Showing preview only (1,069K chars total). Download the full file or copy to clipboard to get everything.
Repository: xueqiandata/xueqiandata.github.io
Branch: master
Commit: 15f952ff29bc
Files: 92
Total size: 825.2 KB
Directory structure:
gitextract_2azug98j/
├── .github/
│ └── ISSUE_TEMPLATE/
│ └── feature_request.md
├── .gitignore
├── .travis.yml
├── 404.html
├── 5ebc4602a40a61502b09471e378ae7ae.txt
├── CNAME
├── Gruntfile.js
├── LICENSE
├── README.md
├── _config.yml
├── _includes/
│ ├── footer.html
│ ├── head.html
│ └── nav.html
├── _layouts/
│ ├── default.html
│ ├── keynote.html
│ ├── page.html
│ └── post.html
├── _posts/
│ ├── 2019-12-12-Power BI创建日期表的几种方式概览.md
│ ├── 2020-01-15-如果雇一个人7d×24h每10秒刷新一次Power BI,我需要每月支付他多少钱?.md
│ ├── 2020-01-16-一行代码无限刷新Power BI,完美突破每天8次限制.md
│ ├── 2020-03-19-【运营】新用户数量?Power BI简单三步计算.md
│ ├── 2020-03-19-【运营】新用户明细?Power BI一招帮你搞定.md
│ ├── 2020-03-20-如何显示数据更新时间.md
│ ├── 2020-03-21-【运营】沉睡、流失客户分析?Power BI一招帮你搞定.md
│ ├── 2020-03-22-【运营】任意两个时间段的复购率?Power BI一招帮你搞定.md
│ ├── 2020-03-26-「强强联合」在Power BI 中使用Python(1)——导入数据.md
│ ├── 2020-03-27-【强强联合】在Power BI 中使用Python(2)——数据清洗.md
│ ├── 2020-03-28-【强强联合】在Power BI 中使用Python(3)——数据可视化.md
│ ├── 2020-03-29-【强强联合】在Power BI 中使用Python(4)——PQ数据导出&写回SQL.md
│ ├── 2020-03-30-【强强联合】在Power BI 中使用Python(5)——数据预警与邮件通知.md
│ ├── 2020-03-31-Power BI数据回写SQL Server(1)没有中间商赚差价.md
│ ├── 2020-04-01-Power BI数据回写SQL Server(2)——存储过程一步到位.md
│ ├── 2020-04-04-同一台电脑管理多家企业Power BI报表的自动更新.md
│ ├── 2020-04-11-Python自动将Power BI页面发送钉钉群.md
│ ├── 2022-04-05-Power BI Desktop 入门 - Power BI Microsoft Docs.md
│ ├── 2022-04-06-以下为发表在公众号及知乎上的旧文章.md
│ ├── 2022-04-07-这是我在GitHub上传的第一篇文章.md
│ ├── 2022-04-08-Extreme DAX中文第0章 前言.md
│ ├── 2022-04-08-Extreme DAX中文第1章 商业智能中的DAX.md
│ ├── 2022-04-08-Extreme DAX中文第2章 模型设计.md
│ ├── 2022-04-10-Power Automate打造的微信聊天记录优质内容存储到notion.md
│ ├── 2022-04-10-纯Power Automate打造的Power BI无限刷新-邮箱版-同时刷新多个数据集.md
│ ├── 2022-04-20-Extreme DAX中文第3章 DAX的用法.md
│ ├── 2022-05-06-这个网站用PowerBI、PowerQuery不好爬?这一招交给你.md
│ ├── 2022-05-10-Extreme DAX中文第4章 上下文和筛选.md
│ ├── 2022-05-10-Power Automate Flow中JSON的增删改查.md
│ ├── 2022-05-11-Extreme DAX中文目录.md
│ ├── 2022-05-12-Power Automate实现PowerBI数据集刷新结束后通知.md
│ ├── 2022-05-16-Power BI 以小易大-破电脑也能搞定大模型.md
│ ├── 2022-05-16-它来了,它来了,Power BI的5月更新带着“字段参数”向你走来了.md
│ ├── 2022-05-17-Power BI【字段参数】更多细节说明.md
│ ├── 2022-05-18-Power BI参数自动放大缩小数据集.md
│ ├── 2022-05-24-Power BI 无限刷新-内部指导流程.md
│ ├── 2022-05-25-Power BI 定时导出数据,新版ExecuteQuery.md
│ ├── 2022-05-xx-Power BI execute query.md
│ ├── 2022-06-xx-GitHub Copilot 即将收费?有这钱干点啥不好.md
│ ├── 2022-06-xx-Github学生包申请流程.md
│ ├── 2022-06-xx-PowerBI注册账号申请.md
│ ├── 2022-06-xx-为什么玩转Power BI一定需要Office 365.md
│ ├── 2022-06-xx-增强刷新.md
│ ├── 2022-07-18-Power BI从Dataverse获取数据.md
│ ├── 2022-07-18-恢复删除的flow.md
│ ├── 2022-07-22-几个Power Automate技巧送给你.md
│ ├── 2022-07-22-打破不同组织间的壁垒,Power Automate同步PowerBI报告.md
│ ├── 2022-07-25-Power Automate表达式无法输入和修改时的处理办法.md
│ ├── 2022-08-08在Onedrive for Business中创建文件夹.md
│ ├── 2022-09-23-Craft——制作惊人的文档.md
│ ├── 2022-09-23-Microsoft Loop初见.md
│ ├── 2023-07-01-限量20套!这样的Power BI管理员,你值得拥有!.md
│ └── 2023-07-02-什么是PowerBI全局管理员.md
├── about.html
├── codecov.yml
├── css/
│ ├── bootstrap.css
│ ├── hux-blog.css
│ └── syntax.css
├── feed.xml
├── index.html
├── js/
│ ├── bootstrap.js
│ ├── hux-blog.js
│ ├── jquery.js
│ ├── jquery.nav.js
│ └── jquery.tagcloud.js
├── less/
│ ├── hux-blog.less
│ ├── mixins.less
│ ├── side-catalog.less
│ ├── sidebar.less
│ └── variables.less
├── offline.html
├── package.json
├── pwa/
│ └── manifest.json
├── sw.js
└── tags.html
================================================
FILE CONTENTS
================================================
================================================
FILE: .github/ISSUE_TEMPLATE/feature_request.md
================================================
---
name: Feature request
about: Suggest an idea for this project
title: ''
labels: ''
assignees: ''
---
**Is your feature request related to a problem? Please describe.**
A clear and concise description of what the problem is. Ex. I'm always frustrated when [...]
**Describe the solution you'd like**
A clear and concise description of what you want to happen.
**Describe alternatives you've considered**
A clear and concise description of any alternative solutions or features you've considered.
**Additional context**
Add any other context or screenshots about the feature request here.
================================================
FILE: .gitignore
================================================
# Created by https://www.gitignore.io/api/macos
### macOS ###
*.DS_Store
.AppleDouble
.LSOverride
# Icon must end with two \r
Icon
# Thumbnails
._*
# Files that might appear in the root of a volume
.DocumentRevisions-V100
.fseventsd
.Spotlight-V100
.TemporaryItems
.Trashes
.VolumeIcon.icns
.com.apple.timemachine.donotpresent
# Directories potentially created on remote AFP share
.AppleDB
.AppleDesktop
Network Trash Folder
Temporary Items
.apdisk
# End of https://www.gitignore.io/api/macos
# debug file
_site
================================================
FILE: .travis.yml
================================================
language: ruby
env:
global:
- NOKOGIRI_USE_SYSTEM_LIBRARIES=true
install:
- gem install jekyll
- gem install jekyll-paginate
script:
- jekyll build
after_success:
- bash <(curl -s https://codecov.io/bash)
================================================
FILE: 404.html
================================================
---
layout: default
description: "你来到了没有知识的荒原 🙊"
header-img: "img/404-bg.jpg"
permalink: /404.html
---
<!-- Page Header -->
<header class="intro-header" style="background-image: url('{{ site.baseurl }}/{% if page.header-img %}{{ page.header-img }}{% else %}{{ site.header-img }}{% endif %}')">
<div class="container">
<div class="row">
<div class="col-lg-8 col-lg-offset-2 col-md-10 col-md-offset-1">
<div class="site-heading" id="tag-heading">
<h1>404</h1>
<span class="subheading">{{ page.description }}</span>
</div>
</div>
</div>
</div>
</header>
<script>
document.body.classList.add('page-fullscreen');
</script>
================================================
FILE: 5ebc4602a40a61502b09471e378ae7ae.txt
================================================
2c7be435d8efb8289f7b6c9517e6391ff0cb857c
================================================
FILE: CNAME
================================================
powerbipro.cn
================================================
FILE: Gruntfile.js
================================================
module.exports = function(grunt) {
// Project configuration.
grunt.initConfig({
pkg: grunt.file.readJSON('package.json'),
uglify: {
main: {
src: 'js/<%= pkg.name %>.js',
dest: 'js/<%= pkg.name %>.min.js'
}
},
less: {
expanded: {
options: {
paths: ["css"]
},
files: {
"css/<%= pkg.name %>.css": "less/<%= pkg.name %>.less"
}
},
minified: {
options: {
paths: ["css"],
cleancss: true
},
files: {
"css/<%= pkg.name %>.min.css": "less/<%= pkg.name %>.less"
}
}
},
banner: '/*!\n' +
' * <%= pkg.title %> v<%= pkg.version %> (<%= pkg.homepage %>)\n' +
' * Copyright <%= grunt.template.today("yyyy") %> <%= pkg.author %>\n' +
' */\n',
usebanner: {
dist: {
options: {
position: 'top',
banner: '<%= banner %>'
},
files: {
src: ['css/<%= pkg.name %>.css', 'css/<%= pkg.name %>.min.css', 'js/<%= pkg.name %>.min.js']
}
}
},
watch: {
scripts: {
files: ['js/<%= pkg.name %>.js'],
tasks: ['uglify'],
options: {
spawn: false,
},
},
less: {
files: ['less/*.less'],
tasks: ['less'],
options: {
spawn: false,
}
},
},
});
// Load the plugins.
grunt.loadNpmTasks('grunt-contrib-uglify');
grunt.loadNpmTasks('grunt-contrib-less');
grunt.loadNpmTasks('grunt-banner');
grunt.loadNpmTasks('grunt-contrib-watch');
// Default task(s).
grunt.registerTask('default', ['uglify', 'less', 'usebanner']);
};
================================================
FILE: LICENSE
================================================
MIT License
Copyright (c) 2017 BY
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: README.md
================================================
[](https://travis-ci.org/qiubaiying/qiubaiying.github.io)
[](https://codebeat.co/projects/github-com-qiubaiying-qiubaiying-github-io-master)
[](https://github.com/qiubaiying/qiubaiying.github.io/issues)
[](https://github.com/home-assistant/home-assistant-iOS/blob/master/LICENSE)
[](https://github.com/qiubaiying/qiubaiying.github.io)
[](https://github.com/qiubaiying/qiubaiying.github.io)
博客的搭建教程修改自 [Hux](https://github.com/Huxpro/huxpro.github.io)
更为详细的教程戳这 [《利用 GitHub Pages 快速搭建个人博客》](http://www.jianshu.com/p/e68fba58f75c) 或 [wiki](https://github.com/qiubaiying/qiubaiying.github.io/wiki/%E5%8D%9A%E5%AE%A2%E6%90%AD%E5%BB%BA%E8%AF%A6%E7%BB%86%E6%95%99%E7%A8%8B)
>
### [查看博客戳这里 👆](http://qiubaiying.github.io)
## 使用
* 开始
* [环境](#环境)
* [开始](#开始)
* [撰写博文](#撰写博文)
* 组件
* [侧边栏](#侧边栏)
* [迷你关于我](#mini-about-me)
* [推荐标签](#featured-tags)
* [好友链接](#friends)
* [HTML5 演示文档布局](#keynote-layout)
* 评论与 Google/Baidu Analytics
* [评论](#comment)
* [网站分析](#analytics)
* 高级部分
* [自定义](#customization)
* [标题底图](#header-image)
* [搜索展示标题-头文件](#seo-title)
### 环境
如果你安装了 [jekyll](http://jekyllcn.com/),那你只需要在命令行输入`jekyll serve` 或 `jekyll s`就能在本地浏览器中输入`http://127.0.0.1:4000/`预览主题,对主题的修改也能实时展示(需要强刷浏览器)。
### 开始
你可以通用修改 `_config.yml`文件来轻松的开始搭建自己的博客:
```
# Site settings
title: BY Blog # 你的博客网站标题
SEOTitle: 柏荧的博客 | BY Blog # SEO 标题
description: "Hey" # 随便说点,描述一下
# SNS settings
github_username: qiubaiying # 你的github账号
jianshu_username: e71990ada2fd # 你的简书ID。
# Build settings
# paginate: 10 # 一页你准备放几篇文章
```
Jekyll官方网站还有很多的参数可以调,比如设置文章的链接形式...网址在这里:[Jekyll - Official Site](http://jekyllrb.com/) 中文版的在这里:[Jekyll中文](http://jekyllcn.com/).
### 撰写博文
要发表的文章一般以 **Markdown** 的格式放在这里`_posts/`,你只要看看这篇模板里的文章你就立刻明白该如何设置。
yaml 头文件长这样:
```
---
layout: post
title: 定时器 你真的会使用吗?
subtitle: iOS定时器详解
date: 2016-12-13
author: BY
header-img: img/post-bg-ios9-web.jpg
catalog: true
tags:
- iOS
- 定时器
---
```
### 侧边栏
看右边:
设置是在 `_config.yml`文件里面的`Sidebar settings`那块。
```
# Sidebar settings
sidebar: true #添加侧边栏
sidebar-about-description: "简单的描述一下你自己"
sidebar-avatar: /img/avatar-by.jpg #你的大头贴,请使用绝对地址.注意:名字区分大小写!后缀名也是
```
侧边栏是响应式布局的,当屏幕尺寸小于992px的时候,侧边栏就会移动到底部。具体请见bootstrap栅格系统 <http://v3.bootcss.com/css/>
### Mini About Me
Mini-About-Me 这个模块将在你的头像下面,展示你所有的社交账号。这个也是响应式布局,当屏幕变小时候,会将其移动到页面底部,只不过会稍微有点小变化,具体请看代码。
### Featured Tags
看到这个网站 [Medium](http://medium.com) 的推荐标签非常的炫酷,所以我将他加了进来。
这个模块现在是独立的,可以呈现在所有页面,包括主页和发表的每一篇文章标题的头上。
```
# Featured Tags
featured-tags: true
featured-condition-size: 1 # A tag will be featured if the size of it is more than this condition value
```
唯一需要注意的是`featured-condition-size`: 如果一个标签的 SIZE,也就是使用该标签的文章数大于上面设定的条件值,这个标签就会在首页上被推荐。
内部有一个条件模板 `{% if tag[1].size > {{site.featured-condition-size}} %}` 是用来做筛选过滤的.
### Social-media Account
在下面输入的社交账号,没有的添加的不会显示在侧边框中。新加入了[简书](https:/www.jianshu.com)链接, <http://www.jianshu.com/u/e71990ada2fd>
# SNS settings
RSS: false
jianshu_username: jianshu_id
zhihu_username: username
facebook_username: username
github_username: username
# weibo_username: username

### Friends
好友链接部分。这会在全部页面显示。
设置是在 `_config.yml`文件里面的`Friends`那块,自己加吧。
```
# Friends
friends: [
{
title: "BY Blog",
href: "https://qiubaiying.github.io/"
},
{
title: "Apple",
href: "https://apple.com/"
}
]
```
### Keynote Layout
HTML5幻灯片的排版:

这部分是用于占用html格式的幻灯片的,一般用到的是 Reveal.js, Impress.js, Slides, Prezi 等等.我认为一个现代化的博客怎么能少了放html幻灯的功能呢~
其主要原理是添加一个 `iframe`,在里面加入外部链接。你可以直接写到头文件里面去,详情请见下面的yaml头文件的写法。
```
---
layout: keynote
iframe: "http://huangxuan.me/js-module-7day/"
---
```
iframe在不同的设备中,将会自动的调整大小。保留内边距是为了让手机用户可以向下滑动,以及添加更多的内容。
### Comment
博客不仅支持 [Disqus](http://disqus.com) 评论系统,还加入了 [Gitalk](https://gitalk.github.io/) 评论系统,[支持 Markdwon 语法](https://guides.github.com/features/mastering-markdown/),cool~
#### Disqus
优点:国际比较流行,界面也很大气、简洁,如果有人评论,还能实时通知,直接回复通知的邮件就行了;
缺点:评论必须要去注册一个disqus账号,分享一般只有Facebook和Twitter,另外在墙内加载速度略慢了一点。想要知道长啥样,可以看以前的版本点[这里](http://brucezhaor.github.io/about.html) 最下面就可以看到。
> Node:有很多人反映 Disqus 插件加载不出来,可能墙又架高了,有条件的话翻个墙就好了~
**使用:**
**首先**,你需要去注册一个Disqus帐号。**不要直接使用我的啊!**
**其次**,你只需要在下面的 yaml 头文件中设置一下就可以了。
```
# 评论系统
# Disqus(https://disqus.com/)
disqus_username: qiubaiying
```
#### Gitalk
优点:界面干净简洁,利用 Github issue API 做的评论插件,使用 Github 帐号进行登录和评论,最喜欢的支持 Markdown 语法,对于程序员来说真是太 cool 了。
缺点:配置比较繁琐,每篇文章的评论都需要初始化。
**使用:**
参考我的这篇文章:[《为博客添加 Gitalk 评论插件》](http://qiubaiying.top/2017/12/19/%E4%B8%BA%E5%8D%9A%E5%AE%A2%E6%B7%BB%E5%8A%A0-Gitalk-%E8%AF%84%E8%AE%BA%E6%8F%92%E4%BB%B6/)
### Analytics
网站分析,现在支持百度统计和Google Analytics。需要去官方网站注册一下,然后将返回的code贴在下面:
```
# Baidu Analytics
ba_track_id: 4cc1f2d8f3067386cc5cdb626a202900
# Google Analytics
ga_track_id: 'UA-49627206-1' # 你用Google账号去注册一个就会给你一个这样的id
ga_domain: huangxuan.me # 默认的是 auto, 这里我是自定义了的域名,你如果没有自己的域名,需要改成auto。
```
### Customization
如果你喜欢折腾,你可以去自定义这个模板的 Code。
**如果你可以理解 `_include/` 和 `_layouts/`文件夹下的代码(这里是整个界面布局的地方),你就可以使用 Jekyll 使用的模版引擎 [Liquid](https://github.com/Shopify/liquid/wiki)的语法直接修改/添加代码,来进行更有创意的自定义界面啦!**
### Header Image
博客每页的标题底图是可以自己选的,看看几篇示例post你就知道如何设置了。
标题底图的选取完全是看个人的审美了。每一篇文章可以有不同的底图,你想放什么就放什么,最后宽度要够,大小不要太大,否则加载慢啊。
> 上传的图片最好先压缩,这里推荐 imageOptim 图片压缩软件,让你的博客起飞。
但是需要注意的是本模板的标题是**白色**的,所以背景色要设置为**灰色**或者**黑色**,总之深色系就对了。当然你还可以自定义修改字体颜色,总之,用github pages就是可以完全的个性定制自己的博客。
### SEO Title
我的博客标题是 **“BY Blog”** 但是我想要在搜索的时候显示 **“柏荧的博客 | BY Blog”** ,这个就需要 SEO Title 来定义了。
其实这个 SEO Title 就是定义了<head><title>标题</title></head>这个里面的东西和多说分享的标题,你可以自行修改的。
### 关于收到"Page Build Warning"的 Email
由于jekyll升级到3.0.x,对原来的 pygments 代码高亮不再支持,现只支持一种-rouge,所以你需要在 `_config.yml`文件中修改`highlighter: rouge`.另外还需要在`_config.yml`文件中加上`gems: [jekyll-paginate]`.
同时,你需要更新你的本地 jekyll 环境.
使用`jekyll server`的同学需要这样:
1. `gem update jekyll` # 更新jekyll
2. `gem update github-pages` #更新依赖的包
使用`bundle exec jekyll server`的同学在更新 jekyll 后,需要输入`bundle update`来更新依赖的包.
> Note:
> 可以使用 `jekyll -s` 命令在本地实时配置博客,提高效率。详见 [Jekyll.com](http://jekyllcn.com/)
参考文档:[using jekyll with pages](https://help.github.com/articles/using-jekyll-with-pages/) & [Upgrading from 2.x to 3.x](http://jekyllrb.com/docs/upgrading/2-to-3/)
## 致谢
1. 这个模板是从这里 [Hux](https://github.com/Huxpro/huxpro.github.io) fork 的, 感谢这个作者。
2. 感谢 Jekyll、Github Pages 和 Bootstrap!
## License
遵循 MIT 许可证。有关详细,请参阅 [LICENSE](https://github.com/qiubaiying/qiubaiying.github.io/blob/master/LICENSE)。
================================================
FILE: _config.yml
================================================
# Site settings
title: 学谦PowerBI
SEOTitle: 学谦PowerBI
header-img: img/post-bg-desk.jpg
email: xueqian@powerbipro.cn
description: "Every failure is leading towards success."
keyword: "学谦, 学谦 Blog, 学谦的博客, xueqian, 陈学谦, iOS, Apple, iPhone"
url: "http://powerbipro.cn/" # your host, for absolute URL
baseurl: "" # for example, '/blog' if your blog hosted on 'host/blog'
github_repo: "https://github.com/xueqiandata/xueqiandata.github.io.git" # you code repository
# Sidebar settings
sidebar: true # whether or not using Sidebar.
sidebar-about-description: "满招损,谦受益!"
sidebar-avatar: /img/about-学谦.png # use absolute URL, seeing it's used in both `/` and `/about/`
# SNS settings
RSS: false
# weibo_username: xueqiandata
zhihu_username: xueqiandata
github_username: xueqiandata
#twitter_username: xueqiandata
# Build settings
# from 2016, 'pygments' is unsupported on GitHub Pages. Use 'rouge' for highlighting instead.
permalink: pretty
paginate: 10
exclude: ["less","node_modules","Gruntfile.js","package.json","README.md"]
anchorjs: true # if you want to customize anchor. check out line:181 of `post.html`
# Gems
# from PR#40, to support local preview for Jekyll 3.0
gems: [jekyll-paginate]
# Markdown settings
# replace redcarpet to kramdown,
# although redcarpet can auto highlight code, the lack of header-id make the catalog impossible, so I switch to kramdown
# document: http://jekyllrb.com/docs/configuration/#kramdown
markdown: kramdown
highlighter: rouge
kramdown:
input: GFM # use Github Flavored Markdown !important
# 评论系统
# Disqus(https://disqus.com/)
# disqus_username: xueqiandata
# Gitalk
gitalk:
enable: true #是否开启Gitalk评论
clientID: 14a053a5e3f367d2e515 #生成的clientID
clientSecret: 350401a27d8a01c2c5a657242449692fd592d42a #生成的clientSecret
repo: xueqiandata.github.io #仓库名称
owner: xueqiandata #github用户名
admin: xueqiandata
distractionFreeMode: true #是否启用类似FB的阴影遮罩
# 统计
# Analytics settings
# Baidu Analytics
ba_track_id: b50bf2b12b5338a1845e33832976fd68
# Google Analytics
ga_track_id: 'UA-90855596-1' # Format: UA-xxxxxx-xx
ga_domain: qiubaiying.top # 默认的是 auto, 这里我是自定义了的域名,你如果没有自己的域名,需要改成auto
# Featured Tags
featured-tags: true # 是否使用首页标签
featured-condition-size: 1 # 相同标签数量大于这个数,才会出现在首页
# Progressive Web Apps
chrome-tab-theme-color: "#000000"
service-worker: true
# Friends
friends: [
{
title: "公众号·学谦",
href: "https://mp.weixin.qq.com/s/OrDqdlriIMkNZ_GzYUS92w"
},{
title: "知乎·学谦",
href: "https://www.zhihu.com/people/xueqiandata"
},{
title: "Apple",
href: "https://apple.com"
},{
title: "Apple Developer",
href: "https://developer.apple.com/"
}
]
================================================
FILE: _includes/footer.html
================================================
<!-- Footer -->
<footer>
<div class="container">
<div class="row">
<div class="col-lg-8 col-lg-offset-2 col-md-10 col-md-offset-1">
<ul class="list-inline text-center">
{% if site.RSS %}
<li>
<a href="{{ "/feed.xml" | prepend: site.baseurl }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-rss fa-stack-1x fa-inverse"></i>
</span>
</a>
</li>
{% endif %}
<!-- add jianshu add target = "_blank" to <a> by BY -->
{% if site.jianshu_username %}
<li>
<a target="_blank" href="https://www.jianshu.com/u/{{ site.jianshu_username }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-stack-1x fa-inverse">简</i>
</span>
</a>
</li>
{% endif %}
{% if site.twitter_username %}
<li>
<a href="https://twitter.com/{{ site.twitter_username }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-twitter fa-stack-1x fa-inverse"></i>
</span>
</a>
</li>
{% endif %}
<!-- add Weibo, Zhihu by Hux, add target = "_blank" to <a> by Hux -->
{% if site.zhihu_username %}
<li>
<a target="_blank" href="https://www.zhihu.com/people/{{ site.zhihu_username }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-stack-1x fa-inverse">知</i>
</span>
</a>
</li>
{% endif %}
{% if site.weibo_username %}
<li>
<a target="_blank" href="http://weibo.com/{{ site.weibo_username }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-weibo fa-stack-1x fa-inverse"></i>
</span>
</a>
</li>
{% endif %}
{% if site.facebook_username %}
<li>
<a target="_blank" href="https://www.facebook.com/{{ site.facebook_username }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-facebook fa-stack-1x fa-inverse"></i>
</span>
</a>
</li>
{% endif %}
{% if site.github_username %}
<li>
<a target="_blank" href="https://github.com/{{ site.github_username }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-github fa-stack-1x fa-inverse"></i>
</span>
</a>
</li>
{% endif %}
{% if site.linkedin_username %}
<li>
<a target="_blank" href="https://www.linkedin.com/in/{{ site.linkedin_username }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-linkedin fa-stack-1x fa-inverse"></i>
</span>
</a>
</li>
{% endif %}
</ul>
<p class="copyright text-muted">
Copyright © {{ site.title }} {{ site.time | date: '%Y' }}
<br>
Theme on <a href="{{ site.github_repo }}">GitHub</a> |
<iframe
style="margin-left: 2px; margin-bottom:-5px;"
frameborder="0" scrolling="0" width="100px" height="20px"
src="https://ghbtns.com/github-btn.html?user={{ site.github_username }}&repo={{ site.github_username }}.github.io&type=star&count=true" >
</iframe>
</p>
</div>
</div>
</div>
</footer>
<!-- jQuery -->
<script src="{{ "/js/jquery.min.js " | prepend: site.baseurl }}"></script>
<!-- Bootstrap Core JavaScript -->
<script src="{{ "/js/bootstrap.min.js " | prepend: site.baseurl }}"></script>
<!-- Custom Theme JavaScript -->
<script src="{{ "/js/hux-blog.min.js " | prepend: site.baseurl }}"></script>
<!-- Service Worker -->
{% if site.service-worker %}
<script type="text/javascript">
if(navigator.serviceWorker){
// For security reasons, a service worker can only control the pages that are in the same directory level or below it. That's why we put sw.js at ROOT level.
navigator.serviceWorker
.register('/sw.js')
.then((registration) => {console.log('Service Worker Registered. ', registration)})
.catch((error) => {console.log('ServiceWorker registration failed: ', error)})
}
</script>
{% endif %}
<!-- async load function -->
<script>
function async(u, c) {
var d = document, t = 'script',
o = d.createElement(t),
s = d.getElementsByTagName(t)[0];
o.src = u;
if (c) { o.addEventListener('load', function (e) { c(null, e); }, false); }
s.parentNode.insertBefore(o, s);
}
</script>
<!--
Because of the native support for backtick-style fenced code blocks
right within the Markdown is landed in Github Pages,
From V1.6, There is no need for Highlight.js,
so Huxblog drops it officially.
- https://github.com/blog/2100-github-pages-now-faster-and-simpler-with-jekyll-3-0
- https://help.github.com/articles/creating-and-highlighting-code-blocks/
- https://github.com/jneen/rouge/wiki/list-of-supported-languages-and-lexers
-->
<!--
<script>
async("http://cdn.bootcss.com/highlight.js/8.6/highlight.min.js", function(){
hljs.initHighlightingOnLoad();
})
</script>
<link href="http://cdn.bootcss.com/highlight.js/8.6/styles/github.min.css" rel="stylesheet">
-->
<!-- jquery.tagcloud.js -->
<script>
// only load tagcloud.js in tag.html
if($('#tag_cloud').length !== 0){
async('{{ "/js/jquery.tagcloud.js" | prepend: site.baseurl }}',function(){
$.fn.tagcloud.defaults = {
//size: {start: 1, end: 1, unit: 'em'},
color: {start: '#bbbbee', end: '#0085a1'},
};
$('#tag_cloud a').tagcloud();
})
}
</script>
<!--fastClick.js -->
<script>
async("//cdnjs.cloudflare.com/ajax/libs/fastclick/1.0.6/fastclick.min.js", function(){
var $nav = document.querySelector("nav");
if($nav) FastClick.attach($nav);
})
</script>
<!-- Google Analytics -->
{% if site.ga_track_id %}
<script>
// dynamic User by Hux
var _gaId = '{{ site.ga_track_id }}';
var _gaDomain = '{{ site.ga_domain }}';
// Originial
(function(i,s,o,g,r,a,m){i['GoogleAnalyticsObject']=r;i[r]=i[r]||function(){
(i[r].q=i[r].q||[]).push(arguments)},i[r].l=1*new Date();a=s.createElement(o),
m=s.getElementsByTagName(o)[0];a.async=1;a.src=g;m.parentNode.insertBefore(a,m)
})(window,document,'script','//www.google-analytics.com/analytics.js','ga');
ga('create', _gaId, _gaDomain);
ga('send', 'pageview');
</script>
{% endif %}
<!-- Baidu Tongji -->
{% if site.ba_track_id %}
<script>
// dynamic User by Hux
var _baId = '{{ site.ba_track_id }}';
// Originial
var _hmt = _hmt || [];
(function() {
var hm = document.createElement("script");
hm.src = "//hm.baidu.com/hm.js?" + _baId;
var s = document.getElementsByTagName("script")[0];
s.parentNode.insertBefore(hm, s);
})();
</script>
{% endif %}
<!-- Side Catalog -->
{% if page.catalog %}
<script type="text/javascript">
function generateCatalog (selector) {
var P = $('div.post-container'),a,n,t,l,i,c;
a = P.find('h1,h2,h3,h4,h5,h6');
a.each(function () {
n = $(this).prop('tagName').toLowerCase();
i = "#"+$(this).prop('id');
t = $(this).text();
c = $('<a href="'+i+'" rel="nofollow">'+t+'</a>');
l = $('<li class="'+n+'_nav"></li>').append(c);
$(selector).append(l);
});
return true;
}
generateCatalog(".catalog-body");
// toggle side catalog
$(".catalog-toggle").click((function(e){
e.preventDefault();
$('.side-catalog').toggleClass("fold")
}))
/*
* Doc: https://github.com/davist11/jQuery-One-Page-Nav
* Fork by Hux to support padding
*/
async("{{ '/js/jquery.nav.js' | prepend: site.baseurl }}", function () {
$('.catalog-body').onePageNav({
currentClass: "active",
changeHash: !1,
easing: "swing",
filter: "",
scrollSpeed: 700,
scrollOffset: 0,
scrollThreshold: .2,
begin: null,
end: null,
scrollChange: null,
padding: 80
});
});
</script>
{% endif %}
================================================
FILE: _includes/head.html
================================================
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="google-site-verification" content="xBT4GhYoi5qRD5tr338pgPM5OWHHIDR6mNg1a3euekI" />
<meta name="viewport" content="width=device-width, initial-scale=1">
<meta name="description" content="{{ site.description }}">
<meta name="keywords" content="{{ site.keyword }}">
<meta name="theme-color" content="{{ site.chrome-tab-theme-color }}">
<title>{% if page.title %}{{ page.title }} - {{ site.SEOTitle }}{% else %}{{ site.SEOTitle }}{% endif %}</title>
<!-- Web App Manifest -->
<link rel="manifest" href="{{ site.baseurl }}/pwa/manifest.json">
<!-- Favicon -->
<link rel="shortcut icon" href="{{ site.baseurl }}/img/favicon.ico">
<!-- Safari Webpage Icon by-BY -->
<link rel="apple-touch-icon" href="{{ site.baseurl }}/img/apple-touch-icon.png">
<!-- Canonical URL -->
<link rel="canonical" href="{{ page.url | replace:'index.html','' | prepend: site.baseurl | prepend: site.url }}">
<!-- Bootstrap Core CSS -->
<link rel="stylesheet" href="{{ "/css/bootstrap.min.css" | prepend: site.baseurl }}">
<!-- Custom CSS -->
<link rel="stylesheet" href="{{ "/css/hux-blog.min.css" | prepend: site.baseurl }}">
<!-- Pygments Github CSS -->
<link rel="stylesheet" href="{{ "/css/syntax.css" | prepend: site.baseurl }}">
<!-- Custom Fonts -->
<!-- <link href="http://maxcdn.bootstrapcdn.com/font-awesome/4.3.0/css/font-awesome.min.css" rel="stylesheet" type="text/css"> -->
<!-- Hux change font-awesome CDN to qiniu -->
<link href="//cdnjs.cloudflare.com/ajax/libs/font-awesome/4.6.3/css/font-awesome.min.css" rel="stylesheet" type="text/css">
<!-- Hux Delete, sad but pending in China
<link href='http://fonts.googleapis.com/css?family=Lora:400,700,400italic,700italic' rel='stylesheet' type='text/css'>
<link href='http://fonts.googleapis.com/css?family=Open+Sans:300italic,400italic,600italic,700italic,800italic,400,300,600,700,800' rel='stylesheet' type='text/
css'>
-->
<!-- HTML5 Shim and Respond.js IE8 support of HTML5 elements and media queries -->
<!-- WARNING: Respond.js doesn't work if you view the page via file:// -->
<!--[if lt IE 9]>
<script src="https://oss.maxcdn.com/libs/html5shiv/3.7.0/html5shiv.js"></script>
<script src="https://oss.maxcdn.com/libs/respond.js/1.4.2/respond.min.js"></script>
<![endif]-->
<!-- ga & ba script hoook -->
<script></script>
</head>
================================================
FILE: _includes/nav.html
================================================
<!-- Navigation -->
<nav class="navbar navbar-default navbar-custom navbar-fixed-top">
<div class="container-fluid">
<!-- Brand and toggle get grouped for better mobile display -->
<div class="navbar-header page-scroll">
<button type="button" class="navbar-toggle">
<span class="sr-only">Toggle navigation</span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
<span class="icon-bar"></span>
</button>
<a class="navbar-brand" href="{{ site.baseurl }}/">{{ site.title }}</a>
</div>
<!-- Collect the nav links, forms, and other content for toggling -->
<div id="huxblog_navbar">
<div class="navbar-collapse">
<ul class="nav navbar-nav navbar-right">
<li>
<a href="{{ site.baseurl }}/">Home</a>
</li>
{% for page in site.pages %}{% if page.title %}
<li>
<a href="{{ page.url | prepend: site.baseurl }}">{{ page.title }}</a>
</li>
{% endif %}{% endfor %}
</ul>
</div>
</div>
<!-- /.navbar-collapse -->
</div>
<!-- /.container -->
</nav>
<script>
// Drop Bootstarp low-performance Navbar
// Use customize navbar with high-quality material design animation
// in high-perf jank-free CSS3 implementation
var $body = document.body;
var $toggle = document.querySelector('.navbar-toggle');
var $navbar = document.querySelector('#huxblog_navbar');
var $collapse = document.querySelector('.navbar-collapse');
var __HuxNav__ = {
close: function(){
$navbar.className = " ";
// wait until animation end.
setTimeout(function(){
// prevent frequently toggle
if($navbar.className.indexOf('in') < 0) {
$collapse.style.height = "0px"
}
},400)
},
open: function(){
$collapse.style.height = "auto"
$navbar.className += " in";
}
}
// Bind Event
$toggle.addEventListener('click', function(e){
if ($navbar.className.indexOf('in') > 0) {
__HuxNav__.close()
}else{
__HuxNav__.open()
}
})
/**
* Since Fastclick is used to delegate 'touchstart' globally
* to hack 300ms delay in iOS by performing a fake 'click',
* Using 'e.stopPropagation' to stop 'touchstart' event from
* $toggle/$collapse will break global delegation.
*
* Instead, we use a 'e.target' filter to prevent handler
* added to document close HuxNav.
*
* Also, we use 'click' instead of 'touchstart' as compromise
*/
document.addEventListener('click', function(e){
if(e.target == $toggle) return;
if(e.target.className == 'icon-bar') return;
__HuxNav__.close();
})
</script>
================================================
FILE: _layouts/default.html
================================================
<!DOCTYPE html>
<html lang="en">
{% include head.html %}
<!-- hack iOS CSS :active style -->
<body ontouchstart="">
{% include nav.html %}
{{ content }}
{% include footer.html %}
<!-- Image to hack wechat -->
<img src="/img/apple-touch-icon.png" width="0" height="0" />
<!-- Migrate from head to bottom, no longer block render and still work -->
</body>
</html>
================================================
FILE: _layouts/keynote.html
================================================
---
layout: default
---
<!-- Image to hack wechat -->
<!-- <img src="/img/icon_wechat.png" width="0" height="0"> -->
<!-- <img src="{{ site.baseurl }}/{% if page.header-img %}{{ page.header-img }}{% else %}{{ site.header-img }}{% endif %}" width="0" height="0"> -->
<!-- Post Header -->
<style type="text/css">
header.intro-header{
/*background-image: url('{{ site.baseurl }}/{% if page.header-img %}{{ page.header-img }}{% else %}{{ site.header-img }}{% endif %}')*/
height: 500px;
overflow: hidden;
}
header iframe{
width: 100%;
height: 100%;
border: 0;
}
/* Override Nav Style */
{% if page.navcolor == "invert" %}
.navbar-custom .nav li a,
.navbar-custom .nav li a:hover,
.navbar-custom .navbar-brand,
.navbar-custom .navbar-brand:hover {color:#777;}
.navbar-default .navbar-toggle .icon-bar {background-color:#777;}
{% endif %}
</style>
<header class="intro-header" >
<iframe src="{{page.iframe}}"/>
<div class="container">
<div class="row">
<div class="col-lg-8 col-lg-offset-2 col-md-10 col-md-offset-1">
<div class="post-heading">
<div class="tags">
{% for tag in page.tags %}
<a class="tag" href="{{ site.baseurl }}/tags/#{{ tag }}" title="{{ tag }}">{{ tag }}</a>
{% endfor %}
</div>
<h1>{{ page.title }}</h1>
{% comment %}
always create a h2 for keeping the margin , Hux
{% endcomment %}
{% comment %} if page.subtitle {% endcomment %}
<h2 class="subheading">{{ page.subtitle }}</h2>
{% comment %} endif {% endcomment %}
<span class="meta">Posted by {% if page.author %}{{ page.author }}{% else %}{{ site.title }}{% endif %} on {{ page.date | date: "%B %-d, %Y" }}</span>
</div>
</div>
</div>
</div>
</iframe>
</header>
<!-- Post Content -->
<article>
<div class="container">
<div class="row">
<!-- Post Container -->
<div class="post-container
col-lg-8 col-lg-offset-2
col-md-10 col-md-offset-1 ">
{{ content }}
<hr style="visibility: hidden;">
<ul class="pager">
{% if page.previous.url %}
<li class="previous">
<a href="{{ page.previous.url | prepend: site.baseurl | replace: '//', '/' }}" data-toggle="tooltip" data-placement="top" title="{{page.previous.title}}">
Previous<br>
<span>{{page.previous.title}}</span>
</a>
</li>
{% endif %}
{% if page.next.url %}
<li class="next">
<a href="{{ page.next.url | prepend: site.baseurl | replace: '//', '/' }}" data-toggle="tooltip" data-placement="top" title="{{page.next.title}}">
Next<br>
<span>{{page.next.title}}</span>
</a>
</li>
{% endif %}
</ul>
<!-- Gitalk 评论 start -->
{% if site.gitalk.enable %}
<!-- Gitalk link -->
<link rel="stylesheet" href="https://unpkg.com/gitalk/dist/gitalk.css">
<script src="https://unpkg.com/gitalk@latest/dist/gitalk.min.js"></script>
<div id="gitalk-container"></div>
<script type="text/javascript">
var gitalk = new Gitalk({
clientID: '{{site.gitalk.clientID}}',
clientSecret: '{{site.gitalk.clientSecret}}',
repo: '{{site.gitalk.repo}}',
owner: '{{site.gitalk.owner}}',
admin: ['{{site.gitalk.admin}}'],
id: window.location.pathname,
});
gitalk.render('gitalk-container');
</script>
{% endif %}
<!-- Gitalk end -->
{% if site.disqus.enable %}
<!-- disqus 评论框 start -->
<div class="comment">
<div id="disqus_thread" class="disqus-thread">
</div>
</div>
<!-- disqus 评论框 end -->
{% endif %}
</div>
<!-- Sidebar Container -->
<div class="sidebar-container
col-lg-8 col-lg-offset-2
col-md-10 col-md-offset-1 ">
<!-- Featured Tags -->
{% if site.featured-tags %}
<section>
<hr class="hidden-sm hidden-xs">
<h5><a href="/tags/">FEATURED TAGS</a></h5>
<div class="tags">
{% for tag in site.tags %}
{% if tag[1].size > {{site.featured-condition-size}} %}
<a href="/tags/#{{ tag[0] }}" title="{{ tag[0] }}" rel="{{ tag[1].size }}">
{{ tag[0] }}
</a>
{% endif %}
{% endfor %}
</div>
</section>
{% endif %}
<!-- Friends Blog -->
{% if site.friends %}
<hr>
<h5>FRIENDS</h5>
<ul class="list-inline">
{% for friend in site.friends %}
<li><a href="{{friend.href}}">{{friend.title}}</a></li>
{% endfor %}
</ul>
{% endif %}
</div>
</div>
</div>
</article>
<!-- resize header to fullscreen keynotes -->
<script>
var $header = document.getElementsByTagName("header")[0];
function resize(){
/*
* leave 85px to both
* - told/imply users that there has more content below
* - let user can scroll in mobile device, seeing the keynote-view is unscrollable
*/
$header.style.height = (window.innerHeight-85) + 'px';
}
document.addEventListener('DOMContentLoaded', function(){
resize();
})
window.addEventListener('load', function(){
resize();
})
window.addEventListener('resize', function(){
resize();
})
resize();
</script>
{% if site.disqus.enable %}
<!-- disqus 公共JS代码 start (一个网页只需插入一次) -->
<script type="text/javascript">
/* * * CONFIGURATION VARIABLES * * */
var disqus_shortname = "{{site.disqus.username}}";
var disqus_identifier = "{{page.id}}";
var disqus_url = "{{site.url}}{{page.url}}";
(function() {
var dsq = document.createElement('script'); dsq.type = 'text/javascript'; dsq.async = true;
dsq.src = '//' + disqus_shortname + '.disqus.com/embed.js';
(document.getElementsByTagName('head')[0] || document.getElementsByTagName('body')[0]).appendChild(dsq);
})();
</script>
<!-- disqus 公共JS代码 end -->
{% endif %}
{% if site.anchorjs %}
<!-- async load function -->
<script>
function async(u, c) {
var d = document, t = 'script',
o = d.createElement(t),
s = d.getElementsByTagName(t)[0];
o.src = u;
if (c) { o.addEventListener('load', function (e) { c(null, e); }, false); }
s.parentNode.insertBefore(o, s);
}
</script>
<!-- anchor-js, Doc:http://bryanbraun.github.io/anchorjs/ -->
<script>
async("//cdnjs.cloudflare.com/ajax/libs/anchor-js/1.1.1/anchor.min.js",function(){
anchors.options = {
visible: 'always',
placement: 'right',
icon: '#'
};
anchors.add().remove('.intro-header h1').remove('.subheading').remove('.sidebar-container h5');
})
</script>
<style>
/* place left on bigger screen */
@media all and (min-width: 800px) {
.anchorjs-link{
position: absolute;
left: -0.75em;
font-size: 1.1em;
margin-top : -0.1em;
}
}
</style>
{% endif %}
================================================
FILE: _layouts/page.html
================================================
---
layout: default
---
<!-- Page Header -->
<header class="intro-header" style="background-image: url('{{ site.baseurl }}/{% if page.header-img %}{{ page.header-img }}{% else %}{{ site.header-img }}{% endif %}')">
<div class="container">
<div class="row">
<div class="col-lg-8 col-lg-offset-2 col-md-10 col-md-offset-1 ">
<div class="site-heading">
<h1>{% if page.title %}{{ page.title }}{% else %}{{ site.title }}{% endif %}</h1>
<!--<hr class="small">-->
<span class="subheading">{{ page.description }}</span>
</div>
</div>
</div>
</div>
</header>
<!-- Main Content -->
<div class="container">
<div class="row">
{% if site.sidebar == false %}
<!-- NO SIDEBAR -->
<!-- PostList Container -->
<div class="col-lg-8 col-lg-offset-2 col-md-10 col-md-offset-1 postlist-container">
{{ content }}
</div>
<!-- Sidebar Container -->
<div class="
col-lg-8 col-lg-offset-2
col-md-10 col-md-offset-1
sidebar-container">
<!-- Featured Tags -->
{% if site.featured-tags %}
<section>
<!-- no hr -->
<h5><a href="{{'/tags/' | prepend: site.baseurl }}">FEATURED TAGS</a></h5>
<div class="tags">
{% for tag in site.tags %}
{% if tag[1].size > {{site.featured-condition-size}} %}
<a href="{{ site.baseurl }}/tags/#{{ tag[0] }}" title="{{ tag[0] }}" rel="{{ tag[1].size }}">
{{ tag[0] }}
</a>
{% endif %}
{% endfor %}
</div>
</section>
{% endif %}
<!-- Friends Blog -->
{% if site.friends %}
<hr>
<h5>FRIENDS</h5>
<ul class="list-inline">
{% for friend in site.friends %}
<li><a href="{{friend.href}}">{{friend.title}}</a></li>
{% endfor %}
</ul>
{% endif %}
</div>
{% else %}
<!-- USE SIDEBAR -->
<!-- PostList Container -->
<div class="
col-lg-8 col-lg-offset-1
col-md-8 col-md-offset-1
col-sm-12
col-xs-12
postlist-container
">
{{ content }}
</div>
<!-- Sidebar Container -->
<div class="
col-lg-3 col-lg-offset-0
col-md-3 col-md-offset-0
col-sm-12
col-xs-12
sidebar-container
">
<!-- Featured Tags -->
{% if site.featured-tags %}
<section>
<hr class="hidden-sm hidden-xs">
<h5><a href="{{'/tags/' | prepend: site.baseurl }}">FEATURED TAGS</a></h5>
<div class="tags">
{% for tag in site.tags %}
{% if tag[1].size > {{site.featured-condition-size}} %}
<a href="{{ site.baseurl }}/tags/#{{ tag[0] }}" title="{{ tag[0] }}" rel="{{ tag[1].size }}">
{{ tag[0] }}
</a>
{% endif %}
{% endfor %}
</div>
</section>
{% endif %}
<!-- Short About -->
<section class="visible-md visible-lg">
<hr><h5><a href="{{'/about/' | prepend: site.baseurl }}">ABOUT ME</a></h5>
<div class="short-about">
{% if site.sidebar-avatar %}
<a href="{{ site.baseurl }}/about">
<img src="{{site.sidebar-avatar}}"/>
</a>
{% endif %}
{% if site.sidebar-about-description %}
<p>{{site.sidebar-about-description}}</p>
{% endif %}
<!-- SNS Link -->
<ul class="list-inline">
{% if site.RSS %}
<li>
<a href="{{ "/feed.xml" | prepend: site.baseurl }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-rss fa-stack-1x fa-inverse"></i>
</span>
</a>
</li>
{% endif %}
<!-- add jianshu add target = "_blank" to <a> by BY -->
{% if site.jianshu_username %}
<li>
<a target="_blank" href="https://www.jianshu.com/u/{{ site.jianshu_username }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-stack-1x fa-inverse">简</i>
</span>
</a>
</li>
{% endif %}
{% if site.twitter_username %}
<li>
<a href="https://twitter.com/{{ site.twitter_username }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-twitter fa-stack-1x fa-inverse"></i>
</span>
</a>
</li>
{% endif %}
{% if site.zhihu_username %}
<li>
<a target="_blank" href="https://www.zhihu.com/people/{{ site.zhihu_username }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-stack-1x fa-inverse">知</i>
</span>
</a>
</li>
{% endif %}
{% if site.weibo_username %}
<li>
<a target="_blank" href="http://weibo.com/{{ site.weibo_username }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-weibo fa-stack-1x fa-inverse"></i>
</span>
</a>
</li>
{% endif %}
{% if site.facebook_username %}
<li>
<a target="_blank" href="https://www.facebook.com/{{ site.facebook_username }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-facebook fa-stack-1x fa-inverse"></i>
</span>
</a>
</li>
{% endif %}
{% if site.github_username %}
<li>
<a target="_blank" href="https://github.com/{{ site.github_username }}">
<span class="fa-stack fa-lg">
<i class="fa fa-circle fa-stack-2x"></i>
<i class="fa fa-github fa-stack-1x fa-inverse"></i>
</span>
</a>
</li>
{% endif %}
</ul>
{% if site.email %}
<p>✉️ {{site.email}}</p>
{% endif %}
</div>
</section>
<!-- Friends Blog -->
{% if site.friends %}
<hr>
<h5>FRIENDS</h5>
<ul class="list-inline">
{% for friend in site.friends %}
<li><a href="{{friend.href}}">{{friend.title}}</a></li>
{% endfor %}
</ul>
{% endif %}
</div>
{% endif %}
</div>
</div>
================================================
FILE: _layouts/post.html
================================================
---
layout: default
---
<!-- Image to hack wechat -->
<!-- <img src="/img/icon_wechat.png" width="0" height="0"> -->
<!-- <img src="{{ site.baseurl }}/{% if page.header-img %}{{ page.header-img }}{% else %}{{ site.header-img }}{% endif %}" width="0" height="0"> -->
<!-- Post Header -->
<style type="text/css">
header.intro-header{
position: relative;
background-image: url('{{ site.baseurl }}/{% if page.header-img %}{{ page.header-img }}{% else %}{{ site.header-img }}{% endif %}')
}
{% if page.header-mask %}
header.intro-header .header-mask{
width: 100%;
height: 100%;
position: absolute;
background: rgba(0,0,0, {{ page.header-mask }});
}
{% endif %}
</style>
<header class="intro-header" >
<div class="header-mask"></div>
<div class="container">
<div class="row">
<div class="col-lg-8 col-lg-offset-2 col-md-10 col-md-offset-1">
<div class="post-heading">
<div class="tags">
{% for tag in page.tags %}
<a class="tag" href="{{ site.baseurl }}/tags/#{{ tag }}" title="{{ tag }}">{{ tag }}</a>
{% endfor %}
</div>
<h1>{{ page.title }}</h1>
{% comment %}
always create a h2 for keeping the margin , Hux
{% endcomment %}
{% comment %} if page.subtitle {% endcomment %}
<h2 class="subheading">{{ page.subtitle }}</h2>
{% comment %} endif {% endcomment %}
<span class="meta">Posted by {% if page.author %}{{ page.author }}{% else %}{{ site.title }}{% endif %} on {{ page.date | date: "%B %-d, %Y" }}</span>
</div>
</div>
</div>
</div>
</header>
<!-- Post Content -->
<article>
<div class="container">
<div class="row">
<!-- Post Container -->
<div class="
col-lg-8 col-lg-offset-2
col-md-10 col-md-offset-1
post-container">
{{ content }}
<hr style="visibility: hidden;">
<ul class="pager">
{% if page.previous.url %}
<li class="previous">
<a href="{{ page.previous.url | prepend: site.baseurl | replace: '//', '/' }}" data-toggle="tooltip" data-placement="top" title="{{page.previous.title}}">
Previous<br>
<span>{{page.previous.title}}</span>
</a>
</li>
{% endif %}
{% if page.next.url %}
<li class="next">
<a href="{{ page.next.url | prepend: site.baseurl | replace: '//', '/' }}" data-toggle="tooltip" data-placement="top" title="{{page.next.title}}">
Next<br>
<span>{{page.next.title}}</span>
</a>
</li>
{% endif %}
</ul>
<!--Gitalk评论start -->
{% if site.gitalk.enable %}
<!-- 引入Gitalk评论插件 -->
<link rel="stylesheet" href="https://unpkg.com/gitalk/dist/gitalk.css">
<script src="https://unpkg.com/gitalk@latest/dist/gitalk.min.js"></script>
<div id="gitalk-container"></div>
<!-- 引入一个生产md5的js,用于对id值进行处理,防止其过长 -->
<!-- Thank DF:https://github.com/NSDingFan/NSDingFan.github.io/issues/3#issuecomment-407496538 -->
<script src="{{ site.baseurl }}/js/md5.min.js"></script>
<script type="text/javascript">
var gitalk = new Gitalk({
clientID: '{{site.gitalk.clientID}}',
clientSecret: '{{site.gitalk.clientSecret}}',
repo: '{{site.gitalk.repo}}',
owner: '{{site.gitalk.owner}}',
admin: ['{{site.gitalk.admin}}'],
distractionFreeMode: {{site.gitalk.distractionFreeMode}},
id: md5(location.pathname),
});
gitalk.render('gitalk-container');
</script>
{% endif %}
<!-- Gitalk end -->
{% if site.disqus_username %}
<!-- disqus 评论框 start -->
<div class="comment">
<div id="disqus_thread" class="disqus-thread"></div>
</div>
<!-- disqus 评论框 end -->
{% endif %}
</div>
<!-- Side Catalog Container -->
{% if page.catalog %}
<div class="
col-lg-2 col-lg-offset-0
visible-lg-block
sidebar-container
catalog-container">
<div class="side-catalog">
<hr class="hidden-sm hidden-xs">
<h5>
<a class="catalog-toggle" href="#">CATALOG</a>
</h5>
<ul class="catalog-body"></ul>
</div>
</div>
{% endif %}
<!-- Sidebar Container -->
<div class="
col-lg-8 col-lg-offset-2
col-md-10 col-md-offset-1
sidebar-container">
<!-- Featured Tags -->
{% if site.featured-tags %}
<section>
<hr class="hidden-sm hidden-xs">
<h5><a href="/tags/">FEATURED TAGS</a></h5>
<div class="tags">
{% for tag in site.tags %}
{% if tag[1].size > {{site.featured-condition-size}} %}
<a href="/tags/#{{ tag[0] }}" title="{{ tag[0] }}" rel="{{ tag[1].size }}">
{{ tag[0] }}
</a>
{% endif %}
{% endfor %}
</div>
</section>
{% endif %}
<!-- Friends Blog -->
{% if site.friends %}
<hr>
<h5>FRIENDS</h5>
<ul class="list-inline">
{% for friend in site.friends %}
<li><a href="{{friend.href}}">{{friend.title}}</a></li>
{% endfor %}
</ul>
{% endif %}
</div>
</div>
</div>
</article>
{% if site.disqus_username %}
<!-- disqus 公共JS代码 start (一个网页只需插入一次) -->
<script type="text/javascript">
/* * * CONFIGURATION VARIABLES * * */
var disqus_shortname = "{{site.disqus_username}}";
var disqus_identifier = "{{page.id}}";
var disqus_url = "{{site.url}}{{page.url}}";
(function() {
var dsq = document.createElement('script'); dsq.type = 'text/javascript'; dsq.async = true;
dsq.src = '//' + disqus_shortname + '.disqus.com/embed.js';
(document.getElementsByTagName('head')[0] || document.getElementsByTagName('body')[0]).appendChild(dsq);
})();
</script>
<!-- disqus 公共JS代码 end -->
{% endif %}
{% if site.anchorjs %}
<!-- async load function -->
<script>
function async(u, c) {
var d = document, t = 'script',
o = d.createElement(t),
s = d.getElementsByTagName(t)[0];
o.src = u;
if (c) { o.addEventListener('load', function (e) { c(null, e); }, false); }
s.parentNode.insertBefore(o, s);
}
</script>
<!-- anchor-js, Doc:http://bryanbraun.github.io/anchorjs/ -->
<script>
async("//cdnjs.cloudflare.com/ajax/libs/anchor-js/1.1.1/anchor.min.js",function(){
// BY Fix:去除标题前的‘#’ issues:<https://github.com/qiubaiying/qiubaiying.github.io/issues/137>
// anchors.options = {
// visible: 'always',
// placement: 'right',
// icon: '#'
// };
anchors.add().remove('.intro-header h1').remove('.subheading').remove('.sidebar-container h5');
})
</script>
<style>
/* place left on bigger screen */
@media all and (min-width: 800px) {
.anchorjs-link{
position: absolute;
left: -0.75em;
font-size: 1.1em;
margin-top : -0.1em;
}
}
</style>
{% endif %}
================================================
FILE: _posts/2019-12-12-Power BI创建日期表的几种方式概览.md
================================================
Power BI创建日期表的几种方式概览
几乎所有的报表模型都涉及到日期和时间,因此要创建Power BI报表,日期表就必须得有。虽然最新的Power BI版本已经可以自动为每一个时间列创建日期表。
但这种方式还是存在明显缺点的,一方面如果日期列有两个及以上且分散在不同的table中,无法使用一对多关系来管理这些数据,更何况如果一个table中出现两个时间列(如订单日期和发货日期等)时就无法处理;另一方面,如果数据量特别大,或日期列比较多,自动创建的日期会严重影响性能,因此大部分情况下使用自动智能日期是不合适的。
今天给大家介绍三个创建Power BI日期表的途径,分别对应着一种语言,Excel中的VBA语言,适用于Power BI和PowerPivot的DAX语言,适用于Power BI和PowerQuery的M语言,每一种途径都各有优势和劣势,大家可以视情况而定。
第一种是VBA语言:
直接用excel中的vba语言编写,通过添加简单的按钮可以实现一键创建日期表,并灵活修改起止日期。因为我这个项目的日期有特殊的要求,是截至到当前的,大家需要设置结束日期可以设置一个enddate来控制。

Sub date()
Dim i
Dim origin_date
Dim ws, w As Worksheet
For Each w In Worksheets
If w.Name <> "使用说明" Then
Application.DisplayAlerts = False
w.Delete
Application.DisplayAlerts = True
End If
Next
origin_date = Sheets("使用说明").Range("G10")
Set ws = Worksheets.Add
ws.Name = "日期"
ws.Range("A:A").NumberFormatLocal = "YYYY-MM-DD"
ws.Cells(1, 1) = "日期"
ws.Cells(2, 1) = origin_date
For i = 3 To DateDiff("d", origin_date, Now) + 1
ws.Cells(i, 1) = ws.Cells(i - 1, 1) + 1
Next i
ActiveWorkbook.SaveAs Path & "\date.xlsx", FileFormat:=xlWorkbookDefault
End Sub
使用VBA来编写日期表的最大好处是完全不需要修改pbix文件,尤其是对于在线自动刷新的报表,将连接的日期表修改后,网关自动刷新,而无需重新发布报表。
第二种是DAX语言:
这是使用Power BI绕不过去的坎,需要人人掌握的。利用DAX生成日期表,使用几个不同的函数都可以做到,常用的有以下几种组合:
1、ADDCOLUMNS与CALENDAR函数:
日期表1 =
ADDCOLUMNS (
CALENDAR (DATE(2017,1,1), DATE(2019,12,31)),
"年度", YEAR ( [Date] ),
"季度", "Q" & FORMAT ( [Date], "Q" ),
"月份", FORMAT ( [Date], "MM" ),
"日",FORMAT ( [Date], "DD" ),
"年度季度", FORMAT ( [Date], "YYYY" ) & "Q" & FORMAT ( [Date], "Q" ),
"年度月份", FORMAT ( [Date], "YYYY/MM" ),
"星期几", WEEKDAY ( [Date],2 )
)

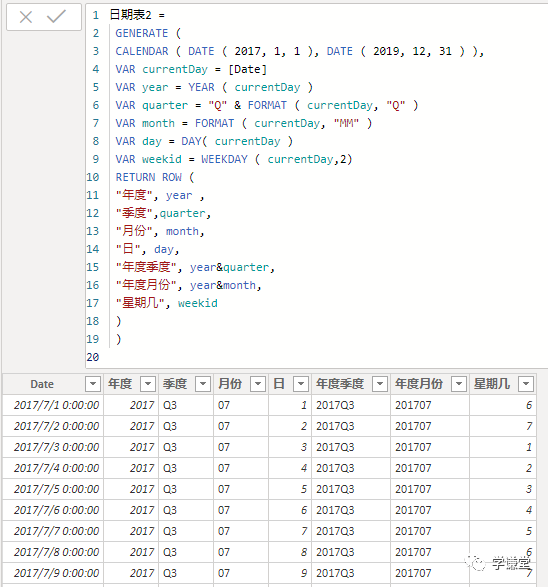
2、GENERATE和CALENDAR函数
日期表2=
GENERATE (
CALENDAR ( DATE ( 2017, 1, 1 ), DATE ( 2019, 12, 31 ) ),
VAR currentDay = [Date]
VAR year = YEAR ( currentDay )
VAR quarter = "Q" & FORMAT ( currentDay, "Q" )
VAR month = FORMAT ( currentDay, "MM" )
VAR day = DAY( currentDay )
VAR weekid = WEEKDAY ( currentDay,2)
RETURN ROW (
"年度", year ,
"季度",quarter,
"月份", month,
"日", day,
"年度季度", year&quarter,
"年度月份", year&month,
"星期几", weekid
)
)
3、GENERATE与CALENDARAUTO函数
日期表3=
GENERATE (
CALENDARAUTO(),
VAR currentDay = [Date]
VAR year = YEAR ( currentDay )
VAR quarter = "Q" & FORMAT ( currentDay, "Q" )
VAR month = FORMAT ( currentDay, "MM" )
VAR day = DAY( currentDay )
VAR weekid = WEEKDAY ( currentDay,2)
RETURN ROW (
"年度", year ,
"季度",quarter,
"月份", month,
"日", day,
"年度季度", year&quarter,
"年度月份", year&month,
"星期几", weekid
)
)

这一段代码中并没有指定起止日期,这就是CALENDARAUTO函数的厉害之处,它可以自动检测模型中其他表中所有日期,然后生成涵盖这些日期的整年日期表。
而且如果模型中其他表的日期范围发生变动,这个日期表也会自动更新到新的日期范围,利用CALENDARAUTO可以很轻松的制作一个动态的日期表。
使用上面三种DAX函数生成日期表还有一个小小的遗憾,就是CALENDAR函数生成的日期列字段名都是英文的[Date],而其他列都是中文,不过可以在生成日期表后进行手动更改,这个比较简单。第三种方法是使用M语言:对于很多Power BI使用者来说,尤其是没有接触过PowerQuery的人来说,M语言比较少用,也比较难一些,在这里直接给出表达式,复制粘贴即可。首先创建两个参数,kaishiDate和jieshuDate来确定起始日期和结束日期,然后在查询编辑器中,新建一个空查询,打开高级编辑器,粘贴以下代码,回车即可。let
日期序列= {Number.From(kaishiDate)..Number.From(jieshuDate)},
转换为表= Table.FromList(日期序列, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
更改的类型= Table.TransformColumnTypes(转换为表,{{"Column1", type date}}),
重命名的列= Table.RenameColumns(更改的类型,{{"Column1", "日期ID"}}),
年= Table.AddColumn(重命名的列, "年份序号", each Date.Year([日期ID]),type number),
月= Table.AddColumn(年, "月", each Date.Month([日期ID]),type number),
月份名称= Table.AddColumn(月, "月份名称", each Date.ToText([日期ID],"M月"),type text),
年月序号= Table.AddColumn(月份名称, "年月序号", each Date.ToText([日期ID],"yyyyMM"),type number),
季度序号= Table.AddColumn(年月序号, "季度序号", each Date.QuarterOfYear([日期ID]),type number),
日= Table.AddColumn(季度序号, "日", each Date.Day([日期ID]),type number),
星期= Table.AddColumn(日, "星期", each Date.DayOfWeek([日期ID],0),type number)
in
星期
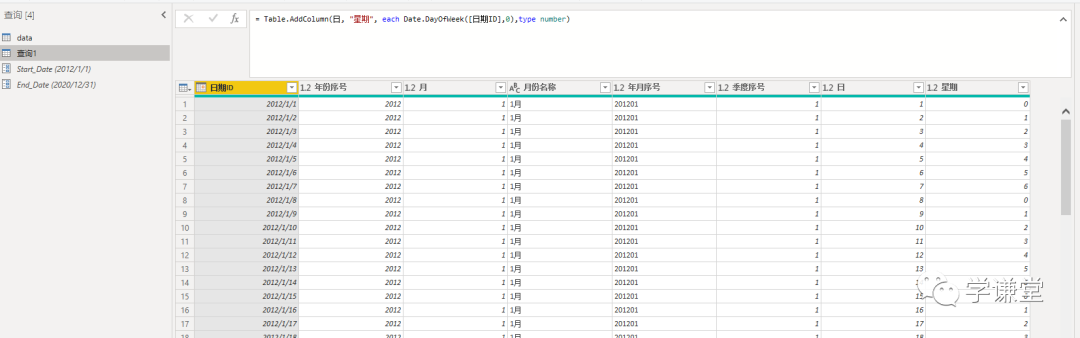
甚至更加霸道的完美版,参考佐罗老师的erBI战友联盟的文章,可以直接调用函数来创建,并且可以自定义设置。
let
CalendarType = type function (
optional CalendarYearStart as (type number meta [
Documentation.FieldCaption = "开始年份,日期表从开始年份1月1日起。",
Documentation.FieldDescription = "日期表从开始年份1月1日起",
Documentation.SampleValues = { Date.Year( DateTime.LocalNow( ) ) - 1 } // Previous Year
]),
optional CalendarYearEnd as (type number meta [
Documentation.FieldCaption = "结束年份,日期表至结束年份12月31日止。",
Documentation.FieldDescription = "日期表至结束年份12月31日止",
Documentation.SampleValues = { Date.Year( DateTime.LocalNow( ) ) } // Current Year
]),
optional CalendarFirstDayOfWeek as (type text meta [
Documentation.FieldCaption = "定义一周开始日,从 Monday,Tuesday,Wednesday,Thursday,Friday,Saturday,Sunday中选择一个,缺省默认为Monday。",
Documentation.FieldDescription = "从 Monday,Tuesday,Wednesday,Thursday,Friday,Saturday,Sunday中选择一个,缺省默认为Monday。",
Documentation.SampleValues = { "Monday" }
]),
optional CalendarCulture as (type text meta [
Documentation.FieldCaption = "指定日期表显示月以及星期几的名称是中文或英文,en 表示英文,zh 表示中文,缺省默认与系统一致。",
Documentation.FieldDescription = " en 表示英文,zh 表示中文,缺省默认与系统一致。",
Documentation.SampleValues = { "zh" }
])
)
as table meta [
Documentation.Name = "构建日期表",
Documentation.LongDescription = "创建指定年份之间的日期表。并可进行各种设置。",
Documentation.Examples = {
[
Description = "返回当前年份日期表",
Code = "CreateCalendar()",
Result = "当前年份日期表。"
],
[
Description = "返回指定年份的日期表",
Code = "CreateCalendar( 2017 )",
Result = "返回2017/01/01至2017/12/31之间的日期表。"
],
[
Description = "返回起止年份之间的日期表",
Code = "CreateCalendar( 2015 , 2017 )",
Result = "返回2015/01/01至2017/12/31之间的日期表。"
],
[
Description = "返回起止年份之间的日期表,并指定周二为每周的第一天",
Code = "CreateCalendar( 2015 , 2017 , ""Tuesday"" )",
Result = "2015/01/01至2017/12/31之间的日期表,且周二是每周的第一天。"
],
[
Description = "返回起止年份之间的日期表,并指定周二为每周的第一天,并使用英文显示名称。",
Code = "CreateCalendar( 2015 , 2017 , ""Tuesday"", ""en"" )",
Result = "2015/01/01至2017/12/31之间的日期表,且周二是每周的第一天,并使用英文显示月名称及星期几的名称。"
]
}
],
CreateCalendar = ( optional CalendarYearStart as number, optional CalendarYearEnd as number, optional CalendarFirstDayOfWeek as text, optional CalendarCulture as text) => let
begin_year = CalendarYearStart ,
end_year = CalendarYearEnd ,
first_day_of_week = if Text.Lower( CalendarFirstDayOfWeek ) = "monday" then Day.Monday
else if Text.Lower( CalendarFirstDayOfWeek ) = "tuesday" then Day.Tuesday
else if Text.Lower( CalendarFirstDayOfWeek ) = "wednesday" then Day.Wednesday
else if Text.Lower( CalendarFirstDayOfWeek ) = "thursday" then Day.Thursday
else if Text.Lower( CalendarFirstDayOfWeek ) = "friday" then Day.Friday
else if Text.Lower( CalendarFirstDayOfWeek ) = "saturday" then Day.Saturday
else if Text.Lower( CalendarFirstDayOfWeek ) = "sunday" then Day.Sunday
else if CalendarFirstDayOfWeek <> null then error "参数错误:参数CalendarFirstDayOfWeek必须是Monday,Tuesday,Wednesday,Thursday,Friday,Saturday,Sunday中的一个。"
else Day.Monday ,
culture = if CalendarCulture <> null then CalendarCulture else "zh" , // "en" , "zh"
y1 = if begin_year <> null then begin_year else if end_year <> null then end_year else Date.Year( DateTime.LocalNow() ) ,
y2 = if end_year <> null then end_year else if begin_year <> null then begin_year else Date.Year( DateTime.LocalNow() ) ,
calendar_list = { Number.From ( #date( Number.From( y1 ) , 1 , 1 ) ) .. Number.From( #date( Number.From( y2 ) , 12, 31 ) ) },
calendar_list_table = Table.FromList(calendar_list, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
\#"Changed Type" = Table.TransformColumnTypes(calendar_list_table,{{"Column1", type date}}),
\#"Renamed Columns" = Table.RenameColumns(#"Changed Type",{{"Column1", "Date"}}),
\#"Inserted Year" = Table.AddColumn(#"Renamed Columns", "Year", each Date.Year([Date]), Int64.Type),
\#"Inserted Quarter" = Table.AddColumn(#"Inserted Year", "Quarter", each Date.QuarterOfYear([Date]), Int64.Type),
\#"Inserted Month" = Table.AddColumn(#"Inserted Quarter", "Month", each Date.Month([Date]), Int64.Type),
\#"Inserted Week of Year" = Table.AddColumn(#"Inserted Month", "WeekOfYear", each Date.WeekOfYear( [Date] , first_day_of_week ), Int64.Type),
\#"Inserted Week of Month" = Table.AddColumn(#"Inserted Week of Year", "WeekOfMonth", each Date.WeekOfMonth( [Date] ), Int64.Type),
\#"Inserted Start of Week" = Table.AddColumn(#"Inserted Week of Month", "DateOfWeekStart", each Date.StartOfWeek( [Date] ), type date),
\#"Inserted End of Week" = Table.AddColumn(#"Inserted Start of Week", "DateOfWeekEnd", each Date.EndOfWeek([Date]), type date),
\#"Inserted Day" = Table.AddColumn(#"Inserted End of Week", "DayOfMonth", each Date.Day([Date]), Int64.Type),
\#"Inserted Day of Week" = Table.AddColumn(#"Inserted Day", "DayOfWeek", each Date.DayOfWeek( [Date] , first_day_of_week ), Int64.Type),
\#"Inserted Day of Year" = Table.AddColumn(#"Inserted Day of Week", "DayOfYear", each Date.DayOfYear([Date]), Int64.Type),
\#"Inserted Day Name" = Table.AddColumn(#"Inserted Day of Year", "DayOfWeekName", each Date.DayOfWeekName( [Date] , culture ), type text),
\#"Inserted Year Name" = Table.AddColumn(#"Inserted Day Name", "YearName", each "Y" & Text.From( [Year] ) , type text ),
\#"Inserted Quarter Name" = Table.AddColumn(#"Inserted Year Name", "QuarterName", each "Q" & Text.From( [Quarter] ) , type text ),
\#"Inserted Month Name" = Table.AddColumn(#"Inserted Quarter Name", "MonthName", each Date.MonthName( [Date] , culture ), type text),
\#"Inserted Week Name" = Table.AddColumn(#"Inserted Month Name", "WeekName", each "W" & Text.From( [WeekOfYear] ) , type text ),
\#"Inserted Year Quarter" = Table.AddColumn(#"Inserted Week Name", "YearQuarter", each [Year] * 100 + [Quarter] , Int64.Type ),
\#"Inserted Year Month" = Table.AddColumn(#"Inserted Year Quarter", "YearMonth", each [Year] * 100 + [Month] , Int64.Type ),
\#"Inserted Year Week" = Table.AddColumn(#"Inserted Year Month", "YearWeek", each [Year] * 100 + [WeekOfYear] , Int64.Type ),
\#"Inserted Date Code" = Table.AddColumn(#"Inserted Year Week", "DateCode", each [Year] * 10000 + [Month] * 100 + [DayOfMonth] , Int64.Type )
in
if culture = "zh"
then Table.RenameColumns( #"Inserted Date Code" ,\{\{"Date", "日期"}, {"Year", "年"}, {"Quarter", "季"}, {"Month", "月"}, {"WeekOfYear", "周"}, {"WeekOfMonth", "月周"}, {"DayOfMonth", "月日"}, {"DateOfWeekStart", "周开始日期"}, {"DateOfWeekEnd", "周结束日期"}, {"DayOfWeek", "周天"}, {"DayOfYear", "年日"}, {"DayOfWeekName", "星期几名称"}, {"YearName", "年份名称"}, {"QuarterName", "季度名称"}, {"MonthName", "月份名称"}, {"WeekName", "周名称"}, {"YearQuarter", "年季"}, {"YearMonth", "年月"}, {"YearWeek", "年周"}, {"DateCode", "日期码"}})
else #"Inserted Date Code"
in
Value.ReplaceType( CreateCalendar , CalendarType )
ok,以上就是三个主要的创建日期表的途径,每一种都有自己的优缺点,具体来说
1.VBA语言最大的好处是只需要修改原始文件,无需重新发布新的报表,缺点是需要用到另一门语言;
2.DAX是最灵活的,也是日常都在用的,且用CALENDARAUTO函数可以自动识别模型中的最大最小日期,实现自动调整,缺点是需要修改相关标题;
3.M语言是最强大的,通过参数自动化设置想要的各种各样的日期格式,缺点是如果日期表设置不合理,需要重新发布新的报表。
以上三个途径都有多种表达式写法,追求简单的有简单的做法,追求完美的有完美的方式。当然,一般随着数据的越来越多,模型越来越复杂,对于日期表的需求也会不断地提升,可以适当采用添加列的方式创建更多符合业务需求的格式。
================================================
FILE: _posts/2020-01-15-如果雇一个人7d×24h每10秒刷新一次Power BI,我需要每月支付他多少钱?.md
================================================
如果雇一个人7d×24h每10秒刷新一次Power BI,我需要每月支付他多少钱?
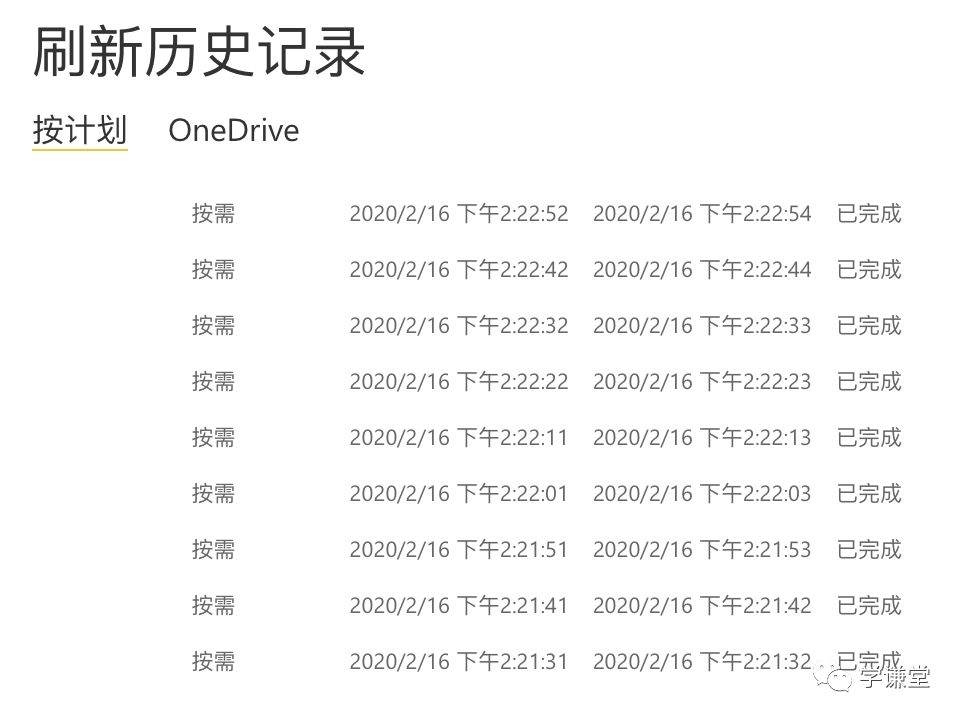
众所周知,powerbi的计划刷新支持每天更新8次,并且计划时间必须是整点或者半点两个选项,这对于很多需要及时刷新的数据来说太慢了,比如双十一、双十二的成交额数据,分毫必争,错失1分钟可能就会产生较严重的问题。
更为严重的是,即便设定整点更新,按计划更新所需的时间执行至少需要10分钟。一开始我以为是数据量大的原因导致,结果,即便更换了一个报表,数据量特别小,只有一张表两行两列的数据,刷新时间仍然需要十几分钟,这我就接受不了了。(下图)
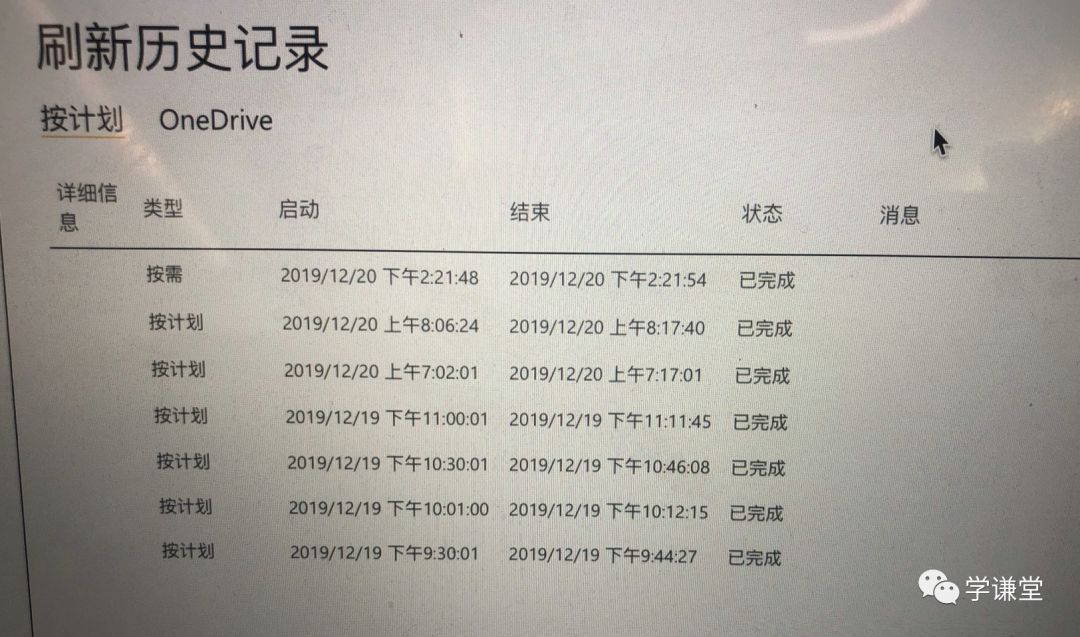
经过各种和世纪互联的沟(si)通(bi),并请教了国外的专家,才得到一个明确的回复,这个事情就是这样,没办法,办不了,等着吧……
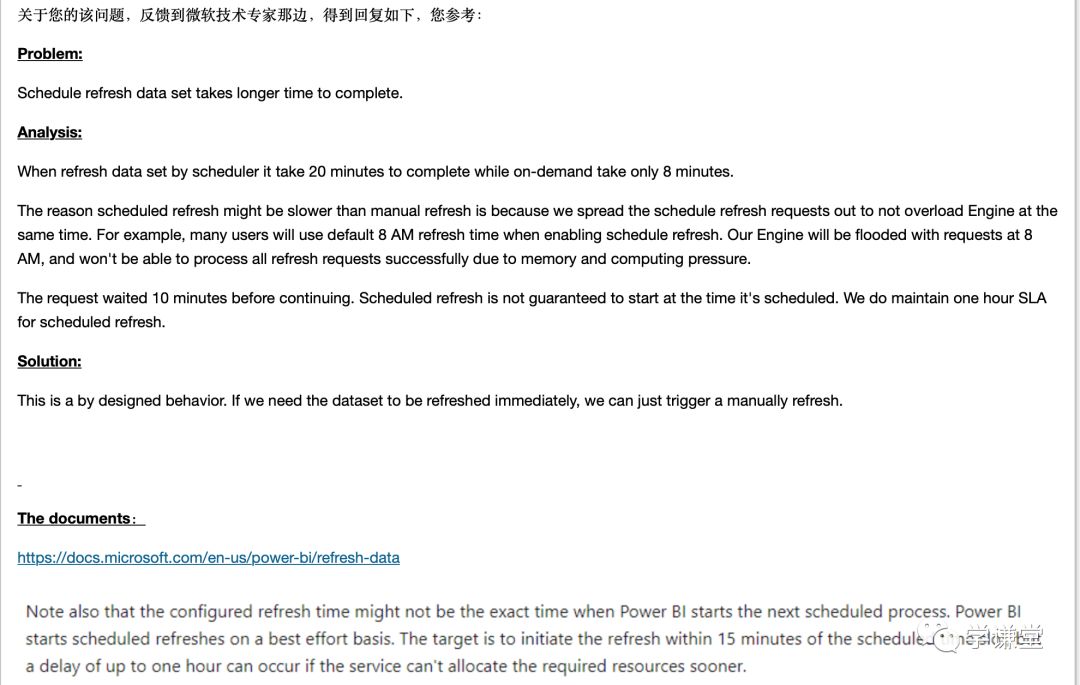
我心想,这肯定不行啊……
于是
python大法用起来

那么问题来了,怎么把大象装进冰箱里?
分三步:
第一步,买一个冰箱
第二步,买一头大象
第三步,把大象装进冰箱里。

那么举一反三,我们就可以得出用Python大法自动刷新powerbi的步骤:
第一步,安装python
第二步,根据powerbi网页编写代码
第三步,运行代码,葛优躺喝咖啡,美滋滋

第一步不用说了,内事不决问度娘,外事不决问谷哥
第三步也不用说了,编好了,狠狠地戳一下鼠标左键搞定
说一下第二步:
1.我们需要使用的库是selenium,一个第三方的Python库,可以模拟浏览器操作,是一个用于Web应用程序测试的工具。我们使用的selenium里的webdriver模块来操控浏览器。
from selenium import webdriver
2.接着,打开Firefox浏览器,路径是你的geckodriver.exe位置,这个在安装软件的时候可以设置的。
brower = webdriver.Firefox(executable_path=r'C:\Program Files\Mozilla Firefox\geckodriver.exe')
3.打开浏览器要输入网址,输入的是这个页面的网址,先拷贝下来,如下的格式:https://app.powerbi.cn/groups/xxxxxxxxxxxxxxxxxxxxxx/list/datasets
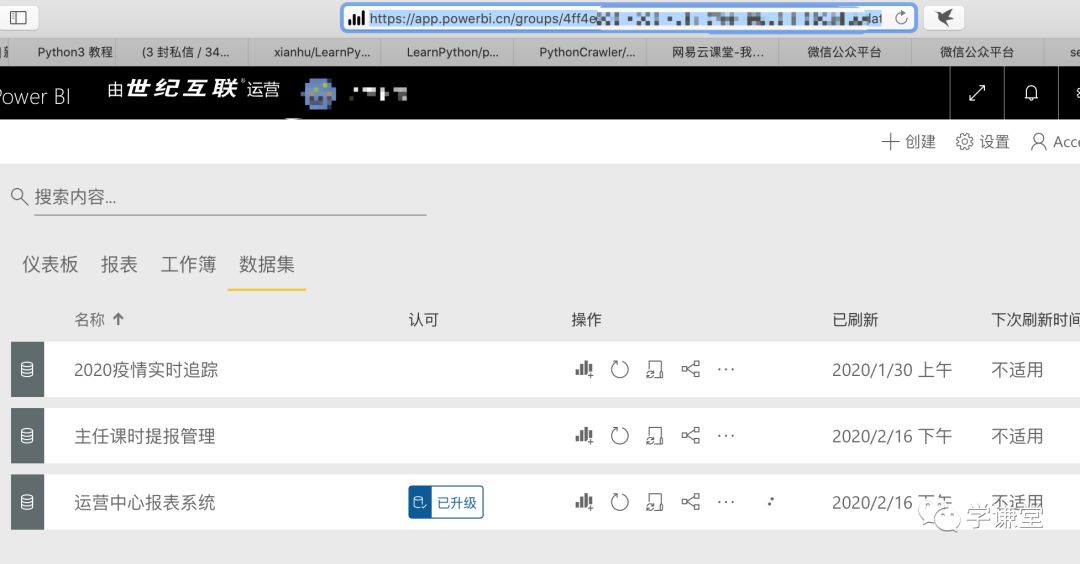
将下面的链接改成你自己的链接:
brower.get("https://app.powerbi.cn/groups/xxxxxxxxxxxxx/list/datasets")
这样selenium就创建好了一个打开的网页,等待登陆
很明显,我们不能手动去填写账号和密码,太掉价了
4.在填写用户名的地方右键-查看元素

发现有一个input id='i0116',我们就通过这个id来确定输入框的位置,使用的是find_element_by_id,用send_keys输入账号,因为我使用的是国内的世纪互联的账号,你们改成自己的账号就行,国际版国内版代码是相同的。
brower.find_element_by_id('i0116').send_keys('xxxxx@xxxxxx.partner.onmschina.cn')
5.输入的账号后,我们应该点击下一步,在下一步的按钮处点击右键-查看元素,有一个id="idSIButton9",那么就好办了

brower.find_element_by_id('idSIButton9').click()
这样就到了输入密码的界面
6.我们发现输入密码界面和输入账号界面是集备一致的,所以直接将代码写出来:
time.sleep(5)
brower.find_element_by_id('i0118').send_keys('duqkyg-qefby1-gipGun')
brower.find_element_by_id('idSIButton9').click()
插入一个time.sleep(5),表示暂停5秒,因为可能网速原因导致输入账号后的跳转需要一点点时间,这个可以自己调整。
这样就直接进入到了数据集刷新的页面:
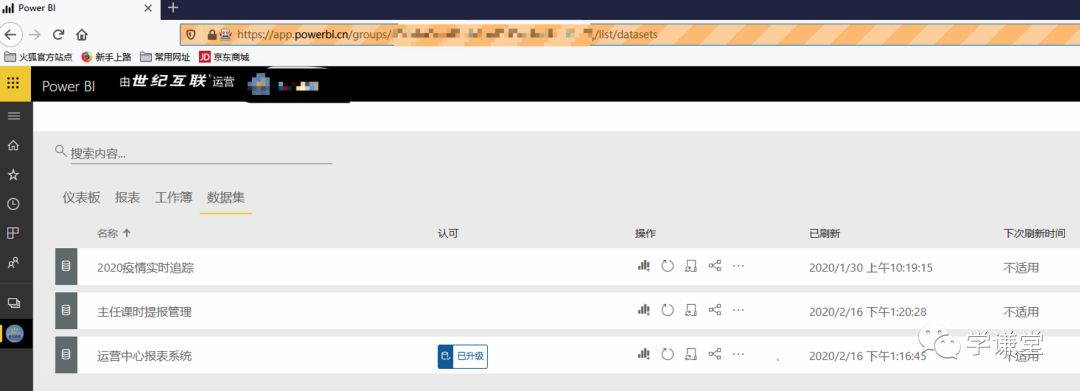
当然,在运行之后的代码前加入time.sleep(10),因为powerbi网页对网速要求很高,看个人网速和电脑配置情况
7.接下来就是要获取刷新按钮的位置并模拟点击了

仍然右键-查看元素

这里我们使用brower.find_element_by_xpath来确定元素的位置
keshi_refresh=brower.find_element_by_xpath(".//*[@class='refreshNow pbi-glyph pbi-glyph-refresh' and @aria-describedby='主任课时提报管理datasetMenu2']")
确定完元素,就要模拟点击
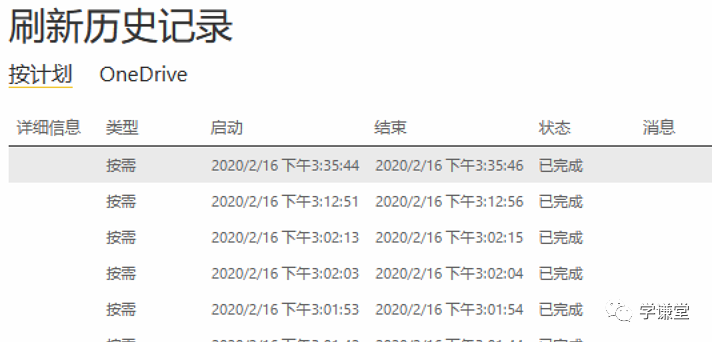
keshi_refresh.click()
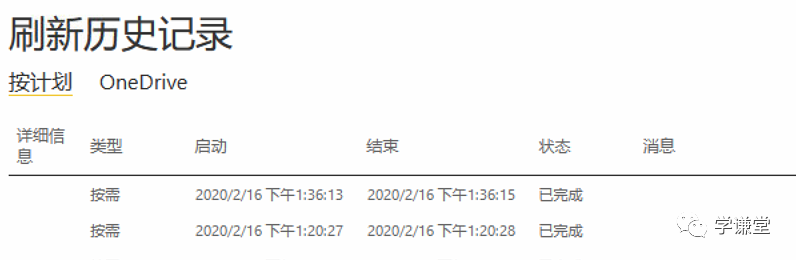
上图最后一条就是刚刚按需刷新的记录。
这样就完成了一次刷新。
但是我们想要的是每隔10秒就进行一次刷新啊,而且是24小时不间断?!!

只要创建一个死循环,10秒运行一下模拟点击click()就好:
while True:
keshi_refresh.click()
time.sleep(10)
效果如下:
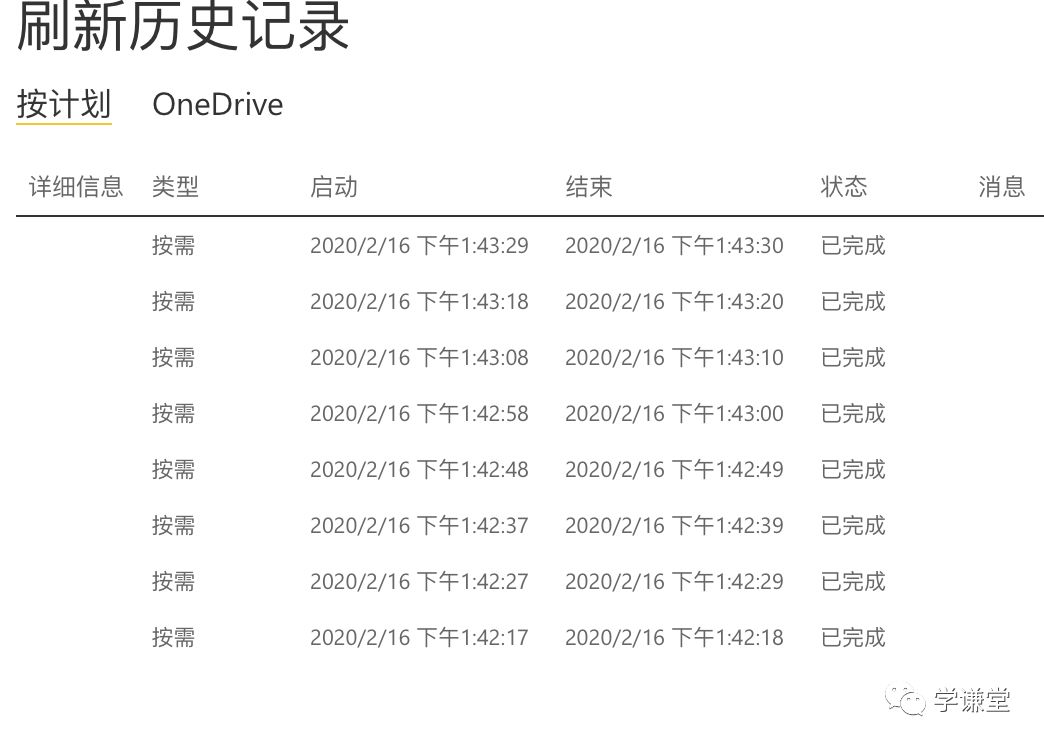
这样,我们就完成了利用Python来突破powerbi每天只有8次自动更新并且自动更新时间特别长的难题了。

那么问题就来了,如果雇一个人7d×24h不简单每10秒刷新一次Power BI,我需要每月支付他多少钱?
完整源代码请关注【学谦数据运营】全网同名回复“1”获取。
————————
以上的使用selenium创建浏览器模拟点击刷新的方式已经可以做到完全不影响正常使用电脑的情况下进行。
因为前几天有人在群里问,我随口说了一句,最简单的办法是找一台破电脑,用按键精灵10秒点击一次,需要占用一台电脑。如果有废旧电脑可以打开网页的话,是可以采用这种方式的。
但是这种方式仍然有一个小小的问题,就是需要打开一个新的浏览器页面,并且如果按照10秒模拟点击一次,其实内存消耗还是比较大的,尤其是配置比较低的电脑。那么该怎么办呢?
在点击刷新按钮的时候,右键网页-查看元素-网络,我们发现每一次刷新,其实就是代表着这一个post请求,那么只要我们将这个post请求的内容用Python发送出去,不就达到我们的目的了吗
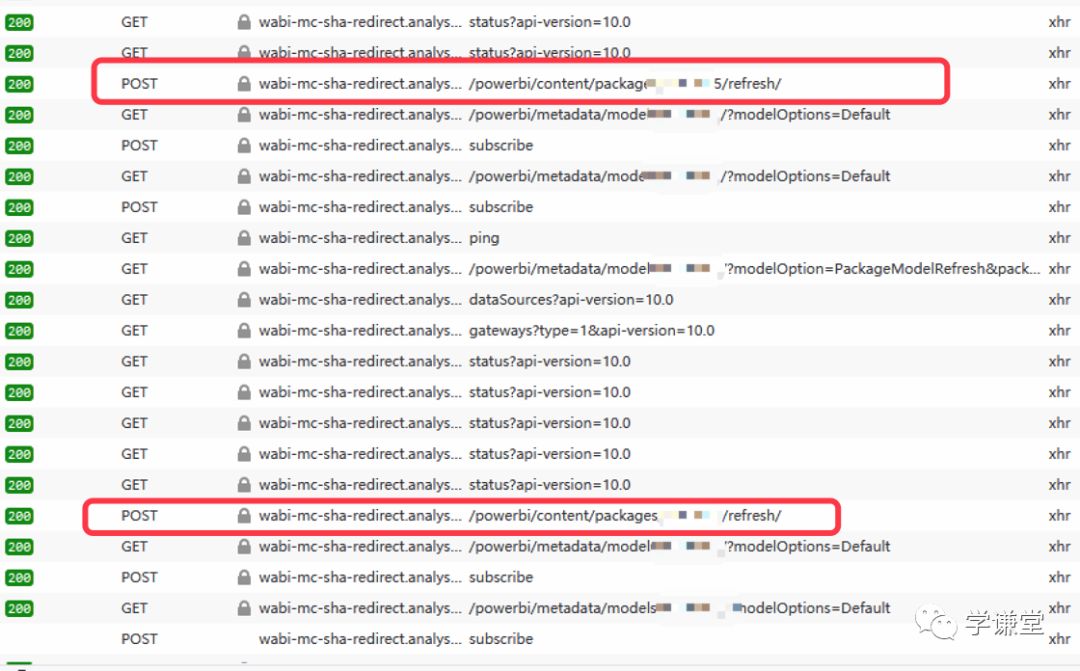
欲知后事如何,请关注【学谦数据运营】全网同名,等待下次更新。

================================================
FILE: _posts/2020-01-16-一行代码无限刷新Power BI,完美突破每天8次限制.md
================================================
一行代码无限刷新Power BI,完美突破每天8次限制
上次我们说到,使用selenium来操控浏览器打开网页,模拟点击进行刷新。
但是这种方式仍然有一个小小的问题,就是需要打开一个新的浏览器页面,并且如果按照10秒模拟点击一次,其实内存消耗还是比较大的,尤其是配置比较低的电脑。
好像遇到了一点小小的障碍……
障碍?

我们换个思路, 在点击刷新按钮的时候,右键网页-查看元素-网络,我们发现每一次刷新,其实就是代表着这一个post请求,那么只要我们将这个post请求的内容用Python发送出去,不就达到我们的目的了吗
那么

1.首先,用Firefox浏览器打开以下的页面:
2.右键空白处-查看元素-网络,然后点一下刷新按钮,在里面找到这个post
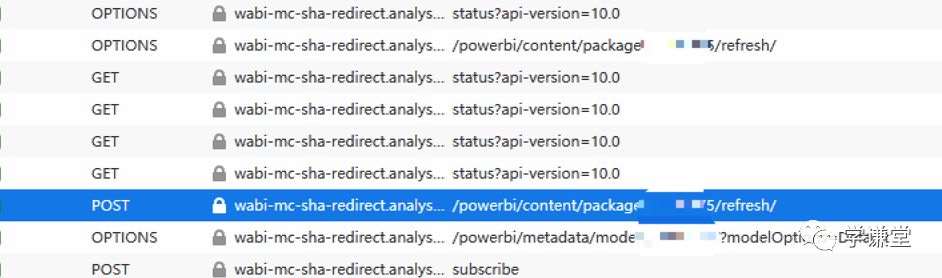
https://wabi-mc-sha-redirect.analysis.chinacloudapi.cn/powerbi/content/packages/xxxxxxxx/refresh/
这个网址就是让powerbi刷新的post请求,packages后面的数字替换成自己的就ok了,但是这个网址可不是直接复制到地址栏按enter就行的,因为这不是get请求,所以会得到这个结果。
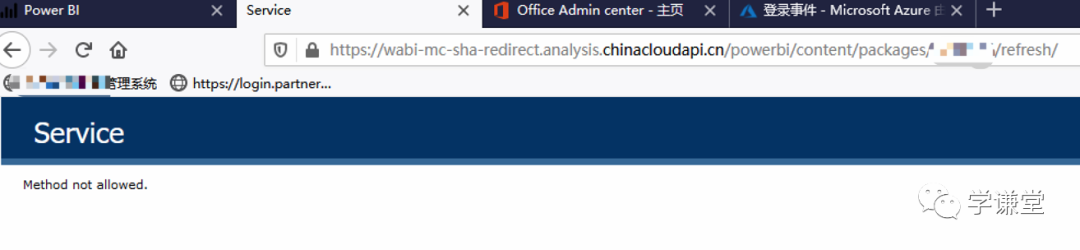
那应该怎么办呢?很明显要用Python构建一个POST去请求了。
3.点击这个post链接,查看消息头
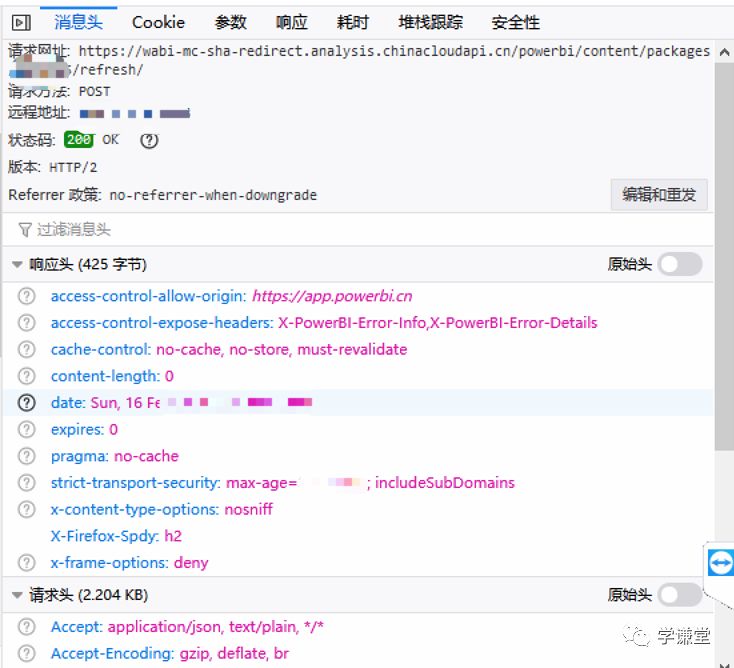
4.点击编辑和重发(注意先不要点击发送)
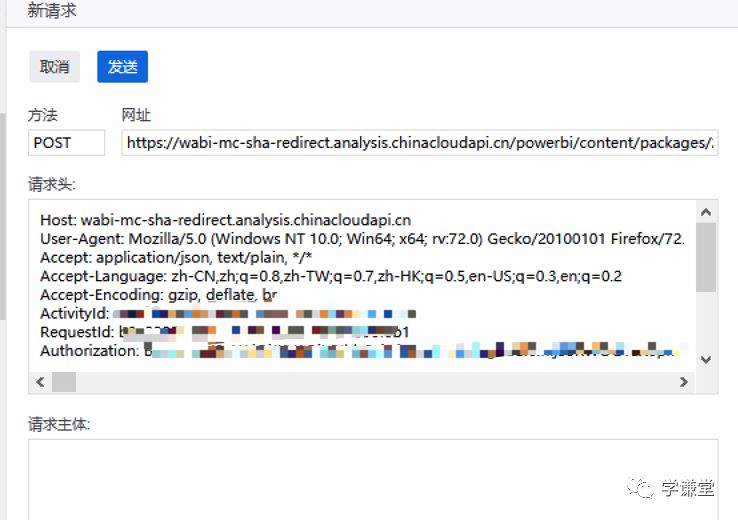
上图我们可以得到需要POST的网址和请求头内容,也就是用python来模拟浏览器的方式,包括cookies
5.开始Python大法
首先是需要用到的库,Requests是用Python语言编写的,基于urllib3来改写的,采用Apache2 Licensed 来源协议的HTTP库。
import requests
requests用法特别简单,refresh_url为以上获取的刷新链接,直接用requests.post请求这个链接即可。
refresh_url= 'https://wabi-mc-sha-redirect.analysis.chinacloudapi.cn/powerbi/content/packages/xxxxxxx/refresh/'
response = requests.post(refresh_url)
print(response)
打印一下响应,发现得到的是<Response [403]>,登录错误,看一下我们的代码,没有任何登录的信息,肯定是无法刷新的。
这里我们就加上请求头内容,请求头里包含了很多信息,其中就有包含登录信息的cookies,还有一些编码信息。
好,接下来我们直接将原网页的请求头复制下来,到python中,当然,需要注意格式,手动编辑一下。
headers = {
'Host': 'wabi-mc-sha-redirect.analysis.chinacloudapi.cn',
'User-Agent': r'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0',
'Accept': 'application/json, text/plain, */*',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'ActivityId': 'xxxxxxxxxxx',
'RequestId': 'xxxxxxxxx',
'Authorization': 'Bearer xxxxxxxxxxxxxxxxxxxxxxxxxxxx',
'Content-Type': 'application/json;charset=UTF-8',
'Origin': 'https://app.powerbi.cn',
'Connection': 'keep-alive',
'Referer': 'https://app.powerbi.cn/groups/xxxxxxxxxx/list/datasets?tenant=xxxxxxx&UPN=xxxxxxx@xxxxxxxxxx',
'Content-Length': '0',
'TE': 'Trailers'
}
然后在POST语句中添加headers=headers这个参数,这样就把请求头的内容放进POST中了
response = requests.post(refresh_url,headers=headers)
print(response)
再打印一下响应,<Response [200]>,ok,搞定!
最后这条就是刚刚完成的POST刷新。

接下来还是每10秒刷新一次,并且加上一个刷新的时间记录,并打印出来,以便我们随时观察有没有什么问题。
from datetime import datetime
while True:
print(datetime.now())
response = requests.post(refresh_url,headers=headers)
print(response)
time.sleep(10)
这样,我们就又完成了操作。

偶尔观察一下打印结果,每次都是<Response [200]>,应该是没问题的,可以观察一段时间。
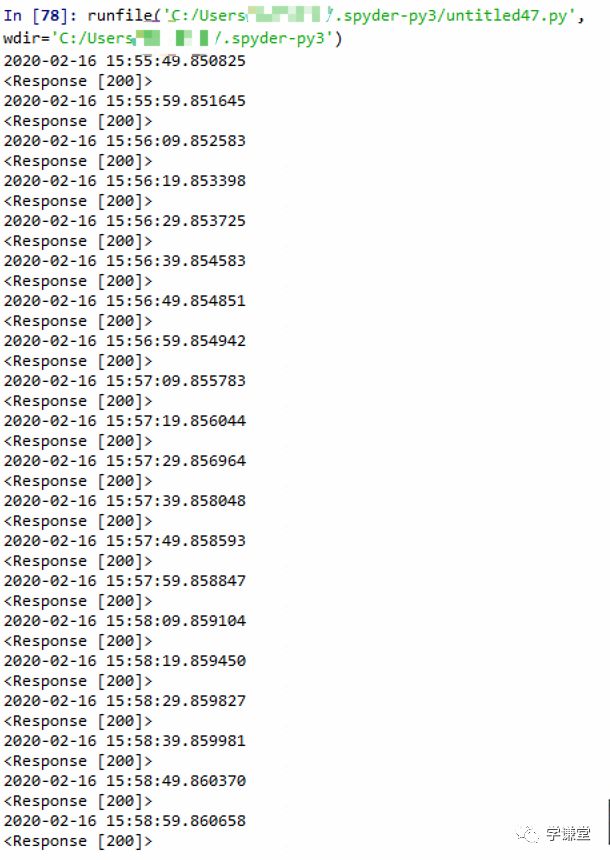
以下是刷新纪录

运行代码,葛优躺喝咖啡,甚至可以抽空来个大保健,美滋滋。

好了,做个总结,我们来对比一下今天讲的response方法和上一篇讲的selenium模拟刷新的优缺点:
用selenium登录Firefox模拟点击的办法很方便,而且能够肉眼看见刷新,也不影响用户对电脑做其他操作,只不过对于配置较低的电脑会造成占用内存较大的问题;
使用response来POST刷新链接,比selenium更进一步,甚至不需要打开浏览器,全部操作都是在后台进行,几乎不会占用内存,几乎对用户无任何影响。
那么还是那个问题,如果雇一个人7d×24h不简单每10秒刷新一次Power BI,我需要每月支付他多少钱?
完整源代码请关注本号【学谦数据运营】回复“1”获取。
————————
留一个悬念,用response来POST刷新链接有一个问题,就是每当刷新一小时后,就会再次出现401错误,为什么呢?
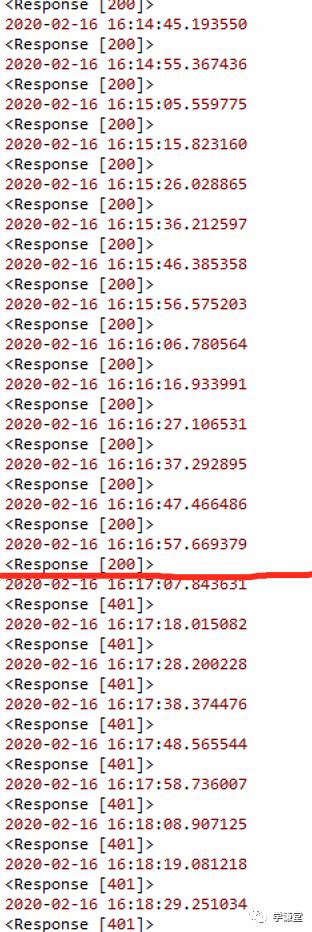
因为powerbi这个网页虽然一直保持登录状态,但是cookies里的Authorization已经发生了变化,比如最开始的时候结尾是……QEgilBRFwTX3ZKUSA,但是过了一段时间,变成了……pyMyPKkznf1bAKSSVg。
所以cookies发生了变化,肯定登录就失效了,登录失效了,自然无法刷新,response也就不是200了。
那么问题就来了,如何得到最新的Authorization呢?
这就是下一篇内容的事情了,请关注本号【学谦数据运营】,等待下次更新。

================================================
FILE: _posts/2020-03-19-【运营】新用户数量?Power BI简单三步计算.md
================================================
【运营】新用户数量?Power BI简单三步计算
今天开始,给大家讲一讲在运营工作中经常用到的几个数据:
新用户数量
复购用户数量
沉睡客户数量
激活客户数量
流失客户数量
日活、周活、月活
……
等等指标
今天先来谈一谈新用户:
拉新招新一直是各大企业业绩增长的命门,在维护好老用户,提升口碑的前提下,新用户的注入无疑会提升各项业绩。
但是如果从大量的订单中筛选出新用户的订单,尤其是要进行按月、按周进行分析时,该项工作靠excel表去计算无疑工作量十分繁重,而使用powerbi来计算时,我们只要编写几个度量值就可以一劳永逸地解决问题。

用户增量方式:
1、找到目标用户,了解你的用户的真正需求是什么。让其他的销售人员也成为你的用户
2、根据用户需求找出用户痛点。销售人员的痛点就是利润返点
3、帮用户解决实际需求和痛点问题,真正帮到用户,然后让用户口碑传播,这样增加的用户才能有粘性
举个栗子:
你的去找一个公司跟你合作,不用直接找他们老板,直接找他们的销售人员,不是让他帮忙你销售。是让他帮你引荐他的朋友或者客户,如果成交了,第一单的利润全部给他,你一分钱不赚。
然后你接着维护这个客户两个月,三个月。。。
如果这样的话,你是不是一分钱的成本都没有投入,也没有冒很大的风险,你每个月都有免费的客户送上门,这样你牺牲的只是第一个月的利润,换来的却是源源不断的客户
以上业务层面的问题,操作起来当然需要十分强大的运营能力,除此之外,不管是业务运营人员还是数据分析人员,都需要明确知晓各月的新用户数量以及新用户占比。那么我们用Power BI如何快速地计算出各月新用户数量呢?
仔细考虑其实比较简单,分为三步:
1. 计算每一个用户首次购买的时间
2. 判断该用户首次购买时间是否落在我们选定的日期范围
3. 如果是,那么他就是新用户,count+1,或者输出明细即可
当然,计算之前我们需要首先创建一个日期表,关于如何创建日期表,参考这篇文章:[Power BI创建日期表的几种方式概览](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483782&idx=1&sn=c756367adfa92bfa0fedb6674e369aa6&chksm=ea674567dd10cc71248d01ad6d7bac06994753c9273a110b60ad4e75f233400a4603b102c6c2&scene=21#wechat_redirect)
以下是数据格式:
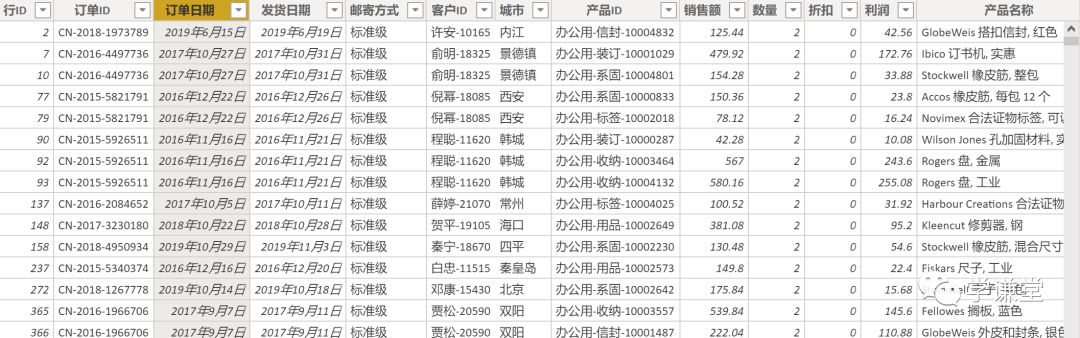
我们用订单日期和客户ID来作为关键的列,直接给出度量值:
NEW CUSTOMERS =
VAR customer_firstsale=
CALCULATETABLE(
ADDCOLUMNS(
VALUES(sales[客户ID]),
"FIRSTSALE",
CALCULATE(MIN('sales'[订单日期]))),ALL('日期'))
VAR customer_first_sale_in_current_period=
FILTER(
customer_firstsale,
[FIRSTSALE] IN VALUES('日期'[日期]))
VAR RESULT=
COUNTROWS(customer_first_sale_in_current_period)
RETURN RESULT
这里用到的是表函数的用法,将表作为筛选器,结构上更加清晰一些,当然,你也可以使用CONTAINS函数来计算:
CONTAINS(VALUES ('日期'[日期]),'日期'[日期], [FIRSTSALE])
为了对比该月的总用户数,我们也写一个度量值:
CUSTOMERS = DISTINCTCOUNT(sales[客户ID])
放在矩阵中显示,再添加一个新客户占比:
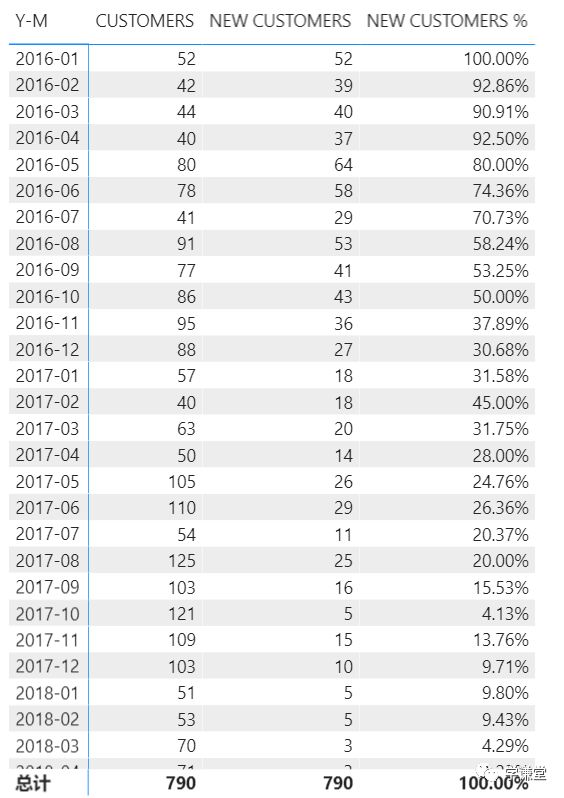
我们发现,第一个月新客户占比是100%,这是很显然的,第一个月购买的客户的购买日期一定在第一个月内。随着业务发展,老用户沉淀,新用户占比会越来越低,也符合业务发展规律。
在总计行用户和新用户都是790,这是因为总计行和每一行的计算方式不同,总计行忽略了月份,总共就一个日期范围,因此这两个数是相同的。
在实际业务中,运营人员可能需要查看具体的每个月的新客户的名单,重点去跟进,那么这个需求我们如何满足呢?
也比较简单,只不过返回的不是COUNTROWS,而是一个明细,预知后话如何,请关注本号,查看后续内容。
================================================
FILE: _posts/2020-03-19-【运营】新用户明细?Power BI一招帮你搞定.md
================================================

上一篇文章中我们讲了如何计算新客户的数量,但是在实际业务中,运营人员可能需要查看具体的每个月的新客户的名单,重点去跟进,那么这个需求我们如何满足呢?
其实也比较简单,只不过返回的不是COUNTROWS,而是一个明细,我们使用的是CONCATENATEX函数:
CONCATENATEX函数的具体用法是:

具体度量值直接给出:
NEW CUSTOMERS LIST =
VAR customerfirstsale=
CALCULATETABLE(
ADDCOLUMNS(VALUES(sales[客户ID]),
"FIRSTSALE",
CALCULATE(MIN('sales'[订单日期]))),ALL('日期'))
VAR customerfirstsaleincurrentperiod=
FILTER(
customerfirstsale,
[FIRSTSALE] IN VALUES('日期'[日期]))
VAR RESULT=
CONCATENATEX(
customerfirstsaleincurrentperiod,
[客户ID],
"、")
RETURN RESULT
放在矩阵中,就可以直接显示了:
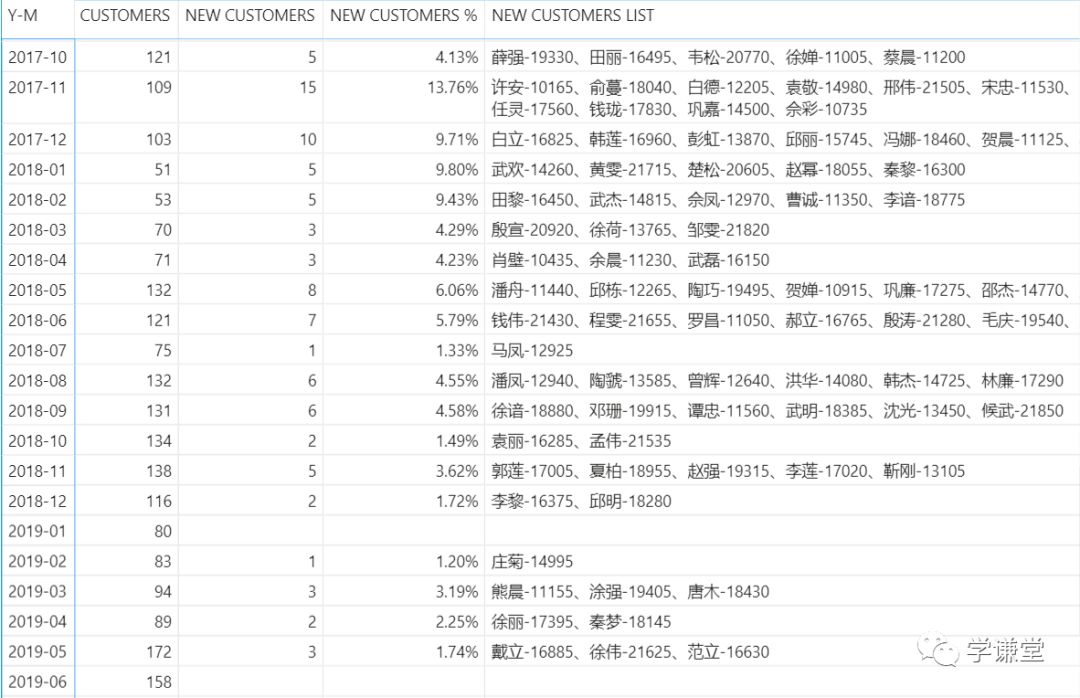
注意如果要显示明细,最好行小计不要显示,因为总计行对于明细来说没有任何意义,它会将里面的所有790个用户都显示在一个格中。
但是关掉行小计,我们就没法直观地看到总的人数了,怎么办呢?
别急,我们还是有办法的,对于行上的显示,我们可以对度量值进行一定的修改,将最后一行改为:
RETURN IF(HASONEVALUE('日期'[Y-M]),RESULT)
这句话的意思是:如果检测到有'日期'[Y-M]筛选器,就显示result,否则不显示,也就是在总计行不显示,结果:
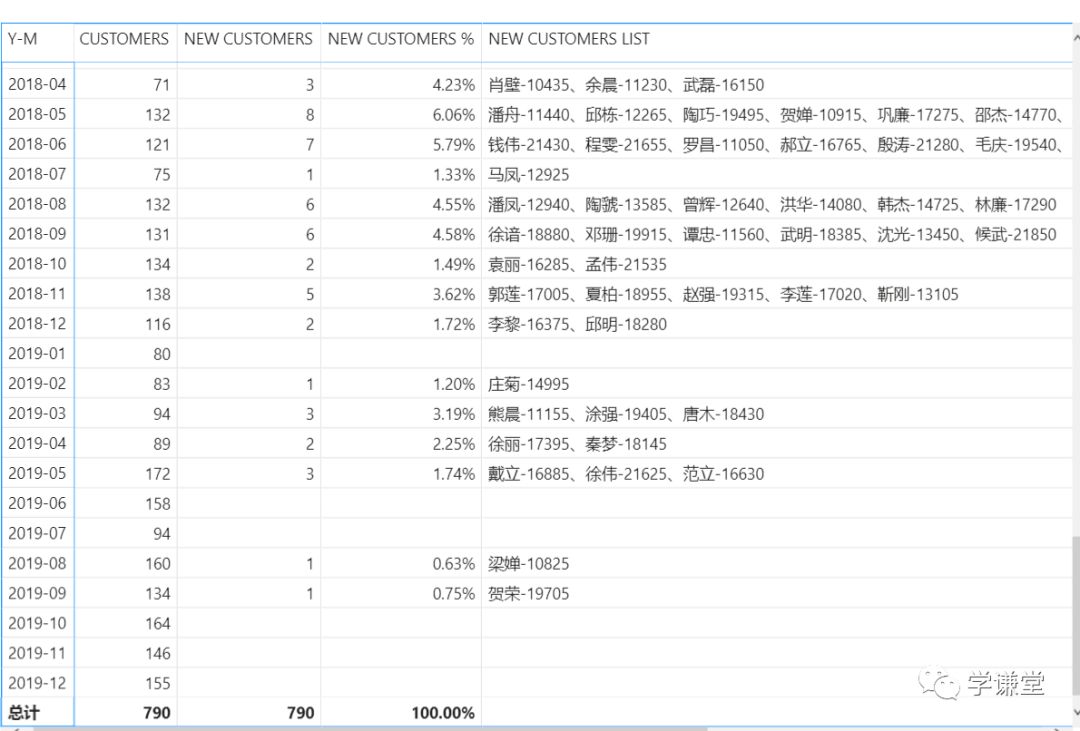
这样就两方面兼顾了。
你学会了吗?
下一篇我们介绍如何计算流失客户数量与分析。
更多PowerBI教程,清关注本号,持续更新。
================================================
FILE: _posts/2020-03-20-如何显示数据更新时间.md
================================================
【PowerBI技巧】如何显示数据更新时间
在某些场景中,我们需要告诉用户,报表中的数据是截止到昨天?截止到今天上午?2小时之前?还是10分钟以前的,这就需要在报表中加入如下的内容:

今天就和大家来讲一下如何实现以上的功能。
我们很容易想到,在DAX语言中有一个NOW函数,用来获取当前的日期和时间:

我们来测试一下,输入公式,得到数据:
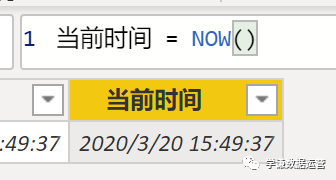
用卡片图呈现出来:

点击刷新,可以看到每次刷新数据,都会更新一个最新的时间。
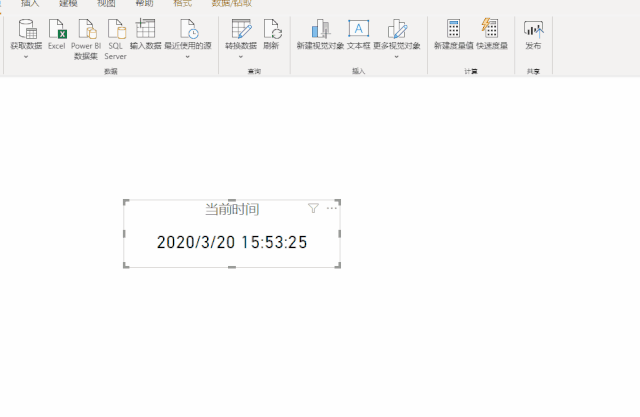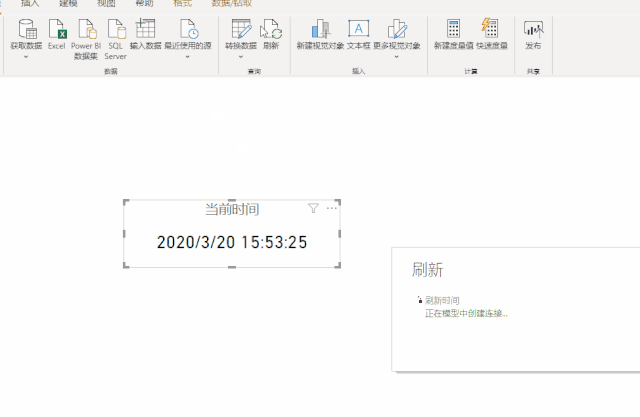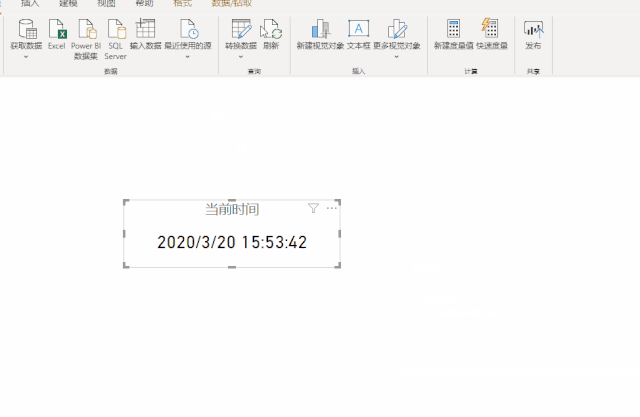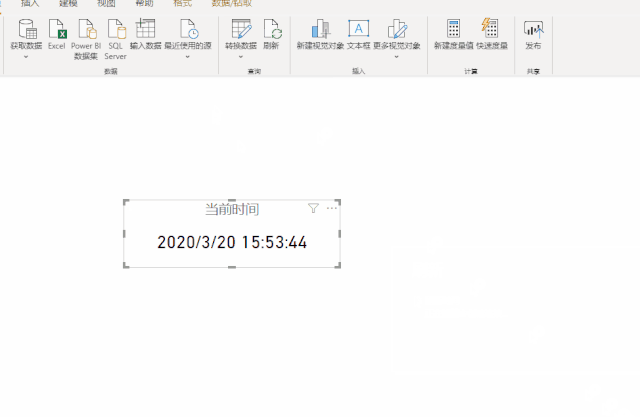
将报表发布到云端,再来查看一下。
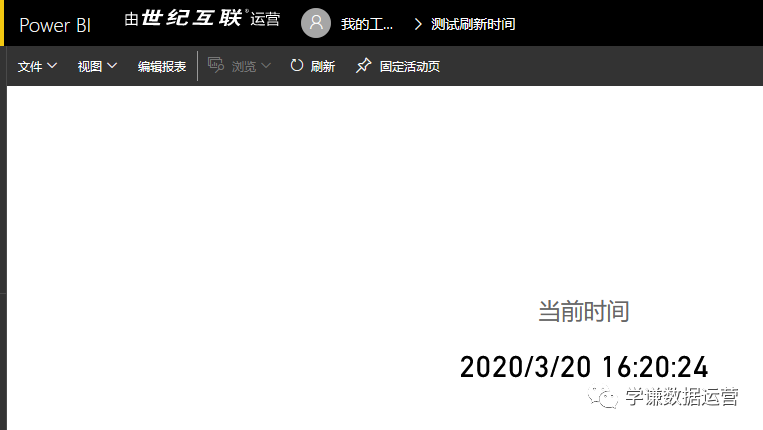
没有问题。
但是!如果到云端进行刷新,就会发现时间变为了8点多,跟发布的时间很明显是不一致的,为什么会这样呢?
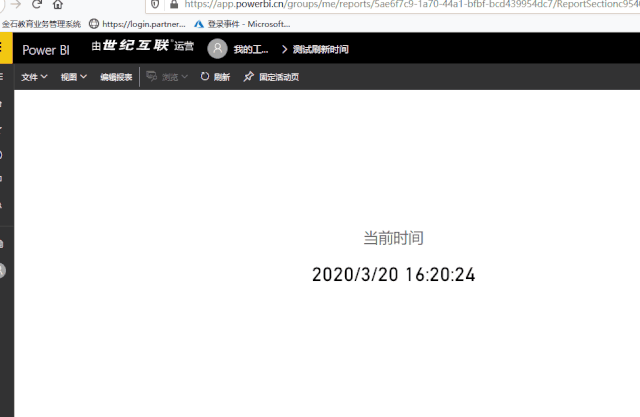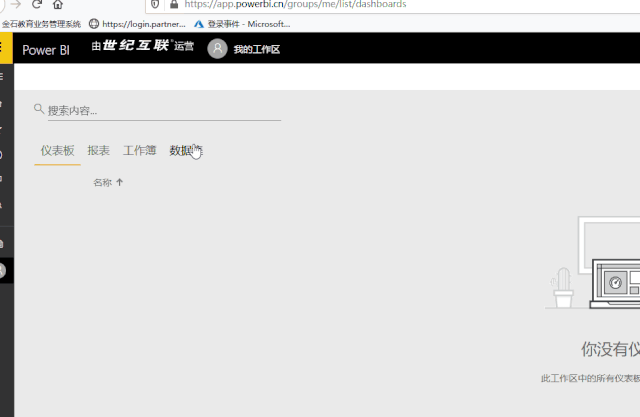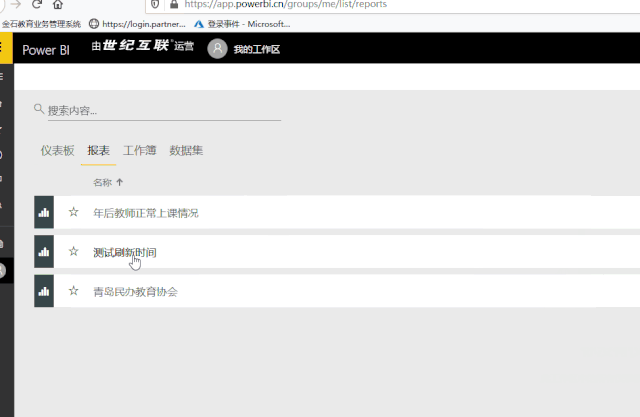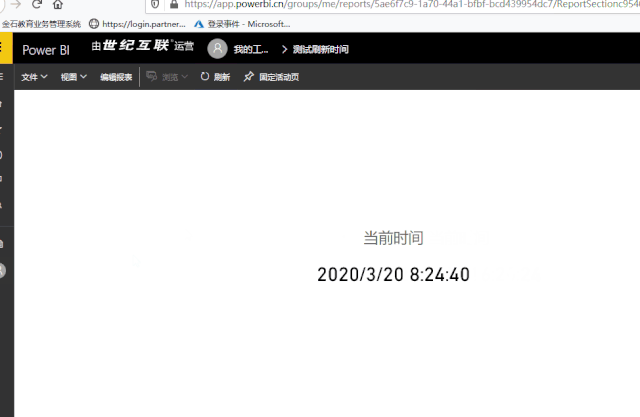
因为powerbi本地刷新和云端刷新是不同的,本地刷新,NOW返回的是当前的系统时间,也就是UTC/GMT+08:00时间,而云端刷新的时间是按照UTC时间来的,所以两者差了8个小时。
所以如果想在云端刷新时显示正确的当地时间,应当在原来的时间上+8小时,但是这样一来,又会出问题,那就是如果修改本地文件并再次发布时,时间就会比当前早8个小时。
也就是说,使用NOW无法同时满足本地发布和云端刷新的需要。
那应当怎么办呢?
这时候我们该用到UTCNOW函数了,顾名思义,这表示的是UTC时间的当前时间,这样只要写出如下的表达式,就能正确得到本地的准确时间了:
当前时间 = UTCNOW()+"08:00:00"
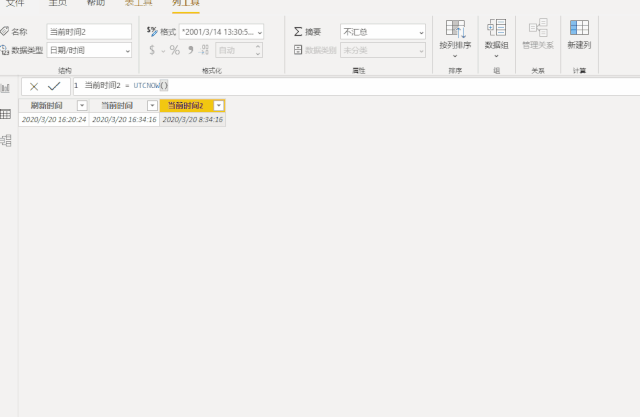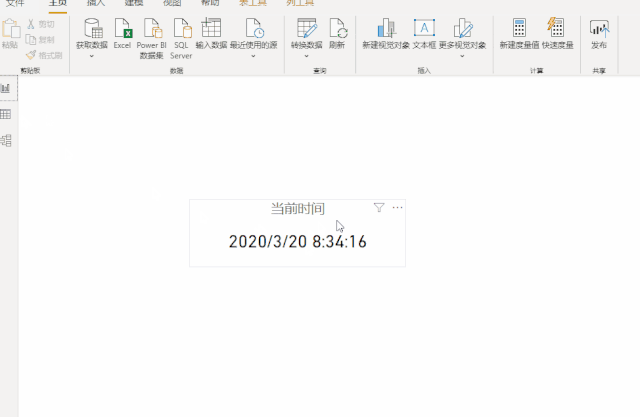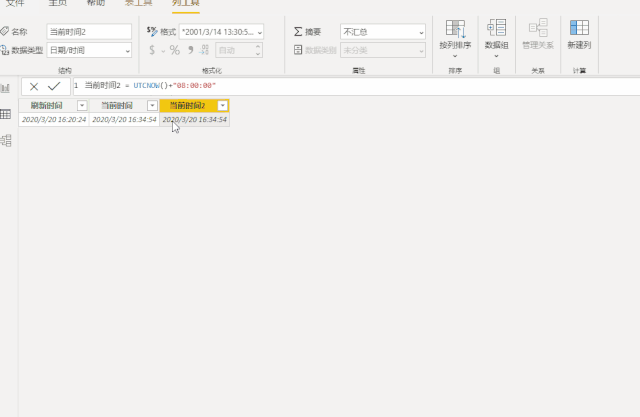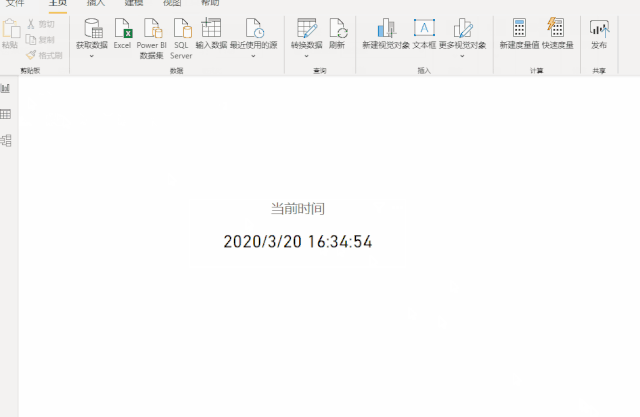
再次发布到云端,刷新看一下:
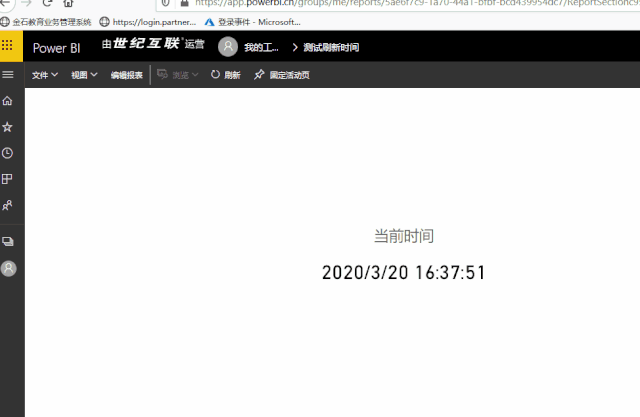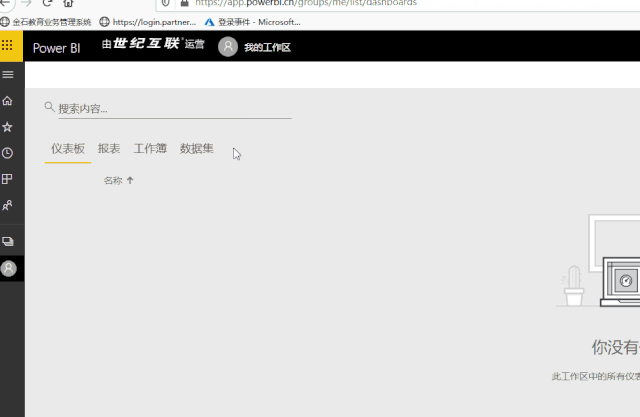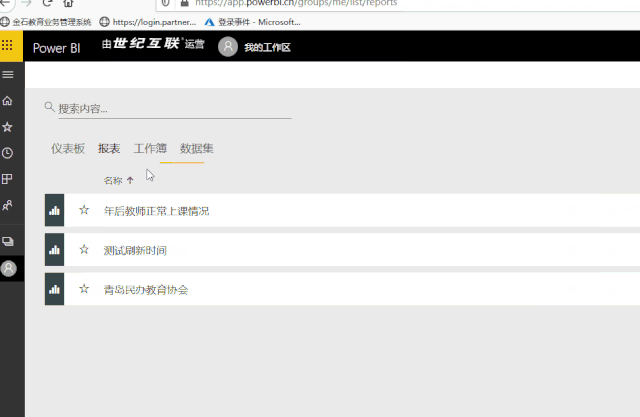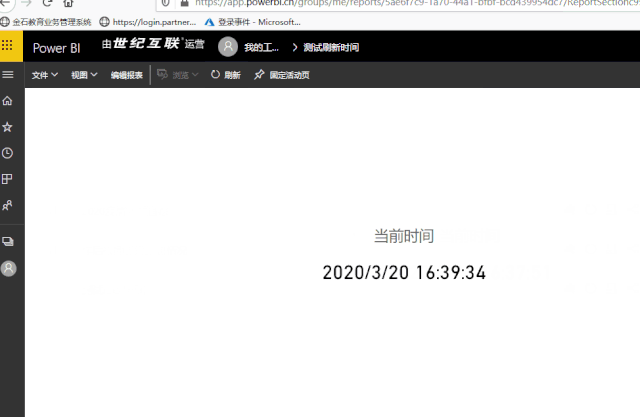
这样,我们就可以同时在本地和云端分别刷新都得到正确的刷新时间了。
你学会了吗?

这里我们需要注意,以上两张gif中,点击网页端报表页面的刷新按钮,仅仅是将数据刷新到数据源中的最新,而不会真的更新数据,因为一旦报表发布后,只要不在数据源中点击立即刷新,报表中的数据是不会变的。
但,事实真的是这样的吗?且看下图:
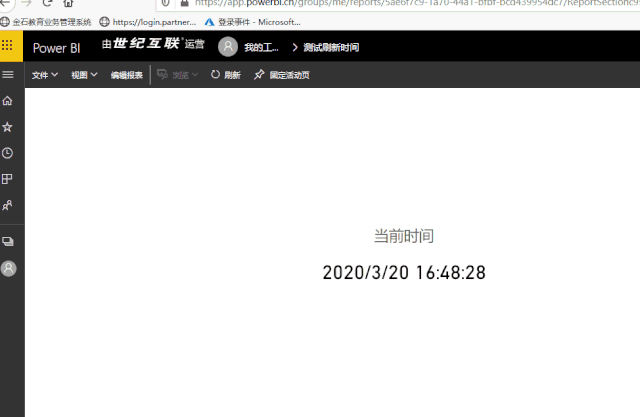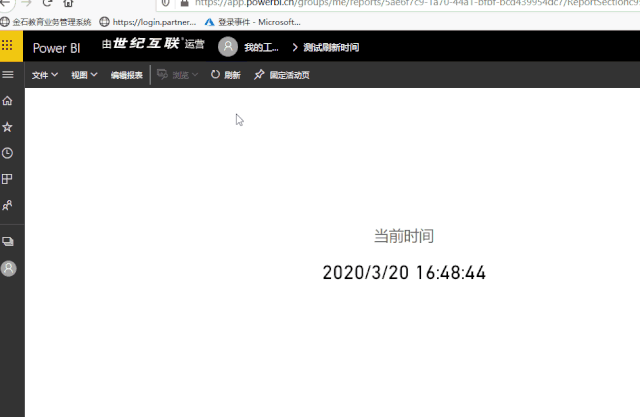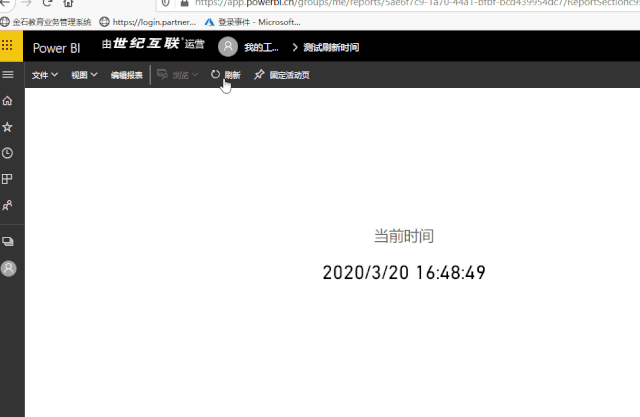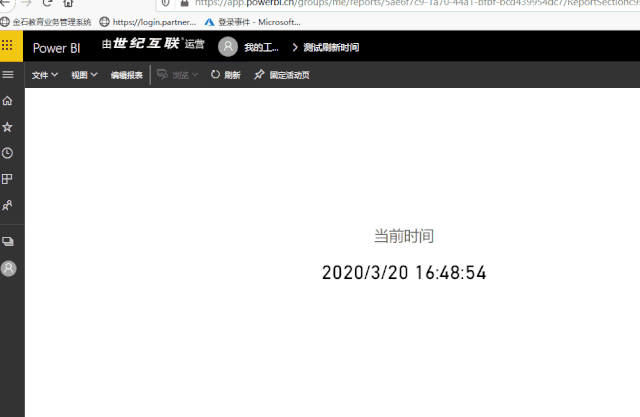
我们可以看到,在这个gif中,我们点击报表页面的刷新按钮,当前时间是一直在变的,一直显示当前的本地时间,这个是怎么做到的呢?
还有另外一个问题,就是我们事先知道当地的时区,所以才会在UTC上+8小时,如果恰好不知道时区呢?有没有不需要知道时区就通用的公式呢?办法肯定是有的。
敬请关注本号,查看后续讲解。

================================================
FILE: _posts/2020-03-21-【运营】沉睡、流失客户分析?Power BI一招帮你搞定.md
================================================
【运营】沉睡、流失客户分析?Power BI一招帮你搞定

上两篇我们讲了如何计算新客户的数量和展示明细
[【运营】新用户数量?Power BI简单三步计算](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483842&idx=1&sn=61ab7df60763e3e61b72676354cf3f17&chksm=ea674523dd10cc358cf27e4c44b6b037d95efb03f23520189580cb2839c5bf04278754411b1b&scene=21#wechat_redirect)
[【运营】新用户明细?Power BI一招帮你搞定](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483853&idx=1&sn=5bef312d354f1c2ad138d814d2df5355&chksm=ea67452cdd10cc3a2efab8b5fb791070c0382e5d20578e58bb3cfef472dbc87ffcd54d7e06ca&scene=21#wechat_redirect)
在实际业务中,新用户很重要,但是如何留存老用户更是一个巨大的课题,总的来讲,就是提升服务质量,增强满意度,具体细分在各个行业,运营思路千差万别,我们今天不详细展开。
但有一点是几乎所有行业都想通的,就是我们要对沉睡、流失的客户进行回访,分析,想尽办法进行唤醒、激活或重新购买。Power BI如何帮助业务人员进行统计汇总呢?结合新用户的计算方式,我们脑海中大概有一个轮廓:
首先,要定义何为流失,因各家企业对该指标的定义有较大差异,就以6个月内曾经有订单,但最近两个月内没有订单的客户定义为流失客户;
第二步,如何写度量值:
1. 计算每一个客户最后一次订单的日期;
2. 日期如果落在最近6个月到2个月之间,就是我们想要的流失客户
直接给出度量值:
LOST CUSTOMERS =
VAR customer_lastsale=
CALCULATETABLE(
ADDCOLUMNS(VALUES(sales[客户ID]),
"LASTSALE",
CALCULATE(MAX('sales'[订单日期]))),
ALL('日期'))
//返回每一个客户最后一次购买的时间,为了不被年月筛选器筛选,添加了一个ALL
VAR BEGINDAY=
CALCULATE(
MIN('日期'[日期]),
DATEADD('日期'[日期],-6,MONTH))
//返回6个月之前的第一天
VAR ENDDAY=
CALCULATE(
MAX('日期'[日期]),
DATEADD('日期'[日期],-2,MONTH))
//返回l两个月前的最后一天
VAR customerlost=
FILTER(
customer_lastsale,
[LASTSALE]>BEGINDAY&&[LASTSALE]<ENDDAY)
//返回最后一次购买日期处于该时间段的行
VAR RESULT=
COUNTROWS(customerlost)
RETURN RESULT
结果如下:
最后一列就是该月流失的客户。
根据上一讲列表显示明细[【运营】新用户明细?Power BI一招帮你搞定](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483853&idx=1&sn=5bef312d354f1c2ad138d814d2df5355&chksm=ea67452cdd10cc3a2efab8b5fb791070c0382e5d20578e58bb3cfef472dbc87ffcd54d7e06ca&scene=21#wechat_redirect),我们也来适当修改上面的度量值,如下:
LOST CUSTOMERS LIST=
VAR customer_lastsale=
CALCULATETABLE(
ADDCOLUMNS(VALUES(sales[客户ID]),
"LASTSALE",
CALCULATE(MAX('sales'[订单日期]))),
ALL('日期'))
//返回每一个客户最后一次购买的时间,为了不被年月筛选器筛选,添加了一个ALL
VAR BEGINDAY=
CALCULATE(
MIN('日期'[日期]),
DATEADD('日期'[日期],-6,MONTH))
//返回6个月之前的第一天
VAR ENDDAY=
CALCULATE(
MAX('日期'[日期]),
DATEADD('日期'[日期],-2,MONTH))
//返回l两个月前的最后一天
VAR customerlost=
FILTER(
customer_lastsale,
[LASTSALE]>BEGINDAY&&[LASTSALE]<ENDDAY)
//返回最后一次购买日期处于该时间段的行
VAR RESULT=CONCATENATEX(customerlost,[客户ID],"、")
RETURN IF(HASONEVALUE('日期'[Y-M]),RESULT)
结果如下:

这样我们就可以得到各月流失的用户了。
你会发现,有些用户在这个月也流失,在下个月还流失,这是由于不同的企业对于流失的概念定义有区别造成的,其实准确来说应当叫做睡眠。
比如曹娜-18580这个用户,最后一笔订单发生在2017年6月,那么在7月8月未发生订单,他在8月属于睡眠用户。同样,他在8月和9月也未发生订单,所以在9月也是睡眠用户,而到了11月,已经过了6个月内有订单了,他就真的属于流失客户了。
一般情况下,一个用户如果连续6个月没有新订单,再重新有订单的可能已经非常小了。
当然,还是希望各位运营的小伙伴,永远用不到这个指标。
在日常的运营管理中,我们经常会遇到想要查看某个时间段的用户在下一个时间段的复购情况,而且时间段是任意的,可以按月,可以按周,可以任意选择时间段,那么这个该如何实现呢?我们下期再说。
================================================
FILE: _posts/2020-03-22-【运营】任意两个时间段的复购率?Power BI一招帮你搞定.md
================================================
【运营】任意两个时间段的复购率?Power BI一招帮你搞定

前面几讲内容,我们分别介绍了新用户和流失客户的分析
[【运营】新用户数量?Power BI简单三步计算](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483842&idx=1&sn=61ab7df60763e3e61b72676354cf3f17&chksm=ea674523dd10cc358cf27e4c44b6b037d95efb03f23520189580cb2839c5bf04278754411b1b&scene=21#wechat_redirect)
[【运营】新用户明细?Power BI一招帮你搞定](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483853&idx=1&sn=5bef312d354f1c2ad138d814d2df5355&chksm=ea67452cdd10cc3a2efab8b5fb791070c0382e5d20578e58bb3cfef472dbc87ffcd54d7e06ca&scene=21#wechat_redirect)
[【运营】沉睡、流失客户分析?Power BI一招帮你搞定](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483892&idx=1&sn=2c6cdbda3b9158fc73abd6ec0f5c5acc&chksm=ea674515dd10cc03e86a043939fe5eca94795898ce38e3fb84ab333de4dcf41ab310f3d93308&scene=21#wechat_redirect)
在日常的运营管理中,我们经常会遇到想要查看某个时间段的用户在下一个时间段的复购情况,而且时间段是任意的,可以按月,可以按周,可以任意选择时间段,那么这个该如何用Power BI实现呢?
我们先整理一下思路:
既然是任意选择时间段,那么切片器一定是直接用日期切片器,选择范围。
前一个日期范围和后一个日期范围,所以需要同时有两个切片器。
那么问题来了,我们知道同一个字段的切片器相互之间是有影响的,所以一个日期表是不能解决问题的,我们需要第二张日期表。
日期表2 = '日期表'
新建表-输入以上内容,就这么简单,它会复制日期表的全部内容到日期表2中。
同样,日期表的日期字段也要和订单表建立关联:
我们将两个日期字段都添加为切片器:
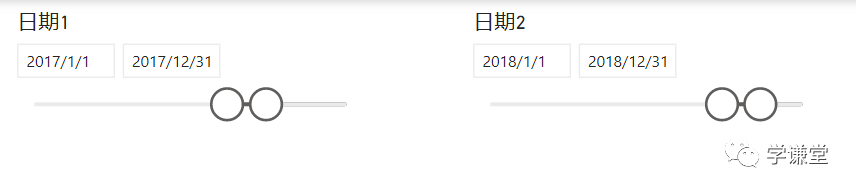
我们要做的就是添加几个度量值:
1. 日期1范围的客户
2. 日期1范围的客户在日期2中也产生了订单
3. 以上两个的百分比
我们直接给出度量值:
日期1的客户数量 =
CALCULATE(
DISTINCTCOUNT(sales[客户ID]),
ALL('日期2')
)
日期1的客户在日期2中复购的数量 =
VAR CUSTOMERSINDATE1=
CALCULATETABLE(
SUMMARIZE(sales,sales[客户ID]),
ALL('日期2'[日期]))
VAR CUSTOMERSINDATE2=
CALCULATETABLE(
SUMMARIZE(sales,sales[客户ID]),
ALL('日期'[日期]))
VAR REPEATCUSTOMERS=
INTERSECT(CUSTOMERSINDATE1,CUSTOMERSINDATE2)
RETURN COUNTROWS(REPEATCUSTOMERS)
复购率% = DIVIDE([日期1的客户在日期2中复购的数量],[日期1的客户数量])
这里用到了一个新的函数:INTERSECT
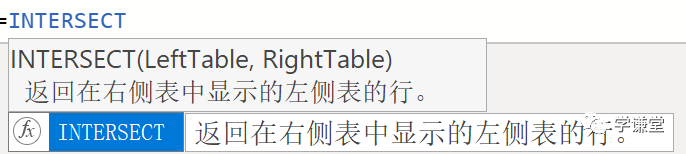
根据函数的描述,也就是求两个表的交集。再用COUNTROWS计算多少行,就是复购的数量,再除以日期1的客户数量,就得到了【复购率%】。
放到矩阵中:
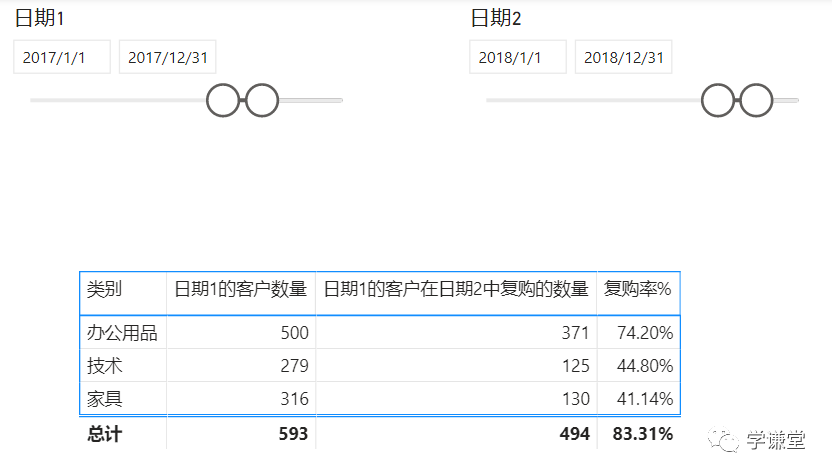
这样,我们随意拖动两个滑竿,就能实现按年、季度、月、周等任意时间段的复购情况。
如果想查看明细,可以添加一个客户ID的字段来下钻:
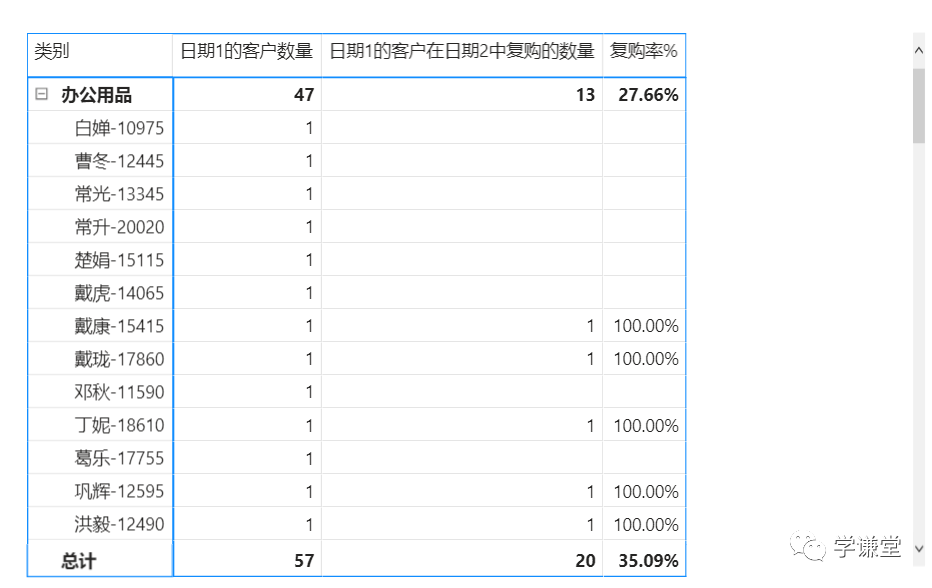
在查看不同维度的复购率时,发现了一个有趣的事情:
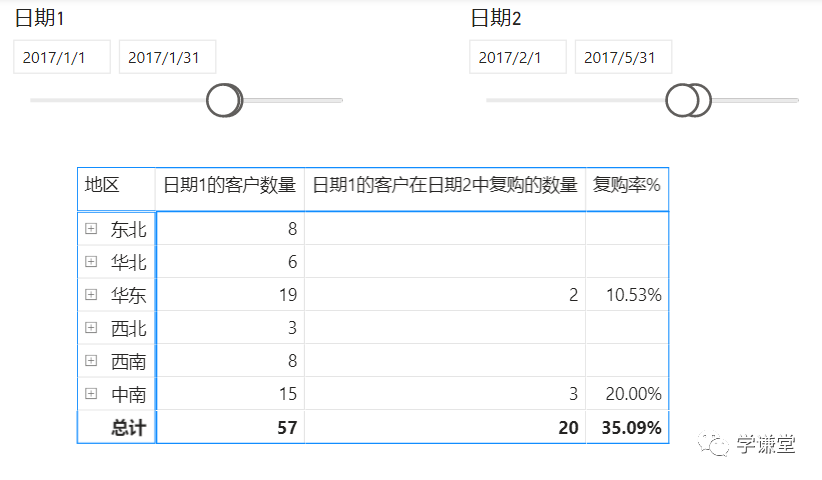
当左侧切片为地区时,发现只有华东和中南复购分别为2和3,总和应该为5,但是总计行是20,20也是用类别做切片器时的总和,这是怎么回事呢?
还是我们之前说的,总计行的计算方式与其他行是不太一致的, 也可以说是完全一致的,为什么这么矛盾呢?
因为普通行受到本行的切片器影响,所以华东地区只查看华东地区内的复购,中南只看地区内的复购,有可能会发生华东地区的客户下一次在华北地区购买,这样,这笔订单,既不属于华东的复购,也不属于华北的复购。
然而总计行,是忽略地区切片器的,不管你在哪个地区购买,在哪个地区继续购买,都是复购。
说总计行和普通行完全一致是因为度量值完全一致,说不一致是因为切片器不同。
我们修改一下度量值:
日期1的客户在日期2中复购的数量 =
VAR CUSTOMERSINDATE1=
CALCULATETABLE(
SUMMARIZE(sales,sales[客户ID]),
ALL('日期2'[日期]))
VAR CUSTOMERSINDATE2=
CALCULATETABLE(
SUMMARIZE(sales,sales[客户ID]),
ALL('日期'[日期]),
ALL(sales[地区]))
VAR REPEATCUSTOMERS=
INTERSECT(CUSTOMERSINDATE1,CUSTOMERSINDATE2)
RETURN COUNTROWS(REPEATCUSTOMERS)
CUSTOMERSINDATE2添加了一个ALL(sales[地区]),也就是不受左侧的类别切片器控制,这样就可以显示正常了:
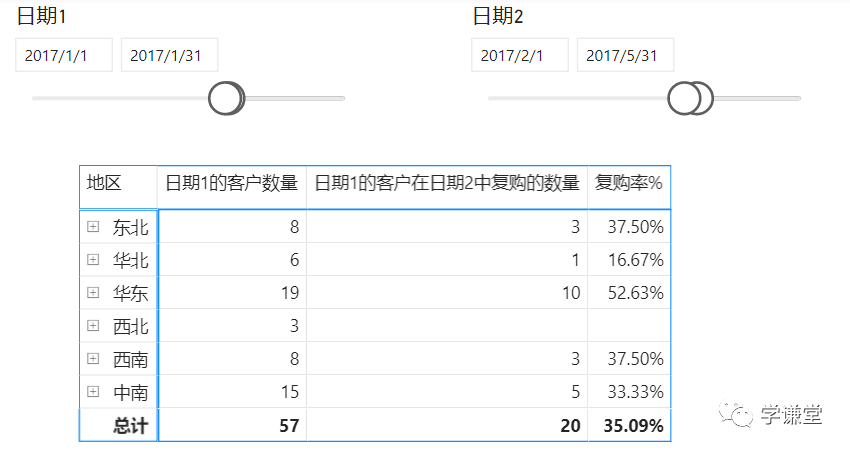
这时候,仍然是总计行20不等于各行相加22,因为毕竟有重复,是符合业务逻辑的。
有时候我们不仅关心客户本身的复购,更关心客户购买产品的复购,即虽然客户A在下一个时间段复购了,但是他在前一个时间段购买3种类别,在后一个时间段只购买了1种类别,我们也需要相应关注,比如:
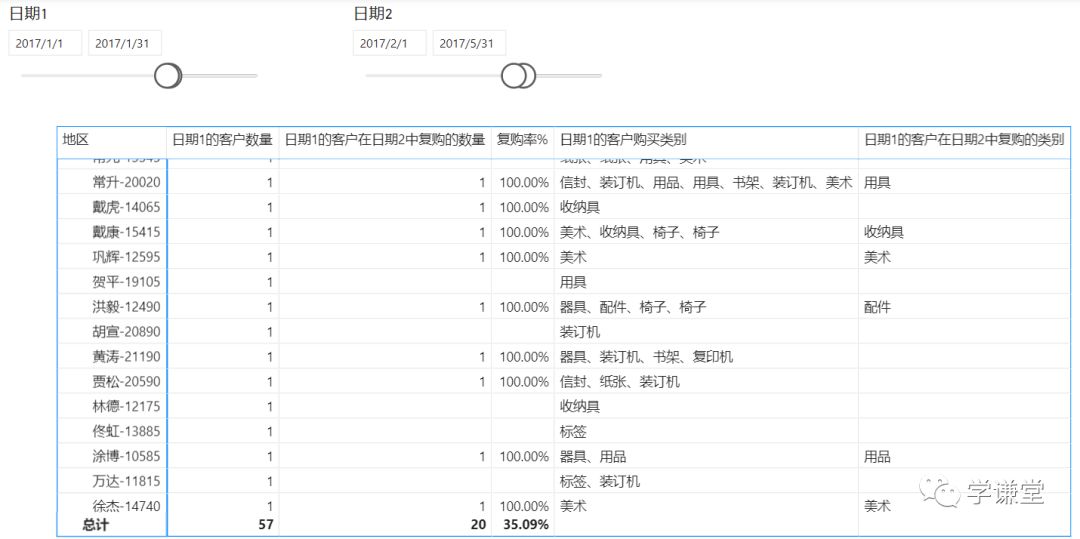
问题来了,比如第二行的戴虎-14065显示复购,但在复购的类别中却是空的,为什么呢?
详细解答,敬请关注本号,咱们下期再见。
预祝各位运营小伙伴,各自岗位的用户复购率为100%!
================================================
FILE: _posts/2020-03-26-「强强联合」在Power BI 中使用Python(1)——导入数据.md
================================================
[「强强联合」在Power BI 中使用Python(1)——导入数据](http://toutiao.com/item/6809844428987957772/)

近几年,Python是越来越火了,就连地产大佬潘石屹都在年近不惑之时开始学习Python编程语言,我们做数据分析和运营的怎能不熟练运用呢?
关于Python的教程,网上铺天盖地,9块9的,99的,999的甚至几千的上万的都有,妖魔鬼怪,乱象丛生,我们这里不去深究,因为Python作为一门胶水语言,各个方向都有成千上万的各种库,发展路径太多了。但是将Python和Power BI组合起来用的还真不多。
那么,我们今天就来讲一讲Python和Power BI组合起来使用,都有哪些场景。我列了如下三种:

其中,关于第三种的Power BI的网页端刷新,完全突破Power BI的网页端刷新每天8次的限制,达到7×24任意时间、任意次数刷新,全方位满足您的需求,请查看以下两篇文章:
[如果雇一个人7d×24h每10秒刷新一次Power BI,我需要每月支付他多少钱?](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483812&idx=1&sn=1d99a342ad280eac128845382886debb&chksm=ea674545dd10cc534548c85c923390ceddb1ea3688d8212f0c5697dbfe863183c52cd1e91128&scene=21#wechat_redirect)
[如果雇一个人7d×24h每10秒刷新一次Power BI,我需要每月支付他多少钱?【2】](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483832&idx=1&sn=57165f8f1e91e463a26589e4652acc88&chksm=ea674559dd10cc4f57a04e48cf7696e54ae150e3a8df155489bdfc8ed69a67350d585f92848f&scene=21#wechat_redirect)
今天我们主要来讲讲第二种应用:**直接在Power BI中使用Python。**
Power BI 2018年8月8日的更新已经支持Python了,和之前支持R语言一样。之前接触过Power BI和R语言联合使用的朋友上手应该会快一些。
那么Power BI 中如何使用python呢?主要有以下5个地方:

想要在Power BI 中使用python,我们需要先配置环境:
1、首先需要安装Python的运行环境,我在电脑中直接安装的的是Anaconda3,关于该包,大家自己在网上找来装吧,或者如果你安装了Visual studio2017的话可以通过VS的安装程序来配置:
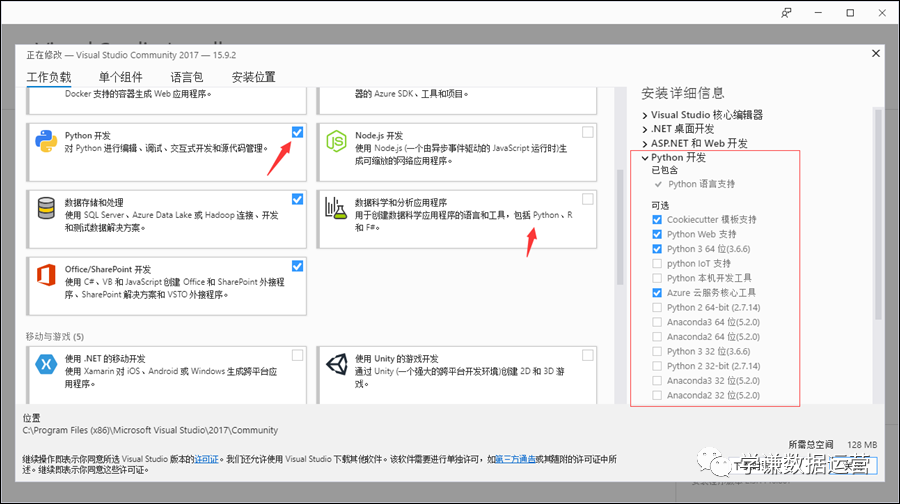
2、如果你是直接安装了Anaconda,那么就不需要自己再单独安装pandas和matplotlib包了,因为这些常用的包anaconda早就给你配置好了,因此建议大家在学习Python的时候尽量直接安装anaconda,否则你还需要自己安装这2个包,打开cmd窗口:
pip install pandas
pip install matplotlib
3、默认情况下Power BI Desktop打开后是无法使用Python进行数据处理和绘图的,如果需要该功能,还需要对Power BI Desktop进行配置。
依次选择“选项和设置/选项/Python脚本编写”,配置Python3所在的目录位置,我这里是安装在C:\programdata\Anaconda3目录下的,点击确定即可:
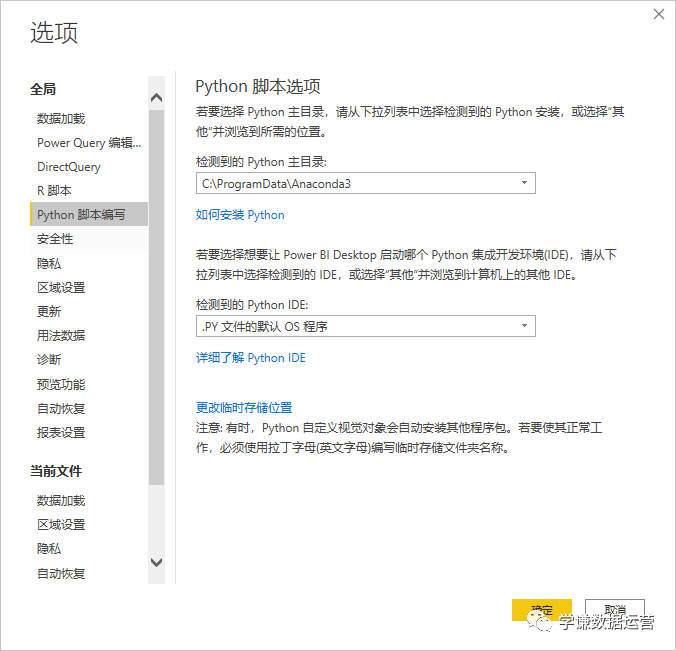
此外,我们可以使用Python自带的IDE或者安装第三方编辑器,比如PyCharm、Spider。如果使用第三方编辑器,应该做一些基本的配置,限于篇幅,这里不详细展开。
4、Python与Power BI的数据传递---Dataframe
Python支持5种常用数据类型,Power BI的M语言支持多种数据类型,两种语言直接以DataFrame数据类型进行传递。由于Python本身并没有支持DataFrame,因此Python会自动调用Pandas库。
M将其Table类型的数据传递给Python,Python会自动将Table转换为Dataframe;Python的处理结果以Dataframe形式输出,M会自动将Dataframe转换为Table格式。
好了,清楚了以上的配置,接下来我们就可以实操演练:

数据获取环节可以通过以下2种方式:
一、图形界面里找“Python脚本”选项;
二、空查询中使用Python.Execute()函数
我们首先看第一种运行方式:
1、在首页-获取数据或者Power Query编辑器中依次点击“新建源/更多…”,随后依次选择“其它/Python脚本”,点击确定按钮,显示Python脚本编辑窗口:
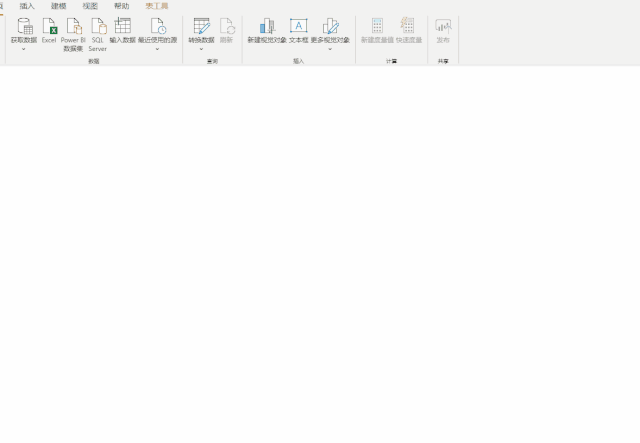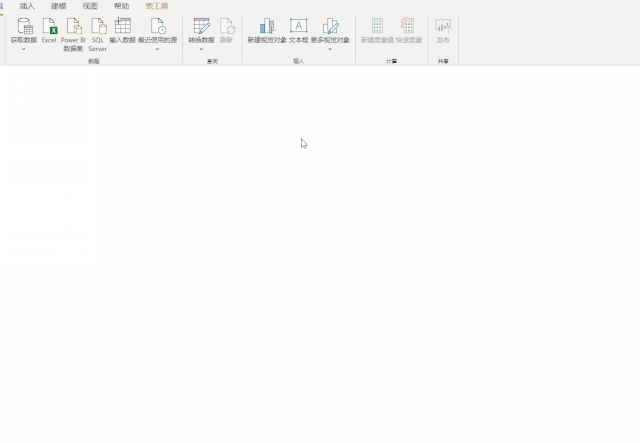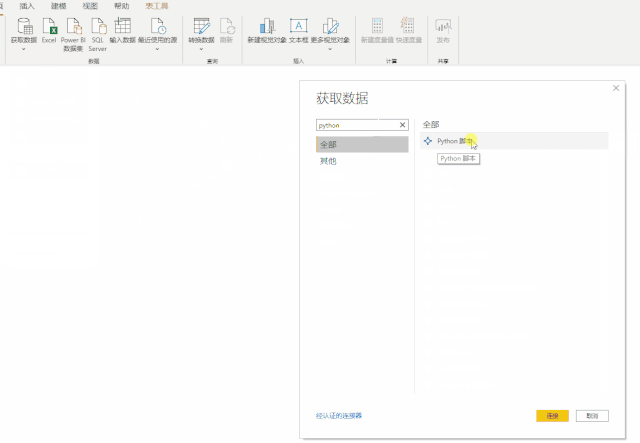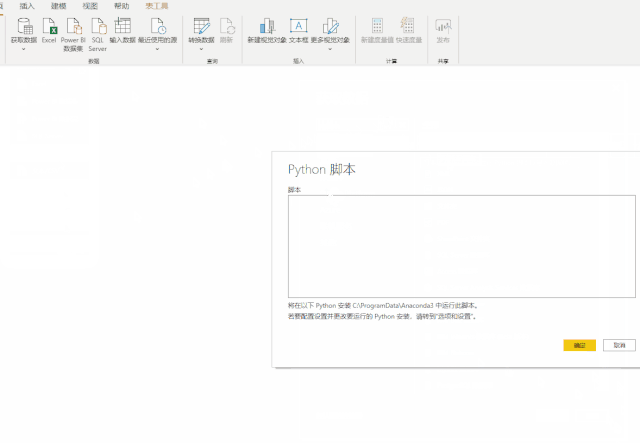
在Python脚本窗口我们就可以将编写好的脚本粘贴并运行了。
如前所述,我们一般是先在第三方编辑器中编辑并运行代码无误之后再放到Power BI 中运行:
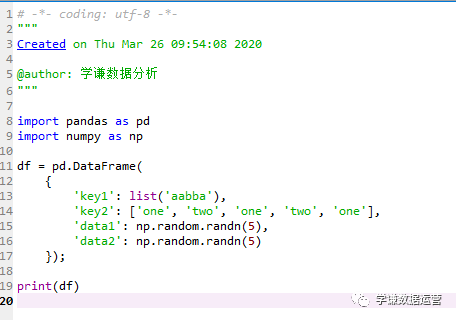
得到结果:
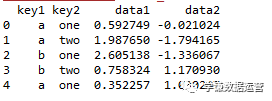
*注意:最后一行print(df)并非是必需的,我只是为了在编辑环境里查看下输出的结果而已,在贴到Power BI Desktop的时候并不需要该行。Power BI Desktop会自动获取Python代码中数据类型是DataFrame的变量数据。*
我们将代码复制到Power BI Desktop的Python脚本编辑器中,并运行:
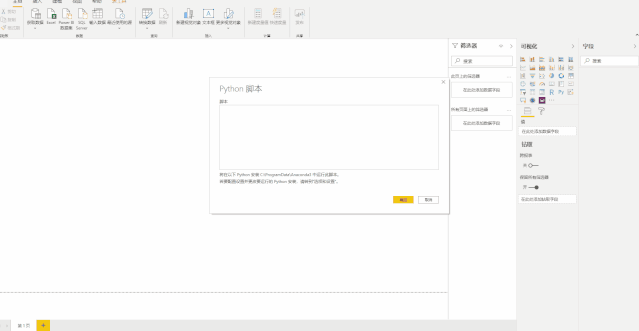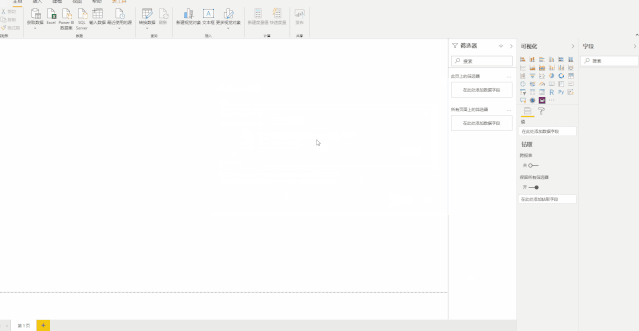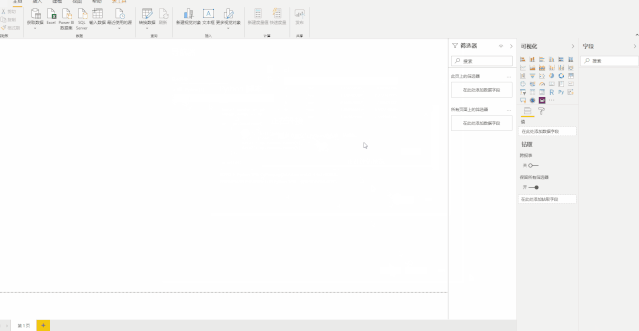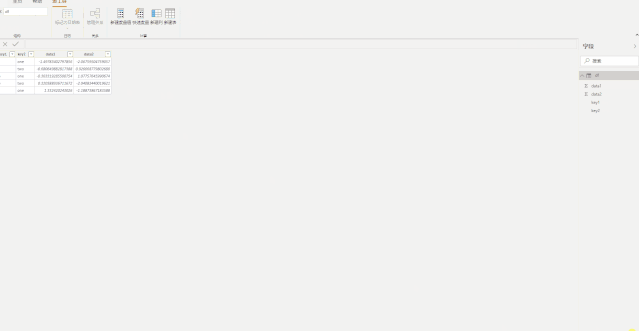
这样我们就将Python运行的结果在Power BI 中显示了。
接下来我们来看第二种方式,直接在空查询中运行函数Python.Execute()函数:
M语言中调用Python的主要函数是 Python.Execute,大家可以看看其基本语法:
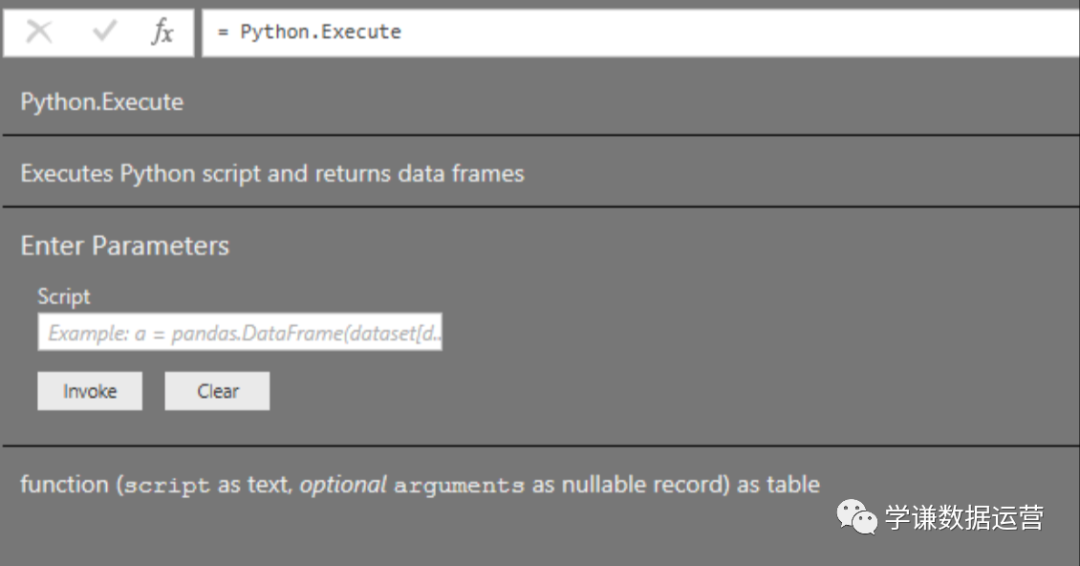
1、在Power Query管理器中依次点击“主页/新建源/空查询”,公式编辑栏输入Py(注意M语言强调大小写),将会自动出现M函数列表智能提示:
2、该函数接受一个字符串参数,所以我们要用成对的双引号,然后再将Python代码粘贴到里面,然后按下回车键,此时会出现“编辑权限”按钮,点击之后,弹出“脚本之行”对话框,点击运行按钮即可:
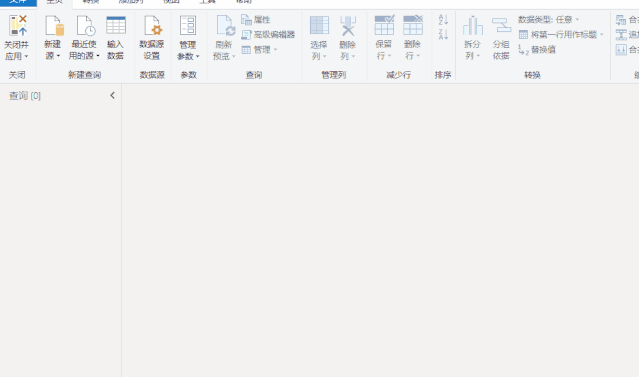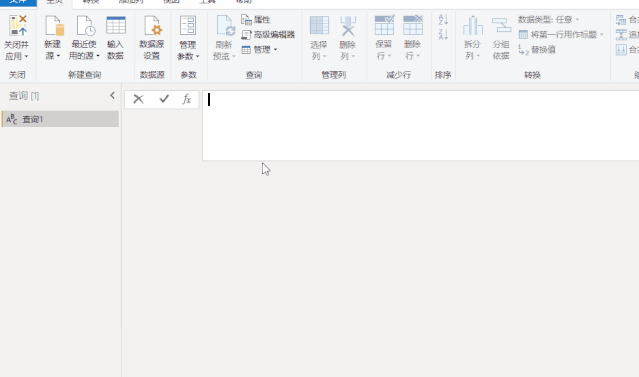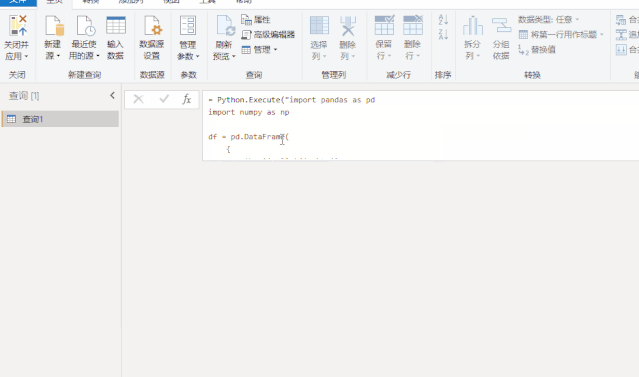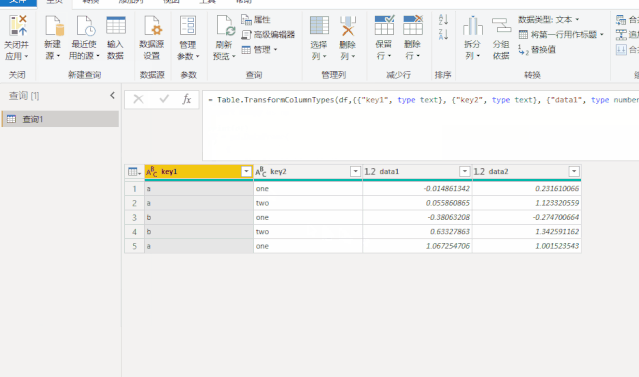
运行Python脚本后,Power BI会提取所有数据类型为DataFrame的变量出来,我们上面只有一个变量df,我们改下代码来看看,直接拷贝第一个变量,然后改下2个变量的名字:
`import pandas as pd`
`import numpy as np`
`df1 = pd.DataFrame(`
`{`
`'key1': list('aabba'),`
`'key2': ['one', 'two', 'one', 'two', 'one'],`
`'data1': np.random.randn(5),`
`'data2': np.random.randn(5)`
`});`
`df2 = pd.DataFrame(`
`{`
`'key1': list('aabba'),`
`'key2': ['one', 'two', 'one', 'two', 'one'],`
`'data1': np.random.randn(5),`
`'data2': np.random.randn(5)`
`});`
运行一下代码:
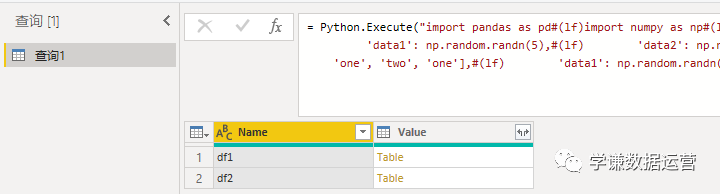
分别右键-将两张表作为新查询添加即可转换为两张单独的表:
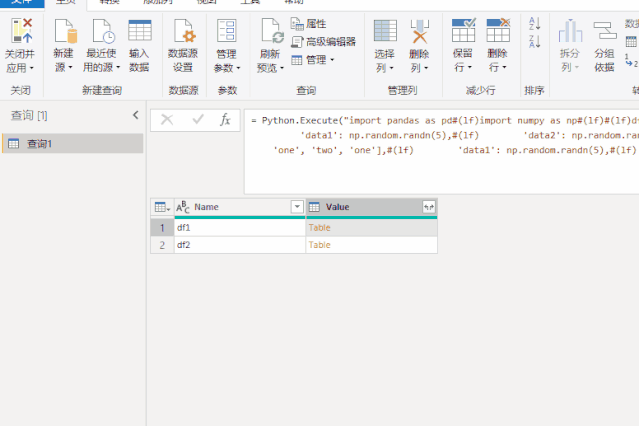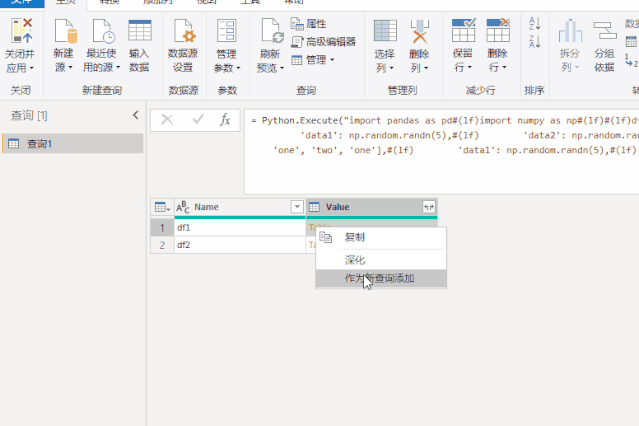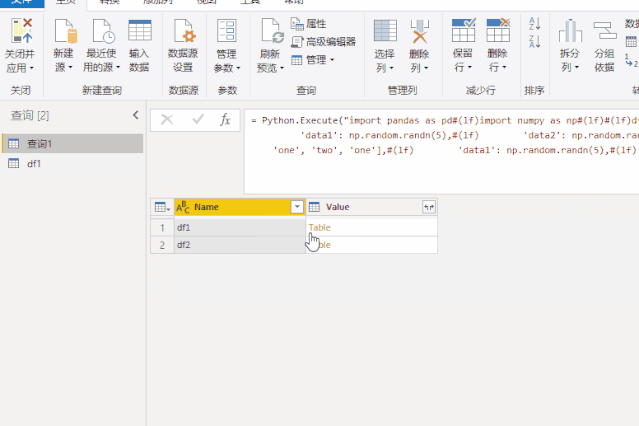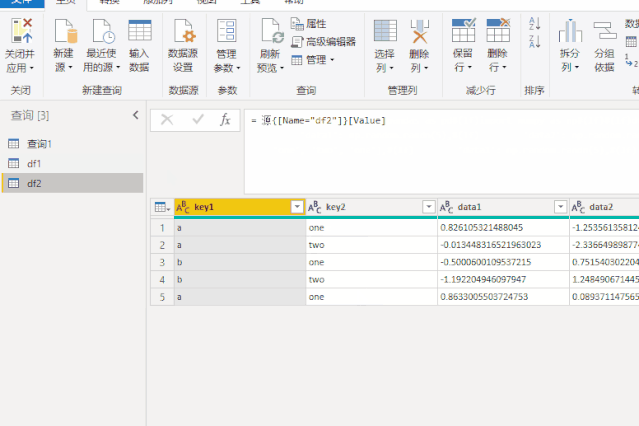
OK!这样我们就成功地用Python来导入数据了。
*Python和R语言在Power BI中的应用要求是一样的,数据传递的类型都要求是DataFrame,具体的使用场景和使用要求完全相同,会R的朋友,也可以按上述思路进行操作。*
本篇文章将Power BI中数据获取环节的Python使用讲解完毕,下一篇我们将继续讲解如何使用Python在Power BI中进行数据清洗。

================================================
FILE: _posts/2020-03-27-【强强联合】在Power BI 中使用Python(2)——数据清洗.md
================================================
【强强联合】在Power BI 中使用Python(2)——数据清洗

上一篇文章我们讲解了在Power BI中使用Python来获取数据的一些应用:
[【强强联合】在Power BI 中使用Python(1)](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483920&idx=1&sn=005dff4caa2c42cf33a0fe2ba130edb9&chksm=ea6746f1dd10cfe7a87d97e1589c11a9a701b771b01041993752821ab999ee3f2f6be92e3da0&scene=21#wechat_redirect)
这一篇我们将继续讲解如何在Power BI中使用Python进行数据清洗工作。

其实我们仔细看一下场景1和场景2,它们之间是个逆过程,场景1是从Python获取数据传递到Power BI,而场景2是Power BI或者Power Query获取了数据,用python来处理。
那么这个逆过程应该如何操作呢?话不多说,抓紧上车:

前文我们讲过,Python与Power BI的数据传递是通过Dataframe格式的数据来实现的。
**Python的处理结果以Dataframe形式输出,M将Dataframe自动转换为Table格式。M将其Table类型的数据传递给Python,Python会自动将Table转换为Dataframe。**
举个简单的例子:
首先我们进入Power Query管理器界面,通过新建一个空查询,并建立一个1到100的列表,再将其转换为表:
= {1..100}
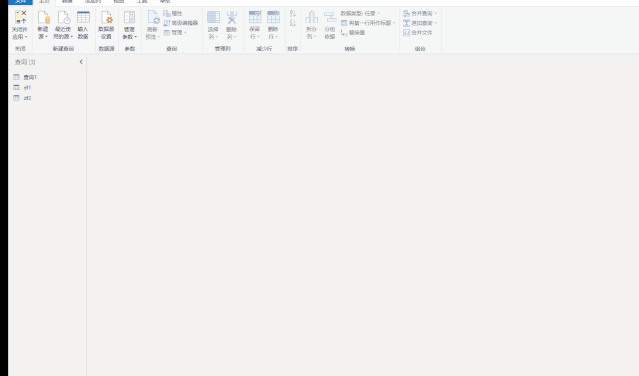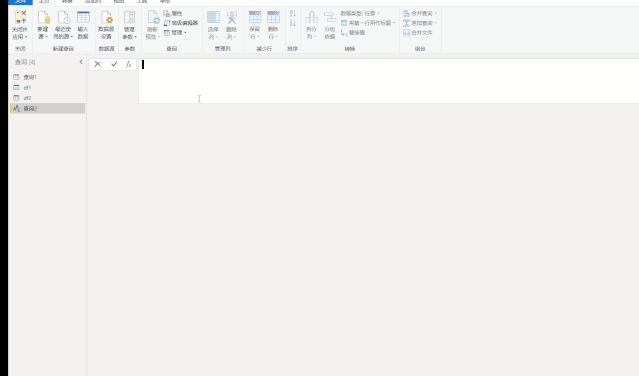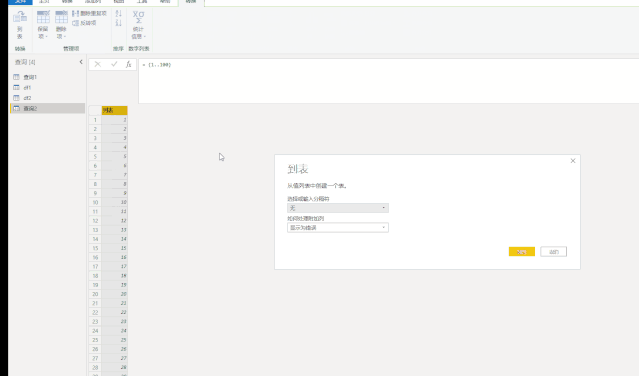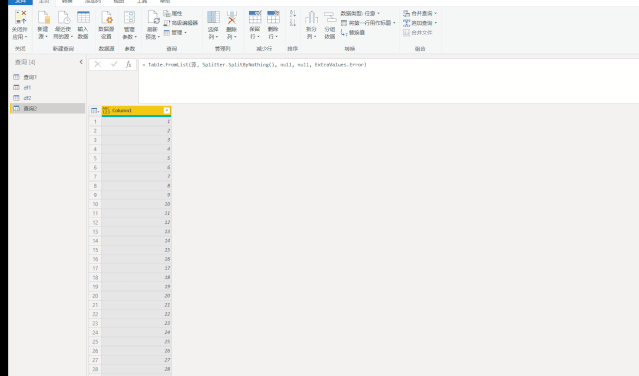
然后点击“转换-运行Python脚本”:
脚本编辑器中自带一句话:
''# 'dataset' 保留此脚本的输入数据
一行以“#”开头的语句,在Python的规范中表示注释,所以这句话并不会运行,它的意思是将你要进行修改的表用dataset来表示,也就是说Python是通过dataset变量来访问数据的。
理论上我们需要在这个地方键入:
import pandas as pd
以表示我们要使用pandas库,但是Power BI在调用Python时,自动导入了pandas和matplotlib库,所以这一行写不写都一样,我们知道下面的代码是在调用pandas库即可。
在脚本编辑器输入框中输入以下代码:
dataset.insert(loc=1,column="add_100",value=dataset["Value"]+100)
dataset就是源数据表自动换换的dataframe格式数据,“loc=1”代表在第一列数据后插入一列,列名是“add_100”,值是“Value”的值+100,第一行是1,add_100列第一行就是101,以此类推:
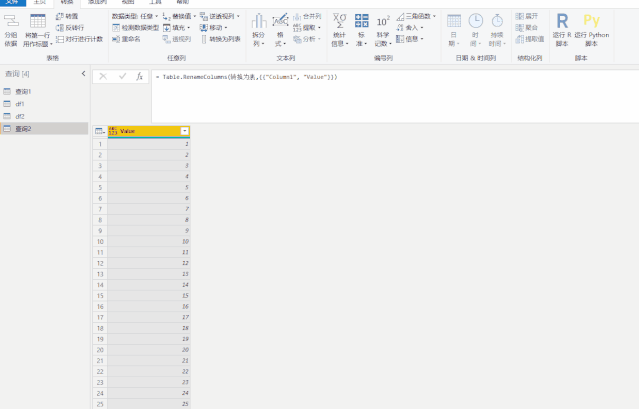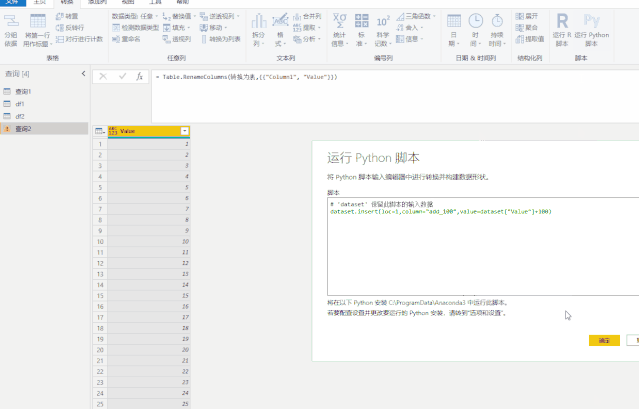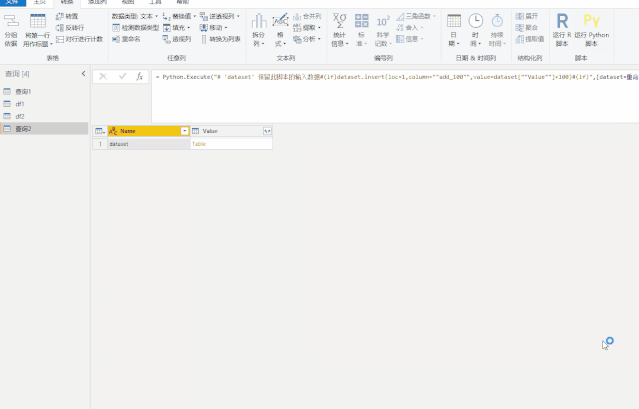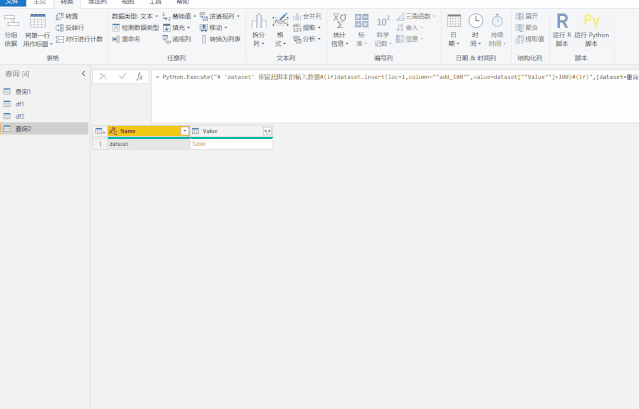
点击运行,得到的是一个子表,将其展开:
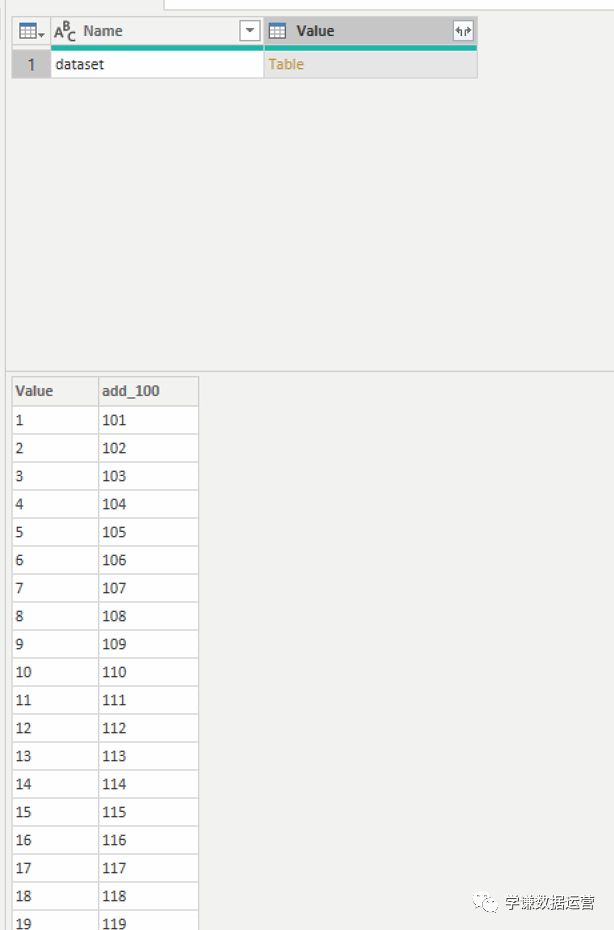
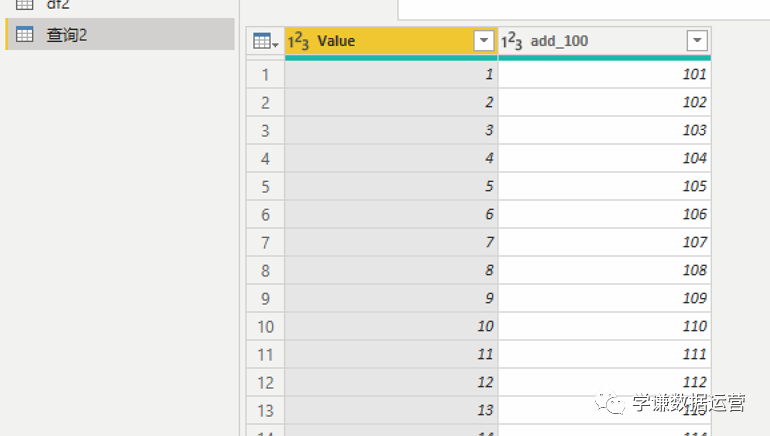
准确无误。
当然,我们也可以继续在这个表里进行一系列操作,比如复制一张表,再创建一个新dataframe表:

运行,得到结果:
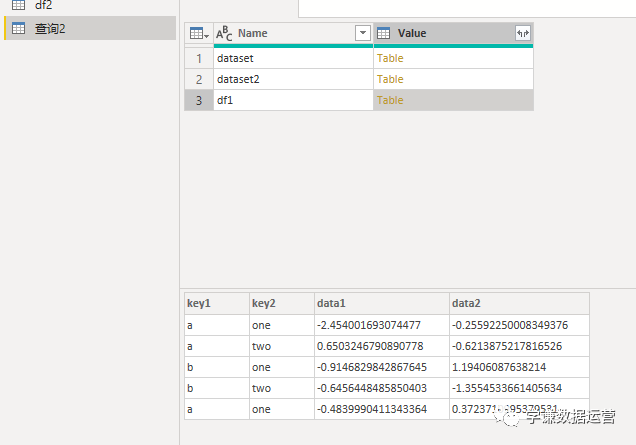
再比如,我们想提取数据的某列,比如上面这张表的“key2”列,我们可以点击运行Python脚本,并写入如下的代码:
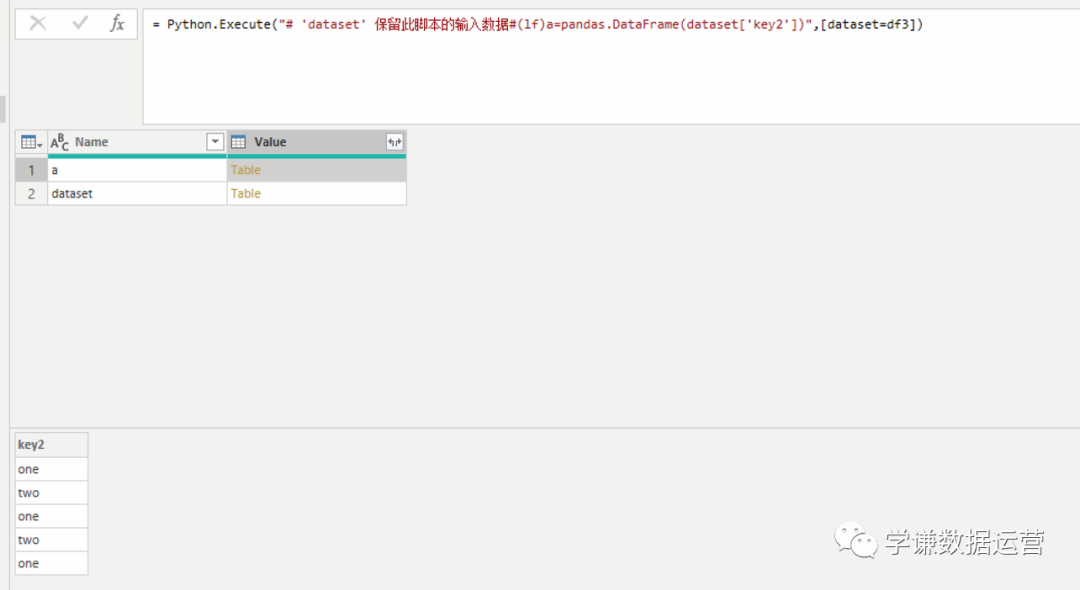
*(power query自动对Python添加 #(lf) 用来进行转义)*
当然,以上所说这些功能直接在powerquery中就可以实现,甚至更简单便捷,所以上述内容都是些:

吗?
并!不!是!以上只是在循序渐进地告诉大家,powerquery中是可以用Python进行数据清洗的,并且清楚地告诉大家调用Python的方法,大家应该很熟练了吧。
以下才是重点(当然上面也是):

在powerquery数据清洗中使用较多的Python功能一定会有正则,因为powerquery本身是没有正则的,所以这时候调用Python来进行正则就显得尤为重要,否则你可能需要在powerquery中添加很多步骤也不一定能得到想要的结果。
比如下面这个例子:
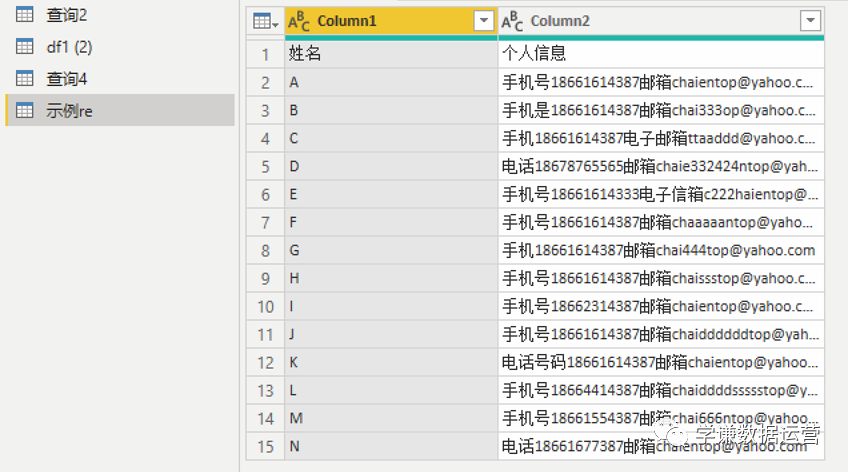
*真实情况可能远远比这个复杂。*
这种数据如果已经导入到Power BI中,在powerquery里是没有办法直接进行处理的,这时候就可以调用Python的re正则表达式了:
import re
import json
# 自定义获取文本电子邮件的函数
def get_find_emails(text):
emails = re.findall(r"[a-z0-9\.\-+_]+@[a-z0-9\.\-+_]+\.[a-z]+", text)
emails=';'.join(emails)
return emails
# 自定义获取文本手机号函数
def get_findAll_mobiles(text):
mobiles = re.findall(r"1\d{10}", text)
mobiles =';'.join(mobiles)
return mobiles
email_list=[]
tele_list=[]
for i in range(len(dataset)):
text=dataset.iat[i,1]
email=get_find_emails(text)
email_list.append(email)
tele=get_findAll_mobiles(text)
tele_list.append(tele)
dataset['email']=email_list
dataset['tele']=tele_list
*正则表达式的使用,大家可以进行相关搜索和学习,网上资源还是很多的。*
这段代码定义了两个函数:get_find_emails(自定义获取文本电子邮件的函数)和get_find_mobiles(自定义获取文本手机号函数),得到两个list,最后再放入dataset数据表中。
在IDE中运行无误后复制到powerquery的Python脚本编辑器中:

点击确定,返回结果:
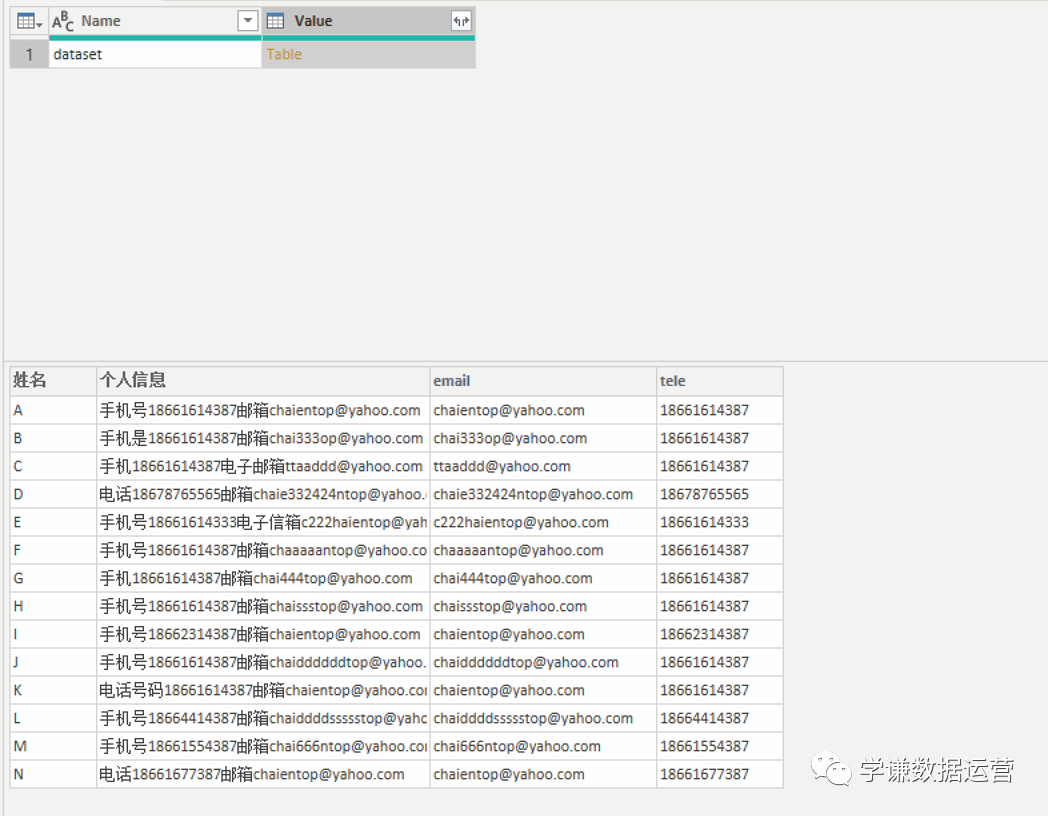
后面两列就是我们想要的手机号和邮箱了。
这样我们就实现了在powerquery中使用正则表达式对数据进行清洗的目的。

*当然,也可以调用R、PHP或者js来实现相同的目的,方法大同小异,各位读者可以自行研究。
*
本文讲解了在powerquery中进行数据清洗工作时如何运用Python来实现一些特定的功能。当然,数据清洗的整个流程是复杂多变的,结合本文所讲的内容,希望大家都能充分挖掘powerquery和Python在数据清洗过程中的优缺点,结合起来使用,势必能事半功倍。
下一篇我们将继续讲解如何使用Python的matplotlib库在Power BI中进行可视化呈现。

感谢您对本号【学谦数据运营】的关注,支持与厚爱,如果您觉得本文对您有用,请不要吝惜您的点赞、转发、点亮在看,有任何问题欢迎大家在留言区留言,谢谢。
================================================
FILE: _posts/2020-03-28-【强强联合】在Power BI 中使用Python(3)——数据可视化.md
================================================
【强强联合】在Power BI 中使用Python(3)——数据可视化

前两篇文章我们讲解了在Power BI中使用Python来获取数据的一些应用:
[【强强联合】在Power BI 中使用Python(1)](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483920&idx=1&sn=005dff4caa2c42cf33a0fe2ba130edb9&chksm=ea6746f1dd10cfe7a87d97e1589c11a9a701b771b01041993752821ab999ee3f2f6be92e3da0&scene=21#wechat_redirect)
以及如何在Power BI中使用Python进行数据清洗工作:
[【强强联合】在Power BI 中使用Python(2)](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483938&idx=1&sn=a67fdd9eb0cebec3217ae6c5b9739215&chksm=ea6746c3dd10cfd53342278ef91f873901e2fdd71e37894e0843b18b44310b5a2662e7c64faf&scene=21#wechat_redirect)
这一篇我们继续讲解如何在Power BI中使用Python进行可视化呈现工作。

打开Power BI Desktop,在右侧可视化区域会看到一个“Py”的图标,打开该图标,并选择启用脚本视觉对象,拖动字段到“值”的位置:
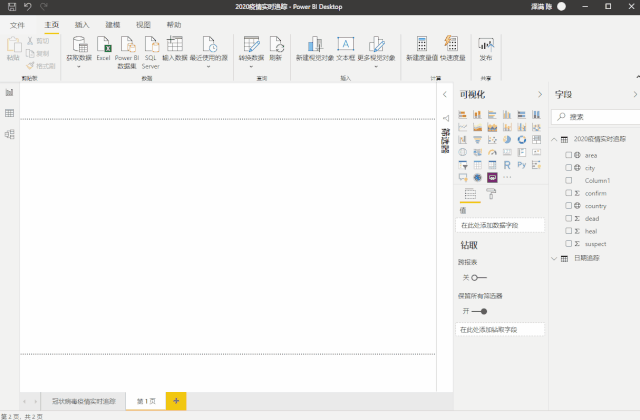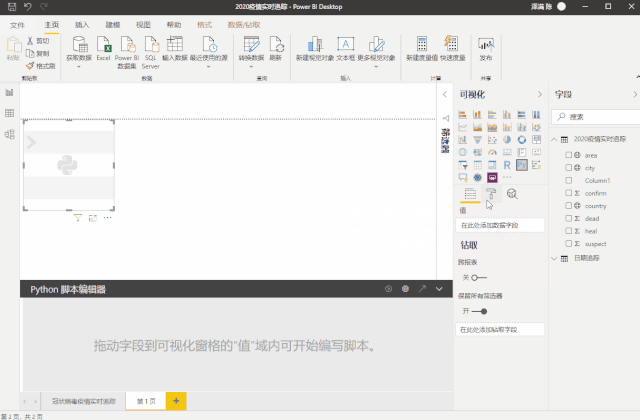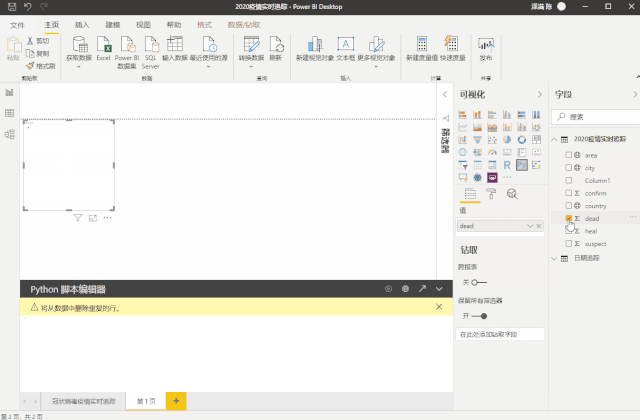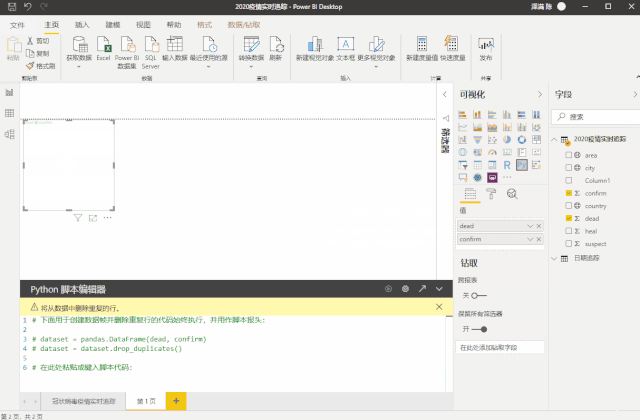
添加了字段之后,在Python脚本编辑器中,自动显示了几行内容:
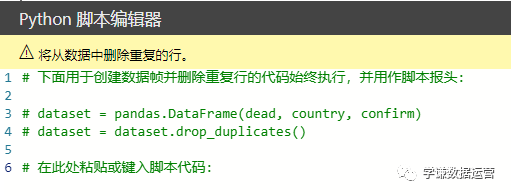
dataset = pandas.DataFrame(dead, country, confirm)
dataset = dataset.drop_duplicates()
*注意:这两行代码显示的是被“#”注释掉了,但是在后台有完全相同的两行代码被真实执行了。另外,第二行代码的意思是去重,需要注意。
*
为了确保图像能够正确显示,可以在python开发界面将代码调试无误后COPY过来,当然,如果你是大神,也可以在里面直接RUN。

*反正我是不敢。溜了溜了~
*
废话不多说,我们直接举两个例子:

First one:
在编辑区域输入代码:
import matplotlib.pyplot as plt
plt.plot(dataset["confirm"],dataset["dead"])
plt.show()
点击运行,发现并没有完整显示数据,且不够美观也不够直观。
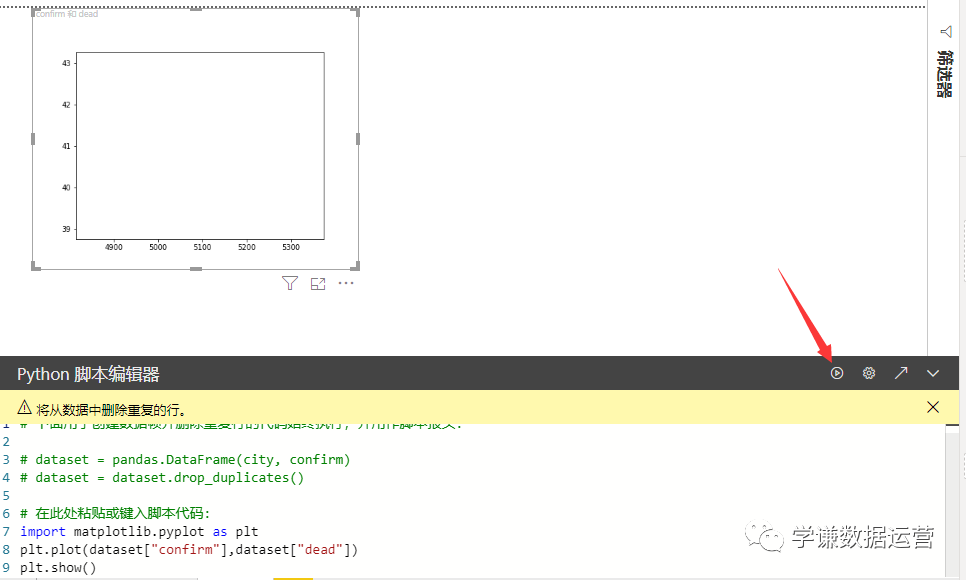
这里需要做一些处理,因为“confirm”和“dead”字段默认是以求和的方式显示的,所以只有一个点的数据。
在可视化的值这里对“confirm”和“dead”字段分别选择“不汇总”。再运行代码,这样出来的就是正常的图形了:
我们也可以对中间这行代码进行适当修饰:
plt.plot(dataset["confirm"],dataset["dead"],color="red",marker="o")
以获得我们想要的形状和信息:
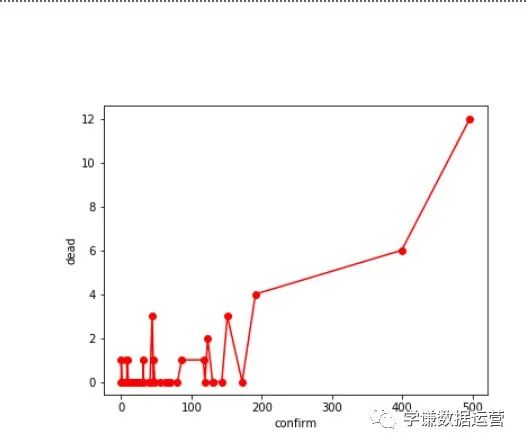
*当然,还是比较丑陋……原谅我的审美。*
我们再举个美观一点的例子:柱状图。仍然是插入可视化对象-添加字段-输入Python代码:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
cams=dataset['cams'].values.tolist()
IncomePercents=dataset['IncomePercents'].values.tolist()
plt.figure(figsize=(60,20))
plt.yticks(fontsize=15)
plt.bar(np.arange(len(cams)),IncomePercents,label='课收完成率',width=0.8)
plt.show()
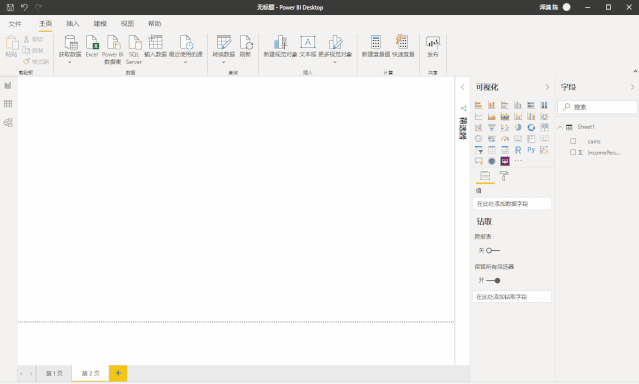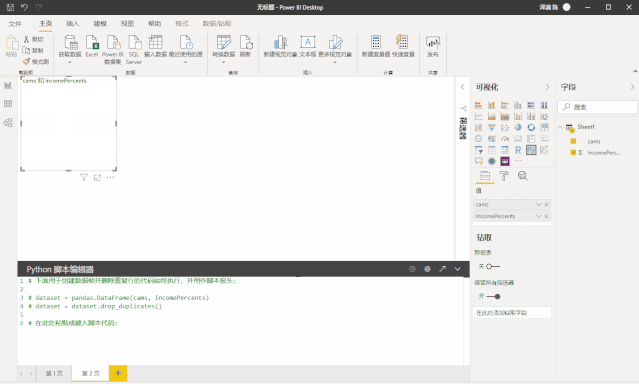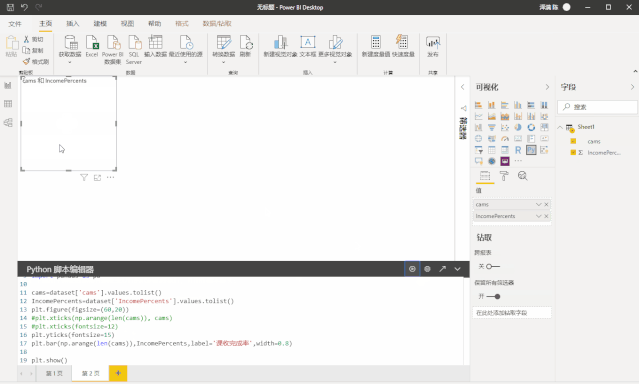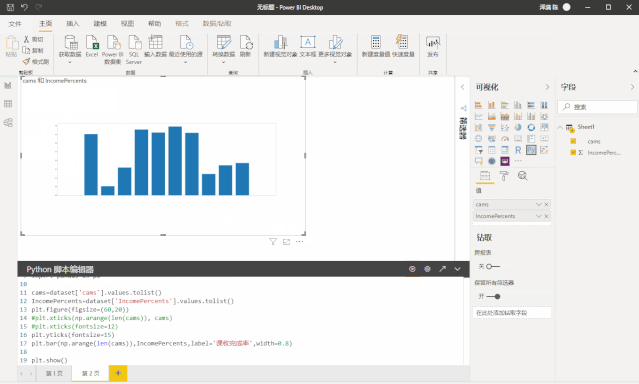
结果得到一个很丑陋的柱状图……还不如直接用Power BI做呢!

没关系,我们只要按照下面的步骤适当调整一下代码:
就得到了我们想要的结果:
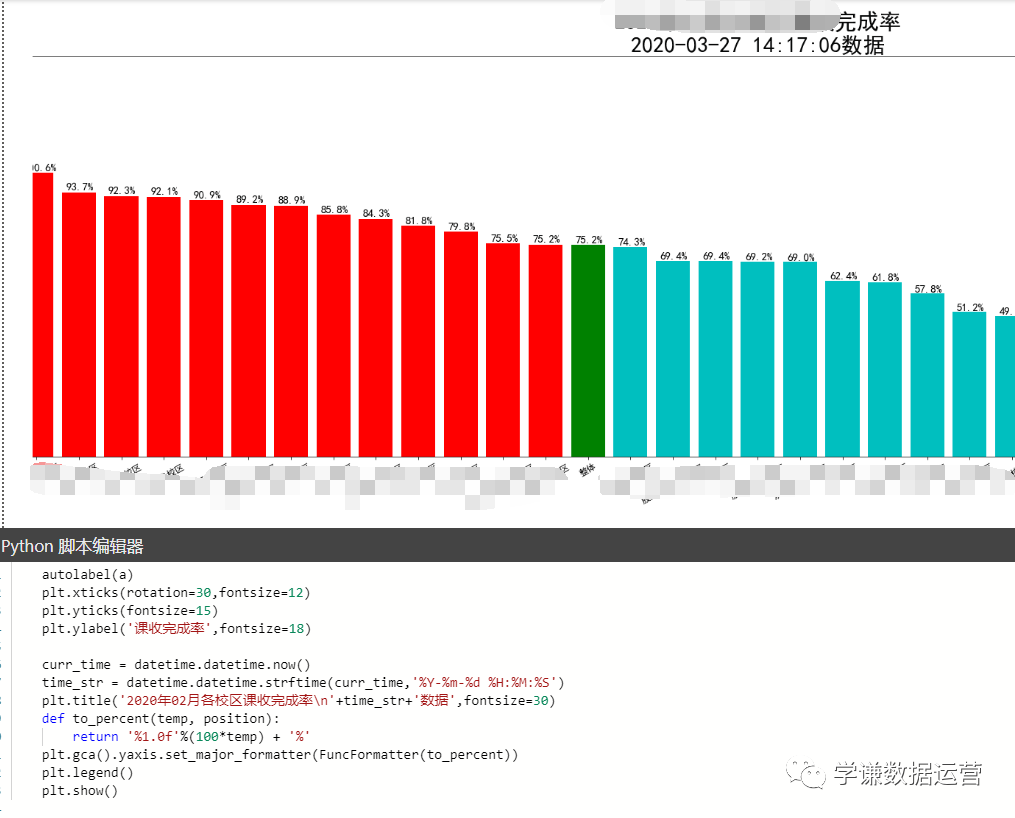
还是乖乖地双手奉上源代码:
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
cams=dataset['cams'].values.tolist()
IncomePercents=dataset['IncomePercents'].values.tolist()
plt.figure(figsize=(60,10))
plt.xticks(np.arange(len(cams)), cams)
colors=[]
cam_num=0
for cam in cams:
cam_num+=1
if cam!='整体':
colors.append('r')
else:
break
colors.append('g')
cam_num+=1
while cam_num<=len(cams):
colors.append('c')
cam_num+=1
a=plt.bar(np.arange(len(cams)),IncomePercents,label='完成率',color=colors,width=0.8)
def autolabel(rects):
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x()+rect.get_width()/2.-0.3, 1.01*height, '{:.1%}'.format(float(height)),fontsize=15)
autolabel(a)
plt.xticks(rotation=30,fontsize=12)
plt.yticks(fontsize=15)
plt.ylabel('完成率',fontsize=18)
curr_time = datetime.datetime.now()
time_str = datetime.datetime.strftime(curr_time,'%Y-%m-%d %H:%M:%S')
plt.title('2020年03月各公司完成率\n'+time_str+'数据',fontsize=30)
def to_percent(temp, position):
return '%1.0f'%(100*temp) + '%'
plt.gca().yaxis.set_major_formatter(FuncFormatter(to_percent))
plt.legend()
plt.show()
*这里面比较复杂的点有两个:一个是添加了整体值,并将高于、低于整体值的部分填充不同颜色,另一个是显示柱状图标签,用到了一个小技巧。*
当然,以上所说这些作图功能直接在Power BI默认视觉对象中就可以实现,甚至更简单便捷,所以上述内容都是些:

吗?
并!不!是!
还是上一篇的套路,以上举的例子只是简单地让大家认识一下如何在Power BI中调用Python作图,接下来我们介绍一些在Power BI中无法原生作图的例子:
比如数学制图,绘制sinx和cosx曲线:
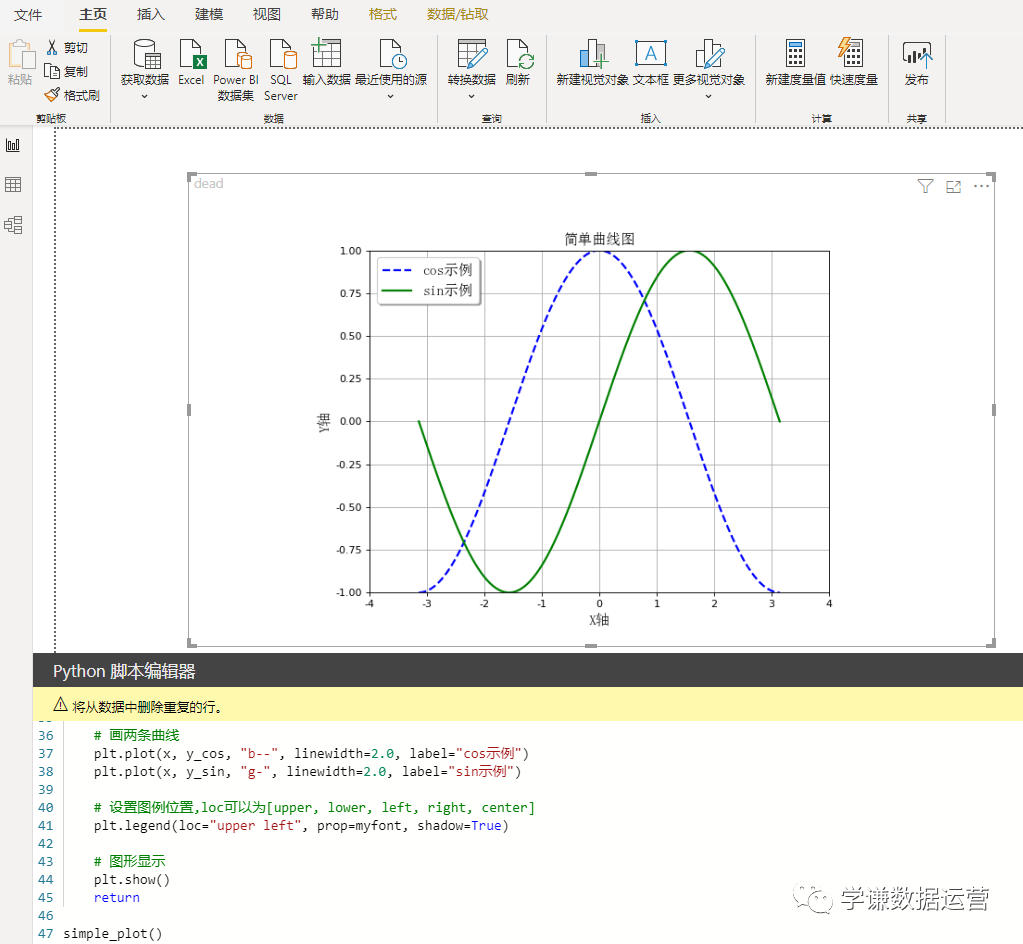
比如绘制子图:
比如绘制特殊的柱状图:
比如绘制三维散点图:

等等等等……
怎么样,Python还是有点用处的吧?
更多精彩作图,需要各位结合自己的业务场景,合理选择得到最优解。

总结:
Power BI的可视化功能本身就很强大(废话么,人家干什么的),但是毕竟可视化种类不是很多,很多特殊的可视化方法也没有办法直接实现,这时候我们就可以调用Python的matplotlib库进行作图了。
因为是几乎完全基于Python的作图,Power BI在这里仅起到了图床的作用,所以该部分内容对Python本身尤其是matplotlib库的要求较高,各位读者需要有较强的matplotlib代码编写能力才行。
好了,本文入门级地讲解了如何使用Python的matplotlib库在Power BI中进行可视化呈现,以补充Power BI自带可视化类型和第三方可视化插件无法实现的功能,想必大家一定能够通过这两个大神级软件的配合使用得到自己想要的可视化呈现。
——————————
以下是万众期待的下期预告环节:

众所周知,Power BI对于数据的输出是有一定限制的,至少有这么两个点:
1.可视化对象导出CSV格式限制3万行数据,这对于数据量动辄上百万甚至上亿的表来说是不可接受的;
2.而一直广为诟病的powerquery数据困难的问题更是一时半会也得不到解决。
那应该怎么办呢?
对于第一个问题,我们推荐使用DAX Studio,轻松导出十万、百万条记录。
第二个问题,很可惜没有现成的工具可以直接解决,但是结合本系列《【强强联合】在Power BI 中使用Python》第二篇的内容:
**Python的处理结果以Dataframe形式输出,M将Dataframe自动转换为Table格式。M将其Table类型的数据传递给Python,Python会自动将Table转换为Dataframe。**
我们是否可以想到如何用Python将powerquery中的表输出为excel甚至实现回写到SQL中呢?
这就是下一篇文章要讲的内容了:

感谢您对【学谦数据运营】的关注,支持与厚爱,如果您觉得本文对您有用,请不要吝惜您的点赞、转发、点亮在看,有任何问题欢迎大家在留言区留言,谢谢。
================================================
FILE: _posts/2020-03-29-【强强联合】在Power BI 中使用Python(4)——PQ数据导出&写回SQL.md
================================================
【重磅来袭】在Power BI 中使用Python(4)——PQ数据导出&写回SQL

各位小伙伴们,大家好,我是学谦,咱们又见面了。
《在Power BI 中使用Python》系列的前三篇文章我们分别讲解了:
如何在Power BI中使用Python来获取数据:
[【强强联合】在Power BI 中使用Python(1)](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483920&idx=1&sn=005dff4caa2c42cf33a0fe2ba130edb9&chksm=ea6746f1dd10cfe7a87d97e1589c11a9a701b771b01041993752821ab999ee3f2f6be92e3da0&scene=21#wechat_redirect)
如何在Power BI中使用Python进行数据清洗:
[【强强联合】在Power BI 中使用Python(2)](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483938&idx=1&sn=a67fdd9eb0cebec3217ae6c5b9739215&chksm=ea6746c3dd10cfd53342278ef91f873901e2fdd71e37894e0843b18b44310b5a2662e7c64faf&scene=21#wechat_redirect)
如何在Power BI中使用Python进行可视化呈现:
[【强强联合】在Power BI 中使用Python(3)数据可视化](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483967&idx=1&sn=5c9551c80d9618219838dea0fbedbe80&chksm=ea6746dedd10cfc829141ab2e134ec66d4fb3dd9109c74252bcec48b75192fa5d8350c3c0e20&scene=21#wechat_redirect)
今天我们继续讲解第四篇——PQ**数据导出与写回SQL**
众所周知,Power BI对于数据的输出是有一定限制的,至少有以下两点:
1.可视化对象导出CSV格式限制3万行数据,这对于数据量动辄上百万甚至上亿的表来说是不可接受的;
2.而一直广为诟病的powerquery数据困难的问题更是一时半会也得不到解决。
那应该怎么办呢?
第一个问题,推荐使用DAX Studio,轻松导出十万、百万条记录;
第二个问题,没有现成的工具可以直接解决,但是结合本系列第二篇的内容,我们是否可以想到如何用Python将powerquery中的表输出为excel甚至实现数据回写到SQL中呢?
这就是我们今天要学习的内容:

我们在第二讲中说过:
**Python的处理结果以Dataframe形式输出,M将Dataframe自动转换为Table格式。M将其Table类型的数据传递给Python,Python会自动将Table转换为Dataframe。**
M将其Table类型的数据传递给Python,Python会自动将Table转换为Dataframe。那么Python中Dataframe如何输出呢?
想必了解pandas库的战友们已经想到答案了。
只要一行简单的代码:
= Python.Execute("# 'dataset' 保留此脚本的输入数据#(lf)dataset.to_excel(r""C:\Users\金石教育\Desktop\abc.xlsx"")",[dataset=源])
简单吧!

运行一下:
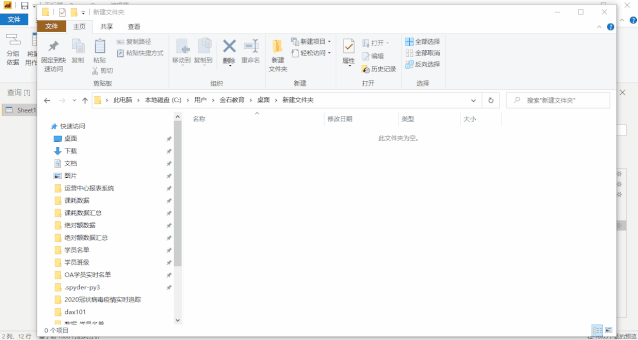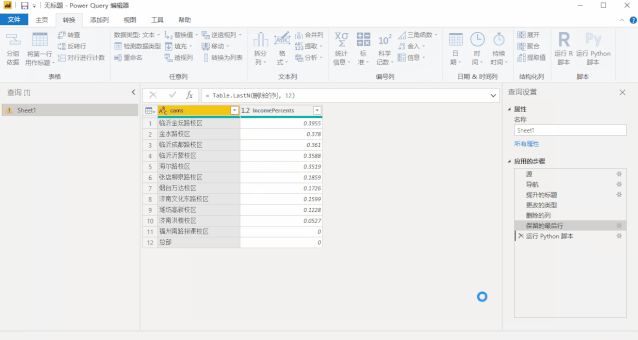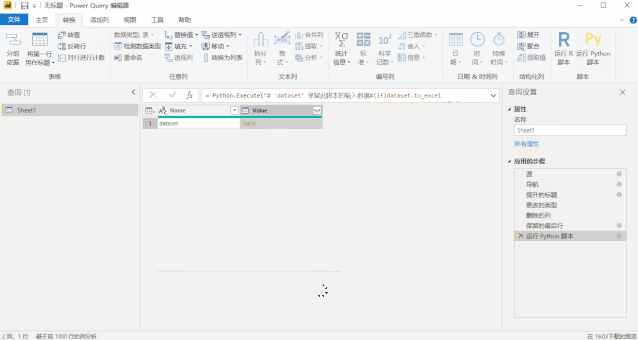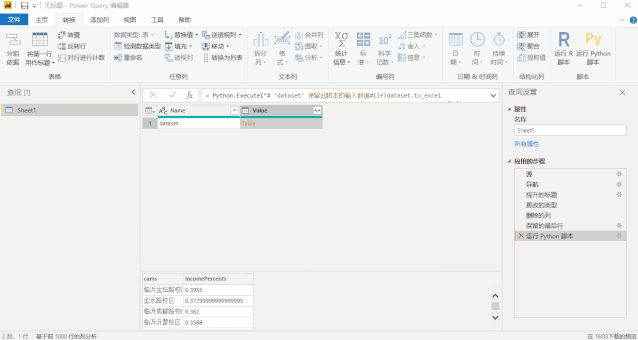
OK啦!
关键是:
只有一行代码!
只要一行代码!
只需一行代码!
重要的事情强调三遍!
多年来powerquery广为人们诟病的——数据清洗后无法导出结果的问题就这么被一行代码轻松地解决,美滋滋。

好了,既然知道了如何导出excel文件,那么各位,写回MySQL数据库的操作是否可以举一反三自行解决呢?
我们直接看下图的神操作:
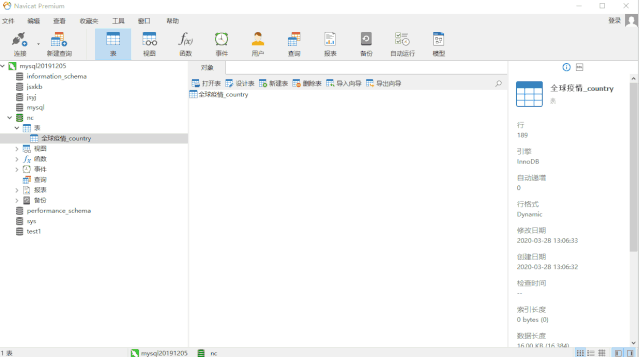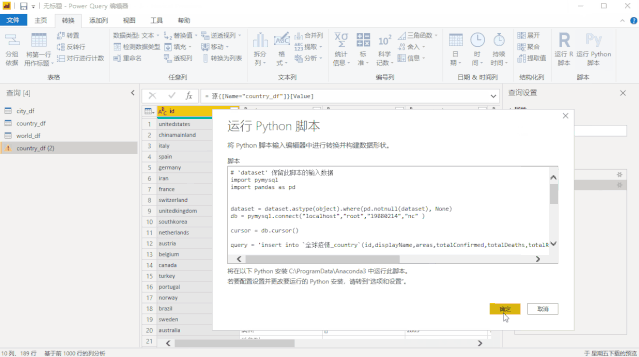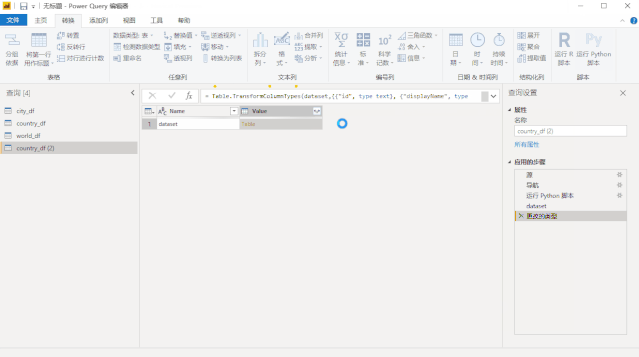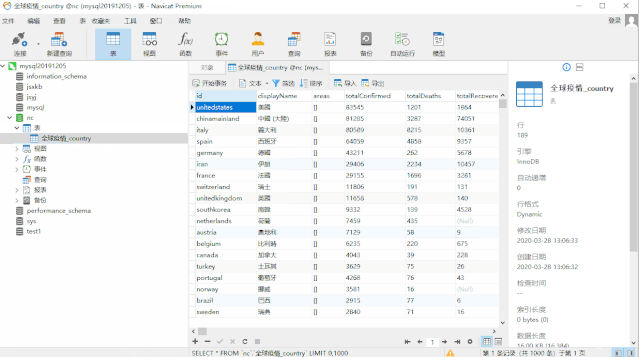
看到了吗,mysql数据库中本来是一张空表,我们在powerquery中运行了一段Python代码后,表中有了数据。

关键代码解释:
db = pymysql.connect("localhost","用户名","密码","nc" )
#连接数据库
query = 'insert into `全球疫情_country`(id,displayName,areas,totalConfirmed,totalDeaths,totalRecovered,lastUpdated,lat,long,parentId)values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)'
#键入数据
for r in range(len(dataset)):
#按行获取数据
id0=dataset.iat[r,0]
displayName=dataset.iat[r,1]
areas=dataset.iat[r,2]
……
values = (id0,displayName,areas,totalConfirmed,totalDeaths,totalRecovered,lastUpdated,lat,long,parentId)
cursor.execute(query, values)
cursor.close()
db.commit()
db.close()
#提交数据并关闭数据库
*获取完整源代码,请关注本号【学谦数据运营】,回复关键字“powerbi-python-mysql”
*
代码没什么难度,用的是Python的一个常用库:pymysql,将dataset中的数据按行导入MySQL中。
但是有一个大BUG一点小问题:
因为全球只有200左右个国家和地区,country层面的数据应该只有200左右。但是,我习惯性地瞥了一眼MySQL右下角,发现:

难道最近的国际局势变化这么大,已经有567个国家和地区了?不可能吧。抓紧查询一下,发现果然有问题:
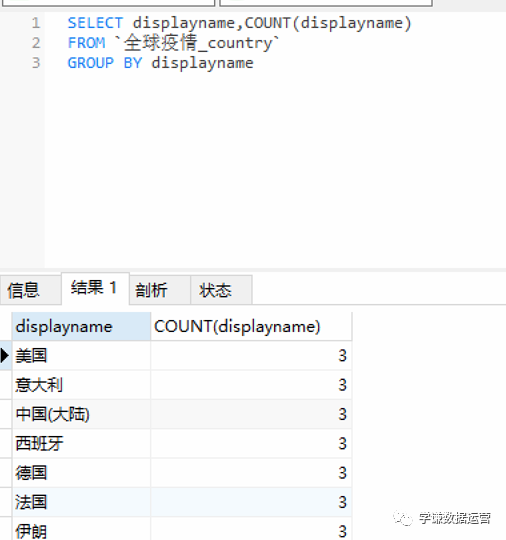
全球每一个国家和地区的数据都显示了三次,567/3=189,这还差不多。
而且清空表后再刷新运行,就会发现有的时候是2次,有的时候5次,这意思就是Python代码运行了多次,造成了数据重复,这背后的原因我们无从得知。这样可不行啊,总不能每次使用的时候先去重吧,不太现实,如果有时候疏忽了就麻烦了,那该怎么办呢?
这个问题先一放,我们来看另一个问题:
每个国家的每日数据我们只保留一次,即便powerquery每次刷新只向MySQL数据库写入一次,但我们也不能保证编写模型的时候只刷新一次吧,因为一旦人工刷新多次,造成的结果和上面被动造成的结果一致,所以,只要我们解决了人工刷新造成数据重复的问题,查询刷新时被动写入多次的问题也就顺带解决了。
我们看一下数据,有一列“lastupdated”,是时间格式,也就是查询的时间,由于我们只关心日期数据,因此只取出日期就可以。所以只要每次写回MySQL之前,先判断一下数据库中是否已经存在当日的数据,如果有,就先删除,再将新的数据写入,这样就达到我们的目的了。
添加以下代码:
#添加一列日期
dataset.insert(loc=10,column="updateday",value=dataset["lastUpdated"].str[0:10])
#获取日期
today_date=dataset.iat[0,10]
#删除当日的已有数据
query_delete='DELETE FROM `全球疫情_country` WHERE updateday='+today_date
运行一下代码:
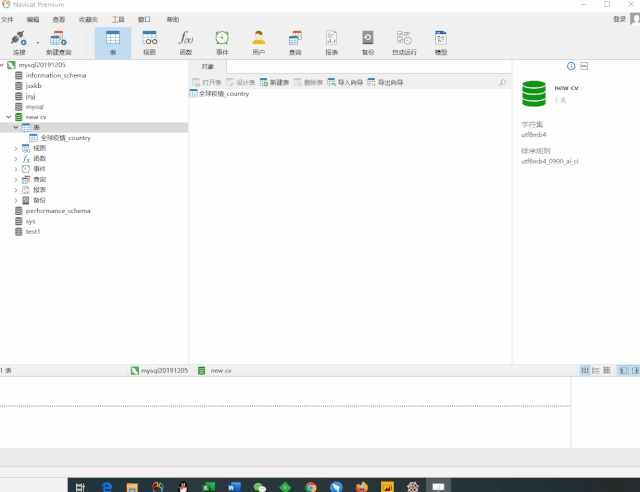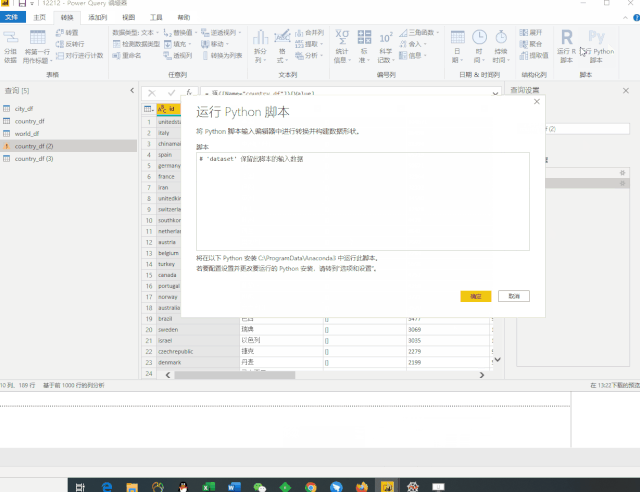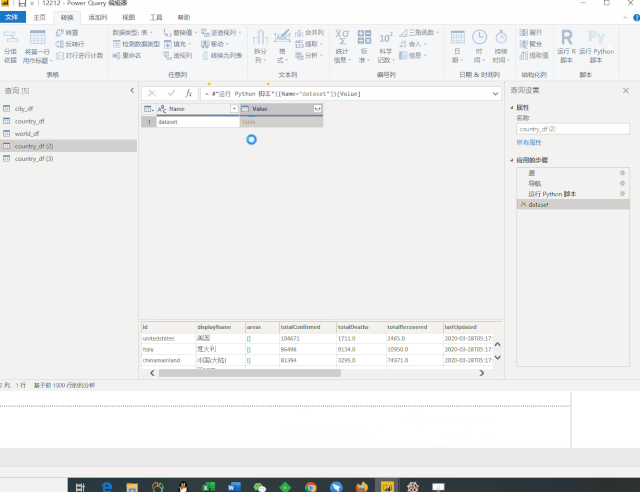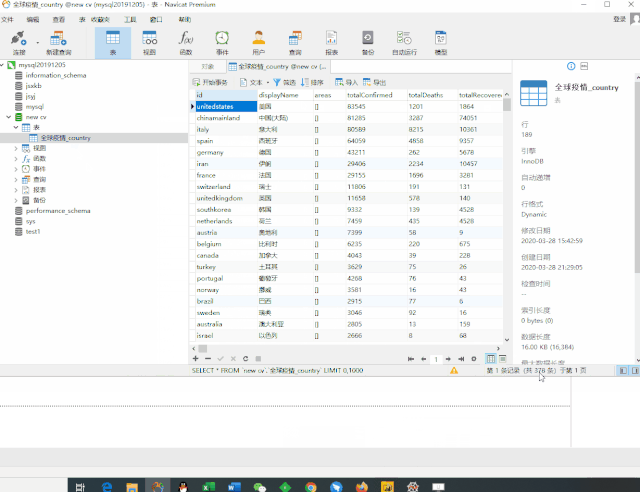
MySQL数据库的表中初始有378条数据(因为包含了3月27日和3月28日两天的数据,共189个国家和地区的数据),运行代码后,仍然是378条,之前已有的3月28日的数据被删除,然后添加了刚刚查询到的最新数据。
完美解决!
好了,写回MySQL数据库的全部操作和遇到的问题与解决措施到这里就讲解完毕了。你学会了吗?
写这篇文章的时候不知道怎么的,远程计算机的MySQL数据库总是出问题,导致我这边文章前前后后写了五六个小时。
本节内容细节的点特别多,大家一定要自己动手操作几遍,后续我会逐步安排相关的视频讲解,大家请注意关注本号号,跟上队伍。
------
以下仍然是下期预告环节:

下一篇我们将继续介绍一个重磅功能——**数据条件触发预警并邮件通知**:
说到数据预警,微软自家的Flow可以设置预警条件并发送邮件,这是原生功能,有兴趣的朋友可以去了解。

------
感谢您对【学谦数据运营】的关注、支持与厚爱,如果本文对您有用,请不要吝惜您的点赞、转发和点亮在看,有任何问题欢迎大家在留言区询问,谢谢。
================================================
FILE: _posts/2020-03-30-【强强联合】在Power BI 中使用Python(5)——数据预警与邮件通知.md
================================================
【重磅来袭】在Power BI 中使用Python(5)——数据预警与邮件通知

*案例背景*
*某连锁门店的区域经理助理小朱为当前区域门店创建了多个重要指标看板,但无论是区域经理还是店长,因为日常工作太忙,经常没空细看所有数据看板。小朱希望对于重要指标,特别是有异常的重要指标,可以单独预警。*
在互联网+时代,一切都讲究“数据化”,而真正用好“数据”,不仅仅是“人看数据”,更要“数据追人”,才能让“数据落地”,如此才称得上将产品/运营/服务等实现“数据化”。
那么,如何做到“数据追人”,也就是设置数据预警条件,当满足条件时就会有邮件自动提醒呢?
这就是我们今天要讲的《在Power BI 中使用Python》系列的第五篇内容:

首先我们需要知道的是,Microsoft自家的Flow可以设置预警条件并发送邮件,这是原生功能,但是很多朋友可能并没有使用权限使用Flow,很多连正版的office都没有使用,希望有条件的朋友还是使用Flow比较好,也更简洁方便。
如果手头没有Flow的应用,那么只能采取如下的方式了。
好,我们来看下面的案例:
目前世界各国的新冠病毒确诊人数急剧增加,比如我想知道什么时候美国的感染人数超过15万(截止3.27是10万多了)或者全球的感染总数超过50万(截止3.27已经有42万了),一旦满足条件,我希望邮件能够通知我。
那么这个想法,Power BI和Python该如何帮我实现呢?
结合上一篇文章实现的数据导出功能,其实也很简单,只要添加一个判断条件和一个能够发送邮件的库就ok了:
首先是判断条件的代码:
for i in range(len(dataset)):
if dataset.iat[i,0]=='unitedstates':
if totalConfirmed>=150000:
#美国人数超过15万的条件满足
#以下添加发送邮件的代码
第二步,能发送邮件的库是smtplib,我们直接测试一下代码:
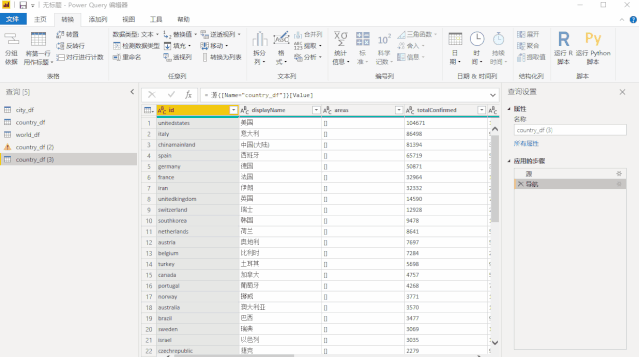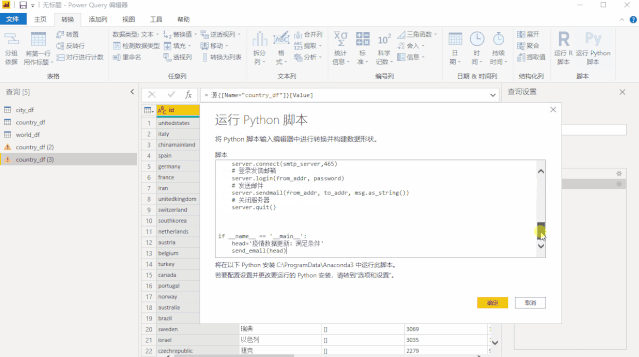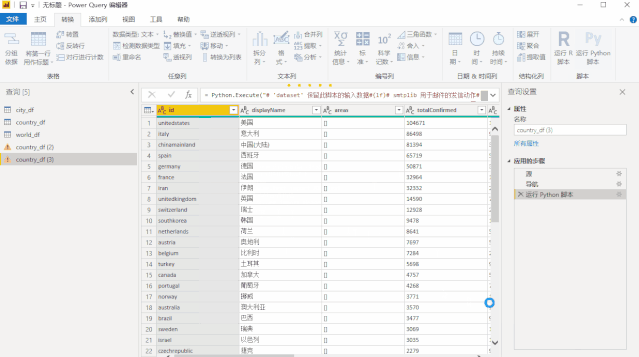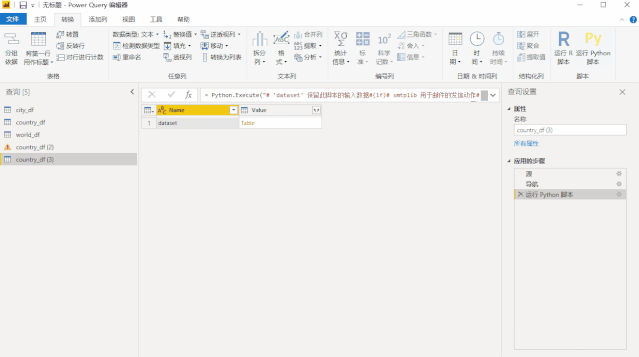
这时,我的邮箱里就收到新邮件了:
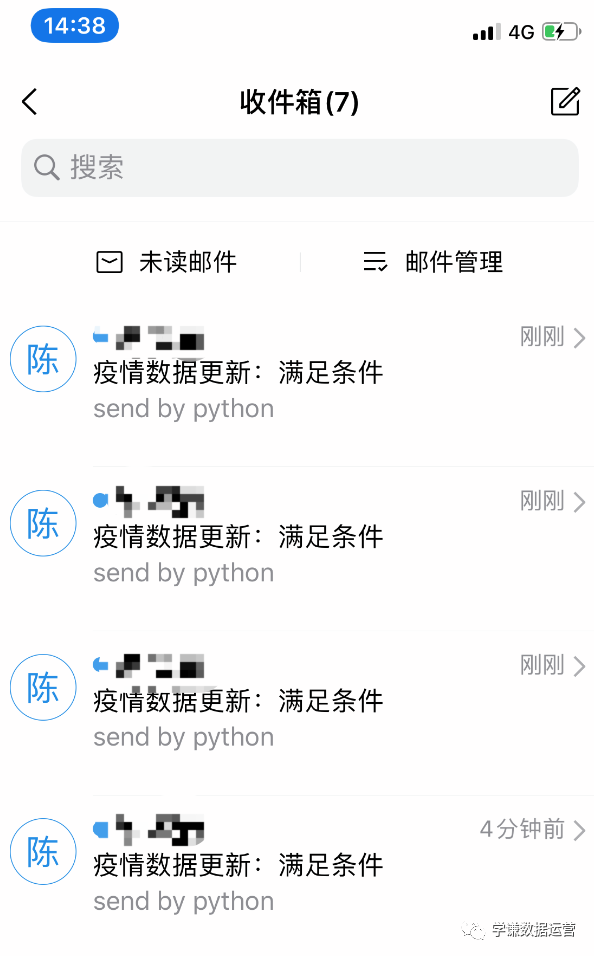
这样,将条件判断代码和发送邮件的代码组合起来使用,我们就可以实现数据预警和邮件自动发送了。
不得不再次说一声:

*获取源代码,请关注【学谦数据运营】,回复关键字“powerbi-python-email”
*
有一点需要注意的是:不知道大家有没有认真看收件箱的邮件,同时来了3封相同的邮件,跟上一篇导入MySQL时相同的现象,都是在PQ处理时,Python代码被执行多次的问题(暂时没有查明原因)。
这个问题其实也好解决,我们将报表发布到云端,再点刷新:
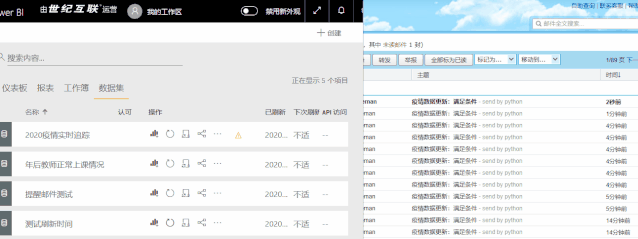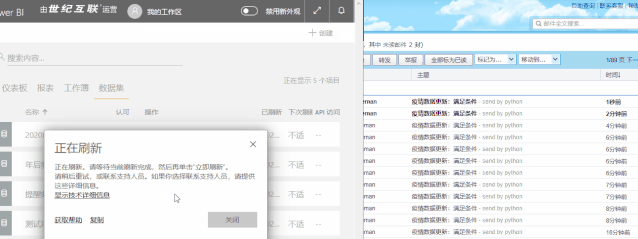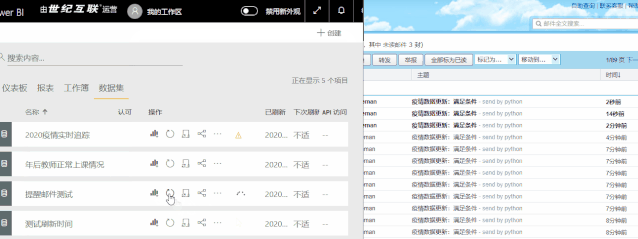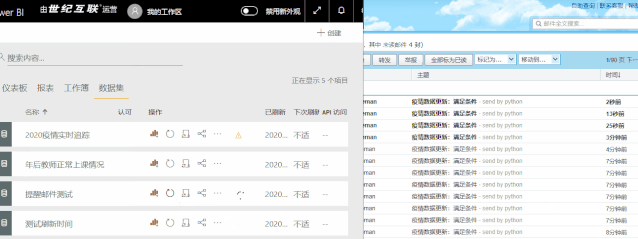
可以看到总共点击刷新按钮3次,每次刷新后增加一封新邮件,加上本身有一封未读邮件,一共是4封。也就是说在云端刷新的报告只会运行一次Python代码。
而实际上我们发布报表前,理论上设定的条件尚未满足,也就是说不会触发邮件发送。只有当云端刷新几次后满足条件了才会触发邮件发送开关。也就是说,发布到云端就可以解决以上问题。
小意思。

还有一个问题,不知道你想到没有:
当美国感染人数超过15万触发邮件发送后,后续的每一次刷新一定也会满足超过15万人的条件,也就是说,每一次刷新都会发送邮件。
尤其是学习了这篇:[如果雇一个人7d×24h每10秒刷新一次Power BI,我需要每月支付他多少钱?](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483812&idx=1&sn=1d99a342ad280eac128845382886debb&chksm=ea674545dd10cc534548c85c923390ceddb1ea3688d8212f0c5697dbfe863183c52cd1e91128&scene=21#wechat_redirect),假设设定了10分钟更新一次数据,邮件就会每10分钟发给我们一次,这很显然不是我们想要的。
好人做到底,解决办法这里也一并告诉大家:

手动创建一个如下的excel文件:
修改发送邮件的条件,添加一条,pandas读取这个值,只有当这个值为0时才运行后面的内容;
当发送邮件的条件满足时,0修改为1,并保存;
这样,当满足一次条件后,条件就不再满足,后续也就不会再发送了:
io=r"C:\Users\学谦数据文化\Desktop\1.xlsx"
df=pd.read_excel(io, sheet_name=0, header=0, names=None)
if df.iat[0,0]==0:
for i in range(len(dataset)):
if dataset.iat[i,0]=='unitedstates':
if totalConfirmed>=150000:
df.iat[0,0]=1
df.to_excel(r'C:\Users\学谦数据文化\Desktop\1.xlsx', sheet_name='Sheet1')
#以下添加发送邮件的代码
完美解决!详细得不能再详细了。

*(对于最后这个问题,如果大家有更好的解决方案,欢迎在留言区留言或公众号内回复)*
终于,我们通过5篇文章大体讲完了在Power BI中使用Python的几个场景:
1、导入数据;
2、清洗数据;
3、数据可视化;
4、PQ数据导出;
5、数据预警与邮件自动发送。
当然,我们需要注意的一点是,这些功能的使用其实很多时候并不是最合理的,也并不是鼓励大家一定要去这样操作,只是提供了一些新的思路。
比如我们一般情况下都是Python爬取数据直接导入MySQL,然后再用pq导入Power BI中建模处理。但是在一些建造时间比较久了的模型中,原本就用pq爬取的数据并进行过大量处理,如果再转移到python,恐怕还得重新编写一遍代码,那么用本系列文章中的操作就会尽可能少地改动原来的代码,并节省不少时间。
所以大家一定要择优选取使用。
这几篇文章细节的点特别多,大家一定要自己动手操作几遍,有问题及时沟通,后续我会逐步安排相关的视频讲解,大家请注意关注本号,跟上队伍。
------
以下仍然是下期预告环节:

不少公司的老板不习惯看报表,而是喜欢直接在群里看图片,尤其是每天定时几个时间点,看看完成率,看看PV、UV等,那么我们能不能设置一下,Power BI做好的报表,定时发送到钉钉群中呢?
下一篇我们将继续介绍将Power BI和Python结合使用的第三种场景:
**Python定时自动将Power BI报告截图发送钉钉群。**
关于使用Python操控Power BI的网页端刷新,请阅读以下两篇文章:
[如果雇一个人7d×24h每10秒刷新一次Power BI,我需要每月支付他多少钱?](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483812&idx=1&sn=1d99a342ad280eac128845382886debb&chksm=ea674545dd10cc534548c85c923390ceddb1ea3688d8212f0c5697dbfe863183c52cd1e91128&scene=21#wechat_redirect)
[如果雇一个人7d×24h每10秒刷新一次Power BI,我需要每月支付他多少钱?【2】](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483832&idx=1&sn=57165f8f1e91e463a26589e4652acc88&chksm=ea674559dd10cc4f57a04e48cf7696e54ae150e3a8df155489bdfc8ed69a67350d585f92848f&scene=21#wechat_redirect)

------
感谢您对【学谦数据运营】的关注、支持与厚爱,如果本文对您有用,请不要吝惜您的点赞、转发和点亮在看,有任何问题欢迎大家在留言区询问,谢谢。
================================================
FILE: _posts/2020-03-31-Power BI数据回写SQL Server(1)没有中间商赚差价.md
================================================
Power BI数据回写SQL Server(1)没有中间商赚差价

我们在[【重磅来袭】在Power BI 中使用Python(4)——PQ数据导出&写回SQL](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483996&idx=1&sn=65fbc72a39ba9168ef611110b3a16e54&chksm=ea6746bddd10cfab9ea97b3e0c418bc5f7c195ad5d7f75edfc11fd41242cbd87cf8ff6f37103&scene=21#wechat_redirect) 讲过如何在Power BI中调用Python实现powerquery获取和处理的数据回写到MySQL中。
有不少朋友提问,能否回写到SQL SERVER中呢?
答案是肯定的。有两个大的解决方案:
第一个,由于本质上我们调用的是Python脚本,所以回写入哪个数据库由Python来决定。写入MySQL的库是pymysql,而如果要写入SQL SERVER我们需要更换一个库:
pip install pymssql
从名字上我们也能看出,这两个库的作者是同一个人,因此用法几乎完全一致。只不过在对待表名是中文时处理方式不太一样,MySQL需要在表名上加“`表名`”符号,SQL SERVER则不需要。
点击:转换-运行Python脚本,编辑代码,运行。
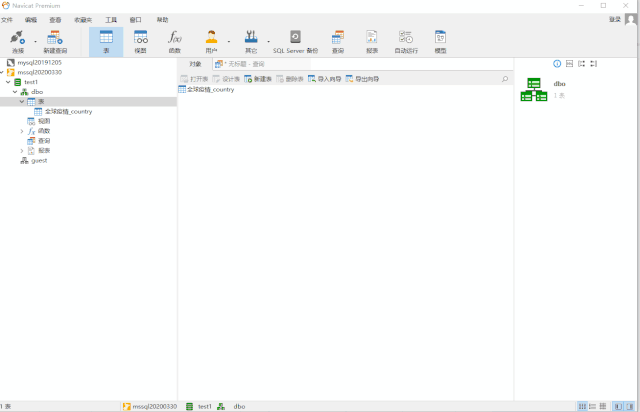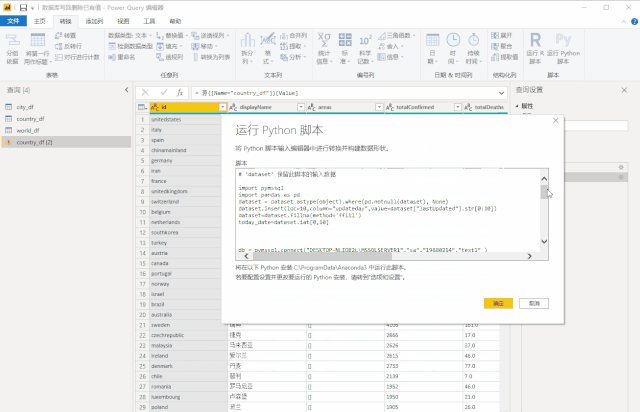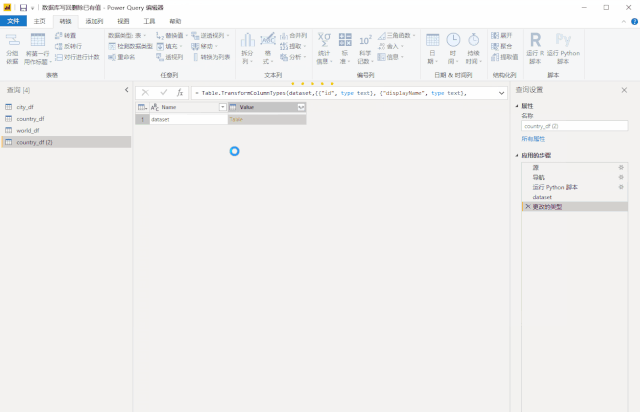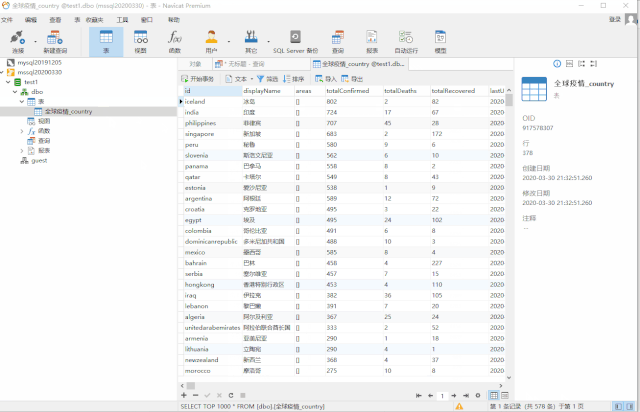
可以看到在运行Python脚本前,SQL数据库共378条数据,运行后是578条,增加了200条,这说明前几天只有189个国家和地区的数据,而今天更新有200个国家和地区的数据,这也直接说明病毒还在继续向更多国家蔓延,防控形势不容乐观。
*获取完整源代码,请关注【学谦数据运营】,回复关键字“powerbi-python-sqlserver”
*

第二个办法,其实更简单一些,而且直接跳过了Python,因为Power BI和SQL Server都是微软家的拳头产品,自家人,肯定办事方便些。
我们先从SQL Server导入一张表到powerquery中:
点开高级编辑器:
`let
源 = Sql.Database("DESKTOP-NLIOB2L\MSSQLSERVER1", "test1"),
dbo_Sheet1 = 源{[Schema="dbo",Item="Sheet1"]}[Data]`
`in dbo_Sheet1`
将以上代码适当进行修改:
`let
源 = Sql.Database("DESKTOP-NLIOB2L\MSSQLSERVER1", "test1",[Query="select * from Sheet1"])`
`in 源`
点运行:
两种查询方式得到的结果完全一致。
但是修改后的代码意义却变了:
`[Query="select * from Sheet1"]`
这实现了在PowerQuery中直接输入SQL Server代码并运行:
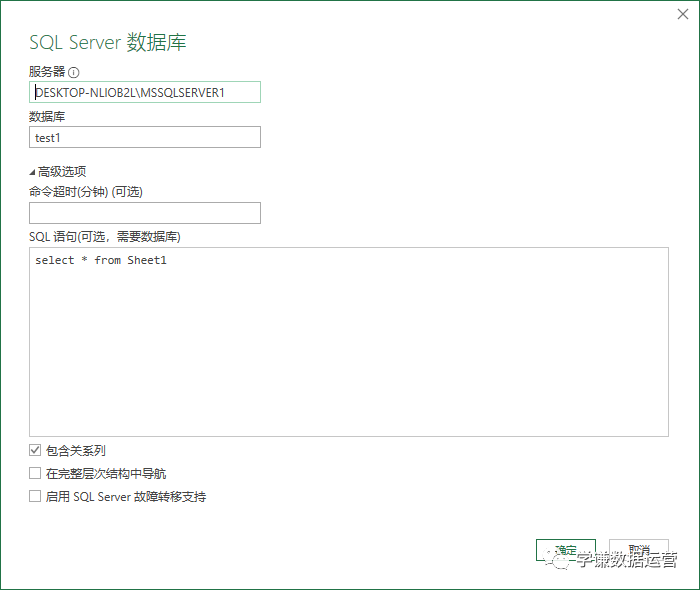
这就代表着我们可以通过编写SQL语句向SQL Server插入数据了:
`let
Source = Excel.CurrentWorkbook(){[Name="表1"]}[Content],
ChangedType = Table.TransformColumnTypes(Source,\{\{"KeyValue", type text}, {"NumberValue", Int64.Type}, {"DateValue", type date}}),
insert=Sql.Database("DESKTOP-NLIOB2L\MSSQLSERVER1", "test1",[Query="INSERT INTO Sheet1(KeyValue,NumberValue,DateValue)VALUES('A',3,'2019/1/1')"])`
`in insert`
看一下运行过程:
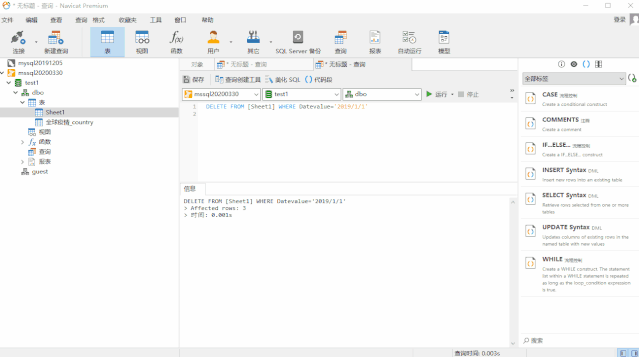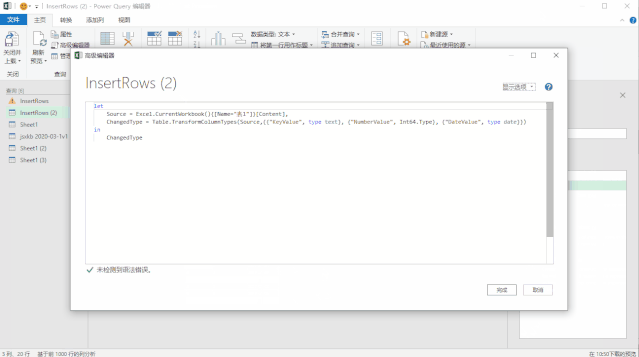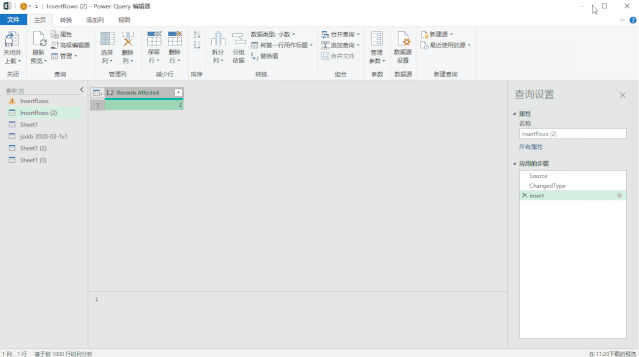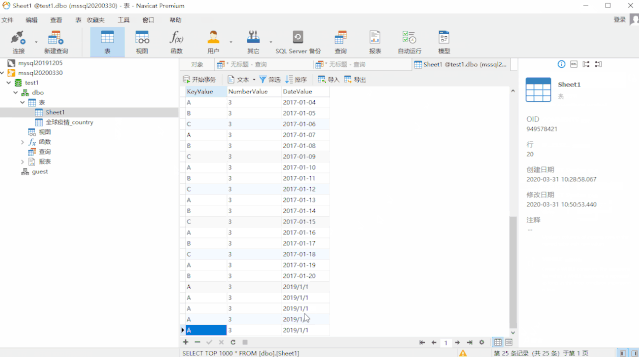
可以看到原表中只有2017年的数据,运行后增加了5行2019/1/1的数据,查询一次却增加多行的原因我们在[【重磅来袭】在Power BI 中使用Python(4)——PQ数据导出&写回SQL](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483996&idx=1&sn=65fbc72a39ba9168ef611110b3a16e54&chksm=ea6746bddd10cfab9ea97b3e0c418bc5f7c195ad5d7f75edfc11fd41242cbd87cf8ff6f37103&scene=21#wechat_redirect)中也说过,尚未明确知晓什么原理,只能通过其他办法来处理,稍后再说。
当然我们也可以同时插入多行数据:
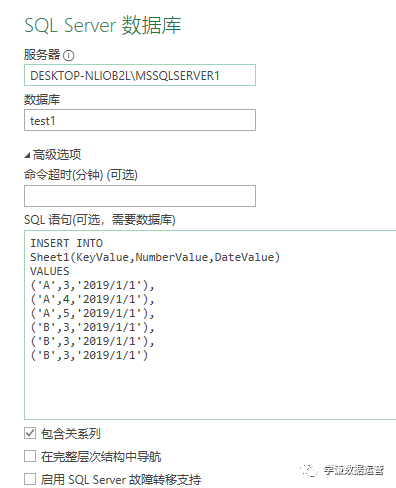
结果:
但是这样我们只能实现自己手动填写数据写入SQL语句去运行,而无法将PQ查询的结果写入SQL。
所以还得想别的办法。
我们再来试试Value.NativeQuery方法,是将一条record记录数据直接插入数据库中:
`Value.N`ativeQuery`
`(`
Sql.Database("DESKTOP-NLIOB2L\MSSQLSERVER1", "test1"),
"INSERT INTO Sheet1 VALUES(@KeyValue,@NumberValue,@DateValue)",
[KeyValue="NativeQuery",NumberValue=3,DateValue="2019/1/1"]
)`
运行结果:
测试没有问题。
那么重要的就来了:
如果我们能够将PQ返回的表按行转换为一条条的record记录,再逐条导入SQL Server,那么我们的需求就得到了解决。
第一步:使用Table.ToRecords函数将table转为record list:
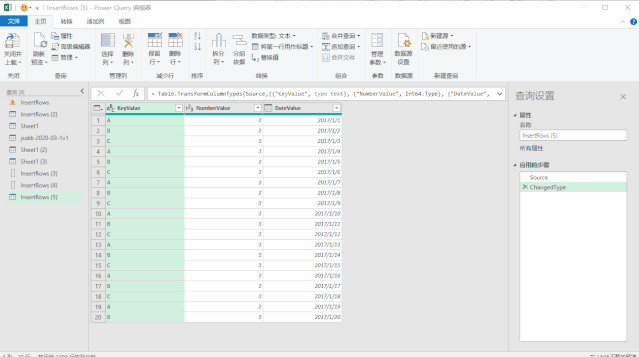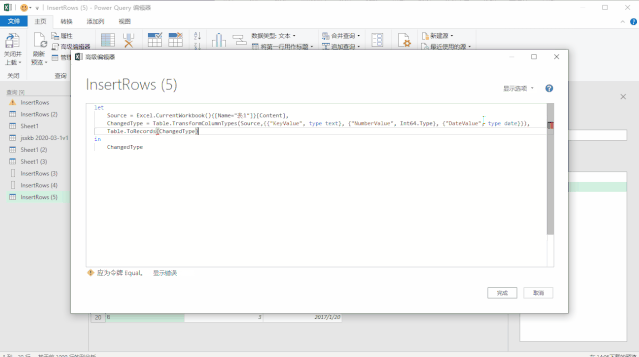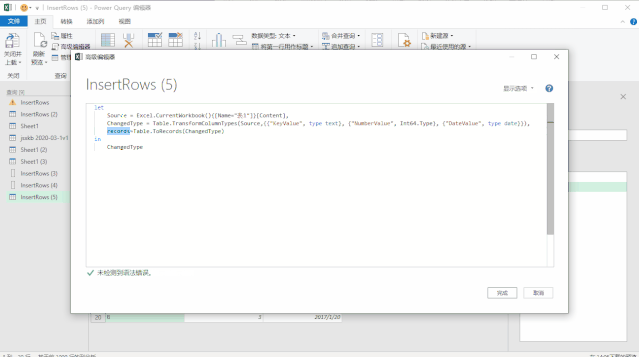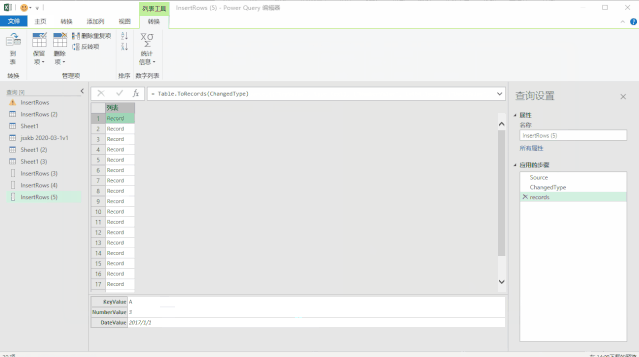
第二步:我们再做一个循环,逐行读取这些records,并用Value.NativeQuery函数套在这些records上:
`insert=List.Transform(records,(x)=>Value.NativeQuery(
Sql.Database("DESKTOP-NLIOB2L\MSSQLSERVER1", "test1"),
"INSERT INTO Sheet1 VALUES(@KeyValue,@NumberValue,@DateValue)",
x
))`
就得到结果了:
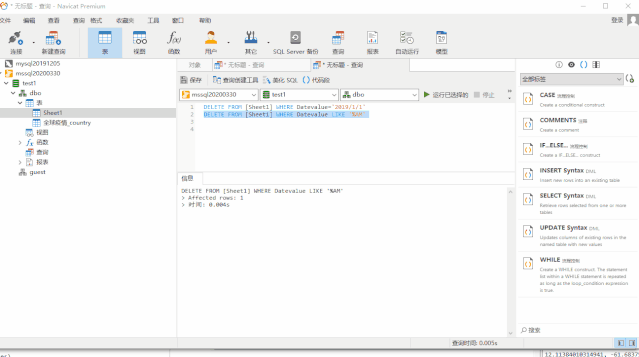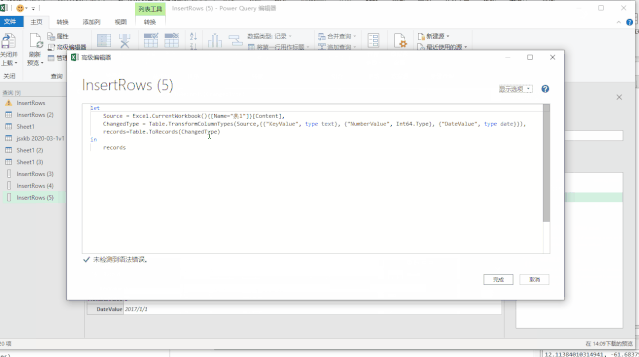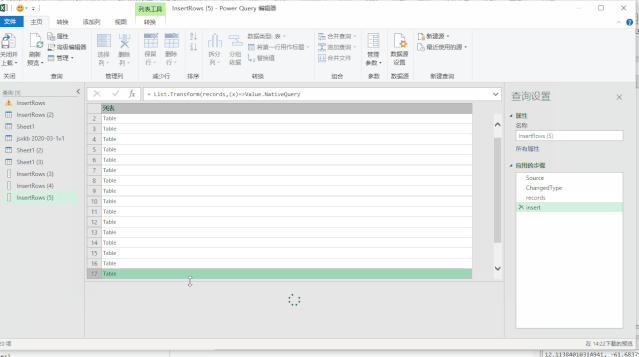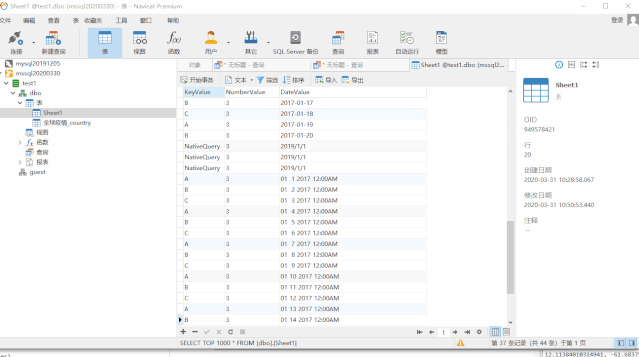
还是那句感叹:

只不过,日期格式跟之前的并不太一致:
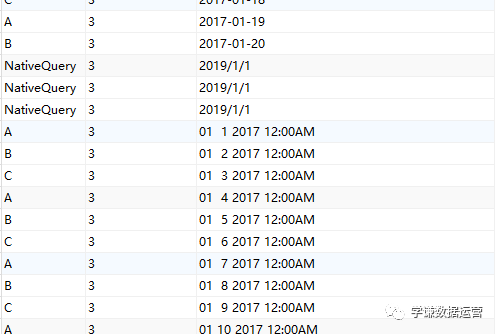
好在这并不是什么大问题,在SQL中设置一下datevalue字段的格式为date就可以搞定:
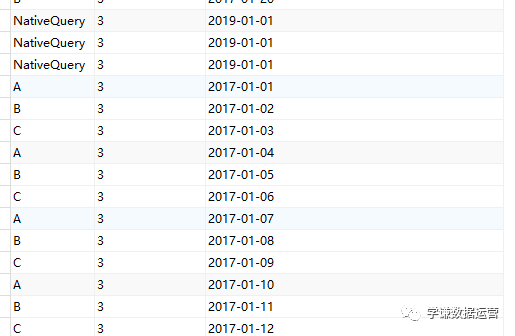

至于刷新时重复导入或者每日刷新多次的问题,大家结合上一篇文章自己就可以解决,无非就是用DELETE函数,这里就不再赘述了。
说到这里,我们再回过头来探讨一下Power BI和MySQL有没有可能也跳过Python这个“中间商”直接交易呢?
看图:
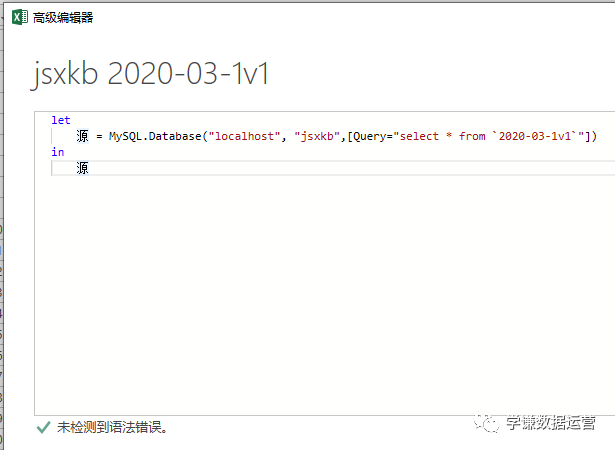
你说呢?

------
以下,后续文章预告:
今天我们讲的是PQ生成record列表,再逐个导入SQL中,那有没有办法将PQ中的table作为一个整体导入SQL中呢?
PowerQuery还为我们提供了其他方式,比如调用存储过程。
由于存储过程是SQL语言中很重要的一个内容,我们将用一整篇文章来详细说明,敬请期待。
================================================
FILE: _posts/2020-04-01-Power BI数据回写SQL Server(2)——存储过程一步到位.md
================================================
Power BI数据回写SQL Server(2)——存储过程一步到位

在上一讲:
[Power BI数据回写SQL Server(1)没有中间商赚差价](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247484034&idx=1&sn=d2dcffec82178d3f88c8812cca68006c&chksm=ea674663dd10cf7556a00cfe8e8d150eb426c08de59605d956d97bdd7e5acbeb5fb0335e3052&scene=21#wechat_redirect) 中,
我们讲过,利用循环的方式将PQ中得到的table表逐行导入SQL Server中,有的朋友怀疑这种方式会不会造成数据量较大时运行慢、能耗大的问题,这种顾虑理论上是恰当的,所以今天再介绍一种能够直接一次性导入SQL的办法。
熟悉SQL的同学可能已经想到了——“存储过程”。我们可以通过创建一个存储过程来读取PQ生成的文件,然后解析到数据库中。
用过这两种语言的朋友应该知道,PQ可以将查询结果的table转化为XML二进制文件或者JSON格式,而SQL恰好也能支持这两种文件格式的输入,这就好办了。
*略微扫一下盲:*
*JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式。它基于JavaScript的一个子集;*
*XML(Extensible Markup Language)即可扩展标记语言,Xml是Internet环境中跨平台的,依赖于内容的技术,是当前处理结构化文档信息的有力工具。*
*两者的共同优点是都是文本表示的数据格式,可以跨平台、跨系统交换数据。*
一、XML篇:
首先我们写一个带xml文件参数的存储过程:
这样我们就可以通过在SQL Server中直接调用这个函数来达到我们预先设定的插入数据的过程。
我们看一下XMLbinary的格式:
<table>
<row>
<KeyValue>学谦数据运营</KeyValue>
<NumberValue>35592</NumberValue>
<DateValue>2020/3/31</DateValue>
</row>
</table>
第二步,要将PQ返回的table转为以上的xml格式,我们需要在数据表中添加一列名为binary的自定义列,输入:
=Text.Format
(
"<row><KeyValue>#[KeyValue]</KeyValue><NumberValue>#[NumberValue]</NumberValue><DateValue>#[DateValue]</DateValue></row> ",
[KeyValue=[KeyValue], NumberValue=[NumberValue], DateValue=[DateValue]]
)
运行:
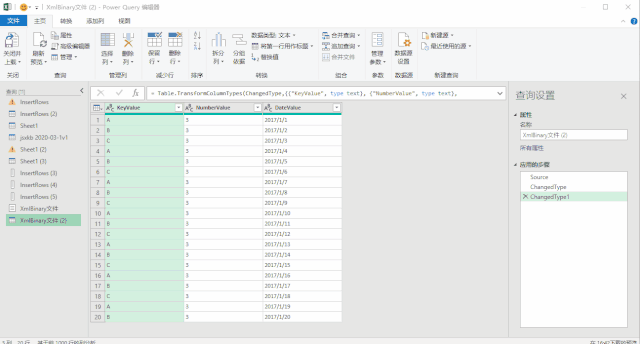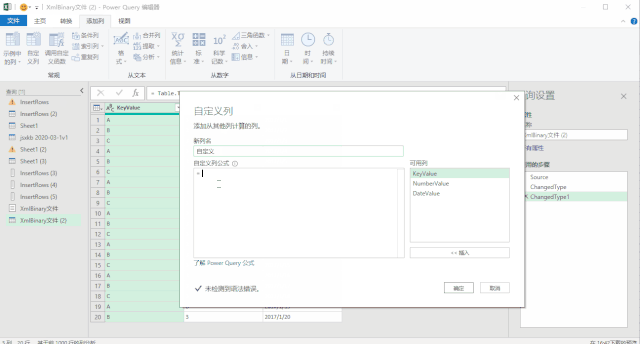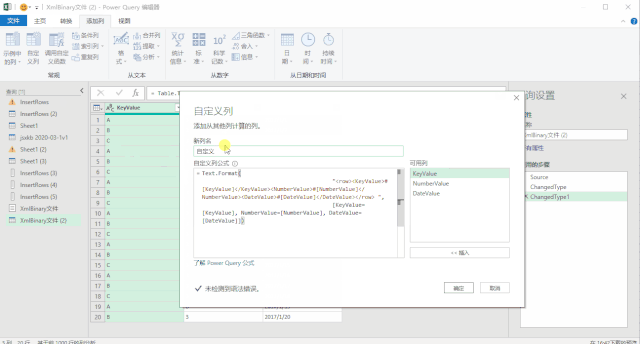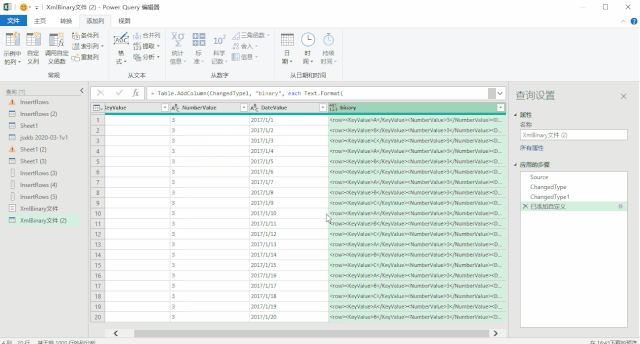
这样我们就得到了新的一列:
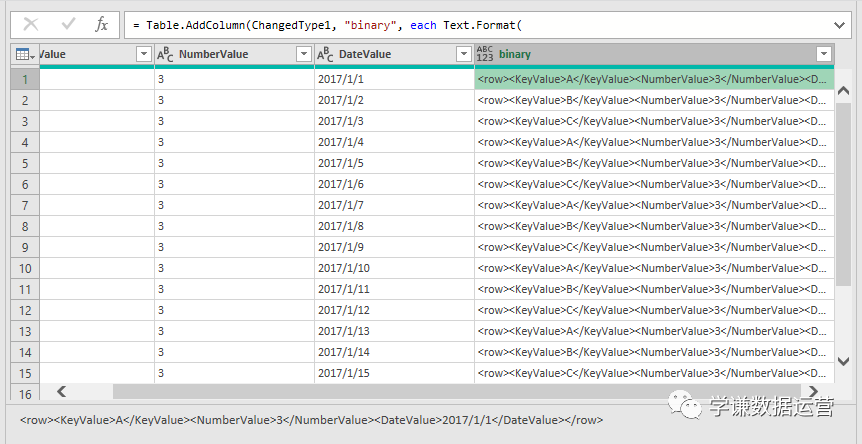
接着,我们只用这一列,将这一列文本前后分别加上一个“table”然后用Text.ToBinary()转为XMLbinary文件:
XmlBinary = Text.ToBinary("<table>" & Text.Combine(AddedCustom[binary]) & "</table>")
运行后我们就得到了一个XML二进制文件:
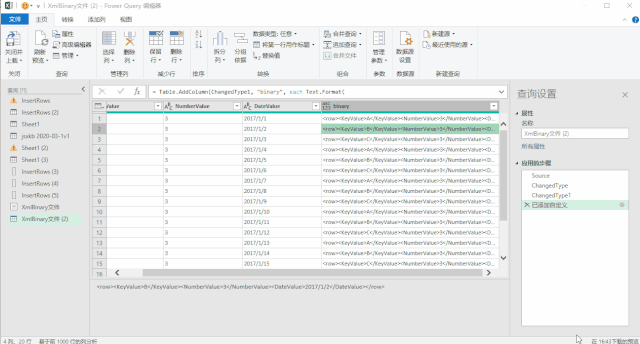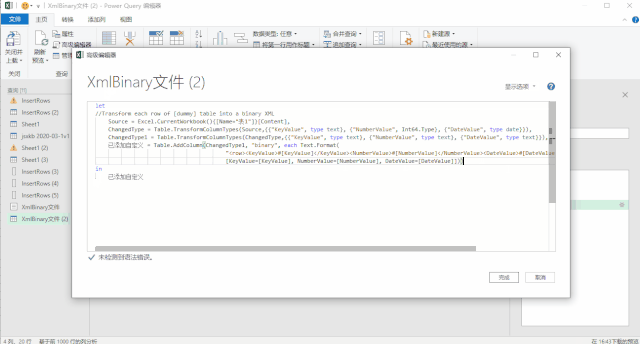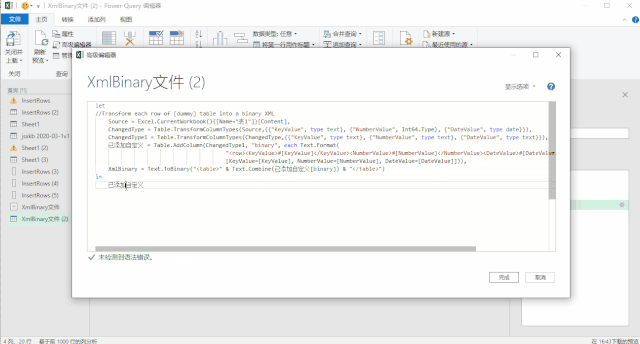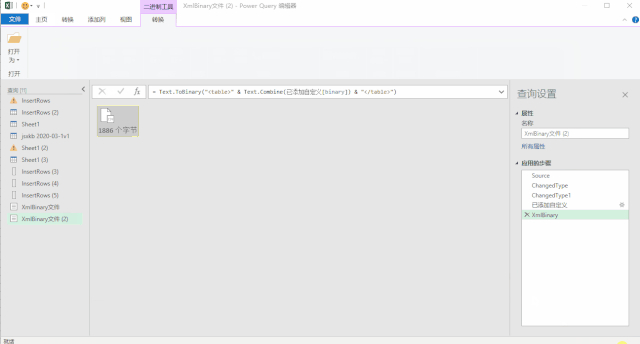
最后,我们要操作的就是将这个文件作为参数传递给SQL Server的存储过程,简单的一行代码:

运行一下看看效果:
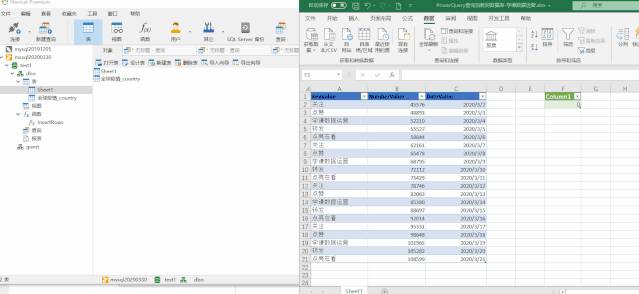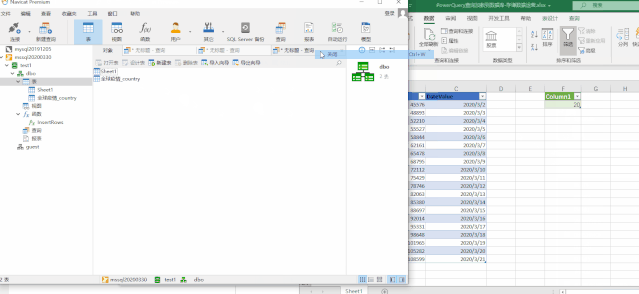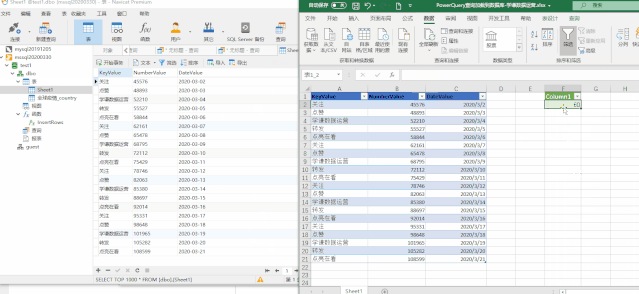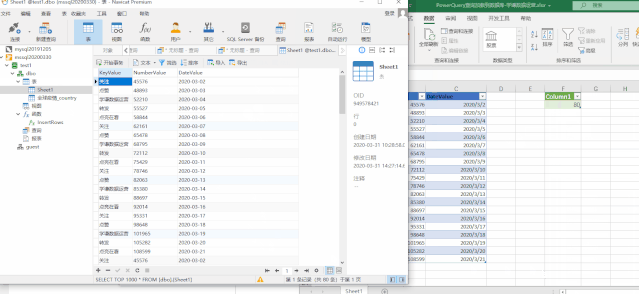
原表中数据为0,刷新一次后插入20行数据,多次刷新后,数据每次增加20行。
WOW,你们应该猜到我要说什么了:

二、JSON篇
第一步,在SQL Server中创建一个存储过程,调用json格式的文本为参数;
第二步,powerquery生成JSON格式其实更加简单,使用Json.FromValue(),直接将table转为JSON文件:
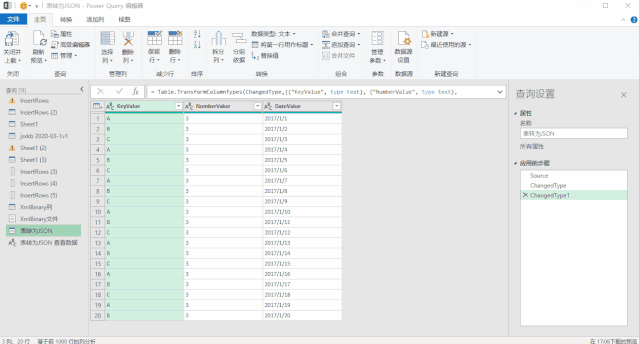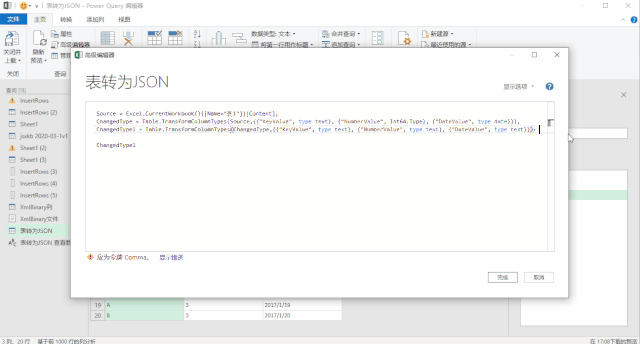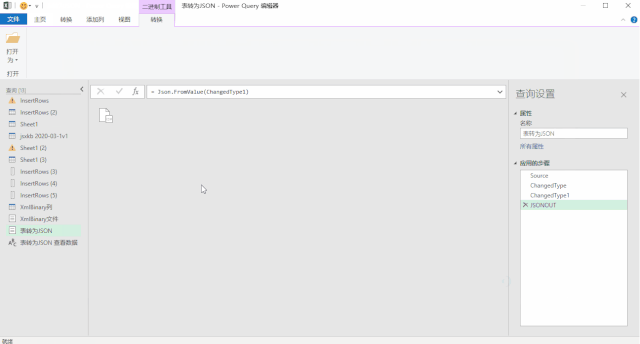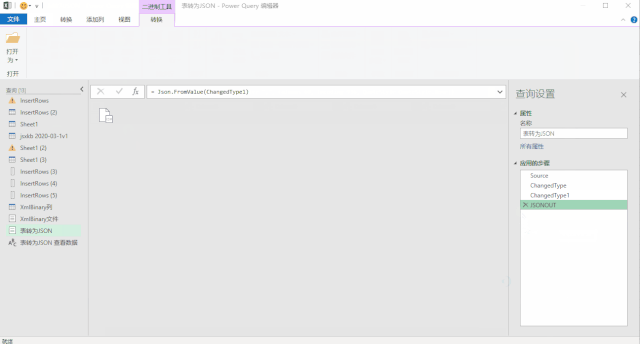
第三步,由于SQL读取的是字符串格式的JSON数据,所以需要使用Text.FromBinary()来返回字符串结果:
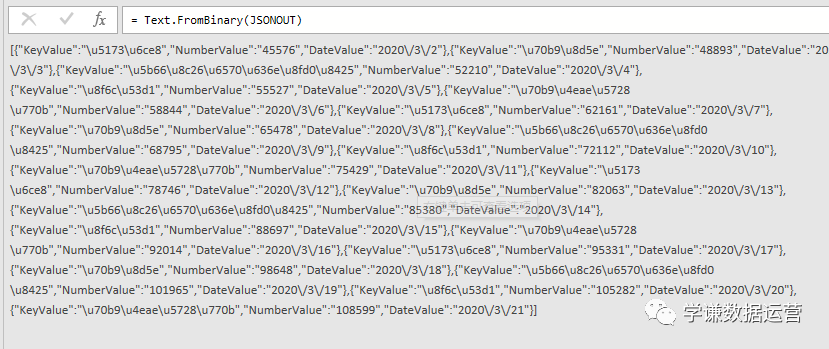
最后依然是向存储过程传递参数,只不过这次传递的是text格式JSON数据。
好了,我们来看一下效果,舞动起来:
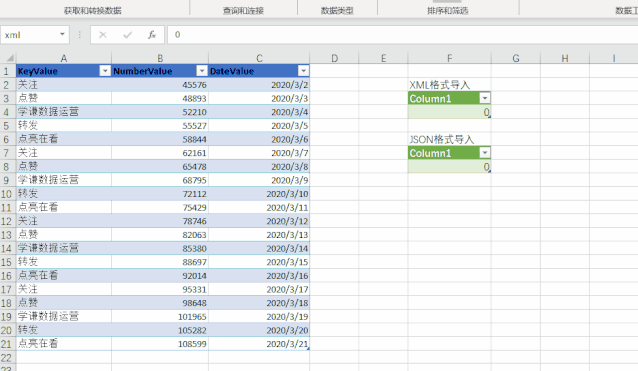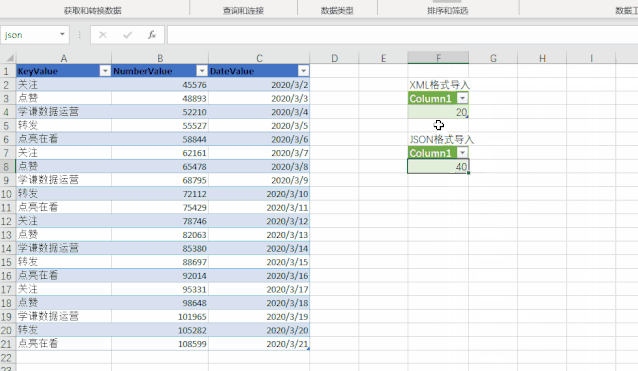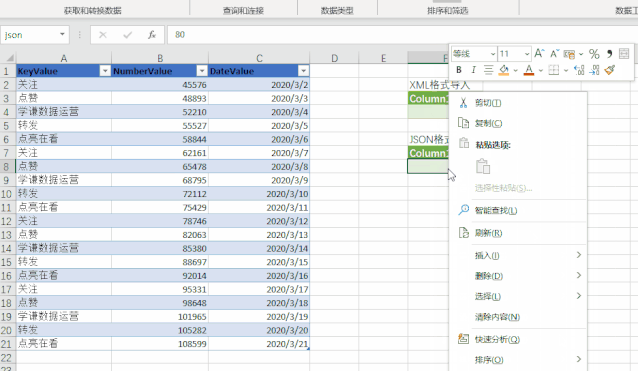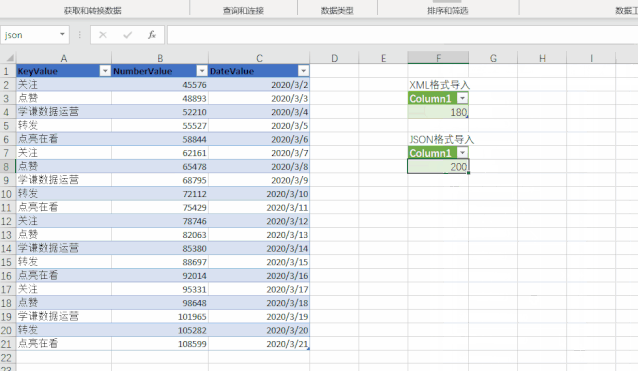
我们需要注意到,Text.FromBinary()获得的JSON字符串中文显示了Unicode编码字符,但是导入SQL中显示是中文没问题的:
*这里留给大家一个问题,如果我就想在powerquery中显示中文,应该怎么办呢?欢迎大家在留言区交流分享。
*
好了,关于如何Power BI如何向SQL回写数据,我们用了三篇文章来讲解。前两篇分别是:
[【重磅来袭】在Power BI 中使用Python(4)——PQ数据导出&写回SQL](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247483996&idx=1&sn=65fbc72a39ba9168ef611110b3a16e54&chksm=ea6746bddd10cfab9ea97b3e0c418bc5f7c195ad5d7f75edfc11fd41242cbd87cf8ff6f37103&scene=21#wechat_redirect)
[Power BI数据回写SQL Server(1)没有中间商赚差价](http://mp.weixin.qq.com/s?__biz=MzI2MDY3NDk1OA==&mid=2247484034&idx=1&sn=d2dcffec82178d3f88c8812cca68006c&chksm=ea674663dd10cf7556a00cfe8e8d150eb426c08de59605d956d97bdd7e5acbeb5fb0335e3052&scene=21#wechat_redirect)
对这几篇文章做一个小总结:
Power BI (PowerQuery)向SQL回写数据本身是一个应用场景并不多的技巧,没想到发了第一篇文章后很多朋友反馈说正是目前能用到的:
所以才有了后面的这两篇文章。
总结起来,方法有这么几个:
1、借助Python的相关库,在PQ中调用,以达到回写SQL的目的;
2、在PQ中循环按行导入SQL;
3、在SQL中创建存储过程,然后在PQ中调用存储过程,JSON或XML文件作为参数
同时,总结了几位朋友的案例,发现应用场景主要集中在这么两个方面:
①pq爬取的数据只是状态数据,转瞬即逝,无法变化记录;
②解决不同数据库之间的壁垒,比如要定期将数据从某个数据库中备份复制到另一个。
所以,如果你在日常工作学习中遇到了以上的应用场景,那么这三篇文章恰好能够帮助你。
不过,我在测试时用的都是几十行的小数据,这几种方法并没有感觉到任何区别,所以对于巨量数据是否会有差异并没有经过实际的测试,欢迎有兴趣的朋友对比一下这几种方式,比较一下优缺点,欢迎反馈。
------
感谢您对【学谦数据运营】的关注、支持与厚爱,如果本文对您有用,请不要吝惜您的点赞、转发和点亮在看,有任何问题欢迎大家在留言区询问或者直接加我个人微信,谢谢。
================================================
FILE: _posts/2020-04-04-同一台电脑管理多家企业Power BI报表的自动更新.md
================================================
# 2021.4.8更新:
其实随着后续做的项目越来越多以及个人测试的需求,在同一台电脑上管理两三个账号的报表已经明显不够用了。
因此几乎所有的数据都会存放在云端SharePoint或者云数据库中。免除了本地网关的烦扰,刷新起来会更加方便,尤其是配合无限刷新来使用更是得心应手。
# 以下为原文
同一台电脑管理多家企业Power BI报表的自动更新
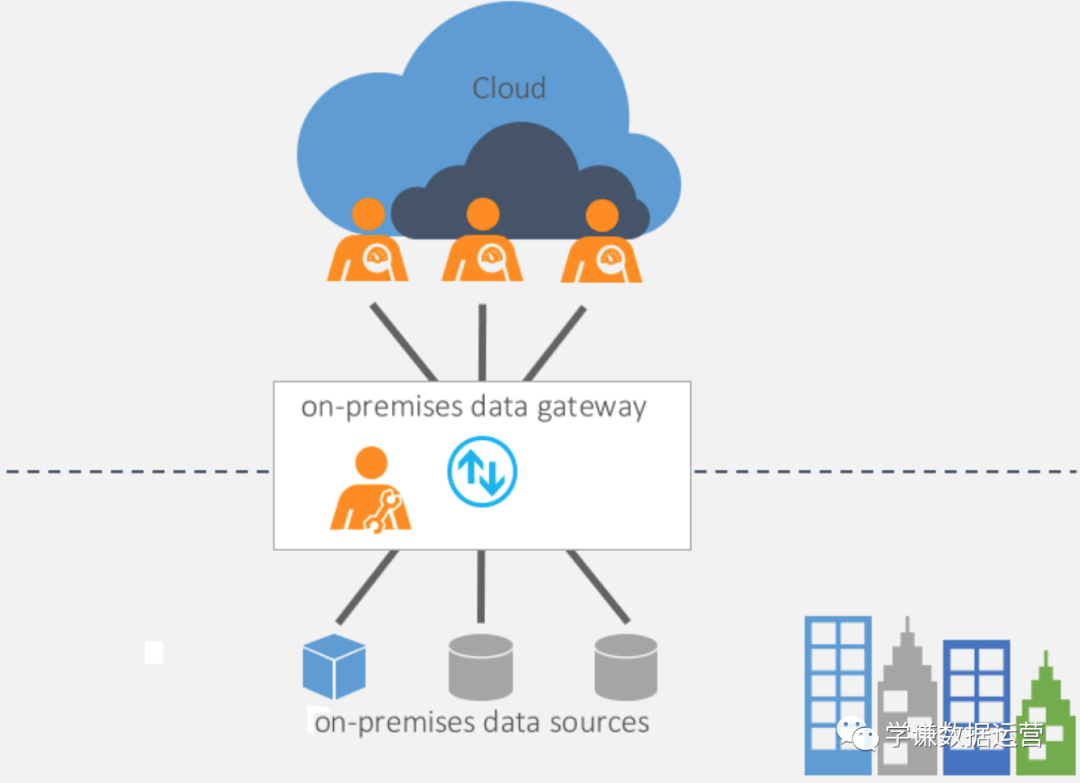
手里头拿着本公司的Power BI管理员账号,原本呢,一台电脑一个人一天处理一家公司的一亿数据是比较得劲的,尤其是有了Python自动任意刷新Power BI更是美滋滋。
可是最近手里头又捏了一家公司的管理员账号(详情见次条),本想着这一台电脑可以同时自动刷新两家公司,但是在登录网关时发现,登录了B公司的账号,A公司的网关自动就断开了,登录了A,B就掉了。
也就是说,同一时间,只能有一家公司自动刷新。这很显然不符合我们一贯的强行绕开微软限制的习惯。
仔细阅读了官方文档,发现,微软也还算仁慈:

原文文档:
https://docs.microsoft.com/zh-cn/data-integration/gateway/service-gateway-install
也就是说我们可以同时安装两个网关,而两个网关分别管理不同的企业。而文档也说的很清楚,同一个网关同一个模式只能登陆一个账号。
所以我们可以在一台电脑上同时用这两个网关了:
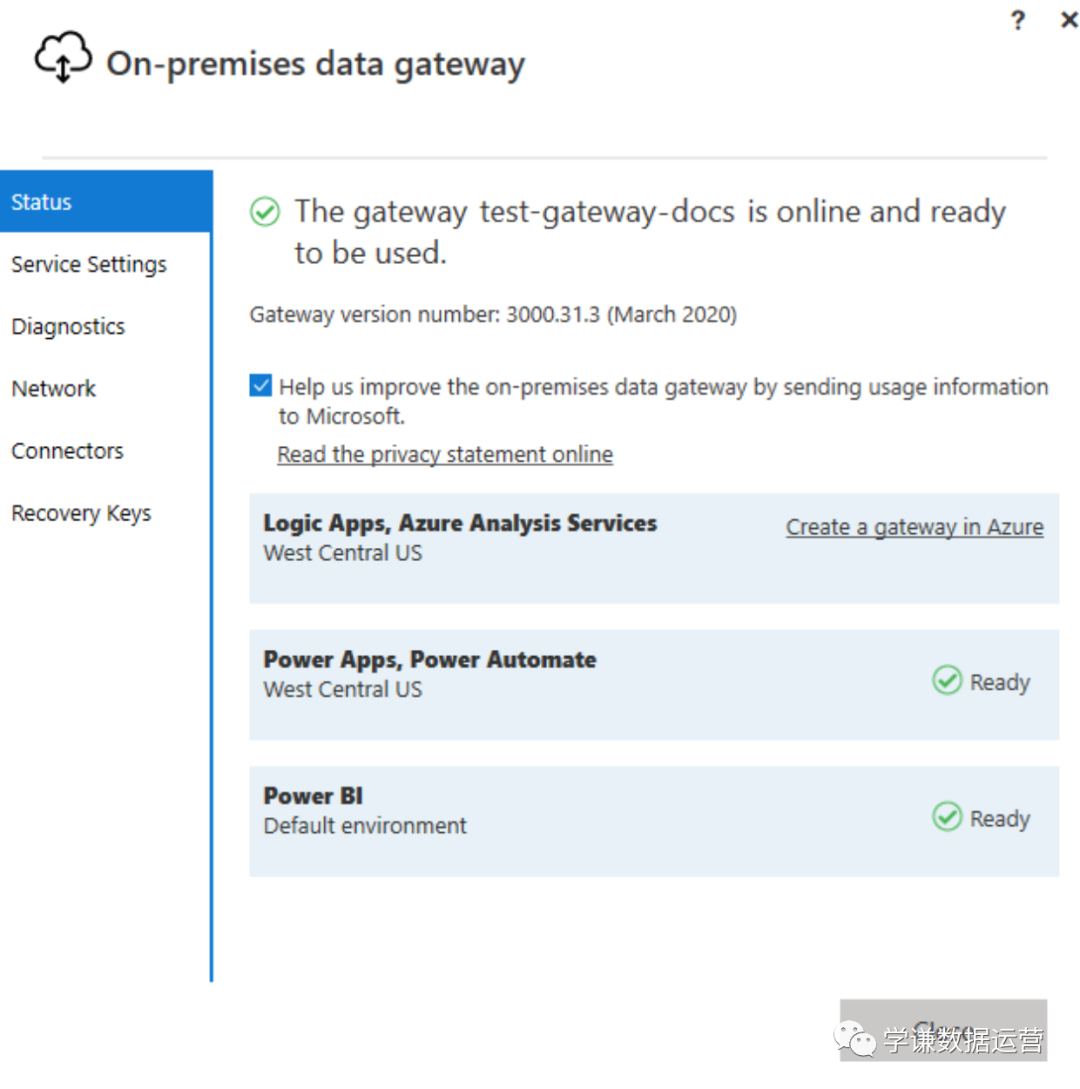
以上是标准模式,以下个人模式:
这样我们就可以同时在同一台电脑上管理两家公司的自动刷新了。
但是,如果两家公司的数据源没有任何交集,那么两个刷新可以任意设定时间,不受影响。而如果两个账号的数据源是同一个而且刷新时间还存在交叉,那么有较大概率其中一个刷新时会发生错误:
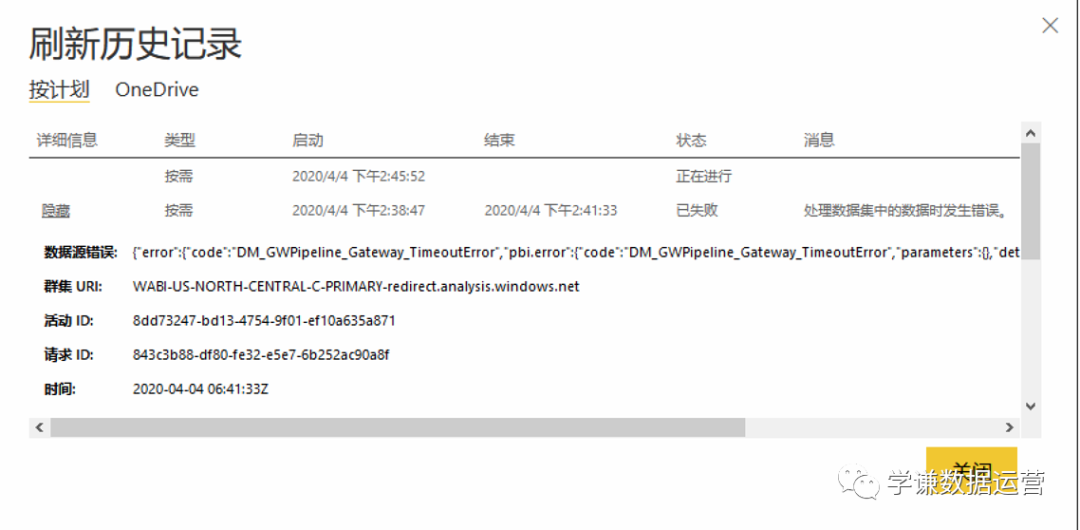
或者更新时间远远超过正常值:

而一旦刷新时间没有交集,一切就会恢复正常:
另一个账号的刷新时间:
这样,我们就实现了同时管理两个公司的目的。
或许这也是为什么微软不允许同一类型网关登录两个账号的原因。
其实我这两个账号的报表内容完全一致,数据源也一模一样,因为本地的模型都是一个。A账号是公司购买的世纪互联的账号,B账号是开发版,模型是同一个,但是使用的人不同。至于为什么,这就是企业内部的怪事之一了。
这里先挖个坑,说不定哪天我们就能像突破每天8次刷新的限制那样突破这个限制了,哈哈。
另外,算是一个建议,也是自己踩过的坑,尽可能数据源都在数据库中,而不是散落在各个excel表中:
每一个excel表都是一个单独的数据源,而无论你从数据库的多少个表中查询数据,数据源只有这一个数据库:
以上只是这一个模型数据源的一部分,说多了都是泪……
------
感谢您对【学谦数据运营】的关注、支持与厚爱,如果本文对您有用,请不要吝惜您的点赞、转发和点亮在看,有任何问题欢迎大家在留言区询问或者直接加我个人微信,谢谢。
================================================
FILE: _posts/2020-04-11-Python自动将Power BI页面发送钉钉群.md
================================================
前文说过,在很多个惬意的下午,我每每爽歪歪地喝着咖啡,看着Power BI每秒钟刷新一次,静静等待某个分公司完成本月绩效任务,自动调用Python在钉钉群中发送喜报:

紧接着再次调用Python将Power BI云端报告中的各分公司最新完成率数据和柱状图截图发在群里:

那么今天就来讲一讲如何使用Python自动将Power BI报表中的页面截图发送到钉钉群或企业微信群中。
首先我们来拆解一下整个过程:
首先需要用Python登录Power BI打开所要截图的页面,并截图保存到本地,是为第一步。
如果要发送图片到钉钉群或企业微信群中,需要以markdown格式发送,图片需要为链接而不是文件,这是第三步。
再来说中间的第二步,要实现本地图片到图片链接的转换,需要一个Python可调用的稳定图床,所以找到合适的图床很重要。
明白了这三步,我们就可以开始干活了。
一、登录Power BI并截图
我们在无限刷新Power BI的第一篇文章中讲过,使用selenium的webdriver就能实现,截图可以用selenium配合PIL库实现。当然,前提是需要提前获取所要截图的报表页面。
登录代码,马赛克区域替换为自己的用户名和密码:

截图代码:

截图时首先截取了全部浏览器,然后用四个角的坐标获取报表范围。最后保存到本地图片文件。
二、将本地文件上传云端并获取链接
这里我们使用的是七牛云。注册一下,然后创建个自有空间,设置好后,参考下文这个链接设置好SDK。
https://developer.qiniu.com/kodo/sdk/1242/python
将文件路径和文件名作为参数传递给函数,获取链接:

第二步结束。
三、发送钉钉群
1.在钉钉群中添加自定义机器人,并获取Webhook(注意Webhook不要泄露):

然后设置好markdown格式的消息,确定好要@的人即可:

好了,我们来看以下成品。

还是很简单的对吧。
获取源代码,请关注【学谦数据运营】,回复“开车”。
================================================
FILE: _posts/2022-04-05-Power BI Desktop 入门 - Power BI Microsoft Docs.md
================================================
# Power BI Desktop 入门 - Power BI | Microsoft Docs
其实接触Power BI这么多年,一直觉得官方给出的入门教程才是最好的。所以,入门课程不要想着去报什么班什么课程,好好看看这篇文章,吃透了,Power BI也就入门了。
原文地址:
[Power BI Desktop 入门 - Power BI | Microsoft Docs](https://docs.microsoft.com/zh-cn/power-bi/fundamentals/desktop-getting-started)
## 本文内容
1. [Power BI Desktop 工作原理](about:blank#how-power-bi-desktop-works)
2. [安装并运行 Power BI Desktop](about:blank#install-and-run-power-bi-desktop)
3. [连接到数据](about:blank#connect-to-data)
4. [调整数据](about:blank#shape-data)
5. [合并数据](about:blank#combine-data)
6. [生成报表](about:blank#build-reports)
7. [共享工作](about:blank#share-your-work)
8. [后续步骤](about:blank#next-steps)
欢迎使用 Power BI Desktop 入门指南。 本教程介绍 Power BI Desktop 的工作原理和功能,并介绍如何生成可靠的数据模型和奇妙的报表来提升你的商业智能。
要快速了解 Power BI Desktop 的工作原理及其使用方式,只需花几分钟浏览一下本指南中的屏幕。 要更深入地了解,可通读各个部分,执行相关步骤,创建自己的 Power BI Desktop 文件并将其发布到 [Power BI 服务](https://app.powerbi.com/)以与他人共享。
还可观看 [Power BI Desktop 入门](https://www.youtube.com/watch?v=Qgam9M8I0xA)视频,并下载 [财务示例](https://go.microsoft.com/fwlink/?LinkID=521962) Excel 工作簿按视频进行操作。
重要
每月更新并发布 Power BI Desktop,在其中包含客户反馈和新增功能。 仅支持 Power BI Desktop 的最新版本;将要求联系 Power BI Desktop 支持的客户升级到最新版本。 可以从 [Windows 应用商店](https://aka.ms/pbidesktopstore)获取 Power BI Desktop 的最新版本,也可以在计算机上以单个可执行文件的形式[下载](https://www.microsoft.com/download/details.aspx?id=58494)并安装所有受支持的语言。
## Power BI Desktop 工作原理
使用 Power BI Desktop,可以:
1. 连接到数据,包括多个数据源。
2. 借助可生成见解深刻、令人信服数据模型的查询来调整数据。
3. 使用数据模型创建可视化效果和报表。
4. 共享报表文件以供他人使用、用作基础文件和共享。 可像任何其他文件一样共享 Power BI Desktop“.pbix” 文件,但最具吸引力的方法是将其上传到 [Power BI 服务](https://preview.powerbi.com/)。
Power BI Desktop 集成了久经考验的 Microsoft 查询引擎、数据建模和可视化技术。 数据分析师和其他人员可以创建查询、数据连接、模型和报表集合,并轻松与他人共享。 通过组合 Power BI Desktop 和 Power BI 服务,数据世界的新见解将更易于建模、生成、共享和扩展。
Power BI Desktop 会集中、简化并效率化设计与创建商业智能存储库和报表的程序,这些程序可能是散乱、不相关且棘手的。 准备好要试一试吗? 现在就开始吧。
备注
对于必须保留在本地的数据和报表,Power BI 提供一个单独的专业版本,名为 [Power BI 报表服务器](https://docs.microsoft.com/zh-cn/power-bi/report-server/get-started)。 Power BI 报表服务器使用单独的专业版 Power BI Desktop,该版本名为用于 Power BI 报表服务器的 Power BI Desktop,并且仅适用于 Power BI 的报表服务器版本。 本文介绍标准版 Power BI Desktop。
## 安装并运行 Power BI Desktop
要下载 Power BI Desktop,请前往 [Power BI Desktop 下载页面](https://powerbi.microsoft.com/desktop),然后选择 “免费下载”。 或者对于下载选项,选择[查看下载或语言选项](https://www.microsoft.com/download/details.aspx?id=58494)。
还可从 Power BI 服务下载 Power BI Desktop。 在顶部菜单栏中选择 “下载” 图标,然后选择“Power BI Desktop” 。
在 Microsoft Store 页面上,选择 “获取”,然后按照提示在计算机上安装 Power BI Desktop。 从 Windows“开始” 菜单或从 Windows 任务栏中的图标启动 Power BI Desktop。
Power BI Desktop 首次启动时,会显示 “欢迎” 屏幕。
在 “欢迎” 屏幕中,可获取数据,查看最近使用的源,打开最近使用的报表,打开其他报表,或选择其他链接 。 选择关闭图标可关闭 “欢迎” 屏幕。

Power BI Desktop 左侧为三个 Power BI Desktop 视图的图标,从上到下为:“报表”、“数据” 和 “模型”。 左侧的黄色栏指示当前视图,可通过选择任一图标来更改视图。
如果使用的是键盘导航,请按 Ctrl + F6,将焦点移到窗口中的相应按钮部分。 若要详细了解辅助功能和 Power BI,请访问[辅助功能文章](https://docs.microsoft.com/zh-cn/power-bi/create-reports/desktop-accessibility-creating-tools)。

“报表” 视图为默认视图。
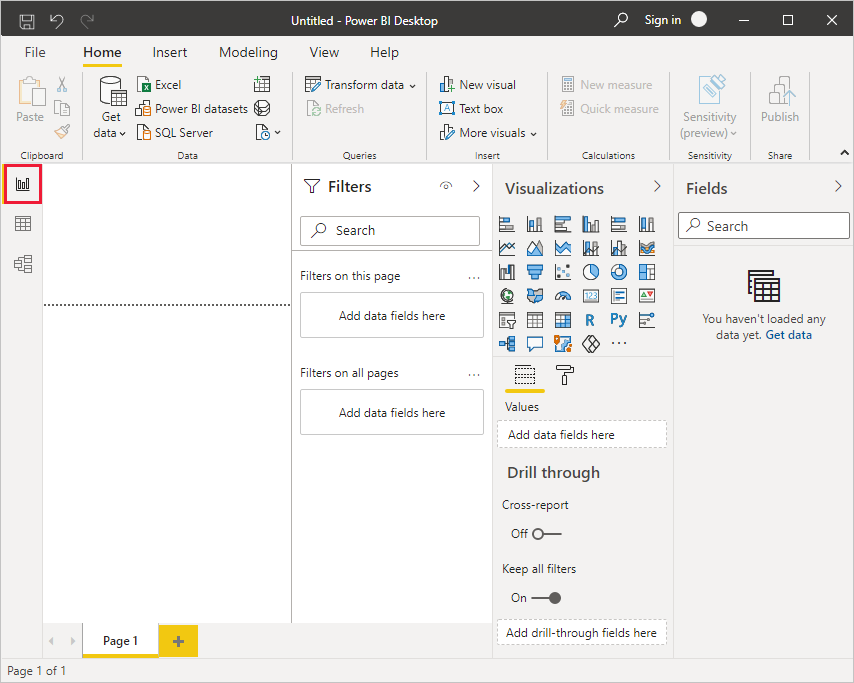
Power BI Desktop 还包括 “Power Query 编辑器”,它将在在单独的窗口中打开。 在“Power Query 编辑器” 中,可生成查询和转换数据,然后将经过细化的数据模型加载到 Power BI Desktop 以创建报表。
## 连接到数据
安装 Power BI Desktop 后,便可连接到不断扩展的数据世界。 要查看多种可用的数据源,请在 Power BI Desktop 的 “主页” 选项卡中选择 “获取数据”>“更多”,然后在“获取数据” 窗口中,滚动浏览 “所有” 数据源的列表 。 在本快速教程中,你将连接到几个不同的 “Web” 数据源。
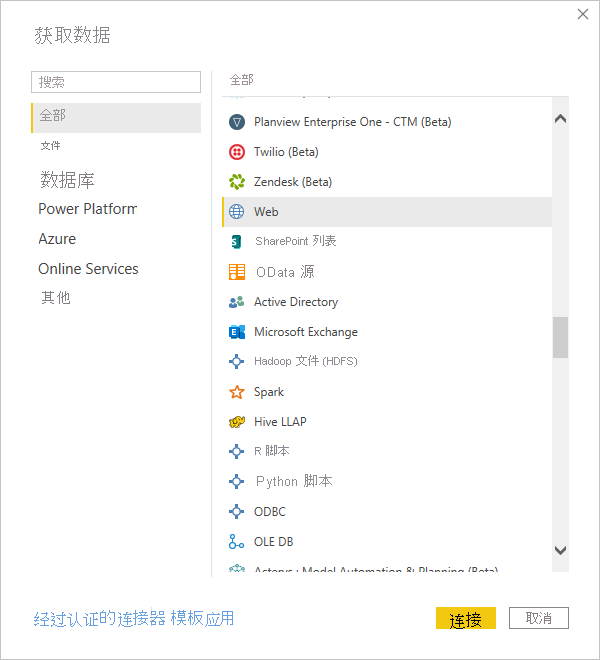
假设你是一家太阳镜零售商的数据分析师。 你希望帮助客户在四季阳光充足的州销售太阳镜。 Bankrate.com [最佳和最糟退休州](https://www.bankrate.com/retirement/best-and-worst-states-for-retirement/)页面上提供了关于本主题的有趣数据。
在 Power BI Desktop 的 “主页” 选项卡中,选择 “获取数据”>“Web” 以连接到 Web 数据源 。
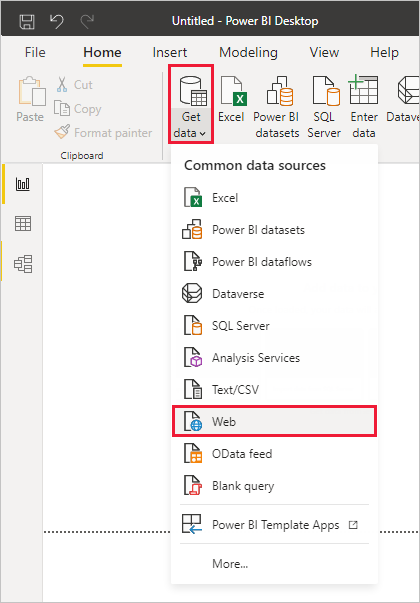
在 “从 Web” 对话框中,将地址 *[https://www.bankrate.com/retirement/best-and-worst-states-for-retirement/](https://www.bankrate.com/retirement/best-and-worst-states-for-retirement/)* 粘贴到 “URL” 字段,然后选择“确定”。

如果出现提示,请在 “访问 Web 内容” 屏幕上,选择 “连接” 以使用匿名访问 。
Power BI Desktop 的查询功能开始运行并与 Web 资源联系。 “导航器” 窗口返回它在网页上找到的内容,在本例中,它返回一个名为 “Ranking of best and worst states for retirement”(全美最佳与最差退休居住州排名)的 HTML 表和其他五个建议的表 。 你对 HTML 表感兴趣,因此选择它进行预览。
此时,你可以选择 “加载” 来加载该表,也可以选择 “转换数据” 以在表中进行更改,然后再加载 。
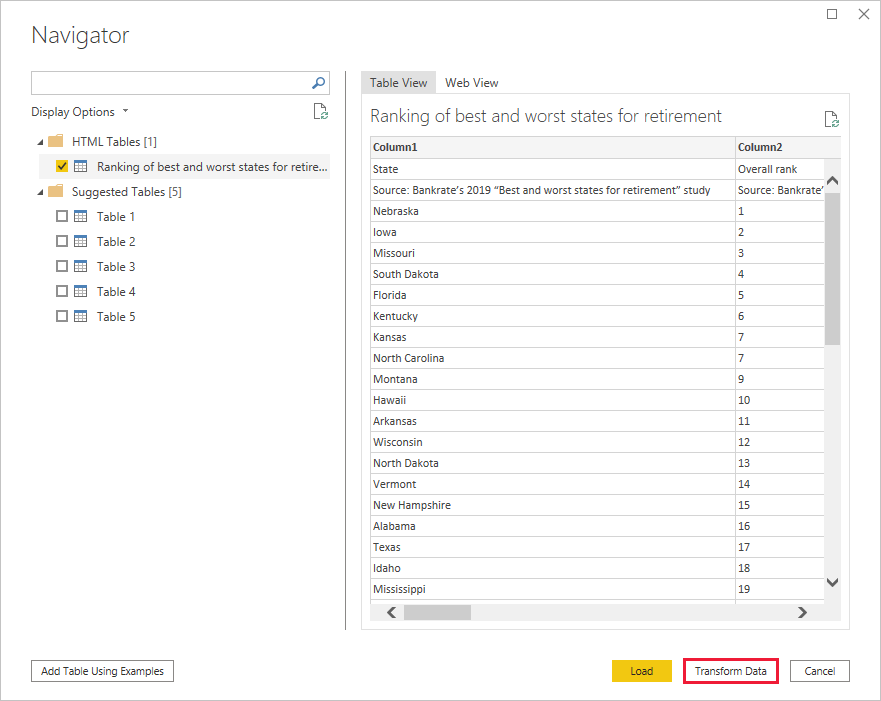
如果选择 “转换数据”,Power Query 编辑器将会启动,并显示表的代表性视图。 “查询设置” 窗格在右侧,你也可以通过如下操作来显示它:在 Power Query 编辑器的 “视图” 选项卡上,选择“查询设置” 。

有关连接到数据的详细信息,请参阅[连接到 Power BI Desktop 中的数据](https://docs.microsoft.com/zh-cn/power-bi/connect-data/desktop-connect-to-data)。
## 调整数据
现在你已经连接到数据源,你可以调整数据以符合需求。 要调整数据,请在加载和呈现数据时为 Power Query 编辑器提供调整数据的分步说明。 调整不会影响原始数据源,只会影响数据的这一特定视图。
备注
本指南中使用的表数据可能随时更改。 因此,你需要遵循的步骤可能有所不同,这就要求你在调整步骤或结果方面具有创造性,这也体现了学习的乐趣。
调整可能意味着转换数据,例如,重命名列或表、删除行或列,或者更改数据类型。 Power Query 编辑器在 “查询设置” 窗格中的 “已应用步骤” 下依次捕获这些步骤 。 每当此查询连接到数据源时,都会执行这些步骤,这样,数据将始终以指定的方式进行调整。 每当你在 Power BI Desktop 中使用查询时,或任何人使用你的共享查询(例如在 Power BI 服务中)时,都会执行此过程。
注意,“查询设置”中的 “已应用步骤” 已经包含了一些步骤 。 你可以选择每个步骤来查看其在 Power Query 编辑器中的效果。 一开始,你指定了一个 Web 源,然后在 “导航器” 窗口中预览了表。 在第三步中,更改了类型,Power BI 在导入时识别了整数数据,并自动将原始 Web“文本”数据类型更改为了“整数”。
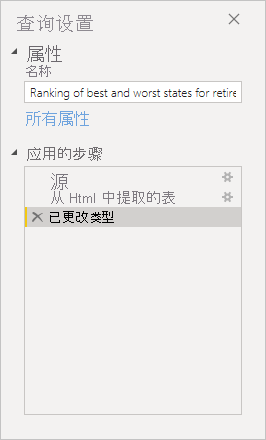
如果需要更改数据类型,请选择一列或多列进行更改。 按住 “Shift” 键可选择多个相邻的列,按住 “Ctrl” 键可选择非相邻列 。 右键单击列标题,选择 “更改类型”,然后在菜单中选择新数据类型;或者在“主页” 选项卡的 “转换” 组中,下拉 “数据类型” 旁边的列表,然后选择新数据类型 。
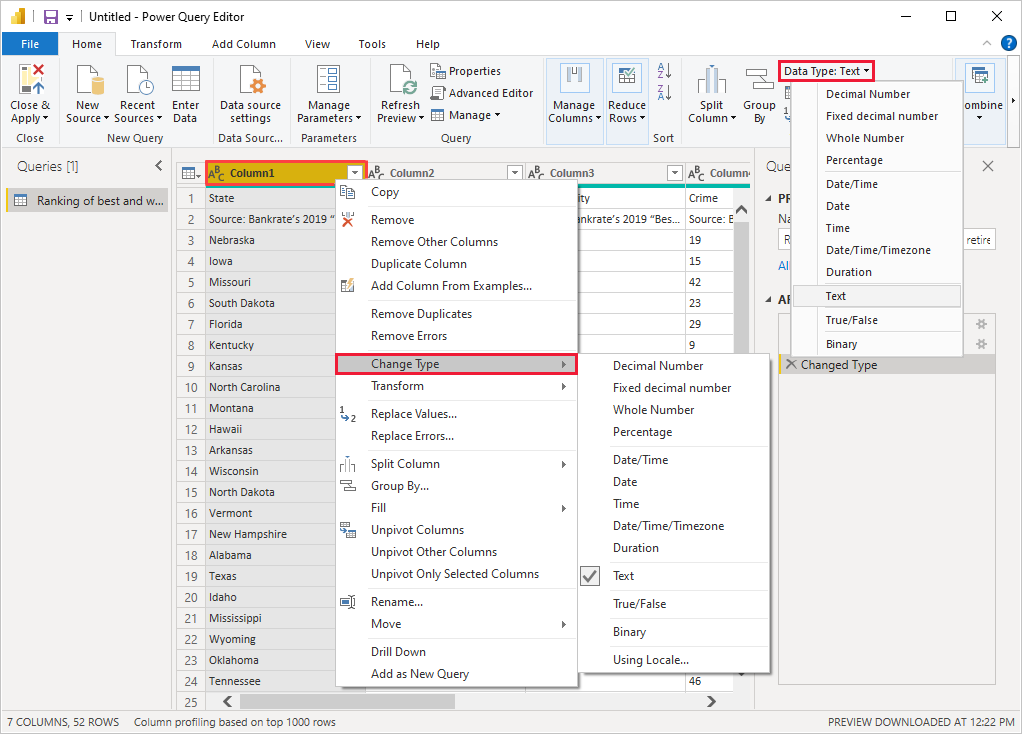
备注
Power BI Desktop 中的 Power Query 编辑器使用功能区或右键单击菜单来执行可用任务。 大部分可在 “主页” 或功能区的 “转换” 选项卡上选择的任务,也可以通过右键单击一个项目并在出现的菜单中进行选择来实现 。
现在,你可以对数据应用自己的更改和转换,并在 “已应用步骤” 中查看。
例如,对于太阳镜销售,你最想了解的是天气排名,因此,你决定按照 “天气” 列而不是 “整体排名” 来对表进行排序 。 下拉 “天气” 标头旁边的箭头,并选择 “升序排序” 。 数据现在按照天气排名排序,并且“已应用步骤” 中会出现 “已对行排序” 这一步骤 。
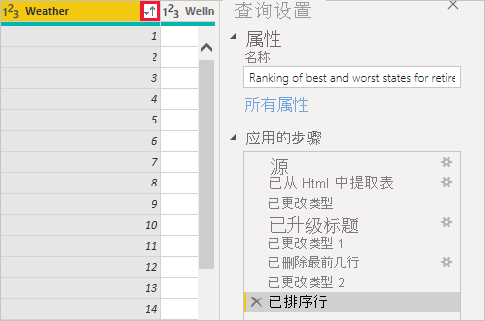
你不是很想把太阳镜卖给天气最糟糕的州,所以你决定将它们从表中删除。 从 “主页” 选项卡中,依次选择 “减少行”>“删除行”>“删除最后几行” 。 在“删除最后几行” 对话框中,输入“10”,然后选择“确定” 。
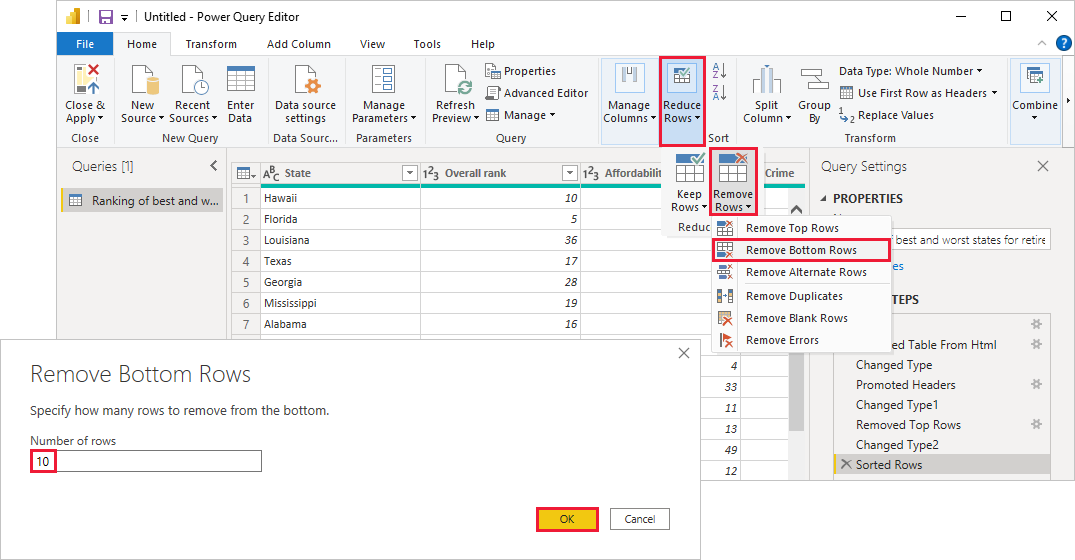
将从表中删除最后 10 行天气最糟糕的州,并且 “已应用步骤” 中会出现 “已删除最后几行” 这一步骤 。
你认为表中包含太多不必要的信息,决定删除 “可购性”、“犯罪”、“文化” 和“健康”列 。 选择要删除的各列的标头。 按住 “Shift” 键可选择多个相邻的列,按住 “Ctrl” 键可选择非相邻列 。
然后,从 “主页” 选项卡的 “管理列” 组中,选择 “删除列” 。 你还可右键单击其中一个选定的列标头,然后在菜单中选择“删除列”。 此操作将删除选定的列,并且“已应用步骤” 中会出现“已删除列” 。
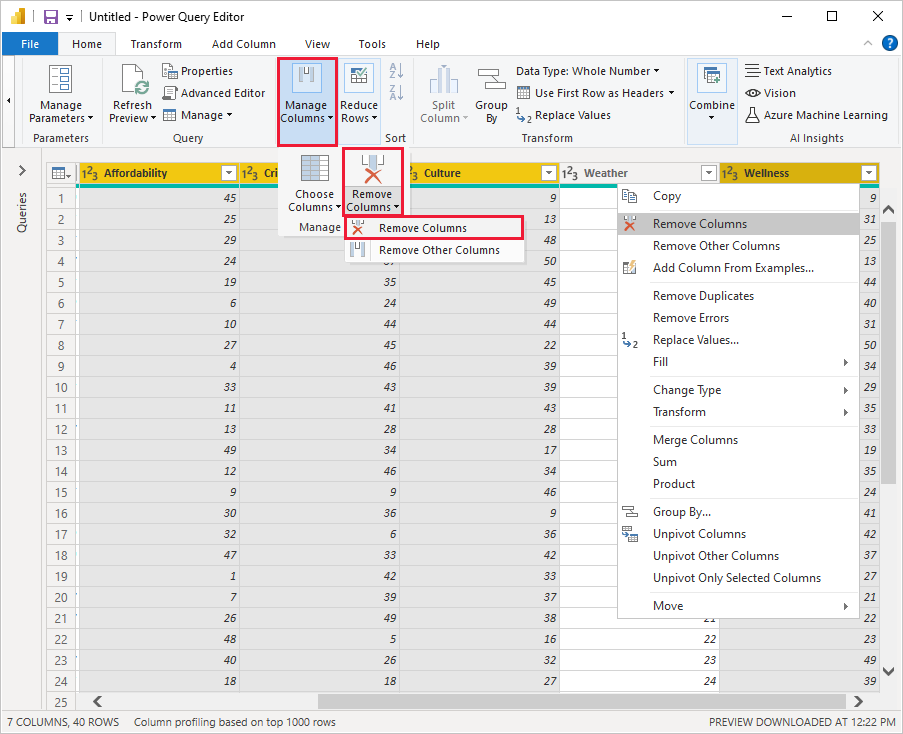
再想想,“可购性”可能与太阳镜的销售有关。 你希望恢复该列。 通过选择步骤旁边的 “X” 删除图标,可以轻松撤消 “已应用步骤” 窗格中的最后一步 。 现在重新执行步骤,仅选择要删除的列。 为了获得更大的灵活性,可以分步删除每一列。
你可以右键单击 “已应用步骤” 窗格中的任何步骤,然后选择删除它、对其进行重命名、在序列中上移或下移,或在其后添加或删除步骤。 对于中间步骤,如果更改可能会影响后续步骤并中断查询,Power BI Desktop 将向你发出警告。
例如,如果不再希望根据 “天气” 对表进行排序,可以尝试删除 “已对行排序” 步骤 。 Power BI Desktop 会警告你删除此步骤可能会导致查询中断。 按天气排序后,你删除了最后 10 行,因此,如果删除排序,将删除不同的行。 如果选择 “已对行排序” 步骤,并尝试在此添加新的中间步骤,也会出现警告。
最后,将表标题更改为关于太阳镜销售,而不是退休。 在 “查询设置” 窗格中的 “属性” 下,将旧的标题替换为“最佳太阳镜销售州” 。
完成后的已调整数据查询如下所示:
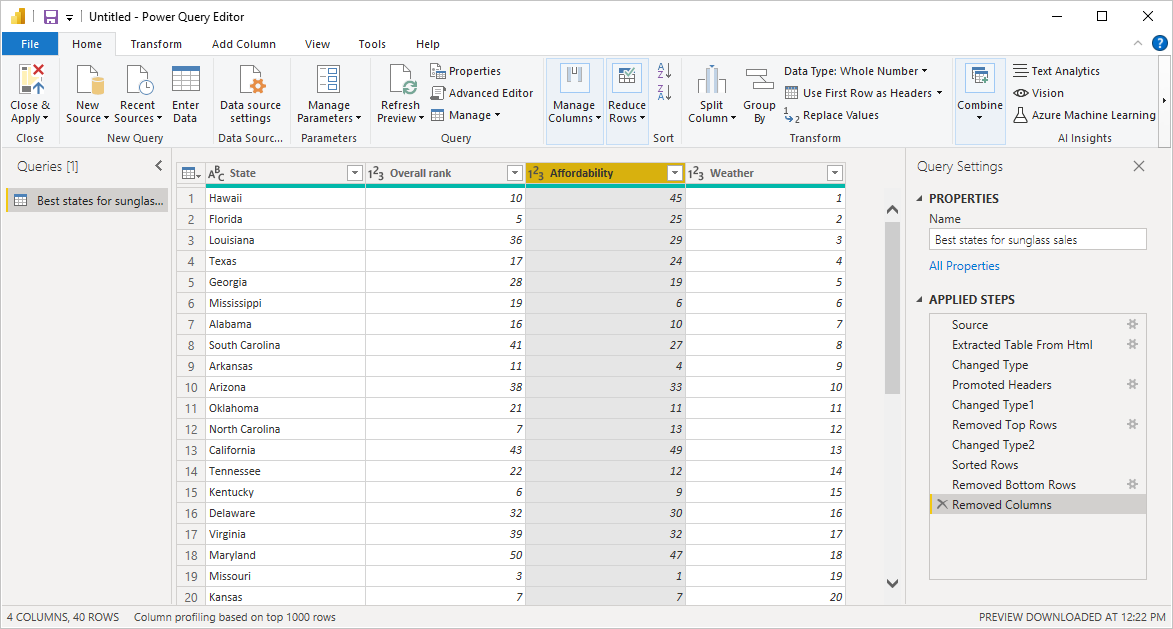
有关调整数据数据的详细信息,请参阅[在 Power BI Desktop 中调整和合并数据](https://docs.microsoft.com/zh-cn/power-bi/connect-data/desktop-shape-and-combine-data)。
## 合并数据
有关各州的那份数据很有趣,而且适用于生成其他分析工作和查询。 但是有一个问题:大多数数据使用两个字母的州代码缩写,而不是完整名称。 要使用该数据,需要通过某种方式来将州名与其缩写关联。
你很幸运。 另一个公共数据源可以做到这一点,但你需要对数据进行大量的调整,然后才能将数据合并到太阳镜表。
要将州缩写数据导入 Power Query 编辑器,请在功能区 “主页” 选项卡上的 “新建查询” 组中,选择“新增源”>“Web” 。

在 “从 Web” 对话框中,输入州缩写站点的 URL:*[https://en.wikipedia.org/wiki/List\_of\_U.S.\_state\_abbreviations](https://en.wikipedia.org/wiki/List_of_U.S._state_abbreviations)*。
在 “导航器” 窗口中,选择 “美国各州、联邦地区、领地及其他区域的代码和缩写” 表,然后选择“确定” 。 该表将在 Power Query 编辑器中打开。
删除 “区域的名称和状态”、“区域的名称和状态” 和“ANSI”之外的所有列 。 要仅保留这些列,请按住 “Ctrl” 并选择相应的列。 然后,右键单击其中一个列标头并选择 “删除其他列”,或者在“主页” 选项卡的 “管理列” 组中,选择“删除其他列” 。
下拉 “区域 1 的名称和状态” 列标头旁边的箭头,并选择 “筛选器”>“等于” 。 在“筛选行” 对话框中,下拉 “等于” 旁边的 “输入或选择值” 字段,然后选择“州” 。 选择“确定”。

删除了 “联邦地区” 和“岛”这样的额外值后,现在就有了一个包含 50 个州及其官方双字母缩写形式的列表 。 你可以重命名列以便更好理解,例如 “州名”、“状态” 和“缩写”,方法是右键单击列标头并选择“重命名” 。
注意,所有这些步骤都记录在 “查询设置” 窗格中的 “已应用步骤” 下 。
调整后的表现在如下所示:
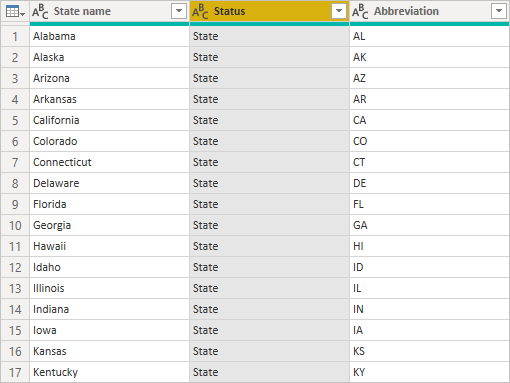
在 “查询设置” 的“属性”字段中,将表重命名为“州代码” 。
“州代码” 表调整完成后,你可以将这两个表合并为一个表。 由于你现在拥有的表是你向数据应用查询之后的结果,因此它们也称为 “查询”。 有两种主要方法可合并查询:合并和追加 。
当你有一列或多列要添加到另一个查询时,你可合并这些查询。 当你有其他数据行要添加到现有查询时,你可追加查询。
在本例中,你希望将 “州代码” 查询合并到 “最佳太阳镜销售州” 查询 。 要合并查询,请切换到 “最佳太阳镜销售州” 查询,方法是从 Power Query 编辑器左侧的 “查询” 窗格中选择它 。 然后在功能区 “主页” 选项卡中的 “合并” 组中,选择“合并查询” 。
在 “合并” 窗口中,下拉字段,可从其他可用查询中选择 “州代码” 。 在每个表中选择要匹配的列,在本例中,为“最佳太阳镜销售州” 查询中的 “州” 和“州代码”查询中的“州名” 。
如果出现 “隐私级别” 对话框,请选择“忽略此文件的隐私级别检查”,然后选择“保存” 。 选择“确定”。
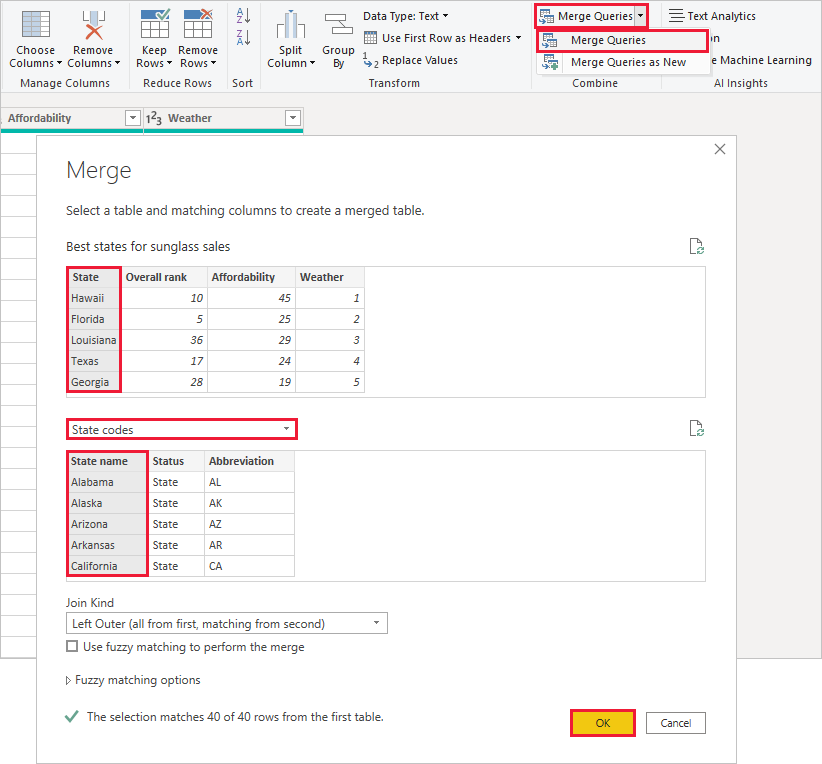
“最佳太阳镜销售州”表的右侧将出现一个名为 “州代码” 的新列 。 它包含与 “最佳太阳镜销售州” 查询合并的 “州代码” 查询。 合并后的表中的所有列都压缩到 “州代码” 列中。 你可以展开合并后的表并仅包含所需的列。
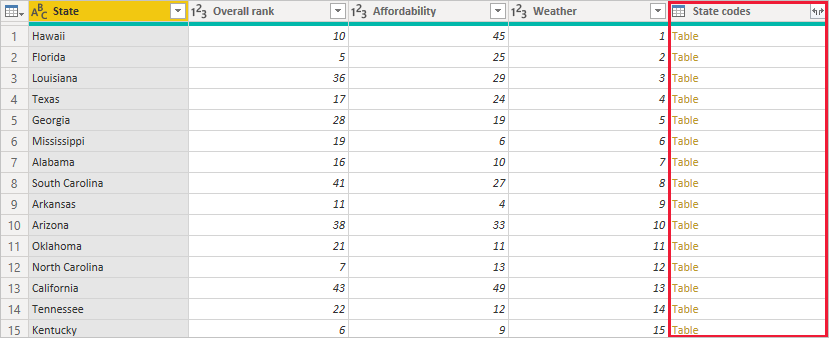
要展开合并后的表,并选择要包含的列,请选择列标头中的 “展开” 图标。 在 “展开” 对话框中,仅选择 “缩写” 列 。 取消选中“使用原始列名作为前缀”,然后选择“确定” 。
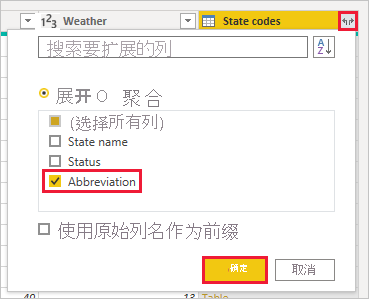
备注
你可以尝试一下如何引入 “州代码” 表。 尝试一下,如果不喜欢结果,只需从 “查询设置” 窗格中的 “已应用步骤” 列表中删除该步骤即可 。 这就像是个自由重做的机会,你可以不限次数地任意执行,直到展开过程看起来是你要的方式为止。
有关调整及合并数据步骤的更完整说明,请参阅[在 Power BI Desktop 调整和合并数据](https://docs.microsoft.com/zh-cn/power-bi/connect-data/desktop-shape-and-combine-data)。
现在,你在单个查询表中合并了两个数据源,每个数据源都已根据需要进行调整。 此查询可以作为许多其他有趣数据连接的基础,例如各州的人口统计、财富水平或娱乐机会。
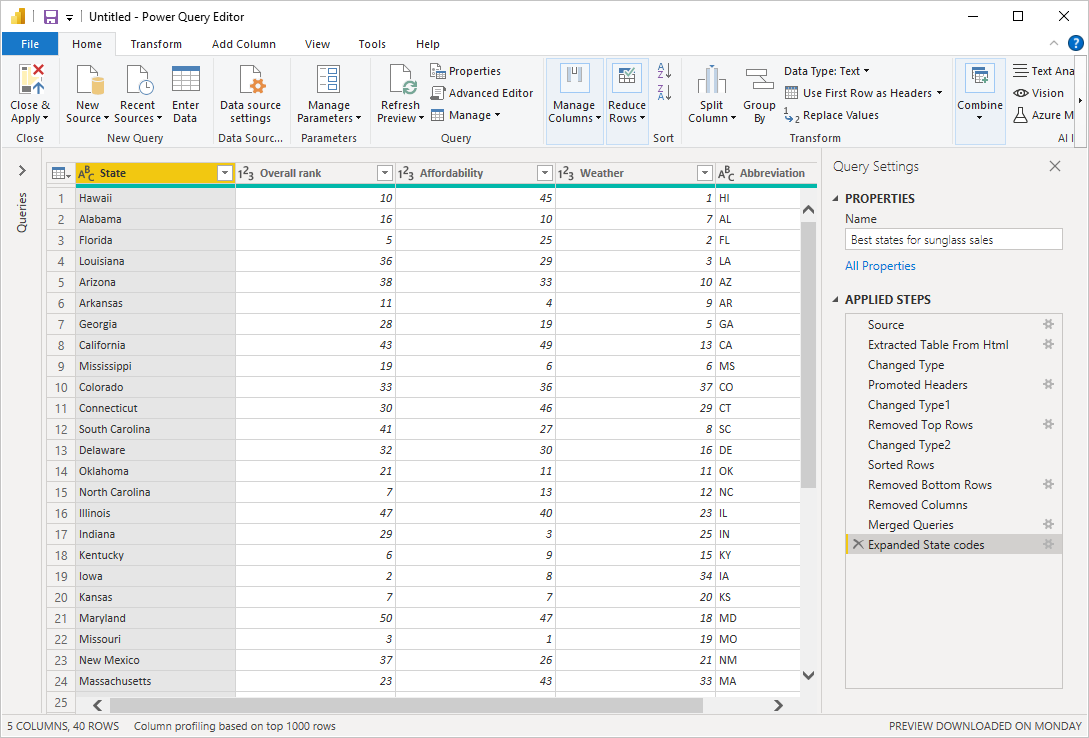
到目前为止,你有足够的数据在 Power BI Desktop 内创建有趣的报表。 由于这是一个里程碑,请在 “Power Query 编辑器” 中应用更改,并将其加载到 Power BI Desktop 中,方法是:在功能区的 “主页” 选项卡中选择“关闭并应用”。 你还可以仅选择“应用”,以确保在 Power Query 工作时使查询在 Power Query 编辑器处于打开状态。
将表加载到 Power BI Desktop 后,你可以对其进行更多更改,并重新加载模型以应用所做的任何更改。 要从 Power BI Desktop 重新打开 “Power Query 编辑器”,请在 Power BI Desktop 功能区的“主页” 选项卡上选择“转换数据”。
## 生成报表
在 Power BI Desktop“报表” 视图中,你可以生成可视化效果和报表。 “报表” 视图包含六个主要区域:

1. 功能区位于顶部,它显示与报表和可视化效果相关联的常见任务。
2. 画布区域位于中间,可在其中创建和排列可视化效果。
3. 页面选项卡区域位于底部,它用于选择或添加报表页。
4. “筛选器” 窗格,可在其中筛选数据可视化效果。
5. “可视化效果” 窗格,可在其中添加、更改或自定义可视化效果,并应用钻取。
6. “字段”窗格,它显示查询中的可用字段。 你可以将这些字段拖放到画布、“筛选器”窗格或 “可视化效果” 窗格,以创建或修改可视化效果 。
通过选择窗格顶部的箭头,可以展开和折叠 “筛选器”、“可视化效果” 和“字段”窗格 。 折叠窗格可在画布上提供更多空间来生成炫酷的视觉化效果。
要创建简单的可视化效果,只需在 “字段” 列表中选择任意字段,或将字段从 “字段” 列表拖到画布上。 例如,将 “州” 字段从 “最佳太阳镜销售州” 拖到画布上,看看会发生什么 。
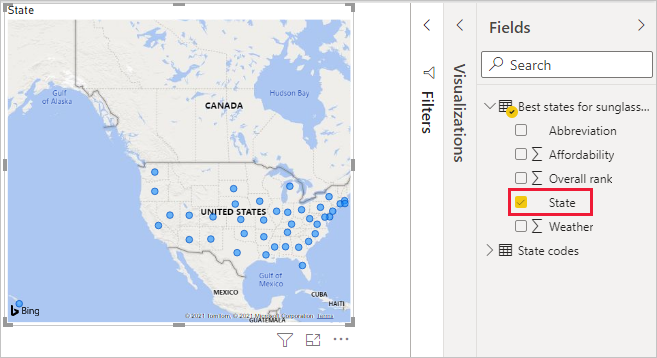
看一下! Power BI Desktop 识别到 “州” 字段包含地理位置数据并自动创建了基于地图的可视化效果。 可视化效果在数据模型中显示了 40 个州的数据点。
“可视化效果” 窗格显示有关可视化效果的信息,并允许你对其进行修改。

1. 图标显示创建的可视化效果的类型。 你可以通过选择不同的图标来更改所选可视化效果的类型,或通过选择未选定现有可视化效果的图标来创建新的可视化效果。
2. 可利用 “可视化效果” 窗格中的 “字段” 选项将数据字段拖动到 “图例” 和窗格中的其他字段 。
3. 可利用 “格式” 选项将格式设置和其他控件应用到可视化效果。
“字段”和 “格式” 区域中的可用选项取决于你拥有的可视化效果和数据类型 。
你希望地图可视化效果仅显示天气最佳的前 10 个州。 要仅显示前 10 个州,请在 “筛选器” 窗格中,将鼠标悬停在 “州为(所有)” 上并展开出现的箭头 。 在 “筛选器类型” 下,下拉并选择 “前 N 个” 。在“显示项目” 下,选择“最后”,因为你希望显示数字级别最低的项目,并在下一个字段中输入“10” 。
在 “字段” 窗格中,将 “天气” 字段拖动到 “按值” 字段中,然后选择“应用筛选器” 。

现在,地图可视化效果中仅显示天气最佳的前 10 个州。
通过以下方式可重新设置可视化效果标题:在 “可视化效果” 窗格中选择 “格式” 图标,选择 “标题”,并在“标题文本” 下键入“天气最佳的前 10 个州” 。

要添加显示天气最佳的前 10 个州的名称及其从 1 到 10 的排名,请选择画布的空白区域,然后在 “可视化效果” 窗格中选择 “柱状图” 图标 。 在 “字段” 窗格中,选择 “州” 和“天气” 。 柱状图显示了查询中的 40 个州,从最高到最低的数字级别或者从最糟到最佳天气进行排名。

要切换排序顺序以使数字 1 第一个出现,请在可视化效果的右上角选择 “更多选项” 省略号,然后在菜单中选择“升序排序” 。

要将表限制为前 10 个州,请应用与地图可视化效果相同的后 10 筛选器。
以与地图可视化效果相同的方式重新命名可视化效果。 同样在 “可视化效果” 窗格的 “格式” 部分,将 “Y 轴”>“轴标题” 从“天气”更改为 “天气排名”,使其更易于理解 。 然后,将“Y 轴” 选择器切换到 “禁用” 。 将缩放滑块切换到“启用”,并将“数据标签” 切换到“启用” 。 最后,沿 Y 轴调整缩放滑块,直到堆积柱形填满图表。
现在,天气最佳的前 10 个州按排名顺序显示,并显示其数字排名。

你可以为 “可购性” 和“总体排名”字段提供类似或其他可视化效果,或将多个字段合并为一个可视化效果 。 你可以创建各种相关报表和可视化效果。 这些 “表” 和“折线和簇状柱形图”可视化效果显示天气最佳的前 10 个州以及其可购性和总体排名 :

你可以在不同的报表页上显示不同的可视化效果。 要添加新页面,请选择页面栏上现有页面旁边的 **+** 符号,或在功能区的 “主页” 选项卡中选择“插入”>“新页面”。 要重命名某个页面,请在页面栏中双击该页面的名称,或右键单击它并选择“重命名页面”,然后键入新名称。 要切换到报表的其他页面,请从页面栏中选择该页面。

你可以通过 “主页” 选项卡的 “插入” 组将文本框、图像和按钮添加到报表页 。要设置可视化效果的格式设置选项,请选择可视化效果,然后在 “可视化效果” 窗格中选择 “格式” 图标 。 要配置页面大小、背景和其他页面信息,请选择未选定可视化效果的 “格式” 图标。
创建好页面和可视化效果后,选择 “文件”>“保存”,可保存报表 。

有关报表的详细信息,请参阅 [Power BI Desktop 中的报表视图](https://docs.microsoft.com/zh-cn/power-bi/create-reports/desktop-report-view)。
现在,你已经有了一个 Power BI Desktop 报表,可以与他人共享。 有几种方法可以共享你的工作。 你可以像任何其他文件一样分发 “.pbix” 文件报表,你可以从 Power BI 服务上传 “.pbix” 文件,也可以直接从 Power BI Desktop 发布到 Power BI 服务 。 必须拥有 Power BI 帐户才能将报表发布或上传到 Power BI 服务。
要从 Power BI Desktop 发布到 “Power BI” 服务,请在功能区的 “主页” 选项卡中,选择“发布” 。

系统可能会提示你登录 Power BI 或选择一个目标。
当此发布过程完成时,你将看到以下对话框:

在 Power BI 中选择打开报表的链接时,报表将在 Power BI 站点中的 “我的工作区”>“报表” 下打开 。
另一种共享工作的方式是从 **Power BI** 服务内加载它。 转到 *[https://app.powerbi.com](https://app.powerbi.com/)* 以在浏览器中打开 Power BI。 在 Power BI“主页” 上,选择左下方的 “获取数据”,可开始加载 Power BI Desktop 报表的过程 。
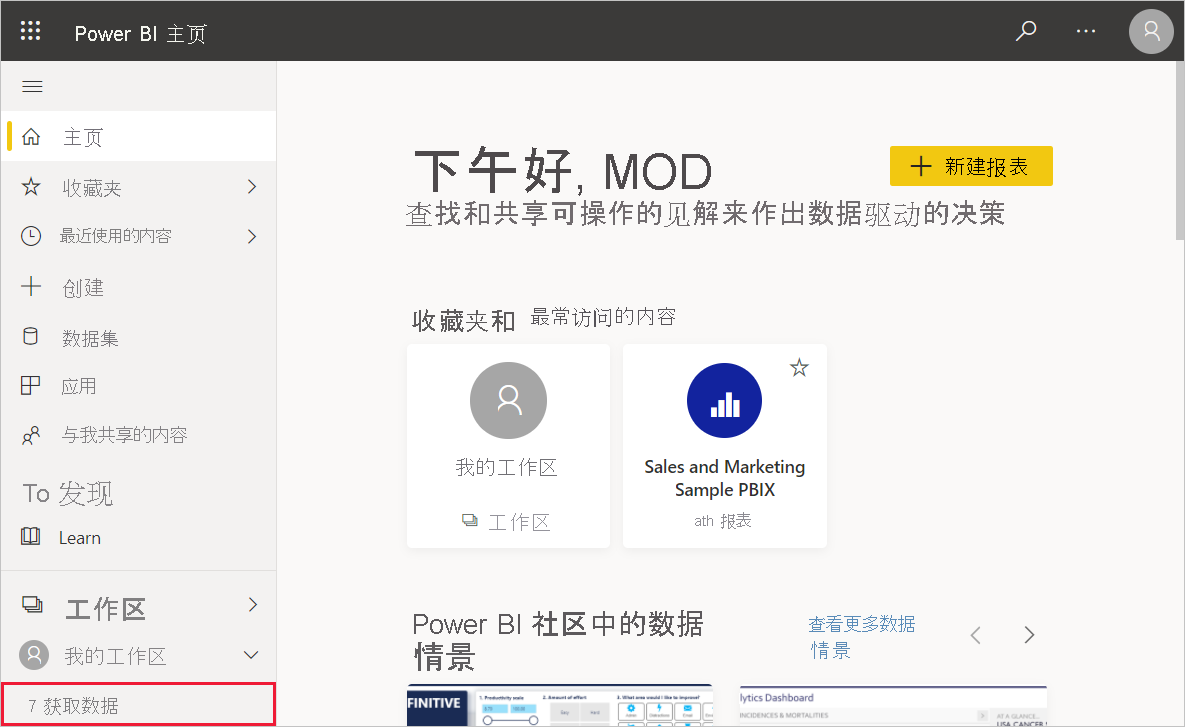
在下一页上,在 “文件” 部分选择“获取” 。

在下一页上,选择 “本地文件”。 浏览到你的 Power BI Desktop“.pbix” 文件并选择,然后选择“打开”。
导入文件后,可以看到它在 Power BI 服务左窗格中的我的工作区”>“报表” 下列出 。
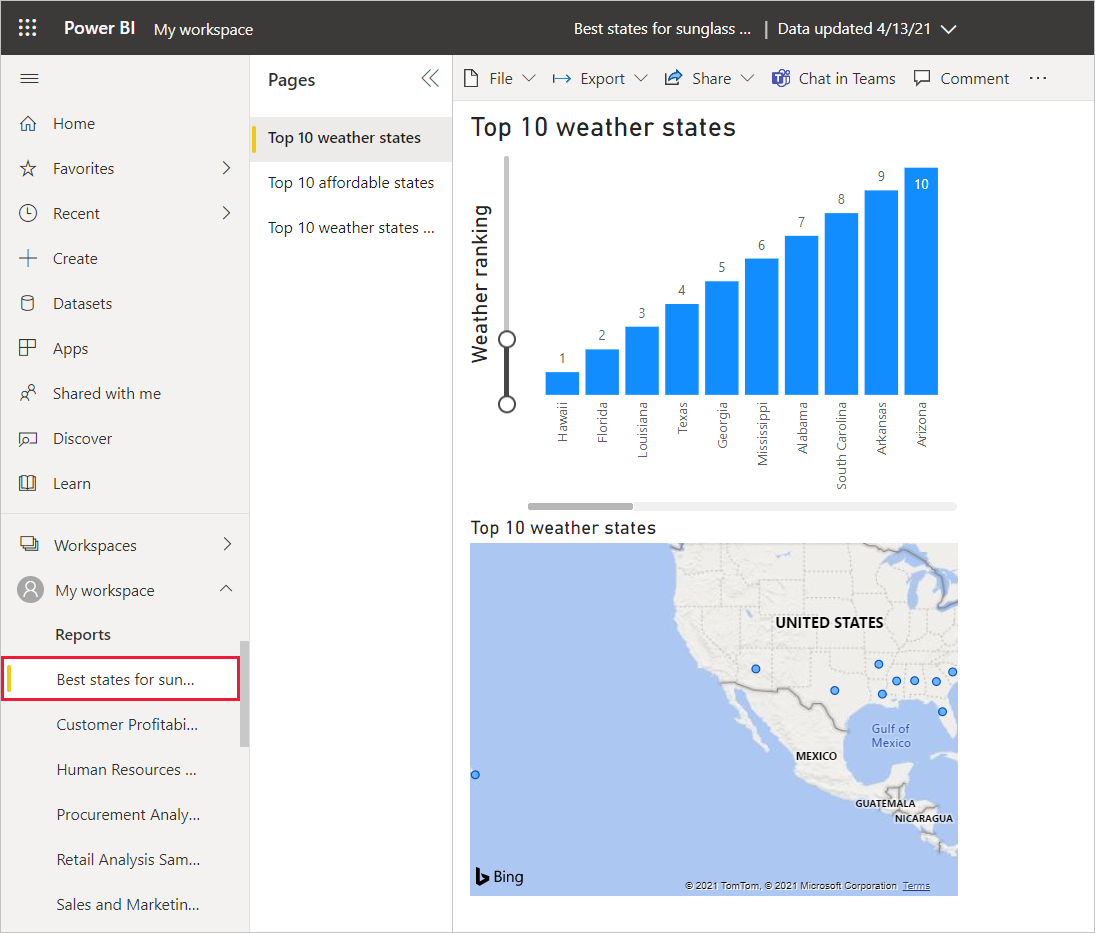
选择该文件时,将显示报表的第一页。 可以在报表左侧的选项卡中选择不同的页面。
你可以在 Power BI 服务中通过从报表画布顶部选择 “更多选项”>“编辑” 来更改报表 。

要保存更改,请选择 “文件”>“保存副本” 。
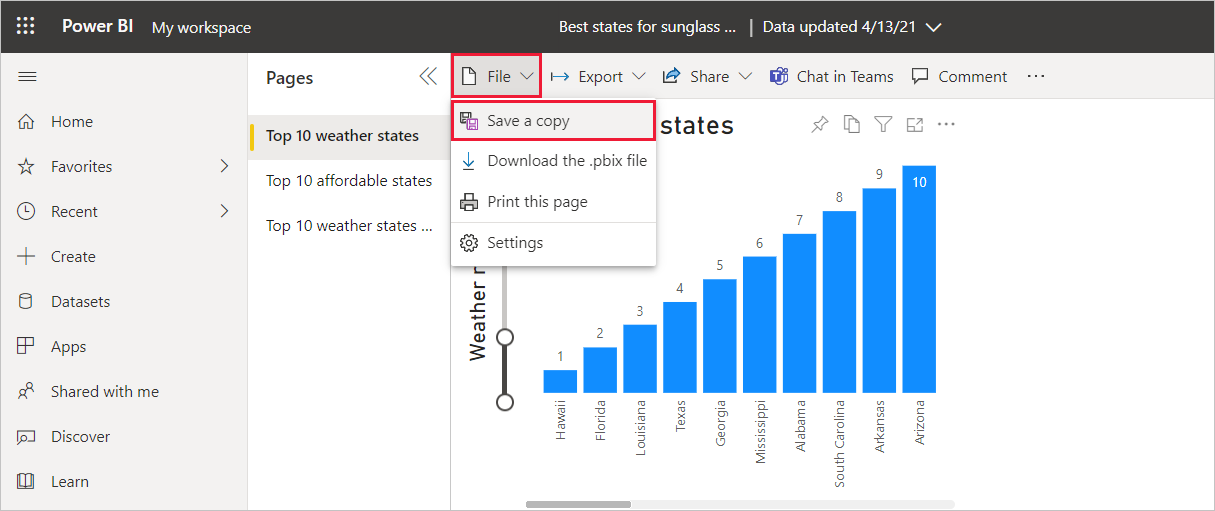
你可以在 Power BI 服务中,从你的报表创建各种有趣的视觉对象,并可以将该报表固定到 “仪表板”。 要了解 Power BI 服务中的仪表板,请参阅[设计出色仪表板的提示](https://docs.microsoft.com/zh-cn/power-bi/create-reports/service-dashboards-design-tips)。 有关创建、共享和修改仪表板的详细信息,请参阅[共享仪表板](https://docs.microsoft.com/zh-cn/power-bi/collaborate-share/service-share-dashboards)。
要共享报表或仪表板,请在打开的报表或仪表板页面的顶部选择 “共享”>“报表”,或者在“我的工作区”>“报表” 或“我的工作区”>“仪表板”列表中,选择报表或仪表板名称旁边的 “共享” 图标 。
完成 “共享报表” 或“共享仪表板”屏幕中的信息,以发送电子邮件或获取链接,与他人共享报表或仪表板 。
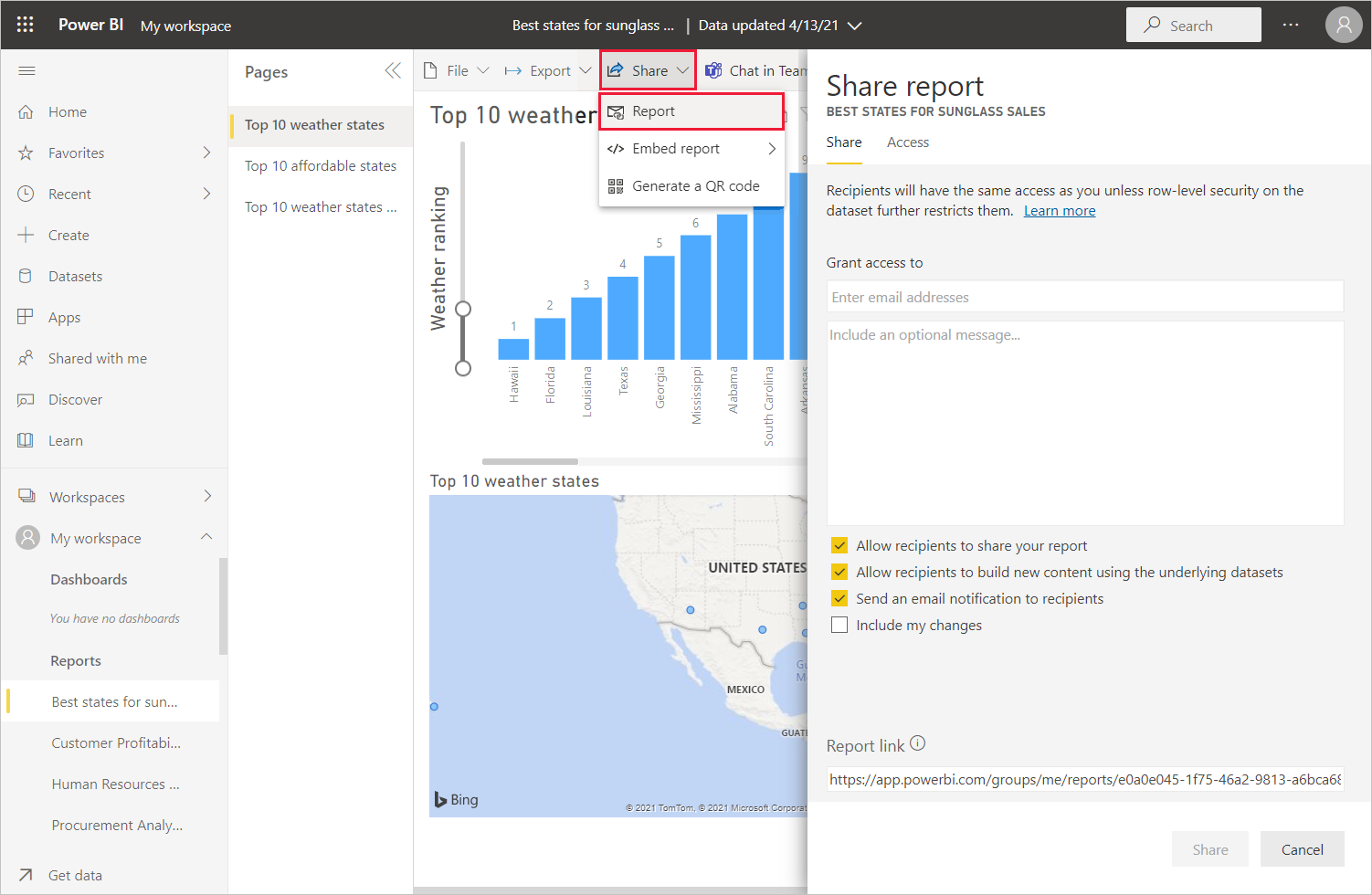
你可以使用 Power BI Desktop 和 Power BI 服务来制作各种与数据相关的惊艳混搭和可视化效果。
## 后续步骤
Power BI Desktop 支持连接到诊断端口。 诊断端口允许连接其他工具并执行跟踪以进行诊断。 使用诊断端口时,不支持对模型进行任何更改 *。* 更改模型可能会导致损坏和数据丢失。
要详细了解 Power BI Desktop 的多种功能,请查看以下资源:
- [Power BI Desktop 中的查询概述](https://docs.microsoft.com/zh-cn/power-bi/transform-model/desktop-query-overview)
- [Power BI Desktop 中的数据源](https://docs.microsoft.com/zh-cn/power-bi/connect-data/desktop-data-sources)
- [连接到 Power BI Desktop 中的数据](https://docs.microsoft.com/zh-cn/power-bi/connect-data/desktop-connect-to-data)
- [教程:使用 Power BI Desktop 调整和合并数据](https://docs.microsoft.com/zh-cn/power-bi/connect-data/desktop-shape-and-combine-data)
- [Power BI Desktop 中的常见查询任务](https://docs.microsoft.com/zh-cn/power-bi/transform-model/desktop-common-query-tasks)
================================================
FILE: _posts/2022-04-06-以下为发表在公众号及知乎上的旧文章.md
================================================
部分内容有所更新。
================================================
FILE: _posts/2022-04-07-这是我在GitHub上传的第一篇文章.md
================================================
我是学谦。
终于,我有了自己的网站。
[powerbipro.cn](http://powerbipro.cn)
记住它!
一个搭建网站的纯小白,也可以在github的强大助力下,轻松实现了这一切。
================================================
FILE: _posts/2022-04-08-Extreme DAX中文第0章 前言.md
================================================
---
layout: post
header-img: img/post-bg-extremedax.jpg
catalog: true
tags:
- Extreme DAX
---
公众号:PowerBI生命管理大师学谦,同步更新,敬请关注

`Power BI 学谦
翻译,是个体力活。
我本来觉得机翻至少可以帮助我解决30%的工作量,可是真正把一段又是倒装又是定语从句的英文用汉语顺畅地翻译出来,并且表达出原汁原味的意思,还是得靠自己一个字一个字地敲出来。能轻松地阅读英文原版书籍和逐字抠清楚每句话到底是什么意思之间还是有较大的距离。
接下来一段时间,学谦会和大家一起学习这本DAX的进阶指南——Extreme DAX,共同提高Power BI水平。
受限于本人的能力,翻译总是避免不了各种瑕疵与问题,也请大家能够批评指正,多多提出宝贵意见。`
**关于作者**
**Michiel Rozema**是世界顶级 Power BI 专家之一,现居荷兰。拥有数学硕士学位,并在IT行业担任顾问和经理超过25年。Michiel 在微软(荷兰)担任数据洞察负责人已有8年,在此期间,他将Power BI在国内发扬光大。他写过两本关于 Power Pivot 和 Power BI 的荷兰书籍。Michiel 是荷兰 Power BI 用户团队的创始人之一,也是Power BI 暑期学校的组织者,并在许多有关 Power BI 的会议上发表演讲。自2019年以来,他一直被授予微软 MVP 荣誉,并与同样是 MVP 的 Henk Vlootman 一起经营着专门从事 Power BI 的咨询公司 Quanto。
**Henk Vlootman**是 Power Platform、Power BI 和 Excel 高级全球业务顾问。自 2013 年以来,Henk 每年都因其杰出的专业知识和社区领导力而获得微软 MVP 荣誉。Henk 同样是荷兰 Power BI 用户团队的创始人之一,Power BI暑期学校的组织者,并曾在世界各地的许多 Power BI 会议上发表演讲。他曾写过两本关于Excel 的书籍和两本关于 PowerPivot/Power BI 的书籍。他于1992年创办自己的公司并开始了他的职业生涯,然后担任 Excel 顾问。如今,他与Michiel Rozema 一起经营着专门从事 Power BI 的咨询公司Quanto。
**关于审稿人**
**Greg Deckler**是微软 DataPlatform 的 MVP,也是美国俄亥俄州哥伦布市 IT 社区的活跃成员,他创立了哥伦布市Azure ML 和 Power BI 用户组(Columbus Azure ML and Power BI User Group,CAMLPUG),并在全国各地的许多会议和活动中发表演讲。Greg 是一位活跃的博主和社区成员,他有兴趣帮助 Power BI 的新用户,积极参与Power BI 社区,提交了 180 多个 Power BI 快速度量库内容并回答解决了 5000 多个社区问题。Greg 是区域咨询公司 Fusion Alliance 的云服务副总裁,帮助客户从云和 Power BI 等云优先技术中获得竞争优势。Greg 撰写了三本关于 Power BI 的书籍:Learn Power BI、DAX Cookbook 和 Power BI Cookbook(第二版)。最后,Greg还为 Power BI Desktop 构建了一个名为 Microsoft Hates Greg's Quick Measures 的外部工具,他还经常在 YouTube 上发布 Power BI 视频。
`Power BI 学谦
本书两位作者:Michiel 和 Henk 都是业内顶级专家。他们运营的公司Quanto的博客地址为:https://quanto-blog.eu/
审稿人 Greg 的个人博客地址:https://gregdeckler.com/`
**前言**
我们可以保证,认真学习完这本书,您的Power BI技术和使用Microsoft一系列工具进行数据分析的能力会有一个质的飞跃。您将发现 DAX 的真正力量,并了解如何为实际业务场景构建高级 DAX 解决方案。
**本书适合那些人群**
如果您是一名分析师,具备 Power BI 或其他 Microsoft 分析工具中的 DAX 应用知识,本书将帮助您升级 DAX 知识并更有效地使用分析模型。
*注意:这本书并不适合初学者,读者需要有 DAX 的实践经验。*
**本书涵盖的内容**
**第一部分:简单介绍。**
**第1章商业智能中的DAX**,讨论了商业智能领域以及分析模型在现代 BI 解决方案中的核心作用。得益于DAX 的强大功能,Power BI 模型非常适合用作此类模型。
**第2章模型设计**,讨论 Power BI 模型的基本概念。你将了解 Power BI 模型与其他数据管理产品的根本区别是什么,最后我们将向您展示PowerBI 模型的最佳设计方案。
**第3章使用 DAX**,总结了 DAX 在 Power BI 模型中的不同用法:计算列、计算表、度量值、安全规则和查询。我们还为您提供了一些使用 DAX 的最佳实践。
**第4章上下文和筛选**,涵盖行上下文、查询上下文和筛选上下文,以及上下文在 DAX 公式评估中所起的作用。我们讨论了如何使用CALCULATE函数通过删除原有筛选并将新的筛选添加到现有上下文来转换上下文。此外,我们还会介绍时间智能函数、DAX 表函数、表和筛选器之间的深层关系以及 DAX 变量。
所有这些都是使用 DAX 进行更高级分析的基本概念。在这一重要的章节之后,本书第二部分的重点是将以上讨论的所有概念应用到实际业务案例中,其中许多案例基于我们多年来从事的项目。
**第二部分:商业案例。**
**第5章DAX 安全性**,多方面阐述如何保护 Power BI 模型以及在此过程中 DAX 起到的强大作用。我们通过结合使用建模、DAX 和行级别安全性来讨论行级安全性的多样性、安全角色以及保护层次结构、属性和聚合级别。
**第6章可视化动态展示**,介绍了如何使用辅助表和SWITCH函数来捕获用户输入。我们将演示如何使用DAX动态地更改数据连接以创建高度动态的视觉效果。根据您的预期用途,辅助表可简可繁,可以小到只包含几行选项,也可以是基于 Power BI 模型中其他数据的更大列表。
**第7章备用日期表**,向您展示了当您的日期表看起来与 Power BI 模型默认的标准日历不同时如何实现时间智能。在本章结束时,我们会提供一个 Power BI 报告中相对日期筛选器的替代方案,该方案更加灵活,也可以处理非标准日历中的选择。
**第8章使用自动匹配 AutoExist**,重点介绍了为从 Power BI 模型填充视觉对象该进行*哪些* 计算。了解 AutoExist 的工作原理将帮助您找出为什么有时在视觉效果中看不到预期的结果。它还有助于避免由于在一个视觉对象中使用过多表中的过多列而导致的报表中的性能问题。
**第9章公司间业务**,讨论了两个主要的业务挑战:公司间业务和合并视图,以及针对未结销售订单发送的发票。我们将讨论如何全面跟踪上下文、如何根据可视化效果设置 DAX 度量值,以及进行高级分析的策略。
**第10章探索未来:预测和未来价值**,向您介绍用于分析投资未来的财务指标。我们讨论了未来价值、现值、净现值和内部收益率的通用指标,以及它们在 DAX 中的计算函数,包括XNPV和XIRR。我们还介绍了假设参数(what-if parameters)以及如何在复杂计算中使用它们。
**第11章库存分析**,涉及分析库存数据,同时本章中的分析可以应用于各种面向状态的数据。我们讨论了对此类数据建模的不同方法,如何计算某个时间点的库存状态,以及如何将实际值与目标值进行比较。您还将看到展望未来的不同方式,包括 DAX 中的线性回归。
**第12章人员规划**,讨论了在开展项目时根据全职等效人员(full-time equivalents,FTE)分析人员需求的方法。从技术角度来看,您将学习使用多个事实表的方法,这些事实表必须结合起来考虑以提供有用的结果。我们所面临的挑战不仅在于得出正确的结果,还在于如何找到计算这些正确结果的最佳方法。
`Power BI 学谦
阅读本书需要有一定的DAX基础,因此建议大家先阅读并实操一段时间的Power BI相关数据,推荐阅读高飞老师翻译的《DAX权威指南》。
本书的重点是第二部分的商业案例,都是可以直接服务于实际业务的经典案例。当然,第一部分的介绍同样十分精彩,作者提纲挈领地将数据分析的过程拆分为五层模型,并系统阐述了为什么自助式BI是商业智能发展的必然结果。
后续译文会逐步在本公众号与大家进行分享,请大家持续关注学谦。`
================================================
FILE: _posts/2022-04-08-Extreme DAX中文第1章 商业智能中的DAX.md
================================================
---
layout: post
header-img: img/post-bg-extremedax.jpg
catalog: true
tags:
- Extreme DAX
---
公众号:PowerBI生命管理大师学谦,同步更新,敬请关注
# 第1章 商业智能中的DAX
毫无疑问,**信息**是当今世界上任何一个组织最宝贵的资产之一。作为消费者,我们随时随地都可以感受到各种企业和平台正费尽心机地获取我们的个人数据。不是因为我们每一个人都很有趣(尽管我们确信正在读这本书的您,一定是一个非常有趣的人!),而是一旦将大量消费者的个人数据组合在一起加以分析,组织便可以获得一系列有价值的见解来推动他们的业务向前发展。
这不仅适用于商业公司。公共机构、医院和大学也可以从信息中受益,以更好地运转核心流程。信息是当今世界进步和创新的基础,人们对此有着普遍的共识。
但是要从数据中获取有用信息,再将信息转化为见解和洞察却是一个枯燥乏味且技术性要求较高的过程。整个过程包括:将不同来源的数据进行整合,挖掘隐藏的结构和相关性,与此同时还需要考虑数据产生的实际环境。这就是为什么长期以来商业智能(Business Intelligence,BI)或数据分析领域只有专业IT人员才能胜任的原因。然而,一个需要扎实的业务能力和商业洞察力的过程,却只能由完全不懂业务的IT人员来实现,这显然是不合理的。矛盾就此产生。
本书讨论的核心是:**DAX**(**Data Analysis eXpressions**,数据分析表达式),它是当今数据分析领域最热门的工具之一,也是解决上述矛盾的有力武器。我们假定:作为本书的读者,您对 DAX 有一定的经验,并且希望提高自己的技能。需要特别强调的是,您必须得清楚DAX适合做什么,不适合做什么,这很重要。此外,如果某个过程可以用DAX做得更好,就要尽量避免用其他方式去做。
本章主要阐述一些基本概念,这些内容对您后续的阅读会起到帮助。本章涵盖以下主题。
• 商业智能的五层模型。
• 企业级BI 和最终用户 BI。
• DAX的优势与使用位置。
• 用于DAX建模的工具。
• 由DAX驱动的可视化与交互式报告。
• 如何开发解决方案。
• 数字化转型循环。
## **1.1 商业智能的五层模型**
为了在探讨商业智能数据分析时能够更加系统全面与条理清晰,我们开发了一个简单的框架,用来阐述一套数据分析方案的主要组成部分和的各部分的主要作用,如图1.1所示。我们给它起了一个同样简单的名字:**五层模型**。

图1.1 商业智能的五层模型
“五层模型”的第一层也是最低层,**数据连接**层,是数据分析的起点。俗话说,巧妇难为无米之炊,想要对数据进行分析,首先您得先有数据。数据来源有很多:可以是 Excel 工作表、文本文件、大型业务数据库中或网络上的某个位置。
一般来说,这些原始的数据并不能直接进行分析,因为它们的格式往往不符合标准,尤其是当它们来自不同数据源时。因此,您需要先对数据进行一些基本准备工作,也就是第二层:**数据预处理**层。数据预处理有多种形式,像更改数据类型、转换数据、构建数据历史记录或基于“键”值合并查询数据等都是常见的方式。
在连接数据和数据预处理这两个过程中,创建出整齐干净、格式标准的数据集往往需要花费大量时间和精力。有些时候真的让人心力交瘁。在常规的IT领域,打造数据仓库是典型的数据预处理环节,而这,通常会导致开发项目持续多年才能完成。然而让人更加沮丧的是,当数据仓库终于完成时,世界早就不是原来的模样,多年的心血已无法满足当前的实际业务需求。
以上的两步工作结束时,理想的情况是:所有的数据都按照标准的格式存放在模型中,接下来便可以开始对数据进行恰当的分析,也就是第三层:**建模分析**层。这正是数据分析解决方案的核心。通过建模分析,您可以对数据进行切片和筛选,进行各类聚合,并添加各种计算以得到特定的见解。
第四层,**可视化**层,主要是创建报表和仪表板,将建模分析的成果可视化展示。我们将这一层称之为可视化,而不仅仅是“输出”,是因为虽然成果很重要,但是让用户关注到那些重要结论同样重要。可视化真正要实现的是提供见解,或者说“洞察”。由一页又一页的详细信息组成的传统报表并不能让人直观地得出结论,反而会让用户将整个报表导出到 Excel 中,然后自行聚合数据进行分析。真正提供洞察的可视化,往往是一针见血地揭示出核心问题,同时让使用者可以在更低粒度、更详细的指标上进行更深层次的分析,然后找到问题解决方案。
“五层模型”的顶层,**共享**层,由一系列平台与流程组成,旨在为相关人员提供对报表和仪表板的访问权限,同时阻止无关人员的访问。
在构建数据分析解决方案的过程中,无论你是使用 Excel、Power BI、自助开发的企业BI系统,还是根本不使用自动化系统,您都会以某种方式涵盖这五个层面的内容。一个优质的数据分析方案,它的每一层之间界限分明,各司其职。这样做有很多好处,比如可以避免大量的重复性逻辑工作。恰当地实施“五层模型”可以相对容易地应对各方面的变化,比如数据源系统的更改。
DAX 位于“建模分析”这一层,且与“数据预处理”和“可视化”层都有很强的联系,本章将详细展开说明。我们也会在单独的部分专门讨论可视化,但首先,让我们讨论一下这个问题:*谁在**BI**中做什么?*
## **1.2 企业级BI和最终用户BI**
企业和组织愈加受到数据的驱动。关键绩效指标(key performance indicators,KPI),几乎每一个组织和每一家企业都在使用,通过一系列仪表板来展现每一个KPI指标的完成情况,相当普遍。这些仪表板通常是高度标准化的:组织往往已经对业务战略、业务流程、如何衡量 KPI 以及如何报告它们非常明确。KPI自动化仪表板通常由IT部门或BI中心构建和维护,它们相对稳定,一般不会发生太大变化,
数据驱动型组织的更高层次是,组织做出的*每一项* 决策都是基于相关数据分析得出的结论。这意味着组织需要一个更加灵活动态的数据分析方法,可以随时随地回答各种临时问题,这种形式的数据分析被称作自助式商业智能(self-service BI,**自助式****BI**)。自助式BI旨在让每个人都能在无需IT中心部门帮助的情况下构建BI解决方案。不过,从五层模型中可以清楚地看出,这并不太现实:想要解决五个层面所有的复杂问题,需要同时具备足够的能力与充足的时间,满足这个条件的最终用户寥寥无几。理想的情况是IT中心部门和最终用户各自发挥自己的特长,彼此合作。
我们使用**企业级****BI**(enterprise BI)和**最终用户****BI**(End-user BI)这两个术语来区分数据分析的这两种形式。**企业级****BI**由IT部门构建和维护,使用大型服务器或云平台,并同时为众多用户提供服务。这通常是一个专业的管理项目,它更侧重于数据质量、平台的可用性和流程的明确定义。最终生成相关的解决方案。
**最终用户****BI**由参与实际业务的用户完成。他们希望在日常工作中可以快速通畅地获取见解,他们对此有强烈的需求。有相当多的人一开始是在Excel中建模分析,但是在复杂的Excel模型中,想要保持数据最新以及维护和扩展解决方案,需要用户投入的时间会越来越多。客观地讲,Excel无法从容应对不断增长的数据量。为了解决这个问题,微软扩展了Excel的功能,引入了Power Query和Power Pivot这两个数据预处理和分析的新工具。这两个强大的工具让Excel成为真正的最终用户BI平台。这些工具经过演变成为了现在的 **Power BI**。
**Power BI**,作为微软的数据分析大杀器,其强大之处在于,将企业 BI 和最终用户 BI这两个矛盾的事物有机地结合在一起。Power BI的底层技术是实现这一目标的驱动力。正如图1.2所展示的那样,借助于Power BI,我们现在可以将企业BI和最终用户BI这两个以前对立的形式统筹到一个体系中,无论用户拥有哪种层次的自助分析能力。
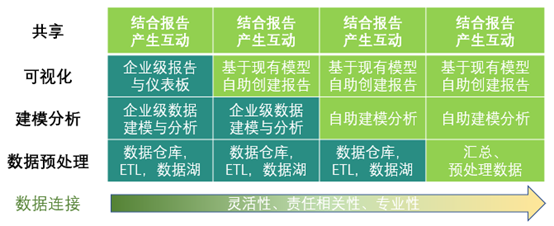
图1.2 企业级BI与最终用户BI的结合
“五层模型”是定位不同自助分析能力的有效框架。那些对于自助式BI有需求的用户可以结合该模型的不同层级来认知自己的能力,从而实现他们的目的。他们可以选择在现有的(企业级)分析模型的基础上创建自己的可视化效果;可以使用企业已经预处理完毕的数据集来自助建模分析;或者自行收集数据,将其与企业数据相结合,并自助创建大部分解决方案。他们甚至可以基于其他最终用户创建的模型来进行建模分析。
应该清楚的是,沿着五层模型逐渐向下移动,需要自己承担的比重会越来越大,那么工作的复杂性也就会急剧增加。这样就导致了不仅需要更专业的知识,而且还增加了遵守公司准则和数据标准的责任。此时,就需要企业的IT或BI部门来帮助这些最终用户创建自己的解决方案。如果实施得当,理想的结果是组织中的所有人都能以最佳方式从见解中受益。我们将此愿景称之为**集体分析**。
为了实现集体分析这一美好的愿景,Power BI提供了多项功能,DAX就是其中之一。DAX凭借其强大的实力赋能业务人员,不仅可以使业务人员自助建模分析并找到解决方案,还可以让他们有能力积极参与到企业级解决方案的开发当中。对于后者,我们将在本章的*如何开发解决方案* 这一部分中展开讨论。首先,还是让我们一睹DAX的真容,以及在 BI解决方案中何处可以发现它的踪迹。
## 1.3 DAX的优势与使用位置
在微软的数据分析解决方案中,DAX主要被用于建模分析层面。它在数据分析模型中的作用,是作为公式语言来定义模型中的各种计算和其他逻辑。事实上,模型与DAX实际上是同一枚硬币的两面:模型的设计方式会影响DAX语句的复杂程度,反过来,您的DAX技能也决定着模型设计的难易程度(我们将在*第2章 模型设计*中详细阐述数据模型的核心概念)。
DAX的强大之处在于其高超的数据聚合能力。DAX语言包含众多函数和结构用于定义各种聚合,用户可以从聚合结果中获得所需的见解。长久以来,许多类型的聚合运算必须先通过一系列复杂而又专门的数据预处理来实现,而不能直接进行。比如,想要计算年初至今的销售总额,在 DAX 中仅仅使用一个函数(YTD)就可以实现,而在 Excel或传统报表工具中,需要一系列额外的指标来确定哪些销售交易属于年初至今这个期间,数据预处理环节耗费了大量的时间。后者不仅实现起来更加复杂,而且最终实现的成果还远不如使用DAX那样灵活,DAX不仅可以直接计算年初至今的销售额,还可以同时计算出以往年份的年初至今数据。
这意味着,相比于传统的 BI 解决方案,借助于DAX,我们在数据预处理环节上可以省去大量的时间与精力。由于 DAX 的语法和许多核心概念与Excel很相似,因此对于熟悉Excel的用户来说,DAX 语言学习起来相对比较容易。但是,这并不意味着您可以轻松地*掌握* DAX:在使用DAX的过程中,当您解决了一些稍微简单一些的问题之后,您会逐步将其用于解决更加复杂的问题,但同时您也将为之写出更复杂的 DAX 代码来解决这些问题。本书将为您提供许多 DAX 高级应用的示例,我们希望这些例子能够帮助您去解决遇到的 DAX 难题。
当前,在微软所有的核心数据产品中,我们都可以使用DAX来做建模分析。不过,让人感到疑惑的是,在不同的产品中,模型的命名方式却不太一样。下面,我们将对微软的不同产品中的模型和 DAX做一个基本的概述。
### 1.3.1 Excel中的DAX
Excel 自2010版开始,就以 **Power Pivot** 的形式提供分析数据建模功能。Power Pivot(在 Excel中也称为**Data Model,数据模型**)是基于 DAX 的分析模型。
### 1.3.2 Power BI中的DAX
Power BI是微软数据分析平台上近些年最闪耀的新星。它最初是作为Office 365的一个加载项被引入的,但在2015年升级为一个单独的服务。Power BI 中的分析模型称为 Power BI 数据集(一般简称为数据集),这是 DAX 的栖身之所。
Power BI 数据集和其他的 Power BI 项目是在Power BI 云服务中运行的,用户可通过 Power BI 网站进行访问。同时,其他一些方式也可以使用 Power BI 服务,例如 Power BI 移动应用、Microsoft Teams,甚至如果有能力自助开发,可以通过使用 Power BI Embedded 嵌入自助开发的应用程序来访问。除此之外,如果用户不想使用Power BI的云服务或者企业基于数据安全考虑而不能使用云服务,那么可以选择本地化的Power BI报表服务器。
### 1.3.3 SQL Server Analysis Services中的DAX
SQL Server是微软的数据服务器平台,它包含一个名为Analysis Services(SQL Server分析服务,SSAS)的分析组件。SSAS自2000年左右作为一项OLAP(Online Analytical Processing,联机分析处理)服务开始,多年来一直是一款经典的OLAP服务器,现在被称为**多维模型**(Multidimensional)。随着SQL Server 2012 的发布,SSAS引入了第二个分析功能,称为**表格模型**(Tabular),它是基于DAX的分析模型。
您可能很想知道SSAS中这两种技术之间的差异。本书不准备深入探讨这里所有的细节,但仍然需要指出的是SSAS 多维模型是基于“经典”关系型数据库技术而生。这项技术的设计初衷并非为了对大数据进行聚合与运算,多维模型或数据集只会在建模过程一开始就将所有这些聚合计算执行完毕。相反,在表格模型中,DAX能够即时聚合运算,这意味着用户可以更动态地分析,因为报表设计不会因为模型设计的聚合程度而受到限制。因此,多维模型的灵活多变程度远不如表格模型。
### 1.3.4 Azure Analysis Services中的DAX
Azure Analysis Services (Azure分析服务,AAS) 是一种完全托管的数据分析云服务,与SSAS一样,基于Tabular引擎。显然,与SSAS的不同之处在于,AAS运行在云上,这样您的组织不必担心硬件和数据库的维护。而且它也是一个灵活的解决方案,因为存储和计算资源可以动态扩展以满足当下的需求。
|  | 综上,在不同的工具里,含DAX的分析模型以诸多不同的名称存在:Power Pivot、Data Model、dataset 或 Tabular Model。 所以当我们在谈论到“分析模型”这一概念时,很容易产生混淆,这对本书来说是一个挑战。由于本书着重于Power BI,因此我们将在本书中使用**Power BI模型**这个术语,或者在不会产生混淆时直接简称为**模型**。并且,本书中的“分析模型”这一术语仅用来表示“五层模型”中的建模分析层。 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
## 1.4 用于DAX建模的工具
根据建模平台的不同,您可以使用以下所列不同的工具来进行DAX建模。
• 对于 Power Pivot 模型,可以在Excel中使用Power Pivot加载项。
• 对于 Power BI 数据集,请使用 Power BI Desktop。
|  | 有趣的是, Power BI Desktop 实际上有三个版本。一个是从 Power BI 网站下载。另一个是从 Windows 应用商店安装的,并且像应用商店中的任何其他应用一样自动更新。当你意识到 Power BI Desktop 几乎每个月都会发布新版本,那么自动更新肯定要方便一些,尽管有些时候新版本可能会更改一些令你意想不到的地方,确实会很烦人。如果需要,可以在同一台电脑上安装这两个版本。第三个版本的 Power BI Desktop(也可以从 Power BI 网站下载)是与 Power BI 报表服务器一起使用的特殊版本。 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
• 对于 SSAS 或 AAS 中的 Tabular 表格模型,可以使用 Visual Studio,它为专业开发提供了许多功能,例如与版本控制系统的集成、脚本编写和兼容性。
• 对于 Power BI Premium 中的 Power BI 数据集,可以在 Power BI Desktop 和 Visual Studio 之间选择合适的方式。这可以通过 XMLA 终结点技术实现,XMLA 终结点是 Power BI Premium中实现的一种技术,可为 Power BI 数据集提供与 Tabular 表格模型完全相同的可视化效果。
• 此外,还有几种基于社区的工具,如 Tabular Editor和 DAX Studio。这些工具甚至可以集成到 Power BI Desktop 中。
在本书中,我们选择使用"朴实无华"的Power BI Desktop,因为这是一个你应该已经安装了的免费应用。本书的每一位读者都可以轻松下载 Power BI Desktop,并使用异步社区本书页面上存储的示例文件。
## 1.5 由DAX驱动的可视化与交互式报告
在讨论五层模型时,我们已经简要地谈到了可视化报告的重要性。通过以下几个示例您可以发现,想要得到有价值的可视化报告,还得借助于DAX建模来实现。
创建可视化报告的目的是为了得到可靠的分析结论,并提供给使用者直接的见解与解决方案,而不仅仅是大量信息的罗列堆积。我们来看看图1.3展示的这个例子。
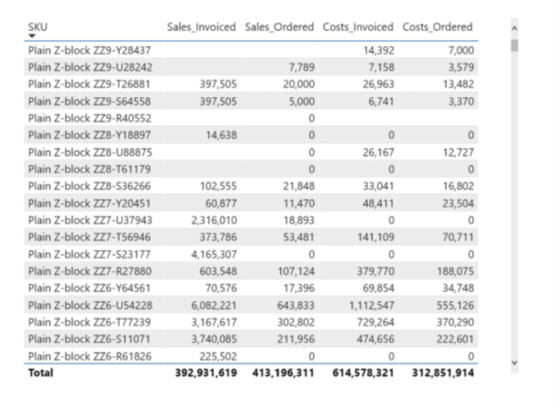
图1.3 表中的部分销售数据
你能一眼就发现这家公司存在的问题或者机遇吗?如果能,那么您对于数字一定十分敏感!然而,大多数人更习惯于视觉的直观感受。图1.4是同一组数据以柱状图的形式展示。
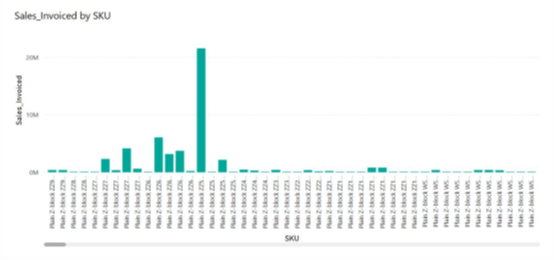
图1.4 更直观地呈现相同的销售数据
从柱状图中可以很明显看出,其中一个SKU的销售表现明显优于其他SKU(Stock Keeping Unit,库存量单位,针对电商而言,指的是识别商品的品项)。这是一个值得注意而且很有价值的见解:如果我们能够使其他SKU达到相同的销售表现,那么公司的整体业绩必将大大改善。这个见解会让人情不自禁地继续往下想:是什么导致了这个SKU卖的这么好呢?是否有某个大客户专门订购了这个SKU?这个SKU是否只在某些特定的地区卖得特别好?它的利润情况怎样呢?它卖得这么好,会不会是因为我们的定价太低了?
以上反映了一个基本的因果关系:每当您通过可视化报告得到一些见解时,这些见解又会让您产生更多新的疑问;解答这些疑问的过程生成新的见解,反过来又产生了其他问题。如此循环。
如何解决这种影响?传统的方法是在一份报告中提供尽可能多的信息。原因很简单,提交一项报告需要花费不少时间。Power BI 却以一种完全不同的方式实现这一点,得益于DAX的强大功能,Power BI在报告报告中添加了交互功能,如图1.5所示。

图1.5 可视化-交互周期
交互功能允许报告的使用者深入挖掘初始见解并找到后续问题的答案,从而将一个简单直接的报告转变为有机的交互性报告。而想要实现交互功能,报表需要有能力实时生成新的可视化对象。对于一个Power BI可视化报表来说,它的所有内容全都来自于Power BI模型,这意味着模型在向报表提供结果时也必须同样迅速。而模型的性能是由其本身的结构和您实施的 DAX 代码共同决定。因此,您的 DAX 代码书写好坏会直接影响着报表的用户体验!
## 1.6 如何开发解决方案
在Power BI 模型和 DAX 的帮助下,业务人员可以更加深入地参与开发 BI 解决方案,这与传统BI很大的区别。很显然,这样的解决方案能够提供深入的洞察,从而更好地提升业务价值。
传统的由IT部门来牵头创建的BI解决方案,首先要着手准备连接到数据源并进行数据预处理。如图1.6所示的那样,循序渐进,没有任何问题。毕竟,如果想得到好的并且有价值的见解,高质量的数据是先决条件。

图 1.6 传统的 BI 解决方案开发过程
此过程常见于企业数据仓库的开发中。拥有数据仓库背后的思想是将组织的所有数据集中存储在一个固定的位置,以此为基础去开发所有的报告。
应该清楚的是,这将会是一个大工程,因为组织中有许多不同部门,不同的部门有不同的系统,不同的系统又会有各种类型的数据。根据传统,数据仓库是以关系型数据库系统作为基础实现的,这意味着企业所有的数据都必须符合数据仓库的数据库结构或模式。
数据的多样性会导致数据仓库的架构高度复杂。此外,每当数据源系统更改或引入新系统时,新系统中的数据必须与数据仓库的架构相匹配,如果不匹配,那么就必须更改数据仓库以适应新数据。而每一次更改都会消耗大量的时间和金钱,因此,数据仓库项目经常因其持续时间太长和成本高昂而广为诟病。以往的许多职业都是建立在数据仓库之上的,不幸的是,许多职业也因为数据仓库而被打破了。真是成也萧何败也萧何。
传统的方法还存在一个更致命的缺陷。当您从接入数据源系统开始,然后沿着五层模型向上逐步开展工作,等到建模分析结束出报告得出结论的时候,您已经错过了实际业务场景需要这些见解的黄金时间。尽管大多数数据仓库项目都**想**把业务需求和对应的实际业务场景包含在流程中,但是实际上,如果以这种方式来实现,在众多的开发项目(也许是绝大多数项目)中,实际业务需求往往会被束之高阁。我们要知道,在整个数据仓库的开发过程中,技术的复杂性实在是太大了,根本无法让业务深入参与其中。经常出现的情况是,当数据仓库最终完成(或者更确切地说,第一次投入生产)时,它已经落后于当时的实际业务需求。
在焦躁地等待企业报告可用的同时,公司内部一些部门往往已经按捺不住急切的心情,部署了“影子IT”来获取所需的见解。他们利用手头现有的工具(通常是Excel)和可以获取的任何数据,自己动手建模分析并得到解决方案。虽然这能在一定程度上满足部门和员工对于分析见解的急切需要,但这对于企业的长足发展并没有利。一旦数据的质量无法保证,那么由此得出的结论是否可靠就值得商榷了。基于可靠性不足的结论做出决策,我想,没有哪一家企业愿意冒这个风险。
### 1.6.1 使用 Power BI 模型加速开发BI解决方案
在五层模型中,Power BI 不仅支持通过自下而上的方式进行开发,而且还支持通过自上而下的方式,图1.7很好地说明了这一点。
图1.7 Power BI支持的解决方案开发方式
通过这种方式,我们不仅可以将 Power BI 用作建模分析得到解决方案的平台,还可以将其作为一个工具来简化项目本身。在这个过程中,您可以充分利用Power BI的这些特定功能:快速创建报表并提供切实的见解,并且无论数据来自于哪里,您都可以从容连接并获取。Power BI模型和DAX发明的初衷就是为了实现上述的功能。
该方式基于两个基本定律如下。
(1)我们并不知道我们到底需要什么。
(2)我们的数据并不规范。
基于这些原则产生的结果是,您不可能在第一次就把它做好。相反,您应该部署一种迭代的工作方式,快速试错并快速改进,然后建立正确的模型。
#### 1.我们并不知道我们到底需要什么
这个定律告诉我们,压根不要指望实际业务人员甚至连你自己都不要指望,能够从一开始就为报告提供标准的规范。如果你曾经接触过并承担了BI项目,那么你会对此深有感触。哪怕是那些拍着胸脯说一切尽在掌握之中的人也会忽略很多细节。
即便他们真的有能力做到面面俱到,不放过任何一个细节,但是只要他们在开发过程中没有完全处于实际业务场景中,那么一定会导致部分解决方案的实施产生偏差。
结果就是,花费大量时间去收集需求或者整理出规范然后再去想尽办法通过审批是徒劳的。你可以确定的是:报告的雏形一定是有问题的。所以更好的方法是尽快将带着问题的报告做出来,然后,马上去改。事实证明,相比于一开始就绞尽脑汁写下所有的细节,指出现有模型中的问题和缺陷然后修修补补要轻松得多。
如图1.8所示,您可以通过多次迭代来将此方法变得正式一些,并在最后使用联合会话来显示原型并收集反馈。(我们喜欢称之为**业务设计会话**来突出它们的本质:它们不是反馈会议或演示,而是共同努力实现正确的结果。)取决于您的Power BI 和 DAX 技能,可能需要两天或更长时间来建立雏形。业务设计会话的结果将作为下一次迭代的输入。
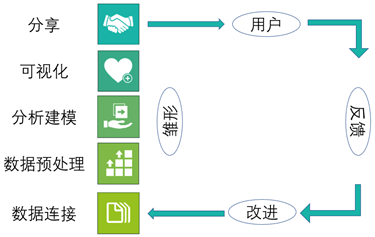
图 1.8 迭代需求捕获
这样,我们就得到了一份真正联合开发的且与业务需求完美契合的报告。更重要的是,此报告和模型是充分利用了五层模型当中的较低层提供的数据而得到的标准规范。
#### 2.我们的数据并不规范
第二个定律对你来说一定并不陌生。我们的数据不可能是规范的!原因很简单,实际业务流程往往异常混乱且复杂,再强大的建模能力也无法模拟出完全相同的流程。
而且,当您考虑到IT系统在设计时考虑到了业务流程应该是什么样子的形象时,很明显,自动化业务流程的系统面临着一个根本性的困境。系统实施严格的数据质量策略,即只能输入符合设计流程的数据(因此无法捕获该流程中的每一个案例),或者该系统提供了捕获业务流程所有实例的灵活性,并且必须允许不适合设计的理想流的数据。
后一种选择是大多数时候选择的。这意味着典型的业务系统允许异常、用户用来输入自定义信息的自定义字段以及不同类型的绕过。因此,来自业务系统的数据并不总是符合您的期望。当您的业务数据位于电子表格或其他文件中时,情况会变得更糟!
在传统的BI解决方案中,凌乱的数据很难检测和解决。原因是,通常,BI系统仅包含聚合数据,或者技术不支持业务用户在详细级别上探索数据。这就是Power BI的用武之地:Power BI 模型的技术非常强大,在许多情况下,数据可以加载到模型中而无需聚合。可视化和交互式报表通过复杂的(DAX)聚合提供见解,同时允许你放大到最深层次的细节。
在 BI 解决方案开发的迭代方法中,前几次迭代后的结果通常充满错误。知识渊博的商人通常能够很容易地发现这些错误。首先,以这种方式发现实现的聚合中的缺陷;但在后来的迭代中,数据的质量会显现出来。能够在Power BI报表中查看详细数据对于推动采用和信任新的BI解决方案有很大的帮助。
## 1.7 数字化转型循环
到目前为止,我们重点介绍了从原始数据到见解所需的内容,以及有DAX强大能力加持的Power BI模型在此过程中的作用。正如我们看到的那样,连接到数据源并准备好数据是获取商业价值的基础,但是更多的商业价值来自于可视化与交互式报表提供的直接见解。
然而,没有哪个组织会因为天天盯着漂亮的报表而变得更好。纸上谈兵是万万不能的,实践才是检验真理的唯一标准。换句话说:想要真正知道BI解决方案到底能带来什么好处,您需要结合报表中的分析见解去指导实际的业务。这还不够,您肯定还需要衡量这些操作到底效果如何,要么是以自动的方式,要么是让用户在某个系统里进行输入反馈。这个过程会再次产生数据。
这会产生一个**数字化转型循环**,或者叫数据驱动的业务改进循环,如图1.9所示。
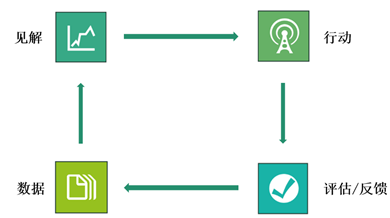
图1.9 数字化转型循环
图1.9所展示的这个循环的左侧,由数据产生见解的过程,Power BI的确能够一展风采,但是对于右侧的由行动到评估和反馈,它可能就无能为力了。这个部分需要其他的功能来实现,例如通过某些组件来实现数据的输入或更新,以及通过相关技术来实现人员与系统的连接。
正是出于这个原因,微软将Power BI作为一个更广阔平台的一部分,这个更大的平台叫做**Power Platform**。Power Platform为了覆盖整个数字化转型循环,采用了同样的基本设计原则:业务人员处于核心地位,易于进入,并且完全有能力满足苛刻的业务需求。
如图1.10所示,Power Platform由Power BI和它旁边的三个主要组件构成。
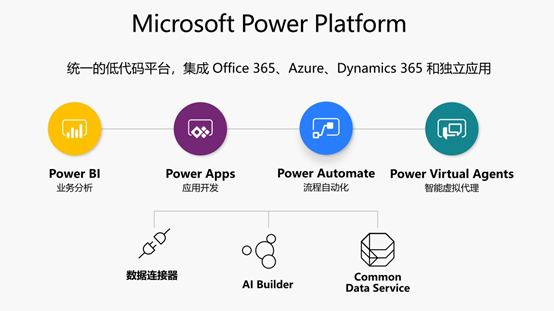
图1.10 Power Platform组成部分[[1\]](#_ftn1)
• Power Apps 提供了一个低代码的环境,以便开发一些可以在智能手机或Web浏览器上使用的应用。这些应用可用于编辑或添加数据。
• Power Automate 允许在各种系统、服务和面向用户的应用程序之间实现各种流程的自动化。举个例子,可以由收到的电子邮件触发流(flow),然后请求业务所有者确认,并自动更新数据,紧接着触发 Power BI 模型和相关报表的刷新。
• Power Virtual Agents提供了一个平台,可以通过一些AI聊天机器人实现与Power Platform的良好交互。有了这些AI机器人,用户可以通过对话式的交互来输入数据或进行相关操作,而不必去学习特定的应用程序界面。
尽管以上这些都是 Power Platform 这个大平台上的独立应用,但它们是紧密结合在一起的。比如,可以在Power BI报表中嵌入Power Apps 应用,这样用户就可以在获取见解的位置直接对数据进行修改,完美符合商业智能要紧随业务环境的要求。同样地,我们可以将Power Automate流嵌入到 Power BI报表当中,以便根据报表提供的见解来采取相应的措施。
## 总结
在本章中,我们讨论了商业智能领域以及分析模型在现代 BI 解决方案中的核心作用。基于DAX的强大功能,Power BI非常适合用作此类模型。
您已经了解了 DAX 的两项功能,它们对 BI 解决方案的设计和开发方式产生了深远的影响。
• DAX支持对各种数据直接进行复杂的聚合运算;过去,在进行聚合运算之前需要先对数据进行一系列的预处理使之规范化。因此,DAX让我们免于被数据(涉及所有繁琐的工作)所困扰,可以专注于生成业务见解的逻辑上。
• DAX作为一门编程语言被创建的初衷,就是让那些熟悉Excel的业务人员能够在不同层次上自行开发BI解决方案。这意味着商业智能可以更好地与业务保持一致,确保业务的优先级。
由于 Power BI 模型和 DAX 是同一枚硬币的两面,因此,如何平衡这两者,很考验建模者的水平。有个简单的秘诀是,让DAX去做那些它擅长的工作,而不是在数据中解决这些问题,反之亦然,也就是说,不要使用DAX来进行数据预处理或生成数据。
接下来的几章将详细阐述这些主题:在第2章 “模型设计”中,我们将讨论设计 Power BI 模型的注意事项。第3章 “使用 DAX”将重点介绍如何使用 DAX 获得最佳结果。第4章 “上下文和筛选”将继续讨论此主题,探讨了编写 DAX 计算时要了解的最重要的概念。本书的第二部分包含许多示例,其中大部分都来自实际客户项目,这些示例将带您领略 DAX 的强大功能以及如何在 DAX 和 Power BI 模型之间找到最佳平衡点。
------
[[1\]](#_ftnref1) 原书无此图,中文版译者添加
================================================
FILE: _posts/2022-04-08-Extreme DAX中文第2章 模型设计.md
================================================
---
layout: post
header-img: img/post-bg-extremedax.jpg
catalog: true
tags:
- Extreme DAX
---
公众号:PowerBI生命管理大师学谦,同步更新,敬请关注
# 第2章 模型设计
设计优良的分析模型是 DAX 高效运行的前提。在本章中,我们将讨论许多与建模有关的主题,这些主题对于理解性能强劲的模型设计非常重要。
本章中的主题包括以下几个方面。
• Power BI 引擎的数据存储方式。
• 选择正确的数据类型。
• 关系。
• 模型的结构。
为了构建良好的模型,您可能需要适当地转变一下自己的思维方式。无论您在之前的工作环境中一直习惯于使用Excel,还是更多地接触关系型数据库,当您开始接触 Power BI 时,都不得不做出一些改变。如果您更习惯于使用Excel,那么,想要理解数据分析模型中的“关系”这一概念,恐怕需要花上一段时间;即便您更熟悉关系型数据库,这两者之间也存在着诸多不同。关系型数据库专业人士对于“关系”一词肯定是非常熟悉的,然而 Power BI 中的关系却不等于关系型数据库中的关系,它们之间有着根本的不同。因此,我们将在本章中着重讨论这些差异。
## 2.1 列式数据存储
Power BI 模型的强大功能主要得益于智能的数据存储机制。Power BI模型本质上是数据库,因为与数据库一样,这些模型也对数据进行组织并存储。但是,其内部结构与您熟悉的其他数据库技术有很大不同。
### 2.1.1 关系型数据库
在过去,企业处理数据的方式是使用**关系型数据库管理系统**(relational database management system,**RDBMS**),如 Microsoft SQL Server。一个 RDBMS 中一般有大量的表,每一张表中列的数量都是固定的。每一列都必须具有固定的数据类型,如整数、文本或十进制数字,基于此,RDBMS 可以得出存储单行数据或记录所需的空间,并计算出磁盘上的一个数据文件可以存储多少行。这个特性使得 RDBMS 成为*处理事务*(process transactions)的应用程序的有效选择,例如来自网购平台的销售记录或公司财务分类帐中的记录。
RDBMS 中有一个概念叫做:**索引**(index)。通过索引可以快速而高效地查找特定的记录,这意味着也可以使用 RDBMS 有效地处理现有记录上的事务。关系型数据库这一术语之由来,是因为其中的表可以通过关系来连接,这确保了这些表中的数据是一致的;比如,某个 RDBMS 会阻止来自未知客户的销售交易插入。
RDBMS 技术经过长期的优化与迭代更新,目前已经非常成熟。因此,大多数传统的分析平台也依赖于RDBMS技术。但是,数据分析解决方案的技术需求与一个事务系统对技术的要求完全不同。在进行数据分析时,您往往不会从单个行中检索所有列的数据,相反,您可能对同时从多个行中获取数据感兴趣,并且往往只分析其中的一列或几列数据。然而想要从单个列中检索信息,RDBMS 仍需要从存储中读取一整行数据。同样,RDBMS并不擅长聚合多行数据,因此速度相对较慢。
图2.1对此过程进行了可视化说明:按行存储数据(由数字标识)无法有效地检索需要列的所有值。
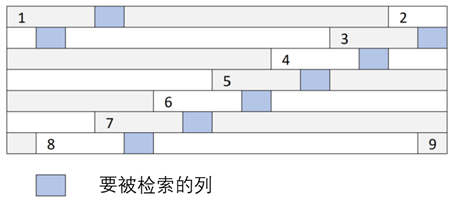
图2.1 从基于行的存储中检索列的值效率低下
### 2.1.2 列式数据库
与RDBMS的按行存储数据不同的是,Power BI模型通过按列存储数据来实现这一过程。这背后的基本原理是,在数据分析解决方案中,往往只需要从存储中读取单独的几列,但所有可用的行都得参与计算。当同一列中的所有数据都存储在相邻的位置时,效率很显然是最高的。
另一个原因是,在实际的业务中,单个列中的许多值是相同的;例如,几千或几万种产品往往对应着数以百万计的销售交易记录。此时,列式数据库可以通过仅存储一次特定值并记录它所属的行来高度压缩数据。
列式数据库实现的高压缩率开辟了将整个数据库保存在内存中的可能性,这意味着所有数据都驻留在运行数据库的计算机或服务器的内存中,而不是存储在磁盘上的文件中。而将数据保留在内存中可进一步加快数据检索速度。
列式模型意味着数据聚合异常高效。例如,列式数据库引擎可以简单地获取每个不同的值,然后将其乘以显示该值的行数,而不是对列中所有单独的值求和。简而言之,Power BI 模型的数据库引擎从一开始设计时就旨在支持数据分析的这种典型工作负荷:处理具有特定特征的大量数据,并在这个过程中执行聚合与计算。
但是,需要提醒的是:最终,您仍然需要知道不同列中的哪些值是放在一行中的。仅仅知道编号为103的产品已经全部售出是不够的;您还需要知道它的价格,销售给哪个客户以及销售日期是哪一天。若要实现这一点,模型必须保留指针列表,以跟踪列中的某个值到底位于哪一行中。当向表中添加更多列时,计算量显然会显著增加。因此,在 Power BI 模型中,“窄”的表比“宽”的表更高效。
## 2.2 数据类型和编码
Power BI 模型包含有限数量的数据类型。为数据选择正确的类型非常重要,因为它决定了数据的存储或编码方式,以及模型处理数据的效率。以下是能够被 Power BI 识别的所有数据类型。
• **文本(Text)**:最常见的数据类型就是文本。几乎所有数据都可以存储为文本。在Power BI 模型中,通过 Power Query 加载数据时,会将所有数据类型统一转换为 Text。很显然,当您忘记在 Power Query 中显式进行类型转换时,数字列也会存储为文本。(当然,你可以更改模型中的数据类型,这将自动在 Power Query 中添加一个更改数据类型的步骤。)
• **整****数(****Whole Number****)**:正如您所猜测的那样, “整数”数据类型用于存储整数。由于 Power BI 模型存储和压缩数据的方式,这是最高效的数据类型之一。
• **十进制数字(Decimal Number)**:通常,数据类型为数字的都使用这个格式存储。从非常小的数到非常大的数,以及分数值,它几乎可以存储。最多可以存储 15 位数字。
• **定点小数(Fixed Decimal Number)**:这种类型用于存储具有固定四位小数的小数值,有时也被称为“货币”类型(Currency)。最多可以存储包括四位小数在内的19位数字。这意味着此数据类型的覆盖范围小于十进制数字类型。定点小数类型通常用于存储货币金额,同时也可用于不需要很多小数的任何值。
• **日期/时间、日期、时间(Date/Time, Date, Time)**:Power BI 模型使用与 Excel 类似的结构存储日期和时间值。这意味着其值是十进制数字,整数部分表示日期,小数表示时间。
与 Excel的不同点在于基本参考日期:在 Power BI 模型中,数字 1 对应于 1899 年 12 月 31 日,而在 Excel 中,数字 1 对应于 1900 年 1 月 1 日(均在零点)。小数是在此基础上添加二十四小时制的一天中的时间;例如,值 2.5 表示 1900 年 1 月 1 日中午。
您有三种选择来存储日期/时间数据。日期/时间数据类型同时存储日期和时间。日期数据类型仅存储日期,这意味着此数据类型等效于整数。时间数据类型仅存储时间部分,它一直是小数。
• **真/假(True/False)**:真/假或布尔数据类型只能存储两个值:真和假。虽然使用时限制比较多,但使用此类型可以非常有效地存储数据。
• **二进制(Binary)**:二进制类型用于存储不能表示为文本的数据,如图像数据或文档。无法使用此数据类型执行聚合或计算,但它可用于存储需要在报表中使用的图像。
为了实现高效的模型,为数据选择合适的数据类型至关重要。Power BI 模型旨在尽可能高效地将一系列唯一值存储在列中。虽然我们在使用计算机时早就不必考虑位和字节的概念了,但是在设计模型时,考虑计算机使用的单个0和1仍然会有所帮助。模型将确定存储值所需的位数;由于所有数据都运行在内存中,因此能节省一些内存就尽量节省一些。
例如,假设有一列都是介于 0 和 10 之间的整数。在数字表示法中,数字 10 表示为 1010 或 4 位。因此,该值便可以用4位的字进行编码,直接表示该值。此方法称为**数值编码(value encoding)**。在配备 64 位处理器的现代计算机中,使用 4 位显然要比将值存储为 64 位的数字要高效得多。
数值编码只对整数有效,因此,整数格式自然可以进行数值编码。但是一些披着其他数据类型外衣但是本质是整数的数据类型,同样也可以使用数值编码:比如日期和布尔值。还有一个是你可能想不到的:定点小数。定点小数由于是**固定**的4位小数:它可以被当成是一个整数除以10000的结果。实际上,DAX 引擎能够在进行数值编码之前先进行基本的转换,例如将所有的值减去相同的数字。
其他数据类型不能直接表示为整数,数据库仍然需要找到一种方法来将这些值存储在最小的位数中。方法是通过保留带编号的值列表并存储数字,而不是直接存储原始值。这称为**哈希编码(hash encoding)**。哈希编码列的工作方式不如数值编码列高效,因为数据库每次使用这一列时都需要在这些数字和值之间进行转换。
需要强调的一点是,Power BI 模型会根据列中的数据类型和值选择最佳编码形式。这意味着,哪怕数据类型是整数或者本质是整数,到最后仍然可能使用哈希编码。举一个极端的例子,有一个数字列,不仅包含0到10之间的数字,还包含数字1,000,000时,直接存储这些值所需的位数比较多,以至于引擎将决定改用哈希编码。
我们在实际项目中经常看到这种情况,特别是在存储日期时。假设您有一个包含员工的表,其中包含他们的入职日期以及离职日期。对于所有在职员工,离职日期当然是空的;但是习惯上我们并不是空着这个字段,而是设置一个特定的未来日期。很多时候这是一种有效的方式,但是如果选择像 9999 年 12 月 31 日这样的日期,则肯定无法享受对日期列进行数值编码的优势。建议使用不太遥远的未来的一天,例如 2029 年 12 月 31 日(当然,具体取决于你的实际方案)[[1\]](#_ftn1)。
## 2.3 关系
Power BI 模型中一个最容易被误解的元素是关系的概念。当你使用Power BI时,无论你之前是更多接触Excel,还是更加熟悉关系型数据库,你都需要从头开始学习Power BI 模型中的关系。
### 2.3.1 Excel 中的数据
让我们先关注 Excel 中的数据。在 Excel 中最接近数据库的概念是 Excel 表的概念。您可以将 Excel 表视为“扁平的”数据库。这种存储数据的方式有许多缺点。
例如,图2.2显示了某个存储在 Excel 工作表中的数据。
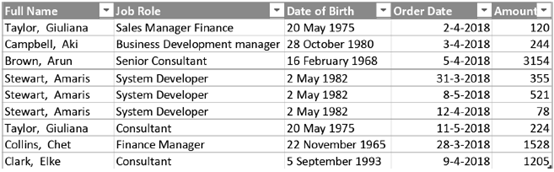
图2.2 Excel中的表格
图2.2展示的表中包含由员工销售订单的订单金额和日期。这样一个扁平的数据库存在诸多问题。
• 显然,有关员工的所有信息(如工作角色和出生日期)都在该员工销售的每个订单中重复。因此,大量信息是冗余的,这占用了大量的存储空间。
• 多次存储信息会增加数据出错的风险。
• 当员工的某些属性(如其工作角色)发生更改时,必须在与该员工关联的所有行中进行更改。
• 当一个实体有多个相同类型的属性时,情况会变得更糟。在我们的示例中,Giuliana 似乎有两个工作角色,并且每个销售订单仅与其中一个工作角色相关联。当我们按工作角色汇总销售额时,顾问(Consultant)的结果将仅包含Giuliana 的其中一个订单,从商业角度来看,有些时候说得通,但是有些时候这样得到的结果是错误的。
• 最大的麻烦可能产生于从多个不同的数据源获取数据时。让我们设想这么一个场景,我们不仅有销售数据,还有目标数据。将来自不同数据源的数据合并到一个扁平的数据表中需要花费大量精力。实际上,Excel 用户将大部分时间花在设置单个扁平的数据表上,以便他们下一步能够使用数据透视表。
在Excel中,这些问题实际上没有解决方法。的确是这样,除非你开始使用 Power Pivot,而它和Power BI模型从本质上而言是等效的。在正式讨论 Power BI 里的方法之前,让我们看一下如何在关系型数据库中处理数据。
### 2.3.2 关系型数据库中的数据
在关系型数据库或 RDBMS 中,数据被分隔到多个表中。通常,这些表通常是关于那些组织的实体(如客户、员工、产品等)。表中的每一行都有一个标识符或**键**(key),可以实现固定地引用其他表中的行;例如,在图2.3所示的销售订单表中,可以只包含客户和产品的键,而无需包含所涉及的客户和产品的所有属性。
图2.3 关系型数据库中的关系
显然,在录入销售订单时,没有客户键或者存在未知键,是没有任何意义的。这就是为什么在关系型数据库中,您需要定义表之间的关系,以表示表中的哪些列指向其他表中的键。关系型数据库会确保定义关系的列仅包含相关表的已知键。如果一条记录未存在于与之相关的表中,那么数据库将阻止其插入或更改。换句话说,关系型数据库中的关系充当对存储数据的约束,并用于强制实施**参照完整性**(referential integrity)。
### 2.3.3 Power BI的关系模型
终于,我们要开始讨论 Power BI 了。在 Power BI 模型中,关系是表与表之间的连接。这么一看,它们应该与关系型数据库中的关系相当,但实际上,它们完全是两个不同的事物。
Power BI 模型中关系的基础是具有唯一键的数据表。具有相同键值的另一个表可以与其相关,但在这个表中,键值不必是唯一的。这种类型的关系称为**一对多**关系,这意味着有一个表的键只出现一次,而另一个表的同一键可以多次出现。同关系型数据库一样,您可以将具有唯一键的列称为**主键列**(primary key column),将具有非唯一键的列称为**外键列**(foreign key column)。
在如图2.4所示的Power BI Desktop中的结构里,我们可以在模型视图中查看 Power BI 模型的结构以及其中的表和关系。
图2.4 Power BI 模型中两个表之间的关系
Power BI 模型中的关系与关系型数据库中的关系之间存在两个根本的区别。首先是参照完整性。关系型数据库中的关系充当数据约束,然而 Power BI 中的关系却并没有这么严格的要求。坦率地说,Power BI 并不在乎你的数据是否一致。当一些值只在外键列出现而不存在于主键列时,关系仍然可以存在。
如图2.5所示,模型会将每个未知的外键的值连接到一个空白行。模型中不会显示这个空白行,但是在报表中会显示。
图2.5 未知值与空白行相对应
这样做的一个优点是,您不必担心加载或刷新数据表的顺序,而在关系型数据库中,这是需要仔细考虑的。当然,缺点也随之而来,那就是在创建关系时必须小心,尤其是在模型视图中通过拖放字段来执行此操作时。当你拖拽字段放在错误的关系目标上时,Power BI 不会报错也不会有任何提示,它只会悄无声息地创建一个没有任何意义的关系。
Power BI和关系型数据库中的关系之间,还有另一个重要区别是筛选器传递(filter propagation)。Power BI 模型中的关系会主动筛选数据。更具体地说,当一个表中的某些行被选择时,另一个表中的相关行也会自动选择(沿着关系的箭头方向)。这是 Power BI 模型的核心设计原则,在进行 DAX 设计计算时需要充分考虑这一点。
而在关系型数据库中,关系并没有此功能。在查询关系型数据库时,用户必须指定要在哪些表上组合哪些(主键和外键)列。这使得查询关系型数据库非常灵活,但同时也迫使数据库为每个查询执行大量的工作。不过,这样导致的结果是,从一系列表中检索数据同时还需要处理大量关系会很低效。
### 2.3.4 关系属性
在 Power BI 模型中的表和表之间创建关系时,可以对驱动其行为的关系设置多个属性。这些属性与关系的主要目的,也就是筛选器传递,直接相关。
#### 1.活动关系和非活动关系
要使关系能够进行筛选器传递,表之间必须存在明确的连接。假设对于销售交易记录,订单日期(order date)和付款日期(payment date)这两列同时存在。如果从这两列到日期表都存在关系,并且在日期表中选择了一行,那么我们在探讨应当筛选哪些销售交易记录时,会产生如下的疑问:是在该日期订购的交易记录,还是已付款的交易记录,还是将两者都筛选出来?
为了处理这个问题,Power BI 模型只允许两个表之间有一个活动的关系存在。当两个表通过其他表连接时,这同样适用:只允许单个活动关系路径。如图2.6所示,它是 fSales 表(销售表)的 Order Date 列(订单日期列)与 Calendar 表(日历表)的 Date 列(日期列)之间的关系。当你创建第二条路径的关系时,之前的关系将变为非活动状态。在模型视图中,非活动关系用虚线来表示。
图2.6展示了继续添加两个关系之后的模型视图:分别在 fSales[Delivery date] 与 Calendar[Date] 两列之间和 fSales[Payment date] 与 Calendar[Date] 两列之间建立关系。
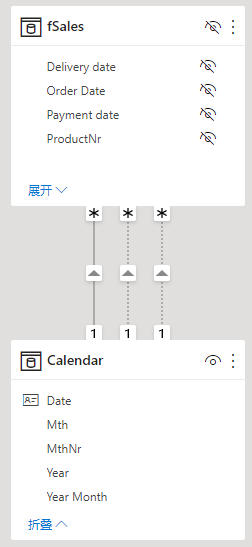
图2.6 一个活动关系和两个非活动关系
在某个特定的计算中,可以使用 USERELATIONSHIP 函数来激活非活动关系,同时原有的活动关系在该计算中暂时失效。
|  | 注意:在包含主键的表上定义行级别安全性 (row-level security,RLS) 时,使用 USERELATIONSHIP 函数来激活关系将导致 DAX 计算中出现错误。原因是,同任何其他筛选器一样,安全筛选器是通过关系传递的。停用传递安全筛选器的关系并激活另一个关系会导致对应选择的内容产生歧义。 因此,在设计模型时要小心谨慎,同时对未来可能需要的安全要求做到心中有数。还有一个建议是:不要过度使用非活跃关系。有关模型安全的深入探讨,请查看本书第5章 “DAX 中的安全性”。 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
#### 2.交叉筛选方向
通过关系进行的筛选器传递通常仅从主表(primary table)到外表(foreign table)。如图2.7所示,在模型视图中,筛选器传递或者交叉筛选(cross filter)的方向通过关系线中间的小箭头显示。
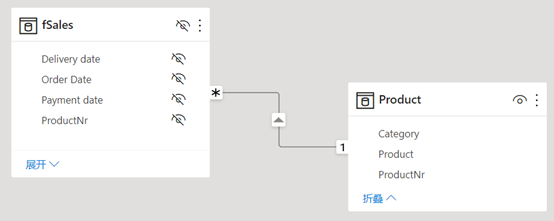
图2.7 关系的交叉筛选方向
我们也可以更改交叉筛选的方向,让筛选器在两个方向上传递。这个操作是在**编辑关系**对话框中完成的,方法是将交叉筛选器方向设置为**两个**。看上去,在两个方向上进行筛选似乎应该是默认的简便设置,但,不要这样做!实际上,只有在某些特定方案中我们才会使用双向的交叉筛选关系。请尽量避免使用双向关系,否则您的报告中将会出现许多奇怪的现象、许多非活动关系以及高度复杂的 DAX 计算。
使用双向交叉筛选的一个特定场景是在处理多对多关系时。举个例子,假设一个包含客户(customer)和分支机构(branch office)的模型,如图2.8所示。每一个客户由一个或多个分支机构提供服务,反过来,每一个分支机构又服务于多个客户。
图2.8 客户和分支机构
Customer 表和 Branch office 表都有唯一的键列,但它们都没有包含外键的列:每一行都必须关联到另一个表中的多行。解决此问题的方法是:使用一个包含所有客户键和分支机构键组合的中间表[[2\]](#_ftn2),Branch office Customer 表。接下来,可以分别从中间表到 Customer 表和 Branch office 表创建关系,如图2.9所示。
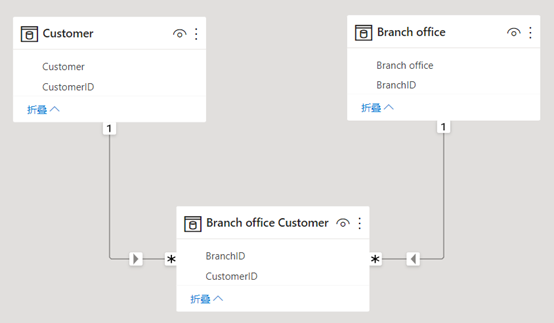
图2.9 中间表
但是,以上的关系并没有正确地从 Customer 表到 Branch office 表进行交叉筛选,反过来也是如此:您可以在 Customer 表中选择一行,关系会将所选内容传递到中间表,但接下来却不会传递到 Branch office 表,因为此关系是单向的。
图2.10给出了解决方案:将两种关系都设置为双向的交叉筛选。此时,在 Customer 表中选择某一行时,左侧的关系将向右传递到中间表,右侧的关系再向右传递到 Branch office 表。反过来,在 Branch office 表中选择某一行时,关系会将所选内容传递到中间表,然后再将该选择传递到 Customer 表。
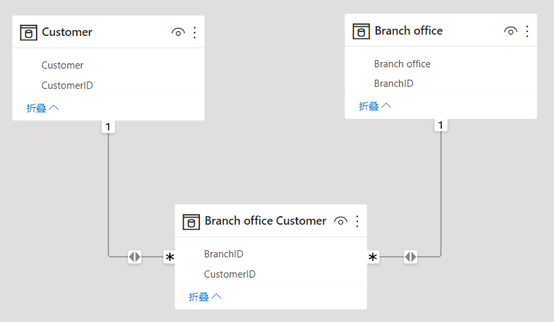
图2.10 通过中间表实现多对多关系
|  | 注意:当您将其中一个表(例如 Customer 表)与包含销售交易记录的表相关联时,此处会出现警告。对于每个销售交易记录,必须记录客户键。该设置允许选择一个客户,比如张三,并查看张三的总销售额。但是,我们无法查看张三在某个特定分支机构的销售额:如图2.11所示,随便选择一个分支机构,只要张三在这里消费过,那么我们只能获取他在所有分支机构中总的销售额。当您按分支机构报告总销售额时,张三的销售额将成为与之相关的每个分支机构销售额的一部分。 在这种情况下,使用中间表将这两个表关联在一起并不是一个很好的选择,通常,我们会将 Customer 表和 Branch office 表直接与销售表相关联,大部分时候,这是最佳实践。 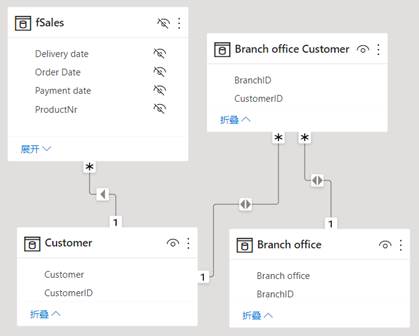 图2.11 在 Branch office Customer 表和 Customer 表以及 Branch office 表之间使用交叉筛选 |
| ------------------------------------------------------------ | ------------------------------------------------------------ |
#### 3.基数
模型中的默认关系是**一对多**关系,其中一个表包含一个唯一的主键,另一个表包含与外键相同的值,这些值并不是唯一的。此关系属性的正式叫法是**基数**(Cardinality)。
关系也可以有其他的基数。将一对多关系中的两个表位置换一下就是**多对一**关系。
关系可以具有**一对一**基数,这意味着在关系的两端,键都是唯一的。默认情况下,一对一关系的交叉筛选器方向是两个。因此,在几乎所有情况下这两个表都充当一个表。需要提醒的是,应避免在模型中建立一对一关系:除非有特定原因将它们分开,否则应将两个相关表合并为一个表(想要了解这些原因可能是什么,请参阅第8章“使用 AutoExist”)。
关系基数的最后一个选项是**多对多**。在这种情况下,两个相关表都不包含唯一的键。同样,您可能有特定的理由使用这种关系。但是,我们强烈建议不要使用多对多关系,因为这些关系很容易将你的模型搞得一团糟。本章后面 “在 Power BI 模型中要避免的关系型数据库原则” 部分将详细介绍多对多关系。
## 2.4 高效的模型设计
关系和筛选器传递的概念让 Power BI 模型可以实现强大的分析能力。因此,在建模时,思考模型的设计非常重要:模型应包含哪些表,这些表中需要包含哪些列,需要建立哪些关系?简而言之,模型的整体结构是什么?您在模型设计中所做的选择将决定模型能够达到什么样的效果。
### 2.4.1 星型结构和雪花结构
使用关系型数据库进行数据分析的最佳做法是使用一个特定的数据库结构,称为**星型结构**(star schema),如图2.12所示。星型结构的基本思想也适用于 Power BI 模型。
图2.12 通用的星型架构的结构
处于星型结构模型中心的表是**事实表**(fact table)。事实表包含已经发生、将要发生或应该发生的事情,如销售交易、财务分类账交易、客户查询、学生注册和销售机会等。
通过外键列,事实表与那些描述事实的不同实体(如客户、产品、成本中心、学生、日期等)的表建立关系。在星型结构的概念中,这些表称为**维度表**(dimension table);但是,在 Power BI 模型中,我们更愿意将它们称为**筛选表**(filter table),原因如下所述。
筛选表中的列被用来筛选报表中的结果,可以将它们用作矩阵或表中的行标签,或者作为图表的轴,又或者将它们作为切片器字段。事实表中包含报告需要进行聚合的数据。每个键值可以在事实表中多次出现,对应于同一天出现的多个事实,或者针对同一客户的多个数据,等等。
在一个纯粹的星型结构模型中,筛选表之间没有任何关系。当筛选表与其他筛选表相关时,生成的模型结构称为**雪花结构**(snowflake),如图2.13所示。
图2.13 雪花结构
### 2.4.2 星型结构的问题
在关系型数据库专业人士的眼中,雪花模式通常被认为
gitextract_2azug98j/ ├── .github/ │ └── ISSUE_TEMPLATE/ │ └── feature_request.md ├── .gitignore ├── .travis.yml ├── 404.html ├── 5ebc4602a40a61502b09471e378ae7ae.txt ├── CNAME ├── Gruntfile.js ├── LICENSE ├── README.md ├── _config.yml ├── _includes/ │ ├── footer.html │ ├── head.html │ └── nav.html ├── _layouts/ │ ├── default.html │ ├── keynote.html │ ├── page.html │ └── post.html ├── _posts/ │ ├── 2019-12-12-Power BI创建日期表的几种方式概览.md │ ├── 2020-01-15-如果雇一个人7d×24h每10秒刷新一次Power BI,我需要每月支付他多少钱?.md │ ├── 2020-01-16-一行代码无限刷新Power BI,完美突破每天8次限制.md │ ├── 2020-03-19-【运营】新用户数量?Power BI简单三步计算.md │ ├── 2020-03-19-【运营】新用户明细?Power BI一招帮你搞定.md │ ├── 2020-03-20-如何显示数据更新时间.md │ ├── 2020-03-21-【运营】沉睡、流失客户分析?Power BI一招帮你搞定.md │ ├── 2020-03-22-【运营】任意两个时间段的复购率?Power BI一招帮你搞定.md │ ├── 2020-03-26-「强强联合」在Power BI 中使用Python(1)——导入数据.md │ ├── 2020-03-27-【强强联合】在Power BI 中使用Python(2)——数据清洗.md │ ├── 2020-03-28-【强强联合】在Power BI 中使用Python(3)——数据可视化.md │ ├── 2020-03-29-【强强联合】在Power BI 中使用Python(4)——PQ数据导出&写回SQL.md │ ├── 2020-03-30-【强强联合】在Power BI 中使用Python(5)——数据预警与邮件通知.md │ ├── 2020-03-31-Power BI数据回写SQL Server(1)没有中间商赚差价.md │ ├── 2020-04-01-Power BI数据回写SQL Server(2)——存储过程一步到位.md │ ├── 2020-04-04-同一台电脑管理多家企业Power BI报表的自动更新.md │ ├── 2020-04-11-Python自动将Power BI页面发送钉钉群.md │ ├── 2022-04-05-Power BI Desktop 入门 - Power BI Microsoft Docs.md │ ├── 2022-04-06-以下为发表在公众号及知乎上的旧文章.md │ ├── 2022-04-07-这是我在GitHub上传的第一篇文章.md │ ├── 2022-04-08-Extreme DAX中文第0章 前言.md │ ├── 2022-04-08-Extreme DAX中文第1章 商业智能中的DAX.md │ ├── 2022-04-08-Extreme DAX中文第2章 模型设计.md │ ├── 2022-04-10-Power Automate打造的微信聊天记录优质内容存储到notion.md │ ├── 2022-04-10-纯Power Automate打造的Power BI无限刷新-邮箱版-同时刷新多个数据集.md │ ├── 2022-04-20-Extreme DAX中文第3章 DAX的用法.md │ ├── 2022-05-06-这个网站用PowerBI、PowerQuery不好爬?这一招交给你.md │ ├── 2022-05-10-Extreme DAX中文第4章 上下文和筛选.md │ ├── 2022-05-10-Power Automate Flow中JSON的增删改查.md │ ├── 2022-05-11-Extreme DAX中文目录.md │ ├── 2022-05-12-Power Automate实现PowerBI数据集刷新结束后通知.md │ ├── 2022-05-16-Power BI 以小易大-破电脑也能搞定大模型.md │ ├── 2022-05-16-它来了,它来了,Power BI的5月更新带着“字段参数”向你走来了.md │ ├── 2022-05-17-Power BI【字段参数】更多细节说明.md │ ├── 2022-05-18-Power BI参数自动放大缩小数据集.md │ ├── 2022-05-24-Power BI 无限刷新-内部指导流程.md │ ├── 2022-05-25-Power BI 定时导出数据,新版ExecuteQuery.md │ ├── 2022-05-xx-Power BI execute query.md │ ├── 2022-06-xx-GitHub Copilot 即将收费?有这钱干点啥不好.md │ ├── 2022-06-xx-Github学生包申请流程.md │ ├── 2022-06-xx-PowerBI注册账号申请.md │ ├── 2022-06-xx-为什么玩转Power BI一定需要Office 365.md │ ├── 2022-06-xx-增强刷新.md │ ├── 2022-07-18-Power BI从Dataverse获取数据.md │ ├── 2022-07-18-恢复删除的flow.md │ ├── 2022-07-22-几个Power Automate技巧送给你.md │ ├── 2022-07-22-打破不同组织间的壁垒,Power Automate同步PowerBI报告.md │ ├── 2022-07-25-Power Automate表达式无法输入和修改时的处理办法.md │ ├── 2022-08-08在Onedrive for Business中创建文件夹.md │ ├── 2022-09-23-Craft——制作惊人的文档.md │ ├── 2022-09-23-Microsoft Loop初见.md │ ├── 2023-07-01-限量20套!这样的Power BI管理员,你值得拥有!.md │ └── 2023-07-02-什么是PowerBI全局管理员.md ├── about.html ├── codecov.yml ├── css/ │ ├── bootstrap.css │ ├── hux-blog.css │ └── syntax.css ├── feed.xml ├── index.html ├── js/ │ ├── bootstrap.js │ ├── hux-blog.js │ ├── jquery.js │ ├── jquery.nav.js │ └── jquery.tagcloud.js ├── less/ │ ├── hux-blog.less │ ├── mixins.less │ ├── side-catalog.less │ ├── sidebar.less │ └── variables.less ├── offline.html ├── package.json ├── pwa/ │ └── manifest.json ├── sw.js └── tags.html
SYMBOL INDEX (88 symbols across 4 files)
FILE: js/bootstrap.js
function transitionEnd (line 34) | function transitionEnd() {
function removeElement (line 126) | function removeElement() {
function Plugin (line 142) | function Plugin(option) {
function Plugin (line 247) | function Plugin(option) {
function Plugin (line 466) | function Plugin(option) {
function getTargetFromTrigger (line 685) | function getTargetFromTrigger($trigger) {
function Plugin (line 697) | function Plugin(option) {
function clearMenus (line 829) | function clearMenus(e) {
function getParent (line 848) | function getParent($this) {
function Plugin (line 865) | function Plugin(option) {
function Plugin (line 1179) | function Plugin(option, _relatedTarget) {
function complete (line 1521) | function complete() {
function Plugin (line 1673) | function Plugin(option) {
function Plugin (line 1787) | function Plugin(option) {
function ScrollSpy (line 1830) | function ScrollSpy(element, options) {
function Plugin (line 1953) | function Plugin(option) {
function next (line 2060) | function next() {
function Plugin (line 2106) | function Plugin(option) {
function Plugin (line 2263) | function Plugin(option) {
FILE: js/jquery.js
function isArraylike (line 533) | function isArraylike( obj ) {
function Sizzle (line 745) | function Sizzle( selector, context, results, seed ) {
function createCache (line 859) | function createCache() {
function markFunction (line 877) | function markFunction( fn ) {
function assert (line 886) | function assert( fn ) {
function addHandle (line 908) | function addHandle( attrs, handler ) {
function siblingCheck (line 923) | function siblingCheck( a, b ) {
function createInputPseudo (line 950) | function createInputPseudo( type ) {
function createButtonPseudo (line 961) | function createButtonPseudo( type ) {
function createPositionalPseudo (line 972) | function createPositionalPseudo( fn ) {
function testContext (line 995) | function testContext( context ) {
function setFilters (line 2004) | function setFilters() {}
function toSelector (line 2075) | function toSelector( tokens ) {
function addCombinator (line 2085) | function addCombinator( matcher, combinator, base ) {
function elementMatcher (line 2138) | function elementMatcher( matchers ) {
function multipleContexts (line 2152) | function multipleContexts( selector, contexts, results ) {
function condense (line 2161) | function condense( unmatched, map, filter, context, xml ) {
function setMatcher (line 2182) | function setMatcher( preFilter, selector, matcher, postFilter, postFinde...
function matcherFromTokens (line 2275) | function matcherFromTokens( tokens ) {
function matcherFromGroupMatchers (line 2333) | function matcherFromGroupMatchers( elementMatchers, setMatchers ) {
function winnow (line 2629) | function winnow( elements, qualifier, not ) {
function sibling (line 2953) | function sibling( cur, dir ) {
function createOptions (line 3031) | function createOptions( options ) {
function completed (line 3425) | function completed() {
function Data (line 3530) | function Data() {
function dataAttr (line 3721) | function dataAttr( elem, key, data ) {
function returnTrue (line 4061) | function returnTrue() {
function returnFalse (line 4065) | function returnFalse() {
function safeActiveElement (line 4069) | function safeActiveElement() {
function manipulationTarget (line 4941) | function manipulationTarget( elem, content ) {
function disableScript (line 4951) | function disableScript( elem ) {
function restoreScript (line 4955) | function restoreScript( elem ) {
function setGlobalEval (line 4968) | function setGlobalEval( elems, refElements ) {
function cloneCopyEvent (line 4979) | function cloneCopyEvent( src, dest ) {
function getAll (line 5013) | function getAll( context, tag ) {
function fixInput (line 5024) | function fixInput( src, dest ) {
function actualDisplay (line 5479) | function actualDisplay( name, doc ) {
function defaultDisplay (line 5501) | function defaultDisplay( nodeName ) {
function curCSS (line 5548) | function curCSS( elem, name, computed ) {
function addGetHookIf (line 5596) | function addGetHookIf( conditionFn, hookFn ) {
function computePixelPositionAndBoxSizingReliable (line 5636) | function computePixelPositionAndBoxSizingReliable() {
function vendorPropName (line 5741) | function vendorPropName( style, name ) {
function setPositiveNumber (line 5763) | function setPositiveNumber( elem, value, subtract ) {
function augmentWidthOrHeight (line 5771) | function augmentWidthOrHeight( elem, name, extra, isBorderBox, styles ) {
function getWidthOrHeight (line 5810) | function getWidthOrHeight( elem, name, extra ) {
function showHide (line 5854) | function showHide( elements, show ) {
function Tween (line 6152) | function Tween( elem, options, prop, end, easing ) {
function createFxNow (line 6321) | function createFxNow() {
function genFx (line 6329) | function genFx( type, includeWidth ) {
function createTween (line 6349) | function createTween( value, prop, animation ) {
function defaultPrefilter (line 6363) | function defaultPrefilter( elem, props, opts ) {
function propFilter (line 6496) | function propFilter( props, specialEasing ) {
function Animation (line 6533) | function Animation( elem, properties, options ) {
function addToPrefiltersOrTransports (line 7581) | function addToPrefiltersOrTransports( structure ) {
function inspectPrefiltersOrTransports (line 7613) | function inspectPrefiltersOrTransports( structure, options, originalOpti...
function ajaxExtend (line 7640) | function ajaxExtend( target, src ) {
function ajaxHandleResponses (line 7660) | function ajaxHandleResponses( s, jqXHR, responses ) {
function ajaxConvert (line 7716) | function ajaxConvert( s, response, jqXHR, isSuccess ) {
function done (line 8174) | function done( status, nativeStatusText, responses, headers ) {
function buildParams (line 8418) | function buildParams( prefix, obj, traditional, add ) {
function getWindow (line 8912) | function getWindow( elem ) {
FILE: js/jquery.tagcloud.js
function toRGB (line 38) | function toRGB (code) {
function toHex (line 47) | function toHex (ary) {
function colorIncrement (line 55) | function colorIncrement (color, range) {
function tagColor (line 61) | function tagColor (color, increment, weighting) {
function compareWeights (line 76) | function compareWeights(a, b)
FILE: sw.js
constant PRECACHE (line 9) | const PRECACHE = 'precache-v1';
constant RUNTIME (line 10) | const RUNTIME = 'runtime';
constant HOSTNAME_WHITELIST (line 11) | const HOSTNAME_WHITELIST = [
Condensed preview — 92 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (1,115K chars).
[
{
"path": ".github/ISSUE_TEMPLATE/feature_request.md",
"chars": 595,
"preview": "---\nname: Feature request\nabout: Suggest an idea for this project\ntitle: ''\nlabels: ''\nassignees: ''\n\n---\n\n**Is your fea"
},
{
"path": ".gitignore",
"chars": 520,
"preview": "\n# Created by https://www.gitignore.io/api/macos\n\n### macOS ###\n*.DS_Store\n.AppleDouble\n.LSOverride\n\n# Icon must end wit"
},
{
"path": ".travis.yml",
"chars": 225,
"preview": "language: ruby\nenv:\n global:\n - NOKOGIRI_USE_SYSTEM_LIBRARIES=true\ninstall: \n - gem install jekyll\n - gem install "
},
{
"path": "404.html",
"chars": 652,
"preview": "---\nlayout: default\ndescription: \"你来到了没有知识的荒原 🙊\"\nheader-img: \"img/404-bg.jpg\"\npermalink: /404.html\n---\n\n\n<!-- Page Heade"
},
{
"path": "5ebc4602a40a61502b09471e378ae7ae.txt",
"chars": 40,
"preview": "2c7be435d8efb8289f7b6c9517e6391ff0cb857c"
},
{
"path": "CNAME",
"chars": 13,
"preview": "powerbipro.cn"
},
{
"path": "Gruntfile.js",
"chars": 2131,
"preview": "module.exports = function(grunt) {\n\n // Project configuration.\n grunt.initConfig({\n pkg: grunt.file.readJSO"
},
{
"path": "LICENSE",
"chars": 1059,
"preview": "MIT License\n\nCopyright (c) 2017 BY \n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof thi"
},
{
"path": "README.md",
"chars": 7487,
"preview": "\n\n[——导入数据.md",
"chars": 5816,
"preview": "[「强强联合」在Power BI 中使用Python(1)——导入数据](http://toutiao.com/item/6809844428987957772/)\n\n——数据清洗.md",
"chars": 5547,
"preview": "【强强联合】在Power BI 中使用Python(2)——数据清洗\n\n——数据可视化.md",
"chars": 7257,
"preview": "【强强联合】在Power BI 中使用Python(3)——数据可视化\n\n——PQ数据导出&写回SQL.md",
"chars": 5586,
"preview": "【重磅来袭】在Power BI 中使用Python(4)——PQ数据导出&写回SQL\n\n——数据预警与邮件通知.md",
"chars": 5420,
"preview": "【重磅来袭】在Power BI 中使用Python(5)——数据预警与邮件通知\n\n没有中间商赚差价.md",
"chars": 6279,
"preview": "Power BI数据回写SQL Server(1)没有中间商赚差价\n\n——存储过程一步到位.md",
"chars": 5490,
"preview": "Power BI数据回写SQL Server(2)——存储过程一步到位\n\n\n\n记住它!\n\n一个搭建网站的纯小白,也可以在github的强大助力下,轻松实现了这一切。\n\n\n\n"
},
{
"path": "_posts/2022-04-08-Extreme DAX中文第0章 前言.md",
"chars": 3884,
"preview": "---\nlayout: post\nheader-img: img/post-bg-extremedax.jpg\ncatalog: true\ntags:\n - Extreme DAX\n---\n\n公众号:PowerBI生命管理大师"
},
{
"path": "_posts/2022-04-08-Extreme DAX中文第1章 商业智能中的DAX.md",
"chars": 14587,
"preview": "---\nlayout: post\nheader-img: img/post-bg-extremedax.jpg\ncatalog: true\ntags:\n - Extreme DAX\n---\n\n公众号:PowerBI生命管理大师"
},
{
"path": "_posts/2022-04-08-Extreme DAX中文第2章 模型设计.md",
"chars": 19626,
"preview": "---\nlayout: post\nheader-img: img/post-bg-extremedax.jpg\ncatalog: true\ntags:\n - Extreme DAX\n---\n\n\n\n公众号:PowerBI生命管理"
},
{
"path": "_posts/2022-04-10-Power Automate打造的微信聊天记录优质内容存储到notion.md",
"chars": 772,
"preview": "---\nlayout: post\nheader-img: img/post-bg-weixin-notion.jpg\ncatalog: true\ntags:\n - PowerAutomate\n - PowerBI\n "
},
{
"path": "_posts/2022-04-10-纯Power Automate打造的Power BI无限刷新-邮箱版-同时刷新多个数据集.md",
"chars": 1554,
"preview": "---\nlayout: post\nheader-img: img/post-bg-parefreshpowerbi.jpg\ncatalog: true\ntags:\n - PowerAutomate\n - PowerBI\n"
},
{
"path": "_posts/2022-04-20-Extreme DAX中文第3章 DAX的用法.md",
"chars": 12954,
"preview": "---\nlayout: post\nheader-img: img/post-bg-extremedax.jpg\ncatalog: true\ntags:\n - Extreme DAX\n---\n\n\n\n公众号:PowerBI生命管理"
},
{
"path": "_posts/2022-05-06-这个网站用PowerBI、PowerQuery不好爬?这一招交给你.md",
"chars": 3664,
"preview": "---\nlayout: post\nheader-img: img/post-bg-parefreshpowerbi.jpg\ncatalog: true\ntags:\n - PowerBI\n - PowerQuery\n---"
},
{
"path": "_posts/2022-05-10-Extreme DAX中文第4章 上下文和筛选.md",
"chars": 38745,
"preview": "---\nlayout: post\nheader-img: img/post-bg-extremedax.jpg\ncatalog: true\ntags:\n - Extreme DAX\n---\n\n\n\n公众号:PowerBI生命管理"
},
{
"path": "_posts/2022-05-10-Power Automate Flow中JSON的增删改查.md",
"chars": 3163,
"preview": "---\nlayout: post\nheader-img: img/post-bg-parefreshpowerbi.jpg\ncatalog: true\ntags:\n - PowerAutomate\n - PowerBI\n"
},
{
"path": "_posts/2022-05-11-Extreme DAX中文目录.md",
"chars": 707,
"preview": "---\nlayout: post\nheader-img: img/post-bg-extremedax.jpg\ncatalog: true\ntags:\n - Extreme DAX\n---\n\n\n\n公众号:PowerBI生命管理"
},
{
"path": "_posts/2022-05-12-Power Automate实现PowerBI数据集刷新结束后通知.md",
"chars": 3433,
"preview": "---\nlayout: post\nheader-img: img/post-bg-parefreshpowerbi.jpg\ncatalog: true\ntags:\n - PowerAutomate\n - PowerBI\n"
},
{
"path": "_posts/2022-05-16-Power BI 以小易大-破电脑也能搞定大模型.md",
"chars": 2447,
"preview": "---\nlayout: post\nheader-img: img/post-bg-bigsmall.png\ncatalog: true\ntags:\n - PowerBI\n---\n\n### 一、背景\n\n数据集过大,尤其是在电脑配"
},
{
"path": "_posts/2022-05-16-它来了,它来了,Power BI的5月更新带着“字段参数”向你走来了.md",
"chars": 2299,
"preview": "---\nlayout: post\nheader-img: img/post-bg-parameter.jpg\ncatalog: true\ntags:\n - PowerBI\n---\n\n\n\n搁在以前,想实现下面这个图,那可真是费心"
},
{
"path": "_posts/2022-05-17-Power BI【字段参数】更多细节说明.md",
"chars": 1629,
"preview": "---\nlayout: post\nheader-img: img/post-bg-parameter.jpg\ncatalog: true\ntags:\n - PowerBI\n---\n\n昨日对刚刚更新的字段参数进行了一些说明,朋友"
},
{
"path": "_posts/2022-05-18-Power BI参数自动放大缩小数据集.md",
"chars": 2530,
"preview": "---\nlayout: post\nheader-img: img/post-bg-bigsmall.png\ncatalog: true\ntags:\n - PowerBI\n---\n\n前些天的文章中阐述了使用参数的改变来实现本地d"
},
{
"path": "_posts/2022-05-24-Power BI 无限刷新-内部指导流程.md",
"chars": 2176,
"preview": "---\nlayout: post\nheader-img: img/post-bg-bigsmall.png\ncatalog: true\ntags:\n - PowerBI\n---\n\n\n\n。由于是分开独立购买,因此域名自然是不同的,即分属两个不同的组织。\n\n财务部"
},
{
"path": "_posts/2022-07-25-Power Automate表达式无法输入和修改时的处理办法.md",
"chars": 1264,
"preview": "自从flow的主页改为https://make.powerautomate.com,速度是快了不少,但是好像bug也多了起来。\n\n正常而言,一个action输入框点击之后,可以在表达式的位置进行自定义添加或者修改。\n\n之前一直很正常,但是这"
},
{
"path": "_posts/2022-08-08在Onedrive for Business中创建文件夹.md",
"chars": 1355,
"preview": "# 在Onedrive for Business中创建文件夹\n\n在Onedrive for Business(以下简称ODB)中创建一个文件是非常轻松的一件事:\n\n\n\n目前个人版账号登录显示尚未开始:\n\n\n * Copyright 2011-2015 Twitter, Inc.\n * Licensed under MIT (https://gi"
},
{
"path": "css/hux-blog.css",
"chars": 25681,
"preview": "@media (min-width: 1200px) {\n .post-container,\n .sidebar-container {\n padding-right: 5%;\n }\n}\n@media (min-width: 7"
},
{
"path": "css/syntax.css",
"chars": 3147,
"preview": "/* to make lines scroll instead of wrap */\n/* from http://stackoverflow.com/a/23393920 */\n\n.highlight pre code * {\n whi"
},
{
"path": "feed.xml",
"chars": 1292,
"preview": "---\nlayout: null\n---\n<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<rss version=\"2.0\" xmlns:atom=\"http://www.w3.org/2005/Atom\">"
},
{
"path": "index.html",
"chars": 1189,
"preview": "---\nlayout: page\ndescription: \"Power BI生命管理大师\"\n---\n\n{% for post in paginator.posts %}\n<div class=\"post-preview\">\n <a "
},
{
"path": "js/bootstrap.js",
"chars": 66732,
"preview": "/*!\n * Bootstrap v3.3.2 (http://getbootstrap.com)\n * Copyright 2011-2015 Twitter, Inc.\n * Licensed under MIT (https://gi"
},
{
"path": "js/hux-blog.js",
"chars": 2937,
"preview": "/*!\n * Clean Blog v1.0.0 (http://startbootstrap.com)\n * Copyright 2015 Start Bootstrap\n * Licensed under Apache 2.0 (htt"
},
{
"path": "js/jquery.js",
"chars": 247387,
"preview": "/*!\n * jQuery JavaScript Library v2.1.3\n * http://jquery.com/\n *\n * Includes Sizzle.js\n * http://sizzlejs.com/\n *\n * Cop"
},
{
"path": "js/jquery.nav.js",
"chars": 5175,
"preview": "/*\n * jQuery One Page Nav Plugin\n * http://github.com/davist11/jQuery-One-Page-Nav\n *\n * Copyright (c) 2010 Trevor Davis"
},
{
"path": "js/jquery.tagcloud.js",
"chars": 2145,
"preview": "(function($) {\n\n $.fn.tagcloud = function(options) {\n var opts = $.extend({}, $.fn.tagcloud.defaults, options);\n "
},
{
"path": "less/hux-blog.less",
"chars": 17913,
"preview": "@import \"variables.less\";\n@import \"mixins.less\";\n@import \"sidebar.less\";\n@import \"side-catalog.less\";\n\n// Global Compone"
},
{
"path": "less/mixins.less",
"chars": 1725,
"preview": "// Mixins\n\n.transition-all() {\n -webkit-transition: all 0.5s;\n -moz-transition: all 0.5s;\n transition: all 0.5s"
},
{
"path": "less/side-catalog.less",
"chars": 1755,
"preview": "// Directory Section\n\n.catalog-container{\n padding: 0px;\n}\n\n.side-catalog {\n &.fixed{\n position: fixed;\n "
},
{
"path": "less/sidebar.less",
"chars": 1121,
"preview": "@import \"variables.less\";\n\n// Sidebar Components\n\n// Large Screen\n@media (min-width: 1200px){\n .post-container, .side"
},
{
"path": "less/variables.less",
"chars": 181,
"preview": "// Variables\n\n@brand-primary: #0085A1;\n@gray-dark: lighten(black, 25%);\n@gray: lighten(black, 50%);\n@gray-l: lighten(bla"
},
{
"path": "offline.html",
"chars": 658,
"preview": "---\nlayout: default\ndescription: \"网络似乎出现了问题 😥\"\nheader-img: \"img/404-bg.jpg\"\npermalink: /offline.html\n---\n\n\n<!-- Page Hea"
},
{
"path": "package.json",
"chars": 1110,
"preview": "{\n \"name\": \"学谦PowerBI\",\n \"title\": \"学谦PowerBI\",\n \"author\": \"学谦 <xueqian@powerbipro.cn>\",\n \"version\": \"1.7.0\","
},
{
"path": "pwa/manifest.json",
"chars": 427,
"preview": "{\n \"name\": \"BY Blog\",\n \"short_name\": \"BY Blog\",\n \"description\": \"A personal blog by engineer\",\n \"icons\": [{\n \"src"
},
{
"path": "sw.js",
"chars": 5784,
"preview": "/* ===========================================================\n * sw.js\n * ============================================="
},
{
"path": "tags.html",
"chars": 2293,
"preview": "---\ntitle: Tags\nlayout: default\ndescription: keep hungry keep foolish\nheader-img: \"img/tag-bg.jpg\"\n---\n\n<!-- Page Header"
}
]
About this extraction
This page contains the full source code of the xueqiandata/xueqiandata.github.io GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 92 files (825.2 KB), approximately 296.9k tokens, and a symbol index with 88 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.