2 Attention Usage
#### 24.1. Paper
[S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072)
#### 24.2. Overview

#### 24.3. Usage Code
```python
from model.attention.S2Attention import S2Attention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
s2att = S2Attention(channels=512)
output=s2att(input)
print(output.shape)
```
***
### 25. GFNet Attention Usage
#### 25.1. Paper
[Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
#### 25.2. Overview

#### 25.3. Usage Code - Implemented by [Wenliang Zhao (Author)](https://scholar.google.com/citations?user=lyPWvuEAAAAJ&hl=en)
```python
from model.attention.gfnet import GFNet
import torch
from torch import nn
from torch.nn import functional as F
x = torch.randn(1, 3, 224, 224)
gfnet = GFNet(embed_dim=384, img_size=224, patch_size=16, num_classes=1000)
out = gfnet(x)
print(out.shape)
```
***
### 26. TripletAttention Usage
#### 26.1. Paper
[Rotate to Attend: Convolutional Triplet Attention Module---CVPR 2021](https://arxiv.org/abs/2010.03045)
#### 26.2. Overview

#### 26.3. Usage Code - Implemented by [digantamisra98](https://github.com/digantamisra98)
```python
from model.attention.TripletAttention import TripletAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
triplet = TripletAttention()
output=triplet(input)
print(output.shape)
```
***
### 27. Coordinate Attention Usage
#### 27.1. Paper
[Coordinate Attention for Efficient Mobile Network Design---CVPR 2021](https://arxiv.org/abs/2103.02907)
#### 27.2. Overview

#### 27.3. Usage Code - Implemented by [Andrew-Qibin](https://github.com/Andrew-Qibin)
```python
from model.attention.CoordAttention import CoordAtt
import torch
from torch import nn
from torch.nn import functional as F
inp=torch.rand([2, 96, 56, 56])
inp_dim, oup_dim = 96, 96
reduction=32
coord_attention = CoordAtt(inp_dim, oup_dim, reduction=reduction)
output=coord_attention(inp)
print(output.shape)
```
***
### 28. MobileViT Attention Usage
#### 28.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2103.02907)
#### 28.2. Overview

#### 28.3. Usage Code
```python
from model.attention.MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
m=MobileViTAttention()
input=torch.randn(1,3,49,49)
output=m(input)
print(output.shape) #output:(1,3,49,49)
```
***
### 29. ParNet Attention Usage
#### 29.1. Paper
[Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
#### 29.2. Overview

#### 29.3. Usage Code
```python
from model.attention.ParNetAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
pna = ParNetAttention(channel=512)
output=pna(input)
print(output.shape) #50,512,7,7
```
***
### 30. UFO Attention Usage
#### 30.1. Paper
[UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2110.07641)
#### 30.2. Overview

#### 30.3. Usage Code
```python
from model.attention.UFOAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
ufo = UFOAttention(d_model=512, d_k=512, d_v=512, h=8)
output=ufo(input,input,input)
print(output.shape) #[50, 49, 512]
```
-
### 31. ACmix Attention Usage
#### 31.1. Paper
[On the Integration of Self-Attention and Convolution](https://arxiv.org/pdf/2111.14556.pdf)
#### 31.2. Usage Code
```python
from model.attention.ACmix import ACmix
import torch
if __name__ == '__main__':
input=torch.randn(50,256,7,7)
acmix = ACmix(in_planes=256, out_planes=256)
output=acmix(input)
print(output.shape)
```
### 32. MobileViTv2 Attention Usage
#### 32.1. Paper
[Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
#### 32.2. Overview

#### 32.3. Usage Code
```python
from model.attention.MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
### 33. DAT Attention Usage
#### 33.1. Paper
[Vision Transformer with Deformable Attention---CVPR2022](https://arxiv.org/abs/2201.00520)
#### 33.2. Usage Code
```python
from model.attention.DAT import DAT
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DAT(
img_size=224,
patch_size=4,
num_classes=1000,
expansion=4,
dim_stem=96,
dims=[96, 192, 384, 768],
depths=[2, 2, 6, 2],
stage_spec=[['L', 'S'], ['L', 'S'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7] ,
groups=[-1, -1, 3, 6],
use_pes=[False, False, True, True],
dwc_pes=[False, False, False, False],
strides=[-1, -1, 1, 1],
sr_ratios=[-1, -1, -1, -1],
offset_range_factor=[-1, -1, 2, 2],
no_offs=[False, False, False, False],
fixed_pes=[False, False, False, False],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
)
output=model(input)
print(output[0].shape)
```
### 34. CrossFormer Attention Usage
#### 34.1. Paper
[CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
#### 34.2. Usage Code
```python
from model.attention.Crossformer import CrossFormer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CrossFormer(img_size=224,
patch_size=[4, 8, 16, 32],
in_chans= 3,
num_classes=1000,
embed_dim=48,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
group_size=[7, 7, 7, 7],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False,
merge_size=[[2, 4], [2,4], [2, 4]]
)
output=model(input)
print(output.shape)
```
### 35. MOATransformer Attention Usage
#### 35.1. Paper
[Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
#### 35.2. Usage Code
```python
from model.attention.MOATransformer import MOATransformer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = MOATransformer(
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=[2, 2, 6],
num_heads=[3, 6, 12],
window_size=14,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False
)
output=model(input)
print(output.shape)
```
### 36. CrissCrossAttention Attention Usage
#### 36.1. Paper
[CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
#### 36.2. Usage Code
```python
from model.attention.CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = CrissCrossAttention(64)
outputs = model(input)
print(outputs.shape)
```
### 37. Axial_attention Attention Usage
#### 37.1. Paper
[Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
#### 37.2. Usage Code
```python
from model.attention.Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__':
input=torch.randn(3, 128, 7, 7)
model = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
outputs = model(input)
print(outputs.shape)
```
***
# Backbone Series
- Pytorch implementation of ["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
- Pytorch implementation of ["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
- Pytorch implementation of [Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer---ArXiv 2021.06.07](https://arxiv.org/abs/2106.03650)
- Pytorch implementation of [ConTNet: Why not use convolution and transformer at the same time?---ArXiv 2021.04.27](https://arxiv.org/abs/2104.13497)
- Pytorch implementation of [Vision Transformers with Hierarchical Attention---ArXiv 2022.06.15](https://arxiv.org/abs/2106.03180)
- Pytorch implementation of [Co-Scale Conv-Attentional Image Transformers---ArXiv 2021.08.26](https://arxiv.org/abs/2104.06399)
- Pytorch implementation of [Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
- Pytorch implementation of [Rethinking Spatial Dimensions of Vision Transformers---ICCV 2021](https://arxiv.org/abs/2103.16302)
- Pytorch implementation of [CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification---ICCV 2021](https://arxiv.org/abs/2103.14899)
- Pytorch implementation of [Transformer in Transformer---NeurIPS 2021](https://arxiv.org/abs/2103.00112)
- Pytorch implementation of [DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
- Pytorch implementation of [Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
***
- Pytorch implementation of [ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
- Pytorch implementation of [Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
- Pytorch implementation of [Going deeper with Image Transformers---ICCV 2021 (Oral)](https://arxiv.org/abs/2103.17239)
- Pytorch implementation of [Training data-efficient image transformers & distillation through attention---ICML 2021](https://arxiv.org/abs/2012.12877)
- Pytorch implementation of [LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
- Pytorch implementation of [Container: Context Aggregation Network---NeuIPS 2021](https://arxiv.org/abs/2106.01401)
- Pytorch implementation of [CMT: Convolutional Neural Networks Meet Vision Transformers---CVPR 2022](https://arxiv.org/abs/2107.06263)
- Pytorch implementation of [Vision Transformer with Deformable Attention---CVPR 2022](https://arxiv.org/abs/2201.00520)
- Pytorch implementation of [EfficientFormer: Vision Transformers at MobileNet Speed](https://arxiv.org/abs/2206.01191)
- Pytorch implementation of [ConvNeXtV2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808)
### 1. ResNet Usage
#### 1.1. Paper
["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
#### 1.2. Overview


#### 1.3. Usage Code
```python
from model.backbone.resnet import ResNet50,ResNet101,ResNet152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnet50=ResNet50(1000)
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out=resnet50(input)
print(out.shape)
```
### 2. ResNeXt Usage
#### 2.1. Paper
["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.backbone.resnext import ResNeXt50,ResNeXt101,ResNeXt152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnext50=ResNeXt50(1000)
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out=resnext50(input)
print(out.shape)
```
### 3. MobileViT Usage
#### 3.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.backbone.MobileViT import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
### mobilevit_xxs
mvit_xxs=mobilevit_xxs()
out=mvit_xxs(input)
print(out.shape)
### mobilevit_xs
mvit_xs=mobilevit_xs()
out=mvit_xs(input)
print(out.shape)
### mobilevit_s
mvit_s=mobilevit_s()
out=mvit_s(input)
print(out.shape)
```
### 4. ConvMixer Usage
#### 4.1. Paper
[Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.backbone.ConvMixer import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
convmixer=ConvMixer(dim=512,depth=12)
out=convmixer(x)
print(out.shape) #[1, 1000]
```
### 5. ShuffleTransformer Usage
#### 5.1. Paper
[Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer](https://arxiv.org/pdf/2106.03650.pdf)
#### 5.2. Usage Code
```python
from model.backbone.ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
sft = ShuffleTransformer()
output=sft(input)
print(output.shape)
```
### 6. ConTNet Usage
#### 6.1. Paper
[ConTNet: Why not use convolution and transformer at the same time?](https://arxiv.org/abs/2104.13497)
#### 6.2. Usage Code
```python
from model.backbone.ConTNet import ConTNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == "__main__":
model = build_model(use_avgdown=True, relative=True, qkv_bias=True, pre_norm=True)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
```
### 7 HATNet Usage
#### 7.1. Paper
[Vision Transformers with Hierarchical Attention](https://arxiv.org/abs/2106.03180)
#### 7.2. Usage Code
```python
from model.backbone.HATNet import HATNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
hat = HATNet(dims=[48, 96, 240, 384], head_dim=48, expansions=[8, 8, 4, 4],
grid_sizes=[8, 7, 7, 1], ds_ratios=[8, 4, 2, 1], depths=[2, 2, 6, 3])
output=hat(input)
print(output.shape)
```
### 8 CoaT Usage
#### 8.1. Paper
[Co-Scale Conv-Attentional Image Transformers](https://arxiv.org/abs/2104.06399)
#### 8.2. Usage Code
```python
from model.backbone.CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4])
output=model(input)
print(output.shape) # torch.Size([1, 1000])
```
### 9 PVT Usage
#### 9.1. Paper
[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/pdf/2106.13797.pdf)
#### 9.2. Usage Code
```python
from model.backbone.PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 10 CPVT Usage
#### 10.1. Paper
[Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
#### 10.2. Usage Code
```python
from model.backbone.CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 11 PIT Usage
#### 11.1. Paper
[Rethinking Spatial Dimensions of Vision Transformers](https://arxiv.org/abs/2103.16302)
#### 11.2. Usage Code
```python
from model.backbone.PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4
)
output=model(input)
print(output.shape)
```
### 12 CrossViT Usage
#### 12.1. Paper
[CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification](https://arxiv.org/abs/2103.14899)
#### 12.2. Usage Code
```python
from model.backbone.CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__":
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[240, 224],
patch_size=[12, 16],
embed_dim=[192, 384],
depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6],
mlp_ratio=[4, 4, 1],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 13 TnT Usage
#### 13.1. Paper
[Transformer in Transformer](https://arxiv.org/abs/2103.00112)
#### 13.2. Usage Code
```python
from model.backbone.TnT import TNT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = TNT(
img_size=224,
patch_size=16,
outer_dim=384,
inner_dim=24,
depth=12,
outer_num_heads=6,
inner_num_heads=4,
qkv_bias=False,
inner_stride=4)
output=model(input)
print(output.shape)
```
### 14 DViT Usage
#### 14.1. Paper
[DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
#### 14.2. Usage Code
```python
from model.backbone.DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DeepVisionTransformer(
patch_size=16, embed_dim=384,
depth=[False] * 16,
apply_transform=[False] * 0 + [True] * 32,
num_heads=12,
mlp_ratio=3,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
)
output=model(input)
print(output.shape)
```
### 15 CeiT Usage
#### 15.1. Paper
[Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
#### 15.2. Usage Code
```python
from model.backbone.CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CeIT(
hybrid_backbone=Image2Tokens(),
patch_size=4,
embed_dim=192,
depth=12,
num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 16 ConViT Usage
#### 16.1. Paper
[ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
#### 16.2. Usage Code
```python
from model.backbone.ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 17 CaiT Usage
#### 17.1. Paper
[Going deeper with Image Transformers](https://arxiv.org/abs/2103.17239)
#### 17.2. Usage Code
```python
from model.backbone.CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CaiT(
img_size= 224,
patch_size=16,
embed_dim=192,
depth=24,
num_heads=4,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2
)
output=model(input)
print(output.shape)
```
### 18 PatchConvnet Usage
#### 18.1. Paper
[Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
#### 18.2. Usage Code
```python
from model.backbone.PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
)
output=model(input)
print(output.shape)
```
### 19 DeiT Usage
#### 19.1. Paper
[Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
#### 19.2. Usage Code
```python
from model.backbone.DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DistilledVisionTransformer(
patch_size=16,
embed_dim=384,
depth=12,
num_heads=6,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output[0].shape)
```
### 20 LeViT Usage
#### 20.1. Paper
[LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
#### 20.2. Usage Code
```python
from model.backbone.LeViT import *
import torch
from torch import nn
if __name__ == '__main__':
for name in specification:
input=torch.randn(1,3,224,224)
model = globals()[name](fuse=True, pretrained=False)
model.eval()
output = model(input)
print(output.shape)
```
### 21 VOLO Usage
#### 21.1. Paper
[VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
#### 21.2. Usage Code
```python
from model.backbone.VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VOLO([4, 4, 8, 2],
embed_dims=[192, 384, 384, 384],
num_heads=[6, 12, 12, 12],
mlp_ratios=[3, 3, 3, 3],
downsamples=[True, False, False, False],
outlook_attention=[True, False, False, False ],
post_layers=['ca', 'ca'],
)
output=model(input)
print(output[0].shape)
```
### 22 Container Usage
#### 22.1. Paper
[Container: Context Aggregation Network](https://arxiv.org/abs/2106.01401)
#### 22.2. Usage Code
```python
from model.backbone.Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[224, 56, 28, 14],
patch_size=[4, 2, 2, 2],
embed_dim=[64, 128, 320, 512],
depth=[3, 4, 8, 3],
num_heads=16,
mlp_ratio=[8, 8, 4, 4],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6))
output=model(input)
print(output.shape)
```
### 23 CMT Usage
#### 23.1. Paper
[CMT: Convolutional Neural Networks Meet Vision Transformers](https://arxiv.org/abs/2107.06263)
#### 23.2. Usage Code
```python
from model.backbone.CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CMT_Tiny()
output=model(input)
print(output[0].shape)
```
### 24 EfficientFormer Usage
#### 24.1. Paper
[EfficientFormer: Vision Transformers at MobileNet Speed](https://arxiv.org/abs/2206.01191)
#### 24.2. Usage Code
```python
from model.backbone.EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = EfficientFormer(
layers=EfficientFormer_depth['l1'],
embed_dims=EfficientFormer_width['l1'],
downsamples=[True, True, True, True],
vit_num=1,
)
output=model(input)
print(output[0].shape)
```
### 25 ConvNeXtV2 Usage
#### 25.1. Paper
[ConvNeXtV2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808)
#### 25.2. Usage Code
```python
from model.backbone.convnextv2 import convnextv2_atto
import torch
from torch import nn
if __name__ == "__main__":
model = convnextv2_atto()
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
```
# MLP Series
- Pytorch implementation of ["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition---arXiv 2021.05.05"](https://arxiv.org/pdf/2105.01883v1.pdf)
- Pytorch implementation of ["MLP-Mixer: An all-MLP Architecture for Vision---arXiv 2021.05.17"](https://arxiv.org/pdf/2105.01601.pdf)
- Pytorch implementation of ["ResMLP: Feedforward networks for image classification with data-efficient training---arXiv 2021.05.07"](https://arxiv.org/pdf/2105.03404.pdf)
- Pytorch implementation of ["Pay Attention to MLPs---arXiv 2021.05.17"](https://arxiv.org/abs/2105.08050)
- Pytorch implementation of ["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?---arXiv 2021.09.12"](https://arxiv.org/abs/2109.05422)
### 1. RepMLP Usage
#### 1.1. Paper
["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition"](https://arxiv.org/pdf/2105.01883v1.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.mlp.repmlp import RepMLP
import torch
from torch import nn
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())
```
### 2. MLP-Mixer Usage
#### 2.1. Paper
["MLP-Mixer: An all-MLP Architecture for Vision"](https://arxiv.org/pdf/2105.01601.pdf)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.mlp.mlp_mixer import MlpMixer
import torch
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)
```
***
### 3. ResMLP Usage
#### 3.1. Paper
["ResMLP: Feedforward networks for image classification with data-efficient training"](https://arxiv.org/pdf/2105.03404.pdf)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.mlp.resmlp import ResMLP
import torch
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape) #the last dimention is class_num
```
***
### 4. gMLP Usage
#### 4.1. Paper
["Pay Attention to MLPs"](https://arxiv.org/abs/2105.08050)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.mlp.g_mlp import gMLP
import torch
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)
```
***
### 5. sMLP Usage
#### 5.1. Paper
["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?"](https://arxiv.org/abs/2109.05422)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.mlp.sMLP_block import sMLPBlock
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
smlp=sMLPBlock(h=224,w=224)
out=smlp(input)
print(out.shape)
```
### 6. vip-mlp Usage
#### 6.1. Paper
["Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 6.2. Usage Code
```python
from model.mlp.vip-mlp import VisionPermutator
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionPermutator(
layers=[4, 3, 8, 3],
embed_dims=[384, 384, 384, 384],
patch_size=14,
transitions=[False, False, False, False],
segment_dim=[16, 16, 16, 16],
mlp_ratios=[3, 3, 3, 3],
mlp_fn=WeightedPermuteMLP
)
output=model(input)
print(output.shape)
```
# Re-Parameter Series
- Pytorch implementation of ["RepVGG: Making VGG-style ConvNets Great Again---CVPR2021"](https://arxiv.org/abs/2101.03697)
- Pytorch implementation of ["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks---ICCV2019"](https://arxiv.org/abs/1908.03930)
- Pytorch implementation of ["Diverse Branch Block: Building a Convolution as an Inception-like Unit---CVPR2021"](https://arxiv.org/abs/2103.13425)
***
### 1. RepVGG Usage
#### 1.1. Paper
["RepVGG: Making VGG-style ConvNets Great Again"](https://arxiv.org/abs/2101.03697)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
```
***
### 2. ACNet Usage
#### 2.1. Paper
["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks"](https://arxiv.org/abs/1908.03930)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
```
***
### 2. Diverse Branch Block Usage
#### 2.1. Paper
["Diverse Branch Block: Building a Convolution as an Inception-like Unit"](https://arxiv.org/abs/2103.13425)
#### 2.2. Overview

#### 2.3. Usage Code
##### 2.3.1 Transform I
```python
from model.rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.2 Transform II
```python
from model.rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.3 Transform III
```python
from model.rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.4 Transform IV
```python
from model.rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.5 Transform V
```python
from model.rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.6 Transform VI
```python
from model.rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
# Convolution Series
- Pytorch implementation of ["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications---CVPR2017"](https://arxiv.org/abs/1704.04861)
- Pytorch implementation of ["Efficientnet: Rethinking model scaling for convolutional neural networks---PMLR2019"](http://proceedings.mlr.press/v97/tan19a.html)
- Pytorch implementation of ["Involution: Inverting the Inherence of Convolution for Visual Recognition---CVPR2021"](https://arxiv.org/abs/2103.06255)
- Pytorch implementation of ["Dynamic Convolution: Attention over Convolution Kernels---CVPR2020 Oral"](https://arxiv.org/abs/1912.03458)
- Pytorch implementation of ["CondConv: Conditionally Parameterized Convolutions for Efficient Inference---NeurIPS2019"](https://arxiv.org/abs/1904.04971)
***
### 1. Depthwise Separable Convolution Usage
#### 1.1. Paper
["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications"](https://arxiv.org/abs/1704.04861)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.conv.DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)
```
***
### 2. MBConv Usage
#### 2.1. Paper
["Efficientnet: Rethinking model scaling for convolutional neural networks"](http://proceedings.mlr.press/v97/tan19a.html)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.conv.MBConv import MBConvBlock
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=512,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 3. Involution Usage
#### 3.1. Paper
["Involution: Inverting the Inherence of Convolution for Visual Recognition"](https://arxiv.org/abs/2103.06255)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.conv.Involution import Involution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)
```
***
### 4. DynamicConv Usage
#### 4.1. Paper
["Dynamic Convolution: Attention over Convolution Kernels"](https://arxiv.org/abs/1912.03458)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.conv.DynamicConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape) # 2,32,64,64
```
***
### 5. CondConv Usage
#### 5.1. Paper
["CondConv: Conditionally Parameterized Convolutions for Efficient Inference"](https://arxiv.org/abs/1904.04971)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.conv.CondConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=CondConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
```
## 其他项目推荐
-------
🔥🔥🔥 重磅!!!作为项目补充,更多论文层面的解析,可以关注新开源的项目 **[FightingCV-Paper-Reading](https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading)** ,里面汇集和整理了各大顶会顶刊的论文解析
🔥🔥🔥重磅!!! 最近为大家整理了网上的各种AI相关的视频教程和必读论文 **[FightingCV-Course
](https://github.com/xmu-xiaoma666/FightingCV-Course)**
🔥🔥🔥 重磅!!!最近全新开源了一个 **[YOLOAir](https://github.com/iscyy/yoloair)** 目标检测代码库 ,里面集成了多种YOLO模型,包括YOLOv5, YOLOv7,YOLOR, YOLOX,YOLOv4, YOLOv3以及其他YOLO模型,还包括多种现有Attention机制。
🔥🔥🔥 **ECCV2022论文汇总:[ECCV2022-Paper-List](https://github.com/xmu-xiaoma666/ECCV2022-Paper-List/blob/master/README.md)**
================================================
FILE: README_EN.md
================================================
English | [简体中文](./README.md)
# FightingCV Codebase For [***Attention***](#attention-series),[***Backbone***](#backbone-series), [***MLP***](#mlp-series), [***Re-parameter***](#re-parameter-series), [**Convolution**](#convolution-series)



-------
🔥🔥🔥As a supplement to the project, a object detection codebase [YOLOAir](https://github.com/iscyy/yoloair) has recently been newly opened, which integrates various attention mechanisms in the object detection algorithm. The code is simple and easy to read. Welcome to play and star🌟!**
-------
Hello, everyone, I'm Xiaoma 🚀🚀🚀
***For beginners (like me):***
Recently, I found a problem when reading the paper. Sometimes the core idea of the paper is very simple, and the core code may be just a dozen lines. However, when I open the source code of the author's release, I find that the proposed module is embedded in the task framework such as classification, detection and segmentation, resulting in redundant code. For me who is not familiar with the specific task framework, it is difficult to find the core code, resulting in some difficulties in understanding the paper and network ideas.
***For advanced (like you):***
If the basic units conv, FC and RNN are regarded as small Lego blocks, and the structures transformer and RESNET are regarded as LEGO castles that have been built. The modules provided by this project are LEGO components with complete semantic informationLet scientific researchers avoid repeatedly building wheels, just think about how to use these "LEGO components" to build more colorful works.
***For proficient (may be like you):***
Limited capacity, do not like light spraying!!!
***For All:***
This project aims to realize a code base that can make beginners of deep learning understand and serve scientific research and industrial communities. As [fightingcv wechat official account]( https://mp.weixin.qq.com/s/m9RiivbbDPdjABsTd6q8FA )The purpose of this project is to achieve 🚀Let there be no hard to read papers in the world🚀。
(at the same time, we also welcome all scientific researchers to sort out the core code of their work into this project, promote the development of the scientific research community, and indicate the author of the code in readme ~)
***
# Contents
- [Attention Series](#attention-series)
- [1. External Attention Usage](#1-external-attention-usage)
- [2. Self Attention Usage](#2-self-attention-usage)
- [3. Simplified Self Attention Usage](#3-simplified-self-attention-usage)
- [4. Squeeze-and-Excitation Attention Usage](#4-squeeze-and-excitation-attention-usage)
- [5. SK Attention Usage](#5-sk-attention-usage)
- [6. CBAM Attention Usage](#6-cbam-attention-usage)
- [7. BAM Attention Usage](#7-bam-attention-usage)
- [8. ECA Attention Usage](#8-eca-attention-usage)
- [9. DANet Attention Usage](#9-danet-attention-usage)
- [10. Pyramid Split Attention (PSA) Usage](#10-Pyramid-Split-Attention-Usage)
- [11. Efficient Multi-Head Self-Attention(EMSA) Usage](#11-Efficient-Multi-Head-Self-Attention-Usage)
- [12. Shuffle Attention Usage](#12-Shuffle-Attention-Usage)
- [13. MUSE Attention Usage](#13-MUSE-Attention-Usage)
- [14. SGE Attention Usage](#14-SGE-Attention-Usage)
- [15. A2 Attention Usage](#15-A2-Attention-Usage)
- [16. AFT Attention Usage](#16-AFT-Attention-Usage)
- [17. Outlook Attention Usage](#17-Outlook-Attention-Usage)
- [18. ViP Attention Usage](#18-ViP-Attention-Usage)
- [19. CoAtNet Attention Usage](#19-CoAtNet-Attention-Usage)
- [20. HaloNet Attention Usage](#20-HaloNet-Attention-Usage)
- [21. Polarized Self-Attention Usage](#21-Polarized-Self-Attention-Usage)
- [22. CoTAttention Usage](#22-CoTAttention-Usage)
- [23. Residual Attention Usage](#23-Residual-Attention-Usage)
- [24. S2 Attention Usage](#24-S2-Attention-Usage)
- [25. GFNet Attention Usage](#25-GFNet-Attention-Usage)
- [26. Triplet Attention Usage](#26-TripletAttention-Usage)
- [27. Coordinate Attention Usage](#27-Coordinate-Attention-Usage)
- [28. MobileViT Attention Usage](#28-MobileViT-Attention-Usage)
- [29. ParNet Attention Usage](#29-ParNet-Attention-Usage)
- [30. UFO Attention Usage](#30-UFO-Attention-Usage)
- [31. ACmix Attention Usage](#31-Acmix-Attention-Usage)
- [32. MobileViTv2 Attention Usage](#32-MobileViTv2-Attention-Usage)
- [33. DAT Attention Usage](#33-DAT-Attention-Usage)
- [34. CrossFormer Attention Usage](#34-CrossFormer-Attention-Usage)
- [35. MOATransformer Attention Usage](#35-MOATransformer-Attention-Usage)
- [36. CrissCrossAttention Attention Usage](#36-CrissCrossAttention-Attention-Usage)
- [37. Axial_attention Attention Usage](#37-Axial_attention-Attention-Usage)
- [Backbone Series](#Backbone-series)
- [1. ResNet Usage](#1-ResNet-Usage)
- [2. ResNeXt Usage](#2-ResNeXt-Usage)
- [3. MobileViT Usage](#3-MobileViT-Usage)
- [4. ConvMixer Usage](#4-ConvMixer-Usage)
- [5. ShuffleTransformer Usage](#5-ShuffleTransformer-Usage)
- [6. ConTNet Usage](#6-ConTNet-Usage)
- [7. HATNet Usage](#7-HATNet-Usage)
- [8. CoaT Usage](#8-CoaT-Usage)
- [9. PVT Usage](#9-PVT-Usage)
- [10. CPVT Usage](#10-CPVT-Usage)
- [11. PIT Usage](#11-PIT-Usage)
- [12. CrossViT Usage](#12-CrossViT-Usage)
- [13. TnT Usage](#13-TnT-Usage)
- [14. DViT Usage](#14-DViT-Usage)
- [15. CeiT Usage](#15-CeiT-Usage)
- [16. ConViT Usage](#16-ConViT-Usage)
- [17. CaiT Usage](#17-CaiT-Usage)
- [18. PatchConvnet Usage](#18-PatchConvnet-Usage)
- [19. DeiT Usage](#19-DeiT-Usage)
- [20. LeViT Usage](#20-LeViT-Usage)
- [21. VOLO Usage](#21-VOLO-Usage)
- [22. Container Usage](#22-Container-Usage)
- [23. CMT Usage](#23-CMT-Usage)
- [MLP Series](#mlp-series)
- [1. RepMLP Usage](#1-RepMLP-Usage)
- [2. MLP-Mixer Usage](#2-MLP-Mixer-Usage)
- [3. ResMLP Usage](#3-ResMLP-Usage)
- [4. gMLP Usage](#4-gMLP-Usage)
- [5. sMLP Usage](#5-sMLP-Usage)
- [6. vip-mlp Usage](#6-vip-mlp-Usage)
- [Re-Parameter(ReP) Series](#Re-Parameter-series)
- [1. RepVGG Usage](#1-RepVGG-Usage)
- [2. ACNet Usage](#2-ACNet-Usage)
- [3. Diverse Branch Block(DDB) Usage](#3-Diverse-Branch-Block-Usage)
- [Convolution Series](#Convolution-series)
- [1. Depthwise Separable Convolution Usage](#1-Depthwise-Separable-Convolution-Usage)
- [2. MBConv Usage](#2-MBConv-Usage)
- [3. Involution Usage](#3-Involution-Usage)
- [4. DynamicConv Usage](#4-DynamicConv-Usage)
- [5. CondConv Usage](#5-CondConv-Usage)
***
# Attention Series
- Pytorch implementation of ["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks---arXiv 2021.05.05"](https://arxiv.org/abs/2105.02358)
- Pytorch implementation of ["Attention Is All You Need---NIPS2017"](https://arxiv.org/pdf/1706.03762.pdf)
- Pytorch implementation of ["Squeeze-and-Excitation Networks---CVPR2018"](https://arxiv.org/abs/1709.01507)
- Pytorch implementation of ["Selective Kernel Networks---CVPR2019"](https://arxiv.org/pdf/1903.06586.pdf)
- Pytorch implementation of ["CBAM: Convolutional Block Attention Module---ECCV2018"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
- Pytorch implementation of ["BAM: Bottleneck Attention Module---BMCV2018"](https://arxiv.org/pdf/1807.06514.pdf)
- Pytorch implementation of ["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020"](https://arxiv.org/pdf/1910.03151.pdf)
- Pytorch implementation of ["Dual Attention Network for Scene Segmentation---CVPR2019"](https://arxiv.org/pdf/1809.02983.pdf)
- Pytorch implementation of ["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30"](https://arxiv.org/pdf/2105.14447.pdf)
- Pytorch implementation of ["ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28"](https://arxiv.org/abs/2105.13677)
- Pytorch implementation of ["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS---ICASSP 2021"](https://arxiv.org/pdf/2102.00240.pdf)
- Pytorch implementation of ["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning---arXiv 2019.11.17"](https://arxiv.org/abs/1911.09483)
- Pytorch implementation of ["Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks---arXiv 2019.05.23"](https://arxiv.org/pdf/1905.09646.pdf)
- Pytorch implementation of ["A2-Nets: Double Attention Networks---NIPS2018"](https://arxiv.org/pdf/1810.11579.pdf)
- Pytorch implementation of ["An Attention Free Transformer---ICLR2021 (Apple New Work)"](https://arxiv.org/pdf/2105.14103v1.pdf)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition---arXiv 2021.06.24"](https://arxiv.org/abs/2106.13112)
[【论文解析】](https://zhuanlan.zhihu.com/p/385561050)
- Pytorch implementation of [Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition---arXiv 2021.06.23](https://arxiv.org/abs/2106.12368)
[【论文解析】](https://mp.weixin.qq.com/s/5gonUQgBho_m2O54jyXF_Q)
- Pytorch implementation of [CoAtNet: Marrying Convolution and Attention for All Data Sizes---arXiv 2021.06.09](https://arxiv.org/abs/2106.04803)
[【论文解析】](https://zhuanlan.zhihu.com/p/385578588)
- Pytorch implementation of [Scaling Local Self-Attention for Parameter Efficient Visual Backbones---CVPR2021 Oral](https://arxiv.org/pdf/2103.12731.pdf) [【论文解析】](https://zhuanlan.zhihu.com/p/388598744)
- Pytorch implementation of [Polarized Self-Attention: Towards High-quality Pixel-wise Regression---arXiv 2021.07.02](https://arxiv.org/abs/2107.00782) [【论文解析】](https://zhuanlan.zhihu.com/p/389770482)
- Pytorch implementation of [Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292) [【论文解析】](https://zhuanlan.zhihu.com/p/394795481)
- Pytorch implementation of [Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
- Pytorch implementation of [S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072) [【论文解析】](https://zhuanlan.zhihu.com/p/397003638)
- Pytorch implementation of [Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
- Pytorch implementation of [Rotate to Attend: Convolutional Triplet Attention Module---WACV 2021](https://arxiv.org/abs/2010.03045)
- Pytorch implementation of [Coordinate Attention for Efficient Mobile Network Design ---CVPR 2021](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2110.02178)
- Pytorch implementation of [Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
- Pytorch implementation of [UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2109.14382)
- Pytorch implementation of [Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
- Pytorch implementation of [On the Integration of Self-Attention and Convolution---ArXiv 2022.03.14](https://arxiv.org/pdf/2111.14556.pdf)
- Pytorch implementation of [CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
- Pytorch implementation of [Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
- Pytorch implementation of [CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
- Pytorch implementation of [Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
***
### 1. External Attention Usage
#### 1.1. Paper
["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks"](https://arxiv.org/abs/2105.02358)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
***
### 2. Self Attention Usage
#### 2.1. Paper
["Attention Is All You Need"](https://arxiv.org/pdf/1706.03762.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 3. Simplified Self Attention Usage
#### 3.1. Paper
[None]()
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)
```
***
### 4. Squeeze-and-Excitation Attention Usage
#### 4.1. Paper
["Squeeze-and-Excitation Networks"](https://arxiv.org/abs/1709.01507)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 5. SK Attention Usage
#### 5.1. Paper
["Selective Kernel Networks"](https://arxiv.org/pdf/1903.06586.pdf)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 6. CBAM Attention Usage
#### 6.1. Paper
["CBAM: Convolutional Block Attention Module"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
#### 6.2. Overview


#### 6.3. Usage Code
```python
from model.attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
***
### 7. BAM Attention Usage
#### 7.1. Paper
["BAM: Bottleneck Attention Module"](https://arxiv.org/pdf/1807.06514.pdf)
#### 7.2. Overview

#### 7.3. Usage Code
```python
from model.attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
***
### 8. ECA Attention Usage
#### 8.1. Paper
["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks"](https://arxiv.org/pdf/1910.03151.pdf)
#### 8.2. Overview

#### 8.3. Usage Code
```python
from model.attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
***
### 9. DANet Attention Usage
#### 9.1. Paper
["Dual Attention Network for Scene Segmentation"](https://arxiv.org/pdf/1809.02983.pdf)
#### 9.2. Overview

#### 9.3. Usage Code
```python
from model.attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
***
### 10. Pyramid Split Attention Usage
#### 10.1. Paper
["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network"](https://arxiv.org/pdf/2105.14447.pdf)
#### 10.2. Overview

#### 10.3. Usage Code
```python
from model.attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
***
### 11. Efficient Multi-Head Self-Attention Usage
#### 11.1. Paper
["ResT: An Efficient Transformer for Visual Recognition"](https://arxiv.org/abs/2105.13677)
#### 11.2. Overview

#### 11.3. Usage Code
```python
from model.attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
***
### 12. Shuffle Attention Usage
#### 12.1. Paper
["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS"](https://arxiv.org/pdf/2102.00240.pdf)
#### 12.2. Overview

#### 12.3. Usage Code
```python
from model.attention.ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
```
***
### 13. MUSE Attention Usage
#### 13.1. Paper
["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning"](https://arxiv.org/abs/1911.09483)
#### 13.2. Overview

#### 13.3. Usage Code
```python
from model.attention.MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 14. SGE Attention Usage
#### 14.1. Paper
[Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks](https://arxiv.org/pdf/1905.09646.pdf)
#### 14.2. Overview

#### 14.3. Usage Code
```python
from model.attention.SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
```
***
### 15. A2 Attention Usage
#### 15.1. Paper
[A2-Nets: Double Attention Networks](https://arxiv.org/pdf/1810.11579.pdf)
#### 15.2. Overview

#### 15.3. Usage Code
```python
from model.attention.A2Atttention import DoubleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
```
### 16. AFT Attention Usage
#### 16.1. Paper
[An Attention Free Transformer](https://arxiv.org/pdf/2105.14103v1.pdf)
#### 16.2. Overview

#### 16.3. Usage Code
```python
from model.attention.AFT import AFT_FULL
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
```
### 17. Outlook Attention Usage
#### 17.1. Paper
[VOLO: Vision Outlooker for Visual Recognition"](https://arxiv.org/abs/2106.13112)
#### 17.2. Overview

#### 17.3. Usage Code
```python
from model.attention.OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)
```
***
### 18. ViP Attention Usage
#### 18.1. Paper
[Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 18.2. Overview

#### 18.3. Usage Code
```python
from model.attention.ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)
```
***
### 19. CoAtNet Attention Usage
#### 19.1. Paper
[CoAtNet: Marrying Convolution and Attention for All Data Sizes"](https://arxiv.org/abs/2106.04803)
#### 19.2. Overview
None
#### 19.3. Usage Code
```python
from model.attention.CoAtNet import CoAtNet
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=CoAtNet(in_ch=3,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 20. HaloNet Attention Usage
#### 20.1. Paper
[Scaling Local Self-Attention for Parameter Efficient Visual Backbones"](https://arxiv.org/pdf/2103.12731.pdf)
#### 20.2. Overview

#### 20.3. Usage Code
```python
from model.attention.HaloAttention import HaloAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)
```
***
### 21. Polarized Self-Attention Usage
#### 21.1. Paper
[Polarized Self-Attention: Towards High-quality Pixel-wise Regression"](https://arxiv.org/abs/2107.00782)
#### 21.2. Overview

#### 21.3. Usage Code
```python
from model.attention.PolarizedSelfAttention import ParallelPolarizedSelfAttention,SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
```
***
### 22. CoTAttention Usage
#### 22.1. Paper
[Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292)
#### 22.2. Overview

#### 22.3. Usage Code
```python
from model.attention.CoTAttention import CoTAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
```
***
### 23. Residual Attention Usage
#### 23.1. Paper
[Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
#### 23.2. Overview

#### 23.3. Usage Code
```python
from model.attention.ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
resatt = ResidualAttention(channel=512,num_class=1000,la=0.2)
output=resatt(input)
print(output.shape)
```
***
### 24. S2 Attention Usage
#### 24.1. Paper
[S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072)
#### 24.2. Overview

#### 24.3. Usage Code
```python
from model.attention.S2Attention import S2Attention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
s2att = S2Attention(channels=512)
output=s2att(input)
print(output.shape)
```
***
### 25. GFNet Attention Usage
#### 25.1. Paper
[Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
#### 25.2. Overview

#### 25.3. Usage Code - Implemented by [Wenliang Zhao (Author)](https://scholar.google.com/citations?user=lyPWvuEAAAAJ&hl=en)
```python
from model.attention.gfnet import GFNet
import torch
from torch import nn
from torch.nn import functional as F
x = torch.randn(1, 3, 224, 224)
gfnet = GFNet(embed_dim=384, img_size=224, patch_size=16, num_classes=1000)
out = gfnet(x)
print(out.shape)
```
***
### 26. TripletAttention Usage
#### 26.1. Paper
[Rotate to Attend: Convolutional Triplet Attention Module---CVPR 2021](https://arxiv.org/abs/2010.03045)
#### 26.2. Overview

#### 26.3. Usage Code - Implemented by [digantamisra98](https://github.com/digantamisra98)
```python
from model.attention.TripletAttention import TripletAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
triplet = TripletAttention()
output=triplet(input)
print(output.shape)
```
***
### 27. Coordinate Attention Usage
#### 27.1. Paper
[Coordinate Attention for Efficient Mobile Network Design---CVPR 2021](https://arxiv.org/abs/2103.02907)
#### 27.2. Overview

#### 27.3. Usage Code - Implemented by [Andrew-Qibin](https://github.com/Andrew-Qibin)
```python
from model.attention.CoordAttention import CoordAtt
import torch
from torch import nn
from torch.nn import functional as F
inp=torch.rand([2, 96, 56, 56])
inp_dim, oup_dim = 96, 96
reduction=32
coord_attention = CoordAtt(inp_dim, oup_dim, reduction=reduction)
output=coord_attention(inp)
print(output.shape)
```
***
### 28. MobileViT Attention Usage
#### 28.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2103.02907)
#### 28.2. Overview

#### 28.3. Usage Code
```python
from model.attention.MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
m=MobileViTAttention()
input=torch.randn(1,3,49,49)
output=m(input)
print(output.shape) #output:(1,3,49,49)
```
***
### 29. ParNet Attention Usage
#### 29.1. Paper
[Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
#### 29.2. Overview

#### 29.3. Usage Code
```python
from model.attention.ParNetAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
pna = ParNetAttention(channel=512)
output=pna(input)
print(output.shape) #50,512,7,7
```
***
### 30. UFO Attention Usage
#### 30.1. Paper
[UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2110.07641)
#### 30.2. Overview

#### 30.3. Usage Code
```python
from model.attention.UFOAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
ufo = UFOAttention(d_model=512, d_k=512, d_v=512, h=8)
output=ufo(input,input,input)
print(output.shape) #[50, 49, 512]
```
-
### 31. ACmix Attention Usage
#### 31.1. Paper
[On the Integration of Self-Attention and Convolution](https://arxiv.org/pdf/2111.14556.pdf)
#### 31.2. Usage Code
```python
from model.attention.ACmix import ACmix
import torch
if __name__ == '__main__':
input=torch.randn(50,256,7,7)
acmix = ACmix(in_planes=256, out_planes=256)
output=acmix(input)
print(output.shape)
```
### 32. MobileViTv2 Attention Usage
#### 32.1. Paper
[Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
#### 32.2. Overview

#### 32.3. Usage Code
```python
from model.attention.MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
### 33. DAT Attention Usage
#### 33.1. Paper
[Vision Transformer with Deformable Attention---CVPR2022](https://arxiv.org/abs/2201.00520)
#### 33.2. Usage Code
```python
from model.attention.DAT import DAT
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DAT(
img_size=224,
patch_size=4,
num_classes=1000,
expansion=4,
dim_stem=96,
dims=[96, 192, 384, 768],
depths=[2, 2, 6, 2],
stage_spec=[['L', 'S'], ['L', 'S'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7] ,
groups=[-1, -1, 3, 6],
use_pes=[False, False, True, True],
dwc_pes=[False, False, False, False],
strides=[-1, -1, 1, 1],
sr_ratios=[-1, -1, -1, -1],
offset_range_factor=[-1, -1, 2, 2],
no_offs=[False, False, False, False],
fixed_pes=[False, False, False, False],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
)
output=model(input)
print(output[0].shape)
```
### 34. CrossFormer Attention Usage
#### 34.1. Paper
[CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
#### 34.2. Usage Code
```python
from model.attention.Crossformer import CrossFormer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CrossFormer(img_size=224,
patch_size=[4, 8, 16, 32],
in_chans= 3,
num_classes=1000,
embed_dim=48,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
group_size=[7, 7, 7, 7],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False,
merge_size=[[2, 4], [2,4], [2, 4]]
)
output=model(input)
print(output.shape)
```
### 35. MOATransformer Attention Usage
#### 35.1. Paper
[Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
#### 35.2. Usage Code
```python
from model.attention.MOATransformer import MOATransformer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = MOATransformer(
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=[2, 2, 6],
num_heads=[3, 6, 12],
window_size=14,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False
)
output=model(input)
print(output.shape)
```
### 36. CrissCrossAttention Attention Usage
#### 36.1. Paper
[CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
#### 36.2. Usage Code
```python
from model.attention.CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = CrissCrossAttention(64)
outputs = model(input)
print(outputs.shape)
```
### 37. Axial_attention Attention Usage
#### 37.1. Paper
[Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
#### 37.2. Usage Code
```python
from model.attention.Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__':
input=torch.randn(3, 128, 7, 7)
model = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
outputs = model(input)
print(outputs.shape)
```
***
# Backbone Series
- Pytorch implementation of ["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
- Pytorch implementation of ["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
- Pytorch implementation of [Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer---ArXiv 2021.06.07](https://arxiv.org/abs/2106.03650)
- Pytorch implementation of [ConTNet: Why not use convolution and transformer at the same time?---ArXiv 2021.04.27](https://arxiv.org/abs/2104.13497)
- Pytorch implementation of [Vision Transformers with Hierarchical Attention---ArXiv 2022.06.15](https://arxiv.org/abs/2106.03180)
- Pytorch implementation of [Co-Scale Conv-Attentional Image Transformers---ArXiv 2021.08.26](https://arxiv.org/abs/2104.06399)
- Pytorch implementation of [Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
- Pytorch implementation of [Rethinking Spatial Dimensions of Vision Transformers---ICCV 2021](https://arxiv.org/abs/2103.16302)
- Pytorch implementation of [CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification---ICCV 2021](https://arxiv.org/abs/2103.14899)
- Pytorch implementation of [Transformer in Transformer---NeurIPS 2021](https://arxiv.org/abs/2103.00112)
- Pytorch implementation of [DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
- Pytorch implementation of [Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
***
- Pytorch implementation of [ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
- Pytorch implementation of [Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
- Pytorch implementation of [Going deeper with Image Transformers---ICCV 2021 (Oral)](https://arxiv.org/abs/2103.17239)
- Pytorch implementation of [Training data-efficient image transformers & distillation through attention---ICML 2021](https://arxiv.org/abs/2012.12877)
- Pytorch implementation of [LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
- Pytorch implementation of [Container: Context Aggregation Network---NeuIPS 2021](https://arxiv.org/abs/2106.01401)
- Pytorch implementation of [CMT: Convolutional Neural Networks Meet Vision Transformers---CVPR 2022](https://arxiv.org/abs/2107.06263)
- Pytorch implementation of [Vision Transformer with Deformable Attention---CVPR 2022](https://arxiv.org/abs/2201.00520)
### 1. ResNet Usage
#### 1.1. Paper
["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
#### 1.2. Overview


#### 1.3. Usage Code
```python
from model.backbone.resnet import ResNet50,ResNet101,ResNet152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnet50=ResNet50(1000)
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out=resnet50(input)
print(out.shape)
```
### 2. ResNeXt Usage
#### 2.1. Paper
["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.backbone.resnext import ResNeXt50,ResNeXt101,ResNeXt152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnext50=ResNeXt50(1000)
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out=resnext50(input)
print(out.shape)
```
### 3. MobileViT Usage
#### 3.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.backbone.MobileViT import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
### mobilevit_xxs
mvit_xxs=mobilevit_xxs()
out=mvit_xxs(input)
print(out.shape)
### mobilevit_xs
mvit_xs=mobilevit_xs()
out=mvit_xs(input)
print(out.shape)
### mobilevit_s
mvit_s=mobilevit_s()
out=mvit_s(input)
print(out.shape)
```
### 4. ConvMixer Usage
#### 4.1. Paper
[Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.backbone.ConvMixer import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
convmixer=ConvMixer(dim=512,depth=12)
out=convmixer(x)
print(out.shape) #[1, 1000]
```
### 5. ShuffleTransformer Usage
#### 5.1. Paper
[Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer](https://arxiv.org/pdf/2106.03650.pdf)
#### 5.2. Usage Code
```python
from model.backbone.ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
sft = ShuffleTransformer()
output=sft(input)
print(output.shape)
```
### 6. ConTNet Usage
#### 6.1. Paper
[ConTNet: Why not use convolution and transformer at the same time?](https://arxiv.org/abs/2104.13497)
#### 6.2. Usage Code
```python
from model.backbone.ConTNet import ConTNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == "__main__":
model = build_model(use_avgdown=True, relative=True, qkv_bias=True, pre_norm=True)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
```
### 7 HATNet Usage
#### 7.1. Paper
[Vision Transformers with Hierarchical Attention](https://arxiv.org/abs/2106.03180)
#### 7.2. Usage Code
```python
from model.backbone.HATNet import HATNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
hat = HATNet(dims=[48, 96, 240, 384], head_dim=48, expansions=[8, 8, 4, 4],
grid_sizes=[8, 7, 7, 1], ds_ratios=[8, 4, 2, 1], depths=[2, 2, 6, 3])
output=hat(input)
print(output.shape)
```
### 8 CoaT Usage
#### 8.1. Paper
[Co-Scale Conv-Attentional Image Transformers](https://arxiv.org/abs/2104.06399)
#### 8.2. Usage Code
```python
from model.backbone.CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4])
output=model(input)
print(output.shape) # torch.Size([1, 1000])
```
### 9 PVT Usage
#### 9.1. Paper
[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/pdf/2106.13797.pdf)
#### 9.2. Usage Code
```python
from model.backbone.PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 10 CPVT Usage
#### 10.1. Paper
[Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
#### 10.2. Usage Code
```python
from model.backbone.CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 11 PIT Usage
#### 11.1. Paper
[Rethinking Spatial Dimensions of Vision Transformers](https://arxiv.org/abs/2103.16302)
#### 11.2. Usage Code
```python
from model.backbone.PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4
)
output=model(input)
print(output.shape)
```
### 12 CrossViT Usage
#### 12.1. Paper
[CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification](https://arxiv.org/abs/2103.14899)
#### 12.2. Usage Code
```python
from model.backbone.CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__":
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[240, 224],
patch_size=[12, 16],
embed_dim=[192, 384],
depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6],
mlp_ratio=[4, 4, 1],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 13 TnT Usage
#### 13.1. Paper
[Transformer in Transformer](https://arxiv.org/abs/2103.00112)
#### 13.2. Usage Code
```python
from model.backbone.TnT import TNT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = TNT(
img_size=224,
patch_size=16,
outer_dim=384,
inner_dim=24,
depth=12,
outer_num_heads=6,
inner_num_heads=4,
qkv_bias=False,
inner_stride=4)
output=model(input)
print(output.shape)
```
### 14 DViT Usage
#### 14.1. Paper
[DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
#### 14.2. Usage Code
```python
from model.backbone.DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DeepVisionTransformer(
patch_size=16, embed_dim=384,
depth=[False] * 16,
apply_transform=[False] * 0 + [True] * 32,
num_heads=12,
mlp_ratio=3,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
)
output=model(input)
print(output.shape)
```
### 15 CeiT Usage
#### 15.1. Paper
[Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
#### 15.2. Usage Code
```python
from model.backbone.CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CeIT(
hybrid_backbone=Image2Tokens(),
patch_size=4,
embed_dim=192,
depth=12,
num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 16 ConViT Usage
#### 16.1. Paper
[ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
#### 16.2. Usage Code
```python
from model.backbone.ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 17 CaiT Usage
#### 17.1. Paper
[Going deeper with Image Transformers](https://arxiv.org/abs/2103.17239)
#### 17.2. Usage Code
```python
from model.backbone.CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CaiT(
img_size= 224,
patch_size=16,
embed_dim=192,
depth=24,
num_heads=4,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2
)
output=model(input)
print(output.shape)
```
### 18 PatchConvnet Usage
#### 18.1. Paper
[Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
#### 18.2. Usage Code
```python
from model.backbone.PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
)
output=model(input)
print(output.shape)
```
### 19 DeiT Usage
#### 19.1. Paper
[Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
#### 19.2. Usage Code
```python
from model.backbone.DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DistilledVisionTransformer(
patch_size=16,
embed_dim=384,
depth=12,
num_heads=6,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output[0].shape)
```
### 20 LeViT Usage
#### 20.1. Paper
[LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
#### 20.2. Usage Code
```python
from model.backbone.LeViT import *
import torch
from torch import nn
if __name__ == '__main__':
for name in specification:
input=torch.randn(1,3,224,224)
model = globals()[name](fuse=True, pretrained=False)
model.eval()
output = model(input)
print(output.shape)
```
### 21 VOLO Usage
#### 21.1. Paper
[VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
#### 21.2. Usage Code
```python
from model.backbone.VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VOLO([4, 4, 8, 2],
embed_dims=[192, 384, 384, 384],
num_heads=[6, 12, 12, 12],
mlp_ratios=[3, 3, 3, 3],
downsamples=[True, False, False, False],
outlook_attention=[True, False, False, False ],
post_layers=['ca', 'ca'],
)
output=model(input)
print(output[0].shape)
```
### 22 Container Usage
#### 22.1. Paper
[Container: Context Aggregation Network](https://arxiv.org/abs/2106.01401)
#### 22.2. Usage Code
```python
from model.backbone.Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[224, 56, 28, 14],
patch_size=[4, 2, 2, 2],
embed_dim=[64, 128, 320, 512],
depth=[3, 4, 8, 3],
num_heads=16,
mlp_ratio=[8, 8, 4, 4],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6))
output=model(input)
print(output.shape)
```
### 23 CMT Usage
#### 23.1. Paper
[CMT: Convolutional Neural Networks Meet Vision Transformers](https://arxiv.org/abs/2107.06263)
#### 23.2. Usage Code
```python
from model.backbone.CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CMT_Tiny()
output=model(input)
print(output[0].shape)
```
# MLP Series
- Pytorch implementation of ["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition---arXiv 2021.05.05"](https://arxiv.org/pdf/2105.01883v1.pdf)
- Pytorch implementation of ["MLP-Mixer: An all-MLP Architecture for Vision---arXiv 2021.05.17"](https://arxiv.org/pdf/2105.01601.pdf)
- Pytorch implementation of ["ResMLP: Feedforward networks for image classification with data-efficient training---arXiv 2021.05.07"](https://arxiv.org/pdf/2105.03404.pdf)
- Pytorch implementation of ["Pay Attention to MLPs---arXiv 2021.05.17"](https://arxiv.org/abs/2105.08050)
- Pytorch implementation of ["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?---arXiv 2021.09.12"](https://arxiv.org/abs/2109.05422)
### 1. RepMLP Usage
#### 1.1. Paper
["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition"](https://arxiv.org/pdf/2105.01883v1.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.mlp.repmlp import RepMLP
import torch
from torch import nn
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())
```
### 2. MLP-Mixer Usage
#### 2.1. Paper
["MLP-Mixer: An all-MLP Architecture for Vision"](https://arxiv.org/pdf/2105.01601.pdf)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.mlp.mlp_mixer import MlpMixer
import torch
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)
```
***
### 3. ResMLP Usage
#### 3.1. Paper
["ResMLP: Feedforward networks for image classification with data-efficient training"](https://arxiv.org/pdf/2105.03404.pdf)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.mlp.resmlp import ResMLP
import torch
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape) #the last dimention is class_num
```
***
### 4. gMLP Usage
#### 4.1. Paper
["Pay Attention to MLPs"](https://arxiv.org/abs/2105.08050)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.mlp.g_mlp import gMLP
import torch
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)
```
***
### 5. sMLP Usage
#### 5.1. Paper
["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?"](https://arxiv.org/abs/2109.05422)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.mlp.sMLP_block import sMLPBlock
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
smlp=sMLPBlock(h=224,w=224)
out=smlp(input)
print(out.shape)
```
### 6. vip-mlp Usage
#### 6.1. Paper
["Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 6.2. Usage Code
```python
from model.mlp.vip-mlp import VisionPermutator
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionPermutator(
layers=[4, 3, 8, 3],
embed_dims=[384, 384, 384, 384],
patch_size=14,
transitions=[False, False, False, False],
segment_dim=[16, 16, 16, 16],
mlp_ratios=[3, 3, 3, 3],
mlp_fn=WeightedPermuteMLP
)
output=model(input)
print(output.shape)
```
# Re-Parameter Series
- Pytorch implementation of ["RepVGG: Making VGG-style ConvNets Great Again---CVPR2021"](https://arxiv.org/abs/2101.03697)
- Pytorch implementation of ["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks---ICCV2019"](https://arxiv.org/abs/1908.03930)
- Pytorch implementation of ["Diverse Branch Block: Building a Convolution as an Inception-like Unit---CVPR2021"](https://arxiv.org/abs/2103.13425)
***
### 1. RepVGG Usage
#### 1.1. Paper
["RepVGG: Making VGG-style ConvNets Great Again"](https://arxiv.org/abs/2101.03697)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
```
***
### 2. ACNet Usage
#### 2.1. Paper
["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks"](https://arxiv.org/abs/1908.03930)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
```
***
### 2. Diverse Branch Block Usage
#### 2.1. Paper
["Diverse Branch Block: Building a Convolution as an Inception-like Unit"](https://arxiv.org/abs/2103.13425)
#### 2.2. Overview

#### 2.3. Usage Code
##### 2.3.1 Transform I
```python
from model.rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.2 Transform II
```python
from model.rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.3 Transform III
```python
from model.rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.4 Transform IV
```python
from model.rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.5 Transform V
```python
from model.rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.6 Transform VI
```python
from model.rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
# Convolution Series
- Pytorch implementation of ["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications---CVPR2017"](https://arxiv.org/abs/1704.04861)
- Pytorch implementation of ["Efficientnet: Rethinking model scaling for convolutional neural networks---PMLR2019"](http://proceedings.mlr.press/v97/tan19a.html)
- Pytorch implementation of ["Involution: Inverting the Inherence of Convolution for Visual Recognition---CVPR2021"](https://arxiv.org/abs/2103.06255)
- Pytorch implementation of ["Dynamic Convolution: Attention over Convolution Kernels---CVPR2020 Oral"](https://arxiv.org/abs/1912.03458)
- Pytorch implementation of ["CondConv: Conditionally Parameterized Convolutions for Efficient Inference---NeurIPS2019"](https://arxiv.org/abs/1904.04971)
***
### 1. Depthwise Separable Convolution Usage
#### 1.1. Paper
["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications"](https://arxiv.org/abs/1704.04861)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.conv.DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)
```
***
### 2. MBConv Usage
#### 2.1. Paper
["Efficientnet: Rethinking model scaling for convolutional neural networks"](http://proceedings.mlr.press/v97/tan19a.html)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.conv.MBConv import MBConvBlock
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=512,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 3. Involution Usage
#### 3.1. Paper
["Involution: Inverting the Inherence of Convolution for Visual Recognition"](https://arxiv.org/abs/2103.06255)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.conv.Involution import Involution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)
```
***
### 4. DynamicConv Usage
#### 4.1. Paper
["Dynamic Convolution: Attention over Convolution Kernels"](https://arxiv.org/abs/1912.03458)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.conv.DynamicConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape) # 2,32,64,64
```
***
### 5. CondConv Usage
#### 5.1. Paper
["CondConv: Conditionally Parameterized Convolutions for Efficient Inference"](https://arxiv.org/abs/1904.04971)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.conv.CondConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=CondConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
```
***
================================================
FILE: README_pip.md
================================================
## pip使用文档
### 安装
直接通过 pip 安装,可直接在其他任务中使用
```shell
pip install fightingcv-attention
```
### 演示
#### 使用 pip 方式
```python
import torch
from torch import nn
from torch.nn import functional as F
# 使用 pip 方式
from fightingcv_attention.attention.MobileViTv2Attention import *
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
## pip包 fightingcv-attention 包含以下模块
# 目录
- [Attention Series](#attention-series)
- [1. External Attention Usage](#1-external-attention-usage)
- [2. Self Attention Usage](#2-self-attention-usage)
- [3. Simplified Self Attention Usage](#3-simplified-self-attention-usage)
- [4. Squeeze-and-Excitation Attention Usage](#4-squeeze-and-excitation-attention-usage)
- [5. SK Attention Usage](#5-sk-attention-usage)
- [6. CBAM Attention Usage](#6-cbam-attention-usage)
- [7. BAM Attention Usage](#7-bam-attention-usage)
- [8. ECA Attention Usage](#8-eca-attention-usage)
- [9. DANet Attention Usage](#9-danet-attention-usage)
- [10. Pyramid Split Attention (PSA) Usage](#10-Pyramid-Split-Attention-Usage)
- [11. Efficient Multi-Head Self-Attention(EMSA) Usage](#11-Efficient-Multi-Head-Self-Attention-Usage)
- [12. Shuffle Attention Usage](#12-Shuffle-Attention-Usage)
- [13. MUSE Attention Usage](#13-MUSE-Attention-Usage)
- [14. SGE Attention Usage](#14-SGE-Attention-Usage)
- [15. A2 Attention Usage](#15-A2-Attention-Usage)
- [16. AFT Attention Usage](#16-AFT-Attention-Usage)
- [17. Outlook Attention Usage](#17-Outlook-Attention-Usage)
- [18. ViP Attention Usage](#18-ViP-Attention-Usage)
- [19. CoAtNet Attention Usage](#19-CoAtNet-Attention-Usage)
- [20. HaloNet Attention Usage](#20-HaloNet-Attention-Usage)
- [21. Polarized Self-Attention Usage](#21-Polarized-Self-Attention-Usage)
- [22. CoTAttention Usage](#22-CoTAttention-Usage)
- [23. Residual Attention Usage](#23-Residual-Attention-Usage)
- [24. S2 Attention Usage](#24-S2-Attention-Usage)
- [25. GFNet Attention Usage](#25-GFNet-Attention-Usage)
- [26. Triplet Attention Usage](#26-TripletAttention-Usage)
- [27. Coordinate Attention Usage](#27-Coordinate-Attention-Usage)
- [28. MobileViT Attention Usage](#28-MobileViT-Attention-Usage)
- [29. ParNet Attention Usage](#29-ParNet-Attention-Usage)
- [30. UFO Attention Usage](#30-UFO-Attention-Usage)
- [31. ACmix Attention Usage](#31-Acmix-Attention-Usage)
- [32. MobileViTv2 Attention Usage](#32-MobileViTv2-Attention-Usage)
- [33. DAT Attention Usage](#33-DAT-Attention-Usage)
- [34. CrossFormer Attention Usage](#34-CrossFormer-Attention-Usage)
- [35. MOATransformer Attention Usage](#35-MOATransformer-Attention-Usage)
- [36. CrissCrossAttention Attention Usage](#36-CrissCrossAttention-Attention-Usage)
- [37. Axial_attention Attention Usage](#37-Axial_attention-Attention-Usage)
- [Backbone Series](#Backbone-series)
- [1. ResNet Usage](#1-ResNet-Usage)
- [2. ResNeXt Usage](#2-ResNeXt-Usage)
- [3. MobileViT Usage](#3-MobileViT-Usage)
- [4. ConvMixer Usage](#4-ConvMixer-Usage)
- [5. ShuffleTransformer Usage](#5-ShuffleTransformer-Usage)
- [6. ConTNet Usage](#6-ConTNet-Usage)
- [7. HATNet Usage](#7-HATNet-Usage)
- [8. CoaT Usage](#8-CoaT-Usage)
- [9. PVT Usage](#9-PVT-Usage)
- [10. CPVT Usage](#10-CPVT-Usage)
- [11. PIT Usage](#11-PIT-Usage)
- [12. CrossViT Usage](#12-CrossViT-Usage)
- [13. TnT Usage](#13-TnT-Usage)
- [14. DViT Usage](#14-DViT-Usage)
- [15. CeiT Usage](#15-CeiT-Usage)
- [16. ConViT Usage](#16-ConViT-Usage)
- [17. CaiT Usage](#17-CaiT-Usage)
- [18. PatchConvnet Usage](#18-PatchConvnet-Usage)
- [19. DeiT Usage](#19-DeiT-Usage)
- [20. LeViT Usage](#20-LeViT-Usage)
- [21. VOLO Usage](#21-VOLO-Usage)
- [22. Container Usage](#22-Container-Usage)
- [23. CMT Usage](#23-CMT-Usage)
- [24. EfficientFormer Usage](#24-EfficientFormer-Usage)
- [MLP Series](#mlp-series)
- [1. RepMLP Usage](#1-RepMLP-Usage)
- [2. MLP-Mixer Usage](#2-MLP-Mixer-Usage)
- [3. ResMLP Usage](#3-ResMLP-Usage)
- [4. gMLP Usage](#4-gMLP-Usage)
- [5. sMLP Usage](#5-sMLP-Usage)
- [6. vip-mlp Usage](#6-vip-mlp-Usage)
- [Re-Parameter(ReP) Series](#Re-Parameter-series)
- [1. RepVGG Usage](#1-RepVGG-Usage)
- [2. ACNet Usage](#2-ACNet-Usage)
- [3. Diverse Branch Block(DDB) Usage](#3-Diverse-Branch-Block-Usage)
- [Convolution Series](#Convolution-series)
- [1. Depthwise Separable Convolution Usage](#1-Depthwise-Separable-Convolution-Usage)
- [2. MBConv Usage](#2-MBConv-Usage)
- [3. Involution Usage](#3-Involution-Usage)
- [4. DynamicConv Usage](#4-DynamicConv-Usage)
- [5. CondConv Usage](#5-CondConv-Usage)
***
# Attention Series
- Pytorch implementation of ["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks---arXiv 2021.05.05"](https://arxiv.org/abs/2105.02358)
- Pytorch implementation of ["Attention Is All You Need---NIPS2017"](https://arxiv.org/pdf/1706.03762.pdf)
- Pytorch implementation of ["Squeeze-and-Excitation Networks---CVPR2018"](https://arxiv.org/abs/1709.01507)
- Pytorch implementation of ["Selective Kernel Networks---CVPR2019"](https://arxiv.org/pdf/1903.06586.pdf)
- Pytorch implementation of ["CBAM: Convolutional Block Attention Module---ECCV2018"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
- Pytorch implementation of ["BAM: Bottleneck Attention Module---BMCV2018"](https://arxiv.org/pdf/1807.06514.pdf)
- Pytorch implementation of ["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020"](https://arxiv.org/pdf/1910.03151.pdf)
- Pytorch implementation of ["Dual Attention Network for Scene Segmentation---CVPR2019"](https://arxiv.org/pdf/1809.02983.pdf)
- Pytorch implementation of ["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30"](https://arxiv.org/pdf/2105.14447.pdf)
- Pytorch implementation of ["ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28"](https://arxiv.org/abs/2105.13677)
- Pytorch implementation of ["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS---ICASSP 2021"](https://arxiv.org/pdf/2102.00240.pdf)
- Pytorch implementation of ["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning---arXiv 2019.11.17"](https://arxiv.org/abs/1911.09483)
- Pytorch implementation of ["Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks---arXiv 2019.05.23"](https://arxiv.org/pdf/1905.09646.pdf)
- Pytorch implementation of ["A2-Nets: Double Attention Networks---NIPS2018"](https://arxiv.org/pdf/1810.11579.pdf)
- Pytorch implementation of ["An Attention Free Transformer---ICLR2021 (Apple New Work)"](https://arxiv.org/pdf/2105.14103v1.pdf)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition---arXiv 2021.06.24"](https://arxiv.org/abs/2106.13112)
[【论文解析】](https://zhuanlan.zhihu.com/p/385561050)
- Pytorch implementation of [Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition---arXiv 2021.06.23](https://arxiv.org/abs/2106.12368)
[【论文解析】](https://mp.weixin.qq.com/s/5gonUQgBho_m2O54jyXF_Q)
- Pytorch implementation of [CoAtNet: Marrying Convolution and Attention for All Data Sizes---arXiv 2021.06.09](https://arxiv.org/abs/2106.04803)
[【论文解析】](https://zhuanlan.zhihu.com/p/385578588)
- Pytorch implementation of [Scaling Local Self-Attention for Parameter Efficient Visual Backbones---CVPR2021 Oral](https://arxiv.org/pdf/2103.12731.pdf) [【论文解析】](https://zhuanlan.zhihu.com/p/388598744)
- Pytorch implementation of [Polarized Self-Attention: Towards High-quality Pixel-wise Regression---arXiv 2021.07.02](https://arxiv.org/abs/2107.00782) [【论文解析】](https://zhuanlan.zhihu.com/p/389770482)
- Pytorch implementation of [Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292) [【论文解析】](https://zhuanlan.zhihu.com/p/394795481)
- Pytorch implementation of [Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
- Pytorch implementation of [S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072) [【论文解析】](https://zhuanlan.zhihu.com/p/397003638)
- Pytorch implementation of [Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
- Pytorch implementation of [Rotate to Attend: Convolutional Triplet Attention Module---WACV 2021](https://arxiv.org/abs/2010.03045)
- Pytorch implementation of [Coordinate Attention for Efficient Mobile Network Design ---CVPR 2021](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2110.02178)
- Pytorch implementation of [Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
- Pytorch implementation of [UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2109.14382)
- Pytorch implementation of [Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
- Pytorch implementation of [On the Integration of Self-Attention and Convolution---ArXiv 2022.03.14](https://arxiv.org/pdf/2111.14556.pdf)
- Pytorch implementation of [CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
- Pytorch implementation of [Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
- Pytorch implementation of [CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
- Pytorch implementation of [Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
***
### 1. External Attention Usage
#### 1.1. Paper
["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks"](https://arxiv.org/abs/2105.02358)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from fightingcv_attention.attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
***
### 2. Self Attention Usage
#### 2.1. Paper
["Attention Is All You Need"](https://arxiv.org/pdf/1706.03762.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from fightingcv_attention.attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 3. Simplified Self Attention Usage
#### 3.1. Paper
[None]()
#### 3.2. Overview

#### 3.3. Usage Code
```python
from fightingcv_attention.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)
```
***
### 4. Squeeze-and-Excitation Attention Usage
#### 4.1. Paper
["Squeeze-and-Excitation Networks"](https://arxiv.org/abs/1709.01507)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from fightingcv_attention.attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 5. SK Attention Usage
#### 5.1. Paper
["Selective Kernel Networks"](https://arxiv.org/pdf/1903.06586.pdf)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from fightingcv_attention.attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 6. CBAM Attention Usage
#### 6.1. Paper
["CBAM: Convolutional Block Attention Module"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
#### 6.2. Overview


#### 6.3. Usage Code
```python
from fightingcv_attention.attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
***
### 7. BAM Attention Usage
#### 7.1. Paper
["BAM: Bottleneck Attention Module"](https://arxiv.org/pdf/1807.06514.pdf)
#### 7.2. Overview

#### 7.3. Usage Code
```python
from fightingcv_attention.attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
***
### 8. ECA Attention Usage
#### 8.1. Paper
["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks"](https://arxiv.org/pdf/1910.03151.pdf)
#### 8.2. Overview

#### 8.3. Usage Code
```python
from fightingcv_attention.attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
***
### 9. DANet Attention Usage
#### 9.1. Paper
["Dual Attention Network for Scene Segmentation"](https://arxiv.org/pdf/1809.02983.pdf)
#### 9.2. Overview

#### 9.3. Usage Code
```python
from fightingcv_attention.attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
***
### 10. Pyramid Split Attention Usage
#### 10.1. Paper
["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network"](https://arxiv.org/pdf/2105.14447.pdf)
#### 10.2. Overview

#### 10.3. Usage Code
```python
from fightingcv_attention.attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
***
### 11. Efficient Multi-Head Self-Attention Usage
#### 11.1. Paper
["ResT: An Efficient Transformer for Visual Recognition"](https://arxiv.org/abs/2105.13677)
#### 11.2. Overview

#### 11.3. Usage Code
```python
from fightingcv_attention.attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
***
### 12. Shuffle Attention Usage
#### 12.1. Paper
["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS"](https://arxiv.org/pdf/2102.00240.pdf)
#### 12.2. Overview

#### 12.3. Usage Code
```python
from fightingcv_attention.attention.ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
```
***
### 13. MUSE Attention Usage
#### 13.1. Paper
["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning"](https://arxiv.org/abs/1911.09483)
#### 13.2. Overview

#### 13.3. Usage Code
```python
from fightingcv_attention.attention.MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 14. SGE Attention Usage
#### 14.1. Paper
[Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks](https://arxiv.org/pdf/1905.09646.pdf)
#### 14.2. Overview

#### 14.3. Usage Code
```python
from fightingcv_attention.attention.SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
```
***
### 15. A2 Attention Usage
#### 15.1. Paper
[A2-Nets: Double Attention Networks](https://arxiv.org/pdf/1810.11579.pdf)
#### 15.2. Overview

#### 15.3. Usage Code
```python
from fightingcv_attention.attention.A2Atttention import DoubleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
```
### 16. AFT Attention Usage
#### 16.1. Paper
[An Attention Free Transformer](https://arxiv.org/pdf/2105.14103v1.pdf)
#### 16.2. Overview

#### 16.3. Usage Code
```python
from fightingcv_attention.attention.AFT import AFT_FULL
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
```
### 17. Outlook Attention Usage
#### 17.1. Paper
[VOLO: Vision Outlooker for Visual Recognition"](https://arxiv.org/abs/2106.13112)
#### 17.2. Overview

#### 17.3. Usage Code
```python
from fightingcv_attention.attention.OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)
```
***
### 18. ViP Attention Usage
#### 18.1. Paper
[Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 18.2. Overview

#### 18.3. Usage Code
```python
from fightingcv_attention.attention.ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)
```
***
### 19. CoAtNet Attention Usage
#### 19.1. Paper
[CoAtNet: Marrying Convolution and Attention for All Data Sizes"](https://arxiv.org/abs/2106.04803)
#### 19.2. Overview
None
#### 19.3. Usage Code
```python
from fightingcv_attention.attention.CoAtNet import CoAtNet
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=CoAtNet(in_ch=3,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 20. HaloNet Attention Usage
#### 20.1. Paper
[Scaling Local Self-Attention for Parameter Efficient Visual Backbones"](https://arxiv.org/pdf/2103.12731.pdf)
#### 20.2. Overview

#### 20.3. Usage Code
```python
from fightingcv_attention.attention.HaloAttention import HaloAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)
```
***
### 21. Polarized Self-Attention Usage
#### 21.1. Paper
[Polarized Self-Attention: Towards High-quality Pixel-wise Regression"](https://arxiv.org/abs/2107.00782)
#### 21.2. Overview

#### 21.3. Usage Code
```python
from fightingcv_attention.attention.PolarizedSelfAttention import ParallelPolarizedSelfAttention,SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
```
***
### 22. CoTAttention Usage
#### 22.1. Paper
[Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292)
#### 22.2. Overview

#### 22.3. Usage Code
```python
from fightingcv_attention.attention.CoTAttention import CoTAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
```
***
### 23. Residual Attention Usage
#### 23.1. Paper
[Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
#### 23.2. Overview

#### 23.3. Usage Code
```python
from fightingcv_attention.attention.ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
resatt = ResidualAttention(channel=512,num_class=1000,la=0.2)
output=resatt(input)
print(output.shape)
```
***
### 24. S2 Attention Usage
#### 24.1. Paper
[S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072)
#### 24.2. Overview

#### 24.3. Usage Code
```python
from fightingcv_attention.attention.S2Attention import S2Attention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
s2att = S2Attention(channels=512)
output=s2att(input)
print(output.shape)
```
***
### 25. GFNet Attention Usage
#### 25.1. Paper
[Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
#### 25.2. Overview

#### 25.3. Usage Code - Implemented by [Wenliang Zhao (Author)](https://scholar.google.com/citations?user=lyPWvuEAAAAJ&hl=en)
```python
from fightingcv_attention.attention.gfnet import GFNet
import torch
from torch import nn
from torch.nn import functional as F
x = torch.randn(1, 3, 224, 224)
gfnet = GFNet(embed_dim=384, img_size=224, patch_size=16, num_classes=1000)
out = gfnet(x)
print(out.shape)
```
***
### 26. TripletAttention Usage
#### 26.1. Paper
[Rotate to Attend: Convolutional Triplet Attention Module---CVPR 2021](https://arxiv.org/abs/2010.03045)
#### 26.2. Overview

#### 26.3. Usage Code - Implemented by [digantamisra98](https://github.com/digantamisra98)
```python
from fightingcv_attention.attention.TripletAttention import TripletAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
triplet = TripletAttention()
output=triplet(input)
print(output.shape)
```
***
### 27. Coordinate Attention Usage
#### 27.1. Paper
[Coordinate Attention for Efficient Mobile Network Design---CVPR 2021](https://arxiv.org/abs/2103.02907)
#### 27.2. Overview

#### 27.3. Usage Code - Implemented by [Andrew-Qibin](https://github.com/Andrew-Qibin)
```python
from fightingcv_attention.attention.CoordAttention import CoordAtt
import torch
from torch import nn
from torch.nn import functional as F
inp=torch.rand([2, 96, 56, 56])
inp_dim, oup_dim = 96, 96
reduction=32
coord_attention = CoordAtt(inp_dim, oup_dim, reduction=reduction)
output=coord_attention(inp)
print(output.shape)
```
***
### 28. MobileViT Attention Usage
#### 28.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2103.02907)
#### 28.2. Overview

#### 28.3. Usage Code
```python
from fightingcv_attention.attention.MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
m=MobileViTAttention()
input=torch.randn(1,3,49,49)
output=m(input)
print(output.shape) #output:(1,3,49,49)
```
***
### 29. ParNet Attention Usage
#### 29.1. Paper
[Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
#### 29.2. Overview

#### 29.3. Usage Code
```python
from fightingcv_attention.attention.ParNetAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
pna = ParNetAttention(channel=512)
output=pna(input)
print(output.shape) #50,512,7,7
```
***
### 30. UFO Attention Usage
#### 30.1. Paper
[UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2110.07641)
#### 30.2. Overview

#### 30.3. Usage Code
```python
from fightingcv_attention.attention.UFOAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
ufo = UFOAttention(d_model=512, d_k=512, d_v=512, h=8)
output=ufo(input,input,input)
print(output.shape) #[50, 49, 512]
```
-
### 31. ACmix Attention Usage
#### 31.1. Paper
[On the Integration of Self-Attention and Convolution](https://arxiv.org/pdf/2111.14556.pdf)
#### 31.2. Usage Code
```python
from fightingcv_attention.attention.ACmix import ACmix
import torch
if __name__ == '__main__':
input=torch.randn(50,256,7,7)
acmix = ACmix(in_planes=256, out_planes=256)
output=acmix(input)
print(output.shape)
```
### 32. MobileViTv2 Attention Usage
#### 32.1. Paper
[Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
#### 32.2. Overview

#### 32.3. Usage Code
```python
from fightingcv_attention.attention.MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
### 33. DAT Attention Usage
#### 33.1. Paper
[Vision Transformer with Deformable Attention---CVPR2022](https://arxiv.org/abs/2201.00520)
#### 33.2. Usage Code
```python
from fightingcv_attention.attention.DAT import DAT
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DAT(
img_size=224,
patch_size=4,
num_classes=1000,
expansion=4,
dim_stem=96,
dims=[96, 192, 384, 768],
depths=[2, 2, 6, 2],
stage_spec=[['L', 'S'], ['L', 'S'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7] ,
groups=[-1, -1, 3, 6],
use_pes=[False, False, True, True],
dwc_pes=[False, False, False, False],
strides=[-1, -1, 1, 1],
sr_ratios=[-1, -1, -1, -1],
offset_range_factor=[-1, -1, 2, 2],
no_offs=[False, False, False, False],
fixed_pes=[False, False, False, False],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
)
output=model(input)
print(output[0].shape)
```
### 34. CrossFormer Attention Usage
#### 34.1. Paper
[CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
#### 34.2. Usage Code
```python
from fightingcv_attention.attention.Crossformer import CrossFormer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CrossFormer(img_size=224,
patch_size=[4, 8, 16, 32],
in_chans= 3,
num_classes=1000,
embed_dim=48,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
group_size=[7, 7, 7, 7],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False,
merge_size=[[2, 4], [2,4], [2, 4]]
)
output=model(input)
print(output.shape)
```
### 35. MOATransformer Attention Usage
#### 35.1. Paper
[Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
#### 35.2. Usage Code
```python
from fightingcv_attention.attention.MOATransformer import MOATransformer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = MOATransformer(
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=[2, 2, 6],
num_heads=[3, 6, 12],
window_size=14,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False
)
output=model(input)
print(output.shape)
```
### 36. CrissCrossAttention Attention Usage
#### 36.1. Paper
[CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
#### 36.2. Usage Code
```python
from fightingcv_attention.attention.CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = CrissCrossAttention(64)
outputs = model(input)
print(outputs.shape)
```
### 37. Axial_attention Attention Usage
#### 37.1. Paper
[Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
#### 37.2. Usage Code
```python
from fightingcv_attention.attention.Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__':
input=torch.randn(3, 128, 7, 7)
model = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
outputs = model(input)
print(outputs.shape)
```
***
# Backbone Series
- Pytorch implementation of ["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
- Pytorch implementation of ["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
- Pytorch implementation of [Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer---ArXiv 2021.06.07](https://arxiv.org/abs/2106.03650)
- Pytorch implementation of [ConTNet: Why not use convolution and transformer at the same time?---ArXiv 2021.04.27](https://arxiv.org/abs/2104.13497)
- Pytorch implementation of [Vision Transformers with Hierarchical Attention---ArXiv 2022.06.15](https://arxiv.org/abs/2106.03180)
- Pytorch implementation of [Co-Scale Conv-Attentional Image Transformers---ArXiv 2021.08.26](https://arxiv.org/abs/2104.06399)
- Pytorch implementation of [Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
- Pytorch implementation of [Rethinking Spatial Dimensions of Vision Transformers---ICCV 2021](https://arxiv.org/abs/2103.16302)
- Pytorch implementation of [CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification---ICCV 2021](https://arxiv.org/abs/2103.14899)
- Pytorch implementation of [Transformer in Transformer---NeurIPS 2021](https://arxiv.org/abs/2103.00112)
- Pytorch implementation of [DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
- Pytorch implementation of [Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
***
- Pytorch implementation of [ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
- Pytorch implementation of [Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
- Pytorch implementation of [Going deeper with Image Transformers---ICCV 2021 (Oral)](https://arxiv.org/abs/2103.17239)
- Pytorch implementation of [Training data-efficient image transformers & distillation through attention---ICML 2021](https://arxiv.org/abs/2012.12877)
- Pytorch implementation of [LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
- Pytorch implementation of [Container: Context Aggregation Network---NeuIPS 2021](https://arxiv.org/abs/2106.01401)
- Pytorch implementation of [CMT: Convolutional Neural Networks Meet Vision Transformers---CVPR 2022](https://arxiv.org/abs/2107.06263)
- Pytorch implementation of [Vision Transformer with Deformable Attention---CVPR 2022](https://arxiv.org/abs/2201.00520)
- Pytorch implementation of [EfficientFormer: Vision Transformers at MobileNet Speed](https://arxiv.org/abs/2206.01191)
### 1. ResNet Usage
#### 1.1. Paper
["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
#### 1.2. Overview


#### 1.3. Usage Code
```python
from fightingcv_attention.backbone.resnet import ResNet50,ResNet101,ResNet152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnet50=ResNet50(1000)
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out=resnet50(input)
print(out.shape)
```
### 2. ResNeXt Usage
#### 2.1. Paper
["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from fightingcv_attention.backbone.resnext import ResNeXt50,ResNeXt101,ResNeXt152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnext50=ResNeXt50(1000)
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out=resnext50(input)
print(out.shape)
```
### 3. MobileViT Usage
#### 3.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from fightingcv_attention.backbone.MobileViT import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
### mobilevit_xxs
mvit_xxs=mobilevit_xxs()
out=mvit_xxs(input)
print(out.shape)
### mobilevit_xs
mvit_xs=mobilevit_xs()
out=mvit_xs(input)
print(out.shape)
### mobilevit_s
mvit_s=mobilevit_s()
out=mvit_s(input)
print(out.shape)
```
### 4. ConvMixer Usage
#### 4.1. Paper
[Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from fightingcv_attention.backbone.ConvMixer import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
convmixer=ConvMixer(dim=512,depth=12)
out=convmixer(x)
print(out.shape) #[1, 1000]
```
### 5. ShuffleTransformer Usage
#### 5.1. Paper
[Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer](https://arxiv.org/pdf/2106.03650.pdf)
#### 5.2. Usage Code
```python
from fightingcv_attention.backbone.ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
sft = ShuffleTransformer()
output=sft(input)
print(output.shape)
```
### 6. ConTNet Usage
#### 6.1. Paper
[ConTNet: Why not use convolution and transformer at the same time?](https://arxiv.org/abs/2104.13497)
#### 6.2. Usage Code
```python
from fightingcv_attention.backbone.ConTNet import ConTNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == "__main__":
model = build_model(use_avgdown=True, relative=True, qkv_bias=True, pre_norm=True)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
```
### 7 HATNet Usage
#### 7.1. Paper
[Vision Transformers with Hierarchical Attention](https://arxiv.org/abs/2106.03180)
#### 7.2. Usage Code
```python
from fightingcv_attention.backbone.HATNet import HATNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
hat = HATNet(dims=[48, 96, 240, 384], head_dim=48, expansions=[8, 8, 4, 4],
grid_sizes=[8, 7, 7, 1], ds_ratios=[8, 4, 2, 1], depths=[2, 2, 6, 3])
output=hat(input)
print(output.shape)
```
### 8 CoaT Usage
#### 8.1. Paper
[Co-Scale Conv-Attentional Image Transformers](https://arxiv.org/abs/2104.06399)
#### 8.2. Usage Code
```python
from fightingcv_attention.backbone.CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4])
output=model(input)
print(output.shape) # torch.Size([1, 1000])
```
### 9 PVT Usage
#### 9.1. Paper
[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/pdf/2106.13797.pdf)
#### 9.2. Usage Code
```python
from fightingcv_attention.backbone.PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 10 CPVT Usage
#### 10.1. Paper
[Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
#### 10.2. Usage Code
```python
from fightingcv_attention.backbone.CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 11 PIT Usage
#### 11.1. Paper
[Rethinking Spatial Dimensions of Vision Transformers](https://arxiv.org/abs/2103.16302)
#### 11.2. Usage Code
```python
from fightingcv_attention.backbone.PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4
)
output=model(input)
print(output.shape)
```
### 12 CrossViT Usage
#### 12.1. Paper
[CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification](https://arxiv.org/abs/2103.14899)
#### 12.2. Usage Code
```python
from fightingcv_attention.backbone.CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__":
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[240, 224],
patch_size=[12, 16],
embed_dim=[192, 384],
depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6],
mlp_ratio=[4, 4, 1],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 13 TnT Usage
#### 13.1. Paper
[Transformer in Transformer](https://arxiv.org/abs/2103.00112)
#### 13.2. Usage Code
```python
from fightingcv_attention.backbone.TnT import TNT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = TNT(
img_size=224,
patch_size=16,
outer_dim=384,
inner_dim=24,
depth=12,
outer_num_heads=6,
inner_num_heads=4,
qkv_bias=False,
inner_stride=4)
output=model(input)
print(output.shape)
```
### 14 DViT Usage
#### 14.1. Paper
[DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
#### 14.2. Usage Code
```python
from fightingcv_attention.backbone.DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DeepVisionTransformer(
patch_size=16, embed_dim=384,
depth=[False] * 16,
apply_transform=[False] * 0 + [True] * 32,
num_heads=12,
mlp_ratio=3,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
)
output=model(input)
print(output.shape)
```
### 15 CeiT Usage
#### 15.1. Paper
[Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
#### 15.2. Usage Code
```python
from fightingcv_attention.backbone.CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CeIT(
hybrid_backbone=Image2Tokens(),
patch_size=4,
embed_dim=192,
depth=12,
num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 16 ConViT Usage
#### 16.1. Paper
[ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
#### 16.2. Usage Code
```python
from fightingcv_attention.backbone.ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 17 CaiT Usage
#### 17.1. Paper
[Going deeper with Image Transformers](https://arxiv.org/abs/2103.17239)
#### 17.2. Usage Code
```python
from fightingcv_attention.backbone.CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CaiT(
img_size= 224,
patch_size=16,
embed_dim=192,
depth=24,
num_heads=4,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2
)
output=model(input)
print(output.shape)
```
### 18 PatchConvnet Usage
#### 18.1. Paper
[Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
#### 18.2. Usage Code
```python
from fightingcv_attention.backbone.PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
)
output=model(input)
print(output.shape)
```
### 19 DeiT Usage
#### 19.1. Paper
[Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
#### 19.2. Usage Code
```python
from fightingcv_attention.backbone.DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DistilledVisionTransformer(
patch_size=16,
embed_dim=384,
depth=12,
num_heads=6,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output[0].shape)
```
### 20 LeViT Usage
#### 20.1. Paper
[LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
#### 20.2. Usage Code
```python
from fightingcv_attention.backbone.LeViT import *
import torch
from torch import nn
if __name__ == '__main__':
for name in specification:
input=torch.randn(1,3,224,224)
model = globals()[name](fuse=True, pretrained=False)
model.eval()
output = model(input)
print(output.shape)
```
### 21 VOLO Usage
#### 21.1. Paper
[VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
#### 21.2. Usage Code
```python
from fightingcv_attention.backbone.VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VOLO([4, 4, 8, 2],
embed_dims=[192, 384, 384, 384],
num_heads=[6, 12, 12, 12],
mlp_ratios=[3, 3, 3, 3],
downsamples=[True, False, False, False],
outlook_attention=[True, False, False, False ],
post_layers=['ca', 'ca'],
)
output=model(input)
print(output[0].shape)
```
### 22 Container Usage
#### 22.1. Paper
[Container: Context Aggregation Network](https://arxiv.org/abs/2106.01401)
#### 22.2. Usage Code
```python
from fightingcv_attention.backbone.Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[224, 56, 28, 14],
patch_size=[4, 2, 2, 2],
embed_dim=[64, 128, 320, 512],
depth=[3, 4, 8, 3],
num_heads=16,
mlp_ratio=[8, 8, 4, 4],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6))
output=model(input)
print(output.shape)
```
### 23 CMT Usage
#### 23.1. Paper
[CMT: Convolutional Neural Networks Meet Vision Transformers](https://arxiv.org/abs/2107.06263)
#### 23.2. Usage Code
```python
from fightingcv_attention.backbone.CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CMT_Tiny()
output=model(input)
print(output[0].shape)
```
### 24 EfficientFormer Usage
#### 24.1. Paper
[EfficientFormer: Vision Transformers at MobileNet Speed](https://arxiv.org/abs/2206.01191)
#### 24.2. Usage Code
```python
from fightingcv_attention.backbone.EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = EfficientFormer(
layers=EfficientFormer_depth['l1'],
embed_dims=EfficientFormer_width['l1'],
downsamples=[True, True, True, True],
vit_num=1,
)
output=model(input)
print(output[0].shape)
```
# MLP Series
- Pytorch implementation of ["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition---arXiv 2021.05.05"](https://arxiv.org/pdf/2105.01883v1.pdf)
- Pytorch implementation of ["MLP-Mixer: An all-MLP Architecture for Vision---arXiv 2021.05.17"](https://arxiv.org/pdf/2105.01601.pdf)
- Pytorch implementation of ["ResMLP: Feedforward networks for image classification with data-efficient training---arXiv 2021.05.07"](https://arxiv.org/pdf/2105.03404.pdf)
- Pytorch implementation of ["Pay Attention to MLPs---arXiv 2021.05.17"](https://arxiv.org/abs/2105.08050)
- Pytorch implementation of ["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?---arXiv 2021.09.12"](https://arxiv.org/abs/2109.05422)
### 1. RepMLP Usage
#### 1.1. Paper
["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition"](https://arxiv.org/pdf/2105.01883v1.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from fightingcv_attention.mlp.repmlp import RepMLP
import torch
from torch import nn
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())
```
### 2. MLP-Mixer Usage
#### 2.1. Paper
["MLP-Mixer: An all-MLP Architecture for Vision"](https://arxiv.org/pdf/2105.01601.pdf)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from fightingcv_attention.mlp.mlp_mixer import MlpMixer
import torch
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)
```
***
### 3. ResMLP Usage
#### 3.1. Paper
["ResMLP: Feedforward networks for image classification with data-efficient training"](https://arxiv.org/pdf/2105.03404.pdf)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from fightingcv_attention.mlp.resmlp import ResMLP
import torch
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape) #the last dimention is class_num
```
***
### 4. gMLP Usage
#### 4.1. Paper
["Pay Attention to MLPs"](https://arxiv.org/abs/2105.08050)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from fightingcv_attention.mlp.g_mlp import gMLP
import torch
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)
```
***
### 5. sMLP Usage
#### 5.1. Paper
["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?"](https://arxiv.org/abs/2109.05422)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from fightingcv_attention.mlp.sMLP_block import sMLPBlock
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
smlp=sMLPBlock(h=224,w=224)
out=smlp(input)
print(out.shape)
```
### 6. vip-mlp Usage
#### 6.1. Paper
["Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 6.2. Usage Code
```python
from fightingcv_attention.mlp.vip-mlp import VisionPermutator
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionPermutator(
layers=[4, 3, 8, 3],
embed_dims=[384, 384, 384, 384],
patch_size=14,
transitions=[False, False, False, False],
segment_dim=[16, 16, 16, 16],
mlp_ratios=[3, 3, 3, 3],
mlp_fn=WeightedPermuteMLP
)
output=model(input)
print(output.shape)
```
# Re-Parameter Series
- Pytorch implementation of ["RepVGG: Making VGG-style ConvNets Great Again---CVPR2021"](https://arxiv.org/abs/2101.03697)
- Pytorch implementation of ["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks---ICCV2019"](https://arxiv.org/abs/1908.03930)
- Pytorch implementation of ["Diverse Branch Block: Building a Convolution as an Inception-like Unit---CVPR2021"](https://arxiv.org/abs/2103.13425)
***
### 1. RepVGG Usage
#### 1.1. Paper
["RepVGG: Making VGG-style ConvNets Great Again"](https://arxiv.org/abs/2101.03697)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from fightingcv_attention.rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
```
***
### 2. ACNet Usage
#### 2.1. Paper
["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks"](https://arxiv.org/abs/1908.03930)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from fightingcv_attention.rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
```
***
### 2. Diverse Branch Block Usage
#### 2.1. Paper
["Diverse Branch Block: Building a Convolution as an Inception-like Unit"](https://arxiv.org/abs/2103.13425)
#### 2.2. Overview

#### 2.3. Usage Code
##### 2.3.1 Transform I
```python
from fightingcv_attention.rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.2 Transform II
```python
from fightingcv_attention.rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.3 Transform III
```python
from fightingcv_attention.rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.4 Transform IV
```python
from fightingcv_attention.rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.5 Transform V
```python
from fightingcv_attention.rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.6 Transform VI
```python
from fightingcv_attention.rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
# Convolution Series
- Pytorch implementation of ["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications---CVPR2017"](https://arxiv.org/abs/1704.04861)
- Pytorch implementation of ["Efficientnet: Rethinking model scaling for convolutional neural networks---PMLR2019"](http://proceedings.mlr.press/v97/tan19a.html)
- Pytorch implementation of ["Involution: Inverting the Inherence of Convolution for Visual Recognition---CVPR2021"](https://arxiv.org/abs/2103.06255)
- Pytorch implementation of ["Dynamic Convolution: Attention over Convolution Kernels---CVPR2020 Oral"](https://arxiv.org/abs/1912.03458)
- Pytorch implementation of ["CondConv: Conditionally Parameterized Convolutions for Efficient Inference---NeurIPS2019"](https://arxiv.org/abs/1904.04971)
***
### 1. Depthwise Separable Convolution Usage
#### 1.1. Paper
["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications"](https://arxiv.org/abs/1704.04861)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from fightingcv_attention.conv.DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)
```
***
### 2. MBConv Usage
#### 2.1. Paper
["Efficientnet: Rethinking model scaling for convolutional neural networks"](http://proceedings.mlr.press/v97/tan19a.html)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from fightingcv_attention.conv.MBConv import MBConvBlock
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=512,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 3. Involution Usage
#### 3.1. Paper
["Involution: Inverting the Inherence of Convolution for Visual Recognition"](https://arxiv.org/abs/2103.06255)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from fightingcv_attention.conv.Involution import Involution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)
```
***
### 4. DynamicConv Usage
#### 4.1. Paper
["Dynamic Convolution: Attention over Convolution Kernels"](https://arxiv.org/abs/1912.03458)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from fightingcv_attention.conv.DynamicConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape) # 2,32,64,64
```
***
### 5. CondConv Usage
#### 5.1. Paper
["CondConv: Conditionally Parameterized Convolutions for Efficient Inference"](https://arxiv.org/abs/1904.04971)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from fightingcv_attention.conv.CondConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=CondConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
```
================================================
FILE: main.py
================================================
from model.attention.MobileViTv2Attention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
================================================
FILE: model/.vscode/settings.json
================================================
{
"python.pythonPath": "D:\\Anaconda\\python.exe"
}
================================================
FILE: model/__init__.py
================================================
def test():
print ("hello world")
if __name__ == '__main__':
test()
================================================
FILE: model/analysis/Attention.md
================================================
## Content
- [1. External Attention](#1-external-attention)
- [2. Self Attention](#2-self-attention)
- [3. Squeeze-and-Excitation(SE) Attention](#3-squeeze-and-excitationse-attention)
- [4. Selective Kernel(SK) Attention](#4-selective-kernelsk-attention)
- [5. CBAM Attention](#5-cbam-attention)
- [6. BAM Attention](#6-bam-attention)
- [7. ECA Attention](#7-eca-attention)
- [8. DANet Attention](#8-danet-attention)
- [9. Pyramid Split Attention(PSA)](#9-pyramid-split-attentionpsa)
- [10. Efficient Multi-Head Self-Attention(EMSA)](#10-efficient-multi-head-self-attentionemsa)
- [Write at the end](#Write_at_the_end)
## 1. External Attention
### 1.1. Citation
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks.---arXiv 2021.05.05
Address:[https://arxiv.org/abs/2105.02358](https://arxiv.org/abs/2105.02358)
### 1.2. Model Structure

### 1.3. Brief
This is an article on arXiv in May. It mainly solves two pain points of Self-Attention (SA): (1) O(n^2) computational complexity; (2) SA is in the same sample The above calculates Attention based on different positions, ignoring the relationship between different samples. Therefore, this paper uses two serial MLP structures as memory units, which reduces the computational complexity to O(n); in addition, these two memory units are learned based on all training data, so they also implicitly consider the differences. The connection between the samples.
### 1.4. Usage
```python
from attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
## 2. Self Attention
### 2.1. Citation
Attention Is All You Need---NeurIPS2017
Address:[https://arxiv.org/abs/1706.03762](https://arxiv.org/abs/1706.03762)
### 2.2. Model Structure

### 2.3. Brief
This is an article published by Google in NeurIPS2017. It has a great influence in various fields such as CV, NLP, and multi-modality. The current citation volume has been 2.2w+. The Self-Attention proposed in Transformer is a kind of Attention, which is used to calculate the weight between different positions in the feature, so as to achieve the effect of updating the feature. First, the input feature is mapped into three features of Q, K, and V through FC, and then Q and K are dot-multiplied to obtain the attention map, and the attention map and V are dot-multiplied to obtain the weighted feature. Finally, the feature is mapped through FC, and a new feature is obtained. (There are many very good explanations about Transformer and Self-Attention on the Internet, so I won’t give a detailed introduction here)
### 2.4. Usage
```python
from attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
## 3. Squeeze-and-Excitation(SE) Attention
### 3.1. Citation
Squeeze-and-Excitation Networks---CVPR2018
Address:[https://arxiv.org/abs/1709.01507](https://arxiv.org/abs/1709.01507)
### 3.2. Model Structure

### 3.3. Brief
This is an article of CVPR2018, which is also very influential. The current citation volume is 7k+. This article is for channel attention. Because of its simple structure and effectiveness, it has set off a wave of channel attention. From the avenue to the simple, the idea of this article can be said to be very simple. First, the spatial dimension is applied to AdaptiveAvgPool, and then the channel attention is learned through two FCs, and the Sigmoid is used for normalization to obtain the Channel Attention Map, and finally the Channel Attention Map is combined with the original Multiply the features to get the weighted features.
### 3.4. Usage
```python
from attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
## 4. Selective Kernel(SK) Attention
### 4.1. Citation
Selective Kernel Networks---CVPR2019
Address:[https://arxiv.org/pdf/1903.06586.pdf](https://arxiv.org/pdf/1903.06586.pdf)
### 4.2. Model Structure

### 4.3. Brief
This is an article from CVPR2019, which pays tribute to SENet's thoughts. In traditional CNN, each convolutional layer uses the same size convolution kernel, which limits the expressive ability of the model; and the "wider" model structure of Inception is also verified, using multiple different convolution kernels. Learning can indeed improve the expressive ability of the model. The author draws on the idea of SENet, obtains the weight of the channel by dynamically calculating each convolution kernel, and dynamically merges the results of each convolution kernel.
I personally think that the reason why this article can also be called lightweight is that when channel attention is performed on the features of different kernels, the parameters are shared (ie because before Attention, the features are first fused, so different The result of the convolution kernel shares a parameter of the SE module).
The method in this article is divided into three parts: Split, Fuse, and Select. Split is a multi-branch operation, convolution with different convolution kernels to get different features; the Fuse part is to use the SE structure to obtain the channel attention matrix (N convolution kernels can get N attention matrices , This step is shared with all the feature parameters), so that the features of different kernels after SE can be obtained; the Select operation is to add these features.
### 4.4. Usage
```python
from attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
## 5. CBAM Attention
### 5.1. Citation
CBAM: Convolutional Block Attention Module---ECCV2018
Address:[https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
### 5.2. Model Structure


### 5.3. Brief
This is an ECCV2018 paper. This article uses Channel Attention and Spatial Attention at the same time and connects the two in series (the article also does ablation experiments in parallel and two series).
In terms of Channel Attention, the general structure is still similar to SE, but the author proposes that AvgPool and MaxPool have different representation effects, so the author performs AvgPool and MaxPool on the original features in the Spatial dimension, and then uses the SE structure to extract channel attention. Note here The parameters are shared, and then the two features are added and normalized to obtain the attention matrix.
Spatial Attention is similar to Channel Attention. After performing two pools in the channel dimension, the two features are spliced, and then a 7x7 convolution is used to extract the Spatial Attention (the reason for using 7x7 is because the spatial attention is extracted, so use The convolution kernel must be large enough). Then do a normalization to get the spatial attention matrix.
### 5.4. Usage
```python
from attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
## 6. BAM Attention
### 6.1. Citation
BAM: Bottleneck Attention Module---BMCV2018
Address:[https://arxiv.org/pdf/1807.06514.pdf](https://arxiv.org/pdf/1807.06514.pdf)
### 6.2. Model Structure

### 6.3. Brief
This is the work of CBAM and the author at the same time. The work is very similar to CBAM, and it is also dual attention. The difference is that CBAM connects the results of two attention in series; while BAM directly adds two attention matrices.
In terms of Channel Attention, the structure is basically the same as SE. In terms of Spatial Attention, the pool is still performed in the channel dimension, and then a 3x3 hole convolution is used twice, and finally a 1x1 convolution will be used to obtain the Spatial Attention matrix.
Finally, the Channel Attention and Spatial Attention matrices are added (the broadcast mechanism is used here) and normalized. In this way, the attention matrix that combines space and channel is obtained.
### 6.4. Usage
```python
from attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
## 7. ECA Attention
### 7.1. Citation
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020
Address:[https://arxiv.org/pdf/1910.03151.pdf](https://arxiv.org/pdf/1910.03151.pdf)
### 7.2. Model Structure

### 7.3. Brief
This is an article of CVPR2020.
As shown in the figure above, SE uses two fully connected layers to achieve channel attention, while ECA requires one convolution. The reason why the author did this is that it is not necessary to calculate the attention between all channels. On the other hand, the use of two fully connected layers does introduce too many parameters and calculations.
Therefore, after the author performed AvgPool, he only used a one-dimensional convolution with a receptive field of k (equivalent to only calculating the attention of the adjacent k channels), which greatly reduced the parameters and calculation amount. (i.e. is equivalent to SE being a global attention, while ECA is a local attention).
### 7.4. Usage
```python
from attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
## 8. DANet Attention
### 8.1. Citation
Dual Attention Network for Scene Segmentation---CVPR2019
Address:[https://arxiv.org/pdf/1809.02983.pdf](https://arxiv.org/pdf/1809.02983.pdf)
### 8.2. Model Structure

### 8.3. Brief
This is an article by CVPR2019. The idea is very simple, that is, self-attention is used in the task of scene segmentation. The difference is that self-attention is to pay attention to the attention between each position, and this article will make a self-attention. To expand, we also made a branch of channel attention. The operation is the same as self-attention. The three Linears that generate Q, K, and V are removed from different channel attention. Finally, the features after the two attentions are summed element-wise.
### 8.4. Usage
```python
from attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
## 9. Pyramid Split Attention(PSA)
### 9.1. Citation
EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30
Address:[https://arxiv.org/pdf/2105.14447.pdf](https://arxiv.org/pdf/2105.14447.pdf)
### 9.2. Model Structure

### 9.3. Brief
This is an article uploaded by Shenzhen University on arXiv on May 30. The purpose of this article is how to obtain and explore spatial information of different scales to enrich the feature space. The network structure is relatively simple, mainly divided into four steps. In the first part, the original feature is divided into n groups according to the channel, and then the different groups are convolved with different scales to obtain the new feature W1; the second part is SE performs SE on the original features to obtain different Attention Map; the third part is to perform softmax on different groups; the fourth part is to multiply the obtained attention with the original feature W1.
### 9.4. Usage
```python
from attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
## 10. Efficient Multi-Head Self-Attention(EMSA)
### 10.1. Citation
ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28
Address:[https://arxiv.org/abs/2105.13677](https://arxiv.org/abs/2105.13677)
### 10.2. Model Structure

### 10.3. Brief
This is an article uploaded by Nanjing University on arXiv on May 28. This article mainly solves two pain points of SA: (1) The computational complexity of Self-Attention is squared with n; (2) Each head has only partial information of q, k, v, if q, k, v If the dimension of is too small, continuous information will not be obtained, resulting in performance loss. The idea given in this article is also very simple. In SA, before FC, a convolution is used to reduce the spatial dimension, thereby obtaining smaller K and V in spatial dimension.
### 10.4. Usage
```python
from attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
## Write at the end
At present, the Attention work organized by this project is indeed not comprehensive enough. As the amount of reading increases, we will continue to improve this project. Welcome everyone star to support. If there are incorrect statements or incorrect code implementations in the article, you are welcome to point out~
================================================
FILE: model/analysis/注意力机制.md
================================================
## 目录
- [1. External Attention](#1-external-attention)
- [2. Self Attention](#2-self-attention)
- [3. Squeeze-and-Excitation(SE) Attention](#3-squeeze-and-excitationse-attention)
- [4. Selective Kernel(SK) Attention](#4-selective-kernelsk-attention)
- [5. CBAM Attention](#5-cbam-attention)
- [6. BAM Attention](#6-bam-attention)
- [7. ECA Attention](#7-eca-attention)
- [8. DANet Attention](#8-danet-attention)
- [9. Pyramid Split Attention(PSA)](#9-pyramid-split-attentionpsa)
- [10. Efficient Multi-Head Self-Attention(EMSA)](#10-efficient-multi-head-self-attentionemsa)
- [【写在最后】](#写在最后)
## 1. External Attention
### 1.1. 引用
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks.---arXiv 2021.05.05
论文地址:[https://arxiv.org/abs/2105.02358](https://arxiv.org/abs/2105.02358)
### 1.2. 模型结构

### 1.3. 简介
这是五月份在arXiv上的一篇文章,主要解决的Self-Attention(SA)的两个痛点问题:(1)O(n^2)的计算复杂度;(2)SA是在同一个样本上根据不同位置计算Attention,忽略了不同样本之间的联系。因此,本文采用了两个串联的MLP结构作为memory units,使得计算复杂度降低到了O(n);此外,这两个memory units是基于全部的训练数据学习的,因此也隐式的考虑了不同样本之间的联系。
### 1.4. 使用方法
```python
from attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
## 2. Self Attention
### 2.1. 引用
Attention Is All You Need---NeurIPS2017
论文地址:[https://arxiv.org/abs/1706.03762](https://arxiv.org/abs/1706.03762)
### 2.2. 模型结构

### 2.3. 简介
这是Google在NeurIPS2017发表的一篇文章,在CV、NLP、多模态等各个领域都有很大的影响力,目前引用量已经2.2w+。Transformer中提出的Self-Attention是Attention的一种,用于计算特征中不同位置之间的权重,从而达到更新特征的效果。首先将input feature通过FC映射成Q、K、V三个特征,然后将Q和K进行点乘的得到attention map,在将attention map与V做点乘得到加权后的特征。最后通过FC进行特征的映射,得到一个新的特征。(关于Transformer和Self-Attention目前网上有许多非常好的讲解,这里就不做详细的介绍了)
### 2.4. 使用方法
```python
from attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
## 3. Squeeze-and-Excitation(SE) Attention
### 3.1. 引用
Squeeze-and-Excitation Networks---CVPR2018
论文地址:[https://arxiv.org/abs/1709.01507](https://arxiv.org/abs/1709.01507)
### 3.2. 模型结构

### 3.3. 简介
这是CVPR2018的一篇文章,同样非常具有影响力,目前引用量7k+。本文是做通道注意力的,因其简单的结构和有效性,将通道注意力掀起了一波小高潮。大道至简,这篇文章的思想可以说非常简单,首先将spatial维度进行AdaptiveAvgPool,然后通过两个FC学习到通道注意力,并用Sigmoid进行归一化得到Channel Attention Map,最后将Channel Attention Map与原特征相乘,就得到了加权后的特征。
### 3.4. 使用方法
```python
from attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
## 4. Selective Kernel(SK) Attention
### 4.1. 引用
Selective Kernel Networks---CVPR2019
论文地址:[https://arxiv.org/pdf/1903.06586.pdf](https://arxiv.org/pdf/1903.06586.pdf)
### 4.2. 模型结构

### 4.3. 简介
这是CVPR2019的一篇文章,致敬了SENet的思想。在传统的CNN中每一个卷积层都是用相同大小的卷积核,限制了模型的表达能力;而Inception这种“更宽”的模型结构也验证了,用多个不同的卷积核进行学习确实可以提升模型的表达能力。作者借鉴了SENet的思想,通过动态计算每个卷积核得到通道的权重,动态的将各个卷积核的结果进行融合。
个人认为,之所以所这篇文章也能够称之为lightweight,是因为对不同kernel的特征进行通道注意力的时候是参数共享的(i.e. 因为在做Attention之前,首先将特征进行了融合,所以不同卷积核的结果共享一个SE模块的参数)。
本文的方法分为三个部分:Split,Fuse,Select。Split就是一个multi-branch的操作,用不同的卷积核进行卷积得到不同的特征;Fuse部分就是用SE的结构获取通道注意力的矩阵(N个卷积核就可以得到N个注意力矩阵,这步操作对所有的特征参数共享),这样就可以得到不同kernel经过SE之后的特征;Select操作就是将这几个特征进行相加。
### 4.4. 使用方法
```python
from attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
## 5. CBAM Attention
### 5.1. 引用
CBAM: Convolutional Block Attention Module---ECCV2018
论文地址:[https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
### 5.2. 模型结构


### 5.3. 简介
这是ECCV2018的一篇论文,这篇文章同时使用了Channel Attention和Spatial Attention,将两者进行了串联(文章也做了并联和两种串联方式的消融实验)。
Channel Attention方面,大致结构还是和SE相似,不过作者提出AvgPool和MaxPool有不同的表示效果,所以作者对原来的特征在Spatial维度分别进行了AvgPool和MaxPool,然后用SE的结构提取channel attention,注意这里是参数共享的,然后将两个特征相加后做归一化,就得到了注意力矩阵。
Spatial Attention和Channel Attention类似,先在channel维度进行两种pool后,将两个特征进行拼接,然后用7x7的卷积来提取Spatial Attention(之所以用7x7是因为提取的是空间注意力,所以用的卷积核必须足够大)。然后做一次归一化,就得到了空间的注意力矩阵。
### 5.4. 使用方法
```python
from attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
## 6. BAM Attention
### 6.1. 引用
BAM: Bottleneck Attention Module---BMCV2018
论文地址:[https://arxiv.org/pdf/1807.06514.pdf](https://arxiv.org/pdf/1807.06514.pdf)
### 6.2. 模型结构

### 6.3. 简介
这是CBAM同作者同时期的工作,工作与CBAM非常相似,也是双重Attention,不同的是CBAM是将两个attention的结果串联;而BAM是直接将两个attention矩阵进行相加。
Channel Attention方面,与SE的结构基本一样。Spatial Attention方面,还是在通道维度进行pool,然后用了两次3x3的空洞卷积,最后将用一次1x1的卷积得到Spatial Attention的矩阵。
最后Channel Attention和Spatial Attention矩阵进行相加(这里用到了广播机制),并进行归一化,这样一来,就得到了空间和通道结合的attention矩阵。
### 6.4.使用方法
```python
from attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
## 7. ECA Attention
### 7.1. 引用
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020
论文地址:[https://arxiv.org/pdf/1910.03151.pdf](https://arxiv.org/pdf/1910.03151.pdf)
### 7.2. 模型结构

### 7.3. 简介
这是CVPR2020的一篇文章。
如上图所示,SE实现通道注意力是使用两个全连接层,而ECA是需要一个的卷积。作者这么做的原因一方面是认为计算所有通道两两之间的注意力是没有必要的,另一方面是用两个全连接层确实引入了太多的参数和计算量。
因此作者进行了AvgPool之后,只是使用了一个感受野为k的一维卷积(相当于只计算与相邻k个通道的注意力),这样做就大大的减少的参数和计算量。(i.e.相当于SE是一个global的注意力,而ECA是一个local的注意力)。
### 7.4. 使用方法:
```python
from attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
## 8. DANet Attention
### 8.1. 引用
Dual Attention Network for Scene Segmentation---CVPR2019
论文地址:[https://arxiv.org/pdf/1809.02983.pdf](https://arxiv.org/pdf/1809.02983.pdf)
### 8.2. 模型结构

### 8.3. 简介
这是CVPR2019的文章,思想上非常简单,就是将self-attention用到场景分割的任务中,不同的是self-attention是关注每个position之间的注意力,而本文将self-attention做了一个拓展,还做了一个通道注意力的分支,操作上和self-attention一样,不同的通道attention中把生成Q,K,V的三个Linear去掉了。最后将两个attention之后的特征进行element-wise sum。
### 8.4. 使用方法
```python
from attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
## 9. Pyramid Split Attention(PSA)
### 9.1. 引用
EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30
论文地址:[https://arxiv.org/pdf/2105.14447.pdf](https://arxiv.org/pdf/2105.14447.pdf)
### 9.2. 模型结构

### 9.3. 简介
这是深大5月30日在arXiv上上传的一篇文章,本文的目的是如何获取并探索不同尺度的空间信息来丰富特征空间。网络结构相对来说也比较简单,主要分成四步,第一步,将原来的feature根据通道分成n组然后对不同的组进行不同尺度的卷积,得到新的特征W1;第二步,用SE在原来的特征上进行SE,从而获得不同的Attention Map;第三步,对不同组进行SOFTMAX;第四步,将获得attention与原来的特征W1相乘。
### 9.4. 使用方法
```python
from attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
## 10. Efficient Multi-Head Self-Attention(EMSA)
### 10.1. 引用
ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28
论文地址:[https://arxiv.org/abs/2105.13677](https://arxiv.org/abs/2105.13677)
### 10.2. 模型结构

### 10.3. 简介
这是南大5月28日在arXiv上上传的一篇文章。本文解决的主要是SA的两个痛点问题:(1)Self-Attention的计算复杂度和n呈平方关系;(2)每个head只有q,k,v的部分信息,如果q,k,v的维度太小,那么就会导致获取不到连续的信息,从而导致性能损失。这篇文章给出的思路也非常简单,在SA中,在FC之前,用了一个卷积来降低了空间的维度,从而得到空间维度上更小的K和V。
### 10.4. 使用方法
```python
from attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
## 【写在最后】
目前该项目整理的Attention的工作确实还不够全面,后面随着阅读量的提高,会不断对本项目进行完善,欢迎大家star支持。若在文章中有表述不恰、代码实现有误的地方,欢迎大家指出~
================================================
FILE: model/analysis/重参数机制.md
================================================
[toc]
## 【写在前面】
最近拜读了丁霄汉大神的一系列重参数的论文,觉得这个思想真的很妙。能够在将所有的cost都放在训练过程中,在测试的时候能够在所有的网络参数和计算量都进行缩减。目前网上也有部分对这些论文进行了解析,为了能够让更多读者进一步、深层的理解重参数的思想,本文将会结合代码,近几年重参数的论文进行详细的解析。
个人理解,重参数其实就是在测试的时候对训练的网络结构进行压缩。比如三个并联的卷积(kernel size相同)结果的和,其实就等于用求和之后的卷积核进行一次卷积的结果。所以,在训练的时候可以用三个卷积来提高模型的学习能力,但是在测试部署的时候,可以无损压缩为一次卷积,从而减少参数量和计算量。
## 【复现框架】
[https://github.com/xmu-xiaoma666/External-Attention-pytorch](https://github.com/xmu-xiaoma666/External-Attention-pytorch)
(欢迎大家***star***、***fork***该工作;如果有任何问题,也欢迎大家在***issue***中提出)
## 【先验知识】
首先向各位读者介绍一下卷积的一些基本性质,这几篇论文所提出的重参数操作,都是基于卷积的这几个性质。
一个普通的卷积操作可以被定义成下面的公式:
$$
O=I*F+REP(b)
$$
其中,$*$为卷积操作,$O \in \mathbb{R}^{D \times H' \times W'}$为输出特征,$I \in \mathbb{R}^{C \times H \times W}$为输入特征,$F \in \mathbb{R}^{D \times C \times K \times K}$为卷积核,$b \in \mathbb{R}^{D}$为偏置项,$Rep(b) \in \mathbb{R}^{D \times H' \times W'}$表示广播后的偏置项。
卷积操作具有以下两个性质:
### 1)同质性(homogeneity)
$$
I*(pF)=p(I*F), \forall p \in \mathbb{R}
$$
这个性质的意思是,一个常数与卷积核相乘之后的结果与特征进行卷积=一个常数乘上卷积之后的结果。
### 2)可加性(additivity)
$$
I*F^{(1)}+I*F^{(2)}=I*(F^{(1)}+F^{(2)})
$$
这个性质的意思是,两个并联的卷积结果相加,等于将这两个卷积核相加之后之后在进行卷积
# 1.ICCV2019-ACNet
## 1.1. 论文地址
ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks
论文地址:[https://arxiv.org/abs/1908.03930](https://arxiv.org/abs/1908.03930)
## 1.2. 网络框架
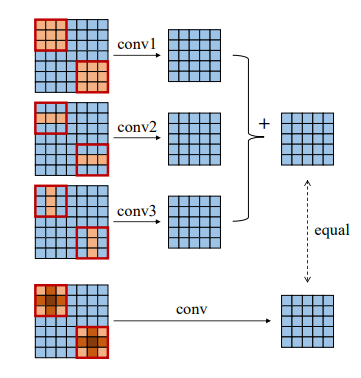
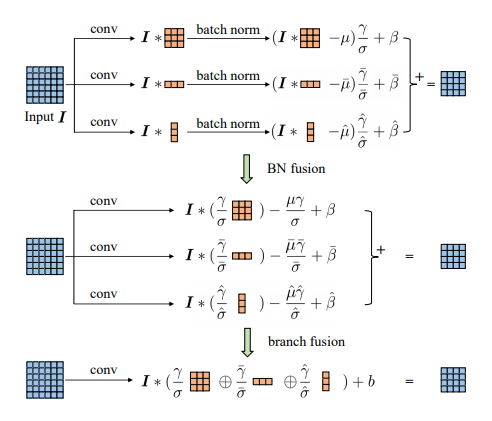
## 1.3. 原理解释
这篇文章做的主要工作如“网络框架”中的展示的那样:将并联的三个卷积(1x3、3x1、3x3)转换成一个卷积(3x3)。
### 首先,考虑不带BatchNorm的情况:
将1x3和3x1的卷积核转换到3x3的卷积核,只需要在水平和竖直方向分别用0padding成3x3的大小即可,然后将三个卷积核(1x3、3x1、3x3)相加进行卷积,就相当于是用三个卷积核分别对feature map卷积后再相加。
### 然后,考虑如何将BatchNorm融合到卷积核中:
卷积操作如下:
$$
O=I*F+REP(b)
$$
BatchNorm操作如下:
$$
BN(x)=\gamma\frac{(x-mean)}{\sqrt{var}}+\beta
$$
将卷积带入到BatchNorm就如:
$$
BN(Conv(x))=\gamma\frac{(I*F+REP(b)-mean)}{\sqrt{var}}+\beta
$$
化简得到:
$$
BN(Conv(x))=I*(\frac{F\gamma}{\sqrt{var}})+\frac{\gamma(REP(b)-mean)}{\sqrt{var}}+\beta
$$
因此新卷积核的weight和bias为:
$$
F_{new}=\frac{F\gamma}{\sqrt{var}} \\
REP(b)=\frac{\gamma(REP(b)-mean)}{\sqrt{var}}+\beta
$$
### 最后,考虑多分支的带BN的结构融合:
第一步,我们将BN层的参数融合到卷积核中
第二步,将BN层的参数融合到卷积核之后,原来带BN层的结构就变成了不带BN层的结构,我们将三个新卷积核相加之后,就得到了融合的卷积核。
## 1.4. 代码调用
```python
from rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
```
# 2. CVPR2021-RepVGG
## 2.1. 论文地址
RepVGG: Making VGG-style ConvNets Great Again
论文地址:[https://arxiv.org/abs/2101.03697](https://arxiv.org/abs/2101.03697)
## 2.2. 网络框架
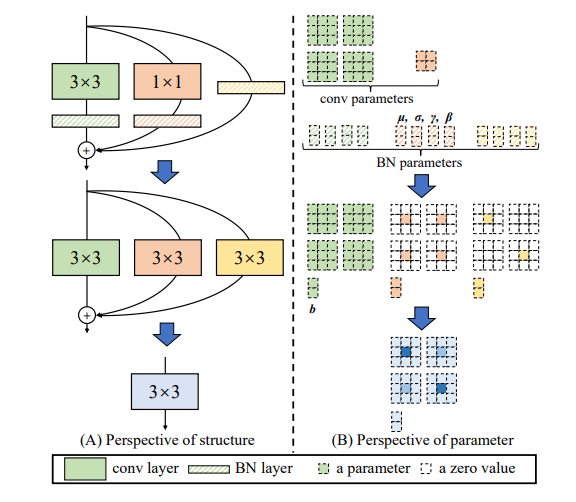
## 2.3. 原理解释
这篇论文是的核心是将并联的带BN的3x3卷积核,1x1卷积核和残差结构转换为一个3x3的卷积核。
首先,带BN的1x1卷积核和带BN的3x3卷积核融合成一个3x3的卷积核,这个操作和第一篇文章ACNet的转换方式非常相似,就是将1x1 的卷积核padding成3x3后,在进行和ACNet相同的操作。
现在的问题是,怎么把残差结构也变成3x3的卷积。残差结构可以其实就是一个value为1的1x1的Depthwise卷积。如果能把Depthwise卷积转换成正常的卷积,那么这个问题也就迎刃而解了。下面这张图形象的展示了如果把Depthwise卷积转换成正常卷积:
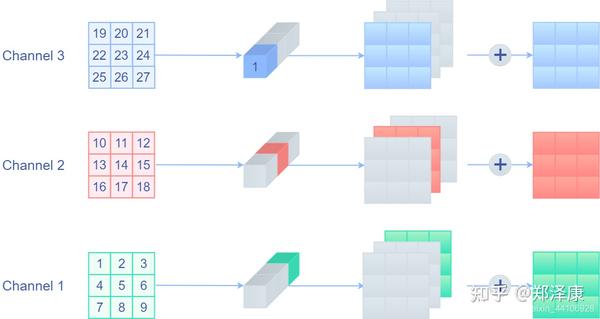
(来自:https://zhuanlan.zhihu.com/p/352239591)
其实就是将对应需要操作的通道赋值为1,其他赋值为0。
输入通道为c,输出通道为c,把这里的参数矩阵比作cxc的矩阵,那么深度可分离矩阵就是一个单位矩阵(对角位置全部为1,其他全部为0)
(来自:https://zhuanlan.zhihu.com/p/352239591)
这样一来,残差结构也能转换成1x1的卷积了,然后与3x3的卷积用上面的方式进行合并,就得到了RepVGG的重参数结构
## 2.4. 代码调用
```python
from rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
```
# 3. CVPR2021-Diverse Branch Block
## 3.1. 论文地址
Diverse Branch Block: Building a Convolution as an Inception-like Unit
论文地址:[https://arxiv.org/abs/2103.13425](https://arxiv.org/abs/2103.13425)
## 3.2. 网络框架

## 3.3. 原理解释
像Inception一样的多分支结构可以增加模型的表达能力,提高性能,但是也会带来额外的参数和显存使用。因此,本文提出了一个方法,在训练时采用多分支的结构,在测试和部署的时候将多分支的结构模型转换成一个单一分支的模型,从而模型在测试的时候就能够“免费”享用多分支结构带来的性能提升。但是怎么把多分支结构无损压缩成一个单分支的结构呢,这就是这篇文章的贡献点所在。
### 3.3.1. Transform I:Conv+BN->BN
这部分的原理在ACNet的解析中已经详细解释了,代码实现如下:
```python
def transI_conv_bn(conv, bn):
std = (bn.running_var + bn.eps).sqrt()
gamma=bn.weight
weight=conv.weight*((gamma/std).reshape(-1, 1, 1, 1))
if(conv.bias is not None):
bias=gamma/std*conv.bias-gamma/std*bn.running_mean+bn.bias
else:
bias=bn.bias-gamma/std*bn.running_mean
return weight,bias
```
### 3.3.2. Transform II:并联Conv->Conv
这部分的原理就是【先验知识】部分的可加性,代码实现如下:
```python
def transII_conv_branch(conv1, conv2):
weight=conv1.weight.data+conv2.weight.data
bias=conv1.bias.data+conv2.bias.data
return weight,bias
```
### 3.3.3 Transform III:1x1Conv + 3x3Conv->3x3Conv
1x1的卷积其实并没有在空间上对feature map进行交互操作(或者说都只是乘了相同的数),所以1x1的Conv其实就是一个全连接层。所以,本质上,我们可以直接后面接着的3x3的卷积进行这个1x1的卷积操作,得到的新的卷积核,就可以是融合之后的卷积核。(可能讲的不是非常清楚,详细解释可以参考这篇文章:https://zhuanlan.zhihu.com/p/360939086)
代码实现如下:
```python
def transIII_conv_sequential(conv1, conv2):
weight=F.conv2d(conv2.weight.data,conv1.weight.data.permute(1,0,2,3))
return weight
```
### 3.3.4 Transform IV:Concat Conv->Conv
将多个卷积之后的结果进行concat,其实就是将多个卷积核权重在输出通道维度上进行拼接即可,代码实现如下:
```python
def transIV_conv_concat(conv1, conv2):
print(conv1.bias.data.shape)
print(conv2.bias.data.shape)
weight=torch.cat([conv1.weight.data,conv2.weight.data],0)
bias=torch.cat([conv1.bias.data,conv2.bias.data],0)
return weight,bias
```
### 3.3.5 Transform V:AvgPooling->Conv
AvgPool就是将感受野的值求平均,那么转换成卷积就是卷积核中每个值的value都等于1/卷积核大小,代码实现如下:
```python
def transV_avg(channel,kernel):
conv=nn.Conv2d(channel,channel,kernel,bias=False)
conv.weight.data[:]=0
for i in range(channel):
conv.weight.data[i,i,:,:]=1/(kernel*kernel)
return conv
```
## 3.3.6 Transform VI:1x1Conv+1x3Conv+3x1Conv(并联)->Conv
这个操作其实就是ACNet的思想,详情可以见上面ACNet的解析,代码实现如下:
```python
def transVI_conv_scale(conv1, conv2, conv3):
weight=F.pad(conv1.weight.data,(1,1,1,1))+F.pad(conv2.weight.data,(0,0,1,1))+F.pad(conv3.weight.data,(1,1,0,0))
bias=conv1.bias.data+conv2.bias.data+conv3.bias.data
return weight,bias
```
## 3.4. 代码调用
### 3.4.1. Transform I:Conv+BN->BN
```python
from rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
### 3.4.2. Transform II:并联Conv->Conv
```python
from rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
### 3.4.3 Transform III:1x1Conv + 3x3Conv->3x3Conv
```python
from rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
### 3.4.4 Transform IV:Concat Conv->Conv
```python
from rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
### 3.4.5 Transform V:AvgPooling->Conv
```python
from rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())
```
### 3.4.6 Transform VI:1x1Conv+1x3Conv+3x1Conv(并联)->Conv
```python
from rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
================================================
FILE: model/attention/A2Atttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn import functional as F
class DoubleAttention(nn.Module):
def __init__(self, in_channels,c_m,c_n,reconstruct = True):
super().__init__()
self.in_channels=in_channels
self.reconstruct = reconstruct
self.c_m=c_m
self.c_n=c_n
self.convA=nn.Conv2d(in_channels,c_m,1)
self.convB=nn.Conv2d(in_channels,c_n,1)
self.convV=nn.Conv2d(in_channels,c_n,1)
if self.reconstruct:
self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size = 1)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, h,w=x.shape
assert c==self.in_channels
A=self.convA(x) #b,c_m,h,w
B=self.convB(x) #b,c_n,h,w
V=self.convV(x) #b,c_n,h,w
tmpA=A.view(b,self.c_m,-1)
attention_maps=F.softmax(B.view(b,self.c_n,-1))
attention_vectors=F.softmax(V.view(b,self.c_n,-1))
# step 1: feature gating
global_descriptors=torch.bmm(tmpA,attention_maps.permute(0,2,1)) #b.c_m,c_n
# step 2: feature distribution
tmpZ = global_descriptors.matmul(attention_vectors) #b,c_m,h*w
tmpZ=tmpZ.view(b,self.c_m,h,w) #b,c_m,h,w
if self.reconstruct:
tmpZ=self.conv_reconstruct(tmpZ)
return tmpZ
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
================================================
FILE: model/attention/ACmixAttention.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
def position(H, W, is_cuda=True):
if is_cuda:
loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W)
else:
loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)
loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)
return loc
def stride(x, stride):
b, c, h, w = x.shape
return x[:, :, ::stride, ::stride]
def init_rate_half(tensor):
if tensor is not None:
tensor.data.fill_(0.5)
def init_rate_0(tensor):
if tensor is not None:
tensor.data.fill_(0.)
class ACmix(nn.Module):
def __init__(self, in_planes, out_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):
super(ACmix, self).__init__()
self.in_planes = in_planes
self.out_planes = out_planes
self.head = head
self.kernel_att = kernel_att
self.kernel_conv = kernel_conv
self.stride = stride
self.dilation = dilation
self.rate1 = torch.nn.Parameter(torch.Tensor(1))
self.rate2 = torch.nn.Parameter(torch.Tensor(1))
self.head_dim = self.out_planes // self.head
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)
self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2
self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)
self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)
self.softmax = torch.nn.Softmax(dim=1)
self.fc = nn.Conv2d(3*self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)
self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes, kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1, stride=stride)
self.reset_parameters()
def reset_parameters(self):
init_rate_half(self.rate1)
init_rate_half(self.rate2)
kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)
for i in range(self.kernel_conv * self.kernel_conv):
kernel[i, i//self.kernel_conv, i%self.kernel_conv] = 1.
kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)
self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)
self.dep_conv.bias = init_rate_0(self.dep_conv.bias)
def forward(self, x):
q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)
scaling = float(self.head_dim) ** -0.5
b, c, h, w = q.shape
h_out, w_out = h//self.stride, w//self.stride
pe = self.conv_p(position(h, w, x.is_cuda))
q_att = q.view(b*self.head, self.head_dim, h, w) * scaling
k_att = k.view(b*self.head, self.head_dim, h, w)
v_att = v.view(b*self.head, self.head_dim, h, w)
if self.stride > 1:
q_att = stride(q_att, self.stride)
q_pe = stride(pe, self.stride)
else:
q_pe = pe
unfold_k = self.unfold(self.pad_att(k_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # b*head, head_dim, k_att^2, h_out, w_out
unfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # 1, head_dim, k_att^2, h_out, w_out
att = (q_att.unsqueeze(2)*(unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(1) # (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)
att = self.softmax(att)
out_att = self.unfold(self.pad_att(v_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out)
out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)
f_all = self.fc(torch.cat([q.view(b, self.head, self.head_dim, h*w), k.view(b, self.head, self.head_dim, h*w), v.view(b, self.head, self.head_dim, h*w)], 1))
f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])
out_conv = self.dep_conv(f_conv)
return self.rate1 * out_att + self.rate2 * out_conv
if __name__ == '__main__':
input=torch.randn(50,256,7,7)
acmix = ACmix(in_planes=256, out_planes=256)
output=acmix(input)
print(output.shape)
================================================
FILE: model/attention/AFT.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class AFT_FULL(nn.Module):
def __init__(self, d_model,n=49,simple=False):
super(AFT_FULL, self).__init__()
self.fc_q = nn.Linear(d_model, d_model)
self.fc_k = nn.Linear(d_model, d_model)
self.fc_v = nn.Linear(d_model,d_model)
if(simple):
self.position_biases=torch.zeros((n,n))
else:
self.position_biases=nn.Parameter(torch.ones((n,n)))
self.d_model = d_model
self.n=n
self.sigmoid=nn.Sigmoid()
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, input):
bs, n,dim = input.shape
q = self.fc_q(input) #bs,n,dim
k = self.fc_k(input).view(1,bs,n,dim) #1,bs,n,dim
v = self.fc_v(input).view(1,bs,n,dim) #1,bs,n,dim
numerator=torch.sum(torch.exp(k+self.position_biases.view(n,1,-1,1))*v,dim=2) #n,bs,dim
denominator=torch.sum(torch.exp(k+self.position_biases.view(n,1,-1,1)),dim=2) #n,bs,dim
out=(numerator/denominator) #n,bs,dim
out=self.sigmoid(q)*(out.permute(1,0,2)) #bs,n,dim
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
================================================
FILE: model/attention/Axial_attention.py
================================================
import torch
from torch import nn
from operator import itemgetter
# from axial_attention.reversible import ReversibleSequence
from torch.autograd.function import Function
from torch.utils.checkpoint import get_device_states, set_device_states
# following example for saving and setting rng here https://pytorch.org/docs/stable/_modules/torch/utils/checkpoint.html
class Deterministic(nn.Module):
def __init__(self, net):
super().__init__()
self.net = net
self.cpu_state = None
self.cuda_in_fwd = None
self.gpu_devices = None
self.gpu_states = None
def record_rng(self, *args):
self.cpu_state = torch.get_rng_state()
if torch.cuda._initialized:
self.cuda_in_fwd = True
self.gpu_devices, self.gpu_states = get_device_states(*args)
def forward(self, *args, record_rng = False, set_rng = False, **kwargs):
if record_rng:
self.record_rng(*args)
if not set_rng:
return self.net(*args, **kwargs)
rng_devices = []
if self.cuda_in_fwd:
rng_devices = self.gpu_devices
with torch.random.fork_rng(devices=rng_devices, enabled=True):
torch.set_rng_state(self.cpu_state)
if self.cuda_in_fwd:
set_device_states(self.gpu_devices, self.gpu_states)
return self.net(*args, **kwargs)
# heavily inspired by https://github.com/RobinBruegger/RevTorch/blob/master/revtorch/revtorch.py
# once multi-GPU is confirmed working, refactor and send PR back to source
class ReversibleBlock(nn.Module):
def __init__(self, f, g):
super().__init__()
self.f = Deterministic(f)
self.g = Deterministic(g)
def forward(self, x, f_args = {}, g_args = {}):
x1, x2 = torch.chunk(x, 2, dim = 1)
y1, y2 = None, None
with torch.no_grad():
y1 = x1 + self.f(x2, record_rng=self.training, **f_args)
y2 = x2 + self.g(y1, record_rng=self.training, **g_args)
return torch.cat([y1, y2], dim = 1)
def backward_pass(self, y, dy, f_args = {}, g_args = {}):
y1, y2 = torch.chunk(y, 2, dim = 1)
del y
dy1, dy2 = torch.chunk(dy, 2, dim = 1)
del dy
with torch.enable_grad():
y1.requires_grad = True
gy1 = self.g(y1, set_rng=True, **g_args)
torch.autograd.backward(gy1, dy2)
with torch.no_grad():
x2 = y2 - gy1
del y2, gy1
dx1 = dy1 + y1.grad
del dy1
y1.grad = None
with torch.enable_grad():
x2.requires_grad = True
fx2 = self.f(x2, set_rng=True, **f_args)
torch.autograd.backward(fx2, dx1, retain_graph=True)
with torch.no_grad():
x1 = y1 - fx2
del y1, fx2
dx2 = dy2 + x2.grad
del dy2
x2.grad = None
x = torch.cat([x1, x2.detach()], dim = 1)
dx = torch.cat([dx1, dx2], dim = 1)
return x, dx
class IrreversibleBlock(nn.Module):
def __init__(self, f, g):
super().__init__()
self.f = f
self.g = g
def forward(self, x, f_args, g_args):
x1, x2 = torch.chunk(x, 2, dim = 1)
y1 = x1 + self.f(x2, **f_args)
y2 = x2 + self.g(y1, **g_args)
return torch.cat([y1, y2], dim = 1)
class _ReversibleFunction(Function):
@staticmethod
def forward(ctx, x, blocks, kwargs):
ctx.kwargs = kwargs
for block in blocks:
x = block(x, **kwargs)
ctx.y = x.detach()
ctx.blocks = blocks
return x
@staticmethod
def backward(ctx, dy):
y = ctx.y
kwargs = ctx.kwargs
for block in ctx.blocks[::-1]:
y, dy = block.backward_pass(y, dy, **kwargs)
return dy, None, None
class ReversibleSequence(nn.Module):
def __init__(self, blocks, ):
super().__init__()
self.blocks = nn.ModuleList([ReversibleBlock(f, g) for (f, g) in blocks])
def forward(self, x, arg_route = (True, True), **kwargs):
f_args, g_args = map(lambda route: kwargs if route else {}, arg_route)
block_kwargs = {'f_args': f_args, 'g_args': g_args}
x = torch.cat((x, x), dim = 1)
x = _ReversibleFunction.apply(x, self.blocks, block_kwargs)
return torch.stack(x.chunk(2, dim = 1)).mean(dim = 0)
# helper functions
def exists(val):
return val is not None
def map_el_ind(arr, ind):
return list(map(itemgetter(ind), arr))
def sort_and_return_indices(arr):
indices = [ind for ind in range(len(arr))]
arr = zip(arr, indices)
arr = sorted(arr)
return map_el_ind(arr, 0), map_el_ind(arr, 1)
# calculates the permutation to bring the input tensor to something attend-able
# also calculates the inverse permutation to bring the tensor back to its original shape
def calculate_permutations(num_dimensions, emb_dim):
total_dimensions = num_dimensions + 2
emb_dim = emb_dim if emb_dim > 0 else (emb_dim + total_dimensions)
axial_dims = [ind for ind in range(1, total_dimensions) if ind != emb_dim]
permutations = []
for axial_dim in axial_dims:
last_two_dims = [axial_dim, emb_dim]
dims_rest = set(range(0, total_dimensions)) - set(last_two_dims)
permutation = [*dims_rest, *last_two_dims]
permutations.append(permutation)
return permutations
# helper classes
class ChanLayerNorm(nn.Module):
def __init__(self, dim, eps = 1e-5):
super().__init__()
self.eps = eps
self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
self.b = nn.Parameter(torch.zeros(1, dim, 1, 1))
def forward(self, x):
std = torch.var(x, dim = 1, unbiased = False, keepdim = True).sqrt()
mean = torch.mean(x, dim = 1, keepdim = True)
return (x - mean) / (std + self.eps) * self.g + self.b
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = nn.LayerNorm(dim)
def forward(self, x):
x = self.norm(x)
return self.fn(x)
class Sequential(nn.Module):
def __init__(self, blocks):
super().__init__()
self.blocks = blocks
def forward(self, x):
for f, g in self.blocks:
x = x + f(x)
x = x + g(x)
return x
class PermuteToFrom(nn.Module):
def __init__(self, permutation, fn):
super().__init__()
self.fn = fn
_, inv_permutation = sort_and_return_indices(permutation)
self.permutation = permutation
self.inv_permutation = inv_permutation
def forward(self, x, **kwargs):
axial = x.permute(*self.permutation).contiguous()
shape = axial.shape
*_, t, d = shape
# merge all but axial dimension
axial = axial.reshape(-1, t, d)
# attention
axial = self.fn(axial, **kwargs)
# restore to original shape and permutation
axial = axial.reshape(*shape)
axial = axial.permute(*self.inv_permutation).contiguous()
return axial
# axial pos emb
class AxialPositionalEmbedding(nn.Module):
def __init__(self, dim, shape, emb_dim_index = 1):
super().__init__()
parameters = []
total_dimensions = len(shape) + 2
ax_dim_indexes = [i for i in range(1, total_dimensions) if i != emb_dim_index]
self.num_axials = len(shape)
for i, (axial_dim, axial_dim_index) in enumerate(zip(shape, ax_dim_indexes)):
shape = [1] * total_dimensions
shape[emb_dim_index] = dim
shape[axial_dim_index] = axial_dim
parameter = nn.Parameter(torch.randn(*shape))
setattr(self, f'param_{i}', parameter)
def forward(self, x):
for i in range(self.num_axials):
x = x + getattr(self, f'param_{i}')
return x
# attention
class SelfAttention(nn.Module):
def __init__(self, dim, heads, dim_heads = None):
super().__init__()
self.dim_heads = (dim // heads) if dim_heads is None else dim_heads
dim_hidden = self.dim_heads * heads
self.heads = heads
self.to_q = nn.Linear(dim, dim_hidden, bias = False)
self.to_kv = nn.Linear(dim, 2 * dim_hidden, bias = False)
self.to_out = nn.Linear(dim_hidden, dim)
def forward(self, x, kv = None):
kv = x if kv is None else kv
q, k, v = (self.to_q(x), *self.to_kv(kv).chunk(2, dim=-1))
b, t, d, h, e = *q.shape, self.heads, self.dim_heads
merge_heads = lambda x: x.reshape(b, -1, h, e).transpose(1, 2).reshape(b * h, -1, e)
q, k, v = map(merge_heads, (q, k, v))
dots = torch.einsum('bie,bje->bij', q, k) * (e ** -0.5)
dots = dots.softmax(dim=-1)
out = torch.einsum('bij,bje->bie', dots, v)
out = out.reshape(b, h, -1, e).transpose(1, 2).reshape(b, -1, d)
out = self.to_out(out)
return out
# axial attention class
class AxialAttention(nn.Module):
def __init__(self, dim, num_dimensions = 2, heads = 8, dim_heads = None, dim_index = -1, sum_axial_out = True):
assert (dim % heads) == 0, 'hidden dimension must be divisible by number of heads'
super().__init__()
self.dim = dim
self.total_dimensions = num_dimensions + 2
self.dim_index = dim_index if dim_index > 0 else (dim_index + self.total_dimensions)
attentions = []
for permutation in calculate_permutations(num_dimensions, dim_index):
attentions.append(PermuteToFrom(permutation, SelfAttention(dim, heads, dim_heads)))
self.axial_attentions = nn.ModuleList(attentions)
self.sum_axial_out = sum_axial_out
def forward(self, x):
assert len(x.shape) == self.total_dimensions, 'input tensor does not have the correct number of dimensions'
assert x.shape[self.dim_index] == self.dim, 'input tensor does not have the correct input dimension'
if self.sum_axial_out:
return sum(map(lambda axial_attn: axial_attn(x), self.axial_attentions))
out = x
for axial_attn in self.axial_attentions:
out = axial_attn(out)
return out
# axial image transformer
class AxialImageTransformer(nn.Module):
def __init__(self, dim, depth, heads = 8, dim_heads = None, dim_index = 1, reversible = True, axial_pos_emb_shape = None):
super().__init__()
permutations = calculate_permutations(2, dim_index)
get_ff = lambda: nn.Sequential(
ChanLayerNorm(dim),
nn.Conv2d(dim, dim * 4, 3, padding = 1),
nn.LeakyReLU(inplace=True),
nn.Conv2d(dim * 4, dim, 3, padding = 1)
)
self.pos_emb = AxialPositionalEmbedding(dim, axial_pos_emb_shape, dim_index) if exists(axial_pos_emb_shape) else nn.Identity()
layers = nn.ModuleList([])
for _ in range(depth):
attn_functions = nn.ModuleList([PermuteToFrom(permutation, PreNorm(dim, SelfAttention(dim, heads, dim_heads))) for permutation in permutations])
conv_functions = nn.ModuleList([get_ff(), get_ff()])
layers.append(attn_functions)
layers.append(conv_functions)
execute_type = ReversibleSequence if reversible else Sequential
self.layers = execute_type(layers)
def forward(self, x):
x = self.pos_emb(x)
return self.layers(x)
# input=torch.randn(3, 128, 7, 7)
# attn = AxialAttention(
# dim = 3, # embedding dimension
# dim_index = 1, # where is the embedding dimension
# dim_heads = 32, # dimension of each head. defaults to dim // heads if not supplied
# heads = 1, # number of heads for multi-head attention
# num_dimensions = 2, # number of axial dimensions (images is 2, video is 3, or more)
# sum_axial_out = True # whether to sum the contributions of attention on each axis, or to run the input through them sequentially. defaults to true
# )
# print(attn(input).shape) # (1, 3, 256, 256)
if __name__ == '__main__':
input=torch.randn(3, 128, 7, 7)
model = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
outputs = model(input)
print(outputs.shape)
================================================
FILE: model/attention/BAM.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class Flatten(nn.Module):
def forward(self,x):
return x.view(x.shape[0],-1)
class ChannelAttention(nn.Module):
def __init__(self,channel,reduction=16,num_layers=3):
super().__init__()
self.avgpool=nn.AdaptiveAvgPool2d(1)
gate_channels=[channel]
gate_channels+=[channel//reduction]*num_layers
gate_channels+=[channel]
self.ca=nn.Sequential()
self.ca.add_module('flatten',Flatten())
for i in range(len(gate_channels)-2):
self.ca.add_module('fc%d'%i,nn.Linear(gate_channels[i],gate_channels[i+1]))
self.ca.add_module('bn%d'%i,nn.BatchNorm1d(gate_channels[i+1]))
self.ca.add_module('relu%d'%i,nn.ReLU())
self.ca.add_module('last_fc',nn.Linear(gate_channels[-2],gate_channels[-1]))
def forward(self, x) :
res=self.avgpool(x)
res=self.ca(res)
res=res.unsqueeze(-1).unsqueeze(-1).expand_as(x)
return res
class SpatialAttention(nn.Module):
def __init__(self,channel,reduction=16,num_layers=3,dia_val=2):
super().__init__()
self.sa=nn.Sequential()
self.sa.add_module('conv_reduce1',nn.Conv2d(kernel_size=1,in_channels=channel,out_channels=channel//reduction))
self.sa.add_module('bn_reduce1',nn.BatchNorm2d(channel//reduction))
self.sa.add_module('relu_reduce1',nn.ReLU())
for i in range(num_layers):
self.sa.add_module('conv_%d'%i,nn.Conv2d(kernel_size=3,in_channels=channel//reduction,out_channels=channel//reduction,padding=1,dilation=dia_val))
self.sa.add_module('bn_%d'%i,nn.BatchNorm2d(channel//reduction))
self.sa.add_module('relu_%d'%i,nn.ReLU())
self.sa.add_module('last_conv',nn.Conv2d(channel//reduction,1,kernel_size=1))
def forward(self, x) :
res=self.sa(x)
res=res.expand_as(x)
return res
class BAMBlock(nn.Module):
def __init__(self, channel=512,reduction=16,dia_val=2):
super().__init__()
self.ca=ChannelAttention(channel=channel,reduction=reduction)
self.sa=SpatialAttention(channel=channel,reduction=reduction,dia_val=dia_val)
self.sigmoid=nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
sa_out=self.sa(x)
ca_out=self.ca(x)
weight=self.sigmoid(sa_out+ca_out)
out=(1+weight)*x
return out
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
================================================
FILE: model/attention/CBAM.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ChannelAttention(nn.Module):
def __init__(self,channel,reduction=16):
super().__init__()
self.maxpool=nn.AdaptiveMaxPool2d(1)
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.se=nn.Sequential(
nn.Conv2d(channel,channel//reduction,1,bias=False),
nn.ReLU(),
nn.Conv2d(channel//reduction,channel,1,bias=False)
)
self.sigmoid=nn.Sigmoid()
def forward(self, x) :
max_result=self.maxpool(x)
avg_result=self.avgpool(x)
max_out=self.se(max_result)
avg_out=self.se(avg_result)
output=self.sigmoid(max_out+avg_out)
return output
class SpatialAttention(nn.Module):
def __init__(self,kernel_size=7):
super().__init__()
self.conv=nn.Conv2d(2,1,kernel_size=kernel_size,padding=kernel_size//2)
self.sigmoid=nn.Sigmoid()
def forward(self, x) :
max_result,_=torch.max(x,dim=1,keepdim=True)
avg_result=torch.mean(x,dim=1,keepdim=True)
result=torch.cat([max_result,avg_result],1)
output=self.conv(result)
output=self.sigmoid(output)
return output
class CBAMBlock(nn.Module):
def __init__(self, channel=512,reduction=16,kernel_size=49):
super().__init__()
self.ca=ChannelAttention(channel=channel,reduction=reduction)
self.sa=SpatialAttention(kernel_size=kernel_size)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
residual=x
out=x*self.ca(x)
out=out*self.sa(out)
return out+residual
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
================================================
FILE: model/attention/CoAtNet.py
================================================
from torch import nn, sqrt
import torch
import sys
from math import sqrt
sys.path.append('.')
from model.conv.MBConv import MBConvBlock
from model.attention.SelfAttention import ScaledDotProductAttention
class CoAtNet(nn.Module):
def __init__(self,in_ch,image_size,out_chs=[64,96,192,384,768]):
super().__init__()
self.out_chs=out_chs
self.maxpool2d=nn.MaxPool2d(kernel_size=2,stride=2)
self.maxpool1d = nn.MaxPool1d(kernel_size=2, stride=2)
self.s0=nn.Sequential(
nn.Conv2d(in_ch,in_ch,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(in_ch,in_ch,kernel_size=3,padding=1)
)
self.mlp0=nn.Sequential(
nn.Conv2d(in_ch,out_chs[0],kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_chs[0],out_chs[0],kernel_size=1)
)
self.s1=MBConvBlock(ksize=3,input_filters=out_chs[0],output_filters=out_chs[0],image_size=image_size//2)
self.mlp1=nn.Sequential(
nn.Conv2d(out_chs[0],out_chs[1],kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_chs[1],out_chs[1],kernel_size=1)
)
self.s2=MBConvBlock(ksize=3,input_filters=out_chs[1],output_filters=out_chs[1],image_size=image_size//4)
self.mlp2=nn.Sequential(
nn.Conv2d(out_chs[1],out_chs[2],kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_chs[2],out_chs[2],kernel_size=1)
)
self.s3=ScaledDotProductAttention(out_chs[2],out_chs[2]//8,out_chs[2]//8,8)
self.mlp3=nn.Sequential(
nn.Linear(out_chs[2],out_chs[3]),
nn.ReLU(),
nn.Linear(out_chs[3],out_chs[3])
)
self.s4=ScaledDotProductAttention(out_chs[3],out_chs[3]//8,out_chs[3]//8,8)
self.mlp4=nn.Sequential(
nn.Linear(out_chs[3],out_chs[4]),
nn.ReLU(),
nn.Linear(out_chs[4],out_chs[4])
)
def forward(self, x) :
B,C,H,W=x.shape
#stage0
y=self.mlp0(self.s0(x))
y=self.maxpool2d(y)
#stage1
y=self.mlp1(self.s1(y))
y=self.maxpool2d(y)
#stage2
y=self.mlp2(self.s2(y))
y=self.maxpool2d(y)
#stage3
y=y.reshape(B,self.out_chs[2],-1).permute(0,2,1) #B,N,C
y=self.mlp3(self.s3(y,y,y))
y=self.maxpool1d(y.permute(0,2,1)).permute(0,2,1)
#stage4
y=self.mlp4(self.s4(y,y,y))
y=self.maxpool1d(y.permute(0,2,1))
N=y.shape[-1]
y=y.reshape(B,self.out_chs[4],int(sqrt(N)),int(sqrt(N)))
return y
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
coatnet=CoAtNet(3,224)
y=coatnet(x)
print(y.shape)
================================================
FILE: model/attention/CoTAttention.py
================================================
import numpy as np
import torch
from torch import flatten, nn
from torch.nn import init
from torch.nn.modules.activation import ReLU
from torch.nn.modules.batchnorm import BatchNorm2d
from torch.nn import functional as F
class CoTAttention(nn.Module):
def __init__(self, dim=512,kernel_size=3):
super().__init__()
self.dim=dim
self.kernel_size=kernel_size
self.key_embed=nn.Sequential(
nn.Conv2d(dim,dim,kernel_size=kernel_size,padding=kernel_size//2,groups=4,bias=False),
nn.BatchNorm2d(dim),
nn.ReLU()
)
self.value_embed=nn.Sequential(
nn.Conv2d(dim,dim,1,bias=False),
nn.BatchNorm2d(dim)
)
factor=4
self.attention_embed=nn.Sequential(
nn.Conv2d(2*dim,2*dim//factor,1,bias=False),
nn.BatchNorm2d(2*dim//factor),
nn.ReLU(),
nn.Conv2d(2*dim//factor,kernel_size*kernel_size*dim,1)
)
def forward(self, x):
bs,c,h,w=x.shape
k1=self.key_embed(x) #bs,c,h,w
v=self.value_embed(x).view(bs,c,-1) #bs,c,h,w
y=torch.cat([k1,x],dim=1) #bs,2c,h,w
att=self.attention_embed(y) #bs,c*k*k,h,w
att=att.reshape(bs,c,self.kernel_size*self.kernel_size,h,w)
att=att.mean(2,keepdim=False).view(bs,c,-1) #bs,c,h*w
k2=F.softmax(att,dim=-1)*v
k2=k2.view(bs,c,h,w)
return k1+k2
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
================================================
FILE: model/attention/CoordAttention.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
================================================
FILE: model/attention/CrissCrossAttention.py
================================================
'''
This code is borrowed from Serge-weihao/CCNet-Pure-Pytorch
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Softmax
def INF(B,H,W):
return -torch.diag(torch.tensor(float("inf")).repeat(H),0).unsqueeze(0).repeat(B*W,1,1)
class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module"""
def __init__(self, in_dim):
super(CrissCrossAttention,self).__init__()
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.softmax = Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
m_batchsize, _, height, width = x.size()
proj_query = self.query_conv(x)
proj_query_H = proj_query.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height).permute(0, 2, 1)
proj_query_W = proj_query.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width).permute(0, 2, 1)
proj_key = self.key_conv(x)
proj_key_H = proj_key.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_key_W = proj_key.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
proj_value = self.value_conv(x)
proj_value_H = proj_value.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_value_W = proj_value.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
energy_H = (torch.bmm(proj_query_H, proj_key_H)+self.INF(m_batchsize, height, width)).view(m_batchsize,width,height,height).permute(0,2,1,3)
energy_W = torch.bmm(proj_query_W, proj_key_W).view(m_batchsize,height,width,width)
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = concate[:,:,:,0:height].permute(0,2,1,3).contiguous().view(m_batchsize*width,height,height)
#print(concate)
#print(att_H)
att_W = concate[:,:,:,height:height+width].contiguous().view(m_batchsize*height,width,width)
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1)).view(m_batchsize,width,-1,height).permute(0,2,3,1)
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1)).view(m_batchsize,height,-1,width).permute(0,2,1,3)
#print(out_H.size(),out_W.size())
return self.gamma*(out_H + out_W) + x
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = CrissCrossAttention(64)
outputs = model(input)
print(outputs.shape)
================================================
FILE: model/attention/Crossformer.py
================================================
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class DynamicPosBias(nn.Module):
def __init__(self, dim, num_heads, residual):
super().__init__()
self.residual = residual
self.num_heads = num_heads
self.pos_dim = dim // 4
self.pos_proj = nn.Linear(2, self.pos_dim)
self.pos1 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.pos_dim),
)
self.pos2 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.pos_dim)
)
self.pos3 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.num_heads)
)
def forward(self, biases):
if self.residual:
pos = self.pos_proj(biases) # 2Wh-1 * 2Ww-1, heads
pos = pos + self.pos1(pos)
pos = pos + self.pos2(pos)
pos = self.pos3(pos)
else:
pos = self.pos3(self.pos2(self.pos1(self.pos_proj(biases))))
return pos
def flops(self, N):
flops = N * 2 * self.pos_dim
flops += N * self.pos_dim * self.pos_dim
flops += N * self.pos_dim * self.pos_dim
flops += N * self.pos_dim * self.num_heads
return flops
class Attention(nn.Module):
r""" Multi-head self attention module with dynamic position bias.
Args:
dim (int): Number of input channels.
group_size (tuple[int]): The height and width of the group.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, group_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.,
position_bias=True):
super().__init__()
self.dim = dim
self.group_size = group_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.position_bias = position_bias
if position_bias:
self.pos = DynamicPosBias(self.dim // 4, self.num_heads, residual=False)
# generate mother-set
position_bias_h = torch.arange(1 - self.group_size[0], self.group_size[0])
position_bias_w = torch.arange(1 - self.group_size[1], self.group_size[1])
biases = torch.stack(torch.meshgrid([position_bias_h, position_bias_w])) # 2, 2Wh-1, 2W2-1
biases = biases.flatten(1).transpose(0, 1).float()
self.register_buffer("biases", biases)
# get pair-wise relative position index for each token inside the group
coords_h = torch.arange(self.group_size[0])
coords_w = torch.arange(self.group_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.group_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.group_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.group_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_groups*B, N, C)
mask: (0/-inf) mask with shape of (num_groups, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
if self.position_bias:
pos = self.pos(self.biases) # 2Wh-1 * 2Ww-1, heads
# select position bias
relative_position_bias = pos[self.relative_position_index.view(-1)].view(
self.group_size[0] * self.group_size[1], self.group_size[0] * self.group_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, group_size={self.group_size}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 group with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
if self.position_bias:
flops += self.pos.flops(N)
return flops
class CrossFormerBlock(nn.Module):
r""" CrossFormer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
group_size (int): Group size.
lsda_flag (int): use SDA or LDA, 0 for SDA and 1 for LDA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, group_size=7, lsda_flag=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm, num_patch_size=1):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.group_size = group_size
self.lsda_flag = lsda_flag
self.mlp_ratio = mlp_ratio
self.num_patch_size = num_patch_size
if min(self.input_resolution) <= self.group_size:
# if group size is larger than input resolution, we don't partition groups
self.lsda_flag = 0
self.group_size = min(self.input_resolution)
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, group_size=to_2tuple(self.group_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
position_bias=True)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size %d, %d, %d" % (L, H, W)
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# group embeddings
G = self.group_size
if self.lsda_flag == 0: # 0 for SDA
x = x.reshape(B, H // G, G, W // G, G, C).permute(0, 1, 3, 2, 4, 5)
else: # 1 for LDA
x = x.reshape(B, G, H // G, G, W // G, C).permute(0, 2, 4, 1, 3, 5)
x = x.reshape(B * H * W // G**2, G**2, C)
# multi-head self-attention
x = self.attn(x, mask=self.attn_mask) # nW*B, G*G, C
# ungroup embeddings
x = x.reshape(B, H // G, W // G, G, G, C)
if self.lsda_flag == 0:
x = x.permute(0, 1, 3, 2, 4, 5).reshape(B, H, W, C)
else:
x = x.permute(0, 3, 1, 4, 2, 5).reshape(B, H, W, C)
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"group_size={self.group_size}, lsda_flag={self.lsda_flag}, mlp_ratio={self.mlp_ratio}"
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# LSDA
nW = H * W / self.group_size / self.group_size
flops += nW * self.attn.flops(self.group_size * self.group_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm, patch_size=[2], num_input_patch_size=1):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reductions = nn.ModuleList()
self.patch_size = patch_size
self.norm = norm_layer(dim)
for i, ps in enumerate(patch_size):
if i == len(patch_size) - 1:
out_dim = 2 * dim // 2 ** i
else:
out_dim = 2 * dim // 2 ** (i + 1)
stride = 2
padding = (ps - stride) // 2
self.reductions.append(nn.Conv2d(dim, out_dim, kernel_size=ps,
stride=stride, padding=padding))
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = self.norm(x)
x = x.view(B, H, W, C).permute(0, 3, 1, 2)
xs = []
for i in range(len(self.reductions)):
tmp_x = self.reductions[i](x).flatten(2).transpose(1, 2)
xs.append(tmp_x)
x = torch.cat(xs, dim=2)
return x
def extra_repr(self) -> str:
return f"input_resolution={self.input_resolution}, dim={self.dim}"
def flops(self):
H, W = self.input_resolution
flops = H * W * self.dim
for i, ps in enumerate(self.patch_size):
if i == len(self.patch_size) - 1:
out_dim = 2 * self.dim // 2 ** i
else:
out_dim = 2 * self.dim // 2 ** (i + 1)
flops += (H // 2) * (W // 2) * ps * ps * out_dim * self.dim
return flops
class Stage(nn.Module):
""" CrossFormer blocks for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
group_size (int): variable G in the paper, one group has GxG embeddings
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, input_resolution, depth, num_heads, group_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,
patch_size_end=[4], num_patch_size=None):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList()
for i in range(depth):
lsda_flag = 0 if (i % 2 == 0) else 1
self.blocks.append(CrossFormerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, group_size=group_size,
lsda_flag=lsda_flag,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer,
num_patch_size=num_patch_size))
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer,
patch_size=patch_size_end, num_input_patch_size=num_patch_size)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
def flops(self):
flops = 0
for blk in self.blocks:
flops += blk.flops()
if self.downsample is not None:
flops += self.downsample.flops()
return flops
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: [4].
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=[4], in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
# patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[0] // patch_size[0]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.projs = nn.ModuleList()
for i, ps in enumerate(patch_size):
if i == len(patch_size) - 1:
dim = embed_dim // 2 ** i
else:
dim = embed_dim // 2 ** (i + 1)
stride = patch_size[0]
padding = (ps - patch_size[0]) // 2
self.projs.append(nn.Conv2d(in_chans, dim, kernel_size=ps, stride=stride, padding=padding))
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
xs = []
for i in range(len(self.projs)):
tx = self.projs[i](x).flatten(2).transpose(1, 2)
xs.append(tx) # B Ph*Pw C
x = torch.cat(xs, dim=2)
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = 0
for i, ps in enumerate(self.patch_size):
if i == len(self.patch_size) - 1:
dim = self.embed_dim // 2 ** i
else:
dim = self.embed_dim // 2 ** (i + 1)
flops += Ho * Wo * dim * self.in_chans * (self.patch_size[i] * self.patch_size[i])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
class CrossFormer(nn.Module):
r""" CrossFormer
A PyTorch impl of : `CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention` -
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each stage.
num_heads (tuple(int)): Number of attention heads in different layers.
group_size (int): Group size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, img_size=224, patch_size=[4], in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
group_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, merge_size=[[2], [2], [2]], **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
num_patch_sizes = [len(patch_size)] + [len(m) for m in merge_size]
for i_layer in range(self.num_layers):
patch_size_end = merge_size[i_layer] if i_layer < self.num_layers - 1 else None
num_patch_size = num_patch_sizes[i_layer]
layer = Stage(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
group_size=group_size[i_layer],
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint,
patch_size_end=patch_size_end,
num_patch_size=num_patch_size)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def flops(self):
flops = 0
flops += self.patch_embed.flops()
for i, layer in enumerate(self.layers):
flops += layer.flops()
flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)
flops += self.num_features * self.num_classes
return flops
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CrossFormer(img_size=224,
patch_size=[4, 8, 16, 32],
in_chans= 3,
num_classes=1000,
embed_dim=48,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
group_size=[7, 7, 7, 7],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False,
merge_size=[[2, 4], [2,4], [2, 4]]
)
output=model(input)
print(output.shape)
================================================
FILE: model/attention/DANet.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
from model.attention.SelfAttention import ScaledDotProductAttention
from model.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
class PositionAttentionModule(nn.Module):
def __init__(self,d_model=512,kernel_size=3,H=7,W=7):
super().__init__()
self.cnn=nn.Conv2d(d_model,d_model,kernel_size=kernel_size,padding=(kernel_size-1)//2)
self.pa=ScaledDotProductAttention(d_model,d_k=d_model,d_v=d_model,h=1)
def forward(self,x):
bs,c,h,w=x.shape
y=self.cnn(x)
y=y.view(bs,c,-1).permute(0,2,1) #bs,h*w,c
y=self.pa(y,y,y) #bs,h*w,c
return y
class ChannelAttentionModule(nn.Module):
def __init__(self,d_model=512,kernel_size=3,H=7,W=7):
super().__init__()
self.cnn=nn.Conv2d(d_model,d_model,kernel_size=kernel_size,padding=(kernel_size-1)//2)
self.pa=SimplifiedScaledDotProductAttention(H*W,h=1)
def forward(self,x):
bs,c,h,w=x.shape
y=self.cnn(x)
y=y.view(bs,c,-1) #bs,c,h*w
y=self.pa(y,y,y) #bs,c,h*w
return y
class DAModule(nn.Module):
def __init__(self,d_model=512,kernel_size=3,H=7,W=7):
super().__init__()
self.position_attention_module=PositionAttentionModule(d_model=512,kernel_size=3,H=7,W=7)
self.channel_attention_module=ChannelAttentionModule(d_model=512,kernel_size=3,H=7,W=7)
def forward(self,input):
bs,c,h,w=input.shape
p_out=self.position_attention_module(input)
c_out=self.channel_attention_module(input)
p_out=p_out.permute(0,2,1).view(bs,c,h,w)
c_out=c_out.view(bs,c,h,w)
return p_out+c_out
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
================================================
FILE: model/attention/DAT.py
================================================
# --------------------------------------------------------
# Swin Transformer
# Copyright (c) 2021 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ze Liu
# --------------------------------------------------------
# Vision Transformer with Deformable Attention
# Modified by Zhuofan Xia
# --------------------------------------------------------
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import einops
from timm.models.layers import to_2tuple, trunc_normal_
from timm.models.layers import DropPath, to_2tuple
class LocalAttention(nn.Module):
def __init__(self, dim, heads, window_size, attn_drop, proj_drop):
super().__init__()
window_size = to_2tuple(window_size)
self.proj_qkv = nn.Linear(dim, 3 * dim)
self.heads = heads
assert dim % heads == 0
head_dim = dim // heads
self.scale = head_dim ** -0.5
self.proj_out = nn.Linear(dim, dim)
self.window_size = window_size
self.proj_drop = nn.Dropout(proj_drop, inplace=True)
self.attn_drop = nn.Dropout(attn_drop, inplace=True)
Wh, Ww = self.window_size
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * Wh - 1) * (2 * Ww - 1), heads)
)
trunc_normal_(self.relative_position_bias_table, std=0.01)
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
def forward(self, x, mask=None):
B, C, H, W = x.size()
r1, r2 = H // self.window_size[0], W // self.window_size[1]
x_total = einops.rearrange(x, 'b c (r1 h1) (r2 w1) -> b (r1 r2) (h1 w1) c', h1=self.window_size[0], w1=self.window_size[1]) # B x Nr x Ws x C
x_total = einops.rearrange(x_total, 'b m n c -> (b m) n c')
qkv = self.proj_qkv(x_total) # B' x N x 3C
q, k, v = torch.chunk(qkv, 3, dim=2)
q = q * self.scale
q, k, v = [einops.rearrange(t, 'b n (h c1) -> b h n c1', h=self.heads) for t in [q, k, v]]
attn = torch.einsum('b h m c, b h n c -> b h m n', q, k)
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn_bias = relative_position_bias
attn = attn + attn_bias.unsqueeze(0)
if mask is not None:
# attn =(b * nW) h w w
# mask =nW ww ww
nW, ww, _ = mask.size()
attn = einops.rearrange(attn, '(b n) h w1 w2 -> b n h w1 w2', n=nW, h=self.heads, w1=ww, w2=ww) + mask.reshape(1, nW, 1, ww, ww)
attn = einops.rearrange(attn, 'b n h w1 w2 -> (b n) h w1 w2')
attn = self.attn_drop(attn.softmax(dim=3))
x = torch.einsum('b h m n, b h n c -> b h m c', attn, v)
x = einops.rearrange(x, 'b h n c1 -> b n (h c1)')
x = self.proj_drop(self.proj_out(x)) # B' x N x C
x = einops.rearrange(x, '(b r1 r2) (h1 w1) c -> b c (r1 h1) (r2 w1)', r1=r1, r2=r2, h1=self.window_size[0], w1=self.window_size[1]) # B x C x H x W
return x, None, None
class ShiftWindowAttention(LocalAttention):
def __init__(self, dim, heads, window_size, attn_drop, proj_drop, shift_size, fmap_size):
super().__init__(dim, heads, window_size, attn_drop, proj_drop)
self.fmap_size = to_2tuple(fmap_size)
self.shift_size = shift_size
assert 0 < self.shift_size < min(self.window_size), "wrong shift size."
img_mask = torch.zeros(*self.fmap_size) # H W
h_slices = (slice(0, -self.window_size[0]),
slice(-self.window_size[0], -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size[1]),
slice(-self.window_size[1], -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[h, w] = cnt
cnt += 1
mask_windows = einops.rearrange(img_mask, '(r1 h1) (r2 w1) -> (r1 r2) (h1 w1)', h1=self.window_size[0],w1=self.window_size[1])
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # nW ww ww
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(2, 3))
sw_x, _, _ = super().forward(shifted_x, self.attn_mask)
x = torch.roll(sw_x, shifts=(self.shift_size, self.shift_size), dims=(2, 3))
return x, None, None
class DAttentionBaseline(nn.Module):
def __init__(
self, q_size, kv_size, n_heads, n_head_channels, n_groups,
attn_drop, proj_drop, stride,
offset_range_factor, use_pe, dwc_pe,
no_off, fixed_pe, stage_idx
):
super().__init__()
self.dwc_pe = dwc_pe
self.n_head_channels = n_head_channels
self.scale = self.n_head_channels ** -0.5
self.n_heads = n_heads
self.q_h, self.q_w = q_size
self.kv_h, self.kv_w = kv_size
self.nc = n_head_channels * n_heads
self.n_groups = n_groups
self.n_group_channels = self.nc // self.n_groups
self.n_group_heads = self.n_heads // self.n_groups
self.use_pe = use_pe
self.fixed_pe = fixed_pe
self.no_off = no_off
self.offset_range_factor = offset_range_factor
ksizes = [9, 7, 5, 3]
kk = ksizes[stage_idx]
self.conv_offset = nn.Sequential(
nn.Conv2d(self.n_group_channels, self.n_group_channels, kk, stride, kk//2, groups=self.n_group_channels),
LayerNormProxy(self.n_group_channels),
nn.GELU(),
nn.Conv2d(self.n_group_channels, 2, 1, 1, 0, bias=False)
)
self.proj_q = nn.Conv2d(
self.nc, self.nc,
kernel_size=1, stride=1, padding=0
)
self.proj_k = nn.Conv2d(
self.nc, self.nc,
kernel_size=1, stride=1, padding=0
)
self.proj_v = nn.Conv2d(
self.nc, self.nc,
kernel_size=1, stride=1, padding=0
)
self.proj_out = nn.Conv2d(
self.nc, self.nc,
kernel_size=1, stride=1, padding=0
)
self.proj_drop = nn.Dropout(proj_drop, inplace=True)
self.attn_drop = nn.Dropout(attn_drop, inplace=True)
if self.use_pe:
if self.dwc_pe:
self.rpe_table = nn.Conv2d(self.nc, self.nc,
kernel_size=3, stride=1, padding=1, groups=self.nc)
elif self.fixed_pe:
self.rpe_table = nn.Parameter(
torch.zeros(self.n_heads, self.q_h * self.q_w, self.kv_h * self.kv_w)
)
trunc_normal_(self.rpe_table, std=0.01)
else:
self.rpe_table = nn.Parameter(
torch.zeros(self.n_heads, self.kv_h * 2 - 1, self.kv_w * 2 - 1)
)
trunc_normal_(self.rpe_table, std=0.01)
else:
self.rpe_table = None
@torch.no_grad()
def _get_ref_points(self, H_key, W_key, B, dtype, device):
ref_y, ref_x = torch.meshgrid(
torch.linspace(0.5, H_key - 0.5, H_key, dtype=dtype, device=device),
torch.linspace(0.5, W_key - 0.5, W_key, dtype=dtype, device=device)
)
ref = torch.stack((ref_y, ref_x), -1)
ref[..., 1].div_(W_key).mul_(2).sub_(1)
ref[..., 0].div_(H_key).mul_(2).sub_(1)
ref = ref[None, ...].expand(B * self.n_groups, -1, -1, -1) # B * g H W 2
return ref
def forward(self, x):
B, C, H, W = x.size()
dtype, device = x.dtype, x.device
q = self.proj_q(x)
q_off = einops.rearrange(q, 'b (g c) h w -> (b g) c h w', g=self.n_groups, c=self.n_group_channels)
offset = self.conv_offset(q_off) # B * g 2 Hg Wg
Hk, Wk = offset.size(2), offset.size(3)
n_sample = Hk * Wk
if self.offset_range_factor > 0:
offset_range = torch.tensor([1.0 / Hk, 1.0 / Wk], device=device).reshape(1, 2, 1, 1)
offset = offset.tanh().mul(offset_range).mul(self.offset_range_factor)
offset = einops.rearrange(offset, 'b p h w -> b h w p')
reference = self._get_ref_points(Hk, Wk, B, dtype, device)
if self.no_off:
offset = offset.fill(0.0)
if self.offset_range_factor >= 0:
pos = offset + reference
else:
pos = (offset + reference).tanh()
x_sampled = F.grid_sample(
input=x.reshape(B * self.n_groups, self.n_group_channels, H, W),
grid=pos[..., (1, 0)], # y, x -> x, y
mode='bilinear', align_corners=True) # B * g, Cg, Hg, Wg
x_sampled = x_sampled.reshape(B, C, 1, n_sample)
q = q.reshape(B * self.n_heads, self.n_head_channels, H * W)
k = self.proj_k(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)
v = self.proj_v(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)
attn = torch.einsum('b c m, b c n -> b m n', q, k) # B * h, HW, Ns
attn = attn.mul(self.scale)
if self.use_pe:
if self.dwc_pe:
residual_lepe = self.rpe_table(q.reshape(B, C, H, W)).reshape(B * self.n_heads, self.n_head_channels, H * W)
elif self.fixed_pe:
rpe_table = self.rpe_table
attn_bias = rpe_table[None, ...].expand(B, -1, -1, -1)
attn = attn + attn_bias.reshape(B * self.n_heads, H * W, self.n_sample)
else:
rpe_table = self.rpe_table
rpe_bias = rpe_table[None, ...].expand(B, -1, -1, -1)
q_grid = self._get_ref_points(H, W, B, dtype, device)
displacement = (q_grid.reshape(B * self.n_groups, H * W, 2).unsqueeze(2) - pos.reshape(B * self.n_groups, n_sample, 2).unsqueeze(1)).mul(0.5)
attn_bias = F.grid_sample(
input=rpe_bias.reshape(B * self.n_groups, self.n_group_heads, 2 * H - 1, 2 * W - 1),
grid=displacement[..., (1, 0)],
mode='bilinear', align_corners=True
) # B * g, h_g, HW, Ns
attn_bias = attn_bias.reshape(B * self.n_heads, H * W, n_sample)
attn = attn + attn_bias
attn = F.softmax(attn, dim=2)
attn = self.attn_drop(attn)
out = torch.einsum('b m n, b c n -> b c m', attn, v)
if self.use_pe and self.dwc_pe:
out = out + residual_lepe
out = out.reshape(B, C, H, W)
y = self.proj_drop(self.proj_out(out))
return y, pos.reshape(B, self.n_groups, Hk, Wk, 2), reference.reshape(B, self.n_groups, Hk, Wk, 2)
class TransformerMLP(nn.Module):
def __init__(self, channels, expansion, drop):
super().__init__()
self.dim1 = channels
self.dim2 = channels * expansion
self.chunk = nn.Sequential()
self.chunk.add_module('linear1', nn.Linear(self.dim1, self.dim2))
self.chunk.add_module('act', nn.GELU())
self.chunk.add_module('drop1', nn.Dropout(drop, inplace=True))
self.chunk.add_module('linear2', nn.Linear(self.dim2, self.dim1))
self.chunk.add_module('drop2', nn.Dropout(drop, inplace=True))
def forward(self, x):
_, _, H, W = x.size()
x = einops.rearrange(x, 'b c h w -> b (h w) c')
x = self.chunk(x)
x = einops.rearrange(x, 'b (h w) c -> b c h w', h=H, w=W)
return x
class LayerNormProxy(nn.Module):
def __init__(self, dim):
super().__init__()
self.norm = nn.LayerNorm(dim)
def forward(self, x):
x = einops.rearrange(x, 'b c h w -> b h w c')
x = self.norm(x)
return einops.rearrange(x, 'b h w c -> b c h w')
class TransformerMLPWithConv(nn.Module):
def __init__(self, channels, expansion, drop):
super().__init__()
self.dim1 = channels
self.dim2 = channels * expansion
self.linear1 = nn.Conv2d(self.dim1, self.dim2, 1, 1, 0)
self.drop1 = nn.Dropout(drop, inplace=True)
self.act = nn.GELU()
self.linear2 = nn.Conv2d(self.dim2, self.dim1, 1, 1, 0)
self.drop2 = nn.Dropout(drop, inplace=True)
self.dwc = nn.Conv2d(self.dim2, self.dim2, 3, 1, 1, groups=self.dim2)
def forward(self, x):
x = self.drop1(self.act(self.dwc(self.linear1(x))))
x = self.drop2(self.linear2(x))
return x
class TransformerStage(nn.Module):
def __init__(self, fmap_size, window_size, ns_per_pt,
dim_in, dim_embed, depths, stage_spec, n_groups,
use_pe, sr_ratio,
heads, stride, offset_range_factor, stage_idx,
dwc_pe, no_off, fixed_pe,
attn_drop, proj_drop, expansion, drop, drop_path_rate, use_dwc_mlp):
super().__init__()
fmap_size = to_2tuple(fmap_size)
self.depths = depths
hc = dim_embed // heads
assert dim_embed == heads * hc
self.proj = nn.Conv2d(dim_in, dim_embed, 1, 1, 0) if dim_in != dim_embed else nn.Identity()
self.layer_norms = nn.ModuleList(
[LayerNormProxy(dim_embed) for _ in range(2 * depths)]
)
self.mlps = nn.ModuleList(
[
TransformerMLPWithConv(dim_embed, expansion, drop)
if use_dwc_mlp else TransformerMLP(dim_embed, expansion, drop)
for _ in range(depths)
]
)
self.attns = nn.ModuleList()
self.drop_path = nn.ModuleList()
for i in range(depths):
if stage_spec[i] == 'L':
self.attns.append(
LocalAttention(dim_embed, heads, window_size, attn_drop, proj_drop)
)
elif stage_spec[i] == 'D':
self.attns.append(
DAttentionBaseline(fmap_size, fmap_size, heads,
hc, n_groups, attn_drop, proj_drop,
stride, offset_range_factor, use_pe, dwc_pe,
no_off, fixed_pe, stage_idx)
)
elif stage_spec[i] == 'S':
shift_size = math.ceil(window_size / 2)
self.attns.append(
ShiftWindowAttention(dim_embed, heads, window_size, attn_drop, proj_drop, shift_size, fmap_size)
)
else:
raise NotImplementedError(f'Spec={stage_spec[i]} is not supported.')
self.drop_path.append(DropPath(drop_path_rate[i]) if drop_path_rate[i] > 0.0 else nn.Identity())
def forward(self, x):
x = self.proj(x)
positions = []
references = []
for d in range(self.depths):
x0 = x
x, pos, ref = self.attns[d](self.layer_norms[2 * d](x))
x = self.drop_path[d](x) + x0
x0 = x
x = self.mlps[d](self.layer_norms[2 * d + 1](x))
x = self.drop_path[d](x) + x0
positions.append(pos)
references.append(ref)
return x, positions, references
class DAT(nn.Module):
def __init__(self, img_size=224, patch_size=4, num_classes=1000, expansion=4,
dim_stem=96, dims=[96, 192, 384, 768], depths=[2, 2, 6, 2],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7],
drop_rate=0.0, attn_drop_rate=0.0, drop_path_rate=0.0,
strides=[-1,-1,-1,-1], offset_range_factor=[1, 2, 3, 4],
stage_spec=[['L', 'D'], ['L', 'D'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
groups=[-1, -1, 3, 6],
use_pes=[False, False, False, False],
dwc_pes=[False, False, False, False],
sr_ratios=[8, 4, 2, 1],
fixed_pes=[False, False, False, False],
no_offs=[False, False, False, False],
ns_per_pts=[4, 4, 4, 4],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
**kwargs):
super().__init__()
self.patch_proj = nn.Sequential(
nn.Conv2d(3, dim_stem, 7, patch_size, 3),
LayerNormProxy(dim_stem)
) if use_conv_patches else nn.Sequential(
nn.Conv2d(3, dim_stem, patch_size, patch_size, 0),
LayerNormProxy(dim_stem)
)
img_size = img_size // patch_size
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
self.stages = nn.ModuleList()
for i in range(4):
dim1 = dim_stem if i == 0 else dims[i - 1] * 2
dim2 = dims[i]
self.stages.append(
TransformerStage(img_size, window_sizes[i], ns_per_pts[i],
dim1, dim2, depths[i], stage_spec[i], groups[i], use_pes[i],
sr_ratios[i], heads[i], strides[i],
offset_range_factor[i], i,
dwc_pes[i], no_offs[i], fixed_pes[i],
attn_drop_rate, drop_rate, expansion, drop_rate,
dpr[sum(depths[:i]):sum(depths[:i + 1])],
use_dwc_mlps[i])
)
img_size = img_size // 2
self.down_projs = nn.ModuleList()
for i in range(3):
self.down_projs.append(
nn.Sequential(
nn.Conv2d(dims[i], dims[i + 1], 3, 2, 1, bias=False),
LayerNormProxy(dims[i + 1])
) if use_conv_patches else nn.Sequential(
nn.Conv2d(dims[i], dims[i + 1], 2, 2, 0, bias=False),
LayerNormProxy(dims[i + 1])
)
)
self.cls_norm = LayerNormProxy(dims[-1])
self.cls_head = nn.Linear(dims[-1], num_classes)
self.reset_parameters()
def reset_parameters(self):
for m in self.parameters():
if isinstance(m, (nn.Linear, nn.Conv2d)):
nn.init.kaiming_normal_(m.weight)
nn.init.zeros_(m.bias)
@torch.no_grad()
def load_pretrained(self, state_dict):
new_state_dict = {}
for state_key, state_value in state_dict.items():
keys = state_key.split('.')
m = self
for key in keys:
if key.isdigit():
m = m[int(key)]
else:
m = getattr(m, key)
if m.shape == state_value.shape:
new_state_dict[state_key] = state_value
else:
# Ignore different shapes
if 'relative_position_index' in keys:
new_state_dict[state_key] = m.data
if 'q_grid' in keys:
new_state_dict[state_key] = m.data
if 'reference' in keys:
new_state_dict[state_key] = m.data
# Bicubic Interpolation
if 'relative_position_bias_table' in keys:
n, c = state_value.size()
l = int(math.sqrt(n))
assert n == l ** 2
L = int(math.sqrt(m.shape[0]))
pre_interp = state_value.reshape(1, l, l, c).permute(0, 3, 1, 2)
post_interp = F.interpolate(pre_interp, (L, L), mode='bicubic')
new_state_dict[state_key] = post_interp.reshape(c, L ** 2).permute(1, 0)
if 'rpe_table' in keys:
c, h, w = state_value.size()
C, H, W = m.data.size()
pre_interp = state_value.unsqueeze(0)
post_interp = F.interpolate(pre_interp, (H, W), mode='bicubic')
new_state_dict[state_key] = post_interp.squeeze(0)
self.load_state_dict(new_state_dict, strict=False)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table', 'rpe_table'}
def forward(self, x):
x = self.patch_proj(x)
positions = []
references = []
for i in range(4):
x, pos, ref = self.stages[i](x)
if i < 3:
x = self.down_projs[i](x)
positions.append(pos)
references.append(ref)
x = self.cls_norm(x)
x = F.adaptive_avg_pool2d(x, 1)
x = torch.flatten(x, 1)
x = self.cls_head(x)
return x, positions, references
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DAT(
img_size=224,
patch_size=4,
num_classes=1000,
expansion=4,
dim_stem=96,
dims=[96, 192, 384, 768],
depths=[2, 2, 6, 2],
stage_spec=[['L', 'S'], ['L', 'S'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7] ,
groups=[-1, -1, 3, 6],
use_pes=[False, False, True, True],
dwc_pes=[False, False, False, False],
strides=[-1, -1, 1, 1],
sr_ratios=[-1, -1, -1, -1],
offset_range_factor=[-1, -1, 2, 2],
no_offs=[False, False, False, False],
fixed_pes=[False, False, False, False],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
)
output=model(input)
print(output[0].shape)
================================================
FILE: model/attention/ECAAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
from collections import OrderedDict
class ECAAttention(nn.Module):
def __init__(self, kernel_size=3):
super().__init__()
self.gap=nn.AdaptiveAvgPool2d(1)
self.conv=nn.Conv1d(1,1,kernel_size=kernel_size,padding=(kernel_size-1)//2)
self.sigmoid=nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
y=self.gap(x) #bs,c,1,1
y=y.squeeze(-1).permute(0,2,1) #bs,1,c
y=self.conv(y) #bs,1,c
y=self.sigmoid(y) #bs,1,c
y=y.permute(0,2,1).unsqueeze(-1) #bs,c,1,1
return x*y.expand_as(x)
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
================================================
FILE: model/attention/EMSA.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class EMSA(nn.Module):
def __init__(self, d_model, d_k, d_v, h,dropout=.1,H=7,W=7,ratio=3,apply_transform=True):
super(EMSA, self).__init__()
self.H=H
self.W=W
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.ratio=ratio
if(self.ratio>1):
self.sr=nn.Sequential()
self.sr_conv=nn.Conv2d(d_model,d_model,kernel_size=ratio+1,stride=ratio,padding=ratio//2,groups=d_model)
self.sr_ln=nn.LayerNorm(d_model)
self.apply_transform=apply_transform and h>1
if(self.apply_transform):
self.transform=nn.Sequential()
self.transform.add_module('conv',nn.Conv2d(h,h,kernel_size=1,stride=1))
self.transform.add_module('softmax',nn.Softmax(-1))
self.transform.add_module('in',nn.InstanceNorm2d(h))
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
b_s, nq ,c = queries.shape
nk = keys.shape[1]
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
if(self.ratio>1):
x=queries.permute(0,2,1).view(b_s,c,self.H,self.W) #bs,c,H,W
x=self.sr_conv(x) #bs,c,h,w
x=x.contiguous().view(b_s,c,-1).permute(0,2,1) #bs,n',c
x=self.sr_ln(x)
k = self.fc_k(x).view(b_s, -1, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, n')
v = self.fc_v(x).view(b_s, -1, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, n', d_v)
else:
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
if(self.apply_transform):
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, n')
att = self.transform(att) # (b_s, h, nq, n')
else:
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, n')
att = torch.softmax(att, -1) # (b_s, h, nq, n')
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att=self.dropout(att)
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
return out
if __name__ == '__main__':
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
================================================
FILE: model/attention/ExternalAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ExternalAttention(nn.Module):
def __init__(self, d_model,S=64):
super().__init__()
self.mk=nn.Linear(d_model,S,bias=False)
self.mv=nn.Linear(S,d_model,bias=False)
self.softmax=nn.Softmax(dim=1)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries):
attn=self.mk(queries) #bs,n,S
attn=self.softmax(attn) #bs,n,S
attn=attn/torch.sum(attn,dim=2,keepdim=True) #bs,n,S
out=self.mv(attn) #bs,n,d_model
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
================================================
FILE: model/attention/HaloAttention.py
================================================
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, repeat
# relative positional embedding
def to(x):
return {'device': x.device, 'dtype': x.dtype}
def pair(x):
return (x, x) if not isinstance(x, tuple) else x
def expand_dim(t, dim, k):
t = t.unsqueeze(dim = dim)
expand_shape = [-1] * len(t.shape)
expand_shape[dim] = k
return t.expand(*expand_shape)
def rel_to_abs(x):
b, l, m = x.shape
r = (m + 1) // 2
col_pad = torch.zeros((b, l, 1), **to(x))
x = torch.cat((x, col_pad), dim = 2)
flat_x = rearrange(x, 'b l c -> b (l c)')
flat_pad = torch.zeros((b, m - l), **to(x))
flat_x_padded = torch.cat((flat_x, flat_pad), dim = 1)
final_x = flat_x_padded.reshape(b, l + 1, m)
final_x = final_x[:, :l, -r:]
return final_x
def relative_logits_1d(q, rel_k):
b, h, w, _ = q.shape
r = (rel_k.shape[0] + 1) // 2
logits = einsum('b x y d, r d -> b x y r', q, rel_k)
logits = rearrange(logits, 'b x y r -> (b x) y r')
logits = rel_to_abs(logits)
logits = logits.reshape(b, h, w, r)
logits = expand_dim(logits, dim = 2, k = r)
return logits
class RelPosEmb(nn.Module):
def __init__(
self,
block_size,
rel_size,
dim_head
):
super().__init__()
height = width = rel_size
scale = dim_head ** -0.5
self.block_size = block_size
self.rel_height = nn.Parameter(torch.randn(height * 2 - 1, dim_head) * scale)
self.rel_width = nn.Parameter(torch.randn(width * 2 - 1, dim_head) * scale)
def forward(self, q):
block = self.block_size
q = rearrange(q, 'b (x y) c -> b x y c', x = block)
rel_logits_w = relative_logits_1d(q, self.rel_width)
rel_logits_w = rearrange(rel_logits_w, 'b x i y j-> b (x y) (i j)')
q = rearrange(q, 'b x y d -> b y x d')
rel_logits_h = relative_logits_1d(q, self.rel_height)
rel_logits_h = rearrange(rel_logits_h, 'b x i y j -> b (y x) (j i)')
return rel_logits_w + rel_logits_h
# classes
class HaloAttention(nn.Module):
def __init__(
self,
*,
dim,
block_size,
halo_size,
dim_head = 64,
heads = 8
):
super().__init__()
assert halo_size > 0, 'halo size must be greater than 0'
self.dim = dim
self.heads = heads
self.scale = dim_head ** -0.5
self.block_size = block_size
self.halo_size = halo_size
inner_dim = dim_head * heads
self.rel_pos_emb = RelPosEmb(
block_size = block_size,
rel_size = block_size + (halo_size * 2),
dim_head = dim_head
)
self.to_q = nn.Linear(dim, inner_dim, bias = False)
self.to_kv = nn.Linear(dim, inner_dim * 2, bias = False)
self.to_out = nn.Linear(inner_dim, dim)
def forward(self, x):
b, c, h, w, block, halo, heads, device = *x.shape, self.block_size, self.halo_size, self.heads, x.device
assert h % block == 0 and w % block == 0, 'fmap dimensions must be divisible by the block size'
assert c == self.dim, f'channels for input ({c}) does not equal to the correct dimension ({self.dim})'
# get block neighborhoods, and prepare a halo-ed version (blocks with padding) for deriving key values
q_inp = rearrange(x, 'b c (h p1) (w p2) -> (b h w) (p1 p2) c', p1 = block, p2 = block)
kv_inp = F.unfold(x, kernel_size = block + halo * 2, stride = block, padding = halo)
kv_inp = rearrange(kv_inp, 'b (c j) i -> (b i) j c', c = c)
# derive queries, keys, values
q = self.to_q(q_inp)
k, v = self.to_kv(kv_inp).chunk(2, dim = -1)
# split heads
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h = heads), (q, k, v))
# scale
q *= self.scale
# attention
sim = einsum('b i d, b j d -> b i j', q, k)
# add relative positional bias
sim += self.rel_pos_emb(q)
# mask out padding (in the paper, they claim to not need masks, but what about padding?)
mask = torch.ones(1, 1, h, w, device = device)
mask = F.unfold(mask, kernel_size = block + (halo * 2), stride = block, padding = halo)
mask = repeat(mask, '() j i -> (b i h) () j', b = b, h = heads)
mask = mask.bool()
max_neg_value = -torch.finfo(sim.dtype).max
sim.masked_fill_(mask, max_neg_value)
# attention
attn = sim.softmax(dim = -1)
# aggregate
out = einsum('b i j, b j d -> b i d', attn, v)
# merge and combine heads
out = rearrange(out, '(b h) n d -> b n (h d)', h = heads)
out = self.to_out(out)
# merge blocks back to original feature map
out = rearrange(out, '(b h w) (p1 p2) c -> b c (h p1) (w p2)', b = b, h = (h // block), w = (w // block), p1 = block, p2 = block)
return out
if __name__ == '__main__':
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)
================================================
FILE: model/attention/MOATransformer.py
================================================
# --------------------------------------------------------
# Adopted from Swin Transformer
# Modified by Krushi Patel
# --------------------------------------------------------
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from einops.layers.torch import Rearrange, Reduce
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.query_size = self.window_size
self.key_size = self.window_size[0] * 2
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
#return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
return f'dim={self.dim}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 window with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
return flops
class GlobalAttention(nn.Module):
r""" MOA - multi-head self attention (W-MSA) module with relative position bias.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, input_resolution,num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.query_size = self.window_size[0]
self.key_size = self.window_size[0] + 2
h,w = input_resolution
self.seq_len = h//self.query_size
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.reduction = 32
self.pre_conv = nn.Conv2d(dim, int(dim//self.reduction), 1)
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * self.seq_len - 1) * (2 * self.seq_len - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
#print(self.relative_position_bias_table.shape)
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.seq_len)
coords_w = torch.arange(self.seq_len)
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.seq_len - 1 # shift to start from 0
relative_coords[:, :, 1] += self.seq_len - 1
relative_coords[:, :, 0] *= 2 * self.seq_len - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.queryembedding = Rearrange('b c (h p1) (w p2) -> b (p1 p2 c) h w', p1 = self.query_size, p2 = self. query_size)
self.keyembedding = nn.Unfold(kernel_size=(self.key_size, self.key_size), stride = 14, padding=1)
self.query_dim = int(dim//self.reduction) * self.query_size * self.query_size
self.key_dim = int(dim//self.reduction) * self.key_size * self.key_size
self.q = nn.Linear(self.query_dim, self.dim,bias=qkv_bias)
self.kv = nn.Linear(self.key_dim, 2*self.dim,bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim,dim)
self.proj_drop = nn.Dropout(proj_drop)
#trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, H, W):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
#B, H, W, C = x.shape
B,_, C = x.shape
x = x.reshape(-1, C, H, W)
x = self.pre_conv(x)
query = self.queryembedding(x).view(B,-1,self.query_dim)
query = self.q(query)
B,N,C = query.size()
q = query.reshape(B,N,self.num_heads, C//self.num_heads).permute(0,2,1,3)
key = self.keyembedding(x).view(B,-1,self.key_dim)
kv = self.kv(key).reshape(B,N,2,self.num_heads,C//self.num_heads).permute(2,0,3,1,4)
k = kv[0]
v = kv[1]
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.seq_len * self.seq_len, self.seq_len * self.seq_len, -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 window with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
return flops
class LocalTransformerBlock(nn.Module):
r""" Local Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.window_size = min(self.input_resolution)
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
x_windows = window_partition(x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
attn_windows = self.attn(x_windows) # nW*B, window_size*window_size, C
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"window_size={self.window_size}, mlp_ratio={self.mlp_ratio}"
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# W-MSA/SW-MSA
nW = H * W / self.window_size / self.window_size
flops += nW * self.attn.flops(self.window_size * self.window_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops
class PatchMerging(nn.Module):
""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
def extra_repr(self) -> str:
return f"input_resolution={self.input_resolution}, dim={self.dim}"
def flops(self):
H, W = self.input_resolution
flops = H * W * self.dim
flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
return flops
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, drop_path_global=0., use_checkpoint=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
self.window_size = window_size
self.drop_path_gl = DropPath(drop_path_global) if drop_path_global > 0. else nn.Identity()
# build blocks
self.blocks = nn.ModuleList([
LocalTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
if min(self.input_resolution) >= self.window_size:
self.glb_attn = GlobalAttention(dim, to_2tuple(window_size), self.input_resolution, num_heads = num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.post_conv = nn.Conv2d(dim, dim, 3, padding=1)
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
else:
self.post_conv = None
self.glb_attn = None
self.norm1 = None
self.norm2 = None
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
if min(self.input_resolution) >= self.window_size:
shortcut = x
x = self.norm1(x)
H, W = self.input_resolution
B,_,C = x.size()
no_window = int(H*W/self.window_size**2)
local_attn = x.view(B,no_window,self.window_size, self.window_size,C)
glb_attn = self.glb_attn(x, H, W)
glb_attn = glb_attn.view(B,no_window,1,1,C)
x = torch.add(local_attn, glb_attn).view(B,C,H,W)
x = shortcut.view(B,C,H,W) + self.drop_path_gl(x)
x = self.norm2(x.view(B,H*W,C))
post_conv = self.drop_path_gl(self.post_conv(x.view(B,C,H,W))).view(B, H*W, C)
x = x + post_conv
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
def flops(self):
flops = 0
for blk in self.blocks:
flops += blk.flops()
if self.downsample is not None:
flops += self.downsample.flops()
return flops
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
class MOATransformer(nn.Module):
r""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
dpr_global = [x.item() for x in torch.linspace(0, 0.2, len(depths)-1)]
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
drop_path_global = (dpr_global[i_layer]) if (i_layer < self.num_layers -1) else 0,
use_checkpoint=use_checkpoint)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def flops(self):
flops = 0
flops += self.patch_embed.flops()
for i, layer in enumerate(self.layers):
flops += layer.flops()
flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)
flops += self.num_features * self.num_classes
return flops
# --------------------------------------------------------
# Adopted from Swin Transformer
# Modified by Krushi Patel
# print(sum(p.numel() for p in model.parameters() if p.requires_grad), 'parameters')
# --------------------------------------------------------
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = MOATransformer(
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=[2, 2, 6],
num_heads=[3, 6, 12],
window_size=14,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False
)
output=model(input)
print(output.shape)
================================================
FILE: model/attention/MUSEAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class Depth_Pointwise_Conv1d(nn.Module):
def __init__(self,in_ch,out_ch,k):
super().__init__()
if(k==1):
self.depth_conv=nn.Identity()
else:
self.depth_conv=nn.Conv1d(
in_channels=in_ch,
out_channels=in_ch,
kernel_size=k,
groups=in_ch,
padding=k//2
)
self.pointwise_conv=nn.Conv1d(
in_channels=in_ch,
out_channels=out_ch,
kernel_size=1,
groups=1
)
def forward(self,x):
out=self.pointwise_conv(self.depth_conv(x))
return out
class MUSEAttention(nn.Module):
def __init__(self, d_model, d_k, d_v, h,dropout=.1):
super(MUSEAttention, self).__init__()
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.conv1=Depth_Pointwise_Conv1d(h * d_v, d_model,1)
self.conv3=Depth_Pointwise_Conv1d(h * d_v, d_model,3)
self.conv5=Depth_Pointwise_Conv1d(h * d_v, d_model,5)
self.dy_paras=nn.Parameter(torch.ones(3))
self.softmax=nn.Softmax(-1)
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
#Self Attention
b_s, nq = queries.shape[:2]
nk = keys.shape[1]
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, nk)
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att = torch.softmax(att, -1)
att=self.dropout(att)
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
v2=v.permute(0,1,3,2).contiguous().view(b_s,-1,nk) #bs,dim,n
self.dy_paras=nn.Parameter(self.softmax(self.dy_paras))
out2=self.dy_paras[0]*self.conv1(v2)+self.dy_paras[1]*self.conv3(v2)+self.dy_paras[2]*self.conv5(v2)
out2=out2.permute(0,2,1) #bs.n.dim
out=out+out2
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
================================================
FILE: model/attention/MobileViTAttention.py
================================================
from torch import nn
import torch
from einops import rearrange
class PreNorm(nn.Module):
def __init__(self,dim,fn):
super().__init__()
self.ln=nn.LayerNorm(dim)
self.fn=fn
def forward(self,x,**kwargs):
return self.fn(self.ln(x),**kwargs)
class FeedForward(nn.Module):
def __init__(self,dim,mlp_dim,dropout) :
super().__init__()
self.net=nn.Sequential(
nn.Linear(dim,mlp_dim),
nn.SiLU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim,dim),
nn.Dropout(dropout)
)
def forward(self,x):
return self.net(x)
class Attention(nn.Module):
def __init__(self,dim,heads,head_dim,dropout):
super().__init__()
inner_dim=heads*head_dim
project_out=not(heads==1 and head_dim==dim)
self.heads=heads
self.scale=head_dim**-0.5
self.attend=nn.Softmax(dim=-1)
self.to_qkv=nn.Linear(dim,inner_dim*3,bias=False)
self.to_out=nn.Sequential(
nn.Linear(inner_dim,dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self,x):
qkv=self.to_qkv(x).chunk(3,dim=-1)
q,k,v=map(lambda t:rearrange(t,'b p n (h d) -> b p h n d',h=self.heads),qkv)
dots=torch.matmul(q,k.transpose(-1,-2))*self.scale
attn=self.attend(dots)
out=torch.matmul(attn,v)
out=rearrange(out,'b p h n d -> b p n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self,dim,depth,heads,head_dim,mlp_dim,dropout=0.):
super().__init__()
self.layers=nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim,Attention(dim,heads,head_dim,dropout)),
PreNorm(dim,FeedForward(dim,mlp_dim,dropout))
]))
def forward(self,x):
out=x
for att,ffn in self.layers:
out=out+att(out)
out=out+ffn(out)
return out
class MobileViTAttention(nn.Module):
def __init__(self,in_channel=3,dim=512,kernel_size=3,patch_size=7):
super().__init__()
self.ph,self.pw=patch_size,patch_size
self.conv1=nn.Conv2d(in_channel,in_channel,kernel_size=kernel_size,padding=kernel_size//2)
self.conv2=nn.Conv2d(in_channel,dim,kernel_size=1)
self.trans=Transformer(dim=dim,depth=3,heads=8,head_dim=64,mlp_dim=1024)
self.conv3=nn.Conv2d(dim,in_channel,kernel_size=1)
self.conv4=nn.Conv2d(2*in_channel,in_channel,kernel_size=kernel_size,padding=kernel_size//2)
def forward(self,x):
y=x.clone() #bs,c,h,w
## Local Representation
y=self.conv2(self.conv1(x)) #bs,dim,h,w
## Global Representation
_,_,h,w=y.shape
y=rearrange(y,'bs dim (nh ph) (nw pw) -> bs (ph pw) (nh nw) dim',ph=self.ph,pw=self.pw) #bs,h,w,dim
y=self.trans(y)
y=rearrange(y,'bs (ph pw) (nh nw) dim -> bs dim (nh ph) (nw pw)',ph=self.ph,pw=self.pw,nh=h//self.ph,nw=w//self.pw) #bs,dim,h,w
## Fusion
y=self.conv3(y) #bs,dim,h,w
y=torch.cat([x,y],1) #bs,2*dim,h,w
y=self.conv4(y) #bs,c,h,w
return y
if __name__ == '__main__':
m=MobileViTAttention()
input=torch.randn(1,3,49,49)
output=m(input)
print(output.shape)
================================================
FILE: model/attention/MobileViTv2Attention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class MobileViTv2Attention(nn.Module):
'''
Scaled dot-product attention
'''
def __init__(self, d_model):
'''
:param d_model: Output dimensionality of the model
:param d_k: Dimensionality of queries and keys
:param d_v: Dimensionality of values
:param h: Number of heads
'''
super(MobileViTv2Attention, self).__init__()
self.fc_i = nn.Linear(d_model,1)
self.fc_k = nn.Linear(d_model, d_model)
self.fc_v = nn.Linear(d_model, d_model)
self.fc_o = nn.Linear(d_model, d_model)
self.d_model = d_model
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, input):
'''
Computes
:param queries: Queries (b_s, nq, d_model)
:return:
'''
i = self.fc_i(input) #(bs,nq,1)
weight_i = torch.softmax(i, dim=1) #bs,nq,1
context_score = weight_i * self.fc_k(input) #bs,nq,d_model
context_vector = torch.sum(context_score,dim=1,keepdim=True) #bs,1,d_model
v = self.fc_v(input) * context_vector #bs,nq,d_model
out = self.fc_o(v) #bs,nq,d_model
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
================================================
FILE: model/attention/OutlookAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
import math
from torch.nn import functional as F
class OutlookAttention(nn.Module):
def __init__(self,dim,num_heads=1,kernel_size=3,padding=1,stride=1,qkv_bias=False,
attn_drop=0.1):
super().__init__()
self.dim=dim
self.num_heads=num_heads
self.head_dim=dim//num_heads
self.kernel_size=kernel_size
self.padding=padding
self.stride=stride
self.scale=self.head_dim**(-0.5)
self.v_pj=nn.Linear(dim,dim,bias=qkv_bias)
self.attn=nn.Linear(dim,kernel_size**4*num_heads)
self.attn_drop=nn.Dropout(attn_drop)
self.proj=nn.Linear(dim,dim)
self.proj_drop=nn.Dropout(attn_drop)
self.unflod=nn.Unfold(kernel_size,padding,stride) #手动卷积
self.pool=nn.AvgPool2d(kernel_size=stride,stride=stride,ceil_mode=True)
def forward(self, x) :
B,H,W,C=x.shape
#映射到新的特征v
v=self.v_pj(x).permute(0,3,1,2) #B,C,H,W
h,w=math.ceil(H/self.stride),math.ceil(W/self.stride)
v=self.unflod(v).reshape(B,self.num_heads,self.head_dim,self.kernel_size*self.kernel_size,h*w).permute(0,1,4,3,2) #B,num_head,H*W,kxk,head_dim
#生成Attention Map
attn=self.pool(x.permute(0,3,1,2)).permute(0,2,3,1) #B,H,W,C
attn=self.attn(attn).reshape(B,h*w,self.num_heads,self.kernel_size*self.kernel_size \
,self.kernel_size*self.kernel_size).permute(0,2,1,3,4) #B,num_head,H*W,kxk,kxk
attn=self.scale*attn
attn=attn.softmax(-1)
attn=self.attn_drop(attn)
#获取weighted特征
out=(attn @ v).permute(0,1,4,3,2).reshape(B,C*self.kernel_size*self.kernel_size,h*w) #B,dimxkxk,H*W
out=F.fold(out,output_size=(H,W),kernel_size=self.kernel_size,
padding=self.padding,stride=self.stride) #B,C,H,W
out=self.proj(out.permute(0,2,3,1)) #B,H,W,C
out=self.proj_drop(out)
return out
if __name__ == '__main__':
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)
================================================
FILE: model/attention/PSA.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class PSA(nn.Module):
def __init__(self, channel=512,reduction=4,S=4):
super().__init__()
self.S=S
self.convs=[]
for i in range(S):
self.convs.append(nn.Conv2d(channel//S,channel//S,kernel_size=2*(i+1)+1,padding=i+1))
self.se_blocks=[]
for i in range(S):
self.se_blocks.append(nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channel//S, channel // (S*reduction),kernel_size=1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(channel // (S*reduction), channel//S,kernel_size=1, bias=False),
nn.Sigmoid()
))
self.softmax=nn.Softmax(dim=1)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, h, w = x.size()
#Step1:SPC module
SPC_out=x.view(b,self.S,c//self.S,h,w) #bs,s,ci,h,w
for idx,conv in enumerate(self.convs):
SPC_out[:,idx,:,:,:]=conv(SPC_out[:,idx,:,:,:])
#Step2:SE weight
se_out=[]
for idx,se in enumerate(self.se_blocks):
se_out.append(se(SPC_out[:,idx,:,:,:]))
SE_out=torch.stack(se_out,dim=1)
SE_out=SE_out.expand_as(SPC_out)
#Step3:Softmax
softmax_out=self.softmax(SE_out)
#Step4:SPA
PSA_out=SPC_out*softmax_out
PSA_out=PSA_out.view(b,-1,h,w)
return PSA_out
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
a=output.view(-1).sum()
a.backward()
print(output.shape)
================================================
FILE: model/attention/ParNetAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ParNetAttention(nn.Module):
def __init__(self, channel=512):
super().__init__()
self.sse = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channel,channel,kernel_size=1),
nn.Sigmoid()
)
self.conv1x1=nn.Sequential(
nn.Conv2d(channel,channel,kernel_size=1),
nn.BatchNorm2d(channel)
)
self.conv3x3=nn.Sequential(
nn.Conv2d(channel,channel,kernel_size=3,padding=1),
nn.BatchNorm2d(channel)
)
self.silu=nn.SiLU()
def forward(self, x):
b, c, _, _ = x.size()
x1=self.conv1x1(x)
x2=self.conv3x3(x)
x3=self.sse(x)*x
y=self.silu(x1+x2+x3)
return y
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
pna = ParNetAttention(channel=512)
output=pna(input)
print(output.shape)
================================================
FILE: model/attention/PolarizedSelfAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ParallelPolarizedSelfAttention(nn.Module):
def __init__(self, channel=512):
super().__init__()
self.ch_wv=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.ch_wq=nn.Conv2d(channel,1,kernel_size=(1,1))
self.softmax_channel=nn.Softmax(1)
self.softmax_spatial=nn.Softmax(-1)
self.ch_wz=nn.Conv2d(channel//2,channel,kernel_size=(1,1))
self.ln=nn.LayerNorm(channel)
self.sigmoid=nn.Sigmoid()
self.sp_wv=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.sp_wq=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.agp=nn.AdaptiveAvgPool2d((1,1))
def forward(self, x):
b, c, h, w = x.size()
#Channel-only Self-Attention
channel_wv=self.ch_wv(x) #bs,c//2,h,w
channel_wq=self.ch_wq(x) #bs,1,h,w
channel_wv=channel_wv.reshape(b,c//2,-1) #bs,c//2,h*w
channel_wq=channel_wq.reshape(b,-1,1) #bs,h*w,1
channel_wq=self.softmax_channel(channel_wq)
channel_wz=torch.matmul(channel_wv,channel_wq).unsqueeze(-1) #bs,c//2,1,1
channel_weight=self.sigmoid(self.ln(self.ch_wz(channel_wz).reshape(b,c,1).permute(0,2,1))).permute(0,2,1).reshape(b,c,1,1) #bs,c,1,1
channel_out=channel_weight*x
#Spatial-only Self-Attention
spatial_wv=self.sp_wv(x) #bs,c//2,h,w
spatial_wq=self.sp_wq(x) #bs,c//2,h,w
spatial_wq=self.agp(spatial_wq) #bs,c//2,1,1
spatial_wv=spatial_wv.reshape(b,c//2,-1) #bs,c//2,h*w
spatial_wq=spatial_wq.permute(0,2,3,1).reshape(b,1,c//2) #bs,1,c//2
spatial_wq=self.softmax_spatial(spatial_wq)
spatial_wz=torch.matmul(spatial_wq,spatial_wv) #bs,1,h*w
spatial_weight=self.sigmoid(spatial_wz.reshape(b,1,h,w)) #bs,1,h,w
spatial_out=spatial_weight*x
out=spatial_out+channel_out
return out
class SequentialPolarizedSelfAttention(nn.Module):
def __init__(self, channel=512):
super().__init__()
self.ch_wv=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.ch_wq=nn.Conv2d(channel,1,kernel_size=(1,1))
self.softmax_channel=nn.Softmax(1)
self.softmax_spatial=nn.Softmax(-1)
self.ch_wz=nn.Conv2d(channel//2,channel,kernel_size=(1,1))
self.ln=nn.LayerNorm(channel)
self.sigmoid=nn.Sigmoid()
self.sp_wv=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.sp_wq=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.agp=nn.AdaptiveAvgPool2d((1,1))
def forward(self, x):
b, c, h, w = x.size()
#Channel-only Self-Attention
channel_wv=self.ch_wv(x) #bs,c//2,h,w
channel_wq=self.ch_wq(x) #bs,1,h,w
channel_wv=channel_wv.reshape(b,c//2,-1) #bs,c//2,h*w
channel_wq=channel_wq.reshape(b,-1,1) #bs,h*w,1
channel_wq=self.softmax_channel(channel_wq)
channel_wz=torch.matmul(channel_wv,channel_wq).unsqueeze(-1) #bs,c//2,1,1
channel_weight=self.sigmoid(self.ln(self.ch_wz(channel_wz).reshape(b,c,1).permute(0,2,1))).permute(0,2,1).reshape(b,c,1,1) #bs,c,1,1
channel_out=channel_weight*x
#Spatial-only Self-Attention
spatial_wv=self.sp_wv(channel_out) #bs,c//2,h,w
spatial_wq=self.sp_wq(channel_out) #bs,c//2,h,w
spatial_wq=self.agp(spatial_wq) #bs,c//2,1,1
spatial_wv=spatial_wv.reshape(b,c//2,-1) #bs,c//2,h*w
spatial_wq=spatial_wq.permute(0,2,3,1).reshape(b,1,c//2) #bs,1,c//2
spatial_wq=self.softmax_spatial(spatial_wq)
spatial_wz=torch.matmul(spatial_wq,spatial_wv) #bs,1,h*w
spatial_weight=self.sigmoid(spatial_wz.reshape(b,1,h,w)) #bs,1,h,w
spatial_out=spatial_weight*channel_out
return spatial_out
if __name__ == '__main__':
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
================================================
FILE: model/attention/ResidualAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ResidualAttention(nn.Module):
def __init__(self, channel=512 , num_class=1000,la=0.2):
super().__init__()
self.la=la
self.fc=nn.Conv2d(in_channels=channel,out_channels=num_class,kernel_size=1,stride=1,bias=False)
def forward(self, x):
b,c,h,w=x.shape
y_raw=self.fc(x).flatten(2) #b,num_class,hxw
y_avg=torch.mean(y_raw,dim=2) #b,num_class
y_max=torch.max(y_raw,dim=2)[0] #b,num_class
score=y_avg+self.la*y_max
return score
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
resatt = ResidualAttention(channel=512,num_class=1000,la=0.2)
output=resatt(input)
print(output.shape)
================================================
FILE: model/attention/S2Attention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
def spatial_shift1(x):
b,w,h,c = x.size()
x[:,1:,:,:c//4] = x[:,:w-1,:,:c//4]
x[:,:w-1,:,c//4:c//2] = x[:,1:,:,c//4:c//2]
x[:,:,1:,c//2:c*3//4] = x[:,:,:h-1,c//2:c*3//4]
x[:,:,:h-1,3*c//4:] = x[:,:,1:,3*c//4:]
return x
def spatial_shift2(x):
b,w,h,c = x.size()
x[:,:,1:,:c//4] = x[:,:,:h-1,:c//4]
x[:,:,:h-1,c//4:c//2] = x[:,:,1:,c//4:c//2]
x[:,1:,:,c//2:c*3//4] = x[:,:w-1,:,c//2:c*3//4]
x[:,:w-1,:,3*c//4:] = x[:,1:,:,3*c//4:]
return x
class SplitAttention(nn.Module):
def __init__(self,channel=512,k=3):
super().__init__()
self.channel=channel
self.k=k
self.mlp1=nn.Linear(channel,channel,bias=False)
self.gelu=nn.GELU()
self.mlp2=nn.Linear(channel,channel*k,bias=False)
self.softmax=nn.Softmax(1)
def forward(self,x_all):
b,k,h,w,c=x_all.shape
x_all=x_all.reshape(b,k,-1,c) #bs,k,n,c
a=torch.sum(torch.sum(x_all,1),1) #bs,c
hat_a=self.mlp2(self.gelu(self.mlp1(a))) #bs,kc
hat_a=hat_a.reshape(b,self.k,c) #bs,k,c
bar_a=self.softmax(hat_a) #bs,k,c
attention=bar_a.unsqueeze(-2) # #bs,k,1,c
out=attention*x_all # #bs,k,n,c
out=torch.sum(out,1).reshape(b,h,w,c)
return out
class S2Attention(nn.Module):
def __init__(self, channels=512 ):
super().__init__()
self.mlp1 = nn.Linear(channels,channels*3)
self.mlp2 = nn.Linear(channels,channels)
self.split_attention = SplitAttention()
def forward(self, x):
b,c,w,h = x.size()
x=x.permute(0,2,3,1)
x = self.mlp1(x)
x1 = spatial_shift1(x[:,:,:,:c])
x2 = spatial_shift2(x[:,:,:,c:c*2])
x3 = x[:,:,:,c*2:]
x_all=torch.stack([x1,x2,x3],1)
a = self.split_attention(x_all)
x = self.mlp2(a)
x=x.permute(0,3,1,2)
return x
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
s2att = S2Attention(channels=512)
output=s2att(input)
print(output.shape)
================================================
FILE: model/attention/SEAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SEAttention(nn.Module):
def __init__(self, channel=512,reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
================================================
FILE: model/attention/SGE.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SpatialGroupEnhance(nn.Module):
def __init__(self, groups):
super().__init__()
self.groups=groups
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.weight=nn.Parameter(torch.zeros(1,groups,1,1))
self.bias=nn.Parameter(torch.zeros(1,groups,1,1))
self.sig=nn.Sigmoid()
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, h,w=x.shape
x=x.view(b*self.groups,-1,h,w) #bs*g,dim//g,h,w
xn=x*self.avg_pool(x) #bs*g,dim//g,h,w
xn=xn.sum(dim=1,keepdim=True) #bs*g,1,h,w
t=xn.view(b*self.groups,-1) #bs*g,h*w
t=t-t.mean(dim=1,keepdim=True) #bs*g,h*w
std=t.std(dim=1,keepdim=True)+1e-5
t=t/std #bs*g,h*w
t=t.view(b,self.groups,h,w) #bs,g,h*w
t=t*self.weight+self.bias #bs,g,h*w
t=t.view(b*self.groups,1,h,w) #bs*g,1,h*w
x=x*self.sig(t)
x=x.view(b,c,h,w)
return x
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
================================================
FILE: model/attention/SKAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
from collections import OrderedDict
class SKAttention(nn.Module):
def __init__(self, channel=512,kernels=[1,3,5,7],reduction=16,group=1,L=32):
super().__init__()
self.d=max(L,channel//reduction)
self.convs=nn.ModuleList([])
for k in kernels:
self.convs.append(
nn.Sequential(OrderedDict([
('conv',nn.Conv2d(channel,channel,kernel_size=k,padding=k//2,groups=group)),
('bn',nn.BatchNorm2d(channel)),
('relu',nn.ReLU())
]))
)
self.fc=nn.Linear(channel,self.d)
self.fcs=nn.ModuleList([])
for i in range(len(kernels)):
self.fcs.append(nn.Linear(self.d,channel))
self.softmax=nn.Softmax(dim=0)
def forward(self, x):
bs, c, _, _ = x.size()
conv_outs=[]
### split
for conv in self.convs:
conv_outs.append(conv(x))
feats=torch.stack(conv_outs,0)#k,bs,channel,h,w
### fuse
U=sum(conv_outs) #bs,c,h,w
### reduction channel
S=U.mean(-1).mean(-1) #bs,c
Z=self.fc(S) #bs,d
### calculate attention weight
weights=[]
for fc in self.fcs:
weight=fc(Z)
weights.append(weight.view(bs,c,1,1)) #bs,channel
attention_weughts=torch.stack(weights,0)#k,bs,channel,1,1
attention_weughts=self.softmax(attention_weughts)#k,bs,channel,1,1
### fuse
V=(attention_weughts*feats).sum(0)
return V
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
================================================
FILE: model/attention/SelfAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ScaledDotProductAttention(nn.Module):
'''
Scaled dot-product attention
'''
def __init__(self, d_model, d_k, d_v, h,dropout=.1):
'''
:param d_model: Output dimensionality of the model
:param d_k: Dimensionality of queries and keys
:param d_v: Dimensionality of values
:param h: Number of heads
'''
super(ScaledDotProductAttention, self).__init__()
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
'''
Computes
:param queries: Queries (b_s, nq, d_model)
:param keys: Keys (b_s, nk, d_model)
:param values: Values (b_s, nk, d_model)
:param attention_mask: Mask over attention values (b_s, h, nq, nk). True indicates masking.
:param attention_weights: Multiplicative weights for attention values (b_s, h, nq, nk).
:return:
'''
b_s, nq = queries.shape[:2]
nk = keys.shape[1]
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, nk)
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att = torch.softmax(att, -1)
att=self.dropout(att)
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
================================================
FILE: model/attention/ShuffleAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn.parameter import Parameter
class ShuffleAttention(nn.Module):
def __init__(self, channel=512,reduction=16,G=8):
super().__init__()
self.G=G
self.channel=channel
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))
self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sigmoid=nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
@staticmethod
def channel_shuffle(x, groups):
b, c, h, w = x.shape
x = x.reshape(b, groups, -1, h, w)
x = x.permute(0, 2, 1, 3, 4)
# flatten
x = x.reshape(b, -1, h, w)
return x
def forward(self, x):
b, c, h, w = x.size()
#group into subfeatures
x=x.view(b*self.G,-1,h,w) #bs*G,c//G,h,w
#channel_split
x_0,x_1=x.chunk(2,dim=1) #bs*G,c//(2*G),h,w
#channel attention
x_channel=self.avg_pool(x_0) #bs*G,c//(2*G),1,1
x_channel=self.cweight*x_channel+self.cbias #bs*G,c//(2*G),1,1
x_channel=x_0*self.sigmoid(x_channel)
#spatial attention
x_spatial=self.gn(x_1) #bs*G,c//(2*G),h,w
x_spatial=self.sweight*x_spatial+self.sbias #bs*G,c//(2*G),h,w
x_spatial=x_1*self.sigmoid(x_spatial) #bs*G,c//(2*G),h,w
# concatenate along channel axis
out=torch.cat([x_channel,x_spatial],dim=1) #bs*G,c//G,h,w
out=out.contiguous().view(b,-1,h,w)
# channel shuffle
out = self.channel_shuffle(out, 2)
return out
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
================================================
FILE: model/attention/SimAM.py
================================================
import torch
import torch.nn as nn
class SimAM(torch.nn.Module):
def __init__(self, channels = None, e_lambda = 1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2,3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2,3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = SimAM(64)
outputs = model(input)
print(outputs.shape)
================================================
FILE: model/attention/SimplifiedSelfAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SimplifiedScaledDotProductAttention(nn.Module):
'''
Scaled dot-product attention
'''
def __init__(self, d_model, h,dropout=.1):
'''
:param d_model: Output dimensionality of the model
:param d_k: Dimensionality of queries and keys
:param d_v: Dimensionality of values
:param h: Number of heads
'''
super(SimplifiedScaledDotProductAttention, self).__init__()
self.d_model = d_model
self.d_k = d_model//h
self.d_v = d_model//h
self.h = h
self.fc_o = nn.Linear(h * self.d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
'''
Computes
:param queries: Queries (b_s, nq, d_model)
:param keys: Keys (b_s, nk, d_model)
:param values: Values (b_s, nk, d_model)
:param attention_mask: Mask over attention values (b_s, h, nq, nk). True indicates masking.
:param attention_weights: Multiplicative weights for attention values (b_s, h, nq, nk).
:return:
'''
b_s, nq = queries.shape[:2]
nk = keys.shape[1]
q = queries.view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = keys.view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = values.view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, nk)
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att = torch.softmax(att, -1)
att=self.dropout(att)
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)
================================================
FILE: model/attention/TripletAttention.py
================================================
import torch
import torch.nn as nn
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes,eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class ZPool(nn.Module):
def forward(self, x):
return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1)
class AttentionGate(nn.Module):
def __init__(self):
super(AttentionGate, self).__init__()
kernel_size = 7
self.compress = ZPool()
self.conv = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.conv(x_compress)
scale = torch.sigmoid_(x_out)
return x * scale
class TripletAttention(nn.Module):
def __init__(self, no_spatial=False):
super(TripletAttention, self).__init__()
self.cw = AttentionGate()
self.hc = AttentionGate()
self.no_spatial=no_spatial
if not no_spatial:
self.hw = AttentionGate()
def forward(self, x):
x_perm1 = x.permute(0,2,1,3).contiguous()
x_out1 = self.cw(x_perm1)
x_out11 = x_out1.permute(0,2,1,3).contiguous()
x_perm2 = x.permute(0,3,2,1).contiguous()
x_out2 = self.hc(x_perm2)
x_out21 = x_out2.permute(0,3,2,1).contiguous()
if not self.no_spatial:
x_out = self.hw(x)
x_out = 1/3 * (x_out + x_out11 + x_out21)
else:
x_out = 1/2 * (x_out11 + x_out21)
return x_out
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
triplet = TripletAttention()
output=triplet(input)
print(output.shape)
================================================
FILE: model/attention/UFOAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.functional import norm
from torch.nn import init
def XNorm(x,gamma):
norm_tensor=torch.norm(x,2,-1,True)
return x*gamma/norm_tensor
class UFOAttention(nn.Module):
'''
Scaled dot-product attention
'''
def __init__(self, d_model, d_k, d_v, h,dropout=.1):
'''
:param d_model: Output dimensionality of the model
:param d_k: Dimensionality of queries and keys
:param d_v: Dimensionality of values
:param h: Number of heads
'''
super(UFOAttention, self).__init__()
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.gamma=nn.Parameter(torch.randn((1,h,1,1)))
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values):
b_s, nq = queries.shape[:2]
nk = keys.shape[1]
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
kv=torch.matmul(k, v) #bs,h,c,c
kv_norm=XNorm(kv,self.gamma) #bs,h,c,c
q_norm=XNorm(q,self.gamma) #bs,h,n,c
out=torch.matmul(q_norm,kv_norm).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
ufo = UFOAttention(d_model=512, d_k=512, d_v=512, h=8)
output=ufo(input,input,input)
print(output.shape)
================================================
FILE: model/attention/ViP.py
================================================
import torch
from torch import nn
class MLP(nn.Module):
def __init__(self,in_features,hidden_features,out_features,act_layer=nn.GELU,drop=0.1):
super().__init__()
self.fc1=nn.Linear(in_features,hidden_features)
self.act=act_layer()
self.fc2=nn.Linear(hidden_features,out_features)
self.drop=nn.Dropout(drop)
def forward(self, x) :
return self.drop(self.fc2(self.drop(self.act(self.fc1(x)))))
class WeightedPermuteMLP(nn.Module):
def __init__(self,dim,seg_dim=8, qkv_bias=False, proj_drop=0.):
super().__init__()
self.seg_dim=seg_dim
self.mlp_c=nn.Linear(dim,dim,bias=qkv_bias)
self.mlp_h=nn.Linear(dim,dim,bias=qkv_bias)
self.mlp_w=nn.Linear(dim,dim,bias=qkv_bias)
self.reweighting=MLP(dim,dim//4,dim*3)
self.proj=nn.Linear(dim,dim)
self.proj_drop=nn.Dropout(proj_drop)
def forward(self,x) :
B,H,W,C=x.shape
c_embed=self.mlp_c(x)
S=C//self.seg_dim
h_embed=x.reshape(B,H,W,self.seg_dim,S).permute(0,3,2,1,4).reshape(B,self.seg_dim,W,H*S)
h_embed=self.mlp_h(h_embed).reshape(B,self.seg_dim,W,H,S).permute(0,3,2,1,4).reshape(B,H,W,C)
w_embed=x.reshape(B,H,W,self.seg_dim,S).permute(0,3,1,2,4).reshape(B,self.seg_dim,H,W*S)
w_embed=self.mlp_w(w_embed).reshape(B,self.seg_dim,H,W,S).permute(0,2,3,1,4).reshape(B,H,W,C)
weight=(c_embed+h_embed+w_embed).permute(0,3,1,2).flatten(2).mean(2)
weight=self.reweighting(weight).reshape(B,C,3).permute(2,0,1).softmax(0).unsqueeze(2).unsqueeze(2)
x=c_embed*weight[0]+w_embed*weight[1]+h_embed*weight[2]
x=self.proj_drop(self.proj(x))
return x
if __name__ == '__main__':
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)
================================================
FILE: model/attention/gfnet.py
================================================
import torch
from torch import nn
import math
from timm.models.layers import DropPath, to_2tuple
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class GlobalFilter(nn.Module):
def __init__(self, dim, h=14, w=8):
super().__init__()
self.complex_weight = nn.Parameter(torch.randn(h, w, dim, 2, dtype=torch.float32) * 0.02)
self.w = w
self.h = h
def forward(self, x, spatial_size=None):
B, N, C = x.shape
if spatial_size is None:
a = b = int(math.sqrt(N))
else:
a, b = spatial_size
x = x.view(B, a, b, C)
x = x.to(torch.float32)
x = torch.fft.rfft2(x, dim=(1, 2), norm='ortho')
weight = torch.view_as_complex(self.complex_weight)
x = x * weight
x = torch.fft.irfft2(x, s=(a, b), dim=(1, 2), norm='ortho')
x = x.reshape(B, N, C)
return x
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, mlp_ratio=4., drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, h=14, w=8):
super().__init__()
self.norm1 = norm_layer(dim)
self.filter = GlobalFilter(dim, h=h, w=w)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.mlp(self.norm2(self.filter(self.norm1(x)))))
return x
class GFNet(nn.Module):
def __init__(self, embed_dim=384, img_size=224, patch_size=16, mlp_ratio=4, depth=4, num_classes=1000):
super().__init__()
self.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, embed_dim=embed_dim)
self.embedding = nn.Linear((patch_size ** 2) * 3, embed_dim)
h = img_size // patch_size
w = h // 2 + 1
self.blocks = nn.ModuleList([
Block(dim=embed_dim, mlp_ratio=mlp_ratio, h=h, w=w)
for i in range(depth)
])
self.head = nn.Linear(embed_dim, num_classes)
self.softmax = nn.Softmax(1)
def forward(self, x):
x = self.patch_embed(x)
for blk in self.blocks:
x = blk(x)
x = x.mean(dim=1)
x = self.softmax(self.head(x))
return x
if __name__ == '__main__':
x = torch.randn(1, 3, 224, 224)
gfnet = GFNet(embed_dim=384, img_size=224, patch_size=16, num_classes=1000)
out = gfnet(x)
print(out.shape)
================================================
FILE: model/backbone/CMT.py
================================================
## Author: Jianyuan Guo (jyguo@pku.edu.cn)
import math
import logging
from functools import partial
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.helpers import load_pretrained
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.resnet import resnet26d, resnet50d
from timm.models.registry import register_model
_logger = logging.getLogger(__name__)
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
# A memory-efficient implementation of Swish function
class SwishImplementation(torch.autograd.Function):
@staticmethod
def forward(ctx, i):
result = i * torch.sigmoid(i)
ctx.save_for_backward(i)
return result
@staticmethod
def backward(ctx, grad_output):
i = ctx.saved_tensors[0]
sigmoid_i = torch.sigmoid(i)
return grad_output * (sigmoid_i * (1 + i * (1 - sigmoid_i)))
class MemoryEfficientSwish(nn.Module):
def forward(self, x):
return SwishImplementation.apply(x)
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.conv1 = nn.Sequential(
nn.Conv2d(in_features, hidden_features, 1, 1, 0, bias=True),
nn.GELU(),
nn.BatchNorm2d(hidden_features, eps=1e-5),
)
self.proj = nn.Conv2d(hidden_features, hidden_features, 3, 1, 1, groups=hidden_features)
self.proj_act = nn.GELU()
self.proj_bn = nn.BatchNorm2d(hidden_features, eps=1e-5)
self.conv2 = nn.Sequential(
nn.Conv2d(hidden_features, out_features, 1, 1, 0, bias=True),
nn.BatchNorm2d(out_features, eps=1e-5),
)
self.drop = nn.Dropout(drop)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.permute(0, 2, 1).reshape(B, C, H, W)
x = self.conv1(x)
x = self.drop(x)
x = self.proj(x) + x
x = self.proj_act(x)
x = self.proj_bn(x)
x = self.conv2(x)
x = x.flatten(2).permute(0, 2, 1)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None,
attn_drop=0., proj_drop=0., qk_ratio=1, sr_ratio=1):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qk_dim = dim // qk_ratio
self.q = nn.Linear(dim, self.qk_dim, bias=qkv_bias)
self.k = nn.Linear(dim, self.qk_dim, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
# Exactly same as PVTv1
if self.sr_ratio > 1:
self.sr = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio, groups=dim, bias=True),
nn.BatchNorm2d(dim, eps=1e-5),
)
def forward(self, x, H, W, relative_pos):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, self.qk_dim // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
k = self.k(x_).reshape(B, -1, self.num_heads, self.qk_dim // self.num_heads).permute(0, 2, 1, 3)
v = self.v(x_).reshape(B, -1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
else:
k = self.k(x).reshape(B, N, self.num_heads, self.qk_dim // self.num_heads).permute(0, 2, 1, 3)
v = self.v(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
attn = (q @ k.transpose(-2, -1)) * self.scale + relative_pos
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, qk_ratio=1, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, qk_ratio=qk_ratio, sr_ratio=sr_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.proj = nn.Conv2d(dim, dim, 3, 1, 1, groups=dim)
def forward(self, x, H, W, relative_pos):
B, N, C = x.shape
cnn_feat = x.permute(0, 2, 1).reshape(B, C, H, W)
x = self.proj(cnn_feat) + cnn_feat
x = x.flatten(2).permute(0, 2, 1)
x = x + self.drop_path(self.attn(self.norm1(x), H, W, relative_pos))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
f"img_size {img_size} should be divided by patch_size {patch_size}."
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)
class CMT(nn.Module):
def __init__(self, img_size=224, in_chans=3, num_classes=1000, embed_dims=[46,92,184,368], stem_channel=16, fc_dim=1280,
num_heads=[1,2,4,8], mlp_ratios=[3.6,3.6,3.6,3.6], qkv_bias=True, qk_scale=None, representation_size=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., hybrid_backbone=None, norm_layer=None,
depths=[2,2,10,2], qk_ratio=1, sr_ratios=[8,4,2,1], dp=0.1):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dims[-1]
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
self.stem_conv1 = nn.Conv2d(3, stem_channel, kernel_size=3, stride=2, padding=1, bias=True)
self.stem_relu1 = nn.GELU()
self.stem_norm1 = nn.BatchNorm2d(stem_channel, eps=1e-5)
self.stem_conv2 = nn.Conv2d(stem_channel, stem_channel, kernel_size=3, stride=1, padding=1, bias=True)
self.stem_relu2 = nn.GELU()
self.stem_norm2 = nn.BatchNorm2d(stem_channel, eps=1e-5)
self.stem_conv3 = nn.Conv2d(stem_channel, stem_channel, kernel_size=3, stride=1, padding=1, bias=True)
self.stem_relu3 = nn.GELU()
self.stem_norm3 = nn.BatchNorm2d(stem_channel, eps=1e-5)
self.patch_embed_a = PatchEmbed(
img_size=img_size//2, patch_size=2, in_chans=stem_channel, embed_dim=embed_dims[0])
self.patch_embed_b = PatchEmbed(
img_size=img_size//4, patch_size=2, in_chans=embed_dims[0], embed_dim=embed_dims[1])
self.patch_embed_c = PatchEmbed(
img_size=img_size//8, patch_size=2, in_chans=embed_dims[1], embed_dim=embed_dims[2])
self.patch_embed_d = PatchEmbed(
img_size=img_size//16, patch_size=2, in_chans=embed_dims[2], embed_dim=embed_dims[3])
self.relative_pos_a = nn.Parameter(torch.randn(
num_heads[0], self.patch_embed_a.num_patches, self.patch_embed_a.num_patches//sr_ratios[0]//sr_ratios[0]))
self.relative_pos_b = nn.Parameter(torch.randn(
num_heads[1], self.patch_embed_b.num_patches, self.patch_embed_b.num_patches//sr_ratios[1]//sr_ratios[1]))
self.relative_pos_c = nn.Parameter(torch.randn(
num_heads[2], self.patch_embed_c.num_patches, self.patch_embed_c.num_patches//sr_ratios[2]//sr_ratios[2]))
self.relative_pos_d = nn.Parameter(torch.randn(
num_heads[3], self.patch_embed_d.num_patches, self.patch_embed_d.num_patches//sr_ratios[3]//sr_ratios[3]))
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
self.blocks_a = nn.ModuleList([
Block(
dim=embed_dims[0], num_heads=num_heads[0], mlp_ratio=mlp_ratios[0], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur+i],
norm_layer=norm_layer, qk_ratio=qk_ratio, sr_ratio=sr_ratios[0])
for i in range(depths[0])])
cur += depths[0]
self.blocks_b = nn.ModuleList([
Block(
dim=embed_dims[1], num_heads=num_heads[1], mlp_ratio=mlp_ratios[1], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur+i],
norm_layer=norm_layer, qk_ratio=qk_ratio, sr_ratio=sr_ratios[1])
for i in range(depths[1])])
cur += depths[1]
self.blocks_c = nn.ModuleList([
Block(
dim=embed_dims[2], num_heads=num_heads[2], mlp_ratio=mlp_ratios[2], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur+i],
norm_layer=norm_layer, qk_ratio=qk_ratio, sr_ratio=sr_ratios[2])
for i in range(depths[2])])
cur += depths[2]
self.blocks_d = nn.ModuleList([
Block(
dim=embed_dims[3], num_heads=num_heads[3], mlp_ratio=mlp_ratios[3], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur+i],
norm_layer=norm_layer, qk_ratio=qk_ratio, sr_ratio=sr_ratios[3])
for i in range(depths[3])])
# Representation layer
if representation_size:
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
('fc', nn.Linear(embed_dim, representation_size)),
('act', nn.Tanh())
]))
else:
self.pre_logits = nn.Identity()
# Classifier head
self._fc = nn.Conv2d(embed_dims[-1], fc_dim, kernel_size=1)
self._bn = nn.BatchNorm2d(fc_dim, eps=1e-5)
self._swish = MemoryEfficientSwish()
self._avg_pooling = nn.AdaptiveAvgPool2d(1)
self._drop = nn.Dropout(dp)
self.head = nn.Linear(fc_dim, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if isinstance(m, nn.Conv2d) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def update_temperature(self):
for m in self.modules():
if isinstance(m, Attention):
m.update_temperature()
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x = self.stem_conv1(x)
x = self.stem_relu1(x)
x = self.stem_norm1(x)
x = self.stem_conv2(x)
x = self.stem_relu2(x)
x = self.stem_norm2(x)
x = self.stem_conv3(x)
x = self.stem_relu3(x)
x = self.stem_norm3(x)
x, (H, W) = self.patch_embed_a(x)
for i, blk in enumerate(self.blocks_a):
x = blk(x, H, W, self.relative_pos_a)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x, (H, W) = self.patch_embed_b(x)
for i, blk in enumerate(self.blocks_b):
x = blk(x, H, W, self.relative_pos_b)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x, (H, W) = self.patch_embed_c(x)
for i, blk in enumerate(self.blocks_c):
x = blk(x, H, W, self.relative_pos_c)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x, (H, W) = self.patch_embed_d(x)
for i, blk in enumerate(self.blocks_d):
x = blk(x, H, W, self.relative_pos_d)
B, N, C = x.shape
x = self._fc(x.permute(0, 2, 1).reshape(B, C, H, W))
x = self._bn(x)
x = self._swish(x)
x = self._avg_pooling(x).flatten(start_dim=1)
x = self._drop(x)
x = self.pre_logits(x)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def resize_pos_embed(posemb, posemb_new):
# Rescale the grid of position embeddings when loading from state_dict. Adapted from
# https://github.com/google-research/vision_transformer/blob/00883dd691c63a6830751563748663526e811cee/vit_jax/checkpoint.py#L224
_logger.info('Resized position embedding: %s to %s', posemb.shape, posemb_new.shape)
ntok_new = posemb_new.shape[1]
if True:
posemb_tok, posemb_grid = posemb[:, :1], posemb[0, 1:]
ntok_new -= 1
else:
posemb_tok, posemb_grid = posemb[:, :0], posemb[0]
gs_old = int(math.sqrt(len(posemb_grid)))
gs_new = int(math.sqrt(ntok_new))
_logger.info('Position embedding grid-size from %s to %s', gs_old, gs_new)
posemb_grid = posemb_grid.reshape(1, gs_old, gs_old, -1).permute(0, 3, 1, 2)
posemb_grid = F.interpolate(posemb_grid, size=(gs_new, gs_new), mode='bilinear')
posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, gs_new * gs_new, -1)
posemb = torch.cat([posemb_tok, posemb_grid], dim=1)
return posemb
def checkpoint_filter_fn(state_dict, model):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
if 'model' in state_dict:
# For deit models
state_dict = state_dict['model']
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k and len(v.shape) < 4:
# For old models that I trained prior to conv based patchification
O, I, H, W = model.patch_embed.proj.weight.shape
v = v.reshape(O, -1, H, W)
elif k == 'pos_embed' and v.shape != model.pos_embed.shape:
# To resize pos embedding when using model at different size from pretrained weights
v = resize_pos_embed(v, model.pos_embed)
out_dict[k] = v
return out_dict
def _create_cmt_model(pretrained=False, distilled=False, **kwargs):
default_cfg = _cfg()
default_num_classes = default_cfg['num_classes']
default_img_size = default_cfg['input_size'][-1]
num_classes = kwargs.pop('num_classes', default_num_classes)
img_size = kwargs.pop('img_size', default_img_size)
repr_size = kwargs.pop('representation_size', None)
if repr_size is not None and num_classes != default_num_classes:
# Remove representation layer if fine-tuning. This may not always be the desired action,
# but I feel better than doing nothing by default for fine-tuning. Perhaps a better interface?
_logger.warning("Removing representation layer for fine-tuning.")
repr_size = None
model = CMT(img_size=img_size, num_classes=num_classes, representation_size=repr_size, **kwargs)
model.default_cfg = default_cfg
if pretrained:
load_pretrained(
model, num_classes=num_classes, in_chans=kwargs.get('in_chans', 3),
filter_fn=partial(checkpoint_filter_fn, model=model))
return model
@register_model
def cmt_ti(pretrained=False, **kwargs):
"""
CMT-Tiny
"""
model_kwargs = dict(qkv_bias=True, **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
@register_model
def cmt_xs(pretrained=False, **kwargs):
"""
CMT-XS: dim x 0.9, depth x 0.8, input 192
"""
model_kwargs = dict(
qkv_bias=True, embed_dims=[52,104,208,416], stem_channel=16, num_heads=[1,2,4,8],
depths=[3,3,12,3], mlp_ratios=[3.77,3.77,3.77,3.77], qk_ratio=1, sr_ratios=[8,4,2,1], **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
@register_model
def cmt_s(pretrained=False, **kwargs):
"""
CMT-Small
"""
model_kwargs = dict(
qkv_bias=True, embed_dims=[64,128,256,512], stem_channel=32, num_heads=[1,2,4,8],
depths=[3,3,16,3], mlp_ratios=[4,4,4,4], qk_ratio=1, sr_ratios=[8,4,2,1], **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
@register_model
def cmt_b(pretrained=False, **kwargs):
"""
CMT-Base
"""
model_kwargs = dict(
qkv_bias=True, embed_dims=[76,152,304,608], stem_channel=38, num_heads=[1,2,4,8],
depths=[4,4,20,4], mlp_ratios=[4,4,4,4], qk_ratio=1, sr_ratios=[8,4,2,1], dp=0.3, **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
@register_model
def CMT_Tiny(pretrained=False, **kwargs):
"""
CMT-Tiny
"""
model_kwargs = dict(qkv_bias=True, **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CMT_Tiny()
output=model(input)
print(output[0].shape)
================================================
FILE: model/backbone/CPVT.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
from timm.models.vision_transformer import Block as TimmBlock
from timm.models.vision_transformer import Attention as TimmAttention
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class GroupAttention(nn.Module):
"""
LSA: self attention within a group
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., ws=1):
assert ws != 1
super(GroupAttention, self).__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.ws = ws
def forward(self, x, H, W):
B, N, C = x.shape
h_group, w_group = H // self.ws, W // self.ws
total_groups = h_group * w_group
x = x.reshape(B, h_group, self.ws, w_group, self.ws, C).transpose(2, 3)
qkv = self.qkv(x).reshape(B, total_groups, -1, 3, self.num_heads, C // self.num_heads).permute(3, 0, 1, 4, 2, 5)
# B, hw, ws*ws, 3, n_head, head_dim -> 3, B, hw, n_head, ws*ws, head_dim
q, k, v = qkv[0], qkv[1], qkv[2] # B, hw, n_head, ws*ws, head_dim
attn = (q @ k.transpose(-2, -1)) * self.scale # B, hw, n_head, ws*ws, ws*ws
attn = attn.softmax(dim=-1)
attn = self.attn_drop(
attn) # attn @ v-> B, hw, n_head, ws*ws, head_dim -> (t(2,3)) B, hw, ws*ws, n_head, head_dim
attn = (attn @ v).transpose(2, 3).reshape(B, h_group, w_group, self.ws, self.ws, C)
x = attn.transpose(2, 3).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Attention(nn.Module):
"""
GSA: using a key to summarize the information for a group to be efficient.
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class SBlock(TimmBlock):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super(SBlock, self).__init__(dim, num_heads, mlp_ratio, qkv_bias, qk_scale, drop, attn_drop,
drop_path, act_layer, norm_layer)
def forward(self, x, H, W):
return super(SBlock, self).forward(x)
class GroupBlock(TimmBlock):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1, ws=1):
super(GroupBlock, self).__init__(dim, num_heads, mlp_ratio, qkv_bias, qk_scale, drop, attn_drop,
drop_path, act_layer, norm_layer)
del self.attn
if ws == 1:
self.attn = Attention(dim, num_heads, qkv_bias, qk_scale, attn_drop, drop, sr_ratio)
else:
self.attn = GroupAttention(dim, num_heads, qkv_bias, qk_scale, attn_drop, drop, ws)
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
f"img_size {img_size} should be divided by patch_size {patch_size}."
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)
# borrow from PVT https://github.com/whai362/PVT.git
class PyramidVisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], block_cls=Block):
super().__init__()
self.num_classes = num_classes
self.depths = depths
# patch_embed
self.patch_embeds = nn.ModuleList()
self.pos_embeds = nn.ParameterList()
self.pos_drops = nn.ModuleList()
self.blocks = nn.ModuleList()
for i in range(len(depths)):
if i == 0:
self.patch_embeds.append(PatchEmbed(img_size, patch_size, in_chans, embed_dims[i]))
else:
self.patch_embeds.append(
PatchEmbed(img_size // patch_size // 2 ** (i - 1), 2, embed_dims[i - 1], embed_dims[i]))
patch_num = self.patch_embeds[-1].num_patches + 1 if i == len(embed_dims) - 1 else self.patch_embeds[
-1].num_patches
self.pos_embeds.append(nn.Parameter(torch.zeros(1, patch_num, embed_dims[i])))
self.pos_drops.append(nn.Dropout(p=drop_rate))
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for k in range(len(depths)):
_block = nn.ModuleList([block_cls(
dim=embed_dims[k], num_heads=num_heads[k], mlp_ratio=mlp_ratios[k], qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[k])
for i in range(depths[k])])
self.blocks.append(_block)
cur += depths[k]
self.norm = norm_layer(embed_dims[-1])
# cls_token
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dims[-1]))
# classification head
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
# init weights
for pos_emb in self.pos_embeds:
trunc_normal_(pos_emb, std=.02)
self.apply(self._init_weights)
def reset_drop_path(self, drop_path_rate):
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(self.depths))]
cur = 0
for k in range(len(self.depths)):
for i in range(self.depths[k]):
self.blocks[k][i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[k]
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
for i in range(len(self.depths)):
x, (H, W) = self.patch_embeds[i](x)
if i == len(self.depths) - 1:
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embeds[i]
x = self.pos_drops[i](x)
for blk in self.blocks[i]:
x = blk(x, H, W)
if i < len(self.depths) - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
# PEG from https://arxiv.org/abs/2102.10882
class PosCNN(nn.Module):
def __init__(self, in_chans, embed_dim=768, s=1):
super(PosCNN, self).__init__()
self.proj = nn.Sequential(nn.Conv2d(in_chans, embed_dim, 3, s, 1, bias=True, groups=embed_dim), )
self.s = s
def forward(self, x, H, W):
B, N, C = x.shape
feat_token = x
cnn_feat = feat_token.transpose(1, 2).view(B, C, H, W)
if self.s == 1:
x = self.proj(cnn_feat) + cnn_feat
else:
x = self.proj(cnn_feat)
x = x.flatten(2).transpose(1, 2)
return x
def no_weight_decay(self):
return ['proj.%d.weight' % i for i in range(4)]
class CPVTV2(PyramidVisionTransformer):
"""
Use useful results from CPVT. PEG and GAP.
Therefore, cls token is no longer required.
PEG is used to encode the absolute position on the fly, which greatly affects the performance when input resolution
changes during the training (such as segmentation, detection)
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], block_cls=Block):
super(CPVTV2, self).__init__(img_size, patch_size, in_chans, num_classes, embed_dims, num_heads, mlp_ratios,
qkv_bias, qk_scale, drop_rate, attn_drop_rate, drop_path_rate, norm_layer, depths,
sr_ratios, block_cls)
del self.pos_embeds
del self.cls_token
self.pos_block = nn.ModuleList(
[PosCNN(embed_dim, embed_dim) for embed_dim in embed_dims]
)
self.apply(self._init_weights)
def _init_weights(self, m):
import math
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1.0)
m.bias.data.zero_()
def no_weight_decay(self):
return set(['cls_token'] + ['pos_block.' + n for n, p in self.pos_block.named_parameters()])
def forward_features(self, x):
B = x.shape[0]
for i in range(len(self.depths)):
x, (H, W) = self.patch_embeds[i](x)
x = self.pos_drops[i](x)
for j, blk in enumerate(self.blocks[i]):
x = blk(x, H, W)
if j == 0:
x = self.pos_block[i](x, H, W) # PEG here
if i < len(self.depths) - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x = self.norm(x)
return x.mean(dim=1) # GAP here
class PCPVT(CPVTV2):
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256],
num_heads=[1, 2, 4], mlp_ratios=[4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[4, 4, 4], sr_ratios=[4, 2, 1], block_cls=SBlock):
super(PCPVT, self).__init__(img_size, patch_size, in_chans, num_classes, embed_dims, num_heads,
mlp_ratios, qkv_bias, qk_scale, drop_rate, attn_drop_rate, drop_path_rate,
norm_layer, depths, sr_ratios, block_cls)
class ALTGVT(PCPVT):
"""
alias Twins-SVT
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256],
num_heads=[1, 2, 4], mlp_ratios=[4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[4, 4, 4], sr_ratios=[4, 2, 1], block_cls=GroupBlock, wss=[7, 7, 7]):
super(ALTGVT, self).__init__(img_size, patch_size, in_chans, num_classes, embed_dims, num_heads,
mlp_ratios, qkv_bias, qk_scale, drop_rate, attn_drop_rate, drop_path_rate,
norm_layer, depths, sr_ratios, block_cls)
del self.blocks
self.wss = wss
# transformer encoder
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
self.blocks = nn.ModuleList()
for k in range(len(depths)):
_block = nn.ModuleList([block_cls(
dim=embed_dims[k], num_heads=num_heads[k], mlp_ratio=mlp_ratios[k], qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[k], ws=1 if i % 2 == 1 else wss[k]) for i in range(depths[k])])
self.blocks.append(_block)
cur += depths[k]
self.apply(self._init_weights)
def _conv_filter(state_dict, patch_size=16):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k:
v = v.reshape((v.shape[0], 3, patch_size, patch_size))
out_dict[k] = v
return out_dict
@register_model
def pcpvt_small_v0(pretrained=False, **kwargs):
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pcpvt_base_v0(pretrained=False, **kwargs):
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 18, 3], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pcpvt_large_v0(pretrained=False, **kwargs):
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 8, 27, 3], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/CaiT.py
================================================
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
import torch
import torch.nn as nn
from functools import partial
from timm.models.vision_transformer import Mlp, PatchEmbed , _cfg
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_, DropPath
__all__ = [
'cait_M48', 'cait_M36',
'cait_S36', 'cait_S24','cait_S24_224',
'cait_XS24','cait_XXS24','cait_XXS24_224',
'cait_XXS36','cait_XXS36_224'
]
class Class_Attention(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to do CA
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.k = nn.Linear(dim, dim, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x ):
B, N, C = x.shape
q = self.q(x[:,0]).unsqueeze(1).reshape(B, 1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
k = self.k(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
q = q * self.scale
v = self.v(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
attn = (q @ k.transpose(-2, -1))
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x_cls = (attn @ v).transpose(1, 2).reshape(B, 1, C)
x_cls = self.proj(x_cls)
x_cls = self.proj_drop(x_cls)
return x_cls
class LayerScale_Block_CA(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to add CA and LayerScale
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, Attention_block = Class_Attention,
Mlp_block=Mlp,init_values=1e-4):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention_block(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp_block(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)),requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)),requires_grad=True)
def forward(self, x, x_cls):
u = torch.cat((x_cls,x),dim=1)
x_cls = x_cls + self.drop_path(self.gamma_1 * self.attn(self.norm1(u)))
x_cls = x_cls + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x_cls)))
return x_cls
class Attention_talking_head(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to add Talking Heads Attention (https://arxiv.org/pdf/2003.02436v1.pdf)
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_l = nn.Linear(num_heads, num_heads)
self.proj_w = nn.Linear(num_heads, num_heads)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0] * self.scale , qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1))
attn = self.proj_l(attn.permute(0,2,3,1)).permute(0,3,1,2)
attn = attn.softmax(dim=-1)
attn = self.proj_w(attn.permute(0,2,3,1)).permute(0,3,1,2)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class LayerScale_Block(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to add layerScale
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,Attention_block = Attention_talking_head,
Mlp_block=Mlp,init_values=1e-4):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention_block(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp_block(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)),requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)),requires_grad=True)
def forward(self, x):
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x)))
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))
return x
class CaiT(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to adapt to our cait models
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., norm_layer=nn.LayerNorm, global_pool=None,
block_layers = LayerScale_Block,
block_layers_token = LayerScale_Block_CA,
Patch_layer=PatchEmbed,act_layer=nn.GELU,
Attention_block = Attention_talking_head,Mlp_block=Mlp,
init_scale=1e-4,
Attention_block_token_only=Class_Attention,
Mlp_block_token_only= Mlp,
depth_token_only=2,
mlp_ratio_clstk = 4.0):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.patch_embed = Patch_layer(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [drop_path_rate for i in range(depth)]
self.blocks = nn.ModuleList([
block_layers(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
act_layer=act_layer,Attention_block=Attention_block,Mlp_block=Mlp_block,init_values=init_scale)
for i in range(depth)])
self.blocks_token_only = nn.ModuleList([
block_layers_token(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio_clstk, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=0.0, attn_drop=0.0, drop_path=0.0, norm_layer=norm_layer,
act_layer=act_layer,Attention_block=Attention_block_token_only,
Mlp_block=Mlp_block_token_only,init_values=init_scale)
for i in range(depth_token_only)])
self.norm = norm_layer(embed_dim)
self.feature_info = [dict(num_chs=embed_dim, reduction=0, module='head')]
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1)
x = x + self.pos_embed
x = self.pos_drop(x)
for i , blk in enumerate(self.blocks):
x = blk(x)
for i , blk in enumerate(self.blocks_token_only):
cls_tokens = blk(x,cls_tokens)
x = torch.cat((cls_tokens, x), dim=1)
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
@register_model
def cait_XXS24_224(pretrained=False, **kwargs):
model = CaiT(
img_size= 224,patch_size=16, embed_dim=192, depth=24, num_heads=4, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/XXS24_224.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_XXS24(pretrained=False, **kwargs):
model = CaiT(
img_size= 384,patch_size=16, embed_dim=192, depth=24, num_heads=4, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/XXS24_384.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_XXS36_224(pretrained=False, **kwargs):
model = CaiT(
img_size= 224,patch_size=16, embed_dim=192, depth=36, num_heads=4, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/XXS36_224.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_XXS36(pretrained=False, **kwargs):
model = CaiT(
img_size= 384,patch_size=16, embed_dim=192, depth=36, num_heads=4, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/XXS36_384.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_XS24(pretrained=False, **kwargs):
model = CaiT(
img_size= 384,patch_size=16, embed_dim=288, depth=24, num_heads=6, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/XS24_384.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_S24_224(pretrained=False, **kwargs):
model = CaiT(
img_size= 224,patch_size=16, embed_dim=384, depth=24, num_heads=8, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/S24_224.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_S24(pretrained=False, **kwargs):
model = CaiT(
img_size= 384,patch_size=16, embed_dim=384, depth=24, num_heads=8, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/S24_384.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_S36(pretrained=False, **kwargs):
model = CaiT(
img_size= 384,patch_size=16, embed_dim=384, depth=36, num_heads=8, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-6,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/S36_384.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_M36(pretrained=False, **kwargs):
model = CaiT(
img_size= 384, patch_size=16, embed_dim=768, depth=36, num_heads=16, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-6,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/M36_384.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_M48(pretrained=False, **kwargs):
model = CaiT(
img_size= 448 , patch_size=16, embed_dim=768, depth=48, num_heads=16, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-6,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/M48_448.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CaiT(
img_size= 224,
patch_size=16,
embed_dim=192,
depth=24,
num_heads=4,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/CeiT.py
================================================
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import default_cfgs, _cfg
__all__ = [
'ceit_tiny_patch16_224', 'ceit_small_patch16_224', 'ceit_base_patch16_224',
'ceit_tiny_patch16_384', 'ceit_small_patch16_384',
]
class Image2Tokens(nn.Module):
def __init__(self, in_chans=3, out_chans=64, kernel_size=7, stride=2):
super(Image2Tokens, self).__init__()
self.conv = nn.Conv2d(in_chans, out_chans, kernel_size=kernel_size, stride=stride,
padding=kernel_size // 2, bias=False)
self.bn = nn.BatchNorm2d(out_chans)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.maxpool(x)
return x
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class LocallyEnhancedFeedForward(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.,
kernel_size=3, with_bn=True):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
# pointwise
self.conv1 = nn.Conv2d(in_features, hidden_features, kernel_size=1, stride=1, padding=0)
# depthwise
self.conv2 = nn.Conv2d(
hidden_features, hidden_features, kernel_size=kernel_size, stride=1,
padding=(kernel_size - 1) // 2, groups=hidden_features
)
# pointwise
self.conv3 = nn.Conv2d(hidden_features, out_features, kernel_size=1, stride=1, padding=0)
self.act = act_layer()
# self.drop = nn.Dropout(drop)
self.with_bn = with_bn
if self.with_bn:
self.bn1 = nn.BatchNorm2d(hidden_features)
self.bn2 = nn.BatchNorm2d(hidden_features)
self.bn3 = nn.BatchNorm2d(out_features)
def forward(self, x):
b, n, k = x.size()
cls_token, tokens = torch.split(x, [1, n - 1], dim=1)
x = tokens.reshape(b, int(math.sqrt(n - 1)), int(math.sqrt(n - 1)), k).permute(0, 3, 1, 2)
if self.with_bn:
x = self.conv1(x)
x = self.bn1(x)
x = self.act(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.act(x)
x = self.conv3(x)
x = self.bn3(x)
else:
x = self.conv1(x)
x = self.act(x)
x = self.conv2(x)
x = self.act(x)
x = self.conv3(x)
tokens = x.flatten(2).permute(0, 2, 1)
out = torch.cat((cls_token, tokens), dim=1)
return out
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.attention_map = None
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# self.attention_map = attn
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class AttentionLCA(Attention):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super(AttentionLCA, self).__init__(dim, num_heads, qkv_bias, qk_scale, attn_drop, proj_drop)
self.dim = dim
self.qkv_bias = qkv_bias
def forward(self, x):
q_weight = self.qkv.weight[:self.dim, :]
q_bias = None if not self.qkv_bias else self.qkv.bias[:self.dim]
kv_weight = self.qkv.weight[self.dim:, :]
kv_bias = None if not self.qkv_bias else self.qkv.bias[self.dim:]
B, N, C = x.shape
_, last_token = torch.split(x, [N-1, 1], dim=1)
q = F.linear(last_token, q_weight, q_bias)\
.reshape(B, 1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
kv = F.linear(x, kv_weight, kv_bias)\
.reshape(B, N, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# self.attention_map = attn
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, 1, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, kernel_size=3, with_bn=True,
feedforward_type='leff'):
super().__init__()
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.norm1 = norm_layer(dim)
self.feedforward_type = feedforward_type
if feedforward_type == 'leff':
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.leff = LocallyEnhancedFeedForward(
in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop,
kernel_size=kernel_size, with_bn=with_bn,
)
else: # LCA
self.attn = AttentionLCA(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.feedforward = Mlp(
in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop
)
def forward(self, x):
if self.feedforward_type == 'leff':
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.leff(self.norm2(x)))
return x, x[:, 0]
else: # LCA
_, last_token = torch.split(x, [x.size(1)-1, 1], dim=1)
x = last_token + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.feedforward(self.norm2(x)))
return x
class HybridEmbed(nn.Module):
""" CNN Feature Map Embedding
Extract feature map from CNN, flatten, project to embedding dim.
"""
def __init__(self, backbone, img_size=224, patch_size=16, feature_size=None, in_chans=3, embed_dim=768):
super().__init__()
assert isinstance(backbone, nn.Module)
img_size = to_2tuple(img_size)
self.img_size = img_size
self.backbone = backbone
if feature_size is None:
with torch.no_grad():
# FIXME this is hacky, but most reliable way of determining the exact dim of the output feature
# map for all networks, the feature metadata has reliable channel and stride info, but using
# stride to calc feature dim requires info about padding of each stage that isn't captured.
training = backbone.training
if training:
backbone.eval()
o = self.backbone(torch.zeros(1, in_chans, img_size[0], img_size[1]))
if isinstance(o, (list, tuple)):
o = o[-1] # last feature if backbone outputs list/tuple of features
feature_size = o.shape[-2:]
feature_dim = o.shape[1]
backbone.train(training)
else:
feature_size = to_2tuple(feature_size)
feature_dim = self.backbone.feature_info.channels()[-1]
print('feature_size is {}, feature_dim is {}, patch_size is {}'.format(
feature_size, feature_dim, patch_size
))
self.num_patches = (feature_size[0] // patch_size) * (feature_size[1] // patch_size)
self.proj = nn.Conv2d(feature_dim, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.backbone(x)
if isinstance(x, (list, tuple)):
x = x[-1] # last feature if backbone outputs list/tuple of features
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class CeIT(nn.Module):
def __init__(self,
img_size=224,
patch_size=16,
in_chans=3,
num_classes=1000,
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.,
hybrid_backbone=None,
norm_layer=nn.LayerNorm,
leff_local_size=3,
leff_with_bn=True):
"""
args:
- img_size (:obj:`int`): input image size
- patch_size (:obj:`int`): patch size
- in_chans (:obj:`int`): input channels
- num_classes (:obj:`int`): number of classes
- embed_dim (:obj:`int`): embedding dimensions for tokens
- depth (:obj:`int`): depth of encoder
- num_heads (:obj:`int`): number of heads in multi-head self-attention
- mlp_ratio (:obj:`float`): expand ratio in feedforward
- qkv_bias (:obj:`bool`): whether to add bias for mlp of qkv
- qk_scale (:obj:`float`): scale ratio for qk, default is head_dim ** -0.5
- drop_rate (:obj:`float`): dropout rate in feedforward module after linear operation
and projection drop rate in attention
- attn_drop_rate (:obj:`float`): dropout rate for attention
- drop_path_rate (:obj:`float`): drop_path rate after attention
- hybrid_backbone (:obj:`nn.Module`): backbone e.g. resnet
- norm_layer (:obj:`nn.Module`): normalization type
- leff_local_size (:obj:`int`): kernel size in LocallyEnhancedFeedForward
- leff_with_bn (:obj:`bool`): whether add bn in LocallyEnhancedFeedForward
"""
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.i2t = HybridEmbed(
hybrid_backbone, img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.i2t.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
kernel_size=leff_local_size, with_bn=leff_with_bn)
for i in range(depth)])
# without droppath
self.lca = Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=0., norm_layer=norm_layer,
feedforward_type = 'lca'
)
self.pos_layer_embed = nn.Parameter(torch.zeros(1, depth, embed_dim))
self.norm = norm_layer(embed_dim)
# NOTE as per official impl, we could have a pre-logits representation dense layer + tanh here
# self.repr = nn.Linear(embed_dim, representation_size)
# self.repr_act = nn.Tanh()
# Classifier head
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x = self.i2t(x)
cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
cls_token_list = []
for blk in self.blocks:
x, curr_cls_token = blk(x)
cls_token_list.append(curr_cls_token)
all_cls_token = torch.stack(cls_token_list, dim=1) # B*D*K
all_cls_token = all_cls_token + self.pos_layer_embed
# attention over cls tokens
last_cls_token = self.lca(all_cls_token)
last_cls_token = self.norm(last_cls_token)
return last_cls_token.view(B, -1)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
@register_model
def ceit_tiny_patch16_224(pretrained=False, **kwargs):
"""
convolutional + pooling stem
local enhanced feedforward
attention over cls_tokens
"""
i2t = Image2Tokens()
model = CeIT(
hybrid_backbone=i2t,
patch_size=4, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
return model
@register_model
def ceit_small_patch16_224(pretrained=False, **kwargs):
"""
convolutional + pooling stem
local enhanced feedforward
attention over cls_tokens
"""
i2t = Image2Tokens()
model = CeIT(
hybrid_backbone=i2t,
patch_size=4, embed_dim=384, depth=12, num_heads=6, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
return model
@register_model
def ceit_base_patch16_224(pretrained=False, **kwargs):
"""
convolutional + pooling stem
local enhanced feedforward
attention over cls_tokens
"""
i2t = Image2Tokens()
model = CeIT(
hybrid_backbone=i2t,
patch_size=4, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
return model
@register_model
def ceit_tiny_patch16_384(pretrained=False, **kwargs):
"""
convolutional + pooling stem
local enhanced feedforward
attention over cls_tokens
"""
i2t = Image2Tokens()
model = CeIT(
hybrid_backbone=i2t, img_size=384,
patch_size=4, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
return model
@register_model
def ceit_small_patch16_384(pretrained=False, **kwargs):
"""
convolutional + pooling stem
local enhanced feedforward
attention over cls_tokens
"""
i2t = Image2Tokens()
model = CeIT(
hybrid_backbone=i2t, img_size=384,
patch_size=4, embed_dim=384, depth=12, num_heads=6, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CeIT(
hybrid_backbone=Image2Tokens(),
patch_size=4,
embed_dim=192,
depth=12,
num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/CoaT.py
================================================
"""
CoaT architecture.
Modified from timm/models/vision_transformer.py
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from einops import rearrange
from functools import partial
from torch import nn, einsum
__all__ = [
"coat_tiny",
"coat_mini",
"coat_small",
"coat_lite_tiny",
"coat_lite_mini",
"coat_lite_small"
]
def _cfg_coat(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
class Mlp(nn.Module):
""" Feed-forward network (FFN, a.k.a. MLP) class. """
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class ConvRelPosEnc(nn.Module):
""" Convolutional relative position encoding. """
def __init__(self, Ch, h, window):
"""
Initialization.
Ch: Channels per head.
h: Number of heads.
window: Window size(s) in convolutional relative positional encoding. It can have two forms:
1. An integer of window size, which assigns all attention heads with the same window size in ConvRelPosEnc.
2. A dict mapping window size to #attention head splits (e.g. {window size 1: #attention head split 1, window size 2: #attention head split 2})
It will apply different window size to the attention head splits.
"""
super().__init__()
if isinstance(window, int):
window = {window: h} # Set the same window size for all attention heads.
self.window = window
elif isinstance(window, dict):
self.window = window
else:
raise ValueError()
self.conv_list = nn.ModuleList()
self.head_splits = []
for cur_window, cur_head_split in window.items():
dilation = 1 # Use dilation=1 at default.
padding_size = (cur_window + (cur_window - 1) * (dilation - 1)) // 2 # Determine padding size. Ref: https://discuss.pytorch.org/t/how-to-keep-the-shape-of-input-and-output-same-when-dilation-conv/14338
cur_conv = nn.Conv2d(cur_head_split*Ch, cur_head_split*Ch,
kernel_size=(cur_window, cur_window),
padding=(padding_size, padding_size),
dilation=(dilation, dilation),
groups=cur_head_split*Ch,
)
self.conv_list.append(cur_conv)
self.head_splits.append(cur_head_split)
self.channel_splits = [x*Ch for x in self.head_splits]
def forward(self, q, v, size):
B, h, N, Ch = q.shape
H, W = size
assert N == 1 + H * W
# Convolutional relative position encoding.
q_img = q[:,:,1:,:] # Shape: [B, h, H*W, Ch].
v_img = v[:,:,1:,:] # Shape: [B, h, H*W, Ch].
v_img = rearrange(v_img, 'B h (H W) Ch -> B (h Ch) H W', H=H, W=W) # Shape: [B, h, H*W, Ch] -> [B, h*Ch, H, W].
v_img_list = torch.split(v_img, self.channel_splits, dim=1) # Split according to channels.
conv_v_img_list = [conv(x) for conv, x in zip(self.conv_list, v_img_list)]
conv_v_img = torch.cat(conv_v_img_list, dim=1)
conv_v_img = rearrange(conv_v_img, 'B (h Ch) H W -> B h (H W) Ch', h=h) # Shape: [B, h*Ch, H, W] -> [B, h, H*W, Ch].
EV_hat_img = q_img * conv_v_img
zero = torch.zeros((B, h, 1, Ch), dtype=q.dtype, layout=q.layout, device=q.device)
EV_hat = torch.cat((zero, EV_hat_img), dim=2) # Shape: [B, h, N, Ch].
return EV_hat
class FactorAtt_ConvRelPosEnc(nn.Module):
""" Factorized attention with convolutional relative position encoding class. """
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., shared_crpe=None):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop) # Note: attn_drop is actually not used.
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
# Shared convolutional relative position encoding.
self.crpe = shared_crpe
def forward(self, x, size):
B, N, C = x.shape
# Generate Q, K, V.
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # Shape: [3, B, h, N, Ch].
q, k, v = qkv[0], qkv[1], qkv[2] # Shape: [B, h, N, Ch].
# Factorized attention.
k_softmax = k.softmax(dim=2) # Softmax on dim N.
k_softmax_T_dot_v = einsum('b h n k, b h n v -> b h k v', k_softmax, v) # Shape: [B, h, Ch, Ch].
factor_att = einsum('b h n k, b h k v -> b h n v', q, k_softmax_T_dot_v) # Shape: [B, h, N, Ch].
# Convolutional relative position encoding.
crpe = self.crpe(q, v, size=size) # Shape: [B, h, N, Ch].
# Merge and reshape.
x = self.scale * factor_att + crpe
x = x.transpose(1, 2).reshape(B, N, C) # Shape: [B, h, N, Ch] -> [B, N, h, Ch] -> [B, N, C].
# Output projection.
x = self.proj(x)
x = self.proj_drop(x)
return x # Shape: [B, N, C].
class ConvPosEnc(nn.Module):
""" Convolutional Position Encoding.
Note: This module is similar to the conditional position encoding in CPVT.
"""
def __init__(self, dim, k=3):
super(ConvPosEnc, self).__init__()
self.proj = nn.Conv2d(dim, dim, k, 1, k//2, groups=dim)
def forward(self, x, size):
B, N, C = x.shape
H, W = size
assert N == 1 + H * W
# Extract CLS token and image tokens.
cls_token, img_tokens = x[:, :1], x[:, 1:] # Shape: [B, 1, C], [B, H*W, C].
# Depthwise convolution.
feat = img_tokens.transpose(1, 2).view(B, C, H, W)
x = self.proj(feat) + feat
x = x.flatten(2).transpose(1, 2)
# Combine with CLS token.
x = torch.cat((cls_token, x), dim=1)
return x
class SerialBlock(nn.Module):
""" Serial block class.
Note: In this implementation, each serial block only contains a conv-attention and a FFN (MLP) module. """
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,
shared_cpe=None, shared_crpe=None):
super().__init__()
# Conv-Attention.
self.cpe = shared_cpe
self.norm1 = norm_layer(dim)
self.factoratt_crpe = FactorAtt_ConvRelPosEnc(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpe)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
# MLP.
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, size):
# Conv-Attention.
x = self.cpe(x, size) # Apply convolutional position encoding.
cur = self.norm1(x)
cur = self.factoratt_crpe(cur, size) # Apply factorized attention and convolutional relative position encoding.
x = x + self.drop_path(cur)
# MLP.
cur = self.norm2(x)
cur = self.mlp(cur)
x = x + self.drop_path(cur)
return x
class ParallelBlock(nn.Module):
""" Parallel block class. """
def __init__(self, dims, num_heads, mlp_ratios=[], qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,
shared_cpes=None, shared_crpes=None):
super().__init__()
# Conv-Attention.
self.cpes = shared_cpes
self.norm12 = norm_layer(dims[1])
self.norm13 = norm_layer(dims[2])
self.norm14 = norm_layer(dims[3])
self.factoratt_crpe2 = FactorAtt_ConvRelPosEnc(
dims[1], num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[1]
)
self.factoratt_crpe3 = FactorAtt_ConvRelPosEnc(
dims[2], num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[2]
)
self.factoratt_crpe4 = FactorAtt_ConvRelPosEnc(
dims[3], num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[3]
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
# MLP.
self.norm22 = norm_layer(dims[1])
self.norm23 = norm_layer(dims[2])
self.norm24 = norm_layer(dims[3])
assert dims[1] == dims[2] == dims[3] # In parallel block, we assume dimensions are the same and share the linear transformation.
assert mlp_ratios[1] == mlp_ratios[2] == mlp_ratios[3]
mlp_hidden_dim = int(dims[1] * mlp_ratios[1])
self.mlp2 = self.mlp3 = self.mlp4 = Mlp(in_features=dims[1], hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def upsample(self, x, output_size, size):
""" Feature map up-sampling. """
return self.interpolate(x, output_size=output_size, size=size)
def downsample(self, x, output_size, size):
""" Feature map down-sampling. """
return self.interpolate(x, output_size=output_size, size=size)
def interpolate(self, x, output_size, size):
""" Feature map interpolation. """
B, N, C = x.shape
H, W = size
assert N == 1 + H * W
cls_token = x[:, :1, :]
img_tokens = x[:, 1:, :]
img_tokens = img_tokens.transpose(1, 2).reshape(B, C, H, W)
img_tokens = F.interpolate(img_tokens, size=output_size, mode='bilinear') # FIXME: May have alignment issue.
img_tokens = img_tokens.reshape(B, C, -1).transpose(1, 2)
out = torch.cat((cls_token, img_tokens), dim=1)
return out
def forward(self, x1, x2, x3, x4, sizes):
_, (H2, W2), (H3, W3), (H4, W4) = sizes
# Conv-Attention.
x2 = self.cpes[1](x2, size=(H2, W2)) # Note: x1 is ignored.
x3 = self.cpes[2](x3, size=(H3, W3))
x4 = self.cpes[3](x4, size=(H4, W4))
cur2 = self.norm12(x2)
cur3 = self.norm13(x3)
cur4 = self.norm14(x4)
cur2 = self.factoratt_crpe2(cur2, size=(H2,W2))
cur3 = self.factoratt_crpe3(cur3, size=(H3,W3))
cur4 = self.factoratt_crpe4(cur4, size=(H4,W4))
upsample3_2 = self.upsample(cur3, output_size=(H2,W2), size=(H3,W3))
upsample4_3 = self.upsample(cur4, output_size=(H3,W3), size=(H4,W4))
upsample4_2 = self.upsample(cur4, output_size=(H2,W2), size=(H4,W4))
downsample2_3 = self.downsample(cur2, output_size=(H3,W3), size=(H2,W2))
downsample3_4 = self.downsample(cur3, output_size=(H4,W4), size=(H3,W3))
downsample2_4 = self.downsample(cur2, output_size=(H4,W4), size=(H2,W2))
cur2 = cur2 + upsample3_2 + upsample4_2
cur3 = cur3 + upsample4_3 + downsample2_3
cur4 = cur4 + downsample3_4 + downsample2_4
x2 = x2 + self.drop_path(cur2)
x3 = x3 + self.drop_path(cur3)
x4 = x4 + self.drop_path(cur4)
# MLP.
cur2 = self.norm22(x2)
cur3 = self.norm23(x3)
cur4 = self.norm24(x4)
cur2 = self.mlp2(cur2)
cur3 = self.mlp3(cur3)
cur4 = self.mlp4(cur4)
x2 = x2 + self.drop_path(cur2)
x3 = x3 + self.drop_path(cur3)
x4 = x4 + self.drop_path(cur4)
return x1, x2, x3, x4
class PatchEmbed(nn.Module):
""" Image to Patch Embedding """
def __init__(self, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
patch_size = to_2tuple(patch_size)
self.patch_size = patch_size
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
_, _, H, W = x.shape
out_H, out_W = H // self.patch_size[0], W // self.patch_size[1]
x = self.proj(x).flatten(2).transpose(1, 2)
out = self.norm(x)
return out, (out_H, out_W)
class CoaT(nn.Module):
""" CoaT class. """
def __init__(self, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[0, 0, 0, 0],
serial_depths=[0, 0, 0, 0], parallel_depth=0,
num_heads=0, mlp_ratios=[0, 0, 0, 0], qkv_bias=True, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., norm_layer=partial(nn.LayerNorm, eps=1e-6),
return_interm_layers=False, out_features=None, crpe_window={3:2, 5:3, 7:3},
**kwargs):
super().__init__()
self.return_interm_layers = return_interm_layers
self.out_features = out_features
self.num_classes = num_classes
# Patch embeddings.
self.patch_embed1 = PatchEmbed(patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dims[0])
self.patch_embed2 = PatchEmbed(patch_size=2, in_chans=embed_dims[0], embed_dim=embed_dims[1])
self.patch_embed3 = PatchEmbed(patch_size=2, in_chans=embed_dims[1], embed_dim=embed_dims[2])
self.patch_embed4 = PatchEmbed(patch_size=2, in_chans=embed_dims[2], embed_dim=embed_dims[3])
# Class tokens.
self.cls_token1 = nn.Parameter(torch.zeros(1, 1, embed_dims[0]))
self.cls_token2 = nn.Parameter(torch.zeros(1, 1, embed_dims[1]))
self.cls_token3 = nn.Parameter(torch.zeros(1, 1, embed_dims[2]))
self.cls_token4 = nn.Parameter(torch.zeros(1, 1, embed_dims[3]))
# Convolutional position encodings.
self.cpe1 = ConvPosEnc(dim=embed_dims[0], k=3)
self.cpe2 = ConvPosEnc(dim=embed_dims[1], k=3)
self.cpe3 = ConvPosEnc(dim=embed_dims[2], k=3)
self.cpe4 = ConvPosEnc(dim=embed_dims[3], k=3)
# Convolutional relative position encodings.
self.crpe1 = ConvRelPosEnc(Ch=embed_dims[0] // num_heads, h=num_heads, window=crpe_window)
self.crpe2 = ConvRelPosEnc(Ch=embed_dims[1] // num_heads, h=num_heads, window=crpe_window)
self.crpe3 = ConvRelPosEnc(Ch=embed_dims[2] // num_heads, h=num_heads, window=crpe_window)
self.crpe4 = ConvRelPosEnc(Ch=embed_dims[3] // num_heads, h=num_heads, window=crpe_window)
# Enable stochastic depth.
dpr = drop_path_rate
# Serial blocks 1.
self.serial_blocks1 = nn.ModuleList([
SerialBlock(
dim=embed_dims[0], num_heads=num_heads, mlp_ratio=mlp_ratios[0], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer,
shared_cpe=self.cpe1, shared_crpe=self.crpe1
)
for _ in range(serial_depths[0])]
)
# Serial blocks 2.
self.serial_blocks2 = nn.ModuleList([
SerialBlock(
dim=embed_dims[1], num_heads=num_heads, mlp_ratio=mlp_ratios[1], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer,
shared_cpe=self.cpe2, shared_crpe=self.crpe2
)
for _ in range(serial_depths[1])]
)
# Serial blocks 3.
self.serial_blocks3 = nn.ModuleList([
SerialBlock(
dim=embed_dims[2], num_heads=num_heads, mlp_ratio=mlp_ratios[2], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer,
shared_cpe=self.cpe3, shared_crpe=self.crpe3
)
for _ in range(serial_depths[2])]
)
# Serial blocks 4.
self.serial_blocks4 = nn.ModuleList([
SerialBlock(
dim=embed_dims[3], num_heads=num_heads, mlp_ratio=mlp_ratios[3], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer,
shared_cpe=self.cpe4, shared_crpe=self.crpe4
)
for _ in range(serial_depths[3])]
)
# Parallel blocks.
self.parallel_depth = parallel_depth
if self.parallel_depth > 0:
self.parallel_blocks = nn.ModuleList([
ParallelBlock(
dims=embed_dims, num_heads=num_heads, mlp_ratios=mlp_ratios, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer,
shared_cpes=[self.cpe1, self.cpe2, self.cpe3, self.cpe4],
shared_crpes=[self.crpe1, self.crpe2, self.crpe3, self.crpe4]
)
for _ in range(parallel_depth)]
)
# Classification head(s).
if not self.return_interm_layers:
self.norm1 = norm_layer(embed_dims[0])
self.norm2 = norm_layer(embed_dims[1])
self.norm3 = norm_layer(embed_dims[2])
self.norm4 = norm_layer(embed_dims[3])
if self.parallel_depth > 0: # CoaT series: Aggregate features of last three scales for classification.
assert embed_dims[1] == embed_dims[2] == embed_dims[3]
self.aggregate = torch.nn.Conv1d(in_channels=3, out_channels=1, kernel_size=1)
self.head = nn.Linear(embed_dims[3], num_classes)
else:
self.head = nn.Linear(embed_dims[3], num_classes) # CoaT-Lite series: Use feature of last scale for classification.
# Initialize weights.
trunc_normal_(self.cls_token1, std=.02)
trunc_normal_(self.cls_token2, std=.02)
trunc_normal_(self.cls_token3, std=.02)
trunc_normal_(self.cls_token4, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'cls_token1', 'cls_token2', 'cls_token3', 'cls_token4'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def insert_cls(self, x, cls_token):
""" Insert CLS token. """
cls_tokens = cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
return x
def remove_cls(self, x):
""" Remove CLS token. """
return x[:, 1:, :]
def forward_features(self, x0):
B = x0.shape[0]
# Serial blocks 1.
x1, (H1, W1) = self.patch_embed1(x0)
x1 = self.insert_cls(x1, self.cls_token1)
for blk in self.serial_blocks1:
x1 = blk(x1, size=(H1, W1))
x1_nocls = self.remove_cls(x1)
x1_nocls = x1_nocls.reshape(B, H1, W1, -1).permute(0, 3, 1, 2).contiguous()
# Serial blocks 2.
x2, (H2, W2) = self.patch_embed2(x1_nocls)
x2 = self.insert_cls(x2, self.cls_token2)
for blk in self.serial_blocks2:
x2 = blk(x2, size=(H2, W2))
x2_nocls = self.remove_cls(x2)
x2_nocls = x2_nocls.reshape(B, H2, W2, -1).permute(0, 3, 1, 2).contiguous()
# Serial blocks 3.
x3, (H3, W3) = self.patch_embed3(x2_nocls)
x3 = self.insert_cls(x3, self.cls_token3)
for blk in self.serial_blocks3:
x3 = blk(x3, size=(H3, W3))
x3_nocls = self.remove_cls(x3)
x3_nocls = x3_nocls.reshape(B, H3, W3, -1).permute(0, 3, 1, 2).contiguous()
# Serial blocks 4.
x4, (H4, W4) = self.patch_embed4(x3_nocls)
x4 = self.insert_cls(x4, self.cls_token4)
for blk in self.serial_blocks4:
x4 = blk(x4, size=(H4, W4))
x4_nocls = self.remove_cls(x4)
x4_nocls = x4_nocls.reshape(B, H4, W4, -1).permute(0, 3, 1, 2).contiguous()
# Only serial blocks: Early return.
if self.parallel_depth == 0:
if self.return_interm_layers: # Return intermediate features for down-stream tasks (e.g. Deformable DETR and Detectron2).
feat_out = {}
if 'x1_nocls' in self.out_features:
feat_out['x1_nocls'] = x1_nocls
if 'x2_nocls' in self.out_features:
feat_out['x2_nocls'] = x2_nocls
if 'x3_nocls' in self.out_features:
feat_out['x3_nocls'] = x3_nocls
if 'x4_nocls' in self.out_features:
feat_out['x4_nocls'] = x4_nocls
return feat_out
else: # Return features for classification.
x4 = self.norm4(x4)
x4_cls = x4[:, 0]
return x4_cls
# Parallel blocks.
for blk in self.parallel_blocks:
x1, x2, x3, x4 = blk(x1, x2, x3, x4, sizes=[(H1, W1), (H2, W2), (H3, W3), (H4, W4)])
if self.return_interm_layers: # Return intermediate features for down-stream tasks (e.g. Deformable DETR and Detectron2).
feat_out = {}
if 'x1_nocls' in self.out_features:
x1_nocls = self.remove_cls(x1)
x1_nocls = x1_nocls.reshape(B, H1, W1, -1).permute(0, 3, 1, 2).contiguous()
feat_out['x1_nocls'] = x1_nocls
if 'x2_nocls' in self.out_features:
x2_nocls = self.remove_cls(x2)
x2_nocls = x2_nocls.reshape(B, H2, W2, -1).permute(0, 3, 1, 2).contiguous()
feat_out['x2_nocls'] = x2_nocls
if 'x3_nocls' in self.out_features:
x3_nocls = self.remove_cls(x3)
x3_nocls = x3_nocls.reshape(B, H3, W3, -1).permute(0, 3, 1, 2).contiguous()
feat_out['x3_nocls'] = x3_nocls
if 'x4_nocls' in self.out_features:
x4_nocls = self.remove_cls(x4)
x4_nocls = x4_nocls.reshape(B, H4, W4, -1).permute(0, 3, 1, 2).contiguous()
feat_out['x4_nocls'] = x4_nocls
return feat_out
else:
x2 = self.norm2(x2)
x3 = self.norm3(x3)
x4 = self.norm4(x4)
x2_cls = x2[:, :1] # Shape: [B, 1, C].
x3_cls = x3[:, :1]
x4_cls = x4[:, :1]
merged_cls = torch.cat((x2_cls, x3_cls, x4_cls), dim=1) # Shape: [B, 3, C].
merged_cls = self.aggregate(merged_cls).squeeze(dim=1) # Shape: [B, C].
return merged_cls
def forward(self, x):
if self.return_interm_layers: # Return intermediate features (for down-stream tasks).
return self.forward_features(x)
else: # Return features for classification.
x = self.forward_features(x)
x = self.head(x)
return x
# CoaT.
@register_model
def coat_tiny(**kwargs):
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
@register_model
def coat_mini(**kwargs):
model = CoaT(patch_size=4, embed_dims=[152, 216, 216, 216], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
@register_model
def coat_small(**kwargs):
model = CoaT(patch_size=4, embed_dims=[152, 320, 320, 320], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
# CoaT-Lite.
@register_model
def coat_lite_tiny(**kwargs):
model = CoaT(patch_size=4, embed_dims=[64, 128, 256, 320], serial_depths=[2, 2, 2, 2], parallel_depth=0, num_heads=8, mlp_ratios=[8, 8, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
@register_model
def coat_lite_mini(**kwargs):
model = CoaT(patch_size=4, embed_dims=[64, 128, 320, 512], serial_depths=[2, 2, 2, 2], parallel_depth=0, num_heads=8, mlp_ratios=[8, 8, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
@register_model
def coat_lite_small(**kwargs):
model = CoaT(patch_size=4, embed_dims=[64, 128, 320, 512], serial_depths=[3, 4, 6, 3], parallel_depth=0, num_heads=8, mlp_ratios=[8, 8, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
@register_model
def coat_lite_medium(**kwargs):
model = CoaT(patch_size=4, embed_dims=[128, 256, 320, 512], serial_depths=[3, 6, 10, 8], parallel_depth=0, num_heads=8, mlp_ratios=[4, 4, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4])
output=model(input)
print(output.shape) # torch.Size([1, 1000])
================================================
FILE: model/backbone/ConTNet.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
from einops.layers.torch import Rearrange
from einops import rearrange
import numpy as np
from typing import Any, List
import math
import warnings
from collections import OrderedDict
__all__ = ['ConTBlock', 'ConTNet']
r""" The following trunc_normal method is pasted from timm https://github.com/rwightman/pytorch-image-models/tree/master/timm
"""
def _no_grad_trunc_normal_(tensor, mean, std, a, b):
# Cut & paste from PyTorch official master until it's in a few official releases - RW
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
def norm_cdf(x):
# Computes standard normal cumulative distribution function
return (1. + math.erf(x / math.sqrt(2.))) / 2.
if (mean < a - 2 * std) or (mean > b + 2 * std):
warnings.warn("mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
"The distribution of values may be incorrect.",
stacklevel=2)
with torch.no_grad():
# Values are generated by using a truncated uniform distribution and
# then using the inverse CDF for the normal distribution.
# Get upper and lower cdf values
l = norm_cdf((a - mean) / std)
u = norm_cdf((b - mean) / std)
# Uniformly fill tensor with values from [l, u], then translate to
# [2l-1, 2u-1].
tensor.uniform_(2 * l - 1, 2 * u - 1)
# Use inverse cdf transform for normal distribution to get truncated
# standard normal
tensor.erfinv_()
# Transform to proper mean, std
tensor.mul_(std * math.sqrt(2.))
tensor.add_(mean)
# Clamp to ensure it's in the proper range
tensor.clamp_(min=a, max=b)
return tensor
def trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
# type: (Tensor, float, float, float, float) -> Tensor
r"""Fills the input Tensor with values drawn from a truncated
normal distribution. The values are effectively drawn from the
normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
with values outside :math:`[a, b]` redrawn until they are within
the bounds. The method used for generating the random values works
best when :math:`a \leq \text{mean} \leq b`.
Args:
tensor: an n-dimensional `torch.Tensor`
mean: the mean of the normal distribution
std: the standard deviation of the normal distribution
a: the minimum cutoff value
b: the maximum cutoff value
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.trunc_normal_(w)
"""
return _no_grad_trunc_normal_(tensor, mean, std, a, b)
def fixed_padding(inputs, kernel_size, dilation):
kernel_size_effective = kernel_size + (kernel_size - 1) * (dilation - 1)
pad_total = kernel_size_effective - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
padded_inputs = F.pad(inputs, (pad_beg, pad_end, pad_beg, pad_end))
return padded_inputs
class ConvBN(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, groups=1, bn=True):
padding = (kernel_size - 1) // 2
if bn:
super(ConvBN, self).__init__(OrderedDict([
('conv', nn.Conv2d(in_planes, out_planes, kernel_size, stride,
padding=padding, groups=groups, bias=False)),
('bn', nn.BatchNorm2d(out_planes))
]))
else:
super(ConvBN, self).__init__(OrderedDict([
('conv', nn.Conv2d(in_planes, out_planes, kernel_size, stride,
padding=padding, groups=groups, bias=False)),
]))
class MHSA(nn.Module):
r"""
Build a Multi-Head Self-Attention:
- https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
"""
def __init__(self,
planes,
head_num,
dropout,
patch_size,
qkv_bias,
relative):
super(MHSA, self).__init__()
self.head_num = head_num
head_dim = planes // head_num
self.qkv = nn.Linear(planes, 3*planes, bias=qkv_bias)
self.relative = relative
self.patch_size = patch_size
self.scale = head_dim ** -0.5
if self.relative:
# print('### relative position embedding ###')
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * patch_size - 1) * (2 * patch_size - 1), head_num))
coords_w = coords_h = torch.arange(patch_size)
coords = torch.stack(torch.meshgrid([coords_h, coords_w]))
coords_flatten = torch.flatten(coords, 1)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
relative_coords[:, :, 0] += patch_size - 1
relative_coords[:, :, 1] += patch_size - 1
relative_coords[:, :, 0] *= 2 * patch_size - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.attn_drop = nn.Dropout(p=dropout)
self.proj = nn.Linear(planes, planes)
self.proj_drop = nn.Dropout(p=dropout)
def forward(self, x):
B, N, C, H = *x.shape, self.head_num
# print(x.shape)
qkv = self.qkv(x).reshape(B, N, 3, H, C // H).permute(2, 0, 3, 1, 4) # x: (3, B, H, N, C//H)
q, k, v = qkv[0], qkv[1], qkv[2] # x: (B, H, N, C//N)
q = q * self.scale
attn = (q @ k.transpose(-2, -1)) # attn: (B, H, N, N)
if self.relative:
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.patch_size ** 2, self.patch_size ** 2, -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
attn = attn + relative_position_bias.unsqueeze(0)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class MLP(nn.Module):
r"""
Build a Multi-Layer Perceptron
- https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
"""
def __init__(self,
planes,
mlp_dim,
dropout):
super(MLP, self).__init__()
self.fc1 = nn.Linear(planes, mlp_dim)
self.act = nn.GELU()
self.fc2 = nn.Linear(mlp_dim, planes)
self.drop = nn.Dropout(dropout)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class STE(nn.Module):
r"""
Build a Standard Transformer Encoder(STE)
input: Tensor (b, c, h, w)
output: Tensor (b, c, h, w)
"""
def __init__(self,
planes: int,
mlp_dim: int,
head_num: int,
dropout: float,
patch_size: int,
relative: bool,
qkv_bias: bool,
pre_norm: bool,
**kwargs):
super(STE, self).__init__()
self.patch_size = patch_size
self.pre_norm = pre_norm
self.relative = relative
self.flatten = nn.Sequential(
Rearrange('b c pnh pnw psh psw -> (b pnh pnw) psh psw c'),
)
if not relative:
self.pe = nn.ParameterList(
[nn.Parameter(torch.zeros(1, patch_size, 1, planes//2)), nn.Parameter(torch.zeros(1, 1, patch_size, planes//2))]
)
self.attn = MHSA(planes, head_num, dropout, patch_size, qkv_bias=qkv_bias, relative=relative)
self.mlp = MLP(planes, mlp_dim, dropout=dropout)
self.norm1 = nn.LayerNorm(planes)
self.norm2 = nn.LayerNorm(planes)
def forward(self, x):
bs, c, h, w = x.shape
patch_size = self.patch_size
patch_num_h, patch_num_w = h // patch_size, w // patch_size
x = (
x.unfold(2, self.patch_size, self.patch_size)
.unfold(3, self.patch_size, self.patch_size)
) # x: (b, c, patch_num, patch_num, patch_size, patch_size)
x = self.flatten(x) # x: (b, patch_size, patch_size, c)
### add 2d position embedding ###
if not self.relative:
x_h, x_w = x.split(c // 2, dim=3)
x = torch.cat((x_h + self.pe[0], x_w + self.pe[1]), dim=3) # x: (b, patch_size, patch_size, c)
x = rearrange(x, 'b psh psw c -> b (psh psw) c')
if self.pre_norm:
x = x + self.attn(self.norm1(x))
x = x + self.mlp(self.norm2(x))
else:
x = self.norm1(x + self.attn(x))
x = self.norm2(x + self.mlp(x))
x = rearrange(x, '(b pnh pnw) (psh psw) c -> b c (pnh psh) (pnw psw)', pnh=patch_num_h, pnw=patch_num_w, psh=patch_size, psw=patch_size)
return x
class ConTBlock(nn.Module):
r"""
Build a ConTBlock
"""
def __init__(self,
planes: int,
out_planes: int,
mlp_dim: int,
head_num: int,
dropout: float,
patch_size: List[int],
downsample: nn.Module = None,
stride: int=1,
last_dropout: float=0.3,
**kwargs):
super(ConTBlock, self).__init__()
self.downsample = downsample
self.identity = nn.Identity()
self.dropout = nn.Identity()
self.bn = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.ste1 = STE(planes=planes, mlp_dim=mlp_dim, head_num=head_num, dropout=dropout, patch_size=patch_size[0], **kwargs)
self.ste2 = STE(planes=planes, mlp_dim=mlp_dim, head_num=head_num, dropout=dropout, patch_size=patch_size[1], **kwargs)
if stride == 1 and downsample is not None:
self.dropout = nn.Dropout(p=last_dropout)
kernel_size = 1
else:
kernel_size = 3
self.out_conv = ConvBN(planes, out_planes, kernel_size, stride, bn=False)
def forward(self, x):
x_preact = self.relu(self.bn(x))
identity = self.identity(x)
if self.downsample is not None:
identity = self.downsample(x_preact)
residual = self.ste1(x_preact)
residual = self.ste2(residual)
residual = self.out_conv(residual)
out = self.dropout(residual+identity)
return out
class ConTNet(nn.Module):
r"""
Build a ConTNet backbone
"""
def __init__(self,
block,
layers: List[int],
mlp_dim: List[int],
head_num: List[int],
dropout: List[float],
in_channels: int=3,
inplanes: int=64,
num_classes: int=1000,
init_weights: bool=True,
first_embedding: bool=False,
tweak_C: bool=False,
**kwargs):
r"""
Args:
block: ConT Block
layers: number of blocks at each layer
mlp_dim: dimension of mlp in each stage
head_num: number of head in each stage
dropout: dropout in the last two stage
relative: if True, relative Position Embedding is used
groups: nunmber of group at each conv layer in the Network
depthwise: if True, depthwise convolution is adopted
in_channels: number of channels of input image
inplanes: channel of the first convolution layer
num_classes: number of classes for classification task
only useful when `with_classifier` is True
with_avgpool: if True, an average pooling is added at the end of resnet stage5
with_classifier: if True, FC layer is registered for classification task
first_embedding: if True, a conv layer with both stride and kernel of 7 is placed at the top
tweakC: if true, the first layer of ResNet-C replace the ori layer
"""
super(ConTNet, self).__init__()
self.inplanes = inplanes
self.block = block
# build the top layer
if tweak_C:
self.layer0 = nn.Sequential(OrderedDict([
('conv_bn1', ConvBN(in_channels, inplanes//2, kernel_size=3, stride=2)),
('relu1', nn.ReLU(inplace=True)),
('conv_bn2', ConvBN(inplanes//2, inplanes//2, kernel_size=3, stride=1)),
('relu2', nn.ReLU(inplace=True)),
('conv_bn3', ConvBN(inplanes//2, inplanes, kernel_size=3, stride=1)),
('relu3', nn.ReLU(inplace=True)),
('maxpool', nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
]))
elif first_embedding:
self.layer0 = nn.Sequential(OrderedDict([
('conv', nn.Conv2d(in_channels, inplanes, kernel_size=4, stride=4)),
('norm', nn.LayerNorm(inplanes))
]))
else:
self.layer0 = nn.Sequential(OrderedDict([
('conv', ConvBN(in_channels, inplanes, kernel_size=7, stride=2, bn=False)),
# ('relu', nn.ReLU(inplace=True)),
('maxpool', nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
]))
# build cont layers
self.cont_layers = []
self.out_channels = OrderedDict()
for i in range(len(layers)):
stride = 2,
patch_size = [7,14]
if i == len(layers)-1:
stride, patch_size[1] = 1, 7 # the last stage does not conduct downsampling
cont_layer = self._make_layer(inplanes * 2**i, layers[i], stride=stride, mlp_dim=mlp_dim[i], head_num=head_num[i], dropout=dropout[i], patch_size=patch_size, **kwargs)
layer_name = 'layer{}'.format(i + 1)
self.add_module(layer_name, cont_layer)
self.cont_layers.append(layer_name)
self.out_channels[layer_name] = 2 * inplanes * 2**i
self.last_out_channels = next(reversed(self.out_channels.values()))
self.fc = nn.Linear(self.last_out_channels, num_classes)
if init_weights:
self._initialize_weights()
def _make_layer(self,
planes: int,
blocks: int,
stride: int,
mlp_dim: int,
head_num: int,
dropout: float,
patch_size: List[int],
use_avgdown: bool=False,
**kwargs):
layers = OrderedDict()
for i in range(0, blocks-1):
layers[f'{self.block.__name__}{i}'] = self.block(
planes, planes, mlp_dim, head_num, dropout, patch_size, **kwargs)
downsample = None
if stride != 1:
if use_avgdown:
downsample = nn.Sequential(OrderedDict([
('avgpool', nn.AvgPool2d(kernel_size=2, stride=2)),
('conv', ConvBN(planes, planes * 2, kernel_size=1, stride=1, bn=False))]))
else:
downsample = ConvBN(planes, planes * 2, kernel_size=1,
stride=2, bn=False)
else:
downsample = ConvBN(planes, planes * 2, kernel_size=1, stride=1, bn=False)
layers[f'{self.block.__name__}{blocks-1}'] = self.block(
planes, planes*2, mlp_dim, head_num, dropout, patch_size, downsample, stride, **kwargs)
return nn.Sequential(layers)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.LayerNorm):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.layer0(x)
for _, layer_name in enumerate(self.cont_layers):
cont_layer = getattr(self, layer_name)
x = cont_layer(x)
x = x.mean([2, 3])
x = self.fc(x)
return x
def create_ConTNet_Ti(kwargs):
return ConTNet(block=ConTBlock,
mlp_dim=[196, 392, 768, 768],
head_num=[1, 2, 4, 8],
dropout=[0,0,0,0],
inplanes=48,
layers=[1,1,1,1],
last_dropout=0,
**kwargs)
def create_ConTNet_S(kwargs):
return ConTNet(block=ConTBlock,
mlp_dim=[256, 512, 1024, 1024],
head_num=[1, 2, 4, 8],
dropout=[0,0,0,0],
inplanes=64,
layers=[1,1,1,1],
last_dropout=0,
**kwargs)
def create_ConTNet_M(kwargs):
return ConTNet(block=ConTBlock,
mlp_dim=[256, 512, 1024, 1024],
head_num=[1, 2, 4, 8],
dropout=[0,0,0,0],
inplanes=64,
layers=[2,2,2,2],
last_dropout=0,
**kwargs)
def create_ConTNet_B(kwargs):
return ConTNet(block=ConTBlock,
mlp_dim=[256, 512, 1024, 1024],
head_num=[1, 2, 4, 8],
dropout=[0,0,0.1,0.1],
inplanes=64,
layers=[3,4,6,3],
last_dropout=0.2,
**kwargs)
def build_model(use_avgdown, relative, qkv_bias, pre_norm):
kwargs = dict(use_avgdown=use_avgdown, relative=relative, qkv_bias=qkv_bias, pre_norm=pre_norm)
return create_ConTNet_Ti(kwargs)
if __name__ == "__main__":
model = build_model(use_avgdown=True, relative=True, qkv_bias=True, pre_norm=True)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
================================================
FILE: model/backbone/ConViT.py
================================================
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the CC-by-NC license found in the
# LICENSE file in the root directory of this source tree.
#
'''These modules are adapted from those of timm, see
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
'''
import torch
import torch.nn as nn
from functools import partial
import torch.nn.functional as F
from timm.models.helpers import load_pretrained
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class GPSA(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.,
locality_strength=1., use_local_init=True):
super().__init__()
self.num_heads = num_heads
self.dim = dim
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qk = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.pos_proj = nn.Linear(3, num_heads)
self.proj_drop = nn.Dropout(proj_drop)
self.locality_strength = locality_strength
self.gating_param = nn.Parameter(torch.ones(self.num_heads))
self.apply(self._init_weights)
if use_local_init:
self.local_init(locality_strength=locality_strength)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
B, N, C = x.shape
if not hasattr(self, 'rel_indices') or self.rel_indices.size(1)!=N:
self.get_rel_indices(N)
attn = self.get_attention(x)
v = self.v(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def get_attention(self, x):
B, N, C = x.shape
qk = self.qk(x).reshape(B, N, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k = qk[0], qk[1]
pos_score = self.rel_indices.expand(B, -1, -1,-1)
pos_score = self.pos_proj(pos_score).permute(0,3,1,2)
patch_score = (q @ k.transpose(-2, -1)) * self.scale
patch_score = patch_score.softmax(dim=-1)
pos_score = pos_score.softmax(dim=-1)
gating = self.gating_param.view(1,-1,1,1)
attn = (1.-torch.sigmoid(gating)) * patch_score + torch.sigmoid(gating) * pos_score
attn /= attn.sum(dim=-1).unsqueeze(-1)
attn = self.attn_drop(attn)
return attn
def get_attention_map(self, x, return_map = False):
attn_map = self.get_attention(x).mean(0) # average over batch
distances = self.rel_indices.squeeze()[:,:,-1]**.5
dist = torch.einsum('nm,hnm->h', (distances, attn_map))
dist /= distances.size(0)
if return_map:
return dist, attn_map
else:
return dist
def local_init(self, locality_strength=1.):
self.v.weight.data.copy_(torch.eye(self.dim))
locality_distance = 1 #max(1,1/locality_strength**.5)
kernel_size = int(self.num_heads**.5)
center = (kernel_size-1)/2 if kernel_size%2==0 else kernel_size//2
for h1 in range(kernel_size):
for h2 in range(kernel_size):
position = h1+kernel_size*h2
self.pos_proj.weight.data[position,2] = -1
self.pos_proj.weight.data[position,1] = 2*(h1-center)*locality_distance
self.pos_proj.weight.data[position,0] = 2*(h2-center)*locality_distance
self.pos_proj.weight.data *= locality_strength
def get_rel_indices(self, num_patches):
img_size = int(num_patches**.5)
rel_indices = torch.zeros(1, num_patches, num_patches, 3)
ind = torch.arange(img_size).view(1,-1) - torch.arange(img_size).view(-1, 1)
indx = ind.repeat(img_size,img_size)
indy = ind.repeat_interleave(img_size,dim=0).repeat_interleave(img_size,dim=1)
indd = indx**2 + indy**2
rel_indices[:,:,:,2] = indd.unsqueeze(0)
rel_indices[:,:,:,1] = indy.unsqueeze(0)
rel_indices[:,:,:,0] = indx.unsqueeze(0)
device = self.qk.weight.device
self.rel_indices = rel_indices.to(device)
class MHSA(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def get_attention_map(self, x, return_map = False):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn_map = (q @ k.transpose(-2, -1)) * self.scale
attn_map = attn_map.softmax(dim=-1).mean(0)
img_size = int(N**.5)
ind = torch.arange(img_size).view(1,-1) - torch.arange(img_size).view(-1, 1)
indx = ind.repeat(img_size,img_size)
indy = ind.repeat_interleave(img_size,dim=0).repeat_interleave(img_size,dim=1)
indd = indx**2 + indy**2
distances = indd**.5
distances = distances.to('cuda')
dist = torch.einsum('nm,hnm->h', (distances, attn_map))
dist /= N
if return_map:
return dist, attn_map
else:
return dist
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, use_gpsa=True, **kwargs):
super().__init__()
self.norm1 = norm_layer(dim)
self.use_gpsa = use_gpsa
if self.use_gpsa:
self.attn = GPSA(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop, **kwargs)
else:
self.attn = MHSA(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop, **kwargs)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding, from timm
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.apply(self._init_weights)
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
class HybridEmbed(nn.Module):
""" CNN Feature Map Embedding, from timm
"""
def __init__(self, backbone, img_size=224, feature_size=None, in_chans=3, embed_dim=768):
super().__init__()
assert isinstance(backbone, nn.Module)
img_size = to_2tuple(img_size)
self.img_size = img_size
self.backbone = backbone
if feature_size is None:
with torch.no_grad():
training = backbone.training
if training:
backbone.eval()
o = self.backbone(torch.zeros(1, in_chans, img_size[0], img_size[1]))[-1]
feature_size = o.shape[-2:]
feature_dim = o.shape[1]
backbone.train(training)
else:
feature_size = to_2tuple(feature_size)
feature_dim = self.backbone.feature_info.channels()[-1]
self.num_patches = feature_size[0] * feature_size[1]
self.proj = nn.Linear(feature_dim, embed_dim)
self.apply(self._init_weights)
def forward(self, x):
x = self.backbone(x)[-1]
x = x.flatten(2).transpose(1, 2)
x = self.proj(x)
return x
class VisionTransformer(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=48, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm, global_pool=None,
local_up_to_layer=10, locality_strength=1., use_pos_embed=True):
super().__init__()
self.num_classes = num_classes
self.local_up_to_layer = local_up_to_layer
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.locality_strength = locality_strength
self.use_pos_embed = use_pos_embed
if hybrid_backbone is not None:
self.patch_embed = HybridEmbed(
hybrid_backbone, img_size=img_size, in_chans=in_chans, embed_dim=embed_dim)
else:
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.num_patches = num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
if self.use_pos_embed:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.pos_embed, std=.02)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
use_gpsa=True,
locality_strength=locality_strength)
if i 0 else nn.Identity()
trunc_normal_(self.cls_token, std=.02)
self.head.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1)
if self.use_pos_embed:
x = x + self.pos_embed
x = self.pos_drop(x)
for u,blk in enumerate(self.blocks):
if u == self.local_up_to_layer :
x = torch.cat((cls_tokens, x), dim=1)
x = blk(x)
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
@register_model
def convit_tiny(pretrained=False, **kwargs):
num_heads = 4
kwargs['embed_dim'] *= num_heads
model = VisionTransformer(
num_heads=num_heads,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/convit/convit_tiny.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
@register_model
def convit_small(pretrained=False, **kwargs):
num_heads = 9
kwargs['embed_dim'] *= num_heads
model = VisionTransformer(
num_heads=num_heads,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/convit/convit_small.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
@register_model
def convit_base(pretrained=False, **kwargs):
num_heads = 16
kwargs['embed_dim'] *= num_heads
model = VisionTransformer(
num_heads=num_heads,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/convit/convit_base.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/Container.py
================================================
import torch
import torch.nn as nn
from functools import partial
import math
from timm.models.vision_transformer import VisionTransformer, _cfg
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_, DropPath, to_2tuple
import pdb
__all__ = [
'deit_tiny_patch16_224', 'deit_small_patch16_224', 'deit_base_patch16_224',
'deit_tiny_distilled_patch16_224', 'deit_small_distilled_patch16_224',
'deit_base_distilled_patch16_224', 'deit_base_patch16_384',
'deit_base_distilled_patch16_384', 'container_light'
]
class Mlp(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class CMlp(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
pdb.set_trace()
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Attention_pure(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.attn_drop = nn.Dropout(attn_drop)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
C = int(C // 3)
qkv = x.reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj_drop(x)
return x
class MixBlock(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.norm1 = nn.BatchNorm2d(dim)
self.conv1 = nn.Conv2d(dim, 3 * dim, 1)
self.conv2 = nn.Conv2d(dim, dim, 1)
self.conv = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.attn = Attention_pure(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = nn.BatchNorm2d(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = CMlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.sa_weight = nn.Parameter(torch.Tensor([0.0]))
def forward(self, x):
x = x + self.pos_embed(x)
B, _, H, W = x.shape
residual = x
x = self.norm1(x)
qkv = self.conv1(x)
conv = qkv[:, 2 * self.dim:, :, :]
conv = self.conv(conv)
sa = qkv.flatten(2).transpose(1, 2)
sa = self.attn(sa)
sa = sa.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x = residual + self.drop_path(self.conv2(torch.sigmoid(self.sa_weight) * sa + (1 - torch.sigmoid(self.sa_weight)) * conv))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class CBlock(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.norm1 = nn.BatchNorm2d(dim)
self.conv1 = nn.Conv2d(dim, dim, 1)
self.conv2 = nn.Conv2d(dim, dim, 1)
self.attn = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = nn.BatchNorm2d(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = CMlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.pos_embed(x)
x = x + self.drop_path(self.conv2(self.attn(self.conv1(self.norm1(x)))))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class Block(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchEmbed(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.norm = nn.LayerNorm(embed_dim)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x)
B, C, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
return x
class HybridEmbed(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, backbone, img_size=224, feature_size=None, in_chans=3, embed_dim=768):
super().__init__()
assert isinstance(backbone, nn.Module)
img_size = to_2tuple(img_size)
self.img_size = img_size
self.backbone = backbone
if feature_size is None:
with torch.no_grad():
# FIXME this is hacky, but most reliable way of determining the exact dim of the output feature
# map for all networks, the feature metadata has reliable channel and stride info, but using
# stride to calc feature dim requires info about padding of each stage that isn't captured.
training = backbone.training
if training:
backbone.eval()
o = self.backbone(torch.zeros(1, in_chans, img_size[0], img_size[1]))
if isinstance(o, (list, tuple)):
o = o[-1] # last feature if backbone outputs list/tuple of features
feature_size = o.shape[-2:]
feature_dim = o.shape[1]
backbone.train(training)
else:
feature_size = to_2tuple(feature_size)
if hasattr(self.backbone, 'feature_info'):
feature_dim = self.backbone.feature_info.channels()[-1]
else:
feature_dim = self.backbone.num_features
self.num_patches = feature_size[0] * feature_size[1]
self.proj = nn.Conv2d(feature_dim, embed_dim, 1)
def forward(self, x):
x = self.backbone(x)
if isinstance(x, (list, tuple)):
x = x[-1] # last feature if backbone outputs list/tuple of features
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class VisionTransformer(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
""" Vision Transformer
A PyTorch impl of : `An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale` -
https://arxiv.org/abs/2010.11929
"""
def __init__(self, img_size=[224, 56, 28, 14], patch_size=[4, 2, 2, 2], in_chans=3, num_classes=1000, embed_dim=[64, 128, 320, 512], depth=[3, 4, 8, 3],
num_heads=12, mlp_ratio=[8, 8, 4, 4], qkv_bias=True, qk_scale=None, representation_size=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., hybrid_backbone=None, norm_layer=None):
"""
Args:
img_size (int, tuple): input image size
patch_size (int, tuple): patch size
in_chans (int): number of input channels
num_classes (int): number of classes for classification head
embed_dim (int): embedding dimension
depth (int): depth of transformer
num_heads (int): number of attention heads
mlp_ratio (int): ratio of mlp hidden dim to embedding dim
qkv_bias (bool): enable bias for qkv if True
qk_scale (float): override default qk scale of head_dim ** -0.5 if set
representation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if set
drop_rate (float): dropout rate
attn_drop_rate (float): attention dropout rate
drop_path_rate (float): stochastic depth rate
hybrid_backbone (nn.Module): CNN backbone to use in-place of PatchEmbed module
norm_layer: (nn.Module): normalization layer
"""
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
self.embed_dim = embed_dim
self.depth = depth
if hybrid_backbone is not None:
self.patch_embed = HybridEmbed(
hybrid_backbone, img_size=img_size, in_chans=in_chans, embed_dim=embed_dim)
else:
self.patch_embed1 = PatchEmbed(
img_size=img_size[0], patch_size=patch_size[0], in_chans=in_chans, embed_dim=embed_dim[0])
self.patch_embed2 = PatchEmbed(
img_size=img_size[1], patch_size=patch_size[1], in_chans=embed_dim[0], embed_dim=embed_dim[1])
self.patch_embed3 = PatchEmbed(
img_size=img_size[2], patch_size=patch_size[2], in_chans=embed_dim[1], embed_dim=embed_dim[2])
self.patch_embed4 = PatchEmbed(
img_size=img_size[3], patch_size=patch_size[3], in_chans=embed_dim[2], embed_dim=embed_dim[3])
num_patches1 = self.patch_embed1.num_patches
num_patches2 = self.patch_embed2.num_patches
num_patches3 = self.patch_embed3.num_patches
num_patches4 = self.patch_embed4.num_patches
self.pos_drop = nn.Dropout(p=drop_rate)
self.mixture =True
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depth))] # stochastic depth decay rule
self.blocks1 = nn.ModuleList([
CBlock(
dim=embed_dim[0], num_heads=num_heads, mlp_ratio=mlp_ratio[0], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth[0])])
self.blocks2 = nn.ModuleList([
CBlock(
dim=embed_dim[1], num_heads=num_heads, mlp_ratio=mlp_ratio[1], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]], norm_layer=norm_layer)
for i in range(depth[1])])
self.blocks3 = nn.ModuleList([
CBlock(
dim=embed_dim[2], num_heads=num_heads, mlp_ratio=mlp_ratio[2], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]], norm_layer=norm_layer)
for i in range(depth[2])])
self.blocks4 = nn.ModuleList([
MixBlock(
dim=embed_dim[3], num_heads=num_heads, mlp_ratio=mlp_ratio[3], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]+depth[2]], norm_layer=norm_layer)
for i in range(depth[3])])
self.norm = nn.BatchNorm2d(embed_dim[-1])
# Representation layer
if representation_size:
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
('fc', nn.Linear(embed_dim, representation_size)),
('act', nn.Tanh())
]))
else:
self.pre_logits = nn.Identity()
# Classifier head
self.head = nn.Linear(embed_dim[-1], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed1(x)
x = self.pos_drop(x)
for blk in self.blocks1:
x = blk(x)
x = self.patch_embed2(x)
for blk in self.blocks2:
x = blk(x)
x = self.patch_embed3(x)
for blk in self.blocks3:
x = blk(x)
x = self.patch_embed4(x)
for blk in self.blocks4:
x = blk(x)
x = self.norm(x)
x = self.pre_logits(x)
return x
def forward(self, x):
x = self.forward_features(x)
x = x.flatten(2).mean(-1)
x = self.head(x)
return x
@register_model
def container_v1_light(pretrained=False, **kwargs):
model = VisionTransformer(
img_size=[224, 56, 28, 14], patch_size=[4, 2, 2, 2], embed_dim=[64, 128, 320, 512], depth=[3, 4, 8, 3], num_heads=16, mlp_ratio=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_tiny_patch16_224-a1311bcf.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[224, 56, 28, 14],
patch_size=[4, 2, 2, 2],
embed_dim=[64, 128, 320, 512],
depth=[3, 4, 8, 3],
num_heads=16,
mlp_ratio=[8, 8, 4, 4],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6))
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/ConvMixer.py
================================================
import torch.nn as nn
from torch.nn.modules.activation import GELU
import torch
from torch.nn.modules.pooling import AdaptiveAvgPool2d
class Residual(nn.Module):
def __init__(self,fn):
super().__init__()
self.fn=fn
def forward(self,x):
return x+self.fn(x)
def ConvMixer(dim,depth,kernel_size=9,patch_size=7,num_classes=1000):
return nn.Sequential(
nn.Conv2d(3,dim,kernel_size=patch_size,stride=patch_size),
nn.GELU(),
nn.BatchNorm2d(dim),
*[nn.Sequential(
Residual(nn.Sequential(
nn.Conv2d(dim,dim,kernel_size=kernel_size,groups=dim,padding=kernel_size//2),
nn.GELU(),
nn.BatchNorm2d(dim)
)),
nn.Conv2d(dim,dim,kernel_size=1),
nn.GELU(),
nn.BatchNorm2d(dim)
) for _ in range(depth)],
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(dim,num_classes)
)
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
convmixer=ConvMixer(dim=512,depth=12)
out=convmixer(x)
print(out.shape) #[1, 1000]
================================================
FILE: model/backbone/CrossViT.py
================================================
# Copyright IBM All Rights Reserved.
# SPDX-License-Identifier: Apache-2.0
"""
Modifed from Timm. https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.hub
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg, Mlp, Block
_model_urls = {
'crossvit_15_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_15_224.pth',
'crossvit_15_dagger_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_15_dagger_224.pth',
'crossvit_15_dagger_384': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_15_dagger_384.pth',
'crossvit_18_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_18_224.pth',
'crossvit_18_dagger_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_18_dagger_224.pth',
'crossvit_18_dagger_384': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_18_dagger_384.pth',
'crossvit_9_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_9_224.pth',
'crossvit_9_dagger_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_9_dagger_224.pth',
'crossvit_base_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_base_224.pth',
'crossvit_small_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_small_224.pth',
'crossvit_tiny_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_tiny_224.pth',
}
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, multi_conv=False):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
if multi_conv:
if patch_size[0] == 12:
self.proj = nn.Sequential(
nn.Conv2d(in_chans, embed_dim // 4, kernel_size=7, stride=4, padding=3),
nn.ReLU(inplace=True),
nn.Conv2d(embed_dim // 4, embed_dim // 2, kernel_size=3, stride=3, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(embed_dim // 2, embed_dim, kernel_size=3, stride=1, padding=1),
)
elif patch_size[0] == 16:
self.proj = nn.Sequential(
nn.Conv2d(in_chans, embed_dim // 4, kernel_size=7, stride=4, padding=3),
nn.ReLU(inplace=True),
nn.Conv2d(embed_dim // 4, embed_dim // 2, kernel_size=3, stride=2, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(embed_dim // 2, embed_dim, kernel_size=3, stride=2, padding=1),
)
else:
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.wq = nn.Linear(dim, dim, bias=qkv_bias)
self.wk = nn.Linear(dim, dim, bias=qkv_bias)
self.wv = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
q = self.wq(x[:, 0:1, ...]).reshape(B, 1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # B1C -> B1H(C/H) -> BH1(C/H)
k = self.wk(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # BNC -> BNH(C/H) -> BHN(C/H)
v = self.wv(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # BNC -> BNH(C/H) -> BHN(C/H)
attn = (q @ k.transpose(-2, -1)) * self.scale # BH1(C/H) @ BH(C/H)N -> BH1N
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, 1, C) # (BH1N @ BHN(C/H)) -> BH1(C/H) -> B1H(C/H) -> B1C
x = self.proj(x)
x = self.proj_drop(x)
return x
class CrossAttentionBlock(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, has_mlp=True):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = CrossAttention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.has_mlp = has_mlp
if has_mlp:
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x[:, 0:1, ...] + self.drop_path(self.attn(self.norm1(x)))
if self.has_mlp:
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class MultiScaleBlock(nn.Module):
def __init__(self, dim, patches, depth, num_heads, mlp_ratio, qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
num_branches = len(dim)
self.num_branches = num_branches
# different branch could have different embedding size, the first one is the base
self.blocks = nn.ModuleList()
for d in range(num_branches):
tmp = []
for i in range(depth[d]):
tmp.append(
Block(dim=dim[d], num_heads=num_heads[d], mlp_ratio=mlp_ratio[d], qkv_bias=qkv_bias,
drop=drop, attn_drop=attn_drop, drop_path=drop_path[i], norm_layer=norm_layer))
if len(tmp) != 0:
self.blocks.append(nn.Sequential(*tmp))
if len(self.blocks) == 0:
self.blocks = None
self.projs = nn.ModuleList()
for d in range(num_branches):
if dim[d] == dim[(d+1) % num_branches] and False:
tmp = [nn.Identity()]
else:
tmp = [norm_layer(dim[d]), act_layer(), nn.Linear(dim[d], dim[(d+1) % num_branches])]
self.projs.append(nn.Sequential(*tmp))
self.fusion = nn.ModuleList()
for d in range(num_branches):
d_ = (d+1) % num_branches
nh = num_heads[d_]
if depth[-1] == 0: # backward capability:
self.fusion.append(CrossAttentionBlock(dim=dim[d_], num_heads=nh, mlp_ratio=mlp_ratio[d], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop, drop_path=drop_path[-1], norm_layer=norm_layer,
has_mlp=False))
else:
tmp = []
for _ in range(depth[-1]):
tmp.append(CrossAttentionBlock(dim=dim[d_], num_heads=nh, mlp_ratio=mlp_ratio[d], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop, drop_path=drop_path[-1], norm_layer=norm_layer,
has_mlp=False))
self.fusion.append(nn.Sequential(*tmp))
self.revert_projs = nn.ModuleList()
for d in range(num_branches):
if dim[(d+1) % num_branches] == dim[d] and False:
tmp = [nn.Identity()]
else:
tmp = [norm_layer(dim[(d+1) % num_branches]), act_layer(), nn.Linear(dim[(d+1) % num_branches], dim[d])]
self.revert_projs.append(nn.Sequential(*tmp))
def forward(self, x):
outs_b = [block(x_) for x_, block in zip(x, self.blocks)]
# only take the cls token out
proj_cls_token = [proj(x[:, 0:1]) for x, proj in zip(outs_b, self.projs)]
# cross attention
outs = []
for i in range(self.num_branches):
tmp = torch.cat((proj_cls_token[i], outs_b[(i + 1) % self.num_branches][:, 1:, ...]), dim=1)
tmp = self.fusion[i](tmp)
reverted_proj_cls_token = self.revert_projs[i](tmp[:, 0:1, ...])
tmp = torch.cat((reverted_proj_cls_token, outs_b[i][:, 1:, ...]), dim=1)
outs.append(tmp)
return outs
def _compute_num_patches(img_size, patches):
return [i // p * i // p for i, p in zip(img_size,patches)]
class VisionTransformer(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=(224, 224), patch_size=(8, 16), in_chans=3, num_classes=1000, embed_dim=(192, 384), depth=([1, 3, 1], [1, 3, 1], [1, 3, 1]),
num_heads=(6, 12), mlp_ratio=(2., 2., 4.), qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm, multi_conv=False):
super().__init__()
self.num_classes = num_classes
if not isinstance(img_size, list):
img_size = to_2tuple(img_size)
self.img_size = img_size
num_patches = _compute_num_patches(img_size, patch_size)
self.num_branches = len(patch_size)
self.patch_embed = nn.ModuleList()
if hybrid_backbone is None:
self.pos_embed = nn.ParameterList([nn.Parameter(torch.zeros(1, 1 + num_patches[i], embed_dim[i])) for i in range(self.num_branches)])
for im_s, p, d in zip(img_size, patch_size, embed_dim):
self.patch_embed.append(PatchEmbed(img_size=im_s, patch_size=p, in_chans=in_chans, embed_dim=d, multi_conv=multi_conv))
else:
self.pos_embed = nn.ParameterList()
from .t2t import T2T, get_sinusoid_encoding
tokens_type = 'transformer' if hybrid_backbone == 't2t' else 'performer'
for idx, (im_s, p, d) in enumerate(zip(img_size, patch_size, embed_dim)):
self.patch_embed.append(T2T(im_s, tokens_type=tokens_type, patch_size=p, embed_dim=d))
self.pos_embed.append(nn.Parameter(data=get_sinusoid_encoding(n_position=1 + num_patches[idx], d_hid=embed_dim[idx]), requires_grad=False))
del self.pos_embed
self.pos_embed = nn.ParameterList([nn.Parameter(torch.zeros(1, 1 + num_patches[i], embed_dim[i])) for i in range(self.num_branches)])
self.cls_token = nn.ParameterList([nn.Parameter(torch.zeros(1, 1, embed_dim[i])) for i in range(self.num_branches)])
self.pos_drop = nn.Dropout(p=drop_rate)
total_depth = sum([sum(x[-2:]) for x in depth])
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, total_depth)] # stochastic depth decay rule
dpr_ptr = 0
self.blocks = nn.ModuleList()
for idx, block_cfg in enumerate(depth):
curr_depth = max(block_cfg[:-1]) + block_cfg[-1]
dpr_ = dpr[dpr_ptr:dpr_ptr + curr_depth]
blk = MultiScaleBlock(embed_dim, num_patches, block_cfg, num_heads=num_heads, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr_,
norm_layer=norm_layer)
dpr_ptr += curr_depth
self.blocks.append(blk)
self.norm = nn.ModuleList([norm_layer(embed_dim[i]) for i in range(self.num_branches)])
self.head = nn.ModuleList([nn.Linear(embed_dim[i], num_classes) if num_classes > 0 else nn.Identity() for i in range(self.num_branches)])
for i in range(self.num_branches):
if self.pos_embed[i].requires_grad:
trunc_normal_(self.pos_embed[i], std=.02)
trunc_normal_(self.cls_token[i], std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
out = {'cls_token'}
if self.pos_embed[0].requires_grad:
out.add('pos_embed')
return out
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B, C, H, W = x.shape
xs = []
for i in range(self.num_branches):
x_ = torch.nn.functional.interpolate(x, size=(self.img_size[i], self.img_size[i]), mode='bicubic') if H != self.img_size[i] else x
tmp = self.patch_embed[i](x_)
cls_tokens = self.cls_token[i].expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
tmp = torch.cat((cls_tokens, tmp), dim=1)
tmp = tmp + self.pos_embed[i]
tmp = self.pos_drop(tmp)
xs.append(tmp)
for blk in self.blocks:
xs = blk(xs)
# NOTE: was before branch token section, move to here to assure all branch token are before layer norm
xs = [self.norm[i](x) for i, x in enumerate(xs)]
out = [x[:, 0] for x in xs]
return out
def forward(self, x):
xs = self.forward_features(x)
ce_logits = [self.head[i](x) for i, x in enumerate(xs)]
ce_logits = torch.mean(torch.stack(ce_logits, dim=0), dim=0)
return ce_logits
@register_model
def crossvit_tiny_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[96, 192], depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[3, 3], mlp_ratio=[4, 4, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_tiny_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_small_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[192, 384], depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6], mlp_ratio=[4, 4, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_small_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_base_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[384, 768], depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[12, 12], mlp_ratio=[4, 4, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_base_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_9_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[128, 256], depth=[[1, 3, 0], [1, 3, 0], [1, 3, 0]],
num_heads=[4, 4], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_9_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_15_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[192, 384], depth=[[1, 5, 0], [1, 5, 0], [1, 5, 0]],
num_heads=[6, 6], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_15_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_18_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[224, 448], depth=[[1, 6, 0], [1, 6, 0], [1, 6, 0]],
num_heads=[7, 7], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_18_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_9_dagger_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[128, 256], depth=[[1, 3, 0], [1, 3, 0], [1, 3, 0]],
num_heads=[4, 4], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), multi_conv=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_9_dagger_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_15_dagger_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[192, 384], depth=[[1, 5, 0], [1, 5, 0], [1, 5, 0]],
num_heads=[6, 6], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), multi_conv=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_15_dagger_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_15_dagger_384(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[408, 384],
patch_size=[12, 16], embed_dim=[192, 384], depth=[[1, 5, 0], [1, 5, 0], [1, 5, 0]],
num_heads=[6, 6], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), multi_conv=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_15_dagger_384'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_18_dagger_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[224, 448], depth=[[1, 6, 0], [1, 6, 0], [1, 6, 0]],
num_heads=[7, 7], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), multi_conv=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_18_dagger_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_18_dagger_384(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[408, 384],
patch_size=[12, 16], embed_dim=[224, 448], depth=[[1, 6, 0], [1, 6, 0], [1, 6, 0]],
num_heads=[7, 7], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), multi_conv=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_18_dagger_384'], map_location='cpu')
model.load_state_dict(state_dict)
return model
if __name__ == "__main__":
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[240, 224],
patch_size=[12, 16],
embed_dim=[192, 384],
depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6],
mlp_ratio=[4, 4, 1],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/DViT.py
================================================
"""
Code for DeepViT. The implementation has heavy reference to timm.
"""
import torch
import torch.nn as nn
from functools import partial
import pickle
from torch.nn.parameter import Parameter
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.helpers import load_pretrained
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.resnet import resnet26d, resnet50d
from timm.models.registry import register_model
import torch.nn.init as init
import torch.nn.functional as F
from torch.nn import functional as F
import numpy as np
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0., expansion_ratio=3):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.fc2 = nn.Linear(hidden_features, out_features)
self.act = act_layer()
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., expansion_ratio=3):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.expansion = expansion_ratio
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * self.expansion, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, atten=None):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x, attn
class ReAttention(nn.Module):
"""
It is observed that similarity along same batch of data is extremely large.
Thus can reduce the bs dimension when calculating the attention map.
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.,expansion_ratio = 3, apply_transform=True, transform_scale=False):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.apply_transform = apply_transform
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
if apply_transform:
self.reatten_matrix = nn.Conv2d(self.num_heads,self.num_heads, 1, 1)
self.var_norm = nn.BatchNorm2d(self.num_heads)
self.qkv = nn.Linear(dim, dim * expansion_ratio, bias=qkv_bias)
self.reatten_scale = self.scale if transform_scale else 1.0
else:
self.qkv = nn.Linear(dim, dim * expansion_ratio, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, atten=None):
B, N, C = x.shape
# x = self.fc(x)
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
if self.apply_transform:
attn = self.var_norm(self.reatten_matrix(attn)) * self.reatten_scale
attn_next = attn
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x, attn_next
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, expansion=3,
group = False, share = False, re_atten=False, bs=False, apply_transform=False,
scale_adjustment=1.0, transform_scale=False):
super().__init__()
self.norm1 = norm_layer(dim)
self.re_atten = re_atten
self.adjust_ratio = scale_adjustment
self.dim = dim
if self.re_atten:
self.attn = ReAttention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
expansion_ratio = expansion, apply_transform=apply_transform, transform_scale=transform_scale)
else:
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
expansion_ratio = expansion)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, atten=None):
if self.re_atten:
x_new, atten = self.attn(self.norm1(x * self.adjust_ratio), atten)
x = x + self.drop_path(x_new/self.adjust_ratio)
x = x + self.drop_path(self.mlp(self.norm2(x * self.adjust_ratio))) / self.adjust_ratio
return x, atten
else:
x_new, atten = self.attn(self.norm1(x), atten)
x= x + self.drop_path(x_new)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x, atten
class PatchEmbed_CNN(nn.Module):
"""
Following T2T, we use 3 layers of CNN for comparison with other methods.
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768,spp=32):
super().__init__()
new_patch_size = to_2tuple(patch_size // 2)
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.conv1 = nn.Conv2d(in_chans, 64, kernel_size=7, stride=2, padding=3, bias=False) # 112x112
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False) # 112x112
self.bn2 = nn.BatchNorm2d(64)
self.proj = nn.Conv2d(64, embed_dim, kernel_size=new_patch_size, stride=new_patch_size)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.proj(x).flatten(2).transpose(1, 2) # [B, C, W, H]
return x
class PatchEmbed(nn.Module):
"""
Same embedding as timm lib.
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class HybridEmbed(nn.Module):
"""
Same embedding as timm lib.
"""
def __init__(self, backbone, img_size=224, feature_size=None, in_chans=3, embed_dim=768):
super().__init__()
assert isinstance(backbone, nn.Module)
img_size = to_2tuple(img_size)
self.img_size = img_size
self.backbone = backbone
if feature_size is None:
with torch.no_grad():
training = backbone.training
if training:
backbone.eval()
o = self.backbone(torch.zeros(1, in_chans, img_size[0], img_size[1]))[-1]
feature_size = o.shape[-2:]
feature_dim = o.shape[1]
backbone.train(training)
else:
feature_size = to_2tuple(feature_size)
feature_dim = self.backbone.feature_info.channels()[-1]
self.num_patches = feature_size[0] * feature_size[1]
self.proj = nn.Linear(feature_dim, embed_dim)
def forward(self, x):
x = self.backbone(x)[-1]
x = x.flatten(2).transpose(1, 2)
x = self.proj(x)
return x
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
# patch models
'Deepvit_base_patch16_224_16B': _cfg(
url='',
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
),
'Deepvit_base_patch16_224_24B': _cfg(
url='',
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
),
'Deepvit_base_patch16_224_32B': _cfg(
url='',
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
),
'Deepvit_L_384': _cfg(
url='',
input_size=(3, 384, 384), mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5), crop_pct=1.0),
}
class DeepVisionTransformer(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm, group = False, re_atten=True, cos_reg = False,
use_cnn_embed=False, apply_transform=None, transform_scale=False, scale_adjustment=1.):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
# use cosine similarity as a regularization term
self.cos_reg = cos_reg
if hybrid_backbone is not None:
self.patch_embed = HybridEmbed(
hybrid_backbone, img_size=img_size, in_chans=in_chans, embed_dim=embed_dim)
else:
if use_cnn_embed:
self.patch_embed = PatchEmbed_CNN(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
else:
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
d = depth if isinstance(depth, int) else len(depth)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, d)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, share=depth[i], num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, group = group,
re_atten=re_atten, apply_transform=apply_transform[i], transform_scale=transform_scale, scale_adjustment=scale_adjustment)
for i in range(len(depth))])
self.norm = norm_layer(embed_dim)
# Classifier head
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
if self.cos_reg:
atten_list = []
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
attn = None
for blk in self.blocks:
x, attn = blk(x, attn)
if self.cos_reg:
atten_list.append(attn)
x = self.norm(x)
if self.cos_reg and self.training:
return x[:, 0], atten_list
else:
return x[:, 0]
def forward(self, x):
if self.cos_reg and self.training:
x, atten = self.forward_features(x)
x = self.head(x)
return x, atten
else:
x = self.forward_features(x)
x = self.head(x)
return x
@register_model
def deepvit_patch16_224_re_attn_16b(pretrained=False, **kwargs):
apply_transform = [False] * 0 + [True] * 16
model = DeepVisionTransformer(
patch_size=16, embed_dim=384, depth=[False] * 16, apply_transform=apply_transform, num_heads=12, mlp_ratio=3, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
# We following the same settings for original ViT
model.default_cfg = default_cfgs['Deepvit_base_patch16_224_16B']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
@register_model
def deepvit_patch16_224_re_attn_24b(pretrained=False, **kwargs):
apply_transform = [False] * 0 + [True] * 24
model = DeepVisionTransformer(
patch_size=16, embed_dim=384, depth=[False] * 24, apply_transform=apply_transform, num_heads=12, mlp_ratio=3, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
# We following the same settings for original ViT
model.default_cfg = default_cfgs['Deepvit_base_patch16_224_24B']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
@register_model
def deepvit_patch16_224_re_attn_32b(pretrained=False, **kwargs):
apply_transform = [False] * 0 + [True] * 32
model = DeepVisionTransformer(
patch_size=16, embed_dim=384, depth=[False] * 32, apply_transform=apply_transform, num_heads=12, mlp_ratio=3, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
# We following the same settings for original ViT
model.default_cfg = default_cfgs['Deepvit_base_patch16_224_32B']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
@register_model
def deepvit_S(pretrained=False, **kwargs):
apply_transform = [False] * 11 + [True] * 5
model = DeepVisionTransformer(
patch_size=16, embed_dim=396, depth=[False] * 16, apply_transform=apply_transform, num_heads=12, mlp_ratio=3, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), transform_scale=True, use_cnn_embed = True, scale_adjustment=0.5, **kwargs)
# We following the same settings for original ViT
model.default_cfg = default_cfgs['Deepvit_base_patch16_224_32B']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
@register_model
def deepvit_L(pretrained=False, **kwargs):
apply_transform = [False] * 20 + [True] * 12
model = DeepVisionTransformer(
patch_size=16, embed_dim=420, depth=[False] * 32, apply_transform=apply_transform, num_heads=12, mlp_ratio=3, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), use_cnn_embed = True, scale_adjustment=0.5, **kwargs)
# We following the same settings for original ViT
model.default_cfg = default_cfgs['Deepvit_base_patch16_224_32B']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
@register_model
def deepvit_L_384(pretrained=False, **kwargs):
apply_transform = [False] * 20 + [True] * 12
model = DeepVisionTransformer(
img_size=384, patch_size=16, embed_dim=420, depth=[False] * 32, apply_transform=apply_transform, num_heads=12, mlp_ratio=3, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), use_cnn_embed = True, scale_adjustment=0.5, **kwargs)
# We following the same settings for original ViT
model.default_cfg = default_cfgs['Deepvit_L_384']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DeepVisionTransformer(
patch_size=16, embed_dim=384,
depth=[False] * 16,
apply_transform=[False] * 0 + [True] * 32,
num_heads=12,
mlp_ratio=3,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/DeiT.py
================================================
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
import torch
import torch.nn as nn
import numpy as np
from functools import partial
from timm.models.vision_transformer import VisionTransformer, _cfg
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_
__all__ = [
'deit_tiny_patch16_224', 'deit_small_patch16_224', 'deit_base_patch16_224',
'deit_tiny_distilled_patch16_224', 'deit_small_distilled_patch16_224',
'deit_base_distilled_patch16_224', 'deit_base_patch16_384',
'deit_base_distilled_patch16_384',
]
class DistilledVisionTransformer(VisionTransformer):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.dist_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
num_patches = self.patch_embed.num_patches
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 2, self.embed_dim))
self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if self.num_classes > 0 else nn.Identity()
trunc_normal_(self.dist_token, std=.02)
trunc_normal_(self.pos_embed, std=.02)
self.head_dist.apply(self._init_weights)
def forward_features(self, x):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to add the dist_token
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
dist_token = self.dist_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, dist_token, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x[:, 0], x[:, 1]
def forward(self, x):
x, x_dist = self.forward_features(x)
x = self.head(x)
x_dist = self.head_dist(x_dist)
if self.training:
return x, x_dist
else:
# during inference, return the average of both classifier predictions
return (x + x_dist) / 2
@register_model
def deit_tiny_patch16_224(pretrained=False, **kwargs):
model = VisionTransformer(
patch_size=16, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_tiny_patch16_224-a1311bcf.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_small_patch16_224(pretrained=False, **kwargs):
model = VisionTransformer(
patch_size=16, embed_dim=384, depth=12, num_heads=6, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_small_patch16_224-cd65a155.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_base_patch16_224(pretrained=False, **kwargs):
model = VisionTransformer(
patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_base_patch16_224-b5f2ef4d.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_tiny_distilled_patch16_224(pretrained=False, **kwargs):
model = DistilledVisionTransformer(
patch_size=16, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_tiny_distilled_patch16_224-b40b3cf7.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_small_distilled_patch16_224(pretrained=False, **kwargs):
model = DistilledVisionTransformer(
patch_size=16, embed_dim=384, depth=12, num_heads=6, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_small_distilled_patch16_224-649709d9.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_base_distilled_patch16_224(pretrained=False, **kwargs):
model = DistilledVisionTransformer(
patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_base_distilled_patch16_224-df68dfff.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_base_patch16_384(pretrained=False, **kwargs):
model = VisionTransformer(
img_size=384, patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_base_patch16_384-8de9b5d1.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_base_distilled_patch16_384(pretrained=False, **kwargs):
model = DistilledVisionTransformer(
img_size=384, patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_base_distilled_patch16_384-d0272ac0.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DistilledVisionTransformer(
patch_size=16,
embed_dim=384,
depth=12,
num_heads=6,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output[0].shape)
================================================
FILE: model/backbone/EfficientFormer.py
================================================
"""
EfficientFormer
"""
import os
import copy
import torch
import torch.nn as nn
from typing import Dict
import itertools
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
from timm.models.layers.helpers import to_2tuple
EfficientFormer_width = {
'l1': [48, 96, 224, 448],
'l3': [64, 128, 320, 512],
'l7': [96, 192, 384, 768],
}
EfficientFormer_depth = {
'l1': [3, 2, 6, 4],
'l3': [4, 4, 12, 6],
'l7': [6, 6, 18, 8],
}
class Attention(torch.nn.Module):
def __init__(self, dim=384, key_dim=32, num_heads=8,
attn_ratio=4,
resolution=7):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
self.qkv = nn.Linear(dim, h)
self.proj = nn.Linear(self.dh, dim)
points = list(itertools.product(range(resolution), range(resolution)))
N = len(points)
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N, N))
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def forward(self, x): # x (B,N,C)
B, N, C = x.shape
qkv = self.qkv(x)
q, k, v = qkv.reshape(B, N, self.num_heads, -1).split([self.key_dim, self.key_dim, self.d], dim=3)
q = q.permute(0, 2, 1, 3)
k = k.permute(0, 2, 1, 3)
v = v.permute(0, 2, 1, 3)
attn = (
(q @ k.transpose(-2, -1)) * self.scale
+
(self.attention_biases[:, self.attention_bias_idxs]
if self.training else self.ab)
)
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, self.dh)
x = self.proj(x)
return x
def stem(in_chs, out_chs):
return nn.Sequential(
nn.Conv2d(in_chs, out_chs // 2, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_chs // 2),
nn.ReLU(),
nn.Conv2d(out_chs // 2, out_chs, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_chs),
nn.ReLU(), )
class Embedding(nn.Module):
"""
Patch Embedding that is implemented by a layer of conv.
Input: tensor in shape [B, C, H, W]
Output: tensor in shape [B, C, H/stride, W/stride]
"""
def __init__(self, patch_size=16, stride=16, padding=0,
in_chans=3, embed_dim=768, norm_layer=nn.BatchNorm2d):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
x = self.norm(x)
return x
class Flat(nn.Module):
def __init__(self, ):
super().__init__()
def forward(self, x):
x = x.flatten(2).transpose(1, 2)
return x
class Pooling(nn.Module):
"""
Implementation of pooling for PoolFormer
--pool_size: pooling size
"""
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2d(
pool_size, stride=1, padding=pool_size // 2, count_include_pad=False)
def forward(self, x):
return self.pool(x) - x
class LinearMlp(nn.Module):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.drop1 = nn.Dropout(drop)
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop2 = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class Mlp(nn.Module):
"""
Implementation of MLP with 1*1 convolutions.
Input: tensor with shape [B, C, H, W]
"""
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
self.norm1 = nn.BatchNorm2d(hidden_features)
self.norm2 = nn.BatchNorm2d(out_features)
def _init_weights(self, m):
if isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.fc1(x)
x = self.norm1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.norm2(x)
x = self.drop(x)
return x
class Meta3D(nn.Module):
def __init__(self, dim, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.norm1 = norm_layer(dim)
self.token_mixer = Attention(dim)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = LinearMlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(0).unsqueeze(0)
* self.token_mixer(self.norm1(x)))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(0).unsqueeze(0)
* self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class Meta4D(nn.Module):
def __init__(self, dim, pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.token_mixer = Pooling(pool_size=pool_size)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(-1).unsqueeze(-1)
* self.token_mixer(x))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(-1).unsqueeze(-1)
* self.mlp(x))
else:
x = x + self.drop_path(self.token_mixer(x))
x = x + self.drop_path(self.mlp(x))
return x
def meta_blocks(dim, index, layers,
pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
drop_rate=.0, drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5, vit_num=1):
blocks = []
if index == 3 and vit_num == layers[index]:
blocks.append(Flat())
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (
block_idx + sum(layers[:index])) / (sum(layers) - 1)
if index == 3 and layers[index] - block_idx <= vit_num:
blocks.append(Meta3D(
dim, mlp_ratio=mlp_ratio,
act_layer=act_layer, norm_layer=norm_layer,
drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
))
else:
blocks.append(Meta4D(
dim, pool_size=pool_size, mlp_ratio=mlp_ratio,
act_layer=act_layer,
drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
))
if index == 3 and layers[index] - block_idx - 1 == vit_num:
blocks.append(Flat())
blocks = nn.Sequential(*blocks)
return blocks
class EfficientFormer(nn.Module):
def __init__(self, layers, embed_dims=None,
mlp_ratios=4, downsamples=None,
pool_size=3,
norm_layer=nn.LayerNorm, act_layer=nn.GELU,
num_classes=1000,
down_patch_size=3, down_stride=2, down_pad=1,
drop_rate=0., drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5,
fork_feat=False,
init_cfg=None,
pretrained=None,
vit_num=0,
distillation=True,
**kwargs):
super().__init__()
if not fork_feat:
self.num_classes = num_classes
self.fork_feat = fork_feat
self.patch_embed = stem(3, embed_dims[0])
network = []
for i in range(len(layers)):
stage = meta_blocks(embed_dims[i], i, layers,
pool_size=pool_size, mlp_ratio=mlp_ratios,
act_layer=act_layer, norm_layer=norm_layer,
drop_rate=drop_rate,
drop_path_rate=drop_path_rate,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
vit_num=vit_num)
network.append(stage)
if i >= len(layers) - 1:
break
if downsamples[i] or embed_dims[i] != embed_dims[i + 1]:
# downsampling between two stages
network.append(
Embedding(
patch_size=down_patch_size, stride=down_stride,
padding=down_pad,
in_chans=embed_dims[i], embed_dim=embed_dims[i + 1]
)
)
self.network = nn.ModuleList(network)
if self.fork_feat:
# add a norm layer for each output
self.out_indices = [0, 2, 4, 6]
for i_emb, i_layer in enumerate(self.out_indices):
if i_emb == 0 and os.environ.get('FORK_LAST3', None):
layer = nn.Identity()
else:
layer = norm_layer(embed_dims[i_emb])
layer_name = f'norm{i_layer}'
self.add_module(layer_name, layer)
else:
# Classifier head
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 \
else nn.Identity()
self.dist = distillation
if self.dist:
self.dist_head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 \
else nn.Identity()
self.apply(self.cls_init_weights)
self.init_cfg = copy.deepcopy(init_cfg)
# load pre-trained model
if self.fork_feat and (
self.init_cfg is not None or pretrained is not None):
self.init_weights()
# init for classification
def cls_init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
# init for mmdetection or mmsegmentation by loading
# imagenet pre-trained weights
def init_weights(self, pretrained=None):
logger = get_root_logger()
if self.init_cfg is None and pretrained is None:
logger.warn(f'No pre-trained weights for '
f'{self.__class__.__name__}, '
f'training start from scratch')
pass
else:
assert 'checkpoint' in self.init_cfg, f'Only support ' \
f'specify `Pretrained` in ' \
f'`init_cfg` in ' \
f'{self.__class__.__name__} '
if self.init_cfg is not None:
ckpt_path = self.init_cfg['checkpoint']
elif pretrained is not None:
ckpt_path = pretrained
ckpt = _load_checkpoint(
ckpt_path, logger=logger, map_location='cpu')
if 'state_dict' in ckpt:
_state_dict = ckpt['state_dict']
elif 'model' in ckpt:
_state_dict = ckpt['model']
else:
_state_dict = ckpt
state_dict = _state_dict
missing_keys, unexpected_keys = \
self.load_state_dict(state_dict, False)
def forward_tokens(self, x):
outs = []
for idx, block in enumerate(self.network):
x = block(x)
if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{idx}')
x_out = norm_layer(x)
outs.append(x_out)
if self.fork_feat:
return outs
return x
def forward(self, x):
x = self.patch_embed(x)
x = self.forward_tokens(x)
if self.fork_feat:
# otuput features of four stages for dense prediction
return x
x = self.norm(x)
if self.dist:
cls_out = self.head(x.mean(-2)), self.dist_head(x.mean(-2))
if not self.training:
cls_out = (cls_out[0] + cls_out[1]) / 2
else:
cls_out = self.head(x.mean(-2))
# for image classification
return cls_out
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .95, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'classifier': 'head',
**kwargs
}
@register_model
def efficientformer_l1(pretrained=False, **kwargs):
model = EfficientFormer(
layers=EfficientFormer_depth['l1'],
embed_dims=EfficientFormer_width['l1'],
downsamples=[True, True, True, True],
vit_num=1,
**kwargs)
model.default_cfg = _cfg(crop_pct=0.9)
return model
@register_model
def efficientformer_l3(pretrained=False, **kwargs):
model = EfficientFormer(
layers=EfficientFormer_depth['l3'],
embed_dims=EfficientFormer_width['l3'],
downsamples=[True, True, True, True],
vit_num=4,
**kwargs)
model.default_cfg = _cfg(crop_pct=0.9)
return model
@register_model
def efficientformer_l7(pretrained=False, **kwargs):
model = EfficientFormer(
layers=EfficientFormer_depth['l7'],
embed_dims=EfficientFormer_width['l7'],
downsamples=[True, True, True, True],
vit_num=8,
**kwargs)
model.default_cfg = _cfg(crop_pct=0.9)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = EfficientFormer(
layers=EfficientFormer_depth['l1'],
embed_dims=EfficientFormer_width['l1'],
downsamples=[True, True, True, True],
vit_num=1,
)
output=model(input)
print(output[0].shape)
================================================
FILE: model/backbone/HATNet.py
================================================
from pyexpat import model
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
class InvertedResidual(nn.Module):
def __init__(self, in_dim, hidden_dim=None, out_dim=None, kernel_size=3,
drop=0., act_layer=nn.SiLU):
super().__init__()
hidden_dim = hidden_dim or in_dim
out_dim = out_dim or in_dim
pad = (kernel_size - 1) // 2
self.conv1 = nn.Sequential(
nn.GroupNorm(1, in_dim, eps=1e-6),
nn.Conv2d(in_dim, hidden_dim, 1, bias=False),
act_layer(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, padding=pad, groups=hidden_dim, bias=False),
act_layer(inplace=True)
)
self.conv3 = nn.Sequential(
nn.Conv2d(hidden_dim, out_dim, 1, bias=False),
nn.GroupNorm(1, out_dim, eps=1e-6)
)
self.drop = nn.Dropout2d(drop, inplace=True)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.drop(x)
x = self.conv3(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, head_dim, grid_size=1, ds_ratio=1, drop=0.):
super().__init__()
assert dim % head_dim == 0
self.num_heads = dim // head_dim
self.head_dim = head_dim
self.scale = self.head_dim ** -0.5
self.grid_size = grid_size
self.norm = nn.GroupNorm(1, dim, eps=1e-6)
self.qkv = nn.Conv2d(dim, dim * 3, 1)
self.proj = nn.Conv2d(dim, dim, 1)
self.proj_norm = nn.GroupNorm(1, dim, eps=1e-6)
self.drop = nn.Dropout2d(drop, inplace=True)
if grid_size > 1:
self.grid_norm = nn.GroupNorm(1, dim, eps=1e-6)
self.avg_pool = nn.AvgPool2d(ds_ratio, stride=ds_ratio)
self.ds_norm = nn.GroupNorm(1, dim, eps=1e-6)
self.q = nn.Conv2d(dim, dim, 1)
self.kv = nn.Conv2d(dim, dim * 2, 1)
def forward(self, x):
B, C, H, W = x.shape
qkv = self.qkv(self.norm(x))
if self.grid_size > 1:
grid_h, grid_w = H // self.grid_size, W // self.grid_size
qkv = qkv.reshape(B, 3, self.num_heads, self.head_dim, grid_h,
self.grid_size, grid_w, self.grid_size)
qkv = qkv.permute(1, 0, 2, 4, 6, 5, 7, 3)
qkv = qkv.reshape(3, -1, self.grid_size * self.grid_size, self.head_dim)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q * self.scale) @ k.transpose(-2, -1)
attn = attn.softmax(dim=-1)
grid_x = (attn @ v).reshape(B, self.num_heads, grid_h, grid_w,
self.grid_size, self.grid_size, self.head_dim)
grid_x = grid_x.permute(0, 1, 6, 2, 4, 3, 5).reshape(B, C, H, W)
grid_x = self.grid_norm(x + grid_x)
q = self.q(grid_x).reshape(B, self.num_heads, self.head_dim, -1)
q = q.transpose(-2, -1)
kv = self.kv(self.ds_norm(self.avg_pool(grid_x)))
kv = kv.reshape(B, 2, self.num_heads, self.head_dim, -1)
kv = kv.permute(1, 0, 2, 4, 3)
k, v = kv[0], kv[1]
else:
qkv = qkv.reshape(B, 3, self.num_heads, self.head_dim, -1)
qkv = qkv.permute(1, 0, 2, 4, 3)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q * self.scale) @ k.transpose(-2, -1)
attn = attn.softmax(dim=-1)
global_x = (attn @ v).transpose(-2, -1).reshape(B, C, H, W)
if self.grid_size > 1:
global_x = global_x + grid_x
x = self.drop(self.proj(global_x))
return x
class Block(nn.Module):
def __init__(self, dim, head_dim, grid_size=1, ds_ratio=1, expansion=4,
drop=0., drop_path=0., kernel_size=3, act_layer=nn.SiLU):
super().__init__()
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.attn = Attention(dim, head_dim, grid_size=grid_size, ds_ratio=ds_ratio, drop=drop)
self.conv = InvertedResidual(dim, hidden_dim=dim * expansion, out_dim=dim,
kernel_size=kernel_size, drop=drop, act_layer=act_layer)
def forward(self, x):
x = x + self.drop_path(self.attn(x))
x = x + self.drop_path(self.conv(x))
return x
class Downsample(nn.Module):
def __init__(self, in_dim, out_dim, kernel_size=3):
super().__init__()
self.conv = nn.Conv2d(in_dim, out_dim, kernel_size, padding=1, stride=2)
self.norm = nn.GroupNorm(1, out_dim, eps=1e-6)
def forward(self, x):
x = self.norm(self.conv(x))
return x
class HATNet(nn.Module):
def __init__(self, img_size=224, in_chans=3, num_classes=1000, dims=[64, 128, 256, 512],
head_dim=64, expansions=[4, 4, 6, 6], grid_sizes=[1, 1, 1, 1],
ds_ratios=[8, 4, 2, 1], depths=[3, 4, 8, 3], drop_rate=0.,
drop_path_rate=0., act_layer=nn.SiLU, kernel_sizes=[3, 3, 3, 3]):
super().__init__()
self.depths = depths
self.patch_embed = nn.Sequential(
nn.Conv2d(3, 16, 3, padding=1, stride=2),
nn.GroupNorm(1, 16, eps=1e-6),
act_layer(inplace=True),
nn.Conv2d(16, dims[0], 3, padding=1, stride=2),
)
self.blocks = []
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
for stage in range(len(dims)):
self.blocks.append(nn.ModuleList([Block(
dims[stage], head_dim, grid_size=grid_sizes[stage], ds_ratio=ds_ratios[stage],
expansion=expansions[stage], drop=drop_rate, drop_path=dpr[sum(depths[:stage]) + i],
kernel_size=kernel_sizes[stage], act_layer=act_layer)
for i in range(depths[stage])]))
self.blocks = nn.ModuleList(self.blocks)
self.ds2 = Downsample(dims[0], dims[1])
self.ds3 = Downsample(dims[1], dims[2])
self.ds4 = Downsample(dims[2], dims[3])
self.classifier = nn.Sequential(
nn.Dropout(0.2, inplace=True),
nn.Linear(dims[-1], num_classes),
)
# init weights
self.apply(self._init_weights)
def reset_drop_path(self, drop_path_rate):
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(self.depths))]
cur = 0
for stage in range(len(self.blocks)):
for idx in range(self.depths[stage]):
self.blocks[stage][idx].drop_path.drop_prob = dpr[cur + idx]
cur += self.depths[stage]
def _init_weights(self, m):
if isinstance(m, (nn.Linear, nn.Conv2d)):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, (nn.LayerNorm, nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
x = self.patch_embed(x)
for block in self.blocks[0]:
x = block(x)
x = self.ds2(x)
for block in self.blocks[1]:
x = block(x)
x = self.ds3(x)
for block in self.blocks[2]:
x = block(x)
x = self.ds4(x)
for block in self.blocks[3]:
x = block(x)
x = F.adaptive_avg_pool2d(x, (1, 1)).flatten(1)
x = self.classifier(x)
return x
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
hat = HATNet(dims=[48, 96, 240, 384], head_dim=48, expansions=[8, 8, 4, 4],
grid_sizes=[8, 7, 7, 1], ds_ratios=[8, 4, 2, 1], depths=[2, 2, 6, 3])
output=hat(input)
print(output.shape)
================================================
FILE: model/backbone/LeViT.py
================================================
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
# Modified from
# https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# Copyright 2020 Ross Wightman, Apache-2.0 License
import torch
import itertools
# import utils
from timm.models.vision_transformer import trunc_normal_
from timm.models.registry import register_model
def replace_batchnorm(net):
for child_name, child in net.named_children():
if hasattr(child, 'fuse'):
setattr(net, child_name, child.fuse())
elif isinstance(child, torch.nn.Conv2d):
child.bias = torch.nn.Parameter(torch.zeros(child.weight.size(0)))
elif isinstance(child, torch.nn.BatchNorm2d):
setattr(net, child_name, torch.nn.Identity())
else:
replace_batchnorm(child)
specification = {
'LeViT_128S': {
'C': '128_256_384', 'D': 16, 'N': '4_6_8', 'X': '2_3_4', 'drop_path': 0,
'weights': 'https://dl.fbaipublicfiles.com/LeViT/LeViT-128S-96703c44.pth'},
'LeViT_128': {
'C': '128_256_384', 'D': 16, 'N': '4_8_12', 'X': '4_4_4', 'drop_path': 0,
'weights': 'https://dl.fbaipublicfiles.com/LeViT/LeViT-128-b88c2750.pth'},
'LeViT_192': {
'C': '192_288_384', 'D': 32, 'N': '3_5_6', 'X': '4_4_4', 'drop_path': 0,
'weights': 'https://dl.fbaipublicfiles.com/LeViT/LeViT-192-92712e41.pth'},
'LeViT_256': {
'C': '256_384_512', 'D': 32, 'N': '4_6_8', 'X': '4_4_4', 'drop_path': 0,
'weights': 'https://dl.fbaipublicfiles.com/LeViT/LeViT-256-13b5763e.pth'},
'LeViT_384': {
'C': '384_512_768', 'D': 32, 'N': '6_9_12', 'X': '4_4_4', 'drop_path': 0.1,
'weights': 'https://dl.fbaipublicfiles.com/LeViT/LeViT-384-9bdaf2e2.pth'},
}
__all__ = [specification.keys()]
@register_model
def LeViT_128S(num_classes=1000, distillation=True,
pretrained=False, fuse=False):
return model_factory(**specification['LeViT_128S'], num_classes=num_classes,
distillation=distillation, pretrained=pretrained, fuse=fuse)
@register_model
def LeViT_128(num_classes=1000, distillation=True,
pretrained=False, fuse=False):
return model_factory(**specification['LeViT_128'], num_classes=num_classes,
distillation=distillation, pretrained=pretrained, fuse=fuse)
@register_model
def LeViT_192(num_classes=1000, distillation=True,
pretrained=False, fuse=False):
return model_factory(**specification['LeViT_192'], num_classes=num_classes,
distillation=distillation, pretrained=pretrained, fuse=fuse)
@register_model
def LeViT_256(num_classes=1000, distillation=True,
pretrained=False, fuse=False):
return model_factory(**specification['LeViT_256'], num_classes=num_classes,
distillation=distillation, pretrained=pretrained, fuse=fuse)
@register_model
def LeViT_384(num_classes=1000, distillation=True,
pretrained=False, fuse=False):
return model_factory(**specification['LeViT_384'], num_classes=num_classes,
distillation=distillation, pretrained=pretrained, fuse=fuse)
FLOPS_COUNTER = 0
class Conv2d_BN(torch.nn.Sequential):
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
groups=1, bn_weight_init=1, resolution=-10000):
super().__init__()
self.add_module('c', torch.nn.Conv2d(
a, b, ks, stride, pad, dilation, groups, bias=False))
bn = torch.nn.BatchNorm2d(b)
torch.nn.init.constant_(bn.weight, bn_weight_init)
torch.nn.init.constant_(bn.bias, 0)
self.add_module('bn', bn)
global FLOPS_COUNTER
output_points = ((resolution + 2 * pad - dilation *
(ks - 1) - 1) // stride + 1)**2
FLOPS_COUNTER += a * b * output_points * (ks**2) // groups
@torch.no_grad()
def fuse(self):
c, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
w = c.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps)**0.5
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
class Linear_BN(torch.nn.Sequential):
def __init__(self, a, b, bn_weight_init=1, resolution=-100000):
super().__init__()
self.add_module('c', torch.nn.Linear(a, b, bias=False))
bn = torch.nn.BatchNorm1d(b)
torch.nn.init.constant_(bn.weight, bn_weight_init)
torch.nn.init.constant_(bn.bias, 0)
self.add_module('bn', bn)
global FLOPS_COUNTER
output_points = resolution**2
FLOPS_COUNTER += a * b * output_points
@torch.no_grad()
def fuse(self):
l, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
w = l.weight * w[:, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps)**0.5
m = torch.nn.Linear(w.size(1), w.size(0))
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
def forward(self, x):
l, bn = self._modules.values()
x = l(x)
return bn(x.flatten(0, 1)).reshape_as(x)
class BN_Linear(torch.nn.Sequential):
def __init__(self, a, b, bias=True, std=0.02):
super().__init__()
self.add_module('bn', torch.nn.BatchNorm1d(a))
l = torch.nn.Linear(a, b, bias=bias)
trunc_normal_(l.weight, std=std)
if bias:
torch.nn.init.constant_(l.bias, 0)
self.add_module('l', l)
global FLOPS_COUNTER
FLOPS_COUNTER += a * b
@torch.no_grad()
def fuse(self):
bn, l = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
b = bn.bias - self.bn.running_mean * \
self.bn.weight / (bn.running_var + bn.eps)**0.5
w = l.weight * w[None, :]
if l.bias is None:
b = b @ self.l.weight.T
else:
b = (l.weight @ b[:, None]).view(-1) + self.l.bias
m = torch.nn.Linear(w.size(1), w.size(0))
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
def b16(n, activation, resolution=224):
return torch.nn.Sequential(
Conv2d_BN(3, n // 8, 3, 2, 1, resolution=resolution),
activation(),
Conv2d_BN(n // 8, n // 4, 3, 2, 1, resolution=resolution // 2),
activation(),
Conv2d_BN(n // 4, n // 2, 3, 2, 1, resolution=resolution // 4),
activation(),
Conv2d_BN(n // 2, n, 3, 2, 1, resolution=resolution // 8))
class Residual(torch.nn.Module):
def __init__(self, m, drop):
super().__init__()
self.m = m
self.drop = drop
def forward(self, x):
if self.training and self.drop > 0:
return x + self.m(x) * torch.rand(x.size(0), 1, 1,
device=x.device).ge_(self.drop).div(1 - self.drop).detach()
else:
return x + self.m(x)
class Attention(torch.nn.Module):
def __init__(self, dim, key_dim, num_heads=8,
attn_ratio=4,
activation=None,
resolution=14):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
self.qkv = Linear_BN(dim, h, resolution=resolution)
self.proj = torch.nn.Sequential(activation(), Linear_BN(
self.dh, dim, bn_weight_init=0, resolution=resolution))
points = list(itertools.product(range(resolution), range(resolution)))
N = len(points)
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N, N))
global FLOPS_COUNTER
#queries * keys
FLOPS_COUNTER += num_heads * (resolution**4) * key_dim
# softmax
FLOPS_COUNTER += num_heads * (resolution**4)
#attention * v
FLOPS_COUNTER += num_heads * self.d * (resolution**4)
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def forward(self, x): # x (B,N,C)
B, N, C = x.shape
qkv = self.qkv(x)
q, k, v = qkv.view(B, N, self.num_heads, -
1).split([self.key_dim, self.key_dim, self.d], dim=3)
q = q.permute(0, 2, 1, 3)
k = k.permute(0, 2, 1, 3)
v = v.permute(0, 2, 1, 3)
attn = (
(q @ k.transpose(-2, -1)) * self.scale
+
(self.attention_biases[:, self.attention_bias_idxs]
if self.training else self.ab)
)
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, self.dh)
x = self.proj(x)
return x
class Subsample(torch.nn.Module):
def __init__(self, stride, resolution):
super().__init__()
self.stride = stride
self.resolution = resolution
def forward(self, x):
B, N, C = x.shape
x = x.view(B, self.resolution, self.resolution, C)[
:, ::self.stride, ::self.stride].reshape(B, -1, C)
return x
class AttentionSubsample(torch.nn.Module):
def __init__(self, in_dim, out_dim, key_dim, num_heads=8,
attn_ratio=2,
activation=None,
stride=2,
resolution=14, resolution_=7):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * self.num_heads
self.attn_ratio = attn_ratio
self.resolution_ = resolution_
self.resolution_2 = resolution_**2
h = self.dh + nh_kd
self.kv = Linear_BN(in_dim, h, resolution=resolution)
self.q = torch.nn.Sequential(
Subsample(stride, resolution),
Linear_BN(in_dim, nh_kd, resolution=resolution_))
self.proj = torch.nn.Sequential(activation(), Linear_BN(
self.dh, out_dim, resolution=resolution_))
self.stride = stride
self.resolution = resolution
points = list(itertools.product(range(resolution), range(resolution)))
points_ = list(itertools.product(
range(resolution_), range(resolution_)))
N = len(points)
N_ = len(points_)
attention_offsets = {}
idxs = []
for p1 in points_:
for p2 in points:
size = 1
offset = (
abs(p1[0] * stride - p2[0] + (size - 1) / 2),
abs(p1[1] * stride - p2[1] + (size - 1) / 2))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N_, N))
global FLOPS_COUNTER
#queries * keys
FLOPS_COUNTER += num_heads * \
(resolution**2) * (resolution_**2) * key_dim
# softmax
FLOPS_COUNTER += num_heads * (resolution**2) * (resolution_**2)
#attention * v
FLOPS_COUNTER += num_heads * \
(resolution**2) * (resolution_**2) * self.d
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def forward(self, x):
B, N, C = x.shape
k, v = self.kv(x).view(B, N, self.num_heads, -
1).split([self.key_dim, self.d], dim=3)
k = k.permute(0, 2, 1, 3) # BHNC
v = v.permute(0, 2, 1, 3) # BHNC
q = self.q(x).view(B, self.resolution_2, self.num_heads,
self.key_dim).permute(0, 2, 1, 3)
attn = (q @ k.transpose(-2, -1)) * self.scale + \
(self.attention_biases[:, self.attention_bias_idxs]
if self.training else self.ab)
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, -1, self.dh)
x = self.proj(x)
return x
class LeViT(torch.nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=224,
patch_size=16,
in_chans=3,
num_classes=1000,
embed_dim=[192],
key_dim=[64],
depth=[12],
num_heads=[3],
attn_ratio=[2],
mlp_ratio=[2],
hybrid_backbone=None,
down_ops=[],
attention_activation=torch.nn.Hardswish,
mlp_activation=torch.nn.Hardswish,
distillation=True,
drop_path=0):
super().__init__()
global FLOPS_COUNTER
self.num_classes = num_classes
self.num_features = embed_dim[-1]
self.embed_dim = embed_dim
self.distillation = distillation
self.patch_embed = hybrid_backbone
self.blocks = []
down_ops.append([''])
resolution = img_size // patch_size
for i, (ed, kd, dpth, nh, ar, mr, do) in enumerate(
zip(embed_dim, key_dim, depth, num_heads, attn_ratio, mlp_ratio, down_ops)):
for _ in range(dpth):
self.blocks.append(
Residual(Attention(
ed, kd, nh,
attn_ratio=ar,
activation=attention_activation,
resolution=resolution,
), drop_path))
if mr > 0:
h = int(ed * mr)
self.blocks.append(
Residual(torch.nn.Sequential(
Linear_BN(ed, h, resolution=resolution),
mlp_activation(),
Linear_BN(h, ed, bn_weight_init=0,
resolution=resolution),
), drop_path))
if do[0] == 'Subsample':
#('Subsample',key_dim, num_heads, attn_ratio, mlp_ratio, stride)
resolution_ = (resolution - 1) // do[5] + 1
self.blocks.append(
AttentionSubsample(
*embed_dim[i:i + 2], key_dim=do[1], num_heads=do[2],
attn_ratio=do[3],
activation=attention_activation,
stride=do[5],
resolution=resolution,
resolution_=resolution_))
resolution = resolution_
if do[4] > 0: # mlp_ratio
h = int(embed_dim[i + 1] * do[4])
self.blocks.append(
Residual(torch.nn.Sequential(
Linear_BN(embed_dim[i + 1], h,
resolution=resolution),
mlp_activation(),
Linear_BN(
h, embed_dim[i + 1], bn_weight_init=0, resolution=resolution),
), drop_path))
self.blocks = torch.nn.Sequential(*self.blocks)
# Classifier head
self.head = BN_Linear(
embed_dim[-1], num_classes) if num_classes > 0 else torch.nn.Identity()
if distillation:
self.head_dist = BN_Linear(
embed_dim[-1], num_classes) if num_classes > 0 else torch.nn.Identity()
self.FLOPS = FLOPS_COUNTER
FLOPS_COUNTER = 0
@torch.jit.ignore
def no_weight_decay(self):
return {x for x in self.state_dict().keys() if 'attention_biases' in x}
def forward(self, x):
x = self.patch_embed(x)
x = x.flatten(2).transpose(1, 2)
x = self.blocks(x)
x = x.mean(1)
if self.distillation:
x = self.head(x), self.head_dist(x)
if not self.training:
x = (x[0] + x[1]) / 2
else:
x = self.head(x)
return x
def model_factory(C, D, X, N, drop_path, weights,
num_classes, distillation, pretrained, fuse):
embed_dim = [int(x) for x in C.split('_')]
num_heads = [int(x) for x in N.split('_')]
depth = [int(x) for x in X.split('_')]
act = torch.nn.Hardswish
model = LeViT(
patch_size=16,
embed_dim=embed_dim,
num_heads=num_heads,
key_dim=[D] * 3,
depth=depth,
attn_ratio=[2, 2, 2],
mlp_ratio=[2, 2, 2],
down_ops=[
#('Subsample',key_dim, num_heads, attn_ratio, mlp_ratio, stride)
['Subsample', D, embed_dim[0] // D, 4, 2, 2],
['Subsample', D, embed_dim[1] // D, 4, 2, 2],
],
attention_activation=act,
mlp_activation=act,
hybrid_backbone=b16(embed_dim[0], activation=act),
num_classes=num_classes,
drop_path=drop_path,
distillation=distillation
)
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
weights, map_location='cpu')
model.load_state_dict(checkpoint['model'])
if fuse:
replace_batchnorm(model)
return model
if __name__ == '__main__':
for name in specification:
model = globals()[name](fuse=True, pretrained=False)
input=torch.randn(1,3,224,224)
model.eval()
output = model(input)
# print(name,
# model.FLOPS, 'FLOPs',
# sum(p.numel() for p in model.parameters() if p.requires_grad), 'parameters')
print(output.shape)
================================================
FILE: model/backbone/MobileNetV3.py
================================================
""" MobileNet V3
A PyTorch impl of MobileNet-V3, compatible with TF weights from official impl.
Paper: Searching for MobileNetV3 - https://arxiv.org/abs/1905.02244
Hacked together by / Copyright 2019, Ross Wightman
"""
from functools import partial
from typing import List
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD, IMAGENET_INCEPTION_MEAN, IMAGENET_INCEPTION_STD
from timm.layers import SelectAdaptivePool2d, Linear, create_conv2d, get_norm_act_layer
from ._builder import build_model_with_cfg, pretrained_cfg_for_features
from ._efficientnet_blocks import SqueezeExcite
from ._efficientnet_builder import EfficientNetBuilder, decode_arch_def, efficientnet_init_weights, \
round_channels, resolve_bn_args, resolve_act_layer, BN_EPS_TF_DEFAULT
from ._features import FeatureInfo, FeatureHooks
from ._manipulate import checkpoint_seq
from ._registry import register_model
__all__ = ['MobileNetV3', 'MobileNetV3Features']
def _cfg(url='', **kwargs):
return {
'url': url, 'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': (7, 7),
'crop_pct': 0.875, 'interpolation': 'bilinear',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'conv_stem', 'classifier': 'classifier',
**kwargs
}
default_cfgs = {
'mobilenetv3_large_075': _cfg(url=''),
'mobilenetv3_large_100': _cfg(
interpolation='bicubic',
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_large_100_ra-f55367f5.pth'),
'mobilenetv3_large_100_miil': _cfg(
interpolation='bilinear', mean=(0., 0., 0.), std=(1., 1., 1.),
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/mobilenetv3_large_100_1k_miil_78_0-66471c13.pth'),
'mobilenetv3_large_100_miil_in21k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/mobilenetv3_large_100_in21k_miil-d71cc17b.pth',
interpolation='bilinear', mean=(0., 0., 0.), std=(1., 1., 1.), num_classes=11221),
'mobilenetv3_small_050': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_small_050_lambc-4b7bbe87.pth',
interpolation='bicubic'),
'mobilenetv3_small_075': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_small_075_lambc-384766db.pth',
interpolation='bicubic'),
'mobilenetv3_small_100': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_small_100_lamb-266a294c.pth',
interpolation='bicubic'),
'mobilenetv3_rw': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_100-35495452.pth',
interpolation='bicubic'),
'tf_mobilenetv3_large_075': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_large_075-150ee8b0.pth',
mean=IMAGENET_INCEPTION_MEAN, std=IMAGENET_INCEPTION_STD),
'tf_mobilenetv3_large_100': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_large_100-427764d5.pth',
mean=IMAGENET_INCEPTION_MEAN, std=IMAGENET_INCEPTION_STD),
'tf_mobilenetv3_large_minimal_100': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_large_minimal_100-8596ae28.pth',
mean=IMAGENET_INCEPTION_MEAN, std=IMAGENET_INCEPTION_STD),
'tf_mobilenetv3_small_075': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_small_075-da427f52.pth',
mean=IMAGENET_INCEPTION_MEAN, std=IMAGENET_INCEPTION_STD),
'tf_mobilenetv3_small_100': _cfg(
url= 'https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_small_100-37f49e2b.pth',
mean=IMAGENET_INCEPTION_MEAN, std=IMAGENET_INCEPTION_STD),
'tf_mobilenetv3_small_minimal_100': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_small_minimal_100-922a7843.pth',
mean=IMAGENET_INCEPTION_MEAN, std=IMAGENET_INCEPTION_STD),
'fbnetv3_b': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/fbnetv3_b_224-ead5d2a1.pth',
test_input_size=(3, 256, 256), crop_pct=0.95),
'fbnetv3_d': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/fbnetv3_d_224-c98bce42.pth',
test_input_size=(3, 256, 256), crop_pct=0.95),
'fbnetv3_g': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/fbnetv3_g_240-0b1df83b.pth',
input_size=(3, 240, 240), test_input_size=(3, 288, 288), crop_pct=0.95, pool_size=(8, 8)),
"lcnet_035": _cfg(),
"lcnet_050": _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/lcnet_050-f447553b.pth',
interpolation='bicubic',
),
"lcnet_075": _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/lcnet_075-318cad2c.pth',
interpolation='bicubic',
),
"lcnet_100": _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/lcnet_100-a929038c.pth',
interpolation='bicubic',
),
"lcnet_150": _cfg(),
}
class MobileNetV3(nn.Module):
""" MobiletNet-V3
Based on my EfficientNet implementation and building blocks, this model utilizes the MobileNet-v3 specific
'efficient head', where global pooling is done before the head convolution without a final batch-norm
layer before the classifier.
Paper: `Searching for MobileNetV3` - https://arxiv.org/abs/1905.02244
Other architectures utilizing MobileNet-V3 efficient head that are supported by this impl include:
* HardCoRe-NAS - https://arxiv.org/abs/2102.11646 (defn in hardcorenas.py uses this class)
* FBNet-V3 - https://arxiv.org/abs/2006.02049
* LCNet - https://arxiv.org/abs/2109.15099
"""
def __init__(
self, block_args, num_classes=1000, in_chans=3, stem_size=16, fix_stem=False, num_features=1280,
head_bias=True, pad_type='', act_layer=None, norm_layer=None, se_layer=None, se_from_exp=True,
round_chs_fn=round_channels, drop_rate=0., drop_path_rate=0., global_pool='avg'):
super(MobileNetV3, self).__init__()
act_layer = act_layer or nn.ReLU
norm_layer = norm_layer or nn.BatchNorm2d
norm_act_layer = get_norm_act_layer(norm_layer, act_layer)
se_layer = se_layer or SqueezeExcite
self.num_classes = num_classes
self.num_features = num_features
self.drop_rate = drop_rate
self.grad_checkpointing = False
# Stem
if not fix_stem:
stem_size = round_chs_fn(stem_size)
self.conv_stem = create_conv2d(in_chans, stem_size, 3, stride=2, padding=pad_type)
self.bn1 = norm_act_layer(stem_size, inplace=True)
# Middle stages (IR/ER/DS Blocks)
builder = EfficientNetBuilder(
output_stride=32, pad_type=pad_type, round_chs_fn=round_chs_fn, se_from_exp=se_from_exp,
act_layer=act_layer, norm_layer=norm_layer, se_layer=se_layer, drop_path_rate=drop_path_rate)
self.blocks = nn.Sequential(*builder(stem_size, block_args))
self.feature_info = builder.features
head_chs = builder.in_chs
# Head + Pooling
self.global_pool = SelectAdaptivePool2d(pool_type=global_pool)
num_pooled_chs = head_chs * self.global_pool.feat_mult()
self.conv_head = create_conv2d(num_pooled_chs, self.num_features, 1, padding=pad_type, bias=head_bias)
self.act2 = act_layer(inplace=True)
self.flatten = nn.Flatten(1) if global_pool else nn.Identity() # don't flatten if pooling disabled
self.classifier = Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
efficientnet_init_weights(self)
def as_sequential(self):
layers = [self.conv_stem, self.bn1]
layers.extend(self.blocks)
layers.extend([self.global_pool, self.conv_head, self.act2])
layers.extend([nn.Flatten(), nn.Dropout(self.drop_rate), self.classifier])
return nn.Sequential(*layers)
@torch.jit.ignore
def group_matcher(self, coarse=False):
return dict(
stem=r'^conv_stem|bn1',
blocks=r'^blocks\.(\d+)' if coarse else r'^blocks\.(\d+)\.(\d+)'
)
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
self.grad_checkpointing = enable
@torch.jit.ignore
def get_classifier(self):
return self.classifier
def reset_classifier(self, num_classes, global_pool='avg'):
self.num_classes = num_classes
# cannot meaningfully change pooling of efficient head after creation
self.global_pool = SelectAdaptivePool2d(pool_type=global_pool)
self.flatten = nn.Flatten(1) if global_pool else nn.Identity() # don't flatten if pooling disabled
self.classifier = Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
x = self.conv_stem(x)
x = self.bn1(x)
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint_seq(self.blocks, x, flatten=True)
else:
x = self.blocks(x)
return x
def forward_head(self, x, pre_logits: bool = False):
x = self.global_pool(x)
x = self.conv_head(x)
x = self.act2(x)
if pre_logits:
return x.flatten(1)
else:
x = self.flatten(x)
if self.drop_rate > 0.:
x = F.dropout(x, p=self.drop_rate, training=self.training)
return self.classifier(x)
def forward(self, x):
x = self.forward_features(x)
x = self.forward_head(x)
return x
class MobileNetV3Features(nn.Module):
""" MobileNetV3 Feature Extractor
A work-in-progress feature extraction module for MobileNet-V3 to use as a backbone for segmentation
and object detection models.
"""
def __init__(
self, block_args, out_indices=(0, 1, 2, 3, 4), feature_location='bottleneck', in_chans=3,
stem_size=16, fix_stem=False, output_stride=32, pad_type='', round_chs_fn=round_channels,
se_from_exp=True, act_layer=None, norm_layer=None, se_layer=None, drop_rate=0., drop_path_rate=0.):
super(MobileNetV3Features, self).__init__()
act_layer = act_layer or nn.ReLU
norm_layer = norm_layer or nn.BatchNorm2d
se_layer = se_layer or SqueezeExcite
self.drop_rate = drop_rate
# Stem
if not fix_stem:
stem_size = round_chs_fn(stem_size)
self.conv_stem = create_conv2d(in_chans, stem_size, 3, stride=2, padding=pad_type)
self.bn1 = norm_layer(stem_size)
self.act1 = act_layer(inplace=True)
# Middle stages (IR/ER/DS Blocks)
builder = EfficientNetBuilder(
output_stride=output_stride, pad_type=pad_type, round_chs_fn=round_chs_fn, se_from_exp=se_from_exp,
act_layer=act_layer, norm_layer=norm_layer, se_layer=se_layer,
drop_path_rate=drop_path_rate, feature_location=feature_location)
self.blocks = nn.Sequential(*builder(stem_size, block_args))
self.feature_info = FeatureInfo(builder.features, out_indices)
self._stage_out_idx = {v['stage']: i for i, v in enumerate(self.feature_info) if i in out_indices}
efficientnet_init_weights(self)
# Register feature extraction hooks with FeatureHooks helper
self.feature_hooks = None
if feature_location != 'bottleneck':
hooks = self.feature_info.get_dicts(keys=('module', 'hook_type'))
self.feature_hooks = FeatureHooks(hooks, self.named_modules())
def forward(self, x) -> List[torch.Tensor]:
x = self.conv_stem(x)
x = self.bn1(x)
x = self.act1(x)
if self.feature_hooks is None:
features = []
if 0 in self._stage_out_idx:
features.append(x) # add stem out
for i, b in enumerate(self.blocks):
x = b(x)
if i + 1 in self._stage_out_idx:
features.append(x)
return features
else:
self.blocks(x)
out = self.feature_hooks.get_output(x.device)
return list(out.values())
def _create_mnv3(variant, pretrained=False, **kwargs):
features_only = False
model_cls = MobileNetV3
kwargs_filter = None
if kwargs.pop('features_only', False):
features_only = True
kwargs_filter = ('num_classes', 'num_features', 'head_conv', 'head_bias', 'global_pool')
model_cls = MobileNetV3Features
model = build_model_with_cfg(
model_cls, variant, pretrained,
pretrained_strict=not features_only,
kwargs_filter=kwargs_filter,
**kwargs)
if features_only:
model.default_cfg = pretrained_cfg_for_features(model.default_cfg)
return model
def _gen_mobilenet_v3_rw(variant, channel_multiplier=1.0, pretrained=False, **kwargs):
"""Creates a MobileNet-V3 model.
Ref impl: ?
Paper: https://arxiv.org/abs/1905.02244
Args:
channel_multiplier: multiplier to number of channels per layer.
"""
arch_def = [
# stage 0, 112x112 in
['ds_r1_k3_s1_e1_c16_nre_noskip'], # relu
# stage 1, 112x112 in
['ir_r1_k3_s2_e4_c24_nre', 'ir_r1_k3_s1_e3_c24_nre'], # relu
# stage 2, 56x56 in
['ir_r3_k5_s2_e3_c40_se0.25_nre'], # relu
# stage 3, 28x28 in
['ir_r1_k3_s2_e6_c80', 'ir_r1_k3_s1_e2.5_c80', 'ir_r2_k3_s1_e2.3_c80'], # hard-swish
# stage 4, 14x14in
['ir_r2_k3_s1_e6_c112_se0.25'], # hard-swish
# stage 5, 14x14in
['ir_r3_k5_s2_e6_c160_se0.25'], # hard-swish
# stage 6, 7x7 in
['cn_r1_k1_s1_c960'], # hard-swish
]
model_kwargs = dict(
block_args=decode_arch_def(arch_def),
head_bias=False,
round_chs_fn=partial(round_channels, multiplier=channel_multiplier),
norm_layer=partial(nn.BatchNorm2d, **resolve_bn_args(kwargs)),
act_layer=resolve_act_layer(kwargs, 'hard_swish'),
se_layer=partial(SqueezeExcite, gate_layer='hard_sigmoid'),
**kwargs,
)
model = _create_mnv3(variant, pretrained, **model_kwargs)
return model
def _gen_mobilenet_v3(variant, channel_multiplier=1.0, pretrained=False, **kwargs):
"""Creates a MobileNet-V3 model.
Ref impl: ?
Paper: https://arxiv.org/abs/1905.02244
Args:
channel_multiplier: multiplier to number of channels per layer.
"""
if 'small' in variant:
num_features = 1024
if 'minimal' in variant:
act_layer = resolve_act_layer(kwargs, 'relu')
arch_def = [
# stage 0, 112x112 in
['ds_r1_k3_s2_e1_c16'],
# stage 1, 56x56 in
['ir_r1_k3_s2_e4.5_c24', 'ir_r1_k3_s1_e3.67_c24'],
# stage 2, 28x28 in
['ir_r1_k3_s2_e4_c40', 'ir_r2_k3_s1_e6_c40'],
# stage 3, 14x14 in
['ir_r2_k3_s1_e3_c48'],
# stage 4, 14x14in
['ir_r3_k3_s2_e6_c96'],
# stage 6, 7x7 in
['cn_r1_k1_s1_c576'],
]
else:
act_layer = resolve_act_layer(kwargs, 'hard_swish')
arch_def = [
# stage 0, 112x112 in
['ds_r1_k3_s2_e1_c16_se0.25_nre'], # relu
# stage 1, 56x56 in
['ir_r1_k3_s2_e4.5_c24_nre', 'ir_r1_k3_s1_e3.67_c24_nre'], # relu
# stage 2, 28x28 in
['ir_r1_k5_s2_e4_c40_se0.25', 'ir_r2_k5_s1_e6_c40_se0.25'], # hard-swish
# stage 3, 14x14 in
['ir_r2_k5_s1_e3_c48_se0.25'], # hard-swish
# stage 4, 14x14in
['ir_r3_k5_s2_e6_c96_se0.25'], # hard-swish
# stage 6, 7x7 in
['cn_r1_k1_s1_c576'], # hard-swish
]
else:
num_features = 1280
if 'minimal' in variant:
act_layer = resolve_act_layer(kwargs, 'relu')
arch_def = [
# stage 0, 112x112 in
['ds_r1_k3_s1_e1_c16'],
# stage 1, 112x112 in
['ir_r1_k3_s2_e4_c24', 'ir_r1_k3_s1_e3_c24'],
# stage 2, 56x56 in
['ir_r3_k3_s2_e3_c40'],
# stage 3, 28x28 in
['ir_r1_k3_s2_e6_c80', 'ir_r1_k3_s1_e2.5_c80', 'ir_r2_k3_s1_e2.3_c80'],
# stage 4, 14x14in
['ir_r2_k3_s1_e6_c112'],
# stage 5, 14x14in
['ir_r3_k3_s2_e6_c160'],
# stage 6, 7x7 in
['cn_r1_k1_s1_c960'],
]
else:
act_layer = resolve_act_layer(kwargs, 'hard_swish')
arch_def = [
# stage 0, 112x112 in
['ds_r1_k3_s1_e1_c16_nre'], # relu
# stage 1, 112x112 in
['ir_r1_k3_s2_e4_c24_nre', 'ir_r1_k3_s1_e3_c24_nre'], # relu
# stage 2, 56x56 in
['ir_r3_k5_s2_e3_c40_se0.25_nre'], # relu
# stage 3, 28x28 in
['ir_r1_k3_s2_e6_c80', 'ir_r1_k3_s1_e2.5_c80', 'ir_r2_k3_s1_e2.3_c80'], # hard-swish
# stage 4, 14x14in
['ir_r2_k3_s1_e6_c112_se0.25'], # hard-swish
# stage 5, 14x14in
['ir_r3_k5_s2_e6_c160_se0.25'], # hard-swish
# stage 6, 7x7 in
['cn_r1_k1_s1_c960'], # hard-swish
]
se_layer = partial(SqueezeExcite, gate_layer='hard_sigmoid', force_act_layer=nn.ReLU, rd_round_fn=round_channels)
model_kwargs = dict(
block_args=decode_arch_def(arch_def),
num_features=num_features,
stem_size=16,
fix_stem=channel_multiplier < 0.75,
round_chs_fn=partial(round_channels, multiplier=channel_multiplier),
norm_layer=partial(nn.BatchNorm2d, **resolve_bn_args(kwargs)),
act_layer=act_layer,
se_layer=se_layer,
**kwargs,
)
model = _create_mnv3(variant, pretrained, **model_kwargs)
return model
def _gen_fbnetv3(variant, channel_multiplier=1.0, pretrained=False, **kwargs):
""" FBNetV3
Paper: `FBNetV3: Joint Architecture-Recipe Search using Predictor Pretraining`
- https://arxiv.org/abs/2006.02049
FIXME untested, this is a preliminary impl of some FBNet-V3 variants.
"""
vl = variant.split('_')[-1]
if vl in ('a', 'b'):
stem_size = 16
arch_def = [
['ds_r2_k3_s1_e1_c16'],
['ir_r1_k5_s2_e4_c24', 'ir_r3_k5_s1_e2_c24'],
['ir_r1_k5_s2_e5_c40_se0.25', 'ir_r4_k5_s1_e3_c40_se0.25'],
['ir_r1_k5_s2_e5_c72', 'ir_r4_k3_s1_e3_c72'],
['ir_r1_k3_s1_e5_c120_se0.25', 'ir_r5_k5_s1_e3_c120_se0.25'],
['ir_r1_k3_s2_e6_c184_se0.25', 'ir_r5_k5_s1_e4_c184_se0.25', 'ir_r1_k5_s1_e6_c224_se0.25'],
['cn_r1_k1_s1_c1344'],
]
elif vl == 'd':
stem_size = 24
arch_def = [
['ds_r2_k3_s1_e1_c16'],
['ir_r1_k3_s2_e5_c24', 'ir_r5_k3_s1_e2_c24'],
['ir_r1_k5_s2_e4_c40_se0.25', 'ir_r4_k3_s1_e3_c40_se0.25'],
['ir_r1_k3_s2_e5_c72', 'ir_r4_k3_s1_e3_c72'],
['ir_r1_k3_s1_e5_c128_se0.25', 'ir_r6_k5_s1_e3_c128_se0.25'],
['ir_r1_k3_s2_e6_c208_se0.25', 'ir_r5_k5_s1_e5_c208_se0.25', 'ir_r1_k5_s1_e6_c240_se0.25'],
['cn_r1_k1_s1_c1440'],
]
elif vl == 'g':
stem_size = 32
arch_def = [
['ds_r3_k3_s1_e1_c24'],
['ir_r1_k5_s2_e4_c40', 'ir_r4_k5_s1_e2_c40'],
['ir_r1_k5_s2_e4_c56_se0.25', 'ir_r4_k5_s1_e3_c56_se0.25'],
['ir_r1_k5_s2_e5_c104', 'ir_r4_k3_s1_e3_c104'],
['ir_r1_k3_s1_e5_c160_se0.25', 'ir_r8_k5_s1_e3_c160_se0.25'],
['ir_r1_k3_s2_e6_c264_se0.25', 'ir_r6_k5_s1_e5_c264_se0.25', 'ir_r2_k5_s1_e6_c288_se0.25'],
['cn_r1_k1_s1_c1728'],
]
else:
raise NotImplemented
round_chs_fn = partial(round_channels, multiplier=channel_multiplier, round_limit=0.95)
se_layer = partial(SqueezeExcite, gate_layer='hard_sigmoid', rd_round_fn=round_chs_fn)
act_layer = resolve_act_layer(kwargs, 'hard_swish')
model_kwargs = dict(
block_args=decode_arch_def(arch_def),
num_features=1984,
head_bias=False,
stem_size=stem_size,
round_chs_fn=round_chs_fn,
se_from_exp=False,
norm_layer=partial(nn.BatchNorm2d, **resolve_bn_args(kwargs)),
act_layer=act_layer,
se_layer=se_layer,
**kwargs,
)
model = _create_mnv3(variant, pretrained, **model_kwargs)
return model
def _gen_lcnet(variant, channel_multiplier=1.0, pretrained=False, **kwargs):
""" LCNet
Essentially a MobileNet-V3 crossed with a MobileNet-V1
Paper: `PP-LCNet: A Lightweight CPU Convolutional Neural Network` - https://arxiv.org/abs/2109.15099
Args:
channel_multiplier: multiplier to number of channels per layer.
"""
arch_def = [
# stage 0, 112x112 in
['dsa_r1_k3_s1_c32'],
# stage 1, 112x112 in
['dsa_r2_k3_s2_c64'],
# stage 2, 56x56 in
['dsa_r2_k3_s2_c128'],
# stage 3, 28x28 in
['dsa_r1_k3_s2_c256', 'dsa_r1_k5_s1_c256'],
# stage 4, 14x14in
['dsa_r4_k5_s1_c256'],
# stage 5, 14x14in
['dsa_r2_k5_s2_c512_se0.25'],
# 7x7
]
model_kwargs = dict(
block_args=decode_arch_def(arch_def),
stem_size=16,
round_chs_fn=partial(round_channels, multiplier=channel_multiplier),
norm_layer=partial(nn.BatchNorm2d, **resolve_bn_args(kwargs)),
act_layer=resolve_act_layer(kwargs, 'hard_swish'),
se_layer=partial(SqueezeExcite, gate_layer='hard_sigmoid', force_act_layer=nn.ReLU),
num_features=1280,
**kwargs,
)
model = _create_mnv3(variant, pretrained, **model_kwargs)
return model
def _gen_lcnet(variant, channel_multiplier=1.0, pretrained=False, **kwargs):
""" LCNet
Essentially a MobileNet-V3 crossed with a MobileNet-V1
Paper: `PP-LCNet: A Lightweight CPU Convolutional Neural Network` - https://arxiv.org/abs/2109.15099
Args:
channel_multiplier: multiplier to number of channels per layer.
"""
arch_def = [
# stage 0, 112x112 in
['dsa_r1_k3_s1_c32'],
# stage 1, 112x112 in
['dsa_r2_k3_s2_c64'],
# stage 2, 56x56 in
['dsa_r2_k3_s2_c128'],
# stage 3, 28x28 in
['dsa_r1_k3_s2_c256', 'dsa_r1_k5_s1_c256'],
# stage 4, 14x14in
['dsa_r4_k5_s1_c256'],
# stage 5, 14x14in
['dsa_r2_k5_s2_c512_se0.25'],
# 7x7
]
model_kwargs = dict(
block_args=decode_arch_def(arch_def),
stem_size=16,
round_chs_fn=partial(round_channels, multiplier=channel_multiplier),
norm_layer=partial(nn.BatchNorm2d, **resolve_bn_args(kwargs)),
act_layer=resolve_act_layer(kwargs, 'hard_swish'),
se_layer=partial(SqueezeExcite, gate_layer='hard_sigmoid', force_act_layer=nn.ReLU),
num_features=1280,
**kwargs,
)
model = _create_mnv3(variant, pretrained, **model_kwargs)
return model
@register_model
def mobilenetv3_large_075(pretrained=False, **kwargs):
""" MobileNet V3 """
model = _gen_mobilenet_v3('mobilenetv3_large_075', 0.75, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_large_100(pretrained=False, **kwargs):
""" MobileNet V3 """
model = _gen_mobilenet_v3('mobilenetv3_large_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_large_100_miil(pretrained=False, **kwargs):
""" MobileNet V3
Weights taken from: https://github.com/Alibaba-MIIL/ImageNet21K
"""
model = _gen_mobilenet_v3('mobilenetv3_large_100_miil', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_large_100_miil_in21k(pretrained=False, **kwargs):
""" MobileNet V3, 21k pretraining
Weights taken from: https://github.com/Alibaba-MIIL/ImageNet21K
"""
model = _gen_mobilenet_v3('mobilenetv3_large_100_miil_in21k', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_small_050(pretrained=False, **kwargs):
""" MobileNet V3 """
model = _gen_mobilenet_v3('mobilenetv3_small_050', 0.50, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_small_075(pretrained=False, **kwargs):
""" MobileNet V3 """
model = _gen_mobilenet_v3('mobilenetv3_small_075', 0.75, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_small_100(pretrained=False, **kwargs):
""" MobileNet V3 """
model = _gen_mobilenet_v3('mobilenetv3_small_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_rw(pretrained=False, **kwargs):
""" MobileNet V3 """
if pretrained:
# pretrained model trained with non-default BN epsilon
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
model = _gen_mobilenet_v3_rw('mobilenetv3_rw', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def tf_mobilenetv3_large_075(pretrained=False, **kwargs):
""" MobileNet V3 """
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
kwargs['pad_type'] = 'same'
model = _gen_mobilenet_v3('tf_mobilenetv3_large_075', 0.75, pretrained=pretrained, **kwargs)
return model
@register_model
def tf_mobilenetv3_large_100(pretrained=False, **kwargs):
""" MobileNet V3 """
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
kwargs['pad_type'] = 'same'
model = _gen_mobilenet_v3('tf_mobilenetv3_large_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def tf_mobilenetv3_large_minimal_100(pretrained=False, **kwargs):
""" MobileNet V3 """
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
kwargs['pad_type'] = 'same'
model = _gen_mobilenet_v3('tf_mobilenetv3_large_minimal_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def tf_mobilenetv3_small_075(pretrained=False, **kwargs):
""" MobileNet V3 """
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
kwargs['pad_type'] = 'same'
model = _gen_mobilenet_v3('tf_mobilenetv3_small_075', 0.75, pretrained=pretrained, **kwargs)
return model
@register_model
def tf_mobilenetv3_small_100(pretrained=False, **kwargs):
""" MobileNet V3 """
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
kwargs['pad_type'] = 'same'
model = _gen_mobilenet_v3('tf_mobilenetv3_small_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def tf_mobilenetv3_small_minimal_100(pretrained=False, **kwargs):
""" MobileNet V3 """
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
kwargs['pad_type'] = 'same'
model = _gen_mobilenet_v3('tf_mobilenetv3_small_minimal_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def fbnetv3_b(pretrained=False, **kwargs):
""" FBNetV3-B """
model = _gen_fbnetv3('fbnetv3_b', pretrained=pretrained, **kwargs)
return model
@register_model
def fbnetv3_d(pretrained=False, **kwargs):
""" FBNetV3-D """
model = _gen_fbnetv3('fbnetv3_d', pretrained=pretrained, **kwargs)
return model
@register_model
def fbnetv3_g(pretrained=False, **kwargs):
""" FBNetV3-G """
model = _gen_fbnetv3('fbnetv3_g', pretrained=pretrained, **kwargs)
return model
@register_model
def lcnet_035(pretrained=False, **kwargs):
""" PP-LCNet 0.35"""
model = _gen_lcnet('lcnet_035', 0.35, pretrained=pretrained, **kwargs)
return model
@register_model
def lcnet_050(pretrained=False, **kwargs):
""" PP-LCNet 0.5"""
model = _gen_lcnet('lcnet_050', 0.5, pretrained=pretrained, **kwargs)
return model
@register_model
def lcnet_075(pretrained=False, **kwargs):
""" PP-LCNet 1.0"""
model = _gen_lcnet('lcnet_075', 0.75, pretrained=pretrained, **kwargs)
return model
@register_model
def lcnet_100(pretrained=False, **kwargs):
""" PP-LCNet 1.0"""
model = _gen_lcnet('lcnet_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def lcnet_150(pretrained=False, **kwargs):
""" PP-LCNet 1.5"""
model = _gen_lcnet('lcnet_150', 1.5, pretrained=pretrained, **kwargs)
return model
================================================
FILE: model/backbone/MobileViT.py
================================================
from torch import nn
import torch
from torch.nn.modules import conv
from torch.nn.modules.conv import Conv2d
from einops import rearrange
def conv_bn(inp,oup,kernel_size=3,stride=1):
return nn.Sequential(
nn.Conv2d(inp,oup,kernel_size=kernel_size,stride=stride,padding=kernel_size//2),
nn.BatchNorm2d(oup),
nn.SiLU()
)
class PreNorm(nn.Module):
def __init__(self,dim,fn):
super().__init__()
self.ln=nn.LayerNorm(dim)
self.fn=fn
def forward(self,x,**kwargs):
return self.fn(self.ln(x),**kwargs)
class FeedForward(nn.Module):
def __init__(self,dim,mlp_dim,dropout) :
super().__init__()
self.net=nn.Sequential(
nn.Linear(dim,mlp_dim),
nn.SiLU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim,dim),
nn.Dropout(dropout)
)
def forward(self,x):
return self.net(x)
class Attention(nn.Module):
def __init__(self,dim,heads,head_dim,dropout):
super().__init__()
inner_dim=heads*head_dim
project_out=not(heads==1 and head_dim==dim)
self.heads=heads
self.scale=head_dim**-0.5
self.attend=nn.Softmax(dim=-1)
self.to_qkv=nn.Linear(dim,inner_dim*3,bias=False)
self.to_out=nn.Sequential(
nn.Linear(inner_dim,dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self,x):
qkv=self.to_qkv(x).chunk(3,dim=-1)
q,k,v=map(lambda t:rearrange(t,'b p n (h d) -> b p h n d',h=self.heads),qkv)
dots=torch.matmul(q,k.transpose(-1,-2))*self.scale
attn=self.attend(dots)
out=torch.matmul(attn,v)
out=rearrange(out,'b p h n d -> b p n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self,dim,depth,heads,head_dim,mlp_dim,dropout=0.):
super().__init__()
self.layers=nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim,Attention(dim,heads,head_dim,dropout)),
PreNorm(dim,FeedForward(dim,mlp_dim,dropout))
]))
def forward(self,x):
out=x
for att,ffn in self.layers:
out=out+att(out)
out=out+ffn(out)
return out
class MobileViTAttention(nn.Module):
def __init__(self,in_channel=3,dim=512,kernel_size=3,patch_size=7,depth=3,mlp_dim=1024):
super().__init__()
self.ph,self.pw=patch_size,patch_size
self.conv1=nn.Conv2d(in_channel,in_channel,kernel_size=kernel_size,padding=kernel_size//2)
self.conv2=nn.Conv2d(in_channel,dim,kernel_size=1)
self.trans=Transformer(dim=dim,depth=depth,heads=8,head_dim=64,mlp_dim=mlp_dim)
self.conv3=nn.Conv2d(dim,in_channel,kernel_size=1)
self.conv4=nn.Conv2d(2*in_channel,in_channel,kernel_size=kernel_size,padding=kernel_size//2)
def forward(self,x):
y=x.clone() #bs,c,h,w
## Local Representation
y=self.conv2(self.conv1(x)) #bs,dim,h,w
## Global Representation
_,_,h,w=y.shape
y=rearrange(y,'bs dim (nh ph) (nw pw) -> bs (ph pw) (nh nw) dim',ph=self.ph,pw=self.pw) #bs,h,w,dim
y=self.trans(y)
y=rearrange(y,'bs (ph pw) (nh nw) dim -> bs dim (nh ph) (nw pw)',ph=self.ph,pw=self.pw,nh=h//self.ph,nw=w//self.pw) #bs,dim,h,w
## Fusion
y=self.conv3(y) #bs,dim,h,w
y=torch.cat([x,y],1) #bs,2*dim,h,w
y=self.conv4(y) #bs,c,h,w
return y
class MV2Block(nn.Module):
def __init__(self,inp,out,stride=1,expansion=4):
super().__init__()
self.stride=stride
hidden_dim=inp*expansion
self.use_res_connection=stride==1 and inp==out
if expansion==1:
self.conv=nn.Sequential(
nn.Conv2d(hidden_dim,hidden_dim,kernel_size=3,stride=self.stride,padding=1,groups=hidden_dim,bias=False),
nn.BatchNorm2d(hidden_dim),
nn.SiLU(),
nn.Conv2d(hidden_dim,out,kernel_size=1,stride=1,bias=False),
nn.BatchNorm2d(out)
)
else:
self.conv=nn.Sequential(
nn.Conv2d(inp,hidden_dim,kernel_size=1,stride=1,bias=False),
nn.BatchNorm2d(hidden_dim),
nn.SiLU(),
nn.Conv2d(hidden_dim,hidden_dim,kernel_size=3,stride=1,padding=1,groups=hidden_dim,bias=False),
nn.BatchNorm2d(hidden_dim),
nn.SiLU(),
nn.Conv2d(hidden_dim,out,kernel_size=1,stride=1,bias=False),
nn.SiLU(),
nn.BatchNorm2d(out)
)
def forward(self,x):
if(self.use_res_connection):
out=x+self.conv(x)
else:
out=self.conv(x)
return out
class MobileViT(nn.Module):
def __init__(self,image_size,dims,channels,num_classes,depths=[2,4,3],expansion=4,kernel_size=3,patch_size=2):
super().__init__()
ih,iw=image_size,image_size
ph,pw=patch_size,patch_size
assert iw%pw==0 and ih%ph==0
self.conv1=conv_bn(3,channels[0],kernel_size=3,stride=patch_size)
self.mv2=nn.ModuleList([])
self.m_vits=nn.ModuleList([])
self.mv2.append(MV2Block(channels[0],channels[1],1))
self.mv2.append(MV2Block(channels[1],channels[2],2))
self.mv2.append(MV2Block(channels[2],channels[3],1))
self.mv2.append(MV2Block(channels[2],channels[3],1)) # x2
self.mv2.append(MV2Block(channels[3],channels[4],2))
self.m_vits.append(MobileViTAttention(channels[4],dim=dims[0],kernel_size=kernel_size,patch_size=patch_size,depth=depths[0],mlp_dim=int(2*dims[0])))
self.mv2.append(MV2Block(channels[4],channels[5],2))
self.m_vits.append(MobileViTAttention(channels[5],dim=dims[1],kernel_size=kernel_size,patch_size=patch_size,depth=depths[1],mlp_dim=int(4*dims[1])))
self.mv2.append(MV2Block(channels[5],channels[6],2))
self.m_vits.append(MobileViTAttention(channels[6],dim=dims[2],kernel_size=kernel_size,patch_size=patch_size,depth=depths[2],mlp_dim=int(4*dims[2])))
self.conv2=conv_bn(channels[-2],channels[-1],kernel_size=1)
self.pool=nn.AvgPool2d(image_size//32,1)
self.fc=nn.Linear(channels[-1],num_classes,bias=False)
def forward(self,x):
y=self.conv1(x) #
y=self.mv2[0](y)
y=self.mv2[1](y) #
y=self.mv2[2](y)
y=self.mv2[3](y)
y=self.mv2[4](y) #
y=self.m_vits[0](y)
y=self.mv2[5](y) #
y=self.m_vits[1](y)
y=self.mv2[6](y) #
y=self.m_vits[2](y)
y=self.conv2(y)
y=self.pool(y).view(y.shape[0],-1)
y=self.fc(y)
return y
def mobilevit_xxs():
dims=[60,80,96]
channels= [16, 16, 24, 24, 48, 64, 80, 320]
return MobileViT(224,dims,channels,num_classes=1000)
def mobilevit_xs():
dims = [96, 120, 144]
channels = [16, 32, 48, 48, 64, 80, 96, 384]
return MobileViT(224, dims, channels, num_classes=1000)
def mobilevit_s():
dims = [144, 192, 240]
channels = [16, 32, 64, 64, 96, 128, 160, 640]
return MobileViT(224, dims, channels, num_classes=1000)
def count_paratermeters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
### mobilevit_xxs
mvit_xxs=mobilevit_xxs()
out=mvit_xxs(input)
print(out.shape)
### mobilevit_xs
mvit_xs=mobilevit_xs()
out=mvit_xs(input)
print(out.shape)
### mobilevit_s
mvit_s=mobilevit_s()
out=mvit_s(input)
print(out.shape)
================================================
FILE: model/backbone/PIT.py
================================================
# PiT
# Copyright 2021-present NAVER Corp.
# Apache License v2.0
import torch
from einops import rearrange
from torch import nn
import math
from functools import partial
from timm.models.layers import trunc_normal_
from timm.models.vision_transformer import Block as transformer_block
from timm.models.registry import register_model
class Transformer(nn.Module):
def __init__(self, base_dim, depth, heads, mlp_ratio,
drop_rate=.0, attn_drop_rate=.0, drop_path_prob=None):
super(Transformer, self).__init__()
self.layers = nn.ModuleList([])
embed_dim = base_dim * heads
if drop_path_prob is None:
drop_path_prob = [0.0 for _ in range(depth)]
self.blocks = nn.ModuleList([
transformer_block(
dim=embed_dim,
num_heads=heads,
mlp_ratio=mlp_ratio,
qkv_bias=True,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=drop_path_prob[i],
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
for i in range(depth)])
def forward(self, x, cls_tokens):
h, w = x.shape[2:4]
x = rearrange(x, 'b c h w -> b (h w) c')
token_length = cls_tokens.shape[1]
x = torch.cat((cls_tokens, x), dim=1)
for blk in self.blocks:
x = blk(x)
cls_tokens = x[:, :token_length]
x = x[:, token_length:]
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
return x, cls_tokens
class conv_head_pooling(nn.Module):
def __init__(self, in_feature, out_feature, stride,
padding_mode='zeros'):
super(conv_head_pooling, self).__init__()
self.conv = nn.Conv2d(in_feature, out_feature, kernel_size=stride + 1,
padding=stride // 2, stride=stride,
padding_mode=padding_mode, groups=in_feature)
self.fc = nn.Linear(in_feature, out_feature)
def forward(self, x, cls_token):
x = self.conv(x)
cls_token = self.fc(cls_token)
return x, cls_token
class conv_embedding(nn.Module):
def __init__(self, in_channels, out_channels, patch_size,
stride, padding):
super(conv_embedding, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=patch_size,
stride=stride, padding=padding, bias=True)
def forward(self, x):
x = self.conv(x)
return x
class PoolingTransformer(nn.Module):
def __init__(self, image_size, patch_size, stride, base_dims, depth, heads,
mlp_ratio, num_classes=1000, in_chans=3,
attn_drop_rate=.0, drop_rate=.0, drop_path_rate=.0):
super(PoolingTransformer, self).__init__()
total_block = sum(depth)
padding = 0
block_idx = 0
width = math.floor(
(image_size + 2 * padding - patch_size) / stride + 1)
self.base_dims = base_dims
self.heads = heads
self.num_classes = num_classes
self.patch_size = patch_size
self.pos_embed = nn.Parameter(
torch.randn(1, base_dims[0] * heads[0], width, width),
requires_grad=True
)
self.patch_embed = conv_embedding(in_chans, base_dims[0] * heads[0],
patch_size, stride, padding)
self.cls_token = nn.Parameter(
torch.randn(1, 1, base_dims[0] * heads[0]),
requires_grad=True
)
self.pos_drop = nn.Dropout(p=drop_rate)
self.transformers = nn.ModuleList([])
self.pools = nn.ModuleList([])
for stage in range(len(depth)):
drop_path_prob = [drop_path_rate * i / total_block
for i in range(block_idx, block_idx + depth[stage])]
block_idx += depth[stage]
self.transformers.append(
Transformer(base_dims[stage], depth[stage], heads[stage],
mlp_ratio,
drop_rate, attn_drop_rate, drop_path_prob)
)
if stage < len(heads) - 1:
self.pools.append(
conv_head_pooling(base_dims[stage] * heads[stage],
base_dims[stage + 1] * heads[stage + 1],
stride=2
)
)
self.norm = nn.LayerNorm(base_dims[-1] * heads[-1], eps=1e-6)
self.embed_dim = base_dims[-1] * heads[-1]
# Classifier head
if num_classes > 0:
self.head = nn.Linear(base_dims[-1] * heads[-1], num_classes)
else:
self.head = nn.Identity()
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
if num_classes > 0:
self.head = nn.Linear(self.embed_dim, num_classes)
else:
self.head = nn.Identity()
def forward_features(self, x):
x = self.patch_embed(x)
pos_embed = self.pos_embed
x = self.pos_drop(x + pos_embed)
cls_tokens = self.cls_token.expand(x.shape[0], -1, -1)
for stage in range(len(self.pools)):
x, cls_tokens = self.transformers[stage](x, cls_tokens)
x, cls_tokens = self.pools[stage](x, cls_tokens)
x, cls_tokens = self.transformers[-1](x, cls_tokens)
cls_tokens = self.norm(cls_tokens)
return cls_tokens
def forward(self, x):
cls_token = self.forward_features(x)
cls_token = self.head(cls_token[:, 0])
return cls_token
class DistilledPoolingTransformer(PoolingTransformer):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.cls_token = nn.Parameter(
torch.randn(1, 2, self.base_dims[0] * self.heads[0]),
requires_grad=True)
if self.num_classes > 0:
self.head_dist = nn.Linear(self.base_dims[-1] * self.heads[-1],
self.num_classes)
else:
self.head_dist = nn.Identity()
trunc_normal_(self.cls_token, std=.02)
self.head_dist.apply(self._init_weights)
def forward(self, x):
cls_token = self.forward_features(x)
x_cls = self.head(cls_token[:, 0])
x_dist = self.head_dist(cls_token[:, 1])
if self.training:
return x_cls, x_dist
else:
return (x_cls + x_dist) / 2
@register_model
def pit_b(pretrained, **kwargs):
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_b_820.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_s(pretrained, **kwargs):
model = PoolingTransformer(
image_size=224,
patch_size=16,
stride=8,
base_dims=[48, 48, 48],
depth=[2, 6, 4],
heads=[3, 6, 12],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_s_809.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_xs(pretrained, **kwargs):
model = PoolingTransformer(
image_size=224,
patch_size=16,
stride=8,
base_dims=[48, 48, 48],
depth=[2, 6, 4],
heads=[2, 4, 8],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_xs_781.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_ti(pretrained, **kwargs):
model = PoolingTransformer(
image_size=224,
patch_size=16,
stride=8,
base_dims=[32, 32, 32],
depth=[2, 6, 4],
heads=[2, 4, 8],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_ti_730.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_b_distilled(pretrained, **kwargs):
model = DistilledPoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_b_distill_840.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_s_distilled(pretrained, **kwargs):
model = DistilledPoolingTransformer(
image_size=224,
patch_size=16,
stride=8,
base_dims=[48, 48, 48],
depth=[2, 6, 4],
heads=[3, 6, 12],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_s_distill_819.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_xs_distilled(pretrained, **kwargs):
model = DistilledPoolingTransformer(
image_size=224,
patch_size=16,
stride=8,
base_dims=[48, 48, 48],
depth=[2, 6, 4],
heads=[2, 4, 8],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_xs_distill_791.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_ti_distilled(pretrained, **kwargs):
model = DistilledPoolingTransformer(
image_size=224,
patch_size=16,
stride=8,
base_dims=[32, 32, 32],
depth=[2, 6, 4],
heads=[2, 4, 8],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_ti_distill_746.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/PVT.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
__all__ = [
'pvt_tiny', 'pvt_small', 'pvt_medium', 'pvt_large'
]
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
# assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
# f"img_size {img_size} should be divided by patch_size {patch_size}."
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)
class PyramidVisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], num_stages=4):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.num_stages = num_stages
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
patch_embed = PatchEmbed(img_size=img_size if i == 0 else img_size // (2 ** (i + 1)),
patch_size=patch_size if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i])
num_patches = patch_embed.num_patches if i != num_stages - 1 else patch_embed.num_patches + 1
pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dims[i]))
pos_drop = nn.Dropout(p=drop_rate)
block = nn.ModuleList([Block(
dim=embed_dims[i], num_heads=num_heads[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + j],
norm_layer=norm_layer, sr_ratio=sr_ratios[i])
for j in range(depths[i])])
cur += depths[i]
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"pos_embed{i + 1}", pos_embed)
setattr(self, f"pos_drop{i + 1}", pos_drop)
setattr(self, f"block{i + 1}", block)
self.norm = norm_layer(embed_dims[3])
# cls_token
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dims[3]))
# classification head
self.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()
# init weights
for i in range(num_stages):
pos_embed = getattr(self, f"pos_embed{i + 1}")
trunc_normal_(pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
# return {'pos_embed', 'cls_token'} # has pos_embed may be better
return {'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def forward_features(self, x):
B = x.shape[0]
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
pos_embed = getattr(self, f"pos_embed{i + 1}")
pos_drop = getattr(self, f"pos_drop{i + 1}")
block = getattr(self, f"block{i + 1}")
x, (H, W) = patch_embed(x)
if i == self.num_stages - 1:
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
pos_embed_ = self._get_pos_embed(pos_embed[:, 1:], patch_embed, H, W)
pos_embed = torch.cat((pos_embed[:, 0:1], pos_embed_), dim=1)
else:
pos_embed = self._get_pos_embed(pos_embed, patch_embed, H, W)
x = pos_drop(x + pos_embed)
for blk in block:
x = blk(x, H, W)
if i != self.num_stages - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def _conv_filter(state_dict, patch_size=16):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k:
v = v.reshape((v.shape[0], 3, patch_size, patch_size))
out_dict[k] = v
return out_dict
@register_model
def pvt_tiny(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pvt_small(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], **kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pvt_medium(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 18, 3], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pvt_large(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 8, 27, 3], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pvt_huge_v2(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[128, 256, 512, 768], num_heads=[2, 4, 8, 12], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 10, 60, 3], sr_ratios=[8, 4, 2, 1],
# drop_rate=0.0, drop_path_rate=0.02)
**kwargs)
model.default_cfg = _cfg()
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/PatchConvnet.py
================================================
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
from functools import partial
from typing import Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.efficientnet_blocks import SqueezeExcite
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
__all__ = ['S60', 'S120', 'B60', 'B120', 'L60', 'L120', 'S60_multi']
class Mlp(nn.Module):
def __init__(
self,
in_features: int,
hidden_features: Optional[int] = None,
out_features: Optional[int] = None,
act_layer: nn.Module = nn.GELU,
drop: float = 0.0,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Learned_Aggregation_Layer(nn.Module):
def __init__(
self,
dim: int,
num_heads: int = 1,
qkv_bias: bool = False,
qk_scale: Optional[float] = None,
attn_drop: float = 0.0,
proj_drop: float = 0.0,
):
super().__init__()
self.num_heads = num_heads
head_dim: int = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim**-0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.k = nn.Linear(dim, dim, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.id = nn.Identity()
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, N, C = x.shape
q = self.q(x[:, 0]).unsqueeze(1).reshape(B, 1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
k = self.k(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
q = q * self.scale
v = self.v(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
attn = q @ k.transpose(-2, -1)
attn = self.id(attn)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x_cls = (attn @ v).transpose(1, 2).reshape(B, 1, C)
x_cls = self.proj(x_cls)
x_cls = self.proj_drop(x_cls)
return x_cls
class Learned_Aggregation_Layer_multi(nn.Module):
def __init__(
self,
dim: int,
num_heads: int = 8,
qkv_bias: bool = False,
qk_scale: Optional[float] = None,
attn_drop: float = 0.0,
proj_drop: float = 0.0,
num_classes: int = 1000,
):
super().__init__()
self.num_heads = num_heads
head_dim: int = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.k = nn.Linear(dim, dim, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.num_classes = num_classes
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, N, C = x.shape
q = (
self.q(x[:, : self.num_classes])
.reshape(B, self.num_classes, self.num_heads, C // self.num_heads)
.permute(0, 2, 1, 3)
)
k = (
self.k(x[:, self.num_classes:])
.reshape(B, N - self.num_classes, self.num_heads, C // self.num_heads)
.permute(0, 2, 1, 3)
)
q = q * self.scale
v = (
self.v(x[:, self.num_classes:])
.reshape(B, N - self.num_classes, self.num_heads, C // self.num_heads)
.permute(0, 2, 1, 3)
)
attn = q @ k.transpose(-2, -1)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x_cls = (attn @ v).transpose(1, 2).reshape(B, self.num_classes, C)
x_cls = self.proj(x_cls)
x_cls = self.proj_drop(x_cls)
return x_cls
class Layer_scale_init_Block_only_token(nn.Module):
def __init__(
self,
dim: int,
num_heads: int,
mlp_ratio: float = 4.0,
qkv_bias: bool = False,
qk_scale: Optional[float] = None,
drop: float = 0.0,
attn_drop: float = 0.0,
drop_path: float = 0.0,
act_layer: nn.Module = nn.GELU,
norm_layer=nn.LayerNorm,
Attention_block=Learned_Aggregation_Layer,
Mlp_block=Mlp,
init_values: float = 1e-4,
):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention_block(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop
)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp_block(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
def forward(self, x: torch.Tensor, x_cls: torch.Tensor) -> torch.Tensor:
u = torch.cat((x_cls, x), dim=1)
x_cls = x_cls + self.drop_path(self.gamma_1 * self.attn(self.norm1(u)))
x_cls = x_cls + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x_cls)))
return x_cls
class Conv_blocks_se(nn.Module):
def __init__(self, dim: int):
super().__init__()
self.qkv_pos = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=1),
nn.GELU(),
nn.Conv2d(dim, dim, groups=dim, kernel_size=3, padding=1, stride=1, bias=True),
nn.GELU(),
SqueezeExcite(dim, rd_ratio=0.25),
nn.Conv2d(dim, dim, kernel_size=1),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, N, C = x.shape
H = W = int(N ** 0.5)
x = x.transpose(-1, -2)
x = x.reshape(B, C, H, W)
x = self.qkv_pos(x)
x = x.reshape(B, C, N)
x = x.transpose(-1, -2)
return x
class Layer_scale_init_Block(nn.Module):
def __init__(
self,
dim: int,
drop_path: float = 0.0,
act_layer: nn.Module = nn.GELU,
norm_layer=nn.LayerNorm,
Attention_block=None,
init_values: float = 1e-4,
):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention_block(dim)
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x)))
def conv3x3(in_planes: int, out_planes: int, stride: int = 1) -> nn.Sequential:
"""3x3 convolution with padding"""
return nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False),
)
class ConvStem(nn.Module):
"""Image to Patch Embedding"""
def __init__(self, img_size: int = 224, patch_size: int = 16, in_chans: int = 3, embed_dim: int = 768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Sequential(
conv3x3(in_chans, embed_dim // 8, 2),
nn.GELU(),
conv3x3(embed_dim // 8, embed_dim // 4, 2),
nn.GELU(),
conv3x3(embed_dim // 4, embed_dim // 2, 2),
nn.GELU(),
conv3x3(embed_dim // 2, embed_dim, 2),
)
def forward(self, x: torch.Tensor, padding_size: Optional[int] = None) -> torch.Tensor:
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class PatchConvnet(nn.Module):
def __init__(
self,
img_size: int = 224,
patch_size: int = 16,
in_chans: int = 3,
num_classes: int = 1000,
embed_dim: int = 768,
depth: int = 12,
num_heads: int = 1,
qkv_bias: bool = False,
qk_scale: Optional[float] = None,
drop_rate: float = 0.0,
attn_drop_rate: float = 0.0,
drop_path_rate: float = 0.0,
norm_layer=nn.LayerNorm,
global_pool: Optional[str] = None,
block_layers=Layer_scale_init_Block,
block_layers_token=Layer_scale_init_Block_only_token,
Patch_layer=ConvStem,
act_layer: nn.Module = nn.GELU,
Attention_block=Conv_blocks_se,
dpr_constant: bool = True,
init_scale: float = 1e-4,
Attention_block_token_only=Learned_Aggregation_Layer,
Mlp_block_token_only=Mlp,
depth_token_only: int = 1,
mlp_ratio_clstk: float = 3.0,
multiclass: bool = False,
):
super().__init__()
self.multiclass = multiclass
self.patch_size = patch_size
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.patch_embed = Patch_layer(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim
)
if not self.multiclass:
self.cls_token = nn.Parameter(torch.zeros(1, 1, int(embed_dim)))
else:
self.cls_token = nn.Parameter(torch.zeros(1, num_classes, int(embed_dim)))
if not dpr_constant:
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]
else:
dpr = [drop_path_rate for i in range(depth)]
self.blocks = nn.ModuleList(
[
block_layers(
dim=embed_dim,
drop_path=dpr[i],
norm_layer=norm_layer,
act_layer=act_layer,
Attention_block=Attention_block,
init_values=init_scale,
)
for i in range(depth)
]
)
self.blocks_token_only = nn.ModuleList(
[
block_layers_token(
dim=int(embed_dim),
num_heads=num_heads,
mlp_ratio=mlp_ratio_clstk,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=0.0,
norm_layer=norm_layer,
act_layer=act_layer,
Attention_block=Attention_block_token_only,
Mlp_block=Mlp_block_token_only,
init_values=init_scale,
)
for i in range(depth_token_only)
]
)
self.norm = norm_layer(int(embed_dim))
self.total_len = depth_token_only + depth
self.feature_info = [dict(num_chs=int(embed_dim), reduction=0, module='head')]
if not self.multiclass:
self.head = nn.Linear(int(embed_dim), num_classes) if num_classes > 0 else nn.Identity()
else:
self.head = nn.ModuleList([nn.Linear(int(embed_dim), 1) for _ in range(num_classes)])
self.rescale: float = 0.02
trunc_normal_(self.cls_token, std=self.rescale)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=self.rescale)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'cls_token'}
def get_classifier(self):
return self.head
def get_num_layers(self):
return len(self.blocks)
def reset_classifier(self, num_classes: int, global_pool: str = ''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x: torch.Tensor) -> torch.Tensor:
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1)
for i, blk in enumerate(self.blocks):
x = blk(x)
for i, blk in enumerate(self.blocks_token_only):
cls_tokens = blk(x, cls_tokens)
x = torch.cat((cls_tokens, x), dim=1)
x = self.norm(x)
if not self.multiclass:
return x[:, 0]
else:
return x[:, : self.num_classes].reshape(B, self.num_classes, -1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
B = x.shape[0]
x = self.forward_features(x)
if not self.multiclass:
x = self.head(x)
return x
else:
all_results = []
for i in range(self.num_classes):
all_results.append(self.head[i](x[:, i]))
return torch.cat(all_results, dim=1).reshape(B, self.num_classes)
@register_model
def S60(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
**kwargs
)
return model
@register_model
def S120(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=120,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
init_scale=1e-6,
mlp_ratio_clstk=3.0,
**kwargs
)
return model
@register_model
def B60(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=768,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Attention_block=Conv_blocks_se,
init_scale=1e-6,
**kwargs
)
return model
@register_model
def B120(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=768,
depth=120,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
init_scale=1e-6,
**kwargs
)
return model
@register_model
def L60(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=1024,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
init_scale=1e-6,
mlp_ratio_clstk=3.0,
**kwargs
)
return model
@register_model
def L120(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=1024,
depth=120,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
init_scale=1e-6,
mlp_ratio_clstk=3.0,
**kwargs
)
return model
@register_model
def S60_multi(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
Attention_block_token_only=Learned_Aggregation_Layer_multi,
depth_token_only=1,
mlp_ratio_clstk=3.0,
multiclass=True,
**kwargs
)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/ShuffleTransformer.py
================================================
import torch
from torch import nn, einsum
from einops import rearrange, repeat
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.ReLU6, drop=0., stride=False):
super().__init__()
self.stride = stride
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1, 1, 0, bias=True)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1, 1, 0, bias=True)
self.drop = nn.Dropout(drop, inplace=True)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads, window_size=1, shuffle=False, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., relative_pos_embedding=False):
super().__init__()
self.num_heads = num_heads
self.relative_pos_embedding = relative_pos_embedding
head_dim = dim // self.num_heads
self.ws = window_size
self.shuffle = shuffle
self.scale = qk_scale or head_dim ** -0.5
self.to_qkv = nn.Conv2d(dim, dim * 3, 1, bias=False)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Conv2d(dim, dim, 1)
self.proj_drop = nn.Dropout(proj_drop)
if self.relative_pos_embedding:
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size - 1) * (2 * window_size - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.ws)
coords_w = torch.arange(self.ws)
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.ws - 1 # shift to start from 0
relative_coords[:, :, 1] += self.ws - 1
relative_coords[:, :, 0] *= 2 * self.ws - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
trunc_normal_(self.relative_position_bias_table, std=.02)
# print('The relative_pos_embedding is used')
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x)
if self.shuffle:
q, k, v = rearrange(qkv, 'b (qkv h d) (ws1 hh) (ws2 ww) -> qkv (b hh ww) h (ws1 ws2) d', h=self.num_heads, qkv=3, ws1=self.ws, ws2=self.ws)
else:
q, k, v = rearrange(qkv, 'b (qkv h d) (hh ws1) (ww ws2) -> qkv (b hh ww) h (ws1 ws2) d', h=self.num_heads, qkv=3, ws1=self.ws, ws2=self.ws)
dots = (q @ k.transpose(-2, -1)) * self.scale
if self.relative_pos_embedding:
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.ws * self.ws, self.ws * self.ws, -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
dots += relative_position_bias.unsqueeze(0)
attn = dots.softmax(dim=-1)
out = attn @ v
if self.shuffle:
out = rearrange(out, '(b hh ww) h (ws1 ws2) d -> b (h d) (ws1 hh) (ws2 ww)', h=self.num_heads, b=b, hh=h//self.ws, ws1=self.ws, ws2=self.ws)
else:
out = rearrange(out, '(b hh ww) h (ws1 ws2) d -> b (h d) (hh ws1) (ww ws2)', h=self.num_heads, b=b, hh=h//self.ws, ws1=self.ws, ws2=self.ws)
out = self.proj(out)
out = self.proj_drop(out)
return out
class Block(nn.Module):
def __init__(self, dim, out_dim, num_heads, window_size=1, shuffle=False, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.ReLU6, norm_layer=nn.BatchNorm2d, stride=False, relative_pos_embedding=False):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, window_size=window_size, shuffle=shuffle, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, relative_pos_embedding=relative_pos_embedding)
self.local = nn.Conv2d(dim, dim, window_size, 1, window_size//2, groups=dim, bias=qkv_bias)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, out_features=out_dim, act_layer=act_layer, drop=drop, stride=stride)
self.norm3 = norm_layer(dim)
# print("input dim={}, output dim={}, stride={}, expand={}, num_heads={}".format(dim, out_dim, stride, shuffle, num_heads))
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.local(self.norm2(x)) # local connection
x = x + self.drop_path(self.mlp(self.norm3(x)))
return x
class PatchMerging(nn.Module):
def __init__(self, dim, out_dim, norm_layer=nn.BatchNorm2d):
super().__init__()
self.dim = dim
self.out_dim = out_dim
self.norm = norm_layer(dim)
self.reduction = nn.Conv2d(dim, out_dim, 2, 2, 0, bias=False)
def forward(self, x):
x = self.norm(x)
x = self.reduction(x)
return x
def extra_repr(self) -> str:
return f"input dim={self.dim}, out dim={self.out_dim}"
class StageModule(nn.Module):
def __init__(self, layers, dim, out_dim, num_heads, window_size=1, shuffle=True, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.ReLU6, norm_layer=nn.BatchNorm2d, relative_pos_embedding=False):
super().__init__()
assert layers % 2 == 0, 'Stage layers need to be divisible by 2 for regular and shifted block.'
if dim != out_dim:
self.patch_partition = PatchMerging(dim, out_dim)
else:
self.patch_partition = None
num = layers // 2
self.layers = nn.ModuleList([])
for idx in range(num):
the_last = (idx==num-1)
self.layers.append(nn.ModuleList([
Block(dim=out_dim, out_dim=out_dim, num_heads=num_heads, window_size=window_size, shuffle=False, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop, attn_drop=attn_drop, drop_path=drop_path,
relative_pos_embedding=relative_pos_embedding),
Block(dim=out_dim, out_dim=out_dim, num_heads=num_heads, window_size=window_size, shuffle=shuffle, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop, attn_drop=attn_drop, drop_path=drop_path,
relative_pos_embedding=relative_pos_embedding)
]))
def forward(self, x):
if self.patch_partition:
x = self.patch_partition(x)
for regular_block, shifted_block in self.layers:
x = regular_block(x)
x = shifted_block(x)
return x
class PatchEmbedding(nn.Module):
def __init__(self, inter_channel=32, out_channels=48):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, inter_channel, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(inter_channel),
nn.ReLU6(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(inter_channel, out_channels, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
self.conv3 = nn.Conv2d(out_channels, out_channels, kernel_size=1, stride=1, padding=0)
def forward(self, x):
x = self.conv3(self.conv2(self.conv1(x)))
return x
class ShuffleTransformer(nn.Module):
def __init__(self, img_size=224, in_chans=3, num_classes=1000, token_dim=32, embed_dim=96, mlp_ratio=4., layers=[2,2,6,2], num_heads=[3,6,12,24],
relative_pos_embedding=True, shuffle=True, window_size=7, qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.,
has_pos_embed=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.has_pos_embed = has_pos_embed
dims = [i*32 for i in num_heads]
self.to_token = PatchEmbedding(inter_channel=token_dim, out_channels=embed_dim)
num_patches = (img_size*img_size) // 16
if self.has_pos_embed:
self.pos_embed = nn.Parameter(data=get_sinusoid_encoding(n_position=num_patches, d_hid=embed_dim), requires_grad=False)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, 4)] # stochastic depth decay rule
self.stage1 = StageModule(layers[0], embed_dim, dims[0], num_heads[0], window_size=window_size, shuffle=shuffle,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[0],
relative_pos_embedding=relative_pos_embedding)
self.stage2 = StageModule(layers[1], dims[0], dims[1], num_heads[1], window_size=window_size, shuffle=shuffle,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[1],
relative_pos_embedding=relative_pos_embedding)
self.stage3 = StageModule(layers[2], dims[1], dims[2], num_heads[2], window_size=window_size, shuffle=shuffle,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[2],
relative_pos_embedding=relative_pos_embedding)
self.stage4 = StageModule(layers[3], dims[2], dims[3], num_heads[3], window_size=window_size, shuffle=shuffle,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[3],
relative_pos_embedding=relative_pos_embedding)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# Classifier head
self.head = nn.Linear(dims[3], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, (nn.BatchNorm2d, nn.GroupNorm, nn.LayerNorm)):
nn.init.constant_(m.weight, 1.0)
nn.init.constant_(m.bias, 0)
elif isinstance(m, (nn.Linear, nn.Conv2d)):
trunc_normal_(m.weight, std=.02)
if isinstance(m, (nn.Linear, nn.Conv2d)) and m.bias is not None:
nn.init.constant_(m.bias, 0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
x = self.to_token(x)
b, c, h, w = x.shape
if self.has_pos_embed:
x = x + self.pos_embed.view(1, h, w, c).permute(0, 3, 1, 2)
x = self.pos_drop(x)
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
sft = ShuffleTransformer()
output=sft(input)
print(output.shape)
================================================
FILE: model/backbone/TnT.py
================================================
# 2021.06.15-Changed for implementation of TNT model
# Huawei Technologies Co., Ltd.
import torch
import torch.nn as nn
from functools import partial
import math
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.helpers import load_pretrained
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.resnet import resnet26d, resnet50d
from timm.models.registry import register_model
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
'tnt_s_patch16_224': _cfg(
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
),
'tnt_b_patch16_224': _cfg(
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
),
}
def make_divisible(v, divisor=8, min_value=None):
min_value = min_value or divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class SE(nn.Module):
def __init__(self, dim, hidden_ratio=None):
super().__init__()
hidden_ratio = hidden_ratio or 1
self.dim = dim
hidden_dim = int(dim * hidden_ratio)
self.fc = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, hidden_dim),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim, dim),
nn.Tanh()
)
def forward(self, x):
a = x.mean(dim=1, keepdim=True) # B, 1, C
a = self.fc(a)
x = a * x
return x
class Attention(nn.Module):
def __init__(self, dim, hidden_dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.hidden_dim = hidden_dim
self.num_heads = num_heads
head_dim = hidden_dim // num_heads
self.head_dim = head_dim
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qk = nn.Linear(dim, hidden_dim * 2, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop, inplace=True)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop, inplace=True)
def forward(self, x):
B, N, C = x.shape
qk = self.qk(x).reshape(B, N, 2, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k = qk[0], qk[1] # make torchscript happy (cannot use tensor as tuple)
v = self.v(x).reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
""" TNT Block
"""
def __init__(self, outer_dim, inner_dim, outer_num_heads, inner_num_heads, num_words, mlp_ratio=4.,
qkv_bias=False, qk_scale=None, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU,
norm_layer=nn.LayerNorm, se=0):
super().__init__()
self.has_inner = inner_dim > 0
if self.has_inner:
# Inner
self.inner_norm1 = norm_layer(inner_dim)
self.inner_attn = Attention(
inner_dim, inner_dim, num_heads=inner_num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.inner_norm2 = norm_layer(inner_dim)
self.inner_mlp = Mlp(in_features=inner_dim, hidden_features=int(inner_dim * mlp_ratio),
out_features=inner_dim, act_layer=act_layer, drop=drop)
self.proj_norm1 = norm_layer(num_words * inner_dim)
self.proj = nn.Linear(num_words * inner_dim, outer_dim, bias=False)
self.proj_norm2 = norm_layer(outer_dim)
# Outer
self.outer_norm1 = norm_layer(outer_dim)
self.outer_attn = Attention(
outer_dim, outer_dim, num_heads=outer_num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.outer_norm2 = norm_layer(outer_dim)
self.outer_mlp = Mlp(in_features=outer_dim, hidden_features=int(outer_dim * mlp_ratio),
out_features=outer_dim, act_layer=act_layer, drop=drop)
# SE
self.se = se
self.se_layer = None
if self.se > 0:
self.se_layer = SE(outer_dim, 0.25)
def forward(self, inner_tokens, outer_tokens):
if self.has_inner:
inner_tokens = inner_tokens + self.drop_path(self.inner_attn(self.inner_norm1(inner_tokens))) # B*N, k*k, c
inner_tokens = inner_tokens + self.drop_path(self.inner_mlp(self.inner_norm2(inner_tokens))) # B*N, k*k, c
B, N, C = outer_tokens.size()
outer_tokens[:,1:] = outer_tokens[:,1:] + self.proj_norm2(self.proj(self.proj_norm1(inner_tokens.reshape(B, N-1, -1)))) # B, N, C
if self.se > 0:
outer_tokens = outer_tokens + self.drop_path(self.outer_attn(self.outer_norm1(outer_tokens)))
tmp_ = self.outer_mlp(self.outer_norm2(outer_tokens))
outer_tokens = outer_tokens + self.drop_path(tmp_ + self.se_layer(tmp_))
else:
outer_tokens = outer_tokens + self.drop_path(self.outer_attn(self.outer_norm1(outer_tokens)))
outer_tokens = outer_tokens + self.drop_path(self.outer_mlp(self.outer_norm2(outer_tokens)))
return inner_tokens, outer_tokens
class PatchEmbed(nn.Module):
""" Image to Visual Word Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, outer_dim=768, inner_dim=24, inner_stride=4):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.inner_dim = inner_dim
self.num_words = math.ceil(patch_size[0] / inner_stride) * math.ceil(patch_size[1] / inner_stride)
self.unfold = nn.Unfold(kernel_size=patch_size, stride=patch_size)
self.proj = nn.Conv2d(in_chans, inner_dim, kernel_size=7, padding=3, stride=inner_stride)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.unfold(x) # B, Ck2, N
x = x.transpose(1, 2).reshape(B * self.num_patches, C, *self.patch_size) # B*N, C, 16, 16
x = self.proj(x) # B*N, C, 8, 8
x = x.reshape(B * self.num_patches, self.inner_dim, -1).transpose(1, 2) # B*N, 8*8, C
return x
class TNT(nn.Module):
""" TNT (Transformer in Transformer) for computer vision
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, outer_dim=768, inner_dim=48,
depth=12, outer_num_heads=12, inner_num_heads=4, mlp_ratio=4., qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm, inner_stride=4, se=0):
super().__init__()
self.num_classes = num_classes
self.num_features = self.outer_dim = outer_dim # num_features for consistency with other models
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, outer_dim=outer_dim,
inner_dim=inner_dim, inner_stride=inner_stride)
self.num_patches = num_patches = self.patch_embed.num_patches
num_words = self.patch_embed.num_words
self.proj_norm1 = norm_layer(num_words * inner_dim)
self.proj = nn.Linear(num_words * inner_dim, outer_dim)
self.proj_norm2 = norm_layer(outer_dim)
self.cls_token = nn.Parameter(torch.zeros(1, 1, outer_dim))
self.outer_tokens = nn.Parameter(torch.zeros(1, num_patches, outer_dim), requires_grad=False)
self.outer_pos = nn.Parameter(torch.zeros(1, num_patches + 1, outer_dim))
self.inner_pos = nn.Parameter(torch.zeros(1, num_words, inner_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
vanilla_idxs = []
blocks = []
for i in range(depth):
if i in vanilla_idxs:
blocks.append(Block(
outer_dim=outer_dim, inner_dim=-1, outer_num_heads=outer_num_heads, inner_num_heads=inner_num_heads,
num_words=num_words, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, se=se))
else:
blocks.append(Block(
outer_dim=outer_dim, inner_dim=inner_dim, outer_num_heads=outer_num_heads, inner_num_heads=inner_num_heads,
num_words=num_words, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, se=se))
self.blocks = nn.ModuleList(blocks)
self.norm = norm_layer(outer_dim)
# NOTE as per official impl, we could have a pre-logits representation dense layer + tanh here
#self.repr = nn.Linear(outer_dim, representation_size)
#self.repr_act = nn.Tanh()
# Classifier head
self.head = nn.Linear(outer_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.cls_token, std=.02)
trunc_normal_(self.outer_pos, std=.02)
trunc_normal_(self.inner_pos, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'outer_pos', 'inner_pos', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.outer_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
inner_tokens = self.patch_embed(x) + self.inner_pos # B*N, 8*8, C
outer_tokens = self.proj_norm2(self.proj(self.proj_norm1(inner_tokens.reshape(B, self.num_patches, -1))))
outer_tokens = torch.cat((self.cls_token.expand(B, -1, -1), outer_tokens), dim=1)
outer_tokens = outer_tokens + self.outer_pos
outer_tokens = self.pos_drop(outer_tokens)
for blk in self.blocks:
inner_tokens, outer_tokens = blk(inner_tokens, outer_tokens)
outer_tokens = self.norm(outer_tokens)
return outer_tokens[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def _conv_filter(state_dict, patch_size=16):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k:
v = v.reshape((v.shape[0], 3, patch_size, patch_size))
out_dict[k] = v
return out_dict
@register_model
def tnt_s_patch16_224(pretrained=False, **kwargs):
patch_size = 16
inner_stride = 4
outer_dim = 384
inner_dim = 24
outer_num_heads = 6
inner_num_heads = 4
outer_dim = make_divisible(outer_dim, outer_num_heads)
inner_dim = make_divisible(inner_dim, inner_num_heads)
model = TNT(img_size=224, patch_size=patch_size, outer_dim=outer_dim, inner_dim=inner_dim, depth=12,
outer_num_heads=outer_num_heads, inner_num_heads=inner_num_heads, qkv_bias=False,
inner_stride=inner_stride, **kwargs)
model.default_cfg = default_cfgs['tnt_s_patch16_224']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
@register_model
def tnt_b_patch16_224(pretrained=False, **kwargs):
patch_size = 16
inner_stride = 4
outer_dim = 640
inner_dim = 40
outer_num_heads = 10
inner_num_heads = 4
outer_dim = make_divisible(outer_dim, outer_num_heads)
inner_dim = make_divisible(inner_dim, inner_num_heads)
model = TNT(img_size=224, patch_size=patch_size, outer_dim=outer_dim, inner_dim=inner_dim, depth=12,
outer_num_heads=outer_num_heads, inner_num_heads=inner_num_heads, qkv_bias=False,
inner_stride=inner_stride, **kwargs)
model.default_cfg = default_cfgs['tnt_b_patch16_224']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = TNT(
img_size=224,
patch_size=16,
outer_dim=384,
inner_dim=24,
depth=12,
outer_num_heads=6,
inner_num_heads=4,
qkv_bias=False,
inner_stride=4)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/VOLO.py
================================================
# Copyright 2021 Sea Limited.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Vision OutLOoker (VOLO) implementation
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
import math
import numpy as np
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .96, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
'volo': _cfg(crop_pct=0.96),
'volo_large': _cfg(crop_pct=1.15),
}
class OutlookAttention(nn.Module):
"""
Implementation of outlook attention
--dim: hidden dim
--num_heads: number of heads
--kernel_size: kernel size in each window for outlook attention
return: token features after outlook attention
"""
def __init__(self, dim, num_heads, kernel_size=3, padding=1, stride=1,
qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
head_dim = dim // num_heads
self.num_heads = num_heads
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.scale = qk_scale or head_dim**-0.5
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn = nn.Linear(dim, kernel_size**4 * num_heads)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.unfold = nn.Unfold(kernel_size=kernel_size, padding=padding, stride=stride)
self.pool = nn.AvgPool2d(kernel_size=stride, stride=stride, ceil_mode=True)
def forward(self, x):
B, H, W, C = x.shape
v = self.v(x).permute(0, 3, 1, 2) # B, C, H, W
h, w = math.ceil(H / self.stride), math.ceil(W / self.stride)
v = self.unfold(v).reshape(B, self.num_heads, C // self.num_heads,
self.kernel_size * self.kernel_size,
h * w).permute(0, 1, 4, 3, 2) # B,H,N,kxk,C/H
attn = self.pool(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
attn = self.attn(attn).reshape(
B, h * w, self.num_heads, self.kernel_size * self.kernel_size,
self.kernel_size * self.kernel_size).permute(0, 2, 1, 3, 4) # B,H,N,kxk,kxk
attn = attn * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).permute(0, 1, 4, 3, 2).reshape(
B, C * self.kernel_size * self.kernel_size, h * w)
x = F.fold(x, output_size=(H, W), kernel_size=self.kernel_size,
padding=self.padding, stride=self.stride)
x = self.proj(x.permute(0, 2, 3, 1))
x = self.proj_drop(x)
return x
class Outlooker(nn.Module):
"""
Implementation of outlooker layer: which includes outlook attention + MLP
Outlooker is the first stage in our VOLO
--dim: hidden dim
--num_heads: number of heads
--mlp_ratio: mlp ratio
--kernel_size: kernel size in each window for outlook attention
return: outlooker layer
"""
def __init__(self, dim, kernel_size, padding, stride=1,
num_heads=1,mlp_ratio=3., attn_drop=0.,
drop_path=0., act_layer=nn.GELU,
norm_layer=nn.LayerNorm, qkv_bias=False,
qk_scale=None):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = OutlookAttention(dim, num_heads, kernel_size=kernel_size,
padding=padding, stride=stride,
qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop)
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class Mlp(nn.Module):
"Implementation of MLP"
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU,
drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
"Implementation of self-attention"
def __init__(self, dim, num_heads=8, qkv_bias=False,
qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads,
C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[
2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, H, W, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Transformer(nn.Module):
"""
Implementation of Transformer,
Transformer is the second stage in our VOLO
"""
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False,
qk_scale=None, attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class ClassAttention(nn.Module):
"""
Class attention layer from CaiT, see details in CaiT
Class attention is the post stage in our VOLO, which is optional.
"""
def __init__(self, dim, num_heads=8, head_dim=None, qkv_bias=False,
qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
if head_dim is not None:
self.head_dim = head_dim
else:
head_dim = dim // num_heads
self.head_dim = head_dim
self.scale = qk_scale or head_dim**-0.5
self.kv = nn.Linear(dim,
self.head_dim * self.num_heads * 2,
bias=qkv_bias)
self.q = nn.Linear(dim, self.head_dim * self.num_heads, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(self.head_dim * self.num_heads, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
kv = self.kv(x).reshape(B, N, 2, self.num_heads,
self.head_dim).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[
1] # make torchscript happy (cannot use tensor as tuple)
q = self.q(x[:, :1, :]).reshape(B, self.num_heads, 1, self.head_dim)
attn = ((q * self.scale) @ k.transpose(-2, -1))
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
cls_embed = (attn @ v).transpose(1, 2).reshape(
B, 1, self.head_dim * self.num_heads)
cls_embed = self.proj(cls_embed)
cls_embed = self.proj_drop(cls_embed)
return cls_embed
class ClassBlock(nn.Module):
"""
Class attention block from CaiT, see details in CaiT
We use two-layers class attention in our VOLO, which is optional.
"""
def __init__(self, dim, num_heads, head_dim=None, mlp_ratio=4.,
qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = ClassAttention(
dim, num_heads=num_heads, head_dim=head_dim, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop)
def forward(self, x):
cls_embed = x[:, :1]
cls_embed = cls_embed + self.drop_path(self.attn(self.norm1(x)))
cls_embed = cls_embed + self.drop_path(self.mlp(self.norm2(cls_embed)))
return torch.cat([cls_embed, x[:, 1:]], dim=1)
def get_block(block_type, **kargs):
"""
get block by name, specifically for class attention block in here
"""
if block_type == 'ca':
return ClassBlock(**kargs)
def rand_bbox(size, lam, scale=1):
"""
get bounding box as token labeling (https://github.com/zihangJiang/TokenLabeling)
return: bounding box
"""
W = size[1] // scale
H = size[2] // scale
cut_rat = np.sqrt(1. - lam)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# uniform
cx = np.random.randint(W)
cy = np.random.randint(H)
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
return bbx1, bby1, bbx2, bby2
class PatchEmbed(nn.Module):
"""
Image to Patch Embedding.
Different with ViT use 1 conv layer, we use 4 conv layers to do patch embedding
"""
def __init__(self, img_size=224, stem_conv=False, stem_stride=1,
patch_size=8, in_chans=3, hidden_dim=64, embed_dim=384):
super().__init__()
assert patch_size in [4, 8, 16]
self.stem_conv = stem_conv
if stem_conv:
self.conv = nn.Sequential(
nn.Conv2d(in_chans, hidden_dim, kernel_size=7, stride=stem_stride,
padding=3, bias=False), # 112x112
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
nn.Conv2d(hidden_dim, hidden_dim, kernel_size=3, stride=1,
padding=1, bias=False), # 112x112
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
nn.Conv2d(hidden_dim, hidden_dim, kernel_size=3, stride=1,
padding=1, bias=False), # 112x112
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
)
self.proj = nn.Conv2d(hidden_dim,
embed_dim,
kernel_size=patch_size // stem_stride,
stride=patch_size // stem_stride)
self.num_patches = (img_size // patch_size) * (img_size // patch_size)
def forward(self, x):
if self.stem_conv:
x = self.conv(x)
x = self.proj(x) # B, C, H, W
return x
class Downsample(nn.Module):
"""
Image to Patch Embedding, downsampling between stage1 and stage2
"""
def __init__(self, in_embed_dim, out_embed_dim, patch_size):
super().__init__()
self.proj = nn.Conv2d(in_embed_dim, out_embed_dim,
kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = x.permute(0, 3, 1, 2)
x = self.proj(x) # B, C, H, W
x = x.permute(0, 2, 3, 1)
return x
def outlooker_blocks(block_fn, index, dim, layers, num_heads=1, kernel_size=3,
padding=1,stride=1, mlp_ratio=3., qkv_bias=False, qk_scale=None,
attn_drop=0, drop_path_rate=0., **kwargs):
"""
generate outlooker layer in stage1
return: outlooker layers
"""
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx +
sum(layers[:index])) / (sum(layers) - 1)
blocks.append(block_fn(dim, kernel_size=kernel_size, padding=padding,
stride=stride, num_heads=num_heads, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop,
drop_path=block_dpr))
blocks = nn.Sequential(*blocks)
return blocks
def transformer_blocks(block_fn, index, dim, layers, num_heads, mlp_ratio=3.,
qkv_bias=False, qk_scale=None, attn_drop=0,
drop_path_rate=0., **kwargs):
"""
generate transformer layers in stage2
return: transformer layers
"""
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx +
sum(layers[:index])) / (sum(layers) - 1)
blocks.append(
block_fn(dim, num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
drop_path=block_dpr))
blocks = nn.Sequential(*blocks)
return blocks
class VOLO(nn.Module):
"""
Vision Outlooker, the main class of our model
--layers: [x,x,x,x], four blocks in two stages, the first block is outlooker, the
other three are transformer, we set four blocks, which are easily
applied to downstream tasks
--img_size, --in_chans, --num_classes: these three are very easy to understand
--patch_size: patch_size in outlook attention
--stem_hidden_dim: hidden dim of patch embedding, d1-d4 is 64, d5 is 128
--embed_dims, --num_heads: embedding dim, number of heads in each block
--downsamples: flags to apply downsampling or not
--outlook_attention: flags to apply outlook attention or not
--mlp_ratios, --qkv_bias, --qk_scale, --drop_rate: easy to undertand
--attn_drop_rate, --drop_path_rate, --norm_layer: easy to undertand
--post_layers: post layers like two class attention layers using [ca, ca],
if yes, return_mean=False
--return_mean: use mean of all feature tokens for classification, if yes, no class token
--return_dense: use token labeling, details are here:
https://github.com/zihangJiang/TokenLabeling
--mix_token: mixing tokens as token labeling, details are here:
https://github.com/zihangJiang/TokenLabeling
--pooling_scale: pooling_scale=2 means we downsample 2x
--out_kernel, --out_stride, --out_padding: kerner size,
stride, and padding for outlook attention
"""
def __init__(self, layers, img_size=224, in_chans=3, num_classes=1000, patch_size=8,
stem_hidden_dim=64, embed_dims=None, num_heads=None, downsamples=None,
outlook_attention=None, mlp_ratios=None, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
post_layers=None, return_mean=False, return_dense=True, mix_token=True,
pooling_scale=2, out_kernel=3, out_stride=2, out_padding=1):
super().__init__()
self.num_classes = num_classes
self.patch_embed = PatchEmbed(stem_conv=True, stem_stride=2, patch_size=patch_size,
in_chans=in_chans, hidden_dim=stem_hidden_dim,
embed_dim=embed_dims[0])
# inital positional encoding, we add positional encoding after outlooker blocks
self.pos_embed = nn.Parameter(
torch.zeros(1, img_size // patch_size // pooling_scale,
img_size // patch_size // pooling_scale,
embed_dims[-1]))
self.pos_drop = nn.Dropout(p=drop_rate)
# set the main block in network
network = []
for i in range(len(layers)):
if outlook_attention[i]:
# stage 1
stage = outlooker_blocks(Outlooker, i, embed_dims[i], layers,
downsample=downsamples[i], num_heads=num_heads[i],
kernel_size=out_kernel, stride=out_stride,
padding=out_padding, mlp_ratio=mlp_ratios[i],
qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop_rate, norm_layer=norm_layer)
network.append(stage)
else:
# stage 2
stage = transformer_blocks(Transformer, i, embed_dims[i], layers,
num_heads[i], mlp_ratio=mlp_ratios[i],
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop_path_rate=drop_path_rate,
attn_drop=attn_drop_rate,
norm_layer=norm_layer)
network.append(stage)
if downsamples[i]:
# downsampling between two stages
network.append(Downsample(embed_dims[i], embed_dims[i + 1], 2))
self.network = nn.ModuleList(network)
# set post block, for example, class attention layers
self.post_network = None
if post_layers is not None:
self.post_network = nn.ModuleList([
get_block(post_layers[i],
dim=embed_dims[-1],
num_heads=num_heads[-1],
mlp_ratio=mlp_ratios[-1],
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop_rate,
drop_path=0.,
norm_layer=norm_layer)
for i in range(len(post_layers))
])
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dims[-1]))
trunc_normal_(self.cls_token, std=.02)
# set output type
self.return_mean = return_mean # if yes, return mean, not use class token
self.return_dense = return_dense # if yes, return class token and all feature tokens
if return_dense:
assert not return_mean, "cannot return both mean and dense"
self.mix_token = mix_token
self.pooling_scale = pooling_scale
if mix_token: # enable token mixing, see token labeling for details.
self.beta = 1.0
assert return_dense, "return all tokens if mix_token is enabled"
if return_dense:
self.aux_head = nn.Linear(
embed_dims[-1],
num_classes) if num_classes > 0 else nn.Identity()
self.norm = norm_layer(embed_dims[-1])
# Classifier head
self.head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.pos_embed, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes):
self.num_classes = num_classes
self.head = nn.Linear(
self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_embeddings(self, x):
# patch embedding
x = self.patch_embed(x)
# B,C,H,W-> B,H,W,C
x = x.permute(0, 2, 3, 1)
return x
def forward_tokens(self, x):
for idx, block in enumerate(self.network):
if idx == 2: # add positional encoding after outlooker blocks
x = x + self.pos_embed
x = self.pos_drop(x)
x = block(x)
B, H, W, C = x.shape
x = x.reshape(B, -1, C)
return x
def forward_cls(self, x):
B, N, C = x.shape
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
for block in self.post_network:
x = block(x)
return x
def forward(self, x):
# step1: patch embedding
x = self.forward_embeddings(x)
# mix token, see token labeling for details.
if self.mix_token and self.training:
lam = np.random.beta(self.beta, self.beta)
patch_h, patch_w = x.shape[1] // self.pooling_scale, x.shape[
2] // self.pooling_scale
bbx1, bby1, bbx2, bby2 = rand_bbox(x.size(), lam, scale=self.pooling_scale)
temp_x = x.clone()
sbbx1,sbby1,sbbx2,sbby2=self.pooling_scale*bbx1,self.pooling_scale*bby1,\
self.pooling_scale*bbx2,self.pooling_scale*bby2
temp_x[:, sbbx1:sbbx2, sbby1:sbby2, :] = x.flip(0)[:, sbbx1:sbbx2, sbby1:sbby2, :]
x = temp_x
else:
bbx1, bby1, bbx2, bby2 = 0, 0, 0, 0
# step2: tokens learning in the two stages
x = self.forward_tokens(x)
# step3: post network, apply class attention or not
if self.post_network is not None:
x = self.forward_cls(x)
x = self.norm(x)
if self.return_mean: # if no class token, return mean
return self.head(x.mean(1))
x_cls = self.head(x[:, 0])
if not self.return_dense:
return x_cls
x_aux = self.aux_head(
x[:, 1:]
) # generate classes in all feature tokens, see token labeling
if not self.training:
return x_cls + 0.5 * x_aux.max(1)[0]
if self.mix_token and self.training: # reverse "mix token", see token labeling for details.
x_aux = x_aux.reshape(x_aux.shape[0], patch_h, patch_w, x_aux.shape[-1])
temp_x = x_aux.clone()
temp_x[:, bbx1:bbx2, bby1:bby2, :] = x_aux.flip(0)[:, bbx1:bbx2, bby1:bby2, :]
x_aux = temp_x
x_aux = x_aux.reshape(x_aux.shape[0], patch_h * patch_w, x_aux.shape[-1])
# return these: 1. class token, 2. classes from all feature tokens, 3. bounding box
return x_cls, x_aux, (bbx1, bby1, bbx2, bby2)
@register_model
def volo_d1(pretrained=False, **kwargs):
"""
VOLO-D1 model, Params: 27M
--layers: [x,x,x,x], four blocks in two stages, the first stage(block) is outlooker,
the other three blocks are transformer, we set four blocks, which are easily
applied to downstream tasks
--embed_dims, --num_heads,: embedding dim, number of heads in each block
--downsamples: flags to apply downsampling or not in four blocks
--outlook_attention: flags to apply outlook attention or not
--mlp_ratios: mlp ratio in four blocks
--post_layers: post layers like two class attention layers using [ca, ca]
See detail for all args in the class VOLO()
"""
layers = [4, 4, 8, 2] # num of layers in the four blocks
embed_dims = [192, 384, 384, 384]
num_heads = [6, 12, 12, 12]
mlp_ratios = [3, 3, 3, 3]
downsamples = [True, False, False, False] # do downsampling after first block
outlook_attention = [True, False, False, False ]
# first block is outlooker (stage1), the other three are transformer (stage2)
model = VOLO(layers,
embed_dims=embed_dims,
num_heads=num_heads,
mlp_ratios=mlp_ratios,
downsamples=downsamples,
outlook_attention=outlook_attention,
post_layers=['ca', 'ca'],
**kwargs)
model.default_cfg = default_cfgs['volo']
return model
@register_model
def volo_d2(pretrained=False, **kwargs):
"""
VOLO-D2 model, Params: 59M
"""
layers = [6, 4, 10, 4]
embed_dims = [256, 512, 512, 512]
num_heads = [8, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
downsamples = [True, False, False, False]
outlook_attention = [True, False, False, False]
model = VOLO(layers,
embed_dims=embed_dims,
num_heads=num_heads,
mlp_ratios=mlp_ratios,
downsamples=downsamples,
outlook_attention=outlook_attention,
post_layers=['ca', 'ca'],
**kwargs)
model.default_cfg = default_cfgs['volo']
return model
@register_model
def volo_d3(pretrained=False, **kwargs):
"""
VOLO-D3 model, Params: 86M
"""
layers = [8, 8, 16, 4]
embed_dims = [256, 512, 512, 512]
num_heads = [8, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
downsamples = [True, False, False, False]
outlook_attention = [True, False, False, False]
model = VOLO(layers,
embed_dims=embed_dims,
num_heads=num_heads,
mlp_ratios=mlp_ratios,
downsamples=downsamples,
outlook_attention=outlook_attention,
post_layers=['ca', 'ca'],
**kwargs)
model.default_cfg = default_cfgs['volo']
return model
@register_model
def volo_d4(pretrained=False, **kwargs):
"""
VOLO-D4 model, Params: 193M
"""
layers = [8, 8, 16, 4]
embed_dims = [384, 768, 768, 768]
num_heads = [12, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
downsamples = [True, False, False, False]
outlook_attention = [True, False, False, False]
model = VOLO(layers,
embed_dims=embed_dims,
num_heads=num_heads,
mlp_ratios=mlp_ratios,
downsamples=downsamples,
outlook_attention=outlook_attention,
post_layers=['ca', 'ca'],
**kwargs)
model.default_cfg = default_cfgs['volo_large']
return model
@register_model
def volo_d5(pretrained=False, **kwargs):
"""
VOLO-D5 model, Params: 296M
stem_hidden_dim=128, the dim in patch embedding is 128 for VOLO-D5
"""
layers = [12, 12, 20, 4]
embed_dims = [384, 768, 768, 768]
num_heads = [12, 16, 16, 16]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, False, False, False]
outlook_attention = [True, False, False, False]
model = VOLO(layers,
embed_dims=embed_dims,
num_heads=num_heads,
mlp_ratios=mlp_ratios,
downsamples=downsamples,
outlook_attention=outlook_attention,
post_layers=['ca', 'ca'],
stem_hidden_dim=128,
**kwargs)
model.default_cfg = default_cfgs['volo_large']
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VOLO([4, 4, 8, 2],
embed_dims=[192, 384, 384, 384],
num_heads=[6, 12, 12, 12],
mlp_ratios=[3, 3, 3, 3],
downsamples=[True, False, False, False],
outlook_attention=[True, False, False, False ],
post_layers=['ca', 'ca'],
)
output=model(input)
print(output[0].shape)
================================================
FILE: model/backbone/convnextv2.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPath
class Block(nn.Module):
""" ConvNeXtV2 Block.
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
"""
def __init__(self, dim, drop_path=0.):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.grn = GRN(4 * dim)
self.pwconv2 = nn.Linear(4 * dim, dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.grn(x)
x = self.pwconv2(x)
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
class LayerNorm(nn.Module):
""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class GRN(nn.Module):
""" GRN (Global Response Normalization) layer
"""
def __init__(self, dim):
super().__init__()
self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))
self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))
def forward(self, x):
Gx = torch.norm(x, p=2, dim=(1,2), keepdim=True)
Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)
return self.gamma * (x * Nx) + self.beta + x
class ConvNeXtV2(nn.Module):
""" ConvNeXt V2
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_path_rate (float): Stochastic depth rate. Default: 0.
head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1.
"""
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768],
drop_path_rate=0., head_init_scale=1.
):
super().__init__()
self.depths = depths
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j]) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward_features(self, x):
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def convnextv2_atto(**kwargs):
model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[40, 80, 160, 320], **kwargs)
return model
def convnextv2_femto(**kwargs):
model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[48, 96, 192, 384], **kwargs)
return model
def convnext_pico(**kwargs):
model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[64, 128, 256, 512], **kwargs)
return model
def convnextv2_nano(**kwargs):
model = ConvNeXtV2(depths=[2, 2, 8, 2], dims=[80, 160, 320, 640], **kwargs)
return model
def convnextv2_tiny(**kwargs):
model = ConvNeXtV2(depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], **kwargs)
return model
def convnextv2_base(**kwargs):
model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[128, 256, 512, 1024], **kwargs)
return model
def convnextv2_large(**kwargs):
model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[192, 384, 768, 1536], **kwargs)
return model
def convnextv2_huge(**kwargs):
model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[352, 704, 1408, 2816], **kwargs)
return model
if __name__ == "__main__":
model = convnextv2_atto()
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
================================================
FILE: model/backbone/resnet.py
================================================
import torch
from torch import nn
"""
# in_channel:输入block之前的通道数
# channel:在block中间处理的时候的通道数(这个值是输出维度的1/4)
# channel * block.expansion:输出的维度
"""
class BottleNeck(nn.Module):
expansion = 4
def __init__(self,in_channel,channel,stride=1,downsample=None):
super().__init__()
self.conv1=nn.Conv2d(in_channel,channel,kernel_size=1,stride=stride,bias=False)
self.bn1=nn.BatchNorm2d(channel)
self.conv2=nn.Conv2d(channel,channel,kernel_size=3,padding=1,bias=False,stride=1)
self.bn2=nn.BatchNorm2d(channel)
self.conv3=nn.Conv2d(channel,channel*self.expansion,kernel_size=1,stride=1,bias=False)
self.bn3=nn.BatchNorm2d(channel*self.expansion)
self.relu=nn.ReLU(False)
self.downsample=downsample
self.stride=stride
def forward(self,x):
residual=x
out=self.relu(self.bn1(self.conv1(x))) #bs,c,h,w
out=self.relu(self.bn2(self.conv2(out))) #bs,c,h,w
out=self.relu(self.bn3(self.conv3(out))) #bs,4c,h,w
if(self.downsample != None):
residual=self.downsample(residual)
out+=residual
return self.relu(out)
class ResNet(nn.Module):
def __init__(self,block,layers,num_classes=1000):
super().__init__()
#定义输入模块的维度
self.in_channel=64
### stem layer
self.conv1=nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3,bias=False)
self.bn1=nn.BatchNorm2d(64)
self.relu=nn.ReLU(False)
self.maxpool=nn.MaxPool2d(kernel_size=3,stride=2,padding=0,ceil_mode=True)
### main layer
self.layer1=self._make_layer(block,64,layers[0])
self.layer2=self._make_layer(block,128,layers[1],stride=2)
self.layer3=self._make_layer(block,256,layers[2],stride=2)
self.layer4=self._make_layer(block,512,layers[3],stride=2)
#classifier
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.classifier=nn.Linear(512*block.expansion,num_classes)
self.softmax=nn.Softmax(-1)
def forward(self,x):
##stem layer
out=self.relu(self.bn1(self.conv1(x))) #bs,112,112,64
out=self.maxpool(out) #bs,56,56,64
##layers:
out=self.layer1(out) #bs,56,56,64*4
out=self.layer2(out) #bs,28,28,128*4
out=self.layer3(out) #bs,14,14,256*4
out=self.layer4(out) #bs,7,7,512*4
##classifier
out=self.avgpool(out) #bs,1,1,512*4
out=out.reshape(out.shape[0],-1) #bs,512*4
out=self.classifier(out) #bs,1000
out=self.softmax(out)
return out
def _make_layer(self,block,channel,blocks,stride=1):
# downsample 主要用来处理H(x)=F(x)+x中F(x)和x的channel维度不匹配问题,即对残差结构的输入进行升维,在做残差相加的时候,必须保证残差的纬度与真正的输出维度(宽、高、以及深度)相同
# 比如步长!=1 或者 in_channel!=channel&self.expansion
downsample = None
if(stride!=1 or self.in_channel!=channel*block.expansion):
self.downsample=nn.Conv2d(self.in_channel,channel*block.expansion,stride=stride,kernel_size=1,bias=False)
#第一个conv部分,可能需要downsample
layers=[]
layers.append(block(self.in_channel,channel,downsample=self.downsample,stride=stride))
self.in_channel=channel*block.expansion
for _ in range(1,blocks):
layers.append(block(self.in_channel,channel))
return nn.Sequential(*layers)
def ResNet50(num_classes=1000):
return ResNet(BottleNeck,[3,4,6,3],num_classes=num_classes)
def ResNet101(num_classes=1000):
return ResNet(BottleNeck,[3,4,23,3],num_classes=num_classes)
def ResNet152(num_classes=1000):
return ResNet(BottleNeck,[3,8,36,3],num_classes=num_classes)
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnet50=ResNet50(1000)
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out=resnet50(input)
print(out.shape)
================================================
FILE: model/backbone/resnext.py
================================================
import torch
from torch import nn
"""
# in_channel:输入block之前的通道数
# channel:在block中间处理的时候的通道数(这个值是输出维度的1/4)
# channel * block.expansion:输出的维度
"""
class BottleNeck(nn.Module):
expansion = 2
def __init__(self,in_channel,channel,stride=1,C=32,downsample=None):
super().__init__()
self.conv1=nn.Conv2d(in_channel,channel,kernel_size=1,stride=stride,bias=False)
self.bn1=nn.BatchNorm2d(channel)
self.conv2=nn.Conv2d(channel,channel,kernel_size=3,padding=1,bias=False,stride=1,groups=C)
self.bn2=nn.BatchNorm2d(channel)
self.conv3=nn.Conv2d(channel,channel*self.expansion,kernel_size=1,stride=1,bias=False)
self.bn3=nn.BatchNorm2d(channel*self.expansion)
self.relu=nn.ReLU(False)
self.downsample=downsample
self.stride=stride
def forward(self,x):
residual=x
out=self.relu(self.bn1(self.conv1(x))) #bs,c,h,w
out=self.relu(self.bn2(self.conv2(out))) #bs,c,h,w
out=self.relu(self.bn3(self.conv3(out))) #bs,4c,h,w
if(self.downsample != None):
residual=self.downsample(residual)
out+=residual
return self.relu(out)
class ResNeXt(nn.Module):
def __init__(self,block,layers,num_classes=1000):
super().__init__()
#定义输入模块的维度
self.in_channel=64
### stem layer
self.conv1=nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3,bias=False)
self.bn1=nn.BatchNorm2d(64)
self.relu=nn.ReLU(False)
self.maxpool=nn.MaxPool2d(kernel_size=3,stride=2,padding=0,ceil_mode=True)
### main layer
self.layer1=self._make_layer(block,128,layers[0])
self.layer2=self._make_layer(block,256,layers[1],stride=2)
self.layer3=self._make_layer(block,512,layers[2],stride=2)
self.layer4=self._make_layer(block,1024,layers[3],stride=2)
#classifier
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.classifier=nn.Linear(1024*block.expansion,num_classes)
self.softmax=nn.Softmax(-1)
def forward(self,x):
##stem layer
out=self.relu(self.bn1(self.conv1(x))) #bs,112,112,64
out=self.maxpool(out) #bs,56,56,64
##layers:
out=self.layer1(out) #bs,56,56,128*2
out=self.layer2(out) #bs,28,28,256*2
out=self.layer3(out) #bs,14,14,512*2
out=self.layer4(out) #bs,7,7,1024*2
##classifier
out=self.avgpool(out) #bs,1,1,1024*2
out=out.reshape(out.shape[0],-1) #bs,1024*2
out=self.classifier(out) #bs,1000
out=self.softmax(out)
return out
def _make_layer(self,block,channel,blocks,stride=1):
# downsample 主要用来处理H(x)=F(x)+x中F(x)和x的channel维度不匹配问题,即对残差结构的输入进行升维,在做残差相加的时候,必须保证残差的纬度与真正的输出维度(宽、高、以及深度)相同
# 比如步长!=1 或者 in_channel!=channel&self.expansion
downsample = None
if(stride!=1 or self.in_channel!=channel*block.expansion):
self.downsample=nn.Conv2d(self.in_channel,channel*block.expansion,stride=stride,kernel_size=1,bias=False)
#第一个conv部分,可能需要downsample
layers=[]
layers.append(block(self.in_channel,channel,downsample=self.downsample,stride=stride))
self.in_channel=channel*block.expansion
for _ in range(1,blocks):
layers.append(block(self.in_channel,channel))
return nn.Sequential(*layers)
def ResNeXt50(num_classes=1000):
return ResNeXt(BottleNeck,[3,4,6,3],num_classes=num_classes)
def ResNeXt101(num_classes=1000):
return ResNeXt(BottleNeck,[3,4,23,3],num_classes=num_classes)
def ResNeXt152(num_classes=1000):
return ResNeXt(BottleNeck,[3,8,36,3],num_classes=num_classes)
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnext50=ResNeXt50(1000)
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out=resnext50(input)
print(out.shape)
================================================
FILE: model/backbone/swin_transformer.py
================================================
""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows`
- https://arxiv.org/pdf/2103.14030
Code/weights from https://github.com/microsoft/Swin-Transformer, original copyright/license info below
S3 (AutoFormerV2, https://arxiv.org/abs/2111.14725) Swin weights from
- https://github.com/microsoft/Cream/tree/main/AutoFormerV2
Modifications and additions for timm hacked together by / Copyright 2021, Ross Wightman
"""
# --------------------------------------------------------
# Swin Transformer
# Copyright (c) 2021 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ze Liu
# --------------------------------------------------------
import logging
import math
from typing import Optional
import torch
import torch.nn as nn
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.layers import PatchEmbed, Mlp, DropPath, to_2tuple, to_ntuple, trunc_normal_, _assert
from ._builder import build_model_with_cfg
from ._features_fx import register_notrace_function
from ._manipulate import checkpoint_seq, named_apply
from ._registry import register_model
from .vision_transformer import checkpoint_filter_fn, get_init_weights_vit
__all__ = ['SwinTransformer'] # model_registry will add each entrypoint fn to this
_logger = logging.getLogger(__name__)
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic', 'fixed_input_size': True,
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
'swin_base_patch4_window12_384': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384_22kto1k.pth',
input_size=(3, 384, 384), crop_pct=1.0),
'swin_base_patch4_window7_224': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22kto1k.pth',
),
'swin_large_patch4_window12_384': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22kto1k.pth',
input_size=(3, 384, 384), crop_pct=1.0),
'swin_large_patch4_window7_224': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window7_224_22kto1k.pth',
),
'swin_small_patch4_window7_224': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth',
),
'swin_tiny_patch4_window7_224': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth',
),
'swin_base_patch4_window12_384_in22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384_22k.pth',
input_size=(3, 384, 384), crop_pct=1.0, num_classes=21841),
'swin_base_patch4_window7_224_in22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth',
num_classes=21841),
'swin_large_patch4_window12_384_in22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22k.pth',
input_size=(3, 384, 384), crop_pct=1.0, num_classes=21841),
'swin_large_patch4_window7_224_in22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window7_224_22k.pth',
num_classes=21841),
'swin_s3_tiny_224': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/s3_t-1d53f6a8.pth'
),
'swin_s3_small_224': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/s3_s-3bb4c69d.pth'
),
'swin_s3_base_224': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/s3_b-a1e95db4.pth'
)
}
def window_partition(x, window_size: int):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
@register_notrace_function # reason: int argument is a Proxy
def window_reverse(windows, window_size: int, H: int, W: int):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
def get_relative_position_index(win_h, win_w):
# get pair-wise relative position index for each token inside the window
coords = torch.stack(torch.meshgrid([torch.arange(win_h), torch.arange(win_w)])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += win_h - 1 # shift to start from 0
relative_coords[:, :, 1] += win_w - 1
relative_coords[:, :, 0] *= 2 * win_w - 1
return relative_coords.sum(-1) # Wh*Ww, Wh*Ww
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
head_dim (int): Number of channels per head (dim // num_heads if not set)
window_size (tuple[int]): The height and width of the window.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, num_heads, head_dim=None, window_size=7, qkv_bias=True, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = to_2tuple(window_size) # Wh, Ww
win_h, win_w = self.window_size
self.window_area = win_h * win_w
self.num_heads = num_heads
head_dim = head_dim or dim // num_heads
attn_dim = head_dim * num_heads
self.scale = head_dim ** -0.5
# define a parameter table of relative position bias, shape: 2*Wh-1 * 2*Ww-1, nH
self.relative_position_bias_table = nn.Parameter(torch.zeros((2 * win_h - 1) * (2 * win_w - 1), num_heads))
# get pair-wise relative position index for each token inside the window
self.register_buffer("relative_position_index", get_relative_position_index(win_h, win_w))
self.qkv = nn.Linear(dim, attn_dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(attn_dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def _get_rel_pos_bias(self) -> torch.Tensor:
relative_position_bias = self.relative_position_bias_table[
self.relative_position_index.view(-1)].view(self.window_area, self.window_area, -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
return relative_position_bias.unsqueeze(0)
def forward(self, x, mask: Optional[torch.Tensor] = None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
attn = attn + self._get_rel_pos_bias()
if mask is not None:
num_win = mask.shape[0]
attn = attn.view(B_ // num_win, num_win, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, -1)
x = self.proj(x)
x = self.proj_drop(x)
return x
#
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
window_size (int): Window size.
num_heads (int): Number of attention heads.
head_dim (int): Enforce the number of channels per head
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(
self, dim, input_resolution, num_heads=4, head_dim=None, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, num_heads=num_heads, head_dim=head_dim, window_size=to_2tuple(self.window_size),
qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
cnt = 0
for h in (
slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None)):
for w in (
slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None)):
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # num_win, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
_assert(L == H * W, "input feature has wrong size")
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # num_win*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # num_win*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # num_win*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, out_dim=None, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.out_dim = out_dim or 2 * dim
self.norm = norm_layer(4 * dim)
self.reduction = nn.Linear(4 * dim, self.out_dim, bias=False)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
_assert(L == H * W, "input feature has wrong size")
_assert(H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even.")
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
head_dim (int): Channels per head (dim // num_heads if not set)
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
"""
def __init__(
self, dim, out_dim, input_resolution, depth, num_heads=4, head_dim=None,
window_size=7, mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.grad_checkpointing = False
# build blocks
self.blocks = nn.Sequential(*[
SwinTransformerBlock(
dim=dim, input_resolution=input_resolution, num_heads=num_heads, head_dim=head_dim,
window_size=window_size, shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path, norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, out_dim=out_dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint_seq(self.blocks, x)
else:
x = self.blocks(x)
if self.downsample is not None:
x = self.downsample(x)
return x
class SwinTransformer(nn.Module):
r""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
head_dim (int, tuple(int)):
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
"""
def __init__(
self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, global_pool='avg',
embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24), head_dim=None,
window_size=7, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True, weight_init='', **kwargs):
super().__init__()
assert global_pool in ('', 'avg')
self.num_classes = num_classes
self.global_pool = global_pool
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if patch_norm else None)
num_patches = self.patch_embed.num_patches
self.patch_grid = self.patch_embed.grid_size
# absolute position embedding
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim)) if ape else None
self.pos_drop = nn.Dropout(p=drop_rate)
# build layers
if not isinstance(embed_dim, (tuple, list)):
embed_dim = [int(embed_dim * 2 ** i) for i in range(self.num_layers)]
embed_out_dim = embed_dim[1:] + [None]
head_dim = to_ntuple(self.num_layers)(head_dim)
window_size = to_ntuple(self.num_layers)(window_size)
mlp_ratio = to_ntuple(self.num_layers)(mlp_ratio)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
layers = []
for i in range(self.num_layers):
layers += [BasicLayer(
dim=embed_dim[i],
out_dim=embed_out_dim[i],
input_resolution=(self.patch_grid[0] // (2 ** i), self.patch_grid[1] // (2 ** i)),
depth=depths[i],
num_heads=num_heads[i],
head_dim=head_dim[i],
window_size=window_size[i],
mlp_ratio=mlp_ratio[i],
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i < self.num_layers - 1) else None
)]
self.layers = nn.Sequential(*layers)
self.norm = norm_layer(self.num_features)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
if weight_init != 'skip':
self.init_weights(weight_init)
@torch.jit.ignore
def init_weights(self, mode=''):
assert mode in ('jax', 'jax_nlhb', 'moco', '')
if self.absolute_pos_embed is not None:
trunc_normal_(self.absolute_pos_embed, std=.02)
head_bias = -math.log(self.num_classes) if 'nlhb' in mode else 0.
named_apply(get_init_weights_vit(mode, head_bias=head_bias), self)
@torch.jit.ignore
def no_weight_decay(self):
nwd = {'absolute_pos_embed'}
for n, _ in self.named_parameters():
if 'relative_position_bias_table' in n:
nwd.add(n)
return nwd
@torch.jit.ignore
def group_matcher(self, coarse=False):
return dict(
stem=r'^absolute_pos_embed|patch_embed', # stem and embed
blocks=r'^layers\.(\d+)' if coarse else [
(r'^layers\.(\d+).downsample', (0,)),
(r'^layers\.(\d+)\.\w+\.(\d+)', None),
(r'^norm', (99999,)),
]
)
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
for l in self.layers:
l.grad_checkpointing = enable
@torch.jit.ignore
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=None):
self.num_classes = num_classes
if global_pool is not None:
assert global_pool in ('', 'avg')
self.global_pool = global_pool
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
x = self.patch_embed(x)
if self.absolute_pos_embed is not None:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
x = self.layers(x)
x = self.norm(x) # B L C
return x
def forward_head(self, x, pre_logits: bool = False):
if self.global_pool == 'avg':
x = x.mean(dim=1)
return x if pre_logits else self.head(x)
def forward(self, x):
x = self.forward_features(x)
x = self.forward_head(x)
return x
def _create_swin_transformer(variant, pretrained=False, **kwargs):
model = build_model_with_cfg(
SwinTransformer, variant, pretrained,
pretrained_filter_fn=checkpoint_filter_fn,
**kwargs)
return model
@register_model
def swin_base_patch4_window12_384(pretrained=False, **kwargs):
""" Swin-B @ 384x384, pretrained ImageNet-22k, fine tune 1k
"""
model_kwargs = dict(
patch_size=4, window_size=12, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer('swin_base_patch4_window12_384', pretrained=pretrained, **model_kwargs)
@register_model
def swin_base_patch4_window7_224(pretrained=False, **kwargs):
""" Swin-B @ 224x224, pretrained ImageNet-22k, fine tune 1k
"""
model_kwargs = dict(
patch_size=4, window_size=7, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer('swin_base_patch4_window7_224', pretrained=pretrained, **model_kwargs)
@register_model
def swin_large_patch4_window12_384(pretrained=False, **kwargs):
""" Swin-L @ 384x384, pretrained ImageNet-22k, fine tune 1k
"""
model_kwargs = dict(
patch_size=4, window_size=12, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48), **kwargs)
return _create_swin_transformer('swin_large_patch4_window12_384', pretrained=pretrained, **model_kwargs)
@register_model
def swin_large_patch4_window7_224(pretrained=False, **kwargs):
""" Swin-L @ 224x224, pretrained ImageNet-22k, fine tune 1k
"""
model_kwargs = dict(
patch_size=4, window_size=7, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48), **kwargs)
return _create_swin_transformer('swin_large_patch4_window7_224', pretrained=pretrained, **model_kwargs)
@register_model
def swin_small_patch4_window7_224(pretrained=False, **kwargs):
""" Swin-S @ 224x224, trained ImageNet-1k
"""
model_kwargs = dict(
patch_size=4, window_size=7, embed_dim=96, depths=(2, 2, 18, 2), num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer('swin_small_patch4_window7_224', pretrained=pretrained, **model_kwargs)
@register_model
def swin_tiny_patch4_window7_224(pretrained=False, **kwargs):
""" Swin-T @ 224x224, trained ImageNet-1k
"""
model_kwargs = dict(
patch_size=4, window_size=7, embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer('swin_tiny_patch4_window7_224', pretrained=pretrained, **model_kwargs)
@register_model
def swin_base_patch4_window12_384_in22k(pretrained=False, **kwargs):
""" Swin-B @ 384x384, trained ImageNet-22k
"""
model_kwargs = dict(
patch_size=4, window_size=12, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer('swin_base_patch4_window12_384_in22k', pretrained=pretrained, **model_kwargs)
@register_model
def swin_base_patch4_window7_224_in22k(pretrained=False, **kwargs):
""" Swin-B @ 224x224, trained ImageNet-22k
"""
model_kwargs = dict(
patch_size=4, window_size=7, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer('swin_base_patch4_window7_224_in22k', pretrained=pretrained, **model_kwargs)
@register_model
def swin_large_patch4_window12_384_in22k(pretrained=False, **kwargs):
""" Swin-L @ 384x384, trained ImageNet-22k
"""
model_kwargs = dict(
patch_size=4, window_size=12, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48), **kwargs)
return _create_swin_transformer('swin_large_patch4_window12_384_in22k', pretrained=pretrained, **model_kwargs)
@register_model
def swin_large_patch4_window7_224_in22k(pretrained=False, **kwargs):
""" Swin-L @ 224x224, trained ImageNet-22k
"""
model_kwargs = dict(
patch_size=4, window_size=7, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48), **kwargs)
return _create_swin_transformer('swin_large_patch4_window7_224_in22k', pretrained=pretrained, **model_kwargs)
@register_model
def swin_s3_tiny_224(pretrained=False, **kwargs):
""" Swin-S3-T @ 224x224, ImageNet-1k. https://arxiv.org/abs/2111.14725
"""
model_kwargs = dict(
patch_size=4, window_size=(7, 7, 14, 7), embed_dim=96, depths=(2, 2, 6, 2),
num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer('swin_s3_tiny_224', pretrained=pretrained, **model_kwargs)
@register_model
def swin_s3_small_224(pretrained=False, **kwargs):
""" Swin-S3-S @ 224x224, trained ImageNet-1k. https://arxiv.org/abs/2111.14725
"""
model_kwargs = dict(
patch_size=4, window_size=(14, 14, 14, 7), embed_dim=96, depths=(2, 2, 18, 2),
num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer('swin_s3_small_224', pretrained=pretrained, **model_kwargs)
@register_model
def swin_s3_base_224(pretrained=False, **kwargs):
""" Swin-S3-B @ 224x224, trained ImageNet-1k. https://arxiv.org/abs/2111.14725
"""
model_kwargs = dict(
patch_size=4, window_size=(7, 7, 14, 7), embed_dim=96, depths=(2, 2, 30, 2),
num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer('swin_s3_base_224', pretrained=pretrained, **model_kwargs)
================================================
FILE: model/backbone/swin_transformer_v2.py
================================================
""" Swin Transformer V2
A PyTorch impl of : `Swin Transformer V2: Scaling Up Capacity and Resolution`
- https://arxiv.org/abs/2111.09883
Code/weights from https://github.com/microsoft/Swin-Transformer, original copyright/license info below
Modifications and additions for timm hacked together by / Copyright 2022, Ross Wightman
"""
# --------------------------------------------------------
# Swin Transformer V2
# Copyright (c) 2022 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ze Liu
# --------------------------------------------------------
import math
from typing import Tuple, Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.layers import PatchEmbed, Mlp, DropPath, to_2tuple, trunc_normal_, _assert
from ._builder import build_model_with_cfg
from ._features_fx import register_notrace_function
from ._registry import register_model
__all__ = ['SwinTransformerV2'] # model_registry will add each entrypoint fn to this
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic', 'fixed_input_size': True,
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
'swinv2_tiny_window8_256': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_tiny_patch4_window8_256.pth',
input_size=(3, 256, 256)
),
'swinv2_tiny_window16_256': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_tiny_patch4_window16_256.pth',
input_size=(3, 256, 256)
),
'swinv2_small_window8_256': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_small_patch4_window8_256.pth',
input_size=(3, 256, 256)
),
'swinv2_small_window16_256': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_small_patch4_window16_256.pth',
input_size=(3, 256, 256)
),
'swinv2_base_window8_256': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window8_256.pth',
input_size=(3, 256, 256)
),
'swinv2_base_window16_256': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window16_256.pth',
input_size=(3, 256, 256)
),
'swinv2_base_window12_192_22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window12_192_22k.pth',
num_classes=21841, input_size=(3, 192, 192)
),
'swinv2_base_window12to16_192to256_22kft1k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window12to16_192to256_22kto1k_ft.pth',
input_size=(3, 256, 256)
),
'swinv2_base_window12to24_192to384_22kft1k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window12to24_192to384_22kto1k_ft.pth',
input_size=(3, 384, 384), crop_pct=1.0,
),
'swinv2_large_window12_192_22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_large_patch4_window12_192_22k.pth',
num_classes=21841, input_size=(3, 192, 192)
),
'swinv2_large_window12to16_192to256_22kft1k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_large_patch4_window12to16_192to256_22kto1k_ft.pth',
input_size=(3, 256, 256)
),
'swinv2_large_window12to24_192to384_22kft1k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_large_patch4_window12to24_192to384_22kto1k_ft.pth',
input_size=(3, 384, 384), crop_pct=1.0,
),
}
def window_partition(x, window_size: Tuple[int, int]):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size[0], window_size[0], W // window_size[1], window_size[1], C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size[0], window_size[1], C)
return windows
@register_notrace_function # reason: int argument is a Proxy
def window_reverse(windows, window_size: Tuple[int, int], img_size: Tuple[int, int]):
"""
Args:
windows: (num_windows * B, window_size[0], window_size[1], C)
window_size (Tuple[int, int]): Window size
img_size (Tuple[int, int]): Image size
Returns:
x: (B, H, W, C)
"""
H, W = img_size
B = int(windows.shape[0] / (H * W / window_size[0] / window_size[1]))
x = windows.view(B, H // window_size[0], W // window_size[1], window_size[0], window_size[1], -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
pretrained_window_size (tuple[int]): The height and width of the window in pre-training.
"""
def __init__(
self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.,
pretrained_window_size=[0, 0]):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.pretrained_window_size = pretrained_window_size
self.num_heads = num_heads
self.logit_scale = nn.Parameter(torch.log(10 * torch.ones((num_heads, 1, 1))))
# mlp to generate continuous relative position bias
self.cpb_mlp = nn.Sequential(
nn.Linear(2, 512, bias=True),
nn.ReLU(inplace=True),
nn.Linear(512, num_heads, bias=False)
)
# get relative_coords_table
relative_coords_h = torch.arange(-(self.window_size[0] - 1), self.window_size[0], dtype=torch.float32)
relative_coords_w = torch.arange(-(self.window_size[1] - 1), self.window_size[1], dtype=torch.float32)
relative_coords_table = torch.stack(torch.meshgrid([
relative_coords_h,
relative_coords_w])).permute(1, 2, 0).contiguous().unsqueeze(0) # 1, 2*Wh-1, 2*Ww-1, 2
if pretrained_window_size[0] > 0:
relative_coords_table[:, :, :, 0] /= (pretrained_window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (pretrained_window_size[1] - 1)
else:
relative_coords_table[:, :, :, 0] /= (self.window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (self.window_size[1] - 1)
relative_coords_table *= 8 # normalize to -8, 8
relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
torch.abs(relative_coords_table) + 1.0) / math.log2(8)
self.register_buffer("relative_coords_table", relative_coords_table, persistent=False)
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index, persistent=False)
self.qkv = nn.Linear(dim, dim * 3, bias=False)
if qkv_bias:
self.q_bias = nn.Parameter(torch.zeros(dim))
self.register_buffer('k_bias', torch.zeros(dim), persistent=False)
self.v_bias = nn.Parameter(torch.zeros(dim))
else:
self.q_bias = None
self.k_bias = None
self.v_bias = None
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask: Optional[torch.Tensor] = None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv_bias = None
if self.q_bias is not None:
qkv_bias = torch.cat((self.q_bias, self.k_bias, self.v_bias))
qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
qkv = qkv.reshape(B_, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0)
# cosine attention
attn = (F.normalize(q, dim=-1) @ F.normalize(k, dim=-1).transpose(-2, -1))
logit_scale = torch.clamp(self.logit_scale, max=math.log(1. / 0.01)).exp()
attn = attn * logit_scale
relative_position_bias_table = self.cpb_mlp(self.relative_coords_table).view(-1, self.num_heads)
relative_position_bias = relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
relative_position_bias = 16 * torch.sigmoid(relative_position_bias)
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
pretrained_window_size (int): Window size in pretraining.
"""
def __init__(
self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm, pretrained_window_size=0):
super().__init__()
self.dim = dim
self.input_resolution = to_2tuple(input_resolution)
self.num_heads = num_heads
ws, ss = self._calc_window_shift(window_size, shift_size)
self.window_size: Tuple[int, int] = ws
self.shift_size: Tuple[int, int] = ss
self.window_area = self.window_size[0] * self.window_size[1]
self.mlp_ratio = mlp_ratio
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop,
pretrained_window_size=to_2tuple(pretrained_window_size))
self.norm1 = norm_layer(dim)
self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)
self.norm2 = norm_layer(dim)
self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
if any(self.shift_size):
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
cnt = 0
for h in (
slice(0, -self.window_size[0]),
slice(-self.window_size[0], -self.shift_size[0]),
slice(-self.shift_size[0], None)):
for w in (
slice(0, -self.window_size[1]),
slice(-self.window_size[1], -self.shift_size[1]),
slice(-self.shift_size[1], None)):
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_area)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def _calc_window_shift(self, target_window_size, target_shift_size) -> Tuple[Tuple[int, int], Tuple[int, int]]:
target_window_size = to_2tuple(target_window_size)
target_shift_size = to_2tuple(target_shift_size)
window_size = [r if r <= w else w for r, w in zip(self.input_resolution, target_window_size)]
shift_size = [0 if r <= w else s for r, w, s in zip(self.input_resolution, window_size, target_shift_size)]
return tuple(window_size), tuple(shift_size)
def _attn(self, x):
H, W = self.input_resolution
B, L, C = x.shape
_assert(L == H * W, "input feature has wrong size")
x = x.view(B, H, W, C)
# cyclic shift
has_shift = any(self.shift_size)
if has_shift:
shifted_x = torch.roll(x, shifts=(-self.shift_size[0], -self.shift_size[1]), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_area, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size[0], self.window_size[1], C)
shifted_x = window_reverse(attn_windows, self.window_size, self.input_resolution) # B H' W' C
# reverse cyclic shift
if has_shift:
x = torch.roll(shifted_x, shifts=self.shift_size, dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
return x
def forward(self, x):
x = x + self.drop_path1(self.norm1(self._attn(x)))
x = x + self.drop_path2(self.norm2(self.mlp(x)))
return x
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(2 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
_assert(L == H * W, "input feature has wrong size")
_assert(H % 2 == 0, f"x size ({H}*{W}) are not even.")
_assert(W % 2 == 0, f"x size ({H}*{W}) are not even.")
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.reduction(x)
x = self.norm(x)
return x
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
pretrained_window_size (int): Local window size in pre-training.
"""
def __init__(
self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
norm_layer=nn.LayerNorm, downsample=None, pretrained_window_size=0):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.grad_checkpointing = False
# build blocks
self.blocks = nn.ModuleList([
SwinTransformerBlock(
dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer,
pretrained_window_size=pretrained_window_size)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = nn.Identity()
def forward(self, x):
for blk in self.blocks:
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
x = self.downsample(x)
return x
def _init_respostnorm(self):
for blk in self.blocks:
nn.init.constant_(blk.norm1.bias, 0)
nn.init.constant_(blk.norm1.weight, 0)
nn.init.constant_(blk.norm2.bias, 0)
nn.init.constant_(blk.norm2.weight, 0)
class SwinTransformerV2(nn.Module):
r""" Swin Transformer V2
A PyTorch impl of : `Swin Transformer V2: Scaling Up Capacity and Resolution`
- https://arxiv.org/abs/2111.09883
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
pretrained_window_sizes (tuple(int)): Pretrained window sizes of each layer.
"""
def __init__(
self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, global_pool='avg',
embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24),
window_size=7, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
pretrained_window_sizes=(0, 0, 0, 0), **kwargs):
super().__init__()
self.num_classes = num_classes
assert global_pool in ('', 'avg')
self.global_pool = global_pool
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
# absolute position embedding
if ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
else:
self.absolute_pos_embed = None
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(
dim=int(embed_dim * 2 ** i_layer),
input_resolution=(
self.patch_embed.grid_size[0] // (2 ** i_layer),
self.patch_embed.grid_size[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
pretrained_window_size=pretrained_window_sizes[i_layer]
)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
for bly in self.layers:
bly._init_respostnorm()
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
@torch.jit.ignore
def no_weight_decay(self):
nod = {'absolute_pos_embed'}
for n, m in self.named_modules():
if any([kw in n for kw in ("cpb_mlp", "logit_scale", 'relative_position_bias_table')]):
nod.add(n)
return nod
@torch.jit.ignore
def group_matcher(self, coarse=False):
return dict(
stem=r'^absolute_pos_embed|patch_embed', # stem and embed
blocks=r'^layers\.(\d+)' if coarse else [
(r'^layers\.(\d+).downsample', (0,)),
(r'^layers\.(\d+)\.\w+\.(\d+)', None),
(r'^norm', (99999,)),
]
)
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
for l in self.layers:
l.grad_checkpointing = enable
@torch.jit.ignore
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=None):
self.num_classes = num_classes
if global_pool is not None:
assert global_pool in ('', 'avg')
self.global_pool = global_pool
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
x = self.patch_embed(x)
if self.absolute_pos_embed is not None:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
return x
def forward_head(self, x, pre_logits: bool = False):
if self.global_pool == 'avg':
x = x.mean(dim=1)
return x if pre_logits else self.head(x)
def forward(self, x):
x = self.forward_features(x)
x = self.forward_head(x)
return x
def checkpoint_filter_fn(state_dict, model):
out_dict = {}
if 'model' in state_dict:
# For deit models
state_dict = state_dict['model']
for k, v in state_dict.items():
if any([n in k for n in ('relative_position_index', 'relative_coords_table')]):
continue # skip buffers that should not be persistent
out_dict[k] = v
return out_dict
def _create_swin_transformer_v2(variant, pretrained=False, **kwargs):
model = build_model_with_cfg(
SwinTransformerV2, variant, pretrained,
pretrained_filter_fn=checkpoint_filter_fn,
**kwargs)
return model
@register_model
def swinv2_tiny_window16_256(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=16, embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer_v2('swinv2_tiny_window16_256', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_tiny_window8_256(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=8, embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer_v2('swinv2_tiny_window8_256', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_small_window16_256(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=16, embed_dim=96, depths=(2, 2, 18, 2), num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer_v2('swinv2_small_window16_256', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_small_window8_256(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=8, embed_dim=96, depths=(2, 2, 18, 2), num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer_v2('swinv2_small_window8_256', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_base_window16_256(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=16, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer_v2('swinv2_base_window16_256', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_base_window8_256(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=8, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer_v2('swinv2_base_window8_256', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_base_window12_192_22k(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=12, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer_v2('swinv2_base_window12_192_22k', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_base_window12to16_192to256_22kft1k(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=16, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32),
pretrained_window_sizes=(12, 12, 12, 6), **kwargs)
return _create_swin_transformer_v2(
'swinv2_base_window12to16_192to256_22kft1k', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_base_window12to24_192to384_22kft1k(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=24, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32),
pretrained_window_sizes=(12, 12, 12, 6), **kwargs)
return _create_swin_transformer_v2(
'swinv2_base_window12to24_192to384_22kft1k', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_large_window12_192_22k(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=12, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48), **kwargs)
return _create_swin_transformer_v2('swinv2_large_window12_192_22k', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_large_window12to16_192to256_22kft1k(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=16, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48),
pretrained_window_sizes=(12, 12, 12, 6), **kwargs)
return _create_swin_transformer_v2(
'swinv2_large_window12to16_192to256_22kft1k', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_large_window12to24_192to384_22kft1k(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=24, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48),
pretrained_window_sizes=(12, 12, 12, 6), **kwargs)
return _create_swin_transformer_v2(
'swinv2_large_window12to24_192to384_22kft1k', pretrained=pretrained, **model_kwargs)
================================================
FILE: model/backbone/swin_transformer_v2_cr.py
================================================
""" Swin Transformer V2
A PyTorch impl of : `Swin Transformer V2: Scaling Up Capacity and Resolution`
- https://arxiv.org/pdf/2111.09883
Code adapted from https://github.com/ChristophReich1996/Swin-Transformer-V2, original copyright/license info below
This implementation is experimental and subject to change in manners that will break weight compat:
* Size of the pos embed MLP are not spelled out in paper in terms of dim, fixed for all models? vary with num_heads?
* currently dim is fixed, I feel it may make sense to scale with num_heads (dim per head)
* The specifics of the memory saving 'sequential attention' are not detailed, Christoph Reich has an impl at
GitHub link above. It needs further investigation as throughput vs mem tradeoff doesn't appear beneficial.
* num_heads per stage is not detailed for Huge and Giant model variants
* 'Giant' is 3B params in paper but ~2.6B here despite matching paper dim + block counts
* experiments are ongoing wrt to 'main branch' norm layer use and weight init scheme
Noteworthy additions over official Swin v1:
* MLP relative position embedding is looking promising and adapts to different image/window sizes
* This impl has been designed to allow easy change of image size with matching window size changes
* Non-square image size and window size are supported
Modifications and additions for timm hacked together by / Copyright 2022, Ross Wightman
"""
# --------------------------------------------------------
# Swin Transformer V2 reimplementation
# Copyright (c) 2021 Christoph Reich
# Licensed under The MIT License [see LICENSE for details]
# Written by Christoph Reich
# --------------------------------------------------------
import logging
import math
from typing import Tuple, Optional, List, Union, Any, Type
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.layers import DropPath, Mlp, to_2tuple, _assert
from ._builder import build_model_with_cfg
from ._features_fx import register_notrace_function
from ._manipulate import named_apply
from ._registry import register_model
__all__ = ['SwinTransformerV2Cr'] # model_registry will add each entrypoint fn to this
_logger = logging.getLogger(__name__)
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000,
'input_size': (3, 224, 224),
'pool_size': (7, 7),
'crop_pct': 0.9,
'interpolation': 'bicubic',
'fixed_input_size': True,
'mean': IMAGENET_DEFAULT_MEAN,
'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj',
'classifier': 'head',
**kwargs,
}
default_cfgs = {
'swinv2_cr_tiny_384': _cfg(
url="", input_size=(3, 384, 384), crop_pct=1.0, pool_size=(12, 12)),
'swinv2_cr_tiny_224': _cfg(
url="", input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_tiny_ns_224': _cfg(
url="https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights-swinv2/swin_v2_cr_tiny_ns_224-ba8166c6.pth",
input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_small_384': _cfg(
url="", input_size=(3, 384, 384), crop_pct=1.0, pool_size=(12, 12)),
'swinv2_cr_small_224': _cfg(
url="https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights-swinv2/swin_v2_cr_small_224-0813c165.pth",
input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_small_ns_224': _cfg(
url="https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights-swinv2/swin_v2_cr_small_ns_224_iv-2ce90f8e.pth",
input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_base_384': _cfg(
url="", input_size=(3, 384, 384), crop_pct=1.0, pool_size=(12, 12)),
'swinv2_cr_base_224': _cfg(
url="", input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_base_ns_224': _cfg(
url="", input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_large_384': _cfg(
url="", input_size=(3, 384, 384), crop_pct=1.0, pool_size=(12, 12)),
'swinv2_cr_large_224': _cfg(
url="", input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_huge_384': _cfg(
url="", input_size=(3, 384, 384), crop_pct=1.0, pool_size=(12, 12)),
'swinv2_cr_huge_224': _cfg(
url="", input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_giant_384': _cfg(
url="", input_size=(3, 384, 384), crop_pct=1.0, pool_size=(12, 12)),
'swinv2_cr_giant_224': _cfg(
url="", input_size=(3, 224, 224), crop_pct=0.9),
}
def bchw_to_bhwc(x: torch.Tensor) -> torch.Tensor:
"""Permutes a tensor from the shape (B, C, H, W) to (B, H, W, C). """
return x.permute(0, 2, 3, 1)
def bhwc_to_bchw(x: torch.Tensor) -> torch.Tensor:
"""Permutes a tensor from the shape (B, H, W, C) to (B, C, H, W). """
return x.permute(0, 3, 1, 2)
def window_partition(x, window_size: Tuple[int, int]):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size[0], window_size[0], W // window_size[1], window_size[1], C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size[0], window_size[1], C)
return windows
@register_notrace_function # reason: int argument is a Proxy
def window_reverse(windows, window_size: Tuple[int, int], img_size: Tuple[int, int]):
"""
Args:
windows: (num_windows * B, window_size[0], window_size[1], C)
window_size (Tuple[int, int]): Window size
img_size (Tuple[int, int]): Image size
Returns:
x: (B, H, W, C)
"""
H, W = img_size
B = int(windows.shape[0] / (H * W / window_size[0] / window_size[1]))
x = windows.view(B, H // window_size[0], W // window_size[1], window_size[0], window_size[1], -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class WindowMultiHeadAttention(nn.Module):
r"""This class implements window-based Multi-Head-Attention with log-spaced continuous position bias.
Args:
dim (int): Number of input features
window_size (int): Window size
num_heads (int): Number of attention heads
drop_attn (float): Dropout rate of attention map
drop_proj (float): Dropout rate after projection
meta_hidden_dim (int): Number of hidden features in the two layer MLP meta network
sequential_attn (bool): If true sequential self-attention is performed
"""
def __init__(
self,
dim: int,
num_heads: int,
window_size: Tuple[int, int],
drop_attn: float = 0.0,
drop_proj: float = 0.0,
meta_hidden_dim: int = 384, # FIXME what's the optimal value?
sequential_attn: bool = False,
) -> None:
super(WindowMultiHeadAttention, self).__init__()
assert dim % num_heads == 0, \
"The number of input features (in_features) are not divisible by the number of heads (num_heads)."
self.in_features: int = dim
self.window_size: Tuple[int, int] = window_size
self.num_heads: int = num_heads
self.sequential_attn: bool = sequential_attn
self.qkv = nn.Linear(in_features=dim, out_features=dim * 3, bias=True)
self.attn_drop = nn.Dropout(drop_attn)
self.proj = nn.Linear(in_features=dim, out_features=dim, bias=True)
self.proj_drop = nn.Dropout(drop_proj)
# meta network for positional encodings
self.meta_mlp = Mlp(
2, # x, y
hidden_features=meta_hidden_dim,
out_features=num_heads,
act_layer=nn.ReLU,
drop=(0.125, 0.) # FIXME should there be stochasticity, appears to 'overfit' without?
)
# NOTE old checkpoints used inverse of logit_scale ('tau') following the paper, see conversion fn
self.logit_scale = nn.Parameter(torch.log(10 * torch.ones(num_heads)))
self._make_pair_wise_relative_positions()
def _make_pair_wise_relative_positions(self) -> None:
"""Method initializes the pair-wise relative positions to compute the positional biases."""
device = self.logit_scale.device
coordinates = torch.stack(torch.meshgrid([
torch.arange(self.window_size[0], device=device),
torch.arange(self.window_size[1], device=device)]), dim=0).flatten(1)
relative_coordinates = coordinates[:, :, None] - coordinates[:, None, :]
relative_coordinates = relative_coordinates.permute(1, 2, 0).reshape(-1, 2).float()
relative_coordinates_log = torch.sign(relative_coordinates) * torch.log(
1.0 + relative_coordinates.abs())
self.register_buffer("relative_coordinates_log", relative_coordinates_log, persistent=False)
def update_input_size(self, new_window_size: int, **kwargs: Any) -> None:
"""Method updates the window size and so the pair-wise relative positions
Args:
new_window_size (int): New window size
kwargs (Any): Unused
"""
# Set new window size and new pair-wise relative positions
self.window_size: int = new_window_size
self._make_pair_wise_relative_positions()
def _relative_positional_encodings(self) -> torch.Tensor:
"""Method computes the relative positional encodings
Returns:
relative_position_bias (torch.Tensor): Relative positional encodings
(1, number of heads, window size ** 2, window size ** 2)
"""
window_area = self.window_size[0] * self.window_size[1]
relative_position_bias = self.meta_mlp(self.relative_coordinates_log)
relative_position_bias = relative_position_bias.transpose(1, 0).reshape(
self.num_heads, window_area, window_area
)
relative_position_bias = relative_position_bias.unsqueeze(0)
return relative_position_bias
def _forward_sequential(
self,
x: torch.Tensor,
mask: Optional[torch.Tensor] = None,
) -> torch.Tensor:
"""
"""
# FIXME TODO figure out 'sequential' attention mentioned in paper (should reduce GPU memory)
assert False, "not implemented"
def _forward_batch(
self,
x: torch.Tensor,
mask: Optional[torch.Tensor] = None,
) -> torch.Tensor:
"""This function performs standard (non-sequential) scaled cosine self-attention.
"""
Bw, L, C = x.shape
qkv = self.qkv(x).view(Bw, L, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
query, key, value = qkv.unbind(0)
# compute attention map with scaled cosine attention
attn = (F.normalize(query, dim=-1) @ F.normalize(key, dim=-1).transpose(-2, -1))
logit_scale = torch.clamp(self.logit_scale.reshape(1, self.num_heads, 1, 1), max=math.log(1. / 0.01)).exp()
attn = attn * logit_scale
attn = attn + self._relative_positional_encodings()
if mask is not None:
# Apply mask if utilized
num_win: int = mask.shape[0]
attn = attn.view(Bw // num_win, num_win, self.num_heads, L, L)
attn = attn + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, L, L)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ value).transpose(1, 2).reshape(Bw, L, -1)
x = self.proj(x)
x = self.proj_drop(x)
return x
def forward(self, x: torch.Tensor, mask: Optional[torch.Tensor] = None) -> torch.Tensor:
""" Forward pass.
Args:
x (torch.Tensor): Input tensor of the shape (B * windows, N, C)
mask (Optional[torch.Tensor]): Attention mask for the shift case
Returns:
Output tensor of the shape [B * windows, N, C]
"""
if self.sequential_attn:
return self._forward_sequential(x, mask)
else:
return self._forward_batch(x, mask)
class SwinTransformerBlock(nn.Module):
r"""This class implements the Swin transformer block.
Args:
dim (int): Number of input channels
num_heads (int): Number of attention heads to be utilized
feat_size (Tuple[int, int]): Input resolution
window_size (Tuple[int, int]): Window size to be utilized
shift_size (int): Shifting size to be used
mlp_ratio (int): Ratio of the hidden dimension in the FFN to the input channels
drop (float): Dropout in input mapping
drop_attn (float): Dropout rate of attention map
drop_path (float): Dropout in main path
extra_norm (bool): Insert extra norm on 'main' branch if True
sequential_attn (bool): If true sequential self-attention is performed
norm_layer (Type[nn.Module]): Type of normalization layer to be utilized
"""
def __init__(
self,
dim: int,
num_heads: int,
feat_size: Tuple[int, int],
window_size: Tuple[int, int],
shift_size: Tuple[int, int] = (0, 0),
mlp_ratio: float = 4.0,
init_values: Optional[float] = 0,
drop: float = 0.0,
drop_attn: float = 0.0,
drop_path: float = 0.0,
extra_norm: bool = False,
sequential_attn: bool = False,
norm_layer: Type[nn.Module] = nn.LayerNorm,
) -> None:
super(SwinTransformerBlock, self).__init__()
self.dim: int = dim
self.feat_size: Tuple[int, int] = feat_size
self.target_shift_size: Tuple[int, int] = to_2tuple(shift_size)
self.window_size, self.shift_size = self._calc_window_shift(to_2tuple(window_size))
self.window_area = self.window_size[0] * self.window_size[1]
self.init_values: Optional[float] = init_values
# attn branch
self.attn = WindowMultiHeadAttention(
dim=dim,
num_heads=num_heads,
window_size=self.window_size,
drop_attn=drop_attn,
drop_proj=drop,
sequential_attn=sequential_attn,
)
self.norm1 = norm_layer(dim)
self.drop_path1 = DropPath(drop_prob=drop_path) if drop_path > 0.0 else nn.Identity()
# mlp branch
self.mlp = Mlp(
in_features=dim,
hidden_features=int(dim * mlp_ratio),
drop=drop,
out_features=dim,
)
self.norm2 = norm_layer(dim)
self.drop_path2 = DropPath(drop_prob=drop_path) if drop_path > 0.0 else nn.Identity()
# Extra main branch norm layer mentioned for Huge/Giant models in V2 paper.
# Also being used as final network norm and optional stage ending norm while still in a C-last format.
self.norm3 = norm_layer(dim) if extra_norm else nn.Identity()
self._make_attention_mask()
self.init_weights()
def _calc_window_shift(self, target_window_size):
window_size = [f if f <= w else w for f, w in zip(self.feat_size, target_window_size)]
shift_size = [0 if f <= w else s for f, w, s in zip(self.feat_size, window_size, self.target_shift_size)]
return tuple(window_size), tuple(shift_size)
def _make_attention_mask(self) -> None:
"""Method generates the attention mask used in shift case."""
# Make masks for shift case
if any(self.shift_size):
# calculate attention mask for SW-MSA
H, W = self.feat_size
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
cnt = 0
for h in (
slice(0, -self.window_size[0]),
slice(-self.window_size[0], -self.shift_size[0]),
slice(-self.shift_size[0], None)):
for w in (
slice(0, -self.window_size[1]),
slice(-self.window_size[1], -self.shift_size[1]),
slice(-self.shift_size[1], None)):
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # num_windows, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_area)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask, persistent=False)
def init_weights(self):
# extra, module specific weight init
if self.init_values is not None:
nn.init.constant_(self.norm1.weight, self.init_values)
nn.init.constant_(self.norm2.weight, self.init_values)
def update_input_size(self, new_window_size: Tuple[int, int], new_feat_size: Tuple[int, int]) -> None:
"""Method updates the image resolution to be processed and window size and so the pair-wise relative positions.
Args:
new_window_size (int): New window size
new_feat_size (Tuple[int, int]): New input resolution
"""
# Update input resolution
self.feat_size: Tuple[int, int] = new_feat_size
self.window_size, self.shift_size = self._calc_window_shift(to_2tuple(new_window_size))
self.window_area = self.window_size[0] * self.window_size[1]
self.attn.update_input_size(new_window_size=self.window_size)
self._make_attention_mask()
def _shifted_window_attn(self, x):
H, W = self.feat_size
B, L, C = x.shape
x = x.view(B, H, W, C)
# cyclic shift
sh, sw = self.shift_size
do_shift: bool = any(self.shift_size)
if do_shift:
# FIXME PyTorch XLA needs cat impl, roll not lowered
# x = torch.cat([x[:, sh:], x[:, :sh]], dim=1)
# x = torch.cat([x[:, :, sw:], x[:, :, :sw]], dim=2)
x = torch.roll(x, shifts=(-sh, -sw), dims=(1, 2))
# partition windows
x_windows = window_partition(x, self.window_size) # num_windows * B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size[0] * self.window_size[1], C)
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # num_windows * B, window_size * window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size[0], self.window_size[1], C)
x = window_reverse(attn_windows, self.window_size, self.feat_size) # B H' W' C
# reverse cyclic shift
if do_shift:
# FIXME PyTorch XLA needs cat impl, roll not lowered
# x = torch.cat([x[:, -sh:], x[:, :-sh]], dim=1)
# x = torch.cat([x[:, :, -sw:], x[:, :, :-sw]], dim=2)
x = torch.roll(x, shifts=(sh, sw), dims=(1, 2))
x = x.view(B, L, C)
return x
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Forward pass.
Args:
x (torch.Tensor): Input tensor of the shape [B, C, H, W]
Returns:
output (torch.Tensor): Output tensor of the shape [B, C, H, W]
"""
# post-norm branches (op -> norm -> drop)
x = x + self.drop_path1(self.norm1(self._shifted_window_attn(x)))
x = x + self.drop_path2(self.norm2(self.mlp(x)))
x = self.norm3(x) # main-branch norm enabled for some blocks / stages (every 6 for Huge/Giant)
return x
class PatchMerging(nn.Module):
""" This class implements the patch merging as a strided convolution with a normalization before.
Args:
dim (int): Number of input channels
norm_layer (Type[nn.Module]): Type of normalization layer to be utilized.
"""
def __init__(self, dim: int, norm_layer: Type[nn.Module] = nn.LayerNorm) -> None:
super(PatchMerging, self).__init__()
self.norm = norm_layer(4 * dim)
self.reduction = nn.Linear(in_features=4 * dim, out_features=2 * dim, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
""" Forward pass.
Args:
x (torch.Tensor): Input tensor of the shape [B, C, H, W]
Returns:
output (torch.Tensor): Output tensor of the shape [B, 2 * C, H // 2, W // 2]
"""
B, C, H, W = x.shape
# unfold + BCHW -> BHWC together
# ordering, 5, 3, 1 instead of 3, 5, 1 maintains compat with original swin v1 merge
x = x.reshape(B, C, H // 2, 2, W // 2, 2).permute(0, 2, 4, 5, 3, 1).flatten(3)
x = self.norm(x)
x = bhwc_to_bchw(self.reduction(x))
return x
class PatchEmbed(nn.Module):
""" 2D Image to Patch Embedding """
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
_assert(H == self.img_size[0], f"Input image height ({H}) doesn't match model ({self.img_size[0]}).")
_assert(W == self.img_size[1], f"Input image width ({W}) doesn't match model ({self.img_size[1]}).")
x = self.proj(x)
x = self.norm(x.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)
return x
class SwinTransformerStage(nn.Module):
r"""This class implements a stage of the Swin transformer including multiple layers.
Args:
embed_dim (int): Number of input channels
depth (int): Depth of the stage (number of layers)
downscale (bool): If true input is downsampled (see Fig. 3 or V1 paper)
feat_size (Tuple[int, int]): input feature map size (H, W)
num_heads (int): Number of attention heads to be utilized
window_size (int): Window size to be utilized
mlp_ratio (int): Ratio of the hidden dimension in the FFN to the input channels
drop (float): Dropout in input mapping
drop_attn (float): Dropout rate of attention map
drop_path (float): Dropout in main path
norm_layer (Type[nn.Module]): Type of normalization layer to be utilized. Default: nn.LayerNorm
extra_norm_period (int): Insert extra norm layer on main branch every N (period) blocks
extra_norm_stage (bool): End each stage with an extra norm layer in main branch
sequential_attn (bool): If true sequential self-attention is performed
"""
def __init__(
self,
embed_dim: int,
depth: int,
downscale: bool,
num_heads: int,
feat_size: Tuple[int, int],
window_size: Tuple[int, int],
mlp_ratio: float = 4.0,
init_values: Optional[float] = 0.0,
drop: float = 0.0,
drop_attn: float = 0.0,
drop_path: Union[List[float], float] = 0.0,
norm_layer: Type[nn.Module] = nn.LayerNorm,
extra_norm_period: int = 0,
extra_norm_stage: bool = False,
sequential_attn: bool = False,
) -> None:
super(SwinTransformerStage, self).__init__()
self.downscale: bool = downscale
self.grad_checkpointing: bool = False
self.feat_size: Tuple[int, int] = (feat_size[0] // 2, feat_size[1] // 2) if downscale else feat_size
self.downsample = PatchMerging(embed_dim, norm_layer=norm_layer) if downscale else nn.Identity()
def _extra_norm(index):
i = index + 1
if extra_norm_period and i % extra_norm_period == 0:
return True
return i == depth if extra_norm_stage else False
embed_dim = embed_dim * 2 if downscale else embed_dim
self.blocks = nn.Sequential(*[
SwinTransformerBlock(
dim=embed_dim,
num_heads=num_heads,
feat_size=self.feat_size,
window_size=window_size,
shift_size=tuple([0 if ((index % 2) == 0) else w // 2 for w in window_size]),
mlp_ratio=mlp_ratio,
init_values=init_values,
drop=drop,
drop_attn=drop_attn,
drop_path=drop_path[index] if isinstance(drop_path, list) else drop_path,
extra_norm=_extra_norm(index),
sequential_attn=sequential_attn,
norm_layer=norm_layer,
)
for index in range(depth)]
)
def update_input_size(self, new_window_size: int, new_feat_size: Tuple[int, int]) -> None:
"""Method updates the resolution to utilize and the window size and so the pair-wise relative positions.
Args:
new_window_size (int): New window size
new_feat_size (Tuple[int, int]): New input resolution
"""
self.feat_size: Tuple[int, int] = (
(new_feat_size[0] // 2, new_feat_size[1] // 2) if self.downscale else new_feat_size
)
for block in self.blocks:
block.update_input_size(new_window_size=new_window_size, new_feat_size=self.feat_size)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Forward pass.
Args:
x (torch.Tensor): Input tensor of the shape [B, C, H, W] or [B, L, C]
Returns:
output (torch.Tensor): Output tensor of the shape [B, 2 * C, H // 2, W // 2]
"""
x = self.downsample(x)
B, C, H, W = x.shape
L = H * W
x = bchw_to_bhwc(x).reshape(B, L, C)
for block in self.blocks:
# Perform checkpointing if utilized
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint.checkpoint(block, x)
else:
x = block(x)
x = bhwc_to_bchw(x.reshape(B, H, W, -1))
return x
class SwinTransformerV2Cr(nn.Module):
r""" Swin Transformer V2
A PyTorch impl of : `Swin Transformer V2: Scaling Up Capacity and Resolution` -
https://arxiv.org/pdf/2111.09883
Args:
img_size (Tuple[int, int]): Input resolution.
window_size (Optional[int]): Window size. If None, img_size // window_div. Default: None
img_window_ratio (int): Window size to image size ratio. Default: 32
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input channels.
depths (int): Depth of the stage (number of layers).
num_heads (int): Number of attention heads to be utilized.
embed_dim (int): Patch embedding dimension. Default: 96
num_classes (int): Number of output classes. Default: 1000
mlp_ratio (int): Ratio of the hidden dimension in the FFN to the input channels. Default: 4
drop_rate (float): Dropout rate. Default: 0.0
attn_drop_rate (float): Dropout rate of attention map. Default: 0.0
drop_path_rate (float): Stochastic depth rate. Default: 0.0
norm_layer (Type[nn.Module]): Type of normalization layer to be utilized. Default: nn.LayerNorm
extra_norm_period (int): Insert extra norm layer on main branch every N (period) blocks in stage
extra_norm_stage (bool): End each stage with an extra norm layer in main branch
sequential_attn (bool): If true sequential self-attention is performed. Default: False
"""
def __init__(
self,
img_size: Tuple[int, int] = (224, 224),
patch_size: int = 4,
window_size: Optional[int] = None,
img_window_ratio: int = 32,
in_chans: int = 3,
num_classes: int = 1000,
embed_dim: int = 96,
depths: Tuple[int, ...] = (2, 2, 6, 2),
num_heads: Tuple[int, ...] = (3, 6, 12, 24),
mlp_ratio: float = 4.0,
init_values: Optional[float] = 0.,
drop_rate: float = 0.0,
attn_drop_rate: float = 0.0,
drop_path_rate: float = 0.0,
norm_layer: Type[nn.Module] = nn.LayerNorm,
extra_norm_period: int = 0,
extra_norm_stage: bool = False,
sequential_attn: bool = False,
global_pool: str = 'avg',
weight_init='skip',
**kwargs: Any
) -> None:
super(SwinTransformerV2Cr, self).__init__()
img_size = to_2tuple(img_size)
window_size = tuple([
s // img_window_ratio for s in img_size]) if window_size is None else to_2tuple(window_size)
self.num_classes: int = num_classes
self.patch_size: int = patch_size
self.img_size: Tuple[int, int] = img_size
self.window_size: int = window_size
self.num_features: int = int(embed_dim * 2 ** (len(depths) - 1))
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans,
embed_dim=embed_dim, norm_layer=norm_layer)
patch_grid_size: Tuple[int, int] = self.patch_embed.grid_size
drop_path_rate = torch.linspace(0.0, drop_path_rate, sum(depths)).tolist()
stages = []
for index, (depth, num_heads) in enumerate(zip(depths, num_heads)):
stage_scale = 2 ** max(index - 1, 0)
stages.append(
SwinTransformerStage(
embed_dim=embed_dim * stage_scale,
depth=depth,
downscale=index != 0,
feat_size=(patch_grid_size[0] // stage_scale, patch_grid_size[1] // stage_scale),
num_heads=num_heads,
window_size=window_size,
mlp_ratio=mlp_ratio,
init_values=init_values,
drop=drop_rate,
drop_attn=attn_drop_rate,
drop_path=drop_path_rate[sum(depths[:index]):sum(depths[:index + 1])],
extra_norm_period=extra_norm_period,
extra_norm_stage=extra_norm_stage or (index + 1) == len(depths), # last stage ends w/ norm
sequential_attn=sequential_attn,
norm_layer=norm_layer,
)
)
self.stages = nn.Sequential(*stages)
self.global_pool: str = global_pool
self.head = nn.Linear(self.num_features, num_classes) if num_classes else nn.Identity()
# current weight init skips custom init and uses pytorch layer defaults, seems to work well
# FIXME more experiments needed
if weight_init != 'skip':
named_apply(init_weights, self)
def update_input_size(
self,
new_img_size: Optional[Tuple[int, int]] = None,
new_window_size: Optional[int] = None,
img_window_ratio: int = 32,
) -> None:
"""Method updates the image resolution to be processed and window size and so the pair-wise relative positions.
Args:
new_window_size (Optional[int]): New window size, if None based on new_img_size // window_div
new_img_size (Optional[Tuple[int, int]]): New input resolution, if None current resolution is used
img_window_ratio (int): divisor for calculating window size from image size
"""
# Check parameters
if new_img_size is None:
new_img_size = self.img_size
else:
new_img_size = to_2tuple(new_img_size)
if new_window_size is None:
new_window_size = tuple([s // img_window_ratio for s in new_img_size])
# Compute new patch resolution & update resolution of each stage
new_patch_grid_size = (new_img_size[0] // self.patch_size, new_img_size[1] // self.patch_size)
for index, stage in enumerate(self.stages):
stage_scale = 2 ** max(index - 1, 0)
stage.update_input_size(
new_window_size=new_window_size,
new_img_size=(new_patch_grid_size[0] // stage_scale, new_patch_grid_size[1] // stage_scale),
)
@torch.jit.ignore
def group_matcher(self, coarse=False):
return dict(
stem=r'^patch_embed', # stem and embed
blocks=r'^stages\.(\d+)' if coarse else [
(r'^stages\.(\d+).downsample', (0,)),
(r'^stages\.(\d+)\.\w+\.(\d+)', None),
]
)
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
for s in self.stages:
s.grad_checkpointing = enable
@torch.jit.ignore()
def get_classifier(self) -> nn.Module:
"""Method returns the classification head of the model.
Returns:
head (nn.Module): Current classification head
"""
return self.head
def reset_classifier(self, num_classes: int, global_pool: Optional[str] = None) -> None:
"""Method results the classification head
Args:
num_classes (int): Number of classes to be predicted
global_pool (str): Unused
"""
self.num_classes: int = num_classes
if global_pool is not None:
self.global_pool = global_pool
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x: torch.Tensor) -> torch.Tensor:
x = self.patch_embed(x)
x = self.stages(x)
return x
def forward_head(self, x, pre_logits: bool = False):
if self.global_pool == 'avg':
x = x.mean(dim=(2, 3))
return x if pre_logits else self.head(x)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.forward_features(x)
x = self.forward_head(x)
return x
def init_weights(module: nn.Module, name: str = ''):
# FIXME WIP determining if there's a better weight init
if isinstance(module, nn.Linear):
if 'qkv' in name:
# treat the weights of Q, K, V separately
val = math.sqrt(6. / float(module.weight.shape[0] // 3 + module.weight.shape[1]))
nn.init.uniform_(module.weight, -val, val)
elif 'head' in name:
nn.init.zeros_(module.weight)
else:
nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif hasattr(module, 'init_weights'):
module.init_weights()
def checkpoint_filter_fn(state_dict, model):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
if 'model' in state_dict:
# For deit models
state_dict = state_dict['model']
for k, v in state_dict.items():
if 'tau' in k:
# convert old tau based checkpoints -> logit_scale (inverse)
v = torch.log(1 / v)
k = k.replace('tau', 'logit_scale')
out_dict[k] = v
return out_dict
def _create_swin_transformer_v2_cr(variant, pretrained=False, **kwargs):
if kwargs.get('features_only', None):
raise RuntimeError('features_only not implemented for Vision Transformer models.')
model = build_model_with_cfg(
SwinTransformerV2Cr, variant, pretrained,
pretrained_filter_fn=checkpoint_filter_fn,
**kwargs
)
return model
@register_model
def swinv2_cr_tiny_384(pretrained=False, **kwargs):
"""Swin-T V2 CR @ 384x384, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=96,
depths=(2, 2, 6, 2),
num_heads=(3, 6, 12, 24),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_tiny_384', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_tiny_224(pretrained=False, **kwargs):
"""Swin-T V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=96,
depths=(2, 2, 6, 2),
num_heads=(3, 6, 12, 24),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_tiny_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_tiny_ns_224(pretrained=False, **kwargs):
"""Swin-T V2 CR @ 224x224, trained ImageNet-1k w/ extra stage norms.
** Experimental, may make default if results are improved. **
"""
model_kwargs = dict(
embed_dim=96,
depths=(2, 2, 6, 2),
num_heads=(3, 6, 12, 24),
extra_norm_stage=True,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_tiny_ns_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_small_384(pretrained=False, **kwargs):
"""Swin-S V2 CR @ 384x384, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=96,
depths=(2, 2, 18, 2),
num_heads=(3, 6, 12, 24),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_small_384', pretrained=pretrained, **model_kwargs
)
@register_model
def swinv2_cr_small_224(pretrained=False, **kwargs):
"""Swin-S V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=96,
depths=(2, 2, 18, 2),
num_heads=(3, 6, 12, 24),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_small_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_small_ns_224(pretrained=False, **kwargs):
"""Swin-S V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=96,
depths=(2, 2, 18, 2),
num_heads=(3, 6, 12, 24),
extra_norm_stage=True,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_small_ns_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_base_384(pretrained=False, **kwargs):
"""Swin-B V2 CR @ 384x384, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_base_384', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_base_224(pretrained=False, **kwargs):
"""Swin-B V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_base_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_base_ns_224(pretrained=False, **kwargs):
"""Swin-B V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
extra_norm_stage=True,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_base_ns_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_large_384(pretrained=False, **kwargs):
"""Swin-L V2 CR @ 384x384, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=192,
depths=(2, 2, 18, 2),
num_heads=(6, 12, 24, 48),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_large_384', pretrained=pretrained, **model_kwargs
)
@register_model
def swinv2_cr_large_224(pretrained=False, **kwargs):
"""Swin-L V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=192,
depths=(2, 2, 18, 2),
num_heads=(6, 12, 24, 48),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_large_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_huge_384(pretrained=False, **kwargs):
"""Swin-H V2 CR @ 384x384, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=352,
depths=(2, 2, 18, 2),
num_heads=(11, 22, 44, 88), # head count not certain for Huge, 384 & 224 trying diff values
extra_norm_period=6,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_huge_384', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_huge_224(pretrained=False, **kwargs):
"""Swin-H V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=352,
depths=(2, 2, 18, 2),
num_heads=(8, 16, 32, 64), # head count not certain for Huge, 384 & 224 trying diff values
extra_norm_period=6,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_huge_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_giant_384(pretrained=False, **kwargs):
"""Swin-G V2 CR @ 384x384, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=512,
depths=(2, 2, 42, 2),
num_heads=(16, 32, 64, 128),
extra_norm_period=6,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_giant_384', pretrained=pretrained, **model_kwargs
)
@register_model
def swinv2_cr_giant_224(pretrained=False, **kwargs):
"""Swin-G V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=512,
depths=(2, 2, 42, 2),
num_heads=(16, 32, 64, 128),
extra_norm_period=6,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_giant_224', pretrained=pretrained, **model_kwargs)
================================================
FILE: model/conv/CondConv.py
================================================
import torch
from torch import nn
from torch.nn import functional as F
class Attention(nn.Module):
def __init__(self,in_planes,K,init_weight=True):
super().__init__()
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.net=nn.Conv2d(in_planes,K,kernel_size=1,bias=False)
self.sigmoid=nn.Sigmoid()
if(init_weight):
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m ,nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self,x):
att=self.avgpool(x) #bs,dim,1,1
att=self.net(att).view(x.shape[0],-1) #bs,K
return self.sigmoid(att)
class CondConv(nn.Module):
def __init__(self,in_planes,out_planes,kernel_size,stride,padding=0,dilation=1,grounps=1,bias=True,K=4,init_weight=True):
super().__init__()
self.in_planes=in_planes
self.out_planes=out_planes
self.kernel_size=kernel_size
self.stride=stride
self.padding=padding
self.dilation=dilation
self.groups=grounps
self.bias=bias
self.K=K
self.init_weight=init_weight
self.attention=Attention(in_planes=in_planes,K=K,init_weight=init_weight)
self.weight=nn.Parameter(torch.randn(K,out_planes,in_planes//grounps,kernel_size,kernel_size),requires_grad=True)
if(bias):
self.bias=nn.Parameter(torch.randn(K,out_planes),requires_grad=True)
else:
self.bias=None
if(self.init_weight):
self._initialize_weights()
#TODO 初始化
def _initialize_weights(self):
for i in range(self.K):
nn.init.kaiming_uniform_(self.weight[i])
def forward(self,x):
bs,in_planels,h,w=x.shape
softmax_att=self.attention(x) #bs,K
x=x.view(1,-1,h,w)
weight=self.weight.view(self.K,-1) #K,-1
aggregate_weight=torch.mm(softmax_att,weight).view(bs*self.out_planes,self.in_planes//self.groups,self.kernel_size,self.kernel_size) #bs*out_p,in_p,k,k
if(self.bias is not None):
bias=self.bias.view(self.K,-1) #K,out_p
aggregate_bias=torch.mm(softmax_att,bias).view(-1) #bs,out_p
output=F.conv2d(x,weight=aggregate_weight,bias=aggregate_bias,stride=self.stride,padding=self.padding,groups=self.groups*bs,dilation=self.dilation)
else:
output=F.conv2d(x,weight=aggregate_weight,bias=None,stride=self.stride,padding=self.padding,groups=self.groups*bs,dilation=self.dilation)
output=output.view(bs,self.out_planes,h,w)
return output
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=CondConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
================================================
FILE: model/conv/DepthwiseSeparableConvolution.py
================================================
import torch
from torch import nn
class DepthwiseSeparableConvolution(nn.Module):
def __init__(self,in_ch,out_ch,kernel_size=3,stride=1,padding=1):
super().__init__()
self.depthwise_conv=nn.Conv2d(
in_channels=in_ch,
out_channels=in_ch,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=in_ch
)
self.pointwise_conv=nn.Conv2d(
in_channels=in_ch,
out_channels=out_ch,
kernel_size=1,
stride=1,
padding=0,
groups=1
)
def forward(self, x):
out=self.depthwise_conv(x)
out=self.pointwise_conv(out)
return out
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)
================================================
FILE: model/conv/DynamicConv.py
================================================
import torch
from torch import nn
from torch.nn import functional as F
class Attention(nn.Module):
def __init__(self,in_planes,ratio,K,temprature=30,init_weight=True):
super().__init__()
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.temprature=temprature
assert in_planes>ratio
hidden_planes=in_planes//ratio
self.net=nn.Sequential(
nn.Conv2d(in_planes,hidden_planes,kernel_size=1,bias=False),
nn.ReLU(),
nn.Conv2d(hidden_planes,K,kernel_size=1,bias=False)
)
if(init_weight):
self._initialize_weights()
def update_temprature(self):
if(self.temprature>1):
self.temprature-=1
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m ,nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self,x):
att=self.avgpool(x) #bs,dim,1,1
att=self.net(att).view(x.shape[0],-1) #bs,K
return F.softmax(att/self.temprature,-1)
class DynamicConv(nn.Module):
def __init__(self,in_planes,out_planes,kernel_size,stride,padding=0,dilation=1,grounps=1,bias=True,K=4,temprature=30,ratio=4,init_weight=True):
super().__init__()
self.in_planes=in_planes
self.out_planes=out_planes
self.kernel_size=kernel_size
self.stride=stride
self.padding=padding
self.dilation=dilation
self.groups=grounps
self.bias=bias
self.K=K
self.init_weight=init_weight
self.attention=Attention(in_planes=in_planes,ratio=ratio,K=K,temprature=temprature,init_weight=init_weight)
self.weight=nn.Parameter(torch.randn(K,out_planes,in_planes//grounps,kernel_size,kernel_size),requires_grad=True)
if(bias):
self.bias=nn.Parameter(torch.randn(K,out_planes),requires_grad=True)
else:
self.bias=None
if(self.init_weight):
self._initialize_weights()
#TODO 初始化
def _initialize_weights(self):
for i in range(self.K):
nn.init.kaiming_uniform_(self.weight[i])
def forward(self,x):
bs,in_planels,h,w=x.shape
softmax_att=self.attention(x) #bs,K
x=x.view(1,-1,h,w)
weight=self.weight.view(self.K,-1) #K,-1
aggregate_weight=torch.mm(softmax_att,weight).view(bs*self.out_planes,self.in_planes//self.groups,self.kernel_size,self.kernel_size) #bs*out_p,in_p,k,k
if(self.bias is not None):
bias=self.bias.view(self.K,-1) #K,out_p
aggregate_bias=torch.mm(softmax_att,bias).view(-1) #bs,out_p
output=F.conv2d(x,weight=aggregate_weight,bias=aggregate_bias,stride=self.stride,padding=self.padding,groups=self.groups*bs,dilation=self.dilation)
else:
output=F.conv2d(x,weight=aggregate_weight,bias=None,stride=self.stride,padding=self.padding,groups=self.groups*bs,dilation=self.dilation)
output=output.view(bs,self.out_planes,h,w)
return output
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
================================================
FILE: model/conv/HorNet.py
================================================
from functools import partial
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPath
from timm.models.registry import register_model
import torch.fft
def get_dwconv(dim, kernel, bias):
return nn.Conv2d(dim, dim, kernel_size=kernel, padding=(kernel-1)//2 ,bias=bias, groups=dim)
class GlobalLocalFilter(nn.Module):
# https://arxiv.org/abs/2207.14284
def __init__(self, dim, h=14, w=8):
super().__init__()
self.dw = nn.Conv2d(dim // 2, dim // 2, kernel_size=3, padding=1, bias=False, groups=dim // 2)
self.complex_weight = nn.Parameter(torch.randn(dim // 2, h, w, 2, dtype=torch.float32) * 0.02)
trunc_normal_(self.complex_weight, std=.02)
self.pre_norm = LayerNorm(dim, eps=1e-6, data_format='channels_first')
self.post_norm = LayerNorm(dim, eps=1e-6, data_format='channels_first')
def forward(self, x):
x = self.pre_norm(x)
x1, x2 = torch.chunk(x, 2, dim=1)
x1 = self.dw(x1)
x2 = x2.to(torch.float32)
B, C, a, b = x2.shape
x2 = torch.fft.rfft2(x2, dim=(2, 3), norm='ortho')
weight = self.complex_weight
if not weight.shape[1:3] == x2.shape[2:4]:
weight = F.interpolate(weight.permute(3,0,1,2), size=x2.shape[2:4], mode='bilinear', align_corners=True).permute(1,2,3,0)
weight = torch.view_as_complex(weight.contiguous())
x2 = x2 * weight
x2 = torch.fft.irfft2(x2, s=(a, b), dim=(2, 3), norm='ortho')
x = torch.cat([x1.unsqueeze(2), x2.unsqueeze(2)], dim=2).reshape(B, 2 * C, a, b)
x = self.post_norm(x)
return x
class gnconv(nn.Module):
def __init__(self, dim, order=5, gflayer=None, h=14, w=8, s=1.0):
super().__init__()
self.order = order
self.dims = [dim // 2 ** i for i in range(order)]
self.dims.reverse()
self.proj_in = nn.Conv2d(dim, 2*dim, 1)
if gflayer is None:
self.dwconv = get_dwconv(sum(self.dims), 7, True)
else:
self.dwconv = gflayer(sum(self.dims), h=h, w=w)
self.proj_out = nn.Conv2d(dim, dim, 1)
self.pws = nn.ModuleList(
[nn.Conv2d(self.dims[i], self.dims[i+1], 1) for i in range(order-1)]
)
self.scale = s
def forward(self, x, mask=None, dummy=False):
B, C, H, W = x.shape
fused_x = self.proj_in(x)
pwa, abc = torch.split(fused_x, (self.dims[0], sum(self.dims)), dim=1)
dw_abc = self.dwconv(abc) * self.scale
dw_list = torch.split(dw_abc, self.dims, dim=1)
x = pwa * dw_list[0]
for i in range(self.order -1):
x = self.pws[i](x) * dw_list[i+1]
x = self.proj_out(x)
return x
class Block(nn.Module):
r""" HorNet block
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6, gnconv=gnconv):
super().__init__()
self.norm1 = LayerNorm(dim, eps=1e-6, data_format='channels_first')
self.gnconv = gnconv(dim) # depthwise conv
self.norm2 = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma1 = nn.Parameter(layer_scale_init_value * torch.ones(dim),
requires_grad=True) if layer_scale_init_value > 0 else None
self.gamma2 = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
if self.gamma1 is not None:
gamma1 = self.gamma1.view(C, 1, 1)
else:
gamma1 = 1
x = x + self.drop_path(gamma1 * self.gnconv(self.norm1(x)))
input = x
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm2(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma2 is not None:
x = self.gamma2 * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
class HorNet(nn.Module):
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], base_dim=96, drop_path_rate=0.,
layer_scale_init_value=1e-6, head_init_scale=1.,
gnconv=gnconv, block=Block, uniform_init=False, **kwargs
):
super().__init__()
dims = [base_dim, base_dim*2, base_dim*4, base_dim*8]
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
if not isinstance(gnconv, list):
gnconv = [gnconv, gnconv, gnconv, gnconv]
else:
gnconv = gnconv
assert len(gnconv) == 4
cur = 0
for i in range(4):
stage = nn.Sequential(
*[block(dim=dims[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value, gnconv=gnconv[i]) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.uniform_init = uniform_init
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
def _init_weights(self, m):
if not self.uniform_init:
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
if hasattr(m, 'bias') and m.bias is not None:
nn.init.constant_(m.bias, 0)
else:
if isinstance(m, (nn.Conv2d, nn.Linear)):
nn.init.xavier_uniform_(m.weight)
if hasattr(m, 'bias') and m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward_features(self, x):
for i in range(4):
x = self.downsample_layers[i](x)
for j, blk in enumerate(self.stages[i]):
x = blk(x)
return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
class LayerNorm(nn.Module):
r""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
@register_model
def hornet_tiny_7x7(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=64, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s),
partial(gnconv, order=5, s=s),
],
**kwargs
)
return model
@register_model
def hornet_tiny_gf(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=64, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s, h=14, w=8, gflayer=GlobalLocalFilter),
partial(gnconv, order=5, s=s, h=7, w=4, gflayer=GlobalLocalFilter),
],
**kwargs
)
return model
@register_model
def hornet_small_7x7(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=96, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s),
partial(gnconv, order=5, s=s),
],
**kwargs
)
return model
@register_model
def hornet_small_gf(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=96, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s, h=14, w=8, gflayer=GlobalLocalFilter),
partial(gnconv, order=5, s=s, h=7, w=4, gflayer=GlobalLocalFilter),
],
**kwargs
)
return model
@register_model
def hornet_base_7x7(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=128, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s),
partial(gnconv, order=5, s=s),
],
**kwargs
)
return model
@register_model
def hornet_base_gf(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=128, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s, h=14, w=8, gflayer=GlobalLocalFilter),
partial(gnconv, order=5, s=s, h=7, w=4, gflayer=GlobalLocalFilter),
],
**kwargs
)
return model
@register_model
def hornet_base_gf_img384(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=128, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s, h=24, w=13, gflayer=GlobalLocalFilter),
partial(gnconv, order=5, s=s, h=12, w=7, gflayer=GlobalLocalFilter),
],
**kwargs
)
return model
@register_model
def hornet_large_7x7(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=192, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s),
partial(gnconv, order=5, s=s),
],
**kwargs
)
return model
@register_model
def hornet_large_gf(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=192, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s, h=14, w=8, gflayer=GlobalLocalFilter),
partial(gnconv, order=5, s=s, h=7, w=4, gflayer=GlobalLocalFilter),
],
**kwargs
)
return model
@register_model
def hornet_large_gf_img384(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=192, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s, h=24, w=13, gflayer=GlobalLocalFilter),
partial(gnconv, order=5, s=s, h=12, w=7, gflayer=GlobalLocalFilter),
],
**kwargs
)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=64, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s),
partial(gnconv, order=5, s=s),
],
)
outputs = model(input)
print(outputs.shape)
================================================
FILE: model/conv/Involution.py
================================================
import math
from functools import partial
import torch
from torch import nn, select
from torch.nn import functional as F
class Involution(nn.Module):
def __init__(self, kernel_size, in_channel=4, stride=1, group=1,ratio=4):
super().__init__()
self.kernel_size=kernel_size
self.in_channel=in_channel
self.stride=stride
self.group=group
assert self.in_channel%group==0
self.group_channel=self.in_channel//group
self.conv1=nn.Conv2d(
self.in_channel,
self.in_channel//ratio,
kernel_size=1
)
self.bn=nn.BatchNorm2d(in_channel//ratio)
self.relu=nn.ReLU()
self.conv2=nn.Conv2d(
self.in_channel//ratio,
self.group*self.kernel_size*self.kernel_size,
kernel_size=1
)
self.avgpool=nn.AvgPool2d(stride,stride) if stride>1 else nn.Identity()
self.unfold=nn.Unfold(kernel_size=kernel_size,stride=stride,padding=kernel_size//2)
def forward(self, inputs):
B,C,H,W=inputs.shape
weight=self.conv2(self.relu(self.bn(self.conv1(self.avgpool(inputs))))) #(bs,G*K*K,H//stride,W//stride)
b,c,h,w=weight.shape
weight=weight.reshape(b,self.group,self.kernel_size*self.kernel_size,h,w).unsqueeze(2) #(bs,G,1,K*K,H//stride,W//stride)
x_unfold=self.unfold(inputs)
x_unfold=x_unfold.reshape(B,self.group,C//self.group,self.kernel_size*self.kernel_size,H//self.stride,W//self.stride) #(bs,G,G//C,K*K,H//stride,W//stride)
out=(x_unfold*weight).sum(dim=3)#(bs,G,G//C,1,H//stride,W//stride)
out=out.reshape(B,C,H//self.stride,W//self.stride) #(bs,C,H//stride,W//stride)
return out
if __name__ == '__main__':
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)
================================================
FILE: model/conv/MBConv.py
================================================
import math
from functools import partial
import torch
from torch import nn
from torch.nn import functional as F
class SwishImplementation(torch.autograd.Function):
@staticmethod
def forward(ctx, i):
result = i * torch.sigmoid(i)
ctx.save_for_backward(i)
return result
@staticmethod
def backward(ctx, grad_output):
i = ctx.saved_variables[0]
sigmoid_i = torch.sigmoid(i)
return grad_output * (sigmoid_i * (1 + i * (1 - sigmoid_i)))
class MemoryEfficientSwish(nn.Module):
def forward(self, x):
return SwishImplementation.apply(x)
def drop_connect(inputs, p, training):
""" Drop connect. """
if not training: return inputs
batch_size = inputs.shape[0]
keep_prob = 1 - p
random_tensor = keep_prob
random_tensor += torch.rand([batch_size, 1, 1, 1], dtype=inputs.dtype, device=inputs.device)
binary_tensor = torch.floor(random_tensor)
output = inputs / keep_prob * binary_tensor
return output
def get_same_padding_conv2d(image_size=None):
return partial(Conv2dStaticSamePadding, image_size=image_size)
def get_width_and_height_from_size(x):
""" Obtains width and height from a int or tuple """
if isinstance(x, int): return x, x
if isinstance(x, list) or isinstance(x, tuple): return x
else: raise TypeError()
def calculate_output_image_size(input_image_size, stride):
"""
计算出 Conv2dSamePadding with a stride.
"""
if input_image_size is None: return None
image_height, image_width = get_width_and_height_from_size(input_image_size)
stride = stride if isinstance(stride, int) else stride[0]
image_height = int(math.ceil(image_height / stride))
image_width = int(math.ceil(image_width / stride))
return [image_height, image_width]
class Conv2dStaticSamePadding(nn.Conv2d):
""" 2D Convolutions like TensorFlow, for a fixed image size"""
def __init__(self, in_channels, out_channels, kernel_size, image_size=None, **kwargs):
super().__init__(in_channels, out_channels, kernel_size, **kwargs)
self.stride = self.stride if len(self.stride) == 2 else [self.stride[0]] * 2
# Calculate padding based on image size and save it
assert image_size is not None
ih, iw = (image_size, image_size) if isinstance(image_size, int) else image_size
kh, kw = self.weight.size()[-2:]
sh, sw = self.stride
oh, ow = math.ceil(ih / sh), math.ceil(iw / sw)
pad_h = max((oh - 1) * self.stride[0] + (kh - 1) * self.dilation[0] + 1 - ih, 0)
pad_w = max((ow - 1) * self.stride[1] + (kw - 1) * self.dilation[1] + 1 - iw, 0)
if pad_h > 0 or pad_w > 0:
self.static_padding = nn.ZeroPad2d((pad_w // 2, pad_w - pad_w // 2, pad_h // 2, pad_h - pad_h // 2))
else:
self.static_padding = Identity()
def forward(self, x):
x = self.static_padding(x)
x = F.conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
return x
class Identity(nn.Module):
def __init__(self, ):
super(Identity, self).__init__()
def forward(self, input):
return input
# MBConvBlock
class MBConvBlock(nn.Module):
'''
层 ksize3*3 输入32 输出16 conv1 stride步长1
'''
def __init__(self, ksize, input_filters, output_filters, expand_ratio=1, stride=1, image_size=224):
super().__init__()
self._bn_mom = 0.1
self._bn_eps = 0.01
self._se_ratio = 0.25
self._input_filters = input_filters
self._output_filters = output_filters
self._expand_ratio = expand_ratio
self._kernel_size = ksize
self._stride = stride
inp = self._input_filters
oup = self._input_filters * self._expand_ratio
if self._expand_ratio != 1:
Conv2d = get_same_padding_conv2d(image_size=image_size)
self._expand_conv = Conv2d(in_channels=inp, out_channels=oup, kernel_size=1, bias=False)
self._bn0 = nn.BatchNorm2d(num_features=oup, momentum=self._bn_mom, eps=self._bn_eps)
# Depthwise convolution
k = self._kernel_size
s = self._stride
Conv2d = get_same_padding_conv2d(image_size=image_size)
self._depthwise_conv = Conv2d(
in_channels=oup, out_channels=oup, groups=oup,
kernel_size=k, stride=s, bias=False)
self._bn1 = nn.BatchNorm2d(num_features=oup, momentum=self._bn_mom, eps=self._bn_eps)
image_size = calculate_output_image_size(image_size, s)
# Squeeze and Excitation layer, if desired
Conv2d = get_same_padding_conv2d(image_size=(1,1))
num_squeezed_channels = max(1, int(self._input_filters * self._se_ratio))
self._se_reduce = Conv2d(in_channels=oup, out_channels=num_squeezed_channels, kernel_size=1)
self._se_expand = Conv2d(in_channels=num_squeezed_channels, out_channels=oup, kernel_size=1)
# Output phase
final_oup = self._output_filters
Conv2d = get_same_padding_conv2d(image_size=image_size)
self._project_conv = Conv2d(in_channels=oup, out_channels=final_oup, kernel_size=1, bias=False)
self._bn2 = nn.BatchNorm2d(num_features=final_oup, momentum=self._bn_mom, eps=self._bn_eps)
self._swish = MemoryEfficientSwish()
def forward(self, inputs, drop_connect_rate=None):
"""
:param inputs: input tensor
:param drop_connect_rate: drop connect rate (float, between 0 and 1)
:return: output of block
"""
# Expansion and Depthwise Convolution
x = inputs
if self._expand_ratio != 1:
expand = self._expand_conv(inputs)
bn0 = self._bn0(expand)
x = self._swish(bn0)
depthwise = self._depthwise_conv(x)
bn1 = self._bn1(depthwise)
x = self._swish(bn1)
# Squeeze and Excitation
x_squeezed = F.adaptive_avg_pool2d(x, 1)
x_squeezed = self._se_reduce(x_squeezed)
x_squeezed = self._swish(x_squeezed)
x_squeezed = self._se_expand(x_squeezed)
x = torch.sigmoid(x_squeezed) * x
x = self._bn2(self._project_conv(x))
# Skip connection and drop connect
input_filters, output_filters = self._input_filters, self._output_filters
if self._stride == 1 and input_filters == output_filters:
if drop_connect_rate:
x = drop_connect(x, p=drop_connect_rate, training=self.training)
x = x + inputs # skip connection
return x
if __name__ == '__main__':
input=torch.randn(1,3,112,112)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=3,image_size=112)
out=mbconv(input)
print(out.shape)
================================================
FILE: model/fighingcv.egg-info/PKG-INFO
================================================
Metadata-Version: 2.1
Name: fighingcv
Version: 1.0.0
Summary: Client library to download and publish models, datasets and other repos on the huggingface.co hub
Home-page: https://github.com/xmu-xiaoma666/External-Attention-pytorch
Author: Hugging Face, Inc.
Author-email: julien@huggingface.co
License: Apache
Keywords: model-hub machine-learning models natural-language-processing deep-learning pytorch pretrained-models
Platform: UNKNOWN
Classifier: Intended Audience :: Developers
Classifier: Intended Audience :: Education
Classifier: Intended Audience :: Science/Research
Classifier: License :: OSI Approved :: Apache Software License
Classifier: Operating System :: OS Independent
Classifier: Programming Language :: Python :: 3
Classifier: Topic :: Scientific/Engineering :: Artificial Intelligence
Requires-Python: >=3.7.0
Description-Content-Type: text/markdown
Provides-Extra: torch
Provides-Extra: fastai
Provides-Extra: tensorflow
Provides-Extra: testing
Provides-Extra: quality
Provides-Extra: all
Provides-Extra: dev
License-File: LICENSE
简体中文 | [English](./README_EN.md)
# FightingCV 代码库, 包含 [***Attention***](#attention-series),[***Backbone***](#backbone-series), [***MLP***](#mlp-series), [***Re-parameter***](#re-parameter-series), [**Convolution**](#convolution-series)



-------
🔥🔥🔥 **重磅!!!作为项目补充,最近全新开源了一个目标检测代码库 [YOLOAir](https://github.com/iscyy/yoloair),里面在目标检测算法中集成了各种Attention机制,代码简洁易读,欢迎大家来玩呀!**

-------
Hello,大家好,我是小马🚀🚀🚀
***For 小白(Like Me):***
最近在读论文的时候会发现一个问题,有时候论文核心思想非常简单,核心代码可能也就十几行。但是打开作者release的源码时,却发现提出的模块嵌入到分类、检测、分割等任务框架中,导致代码比较冗余,对于特定任务框架不熟悉的我,**很难找到核心代码**,导致在论文和网络思想的理解上会有一定困难。
***For 进阶者(Like You):***
如果把Conv、FC、RNN这些基本单元看做小的Lego积木,把Transformer、ResNet这些结构看成已经搭好的Lego城堡。那么本项目提供的模块就是一个个具有完整语义信息的Lego组件。**让科研工作者们避免反复造轮子**,只需思考如何利用这些“Lego组件”,搭建出更多绚烂多彩的作品。
***For 大神(May Be Like You):***
能力有限,**不喜轻喷**!!!
***For All:***
本项目就是要实现一个既能**让深度学习小白也能搞懂**,又能**服务科研和工业社区**的代码库。作为[**FightingCV公众号**](https://mp.weixin.qq.com/s/m9RiivbbDPdjABsTd6q8FA)的补充,本项目的宗旨是从代码角度,实现🚀**让世界上没有难读的论文**🚀。
(同时也非常欢迎各位科研工作者将自己的工作的核心代码整理到本项目中,推动科研社区的发展,会在readme中注明代码的作者~)
## 公众号 & 微信交流群
欢迎大家关注公众号:**FightingCV**
公众号**每天**都会进行**论文、算法和代码的干货分享**哦~
**每天在群里分享一些近期的论文和解析**,欢迎大家一起**学习交流**哈~~~
(加不进去可以加微信:**775629340**,记得备注【**公司/学校+方向+ID**】)

强烈推荐大家关注[**知乎**](https://www.zhihu.com/people/jason-14-58-38/posts)账号和[**FightingCV公众号**](https://mp.weixin.qq.com/s/m9RiivbbDPdjABsTd6q8FA),可以快速了解到最新优质的干货资源。
***
# 目录
- [Attention Series](#attention-series)
- [1. External Attention Usage](#1-external-attention-usage)
- [2. Self Attention Usage](#2-self-attention-usage)
- [3. Simplified Self Attention Usage](#3-simplified-self-attention-usage)
- [4. Squeeze-and-Excitation Attention Usage](#4-squeeze-and-excitation-attention-usage)
- [5. SK Attention Usage](#5-sk-attention-usage)
- [6. CBAM Attention Usage](#6-cbam-attention-usage)
- [7. BAM Attention Usage](#7-bam-attention-usage)
- [8. ECA Attention Usage](#8-eca-attention-usage)
- [9. DANet Attention Usage](#9-danet-attention-usage)
- [10. Pyramid Split Attention (PSA) Usage](#10-Pyramid-Split-Attention-Usage)
- [11. Efficient Multi-Head Self-Attention(EMSA) Usage](#11-Efficient-Multi-Head-Self-Attention-Usage)
- [12. Shuffle Attention Usage](#12-Shuffle-Attention-Usage)
- [13. MUSE Attention Usage](#13-MUSE-Attention-Usage)
- [14. SGE Attention Usage](#14-SGE-Attention-Usage)
- [15. A2 Attention Usage](#15-A2-Attention-Usage)
- [16. AFT Attention Usage](#16-AFT-Attention-Usage)
- [17. Outlook Attention Usage](#17-Outlook-Attention-Usage)
- [18. ViP Attention Usage](#18-ViP-Attention-Usage)
- [19. CoAtNet Attention Usage](#19-CoAtNet-Attention-Usage)
- [20. HaloNet Attention Usage](#20-HaloNet-Attention-Usage)
- [21. Polarized Self-Attention Usage](#21-Polarized-Self-Attention-Usage)
- [22. CoTAttention Usage](#22-CoTAttention-Usage)
- [23. Residual Attention Usage](#23-Residual-Attention-Usage)
- [24. S2 Attention Usage](#24-S2-Attention-Usage)
- [25. GFNet Attention Usage](#25-GFNet-Attention-Usage)
- [26. Triplet Attention Usage](#26-TripletAttention-Usage)
- [27. Coordinate Attention Usage](#27-Coordinate-Attention-Usage)
- [28. MobileViT Attention Usage](#28-MobileViT-Attention-Usage)
- [29. ParNet Attention Usage](#29-ParNet-Attention-Usage)
- [30. UFO Attention Usage](#30-UFO-Attention-Usage)
- [31. ACmix Attention Usage](#31-Acmix-Attention-Usage)
- [32. MobileViTv2 Attention Usage](#32-MobileViTv2-Attention-Usage)
- [33. DAT Attention Usage](#33-DAT-Attention-Usage)
- [34. CrossFormer Attention Usage](#34-CrossFormer-Attention-Usage)
- [35. MOATransformer Attention Usage](#35-MOATransformer-Attention-Usage)
- [36. CrissCrossAttention Attention Usage](#36-CrissCrossAttention-Attention-Usage)
- [37. Axial_attention Attention Usage](#37-Axial_attention-Attention-Usage)
- [Backbone Series](#Backbone-series)
- [1. ResNet Usage](#1-ResNet-Usage)
- [2. ResNeXt Usage](#2-ResNeXt-Usage)
- [3. MobileViT Usage](#3-MobileViT-Usage)
- [4. ConvMixer Usage](#4-ConvMixer-Usage)
- [5. ShuffleTransformer Usage](#5-ShuffleTransformer-Usage)
- [6. ConTNet Usage](#6-ConTNet-Usage)
- [7. HATNet Usage](#7-HATNet-Usage)
- [8. CoaT Usage](#8-CoaT-Usage)
- [9. PVT Usage](#9-PVT-Usage)
- [10. CPVT Usage](#10-CPVT-Usage)
- [11. PIT Usage](#11-PIT-Usage)
- [12. CrossViT Usage](#12-CrossViT-Usage)
- [13. TnT Usage](#13-TnT-Usage)
- [14. DViT Usage](#14-DViT-Usage)
- [15. CeiT Usage](#15-CeiT-Usage)
- [16. ConViT Usage](#16-ConViT-Usage)
- [17. CaiT Usage](#17-CaiT-Usage)
- [18. PatchConvnet Usage](#18-PatchConvnet-Usage)
- [19. DeiT Usage](#19-DeiT-Usage)
- [20. LeViT Usage](#20-LeViT-Usage)
- [21. VOLO Usage](#21-VOLO-Usage)
- [22. Container Usage](#22-Container-Usage)
- [23. CMT Usage](#23-CMT-Usage)
- [MLP Series](#mlp-series)
- [1. RepMLP Usage](#1-RepMLP-Usage)
- [2. MLP-Mixer Usage](#2-MLP-Mixer-Usage)
- [3. ResMLP Usage](#3-ResMLP-Usage)
- [4. gMLP Usage](#4-gMLP-Usage)
- [5. sMLP Usage](#5-sMLP-Usage)
- [6. vip-mlp Usage](#6-vip-mlp-Usage)
- [Re-Parameter(ReP) Series](#Re-Parameter-series)
- [1. RepVGG Usage](#1-RepVGG-Usage)
- [2. ACNet Usage](#2-ACNet-Usage)
- [3. Diverse Branch Block(DDB) Usage](#3-Diverse-Branch-Block-Usage)
- [Convolution Series](#Convolution-series)
- [1. Depthwise Separable Convolution Usage](#1-Depthwise-Separable-Convolution-Usage)
- [2. MBConv Usage](#2-MBConv-Usage)
- [3. Involution Usage](#3-Involution-Usage)
- [4. DynamicConv Usage](#4-DynamicConv-Usage)
- [5. CondConv Usage](#5-CondConv-Usage)
***
# Attention Series
- Pytorch implementation of ["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks---arXiv 2021.05.05"](https://arxiv.org/abs/2105.02358)
- Pytorch implementation of ["Attention Is All You Need---NIPS2017"](https://arxiv.org/pdf/1706.03762.pdf)
- Pytorch implementation of ["Squeeze-and-Excitation Networks---CVPR2018"](https://arxiv.org/abs/1709.01507)
- Pytorch implementation of ["Selective Kernel Networks---CVPR2019"](https://arxiv.org/pdf/1903.06586.pdf)
- Pytorch implementation of ["CBAM: Convolutional Block Attention Module---ECCV2018"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
- Pytorch implementation of ["BAM: Bottleneck Attention Module---BMCV2018"](https://arxiv.org/pdf/1807.06514.pdf)
- Pytorch implementation of ["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020"](https://arxiv.org/pdf/1910.03151.pdf)
- Pytorch implementation of ["Dual Attention Network for Scene Segmentation---CVPR2019"](https://arxiv.org/pdf/1809.02983.pdf)
- Pytorch implementation of ["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30"](https://arxiv.org/pdf/2105.14447.pdf)
- Pytorch implementation of ["ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28"](https://arxiv.org/abs/2105.13677)
- Pytorch implementation of ["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS---ICASSP 2021"](https://arxiv.org/pdf/2102.00240.pdf)
- Pytorch implementation of ["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning---arXiv 2019.11.17"](https://arxiv.org/abs/1911.09483)
- Pytorch implementation of ["Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks---arXiv 2019.05.23"](https://arxiv.org/pdf/1905.09646.pdf)
- Pytorch implementation of ["A2-Nets: Double Attention Networks---NIPS2018"](https://arxiv.org/pdf/1810.11579.pdf)
- Pytorch implementation of ["An Attention Free Transformer---ICLR2021 (Apple New Work)"](https://arxiv.org/pdf/2105.14103v1.pdf)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition---arXiv 2021.06.24"](https://arxiv.org/abs/2106.13112)
[【论文解析】](https://zhuanlan.zhihu.com/p/385561050)
- Pytorch implementation of [Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition---arXiv 2021.06.23](https://arxiv.org/abs/2106.12368)
[【论文解析】](https://mp.weixin.qq.com/s/5gonUQgBho_m2O54jyXF_Q)
- Pytorch implementation of [CoAtNet: Marrying Convolution and Attention for All Data Sizes---arXiv 2021.06.09](https://arxiv.org/abs/2106.04803)
[【论文解析】](https://zhuanlan.zhihu.com/p/385578588)
- Pytorch implementation of [Scaling Local Self-Attention for Parameter Efficient Visual Backbones---CVPR2021 Oral](https://arxiv.org/pdf/2103.12731.pdf) [【论文解析】](https://zhuanlan.zhihu.com/p/388598744)
- Pytorch implementation of [Polarized Self-Attention: Towards High-quality Pixel-wise Regression---arXiv 2021.07.02](https://arxiv.org/abs/2107.00782) [【论文解析】](https://zhuanlan.zhihu.com/p/389770482)
- Pytorch implementation of [Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292) [【论文解析】](https://zhuanlan.zhihu.com/p/394795481)
- Pytorch implementation of [Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
- Pytorch implementation of [S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072) [【论文解析】](https://zhuanlan.zhihu.com/p/397003638)
- Pytorch implementation of [Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
- Pytorch implementation of [Rotate to Attend: Convolutional Triplet Attention Module---WACV 2021](https://arxiv.org/abs/2010.03045)
- Pytorch implementation of [Coordinate Attention for Efficient Mobile Network Design ---CVPR 2021](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2110.02178)
- Pytorch implementation of [Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
- Pytorch implementation of [UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2109.14382)
- Pytorch implementation of [Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
- Pytorch implementation of [On the Integration of Self-Attention and Convolution---ArXiv 2022.03.14](https://arxiv.org/pdf/2111.14556.pdf)
- Pytorch implementation of [CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
- Pytorch implementation of [Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
- Pytorch implementation of [CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
- Pytorch implementation of [Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
***
### 1. External Attention Usage
#### 1.1. Paper
["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks"](https://arxiv.org/abs/2105.02358)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
***
### 2. Self Attention Usage
#### 2.1. Paper
["Attention Is All You Need"](https://arxiv.org/pdf/1706.03762.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 3. Simplified Self Attention Usage
#### 3.1. Paper
[None]()
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)
```
***
### 4. Squeeze-and-Excitation Attention Usage
#### 4.1. Paper
["Squeeze-and-Excitation Networks"](https://arxiv.org/abs/1709.01507)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 5. SK Attention Usage
#### 5.1. Paper
["Selective Kernel Networks"](https://arxiv.org/pdf/1903.06586.pdf)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 6. CBAM Attention Usage
#### 6.1. Paper
["CBAM: Convolutional Block Attention Module"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
#### 6.2. Overview


#### 6.3. Usage Code
```python
from model.attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
***
### 7. BAM Attention Usage
#### 7.1. Paper
["BAM: Bottleneck Attention Module"](https://arxiv.org/pdf/1807.06514.pdf)
#### 7.2. Overview

#### 7.3. Usage Code
```python
from model.attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
***
### 8. ECA Attention Usage
#### 8.1. Paper
["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks"](https://arxiv.org/pdf/1910.03151.pdf)
#### 8.2. Overview

#### 8.3. Usage Code
```python
from model.attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
***
### 9. DANet Attention Usage
#### 9.1. Paper
["Dual Attention Network for Scene Segmentation"](https://arxiv.org/pdf/1809.02983.pdf)
#### 9.2. Overview

#### 9.3. Usage Code
```python
from model.attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
***
### 10. Pyramid Split Attention Usage
#### 10.1. Paper
["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network"](https://arxiv.org/pdf/2105.14447.pdf)
#### 10.2. Overview

#### 10.3. Usage Code
```python
from model.attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
***
### 11. Efficient Multi-Head Self-Attention Usage
#### 11.1. Paper
["ResT: An Efficient Transformer for Visual Recognition"](https://arxiv.org/abs/2105.13677)
#### 11.2. Overview

#### 11.3. Usage Code
```python
from model.attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
***
### 12. Shuffle Attention Usage
#### 12.1. Paper
["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS"](https://arxiv.org/pdf/2102.00240.pdf)
#### 12.2. Overview

#### 12.3. Usage Code
```python
from model.attention.ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
```
***
### 13. MUSE Attention Usage
#### 13.1. Paper
["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning"](https://arxiv.org/abs/1911.09483)
#### 13.2. Overview

#### 13.3. Usage Code
```python
from model.attention.MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 14. SGE Attention Usage
#### 14.1. Paper
[Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks](https://arxiv.org/pdf/1905.09646.pdf)
#### 14.2. Overview

#### 14.3. Usage Code
```python
from model.attention.SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
```
***
### 15. A2 Attention Usage
#### 15.1. Paper
[A2-Nets: Double Attention Networks](https://arxiv.org/pdf/1810.11579.pdf)
#### 15.2. Overview

#### 15.3. Usage Code
```python
from model.attention.A2Atttention import DoubleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
```
### 16. AFT Attention Usage
#### 16.1. Paper
[An Attention Free Transformer](https://arxiv.org/pdf/2105.14103v1.pdf)
#### 16.2. Overview

#### 16.3. Usage Code
```python
from model.attention.AFT import AFT_FULL
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
```
### 17. Outlook Attention Usage
#### 17.1. Paper
[VOLO: Vision Outlooker for Visual Recognition"](https://arxiv.org/abs/2106.13112)
#### 17.2. Overview

#### 17.3. Usage Code
```python
from model.attention.OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)
```
***
### 18. ViP Attention Usage
#### 18.1. Paper
[Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 18.2. Overview

#### 18.3. Usage Code
```python
from model.attention.ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)
```
***
### 19. CoAtNet Attention Usage
#### 19.1. Paper
[CoAtNet: Marrying Convolution and Attention for All Data Sizes"](https://arxiv.org/abs/2106.04803)
#### 19.2. Overview
None
#### 19.3. Usage Code
```python
from model.attention.CoAtNet import CoAtNet
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=CoAtNet(in_ch=3,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 20. HaloNet Attention Usage
#### 20.1. Paper
[Scaling Local Self-Attention for Parameter Efficient Visual Backbones"](https://arxiv.org/pdf/2103.12731.pdf)
#### 20.2. Overview

#### 20.3. Usage Code
```python
from model.attention.HaloAttention import HaloAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)
```
***
### 21. Polarized Self-Attention Usage
#### 21.1. Paper
[Polarized Self-Attention: Towards High-quality Pixel-wise Regression"](https://arxiv.org/abs/2107.00782)
#### 21.2. Overview

#### 21.3. Usage Code
```python
from model.attention.PolarizedSelfAttention import ParallelPolarizedSelfAttention,SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
```
***
### 22. CoTAttention Usage
#### 22.1. Paper
[Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292)
#### 22.2. Overview

#### 22.3. Usage Code
```python
from model.attention.CoTAttention import CoTAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
```
***
### 23. Residual Attention Usage
#### 23.1. Paper
[Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
#### 23.2. Overview

#### 23.3. Usage Code
```python
from model.attention.ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
resatt = ResidualAttention(channel=512,num_class=1000,la=0.2)
output=resatt(input)
print(output.shape)
```
***
### 24. S2 Attention Usage
#### 24.1. Paper
[S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072)
#### 24.2. Overview

#### 24.3. Usage Code
```python
from model.attention.S2Attention import S2Attention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
s2att = S2Attention(channels=512)
output=s2att(input)
print(output.shape)
```
***
### 25. GFNet Attention Usage
#### 25.1. Paper
[Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
#### 25.2. Overview

#### 25.3. Usage Code - Implemented by [Wenliang Zhao (Author)](https://scholar.google.com/citations?user=lyPWvuEAAAAJ&hl=en)
```python
from model.attention.gfnet import GFNet
import torch
from torch import nn
from torch.nn import functional as F
x = torch.randn(1, 3, 224, 224)
gfnet = GFNet(embed_dim=384, img_size=224, patch_size=16, num_classes=1000)
out = gfnet(x)
print(out.shape)
```
***
### 26. TripletAttention Usage
#### 26.1. Paper
[Rotate to Attend: Convolutional Triplet Attention Module---CVPR 2021](https://arxiv.org/abs/2010.03045)
#### 26.2. Overview

#### 26.3. Usage Code - Implemented by [digantamisra98](https://github.com/digantamisra98)
```python
from model.attention.TripletAttention import TripletAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
triplet = TripletAttention()
output=triplet(input)
print(output.shape)
```
***
### 27. Coordinate Attention Usage
#### 27.1. Paper
[Coordinate Attention for Efficient Mobile Network Design---CVPR 2021](https://arxiv.org/abs/2103.02907)
#### 27.2. Overview

#### 27.3. Usage Code - Implemented by [Andrew-Qibin](https://github.com/Andrew-Qibin)
```python
from model.attention.CoordAttention import CoordAtt
import torch
from torch import nn
from torch.nn import functional as F
inp=torch.rand([2, 96, 56, 56])
inp_dim, oup_dim = 96, 96
reduction=32
coord_attention = CoordAtt(inp_dim, oup_dim, reduction=reduction)
output=coord_attention(inp)
print(output.shape)
```
***
### 28. MobileViT Attention Usage
#### 28.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2103.02907)
#### 28.2. Overview

#### 28.3. Usage Code
```python
from model.attention.MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
m=MobileViTAttention()
input=torch.randn(1,3,49,49)
output=m(input)
print(output.shape) #output:(1,3,49,49)
```
***
### 29. ParNet Attention Usage
#### 29.1. Paper
[Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
#### 29.2. Overview

#### 29.3. Usage Code
```python
from model.attention.ParNetAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
pna = ParNetAttention(channel=512)
output=pna(input)
print(output.shape) #50,512,7,7
```
***
### 30. UFO Attention Usage
#### 30.1. Paper
[UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2110.07641)
#### 30.2. Overview

#### 30.3. Usage Code
```python
from model.attention.UFOAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
ufo = UFOAttention(d_model=512, d_k=512, d_v=512, h=8)
output=ufo(input,input,input)
print(output.shape) #[50, 49, 512]
```
-
### 31. ACmix Attention Usage
#### 31.1. Paper
[On the Integration of Self-Attention and Convolution](https://arxiv.org/pdf/2111.14556.pdf)
#### 31.2. Usage Code
```python
from model.attention.ACmix import ACmix
import torch
if __name__ == '__main__':
input=torch.randn(50,256,7,7)
acmix = ACmix(in_planes=256, out_planes=256)
output=acmix(input)
print(output.shape)
```
### 32. MobileViTv2 Attention Usage
#### 32.1. Paper
[Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
#### 32.2. Overview

#### 32.3. Usage Code
```python
from model.attention.MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
### 33. DAT Attention Usage
#### 33.1. Paper
[Vision Transformer with Deformable Attention---CVPR2022](https://arxiv.org/abs/2201.00520)
#### 33.2. Usage Code
```python
from model.attention.DAT import DAT
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DAT(
img_size=224,
patch_size=4,
num_classes=1000,
expansion=4,
dim_stem=96,
dims=[96, 192, 384, 768],
depths=[2, 2, 6, 2],
stage_spec=[['L', 'S'], ['L', 'S'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7] ,
groups=[-1, -1, 3, 6],
use_pes=[False, False, True, True],
dwc_pes=[False, False, False, False],
strides=[-1, -1, 1, 1],
sr_ratios=[-1, -1, -1, -1],
offset_range_factor=[-1, -1, 2, 2],
no_offs=[False, False, False, False],
fixed_pes=[False, False, False, False],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
)
output=model(input)
print(output[0].shape)
```
### 34. CrossFormer Attention Usage
#### 34.1. Paper
[CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
#### 34.2. Usage Code
```python
from model.attention.Crossformer import CrossFormer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CrossFormer(img_size=224,
patch_size=[4, 8, 16, 32],
in_chans= 3,
num_classes=1000,
embed_dim=48,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
group_size=[7, 7, 7, 7],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False,
merge_size=[[2, 4], [2,4], [2, 4]]
)
output=model(input)
print(output.shape)
```
### 35. MOATransformer Attention Usage
#### 35.1. Paper
[Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
#### 35.2. Usage Code
```python
from model.attention.MOATransformer import MOATransformer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = MOATransformer(
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=[2, 2, 6],
num_heads=[3, 6, 12],
window_size=14,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False
)
output=model(input)
print(output.shape)
```
### 36. CrissCrossAttention Attention Usage
#### 36.1. Paper
[CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
#### 36.2. Usage Code
```python
from model.attention.CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = CrissCrossAttention(64)
outputs = model(input)
print(outputs.shape)
```
### 37. Axial_attention Attention Usage
#### 37.1. Paper
[Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
#### 37.2. Usage Code
```python
from model.attention.Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__':
input=torch.randn(3, 128, 7, 7)
model = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
outputs = model(input)
print(outputs.shape)
```
***
# Backbone Series
- Pytorch implementation of ["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
- Pytorch implementation of ["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
- Pytorch implementation of [Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer---ArXiv 2021.06.07](https://arxiv.org/abs/2106.03650)
- Pytorch implementation of [ConTNet: Why not use convolution and transformer at the same time?---ArXiv 2021.04.27](https://arxiv.org/abs/2104.13497)
- Pytorch implementation of [Vision Transformers with Hierarchical Attention---ArXiv 2022.06.15](https://arxiv.org/abs/2106.03180)
- Pytorch implementation of [Co-Scale Conv-Attentional Image Transformers---ArXiv 2021.08.26](https://arxiv.org/abs/2104.06399)
- Pytorch implementation of [Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
- Pytorch implementation of [Rethinking Spatial Dimensions of Vision Transformers---ICCV 2021](https://arxiv.org/abs/2103.16302)
- Pytorch implementation of [CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification---ICCV 2021](https://arxiv.org/abs/2103.14899)
- Pytorch implementation of [Transformer in Transformer---NeurIPS 2021](https://arxiv.org/abs/2103.00112)
- Pytorch implementation of [DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
- Pytorch implementation of [Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
***
- Pytorch implementation of [ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
- Pytorch implementation of [Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
- Pytorch implementation of [Going deeper with Image Transformers---ICCV 2021 (Oral)](https://arxiv.org/abs/2103.17239)
- Pytorch implementation of [Training data-efficient image transformers & distillation through attention---ICML 2021](https://arxiv.org/abs/2012.12877)
- Pytorch implementation of [LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
- Pytorch implementation of [Container: Context Aggregation Network---NeuIPS 2021](https://arxiv.org/abs/2106.01401)
- Pytorch implementation of [CMT: Convolutional Neural Networks Meet Vision Transformers---CVPR 2022](https://arxiv.org/abs/2107.06263)
- Pytorch implementation of [Vision Transformer with Deformable Attention---CVPR 2022](https://arxiv.org/abs/2201.00520)
### 1. ResNet Usage
#### 1.1. Paper
["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
#### 1.2. Overview


#### 1.3. Usage Code
```python
from model.backbone.resnet import ResNet50,ResNet101,ResNet152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnet50=ResNet50(1000)
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out=resnet50(input)
print(out.shape)
```
### 2. ResNeXt Usage
#### 2.1. Paper
["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.backbone.resnext import ResNeXt50,ResNeXt101,ResNeXt152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnext50=ResNeXt50(1000)
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out=resnext50(input)
print(out.shape)
```
### 3. MobileViT Usage
#### 3.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.backbone.MobileViT import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
### mobilevit_xxs
mvit_xxs=mobilevit_xxs()
out=mvit_xxs(input)
print(out.shape)
### mobilevit_xs
mvit_xs=mobilevit_xs()
out=mvit_xs(input)
print(out.shape)
### mobilevit_s
mvit_s=mobilevit_s()
out=mvit_s(input)
print(out.shape)
```
### 4. ConvMixer Usage
#### 4.1. Paper
[Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.backbone.ConvMixer import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
convmixer=ConvMixer(dim=512,depth=12)
out=convmixer(x)
print(out.shape) #[1, 1000]
```
### 5. ShuffleTransformer Usage
#### 5.1. Paper
[Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer](https://arxiv.org/pdf/2106.03650.pdf)
#### 5.2. Usage Code
```python
from model.backbone.ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
sft = ShuffleTransformer()
output=sft(input)
print(output.shape)
```
### 6. ConTNet Usage
#### 6.1. Paper
[ConTNet: Why not use convolution and transformer at the same time?](https://arxiv.org/abs/2104.13497)
#### 6.2. Usage Code
```python
from model.backbone.ConTNet import ConTNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == "__main__":
model = build_model(use_avgdown=True, relative=True, qkv_bias=True, pre_norm=True)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
```
### 7 HATNet Usage
#### 7.1. Paper
[Vision Transformers with Hierarchical Attention](https://arxiv.org/abs/2106.03180)
#### 7.2. Usage Code
```python
from model.backbone.HATNet import HATNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
hat = HATNet(dims=[48, 96, 240, 384], head_dim=48, expansions=[8, 8, 4, 4],
grid_sizes=[8, 7, 7, 1], ds_ratios=[8, 4, 2, 1], depths=[2, 2, 6, 3])
output=hat(input)
print(output.shape)
```
### 8 CoaT Usage
#### 8.1. Paper
[Co-Scale Conv-Attentional Image Transformers](https://arxiv.org/abs/2104.06399)
#### 8.2. Usage Code
```python
from model.backbone.CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4])
output=model(input)
print(output.shape) # torch.Size([1, 1000])
```
### 9 PVT Usage
#### 9.1. Paper
[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/pdf/2106.13797.pdf)
#### 9.2. Usage Code
```python
from model.backbone.PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 10 CPVT Usage
#### 10.1. Paper
[Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
#### 10.2. Usage Code
```python
from model.backbone.CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 11 PIT Usage
#### 11.1. Paper
[Rethinking Spatial Dimensions of Vision Transformers](https://arxiv.org/abs/2103.16302)
#### 11.2. Usage Code
```python
from model.backbone.PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4
)
output=model(input)
print(output.shape)
```
### 12 CrossViT Usage
#### 12.1. Paper
[CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification](https://arxiv.org/abs/2103.14899)
#### 12.2. Usage Code
```python
from model.backbone.CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__":
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[240, 224],
patch_size=[12, 16],
embed_dim=[192, 384],
depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6],
mlp_ratio=[4, 4, 1],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 13 TnT Usage
#### 13.1. Paper
[Transformer in Transformer](https://arxiv.org/abs/2103.00112)
#### 13.2. Usage Code
```python
from model.backbone.TnT import TNT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = TNT(
img_size=224,
patch_size=16,
outer_dim=384,
inner_dim=24,
depth=12,
outer_num_heads=6,
inner_num_heads=4,
qkv_bias=False,
inner_stride=4)
output=model(input)
print(output.shape)
```
### 14 DViT Usage
#### 14.1. Paper
[DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
#### 14.2. Usage Code
```python
from model.backbone.DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DeepVisionTransformer(
patch_size=16, embed_dim=384,
depth=[False] * 16,
apply_transform=[False] * 0 + [True] * 32,
num_heads=12,
mlp_ratio=3,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
)
output=model(input)
print(output.shape)
```
### 15 CeiT Usage
#### 15.1. Paper
[Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
#### 15.2. Usage Code
```python
from model.backbone.CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CeIT(
hybrid_backbone=Image2Tokens(),
patch_size=4,
embed_dim=192,
depth=12,
num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 16 ConViT Usage
#### 16.1. Paper
[ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
#### 16.2. Usage Code
```python
from model.backbone.ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 17 CaiT Usage
#### 17.1. Paper
[Going deeper with Image Transformers](https://arxiv.org/abs/2103.17239)
#### 17.2. Usage Code
```python
from model.backbone.CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CaiT(
img_size= 224,
patch_size=16,
embed_dim=192,
depth=24,
num_heads=4,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2
)
output=model(input)
print(output.shape)
```
### 18 PatchConvnet Usage
#### 18.1. Paper
[Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
#### 18.2. Usage Code
```python
from model.backbone.PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
)
output=model(input)
print(output.shape)
```
### 19 DeiT Usage
#### 19.1. Paper
[Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
#### 19.2. Usage Code
```python
from model.backbone.DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DistilledVisionTransformer(
patch_size=16,
embed_dim=384,
depth=12,
num_heads=6,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output[0].shape)
```
### 20 LeViT Usage
#### 20.1. Paper
[LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
#### 20.2. Usage Code
```python
from model.backbone.LeViT import *
import torch
from torch import nn
if __name__ == '__main__':
for name in specification:
input=torch.randn(1,3,224,224)
model = globals()[name](fuse=True, pretrained=False)
model.eval()
output = model(input)
print(output.shape)
```
### 21 VOLO Usage
#### 21.1. Paper
[VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
#### 21.2. Usage Code
```python
from model.backbone.VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VOLO([4, 4, 8, 2],
embed_dims=[192, 384, 384, 384],
num_heads=[6, 12, 12, 12],
mlp_ratios=[3, 3, 3, 3],
downsamples=[True, False, False, False],
outlook_attention=[True, False, False, False ],
post_layers=['ca', 'ca'],
)
output=model(input)
print(output[0].shape)
```
### 22 Container Usage
#### 22.1. Paper
[Container: Context Aggregation Network](https://arxiv.org/abs/2106.01401)
#### 22.2. Usage Code
```python
from model.backbone.Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[224, 56, 28, 14],
patch_size=[4, 2, 2, 2],
embed_dim=[64, 128, 320, 512],
depth=[3, 4, 8, 3],
num_heads=16,
mlp_ratio=[8, 8, 4, 4],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6))
output=model(input)
print(output.shape)
```
### 23 CMT Usage
#### 23.1. Paper
[CMT: Convolutional Neural Networks Meet Vision Transformers](https://arxiv.org/abs/2107.06263)
#### 23.2. Usage Code
```python
from model.backbone.CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CMT_Tiny()
output=model(input)
print(output[0].shape)
```
# MLP Series
- Pytorch implementation of ["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition---arXiv 2021.05.05"](https://arxiv.org/pdf/2105.01883v1.pdf)
- Pytorch implementation of ["MLP-Mixer: An all-MLP Architecture for Vision---arXiv 2021.05.17"](https://arxiv.org/pdf/2105.01601.pdf)
- Pytorch implementation of ["ResMLP: Feedforward networks for image classification with data-efficient training---arXiv 2021.05.07"](https://arxiv.org/pdf/2105.03404.pdf)
- Pytorch implementation of ["Pay Attention to MLPs---arXiv 2021.05.17"](https://arxiv.org/abs/2105.08050)
- Pytorch implementation of ["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?---arXiv 2021.09.12"](https://arxiv.org/abs/2109.05422)
### 1. RepMLP Usage
#### 1.1. Paper
["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition"](https://arxiv.org/pdf/2105.01883v1.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.mlp.repmlp import RepMLP
import torch
from torch import nn
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())
```
### 2. MLP-Mixer Usage
#### 2.1. Paper
["MLP-Mixer: An all-MLP Architecture for Vision"](https://arxiv.org/pdf/2105.01601.pdf)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.mlp.mlp_mixer import MlpMixer
import torch
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)
```
***
### 3. ResMLP Usage
#### 3.1. Paper
["ResMLP: Feedforward networks for image classification with data-efficient training"](https://arxiv.org/pdf/2105.03404.pdf)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.mlp.resmlp import ResMLP
import torch
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape) #the last dimention is class_num
```
***
### 4. gMLP Usage
#### 4.1. Paper
["Pay Attention to MLPs"](https://arxiv.org/abs/2105.08050)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.mlp.g_mlp import gMLP
import torch
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)
```
***
### 5. sMLP Usage
#### 5.1. Paper
["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?"](https://arxiv.org/abs/2109.05422)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.mlp.sMLP_block import sMLPBlock
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
smlp=sMLPBlock(h=224,w=224)
out=smlp(input)
print(out.shape)
```
### 6. vip-mlp Usage
#### 6.1. Paper
["Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 6.2. Usage Code
```python
from model.mlp.vip-mlp import VisionPermutator
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionPermutator(
layers=[4, 3, 8, 3],
embed_dims=[384, 384, 384, 384],
patch_size=14,
transitions=[False, False, False, False],
segment_dim=[16, 16, 16, 16],
mlp_ratios=[3, 3, 3, 3],
mlp_fn=WeightedPermuteMLP
)
output=model(input)
print(output.shape)
```
# Re-Parameter Series
- Pytorch implementation of ["RepVGG: Making VGG-style ConvNets Great Again---CVPR2021"](https://arxiv.org/abs/2101.03697)
- Pytorch implementation of ["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks---ICCV2019"](https://arxiv.org/abs/1908.03930)
- Pytorch implementation of ["Diverse Branch Block: Building a Convolution as an Inception-like Unit---CVPR2021"](https://arxiv.org/abs/2103.13425)
***
### 1. RepVGG Usage
#### 1.1. Paper
["RepVGG: Making VGG-style ConvNets Great Again"](https://arxiv.org/abs/2101.03697)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
```
***
### 2. ACNet Usage
#### 2.1. Paper
["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks"](https://arxiv.org/abs/1908.03930)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
```
***
### 2. Diverse Branch Block Usage
#### 2.1. Paper
["Diverse Branch Block: Building a Convolution as an Inception-like Unit"](https://arxiv.org/abs/2103.13425)
#### 2.2. Overview

#### 2.3. Usage Code
##### 2.3.1 Transform I
```python
from model.rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.2 Transform II
```python
from model.rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.3 Transform III
```python
from model.rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.4 Transform IV
```python
from model.rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.5 Transform V
```python
from model.rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.6 Transform VI
```python
from model.rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
# Convolution Series
- Pytorch implementation of ["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications---CVPR2017"](https://arxiv.org/abs/1704.04861)
- Pytorch implementation of ["Efficientnet: Rethinking model scaling for convolutional neural networks---PMLR2019"](http://proceedings.mlr.press/v97/tan19a.html)
- Pytorch implementation of ["Involution: Inverting the Inherence of Convolution for Visual Recognition---CVPR2021"](https://arxiv.org/abs/2103.06255)
- Pytorch implementation of ["Dynamic Convolution: Attention over Convolution Kernels---CVPR2020 Oral"](https://arxiv.org/abs/1912.03458)
- Pytorch implementation of ["CondConv: Conditionally Parameterized Convolutions for Efficient Inference---NeurIPS2019"](https://arxiv.org/abs/1904.04971)
***
### 1. Depthwise Separable Convolution Usage
#### 1.1. Paper
["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications"](https://arxiv.org/abs/1704.04861)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.conv.DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)
```
***
### 2. MBConv Usage
#### 2.1. Paper
["Efficientnet: Rethinking model scaling for convolutional neural networks"](http://proceedings.mlr.press/v97/tan19a.html)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.conv.MBConv import MBConvBlock
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=512,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 3. Involution Usage
#### 3.1. Paper
["Involution: Inverting the Inherence of Convolution for Visual Recognition"](https://arxiv.org/abs/2103.06255)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.conv.Involution import Involution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)
```
***
### 4. DynamicConv Usage
#### 4.1. Paper
["Dynamic Convolution: Attention over Convolution Kernels"](https://arxiv.org/abs/1912.03458)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.conv.DynamicConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape) # 2,32,64,64
```
***
### 5. CondConv Usage
#### 5.1. Paper
["CondConv: Conditionally Parameterized Convolutions for Efficient Inference"](https://arxiv.org/abs/1904.04971)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.conv.CondConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=CondConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
```
***
================================================
FILE: model/fighingcv.egg-info/SOURCES.txt
================================================
LICENSE
README.md
setup.py
model/fighingcv.egg-info/PKG-INFO
model/fighingcv.egg-info/SOURCES.txt
model/fighingcv.egg-info/dependency_links.txt
model/fighingcv.egg-info/entry_points.txt
model/fighingcv.egg-info/requires.txt
model/fighingcv.egg-info/top_level.txt
================================================
FILE: model/fighingcv.egg-info/dependency_links.txt
================================================
================================================
FILE: model/fighingcv.egg-info/entry_points.txt
================================================
[console_scripts]
huggingface-cli = huggingface_hub.commands.huggingface_cli:main
================================================
FILE: model/fighingcv.egg-info/requires.txt
================================================
filelock
requests
tqdm
pyyaml>=5.1
typing-extensions>=3.7.4.3
packaging>=20.9
[:python_version < "3.8"]
importlib_metadata
[all]
pytest
pytest-cov
datasets
soundfile
black==22.3
isort>=5.5.4
flake8>=3.8.3
flake8-bugbear
[dev]
pytest
pytest-cov
datasets
soundfile
black==22.3
isort>=5.5.4
flake8>=3.8.3
flake8-bugbear
[fastai]
toml
fastai>=2.4
fastcore>=1.3.27
[quality]
black==22.3
isort>=5.5.4
flake8>=3.8.3
flake8-bugbear
[tensorflow]
tensorflow
pydot
graphviz
[testing]
pytest
pytest-cov
datasets
soundfile
[torch]
torch
================================================
FILE: model/fighingcv.egg-info/top_level.txt
================================================
================================================
FILE: model/huggingface_hub.egg-info/PKG-INFO
================================================
Metadata-Version: 2.1
Name: huggingface-hub
Version: 1.0.0
Summary: Client library to download and publish models, datasets and other repos on the huggingface.co hub
Home-page: https://github.com/xmu-xiaoma666/External-Attention-pytorch
Author: Hugging Face, Inc.
Author-email: julien@huggingface.co
License: Apache
Keywords: model-hub machine-learning models natural-language-processing deep-learning pytorch pretrained-models
Platform: UNKNOWN
Classifier: Intended Audience :: Developers
Classifier: Intended Audience :: Education
Classifier: Intended Audience :: Science/Research
Classifier: License :: OSI Approved :: Apache Software License
Classifier: Operating System :: OS Independent
Classifier: Programming Language :: Python :: 3
Classifier: Topic :: Scientific/Engineering :: Artificial Intelligence
Requires-Python: >=3.7.0
Description-Content-Type: text/markdown
Provides-Extra: torch
Provides-Extra: fastai
Provides-Extra: tensorflow
Provides-Extra: testing
Provides-Extra: quality
Provides-Extra: all
Provides-Extra: dev
License-File: LICENSE
简体中文 | [English](./README_EN.md)
# FightingCV 代码库, 包含 [***Attention***](#attention-series),[***Backbone***](#backbone-series), [***MLP***](#mlp-series), [***Re-parameter***](#re-parameter-series), [**Convolution**](#convolution-series)



-------
🔥🔥🔥 **重磅!!!作为项目补充,最近全新开源了一个目标检测代码库 [YOLOAir](https://github.com/iscyy/yoloair),里面在目标检测算法中集成了各种Attention机制,代码简洁易读,欢迎大家来玩呀!**

-------
Hello,大家好,我是小马🚀🚀🚀
***For 小白(Like Me):***
最近在读论文的时候会发现一个问题,有时候论文核心思想非常简单,核心代码可能也就十几行。但是打开作者release的源码时,却发现提出的模块嵌入到分类、检测、分割等任务框架中,导致代码比较冗余,对于特定任务框架不熟悉的我,**很难找到核心代码**,导致在论文和网络思想的理解上会有一定困难。
***For 进阶者(Like You):***
如果把Conv、FC、RNN这些基本单元看做小的Lego积木,把Transformer、ResNet这些结构看成已经搭好的Lego城堡。那么本项目提供的模块就是一个个具有完整语义信息的Lego组件。**让科研工作者们避免反复造轮子**,只需思考如何利用这些“Lego组件”,搭建出更多绚烂多彩的作品。
***For 大神(May Be Like You):***
能力有限,**不喜轻喷**!!!
***For All:***
本项目就是要实现一个既能**让深度学习小白也能搞懂**,又能**服务科研和工业社区**的代码库。作为[**FightingCV公众号**](https://mp.weixin.qq.com/s/m9RiivbbDPdjABsTd6q8FA)的补充,本项目的宗旨是从代码角度,实现🚀**让世界上没有难读的论文**🚀。
(同时也非常欢迎各位科研工作者将自己的工作的核心代码整理到本项目中,推动科研社区的发展,会在readme中注明代码的作者~)
## 公众号 & 微信交流群
欢迎大家关注公众号:**FightingCV**
公众号**每天**都会进行**论文、算法和代码的干货分享**哦~
**每天在群里分享一些近期的论文和解析**,欢迎大家一起**学习交流**哈~~~
(加不进去可以加微信:**775629340**,记得备注【**公司/学校+方向+ID**】)

强烈推荐大家关注[**知乎**](https://www.zhihu.com/people/jason-14-58-38/posts)账号和[**FightingCV公众号**](https://mp.weixin.qq.com/s/m9RiivbbDPdjABsTd6q8FA),可以快速了解到最新优质的干货资源。
***
# 目录
- [Attention Series](#attention-series)
- [1. External Attention Usage](#1-external-attention-usage)
- [2. Self Attention Usage](#2-self-attention-usage)
- [3. Simplified Self Attention Usage](#3-simplified-self-attention-usage)
- [4. Squeeze-and-Excitation Attention Usage](#4-squeeze-and-excitation-attention-usage)
- [5. SK Attention Usage](#5-sk-attention-usage)
- [6. CBAM Attention Usage](#6-cbam-attention-usage)
- [7. BAM Attention Usage](#7-bam-attention-usage)
- [8. ECA Attention Usage](#8-eca-attention-usage)
- [9. DANet Attention Usage](#9-danet-attention-usage)
- [10. Pyramid Split Attention (PSA) Usage](#10-Pyramid-Split-Attention-Usage)
- [11. Efficient Multi-Head Self-Attention(EMSA) Usage](#11-Efficient-Multi-Head-Self-Attention-Usage)
- [12. Shuffle Attention Usage](#12-Shuffle-Attention-Usage)
- [13. MUSE Attention Usage](#13-MUSE-Attention-Usage)
- [14. SGE Attention Usage](#14-SGE-Attention-Usage)
- [15. A2 Attention Usage](#15-A2-Attention-Usage)
- [16. AFT Attention Usage](#16-AFT-Attention-Usage)
- [17. Outlook Attention Usage](#17-Outlook-Attention-Usage)
- [18. ViP Attention Usage](#18-ViP-Attention-Usage)
- [19. CoAtNet Attention Usage](#19-CoAtNet-Attention-Usage)
- [20. HaloNet Attention Usage](#20-HaloNet-Attention-Usage)
- [21. Polarized Self-Attention Usage](#21-Polarized-Self-Attention-Usage)
- [22. CoTAttention Usage](#22-CoTAttention-Usage)
- [23. Residual Attention Usage](#23-Residual-Attention-Usage)
- [24. S2 Attention Usage](#24-S2-Attention-Usage)
- [25. GFNet Attention Usage](#25-GFNet-Attention-Usage)
- [26. Triplet Attention Usage](#26-TripletAttention-Usage)
- [27. Coordinate Attention Usage](#27-Coordinate-Attention-Usage)
- [28. MobileViT Attention Usage](#28-MobileViT-Attention-Usage)
- [29. ParNet Attention Usage](#29-ParNet-Attention-Usage)
- [30. UFO Attention Usage](#30-UFO-Attention-Usage)
- [31. ACmix Attention Usage](#31-Acmix-Attention-Usage)
- [32. MobileViTv2 Attention Usage](#32-MobileViTv2-Attention-Usage)
- [33. DAT Attention Usage](#33-DAT-Attention-Usage)
- [34. CrossFormer Attention Usage](#34-CrossFormer-Attention-Usage)
- [35. MOATransformer Attention Usage](#35-MOATransformer-Attention-Usage)
- [36. CrissCrossAttention Attention Usage](#36-CrissCrossAttention-Attention-Usage)
- [37. Axial_attention Attention Usage](#37-Axial_attention-Attention-Usage)
- [Backbone Series](#Backbone-series)
- [1. ResNet Usage](#1-ResNet-Usage)
- [2. ResNeXt Usage](#2-ResNeXt-Usage)
- [3. MobileViT Usage](#3-MobileViT-Usage)
- [4. ConvMixer Usage](#4-ConvMixer-Usage)
- [5. ShuffleTransformer Usage](#5-ShuffleTransformer-Usage)
- [6. ConTNet Usage](#6-ConTNet-Usage)
- [7. HATNet Usage](#7-HATNet-Usage)
- [8. CoaT Usage](#8-CoaT-Usage)
- [9. PVT Usage](#9-PVT-Usage)
- [10. CPVT Usage](#10-CPVT-Usage)
- [11. PIT Usage](#11-PIT-Usage)
- [12. CrossViT Usage](#12-CrossViT-Usage)
- [13. TnT Usage](#13-TnT-Usage)
- [14. DViT Usage](#14-DViT-Usage)
- [15. CeiT Usage](#15-CeiT-Usage)
- [16. ConViT Usage](#16-ConViT-Usage)
- [17. CaiT Usage](#17-CaiT-Usage)
- [18. PatchConvnet Usage](#18-PatchConvnet-Usage)
- [19. DeiT Usage](#19-DeiT-Usage)
- [20. LeViT Usage](#20-LeViT-Usage)
- [21. VOLO Usage](#21-VOLO-Usage)
- [22. Container Usage](#22-Container-Usage)
- [23. CMT Usage](#23-CMT-Usage)
- [MLP Series](#mlp-series)
- [1. RepMLP Usage](#1-RepMLP-Usage)
- [2. MLP-Mixer Usage](#2-MLP-Mixer-Usage)
- [3. ResMLP Usage](#3-ResMLP-Usage)
- [4. gMLP Usage](#4-gMLP-Usage)
- [5. sMLP Usage](#5-sMLP-Usage)
- [6. vip-mlp Usage](#6-vip-mlp-Usage)
- [Re-Parameter(ReP) Series](#Re-Parameter-series)
- [1. RepVGG Usage](#1-RepVGG-Usage)
- [2. ACNet Usage](#2-ACNet-Usage)
- [3. Diverse Branch Block(DDB) Usage](#3-Diverse-Branch-Block-Usage)
- [Convolution Series](#Convolution-series)
- [1. Depthwise Separable Convolution Usage](#1-Depthwise-Separable-Convolution-Usage)
- [2. MBConv Usage](#2-MBConv-Usage)
- [3. Involution Usage](#3-Involution-Usage)
- [4. DynamicConv Usage](#4-DynamicConv-Usage)
- [5. CondConv Usage](#5-CondConv-Usage)
***
# Attention Series
- Pytorch implementation of ["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks---arXiv 2021.05.05"](https://arxiv.org/abs/2105.02358)
- Pytorch implementation of ["Attention Is All You Need---NIPS2017"](https://arxiv.org/pdf/1706.03762.pdf)
- Pytorch implementation of ["Squeeze-and-Excitation Networks---CVPR2018"](https://arxiv.org/abs/1709.01507)
- Pytorch implementation of ["Selective Kernel Networks---CVPR2019"](https://arxiv.org/pdf/1903.06586.pdf)
- Pytorch implementation of ["CBAM: Convolutional Block Attention Module---ECCV2018"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
- Pytorch implementation of ["BAM: Bottleneck Attention Module---BMCV2018"](https://arxiv.org/pdf/1807.06514.pdf)
- Pytorch implementation of ["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020"](https://arxiv.org/pdf/1910.03151.pdf)
- Pytorch implementation of ["Dual Attention Network for Scene Segmentation---CVPR2019"](https://arxiv.org/pdf/1809.02983.pdf)
- Pytorch implementation of ["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30"](https://arxiv.org/pdf/2105.14447.pdf)
- Pytorch implementation of ["ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28"](https://arxiv.org/abs/2105.13677)
- Pytorch implementation of ["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS---ICASSP 2021"](https://arxiv.org/pdf/2102.00240.pdf)
- Pytorch implementation of ["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning---arXiv 2019.11.17"](https://arxiv.org/abs/1911.09483)
- Pytorch implementation of ["Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks---arXiv 2019.05.23"](https://arxiv.org/pdf/1905.09646.pdf)
- Pytorch implementation of ["A2-Nets: Double Attention Networks---NIPS2018"](https://arxiv.org/pdf/1810.11579.pdf)
- Pytorch implementation of ["An Attention Free Transformer---ICLR2021 (Apple New Work)"](https://arxiv.org/pdf/2105.14103v1.pdf)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition---arXiv 2021.06.24"](https://arxiv.org/abs/2106.13112)
[【论文解析】](https://zhuanlan.zhihu.com/p/385561050)
- Pytorch implementation of [Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition---arXiv 2021.06.23](https://arxiv.org/abs/2106.12368)
[【论文解析】](https://mp.weixin.qq.com/s/5gonUQgBho_m2O54jyXF_Q)
- Pytorch implementation of [CoAtNet: Marrying Convolution and Attention for All Data Sizes---arXiv 2021.06.09](https://arxiv.org/abs/2106.04803)
[【论文解析】](https://zhuanlan.zhihu.com/p/385578588)
- Pytorch implementation of [Scaling Local Self-Attention for Parameter Efficient Visual Backbones---CVPR2021 Oral](https://arxiv.org/pdf/2103.12731.pdf) [【论文解析】](https://zhuanlan.zhihu.com/p/388598744)
- Pytorch implementation of [Polarized Self-Attention: Towards High-quality Pixel-wise Regression---arXiv 2021.07.02](https://arxiv.org/abs/2107.00782) [【论文解析】](https://zhuanlan.zhihu.com/p/389770482)
- Pytorch implementation of [Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292) [【论文解析】](https://zhuanlan.zhihu.com/p/394795481)
- Pytorch implementation of [Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
- Pytorch implementation of [S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072) [【论文解析】](https://zhuanlan.zhihu.com/p/397003638)
- Pytorch implementation of [Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
- Pytorch implementation of [Rotate to Attend: Convolutional Triplet Attention Module---WACV 2021](https://arxiv.org/abs/2010.03045)
- Pytorch implementation of [Coordinate Attention for Efficient Mobile Network Design ---CVPR 2021](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2110.02178)
- Pytorch implementation of [Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
- Pytorch implementation of [UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2109.14382)
- Pytorch implementation of [Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
- Pytorch implementation of [On the Integration of Self-Attention and Convolution---ArXiv 2022.03.14](https://arxiv.org/pdf/2111.14556.pdf)
- Pytorch implementation of [CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
- Pytorch implementation of [Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
- Pytorch implementation of [CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
- Pytorch implementation of [Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
***
### 1. External Attention Usage
#### 1.1. Paper
["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks"](https://arxiv.org/abs/2105.02358)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
***
### 2. Self Attention Usage
#### 2.1. Paper
["Attention Is All You Need"](https://arxiv.org/pdf/1706.03762.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 3. Simplified Self Attention Usage
#### 3.1. Paper
[None]()
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)
```
***
### 4. Squeeze-and-Excitation Attention Usage
#### 4.1. Paper
["Squeeze-and-Excitation Networks"](https://arxiv.org/abs/1709.01507)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 5. SK Attention Usage
#### 5.1. Paper
["Selective Kernel Networks"](https://arxiv.org/pdf/1903.06586.pdf)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 6. CBAM Attention Usage
#### 6.1. Paper
["CBAM: Convolutional Block Attention Module"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
#### 6.2. Overview


#### 6.3. Usage Code
```python
from model.attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
***
### 7. BAM Attention Usage
#### 7.1. Paper
["BAM: Bottleneck Attention Module"](https://arxiv.org/pdf/1807.06514.pdf)
#### 7.2. Overview

#### 7.3. Usage Code
```python
from model.attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
***
### 8. ECA Attention Usage
#### 8.1. Paper
["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks"](https://arxiv.org/pdf/1910.03151.pdf)
#### 8.2. Overview

#### 8.3. Usage Code
```python
from model.attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
***
### 9. DANet Attention Usage
#### 9.1. Paper
["Dual Attention Network for Scene Segmentation"](https://arxiv.org/pdf/1809.02983.pdf)
#### 9.2. Overview

#### 9.3. Usage Code
```python
from model.attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
***
### 10. Pyramid Split Attention Usage
#### 10.1. Paper
["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network"](https://arxiv.org/pdf/2105.14447.pdf)
#### 10.2. Overview

#### 10.3. Usage Code
```python
from model.attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
***
### 11. Efficient Multi-Head Self-Attention Usage
#### 11.1. Paper
["ResT: An Efficient Transformer for Visual Recognition"](https://arxiv.org/abs/2105.13677)
#### 11.2. Overview

#### 11.3. Usage Code
```python
from model.attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
***
### 12. Shuffle Attention Usage
#### 12.1. Paper
["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS"](https://arxiv.org/pdf/2102.00240.pdf)
#### 12.2. Overview

#### 12.3. Usage Code
```python
from model.attention.ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
```
***
### 13. MUSE Attention Usage
#### 13.1. Paper
["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning"](https://arxiv.org/abs/1911.09483)
#### 13.2. Overview

#### 13.3. Usage Code
```python
from model.attention.MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 14. SGE Attention Usage
#### 14.1. Paper
[Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks](https://arxiv.org/pdf/1905.09646.pdf)
#### 14.2. Overview

#### 14.3. Usage Code
```python
from model.attention.SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
```
***
### 15. A2 Attention Usage
#### 15.1. Paper
[A2-Nets: Double Attention Networks](https://arxiv.org/pdf/1810.11579.pdf)
#### 15.2. Overview

#### 15.3. Usage Code
```python
from model.attention.A2Atttention import DoubleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
```
### 16. AFT Attention Usage
#### 16.1. Paper
[An Attention Free Transformer](https://arxiv.org/pdf/2105.14103v1.pdf)
#### 16.2. Overview

#### 16.3. Usage Code
```python
from model.attention.AFT import AFT_FULL
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
```
### 17. Outlook Attention Usage
#### 17.1. Paper
[VOLO: Vision Outlooker for Visual Recognition"](https://arxiv.org/abs/2106.13112)
#### 17.2. Overview

#### 17.3. Usage Code
```python
from model.attention.OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)
```
***
### 18. ViP Attention Usage
#### 18.1. Paper
[Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 18.2. Overview

#### 18.3. Usage Code
```python
from model.attention.ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)
```
***
### 19. CoAtNet Attention Usage
#### 19.1. Paper
[CoAtNet: Marrying Convolution and Attention for All Data Sizes"](https://arxiv.org/abs/2106.04803)
#### 19.2. Overview
None
#### 19.3. Usage Code
```python
from model.attention.CoAtNet import CoAtNet
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=CoAtNet(in_ch=3,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 20. HaloNet Attention Usage
#### 20.1. Paper
[Scaling Local Self-Attention for Parameter Efficient Visual Backbones"](https://arxiv.org/pdf/2103.12731.pdf)
#### 20.2. Overview

#### 20.3. Usage Code
```python
from model.attention.HaloAttention import HaloAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)
```
***
### 21. Polarized Self-Attention Usage
#### 21.1. Paper
[Polarized Self-Attention: Towards High-quality Pixel-wise Regression"](https://arxiv.org/abs/2107.00782)
#### 21.2. Overview

#### 21.3. Usage Code
```python
from model.attention.PolarizedSelfAttention import ParallelPolarizedSelfAttention,SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
```
***
### 22. CoTAttention Usage
#### 22.1. Paper
[Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292)
#### 22.2. Overview

#### 22.3. Usage Code
```python
from model.attention.CoTAttention import CoTAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
```
***
### 23. Residual Attention Usage
#### 23.1. Paper
[Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
#### 23.2. Overview

#### 23.3. Usage Code
```python
from model.attention.ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
resatt = ResidualAttention(channel=512,num_class=1000,la=0.2)
output=resatt(input)
print(output.shape)
```
***
### 24. S2 Attention Usage
#### 24.1. Paper
[S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072)
#### 24.2. Overview

#### 24.3. Usage Code
```python
from model.attention.S2Attention import S2Attention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
s2att = S2Attention(channels=512)
output=s2att(input)
print(output.shape)
```
***
### 25. GFNet Attention Usage
#### 25.1. Paper
[Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
#### 25.2. Overview

#### 25.3. Usage Code - Implemented by [Wenliang Zhao (Author)](https://scholar.google.com/citations?user=lyPWvuEAAAAJ&hl=en)
```python
from model.attention.gfnet import GFNet
import torch
from torch import nn
from torch.nn import functional as F
x = torch.randn(1, 3, 224, 224)
gfnet = GFNet(embed_dim=384, img_size=224, patch_size=16, num_classes=1000)
out = gfnet(x)
print(out.shape)
```
***
### 26. TripletAttention Usage
#### 26.1. Paper
[Rotate to Attend: Convolutional Triplet Attention Module---CVPR 2021](https://arxiv.org/abs/2010.03045)
#### 26.2. Overview

#### 26.3. Usage Code - Implemented by [digantamisra98](https://github.com/digantamisra98)
```python
from model.attention.TripletAttention import TripletAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
triplet = TripletAttention()
output=triplet(input)
print(output.shape)
```
***
### 27. Coordinate Attention Usage
#### 27.1. Paper
[Coordinate Attention for Efficient Mobile Network Design---CVPR 2021](https://arxiv.org/abs/2103.02907)
#### 27.2. Overview

#### 27.3. Usage Code - Implemented by [Andrew-Qibin](https://github.com/Andrew-Qibin)
```python
from model.attention.CoordAttention import CoordAtt
import torch
from torch import nn
from torch.nn import functional as F
inp=torch.rand([2, 96, 56, 56])
inp_dim, oup_dim = 96, 96
reduction=32
coord_attention = CoordAtt(inp_dim, oup_dim, reduction=reduction)
output=coord_attention(inp)
print(output.shape)
```
***
### 28. MobileViT Attention Usage
#### 28.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2103.02907)
#### 28.2. Overview

#### 28.3. Usage Code
```python
from model.attention.MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
m=MobileViTAttention()
input=torch.randn(1,3,49,49)
output=m(input)
print(output.shape) #output:(1,3,49,49)
```
***
### 29. ParNet Attention Usage
#### 29.1. Paper
[Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
#### 29.2. Overview

#### 29.3. Usage Code
```python
from model.attention.ParNetAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
pna = ParNetAttention(channel=512)
output=pna(input)
print(output.shape) #50,512,7,7
```
***
### 30. UFO Attention Usage
#### 30.1. Paper
[UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2110.07641)
#### 30.2. Overview

#### 30.3. Usage Code
```python
from model.attention.UFOAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
ufo = UFOAttention(d_model=512, d_k=512, d_v=512, h=8)
output=ufo(input,input,input)
print(output.shape) #[50, 49, 512]
```
-
### 31. ACmix Attention Usage
#### 31.1. Paper
[On the Integration of Self-Attention and Convolution](https://arxiv.org/pdf/2111.14556.pdf)
#### 31.2. Usage Code
```python
from model.attention.ACmix import ACmix
import torch
if __name__ == '__main__':
input=torch.randn(50,256,7,7)
acmix = ACmix(in_planes=256, out_planes=256)
output=acmix(input)
print(output.shape)
```
### 32. MobileViTv2 Attention Usage
#### 32.1. Paper
[Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
#### 32.2. Overview

#### 32.3. Usage Code
```python
from model.attention.MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
### 33. DAT Attention Usage
#### 33.1. Paper
[Vision Transformer with Deformable Attention---CVPR2022](https://arxiv.org/abs/2201.00520)
#### 33.2. Usage Code
```python
from model.attention.DAT import DAT
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DAT(
img_size=224,
patch_size=4,
num_classes=1000,
expansion=4,
dim_stem=96,
dims=[96, 192, 384, 768],
depths=[2, 2, 6, 2],
stage_spec=[['L', 'S'], ['L', 'S'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7] ,
groups=[-1, -1, 3, 6],
use_pes=[False, False, True, True],
dwc_pes=[False, False, False, False],
strides=[-1, -1, 1, 1],
sr_ratios=[-1, -1, -1, -1],
offset_range_factor=[-1, -1, 2, 2],
no_offs=[False, False, False, False],
fixed_pes=[False, False, False, False],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
)
output=model(input)
print(output[0].shape)
```
### 34. CrossFormer Attention Usage
#### 34.1. Paper
[CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
#### 34.2. Usage Code
```python
from model.attention.Crossformer import CrossFormer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CrossFormer(img_size=224,
patch_size=[4, 8, 16, 32],
in_chans= 3,
num_classes=1000,
embed_dim=48,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
group_size=[7, 7, 7, 7],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False,
merge_size=[[2, 4], [2,4], [2, 4]]
)
output=model(input)
print(output.shape)
```
### 35. MOATransformer Attention Usage
#### 35.1. Paper
[Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
#### 35.2. Usage Code
```python
from model.attention.MOATransformer import MOATransformer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = MOATransformer(
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=[2, 2, 6],
num_heads=[3, 6, 12],
window_size=14,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False
)
output=model(input)
print(output.shape)
```
### 36. CrissCrossAttention Attention Usage
#### 36.1. Paper
[CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
#### 36.2. Usage Code
```python
from model.attention.CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = CrissCrossAttention(64)
outputs = model(input)
print(outputs.shape)
```
### 37. Axial_attention Attention Usage
#### 37.1. Paper
[Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
#### 37.2. Usage Code
```python
from model.attention.Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__':
input=torch.randn(3, 128, 7, 7)
model = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
outputs = model(input)
print(outputs.shape)
```
***
# Backbone Series
- Pytorch implementation of ["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
- Pytorch implementation of ["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
- Pytorch implementation of [Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer---ArXiv 2021.06.07](https://arxiv.org/abs/2106.03650)
- Pytorch implementation of [ConTNet: Why not use convolution and transformer at the same time?---ArXiv 2021.04.27](https://arxiv.org/abs/2104.13497)
- Pytorch implementation of [Vision Transformers with Hierarchical Attention---ArXiv 2022.06.15](https://arxiv.org/abs/2106.03180)
- Pytorch implementation of [Co-Scale Conv-Attentional Image Transformers---ArXiv 2021.08.26](https://arxiv.org/abs/2104.06399)
- Pytorch implementation of [Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
- Pytorch implementation of [Rethinking Spatial Dimensions of Vision Transformers---ICCV 2021](https://arxiv.org/abs/2103.16302)
- Pytorch implementation of [CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification---ICCV 2021](https://arxiv.org/abs/2103.14899)
- Pytorch implementation of [Transformer in Transformer---NeurIPS 2021](https://arxiv.org/abs/2103.00112)
- Pytorch implementation of [DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
- Pytorch implementation of [Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
***
- Pytorch implementation of [ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
- Pytorch implementation of [Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
- Pytorch implementation of [Going deeper with Image Transformers---ICCV 2021 (Oral)](https://arxiv.org/abs/2103.17239)
- Pytorch implementation of [Training data-efficient image transformers & distillation through attention---ICML 2021](https://arxiv.org/abs/2012.12877)
- Pytorch implementation of [LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
- Pytorch implementation of [Container: Context Aggregation Network---NeuIPS 2021](https://arxiv.org/abs/2106.01401)
- Pytorch implementation of [CMT: Convolutional Neural Networks Meet Vision Transformers---CVPR 2022](https://arxiv.org/abs/2107.06263)
- Pytorch implementation of [Vision Transformer with Deformable Attention---CVPR 2022](https://arxiv.org/abs/2201.00520)
### 1. ResNet Usage
#### 1.1. Paper
["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
#### 1.2. Overview


#### 1.3. Usage Code
```python
from model.backbone.resnet import ResNet50,ResNet101,ResNet152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnet50=ResNet50(1000)
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out=resnet50(input)
print(out.shape)
```
### 2. ResNeXt Usage
#### 2.1. Paper
["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.backbone.resnext import ResNeXt50,ResNeXt101,ResNeXt152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnext50=ResNeXt50(1000)
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out=resnext50(input)
print(out.shape)
```
### 3. MobileViT Usage
#### 3.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.backbone.MobileViT import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
### mobilevit_xxs
mvit_xxs=mobilevit_xxs()
out=mvit_xxs(input)
print(out.shape)
### mobilevit_xs
mvit_xs=mobilevit_xs()
out=mvit_xs(input)
print(out.shape)
### mobilevit_s
mvit_s=mobilevit_s()
out=mvit_s(input)
print(out.shape)
```
### 4. ConvMixer Usage
#### 4.1. Paper
[Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.backbone.ConvMixer import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
convmixer=ConvMixer(dim=512,depth=12)
out=convmixer(x)
print(out.shape) #[1, 1000]
```
### 5. ShuffleTransformer Usage
#### 5.1. Paper
[Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer](https://arxiv.org/pdf/2106.03650.pdf)
#### 5.2. Usage Code
```python
from model.backbone.ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
sft = ShuffleTransformer()
output=sft(input)
print(output.shape)
```
### 6. ConTNet Usage
#### 6.1. Paper
[ConTNet: Why not use convolution and transformer at the same time?](https://arxiv.org/abs/2104.13497)
#### 6.2. Usage Code
```python
from model.backbone.ConTNet import ConTNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == "__main__":
model = build_model(use_avgdown=True, relative=True, qkv_bias=True, pre_norm=True)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
```
### 7 HATNet Usage
#### 7.1. Paper
[Vision Transformers with Hierarchical Attention](https://arxiv.org/abs/2106.03180)
#### 7.2. Usage Code
```python
from model.backbone.HATNet import HATNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
hat = HATNet(dims=[48, 96, 240, 384], head_dim=48, expansions=[8, 8, 4, 4],
grid_sizes=[8, 7, 7, 1], ds_ratios=[8, 4, 2, 1], depths=[2, 2, 6, 3])
output=hat(input)
print(output.shape)
```
### 8 CoaT Usage
#### 8.1. Paper
[Co-Scale Conv-Attentional Image Transformers](https://arxiv.org/abs/2104.06399)
#### 8.2. Usage Code
```python
from model.backbone.CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4])
output=model(input)
print(output.shape) # torch.Size([1, 1000])
```
### 9 PVT Usage
#### 9.1. Paper
[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/pdf/2106.13797.pdf)
#### 9.2. Usage Code
```python
from model.backbone.PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 10 CPVT Usage
#### 10.1. Paper
[Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
#### 10.2. Usage Code
```python
from model.backbone.CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 11 PIT Usage
#### 11.1. Paper
[Rethinking Spatial Dimensions of Vision Transformers](https://arxiv.org/abs/2103.16302)
#### 11.2. Usage Code
```python
from model.backbone.PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4
)
output=model(input)
print(output.shape)
```
### 12 CrossViT Usage
#### 12.1. Paper
[CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification](https://arxiv.org/abs/2103.14899)
#### 12.2. Usage Code
```python
from model.backbone.CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__":
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[240, 224],
patch_size=[12, 16],
embed_dim=[192, 384],
depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6],
mlp_ratio=[4, 4, 1],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 13 TnT Usage
#### 13.1. Paper
[Transformer in Transformer](https://arxiv.org/abs/2103.00112)
#### 13.2. Usage Code
```python
from model.backbone.TnT import TNT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = TNT(
img_size=224,
patch_size=16,
outer_dim=384,
inner_dim=24,
depth=12,
outer_num_heads=6,
inner_num_heads=4,
qkv_bias=False,
inner_stride=4)
output=model(input)
print(output.shape)
```
### 14 DViT Usage
#### 14.1. Paper
[DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
#### 14.2. Usage Code
```python
from model.backbone.DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DeepVisionTransformer(
patch_size=16, embed_dim=384,
depth=[False] * 16,
apply_transform=[False] * 0 + [True] * 32,
num_heads=12,
mlp_ratio=3,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
)
output=model(input)
print(output.shape)
```
### 15 CeiT Usage
#### 15.1. Paper
[Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
#### 15.2. Usage Code
```python
from model.backbone.CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CeIT(
hybrid_backbone=Image2Tokens(),
patch_size=4,
embed_dim=192,
depth=12,
num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 16 ConViT Usage
#### 16.1. Paper
[ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
#### 16.2. Usage Code
```python
from model.backbone.ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 17 CaiT Usage
#### 17.1. Paper
[Going deeper with Image Transformers](https://arxiv.org/abs/2103.17239)
#### 17.2. Usage Code
```python
from model.backbone.CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CaiT(
img_size= 224,
patch_size=16,
embed_dim=192,
depth=24,
num_heads=4,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2
)
output=model(input)
print(output.shape)
```
### 18 PatchConvnet Usage
#### 18.1. Paper
[Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
#### 18.2. Usage Code
```python
from model.backbone.PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
)
output=model(input)
print(output.shape)
```
### 19 DeiT Usage
#### 19.1. Paper
[Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
#### 19.2. Usage Code
```python
from model.backbone.DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DistilledVisionTransformer(
patch_size=16,
embed_dim=384,
depth=12,
num_heads=6,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output[0].shape)
```
### 20 LeViT Usage
#### 20.1. Paper
[LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
#### 20.2. Usage Code
```python
from model.backbone.LeViT import *
import torch
from torch import nn
if __name__ == '__main__':
for name in specification:
input=torch.randn(1,3,224,224)
model = globals()[name](fuse=True, pretrained=False)
model.eval()
output = model(input)
print(output.shape)
```
### 21 VOLO Usage
#### 21.1. Paper
[VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
#### 21.2. Usage Code
```python
from model.backbone.VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VOLO([4, 4, 8, 2],
embed_dims=[192, 384, 384, 384],
num_heads=[6, 12, 12, 12],
mlp_ratios=[3, 3, 3, 3],
downsamples=[True, False, False, False],
outlook_attention=[True, False, False, False ],
post_layers=['ca', 'ca'],
)
output=model(input)
print(output[0].shape)
```
### 22 Container Usage
#### 22.1. Paper
[Container: Context Aggregation Network](https://arxiv.org/abs/2106.01401)
#### 22.2. Usage Code
```python
from model.backbone.Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[224, 56, 28, 14],
patch_size=[4, 2, 2, 2],
embed_dim=[64, 128, 320, 512],
depth=[3, 4, 8, 3],
num_heads=16,
mlp_ratio=[8, 8, 4, 4],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6))
output=model(input)
print(output.shape)
```
### 23 CMT Usage
#### 23.1. Paper
[CMT: Convolutional Neural Networks Meet Vision Transformers](https://arxiv.org/abs/2107.06263)
#### 23.2. Usage Code
```python
from model.backbone.CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CMT_Tiny()
output=model(input)
print(output[0].shape)
```
# MLP Series
- Pytorch implementation of ["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition---arXiv 2021.05.05"](https://arxiv.org/pdf/2105.01883v1.pdf)
- Pytorch implementation of ["MLP-Mixer: An all-MLP Architecture for Vision---arXiv 2021.05.17"](https://arxiv.org/pdf/2105.01601.pdf)
- Pytorch implementation of ["ResMLP: Feedforward networks for image classification with data-efficient training---arXiv 2021.05.07"](https://arxiv.org/pdf/2105.03404.pdf)
- Pytorch implementation of ["Pay Attention to MLPs---arXiv 2021.05.17"](https://arxiv.org/abs/2105.08050)
- Pytorch implementation of ["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?---arXiv 2021.09.12"](https://arxiv.org/abs/2109.05422)
### 1. RepMLP Usage
#### 1.1. Paper
["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition"](https://arxiv.org/pdf/2105.01883v1.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.mlp.repmlp import RepMLP
import torch
from torch import nn
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())
```
### 2. MLP-Mixer Usage
#### 2.1. Paper
["MLP-Mixer: An all-MLP Architecture for Vision"](https://arxiv.org/pdf/2105.01601.pdf)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.mlp.mlp_mixer import MlpMixer
import torch
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)
```
***
### 3. ResMLP Usage
#### 3.1. Paper
["ResMLP: Feedforward networks for image classification with data-efficient training"](https://arxiv.org/pdf/2105.03404.pdf)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.mlp.resmlp import ResMLP
import torch
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape) #the last dimention is class_num
```
***
### 4. gMLP Usage
#### 4.1. Paper
["Pay Attention to MLPs"](https://arxiv.org/abs/2105.08050)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.mlp.g_mlp import gMLP
import torch
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)
```
***
### 5. sMLP Usage
#### 5.1. Paper
["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?"](https://arxiv.org/abs/2109.05422)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.mlp.sMLP_block import sMLPBlock
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
smlp=sMLPBlock(h=224,w=224)
out=smlp(input)
print(out.shape)
```
### 6. vip-mlp Usage
#### 6.1. Paper
["Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 6.2. Usage Code
```python
from model.mlp.vip-mlp import VisionPermutator
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionPermutator(
layers=[4, 3, 8, 3],
embed_dims=[384, 384, 384, 384],
patch_size=14,
transitions=[False, False, False, False],
segment_dim=[16, 16, 16, 16],
mlp_ratios=[3, 3, 3, 3],
mlp_fn=WeightedPermuteMLP
)
output=model(input)
print(output.shape)
```
# Re-Parameter Series
- Pytorch implementation of ["RepVGG: Making VGG-style ConvNets Great Again---CVPR2021"](https://arxiv.org/abs/2101.03697)
- Pytorch implementation of ["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks---ICCV2019"](https://arxiv.org/abs/1908.03930)
- Pytorch implementation of ["Diverse Branch Block: Building a Convolution as an Inception-like Unit---CVPR2021"](https://arxiv.org/abs/2103.13425)
***
### 1. RepVGG Usage
#### 1.1. Paper
["RepVGG: Making VGG-style ConvNets Great Again"](https://arxiv.org/abs/2101.03697)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
```
***
### 2. ACNet Usage
#### 2.1. Paper
["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks"](https://arxiv.org/abs/1908.03930)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
```
***
### 2. Diverse Branch Block Usage
#### 2.1. Paper
["Diverse Branch Block: Building a Convolution as an Inception-like Unit"](https://arxiv.org/abs/2103.13425)
#### 2.2. Overview

#### 2.3. Usage Code
##### 2.3.1 Transform I
```python
from model.rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.2 Transform II
```python
from model.rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.3 Transform III
```python
from model.rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.4 Transform IV
```python
from model.rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.5 Transform V
```python
from model.rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.6 Transform VI
```python
from model.rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
# Convolution Series
- Pytorch implementation of ["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications---CVPR2017"](https://arxiv.org/abs/1704.04861)
- Pytorch implementation of ["Efficientnet: Rethinking model scaling for convolutional neural networks---PMLR2019"](http://proceedings.mlr.press/v97/tan19a.html)
- Pytorch implementation of ["Involution: Inverting the Inherence of Convolution for Visual Recognition---CVPR2021"](https://arxiv.org/abs/2103.06255)
- Pytorch implementation of ["Dynamic Convolution: Attention over Convolution Kernels---CVPR2020 Oral"](https://arxiv.org/abs/1912.03458)
- Pytorch implementation of ["CondConv: Conditionally Parameterized Convolutions for Efficient Inference---NeurIPS2019"](https://arxiv.org/abs/1904.04971)
***
### 1. Depthwise Separable Convolution Usage
#### 1.1. Paper
["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications"](https://arxiv.org/abs/1704.04861)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.conv.DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)
```
***
### 2. MBConv Usage
#### 2.1. Paper
["Efficientnet: Rethinking model scaling for convolutional neural networks"](http://proceedings.mlr.press/v97/tan19a.html)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.conv.MBConv import MBConvBlock
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=512,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 3. Involution Usage
#### 3.1. Paper
["Involution: Inverting the Inherence of Convolution for Visual Recognition"](https://arxiv.org/abs/2103.06255)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.conv.Involution import Involution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)
```
***
### 4. DynamicConv Usage
#### 4.1. Paper
["Dynamic Convolution: Attention over Convolution Kernels"](https://arxiv.org/abs/1912.03458)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.conv.DynamicConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape) # 2,32,64,64
```
***
### 5. CondConv Usage
#### 5.1. Paper
["CondConv: Conditionally Parameterized Convolutions for Efficient Inference"](https://arxiv.org/abs/1904.04971)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.conv.CondConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=CondConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
```
***
================================================
FILE: model/huggingface_hub.egg-info/SOURCES.txt
================================================
LICENSE
README.md
setup.py
model/huggingface_hub.egg-info/PKG-INFO
model/huggingface_hub.egg-info/SOURCES.txt
model/huggingface_hub.egg-info/dependency_links.txt
model/huggingface_hub.egg-info/entry_points.txt
model/huggingface_hub.egg-info/requires.txt
model/huggingface_hub.egg-info/top_level.txt
================================================
FILE: model/huggingface_hub.egg-info/dependency_links.txt
================================================
================================================
FILE: model/huggingface_hub.egg-info/entry_points.txt
================================================
[console_scripts]
huggingface-cli = huggingface_hub.commands.huggingface_cli:main
================================================
FILE: model/huggingface_hub.egg-info/requires.txt
================================================
filelock
requests
tqdm
pyyaml>=5.1
typing-extensions>=3.7.4.3
packaging>=20.9
[:python_version < "3.8"]
importlib_metadata
[all]
pytest
pytest-cov
datasets
soundfile
black==22.3
isort>=5.5.4
flake8>=3.8.3
flake8-bugbear
[dev]
pytest
pytest-cov
datasets
soundfile
black==22.3
isort>=5.5.4
flake8>=3.8.3
flake8-bugbear
[fastai]
toml
fastai>=2.4
fastcore>=1.3.27
[quality]
black==22.3
isort>=5.5.4
flake8>=3.8.3
flake8-bugbear
[tensorflow]
tensorflow
pydot
graphviz
[testing]
pytest
pytest-cov
datasets
soundfile
[torch]
torch
================================================
FILE: model/huggingface_hub.egg-info/top_level.txt
================================================
================================================
FILE: model/mlp/g_mlp.py
================================================
from collections import OrderedDict
import torch
from torch import nn
def exist(x):
return x is not None
class Residual(nn.Module):
def __init__(self,fn):
super().__init__()
self.fn=fn
def forward(self,x):
return self.fn(x)+x
class SpatialGatingUnit(nn.Module):
def __init__(self,dim,len_sen):
super().__init__()
self.ln=nn.LayerNorm(dim)
self.proj=nn.Conv1d(len_sen,len_sen,1)
nn.init.zeros_(self.proj.weight)
nn.init.ones_(self.proj.bias)
def forward(self,x):
res,gate=torch.chunk(x,2,-1) #bs,n,d_ff
###Norm
gate=self.ln(gate) #bs,n,d_ff
###Spatial Proj
gate=self.proj(gate) #bs,n,d_ff
return res*gate
class gMLP(nn.Module):
def __init__(self,num_tokens=None,len_sen=49,dim=512,d_ff=1024,num_layers=6):
super().__init__()
self.num_layers=num_layers
self.embedding=nn.Embedding(num_tokens,dim) if exist(num_tokens) else nn.Identity()
self.gmlp=nn.ModuleList([Residual(nn.Sequential(OrderedDict([
('ln1_%d'%i,nn.LayerNorm(dim)),
('fc1_%d'%i,nn.Linear(dim,d_ff*2)),
('gelu_%d'%i,nn.GELU()),
('sgu_%d'%i,SpatialGatingUnit(d_ff,len_sen)),
('fc2_%d'%i,nn.Linear(d_ff,dim)),
]))) for i in range(num_layers)])
self.to_logits=nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim,num_tokens),
nn.Softmax(-1)
)
def forward(self,x):
#embedding
embeded=self.embedding(x)
#gMLP
y=nn.Sequential(*self.gmlp)(embeded)
#to logits
logits=self.to_logits(y)
return logits
if __name__ == '__main__':
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)
================================================
FILE: model/mlp/mlp_mixer.py
================================================
import torch
from torch import nn
class MlpBlock(nn.Module):
def __init__(self,input_dim,mlp_dim=512) :
super().__init__()
self.fc1=nn.Linear(input_dim,mlp_dim)
self.gelu=nn.GELU()
self.fc2=nn.Linear(mlp_dim,input_dim)
def forward(self,x):
#x: (bs,tokens,channels) or (bs,channels,tokens)
return self.fc2(self.gelu(self.fc1(x)))
class MixerBlock(nn.Module):
def __init__(self,tokens_mlp_dim=16,channels_mlp_dim=1024,tokens_hidden_dim=32,channels_hidden_dim=1024):
super().__init__()
self.ln=nn.LayerNorm(channels_mlp_dim)
self.tokens_mlp_block=MlpBlock(tokens_mlp_dim,mlp_dim=tokens_hidden_dim)
self.channels_mlp_block=MlpBlock(channels_mlp_dim,mlp_dim=channels_hidden_dim)
def forward(self,x):
"""
x: (bs,tokens,channels)
"""
### tokens mixing
y=self.ln(x)
y=y.transpose(1,2) #(bs,channels,tokens)
y=self.tokens_mlp_block(y) #(bs,channels,tokens)
### channels mixing
y=y.transpose(1,2) #(bs,tokens,channels)
out =x+y #(bs,tokens,channels)
y=self.ln(out) #(bs,tokens,channels)
y=out+self.channels_mlp_block(y) #(bs,tokens,channels)
return y
class MlpMixer(nn.Module):
def __init__(self,num_classes,num_blocks,patch_size,tokens_hidden_dim,channels_hidden_dim,tokens_mlp_dim,channels_mlp_dim):
super().__init__()
self.num_classes=num_classes
self.num_blocks=num_blocks #num of mlp layers
self.patch_size=patch_size
self.tokens_mlp_dim=tokens_mlp_dim
self.channels_mlp_dim=channels_mlp_dim
self.embd=nn.Conv2d(3,channels_mlp_dim,kernel_size=patch_size,stride=patch_size)
self.ln=nn.LayerNorm(channels_mlp_dim)
self.mlp_blocks=[]
for _ in range(num_blocks):
self.mlp_blocks.append(MixerBlock(tokens_mlp_dim,channels_mlp_dim,tokens_hidden_dim,channels_hidden_dim))
self.fc=nn.Linear(channels_mlp_dim,num_classes)
def forward(self,x):
y=self.embd(x) # bs,channels,h,w
bs,c,h,w=y.shape
y=y.view(bs,c,-1).transpose(1,2) # bs,tokens,channels
if(self.tokens_mlp_dim!=y.shape[1]):
raise ValueError('Tokens_mlp_dim is not correct.')
for i in range(self.num_blocks):
y=self.mlp_blocks[i](y) # bs,tokens,channels
y=self.ln(y) # bs,tokens,channels
y=torch.mean(y,dim=1,keepdim=False) # bs,channels
probs=self.fc(y) # bs,num_classes
return probs
if __name__ == '__main__':
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)
================================================
FILE: model/mlp/repmlp.py
================================================
import torch
from torch import nn
from collections import OrderedDict
from torch.nn import functional as F
import numpy as np
from numpy import random
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
class RepMLP(nn.Module):
def __init__(self,C,O,H,W,h,w,fc1_fc2_reduction=1,fc3_groups=8,repconv_kernels=None,deploy=False):
super().__init__()
self.C=C
self.O=O
self.H=H
self.W=W
self.h=h
self.w=w
self.fc1_fc2_reduction=fc1_fc2_reduction
self.repconv_kernels=repconv_kernels
self.h_part=H//h
self.w_part=W//w
self.deploy=deploy
self.fc3_groups=fc3_groups
# make sure H,W can divided by h,w respectively
assert H%h==0
assert W%w==0
self.is_global_perceptron= (H!=h) or (W!=w)
### global perceptron
if(self.is_global_perceptron):
if(not self.deploy):
self.avg=nn.Sequential(OrderedDict([
('avg',nn.AvgPool2d(kernel_size=(self.h,self.w))),
('bn',nn.BatchNorm2d(num_features=C))
])
)
else:
self.avg=nn.AvgPool2d(kernel_size=(self.h,self.w))
hidden_dim=self.C//self.fc1_fc2_reduction
self.fc1_fc2=nn.Sequential(OrderedDict([
('fc1',nn.Linear(C*self.h_part*self.w_part,hidden_dim)),
('relu',nn.ReLU()),
('fc2',nn.Linear(hidden_dim,C*self.h_part*self.w_part))
])
)
self.fc3=nn.Conv2d(self.C*self.h*self.w,self.O*self.h*self.w,kernel_size=1,groups=fc3_groups,bias=self.deploy)
self.fc3_bn=nn.Identity() if self.deploy else nn.BatchNorm2d(self.O*self.h*self.w)
if not self.deploy and self.repconv_kernels is not None:
for k in self.repconv_kernels:
repconv=nn.Sequential(OrderedDict([
('conv',nn.Conv2d(self.C,self.O,kernel_size=k,padding=(k-1)//2, groups=fc3_groups,bias=False)),
('bn',nn.BatchNorm2d(self.O))
])
)
self.__setattr__('repconv{}'.format(k),repconv)
def switch_to_deploy(self):
self.deploy=True
fc1_weight,fc1_bias,fc3_weight,fc3_bias=self.get_equivalent_fc1_fc3_params()
#del conv
if(self.repconv_kernels is not None):
for k in self.repconv_kernels:
self.__delattr__('repconv{}'.format(k))
#del fc3,bn
self.__delattr__('fc3')
self.__delattr__('fc3_bn')
self.fc3 = nn.Conv2d(self.C * self.h * self.w, self.O * self.h * self.w, 1, 1, 0, bias=True, groups=self.fc3_groups)
self.fc3_bn = nn.Identity()
# Remove the BN after AVG
if self.is_global_perceptron:
self.__delattr__('avg')
self.avg = nn.AvgPool2d(kernel_size=(self.h, self.w))
# Set values
if fc1_weight is not None:
self.fc1_fc2.fc1.weight.data = fc1_weight
self.fc1_fc2.fc1.bias.data = fc1_bias
self.fc3.weight.data = fc3_weight
self.fc3.bias.data = fc3_bias
def get_equivalent_fc1_fc3_params(self):
#training fc3+bn weight
fc_weight,fc_bias=self._fuse_bn(self.fc3,self.fc3_bn)
#training conv weight
if(self.repconv_kernels is not None):
max_kernel=max(self.repconv_kernels)
max_branch=self.__getattr__('repconv{}'.format(max_kernel))
conv_weight,conv_bias=self._fuse_bn(max_branch.conv,max_branch.bn)
for k in self.repconv_kernels:
if(k!=max_kernel):
tmp_branch=self.__getattr__('repconv{}'.format(k))
tmp_weight,tmp_bias=self._fuse_bn(tmp_branch.conv,tmp_branch.bn)
tmp_weight=F.pad(tmp_weight,[(max_kernel-k)//2]*4)
conv_weight+=tmp_weight
conv_bias+=tmp_bias
repconv_weight,repconv_bias=self._conv_to_fc(conv_weight,conv_bias)
final_fc3_weight=fc_weight+repconv_weight.reshape_as(fc_weight)
final_fc3_bias=fc_bias+repconv_bias
else:
final_fc3_weight=fc_weight
final_fc3_bias=fc_bias
#fc1
if(self.is_global_perceptron):
#remove BN after avg
avgbn = self.avg.bn
std = (avgbn.running_var + avgbn.eps).sqrt()
scale = avgbn.weight / std
avgbias = avgbn.bias - avgbn.running_mean * scale
fc1 = self.fc1_fc2.fc1
replicate_times = fc1.in_features // len(avgbias)
replicated_avgbias = avgbias.repeat_interleave(replicate_times).view(-1, 1)
bias_diff = fc1.weight.matmul(replicated_avgbias).squeeze()
final_fc1_bias = fc1.bias + bias_diff
final_fc1_weight = fc1.weight * scale.repeat_interleave(replicate_times).view(1, -1)
else:
final_fc1_weight=None
final_fc1_bias=None
return final_fc1_weight,final_fc1_bias,final_fc3_weight,final_fc3_bias
# def _conv_to_fc(self,weight,bias):
# i_maxtrix=torch.eye(self.C*self.h*self.w//self.fc3_groups).repeat(1,self.fc3_groups).reshape(self.C*self.h*self.w//self.fc3_groups,self.C,self.h,self.w)
# fc_weight=F.conv2d(i_maxtrix,weight=weight,bias=bias,padding=weight.shape[2]//2,groups=self.fc3_groups)
# fc_weight=fc_weight.reshape(self.C*self.h*self.w//self.fc3_groups,-1)
# fc_bias = bias.repeat_interleave(self.h * self.w)
# return fc_weight,fc_bias
def _conv_to_fc(self,conv_kernel, conv_bias):
I = torch.eye(self.C * self.h * self.w // self.fc3_groups).repeat(1, self.fc3_groups).reshape(self.C * self.h * self.w // self.fc3_groups, self.C, self.h, self.w).to(conv_kernel.device)
fc_k = F.conv2d(I, conv_kernel, padding=conv_kernel.size(2)//2, groups=self.fc3_groups)
fc_k = fc_k.reshape(self.C * self.h * self.w // self.fc3_groups, self.O * self.h * self.w).t()
fc_bias = conv_bias.repeat_interleave(self.h * self.w)
return fc_k, fc_bias
def _fuse_bn(self, conv_or_fc, bn):
std = (bn.running_var + bn.eps).sqrt()
t = bn.weight / std
if conv_or_fc.weight.ndim == 4:
t = t.reshape(-1, 1, 1, 1)
else:
t = t.reshape(-1, 1)
return conv_or_fc.weight * t, bn.bias - bn.running_mean * bn.weight / std
def forward(self,x) :
### global partition
if(self.is_global_perceptron):
input=x
v=self.avg(x) #bs,C,h_part,w_part
v=v.reshape(-1,self.C*self.h_part*self.w_part) #bs,C*h_part*w_part
v=self.fc1_fc2(v) #bs,C*h_part*w_part
v=v.reshape(-1,self.C,self.h_part,1,self.w_part,1) #bs,C,h_part,w_part
input=input.reshape(-1,self.C,self.h_part,self.h,self.w_part,self.w) #bs,C,h_part,h,w_part,w
input=v+input
else:
input=x.view(-1,self.C,self.h_part,self.h,self.w_part,self.w) #bs,C,h_part,h,w_part,w
partition=input.permute(0,2,4,1,3,5) #bs,h_part,w_part,C,h,w
### partition partition
fc3_out=partition.reshape(-1,self.C*self.h*self.w,1,1) #bs*h_part*w_part,C*h*w,1,1
fc3_out=self.fc3_bn(self.fc3(fc3_out)) #bs*h_part*w_part,O*h*w,1,1
fc3_out=fc3_out.reshape(-1,self.h_part,self.w_part,self.O,self.h,self.w) #bs,h_part,w_part,O,h,w
### local perceptron
if(self.repconv_kernels is not None and not self.deploy):
conv_input=partition.reshape(-1,self.C,self.h,self.w) #bs*h_part*w_part,C,h,w
conv_out=0
for k in self.repconv_kernels:
repconv=self.__getattr__('repconv{}'.format(k))
conv_out+=repconv(conv_input) ##bs*h_part*w_part,O,h,w
conv_out=conv_out.view(-1,self.h_part,self.w_part,self.O,self.h,self.w) #bs,h_part,w_part,O,h,w
fc3_out+=conv_out
fc3_out=fc3_out.permute(0,3,1,4,2,5)#bs,O,h_part,h,w_part,w
fc3_out=fc3_out.reshape(-1,self.C,self.H,self.W) #bs,O,H,W
return fc3_out
if __name__ == '__main__':
setup_seed(20)
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())
================================================
FILE: model/mlp/resmlp.py
================================================
import torch
from torch import nn
class Rearange(nn.Module):
def __init__(self,image_size=14,patch_size=7) :
self.h=patch_size
self.w=patch_size
self.nw=image_size // patch_size
self.nh=image_size // patch_size
num_patches = (image_size // patch_size) ** 2
super().__init__()
def forward(self,x):
### bs,c,H,W
bs,c,H,W=x.shape
y=x.reshape(bs,c,self.h,self.nh,self.w,self.nw)
y=y.permute(0,3,5,2,4,1) #bs,nh,nw,h,w,c
y=y.contiguous().view(bs,self.nh*self.nw,-1) #bs,nh*nw,h*w*c
return y
class Affine(nn.Module):
def __init__(self, channel):
super().__init__()
self.g = nn.Parameter(torch.ones(1, 1, channel))
self.b = nn.Parameter(torch.zeros(1, 1, channel))
def forward(self, x):
return x * self.g + self.b
class PreAffinePostLayerScale(nn.Module): # https://arxiv.org/abs/2103.17239
def __init__(self, dim, depth, fn):
super().__init__()
if depth <= 18:
init_eps = 0.1
elif depth > 18 and depth <= 24:
init_eps = 1e-5
else:
init_eps = 1e-6
scale = torch.zeros(1, 1, dim).fill_(init_eps)
self.scale = nn.Parameter(scale)
self.affine = Affine(dim)
self.fn = fn
def forward(self, x):
return self.fn(self.affine(x)) * self.scale + x
class ResMLP(nn.Module):
def __init__(self,dim=128,image_size=14,patch_size=7,expansion_factor=4,depth=4,class_num=1000):
super().__init__()
self.flatten=Rearange(image_size,patch_size)
num_patches = (image_size // patch_size) ** 2
wrapper = lambda i, fn: PreAffinePostLayerScale(dim, i + 1, fn)
self.embedding=nn.Linear((patch_size ** 2) * 3, dim)
self.mlp=nn.Sequential()
for i in range(depth):
self.mlp.add_module('fc1_%d'%i,wrapper(i, nn.Conv1d(patch_size ** 2, patch_size ** 2, 1)))
self.mlp.add_module('fc1_%d'%i,wrapper(i, nn.Sequential(
nn.Linear(dim, dim * expansion_factor),
nn.GELU(),
nn.Linear(dim * expansion_factor, dim)
)))
self.aff=Affine(dim)
self.classifier=nn.Linear(dim,class_num)
self.softmax=nn.Softmax(1)
def forward(self, x) :
y=self.flatten(x)
y=self.embedding(y)
y=self.mlp(y)
y=self.aff(y)
y=torch.mean(y,dim=1) #bs,dim
out=self.softmax(self.classifier(y))
return out
if __name__ == '__main__':
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape)
================================================
FILE: model/mlp/sMLP_block.py
================================================
import torch
from torch import nn
class sMLPBlock(nn.Module):
def __init__(self,h=224,w=224,c=3):
super().__init__()
self.proj_h=nn.Linear(h,h)
self.proj_w=nn.Linear(w,w)
self.fuse=nn.Linear(3*c,c)
def forward(self,x):
x_h=self.proj_h(x.permute(0,1,3,2)).permute(0,1,3,2)
x_w=self.proj_w(x)
x_id=x
x_fuse=torch.cat([x_h,x_w,x_id],dim=1)
out=self.fuse(x_fuse.permute(0,2,3,1)).permute(0,3,1,2)
return out
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
smlp=sMLPBlock(h=224,w=224)
out=smlp(input)
print(out.shape)
================================================
FILE: model/mlp/vip-mlp.py
================================================
import torch
import torch.nn as nn
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .96, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD, 'classifier': 'head',
**kwargs
}
default_cfgs = {
'ViP_S': _cfg(crop_pct=0.9),
'ViP_M': _cfg(crop_pct=0.9),
'ViP_L': _cfg(crop_pct=0.875),
}
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class WeightedPermuteMLP(nn.Module):
def __init__(self, dim, segment_dim=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.segment_dim = segment_dim
self.mlp_c = nn.Linear(dim, dim, bias=qkv_bias)
self.mlp_h = nn.Linear(dim, dim, bias=qkv_bias)
self.mlp_w = nn.Linear(dim, dim, bias=qkv_bias)
self.reweight = Mlp(dim, dim // 4, dim *3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
S = C // self.segment_dim
h = x.reshape(B, H, W, self.segment_dim, S).permute(0, 3, 2, 1, 4).reshape(B, self.segment_dim, W, H*S)
h = self.mlp_h(h).reshape(B, self.segment_dim, W, H, S).permute(0, 3, 2, 1, 4).reshape(B, H, W, C)
w = x.reshape(B, H, W, self.segment_dim, S).permute(0, 1, 3, 2, 4).reshape(B, H, self.segment_dim, W*S)
w = self.mlp_w(w).reshape(B, H, self.segment_dim, W, S).permute(0, 1, 3, 2, 4).reshape(B, H, W, C)
c = self.mlp_c(x)
a = (h + w + c).permute(0, 3, 1, 2).flatten(2).mean(2)
a = self.reweight(a).reshape(B, C, 3).permute(2, 0, 1).softmax(dim=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x)
return x
class PermutatorBlock(nn.Module):
def __init__(self, dim, segment_dim, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, skip_lam=1.0, mlp_fn = WeightedPermuteMLP):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = mlp_fn(dim, segment_dim=segment_dim, qkv_bias=qkv_bias, qk_scale=None, attn_drop=attn_drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer)
self.skip_lam = skip_lam
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x))) / self.skip_lam
x = x + self.drop_path(self.mlp(self.norm2(x))) / self.skip_lam
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x) # B, C, H, W
return x
class Downsample(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, in_embed_dim, out_embed_dim, patch_size):
super().__init__()
self.proj = nn.Conv2d(in_embed_dim, out_embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = x.permute(0, 3, 1, 2)
x = self.proj(x) # B, C, H, W
x = x.permute(0, 2, 3, 1)
return x
def basic_blocks(dim, index, layers, segment_dim, mlp_ratio=3., qkv_bias=False, qk_scale=None, \
attn_drop=0, drop_path_rate=0., skip_lam=1.0, mlp_fn = WeightedPermuteMLP, **kwargs):
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(PermutatorBlock(dim, segment_dim, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,\
attn_drop=attn_drop, drop_path=block_dpr, skip_lam=skip_lam, mlp_fn = mlp_fn))
blocks = nn.Sequential(*blocks)
return blocks
class VisionPermutator(nn.Module):
""" Vision Permutator
"""
def __init__(self, layers, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dims=None, transitions=None, segment_dim=None, mlp_ratios=None, skip_lam=1.0,
qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.,
norm_layer=nn.LayerNorm,mlp_fn = WeightedPermuteMLP):
super().__init__()
self.num_classes = num_classes
self.patch_embed = PatchEmbed(img_size = img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dims[0])
network = []
for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers, segment_dim[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop_rate, drop_path_rate=drop_path_rate, norm_layer=norm_layer, skip_lam=skip_lam,
mlp_fn = mlp_fn)
network.append(stage)
if i >= len(layers) - 1:
break
if transitions[i] or embed_dims[i] != embed_dims[i+1]:
patch_size = 2 if transitions[i] else 1
network.append(Downsample(embed_dims[i], embed_dims[i+1], patch_size))
self.network = nn.ModuleList(network)
self.norm = norm_layer(embed_dims[-1])
# Classifier head
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_embeddings(self, x):
x = self.patch_embed(x)
# B,C,H,W-> B,H,W,C
x = x.permute(0, 2, 3, 1)
return x
def forward_tokens(self,x):
for idx, block in enumerate(self.network):
x = block(x)
B, H, W, C = x.shape
x = x.reshape(B, -1, C)
return x
def forward(self, x):
x = self.forward_embeddings(x)
# B, H, W, C -> B, N, C
x = self.forward_tokens(x)
x = self.norm(x)
return self.head(x.mean(1))
@register_model
def vip_s14(pretrained=False, **kwargs):
layers = [4, 3, 8, 3]
transitions = [False, False, False, False]
segment_dim = [16, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
embed_dims = [384, 384, 384, 384]
model = VisionPermutator(layers, embed_dims=embed_dims, patch_size=14, transitions=transitions,
segment_dim=segment_dim, mlp_ratios=mlp_ratios, mlp_fn=WeightedPermuteMLP, **kwargs)
model.default_cfg = default_cfgs['ViP_S']
return model
@register_model
def vip_s7(pretrained=False, **kwargs):
layers = [4, 3, 8, 3]
transitions = [True, False, False, False]
segment_dim = [32, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
embed_dims = [192, 384, 384, 384]
model = VisionPermutator(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
segment_dim=segment_dim, mlp_ratios=mlp_ratios, mlp_fn=WeightedPermuteMLP, **kwargs)
model.default_cfg = default_cfgs['ViP_S']
return model
@register_model
def vip_m7(pretrained=False, **kwargs):
# 55534632
layers = [4, 3, 14, 3]
transitions = [False, True, False, False]
segment_dim = [32, 32, 16, 16]
mlp_ratios = [3, 3, 3, 3]
embed_dims = [256, 256, 512, 512]
model = VisionPermutator(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
segment_dim=segment_dim, mlp_ratios=mlp_ratios, mlp_fn=WeightedPermuteMLP, **kwargs)
model.default_cfg = default_cfgs['ViP_M']
return model
@register_model
def vip_l7(pretrained=False, **kwargs):
layers = [8, 8, 16, 4]
transitions = [True, False, False, False]
segment_dim = [32, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
embed_dims = [256, 512, 512, 512]
model = VisionPermutator(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
segment_dim=segment_dim, mlp_ratios=mlp_ratios, mlp_fn=WeightedPermuteMLP, **kwargs)
model.default_cfg = default_cfgs['ViP_L']
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionPermutator(
layers=[4, 3, 8, 3],
embed_dims=[384, 384, 384, 384],
patch_size=14,
transitions=[False, False, False, False],
segment_dim=[16, 16, 16, 16],
mlp_ratios=[3, 3, 3, 3],
mlp_fn=WeightedPermuteMLP
)
output=model(input)
print(output.shape)
================================================
FILE: model/rep/acnet.py
================================================
import torch
from torch import mean, nn
from collections import OrderedDict
from torch.nn import functional as F
import numpy as np
from numpy import random
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
def _conv_bn(input_channel,output_channel,kernel_size=3,padding=1,stride=1,groups=1):
res=nn.Sequential()
res.add_module('conv',nn.Conv2d(in_channels=input_channel,out_channels=output_channel,kernel_size=kernel_size,padding=padding,padding_mode='zeros',stride=stride,groups=groups,bias=False))
res.add_module('bn',nn.BatchNorm2d(output_channel))
return res
class ACNet(nn.Module):
def __init__(self,input_channel,output_channel,kernel_size=3,groups=1,stride=1,deploy=False,use_se=False):
super().__init__()
self.use_se=use_se
self.input_channel=input_channel
self.output_channel=output_channel
self.deploy=deploy
self.kernel_size=kernel_size
self.padding=kernel_size//2
self.groups=groups
self.activation=nn.ReLU()
if(not self.deploy):
self.brb_3x3=_conv_bn(input_channel,output_channel,kernel_size=3,padding=1,groups=groups)
self.brb_1x3=_conv_bn(input_channel,output_channel,kernel_size=(1,3),padding=(0,1),groups=groups)
self.brb_3x1=_conv_bn(input_channel,output_channel,kernel_size=(3,1),padding=(1,0),groups=groups)
else:
self.brb_rep=nn.Conv2d(in_channels=input_channel,out_channels=output_channel,kernel_size=self.kernel_size,padding=self.padding,padding_mode='zeros',stride=stride,bias=True)
def forward(self, inputs):
if(self.deploy):
return self.activation(self.brb_rep(inputs))
return self.activation(self.brb_1x3(inputs)+self.brb_3x1(inputs)+self.brb_3x3(inputs))
def _switch_to_deploy(self):
self.deploy=True
kernel,bias=self._get_equivalent_kernel_bias()
self.brb_rep=nn.Conv2d(in_channels=self.brb_3x3.conv.in_channels,out_channels=self.brb_3x3.conv.out_channels,
kernel_size=self.brb_3x3.conv.kernel_size,padding=self.brb_3x3.conv.padding,
padding_mode=self.brb_3x3.conv.padding_mode,stride=self.brb_3x3.conv.stride,
groups=self.brb_3x3.conv.groups,bias=True)
self.brb_rep.weight.data=kernel
self.brb_rep.bias.data=bias
#消除梯度更新
for para in self.parameters():
para.detach_()
#删除没用的分支
self.__delattr__('brb_3x3')
self.__delattr__('brb_3x1')
self.__delattr__('brb_1x3')
#将1x3的卷积变成3x3的卷积参数
def _pad_1x3_kernel(self,kernel):
if(kernel is None):
return 0
else:
return F.pad(kernel,[0,0,1,1])
#将3x1的卷积变成3x3的卷积参数
def _pad_3x1_kernel(self,kernel):
if(kernel is None):
return 0
else:
return F.pad(kernel,[1,1,0,0])
#将identity,1x1,3x3的卷积融合到一起,变成一个3x3卷积的参数
def _get_equivalent_kernel_bias(self):
brb_3x3_weight,brb_3x3_bias=self._fuse_conv_bn(self.brb_3x3)
brb_1x3_weight,brb_1x3_bias=self._fuse_conv_bn(self.brb_1x3)
brb_3x1_weight,brb_3x1_bias=self._fuse_conv_bn(self.brb_3x1)
return brb_3x3_weight+self._pad_1x3_kernel(brb_1x3_weight)+self._pad_3x1_kernel(brb_3x1_weight),brb_3x3_bias+brb_1x3_bias+brb_3x1_bias
### 将卷积和BN的参数融合到一起
def _fuse_conv_bn(self,branch):
kernel=branch.conv.weight
running_mean=branch.bn.running_mean
running_var=branch.bn.running_var
gamma=branch.bn.weight
beta=branch.bn.bias
eps=branch.bn.eps
std=(running_var+eps).sqrt()
t=gamma/std
t=t.view(-1,1,1,1)
return kernel*t,beta-running_mean*gamma/std
if __name__ == '__main__':
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
================================================
FILE: model/rep/ddb.py
================================================
from torch import conv2d, nn
import torch
from torch.nn import functional as F
def transI_conv_bn(conv, bn):
std = (bn.running_var + bn.eps).sqrt()
gamma=bn.weight
weight=conv.weight*((gamma/std).reshape(-1, 1, 1, 1))
if(conv.bias is not None):
bias=gamma/std*conv.bias-gamma/std*bn.running_mean+bn.bias
else:
bias=bn.bias-gamma/std*bn.running_mean
return weight,bias
def transII_conv_branch(conv1, conv2):
weight=conv1.weight.data+conv2.weight.data
bias=conv1.bias.data+conv2.bias.data
return weight,bias
def transIII_conv_sequential(conv1, conv2):
weight=F.conv2d(conv2.weight.data,conv1.weight.data.permute(1,0,2,3))
# bias=((conv2.weight.data*(conv1.bias.data.reshape(1,-1,1,1))).sum(-1).sum(-1).sum(-1))+conv2.bias.data
return weight#,bias
def transIV_conv_concat(conv1, conv2):
print(conv1.bias.data.shape)
print(conv2.bias.data.shape)
weight=torch.cat([conv1.weight.data,conv2.weight.data],0)
bias=torch.cat([conv1.bias.data,conv2.bias.data],0)
return weight,bias
def transV_avg(channel,kernel):
conv=nn.Conv2d(channel,channel,kernel,bias=False)
conv.weight.data[:]=0
for i in range(channel):
conv.weight.data[i,i,:,:]=1/(kernel*kernel)
return conv
def transVI_conv_scale(conv1, conv2, conv3):
weight=F.pad(conv1.weight.data,(1,1,1,1))+F.pad(conv2.weight.data,(0,0,1,1))+F.pad(conv3.weight.data,(1,1,0,0))
bias=conv1.bias.data+conv2.bias.data+conv3.bias.data
return weight,bias
if __name__ == '__main__':
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
================================================
FILE: model/rep/mobileone.py
================================================
================================================
FILE: model/rep/repvgg.py
================================================
import torch
from torch import mean, nn
from collections import OrderedDict
from torch.nn import functional as F
import numpy as np
from numpy import random
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
def _conv_bn(input_channel,output_channel,kernel_size=3,padding=1,stride=1,groups=1):
res=nn.Sequential()
res.add_module('conv',nn.Conv2d(in_channels=input_channel,out_channels=output_channel,kernel_size=kernel_size,padding=padding,padding_mode='zeros',stride=stride,groups=groups,bias=False))
res.add_module('bn',nn.BatchNorm2d(output_channel))
return res
class RepBlock(nn.Module):
def __init__(self,input_channel,output_channel,kernel_size=3,groups=1,stride=1,deploy=False,use_se=False):
super().__init__()
self.use_se=use_se
self.input_channel=input_channel
self.output_channel=output_channel
self.deploy=deploy
self.kernel_size=kernel_size
self.padding=kernel_size//2
self.groups=groups
self.activation=nn.ReLU()
#make sure kernel_size=3 padding=1
assert self.kernel_size==3
assert self.padding==1
if(not self.deploy):
self.brb_3x3=_conv_bn(input_channel,output_channel,kernel_size=self.kernel_size,padding=self.padding,groups=groups)
self.brb_1x1=_conv_bn(input_channel,output_channel,kernel_size=1,padding=0,groups=groups)
self.brb_identity=nn.BatchNorm2d(self.input_channel) if self.input_channel == self.output_channel else None
else:
self.brb_rep=nn.Conv2d(in_channels=input_channel,out_channels=output_channel,kernel_size=self.kernel_size,padding=self.padding,padding_mode='zeros',stride=stride,bias=True)
def forward(self, inputs):
if(self.deploy):
return self.activation(self.brb_rep(inputs))
if(self.brb_identity==None):
identity_out=0
else:
identity_out=self.brb_identity(inputs)
return self.activation(self.brb_1x1(inputs)+self.brb_3x3(inputs)+identity_out)
def _switch_to_deploy(self):
self.deploy=True
kernel,bias=self._get_equivalent_kernel_bias()
self.brb_rep=nn.Conv2d(in_channels=self.brb_3x3.conv.in_channels,out_channels=self.brb_3x3.conv.out_channels,
kernel_size=self.brb_3x3.conv.kernel_size,padding=self.brb_3x3.conv.padding,
padding_mode=self.brb_3x3.conv.padding_mode,stride=self.brb_3x3.conv.stride,
groups=self.brb_3x3.conv.groups,bias=True)
self.brb_rep.weight.data=kernel
self.brb_rep.bias.data=bias
#消除梯度更新
for para in self.parameters():
para.detach_()
#删除没用的分支
self.__delattr__('brb_3x3')
self.__delattr__('brb_1x1')
self.__delattr__('brb_identity')
#将1x1的卷积变成3x3的卷积参数
def _pad_1x1_kernel(self,kernel):
if(kernel is None):
return 0
else:
return F.pad(kernel,[1]*4)
#将identity,1x1,3x3的卷积融合到一起,变成一个3x3卷积的参数
def _get_equivalent_kernel_bias(self):
brb_3x3_weight,brb_3x3_bias=self._fuse_conv_bn(self.brb_3x3)
brb_1x1_weight,brb_1x1_bias=self._fuse_conv_bn(self.brb_1x1)
brb_id_weight,brb_id_bias=self._fuse_conv_bn(self.brb_identity)
return brb_3x3_weight+self._pad_1x1_kernel(brb_1x1_weight)+brb_id_weight,brb_3x3_bias+brb_1x1_bias+brb_id_bias
### 将卷积和BN的参数融合到一起
def _fuse_conv_bn(self,branch):
if(branch is None):
return 0,0
elif(isinstance(branch,nn.Sequential)):
kernel=branch.conv.weight
running_mean=branch.bn.running_mean
running_var=branch.bn.running_var
gamma=branch.bn.weight
beta=branch.bn.bias
eps=branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.input_channel // self.groups
kernel_value = np.zeros((self.input_channel, input_dim, 3, 3), dtype=np.float32)
for i in range(self.input_channel):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std=(running_var+eps).sqrt()
t=gamma/std
t=t.view(-1,1,1,1)
return kernel*t,beta-running_mean*gamma/std
if __name__ == '__main__':
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
================================================
FILE: setup.py
================================================
from setuptools import find_packages, setup
setup(
name="fighingcv",
version="1.0.0",
author="xmu-xiaoma666",
author_email="julien@huggingface.co",
description=(
"FightingCV Codebase For Attention,Backbone, MLP, Re-parameter, Convolution"
),
long_description=open("README.md", "r", encoding="utf-8").read(),
long_description_content_type="text/markdown",
keywords=(
"Attention"
"Backbone"
),
license="Apache",
url="https://github.com/xmu-xiaoma666/External-Attention-pytorch",
package_dir={"": "."},
packages=find_packages("."),
# entry_points={
# "console_scripts": [
# "huggingface-cli=huggingface_hub.commands.huggingface_cli:main"
# ]
# },
python_requires=">=3.7.0",
# install_requires=install_requires,
classifiers=[
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
],
)
简体中文 | [English](./README_EN.md)
# FightingCV 代码库, 包含 [***Attention***](#attention-series),[***Backbone***](#backbone-series), [***MLP***](#mlp-series), [***Re-parameter***](#re-parameter-series), [**Convolution**](#convolution-series)



## 🌟 Star History
[](https://star-history.com/#xmu-xiaoma666/External-Attention-pytorch&Date)
## 使用
### 安装
直接通过 pip 安装
```shell
pip install fightingcv-attention
```
或克隆该仓库
```shell
git clone https://github.com/xmu-xiaoma666/External-Attention-pytorch.git
cd External-Attention-pytorch
```
### 演示
#### 使用 pip 方式
```python
import torch
from torch import nn
from torch.nn import functional as F
# 使用 pip 方式
from fightingcv_attention.attention.MobileViTv2Attention import *
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
- pip包 内置模块使用参考: [fightingcv-attention 说明文档](./README_pip.md)
#### 使用 git 方式
```python
import torch
from torch import nn
from torch.nn import functional as F
# 与 pip方式 区别在于 将 `fightingcv_attention` 替换 `model`
from model.attention.MobileViTv2Attention import *
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
-------
# 目录
- [Attention Series](#attention-series)
- [1. External Attention Usage](#1-external-attention-usage)
- [2. Self Attention Usage](#2-self-attention-usage)
- [3. Simplified Self Attention Usage](#3-simplified-self-attention-usage)
- [4. Squeeze-and-Excitation Attention Usage](#4-squeeze-and-excitation-attention-usage)
- [5. SK Attention Usage](#5-sk-attention-usage)
- [6. CBAM Attention Usage](#6-cbam-attention-usage)
- [7. BAM Attention Usage](#7-bam-attention-usage)
- [8. ECA Attention Usage](#8-eca-attention-usage)
- [9. DANet Attention Usage](#9-danet-attention-usage)
- [10. Pyramid Split Attention (PSA) Usage](#10-Pyramid-Split-Attention-Usage)
- [11. Efficient Multi-Head Self-Attention(EMSA) Usage](#11-Efficient-Multi-Head-Self-Attention-Usage)
- [12. Shuffle Attention Usage](#12-Shuffle-Attention-Usage)
- [13. MUSE Attention Usage](#13-MUSE-Attention-Usage)
- [14. SGE Attention Usage](#14-SGE-Attention-Usage)
- [15. A2 Attention Usage](#15-A2-Attention-Usage)
- [16. AFT Attention Usage](#16-AFT-Attention-Usage)
- [17. Outlook Attention Usage](#17-Outlook-Attention-Usage)
- [18. ViP Attention Usage](#18-ViP-Attention-Usage)
- [19. CoAtNet Attention Usage](#19-CoAtNet-Attention-Usage)
- [20. HaloNet Attention Usage](#20-HaloNet-Attention-Usage)
- [21. Polarized Self-Attention Usage](#21-Polarized-Self-Attention-Usage)
- [22. CoTAttention Usage](#22-CoTAttention-Usage)
- [23. Residual Attention Usage](#23-Residual-Attention-Usage)
- [24. S2 Attention Usage](#24-S2-Attention-Usage)
- [25. GFNet Attention Usage](#25-GFNet-Attention-Usage)
- [26. Triplet Attention Usage](#26-TripletAttention-Usage)
- [27. Coordinate Attention Usage](#27-Coordinate-Attention-Usage)
- [28. MobileViT Attention Usage](#28-MobileViT-Attention-Usage)
- [29. ParNet Attention Usage](#29-ParNet-Attention-Usage)
- [30. UFO Attention Usage](#30-UFO-Attention-Usage)
- [31. ACmix Attention Usage](#31-Acmix-Attention-Usage)
- [32. MobileViTv2 Attention Usage](#32-MobileViTv2-Attention-Usage)
- [33. DAT Attention Usage](#33-DAT-Attention-Usage)
- [34. CrossFormer Attention Usage](#34-CrossFormer-Attention-Usage)
- [35. MOATransformer Attention Usage](#35-MOATransformer-Attention-Usage)
- [36. CrissCrossAttention Attention Usage](#36-CrissCrossAttention-Attention-Usage)
- [37. Axial_attention Attention Usage](#37-Axial_attention-Attention-Usage)
- [Backbone Series](#Backbone-series)
- [1. ResNet Usage](#1-ResNet-Usage)
- [2. ResNeXt Usage](#2-ResNeXt-Usage)
- [3. MobileViT Usage](#3-MobileViT-Usage)
- [4. ConvMixer Usage](#4-ConvMixer-Usage)
- [5. ShuffleTransformer Usage](#5-ShuffleTransformer-Usage)
- [6. ConTNet Usage](#6-ConTNet-Usage)
- [7. HATNet Usage](#7-HATNet-Usage)
- [8. CoaT Usage](#8-CoaT-Usage)
- [9. PVT Usage](#9-PVT-Usage)
- [10. CPVT Usage](#10-CPVT-Usage)
- [11. PIT Usage](#11-PIT-Usage)
- [12. CrossViT Usage](#12-CrossViT-Usage)
- [13. TnT Usage](#13-TnT-Usage)
- [14. DViT Usage](#14-DViT-Usage)
- [15. CeiT Usage](#15-CeiT-Usage)
- [16. ConViT Usage](#16-ConViT-Usage)
- [17. CaiT Usage](#17-CaiT-Usage)
- [18. PatchConvnet Usage](#18-PatchConvnet-Usage)
- [19. DeiT Usage](#19-DeiT-Usage)
- [20. LeViT Usage](#20-LeViT-Usage)
- [21. VOLO Usage](#21-VOLO-Usage)
- [22. Container Usage](#22-Container-Usage)
- [23. CMT Usage](#23-CMT-Usage)
- [24. EfficientFormer Usage](#24-EfficientFormer-Usage)
- [25. ConvNeXtV2 Usage](#25-ConvNeXtV2-Usage)
- [MLP Series](#mlp-series)
- [1. RepMLP Usage](#1-RepMLP-Usage)
- [2. MLP-Mixer Usage](#2-MLP-Mixer-Usage)
- [3. ResMLP Usage](#3-ResMLP-Usage)
- [4. gMLP Usage](#4-gMLP-Usage)
- [5. sMLP Usage](#5-sMLP-Usage)
- [6. vip-mlp Usage](#6-vip-mlp-Usage)
- [Re-Parameter(ReP) Series](#Re-Parameter-series)
- [1. RepVGG Usage](#1-RepVGG-Usage)
- [2. ACNet Usage](#2-ACNet-Usage)
- [3. Diverse Branch Block(DDB) Usage](#3-Diverse-Branch-Block-Usage)
- [Convolution Series](#Convolution-series)
- [1. Depthwise Separable Convolution Usage](#1-Depthwise-Separable-Convolution-Usage)
- [2. MBConv Usage](#2-MBConv-Usage)
- [3. Involution Usage](#3-Involution-Usage)
- [4. DynamicConv Usage](#4-DynamicConv-Usage)
- [5. CondConv Usage](#5-CondConv-Usage)
***
# Attention Series
- Pytorch implementation of ["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks---arXiv 2021.05.05"](https://arxiv.org/abs/2105.02358)
- Pytorch implementation of ["Attention Is All You Need---NIPS2017"](https://arxiv.org/pdf/1706.03762.pdf)
- Pytorch implementation of ["Squeeze-and-Excitation Networks---CVPR2018"](https://arxiv.org/abs/1709.01507)
- Pytorch implementation of ["Selective Kernel Networks---CVPR2019"](https://arxiv.org/pdf/1903.06586.pdf)
- Pytorch implementation of ["CBAM: Convolutional Block Attention Module---ECCV2018"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
- Pytorch implementation of ["BAM: Bottleneck Attention Module---BMCV2018"](https://arxiv.org/pdf/1807.06514.pdf)
- Pytorch implementation of ["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020"](https://arxiv.org/pdf/1910.03151.pdf)
- Pytorch implementation of ["Dual Attention Network for Scene Segmentation---CVPR2019"](https://arxiv.org/pdf/1809.02983.pdf)
- Pytorch implementation of ["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30"](https://arxiv.org/pdf/2105.14447.pdf)
- Pytorch implementation of ["ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28"](https://arxiv.org/abs/2105.13677)
- Pytorch implementation of ["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS---ICASSP 2021"](https://arxiv.org/pdf/2102.00240.pdf)
- Pytorch implementation of ["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning---arXiv 2019.11.17"](https://arxiv.org/abs/1911.09483)
- Pytorch implementation of ["Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks---arXiv 2019.05.23"](https://arxiv.org/pdf/1905.09646.pdf)
- Pytorch implementation of ["A2-Nets: Double Attention Networks---NIPS2018"](https://arxiv.org/pdf/1810.11579.pdf)
- Pytorch implementation of ["An Attention Free Transformer---ICLR2021 (Apple New Work)"](https://arxiv.org/pdf/2105.14103v1.pdf)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition---arXiv 2021.06.24"](https://arxiv.org/abs/2106.13112)
[【论文解析】](https://zhuanlan.zhihu.com/p/385561050)
- Pytorch implementation of [Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition---arXiv 2021.06.23](https://arxiv.org/abs/2106.12368)
[【论文解析】](https://mp.weixin.qq.com/s/5gonUQgBho_m2O54jyXF_Q)
- Pytorch implementation of [CoAtNet: Marrying Convolution and Attention for All Data Sizes---arXiv 2021.06.09](https://arxiv.org/abs/2106.04803)
[【论文解析】](https://zhuanlan.zhihu.com/p/385578588)
- Pytorch implementation of [Scaling Local Self-Attention for Parameter Efficient Visual Backbones---CVPR2021 Oral](https://arxiv.org/pdf/2103.12731.pdf) [【论文解析】](https://zhuanlan.zhihu.com/p/388598744)
- Pytorch implementation of [Polarized Self-Attention: Towards High-quality Pixel-wise Regression---arXiv 2021.07.02](https://arxiv.org/abs/2107.00782) [【论文解析】](https://zhuanlan.zhihu.com/p/389770482)
- Pytorch implementation of [Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292) [【论文解析】](https://zhuanlan.zhihu.com/p/394795481)
- Pytorch implementation of [Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
- Pytorch implementation of [S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072) [【论文解析】](https://zhuanlan.zhihu.com/p/397003638)
- Pytorch implementation of [Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
- Pytorch implementation of [Rotate to Attend: Convolutional Triplet Attention Module---WACV 2021](https://arxiv.org/abs/2010.03045)
- Pytorch implementation of [Coordinate Attention for Efficient Mobile Network Design ---CVPR 2021](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2110.02178)
- Pytorch implementation of [Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
- Pytorch implementation of [UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2109.14382)
- Pytorch implementation of [Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
- Pytorch implementation of [On the Integration of Self-Attention and Convolution---ArXiv 2022.03.14](https://arxiv.org/pdf/2111.14556.pdf)
- Pytorch implementation of [CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
- Pytorch implementation of [Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
- Pytorch implementation of [CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
- Pytorch implementation of [Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
***
### 1. External Attention Usage
#### 1.1. Paper
["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks"](https://arxiv.org/abs/2105.02358)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
***
### 2. Self Attention Usage
#### 2.1. Paper
["Attention Is All You Need"](https://arxiv.org/pdf/1706.03762.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 3. Simplified Self Attention Usage
#### 3.1. Paper
[None]()
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)
```
***
### 4. Squeeze-and-Excitation Attention Usage
#### 4.1. Paper
["Squeeze-and-Excitation Networks"](https://arxiv.org/abs/1709.01507)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 5. SK Attention Usage
#### 5.1. Paper
["Selective Kernel Networks"](https://arxiv.org/pdf/1903.06586.pdf)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 6. CBAM Attention Usage
#### 6.1. Paper
["CBAM: Convolutional Block Attention Module"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
#### 6.2. Overview


#### 6.3. Usage Code
```python
from model.attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
***
### 7. BAM Attention Usage
#### 7.1. Paper
["BAM: Bottleneck Attention Module"](https://arxiv.org/pdf/1807.06514.pdf)
#### 7.2. Overview

#### 7.3. Usage Code
```python
from model.attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
***
### 8. ECA Attention Usage
#### 8.1. Paper
["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks"](https://arxiv.org/pdf/1910.03151.pdf)
#### 8.2. Overview

#### 8.3. Usage Code
```python
from model.attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
***
### 9. DANet Attention Usage
#### 9.1. Paper
["Dual Attention Network for Scene Segmentation"](https://arxiv.org/pdf/1809.02983.pdf)
#### 9.2. Overview

#### 9.3. Usage Code
```python
from model.attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
***
### 10. Pyramid Split Attention Usage
#### 10.1. Paper
["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network"](https://arxiv.org/pdf/2105.14447.pdf)
#### 10.2. Overview

#### 10.3. Usage Code
```python
from model.attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
***
### 11. Efficient Multi-Head Self-Attention Usage
#### 11.1. Paper
["ResT: An Efficient Transformer for Visual Recognition"](https://arxiv.org/abs/2105.13677)
#### 11.2. Overview

#### 11.3. Usage Code
```python
from model.attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
***
### 12. Shuffle Attention Usage
#### 12.1. Paper
["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS"](https://arxiv.org/pdf/2102.00240.pdf)
#### 12.2. Overview

#### 12.3. Usage Code
```python
from model.attention.ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
```
***
### 13. MUSE Attention Usage
#### 13.1. Paper
["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning"](https://arxiv.org/abs/1911.09483)
#### 13.2. Overview

#### 13.3. Usage Code
```python
from model.attention.MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 14. SGE Attention Usage
#### 14.1. Paper
[Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks](https://arxiv.org/pdf/1905.09646.pdf)
#### 14.2. Overview

#### 14.3. Usage Code
```python
from model.attention.SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
```
***
### 15. A2 Attention Usage
#### 15.1. Paper
[A2-Nets: Double Attention Networks](https://arxiv.org/pdf/1810.11579.pdf)
#### 15.2. Overview

#### 15.3. Usage Code
```python
from model.attention.A2Atttention import DoubleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
```
### 16. AFT Attention Usage
#### 16.1. Paper
[An Attention Free Transformer](https://arxiv.org/pdf/2105.14103v1.pdf)
#### 16.2. Overview

#### 16.3. Usage Code
```python
from model.attention.AFT import AFT_FULL
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
```
### 17. Outlook Attention Usage
#### 17.1. Paper
[VOLO: Vision Outlooker for Visual Recognition"](https://arxiv.org/abs/2106.13112)
#### 17.2. Overview

#### 17.3. Usage Code
```python
from model.attention.OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)
```
***
### 18. ViP Attention Usage
#### 18.1. Paper
[Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 18.2. Overview

#### 18.3. Usage Code
```python
from model.attention.ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)
```
***
### 19. CoAtNet Attention Usage
#### 19.1. Paper
[CoAtNet: Marrying Convolution and Attention for All Data Sizes"](https://arxiv.org/abs/2106.04803)
#### 19.2. Overview
None
#### 19.3. Usage Code
```python
from model.attention.CoAtNet import CoAtNet
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=CoAtNet(in_ch=3,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 20. HaloNet Attention Usage
#### 20.1. Paper
[Scaling Local Self-Attention for Parameter Efficient Visual Backbones"](https://arxiv.org/pdf/2103.12731.pdf)
#### 20.2. Overview

#### 20.3. Usage Code
```python
from model.attention.HaloAttention import HaloAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)
```
***
### 21. Polarized Self-Attention Usage
#### 21.1. Paper
[Polarized Self-Attention: Towards High-quality Pixel-wise Regression"](https://arxiv.org/abs/2107.00782)
#### 21.2. Overview

#### 21.3. Usage Code
```python
from model.attention.PolarizedSelfAttention import ParallelPolarizedSelfAttention,SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
```
***
### 22. CoTAttention Usage
#### 22.1. Paper
[Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292)
#### 22.2. Overview

#### 22.3. Usage Code
```python
from model.attention.CoTAttention import CoTAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
```
***
### 23. Residual Attention Usage
#### 23.1. Paper
[Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
#### 23.2. Overview

#### 23.3. Usage Code
```python
from model.attention.ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
resatt = ResidualAttention(channel=512,num_class=1000,la=0.2)
output=resatt(input)
print(output.shape)
```
***
### 24. S2 Attention Usage
#### 24.1. Paper
[S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072)
#### 24.2. Overview

#### 24.3. Usage Code
```python
from model.attention.S2Attention import S2Attention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
s2att = S2Attention(channels=512)
output=s2att(input)
print(output.shape)
```
***
### 25. GFNet Attention Usage
#### 25.1. Paper
[Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
#### 25.2. Overview

#### 25.3. Usage Code - Implemented by [Wenliang Zhao (Author)](https://scholar.google.com/citations?user=lyPWvuEAAAAJ&hl=en)
```python
from model.attention.gfnet import GFNet
import torch
from torch import nn
from torch.nn import functional as F
x = torch.randn(1, 3, 224, 224)
gfnet = GFNet(embed_dim=384, img_size=224, patch_size=16, num_classes=1000)
out = gfnet(x)
print(out.shape)
```
***
### 26. TripletAttention Usage
#### 26.1. Paper
[Rotate to Attend: Convolutional Triplet Attention Module---CVPR 2021](https://arxiv.org/abs/2010.03045)
#### 26.2. Overview

#### 26.3. Usage Code - Implemented by [digantamisra98](https://github.com/digantamisra98)
```python
from model.attention.TripletAttention import TripletAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
triplet = TripletAttention()
output=triplet(input)
print(output.shape)
```
***
### 27. Coordinate Attention Usage
#### 27.1. Paper
[Coordinate Attention for Efficient Mobile Network Design---CVPR 2021](https://arxiv.org/abs/2103.02907)
#### 27.2. Overview

#### 27.3. Usage Code - Implemented by [Andrew-Qibin](https://github.com/Andrew-Qibin)
```python
from model.attention.CoordAttention import CoordAtt
import torch
from torch import nn
from torch.nn import functional as F
inp=torch.rand([2, 96, 56, 56])
inp_dim, oup_dim = 96, 96
reduction=32
coord_attention = CoordAtt(inp_dim, oup_dim, reduction=reduction)
output=coord_attention(inp)
print(output.shape)
```
***
### 28. MobileViT Attention Usage
#### 28.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2103.02907)
#### 28.2. Overview

#### 28.3. Usage Code
```python
from model.attention.MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
m=MobileViTAttention()
input=torch.randn(1,3,49,49)
output=m(input)
print(output.shape) #output:(1,3,49,49)
```
***
### 29. ParNet Attention Usage
#### 29.1. Paper
[Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
#### 29.2. Overview

#### 29.3. Usage Code
```python
from model.attention.ParNetAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
pna = ParNetAttention(channel=512)
output=pna(input)
print(output.shape) #50,512,7,7
```
***
### 30. UFO Attention Usage
#### 30.1. Paper
[UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2110.07641)
#### 30.2. Overview

#### 30.3. Usage Code
```python
from model.attention.UFOAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
ufo = UFOAttention(d_model=512, d_k=512, d_v=512, h=8)
output=ufo(input,input,input)
print(output.shape) #[50, 49, 512]
```
-
### 31. ACmix Attention Usage
#### 31.1. Paper
[On the Integration of Self-Attention and Convolution](https://arxiv.org/pdf/2111.14556.pdf)
#### 31.2. Usage Code
```python
from model.attention.ACmix import ACmix
import torch
if __name__ == '__main__':
input=torch.randn(50,256,7,7)
acmix = ACmix(in_planes=256, out_planes=256)
output=acmix(input)
print(output.shape)
```
### 32. MobileViTv2 Attention Usage
#### 32.1. Paper
[Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
#### 32.2. Overview

#### 32.3. Usage Code
```python
from model.attention.MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
### 33. DAT Attention Usage
#### 33.1. Paper
[Vision Transformer with Deformable Attention---CVPR2022](https://arxiv.org/abs/2201.00520)
#### 33.2. Usage Code
```python
from model.attention.DAT import DAT
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DAT(
img_size=224,
patch_size=4,
num_classes=1000,
expansion=4,
dim_stem=96,
dims=[96, 192, 384, 768],
depths=[2, 2, 6, 2],
stage_spec=[['L', 'S'], ['L', 'S'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7] ,
groups=[-1, -1, 3, 6],
use_pes=[False, False, True, True],
dwc_pes=[False, False, False, False],
strides=[-1, -1, 1, 1],
sr_ratios=[-1, -1, -1, -1],
offset_range_factor=[-1, -1, 2, 2],
no_offs=[False, False, False, False],
fixed_pes=[False, False, False, False],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
)
output=model(input)
print(output[0].shape)
```
### 34. CrossFormer Attention Usage
#### 34.1. Paper
[CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
#### 34.2. Usage Code
```python
from model.attention.Crossformer import CrossFormer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CrossFormer(img_size=224,
patch_size=[4, 8, 16, 32],
in_chans= 3,
num_classes=1000,
embed_dim=48,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
group_size=[7, 7, 7, 7],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False,
merge_size=[[2, 4], [2,4], [2, 4]]
)
output=model(input)
print(output.shape)
```
### 35. MOATransformer Attention Usage
#### 35.1. Paper
[Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
#### 35.2. Usage Code
```python
from model.attention.MOATransformer import MOATransformer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = MOATransformer(
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=[2, 2, 6],
num_heads=[3, 6, 12],
window_size=14,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False
)
output=model(input)
print(output.shape)
```
### 36. CrissCrossAttention Attention Usage
#### 36.1. Paper
[CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
#### 36.2. Usage Code
```python
from model.attention.CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = CrissCrossAttention(64)
outputs = model(input)
print(outputs.shape)
```
### 37. Axial_attention Attention Usage
#### 37.1. Paper
[Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
#### 37.2. Usage Code
```python
from model.attention.Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__':
input=torch.randn(3, 128, 7, 7)
model = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
outputs = model(input)
print(outputs.shape)
```
***
# Backbone Series
- Pytorch implementation of ["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
- Pytorch implementation of ["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
- Pytorch implementation of [Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer---ArXiv 2021.06.07](https://arxiv.org/abs/2106.03650)
- Pytorch implementation of [ConTNet: Why not use convolution and transformer at the same time?---ArXiv 2021.04.27](https://arxiv.org/abs/2104.13497)
- Pytorch implementation of [Vision Transformers with Hierarchical Attention---ArXiv 2022.06.15](https://arxiv.org/abs/2106.03180)
- Pytorch implementation of [Co-Scale Conv-Attentional Image Transformers---ArXiv 2021.08.26](https://arxiv.org/abs/2104.06399)
- Pytorch implementation of [Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
- Pytorch implementation of [Rethinking Spatial Dimensions of Vision Transformers---ICCV 2021](https://arxiv.org/abs/2103.16302)
- Pytorch implementation of [CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification---ICCV 2021](https://arxiv.org/abs/2103.14899)
- Pytorch implementation of [Transformer in Transformer---NeurIPS 2021](https://arxiv.org/abs/2103.00112)
- Pytorch implementation of [DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
- Pytorch implementation of [Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
***
- Pytorch implementation of [ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
- Pytorch implementation of [Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
- Pytorch implementation of [Going deeper with Image Transformers---ICCV 2021 (Oral)](https://arxiv.org/abs/2103.17239)
- Pytorch implementation of [Training data-efficient image transformers & distillation through attention---ICML 2021](https://arxiv.org/abs/2012.12877)
- Pytorch implementation of [LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
- Pytorch implementation of [Container: Context Aggregation Network---NeuIPS 2021](https://arxiv.org/abs/2106.01401)
- Pytorch implementation of [CMT: Convolutional Neural Networks Meet Vision Transformers---CVPR 2022](https://arxiv.org/abs/2107.06263)
- Pytorch implementation of [Vision Transformer with Deformable Attention---CVPR 2022](https://arxiv.org/abs/2201.00520)
- Pytorch implementation of [EfficientFormer: Vision Transformers at MobileNet Speed](https://arxiv.org/abs/2206.01191)
- Pytorch implementation of [ConvNeXtV2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808)
### 1. ResNet Usage
#### 1.1. Paper
["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
#### 1.2. Overview


#### 1.3. Usage Code
```python
from model.backbone.resnet import ResNet50,ResNet101,ResNet152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnet50=ResNet50(1000)
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out=resnet50(input)
print(out.shape)
```
### 2. ResNeXt Usage
#### 2.1. Paper
["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.backbone.resnext import ResNeXt50,ResNeXt101,ResNeXt152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnext50=ResNeXt50(1000)
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out=resnext50(input)
print(out.shape)
```
### 3. MobileViT Usage
#### 3.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.backbone.MobileViT import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
### mobilevit_xxs
mvit_xxs=mobilevit_xxs()
out=mvit_xxs(input)
print(out.shape)
### mobilevit_xs
mvit_xs=mobilevit_xs()
out=mvit_xs(input)
print(out.shape)
### mobilevit_s
mvit_s=mobilevit_s()
out=mvit_s(input)
print(out.shape)
```
### 4. ConvMixer Usage
#### 4.1. Paper
[Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.backbone.ConvMixer import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
convmixer=ConvMixer(dim=512,depth=12)
out=convmixer(x)
print(out.shape) #[1, 1000]
```
### 5. ShuffleTransformer Usage
#### 5.1. Paper
[Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer](https://arxiv.org/pdf/2106.03650.pdf)
#### 5.2. Usage Code
```python
from model.backbone.ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
sft = ShuffleTransformer()
output=sft(input)
print(output.shape)
```
### 6. ConTNet Usage
#### 6.1. Paper
[ConTNet: Why not use convolution and transformer at the same time?](https://arxiv.org/abs/2104.13497)
#### 6.2. Usage Code
```python
from model.backbone.ConTNet import ConTNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == "__main__":
model = build_model(use_avgdown=True, relative=True, qkv_bias=True, pre_norm=True)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
```
### 7 HATNet Usage
#### 7.1. Paper
[Vision Transformers with Hierarchical Attention](https://arxiv.org/abs/2106.03180)
#### 7.2. Usage Code
```python
from model.backbone.HATNet import HATNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
hat = HATNet(dims=[48, 96, 240, 384], head_dim=48, expansions=[8, 8, 4, 4],
grid_sizes=[8, 7, 7, 1], ds_ratios=[8, 4, 2, 1], depths=[2, 2, 6, 3])
output=hat(input)
print(output.shape)
```
### 8 CoaT Usage
#### 8.1. Paper
[Co-Scale Conv-Attentional Image Transformers](https://arxiv.org/abs/2104.06399)
#### 8.2. Usage Code
```python
from model.backbone.CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4])
output=model(input)
print(output.shape) # torch.Size([1, 1000])
```
### 9 PVT Usage
#### 9.1. Paper
[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/pdf/2106.13797.pdf)
#### 9.2. Usage Code
```python
from model.backbone.PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 10 CPVT Usage
#### 10.1. Paper
[Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
#### 10.2. Usage Code
```python
from model.backbone.CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 11 PIT Usage
#### 11.1. Paper
[Rethinking Spatial Dimensions of Vision Transformers](https://arxiv.org/abs/2103.16302)
#### 11.2. Usage Code
```python
from model.backbone.PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4
)
output=model(input)
print(output.shape)
```
### 12 CrossViT Usage
#### 12.1. Paper
[CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification](https://arxiv.org/abs/2103.14899)
#### 12.2. Usage Code
```python
from model.backbone.CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__":
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[240, 224],
patch_size=[12, 16],
embed_dim=[192, 384],
depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6],
mlp_ratio=[4, 4, 1],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 13 TnT Usage
#### 13.1. Paper
[Transformer in Transformer](https://arxiv.org/abs/2103.00112)
#### 13.2. Usage Code
```python
from model.backbone.TnT import TNT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = TNT(
img_size=224,
patch_size=16,
outer_dim=384,
inner_dim=24,
depth=12,
outer_num_heads=6,
inner_num_heads=4,
qkv_bias=False,
inner_stride=4)
output=model(input)
print(output.shape)
```
### 14 DViT Usage
#### 14.1. Paper
[DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
#### 14.2. Usage Code
```python
from model.backbone.DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DeepVisionTransformer(
patch_size=16, embed_dim=384,
depth=[False] * 16,
apply_transform=[False] * 0 + [True] * 32,
num_heads=12,
mlp_ratio=3,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
)
output=model(input)
print(output.shape)
```
### 15 CeiT Usage
#### 15.1. Paper
[Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
#### 15.2. Usage Code
```python
from model.backbone.CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CeIT(
hybrid_backbone=Image2Tokens(),
patch_size=4,
embed_dim=192,
depth=12,
num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 16 ConViT Usage
#### 16.1. Paper
[ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
#### 16.2. Usage Code
```python
from model.backbone.ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 17 CaiT Usage
#### 17.1. Paper
[Going deeper with Image Transformers](https://arxiv.org/abs/2103.17239)
#### 17.2. Usage Code
```python
from model.backbone.CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CaiT(
img_size= 224,
patch_size=16,
embed_dim=192,
depth=24,
num_heads=4,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2
)
output=model(input)
print(output.shape)
```
### 18 PatchConvnet Usage
#### 18.1. Paper
[Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
#### 18.2. Usage Code
```python
from model.backbone.PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
)
output=model(input)
print(output.shape)
```
### 19 DeiT Usage
#### 19.1. Paper
[Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
#### 19.2. Usage Code
```python
from model.backbone.DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DistilledVisionTransformer(
patch_size=16,
embed_dim=384,
depth=12,
num_heads=6,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output[0].shape)
```
### 20 LeViT Usage
#### 20.1. Paper
[LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
#### 20.2. Usage Code
```python
from model.backbone.LeViT import *
import torch
from torch import nn
if __name__ == '__main__':
for name in specification:
input=torch.randn(1,3,224,224)
model = globals()[name](fuse=True, pretrained=False)
model.eval()
output = model(input)
print(output.shape)
```
### 21 VOLO Usage
#### 21.1. Paper
[VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
#### 21.2. Usage Code
```python
from model.backbone.VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VOLO([4, 4, 8, 2],
embed_dims=[192, 384, 384, 384],
num_heads=[6, 12, 12, 12],
mlp_ratios=[3, 3, 3, 3],
downsamples=[True, False, False, False],
outlook_attention=[True, False, False, False ],
post_layers=['ca', 'ca'],
)
output=model(input)
print(output[0].shape)
```
### 22 Container Usage
#### 22.1. Paper
[Container: Context Aggregation Network](https://arxiv.org/abs/2106.01401)
#### 22.2. Usage Code
```python
from model.backbone.Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[224, 56, 28, 14],
patch_size=[4, 2, 2, 2],
embed_dim=[64, 128, 320, 512],
depth=[3, 4, 8, 3],
num_heads=16,
mlp_ratio=[8, 8, 4, 4],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6))
output=model(input)
print(output.shape)
```
### 23 CMT Usage
#### 23.1. Paper
[CMT: Convolutional Neural Networks Meet Vision Transformers](https://arxiv.org/abs/2107.06263)
#### 23.2. Usage Code
```python
from model.backbone.CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CMT_Tiny()
output=model(input)
print(output[0].shape)
```
### 24 EfficientFormer Usage
#### 24.1. Paper
[EfficientFormer: Vision Transformers at MobileNet Speed](https://arxiv.org/abs/2206.01191)
#### 24.2. Usage Code
```python
from model.backbone.EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = EfficientFormer(
layers=EfficientFormer_depth['l1'],
embed_dims=EfficientFormer_width['l1'],
downsamples=[True, True, True, True],
vit_num=1,
)
output=model(input)
print(output[0].shape)
```
### 25 ConvNeXtV2 Usage
#### 25.1. Paper
[ConvNeXtV2: Co-designing and Scaling ConvNets with Masked Autoencoders](https://arxiv.org/abs/2301.00808)
#### 25.2. Usage Code
```python
from model.backbone.convnextv2 import convnextv2_atto
import torch
from torch import nn
if __name__ == "__main__":
model = convnextv2_atto()
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
```
# MLP Series
- Pytorch implementation of ["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition---arXiv 2021.05.05"](https://arxiv.org/pdf/2105.01883v1.pdf)
- Pytorch implementation of ["MLP-Mixer: An all-MLP Architecture for Vision---arXiv 2021.05.17"](https://arxiv.org/pdf/2105.01601.pdf)
- Pytorch implementation of ["ResMLP: Feedforward networks for image classification with data-efficient training---arXiv 2021.05.07"](https://arxiv.org/pdf/2105.03404.pdf)
- Pytorch implementation of ["Pay Attention to MLPs---arXiv 2021.05.17"](https://arxiv.org/abs/2105.08050)
- Pytorch implementation of ["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?---arXiv 2021.09.12"](https://arxiv.org/abs/2109.05422)
### 1. RepMLP Usage
#### 1.1. Paper
["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition"](https://arxiv.org/pdf/2105.01883v1.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.mlp.repmlp import RepMLP
import torch
from torch import nn
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())
```
### 2. MLP-Mixer Usage
#### 2.1. Paper
["MLP-Mixer: An all-MLP Architecture for Vision"](https://arxiv.org/pdf/2105.01601.pdf)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.mlp.mlp_mixer import MlpMixer
import torch
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)
```
***
### 3. ResMLP Usage
#### 3.1. Paper
["ResMLP: Feedforward networks for image classification with data-efficient training"](https://arxiv.org/pdf/2105.03404.pdf)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.mlp.resmlp import ResMLP
import torch
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape) #the last dimention is class_num
```
***
### 4. gMLP Usage
#### 4.1. Paper
["Pay Attention to MLPs"](https://arxiv.org/abs/2105.08050)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.mlp.g_mlp import gMLP
import torch
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)
```
***
### 5. sMLP Usage
#### 5.1. Paper
["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?"](https://arxiv.org/abs/2109.05422)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.mlp.sMLP_block import sMLPBlock
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
smlp=sMLPBlock(h=224,w=224)
out=smlp(input)
print(out.shape)
```
### 6. vip-mlp Usage
#### 6.1. Paper
["Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 6.2. Usage Code
```python
from model.mlp.vip-mlp import VisionPermutator
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionPermutator(
layers=[4, 3, 8, 3],
embed_dims=[384, 384, 384, 384],
patch_size=14,
transitions=[False, False, False, False],
segment_dim=[16, 16, 16, 16],
mlp_ratios=[3, 3, 3, 3],
mlp_fn=WeightedPermuteMLP
)
output=model(input)
print(output.shape)
```
# Re-Parameter Series
- Pytorch implementation of ["RepVGG: Making VGG-style ConvNets Great Again---CVPR2021"](https://arxiv.org/abs/2101.03697)
- Pytorch implementation of ["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks---ICCV2019"](https://arxiv.org/abs/1908.03930)
- Pytorch implementation of ["Diverse Branch Block: Building a Convolution as an Inception-like Unit---CVPR2021"](https://arxiv.org/abs/2103.13425)
***
### 1. RepVGG Usage
#### 1.1. Paper
["RepVGG: Making VGG-style ConvNets Great Again"](https://arxiv.org/abs/2101.03697)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
```
***
### 2. ACNet Usage
#### 2.1. Paper
["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks"](https://arxiv.org/abs/1908.03930)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
```
***
### 2. Diverse Branch Block Usage
#### 2.1. Paper
["Diverse Branch Block: Building a Convolution as an Inception-like Unit"](https://arxiv.org/abs/2103.13425)
#### 2.2. Overview

#### 2.3. Usage Code
##### 2.3.1 Transform I
```python
from model.rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.2 Transform II
```python
from model.rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.3 Transform III
```python
from model.rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.4 Transform IV
```python
from model.rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.5 Transform V
```python
from model.rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.6 Transform VI
```python
from model.rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
# Convolution Series
- Pytorch implementation of ["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications---CVPR2017"](https://arxiv.org/abs/1704.04861)
- Pytorch implementation of ["Efficientnet: Rethinking model scaling for convolutional neural networks---PMLR2019"](http://proceedings.mlr.press/v97/tan19a.html)
- Pytorch implementation of ["Involution: Inverting the Inherence of Convolution for Visual Recognition---CVPR2021"](https://arxiv.org/abs/2103.06255)
- Pytorch implementation of ["Dynamic Convolution: Attention over Convolution Kernels---CVPR2020 Oral"](https://arxiv.org/abs/1912.03458)
- Pytorch implementation of ["CondConv: Conditionally Parameterized Convolutions for Efficient Inference---NeurIPS2019"](https://arxiv.org/abs/1904.04971)
***
### 1. Depthwise Separable Convolution Usage
#### 1.1. Paper
["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications"](https://arxiv.org/abs/1704.04861)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.conv.DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)
```
***
### 2. MBConv Usage
#### 2.1. Paper
["Efficientnet: Rethinking model scaling for convolutional neural networks"](http://proceedings.mlr.press/v97/tan19a.html)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.conv.MBConv import MBConvBlock
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=512,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 3. Involution Usage
#### 3.1. Paper
["Involution: Inverting the Inherence of Convolution for Visual Recognition"](https://arxiv.org/abs/2103.06255)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.conv.Involution import Involution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)
```
***
### 4. DynamicConv Usage
#### 4.1. Paper
["Dynamic Convolution: Attention over Convolution Kernels"](https://arxiv.org/abs/1912.03458)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.conv.DynamicConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape) # 2,32,64,64
```
***
### 5. CondConv Usage
#### 5.1. Paper
["CondConv: Conditionally Parameterized Convolutions for Efficient Inference"](https://arxiv.org/abs/1904.04971)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.conv.CondConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=CondConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
```
## 其他项目推荐
-------
🔥🔥🔥 重磅!!!作为项目补充,更多论文层面的解析,可以关注新开源的项目 **[FightingCV-Paper-Reading](https://github.com/xmu-xiaoma666/FightingCV-Paper-Reading)** ,里面汇集和整理了各大顶会顶刊的论文解析
🔥🔥🔥重磅!!! 最近为大家整理了网上的各种AI相关的视频教程和必读论文 **[FightingCV-Course
](https://github.com/xmu-xiaoma666/FightingCV-Course)**
🔥🔥🔥 重磅!!!最近全新开源了一个 **[YOLOAir](https://github.com/iscyy/yoloair)** 目标检测代码库 ,里面集成了多种YOLO模型,包括YOLOv5, YOLOv7,YOLOR, YOLOX,YOLOv4, YOLOv3以及其他YOLO模型,还包括多种现有Attention机制。
🔥🔥🔥 **ECCV2022论文汇总:[ECCV2022-Paper-List](https://github.com/xmu-xiaoma666/ECCV2022-Paper-List/blob/master/README.md)**
================================================
FILE: README_EN.md
================================================
English | [简体中文](./README.md)
# FightingCV Codebase For [***Attention***](#attention-series),[***Backbone***](#backbone-series), [***MLP***](#mlp-series), [***Re-parameter***](#re-parameter-series), [**Convolution**](#convolution-series)



-------
🔥🔥🔥As a supplement to the project, a object detection codebase [YOLOAir](https://github.com/iscyy/yoloair) has recently been newly opened, which integrates various attention mechanisms in the object detection algorithm. The code is simple and easy to read. Welcome to play and star🌟!**
-------
Hello, everyone, I'm Xiaoma 🚀🚀🚀
***For beginners (like me):***
Recently, I found a problem when reading the paper. Sometimes the core idea of the paper is very simple, and the core code may be just a dozen lines. However, when I open the source code of the author's release, I find that the proposed module is embedded in the task framework such as classification, detection and segmentation, resulting in redundant code. For me who is not familiar with the specific task framework, it is difficult to find the core code, resulting in some difficulties in understanding the paper and network ideas.
***For advanced (like you):***
If the basic units conv, FC and RNN are regarded as small Lego blocks, and the structures transformer and RESNET are regarded as LEGO castles that have been built. The modules provided by this project are LEGO components with complete semantic informationLet scientific researchers avoid repeatedly building wheels, just think about how to use these "LEGO components" to build more colorful works.
***For proficient (may be like you):***
Limited capacity, do not like light spraying!!!
***For All:***
This project aims to realize a code base that can make beginners of deep learning understand and serve scientific research and industrial communities. As [fightingcv wechat official account]( https://mp.weixin.qq.com/s/m9RiivbbDPdjABsTd6q8FA )The purpose of this project is to achieve 🚀Let there be no hard to read papers in the world🚀。
(at the same time, we also welcome all scientific researchers to sort out the core code of their work into this project, promote the development of the scientific research community, and indicate the author of the code in readme ~)
***
# Contents
- [Attention Series](#attention-series)
- [1. External Attention Usage](#1-external-attention-usage)
- [2. Self Attention Usage](#2-self-attention-usage)
- [3. Simplified Self Attention Usage](#3-simplified-self-attention-usage)
- [4. Squeeze-and-Excitation Attention Usage](#4-squeeze-and-excitation-attention-usage)
- [5. SK Attention Usage](#5-sk-attention-usage)
- [6. CBAM Attention Usage](#6-cbam-attention-usage)
- [7. BAM Attention Usage](#7-bam-attention-usage)
- [8. ECA Attention Usage](#8-eca-attention-usage)
- [9. DANet Attention Usage](#9-danet-attention-usage)
- [10. Pyramid Split Attention (PSA) Usage](#10-Pyramid-Split-Attention-Usage)
- [11. Efficient Multi-Head Self-Attention(EMSA) Usage](#11-Efficient-Multi-Head-Self-Attention-Usage)
- [12. Shuffle Attention Usage](#12-Shuffle-Attention-Usage)
- [13. MUSE Attention Usage](#13-MUSE-Attention-Usage)
- [14. SGE Attention Usage](#14-SGE-Attention-Usage)
- [15. A2 Attention Usage](#15-A2-Attention-Usage)
- [16. AFT Attention Usage](#16-AFT-Attention-Usage)
- [17. Outlook Attention Usage](#17-Outlook-Attention-Usage)
- [18. ViP Attention Usage](#18-ViP-Attention-Usage)
- [19. CoAtNet Attention Usage](#19-CoAtNet-Attention-Usage)
- [20. HaloNet Attention Usage](#20-HaloNet-Attention-Usage)
- [21. Polarized Self-Attention Usage](#21-Polarized-Self-Attention-Usage)
- [22. CoTAttention Usage](#22-CoTAttention-Usage)
- [23. Residual Attention Usage](#23-Residual-Attention-Usage)
- [24. S2 Attention Usage](#24-S2-Attention-Usage)
- [25. GFNet Attention Usage](#25-GFNet-Attention-Usage)
- [26. Triplet Attention Usage](#26-TripletAttention-Usage)
- [27. Coordinate Attention Usage](#27-Coordinate-Attention-Usage)
- [28. MobileViT Attention Usage](#28-MobileViT-Attention-Usage)
- [29. ParNet Attention Usage](#29-ParNet-Attention-Usage)
- [30. UFO Attention Usage](#30-UFO-Attention-Usage)
- [31. ACmix Attention Usage](#31-Acmix-Attention-Usage)
- [32. MobileViTv2 Attention Usage](#32-MobileViTv2-Attention-Usage)
- [33. DAT Attention Usage](#33-DAT-Attention-Usage)
- [34. CrossFormer Attention Usage](#34-CrossFormer-Attention-Usage)
- [35. MOATransformer Attention Usage](#35-MOATransformer-Attention-Usage)
- [36. CrissCrossAttention Attention Usage](#36-CrissCrossAttention-Attention-Usage)
- [37. Axial_attention Attention Usage](#37-Axial_attention-Attention-Usage)
- [Backbone Series](#Backbone-series)
- [1. ResNet Usage](#1-ResNet-Usage)
- [2. ResNeXt Usage](#2-ResNeXt-Usage)
- [3. MobileViT Usage](#3-MobileViT-Usage)
- [4. ConvMixer Usage](#4-ConvMixer-Usage)
- [5. ShuffleTransformer Usage](#5-ShuffleTransformer-Usage)
- [6. ConTNet Usage](#6-ConTNet-Usage)
- [7. HATNet Usage](#7-HATNet-Usage)
- [8. CoaT Usage](#8-CoaT-Usage)
- [9. PVT Usage](#9-PVT-Usage)
- [10. CPVT Usage](#10-CPVT-Usage)
- [11. PIT Usage](#11-PIT-Usage)
- [12. CrossViT Usage](#12-CrossViT-Usage)
- [13. TnT Usage](#13-TnT-Usage)
- [14. DViT Usage](#14-DViT-Usage)
- [15. CeiT Usage](#15-CeiT-Usage)
- [16. ConViT Usage](#16-ConViT-Usage)
- [17. CaiT Usage](#17-CaiT-Usage)
- [18. PatchConvnet Usage](#18-PatchConvnet-Usage)
- [19. DeiT Usage](#19-DeiT-Usage)
- [20. LeViT Usage](#20-LeViT-Usage)
- [21. VOLO Usage](#21-VOLO-Usage)
- [22. Container Usage](#22-Container-Usage)
- [23. CMT Usage](#23-CMT-Usage)
- [MLP Series](#mlp-series)
- [1. RepMLP Usage](#1-RepMLP-Usage)
- [2. MLP-Mixer Usage](#2-MLP-Mixer-Usage)
- [3. ResMLP Usage](#3-ResMLP-Usage)
- [4. gMLP Usage](#4-gMLP-Usage)
- [5. sMLP Usage](#5-sMLP-Usage)
- [6. vip-mlp Usage](#6-vip-mlp-Usage)
- [Re-Parameter(ReP) Series](#Re-Parameter-series)
- [1. RepVGG Usage](#1-RepVGG-Usage)
- [2. ACNet Usage](#2-ACNet-Usage)
- [3. Diverse Branch Block(DDB) Usage](#3-Diverse-Branch-Block-Usage)
- [Convolution Series](#Convolution-series)
- [1. Depthwise Separable Convolution Usage](#1-Depthwise-Separable-Convolution-Usage)
- [2. MBConv Usage](#2-MBConv-Usage)
- [3. Involution Usage](#3-Involution-Usage)
- [4. DynamicConv Usage](#4-DynamicConv-Usage)
- [5. CondConv Usage](#5-CondConv-Usage)
***
# Attention Series
- Pytorch implementation of ["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks---arXiv 2021.05.05"](https://arxiv.org/abs/2105.02358)
- Pytorch implementation of ["Attention Is All You Need---NIPS2017"](https://arxiv.org/pdf/1706.03762.pdf)
- Pytorch implementation of ["Squeeze-and-Excitation Networks---CVPR2018"](https://arxiv.org/abs/1709.01507)
- Pytorch implementation of ["Selective Kernel Networks---CVPR2019"](https://arxiv.org/pdf/1903.06586.pdf)
- Pytorch implementation of ["CBAM: Convolutional Block Attention Module---ECCV2018"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
- Pytorch implementation of ["BAM: Bottleneck Attention Module---BMCV2018"](https://arxiv.org/pdf/1807.06514.pdf)
- Pytorch implementation of ["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020"](https://arxiv.org/pdf/1910.03151.pdf)
- Pytorch implementation of ["Dual Attention Network for Scene Segmentation---CVPR2019"](https://arxiv.org/pdf/1809.02983.pdf)
- Pytorch implementation of ["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30"](https://arxiv.org/pdf/2105.14447.pdf)
- Pytorch implementation of ["ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28"](https://arxiv.org/abs/2105.13677)
- Pytorch implementation of ["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS---ICASSP 2021"](https://arxiv.org/pdf/2102.00240.pdf)
- Pytorch implementation of ["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning---arXiv 2019.11.17"](https://arxiv.org/abs/1911.09483)
- Pytorch implementation of ["Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks---arXiv 2019.05.23"](https://arxiv.org/pdf/1905.09646.pdf)
- Pytorch implementation of ["A2-Nets: Double Attention Networks---NIPS2018"](https://arxiv.org/pdf/1810.11579.pdf)
- Pytorch implementation of ["An Attention Free Transformer---ICLR2021 (Apple New Work)"](https://arxiv.org/pdf/2105.14103v1.pdf)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition---arXiv 2021.06.24"](https://arxiv.org/abs/2106.13112)
[【论文解析】](https://zhuanlan.zhihu.com/p/385561050)
- Pytorch implementation of [Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition---arXiv 2021.06.23](https://arxiv.org/abs/2106.12368)
[【论文解析】](https://mp.weixin.qq.com/s/5gonUQgBho_m2O54jyXF_Q)
- Pytorch implementation of [CoAtNet: Marrying Convolution and Attention for All Data Sizes---arXiv 2021.06.09](https://arxiv.org/abs/2106.04803)
[【论文解析】](https://zhuanlan.zhihu.com/p/385578588)
- Pytorch implementation of [Scaling Local Self-Attention for Parameter Efficient Visual Backbones---CVPR2021 Oral](https://arxiv.org/pdf/2103.12731.pdf) [【论文解析】](https://zhuanlan.zhihu.com/p/388598744)
- Pytorch implementation of [Polarized Self-Attention: Towards High-quality Pixel-wise Regression---arXiv 2021.07.02](https://arxiv.org/abs/2107.00782) [【论文解析】](https://zhuanlan.zhihu.com/p/389770482)
- Pytorch implementation of [Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292) [【论文解析】](https://zhuanlan.zhihu.com/p/394795481)
- Pytorch implementation of [Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
- Pytorch implementation of [S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072) [【论文解析】](https://zhuanlan.zhihu.com/p/397003638)
- Pytorch implementation of [Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
- Pytorch implementation of [Rotate to Attend: Convolutional Triplet Attention Module---WACV 2021](https://arxiv.org/abs/2010.03045)
- Pytorch implementation of [Coordinate Attention for Efficient Mobile Network Design ---CVPR 2021](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2110.02178)
- Pytorch implementation of [Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
- Pytorch implementation of [UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2109.14382)
- Pytorch implementation of [Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
- Pytorch implementation of [On the Integration of Self-Attention and Convolution---ArXiv 2022.03.14](https://arxiv.org/pdf/2111.14556.pdf)
- Pytorch implementation of [CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
- Pytorch implementation of [Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
- Pytorch implementation of [CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
- Pytorch implementation of [Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
***
### 1. External Attention Usage
#### 1.1. Paper
["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks"](https://arxiv.org/abs/2105.02358)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
***
### 2. Self Attention Usage
#### 2.1. Paper
["Attention Is All You Need"](https://arxiv.org/pdf/1706.03762.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 3. Simplified Self Attention Usage
#### 3.1. Paper
[None]()
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)
```
***
### 4. Squeeze-and-Excitation Attention Usage
#### 4.1. Paper
["Squeeze-and-Excitation Networks"](https://arxiv.org/abs/1709.01507)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 5. SK Attention Usage
#### 5.1. Paper
["Selective Kernel Networks"](https://arxiv.org/pdf/1903.06586.pdf)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 6. CBAM Attention Usage
#### 6.1. Paper
["CBAM: Convolutional Block Attention Module"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
#### 6.2. Overview


#### 6.3. Usage Code
```python
from model.attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
***
### 7. BAM Attention Usage
#### 7.1. Paper
["BAM: Bottleneck Attention Module"](https://arxiv.org/pdf/1807.06514.pdf)
#### 7.2. Overview

#### 7.3. Usage Code
```python
from model.attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
***
### 8. ECA Attention Usage
#### 8.1. Paper
["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks"](https://arxiv.org/pdf/1910.03151.pdf)
#### 8.2. Overview

#### 8.3. Usage Code
```python
from model.attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
***
### 9. DANet Attention Usage
#### 9.1. Paper
["Dual Attention Network for Scene Segmentation"](https://arxiv.org/pdf/1809.02983.pdf)
#### 9.2. Overview

#### 9.3. Usage Code
```python
from model.attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
***
### 10. Pyramid Split Attention Usage
#### 10.1. Paper
["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network"](https://arxiv.org/pdf/2105.14447.pdf)
#### 10.2. Overview

#### 10.3. Usage Code
```python
from model.attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
***
### 11. Efficient Multi-Head Self-Attention Usage
#### 11.1. Paper
["ResT: An Efficient Transformer for Visual Recognition"](https://arxiv.org/abs/2105.13677)
#### 11.2. Overview

#### 11.3. Usage Code
```python
from model.attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
***
### 12. Shuffle Attention Usage
#### 12.1. Paper
["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS"](https://arxiv.org/pdf/2102.00240.pdf)
#### 12.2. Overview

#### 12.3. Usage Code
```python
from model.attention.ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
```
***
### 13. MUSE Attention Usage
#### 13.1. Paper
["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning"](https://arxiv.org/abs/1911.09483)
#### 13.2. Overview

#### 13.3. Usage Code
```python
from model.attention.MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 14. SGE Attention Usage
#### 14.1. Paper
[Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks](https://arxiv.org/pdf/1905.09646.pdf)
#### 14.2. Overview

#### 14.3. Usage Code
```python
from model.attention.SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
```
***
### 15. A2 Attention Usage
#### 15.1. Paper
[A2-Nets: Double Attention Networks](https://arxiv.org/pdf/1810.11579.pdf)
#### 15.2. Overview

#### 15.3. Usage Code
```python
from model.attention.A2Atttention import DoubleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
```
### 16. AFT Attention Usage
#### 16.1. Paper
[An Attention Free Transformer](https://arxiv.org/pdf/2105.14103v1.pdf)
#### 16.2. Overview

#### 16.3. Usage Code
```python
from model.attention.AFT import AFT_FULL
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
```
### 17. Outlook Attention Usage
#### 17.1. Paper
[VOLO: Vision Outlooker for Visual Recognition"](https://arxiv.org/abs/2106.13112)
#### 17.2. Overview

#### 17.3. Usage Code
```python
from model.attention.OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)
```
***
### 18. ViP Attention Usage
#### 18.1. Paper
[Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 18.2. Overview

#### 18.3. Usage Code
```python
from model.attention.ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)
```
***
### 19. CoAtNet Attention Usage
#### 19.1. Paper
[CoAtNet: Marrying Convolution and Attention for All Data Sizes"](https://arxiv.org/abs/2106.04803)
#### 19.2. Overview
None
#### 19.3. Usage Code
```python
from model.attention.CoAtNet import CoAtNet
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=CoAtNet(in_ch=3,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 20. HaloNet Attention Usage
#### 20.1. Paper
[Scaling Local Self-Attention for Parameter Efficient Visual Backbones"](https://arxiv.org/pdf/2103.12731.pdf)
#### 20.2. Overview

#### 20.3. Usage Code
```python
from model.attention.HaloAttention import HaloAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)
```
***
### 21. Polarized Self-Attention Usage
#### 21.1. Paper
[Polarized Self-Attention: Towards High-quality Pixel-wise Regression"](https://arxiv.org/abs/2107.00782)
#### 21.2. Overview

#### 21.3. Usage Code
```python
from model.attention.PolarizedSelfAttention import ParallelPolarizedSelfAttention,SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
```
***
### 22. CoTAttention Usage
#### 22.1. Paper
[Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292)
#### 22.2. Overview

#### 22.3. Usage Code
```python
from model.attention.CoTAttention import CoTAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
```
***
### 23. Residual Attention Usage
#### 23.1. Paper
[Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
#### 23.2. Overview

#### 23.3. Usage Code
```python
from model.attention.ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
resatt = ResidualAttention(channel=512,num_class=1000,la=0.2)
output=resatt(input)
print(output.shape)
```
***
### 24. S2 Attention Usage
#### 24.1. Paper
[S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072)
#### 24.2. Overview

#### 24.3. Usage Code
```python
from model.attention.S2Attention import S2Attention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
s2att = S2Attention(channels=512)
output=s2att(input)
print(output.shape)
```
***
### 25. GFNet Attention Usage
#### 25.1. Paper
[Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
#### 25.2. Overview

#### 25.3. Usage Code - Implemented by [Wenliang Zhao (Author)](https://scholar.google.com/citations?user=lyPWvuEAAAAJ&hl=en)
```python
from model.attention.gfnet import GFNet
import torch
from torch import nn
from torch.nn import functional as F
x = torch.randn(1, 3, 224, 224)
gfnet = GFNet(embed_dim=384, img_size=224, patch_size=16, num_classes=1000)
out = gfnet(x)
print(out.shape)
```
***
### 26. TripletAttention Usage
#### 26.1. Paper
[Rotate to Attend: Convolutional Triplet Attention Module---CVPR 2021](https://arxiv.org/abs/2010.03045)
#### 26.2. Overview

#### 26.3. Usage Code - Implemented by [digantamisra98](https://github.com/digantamisra98)
```python
from model.attention.TripletAttention import TripletAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
triplet = TripletAttention()
output=triplet(input)
print(output.shape)
```
***
### 27. Coordinate Attention Usage
#### 27.1. Paper
[Coordinate Attention for Efficient Mobile Network Design---CVPR 2021](https://arxiv.org/abs/2103.02907)
#### 27.2. Overview

#### 27.3. Usage Code - Implemented by [Andrew-Qibin](https://github.com/Andrew-Qibin)
```python
from model.attention.CoordAttention import CoordAtt
import torch
from torch import nn
from torch.nn import functional as F
inp=torch.rand([2, 96, 56, 56])
inp_dim, oup_dim = 96, 96
reduction=32
coord_attention = CoordAtt(inp_dim, oup_dim, reduction=reduction)
output=coord_attention(inp)
print(output.shape)
```
***
### 28. MobileViT Attention Usage
#### 28.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2103.02907)
#### 28.2. Overview

#### 28.3. Usage Code
```python
from model.attention.MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
m=MobileViTAttention()
input=torch.randn(1,3,49,49)
output=m(input)
print(output.shape) #output:(1,3,49,49)
```
***
### 29. ParNet Attention Usage
#### 29.1. Paper
[Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
#### 29.2. Overview

#### 29.3. Usage Code
```python
from model.attention.ParNetAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
pna = ParNetAttention(channel=512)
output=pna(input)
print(output.shape) #50,512,7,7
```
***
### 30. UFO Attention Usage
#### 30.1. Paper
[UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2110.07641)
#### 30.2. Overview

#### 30.3. Usage Code
```python
from model.attention.UFOAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
ufo = UFOAttention(d_model=512, d_k=512, d_v=512, h=8)
output=ufo(input,input,input)
print(output.shape) #[50, 49, 512]
```
-
### 31. ACmix Attention Usage
#### 31.1. Paper
[On the Integration of Self-Attention and Convolution](https://arxiv.org/pdf/2111.14556.pdf)
#### 31.2. Usage Code
```python
from model.attention.ACmix import ACmix
import torch
if __name__ == '__main__':
input=torch.randn(50,256,7,7)
acmix = ACmix(in_planes=256, out_planes=256)
output=acmix(input)
print(output.shape)
```
### 32. MobileViTv2 Attention Usage
#### 32.1. Paper
[Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
#### 32.2. Overview

#### 32.3. Usage Code
```python
from model.attention.MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
### 33. DAT Attention Usage
#### 33.1. Paper
[Vision Transformer with Deformable Attention---CVPR2022](https://arxiv.org/abs/2201.00520)
#### 33.2. Usage Code
```python
from model.attention.DAT import DAT
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DAT(
img_size=224,
patch_size=4,
num_classes=1000,
expansion=4,
dim_stem=96,
dims=[96, 192, 384, 768],
depths=[2, 2, 6, 2],
stage_spec=[['L', 'S'], ['L', 'S'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7] ,
groups=[-1, -1, 3, 6],
use_pes=[False, False, True, True],
dwc_pes=[False, False, False, False],
strides=[-1, -1, 1, 1],
sr_ratios=[-1, -1, -1, -1],
offset_range_factor=[-1, -1, 2, 2],
no_offs=[False, False, False, False],
fixed_pes=[False, False, False, False],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
)
output=model(input)
print(output[0].shape)
```
### 34. CrossFormer Attention Usage
#### 34.1. Paper
[CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
#### 34.2. Usage Code
```python
from model.attention.Crossformer import CrossFormer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CrossFormer(img_size=224,
patch_size=[4, 8, 16, 32],
in_chans= 3,
num_classes=1000,
embed_dim=48,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
group_size=[7, 7, 7, 7],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False,
merge_size=[[2, 4], [2,4], [2, 4]]
)
output=model(input)
print(output.shape)
```
### 35. MOATransformer Attention Usage
#### 35.1. Paper
[Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
#### 35.2. Usage Code
```python
from model.attention.MOATransformer import MOATransformer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = MOATransformer(
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=[2, 2, 6],
num_heads=[3, 6, 12],
window_size=14,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False
)
output=model(input)
print(output.shape)
```
### 36. CrissCrossAttention Attention Usage
#### 36.1. Paper
[CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
#### 36.2. Usage Code
```python
from model.attention.CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = CrissCrossAttention(64)
outputs = model(input)
print(outputs.shape)
```
### 37. Axial_attention Attention Usage
#### 37.1. Paper
[Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
#### 37.2. Usage Code
```python
from model.attention.Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__':
input=torch.randn(3, 128, 7, 7)
model = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
outputs = model(input)
print(outputs.shape)
```
***
# Backbone Series
- Pytorch implementation of ["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
- Pytorch implementation of ["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
- Pytorch implementation of [Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer---ArXiv 2021.06.07](https://arxiv.org/abs/2106.03650)
- Pytorch implementation of [ConTNet: Why not use convolution and transformer at the same time?---ArXiv 2021.04.27](https://arxiv.org/abs/2104.13497)
- Pytorch implementation of [Vision Transformers with Hierarchical Attention---ArXiv 2022.06.15](https://arxiv.org/abs/2106.03180)
- Pytorch implementation of [Co-Scale Conv-Attentional Image Transformers---ArXiv 2021.08.26](https://arxiv.org/abs/2104.06399)
- Pytorch implementation of [Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
- Pytorch implementation of [Rethinking Spatial Dimensions of Vision Transformers---ICCV 2021](https://arxiv.org/abs/2103.16302)
- Pytorch implementation of [CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification---ICCV 2021](https://arxiv.org/abs/2103.14899)
- Pytorch implementation of [Transformer in Transformer---NeurIPS 2021](https://arxiv.org/abs/2103.00112)
- Pytorch implementation of [DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
- Pytorch implementation of [Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
***
- Pytorch implementation of [ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
- Pytorch implementation of [Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
- Pytorch implementation of [Going deeper with Image Transformers---ICCV 2021 (Oral)](https://arxiv.org/abs/2103.17239)
- Pytorch implementation of [Training data-efficient image transformers & distillation through attention---ICML 2021](https://arxiv.org/abs/2012.12877)
- Pytorch implementation of [LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
- Pytorch implementation of [Container: Context Aggregation Network---NeuIPS 2021](https://arxiv.org/abs/2106.01401)
- Pytorch implementation of [CMT: Convolutional Neural Networks Meet Vision Transformers---CVPR 2022](https://arxiv.org/abs/2107.06263)
- Pytorch implementation of [Vision Transformer with Deformable Attention---CVPR 2022](https://arxiv.org/abs/2201.00520)
### 1. ResNet Usage
#### 1.1. Paper
["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
#### 1.2. Overview


#### 1.3. Usage Code
```python
from model.backbone.resnet import ResNet50,ResNet101,ResNet152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnet50=ResNet50(1000)
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out=resnet50(input)
print(out.shape)
```
### 2. ResNeXt Usage
#### 2.1. Paper
["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.backbone.resnext import ResNeXt50,ResNeXt101,ResNeXt152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnext50=ResNeXt50(1000)
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out=resnext50(input)
print(out.shape)
```
### 3. MobileViT Usage
#### 3.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.backbone.MobileViT import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
### mobilevit_xxs
mvit_xxs=mobilevit_xxs()
out=mvit_xxs(input)
print(out.shape)
### mobilevit_xs
mvit_xs=mobilevit_xs()
out=mvit_xs(input)
print(out.shape)
### mobilevit_s
mvit_s=mobilevit_s()
out=mvit_s(input)
print(out.shape)
```
### 4. ConvMixer Usage
#### 4.1. Paper
[Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.backbone.ConvMixer import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
convmixer=ConvMixer(dim=512,depth=12)
out=convmixer(x)
print(out.shape) #[1, 1000]
```
### 5. ShuffleTransformer Usage
#### 5.1. Paper
[Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer](https://arxiv.org/pdf/2106.03650.pdf)
#### 5.2. Usage Code
```python
from model.backbone.ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
sft = ShuffleTransformer()
output=sft(input)
print(output.shape)
```
### 6. ConTNet Usage
#### 6.1. Paper
[ConTNet: Why not use convolution and transformer at the same time?](https://arxiv.org/abs/2104.13497)
#### 6.2. Usage Code
```python
from model.backbone.ConTNet import ConTNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == "__main__":
model = build_model(use_avgdown=True, relative=True, qkv_bias=True, pre_norm=True)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
```
### 7 HATNet Usage
#### 7.1. Paper
[Vision Transformers with Hierarchical Attention](https://arxiv.org/abs/2106.03180)
#### 7.2. Usage Code
```python
from model.backbone.HATNet import HATNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
hat = HATNet(dims=[48, 96, 240, 384], head_dim=48, expansions=[8, 8, 4, 4],
grid_sizes=[8, 7, 7, 1], ds_ratios=[8, 4, 2, 1], depths=[2, 2, 6, 3])
output=hat(input)
print(output.shape)
```
### 8 CoaT Usage
#### 8.1. Paper
[Co-Scale Conv-Attentional Image Transformers](https://arxiv.org/abs/2104.06399)
#### 8.2. Usage Code
```python
from model.backbone.CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4])
output=model(input)
print(output.shape) # torch.Size([1, 1000])
```
### 9 PVT Usage
#### 9.1. Paper
[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/pdf/2106.13797.pdf)
#### 9.2. Usage Code
```python
from model.backbone.PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 10 CPVT Usage
#### 10.1. Paper
[Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
#### 10.2. Usage Code
```python
from model.backbone.CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 11 PIT Usage
#### 11.1. Paper
[Rethinking Spatial Dimensions of Vision Transformers](https://arxiv.org/abs/2103.16302)
#### 11.2. Usage Code
```python
from model.backbone.PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4
)
output=model(input)
print(output.shape)
```
### 12 CrossViT Usage
#### 12.1. Paper
[CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification](https://arxiv.org/abs/2103.14899)
#### 12.2. Usage Code
```python
from model.backbone.CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__":
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[240, 224],
patch_size=[12, 16],
embed_dim=[192, 384],
depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6],
mlp_ratio=[4, 4, 1],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 13 TnT Usage
#### 13.1. Paper
[Transformer in Transformer](https://arxiv.org/abs/2103.00112)
#### 13.2. Usage Code
```python
from model.backbone.TnT import TNT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = TNT(
img_size=224,
patch_size=16,
outer_dim=384,
inner_dim=24,
depth=12,
outer_num_heads=6,
inner_num_heads=4,
qkv_bias=False,
inner_stride=4)
output=model(input)
print(output.shape)
```
### 14 DViT Usage
#### 14.1. Paper
[DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
#### 14.2. Usage Code
```python
from model.backbone.DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DeepVisionTransformer(
patch_size=16, embed_dim=384,
depth=[False] * 16,
apply_transform=[False] * 0 + [True] * 32,
num_heads=12,
mlp_ratio=3,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
)
output=model(input)
print(output.shape)
```
### 15 CeiT Usage
#### 15.1. Paper
[Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
#### 15.2. Usage Code
```python
from model.backbone.CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CeIT(
hybrid_backbone=Image2Tokens(),
patch_size=4,
embed_dim=192,
depth=12,
num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 16 ConViT Usage
#### 16.1. Paper
[ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
#### 16.2. Usage Code
```python
from model.backbone.ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 17 CaiT Usage
#### 17.1. Paper
[Going deeper with Image Transformers](https://arxiv.org/abs/2103.17239)
#### 17.2. Usage Code
```python
from model.backbone.CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CaiT(
img_size= 224,
patch_size=16,
embed_dim=192,
depth=24,
num_heads=4,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2
)
output=model(input)
print(output.shape)
```
### 18 PatchConvnet Usage
#### 18.1. Paper
[Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
#### 18.2. Usage Code
```python
from model.backbone.PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
)
output=model(input)
print(output.shape)
```
### 19 DeiT Usage
#### 19.1. Paper
[Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
#### 19.2. Usage Code
```python
from model.backbone.DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DistilledVisionTransformer(
patch_size=16,
embed_dim=384,
depth=12,
num_heads=6,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output[0].shape)
```
### 20 LeViT Usage
#### 20.1. Paper
[LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
#### 20.2. Usage Code
```python
from model.backbone.LeViT import *
import torch
from torch import nn
if __name__ == '__main__':
for name in specification:
input=torch.randn(1,3,224,224)
model = globals()[name](fuse=True, pretrained=False)
model.eval()
output = model(input)
print(output.shape)
```
### 21 VOLO Usage
#### 21.1. Paper
[VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
#### 21.2. Usage Code
```python
from model.backbone.VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VOLO([4, 4, 8, 2],
embed_dims=[192, 384, 384, 384],
num_heads=[6, 12, 12, 12],
mlp_ratios=[3, 3, 3, 3],
downsamples=[True, False, False, False],
outlook_attention=[True, False, False, False ],
post_layers=['ca', 'ca'],
)
output=model(input)
print(output[0].shape)
```
### 22 Container Usage
#### 22.1. Paper
[Container: Context Aggregation Network](https://arxiv.org/abs/2106.01401)
#### 22.2. Usage Code
```python
from model.backbone.Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[224, 56, 28, 14],
patch_size=[4, 2, 2, 2],
embed_dim=[64, 128, 320, 512],
depth=[3, 4, 8, 3],
num_heads=16,
mlp_ratio=[8, 8, 4, 4],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6))
output=model(input)
print(output.shape)
```
### 23 CMT Usage
#### 23.1. Paper
[CMT: Convolutional Neural Networks Meet Vision Transformers](https://arxiv.org/abs/2107.06263)
#### 23.2. Usage Code
```python
from model.backbone.CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CMT_Tiny()
output=model(input)
print(output[0].shape)
```
# MLP Series
- Pytorch implementation of ["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition---arXiv 2021.05.05"](https://arxiv.org/pdf/2105.01883v1.pdf)
- Pytorch implementation of ["MLP-Mixer: An all-MLP Architecture for Vision---arXiv 2021.05.17"](https://arxiv.org/pdf/2105.01601.pdf)
- Pytorch implementation of ["ResMLP: Feedforward networks for image classification with data-efficient training---arXiv 2021.05.07"](https://arxiv.org/pdf/2105.03404.pdf)
- Pytorch implementation of ["Pay Attention to MLPs---arXiv 2021.05.17"](https://arxiv.org/abs/2105.08050)
- Pytorch implementation of ["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?---arXiv 2021.09.12"](https://arxiv.org/abs/2109.05422)
### 1. RepMLP Usage
#### 1.1. Paper
["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition"](https://arxiv.org/pdf/2105.01883v1.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.mlp.repmlp import RepMLP
import torch
from torch import nn
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())
```
### 2. MLP-Mixer Usage
#### 2.1. Paper
["MLP-Mixer: An all-MLP Architecture for Vision"](https://arxiv.org/pdf/2105.01601.pdf)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.mlp.mlp_mixer import MlpMixer
import torch
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)
```
***
### 3. ResMLP Usage
#### 3.1. Paper
["ResMLP: Feedforward networks for image classification with data-efficient training"](https://arxiv.org/pdf/2105.03404.pdf)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.mlp.resmlp import ResMLP
import torch
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape) #the last dimention is class_num
```
***
### 4. gMLP Usage
#### 4.1. Paper
["Pay Attention to MLPs"](https://arxiv.org/abs/2105.08050)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.mlp.g_mlp import gMLP
import torch
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)
```
***
### 5. sMLP Usage
#### 5.1. Paper
["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?"](https://arxiv.org/abs/2109.05422)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.mlp.sMLP_block import sMLPBlock
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
smlp=sMLPBlock(h=224,w=224)
out=smlp(input)
print(out.shape)
```
### 6. vip-mlp Usage
#### 6.1. Paper
["Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 6.2. Usage Code
```python
from model.mlp.vip-mlp import VisionPermutator
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionPermutator(
layers=[4, 3, 8, 3],
embed_dims=[384, 384, 384, 384],
patch_size=14,
transitions=[False, False, False, False],
segment_dim=[16, 16, 16, 16],
mlp_ratios=[3, 3, 3, 3],
mlp_fn=WeightedPermuteMLP
)
output=model(input)
print(output.shape)
```
# Re-Parameter Series
- Pytorch implementation of ["RepVGG: Making VGG-style ConvNets Great Again---CVPR2021"](https://arxiv.org/abs/2101.03697)
- Pytorch implementation of ["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks---ICCV2019"](https://arxiv.org/abs/1908.03930)
- Pytorch implementation of ["Diverse Branch Block: Building a Convolution as an Inception-like Unit---CVPR2021"](https://arxiv.org/abs/2103.13425)
***
### 1. RepVGG Usage
#### 1.1. Paper
["RepVGG: Making VGG-style ConvNets Great Again"](https://arxiv.org/abs/2101.03697)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
```
***
### 2. ACNet Usage
#### 2.1. Paper
["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks"](https://arxiv.org/abs/1908.03930)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
```
***
### 2. Diverse Branch Block Usage
#### 2.1. Paper
["Diverse Branch Block: Building a Convolution as an Inception-like Unit"](https://arxiv.org/abs/2103.13425)
#### 2.2. Overview

#### 2.3. Usage Code
##### 2.3.1 Transform I
```python
from model.rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.2 Transform II
```python
from model.rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.3 Transform III
```python
from model.rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.4 Transform IV
```python
from model.rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.5 Transform V
```python
from model.rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.6 Transform VI
```python
from model.rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
# Convolution Series
- Pytorch implementation of ["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications---CVPR2017"](https://arxiv.org/abs/1704.04861)
- Pytorch implementation of ["Efficientnet: Rethinking model scaling for convolutional neural networks---PMLR2019"](http://proceedings.mlr.press/v97/tan19a.html)
- Pytorch implementation of ["Involution: Inverting the Inherence of Convolution for Visual Recognition---CVPR2021"](https://arxiv.org/abs/2103.06255)
- Pytorch implementation of ["Dynamic Convolution: Attention over Convolution Kernels---CVPR2020 Oral"](https://arxiv.org/abs/1912.03458)
- Pytorch implementation of ["CondConv: Conditionally Parameterized Convolutions for Efficient Inference---NeurIPS2019"](https://arxiv.org/abs/1904.04971)
***
### 1. Depthwise Separable Convolution Usage
#### 1.1. Paper
["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications"](https://arxiv.org/abs/1704.04861)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.conv.DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)
```
***
### 2. MBConv Usage
#### 2.1. Paper
["Efficientnet: Rethinking model scaling for convolutional neural networks"](http://proceedings.mlr.press/v97/tan19a.html)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.conv.MBConv import MBConvBlock
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=512,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 3. Involution Usage
#### 3.1. Paper
["Involution: Inverting the Inherence of Convolution for Visual Recognition"](https://arxiv.org/abs/2103.06255)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.conv.Involution import Involution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)
```
***
### 4. DynamicConv Usage
#### 4.1. Paper
["Dynamic Convolution: Attention over Convolution Kernels"](https://arxiv.org/abs/1912.03458)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.conv.DynamicConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape) # 2,32,64,64
```
***
### 5. CondConv Usage
#### 5.1. Paper
["CondConv: Conditionally Parameterized Convolutions for Efficient Inference"](https://arxiv.org/abs/1904.04971)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.conv.CondConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=CondConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
```
***
================================================
FILE: README_pip.md
================================================
## pip使用文档
### 安装
直接通过 pip 安装,可直接在其他任务中使用
```shell
pip install fightingcv-attention
```
### 演示
#### 使用 pip 方式
```python
import torch
from torch import nn
from torch.nn import functional as F
# 使用 pip 方式
from fightingcv_attention.attention.MobileViTv2Attention import *
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
## pip包 fightingcv-attention 包含以下模块
# 目录
- [Attention Series](#attention-series)
- [1. External Attention Usage](#1-external-attention-usage)
- [2. Self Attention Usage](#2-self-attention-usage)
- [3. Simplified Self Attention Usage](#3-simplified-self-attention-usage)
- [4. Squeeze-and-Excitation Attention Usage](#4-squeeze-and-excitation-attention-usage)
- [5. SK Attention Usage](#5-sk-attention-usage)
- [6. CBAM Attention Usage](#6-cbam-attention-usage)
- [7. BAM Attention Usage](#7-bam-attention-usage)
- [8. ECA Attention Usage](#8-eca-attention-usage)
- [9. DANet Attention Usage](#9-danet-attention-usage)
- [10. Pyramid Split Attention (PSA) Usage](#10-Pyramid-Split-Attention-Usage)
- [11. Efficient Multi-Head Self-Attention(EMSA) Usage](#11-Efficient-Multi-Head-Self-Attention-Usage)
- [12. Shuffle Attention Usage](#12-Shuffle-Attention-Usage)
- [13. MUSE Attention Usage](#13-MUSE-Attention-Usage)
- [14. SGE Attention Usage](#14-SGE-Attention-Usage)
- [15. A2 Attention Usage](#15-A2-Attention-Usage)
- [16. AFT Attention Usage](#16-AFT-Attention-Usage)
- [17. Outlook Attention Usage](#17-Outlook-Attention-Usage)
- [18. ViP Attention Usage](#18-ViP-Attention-Usage)
- [19. CoAtNet Attention Usage](#19-CoAtNet-Attention-Usage)
- [20. HaloNet Attention Usage](#20-HaloNet-Attention-Usage)
- [21. Polarized Self-Attention Usage](#21-Polarized-Self-Attention-Usage)
- [22. CoTAttention Usage](#22-CoTAttention-Usage)
- [23. Residual Attention Usage](#23-Residual-Attention-Usage)
- [24. S2 Attention Usage](#24-S2-Attention-Usage)
- [25. GFNet Attention Usage](#25-GFNet-Attention-Usage)
- [26. Triplet Attention Usage](#26-TripletAttention-Usage)
- [27. Coordinate Attention Usage](#27-Coordinate-Attention-Usage)
- [28. MobileViT Attention Usage](#28-MobileViT-Attention-Usage)
- [29. ParNet Attention Usage](#29-ParNet-Attention-Usage)
- [30. UFO Attention Usage](#30-UFO-Attention-Usage)
- [31. ACmix Attention Usage](#31-Acmix-Attention-Usage)
- [32. MobileViTv2 Attention Usage](#32-MobileViTv2-Attention-Usage)
- [33. DAT Attention Usage](#33-DAT-Attention-Usage)
- [34. CrossFormer Attention Usage](#34-CrossFormer-Attention-Usage)
- [35. MOATransformer Attention Usage](#35-MOATransformer-Attention-Usage)
- [36. CrissCrossAttention Attention Usage](#36-CrissCrossAttention-Attention-Usage)
- [37. Axial_attention Attention Usage](#37-Axial_attention-Attention-Usage)
- [Backbone Series](#Backbone-series)
- [1. ResNet Usage](#1-ResNet-Usage)
- [2. ResNeXt Usage](#2-ResNeXt-Usage)
- [3. MobileViT Usage](#3-MobileViT-Usage)
- [4. ConvMixer Usage](#4-ConvMixer-Usage)
- [5. ShuffleTransformer Usage](#5-ShuffleTransformer-Usage)
- [6. ConTNet Usage](#6-ConTNet-Usage)
- [7. HATNet Usage](#7-HATNet-Usage)
- [8. CoaT Usage](#8-CoaT-Usage)
- [9. PVT Usage](#9-PVT-Usage)
- [10. CPVT Usage](#10-CPVT-Usage)
- [11. PIT Usage](#11-PIT-Usage)
- [12. CrossViT Usage](#12-CrossViT-Usage)
- [13. TnT Usage](#13-TnT-Usage)
- [14. DViT Usage](#14-DViT-Usage)
- [15. CeiT Usage](#15-CeiT-Usage)
- [16. ConViT Usage](#16-ConViT-Usage)
- [17. CaiT Usage](#17-CaiT-Usage)
- [18. PatchConvnet Usage](#18-PatchConvnet-Usage)
- [19. DeiT Usage](#19-DeiT-Usage)
- [20. LeViT Usage](#20-LeViT-Usage)
- [21. VOLO Usage](#21-VOLO-Usage)
- [22. Container Usage](#22-Container-Usage)
- [23. CMT Usage](#23-CMT-Usage)
- [24. EfficientFormer Usage](#24-EfficientFormer-Usage)
- [MLP Series](#mlp-series)
- [1. RepMLP Usage](#1-RepMLP-Usage)
- [2. MLP-Mixer Usage](#2-MLP-Mixer-Usage)
- [3. ResMLP Usage](#3-ResMLP-Usage)
- [4. gMLP Usage](#4-gMLP-Usage)
- [5. sMLP Usage](#5-sMLP-Usage)
- [6. vip-mlp Usage](#6-vip-mlp-Usage)
- [Re-Parameter(ReP) Series](#Re-Parameter-series)
- [1. RepVGG Usage](#1-RepVGG-Usage)
- [2. ACNet Usage](#2-ACNet-Usage)
- [3. Diverse Branch Block(DDB) Usage](#3-Diverse-Branch-Block-Usage)
- [Convolution Series](#Convolution-series)
- [1. Depthwise Separable Convolution Usage](#1-Depthwise-Separable-Convolution-Usage)
- [2. MBConv Usage](#2-MBConv-Usage)
- [3. Involution Usage](#3-Involution-Usage)
- [4. DynamicConv Usage](#4-DynamicConv-Usage)
- [5. CondConv Usage](#5-CondConv-Usage)
***
# Attention Series
- Pytorch implementation of ["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks---arXiv 2021.05.05"](https://arxiv.org/abs/2105.02358)
- Pytorch implementation of ["Attention Is All You Need---NIPS2017"](https://arxiv.org/pdf/1706.03762.pdf)
- Pytorch implementation of ["Squeeze-and-Excitation Networks---CVPR2018"](https://arxiv.org/abs/1709.01507)
- Pytorch implementation of ["Selective Kernel Networks---CVPR2019"](https://arxiv.org/pdf/1903.06586.pdf)
- Pytorch implementation of ["CBAM: Convolutional Block Attention Module---ECCV2018"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
- Pytorch implementation of ["BAM: Bottleneck Attention Module---BMCV2018"](https://arxiv.org/pdf/1807.06514.pdf)
- Pytorch implementation of ["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020"](https://arxiv.org/pdf/1910.03151.pdf)
- Pytorch implementation of ["Dual Attention Network for Scene Segmentation---CVPR2019"](https://arxiv.org/pdf/1809.02983.pdf)
- Pytorch implementation of ["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30"](https://arxiv.org/pdf/2105.14447.pdf)
- Pytorch implementation of ["ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28"](https://arxiv.org/abs/2105.13677)
- Pytorch implementation of ["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS---ICASSP 2021"](https://arxiv.org/pdf/2102.00240.pdf)
- Pytorch implementation of ["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning---arXiv 2019.11.17"](https://arxiv.org/abs/1911.09483)
- Pytorch implementation of ["Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks---arXiv 2019.05.23"](https://arxiv.org/pdf/1905.09646.pdf)
- Pytorch implementation of ["A2-Nets: Double Attention Networks---NIPS2018"](https://arxiv.org/pdf/1810.11579.pdf)
- Pytorch implementation of ["An Attention Free Transformer---ICLR2021 (Apple New Work)"](https://arxiv.org/pdf/2105.14103v1.pdf)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition---arXiv 2021.06.24"](https://arxiv.org/abs/2106.13112)
[【论文解析】](https://zhuanlan.zhihu.com/p/385561050)
- Pytorch implementation of [Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition---arXiv 2021.06.23](https://arxiv.org/abs/2106.12368)
[【论文解析】](https://mp.weixin.qq.com/s/5gonUQgBho_m2O54jyXF_Q)
- Pytorch implementation of [CoAtNet: Marrying Convolution and Attention for All Data Sizes---arXiv 2021.06.09](https://arxiv.org/abs/2106.04803)
[【论文解析】](https://zhuanlan.zhihu.com/p/385578588)
- Pytorch implementation of [Scaling Local Self-Attention for Parameter Efficient Visual Backbones---CVPR2021 Oral](https://arxiv.org/pdf/2103.12731.pdf) [【论文解析】](https://zhuanlan.zhihu.com/p/388598744)
- Pytorch implementation of [Polarized Self-Attention: Towards High-quality Pixel-wise Regression---arXiv 2021.07.02](https://arxiv.org/abs/2107.00782) [【论文解析】](https://zhuanlan.zhihu.com/p/389770482)
- Pytorch implementation of [Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292) [【论文解析】](https://zhuanlan.zhihu.com/p/394795481)
- Pytorch implementation of [Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
- Pytorch implementation of [S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072) [【论文解析】](https://zhuanlan.zhihu.com/p/397003638)
- Pytorch implementation of [Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
- Pytorch implementation of [Rotate to Attend: Convolutional Triplet Attention Module---WACV 2021](https://arxiv.org/abs/2010.03045)
- Pytorch implementation of [Coordinate Attention for Efficient Mobile Network Design ---CVPR 2021](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2110.02178)
- Pytorch implementation of [Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
- Pytorch implementation of [UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2109.14382)
- Pytorch implementation of [Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
- Pytorch implementation of [On the Integration of Self-Attention and Convolution---ArXiv 2022.03.14](https://arxiv.org/pdf/2111.14556.pdf)
- Pytorch implementation of [CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
- Pytorch implementation of [Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
- Pytorch implementation of [CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
- Pytorch implementation of [Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
***
### 1. External Attention Usage
#### 1.1. Paper
["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks"](https://arxiv.org/abs/2105.02358)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from fightingcv_attention.attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
***
### 2. Self Attention Usage
#### 2.1. Paper
["Attention Is All You Need"](https://arxiv.org/pdf/1706.03762.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from fightingcv_attention.attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 3. Simplified Self Attention Usage
#### 3.1. Paper
[None]()
#### 3.2. Overview

#### 3.3. Usage Code
```python
from fightingcv_attention.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)
```
***
### 4. Squeeze-and-Excitation Attention Usage
#### 4.1. Paper
["Squeeze-and-Excitation Networks"](https://arxiv.org/abs/1709.01507)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from fightingcv_attention.attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 5. SK Attention Usage
#### 5.1. Paper
["Selective Kernel Networks"](https://arxiv.org/pdf/1903.06586.pdf)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from fightingcv_attention.attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 6. CBAM Attention Usage
#### 6.1. Paper
["CBAM: Convolutional Block Attention Module"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
#### 6.2. Overview


#### 6.3. Usage Code
```python
from fightingcv_attention.attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
***
### 7. BAM Attention Usage
#### 7.1. Paper
["BAM: Bottleneck Attention Module"](https://arxiv.org/pdf/1807.06514.pdf)
#### 7.2. Overview

#### 7.3. Usage Code
```python
from fightingcv_attention.attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
***
### 8. ECA Attention Usage
#### 8.1. Paper
["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks"](https://arxiv.org/pdf/1910.03151.pdf)
#### 8.2. Overview

#### 8.3. Usage Code
```python
from fightingcv_attention.attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
***
### 9. DANet Attention Usage
#### 9.1. Paper
["Dual Attention Network for Scene Segmentation"](https://arxiv.org/pdf/1809.02983.pdf)
#### 9.2. Overview

#### 9.3. Usage Code
```python
from fightingcv_attention.attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
***
### 10. Pyramid Split Attention Usage
#### 10.1. Paper
["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network"](https://arxiv.org/pdf/2105.14447.pdf)
#### 10.2. Overview

#### 10.3. Usage Code
```python
from fightingcv_attention.attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
***
### 11. Efficient Multi-Head Self-Attention Usage
#### 11.1. Paper
["ResT: An Efficient Transformer for Visual Recognition"](https://arxiv.org/abs/2105.13677)
#### 11.2. Overview

#### 11.3. Usage Code
```python
from fightingcv_attention.attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
***
### 12. Shuffle Attention Usage
#### 12.1. Paper
["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS"](https://arxiv.org/pdf/2102.00240.pdf)
#### 12.2. Overview

#### 12.3. Usage Code
```python
from fightingcv_attention.attention.ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
```
***
### 13. MUSE Attention Usage
#### 13.1. Paper
["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning"](https://arxiv.org/abs/1911.09483)
#### 13.2. Overview

#### 13.3. Usage Code
```python
from fightingcv_attention.attention.MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 14. SGE Attention Usage
#### 14.1. Paper
[Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks](https://arxiv.org/pdf/1905.09646.pdf)
#### 14.2. Overview

#### 14.3. Usage Code
```python
from fightingcv_attention.attention.SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
```
***
### 15. A2 Attention Usage
#### 15.1. Paper
[A2-Nets: Double Attention Networks](https://arxiv.org/pdf/1810.11579.pdf)
#### 15.2. Overview

#### 15.3. Usage Code
```python
from fightingcv_attention.attention.A2Atttention import DoubleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
```
### 16. AFT Attention Usage
#### 16.1. Paper
[An Attention Free Transformer](https://arxiv.org/pdf/2105.14103v1.pdf)
#### 16.2. Overview

#### 16.3. Usage Code
```python
from fightingcv_attention.attention.AFT import AFT_FULL
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
```
### 17. Outlook Attention Usage
#### 17.1. Paper
[VOLO: Vision Outlooker for Visual Recognition"](https://arxiv.org/abs/2106.13112)
#### 17.2. Overview

#### 17.3. Usage Code
```python
from fightingcv_attention.attention.OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)
```
***
### 18. ViP Attention Usage
#### 18.1. Paper
[Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 18.2. Overview

#### 18.3. Usage Code
```python
from fightingcv_attention.attention.ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)
```
***
### 19. CoAtNet Attention Usage
#### 19.1. Paper
[CoAtNet: Marrying Convolution and Attention for All Data Sizes"](https://arxiv.org/abs/2106.04803)
#### 19.2. Overview
None
#### 19.3. Usage Code
```python
from fightingcv_attention.attention.CoAtNet import CoAtNet
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=CoAtNet(in_ch=3,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 20. HaloNet Attention Usage
#### 20.1. Paper
[Scaling Local Self-Attention for Parameter Efficient Visual Backbones"](https://arxiv.org/pdf/2103.12731.pdf)
#### 20.2. Overview

#### 20.3. Usage Code
```python
from fightingcv_attention.attention.HaloAttention import HaloAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)
```
***
### 21. Polarized Self-Attention Usage
#### 21.1. Paper
[Polarized Self-Attention: Towards High-quality Pixel-wise Regression"](https://arxiv.org/abs/2107.00782)
#### 21.2. Overview

#### 21.3. Usage Code
```python
from fightingcv_attention.attention.PolarizedSelfAttention import ParallelPolarizedSelfAttention,SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
```
***
### 22. CoTAttention Usage
#### 22.1. Paper
[Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292)
#### 22.2. Overview

#### 22.3. Usage Code
```python
from fightingcv_attention.attention.CoTAttention import CoTAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
```
***
### 23. Residual Attention Usage
#### 23.1. Paper
[Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
#### 23.2. Overview

#### 23.3. Usage Code
```python
from fightingcv_attention.attention.ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
resatt = ResidualAttention(channel=512,num_class=1000,la=0.2)
output=resatt(input)
print(output.shape)
```
***
### 24. S2 Attention Usage
#### 24.1. Paper
[S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072)
#### 24.2. Overview

#### 24.3. Usage Code
```python
from fightingcv_attention.attention.S2Attention import S2Attention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
s2att = S2Attention(channels=512)
output=s2att(input)
print(output.shape)
```
***
### 25. GFNet Attention Usage
#### 25.1. Paper
[Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
#### 25.2. Overview

#### 25.3. Usage Code - Implemented by [Wenliang Zhao (Author)](https://scholar.google.com/citations?user=lyPWvuEAAAAJ&hl=en)
```python
from fightingcv_attention.attention.gfnet import GFNet
import torch
from torch import nn
from torch.nn import functional as F
x = torch.randn(1, 3, 224, 224)
gfnet = GFNet(embed_dim=384, img_size=224, patch_size=16, num_classes=1000)
out = gfnet(x)
print(out.shape)
```
***
### 26. TripletAttention Usage
#### 26.1. Paper
[Rotate to Attend: Convolutional Triplet Attention Module---CVPR 2021](https://arxiv.org/abs/2010.03045)
#### 26.2. Overview

#### 26.3. Usage Code - Implemented by [digantamisra98](https://github.com/digantamisra98)
```python
from fightingcv_attention.attention.TripletAttention import TripletAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
triplet = TripletAttention()
output=triplet(input)
print(output.shape)
```
***
### 27. Coordinate Attention Usage
#### 27.1. Paper
[Coordinate Attention for Efficient Mobile Network Design---CVPR 2021](https://arxiv.org/abs/2103.02907)
#### 27.2. Overview

#### 27.3. Usage Code - Implemented by [Andrew-Qibin](https://github.com/Andrew-Qibin)
```python
from fightingcv_attention.attention.CoordAttention import CoordAtt
import torch
from torch import nn
from torch.nn import functional as F
inp=torch.rand([2, 96, 56, 56])
inp_dim, oup_dim = 96, 96
reduction=32
coord_attention = CoordAtt(inp_dim, oup_dim, reduction=reduction)
output=coord_attention(inp)
print(output.shape)
```
***
### 28. MobileViT Attention Usage
#### 28.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2103.02907)
#### 28.2. Overview

#### 28.3. Usage Code
```python
from fightingcv_attention.attention.MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
m=MobileViTAttention()
input=torch.randn(1,3,49,49)
output=m(input)
print(output.shape) #output:(1,3,49,49)
```
***
### 29. ParNet Attention Usage
#### 29.1. Paper
[Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
#### 29.2. Overview

#### 29.3. Usage Code
```python
from fightingcv_attention.attention.ParNetAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
pna = ParNetAttention(channel=512)
output=pna(input)
print(output.shape) #50,512,7,7
```
***
### 30. UFO Attention Usage
#### 30.1. Paper
[UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2110.07641)
#### 30.2. Overview

#### 30.3. Usage Code
```python
from fightingcv_attention.attention.UFOAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
ufo = UFOAttention(d_model=512, d_k=512, d_v=512, h=8)
output=ufo(input,input,input)
print(output.shape) #[50, 49, 512]
```
-
### 31. ACmix Attention Usage
#### 31.1. Paper
[On the Integration of Self-Attention and Convolution](https://arxiv.org/pdf/2111.14556.pdf)
#### 31.2. Usage Code
```python
from fightingcv_attention.attention.ACmix import ACmix
import torch
if __name__ == '__main__':
input=torch.randn(50,256,7,7)
acmix = ACmix(in_planes=256, out_planes=256)
output=acmix(input)
print(output.shape)
```
### 32. MobileViTv2 Attention Usage
#### 32.1. Paper
[Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
#### 32.2. Overview

#### 32.3. Usage Code
```python
from fightingcv_attention.attention.MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
### 33. DAT Attention Usage
#### 33.1. Paper
[Vision Transformer with Deformable Attention---CVPR2022](https://arxiv.org/abs/2201.00520)
#### 33.2. Usage Code
```python
from fightingcv_attention.attention.DAT import DAT
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DAT(
img_size=224,
patch_size=4,
num_classes=1000,
expansion=4,
dim_stem=96,
dims=[96, 192, 384, 768],
depths=[2, 2, 6, 2],
stage_spec=[['L', 'S'], ['L', 'S'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7] ,
groups=[-1, -1, 3, 6],
use_pes=[False, False, True, True],
dwc_pes=[False, False, False, False],
strides=[-1, -1, 1, 1],
sr_ratios=[-1, -1, -1, -1],
offset_range_factor=[-1, -1, 2, 2],
no_offs=[False, False, False, False],
fixed_pes=[False, False, False, False],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
)
output=model(input)
print(output[0].shape)
```
### 34. CrossFormer Attention Usage
#### 34.1. Paper
[CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
#### 34.2. Usage Code
```python
from fightingcv_attention.attention.Crossformer import CrossFormer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CrossFormer(img_size=224,
patch_size=[4, 8, 16, 32],
in_chans= 3,
num_classes=1000,
embed_dim=48,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
group_size=[7, 7, 7, 7],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False,
merge_size=[[2, 4], [2,4], [2, 4]]
)
output=model(input)
print(output.shape)
```
### 35. MOATransformer Attention Usage
#### 35.1. Paper
[Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
#### 35.2. Usage Code
```python
from fightingcv_attention.attention.MOATransformer import MOATransformer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = MOATransformer(
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=[2, 2, 6],
num_heads=[3, 6, 12],
window_size=14,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False
)
output=model(input)
print(output.shape)
```
### 36. CrissCrossAttention Attention Usage
#### 36.1. Paper
[CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
#### 36.2. Usage Code
```python
from fightingcv_attention.attention.CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = CrissCrossAttention(64)
outputs = model(input)
print(outputs.shape)
```
### 37. Axial_attention Attention Usage
#### 37.1. Paper
[Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
#### 37.2. Usage Code
```python
from fightingcv_attention.attention.Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__':
input=torch.randn(3, 128, 7, 7)
model = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
outputs = model(input)
print(outputs.shape)
```
***
# Backbone Series
- Pytorch implementation of ["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
- Pytorch implementation of ["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
- Pytorch implementation of [Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer---ArXiv 2021.06.07](https://arxiv.org/abs/2106.03650)
- Pytorch implementation of [ConTNet: Why not use convolution and transformer at the same time?---ArXiv 2021.04.27](https://arxiv.org/abs/2104.13497)
- Pytorch implementation of [Vision Transformers with Hierarchical Attention---ArXiv 2022.06.15](https://arxiv.org/abs/2106.03180)
- Pytorch implementation of [Co-Scale Conv-Attentional Image Transformers---ArXiv 2021.08.26](https://arxiv.org/abs/2104.06399)
- Pytorch implementation of [Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
- Pytorch implementation of [Rethinking Spatial Dimensions of Vision Transformers---ICCV 2021](https://arxiv.org/abs/2103.16302)
- Pytorch implementation of [CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification---ICCV 2021](https://arxiv.org/abs/2103.14899)
- Pytorch implementation of [Transformer in Transformer---NeurIPS 2021](https://arxiv.org/abs/2103.00112)
- Pytorch implementation of [DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
- Pytorch implementation of [Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
***
- Pytorch implementation of [ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
- Pytorch implementation of [Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
- Pytorch implementation of [Going deeper with Image Transformers---ICCV 2021 (Oral)](https://arxiv.org/abs/2103.17239)
- Pytorch implementation of [Training data-efficient image transformers & distillation through attention---ICML 2021](https://arxiv.org/abs/2012.12877)
- Pytorch implementation of [LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
- Pytorch implementation of [Container: Context Aggregation Network---NeuIPS 2021](https://arxiv.org/abs/2106.01401)
- Pytorch implementation of [CMT: Convolutional Neural Networks Meet Vision Transformers---CVPR 2022](https://arxiv.org/abs/2107.06263)
- Pytorch implementation of [Vision Transformer with Deformable Attention---CVPR 2022](https://arxiv.org/abs/2201.00520)
- Pytorch implementation of [EfficientFormer: Vision Transformers at MobileNet Speed](https://arxiv.org/abs/2206.01191)
### 1. ResNet Usage
#### 1.1. Paper
["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
#### 1.2. Overview


#### 1.3. Usage Code
```python
from fightingcv_attention.backbone.resnet import ResNet50,ResNet101,ResNet152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnet50=ResNet50(1000)
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out=resnet50(input)
print(out.shape)
```
### 2. ResNeXt Usage
#### 2.1. Paper
["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from fightingcv_attention.backbone.resnext import ResNeXt50,ResNeXt101,ResNeXt152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnext50=ResNeXt50(1000)
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out=resnext50(input)
print(out.shape)
```
### 3. MobileViT Usage
#### 3.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from fightingcv_attention.backbone.MobileViT import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
### mobilevit_xxs
mvit_xxs=mobilevit_xxs()
out=mvit_xxs(input)
print(out.shape)
### mobilevit_xs
mvit_xs=mobilevit_xs()
out=mvit_xs(input)
print(out.shape)
### mobilevit_s
mvit_s=mobilevit_s()
out=mvit_s(input)
print(out.shape)
```
### 4. ConvMixer Usage
#### 4.1. Paper
[Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from fightingcv_attention.backbone.ConvMixer import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
convmixer=ConvMixer(dim=512,depth=12)
out=convmixer(x)
print(out.shape) #[1, 1000]
```
### 5. ShuffleTransformer Usage
#### 5.1. Paper
[Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer](https://arxiv.org/pdf/2106.03650.pdf)
#### 5.2. Usage Code
```python
from fightingcv_attention.backbone.ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
sft = ShuffleTransformer()
output=sft(input)
print(output.shape)
```
### 6. ConTNet Usage
#### 6.1. Paper
[ConTNet: Why not use convolution and transformer at the same time?](https://arxiv.org/abs/2104.13497)
#### 6.2. Usage Code
```python
from fightingcv_attention.backbone.ConTNet import ConTNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == "__main__":
model = build_model(use_avgdown=True, relative=True, qkv_bias=True, pre_norm=True)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
```
### 7 HATNet Usage
#### 7.1. Paper
[Vision Transformers with Hierarchical Attention](https://arxiv.org/abs/2106.03180)
#### 7.2. Usage Code
```python
from fightingcv_attention.backbone.HATNet import HATNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
hat = HATNet(dims=[48, 96, 240, 384], head_dim=48, expansions=[8, 8, 4, 4],
grid_sizes=[8, 7, 7, 1], ds_ratios=[8, 4, 2, 1], depths=[2, 2, 6, 3])
output=hat(input)
print(output.shape)
```
### 8 CoaT Usage
#### 8.1. Paper
[Co-Scale Conv-Attentional Image Transformers](https://arxiv.org/abs/2104.06399)
#### 8.2. Usage Code
```python
from fightingcv_attention.backbone.CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4])
output=model(input)
print(output.shape) # torch.Size([1, 1000])
```
### 9 PVT Usage
#### 9.1. Paper
[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/pdf/2106.13797.pdf)
#### 9.2. Usage Code
```python
from fightingcv_attention.backbone.PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 10 CPVT Usage
#### 10.1. Paper
[Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
#### 10.2. Usage Code
```python
from fightingcv_attention.backbone.CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 11 PIT Usage
#### 11.1. Paper
[Rethinking Spatial Dimensions of Vision Transformers](https://arxiv.org/abs/2103.16302)
#### 11.2. Usage Code
```python
from fightingcv_attention.backbone.PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4
)
output=model(input)
print(output.shape)
```
### 12 CrossViT Usage
#### 12.1. Paper
[CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification](https://arxiv.org/abs/2103.14899)
#### 12.2. Usage Code
```python
from fightingcv_attention.backbone.CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__":
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[240, 224],
patch_size=[12, 16],
embed_dim=[192, 384],
depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6],
mlp_ratio=[4, 4, 1],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 13 TnT Usage
#### 13.1. Paper
[Transformer in Transformer](https://arxiv.org/abs/2103.00112)
#### 13.2. Usage Code
```python
from fightingcv_attention.backbone.TnT import TNT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = TNT(
img_size=224,
patch_size=16,
outer_dim=384,
inner_dim=24,
depth=12,
outer_num_heads=6,
inner_num_heads=4,
qkv_bias=False,
inner_stride=4)
output=model(input)
print(output.shape)
```
### 14 DViT Usage
#### 14.1. Paper
[DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
#### 14.2. Usage Code
```python
from fightingcv_attention.backbone.DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DeepVisionTransformer(
patch_size=16, embed_dim=384,
depth=[False] * 16,
apply_transform=[False] * 0 + [True] * 32,
num_heads=12,
mlp_ratio=3,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
)
output=model(input)
print(output.shape)
```
### 15 CeiT Usage
#### 15.1. Paper
[Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
#### 15.2. Usage Code
```python
from fightingcv_attention.backbone.CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CeIT(
hybrid_backbone=Image2Tokens(),
patch_size=4,
embed_dim=192,
depth=12,
num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 16 ConViT Usage
#### 16.1. Paper
[ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
#### 16.2. Usage Code
```python
from fightingcv_attention.backbone.ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 17 CaiT Usage
#### 17.1. Paper
[Going deeper with Image Transformers](https://arxiv.org/abs/2103.17239)
#### 17.2. Usage Code
```python
from fightingcv_attention.backbone.CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CaiT(
img_size= 224,
patch_size=16,
embed_dim=192,
depth=24,
num_heads=4,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2
)
output=model(input)
print(output.shape)
```
### 18 PatchConvnet Usage
#### 18.1. Paper
[Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
#### 18.2. Usage Code
```python
from fightingcv_attention.backbone.PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
)
output=model(input)
print(output.shape)
```
### 19 DeiT Usage
#### 19.1. Paper
[Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
#### 19.2. Usage Code
```python
from fightingcv_attention.backbone.DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DistilledVisionTransformer(
patch_size=16,
embed_dim=384,
depth=12,
num_heads=6,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output[0].shape)
```
### 20 LeViT Usage
#### 20.1. Paper
[LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
#### 20.2. Usage Code
```python
from fightingcv_attention.backbone.LeViT import *
import torch
from torch import nn
if __name__ == '__main__':
for name in specification:
input=torch.randn(1,3,224,224)
model = globals()[name](fuse=True, pretrained=False)
model.eval()
output = model(input)
print(output.shape)
```
### 21 VOLO Usage
#### 21.1. Paper
[VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
#### 21.2. Usage Code
```python
from fightingcv_attention.backbone.VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VOLO([4, 4, 8, 2],
embed_dims=[192, 384, 384, 384],
num_heads=[6, 12, 12, 12],
mlp_ratios=[3, 3, 3, 3],
downsamples=[True, False, False, False],
outlook_attention=[True, False, False, False ],
post_layers=['ca', 'ca'],
)
output=model(input)
print(output[0].shape)
```
### 22 Container Usage
#### 22.1. Paper
[Container: Context Aggregation Network](https://arxiv.org/abs/2106.01401)
#### 22.2. Usage Code
```python
from fightingcv_attention.backbone.Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[224, 56, 28, 14],
patch_size=[4, 2, 2, 2],
embed_dim=[64, 128, 320, 512],
depth=[3, 4, 8, 3],
num_heads=16,
mlp_ratio=[8, 8, 4, 4],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6))
output=model(input)
print(output.shape)
```
### 23 CMT Usage
#### 23.1. Paper
[CMT: Convolutional Neural Networks Meet Vision Transformers](https://arxiv.org/abs/2107.06263)
#### 23.2. Usage Code
```python
from fightingcv_attention.backbone.CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CMT_Tiny()
output=model(input)
print(output[0].shape)
```
### 24 EfficientFormer Usage
#### 24.1. Paper
[EfficientFormer: Vision Transformers at MobileNet Speed](https://arxiv.org/abs/2206.01191)
#### 24.2. Usage Code
```python
from fightingcv_attention.backbone.EfficientFormer import EfficientFormer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = EfficientFormer(
layers=EfficientFormer_depth['l1'],
embed_dims=EfficientFormer_width['l1'],
downsamples=[True, True, True, True],
vit_num=1,
)
output=model(input)
print(output[0].shape)
```
# MLP Series
- Pytorch implementation of ["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition---arXiv 2021.05.05"](https://arxiv.org/pdf/2105.01883v1.pdf)
- Pytorch implementation of ["MLP-Mixer: An all-MLP Architecture for Vision---arXiv 2021.05.17"](https://arxiv.org/pdf/2105.01601.pdf)
- Pytorch implementation of ["ResMLP: Feedforward networks for image classification with data-efficient training---arXiv 2021.05.07"](https://arxiv.org/pdf/2105.03404.pdf)
- Pytorch implementation of ["Pay Attention to MLPs---arXiv 2021.05.17"](https://arxiv.org/abs/2105.08050)
- Pytorch implementation of ["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?---arXiv 2021.09.12"](https://arxiv.org/abs/2109.05422)
### 1. RepMLP Usage
#### 1.1. Paper
["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition"](https://arxiv.org/pdf/2105.01883v1.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from fightingcv_attention.mlp.repmlp import RepMLP
import torch
from torch import nn
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())
```
### 2. MLP-Mixer Usage
#### 2.1. Paper
["MLP-Mixer: An all-MLP Architecture for Vision"](https://arxiv.org/pdf/2105.01601.pdf)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from fightingcv_attention.mlp.mlp_mixer import MlpMixer
import torch
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)
```
***
### 3. ResMLP Usage
#### 3.1. Paper
["ResMLP: Feedforward networks for image classification with data-efficient training"](https://arxiv.org/pdf/2105.03404.pdf)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from fightingcv_attention.mlp.resmlp import ResMLP
import torch
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape) #the last dimention is class_num
```
***
### 4. gMLP Usage
#### 4.1. Paper
["Pay Attention to MLPs"](https://arxiv.org/abs/2105.08050)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from fightingcv_attention.mlp.g_mlp import gMLP
import torch
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)
```
***
### 5. sMLP Usage
#### 5.1. Paper
["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?"](https://arxiv.org/abs/2109.05422)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from fightingcv_attention.mlp.sMLP_block import sMLPBlock
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
smlp=sMLPBlock(h=224,w=224)
out=smlp(input)
print(out.shape)
```
### 6. vip-mlp Usage
#### 6.1. Paper
["Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 6.2. Usage Code
```python
from fightingcv_attention.mlp.vip-mlp import VisionPermutator
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionPermutator(
layers=[4, 3, 8, 3],
embed_dims=[384, 384, 384, 384],
patch_size=14,
transitions=[False, False, False, False],
segment_dim=[16, 16, 16, 16],
mlp_ratios=[3, 3, 3, 3],
mlp_fn=WeightedPermuteMLP
)
output=model(input)
print(output.shape)
```
# Re-Parameter Series
- Pytorch implementation of ["RepVGG: Making VGG-style ConvNets Great Again---CVPR2021"](https://arxiv.org/abs/2101.03697)
- Pytorch implementation of ["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks---ICCV2019"](https://arxiv.org/abs/1908.03930)
- Pytorch implementation of ["Diverse Branch Block: Building a Convolution as an Inception-like Unit---CVPR2021"](https://arxiv.org/abs/2103.13425)
***
### 1. RepVGG Usage
#### 1.1. Paper
["RepVGG: Making VGG-style ConvNets Great Again"](https://arxiv.org/abs/2101.03697)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from fightingcv_attention.rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
```
***
### 2. ACNet Usage
#### 2.1. Paper
["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks"](https://arxiv.org/abs/1908.03930)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from fightingcv_attention.rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
```
***
### 2. Diverse Branch Block Usage
#### 2.1. Paper
["Diverse Branch Block: Building a Convolution as an Inception-like Unit"](https://arxiv.org/abs/2103.13425)
#### 2.2. Overview

#### 2.3. Usage Code
##### 2.3.1 Transform I
```python
from fightingcv_attention.rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.2 Transform II
```python
from fightingcv_attention.rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.3 Transform III
```python
from fightingcv_attention.rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.4 Transform IV
```python
from fightingcv_attention.rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.5 Transform V
```python
from fightingcv_attention.rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.6 Transform VI
```python
from fightingcv_attention.rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
# Convolution Series
- Pytorch implementation of ["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications---CVPR2017"](https://arxiv.org/abs/1704.04861)
- Pytorch implementation of ["Efficientnet: Rethinking model scaling for convolutional neural networks---PMLR2019"](http://proceedings.mlr.press/v97/tan19a.html)
- Pytorch implementation of ["Involution: Inverting the Inherence of Convolution for Visual Recognition---CVPR2021"](https://arxiv.org/abs/2103.06255)
- Pytorch implementation of ["Dynamic Convolution: Attention over Convolution Kernels---CVPR2020 Oral"](https://arxiv.org/abs/1912.03458)
- Pytorch implementation of ["CondConv: Conditionally Parameterized Convolutions for Efficient Inference---NeurIPS2019"](https://arxiv.org/abs/1904.04971)
***
### 1. Depthwise Separable Convolution Usage
#### 1.1. Paper
["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications"](https://arxiv.org/abs/1704.04861)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from fightingcv_attention.conv.DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)
```
***
### 2. MBConv Usage
#### 2.1. Paper
["Efficientnet: Rethinking model scaling for convolutional neural networks"](http://proceedings.mlr.press/v97/tan19a.html)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from fightingcv_attention.conv.MBConv import MBConvBlock
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=512,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 3. Involution Usage
#### 3.1. Paper
["Involution: Inverting the Inherence of Convolution for Visual Recognition"](https://arxiv.org/abs/2103.06255)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from fightingcv_attention.conv.Involution import Involution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)
```
***
### 4. DynamicConv Usage
#### 4.1. Paper
["Dynamic Convolution: Attention over Convolution Kernels"](https://arxiv.org/abs/1912.03458)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from fightingcv_attention.conv.DynamicConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape) # 2,32,64,64
```
***
### 5. CondConv Usage
#### 5.1. Paper
["CondConv: Conditionally Parameterized Convolutions for Efficient Inference"](https://arxiv.org/abs/1904.04971)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from fightingcv_attention.conv.CondConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=CondConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
```
================================================
FILE: main.py
================================================
from model.attention.MobileViTv2Attention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
================================================
FILE: model/.vscode/settings.json
================================================
{
"python.pythonPath": "D:\\Anaconda\\python.exe"
}
================================================
FILE: model/__init__.py
================================================
def test():
print ("hello world")
if __name__ == '__main__':
test()
================================================
FILE: model/analysis/Attention.md
================================================
## Content
- [1. External Attention](#1-external-attention)
- [2. Self Attention](#2-self-attention)
- [3. Squeeze-and-Excitation(SE) Attention](#3-squeeze-and-excitationse-attention)
- [4. Selective Kernel(SK) Attention](#4-selective-kernelsk-attention)
- [5. CBAM Attention](#5-cbam-attention)
- [6. BAM Attention](#6-bam-attention)
- [7. ECA Attention](#7-eca-attention)
- [8. DANet Attention](#8-danet-attention)
- [9. Pyramid Split Attention(PSA)](#9-pyramid-split-attentionpsa)
- [10. Efficient Multi-Head Self-Attention(EMSA)](#10-efficient-multi-head-self-attentionemsa)
- [Write at the end](#Write_at_the_end)
## 1. External Attention
### 1.1. Citation
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks.---arXiv 2021.05.05
Address:[https://arxiv.org/abs/2105.02358](https://arxiv.org/abs/2105.02358)
### 1.2. Model Structure

### 1.3. Brief
This is an article on arXiv in May. It mainly solves two pain points of Self-Attention (SA): (1) O(n^2) computational complexity; (2) SA is in the same sample The above calculates Attention based on different positions, ignoring the relationship between different samples. Therefore, this paper uses two serial MLP structures as memory units, which reduces the computational complexity to O(n); in addition, these two memory units are learned based on all training data, so they also implicitly consider the differences. The connection between the samples.
### 1.4. Usage
```python
from attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
## 2. Self Attention
### 2.1. Citation
Attention Is All You Need---NeurIPS2017
Address:[https://arxiv.org/abs/1706.03762](https://arxiv.org/abs/1706.03762)
### 2.2. Model Structure

### 2.3. Brief
This is an article published by Google in NeurIPS2017. It has a great influence in various fields such as CV, NLP, and multi-modality. The current citation volume has been 2.2w+. The Self-Attention proposed in Transformer is a kind of Attention, which is used to calculate the weight between different positions in the feature, so as to achieve the effect of updating the feature. First, the input feature is mapped into three features of Q, K, and V through FC, and then Q and K are dot-multiplied to obtain the attention map, and the attention map and V are dot-multiplied to obtain the weighted feature. Finally, the feature is mapped through FC, and a new feature is obtained. (There are many very good explanations about Transformer and Self-Attention on the Internet, so I won’t give a detailed introduction here)
### 2.4. Usage
```python
from attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
## 3. Squeeze-and-Excitation(SE) Attention
### 3.1. Citation
Squeeze-and-Excitation Networks---CVPR2018
Address:[https://arxiv.org/abs/1709.01507](https://arxiv.org/abs/1709.01507)
### 3.2. Model Structure

### 3.3. Brief
This is an article of CVPR2018, which is also very influential. The current citation volume is 7k+. This article is for channel attention. Because of its simple structure and effectiveness, it has set off a wave of channel attention. From the avenue to the simple, the idea of this article can be said to be very simple. First, the spatial dimension is applied to AdaptiveAvgPool, and then the channel attention is learned through two FCs, and the Sigmoid is used for normalization to obtain the Channel Attention Map, and finally the Channel Attention Map is combined with the original Multiply the features to get the weighted features.
### 3.4. Usage
```python
from attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
## 4. Selective Kernel(SK) Attention
### 4.1. Citation
Selective Kernel Networks---CVPR2019
Address:[https://arxiv.org/pdf/1903.06586.pdf](https://arxiv.org/pdf/1903.06586.pdf)
### 4.2. Model Structure

### 4.3. Brief
This is an article from CVPR2019, which pays tribute to SENet's thoughts. In traditional CNN, each convolutional layer uses the same size convolution kernel, which limits the expressive ability of the model; and the "wider" model structure of Inception is also verified, using multiple different convolution kernels. Learning can indeed improve the expressive ability of the model. The author draws on the idea of SENet, obtains the weight of the channel by dynamically calculating each convolution kernel, and dynamically merges the results of each convolution kernel.
I personally think that the reason why this article can also be called lightweight is that when channel attention is performed on the features of different kernels, the parameters are shared (ie because before Attention, the features are first fused, so different The result of the convolution kernel shares a parameter of the SE module).
The method in this article is divided into three parts: Split, Fuse, and Select. Split is a multi-branch operation, convolution with different convolution kernels to get different features; the Fuse part is to use the SE structure to obtain the channel attention matrix (N convolution kernels can get N attention matrices , This step is shared with all the feature parameters), so that the features of different kernels after SE can be obtained; the Select operation is to add these features.
### 4.4. Usage
```python
from attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
## 5. CBAM Attention
### 5.1. Citation
CBAM: Convolutional Block Attention Module---ECCV2018
Address:[https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
### 5.2. Model Structure


### 5.3. Brief
This is an ECCV2018 paper. This article uses Channel Attention and Spatial Attention at the same time and connects the two in series (the article also does ablation experiments in parallel and two series).
In terms of Channel Attention, the general structure is still similar to SE, but the author proposes that AvgPool and MaxPool have different representation effects, so the author performs AvgPool and MaxPool on the original features in the Spatial dimension, and then uses the SE structure to extract channel attention. Note here The parameters are shared, and then the two features are added and normalized to obtain the attention matrix.
Spatial Attention is similar to Channel Attention. After performing two pools in the channel dimension, the two features are spliced, and then a 7x7 convolution is used to extract the Spatial Attention (the reason for using 7x7 is because the spatial attention is extracted, so use The convolution kernel must be large enough). Then do a normalization to get the spatial attention matrix.
### 5.4. Usage
```python
from attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
## 6. BAM Attention
### 6.1. Citation
BAM: Bottleneck Attention Module---BMCV2018
Address:[https://arxiv.org/pdf/1807.06514.pdf](https://arxiv.org/pdf/1807.06514.pdf)
### 6.2. Model Structure

### 6.3. Brief
This is the work of CBAM and the author at the same time. The work is very similar to CBAM, and it is also dual attention. The difference is that CBAM connects the results of two attention in series; while BAM directly adds two attention matrices.
In terms of Channel Attention, the structure is basically the same as SE. In terms of Spatial Attention, the pool is still performed in the channel dimension, and then a 3x3 hole convolution is used twice, and finally a 1x1 convolution will be used to obtain the Spatial Attention matrix.
Finally, the Channel Attention and Spatial Attention matrices are added (the broadcast mechanism is used here) and normalized. In this way, the attention matrix that combines space and channel is obtained.
### 6.4. Usage
```python
from attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
## 7. ECA Attention
### 7.1. Citation
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020
Address:[https://arxiv.org/pdf/1910.03151.pdf](https://arxiv.org/pdf/1910.03151.pdf)
### 7.2. Model Structure

### 7.3. Brief
This is an article of CVPR2020.
As shown in the figure above, SE uses two fully connected layers to achieve channel attention, while ECA requires one convolution. The reason why the author did this is that it is not necessary to calculate the attention between all channels. On the other hand, the use of two fully connected layers does introduce too many parameters and calculations.
Therefore, after the author performed AvgPool, he only used a one-dimensional convolution with a receptive field of k (equivalent to only calculating the attention of the adjacent k channels), which greatly reduced the parameters and calculation amount. (i.e. is equivalent to SE being a global attention, while ECA is a local attention).
### 7.4. Usage
```python
from attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
## 8. DANet Attention
### 8.1. Citation
Dual Attention Network for Scene Segmentation---CVPR2019
Address:[https://arxiv.org/pdf/1809.02983.pdf](https://arxiv.org/pdf/1809.02983.pdf)
### 8.2. Model Structure

### 8.3. Brief
This is an article by CVPR2019. The idea is very simple, that is, self-attention is used in the task of scene segmentation. The difference is that self-attention is to pay attention to the attention between each position, and this article will make a self-attention. To expand, we also made a branch of channel attention. The operation is the same as self-attention. The three Linears that generate Q, K, and V are removed from different channel attention. Finally, the features after the two attentions are summed element-wise.
### 8.4. Usage
```python
from attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
## 9. Pyramid Split Attention(PSA)
### 9.1. Citation
EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30
Address:[https://arxiv.org/pdf/2105.14447.pdf](https://arxiv.org/pdf/2105.14447.pdf)
### 9.2. Model Structure

### 9.3. Brief
This is an article uploaded by Shenzhen University on arXiv on May 30. The purpose of this article is how to obtain and explore spatial information of different scales to enrich the feature space. The network structure is relatively simple, mainly divided into four steps. In the first part, the original feature is divided into n groups according to the channel, and then the different groups are convolved with different scales to obtain the new feature W1; the second part is SE performs SE on the original features to obtain different Attention Map; the third part is to perform softmax on different groups; the fourth part is to multiply the obtained attention with the original feature W1.
### 9.4. Usage
```python
from attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
## 10. Efficient Multi-Head Self-Attention(EMSA)
### 10.1. Citation
ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28
Address:[https://arxiv.org/abs/2105.13677](https://arxiv.org/abs/2105.13677)
### 10.2. Model Structure

### 10.3. Brief
This is an article uploaded by Nanjing University on arXiv on May 28. This article mainly solves two pain points of SA: (1) The computational complexity of Self-Attention is squared with n; (2) Each head has only partial information of q, k, v, if q, k, v If the dimension of is too small, continuous information will not be obtained, resulting in performance loss. The idea given in this article is also very simple. In SA, before FC, a convolution is used to reduce the spatial dimension, thereby obtaining smaller K and V in spatial dimension.
### 10.4. Usage
```python
from attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
## Write at the end
At present, the Attention work organized by this project is indeed not comprehensive enough. As the amount of reading increases, we will continue to improve this project. Welcome everyone star to support. If there are incorrect statements or incorrect code implementations in the article, you are welcome to point out~
================================================
FILE: model/analysis/注意力机制.md
================================================
## 目录
- [1. External Attention](#1-external-attention)
- [2. Self Attention](#2-self-attention)
- [3. Squeeze-and-Excitation(SE) Attention](#3-squeeze-and-excitationse-attention)
- [4. Selective Kernel(SK) Attention](#4-selective-kernelsk-attention)
- [5. CBAM Attention](#5-cbam-attention)
- [6. BAM Attention](#6-bam-attention)
- [7. ECA Attention](#7-eca-attention)
- [8. DANet Attention](#8-danet-attention)
- [9. Pyramid Split Attention(PSA)](#9-pyramid-split-attentionpsa)
- [10. Efficient Multi-Head Self-Attention(EMSA)](#10-efficient-multi-head-self-attentionemsa)
- [【写在最后】](#写在最后)
## 1. External Attention
### 1.1. 引用
Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks.---arXiv 2021.05.05
论文地址:[https://arxiv.org/abs/2105.02358](https://arxiv.org/abs/2105.02358)
### 1.2. 模型结构

### 1.3. 简介
这是五月份在arXiv上的一篇文章,主要解决的Self-Attention(SA)的两个痛点问题:(1)O(n^2)的计算复杂度;(2)SA是在同一个样本上根据不同位置计算Attention,忽略了不同样本之间的联系。因此,本文采用了两个串联的MLP结构作为memory units,使得计算复杂度降低到了O(n);此外,这两个memory units是基于全部的训练数据学习的,因此也隐式的考虑了不同样本之间的联系。
### 1.4. 使用方法
```python
from attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
## 2. Self Attention
### 2.1. 引用
Attention Is All You Need---NeurIPS2017
论文地址:[https://arxiv.org/abs/1706.03762](https://arxiv.org/abs/1706.03762)
### 2.2. 模型结构

### 2.3. 简介
这是Google在NeurIPS2017发表的一篇文章,在CV、NLP、多模态等各个领域都有很大的影响力,目前引用量已经2.2w+。Transformer中提出的Self-Attention是Attention的一种,用于计算特征中不同位置之间的权重,从而达到更新特征的效果。首先将input feature通过FC映射成Q、K、V三个特征,然后将Q和K进行点乘的得到attention map,在将attention map与V做点乘得到加权后的特征。最后通过FC进行特征的映射,得到一个新的特征。(关于Transformer和Self-Attention目前网上有许多非常好的讲解,这里就不做详细的介绍了)
### 2.4. 使用方法
```python
from attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
## 3. Squeeze-and-Excitation(SE) Attention
### 3.1. 引用
Squeeze-and-Excitation Networks---CVPR2018
论文地址:[https://arxiv.org/abs/1709.01507](https://arxiv.org/abs/1709.01507)
### 3.2. 模型结构

### 3.3. 简介
这是CVPR2018的一篇文章,同样非常具有影响力,目前引用量7k+。本文是做通道注意力的,因其简单的结构和有效性,将通道注意力掀起了一波小高潮。大道至简,这篇文章的思想可以说非常简单,首先将spatial维度进行AdaptiveAvgPool,然后通过两个FC学习到通道注意力,并用Sigmoid进行归一化得到Channel Attention Map,最后将Channel Attention Map与原特征相乘,就得到了加权后的特征。
### 3.4. 使用方法
```python
from attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
## 4. Selective Kernel(SK) Attention
### 4.1. 引用
Selective Kernel Networks---CVPR2019
论文地址:[https://arxiv.org/pdf/1903.06586.pdf](https://arxiv.org/pdf/1903.06586.pdf)
### 4.2. 模型结构

### 4.3. 简介
这是CVPR2019的一篇文章,致敬了SENet的思想。在传统的CNN中每一个卷积层都是用相同大小的卷积核,限制了模型的表达能力;而Inception这种“更宽”的模型结构也验证了,用多个不同的卷积核进行学习确实可以提升模型的表达能力。作者借鉴了SENet的思想,通过动态计算每个卷积核得到通道的权重,动态的将各个卷积核的结果进行融合。
个人认为,之所以所这篇文章也能够称之为lightweight,是因为对不同kernel的特征进行通道注意力的时候是参数共享的(i.e. 因为在做Attention之前,首先将特征进行了融合,所以不同卷积核的结果共享一个SE模块的参数)。
本文的方法分为三个部分:Split,Fuse,Select。Split就是一个multi-branch的操作,用不同的卷积核进行卷积得到不同的特征;Fuse部分就是用SE的结构获取通道注意力的矩阵(N个卷积核就可以得到N个注意力矩阵,这步操作对所有的特征参数共享),这样就可以得到不同kernel经过SE之后的特征;Select操作就是将这几个特征进行相加。
### 4.4. 使用方法
```python
from attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
## 5. CBAM Attention
### 5.1. 引用
CBAM: Convolutional Block Attention Module---ECCV2018
论文地址:[https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
### 5.2. 模型结构


### 5.3. 简介
这是ECCV2018的一篇论文,这篇文章同时使用了Channel Attention和Spatial Attention,将两者进行了串联(文章也做了并联和两种串联方式的消融实验)。
Channel Attention方面,大致结构还是和SE相似,不过作者提出AvgPool和MaxPool有不同的表示效果,所以作者对原来的特征在Spatial维度分别进行了AvgPool和MaxPool,然后用SE的结构提取channel attention,注意这里是参数共享的,然后将两个特征相加后做归一化,就得到了注意力矩阵。
Spatial Attention和Channel Attention类似,先在channel维度进行两种pool后,将两个特征进行拼接,然后用7x7的卷积来提取Spatial Attention(之所以用7x7是因为提取的是空间注意力,所以用的卷积核必须足够大)。然后做一次归一化,就得到了空间的注意力矩阵。
### 5.4. 使用方法
```python
from attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
## 6. BAM Attention
### 6.1. 引用
BAM: Bottleneck Attention Module---BMCV2018
论文地址:[https://arxiv.org/pdf/1807.06514.pdf](https://arxiv.org/pdf/1807.06514.pdf)
### 6.2. 模型结构

### 6.3. 简介
这是CBAM同作者同时期的工作,工作与CBAM非常相似,也是双重Attention,不同的是CBAM是将两个attention的结果串联;而BAM是直接将两个attention矩阵进行相加。
Channel Attention方面,与SE的结构基本一样。Spatial Attention方面,还是在通道维度进行pool,然后用了两次3x3的空洞卷积,最后将用一次1x1的卷积得到Spatial Attention的矩阵。
最后Channel Attention和Spatial Attention矩阵进行相加(这里用到了广播机制),并进行归一化,这样一来,就得到了空间和通道结合的attention矩阵。
### 6.4.使用方法
```python
from attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
## 7. ECA Attention
### 7.1. 引用
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020
论文地址:[https://arxiv.org/pdf/1910.03151.pdf](https://arxiv.org/pdf/1910.03151.pdf)
### 7.2. 模型结构

### 7.3. 简介
这是CVPR2020的一篇文章。
如上图所示,SE实现通道注意力是使用两个全连接层,而ECA是需要一个的卷积。作者这么做的原因一方面是认为计算所有通道两两之间的注意力是没有必要的,另一方面是用两个全连接层确实引入了太多的参数和计算量。
因此作者进行了AvgPool之后,只是使用了一个感受野为k的一维卷积(相当于只计算与相邻k个通道的注意力),这样做就大大的减少的参数和计算量。(i.e.相当于SE是一个global的注意力,而ECA是一个local的注意力)。
### 7.4. 使用方法:
```python
from attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
## 8. DANet Attention
### 8.1. 引用
Dual Attention Network for Scene Segmentation---CVPR2019
论文地址:[https://arxiv.org/pdf/1809.02983.pdf](https://arxiv.org/pdf/1809.02983.pdf)
### 8.2. 模型结构

### 8.3. 简介
这是CVPR2019的文章,思想上非常简单,就是将self-attention用到场景分割的任务中,不同的是self-attention是关注每个position之间的注意力,而本文将self-attention做了一个拓展,还做了一个通道注意力的分支,操作上和self-attention一样,不同的通道attention中把生成Q,K,V的三个Linear去掉了。最后将两个attention之后的特征进行element-wise sum。
### 8.4. 使用方法
```python
from attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
## 9. Pyramid Split Attention(PSA)
### 9.1. 引用
EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30
论文地址:[https://arxiv.org/pdf/2105.14447.pdf](https://arxiv.org/pdf/2105.14447.pdf)
### 9.2. 模型结构

### 9.3. 简介
这是深大5月30日在arXiv上上传的一篇文章,本文的目的是如何获取并探索不同尺度的空间信息来丰富特征空间。网络结构相对来说也比较简单,主要分成四步,第一步,将原来的feature根据通道分成n组然后对不同的组进行不同尺度的卷积,得到新的特征W1;第二步,用SE在原来的特征上进行SE,从而获得不同的Attention Map;第三步,对不同组进行SOFTMAX;第四步,将获得attention与原来的特征W1相乘。
### 9.4. 使用方法
```python
from attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
## 10. Efficient Multi-Head Self-Attention(EMSA)
### 10.1. 引用
ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28
论文地址:[https://arxiv.org/abs/2105.13677](https://arxiv.org/abs/2105.13677)
### 10.2. 模型结构

### 10.3. 简介
这是南大5月28日在arXiv上上传的一篇文章。本文解决的主要是SA的两个痛点问题:(1)Self-Attention的计算复杂度和n呈平方关系;(2)每个head只有q,k,v的部分信息,如果q,k,v的维度太小,那么就会导致获取不到连续的信息,从而导致性能损失。这篇文章给出的思路也非常简单,在SA中,在FC之前,用了一个卷积来降低了空间的维度,从而得到空间维度上更小的K和V。
### 10.4. 使用方法
```python
from attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
## 【写在最后】
目前该项目整理的Attention的工作确实还不够全面,后面随着阅读量的提高,会不断对本项目进行完善,欢迎大家star支持。若在文章中有表述不恰、代码实现有误的地方,欢迎大家指出~
================================================
FILE: model/analysis/重参数机制.md
================================================
[toc]
## 【写在前面】
最近拜读了丁霄汉大神的一系列重参数的论文,觉得这个思想真的很妙。能够在将所有的cost都放在训练过程中,在测试的时候能够在所有的网络参数和计算量都进行缩减。目前网上也有部分对这些论文进行了解析,为了能够让更多读者进一步、深层的理解重参数的思想,本文将会结合代码,近几年重参数的论文进行详细的解析。
个人理解,重参数其实就是在测试的时候对训练的网络结构进行压缩。比如三个并联的卷积(kernel size相同)结果的和,其实就等于用求和之后的卷积核进行一次卷积的结果。所以,在训练的时候可以用三个卷积来提高模型的学习能力,但是在测试部署的时候,可以无损压缩为一次卷积,从而减少参数量和计算量。
## 【复现框架】
[https://github.com/xmu-xiaoma666/External-Attention-pytorch](https://github.com/xmu-xiaoma666/External-Attention-pytorch)
(欢迎大家***star***、***fork***该工作;如果有任何问题,也欢迎大家在***issue***中提出)
## 【先验知识】
首先向各位读者介绍一下卷积的一些基本性质,这几篇论文所提出的重参数操作,都是基于卷积的这几个性质。
一个普通的卷积操作可以被定义成下面的公式:
$$
O=I*F+REP(b)
$$
其中,$*$为卷积操作,$O \in \mathbb{R}^{D \times H' \times W'}$为输出特征,$I \in \mathbb{R}^{C \times H \times W}$为输入特征,$F \in \mathbb{R}^{D \times C \times K \times K}$为卷积核,$b \in \mathbb{R}^{D}$为偏置项,$Rep(b) \in \mathbb{R}^{D \times H' \times W'}$表示广播后的偏置项。
卷积操作具有以下两个性质:
### 1)同质性(homogeneity)
$$
I*(pF)=p(I*F), \forall p \in \mathbb{R}
$$
这个性质的意思是,一个常数与卷积核相乘之后的结果与特征进行卷积=一个常数乘上卷积之后的结果。
### 2)可加性(additivity)
$$
I*F^{(1)}+I*F^{(2)}=I*(F^{(1)}+F^{(2)})
$$
这个性质的意思是,两个并联的卷积结果相加,等于将这两个卷积核相加之后之后在进行卷积
# 1.ICCV2019-ACNet
## 1.1. 论文地址
ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks
论文地址:[https://arxiv.org/abs/1908.03930](https://arxiv.org/abs/1908.03930)
## 1.2. 网络框架


## 1.3. 原理解释
这篇文章做的主要工作如“网络框架”中的展示的那样:将并联的三个卷积(1x3、3x1、3x3)转换成一个卷积(3x3)。
### 首先,考虑不带BatchNorm的情况:
将1x3和3x1的卷积核转换到3x3的卷积核,只需要在水平和竖直方向分别用0padding成3x3的大小即可,然后将三个卷积核(1x3、3x1、3x3)相加进行卷积,就相当于是用三个卷积核分别对feature map卷积后再相加。
### 然后,考虑如何将BatchNorm融合到卷积核中:
卷积操作如下:
$$
O=I*F+REP(b)
$$
BatchNorm操作如下:
$$
BN(x)=\gamma\frac{(x-mean)}{\sqrt{var}}+\beta
$$
将卷积带入到BatchNorm就如:
$$
BN(Conv(x))=\gamma\frac{(I*F+REP(b)-mean)}{\sqrt{var}}+\beta
$$
化简得到:
$$
BN(Conv(x))=I*(\frac{F\gamma}{\sqrt{var}})+\frac{\gamma(REP(b)-mean)}{\sqrt{var}}+\beta
$$
因此新卷积核的weight和bias为:
$$
F_{new}=\frac{F\gamma}{\sqrt{var}} \\
REP(b)=\frac{\gamma(REP(b)-mean)}{\sqrt{var}}+\beta
$$
### 最后,考虑多分支的带BN的结构融合:
第一步,我们将BN层的参数融合到卷积核中
第二步,将BN层的参数融合到卷积核之后,原来带BN层的结构就变成了不带BN层的结构,我们将三个新卷积核相加之后,就得到了融合的卷积核。
## 1.4. 代码调用
```python
from rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
```
# 2. CVPR2021-RepVGG
## 2.1. 论文地址
RepVGG: Making VGG-style ConvNets Great Again
论文地址:[https://arxiv.org/abs/2101.03697](https://arxiv.org/abs/2101.03697)
## 2.2. 网络框架

## 2.3. 原理解释
这篇论文是的核心是将并联的带BN的3x3卷积核,1x1卷积核和残差结构转换为一个3x3的卷积核。
首先,带BN的1x1卷积核和带BN的3x3卷积核融合成一个3x3的卷积核,这个操作和第一篇文章ACNet的转换方式非常相似,就是将1x1 的卷积核padding成3x3后,在进行和ACNet相同的操作。
现在的问题是,怎么把残差结构也变成3x3的卷积。残差结构可以其实就是一个value为1的1x1的Depthwise卷积。如果能把Depthwise卷积转换成正常的卷积,那么这个问题也就迎刃而解了。下面这张图形象的展示了如果把Depthwise卷积转换成正常卷积:

(来自:https://zhuanlan.zhihu.com/p/352239591)
其实就是将对应需要操作的通道赋值为1,其他赋值为0。
输入通道为c,输出通道为c,把这里的参数矩阵比作cxc的矩阵,那么深度可分离矩阵就是一个单位矩阵(对角位置全部为1,其他全部为0)

(来自:https://zhuanlan.zhihu.com/p/352239591)
这样一来,残差结构也能转换成1x1的卷积了,然后与3x3的卷积用上面的方式进行合并,就得到了RepVGG的重参数结构
## 2.4. 代码调用
```python
from rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
```
# 3. CVPR2021-Diverse Branch Block
## 3.1. 论文地址
Diverse Branch Block: Building a Convolution as an Inception-like Unit
论文地址:[https://arxiv.org/abs/2103.13425](https://arxiv.org/abs/2103.13425)
## 3.2. 网络框架

## 3.3. 原理解释
像Inception一样的多分支结构可以增加模型的表达能力,提高性能,但是也会带来额外的参数和显存使用。因此,本文提出了一个方法,在训练时采用多分支的结构,在测试和部署的时候将多分支的结构模型转换成一个单一分支的模型,从而模型在测试的时候就能够“免费”享用多分支结构带来的性能提升。但是怎么把多分支结构无损压缩成一个单分支的结构呢,这就是这篇文章的贡献点所在。
### 3.3.1. Transform I:Conv+BN->BN
这部分的原理在ACNet的解析中已经详细解释了,代码实现如下:
```python
def transI_conv_bn(conv, bn):
std = (bn.running_var + bn.eps).sqrt()
gamma=bn.weight
weight=conv.weight*((gamma/std).reshape(-1, 1, 1, 1))
if(conv.bias is not None):
bias=gamma/std*conv.bias-gamma/std*bn.running_mean+bn.bias
else:
bias=bn.bias-gamma/std*bn.running_mean
return weight,bias
```
### 3.3.2. Transform II:并联Conv->Conv
这部分的原理就是【先验知识】部分的可加性,代码实现如下:
```python
def transII_conv_branch(conv1, conv2):
weight=conv1.weight.data+conv2.weight.data
bias=conv1.bias.data+conv2.bias.data
return weight,bias
```
### 3.3.3 Transform III:1x1Conv + 3x3Conv->3x3Conv
1x1的卷积其实并没有在空间上对feature map进行交互操作(或者说都只是乘了相同的数),所以1x1的Conv其实就是一个全连接层。所以,本质上,我们可以直接后面接着的3x3的卷积进行这个1x1的卷积操作,得到的新的卷积核,就可以是融合之后的卷积核。(可能讲的不是非常清楚,详细解释可以参考这篇文章:https://zhuanlan.zhihu.com/p/360939086)
代码实现如下:
```python
def transIII_conv_sequential(conv1, conv2):
weight=F.conv2d(conv2.weight.data,conv1.weight.data.permute(1,0,2,3))
return weight
```
### 3.3.4 Transform IV:Concat Conv->Conv
将多个卷积之后的结果进行concat,其实就是将多个卷积核权重在输出通道维度上进行拼接即可,代码实现如下:
```python
def transIV_conv_concat(conv1, conv2):
print(conv1.bias.data.shape)
print(conv2.bias.data.shape)
weight=torch.cat([conv1.weight.data,conv2.weight.data],0)
bias=torch.cat([conv1.bias.data,conv2.bias.data],0)
return weight,bias
```
### 3.3.5 Transform V:AvgPooling->Conv
AvgPool就是将感受野的值求平均,那么转换成卷积就是卷积核中每个值的value都等于1/卷积核大小,代码实现如下:
```python
def transV_avg(channel,kernel):
conv=nn.Conv2d(channel,channel,kernel,bias=False)
conv.weight.data[:]=0
for i in range(channel):
conv.weight.data[i,i,:,:]=1/(kernel*kernel)
return conv
```
## 3.3.6 Transform VI:1x1Conv+1x3Conv+3x1Conv(并联)->Conv
这个操作其实就是ACNet的思想,详情可以见上面ACNet的解析,代码实现如下:
```python
def transVI_conv_scale(conv1, conv2, conv3):
weight=F.pad(conv1.weight.data,(1,1,1,1))+F.pad(conv2.weight.data,(0,0,1,1))+F.pad(conv3.weight.data,(1,1,0,0))
bias=conv1.bias.data+conv2.bias.data+conv3.bias.data
return weight,bias
```
## 3.4. 代码调用
### 3.4.1. Transform I:Conv+BN->BN
```python
from rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
### 3.4.2. Transform II:并联Conv->Conv
```python
from rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
### 3.4.3 Transform III:1x1Conv + 3x3Conv->3x3Conv
```python
from rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
### 3.4.4 Transform IV:Concat Conv->Conv
```python
from rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
### 3.4.5 Transform V:AvgPooling->Conv
```python
from rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())
```
### 3.4.6 Transform VI:1x1Conv+1x3Conv+3x1Conv(并联)->Conv
```python
from rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
================================================
FILE: model/attention/A2Atttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn import functional as F
class DoubleAttention(nn.Module):
def __init__(self, in_channels,c_m,c_n,reconstruct = True):
super().__init__()
self.in_channels=in_channels
self.reconstruct = reconstruct
self.c_m=c_m
self.c_n=c_n
self.convA=nn.Conv2d(in_channels,c_m,1)
self.convB=nn.Conv2d(in_channels,c_n,1)
self.convV=nn.Conv2d(in_channels,c_n,1)
if self.reconstruct:
self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size = 1)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, h,w=x.shape
assert c==self.in_channels
A=self.convA(x) #b,c_m,h,w
B=self.convB(x) #b,c_n,h,w
V=self.convV(x) #b,c_n,h,w
tmpA=A.view(b,self.c_m,-1)
attention_maps=F.softmax(B.view(b,self.c_n,-1))
attention_vectors=F.softmax(V.view(b,self.c_n,-1))
# step 1: feature gating
global_descriptors=torch.bmm(tmpA,attention_maps.permute(0,2,1)) #b.c_m,c_n
# step 2: feature distribution
tmpZ = global_descriptors.matmul(attention_vectors) #b,c_m,h*w
tmpZ=tmpZ.view(b,self.c_m,h,w) #b,c_m,h,w
if self.reconstruct:
tmpZ=self.conv_reconstruct(tmpZ)
return tmpZ
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
================================================
FILE: model/attention/ACmixAttention.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
def position(H, W, is_cuda=True):
if is_cuda:
loc_w = torch.linspace(-1.0, 1.0, W).cuda().unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).cuda().unsqueeze(1).repeat(1, W)
else:
loc_w = torch.linspace(-1.0, 1.0, W).unsqueeze(0).repeat(H, 1)
loc_h = torch.linspace(-1.0, 1.0, H).unsqueeze(1).repeat(1, W)
loc = torch.cat([loc_w.unsqueeze(0), loc_h.unsqueeze(0)], 0).unsqueeze(0)
return loc
def stride(x, stride):
b, c, h, w = x.shape
return x[:, :, ::stride, ::stride]
def init_rate_half(tensor):
if tensor is not None:
tensor.data.fill_(0.5)
def init_rate_0(tensor):
if tensor is not None:
tensor.data.fill_(0.)
class ACmix(nn.Module):
def __init__(self, in_planes, out_planes, kernel_att=7, head=4, kernel_conv=3, stride=1, dilation=1):
super(ACmix, self).__init__()
self.in_planes = in_planes
self.out_planes = out_planes
self.head = head
self.kernel_att = kernel_att
self.kernel_conv = kernel_conv
self.stride = stride
self.dilation = dilation
self.rate1 = torch.nn.Parameter(torch.Tensor(1))
self.rate2 = torch.nn.Parameter(torch.Tensor(1))
self.head_dim = self.out_planes // self.head
self.conv1 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv2 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv3 = nn.Conv2d(in_planes, out_planes, kernel_size=1)
self.conv_p = nn.Conv2d(2, self.head_dim, kernel_size=1)
self.padding_att = (self.dilation * (self.kernel_att - 1) + 1) // 2
self.pad_att = torch.nn.ReflectionPad2d(self.padding_att)
self.unfold = nn.Unfold(kernel_size=self.kernel_att, padding=0, stride=self.stride)
self.softmax = torch.nn.Softmax(dim=1)
self.fc = nn.Conv2d(3*self.head, self.kernel_conv * self.kernel_conv, kernel_size=1, bias=False)
self.dep_conv = nn.Conv2d(self.kernel_conv * self.kernel_conv * self.head_dim, out_planes, kernel_size=self.kernel_conv, bias=True, groups=self.head_dim, padding=1, stride=stride)
self.reset_parameters()
def reset_parameters(self):
init_rate_half(self.rate1)
init_rate_half(self.rate2)
kernel = torch.zeros(self.kernel_conv * self.kernel_conv, self.kernel_conv, self.kernel_conv)
for i in range(self.kernel_conv * self.kernel_conv):
kernel[i, i//self.kernel_conv, i%self.kernel_conv] = 1.
kernel = kernel.squeeze(0).repeat(self.out_planes, 1, 1, 1)
self.dep_conv.weight = nn.Parameter(data=kernel, requires_grad=True)
self.dep_conv.bias = init_rate_0(self.dep_conv.bias)
def forward(self, x):
q, k, v = self.conv1(x), self.conv2(x), self.conv3(x)
scaling = float(self.head_dim) ** -0.5
b, c, h, w = q.shape
h_out, w_out = h//self.stride, w//self.stride
pe = self.conv_p(position(h, w, x.is_cuda))
q_att = q.view(b*self.head, self.head_dim, h, w) * scaling
k_att = k.view(b*self.head, self.head_dim, h, w)
v_att = v.view(b*self.head, self.head_dim, h, w)
if self.stride > 1:
q_att = stride(q_att, self.stride)
q_pe = stride(pe, self.stride)
else:
q_pe = pe
unfold_k = self.unfold(self.pad_att(k_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # b*head, head_dim, k_att^2, h_out, w_out
unfold_rpe = self.unfold(self.pad_att(pe)).view(1, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out) # 1, head_dim, k_att^2, h_out, w_out
att = (q_att.unsqueeze(2)*(unfold_k + q_pe.unsqueeze(2) - unfold_rpe)).sum(1) # (b*head, head_dim, 1, h_out, w_out) * (b*head, head_dim, k_att^2, h_out, w_out) -> (b*head, k_att^2, h_out, w_out)
att = self.softmax(att)
out_att = self.unfold(self.pad_att(v_att)).view(b*self.head, self.head_dim, self.kernel_att*self.kernel_att, h_out, w_out)
out_att = (att.unsqueeze(1) * out_att).sum(2).view(b, self.out_planes, h_out, w_out)
f_all = self.fc(torch.cat([q.view(b, self.head, self.head_dim, h*w), k.view(b, self.head, self.head_dim, h*w), v.view(b, self.head, self.head_dim, h*w)], 1))
f_conv = f_all.permute(0, 2, 1, 3).reshape(x.shape[0], -1, x.shape[-2], x.shape[-1])
out_conv = self.dep_conv(f_conv)
return self.rate1 * out_att + self.rate2 * out_conv
if __name__ == '__main__':
input=torch.randn(50,256,7,7)
acmix = ACmix(in_planes=256, out_planes=256)
output=acmix(input)
print(output.shape)
================================================
FILE: model/attention/AFT.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class AFT_FULL(nn.Module):
def __init__(self, d_model,n=49,simple=False):
super(AFT_FULL, self).__init__()
self.fc_q = nn.Linear(d_model, d_model)
self.fc_k = nn.Linear(d_model, d_model)
self.fc_v = nn.Linear(d_model,d_model)
if(simple):
self.position_biases=torch.zeros((n,n))
else:
self.position_biases=nn.Parameter(torch.ones((n,n)))
self.d_model = d_model
self.n=n
self.sigmoid=nn.Sigmoid()
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, input):
bs, n,dim = input.shape
q = self.fc_q(input) #bs,n,dim
k = self.fc_k(input).view(1,bs,n,dim) #1,bs,n,dim
v = self.fc_v(input).view(1,bs,n,dim) #1,bs,n,dim
numerator=torch.sum(torch.exp(k+self.position_biases.view(n,1,-1,1))*v,dim=2) #n,bs,dim
denominator=torch.sum(torch.exp(k+self.position_biases.view(n,1,-1,1)),dim=2) #n,bs,dim
out=(numerator/denominator) #n,bs,dim
out=self.sigmoid(q)*(out.permute(1,0,2)) #bs,n,dim
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
================================================
FILE: model/attention/Axial_attention.py
================================================
import torch
from torch import nn
from operator import itemgetter
# from axial_attention.reversible import ReversibleSequence
from torch.autograd.function import Function
from torch.utils.checkpoint import get_device_states, set_device_states
# following example for saving and setting rng here https://pytorch.org/docs/stable/_modules/torch/utils/checkpoint.html
class Deterministic(nn.Module):
def __init__(self, net):
super().__init__()
self.net = net
self.cpu_state = None
self.cuda_in_fwd = None
self.gpu_devices = None
self.gpu_states = None
def record_rng(self, *args):
self.cpu_state = torch.get_rng_state()
if torch.cuda._initialized:
self.cuda_in_fwd = True
self.gpu_devices, self.gpu_states = get_device_states(*args)
def forward(self, *args, record_rng = False, set_rng = False, **kwargs):
if record_rng:
self.record_rng(*args)
if not set_rng:
return self.net(*args, **kwargs)
rng_devices = []
if self.cuda_in_fwd:
rng_devices = self.gpu_devices
with torch.random.fork_rng(devices=rng_devices, enabled=True):
torch.set_rng_state(self.cpu_state)
if self.cuda_in_fwd:
set_device_states(self.gpu_devices, self.gpu_states)
return self.net(*args, **kwargs)
# heavily inspired by https://github.com/RobinBruegger/RevTorch/blob/master/revtorch/revtorch.py
# once multi-GPU is confirmed working, refactor and send PR back to source
class ReversibleBlock(nn.Module):
def __init__(self, f, g):
super().__init__()
self.f = Deterministic(f)
self.g = Deterministic(g)
def forward(self, x, f_args = {}, g_args = {}):
x1, x2 = torch.chunk(x, 2, dim = 1)
y1, y2 = None, None
with torch.no_grad():
y1 = x1 + self.f(x2, record_rng=self.training, **f_args)
y2 = x2 + self.g(y1, record_rng=self.training, **g_args)
return torch.cat([y1, y2], dim = 1)
def backward_pass(self, y, dy, f_args = {}, g_args = {}):
y1, y2 = torch.chunk(y, 2, dim = 1)
del y
dy1, dy2 = torch.chunk(dy, 2, dim = 1)
del dy
with torch.enable_grad():
y1.requires_grad = True
gy1 = self.g(y1, set_rng=True, **g_args)
torch.autograd.backward(gy1, dy2)
with torch.no_grad():
x2 = y2 - gy1
del y2, gy1
dx1 = dy1 + y1.grad
del dy1
y1.grad = None
with torch.enable_grad():
x2.requires_grad = True
fx2 = self.f(x2, set_rng=True, **f_args)
torch.autograd.backward(fx2, dx1, retain_graph=True)
with torch.no_grad():
x1 = y1 - fx2
del y1, fx2
dx2 = dy2 + x2.grad
del dy2
x2.grad = None
x = torch.cat([x1, x2.detach()], dim = 1)
dx = torch.cat([dx1, dx2], dim = 1)
return x, dx
class IrreversibleBlock(nn.Module):
def __init__(self, f, g):
super().__init__()
self.f = f
self.g = g
def forward(self, x, f_args, g_args):
x1, x2 = torch.chunk(x, 2, dim = 1)
y1 = x1 + self.f(x2, **f_args)
y2 = x2 + self.g(y1, **g_args)
return torch.cat([y1, y2], dim = 1)
class _ReversibleFunction(Function):
@staticmethod
def forward(ctx, x, blocks, kwargs):
ctx.kwargs = kwargs
for block in blocks:
x = block(x, **kwargs)
ctx.y = x.detach()
ctx.blocks = blocks
return x
@staticmethod
def backward(ctx, dy):
y = ctx.y
kwargs = ctx.kwargs
for block in ctx.blocks[::-1]:
y, dy = block.backward_pass(y, dy, **kwargs)
return dy, None, None
class ReversibleSequence(nn.Module):
def __init__(self, blocks, ):
super().__init__()
self.blocks = nn.ModuleList([ReversibleBlock(f, g) for (f, g) in blocks])
def forward(self, x, arg_route = (True, True), **kwargs):
f_args, g_args = map(lambda route: kwargs if route else {}, arg_route)
block_kwargs = {'f_args': f_args, 'g_args': g_args}
x = torch.cat((x, x), dim = 1)
x = _ReversibleFunction.apply(x, self.blocks, block_kwargs)
return torch.stack(x.chunk(2, dim = 1)).mean(dim = 0)
# helper functions
def exists(val):
return val is not None
def map_el_ind(arr, ind):
return list(map(itemgetter(ind), arr))
def sort_and_return_indices(arr):
indices = [ind for ind in range(len(arr))]
arr = zip(arr, indices)
arr = sorted(arr)
return map_el_ind(arr, 0), map_el_ind(arr, 1)
# calculates the permutation to bring the input tensor to something attend-able
# also calculates the inverse permutation to bring the tensor back to its original shape
def calculate_permutations(num_dimensions, emb_dim):
total_dimensions = num_dimensions + 2
emb_dim = emb_dim if emb_dim > 0 else (emb_dim + total_dimensions)
axial_dims = [ind for ind in range(1, total_dimensions) if ind != emb_dim]
permutations = []
for axial_dim in axial_dims:
last_two_dims = [axial_dim, emb_dim]
dims_rest = set(range(0, total_dimensions)) - set(last_two_dims)
permutation = [*dims_rest, *last_two_dims]
permutations.append(permutation)
return permutations
# helper classes
class ChanLayerNorm(nn.Module):
def __init__(self, dim, eps = 1e-5):
super().__init__()
self.eps = eps
self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
self.b = nn.Parameter(torch.zeros(1, dim, 1, 1))
def forward(self, x):
std = torch.var(x, dim = 1, unbiased = False, keepdim = True).sqrt()
mean = torch.mean(x, dim = 1, keepdim = True)
return (x - mean) / (std + self.eps) * self.g + self.b
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = nn.LayerNorm(dim)
def forward(self, x):
x = self.norm(x)
return self.fn(x)
class Sequential(nn.Module):
def __init__(self, blocks):
super().__init__()
self.blocks = blocks
def forward(self, x):
for f, g in self.blocks:
x = x + f(x)
x = x + g(x)
return x
class PermuteToFrom(nn.Module):
def __init__(self, permutation, fn):
super().__init__()
self.fn = fn
_, inv_permutation = sort_and_return_indices(permutation)
self.permutation = permutation
self.inv_permutation = inv_permutation
def forward(self, x, **kwargs):
axial = x.permute(*self.permutation).contiguous()
shape = axial.shape
*_, t, d = shape
# merge all but axial dimension
axial = axial.reshape(-1, t, d)
# attention
axial = self.fn(axial, **kwargs)
# restore to original shape and permutation
axial = axial.reshape(*shape)
axial = axial.permute(*self.inv_permutation).contiguous()
return axial
# axial pos emb
class AxialPositionalEmbedding(nn.Module):
def __init__(self, dim, shape, emb_dim_index = 1):
super().__init__()
parameters = []
total_dimensions = len(shape) + 2
ax_dim_indexes = [i for i in range(1, total_dimensions) if i != emb_dim_index]
self.num_axials = len(shape)
for i, (axial_dim, axial_dim_index) in enumerate(zip(shape, ax_dim_indexes)):
shape = [1] * total_dimensions
shape[emb_dim_index] = dim
shape[axial_dim_index] = axial_dim
parameter = nn.Parameter(torch.randn(*shape))
setattr(self, f'param_{i}', parameter)
def forward(self, x):
for i in range(self.num_axials):
x = x + getattr(self, f'param_{i}')
return x
# attention
class SelfAttention(nn.Module):
def __init__(self, dim, heads, dim_heads = None):
super().__init__()
self.dim_heads = (dim // heads) if dim_heads is None else dim_heads
dim_hidden = self.dim_heads * heads
self.heads = heads
self.to_q = nn.Linear(dim, dim_hidden, bias = False)
self.to_kv = nn.Linear(dim, 2 * dim_hidden, bias = False)
self.to_out = nn.Linear(dim_hidden, dim)
def forward(self, x, kv = None):
kv = x if kv is None else kv
q, k, v = (self.to_q(x), *self.to_kv(kv).chunk(2, dim=-1))
b, t, d, h, e = *q.shape, self.heads, self.dim_heads
merge_heads = lambda x: x.reshape(b, -1, h, e).transpose(1, 2).reshape(b * h, -1, e)
q, k, v = map(merge_heads, (q, k, v))
dots = torch.einsum('bie,bje->bij', q, k) * (e ** -0.5)
dots = dots.softmax(dim=-1)
out = torch.einsum('bij,bje->bie', dots, v)
out = out.reshape(b, h, -1, e).transpose(1, 2).reshape(b, -1, d)
out = self.to_out(out)
return out
# axial attention class
class AxialAttention(nn.Module):
def __init__(self, dim, num_dimensions = 2, heads = 8, dim_heads = None, dim_index = -1, sum_axial_out = True):
assert (dim % heads) == 0, 'hidden dimension must be divisible by number of heads'
super().__init__()
self.dim = dim
self.total_dimensions = num_dimensions + 2
self.dim_index = dim_index if dim_index > 0 else (dim_index + self.total_dimensions)
attentions = []
for permutation in calculate_permutations(num_dimensions, dim_index):
attentions.append(PermuteToFrom(permutation, SelfAttention(dim, heads, dim_heads)))
self.axial_attentions = nn.ModuleList(attentions)
self.sum_axial_out = sum_axial_out
def forward(self, x):
assert len(x.shape) == self.total_dimensions, 'input tensor does not have the correct number of dimensions'
assert x.shape[self.dim_index] == self.dim, 'input tensor does not have the correct input dimension'
if self.sum_axial_out:
return sum(map(lambda axial_attn: axial_attn(x), self.axial_attentions))
out = x
for axial_attn in self.axial_attentions:
out = axial_attn(out)
return out
# axial image transformer
class AxialImageTransformer(nn.Module):
def __init__(self, dim, depth, heads = 8, dim_heads = None, dim_index = 1, reversible = True, axial_pos_emb_shape = None):
super().__init__()
permutations = calculate_permutations(2, dim_index)
get_ff = lambda: nn.Sequential(
ChanLayerNorm(dim),
nn.Conv2d(dim, dim * 4, 3, padding = 1),
nn.LeakyReLU(inplace=True),
nn.Conv2d(dim * 4, dim, 3, padding = 1)
)
self.pos_emb = AxialPositionalEmbedding(dim, axial_pos_emb_shape, dim_index) if exists(axial_pos_emb_shape) else nn.Identity()
layers = nn.ModuleList([])
for _ in range(depth):
attn_functions = nn.ModuleList([PermuteToFrom(permutation, PreNorm(dim, SelfAttention(dim, heads, dim_heads))) for permutation in permutations])
conv_functions = nn.ModuleList([get_ff(), get_ff()])
layers.append(attn_functions)
layers.append(conv_functions)
execute_type = ReversibleSequence if reversible else Sequential
self.layers = execute_type(layers)
def forward(self, x):
x = self.pos_emb(x)
return self.layers(x)
# input=torch.randn(3, 128, 7, 7)
# attn = AxialAttention(
# dim = 3, # embedding dimension
# dim_index = 1, # where is the embedding dimension
# dim_heads = 32, # dimension of each head. defaults to dim // heads if not supplied
# heads = 1, # number of heads for multi-head attention
# num_dimensions = 2, # number of axial dimensions (images is 2, video is 3, or more)
# sum_axial_out = True # whether to sum the contributions of attention on each axis, or to run the input through them sequentially. defaults to true
# )
# print(attn(input).shape) # (1, 3, 256, 256)
if __name__ == '__main__':
input=torch.randn(3, 128, 7, 7)
model = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
outputs = model(input)
print(outputs.shape)
================================================
FILE: model/attention/BAM.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class Flatten(nn.Module):
def forward(self,x):
return x.view(x.shape[0],-1)
class ChannelAttention(nn.Module):
def __init__(self,channel,reduction=16,num_layers=3):
super().__init__()
self.avgpool=nn.AdaptiveAvgPool2d(1)
gate_channels=[channel]
gate_channels+=[channel//reduction]*num_layers
gate_channels+=[channel]
self.ca=nn.Sequential()
self.ca.add_module('flatten',Flatten())
for i in range(len(gate_channels)-2):
self.ca.add_module('fc%d'%i,nn.Linear(gate_channels[i],gate_channels[i+1]))
self.ca.add_module('bn%d'%i,nn.BatchNorm1d(gate_channels[i+1]))
self.ca.add_module('relu%d'%i,nn.ReLU())
self.ca.add_module('last_fc',nn.Linear(gate_channels[-2],gate_channels[-1]))
def forward(self, x) :
res=self.avgpool(x)
res=self.ca(res)
res=res.unsqueeze(-1).unsqueeze(-1).expand_as(x)
return res
class SpatialAttention(nn.Module):
def __init__(self,channel,reduction=16,num_layers=3,dia_val=2):
super().__init__()
self.sa=nn.Sequential()
self.sa.add_module('conv_reduce1',nn.Conv2d(kernel_size=1,in_channels=channel,out_channels=channel//reduction))
self.sa.add_module('bn_reduce1',nn.BatchNorm2d(channel//reduction))
self.sa.add_module('relu_reduce1',nn.ReLU())
for i in range(num_layers):
self.sa.add_module('conv_%d'%i,nn.Conv2d(kernel_size=3,in_channels=channel//reduction,out_channels=channel//reduction,padding=1,dilation=dia_val))
self.sa.add_module('bn_%d'%i,nn.BatchNorm2d(channel//reduction))
self.sa.add_module('relu_%d'%i,nn.ReLU())
self.sa.add_module('last_conv',nn.Conv2d(channel//reduction,1,kernel_size=1))
def forward(self, x) :
res=self.sa(x)
res=res.expand_as(x)
return res
class BAMBlock(nn.Module):
def __init__(self, channel=512,reduction=16,dia_val=2):
super().__init__()
self.ca=ChannelAttention(channel=channel,reduction=reduction)
self.sa=SpatialAttention(channel=channel,reduction=reduction,dia_val=dia_val)
self.sigmoid=nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
sa_out=self.sa(x)
ca_out=self.ca(x)
weight=self.sigmoid(sa_out+ca_out)
out=(1+weight)*x
return out
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
================================================
FILE: model/attention/CBAM.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ChannelAttention(nn.Module):
def __init__(self,channel,reduction=16):
super().__init__()
self.maxpool=nn.AdaptiveMaxPool2d(1)
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.se=nn.Sequential(
nn.Conv2d(channel,channel//reduction,1,bias=False),
nn.ReLU(),
nn.Conv2d(channel//reduction,channel,1,bias=False)
)
self.sigmoid=nn.Sigmoid()
def forward(self, x) :
max_result=self.maxpool(x)
avg_result=self.avgpool(x)
max_out=self.se(max_result)
avg_out=self.se(avg_result)
output=self.sigmoid(max_out+avg_out)
return output
class SpatialAttention(nn.Module):
def __init__(self,kernel_size=7):
super().__init__()
self.conv=nn.Conv2d(2,1,kernel_size=kernel_size,padding=kernel_size//2)
self.sigmoid=nn.Sigmoid()
def forward(self, x) :
max_result,_=torch.max(x,dim=1,keepdim=True)
avg_result=torch.mean(x,dim=1,keepdim=True)
result=torch.cat([max_result,avg_result],1)
output=self.conv(result)
output=self.sigmoid(output)
return output
class CBAMBlock(nn.Module):
def __init__(self, channel=512,reduction=16,kernel_size=49):
super().__init__()
self.ca=ChannelAttention(channel=channel,reduction=reduction)
self.sa=SpatialAttention(kernel_size=kernel_size)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
residual=x
out=x*self.ca(x)
out=out*self.sa(out)
return out+residual
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
================================================
FILE: model/attention/CoAtNet.py
================================================
from torch import nn, sqrt
import torch
import sys
from math import sqrt
sys.path.append('.')
from model.conv.MBConv import MBConvBlock
from model.attention.SelfAttention import ScaledDotProductAttention
class CoAtNet(nn.Module):
def __init__(self,in_ch,image_size,out_chs=[64,96,192,384,768]):
super().__init__()
self.out_chs=out_chs
self.maxpool2d=nn.MaxPool2d(kernel_size=2,stride=2)
self.maxpool1d = nn.MaxPool1d(kernel_size=2, stride=2)
self.s0=nn.Sequential(
nn.Conv2d(in_ch,in_ch,kernel_size=3,padding=1),
nn.ReLU(),
nn.Conv2d(in_ch,in_ch,kernel_size=3,padding=1)
)
self.mlp0=nn.Sequential(
nn.Conv2d(in_ch,out_chs[0],kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_chs[0],out_chs[0],kernel_size=1)
)
self.s1=MBConvBlock(ksize=3,input_filters=out_chs[0],output_filters=out_chs[0],image_size=image_size//2)
self.mlp1=nn.Sequential(
nn.Conv2d(out_chs[0],out_chs[1],kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_chs[1],out_chs[1],kernel_size=1)
)
self.s2=MBConvBlock(ksize=3,input_filters=out_chs[1],output_filters=out_chs[1],image_size=image_size//4)
self.mlp2=nn.Sequential(
nn.Conv2d(out_chs[1],out_chs[2],kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_chs[2],out_chs[2],kernel_size=1)
)
self.s3=ScaledDotProductAttention(out_chs[2],out_chs[2]//8,out_chs[2]//8,8)
self.mlp3=nn.Sequential(
nn.Linear(out_chs[2],out_chs[3]),
nn.ReLU(),
nn.Linear(out_chs[3],out_chs[3])
)
self.s4=ScaledDotProductAttention(out_chs[3],out_chs[3]//8,out_chs[3]//8,8)
self.mlp4=nn.Sequential(
nn.Linear(out_chs[3],out_chs[4]),
nn.ReLU(),
nn.Linear(out_chs[4],out_chs[4])
)
def forward(self, x) :
B,C,H,W=x.shape
#stage0
y=self.mlp0(self.s0(x))
y=self.maxpool2d(y)
#stage1
y=self.mlp1(self.s1(y))
y=self.maxpool2d(y)
#stage2
y=self.mlp2(self.s2(y))
y=self.maxpool2d(y)
#stage3
y=y.reshape(B,self.out_chs[2],-1).permute(0,2,1) #B,N,C
y=self.mlp3(self.s3(y,y,y))
y=self.maxpool1d(y.permute(0,2,1)).permute(0,2,1)
#stage4
y=self.mlp4(self.s4(y,y,y))
y=self.maxpool1d(y.permute(0,2,1))
N=y.shape[-1]
y=y.reshape(B,self.out_chs[4],int(sqrt(N)),int(sqrt(N)))
return y
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
coatnet=CoAtNet(3,224)
y=coatnet(x)
print(y.shape)
================================================
FILE: model/attention/CoTAttention.py
================================================
import numpy as np
import torch
from torch import flatten, nn
from torch.nn import init
from torch.nn.modules.activation import ReLU
from torch.nn.modules.batchnorm import BatchNorm2d
from torch.nn import functional as F
class CoTAttention(nn.Module):
def __init__(self, dim=512,kernel_size=3):
super().__init__()
self.dim=dim
self.kernel_size=kernel_size
self.key_embed=nn.Sequential(
nn.Conv2d(dim,dim,kernel_size=kernel_size,padding=kernel_size//2,groups=4,bias=False),
nn.BatchNorm2d(dim),
nn.ReLU()
)
self.value_embed=nn.Sequential(
nn.Conv2d(dim,dim,1,bias=False),
nn.BatchNorm2d(dim)
)
factor=4
self.attention_embed=nn.Sequential(
nn.Conv2d(2*dim,2*dim//factor,1,bias=False),
nn.BatchNorm2d(2*dim//factor),
nn.ReLU(),
nn.Conv2d(2*dim//factor,kernel_size*kernel_size*dim,1)
)
def forward(self, x):
bs,c,h,w=x.shape
k1=self.key_embed(x) #bs,c,h,w
v=self.value_embed(x).view(bs,c,-1) #bs,c,h,w
y=torch.cat([k1,x],dim=1) #bs,2c,h,w
att=self.attention_embed(y) #bs,c*k*k,h,w
att=att.reshape(bs,c,self.kernel_size*self.kernel_size,h,w)
att=att.mean(2,keepdim=False).view(bs,c,-1) #bs,c,h*w
k2=F.softmax(att,dim=-1)*v
k2=k2.view(bs,c,h,w)
return k1+k2
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
================================================
FILE: model/attention/CoordAttention.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n,c,h,w = x.size()
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out
================================================
FILE: model/attention/CrissCrossAttention.py
================================================
'''
This code is borrowed from Serge-weihao/CCNet-Pure-Pytorch
'''
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import Softmax
def INF(B,H,W):
return -torch.diag(torch.tensor(float("inf")).repeat(H),0).unsqueeze(0).repeat(B*W,1,1)
class CrissCrossAttention(nn.Module):
""" Criss-Cross Attention Module"""
def __init__(self, in_dim):
super(CrissCrossAttention,self).__init__()
self.query_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.key_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim//8, kernel_size=1)
self.value_conv = nn.Conv2d(in_channels=in_dim, out_channels=in_dim, kernel_size=1)
self.softmax = Softmax(dim=3)
self.INF = INF
self.gamma = nn.Parameter(torch.zeros(1))
def forward(self, x):
m_batchsize, _, height, width = x.size()
proj_query = self.query_conv(x)
proj_query_H = proj_query.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height).permute(0, 2, 1)
proj_query_W = proj_query.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width).permute(0, 2, 1)
proj_key = self.key_conv(x)
proj_key_H = proj_key.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_key_W = proj_key.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
proj_value = self.value_conv(x)
proj_value_H = proj_value.permute(0,3,1,2).contiguous().view(m_batchsize*width,-1,height)
proj_value_W = proj_value.permute(0,2,1,3).contiguous().view(m_batchsize*height,-1,width)
energy_H = (torch.bmm(proj_query_H, proj_key_H)+self.INF(m_batchsize, height, width)).view(m_batchsize,width,height,height).permute(0,2,1,3)
energy_W = torch.bmm(proj_query_W, proj_key_W).view(m_batchsize,height,width,width)
concate = self.softmax(torch.cat([energy_H, energy_W], 3))
att_H = concate[:,:,:,0:height].permute(0,2,1,3).contiguous().view(m_batchsize*width,height,height)
#print(concate)
#print(att_H)
att_W = concate[:,:,:,height:height+width].contiguous().view(m_batchsize*height,width,width)
out_H = torch.bmm(proj_value_H, att_H.permute(0, 2, 1)).view(m_batchsize,width,-1,height).permute(0,2,3,1)
out_W = torch.bmm(proj_value_W, att_W.permute(0, 2, 1)).view(m_batchsize,height,-1,width).permute(0,2,1,3)
#print(out_H.size(),out_W.size())
return self.gamma*(out_H + out_W) + x
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = CrissCrossAttention(64)
outputs = model(input)
print(outputs.shape)
================================================
FILE: model/attention/Crossformer.py
================================================
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class DynamicPosBias(nn.Module):
def __init__(self, dim, num_heads, residual):
super().__init__()
self.residual = residual
self.num_heads = num_heads
self.pos_dim = dim // 4
self.pos_proj = nn.Linear(2, self.pos_dim)
self.pos1 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.pos_dim),
)
self.pos2 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.pos_dim)
)
self.pos3 = nn.Sequential(
nn.LayerNorm(self.pos_dim),
nn.ReLU(inplace=True),
nn.Linear(self.pos_dim, self.num_heads)
)
def forward(self, biases):
if self.residual:
pos = self.pos_proj(biases) # 2Wh-1 * 2Ww-1, heads
pos = pos + self.pos1(pos)
pos = pos + self.pos2(pos)
pos = self.pos3(pos)
else:
pos = self.pos3(self.pos2(self.pos1(self.pos_proj(biases))))
return pos
def flops(self, N):
flops = N * 2 * self.pos_dim
flops += N * self.pos_dim * self.pos_dim
flops += N * self.pos_dim * self.pos_dim
flops += N * self.pos_dim * self.num_heads
return flops
class Attention(nn.Module):
r""" Multi-head self attention module with dynamic position bias.
Args:
dim (int): Number of input channels.
group_size (tuple[int]): The height and width of the group.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, group_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.,
position_bias=True):
super().__init__()
self.dim = dim
self.group_size = group_size # Wh, Ww
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.position_bias = position_bias
if position_bias:
self.pos = DynamicPosBias(self.dim // 4, self.num_heads, residual=False)
# generate mother-set
position_bias_h = torch.arange(1 - self.group_size[0], self.group_size[0])
position_bias_w = torch.arange(1 - self.group_size[1], self.group_size[1])
biases = torch.stack(torch.meshgrid([position_bias_h, position_bias_w])) # 2, 2Wh-1, 2W2-1
biases = biases.flatten(1).transpose(0, 1).float()
self.register_buffer("biases", biases)
# get pair-wise relative position index for each token inside the group
coords_h = torch.arange(self.group_size[0])
coords_w = torch.arange(self.group_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.group_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.group_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.group_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask=None):
"""
Args:
x: input features with shape of (num_groups*B, N, C)
mask: (0/-inf) mask with shape of (num_groups, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
if self.position_bias:
pos = self.pos(self.biases) # 2Wh-1 * 2Ww-1, heads
# select position bias
relative_position_bias = pos[self.relative_position_index.view(-1)].view(
self.group_size[0] * self.group_size[1], self.group_size[0] * self.group_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, group_size={self.group_size}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 group with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
if self.position_bias:
flops += self.pos.flops(N)
return flops
class CrossFormerBlock(nn.Module):
r""" CrossFormer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
group_size (int): Group size.
lsda_flag (int): use SDA or LDA, 0 for SDA and 1 for LDA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, group_size=7, lsda_flag=0,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm, num_patch_size=1):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.group_size = group_size
self.lsda_flag = lsda_flag
self.mlp_ratio = mlp_ratio
self.num_patch_size = num_patch_size
if min(self.input_resolution) <= self.group_size:
# if group size is larger than input resolution, we don't partition groups
self.lsda_flag = 0
self.group_size = min(self.input_resolution)
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, group_size=to_2tuple(self.group_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
position_bias=True)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size %d, %d, %d" % (L, H, W)
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# group embeddings
G = self.group_size
if self.lsda_flag == 0: # 0 for SDA
x = x.reshape(B, H // G, G, W // G, G, C).permute(0, 1, 3, 2, 4, 5)
else: # 1 for LDA
x = x.reshape(B, G, H // G, G, W // G, C).permute(0, 2, 4, 1, 3, 5)
x = x.reshape(B * H * W // G**2, G**2, C)
# multi-head self-attention
x = self.attn(x, mask=self.attn_mask) # nW*B, G*G, C
# ungroup embeddings
x = x.reshape(B, H // G, W // G, G, G, C)
if self.lsda_flag == 0:
x = x.permute(0, 1, 3, 2, 4, 5).reshape(B, H, W, C)
else:
x = x.permute(0, 3, 1, 4, 2, 5).reshape(B, H, W, C)
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"group_size={self.group_size}, lsda_flag={self.lsda_flag}, mlp_ratio={self.mlp_ratio}"
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# LSDA
nW = H * W / self.group_size / self.group_size
flops += nW * self.attn.flops(self.group_size * self.group_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm, patch_size=[2], num_input_patch_size=1):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reductions = nn.ModuleList()
self.patch_size = patch_size
self.norm = norm_layer(dim)
for i, ps in enumerate(patch_size):
if i == len(patch_size) - 1:
out_dim = 2 * dim // 2 ** i
else:
out_dim = 2 * dim // 2 ** (i + 1)
stride = 2
padding = (ps - stride) // 2
self.reductions.append(nn.Conv2d(dim, out_dim, kernel_size=ps,
stride=stride, padding=padding))
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = self.norm(x)
x = x.view(B, H, W, C).permute(0, 3, 1, 2)
xs = []
for i in range(len(self.reductions)):
tmp_x = self.reductions[i](x).flatten(2).transpose(1, 2)
xs.append(tmp_x)
x = torch.cat(xs, dim=2)
return x
def extra_repr(self) -> str:
return f"input_resolution={self.input_resolution}, dim={self.dim}"
def flops(self):
H, W = self.input_resolution
flops = H * W * self.dim
for i, ps in enumerate(self.patch_size):
if i == len(self.patch_size) - 1:
out_dim = 2 * self.dim // 2 ** i
else:
out_dim = 2 * self.dim // 2 ** (i + 1)
flops += (H // 2) * (W // 2) * ps * ps * out_dim * self.dim
return flops
class Stage(nn.Module):
""" CrossFormer blocks for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
group_size (int): variable G in the paper, one group has GxG embeddings
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, input_resolution, depth, num_heads, group_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, use_checkpoint=False,
patch_size_end=[4], num_patch_size=None):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
# build blocks
self.blocks = nn.ModuleList()
for i in range(depth):
lsda_flag = 0 if (i % 2 == 0) else 1
self.blocks.append(CrossFormerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, group_size=group_size,
lsda_flag=lsda_flag,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer,
num_patch_size=num_patch_size))
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer,
patch_size=patch_size_end, num_input_patch_size=num_patch_size)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
def flops(self):
flops = 0
for blk in self.blocks:
flops += blk.flops()
if self.downsample is not None:
flops += self.downsample.flops()
return flops
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: [4].
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=[4], in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
# patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[0] // patch_size[0]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.projs = nn.ModuleList()
for i, ps in enumerate(patch_size):
if i == len(patch_size) - 1:
dim = embed_dim // 2 ** i
else:
dim = embed_dim // 2 ** (i + 1)
stride = patch_size[0]
padding = (ps - patch_size[0]) // 2
self.projs.append(nn.Conv2d(in_chans, dim, kernel_size=ps, stride=stride, padding=padding))
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
xs = []
for i in range(len(self.projs)):
tx = self.projs[i](x).flatten(2).transpose(1, 2)
xs.append(tx) # B Ph*Pw C
x = torch.cat(xs, dim=2)
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = 0
for i, ps in enumerate(self.patch_size):
if i == len(self.patch_size) - 1:
dim = self.embed_dim // 2 ** i
else:
dim = self.embed_dim // 2 ** (i + 1)
flops += Ho * Wo * dim * self.in_chans * (self.patch_size[i] * self.patch_size[i])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
class CrossFormer(nn.Module):
r""" CrossFormer
A PyTorch impl of : `CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention` -
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each stage.
num_heads (tuple(int)): Number of attention heads in different layers.
group_size (int): Group size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, img_size=224, patch_size=[4], in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
group_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, merge_size=[[2], [2], [2]], **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
num_patch_sizes = [len(patch_size)] + [len(m) for m in merge_size]
for i_layer in range(self.num_layers):
patch_size_end = merge_size[i_layer] if i_layer < self.num_layers - 1 else None
num_patch_size = num_patch_sizes[i_layer]
layer = Stage(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
group_size=group_size[i_layer],
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint,
patch_size_end=patch_size_end,
num_patch_size=num_patch_size)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def flops(self):
flops = 0
flops += self.patch_embed.flops()
for i, layer in enumerate(self.layers):
flops += layer.flops()
flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)
flops += self.num_features * self.num_classes
return flops
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CrossFormer(img_size=224,
patch_size=[4, 8, 16, 32],
in_chans= 3,
num_classes=1000,
embed_dim=48,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
group_size=[7, 7, 7, 7],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False,
merge_size=[[2, 4], [2,4], [2, 4]]
)
output=model(input)
print(output.shape)
================================================
FILE: model/attention/DANet.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
from model.attention.SelfAttention import ScaledDotProductAttention
from model.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
class PositionAttentionModule(nn.Module):
def __init__(self,d_model=512,kernel_size=3,H=7,W=7):
super().__init__()
self.cnn=nn.Conv2d(d_model,d_model,kernel_size=kernel_size,padding=(kernel_size-1)//2)
self.pa=ScaledDotProductAttention(d_model,d_k=d_model,d_v=d_model,h=1)
def forward(self,x):
bs,c,h,w=x.shape
y=self.cnn(x)
y=y.view(bs,c,-1).permute(0,2,1) #bs,h*w,c
y=self.pa(y,y,y) #bs,h*w,c
return y
class ChannelAttentionModule(nn.Module):
def __init__(self,d_model=512,kernel_size=3,H=7,W=7):
super().__init__()
self.cnn=nn.Conv2d(d_model,d_model,kernel_size=kernel_size,padding=(kernel_size-1)//2)
self.pa=SimplifiedScaledDotProductAttention(H*W,h=1)
def forward(self,x):
bs,c,h,w=x.shape
y=self.cnn(x)
y=y.view(bs,c,-1) #bs,c,h*w
y=self.pa(y,y,y) #bs,c,h*w
return y
class DAModule(nn.Module):
def __init__(self,d_model=512,kernel_size=3,H=7,W=7):
super().__init__()
self.position_attention_module=PositionAttentionModule(d_model=512,kernel_size=3,H=7,W=7)
self.channel_attention_module=ChannelAttentionModule(d_model=512,kernel_size=3,H=7,W=7)
def forward(self,input):
bs,c,h,w=input.shape
p_out=self.position_attention_module(input)
c_out=self.channel_attention_module(input)
p_out=p_out.permute(0,2,1).view(bs,c,h,w)
c_out=c_out.view(bs,c,h,w)
return p_out+c_out
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
================================================
FILE: model/attention/DAT.py
================================================
# --------------------------------------------------------
# Swin Transformer
# Copyright (c) 2021 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ze Liu
# --------------------------------------------------------
# Vision Transformer with Deformable Attention
# Modified by Zhuofan Xia
# --------------------------------------------------------
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import einops
from timm.models.layers import to_2tuple, trunc_normal_
from timm.models.layers import DropPath, to_2tuple
class LocalAttention(nn.Module):
def __init__(self, dim, heads, window_size, attn_drop, proj_drop):
super().__init__()
window_size = to_2tuple(window_size)
self.proj_qkv = nn.Linear(dim, 3 * dim)
self.heads = heads
assert dim % heads == 0
head_dim = dim // heads
self.scale = head_dim ** -0.5
self.proj_out = nn.Linear(dim, dim)
self.window_size = window_size
self.proj_drop = nn.Dropout(proj_drop, inplace=True)
self.attn_drop = nn.Dropout(attn_drop, inplace=True)
Wh, Ww = self.window_size
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * Wh - 1) * (2 * Ww - 1), heads)
)
trunc_normal_(self.relative_position_bias_table, std=0.01)
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
def forward(self, x, mask=None):
B, C, H, W = x.size()
r1, r2 = H // self.window_size[0], W // self.window_size[1]
x_total = einops.rearrange(x, 'b c (r1 h1) (r2 w1) -> b (r1 r2) (h1 w1) c', h1=self.window_size[0], w1=self.window_size[1]) # B x Nr x Ws x C
x_total = einops.rearrange(x_total, 'b m n c -> (b m) n c')
qkv = self.proj_qkv(x_total) # B' x N x 3C
q, k, v = torch.chunk(qkv, 3, dim=2)
q = q * self.scale
q, k, v = [einops.rearrange(t, 'b n (h c1) -> b h n c1', h=self.heads) for t in [q, k, v]]
attn = torch.einsum('b h m c, b h n c -> b h m n', q, k)
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn_bias = relative_position_bias
attn = attn + attn_bias.unsqueeze(0)
if mask is not None:
# attn =(b * nW) h w w
# mask =nW ww ww
nW, ww, _ = mask.size()
attn = einops.rearrange(attn, '(b n) h w1 w2 -> b n h w1 w2', n=nW, h=self.heads, w1=ww, w2=ww) + mask.reshape(1, nW, 1, ww, ww)
attn = einops.rearrange(attn, 'b n h w1 w2 -> (b n) h w1 w2')
attn = self.attn_drop(attn.softmax(dim=3))
x = torch.einsum('b h m n, b h n c -> b h m c', attn, v)
x = einops.rearrange(x, 'b h n c1 -> b n (h c1)')
x = self.proj_drop(self.proj_out(x)) # B' x N x C
x = einops.rearrange(x, '(b r1 r2) (h1 w1) c -> b c (r1 h1) (r2 w1)', r1=r1, r2=r2, h1=self.window_size[0], w1=self.window_size[1]) # B x C x H x W
return x, None, None
class ShiftWindowAttention(LocalAttention):
def __init__(self, dim, heads, window_size, attn_drop, proj_drop, shift_size, fmap_size):
super().__init__(dim, heads, window_size, attn_drop, proj_drop)
self.fmap_size = to_2tuple(fmap_size)
self.shift_size = shift_size
assert 0 < self.shift_size < min(self.window_size), "wrong shift size."
img_mask = torch.zeros(*self.fmap_size) # H W
h_slices = (slice(0, -self.window_size[0]),
slice(-self.window_size[0], -self.shift_size),
slice(-self.shift_size, None))
w_slices = (slice(0, -self.window_size[1]),
slice(-self.window_size[1], -self.shift_size),
slice(-self.shift_size, None))
cnt = 0
for h in h_slices:
for w in w_slices:
img_mask[h, w] = cnt
cnt += 1
mask_windows = einops.rearrange(img_mask, '(r1 h1) (r2 w1) -> (r1 r2) (h1 w1)', h1=self.window_size[0],w1=self.window_size[1])
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2) # nW ww ww
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(2, 3))
sw_x, _, _ = super().forward(shifted_x, self.attn_mask)
x = torch.roll(sw_x, shifts=(self.shift_size, self.shift_size), dims=(2, 3))
return x, None, None
class DAttentionBaseline(nn.Module):
def __init__(
self, q_size, kv_size, n_heads, n_head_channels, n_groups,
attn_drop, proj_drop, stride,
offset_range_factor, use_pe, dwc_pe,
no_off, fixed_pe, stage_idx
):
super().__init__()
self.dwc_pe = dwc_pe
self.n_head_channels = n_head_channels
self.scale = self.n_head_channels ** -0.5
self.n_heads = n_heads
self.q_h, self.q_w = q_size
self.kv_h, self.kv_w = kv_size
self.nc = n_head_channels * n_heads
self.n_groups = n_groups
self.n_group_channels = self.nc // self.n_groups
self.n_group_heads = self.n_heads // self.n_groups
self.use_pe = use_pe
self.fixed_pe = fixed_pe
self.no_off = no_off
self.offset_range_factor = offset_range_factor
ksizes = [9, 7, 5, 3]
kk = ksizes[stage_idx]
self.conv_offset = nn.Sequential(
nn.Conv2d(self.n_group_channels, self.n_group_channels, kk, stride, kk//2, groups=self.n_group_channels),
LayerNormProxy(self.n_group_channels),
nn.GELU(),
nn.Conv2d(self.n_group_channels, 2, 1, 1, 0, bias=False)
)
self.proj_q = nn.Conv2d(
self.nc, self.nc,
kernel_size=1, stride=1, padding=0
)
self.proj_k = nn.Conv2d(
self.nc, self.nc,
kernel_size=1, stride=1, padding=0
)
self.proj_v = nn.Conv2d(
self.nc, self.nc,
kernel_size=1, stride=1, padding=0
)
self.proj_out = nn.Conv2d(
self.nc, self.nc,
kernel_size=1, stride=1, padding=0
)
self.proj_drop = nn.Dropout(proj_drop, inplace=True)
self.attn_drop = nn.Dropout(attn_drop, inplace=True)
if self.use_pe:
if self.dwc_pe:
self.rpe_table = nn.Conv2d(self.nc, self.nc,
kernel_size=3, stride=1, padding=1, groups=self.nc)
elif self.fixed_pe:
self.rpe_table = nn.Parameter(
torch.zeros(self.n_heads, self.q_h * self.q_w, self.kv_h * self.kv_w)
)
trunc_normal_(self.rpe_table, std=0.01)
else:
self.rpe_table = nn.Parameter(
torch.zeros(self.n_heads, self.kv_h * 2 - 1, self.kv_w * 2 - 1)
)
trunc_normal_(self.rpe_table, std=0.01)
else:
self.rpe_table = None
@torch.no_grad()
def _get_ref_points(self, H_key, W_key, B, dtype, device):
ref_y, ref_x = torch.meshgrid(
torch.linspace(0.5, H_key - 0.5, H_key, dtype=dtype, device=device),
torch.linspace(0.5, W_key - 0.5, W_key, dtype=dtype, device=device)
)
ref = torch.stack((ref_y, ref_x), -1)
ref[..., 1].div_(W_key).mul_(2).sub_(1)
ref[..., 0].div_(H_key).mul_(2).sub_(1)
ref = ref[None, ...].expand(B * self.n_groups, -1, -1, -1) # B * g H W 2
return ref
def forward(self, x):
B, C, H, W = x.size()
dtype, device = x.dtype, x.device
q = self.proj_q(x)
q_off = einops.rearrange(q, 'b (g c) h w -> (b g) c h w', g=self.n_groups, c=self.n_group_channels)
offset = self.conv_offset(q_off) # B * g 2 Hg Wg
Hk, Wk = offset.size(2), offset.size(3)
n_sample = Hk * Wk
if self.offset_range_factor > 0:
offset_range = torch.tensor([1.0 / Hk, 1.0 / Wk], device=device).reshape(1, 2, 1, 1)
offset = offset.tanh().mul(offset_range).mul(self.offset_range_factor)
offset = einops.rearrange(offset, 'b p h w -> b h w p')
reference = self._get_ref_points(Hk, Wk, B, dtype, device)
if self.no_off:
offset = offset.fill(0.0)
if self.offset_range_factor >= 0:
pos = offset + reference
else:
pos = (offset + reference).tanh()
x_sampled = F.grid_sample(
input=x.reshape(B * self.n_groups, self.n_group_channels, H, W),
grid=pos[..., (1, 0)], # y, x -> x, y
mode='bilinear', align_corners=True) # B * g, Cg, Hg, Wg
x_sampled = x_sampled.reshape(B, C, 1, n_sample)
q = q.reshape(B * self.n_heads, self.n_head_channels, H * W)
k = self.proj_k(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)
v = self.proj_v(x_sampled).reshape(B * self.n_heads, self.n_head_channels, n_sample)
attn = torch.einsum('b c m, b c n -> b m n', q, k) # B * h, HW, Ns
attn = attn.mul(self.scale)
if self.use_pe:
if self.dwc_pe:
residual_lepe = self.rpe_table(q.reshape(B, C, H, W)).reshape(B * self.n_heads, self.n_head_channels, H * W)
elif self.fixed_pe:
rpe_table = self.rpe_table
attn_bias = rpe_table[None, ...].expand(B, -1, -1, -1)
attn = attn + attn_bias.reshape(B * self.n_heads, H * W, self.n_sample)
else:
rpe_table = self.rpe_table
rpe_bias = rpe_table[None, ...].expand(B, -1, -1, -1)
q_grid = self._get_ref_points(H, W, B, dtype, device)
displacement = (q_grid.reshape(B * self.n_groups, H * W, 2).unsqueeze(2) - pos.reshape(B * self.n_groups, n_sample, 2).unsqueeze(1)).mul(0.5)
attn_bias = F.grid_sample(
input=rpe_bias.reshape(B * self.n_groups, self.n_group_heads, 2 * H - 1, 2 * W - 1),
grid=displacement[..., (1, 0)],
mode='bilinear', align_corners=True
) # B * g, h_g, HW, Ns
attn_bias = attn_bias.reshape(B * self.n_heads, H * W, n_sample)
attn = attn + attn_bias
attn = F.softmax(attn, dim=2)
attn = self.attn_drop(attn)
out = torch.einsum('b m n, b c n -> b c m', attn, v)
if self.use_pe and self.dwc_pe:
out = out + residual_lepe
out = out.reshape(B, C, H, W)
y = self.proj_drop(self.proj_out(out))
return y, pos.reshape(B, self.n_groups, Hk, Wk, 2), reference.reshape(B, self.n_groups, Hk, Wk, 2)
class TransformerMLP(nn.Module):
def __init__(self, channels, expansion, drop):
super().__init__()
self.dim1 = channels
self.dim2 = channels * expansion
self.chunk = nn.Sequential()
self.chunk.add_module('linear1', nn.Linear(self.dim1, self.dim2))
self.chunk.add_module('act', nn.GELU())
self.chunk.add_module('drop1', nn.Dropout(drop, inplace=True))
self.chunk.add_module('linear2', nn.Linear(self.dim2, self.dim1))
self.chunk.add_module('drop2', nn.Dropout(drop, inplace=True))
def forward(self, x):
_, _, H, W = x.size()
x = einops.rearrange(x, 'b c h w -> b (h w) c')
x = self.chunk(x)
x = einops.rearrange(x, 'b (h w) c -> b c h w', h=H, w=W)
return x
class LayerNormProxy(nn.Module):
def __init__(self, dim):
super().__init__()
self.norm = nn.LayerNorm(dim)
def forward(self, x):
x = einops.rearrange(x, 'b c h w -> b h w c')
x = self.norm(x)
return einops.rearrange(x, 'b h w c -> b c h w')
class TransformerMLPWithConv(nn.Module):
def __init__(self, channels, expansion, drop):
super().__init__()
self.dim1 = channels
self.dim2 = channels * expansion
self.linear1 = nn.Conv2d(self.dim1, self.dim2, 1, 1, 0)
self.drop1 = nn.Dropout(drop, inplace=True)
self.act = nn.GELU()
self.linear2 = nn.Conv2d(self.dim2, self.dim1, 1, 1, 0)
self.drop2 = nn.Dropout(drop, inplace=True)
self.dwc = nn.Conv2d(self.dim2, self.dim2, 3, 1, 1, groups=self.dim2)
def forward(self, x):
x = self.drop1(self.act(self.dwc(self.linear1(x))))
x = self.drop2(self.linear2(x))
return x
class TransformerStage(nn.Module):
def __init__(self, fmap_size, window_size, ns_per_pt,
dim_in, dim_embed, depths, stage_spec, n_groups,
use_pe, sr_ratio,
heads, stride, offset_range_factor, stage_idx,
dwc_pe, no_off, fixed_pe,
attn_drop, proj_drop, expansion, drop, drop_path_rate, use_dwc_mlp):
super().__init__()
fmap_size = to_2tuple(fmap_size)
self.depths = depths
hc = dim_embed // heads
assert dim_embed == heads * hc
self.proj = nn.Conv2d(dim_in, dim_embed, 1, 1, 0) if dim_in != dim_embed else nn.Identity()
self.layer_norms = nn.ModuleList(
[LayerNormProxy(dim_embed) for _ in range(2 * depths)]
)
self.mlps = nn.ModuleList(
[
TransformerMLPWithConv(dim_embed, expansion, drop)
if use_dwc_mlp else TransformerMLP(dim_embed, expansion, drop)
for _ in range(depths)
]
)
self.attns = nn.ModuleList()
self.drop_path = nn.ModuleList()
for i in range(depths):
if stage_spec[i] == 'L':
self.attns.append(
LocalAttention(dim_embed, heads, window_size, attn_drop, proj_drop)
)
elif stage_spec[i] == 'D':
self.attns.append(
DAttentionBaseline(fmap_size, fmap_size, heads,
hc, n_groups, attn_drop, proj_drop,
stride, offset_range_factor, use_pe, dwc_pe,
no_off, fixed_pe, stage_idx)
)
elif stage_spec[i] == 'S':
shift_size = math.ceil(window_size / 2)
self.attns.append(
ShiftWindowAttention(dim_embed, heads, window_size, attn_drop, proj_drop, shift_size, fmap_size)
)
else:
raise NotImplementedError(f'Spec={stage_spec[i]} is not supported.')
self.drop_path.append(DropPath(drop_path_rate[i]) if drop_path_rate[i] > 0.0 else nn.Identity())
def forward(self, x):
x = self.proj(x)
positions = []
references = []
for d in range(self.depths):
x0 = x
x, pos, ref = self.attns[d](self.layer_norms[2 * d](x))
x = self.drop_path[d](x) + x0
x0 = x
x = self.mlps[d](self.layer_norms[2 * d + 1](x))
x = self.drop_path[d](x) + x0
positions.append(pos)
references.append(ref)
return x, positions, references
class DAT(nn.Module):
def __init__(self, img_size=224, patch_size=4, num_classes=1000, expansion=4,
dim_stem=96, dims=[96, 192, 384, 768], depths=[2, 2, 6, 2],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7],
drop_rate=0.0, attn_drop_rate=0.0, drop_path_rate=0.0,
strides=[-1,-1,-1,-1], offset_range_factor=[1, 2, 3, 4],
stage_spec=[['L', 'D'], ['L', 'D'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
groups=[-1, -1, 3, 6],
use_pes=[False, False, False, False],
dwc_pes=[False, False, False, False],
sr_ratios=[8, 4, 2, 1],
fixed_pes=[False, False, False, False],
no_offs=[False, False, False, False],
ns_per_pts=[4, 4, 4, 4],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
**kwargs):
super().__init__()
self.patch_proj = nn.Sequential(
nn.Conv2d(3, dim_stem, 7, patch_size, 3),
LayerNormProxy(dim_stem)
) if use_conv_patches else nn.Sequential(
nn.Conv2d(3, dim_stem, patch_size, patch_size, 0),
LayerNormProxy(dim_stem)
)
img_size = img_size // patch_size
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
self.stages = nn.ModuleList()
for i in range(4):
dim1 = dim_stem if i == 0 else dims[i - 1] * 2
dim2 = dims[i]
self.stages.append(
TransformerStage(img_size, window_sizes[i], ns_per_pts[i],
dim1, dim2, depths[i], stage_spec[i], groups[i], use_pes[i],
sr_ratios[i], heads[i], strides[i],
offset_range_factor[i], i,
dwc_pes[i], no_offs[i], fixed_pes[i],
attn_drop_rate, drop_rate, expansion, drop_rate,
dpr[sum(depths[:i]):sum(depths[:i + 1])],
use_dwc_mlps[i])
)
img_size = img_size // 2
self.down_projs = nn.ModuleList()
for i in range(3):
self.down_projs.append(
nn.Sequential(
nn.Conv2d(dims[i], dims[i + 1], 3, 2, 1, bias=False),
LayerNormProxy(dims[i + 1])
) if use_conv_patches else nn.Sequential(
nn.Conv2d(dims[i], dims[i + 1], 2, 2, 0, bias=False),
LayerNormProxy(dims[i + 1])
)
)
self.cls_norm = LayerNormProxy(dims[-1])
self.cls_head = nn.Linear(dims[-1], num_classes)
self.reset_parameters()
def reset_parameters(self):
for m in self.parameters():
if isinstance(m, (nn.Linear, nn.Conv2d)):
nn.init.kaiming_normal_(m.weight)
nn.init.zeros_(m.bias)
@torch.no_grad()
def load_pretrained(self, state_dict):
new_state_dict = {}
for state_key, state_value in state_dict.items():
keys = state_key.split('.')
m = self
for key in keys:
if key.isdigit():
m = m[int(key)]
else:
m = getattr(m, key)
if m.shape == state_value.shape:
new_state_dict[state_key] = state_value
else:
# Ignore different shapes
if 'relative_position_index' in keys:
new_state_dict[state_key] = m.data
if 'q_grid' in keys:
new_state_dict[state_key] = m.data
if 'reference' in keys:
new_state_dict[state_key] = m.data
# Bicubic Interpolation
if 'relative_position_bias_table' in keys:
n, c = state_value.size()
l = int(math.sqrt(n))
assert n == l ** 2
L = int(math.sqrt(m.shape[0]))
pre_interp = state_value.reshape(1, l, l, c).permute(0, 3, 1, 2)
post_interp = F.interpolate(pre_interp, (L, L), mode='bicubic')
new_state_dict[state_key] = post_interp.reshape(c, L ** 2).permute(1, 0)
if 'rpe_table' in keys:
c, h, w = state_value.size()
C, H, W = m.data.size()
pre_interp = state_value.unsqueeze(0)
post_interp = F.interpolate(pre_interp, (H, W), mode='bicubic')
new_state_dict[state_key] = post_interp.squeeze(0)
self.load_state_dict(new_state_dict, strict=False)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table', 'rpe_table'}
def forward(self, x):
x = self.patch_proj(x)
positions = []
references = []
for i in range(4):
x, pos, ref = self.stages[i](x)
if i < 3:
x = self.down_projs[i](x)
positions.append(pos)
references.append(ref)
x = self.cls_norm(x)
x = F.adaptive_avg_pool2d(x, 1)
x = torch.flatten(x, 1)
x = self.cls_head(x)
return x, positions, references
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DAT(
img_size=224,
patch_size=4,
num_classes=1000,
expansion=4,
dim_stem=96,
dims=[96, 192, 384, 768],
depths=[2, 2, 6, 2],
stage_spec=[['L', 'S'], ['L', 'S'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7] ,
groups=[-1, -1, 3, 6],
use_pes=[False, False, True, True],
dwc_pes=[False, False, False, False],
strides=[-1, -1, 1, 1],
sr_ratios=[-1, -1, -1, -1],
offset_range_factor=[-1, -1, 2, 2],
no_offs=[False, False, False, False],
fixed_pes=[False, False, False, False],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
)
output=model(input)
print(output[0].shape)
================================================
FILE: model/attention/ECAAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
from collections import OrderedDict
class ECAAttention(nn.Module):
def __init__(self, kernel_size=3):
super().__init__()
self.gap=nn.AdaptiveAvgPool2d(1)
self.conv=nn.Conv1d(1,1,kernel_size=kernel_size,padding=(kernel_size-1)//2)
self.sigmoid=nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
y=self.gap(x) #bs,c,1,1
y=y.squeeze(-1).permute(0,2,1) #bs,1,c
y=self.conv(y) #bs,1,c
y=self.sigmoid(y) #bs,1,c
y=y.permute(0,2,1).unsqueeze(-1) #bs,c,1,1
return x*y.expand_as(x)
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
================================================
FILE: model/attention/EMSA.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class EMSA(nn.Module):
def __init__(self, d_model, d_k, d_v, h,dropout=.1,H=7,W=7,ratio=3,apply_transform=True):
super(EMSA, self).__init__()
self.H=H
self.W=W
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.ratio=ratio
if(self.ratio>1):
self.sr=nn.Sequential()
self.sr_conv=nn.Conv2d(d_model,d_model,kernel_size=ratio+1,stride=ratio,padding=ratio//2,groups=d_model)
self.sr_ln=nn.LayerNorm(d_model)
self.apply_transform=apply_transform and h>1
if(self.apply_transform):
self.transform=nn.Sequential()
self.transform.add_module('conv',nn.Conv2d(h,h,kernel_size=1,stride=1))
self.transform.add_module('softmax',nn.Softmax(-1))
self.transform.add_module('in',nn.InstanceNorm2d(h))
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
b_s, nq ,c = queries.shape
nk = keys.shape[1]
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
if(self.ratio>1):
x=queries.permute(0,2,1).view(b_s,c,self.H,self.W) #bs,c,H,W
x=self.sr_conv(x) #bs,c,h,w
x=x.contiguous().view(b_s,c,-1).permute(0,2,1) #bs,n',c
x=self.sr_ln(x)
k = self.fc_k(x).view(b_s, -1, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, n')
v = self.fc_v(x).view(b_s, -1, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, n', d_v)
else:
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
if(self.apply_transform):
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, n')
att = self.transform(att) # (b_s, h, nq, n')
else:
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, n')
att = torch.softmax(att, -1) # (b_s, h, nq, n')
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att=self.dropout(att)
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
return out
if __name__ == '__main__':
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
================================================
FILE: model/attention/ExternalAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ExternalAttention(nn.Module):
def __init__(self, d_model,S=64):
super().__init__()
self.mk=nn.Linear(d_model,S,bias=False)
self.mv=nn.Linear(S,d_model,bias=False)
self.softmax=nn.Softmax(dim=1)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries):
attn=self.mk(queries) #bs,n,S
attn=self.softmax(attn) #bs,n,S
attn=attn/torch.sum(attn,dim=2,keepdim=True) #bs,n,S
out=self.mv(attn) #bs,n,d_model
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
================================================
FILE: model/attention/HaloAttention.py
================================================
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, repeat
# relative positional embedding
def to(x):
return {'device': x.device, 'dtype': x.dtype}
def pair(x):
return (x, x) if not isinstance(x, tuple) else x
def expand_dim(t, dim, k):
t = t.unsqueeze(dim = dim)
expand_shape = [-1] * len(t.shape)
expand_shape[dim] = k
return t.expand(*expand_shape)
def rel_to_abs(x):
b, l, m = x.shape
r = (m + 1) // 2
col_pad = torch.zeros((b, l, 1), **to(x))
x = torch.cat((x, col_pad), dim = 2)
flat_x = rearrange(x, 'b l c -> b (l c)')
flat_pad = torch.zeros((b, m - l), **to(x))
flat_x_padded = torch.cat((flat_x, flat_pad), dim = 1)
final_x = flat_x_padded.reshape(b, l + 1, m)
final_x = final_x[:, :l, -r:]
return final_x
def relative_logits_1d(q, rel_k):
b, h, w, _ = q.shape
r = (rel_k.shape[0] + 1) // 2
logits = einsum('b x y d, r d -> b x y r', q, rel_k)
logits = rearrange(logits, 'b x y r -> (b x) y r')
logits = rel_to_abs(logits)
logits = logits.reshape(b, h, w, r)
logits = expand_dim(logits, dim = 2, k = r)
return logits
class RelPosEmb(nn.Module):
def __init__(
self,
block_size,
rel_size,
dim_head
):
super().__init__()
height = width = rel_size
scale = dim_head ** -0.5
self.block_size = block_size
self.rel_height = nn.Parameter(torch.randn(height * 2 - 1, dim_head) * scale)
self.rel_width = nn.Parameter(torch.randn(width * 2 - 1, dim_head) * scale)
def forward(self, q):
block = self.block_size
q = rearrange(q, 'b (x y) c -> b x y c', x = block)
rel_logits_w = relative_logits_1d(q, self.rel_width)
rel_logits_w = rearrange(rel_logits_w, 'b x i y j-> b (x y) (i j)')
q = rearrange(q, 'b x y d -> b y x d')
rel_logits_h = relative_logits_1d(q, self.rel_height)
rel_logits_h = rearrange(rel_logits_h, 'b x i y j -> b (y x) (j i)')
return rel_logits_w + rel_logits_h
# classes
class HaloAttention(nn.Module):
def __init__(
self,
*,
dim,
block_size,
halo_size,
dim_head = 64,
heads = 8
):
super().__init__()
assert halo_size > 0, 'halo size must be greater than 0'
self.dim = dim
self.heads = heads
self.scale = dim_head ** -0.5
self.block_size = block_size
self.halo_size = halo_size
inner_dim = dim_head * heads
self.rel_pos_emb = RelPosEmb(
block_size = block_size,
rel_size = block_size + (halo_size * 2),
dim_head = dim_head
)
self.to_q = nn.Linear(dim, inner_dim, bias = False)
self.to_kv = nn.Linear(dim, inner_dim * 2, bias = False)
self.to_out = nn.Linear(inner_dim, dim)
def forward(self, x):
b, c, h, w, block, halo, heads, device = *x.shape, self.block_size, self.halo_size, self.heads, x.device
assert h % block == 0 and w % block == 0, 'fmap dimensions must be divisible by the block size'
assert c == self.dim, f'channels for input ({c}) does not equal to the correct dimension ({self.dim})'
# get block neighborhoods, and prepare a halo-ed version (blocks with padding) for deriving key values
q_inp = rearrange(x, 'b c (h p1) (w p2) -> (b h w) (p1 p2) c', p1 = block, p2 = block)
kv_inp = F.unfold(x, kernel_size = block + halo * 2, stride = block, padding = halo)
kv_inp = rearrange(kv_inp, 'b (c j) i -> (b i) j c', c = c)
# derive queries, keys, values
q = self.to_q(q_inp)
k, v = self.to_kv(kv_inp).chunk(2, dim = -1)
# split heads
q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> (b h) n d', h = heads), (q, k, v))
# scale
q *= self.scale
# attention
sim = einsum('b i d, b j d -> b i j', q, k)
# add relative positional bias
sim += self.rel_pos_emb(q)
# mask out padding (in the paper, they claim to not need masks, but what about padding?)
mask = torch.ones(1, 1, h, w, device = device)
mask = F.unfold(mask, kernel_size = block + (halo * 2), stride = block, padding = halo)
mask = repeat(mask, '() j i -> (b i h) () j', b = b, h = heads)
mask = mask.bool()
max_neg_value = -torch.finfo(sim.dtype).max
sim.masked_fill_(mask, max_neg_value)
# attention
attn = sim.softmax(dim = -1)
# aggregate
out = einsum('b i j, b j d -> b i d', attn, v)
# merge and combine heads
out = rearrange(out, '(b h) n d -> b n (h d)', h = heads)
out = self.to_out(out)
# merge blocks back to original feature map
out = rearrange(out, '(b h w) (p1 p2) c -> b c (h p1) (w p2)', b = b, h = (h // block), w = (w // block), p1 = block, p2 = block)
return out
if __name__ == '__main__':
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)
================================================
FILE: model/attention/MOATransformer.py
================================================
# --------------------------------------------------------
# Adopted from Swin Transformer
# Modified by Krushi Patel
# --------------------------------------------------------
import torch
import torch.nn as nn
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from einops.layers.torch import Rearrange, Reduce
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
def window_partition(x, window_size):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
def window_reverse(windows, window_size, H, W):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.query_size = self.window_size
self.key_size = self.window_size[0] * 2
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size[0] - 1) * (2 * window_size[1] - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
#return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
return f'dim={self.dim}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 window with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
return flops
class GlobalAttention(nn.Module):
r""" MOA - multi-head self attention (W-MSA) module with relative position bias.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, window_size, input_resolution,num_heads, qkv_bias=True, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.query_size = self.window_size[0]
self.key_size = self.window_size[0] + 2
h,w = input_resolution
self.seq_len = h//self.query_size
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.reduction = 32
self.pre_conv = nn.Conv2d(dim, int(dim//self.reduction), 1)
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * self.seq_len - 1) * (2 * self.seq_len - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
#print(self.relative_position_bias_table.shape)
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.seq_len)
coords_w = torch.arange(self.seq_len)
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.seq_len - 1 # shift to start from 0
relative_coords[:, :, 1] += self.seq_len - 1
relative_coords[:, :, 0] *= 2 * self.seq_len - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
self.queryembedding = Rearrange('b c (h p1) (w p2) -> b (p1 p2 c) h w', p1 = self.query_size, p2 = self. query_size)
self.keyembedding = nn.Unfold(kernel_size=(self.key_size, self.key_size), stride = 14, padding=1)
self.query_dim = int(dim//self.reduction) * self.query_size * self.query_size
self.key_dim = int(dim//self.reduction) * self.key_size * self.key_size
self.q = nn.Linear(self.query_dim, self.dim,bias=qkv_bias)
self.kv = nn.Linear(self.key_dim, 2*self.dim,bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim,dim)
self.proj_drop = nn.Dropout(proj_drop)
#trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, H, W):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
#B, H, W, C = x.shape
B,_, C = x.shape
x = x.reshape(-1, C, H, W)
x = self.pre_conv(x)
query = self.queryembedding(x).view(B,-1,self.query_dim)
query = self.q(query)
B,N,C = query.size()
q = query.reshape(B,N,self.num_heads, C//self.num_heads).permute(0,2,1,3)
key = self.keyembedding(x).view(B,-1,self.key_dim)
kv = self.kv(key).reshape(B,N,2,self.num_heads,C//self.num_heads).permute(2,0,3,1,4)
k = kv[0]
v = kv[1]
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.seq_len * self.seq_len, self.seq_len * self.seq_len, -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
attn = attn + relative_position_bias.unsqueeze(0)
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def extra_repr(self) -> str:
return f'dim={self.dim}, window_size={self.window_size}, num_heads={self.num_heads}'
def flops(self, N):
# calculate flops for 1 window with token length of N
flops = 0
# qkv = self.qkv(x)
flops += N * self.dim * 3 * self.dim
# attn = (q @ k.transpose(-2, -1))
flops += self.num_heads * N * (self.dim // self.num_heads) * N
# x = (attn @ v)
flops += self.num_heads * N * N * (self.dim // self.num_heads)
# x = self.proj(x)
flops += N * self.dim * self.dim
return flops
class LocalTransformerBlock(nn.Module):
r""" Local Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, dim, input_resolution, num_heads, window_size=7,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.num_heads = num_heads
self.window_size = window_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.window_size = min(self.input_resolution)
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
x_windows = window_partition(x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # nW*B, window_size*window_size, C
attn_windows = self.attn(x_windows) # nW*B, window_size*window_size, C
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
x = x.view(B, H * W, C)
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, num_heads={self.num_heads}, " \
f"window_size={self.window_size}, mlp_ratio={self.mlp_ratio}"
def flops(self):
flops = 0
H, W = self.input_resolution
# norm1
flops += self.dim * H * W
# W-MSA/SW-MSA
nW = H * W / self.window_size / self.window_size
flops += nW * self.attn.flops(self.window_size * self.window_size)
# mlp
flops += 2 * H * W * self.dim * self.dim * self.mlp_ratio
# norm2
flops += self.dim * H * W
return flops
class PatchMerging(nn.Module):
""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(4 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
assert L == H * W, "input feature has wrong size"
assert H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even."
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
def extra_repr(self) -> str:
return f"input_resolution={self.input_resolution}, dim={self.dim}"
def flops(self):
H, W = self.input_resolution
flops = H * W * self.dim
flops += (H // 2) * (W // 2) * 4 * self.dim * 2 * self.dim
return flops
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float | None, optional): Override default qk scale of head_dim ** -0.5 if set.
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False.
"""
def __init__(self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None, drop_path_global=0., use_checkpoint=False):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.use_checkpoint = use_checkpoint
self.window_size = window_size
self.drop_path_gl = DropPath(drop_path_global) if drop_path_global > 0. else nn.Identity()
# build blocks
self.blocks = nn.ModuleList([
LocalTransformerBlock(dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
if min(self.input_resolution) >= self.window_size:
self.glb_attn = GlobalAttention(dim, to_2tuple(window_size), self.input_resolution, num_heads = num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.post_conv = nn.Conv2d(dim, dim, 3, padding=1)
self.norm1 = norm_layer(dim)
self.norm2 = norm_layer(dim)
else:
self.post_conv = None
self.glb_attn = None
self.norm1 = None
self.norm2 = None
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
for blk in self.blocks:
if self.use_checkpoint:
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
if self.downsample is not None:
if min(self.input_resolution) >= self.window_size:
shortcut = x
x = self.norm1(x)
H, W = self.input_resolution
B,_,C = x.size()
no_window = int(H*W/self.window_size**2)
local_attn = x.view(B,no_window,self.window_size, self.window_size,C)
glb_attn = self.glb_attn(x, H, W)
glb_attn = glb_attn.view(B,no_window,1,1,C)
x = torch.add(local_attn, glb_attn).view(B,C,H,W)
x = shortcut.view(B,C,H,W) + self.drop_path_gl(x)
x = self.norm2(x.view(B,H*W,C))
post_conv = self.drop_path_gl(self.post_conv(x.view(B,C,H,W))).view(B, H*W, C)
x = x + post_conv
x = self.downsample(x)
return x
def extra_repr(self) -> str:
return f"dim={self.dim}, input_resolution={self.input_resolution}, depth={self.depth}"
def flops(self):
flops = 0
for blk in self.blocks:
flops += blk.flops()
if self.downsample is not None:
flops += self.downsample.flops()
return flops
class PatchEmbed(nn.Module):
r""" Image to Patch Embedding
Args:
img_size (int): Image size. Default: 224.
patch_size (int): Patch token size. Default: 4.
in_chans (int): Number of input image channels. Default: 3.
embed_dim (int): Number of linear projection output channels. Default: 96.
norm_layer (nn.Module, optional): Normalization layer. Default: None
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, embed_dim=96, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
patches_resolution = [img_size[0] // patch_size[0], img_size[1] // patch_size[1]]
self.img_size = img_size
self.patch_size = patch_size
self.patches_resolution = patches_resolution
self.num_patches = patches_resolution[0] * patches_resolution[1]
self.in_chans = in_chans
self.embed_dim = embed_dim
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
if norm_layer is not None:
self.norm = norm_layer(embed_dim)
else:
self.norm = None
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2) # B Ph*Pw C
if self.norm is not None:
x = self.norm(x)
return x
def flops(self):
Ho, Wo = self.patches_resolution
flops = Ho * Wo * self.embed_dim * self.in_chans * (self.patch_size[0] * self.patch_size[1])
if self.norm is not None:
flops += Ho * Wo * self.embed_dim
return flops
class MOATransformer(nn.Module):
r""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
qk_scale (float): Override default qk scale of head_dim ** -0.5 if set. Default: None
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24],
window_size=7, mlp_ratio=4., qkv_bias=True, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
use_checkpoint=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.ape = ape
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
self.mlp_ratio = mlp_ratio
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
patches_resolution = self.patch_embed.patches_resolution
self.patches_resolution = patches_resolution
# absolute position embedding
if self.ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
dpr_global = [x.item() for x in torch.linspace(0, 0.2, len(depths)-1)]
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(dim=int(embed_dim * 2 ** i_layer),
input_resolution=(patches_resolution[0] // (2 ** i_layer),
patches_resolution[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
drop_path_global = (dpr_global[i_layer]) if (i_layer < self.num_layers -1) else 0,
use_checkpoint=use_checkpoint)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.avgpool = nn.AdaptiveAvgPool1d(1)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'absolute_pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def forward_features(self, x):
x = self.patch_embed(x)
if self.ape:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
x = self.avgpool(x.transpose(1, 2)) # B C 1
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def flops(self):
flops = 0
flops += self.patch_embed.flops()
for i, layer in enumerate(self.layers):
flops += layer.flops()
flops += self.num_features * self.patches_resolution[0] * self.patches_resolution[1] // (2 ** self.num_layers)
flops += self.num_features * self.num_classes
return flops
# --------------------------------------------------------
# Adopted from Swin Transformer
# Modified by Krushi Patel
# print(sum(p.numel() for p in model.parameters() if p.requires_grad), 'parameters')
# --------------------------------------------------------
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = MOATransformer(
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=[2, 2, 6],
num_heads=[3, 6, 12],
window_size=14,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False
)
output=model(input)
print(output.shape)
================================================
FILE: model/attention/MUSEAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class Depth_Pointwise_Conv1d(nn.Module):
def __init__(self,in_ch,out_ch,k):
super().__init__()
if(k==1):
self.depth_conv=nn.Identity()
else:
self.depth_conv=nn.Conv1d(
in_channels=in_ch,
out_channels=in_ch,
kernel_size=k,
groups=in_ch,
padding=k//2
)
self.pointwise_conv=nn.Conv1d(
in_channels=in_ch,
out_channels=out_ch,
kernel_size=1,
groups=1
)
def forward(self,x):
out=self.pointwise_conv(self.depth_conv(x))
return out
class MUSEAttention(nn.Module):
def __init__(self, d_model, d_k, d_v, h,dropout=.1):
super(MUSEAttention, self).__init__()
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.conv1=Depth_Pointwise_Conv1d(h * d_v, d_model,1)
self.conv3=Depth_Pointwise_Conv1d(h * d_v, d_model,3)
self.conv5=Depth_Pointwise_Conv1d(h * d_v, d_model,5)
self.dy_paras=nn.Parameter(torch.ones(3))
self.softmax=nn.Softmax(-1)
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
#Self Attention
b_s, nq = queries.shape[:2]
nk = keys.shape[1]
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, nk)
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att = torch.softmax(att, -1)
att=self.dropout(att)
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
v2=v.permute(0,1,3,2).contiguous().view(b_s,-1,nk) #bs,dim,n
self.dy_paras=nn.Parameter(self.softmax(self.dy_paras))
out2=self.dy_paras[0]*self.conv1(v2)+self.dy_paras[1]*self.conv3(v2)+self.dy_paras[2]*self.conv5(v2)
out2=out2.permute(0,2,1) #bs.n.dim
out=out+out2
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
================================================
FILE: model/attention/MobileViTAttention.py
================================================
from torch import nn
import torch
from einops import rearrange
class PreNorm(nn.Module):
def __init__(self,dim,fn):
super().__init__()
self.ln=nn.LayerNorm(dim)
self.fn=fn
def forward(self,x,**kwargs):
return self.fn(self.ln(x),**kwargs)
class FeedForward(nn.Module):
def __init__(self,dim,mlp_dim,dropout) :
super().__init__()
self.net=nn.Sequential(
nn.Linear(dim,mlp_dim),
nn.SiLU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim,dim),
nn.Dropout(dropout)
)
def forward(self,x):
return self.net(x)
class Attention(nn.Module):
def __init__(self,dim,heads,head_dim,dropout):
super().__init__()
inner_dim=heads*head_dim
project_out=not(heads==1 and head_dim==dim)
self.heads=heads
self.scale=head_dim**-0.5
self.attend=nn.Softmax(dim=-1)
self.to_qkv=nn.Linear(dim,inner_dim*3,bias=False)
self.to_out=nn.Sequential(
nn.Linear(inner_dim,dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self,x):
qkv=self.to_qkv(x).chunk(3,dim=-1)
q,k,v=map(lambda t:rearrange(t,'b p n (h d) -> b p h n d',h=self.heads),qkv)
dots=torch.matmul(q,k.transpose(-1,-2))*self.scale
attn=self.attend(dots)
out=torch.matmul(attn,v)
out=rearrange(out,'b p h n d -> b p n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self,dim,depth,heads,head_dim,mlp_dim,dropout=0.):
super().__init__()
self.layers=nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim,Attention(dim,heads,head_dim,dropout)),
PreNorm(dim,FeedForward(dim,mlp_dim,dropout))
]))
def forward(self,x):
out=x
for att,ffn in self.layers:
out=out+att(out)
out=out+ffn(out)
return out
class MobileViTAttention(nn.Module):
def __init__(self,in_channel=3,dim=512,kernel_size=3,patch_size=7):
super().__init__()
self.ph,self.pw=patch_size,patch_size
self.conv1=nn.Conv2d(in_channel,in_channel,kernel_size=kernel_size,padding=kernel_size//2)
self.conv2=nn.Conv2d(in_channel,dim,kernel_size=1)
self.trans=Transformer(dim=dim,depth=3,heads=8,head_dim=64,mlp_dim=1024)
self.conv3=nn.Conv2d(dim,in_channel,kernel_size=1)
self.conv4=nn.Conv2d(2*in_channel,in_channel,kernel_size=kernel_size,padding=kernel_size//2)
def forward(self,x):
y=x.clone() #bs,c,h,w
## Local Representation
y=self.conv2(self.conv1(x)) #bs,dim,h,w
## Global Representation
_,_,h,w=y.shape
y=rearrange(y,'bs dim (nh ph) (nw pw) -> bs (ph pw) (nh nw) dim',ph=self.ph,pw=self.pw) #bs,h,w,dim
y=self.trans(y)
y=rearrange(y,'bs (ph pw) (nh nw) dim -> bs dim (nh ph) (nw pw)',ph=self.ph,pw=self.pw,nh=h//self.ph,nw=w//self.pw) #bs,dim,h,w
## Fusion
y=self.conv3(y) #bs,dim,h,w
y=torch.cat([x,y],1) #bs,2*dim,h,w
y=self.conv4(y) #bs,c,h,w
return y
if __name__ == '__main__':
m=MobileViTAttention()
input=torch.randn(1,3,49,49)
output=m(input)
print(output.shape)
================================================
FILE: model/attention/MobileViTv2Attention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class MobileViTv2Attention(nn.Module):
'''
Scaled dot-product attention
'''
def __init__(self, d_model):
'''
:param d_model: Output dimensionality of the model
:param d_k: Dimensionality of queries and keys
:param d_v: Dimensionality of values
:param h: Number of heads
'''
super(MobileViTv2Attention, self).__init__()
self.fc_i = nn.Linear(d_model,1)
self.fc_k = nn.Linear(d_model, d_model)
self.fc_v = nn.Linear(d_model, d_model)
self.fc_o = nn.Linear(d_model, d_model)
self.d_model = d_model
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, input):
'''
Computes
:param queries: Queries (b_s, nq, d_model)
:return:
'''
i = self.fc_i(input) #(bs,nq,1)
weight_i = torch.softmax(i, dim=1) #bs,nq,1
context_score = weight_i * self.fc_k(input) #bs,nq,d_model
context_vector = torch.sum(context_score,dim=1,keepdim=True) #bs,1,d_model
v = self.fc_v(input) * context_vector #bs,nq,d_model
out = self.fc_o(v) #bs,nq,d_model
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
================================================
FILE: model/attention/OutlookAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
import math
from torch.nn import functional as F
class OutlookAttention(nn.Module):
def __init__(self,dim,num_heads=1,kernel_size=3,padding=1,stride=1,qkv_bias=False,
attn_drop=0.1):
super().__init__()
self.dim=dim
self.num_heads=num_heads
self.head_dim=dim//num_heads
self.kernel_size=kernel_size
self.padding=padding
self.stride=stride
self.scale=self.head_dim**(-0.5)
self.v_pj=nn.Linear(dim,dim,bias=qkv_bias)
self.attn=nn.Linear(dim,kernel_size**4*num_heads)
self.attn_drop=nn.Dropout(attn_drop)
self.proj=nn.Linear(dim,dim)
self.proj_drop=nn.Dropout(attn_drop)
self.unflod=nn.Unfold(kernel_size,padding,stride) #手动卷积
self.pool=nn.AvgPool2d(kernel_size=stride,stride=stride,ceil_mode=True)
def forward(self, x) :
B,H,W,C=x.shape
#映射到新的特征v
v=self.v_pj(x).permute(0,3,1,2) #B,C,H,W
h,w=math.ceil(H/self.stride),math.ceil(W/self.stride)
v=self.unflod(v).reshape(B,self.num_heads,self.head_dim,self.kernel_size*self.kernel_size,h*w).permute(0,1,4,3,2) #B,num_head,H*W,kxk,head_dim
#生成Attention Map
attn=self.pool(x.permute(0,3,1,2)).permute(0,2,3,1) #B,H,W,C
attn=self.attn(attn).reshape(B,h*w,self.num_heads,self.kernel_size*self.kernel_size \
,self.kernel_size*self.kernel_size).permute(0,2,1,3,4) #B,num_head,H*W,kxk,kxk
attn=self.scale*attn
attn=attn.softmax(-1)
attn=self.attn_drop(attn)
#获取weighted特征
out=(attn @ v).permute(0,1,4,3,2).reshape(B,C*self.kernel_size*self.kernel_size,h*w) #B,dimxkxk,H*W
out=F.fold(out,output_size=(H,W),kernel_size=self.kernel_size,
padding=self.padding,stride=self.stride) #B,C,H,W
out=self.proj(out.permute(0,2,3,1)) #B,H,W,C
out=self.proj_drop(out)
return out
if __name__ == '__main__':
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)
================================================
FILE: model/attention/PSA.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class PSA(nn.Module):
def __init__(self, channel=512,reduction=4,S=4):
super().__init__()
self.S=S
self.convs=[]
for i in range(S):
self.convs.append(nn.Conv2d(channel//S,channel//S,kernel_size=2*(i+1)+1,padding=i+1))
self.se_blocks=[]
for i in range(S):
self.se_blocks.append(nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channel//S, channel // (S*reduction),kernel_size=1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(channel // (S*reduction), channel//S,kernel_size=1, bias=False),
nn.Sigmoid()
))
self.softmax=nn.Softmax(dim=1)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, h, w = x.size()
#Step1:SPC module
SPC_out=x.view(b,self.S,c//self.S,h,w) #bs,s,ci,h,w
for idx,conv in enumerate(self.convs):
SPC_out[:,idx,:,:,:]=conv(SPC_out[:,idx,:,:,:])
#Step2:SE weight
se_out=[]
for idx,se in enumerate(self.se_blocks):
se_out.append(se(SPC_out[:,idx,:,:,:]))
SE_out=torch.stack(se_out,dim=1)
SE_out=SE_out.expand_as(SPC_out)
#Step3:Softmax
softmax_out=self.softmax(SE_out)
#Step4:SPA
PSA_out=SPC_out*softmax_out
PSA_out=PSA_out.view(b,-1,h,w)
return PSA_out
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
a=output.view(-1).sum()
a.backward()
print(output.shape)
================================================
FILE: model/attention/ParNetAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ParNetAttention(nn.Module):
def __init__(self, channel=512):
super().__init__()
self.sse = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(channel,channel,kernel_size=1),
nn.Sigmoid()
)
self.conv1x1=nn.Sequential(
nn.Conv2d(channel,channel,kernel_size=1),
nn.BatchNorm2d(channel)
)
self.conv3x3=nn.Sequential(
nn.Conv2d(channel,channel,kernel_size=3,padding=1),
nn.BatchNorm2d(channel)
)
self.silu=nn.SiLU()
def forward(self, x):
b, c, _, _ = x.size()
x1=self.conv1x1(x)
x2=self.conv3x3(x)
x3=self.sse(x)*x
y=self.silu(x1+x2+x3)
return y
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
pna = ParNetAttention(channel=512)
output=pna(input)
print(output.shape)
================================================
FILE: model/attention/PolarizedSelfAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ParallelPolarizedSelfAttention(nn.Module):
def __init__(self, channel=512):
super().__init__()
self.ch_wv=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.ch_wq=nn.Conv2d(channel,1,kernel_size=(1,1))
self.softmax_channel=nn.Softmax(1)
self.softmax_spatial=nn.Softmax(-1)
self.ch_wz=nn.Conv2d(channel//2,channel,kernel_size=(1,1))
self.ln=nn.LayerNorm(channel)
self.sigmoid=nn.Sigmoid()
self.sp_wv=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.sp_wq=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.agp=nn.AdaptiveAvgPool2d((1,1))
def forward(self, x):
b, c, h, w = x.size()
#Channel-only Self-Attention
channel_wv=self.ch_wv(x) #bs,c//2,h,w
channel_wq=self.ch_wq(x) #bs,1,h,w
channel_wv=channel_wv.reshape(b,c//2,-1) #bs,c//2,h*w
channel_wq=channel_wq.reshape(b,-1,1) #bs,h*w,1
channel_wq=self.softmax_channel(channel_wq)
channel_wz=torch.matmul(channel_wv,channel_wq).unsqueeze(-1) #bs,c//2,1,1
channel_weight=self.sigmoid(self.ln(self.ch_wz(channel_wz).reshape(b,c,1).permute(0,2,1))).permute(0,2,1).reshape(b,c,1,1) #bs,c,1,1
channel_out=channel_weight*x
#Spatial-only Self-Attention
spatial_wv=self.sp_wv(x) #bs,c//2,h,w
spatial_wq=self.sp_wq(x) #bs,c//2,h,w
spatial_wq=self.agp(spatial_wq) #bs,c//2,1,1
spatial_wv=spatial_wv.reshape(b,c//2,-1) #bs,c//2,h*w
spatial_wq=spatial_wq.permute(0,2,3,1).reshape(b,1,c//2) #bs,1,c//2
spatial_wq=self.softmax_spatial(spatial_wq)
spatial_wz=torch.matmul(spatial_wq,spatial_wv) #bs,1,h*w
spatial_weight=self.sigmoid(spatial_wz.reshape(b,1,h,w)) #bs,1,h,w
spatial_out=spatial_weight*x
out=spatial_out+channel_out
return out
class SequentialPolarizedSelfAttention(nn.Module):
def __init__(self, channel=512):
super().__init__()
self.ch_wv=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.ch_wq=nn.Conv2d(channel,1,kernel_size=(1,1))
self.softmax_channel=nn.Softmax(1)
self.softmax_spatial=nn.Softmax(-1)
self.ch_wz=nn.Conv2d(channel//2,channel,kernel_size=(1,1))
self.ln=nn.LayerNorm(channel)
self.sigmoid=nn.Sigmoid()
self.sp_wv=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.sp_wq=nn.Conv2d(channel,channel//2,kernel_size=(1,1))
self.agp=nn.AdaptiveAvgPool2d((1,1))
def forward(self, x):
b, c, h, w = x.size()
#Channel-only Self-Attention
channel_wv=self.ch_wv(x) #bs,c//2,h,w
channel_wq=self.ch_wq(x) #bs,1,h,w
channel_wv=channel_wv.reshape(b,c//2,-1) #bs,c//2,h*w
channel_wq=channel_wq.reshape(b,-1,1) #bs,h*w,1
channel_wq=self.softmax_channel(channel_wq)
channel_wz=torch.matmul(channel_wv,channel_wq).unsqueeze(-1) #bs,c//2,1,1
channel_weight=self.sigmoid(self.ln(self.ch_wz(channel_wz).reshape(b,c,1).permute(0,2,1))).permute(0,2,1).reshape(b,c,1,1) #bs,c,1,1
channel_out=channel_weight*x
#Spatial-only Self-Attention
spatial_wv=self.sp_wv(channel_out) #bs,c//2,h,w
spatial_wq=self.sp_wq(channel_out) #bs,c//2,h,w
spatial_wq=self.agp(spatial_wq) #bs,c//2,1,1
spatial_wv=spatial_wv.reshape(b,c//2,-1) #bs,c//2,h*w
spatial_wq=spatial_wq.permute(0,2,3,1).reshape(b,1,c//2) #bs,1,c//2
spatial_wq=self.softmax_spatial(spatial_wq)
spatial_wz=torch.matmul(spatial_wq,spatial_wv) #bs,1,h*w
spatial_weight=self.sigmoid(spatial_wz.reshape(b,1,h,w)) #bs,1,h,w
spatial_out=spatial_weight*channel_out
return spatial_out
if __name__ == '__main__':
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
================================================
FILE: model/attention/ResidualAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ResidualAttention(nn.Module):
def __init__(self, channel=512 , num_class=1000,la=0.2):
super().__init__()
self.la=la
self.fc=nn.Conv2d(in_channels=channel,out_channels=num_class,kernel_size=1,stride=1,bias=False)
def forward(self, x):
b,c,h,w=x.shape
y_raw=self.fc(x).flatten(2) #b,num_class,hxw
y_avg=torch.mean(y_raw,dim=2) #b,num_class
y_max=torch.max(y_raw,dim=2)[0] #b,num_class
score=y_avg+self.la*y_max
return score
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
resatt = ResidualAttention(channel=512,num_class=1000,la=0.2)
output=resatt(input)
print(output.shape)
================================================
FILE: model/attention/S2Attention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
def spatial_shift1(x):
b,w,h,c = x.size()
x[:,1:,:,:c//4] = x[:,:w-1,:,:c//4]
x[:,:w-1,:,c//4:c//2] = x[:,1:,:,c//4:c//2]
x[:,:,1:,c//2:c*3//4] = x[:,:,:h-1,c//2:c*3//4]
x[:,:,:h-1,3*c//4:] = x[:,:,1:,3*c//4:]
return x
def spatial_shift2(x):
b,w,h,c = x.size()
x[:,:,1:,:c//4] = x[:,:,:h-1,:c//4]
x[:,:,:h-1,c//4:c//2] = x[:,:,1:,c//4:c//2]
x[:,1:,:,c//2:c*3//4] = x[:,:w-1,:,c//2:c*3//4]
x[:,:w-1,:,3*c//4:] = x[:,1:,:,3*c//4:]
return x
class SplitAttention(nn.Module):
def __init__(self,channel=512,k=3):
super().__init__()
self.channel=channel
self.k=k
self.mlp1=nn.Linear(channel,channel,bias=False)
self.gelu=nn.GELU()
self.mlp2=nn.Linear(channel,channel*k,bias=False)
self.softmax=nn.Softmax(1)
def forward(self,x_all):
b,k,h,w,c=x_all.shape
x_all=x_all.reshape(b,k,-1,c) #bs,k,n,c
a=torch.sum(torch.sum(x_all,1),1) #bs,c
hat_a=self.mlp2(self.gelu(self.mlp1(a))) #bs,kc
hat_a=hat_a.reshape(b,self.k,c) #bs,k,c
bar_a=self.softmax(hat_a) #bs,k,c
attention=bar_a.unsqueeze(-2) # #bs,k,1,c
out=attention*x_all # #bs,k,n,c
out=torch.sum(out,1).reshape(b,h,w,c)
return out
class S2Attention(nn.Module):
def __init__(self, channels=512 ):
super().__init__()
self.mlp1 = nn.Linear(channels,channels*3)
self.mlp2 = nn.Linear(channels,channels)
self.split_attention = SplitAttention()
def forward(self, x):
b,c,w,h = x.size()
x=x.permute(0,2,3,1)
x = self.mlp1(x)
x1 = spatial_shift1(x[:,:,:,:c])
x2 = spatial_shift2(x[:,:,:,c:c*2])
x3 = x[:,:,:,c*2:]
x_all=torch.stack([x1,x2,x3],1)
a = self.split_attention(x_all)
x = self.mlp2(a)
x=x.permute(0,3,1,2)
return x
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
s2att = S2Attention(channels=512)
output=s2att(input)
print(output.shape)
================================================
FILE: model/attention/SEAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SEAttention(nn.Module):
def __init__(self, channel=512,reduction=16):
super().__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
================================================
FILE: model/attention/SGE.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SpatialGroupEnhance(nn.Module):
def __init__(self, groups):
super().__init__()
self.groups=groups
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.weight=nn.Parameter(torch.zeros(1,groups,1,1))
self.bias=nn.Parameter(torch.zeros(1,groups,1,1))
self.sig=nn.Sigmoid()
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, h,w=x.shape
x=x.view(b*self.groups,-1,h,w) #bs*g,dim//g,h,w
xn=x*self.avg_pool(x) #bs*g,dim//g,h,w
xn=xn.sum(dim=1,keepdim=True) #bs*g,1,h,w
t=xn.view(b*self.groups,-1) #bs*g,h*w
t=t-t.mean(dim=1,keepdim=True) #bs*g,h*w
std=t.std(dim=1,keepdim=True)+1e-5
t=t/std #bs*g,h*w
t=t.view(b,self.groups,h,w) #bs,g,h*w
t=t*self.weight+self.bias #bs,g,h*w
t=t.view(b*self.groups,1,h,w) #bs*g,1,h*w
x=x*self.sig(t)
x=x.view(b,c,h,w)
return x
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
================================================
FILE: model/attention/SKAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
from collections import OrderedDict
class SKAttention(nn.Module):
def __init__(self, channel=512,kernels=[1,3,5,7],reduction=16,group=1,L=32):
super().__init__()
self.d=max(L,channel//reduction)
self.convs=nn.ModuleList([])
for k in kernels:
self.convs.append(
nn.Sequential(OrderedDict([
('conv',nn.Conv2d(channel,channel,kernel_size=k,padding=k//2,groups=group)),
('bn',nn.BatchNorm2d(channel)),
('relu',nn.ReLU())
]))
)
self.fc=nn.Linear(channel,self.d)
self.fcs=nn.ModuleList([])
for i in range(len(kernels)):
self.fcs.append(nn.Linear(self.d,channel))
self.softmax=nn.Softmax(dim=0)
def forward(self, x):
bs, c, _, _ = x.size()
conv_outs=[]
### split
for conv in self.convs:
conv_outs.append(conv(x))
feats=torch.stack(conv_outs,0)#k,bs,channel,h,w
### fuse
U=sum(conv_outs) #bs,c,h,w
### reduction channel
S=U.mean(-1).mean(-1) #bs,c
Z=self.fc(S) #bs,d
### calculate attention weight
weights=[]
for fc in self.fcs:
weight=fc(Z)
weights.append(weight.view(bs,c,1,1)) #bs,channel
attention_weughts=torch.stack(weights,0)#k,bs,channel,1,1
attention_weughts=self.softmax(attention_weughts)#k,bs,channel,1,1
### fuse
V=(attention_weughts*feats).sum(0)
return V
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
================================================
FILE: model/attention/SelfAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class ScaledDotProductAttention(nn.Module):
'''
Scaled dot-product attention
'''
def __init__(self, d_model, d_k, d_v, h,dropout=.1):
'''
:param d_model: Output dimensionality of the model
:param d_k: Dimensionality of queries and keys
:param d_v: Dimensionality of values
:param h: Number of heads
'''
super(ScaledDotProductAttention, self).__init__()
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
'''
Computes
:param queries: Queries (b_s, nq, d_model)
:param keys: Keys (b_s, nk, d_model)
:param values: Values (b_s, nk, d_model)
:param attention_mask: Mask over attention values (b_s, h, nq, nk). True indicates masking.
:param attention_weights: Multiplicative weights for attention values (b_s, h, nq, nk).
:return:
'''
b_s, nq = queries.shape[:2]
nk = keys.shape[1]
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, nk)
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att = torch.softmax(att, -1)
att=self.dropout(att)
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
================================================
FILE: model/attention/ShuffleAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn.parameter import Parameter
class ShuffleAttention(nn.Module):
def __init__(self, channel=512,reduction=16,G=8):
super().__init__()
self.G=G
self.channel=channel
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G))
self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1))
self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1))
self.sigmoid=nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
@staticmethod
def channel_shuffle(x, groups):
b, c, h, w = x.shape
x = x.reshape(b, groups, -1, h, w)
x = x.permute(0, 2, 1, 3, 4)
# flatten
x = x.reshape(b, -1, h, w)
return x
def forward(self, x):
b, c, h, w = x.size()
#group into subfeatures
x=x.view(b*self.G,-1,h,w) #bs*G,c//G,h,w
#channel_split
x_0,x_1=x.chunk(2,dim=1) #bs*G,c//(2*G),h,w
#channel attention
x_channel=self.avg_pool(x_0) #bs*G,c//(2*G),1,1
x_channel=self.cweight*x_channel+self.cbias #bs*G,c//(2*G),1,1
x_channel=x_0*self.sigmoid(x_channel)
#spatial attention
x_spatial=self.gn(x_1) #bs*G,c//(2*G),h,w
x_spatial=self.sweight*x_spatial+self.sbias #bs*G,c//(2*G),h,w
x_spatial=x_1*self.sigmoid(x_spatial) #bs*G,c//(2*G),h,w
# concatenate along channel axis
out=torch.cat([x_channel,x_spatial],dim=1) #bs*G,c//G,h,w
out=out.contiguous().view(b,-1,h,w)
# channel shuffle
out = self.channel_shuffle(out, 2)
return out
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
================================================
FILE: model/attention/SimAM.py
================================================
import torch
import torch.nn as nn
class SimAM(torch.nn.Module):
def __init__(self, channels = None, e_lambda = 1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2,3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2,3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = SimAM(64)
outputs = model(input)
print(outputs.shape)
================================================
FILE: model/attention/SimplifiedSelfAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.nn import init
class SimplifiedScaledDotProductAttention(nn.Module):
'''
Scaled dot-product attention
'''
def __init__(self, d_model, h,dropout=.1):
'''
:param d_model: Output dimensionality of the model
:param d_k: Dimensionality of queries and keys
:param d_v: Dimensionality of values
:param h: Number of heads
'''
super(SimplifiedScaledDotProductAttention, self).__init__()
self.d_model = d_model
self.d_k = d_model//h
self.d_v = d_model//h
self.h = h
self.fc_o = nn.Linear(h * self.d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values, attention_mask=None, attention_weights=None):
'''
Computes
:param queries: Queries (b_s, nq, d_model)
:param keys: Keys (b_s, nk, d_model)
:param values: Values (b_s, nk, d_model)
:param attention_mask: Mask over attention values (b_s, h, nq, nk). True indicates masking.
:param attention_weights: Multiplicative weights for attention values (b_s, h, nq, nk).
:return:
'''
b_s, nq = queries.shape[:2]
nk = keys.shape[1]
q = queries.view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = keys.view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = values.view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
att = torch.matmul(q, k) / np.sqrt(self.d_k) # (b_s, h, nq, nk)
if attention_weights is not None:
att = att * attention_weights
if attention_mask is not None:
att = att.masked_fill(attention_mask, -np.inf)
att = torch.softmax(att, -1)
att=self.dropout(att)
out = torch.matmul(att, v).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v) # (b_s, nq, h*d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)
================================================
FILE: model/attention/TripletAttention.py
================================================
import torch
import torch.nn as nn
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True, bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes,eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class ZPool(nn.Module):
def forward(self, x):
return torch.cat( (torch.max(x,1)[0].unsqueeze(1), torch.mean(x,1).unsqueeze(1)), dim=1)
class AttentionGate(nn.Module):
def __init__(self):
super(AttentionGate, self).__init__()
kernel_size = 7
self.compress = ZPool()
self.conv = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size-1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.conv(x_compress)
scale = torch.sigmoid_(x_out)
return x * scale
class TripletAttention(nn.Module):
def __init__(self, no_spatial=False):
super(TripletAttention, self).__init__()
self.cw = AttentionGate()
self.hc = AttentionGate()
self.no_spatial=no_spatial
if not no_spatial:
self.hw = AttentionGate()
def forward(self, x):
x_perm1 = x.permute(0,2,1,3).contiguous()
x_out1 = self.cw(x_perm1)
x_out11 = x_out1.permute(0,2,1,3).contiguous()
x_perm2 = x.permute(0,3,2,1).contiguous()
x_out2 = self.hc(x_perm2)
x_out21 = x_out2.permute(0,3,2,1).contiguous()
if not self.no_spatial:
x_out = self.hw(x)
x_out = 1/3 * (x_out + x_out11 + x_out21)
else:
x_out = 1/2 * (x_out11 + x_out21)
return x_out
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
triplet = TripletAttention()
output=triplet(input)
print(output.shape)
================================================
FILE: model/attention/UFOAttention.py
================================================
import numpy as np
import torch
from torch import nn
from torch.functional import norm
from torch.nn import init
def XNorm(x,gamma):
norm_tensor=torch.norm(x,2,-1,True)
return x*gamma/norm_tensor
class UFOAttention(nn.Module):
'''
Scaled dot-product attention
'''
def __init__(self, d_model, d_k, d_v, h,dropout=.1):
'''
:param d_model: Output dimensionality of the model
:param d_k: Dimensionality of queries and keys
:param d_v: Dimensionality of values
:param h: Number of heads
'''
super(UFOAttention, self).__init__()
self.fc_q = nn.Linear(d_model, h * d_k)
self.fc_k = nn.Linear(d_model, h * d_k)
self.fc_v = nn.Linear(d_model, h * d_v)
self.fc_o = nn.Linear(h * d_v, d_model)
self.dropout=nn.Dropout(dropout)
self.gamma=nn.Parameter(torch.randn((1,h,1,1)))
self.d_model = d_model
self.d_k = d_k
self.d_v = d_v
self.h = h
self.init_weights()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, queries, keys, values):
b_s, nq = queries.shape[:2]
nk = keys.shape[1]
q = self.fc_q(queries).view(b_s, nq, self.h, self.d_k).permute(0, 2, 1, 3) # (b_s, h, nq, d_k)
k = self.fc_k(keys).view(b_s, nk, self.h, self.d_k).permute(0, 2, 3, 1) # (b_s, h, d_k, nk)
v = self.fc_v(values).view(b_s, nk, self.h, self.d_v).permute(0, 2, 1, 3) # (b_s, h, nk, d_v)
kv=torch.matmul(k, v) #bs,h,c,c
kv_norm=XNorm(kv,self.gamma) #bs,h,c,c
q_norm=XNorm(q,self.gamma) #bs,h,n,c
out=torch.matmul(q_norm,kv_norm).permute(0, 2, 1, 3).contiguous().view(b_s, nq, self.h * self.d_v)
out = self.fc_o(out) # (b_s, nq, d_model)
return out
if __name__ == '__main__':
input=torch.randn(50,49,512)
ufo = UFOAttention(d_model=512, d_k=512, d_v=512, h=8)
output=ufo(input,input,input)
print(output.shape)
================================================
FILE: model/attention/ViP.py
================================================
import torch
from torch import nn
class MLP(nn.Module):
def __init__(self,in_features,hidden_features,out_features,act_layer=nn.GELU,drop=0.1):
super().__init__()
self.fc1=nn.Linear(in_features,hidden_features)
self.act=act_layer()
self.fc2=nn.Linear(hidden_features,out_features)
self.drop=nn.Dropout(drop)
def forward(self, x) :
return self.drop(self.fc2(self.drop(self.act(self.fc1(x)))))
class WeightedPermuteMLP(nn.Module):
def __init__(self,dim,seg_dim=8, qkv_bias=False, proj_drop=0.):
super().__init__()
self.seg_dim=seg_dim
self.mlp_c=nn.Linear(dim,dim,bias=qkv_bias)
self.mlp_h=nn.Linear(dim,dim,bias=qkv_bias)
self.mlp_w=nn.Linear(dim,dim,bias=qkv_bias)
self.reweighting=MLP(dim,dim//4,dim*3)
self.proj=nn.Linear(dim,dim)
self.proj_drop=nn.Dropout(proj_drop)
def forward(self,x) :
B,H,W,C=x.shape
c_embed=self.mlp_c(x)
S=C//self.seg_dim
h_embed=x.reshape(B,H,W,self.seg_dim,S).permute(0,3,2,1,4).reshape(B,self.seg_dim,W,H*S)
h_embed=self.mlp_h(h_embed).reshape(B,self.seg_dim,W,H,S).permute(0,3,2,1,4).reshape(B,H,W,C)
w_embed=x.reshape(B,H,W,self.seg_dim,S).permute(0,3,1,2,4).reshape(B,self.seg_dim,H,W*S)
w_embed=self.mlp_w(w_embed).reshape(B,self.seg_dim,H,W,S).permute(0,2,3,1,4).reshape(B,H,W,C)
weight=(c_embed+h_embed+w_embed).permute(0,3,1,2).flatten(2).mean(2)
weight=self.reweighting(weight).reshape(B,C,3).permute(2,0,1).softmax(0).unsqueeze(2).unsqueeze(2)
x=c_embed*weight[0]+w_embed*weight[1]+h_embed*weight[2]
x=self.proj_drop(self.proj(x))
return x
if __name__ == '__main__':
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)
================================================
FILE: model/attention/gfnet.py
================================================
import torch
from torch import nn
import math
from timm.models.layers import DropPath, to_2tuple
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class GlobalFilter(nn.Module):
def __init__(self, dim, h=14, w=8):
super().__init__()
self.complex_weight = nn.Parameter(torch.randn(h, w, dim, 2, dtype=torch.float32) * 0.02)
self.w = w
self.h = h
def forward(self, x, spatial_size=None):
B, N, C = x.shape
if spatial_size is None:
a = b = int(math.sqrt(N))
else:
a, b = spatial_size
x = x.view(B, a, b, C)
x = x.to(torch.float32)
x = torch.fft.rfft2(x, dim=(1, 2), norm='ortho')
weight = torch.view_as_complex(self.complex_weight)
x = x * weight
x = torch.fft.irfft2(x, s=(a, b), dim=(1, 2), norm='ortho')
x = x.reshape(B, N, C)
return x
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, mlp_ratio=4., drop=0., drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, h=14, w=8):
super().__init__()
self.norm1 = norm_layer(dim)
self.filter = GlobalFilter(dim, h=h, w=w)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.mlp(self.norm2(self.filter(self.norm1(x)))))
return x
class GFNet(nn.Module):
def __init__(self, embed_dim=384, img_size=224, patch_size=16, mlp_ratio=4, depth=4, num_classes=1000):
super().__init__()
self.patch_embed = PatchEmbed(img_size=img_size, patch_size=patch_size, embed_dim=embed_dim)
self.embedding = nn.Linear((patch_size ** 2) * 3, embed_dim)
h = img_size // patch_size
w = h // 2 + 1
self.blocks = nn.ModuleList([
Block(dim=embed_dim, mlp_ratio=mlp_ratio, h=h, w=w)
for i in range(depth)
])
self.head = nn.Linear(embed_dim, num_classes)
self.softmax = nn.Softmax(1)
def forward(self, x):
x = self.patch_embed(x)
for blk in self.blocks:
x = blk(x)
x = x.mean(dim=1)
x = self.softmax(self.head(x))
return x
if __name__ == '__main__':
x = torch.randn(1, 3, 224, 224)
gfnet = GFNet(embed_dim=384, img_size=224, patch_size=16, num_classes=1000)
out = gfnet(x)
print(out.shape)
================================================
FILE: model/backbone/CMT.py
================================================
## Author: Jianyuan Guo (jyguo@pku.edu.cn)
import math
import logging
from functools import partial
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.helpers import load_pretrained
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.resnet import resnet26d, resnet50d
from timm.models.registry import register_model
_logger = logging.getLogger(__name__)
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
# A memory-efficient implementation of Swish function
class SwishImplementation(torch.autograd.Function):
@staticmethod
def forward(ctx, i):
result = i * torch.sigmoid(i)
ctx.save_for_backward(i)
return result
@staticmethod
def backward(ctx, grad_output):
i = ctx.saved_tensors[0]
sigmoid_i = torch.sigmoid(i)
return grad_output * (sigmoid_i * (1 + i * (1 - sigmoid_i)))
class MemoryEfficientSwish(nn.Module):
def forward(self, x):
return SwishImplementation.apply(x)
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.conv1 = nn.Sequential(
nn.Conv2d(in_features, hidden_features, 1, 1, 0, bias=True),
nn.GELU(),
nn.BatchNorm2d(hidden_features, eps=1e-5),
)
self.proj = nn.Conv2d(hidden_features, hidden_features, 3, 1, 1, groups=hidden_features)
self.proj_act = nn.GELU()
self.proj_bn = nn.BatchNorm2d(hidden_features, eps=1e-5)
self.conv2 = nn.Sequential(
nn.Conv2d(hidden_features, out_features, 1, 1, 0, bias=True),
nn.BatchNorm2d(out_features, eps=1e-5),
)
self.drop = nn.Dropout(drop)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.permute(0, 2, 1).reshape(B, C, H, W)
x = self.conv1(x)
x = self.drop(x)
x = self.proj(x) + x
x = self.proj_act(x)
x = self.proj_bn(x)
x = self.conv2(x)
x = x.flatten(2).permute(0, 2, 1)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None,
attn_drop=0., proj_drop=0., qk_ratio=1, sr_ratio=1):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qk_dim = dim // qk_ratio
self.q = nn.Linear(dim, self.qk_dim, bias=qkv_bias)
self.k = nn.Linear(dim, self.qk_dim, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
# Exactly same as PVTv1
if self.sr_ratio > 1:
self.sr = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio, groups=dim, bias=True),
nn.BatchNorm2d(dim, eps=1e-5),
)
def forward(self, x, H, W, relative_pos):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, self.qk_dim // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
k = self.k(x_).reshape(B, -1, self.num_heads, self.qk_dim // self.num_heads).permute(0, 2, 1, 3)
v = self.v(x_).reshape(B, -1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
else:
k = self.k(x).reshape(B, N, self.num_heads, self.qk_dim // self.num_heads).permute(0, 2, 1, 3)
v = self.v(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
attn = (q @ k.transpose(-2, -1)) * self.scale + relative_pos
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, qk_ratio=1, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, qk_ratio=qk_ratio, sr_ratio=sr_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.proj = nn.Conv2d(dim, dim, 3, 1, 1, groups=dim)
def forward(self, x, H, W, relative_pos):
B, N, C = x.shape
cnn_feat = x.permute(0, 2, 1).reshape(B, C, H, W)
x = self.proj(cnn_feat) + cnn_feat
x = x.flatten(2).permute(0, 2, 1)
x = x + self.drop_path(self.attn(self.norm1(x), H, W, relative_pos))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
f"img_size {img_size} should be divided by patch_size {patch_size}."
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)
class CMT(nn.Module):
def __init__(self, img_size=224, in_chans=3, num_classes=1000, embed_dims=[46,92,184,368], stem_channel=16, fc_dim=1280,
num_heads=[1,2,4,8], mlp_ratios=[3.6,3.6,3.6,3.6], qkv_bias=True, qk_scale=None, representation_size=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., hybrid_backbone=None, norm_layer=None,
depths=[2,2,10,2], qk_ratio=1, sr_ratios=[8,4,2,1], dp=0.1):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dims[-1]
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
self.stem_conv1 = nn.Conv2d(3, stem_channel, kernel_size=3, stride=2, padding=1, bias=True)
self.stem_relu1 = nn.GELU()
self.stem_norm1 = nn.BatchNorm2d(stem_channel, eps=1e-5)
self.stem_conv2 = nn.Conv2d(stem_channel, stem_channel, kernel_size=3, stride=1, padding=1, bias=True)
self.stem_relu2 = nn.GELU()
self.stem_norm2 = nn.BatchNorm2d(stem_channel, eps=1e-5)
self.stem_conv3 = nn.Conv2d(stem_channel, stem_channel, kernel_size=3, stride=1, padding=1, bias=True)
self.stem_relu3 = nn.GELU()
self.stem_norm3 = nn.BatchNorm2d(stem_channel, eps=1e-5)
self.patch_embed_a = PatchEmbed(
img_size=img_size//2, patch_size=2, in_chans=stem_channel, embed_dim=embed_dims[0])
self.patch_embed_b = PatchEmbed(
img_size=img_size//4, patch_size=2, in_chans=embed_dims[0], embed_dim=embed_dims[1])
self.patch_embed_c = PatchEmbed(
img_size=img_size//8, patch_size=2, in_chans=embed_dims[1], embed_dim=embed_dims[2])
self.patch_embed_d = PatchEmbed(
img_size=img_size//16, patch_size=2, in_chans=embed_dims[2], embed_dim=embed_dims[3])
self.relative_pos_a = nn.Parameter(torch.randn(
num_heads[0], self.patch_embed_a.num_patches, self.patch_embed_a.num_patches//sr_ratios[0]//sr_ratios[0]))
self.relative_pos_b = nn.Parameter(torch.randn(
num_heads[1], self.patch_embed_b.num_patches, self.patch_embed_b.num_patches//sr_ratios[1]//sr_ratios[1]))
self.relative_pos_c = nn.Parameter(torch.randn(
num_heads[2], self.patch_embed_c.num_patches, self.patch_embed_c.num_patches//sr_ratios[2]//sr_ratios[2]))
self.relative_pos_d = nn.Parameter(torch.randn(
num_heads[3], self.patch_embed_d.num_patches, self.patch_embed_d.num_patches//sr_ratios[3]//sr_ratios[3]))
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
self.blocks_a = nn.ModuleList([
Block(
dim=embed_dims[0], num_heads=num_heads[0], mlp_ratio=mlp_ratios[0], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur+i],
norm_layer=norm_layer, qk_ratio=qk_ratio, sr_ratio=sr_ratios[0])
for i in range(depths[0])])
cur += depths[0]
self.blocks_b = nn.ModuleList([
Block(
dim=embed_dims[1], num_heads=num_heads[1], mlp_ratio=mlp_ratios[1], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur+i],
norm_layer=norm_layer, qk_ratio=qk_ratio, sr_ratio=sr_ratios[1])
for i in range(depths[1])])
cur += depths[1]
self.blocks_c = nn.ModuleList([
Block(
dim=embed_dims[2], num_heads=num_heads[2], mlp_ratio=mlp_ratios[2], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur+i],
norm_layer=norm_layer, qk_ratio=qk_ratio, sr_ratio=sr_ratios[2])
for i in range(depths[2])])
cur += depths[2]
self.blocks_d = nn.ModuleList([
Block(
dim=embed_dims[3], num_heads=num_heads[3], mlp_ratio=mlp_ratios[3], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur+i],
norm_layer=norm_layer, qk_ratio=qk_ratio, sr_ratio=sr_ratios[3])
for i in range(depths[3])])
# Representation layer
if representation_size:
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
('fc', nn.Linear(embed_dim, representation_size)),
('act', nn.Tanh())
]))
else:
self.pre_logits = nn.Identity()
# Classifier head
self._fc = nn.Conv2d(embed_dims[-1], fc_dim, kernel_size=1)
self._bn = nn.BatchNorm2d(fc_dim, eps=1e-5)
self._swish = MemoryEfficientSwish()
self._avg_pooling = nn.AdaptiveAvgPool2d(1)
self._drop = nn.Dropout(dp)
self.head = nn.Linear(fc_dim, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if isinstance(m, nn.Conv2d) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def update_temperature(self):
for m in self.modules():
if isinstance(m, Attention):
m.update_temperature()
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x = self.stem_conv1(x)
x = self.stem_relu1(x)
x = self.stem_norm1(x)
x = self.stem_conv2(x)
x = self.stem_relu2(x)
x = self.stem_norm2(x)
x = self.stem_conv3(x)
x = self.stem_relu3(x)
x = self.stem_norm3(x)
x, (H, W) = self.patch_embed_a(x)
for i, blk in enumerate(self.blocks_a):
x = blk(x, H, W, self.relative_pos_a)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x, (H, W) = self.patch_embed_b(x)
for i, blk in enumerate(self.blocks_b):
x = blk(x, H, W, self.relative_pos_b)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x, (H, W) = self.patch_embed_c(x)
for i, blk in enumerate(self.blocks_c):
x = blk(x, H, W, self.relative_pos_c)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x, (H, W) = self.patch_embed_d(x)
for i, blk in enumerate(self.blocks_d):
x = blk(x, H, W, self.relative_pos_d)
B, N, C = x.shape
x = self._fc(x.permute(0, 2, 1).reshape(B, C, H, W))
x = self._bn(x)
x = self._swish(x)
x = self._avg_pooling(x).flatten(start_dim=1)
x = self._drop(x)
x = self.pre_logits(x)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def resize_pos_embed(posemb, posemb_new):
# Rescale the grid of position embeddings when loading from state_dict. Adapted from
# https://github.com/google-research/vision_transformer/blob/00883dd691c63a6830751563748663526e811cee/vit_jax/checkpoint.py#L224
_logger.info('Resized position embedding: %s to %s', posemb.shape, posemb_new.shape)
ntok_new = posemb_new.shape[1]
if True:
posemb_tok, posemb_grid = posemb[:, :1], posemb[0, 1:]
ntok_new -= 1
else:
posemb_tok, posemb_grid = posemb[:, :0], posemb[0]
gs_old = int(math.sqrt(len(posemb_grid)))
gs_new = int(math.sqrt(ntok_new))
_logger.info('Position embedding grid-size from %s to %s', gs_old, gs_new)
posemb_grid = posemb_grid.reshape(1, gs_old, gs_old, -1).permute(0, 3, 1, 2)
posemb_grid = F.interpolate(posemb_grid, size=(gs_new, gs_new), mode='bilinear')
posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, gs_new * gs_new, -1)
posemb = torch.cat([posemb_tok, posemb_grid], dim=1)
return posemb
def checkpoint_filter_fn(state_dict, model):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
if 'model' in state_dict:
# For deit models
state_dict = state_dict['model']
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k and len(v.shape) < 4:
# For old models that I trained prior to conv based patchification
O, I, H, W = model.patch_embed.proj.weight.shape
v = v.reshape(O, -1, H, W)
elif k == 'pos_embed' and v.shape != model.pos_embed.shape:
# To resize pos embedding when using model at different size from pretrained weights
v = resize_pos_embed(v, model.pos_embed)
out_dict[k] = v
return out_dict
def _create_cmt_model(pretrained=False, distilled=False, **kwargs):
default_cfg = _cfg()
default_num_classes = default_cfg['num_classes']
default_img_size = default_cfg['input_size'][-1]
num_classes = kwargs.pop('num_classes', default_num_classes)
img_size = kwargs.pop('img_size', default_img_size)
repr_size = kwargs.pop('representation_size', None)
if repr_size is not None and num_classes != default_num_classes:
# Remove representation layer if fine-tuning. This may not always be the desired action,
# but I feel better than doing nothing by default for fine-tuning. Perhaps a better interface?
_logger.warning("Removing representation layer for fine-tuning.")
repr_size = None
model = CMT(img_size=img_size, num_classes=num_classes, representation_size=repr_size, **kwargs)
model.default_cfg = default_cfg
if pretrained:
load_pretrained(
model, num_classes=num_classes, in_chans=kwargs.get('in_chans', 3),
filter_fn=partial(checkpoint_filter_fn, model=model))
return model
@register_model
def cmt_ti(pretrained=False, **kwargs):
"""
CMT-Tiny
"""
model_kwargs = dict(qkv_bias=True, **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
@register_model
def cmt_xs(pretrained=False, **kwargs):
"""
CMT-XS: dim x 0.9, depth x 0.8, input 192
"""
model_kwargs = dict(
qkv_bias=True, embed_dims=[52,104,208,416], stem_channel=16, num_heads=[1,2,4,8],
depths=[3,3,12,3], mlp_ratios=[3.77,3.77,3.77,3.77], qk_ratio=1, sr_ratios=[8,4,2,1], **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
@register_model
def cmt_s(pretrained=False, **kwargs):
"""
CMT-Small
"""
model_kwargs = dict(
qkv_bias=True, embed_dims=[64,128,256,512], stem_channel=32, num_heads=[1,2,4,8],
depths=[3,3,16,3], mlp_ratios=[4,4,4,4], qk_ratio=1, sr_ratios=[8,4,2,1], **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
@register_model
def cmt_b(pretrained=False, **kwargs):
"""
CMT-Base
"""
model_kwargs = dict(
qkv_bias=True, embed_dims=[76,152,304,608], stem_channel=38, num_heads=[1,2,4,8],
depths=[4,4,20,4], mlp_ratios=[4,4,4,4], qk_ratio=1, sr_ratios=[8,4,2,1], dp=0.3, **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
@register_model
def CMT_Tiny(pretrained=False, **kwargs):
"""
CMT-Tiny
"""
model_kwargs = dict(qkv_bias=True, **kwargs)
model = _create_cmt_model(pretrained=pretrained, **model_kwargs)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CMT_Tiny()
output=model(input)
print(output[0].shape)
================================================
FILE: model/backbone/CPVT.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
from timm.models.vision_transformer import Block as TimmBlock
from timm.models.vision_transformer import Attention as TimmAttention
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class GroupAttention(nn.Module):
"""
LSA: self attention within a group
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., ws=1):
assert ws != 1
super(GroupAttention, self).__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.ws = ws
def forward(self, x, H, W):
B, N, C = x.shape
h_group, w_group = H // self.ws, W // self.ws
total_groups = h_group * w_group
x = x.reshape(B, h_group, self.ws, w_group, self.ws, C).transpose(2, 3)
qkv = self.qkv(x).reshape(B, total_groups, -1, 3, self.num_heads, C // self.num_heads).permute(3, 0, 1, 4, 2, 5)
# B, hw, ws*ws, 3, n_head, head_dim -> 3, B, hw, n_head, ws*ws, head_dim
q, k, v = qkv[0], qkv[1], qkv[2] # B, hw, n_head, ws*ws, head_dim
attn = (q @ k.transpose(-2, -1)) * self.scale # B, hw, n_head, ws*ws, ws*ws
attn = attn.softmax(dim=-1)
attn = self.attn_drop(
attn) # attn @ v-> B, hw, n_head, ws*ws, head_dim -> (t(2,3)) B, hw, ws*ws, n_head, head_dim
attn = (attn @ v).transpose(2, 3).reshape(B, h_group, w_group, self.ws, self.ws, C)
x = attn.transpose(2, 3).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Attention(nn.Module):
"""
GSA: using a key to summarize the information for a group to be efficient.
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class SBlock(TimmBlock):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super(SBlock, self).__init__(dim, num_heads, mlp_ratio, qkv_bias, qk_scale, drop, attn_drop,
drop_path, act_layer, norm_layer)
def forward(self, x, H, W):
return super(SBlock, self).forward(x)
class GroupBlock(TimmBlock):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1, ws=1):
super(GroupBlock, self).__init__(dim, num_heads, mlp_ratio, qkv_bias, qk_scale, drop, attn_drop,
drop_path, act_layer, norm_layer)
del self.attn
if ws == 1:
self.attn = Attention(dim, num_heads, qkv_bias, qk_scale, attn_drop, drop, sr_ratio)
else:
self.attn = GroupAttention(dim, num_heads, qkv_bias, qk_scale, attn_drop, drop, ws)
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
f"img_size {img_size} should be divided by patch_size {patch_size}."
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)
# borrow from PVT https://github.com/whai362/PVT.git
class PyramidVisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], block_cls=Block):
super().__init__()
self.num_classes = num_classes
self.depths = depths
# patch_embed
self.patch_embeds = nn.ModuleList()
self.pos_embeds = nn.ParameterList()
self.pos_drops = nn.ModuleList()
self.blocks = nn.ModuleList()
for i in range(len(depths)):
if i == 0:
self.patch_embeds.append(PatchEmbed(img_size, patch_size, in_chans, embed_dims[i]))
else:
self.patch_embeds.append(
PatchEmbed(img_size // patch_size // 2 ** (i - 1), 2, embed_dims[i - 1], embed_dims[i]))
patch_num = self.patch_embeds[-1].num_patches + 1 if i == len(embed_dims) - 1 else self.patch_embeds[
-1].num_patches
self.pos_embeds.append(nn.Parameter(torch.zeros(1, patch_num, embed_dims[i])))
self.pos_drops.append(nn.Dropout(p=drop_rate))
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for k in range(len(depths)):
_block = nn.ModuleList([block_cls(
dim=embed_dims[k], num_heads=num_heads[k], mlp_ratio=mlp_ratios[k], qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[k])
for i in range(depths[k])])
self.blocks.append(_block)
cur += depths[k]
self.norm = norm_layer(embed_dims[-1])
# cls_token
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dims[-1]))
# classification head
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
# init weights
for pos_emb in self.pos_embeds:
trunc_normal_(pos_emb, std=.02)
self.apply(self._init_weights)
def reset_drop_path(self, drop_path_rate):
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(self.depths))]
cur = 0
for k in range(len(self.depths)):
for i in range(self.depths[k]):
self.blocks[k][i].drop_path.drop_prob = dpr[cur + i]
cur += self.depths[k]
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
for i in range(len(self.depths)):
x, (H, W) = self.patch_embeds[i](x)
if i == len(self.depths) - 1:
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embeds[i]
x = self.pos_drops[i](x)
for blk in self.blocks[i]:
x = blk(x, H, W)
if i < len(self.depths) - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
# PEG from https://arxiv.org/abs/2102.10882
class PosCNN(nn.Module):
def __init__(self, in_chans, embed_dim=768, s=1):
super(PosCNN, self).__init__()
self.proj = nn.Sequential(nn.Conv2d(in_chans, embed_dim, 3, s, 1, bias=True, groups=embed_dim), )
self.s = s
def forward(self, x, H, W):
B, N, C = x.shape
feat_token = x
cnn_feat = feat_token.transpose(1, 2).view(B, C, H, W)
if self.s == 1:
x = self.proj(cnn_feat) + cnn_feat
else:
x = self.proj(cnn_feat)
x = x.flatten(2).transpose(1, 2)
return x
def no_weight_decay(self):
return ['proj.%d.weight' % i for i in range(4)]
class CPVTV2(PyramidVisionTransformer):
"""
Use useful results from CPVT. PEG and GAP.
Therefore, cls token is no longer required.
PEG is used to encode the absolute position on the fly, which greatly affects the performance when input resolution
changes during the training (such as segmentation, detection)
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], block_cls=Block):
super(CPVTV2, self).__init__(img_size, patch_size, in_chans, num_classes, embed_dims, num_heads, mlp_ratios,
qkv_bias, qk_scale, drop_rate, attn_drop_rate, drop_path_rate, norm_layer, depths,
sr_ratios, block_cls)
del self.pos_embeds
del self.cls_token
self.pos_block = nn.ModuleList(
[PosCNN(embed_dim, embed_dim) for embed_dim in embed_dims]
)
self.apply(self._init_weights)
def _init_weights(self, m):
import math
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1.0)
m.bias.data.zero_()
def no_weight_decay(self):
return set(['cls_token'] + ['pos_block.' + n for n, p in self.pos_block.named_parameters()])
def forward_features(self, x):
B = x.shape[0]
for i in range(len(self.depths)):
x, (H, W) = self.patch_embeds[i](x)
x = self.pos_drops[i](x)
for j, blk in enumerate(self.blocks[i]):
x = blk(x, H, W)
if j == 0:
x = self.pos_block[i](x, H, W) # PEG here
if i < len(self.depths) - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x = self.norm(x)
return x.mean(dim=1) # GAP here
class PCPVT(CPVTV2):
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256],
num_heads=[1, 2, 4], mlp_ratios=[4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[4, 4, 4], sr_ratios=[4, 2, 1], block_cls=SBlock):
super(PCPVT, self).__init__(img_size, patch_size, in_chans, num_classes, embed_dims, num_heads,
mlp_ratios, qkv_bias, qk_scale, drop_rate, attn_drop_rate, drop_path_rate,
norm_layer, depths, sr_ratios, block_cls)
class ALTGVT(PCPVT):
"""
alias Twins-SVT
"""
def __init__(self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256],
num_heads=[1, 2, 4], mlp_ratios=[4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[4, 4, 4], sr_ratios=[4, 2, 1], block_cls=GroupBlock, wss=[7, 7, 7]):
super(ALTGVT, self).__init__(img_size, patch_size, in_chans, num_classes, embed_dims, num_heads,
mlp_ratios, qkv_bias, qk_scale, drop_rate, attn_drop_rate, drop_path_rate,
norm_layer, depths, sr_ratios, block_cls)
del self.blocks
self.wss = wss
# transformer encoder
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
self.blocks = nn.ModuleList()
for k in range(len(depths)):
_block = nn.ModuleList([block_cls(
dim=embed_dims[k], num_heads=num_heads[k], mlp_ratio=mlp_ratios[k], qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[k], ws=1 if i % 2 == 1 else wss[k]) for i in range(depths[k])])
self.blocks.append(_block)
cur += depths[k]
self.apply(self._init_weights)
def _conv_filter(state_dict, patch_size=16):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k:
v = v.reshape((v.shape[0], 3, patch_size, patch_size))
out_dict[k] = v
return out_dict
@register_model
def pcpvt_small_v0(pretrained=False, **kwargs):
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pcpvt_base_v0(pretrained=False, **kwargs):
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 18, 3], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pcpvt_large_v0(pretrained=False, **kwargs):
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 8, 27, 3], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/CaiT.py
================================================
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
import torch
import torch.nn as nn
from functools import partial
from timm.models.vision_transformer import Mlp, PatchEmbed , _cfg
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_, DropPath
__all__ = [
'cait_M48', 'cait_M36',
'cait_S36', 'cait_S24','cait_S24_224',
'cait_XS24','cait_XXS24','cait_XXS24_224',
'cait_XXS36','cait_XXS36_224'
]
class Class_Attention(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to do CA
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.k = nn.Linear(dim, dim, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x ):
B, N, C = x.shape
q = self.q(x[:,0]).unsqueeze(1).reshape(B, 1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
k = self.k(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
q = q * self.scale
v = self.v(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
attn = (q @ k.transpose(-2, -1))
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x_cls = (attn @ v).transpose(1, 2).reshape(B, 1, C)
x_cls = self.proj(x_cls)
x_cls = self.proj_drop(x_cls)
return x_cls
class LayerScale_Block_CA(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to add CA and LayerScale
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, Attention_block = Class_Attention,
Mlp_block=Mlp,init_values=1e-4):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention_block(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp_block(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)),requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)),requires_grad=True)
def forward(self, x, x_cls):
u = torch.cat((x_cls,x),dim=1)
x_cls = x_cls + self.drop_path(self.gamma_1 * self.attn(self.norm1(u)))
x_cls = x_cls + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x_cls)))
return x_cls
class Attention_talking_head(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to add Talking Heads Attention (https://arxiv.org/pdf/2003.02436v1.pdf)
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_l = nn.Linear(num_heads, num_heads)
self.proj_w = nn.Linear(num_heads, num_heads)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0] * self.scale , qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1))
attn = self.proj_l(attn.permute(0,2,3,1)).permute(0,3,1,2)
attn = attn.softmax(dim=-1)
attn = self.proj_w(attn.permute(0,2,3,1)).permute(0,3,1,2)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class LayerScale_Block(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to add layerScale
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,Attention_block = Attention_talking_head,
Mlp_block=Mlp,init_values=1e-4):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention_block(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp_block(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)),requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)),requires_grad=True)
def forward(self, x):
x = x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x)))
x = x + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x)))
return x
class CaiT(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to adapt to our cait models
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., norm_layer=nn.LayerNorm, global_pool=None,
block_layers = LayerScale_Block,
block_layers_token = LayerScale_Block_CA,
Patch_layer=PatchEmbed,act_layer=nn.GELU,
Attention_block = Attention_talking_head,Mlp_block=Mlp,
init_scale=1e-4,
Attention_block_token_only=Class_Attention,
Mlp_block_token_only= Mlp,
depth_token_only=2,
mlp_ratio_clstk = 4.0):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.patch_embed = Patch_layer(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [drop_path_rate for i in range(depth)]
self.blocks = nn.ModuleList([
block_layers(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
act_layer=act_layer,Attention_block=Attention_block,Mlp_block=Mlp_block,init_values=init_scale)
for i in range(depth)])
self.blocks_token_only = nn.ModuleList([
block_layers_token(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio_clstk, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=0.0, attn_drop=0.0, drop_path=0.0, norm_layer=norm_layer,
act_layer=act_layer,Attention_block=Attention_block_token_only,
Mlp_block=Mlp_block_token_only,init_values=init_scale)
for i in range(depth_token_only)])
self.norm = norm_layer(embed_dim)
self.feature_info = [dict(num_chs=embed_dim, reduction=0, module='head')]
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1)
x = x + self.pos_embed
x = self.pos_drop(x)
for i , blk in enumerate(self.blocks):
x = blk(x)
for i , blk in enumerate(self.blocks_token_only):
cls_tokens = blk(x,cls_tokens)
x = torch.cat((cls_tokens, x), dim=1)
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
@register_model
def cait_XXS24_224(pretrained=False, **kwargs):
model = CaiT(
img_size= 224,patch_size=16, embed_dim=192, depth=24, num_heads=4, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/XXS24_224.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_XXS24(pretrained=False, **kwargs):
model = CaiT(
img_size= 384,patch_size=16, embed_dim=192, depth=24, num_heads=4, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/XXS24_384.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_XXS36_224(pretrained=False, **kwargs):
model = CaiT(
img_size= 224,patch_size=16, embed_dim=192, depth=36, num_heads=4, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/XXS36_224.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_XXS36(pretrained=False, **kwargs):
model = CaiT(
img_size= 384,patch_size=16, embed_dim=192, depth=36, num_heads=4, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/XXS36_384.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_XS24(pretrained=False, **kwargs):
model = CaiT(
img_size= 384,patch_size=16, embed_dim=288, depth=24, num_heads=6, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/XS24_384.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_S24_224(pretrained=False, **kwargs):
model = CaiT(
img_size= 224,patch_size=16, embed_dim=384, depth=24, num_heads=8, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/S24_224.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_S24(pretrained=False, **kwargs):
model = CaiT(
img_size= 384,patch_size=16, embed_dim=384, depth=24, num_heads=8, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/S24_384.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_S36(pretrained=False, **kwargs):
model = CaiT(
img_size= 384,patch_size=16, embed_dim=384, depth=36, num_heads=8, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-6,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/S36_384.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_M36(pretrained=False, **kwargs):
model = CaiT(
img_size= 384, patch_size=16, embed_dim=768, depth=36, num_heads=16, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-6,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/M36_384.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
@register_model
def cait_M48(pretrained=False, **kwargs):
model = CaiT(
img_size= 448 , patch_size=16, embed_dim=768, depth=48, num_heads=16, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-6,
depth_token_only=2,**kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/M48_448.pth",
map_location="cpu", check_hash=True
)
checkpoint_no_module = {}
for k in model.state_dict().keys():
checkpoint_no_module[k] = checkpoint["model"]['module.'+k]
model.load_state_dict(checkpoint_no_module)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CaiT(
img_size= 224,
patch_size=16,
embed_dim=192,
depth=24,
num_heads=4,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/CeiT.py
================================================
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import default_cfgs, _cfg
__all__ = [
'ceit_tiny_patch16_224', 'ceit_small_patch16_224', 'ceit_base_patch16_224',
'ceit_tiny_patch16_384', 'ceit_small_patch16_384',
]
class Image2Tokens(nn.Module):
def __init__(self, in_chans=3, out_chans=64, kernel_size=7, stride=2):
super(Image2Tokens, self).__init__()
self.conv = nn.Conv2d(in_chans, out_chans, kernel_size=kernel_size, stride=stride,
padding=kernel_size // 2, bias=False)
self.bn = nn.BatchNorm2d(out_chans)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.maxpool(x)
return x
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class LocallyEnhancedFeedForward(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.,
kernel_size=3, with_bn=True):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
# pointwise
self.conv1 = nn.Conv2d(in_features, hidden_features, kernel_size=1, stride=1, padding=0)
# depthwise
self.conv2 = nn.Conv2d(
hidden_features, hidden_features, kernel_size=kernel_size, stride=1,
padding=(kernel_size - 1) // 2, groups=hidden_features
)
# pointwise
self.conv3 = nn.Conv2d(hidden_features, out_features, kernel_size=1, stride=1, padding=0)
self.act = act_layer()
# self.drop = nn.Dropout(drop)
self.with_bn = with_bn
if self.with_bn:
self.bn1 = nn.BatchNorm2d(hidden_features)
self.bn2 = nn.BatchNorm2d(hidden_features)
self.bn3 = nn.BatchNorm2d(out_features)
def forward(self, x):
b, n, k = x.size()
cls_token, tokens = torch.split(x, [1, n - 1], dim=1)
x = tokens.reshape(b, int(math.sqrt(n - 1)), int(math.sqrt(n - 1)), k).permute(0, 3, 1, 2)
if self.with_bn:
x = self.conv1(x)
x = self.bn1(x)
x = self.act(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.act(x)
x = self.conv3(x)
x = self.bn3(x)
else:
x = self.conv1(x)
x = self.act(x)
x = self.conv2(x)
x = self.act(x)
x = self.conv3(x)
tokens = x.flatten(2).permute(0, 2, 1)
out = torch.cat((cls_token, tokens), dim=1)
return out
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.attention_map = None
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# self.attention_map = attn
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class AttentionLCA(Attention):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super(AttentionLCA, self).__init__(dim, num_heads, qkv_bias, qk_scale, attn_drop, proj_drop)
self.dim = dim
self.qkv_bias = qkv_bias
def forward(self, x):
q_weight = self.qkv.weight[:self.dim, :]
q_bias = None if not self.qkv_bias else self.qkv.bias[:self.dim]
kv_weight = self.qkv.weight[self.dim:, :]
kv_bias = None if not self.qkv_bias else self.qkv.bias[self.dim:]
B, N, C = x.shape
_, last_token = torch.split(x, [N-1, 1], dim=1)
q = F.linear(last_token, q_weight, q_bias)\
.reshape(B, 1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
kv = F.linear(x, kv_weight, kv_bias)\
.reshape(B, N, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
# self.attention_map = attn
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, 1, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, kernel_size=3, with_bn=True,
feedforward_type='leff'):
super().__init__()
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.norm1 = norm_layer(dim)
self.feedforward_type = feedforward_type
if feedforward_type == 'leff':
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.leff = LocallyEnhancedFeedForward(
in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop,
kernel_size=kernel_size, with_bn=with_bn,
)
else: # LCA
self.attn = AttentionLCA(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.feedforward = Mlp(
in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop
)
def forward(self, x):
if self.feedforward_type == 'leff':
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.leff(self.norm2(x)))
return x, x[:, 0]
else: # LCA
_, last_token = torch.split(x, [x.size(1)-1, 1], dim=1)
x = last_token + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.feedforward(self.norm2(x)))
return x
class HybridEmbed(nn.Module):
""" CNN Feature Map Embedding
Extract feature map from CNN, flatten, project to embedding dim.
"""
def __init__(self, backbone, img_size=224, patch_size=16, feature_size=None, in_chans=3, embed_dim=768):
super().__init__()
assert isinstance(backbone, nn.Module)
img_size = to_2tuple(img_size)
self.img_size = img_size
self.backbone = backbone
if feature_size is None:
with torch.no_grad():
# FIXME this is hacky, but most reliable way of determining the exact dim of the output feature
# map for all networks, the feature metadata has reliable channel and stride info, but using
# stride to calc feature dim requires info about padding of each stage that isn't captured.
training = backbone.training
if training:
backbone.eval()
o = self.backbone(torch.zeros(1, in_chans, img_size[0], img_size[1]))
if isinstance(o, (list, tuple)):
o = o[-1] # last feature if backbone outputs list/tuple of features
feature_size = o.shape[-2:]
feature_dim = o.shape[1]
backbone.train(training)
else:
feature_size = to_2tuple(feature_size)
feature_dim = self.backbone.feature_info.channels()[-1]
print('feature_size is {}, feature_dim is {}, patch_size is {}'.format(
feature_size, feature_dim, patch_size
))
self.num_patches = (feature_size[0] // patch_size) * (feature_size[1] // patch_size)
self.proj = nn.Conv2d(feature_dim, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.backbone(x)
if isinstance(x, (list, tuple)):
x = x[-1] # last feature if backbone outputs list/tuple of features
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class CeIT(nn.Module):
def __init__(self,
img_size=224,
patch_size=16,
in_chans=3,
num_classes=1000,
embed_dim=768,
depth=12,
num_heads=12,
mlp_ratio=4.,
qkv_bias=False,
qk_scale=None,
drop_rate=0.,
attn_drop_rate=0.,
drop_path_rate=0.,
hybrid_backbone=None,
norm_layer=nn.LayerNorm,
leff_local_size=3,
leff_with_bn=True):
"""
args:
- img_size (:obj:`int`): input image size
- patch_size (:obj:`int`): patch size
- in_chans (:obj:`int`): input channels
- num_classes (:obj:`int`): number of classes
- embed_dim (:obj:`int`): embedding dimensions for tokens
- depth (:obj:`int`): depth of encoder
- num_heads (:obj:`int`): number of heads in multi-head self-attention
- mlp_ratio (:obj:`float`): expand ratio in feedforward
- qkv_bias (:obj:`bool`): whether to add bias for mlp of qkv
- qk_scale (:obj:`float`): scale ratio for qk, default is head_dim ** -0.5
- drop_rate (:obj:`float`): dropout rate in feedforward module after linear operation
and projection drop rate in attention
- attn_drop_rate (:obj:`float`): dropout rate for attention
- drop_path_rate (:obj:`float`): drop_path rate after attention
- hybrid_backbone (:obj:`nn.Module`): backbone e.g. resnet
- norm_layer (:obj:`nn.Module`): normalization type
- leff_local_size (:obj:`int`): kernel size in LocallyEnhancedFeedForward
- leff_with_bn (:obj:`bool`): whether add bn in LocallyEnhancedFeedForward
"""
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.i2t = HybridEmbed(
hybrid_backbone, img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.i2t.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
kernel_size=leff_local_size, with_bn=leff_with_bn)
for i in range(depth)])
# without droppath
self.lca = Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=0., norm_layer=norm_layer,
feedforward_type = 'lca'
)
self.pos_layer_embed = nn.Parameter(torch.zeros(1, depth, embed_dim))
self.norm = norm_layer(embed_dim)
# NOTE as per official impl, we could have a pre-logits representation dense layer + tanh here
# self.repr = nn.Linear(embed_dim, representation_size)
# self.repr_act = nn.Tanh()
# Classifier head
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x = self.i2t(x)
cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
cls_token_list = []
for blk in self.blocks:
x, curr_cls_token = blk(x)
cls_token_list.append(curr_cls_token)
all_cls_token = torch.stack(cls_token_list, dim=1) # B*D*K
all_cls_token = all_cls_token + self.pos_layer_embed
# attention over cls tokens
last_cls_token = self.lca(all_cls_token)
last_cls_token = self.norm(last_cls_token)
return last_cls_token.view(B, -1)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
@register_model
def ceit_tiny_patch16_224(pretrained=False, **kwargs):
"""
convolutional + pooling stem
local enhanced feedforward
attention over cls_tokens
"""
i2t = Image2Tokens()
model = CeIT(
hybrid_backbone=i2t,
patch_size=4, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
return model
@register_model
def ceit_small_patch16_224(pretrained=False, **kwargs):
"""
convolutional + pooling stem
local enhanced feedforward
attention over cls_tokens
"""
i2t = Image2Tokens()
model = CeIT(
hybrid_backbone=i2t,
patch_size=4, embed_dim=384, depth=12, num_heads=6, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
return model
@register_model
def ceit_base_patch16_224(pretrained=False, **kwargs):
"""
convolutional + pooling stem
local enhanced feedforward
attention over cls_tokens
"""
i2t = Image2Tokens()
model = CeIT(
hybrid_backbone=i2t,
patch_size=4, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
return model
@register_model
def ceit_tiny_patch16_384(pretrained=False, **kwargs):
"""
convolutional + pooling stem
local enhanced feedforward
attention over cls_tokens
"""
i2t = Image2Tokens()
model = CeIT(
hybrid_backbone=i2t, img_size=384,
patch_size=4, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
return model
@register_model
def ceit_small_patch16_384(pretrained=False, **kwargs):
"""
convolutional + pooling stem
local enhanced feedforward
attention over cls_tokens
"""
i2t = Image2Tokens()
model = CeIT(
hybrid_backbone=i2t, img_size=384,
patch_size=4, embed_dim=384, depth=12, num_heads=6, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CeIT(
hybrid_backbone=Image2Tokens(),
patch_size=4,
embed_dim=192,
depth=12,
num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/CoaT.py
================================================
"""
CoaT architecture.
Modified from timm/models/vision_transformer.py
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from einops import rearrange
from functools import partial
from torch import nn, einsum
__all__ = [
"coat_tiny",
"coat_mini",
"coat_small",
"coat_lite_tiny",
"coat_lite_mini",
"coat_lite_small"
]
def _cfg_coat(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
class Mlp(nn.Module):
""" Feed-forward network (FFN, a.k.a. MLP) class. """
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class ConvRelPosEnc(nn.Module):
""" Convolutional relative position encoding. """
def __init__(self, Ch, h, window):
"""
Initialization.
Ch: Channels per head.
h: Number of heads.
window: Window size(s) in convolutional relative positional encoding. It can have two forms:
1. An integer of window size, which assigns all attention heads with the same window size in ConvRelPosEnc.
2. A dict mapping window size to #attention head splits (e.g. {window size 1: #attention head split 1, window size 2: #attention head split 2})
It will apply different window size to the attention head splits.
"""
super().__init__()
if isinstance(window, int):
window = {window: h} # Set the same window size for all attention heads.
self.window = window
elif isinstance(window, dict):
self.window = window
else:
raise ValueError()
self.conv_list = nn.ModuleList()
self.head_splits = []
for cur_window, cur_head_split in window.items():
dilation = 1 # Use dilation=1 at default.
padding_size = (cur_window + (cur_window - 1) * (dilation - 1)) // 2 # Determine padding size. Ref: https://discuss.pytorch.org/t/how-to-keep-the-shape-of-input-and-output-same-when-dilation-conv/14338
cur_conv = nn.Conv2d(cur_head_split*Ch, cur_head_split*Ch,
kernel_size=(cur_window, cur_window),
padding=(padding_size, padding_size),
dilation=(dilation, dilation),
groups=cur_head_split*Ch,
)
self.conv_list.append(cur_conv)
self.head_splits.append(cur_head_split)
self.channel_splits = [x*Ch for x in self.head_splits]
def forward(self, q, v, size):
B, h, N, Ch = q.shape
H, W = size
assert N == 1 + H * W
# Convolutional relative position encoding.
q_img = q[:,:,1:,:] # Shape: [B, h, H*W, Ch].
v_img = v[:,:,1:,:] # Shape: [B, h, H*W, Ch].
v_img = rearrange(v_img, 'B h (H W) Ch -> B (h Ch) H W', H=H, W=W) # Shape: [B, h, H*W, Ch] -> [B, h*Ch, H, W].
v_img_list = torch.split(v_img, self.channel_splits, dim=1) # Split according to channels.
conv_v_img_list = [conv(x) for conv, x in zip(self.conv_list, v_img_list)]
conv_v_img = torch.cat(conv_v_img_list, dim=1)
conv_v_img = rearrange(conv_v_img, 'B (h Ch) H W -> B h (H W) Ch', h=h) # Shape: [B, h*Ch, H, W] -> [B, h, H*W, Ch].
EV_hat_img = q_img * conv_v_img
zero = torch.zeros((B, h, 1, Ch), dtype=q.dtype, layout=q.layout, device=q.device)
EV_hat = torch.cat((zero, EV_hat_img), dim=2) # Shape: [B, h, N, Ch].
return EV_hat
class FactorAtt_ConvRelPosEnc(nn.Module):
""" Factorized attention with convolutional relative position encoding class. """
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., shared_crpe=None):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop) # Note: attn_drop is actually not used.
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
# Shared convolutional relative position encoding.
self.crpe = shared_crpe
def forward(self, x, size):
B, N, C = x.shape
# Generate Q, K, V.
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4) # Shape: [3, B, h, N, Ch].
q, k, v = qkv[0], qkv[1], qkv[2] # Shape: [B, h, N, Ch].
# Factorized attention.
k_softmax = k.softmax(dim=2) # Softmax on dim N.
k_softmax_T_dot_v = einsum('b h n k, b h n v -> b h k v', k_softmax, v) # Shape: [B, h, Ch, Ch].
factor_att = einsum('b h n k, b h k v -> b h n v', q, k_softmax_T_dot_v) # Shape: [B, h, N, Ch].
# Convolutional relative position encoding.
crpe = self.crpe(q, v, size=size) # Shape: [B, h, N, Ch].
# Merge and reshape.
x = self.scale * factor_att + crpe
x = x.transpose(1, 2).reshape(B, N, C) # Shape: [B, h, N, Ch] -> [B, N, h, Ch] -> [B, N, C].
# Output projection.
x = self.proj(x)
x = self.proj_drop(x)
return x # Shape: [B, N, C].
class ConvPosEnc(nn.Module):
""" Convolutional Position Encoding.
Note: This module is similar to the conditional position encoding in CPVT.
"""
def __init__(self, dim, k=3):
super(ConvPosEnc, self).__init__()
self.proj = nn.Conv2d(dim, dim, k, 1, k//2, groups=dim)
def forward(self, x, size):
B, N, C = x.shape
H, W = size
assert N == 1 + H * W
# Extract CLS token and image tokens.
cls_token, img_tokens = x[:, :1], x[:, 1:] # Shape: [B, 1, C], [B, H*W, C].
# Depthwise convolution.
feat = img_tokens.transpose(1, 2).view(B, C, H, W)
x = self.proj(feat) + feat
x = x.flatten(2).transpose(1, 2)
# Combine with CLS token.
x = torch.cat((cls_token, x), dim=1)
return x
class SerialBlock(nn.Module):
""" Serial block class.
Note: In this implementation, each serial block only contains a conv-attention and a FFN (MLP) module. """
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,
shared_cpe=None, shared_crpe=None):
super().__init__()
# Conv-Attention.
self.cpe = shared_cpe
self.norm1 = norm_layer(dim)
self.factoratt_crpe = FactorAtt_ConvRelPosEnc(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpe)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
# MLP.
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, size):
# Conv-Attention.
x = self.cpe(x, size) # Apply convolutional position encoding.
cur = self.norm1(x)
cur = self.factoratt_crpe(cur, size) # Apply factorized attention and convolutional relative position encoding.
x = x + self.drop_path(cur)
# MLP.
cur = self.norm2(x)
cur = self.mlp(cur)
x = x + self.drop_path(cur)
return x
class ParallelBlock(nn.Module):
""" Parallel block class. """
def __init__(self, dims, num_heads, mlp_ratios=[], qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm,
shared_cpes=None, shared_crpes=None):
super().__init__()
# Conv-Attention.
self.cpes = shared_cpes
self.norm12 = norm_layer(dims[1])
self.norm13 = norm_layer(dims[2])
self.norm14 = norm_layer(dims[3])
self.factoratt_crpe2 = FactorAtt_ConvRelPosEnc(
dims[1], num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[1]
)
self.factoratt_crpe3 = FactorAtt_ConvRelPosEnc(
dims[2], num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[2]
)
self.factoratt_crpe4 = FactorAtt_ConvRelPosEnc(
dims[3], num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
shared_crpe=shared_crpes[3]
)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
# MLP.
self.norm22 = norm_layer(dims[1])
self.norm23 = norm_layer(dims[2])
self.norm24 = norm_layer(dims[3])
assert dims[1] == dims[2] == dims[3] # In parallel block, we assume dimensions are the same and share the linear transformation.
assert mlp_ratios[1] == mlp_ratios[2] == mlp_ratios[3]
mlp_hidden_dim = int(dims[1] * mlp_ratios[1])
self.mlp2 = self.mlp3 = self.mlp4 = Mlp(in_features=dims[1], hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def upsample(self, x, output_size, size):
""" Feature map up-sampling. """
return self.interpolate(x, output_size=output_size, size=size)
def downsample(self, x, output_size, size):
""" Feature map down-sampling. """
return self.interpolate(x, output_size=output_size, size=size)
def interpolate(self, x, output_size, size):
""" Feature map interpolation. """
B, N, C = x.shape
H, W = size
assert N == 1 + H * W
cls_token = x[:, :1, :]
img_tokens = x[:, 1:, :]
img_tokens = img_tokens.transpose(1, 2).reshape(B, C, H, W)
img_tokens = F.interpolate(img_tokens, size=output_size, mode='bilinear') # FIXME: May have alignment issue.
img_tokens = img_tokens.reshape(B, C, -1).transpose(1, 2)
out = torch.cat((cls_token, img_tokens), dim=1)
return out
def forward(self, x1, x2, x3, x4, sizes):
_, (H2, W2), (H3, W3), (H4, W4) = sizes
# Conv-Attention.
x2 = self.cpes[1](x2, size=(H2, W2)) # Note: x1 is ignored.
x3 = self.cpes[2](x3, size=(H3, W3))
x4 = self.cpes[3](x4, size=(H4, W4))
cur2 = self.norm12(x2)
cur3 = self.norm13(x3)
cur4 = self.norm14(x4)
cur2 = self.factoratt_crpe2(cur2, size=(H2,W2))
cur3 = self.factoratt_crpe3(cur3, size=(H3,W3))
cur4 = self.factoratt_crpe4(cur4, size=(H4,W4))
upsample3_2 = self.upsample(cur3, output_size=(H2,W2), size=(H3,W3))
upsample4_3 = self.upsample(cur4, output_size=(H3,W3), size=(H4,W4))
upsample4_2 = self.upsample(cur4, output_size=(H2,W2), size=(H4,W4))
downsample2_3 = self.downsample(cur2, output_size=(H3,W3), size=(H2,W2))
downsample3_4 = self.downsample(cur3, output_size=(H4,W4), size=(H3,W3))
downsample2_4 = self.downsample(cur2, output_size=(H4,W4), size=(H2,W2))
cur2 = cur2 + upsample3_2 + upsample4_2
cur3 = cur3 + upsample4_3 + downsample2_3
cur4 = cur4 + downsample3_4 + downsample2_4
x2 = x2 + self.drop_path(cur2)
x3 = x3 + self.drop_path(cur3)
x4 = x4 + self.drop_path(cur4)
# MLP.
cur2 = self.norm22(x2)
cur3 = self.norm23(x3)
cur4 = self.norm24(x4)
cur2 = self.mlp2(cur2)
cur3 = self.mlp3(cur3)
cur4 = self.mlp4(cur4)
x2 = x2 + self.drop_path(cur2)
x3 = x3 + self.drop_path(cur3)
x4 = x4 + self.drop_path(cur4)
return x1, x2, x3, x4
class PatchEmbed(nn.Module):
""" Image to Patch Embedding """
def __init__(self, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
patch_size = to_2tuple(patch_size)
self.patch_size = patch_size
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
_, _, H, W = x.shape
out_H, out_W = H // self.patch_size[0], W // self.patch_size[1]
x = self.proj(x).flatten(2).transpose(1, 2)
out = self.norm(x)
return out, (out_H, out_W)
class CoaT(nn.Module):
""" CoaT class. """
def __init__(self, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[0, 0, 0, 0],
serial_depths=[0, 0, 0, 0], parallel_depth=0,
num_heads=0, mlp_ratios=[0, 0, 0, 0], qkv_bias=True, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., norm_layer=partial(nn.LayerNorm, eps=1e-6),
return_interm_layers=False, out_features=None, crpe_window={3:2, 5:3, 7:3},
**kwargs):
super().__init__()
self.return_interm_layers = return_interm_layers
self.out_features = out_features
self.num_classes = num_classes
# Patch embeddings.
self.patch_embed1 = PatchEmbed(patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dims[0])
self.patch_embed2 = PatchEmbed(patch_size=2, in_chans=embed_dims[0], embed_dim=embed_dims[1])
self.patch_embed3 = PatchEmbed(patch_size=2, in_chans=embed_dims[1], embed_dim=embed_dims[2])
self.patch_embed4 = PatchEmbed(patch_size=2, in_chans=embed_dims[2], embed_dim=embed_dims[3])
# Class tokens.
self.cls_token1 = nn.Parameter(torch.zeros(1, 1, embed_dims[0]))
self.cls_token2 = nn.Parameter(torch.zeros(1, 1, embed_dims[1]))
self.cls_token3 = nn.Parameter(torch.zeros(1, 1, embed_dims[2]))
self.cls_token4 = nn.Parameter(torch.zeros(1, 1, embed_dims[3]))
# Convolutional position encodings.
self.cpe1 = ConvPosEnc(dim=embed_dims[0], k=3)
self.cpe2 = ConvPosEnc(dim=embed_dims[1], k=3)
self.cpe3 = ConvPosEnc(dim=embed_dims[2], k=3)
self.cpe4 = ConvPosEnc(dim=embed_dims[3], k=3)
# Convolutional relative position encodings.
self.crpe1 = ConvRelPosEnc(Ch=embed_dims[0] // num_heads, h=num_heads, window=crpe_window)
self.crpe2 = ConvRelPosEnc(Ch=embed_dims[1] // num_heads, h=num_heads, window=crpe_window)
self.crpe3 = ConvRelPosEnc(Ch=embed_dims[2] // num_heads, h=num_heads, window=crpe_window)
self.crpe4 = ConvRelPosEnc(Ch=embed_dims[3] // num_heads, h=num_heads, window=crpe_window)
# Enable stochastic depth.
dpr = drop_path_rate
# Serial blocks 1.
self.serial_blocks1 = nn.ModuleList([
SerialBlock(
dim=embed_dims[0], num_heads=num_heads, mlp_ratio=mlp_ratios[0], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer,
shared_cpe=self.cpe1, shared_crpe=self.crpe1
)
for _ in range(serial_depths[0])]
)
# Serial blocks 2.
self.serial_blocks2 = nn.ModuleList([
SerialBlock(
dim=embed_dims[1], num_heads=num_heads, mlp_ratio=mlp_ratios[1], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer,
shared_cpe=self.cpe2, shared_crpe=self.crpe2
)
for _ in range(serial_depths[1])]
)
# Serial blocks 3.
self.serial_blocks3 = nn.ModuleList([
SerialBlock(
dim=embed_dims[2], num_heads=num_heads, mlp_ratio=mlp_ratios[2], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer,
shared_cpe=self.cpe3, shared_crpe=self.crpe3
)
for _ in range(serial_depths[2])]
)
# Serial blocks 4.
self.serial_blocks4 = nn.ModuleList([
SerialBlock(
dim=embed_dims[3], num_heads=num_heads, mlp_ratio=mlp_ratios[3], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer,
shared_cpe=self.cpe4, shared_crpe=self.crpe4
)
for _ in range(serial_depths[3])]
)
# Parallel blocks.
self.parallel_depth = parallel_depth
if self.parallel_depth > 0:
self.parallel_blocks = nn.ModuleList([
ParallelBlock(
dims=embed_dims, num_heads=num_heads, mlp_ratios=mlp_ratios, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr, norm_layer=norm_layer,
shared_cpes=[self.cpe1, self.cpe2, self.cpe3, self.cpe4],
shared_crpes=[self.crpe1, self.crpe2, self.crpe3, self.crpe4]
)
for _ in range(parallel_depth)]
)
# Classification head(s).
if not self.return_interm_layers:
self.norm1 = norm_layer(embed_dims[0])
self.norm2 = norm_layer(embed_dims[1])
self.norm3 = norm_layer(embed_dims[2])
self.norm4 = norm_layer(embed_dims[3])
if self.parallel_depth > 0: # CoaT series: Aggregate features of last three scales for classification.
assert embed_dims[1] == embed_dims[2] == embed_dims[3]
self.aggregate = torch.nn.Conv1d(in_channels=3, out_channels=1, kernel_size=1)
self.head = nn.Linear(embed_dims[3], num_classes)
else:
self.head = nn.Linear(embed_dims[3], num_classes) # CoaT-Lite series: Use feature of last scale for classification.
# Initialize weights.
trunc_normal_(self.cls_token1, std=.02)
trunc_normal_(self.cls_token2, std=.02)
trunc_normal_(self.cls_token3, std=.02)
trunc_normal_(self.cls_token4, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'cls_token1', 'cls_token2', 'cls_token3', 'cls_token4'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def insert_cls(self, x, cls_token):
""" Insert CLS token. """
cls_tokens = cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
return x
def remove_cls(self, x):
""" Remove CLS token. """
return x[:, 1:, :]
def forward_features(self, x0):
B = x0.shape[0]
# Serial blocks 1.
x1, (H1, W1) = self.patch_embed1(x0)
x1 = self.insert_cls(x1, self.cls_token1)
for blk in self.serial_blocks1:
x1 = blk(x1, size=(H1, W1))
x1_nocls = self.remove_cls(x1)
x1_nocls = x1_nocls.reshape(B, H1, W1, -1).permute(0, 3, 1, 2).contiguous()
# Serial blocks 2.
x2, (H2, W2) = self.patch_embed2(x1_nocls)
x2 = self.insert_cls(x2, self.cls_token2)
for blk in self.serial_blocks2:
x2 = blk(x2, size=(H2, W2))
x2_nocls = self.remove_cls(x2)
x2_nocls = x2_nocls.reshape(B, H2, W2, -1).permute(0, 3, 1, 2).contiguous()
# Serial blocks 3.
x3, (H3, W3) = self.patch_embed3(x2_nocls)
x3 = self.insert_cls(x3, self.cls_token3)
for blk in self.serial_blocks3:
x3 = blk(x3, size=(H3, W3))
x3_nocls = self.remove_cls(x3)
x3_nocls = x3_nocls.reshape(B, H3, W3, -1).permute(0, 3, 1, 2).contiguous()
# Serial blocks 4.
x4, (H4, W4) = self.patch_embed4(x3_nocls)
x4 = self.insert_cls(x4, self.cls_token4)
for blk in self.serial_blocks4:
x4 = blk(x4, size=(H4, W4))
x4_nocls = self.remove_cls(x4)
x4_nocls = x4_nocls.reshape(B, H4, W4, -1).permute(0, 3, 1, 2).contiguous()
# Only serial blocks: Early return.
if self.parallel_depth == 0:
if self.return_interm_layers: # Return intermediate features for down-stream tasks (e.g. Deformable DETR and Detectron2).
feat_out = {}
if 'x1_nocls' in self.out_features:
feat_out['x1_nocls'] = x1_nocls
if 'x2_nocls' in self.out_features:
feat_out['x2_nocls'] = x2_nocls
if 'x3_nocls' in self.out_features:
feat_out['x3_nocls'] = x3_nocls
if 'x4_nocls' in self.out_features:
feat_out['x4_nocls'] = x4_nocls
return feat_out
else: # Return features for classification.
x4 = self.norm4(x4)
x4_cls = x4[:, 0]
return x4_cls
# Parallel blocks.
for blk in self.parallel_blocks:
x1, x2, x3, x4 = blk(x1, x2, x3, x4, sizes=[(H1, W1), (H2, W2), (H3, W3), (H4, W4)])
if self.return_interm_layers: # Return intermediate features for down-stream tasks (e.g. Deformable DETR and Detectron2).
feat_out = {}
if 'x1_nocls' in self.out_features:
x1_nocls = self.remove_cls(x1)
x1_nocls = x1_nocls.reshape(B, H1, W1, -1).permute(0, 3, 1, 2).contiguous()
feat_out['x1_nocls'] = x1_nocls
if 'x2_nocls' in self.out_features:
x2_nocls = self.remove_cls(x2)
x2_nocls = x2_nocls.reshape(B, H2, W2, -1).permute(0, 3, 1, 2).contiguous()
feat_out['x2_nocls'] = x2_nocls
if 'x3_nocls' in self.out_features:
x3_nocls = self.remove_cls(x3)
x3_nocls = x3_nocls.reshape(B, H3, W3, -1).permute(0, 3, 1, 2).contiguous()
feat_out['x3_nocls'] = x3_nocls
if 'x4_nocls' in self.out_features:
x4_nocls = self.remove_cls(x4)
x4_nocls = x4_nocls.reshape(B, H4, W4, -1).permute(0, 3, 1, 2).contiguous()
feat_out['x4_nocls'] = x4_nocls
return feat_out
else:
x2 = self.norm2(x2)
x3 = self.norm3(x3)
x4 = self.norm4(x4)
x2_cls = x2[:, :1] # Shape: [B, 1, C].
x3_cls = x3[:, :1]
x4_cls = x4[:, :1]
merged_cls = torch.cat((x2_cls, x3_cls, x4_cls), dim=1) # Shape: [B, 3, C].
merged_cls = self.aggregate(merged_cls).squeeze(dim=1) # Shape: [B, C].
return merged_cls
def forward(self, x):
if self.return_interm_layers: # Return intermediate features (for down-stream tasks).
return self.forward_features(x)
else: # Return features for classification.
x = self.forward_features(x)
x = self.head(x)
return x
# CoaT.
@register_model
def coat_tiny(**kwargs):
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
@register_model
def coat_mini(**kwargs):
model = CoaT(patch_size=4, embed_dims=[152, 216, 216, 216], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
@register_model
def coat_small(**kwargs):
model = CoaT(patch_size=4, embed_dims=[152, 320, 320, 320], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
# CoaT-Lite.
@register_model
def coat_lite_tiny(**kwargs):
model = CoaT(patch_size=4, embed_dims=[64, 128, 256, 320], serial_depths=[2, 2, 2, 2], parallel_depth=0, num_heads=8, mlp_ratios=[8, 8, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
@register_model
def coat_lite_mini(**kwargs):
model = CoaT(patch_size=4, embed_dims=[64, 128, 320, 512], serial_depths=[2, 2, 2, 2], parallel_depth=0, num_heads=8, mlp_ratios=[8, 8, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
@register_model
def coat_lite_small(**kwargs):
model = CoaT(patch_size=4, embed_dims=[64, 128, 320, 512], serial_depths=[3, 4, 6, 3], parallel_depth=0, num_heads=8, mlp_ratios=[8, 8, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
@register_model
def coat_lite_medium(**kwargs):
model = CoaT(patch_size=4, embed_dims=[128, 256, 320, 512], serial_depths=[3, 6, 10, 8], parallel_depth=0, num_heads=8, mlp_ratios=[4, 4, 4, 4], **kwargs)
model.default_cfg = _cfg_coat()
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4])
output=model(input)
print(output.shape) # torch.Size([1, 1000])
================================================
FILE: model/backbone/ConTNet.py
================================================
import torch.nn as nn
import torch.nn.functional as F
import torch
from einops.layers.torch import Rearrange
from einops import rearrange
import numpy as np
from typing import Any, List
import math
import warnings
from collections import OrderedDict
__all__ = ['ConTBlock', 'ConTNet']
r""" The following trunc_normal method is pasted from timm https://github.com/rwightman/pytorch-image-models/tree/master/timm
"""
def _no_grad_trunc_normal_(tensor, mean, std, a, b):
# Cut & paste from PyTorch official master until it's in a few official releases - RW
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
def norm_cdf(x):
# Computes standard normal cumulative distribution function
return (1. + math.erf(x / math.sqrt(2.))) / 2.
if (mean < a - 2 * std) or (mean > b + 2 * std):
warnings.warn("mean is more than 2 std from [a, b] in nn.init.trunc_normal_. "
"The distribution of values may be incorrect.",
stacklevel=2)
with torch.no_grad():
# Values are generated by using a truncated uniform distribution and
# then using the inverse CDF for the normal distribution.
# Get upper and lower cdf values
l = norm_cdf((a - mean) / std)
u = norm_cdf((b - mean) / std)
# Uniformly fill tensor with values from [l, u], then translate to
# [2l-1, 2u-1].
tensor.uniform_(2 * l - 1, 2 * u - 1)
# Use inverse cdf transform for normal distribution to get truncated
# standard normal
tensor.erfinv_()
# Transform to proper mean, std
tensor.mul_(std * math.sqrt(2.))
tensor.add_(mean)
# Clamp to ensure it's in the proper range
tensor.clamp_(min=a, max=b)
return tensor
def trunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
# type: (Tensor, float, float, float, float) -> Tensor
r"""Fills the input Tensor with values drawn from a truncated
normal distribution. The values are effectively drawn from the
normal distribution :math:`\mathcal{N}(\text{mean}, \text{std}^2)`
with values outside :math:`[a, b]` redrawn until they are within
the bounds. The method used for generating the random values works
best when :math:`a \leq \text{mean} \leq b`.
Args:
tensor: an n-dimensional `torch.Tensor`
mean: the mean of the normal distribution
std: the standard deviation of the normal distribution
a: the minimum cutoff value
b: the maximum cutoff value
Examples:
>>> w = torch.empty(3, 5)
>>> nn.init.trunc_normal_(w)
"""
return _no_grad_trunc_normal_(tensor, mean, std, a, b)
def fixed_padding(inputs, kernel_size, dilation):
kernel_size_effective = kernel_size + (kernel_size - 1) * (dilation - 1)
pad_total = kernel_size_effective - 1
pad_beg = pad_total // 2
pad_end = pad_total - pad_beg
padded_inputs = F.pad(inputs, (pad_beg, pad_end, pad_beg, pad_end))
return padded_inputs
class ConvBN(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, groups=1, bn=True):
padding = (kernel_size - 1) // 2
if bn:
super(ConvBN, self).__init__(OrderedDict([
('conv', nn.Conv2d(in_planes, out_planes, kernel_size, stride,
padding=padding, groups=groups, bias=False)),
('bn', nn.BatchNorm2d(out_planes))
]))
else:
super(ConvBN, self).__init__(OrderedDict([
('conv', nn.Conv2d(in_planes, out_planes, kernel_size, stride,
padding=padding, groups=groups, bias=False)),
]))
class MHSA(nn.Module):
r"""
Build a Multi-Head Self-Attention:
- https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
"""
def __init__(self,
planes,
head_num,
dropout,
patch_size,
qkv_bias,
relative):
super(MHSA, self).__init__()
self.head_num = head_num
head_dim = planes // head_num
self.qkv = nn.Linear(planes, 3*planes, bias=qkv_bias)
self.relative = relative
self.patch_size = patch_size
self.scale = head_dim ** -0.5
if self.relative:
# print('### relative position embedding ###')
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * patch_size - 1) * (2 * patch_size - 1), head_num))
coords_w = coords_h = torch.arange(patch_size)
coords = torch.stack(torch.meshgrid([coords_h, coords_w]))
coords_flatten = torch.flatten(coords, 1)
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :]
relative_coords = relative_coords.permute(1, 2, 0).contiguous()
relative_coords[:, :, 0] += patch_size - 1
relative_coords[:, :, 1] += patch_size - 1
relative_coords[:, :, 0] *= 2 * patch_size - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.attn_drop = nn.Dropout(p=dropout)
self.proj = nn.Linear(planes, planes)
self.proj_drop = nn.Dropout(p=dropout)
def forward(self, x):
B, N, C, H = *x.shape, self.head_num
# print(x.shape)
qkv = self.qkv(x).reshape(B, N, 3, H, C // H).permute(2, 0, 3, 1, 4) # x: (3, B, H, N, C//H)
q, k, v = qkv[0], qkv[1], qkv[2] # x: (B, H, N, C//N)
q = q * self.scale
attn = (q @ k.transpose(-2, -1)) # attn: (B, H, N, N)
if self.relative:
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.patch_size ** 2, self.patch_size ** 2, -1)
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous()
attn = attn + relative_position_bias.unsqueeze(0)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class MLP(nn.Module):
r"""
Build a Multi-Layer Perceptron
- https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
"""
def __init__(self,
planes,
mlp_dim,
dropout):
super(MLP, self).__init__()
self.fc1 = nn.Linear(planes, mlp_dim)
self.act = nn.GELU()
self.fc2 = nn.Linear(mlp_dim, planes)
self.drop = nn.Dropout(dropout)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class STE(nn.Module):
r"""
Build a Standard Transformer Encoder(STE)
input: Tensor (b, c, h, w)
output: Tensor (b, c, h, w)
"""
def __init__(self,
planes: int,
mlp_dim: int,
head_num: int,
dropout: float,
patch_size: int,
relative: bool,
qkv_bias: bool,
pre_norm: bool,
**kwargs):
super(STE, self).__init__()
self.patch_size = patch_size
self.pre_norm = pre_norm
self.relative = relative
self.flatten = nn.Sequential(
Rearrange('b c pnh pnw psh psw -> (b pnh pnw) psh psw c'),
)
if not relative:
self.pe = nn.ParameterList(
[nn.Parameter(torch.zeros(1, patch_size, 1, planes//2)), nn.Parameter(torch.zeros(1, 1, patch_size, planes//2))]
)
self.attn = MHSA(planes, head_num, dropout, patch_size, qkv_bias=qkv_bias, relative=relative)
self.mlp = MLP(planes, mlp_dim, dropout=dropout)
self.norm1 = nn.LayerNorm(planes)
self.norm2 = nn.LayerNorm(planes)
def forward(self, x):
bs, c, h, w = x.shape
patch_size = self.patch_size
patch_num_h, patch_num_w = h // patch_size, w // patch_size
x = (
x.unfold(2, self.patch_size, self.patch_size)
.unfold(3, self.patch_size, self.patch_size)
) # x: (b, c, patch_num, patch_num, patch_size, patch_size)
x = self.flatten(x) # x: (b, patch_size, patch_size, c)
### add 2d position embedding ###
if not self.relative:
x_h, x_w = x.split(c // 2, dim=3)
x = torch.cat((x_h + self.pe[0], x_w + self.pe[1]), dim=3) # x: (b, patch_size, patch_size, c)
x = rearrange(x, 'b psh psw c -> b (psh psw) c')
if self.pre_norm:
x = x + self.attn(self.norm1(x))
x = x + self.mlp(self.norm2(x))
else:
x = self.norm1(x + self.attn(x))
x = self.norm2(x + self.mlp(x))
x = rearrange(x, '(b pnh pnw) (psh psw) c -> b c (pnh psh) (pnw psw)', pnh=patch_num_h, pnw=patch_num_w, psh=patch_size, psw=patch_size)
return x
class ConTBlock(nn.Module):
r"""
Build a ConTBlock
"""
def __init__(self,
planes: int,
out_planes: int,
mlp_dim: int,
head_num: int,
dropout: float,
patch_size: List[int],
downsample: nn.Module = None,
stride: int=1,
last_dropout: float=0.3,
**kwargs):
super(ConTBlock, self).__init__()
self.downsample = downsample
self.identity = nn.Identity()
self.dropout = nn.Identity()
self.bn = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.ste1 = STE(planes=planes, mlp_dim=mlp_dim, head_num=head_num, dropout=dropout, patch_size=patch_size[0], **kwargs)
self.ste2 = STE(planes=planes, mlp_dim=mlp_dim, head_num=head_num, dropout=dropout, patch_size=patch_size[1], **kwargs)
if stride == 1 and downsample is not None:
self.dropout = nn.Dropout(p=last_dropout)
kernel_size = 1
else:
kernel_size = 3
self.out_conv = ConvBN(planes, out_planes, kernel_size, stride, bn=False)
def forward(self, x):
x_preact = self.relu(self.bn(x))
identity = self.identity(x)
if self.downsample is not None:
identity = self.downsample(x_preact)
residual = self.ste1(x_preact)
residual = self.ste2(residual)
residual = self.out_conv(residual)
out = self.dropout(residual+identity)
return out
class ConTNet(nn.Module):
r"""
Build a ConTNet backbone
"""
def __init__(self,
block,
layers: List[int],
mlp_dim: List[int],
head_num: List[int],
dropout: List[float],
in_channels: int=3,
inplanes: int=64,
num_classes: int=1000,
init_weights: bool=True,
first_embedding: bool=False,
tweak_C: bool=False,
**kwargs):
r"""
Args:
block: ConT Block
layers: number of blocks at each layer
mlp_dim: dimension of mlp in each stage
head_num: number of head in each stage
dropout: dropout in the last two stage
relative: if True, relative Position Embedding is used
groups: nunmber of group at each conv layer in the Network
depthwise: if True, depthwise convolution is adopted
in_channels: number of channels of input image
inplanes: channel of the first convolution layer
num_classes: number of classes for classification task
only useful when `with_classifier` is True
with_avgpool: if True, an average pooling is added at the end of resnet stage5
with_classifier: if True, FC layer is registered for classification task
first_embedding: if True, a conv layer with both stride and kernel of 7 is placed at the top
tweakC: if true, the first layer of ResNet-C replace the ori layer
"""
super(ConTNet, self).__init__()
self.inplanes = inplanes
self.block = block
# build the top layer
if tweak_C:
self.layer0 = nn.Sequential(OrderedDict([
('conv_bn1', ConvBN(in_channels, inplanes//2, kernel_size=3, stride=2)),
('relu1', nn.ReLU(inplace=True)),
('conv_bn2', ConvBN(inplanes//2, inplanes//2, kernel_size=3, stride=1)),
('relu2', nn.ReLU(inplace=True)),
('conv_bn3', ConvBN(inplanes//2, inplanes, kernel_size=3, stride=1)),
('relu3', nn.ReLU(inplace=True)),
('maxpool', nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
]))
elif first_embedding:
self.layer0 = nn.Sequential(OrderedDict([
('conv', nn.Conv2d(in_channels, inplanes, kernel_size=4, stride=4)),
('norm', nn.LayerNorm(inplanes))
]))
else:
self.layer0 = nn.Sequential(OrderedDict([
('conv', ConvBN(in_channels, inplanes, kernel_size=7, stride=2, bn=False)),
# ('relu', nn.ReLU(inplace=True)),
('maxpool', nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
]))
# build cont layers
self.cont_layers = []
self.out_channels = OrderedDict()
for i in range(len(layers)):
stride = 2,
patch_size = [7,14]
if i == len(layers)-1:
stride, patch_size[1] = 1, 7 # the last stage does not conduct downsampling
cont_layer = self._make_layer(inplanes * 2**i, layers[i], stride=stride, mlp_dim=mlp_dim[i], head_num=head_num[i], dropout=dropout[i], patch_size=patch_size, **kwargs)
layer_name = 'layer{}'.format(i + 1)
self.add_module(layer_name, cont_layer)
self.cont_layers.append(layer_name)
self.out_channels[layer_name] = 2 * inplanes * 2**i
self.last_out_channels = next(reversed(self.out_channels.values()))
self.fc = nn.Linear(self.last_out_channels, num_classes)
if init_weights:
self._initialize_weights()
def _make_layer(self,
planes: int,
blocks: int,
stride: int,
mlp_dim: int,
head_num: int,
dropout: float,
patch_size: List[int],
use_avgdown: bool=False,
**kwargs):
layers = OrderedDict()
for i in range(0, blocks-1):
layers[f'{self.block.__name__}{i}'] = self.block(
planes, planes, mlp_dim, head_num, dropout, patch_size, **kwargs)
downsample = None
if stride != 1:
if use_avgdown:
downsample = nn.Sequential(OrderedDict([
('avgpool', nn.AvgPool2d(kernel_size=2, stride=2)),
('conv', ConvBN(planes, planes * 2, kernel_size=1, stride=1, bn=False))]))
else:
downsample = ConvBN(planes, planes * 2, kernel_size=1,
stride=2, bn=False)
else:
downsample = ConvBN(planes, planes * 2, kernel_size=1, stride=1, bn=False)
layers[f'{self.block.__name__}{blocks-1}'] = self.block(
planes, planes*2, mlp_dim, head_num, dropout, patch_size, downsample, stride, **kwargs)
return nn.Sequential(layers)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.LayerNorm):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.layer0(x)
for _, layer_name in enumerate(self.cont_layers):
cont_layer = getattr(self, layer_name)
x = cont_layer(x)
x = x.mean([2, 3])
x = self.fc(x)
return x
def create_ConTNet_Ti(kwargs):
return ConTNet(block=ConTBlock,
mlp_dim=[196, 392, 768, 768],
head_num=[1, 2, 4, 8],
dropout=[0,0,0,0],
inplanes=48,
layers=[1,1,1,1],
last_dropout=0,
**kwargs)
def create_ConTNet_S(kwargs):
return ConTNet(block=ConTBlock,
mlp_dim=[256, 512, 1024, 1024],
head_num=[1, 2, 4, 8],
dropout=[0,0,0,0],
inplanes=64,
layers=[1,1,1,1],
last_dropout=0,
**kwargs)
def create_ConTNet_M(kwargs):
return ConTNet(block=ConTBlock,
mlp_dim=[256, 512, 1024, 1024],
head_num=[1, 2, 4, 8],
dropout=[0,0,0,0],
inplanes=64,
layers=[2,2,2,2],
last_dropout=0,
**kwargs)
def create_ConTNet_B(kwargs):
return ConTNet(block=ConTBlock,
mlp_dim=[256, 512, 1024, 1024],
head_num=[1, 2, 4, 8],
dropout=[0,0,0.1,0.1],
inplanes=64,
layers=[3,4,6,3],
last_dropout=0.2,
**kwargs)
def build_model(use_avgdown, relative, qkv_bias, pre_norm):
kwargs = dict(use_avgdown=use_avgdown, relative=relative, qkv_bias=qkv_bias, pre_norm=pre_norm)
return create_ConTNet_Ti(kwargs)
if __name__ == "__main__":
model = build_model(use_avgdown=True, relative=True, qkv_bias=True, pre_norm=True)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
================================================
FILE: model/backbone/ConViT.py
================================================
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
#
# This source code is licensed under the CC-by-NC license found in the
# LICENSE file in the root directory of this source tree.
#
'''These modules are adapted from those of timm, see
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
'''
import torch
import torch.nn as nn
from functools import partial
import torch.nn.functional as F
from timm.models.helpers import load_pretrained
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class GPSA(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.,
locality_strength=1., use_local_init=True):
super().__init__()
self.num_heads = num_heads
self.dim = dim
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qk = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.pos_proj = nn.Linear(3, num_heads)
self.proj_drop = nn.Dropout(proj_drop)
self.locality_strength = locality_strength
self.gating_param = nn.Parameter(torch.ones(self.num_heads))
self.apply(self._init_weights)
if use_local_init:
self.local_init(locality_strength=locality_strength)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
B, N, C = x.shape
if not hasattr(self, 'rel_indices') or self.rel_indices.size(1)!=N:
self.get_rel_indices(N)
attn = self.get_attention(x)
v = self.v(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
def get_attention(self, x):
B, N, C = x.shape
qk = self.qk(x).reshape(B, N, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k = qk[0], qk[1]
pos_score = self.rel_indices.expand(B, -1, -1,-1)
pos_score = self.pos_proj(pos_score).permute(0,3,1,2)
patch_score = (q @ k.transpose(-2, -1)) * self.scale
patch_score = patch_score.softmax(dim=-1)
pos_score = pos_score.softmax(dim=-1)
gating = self.gating_param.view(1,-1,1,1)
attn = (1.-torch.sigmoid(gating)) * patch_score + torch.sigmoid(gating) * pos_score
attn /= attn.sum(dim=-1).unsqueeze(-1)
attn = self.attn_drop(attn)
return attn
def get_attention_map(self, x, return_map = False):
attn_map = self.get_attention(x).mean(0) # average over batch
distances = self.rel_indices.squeeze()[:,:,-1]**.5
dist = torch.einsum('nm,hnm->h', (distances, attn_map))
dist /= distances.size(0)
if return_map:
return dist, attn_map
else:
return dist
def local_init(self, locality_strength=1.):
self.v.weight.data.copy_(torch.eye(self.dim))
locality_distance = 1 #max(1,1/locality_strength**.5)
kernel_size = int(self.num_heads**.5)
center = (kernel_size-1)/2 if kernel_size%2==0 else kernel_size//2
for h1 in range(kernel_size):
for h2 in range(kernel_size):
position = h1+kernel_size*h2
self.pos_proj.weight.data[position,2] = -1
self.pos_proj.weight.data[position,1] = 2*(h1-center)*locality_distance
self.pos_proj.weight.data[position,0] = 2*(h2-center)*locality_distance
self.pos_proj.weight.data *= locality_strength
def get_rel_indices(self, num_patches):
img_size = int(num_patches**.5)
rel_indices = torch.zeros(1, num_patches, num_patches, 3)
ind = torch.arange(img_size).view(1,-1) - torch.arange(img_size).view(-1, 1)
indx = ind.repeat(img_size,img_size)
indy = ind.repeat_interleave(img_size,dim=0).repeat_interleave(img_size,dim=1)
indd = indx**2 + indy**2
rel_indices[:,:,:,2] = indd.unsqueeze(0)
rel_indices[:,:,:,1] = indy.unsqueeze(0)
rel_indices[:,:,:,0] = indx.unsqueeze(0)
device = self.qk.weight.device
self.rel_indices = rel_indices.to(device)
class MHSA(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def get_attention_map(self, x, return_map = False):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn_map = (q @ k.transpose(-2, -1)) * self.scale
attn_map = attn_map.softmax(dim=-1).mean(0)
img_size = int(N**.5)
ind = torch.arange(img_size).view(1,-1) - torch.arange(img_size).view(-1, 1)
indx = ind.repeat(img_size,img_size)
indy = ind.repeat_interleave(img_size,dim=0).repeat_interleave(img_size,dim=1)
indd = indx**2 + indy**2
distances = indd**.5
distances = distances.to('cuda')
dist = torch.einsum('nm,hnm->h', (distances, attn_map))
dist /= N
if return_map:
return dist, attn_map
else:
return dist
def forward(self, x):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, use_gpsa=True, **kwargs):
super().__init__()
self.norm1 = norm_layer(dim)
self.use_gpsa = use_gpsa
if self.use_gpsa:
self.attn = GPSA(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop, **kwargs)
else:
self.attn = MHSA(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop, **kwargs)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding, from timm
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.apply(self._init_weights)
def forward(self, x):
B, C, H, W = x.shape
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
class HybridEmbed(nn.Module):
""" CNN Feature Map Embedding, from timm
"""
def __init__(self, backbone, img_size=224, feature_size=None, in_chans=3, embed_dim=768):
super().__init__()
assert isinstance(backbone, nn.Module)
img_size = to_2tuple(img_size)
self.img_size = img_size
self.backbone = backbone
if feature_size is None:
with torch.no_grad():
training = backbone.training
if training:
backbone.eval()
o = self.backbone(torch.zeros(1, in_chans, img_size[0], img_size[1]))[-1]
feature_size = o.shape[-2:]
feature_dim = o.shape[1]
backbone.train(training)
else:
feature_size = to_2tuple(feature_size)
feature_dim = self.backbone.feature_info.channels()[-1]
self.num_patches = feature_size[0] * feature_size[1]
self.proj = nn.Linear(feature_dim, embed_dim)
self.apply(self._init_weights)
def forward(self, x):
x = self.backbone(x)[-1]
x = x.flatten(2).transpose(1, 2)
x = self.proj(x)
return x
class VisionTransformer(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=48, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm, global_pool=None,
local_up_to_layer=10, locality_strength=1., use_pos_embed=True):
super().__init__()
self.num_classes = num_classes
self.local_up_to_layer = local_up_to_layer
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.locality_strength = locality_strength
self.use_pos_embed = use_pos_embed
if hybrid_backbone is not None:
self.patch_embed = HybridEmbed(
hybrid_backbone, img_size=img_size, in_chans=in_chans, embed_dim=embed_dim)
else:
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.num_patches = num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
if self.use_pos_embed:
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.pos_embed, std=.02)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
use_gpsa=True,
locality_strength=locality_strength)
if i 0 else nn.Identity()
trunc_normal_(self.cls_token, std=.02)
self.head.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1)
if self.use_pos_embed:
x = x + self.pos_embed
x = self.pos_drop(x)
for u,blk in enumerate(self.blocks):
if u == self.local_up_to_layer :
x = torch.cat((cls_tokens, x), dim=1)
x = blk(x)
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
@register_model
def convit_tiny(pretrained=False, **kwargs):
num_heads = 4
kwargs['embed_dim'] *= num_heads
model = VisionTransformer(
num_heads=num_heads,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/convit/convit_tiny.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
@register_model
def convit_small(pretrained=False, **kwargs):
num_heads = 9
kwargs['embed_dim'] *= num_heads
model = VisionTransformer(
num_heads=num_heads,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/convit/convit_small.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
@register_model
def convit_base(pretrained=False, **kwargs):
num_heads = 16
kwargs['embed_dim'] *= num_heads
model = VisionTransformer(
num_heads=num_heads,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/convit/convit_base.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/Container.py
================================================
import torch
import torch.nn as nn
from functools import partial
import math
from timm.models.vision_transformer import VisionTransformer, _cfg
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_, DropPath, to_2tuple
import pdb
__all__ = [
'deit_tiny_patch16_224', 'deit_small_patch16_224', 'deit_base_patch16_224',
'deit_tiny_distilled_patch16_224', 'deit_small_distilled_patch16_224',
'deit_base_distilled_patch16_224', 'deit_base_patch16_384',
'deit_base_distilled_patch16_384', 'container_light'
]
class Mlp(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class CMlp(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
pdb.set_trace()
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Attention_pure(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.attn_drop = nn.Dropout(attn_drop)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
C = int(C // 3)
qkv = x.reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj_drop(x)
return x
class MixBlock(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.norm1 = nn.BatchNorm2d(dim)
self.conv1 = nn.Conv2d(dim, 3 * dim, 1)
self.conv2 = nn.Conv2d(dim, dim, 1)
self.conv = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.attn = Attention_pure(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = nn.BatchNorm2d(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = CMlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.sa_weight = nn.Parameter(torch.Tensor([0.0]))
def forward(self, x):
x = x + self.pos_embed(x)
B, _, H, W = x.shape
residual = x
x = self.norm1(x)
qkv = self.conv1(x)
conv = qkv[:, 2 * self.dim:, :, :]
conv = self.conv(conv)
sa = qkv.flatten(2).transpose(1, 2)
sa = self.attn(sa)
sa = sa.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x = residual + self.drop_path(self.conv2(torch.sigmoid(self.sa_weight) * sa + (1 - torch.sigmoid(self.sa_weight)) * conv))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class CBlock(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.pos_embed = nn.Conv2d(dim, dim, 3, padding=1, groups=dim)
self.norm1 = nn.BatchNorm2d(dim)
self.conv1 = nn.Conv2d(dim, dim, 1)
self.conv2 = nn.Conv2d(dim, dim, 1)
self.attn = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = nn.BatchNorm2d(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = CMlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.pos_embed(x)
x = x + self.drop_path(self.conv2(self.attn(self.conv1(self.norm1(x)))))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class Block(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchEmbed(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.norm = nn.LayerNorm(embed_dim)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x)
B, C, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
return x
class HybridEmbed(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
def __init__(self, backbone, img_size=224, feature_size=None, in_chans=3, embed_dim=768):
super().__init__()
assert isinstance(backbone, nn.Module)
img_size = to_2tuple(img_size)
self.img_size = img_size
self.backbone = backbone
if feature_size is None:
with torch.no_grad():
# FIXME this is hacky, but most reliable way of determining the exact dim of the output feature
# map for all networks, the feature metadata has reliable channel and stride info, but using
# stride to calc feature dim requires info about padding of each stage that isn't captured.
training = backbone.training
if training:
backbone.eval()
o = self.backbone(torch.zeros(1, in_chans, img_size[0], img_size[1]))
if isinstance(o, (list, tuple)):
o = o[-1] # last feature if backbone outputs list/tuple of features
feature_size = o.shape[-2:]
feature_dim = o.shape[1]
backbone.train(training)
else:
feature_size = to_2tuple(feature_size)
if hasattr(self.backbone, 'feature_info'):
feature_dim = self.backbone.feature_info.channels()[-1]
else:
feature_dim = self.backbone.num_features
self.num_patches = feature_size[0] * feature_size[1]
self.proj = nn.Conv2d(feature_dim, embed_dim, 1)
def forward(self, x):
x = self.backbone(x)
if isinstance(x, (list, tuple)):
x = x[-1] # last feature if backbone outputs list/tuple of features
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class VisionTransformer(nn.Module):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
""" Vision Transformer
A PyTorch impl of : `An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale` -
https://arxiv.org/abs/2010.11929
"""
def __init__(self, img_size=[224, 56, 28, 14], patch_size=[4, 2, 2, 2], in_chans=3, num_classes=1000, embed_dim=[64, 128, 320, 512], depth=[3, 4, 8, 3],
num_heads=12, mlp_ratio=[8, 8, 4, 4], qkv_bias=True, qk_scale=None, representation_size=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., hybrid_backbone=None, norm_layer=None):
"""
Args:
img_size (int, tuple): input image size
patch_size (int, tuple): patch size
in_chans (int): number of input channels
num_classes (int): number of classes for classification head
embed_dim (int): embedding dimension
depth (int): depth of transformer
num_heads (int): number of attention heads
mlp_ratio (int): ratio of mlp hidden dim to embedding dim
qkv_bias (bool): enable bias for qkv if True
qk_scale (float): override default qk scale of head_dim ** -0.5 if set
representation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if set
drop_rate (float): dropout rate
attn_drop_rate (float): attention dropout rate
drop_path_rate (float): stochastic depth rate
hybrid_backbone (nn.Module): CNN backbone to use in-place of PatchEmbed module
norm_layer: (nn.Module): normalization layer
"""
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
self.embed_dim = embed_dim
self.depth = depth
if hybrid_backbone is not None:
self.patch_embed = HybridEmbed(
hybrid_backbone, img_size=img_size, in_chans=in_chans, embed_dim=embed_dim)
else:
self.patch_embed1 = PatchEmbed(
img_size=img_size[0], patch_size=patch_size[0], in_chans=in_chans, embed_dim=embed_dim[0])
self.patch_embed2 = PatchEmbed(
img_size=img_size[1], patch_size=patch_size[1], in_chans=embed_dim[0], embed_dim=embed_dim[1])
self.patch_embed3 = PatchEmbed(
img_size=img_size[2], patch_size=patch_size[2], in_chans=embed_dim[1], embed_dim=embed_dim[2])
self.patch_embed4 = PatchEmbed(
img_size=img_size[3], patch_size=patch_size[3], in_chans=embed_dim[2], embed_dim=embed_dim[3])
num_patches1 = self.patch_embed1.num_patches
num_patches2 = self.patch_embed2.num_patches
num_patches3 = self.patch_embed3.num_patches
num_patches4 = self.patch_embed4.num_patches
self.pos_drop = nn.Dropout(p=drop_rate)
self.mixture =True
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depth))] # stochastic depth decay rule
self.blocks1 = nn.ModuleList([
CBlock(
dim=embed_dim[0], num_heads=num_heads, mlp_ratio=mlp_ratio[0], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
for i in range(depth[0])])
self.blocks2 = nn.ModuleList([
CBlock(
dim=embed_dim[1], num_heads=num_heads, mlp_ratio=mlp_ratio[1], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]], norm_layer=norm_layer)
for i in range(depth[1])])
self.blocks3 = nn.ModuleList([
CBlock(
dim=embed_dim[2], num_heads=num_heads, mlp_ratio=mlp_ratio[2], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]], norm_layer=norm_layer)
for i in range(depth[2])])
self.blocks4 = nn.ModuleList([
MixBlock(
dim=embed_dim[3], num_heads=num_heads, mlp_ratio=mlp_ratio[3], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i+depth[0]+depth[1]+depth[2]], norm_layer=norm_layer)
for i in range(depth[3])])
self.norm = nn.BatchNorm2d(embed_dim[-1])
# Representation layer
if representation_size:
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
('fc', nn.Linear(embed_dim, representation_size)),
('act', nn.Tanh())
]))
else:
self.pre_logits = nn.Identity()
# Classifier head
self.head = nn.Linear(embed_dim[-1], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
x = self.patch_embed1(x)
x = self.pos_drop(x)
for blk in self.blocks1:
x = blk(x)
x = self.patch_embed2(x)
for blk in self.blocks2:
x = blk(x)
x = self.patch_embed3(x)
for blk in self.blocks3:
x = blk(x)
x = self.patch_embed4(x)
for blk in self.blocks4:
x = blk(x)
x = self.norm(x)
x = self.pre_logits(x)
return x
def forward(self, x):
x = self.forward_features(x)
x = x.flatten(2).mean(-1)
x = self.head(x)
return x
@register_model
def container_v1_light(pretrained=False, **kwargs):
model = VisionTransformer(
img_size=[224, 56, 28, 14], patch_size=[4, 2, 2, 2], embed_dim=[64, 128, 320, 512], depth=[3, 4, 8, 3], num_heads=16, mlp_ratio=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_tiny_patch16_224-a1311bcf.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[224, 56, 28, 14],
patch_size=[4, 2, 2, 2],
embed_dim=[64, 128, 320, 512],
depth=[3, 4, 8, 3],
num_heads=16,
mlp_ratio=[8, 8, 4, 4],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6))
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/ConvMixer.py
================================================
import torch.nn as nn
from torch.nn.modules.activation import GELU
import torch
from torch.nn.modules.pooling import AdaptiveAvgPool2d
class Residual(nn.Module):
def __init__(self,fn):
super().__init__()
self.fn=fn
def forward(self,x):
return x+self.fn(x)
def ConvMixer(dim,depth,kernel_size=9,patch_size=7,num_classes=1000):
return nn.Sequential(
nn.Conv2d(3,dim,kernel_size=patch_size,stride=patch_size),
nn.GELU(),
nn.BatchNorm2d(dim),
*[nn.Sequential(
Residual(nn.Sequential(
nn.Conv2d(dim,dim,kernel_size=kernel_size,groups=dim,padding=kernel_size//2),
nn.GELU(),
nn.BatchNorm2d(dim)
)),
nn.Conv2d(dim,dim,kernel_size=1),
nn.GELU(),
nn.BatchNorm2d(dim)
) for _ in range(depth)],
nn.AdaptiveAvgPool2d(1),
nn.Flatten(),
nn.Linear(dim,num_classes)
)
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
convmixer=ConvMixer(dim=512,depth=12)
out=convmixer(x)
print(out.shape) #[1, 1000]
================================================
FILE: model/backbone/CrossViT.py
================================================
# Copyright IBM All Rights Reserved.
# SPDX-License-Identifier: Apache-2.0
"""
Modifed from Timm. https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.hub
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg, Mlp, Block
_model_urls = {
'crossvit_15_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_15_224.pth',
'crossvit_15_dagger_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_15_dagger_224.pth',
'crossvit_15_dagger_384': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_15_dagger_384.pth',
'crossvit_18_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_18_224.pth',
'crossvit_18_dagger_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_18_dagger_224.pth',
'crossvit_18_dagger_384': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_18_dagger_384.pth',
'crossvit_9_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_9_224.pth',
'crossvit_9_dagger_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_9_dagger_224.pth',
'crossvit_base_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_base_224.pth',
'crossvit_small_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_small_224.pth',
'crossvit_tiny_224': 'https://github.com/IBM/CrossViT/releases/download/weights-0.1/crossvit_tiny_224.pth',
}
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, multi_conv=False):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
if multi_conv:
if patch_size[0] == 12:
self.proj = nn.Sequential(
nn.Conv2d(in_chans, embed_dim // 4, kernel_size=7, stride=4, padding=3),
nn.ReLU(inplace=True),
nn.Conv2d(embed_dim // 4, embed_dim // 2, kernel_size=3, stride=3, padding=0),
nn.ReLU(inplace=True),
nn.Conv2d(embed_dim // 2, embed_dim, kernel_size=3, stride=1, padding=1),
)
elif patch_size[0] == 16:
self.proj = nn.Sequential(
nn.Conv2d(in_chans, embed_dim // 4, kernel_size=7, stride=4, padding=3),
nn.ReLU(inplace=True),
nn.Conv2d(embed_dim // 4, embed_dim // 2, kernel_size=3, stride=2, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(embed_dim // 2, embed_dim, kernel_size=3, stride=2, padding=1),
)
else:
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class CrossAttention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.wq = nn.Linear(dim, dim, bias=qkv_bias)
self.wk = nn.Linear(dim, dim, bias=qkv_bias)
self.wv = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
q = self.wq(x[:, 0:1, ...]).reshape(B, 1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # B1C -> B1H(C/H) -> BH1(C/H)
k = self.wk(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # BNC -> BNH(C/H) -> BHN(C/H)
v = self.wv(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3) # BNC -> BNH(C/H) -> BHN(C/H)
attn = (q @ k.transpose(-2, -1)) * self.scale # BH1(C/H) @ BH(C/H)N -> BH1N
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, 1, C) # (BH1N @ BHN(C/H)) -> BH1(C/H) -> B1H(C/H) -> B1C
x = self.proj(x)
x = self.proj_drop(x)
return x
class CrossAttentionBlock(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, has_mlp=True):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = CrossAttention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.has_mlp = has_mlp
if has_mlp:
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x):
x = x[:, 0:1, ...] + self.drop_path(self.attn(self.norm1(x)))
if self.has_mlp:
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class MultiScaleBlock(nn.Module):
def __init__(self, dim, patches, depth, num_heads, mlp_ratio, qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
num_branches = len(dim)
self.num_branches = num_branches
# different branch could have different embedding size, the first one is the base
self.blocks = nn.ModuleList()
for d in range(num_branches):
tmp = []
for i in range(depth[d]):
tmp.append(
Block(dim=dim[d], num_heads=num_heads[d], mlp_ratio=mlp_ratio[d], qkv_bias=qkv_bias,
drop=drop, attn_drop=attn_drop, drop_path=drop_path[i], norm_layer=norm_layer))
if len(tmp) != 0:
self.blocks.append(nn.Sequential(*tmp))
if len(self.blocks) == 0:
self.blocks = None
self.projs = nn.ModuleList()
for d in range(num_branches):
if dim[d] == dim[(d+1) % num_branches] and False:
tmp = [nn.Identity()]
else:
tmp = [norm_layer(dim[d]), act_layer(), nn.Linear(dim[d], dim[(d+1) % num_branches])]
self.projs.append(nn.Sequential(*tmp))
self.fusion = nn.ModuleList()
for d in range(num_branches):
d_ = (d+1) % num_branches
nh = num_heads[d_]
if depth[-1] == 0: # backward capability:
self.fusion.append(CrossAttentionBlock(dim=dim[d_], num_heads=nh, mlp_ratio=mlp_ratio[d], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop, drop_path=drop_path[-1], norm_layer=norm_layer,
has_mlp=False))
else:
tmp = []
for _ in range(depth[-1]):
tmp.append(CrossAttentionBlock(dim=dim[d_], num_heads=nh, mlp_ratio=mlp_ratio[d], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop, attn_drop=attn_drop, drop_path=drop_path[-1], norm_layer=norm_layer,
has_mlp=False))
self.fusion.append(nn.Sequential(*tmp))
self.revert_projs = nn.ModuleList()
for d in range(num_branches):
if dim[(d+1) % num_branches] == dim[d] and False:
tmp = [nn.Identity()]
else:
tmp = [norm_layer(dim[(d+1) % num_branches]), act_layer(), nn.Linear(dim[(d+1) % num_branches], dim[d])]
self.revert_projs.append(nn.Sequential(*tmp))
def forward(self, x):
outs_b = [block(x_) for x_, block in zip(x, self.blocks)]
# only take the cls token out
proj_cls_token = [proj(x[:, 0:1]) for x, proj in zip(outs_b, self.projs)]
# cross attention
outs = []
for i in range(self.num_branches):
tmp = torch.cat((proj_cls_token[i], outs_b[(i + 1) % self.num_branches][:, 1:, ...]), dim=1)
tmp = self.fusion[i](tmp)
reverted_proj_cls_token = self.revert_projs[i](tmp[:, 0:1, ...])
tmp = torch.cat((reverted_proj_cls_token, outs_b[i][:, 1:, ...]), dim=1)
outs.append(tmp)
return outs
def _compute_num_patches(img_size, patches):
return [i // p * i // p for i, p in zip(img_size,patches)]
class VisionTransformer(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=(224, 224), patch_size=(8, 16), in_chans=3, num_classes=1000, embed_dim=(192, 384), depth=([1, 3, 1], [1, 3, 1], [1, 3, 1]),
num_heads=(6, 12), mlp_ratio=(2., 2., 4.), qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm, multi_conv=False):
super().__init__()
self.num_classes = num_classes
if not isinstance(img_size, list):
img_size = to_2tuple(img_size)
self.img_size = img_size
num_patches = _compute_num_patches(img_size, patch_size)
self.num_branches = len(patch_size)
self.patch_embed = nn.ModuleList()
if hybrid_backbone is None:
self.pos_embed = nn.ParameterList([nn.Parameter(torch.zeros(1, 1 + num_patches[i], embed_dim[i])) for i in range(self.num_branches)])
for im_s, p, d in zip(img_size, patch_size, embed_dim):
self.patch_embed.append(PatchEmbed(img_size=im_s, patch_size=p, in_chans=in_chans, embed_dim=d, multi_conv=multi_conv))
else:
self.pos_embed = nn.ParameterList()
from .t2t import T2T, get_sinusoid_encoding
tokens_type = 'transformer' if hybrid_backbone == 't2t' else 'performer'
for idx, (im_s, p, d) in enumerate(zip(img_size, patch_size, embed_dim)):
self.patch_embed.append(T2T(im_s, tokens_type=tokens_type, patch_size=p, embed_dim=d))
self.pos_embed.append(nn.Parameter(data=get_sinusoid_encoding(n_position=1 + num_patches[idx], d_hid=embed_dim[idx]), requires_grad=False))
del self.pos_embed
self.pos_embed = nn.ParameterList([nn.Parameter(torch.zeros(1, 1 + num_patches[i], embed_dim[i])) for i in range(self.num_branches)])
self.cls_token = nn.ParameterList([nn.Parameter(torch.zeros(1, 1, embed_dim[i])) for i in range(self.num_branches)])
self.pos_drop = nn.Dropout(p=drop_rate)
total_depth = sum([sum(x[-2:]) for x in depth])
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, total_depth)] # stochastic depth decay rule
dpr_ptr = 0
self.blocks = nn.ModuleList()
for idx, block_cfg in enumerate(depth):
curr_depth = max(block_cfg[:-1]) + block_cfg[-1]
dpr_ = dpr[dpr_ptr:dpr_ptr + curr_depth]
blk = MultiScaleBlock(embed_dim, num_patches, block_cfg, num_heads=num_heads, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr_,
norm_layer=norm_layer)
dpr_ptr += curr_depth
self.blocks.append(blk)
self.norm = nn.ModuleList([norm_layer(embed_dim[i]) for i in range(self.num_branches)])
self.head = nn.ModuleList([nn.Linear(embed_dim[i], num_classes) if num_classes > 0 else nn.Identity() for i in range(self.num_branches)])
for i in range(self.num_branches):
if self.pos_embed[i].requires_grad:
trunc_normal_(self.pos_embed[i], std=.02)
trunc_normal_(self.cls_token[i], std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
out = {'cls_token'}
if self.pos_embed[0].requires_grad:
out.add('pos_embed')
return out
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B, C, H, W = x.shape
xs = []
for i in range(self.num_branches):
x_ = torch.nn.functional.interpolate(x, size=(self.img_size[i], self.img_size[i]), mode='bicubic') if H != self.img_size[i] else x
tmp = self.patch_embed[i](x_)
cls_tokens = self.cls_token[i].expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
tmp = torch.cat((cls_tokens, tmp), dim=1)
tmp = tmp + self.pos_embed[i]
tmp = self.pos_drop(tmp)
xs.append(tmp)
for blk in self.blocks:
xs = blk(xs)
# NOTE: was before branch token section, move to here to assure all branch token are before layer norm
xs = [self.norm[i](x) for i, x in enumerate(xs)]
out = [x[:, 0] for x in xs]
return out
def forward(self, x):
xs = self.forward_features(x)
ce_logits = [self.head[i](x) for i, x in enumerate(xs)]
ce_logits = torch.mean(torch.stack(ce_logits, dim=0), dim=0)
return ce_logits
@register_model
def crossvit_tiny_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[96, 192], depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[3, 3], mlp_ratio=[4, 4, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_tiny_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_small_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[192, 384], depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6], mlp_ratio=[4, 4, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_small_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_base_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[384, 768], depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[12, 12], mlp_ratio=[4, 4, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_base_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_9_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[128, 256], depth=[[1, 3, 0], [1, 3, 0], [1, 3, 0]],
num_heads=[4, 4], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_9_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_15_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[192, 384], depth=[[1, 5, 0], [1, 5, 0], [1, 5, 0]],
num_heads=[6, 6], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_15_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_18_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[224, 448], depth=[[1, 6, 0], [1, 6, 0], [1, 6, 0]],
num_heads=[7, 7], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_18_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_9_dagger_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[128, 256], depth=[[1, 3, 0], [1, 3, 0], [1, 3, 0]],
num_heads=[4, 4], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), multi_conv=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_9_dagger_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_15_dagger_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[192, 384], depth=[[1, 5, 0], [1, 5, 0], [1, 5, 0]],
num_heads=[6, 6], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), multi_conv=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_15_dagger_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_15_dagger_384(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[408, 384],
patch_size=[12, 16], embed_dim=[192, 384], depth=[[1, 5, 0], [1, 5, 0], [1, 5, 0]],
num_heads=[6, 6], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), multi_conv=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_15_dagger_384'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_18_dagger_224(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[240, 224],
patch_size=[12, 16], embed_dim=[224, 448], depth=[[1, 6, 0], [1, 6, 0], [1, 6, 0]],
num_heads=[7, 7], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), multi_conv=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_18_dagger_224'], map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def crossvit_18_dagger_384(pretrained=False, **kwargs):
model = VisionTransformer(img_size=[408, 384],
patch_size=[12, 16], embed_dim=[224, 448], depth=[[1, 6, 0], [1, 6, 0], [1, 6, 0]],
num_heads=[7, 7], mlp_ratio=[3, 3, 1], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), multi_conv=True, **kwargs)
model.default_cfg = _cfg()
if pretrained:
state_dict = torch.hub.load_state_dict_from_url(_model_urls['crossvit_18_dagger_384'], map_location='cpu')
model.load_state_dict(state_dict)
return model
if __name__ == "__main__":
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[240, 224],
patch_size=[12, 16],
embed_dim=[192, 384],
depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6],
mlp_ratio=[4, 4, 1],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/DViT.py
================================================
"""
Code for DeepViT. The implementation has heavy reference to timm.
"""
import torch
import torch.nn as nn
from functools import partial
import pickle
from torch.nn.parameter import Parameter
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.helpers import load_pretrained
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.resnet import resnet26d, resnet50d
from timm.models.registry import register_model
import torch.nn.init as init
import torch.nn.functional as F
from torch.nn import functional as F
import numpy as np
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0., expansion_ratio=3):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.fc2 = nn.Linear(hidden_features, out_features)
self.act = act_layer()
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., expansion_ratio=3):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.expansion = expansion_ratio
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * self.expansion, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, atten=None):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x, attn
class ReAttention(nn.Module):
"""
It is observed that similarity along same batch of data is extremely large.
Thus can reduce the bs dimension when calculating the attention map.
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.,expansion_ratio = 3, apply_transform=True, transform_scale=False):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.apply_transform = apply_transform
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
if apply_transform:
self.reatten_matrix = nn.Conv2d(self.num_heads,self.num_heads, 1, 1)
self.var_norm = nn.BatchNorm2d(self.num_heads)
self.qkv = nn.Linear(dim, dim * expansion_ratio, bias=qkv_bias)
self.reatten_scale = self.scale if transform_scale else 1.0
else:
self.qkv = nn.Linear(dim, dim * expansion_ratio, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x, atten=None):
B, N, C = x.shape
# x = self.fc(x)
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
if self.apply_transform:
attn = self.var_norm(self.reatten_matrix(attn)) * self.reatten_scale
attn_next = attn
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x, attn_next
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, expansion=3,
group = False, share = False, re_atten=False, bs=False, apply_transform=False,
scale_adjustment=1.0, transform_scale=False):
super().__init__()
self.norm1 = norm_layer(dim)
self.re_atten = re_atten
self.adjust_ratio = scale_adjustment
self.dim = dim
if self.re_atten:
self.attn = ReAttention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
expansion_ratio = expansion, apply_transform=apply_transform, transform_scale=transform_scale)
else:
self.attn = Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop,
expansion_ratio = expansion)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, atten=None):
if self.re_atten:
x_new, atten = self.attn(self.norm1(x * self.adjust_ratio), atten)
x = x + self.drop_path(x_new/self.adjust_ratio)
x = x + self.drop_path(self.mlp(self.norm2(x * self.adjust_ratio))) / self.adjust_ratio
return x, atten
else:
x_new, atten = self.attn(self.norm1(x), atten)
x= x + self.drop_path(x_new)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x, atten
class PatchEmbed_CNN(nn.Module):
"""
Following T2T, we use 3 layers of CNN for comparison with other methods.
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768,spp=32):
super().__init__()
new_patch_size = to_2tuple(patch_size // 2)
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.conv1 = nn.Conv2d(in_chans, 64, kernel_size=7, stride=2, padding=3, bias=False) # 112x112
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1, bias=False) # 112x112
self.bn2 = nn.BatchNorm2d(64)
self.proj = nn.Conv2d(64, embed_dim, kernel_size=new_patch_size, stride=new_patch_size)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.proj(x).flatten(2).transpose(1, 2) # [B, C, W, H]
return x
class PatchEmbed(nn.Module):
"""
Same embedding as timm lib.
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class HybridEmbed(nn.Module):
"""
Same embedding as timm lib.
"""
def __init__(self, backbone, img_size=224, feature_size=None, in_chans=3, embed_dim=768):
super().__init__()
assert isinstance(backbone, nn.Module)
img_size = to_2tuple(img_size)
self.img_size = img_size
self.backbone = backbone
if feature_size is None:
with torch.no_grad():
training = backbone.training
if training:
backbone.eval()
o = self.backbone(torch.zeros(1, in_chans, img_size[0], img_size[1]))[-1]
feature_size = o.shape[-2:]
feature_dim = o.shape[1]
backbone.train(training)
else:
feature_size = to_2tuple(feature_size)
feature_dim = self.backbone.feature_info.channels()[-1]
self.num_patches = feature_size[0] * feature_size[1]
self.proj = nn.Linear(feature_dim, embed_dim)
def forward(self, x):
x = self.backbone(x)[-1]
x = x.flatten(2).transpose(1, 2)
x = self.proj(x)
return x
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
# patch models
'Deepvit_base_patch16_224_16B': _cfg(
url='',
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
),
'Deepvit_base_patch16_224_24B': _cfg(
url='',
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
),
'Deepvit_base_patch16_224_32B': _cfg(
url='',
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
),
'Deepvit_L_384': _cfg(
url='',
input_size=(3, 384, 384), mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5), crop_pct=1.0),
}
class DeepVisionTransformer(nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., hybrid_backbone=None, norm_layer=nn.LayerNorm, group = False, re_atten=True, cos_reg = False,
use_cnn_embed=False, apply_transform=None, transform_scale=False, scale_adjustment=1.):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
# use cosine similarity as a regularization term
self.cos_reg = cos_reg
if hybrid_backbone is not None:
self.patch_embed = HybridEmbed(
hybrid_backbone, img_size=img_size, in_chans=in_chans, embed_dim=embed_dim)
else:
if use_cnn_embed:
self.patch_embed = PatchEmbed_CNN(img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
else:
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
d = depth if isinstance(depth, int) else len(depth)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, d)] # stochastic depth decay rule
self.blocks = nn.ModuleList([
Block(
dim=embed_dim, share=depth[i], num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, group = group,
re_atten=re_atten, apply_transform=apply_transform[i], transform_scale=transform_scale, scale_adjustment=scale_adjustment)
for i in range(len(depth))])
self.norm = norm_layer(embed_dim)
# Classifier head
self.head = nn.Linear(embed_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
if self.cos_reg:
atten_list = []
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
x = torch.cat((cls_tokens, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
attn = None
for blk in self.blocks:
x, attn = blk(x, attn)
if self.cos_reg:
atten_list.append(attn)
x = self.norm(x)
if self.cos_reg and self.training:
return x[:, 0], atten_list
else:
return x[:, 0]
def forward(self, x):
if self.cos_reg and self.training:
x, atten = self.forward_features(x)
x = self.head(x)
return x, atten
else:
x = self.forward_features(x)
x = self.head(x)
return x
@register_model
def deepvit_patch16_224_re_attn_16b(pretrained=False, **kwargs):
apply_transform = [False] * 0 + [True] * 16
model = DeepVisionTransformer(
patch_size=16, embed_dim=384, depth=[False] * 16, apply_transform=apply_transform, num_heads=12, mlp_ratio=3, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
# We following the same settings for original ViT
model.default_cfg = default_cfgs['Deepvit_base_patch16_224_16B']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
@register_model
def deepvit_patch16_224_re_attn_24b(pretrained=False, **kwargs):
apply_transform = [False] * 0 + [True] * 24
model = DeepVisionTransformer(
patch_size=16, embed_dim=384, depth=[False] * 24, apply_transform=apply_transform, num_heads=12, mlp_ratio=3, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
# We following the same settings for original ViT
model.default_cfg = default_cfgs['Deepvit_base_patch16_224_24B']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
@register_model
def deepvit_patch16_224_re_attn_32b(pretrained=False, **kwargs):
apply_transform = [False] * 0 + [True] * 32
model = DeepVisionTransformer(
patch_size=16, embed_dim=384, depth=[False] * 32, apply_transform=apply_transform, num_heads=12, mlp_ratio=3, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
# We following the same settings for original ViT
model.default_cfg = default_cfgs['Deepvit_base_patch16_224_32B']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
@register_model
def deepvit_S(pretrained=False, **kwargs):
apply_transform = [False] * 11 + [True] * 5
model = DeepVisionTransformer(
patch_size=16, embed_dim=396, depth=[False] * 16, apply_transform=apply_transform, num_heads=12, mlp_ratio=3, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), transform_scale=True, use_cnn_embed = True, scale_adjustment=0.5, **kwargs)
# We following the same settings for original ViT
model.default_cfg = default_cfgs['Deepvit_base_patch16_224_32B']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
@register_model
def deepvit_L(pretrained=False, **kwargs):
apply_transform = [False] * 20 + [True] * 12
model = DeepVisionTransformer(
patch_size=16, embed_dim=420, depth=[False] * 32, apply_transform=apply_transform, num_heads=12, mlp_ratio=3, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), use_cnn_embed = True, scale_adjustment=0.5, **kwargs)
# We following the same settings for original ViT
model.default_cfg = default_cfgs['Deepvit_base_patch16_224_32B']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
@register_model
def deepvit_L_384(pretrained=False, **kwargs):
apply_transform = [False] * 20 + [True] * 12
model = DeepVisionTransformer(
img_size=384, patch_size=16, embed_dim=420, depth=[False] * 32, apply_transform=apply_transform, num_heads=12, mlp_ratio=3, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), use_cnn_embed = True, scale_adjustment=0.5, **kwargs)
# We following the same settings for original ViT
model.default_cfg = default_cfgs['Deepvit_L_384']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DeepVisionTransformer(
patch_size=16, embed_dim=384,
depth=[False] * 16,
apply_transform=[False] * 0 + [True] * 32,
num_heads=12,
mlp_ratio=3,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/DeiT.py
================================================
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
import torch
import torch.nn as nn
import numpy as np
from functools import partial
from timm.models.vision_transformer import VisionTransformer, _cfg
from timm.models.registry import register_model
from timm.models.layers import trunc_normal_
__all__ = [
'deit_tiny_patch16_224', 'deit_small_patch16_224', 'deit_base_patch16_224',
'deit_tiny_distilled_patch16_224', 'deit_small_distilled_patch16_224',
'deit_base_distilled_patch16_224', 'deit_base_patch16_384',
'deit_base_distilled_patch16_384',
]
class DistilledVisionTransformer(VisionTransformer):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.dist_token = nn.Parameter(torch.zeros(1, 1, self.embed_dim))
num_patches = self.patch_embed.num_patches
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 2, self.embed_dim))
self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if self.num_classes > 0 else nn.Identity()
trunc_normal_(self.dist_token, std=.02)
trunc_normal_(self.pos_embed, std=.02)
self.head_dist.apply(self._init_weights)
def forward_features(self, x):
# taken from https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# with slight modifications to add the dist_token
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
dist_token = self.dist_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, dist_token, x), dim=1)
x = x + self.pos_embed
x = self.pos_drop(x)
for blk in self.blocks:
x = blk(x)
x = self.norm(x)
return x[:, 0], x[:, 1]
def forward(self, x):
x, x_dist = self.forward_features(x)
x = self.head(x)
x_dist = self.head_dist(x_dist)
if self.training:
return x, x_dist
else:
# during inference, return the average of both classifier predictions
return (x + x_dist) / 2
@register_model
def deit_tiny_patch16_224(pretrained=False, **kwargs):
model = VisionTransformer(
patch_size=16, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_tiny_patch16_224-a1311bcf.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_small_patch16_224(pretrained=False, **kwargs):
model = VisionTransformer(
patch_size=16, embed_dim=384, depth=12, num_heads=6, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_small_patch16_224-cd65a155.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_base_patch16_224(pretrained=False, **kwargs):
model = VisionTransformer(
patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_base_patch16_224-b5f2ef4d.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_tiny_distilled_patch16_224(pretrained=False, **kwargs):
model = DistilledVisionTransformer(
patch_size=16, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_tiny_distilled_patch16_224-b40b3cf7.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_small_distilled_patch16_224(pretrained=False, **kwargs):
model = DistilledVisionTransformer(
patch_size=16, embed_dim=384, depth=12, num_heads=6, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_small_distilled_patch16_224-649709d9.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_base_distilled_patch16_224(pretrained=False, **kwargs):
model = DistilledVisionTransformer(
patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_base_distilled_patch16_224-df68dfff.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_base_patch16_384(pretrained=False, **kwargs):
model = VisionTransformer(
img_size=384, patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_base_patch16_384-8de9b5d1.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
@register_model
def deit_base_distilled_patch16_384(pretrained=False, **kwargs):
model = DistilledVisionTransformer(
img_size=384, patch_size=16, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4, qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), **kwargs)
model.default_cfg = _cfg()
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/deit/deit_base_distilled_patch16_384-d0272ac0.pth",
map_location="cpu", check_hash=True
)
model.load_state_dict(checkpoint["model"])
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DistilledVisionTransformer(
patch_size=16,
embed_dim=384,
depth=12,
num_heads=6,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output[0].shape)
================================================
FILE: model/backbone/EfficientFormer.py
================================================
"""
EfficientFormer
"""
import os
import copy
import torch
import torch.nn as nn
from typing import Dict
import itertools
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
from timm.models.layers.helpers import to_2tuple
EfficientFormer_width = {
'l1': [48, 96, 224, 448],
'l3': [64, 128, 320, 512],
'l7': [96, 192, 384, 768],
}
EfficientFormer_depth = {
'l1': [3, 2, 6, 4],
'l3': [4, 4, 12, 6],
'l7': [6, 6, 18, 8],
}
class Attention(torch.nn.Module):
def __init__(self, dim=384, key_dim=32, num_heads=8,
attn_ratio=4,
resolution=7):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
self.qkv = nn.Linear(dim, h)
self.proj = nn.Linear(self.dh, dim)
points = list(itertools.product(range(resolution), range(resolution)))
N = len(points)
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N, N))
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def forward(self, x): # x (B,N,C)
B, N, C = x.shape
qkv = self.qkv(x)
q, k, v = qkv.reshape(B, N, self.num_heads, -1).split([self.key_dim, self.key_dim, self.d], dim=3)
q = q.permute(0, 2, 1, 3)
k = k.permute(0, 2, 1, 3)
v = v.permute(0, 2, 1, 3)
attn = (
(q @ k.transpose(-2, -1)) * self.scale
+
(self.attention_biases[:, self.attention_bias_idxs]
if self.training else self.ab)
)
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, self.dh)
x = self.proj(x)
return x
def stem(in_chs, out_chs):
return nn.Sequential(
nn.Conv2d(in_chs, out_chs // 2, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_chs // 2),
nn.ReLU(),
nn.Conv2d(out_chs // 2, out_chs, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_chs),
nn.ReLU(), )
class Embedding(nn.Module):
"""
Patch Embedding that is implemented by a layer of conv.
Input: tensor in shape [B, C, H, W]
Output: tensor in shape [B, C, H/stride, W/stride]
"""
def __init__(self, patch_size=16, stride=16, padding=0,
in_chans=3, embed_dim=768, norm_layer=nn.BatchNorm2d):
super().__init__()
patch_size = to_2tuple(patch_size)
stride = to_2tuple(stride)
padding = to_2tuple(padding)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size,
stride=stride, padding=padding)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
x = self.proj(x)
x = self.norm(x)
return x
class Flat(nn.Module):
def __init__(self, ):
super().__init__()
def forward(self, x):
x = x.flatten(2).transpose(1, 2)
return x
class Pooling(nn.Module):
"""
Implementation of pooling for PoolFormer
--pool_size: pooling size
"""
def __init__(self, pool_size=3):
super().__init__()
self.pool = nn.AvgPool2d(
pool_size, stride=1, padding=pool_size // 2, count_include_pad=False)
def forward(self, x):
return self.pool(x) - x
class LinearMlp(nn.Module):
""" MLP as used in Vision Transformer, MLP-Mixer and related networks
"""
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.drop1 = nn.Dropout(drop)
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop2 = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop1(x)
x = self.fc2(x)
x = self.drop2(x)
return x
class Mlp(nn.Module):
"""
Implementation of MLP with 1*1 convolutions.
Input: tensor with shape [B, C, H, W]
"""
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
self.norm1 = nn.BatchNorm2d(hidden_features)
self.norm2 = nn.BatchNorm2d(out_features)
def _init_weights(self, m):
if isinstance(m, nn.Conv2d):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.fc1(x)
x = self.norm1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.norm2(x)
x = self.drop(x)
return x
class Meta3D(nn.Module):
def __init__(self, dim, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.norm1 = norm_layer(dim)
self.token_mixer = Attention(dim)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = LinearMlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(0).unsqueeze(0)
* self.token_mixer(self.norm1(x)))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(0).unsqueeze(0)
* self.mlp(self.norm2(x)))
else:
x = x + self.drop_path(self.token_mixer(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class Meta4D(nn.Module):
def __init__(self, dim, pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU,
drop=0., drop_path=0.,
use_layer_scale=True, layer_scale_init_value=1e-5):
super().__init__()
self.token_mixer = Pooling(pool_size=pool_size)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. \
else nn.Identity()
self.use_layer_scale = use_layer_scale
if use_layer_scale:
self.layer_scale_1 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
self.layer_scale_2 = nn.Parameter(
layer_scale_init_value * torch.ones((dim)), requires_grad=True)
def forward(self, x):
if self.use_layer_scale:
x = x + self.drop_path(
self.layer_scale_1.unsqueeze(-1).unsqueeze(-1)
* self.token_mixer(x))
x = x + self.drop_path(
self.layer_scale_2.unsqueeze(-1).unsqueeze(-1)
* self.mlp(x))
else:
x = x + self.drop_path(self.token_mixer(x))
x = x + self.drop_path(self.mlp(x))
return x
def meta_blocks(dim, index, layers,
pool_size=3, mlp_ratio=4.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm,
drop_rate=.0, drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5, vit_num=1):
blocks = []
if index == 3 and vit_num == layers[index]:
blocks.append(Flat())
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (
block_idx + sum(layers[:index])) / (sum(layers) - 1)
if index == 3 and layers[index] - block_idx <= vit_num:
blocks.append(Meta3D(
dim, mlp_ratio=mlp_ratio,
act_layer=act_layer, norm_layer=norm_layer,
drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
))
else:
blocks.append(Meta4D(
dim, pool_size=pool_size, mlp_ratio=mlp_ratio,
act_layer=act_layer,
drop=drop_rate, drop_path=block_dpr,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
))
if index == 3 and layers[index] - block_idx - 1 == vit_num:
blocks.append(Flat())
blocks = nn.Sequential(*blocks)
return blocks
class EfficientFormer(nn.Module):
def __init__(self, layers, embed_dims=None,
mlp_ratios=4, downsamples=None,
pool_size=3,
norm_layer=nn.LayerNorm, act_layer=nn.GELU,
num_classes=1000,
down_patch_size=3, down_stride=2, down_pad=1,
drop_rate=0., drop_path_rate=0.,
use_layer_scale=True, layer_scale_init_value=1e-5,
fork_feat=False,
init_cfg=None,
pretrained=None,
vit_num=0,
distillation=True,
**kwargs):
super().__init__()
if not fork_feat:
self.num_classes = num_classes
self.fork_feat = fork_feat
self.patch_embed = stem(3, embed_dims[0])
network = []
for i in range(len(layers)):
stage = meta_blocks(embed_dims[i], i, layers,
pool_size=pool_size, mlp_ratio=mlp_ratios,
act_layer=act_layer, norm_layer=norm_layer,
drop_rate=drop_rate,
drop_path_rate=drop_path_rate,
use_layer_scale=use_layer_scale,
layer_scale_init_value=layer_scale_init_value,
vit_num=vit_num)
network.append(stage)
if i >= len(layers) - 1:
break
if downsamples[i] or embed_dims[i] != embed_dims[i + 1]:
# downsampling between two stages
network.append(
Embedding(
patch_size=down_patch_size, stride=down_stride,
padding=down_pad,
in_chans=embed_dims[i], embed_dim=embed_dims[i + 1]
)
)
self.network = nn.ModuleList(network)
if self.fork_feat:
# add a norm layer for each output
self.out_indices = [0, 2, 4, 6]
for i_emb, i_layer in enumerate(self.out_indices):
if i_emb == 0 and os.environ.get('FORK_LAST3', None):
layer = nn.Identity()
else:
layer = norm_layer(embed_dims[i_emb])
layer_name = f'norm{i_layer}'
self.add_module(layer_name, layer)
else:
# Classifier head
self.norm = norm_layer(embed_dims[-1])
self.head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 \
else nn.Identity()
self.dist = distillation
if self.dist:
self.dist_head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 \
else nn.Identity()
self.apply(self.cls_init_weights)
self.init_cfg = copy.deepcopy(init_cfg)
# load pre-trained model
if self.fork_feat and (
self.init_cfg is not None or pretrained is not None):
self.init_weights()
# init for classification
def cls_init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
# init for mmdetection or mmsegmentation by loading
# imagenet pre-trained weights
def init_weights(self, pretrained=None):
logger = get_root_logger()
if self.init_cfg is None and pretrained is None:
logger.warn(f'No pre-trained weights for '
f'{self.__class__.__name__}, '
f'training start from scratch')
pass
else:
assert 'checkpoint' in self.init_cfg, f'Only support ' \
f'specify `Pretrained` in ' \
f'`init_cfg` in ' \
f'{self.__class__.__name__} '
if self.init_cfg is not None:
ckpt_path = self.init_cfg['checkpoint']
elif pretrained is not None:
ckpt_path = pretrained
ckpt = _load_checkpoint(
ckpt_path, logger=logger, map_location='cpu')
if 'state_dict' in ckpt:
_state_dict = ckpt['state_dict']
elif 'model' in ckpt:
_state_dict = ckpt['model']
else:
_state_dict = ckpt
state_dict = _state_dict
missing_keys, unexpected_keys = \
self.load_state_dict(state_dict, False)
def forward_tokens(self, x):
outs = []
for idx, block in enumerate(self.network):
x = block(x)
if self.fork_feat and idx in self.out_indices:
norm_layer = getattr(self, f'norm{idx}')
x_out = norm_layer(x)
outs.append(x_out)
if self.fork_feat:
return outs
return x
def forward(self, x):
x = self.patch_embed(x)
x = self.forward_tokens(x)
if self.fork_feat:
# otuput features of four stages for dense prediction
return x
x = self.norm(x)
if self.dist:
cls_out = self.head(x.mean(-2)), self.dist_head(x.mean(-2))
if not self.training:
cls_out = (cls_out[0] + cls_out[1]) / 2
else:
cls_out = self.head(x.mean(-2))
# for image classification
return cls_out
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .95, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'classifier': 'head',
**kwargs
}
@register_model
def efficientformer_l1(pretrained=False, **kwargs):
model = EfficientFormer(
layers=EfficientFormer_depth['l1'],
embed_dims=EfficientFormer_width['l1'],
downsamples=[True, True, True, True],
vit_num=1,
**kwargs)
model.default_cfg = _cfg(crop_pct=0.9)
return model
@register_model
def efficientformer_l3(pretrained=False, **kwargs):
model = EfficientFormer(
layers=EfficientFormer_depth['l3'],
embed_dims=EfficientFormer_width['l3'],
downsamples=[True, True, True, True],
vit_num=4,
**kwargs)
model.default_cfg = _cfg(crop_pct=0.9)
return model
@register_model
def efficientformer_l7(pretrained=False, **kwargs):
model = EfficientFormer(
layers=EfficientFormer_depth['l7'],
embed_dims=EfficientFormer_width['l7'],
downsamples=[True, True, True, True],
vit_num=8,
**kwargs)
model.default_cfg = _cfg(crop_pct=0.9)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = EfficientFormer(
layers=EfficientFormer_depth['l1'],
embed_dims=EfficientFormer_width['l1'],
downsamples=[True, True, True, True],
vit_num=1,
)
output=model(input)
print(output[0].shape)
================================================
FILE: model/backbone/HATNet.py
================================================
from pyexpat import model
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
class InvertedResidual(nn.Module):
def __init__(self, in_dim, hidden_dim=None, out_dim=None, kernel_size=3,
drop=0., act_layer=nn.SiLU):
super().__init__()
hidden_dim = hidden_dim or in_dim
out_dim = out_dim or in_dim
pad = (kernel_size - 1) // 2
self.conv1 = nn.Sequential(
nn.GroupNorm(1, in_dim, eps=1e-6),
nn.Conv2d(in_dim, hidden_dim, 1, bias=False),
act_layer(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(hidden_dim, hidden_dim, kernel_size, padding=pad, groups=hidden_dim, bias=False),
act_layer(inplace=True)
)
self.conv3 = nn.Sequential(
nn.Conv2d(hidden_dim, out_dim, 1, bias=False),
nn.GroupNorm(1, out_dim, eps=1e-6)
)
self.drop = nn.Dropout2d(drop, inplace=True)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.drop(x)
x = self.conv3(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, head_dim, grid_size=1, ds_ratio=1, drop=0.):
super().__init__()
assert dim % head_dim == 0
self.num_heads = dim // head_dim
self.head_dim = head_dim
self.scale = self.head_dim ** -0.5
self.grid_size = grid_size
self.norm = nn.GroupNorm(1, dim, eps=1e-6)
self.qkv = nn.Conv2d(dim, dim * 3, 1)
self.proj = nn.Conv2d(dim, dim, 1)
self.proj_norm = nn.GroupNorm(1, dim, eps=1e-6)
self.drop = nn.Dropout2d(drop, inplace=True)
if grid_size > 1:
self.grid_norm = nn.GroupNorm(1, dim, eps=1e-6)
self.avg_pool = nn.AvgPool2d(ds_ratio, stride=ds_ratio)
self.ds_norm = nn.GroupNorm(1, dim, eps=1e-6)
self.q = nn.Conv2d(dim, dim, 1)
self.kv = nn.Conv2d(dim, dim * 2, 1)
def forward(self, x):
B, C, H, W = x.shape
qkv = self.qkv(self.norm(x))
if self.grid_size > 1:
grid_h, grid_w = H // self.grid_size, W // self.grid_size
qkv = qkv.reshape(B, 3, self.num_heads, self.head_dim, grid_h,
self.grid_size, grid_w, self.grid_size)
qkv = qkv.permute(1, 0, 2, 4, 6, 5, 7, 3)
qkv = qkv.reshape(3, -1, self.grid_size * self.grid_size, self.head_dim)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q * self.scale) @ k.transpose(-2, -1)
attn = attn.softmax(dim=-1)
grid_x = (attn @ v).reshape(B, self.num_heads, grid_h, grid_w,
self.grid_size, self.grid_size, self.head_dim)
grid_x = grid_x.permute(0, 1, 6, 2, 4, 3, 5).reshape(B, C, H, W)
grid_x = self.grid_norm(x + grid_x)
q = self.q(grid_x).reshape(B, self.num_heads, self.head_dim, -1)
q = q.transpose(-2, -1)
kv = self.kv(self.ds_norm(self.avg_pool(grid_x)))
kv = kv.reshape(B, 2, self.num_heads, self.head_dim, -1)
kv = kv.permute(1, 0, 2, 4, 3)
k, v = kv[0], kv[1]
else:
qkv = qkv.reshape(B, 3, self.num_heads, self.head_dim, -1)
qkv = qkv.permute(1, 0, 2, 4, 3)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q * self.scale) @ k.transpose(-2, -1)
attn = attn.softmax(dim=-1)
global_x = (attn @ v).transpose(-2, -1).reshape(B, C, H, W)
if self.grid_size > 1:
global_x = global_x + grid_x
x = self.drop(self.proj(global_x))
return x
class Block(nn.Module):
def __init__(self, dim, head_dim, grid_size=1, ds_ratio=1, expansion=4,
drop=0., drop_path=0., kernel_size=3, act_layer=nn.SiLU):
super().__init__()
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.attn = Attention(dim, head_dim, grid_size=grid_size, ds_ratio=ds_ratio, drop=drop)
self.conv = InvertedResidual(dim, hidden_dim=dim * expansion, out_dim=dim,
kernel_size=kernel_size, drop=drop, act_layer=act_layer)
def forward(self, x):
x = x + self.drop_path(self.attn(x))
x = x + self.drop_path(self.conv(x))
return x
class Downsample(nn.Module):
def __init__(self, in_dim, out_dim, kernel_size=3):
super().__init__()
self.conv = nn.Conv2d(in_dim, out_dim, kernel_size, padding=1, stride=2)
self.norm = nn.GroupNorm(1, out_dim, eps=1e-6)
def forward(self, x):
x = self.norm(self.conv(x))
return x
class HATNet(nn.Module):
def __init__(self, img_size=224, in_chans=3, num_classes=1000, dims=[64, 128, 256, 512],
head_dim=64, expansions=[4, 4, 6, 6], grid_sizes=[1, 1, 1, 1],
ds_ratios=[8, 4, 2, 1], depths=[3, 4, 8, 3], drop_rate=0.,
drop_path_rate=0., act_layer=nn.SiLU, kernel_sizes=[3, 3, 3, 3]):
super().__init__()
self.depths = depths
self.patch_embed = nn.Sequential(
nn.Conv2d(3, 16, 3, padding=1, stride=2),
nn.GroupNorm(1, 16, eps=1e-6),
act_layer(inplace=True),
nn.Conv2d(16, dims[0], 3, padding=1, stride=2),
)
self.blocks = []
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
for stage in range(len(dims)):
self.blocks.append(nn.ModuleList([Block(
dims[stage], head_dim, grid_size=grid_sizes[stage], ds_ratio=ds_ratios[stage],
expansion=expansions[stage], drop=drop_rate, drop_path=dpr[sum(depths[:stage]) + i],
kernel_size=kernel_sizes[stage], act_layer=act_layer)
for i in range(depths[stage])]))
self.blocks = nn.ModuleList(self.blocks)
self.ds2 = Downsample(dims[0], dims[1])
self.ds3 = Downsample(dims[1], dims[2])
self.ds4 = Downsample(dims[2], dims[3])
self.classifier = nn.Sequential(
nn.Dropout(0.2, inplace=True),
nn.Linear(dims[-1], num_classes),
)
# init weights
self.apply(self._init_weights)
def reset_drop_path(self, drop_path_rate):
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(self.depths))]
cur = 0
for stage in range(len(self.blocks)):
for idx in range(self.depths[stage]):
self.blocks[stage][idx].drop_path.drop_prob = dpr[cur + idx]
cur += self.depths[stage]
def _init_weights(self, m):
if isinstance(m, (nn.Linear, nn.Conv2d)):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, (nn.LayerNorm, nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def forward(self, x):
x = self.patch_embed(x)
for block in self.blocks[0]:
x = block(x)
x = self.ds2(x)
for block in self.blocks[1]:
x = block(x)
x = self.ds3(x)
for block in self.blocks[2]:
x = block(x)
x = self.ds4(x)
for block in self.blocks[3]:
x = block(x)
x = F.adaptive_avg_pool2d(x, (1, 1)).flatten(1)
x = self.classifier(x)
return x
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
hat = HATNet(dims=[48, 96, 240, 384], head_dim=48, expansions=[8, 8, 4, 4],
grid_sizes=[8, 7, 7, 1], ds_ratios=[8, 4, 2, 1], depths=[2, 2, 6, 3])
output=hat(input)
print(output.shape)
================================================
FILE: model/backbone/LeViT.py
================================================
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
# Modified from
# https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
# Copyright 2020 Ross Wightman, Apache-2.0 License
import torch
import itertools
# import utils
from timm.models.vision_transformer import trunc_normal_
from timm.models.registry import register_model
def replace_batchnorm(net):
for child_name, child in net.named_children():
if hasattr(child, 'fuse'):
setattr(net, child_name, child.fuse())
elif isinstance(child, torch.nn.Conv2d):
child.bias = torch.nn.Parameter(torch.zeros(child.weight.size(0)))
elif isinstance(child, torch.nn.BatchNorm2d):
setattr(net, child_name, torch.nn.Identity())
else:
replace_batchnorm(child)
specification = {
'LeViT_128S': {
'C': '128_256_384', 'D': 16, 'N': '4_6_8', 'X': '2_3_4', 'drop_path': 0,
'weights': 'https://dl.fbaipublicfiles.com/LeViT/LeViT-128S-96703c44.pth'},
'LeViT_128': {
'C': '128_256_384', 'D': 16, 'N': '4_8_12', 'X': '4_4_4', 'drop_path': 0,
'weights': 'https://dl.fbaipublicfiles.com/LeViT/LeViT-128-b88c2750.pth'},
'LeViT_192': {
'C': '192_288_384', 'D': 32, 'N': '3_5_6', 'X': '4_4_4', 'drop_path': 0,
'weights': 'https://dl.fbaipublicfiles.com/LeViT/LeViT-192-92712e41.pth'},
'LeViT_256': {
'C': '256_384_512', 'D': 32, 'N': '4_6_8', 'X': '4_4_4', 'drop_path': 0,
'weights': 'https://dl.fbaipublicfiles.com/LeViT/LeViT-256-13b5763e.pth'},
'LeViT_384': {
'C': '384_512_768', 'D': 32, 'N': '6_9_12', 'X': '4_4_4', 'drop_path': 0.1,
'weights': 'https://dl.fbaipublicfiles.com/LeViT/LeViT-384-9bdaf2e2.pth'},
}
__all__ = [specification.keys()]
@register_model
def LeViT_128S(num_classes=1000, distillation=True,
pretrained=False, fuse=False):
return model_factory(**specification['LeViT_128S'], num_classes=num_classes,
distillation=distillation, pretrained=pretrained, fuse=fuse)
@register_model
def LeViT_128(num_classes=1000, distillation=True,
pretrained=False, fuse=False):
return model_factory(**specification['LeViT_128'], num_classes=num_classes,
distillation=distillation, pretrained=pretrained, fuse=fuse)
@register_model
def LeViT_192(num_classes=1000, distillation=True,
pretrained=False, fuse=False):
return model_factory(**specification['LeViT_192'], num_classes=num_classes,
distillation=distillation, pretrained=pretrained, fuse=fuse)
@register_model
def LeViT_256(num_classes=1000, distillation=True,
pretrained=False, fuse=False):
return model_factory(**specification['LeViT_256'], num_classes=num_classes,
distillation=distillation, pretrained=pretrained, fuse=fuse)
@register_model
def LeViT_384(num_classes=1000, distillation=True,
pretrained=False, fuse=False):
return model_factory(**specification['LeViT_384'], num_classes=num_classes,
distillation=distillation, pretrained=pretrained, fuse=fuse)
FLOPS_COUNTER = 0
class Conv2d_BN(torch.nn.Sequential):
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
groups=1, bn_weight_init=1, resolution=-10000):
super().__init__()
self.add_module('c', torch.nn.Conv2d(
a, b, ks, stride, pad, dilation, groups, bias=False))
bn = torch.nn.BatchNorm2d(b)
torch.nn.init.constant_(bn.weight, bn_weight_init)
torch.nn.init.constant_(bn.bias, 0)
self.add_module('bn', bn)
global FLOPS_COUNTER
output_points = ((resolution + 2 * pad - dilation *
(ks - 1) - 1) // stride + 1)**2
FLOPS_COUNTER += a * b * output_points * (ks**2) // groups
@torch.no_grad()
def fuse(self):
c, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
w = c.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps)**0.5
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation, groups=self.c.groups)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
class Linear_BN(torch.nn.Sequential):
def __init__(self, a, b, bn_weight_init=1, resolution=-100000):
super().__init__()
self.add_module('c', torch.nn.Linear(a, b, bias=False))
bn = torch.nn.BatchNorm1d(b)
torch.nn.init.constant_(bn.weight, bn_weight_init)
torch.nn.init.constant_(bn.bias, 0)
self.add_module('bn', bn)
global FLOPS_COUNTER
output_points = resolution**2
FLOPS_COUNTER += a * b * output_points
@torch.no_grad()
def fuse(self):
l, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
w = l.weight * w[:, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps)**0.5
m = torch.nn.Linear(w.size(1), w.size(0))
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
def forward(self, x):
l, bn = self._modules.values()
x = l(x)
return bn(x.flatten(0, 1)).reshape_as(x)
class BN_Linear(torch.nn.Sequential):
def __init__(self, a, b, bias=True, std=0.02):
super().__init__()
self.add_module('bn', torch.nn.BatchNorm1d(a))
l = torch.nn.Linear(a, b, bias=bias)
trunc_normal_(l.weight, std=std)
if bias:
torch.nn.init.constant_(l.bias, 0)
self.add_module('l', l)
global FLOPS_COUNTER
FLOPS_COUNTER += a * b
@torch.no_grad()
def fuse(self):
bn, l = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps)**0.5
b = bn.bias - self.bn.running_mean * \
self.bn.weight / (bn.running_var + bn.eps)**0.5
w = l.weight * w[None, :]
if l.bias is None:
b = b @ self.l.weight.T
else:
b = (l.weight @ b[:, None]).view(-1) + self.l.bias
m = torch.nn.Linear(w.size(1), w.size(0))
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
def b16(n, activation, resolution=224):
return torch.nn.Sequential(
Conv2d_BN(3, n // 8, 3, 2, 1, resolution=resolution),
activation(),
Conv2d_BN(n // 8, n // 4, 3, 2, 1, resolution=resolution // 2),
activation(),
Conv2d_BN(n // 4, n // 2, 3, 2, 1, resolution=resolution // 4),
activation(),
Conv2d_BN(n // 2, n, 3, 2, 1, resolution=resolution // 8))
class Residual(torch.nn.Module):
def __init__(self, m, drop):
super().__init__()
self.m = m
self.drop = drop
def forward(self, x):
if self.training and self.drop > 0:
return x + self.m(x) * torch.rand(x.size(0), 1, 1,
device=x.device).ge_(self.drop).div(1 - self.drop).detach()
else:
return x + self.m(x)
class Attention(torch.nn.Module):
def __init__(self, dim, key_dim, num_heads=8,
attn_ratio=4,
activation=None,
resolution=14):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * num_heads
self.attn_ratio = attn_ratio
h = self.dh + nh_kd * 2
self.qkv = Linear_BN(dim, h, resolution=resolution)
self.proj = torch.nn.Sequential(activation(), Linear_BN(
self.dh, dim, bn_weight_init=0, resolution=resolution))
points = list(itertools.product(range(resolution), range(resolution)))
N = len(points)
attention_offsets = {}
idxs = []
for p1 in points:
for p2 in points:
offset = (abs(p1[0] - p2[0]), abs(p1[1] - p2[1]))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N, N))
global FLOPS_COUNTER
#queries * keys
FLOPS_COUNTER += num_heads * (resolution**4) * key_dim
# softmax
FLOPS_COUNTER += num_heads * (resolution**4)
#attention * v
FLOPS_COUNTER += num_heads * self.d * (resolution**4)
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def forward(self, x): # x (B,N,C)
B, N, C = x.shape
qkv = self.qkv(x)
q, k, v = qkv.view(B, N, self.num_heads, -
1).split([self.key_dim, self.key_dim, self.d], dim=3)
q = q.permute(0, 2, 1, 3)
k = k.permute(0, 2, 1, 3)
v = v.permute(0, 2, 1, 3)
attn = (
(q @ k.transpose(-2, -1)) * self.scale
+
(self.attention_biases[:, self.attention_bias_idxs]
if self.training else self.ab)
)
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, N, self.dh)
x = self.proj(x)
return x
class Subsample(torch.nn.Module):
def __init__(self, stride, resolution):
super().__init__()
self.stride = stride
self.resolution = resolution
def forward(self, x):
B, N, C = x.shape
x = x.view(B, self.resolution, self.resolution, C)[
:, ::self.stride, ::self.stride].reshape(B, -1, C)
return x
class AttentionSubsample(torch.nn.Module):
def __init__(self, in_dim, out_dim, key_dim, num_heads=8,
attn_ratio=2,
activation=None,
stride=2,
resolution=14, resolution_=7):
super().__init__()
self.num_heads = num_heads
self.scale = key_dim ** -0.5
self.key_dim = key_dim
self.nh_kd = nh_kd = key_dim * num_heads
self.d = int(attn_ratio * key_dim)
self.dh = int(attn_ratio * key_dim) * self.num_heads
self.attn_ratio = attn_ratio
self.resolution_ = resolution_
self.resolution_2 = resolution_**2
h = self.dh + nh_kd
self.kv = Linear_BN(in_dim, h, resolution=resolution)
self.q = torch.nn.Sequential(
Subsample(stride, resolution),
Linear_BN(in_dim, nh_kd, resolution=resolution_))
self.proj = torch.nn.Sequential(activation(), Linear_BN(
self.dh, out_dim, resolution=resolution_))
self.stride = stride
self.resolution = resolution
points = list(itertools.product(range(resolution), range(resolution)))
points_ = list(itertools.product(
range(resolution_), range(resolution_)))
N = len(points)
N_ = len(points_)
attention_offsets = {}
idxs = []
for p1 in points_:
for p2 in points:
size = 1
offset = (
abs(p1[0] * stride - p2[0] + (size - 1) / 2),
abs(p1[1] * stride - p2[1] + (size - 1) / 2))
if offset not in attention_offsets:
attention_offsets[offset] = len(attention_offsets)
idxs.append(attention_offsets[offset])
self.attention_biases = torch.nn.Parameter(
torch.zeros(num_heads, len(attention_offsets)))
self.register_buffer('attention_bias_idxs',
torch.LongTensor(idxs).view(N_, N))
global FLOPS_COUNTER
#queries * keys
FLOPS_COUNTER += num_heads * \
(resolution**2) * (resolution_**2) * key_dim
# softmax
FLOPS_COUNTER += num_heads * (resolution**2) * (resolution_**2)
#attention * v
FLOPS_COUNTER += num_heads * \
(resolution**2) * (resolution_**2) * self.d
@torch.no_grad()
def train(self, mode=True):
super().train(mode)
if mode and hasattr(self, 'ab'):
del self.ab
else:
self.ab = self.attention_biases[:, self.attention_bias_idxs]
def forward(self, x):
B, N, C = x.shape
k, v = self.kv(x).view(B, N, self.num_heads, -
1).split([self.key_dim, self.d], dim=3)
k = k.permute(0, 2, 1, 3) # BHNC
v = v.permute(0, 2, 1, 3) # BHNC
q = self.q(x).view(B, self.resolution_2, self.num_heads,
self.key_dim).permute(0, 2, 1, 3)
attn = (q @ k.transpose(-2, -1)) * self.scale + \
(self.attention_biases[:, self.attention_bias_idxs]
if self.training else self.ab)
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, -1, self.dh)
x = self.proj(x)
return x
class LeViT(torch.nn.Module):
""" Vision Transformer with support for patch or hybrid CNN input stage
"""
def __init__(self, img_size=224,
patch_size=16,
in_chans=3,
num_classes=1000,
embed_dim=[192],
key_dim=[64],
depth=[12],
num_heads=[3],
attn_ratio=[2],
mlp_ratio=[2],
hybrid_backbone=None,
down_ops=[],
attention_activation=torch.nn.Hardswish,
mlp_activation=torch.nn.Hardswish,
distillation=True,
drop_path=0):
super().__init__()
global FLOPS_COUNTER
self.num_classes = num_classes
self.num_features = embed_dim[-1]
self.embed_dim = embed_dim
self.distillation = distillation
self.patch_embed = hybrid_backbone
self.blocks = []
down_ops.append([''])
resolution = img_size // patch_size
for i, (ed, kd, dpth, nh, ar, mr, do) in enumerate(
zip(embed_dim, key_dim, depth, num_heads, attn_ratio, mlp_ratio, down_ops)):
for _ in range(dpth):
self.blocks.append(
Residual(Attention(
ed, kd, nh,
attn_ratio=ar,
activation=attention_activation,
resolution=resolution,
), drop_path))
if mr > 0:
h = int(ed * mr)
self.blocks.append(
Residual(torch.nn.Sequential(
Linear_BN(ed, h, resolution=resolution),
mlp_activation(),
Linear_BN(h, ed, bn_weight_init=0,
resolution=resolution),
), drop_path))
if do[0] == 'Subsample':
#('Subsample',key_dim, num_heads, attn_ratio, mlp_ratio, stride)
resolution_ = (resolution - 1) // do[5] + 1
self.blocks.append(
AttentionSubsample(
*embed_dim[i:i + 2], key_dim=do[1], num_heads=do[2],
attn_ratio=do[3],
activation=attention_activation,
stride=do[5],
resolution=resolution,
resolution_=resolution_))
resolution = resolution_
if do[4] > 0: # mlp_ratio
h = int(embed_dim[i + 1] * do[4])
self.blocks.append(
Residual(torch.nn.Sequential(
Linear_BN(embed_dim[i + 1], h,
resolution=resolution),
mlp_activation(),
Linear_BN(
h, embed_dim[i + 1], bn_weight_init=0, resolution=resolution),
), drop_path))
self.blocks = torch.nn.Sequential(*self.blocks)
# Classifier head
self.head = BN_Linear(
embed_dim[-1], num_classes) if num_classes > 0 else torch.nn.Identity()
if distillation:
self.head_dist = BN_Linear(
embed_dim[-1], num_classes) if num_classes > 0 else torch.nn.Identity()
self.FLOPS = FLOPS_COUNTER
FLOPS_COUNTER = 0
@torch.jit.ignore
def no_weight_decay(self):
return {x for x in self.state_dict().keys() if 'attention_biases' in x}
def forward(self, x):
x = self.patch_embed(x)
x = x.flatten(2).transpose(1, 2)
x = self.blocks(x)
x = x.mean(1)
if self.distillation:
x = self.head(x), self.head_dist(x)
if not self.training:
x = (x[0] + x[1]) / 2
else:
x = self.head(x)
return x
def model_factory(C, D, X, N, drop_path, weights,
num_classes, distillation, pretrained, fuse):
embed_dim = [int(x) for x in C.split('_')]
num_heads = [int(x) for x in N.split('_')]
depth = [int(x) for x in X.split('_')]
act = torch.nn.Hardswish
model = LeViT(
patch_size=16,
embed_dim=embed_dim,
num_heads=num_heads,
key_dim=[D] * 3,
depth=depth,
attn_ratio=[2, 2, 2],
mlp_ratio=[2, 2, 2],
down_ops=[
#('Subsample',key_dim, num_heads, attn_ratio, mlp_ratio, stride)
['Subsample', D, embed_dim[0] // D, 4, 2, 2],
['Subsample', D, embed_dim[1] // D, 4, 2, 2],
],
attention_activation=act,
mlp_activation=act,
hybrid_backbone=b16(embed_dim[0], activation=act),
num_classes=num_classes,
drop_path=drop_path,
distillation=distillation
)
if pretrained:
checkpoint = torch.hub.load_state_dict_from_url(
weights, map_location='cpu')
model.load_state_dict(checkpoint['model'])
if fuse:
replace_batchnorm(model)
return model
if __name__ == '__main__':
for name in specification:
model = globals()[name](fuse=True, pretrained=False)
input=torch.randn(1,3,224,224)
model.eval()
output = model(input)
# print(name,
# model.FLOPS, 'FLOPs',
# sum(p.numel() for p in model.parameters() if p.requires_grad), 'parameters')
print(output.shape)
================================================
FILE: model/backbone/MobileNetV3.py
================================================
""" MobileNet V3
A PyTorch impl of MobileNet-V3, compatible with TF weights from official impl.
Paper: Searching for MobileNetV3 - https://arxiv.org/abs/1905.02244
Hacked together by / Copyright 2019, Ross Wightman
"""
from functools import partial
from typing import List
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD, IMAGENET_INCEPTION_MEAN, IMAGENET_INCEPTION_STD
from timm.layers import SelectAdaptivePool2d, Linear, create_conv2d, get_norm_act_layer
from ._builder import build_model_with_cfg, pretrained_cfg_for_features
from ._efficientnet_blocks import SqueezeExcite
from ._efficientnet_builder import EfficientNetBuilder, decode_arch_def, efficientnet_init_weights, \
round_channels, resolve_bn_args, resolve_act_layer, BN_EPS_TF_DEFAULT
from ._features import FeatureInfo, FeatureHooks
from ._manipulate import checkpoint_seq
from ._registry import register_model
__all__ = ['MobileNetV3', 'MobileNetV3Features']
def _cfg(url='', **kwargs):
return {
'url': url, 'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': (7, 7),
'crop_pct': 0.875, 'interpolation': 'bilinear',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'conv_stem', 'classifier': 'classifier',
**kwargs
}
default_cfgs = {
'mobilenetv3_large_075': _cfg(url=''),
'mobilenetv3_large_100': _cfg(
interpolation='bicubic',
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_large_100_ra-f55367f5.pth'),
'mobilenetv3_large_100_miil': _cfg(
interpolation='bilinear', mean=(0., 0., 0.), std=(1., 1., 1.),
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/mobilenetv3_large_100_1k_miil_78_0-66471c13.pth'),
'mobilenetv3_large_100_miil_in21k': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-tresnet/mobilenetv3_large_100_in21k_miil-d71cc17b.pth',
interpolation='bilinear', mean=(0., 0., 0.), std=(1., 1., 1.), num_classes=11221),
'mobilenetv3_small_050': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_small_050_lambc-4b7bbe87.pth',
interpolation='bicubic'),
'mobilenetv3_small_075': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_small_075_lambc-384766db.pth',
interpolation='bicubic'),
'mobilenetv3_small_100': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_small_100_lamb-266a294c.pth',
interpolation='bicubic'),
'mobilenetv3_rw': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/mobilenetv3_100-35495452.pth',
interpolation='bicubic'),
'tf_mobilenetv3_large_075': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_large_075-150ee8b0.pth',
mean=IMAGENET_INCEPTION_MEAN, std=IMAGENET_INCEPTION_STD),
'tf_mobilenetv3_large_100': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_large_100-427764d5.pth',
mean=IMAGENET_INCEPTION_MEAN, std=IMAGENET_INCEPTION_STD),
'tf_mobilenetv3_large_minimal_100': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_large_minimal_100-8596ae28.pth',
mean=IMAGENET_INCEPTION_MEAN, std=IMAGENET_INCEPTION_STD),
'tf_mobilenetv3_small_075': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_small_075-da427f52.pth',
mean=IMAGENET_INCEPTION_MEAN, std=IMAGENET_INCEPTION_STD),
'tf_mobilenetv3_small_100': _cfg(
url= 'https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_small_100-37f49e2b.pth',
mean=IMAGENET_INCEPTION_MEAN, std=IMAGENET_INCEPTION_STD),
'tf_mobilenetv3_small_minimal_100': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/tf_mobilenetv3_small_minimal_100-922a7843.pth',
mean=IMAGENET_INCEPTION_MEAN, std=IMAGENET_INCEPTION_STD),
'fbnetv3_b': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/fbnetv3_b_224-ead5d2a1.pth',
test_input_size=(3, 256, 256), crop_pct=0.95),
'fbnetv3_d': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/fbnetv3_d_224-c98bce42.pth',
test_input_size=(3, 256, 256), crop_pct=0.95),
'fbnetv3_g': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/fbnetv3_g_240-0b1df83b.pth',
input_size=(3, 240, 240), test_input_size=(3, 288, 288), crop_pct=0.95, pool_size=(8, 8)),
"lcnet_035": _cfg(),
"lcnet_050": _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/lcnet_050-f447553b.pth',
interpolation='bicubic',
),
"lcnet_075": _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/lcnet_075-318cad2c.pth',
interpolation='bicubic',
),
"lcnet_100": _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/lcnet_100-a929038c.pth',
interpolation='bicubic',
),
"lcnet_150": _cfg(),
}
class MobileNetV3(nn.Module):
""" MobiletNet-V3
Based on my EfficientNet implementation and building blocks, this model utilizes the MobileNet-v3 specific
'efficient head', where global pooling is done before the head convolution without a final batch-norm
layer before the classifier.
Paper: `Searching for MobileNetV3` - https://arxiv.org/abs/1905.02244
Other architectures utilizing MobileNet-V3 efficient head that are supported by this impl include:
* HardCoRe-NAS - https://arxiv.org/abs/2102.11646 (defn in hardcorenas.py uses this class)
* FBNet-V3 - https://arxiv.org/abs/2006.02049
* LCNet - https://arxiv.org/abs/2109.15099
"""
def __init__(
self, block_args, num_classes=1000, in_chans=3, stem_size=16, fix_stem=False, num_features=1280,
head_bias=True, pad_type='', act_layer=None, norm_layer=None, se_layer=None, se_from_exp=True,
round_chs_fn=round_channels, drop_rate=0., drop_path_rate=0., global_pool='avg'):
super(MobileNetV3, self).__init__()
act_layer = act_layer or nn.ReLU
norm_layer = norm_layer or nn.BatchNorm2d
norm_act_layer = get_norm_act_layer(norm_layer, act_layer)
se_layer = se_layer or SqueezeExcite
self.num_classes = num_classes
self.num_features = num_features
self.drop_rate = drop_rate
self.grad_checkpointing = False
# Stem
if not fix_stem:
stem_size = round_chs_fn(stem_size)
self.conv_stem = create_conv2d(in_chans, stem_size, 3, stride=2, padding=pad_type)
self.bn1 = norm_act_layer(stem_size, inplace=True)
# Middle stages (IR/ER/DS Blocks)
builder = EfficientNetBuilder(
output_stride=32, pad_type=pad_type, round_chs_fn=round_chs_fn, se_from_exp=se_from_exp,
act_layer=act_layer, norm_layer=norm_layer, se_layer=se_layer, drop_path_rate=drop_path_rate)
self.blocks = nn.Sequential(*builder(stem_size, block_args))
self.feature_info = builder.features
head_chs = builder.in_chs
# Head + Pooling
self.global_pool = SelectAdaptivePool2d(pool_type=global_pool)
num_pooled_chs = head_chs * self.global_pool.feat_mult()
self.conv_head = create_conv2d(num_pooled_chs, self.num_features, 1, padding=pad_type, bias=head_bias)
self.act2 = act_layer(inplace=True)
self.flatten = nn.Flatten(1) if global_pool else nn.Identity() # don't flatten if pooling disabled
self.classifier = Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
efficientnet_init_weights(self)
def as_sequential(self):
layers = [self.conv_stem, self.bn1]
layers.extend(self.blocks)
layers.extend([self.global_pool, self.conv_head, self.act2])
layers.extend([nn.Flatten(), nn.Dropout(self.drop_rate), self.classifier])
return nn.Sequential(*layers)
@torch.jit.ignore
def group_matcher(self, coarse=False):
return dict(
stem=r'^conv_stem|bn1',
blocks=r'^blocks\.(\d+)' if coarse else r'^blocks\.(\d+)\.(\d+)'
)
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
self.grad_checkpointing = enable
@torch.jit.ignore
def get_classifier(self):
return self.classifier
def reset_classifier(self, num_classes, global_pool='avg'):
self.num_classes = num_classes
# cannot meaningfully change pooling of efficient head after creation
self.global_pool = SelectAdaptivePool2d(pool_type=global_pool)
self.flatten = nn.Flatten(1) if global_pool else nn.Identity() # don't flatten if pooling disabled
self.classifier = Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
x = self.conv_stem(x)
x = self.bn1(x)
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint_seq(self.blocks, x, flatten=True)
else:
x = self.blocks(x)
return x
def forward_head(self, x, pre_logits: bool = False):
x = self.global_pool(x)
x = self.conv_head(x)
x = self.act2(x)
if pre_logits:
return x.flatten(1)
else:
x = self.flatten(x)
if self.drop_rate > 0.:
x = F.dropout(x, p=self.drop_rate, training=self.training)
return self.classifier(x)
def forward(self, x):
x = self.forward_features(x)
x = self.forward_head(x)
return x
class MobileNetV3Features(nn.Module):
""" MobileNetV3 Feature Extractor
A work-in-progress feature extraction module for MobileNet-V3 to use as a backbone for segmentation
and object detection models.
"""
def __init__(
self, block_args, out_indices=(0, 1, 2, 3, 4), feature_location='bottleneck', in_chans=3,
stem_size=16, fix_stem=False, output_stride=32, pad_type='', round_chs_fn=round_channels,
se_from_exp=True, act_layer=None, norm_layer=None, se_layer=None, drop_rate=0., drop_path_rate=0.):
super(MobileNetV3Features, self).__init__()
act_layer = act_layer or nn.ReLU
norm_layer = norm_layer or nn.BatchNorm2d
se_layer = se_layer or SqueezeExcite
self.drop_rate = drop_rate
# Stem
if not fix_stem:
stem_size = round_chs_fn(stem_size)
self.conv_stem = create_conv2d(in_chans, stem_size, 3, stride=2, padding=pad_type)
self.bn1 = norm_layer(stem_size)
self.act1 = act_layer(inplace=True)
# Middle stages (IR/ER/DS Blocks)
builder = EfficientNetBuilder(
output_stride=output_stride, pad_type=pad_type, round_chs_fn=round_chs_fn, se_from_exp=se_from_exp,
act_layer=act_layer, norm_layer=norm_layer, se_layer=se_layer,
drop_path_rate=drop_path_rate, feature_location=feature_location)
self.blocks = nn.Sequential(*builder(stem_size, block_args))
self.feature_info = FeatureInfo(builder.features, out_indices)
self._stage_out_idx = {v['stage']: i for i, v in enumerate(self.feature_info) if i in out_indices}
efficientnet_init_weights(self)
# Register feature extraction hooks with FeatureHooks helper
self.feature_hooks = None
if feature_location != 'bottleneck':
hooks = self.feature_info.get_dicts(keys=('module', 'hook_type'))
self.feature_hooks = FeatureHooks(hooks, self.named_modules())
def forward(self, x) -> List[torch.Tensor]:
x = self.conv_stem(x)
x = self.bn1(x)
x = self.act1(x)
if self.feature_hooks is None:
features = []
if 0 in self._stage_out_idx:
features.append(x) # add stem out
for i, b in enumerate(self.blocks):
x = b(x)
if i + 1 in self._stage_out_idx:
features.append(x)
return features
else:
self.blocks(x)
out = self.feature_hooks.get_output(x.device)
return list(out.values())
def _create_mnv3(variant, pretrained=False, **kwargs):
features_only = False
model_cls = MobileNetV3
kwargs_filter = None
if kwargs.pop('features_only', False):
features_only = True
kwargs_filter = ('num_classes', 'num_features', 'head_conv', 'head_bias', 'global_pool')
model_cls = MobileNetV3Features
model = build_model_with_cfg(
model_cls, variant, pretrained,
pretrained_strict=not features_only,
kwargs_filter=kwargs_filter,
**kwargs)
if features_only:
model.default_cfg = pretrained_cfg_for_features(model.default_cfg)
return model
def _gen_mobilenet_v3_rw(variant, channel_multiplier=1.0, pretrained=False, **kwargs):
"""Creates a MobileNet-V3 model.
Ref impl: ?
Paper: https://arxiv.org/abs/1905.02244
Args:
channel_multiplier: multiplier to number of channels per layer.
"""
arch_def = [
# stage 0, 112x112 in
['ds_r1_k3_s1_e1_c16_nre_noskip'], # relu
# stage 1, 112x112 in
['ir_r1_k3_s2_e4_c24_nre', 'ir_r1_k3_s1_e3_c24_nre'], # relu
# stage 2, 56x56 in
['ir_r3_k5_s2_e3_c40_se0.25_nre'], # relu
# stage 3, 28x28 in
['ir_r1_k3_s2_e6_c80', 'ir_r1_k3_s1_e2.5_c80', 'ir_r2_k3_s1_e2.3_c80'], # hard-swish
# stage 4, 14x14in
['ir_r2_k3_s1_e6_c112_se0.25'], # hard-swish
# stage 5, 14x14in
['ir_r3_k5_s2_e6_c160_se0.25'], # hard-swish
# stage 6, 7x7 in
['cn_r1_k1_s1_c960'], # hard-swish
]
model_kwargs = dict(
block_args=decode_arch_def(arch_def),
head_bias=False,
round_chs_fn=partial(round_channels, multiplier=channel_multiplier),
norm_layer=partial(nn.BatchNorm2d, **resolve_bn_args(kwargs)),
act_layer=resolve_act_layer(kwargs, 'hard_swish'),
se_layer=partial(SqueezeExcite, gate_layer='hard_sigmoid'),
**kwargs,
)
model = _create_mnv3(variant, pretrained, **model_kwargs)
return model
def _gen_mobilenet_v3(variant, channel_multiplier=1.0, pretrained=False, **kwargs):
"""Creates a MobileNet-V3 model.
Ref impl: ?
Paper: https://arxiv.org/abs/1905.02244
Args:
channel_multiplier: multiplier to number of channels per layer.
"""
if 'small' in variant:
num_features = 1024
if 'minimal' in variant:
act_layer = resolve_act_layer(kwargs, 'relu')
arch_def = [
# stage 0, 112x112 in
['ds_r1_k3_s2_e1_c16'],
# stage 1, 56x56 in
['ir_r1_k3_s2_e4.5_c24', 'ir_r1_k3_s1_e3.67_c24'],
# stage 2, 28x28 in
['ir_r1_k3_s2_e4_c40', 'ir_r2_k3_s1_e6_c40'],
# stage 3, 14x14 in
['ir_r2_k3_s1_e3_c48'],
# stage 4, 14x14in
['ir_r3_k3_s2_e6_c96'],
# stage 6, 7x7 in
['cn_r1_k1_s1_c576'],
]
else:
act_layer = resolve_act_layer(kwargs, 'hard_swish')
arch_def = [
# stage 0, 112x112 in
['ds_r1_k3_s2_e1_c16_se0.25_nre'], # relu
# stage 1, 56x56 in
['ir_r1_k3_s2_e4.5_c24_nre', 'ir_r1_k3_s1_e3.67_c24_nre'], # relu
# stage 2, 28x28 in
['ir_r1_k5_s2_e4_c40_se0.25', 'ir_r2_k5_s1_e6_c40_se0.25'], # hard-swish
# stage 3, 14x14 in
['ir_r2_k5_s1_e3_c48_se0.25'], # hard-swish
# stage 4, 14x14in
['ir_r3_k5_s2_e6_c96_se0.25'], # hard-swish
# stage 6, 7x7 in
['cn_r1_k1_s1_c576'], # hard-swish
]
else:
num_features = 1280
if 'minimal' in variant:
act_layer = resolve_act_layer(kwargs, 'relu')
arch_def = [
# stage 0, 112x112 in
['ds_r1_k3_s1_e1_c16'],
# stage 1, 112x112 in
['ir_r1_k3_s2_e4_c24', 'ir_r1_k3_s1_e3_c24'],
# stage 2, 56x56 in
['ir_r3_k3_s2_e3_c40'],
# stage 3, 28x28 in
['ir_r1_k3_s2_e6_c80', 'ir_r1_k3_s1_e2.5_c80', 'ir_r2_k3_s1_e2.3_c80'],
# stage 4, 14x14in
['ir_r2_k3_s1_e6_c112'],
# stage 5, 14x14in
['ir_r3_k3_s2_e6_c160'],
# stage 6, 7x7 in
['cn_r1_k1_s1_c960'],
]
else:
act_layer = resolve_act_layer(kwargs, 'hard_swish')
arch_def = [
# stage 0, 112x112 in
['ds_r1_k3_s1_e1_c16_nre'], # relu
# stage 1, 112x112 in
['ir_r1_k3_s2_e4_c24_nre', 'ir_r1_k3_s1_e3_c24_nre'], # relu
# stage 2, 56x56 in
['ir_r3_k5_s2_e3_c40_se0.25_nre'], # relu
# stage 3, 28x28 in
['ir_r1_k3_s2_e6_c80', 'ir_r1_k3_s1_e2.5_c80', 'ir_r2_k3_s1_e2.3_c80'], # hard-swish
# stage 4, 14x14in
['ir_r2_k3_s1_e6_c112_se0.25'], # hard-swish
# stage 5, 14x14in
['ir_r3_k5_s2_e6_c160_se0.25'], # hard-swish
# stage 6, 7x7 in
['cn_r1_k1_s1_c960'], # hard-swish
]
se_layer = partial(SqueezeExcite, gate_layer='hard_sigmoid', force_act_layer=nn.ReLU, rd_round_fn=round_channels)
model_kwargs = dict(
block_args=decode_arch_def(arch_def),
num_features=num_features,
stem_size=16,
fix_stem=channel_multiplier < 0.75,
round_chs_fn=partial(round_channels, multiplier=channel_multiplier),
norm_layer=partial(nn.BatchNorm2d, **resolve_bn_args(kwargs)),
act_layer=act_layer,
se_layer=se_layer,
**kwargs,
)
model = _create_mnv3(variant, pretrained, **model_kwargs)
return model
def _gen_fbnetv3(variant, channel_multiplier=1.0, pretrained=False, **kwargs):
""" FBNetV3
Paper: `FBNetV3: Joint Architecture-Recipe Search using Predictor Pretraining`
- https://arxiv.org/abs/2006.02049
FIXME untested, this is a preliminary impl of some FBNet-V3 variants.
"""
vl = variant.split('_')[-1]
if vl in ('a', 'b'):
stem_size = 16
arch_def = [
['ds_r2_k3_s1_e1_c16'],
['ir_r1_k5_s2_e4_c24', 'ir_r3_k5_s1_e2_c24'],
['ir_r1_k5_s2_e5_c40_se0.25', 'ir_r4_k5_s1_e3_c40_se0.25'],
['ir_r1_k5_s2_e5_c72', 'ir_r4_k3_s1_e3_c72'],
['ir_r1_k3_s1_e5_c120_se0.25', 'ir_r5_k5_s1_e3_c120_se0.25'],
['ir_r1_k3_s2_e6_c184_se0.25', 'ir_r5_k5_s1_e4_c184_se0.25', 'ir_r1_k5_s1_e6_c224_se0.25'],
['cn_r1_k1_s1_c1344'],
]
elif vl == 'd':
stem_size = 24
arch_def = [
['ds_r2_k3_s1_e1_c16'],
['ir_r1_k3_s2_e5_c24', 'ir_r5_k3_s1_e2_c24'],
['ir_r1_k5_s2_e4_c40_se0.25', 'ir_r4_k3_s1_e3_c40_se0.25'],
['ir_r1_k3_s2_e5_c72', 'ir_r4_k3_s1_e3_c72'],
['ir_r1_k3_s1_e5_c128_se0.25', 'ir_r6_k5_s1_e3_c128_se0.25'],
['ir_r1_k3_s2_e6_c208_se0.25', 'ir_r5_k5_s1_e5_c208_se0.25', 'ir_r1_k5_s1_e6_c240_se0.25'],
['cn_r1_k1_s1_c1440'],
]
elif vl == 'g':
stem_size = 32
arch_def = [
['ds_r3_k3_s1_e1_c24'],
['ir_r1_k5_s2_e4_c40', 'ir_r4_k5_s1_e2_c40'],
['ir_r1_k5_s2_e4_c56_se0.25', 'ir_r4_k5_s1_e3_c56_se0.25'],
['ir_r1_k5_s2_e5_c104', 'ir_r4_k3_s1_e3_c104'],
['ir_r1_k3_s1_e5_c160_se0.25', 'ir_r8_k5_s1_e3_c160_se0.25'],
['ir_r1_k3_s2_e6_c264_se0.25', 'ir_r6_k5_s1_e5_c264_se0.25', 'ir_r2_k5_s1_e6_c288_se0.25'],
['cn_r1_k1_s1_c1728'],
]
else:
raise NotImplemented
round_chs_fn = partial(round_channels, multiplier=channel_multiplier, round_limit=0.95)
se_layer = partial(SqueezeExcite, gate_layer='hard_sigmoid', rd_round_fn=round_chs_fn)
act_layer = resolve_act_layer(kwargs, 'hard_swish')
model_kwargs = dict(
block_args=decode_arch_def(arch_def),
num_features=1984,
head_bias=False,
stem_size=stem_size,
round_chs_fn=round_chs_fn,
se_from_exp=False,
norm_layer=partial(nn.BatchNorm2d, **resolve_bn_args(kwargs)),
act_layer=act_layer,
se_layer=se_layer,
**kwargs,
)
model = _create_mnv3(variant, pretrained, **model_kwargs)
return model
def _gen_lcnet(variant, channel_multiplier=1.0, pretrained=False, **kwargs):
""" LCNet
Essentially a MobileNet-V3 crossed with a MobileNet-V1
Paper: `PP-LCNet: A Lightweight CPU Convolutional Neural Network` - https://arxiv.org/abs/2109.15099
Args:
channel_multiplier: multiplier to number of channels per layer.
"""
arch_def = [
# stage 0, 112x112 in
['dsa_r1_k3_s1_c32'],
# stage 1, 112x112 in
['dsa_r2_k3_s2_c64'],
# stage 2, 56x56 in
['dsa_r2_k3_s2_c128'],
# stage 3, 28x28 in
['dsa_r1_k3_s2_c256', 'dsa_r1_k5_s1_c256'],
# stage 4, 14x14in
['dsa_r4_k5_s1_c256'],
# stage 5, 14x14in
['dsa_r2_k5_s2_c512_se0.25'],
# 7x7
]
model_kwargs = dict(
block_args=decode_arch_def(arch_def),
stem_size=16,
round_chs_fn=partial(round_channels, multiplier=channel_multiplier),
norm_layer=partial(nn.BatchNorm2d, **resolve_bn_args(kwargs)),
act_layer=resolve_act_layer(kwargs, 'hard_swish'),
se_layer=partial(SqueezeExcite, gate_layer='hard_sigmoid', force_act_layer=nn.ReLU),
num_features=1280,
**kwargs,
)
model = _create_mnv3(variant, pretrained, **model_kwargs)
return model
def _gen_lcnet(variant, channel_multiplier=1.0, pretrained=False, **kwargs):
""" LCNet
Essentially a MobileNet-V3 crossed with a MobileNet-V1
Paper: `PP-LCNet: A Lightweight CPU Convolutional Neural Network` - https://arxiv.org/abs/2109.15099
Args:
channel_multiplier: multiplier to number of channels per layer.
"""
arch_def = [
# stage 0, 112x112 in
['dsa_r1_k3_s1_c32'],
# stage 1, 112x112 in
['dsa_r2_k3_s2_c64'],
# stage 2, 56x56 in
['dsa_r2_k3_s2_c128'],
# stage 3, 28x28 in
['dsa_r1_k3_s2_c256', 'dsa_r1_k5_s1_c256'],
# stage 4, 14x14in
['dsa_r4_k5_s1_c256'],
# stage 5, 14x14in
['dsa_r2_k5_s2_c512_se0.25'],
# 7x7
]
model_kwargs = dict(
block_args=decode_arch_def(arch_def),
stem_size=16,
round_chs_fn=partial(round_channels, multiplier=channel_multiplier),
norm_layer=partial(nn.BatchNorm2d, **resolve_bn_args(kwargs)),
act_layer=resolve_act_layer(kwargs, 'hard_swish'),
se_layer=partial(SqueezeExcite, gate_layer='hard_sigmoid', force_act_layer=nn.ReLU),
num_features=1280,
**kwargs,
)
model = _create_mnv3(variant, pretrained, **model_kwargs)
return model
@register_model
def mobilenetv3_large_075(pretrained=False, **kwargs):
""" MobileNet V3 """
model = _gen_mobilenet_v3('mobilenetv3_large_075', 0.75, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_large_100(pretrained=False, **kwargs):
""" MobileNet V3 """
model = _gen_mobilenet_v3('mobilenetv3_large_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_large_100_miil(pretrained=False, **kwargs):
""" MobileNet V3
Weights taken from: https://github.com/Alibaba-MIIL/ImageNet21K
"""
model = _gen_mobilenet_v3('mobilenetv3_large_100_miil', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_large_100_miil_in21k(pretrained=False, **kwargs):
""" MobileNet V3, 21k pretraining
Weights taken from: https://github.com/Alibaba-MIIL/ImageNet21K
"""
model = _gen_mobilenet_v3('mobilenetv3_large_100_miil_in21k', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_small_050(pretrained=False, **kwargs):
""" MobileNet V3 """
model = _gen_mobilenet_v3('mobilenetv3_small_050', 0.50, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_small_075(pretrained=False, **kwargs):
""" MobileNet V3 """
model = _gen_mobilenet_v3('mobilenetv3_small_075', 0.75, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_small_100(pretrained=False, **kwargs):
""" MobileNet V3 """
model = _gen_mobilenet_v3('mobilenetv3_small_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def mobilenetv3_rw(pretrained=False, **kwargs):
""" MobileNet V3 """
if pretrained:
# pretrained model trained with non-default BN epsilon
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
model = _gen_mobilenet_v3_rw('mobilenetv3_rw', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def tf_mobilenetv3_large_075(pretrained=False, **kwargs):
""" MobileNet V3 """
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
kwargs['pad_type'] = 'same'
model = _gen_mobilenet_v3('tf_mobilenetv3_large_075', 0.75, pretrained=pretrained, **kwargs)
return model
@register_model
def tf_mobilenetv3_large_100(pretrained=False, **kwargs):
""" MobileNet V3 """
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
kwargs['pad_type'] = 'same'
model = _gen_mobilenet_v3('tf_mobilenetv3_large_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def tf_mobilenetv3_large_minimal_100(pretrained=False, **kwargs):
""" MobileNet V3 """
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
kwargs['pad_type'] = 'same'
model = _gen_mobilenet_v3('tf_mobilenetv3_large_minimal_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def tf_mobilenetv3_small_075(pretrained=False, **kwargs):
""" MobileNet V3 """
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
kwargs['pad_type'] = 'same'
model = _gen_mobilenet_v3('tf_mobilenetv3_small_075', 0.75, pretrained=pretrained, **kwargs)
return model
@register_model
def tf_mobilenetv3_small_100(pretrained=False, **kwargs):
""" MobileNet V3 """
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
kwargs['pad_type'] = 'same'
model = _gen_mobilenet_v3('tf_mobilenetv3_small_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def tf_mobilenetv3_small_minimal_100(pretrained=False, **kwargs):
""" MobileNet V3 """
kwargs['bn_eps'] = BN_EPS_TF_DEFAULT
kwargs['pad_type'] = 'same'
model = _gen_mobilenet_v3('tf_mobilenetv3_small_minimal_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def fbnetv3_b(pretrained=False, **kwargs):
""" FBNetV3-B """
model = _gen_fbnetv3('fbnetv3_b', pretrained=pretrained, **kwargs)
return model
@register_model
def fbnetv3_d(pretrained=False, **kwargs):
""" FBNetV3-D """
model = _gen_fbnetv3('fbnetv3_d', pretrained=pretrained, **kwargs)
return model
@register_model
def fbnetv3_g(pretrained=False, **kwargs):
""" FBNetV3-G """
model = _gen_fbnetv3('fbnetv3_g', pretrained=pretrained, **kwargs)
return model
@register_model
def lcnet_035(pretrained=False, **kwargs):
""" PP-LCNet 0.35"""
model = _gen_lcnet('lcnet_035', 0.35, pretrained=pretrained, **kwargs)
return model
@register_model
def lcnet_050(pretrained=False, **kwargs):
""" PP-LCNet 0.5"""
model = _gen_lcnet('lcnet_050', 0.5, pretrained=pretrained, **kwargs)
return model
@register_model
def lcnet_075(pretrained=False, **kwargs):
""" PP-LCNet 1.0"""
model = _gen_lcnet('lcnet_075', 0.75, pretrained=pretrained, **kwargs)
return model
@register_model
def lcnet_100(pretrained=False, **kwargs):
""" PP-LCNet 1.0"""
model = _gen_lcnet('lcnet_100', 1.0, pretrained=pretrained, **kwargs)
return model
@register_model
def lcnet_150(pretrained=False, **kwargs):
""" PP-LCNet 1.5"""
model = _gen_lcnet('lcnet_150', 1.5, pretrained=pretrained, **kwargs)
return model
================================================
FILE: model/backbone/MobileViT.py
================================================
from torch import nn
import torch
from torch.nn.modules import conv
from torch.nn.modules.conv import Conv2d
from einops import rearrange
def conv_bn(inp,oup,kernel_size=3,stride=1):
return nn.Sequential(
nn.Conv2d(inp,oup,kernel_size=kernel_size,stride=stride,padding=kernel_size//2),
nn.BatchNorm2d(oup),
nn.SiLU()
)
class PreNorm(nn.Module):
def __init__(self,dim,fn):
super().__init__()
self.ln=nn.LayerNorm(dim)
self.fn=fn
def forward(self,x,**kwargs):
return self.fn(self.ln(x),**kwargs)
class FeedForward(nn.Module):
def __init__(self,dim,mlp_dim,dropout) :
super().__init__()
self.net=nn.Sequential(
nn.Linear(dim,mlp_dim),
nn.SiLU(),
nn.Dropout(dropout),
nn.Linear(mlp_dim,dim),
nn.Dropout(dropout)
)
def forward(self,x):
return self.net(x)
class Attention(nn.Module):
def __init__(self,dim,heads,head_dim,dropout):
super().__init__()
inner_dim=heads*head_dim
project_out=not(heads==1 and head_dim==dim)
self.heads=heads
self.scale=head_dim**-0.5
self.attend=nn.Softmax(dim=-1)
self.to_qkv=nn.Linear(dim,inner_dim*3,bias=False)
self.to_out=nn.Sequential(
nn.Linear(inner_dim,dim),
nn.Dropout(dropout)
) if project_out else nn.Identity()
def forward(self,x):
qkv=self.to_qkv(x).chunk(3,dim=-1)
q,k,v=map(lambda t:rearrange(t,'b p n (h d) -> b p h n d',h=self.heads),qkv)
dots=torch.matmul(q,k.transpose(-1,-2))*self.scale
attn=self.attend(dots)
out=torch.matmul(attn,v)
out=rearrange(out,'b p h n d -> b p n (h d)')
return self.to_out(out)
class Transformer(nn.Module):
def __init__(self,dim,depth,heads,head_dim,mlp_dim,dropout=0.):
super().__init__()
self.layers=nn.ModuleList([])
for _ in range(depth):
self.layers.append(nn.ModuleList([
PreNorm(dim,Attention(dim,heads,head_dim,dropout)),
PreNorm(dim,FeedForward(dim,mlp_dim,dropout))
]))
def forward(self,x):
out=x
for att,ffn in self.layers:
out=out+att(out)
out=out+ffn(out)
return out
class MobileViTAttention(nn.Module):
def __init__(self,in_channel=3,dim=512,kernel_size=3,patch_size=7,depth=3,mlp_dim=1024):
super().__init__()
self.ph,self.pw=patch_size,patch_size
self.conv1=nn.Conv2d(in_channel,in_channel,kernel_size=kernel_size,padding=kernel_size//2)
self.conv2=nn.Conv2d(in_channel,dim,kernel_size=1)
self.trans=Transformer(dim=dim,depth=depth,heads=8,head_dim=64,mlp_dim=mlp_dim)
self.conv3=nn.Conv2d(dim,in_channel,kernel_size=1)
self.conv4=nn.Conv2d(2*in_channel,in_channel,kernel_size=kernel_size,padding=kernel_size//2)
def forward(self,x):
y=x.clone() #bs,c,h,w
## Local Representation
y=self.conv2(self.conv1(x)) #bs,dim,h,w
## Global Representation
_,_,h,w=y.shape
y=rearrange(y,'bs dim (nh ph) (nw pw) -> bs (ph pw) (nh nw) dim',ph=self.ph,pw=self.pw) #bs,h,w,dim
y=self.trans(y)
y=rearrange(y,'bs (ph pw) (nh nw) dim -> bs dim (nh ph) (nw pw)',ph=self.ph,pw=self.pw,nh=h//self.ph,nw=w//self.pw) #bs,dim,h,w
## Fusion
y=self.conv3(y) #bs,dim,h,w
y=torch.cat([x,y],1) #bs,2*dim,h,w
y=self.conv4(y) #bs,c,h,w
return y
class MV2Block(nn.Module):
def __init__(self,inp,out,stride=1,expansion=4):
super().__init__()
self.stride=stride
hidden_dim=inp*expansion
self.use_res_connection=stride==1 and inp==out
if expansion==1:
self.conv=nn.Sequential(
nn.Conv2d(hidden_dim,hidden_dim,kernel_size=3,stride=self.stride,padding=1,groups=hidden_dim,bias=False),
nn.BatchNorm2d(hidden_dim),
nn.SiLU(),
nn.Conv2d(hidden_dim,out,kernel_size=1,stride=1,bias=False),
nn.BatchNorm2d(out)
)
else:
self.conv=nn.Sequential(
nn.Conv2d(inp,hidden_dim,kernel_size=1,stride=1,bias=False),
nn.BatchNorm2d(hidden_dim),
nn.SiLU(),
nn.Conv2d(hidden_dim,hidden_dim,kernel_size=3,stride=1,padding=1,groups=hidden_dim,bias=False),
nn.BatchNorm2d(hidden_dim),
nn.SiLU(),
nn.Conv2d(hidden_dim,out,kernel_size=1,stride=1,bias=False),
nn.SiLU(),
nn.BatchNorm2d(out)
)
def forward(self,x):
if(self.use_res_connection):
out=x+self.conv(x)
else:
out=self.conv(x)
return out
class MobileViT(nn.Module):
def __init__(self,image_size,dims,channels,num_classes,depths=[2,4,3],expansion=4,kernel_size=3,patch_size=2):
super().__init__()
ih,iw=image_size,image_size
ph,pw=patch_size,patch_size
assert iw%pw==0 and ih%ph==0
self.conv1=conv_bn(3,channels[0],kernel_size=3,stride=patch_size)
self.mv2=nn.ModuleList([])
self.m_vits=nn.ModuleList([])
self.mv2.append(MV2Block(channels[0],channels[1],1))
self.mv2.append(MV2Block(channels[1],channels[2],2))
self.mv2.append(MV2Block(channels[2],channels[3],1))
self.mv2.append(MV2Block(channels[2],channels[3],1)) # x2
self.mv2.append(MV2Block(channels[3],channels[4],2))
self.m_vits.append(MobileViTAttention(channels[4],dim=dims[0],kernel_size=kernel_size,patch_size=patch_size,depth=depths[0],mlp_dim=int(2*dims[0])))
self.mv2.append(MV2Block(channels[4],channels[5],2))
self.m_vits.append(MobileViTAttention(channels[5],dim=dims[1],kernel_size=kernel_size,patch_size=patch_size,depth=depths[1],mlp_dim=int(4*dims[1])))
self.mv2.append(MV2Block(channels[5],channels[6],2))
self.m_vits.append(MobileViTAttention(channels[6],dim=dims[2],kernel_size=kernel_size,patch_size=patch_size,depth=depths[2],mlp_dim=int(4*dims[2])))
self.conv2=conv_bn(channels[-2],channels[-1],kernel_size=1)
self.pool=nn.AvgPool2d(image_size//32,1)
self.fc=nn.Linear(channels[-1],num_classes,bias=False)
def forward(self,x):
y=self.conv1(x) #
y=self.mv2[0](y)
y=self.mv2[1](y) #
y=self.mv2[2](y)
y=self.mv2[3](y)
y=self.mv2[4](y) #
y=self.m_vits[0](y)
y=self.mv2[5](y) #
y=self.m_vits[1](y)
y=self.mv2[6](y) #
y=self.m_vits[2](y)
y=self.conv2(y)
y=self.pool(y).view(y.shape[0],-1)
y=self.fc(y)
return y
def mobilevit_xxs():
dims=[60,80,96]
channels= [16, 16, 24, 24, 48, 64, 80, 320]
return MobileViT(224,dims,channels,num_classes=1000)
def mobilevit_xs():
dims = [96, 120, 144]
channels = [16, 32, 48, 48, 64, 80, 96, 384]
return MobileViT(224, dims, channels, num_classes=1000)
def mobilevit_s():
dims = [144, 192, 240]
channels = [16, 32, 64, 64, 96, 128, 160, 640]
return MobileViT(224, dims, channels, num_classes=1000)
def count_paratermeters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
### mobilevit_xxs
mvit_xxs=mobilevit_xxs()
out=mvit_xxs(input)
print(out.shape)
### mobilevit_xs
mvit_xs=mobilevit_xs()
out=mvit_xs(input)
print(out.shape)
### mobilevit_s
mvit_s=mobilevit_s()
out=mvit_s(input)
print(out.shape)
================================================
FILE: model/backbone/PIT.py
================================================
# PiT
# Copyright 2021-present NAVER Corp.
# Apache License v2.0
import torch
from einops import rearrange
from torch import nn
import math
from functools import partial
from timm.models.layers import trunc_normal_
from timm.models.vision_transformer import Block as transformer_block
from timm.models.registry import register_model
class Transformer(nn.Module):
def __init__(self, base_dim, depth, heads, mlp_ratio,
drop_rate=.0, attn_drop_rate=.0, drop_path_prob=None):
super(Transformer, self).__init__()
self.layers = nn.ModuleList([])
embed_dim = base_dim * heads
if drop_path_prob is None:
drop_path_prob = [0.0 for _ in range(depth)]
self.blocks = nn.ModuleList([
transformer_block(
dim=embed_dim,
num_heads=heads,
mlp_ratio=mlp_ratio,
qkv_bias=True,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=drop_path_prob[i],
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
for i in range(depth)])
def forward(self, x, cls_tokens):
h, w = x.shape[2:4]
x = rearrange(x, 'b c h w -> b (h w) c')
token_length = cls_tokens.shape[1]
x = torch.cat((cls_tokens, x), dim=1)
for blk in self.blocks:
x = blk(x)
cls_tokens = x[:, :token_length]
x = x[:, token_length:]
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
return x, cls_tokens
class conv_head_pooling(nn.Module):
def __init__(self, in_feature, out_feature, stride,
padding_mode='zeros'):
super(conv_head_pooling, self).__init__()
self.conv = nn.Conv2d(in_feature, out_feature, kernel_size=stride + 1,
padding=stride // 2, stride=stride,
padding_mode=padding_mode, groups=in_feature)
self.fc = nn.Linear(in_feature, out_feature)
def forward(self, x, cls_token):
x = self.conv(x)
cls_token = self.fc(cls_token)
return x, cls_token
class conv_embedding(nn.Module):
def __init__(self, in_channels, out_channels, patch_size,
stride, padding):
super(conv_embedding, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=patch_size,
stride=stride, padding=padding, bias=True)
def forward(self, x):
x = self.conv(x)
return x
class PoolingTransformer(nn.Module):
def __init__(self, image_size, patch_size, stride, base_dims, depth, heads,
mlp_ratio, num_classes=1000, in_chans=3,
attn_drop_rate=.0, drop_rate=.0, drop_path_rate=.0):
super(PoolingTransformer, self).__init__()
total_block = sum(depth)
padding = 0
block_idx = 0
width = math.floor(
(image_size + 2 * padding - patch_size) / stride + 1)
self.base_dims = base_dims
self.heads = heads
self.num_classes = num_classes
self.patch_size = patch_size
self.pos_embed = nn.Parameter(
torch.randn(1, base_dims[0] * heads[0], width, width),
requires_grad=True
)
self.patch_embed = conv_embedding(in_chans, base_dims[0] * heads[0],
patch_size, stride, padding)
self.cls_token = nn.Parameter(
torch.randn(1, 1, base_dims[0] * heads[0]),
requires_grad=True
)
self.pos_drop = nn.Dropout(p=drop_rate)
self.transformers = nn.ModuleList([])
self.pools = nn.ModuleList([])
for stage in range(len(depth)):
drop_path_prob = [drop_path_rate * i / total_block
for i in range(block_idx, block_idx + depth[stage])]
block_idx += depth[stage]
self.transformers.append(
Transformer(base_dims[stage], depth[stage], heads[stage],
mlp_ratio,
drop_rate, attn_drop_rate, drop_path_prob)
)
if stage < len(heads) - 1:
self.pools.append(
conv_head_pooling(base_dims[stage] * heads[stage],
base_dims[stage + 1] * heads[stage + 1],
stride=2
)
)
self.norm = nn.LayerNorm(base_dims[-1] * heads[-1], eps=1e-6)
self.embed_dim = base_dims[-1] * heads[-1]
# Classifier head
if num_classes > 0:
self.head = nn.Linear(base_dims[-1] * heads[-1], num_classes)
else:
self.head = nn.Identity()
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
if num_classes > 0:
self.head = nn.Linear(self.embed_dim, num_classes)
else:
self.head = nn.Identity()
def forward_features(self, x):
x = self.patch_embed(x)
pos_embed = self.pos_embed
x = self.pos_drop(x + pos_embed)
cls_tokens = self.cls_token.expand(x.shape[0], -1, -1)
for stage in range(len(self.pools)):
x, cls_tokens = self.transformers[stage](x, cls_tokens)
x, cls_tokens = self.pools[stage](x, cls_tokens)
x, cls_tokens = self.transformers[-1](x, cls_tokens)
cls_tokens = self.norm(cls_tokens)
return cls_tokens
def forward(self, x):
cls_token = self.forward_features(x)
cls_token = self.head(cls_token[:, 0])
return cls_token
class DistilledPoolingTransformer(PoolingTransformer):
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.cls_token = nn.Parameter(
torch.randn(1, 2, self.base_dims[0] * self.heads[0]),
requires_grad=True)
if self.num_classes > 0:
self.head_dist = nn.Linear(self.base_dims[-1] * self.heads[-1],
self.num_classes)
else:
self.head_dist = nn.Identity()
trunc_normal_(self.cls_token, std=.02)
self.head_dist.apply(self._init_weights)
def forward(self, x):
cls_token = self.forward_features(x)
x_cls = self.head(cls_token[:, 0])
x_dist = self.head_dist(cls_token[:, 1])
if self.training:
return x_cls, x_dist
else:
return (x_cls + x_dist) / 2
@register_model
def pit_b(pretrained, **kwargs):
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_b_820.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_s(pretrained, **kwargs):
model = PoolingTransformer(
image_size=224,
patch_size=16,
stride=8,
base_dims=[48, 48, 48],
depth=[2, 6, 4],
heads=[3, 6, 12],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_s_809.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_xs(pretrained, **kwargs):
model = PoolingTransformer(
image_size=224,
patch_size=16,
stride=8,
base_dims=[48, 48, 48],
depth=[2, 6, 4],
heads=[2, 4, 8],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_xs_781.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_ti(pretrained, **kwargs):
model = PoolingTransformer(
image_size=224,
patch_size=16,
stride=8,
base_dims=[32, 32, 32],
depth=[2, 6, 4],
heads=[2, 4, 8],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_ti_730.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_b_distilled(pretrained, **kwargs):
model = DistilledPoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_b_distill_840.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_s_distilled(pretrained, **kwargs):
model = DistilledPoolingTransformer(
image_size=224,
patch_size=16,
stride=8,
base_dims=[48, 48, 48],
depth=[2, 6, 4],
heads=[3, 6, 12],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_s_distill_819.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_xs_distilled(pretrained, **kwargs):
model = DistilledPoolingTransformer(
image_size=224,
patch_size=16,
stride=8,
base_dims=[48, 48, 48],
depth=[2, 6, 4],
heads=[2, 4, 8],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_xs_distill_791.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
@register_model
def pit_ti_distilled(pretrained, **kwargs):
model = DistilledPoolingTransformer(
image_size=224,
patch_size=16,
stride=8,
base_dims=[32, 32, 32],
depth=[2, 6, 4],
heads=[2, 4, 8],
mlp_ratio=4,
**kwargs
)
if pretrained:
state_dict = \
torch.load('weights/pit_ti_distill_746.pth', map_location='cpu')
model.load_state_dict(state_dict)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/PVT.py
================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
from timm.models.vision_transformer import _cfg
__all__ = [
'pvt_tiny', 'pvt_small', 'pvt_medium', 'pvt_large'
]
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
# assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
# f"img_size {img_size} should be divided by patch_size {patch_size}."
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
H, W = H // self.patch_size[0], W // self.patch_size[1]
return x, (H, W)
class PyramidVisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], num_stages=4):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.num_stages = num_stages
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
patch_embed = PatchEmbed(img_size=img_size if i == 0 else img_size // (2 ** (i + 1)),
patch_size=patch_size if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i])
num_patches = patch_embed.num_patches if i != num_stages - 1 else patch_embed.num_patches + 1
pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dims[i]))
pos_drop = nn.Dropout(p=drop_rate)
block = nn.ModuleList([Block(
dim=embed_dims[i], num_heads=num_heads[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + j],
norm_layer=norm_layer, sr_ratio=sr_ratios[i])
for j in range(depths[i])])
cur += depths[i]
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"pos_embed{i + 1}", pos_embed)
setattr(self, f"pos_drop{i + 1}", pos_drop)
setattr(self, f"block{i + 1}", block)
self.norm = norm_layer(embed_dims[3])
# cls_token
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dims[3]))
# classification head
self.head = nn.Linear(embed_dims[3], num_classes) if num_classes > 0 else nn.Identity()
# init weights
for i in range(num_stages):
pos_embed = getattr(self, f"pos_embed{i + 1}")
trunc_normal_(pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
# return {'pos_embed', 'cls_token'} # has pos_embed may be better
return {'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def _get_pos_embed(self, pos_embed, patch_embed, H, W):
if H * W == self.patch_embed1.num_patches:
return pos_embed
else:
return F.interpolate(
pos_embed.reshape(1, patch_embed.H, patch_embed.W, -1).permute(0, 3, 1, 2),
size=(H, W), mode="bilinear").reshape(1, -1, H * W).permute(0, 2, 1)
def forward_features(self, x):
B = x.shape[0]
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
pos_embed = getattr(self, f"pos_embed{i + 1}")
pos_drop = getattr(self, f"pos_drop{i + 1}")
block = getattr(self, f"block{i + 1}")
x, (H, W) = patch_embed(x)
if i == self.num_stages - 1:
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
pos_embed_ = self._get_pos_embed(pos_embed[:, 1:], patch_embed, H, W)
pos_embed = torch.cat((pos_embed[:, 0:1], pos_embed_), dim=1)
else:
pos_embed = self._get_pos_embed(pos_embed, patch_embed, H, W)
x = pos_drop(x + pos_embed)
for blk in block:
x = blk(x, H, W)
if i != self.num_stages - 1:
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
x = self.norm(x)
return x[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def _conv_filter(state_dict, patch_size=16):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k:
v = v.reshape((v.shape[0], 3, patch_size, patch_size))
out_dict[k] = v
return out_dict
@register_model
def pvt_tiny(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pvt_small(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], **kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pvt_medium(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 18, 3], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pvt_large(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 8, 27, 3], sr_ratios=[8, 4, 2, 1],
**kwargs)
model.default_cfg = _cfg()
return model
@register_model
def pvt_huge_v2(pretrained=False, **kwargs):
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[128, 256, 512, 768], num_heads=[2, 4, 8, 12], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 10, 60, 3], sr_ratios=[8, 4, 2, 1],
# drop_rate=0.0, drop_path_rate=0.02)
**kwargs)
model.default_cfg = _cfg()
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/PatchConvnet.py
================================================
# Copyright (c) 2015-present, Facebook, Inc.
# All rights reserved.
from functools import partial
from typing import Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.efficientnet_blocks import SqueezeExcite
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
__all__ = ['S60', 'S120', 'B60', 'B120', 'L60', 'L120', 'S60_multi']
class Mlp(nn.Module):
def __init__(
self,
in_features: int,
hidden_features: Optional[int] = None,
out_features: Optional[int] = None,
act_layer: nn.Module = nn.GELU,
drop: float = 0.0,
):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Learned_Aggregation_Layer(nn.Module):
def __init__(
self,
dim: int,
num_heads: int = 1,
qkv_bias: bool = False,
qk_scale: Optional[float] = None,
attn_drop: float = 0.0,
proj_drop: float = 0.0,
):
super().__init__()
self.num_heads = num_heads
head_dim: int = dim // num_heads
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim**-0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.k = nn.Linear(dim, dim, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.id = nn.Identity()
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, N, C = x.shape
q = self.q(x[:, 0]).unsqueeze(1).reshape(B, 1, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
k = self.k(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
q = q * self.scale
v = self.v(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
attn = q @ k.transpose(-2, -1)
attn = self.id(attn)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x_cls = (attn @ v).transpose(1, 2).reshape(B, 1, C)
x_cls = self.proj(x_cls)
x_cls = self.proj_drop(x_cls)
return x_cls
class Learned_Aggregation_Layer_multi(nn.Module):
def __init__(
self,
dim: int,
num_heads: int = 8,
qkv_bias: bool = False,
qk_scale: Optional[float] = None,
attn_drop: float = 0.0,
proj_drop: float = 0.0,
num_classes: int = 1000,
):
super().__init__()
self.num_heads = num_heads
head_dim: int = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.k = nn.Linear(dim, dim, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.num_classes = num_classes
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, N, C = x.shape
q = (
self.q(x[:, : self.num_classes])
.reshape(B, self.num_classes, self.num_heads, C // self.num_heads)
.permute(0, 2, 1, 3)
)
k = (
self.k(x[:, self.num_classes:])
.reshape(B, N - self.num_classes, self.num_heads, C // self.num_heads)
.permute(0, 2, 1, 3)
)
q = q * self.scale
v = (
self.v(x[:, self.num_classes:])
.reshape(B, N - self.num_classes, self.num_heads, C // self.num_heads)
.permute(0, 2, 1, 3)
)
attn = q @ k.transpose(-2, -1)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x_cls = (attn @ v).transpose(1, 2).reshape(B, self.num_classes, C)
x_cls = self.proj(x_cls)
x_cls = self.proj_drop(x_cls)
return x_cls
class Layer_scale_init_Block_only_token(nn.Module):
def __init__(
self,
dim: int,
num_heads: int,
mlp_ratio: float = 4.0,
qkv_bias: bool = False,
qk_scale: Optional[float] = None,
drop: float = 0.0,
attn_drop: float = 0.0,
drop_path: float = 0.0,
act_layer: nn.Module = nn.GELU,
norm_layer=nn.LayerNorm,
Attention_block=Learned_Aggregation_Layer,
Mlp_block=Mlp,
init_values: float = 1e-4,
):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention_block(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop
)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp_block(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
self.gamma_2 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
def forward(self, x: torch.Tensor, x_cls: torch.Tensor) -> torch.Tensor:
u = torch.cat((x_cls, x), dim=1)
x_cls = x_cls + self.drop_path(self.gamma_1 * self.attn(self.norm1(u)))
x_cls = x_cls + self.drop_path(self.gamma_2 * self.mlp(self.norm2(x_cls)))
return x_cls
class Conv_blocks_se(nn.Module):
def __init__(self, dim: int):
super().__init__()
self.qkv_pos = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=1),
nn.GELU(),
nn.Conv2d(dim, dim, groups=dim, kernel_size=3, padding=1, stride=1, bias=True),
nn.GELU(),
SqueezeExcite(dim, rd_ratio=0.25),
nn.Conv2d(dim, dim, kernel_size=1),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, N, C = x.shape
H = W = int(N ** 0.5)
x = x.transpose(-1, -2)
x = x.reshape(B, C, H, W)
x = self.qkv_pos(x)
x = x.reshape(B, C, N)
x = x.transpose(-1, -2)
return x
class Layer_scale_init_Block(nn.Module):
def __init__(
self,
dim: int,
drop_path: float = 0.0,
act_layer: nn.Module = nn.GELU,
norm_layer=nn.LayerNorm,
Attention_block=None,
init_values: float = 1e-4,
):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention_block(dim)
self.drop_path = DropPath(drop_path) if drop_path > 0.0 else nn.Identity()
self.gamma_1 = nn.Parameter(init_values * torch.ones((dim)), requires_grad=True)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return x + self.drop_path(self.gamma_1 * self.attn(self.norm1(x)))
def conv3x3(in_planes: int, out_planes: int, stride: int = 1) -> nn.Sequential:
"""3x3 convolution with padding"""
return nn.Sequential(
nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride, padding=1, bias=False),
)
class ConvStem(nn.Module):
"""Image to Patch Embedding"""
def __init__(self, img_size: int = 224, patch_size: int = 16, in_chans: int = 3, embed_dim: int = 768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.proj = nn.Sequential(
conv3x3(in_chans, embed_dim // 8, 2),
nn.GELU(),
conv3x3(embed_dim // 8, embed_dim // 4, 2),
nn.GELU(),
conv3x3(embed_dim // 4, embed_dim // 2, 2),
nn.GELU(),
conv3x3(embed_dim // 2, embed_dim, 2),
)
def forward(self, x: torch.Tensor, padding_size: Optional[int] = None) -> torch.Tensor:
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class PatchConvnet(nn.Module):
def __init__(
self,
img_size: int = 224,
patch_size: int = 16,
in_chans: int = 3,
num_classes: int = 1000,
embed_dim: int = 768,
depth: int = 12,
num_heads: int = 1,
qkv_bias: bool = False,
qk_scale: Optional[float] = None,
drop_rate: float = 0.0,
attn_drop_rate: float = 0.0,
drop_path_rate: float = 0.0,
norm_layer=nn.LayerNorm,
global_pool: Optional[str] = None,
block_layers=Layer_scale_init_Block,
block_layers_token=Layer_scale_init_Block_only_token,
Patch_layer=ConvStem,
act_layer: nn.Module = nn.GELU,
Attention_block=Conv_blocks_se,
dpr_constant: bool = True,
init_scale: float = 1e-4,
Attention_block_token_only=Learned_Aggregation_Layer,
Mlp_block_token_only=Mlp,
depth_token_only: int = 1,
mlp_ratio_clstk: float = 3.0,
multiclass: bool = False,
):
super().__init__()
self.multiclass = multiclass
self.patch_size = patch_size
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.patch_embed = Patch_layer(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim
)
if not self.multiclass:
self.cls_token = nn.Parameter(torch.zeros(1, 1, int(embed_dim)))
else:
self.cls_token = nn.Parameter(torch.zeros(1, num_classes, int(embed_dim)))
if not dpr_constant:
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)]
else:
dpr = [drop_path_rate for i in range(depth)]
self.blocks = nn.ModuleList(
[
block_layers(
dim=embed_dim,
drop_path=dpr[i],
norm_layer=norm_layer,
act_layer=act_layer,
Attention_block=Attention_block,
init_values=init_scale,
)
for i in range(depth)
]
)
self.blocks_token_only = nn.ModuleList(
[
block_layers_token(
dim=int(embed_dim),
num_heads=num_heads,
mlp_ratio=mlp_ratio_clstk,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=0.0,
norm_layer=norm_layer,
act_layer=act_layer,
Attention_block=Attention_block_token_only,
Mlp_block=Mlp_block_token_only,
init_values=init_scale,
)
for i in range(depth_token_only)
]
)
self.norm = norm_layer(int(embed_dim))
self.total_len = depth_token_only + depth
self.feature_info = [dict(num_chs=int(embed_dim), reduction=0, module='head')]
if not self.multiclass:
self.head = nn.Linear(int(embed_dim), num_classes) if num_classes > 0 else nn.Identity()
else:
self.head = nn.ModuleList([nn.Linear(int(embed_dim), 1) for _ in range(num_classes)])
self.rescale: float = 0.02
trunc_normal_(self.cls_token, std=self.rescale)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=self.rescale)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'cls_token'}
def get_classifier(self):
return self.head
def get_num_layers(self):
return len(self.blocks)
def reset_classifier(self, num_classes: int, global_pool: str = ''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x: torch.Tensor) -> torch.Tensor:
B = x.shape[0]
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(B, -1, -1)
for i, blk in enumerate(self.blocks):
x = blk(x)
for i, blk in enumerate(self.blocks_token_only):
cls_tokens = blk(x, cls_tokens)
x = torch.cat((cls_tokens, x), dim=1)
x = self.norm(x)
if not self.multiclass:
return x[:, 0]
else:
return x[:, : self.num_classes].reshape(B, self.num_classes, -1)
def forward(self, x: torch.Tensor) -> torch.Tensor:
B = x.shape[0]
x = self.forward_features(x)
if not self.multiclass:
x = self.head(x)
return x
else:
all_results = []
for i in range(self.num_classes):
all_results.append(self.head[i](x[:, i]))
return torch.cat(all_results, dim=1).reshape(B, self.num_classes)
@register_model
def S60(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
**kwargs
)
return model
@register_model
def S120(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=120,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
init_scale=1e-6,
mlp_ratio_clstk=3.0,
**kwargs
)
return model
@register_model
def B60(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=768,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Attention_block=Conv_blocks_se,
init_scale=1e-6,
**kwargs
)
return model
@register_model
def B120(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=768,
depth=120,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
init_scale=1e-6,
**kwargs
)
return model
@register_model
def L60(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=1024,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
init_scale=1e-6,
mlp_ratio_clstk=3.0,
**kwargs
)
return model
@register_model
def L120(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=1024,
depth=120,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
init_scale=1e-6,
mlp_ratio_clstk=3.0,
**kwargs
)
return model
@register_model
def S60_multi(pretrained: bool = False, **kwargs):
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
Attention_block_token_only=Learned_Aggregation_Layer_multi,
depth_token_only=1,
mlp_ratio_clstk=3.0,
multiclass=True,
**kwargs
)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/ShuffleTransformer.py
================================================
import torch
from torch import nn, einsum
from einops import rearrange, repeat
import torch.utils.checkpoint as checkpoint
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.ReLU6, drop=0., stride=False):
super().__init__()
self.stride = stride
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1, 1, 0, bias=True)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1, 1, 0, bias=True)
self.drop = nn.Dropout(drop, inplace=True)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads, window_size=1, shuffle=False, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., relative_pos_embedding=False):
super().__init__()
self.num_heads = num_heads
self.relative_pos_embedding = relative_pos_embedding
head_dim = dim // self.num_heads
self.ws = window_size
self.shuffle = shuffle
self.scale = qk_scale or head_dim ** -0.5
self.to_qkv = nn.Conv2d(dim, dim * 3, 1, bias=False)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Conv2d(dim, dim, 1)
self.proj_drop = nn.Dropout(proj_drop)
if self.relative_pos_embedding:
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size - 1) * (2 * window_size - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.ws)
coords_w = torch.arange(self.ws)
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.ws - 1 # shift to start from 0
relative_coords[:, :, 1] += self.ws - 1
relative_coords[:, :, 0] *= 2 * self.ws - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
trunc_normal_(self.relative_position_bias_table, std=.02)
# print('The relative_pos_embedding is used')
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x)
if self.shuffle:
q, k, v = rearrange(qkv, 'b (qkv h d) (ws1 hh) (ws2 ww) -> qkv (b hh ww) h (ws1 ws2) d', h=self.num_heads, qkv=3, ws1=self.ws, ws2=self.ws)
else:
q, k, v = rearrange(qkv, 'b (qkv h d) (hh ws1) (ww ws2) -> qkv (b hh ww) h (ws1 ws2) d', h=self.num_heads, qkv=3, ws1=self.ws, ws2=self.ws)
dots = (q @ k.transpose(-2, -1)) * self.scale
if self.relative_pos_embedding:
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.ws * self.ws, self.ws * self.ws, -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
dots += relative_position_bias.unsqueeze(0)
attn = dots.softmax(dim=-1)
out = attn @ v
if self.shuffle:
out = rearrange(out, '(b hh ww) h (ws1 ws2) d -> b (h d) (ws1 hh) (ws2 ww)', h=self.num_heads, b=b, hh=h//self.ws, ws1=self.ws, ws2=self.ws)
else:
out = rearrange(out, '(b hh ww) h (ws1 ws2) d -> b (h d) (hh ws1) (ww ws2)', h=self.num_heads, b=b, hh=h//self.ws, ws1=self.ws, ws2=self.ws)
out = self.proj(out)
out = self.proj_drop(out)
return out
class Block(nn.Module):
def __init__(self, dim, out_dim, num_heads, window_size=1, shuffle=False, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.ReLU6, norm_layer=nn.BatchNorm2d, stride=False, relative_pos_embedding=False):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim, num_heads=num_heads, window_size=window_size, shuffle=shuffle, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, relative_pos_embedding=relative_pos_embedding)
self.local = nn.Conv2d(dim, dim, window_size, 1, window_size//2, groups=dim, bias=qkv_bias)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, out_features=out_dim, act_layer=act_layer, drop=drop, stride=stride)
self.norm3 = norm_layer(dim)
# print("input dim={}, output dim={}, stride={}, expand={}, num_heads={}".format(dim, out_dim, stride, shuffle, num_heads))
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.local(self.norm2(x)) # local connection
x = x + self.drop_path(self.mlp(self.norm3(x)))
return x
class PatchMerging(nn.Module):
def __init__(self, dim, out_dim, norm_layer=nn.BatchNorm2d):
super().__init__()
self.dim = dim
self.out_dim = out_dim
self.norm = norm_layer(dim)
self.reduction = nn.Conv2d(dim, out_dim, 2, 2, 0, bias=False)
def forward(self, x):
x = self.norm(x)
x = self.reduction(x)
return x
def extra_repr(self) -> str:
return f"input dim={self.dim}, out dim={self.out_dim}"
class StageModule(nn.Module):
def __init__(self, layers, dim, out_dim, num_heads, window_size=1, shuffle=True, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.ReLU6, norm_layer=nn.BatchNorm2d, relative_pos_embedding=False):
super().__init__()
assert layers % 2 == 0, 'Stage layers need to be divisible by 2 for regular and shifted block.'
if dim != out_dim:
self.patch_partition = PatchMerging(dim, out_dim)
else:
self.patch_partition = None
num = layers // 2
self.layers = nn.ModuleList([])
for idx in range(num):
the_last = (idx==num-1)
self.layers.append(nn.ModuleList([
Block(dim=out_dim, out_dim=out_dim, num_heads=num_heads, window_size=window_size, shuffle=False, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop, attn_drop=attn_drop, drop_path=drop_path,
relative_pos_embedding=relative_pos_embedding),
Block(dim=out_dim, out_dim=out_dim, num_heads=num_heads, window_size=window_size, shuffle=shuffle, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop, attn_drop=attn_drop, drop_path=drop_path,
relative_pos_embedding=relative_pos_embedding)
]))
def forward(self, x):
if self.patch_partition:
x = self.patch_partition(x)
for regular_block, shifted_block in self.layers:
x = regular_block(x)
x = shifted_block(x)
return x
class PatchEmbedding(nn.Module):
def __init__(self, inter_channel=32, out_channels=48):
super().__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, inter_channel, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(inter_channel),
nn.ReLU6(inplace=True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(inter_channel, out_channels, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True)
)
self.conv3 = nn.Conv2d(out_channels, out_channels, kernel_size=1, stride=1, padding=0)
def forward(self, x):
x = self.conv3(self.conv2(self.conv1(x)))
return x
class ShuffleTransformer(nn.Module):
def __init__(self, img_size=224, in_chans=3, num_classes=1000, token_dim=32, embed_dim=96, mlp_ratio=4., layers=[2,2,6,2], num_heads=[3,6,12,24],
relative_pos_embedding=True, shuffle=True, window_size=7, qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.,
has_pos_embed=False, **kwargs):
super().__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
self.has_pos_embed = has_pos_embed
dims = [i*32 for i in num_heads]
self.to_token = PatchEmbedding(inter_channel=token_dim, out_channels=embed_dim)
num_patches = (img_size*img_size) // 16
if self.has_pos_embed:
self.pos_embed = nn.Parameter(data=get_sinusoid_encoding(n_position=num_patches, d_hid=embed_dim), requires_grad=False)
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, 4)] # stochastic depth decay rule
self.stage1 = StageModule(layers[0], embed_dim, dims[0], num_heads[0], window_size=window_size, shuffle=shuffle,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[0],
relative_pos_embedding=relative_pos_embedding)
self.stage2 = StageModule(layers[1], dims[0], dims[1], num_heads[1], window_size=window_size, shuffle=shuffle,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[1],
relative_pos_embedding=relative_pos_embedding)
self.stage3 = StageModule(layers[2], dims[1], dims[2], num_heads[2], window_size=window_size, shuffle=shuffle,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[2],
relative_pos_embedding=relative_pos_embedding)
self.stage4 = StageModule(layers[3], dims[2], dims[3], num_heads[3], window_size=window_size, shuffle=shuffle,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[3],
relative_pos_embedding=relative_pos_embedding)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
# Classifier head
self.head = nn.Linear(dims[3], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, (nn.BatchNorm2d, nn.GroupNorm, nn.LayerNorm)):
nn.init.constant_(m.weight, 1.0)
nn.init.constant_(m.bias, 0)
elif isinstance(m, (nn.Linear, nn.Conv2d)):
trunc_normal_(m.weight, std=.02)
if isinstance(m, (nn.Linear, nn.Conv2d)) and m.bias is not None:
nn.init.constant_(m.bias, 0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed'}
@torch.jit.ignore
def no_weight_decay_keywords(self):
return {'relative_position_bias_table'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
x = self.to_token(x)
b, c, h, w = x.shape
if self.has_pos_embed:
x = x + self.pos_embed.view(1, h, w, c).permute(0, 3, 1, 2)
x = self.pos_drop(x)
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
return x
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
sft = ShuffleTransformer()
output=sft(input)
print(output.shape)
================================================
FILE: model/backbone/TnT.py
================================================
# 2021.06.15-Changed for implementation of TNT model
# Huawei Technologies Co., Ltd.
import torch
import torch.nn as nn
from functools import partial
import math
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.helpers import load_pretrained
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.resnet import resnet26d, resnet50d
from timm.models.registry import register_model
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
'tnt_s_patch16_224': _cfg(
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
),
'tnt_b_patch16_224': _cfg(
mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5),
),
}
def make_divisible(v, divisor=8, min_value=None):
min_value = min_value or divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class SE(nn.Module):
def __init__(self, dim, hidden_ratio=None):
super().__init__()
hidden_ratio = hidden_ratio or 1
self.dim = dim
hidden_dim = int(dim * hidden_ratio)
self.fc = nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim, hidden_dim),
nn.ReLU(inplace=True),
nn.Linear(hidden_dim, dim),
nn.Tanh()
)
def forward(self, x):
a = x.mean(dim=1, keepdim=True) # B, 1, C
a = self.fc(a)
x = a * x
return x
class Attention(nn.Module):
def __init__(self, dim, hidden_dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.hidden_dim = hidden_dim
self.num_heads = num_heads
head_dim = hidden_dim // num_heads
self.head_dim = head_dim
# NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
self.scale = qk_scale or head_dim ** -0.5
self.qk = nn.Linear(dim, hidden_dim * 2, bias=qkv_bias)
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop, inplace=True)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop, inplace=True)
def forward(self, x):
B, N, C = x.shape
qk = self.qk(x).reshape(B, N, 2, self.num_heads, self.head_dim).permute(2, 0, 3, 1, 4)
q, k = qk[0], qk[1] # make torchscript happy (cannot use tensor as tuple)
v = self.v(x).reshape(B, N, self.num_heads, -1).permute(0, 2, 1, 3)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, -1)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
""" TNT Block
"""
def __init__(self, outer_dim, inner_dim, outer_num_heads, inner_num_heads, num_words, mlp_ratio=4.,
qkv_bias=False, qk_scale=None, drop=0., attn_drop=0., drop_path=0., act_layer=nn.GELU,
norm_layer=nn.LayerNorm, se=0):
super().__init__()
self.has_inner = inner_dim > 0
if self.has_inner:
# Inner
self.inner_norm1 = norm_layer(inner_dim)
self.inner_attn = Attention(
inner_dim, inner_dim, num_heads=inner_num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.inner_norm2 = norm_layer(inner_dim)
self.inner_mlp = Mlp(in_features=inner_dim, hidden_features=int(inner_dim * mlp_ratio),
out_features=inner_dim, act_layer=act_layer, drop=drop)
self.proj_norm1 = norm_layer(num_words * inner_dim)
self.proj = nn.Linear(num_words * inner_dim, outer_dim, bias=False)
self.proj_norm2 = norm_layer(outer_dim)
# Outer
self.outer_norm1 = norm_layer(outer_dim)
self.outer_attn = Attention(
outer_dim, outer_dim, num_heads=outer_num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.outer_norm2 = norm_layer(outer_dim)
self.outer_mlp = Mlp(in_features=outer_dim, hidden_features=int(outer_dim * mlp_ratio),
out_features=outer_dim, act_layer=act_layer, drop=drop)
# SE
self.se = se
self.se_layer = None
if self.se > 0:
self.se_layer = SE(outer_dim, 0.25)
def forward(self, inner_tokens, outer_tokens):
if self.has_inner:
inner_tokens = inner_tokens + self.drop_path(self.inner_attn(self.inner_norm1(inner_tokens))) # B*N, k*k, c
inner_tokens = inner_tokens + self.drop_path(self.inner_mlp(self.inner_norm2(inner_tokens))) # B*N, k*k, c
B, N, C = outer_tokens.size()
outer_tokens[:,1:] = outer_tokens[:,1:] + self.proj_norm2(self.proj(self.proj_norm1(inner_tokens.reshape(B, N-1, -1)))) # B, N, C
if self.se > 0:
outer_tokens = outer_tokens + self.drop_path(self.outer_attn(self.outer_norm1(outer_tokens)))
tmp_ = self.outer_mlp(self.outer_norm2(outer_tokens))
outer_tokens = outer_tokens + self.drop_path(tmp_ + self.se_layer(tmp_))
else:
outer_tokens = outer_tokens + self.drop_path(self.outer_attn(self.outer_norm1(outer_tokens)))
outer_tokens = outer_tokens + self.drop_path(self.outer_mlp(self.outer_norm2(outer_tokens)))
return inner_tokens, outer_tokens
class PatchEmbed(nn.Module):
""" Image to Visual Word Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, outer_dim=768, inner_dim=24, inner_stride=4):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
num_patches = (img_size[1] // patch_size[1]) * (img_size[0] // patch_size[0])
self.img_size = img_size
self.patch_size = patch_size
self.num_patches = num_patches
self.inner_dim = inner_dim
self.num_words = math.ceil(patch_size[0] / inner_stride) * math.ceil(patch_size[1] / inner_stride)
self.unfold = nn.Unfold(kernel_size=patch_size, stride=patch_size)
self.proj = nn.Conv2d(in_chans, inner_dim, kernel_size=7, padding=3, stride=inner_stride)
def forward(self, x):
B, C, H, W = x.shape
# FIXME look at relaxing size constraints
assert H == self.img_size[0] and W == self.img_size[1], \
f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."
x = self.unfold(x) # B, Ck2, N
x = x.transpose(1, 2).reshape(B * self.num_patches, C, *self.patch_size) # B*N, C, 16, 16
x = self.proj(x) # B*N, C, 8, 8
x = x.reshape(B * self.num_patches, self.inner_dim, -1).transpose(1, 2) # B*N, 8*8, C
return x
class TNT(nn.Module):
""" TNT (Transformer in Transformer) for computer vision
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, outer_dim=768, inner_dim=48,
depth=12, outer_num_heads=12, inner_num_heads=4, mlp_ratio=4., qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm, inner_stride=4, se=0):
super().__init__()
self.num_classes = num_classes
self.num_features = self.outer_dim = outer_dim # num_features for consistency with other models
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, outer_dim=outer_dim,
inner_dim=inner_dim, inner_stride=inner_stride)
self.num_patches = num_patches = self.patch_embed.num_patches
num_words = self.patch_embed.num_words
self.proj_norm1 = norm_layer(num_words * inner_dim)
self.proj = nn.Linear(num_words * inner_dim, outer_dim)
self.proj_norm2 = norm_layer(outer_dim)
self.cls_token = nn.Parameter(torch.zeros(1, 1, outer_dim))
self.outer_tokens = nn.Parameter(torch.zeros(1, num_patches, outer_dim), requires_grad=False)
self.outer_pos = nn.Parameter(torch.zeros(1, num_patches + 1, outer_dim))
self.inner_pos = nn.Parameter(torch.zeros(1, num_words, inner_dim))
self.pos_drop = nn.Dropout(p=drop_rate)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
vanilla_idxs = []
blocks = []
for i in range(depth):
if i in vanilla_idxs:
blocks.append(Block(
outer_dim=outer_dim, inner_dim=-1, outer_num_heads=outer_num_heads, inner_num_heads=inner_num_heads,
num_words=num_words, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, se=se))
else:
blocks.append(Block(
outer_dim=outer_dim, inner_dim=inner_dim, outer_num_heads=outer_num_heads, inner_num_heads=inner_num_heads,
num_words=num_words, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale, drop=drop_rate,
attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer, se=se))
self.blocks = nn.ModuleList(blocks)
self.norm = norm_layer(outer_dim)
# NOTE as per official impl, we could have a pre-logits representation dense layer + tanh here
#self.repr = nn.Linear(outer_dim, representation_size)
#self.repr_act = nn.Tanh()
# Classifier head
self.head = nn.Linear(outer_dim, num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.cls_token, std=.02)
trunc_normal_(self.outer_pos, std=.02)
trunc_normal_(self.inner_pos, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'outer_pos', 'inner_pos', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.outer_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
B = x.shape[0]
inner_tokens = self.patch_embed(x) + self.inner_pos # B*N, 8*8, C
outer_tokens = self.proj_norm2(self.proj(self.proj_norm1(inner_tokens.reshape(B, self.num_patches, -1))))
outer_tokens = torch.cat((self.cls_token.expand(B, -1, -1), outer_tokens), dim=1)
outer_tokens = outer_tokens + self.outer_pos
outer_tokens = self.pos_drop(outer_tokens)
for blk in self.blocks:
inner_tokens, outer_tokens = blk(inner_tokens, outer_tokens)
outer_tokens = self.norm(outer_tokens)
return outer_tokens[:, 0]
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def _conv_filter(state_dict, patch_size=16):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
for k, v in state_dict.items():
if 'patch_embed.proj.weight' in k:
v = v.reshape((v.shape[0], 3, patch_size, patch_size))
out_dict[k] = v
return out_dict
@register_model
def tnt_s_patch16_224(pretrained=False, **kwargs):
patch_size = 16
inner_stride = 4
outer_dim = 384
inner_dim = 24
outer_num_heads = 6
inner_num_heads = 4
outer_dim = make_divisible(outer_dim, outer_num_heads)
inner_dim = make_divisible(inner_dim, inner_num_heads)
model = TNT(img_size=224, patch_size=patch_size, outer_dim=outer_dim, inner_dim=inner_dim, depth=12,
outer_num_heads=outer_num_heads, inner_num_heads=inner_num_heads, qkv_bias=False,
inner_stride=inner_stride, **kwargs)
model.default_cfg = default_cfgs['tnt_s_patch16_224']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
@register_model
def tnt_b_patch16_224(pretrained=False, **kwargs):
patch_size = 16
inner_stride = 4
outer_dim = 640
inner_dim = 40
outer_num_heads = 10
inner_num_heads = 4
outer_dim = make_divisible(outer_dim, outer_num_heads)
inner_dim = make_divisible(inner_dim, inner_num_heads)
model = TNT(img_size=224, patch_size=patch_size, outer_dim=outer_dim, inner_dim=inner_dim, depth=12,
outer_num_heads=outer_num_heads, inner_num_heads=inner_num_heads, qkv_bias=False,
inner_stride=inner_stride, **kwargs)
model.default_cfg = default_cfgs['tnt_b_patch16_224']
if pretrained:
load_pretrained(
model, num_classes=model.num_classes, in_chans=kwargs.get('in_chans', 3), filter_fn=_conv_filter)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = TNT(
img_size=224,
patch_size=16,
outer_dim=384,
inner_dim=24,
depth=12,
outer_num_heads=6,
inner_num_heads=4,
qkv_bias=False,
inner_stride=4)
output=model(input)
print(output.shape)
================================================
FILE: model/backbone/VOLO.py
================================================
# Copyright 2021 Sea Limited.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
Vision OutLOoker (VOLO) implementation
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
from timm.models.registry import register_model
import math
import numpy as np
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .96, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
'volo': _cfg(crop_pct=0.96),
'volo_large': _cfg(crop_pct=1.15),
}
class OutlookAttention(nn.Module):
"""
Implementation of outlook attention
--dim: hidden dim
--num_heads: number of heads
--kernel_size: kernel size in each window for outlook attention
return: token features after outlook attention
"""
def __init__(self, dim, num_heads, kernel_size=3, padding=1, stride=1,
qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
head_dim = dim // num_heads
self.num_heads = num_heads
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.scale = qk_scale or head_dim**-0.5
self.v = nn.Linear(dim, dim, bias=qkv_bias)
self.attn = nn.Linear(dim, kernel_size**4 * num_heads)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.unfold = nn.Unfold(kernel_size=kernel_size, padding=padding, stride=stride)
self.pool = nn.AvgPool2d(kernel_size=stride, stride=stride, ceil_mode=True)
def forward(self, x):
B, H, W, C = x.shape
v = self.v(x).permute(0, 3, 1, 2) # B, C, H, W
h, w = math.ceil(H / self.stride), math.ceil(W / self.stride)
v = self.unfold(v).reshape(B, self.num_heads, C // self.num_heads,
self.kernel_size * self.kernel_size,
h * w).permute(0, 1, 4, 3, 2) # B,H,N,kxk,C/H
attn = self.pool(x.permute(0, 3, 1, 2)).permute(0, 2, 3, 1)
attn = self.attn(attn).reshape(
B, h * w, self.num_heads, self.kernel_size * self.kernel_size,
self.kernel_size * self.kernel_size).permute(0, 2, 1, 3, 4) # B,H,N,kxk,kxk
attn = attn * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).permute(0, 1, 4, 3, 2).reshape(
B, C * self.kernel_size * self.kernel_size, h * w)
x = F.fold(x, output_size=(H, W), kernel_size=self.kernel_size,
padding=self.padding, stride=self.stride)
x = self.proj(x.permute(0, 2, 3, 1))
x = self.proj_drop(x)
return x
class Outlooker(nn.Module):
"""
Implementation of outlooker layer: which includes outlook attention + MLP
Outlooker is the first stage in our VOLO
--dim: hidden dim
--num_heads: number of heads
--mlp_ratio: mlp ratio
--kernel_size: kernel size in each window for outlook attention
return: outlooker layer
"""
def __init__(self, dim, kernel_size, padding, stride=1,
num_heads=1,mlp_ratio=3., attn_drop=0.,
drop_path=0., act_layer=nn.GELU,
norm_layer=nn.LayerNorm, qkv_bias=False,
qk_scale=None):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = OutlookAttention(dim, num_heads, kernel_size=kernel_size,
padding=padding, stride=stride,
qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop)
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class Mlp(nn.Module):
"Implementation of MLP"
def __init__(self, in_features, hidden_features=None,
out_features=None, act_layer=nn.GELU,
drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
"Implementation of self-attention"
def __init__(self, dim, num_heads=8, qkv_bias=False,
qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads,
C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[
2] # make torchscript happy (cannot use tensor as tuple)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, H, W, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Transformer(nn.Module):
"""
Implementation of Transformer,
Transformer is the second stage in our VOLO
"""
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False,
qk_scale=None, attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class ClassAttention(nn.Module):
"""
Class attention layer from CaiT, see details in CaiT
Class attention is the post stage in our VOLO, which is optional.
"""
def __init__(self, dim, num_heads=8, head_dim=None, qkv_bias=False,
qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads = num_heads
if head_dim is not None:
self.head_dim = head_dim
else:
head_dim = dim // num_heads
self.head_dim = head_dim
self.scale = qk_scale or head_dim**-0.5
self.kv = nn.Linear(dim,
self.head_dim * self.num_heads * 2,
bias=qkv_bias)
self.q = nn.Linear(dim, self.head_dim * self.num_heads, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(self.head_dim * self.num_heads, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, N, C = x.shape
kv = self.kv(x).reshape(B, N, 2, self.num_heads,
self.head_dim).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[
1] # make torchscript happy (cannot use tensor as tuple)
q = self.q(x[:, :1, :]).reshape(B, self.num_heads, 1, self.head_dim)
attn = ((q * self.scale) @ k.transpose(-2, -1))
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
cls_embed = (attn @ v).transpose(1, 2).reshape(
B, 1, self.head_dim * self.num_heads)
cls_embed = self.proj(cls_embed)
cls_embed = self.proj_drop(cls_embed)
return cls_embed
class ClassBlock(nn.Module):
"""
Class attention block from CaiT, see details in CaiT
We use two-layers class attention in our VOLO, which is optional.
"""
def __init__(self, dim, num_heads, head_dim=None, mlp_ratio=4.,
qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = ClassAttention(
dim, num_heads=num_heads, head_dim=head_dim, qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
# NOTE: drop path for stochastic depth
self.drop_path = DropPath(
drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim,
hidden_features=mlp_hidden_dim,
act_layer=act_layer,
drop=drop)
def forward(self, x):
cls_embed = x[:, :1]
cls_embed = cls_embed + self.drop_path(self.attn(self.norm1(x)))
cls_embed = cls_embed + self.drop_path(self.mlp(self.norm2(cls_embed)))
return torch.cat([cls_embed, x[:, 1:]], dim=1)
def get_block(block_type, **kargs):
"""
get block by name, specifically for class attention block in here
"""
if block_type == 'ca':
return ClassBlock(**kargs)
def rand_bbox(size, lam, scale=1):
"""
get bounding box as token labeling (https://github.com/zihangJiang/TokenLabeling)
return: bounding box
"""
W = size[1] // scale
H = size[2] // scale
cut_rat = np.sqrt(1. - lam)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# uniform
cx = np.random.randint(W)
cy = np.random.randint(H)
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
return bbx1, bby1, bbx2, bby2
class PatchEmbed(nn.Module):
"""
Image to Patch Embedding.
Different with ViT use 1 conv layer, we use 4 conv layers to do patch embedding
"""
def __init__(self, img_size=224, stem_conv=False, stem_stride=1,
patch_size=8, in_chans=3, hidden_dim=64, embed_dim=384):
super().__init__()
assert patch_size in [4, 8, 16]
self.stem_conv = stem_conv
if stem_conv:
self.conv = nn.Sequential(
nn.Conv2d(in_chans, hidden_dim, kernel_size=7, stride=stem_stride,
padding=3, bias=False), # 112x112
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
nn.Conv2d(hidden_dim, hidden_dim, kernel_size=3, stride=1,
padding=1, bias=False), # 112x112
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
nn.Conv2d(hidden_dim, hidden_dim, kernel_size=3, stride=1,
padding=1, bias=False), # 112x112
nn.BatchNorm2d(hidden_dim),
nn.ReLU(inplace=True),
)
self.proj = nn.Conv2d(hidden_dim,
embed_dim,
kernel_size=patch_size // stem_stride,
stride=patch_size // stem_stride)
self.num_patches = (img_size // patch_size) * (img_size // patch_size)
def forward(self, x):
if self.stem_conv:
x = self.conv(x)
x = self.proj(x) # B, C, H, W
return x
class Downsample(nn.Module):
"""
Image to Patch Embedding, downsampling between stage1 and stage2
"""
def __init__(self, in_embed_dim, out_embed_dim, patch_size):
super().__init__()
self.proj = nn.Conv2d(in_embed_dim, out_embed_dim,
kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = x.permute(0, 3, 1, 2)
x = self.proj(x) # B, C, H, W
x = x.permute(0, 2, 3, 1)
return x
def outlooker_blocks(block_fn, index, dim, layers, num_heads=1, kernel_size=3,
padding=1,stride=1, mlp_ratio=3., qkv_bias=False, qk_scale=None,
attn_drop=0, drop_path_rate=0., **kwargs):
"""
generate outlooker layer in stage1
return: outlooker layers
"""
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx +
sum(layers[:index])) / (sum(layers) - 1)
blocks.append(block_fn(dim, kernel_size=kernel_size, padding=padding,
stride=stride, num_heads=num_heads, mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop,
drop_path=block_dpr))
blocks = nn.Sequential(*blocks)
return blocks
def transformer_blocks(block_fn, index, dim, layers, num_heads, mlp_ratio=3.,
qkv_bias=False, qk_scale=None, attn_drop=0,
drop_path_rate=0., **kwargs):
"""
generate transformer layers in stage2
return: transformer layers
"""
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx +
sum(layers[:index])) / (sum(layers) - 1)
blocks.append(
block_fn(dim, num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop,
drop_path=block_dpr))
blocks = nn.Sequential(*blocks)
return blocks
class VOLO(nn.Module):
"""
Vision Outlooker, the main class of our model
--layers: [x,x,x,x], four blocks in two stages, the first block is outlooker, the
other three are transformer, we set four blocks, which are easily
applied to downstream tasks
--img_size, --in_chans, --num_classes: these three are very easy to understand
--patch_size: patch_size in outlook attention
--stem_hidden_dim: hidden dim of patch embedding, d1-d4 is 64, d5 is 128
--embed_dims, --num_heads: embedding dim, number of heads in each block
--downsamples: flags to apply downsampling or not
--outlook_attention: flags to apply outlook attention or not
--mlp_ratios, --qkv_bias, --qk_scale, --drop_rate: easy to undertand
--attn_drop_rate, --drop_path_rate, --norm_layer: easy to undertand
--post_layers: post layers like two class attention layers using [ca, ca],
if yes, return_mean=False
--return_mean: use mean of all feature tokens for classification, if yes, no class token
--return_dense: use token labeling, details are here:
https://github.com/zihangJiang/TokenLabeling
--mix_token: mixing tokens as token labeling, details are here:
https://github.com/zihangJiang/TokenLabeling
--pooling_scale: pooling_scale=2 means we downsample 2x
--out_kernel, --out_stride, --out_padding: kerner size,
stride, and padding for outlook attention
"""
def __init__(self, layers, img_size=224, in_chans=3, num_classes=1000, patch_size=8,
stem_hidden_dim=64, embed_dims=None, num_heads=None, downsamples=None,
outlook_attention=None, mlp_ratios=None, qkv_bias=False, qk_scale=None,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
post_layers=None, return_mean=False, return_dense=True, mix_token=True,
pooling_scale=2, out_kernel=3, out_stride=2, out_padding=1):
super().__init__()
self.num_classes = num_classes
self.patch_embed = PatchEmbed(stem_conv=True, stem_stride=2, patch_size=patch_size,
in_chans=in_chans, hidden_dim=stem_hidden_dim,
embed_dim=embed_dims[0])
# inital positional encoding, we add positional encoding after outlooker blocks
self.pos_embed = nn.Parameter(
torch.zeros(1, img_size // patch_size // pooling_scale,
img_size // patch_size // pooling_scale,
embed_dims[-1]))
self.pos_drop = nn.Dropout(p=drop_rate)
# set the main block in network
network = []
for i in range(len(layers)):
if outlook_attention[i]:
# stage 1
stage = outlooker_blocks(Outlooker, i, embed_dims[i], layers,
downsample=downsamples[i], num_heads=num_heads[i],
kernel_size=out_kernel, stride=out_stride,
padding=out_padding, mlp_ratio=mlp_ratios[i],
qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop_rate, norm_layer=norm_layer)
network.append(stage)
else:
# stage 2
stage = transformer_blocks(Transformer, i, embed_dims[i], layers,
num_heads[i], mlp_ratio=mlp_ratios[i],
qkv_bias=qkv_bias, qk_scale=qk_scale,
drop_path_rate=drop_path_rate,
attn_drop=attn_drop_rate,
norm_layer=norm_layer)
network.append(stage)
if downsamples[i]:
# downsampling between two stages
network.append(Downsample(embed_dims[i], embed_dims[i + 1], 2))
self.network = nn.ModuleList(network)
# set post block, for example, class attention layers
self.post_network = None
if post_layers is not None:
self.post_network = nn.ModuleList([
get_block(post_layers[i],
dim=embed_dims[-1],
num_heads=num_heads[-1],
mlp_ratio=mlp_ratios[-1],
qkv_bias=qkv_bias,
qk_scale=qk_scale,
attn_drop=attn_drop_rate,
drop_path=0.,
norm_layer=norm_layer)
for i in range(len(post_layers))
])
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dims[-1]))
trunc_normal_(self.cls_token, std=.02)
# set output type
self.return_mean = return_mean # if yes, return mean, not use class token
self.return_dense = return_dense # if yes, return class token and all feature tokens
if return_dense:
assert not return_mean, "cannot return both mean and dense"
self.mix_token = mix_token
self.pooling_scale = pooling_scale
if mix_token: # enable token mixing, see token labeling for details.
self.beta = 1.0
assert return_dense, "return all tokens if mix_token is enabled"
if return_dense:
self.aux_head = nn.Linear(
embed_dims[-1],
num_classes) if num_classes > 0 else nn.Identity()
self.norm = norm_layer(embed_dims[-1])
# Classifier head
self.head = nn.Linear(
embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
trunc_normal_(self.pos_embed, std=.02)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
@torch.jit.ignore
def no_weight_decay(self):
return {'pos_embed', 'cls_token'}
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes):
self.num_classes = num_classes
self.head = nn.Linear(
self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_embeddings(self, x):
# patch embedding
x = self.patch_embed(x)
# B,C,H,W-> B,H,W,C
x = x.permute(0, 2, 3, 1)
return x
def forward_tokens(self, x):
for idx, block in enumerate(self.network):
if idx == 2: # add positional encoding after outlooker blocks
x = x + self.pos_embed
x = self.pos_drop(x)
x = block(x)
B, H, W, C = x.shape
x = x.reshape(B, -1, C)
return x
def forward_cls(self, x):
B, N, C = x.shape
cls_tokens = self.cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
for block in self.post_network:
x = block(x)
return x
def forward(self, x):
# step1: patch embedding
x = self.forward_embeddings(x)
# mix token, see token labeling for details.
if self.mix_token and self.training:
lam = np.random.beta(self.beta, self.beta)
patch_h, patch_w = x.shape[1] // self.pooling_scale, x.shape[
2] // self.pooling_scale
bbx1, bby1, bbx2, bby2 = rand_bbox(x.size(), lam, scale=self.pooling_scale)
temp_x = x.clone()
sbbx1,sbby1,sbbx2,sbby2=self.pooling_scale*bbx1,self.pooling_scale*bby1,\
self.pooling_scale*bbx2,self.pooling_scale*bby2
temp_x[:, sbbx1:sbbx2, sbby1:sbby2, :] = x.flip(0)[:, sbbx1:sbbx2, sbby1:sbby2, :]
x = temp_x
else:
bbx1, bby1, bbx2, bby2 = 0, 0, 0, 0
# step2: tokens learning in the two stages
x = self.forward_tokens(x)
# step3: post network, apply class attention or not
if self.post_network is not None:
x = self.forward_cls(x)
x = self.norm(x)
if self.return_mean: # if no class token, return mean
return self.head(x.mean(1))
x_cls = self.head(x[:, 0])
if not self.return_dense:
return x_cls
x_aux = self.aux_head(
x[:, 1:]
) # generate classes in all feature tokens, see token labeling
if not self.training:
return x_cls + 0.5 * x_aux.max(1)[0]
if self.mix_token and self.training: # reverse "mix token", see token labeling for details.
x_aux = x_aux.reshape(x_aux.shape[0], patch_h, patch_w, x_aux.shape[-1])
temp_x = x_aux.clone()
temp_x[:, bbx1:bbx2, bby1:bby2, :] = x_aux.flip(0)[:, bbx1:bbx2, bby1:bby2, :]
x_aux = temp_x
x_aux = x_aux.reshape(x_aux.shape[0], patch_h * patch_w, x_aux.shape[-1])
# return these: 1. class token, 2. classes from all feature tokens, 3. bounding box
return x_cls, x_aux, (bbx1, bby1, bbx2, bby2)
@register_model
def volo_d1(pretrained=False, **kwargs):
"""
VOLO-D1 model, Params: 27M
--layers: [x,x,x,x], four blocks in two stages, the first stage(block) is outlooker,
the other three blocks are transformer, we set four blocks, which are easily
applied to downstream tasks
--embed_dims, --num_heads,: embedding dim, number of heads in each block
--downsamples: flags to apply downsampling or not in four blocks
--outlook_attention: flags to apply outlook attention or not
--mlp_ratios: mlp ratio in four blocks
--post_layers: post layers like two class attention layers using [ca, ca]
See detail for all args in the class VOLO()
"""
layers = [4, 4, 8, 2] # num of layers in the four blocks
embed_dims = [192, 384, 384, 384]
num_heads = [6, 12, 12, 12]
mlp_ratios = [3, 3, 3, 3]
downsamples = [True, False, False, False] # do downsampling after first block
outlook_attention = [True, False, False, False ]
# first block is outlooker (stage1), the other three are transformer (stage2)
model = VOLO(layers,
embed_dims=embed_dims,
num_heads=num_heads,
mlp_ratios=mlp_ratios,
downsamples=downsamples,
outlook_attention=outlook_attention,
post_layers=['ca', 'ca'],
**kwargs)
model.default_cfg = default_cfgs['volo']
return model
@register_model
def volo_d2(pretrained=False, **kwargs):
"""
VOLO-D2 model, Params: 59M
"""
layers = [6, 4, 10, 4]
embed_dims = [256, 512, 512, 512]
num_heads = [8, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
downsamples = [True, False, False, False]
outlook_attention = [True, False, False, False]
model = VOLO(layers,
embed_dims=embed_dims,
num_heads=num_heads,
mlp_ratios=mlp_ratios,
downsamples=downsamples,
outlook_attention=outlook_attention,
post_layers=['ca', 'ca'],
**kwargs)
model.default_cfg = default_cfgs['volo']
return model
@register_model
def volo_d3(pretrained=False, **kwargs):
"""
VOLO-D3 model, Params: 86M
"""
layers = [8, 8, 16, 4]
embed_dims = [256, 512, 512, 512]
num_heads = [8, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
downsamples = [True, False, False, False]
outlook_attention = [True, False, False, False]
model = VOLO(layers,
embed_dims=embed_dims,
num_heads=num_heads,
mlp_ratios=mlp_ratios,
downsamples=downsamples,
outlook_attention=outlook_attention,
post_layers=['ca', 'ca'],
**kwargs)
model.default_cfg = default_cfgs['volo']
return model
@register_model
def volo_d4(pretrained=False, **kwargs):
"""
VOLO-D4 model, Params: 193M
"""
layers = [8, 8, 16, 4]
embed_dims = [384, 768, 768, 768]
num_heads = [12, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
downsamples = [True, False, False, False]
outlook_attention = [True, False, False, False]
model = VOLO(layers,
embed_dims=embed_dims,
num_heads=num_heads,
mlp_ratios=mlp_ratios,
downsamples=downsamples,
outlook_attention=outlook_attention,
post_layers=['ca', 'ca'],
**kwargs)
model.default_cfg = default_cfgs['volo_large']
return model
@register_model
def volo_d5(pretrained=False, **kwargs):
"""
VOLO-D5 model, Params: 296M
stem_hidden_dim=128, the dim in patch embedding is 128 for VOLO-D5
"""
layers = [12, 12, 20, 4]
embed_dims = [384, 768, 768, 768]
num_heads = [12, 16, 16, 16]
mlp_ratios = [4, 4, 4, 4]
downsamples = [True, False, False, False]
outlook_attention = [True, False, False, False]
model = VOLO(layers,
embed_dims=embed_dims,
num_heads=num_heads,
mlp_ratios=mlp_ratios,
downsamples=downsamples,
outlook_attention=outlook_attention,
post_layers=['ca', 'ca'],
stem_hidden_dim=128,
**kwargs)
model.default_cfg = default_cfgs['volo_large']
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VOLO([4, 4, 8, 2],
embed_dims=[192, 384, 384, 384],
num_heads=[6, 12, 12, 12],
mlp_ratios=[3, 3, 3, 3],
downsamples=[True, False, False, False],
outlook_attention=[True, False, False, False ],
post_layers=['ca', 'ca'],
)
output=model(input)
print(output[0].shape)
================================================
FILE: model/backbone/convnextv2.py
================================================
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPath
class Block(nn.Module):
""" ConvNeXtV2 Block.
Args:
dim (int): Number of input channels.
drop_path (float): Stochastic depth rate. Default: 0.0
"""
def __init__(self, dim, drop_path=0.):
super().__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=7, padding=3, groups=dim) # depthwise conv
self.norm = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.grn = GRN(4 * dim)
self.pwconv2 = nn.Linear(4 * dim, dim)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.grn(x)
x = self.pwconv2(x)
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
class LayerNorm(nn.Module):
""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class GRN(nn.Module):
""" GRN (Global Response Normalization) layer
"""
def __init__(self, dim):
super().__init__()
self.gamma = nn.Parameter(torch.zeros(1, 1, 1, dim))
self.beta = nn.Parameter(torch.zeros(1, 1, 1, dim))
def forward(self, x):
Gx = torch.norm(x, p=2, dim=(1,2), keepdim=True)
Nx = Gx / (Gx.mean(dim=-1, keepdim=True) + 1e-6)
return self.gamma * (x * Nx) + self.beta + x
class ConvNeXtV2(nn.Module):
""" ConvNeXt V2
Args:
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
depths (tuple(int)): Number of blocks at each stage. Default: [3, 3, 9, 3]
dims (int): Feature dimension at each stage. Default: [96, 192, 384, 768]
drop_path_rate (float): Stochastic depth rate. Default: 0.
head_init_scale (float): Init scaling value for classifier weights and biases. Default: 1.
"""
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], dims=[96, 192, 384, 768],
drop_path_rate=0., head_init_scale=1.
):
super().__init__()
self.depths = depths
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
cur = 0
for i in range(4):
stage = nn.Sequential(
*[Block(dim=dims[i], drop_path=dp_rates[cur + j]) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward_features(self, x):
for i in range(4):
x = self.downsample_layers[i](x)
x = self.stages[i](x)
return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
def convnextv2_atto(**kwargs):
model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[40, 80, 160, 320], **kwargs)
return model
def convnextv2_femto(**kwargs):
model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[48, 96, 192, 384], **kwargs)
return model
def convnext_pico(**kwargs):
model = ConvNeXtV2(depths=[2, 2, 6, 2], dims=[64, 128, 256, 512], **kwargs)
return model
def convnextv2_nano(**kwargs):
model = ConvNeXtV2(depths=[2, 2, 8, 2], dims=[80, 160, 320, 640], **kwargs)
return model
def convnextv2_tiny(**kwargs):
model = ConvNeXtV2(depths=[3, 3, 9, 3], dims=[96, 192, 384, 768], **kwargs)
return model
def convnextv2_base(**kwargs):
model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[128, 256, 512, 1024], **kwargs)
return model
def convnextv2_large(**kwargs):
model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[192, 384, 768, 1536], **kwargs)
return model
def convnextv2_huge(**kwargs):
model = ConvNeXtV2(depths=[3, 3, 27, 3], dims=[352, 704, 1408, 2816], **kwargs)
return model
if __name__ == "__main__":
model = convnextv2_atto()
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
================================================
FILE: model/backbone/resnet.py
================================================
import torch
from torch import nn
"""
# in_channel:输入block之前的通道数
# channel:在block中间处理的时候的通道数(这个值是输出维度的1/4)
# channel * block.expansion:输出的维度
"""
class BottleNeck(nn.Module):
expansion = 4
def __init__(self,in_channel,channel,stride=1,downsample=None):
super().__init__()
self.conv1=nn.Conv2d(in_channel,channel,kernel_size=1,stride=stride,bias=False)
self.bn1=nn.BatchNorm2d(channel)
self.conv2=nn.Conv2d(channel,channel,kernel_size=3,padding=1,bias=False,stride=1)
self.bn2=nn.BatchNorm2d(channel)
self.conv3=nn.Conv2d(channel,channel*self.expansion,kernel_size=1,stride=1,bias=False)
self.bn3=nn.BatchNorm2d(channel*self.expansion)
self.relu=nn.ReLU(False)
self.downsample=downsample
self.stride=stride
def forward(self,x):
residual=x
out=self.relu(self.bn1(self.conv1(x))) #bs,c,h,w
out=self.relu(self.bn2(self.conv2(out))) #bs,c,h,w
out=self.relu(self.bn3(self.conv3(out))) #bs,4c,h,w
if(self.downsample != None):
residual=self.downsample(residual)
out+=residual
return self.relu(out)
class ResNet(nn.Module):
def __init__(self,block,layers,num_classes=1000):
super().__init__()
#定义输入模块的维度
self.in_channel=64
### stem layer
self.conv1=nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3,bias=False)
self.bn1=nn.BatchNorm2d(64)
self.relu=nn.ReLU(False)
self.maxpool=nn.MaxPool2d(kernel_size=3,stride=2,padding=0,ceil_mode=True)
### main layer
self.layer1=self._make_layer(block,64,layers[0])
self.layer2=self._make_layer(block,128,layers[1],stride=2)
self.layer3=self._make_layer(block,256,layers[2],stride=2)
self.layer4=self._make_layer(block,512,layers[3],stride=2)
#classifier
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.classifier=nn.Linear(512*block.expansion,num_classes)
self.softmax=nn.Softmax(-1)
def forward(self,x):
##stem layer
out=self.relu(self.bn1(self.conv1(x))) #bs,112,112,64
out=self.maxpool(out) #bs,56,56,64
##layers:
out=self.layer1(out) #bs,56,56,64*4
out=self.layer2(out) #bs,28,28,128*4
out=self.layer3(out) #bs,14,14,256*4
out=self.layer4(out) #bs,7,7,512*4
##classifier
out=self.avgpool(out) #bs,1,1,512*4
out=out.reshape(out.shape[0],-1) #bs,512*4
out=self.classifier(out) #bs,1000
out=self.softmax(out)
return out
def _make_layer(self,block,channel,blocks,stride=1):
# downsample 主要用来处理H(x)=F(x)+x中F(x)和x的channel维度不匹配问题,即对残差结构的输入进行升维,在做残差相加的时候,必须保证残差的纬度与真正的输出维度(宽、高、以及深度)相同
# 比如步长!=1 或者 in_channel!=channel&self.expansion
downsample = None
if(stride!=1 or self.in_channel!=channel*block.expansion):
self.downsample=nn.Conv2d(self.in_channel,channel*block.expansion,stride=stride,kernel_size=1,bias=False)
#第一个conv部分,可能需要downsample
layers=[]
layers.append(block(self.in_channel,channel,downsample=self.downsample,stride=stride))
self.in_channel=channel*block.expansion
for _ in range(1,blocks):
layers.append(block(self.in_channel,channel))
return nn.Sequential(*layers)
def ResNet50(num_classes=1000):
return ResNet(BottleNeck,[3,4,6,3],num_classes=num_classes)
def ResNet101(num_classes=1000):
return ResNet(BottleNeck,[3,4,23,3],num_classes=num_classes)
def ResNet152(num_classes=1000):
return ResNet(BottleNeck,[3,8,36,3],num_classes=num_classes)
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnet50=ResNet50(1000)
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out=resnet50(input)
print(out.shape)
================================================
FILE: model/backbone/resnext.py
================================================
import torch
from torch import nn
"""
# in_channel:输入block之前的通道数
# channel:在block中间处理的时候的通道数(这个值是输出维度的1/4)
# channel * block.expansion:输出的维度
"""
class BottleNeck(nn.Module):
expansion = 2
def __init__(self,in_channel,channel,stride=1,C=32,downsample=None):
super().__init__()
self.conv1=nn.Conv2d(in_channel,channel,kernel_size=1,stride=stride,bias=False)
self.bn1=nn.BatchNorm2d(channel)
self.conv2=nn.Conv2d(channel,channel,kernel_size=3,padding=1,bias=False,stride=1,groups=C)
self.bn2=nn.BatchNorm2d(channel)
self.conv3=nn.Conv2d(channel,channel*self.expansion,kernel_size=1,stride=1,bias=False)
self.bn3=nn.BatchNorm2d(channel*self.expansion)
self.relu=nn.ReLU(False)
self.downsample=downsample
self.stride=stride
def forward(self,x):
residual=x
out=self.relu(self.bn1(self.conv1(x))) #bs,c,h,w
out=self.relu(self.bn2(self.conv2(out))) #bs,c,h,w
out=self.relu(self.bn3(self.conv3(out))) #bs,4c,h,w
if(self.downsample != None):
residual=self.downsample(residual)
out+=residual
return self.relu(out)
class ResNeXt(nn.Module):
def __init__(self,block,layers,num_classes=1000):
super().__init__()
#定义输入模块的维度
self.in_channel=64
### stem layer
self.conv1=nn.Conv2d(3,64,kernel_size=7,stride=2,padding=3,bias=False)
self.bn1=nn.BatchNorm2d(64)
self.relu=nn.ReLU(False)
self.maxpool=nn.MaxPool2d(kernel_size=3,stride=2,padding=0,ceil_mode=True)
### main layer
self.layer1=self._make_layer(block,128,layers[0])
self.layer2=self._make_layer(block,256,layers[1],stride=2)
self.layer3=self._make_layer(block,512,layers[2],stride=2)
self.layer4=self._make_layer(block,1024,layers[3],stride=2)
#classifier
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.classifier=nn.Linear(1024*block.expansion,num_classes)
self.softmax=nn.Softmax(-1)
def forward(self,x):
##stem layer
out=self.relu(self.bn1(self.conv1(x))) #bs,112,112,64
out=self.maxpool(out) #bs,56,56,64
##layers:
out=self.layer1(out) #bs,56,56,128*2
out=self.layer2(out) #bs,28,28,256*2
out=self.layer3(out) #bs,14,14,512*2
out=self.layer4(out) #bs,7,7,1024*2
##classifier
out=self.avgpool(out) #bs,1,1,1024*2
out=out.reshape(out.shape[0],-1) #bs,1024*2
out=self.classifier(out) #bs,1000
out=self.softmax(out)
return out
def _make_layer(self,block,channel,blocks,stride=1):
# downsample 主要用来处理H(x)=F(x)+x中F(x)和x的channel维度不匹配问题,即对残差结构的输入进行升维,在做残差相加的时候,必须保证残差的纬度与真正的输出维度(宽、高、以及深度)相同
# 比如步长!=1 或者 in_channel!=channel&self.expansion
downsample = None
if(stride!=1 or self.in_channel!=channel*block.expansion):
self.downsample=nn.Conv2d(self.in_channel,channel*block.expansion,stride=stride,kernel_size=1,bias=False)
#第一个conv部分,可能需要downsample
layers=[]
layers.append(block(self.in_channel,channel,downsample=self.downsample,stride=stride))
self.in_channel=channel*block.expansion
for _ in range(1,blocks):
layers.append(block(self.in_channel,channel))
return nn.Sequential(*layers)
def ResNeXt50(num_classes=1000):
return ResNeXt(BottleNeck,[3,4,6,3],num_classes=num_classes)
def ResNeXt101(num_classes=1000):
return ResNeXt(BottleNeck,[3,4,23,3],num_classes=num_classes)
def ResNeXt152(num_classes=1000):
return ResNeXt(BottleNeck,[3,8,36,3],num_classes=num_classes)
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnext50=ResNeXt50(1000)
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out=resnext50(input)
print(out.shape)
================================================
FILE: model/backbone/swin_transformer.py
================================================
""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows`
- https://arxiv.org/pdf/2103.14030
Code/weights from https://github.com/microsoft/Swin-Transformer, original copyright/license info below
S3 (AutoFormerV2, https://arxiv.org/abs/2111.14725) Swin weights from
- https://github.com/microsoft/Cream/tree/main/AutoFormerV2
Modifications and additions for timm hacked together by / Copyright 2021, Ross Wightman
"""
# --------------------------------------------------------
# Swin Transformer
# Copyright (c) 2021 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ze Liu
# --------------------------------------------------------
import logging
import math
from typing import Optional
import torch
import torch.nn as nn
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.layers import PatchEmbed, Mlp, DropPath, to_2tuple, to_ntuple, trunc_normal_, _assert
from ._builder import build_model_with_cfg
from ._features_fx import register_notrace_function
from ._manipulate import checkpoint_seq, named_apply
from ._registry import register_model
from .vision_transformer import checkpoint_filter_fn, get_init_weights_vit
__all__ = ['SwinTransformer'] # model_registry will add each entrypoint fn to this
_logger = logging.getLogger(__name__)
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic', 'fixed_input_size': True,
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
'swin_base_patch4_window12_384': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384_22kto1k.pth',
input_size=(3, 384, 384), crop_pct=1.0),
'swin_base_patch4_window7_224': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22kto1k.pth',
),
'swin_large_patch4_window12_384': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22kto1k.pth',
input_size=(3, 384, 384), crop_pct=1.0),
'swin_large_patch4_window7_224': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window7_224_22kto1k.pth',
),
'swin_small_patch4_window7_224': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_small_patch4_window7_224.pth',
),
'swin_tiny_patch4_window7_224': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_tiny_patch4_window7_224.pth',
),
'swin_base_patch4_window12_384_in22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window12_384_22k.pth',
input_size=(3, 384, 384), crop_pct=1.0, num_classes=21841),
'swin_base_patch4_window7_224_in22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_base_patch4_window7_224_22k.pth',
num_classes=21841),
'swin_large_patch4_window12_384_in22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window12_384_22k.pth',
input_size=(3, 384, 384), crop_pct=1.0, num_classes=21841),
'swin_large_patch4_window7_224_in22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v1.0.0/swin_large_patch4_window7_224_22k.pth',
num_classes=21841),
'swin_s3_tiny_224': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/s3_t-1d53f6a8.pth'
),
'swin_s3_small_224': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/s3_s-3bb4c69d.pth'
),
'swin_s3_base_224': _cfg(
url='https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights/s3_b-a1e95db4.pth'
)
}
def window_partition(x, window_size: int):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size, window_size, W // window_size, window_size, C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows
@register_notrace_function # reason: int argument is a Proxy
def window_reverse(windows, window_size: int, H: int, W: int):
"""
Args:
windows: (num_windows*B, window_size, window_size, C)
window_size (int): Window size
H (int): Height of image
W (int): Width of image
Returns:
x: (B, H, W, C)
"""
B = int(windows.shape[0] / (H * W / window_size / window_size))
x = windows.view(B, H // window_size, W // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
def get_relative_position_index(win_h, win_w):
# get pair-wise relative position index for each token inside the window
coords = torch.stack(torch.meshgrid([torch.arange(win_h), torch.arange(win_w)])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += win_h - 1 # shift to start from 0
relative_coords[:, :, 1] += win_w - 1
relative_coords[:, :, 0] *= 2 * win_w - 1
return relative_coords.sum(-1) # Wh*Ww, Wh*Ww
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
head_dim (int): Number of channels per head (dim // num_heads if not set)
window_size (tuple[int]): The height and width of the window.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
"""
def __init__(self, dim, num_heads, head_dim=None, window_size=7, qkv_bias=True, attn_drop=0., proj_drop=0.):
super().__init__()
self.dim = dim
self.window_size = to_2tuple(window_size) # Wh, Ww
win_h, win_w = self.window_size
self.window_area = win_h * win_w
self.num_heads = num_heads
head_dim = head_dim or dim // num_heads
attn_dim = head_dim * num_heads
self.scale = head_dim ** -0.5
# define a parameter table of relative position bias, shape: 2*Wh-1 * 2*Ww-1, nH
self.relative_position_bias_table = nn.Parameter(torch.zeros((2 * win_h - 1) * (2 * win_w - 1), num_heads))
# get pair-wise relative position index for each token inside the window
self.register_buffer("relative_position_index", get_relative_position_index(win_h, win_w))
self.qkv = nn.Linear(dim, attn_dim * 3, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(attn_dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
trunc_normal_(self.relative_position_bias_table, std=.02)
self.softmax = nn.Softmax(dim=-1)
def _get_rel_pos_bias(self) -> torch.Tensor:
relative_position_bias = self.relative_position_bias_table[
self.relative_position_index.view(-1)].view(self.window_area, self.window_area, -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
return relative_position_bias.unsqueeze(0)
def forward(self, x, mask: Optional[torch.Tensor] = None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv = self.qkv(x).reshape(B_, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0) # make torchscript happy (cannot use tensor as tuple)
q = q * self.scale
attn = (q @ k.transpose(-2, -1))
attn = attn + self._get_rel_pos_bias()
if mask is not None:
num_win = mask.shape[0]
attn = attn.view(B_ // num_win, num_win, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, -1)
x = self.proj(x)
x = self.proj_drop(x)
return x
#
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resulotion.
window_size (int): Window size.
num_heads (int): Number of attention heads.
head_dim (int): Enforce the number of channels per head
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(
self, dim, input_resolution, num_heads=4, head_dim=None, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.window_size = window_size
self.shift_size = shift_size
self.mlp_ratio = mlp_ratio
if min(self.input_resolution) <= self.window_size:
# if window size is larger than input resolution, we don't partition windows
self.shift_size = 0
self.window_size = min(self.input_resolution)
assert 0 <= self.shift_size < self.window_size, "shift_size must in 0-window_size"
self.norm1 = norm_layer(dim)
self.attn = WindowAttention(
dim, num_heads=num_heads, head_dim=head_dim, window_size=to_2tuple(self.window_size),
qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)
if self.shift_size > 0:
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
cnt = 0
for h in (
slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None)):
for w in (
slice(0, -self.window_size),
slice(-self.window_size, -self.shift_size),
slice(-self.shift_size, None)):
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # num_win, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_size * self.window_size)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def forward(self, x):
H, W = self.input_resolution
B, L, C = x.shape
_assert(L == H * W, "input feature has wrong size")
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, C)
# cyclic shift
if self.shift_size > 0:
shifted_x = torch.roll(x, shifts=(-self.shift_size, -self.shift_size), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # num_win*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size * self.window_size, C) # num_win*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # num_win*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size, self.window_size, C)
shifted_x = window_reverse(attn_windows, self.window_size, H, W) # B H' W' C
# reverse cyclic shift
if self.shift_size > 0:
x = torch.roll(shifted_x, shifts=(self.shift_size, self.shift_size), dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, out_dim=None, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.out_dim = out_dim or 2 * dim
self.norm = norm_layer(4 * dim)
self.reduction = nn.Linear(4 * dim, self.out_dim, bias=False)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
_assert(L == H * W, "input feature has wrong size")
_assert(H % 2 == 0 and W % 2 == 0, f"x size ({H}*{W}) are not even.")
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.norm(x)
x = self.reduction(x)
return x
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
head_dim (int): Channels per head (dim // num_heads if not set)
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
"""
def __init__(
self, dim, out_dim, input_resolution, depth, num_heads=4, head_dim=None,
window_size=7, mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0.,
drop_path=0., norm_layer=nn.LayerNorm, downsample=None):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.grad_checkpointing = False
# build blocks
self.blocks = nn.Sequential(*[
SwinTransformerBlock(
dim=dim, input_resolution=input_resolution, num_heads=num_heads, head_dim=head_dim,
window_size=window_size, shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path, norm_layer=norm_layer)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, out_dim=out_dim, norm_layer=norm_layer)
else:
self.downsample = None
def forward(self, x):
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint_seq(self.blocks, x)
else:
x = self.blocks(x)
if self.downsample is not None:
x = self.downsample(x)
return x
class SwinTransformer(nn.Module):
r""" Swin Transformer
A PyTorch impl of : `Swin Transformer: Hierarchical Vision Transformer using Shifted Windows` -
https://arxiv.org/pdf/2103.14030
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
head_dim (int, tuple(int)):
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
"""
def __init__(
self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, global_pool='avg',
embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24), head_dim=None,
window_size=7, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True, weight_init='', **kwargs):
super().__init__()
assert global_pool in ('', 'avg')
self.num_classes = num_classes
self.global_pool = global_pool
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if patch_norm else None)
num_patches = self.patch_embed.num_patches
self.patch_grid = self.patch_embed.grid_size
# absolute position embedding
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim)) if ape else None
self.pos_drop = nn.Dropout(p=drop_rate)
# build layers
if not isinstance(embed_dim, (tuple, list)):
embed_dim = [int(embed_dim * 2 ** i) for i in range(self.num_layers)]
embed_out_dim = embed_dim[1:] + [None]
head_dim = to_ntuple(self.num_layers)(head_dim)
window_size = to_ntuple(self.num_layers)(window_size)
mlp_ratio = to_ntuple(self.num_layers)(mlp_ratio)
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
layers = []
for i in range(self.num_layers):
layers += [BasicLayer(
dim=embed_dim[i],
out_dim=embed_out_dim[i],
input_resolution=(self.patch_grid[0] // (2 ** i), self.patch_grid[1] // (2 ** i)),
depth=depths[i],
num_heads=num_heads[i],
head_dim=head_dim[i],
window_size=window_size[i],
mlp_ratio=mlp_ratio[i],
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i]):sum(depths[:i + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i < self.num_layers - 1) else None
)]
self.layers = nn.Sequential(*layers)
self.norm = norm_layer(self.num_features)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
if weight_init != 'skip':
self.init_weights(weight_init)
@torch.jit.ignore
def init_weights(self, mode=''):
assert mode in ('jax', 'jax_nlhb', 'moco', '')
if self.absolute_pos_embed is not None:
trunc_normal_(self.absolute_pos_embed, std=.02)
head_bias = -math.log(self.num_classes) if 'nlhb' in mode else 0.
named_apply(get_init_weights_vit(mode, head_bias=head_bias), self)
@torch.jit.ignore
def no_weight_decay(self):
nwd = {'absolute_pos_embed'}
for n, _ in self.named_parameters():
if 'relative_position_bias_table' in n:
nwd.add(n)
return nwd
@torch.jit.ignore
def group_matcher(self, coarse=False):
return dict(
stem=r'^absolute_pos_embed|patch_embed', # stem and embed
blocks=r'^layers\.(\d+)' if coarse else [
(r'^layers\.(\d+).downsample', (0,)),
(r'^layers\.(\d+)\.\w+\.(\d+)', None),
(r'^norm', (99999,)),
]
)
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
for l in self.layers:
l.grad_checkpointing = enable
@torch.jit.ignore
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=None):
self.num_classes = num_classes
if global_pool is not None:
assert global_pool in ('', 'avg')
self.global_pool = global_pool
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
x = self.patch_embed(x)
if self.absolute_pos_embed is not None:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
x = self.layers(x)
x = self.norm(x) # B L C
return x
def forward_head(self, x, pre_logits: bool = False):
if self.global_pool == 'avg':
x = x.mean(dim=1)
return x if pre_logits else self.head(x)
def forward(self, x):
x = self.forward_features(x)
x = self.forward_head(x)
return x
def _create_swin_transformer(variant, pretrained=False, **kwargs):
model = build_model_with_cfg(
SwinTransformer, variant, pretrained,
pretrained_filter_fn=checkpoint_filter_fn,
**kwargs)
return model
@register_model
def swin_base_patch4_window12_384(pretrained=False, **kwargs):
""" Swin-B @ 384x384, pretrained ImageNet-22k, fine tune 1k
"""
model_kwargs = dict(
patch_size=4, window_size=12, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer('swin_base_patch4_window12_384', pretrained=pretrained, **model_kwargs)
@register_model
def swin_base_patch4_window7_224(pretrained=False, **kwargs):
""" Swin-B @ 224x224, pretrained ImageNet-22k, fine tune 1k
"""
model_kwargs = dict(
patch_size=4, window_size=7, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer('swin_base_patch4_window7_224', pretrained=pretrained, **model_kwargs)
@register_model
def swin_large_patch4_window12_384(pretrained=False, **kwargs):
""" Swin-L @ 384x384, pretrained ImageNet-22k, fine tune 1k
"""
model_kwargs = dict(
patch_size=4, window_size=12, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48), **kwargs)
return _create_swin_transformer('swin_large_patch4_window12_384', pretrained=pretrained, **model_kwargs)
@register_model
def swin_large_patch4_window7_224(pretrained=False, **kwargs):
""" Swin-L @ 224x224, pretrained ImageNet-22k, fine tune 1k
"""
model_kwargs = dict(
patch_size=4, window_size=7, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48), **kwargs)
return _create_swin_transformer('swin_large_patch4_window7_224', pretrained=pretrained, **model_kwargs)
@register_model
def swin_small_patch4_window7_224(pretrained=False, **kwargs):
""" Swin-S @ 224x224, trained ImageNet-1k
"""
model_kwargs = dict(
patch_size=4, window_size=7, embed_dim=96, depths=(2, 2, 18, 2), num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer('swin_small_patch4_window7_224', pretrained=pretrained, **model_kwargs)
@register_model
def swin_tiny_patch4_window7_224(pretrained=False, **kwargs):
""" Swin-T @ 224x224, trained ImageNet-1k
"""
model_kwargs = dict(
patch_size=4, window_size=7, embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer('swin_tiny_patch4_window7_224', pretrained=pretrained, **model_kwargs)
@register_model
def swin_base_patch4_window12_384_in22k(pretrained=False, **kwargs):
""" Swin-B @ 384x384, trained ImageNet-22k
"""
model_kwargs = dict(
patch_size=4, window_size=12, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer('swin_base_patch4_window12_384_in22k', pretrained=pretrained, **model_kwargs)
@register_model
def swin_base_patch4_window7_224_in22k(pretrained=False, **kwargs):
""" Swin-B @ 224x224, trained ImageNet-22k
"""
model_kwargs = dict(
patch_size=4, window_size=7, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer('swin_base_patch4_window7_224_in22k', pretrained=pretrained, **model_kwargs)
@register_model
def swin_large_patch4_window12_384_in22k(pretrained=False, **kwargs):
""" Swin-L @ 384x384, trained ImageNet-22k
"""
model_kwargs = dict(
patch_size=4, window_size=12, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48), **kwargs)
return _create_swin_transformer('swin_large_patch4_window12_384_in22k', pretrained=pretrained, **model_kwargs)
@register_model
def swin_large_patch4_window7_224_in22k(pretrained=False, **kwargs):
""" Swin-L @ 224x224, trained ImageNet-22k
"""
model_kwargs = dict(
patch_size=4, window_size=7, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48), **kwargs)
return _create_swin_transformer('swin_large_patch4_window7_224_in22k', pretrained=pretrained, **model_kwargs)
@register_model
def swin_s3_tiny_224(pretrained=False, **kwargs):
""" Swin-S3-T @ 224x224, ImageNet-1k. https://arxiv.org/abs/2111.14725
"""
model_kwargs = dict(
patch_size=4, window_size=(7, 7, 14, 7), embed_dim=96, depths=(2, 2, 6, 2),
num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer('swin_s3_tiny_224', pretrained=pretrained, **model_kwargs)
@register_model
def swin_s3_small_224(pretrained=False, **kwargs):
""" Swin-S3-S @ 224x224, trained ImageNet-1k. https://arxiv.org/abs/2111.14725
"""
model_kwargs = dict(
patch_size=4, window_size=(14, 14, 14, 7), embed_dim=96, depths=(2, 2, 18, 2),
num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer('swin_s3_small_224', pretrained=pretrained, **model_kwargs)
@register_model
def swin_s3_base_224(pretrained=False, **kwargs):
""" Swin-S3-B @ 224x224, trained ImageNet-1k. https://arxiv.org/abs/2111.14725
"""
model_kwargs = dict(
patch_size=4, window_size=(7, 7, 14, 7), embed_dim=96, depths=(2, 2, 30, 2),
num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer('swin_s3_base_224', pretrained=pretrained, **model_kwargs)
================================================
FILE: model/backbone/swin_transformer_v2.py
================================================
""" Swin Transformer V2
A PyTorch impl of : `Swin Transformer V2: Scaling Up Capacity and Resolution`
- https://arxiv.org/abs/2111.09883
Code/weights from https://github.com/microsoft/Swin-Transformer, original copyright/license info below
Modifications and additions for timm hacked together by / Copyright 2022, Ross Wightman
"""
# --------------------------------------------------------
# Swin Transformer V2
# Copyright (c) 2022 Microsoft
# Licensed under The MIT License [see LICENSE for details]
# Written by Ze Liu
# --------------------------------------------------------
import math
from typing import Tuple, Optional
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.layers import PatchEmbed, Mlp, DropPath, to_2tuple, trunc_normal_, _assert
from ._builder import build_model_with_cfg
from ._features_fx import register_notrace_function
from ._registry import register_model
__all__ = ['SwinTransformerV2'] # model_registry will add each entrypoint fn to this
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .9, 'interpolation': 'bicubic', 'fixed_input_size': True,
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj', 'classifier': 'head',
**kwargs
}
default_cfgs = {
'swinv2_tiny_window8_256': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_tiny_patch4_window8_256.pth',
input_size=(3, 256, 256)
),
'swinv2_tiny_window16_256': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_tiny_patch4_window16_256.pth',
input_size=(3, 256, 256)
),
'swinv2_small_window8_256': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_small_patch4_window8_256.pth',
input_size=(3, 256, 256)
),
'swinv2_small_window16_256': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_small_patch4_window16_256.pth',
input_size=(3, 256, 256)
),
'swinv2_base_window8_256': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window8_256.pth',
input_size=(3, 256, 256)
),
'swinv2_base_window16_256': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window16_256.pth',
input_size=(3, 256, 256)
),
'swinv2_base_window12_192_22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window12_192_22k.pth',
num_classes=21841, input_size=(3, 192, 192)
),
'swinv2_base_window12to16_192to256_22kft1k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window12to16_192to256_22kto1k_ft.pth',
input_size=(3, 256, 256)
),
'swinv2_base_window12to24_192to384_22kft1k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_base_patch4_window12to24_192to384_22kto1k_ft.pth',
input_size=(3, 384, 384), crop_pct=1.0,
),
'swinv2_large_window12_192_22k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_large_patch4_window12_192_22k.pth',
num_classes=21841, input_size=(3, 192, 192)
),
'swinv2_large_window12to16_192to256_22kft1k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_large_patch4_window12to16_192to256_22kto1k_ft.pth',
input_size=(3, 256, 256)
),
'swinv2_large_window12to24_192to384_22kft1k': _cfg(
url='https://github.com/SwinTransformer/storage/releases/download/v2.0.0/swinv2_large_patch4_window12to24_192to384_22kto1k_ft.pth',
input_size=(3, 384, 384), crop_pct=1.0,
),
}
def window_partition(x, window_size: Tuple[int, int]):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size[0], window_size[0], W // window_size[1], window_size[1], C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size[0], window_size[1], C)
return windows
@register_notrace_function # reason: int argument is a Proxy
def window_reverse(windows, window_size: Tuple[int, int], img_size: Tuple[int, int]):
"""
Args:
windows: (num_windows * B, window_size[0], window_size[1], C)
window_size (Tuple[int, int]): Window size
img_size (Tuple[int, int]): Image size
Returns:
x: (B, H, W, C)
"""
H, W = img_size
B = int(windows.shape[0] / (H * W / window_size[0] / window_size[1]))
x = windows.view(B, H // window_size[0], W // window_size[1], window_size[0], window_size[1], -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class WindowAttention(nn.Module):
r""" Window based multi-head self attention (W-MSA) module with relative position bias.
It supports both of shifted and non-shifted window.
Args:
dim (int): Number of input channels.
window_size (tuple[int]): The height and width of the window.
num_heads (int): Number of attention heads.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
attn_drop (float, optional): Dropout ratio of attention weight. Default: 0.0
proj_drop (float, optional): Dropout ratio of output. Default: 0.0
pretrained_window_size (tuple[int]): The height and width of the window in pre-training.
"""
def __init__(
self, dim, window_size, num_heads, qkv_bias=True, attn_drop=0., proj_drop=0.,
pretrained_window_size=[0, 0]):
super().__init__()
self.dim = dim
self.window_size = window_size # Wh, Ww
self.pretrained_window_size = pretrained_window_size
self.num_heads = num_heads
self.logit_scale = nn.Parameter(torch.log(10 * torch.ones((num_heads, 1, 1))))
# mlp to generate continuous relative position bias
self.cpb_mlp = nn.Sequential(
nn.Linear(2, 512, bias=True),
nn.ReLU(inplace=True),
nn.Linear(512, num_heads, bias=False)
)
# get relative_coords_table
relative_coords_h = torch.arange(-(self.window_size[0] - 1), self.window_size[0], dtype=torch.float32)
relative_coords_w = torch.arange(-(self.window_size[1] - 1), self.window_size[1], dtype=torch.float32)
relative_coords_table = torch.stack(torch.meshgrid([
relative_coords_h,
relative_coords_w])).permute(1, 2, 0).contiguous().unsqueeze(0) # 1, 2*Wh-1, 2*Ww-1, 2
if pretrained_window_size[0] > 0:
relative_coords_table[:, :, :, 0] /= (pretrained_window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (pretrained_window_size[1] - 1)
else:
relative_coords_table[:, :, :, 0] /= (self.window_size[0] - 1)
relative_coords_table[:, :, :, 1] /= (self.window_size[1] - 1)
relative_coords_table *= 8 # normalize to -8, 8
relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
torch.abs(relative_coords_table) + 1.0) / math.log2(8)
self.register_buffer("relative_coords_table", relative_coords_table, persistent=False)
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.window_size[0])
coords_w = torch.arange(self.window_size[1])
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.window_size[0] - 1 # shift to start from 0
relative_coords[:, :, 1] += self.window_size[1] - 1
relative_coords[:, :, 0] *= 2 * self.window_size[1] - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index, persistent=False)
self.qkv = nn.Linear(dim, dim * 3, bias=False)
if qkv_bias:
self.q_bias = nn.Parameter(torch.zeros(dim))
self.register_buffer('k_bias', torch.zeros(dim), persistent=False)
self.v_bias = nn.Parameter(torch.zeros(dim))
else:
self.q_bias = None
self.k_bias = None
self.v_bias = None
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x, mask: Optional[torch.Tensor] = None):
"""
Args:
x: input features with shape of (num_windows*B, N, C)
mask: (0/-inf) mask with shape of (num_windows, Wh*Ww, Wh*Ww) or None
"""
B_, N, C = x.shape
qkv_bias = None
if self.q_bias is not None:
qkv_bias = torch.cat((self.q_bias, self.k_bias, self.v_bias))
qkv = F.linear(input=x, weight=self.qkv.weight, bias=qkv_bias)
qkv = qkv.reshape(B_, N, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0)
# cosine attention
attn = (F.normalize(q, dim=-1) @ F.normalize(k, dim=-1).transpose(-2, -1))
logit_scale = torch.clamp(self.logit_scale, max=math.log(1. / 0.01)).exp()
attn = attn * logit_scale
relative_position_bias_table = self.cpb_mlp(self.relative_coords_table).view(-1, self.num_heads)
relative_position_bias = relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.window_size[0] * self.window_size[1], self.window_size[0] * self.window_size[1], -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
relative_position_bias = 16 * torch.sigmoid(relative_position_bias)
attn = attn + relative_position_bias.unsqueeze(0)
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B_ // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B_, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class SwinTransformerBlock(nn.Module):
r""" Swin Transformer Block.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
num_heads (int): Number of attention heads.
window_size (int): Window size.
shift_size (int): Shift size for SW-MSA.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float, optional): Stochastic depth rate. Default: 0.0
act_layer (nn.Module, optional): Activation layer. Default: nn.GELU
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
pretrained_window_size (int): Window size in pretraining.
"""
def __init__(
self, dim, input_resolution, num_heads, window_size=7, shift_size=0,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
act_layer=nn.GELU, norm_layer=nn.LayerNorm, pretrained_window_size=0):
super().__init__()
self.dim = dim
self.input_resolution = to_2tuple(input_resolution)
self.num_heads = num_heads
ws, ss = self._calc_window_shift(window_size, shift_size)
self.window_size: Tuple[int, int] = ws
self.shift_size: Tuple[int, int] = ss
self.window_area = self.window_size[0] * self.window_size[1]
self.mlp_ratio = mlp_ratio
self.attn = WindowAttention(
dim, window_size=to_2tuple(self.window_size), num_heads=num_heads,
qkv_bias=qkv_bias, attn_drop=attn_drop, proj_drop=drop,
pretrained_window_size=to_2tuple(pretrained_window_size))
self.norm1 = norm_layer(dim)
self.drop_path1 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.mlp = Mlp(in_features=dim, hidden_features=int(dim * mlp_ratio), act_layer=act_layer, drop=drop)
self.norm2 = norm_layer(dim)
self.drop_path2 = DropPath(drop_path) if drop_path > 0. else nn.Identity()
if any(self.shift_size):
# calculate attention mask for SW-MSA
H, W = self.input_resolution
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
cnt = 0
for h in (
slice(0, -self.window_size[0]),
slice(-self.window_size[0], -self.shift_size[0]),
slice(-self.shift_size[0], None)):
for w in (
slice(0, -self.window_size[1]),
slice(-self.window_size[1], -self.shift_size[1]),
slice(-self.shift_size[1], None)):
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # nW, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_area)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask)
def _calc_window_shift(self, target_window_size, target_shift_size) -> Tuple[Tuple[int, int], Tuple[int, int]]:
target_window_size = to_2tuple(target_window_size)
target_shift_size = to_2tuple(target_shift_size)
window_size = [r if r <= w else w for r, w in zip(self.input_resolution, target_window_size)]
shift_size = [0 if r <= w else s for r, w, s in zip(self.input_resolution, window_size, target_shift_size)]
return tuple(window_size), tuple(shift_size)
def _attn(self, x):
H, W = self.input_resolution
B, L, C = x.shape
_assert(L == H * W, "input feature has wrong size")
x = x.view(B, H, W, C)
# cyclic shift
has_shift = any(self.shift_size)
if has_shift:
shifted_x = torch.roll(x, shifts=(-self.shift_size[0], -self.shift_size[1]), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_area, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size[0], self.window_size[1], C)
shifted_x = window_reverse(attn_windows, self.window_size, self.input_resolution) # B H' W' C
# reverse cyclic shift
if has_shift:
x = torch.roll(shifted_x, shifts=self.shift_size, dims=(1, 2))
else:
x = shifted_x
x = x.view(B, H * W, C)
return x
def forward(self, x):
x = x + self.drop_path1(self.norm1(self._attn(x)))
x = x + self.drop_path2(self.norm2(self.mlp(x)))
return x
class PatchMerging(nn.Module):
r""" Patch Merging Layer.
Args:
input_resolution (tuple[int]): Resolution of input feature.
dim (int): Number of input channels.
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
"""
def __init__(self, input_resolution, dim, norm_layer=nn.LayerNorm):
super().__init__()
self.input_resolution = input_resolution
self.dim = dim
self.reduction = nn.Linear(4 * dim, 2 * dim, bias=False)
self.norm = norm_layer(2 * dim)
def forward(self, x):
"""
x: B, H*W, C
"""
H, W = self.input_resolution
B, L, C = x.shape
_assert(L == H * W, "input feature has wrong size")
_assert(H % 2 == 0, f"x size ({H}*{W}) are not even.")
_assert(W % 2 == 0, f"x size ({H}*{W}) are not even.")
x = x.view(B, H, W, C)
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
x = self.reduction(x)
x = self.norm(x)
return x
class BasicLayer(nn.Module):
""" A basic Swin Transformer layer for one stage.
Args:
dim (int): Number of input channels.
input_resolution (tuple[int]): Input resolution.
depth (int): Number of blocks.
num_heads (int): Number of attention heads.
window_size (int): Local window size.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool, optional): If True, add a learnable bias to query, key, value. Default: True
drop (float, optional): Dropout rate. Default: 0.0
attn_drop (float, optional): Attention dropout rate. Default: 0.0
drop_path (float | tuple[float], optional): Stochastic depth rate. Default: 0.0
norm_layer (nn.Module, optional): Normalization layer. Default: nn.LayerNorm
downsample (nn.Module | None, optional): Downsample layer at the end of the layer. Default: None
pretrained_window_size (int): Local window size in pre-training.
"""
def __init__(
self, dim, input_resolution, depth, num_heads, window_size,
mlp_ratio=4., qkv_bias=True, drop=0., attn_drop=0., drop_path=0.,
norm_layer=nn.LayerNorm, downsample=None, pretrained_window_size=0):
super().__init__()
self.dim = dim
self.input_resolution = input_resolution
self.depth = depth
self.grad_checkpointing = False
# build blocks
self.blocks = nn.ModuleList([
SwinTransformerBlock(
dim=dim, input_resolution=input_resolution,
num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop, attn_drop=attn_drop,
drop_path=drop_path[i] if isinstance(drop_path, list) else drop_path,
norm_layer=norm_layer,
pretrained_window_size=pretrained_window_size)
for i in range(depth)])
# patch merging layer
if downsample is not None:
self.downsample = downsample(input_resolution, dim=dim, norm_layer=norm_layer)
else:
self.downsample = nn.Identity()
def forward(self, x):
for blk in self.blocks:
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint.checkpoint(blk, x)
else:
x = blk(x)
x = self.downsample(x)
return x
def _init_respostnorm(self):
for blk in self.blocks:
nn.init.constant_(blk.norm1.bias, 0)
nn.init.constant_(blk.norm1.weight, 0)
nn.init.constant_(blk.norm2.bias, 0)
nn.init.constant_(blk.norm2.weight, 0)
class SwinTransformerV2(nn.Module):
r""" Swin Transformer V2
A PyTorch impl of : `Swin Transformer V2: Scaling Up Capacity and Resolution`
- https://arxiv.org/abs/2111.09883
Args:
img_size (int | tuple(int)): Input image size. Default 224
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input image channels. Default: 3
num_classes (int): Number of classes for classification head. Default: 1000
embed_dim (int): Patch embedding dimension. Default: 96
depths (tuple(int)): Depth of each Swin Transformer layer.
num_heads (tuple(int)): Number of attention heads in different layers.
window_size (int): Window size. Default: 7
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim. Default: 4
qkv_bias (bool): If True, add a learnable bias to query, key, value. Default: True
drop_rate (float): Dropout rate. Default: 0
attn_drop_rate (float): Attention dropout rate. Default: 0
drop_path_rate (float): Stochastic depth rate. Default: 0.1
norm_layer (nn.Module): Normalization layer. Default: nn.LayerNorm.
ape (bool): If True, add absolute position embedding to the patch embedding. Default: False
patch_norm (bool): If True, add normalization after patch embedding. Default: True
use_checkpoint (bool): Whether to use checkpointing to save memory. Default: False
pretrained_window_sizes (tuple(int)): Pretrained window sizes of each layer.
"""
def __init__(
self, img_size=224, patch_size=4, in_chans=3, num_classes=1000, global_pool='avg',
embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24),
window_size=7, mlp_ratio=4., qkv_bias=True,
drop_rate=0., attn_drop_rate=0., drop_path_rate=0.1,
norm_layer=nn.LayerNorm, ape=False, patch_norm=True,
pretrained_window_sizes=(0, 0, 0, 0), **kwargs):
super().__init__()
self.num_classes = num_classes
assert global_pool in ('', 'avg')
self.global_pool = global_pool
self.num_layers = len(depths)
self.embed_dim = embed_dim
self.patch_norm = patch_norm
self.num_features = int(embed_dim * 2 ** (self.num_layers - 1))
# split image into non-overlapping patches
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim,
norm_layer=norm_layer if self.patch_norm else None)
num_patches = self.patch_embed.num_patches
# absolute position embedding
if ape:
self.absolute_pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
trunc_normal_(self.absolute_pos_embed, std=.02)
else:
self.absolute_pos_embed = None
self.pos_drop = nn.Dropout(p=drop_rate)
# stochastic depth
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
# build layers
self.layers = nn.ModuleList()
for i_layer in range(self.num_layers):
layer = BasicLayer(
dim=int(embed_dim * 2 ** i_layer),
input_resolution=(
self.patch_embed.grid_size[0] // (2 ** i_layer),
self.patch_embed.grid_size[1] // (2 ** i_layer)),
depth=depths[i_layer],
num_heads=num_heads[i_layer],
window_size=window_size,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate, attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:i_layer]):sum(depths[:i_layer + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (i_layer < self.num_layers - 1) else None,
pretrained_window_size=pretrained_window_sizes[i_layer]
)
self.layers.append(layer)
self.norm = norm_layer(self.num_features)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
for bly in self.layers:
bly._init_respostnorm()
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
@torch.jit.ignore
def no_weight_decay(self):
nod = {'absolute_pos_embed'}
for n, m in self.named_modules():
if any([kw in n for kw in ("cpb_mlp", "logit_scale", 'relative_position_bias_table')]):
nod.add(n)
return nod
@torch.jit.ignore
def group_matcher(self, coarse=False):
return dict(
stem=r'^absolute_pos_embed|patch_embed', # stem and embed
blocks=r'^layers\.(\d+)' if coarse else [
(r'^layers\.(\d+).downsample', (0,)),
(r'^layers\.(\d+)\.\w+\.(\d+)', None),
(r'^norm', (99999,)),
]
)
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
for l in self.layers:
l.grad_checkpointing = enable
@torch.jit.ignore
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=None):
self.num_classes = num_classes
if global_pool is not None:
assert global_pool in ('', 'avg')
self.global_pool = global_pool
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x):
x = self.patch_embed(x)
if self.absolute_pos_embed is not None:
x = x + self.absolute_pos_embed
x = self.pos_drop(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x) # B L C
return x
def forward_head(self, x, pre_logits: bool = False):
if self.global_pool == 'avg':
x = x.mean(dim=1)
return x if pre_logits else self.head(x)
def forward(self, x):
x = self.forward_features(x)
x = self.forward_head(x)
return x
def checkpoint_filter_fn(state_dict, model):
out_dict = {}
if 'model' in state_dict:
# For deit models
state_dict = state_dict['model']
for k, v in state_dict.items():
if any([n in k for n in ('relative_position_index', 'relative_coords_table')]):
continue # skip buffers that should not be persistent
out_dict[k] = v
return out_dict
def _create_swin_transformer_v2(variant, pretrained=False, **kwargs):
model = build_model_with_cfg(
SwinTransformerV2, variant, pretrained,
pretrained_filter_fn=checkpoint_filter_fn,
**kwargs)
return model
@register_model
def swinv2_tiny_window16_256(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=16, embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer_v2('swinv2_tiny_window16_256', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_tiny_window8_256(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=8, embed_dim=96, depths=(2, 2, 6, 2), num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer_v2('swinv2_tiny_window8_256', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_small_window16_256(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=16, embed_dim=96, depths=(2, 2, 18, 2), num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer_v2('swinv2_small_window16_256', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_small_window8_256(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=8, embed_dim=96, depths=(2, 2, 18, 2), num_heads=(3, 6, 12, 24), **kwargs)
return _create_swin_transformer_v2('swinv2_small_window8_256', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_base_window16_256(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=16, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer_v2('swinv2_base_window16_256', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_base_window8_256(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=8, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer_v2('swinv2_base_window8_256', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_base_window12_192_22k(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=12, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32), **kwargs)
return _create_swin_transformer_v2('swinv2_base_window12_192_22k', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_base_window12to16_192to256_22kft1k(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=16, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32),
pretrained_window_sizes=(12, 12, 12, 6), **kwargs)
return _create_swin_transformer_v2(
'swinv2_base_window12to16_192to256_22kft1k', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_base_window12to24_192to384_22kft1k(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=24, embed_dim=128, depths=(2, 2, 18, 2), num_heads=(4, 8, 16, 32),
pretrained_window_sizes=(12, 12, 12, 6), **kwargs)
return _create_swin_transformer_v2(
'swinv2_base_window12to24_192to384_22kft1k', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_large_window12_192_22k(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=12, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48), **kwargs)
return _create_swin_transformer_v2('swinv2_large_window12_192_22k', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_large_window12to16_192to256_22kft1k(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=16, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48),
pretrained_window_sizes=(12, 12, 12, 6), **kwargs)
return _create_swin_transformer_v2(
'swinv2_large_window12to16_192to256_22kft1k', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_large_window12to24_192to384_22kft1k(pretrained=False, **kwargs):
"""
"""
model_kwargs = dict(
window_size=24, embed_dim=192, depths=(2, 2, 18, 2), num_heads=(6, 12, 24, 48),
pretrained_window_sizes=(12, 12, 12, 6), **kwargs)
return _create_swin_transformer_v2(
'swinv2_large_window12to24_192to384_22kft1k', pretrained=pretrained, **model_kwargs)
================================================
FILE: model/backbone/swin_transformer_v2_cr.py
================================================
""" Swin Transformer V2
A PyTorch impl of : `Swin Transformer V2: Scaling Up Capacity and Resolution`
- https://arxiv.org/pdf/2111.09883
Code adapted from https://github.com/ChristophReich1996/Swin-Transformer-V2, original copyright/license info below
This implementation is experimental and subject to change in manners that will break weight compat:
* Size of the pos embed MLP are not spelled out in paper in terms of dim, fixed for all models? vary with num_heads?
* currently dim is fixed, I feel it may make sense to scale with num_heads (dim per head)
* The specifics of the memory saving 'sequential attention' are not detailed, Christoph Reich has an impl at
GitHub link above. It needs further investigation as throughput vs mem tradeoff doesn't appear beneficial.
* num_heads per stage is not detailed for Huge and Giant model variants
* 'Giant' is 3B params in paper but ~2.6B here despite matching paper dim + block counts
* experiments are ongoing wrt to 'main branch' norm layer use and weight init scheme
Noteworthy additions over official Swin v1:
* MLP relative position embedding is looking promising and adapts to different image/window sizes
* This impl has been designed to allow easy change of image size with matching window size changes
* Non-square image size and window size are supported
Modifications and additions for timm hacked together by / Copyright 2022, Ross Wightman
"""
# --------------------------------------------------------
# Swin Transformer V2 reimplementation
# Copyright (c) 2021 Christoph Reich
# Licensed under The MIT License [see LICENSE for details]
# Written by Christoph Reich
# --------------------------------------------------------
import logging
import math
from typing import Tuple, Optional, List, Union, Any, Type
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.utils.checkpoint as checkpoint
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.layers import DropPath, Mlp, to_2tuple, _assert
from ._builder import build_model_with_cfg
from ._features_fx import register_notrace_function
from ._manipulate import named_apply
from ._registry import register_model
__all__ = ['SwinTransformerV2Cr'] # model_registry will add each entrypoint fn to this
_logger = logging.getLogger(__name__)
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000,
'input_size': (3, 224, 224),
'pool_size': (7, 7),
'crop_pct': 0.9,
'interpolation': 'bicubic',
'fixed_input_size': True,
'mean': IMAGENET_DEFAULT_MEAN,
'std': IMAGENET_DEFAULT_STD,
'first_conv': 'patch_embed.proj',
'classifier': 'head',
**kwargs,
}
default_cfgs = {
'swinv2_cr_tiny_384': _cfg(
url="", input_size=(3, 384, 384), crop_pct=1.0, pool_size=(12, 12)),
'swinv2_cr_tiny_224': _cfg(
url="", input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_tiny_ns_224': _cfg(
url="https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights-swinv2/swin_v2_cr_tiny_ns_224-ba8166c6.pth",
input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_small_384': _cfg(
url="", input_size=(3, 384, 384), crop_pct=1.0, pool_size=(12, 12)),
'swinv2_cr_small_224': _cfg(
url="https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights-swinv2/swin_v2_cr_small_224-0813c165.pth",
input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_small_ns_224': _cfg(
url="https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-weights-swinv2/swin_v2_cr_small_ns_224_iv-2ce90f8e.pth",
input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_base_384': _cfg(
url="", input_size=(3, 384, 384), crop_pct=1.0, pool_size=(12, 12)),
'swinv2_cr_base_224': _cfg(
url="", input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_base_ns_224': _cfg(
url="", input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_large_384': _cfg(
url="", input_size=(3, 384, 384), crop_pct=1.0, pool_size=(12, 12)),
'swinv2_cr_large_224': _cfg(
url="", input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_huge_384': _cfg(
url="", input_size=(3, 384, 384), crop_pct=1.0, pool_size=(12, 12)),
'swinv2_cr_huge_224': _cfg(
url="", input_size=(3, 224, 224), crop_pct=0.9),
'swinv2_cr_giant_384': _cfg(
url="", input_size=(3, 384, 384), crop_pct=1.0, pool_size=(12, 12)),
'swinv2_cr_giant_224': _cfg(
url="", input_size=(3, 224, 224), crop_pct=0.9),
}
def bchw_to_bhwc(x: torch.Tensor) -> torch.Tensor:
"""Permutes a tensor from the shape (B, C, H, W) to (B, H, W, C). """
return x.permute(0, 2, 3, 1)
def bhwc_to_bchw(x: torch.Tensor) -> torch.Tensor:
"""Permutes a tensor from the shape (B, H, W, C) to (B, C, H, W). """
return x.permute(0, 3, 1, 2)
def window_partition(x, window_size: Tuple[int, int]):
"""
Args:
x: (B, H, W, C)
window_size (int): window size
Returns:
windows: (num_windows*B, window_size, window_size, C)
"""
B, H, W, C = x.shape
x = x.view(B, H // window_size[0], window_size[0], W // window_size[1], window_size[1], C)
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size[0], window_size[1], C)
return windows
@register_notrace_function # reason: int argument is a Proxy
def window_reverse(windows, window_size: Tuple[int, int], img_size: Tuple[int, int]):
"""
Args:
windows: (num_windows * B, window_size[0], window_size[1], C)
window_size (Tuple[int, int]): Window size
img_size (Tuple[int, int]): Image size
Returns:
x: (B, H, W, C)
"""
H, W = img_size
B = int(windows.shape[0] / (H * W / window_size[0] / window_size[1]))
x = windows.view(B, H // window_size[0], W // window_size[1], window_size[0], window_size[1], -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, H, W, -1)
return x
class WindowMultiHeadAttention(nn.Module):
r"""This class implements window-based Multi-Head-Attention with log-spaced continuous position bias.
Args:
dim (int): Number of input features
window_size (int): Window size
num_heads (int): Number of attention heads
drop_attn (float): Dropout rate of attention map
drop_proj (float): Dropout rate after projection
meta_hidden_dim (int): Number of hidden features in the two layer MLP meta network
sequential_attn (bool): If true sequential self-attention is performed
"""
def __init__(
self,
dim: int,
num_heads: int,
window_size: Tuple[int, int],
drop_attn: float = 0.0,
drop_proj: float = 0.0,
meta_hidden_dim: int = 384, # FIXME what's the optimal value?
sequential_attn: bool = False,
) -> None:
super(WindowMultiHeadAttention, self).__init__()
assert dim % num_heads == 0, \
"The number of input features (in_features) are not divisible by the number of heads (num_heads)."
self.in_features: int = dim
self.window_size: Tuple[int, int] = window_size
self.num_heads: int = num_heads
self.sequential_attn: bool = sequential_attn
self.qkv = nn.Linear(in_features=dim, out_features=dim * 3, bias=True)
self.attn_drop = nn.Dropout(drop_attn)
self.proj = nn.Linear(in_features=dim, out_features=dim, bias=True)
self.proj_drop = nn.Dropout(drop_proj)
# meta network for positional encodings
self.meta_mlp = Mlp(
2, # x, y
hidden_features=meta_hidden_dim,
out_features=num_heads,
act_layer=nn.ReLU,
drop=(0.125, 0.) # FIXME should there be stochasticity, appears to 'overfit' without?
)
# NOTE old checkpoints used inverse of logit_scale ('tau') following the paper, see conversion fn
self.logit_scale = nn.Parameter(torch.log(10 * torch.ones(num_heads)))
self._make_pair_wise_relative_positions()
def _make_pair_wise_relative_positions(self) -> None:
"""Method initializes the pair-wise relative positions to compute the positional biases."""
device = self.logit_scale.device
coordinates = torch.stack(torch.meshgrid([
torch.arange(self.window_size[0], device=device),
torch.arange(self.window_size[1], device=device)]), dim=0).flatten(1)
relative_coordinates = coordinates[:, :, None] - coordinates[:, None, :]
relative_coordinates = relative_coordinates.permute(1, 2, 0).reshape(-1, 2).float()
relative_coordinates_log = torch.sign(relative_coordinates) * torch.log(
1.0 + relative_coordinates.abs())
self.register_buffer("relative_coordinates_log", relative_coordinates_log, persistent=False)
def update_input_size(self, new_window_size: int, **kwargs: Any) -> None:
"""Method updates the window size and so the pair-wise relative positions
Args:
new_window_size (int): New window size
kwargs (Any): Unused
"""
# Set new window size and new pair-wise relative positions
self.window_size: int = new_window_size
self._make_pair_wise_relative_positions()
def _relative_positional_encodings(self) -> torch.Tensor:
"""Method computes the relative positional encodings
Returns:
relative_position_bias (torch.Tensor): Relative positional encodings
(1, number of heads, window size ** 2, window size ** 2)
"""
window_area = self.window_size[0] * self.window_size[1]
relative_position_bias = self.meta_mlp(self.relative_coordinates_log)
relative_position_bias = relative_position_bias.transpose(1, 0).reshape(
self.num_heads, window_area, window_area
)
relative_position_bias = relative_position_bias.unsqueeze(0)
return relative_position_bias
def _forward_sequential(
self,
x: torch.Tensor,
mask: Optional[torch.Tensor] = None,
) -> torch.Tensor:
"""
"""
# FIXME TODO figure out 'sequential' attention mentioned in paper (should reduce GPU memory)
assert False, "not implemented"
def _forward_batch(
self,
x: torch.Tensor,
mask: Optional[torch.Tensor] = None,
) -> torch.Tensor:
"""This function performs standard (non-sequential) scaled cosine self-attention.
"""
Bw, L, C = x.shape
qkv = self.qkv(x).view(Bw, L, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
query, key, value = qkv.unbind(0)
# compute attention map with scaled cosine attention
attn = (F.normalize(query, dim=-1) @ F.normalize(key, dim=-1).transpose(-2, -1))
logit_scale = torch.clamp(self.logit_scale.reshape(1, self.num_heads, 1, 1), max=math.log(1. / 0.01)).exp()
attn = attn * logit_scale
attn = attn + self._relative_positional_encodings()
if mask is not None:
# Apply mask if utilized
num_win: int = mask.shape[0]
attn = attn.view(Bw // num_win, num_win, self.num_heads, L, L)
attn = attn + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, L, L)
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ value).transpose(1, 2).reshape(Bw, L, -1)
x = self.proj(x)
x = self.proj_drop(x)
return x
def forward(self, x: torch.Tensor, mask: Optional[torch.Tensor] = None) -> torch.Tensor:
""" Forward pass.
Args:
x (torch.Tensor): Input tensor of the shape (B * windows, N, C)
mask (Optional[torch.Tensor]): Attention mask for the shift case
Returns:
Output tensor of the shape [B * windows, N, C]
"""
if self.sequential_attn:
return self._forward_sequential(x, mask)
else:
return self._forward_batch(x, mask)
class SwinTransformerBlock(nn.Module):
r"""This class implements the Swin transformer block.
Args:
dim (int): Number of input channels
num_heads (int): Number of attention heads to be utilized
feat_size (Tuple[int, int]): Input resolution
window_size (Tuple[int, int]): Window size to be utilized
shift_size (int): Shifting size to be used
mlp_ratio (int): Ratio of the hidden dimension in the FFN to the input channels
drop (float): Dropout in input mapping
drop_attn (float): Dropout rate of attention map
drop_path (float): Dropout in main path
extra_norm (bool): Insert extra norm on 'main' branch if True
sequential_attn (bool): If true sequential self-attention is performed
norm_layer (Type[nn.Module]): Type of normalization layer to be utilized
"""
def __init__(
self,
dim: int,
num_heads: int,
feat_size: Tuple[int, int],
window_size: Tuple[int, int],
shift_size: Tuple[int, int] = (0, 0),
mlp_ratio: float = 4.0,
init_values: Optional[float] = 0,
drop: float = 0.0,
drop_attn: float = 0.0,
drop_path: float = 0.0,
extra_norm: bool = False,
sequential_attn: bool = False,
norm_layer: Type[nn.Module] = nn.LayerNorm,
) -> None:
super(SwinTransformerBlock, self).__init__()
self.dim: int = dim
self.feat_size: Tuple[int, int] = feat_size
self.target_shift_size: Tuple[int, int] = to_2tuple(shift_size)
self.window_size, self.shift_size = self._calc_window_shift(to_2tuple(window_size))
self.window_area = self.window_size[0] * self.window_size[1]
self.init_values: Optional[float] = init_values
# attn branch
self.attn = WindowMultiHeadAttention(
dim=dim,
num_heads=num_heads,
window_size=self.window_size,
drop_attn=drop_attn,
drop_proj=drop,
sequential_attn=sequential_attn,
)
self.norm1 = norm_layer(dim)
self.drop_path1 = DropPath(drop_prob=drop_path) if drop_path > 0.0 else nn.Identity()
# mlp branch
self.mlp = Mlp(
in_features=dim,
hidden_features=int(dim * mlp_ratio),
drop=drop,
out_features=dim,
)
self.norm2 = norm_layer(dim)
self.drop_path2 = DropPath(drop_prob=drop_path) if drop_path > 0.0 else nn.Identity()
# Extra main branch norm layer mentioned for Huge/Giant models in V2 paper.
# Also being used as final network norm and optional stage ending norm while still in a C-last format.
self.norm3 = norm_layer(dim) if extra_norm else nn.Identity()
self._make_attention_mask()
self.init_weights()
def _calc_window_shift(self, target_window_size):
window_size = [f if f <= w else w for f, w in zip(self.feat_size, target_window_size)]
shift_size = [0 if f <= w else s for f, w, s in zip(self.feat_size, window_size, self.target_shift_size)]
return tuple(window_size), tuple(shift_size)
def _make_attention_mask(self) -> None:
"""Method generates the attention mask used in shift case."""
# Make masks for shift case
if any(self.shift_size):
# calculate attention mask for SW-MSA
H, W = self.feat_size
img_mask = torch.zeros((1, H, W, 1)) # 1 H W 1
cnt = 0
for h in (
slice(0, -self.window_size[0]),
slice(-self.window_size[0], -self.shift_size[0]),
slice(-self.shift_size[0], None)):
for w in (
slice(0, -self.window_size[1]),
slice(-self.window_size[1], -self.shift_size[1]),
slice(-self.shift_size[1], None)):
img_mask[:, h, w, :] = cnt
cnt += 1
mask_windows = window_partition(img_mask, self.window_size) # num_windows, window_size, window_size, 1
mask_windows = mask_windows.view(-1, self.window_area)
attn_mask = mask_windows.unsqueeze(1) - mask_windows.unsqueeze(2)
attn_mask = attn_mask.masked_fill(attn_mask != 0, float(-100.0)).masked_fill(attn_mask == 0, float(0.0))
else:
attn_mask = None
self.register_buffer("attn_mask", attn_mask, persistent=False)
def init_weights(self):
# extra, module specific weight init
if self.init_values is not None:
nn.init.constant_(self.norm1.weight, self.init_values)
nn.init.constant_(self.norm2.weight, self.init_values)
def update_input_size(self, new_window_size: Tuple[int, int], new_feat_size: Tuple[int, int]) -> None:
"""Method updates the image resolution to be processed and window size and so the pair-wise relative positions.
Args:
new_window_size (int): New window size
new_feat_size (Tuple[int, int]): New input resolution
"""
# Update input resolution
self.feat_size: Tuple[int, int] = new_feat_size
self.window_size, self.shift_size = self._calc_window_shift(to_2tuple(new_window_size))
self.window_area = self.window_size[0] * self.window_size[1]
self.attn.update_input_size(new_window_size=self.window_size)
self._make_attention_mask()
def _shifted_window_attn(self, x):
H, W = self.feat_size
B, L, C = x.shape
x = x.view(B, H, W, C)
# cyclic shift
sh, sw = self.shift_size
do_shift: bool = any(self.shift_size)
if do_shift:
# FIXME PyTorch XLA needs cat impl, roll not lowered
# x = torch.cat([x[:, sh:], x[:, :sh]], dim=1)
# x = torch.cat([x[:, :, sw:], x[:, :, :sw]], dim=2)
x = torch.roll(x, shifts=(-sh, -sw), dims=(1, 2))
# partition windows
x_windows = window_partition(x, self.window_size) # num_windows * B, window_size, window_size, C
x_windows = x_windows.view(-1, self.window_size[0] * self.window_size[1], C)
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # num_windows * B, window_size * window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.window_size[0], self.window_size[1], C)
x = window_reverse(attn_windows, self.window_size, self.feat_size) # B H' W' C
# reverse cyclic shift
if do_shift:
# FIXME PyTorch XLA needs cat impl, roll not lowered
# x = torch.cat([x[:, -sh:], x[:, :-sh]], dim=1)
# x = torch.cat([x[:, :, -sw:], x[:, :, :-sw]], dim=2)
x = torch.roll(x, shifts=(sh, sw), dims=(1, 2))
x = x.view(B, L, C)
return x
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Forward pass.
Args:
x (torch.Tensor): Input tensor of the shape [B, C, H, W]
Returns:
output (torch.Tensor): Output tensor of the shape [B, C, H, W]
"""
# post-norm branches (op -> norm -> drop)
x = x + self.drop_path1(self.norm1(self._shifted_window_attn(x)))
x = x + self.drop_path2(self.norm2(self.mlp(x)))
x = self.norm3(x) # main-branch norm enabled for some blocks / stages (every 6 for Huge/Giant)
return x
class PatchMerging(nn.Module):
""" This class implements the patch merging as a strided convolution with a normalization before.
Args:
dim (int): Number of input channels
norm_layer (Type[nn.Module]): Type of normalization layer to be utilized.
"""
def __init__(self, dim: int, norm_layer: Type[nn.Module] = nn.LayerNorm) -> None:
super(PatchMerging, self).__init__()
self.norm = norm_layer(4 * dim)
self.reduction = nn.Linear(in_features=4 * dim, out_features=2 * dim, bias=False)
def forward(self, x: torch.Tensor) -> torch.Tensor:
""" Forward pass.
Args:
x (torch.Tensor): Input tensor of the shape [B, C, H, W]
Returns:
output (torch.Tensor): Output tensor of the shape [B, 2 * C, H // 2, W // 2]
"""
B, C, H, W = x.shape
# unfold + BCHW -> BHWC together
# ordering, 5, 3, 1 instead of 3, 5, 1 maintains compat with original swin v1 merge
x = x.reshape(B, C, H // 2, 2, W // 2, 2).permute(0, 2, 4, 5, 3, 1).flatten(3)
x = self.norm(x)
x = bhwc_to_bchw(self.reduction(x))
return x
class PatchEmbed(nn.Module):
""" 2D Image to Patch Embedding """
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768, norm_layer=None):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])
self.num_patches = self.grid_size[0] * self.grid_size[1]
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
_assert(H == self.img_size[0], f"Input image height ({H}) doesn't match model ({self.img_size[0]}).")
_assert(W == self.img_size[1], f"Input image width ({W}) doesn't match model ({self.img_size[1]}).")
x = self.proj(x)
x = self.norm(x.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)
return x
class SwinTransformerStage(nn.Module):
r"""This class implements a stage of the Swin transformer including multiple layers.
Args:
embed_dim (int): Number of input channels
depth (int): Depth of the stage (number of layers)
downscale (bool): If true input is downsampled (see Fig. 3 or V1 paper)
feat_size (Tuple[int, int]): input feature map size (H, W)
num_heads (int): Number of attention heads to be utilized
window_size (int): Window size to be utilized
mlp_ratio (int): Ratio of the hidden dimension in the FFN to the input channels
drop (float): Dropout in input mapping
drop_attn (float): Dropout rate of attention map
drop_path (float): Dropout in main path
norm_layer (Type[nn.Module]): Type of normalization layer to be utilized. Default: nn.LayerNorm
extra_norm_period (int): Insert extra norm layer on main branch every N (period) blocks
extra_norm_stage (bool): End each stage with an extra norm layer in main branch
sequential_attn (bool): If true sequential self-attention is performed
"""
def __init__(
self,
embed_dim: int,
depth: int,
downscale: bool,
num_heads: int,
feat_size: Tuple[int, int],
window_size: Tuple[int, int],
mlp_ratio: float = 4.0,
init_values: Optional[float] = 0.0,
drop: float = 0.0,
drop_attn: float = 0.0,
drop_path: Union[List[float], float] = 0.0,
norm_layer: Type[nn.Module] = nn.LayerNorm,
extra_norm_period: int = 0,
extra_norm_stage: bool = False,
sequential_attn: bool = False,
) -> None:
super(SwinTransformerStage, self).__init__()
self.downscale: bool = downscale
self.grad_checkpointing: bool = False
self.feat_size: Tuple[int, int] = (feat_size[0] // 2, feat_size[1] // 2) if downscale else feat_size
self.downsample = PatchMerging(embed_dim, norm_layer=norm_layer) if downscale else nn.Identity()
def _extra_norm(index):
i = index + 1
if extra_norm_period and i % extra_norm_period == 0:
return True
return i == depth if extra_norm_stage else False
embed_dim = embed_dim * 2 if downscale else embed_dim
self.blocks = nn.Sequential(*[
SwinTransformerBlock(
dim=embed_dim,
num_heads=num_heads,
feat_size=self.feat_size,
window_size=window_size,
shift_size=tuple([0 if ((index % 2) == 0) else w // 2 for w in window_size]),
mlp_ratio=mlp_ratio,
init_values=init_values,
drop=drop,
drop_attn=drop_attn,
drop_path=drop_path[index] if isinstance(drop_path, list) else drop_path,
extra_norm=_extra_norm(index),
sequential_attn=sequential_attn,
norm_layer=norm_layer,
)
for index in range(depth)]
)
def update_input_size(self, new_window_size: int, new_feat_size: Tuple[int, int]) -> None:
"""Method updates the resolution to utilize and the window size and so the pair-wise relative positions.
Args:
new_window_size (int): New window size
new_feat_size (Tuple[int, int]): New input resolution
"""
self.feat_size: Tuple[int, int] = (
(new_feat_size[0] // 2, new_feat_size[1] // 2) if self.downscale else new_feat_size
)
for block in self.blocks:
block.update_input_size(new_window_size=new_window_size, new_feat_size=self.feat_size)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Forward pass.
Args:
x (torch.Tensor): Input tensor of the shape [B, C, H, W] or [B, L, C]
Returns:
output (torch.Tensor): Output tensor of the shape [B, 2 * C, H // 2, W // 2]
"""
x = self.downsample(x)
B, C, H, W = x.shape
L = H * W
x = bchw_to_bhwc(x).reshape(B, L, C)
for block in self.blocks:
# Perform checkpointing if utilized
if self.grad_checkpointing and not torch.jit.is_scripting():
x = checkpoint.checkpoint(block, x)
else:
x = block(x)
x = bhwc_to_bchw(x.reshape(B, H, W, -1))
return x
class SwinTransformerV2Cr(nn.Module):
r""" Swin Transformer V2
A PyTorch impl of : `Swin Transformer V2: Scaling Up Capacity and Resolution` -
https://arxiv.org/pdf/2111.09883
Args:
img_size (Tuple[int, int]): Input resolution.
window_size (Optional[int]): Window size. If None, img_size // window_div. Default: None
img_window_ratio (int): Window size to image size ratio. Default: 32
patch_size (int | tuple(int)): Patch size. Default: 4
in_chans (int): Number of input channels.
depths (int): Depth of the stage (number of layers).
num_heads (int): Number of attention heads to be utilized.
embed_dim (int): Patch embedding dimension. Default: 96
num_classes (int): Number of output classes. Default: 1000
mlp_ratio (int): Ratio of the hidden dimension in the FFN to the input channels. Default: 4
drop_rate (float): Dropout rate. Default: 0.0
attn_drop_rate (float): Dropout rate of attention map. Default: 0.0
drop_path_rate (float): Stochastic depth rate. Default: 0.0
norm_layer (Type[nn.Module]): Type of normalization layer to be utilized. Default: nn.LayerNorm
extra_norm_period (int): Insert extra norm layer on main branch every N (period) blocks in stage
extra_norm_stage (bool): End each stage with an extra norm layer in main branch
sequential_attn (bool): If true sequential self-attention is performed. Default: False
"""
def __init__(
self,
img_size: Tuple[int, int] = (224, 224),
patch_size: int = 4,
window_size: Optional[int] = None,
img_window_ratio: int = 32,
in_chans: int = 3,
num_classes: int = 1000,
embed_dim: int = 96,
depths: Tuple[int, ...] = (2, 2, 6, 2),
num_heads: Tuple[int, ...] = (3, 6, 12, 24),
mlp_ratio: float = 4.0,
init_values: Optional[float] = 0.,
drop_rate: float = 0.0,
attn_drop_rate: float = 0.0,
drop_path_rate: float = 0.0,
norm_layer: Type[nn.Module] = nn.LayerNorm,
extra_norm_period: int = 0,
extra_norm_stage: bool = False,
sequential_attn: bool = False,
global_pool: str = 'avg',
weight_init='skip',
**kwargs: Any
) -> None:
super(SwinTransformerV2Cr, self).__init__()
img_size = to_2tuple(img_size)
window_size = tuple([
s // img_window_ratio for s in img_size]) if window_size is None else to_2tuple(window_size)
self.num_classes: int = num_classes
self.patch_size: int = patch_size
self.img_size: Tuple[int, int] = img_size
self.window_size: int = window_size
self.num_features: int = int(embed_dim * 2 ** (len(depths) - 1))
self.patch_embed = PatchEmbed(
img_size=img_size, patch_size=patch_size, in_chans=in_chans,
embed_dim=embed_dim, norm_layer=norm_layer)
patch_grid_size: Tuple[int, int] = self.patch_embed.grid_size
drop_path_rate = torch.linspace(0.0, drop_path_rate, sum(depths)).tolist()
stages = []
for index, (depth, num_heads) in enumerate(zip(depths, num_heads)):
stage_scale = 2 ** max(index - 1, 0)
stages.append(
SwinTransformerStage(
embed_dim=embed_dim * stage_scale,
depth=depth,
downscale=index != 0,
feat_size=(patch_grid_size[0] // stage_scale, patch_grid_size[1] // stage_scale),
num_heads=num_heads,
window_size=window_size,
mlp_ratio=mlp_ratio,
init_values=init_values,
drop=drop_rate,
drop_attn=attn_drop_rate,
drop_path=drop_path_rate[sum(depths[:index]):sum(depths[:index + 1])],
extra_norm_period=extra_norm_period,
extra_norm_stage=extra_norm_stage or (index + 1) == len(depths), # last stage ends w/ norm
sequential_attn=sequential_attn,
norm_layer=norm_layer,
)
)
self.stages = nn.Sequential(*stages)
self.global_pool: str = global_pool
self.head = nn.Linear(self.num_features, num_classes) if num_classes else nn.Identity()
# current weight init skips custom init and uses pytorch layer defaults, seems to work well
# FIXME more experiments needed
if weight_init != 'skip':
named_apply(init_weights, self)
def update_input_size(
self,
new_img_size: Optional[Tuple[int, int]] = None,
new_window_size: Optional[int] = None,
img_window_ratio: int = 32,
) -> None:
"""Method updates the image resolution to be processed and window size and so the pair-wise relative positions.
Args:
new_window_size (Optional[int]): New window size, if None based on new_img_size // window_div
new_img_size (Optional[Tuple[int, int]]): New input resolution, if None current resolution is used
img_window_ratio (int): divisor for calculating window size from image size
"""
# Check parameters
if new_img_size is None:
new_img_size = self.img_size
else:
new_img_size = to_2tuple(new_img_size)
if new_window_size is None:
new_window_size = tuple([s // img_window_ratio for s in new_img_size])
# Compute new patch resolution & update resolution of each stage
new_patch_grid_size = (new_img_size[0] // self.patch_size, new_img_size[1] // self.patch_size)
for index, stage in enumerate(self.stages):
stage_scale = 2 ** max(index - 1, 0)
stage.update_input_size(
new_window_size=new_window_size,
new_img_size=(new_patch_grid_size[0] // stage_scale, new_patch_grid_size[1] // stage_scale),
)
@torch.jit.ignore
def group_matcher(self, coarse=False):
return dict(
stem=r'^patch_embed', # stem and embed
blocks=r'^stages\.(\d+)' if coarse else [
(r'^stages\.(\d+).downsample', (0,)),
(r'^stages\.(\d+)\.\w+\.(\d+)', None),
]
)
@torch.jit.ignore
def set_grad_checkpointing(self, enable=True):
for s in self.stages:
s.grad_checkpointing = enable
@torch.jit.ignore()
def get_classifier(self) -> nn.Module:
"""Method returns the classification head of the model.
Returns:
head (nn.Module): Current classification head
"""
return self.head
def reset_classifier(self, num_classes: int, global_pool: Optional[str] = None) -> None:
"""Method results the classification head
Args:
num_classes (int): Number of classes to be predicted
global_pool (str): Unused
"""
self.num_classes: int = num_classes
if global_pool is not None:
self.global_pool = global_pool
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
def forward_features(self, x: torch.Tensor) -> torch.Tensor:
x = self.patch_embed(x)
x = self.stages(x)
return x
def forward_head(self, x, pre_logits: bool = False):
if self.global_pool == 'avg':
x = x.mean(dim=(2, 3))
return x if pre_logits else self.head(x)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.forward_features(x)
x = self.forward_head(x)
return x
def init_weights(module: nn.Module, name: str = ''):
# FIXME WIP determining if there's a better weight init
if isinstance(module, nn.Linear):
if 'qkv' in name:
# treat the weights of Q, K, V separately
val = math.sqrt(6. / float(module.weight.shape[0] // 3 + module.weight.shape[1]))
nn.init.uniform_(module.weight, -val, val)
elif 'head' in name:
nn.init.zeros_(module.weight)
else:
nn.init.xavier_uniform_(module.weight)
if module.bias is not None:
nn.init.zeros_(module.bias)
elif hasattr(module, 'init_weights'):
module.init_weights()
def checkpoint_filter_fn(state_dict, model):
""" convert patch embedding weight from manual patchify + linear proj to conv"""
out_dict = {}
if 'model' in state_dict:
# For deit models
state_dict = state_dict['model']
for k, v in state_dict.items():
if 'tau' in k:
# convert old tau based checkpoints -> logit_scale (inverse)
v = torch.log(1 / v)
k = k.replace('tau', 'logit_scale')
out_dict[k] = v
return out_dict
def _create_swin_transformer_v2_cr(variant, pretrained=False, **kwargs):
if kwargs.get('features_only', None):
raise RuntimeError('features_only not implemented for Vision Transformer models.')
model = build_model_with_cfg(
SwinTransformerV2Cr, variant, pretrained,
pretrained_filter_fn=checkpoint_filter_fn,
**kwargs
)
return model
@register_model
def swinv2_cr_tiny_384(pretrained=False, **kwargs):
"""Swin-T V2 CR @ 384x384, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=96,
depths=(2, 2, 6, 2),
num_heads=(3, 6, 12, 24),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_tiny_384', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_tiny_224(pretrained=False, **kwargs):
"""Swin-T V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=96,
depths=(2, 2, 6, 2),
num_heads=(3, 6, 12, 24),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_tiny_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_tiny_ns_224(pretrained=False, **kwargs):
"""Swin-T V2 CR @ 224x224, trained ImageNet-1k w/ extra stage norms.
** Experimental, may make default if results are improved. **
"""
model_kwargs = dict(
embed_dim=96,
depths=(2, 2, 6, 2),
num_heads=(3, 6, 12, 24),
extra_norm_stage=True,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_tiny_ns_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_small_384(pretrained=False, **kwargs):
"""Swin-S V2 CR @ 384x384, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=96,
depths=(2, 2, 18, 2),
num_heads=(3, 6, 12, 24),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_small_384', pretrained=pretrained, **model_kwargs
)
@register_model
def swinv2_cr_small_224(pretrained=False, **kwargs):
"""Swin-S V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=96,
depths=(2, 2, 18, 2),
num_heads=(3, 6, 12, 24),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_small_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_small_ns_224(pretrained=False, **kwargs):
"""Swin-S V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=96,
depths=(2, 2, 18, 2),
num_heads=(3, 6, 12, 24),
extra_norm_stage=True,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_small_ns_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_base_384(pretrained=False, **kwargs):
"""Swin-B V2 CR @ 384x384, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_base_384', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_base_224(pretrained=False, **kwargs):
"""Swin-B V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_base_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_base_ns_224(pretrained=False, **kwargs):
"""Swin-B V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=128,
depths=(2, 2, 18, 2),
num_heads=(4, 8, 16, 32),
extra_norm_stage=True,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_base_ns_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_large_384(pretrained=False, **kwargs):
"""Swin-L V2 CR @ 384x384, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=192,
depths=(2, 2, 18, 2),
num_heads=(6, 12, 24, 48),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_large_384', pretrained=pretrained, **model_kwargs
)
@register_model
def swinv2_cr_large_224(pretrained=False, **kwargs):
"""Swin-L V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=192,
depths=(2, 2, 18, 2),
num_heads=(6, 12, 24, 48),
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_large_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_huge_384(pretrained=False, **kwargs):
"""Swin-H V2 CR @ 384x384, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=352,
depths=(2, 2, 18, 2),
num_heads=(11, 22, 44, 88), # head count not certain for Huge, 384 & 224 trying diff values
extra_norm_period=6,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_huge_384', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_huge_224(pretrained=False, **kwargs):
"""Swin-H V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=352,
depths=(2, 2, 18, 2),
num_heads=(8, 16, 32, 64), # head count not certain for Huge, 384 & 224 trying diff values
extra_norm_period=6,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_huge_224', pretrained=pretrained, **model_kwargs)
@register_model
def swinv2_cr_giant_384(pretrained=False, **kwargs):
"""Swin-G V2 CR @ 384x384, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=512,
depths=(2, 2, 42, 2),
num_heads=(16, 32, 64, 128),
extra_norm_period=6,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_giant_384', pretrained=pretrained, **model_kwargs
)
@register_model
def swinv2_cr_giant_224(pretrained=False, **kwargs):
"""Swin-G V2 CR @ 224x224, trained ImageNet-1k"""
model_kwargs = dict(
embed_dim=512,
depths=(2, 2, 42, 2),
num_heads=(16, 32, 64, 128),
extra_norm_period=6,
**kwargs
)
return _create_swin_transformer_v2_cr('swinv2_cr_giant_224', pretrained=pretrained, **model_kwargs)
================================================
FILE: model/conv/CondConv.py
================================================
import torch
from torch import nn
from torch.nn import functional as F
class Attention(nn.Module):
def __init__(self,in_planes,K,init_weight=True):
super().__init__()
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.net=nn.Conv2d(in_planes,K,kernel_size=1,bias=False)
self.sigmoid=nn.Sigmoid()
if(init_weight):
self._initialize_weights()
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m ,nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self,x):
att=self.avgpool(x) #bs,dim,1,1
att=self.net(att).view(x.shape[0],-1) #bs,K
return self.sigmoid(att)
class CondConv(nn.Module):
def __init__(self,in_planes,out_planes,kernel_size,stride,padding=0,dilation=1,grounps=1,bias=True,K=4,init_weight=True):
super().__init__()
self.in_planes=in_planes
self.out_planes=out_planes
self.kernel_size=kernel_size
self.stride=stride
self.padding=padding
self.dilation=dilation
self.groups=grounps
self.bias=bias
self.K=K
self.init_weight=init_weight
self.attention=Attention(in_planes=in_planes,K=K,init_weight=init_weight)
self.weight=nn.Parameter(torch.randn(K,out_planes,in_planes//grounps,kernel_size,kernel_size),requires_grad=True)
if(bias):
self.bias=nn.Parameter(torch.randn(K,out_planes),requires_grad=True)
else:
self.bias=None
if(self.init_weight):
self._initialize_weights()
#TODO 初始化
def _initialize_weights(self):
for i in range(self.K):
nn.init.kaiming_uniform_(self.weight[i])
def forward(self,x):
bs,in_planels,h,w=x.shape
softmax_att=self.attention(x) #bs,K
x=x.view(1,-1,h,w)
weight=self.weight.view(self.K,-1) #K,-1
aggregate_weight=torch.mm(softmax_att,weight).view(bs*self.out_planes,self.in_planes//self.groups,self.kernel_size,self.kernel_size) #bs*out_p,in_p,k,k
if(self.bias is not None):
bias=self.bias.view(self.K,-1) #K,out_p
aggregate_bias=torch.mm(softmax_att,bias).view(-1) #bs,out_p
output=F.conv2d(x,weight=aggregate_weight,bias=aggregate_bias,stride=self.stride,padding=self.padding,groups=self.groups*bs,dilation=self.dilation)
else:
output=F.conv2d(x,weight=aggregate_weight,bias=None,stride=self.stride,padding=self.padding,groups=self.groups*bs,dilation=self.dilation)
output=output.view(bs,self.out_planes,h,w)
return output
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=CondConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
================================================
FILE: model/conv/DepthwiseSeparableConvolution.py
================================================
import torch
from torch import nn
class DepthwiseSeparableConvolution(nn.Module):
def __init__(self,in_ch,out_ch,kernel_size=3,stride=1,padding=1):
super().__init__()
self.depthwise_conv=nn.Conv2d(
in_channels=in_ch,
out_channels=in_ch,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=in_ch
)
self.pointwise_conv=nn.Conv2d(
in_channels=in_ch,
out_channels=out_ch,
kernel_size=1,
stride=1,
padding=0,
groups=1
)
def forward(self, x):
out=self.depthwise_conv(x)
out=self.pointwise_conv(out)
return out
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)
================================================
FILE: model/conv/DynamicConv.py
================================================
import torch
from torch import nn
from torch.nn import functional as F
class Attention(nn.Module):
def __init__(self,in_planes,ratio,K,temprature=30,init_weight=True):
super().__init__()
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.temprature=temprature
assert in_planes>ratio
hidden_planes=in_planes//ratio
self.net=nn.Sequential(
nn.Conv2d(in_planes,hidden_planes,kernel_size=1,bias=False),
nn.ReLU(),
nn.Conv2d(hidden_planes,K,kernel_size=1,bias=False)
)
if(init_weight):
self._initialize_weights()
def update_temprature(self):
if(self.temprature>1):
self.temprature-=1
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
if isinstance(m ,nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self,x):
att=self.avgpool(x) #bs,dim,1,1
att=self.net(att).view(x.shape[0],-1) #bs,K
return F.softmax(att/self.temprature,-1)
class DynamicConv(nn.Module):
def __init__(self,in_planes,out_planes,kernel_size,stride,padding=0,dilation=1,grounps=1,bias=True,K=4,temprature=30,ratio=4,init_weight=True):
super().__init__()
self.in_planes=in_planes
self.out_planes=out_planes
self.kernel_size=kernel_size
self.stride=stride
self.padding=padding
self.dilation=dilation
self.groups=grounps
self.bias=bias
self.K=K
self.init_weight=init_weight
self.attention=Attention(in_planes=in_planes,ratio=ratio,K=K,temprature=temprature,init_weight=init_weight)
self.weight=nn.Parameter(torch.randn(K,out_planes,in_planes//grounps,kernel_size,kernel_size),requires_grad=True)
if(bias):
self.bias=nn.Parameter(torch.randn(K,out_planes),requires_grad=True)
else:
self.bias=None
if(self.init_weight):
self._initialize_weights()
#TODO 初始化
def _initialize_weights(self):
for i in range(self.K):
nn.init.kaiming_uniform_(self.weight[i])
def forward(self,x):
bs,in_planels,h,w=x.shape
softmax_att=self.attention(x) #bs,K
x=x.view(1,-1,h,w)
weight=self.weight.view(self.K,-1) #K,-1
aggregate_weight=torch.mm(softmax_att,weight).view(bs*self.out_planes,self.in_planes//self.groups,self.kernel_size,self.kernel_size) #bs*out_p,in_p,k,k
if(self.bias is not None):
bias=self.bias.view(self.K,-1) #K,out_p
aggregate_bias=torch.mm(softmax_att,bias).view(-1) #bs,out_p
output=F.conv2d(x,weight=aggregate_weight,bias=aggregate_bias,stride=self.stride,padding=self.padding,groups=self.groups*bs,dilation=self.dilation)
else:
output=F.conv2d(x,weight=aggregate_weight,bias=None,stride=self.stride,padding=self.padding,groups=self.groups*bs,dilation=self.dilation)
output=output.view(bs,self.out_planes,h,w)
return output
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
================================================
FILE: model/conv/HorNet.py
================================================
from functools import partial
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.models.layers import trunc_normal_, DropPath
from timm.models.registry import register_model
import torch.fft
def get_dwconv(dim, kernel, bias):
return nn.Conv2d(dim, dim, kernel_size=kernel, padding=(kernel-1)//2 ,bias=bias, groups=dim)
class GlobalLocalFilter(nn.Module):
# https://arxiv.org/abs/2207.14284
def __init__(self, dim, h=14, w=8):
super().__init__()
self.dw = nn.Conv2d(dim // 2, dim // 2, kernel_size=3, padding=1, bias=False, groups=dim // 2)
self.complex_weight = nn.Parameter(torch.randn(dim // 2, h, w, 2, dtype=torch.float32) * 0.02)
trunc_normal_(self.complex_weight, std=.02)
self.pre_norm = LayerNorm(dim, eps=1e-6, data_format='channels_first')
self.post_norm = LayerNorm(dim, eps=1e-6, data_format='channels_first')
def forward(self, x):
x = self.pre_norm(x)
x1, x2 = torch.chunk(x, 2, dim=1)
x1 = self.dw(x1)
x2 = x2.to(torch.float32)
B, C, a, b = x2.shape
x2 = torch.fft.rfft2(x2, dim=(2, 3), norm='ortho')
weight = self.complex_weight
if not weight.shape[1:3] == x2.shape[2:4]:
weight = F.interpolate(weight.permute(3,0,1,2), size=x2.shape[2:4], mode='bilinear', align_corners=True).permute(1,2,3,0)
weight = torch.view_as_complex(weight.contiguous())
x2 = x2 * weight
x2 = torch.fft.irfft2(x2, s=(a, b), dim=(2, 3), norm='ortho')
x = torch.cat([x1.unsqueeze(2), x2.unsqueeze(2)], dim=2).reshape(B, 2 * C, a, b)
x = self.post_norm(x)
return x
class gnconv(nn.Module):
def __init__(self, dim, order=5, gflayer=None, h=14, w=8, s=1.0):
super().__init__()
self.order = order
self.dims = [dim // 2 ** i for i in range(order)]
self.dims.reverse()
self.proj_in = nn.Conv2d(dim, 2*dim, 1)
if gflayer is None:
self.dwconv = get_dwconv(sum(self.dims), 7, True)
else:
self.dwconv = gflayer(sum(self.dims), h=h, w=w)
self.proj_out = nn.Conv2d(dim, dim, 1)
self.pws = nn.ModuleList(
[nn.Conv2d(self.dims[i], self.dims[i+1], 1) for i in range(order-1)]
)
self.scale = s
def forward(self, x, mask=None, dummy=False):
B, C, H, W = x.shape
fused_x = self.proj_in(x)
pwa, abc = torch.split(fused_x, (self.dims[0], sum(self.dims)), dim=1)
dw_abc = self.dwconv(abc) * self.scale
dw_list = torch.split(dw_abc, self.dims, dim=1)
x = pwa * dw_list[0]
for i in range(self.order -1):
x = self.pws[i](x) * dw_list[i+1]
x = self.proj_out(x)
return x
class Block(nn.Module):
r""" HorNet block
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6, gnconv=gnconv):
super().__init__()
self.norm1 = LayerNorm(dim, eps=1e-6, data_format='channels_first')
self.gnconv = gnconv(dim) # depthwise conv
self.norm2 = LayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim) # pointwise/1x1 convs, implemented with linear layers
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma1 = nn.Parameter(layer_scale_init_value * torch.ones(dim),
requires_grad=True) if layer_scale_init_value > 0 else None
self.gamma2 = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape
if self.gamma1 is not None:
gamma1 = self.gamma1.view(C, 1, 1)
else:
gamma1 = 1
x = x + self.drop_path(gamma1 * self.gnconv(self.norm1(x)))
input = x
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm2(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma2 is not None:
x = self.gamma2 * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
class HorNet(nn.Module):
def __init__(self, in_chans=3, num_classes=1000,
depths=[3, 3, 9, 3], base_dim=96, drop_path_rate=0.,
layer_scale_init_value=1e-6, head_init_scale=1.,
gnconv=gnconv, block=Block, uniform_init=False, **kwargs
):
super().__init__()
dims = [base_dim, base_dim*2, base_dim*4, base_dim*8]
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
LayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
if not isinstance(gnconv, list):
gnconv = [gnconv, gnconv, gnconv, gnconv]
else:
gnconv = gnconv
assert len(gnconv) == 4
cur = 0
for i in range(4):
stage = nn.Sequential(
*[block(dim=dims[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value, gnconv=gnconv[i]) for j in range(depths[i])]
)
self.stages.append(stage)
cur += depths[i]
self.norm = nn.LayerNorm(dims[-1], eps=1e-6) # final norm layer
self.head = nn.Linear(dims[-1], num_classes)
self.uniform_init = uniform_init
self.apply(self._init_weights)
self.head.weight.data.mul_(head_init_scale)
self.head.bias.data.mul_(head_init_scale)
def _init_weights(self, m):
if not self.uniform_init:
if isinstance(m, (nn.Conv2d, nn.Linear)):
trunc_normal_(m.weight, std=.02)
if hasattr(m, 'bias') and m.bias is not None:
nn.init.constant_(m.bias, 0)
else:
if isinstance(m, (nn.Conv2d, nn.Linear)):
nn.init.xavier_uniform_(m.weight)
if hasattr(m, 'bias') and m.bias is not None:
nn.init.constant_(m.bias, 0)
def forward_features(self, x):
for i in range(4):
x = self.downsample_layers[i](x)
for j, blk in enumerate(self.stages[i]):
x = blk(x)
return self.norm(x.mean([-2, -1])) # global average pooling, (N, C, H, W) -> (N, C)
def forward(self, x):
x = self.forward_features(x)
x = self.head(x)
return x
class LayerNorm(nn.Module):
r""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_last"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
@register_model
def hornet_tiny_7x7(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=64, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s),
partial(gnconv, order=5, s=s),
],
**kwargs
)
return model
@register_model
def hornet_tiny_gf(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=64, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s, h=14, w=8, gflayer=GlobalLocalFilter),
partial(gnconv, order=5, s=s, h=7, w=4, gflayer=GlobalLocalFilter),
],
**kwargs
)
return model
@register_model
def hornet_small_7x7(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=96, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s),
partial(gnconv, order=5, s=s),
],
**kwargs
)
return model
@register_model
def hornet_small_gf(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=96, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s, h=14, w=8, gflayer=GlobalLocalFilter),
partial(gnconv, order=5, s=s, h=7, w=4, gflayer=GlobalLocalFilter),
],
**kwargs
)
return model
@register_model
def hornet_base_7x7(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=128, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s),
partial(gnconv, order=5, s=s),
],
**kwargs
)
return model
@register_model
def hornet_base_gf(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=128, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s, h=14, w=8, gflayer=GlobalLocalFilter),
partial(gnconv, order=5, s=s, h=7, w=4, gflayer=GlobalLocalFilter),
],
**kwargs
)
return model
@register_model
def hornet_base_gf_img384(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=128, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s, h=24, w=13, gflayer=GlobalLocalFilter),
partial(gnconv, order=5, s=s, h=12, w=7, gflayer=GlobalLocalFilter),
],
**kwargs
)
return model
@register_model
def hornet_large_7x7(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=192, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s),
partial(gnconv, order=5, s=s),
],
**kwargs
)
return model
@register_model
def hornet_large_gf(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=192, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s, h=14, w=8, gflayer=GlobalLocalFilter),
partial(gnconv, order=5, s=s, h=7, w=4, gflayer=GlobalLocalFilter),
],
**kwargs
)
return model
@register_model
def hornet_large_gf_img384(pretrained=False,in_22k=False, **kwargs):
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=192, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s, h=24, w=13, gflayer=GlobalLocalFilter),
partial(gnconv, order=5, s=s, h=12, w=7, gflayer=GlobalLocalFilter),
],
**kwargs
)
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
s = 1.0/3.0
model = HorNet(depths=[2, 3, 18, 2], base_dim=64, block=Block,
gnconv=[
partial(gnconv, order=2, s=s),
partial(gnconv, order=3, s=s),
partial(gnconv, order=4, s=s),
partial(gnconv, order=5, s=s),
],
)
outputs = model(input)
print(outputs.shape)
================================================
FILE: model/conv/Involution.py
================================================
import math
from functools import partial
import torch
from torch import nn, select
from torch.nn import functional as F
class Involution(nn.Module):
def __init__(self, kernel_size, in_channel=4, stride=1, group=1,ratio=4):
super().__init__()
self.kernel_size=kernel_size
self.in_channel=in_channel
self.stride=stride
self.group=group
assert self.in_channel%group==0
self.group_channel=self.in_channel//group
self.conv1=nn.Conv2d(
self.in_channel,
self.in_channel//ratio,
kernel_size=1
)
self.bn=nn.BatchNorm2d(in_channel//ratio)
self.relu=nn.ReLU()
self.conv2=nn.Conv2d(
self.in_channel//ratio,
self.group*self.kernel_size*self.kernel_size,
kernel_size=1
)
self.avgpool=nn.AvgPool2d(stride,stride) if stride>1 else nn.Identity()
self.unfold=nn.Unfold(kernel_size=kernel_size,stride=stride,padding=kernel_size//2)
def forward(self, inputs):
B,C,H,W=inputs.shape
weight=self.conv2(self.relu(self.bn(self.conv1(self.avgpool(inputs))))) #(bs,G*K*K,H//stride,W//stride)
b,c,h,w=weight.shape
weight=weight.reshape(b,self.group,self.kernel_size*self.kernel_size,h,w).unsqueeze(2) #(bs,G,1,K*K,H//stride,W//stride)
x_unfold=self.unfold(inputs)
x_unfold=x_unfold.reshape(B,self.group,C//self.group,self.kernel_size*self.kernel_size,H//self.stride,W//self.stride) #(bs,G,G//C,K*K,H//stride,W//stride)
out=(x_unfold*weight).sum(dim=3)#(bs,G,G//C,1,H//stride,W//stride)
out=out.reshape(B,C,H//self.stride,W//self.stride) #(bs,C,H//stride,W//stride)
return out
if __name__ == '__main__':
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)
================================================
FILE: model/conv/MBConv.py
================================================
import math
from functools import partial
import torch
from torch import nn
from torch.nn import functional as F
class SwishImplementation(torch.autograd.Function):
@staticmethod
def forward(ctx, i):
result = i * torch.sigmoid(i)
ctx.save_for_backward(i)
return result
@staticmethod
def backward(ctx, grad_output):
i = ctx.saved_variables[0]
sigmoid_i = torch.sigmoid(i)
return grad_output * (sigmoid_i * (1 + i * (1 - sigmoid_i)))
class MemoryEfficientSwish(nn.Module):
def forward(self, x):
return SwishImplementation.apply(x)
def drop_connect(inputs, p, training):
""" Drop connect. """
if not training: return inputs
batch_size = inputs.shape[0]
keep_prob = 1 - p
random_tensor = keep_prob
random_tensor += torch.rand([batch_size, 1, 1, 1], dtype=inputs.dtype, device=inputs.device)
binary_tensor = torch.floor(random_tensor)
output = inputs / keep_prob * binary_tensor
return output
def get_same_padding_conv2d(image_size=None):
return partial(Conv2dStaticSamePadding, image_size=image_size)
def get_width_and_height_from_size(x):
""" Obtains width and height from a int or tuple """
if isinstance(x, int): return x, x
if isinstance(x, list) or isinstance(x, tuple): return x
else: raise TypeError()
def calculate_output_image_size(input_image_size, stride):
"""
计算出 Conv2dSamePadding with a stride.
"""
if input_image_size is None: return None
image_height, image_width = get_width_and_height_from_size(input_image_size)
stride = stride if isinstance(stride, int) else stride[0]
image_height = int(math.ceil(image_height / stride))
image_width = int(math.ceil(image_width / stride))
return [image_height, image_width]
class Conv2dStaticSamePadding(nn.Conv2d):
""" 2D Convolutions like TensorFlow, for a fixed image size"""
def __init__(self, in_channels, out_channels, kernel_size, image_size=None, **kwargs):
super().__init__(in_channels, out_channels, kernel_size, **kwargs)
self.stride = self.stride if len(self.stride) == 2 else [self.stride[0]] * 2
# Calculate padding based on image size and save it
assert image_size is not None
ih, iw = (image_size, image_size) if isinstance(image_size, int) else image_size
kh, kw = self.weight.size()[-2:]
sh, sw = self.stride
oh, ow = math.ceil(ih / sh), math.ceil(iw / sw)
pad_h = max((oh - 1) * self.stride[0] + (kh - 1) * self.dilation[0] + 1 - ih, 0)
pad_w = max((ow - 1) * self.stride[1] + (kw - 1) * self.dilation[1] + 1 - iw, 0)
if pad_h > 0 or pad_w > 0:
self.static_padding = nn.ZeroPad2d((pad_w // 2, pad_w - pad_w // 2, pad_h // 2, pad_h - pad_h // 2))
else:
self.static_padding = Identity()
def forward(self, x):
x = self.static_padding(x)
x = F.conv2d(x, self.weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
return x
class Identity(nn.Module):
def __init__(self, ):
super(Identity, self).__init__()
def forward(self, input):
return input
# MBConvBlock
class MBConvBlock(nn.Module):
'''
层 ksize3*3 输入32 输出16 conv1 stride步长1
'''
def __init__(self, ksize, input_filters, output_filters, expand_ratio=1, stride=1, image_size=224):
super().__init__()
self._bn_mom = 0.1
self._bn_eps = 0.01
self._se_ratio = 0.25
self._input_filters = input_filters
self._output_filters = output_filters
self._expand_ratio = expand_ratio
self._kernel_size = ksize
self._stride = stride
inp = self._input_filters
oup = self._input_filters * self._expand_ratio
if self._expand_ratio != 1:
Conv2d = get_same_padding_conv2d(image_size=image_size)
self._expand_conv = Conv2d(in_channels=inp, out_channels=oup, kernel_size=1, bias=False)
self._bn0 = nn.BatchNorm2d(num_features=oup, momentum=self._bn_mom, eps=self._bn_eps)
# Depthwise convolution
k = self._kernel_size
s = self._stride
Conv2d = get_same_padding_conv2d(image_size=image_size)
self._depthwise_conv = Conv2d(
in_channels=oup, out_channels=oup, groups=oup,
kernel_size=k, stride=s, bias=False)
self._bn1 = nn.BatchNorm2d(num_features=oup, momentum=self._bn_mom, eps=self._bn_eps)
image_size = calculate_output_image_size(image_size, s)
# Squeeze and Excitation layer, if desired
Conv2d = get_same_padding_conv2d(image_size=(1,1))
num_squeezed_channels = max(1, int(self._input_filters * self._se_ratio))
self._se_reduce = Conv2d(in_channels=oup, out_channels=num_squeezed_channels, kernel_size=1)
self._se_expand = Conv2d(in_channels=num_squeezed_channels, out_channels=oup, kernel_size=1)
# Output phase
final_oup = self._output_filters
Conv2d = get_same_padding_conv2d(image_size=image_size)
self._project_conv = Conv2d(in_channels=oup, out_channels=final_oup, kernel_size=1, bias=False)
self._bn2 = nn.BatchNorm2d(num_features=final_oup, momentum=self._bn_mom, eps=self._bn_eps)
self._swish = MemoryEfficientSwish()
def forward(self, inputs, drop_connect_rate=None):
"""
:param inputs: input tensor
:param drop_connect_rate: drop connect rate (float, between 0 and 1)
:return: output of block
"""
# Expansion and Depthwise Convolution
x = inputs
if self._expand_ratio != 1:
expand = self._expand_conv(inputs)
bn0 = self._bn0(expand)
x = self._swish(bn0)
depthwise = self._depthwise_conv(x)
bn1 = self._bn1(depthwise)
x = self._swish(bn1)
# Squeeze and Excitation
x_squeezed = F.adaptive_avg_pool2d(x, 1)
x_squeezed = self._se_reduce(x_squeezed)
x_squeezed = self._swish(x_squeezed)
x_squeezed = self._se_expand(x_squeezed)
x = torch.sigmoid(x_squeezed) * x
x = self._bn2(self._project_conv(x))
# Skip connection and drop connect
input_filters, output_filters = self._input_filters, self._output_filters
if self._stride == 1 and input_filters == output_filters:
if drop_connect_rate:
x = drop_connect(x, p=drop_connect_rate, training=self.training)
x = x + inputs # skip connection
return x
if __name__ == '__main__':
input=torch.randn(1,3,112,112)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=3,image_size=112)
out=mbconv(input)
print(out.shape)
================================================
FILE: model/fighingcv.egg-info/PKG-INFO
================================================
Metadata-Version: 2.1
Name: fighingcv
Version: 1.0.0
Summary: Client library to download and publish models, datasets and other repos on the huggingface.co hub
Home-page: https://github.com/xmu-xiaoma666/External-Attention-pytorch
Author: Hugging Face, Inc.
Author-email: julien@huggingface.co
License: Apache
Keywords: model-hub machine-learning models natural-language-processing deep-learning pytorch pretrained-models
Platform: UNKNOWN
Classifier: Intended Audience :: Developers
Classifier: Intended Audience :: Education
Classifier: Intended Audience :: Science/Research
Classifier: License :: OSI Approved :: Apache Software License
Classifier: Operating System :: OS Independent
Classifier: Programming Language :: Python :: 3
Classifier: Topic :: Scientific/Engineering :: Artificial Intelligence
Requires-Python: >=3.7.0
Description-Content-Type: text/markdown
Provides-Extra: torch
Provides-Extra: fastai
Provides-Extra: tensorflow
Provides-Extra: testing
Provides-Extra: quality
Provides-Extra: all
Provides-Extra: dev
License-File: LICENSE
简体中文 | [English](./README_EN.md)
# FightingCV 代码库, 包含 [***Attention***](#attention-series),[***Backbone***](#backbone-series), [***MLP***](#mlp-series), [***Re-parameter***](#re-parameter-series), [**Convolution**](#convolution-series)



-------
🔥🔥🔥 **重磅!!!作为项目补充,最近全新开源了一个目标检测代码库 [YOLOAir](https://github.com/iscyy/yoloair),里面在目标检测算法中集成了各种Attention机制,代码简洁易读,欢迎大家来玩呀!**

-------
Hello,大家好,我是小马🚀🚀🚀
***For 小白(Like Me):***
最近在读论文的时候会发现一个问题,有时候论文核心思想非常简单,核心代码可能也就十几行。但是打开作者release的源码时,却发现提出的模块嵌入到分类、检测、分割等任务框架中,导致代码比较冗余,对于特定任务框架不熟悉的我,**很难找到核心代码**,导致在论文和网络思想的理解上会有一定困难。
***For 进阶者(Like You):***
如果把Conv、FC、RNN这些基本单元看做小的Lego积木,把Transformer、ResNet这些结构看成已经搭好的Lego城堡。那么本项目提供的模块就是一个个具有完整语义信息的Lego组件。**让科研工作者们避免反复造轮子**,只需思考如何利用这些“Lego组件”,搭建出更多绚烂多彩的作品。
***For 大神(May Be Like You):***
能力有限,**不喜轻喷**!!!
***For All:***
本项目就是要实现一个既能**让深度学习小白也能搞懂**,又能**服务科研和工业社区**的代码库。作为[**FightingCV公众号**](https://mp.weixin.qq.com/s/m9RiivbbDPdjABsTd6q8FA)的补充,本项目的宗旨是从代码角度,实现🚀**让世界上没有难读的论文**🚀。
(同时也非常欢迎各位科研工作者将自己的工作的核心代码整理到本项目中,推动科研社区的发展,会在readme中注明代码的作者~)
## 公众号 & 微信交流群
欢迎大家关注公众号:**FightingCV**
公众号**每天**都会进行**论文、算法和代码的干货分享**哦~
**每天在群里分享一些近期的论文和解析**,欢迎大家一起**学习交流**哈~~~
(加不进去可以加微信:**775629340**,记得备注【**公司/学校+方向+ID**】)

强烈推荐大家关注[**知乎**](https://www.zhihu.com/people/jason-14-58-38/posts)账号和[**FightingCV公众号**](https://mp.weixin.qq.com/s/m9RiivbbDPdjABsTd6q8FA),可以快速了解到最新优质的干货资源。
***
# 目录
- [Attention Series](#attention-series)
- [1. External Attention Usage](#1-external-attention-usage)
- [2. Self Attention Usage](#2-self-attention-usage)
- [3. Simplified Self Attention Usage](#3-simplified-self-attention-usage)
- [4. Squeeze-and-Excitation Attention Usage](#4-squeeze-and-excitation-attention-usage)
- [5. SK Attention Usage](#5-sk-attention-usage)
- [6. CBAM Attention Usage](#6-cbam-attention-usage)
- [7. BAM Attention Usage](#7-bam-attention-usage)
- [8. ECA Attention Usage](#8-eca-attention-usage)
- [9. DANet Attention Usage](#9-danet-attention-usage)
- [10. Pyramid Split Attention (PSA) Usage](#10-Pyramid-Split-Attention-Usage)
- [11. Efficient Multi-Head Self-Attention(EMSA) Usage](#11-Efficient-Multi-Head-Self-Attention-Usage)
- [12. Shuffle Attention Usage](#12-Shuffle-Attention-Usage)
- [13. MUSE Attention Usage](#13-MUSE-Attention-Usage)
- [14. SGE Attention Usage](#14-SGE-Attention-Usage)
- [15. A2 Attention Usage](#15-A2-Attention-Usage)
- [16. AFT Attention Usage](#16-AFT-Attention-Usage)
- [17. Outlook Attention Usage](#17-Outlook-Attention-Usage)
- [18. ViP Attention Usage](#18-ViP-Attention-Usage)
- [19. CoAtNet Attention Usage](#19-CoAtNet-Attention-Usage)
- [20. HaloNet Attention Usage](#20-HaloNet-Attention-Usage)
- [21. Polarized Self-Attention Usage](#21-Polarized-Self-Attention-Usage)
- [22. CoTAttention Usage](#22-CoTAttention-Usage)
- [23. Residual Attention Usage](#23-Residual-Attention-Usage)
- [24. S2 Attention Usage](#24-S2-Attention-Usage)
- [25. GFNet Attention Usage](#25-GFNet-Attention-Usage)
- [26. Triplet Attention Usage](#26-TripletAttention-Usage)
- [27. Coordinate Attention Usage](#27-Coordinate-Attention-Usage)
- [28. MobileViT Attention Usage](#28-MobileViT-Attention-Usage)
- [29. ParNet Attention Usage](#29-ParNet-Attention-Usage)
- [30. UFO Attention Usage](#30-UFO-Attention-Usage)
- [31. ACmix Attention Usage](#31-Acmix-Attention-Usage)
- [32. MobileViTv2 Attention Usage](#32-MobileViTv2-Attention-Usage)
- [33. DAT Attention Usage](#33-DAT-Attention-Usage)
- [34. CrossFormer Attention Usage](#34-CrossFormer-Attention-Usage)
- [35. MOATransformer Attention Usage](#35-MOATransformer-Attention-Usage)
- [36. CrissCrossAttention Attention Usage](#36-CrissCrossAttention-Attention-Usage)
- [37. Axial_attention Attention Usage](#37-Axial_attention-Attention-Usage)
- [Backbone Series](#Backbone-series)
- [1. ResNet Usage](#1-ResNet-Usage)
- [2. ResNeXt Usage](#2-ResNeXt-Usage)
- [3. MobileViT Usage](#3-MobileViT-Usage)
- [4. ConvMixer Usage](#4-ConvMixer-Usage)
- [5. ShuffleTransformer Usage](#5-ShuffleTransformer-Usage)
- [6. ConTNet Usage](#6-ConTNet-Usage)
- [7. HATNet Usage](#7-HATNet-Usage)
- [8. CoaT Usage](#8-CoaT-Usage)
- [9. PVT Usage](#9-PVT-Usage)
- [10. CPVT Usage](#10-CPVT-Usage)
- [11. PIT Usage](#11-PIT-Usage)
- [12. CrossViT Usage](#12-CrossViT-Usage)
- [13. TnT Usage](#13-TnT-Usage)
- [14. DViT Usage](#14-DViT-Usage)
- [15. CeiT Usage](#15-CeiT-Usage)
- [16. ConViT Usage](#16-ConViT-Usage)
- [17. CaiT Usage](#17-CaiT-Usage)
- [18. PatchConvnet Usage](#18-PatchConvnet-Usage)
- [19. DeiT Usage](#19-DeiT-Usage)
- [20. LeViT Usage](#20-LeViT-Usage)
- [21. VOLO Usage](#21-VOLO-Usage)
- [22. Container Usage](#22-Container-Usage)
- [23. CMT Usage](#23-CMT-Usage)
- [MLP Series](#mlp-series)
- [1. RepMLP Usage](#1-RepMLP-Usage)
- [2. MLP-Mixer Usage](#2-MLP-Mixer-Usage)
- [3. ResMLP Usage](#3-ResMLP-Usage)
- [4. gMLP Usage](#4-gMLP-Usage)
- [5. sMLP Usage](#5-sMLP-Usage)
- [6. vip-mlp Usage](#6-vip-mlp-Usage)
- [Re-Parameter(ReP) Series](#Re-Parameter-series)
- [1. RepVGG Usage](#1-RepVGG-Usage)
- [2. ACNet Usage](#2-ACNet-Usage)
- [3. Diverse Branch Block(DDB) Usage](#3-Diverse-Branch-Block-Usage)
- [Convolution Series](#Convolution-series)
- [1. Depthwise Separable Convolution Usage](#1-Depthwise-Separable-Convolution-Usage)
- [2. MBConv Usage](#2-MBConv-Usage)
- [3. Involution Usage](#3-Involution-Usage)
- [4. DynamicConv Usage](#4-DynamicConv-Usage)
- [5. CondConv Usage](#5-CondConv-Usage)
***
# Attention Series
- Pytorch implementation of ["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks---arXiv 2021.05.05"](https://arxiv.org/abs/2105.02358)
- Pytorch implementation of ["Attention Is All You Need---NIPS2017"](https://arxiv.org/pdf/1706.03762.pdf)
- Pytorch implementation of ["Squeeze-and-Excitation Networks---CVPR2018"](https://arxiv.org/abs/1709.01507)
- Pytorch implementation of ["Selective Kernel Networks---CVPR2019"](https://arxiv.org/pdf/1903.06586.pdf)
- Pytorch implementation of ["CBAM: Convolutional Block Attention Module---ECCV2018"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
- Pytorch implementation of ["BAM: Bottleneck Attention Module---BMCV2018"](https://arxiv.org/pdf/1807.06514.pdf)
- Pytorch implementation of ["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020"](https://arxiv.org/pdf/1910.03151.pdf)
- Pytorch implementation of ["Dual Attention Network for Scene Segmentation---CVPR2019"](https://arxiv.org/pdf/1809.02983.pdf)
- Pytorch implementation of ["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30"](https://arxiv.org/pdf/2105.14447.pdf)
- Pytorch implementation of ["ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28"](https://arxiv.org/abs/2105.13677)
- Pytorch implementation of ["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS---ICASSP 2021"](https://arxiv.org/pdf/2102.00240.pdf)
- Pytorch implementation of ["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning---arXiv 2019.11.17"](https://arxiv.org/abs/1911.09483)
- Pytorch implementation of ["Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks---arXiv 2019.05.23"](https://arxiv.org/pdf/1905.09646.pdf)
- Pytorch implementation of ["A2-Nets: Double Attention Networks---NIPS2018"](https://arxiv.org/pdf/1810.11579.pdf)
- Pytorch implementation of ["An Attention Free Transformer---ICLR2021 (Apple New Work)"](https://arxiv.org/pdf/2105.14103v1.pdf)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition---arXiv 2021.06.24"](https://arxiv.org/abs/2106.13112)
[【论文解析】](https://zhuanlan.zhihu.com/p/385561050)
- Pytorch implementation of [Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition---arXiv 2021.06.23](https://arxiv.org/abs/2106.12368)
[【论文解析】](https://mp.weixin.qq.com/s/5gonUQgBho_m2O54jyXF_Q)
- Pytorch implementation of [CoAtNet: Marrying Convolution and Attention for All Data Sizes---arXiv 2021.06.09](https://arxiv.org/abs/2106.04803)
[【论文解析】](https://zhuanlan.zhihu.com/p/385578588)
- Pytorch implementation of [Scaling Local Self-Attention for Parameter Efficient Visual Backbones---CVPR2021 Oral](https://arxiv.org/pdf/2103.12731.pdf) [【论文解析】](https://zhuanlan.zhihu.com/p/388598744)
- Pytorch implementation of [Polarized Self-Attention: Towards High-quality Pixel-wise Regression---arXiv 2021.07.02](https://arxiv.org/abs/2107.00782) [【论文解析】](https://zhuanlan.zhihu.com/p/389770482)
- Pytorch implementation of [Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292) [【论文解析】](https://zhuanlan.zhihu.com/p/394795481)
- Pytorch implementation of [Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
- Pytorch implementation of [S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072) [【论文解析】](https://zhuanlan.zhihu.com/p/397003638)
- Pytorch implementation of [Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
- Pytorch implementation of [Rotate to Attend: Convolutional Triplet Attention Module---WACV 2021](https://arxiv.org/abs/2010.03045)
- Pytorch implementation of [Coordinate Attention for Efficient Mobile Network Design ---CVPR 2021](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2110.02178)
- Pytorch implementation of [Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
- Pytorch implementation of [UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2109.14382)
- Pytorch implementation of [Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
- Pytorch implementation of [On the Integration of Self-Attention and Convolution---ArXiv 2022.03.14](https://arxiv.org/pdf/2111.14556.pdf)
- Pytorch implementation of [CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
- Pytorch implementation of [Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
- Pytorch implementation of [CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
- Pytorch implementation of [Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
***
### 1. External Attention Usage
#### 1.1. Paper
["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks"](https://arxiv.org/abs/2105.02358)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
***
### 2. Self Attention Usage
#### 2.1. Paper
["Attention Is All You Need"](https://arxiv.org/pdf/1706.03762.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 3. Simplified Self Attention Usage
#### 3.1. Paper
[None]()
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)
```
***
### 4. Squeeze-and-Excitation Attention Usage
#### 4.1. Paper
["Squeeze-and-Excitation Networks"](https://arxiv.org/abs/1709.01507)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 5. SK Attention Usage
#### 5.1. Paper
["Selective Kernel Networks"](https://arxiv.org/pdf/1903.06586.pdf)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 6. CBAM Attention Usage
#### 6.1. Paper
["CBAM: Convolutional Block Attention Module"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
#### 6.2. Overview


#### 6.3. Usage Code
```python
from model.attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
***
### 7. BAM Attention Usage
#### 7.1. Paper
["BAM: Bottleneck Attention Module"](https://arxiv.org/pdf/1807.06514.pdf)
#### 7.2. Overview

#### 7.3. Usage Code
```python
from model.attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
***
### 8. ECA Attention Usage
#### 8.1. Paper
["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks"](https://arxiv.org/pdf/1910.03151.pdf)
#### 8.2. Overview

#### 8.3. Usage Code
```python
from model.attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
***
### 9. DANet Attention Usage
#### 9.1. Paper
["Dual Attention Network for Scene Segmentation"](https://arxiv.org/pdf/1809.02983.pdf)
#### 9.2. Overview

#### 9.3. Usage Code
```python
from model.attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
***
### 10. Pyramid Split Attention Usage
#### 10.1. Paper
["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network"](https://arxiv.org/pdf/2105.14447.pdf)
#### 10.2. Overview

#### 10.3. Usage Code
```python
from model.attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
***
### 11. Efficient Multi-Head Self-Attention Usage
#### 11.1. Paper
["ResT: An Efficient Transformer for Visual Recognition"](https://arxiv.org/abs/2105.13677)
#### 11.2. Overview

#### 11.3. Usage Code
```python
from model.attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
***
### 12. Shuffle Attention Usage
#### 12.1. Paper
["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS"](https://arxiv.org/pdf/2102.00240.pdf)
#### 12.2. Overview

#### 12.3. Usage Code
```python
from model.attention.ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
```
***
### 13. MUSE Attention Usage
#### 13.1. Paper
["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning"](https://arxiv.org/abs/1911.09483)
#### 13.2. Overview

#### 13.3. Usage Code
```python
from model.attention.MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 14. SGE Attention Usage
#### 14.1. Paper
[Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks](https://arxiv.org/pdf/1905.09646.pdf)
#### 14.2. Overview

#### 14.3. Usage Code
```python
from model.attention.SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
```
***
### 15. A2 Attention Usage
#### 15.1. Paper
[A2-Nets: Double Attention Networks](https://arxiv.org/pdf/1810.11579.pdf)
#### 15.2. Overview

#### 15.3. Usage Code
```python
from model.attention.A2Atttention import DoubleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
```
### 16. AFT Attention Usage
#### 16.1. Paper
[An Attention Free Transformer](https://arxiv.org/pdf/2105.14103v1.pdf)
#### 16.2. Overview

#### 16.3. Usage Code
```python
from model.attention.AFT import AFT_FULL
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
```
### 17. Outlook Attention Usage
#### 17.1. Paper
[VOLO: Vision Outlooker for Visual Recognition"](https://arxiv.org/abs/2106.13112)
#### 17.2. Overview

#### 17.3. Usage Code
```python
from model.attention.OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)
```
***
### 18. ViP Attention Usage
#### 18.1. Paper
[Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 18.2. Overview

#### 18.3. Usage Code
```python
from model.attention.ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)
```
***
### 19. CoAtNet Attention Usage
#### 19.1. Paper
[CoAtNet: Marrying Convolution and Attention for All Data Sizes"](https://arxiv.org/abs/2106.04803)
#### 19.2. Overview
None
#### 19.3. Usage Code
```python
from model.attention.CoAtNet import CoAtNet
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=CoAtNet(in_ch=3,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 20. HaloNet Attention Usage
#### 20.1. Paper
[Scaling Local Self-Attention for Parameter Efficient Visual Backbones"](https://arxiv.org/pdf/2103.12731.pdf)
#### 20.2. Overview

#### 20.3. Usage Code
```python
from model.attention.HaloAttention import HaloAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)
```
***
### 21. Polarized Self-Attention Usage
#### 21.1. Paper
[Polarized Self-Attention: Towards High-quality Pixel-wise Regression"](https://arxiv.org/abs/2107.00782)
#### 21.2. Overview

#### 21.3. Usage Code
```python
from model.attention.PolarizedSelfAttention import ParallelPolarizedSelfAttention,SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
```
***
### 22. CoTAttention Usage
#### 22.1. Paper
[Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292)
#### 22.2. Overview

#### 22.3. Usage Code
```python
from model.attention.CoTAttention import CoTAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
```
***
### 23. Residual Attention Usage
#### 23.1. Paper
[Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
#### 23.2. Overview

#### 23.3. Usage Code
```python
from model.attention.ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
resatt = ResidualAttention(channel=512,num_class=1000,la=0.2)
output=resatt(input)
print(output.shape)
```
***
### 24. S2 Attention Usage
#### 24.1. Paper
[S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072)
#### 24.2. Overview

#### 24.3. Usage Code
```python
from model.attention.S2Attention import S2Attention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
s2att = S2Attention(channels=512)
output=s2att(input)
print(output.shape)
```
***
### 25. GFNet Attention Usage
#### 25.1. Paper
[Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
#### 25.2. Overview

#### 25.3. Usage Code - Implemented by [Wenliang Zhao (Author)](https://scholar.google.com/citations?user=lyPWvuEAAAAJ&hl=en)
```python
from model.attention.gfnet import GFNet
import torch
from torch import nn
from torch.nn import functional as F
x = torch.randn(1, 3, 224, 224)
gfnet = GFNet(embed_dim=384, img_size=224, patch_size=16, num_classes=1000)
out = gfnet(x)
print(out.shape)
```
***
### 26. TripletAttention Usage
#### 26.1. Paper
[Rotate to Attend: Convolutional Triplet Attention Module---CVPR 2021](https://arxiv.org/abs/2010.03045)
#### 26.2. Overview

#### 26.3. Usage Code - Implemented by [digantamisra98](https://github.com/digantamisra98)
```python
from model.attention.TripletAttention import TripletAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
triplet = TripletAttention()
output=triplet(input)
print(output.shape)
```
***
### 27. Coordinate Attention Usage
#### 27.1. Paper
[Coordinate Attention for Efficient Mobile Network Design---CVPR 2021](https://arxiv.org/abs/2103.02907)
#### 27.2. Overview

#### 27.3. Usage Code - Implemented by [Andrew-Qibin](https://github.com/Andrew-Qibin)
```python
from model.attention.CoordAttention import CoordAtt
import torch
from torch import nn
from torch.nn import functional as F
inp=torch.rand([2, 96, 56, 56])
inp_dim, oup_dim = 96, 96
reduction=32
coord_attention = CoordAtt(inp_dim, oup_dim, reduction=reduction)
output=coord_attention(inp)
print(output.shape)
```
***
### 28. MobileViT Attention Usage
#### 28.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2103.02907)
#### 28.2. Overview

#### 28.3. Usage Code
```python
from model.attention.MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
m=MobileViTAttention()
input=torch.randn(1,3,49,49)
output=m(input)
print(output.shape) #output:(1,3,49,49)
```
***
### 29. ParNet Attention Usage
#### 29.1. Paper
[Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
#### 29.2. Overview

#### 29.3. Usage Code
```python
from model.attention.ParNetAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
pna = ParNetAttention(channel=512)
output=pna(input)
print(output.shape) #50,512,7,7
```
***
### 30. UFO Attention Usage
#### 30.1. Paper
[UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2110.07641)
#### 30.2. Overview

#### 30.3. Usage Code
```python
from model.attention.UFOAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
ufo = UFOAttention(d_model=512, d_k=512, d_v=512, h=8)
output=ufo(input,input,input)
print(output.shape) #[50, 49, 512]
```
-
### 31. ACmix Attention Usage
#### 31.1. Paper
[On the Integration of Self-Attention and Convolution](https://arxiv.org/pdf/2111.14556.pdf)
#### 31.2. Usage Code
```python
from model.attention.ACmix import ACmix
import torch
if __name__ == '__main__':
input=torch.randn(50,256,7,7)
acmix = ACmix(in_planes=256, out_planes=256)
output=acmix(input)
print(output.shape)
```
### 32. MobileViTv2 Attention Usage
#### 32.1. Paper
[Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
#### 32.2. Overview

#### 32.3. Usage Code
```python
from model.attention.MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
### 33. DAT Attention Usage
#### 33.1. Paper
[Vision Transformer with Deformable Attention---CVPR2022](https://arxiv.org/abs/2201.00520)
#### 33.2. Usage Code
```python
from model.attention.DAT import DAT
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DAT(
img_size=224,
patch_size=4,
num_classes=1000,
expansion=4,
dim_stem=96,
dims=[96, 192, 384, 768],
depths=[2, 2, 6, 2],
stage_spec=[['L', 'S'], ['L', 'S'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7] ,
groups=[-1, -1, 3, 6],
use_pes=[False, False, True, True],
dwc_pes=[False, False, False, False],
strides=[-1, -1, 1, 1],
sr_ratios=[-1, -1, -1, -1],
offset_range_factor=[-1, -1, 2, 2],
no_offs=[False, False, False, False],
fixed_pes=[False, False, False, False],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
)
output=model(input)
print(output[0].shape)
```
### 34. CrossFormer Attention Usage
#### 34.1. Paper
[CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
#### 34.2. Usage Code
```python
from model.attention.Crossformer import CrossFormer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CrossFormer(img_size=224,
patch_size=[4, 8, 16, 32],
in_chans= 3,
num_classes=1000,
embed_dim=48,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
group_size=[7, 7, 7, 7],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False,
merge_size=[[2, 4], [2,4], [2, 4]]
)
output=model(input)
print(output.shape)
```
### 35. MOATransformer Attention Usage
#### 35.1. Paper
[Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
#### 35.2. Usage Code
```python
from model.attention.MOATransformer import MOATransformer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = MOATransformer(
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=[2, 2, 6],
num_heads=[3, 6, 12],
window_size=14,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False
)
output=model(input)
print(output.shape)
```
### 36. CrissCrossAttention Attention Usage
#### 36.1. Paper
[CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
#### 36.2. Usage Code
```python
from model.attention.CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = CrissCrossAttention(64)
outputs = model(input)
print(outputs.shape)
```
### 37. Axial_attention Attention Usage
#### 37.1. Paper
[Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
#### 37.2. Usage Code
```python
from model.attention.Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__':
input=torch.randn(3, 128, 7, 7)
model = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
outputs = model(input)
print(outputs.shape)
```
***
# Backbone Series
- Pytorch implementation of ["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
- Pytorch implementation of ["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
- Pytorch implementation of [Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer---ArXiv 2021.06.07](https://arxiv.org/abs/2106.03650)
- Pytorch implementation of [ConTNet: Why not use convolution and transformer at the same time?---ArXiv 2021.04.27](https://arxiv.org/abs/2104.13497)
- Pytorch implementation of [Vision Transformers with Hierarchical Attention---ArXiv 2022.06.15](https://arxiv.org/abs/2106.03180)
- Pytorch implementation of [Co-Scale Conv-Attentional Image Transformers---ArXiv 2021.08.26](https://arxiv.org/abs/2104.06399)
- Pytorch implementation of [Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
- Pytorch implementation of [Rethinking Spatial Dimensions of Vision Transformers---ICCV 2021](https://arxiv.org/abs/2103.16302)
- Pytorch implementation of [CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification---ICCV 2021](https://arxiv.org/abs/2103.14899)
- Pytorch implementation of [Transformer in Transformer---NeurIPS 2021](https://arxiv.org/abs/2103.00112)
- Pytorch implementation of [DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
- Pytorch implementation of [Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
***
- Pytorch implementation of [ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
- Pytorch implementation of [Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
- Pytorch implementation of [Going deeper with Image Transformers---ICCV 2021 (Oral)](https://arxiv.org/abs/2103.17239)
- Pytorch implementation of [Training data-efficient image transformers & distillation through attention---ICML 2021](https://arxiv.org/abs/2012.12877)
- Pytorch implementation of [LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
- Pytorch implementation of [Container: Context Aggregation Network---NeuIPS 2021](https://arxiv.org/abs/2106.01401)
- Pytorch implementation of [CMT: Convolutional Neural Networks Meet Vision Transformers---CVPR 2022](https://arxiv.org/abs/2107.06263)
- Pytorch implementation of [Vision Transformer with Deformable Attention---CVPR 2022](https://arxiv.org/abs/2201.00520)
### 1. ResNet Usage
#### 1.1. Paper
["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
#### 1.2. Overview


#### 1.3. Usage Code
```python
from model.backbone.resnet import ResNet50,ResNet101,ResNet152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnet50=ResNet50(1000)
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out=resnet50(input)
print(out.shape)
```
### 2. ResNeXt Usage
#### 2.1. Paper
["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.backbone.resnext import ResNeXt50,ResNeXt101,ResNeXt152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnext50=ResNeXt50(1000)
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out=resnext50(input)
print(out.shape)
```
### 3. MobileViT Usage
#### 3.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.backbone.MobileViT import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
### mobilevit_xxs
mvit_xxs=mobilevit_xxs()
out=mvit_xxs(input)
print(out.shape)
### mobilevit_xs
mvit_xs=mobilevit_xs()
out=mvit_xs(input)
print(out.shape)
### mobilevit_s
mvit_s=mobilevit_s()
out=mvit_s(input)
print(out.shape)
```
### 4. ConvMixer Usage
#### 4.1. Paper
[Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.backbone.ConvMixer import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
convmixer=ConvMixer(dim=512,depth=12)
out=convmixer(x)
print(out.shape) #[1, 1000]
```
### 5. ShuffleTransformer Usage
#### 5.1. Paper
[Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer](https://arxiv.org/pdf/2106.03650.pdf)
#### 5.2. Usage Code
```python
from model.backbone.ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
sft = ShuffleTransformer()
output=sft(input)
print(output.shape)
```
### 6. ConTNet Usage
#### 6.1. Paper
[ConTNet: Why not use convolution and transformer at the same time?](https://arxiv.org/abs/2104.13497)
#### 6.2. Usage Code
```python
from model.backbone.ConTNet import ConTNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == "__main__":
model = build_model(use_avgdown=True, relative=True, qkv_bias=True, pre_norm=True)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
```
### 7 HATNet Usage
#### 7.1. Paper
[Vision Transformers with Hierarchical Attention](https://arxiv.org/abs/2106.03180)
#### 7.2. Usage Code
```python
from model.backbone.HATNet import HATNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
hat = HATNet(dims=[48, 96, 240, 384], head_dim=48, expansions=[8, 8, 4, 4],
grid_sizes=[8, 7, 7, 1], ds_ratios=[8, 4, 2, 1], depths=[2, 2, 6, 3])
output=hat(input)
print(output.shape)
```
### 8 CoaT Usage
#### 8.1. Paper
[Co-Scale Conv-Attentional Image Transformers](https://arxiv.org/abs/2104.06399)
#### 8.2. Usage Code
```python
from model.backbone.CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4])
output=model(input)
print(output.shape) # torch.Size([1, 1000])
```
### 9 PVT Usage
#### 9.1. Paper
[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/pdf/2106.13797.pdf)
#### 9.2. Usage Code
```python
from model.backbone.PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 10 CPVT Usage
#### 10.1. Paper
[Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
#### 10.2. Usage Code
```python
from model.backbone.CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 11 PIT Usage
#### 11.1. Paper
[Rethinking Spatial Dimensions of Vision Transformers](https://arxiv.org/abs/2103.16302)
#### 11.2. Usage Code
```python
from model.backbone.PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4
)
output=model(input)
print(output.shape)
```
### 12 CrossViT Usage
#### 12.1. Paper
[CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification](https://arxiv.org/abs/2103.14899)
#### 12.2. Usage Code
```python
from model.backbone.CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__":
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[240, 224],
patch_size=[12, 16],
embed_dim=[192, 384],
depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6],
mlp_ratio=[4, 4, 1],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 13 TnT Usage
#### 13.1. Paper
[Transformer in Transformer](https://arxiv.org/abs/2103.00112)
#### 13.2. Usage Code
```python
from model.backbone.TnT import TNT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = TNT(
img_size=224,
patch_size=16,
outer_dim=384,
inner_dim=24,
depth=12,
outer_num_heads=6,
inner_num_heads=4,
qkv_bias=False,
inner_stride=4)
output=model(input)
print(output.shape)
```
### 14 DViT Usage
#### 14.1. Paper
[DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
#### 14.2. Usage Code
```python
from model.backbone.DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DeepVisionTransformer(
patch_size=16, embed_dim=384,
depth=[False] * 16,
apply_transform=[False] * 0 + [True] * 32,
num_heads=12,
mlp_ratio=3,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
)
output=model(input)
print(output.shape)
```
### 15 CeiT Usage
#### 15.1. Paper
[Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
#### 15.2. Usage Code
```python
from model.backbone.CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CeIT(
hybrid_backbone=Image2Tokens(),
patch_size=4,
embed_dim=192,
depth=12,
num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 16 ConViT Usage
#### 16.1. Paper
[ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
#### 16.2. Usage Code
```python
from model.backbone.ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 17 CaiT Usage
#### 17.1. Paper
[Going deeper with Image Transformers](https://arxiv.org/abs/2103.17239)
#### 17.2. Usage Code
```python
from model.backbone.CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CaiT(
img_size= 224,
patch_size=16,
embed_dim=192,
depth=24,
num_heads=4,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2
)
output=model(input)
print(output.shape)
```
### 18 PatchConvnet Usage
#### 18.1. Paper
[Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
#### 18.2. Usage Code
```python
from model.backbone.PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
)
output=model(input)
print(output.shape)
```
### 19 DeiT Usage
#### 19.1. Paper
[Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
#### 19.2. Usage Code
```python
from model.backbone.DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DistilledVisionTransformer(
patch_size=16,
embed_dim=384,
depth=12,
num_heads=6,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output[0].shape)
```
### 20 LeViT Usage
#### 20.1. Paper
[LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
#### 20.2. Usage Code
```python
from model.backbone.LeViT import *
import torch
from torch import nn
if __name__ == '__main__':
for name in specification:
input=torch.randn(1,3,224,224)
model = globals()[name](fuse=True, pretrained=False)
model.eval()
output = model(input)
print(output.shape)
```
### 21 VOLO Usage
#### 21.1. Paper
[VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
#### 21.2. Usage Code
```python
from model.backbone.VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VOLO([4, 4, 8, 2],
embed_dims=[192, 384, 384, 384],
num_heads=[6, 12, 12, 12],
mlp_ratios=[3, 3, 3, 3],
downsamples=[True, False, False, False],
outlook_attention=[True, False, False, False ],
post_layers=['ca', 'ca'],
)
output=model(input)
print(output[0].shape)
```
### 22 Container Usage
#### 22.1. Paper
[Container: Context Aggregation Network](https://arxiv.org/abs/2106.01401)
#### 22.2. Usage Code
```python
from model.backbone.Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[224, 56, 28, 14],
patch_size=[4, 2, 2, 2],
embed_dim=[64, 128, 320, 512],
depth=[3, 4, 8, 3],
num_heads=16,
mlp_ratio=[8, 8, 4, 4],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6))
output=model(input)
print(output.shape)
```
### 23 CMT Usage
#### 23.1. Paper
[CMT: Convolutional Neural Networks Meet Vision Transformers](https://arxiv.org/abs/2107.06263)
#### 23.2. Usage Code
```python
from model.backbone.CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CMT_Tiny()
output=model(input)
print(output[0].shape)
```
# MLP Series
- Pytorch implementation of ["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition---arXiv 2021.05.05"](https://arxiv.org/pdf/2105.01883v1.pdf)
- Pytorch implementation of ["MLP-Mixer: An all-MLP Architecture for Vision---arXiv 2021.05.17"](https://arxiv.org/pdf/2105.01601.pdf)
- Pytorch implementation of ["ResMLP: Feedforward networks for image classification with data-efficient training---arXiv 2021.05.07"](https://arxiv.org/pdf/2105.03404.pdf)
- Pytorch implementation of ["Pay Attention to MLPs---arXiv 2021.05.17"](https://arxiv.org/abs/2105.08050)
- Pytorch implementation of ["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?---arXiv 2021.09.12"](https://arxiv.org/abs/2109.05422)
### 1. RepMLP Usage
#### 1.1. Paper
["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition"](https://arxiv.org/pdf/2105.01883v1.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.mlp.repmlp import RepMLP
import torch
from torch import nn
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())
```
### 2. MLP-Mixer Usage
#### 2.1. Paper
["MLP-Mixer: An all-MLP Architecture for Vision"](https://arxiv.org/pdf/2105.01601.pdf)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.mlp.mlp_mixer import MlpMixer
import torch
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)
```
***
### 3. ResMLP Usage
#### 3.1. Paper
["ResMLP: Feedforward networks for image classification with data-efficient training"](https://arxiv.org/pdf/2105.03404.pdf)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.mlp.resmlp import ResMLP
import torch
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape) #the last dimention is class_num
```
***
### 4. gMLP Usage
#### 4.1. Paper
["Pay Attention to MLPs"](https://arxiv.org/abs/2105.08050)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.mlp.g_mlp import gMLP
import torch
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)
```
***
### 5. sMLP Usage
#### 5.1. Paper
["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?"](https://arxiv.org/abs/2109.05422)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.mlp.sMLP_block import sMLPBlock
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
smlp=sMLPBlock(h=224,w=224)
out=smlp(input)
print(out.shape)
```
### 6. vip-mlp Usage
#### 6.1. Paper
["Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 6.2. Usage Code
```python
from model.mlp.vip-mlp import VisionPermutator
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionPermutator(
layers=[4, 3, 8, 3],
embed_dims=[384, 384, 384, 384],
patch_size=14,
transitions=[False, False, False, False],
segment_dim=[16, 16, 16, 16],
mlp_ratios=[3, 3, 3, 3],
mlp_fn=WeightedPermuteMLP
)
output=model(input)
print(output.shape)
```
# Re-Parameter Series
- Pytorch implementation of ["RepVGG: Making VGG-style ConvNets Great Again---CVPR2021"](https://arxiv.org/abs/2101.03697)
- Pytorch implementation of ["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks---ICCV2019"](https://arxiv.org/abs/1908.03930)
- Pytorch implementation of ["Diverse Branch Block: Building a Convolution as an Inception-like Unit---CVPR2021"](https://arxiv.org/abs/2103.13425)
***
### 1. RepVGG Usage
#### 1.1. Paper
["RepVGG: Making VGG-style ConvNets Great Again"](https://arxiv.org/abs/2101.03697)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
```
***
### 2. ACNet Usage
#### 2.1. Paper
["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks"](https://arxiv.org/abs/1908.03930)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
```
***
### 2. Diverse Branch Block Usage
#### 2.1. Paper
["Diverse Branch Block: Building a Convolution as an Inception-like Unit"](https://arxiv.org/abs/2103.13425)
#### 2.2. Overview

#### 2.3. Usage Code
##### 2.3.1 Transform I
```python
from model.rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.2 Transform II
```python
from model.rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.3 Transform III
```python
from model.rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.4 Transform IV
```python
from model.rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.5 Transform V
```python
from model.rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.6 Transform VI
```python
from model.rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
# Convolution Series
- Pytorch implementation of ["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications---CVPR2017"](https://arxiv.org/abs/1704.04861)
- Pytorch implementation of ["Efficientnet: Rethinking model scaling for convolutional neural networks---PMLR2019"](http://proceedings.mlr.press/v97/tan19a.html)
- Pytorch implementation of ["Involution: Inverting the Inherence of Convolution for Visual Recognition---CVPR2021"](https://arxiv.org/abs/2103.06255)
- Pytorch implementation of ["Dynamic Convolution: Attention over Convolution Kernels---CVPR2020 Oral"](https://arxiv.org/abs/1912.03458)
- Pytorch implementation of ["CondConv: Conditionally Parameterized Convolutions for Efficient Inference---NeurIPS2019"](https://arxiv.org/abs/1904.04971)
***
### 1. Depthwise Separable Convolution Usage
#### 1.1. Paper
["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications"](https://arxiv.org/abs/1704.04861)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.conv.DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)
```
***
### 2. MBConv Usage
#### 2.1. Paper
["Efficientnet: Rethinking model scaling for convolutional neural networks"](http://proceedings.mlr.press/v97/tan19a.html)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.conv.MBConv import MBConvBlock
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=512,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 3. Involution Usage
#### 3.1. Paper
["Involution: Inverting the Inherence of Convolution for Visual Recognition"](https://arxiv.org/abs/2103.06255)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.conv.Involution import Involution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)
```
***
### 4. DynamicConv Usage
#### 4.1. Paper
["Dynamic Convolution: Attention over Convolution Kernels"](https://arxiv.org/abs/1912.03458)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.conv.DynamicConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape) # 2,32,64,64
```
***
### 5. CondConv Usage
#### 5.1. Paper
["CondConv: Conditionally Parameterized Convolutions for Efficient Inference"](https://arxiv.org/abs/1904.04971)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.conv.CondConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=CondConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
```
***
================================================
FILE: model/fighingcv.egg-info/SOURCES.txt
================================================
LICENSE
README.md
setup.py
model/fighingcv.egg-info/PKG-INFO
model/fighingcv.egg-info/SOURCES.txt
model/fighingcv.egg-info/dependency_links.txt
model/fighingcv.egg-info/entry_points.txt
model/fighingcv.egg-info/requires.txt
model/fighingcv.egg-info/top_level.txt
================================================
FILE: model/fighingcv.egg-info/dependency_links.txt
================================================
================================================
FILE: model/fighingcv.egg-info/entry_points.txt
================================================
[console_scripts]
huggingface-cli = huggingface_hub.commands.huggingface_cli:main
================================================
FILE: model/fighingcv.egg-info/requires.txt
================================================
filelock
requests
tqdm
pyyaml>=5.1
typing-extensions>=3.7.4.3
packaging>=20.9
[:python_version < "3.8"]
importlib_metadata
[all]
pytest
pytest-cov
datasets
soundfile
black==22.3
isort>=5.5.4
flake8>=3.8.3
flake8-bugbear
[dev]
pytest
pytest-cov
datasets
soundfile
black==22.3
isort>=5.5.4
flake8>=3.8.3
flake8-bugbear
[fastai]
toml
fastai>=2.4
fastcore>=1.3.27
[quality]
black==22.3
isort>=5.5.4
flake8>=3.8.3
flake8-bugbear
[tensorflow]
tensorflow
pydot
graphviz
[testing]
pytest
pytest-cov
datasets
soundfile
[torch]
torch
================================================
FILE: model/fighingcv.egg-info/top_level.txt
================================================
================================================
FILE: model/huggingface_hub.egg-info/PKG-INFO
================================================
Metadata-Version: 2.1
Name: huggingface-hub
Version: 1.0.0
Summary: Client library to download and publish models, datasets and other repos on the huggingface.co hub
Home-page: https://github.com/xmu-xiaoma666/External-Attention-pytorch
Author: Hugging Face, Inc.
Author-email: julien@huggingface.co
License: Apache
Keywords: model-hub machine-learning models natural-language-processing deep-learning pytorch pretrained-models
Platform: UNKNOWN
Classifier: Intended Audience :: Developers
Classifier: Intended Audience :: Education
Classifier: Intended Audience :: Science/Research
Classifier: License :: OSI Approved :: Apache Software License
Classifier: Operating System :: OS Independent
Classifier: Programming Language :: Python :: 3
Classifier: Topic :: Scientific/Engineering :: Artificial Intelligence
Requires-Python: >=3.7.0
Description-Content-Type: text/markdown
Provides-Extra: torch
Provides-Extra: fastai
Provides-Extra: tensorflow
Provides-Extra: testing
Provides-Extra: quality
Provides-Extra: all
Provides-Extra: dev
License-File: LICENSE
简体中文 | [English](./README_EN.md)
# FightingCV 代码库, 包含 [***Attention***](#attention-series),[***Backbone***](#backbone-series), [***MLP***](#mlp-series), [***Re-parameter***](#re-parameter-series), [**Convolution**](#convolution-series)



-------
🔥🔥🔥 **重磅!!!作为项目补充,最近全新开源了一个目标检测代码库 [YOLOAir](https://github.com/iscyy/yoloair),里面在目标检测算法中集成了各种Attention机制,代码简洁易读,欢迎大家来玩呀!**

-------
Hello,大家好,我是小马🚀🚀🚀
***For 小白(Like Me):***
最近在读论文的时候会发现一个问题,有时候论文核心思想非常简单,核心代码可能也就十几行。但是打开作者release的源码时,却发现提出的模块嵌入到分类、检测、分割等任务框架中,导致代码比较冗余,对于特定任务框架不熟悉的我,**很难找到核心代码**,导致在论文和网络思想的理解上会有一定困难。
***For 进阶者(Like You):***
如果把Conv、FC、RNN这些基本单元看做小的Lego积木,把Transformer、ResNet这些结构看成已经搭好的Lego城堡。那么本项目提供的模块就是一个个具有完整语义信息的Lego组件。**让科研工作者们避免反复造轮子**,只需思考如何利用这些“Lego组件”,搭建出更多绚烂多彩的作品。
***For 大神(May Be Like You):***
能力有限,**不喜轻喷**!!!
***For All:***
本项目就是要实现一个既能**让深度学习小白也能搞懂**,又能**服务科研和工业社区**的代码库。作为[**FightingCV公众号**](https://mp.weixin.qq.com/s/m9RiivbbDPdjABsTd6q8FA)的补充,本项目的宗旨是从代码角度,实现🚀**让世界上没有难读的论文**🚀。
(同时也非常欢迎各位科研工作者将自己的工作的核心代码整理到本项目中,推动科研社区的发展,会在readme中注明代码的作者~)
## 公众号 & 微信交流群
欢迎大家关注公众号:**FightingCV**
公众号**每天**都会进行**论文、算法和代码的干货分享**哦~
**每天在群里分享一些近期的论文和解析**,欢迎大家一起**学习交流**哈~~~
(加不进去可以加微信:**775629340**,记得备注【**公司/学校+方向+ID**】)

强烈推荐大家关注[**知乎**](https://www.zhihu.com/people/jason-14-58-38/posts)账号和[**FightingCV公众号**](https://mp.weixin.qq.com/s/m9RiivbbDPdjABsTd6q8FA),可以快速了解到最新优质的干货资源。
***
# 目录
- [Attention Series](#attention-series)
- [1. External Attention Usage](#1-external-attention-usage)
- [2. Self Attention Usage](#2-self-attention-usage)
- [3. Simplified Self Attention Usage](#3-simplified-self-attention-usage)
- [4. Squeeze-and-Excitation Attention Usage](#4-squeeze-and-excitation-attention-usage)
- [5. SK Attention Usage](#5-sk-attention-usage)
- [6. CBAM Attention Usage](#6-cbam-attention-usage)
- [7. BAM Attention Usage](#7-bam-attention-usage)
- [8. ECA Attention Usage](#8-eca-attention-usage)
- [9. DANet Attention Usage](#9-danet-attention-usage)
- [10. Pyramid Split Attention (PSA) Usage](#10-Pyramid-Split-Attention-Usage)
- [11. Efficient Multi-Head Self-Attention(EMSA) Usage](#11-Efficient-Multi-Head-Self-Attention-Usage)
- [12. Shuffle Attention Usage](#12-Shuffle-Attention-Usage)
- [13. MUSE Attention Usage](#13-MUSE-Attention-Usage)
- [14. SGE Attention Usage](#14-SGE-Attention-Usage)
- [15. A2 Attention Usage](#15-A2-Attention-Usage)
- [16. AFT Attention Usage](#16-AFT-Attention-Usage)
- [17. Outlook Attention Usage](#17-Outlook-Attention-Usage)
- [18. ViP Attention Usage](#18-ViP-Attention-Usage)
- [19. CoAtNet Attention Usage](#19-CoAtNet-Attention-Usage)
- [20. HaloNet Attention Usage](#20-HaloNet-Attention-Usage)
- [21. Polarized Self-Attention Usage](#21-Polarized-Self-Attention-Usage)
- [22. CoTAttention Usage](#22-CoTAttention-Usage)
- [23. Residual Attention Usage](#23-Residual-Attention-Usage)
- [24. S2 Attention Usage](#24-S2-Attention-Usage)
- [25. GFNet Attention Usage](#25-GFNet-Attention-Usage)
- [26. Triplet Attention Usage](#26-TripletAttention-Usage)
- [27. Coordinate Attention Usage](#27-Coordinate-Attention-Usage)
- [28. MobileViT Attention Usage](#28-MobileViT-Attention-Usage)
- [29. ParNet Attention Usage](#29-ParNet-Attention-Usage)
- [30. UFO Attention Usage](#30-UFO-Attention-Usage)
- [31. ACmix Attention Usage](#31-Acmix-Attention-Usage)
- [32. MobileViTv2 Attention Usage](#32-MobileViTv2-Attention-Usage)
- [33. DAT Attention Usage](#33-DAT-Attention-Usage)
- [34. CrossFormer Attention Usage](#34-CrossFormer-Attention-Usage)
- [35. MOATransformer Attention Usage](#35-MOATransformer-Attention-Usage)
- [36. CrissCrossAttention Attention Usage](#36-CrissCrossAttention-Attention-Usage)
- [37. Axial_attention Attention Usage](#37-Axial_attention-Attention-Usage)
- [Backbone Series](#Backbone-series)
- [1. ResNet Usage](#1-ResNet-Usage)
- [2. ResNeXt Usage](#2-ResNeXt-Usage)
- [3. MobileViT Usage](#3-MobileViT-Usage)
- [4. ConvMixer Usage](#4-ConvMixer-Usage)
- [5. ShuffleTransformer Usage](#5-ShuffleTransformer-Usage)
- [6. ConTNet Usage](#6-ConTNet-Usage)
- [7. HATNet Usage](#7-HATNet-Usage)
- [8. CoaT Usage](#8-CoaT-Usage)
- [9. PVT Usage](#9-PVT-Usage)
- [10. CPVT Usage](#10-CPVT-Usage)
- [11. PIT Usage](#11-PIT-Usage)
- [12. CrossViT Usage](#12-CrossViT-Usage)
- [13. TnT Usage](#13-TnT-Usage)
- [14. DViT Usage](#14-DViT-Usage)
- [15. CeiT Usage](#15-CeiT-Usage)
- [16. ConViT Usage](#16-ConViT-Usage)
- [17. CaiT Usage](#17-CaiT-Usage)
- [18. PatchConvnet Usage](#18-PatchConvnet-Usage)
- [19. DeiT Usage](#19-DeiT-Usage)
- [20. LeViT Usage](#20-LeViT-Usage)
- [21. VOLO Usage](#21-VOLO-Usage)
- [22. Container Usage](#22-Container-Usage)
- [23. CMT Usage](#23-CMT-Usage)
- [MLP Series](#mlp-series)
- [1. RepMLP Usage](#1-RepMLP-Usage)
- [2. MLP-Mixer Usage](#2-MLP-Mixer-Usage)
- [3. ResMLP Usage](#3-ResMLP-Usage)
- [4. gMLP Usage](#4-gMLP-Usage)
- [5. sMLP Usage](#5-sMLP-Usage)
- [6. vip-mlp Usage](#6-vip-mlp-Usage)
- [Re-Parameter(ReP) Series](#Re-Parameter-series)
- [1. RepVGG Usage](#1-RepVGG-Usage)
- [2. ACNet Usage](#2-ACNet-Usage)
- [3. Diverse Branch Block(DDB) Usage](#3-Diverse-Branch-Block-Usage)
- [Convolution Series](#Convolution-series)
- [1. Depthwise Separable Convolution Usage](#1-Depthwise-Separable-Convolution-Usage)
- [2. MBConv Usage](#2-MBConv-Usage)
- [3. Involution Usage](#3-Involution-Usage)
- [4. DynamicConv Usage](#4-DynamicConv-Usage)
- [5. CondConv Usage](#5-CondConv-Usage)
***
# Attention Series
- Pytorch implementation of ["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks---arXiv 2021.05.05"](https://arxiv.org/abs/2105.02358)
- Pytorch implementation of ["Attention Is All You Need---NIPS2017"](https://arxiv.org/pdf/1706.03762.pdf)
- Pytorch implementation of ["Squeeze-and-Excitation Networks---CVPR2018"](https://arxiv.org/abs/1709.01507)
- Pytorch implementation of ["Selective Kernel Networks---CVPR2019"](https://arxiv.org/pdf/1903.06586.pdf)
- Pytorch implementation of ["CBAM: Convolutional Block Attention Module---ECCV2018"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
- Pytorch implementation of ["BAM: Bottleneck Attention Module---BMCV2018"](https://arxiv.org/pdf/1807.06514.pdf)
- Pytorch implementation of ["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks---CVPR2020"](https://arxiv.org/pdf/1910.03151.pdf)
- Pytorch implementation of ["Dual Attention Network for Scene Segmentation---CVPR2019"](https://arxiv.org/pdf/1809.02983.pdf)
- Pytorch implementation of ["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network---arXiv 2021.05.30"](https://arxiv.org/pdf/2105.14447.pdf)
- Pytorch implementation of ["ResT: An Efficient Transformer for Visual Recognition---arXiv 2021.05.28"](https://arxiv.org/abs/2105.13677)
- Pytorch implementation of ["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS---ICASSP 2021"](https://arxiv.org/pdf/2102.00240.pdf)
- Pytorch implementation of ["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning---arXiv 2019.11.17"](https://arxiv.org/abs/1911.09483)
- Pytorch implementation of ["Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks---arXiv 2019.05.23"](https://arxiv.org/pdf/1905.09646.pdf)
- Pytorch implementation of ["A2-Nets: Double Attention Networks---NIPS2018"](https://arxiv.org/pdf/1810.11579.pdf)
- Pytorch implementation of ["An Attention Free Transformer---ICLR2021 (Apple New Work)"](https://arxiv.org/pdf/2105.14103v1.pdf)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition---arXiv 2021.06.24"](https://arxiv.org/abs/2106.13112)
[【论文解析】](https://zhuanlan.zhihu.com/p/385561050)
- Pytorch implementation of [Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition---arXiv 2021.06.23](https://arxiv.org/abs/2106.12368)
[【论文解析】](https://mp.weixin.qq.com/s/5gonUQgBho_m2O54jyXF_Q)
- Pytorch implementation of [CoAtNet: Marrying Convolution and Attention for All Data Sizes---arXiv 2021.06.09](https://arxiv.org/abs/2106.04803)
[【论文解析】](https://zhuanlan.zhihu.com/p/385578588)
- Pytorch implementation of [Scaling Local Self-Attention for Parameter Efficient Visual Backbones---CVPR2021 Oral](https://arxiv.org/pdf/2103.12731.pdf) [【论文解析】](https://zhuanlan.zhihu.com/p/388598744)
- Pytorch implementation of [Polarized Self-Attention: Towards High-quality Pixel-wise Regression---arXiv 2021.07.02](https://arxiv.org/abs/2107.00782) [【论文解析】](https://zhuanlan.zhihu.com/p/389770482)
- Pytorch implementation of [Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292) [【论文解析】](https://zhuanlan.zhihu.com/p/394795481)
- Pytorch implementation of [Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
- Pytorch implementation of [S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072) [【论文解析】](https://zhuanlan.zhihu.com/p/397003638)
- Pytorch implementation of [Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
- Pytorch implementation of [Rotate to Attend: Convolutional Triplet Attention Module---WACV 2021](https://arxiv.org/abs/2010.03045)
- Pytorch implementation of [Coordinate Attention for Efficient Mobile Network Design ---CVPR 2021](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2110.02178)
- Pytorch implementation of [Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
- Pytorch implementation of [UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2109.14382)
- Pytorch implementation of [Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
- Pytorch implementation of [On the Integration of Self-Attention and Convolution---ArXiv 2022.03.14](https://arxiv.org/pdf/2111.14556.pdf)
- Pytorch implementation of [CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
- Pytorch implementation of [Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
- Pytorch implementation of [CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
- Pytorch implementation of [Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
***
### 1. External Attention Usage
#### 1.1. Paper
["Beyond Self-attention: External Attention using Two Linear Layers for Visual Tasks"](https://arxiv.org/abs/2105.02358)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.ExternalAttention import ExternalAttention
import torch
input=torch.randn(50,49,512)
ea = ExternalAttention(d_model=512,S=8)
output=ea(input)
print(output.shape)
```
***
### 2. Self Attention Usage
#### 2.1. Paper
["Attention Is All You Need"](https://arxiv.org/pdf/1706.03762.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.attention.SelfAttention import ScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
sa = ScaledDotProductAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 3. Simplified Self Attention Usage
#### 3.1. Paper
[None]()
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.attention.SimplifiedSelfAttention import SimplifiedScaledDotProductAttention
import torch
input=torch.randn(50,49,512)
ssa = SimplifiedScaledDotProductAttention(d_model=512, h=8)
output=ssa(input,input,input)
print(output.shape)
```
***
### 4. Squeeze-and-Excitation Attention Usage
#### 4.1. Paper
["Squeeze-and-Excitation Networks"](https://arxiv.org/abs/1709.01507)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.attention.SEAttention import SEAttention
import torch
input=torch.randn(50,512,7,7)
se = SEAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 5. SK Attention Usage
#### 5.1. Paper
["Selective Kernel Networks"](https://arxiv.org/pdf/1903.06586.pdf)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.attention.SKAttention import SKAttention
import torch
input=torch.randn(50,512,7,7)
se = SKAttention(channel=512,reduction=8)
output=se(input)
print(output.shape)
```
***
### 6. CBAM Attention Usage
#### 6.1. Paper
["CBAM: Convolutional Block Attention Module"](https://openaccess.thecvf.com/content_ECCV_2018/papers/Sanghyun_Woo_Convolutional_Block_Attention_ECCV_2018_paper.pdf)
#### 6.2. Overview


#### 6.3. Usage Code
```python
from model.attention.CBAM import CBAMBlock
import torch
input=torch.randn(50,512,7,7)
kernel_size=input.shape[2]
cbam = CBAMBlock(channel=512,reduction=16,kernel_size=kernel_size)
output=cbam(input)
print(output.shape)
```
***
### 7. BAM Attention Usage
#### 7.1. Paper
["BAM: Bottleneck Attention Module"](https://arxiv.org/pdf/1807.06514.pdf)
#### 7.2. Overview

#### 7.3. Usage Code
```python
from model.attention.BAM import BAMBlock
import torch
input=torch.randn(50,512,7,7)
bam = BAMBlock(channel=512,reduction=16,dia_val=2)
output=bam(input)
print(output.shape)
```
***
### 8. ECA Attention Usage
#### 8.1. Paper
["ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks"](https://arxiv.org/pdf/1910.03151.pdf)
#### 8.2. Overview

#### 8.3. Usage Code
```python
from model.attention.ECAAttention import ECAAttention
import torch
input=torch.randn(50,512,7,7)
eca = ECAAttention(kernel_size=3)
output=eca(input)
print(output.shape)
```
***
### 9. DANet Attention Usage
#### 9.1. Paper
["Dual Attention Network for Scene Segmentation"](https://arxiv.org/pdf/1809.02983.pdf)
#### 9.2. Overview

#### 9.3. Usage Code
```python
from model.attention.DANet import DAModule
import torch
input=torch.randn(50,512,7,7)
danet=DAModule(d_model=512,kernel_size=3,H=7,W=7)
print(danet(input).shape)
```
***
### 10. Pyramid Split Attention Usage
#### 10.1. Paper
["EPSANet: An Efficient Pyramid Split Attention Block on Convolutional Neural Network"](https://arxiv.org/pdf/2105.14447.pdf)
#### 10.2. Overview

#### 10.3. Usage Code
```python
from model.attention.PSA import PSA
import torch
input=torch.randn(50,512,7,7)
psa = PSA(channel=512,reduction=8)
output=psa(input)
print(output.shape)
```
***
### 11. Efficient Multi-Head Self-Attention Usage
#### 11.1. Paper
["ResT: An Efficient Transformer for Visual Recognition"](https://arxiv.org/abs/2105.13677)
#### 11.2. Overview

#### 11.3. Usage Code
```python
from model.attention.EMSA import EMSA
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,64,512)
emsa = EMSA(d_model=512, d_k=512, d_v=512, h=8,H=8,W=8,ratio=2,apply_transform=True)
output=emsa(input,input,input)
print(output.shape)
```
***
### 12. Shuffle Attention Usage
#### 12.1. Paper
["SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS"](https://arxiv.org/pdf/2102.00240.pdf)
#### 12.2. Overview

#### 12.3. Usage Code
```python
from model.attention.ShuffleAttention import ShuffleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
se = ShuffleAttention(channel=512,G=8)
output=se(input)
print(output.shape)
```
***
### 13. MUSE Attention Usage
#### 13.1. Paper
["MUSE: Parallel Multi-Scale Attention for Sequence to Sequence Learning"](https://arxiv.org/abs/1911.09483)
#### 13.2. Overview

#### 13.3. Usage Code
```python
from model.attention.MUSEAttention import MUSEAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
sa = MUSEAttention(d_model=512, d_k=512, d_v=512, h=8)
output=sa(input,input,input)
print(output.shape)
```
***
### 14. SGE Attention Usage
#### 14.1. Paper
[Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks](https://arxiv.org/pdf/1905.09646.pdf)
#### 14.2. Overview

#### 14.3. Usage Code
```python
from model.attention.SGE import SpatialGroupEnhance
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
sge = SpatialGroupEnhance(groups=8)
output=sge(input)
print(output.shape)
```
***
### 15. A2 Attention Usage
#### 15.1. Paper
[A2-Nets: Double Attention Networks](https://arxiv.org/pdf/1810.11579.pdf)
#### 15.2. Overview

#### 15.3. Usage Code
```python
from model.attention.A2Atttention import DoubleAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
a2 = DoubleAttention(512,128,128,True)
output=a2(input)
print(output.shape)
```
### 16. AFT Attention Usage
#### 16.1. Paper
[An Attention Free Transformer](https://arxiv.org/pdf/2105.14103v1.pdf)
#### 16.2. Overview

#### 16.3. Usage Code
```python
from model.attention.AFT import AFT_FULL
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,49,512)
aft_full = AFT_FULL(d_model=512, n=49)
output=aft_full(input)
print(output.shape)
```
### 17. Outlook Attention Usage
#### 17.1. Paper
[VOLO: Vision Outlooker for Visual Recognition"](https://arxiv.org/abs/2106.13112)
#### 17.2. Overview

#### 17.3. Usage Code
```python
from model.attention.OutlookAttention import OutlookAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,28,28,512)
outlook = OutlookAttention(dim=512)
output=outlook(input)
print(output.shape)
```
***
### 18. ViP Attention Usage
#### 18.1. Paper
[Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 18.2. Overview

#### 18.3. Usage Code
```python
from model.attention.ViP import WeightedPermuteMLP
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(64,8,8,512)
seg_dim=8
vip=WeightedPermuteMLP(512,seg_dim)
out=vip(input)
print(out.shape)
```
***
### 19. CoAtNet Attention Usage
#### 19.1. Paper
[CoAtNet: Marrying Convolution and Attention for All Data Sizes"](https://arxiv.org/abs/2106.04803)
#### 19.2. Overview
None
#### 19.3. Usage Code
```python
from model.attention.CoAtNet import CoAtNet
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=CoAtNet(in_ch=3,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 20. HaloNet Attention Usage
#### 20.1. Paper
[Scaling Local Self-Attention for Parameter Efficient Visual Backbones"](https://arxiv.org/pdf/2103.12731.pdf)
#### 20.2. Overview

#### 20.3. Usage Code
```python
from model.attention.HaloAttention import HaloAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,8,8)
halo = HaloAttention(dim=512,
block_size=2,
halo_size=1,)
output=halo(input)
print(output.shape)
```
***
### 21. Polarized Self-Attention Usage
#### 21.1. Paper
[Polarized Self-Attention: Towards High-quality Pixel-wise Regression"](https://arxiv.org/abs/2107.00782)
#### 21.2. Overview

#### 21.3. Usage Code
```python
from model.attention.PolarizedSelfAttention import ParallelPolarizedSelfAttention,SequentialPolarizedSelfAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,512,7,7)
psa = SequentialPolarizedSelfAttention(channel=512)
output=psa(input)
print(output.shape)
```
***
### 22. CoTAttention Usage
#### 22.1. Paper
[Contextual Transformer Networks for Visual Recognition---arXiv 2021.07.26](https://arxiv.org/abs/2107.12292)
#### 22.2. Overview

#### 22.3. Usage Code
```python
from model.attention.CoTAttention import CoTAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
cot = CoTAttention(dim=512,kernel_size=3)
output=cot(input)
print(output.shape)
```
***
### 23. Residual Attention Usage
#### 23.1. Paper
[Residual Attention: A Simple but Effective Method for Multi-Label Recognition---ICCV2021](https://arxiv.org/abs/2108.02456)
#### 23.2. Overview

#### 23.3. Usage Code
```python
from model.attention.ResidualAttention import ResidualAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
resatt = ResidualAttention(channel=512,num_class=1000,la=0.2)
output=resatt(input)
print(output.shape)
```
***
### 24. S2 Attention Usage
#### 24.1. Paper
[S²-MLPv2: Improved Spatial-Shift MLP Architecture for Vision---arXiv 2021.08.02](https://arxiv.org/abs/2108.01072)
#### 24.2. Overview

#### 24.3. Usage Code
```python
from model.attention.S2Attention import S2Attention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
s2att = S2Attention(channels=512)
output=s2att(input)
print(output.shape)
```
***
### 25. GFNet Attention Usage
#### 25.1. Paper
[Global Filter Networks for Image Classification---arXiv 2021.07.01](https://arxiv.org/abs/2107.00645)
#### 25.2. Overview

#### 25.3. Usage Code - Implemented by [Wenliang Zhao (Author)](https://scholar.google.com/citations?user=lyPWvuEAAAAJ&hl=en)
```python
from model.attention.gfnet import GFNet
import torch
from torch import nn
from torch.nn import functional as F
x = torch.randn(1, 3, 224, 224)
gfnet = GFNet(embed_dim=384, img_size=224, patch_size=16, num_classes=1000)
out = gfnet(x)
print(out.shape)
```
***
### 26. TripletAttention Usage
#### 26.1. Paper
[Rotate to Attend: Convolutional Triplet Attention Module---CVPR 2021](https://arxiv.org/abs/2010.03045)
#### 26.2. Overview

#### 26.3. Usage Code - Implemented by [digantamisra98](https://github.com/digantamisra98)
```python
from model.attention.TripletAttention import TripletAttention
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(50,512,7,7)
triplet = TripletAttention()
output=triplet(input)
print(output.shape)
```
***
### 27. Coordinate Attention Usage
#### 27.1. Paper
[Coordinate Attention for Efficient Mobile Network Design---CVPR 2021](https://arxiv.org/abs/2103.02907)
#### 27.2. Overview

#### 27.3. Usage Code - Implemented by [Andrew-Qibin](https://github.com/Andrew-Qibin)
```python
from model.attention.CoordAttention import CoordAtt
import torch
from torch import nn
from torch.nn import functional as F
inp=torch.rand([2, 96, 56, 56])
inp_dim, oup_dim = 96, 96
reduction=32
coord_attention = CoordAtt(inp_dim, oup_dim, reduction=reduction)
output=coord_attention(inp)
print(output.shape)
```
***
### 28. MobileViT Attention Usage
#### 28.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2021.10.05](https://arxiv.org/abs/2103.02907)
#### 28.2. Overview

#### 28.3. Usage Code
```python
from model.attention.MobileViTAttention import MobileViTAttention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
m=MobileViTAttention()
input=torch.randn(1,3,49,49)
output=m(input)
print(output.shape) #output:(1,3,49,49)
```
***
### 29. ParNet Attention Usage
#### 29.1. Paper
[Non-deep Networks---ArXiv 2021.10.20](https://arxiv.org/abs/2110.07641)
#### 29.2. Overview

#### 29.3. Usage Code
```python
from model.attention.ParNetAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
pna = ParNetAttention(channel=512)
output=pna(input)
print(output.shape) #50,512,7,7
```
***
### 30. UFO Attention Usage
#### 30.1. Paper
[UFO-ViT: High Performance Linear Vision Transformer without Softmax---ArXiv 2021.09.29](https://arxiv.org/abs/2110.07641)
#### 30.2. Overview

#### 30.3. Usage Code
```python
from model.attention.UFOAttention import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
ufo = UFOAttention(d_model=512, d_k=512, d_v=512, h=8)
output=ufo(input,input,input)
print(output.shape) #[50, 49, 512]
```
-
### 31. ACmix Attention Usage
#### 31.1. Paper
[On the Integration of Self-Attention and Convolution](https://arxiv.org/pdf/2111.14556.pdf)
#### 31.2. Usage Code
```python
from model.attention.ACmix import ACmix
import torch
if __name__ == '__main__':
input=torch.randn(50,256,7,7)
acmix = ACmix(in_planes=256, out_planes=256)
output=acmix(input)
print(output.shape)
```
### 32. MobileViTv2 Attention Usage
#### 32.1. Paper
[Separable Self-attention for Mobile Vision Transformers---ArXiv 2022.06.06](https://arxiv.org/abs/2206.02680)
#### 32.2. Overview

#### 32.3. Usage Code
```python
from model.attention.MobileViTv2Attention import MobileViTv2Attention
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,49,512)
sa = MobileViTv2Attention(d_model=512)
output=sa(input)
print(output.shape)
```
### 33. DAT Attention Usage
#### 33.1. Paper
[Vision Transformer with Deformable Attention---CVPR2022](https://arxiv.org/abs/2201.00520)
#### 33.2. Usage Code
```python
from model.attention.DAT import DAT
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DAT(
img_size=224,
patch_size=4,
num_classes=1000,
expansion=4,
dim_stem=96,
dims=[96, 192, 384, 768],
depths=[2, 2, 6, 2],
stage_spec=[['L', 'S'], ['L', 'S'], ['L', 'D', 'L', 'D', 'L', 'D'], ['L', 'D']],
heads=[3, 6, 12, 24],
window_sizes=[7, 7, 7, 7] ,
groups=[-1, -1, 3, 6],
use_pes=[False, False, True, True],
dwc_pes=[False, False, False, False],
strides=[-1, -1, 1, 1],
sr_ratios=[-1, -1, -1, -1],
offset_range_factor=[-1, -1, 2, 2],
no_offs=[False, False, False, False],
fixed_pes=[False, False, False, False],
use_dwc_mlps=[False, False, False, False],
use_conv_patches=False,
drop_rate=0.0,
attn_drop_rate=0.0,
drop_path_rate=0.2,
)
output=model(input)
print(output[0].shape)
```
### 34. CrossFormer Attention Usage
#### 34.1. Paper
[CROSSFORMER: A VERSATILE VISION TRANSFORMER HINGING ON CROSS-SCALE ATTENTION---ICLR 2022](https://arxiv.org/pdf/2108.00154.pdf)
#### 34.2. Usage Code
```python
from model.attention.Crossformer import CrossFormer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CrossFormer(img_size=224,
patch_size=[4, 8, 16, 32],
in_chans= 3,
num_classes=1000,
embed_dim=48,
depths=[2, 2, 6, 2],
num_heads=[3, 6, 12, 24],
group_size=[7, 7, 7, 7],
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False,
merge_size=[[2, 4], [2,4], [2, 4]]
)
output=model(input)
print(output.shape)
```
### 35. MOATransformer Attention Usage
#### 35.1. Paper
[Aggregating Global Features into Local Vision Transformer](https://arxiv.org/abs/2201.12903)
#### 35.2. Usage Code
```python
from model.attention.MOATransformer import MOATransformer
import torch
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = MOATransformer(
img_size=224,
patch_size=4,
in_chans=3,
num_classes=1000,
embed_dim=96,
depths=[2, 2, 6],
num_heads=[3, 6, 12],
window_size=14,
mlp_ratio=4.,
qkv_bias=True,
qk_scale=None,
drop_rate=0.0,
drop_path_rate=0.1,
ape=False,
patch_norm=True,
use_checkpoint=False
)
output=model(input)
print(output.shape)
```
### 36. CrissCrossAttention Attention Usage
#### 36.1. Paper
[CCNet: Criss-Cross Attention for Semantic Segmentation](https://arxiv.org/abs/1811.11721)
#### 36.2. Usage Code
```python
from model.attention.CrissCrossAttention import CrissCrossAttention
import torch
if __name__ == '__main__':
input=torch.randn(3, 64, 7, 7)
model = CrissCrossAttention(64)
outputs = model(input)
print(outputs.shape)
```
### 37. Axial_attention Attention Usage
#### 37.1. Paper
[Axial Attention in Multidimensional Transformers](https://arxiv.org/abs/1912.12180)
#### 37.2. Usage Code
```python
from model.attention.Axial_attention import AxialImageTransformer
import torch
if __name__ == '__main__':
input=torch.randn(3, 128, 7, 7)
model = AxialImageTransformer(
dim = 128,
depth = 12,
reversible = True
)
outputs = model(input)
print(outputs.shape)
```
***
# Backbone Series
- Pytorch implementation of ["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
- Pytorch implementation of ["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
- Pytorch implementation of [MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
- Pytorch implementation of [Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
- Pytorch implementation of [Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer---ArXiv 2021.06.07](https://arxiv.org/abs/2106.03650)
- Pytorch implementation of [ConTNet: Why not use convolution and transformer at the same time?---ArXiv 2021.04.27](https://arxiv.org/abs/2104.13497)
- Pytorch implementation of [Vision Transformers with Hierarchical Attention---ArXiv 2022.06.15](https://arxiv.org/abs/2106.03180)
- Pytorch implementation of [Co-Scale Conv-Attentional Image Transformers---ArXiv 2021.08.26](https://arxiv.org/abs/2104.06399)
- Pytorch implementation of [Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
- Pytorch implementation of [Rethinking Spatial Dimensions of Vision Transformers---ICCV 2021](https://arxiv.org/abs/2103.16302)
- Pytorch implementation of [CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification---ICCV 2021](https://arxiv.org/abs/2103.14899)
- Pytorch implementation of [Transformer in Transformer---NeurIPS 2021](https://arxiv.org/abs/2103.00112)
- Pytorch implementation of [DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
- Pytorch implementation of [Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
***
- Pytorch implementation of [ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
- Pytorch implementation of [Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
- Pytorch implementation of [Going deeper with Image Transformers---ICCV 2021 (Oral)](https://arxiv.org/abs/2103.17239)
- Pytorch implementation of [Training data-efficient image transformers & distillation through attention---ICML 2021](https://arxiv.org/abs/2012.12877)
- Pytorch implementation of [LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
- Pytorch implementation of [VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
- Pytorch implementation of [Container: Context Aggregation Network---NeuIPS 2021](https://arxiv.org/abs/2106.01401)
- Pytorch implementation of [CMT: Convolutional Neural Networks Meet Vision Transformers---CVPR 2022](https://arxiv.org/abs/2107.06263)
- Pytorch implementation of [Vision Transformer with Deformable Attention---CVPR 2022](https://arxiv.org/abs/2201.00520)
### 1. ResNet Usage
#### 1.1. Paper
["Deep Residual Learning for Image Recognition---CVPR2016 Best Paper"](https://arxiv.org/pdf/1512.03385.pdf)
#### 1.2. Overview


#### 1.3. Usage Code
```python
from model.backbone.resnet import ResNet50,ResNet101,ResNet152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnet50=ResNet50(1000)
# resnet101=ResNet101(1000)
# resnet152=ResNet152(1000)
out=resnet50(input)
print(out.shape)
```
### 2. ResNeXt Usage
#### 2.1. Paper
["Aggregated Residual Transformations for Deep Neural Networks---CVPR2017"](https://arxiv.org/abs/1611.05431v2)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.backbone.resnext import ResNeXt50,ResNeXt101,ResNeXt152
import torch
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
resnext50=ResNeXt50(1000)
# resnext101=ResNeXt101(1000)
# resnext152=ResNeXt152(1000)
out=resnext50(input)
print(out.shape)
```
### 3. MobileViT Usage
#### 3.1. Paper
[MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer---ArXiv 2020.10.05](https://arxiv.org/abs/2103.02907)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.backbone.MobileViT import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
### mobilevit_xxs
mvit_xxs=mobilevit_xxs()
out=mvit_xxs(input)
print(out.shape)
### mobilevit_xs
mvit_xs=mobilevit_xs()
out=mvit_xs(input)
print(out.shape)
### mobilevit_s
mvit_s=mobilevit_s()
out=mvit_s(input)
print(out.shape)
```
### 4. ConvMixer Usage
#### 4.1. Paper
[Patches Are All You Need?---ICLR2022 (Under Review)](https://openreview.net/forum?id=TVHS5Y4dNvM)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.backbone.ConvMixer import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
x=torch.randn(1,3,224,224)
convmixer=ConvMixer(dim=512,depth=12)
out=convmixer(x)
print(out.shape) #[1, 1000]
```
### 5. ShuffleTransformer Usage
#### 5.1. Paper
[Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer](https://arxiv.org/pdf/2106.03650.pdf)
#### 5.2. Usage Code
```python
from model.backbone.ShuffleTransformer import ShuffleTransformer
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
sft = ShuffleTransformer()
output=sft(input)
print(output.shape)
```
### 6. ConTNet Usage
#### 6.1. Paper
[ConTNet: Why not use convolution and transformer at the same time?](https://arxiv.org/abs/2104.13497)
#### 6.2. Usage Code
```python
from model.backbone.ConTNet import ConTNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == "__main__":
model = build_model(use_avgdown=True, relative=True, qkv_bias=True, pre_norm=True)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
```
### 7 HATNet Usage
#### 7.1. Paper
[Vision Transformers with Hierarchical Attention](https://arxiv.org/abs/2106.03180)
#### 7.2. Usage Code
```python
from model.backbone.HATNet import HATNet
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
hat = HATNet(dims=[48, 96, 240, 384], head_dim=48, expansions=[8, 8, 4, 4],
grid_sizes=[8, 7, 7, 1], ds_ratios=[8, 4, 2, 1], depths=[2, 2, 6, 3])
output=hat(input)
print(output.shape)
```
### 8 CoaT Usage
#### 8.1. Paper
[Co-Scale Conv-Attentional Image Transformers](https://arxiv.org/abs/2104.06399)
#### 8.2. Usage Code
```python
from model.backbone.CoaT import CoaT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CoaT(patch_size=4, embed_dims=[152, 152, 152, 152], serial_depths=[2, 2, 2, 2], parallel_depth=6, num_heads=8, mlp_ratios=[4, 4, 4, 4])
output=model(input)
print(output.shape) # torch.Size([1, 1000])
```
### 9 PVT Usage
#### 9.1. Paper
[PVT v2: Improved Baselines with Pyramid Vision Transformer](https://arxiv.org/pdf/2106.13797.pdf)
#### 9.2. Usage Code
```python
from model.backbone.PVT import PyramidVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PyramidVisionTransformer(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 2, 2], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 10 CPVT Usage
#### 10.1. Paper
[Conditional Positional Encodings for Vision Transformers](https://arxiv.org/abs/2102.10882)
#### 10.2. Usage Code
```python
from model.backbone.CPVT import CPVTV2
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CPVTV2(
patch_size=4, embed_dims=[64, 128, 320, 512], num_heads=[1, 2, 5, 8], mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1])
output=model(input)
print(output.shape)
```
### 11 PIT Usage
#### 11.1. Paper
[Rethinking Spatial Dimensions of Vision Transformers](https://arxiv.org/abs/2103.16302)
#### 11.2. Usage Code
```python
from model.backbone.PIT import PoolingTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PoolingTransformer(
image_size=224,
patch_size=14,
stride=7,
base_dims=[64, 64, 64],
depth=[3, 6, 4],
heads=[4, 8, 16],
mlp_ratio=4
)
output=model(input)
print(output.shape)
```
### 12 CrossViT Usage
#### 12.1. Paper
[CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification](https://arxiv.org/abs/2103.14899)
#### 12.2. Usage Code
```python
from model.backbone.CrossViT import VisionTransformer
import torch
from torch import nn
if __name__ == "__main__":
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[240, 224],
patch_size=[12, 16],
embed_dim=[192, 384],
depth=[[1, 4, 0], [1, 4, 0], [1, 4, 0]],
num_heads=[6, 6],
mlp_ratio=[4, 4, 1],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 13 TnT Usage
#### 13.1. Paper
[Transformer in Transformer](https://arxiv.org/abs/2103.00112)
#### 13.2. Usage Code
```python
from model.backbone.TnT import TNT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = TNT(
img_size=224,
patch_size=16,
outer_dim=384,
inner_dim=24,
depth=12,
outer_num_heads=6,
inner_num_heads=4,
qkv_bias=False,
inner_stride=4)
output=model(input)
print(output.shape)
```
### 14 DViT Usage
#### 14.1. Paper
[DeepViT: Towards Deeper Vision Transformer](https://arxiv.org/abs/2103.11886)
#### 14.2. Usage Code
```python
from model.backbone.DViT import DeepVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DeepVisionTransformer(
patch_size=16, embed_dim=384,
depth=[False] * 16,
apply_transform=[False] * 0 + [True] * 32,
num_heads=12,
mlp_ratio=3,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
)
output=model(input)
print(output.shape)
```
### 15 CeiT Usage
#### 15.1. Paper
[Incorporating Convolution Designs into Visual Transformers](https://arxiv.org/abs/2103.11816)
#### 15.2. Usage Code
```python
from model.backbone.CeiT import CeIT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CeIT(
hybrid_backbone=Image2Tokens(),
patch_size=4,
embed_dim=192,
depth=12,
num_heads=3,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 16 ConViT Usage
#### 16.1. Paper
[ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases](https://arxiv.org/abs/2103.10697)
#### 16.2. Usage Code
```python
from model.backbone.ConViT import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
num_heads=16,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output.shape)
```
### 17 CaiT Usage
#### 17.1. Paper
[Going deeper with Image Transformers](https://arxiv.org/abs/2103.17239)
#### 17.2. Usage Code
```python
from model.backbone.CaiT import CaiT
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CaiT(
img_size= 224,
patch_size=16,
embed_dim=192,
depth=24,
num_heads=4,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
init_scale=1e-5,
depth_token_only=2
)
output=model(input)
print(output.shape)
```
### 18 PatchConvnet Usage
#### 18.1. Paper
[Augmenting Convolutional networks with attention-based aggregation](https://arxiv.org/abs/2112.13692)
#### 18.2. Usage Code
```python
from model.backbone.PatchConvnet import PatchConvnet
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = PatchConvnet(
patch_size=16,
embed_dim=384,
depth=60,
num_heads=1,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6),
Patch_layer=ConvStem,
Attention_block=Conv_blocks_se,
depth_token_only=1,
mlp_ratio_clstk=3.0,
)
output=model(input)
print(output.shape)
```
### 19 DeiT Usage
#### 19.1. Paper
[Training data-efficient image transformers & distillation through attention](https://arxiv.org/abs/2012.12877)
#### 19.2. Usage Code
```python
from model.backbone.DeiT import DistilledVisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = DistilledVisionTransformer(
patch_size=16,
embed_dim=384,
depth=12,
num_heads=6,
mlp_ratio=4,
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6)
)
output=model(input)
print(output[0].shape)
```
### 20 LeViT Usage
#### 20.1. Paper
[LeViT: a Vision Transformer in ConvNet’s Clothing for Faster Inference](https://arxiv.org/abs/2104.01136)
#### 20.2. Usage Code
```python
from model.backbone.LeViT import *
import torch
from torch import nn
if __name__ == '__main__':
for name in specification:
input=torch.randn(1,3,224,224)
model = globals()[name](fuse=True, pretrained=False)
model.eval()
output = model(input)
print(output.shape)
```
### 21 VOLO Usage
#### 21.1. Paper
[VOLO: Vision Outlooker for Visual Recognition](https://arxiv.org/abs/2106.13112)
#### 21.2. Usage Code
```python
from model.backbone.VOLO import VOLO
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VOLO([4, 4, 8, 2],
embed_dims=[192, 384, 384, 384],
num_heads=[6, 12, 12, 12],
mlp_ratios=[3, 3, 3, 3],
downsamples=[True, False, False, False],
outlook_attention=[True, False, False, False ],
post_layers=['ca', 'ca'],
)
output=model(input)
print(output[0].shape)
```
### 22 Container Usage
#### 22.1. Paper
[Container: Context Aggregation Network](https://arxiv.org/abs/2106.01401)
#### 22.2. Usage Code
```python
from model.backbone.Container import VisionTransformer
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionTransformer(
img_size=[224, 56, 28, 14],
patch_size=[4, 2, 2, 2],
embed_dim=[64, 128, 320, 512],
depth=[3, 4, 8, 3],
num_heads=16,
mlp_ratio=[8, 8, 4, 4],
qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6))
output=model(input)
print(output.shape)
```
### 23 CMT Usage
#### 23.1. Paper
[CMT: Convolutional Neural Networks Meet Vision Transformers](https://arxiv.org/abs/2107.06263)
#### 23.2. Usage Code
```python
from model.backbone.CMT import CMT_Tiny
import torch
from torch import nn
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = CMT_Tiny()
output=model(input)
print(output[0].shape)
```
# MLP Series
- Pytorch implementation of ["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition---arXiv 2021.05.05"](https://arxiv.org/pdf/2105.01883v1.pdf)
- Pytorch implementation of ["MLP-Mixer: An all-MLP Architecture for Vision---arXiv 2021.05.17"](https://arxiv.org/pdf/2105.01601.pdf)
- Pytorch implementation of ["ResMLP: Feedforward networks for image classification with data-efficient training---arXiv 2021.05.07"](https://arxiv.org/pdf/2105.03404.pdf)
- Pytorch implementation of ["Pay Attention to MLPs---arXiv 2021.05.17"](https://arxiv.org/abs/2105.08050)
- Pytorch implementation of ["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?---arXiv 2021.09.12"](https://arxiv.org/abs/2109.05422)
### 1. RepMLP Usage
#### 1.1. Paper
["RepMLP: Re-parameterizing Convolutions into Fully-connected Layers for Image Recognition"](https://arxiv.org/pdf/2105.01883v1.pdf)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.mlp.repmlp import RepMLP
import torch
from torch import nn
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())
```
### 2. MLP-Mixer Usage
#### 2.1. Paper
["MLP-Mixer: An all-MLP Architecture for Vision"](https://arxiv.org/pdf/2105.01601.pdf)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.mlp.mlp_mixer import MlpMixer
import torch
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)
```
***
### 3. ResMLP Usage
#### 3.1. Paper
["ResMLP: Feedforward networks for image classification with data-efficient training"](https://arxiv.org/pdf/2105.03404.pdf)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.mlp.resmlp import ResMLP
import torch
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape) #the last dimention is class_num
```
***
### 4. gMLP Usage
#### 4.1. Paper
["Pay Attention to MLPs"](https://arxiv.org/abs/2105.08050)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.mlp.g_mlp import gMLP
import torch
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)
```
***
### 5. sMLP Usage
#### 5.1. Paper
["Sparse MLP for Image Recognition: Is Self-Attention Really Necessary?"](https://arxiv.org/abs/2109.05422)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.mlp.sMLP_block import sMLPBlock
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
smlp=sMLPBlock(h=224,w=224)
out=smlp(input)
print(out.shape)
```
### 6. vip-mlp Usage
#### 6.1. Paper
["Vision Permutator: A Permutable MLP-Like Architecture for Visual Recognition"](https://arxiv.org/abs/2106.12368)
#### 6.2. Usage Code
```python
from model.mlp.vip-mlp import VisionPermutator
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionPermutator(
layers=[4, 3, 8, 3],
embed_dims=[384, 384, 384, 384],
patch_size=14,
transitions=[False, False, False, False],
segment_dim=[16, 16, 16, 16],
mlp_ratios=[3, 3, 3, 3],
mlp_fn=WeightedPermuteMLP
)
output=model(input)
print(output.shape)
```
# Re-Parameter Series
- Pytorch implementation of ["RepVGG: Making VGG-style ConvNets Great Again---CVPR2021"](https://arxiv.org/abs/2101.03697)
- Pytorch implementation of ["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks---ICCV2019"](https://arxiv.org/abs/1908.03930)
- Pytorch implementation of ["Diverse Branch Block: Building a Convolution as an Inception-like Unit---CVPR2021"](https://arxiv.org/abs/2103.13425)
***
### 1. RepVGG Usage
#### 1.1. Paper
["RepVGG: Making VGG-style ConvNets Great Again"](https://arxiv.org/abs/2101.03697)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.rep.repvgg import RepBlock
import torch
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
```
***
### 2. ACNet Usage
#### 2.1. Paper
["ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks"](https://arxiv.org/abs/1908.03930)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.rep.acnet import ACNet
import torch
from torch import nn
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
```
***
### 2. Diverse Branch Block Usage
#### 2.1. Paper
["Diverse Branch Block: Building a Convolution as an Inception-like Unit"](https://arxiv.org/abs/2103.13425)
#### 2.2. Overview

#### 2.3. Usage Code
##### 2.3.1 Transform I
```python
from model.rep.ddb import transI_conv_bn
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+bn
conv1=nn.Conv2d(64,64,3,padding=1)
bn1=nn.BatchNorm2d(64)
bn1.eval()
out1=bn1(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transI_conv_bn(conv1,bn1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.2 Transform II
```python
from model.rep.ddb import transII_conv_branch
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,3,padding=1)
conv2=nn.Conv2d(64,64,3,padding=1)
out1=conv1(input)+conv2(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transII_conv_branch(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.3 Transform III
```python
from model.rep.ddb import transIII_conv_sequential
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,64,1,padding=0,bias=False)
conv2=nn.Conv2d(64,64,3,padding=1,bias=False)
out1=conv2(conv1(input))
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1,bias=False)
conv_fuse.weight.data=transIII_conv_sequential(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.4 Transform IV
```python
from model.rep.ddb import transIV_conv_concat
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1=nn.Conv2d(64,32,3,padding=1)
conv2=nn.Conv2d(64,32,3,padding=1)
out1=torch.cat([conv1(input),conv2(input)],dim=1)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transIV_conv_concat(conv1,conv2)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.5 Transform V
```python
from model.rep.ddb import transV_avg
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
avg=nn.AvgPool2d(kernel_size=3,stride=1)
out1=avg(input)
conv=transV_avg(64,3)
out2=conv(input)
print("difference:",((out2-out1)**2).sum().item())
```
##### 2.3.6 Transform VI
```python
from model.rep.ddb import transVI_conv_scale
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
```
# Convolution Series
- Pytorch implementation of ["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications---CVPR2017"](https://arxiv.org/abs/1704.04861)
- Pytorch implementation of ["Efficientnet: Rethinking model scaling for convolutional neural networks---PMLR2019"](http://proceedings.mlr.press/v97/tan19a.html)
- Pytorch implementation of ["Involution: Inverting the Inherence of Convolution for Visual Recognition---CVPR2021"](https://arxiv.org/abs/2103.06255)
- Pytorch implementation of ["Dynamic Convolution: Attention over Convolution Kernels---CVPR2020 Oral"](https://arxiv.org/abs/1912.03458)
- Pytorch implementation of ["CondConv: Conditionally Parameterized Convolutions for Efficient Inference---NeurIPS2019"](https://arxiv.org/abs/1904.04971)
***
### 1. Depthwise Separable Convolution Usage
#### 1.1. Paper
["MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications"](https://arxiv.org/abs/1704.04861)
#### 1.2. Overview

#### 1.3. Usage Code
```python
from model.conv.DepthwiseSeparableConvolution import DepthwiseSeparableConvolution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
dsconv=DepthwiseSeparableConvolution(3,64)
out=dsconv(input)
print(out.shape)
```
***
### 2. MBConv Usage
#### 2.1. Paper
["Efficientnet: Rethinking model scaling for convolutional neural networks"](http://proceedings.mlr.press/v97/tan19a.html)
#### 2.2. Overview

#### 2.3. Usage Code
```python
from model.conv.MBConv import MBConvBlock
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,3,224,224)
mbconv=MBConvBlock(ksize=3,input_filters=3,output_filters=512,image_size=224)
out=mbconv(input)
print(out.shape)
```
***
### 3. Involution Usage
#### 3.1. Paper
["Involution: Inverting the Inherence of Convolution for Visual Recognition"](https://arxiv.org/abs/2103.06255)
#### 3.2. Overview

#### 3.3. Usage Code
```python
from model.conv.Involution import Involution
import torch
from torch import nn
from torch.nn import functional as F
input=torch.randn(1,4,64,64)
involution=Involution(kernel_size=3,in_channel=4,stride=2)
out=involution(input)
print(out.shape)
```
***
### 4. DynamicConv Usage
#### 4.1. Paper
["Dynamic Convolution: Attention over Convolution Kernels"](https://arxiv.org/abs/1912.03458)
#### 4.2. Overview

#### 4.3. Usage Code
```python
from model.conv.DynamicConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=DynamicConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape) # 2,32,64,64
```
***
### 5. CondConv Usage
#### 5.1. Paper
["CondConv: Conditionally Parameterized Convolutions for Efficient Inference"](https://arxiv.org/abs/1904.04971)
#### 5.2. Overview

#### 5.3. Usage Code
```python
from model.conv.CondConv import *
import torch
from torch import nn
from torch.nn import functional as F
if __name__ == '__main__':
input=torch.randn(2,32,64,64)
m=CondConv(in_planes=32,out_planes=64,kernel_size=3,stride=1,padding=1,bias=False)
out=m(input)
print(out.shape)
```
***
================================================
FILE: model/huggingface_hub.egg-info/SOURCES.txt
================================================
LICENSE
README.md
setup.py
model/huggingface_hub.egg-info/PKG-INFO
model/huggingface_hub.egg-info/SOURCES.txt
model/huggingface_hub.egg-info/dependency_links.txt
model/huggingface_hub.egg-info/entry_points.txt
model/huggingface_hub.egg-info/requires.txt
model/huggingface_hub.egg-info/top_level.txt
================================================
FILE: model/huggingface_hub.egg-info/dependency_links.txt
================================================
================================================
FILE: model/huggingface_hub.egg-info/entry_points.txt
================================================
[console_scripts]
huggingface-cli = huggingface_hub.commands.huggingface_cli:main
================================================
FILE: model/huggingface_hub.egg-info/requires.txt
================================================
filelock
requests
tqdm
pyyaml>=5.1
typing-extensions>=3.7.4.3
packaging>=20.9
[:python_version < "3.8"]
importlib_metadata
[all]
pytest
pytest-cov
datasets
soundfile
black==22.3
isort>=5.5.4
flake8>=3.8.3
flake8-bugbear
[dev]
pytest
pytest-cov
datasets
soundfile
black==22.3
isort>=5.5.4
flake8>=3.8.3
flake8-bugbear
[fastai]
toml
fastai>=2.4
fastcore>=1.3.27
[quality]
black==22.3
isort>=5.5.4
flake8>=3.8.3
flake8-bugbear
[tensorflow]
tensorflow
pydot
graphviz
[testing]
pytest
pytest-cov
datasets
soundfile
[torch]
torch
================================================
FILE: model/huggingface_hub.egg-info/top_level.txt
================================================
================================================
FILE: model/mlp/g_mlp.py
================================================
from collections import OrderedDict
import torch
from torch import nn
def exist(x):
return x is not None
class Residual(nn.Module):
def __init__(self,fn):
super().__init__()
self.fn=fn
def forward(self,x):
return self.fn(x)+x
class SpatialGatingUnit(nn.Module):
def __init__(self,dim,len_sen):
super().__init__()
self.ln=nn.LayerNorm(dim)
self.proj=nn.Conv1d(len_sen,len_sen,1)
nn.init.zeros_(self.proj.weight)
nn.init.ones_(self.proj.bias)
def forward(self,x):
res,gate=torch.chunk(x,2,-1) #bs,n,d_ff
###Norm
gate=self.ln(gate) #bs,n,d_ff
###Spatial Proj
gate=self.proj(gate) #bs,n,d_ff
return res*gate
class gMLP(nn.Module):
def __init__(self,num_tokens=None,len_sen=49,dim=512,d_ff=1024,num_layers=6):
super().__init__()
self.num_layers=num_layers
self.embedding=nn.Embedding(num_tokens,dim) if exist(num_tokens) else nn.Identity()
self.gmlp=nn.ModuleList([Residual(nn.Sequential(OrderedDict([
('ln1_%d'%i,nn.LayerNorm(dim)),
('fc1_%d'%i,nn.Linear(dim,d_ff*2)),
('gelu_%d'%i,nn.GELU()),
('sgu_%d'%i,SpatialGatingUnit(d_ff,len_sen)),
('fc2_%d'%i,nn.Linear(d_ff,dim)),
]))) for i in range(num_layers)])
self.to_logits=nn.Sequential(
nn.LayerNorm(dim),
nn.Linear(dim,num_tokens),
nn.Softmax(-1)
)
def forward(self,x):
#embedding
embeded=self.embedding(x)
#gMLP
y=nn.Sequential(*self.gmlp)(embeded)
#to logits
logits=self.to_logits(y)
return logits
if __name__ == '__main__':
num_tokens=10000
bs=50
len_sen=49
num_layers=6
input=torch.randint(num_tokens,(bs,len_sen)) #bs,len_sen
gmlp = gMLP(num_tokens=num_tokens,len_sen=len_sen,dim=512,d_ff=1024)
output=gmlp(input)
print(output.shape)
================================================
FILE: model/mlp/mlp_mixer.py
================================================
import torch
from torch import nn
class MlpBlock(nn.Module):
def __init__(self,input_dim,mlp_dim=512) :
super().__init__()
self.fc1=nn.Linear(input_dim,mlp_dim)
self.gelu=nn.GELU()
self.fc2=nn.Linear(mlp_dim,input_dim)
def forward(self,x):
#x: (bs,tokens,channels) or (bs,channels,tokens)
return self.fc2(self.gelu(self.fc1(x)))
class MixerBlock(nn.Module):
def __init__(self,tokens_mlp_dim=16,channels_mlp_dim=1024,tokens_hidden_dim=32,channels_hidden_dim=1024):
super().__init__()
self.ln=nn.LayerNorm(channels_mlp_dim)
self.tokens_mlp_block=MlpBlock(tokens_mlp_dim,mlp_dim=tokens_hidden_dim)
self.channels_mlp_block=MlpBlock(channels_mlp_dim,mlp_dim=channels_hidden_dim)
def forward(self,x):
"""
x: (bs,tokens,channels)
"""
### tokens mixing
y=self.ln(x)
y=y.transpose(1,2) #(bs,channels,tokens)
y=self.tokens_mlp_block(y) #(bs,channels,tokens)
### channels mixing
y=y.transpose(1,2) #(bs,tokens,channels)
out =x+y #(bs,tokens,channels)
y=self.ln(out) #(bs,tokens,channels)
y=out+self.channels_mlp_block(y) #(bs,tokens,channels)
return y
class MlpMixer(nn.Module):
def __init__(self,num_classes,num_blocks,patch_size,tokens_hidden_dim,channels_hidden_dim,tokens_mlp_dim,channels_mlp_dim):
super().__init__()
self.num_classes=num_classes
self.num_blocks=num_blocks #num of mlp layers
self.patch_size=patch_size
self.tokens_mlp_dim=tokens_mlp_dim
self.channels_mlp_dim=channels_mlp_dim
self.embd=nn.Conv2d(3,channels_mlp_dim,kernel_size=patch_size,stride=patch_size)
self.ln=nn.LayerNorm(channels_mlp_dim)
self.mlp_blocks=[]
for _ in range(num_blocks):
self.mlp_blocks.append(MixerBlock(tokens_mlp_dim,channels_mlp_dim,tokens_hidden_dim,channels_hidden_dim))
self.fc=nn.Linear(channels_mlp_dim,num_classes)
def forward(self,x):
y=self.embd(x) # bs,channels,h,w
bs,c,h,w=y.shape
y=y.view(bs,c,-1).transpose(1,2) # bs,tokens,channels
if(self.tokens_mlp_dim!=y.shape[1]):
raise ValueError('Tokens_mlp_dim is not correct.')
for i in range(self.num_blocks):
y=self.mlp_blocks[i](y) # bs,tokens,channels
y=self.ln(y) # bs,tokens,channels
y=torch.mean(y,dim=1,keepdim=False) # bs,channels
probs=self.fc(y) # bs,num_classes
return probs
if __name__ == '__main__':
mlp_mixer=MlpMixer(num_classes=1000,num_blocks=10,patch_size=10,tokens_hidden_dim=32,channels_hidden_dim=1024,tokens_mlp_dim=16,channels_mlp_dim=1024)
input=torch.randn(50,3,40,40)
output=mlp_mixer(input)
print(output.shape)
================================================
FILE: model/mlp/repmlp.py
================================================
import torch
from torch import nn
from collections import OrderedDict
from torch.nn import functional as F
import numpy as np
from numpy import random
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
class RepMLP(nn.Module):
def __init__(self,C,O,H,W,h,w,fc1_fc2_reduction=1,fc3_groups=8,repconv_kernels=None,deploy=False):
super().__init__()
self.C=C
self.O=O
self.H=H
self.W=W
self.h=h
self.w=w
self.fc1_fc2_reduction=fc1_fc2_reduction
self.repconv_kernels=repconv_kernels
self.h_part=H//h
self.w_part=W//w
self.deploy=deploy
self.fc3_groups=fc3_groups
# make sure H,W can divided by h,w respectively
assert H%h==0
assert W%w==0
self.is_global_perceptron= (H!=h) or (W!=w)
### global perceptron
if(self.is_global_perceptron):
if(not self.deploy):
self.avg=nn.Sequential(OrderedDict([
('avg',nn.AvgPool2d(kernel_size=(self.h,self.w))),
('bn',nn.BatchNorm2d(num_features=C))
])
)
else:
self.avg=nn.AvgPool2d(kernel_size=(self.h,self.w))
hidden_dim=self.C//self.fc1_fc2_reduction
self.fc1_fc2=nn.Sequential(OrderedDict([
('fc1',nn.Linear(C*self.h_part*self.w_part,hidden_dim)),
('relu',nn.ReLU()),
('fc2',nn.Linear(hidden_dim,C*self.h_part*self.w_part))
])
)
self.fc3=nn.Conv2d(self.C*self.h*self.w,self.O*self.h*self.w,kernel_size=1,groups=fc3_groups,bias=self.deploy)
self.fc3_bn=nn.Identity() if self.deploy else nn.BatchNorm2d(self.O*self.h*self.w)
if not self.deploy and self.repconv_kernels is not None:
for k in self.repconv_kernels:
repconv=nn.Sequential(OrderedDict([
('conv',nn.Conv2d(self.C,self.O,kernel_size=k,padding=(k-1)//2, groups=fc3_groups,bias=False)),
('bn',nn.BatchNorm2d(self.O))
])
)
self.__setattr__('repconv{}'.format(k),repconv)
def switch_to_deploy(self):
self.deploy=True
fc1_weight,fc1_bias,fc3_weight,fc3_bias=self.get_equivalent_fc1_fc3_params()
#del conv
if(self.repconv_kernels is not None):
for k in self.repconv_kernels:
self.__delattr__('repconv{}'.format(k))
#del fc3,bn
self.__delattr__('fc3')
self.__delattr__('fc3_bn')
self.fc3 = nn.Conv2d(self.C * self.h * self.w, self.O * self.h * self.w, 1, 1, 0, bias=True, groups=self.fc3_groups)
self.fc3_bn = nn.Identity()
# Remove the BN after AVG
if self.is_global_perceptron:
self.__delattr__('avg')
self.avg = nn.AvgPool2d(kernel_size=(self.h, self.w))
# Set values
if fc1_weight is not None:
self.fc1_fc2.fc1.weight.data = fc1_weight
self.fc1_fc2.fc1.bias.data = fc1_bias
self.fc3.weight.data = fc3_weight
self.fc3.bias.data = fc3_bias
def get_equivalent_fc1_fc3_params(self):
#training fc3+bn weight
fc_weight,fc_bias=self._fuse_bn(self.fc3,self.fc3_bn)
#training conv weight
if(self.repconv_kernels is not None):
max_kernel=max(self.repconv_kernels)
max_branch=self.__getattr__('repconv{}'.format(max_kernel))
conv_weight,conv_bias=self._fuse_bn(max_branch.conv,max_branch.bn)
for k in self.repconv_kernels:
if(k!=max_kernel):
tmp_branch=self.__getattr__('repconv{}'.format(k))
tmp_weight,tmp_bias=self._fuse_bn(tmp_branch.conv,tmp_branch.bn)
tmp_weight=F.pad(tmp_weight,[(max_kernel-k)//2]*4)
conv_weight+=tmp_weight
conv_bias+=tmp_bias
repconv_weight,repconv_bias=self._conv_to_fc(conv_weight,conv_bias)
final_fc3_weight=fc_weight+repconv_weight.reshape_as(fc_weight)
final_fc3_bias=fc_bias+repconv_bias
else:
final_fc3_weight=fc_weight
final_fc3_bias=fc_bias
#fc1
if(self.is_global_perceptron):
#remove BN after avg
avgbn = self.avg.bn
std = (avgbn.running_var + avgbn.eps).sqrt()
scale = avgbn.weight / std
avgbias = avgbn.bias - avgbn.running_mean * scale
fc1 = self.fc1_fc2.fc1
replicate_times = fc1.in_features // len(avgbias)
replicated_avgbias = avgbias.repeat_interleave(replicate_times).view(-1, 1)
bias_diff = fc1.weight.matmul(replicated_avgbias).squeeze()
final_fc1_bias = fc1.bias + bias_diff
final_fc1_weight = fc1.weight * scale.repeat_interleave(replicate_times).view(1, -1)
else:
final_fc1_weight=None
final_fc1_bias=None
return final_fc1_weight,final_fc1_bias,final_fc3_weight,final_fc3_bias
# def _conv_to_fc(self,weight,bias):
# i_maxtrix=torch.eye(self.C*self.h*self.w//self.fc3_groups).repeat(1,self.fc3_groups).reshape(self.C*self.h*self.w//self.fc3_groups,self.C,self.h,self.w)
# fc_weight=F.conv2d(i_maxtrix,weight=weight,bias=bias,padding=weight.shape[2]//2,groups=self.fc3_groups)
# fc_weight=fc_weight.reshape(self.C*self.h*self.w//self.fc3_groups,-1)
# fc_bias = bias.repeat_interleave(self.h * self.w)
# return fc_weight,fc_bias
def _conv_to_fc(self,conv_kernel, conv_bias):
I = torch.eye(self.C * self.h * self.w // self.fc3_groups).repeat(1, self.fc3_groups).reshape(self.C * self.h * self.w // self.fc3_groups, self.C, self.h, self.w).to(conv_kernel.device)
fc_k = F.conv2d(I, conv_kernel, padding=conv_kernel.size(2)//2, groups=self.fc3_groups)
fc_k = fc_k.reshape(self.C * self.h * self.w // self.fc3_groups, self.O * self.h * self.w).t()
fc_bias = conv_bias.repeat_interleave(self.h * self.w)
return fc_k, fc_bias
def _fuse_bn(self, conv_or_fc, bn):
std = (bn.running_var + bn.eps).sqrt()
t = bn.weight / std
if conv_or_fc.weight.ndim == 4:
t = t.reshape(-1, 1, 1, 1)
else:
t = t.reshape(-1, 1)
return conv_or_fc.weight * t, bn.bias - bn.running_mean * bn.weight / std
def forward(self,x) :
### global partition
if(self.is_global_perceptron):
input=x
v=self.avg(x) #bs,C,h_part,w_part
v=v.reshape(-1,self.C*self.h_part*self.w_part) #bs,C*h_part*w_part
v=self.fc1_fc2(v) #bs,C*h_part*w_part
v=v.reshape(-1,self.C,self.h_part,1,self.w_part,1) #bs,C,h_part,w_part
input=input.reshape(-1,self.C,self.h_part,self.h,self.w_part,self.w) #bs,C,h_part,h,w_part,w
input=v+input
else:
input=x.view(-1,self.C,self.h_part,self.h,self.w_part,self.w) #bs,C,h_part,h,w_part,w
partition=input.permute(0,2,4,1,3,5) #bs,h_part,w_part,C,h,w
### partition partition
fc3_out=partition.reshape(-1,self.C*self.h*self.w,1,1) #bs*h_part*w_part,C*h*w,1,1
fc3_out=self.fc3_bn(self.fc3(fc3_out)) #bs*h_part*w_part,O*h*w,1,1
fc3_out=fc3_out.reshape(-1,self.h_part,self.w_part,self.O,self.h,self.w) #bs,h_part,w_part,O,h,w
### local perceptron
if(self.repconv_kernels is not None and not self.deploy):
conv_input=partition.reshape(-1,self.C,self.h,self.w) #bs*h_part*w_part,C,h,w
conv_out=0
for k in self.repconv_kernels:
repconv=self.__getattr__('repconv{}'.format(k))
conv_out+=repconv(conv_input) ##bs*h_part*w_part,O,h,w
conv_out=conv_out.view(-1,self.h_part,self.w_part,self.O,self.h,self.w) #bs,h_part,w_part,O,h,w
fc3_out+=conv_out
fc3_out=fc3_out.permute(0,3,1,4,2,5)#bs,O,h_part,h,w_part,w
fc3_out=fc3_out.reshape(-1,self.C,self.H,self.W) #bs,O,H,W
return fc3_out
if __name__ == '__main__':
setup_seed(20)
N=4 #batch size
C=512 #input dim
O=1024 #output dim
H=14 #image height
W=14 #image width
h=7 #patch height
w=7 #patch width
fc1_fc2_reduction=1 #reduction ratio
fc3_groups=8 # groups
repconv_kernels=[1,3,5,7] #kernel list
repmlp=RepMLP(C,O,H,W,h,w,fc1_fc2_reduction,fc3_groups,repconv_kernels=repconv_kernels)
x=torch.randn(N,C,H,W)
repmlp.eval()
for module in repmlp.modules():
if isinstance(module, nn.BatchNorm2d) or isinstance(module, nn.BatchNorm1d):
nn.init.uniform_(module.running_mean, 0, 0.1)
nn.init.uniform_(module.running_var, 0, 0.1)
nn.init.uniform_(module.weight, 0, 0.1)
nn.init.uniform_(module.bias, 0, 0.1)
#training result
out=repmlp(x)
#inference result
repmlp.switch_to_deploy()
deployout = repmlp(x)
print(((deployout-out)**2).sum())
================================================
FILE: model/mlp/resmlp.py
================================================
import torch
from torch import nn
class Rearange(nn.Module):
def __init__(self,image_size=14,patch_size=7) :
self.h=patch_size
self.w=patch_size
self.nw=image_size // patch_size
self.nh=image_size // patch_size
num_patches = (image_size // patch_size) ** 2
super().__init__()
def forward(self,x):
### bs,c,H,W
bs,c,H,W=x.shape
y=x.reshape(bs,c,self.h,self.nh,self.w,self.nw)
y=y.permute(0,3,5,2,4,1) #bs,nh,nw,h,w,c
y=y.contiguous().view(bs,self.nh*self.nw,-1) #bs,nh*nw,h*w*c
return y
class Affine(nn.Module):
def __init__(self, channel):
super().__init__()
self.g = nn.Parameter(torch.ones(1, 1, channel))
self.b = nn.Parameter(torch.zeros(1, 1, channel))
def forward(self, x):
return x * self.g + self.b
class PreAffinePostLayerScale(nn.Module): # https://arxiv.org/abs/2103.17239
def __init__(self, dim, depth, fn):
super().__init__()
if depth <= 18:
init_eps = 0.1
elif depth > 18 and depth <= 24:
init_eps = 1e-5
else:
init_eps = 1e-6
scale = torch.zeros(1, 1, dim).fill_(init_eps)
self.scale = nn.Parameter(scale)
self.affine = Affine(dim)
self.fn = fn
def forward(self, x):
return self.fn(self.affine(x)) * self.scale + x
class ResMLP(nn.Module):
def __init__(self,dim=128,image_size=14,patch_size=7,expansion_factor=4,depth=4,class_num=1000):
super().__init__()
self.flatten=Rearange(image_size,patch_size)
num_patches = (image_size // patch_size) ** 2
wrapper = lambda i, fn: PreAffinePostLayerScale(dim, i + 1, fn)
self.embedding=nn.Linear((patch_size ** 2) * 3, dim)
self.mlp=nn.Sequential()
for i in range(depth):
self.mlp.add_module('fc1_%d'%i,wrapper(i, nn.Conv1d(patch_size ** 2, patch_size ** 2, 1)))
self.mlp.add_module('fc1_%d'%i,wrapper(i, nn.Sequential(
nn.Linear(dim, dim * expansion_factor),
nn.GELU(),
nn.Linear(dim * expansion_factor, dim)
)))
self.aff=Affine(dim)
self.classifier=nn.Linear(dim,class_num)
self.softmax=nn.Softmax(1)
def forward(self, x) :
y=self.flatten(x)
y=self.embedding(y)
y=self.mlp(y)
y=self.aff(y)
y=torch.mean(y,dim=1) #bs,dim
out=self.softmax(self.classifier(y))
return out
if __name__ == '__main__':
input=torch.randn(50,3,14,14)
resmlp=ResMLP(dim=128,image_size=14,patch_size=7,class_num=1000)
out=resmlp(input)
print(out.shape)
================================================
FILE: model/mlp/sMLP_block.py
================================================
import torch
from torch import nn
class sMLPBlock(nn.Module):
def __init__(self,h=224,w=224,c=3):
super().__init__()
self.proj_h=nn.Linear(h,h)
self.proj_w=nn.Linear(w,w)
self.fuse=nn.Linear(3*c,c)
def forward(self,x):
x_h=self.proj_h(x.permute(0,1,3,2)).permute(0,1,3,2)
x_w=self.proj_w(x)
x_id=x
x_fuse=torch.cat([x_h,x_w,x_id],dim=1)
out=self.fuse(x_fuse.permute(0,2,3,1)).permute(0,3,1,2)
return out
if __name__ == '__main__':
input=torch.randn(50,3,224,224)
smlp=sMLPBlock(h=224,w=224)
out=smlp(input)
print(out.shape)
================================================
FILE: model/mlp/vip-mlp.py
================================================
import torch
import torch.nn as nn
from timm.data import IMAGENET_DEFAULT_MEAN, IMAGENET_DEFAULT_STD
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
def _cfg(url='', **kwargs):
return {
'url': url,
'num_classes': 1000, 'input_size': (3, 224, 224), 'pool_size': None,
'crop_pct': .96, 'interpolation': 'bicubic',
'mean': IMAGENET_DEFAULT_MEAN, 'std': IMAGENET_DEFAULT_STD, 'classifier': 'head',
**kwargs
}
default_cfgs = {
'ViP_S': _cfg(crop_pct=0.9),
'ViP_M': _cfg(crop_pct=0.9),
'ViP_L': _cfg(crop_pct=0.875),
}
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class WeightedPermuteMLP(nn.Module):
def __init__(self, dim, segment_dim=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.segment_dim = segment_dim
self.mlp_c = nn.Linear(dim, dim, bias=qkv_bias)
self.mlp_h = nn.Linear(dim, dim, bias=qkv_bias)
self.mlp_w = nn.Linear(dim, dim, bias=qkv_bias)
self.reweight = Mlp(dim, dim // 4, dim *3)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
def forward(self, x):
B, H, W, C = x.shape
S = C // self.segment_dim
h = x.reshape(B, H, W, self.segment_dim, S).permute(0, 3, 2, 1, 4).reshape(B, self.segment_dim, W, H*S)
h = self.mlp_h(h).reshape(B, self.segment_dim, W, H, S).permute(0, 3, 2, 1, 4).reshape(B, H, W, C)
w = x.reshape(B, H, W, self.segment_dim, S).permute(0, 1, 3, 2, 4).reshape(B, H, self.segment_dim, W*S)
w = self.mlp_w(w).reshape(B, H, self.segment_dim, W, S).permute(0, 1, 3, 2, 4).reshape(B, H, W, C)
c = self.mlp_c(x)
a = (h + w + c).permute(0, 3, 1, 2).flatten(2).mean(2)
a = self.reweight(a).reshape(B, C, 3).permute(2, 0, 1).softmax(dim=0).unsqueeze(2).unsqueeze(2)
x = h * a[0] + w * a[1] + c * a[2]
x = self.proj(x)
x = self.proj_drop(x)
return x
class PermutatorBlock(nn.Module):
def __init__(self, dim, segment_dim, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, skip_lam=1.0, mlp_fn = WeightedPermuteMLP):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = mlp_fn(dim, segment_dim=segment_dim, qkv_bias=qkv_bias, qk_scale=None, attn_drop=attn_drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer)
self.skip_lam = skip_lam
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x))) / self.skip_lam
x = x + self.drop_path(self.mlp(self.norm2(x))) / self.skip_lam
return x
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x) # B, C, H, W
return x
class Downsample(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, in_embed_dim, out_embed_dim, patch_size):
super().__init__()
self.proj = nn.Conv2d(in_embed_dim, out_embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = x.permute(0, 3, 1, 2)
x = self.proj(x) # B, C, H, W
x = x.permute(0, 2, 3, 1)
return x
def basic_blocks(dim, index, layers, segment_dim, mlp_ratio=3., qkv_bias=False, qk_scale=None, \
attn_drop=0, drop_path_rate=0., skip_lam=1.0, mlp_fn = WeightedPermuteMLP, **kwargs):
blocks = []
for block_idx in range(layers[index]):
block_dpr = drop_path_rate * (block_idx + sum(layers[:index])) / (sum(layers) - 1)
blocks.append(PermutatorBlock(dim, segment_dim, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,\
attn_drop=attn_drop, drop_path=block_dpr, skip_lam=skip_lam, mlp_fn = mlp_fn))
blocks = nn.Sequential(*blocks)
return blocks
class VisionPermutator(nn.Module):
""" Vision Permutator
"""
def __init__(self, layers, img_size=224, patch_size=4, in_chans=3, num_classes=1000,
embed_dims=None, transitions=None, segment_dim=None, mlp_ratios=None, skip_lam=1.0,
qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0., drop_path_rate=0.,
norm_layer=nn.LayerNorm,mlp_fn = WeightedPermuteMLP):
super().__init__()
self.num_classes = num_classes
self.patch_embed = PatchEmbed(img_size = img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dims[0])
network = []
for i in range(len(layers)):
stage = basic_blocks(embed_dims[i], i, layers, segment_dim[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
qk_scale=qk_scale, attn_drop=attn_drop_rate, drop_path_rate=drop_path_rate, norm_layer=norm_layer, skip_lam=skip_lam,
mlp_fn = mlp_fn)
network.append(stage)
if i >= len(layers) - 1:
break
if transitions[i] or embed_dims[i] != embed_dims[i+1]:
patch_size = 2 if transitions[i] else 1
network.append(Downsample(embed_dims[i], embed_dims[i+1], patch_size))
self.network = nn.ModuleList(network)
self.norm = norm_layer(embed_dims[-1])
# Classifier head
self.head = nn.Linear(embed_dims[-1], num_classes) if num_classes > 0 else nn.Identity()
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
def get_classifier(self):
return self.head
def reset_classifier(self, num_classes, global_pool=''):
self.num_classes = num_classes
self.head = nn.Linear(self.embed_dim, num_classes) if num_classes > 0 else nn.Identity()
def forward_embeddings(self, x):
x = self.patch_embed(x)
# B,C,H,W-> B,H,W,C
x = x.permute(0, 2, 3, 1)
return x
def forward_tokens(self,x):
for idx, block in enumerate(self.network):
x = block(x)
B, H, W, C = x.shape
x = x.reshape(B, -1, C)
return x
def forward(self, x):
x = self.forward_embeddings(x)
# B, H, W, C -> B, N, C
x = self.forward_tokens(x)
x = self.norm(x)
return self.head(x.mean(1))
@register_model
def vip_s14(pretrained=False, **kwargs):
layers = [4, 3, 8, 3]
transitions = [False, False, False, False]
segment_dim = [16, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
embed_dims = [384, 384, 384, 384]
model = VisionPermutator(layers, embed_dims=embed_dims, patch_size=14, transitions=transitions,
segment_dim=segment_dim, mlp_ratios=mlp_ratios, mlp_fn=WeightedPermuteMLP, **kwargs)
model.default_cfg = default_cfgs['ViP_S']
return model
@register_model
def vip_s7(pretrained=False, **kwargs):
layers = [4, 3, 8, 3]
transitions = [True, False, False, False]
segment_dim = [32, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
embed_dims = [192, 384, 384, 384]
model = VisionPermutator(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
segment_dim=segment_dim, mlp_ratios=mlp_ratios, mlp_fn=WeightedPermuteMLP, **kwargs)
model.default_cfg = default_cfgs['ViP_S']
return model
@register_model
def vip_m7(pretrained=False, **kwargs):
# 55534632
layers = [4, 3, 14, 3]
transitions = [False, True, False, False]
segment_dim = [32, 32, 16, 16]
mlp_ratios = [3, 3, 3, 3]
embed_dims = [256, 256, 512, 512]
model = VisionPermutator(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
segment_dim=segment_dim, mlp_ratios=mlp_ratios, mlp_fn=WeightedPermuteMLP, **kwargs)
model.default_cfg = default_cfgs['ViP_M']
return model
@register_model
def vip_l7(pretrained=False, **kwargs):
layers = [8, 8, 16, 4]
transitions = [True, False, False, False]
segment_dim = [32, 16, 16, 16]
mlp_ratios = [3, 3, 3, 3]
embed_dims = [256, 512, 512, 512]
model = VisionPermutator(layers, embed_dims=embed_dims, patch_size=7, transitions=transitions,
segment_dim=segment_dim, mlp_ratios=mlp_ratios, mlp_fn=WeightedPermuteMLP, **kwargs)
model.default_cfg = default_cfgs['ViP_L']
return model
if __name__ == '__main__':
input=torch.randn(1,3,224,224)
model = VisionPermutator(
layers=[4, 3, 8, 3],
embed_dims=[384, 384, 384, 384],
patch_size=14,
transitions=[False, False, False, False],
segment_dim=[16, 16, 16, 16],
mlp_ratios=[3, 3, 3, 3],
mlp_fn=WeightedPermuteMLP
)
output=model(input)
print(output.shape)
================================================
FILE: model/rep/acnet.py
================================================
import torch
from torch import mean, nn
from collections import OrderedDict
from torch.nn import functional as F
import numpy as np
from numpy import random
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
def _conv_bn(input_channel,output_channel,kernel_size=3,padding=1,stride=1,groups=1):
res=nn.Sequential()
res.add_module('conv',nn.Conv2d(in_channels=input_channel,out_channels=output_channel,kernel_size=kernel_size,padding=padding,padding_mode='zeros',stride=stride,groups=groups,bias=False))
res.add_module('bn',nn.BatchNorm2d(output_channel))
return res
class ACNet(nn.Module):
def __init__(self,input_channel,output_channel,kernel_size=3,groups=1,stride=1,deploy=False,use_se=False):
super().__init__()
self.use_se=use_se
self.input_channel=input_channel
self.output_channel=output_channel
self.deploy=deploy
self.kernel_size=kernel_size
self.padding=kernel_size//2
self.groups=groups
self.activation=nn.ReLU()
if(not self.deploy):
self.brb_3x3=_conv_bn(input_channel,output_channel,kernel_size=3,padding=1,groups=groups)
self.brb_1x3=_conv_bn(input_channel,output_channel,kernel_size=(1,3),padding=(0,1),groups=groups)
self.brb_3x1=_conv_bn(input_channel,output_channel,kernel_size=(3,1),padding=(1,0),groups=groups)
else:
self.brb_rep=nn.Conv2d(in_channels=input_channel,out_channels=output_channel,kernel_size=self.kernel_size,padding=self.padding,padding_mode='zeros',stride=stride,bias=True)
def forward(self, inputs):
if(self.deploy):
return self.activation(self.brb_rep(inputs))
return self.activation(self.brb_1x3(inputs)+self.brb_3x1(inputs)+self.brb_3x3(inputs))
def _switch_to_deploy(self):
self.deploy=True
kernel,bias=self._get_equivalent_kernel_bias()
self.brb_rep=nn.Conv2d(in_channels=self.brb_3x3.conv.in_channels,out_channels=self.brb_3x3.conv.out_channels,
kernel_size=self.brb_3x3.conv.kernel_size,padding=self.brb_3x3.conv.padding,
padding_mode=self.brb_3x3.conv.padding_mode,stride=self.brb_3x3.conv.stride,
groups=self.brb_3x3.conv.groups,bias=True)
self.brb_rep.weight.data=kernel
self.brb_rep.bias.data=bias
#消除梯度更新
for para in self.parameters():
para.detach_()
#删除没用的分支
self.__delattr__('brb_3x3')
self.__delattr__('brb_3x1')
self.__delattr__('brb_1x3')
#将1x3的卷积变成3x3的卷积参数
def _pad_1x3_kernel(self,kernel):
if(kernel is None):
return 0
else:
return F.pad(kernel,[0,0,1,1])
#将3x1的卷积变成3x3的卷积参数
def _pad_3x1_kernel(self,kernel):
if(kernel is None):
return 0
else:
return F.pad(kernel,[1,1,0,0])
#将identity,1x1,3x3的卷积融合到一起,变成一个3x3卷积的参数
def _get_equivalent_kernel_bias(self):
brb_3x3_weight,brb_3x3_bias=self._fuse_conv_bn(self.brb_3x3)
brb_1x3_weight,brb_1x3_bias=self._fuse_conv_bn(self.brb_1x3)
brb_3x1_weight,brb_3x1_bias=self._fuse_conv_bn(self.brb_3x1)
return brb_3x3_weight+self._pad_1x3_kernel(brb_1x3_weight)+self._pad_3x1_kernel(brb_3x1_weight),brb_3x3_bias+brb_1x3_bias+brb_3x1_bias
### 将卷积和BN的参数融合到一起
def _fuse_conv_bn(self,branch):
kernel=branch.conv.weight
running_mean=branch.bn.running_mean
running_var=branch.bn.running_var
gamma=branch.bn.weight
beta=branch.bn.bias
eps=branch.bn.eps
std=(running_var+eps).sqrt()
t=gamma/std
t=t.view(-1,1,1,1)
return kernel*t,beta-running_mean*gamma/std
if __name__ == '__main__':
input=torch.randn(50,512,49,49)
acnet=ACNet(512,512)
acnet.eval()
out=acnet(input)
acnet._switch_to_deploy()
out2=acnet(input)
print('difference:')
print(((out2-out)**2).sum())
================================================
FILE: model/rep/ddb.py
================================================
from torch import conv2d, nn
import torch
from torch.nn import functional as F
def transI_conv_bn(conv, bn):
std = (bn.running_var + bn.eps).sqrt()
gamma=bn.weight
weight=conv.weight*((gamma/std).reshape(-1, 1, 1, 1))
if(conv.bias is not None):
bias=gamma/std*conv.bias-gamma/std*bn.running_mean+bn.bias
else:
bias=bn.bias-gamma/std*bn.running_mean
return weight,bias
def transII_conv_branch(conv1, conv2):
weight=conv1.weight.data+conv2.weight.data
bias=conv1.bias.data+conv2.bias.data
return weight,bias
def transIII_conv_sequential(conv1, conv2):
weight=F.conv2d(conv2.weight.data,conv1.weight.data.permute(1,0,2,3))
# bias=((conv2.weight.data*(conv1.bias.data.reshape(1,-1,1,1))).sum(-1).sum(-1).sum(-1))+conv2.bias.data
return weight#,bias
def transIV_conv_concat(conv1, conv2):
print(conv1.bias.data.shape)
print(conv2.bias.data.shape)
weight=torch.cat([conv1.weight.data,conv2.weight.data],0)
bias=torch.cat([conv1.bias.data,conv2.bias.data],0)
return weight,bias
def transV_avg(channel,kernel):
conv=nn.Conv2d(channel,channel,kernel,bias=False)
conv.weight.data[:]=0
for i in range(channel):
conv.weight.data[i,i,:,:]=1/(kernel*kernel)
return conv
def transVI_conv_scale(conv1, conv2, conv3):
weight=F.pad(conv1.weight.data,(1,1,1,1))+F.pad(conv2.weight.data,(0,0,1,1))+F.pad(conv3.weight.data,(1,1,0,0))
bias=conv1.bias.data+conv2.bias.data+conv3.bias.data
return weight,bias
if __name__ == '__main__':
input=torch.randn(1,64,7,7)
#conv+conv
conv1x1=nn.Conv2d(64,64,1)
conv1x3=nn.Conv2d(64,64,(1,3),padding=(0,1))
conv3x1=nn.Conv2d(64,64,(3,1),padding=(1,0))
out1=conv1x1(input)+conv1x3(input)+conv3x1(input)
#conv_fuse
conv_fuse=nn.Conv2d(64,64,3,padding=1)
conv_fuse.weight.data,conv_fuse.bias.data=transVI_conv_scale(conv1x1,conv1x3,conv3x1)
out2=conv_fuse(input)
print("difference:",((out2-out1)**2).sum().item())
================================================
FILE: model/rep/mobileone.py
================================================
================================================
FILE: model/rep/repvgg.py
================================================
import torch
from torch import mean, nn
from collections import OrderedDict
from torch.nn import functional as F
import numpy as np
from numpy import random
def setup_seed(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
np.random.seed(seed)
random.seed(seed)
torch.backends.cudnn.deterministic = True
def _conv_bn(input_channel,output_channel,kernel_size=3,padding=1,stride=1,groups=1):
res=nn.Sequential()
res.add_module('conv',nn.Conv2d(in_channels=input_channel,out_channels=output_channel,kernel_size=kernel_size,padding=padding,padding_mode='zeros',stride=stride,groups=groups,bias=False))
res.add_module('bn',nn.BatchNorm2d(output_channel))
return res
class RepBlock(nn.Module):
def __init__(self,input_channel,output_channel,kernel_size=3,groups=1,stride=1,deploy=False,use_se=False):
super().__init__()
self.use_se=use_se
self.input_channel=input_channel
self.output_channel=output_channel
self.deploy=deploy
self.kernel_size=kernel_size
self.padding=kernel_size//2
self.groups=groups
self.activation=nn.ReLU()
#make sure kernel_size=3 padding=1
assert self.kernel_size==3
assert self.padding==1
if(not self.deploy):
self.brb_3x3=_conv_bn(input_channel,output_channel,kernel_size=self.kernel_size,padding=self.padding,groups=groups)
self.brb_1x1=_conv_bn(input_channel,output_channel,kernel_size=1,padding=0,groups=groups)
self.brb_identity=nn.BatchNorm2d(self.input_channel) if self.input_channel == self.output_channel else None
else:
self.brb_rep=nn.Conv2d(in_channels=input_channel,out_channels=output_channel,kernel_size=self.kernel_size,padding=self.padding,padding_mode='zeros',stride=stride,bias=True)
def forward(self, inputs):
if(self.deploy):
return self.activation(self.brb_rep(inputs))
if(self.brb_identity==None):
identity_out=0
else:
identity_out=self.brb_identity(inputs)
return self.activation(self.brb_1x1(inputs)+self.brb_3x3(inputs)+identity_out)
def _switch_to_deploy(self):
self.deploy=True
kernel,bias=self._get_equivalent_kernel_bias()
self.brb_rep=nn.Conv2d(in_channels=self.brb_3x3.conv.in_channels,out_channels=self.brb_3x3.conv.out_channels,
kernel_size=self.brb_3x3.conv.kernel_size,padding=self.brb_3x3.conv.padding,
padding_mode=self.brb_3x3.conv.padding_mode,stride=self.brb_3x3.conv.stride,
groups=self.brb_3x3.conv.groups,bias=True)
self.brb_rep.weight.data=kernel
self.brb_rep.bias.data=bias
#消除梯度更新
for para in self.parameters():
para.detach_()
#删除没用的分支
self.__delattr__('brb_3x3')
self.__delattr__('brb_1x1')
self.__delattr__('brb_identity')
#将1x1的卷积变成3x3的卷积参数
def _pad_1x1_kernel(self,kernel):
if(kernel is None):
return 0
else:
return F.pad(kernel,[1]*4)
#将identity,1x1,3x3的卷积融合到一起,变成一个3x3卷积的参数
def _get_equivalent_kernel_bias(self):
brb_3x3_weight,brb_3x3_bias=self._fuse_conv_bn(self.brb_3x3)
brb_1x1_weight,brb_1x1_bias=self._fuse_conv_bn(self.brb_1x1)
brb_id_weight,brb_id_bias=self._fuse_conv_bn(self.brb_identity)
return brb_3x3_weight+self._pad_1x1_kernel(brb_1x1_weight)+brb_id_weight,brb_3x3_bias+brb_1x1_bias+brb_id_bias
### 将卷积和BN的参数融合到一起
def _fuse_conv_bn(self,branch):
if(branch is None):
return 0,0
elif(isinstance(branch,nn.Sequential)):
kernel=branch.conv.weight
running_mean=branch.bn.running_mean
running_var=branch.bn.running_var
gamma=branch.bn.weight
beta=branch.bn.bias
eps=branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.input_channel // self.groups
kernel_value = np.zeros((self.input_channel, input_dim, 3, 3), dtype=np.float32)
for i in range(self.input_channel):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std=(running_var+eps).sqrt()
t=gamma/std
t=t.view(-1,1,1,1)
return kernel*t,beta-running_mean*gamma/std
if __name__ == '__main__':
input=torch.randn(50,512,49,49)
repblock=RepBlock(512,512)
repblock.eval()
out=repblock(input)
repblock._switch_to_deploy()
out2=repblock(input)
print('difference between vgg and repvgg')
print(((out2-out)**2).sum())
================================================
FILE: setup.py
================================================
from setuptools import find_packages, setup
setup(
name="fighingcv",
version="1.0.0",
author="xmu-xiaoma666",
author_email="julien@huggingface.co",
description=(
"FightingCV Codebase For Attention,Backbone, MLP, Re-parameter, Convolution"
),
long_description=open("README.md", "r", encoding="utf-8").read(),
long_description_content_type="text/markdown",
keywords=(
"Attention"
"Backbone"
),
license="Apache",
url="https://github.com/xmu-xiaoma666/External-Attention-pytorch",
package_dir={"": "."},
packages=find_packages("."),
# entry_points={
# "console_scripts": [
# "huggingface-cli=huggingface_hub.commands.huggingface_cli:main"
# ]
# },
python_requires=">=3.7.0",
# install_requires=install_requires,
classifiers=[
"Intended Audience :: Developers",
"Intended Audience :: Education",
"Intended Audience :: Science/Research",
"License :: OSI Approved :: Apache Software License",
"Operating System :: OS Independent",
"Programming Language :: Python :: 3",
"Topic :: Scientific/Engineering :: Artificial Intelligence",
],
)