Showing preview only (230K chars total). Download the full file or copy to clipboard to get everything.
Repository: yangyangwithgnu/hardseed
Branch: master
Commit: a1cf1be1d71f
Files: 42
Total size: 217.2 KB
Directory structure:
gitextract_hyme3a89/
├── LICENSE
├── README.md
├── build/
│ └── CMakeLists.txt
├── config/
│ └── portals_list.json
└── src/
├── .ycm_extra_conf.py
├── lib/
│ ├── 3rd/
│ │ └── json11/
│ │ ├── LICENSE.txt
│ │ ├── README.md
│ │ ├── json11.cpp
│ │ ├── json11.hpp
│ │ └── test.cpp
│ ├── helper/
│ │ ├── CmdlineOption.cpp
│ │ ├── CmdlineOption.h
│ │ ├── Misc.cpp
│ │ ├── Misc.h
│ │ ├── RichTxt.h
│ │ ├── Time.cpp
│ │ ├── Time.h
│ │ ├── Webpage.cpp
│ │ └── Webpage.h
│ └── self/
│ ├── Aicheng.cpp
│ ├── Aicheng.h
│ ├── AichengTopicWebpage.cpp
│ ├── AichengTopicWebpage.h
│ ├── AichengTopicsListWebpage.cpp
│ ├── AichengTopicsListWebpage.h
│ ├── Caoliu.cpp
│ ├── Caoliu.h
│ ├── CaoliuTopicWebpage.cpp
│ ├── CaoliuTopicWebpage.h
│ ├── CaoliuTopicsListWebpage.cpp
│ ├── CaoliuTopicsListWebpage.h
│ ├── JandownSeedWebpage.cpp
│ ├── JandownSeedWebpage.h
│ ├── RmdownSeedWebpage.cpp
│ ├── RmdownSeedWebpage.h
│ ├── SeedWebpage.cpp
│ ├── SeedWebpage.h
│ ├── TopicWebpage.cpp
│ ├── TopicWebpage.h
│ ├── TopicsListWebpage.cpp
│ └── TopicsListWebpage.h
└── main.cpp
================================================
FILE CONTENTS
================================================
================================================
FILE: LICENSE
================================================
GNU GENERAL PUBLIC LICENSE
Version 2, June 1991
Copyright (C) 1989, 1991 Free Software Foundation, Inc., <http://fsf.org/>
51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA
Everyone is permitted to copy and distribute verbatim copies
of this license document, but changing it is not allowed.
Preamble
The licenses for most software are designed to take away your
freedom to share and change it. By contrast, the GNU General Public
License is intended to guarantee your freedom to share and change free
software--to make sure the software is free for all its users. This
General Public License applies to most of the Free Software
Foundation's software and to any other program whose authors commit to
using it. (Some other Free Software Foundation software is covered by
the GNU Lesser General Public License instead.) You can apply it to
your programs, too.
When we speak of free software, we are referring to freedom, not
price. Our General Public Licenses are designed to make sure that you
have the freedom to distribute copies of free software (and charge for
this service if you wish), that you receive source code or can get it
if you want it, that you can change the software or use pieces of it
in new free programs; and that you know you can do these things.
To protect your rights, we need to make restrictions that forbid
anyone to deny you these rights or to ask you to surrender the rights.
These restrictions translate to certain responsibilities for you if you
distribute copies of the software, or if you modify it.
For example, if you distribute copies of such a program, whether
gratis or for a fee, you must give the recipients all the rights that
you have. You must make sure that they, too, receive or can get the
source code. And you must show them these terms so they know their
rights.
We protect your rights with two steps: (1) copyright the software, and
(2) offer you this license which gives you legal permission to copy,
distribute and/or modify the software.
Also, for each author's protection and ours, we want to make certain
that everyone understands that there is no warranty for this free
software. If the software is modified by someone else and passed on, we
want its recipients to know that what they have is not the original, so
that any problems introduced by others will not reflect on the original
authors' reputations.
Finally, any free program is threatened constantly by software
patents. We wish to avoid the danger that redistributors of a free
program will individually obtain patent licenses, in effect making the
program proprietary. To prevent this, we have made it clear that any
patent must be licensed for everyone's free use or not licensed at all.
The precise terms and conditions for copying, distribution and
modification follow.
GNU GENERAL PUBLIC LICENSE
TERMS AND CONDITIONS FOR COPYING, DISTRIBUTION AND MODIFICATION
0. This License applies to any program or other work which contains
a notice placed by the copyright holder saying it may be distributed
under the terms of this General Public License. The "Program", below,
refers to any such program or work, and a "work based on the Program"
means either the Program or any derivative work under copyright law:
that is to say, a work containing the Program or a portion of it,
either verbatim or with modifications and/or translated into another
language. (Hereinafter, translation is included without limitation in
the term "modification".) Each licensee is addressed as "you".
Activities other than copying, distribution and modification are not
covered by this License; they are outside its scope. The act of
running the Program is not restricted, and the output from the Program
is covered only if its contents constitute a work based on the
Program (independent of having been made by running the Program).
Whether that is true depends on what the Program does.
1. You may copy and distribute verbatim copies of the Program's
source code as you receive it, in any medium, provided that you
conspicuously and appropriately publish on each copy an appropriate
copyright notice and disclaimer of warranty; keep intact all the
notices that refer to this License and to the absence of any warranty;
and give any other recipients of the Program a copy of this License
along with the Program.
You may charge a fee for the physical act of transferring a copy, and
you may at your option offer warranty protection in exchange for a fee.
2. You may modify your copy or copies of the Program or any portion
of it, thus forming a work based on the Program, and copy and
distribute such modifications or work under the terms of Section 1
above, provided that you also meet all of these conditions:
a) You must cause the modified files to carry prominent notices
stating that you changed the files and the date of any change.
b) You must cause any work that you distribute or publish, that in
whole or in part contains or is derived from the Program or any
part thereof, to be licensed as a whole at no charge to all third
parties under the terms of this License.
c) If the modified program normally reads commands interactively
when run, you must cause it, when started running for such
interactive use in the most ordinary way, to print or display an
announcement including an appropriate copyright notice and a
notice that there is no warranty (or else, saying that you provide
a warranty) and that users may redistribute the program under
these conditions, and telling the user how to view a copy of this
License. (Exception: if the Program itself is interactive but
does not normally print such an announcement, your work based on
the Program is not required to print an announcement.)
These requirements apply to the modified work as a whole. If
identifiable sections of that work are not derived from the Program,
and can be reasonably considered independent and separate works in
themselves, then this License, and its terms, do not apply to those
sections when you distribute them as separate works. But when you
distribute the same sections as part of a whole which is a work based
on the Program, the distribution of the whole must be on the terms of
this License, whose permissions for other licensees extend to the
entire whole, and thus to each and every part regardless of who wrote it.
Thus, it is not the intent of this section to claim rights or contest
your rights to work written entirely by you; rather, the intent is to
exercise the right to control the distribution of derivative or
collective works based on the Program.
In addition, mere aggregation of another work not based on the Program
with the Program (or with a work based on the Program) on a volume of
a storage or distribution medium does not bring the other work under
the scope of this License.
3. You may copy and distribute the Program (or a work based on it,
under Section 2) in object code or executable form under the terms of
Sections 1 and 2 above provided that you also do one of the following:
a) Accompany it with the complete corresponding machine-readable
source code, which must be distributed under the terms of Sections
1 and 2 above on a medium customarily used for software interchange; or,
b) Accompany it with a written offer, valid for at least three
years, to give any third party, for a charge no more than your
cost of physically performing source distribution, a complete
machine-readable copy of the corresponding source code, to be
distributed under the terms of Sections 1 and 2 above on a medium
customarily used for software interchange; or,
c) Accompany it with the information you received as to the offer
to distribute corresponding source code. (This alternative is
allowed only for noncommercial distribution and only if you
received the program in object code or executable form with such
an offer, in accord with Subsection b above.)
The source code for a work means the preferred form of the work for
making modifications to it. For an executable work, complete source
code means all the source code for all modules it contains, plus any
associated interface definition files, plus the scripts used to
control compilation and installation of the executable. However, as a
special exception, the source code distributed need not include
anything that is normally distributed (in either source or binary
form) with the major components (compiler, kernel, and so on) of the
operating system on which the executable runs, unless that component
itself accompanies the executable.
If distribution of executable or object code is made by offering
access to copy from a designated place, then offering equivalent
access to copy the source code from the same place counts as
distribution of the source code, even though third parties are not
compelled to copy the source along with the object code.
4. You may not copy, modify, sublicense, or distribute the Program
except as expressly provided under this License. Any attempt
otherwise to copy, modify, sublicense or distribute the Program is
void, and will automatically terminate your rights under this License.
However, parties who have received copies, or rights, from you under
this License will not have their licenses terminated so long as such
parties remain in full compliance.
5. You are not required to accept this License, since you have not
signed it. However, nothing else grants you permission to modify or
distribute the Program or its derivative works. These actions are
prohibited by law if you do not accept this License. Therefore, by
modifying or distributing the Program (or any work based on the
Program), you indicate your acceptance of this License to do so, and
all its terms and conditions for copying, distributing or modifying
the Program or works based on it.
6. Each time you redistribute the Program (or any work based on the
Program), the recipient automatically receives a license from the
original licensor to copy, distribute or modify the Program subject to
these terms and conditions. You may not impose any further
restrictions on the recipients' exercise of the rights granted herein.
You are not responsible for enforcing compliance by third parties to
this License.
7. If, as a consequence of a court judgment or allegation of patent
infringement or for any other reason (not limited to patent issues),
conditions are imposed on you (whether by court order, agreement or
otherwise) that contradict the conditions of this License, they do not
excuse you from the conditions of this License. If you cannot
distribute so as to satisfy simultaneously your obligations under this
License and any other pertinent obligations, then as a consequence you
may not distribute the Program at all. For example, if a patent
license would not permit royalty-free redistribution of the Program by
all those who receive copies directly or indirectly through you, then
the only way you could satisfy both it and this License would be to
refrain entirely from distribution of the Program.
If any portion of this section is held invalid or unenforceable under
any particular circumstance, the balance of the section is intended to
apply and the section as a whole is intended to apply in other
circumstances.
It is not the purpose of this section to induce you to infringe any
patents or other property right claims or to contest validity of any
such claims; this section has the sole purpose of protecting the
integrity of the free software distribution system, which is
implemented by public license practices. Many people have made
generous contributions to the wide range of software distributed
through that system in reliance on consistent application of that
system; it is up to the author/donor to decide if he or she is willing
to distribute software through any other system and a licensee cannot
impose that choice.
This section is intended to make thoroughly clear what is believed to
be a consequence of the rest of this License.
8. If the distribution and/or use of the Program is restricted in
certain countries either by patents or by copyrighted interfaces, the
original copyright holder who places the Program under this License
may add an explicit geographical distribution limitation excluding
those countries, so that distribution is permitted only in or among
countries not thus excluded. In such case, this License incorporates
the limitation as if written in the body of this License.
9. The Free Software Foundation may publish revised and/or new versions
of the General Public License from time to time. Such new versions will
be similar in spirit to the present version, but may differ in detail to
address new problems or concerns.
Each version is given a distinguishing version number. If the Program
specifies a version number of this License which applies to it and "any
later version", you have the option of following the terms and conditions
either of that version or of any later version published by the Free
Software Foundation. If the Program does not specify a version number of
this License, you may choose any version ever published by the Free Software
Foundation.
10. If you wish to incorporate parts of the Program into other free
programs whose distribution conditions are different, write to the author
to ask for permission. For software which is copyrighted by the Free
Software Foundation, write to the Free Software Foundation; we sometimes
make exceptions for this. Our decision will be guided by the two goals
of preserving the free status of all derivatives of our free software and
of promoting the sharing and reuse of software generally.
NO WARRANTY
11. BECAUSE THE PROGRAM IS LICENSED FREE OF CHARGE, THERE IS NO WARRANTY
FOR THE PROGRAM, TO THE EXTENT PERMITTED BY APPLICABLE LAW. EXCEPT WHEN
OTHERWISE STATED IN WRITING THE COPYRIGHT HOLDERS AND/OR OTHER PARTIES
PROVIDE THE PROGRAM "AS IS" WITHOUT WARRANTY OF ANY KIND, EITHER EXPRESSED
OR IMPLIED, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF
MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE. THE ENTIRE RISK AS
TO THE QUALITY AND PERFORMANCE OF THE PROGRAM IS WITH YOU. SHOULD THE
PROGRAM PROVE DEFECTIVE, YOU ASSUME THE COST OF ALL NECESSARY SERVICING,
REPAIR OR CORRECTION.
12. IN NO EVENT UNLESS REQUIRED BY APPLICABLE LAW OR AGREED TO IN WRITING
WILL ANY COPYRIGHT HOLDER, OR ANY OTHER PARTY WHO MAY MODIFY AND/OR
REDISTRIBUTE THE PROGRAM AS PERMITTED ABOVE, BE LIABLE TO YOU FOR DAMAGES,
INCLUDING ANY GENERAL, SPECIAL, INCIDENTAL OR CONSEQUENTIAL DAMAGES ARISING
OUT OF THE USE OR INABILITY TO USE THE PROGRAM (INCLUDING BUT NOT LIMITED
TO LOSS OF DATA OR DATA BEING RENDERED INACCURATE OR LOSSES SUSTAINED BY
YOU OR THIRD PARTIES OR A FAILURE OF THE PROGRAM TO OPERATE WITH ANY OTHER
PROGRAMS), EVEN IF SUCH HOLDER OR OTHER PARTY HAS BEEN ADVISED OF THE
POSSIBILITY OF SUCH DAMAGES.
END OF TERMS AND CONDITIONS
How to Apply These Terms to Your New Programs
If you develop a new program, and you want it to be of the greatest
possible use to the public, the best way to achieve this is to make it
free software which everyone can redistribute and change under these terms.
To do so, attach the following notices to the program. It is safest
to attach them to the start of each source file to most effectively
convey the exclusion of warranty; and each file should have at least
the "copyright" line and a pointer to where the full notice is found.
{description}
Copyright (C) {year} {fullname}
This program is free software; you can redistribute it and/or modify
it under the terms of the GNU General Public License as published by
the Free Software Foundation; either version 2 of the License, or
(at your option) any later version.
This program is distributed in the hope that it will be useful,
but WITHOUT ANY WARRANTY; without even the implied warranty of
MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the
GNU General Public License for more details.
You should have received a copy of the GNU General Public License along
with this program; if not, write to the Free Software Foundation, Inc.,
51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.
Also add information on how to contact you by electronic and paper mail.
If the program is interactive, make it output a short notice like this
when it starts in an interactive mode:
Gnomovision version 69, Copyright (C) year name of author
Gnomovision comes with ABSOLUTELY NO WARRANTY; for details type `show w'.
This is free software, and you are welcome to redistribute it
under certain conditions; type `show c' for details.
The hypothetical commands `show w' and `show c' should show the appropriate
parts of the General Public License. Of course, the commands you use may
be called something other than `show w' and `show c'; they could even be
mouse-clicks or menu items--whatever suits your program.
You should also get your employer (if you work as a programmer) or your
school, if any, to sign a "copyright disclaimer" for the program, if
necessary. Here is a sample; alter the names:
Yoyodyne, Inc., hereby disclaims all copyright interest in the program
`Gnomovision' (which makes passes at compilers) written by James Hacker.
{signature of Ty Coon}, 1 April 1989
Ty Coon, President of Vice
This General Public License does not permit incorporating your program into
proprietary programs. If your program is a subroutine library, you may
consider it more useful to permit linking proprietary applications with the
library. If this is what you want to do, use the GNU Lesser General
Public License instead of this License.
================================================
FILE: README.md
================================================
<h1 align="center">给不了你梦中情人,至少还有硬盘女神:hardseed</h1>
yangyangwithgnu@yeah.net
http://yangyangwithgnu.github.io/
2016-02-04 14:53:51
##谢谢
**捐赠:支付宝 yangyangwithgnu@yeah.net ,支付宝二维码(左),微信二维码(右)**
<div align="center">
<img src="https://raw.githubusercontent.com/yangyangwithgnu/yangyangwithgnu.github.io/master/pics/alipay_donate_qr.png" alt=""/>
<img src="https://raw.githubusercontent.com/yangyangwithgnu/yangyangwithgnu.github.io/master/pics/wechat_donate_qr.png" alt=""/><br>
</div>
**二手书**:书,我提高开发技能的重要手段之一,随着职业生涯的发展,书籍也在不断增多,对我而言,一本书最多读三遍,再往后,几乎没有什么营养吸收,这部分书对我已基本无用,但对其他人可能仍有价值,所以,为合理利用资源,我决定低价出售这些书,希望达到两个目的:0)用售出的钱购买更多新书(没当过雷锋的朋友 (๑´ڡ`๑));1)你低价购得需要的书(虽然二手)。到 https://github.com/yangyangwithgnu/used_books 看看有无你钟意的。
##公告
----------------
**讨论**:任何意见建议移步 https://www.v2ex.com/t/123175
**声明**:我本人绝对尊重各大爱的论坛,提供的资源不仅优质而且免费,我只是懒、足够的懒。请大家支持这些论坛,多用页面访问、多点击广告、多解囊捐赠。*我..在..干..嘛 @_@#*
**注意**
+ 代理是一切的先决条件。你可以使用自己的代理工具,用 hardseed 的命令行选项 --proxy 指定本地中转地址及端口,也可以用我为你预配置的 goagent 代理工具,位于 https://github.com/yangyangwithgnu/goagent_out_of_box_yang
##版本
----------------
**[v0.2.14-1,修正,2016-02-04]**:0)行了、行了,我抱歉,不知道有这么多 win 用户需要 hardseed,之前是我狭隘了,只考虑到 unix-like 用户。编译好的 win 版本程序送你,位于 bin\build_4_win.7z;1)另外,osX 下的构建方面进行了细化。新年快乐!
**[v0.2.14,修正,2016-01-31]**:0)忽略解析 aicheng 站务相关帖子。
**[v0.2.13,修正,2016-01-17]**:0)修正 caoliu 翻页的错误。
**[v0.2.12,优化,2015-05-26]**:0)先前 hardseed 中硬编码 aicheng 和 caoliu 论坛入口地址,地址一旦变更,每次需要重新调整代码,很是麻烦,现在我在本项目主页中放了一份配置文件 config/portals_list.json,hardseed 自动从该文件中获取最新论坛入口地址(安啦,我会及时更新的);1)调整部分公共库代码。
**[v0.2.11,修正,2015-03-22]**:修正 aicheng 种子和图片解析错误的问题(别发邮件了哈,亲,邮箱都他妈快撑爆了) 。
**[v0.2.10,修正,2014-12-07]**:caoliu 地址变更,shit :-P
**[v0.2.09,修正,2014-11-30]**:caoliu 地址变更。
**[v0.2.08,修正,2014-10-21]**:0)仅解析主贴的图片而不再解析回帖,以避免下载无关图片;1)aicheng 论坛地址变更;2)部分用户有自己的代理工具,为缩短下载时长,将预配置的 goagent 独立成一个 github 项目。
**[v0.2.07,修正,2014-09-25]**:windows 禁止文件名中含有 /:\*?\\<>"| 等字符,否则将导致非法路径错误,修正 hardseed 生成的文件名中可能含有如上字符的问题。
**[v0.2.06,优化,2014-09-09]**:caoliu 原地址无法访问,更新地址;取消 caoliu 自拍套图最多只能下载 256 张的限制。
**[v0.2.05,优化,2014-08-17]**:程序功能无任何更新,仅更新代理工具 goagent 配置文件 proxy.ini:一是设置 obfuscate = 1 开启流量混淆以正确解析出可用 GGC IP,一是设置 pagespeed = 1 以提升 GAE 的下行速度。
**[v0.2.05,修正,2014-08-13]**:0)修正帖子部分图片 URL 未解析的问题;1)修正图片序号错误的问题;2)优化图片下载等待时长算法,不再以 --timeout-download-picture 作为绝对等待时长,而是将其作为指导值,一旦图片下载失败 hardseed 将自动计算下次重新下载所需的等待时长,同时,与“速度过低视为下载失败”的机制结合,提升图片下载等待耗时;3)升级 goagent 至 3.1.21,采用 goagent 默认 proxy.ini,而不再使用自定义 iplist (很多朋友反应采用先前我自定义 iplist 版本的 goagent 速度不理想,这是由于 GGC IP 与不同网络环境有关,我用 checkgoogleip 跑出来 GGC IP 最适合我的网络环境,不见得适合你,所以,权衡之下,还是用 goagent 自带的 GGC IP,至少这合适于大多数人)。
**[v0.2.04,修正,2014-08-10]**:0)由于对 % 进行 URL 转义使得部分图片的 URL 生成错误,导致图片下载失败,本版本已修正;1)剔除长年显示异常的图床网站 iceimg.com;2)引入均速过低视为下载失败的机制,持续(8s)低速(4KB/s)终止当次下载,重新向服务端发起新请求,开启新一次的下载,以缩短下载错误 URL 图片等待时长;3)修正 aicheng 帖子列表页面中帖子名解析错误的问题;4)取消单个代理服务器并行下载上限数 8 的限制。
**[v0.2.03,修正,2014-08-08]**:0)修正部分图片缺失扩展名的问题;1)默认下载帖子数量从 128 调整为 64;2)更换新的 GGC IP 进代理工具 goagent 的 proxy.ini 中以提升代理速度。
**[v0.2.02,优化,2014-08-06]**:程序无任何功能变更,仅是优化代码,合并部分通用代码至公共库、增加用于验证代理出口 IP 和伪装浏览器的 user-agent 的接口。
**[v0.2.01,修正,2014-07-28]**:修正临时文件未删除的错误。
**[v0.2.00,新增,2014-07-23]**:应 @sigmadog 需求,增加抓取 caoliu 上自拍套图(江湖人称“達蓋爾的旗幟”)的功能。
**[v0.1.00,修正,2014-07-21]**:caoliu 论坛增加了反机器人机制,若翻页过快则视为机器人行为,下载页面为空白页。此版本可应对它的反机器人机制。
##演示
----------------
*hardseed*
*running*
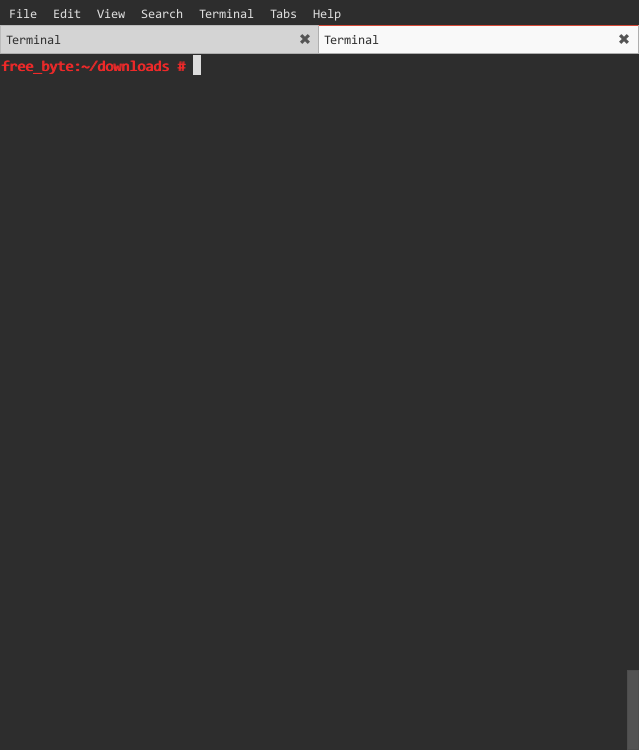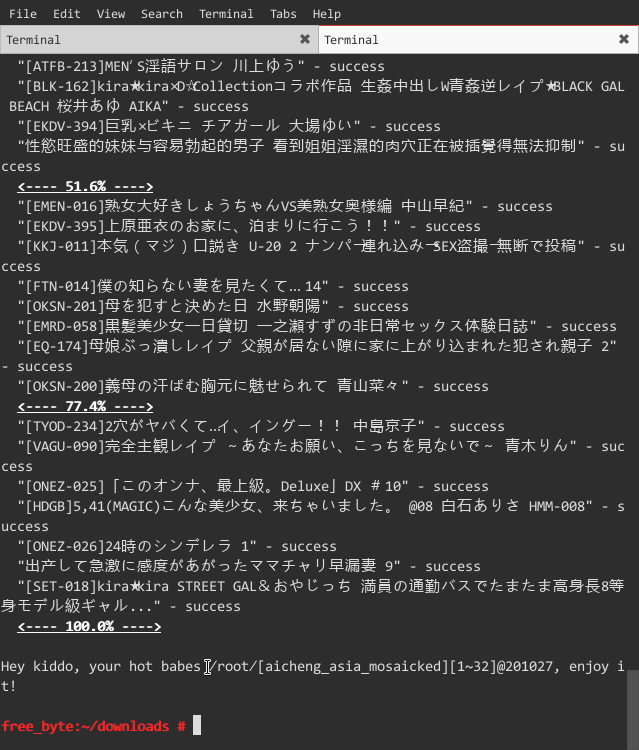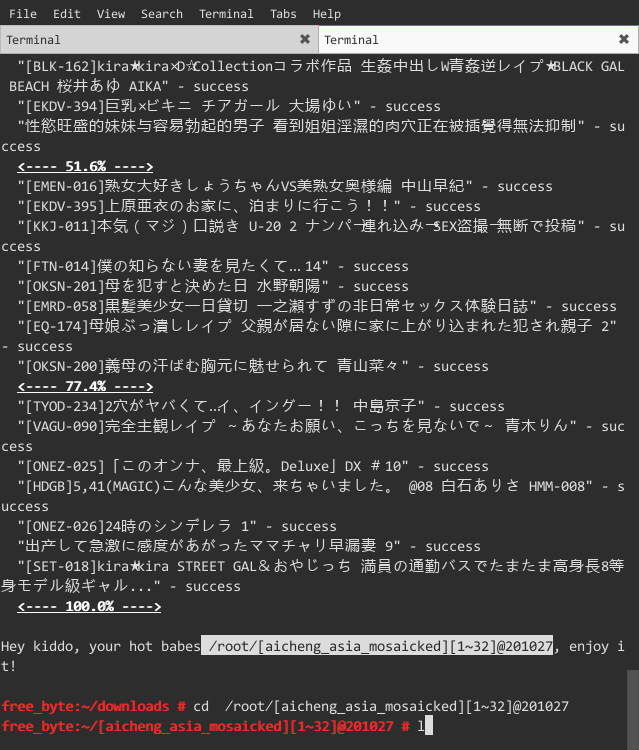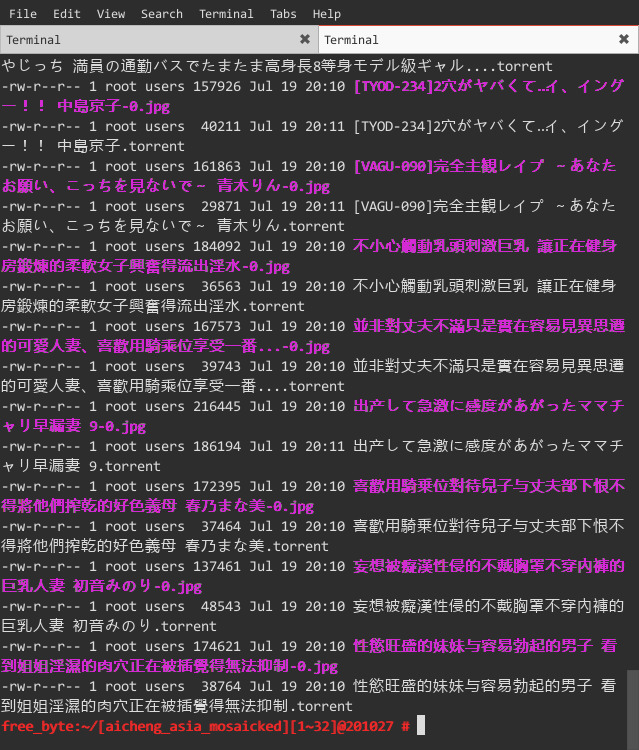
*more seeds and pictures*

http://v.youku.com/v_show/id_XNzQxOTk0NTE2.html
##man
----------------
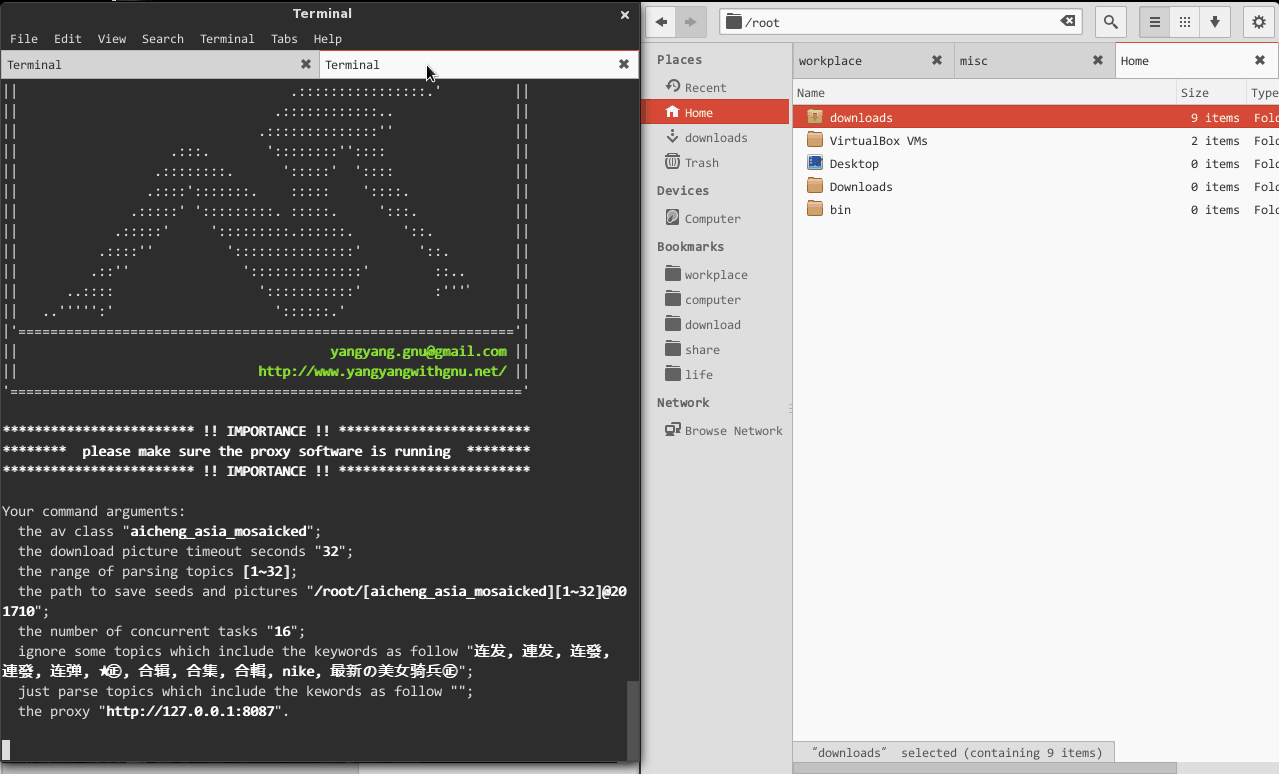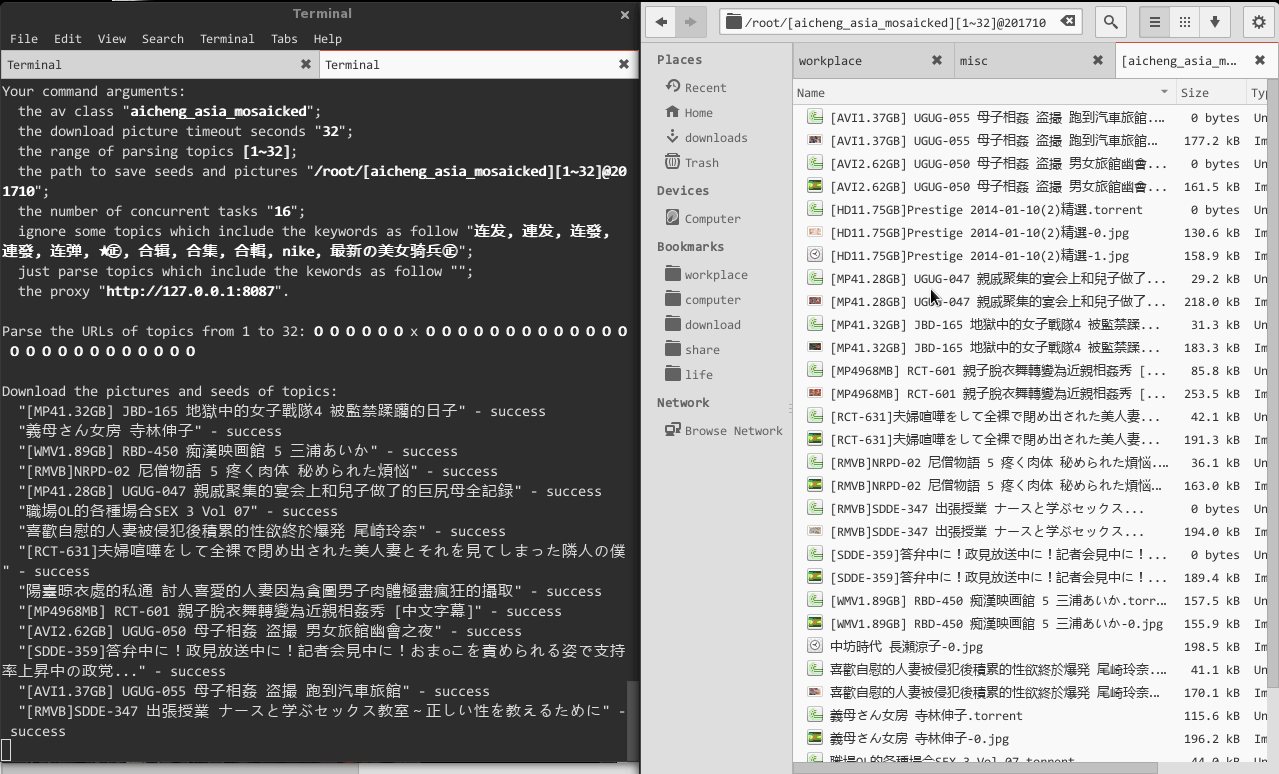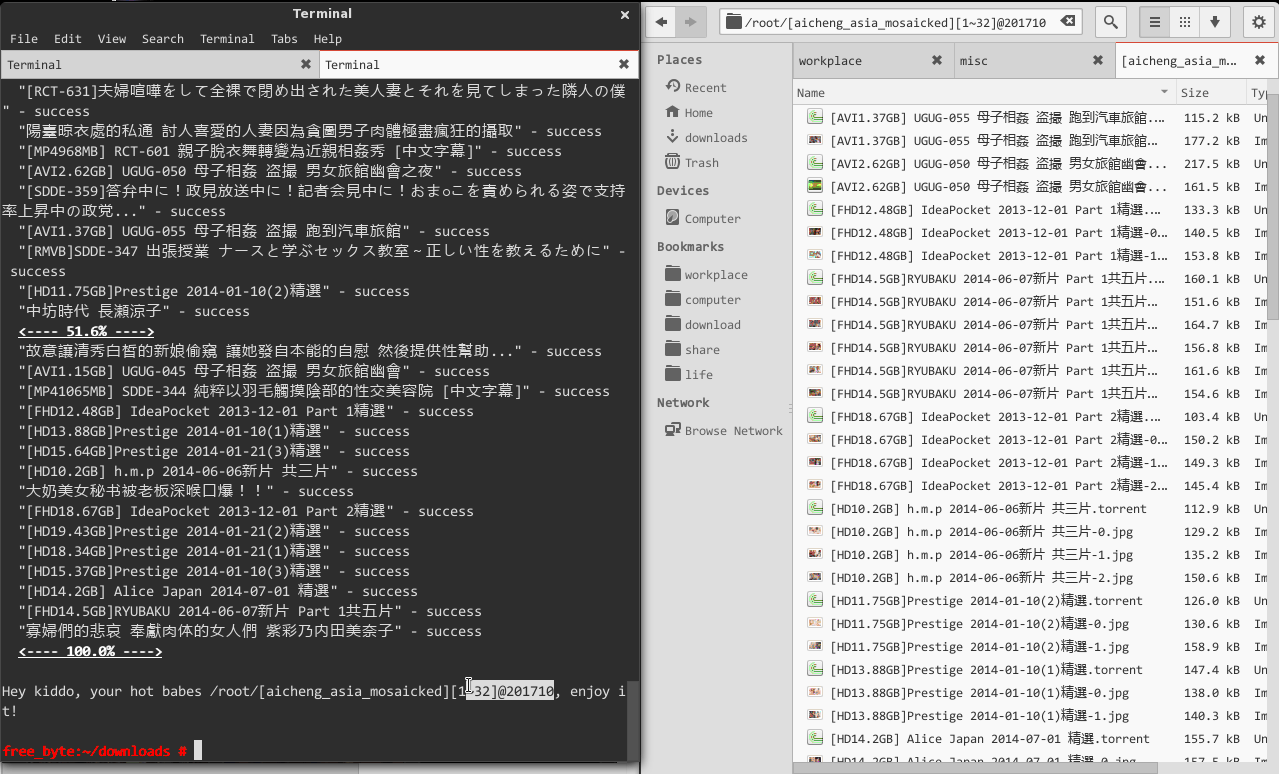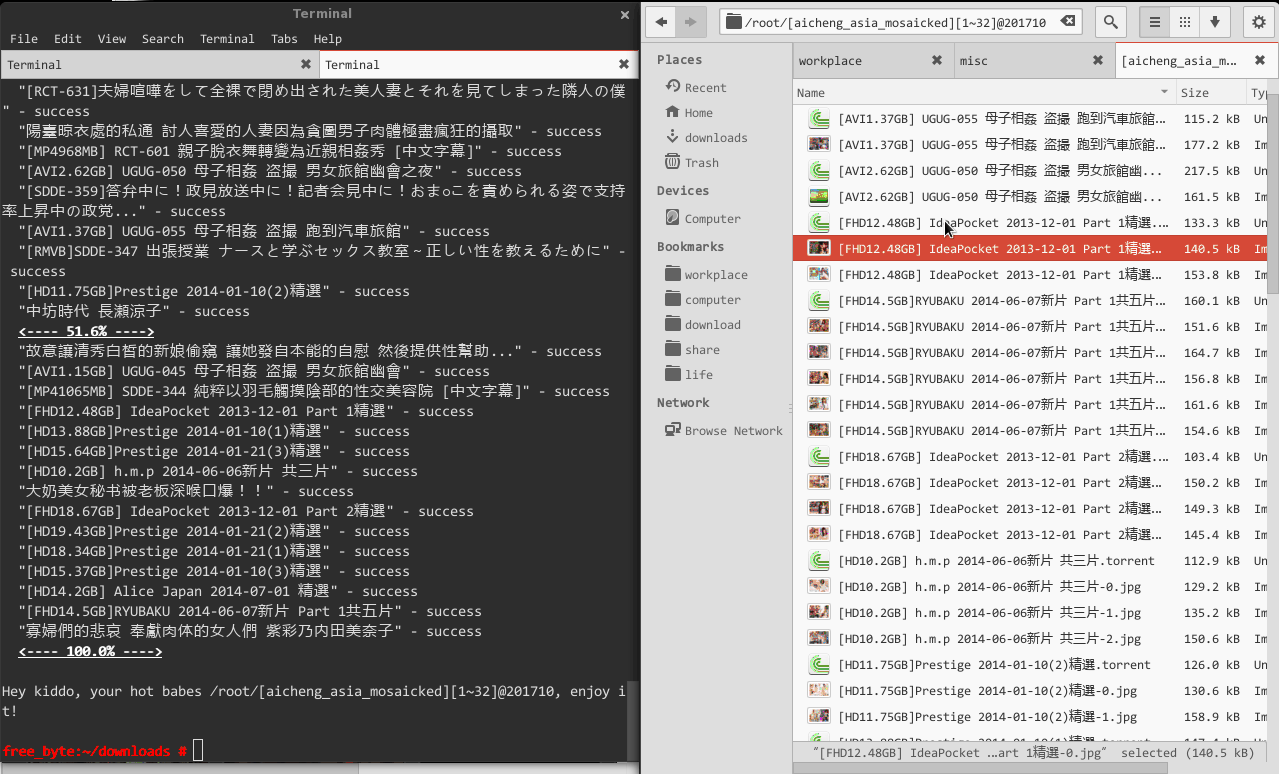
**hardseed** is a batch seeds and pictures download utiltiy from CaoLiu and AiCheng forum. It's easy and simple to use. Usually, you could issue it as follow:
```
$ hardseed
```
or
```
$ hardseed --saveas-path ~/downloads --topics-range 8 64 --av-class aicheng_west --timeout-download-picture 32 --hate X-Art --proxy http://127.0.0.1:8087
```
--help
Show this help infomation what you are seeing.
--version
Show current version.
--av-class
There are 13 av classes:
- caoliu_west_reposted
- caoliu_cartoon_reposted
- caoliu_asia_mosaicked_reposted
- caoliu_asia_non_mosaicked_reposted
- caoliu_west_original
- caoliu_cartoon_original
- caoliu_asia_mosaicked_original
- caoliu_asia_non_mosaicked_original
- caoliu_selfie
- aicheng_west
- aicheng_cartoon
- aicheng_asia_mosaicked
- aicheng_asia_non_mosaicked
As the name implies, "caoliu" stands for CaoLiu forum, "aicheng" for AiCheng forum, "reposted" and "original" are clearity, you konw which one is your best lover (yes, only one).
The default is aicheng_asia_mosaicked.
--concurrent-tasks
You can set more than one proxy, each proxy could more than one concurrent tasks. This option set the number of concurrent tasks of each proxy.
The max and default number is 8.
--timeout-download-picture
Some pictures too big to download in few seconds. So, you should set the download picture timeout seconds.
The default timeout is 16 seconds.
--topics-range
Set the range of to download topics. E.G.:
- topics-range 2 16
- topics-range 8 (I.E., --topics-range 1 8)
- topics-range -1 (I.E., all topics of this av class)
The default topics range is 64.
--saveas-path
Set the path to save seeds and pictures. The rule of dir: [avclass][range]@hhmmss. E.G., [aicheng_west][2~32]@124908/.
The default directory is home directory (or windows is C:\\).
--hate
If you hate some subject topics, you can ignore them by setting this option with keywords in topic title, split by space-char ' ', and case sensitive. E.G., --hate 孕妇 重口味. When --hate keywords list conflict with --like, --hate first.
--like
If you like some subject topics, you can grab them by setting this option with keywords in topic title, split by space-char ' ', and case sensitive. E.G., --like 苍井空 小泽玛利亚. When --like keywords list conflict with --hate, --hate first.
--proxy
As you know, the government likes blocking adult websites, so, I do suggest you to set --proxy option. Hardseed supports more proxys:
- GoAgent (STRONGLY recommended), --proxy http://127.0.0.1:8087
- shadowsocks, --proxy socks5://127.0.0.1:1080, or socks5h://127.0.0.1:1080
- SSH, --proxy socks4://127.0.0.1:7070
- VPN (PPTP and openVPN), --proxy ""
It is important that you should know, you can set more proxys at the same time, split by space-char ' '. As the --concurrent-tasks option says, each proxy could more than one concurrent tasks, now, what about more proxys? Yes, yes, the speed of downloading seed and pictures is very very fast. E.G., --concurrent-tasks 8 --proxy http://127.0.0.1:8087 socks5://127.0.0.1:1080 socks4://127.0.0.1:7070, the number of concurrent tasks is 8\*3.
If you wanna how to install and configure various kinds of proxy, please access my homepage "3.2 搭梯翻墙" https://github.com/yangyangwithgnu/the_new_world_linux#3.2
If you are not good at computer, there is a newest goagent for floks who are not good at computer by me, yes, out of box. see https://github.com/yangyangwithgnu/goagent_out_of_box_yang
The default http://127.0.0.1:8087.
That's all. Any suggestions let me know by yangyangwithgnu@yeah.net or http://yangyangwithgnu.github.io/, big thanks to you. Kiddo, take care of your body. :-)
##中文
--------
hardseed 希望带给你(硬盘)女神!女神的种子和图片。
###【翻墙】
你知道,这一切的一切都在墙外,所以你得具备翻墙环境,hardseed 才能帮你拉女神。hardseed 支持 goagent、shadowsocks、SSH、VPN (PPTP 和 openVPN)等各类代理模式,甚至你可以同时使用多种代理以极速下载。从普及度、稳定性、高效性来看,goagent 最优。“我一小白,平时工作压力本来就大,就想看看女神轻松下,你还让我折腾代理!没人性!”,嘚,亲,咱是做服务的。我帮你配置了一份开箱即用的 goagent,位于 https://github.com/yangyangwithgnu/goagent_out_of_box_yang ,下载后,linux 用户,命令行中运行
```
$ python proxy.py
```
windows 亲,双击运行 goagent.exe (**管理员权限**)。
###【下载】
####『windows』
亲,往右上看,找到“download ZIP”,点击下载。
####『linux』
```
$ git clone https://github.com/yangyangwithgnu/hardseed.git
```
###【源码安装】
####『windows』
这基本没 windows 用户什么事儿,除非你有 cygwin,否则你没法编译源码,没事,帮你弄好了,我的定位是牙医界的服务人员,服务很重要,二进制执行程序位于 hardseed\bin\build_4_win.7z。
####『linux』
0)唯一依赖 libcurl,请自行安装;
1)代码采用 C++11 编写,gcc 版本不低于 4.7.1。
2)命令行下运行:
```
$ cd hardseed/build/
$ cmake .
$ make && make install
```
####『osX』
首先,将 build/CMakeLists.txt 中的
```
TARGET_LINK_LIBRARIES(hardseed curl pthread)
```
替换成
```
TARGET_LINK_LIBRARIES(hardseed curl pthread iconv)
```
然后,将 build/CMakeLists.txt 中
```
## osX
##>>>>>>>>>>>>>>>>>>>>>>
#SET(CMAKE_CXX_COMPILER "g++")
#SET(CMAKE_CXX_FLAGS "-std=c++11 -O3")
#SET(CMAKE_BUILD_TYPE release)
#ADD_EXECUTABLE(hardseed ${SRC_LIST})
#TARGET_LINK_LIBRARIES(hardseed curl pthread iconv)
#INSTALL(PROGRAMS hardseed DESTINATION /usr/bin/)
```
第一列的 # 删除;
接着,将 build/CMakeLists.txt 中
```
# release
SET(CMAKE_CXX_COMPILER "g++")
SET(CMAKE_CXX_FLAGS "-std=c++11 -O3")
SET(CMAKE_BUILD_TYPE release)
ADD_EXECUTABLE(hardseed ${SRC_LIST})
TARGET_LINK_LIBRARIES(hardseed curl pthread)
INSTALL(PROGRAMS hardseed DESTINATION /usr/bin/)
```
删掉;
最后,剩下步骤同 linux 构建方法。
###【使用】
**亲,听好了,运行 hardseed 前务必确保代理程序已正常运行,否则,别说女神,蚊子都碰不到。**
####『windows』
先进入 hardseed\bin\,解压 build_4_win.7z,选中 hardseed.exe,右键设置**以管理员权限运行该程序**,接着键入 alt-d 将光标定位到文件管理器的地址栏中,键入 CMD 启动命令行窗口,在 CMD 中键入
```
X:\hardseed\bin\windows> hardseed.exe
```
这时,hardseed 开始玩命儿地为你下载女神图片和种子,经过 2 分 8 秒,找到类似 C:\\[aicheng_asia_mosaicked][1~128]@20140822\ 的目录,女神们那儿等你!
####『linux』
同 windows 下运行一样,全用默认命令行参数运行
```
$ hardseed
```
执行完成后,你会看到 ~/[aicheng_asia_mosaicked][1~128]@014822/,你要的都在那儿。或者,玩点高级的
```
$ hardseed --saveas-path ~/downloads --topics-range 256 --av-class aicheng_west
```
其中,--saveas-path 指定存放路径为 ~/downloads/;--topics-range 指定解析的帖子范围从第 1 张到第 256 张帖子;--av-class 指定女神类型为欧美。完整命令行选项请 --hlep 查看。
###【FQA】
**Q1**:为何 windows 版的可执行文件目录 build_4_win\ 下有一堆 cyg\*.dll 文件?
**A1**:hardseed 是用 C++ 编写的遵循 SUS(单一 unix 规范)的原生 linux 程序,理论上,在任何 unix-like(linux、BSD、osX) 系统上均可正常源码编译,唯独不支持 windows,为让 hardseed 具备跨平台能力,须借由某种工具(或环境)将 hardseed 转换成 windows 下的执行程序。cygwin 就是这种环境,我把 hardseed 源码纳入 cygwin 环境中重新编译,即可生成 windows 下的可执行程序 hardseed.exe,在这个过程中,cygwin 会加入些自己的代码和中转库到 hardseed.exe 中,cyg\*.dll 就是各类中转库。
**Q2**:为何运行 windows 版的执行程序总有如下警告
```
Preferred POSIX equivalent is: /cygdrive/c/xxxx, CYGWIN environment variable option "nodosfilewarning" turns off this warning. Consult the user's guide for more details about POSIX paths ...
```
影响正常运行么?
**A2**:linux 与 windows 有很多基础设施的差异,路径表示方式就算其一,如,前者是 /this/is/linux/path/,后者 C:\this\is\windows\path\,A1 中提过 hardseed 是 linux 下的原生程序,代码中全采用的 linux 路径规则,运行 hardseed.exe 时, cygwin 自动进行路径规则转换,所以出现本问题中的警告信息以告知用户路径可能有变化。这完全不影响 hardseed.exe 正常运行。如果厌恶这些提示,可以在环境变量中增加 CYGWIN=nodosfilewarning (win7 用户:computer - properties - advanced system settings - advanced - environment variables - new,variable name 填入 CYGWIN,variable value 中填入 nodosfilewarning,保存即可)。
**Q3**:运行 hardseed 后啥都没下载呢?还提示 There is no topic which you like?
**A3**:有几种可能:
* 未成功翻墙。请自行参阅你的翻墙工具帮助文档,修正即可。windows 用户注意检查是否以**管理员权限运行翻墙工具**;
* 网页翻墙已成功但仍无法下载。请检查你的代理工具是否成功接收 hardseed 的代理请求(如,goagent 窗口中可查看),windows 用户注意检查是否以**管理员权限运行 hardseed.exe**;
* hardseed 翻墙已成功但仍无法下载。你指定了 --like xxxx 命令行选项,hardseed 将查找标题中是否含有关键字 xxxx,若没有则忽略相关帖子。更换其他关键字。
**Q4**:我已经在墙外,为何仍下载失败?
**A4**:hardseed 默认采用 goagent 作为代理工具,即,默认本地代理中转地址为 http://127.0.0.1:8087 。如果你已在墙外无须代理即可访问 caoliu 和 aicheng 论坛,那么需要告知 hardseed 不再走本地代理中转而应直接访问,即:
```
--proxy ""
```
**Q5**:如何加快下载速度?
**A5**:最直接会想到多线程下载,一条线程负责下载一个页面,逻辑上,线程数越多、下载速度越快,实际上,存在代理服务器和被访服务器两方面的限制:
* 代理服务器方面的限制,代理服务器为不同用户提供代理服务,为避免相互影响,通常它会限制单个用户的流量和请求频率,所以,hardseed 在指定代理服务器上的线程数一定是有个上限;
* 被访服务器方面的限制,你访问的论坛不会低能到不控制请求频率,举个例,正常情况你 4 秒钟可以打开 4 张 caoliu 论坛的帖子,一旦 caoliu 服务器发现你 1 秒钟打开了 32 张帖子那一定将此视为机器人行为,从而拒绝响应。
正由于存在代理服务器和被访服务器两方面的限制,线程数不能无限大,从我多次测试的经验来看,**单个代理服务器**访问被访服务器的并行线程数设定为 8 条最为稳定,否则容易引起代理服务器和被访服务器停服。同个时刻有大量用户在访问 caoliu 论坛,肯定远超 1 秒钟打开了 32 张帖子的频率,为何 caoliu 没对所有用户拒绝请求?显然,这些请求来自不同 IP 的电脑终端,按这个思路,如果 hardseed 若能通过多个不同 IP 访问 caoliu,对于代理服务器和被访服务器来说请求数量都变少了,那完全可以绕开 caoliu 对单个 IP 请求频率过快的限制。由于我们采用代理访问,发起访问请求的 IP 就是代理服务器的 IP,显然,只要 hardseed 支持同时使用多个代理服务器,那么一切问题就简单了。所以,我**赋予了 hardseed 多路代理的能力**。hardseed 支持 4 种代理模式:
* goagent (STRONGLY recommended), --proxy http://127.0.0.1:8087
* shadowsocks, --proxy socks5://127.0.0.1:1080, or socks5h://127.0.0.1:1080
* SSH, --proxy socks4://127.0.0.1:7070
* VPN (PPTP and openVPN), --proxy ""
其中,除 VPN 外(这是种全局代理模式),其他三种代理模式可混用,也就是说,你可以同时指定 goagent、shadowsocks、SSH 等三种代理模式
```
--proxy http://127.0.0.1:8087 socks5://127.0.0.1:1080 socks4://127.0.0.1:7070
```
这样,hardseed 就能用 8 * 3 条线程并行下载。另外,goagent 都是通过 GAE 集群发起到网络请求,所以不存在同个机器上配置多个 goagent 的做法;SSH(获取免费帐号 http://www.fastssh.com/ ) 和 shadowsocks(获取免费帐号 https://shadowsocks.net/get ) 代理,你可以获取多个不同的代理服务器(不同的 SSH 或者 shadowsocks 代理的本地端口必须自行设置成不同的),因此可以实现多个不同 IP 发起网络请求。换言之,你可以同时拥有 1 个 goagent、n 个 SSH、m 个 shadowsocks 个代理出口 IP,每个 IP 本来允许使用 8 条线程,那么共计就有 (1 + n + m) * 8 条线程并行下载,速度自然上去了。
我个人偏爱 shadowsocks,以此举例来说:先在 https://shadowsocks.net/get 获取了 4 个 shadowsocks 帐号,本地端口分别配置成 1080、1081、1082、1083,运行此 4 个 shadowsocks 代理程序;同时,运行 goagent 代理程序;然后,在 hardseed 的命令行参数设定
```
--proxy http://127.0.0.1:8087 socks5://127.0.0.1:1080 socks5://127.0.0.1:1081 socks5://127.0.0.1:1082 socks5://127.0.0.1:1083
```
这时,如果你的 --concurrent-tasks 设定为 8(默认值),那么,hardseed 将启用 (4 + 1) * 8 条线程并行下载。那速度,飞快、快 ... *(注,有些 shadowsocks 代理服务器禁止下载,若有异常,将其从 --proxy 代理列表中剔除之。若求稳定,只用 goagent)*
**Q6**:如何搜索喜欢的视频?
**A6**:--like 选项可以指定多个关键字(空格隔开)参数,帖子标题中出现相关关键字之一便纳入下载范围,否则不下载。通常来说,帖子标题中文字有简体、繁体、日文等三种可能,所以你应该都指定,比如,喜欢“护士”和“情侣”系列,先简译繁 http://www.aies.cn/ ,简译日 http://fanyi.baidu.com/#zh/jp/ ,再由 --topics-range 指定搜索的帖子数量,由 --like 指定搜索关键字:
```
--topics-range 1024 --like 护士 護士 看護婦 情侣 情侶 カップル
```
**Q7**:如何下载高清?
**A7**:hardseed 并不直接支持高清类型下载,只能间接实现,由 --topics-range 指定搜索的帖子数量,由 --like 指定“高清”相关关键字进行下载,比如:
```
--topics-range 1024 --like 1080P 720P HD 高清 ハイビジョン
```
**Q8**:为何有些种子和图片名是无意义字符,类似 (rename)bltouujdrbwcrrcg.torrent?
**A8**:OS 对文件名长度是有限制的,hardseed 是以帖子名作为种子和图片的文件名,一旦帖子名超长将导致文件名超长。由于 hardseed 是采用 ASCII 而非 UNICODE 作为字符存储方式,一个文字可能占一个字节(如,字母“a”)也可能占两个字节(如,汉字“好”),假如文件名最后一个文字是“好”,且刚好文件名超长了一个字节,如果 hardseed 简单地截断“好”的第二个字节,那将导致整个文件名变成乱码。所以,hardseed 用了另外种变通方式,取 16 个 a-z 间的随机字母以及前缀“(rename)”作为文件基础名。
**Q9**:为何相同的图片要下载两次?
**A9**:有些发帖者担心单一图床挂掉,一般将同个图片上传到两个不同图床上,在帖子中同时发布两个图床的不同地址,hardseed 无法判断图片是否相同(其实非要弄也是可以实现的,只请求 HTTP 头,判断下两个图片的大小及最后更新时间,我觉得没这个必要),所以都下载。
**Q10**:为何常有类似下面的图片下载报错
```
failure (download error from http://cl.man.lv/htm_data/2/1407/1174338.html. pictures error: http://p1.imageab.com/2014/07/24/902135bff7a83cd71836764b795c0879.jpg, http://p1.imageab.com/2014/07/24/6cea50f80bba80536ba6cd9da7ba17df.jpg )
```
**A10**:几张图片下载失败无伤大雅。具体原因很多,常见如下:
* 图床挂了,hardseed 无能为力;
* 发帖者发布的图片 URL 有误,hardseed 无能为力;
* 图片太大、网速太慢,hardseed 在 --timeout-download-picture 指定时间内(默认 16 秒)未下载完整,这时,你可以将 --timeout-download-picture 指定为更大的下载等待时长(如,64),但这会增加整个下载时长;
* 代理服务器限制下载,禁用其他代理只用 goagent。
**Q11**:我没指定任何忽略关键字,为什么 hardseed 强制取消下载“连发, 連发, 连發, 連發, 连弹, ★㊣, 合辑, 合集, 合輯, nike, 最新の美女骑兵㊣, 精選, 精选”这类合集帖子?
**A11**:两方面原因。一方面,合集均是把以往的单个帖子合并一起再发布,完全重复;一方面,虽然帖子中有多部不同片子的图片,但实际上帖子中的种子只是其中一部片子的,没有意义。
**Q12**:很多片子迅雷报违规资源,下载速度奇慢,如何破?
**A12**:**第一**,尽可能下新片,道理很简单,越新的片子被举报违规的可能性越小,具体而言,你应该用 hardseed 抓取最新帖子的种子,并且尽可能及时下载;**第二**,借助第三方工具一定程度绕开迅雷对违规资源的限制,ThunderSuperSpeedHacker(《论逆向工程的重要性》,唉,当年多么痴迷 (°Д°)),前提你必须是迅雷会员,否则任何方法均无效。迅雷通过离线空间和高速通道两种途径为会员提速,一旦发现违规资源则关闭离线空间和高速通道两个途径,离线空间是否开启是在服务端控制,客户端的任何外力作用均无效,但是,高速通道是否开启则是在客户端控制,这就为第三方工具强制开启高速通道提供了环境,ThunderSuperSpeedHacker 可以做到。用法很简单,先退出迅雷相关进程(thunder.exe、thunderplatform.exe),再运行 ThunderSuperSpeedHacker 点击“破解”即可。那么,有了 ThunderSuperSpeedHacker 是否一定就能享受高速通道了么?不一定,ThunderSuperSpeedHacker 对迅雷版本敏感。对于迅雷 v7.9.37.4952 及后续版本,一旦 ThunderSuperSpeedHacker 介入将导致迅雷僵死。解决办法:
0)首先,下载老版本迅雷。有很多网站提供迅雷历史版本下载,不过,安全原则之一,尽可能从官网下载,所以,我只信任迅雷官网上的历史版本。在迅雷首页(http://www.kankan.com/ )右上角有最新版迅雷下载地址,也就是说,要找到迅雷历史版本下载地址,只要找到迅雷官网首页某个历史快照即可,用时光机器(http://web.archive.org/web/ 墙外)很容易做到,比如,4 月 1 号的首页快照(http://web.archive.org/web/20150401032902/http://www.kankan.com/ )对应版本 v7.9.34.4908,下载地址为 http://down.sandai.net/thunder7/Thunder_kk_7.9.34.4908Preview.exe ;
1)接着,防止自动升级。一旦运行迅雷,它将在后台自动强制升级至最新版,所以,你得暴力阻止其升级,删除升级相关程序(xlliveud.exe、liveudinstaller.exe、thunderliveupdate.xar)即可;
2)最后,使用 ThunderSuperSpeedHacker 破解违规资源高速通道限制即可。
**Q13**:hardseed 在 windows 环境下载的文件部分无法删除?
**A13**:hardseed 正在写文件时被 ctrl-c 强制退出,文件锁未被 cyg\*.dll 释放,而 cyg\*.dll 已加载至 CMD 进程空间,所以,请先关闭所有 CMD 窗口,尝试删除相关文件,若不行,请再开新 CMD 窗口后执行
```
X:\> rd /S C:\[aicheng_west][1~128]@010825\
```
**Q14**:为何出现类似如下报错?
```
"" - failure (download error from http://cl.man.lv/htm_data/4/1408/1189943.html. seed error: )
```
**A14**:代理工具的问题。你知道,hardseed 默认采用使用 goagent 作为代理工具,一方面它算是目前使用门槛最低的代理工具,但同时,另一方面它也存在并发请求数过低的限制,一旦并发数过高,goagent 代理返回的都是空白文件,这直接导致 hardseed 抛出如上错误信息。所以,我给你两方面的建议:
* 弃用 goagent,换用 shadowsocks。shadowsocks 轻量代理,速度非常优雅,我曾对它有过简单介绍,https://github.com/yangyangwithgnu/the_new_world_linux#3.2.4 。考虑到 goagent 的并发限制,--concurrent-tasks 默认设置为 8,现在改用 shadowsocks,你完全可以将 --concurrent-tasks 设置成 32 或者更大的数字,你会发现,下载 128 张帖子也就半分钟的事儿;
* 如果你仍坚持使用 goagent,请 --concurrent-tasks 减小至 4 或者更小的数字。
##忠告
-------------
你,党之栋梁、国之人才,注意身体,千万!
================================================
FILE: build/CMakeLists.txt
================================================
PROJECT(main)
SET(SRC_LIST ../src/main.cpp
../src/lib/self/TopicsListWebpage.cpp ../src/lib/self/AichengTopicsListWebpage.cpp ../src/lib/self/CaoliuTopicsListWebpage.cpp
../src/lib/self/TopicWebpage.cpp ../src/lib/self/AichengTopicWebpage.cpp ../src/lib/self/CaoliuTopicWebpage.cpp
../src/lib/self/SeedWebpage.cpp ../src/lib/self/JandownSeedWebpage.cpp ../src/lib/self/RmdownSeedWebpage.cpp
../src/lib/self/Aicheng.cpp ../src/lib/self/Caoliu.cpp
../src/lib/helper/Webpage.cpp
../src/lib/helper/Time.cpp ../src/lib/helper/CmdlineOption.cpp ../src/lib/helper/Misc.cpp
../src/lib/3rd/json11/json11.cpp)
# linux
#>>>>>>>>>>>>>>>>>>>>>>
## debug
#SET(CMAKE_CXX_COMPILER "clang++")
#SET(CMAKE_CXX_FLAGS "-std=c++11 -Werror -Weverything -Wno-documentation -Wno-disabled-macro-expansion -Wno-float-equal -Wno-c++98-compat -Wno-c++98-compat-pedantic -Wno-global-constructors -Wno-exit-time-destructors -Wno-missing-prototypes -Wno-padded -Wno-old-style-cast -Wno-weak-vtables")
#SET(CMAKE_BUILD_TYPE debug)
#ADD_EXECUTABLE(main ${SRC_LIST})
#TARGET_LINK_LIBRARIES(main curl pthread)
# release
SET(CMAKE_CXX_COMPILER "g++")
SET(CMAKE_CXX_FLAGS "-std=c++11 -O3")
SET(CMAKE_BUILD_TYPE release)
ADD_EXECUTABLE(hardseed ${SRC_LIST})
TARGET_LINK_LIBRARIES(hardseed curl pthread)
INSTALL(PROGRAMS hardseed DESTINATION /usr/local/bin)
#<<<<<<<<<<<<<<<<<<<<<<
## cygwin
##>>>>>>>>>>>>>>>>>>>>>>
#SET(CMAKE_CXX_COMPILER "g++")
#SET(CMAKE_CXX_FLAGS "-std=c++11 -O3 -s -DCYGWIN")
#SET(CMAKE_BUILD_TYPE release)
#ADD_EXECUTABLE(hardseed ${SRC_LIST})
#target_link_libraries(hardseed /bin/cygcurl-4.dll)
#target_link_libraries(hardseed /lib/libiconv.a)
##<<<<<<<<<<<<<<<<<<<<<<
## osX
##>>>>>>>>>>>>>>>>>>>>>>
#SET(CMAKE_CXX_COMPILER "g++")
#SET(CMAKE_CXX_FLAGS "-std=c++11 -O3")
#SET(CMAKE_BUILD_TYPE release)
#ADD_EXECUTABLE(hardseed ${SRC_LIST})
#TARGET_LINK_LIBRARIES(hardseed curl pthread iconv)
#INSTALL(PROGRAMS hardseed DESTINATION /usr/local/bin)
##<<<<<<<<<<<<<<<<<<<<<<
================================================
FILE: config/portals_list.json
================================================
{
"caoliu":"http://cl.bearhk.info/",
"aicheng":"http://www.ac168.info/bt/"
}
================================================
FILE: src/.ycm_extra_conf.py
================================================
# This file is NOT licensed under the GPLv3, which is the license for the rest
# of YouCompleteMe.
#
# Here's the license text for this file:
#
# This is free and unencumbered software released into the public domain.
#
# Anyone is free to copy, modify, publish, use, compile, sell, or
# distribute this software, either in source code form or as a compiled
# binary, for any purpose, commercial or non-commercial, and by any
# means.
#
# In jurisdictions that recognize copyright laws, the author or authors
# of this software dedicate any and all copyright interest in the
# software to the public domain. We make this dedication for the benefit
# of the public at large and to the detriment of our heirs and
# successors. We intend this dedication to be an overt act of
# relinquishment in perpetuity of all present and future rights to this
# software under copyright law.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND,
# EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF
# MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT.
# IN NO EVENT SHALL THE AUTHORS BE LIABLE FOR ANY CLAIM, DAMAGES OR
# OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE,
# ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR
# OTHER DEALINGS IN THE SOFTWARE.
#
# For more information, please refer to <http://unlicense.org/>
import os
import ycm_core
# These are the compilation flags that will be used in case there's no
# compilation database set (by default, one is not set).
# CHANGE THIS LIST OF FLAGS. YES, THIS IS THE DROID YOU HAVE BEEN LOOKING FOR.
flags = [
'-std=c++11',
'-Werror',
'-Weverything',
'-Wno-documentation',
'-Wno-deprecated-declarations',
'-Wno-disabled-macro-expansion',
'-Wno-float-equal',
'-Wno-c++98-compat',
'-Wno-c++98-compat-pedantic',
'-Wno-global-constructors',
'-Wno-exit-time-destructors',
'-Wno-missing-prototypes',
'-Wno-padded',
'-Wno-old-style-cast',
'-x',
'c++',
'-I',
'.',
'isystem',
'/usr/include/',
]
# Set this to the absolute path to the folder (NOT the file!) containing the
# compile_commands.json file to use that instead of 'flags'. See here for
# more details: http://clang.llvm.org/docs/JSONCompilationDatabase.html
#
# Most projects will NOT need to set this to anything; you can just change the
# 'flags' list of compilation flags. Notice that YCM itself uses that approach.
compilation_database_folder = ''
if compilation_database_folder:
database = ycm_core.CompilationDatabase( compilation_database_folder )
else:
database = None
SOURCE_EXTENSIONS = [ '.cpp', '.cxx', '.cc', '.c', '.m', '.mm' ]
def DirectoryOfThisScript():
return os.path.dirname( os.path.abspath( __file__ ) )
def MakeRelativePathsInFlagsAbsolute( flags, working_directory ):
if not working_directory:
return list( flags )
new_flags = []
make_next_absolute = False
path_flags = [ '-isystem', '-I', '-iquote', '--sysroot=' ]
for flag in flags:
new_flag = flag
if make_next_absolute:
make_next_absolute = False
if not flag.startswith( '/' ):
new_flag = os.path.join( working_directory, flag )
for path_flag in path_flags:
if flag == path_flag:
make_next_absolute = True
break
if flag.startswith( path_flag ):
path = flag[ len( path_flag ): ]
new_flag = path_flag + os.path.join( working_directory, path )
break
if new_flag:
new_flags.append( new_flag )
return new_flags
def IsHeaderFile( filename ):
extension = os.path.splitext( filename )[ 1 ]
return extension in [ '.h', '.hxx', '.hpp', '.hh' ]
def GetCompilationInfoForFile( filename ):
# The compilation_commands.json file generated by CMake does not have entries
# for header files. So we do our best by asking the db for flags for a
# corresponding source file, if any. If one exists, the flags for that file
# should be good enough.
if IsHeaderFile( filename ):
basename = os.path.splitext( filename )[ 0 ]
for extension in SOURCE_EXTENSIONS:
replacement_file = basename + extension
if os.path.exists( replacement_file ):
compilation_info = database.GetCompilationInfoForFile(
replacement_file )
if compilation_info.compiler_flags_:
return compilation_info
return None
return database.GetCompilationInfoForFile( filename )
def FlagsForFile( filename, **kwargs ):
if database:
# Bear in mind that compilation_info.compiler_flags_ does NOT return a
# python list, but a "list-like" StringVec object
compilation_info = GetCompilationInfoForFile( filename )
if not compilation_info:
return None
final_flags = MakeRelativePathsInFlagsAbsolute(
compilation_info.compiler_flags_,
compilation_info.compiler_working_dir_ )
else:
relative_to = DirectoryOfThisScript()
final_flags = MakeRelativePathsInFlagsAbsolute( flags, relative_to )
return {
'flags': final_flags,
'do_cache': True
}
================================================
FILE: src/lib/3rd/json11/LICENSE.txt
================================================
Copyright (c) 2013 Dropbox, Inc.
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
THE SOFTWARE.
================================================
FILE: src/lib/3rd/json11/README.md
================================================
json11
------
json11 is a tiny JSON library for C++11, providing JSON parsing and serialization.
The core object provided by the library is json11::Json. A Json object represents any JSON
value: null, bool, number (int or double), string (std::string), array (std::vector), or
object (std::map).
Json objects act like values. They can be assigned, copied, moved, compared for equality or
order, and so on. There are also helper methods Json::dump, to serialize a Json to a string, and
Json::parse (static) to parse a std::string as a Json object.
It's easy to make a JSON object with C++11's new initializer syntax:
Json my_json = Json::object {
{ "key1", "value1" },
{ "key2", false },
{ "key3", Json::array { 1, 2, 3 } },
};
std::string json_str = my_json.dump();
There are also implicit constructors that allow standard and user-defined types to be
automatically converted to JSON. For example:
class Point {
public:
int x;
int y;
Point (int x, int y) : x(x), y(y) {}
Json to_json() const { return Json::array { x, y }; }
};
std::vector<Point> points = { { 1, 2 }, { 10, 20 }, { 100, 200 } };
std::string points_json = Json(points).dump();
JSON values can have their values queried and inspected:
Json json = Json::array { Json::object { { "k", "v" } } };
std::string str = json[0]["k"].string_value();
More documentation is still to come. For now, see json11.hpp.
================================================
FILE: src/lib/3rd/json11/json11.cpp
================================================
/* Copyright (c) 2013 Dropbox, Inc.
*
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
* THE SOFTWARE.
*/
#include "json11.hpp"
#include <cassert>
#include <cstdlib>
#include <cstdio>
#include <limits>
namespace json11 {
static const int max_depth = 200;
using std::string;
using std::vector;
using std::map;
using std::make_shared;
using std::initializer_list;
using std::move;
/* * * * * * * * * * * * * * * * * * * *
* Serialization
*/
static void dump(std::nullptr_t, string &out) {
out += "null";
}
static void dump(double value, string &out) {
char buf[32];
snprintf(buf, sizeof buf, "%.17g", value);
out += buf;
}
static void dump(int value, string &out) {
char buf[32];
snprintf(buf, sizeof buf, "%d", value);
out += buf;
}
static void dump(bool value, string &out) {
out += value ? "true" : "false";
}
static void dump(const string &value, string &out) {
out += '"';
for (size_t i = 0; i < value.length(); i++) {
const char ch = value[i];
if (ch == '\\') {
out += "\\\\";
} else if (ch == '"') {
out += "\\\"";
} else if (ch == '\b') {
out += "\\b";
} else if (ch == '\f') {
out += "\\f";
} else if (ch == '\n') {
out += "\\n";
} else if (ch == '\r') {
out += "\\r";
} else if (ch == '\t') {
out += "\\t";
} else if (static_cast<uint8_t>(ch) <= 0x1f) {
char buf[8];
snprintf(buf, sizeof buf, "\\u%04x", ch);
out += buf;
} else if (static_cast<uint8_t>(ch) == 0xe2 && static_cast<uint8_t>(value[i+1]) == 0x80
&& static_cast<uint8_t>(value[i+2]) == 0xa8) {
out += "\\u2028";
i += 2;
} else if (static_cast<uint8_t>(ch) == 0xe2 && static_cast<uint8_t>(value[i+1]) == 0x80
&& static_cast<uint8_t>(value[i+2]) == 0xa9) {
out += "\\u2029";
i += 2;
} else {
out += ch;
}
}
out += '"';
}
static void dump(const Json::array &values, string &out) {
bool first = true;
out += "[";
for (const auto &value : values) {
if (!first)
out += ", ";
value.dump(out);
first = false;
}
out += "]";
}
static void dump(const Json::object &values, string &out) {
bool first = true;
out += "{";
for (const auto &kv : values) {
if (!first)
out += ", ";
dump(kv.first, out);
out += ": ";
kv.second.dump(out);
first = false;
}
out += "}";
}
void Json::dump(string &out) const {
m_ptr->dump(out);
}
/* * * * * * * * * * * * * * * * * * * *
* Value wrappers
*/
template <Json::Type tag, typename T>
class Value : public JsonValue {
protected:
// Constructors
explicit Value(const T &value) : m_value(value) {}
explicit Value(T &&value) : m_value(move(value)) {}
// Get type tag
Json::Type type() const override {
return tag;
}
// Comparisons
bool equals(const JsonValue * other) const override {
return m_value == static_cast<const Value<tag, T> *>(other)->m_value;
}
bool less(const JsonValue * other) const override {
return m_value < static_cast<const Value<tag, T> *>(other)->m_value;
}
const T m_value;
void dump(string &out) const override { json11::dump(m_value, out); }
};
class JsonDouble final : public Value<Json::NUMBER, double> {
double number_value() const override { return m_value; }
int int_value() const override { return static_cast<int>(m_value); }
bool equals(const JsonValue * other) const override { return m_value == other->number_value(); }
bool less(const JsonValue * other) const override { return m_value < other->number_value(); }
public:
explicit JsonDouble(double value) : Value(value) {}
};
class JsonInt final : public Value<Json::NUMBER, int> {
double number_value() const override { return m_value; }
int int_value() const override { return m_value; }
bool equals(const JsonValue * other) const override { return m_value == other->number_value(); }
bool less(const JsonValue * other) const override { return m_value < other->number_value(); }
public:
explicit JsonInt(int value) : Value(value) {}
};
class JsonBoolean final : public Value<Json::BOOL, bool> {
bool bool_value() const override { return m_value; }
public:
explicit JsonBoolean(bool value) : Value(value) {}
};
class JsonString final : public Value<Json::STRING, string> {
const string &string_value() const override { return m_value; }
public:
explicit JsonString(const string &value) : Value(value) {}
explicit JsonString(string &&value) : Value(move(value)) {}
};
class JsonArray final : public Value<Json::ARRAY, Json::array> {
const Json::array &array_items() const override { return m_value; }
const Json & operator[](size_t i) const override;
public:
explicit JsonArray(const Json::array &value) : Value(value) {}
explicit JsonArray(Json::array &&value) : Value(move(value)) {}
};
class JsonObject final : public Value<Json::OBJECT, Json::object> {
const Json::object &object_items() const override { return m_value; }
const Json & operator[](const string &key) const override;
public:
explicit JsonObject(const Json::object &value) : Value(value) {}
explicit JsonObject(Json::object &&value) : Value(move(value)) {}
};
class JsonNull final : public Value<Json::NUL, std::nullptr_t> {
public:
JsonNull() : Value(nullptr) {}
};
/* * * * * * * * * * * * * * * * * * * *
* Static globals - static-init-safe
*/
struct Statics {
const std::shared_ptr<JsonValue> null = make_shared<JsonNull>();
const std::shared_ptr<JsonValue> t = make_shared<JsonBoolean>(true);
const std::shared_ptr<JsonValue> f = make_shared<JsonBoolean>(false);
const string empty_string;
const vector<Json> empty_vector;
const map<string, Json> empty_map;
Statics() {}
};
const Statics & statics() {
static const Statics s {};
return s;
}
const Json & static_null() {
// This has to be separate, not in Statics, because Json() accesses statics().null.
static const Json json_null;
return json_null;
}
/* * * * * * * * * * * * * * * * * * * *
* Constructors
*/
Json::Json() noexcept : m_ptr(statics().null) {}
Json::Json(std::nullptr_t) noexcept : m_ptr(statics().null) {}
Json::Json(double value) : m_ptr(make_shared<JsonDouble>(value)) {}
Json::Json(int value) : m_ptr(make_shared<JsonInt>(value)) {}
Json::Json(bool value) : m_ptr(value ? statics().t : statics().f) {}
Json::Json(const string &value) : m_ptr(make_shared<JsonString>(value)) {}
Json::Json(string &&value) : m_ptr(make_shared<JsonString>(move(value))) {}
Json::Json(const char * value) : m_ptr(make_shared<JsonString>(value)) {}
Json::Json(const Json::array &values) : m_ptr(make_shared<JsonArray>(values)) {}
Json::Json(Json::array &&values) : m_ptr(make_shared<JsonArray>(move(values))) {}
Json::Json(const Json::object &values) : m_ptr(make_shared<JsonObject>(values)) {}
Json::Json(Json::object &&values) : m_ptr(make_shared<JsonObject>(move(values))) {}
/* * * * * * * * * * * * * * * * * * * *
* Accessors
*/
Json::Type Json::type() const { return m_ptr->type(); }
double Json::number_value() const { return m_ptr->number_value(); }
int Json::int_value() const { return m_ptr->int_value(); }
bool Json::bool_value() const { return m_ptr->bool_value(); }
const string & Json::string_value() const { return m_ptr->string_value(); }
const vector<Json> & Json::array_items() const { return m_ptr->array_items(); }
const map<string, Json> & Json::object_items() const { return m_ptr->object_items(); }
const Json & Json::operator[] (size_t i) const { return (*m_ptr)[i]; }
const Json & Json::operator[] (const string &key) const { return (*m_ptr)[key]; }
double JsonValue::number_value() const { return 0; }
int JsonValue::int_value() const { return 0; }
bool JsonValue::bool_value() const { return false; }
const string & JsonValue::string_value() const { return statics().empty_string; }
const vector<Json> & JsonValue::array_items() const { return statics().empty_vector; }
const map<string, Json> & JsonValue::object_items() const { return statics().empty_map; }
const Json & JsonValue::operator[] (size_t) const { return static_null(); }
const Json & JsonValue::operator[] (const string &) const { return static_null(); }
const Json & JsonObject::operator[] (const string &key) const {
auto iter = m_value.find(key);
return (iter == m_value.end()) ? static_null() : iter->second;
}
const Json & JsonArray::operator[] (size_t i) const {
if (i >= m_value.size()) return static_null();
else return m_value[i];
}
/* * * * * * * * * * * * * * * * * * * *
* Comparison
*/
bool Json::operator== (const Json &other) const {
if (m_ptr->type() != other.m_ptr->type())
return false;
return m_ptr->equals(other.m_ptr.get());
}
bool Json::operator< (const Json &other) const {
if (m_ptr->type() != other.m_ptr->type())
return m_ptr->type() < other.m_ptr->type();
return m_ptr->less(other.m_ptr.get());
}
/* * * * * * * * * * * * * * * * * * * *
* Parsing
*/
/* esc(c)
*
* Format char c suitable for printing in an error message.
*/
static inline string esc(char c) {
char buf[12];
if (static_cast<uint8_t>(c) >= 0x20 && static_cast<uint8_t>(c) <= 0x7f) {
snprintf(buf, sizeof buf, "'%c' (%d)", c, c);
} else {
snprintf(buf, sizeof buf, "(%d)", c);
}
return string(buf);
}
static inline bool in_range(long x, long lower, long upper) {
return (x >= lower && x <= upper);
}
/* JsonParser
*
* Object that tracks all state of an in-progress parse.
*/
struct JsonParser {
/* State
*/
const string &str;
size_t i;
string &err;
bool failed;
/* fail(msg, err_ret = Json())
*
* Mark this parse as failed.
*/
Json fail(string &&msg) {
return fail(move(msg), Json());
}
template <typename T>
T fail(string &&msg, const T err_ret) {
if (!failed)
err = std::move(msg);
failed = true;
return err_ret;
}
/* consume_whitespace()
*
* Advance until the current character is non-whitespace.
*/
void consume_whitespace() {
while (str[i] == ' ' || str[i] == '\r' || str[i] == '\n' || str[i] == '\t')
i++;
}
/* get_next_token()
*
* Return the next non-whitespace character. If the end of the input is reached,
* flag an error and return 0.
*/
char get_next_token() {
consume_whitespace();
if (i == str.size())
return (char)(fail("unexpected end of input", 0));
return str[i++];
}
/* encode_utf8(pt, out)
*
* Encode pt as UTF-8 and add it to out.
*/
void encode_utf8(long pt, string & out) {
if (pt < 0)
return;
if (pt < 0x80) {
out += static_cast<char>(pt);
} else if (pt < 0x800) {
out += static_cast<char>((pt >> 6) | 0xC0);
out += static_cast<char>((pt & 0x3F) | 0x80);
} else if (pt < 0x10000) {
out += static_cast<char>((pt >> 12) | 0xE0);
out += static_cast<char>(((pt >> 6) & 0x3F) | 0x80);
out += static_cast<char>((pt & 0x3F) | 0x80);
} else {
out += static_cast<char>((pt >> 18) | 0xF0);
out += static_cast<char>(((pt >> 12) & 0x3F) | 0x80);
out += static_cast<char>(((pt >> 6) & 0x3F) | 0x80);
out += static_cast<char>((pt & 0x3F) | 0x80);
}
}
/* parse_string()
*
* Parse a string, starting at the current position.
*/
string parse_string() {
string out;
long last_escaped_codepoint = -1;
while (true) {
if (i == str.size())
return fail("unexpected end of input in string", "");
char ch = str[i++];
if (ch == '"') {
encode_utf8(last_escaped_codepoint, out);
return out;
}
if (in_range(ch, 0, 0x1f))
return fail("unescaped " + esc(ch) + " in string", "");
// The usual case: non-escaped characters
if (ch != '\\') {
encode_utf8(last_escaped_codepoint, out);
last_escaped_codepoint = -1;
out += ch;
continue;
}
// Handle escapes
if (i == str.size())
return fail("unexpected end of input in string", "");
ch = str[i++];
if (ch == 'u') {
// Extract 4-byte escape sequence
string esc = str.substr(i, 4);
// Explicitly check length of the substring. The following loop
// relies on std::string returning the terminating NUL when
// accessing str[length]. Checking here reduces brittleness.
if (esc.length() < 4) {
return fail("bad \\u escape: " + esc, "");
}
for (int j = 0; j < 4; j++) {
if (!in_range(esc[(unsigned int)j], 'a', 'f') && !in_range(esc[(unsigned int)j], 'A', 'F')
&& !in_range(esc[(unsigned int)j], '0', '9'))
return fail("bad \\u escape: " + esc, "");
}
long codepoint = strtol(esc.data(), nullptr, 16);
// JSON specifies that characters outside the BMP shall be encoded as a pair
// of 4-hex-digit \u escapes encoding their surrogate pair components. Check
// whether we're in the middle of such a beast: the previous codepoint was an
// escaped lead (high) surrogate, and this is a trail (low) surrogate.
if (in_range(last_escaped_codepoint, 0xD800, 0xDBFF)
&& in_range(codepoint, 0xDC00, 0xDFFF)) {
// Reassemble the two surrogate pairs into one astral-plane character, per
// the UTF-16 algorithm.
encode_utf8((((last_escaped_codepoint - 0xD800) << 10)
| (codepoint - 0xDC00)) + 0x10000, out);
last_escaped_codepoint = -1;
} else {
encode_utf8(last_escaped_codepoint, out);
last_escaped_codepoint = codepoint;
}
i += 4;
continue;
}
encode_utf8(last_escaped_codepoint, out);
last_escaped_codepoint = -1;
if (ch == 'b') {
out += '\b';
} else if (ch == 'f') {
out += '\f';
} else if (ch == 'n') {
out += '\n';
} else if (ch == 'r') {
out += '\r';
} else if (ch == 't') {
out += '\t';
} else if (ch == '"' || ch == '\\' || ch == '/') {
out += ch;
} else {
return fail("invalid escape character " + esc(ch), "");
}
}
}
/* parse_number()
*
* Parse a double.
*/
Json parse_number() {
size_t start_pos = i;
if (str[i] == '-')
i++;
// Integer part
if (str[i] == '0') {
i++;
if (in_range(str[i], '0', '9'))
return fail("leading 0s not permitted in numbers");
} else if (in_range(str[i], '1', '9')) {
i++;
while (in_range(str[i], '0', '9'))
i++;
} else {
return fail("invalid " + esc(str[i]) + " in number");
}
if (str[i] != '.' && str[i] != 'e' && str[i] != 'E'
&& (i - start_pos) <= static_cast<size_t>(std::numeric_limits<int>::digits10)) {
return std::atoi(str.c_str() + start_pos);
}
// Decimal part
if (str[i] == '.') {
i++;
if (!in_range(str[i], '0', '9'))
return fail("at least one digit required in fractional part");
while (in_range(str[i], '0', '9'))
i++;
}
// Exponent part
if (str[i] == 'e' || str[i] == 'E') {
i++;
if (str[i] == '+' || str[i] == '-')
i++;
if (!in_range(str[i], '0', '9'))
return fail("at least one digit required in exponent");
while (in_range(str[i], '0', '9'))
i++;
}
return std::strtod(str.c_str() + start_pos, nullptr);
}
/* expect(str, res)
*
* Expect that 'str' starts at the character that was just read. If it does, advance
* the input and return res. If not, flag an error.
*/
Json expect(const string &expected, Json res) {
assert(i != 0);
i--;
if (str.compare(i, expected.length(), expected) == 0) {
i += expected.length();
return res;
} else {
return fail("parse error: expected " + expected + ", got " + str.substr(i, expected.length()));
}
}
/* parse_json()
*
* Parse a JSON object.
*/
Json parse_json(int depth) {
if (depth > max_depth) {
return fail("exceeded maximum nesting depth");
}
char ch = get_next_token();
if (failed)
return Json();
if (ch == '-' || (ch >= '0' && ch <= '9')) {
i--;
return parse_number();
}
if (ch == 't')
return expect("true", true);
if (ch == 'f')
return expect("false", false);
if (ch == 'n')
return expect("null", Json());
if (ch == '"')
return parse_string();
if (ch == '{') {
map<string, Json> data;
ch = get_next_token();
if (ch == '}')
return data;
while (1) {
if (ch != '"')
return fail("expected '\"' in object, got " + esc(ch));
string key = parse_string();
if (failed)
return Json();
ch = get_next_token();
if (ch != ':')
return fail("expected ':' in object, got " + esc(ch));
data[std::move(key)] = parse_json(depth + 1);
if (failed)
return Json();
ch = get_next_token();
if (ch == '}')
break;
if (ch != ',')
return fail("expected ',' in object, got " + esc(ch));
ch = get_next_token();
}
return data;
}
if (ch == '[') {
vector<Json> data;
ch = get_next_token();
if (ch == ']')
return data;
while (1) {
i--;
data.push_back(parse_json(depth + 1));
if (failed)
return Json();
ch = get_next_token();
if (ch == ']')
break;
if (ch != ',')
return fail("expected ',' in list, got " + esc(ch));
ch = get_next_token();
(void)ch;
}
return data;
}
return fail("expected value, got " + esc(ch));
}
};
Json Json::parse(const string &in, string &err) {
JsonParser parser { in, 0, err, false };
Json result = parser.parse_json(0);
// Check for any trailing garbage
parser.consume_whitespace();
if (parser.i != in.size())
return parser.fail("unexpected trailing " + esc(in[parser.i]));
return result;
}
// Documented in json11.hpp
vector<Json> Json::parse_multi(const string &in, string &err) {
JsonParser parser { in, 0, err, false };
vector<Json> json_vec;
while (parser.i != in.size() && !parser.failed) {
json_vec.push_back(parser.parse_json(0));
// Check for another object
parser.consume_whitespace();
}
return json_vec;
}
/* * * * * * * * * * * * * * * * * * * *
* Shape-checking
*/
bool Json::has_shape(const shape & types, string & err) const {
if (!is_object()) {
err = "expected JSON object, got " + dump();
return false;
}
for (auto & item : types) {
if ((*this)[item.first].type() != item.second) {
err = "bad type for " + item.first + " in " + dump();
return false;
}
}
return true;
}
} // namespace json11
================================================
FILE: src/lib/3rd/json11/json11.hpp
================================================
/* json11
*
* json11 is a tiny JSON library for C++11, providing JSON parsing and serialization.
*
* The core object provided by the library is json11::Json. A Json object represents any JSON
* value: null, bool, number (int or double), string (std::string), array (std::vector), or
* object (std::map).
*
* Json objects act like values: they can be assigned, copied, moved, compared for equality or
* order, etc. There are also helper methods Json::dump, to serialize a Json to a string, and
* Json::parse (static) to parse a std::string as a Json object.
*
* Internally, the various types of Json object are represented by the JsonValue class
* hierarchy.
*
* A note on numbers - JSON specifies the syntax of number formatting but not its semantics,
* so some JSON implementations distinguish between integers and floating-point numbers, while
* some don't. In json11, we choose the latter. Because some JSON implementations (namely
* Javascript itself) treat all numbers as the same type, distinguishing the two leads
* to JSON that will be *silently* changed by a round-trip through those implementations.
* Dangerous! To avoid that risk, json11 stores all numbers as double internally, but also
* provides integer helpers.
*
* Fortunately, double-precision IEEE754 ('double') can precisely store any integer in the
* range +/-2^53, which includes every 'int' on most systems. (Timestamps often use int64
* or long long to avoid the Y2038K problem; a double storing microseconds since some epoch
* will be exact for +/- 275 years.)
*/
/* Copyright (c) 2013 Dropbox, Inc.
*
* Permission is hereby granted, free of charge, to any person obtaining a copy
* of this software and associated documentation files (the "Software"), to deal
* in the Software without restriction, including without limitation the rights
* to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
* copies of the Software, and to permit persons to whom the Software is
* furnished to do so, subject to the following conditions:
*
* The above copyright notice and this permission notice shall be included in
* all copies or substantial portions of the Software.
*
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
* OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN
* THE SOFTWARE.
*/
#pragma once
#include <string>
#include <vector>
#include <map>
#include <memory>
#include <initializer_list>
namespace json11 {
class JsonValue;
class Json final {
public:
// Types
enum Type {
NUL, NUMBER, BOOL, STRING, ARRAY, OBJECT
};
// Array and object typedefs
typedef std::vector<Json> array;
typedef std::map<std::string, Json> object;
// Constructors for the various types of JSON value.
Json() noexcept; // NUL
Json(std::nullptr_t) noexcept; // NUL
Json(double value); // NUMBER
Json(int value); // NUMBER
Json(bool value); // BOOL
Json(const std::string &value); // STRING
Json(std::string &&value); // STRING
Json(const char * value); // STRING
Json(const array &values); // ARRAY
Json(array &&values); // ARRAY
Json(const object &values); // OBJECT
Json(object &&values); // OBJECT
// Implicit constructor: anything with a to_json() function.
template <class T, class = decltype(&T::to_json)>
Json(const T & t) : Json(t.to_json()) {}
// Implicit constructor: map-like objects (std::map, std::unordered_map, etc)
template <class M, typename std::enable_if<
std::is_constructible<std::string, typename M::key_type>::value
&& std::is_constructible<Json, typename M::mapped_type>::value,
int>::type = 0>
Json(const M & m) : Json(object(m.begin(), m.end())) {}
// Implicit constructor: vector-like objects (std::list, std::vector, std::set, etc)
template <class V, typename std::enable_if<
std::is_constructible<Json, typename V::value_type>::value,
int>::type = 0>
Json(const V & v) : Json(array(v.begin(), v.end())) {}
// This prevents Json(some_pointer) from accidentally producing a bool. Use
// Json(bool(some_pointer)) if that behavior is desired.
Json(void *) = delete;
// Accessors
Type type() const;
bool is_null() const { return type() == NUL; }
bool is_number() const { return type() == NUMBER; }
bool is_bool() const { return type() == BOOL; }
bool is_string() const { return type() == STRING; }
bool is_array() const { return type() == ARRAY; }
bool is_object() const { return type() == OBJECT; }
// Return the enclosed value if this is a number, 0 otherwise. Note that json11 does not
// distinguish between integer and non-integer numbers - number_value() and int_value()
// can both be applied to a NUMBER-typed object.
double number_value() const;
int int_value() const;
// Return the enclosed value if this is a boolean, false otherwise.
bool bool_value() const;
// Return the enclosed string if this is a string, "" otherwise.
const std::string &string_value() const;
// Return the enclosed std::vector if this is an array, or an empty vector otherwise.
const array &array_items() const;
// Return the enclosed std::map if this is an object, or an empty map otherwise.
const object &object_items() const;
// Return a reference to arr[i] if this is an array, Json() otherwise.
const Json & operator[](size_t i) const;
// Return a reference to obj[key] if this is an object, Json() otherwise.
const Json & operator[](const std::string &key) const;
// Serialize.
void dump(std::string &out) const;
std::string dump() const {
std::string out;
dump(out);
return out;
}
// Parse. If parse fails, return Json() and assign an error message to err.
static Json parse(const std::string & in, std::string & err);
static Json parse(const char * in, std::string & err) {
if (in) {
return parse(std::string(in), err);
} else {
err = "null input";
return nullptr;
}
}
// Parse multiple objects, concatenated or separated by whitespace
static std::vector<Json> parse_multi(const std::string & in, std::string & err);
bool operator== (const Json &rhs) const;
bool operator< (const Json &rhs) const;
bool operator!= (const Json &rhs) const { return !(*this == rhs); }
bool operator<= (const Json &rhs) const { return !(rhs < *this); }
bool operator> (const Json &rhs) const { return (rhs < *this); }
bool operator>= (const Json &rhs) const { return !(*this < rhs); }
/* has_shape(types, err)
*
* Return true if this is a JSON object and, for each item in types, has a field of
* the given type. If not, return false and set err to a descriptive message.
*/
typedef std::initializer_list<std::pair<std::string, Type>> shape;
bool has_shape(const shape & types, std::string & err) const;
private:
std::shared_ptr<JsonValue> m_ptr;
};
// Internal class hierarchy - JsonValue objects are not exposed to users of this API.
class JsonValue {
protected:
friend class Json;
friend class JsonInt;
friend class JsonDouble;
virtual Json::Type type() const = 0;
virtual bool equals(const JsonValue * other) const = 0;
virtual bool less(const JsonValue * other) const = 0;
virtual void dump(std::string &out) const = 0;
virtual double number_value() const;
virtual int int_value() const;
virtual bool bool_value() const;
virtual const std::string &string_value() const;
virtual const Json::array &array_items() const;
virtual const Json &operator[](size_t i) const;
virtual const Json::object &object_items() const;
virtual const Json &operator[](const std::string &key) const;
virtual ~JsonValue() {}
};
} // namespace json11
================================================
FILE: src/lib/3rd/json11/test.cpp
================================================
#include <string>
#include <cstdio>
#include <iostream>
#include <sstream>
#include "json11.hpp"
#include <cassert>
#include <list>
#include <set>
#include <unordered_map>
using namespace json11;
using std::string;
// Check that Json has the properties we want.
#include <type_traits>
#define CHECK_TRAIT(x) static_assert(std::x::value, #x)
CHECK_TRAIT(is_nothrow_constructible<Json>);
CHECK_TRAIT(is_nothrow_default_constructible<Json>);
CHECK_TRAIT(is_copy_constructible<Json>);
CHECK_TRAIT(is_nothrow_move_constructible<Json>);
CHECK_TRAIT(is_copy_assignable<Json>);
CHECK_TRAIT(is_nothrow_move_assignable<Json>);
CHECK_TRAIT(is_nothrow_destructible<Json>);
void parse_from_stdin() {
string buf;
while (!std::cin.eof()) buf += std::cin.get();
string err;
auto json = Json::parse(buf, err);
if (!err.empty()) {
printf("Failed: %s\n", err.c_str());
} else {
printf("Result: %s\n", json.dump().c_str());
}
}
int main(int argc, char **argv) {
if (argc == 2 && argv[1] == string("--stdin")) {
parse_from_stdin();
return 0;
}
const string simple_test =
R"({"k1":"v1", "k2":42, "k3":["a",123,true,false,null]})";
string err;
auto json = Json::parse(simple_test, err);
std::cout << "k1: " << json["k1"].string_value() << "\n";
std::cout << "k3: " << json["k3"].dump() << "\n";
for (auto &k : json["k3"].array_items()) {
std::cout << " - " << k.dump() << "\n";
}
std::list<int> l1 { 1, 2, 3 };
std::vector<int> l2 { 1, 2, 3 };
std::set<int> l3 { 1, 2, 3 };
assert(Json(l1) == Json(l2));
assert(Json(l2) == Json(l3));
std::map<string, string> m1 { { "k1", "v1" }, { "k2", "v2" } };
std::unordered_map<string, string> m2 { { "k1", "v1" }, { "k2", "v2" } };
assert(Json(m1) == Json(m2));
// Json literals
Json obj = Json::object({
{ "k1", "v1" },
{ "k2", 42.0 },
{ "k3", Json::array({ "a", 123.0, true, false, nullptr }) },
});
std::cout << "obj: " << obj.dump() << "\n";
assert(Json("a").number_value() == 0);
assert(Json("a").string_value() == "a");
assert(Json().number_value() == 0);
assert(obj == json);
assert(Json(42) == Json(42.0));
assert(Json(42) != Json(42.1));
const string unicode_escape_test =
R"([ "blah\ud83d\udca9blah\ud83dblah\udca9blah\u0000blah\u1234" ])";
const char utf8[] = "blah" "\xf0\x9f\x92\xa9" "blah" "\xed\xa0\xbd" "blah"
"\xed\xb2\xa9" "blah" "\0" "blah" "\xe1\x88\xb4";
Json uni = Json::parse(unicode_escape_test, err);
assert(uni[0].string_value().size() == (sizeof utf8) - 1);
assert(memcmp(uni[0].string_value().data(), utf8, sizeof utf8) == 0);
Json my_json = Json::object {
{ "key1", "value1" },
{ "key2", false },
{ "key3", Json::array { 1, 2, 3 } },
};
std::string json_str = my_json.dump();
printf("%s\n", json_str.c_str());
class Point {
public:
int x;
int y;
Point (int x, int y) : x(x), y(y) {}
Json to_json() const { return Json::array { x, y }; }
};
std::vector<Point> points = { { 1, 2 }, { 10, 20 }, { 100, 200 } };
std::string points_json = Json(points).dump();
printf("%s\n", points_json.c_str());
}
================================================
FILE: src/lib/helper/CmdlineOption.cpp
================================================
// last modified
#include "CmdlineOption.h"
#include <unordered_map>
#include <vector>
#include <string>
#include <iostream>
#include <iterator>
using namespace std;
static bool
isOption (const string& str)
{
return( str.size() >= 3 && // the shortest option "--x"
'-' == str[0] &&
'-' == str[1] &&
'-' != str[2] );
}
// cmdname --foo aa, for example, --foo is an option, aa is an argument.
// convention about command line option:
// 0) option must begin with -- (so, the shortest option --x has three characters), and the argument cannot begin with --;
// 1) an argument must follow after an option;
// 2) an option can follow as an argument or not, E.G., some option for true or false.
// one option by one more arguments? E.G., --bar a b c d. It's ok.
CmdlineOption::CmdlineOption (unsigned argc, char* argv[])
{
if (argc < 2) {
return;
}
vector<string> raw_options_list(argv + 1, argv + argc);
string last_option;
for (const auto& e : raw_options_list) {
if (isOption(e)) {
options_and_arguments_list_[e];
last_option = e;
} else {
if (!last_option.empty()) {
options_and_arguments_list_[last_option].push_back(e);
}
}
}
//// DEBUG. show the result of parsing command options
//for (const auto& e : options_and_arguments_list_) {
//const vector<string>& arguments_list = e.second;
//cout << e.first << "(" << arguments_list.size() << "): ";
//copy(e.second.cbegin(), e.second.cend(), ostream_iterator<string>(cout, ","));
//cout << endl;
//}
}
CmdlineOption::~CmdlineOption ()
{
;
}
bool
CmdlineOption::hasOption (const string& option) const
{
return(options_and_arguments_list_.cend() != options_and_arguments_list_.find(option));
}
const vector<string>&
CmdlineOption::getArgumentsList (const string& option)
{
static const vector<string> empty_arguments_list;
return(hasOption(option) ? options_and_arguments_list_[option] : empty_arguments_list);
}
================================================
FILE: src/lib/helper/CmdlineOption.h
================================================
// last modified
#pragma once
#include <string>
#include <vector>
#include <unordered_map>
using std::string;
using std::pair;
using std::vector;
using std::unordered_map;
class CmdlineOption
{
public:
CmdlineOption (unsigned argc, char* argv[]);
virtual ~CmdlineOption ();
bool hasOption (const string& option) const;
const vector<string>& getArgumentsList (const string& option);
private:
unordered_map<string, vector<string>> options_and_arguments_list_;
};
================================================
FILE: src/lib/helper/Misc.cpp
================================================
// last modified
#include "Misc.h"
#include <algorithm>
#include <iostream>
#include <iterator>
#include <cstdlib>
#include <cstdio>
#include <bitset>
#include <ctime>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
using std::bitset;
using std::cout;
using std::cerr;
using std::endl;
using std::make_pair;
using std::ostream_iterator;
// split raw string to more sub-str by token-chars.
// note:
// 0) case sensitive;
// 1) if there are consecutive two token-chars in raw string, splitStr()
// will make a empty sub-str into splited_substr_list.
void
splitStr ( const string& str,
const string& tokens_list,
vector<string>& splited_substr_list,
vector<char>& appeared_tokens_list )
{
size_t begin_pos = 0, end_pos;
while (begin_pos < str.size()) {
const auto iter_token = find_first_of( str.cbegin() + (int)begin_pos, str.cend(),
tokens_list.cbegin(), tokens_list.cend() );
if (str.cend() == iter_token) {
splited_substr_list.push_back(str.substr(begin_pos));
break;
}
appeared_tokens_list.push_back(*iter_token);
end_pos = (unsigned)(iter_token - str.cbegin());
splited_substr_list.push_back(str.substr(begin_pos, end_pos - begin_pos));
begin_pos = end_pos + 1;
}
if (splited_substr_list[0].empty()) {
splited_substr_list.erase(splited_substr_list.begin());
}
}
// first return is the string between keyword_begin and keyword_end;
// second return is end_pos + keyword_end.size().
pair<string, size_t>
fetchStringBetweenKeywords ( const string& txt,
const string& keyword_begin,
const string& keyword_end,
size_t from_pos )
{
const auto begin_pos = txt.find(keyword_begin, from_pos);
if (string::npos == begin_pos) {
//cerr << "WARNING! fetchStringBetweenKeywords() CANNOT find the keyword \"" << kyeword_begin << "\"" << endl;
return(make_pair("", 0));
}
const auto end_pos = txt.find(keyword_end, begin_pos + keyword_begin.size());
if (string::npos == end_pos) {
//cerr << "WARNING! fetchStringBetweenKeywords() CANNOT find the keyword \"" << kyeword_end << "\"" << endl;
return(make_pair("", 0));
}
return(make_pair( txt.substr(begin_pos + keyword_begin.size(), end_pos - begin_pos - keyword_begin.size()),
end_pos + keyword_end.size() ));
}
// get file size by FILE*.
// return -1 if failure
long
getFileSize (FILE* fs)
{
// backup current offset
long offset_bak = ftell(fs);
// get the filesize
fseek(fs, 0, SEEK_END);
long file_size = ftell(fs);
// restore last offset
fseek(fs, offset_bak, SEEK_SET);
return(file_size);
}
// process_name + process_id + thread_id + rand
extern char *__progname;
string
makeRandomFilename (void)
{
static bool b_first = true;
if (b_first) {
srand((unsigned)time(NULL));
b_first = false;
}
const string& filename = string(__progname) + "_" +
convNumToStr(getpid()) + "_"
+ convNumToStr(pthread_self()) + "_"
+ convNumToStr(rand());
#ifdef CYGWIN
return("c:\\" + filename);
#else
return("/tmp/" + filename);
#endif
}
// unicode 与 UTF8 间转换规则:
// =================================================================================
// | unicode 符号范围 | UTF8编码方式
// n | (十六进制) | (二进制)
// --+-----------------------+------------------------------------------------------
// 1 | 0000 0000 - 0000 007F | 0xxxxxxx
// 2 | 0000 0080 - 0000 07FF | 110xxxxx 10xxxxxx
// 3 | 0000 0800 - 0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
// 4 | 0001 0000 - 0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
// 5 | 0020 0000 - 03FF FFFF | 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
// 6 | 0400 0000 - 7FFF FFFF | 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
// =================================================================================
// UTF8 中剩余的 x 用其 unicode 中各位从右向左填充,若还有多余的位则 0 填。如,"严"
// 的 unicode 是 4E25(100111000100101),根据上表,可以发现 4E25 处在第三行的范围内
// (0000 0800-0000 FFFF),"严"的 UTF8 编码需要三个字节,即格式是
// "1110xxxx 10xxxxxx 10xxxxxx",然后,从"严"的最后一个二进制位开始,依次从后向前填
// 入格式中的 x,多出的位补 0。这样就得到了,"严"的 UTF8 编码是
// "11100100 10111000 10100101",转换成十六进制就是 E4B8A5。
//
// 返回值:由于 UTF8 是变长编码格式,所以,需要返回转换后的 UTF8 编码有效字节数,以
// 具体值。
//
// 注意:
// 0)假定小尾存储;
// 1)unicode 最多需要 4 个字节,UTF8 最多需要 6 个字节,所以,这就决定了型参类
// 型必须为 unsigned int,返回值类型为 unsigned long long;
//
// 更多细节参见:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
pair<size_t, unsigned long long>
convertUnicodeToUtf8 (unsigned int unicode)
{
if (unicode <= 0x0000007F) {
return(make_pair(1, unicode));
} else if (0x00000080 <= unicode && unicode <= 0x000007FF) {
bitset<16> unicode_bits(unicode);
const string unicode_bits_str = unicode_bits.to_string<char, string::traits_type, string::allocator_type>();
string unicode_bits_str_reverse(unicode_bits_str.crbegin(), unicode_bits_str.crend());
unicode_bits_str_reverse.insert(6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 5, "000");
unicode_bits_str_reverse.resize(16);
const bitset<16> masker(string(unicode_bits_str_reverse.crbegin(), unicode_bits_str_reverse.crend()));
bitset<16> utf8_lower("1100000010000000");
bitset<16> utf8_bits = utf8_lower | masker;
return(make_pair(2, utf8_bits.to_ullong()));
} else if (0x00000800 <= unicode && unicode <= 0x0000FFFF) {
bitset<16> unicode_bits(unicode);
const string unicode_bits_str = unicode_bits.to_string<char, string::traits_type, string::allocator_type>();
string unicode_bits_str_reverse(unicode_bits_str.crbegin(), unicode_bits_str.crend());
unicode_bits_str_reverse.insert(6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6 + 2 + 4, "0000");
unicode_bits_str_reverse.resize(24);
const bitset<24> masker(string(unicode_bits_str_reverse.crbegin(), unicode_bits_str_reverse.crend()));
bitset<24> utf8_lower("111000001000000010000000");
bitset<24> utf8_bits = utf8_lower | masker;
return(make_pair(3, utf8_bits.to_ullong()));
} else if (0x00010000 <= unicode && unicode <= 0x0010FFFF) {
bitset<32> unicode_bits(unicode);
const string unicode_bits_str = unicode_bits.to_string<char, string::traits_type, string::allocator_type>();
string unicode_bits_str_reverse(unicode_bits_str.crbegin(), unicode_bits_str.crend());
unicode_bits_str_reverse.insert(6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6 + 2 + 6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6 + 2 + 6 + 2 + 3, "000");
unicode_bits_str_reverse.resize(32);
const bitset<32> masker(string(unicode_bits_str_reverse.crbegin(), unicode_bits_str_reverse.crend()));
bitset<32> utf8_lower("11110000100000001000000010000000");
bitset<32> utf8_bits = utf8_lower | masker;
return(make_pair(4, utf8_bits.to_ullong()));
} else if (0x00200000 <= unicode && unicode <= 0x03FFFFFF) {
bitset<32> unicode_bits(unicode);
const string unicode_bits_str = unicode_bits.to_string<char, string::traits_type, string::allocator_type>();
string unicode_bits_str_reverse(unicode_bits_str.crbegin(), unicode_bits_str.crend());
unicode_bits_str_reverse.insert(6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6 + 2 + 6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6 + 2 + 6 + 2 + 6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6 + 2 + 6 + 2 + 6 + 2 + 2, "00");
unicode_bits_str_reverse.resize(40);
const bitset<40> masker(string(unicode_bits_str_reverse.crbegin(), unicode_bits_str_reverse.crend()));
bitset<40> utf8_lower("1111100010000000100000001000000010000000");
bitset<40> utf8_bits = utf8_lower | masker;
return(make_pair(5, utf8_bits.to_ullong()));
} else if (0x04000000 <= unicode && unicode <= 0x7FFFFFFF) {
bitset<64> unicode_bits(unicode);
const string unicode_bits_str = unicode_bits.to_string<char, string::traits_type, string::allocator_type>();
string unicode_bits_str_reverse(unicode_bits_str.crbegin(), unicode_bits_str.crend());
unicode_bits_str_reverse.insert(6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6 + 2 + 6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6 + 2 + 6 + 2 + 6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6 + 2 + 6 + 2 + 6 + 2 + 6, "00");
unicode_bits_str_reverse.insert(6 + 2 + 6 + 2 + 6 + 2 + 6 + 2 + 6 + 2 + 1, "0");
unicode_bits_str_reverse.resize(48);
const bitset<48> masker(string(unicode_bits_str_reverse.crbegin(), unicode_bits_str_reverse.crend()));
bitset<48> utf8_lower("111111001000000010000000100000001000000010000000");
bitset<48> utf8_bits = utf8_lower | masker;
return(make_pair(6, utf8_bits.to_ullong()));
} else {
cerr << "WARNING! " << unicode << "is not a vaild unicode. " << endl;
return(make_pair(0, 0));
}
}
bool
wait_cmd ( const string& cmd,
const vector<string>& argv,
int* p_exitCode,
bool b_echo )
{
bool b_executed_success = false;
char** argv_tmp;
// 回显命令行
if (b_echo) {
copy(argv.cbegin(), argv.cend(), ostream_iterator<string>(cout, " "));
cout << endl;
}
// 将vector<string>中的命令行参数转换为char* []
argv_tmp = new char* [argv.size() + 1]; // !!!子进程中是否产生内存泄漏??
for (size_t i = 0; i != argv.size(); ++i) {
argv_tmp[i] = const_cast<char*>(argv[i].c_str());
}
argv_tmp[argv.size()] = NULL;
// 运行并等待子进程
pid_t pid = fork();
if (0 == pid) { // 子进程
execvp(cmd.c_str(), argv_tmp);
} else if (pid > 0) { // 父进程
int status;
waitpid(pid, &status, 0);
// 命令正常结束。即通过exit()正常退出,而非通过kill异常结束,与exit()的返回值无关
if (WIFEXITED(status)) {
int exit_code = WEXITSTATUS(status); // 命令通过正常exit()结束时的返回值
if (EXIT_SUCCESS == exit_code) {
b_executed_success = true;
}
if (NULL != p_exitCode) {
*p_exitCode = exit_code;
}
}
}
delete [] argv_tmp;
return (b_executed_success );
}
================================================
FILE: src/lib/helper/Misc.h
================================================
// last modified
#pragma once
#include <sstream>
#include <string>
#include <vector>
using std::string;
using std::ostringstream;
using std::vector;
using std::pair;
// why not std::to_string()?
// you know, I have to port this linux code to win32 by cygwin, and there
// is a bug on cygwin case it cannot find to_string(), so, I must do it
// by myself
template<typename T>
string
convNumToStr (T num)
{
ostringstream oss;
oss << num;
return(oss.str());
}
// split raw string to more sub-str by token-chars.
void
splitStr ( const string& str,
const string& tokens_list,
vector<string>& splited_substr_list,
vector<char>& appeared_tokens_list );
// fetch string from txt betwen keyword_begin and keyword_end.
// case sensitive
pair<string, size_t>
fetchStringBetweenKeywords ( const string& txt,
const string& keyword_begin,
const string& keyword_end,
size_t from_pos = 0 );
// get file size by FILE*
long
getFileSize (FILE* fs);
// get random filename, include path
string
makeRandomFilename (void);
// unicode 转 UTF8
pair<size_t, unsigned long long>
convertUnicodeToUtf8 (unsigned int unicode);
// fork() 启动新进程后立即返回,而本函数将等待新进程执行完毕后再返回
bool
wait_cmd ( const string& cmd,
const vector<string>& argv,
int* p_exitCode = nullptr,
bool b_echo = false );
================================================
FILE: src/lib/helper/RichTxt.h
================================================
// last modified
#pragma once
#include <string>
using std::string;
namespace RichTxt
{
// bold
static const string bold_on("\x1b[1m");
static const string bold_off("\x1b[21m");
// italic
static const string italic_on("\x1b[3m");
static const string italic_off("\x1b[23m");
// underline
static const string underline_on("\x1b[4m");
static const string underline_off("\x1b[24m");
// hide
static const string hide_on("\x1b[8m");
static const string hide_off("\x1b[28m");
// deletline
static const string deletline_on("\x1b[9m");
static const string deletline_off("\x1b[29m");
// foreground
static const string foreground_black("\x1b[30m");
static const string foreground_red("\x1b[31m");
static const string foreground_green("\x1b[32m");
static const string foreground_yellow("\x1b[33m");
static const string foreground_blue("\x1b[34m");
static const string foreground_magenta("\x1b[35m");
static const string foreground_cyan("\x1b[36m");
static const string foreground_white("\x1b[37m");
// background
static const string background_black("\x1b[40m");
static const string background_red("\x1b[41m");
static const string background_green("\x1b[42m");
static const string background_yellow("\x1b[43m");
static const string background_blue("\x1b[44m");
static const string background_magenta("\x1b[45m");
static const string background_cyan("\x1b[46m");
static const string background_white("\x1b[47m");
// reset all
static const string reset_all("\x1b[0m");
};
// normal usage:
// 0) cout << "email: " << RichTxt::bold_on << "yangyang.gnu@gmail.com" << RichTxt::bold_off << endl;
// 1) string name("yangyang.gnu"); string name_italic = RichTxt::italic_on + RichTxt::background_green + name + RichTxt::italic_off;
================================================
FILE: src/lib/helper/Time.cpp
================================================
// last modified
#include "Time.h"
#include <algorithm>
#include <string>
#include <sstream>
#include <ctime>
using namespace std;
// why not std::to_string()?
// you know, I have to port this linux code to win32 by cygwin, and there
// is a bug on cygwin case it cannot find to_string(), so, I must do it by myself
static string
convUnsignedToStr (unsigned num)
{
ostringstream oss;
oss << num;
return(oss.str());
}
// string::resize() resize string from the first char to the last char,
// resizeStringByEndian() resize string from the last char to the first char
static string
resizeStringByEndian (const string& str, unsigned digits, char ch = '0')
{
string strtmp(str.crbegin(), str.crend());
strtmp.resize(digits, ch);
reverse(strtmp.begin(), strtmp.end());
return(strtmp);
}
Time::Time ()
{
time_t raw_time = time(nullptr);
const struct tm* p_st = localtime(&raw_time);
year_ = (unsigned)p_st->tm_year + 1900;
month_ = (unsigned)p_st->tm_mon + 1;
day_in_month_ = (unsigned)p_st->tm_mday;
day_in_year_ = (unsigned)p_st->tm_yday + 1;
day_in_week_ = (unsigned)p_st->tm_wday;
hour_ = (unsigned)p_st->tm_hour;
minute_ = (unsigned)p_st->tm_min;
second_ = (unsigned)p_st->tm_sec;
}
Time::~Time ()
{
;
}
unsigned
Time::getYear (void) const
{
return(year_);
}
string
Time::getYear (unsigned digits) const
{
return( 0 == digits ?
convUnsignedToStr(getYear()) : resizeStringByEndian(convUnsignedToStr(getYear()), digits) );
}
unsigned
Time::getMonth (void) const
{
return(month_);
}
string
Time::getMonth (unsigned digits) const
{
return( 0 == digits ?
convUnsignedToStr(getMonth()) : resizeStringByEndian(convUnsignedToStr(getMonth()), digits) );
}
unsigned
Time::getDayInWeek (void) const
{
return(day_in_week_);
}
string
Time::getDayInWeek (bool b_abbr) const
{
switch (getDayInWeek()) {
case 1:
return(b_abbr ? "mon" : "monday");
case 2:
return(b_abbr ? "tues" : "tuesday");
case 3:
return(b_abbr ? "wed" : "wednesday");
case 4:
return(b_abbr ? "thurs" : "thursday");
case 5:
return(b_abbr ? "fri" : "friday");
case 6:
return(b_abbr ? "sat" : "saturday");
case 0:
return(b_abbr ? "sun" : "sunday");
default:
return("");
}
}
unsigned
Time::getDayInMonth (void) const
{
return(day_in_month_);
}
string
Time::getDayInMonth (unsigned digits) const
{
return( 0 == digits ?
convUnsignedToStr(getDayInMonth()) : resizeStringByEndian(convUnsignedToStr(getDayInMonth()), digits) );
}
unsigned
Time::getDayInYear (void) const
{
return(day_in_year_);
}
string
Time::getDayInYear (unsigned digits) const
{
return( 0 == digits ?
convUnsignedToStr(getDayInYear()) : resizeStringByEndian(convUnsignedToStr(getDayInYear()), digits) );
}
unsigned
Time::getHour (void) const
{
return(hour_);
}
string
Time::getHour (unsigned digits) const
{
return( 0 == digits ?
convUnsignedToStr(getHour()) : resizeStringByEndian(convUnsignedToStr(getHour()), digits) );
}
unsigned
Time::getMinute (void) const
{
return(minute_);
}
string
Time::getMinute (unsigned digits) const
{
return( 0 == digits ?
convUnsignedToStr(getMinute()) : resizeStringByEndian(convUnsignedToStr(getMinute()), digits) );
}
unsigned
Time::getSecond (void) const
{
return(second_);
}
string
Time::getSecond (unsigned digits) const
{
return( 0 == digits ?
convUnsignedToStr(getSecond()) : resizeStringByEndian(convUnsignedToStr(getSecond()), digits) );
}
================================================
FILE: src/lib/helper/Time.h
================================================
// last modified
#pragma once
#include <string>
using std::string;
class Time
{
public:
Time ();
virtual ~Time ();
unsigned getYear (void) const;
string getYear (unsigned digits) const;
unsigned getMonth (void) const;
string getMonth (unsigned digits) const;
unsigned getDayInWeek (void) const;
string getDayInWeek (bool b_abbr) const;
unsigned getDayInMonth (void) const;
string getDayInMonth (unsigned digits) const;
unsigned getDayInYear (void) const;
string getDayInYear (unsigned digits) const;
unsigned getHour (void) const;
string getHour (unsigned digits) const;
unsigned getMinute (void) const;
string getMinute (unsigned digits) const;
unsigned getSecond (void) const;
string getSecond (unsigned digits) const;
private:
unsigned year_;
unsigned month_;
unsigned day_in_month_;
unsigned day_in_week_;
unsigned day_in_year_;
unsigned hour_;
unsigned minute_;
unsigned second_;
};
================================================
FILE: src/lib/helper/Webpage.cpp
================================================
// last modified
#include "Webpage.h"
#include <iostream>
#include <algorithm>
#include <sstream>
#include <iterator>
#include <cstring>
#include <cstdlib>
#include <string>
#include <fstream>
#include <cstdio>
#include <iconv.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <curl/curl.h>
#include "../helper/Misc.h"
using namespace std;
static bool
checkErrLibcurl (const CURLcode curl_code, const char* libcurl_err_info, bool b_exit = false, bool b_show_err_info = false)
{
bool b_success = true;
if (CURLE_OK != curl_code) {
if (b_show_err_info) {
cerr << "WARNING! " << libcurl_err_info << endl;
}
b_success = false;
if (b_exit) {
exit(EXIT_FAILURE);
}
}
return(b_success);
}
static CURL*
initLibcurl (const char* libcurl_err_info_buff)
{
CURL* p_curl = nullptr;
// libcurl global and easy init
if (nullptr == (p_curl = curl_easy_init())) {
cerr << "ERROR! cannot easy init libcurl. " << endl;
exit(EXIT_FAILURE);
}
// the libcurl error info buffer
if (CURLE_OK != curl_easy_setopt(p_curl, CURLOPT_ERRORBUFFER, libcurl_err_info_buff)) {
cerr << "ERROR! " << libcurl_err_info_buff << endl;
exit(EXIT_FAILURE);
}
// automatically set the Referer to redirect source
checkErrLibcurl(curl_easy_setopt(p_curl, CURLOPT_AUTOREFERER, true), libcurl_err_info_buff);
// Set low speed limit in bytes per second.
// It contains the average transfer speed in bytes per second that the transfer should be below
// during CURLOPT_LOW_SPEED_TIME seconds for libcurl to consider it to be too slow and abort.
// The default is 8KB/s.
checkErrLibcurl(curl_easy_setopt(p_curl, CURLOPT_LOW_SPEED_LIMIT, 8 * 1024), libcurl_err_info_buff);
//// display libcurl action info
//checkErrLibcurl(curl_easy_setopt(p_curl, CURLOPT_VERBOSE, true), libcurl_err_info_buff);
return(p_curl);
}
static void
cleanupLibcul (CURL* p_curl)
{
curl_easy_cleanup(p_curl);
}
// check proxy by http://www.ip-adress.com/
static pair<string, string>
parseProxyOutIpAndRegionByThirdparty (const string& proxy_addr)
{
static const string thirdparty("http://www.ip-adress.com/");
Webpage webpage(thirdparty, "", proxy_addr, 16, 2, 2);
if (!webpage.isLoaded()) {
cerr << "ERROR! " << thirdparty << " loaded failure. " << endl;
return(make_pair("", ""));
}
//webpage.convertCharset("GBK", "UTF-8");
const string& webpage_txt = webpage.getTxt();
static const string keyword_outip_begin("<h3>Your IP address is: ");
static const string keyword_outip_end("</h3>");
const pair<string, size_t> pair_tmp = fetchStringBetweenKeywords( webpage_txt,
keyword_outip_begin,
keyword_outip_end );
const string outip = pair_tmp.first;
const size_t outip_end_pos = pair_tmp.second;
static const string keyword_region_begin("height=\"11\"> ");
static const string keyword_region_end("</h3>");
const string region = fetchStringBetweenKeywords( webpage_txt,
keyword_region_begin,
keyword_region_end,
outip_end_pos ).first;
return(make_pair(outip, region));
}
string
Webpage::checkProxyOutIpByThirdparty (void) const
{
return(parseProxyOutIpAndRegionByThirdparty(proxy_addr_).first);
}
string
Webpage::checkProxyOutRegionByThirdparty (void) const
{
return(parseProxyOutIpAndRegionByThirdparty(proxy_addr_).second);
}
string
Webpage::getProxyAddr (void) const
{
return(proxy_addr_);
}
string
Webpage::getUserAgent (void) const
{
return(user_agent_);
}
// check user agent by http://www.useragentstring.com/index.php string
string
Webpage::checkUserAgentByThirdparty (void) const
{
static const string thirdparty("http://www.useragentstring.com");
Webpage webpage(thirdparty, "", "", 16, 2, 2, user_agent_);
if (!webpage.isLoaded()) {
//cerr << "ERROR! " << thirdparty << " loaded failure. " << endl;
return("");
}
static const string keyword_user_agent_begin("<textarea name=\'uas\' id=\'uas_textfeld\' rows=\'4\' cols=\'30\'>");
static const string keyword_user_agent_end("</textarea>");
const string user_agent = fetchStringBetweenKeywords( webpage.getTxt(),
keyword_user_agent_begin,
keyword_user_agent_end ).first;
return(user_agent);
}
// some chars invalid in URL string, such as, space char, chinese char, so I have to
// escape to legal URL.
// OK, curl_easy_escape() likely do this job, but it's stupid: the function converts
// all characters that are not a-z, A-Z, 0-9, '-', '.', '_' or '~' to their "URL escaped"
// version (%NN where NN is a two-digit hexadecimal number), in the other words, it always
// convert ':', '/', '?', and so on, that's a bad news.
// This is my way to escape URL:
// 0) split one raw URL string to more sub-string by token chars, such as ':', '/', '='
// and '?' (may be more);
// 1) escape all sub-str by curl_easy_escape();
// 2) splice escaped sub-string to URL.
string
Webpage::escapeUrl (const string& raw_url) const
{
// split one raw URL string to more sub-string by token chars
static const string tokens_list(":/=?&,;%");
vector<string> splited_substr_list;
vector<char> appeared_tokens_list;
splitStr(raw_url, tokens_list, splited_substr_list, appeared_tokens_list);
// escape all sub-string
vector<string> escaped_substr_list;
for (const auto& e : splited_substr_list) {
char* p_str_escaped = curl_easy_escape(p_curl_, e.c_str(), 0);
if (nullptr == p_str_escaped) {
cerr << "WARNING! " << libcurl_err_info_buff_ << endl;
}
escaped_substr_list.push_back(p_str_escaped);
curl_free(p_str_escaped);
}
// splice escaped sub-string to URL
string url_escaped;
bool b_tokens_first = (string::npos != tokens_list.find(raw_url[0]));
for (unsigned i = 0; i < escaped_substr_list.size() && i < appeared_tokens_list.size(); ++i) {
if (b_tokens_first) {
url_escaped += appeared_tokens_list[i] + escaped_substr_list[i];
} else {
url_escaped += escaped_substr_list[i] + appeared_tokens_list[i];
} }
if (escaped_substr_list.size() > appeared_tokens_list.size()) {
url_escaped += escaped_substr_list[escaped_substr_list.size() - 1];
}
return(url_escaped);
}
string
Webpage::requestHttpHeader_ ( const string& raw_url,
HttpHeader_ header_item,
const unsigned timeout_second,
const unsigned retry_times,
const unsigned retry_sleep_second ) const
{
const string random_filename = makeRandomFilename();
FILE* fs_http_header = fopen(random_filename.c_str(), "w");
if (nullptr == fs_http_header) {
return("");
}
// deal with raw URL, first unescape html, second escape URL
const string url = escapeUrl(unescapeHtml(raw_url));
// timeout
checkErrLibcurl(curl_easy_setopt(p_curl_, CURLOPT_TIMEOUT, timeout_second), libcurl_err_info_buff_);
// get HTTP header
checkErrLibcurl(curl_easy_setopt(p_curl_, CURLOPT_URL, url.c_str()), libcurl_err_info_buff_);
checkErrLibcurl(curl_easy_setopt(p_curl_, CURLOPT_PROXY, proxy_addr_.c_str()), libcurl_err_info_buff_);
checkErrLibcurl(curl_easy_setopt(p_curl_, CURLOPT_NOBODY, true), libcurl_err_info_buff_); // just request the HTTP header
checkErrLibcurl(curl_easy_setopt(p_curl_, CURLOPT_WRITEHEADER, fs_http_header), libcurl_err_info_buff_);
for (unsigned i = 0; i < retry_times; ++i) {
if (checkErrLibcurl(curl_easy_perform(p_curl_), libcurl_err_info_buff_)) {
break;
}
sleep(retry_sleep_second);
}
// reset, I.E., request HTTP body
checkErrLibcurl(curl_easy_setopt(p_curl_, CURLOPT_NOBODY, false), libcurl_err_info_buff_);
checkErrLibcurl(curl_easy_setopt(p_curl_, CURLOPT_WRITEHEADER, nullptr), libcurl_err_info_buff_);
fclose(fs_http_header);
// load the file to memory, and parse HTTP header info
string http_header, remote_filename, remote_filesize, remote_filetype, remote_filecharset, remote_filetime;
static const vector<string> httpheader_keywords_list = { "Content-Type: ", // file type
"Content-Length: ", // file size
"Content-Disposition: ", // file name
"Last-Modified: " }; // file modified time
ifstream ifs(random_filename);
string line;
while (getline(ifs, line)) {
// load to memory
http_header += (line + '\n');
// parse HTTP header item
for (const auto& e : httpheader_keywords_list) {
const auto item_name_pos = line.find(e);
if (string::npos == item_name_pos) {
continue;
}
line.pop_back(); // the last char in line is '\r'
const string& item_content = line.substr(item_name_pos + e.size());
if ("Content-Type: " == e) {
static const string kyeword_separator(";");
const auto separator_pos = item_content.find(kyeword_separator);
if (string::npos == separator_pos) {
remote_filetype = item_content;
} else {
remote_filetype = item_content.substr(0, separator_pos);
remote_filecharset = item_content.substr(separator_pos + kyeword_separator.size());
}
} else if ("Content-Length: " == e) {
remote_filesize = item_content;
} else if ("Content-Disposition: " == e) {
remote_filename = item_content;
} else if ("Last-Modified: " == e) {
remote_filetime = item_content;
}
}
}
ifs.close();
remove(random_filename.c_str());
// return http header item
switch (header_item) {
case header:
return(http_header);
case name:
return(remote_filename);
case type:
return(remote_filetype);
case charset:
return(remote_filecharset);
case length:
return(remote_filesize);
case modified:
return(remote_filetime);
}
}
string
Webpage::getHttpHeader (const string& url) const
{
return(requestHttpHeader_(url, header));
}
string
Webpage::getRemoteFiletype (const string& url) const
{
return(requestHttpHeader_(url, type));
}
string
Webpage::getRemoteFilecharset (const string& url) const
{
return(requestHttpHeader_(url, charset));
}
string
Webpage::getRemoteFilename (const string& url) const
{
return(requestHttpHeader_(url, name));
}
string
Webpage::getRemoteFilesize (const string& url) const
{
return(requestHttpHeader_(url, length));
}
string
Webpage::getRemoteFiletime (const string& url) const
{
return(requestHttpHeader_(url, modified));
}
// once maked Webpage obj, the page in memory, but if filename is not empty,
// it will saveas file, otherwise, no file.
// notes:
// 0) no https
// 1) List of User Agent Strings, see http://www.useragentstring.com/pages/useragentstring.php
// 2) post_cookies 可包含多个 cookie 项,如:
// .baidu.com TRUE / FALSE 1461859872 BAIDUID 7CDCF85BC9A130D867AD3016C3994D96:FG=1
// .wappass.baidu.com TRUE / FALSE 1689523774 PTOKEN 6d7057ded7970d292eb54027762b6d7a
// 则应合并为:
// ".baidu.com TRUE / FALSE 1461859872 BAIDUID 7CDCF85BC9A130D867AD3016C3994D96:FG=1\n
// .wappass.baidu.com TRUE / FALSE 1689523774 PTOKEN 6d7057ded7970d292eb54027762b6d7a"
Webpage::Webpage ( const string& url,
const string& filename,
const string& proxy_addr,
const unsigned timeout_second,
const unsigned retry_times,
const unsigned retry_sleep_second,
const string& user_agent,
const string& post_cookies,
const vector<pair<string, string>>& post_sections_list,
bool b_redirct )
: p_curl_(initLibcurl(libcurl_err_info_buff_)),
url_(url),
proxy_addr_(proxy_addr),
b_loaded_ok_(false),
user_agent_(user_agent)
{
// set proxy.
// proxy_addr is made up of protocol, IP and port.
// [protocol://][IP][:port], e.g.,
// http://127.0.0.1:8087, this is for GoAgent proxy;
// socks4://127.0.0.1:7070, this is for ssh proxy (yes, the port is setted by ssh -D);
// protocol support as follow: http, https, socks4, socks4a, socks5, socks5h.
// if proxy_addr is "", disable proxy
checkErrLibcurl(curl_easy_setopt(p_curl_, CURLOPT_PROXY, proxy_addr_.c_str()), libcurl_err_info_buff_);
// follow the URL redirect
checkErrLibcurl(curl_easy_setopt(p_curl_, CURLOPT_FOLLOWLOCATION, b_redirct), libcurl_err_info_buff_);
// cookies
checkErrLibcurl(curl_easy_setopt(p_curl_, CURLOPT_COOKIEFILE, ""), libcurl_err_info_buff_); // enable the cookie engine
if (!post_cookies.empty()) {
checkErrLibcurl(curl_easy_setopt(p_curl_, CURLOPT_COOKIE, post_cookies.c_str()), libcurl_err_info_buff_); // set the cookie
if (!post_sections_list.empty()) {
if (!setMultiPostSectionsList(post_sections_list)) { // set multi post sections
cerr << "ERROR! fail to set multi post sections. " << endl;
exit(EXIT_FAILURE);
}
}
}
// pretend as browser
if (!user_agent.empty()) {
checkErrLibcurl( curl_easy_setopt(p_curl_, CURLOPT_USERAGENT, user_agent_.c_str()),
libcurl_err_info_buff_ );
}
//// don't download none-webpage file when construct the obj
//const string& remote_filetype = getRemoteFiletype(url_);
//if ("text/html" != remote_filetype && "text/javascript" != remote_filetype) {
//return;
//}
// download webpage to local file
const string& localfile = (filename.empty() ? makeRandomFilename() : filename);
b_loaded_ok_ = download_(url_, localfile, "", timeout_second, retry_times, retry_sleep_second);
if (!b_loaded_ok_) {
if (filename.empty()) {
remove(localfile.c_str());
}
return;
}
// 保存获取的 cookies
struct curl_slist* p_cookies = nullptr;
checkErrLibcurl(curl_easy_getinfo(p_curl_, CURLINFO_COOKIELIST, &p_cookies), libcurl_err_info_buff_); // enable the cookie engine
struct curl_slist* p_cookies_old = p_cookies;;
while (p_cookies) {
cookie_items_list_.push_back(p_cookies->data);
p_cookies = p_cookies->next;
}
curl_slist_free_all(p_cookies_old);
// read webpage file into string
ifstream ifs(localfile);
string line;
txt_.clear();
while (getline(ifs, line)) {
txt_ += (line + '\n');
}
ifs.close();
// the caller don't care the loacl file, so delete it
if (filename.empty()) {
remove(localfile.c_str());
}
// parse title
static const string title_keyword_begin("<title>"), title_keyword_end("</title>");
title_ = unescapeHtml(fetchStringBetweenKeywords(txt_, title_keyword_begin, title_keyword_end).first);
}
Webpage::~Webpage ()
{
cleanupLibcul(p_curl_);
}
// why same as download_()?
// for future
bool
Webpage::downloadFile ( const string& url,
const string& filename,
const string& referer,
const unsigned timeout_second,
const unsigned retry_times,
const unsigned retry_sleep_second )
{
return(download_( url,
filename,
referer,
timeout_second,
retry_times,
retry_sleep_second ));
}
double
Webpage::getAvarSpeedDownload (void) const
{
checkErrLibcurl(curl_easy_getinfo(p_curl_, CURLINFO_SPEED_DOWNLOAD, &aver_speed_download_), libcurl_err_info_buff_);
return(aver_speed_download_);
}
long
Webpage::parseLatestHttpStatusCode_ (void)
{
checkErrLibcurl(curl_easy_getinfo(p_curl_, CURLINFO_RESPONSE_CODE, &latest_http_status_code_), libcurl_err_info_buff_);
return(latest_http_status_code_);
}
long
Webpage::getLatestHttpStatusCode (void) const
{
return(latest_http_status_code_);
}
bool
Webpage::isValidLatestHttpStatusCode (void) const
{
// HTTP status code, 4XX stand for client error, 5XX for server error,
// More info http://en.wikipedia.org/wiki/List_of_HTTP_status_codes
static const char client_error_code = '4', server_error_code = '5';
const string& latest_http_status_code_str = convNumToStr(latest_http_status_code_);
return( client_error_code != latest_http_status_code_str[0] &&
server_error_code != latest_http_status_code_str[0] );
}
// download internet file to local file, such as, webpage, picture, mp3, etc.
// if non-webpage, b_normal_file set true. for check whether this is a webpage by <body>.
// note: URL must be http, CANNOT be https
bool
Webpage::download_ ( const string& raw_url,
const string& filename,
const string& referer,
const unsigned timeout_second,
const unsigned retry_times,
const unsigned retry_sleep_second )
{
// deal with raw URL, first unescape html, second escape URL
string url = escapeUrl(unescapeHtml(raw_url));
// convert https to http
static const string keyword_https("https://");
const auto https_pos = url.find(keyword_https);
if (string::npos != https_pos) {
static const string keyword_http("http://");
url.replace(https_pos, keyword_https.size(), keyword_http);
}
// set the target URL
curl_easy_setopt(p_curl_, CURLOPT_URL, url.c_str());
// set the referer page.
// note curl_easy_setopt(p_curl_, CURLOPT_REFERER, "") still send referer
// in HTTP header (empty string ""), if you don't wanna sent referer info,
// never touch CURLOPT_REFERER.
if (!referer.empty()) {
curl_easy_setopt(p_curl_, CURLOPT_REFERER, referer.c_str());
}
// low speed to abort.
// If the speed below the CURLOPT_LOW_SPEED_LIMIT too long time, abort it.
static const unsigned low_speed_timeout = 4;
checkErrLibcurl( curl_easy_setopt(p_curl_, CURLOPT_LOW_SPEED_TIME, low_speed_timeout),
libcurl_err_info_buff_ );
// ready for downloading webpage to locale tmp file
FILE* fs = fopen(filename.c_str(), "w+");
if (nullptr == fs) {
cerr << "ERROR! Webpage::download_() something happened. Fail to open file " << filename << endl;
return(false);
}
checkErrLibcurl(curl_easy_setopt(p_curl_, CURLOPT_WRITEDATA, fs), libcurl_err_info_buff_);
// download the URL webpage to locale file
bool b_downloaded = false;
for (unsigned i = 0; i < retry_times; ++i) {
// timeout to abort. if current download failured, next time
// the download timeout increase one timeout_second
checkErrLibcurl( curl_easy_setopt(p_curl_, CURLOPT_TIMEOUT, (long)(timeout_second * (i + 1))),
libcurl_err_info_buff_ );
// download
bool b_ok = checkErrLibcurl(curl_easy_perform(p_curl_), libcurl_err_info_buff_);
latest_http_status_code_ = parseLatestHttpStatusCode_(); // notice, parseLatestHttpStatusCode_() must
// very close every curl_easy_perform(p_curl_)
// notice, even though there is HTTP request status error, libcurl still download
// web file success, of course, this is not real success, so, I have to check the
// http status code
if (b_ok && isValidLatestHttpStatusCode() && (getFileSize(fs) > 0)) {
b_downloaded = true;
break;
}
//cerr << "WARNING! Webpage::download() something happened. Fail to download " << url
//<< ", sleeping " << retry_sleep_second << " seconds will retry " << i + 1 << ". " << endl;
// if libcurl download internet file failure,
// the next retry will append data to local file.
// so, I must clear the filestream by freopen(),
// and, neither rewind() nor fseek(fs, 0L, SEEK_SET) works.
fs = freopen(filename.c_str(), "w+", fs);
if (nullptr == fs) {
cerr << "ERROR! Webpage::download() something happened. Fail to reopen file " << filename << endl;
fclose(fs);
return(false);
}
sleep(retry_sleep_second);
}
fclose(fs);
return(b_downloaded);
}
// construct the all sections for multipart/formdata style HTTP post
bool
Webpage::setMultiPostSectionsList (const vector<pair<string, string>>& post_sections_list)
{
struct curl_httppost* p_first_section = nullptr;
struct curl_httppost* p_last_section = nullptr;
for (const auto& e : post_sections_list) {
const string& name = e.first;
const string& content = e.second;
if (curl_formadd( &p_first_section, &p_last_section,
CURLFORM_PTRNAME, name.c_str(),
CURLFORM_PTRCONTENTS, content.c_str(),
CURLFORM_END )) {
return(false);
}
}
if (!checkErrLibcurl(curl_easy_setopt(p_curl_, CURLOPT_HTTPPOST, p_first_section), libcurl_err_info_buff_)) {
return(false);
}
return(true);
}
bool
Webpage::submitMultiPost ( const string& url,
const string& filename,
const vector<pair<string, string>>& post_sections_list,
const unsigned timeout_second,
const unsigned retry_times,
const unsigned retry_sleep_second )
{
if (!setMultiPostSectionsList(post_sections_list)) {
return(false);
}
bool b_success = download_(url, filename, url_, timeout_second, retry_times, retry_sleep_second);
// TODO. reset CURLOPT_HTTPPOST, are you sure it works?
static struct curl_httppost empty_httppost;
curl_easy_setopt(p_curl_, CURLOPT_HTTPPOST, &empty_httppost);
return(b_success);
}
const string&
Webpage::getTxt (void) const
{
return(txt_);
}
bool
Webpage::isLoaded (void) const
{
return(b_loaded_ok_);
}
bool
Webpage::saveasFile (const string& filename) const
{
ofstream ofs_webpage(filename);
istringstream iss_webpage_txt(txt_);
string line;
while (getline(iss_webpage_txt, line)) {
ofs_webpage << line << "\n";
}
ofs_webpage.close();
return(true);
}
size_t
Webpage::convertCharset (const string& src_charset, const string& dest_charset)
{
string dest_charset_str;
istringstream iss_webpage_txt(txt_);
string line;
iconv_t cd = iconv_open((dest_charset + "//IGNORE").c_str(), src_charset.c_str()); // why "//IGNORE"? When the string "//IGNORE" is
// appended to dest char set, some char that cannot
// be represented in the target character set will
// be silently discarded, ohterwise iconv() will
// stop at this char
while (getline(iss_webpage_txt, line)) {
line += "\n";
size_t inbytes_left = line.size();
char* p_inbuff = (char*)line.c_str();
size_t outbytes_left = 2 * inbytes_left; // TODO. why 2? utf8 use 3 bytes for one asia character, 1 byte for one west wcharacter; gbk use 2 bytes for everyone character, so double is the guard value
char* outbuff = new char [outbytes_left];
memset(outbuff, '\0', outbytes_left);
char* p_outbuff = outbuff;
if ((size_t)-1 == iconv(cd, &p_inbuff, &inbytes_left, &p_outbuff, &outbytes_left)) {
//cerr << "WARNING! iconv() "<< strerror(errno) << endl;
;
}
dest_charset_str += outbuff;
delete [] outbuff;
}
iconv_close(cd);
txt_ = dest_charset_str;
static const string title_keyword_begin("<title>"), title_keyword_end("</title>");
title_ = unescapeHtml(fetchStringBetweenKeywords(txt_, title_keyword_begin, title_keyword_end).first);
return(txt_.size());
}
const string&
Webpage::getTitle (void) const
{
return(title_);
}
string
convertUnicodeTxtToUtf8 (const string& unicode_txt)
{
string utf8_txt(unicode_txt);
size_t unicode_prefix_pos = 0;
while (true) {
static const string unicode_prefix("\\u"); // \u
// 查找 \u
unicode_prefix_pos = utf8_txt.find(unicode_prefix, unicode_prefix_pos);
if (string::npos == unicode_prefix_pos) {
break;
}
// 找到的 \u 后至少得有 4 个字符
if (unicode_prefix_pos + unicode_prefix.length() + 4 >= utf8_txt.length()) {
cerr << "WARNING! the end unicode incomplete. " << endl;
break;
}
// 提取字符串形式的 unicode
const string unicode_str = utf8_txt.substr(unicode_prefix_pos + unicode_prefix.length(), 4);
// 将字符串形式 unicode 转换为对应数值
istringstream iss(unicode_str);
unsigned unicode_hex;
if (!(iss >> std::hex >> unicode_hex)) {
cerr << "WARNING! " << unicode_str << " is not a vaild unicode. " << endl;
break;
}
// 将数值的 unicode 转换为数值的 UTF8
const pair<size_t, unsigned long long> utf8_pair = convertUnicodeToUtf8(unicode_hex);
const size_t utf8_size = utf8_pair.first;
const unsigned long long utf8 = utf8_pair.second;
// 将数值的 UTF8 转换为多字节字符串
char utf8_str[8] = {'\0'};
for (unsigned i = 0; i < utf8_size; ++i) {
utf8_str[utf8_size - 1 - i] = char(utf8 >> (i * 8));
}
// 用 UTF8 多字节字符串替换对应 \u 开头的 unicode 字符串
utf8_txt.replace(unicode_prefix_pos, unicode_prefix.length() + 4, utf8_str);
}
return(utf8_txt);
}
string
unescapeHtml (const string& raw_txt)
{
string unescaped_html_str = raw_txt;
// more see http://www.theukwebdesigncompany.com/articles/entity-escape-characters.php
static const vector<pair<string, string>> escaped_html_chars_list = { make_pair("'", "'"),
make_pair(""", "\""),
make_pair("’", "’"),
make_pair("&", "&"),
make_pair("´", "´"),
make_pair("<", "<"),
make_pair("·", "·"),
make_pair(">", ">"),
make_pair(" ", " "),
make_pair(" ", " "),
make_pair("・", "・"),
make_pair("◯", "◯"),
make_pair("—", "—"),
make_pair("“", "“"),
make_pair("”", "”"),
make_pair("♪", "♪"),
make_pair("√", "√"),
make_pair("√", "√"),
make_pair("∞", "∞"),
make_pair("∞", "∞"),
make_pair("…", "…"),
make_pair("…", "…"),
make_pair("'", "'"),
make_pair("'", "'") };
bool b_find;
size_t pos = 0;
do {
b_find = false;
for (const auto& e : escaped_html_chars_list) {
pos = 0;
const string& escaped_str = e.first, unescaped_str = e.second;
pos = unescaped_html_str.find(escaped_str, pos);
if (string::npos != pos) {
unescaped_html_str.replace(pos, escaped_str.size(), unescaped_str);
b_find = true;
break;
}
}
} while (b_find);
return(unescaped_html_str);
}
const vector<string>&
Webpage::getCookies (void) const
{
return(cookie_items_list_);
}
================================================
FILE: src/lib/helper/Webpage.h
================================================
// last modified
#pragma once
#include <string>
#include <vector>
#include <curl/curl.h>
using std::string;
using std::vector;
using std::pair;
class Webpage
{
public:
explicit Webpage ( const string& url,
const string& filename = "",
const string& proxy_addr = "",
const unsigned timeout_second = 16,
const unsigned retry_times = 2,
const unsigned retry_sleep_second = 4,
const string& user_agent = "Mozilla/5.0 (X11; Linux i686; rv:30.0) Gecko/20100101 Firefox/30.0",
const string& post_cookies = "",
const vector<pair<string, string>>& post_sections_list = vector<pair<string, string>>(),
bool b_redirct = true );
virtual ~Webpage ();
string getProxyAddr (void) const;
string checkProxyOutIpByThirdparty (void) const;
string checkProxyOutRegionByThirdparty (void) const;
string getUserAgent (void) const;
string checkUserAgentByThirdparty (void) const;
const string& getTxt (void) const;
const string& getTitle (void) const;
long getLatestHttpStatusCode (void) const;
bool isValidLatestHttpStatusCode (void) const;
string getHttpHeader (const string& url) const;
string getRemoteFiletype (const string& url) const;
string getRemoteFilecharset (const string& url) const;
string getRemoteFilesize (const string& url) const;
string getRemoteFilename (const string& url) const;
string getRemoteFiletime (const string& url) const;
double getAvarSpeedDownload (void) const;
bool isLoaded (void) const;
size_t convertCharset (const string& src_charset, const string& dest_charset);
bool saveasFile (const string& filename) const;
bool downloadFile ( const string& url,
const string& filename,
const string& referer = "",
const unsigned timeout_second = 0,
const unsigned retry_times = 4,
const unsigned retry_sleep_second = 4 );
bool setMultiPostSectionsList (const vector<pair<string, string>>& post_sections_list);
bool submitMultiPost ( const string& url,
const string& filename,
const vector<pair<string, string>>& post_sections_list,
const unsigned timeout_second = 32,
const unsigned retry_times = 4,
const unsigned retry_sleep_second = 4 );
string escapeUrl (const string& raw_url) const;
const vector<string>& getCookies (void) const;
private:
bool download_ ( const string& raw_url,
const string& filename,
const string& referer,
const unsigned timeout_second,
const unsigned retry_times,
const unsigned retry_sleep_second );
long parseLatestHttpStatusCode_ (void);
private:
enum HttpHeader_ {header, type, charset, length, name, modified};
string requestHttpHeader_ ( const string& raw_url,
HttpHeader_ header_item,
const unsigned timeout_second = 4,
const unsigned retry_times = 2,
const unsigned retry_sleep_second = 2 ) const;
private:
CURL* p_curl_;
string url_;
char libcurl_err_info_buff_[CURL_ERROR_SIZE];
string proxy_addr_;
string txt_;
string title_;
bool b_loaded_ok_;
long latest_http_status_code_;
double aver_speed_download_;
const string user_agent_;
vector<string> cookie_items_list_;
};
string convertUnicodeTxtToUtf8 (const string& unicode_txt);
string unescapeHtml (const string& raw_txt);
================================================
FILE: src/lib/self/Aicheng.cpp
================================================
// last modified
#include "Aicheng.h"
#include <iostream>
#include <iomanip>
#include <algorithm>
#include <iterator>
#include <thread>
#include <mutex>
#include <cstdlib>
#include <unistd.h>
#include "AichengTopicsListWebpage.h"
#include "AichengTopicWebpage.h"
#include "JandownSeedWebpage.h"
#include "../helper/RichTxt.h"
using namespace std;
static mutex g_mtx;
const string&
Aicheng::getPortalWebpageUrl (void) const
{
return(portal_url_);
}
static const string&
getTopicsListWebpagePartUrl (Aicheng::AvClass av_class)
{
static const string west_part_url("thread.php?fid=5");
static const string cartoon_part_url("thread.php?fid=6");
static const string asia_mosaicked_part_url("thread.php?fid=4");
static const string asia_non_mosaicked_part_url("thread.php?fid=16");
switch (av_class) {
case Aicheng::west:
return(west_part_url);
case Aicheng::cartoon:
return(cartoon_part_url);
case Aicheng::asia_mosaicked:
return(asia_mosaicked_part_url);
case Aicheng::asia_non_mosaicked:
return(asia_non_mosaicked_part_url);
}
}
static const string
getTopicsListWebpageUrl (const string& portal_url, Aicheng::AvClass av_class)
{
return(portal_url + getTopicsListWebpagePartUrl(av_class));
}
static bool
isThereInList ( const string& webpage_title,
const vector<string>& ignore_keywords_list,
string& which_keyword )
{
for (const auto& e : ignore_keywords_list) {
if (!e.empty() && string::npos != webpage_title.find(e)) {
which_keyword = e;
return(true);
}
}
return(false);
}
static bool
parseValidTopicsUrls ( Aicheng::AvClass av_class,
const string& portal_url,
const string& proxy_addr,
unsigned range_begin, unsigned range_end,
const vector<string>& hate_keywords_list,
const vector<string>& like_keywords_list,
vector<string>& valid_topics_urls_list,
bool b_progress )
{
valid_topics_urls_list.clear();
string current_url = getTopicsListWebpageUrl(portal_url, av_class);
bool b_stop = false;
unsigned topics_cnt = 0;
while (!current_url.empty() && !b_stop) {
AichengTopicsListWebpage aicheng_topicslist_webpage(portal_url, current_url, proxy_addr);
if (!aicheng_topicslist_webpage.isLoaded()) {
return(false);
}
const vector<pair<string, string>>& topics_title_and_url = aicheng_topicslist_webpage.getTitlesAndUrlsList();
for (const auto& e : topics_title_and_url) {
if (++topics_cnt > range_end) {
b_stop = true;
break;
}
const string& topic_title = e.first;
const string& topic_url = e.second;
static const string o_flag(RichTxt::bold_on + "O" + RichTxt::bold_off);
static const string x_flag("x");
// ignore the topics which do not in range
if (topics_cnt < range_begin) {
if (b_progress) {
cout << x_flag << " " << flush;
}
continue;
}
// ignore the topics which contain hate keyword by user set
string which_keyword;
if (isThereInList(topic_title, hate_keywords_list, which_keyword)) {
if (b_progress) {
cout << x_flag << " " << flush;
}
continue;
}
// ignore the topics which do not contain like keyword by user set
if ( !like_keywords_list.empty() &&
!isThereInList(topic_title, like_keywords_list, which_keyword) ) {
if (b_progress) {
cout << x_flag << " " << flush;
}
continue;
}
valid_topics_urls_list.push_back(topic_url);
if (b_progress) {
cout << o_flag << " " << flush;
}
}
current_url = aicheng_topicslist_webpage.getNextpageUrl();
}
return(true);
}
static void
downloadTopicPicsAndSeed ( const string& topic_url,
const string& proxy_addr,
const string& path,
unsigned timeout_download_pic,
bool b_show_info )
{
AichengTopicWebpage aicheng_topics_webpage(topic_url, proxy_addr);
// ready for the basename of pictures and seed.
// >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
string base_name; // from topic title
// 0) delete the web logo info;
// 1) clear the "/" in topictitle string, if the "/" present in filename,
// linux will treat it as directory, again, clear the "\" for windows;
static const vector<string> keyword_logos_list = { " 亚洲无码区 bt下载 - powered by phpwind.net",
" 亚洲有码区 bt下载 - powered by phpwind.net",
" 欧美区 bt下载 - powered by phpwind.net",
" 动漫区 bt下载 - powered by phpwind.net",
"|亚洲无码区 - bt下载 爱城 bt下载 ",
"亚洲无码区 - bt下载 爱城 bt下载 ",
"|亚洲有码区 - bt下载 爱城 bt下载 ",
"亚洲有码区 - bt下载 爱城 bt下载 ",
"|动漫区 - bt下载 爱城 bt下载 ",
"动漫区 - bt下载 爱城 bt下载 ",
"|欧美区 - bt下载 爱城 bt下载 ",
"欧美区 - bt下载 爱城 bt下载 " };
const string& topic_webpage_title = aicheng_topics_webpage.getTitle();
auto keyword_logo_pos = string::npos;
for (const auto& f : keyword_logos_list) {
keyword_logo_pos = topic_webpage_title.find(f);
if (string::npos != keyword_logo_pos) {
break;
}
}
remove_copy_if( topic_webpage_title.cbegin(),
(string::npos == keyword_logo_pos) ? topic_webpage_title.cend() : topic_webpage_title.cbegin() + (int)keyword_logo_pos,
back_inserter(base_name),
[] (char ch) {return( '|' == ch || // invalid chars in windows-style filename
'/' == ch ||
'<' == ch ||
'>' == ch ||
'?' == ch ||
'*' == ch ||
':' == ch ||
'\\' == ch );} );
// 2) the path + filename max length must less than pathconf(, _PC_NAME_MAX)
const unsigned filename_max_length_without_postfix = (unsigned)pathconf(path.c_str(), _PC_NAME_MAX)
- string("99").size() // picture number
- string(".torrent").size();
if (base_name.size() >= filename_max_length_without_postfix) {
// the filename too long to create file. the way as following doesn't work, case filename encoding error:
// base_name.resize(filename_max_length_without_postfix - 1), because this is string on char not wstring on wchar.
// there is another stupid way, random name from 'a' to 'z'
base_name.resize(16);
generate( base_name.begin(), base_name.end(),
[] () {return('a' + rand() % ('z' - 'a'));} );
base_name = "(rename)" + base_name;
}
// <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
// download all pictures
vector<string> fail_download_pics_urls_list;
bool b_download_pics_success = aicheng_topics_webpage.downloadAllPictures( path,
base_name,
timeout_download_pic,
fail_download_pics_urls_list,
32 );
// download seed
bool b_downloaded_seed_success = false;
if (!aicheng_topics_webpage.getSeedUrl().empty()) {
JandownSeedWebpage jan_seed_webpage(aicheng_topics_webpage.getSeedUrl(), proxy_addr);
b_downloaded_seed_success = jan_seed_webpage.downloadSeed(path, base_name);
}
// show result info
if (!b_show_info) {
return;
}
static const string success_info("success");
static const string fail_info = RichTxt::foreground_red + "failure" + RichTxt::reset_all;
g_mtx.lock();
cout << " \"" << base_name << "\" - ";
if (b_download_pics_success && b_downloaded_seed_success) {
cout << success_info;
} else {
cout << fail_info << " (download error from " << topic_url << ". ";
if (!b_download_pics_success) {
cout << "pictures error: ";
copy(fail_download_pics_urls_list.cbegin(), fail_download_pics_urls_list.cend(), ostream_iterator<const string&>(cout, ", "));
cout << "\b\b";
}
if (!b_downloaded_seed_success) {
if (!b_download_pics_success) {
cout << "; ";
}
cout << "seed error: " << aicheng_topics_webpage.getSeedUrl();
}
cout << ")";
}
cout << endl;
g_mtx.unlock();
}
static const string&
getNextProxyAddr (const vector<string>& proxy_addrs_list)
{
if (proxy_addrs_list.empty()) {
static const string empty_str("");
return(empty_str);
}
static unsigned current_pos;
if (current_pos >= proxy_addrs_list.size()) {
current_pos = 0;
}
return(proxy_addrs_list[current_pos++]);
}
Aicheng::Aicheng ( const string& portal_url,
AvClass av_class,
const vector<string>& proxy_addrs_list,
unsigned range_begin, unsigned range_end,
const vector<string>& hate_keywords_list,
const vector<string>& like_keywords_list,
unsigned threads_total,
unsigned timeout_download_pic,
const string& path )
: portal_url_(portal_url)
{
// parse the URLs of valid topics by: range, hate keywords, like keywords
cout << "Parse the URLs of topics from " << range_begin << " to " << range_end << ": " << flush;
vector<string> valid_topics_urls_list;
parseValidTopicsUrls( av_class,
portal_url,
getNextProxyAddr(proxy_addrs_list),
range_begin, range_end,
hate_keywords_list,
like_keywords_list,
valid_topics_urls_list,
true );
if (valid_topics_urls_list.empty()) {
cout << "(There is no topic which you like) " << endl;
return;
}
cout << endl << endl;
// download all pictures and seeds of topics
cout << "Download the pictures and seeds of topics: " << endl;
unsigned parsed_topics_cnt = 0;
for (unsigned i = 0; i < (valid_topics_urls_list.size() / threads_total); ++i) {
vector<thread> threads_list;
for (unsigned j = 0; j < threads_total; ++j) {
++parsed_topics_cnt;
threads_list.push_back(thread( &downloadTopicPicsAndSeed,
ref(valid_topics_urls_list[i * threads_total + j]),
ref(getNextProxyAddr(proxy_addrs_list)),
ref(path),
timeout_download_pic,
true ));
}
for (auto& e : threads_list) {
if (e.joinable()) {
e.join();
}
}
if (!threads_list.empty()) {
cout << setprecision(1) << setiosflags(ios::fixed);
cout << " " << RichTxt::bold_on << RichTxt::underline_on << "<---- "
<< 100.0 * parsed_topics_cnt / valid_topics_urls_list.size()
<< "% ---->" << RichTxt::underline_off << RichTxt::bold_off << endl;
cout << resetiosflags(ios::fixed);
}
}
vector<thread> threads_list;
for ( unsigned i = (valid_topics_urls_list.size() / threads_total) * threads_total;
i < valid_topics_urls_list.size();
++i ) {
++parsed_topics_cnt;
threads_list.push_back(thread( &downloadTopicPicsAndSeed,
ref(valid_topics_urls_list[i]),
ref(getNextProxyAddr(proxy_addrs_list)),
ref(path),
timeout_download_pic,
true ));
}
for (auto& e : threads_list) {
if (e.joinable()) {
e.join();
}
}
if (!threads_list.empty()) {
cout << setprecision(1) << setiosflags(ios::fixed);
cout << " " << RichTxt::bold_on << RichTxt::underline_on << "<---- "
<< 100.0 * parsed_topics_cnt / valid_topics_urls_list.size()
<< "% ---->" << RichTxt::underline_off << RichTxt::bold_off << endl;
cout << resetiosflags(ios::fixed);
}
cout << endl;
cout << "Hey kiddo, your hot babes " << path << ", enjoy it! " << endl;
}
Aicheng::~Aicheng ()
{
;
}
================================================
FILE: src/lib/self/Aicheng.h
================================================
// last modified
#pragma once
#include <string>
#include <vector>
using std::string;
using std::vector;
class Aicheng
{
public:
enum AvClass {west, cartoon, asia_mosaicked, asia_non_mosaicked};
public:
Aicheng ( const string& portal_url,
AvClass av_class,
const vector<string>& proxy_addrs_list,
unsigned range_begin, unsigned range_end,
const vector<string>& hate_keywords_list,
const vector<string>& like_keywords_list,
unsigned threads_total,
unsigned timeout_download_pic,
const string& path );
virtual ~Aicheng ();
const string& getPortalWebpageUrl (void) const;
private:
const string portal_url_;
};
================================================
FILE: src/lib/self/AichengTopicWebpage.cpp
================================================
// last modified
#include "AichengTopicWebpage.h"
#include <iostream>
#include <iterator>
#include <algorithm>
#include "../helper/Misc.h"
using namespace std;
static bool
parsePicturesUrlsHelper ( const string& webpage_txt,
vector<string>& pictures_urls_list,
const string& keyword_begin,
const string& keyword_end )
{
bool b_ok = false;
size_t keyword_pic_begin_pos = 0;
while (true) {
// parse picture URL
const pair<string, size_t>& pair_tmp = fetchStringBetweenKeywords( webpage_txt,
keyword_begin,
keyword_end,
keyword_pic_begin_pos );
string pic_url = pair_tmp.first;
if (pic_url.empty()) {
break;
}
keyword_pic_begin_pos = pair_tmp.second;
b_ok = true;
// there are some bad picture-webspaces and logo pci, ignore them
bool b_ignore_url = false;
static const vector<string> ignore_urls_keywords_list = {
"iceimg.com",
};
for (const auto& e : ignore_urls_keywords_list) {
if (string::npos != pic_url.find(e)) {
b_ignore_url = true;
break;
}
}
if (b_ignore_url) {
continue;
}
// convert https to http
static const string keyword_https("https://");
const auto https_pos = pic_url.find(keyword_https);
if (string::npos != https_pos) {
static const string keyword_http("http://");
pic_url.replace(https_pos, keyword_https.size(), keyword_http);
}
// save the picture URL
pictures_urls_list.push_back(pic_url);
}
return(b_ok);
}
static bool
parsePicturesUrls (const string& webpage_txt, vector<string>& pictures_urls_list)
{
pictures_urls_list.clear();
// just parse the toptip
static const string keyword_toptip_begin("<tr><td class=\"h\"><b>本页主题:</b>");
static const string keyword_toptip_end(">[楼 主]</a></span>");
const pair<string, size_t>& pair_tmp = fetchStringBetweenKeywords( webpage_txt,
keyword_toptip_begin,
keyword_toptip_end );
string toptip = pair_tmp.first;
if (toptip.empty()) {
cerr << "ERROR! there is no toptip. " << endl;
return(false);
}
// the list may be on the webpage at the same time
static const vector<pair<string, string>> begin_and_end_keywords_list = { make_pair("<img src=\"", "\""),
make_pair("<img src='", "'"),
make_pair("<img src=", " ") };
bool b_ok = false;
for (const auto& e : begin_and_end_keywords_list) {
if (parsePicturesUrlsHelper(toptip, pictures_urls_list, e.first, e.second)) {
b_ok = true;
}
}
return(b_ok);
}
static bool
parseSeedUrl (const string& webpage_txt, string& seed_url)
{
static const vector<string> keywords_seed_begin_list = { "http://www.jandown.com",
"http://jandown.com",
"http://www6.mimima.com",
"http://mimima.com" };
const auto body_pos = webpage_txt.find("<body>");
if (string::npos == body_pos) {
//cerr << "warning! parseseedurl() cannot find the keyword \"<body>\"" << endl;
return(false);
}
const string& body = webpage_txt.substr(body_pos);
for (const auto& e : keywords_seed_begin_list) {
const string& keyword_seed_begin = e;
static const string keyword_seed_end("\"");
const pair<string, size_t>& pair_tmp = fetchStringBetweenKeywords( body,
keyword_seed_begin,
keyword_seed_end );
if (!pair_tmp.first.empty()) {
seed_url = keyword_seed_begin + pair_tmp.first;
return(true);
}
}
return(false);
}
AichengTopicWebpage::AichengTopicWebpage (const string& url, const string& proxy_addr)
: TopicWebpage(url, parsePicturesUrls, parseSeedUrl, proxy_addr, "gbk", "UTF-8")
{
;
}
AichengTopicWebpage::~AichengTopicWebpage ()
{
;
}
================================================
FILE: src/lib/self/AichengTopicWebpage.h
================================================
// last modified
#pragma once
#include <string>
#include <vector>
#include "TopicWebpage.h"
using std::string;
using std::vector;
class AichengTopicWebpage : public TopicWebpage
{
public:
AichengTopicWebpage (const string& url, const string& proxy_addr);
virtual ~AichengTopicWebpage ();
};
================================================
FILE: src/lib/self/AichengTopicsListWebpage.cpp
================================================
// last modified
#include "AichengTopicsListWebpage.h"
#include <iostream>
#include <cstdlib>
#include "../helper/Misc.h"
using namespace std;
static bool
parseTitlesAndUrls ( const string& webpage_txt,
const string& portal_url,
vector<pair<string, string>>& titles_and_urls_list )
{
const unsigned size_back = titles_and_urls_list.size();
const auto topics_list_txt_pos = webpage_txt.find(R"(style="border-top:0">普通主题</td></tr>)");
size_t keyword_topic_url_begin_pos = ((string::npos == topics_list_txt_pos) ? 0 : topics_list_txt_pos);
size_t keyword_topic_url_end_pos = 0;
while (true) {
// parse topic URL
static const string keyword_topic_url_begin("<h3><a href=\"");
static const string keyword_topic_url_end("\"");
const pair<string, size_t>& pair_url = fetchStringBetweenKeywords( webpage_txt,
keyword_topic_url_begin,
keyword_topic_url_end,
keyword_topic_url_begin_pos );
const string& topic_url_part = pair_url.first;
if (topic_url_part.empty()) {
break;
}
const string topic_url = portal_url + topic_url_part;
keyword_topic_url_end_pos = pair_url.second;
// parse topic title
static const string keyword_topic_title_begin("target=_blank>");
static const string keyword_topic_title_end("</a></h3>");
const pair<string, size_t>& pair_title = fetchStringBetweenKeywords( webpage_txt,
keyword_topic_title_begin,
keyword_topic_title_end,
//keyword_topic_url_end_pos - keyword_topic_title_begin.size() );
keyword_topic_url_end_pos );
const string& topic_title = pair_title.first;
keyword_topic_url_begin_pos = pair_title.second;
// save url and title of the topic
titles_and_urls_list.push_back(make_pair(topic_title, topic_url));
}
return(titles_and_urls_list.size() > size_back);
}
static bool
parseNextpageUrl (const string& webpage_txt, const string& portal_url, string& nextpage_url)
{
nextpage_url.empty();
static const string keyword_nextpage_begin("</b><a href=\"");
static const string keyword_nextpage_end("\">");
const string& nextpage_url_part = fetchStringBetweenKeywords( webpage_txt,
keyword_nextpage_begin,
keyword_nextpage_end ).first;
if (nextpage_url_part.empty()) {
return(false);
}
// portal_url 中多了 "/bt"
nextpage_url = string(portal_url.cbegin(), portal_url.cend() - (const int)string("/bt").length()) + nextpage_url_part;
return(true);
}
AichengTopicsListWebpage::AichengTopicsListWebpage (const string& portal_url, const string& url, const string& proxy_addr)
: TopicsListWebpage(portal_url, url, parseTitlesAndUrls, parseNextpageUrl, proxy_addr, "gbk", "UTF-8")
{
;
}
AichengTopicsListWebpage::~AichengTopicsListWebpage ()
{
;
}
================================================
FILE: src/lib/self/AichengTopicsListWebpage.h
================================================
// last modified
#pragma once
#include <string>
#include <vector>
#include "TopicsListWebpage.h"
using std::string;
using std::vector;
class AichengTopicsListWebpage : public TopicsListWebpage
{
public:
AichengTopicsListWebpage (const string& portal_url, const string& url, const string& proxy_addr);
virtual ~AichengTopicsListWebpage ();
};
================================================
FILE: src/lib/self/Caoliu.cpp
================================================
// last modified
#include "Caoliu.h"
#include <iostream>
#include <iomanip>
#include <algorithm>
#include <iterator>
#include <thread>
#include <mutex>
#include <cstdlib>
#include <unistd.h>
#include "CaoliuTopicsListWebpage.h"
#include "CaoliuTopicWebpage.h"
#include "RmdownSeedWebpage.h"
#include "../helper/RichTxt.h"
using namespace std;
static mutex g_mtx;
const string&
Caoliu::getPortalWebpageUrl (void) const
{
return(portal_url_);
}
static const string&
getTopicsListWebpagePartUrl (Caoliu::AvClass av_class)
{
// reposted
static const string west_reposted_part_url("thread0806.php?fid=19");
static const string cartoon_reposted_part_url("thread0806.php?fid=24");
static const string asia_mosaicked_reposted_part_url("thread0806.php?fid=18");
static const string asia_non_mosaicked_reposted_part_url("thread0806.php?fid=17");
// original
static const string west_original_part_url("thread0806.php?fid=4");
static const string cartoon_original_part_url("thread0806.php?fid=5");
static const string asia_mosaicked_original_part_url("thread0806.php?fid=15");
static const string asia_non_mosaicked_original_part_url("thread0806.php?fid=2");
// selfie
static const string selfie_part_url("thread0806.php?fid=16");
switch (av_class) {
case Caoliu::west_reposted:
return(west_reposted_part_url);
case Caoliu::cartoon_reposted:
return(cartoon_reposted_part_url);
case Caoliu::asia_mosaicked_reposted:
return(asia_mosaicked_reposted_part_url);
case Caoliu::asia_non_mosaicked_reposted:
return(asia_non_mosaicked_reposted_part_url);
case Caoliu::west_original:
return(west_original_part_url);
case Caoliu::cartoon_original:
return(cartoon_original_part_url);
case Caoliu::asia_mosaicked_original:
return(asia_mosaicked_original_part_url);
case Caoliu::asia_non_mosaicked_original:
return(asia_non_mosaicked_original_part_url);
case Caoliu::selfie:
return(selfie_part_url);
}
}
static const string
getTopicsListWebpageUrl (const string& portal_url, Caoliu::AvClass av_class)
{
return(portal_url + getTopicsListWebpagePartUrl(av_class));
}
static bool
isThereInList ( const string& webpage_title,
const vector<string>& ignore_keywords_list,
string& which_keyword )
{
for (const auto& e : ignore_keywords_list) {
if (!e.empty() && string::npos != webpage_title.find(e)) {
which_keyword = e;
return(true);
}
}
return(false);
}
static bool
parseValidTopicsUrls ( Caoliu::AvClass av_class,
const string& portal_url,
const string& proxy_addr,
unsigned range_begin, unsigned range_end,
const vector<string>& hate_keywords_list,
const vector<string>& like_keywords_list,
vector<string>& valid_topics_urls_list,
bool b_progress )
{
valid_topics_urls_list.clear();
string current_url = getTopicsListWebpageUrl(portal_url, av_class);
bool b_stop = false;
unsigned topics_cnt = 0;
while (!current_url.empty() && !b_stop) {
CaoliuTopicsListWebpage caoliu_topicslist_webpage(portal_url, current_url, proxy_addr);
if (!caoliu_topicslist_webpage.isLoaded()) {
return(false);
}
const vector<pair<string, string>>& topics_title_and_url = caoliu_topicslist_webpage.getTitlesAndUrlsList();
for (const auto& e : topics_title_and_url) {
if (++topics_cnt > range_end) {
b_stop = true;
break;
}
const string& topic_title = e.first;
const string& topic_url = e.second;
static const string o_flag(RichTxt::bold_on + "O" + RichTxt::bold_off);
static const string x_flag("x");
// ignore the topics which do not in range
if (topics_cnt < range_begin) {
if (b_progress) {
cout << x_flag << " " << flush;
}
continue;
}
// ignore the topics which contain hate keyword by user set
string which_keyword;
if (isThereInList(topic_title, hate_keywords_list, which_keyword)) {
if (b_progress) {
cout << x_flag << " " << flush;
}
continue;
}
// ignore the topics which do not contain like keyword by user set
if ( !like_keywords_list.empty() &&
!isThereInList(topic_title, like_keywords_list, which_keyword) ) {
if (b_progress) {
cout << x_flag << " " << flush;
}
continue;
}
valid_topics_urls_list.push_back(topic_url);
if (b_progress) {
cout << o_flag << " " << flush;
}
}
current_url = caoliu_topicslist_webpage.getNextpageUrl();
}
return(true);
}
static void
downloadTopicPicsAndSeed ( const string& topic_url,
const string& proxy_addr,
const string& path,
unsigned timeout_download_pic,
unsigned pictures_total,
bool b_download_seed,
bool b_show_info )
{
CaoliuTopicWebpage caoliu_topics_webpage(topic_url, proxy_addr);
// ready for the basename of pictures and seed.
// >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
string base_name; // from topic title
// 0) delete the web logo info;
// 1) clear the "/" in topictitle string, if the "/" present in filename,
// linux will treat it as directory, again, clear the "\" for windows;
static const vector<string> keyword_logos_list = {" 草榴社區 - powered by phpwind.net"};
const string& topic_webpage_title = caoliu_topics_webpage.getTitle();
auto keyword_logo_pos = string::npos;
for (const auto& f : keyword_logos_list) {
keyword_logo_pos = topic_webpage_title.find(f);
if (string::npos != keyword_logo_pos) {
break;
}
}
remove_copy_if( topic_webpage_title.cbegin(),
(string::npos == keyword_logo_pos) ? topic_webpage_title.cend() : topic_webpage_title.cbegin() + (int)keyword_logo_pos,
back_inserter(base_name),
[] (char ch) {return( '|' == ch || // invalid chars in windows-sytle filename
'/' == ch ||
'<' == ch ||
'>' == ch ||
'?' == ch ||
'*' == ch ||
':' == ch ||
'\\' == ch );} );
// 2) the path + filename max length must less than pathconf(, _PC_NAME_MAX)
const unsigned filename_max_length_without_postfix = (unsigned)pathconf(path.c_str(), _PC_NAME_MAX)
- string("99").size() // picture number
- string(".torrent").size();
if (base_name.size() >= filename_max_length_without_postfix) {
// the filename too long to create file. the way as following doesn't work, case filename encoding error:
// base_name.resize(filename_max_length_without_postfix - 1), because this is string on char not wstring on wchar.
// there is another stupid way, random name from 'a' to 'z'
base_name.resize(16);
generate( base_name.begin(), base_name.end(),
[] () {return('a' + rand() % ('z' - 'a'));} );
base_name = "(rename)" + base_name;
}
// <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
// download all pictures
//const vector<string>& urls = caoliu_topics_webpage.getPicturesUrlsList();
//for (const auto& e : urls) {
////cout << "------------" << endl;
//cout << e << "\n\t";
//cout << caoliu_topics_webpage.getRemoteFiletype(e) << endl;
////cout << "------------" << endl;
//}
vector<string> fail_download_pics_urls_list;
bool b_download_pics_success = caoliu_topics_webpage.downloadAllPictures( path,
base_name,
timeout_download_pic,
fail_download_pics_urls_list,
pictures_total );
// download seed
bool b_downloaded_seed_success = true;
if (b_download_seed) {
b_downloaded_seed_success = false;
if (!caoliu_topics_webpage.getSeedUrl().empty()) {
RmdownSeedWebpage rm_seed_webpage(caoliu_topics_webpage.getSeedUrl(), proxy_addr);
b_downloaded_seed_success = rm_seed_webpage.downloadSeed(path, base_name);
}
}
// show result info
if (!b_show_info) {
return;
}
static const string success_info("success");
static const string fail_info = RichTxt::foreground_red + "failure" + RichTxt::reset_all;
g_mtx.lock();
cout << " \"" << base_name << "\" - ";
if (b_download_pics_success && b_downloaded_seed_success) {
cout << success_info;
} else {
cout << fail_info << " (download error from " << topic_url << ". ";
if (!b_download_pics_success) {
cout << "pictures error: ";
copy(fail_download_pics_urls_list.cbegin(), fail_download_pics_urls_list.cend(), ostream_iterator<const string&>(cout, ", "));
cout << "\b\b";
}
if (b_download_seed && !b_downloaded_seed_success) {
if (!b_download_pics_success) {
cout << "; ";
}
cout << "seed error: " << caoliu_topics_webpage.getSeedUrl();
}
cout << ")";
}
cout << endl;
g_mtx.unlock();
}
static const string&
getNextProxyAddr (const vector<string>& proxy_addrs_list)
{
if (proxy_addrs_list.empty()) {
static const string empty_str("");
return(empty_str);
}
static unsigned current_pos;
if (current_pos >= proxy_addrs_list.size()) {
current_pos = 0;
}
return(proxy_addrs_list[current_pos++]);
}
Caoliu::Caoliu ( const string& portal_url,
AvClass av_class,
const vector<string>& proxy_addrs_list,
unsigned range_begin, unsigned range_end,
const vector<string>& hate_keywords_list,
const vector<string>& like_keywords_list,
unsigned threads_total,
unsigned timeout_download_pic,
const string& path )
: portal_url_(portal_url)
{
// parse the URLs of valid topics by: range, hate keywords, like keywords
cout << "Parse the URLs of topics from " << range_begin << " to " << range_end << ": " << flush;
vector<string> valid_topics_urls_list;
parseValidTopicsUrls( av_class,
portal_url,
getNextProxyAddr(proxy_addrs_list),
range_begin, range_end,
hate_keywords_list,
like_keywords_list,
valid_topics_urls_list,
true );
cout << endl;
if (valid_topics_urls_list.empty()) {
cout << "There is no topic which you like. " << endl;
return;
}
cout << endl;
// check just download picutures for dagaier?
unsigned pictures_total = 2;
bool b_download_seed = true;
if (Caoliu::selfie == av_class) {
pictures_total = 1024; // the max total
b_download_seed = false;
}
// download all pictures and seeds of topics
cout << "Download the pictures and seeds of topics: " << endl;
unsigned parsed_topics_cnt = 0;
for (unsigned i = 0; i < (valid_topics_urls_list.size() / threads_total); ++i) {
vector<thread> threads_list;
for (unsigned j = 0; j < threads_total; ++j) {
++parsed_topics_cnt;
threads_list.push_back(thread( &downloadTopicPicsAndSeed,
ref(valid_topics_urls_list[i * threads_total + j]),
ref(getNextProxyAddr(proxy_addrs_list)),
ref(path),
timeout_download_pic,
pictures_total,
b_download_seed,
true ));
}
for (auto& e : threads_list) {
if (e.joinable()) {
e.join();
}
}
if (!threads_list.empty()) {
cout << setprecision(1) << setiosflags(ios::fixed);
cout << " " << RichTxt::bold_on << RichTxt::underline_on << "<---- "
<< 100.0 * parsed_topics_cnt / valid_topics_urls_list.size()
<< "% ---->" << RichTxt::underline_off << RichTxt::bold_off << endl;
cout << resetiosflags(ios::fixed);
}
}
vector<thread> threads_list;
for (unsigned i = (valid_topics_urls_list.size() / threads_total) * threads_total; i < valid_topics_urls_list.size(); ++i) {
++parsed_topics_cnt;
threads_list.push_back(thread( &downloadTopicPicsAndSeed,
ref(valid_topics_urls_list[i]),
ref(getNextProxyAddr(proxy_addrs_list)),
ref(path),
timeout_download_pic,
pictures_total,
b_download_seed,
true ));
}
for (auto& e : threads_list) {
if (e.joinable()) {
e.join();
}
}
if (!threads_list.empty()) {
cout << setprecision(1) << setiosflags(ios::fixed);
cout << " " << RichTxt::bold_on << RichTxt::underline_on << "<---- "
<< 100.0 * parsed_topics_cnt / valid_topics_urls_list.size()
<< "% ---->" << RichTxt::underline_off << RichTxt::bold_off << endl;
cout << resetiosflags(ios::fixed);
}
cout << endl;
cout << "Hey kiddo, your hot babes " << path << ", enjoy it! " << endl;
}
Caoliu::~Caoliu ()
{
;
}
================================================
FILE: src/lib/self/Caoliu.h
================================================
// last modified
#pragma once
#include <string>
#include <vector>
using std::string;
using std::vector;
class Caoliu
{
public:
enum AvClass { west_reposted, cartoon_reposted, asia_mosaicked_reposted, asia_non_mosaicked_reposted,
west_original, cartoon_original, asia_mosaicked_original, asia_non_mosaicked_original,
selfie };
public:
Caoliu ( const string& portal_url,
AvClass av_class,
const vector<string>& proxy_addrs_list,
unsigned range_begin, unsigned range_end,
const vector<string>& hate_keywords_list,
const vector<string>& like_keywords_list,
unsigned threads_total,
unsigned timeout_download_pic,
const string& path );
virtual ~Caoliu ();
const string& getPortalWebpageUrl (void) const;
private:
const string portal_url_;
};
================================================
FILE: src/lib/self/CaoliuTopicWebpage.cpp
================================================
// last modified
#include "CaoliuTopicWebpage.h"
#include <iostream>
#include <iterator>
#include <algorithm>
#include "../helper/Misc.h"
using namespace std;
static bool
parsePicturesUrlsHelper ( const string& webpage_txt,
vector<string>& pictures_urls_list,
const string& keyword_begin,
const string& keyword_end )
{
bool b_ok = false;
size_t start_pos = 0;
while (true) {
// parse picture URL
const pair<string, size_t>& pair_tmp = fetchStringBetweenKeywords( webpage_txt,
keyword_begin,
keyword_end,
start_pos );
string pic_url = pair_tmp.first;
if (pic_url.empty()) {
break;
}
start_pos = pair_tmp.second;
b_ok = true;
// there are some bad picture-webspaces and logo pci, ignore them
bool b_ignore_url = false;
static const vector<string> ignore_urls_keywords_list = {
"iceimg.com",
"picuphost.com",
// caoliu froum selfie member's logo.
// http://ww4.sinaimg.cn/mw690/005uMz33gw1egsm41zq6qj30f80b4gm9.jpg
// >>>>
"005uMz33gw1eh3a1r6ak0j30d005zt98.jpg",
"005uMz33gw1egsm41zq6qj30f80b4gm9.jpg",
// <<<<
};
for (const auto& e : ignore_urls_keywords_list) {
if (string::npos != pic_url.find(e)) {
b_ignore_url = true;
break;
}
}
if (b_ignore_url) {
continue;
}
// save the picture URL
pictures_urls_list.push_back(pic_url);
}
return(b_ok);
}
static bool
parsePicturesUrls (const string& webpage_txt, vector<string>& pictures_urls_list)
{
pictures_urls_list.clear();
// just parse the toptip
static const string keyword_toptip_begin("<b>本頁主題:</b>");
static const string keyword_toptip_end("[樓主]</a></span>");
const pair<string, size_t>& pair_tmp = fetchStringBetweenKeywords( webpage_txt,
keyword_toptip_begin,
keyword_toptip_end );
string toptip = pair_tmp.first;
if (toptip.empty()) {
cerr << "ERROR! there is no toptip. " << endl;
return(false);
}
// the list may be on the webpage at the same time
static const vector<pair<string, string>> begin_and_end_keywords_list = { make_pair("<img src='", "'"),
make_pair("input type='image' src='", "'"),
make_pair("<input src='", "'") };
bool b_ok = false;
for (const auto& e : begin_and_end_keywords_list) {
if (parsePicturesUrlsHelper(toptip, pictures_urls_list, e.first, e.second)) {
b_ok = true;
}
}
return(b_ok);
}
static bool
parseSeedUrl (const string& webpage_txt, string& seed_url)
{
static const vector<string> keywords_seed_begin_list = { "http://www.rmdown.com/link.php?hash=",
"http://rmdown.com/link.php?hash=",
"http://www.xunfs.com/link.php?hash=",
"http://xunfs.com/link.php?hash=" };
for (const auto& e : keywords_seed_begin_list) {
const string& keyword_seed_begin = e;
static const string keyword_seed_end("</a>");
const pair<string, size_t>& pair_tmp = fetchStringBetweenKeywords( webpage_txt,
keyword_seed_begin,
keyword_seed_end );
if (!pair_tmp.first.empty()) {
seed_url = keyword_seed_begin + pair_tmp.first;
return(true);
}
}
return(false);
}
CaoliuTopicWebpage::CaoliuTopicWebpage (const string& url, const string& proxy_addr)
: TopicWebpage(url, parsePicturesUrls, parseSeedUrl, proxy_addr, "gbk", "UTF-8")
{
;
}
CaoliuTopicWebpage::~CaoliuTopicWebpage ()
{
;
}
================================================
FILE: src/lib/self/CaoliuTopicWebpage.h
================================================
// last modified
#pragma once
#include <string>
#include <vector>
#include "TopicWebpage.h"
using std::string;
using std::vector;
class CaoliuTopicWebpage : public TopicWebpage
{
public:
CaoliuTopicWebpage (const string& url, const string& proxy_addr);
virtual ~CaoliuTopicWebpage ();
};
================================================
FILE: src/lib/self/CaoliuTopicsListWebpage.cpp
================================================
// last modified
#include "CaoliuTopicsListWebpage.h"
#include <iostream>
#include <cstdlib>
#include "../helper/Misc.h"
using namespace std;
static bool
parseTitlesAndUrls ( const string& webpage_txt,
const string& portal_url,
vector<pair<string, string>>& titles_and_urls_list )
{
const unsigned size_back = titles_and_urls_list.size();
size_t keyword_topic_url_begin_pos = 0, keyword_topic_url_end_pos = 0;
keyword_topic_url_begin_pos = webpage_txt.find("普通主題");
if (string::npos == keyword_topic_url_begin_pos) {
keyword_topic_url_begin_pos = 0;
}
while (true) {
// parse topic URL
static const string keyword_topic_url_begin("<h3><a href=\"");
static const string keyword_topic_url_begin2("htm_data");
static const string keyword_topic_url_end("\"");
const pair<string, size_t>& pair_url = fetchStringBetweenKeywords( webpage_txt,
keyword_topic_url_begin + keyword_topic_url_begin2,
keyword_topic_url_end,
keyword_topic_url_begin_pos );
const string& topic_url_part = pair_url.first;
if (topic_url_part.empty()) {
break;
}
const string& topic_url = portal_url + keyword_topic_url_begin2 + topic_url_part;
keyword_topic_url_end_pos = pair_url.second;
// parse topic title
static const string keyword_topic_title_begin("id=\"\">");
static const string keyword_topic_title_end("</a></h3>");
const pair<string, size_t>& pair_title = fetchStringBetweenKeywords( webpage_txt,
keyword_topic_title_begin,
keyword_topic_title_end,
keyword_topic_url_end_pos );
const string& topic_title = pair_title.first;
keyword_topic_url_begin_pos = pair_title.second;
// save url and title of the topic
titles_and_urls_list.push_back(make_pair(topic_title, topic_url));
}
return(titles_and_urls_list.size() > size_back);
}
static bool
parseNextpageUrl (const string& webpage_txt, const string& portal_url, string& nextpage_url)
{
nextpage_url.empty();
static const string keyword_nextpage("下一頁");
const auto keyword_nextpage_pos = webpage_txt.find(keyword_nextpage);
if (string::npos == keyword_nextpage_pos) {
return(false);
}
static const string keyword_href("<a href=\"");
const auto keyword_href_pos = webpage_txt.rfind(keyword_href, keyword_nextpage_pos);
if (string::npos == keyword_href_pos) {
cerr << "WARNING! parseNextpageUrl() cannot find the keyword " << keyword_href << ". " << endl;
return(false);
}
const auto nextpage_suburl_begin_pos = keyword_href_pos + keyword_href.size();
const auto nextpage_suburl_end_pos = webpage_txt.find("\"", nextpage_suburl_begin_pos);
if (string::npos == nextpage_suburl_end_pos) {
cerr << "WARNING! parseNextpageUrl() cannot find the keyword '. " << endl;
return(false);
}
nextpage_url = portal_url +
webpage_txt.substr(nextpage_suburl_begin_pos, nextpage_suburl_end_pos - nextpage_suburl_begin_pos);
return(true);
}
CaoliuTopicsListWebpage::CaoliuTopicsListWebpage (const string& portal_url, const string& url, const string& proxy_addr)
: TopicsListWebpage(portal_url, url, parseTitlesAndUrls, parseNextpageUrl, proxy_addr, "gbk", "UTF-8")
{
;
}
CaoliuTopicsListWebpage::~CaoliuTopicsListWebpage ()
{
;
}
================================================
FILE: src/lib/self/CaoliuTopicsListWebpage.h
================================================
// last modified
#pragma once
#include <string>
#include <vector>
#include "TopicsListWebpage.h"
using std::string;
using std::vector;
class CaoliuTopicsListWebpage : public TopicsListWebpage
{
public:
CaoliuTopicsListWebpage (const string& portal_url, const string& url, const string& proxy_addr);
virtual ~CaoliuTopicsListWebpage ();
};
================================================
FILE: src/lib/self/JandownSeedWebpage.cpp
================================================
// last modified
#include "JandownSeedWebpage.h"
#include <iostream>
#include <algorithm>
#include <unistd.h>
#include "../helper/Misc.h"
using namespace std;
static bool
parsePostMultiSections ( const string& webpage_txt,
vector<pair<string, string>>& post_sections_list )
{
// parse the code section
static const string keyword_code_section_begin("<input type=text name=code size=30 value=");
static const string keyword_code_section_end(" >");
const pair<string, size_t>& pair_tmp = fetchStringBetweenKeywords( webpage_txt,
keyword_code_section_begin,
keyword_code_section_end );
const string& ref_content = pair_tmp.first;
if (ref_content.empty()) {
cerr << "WARNING! parsePostMultiSections() CANNOT find the keyword "
<< "\"" << keyword_code_section_begin << "\"" << " and "
<< "\"" << keyword_code_section_end << "\"" << endl;
return(false);
}
post_sections_list.push_back(make_pair("code", ref_content));
return(true);
}
// seed fetch URL. http://www.jandown.com/ and http://www6.mimima.com/ are
// the same one website, on the other word, from http://www.jandown.com/abcd
// download the seed file same as from http://www6.mimima.com/abcd, so, I need
// just ONE fetch URL
JandownSeedWebpage::JandownSeedWebpage (const string& url, const string& proxy_addr)
: SeedWebpage(url, proxy_addr, "http://www.jandown.com/fetch.php", parsePostMultiSections)
{
;
}
JandownSeedWebpage::~JandownSeedWebpage ()
{
;
}
================================================
FILE: src/lib/self/JandownSeedWebpage.h
================================================
// last modified
#pragma once
#include <string>
#include "SeedWebpage.h"
using std::string;
class JandownSeedWebpage : public SeedWebpage
{
public:
JandownSeedWebpage (const string& url, const string& proxy_addr);
virtual ~JandownSeedWebpage ();
};
================================================
FILE: src/lib/self/RmdownSeedWebpage.cpp
================================================
// last modified
#include "RmdownSeedWebpage.h"
#include <iostream>
#include <algorithm>
#include <unistd.h>
#include "../helper/Misc.h"
using namespace std;
static bool
parsePostMultiSections ( const string& webpage_txt,
vector<pair<string, string>>& post_sections_list )
{
// parse the ref section
static const string& keyword_ref_section_begin("<INPUT size=58 name=\"ref\" value=\"");
static const string& keyword_ref_section_end("\"");
const pair<string, size_t>& pair_tmp = fetchStringBetweenKeywords( webpage_txt,
keyword_ref_section_begin,
keyword_ref_section_end );
const string& ref_content = pair_tmp.first;
if (ref_content.empty()) {
cerr << "WARNING! parsePostMultiSections() CANNOT find the keyword "
<< "\"" << keyword_ref_section_begin << "\"" << " and "
<< "\"" << keyword_ref_section_end << "\"" << endl;
return(false);
}
post_sections_list.push_back(make_pair("ref", ref_content));
const auto keyword_ref_section_end_pos = pair_tmp.second;
// parse the reff section
static const string& keyword_reff_section_begin("value=\"");
static const string& keyword_reff_section_end("\"");
const pair<string, size_t>& pair_tmp2 = fetchStringBetweenKeywords( webpage_txt,
keyword_reff_section_begin,
keyword_reff_section_end,
keyword_ref_section_end_pos );
const string& reff_content = pair_tmp2.first;
if (reff_content.empty()) {
cerr << "WARNING! parsePostMultiSections() CANNOT find the keyword "
<< "\"" << keyword_reff_section_begin << "\"" << " and "
<< "\"" << keyword_reff_section_end << "\"" << endl;
return(false);
}
post_sections_list.push_back(make_pair("reff", reff_content));
return(true);
}
// seed fetch URL. http://www.rmdown.com/ and http://www.xunfs.com/ are
// the same one website, on the other word, from http://www.rmdown.com/abcd
// download the seed file same as from http://www.xunfs.com/abcd, so, I need
// just ONE fetch URL
RmdownSeedWebpage::RmdownSeedWebpage (const string& url, const string& proxy_addr)
: SeedWebpage(url, proxy_addr, "http://www.rmdown.com/download.php", parsePostMultiSections)
{
;
}
RmdownSeedWebpage::~RmdownSeedWebpage ()
{
;
}
================================================
FILE: src/lib/self/RmdownSeedWebpage.h
================================================
// last modified
#pragma once
#include <string>
#include "SeedWebpage.h"
using std::string;
class RmdownSeedWebpage : public SeedWebpage
{
public:
RmdownSeedWebpage (const string& url, const string& proxy_addr);
virtual ~RmdownSeedWebpage ();
};
================================================
FILE: src/lib/self/SeedWebpage.cpp
================================================
// last modified
#include "SeedWebpage.h"
#include <iostream>
#include <algorithm>
#include <unistd.h>
using namespace std;
SeedWebpage::SeedWebpage ( const string& url,
const string& proxy_addr,
const string& post_url,
ParsePostMultiSections parsePostMultiSections )
: Webpage(url, "", proxy_addr), post_url_(post_url)
{
if (!isLoaded()) {
cerr << "WARNING! SeedWebpage::SeedWebpage() CANNOT load webpage \""
<< url << "\"" << endl;
return;
}
// parse the post method multi sections
parsePostMultiSections(getTxt(), post_sections_list_);
}
SeedWebpage::~SeedWebpage ()
{
;
}
// this is a multipart/formdata style HTTP post method
bool
SeedWebpage::downloadSeed (const string& path, const string& base_name)
{
if (post_sections_list_.empty()) {
return(false);
}
// make seed name
static const string seed_postfix(".torrent");
string seed_filename = path + "/" + base_name + seed_postfix;
return(submitMultiPost(post_url_, seed_filename, post_sections_list_));
}
================================================
FILE: src/lib/self/SeedWebpage.h
================================================
// last modified
#pragma once
#include <string>
#include <vector>
#include "../helper/Webpage.h"
using std::string;
using std::vector;
using std::pair;
class SeedWebpage : public Webpage
{
public:
// callback function for parse the multi sections of post
typedef bool (*ParsePostMultiSections) ( const string& webpage_txt,
vector<pair<string, string>>& post_sections_list );
public:
SeedWebpage ( const string& url,
const string& proxy_addr,
const string& post_url,
ParsePostMultiSections parsePostMultiSections );
virtual ~SeedWebpage ();
bool downloadSeed (const string& path, const string& base_name);
private:
const string post_url_;
vector<pair<string, string>> post_sections_list_;
};
================================================
FILE: src/lib/self/TopicWebpage.cpp
================================================
// last modified
#include "TopicWebpage.h"
#include <iostream>
#include <sstream>
#include "../helper/Misc.h"
#include <unistd.h>
using namespace std;
TopicWebpage::TopicWebpage ( const string& url,
ParsePicturesUrls parsePicturesUrls,
ParseSeedUrl parseSeedUrl,
const string& proxy_addr,
const string& src_charset,
const string& dest_charset )
: Webpage(url, "", proxy_addr)
{
if (!isLoaded()) {
return;
}
// charset convert
if (!src_charset.empty() && !dest_charset.empty()) {
convertCharset(src_charset, dest_charset);
}
// parse the URLs of av pictures
if (!parsePicturesUrls(getTxt(), pictures_urls_list_)) {
//cerr << "WARNING! parsePicturesUrls() failure from " << url << endl;
;
}
// parse the URLs of seed
if (!parseSeedUrl(getTxt(), seed_url_)) {
//cerr << "WARNING! parseSeedUrl() failure from " << url << endl;
;
}
}
TopicWebpage::~TopicWebpage ()
{
;
}
const vector<string>&
TopicWebpage::getPicturesUrlsList (void) const
{
return(pictures_urls_list_);
}
const string&
TopicWebpage::getSeedUrl (void) const
{
return(seed_url_);
}
// the name rule of pictures: topictitle-0.jpg, topictitle-1.jpg, topictitle-[x].jpg
bool
TopicWebpage::downloadAllPictures ( const string& path,
const string& base_name,
unsigned timeout_download_pic,
vector<string>& fail_download_pics_urls_list,
unsigned pictures_max_num )
{
fail_download_pics_urls_list.clear();
for ( unsigned i = 0, sucess_cnt = 0;
i < pictures_urls_list_.size() && sucess_cnt < pictures_max_num;
++i ) {
const string& picture_url = pictures_urls_list_[i];
// make picture postfix name
//string postfix_name("jpeg"); // sometime get the remote filetype failure, so I set the default postfix
string postfix_name("");
static const unsigned get_remote_filetype_retry_times = 2;
static const unsigned get_remote_filetype_sleep_second = 2;
for (unsigned j = 0; j < get_remote_filetype_retry_times; ++j) {
const string& tmp = getRemoteFiletype(picture_url);
static const string keyword("image/");
const auto pos = tmp.find(keyword);
if (string::npos != pos) {
postfix_name = tmp.substr(pos + keyword.size());
break;
}
sleep(get_remote_filetype_sleep_second);
}
// neither gif (because gifs almost be AD) nor cannot get the file type, ignore
if ("gif" == postfix_name || "" == postfix_name) {
continue;
}
// download pic
const string& pic_filename = path + "/" + base_name + "-" + convNumToStr(sucess_cnt) + "." + postfix_name;
if (downloadFile(picture_url, pic_filename, "", timeout_download_pic)) {
++sucess_cnt;
continue;
}
//cerr << "W
gitextract_hyme3a89/
├── LICENSE
├── README.md
├── build/
│ └── CMakeLists.txt
├── config/
│ └── portals_list.json
└── src/
├── .ycm_extra_conf.py
├── lib/
│ ├── 3rd/
│ │ └── json11/
│ │ ├── LICENSE.txt
│ │ ├── README.md
│ │ ├── json11.cpp
│ │ ├── json11.hpp
│ │ └── test.cpp
│ ├── helper/
│ │ ├── CmdlineOption.cpp
│ │ ├── CmdlineOption.h
│ │ ├── Misc.cpp
│ │ ├── Misc.h
│ │ ├── RichTxt.h
│ │ ├── Time.cpp
│ │ ├── Time.h
│ │ ├── Webpage.cpp
│ │ └── Webpage.h
│ └── self/
│ ├── Aicheng.cpp
│ ├── Aicheng.h
│ ├── AichengTopicWebpage.cpp
│ ├── AichengTopicWebpage.h
│ ├── AichengTopicsListWebpage.cpp
│ ├── AichengTopicsListWebpage.h
│ ├── Caoliu.cpp
│ ├── Caoliu.h
│ ├── CaoliuTopicWebpage.cpp
│ ├── CaoliuTopicWebpage.h
│ ├── CaoliuTopicsListWebpage.cpp
│ ├── CaoliuTopicsListWebpage.h
│ ├── JandownSeedWebpage.cpp
│ ├── JandownSeedWebpage.h
│ ├── RmdownSeedWebpage.cpp
│ ├── RmdownSeedWebpage.h
│ ├── SeedWebpage.cpp
│ ├── SeedWebpage.h
│ ├── TopicWebpage.cpp
│ ├── TopicWebpage.h
│ ├── TopicsListWebpage.cpp
│ └── TopicsListWebpage.h
└── main.cpp
SYMBOL INDEX (185 symbols across 34 files)
FILE: src/.ycm_extra_conf.py
function DirectoryOfThisScript (line 76) | def DirectoryOfThisScript():
function MakeRelativePathsInFlagsAbsolute (line 80) | def MakeRelativePathsInFlagsAbsolute( flags, working_directory ):
function IsHeaderFile (line 109) | def IsHeaderFile( filename ):
function GetCompilationInfoForFile (line 114) | def GetCompilationInfoForFile( filename ):
function FlagsForFile (line 132) | def FlagsForFile( filename, **kwargs ):
FILE: src/lib/3rd/json11/json11.cpp
type json11 (line 28) | namespace json11 {
function dump (line 43) | static void dump(std::nullptr_t, string &out) {
function dump (line 47) | static void dump(double value, string &out) {
function dump (line 53) | static void dump(int value, string &out) {
function dump (line 59) | static void dump(bool value, string &out) {
function dump (line 63) | static void dump(const string &value, string &out) {
function dump (line 100) | static void dump(const Json::array &values, string &out) {
function dump (line 112) | static void dump(const Json::object &values, string &out) {
class Value (line 135) | class Value : public JsonValue {
method Value (line 139) | explicit Value(const T &value) : m_value(value) {}
method Value (line 140) | explicit Value(T &&value) : m_value(move(value)) {}
method type (line 143) | Json::Type type() const override {
method equals (line 148) | bool equals(const JsonValue * other) const override {
method less (line 151) | bool less(const JsonValue * other) const override {
method dump (line 156) | void dump(string &out) const override { json11::dump(m_value, out); }
class JsonDouble (line 159) | class JsonDouble final : public Value<Json::NUMBER, double> {
method number_value (line 160) | double number_value() const override { return m_value; }
method int_value (line 161) | int int_value() const override { return static_cast<int>(m_value); }
method equals (line 162) | bool equals(const JsonValue * other) const override { return m_value...
method less (line 163) | bool less(const JsonValue * other) const override { return m_value...
method JsonDouble (line 165) | explicit JsonDouble(double value) : Value(value) {}
class JsonInt (line 168) | class JsonInt final : public Value<Json::NUMBER, int> {
method number_value (line 169) | double number_value() const override { return m_value; }
method int_value (line 170) | int int_value() const override { return m_value; }
method equals (line 171) | bool equals(const JsonValue * other) const override { return m_value...
method less (line 172) | bool less(const JsonValue * other) const override { return m_value...
method JsonInt (line 174) | explicit JsonInt(int value) : Value(value) {}
class JsonBoolean (line 177) | class JsonBoolean final : public Value<Json::BOOL, bool> {
method bool_value (line 178) | bool bool_value() const override { return m_value; }
method JsonBoolean (line 180) | explicit JsonBoolean(bool value) : Value(value) {}
class JsonString (line 183) | class JsonString final : public Value<Json::STRING, string> {
method string (line 184) | const string &string_value() const override { return m_value; }
method JsonString (line 186) | explicit JsonString(const string &value) : Value(value) {}
method JsonString (line 187) | explicit JsonString(string &&value) : Value(move(value)) {}
class JsonArray (line 190) | class JsonArray final : public Value<Json::ARRAY, Json::array> {
method JsonArray (line 194) | explicit JsonArray(const Json::array &value) : Value(value) {}
method JsonArray (line 195) | explicit JsonArray(Json::array &&value) : Value(move(value)) {}
class JsonObject (line 198) | class JsonObject final : public Value<Json::OBJECT, Json::object> {
method JsonObject (line 202) | explicit JsonObject(const Json::object &value) : Value(value) {}
method JsonObject (line 203) | explicit JsonObject(Json::object &&value) : Value(move(value)) {}
class JsonNull (line 206) | class JsonNull final : public Value<Json::NUL, std::nullptr_t> {
method JsonNull (line 208) | JsonNull() : Value(nullptr) {}
type Statics (line 214) | struct Statics {
method Statics (line 221) | Statics() {}
function Statics (line 224) | const Statics & statics() {
method Statics (line 221) | Statics() {}
function Json (line 229) | const Json & static_null() {
function string (line 260) | const string & Json::string_value() const { return m_ptr...
function Json (line 263) | const Json & Json::operator[] (size_t i) const { return (*m_p...
function Json (line 264) | const Json & Json::operator[] (const string &key) const { return (*m_p...
function string (line 269) | const string & JsonValue::string_value() const...
function Json (line 272) | const Json & JsonValue::operator[] (size_t) const...
function Json (line 273) | const Json & JsonValue::operator[] (const string &) const...
function Json (line 275) | const Json & JsonObject::operator[] (const string &key) const {
function Json (line 279) | const Json & JsonArray::operator[] (size_t i) const {
function string (line 310) | static inline string esc(char c) {
function in_range (line 320) | static inline bool in_range(long x, long lower, long upper) {
type JsonParser (line 328) | struct JsonParser {
method Json (line 341) | Json fail(string &&msg) {
method T (line 346) | T fail(string &&msg, const T err_ret) {
method consume_whitespace (line 357) | void consume_whitespace() {
method get_next_token (line 367) | char get_next_token() {
method encode_utf8 (line 379) | void encode_utf8(long pt, string & out) {
method string (line 404) | string parse_string() {
method Json (line 497) | Json parse_number() {
method Json (line 553) | Json expect(const string &expected, Json res) {
method Json (line 568) | Json parse_json(int depth) {
function Json (line 655) | Json Json::parse(const string &in, string &err) {
FILE: src/lib/3rd/json11/json11.hpp
type json11 (line 59) | namespace json11 {
class JsonValue (line 61) | class JsonValue
class Json (line 63) | class Json final {
type Type (line 66) | enum Type {
method Json (line 90) | Json(const T & t) : Json(t.to_json()) {}
method Json (line 97) | Json(const M & m) : Json(object(m.begin(), m.end())) {}
method Json (line 103) | Json(const V & v) : Json(array(v.begin(), v.end())) {}
method Json (line 107) | Json(void *) = delete;
method is_null (line 112) | bool is_null() const { return type() == NUL; }
method is_number (line 113) | bool is_number() const { return type() == NUMBER; }
method is_bool (line 114) | bool is_bool() const { return type() == BOOL; }
method is_string (line 115) | bool is_string() const { return type() == STRING; }
method is_array (line 116) | bool is_array() const { return type() == ARRAY; }
method is_object (line 117) | bool is_object() const { return type() == OBJECT; }
method dump (line 141) | std::string dump() const {
method Json (line 149) | static Json parse(const char * in, std::string & err) {
class JsonValue (line 180) | class JsonValue {
FILE: src/lib/3rd/json11/test.cpp
function parse_from_stdin (line 25) | void parse_from_stdin() {
function main (line 38) | int main(int argc, char **argv) {
FILE: src/lib/helper/CmdlineOption.cpp
function isOption (line 12) | static bool
FILE: src/lib/helper/CmdlineOption.h
function class (line 13) | class CmdlineOption
FILE: src/lib/helper/Misc.cpp
function splitStr (line 27) | void
function fetchStringBetweenKeywords (line 56) | pair<string, size_t>
function getFileSize (line 80) | long
function string (line 99) | string
function convertUnicodeToUtf8 (line 148) | pair<size_t, unsigned long long>
function wait_cmd (line 239) | bool
FILE: src/lib/helper/RichTxt.h
function namespace (line 8) | namespace RichTxt
FILE: src/lib/helper/Time.cpp
function string (line 15) | static string
function string (line 26) | static string
type tm (line 39) | struct tm
function string (line 62) | string
function string (line 75) | string
function string (line 88) | string
function string (line 117) | string
function string (line 130) | string
function string (line 142) | string
function string (line 155) | string
function string (line 168) | string
FILE: src/lib/helper/Time.h
function class (line 8) | class Time
FILE: src/lib/helper/Webpage.cpp
function checkErrLibcurl (line 24) | static bool
function CURL (line 40) | static CURL*
function cleanupLibcul (line 73) | static void
function parseProxyOutIpAndRegionByThirdparty (line 80) | static pair<string, string>
function string (line 112) | string
function string (line 118) | string
function string (line 124) | string
function string (line 130) | string
function string (line 137) | string
function string (line 168) | string
function string (line 205) | string
function string (line 300) | string
function string (line 306) | string
function string (line 312) | string
function string (line 318) | string
function string (line 324) | string
function string (line 330) | string
type curl_slist (line 410) | struct curl_slist
type curl_slist (line 412) | struct curl_slist
type curl_httppost (line 585) | struct curl_httppost
type curl_httppost (line 586) | struct curl_httppost
type curl_httppost (line 624) | struct curl_httppost
function string (line 631) | const string&
function string (line 698) | const string&
function string (line 704) | string
function string (line 755) | string
FILE: src/lib/helper/Webpage.h
function class (line 13) | class Webpage
FILE: src/lib/self/Aicheng.cpp
function string (line 23) | const string&
function string (line 29) | static const string&
function string (line 49) | static const string
function isThereInList (line 55) | static bool
function parseValidTopicsUrls (line 70) | static bool
function downloadTopicPicsAndSeed (line 141) | static void
function string (line 248) | static const string&
FILE: src/lib/self/Aicheng.h
function class (line 12) | class Aicheng
FILE: src/lib/self/AichengTopicWebpage.cpp
function parsePicturesUrlsHelper (line 12) | static bool
function parsePicturesUrls (line 64) | static bool
function parseSeedUrl (line 97) | static bool
FILE: src/lib/self/AichengTopicWebpage.h
function class (line 13) | class AichengTopicWebpage : public TopicWebpage
FILE: src/lib/self/AichengTopicsListWebpage.cpp
function parseTitlesAndUrls (line 13) | static bool
function parseNextpageUrl (line 57) | static bool
FILE: src/lib/self/AichengTopicsListWebpage.h
function class (line 13) | class AichengTopicsListWebpage : public TopicsListWebpage
FILE: src/lib/self/Caoliu.cpp
function string (line 22) | const string&
function string (line 28) | static const string&
function string (line 68) | static const string
function isThereInList (line 74) | static bool
function parseValidTopicsUrls (line 89) | static bool
function downloadTopicPicsAndSeed (line 160) | static void
function string (line 268) | static const string&
FILE: src/lib/self/Caoliu.h
function class (line 12) | class Caoliu
FILE: src/lib/self/CaoliuTopicWebpage.cpp
function parsePicturesUrlsHelper (line 13) | static bool
function parsePicturesUrls (line 64) | static bool
function parseSeedUrl (line 97) | static bool
FILE: src/lib/self/CaoliuTopicWebpage.h
function class (line 13) | class CaoliuTopicWebpage : public TopicWebpage
FILE: src/lib/self/CaoliuTopicsListWebpage.cpp
function parseTitlesAndUrls (line 12) | static bool
function parseNextpageUrl (line 58) | static bool
FILE: src/lib/self/CaoliuTopicsListWebpage.h
function class (line 13) | class CaoliuTopicsListWebpage : public TopicsListWebpage
FILE: src/lib/self/JandownSeedWebpage.cpp
function parsePostMultiSections (line 12) | static bool
FILE: src/lib/self/JandownSeedWebpage.h
function class (line 11) | class JandownSeedWebpage : public SeedWebpage
FILE: src/lib/self/RmdownSeedWebpage.cpp
function parsePostMultiSections (line 12) | static bool
FILE: src/lib/self/RmdownSeedWebpage.h
function class (line 11) | class RmdownSeedWebpage : public SeedWebpage
FILE: src/lib/self/SeedWebpage.h
function class (line 14) | class SeedWebpage : public Webpage
FILE: src/lib/self/TopicWebpage.cpp
function string (line 54) | const string&
FILE: src/lib/self/TopicWebpage.h
function class (line 13) | class TopicWebpage : public Webpage
FILE: src/lib/self/TopicsListWebpage.cpp
function string (line 49) | const string&
function string (line 62) | const string&
FILE: src/lib/self/TopicsListWebpage.h
function class (line 14) | class TopicsListWebpage : public Webpage
FILE: src/main.cpp
function showSexyGirl (line 34) | static void
function showHelpInfo (line 70) | static void
function showVersionInfo (line 166) | static void
function parseTopicsRangeArgument (line 174) | static bool
function getPortalUrls (line 214) | static void
function main (line 254) | int
Condensed preview — 42 files, each showing path, character count, and a content snippet. Download the .json file or copy for the full structured content (233K chars).
[
{
"path": "LICENSE",
"chars": 18025,
"preview": "GNU GENERAL PUBLIC LICENSE\n Version 2, June 1991\n\n Copyright (C) 1989, 1991 Free Software Foundati"
},
{
"path": "README.md",
"chars": 17054,
"preview": "<h1 align=\"center\">给不了你梦中情人,至少还有硬盘女神:hardseed</h1>\nyangyangwithgnu@yeah.net \nhttp://yangyangwithgnu.github.io/ \n2016-0"
},
{
"path": "build/CMakeLists.txt",
"chars": 2062,
"preview": "PROJECT(main)\n\n\nSET(SRC_LIST ../src/main.cpp\n ../src/lib/self/TopicsListWebpage.cpp ../src/lib/self/AichengT"
},
{
"path": "config/portals_list.json",
"chars": 86,
"preview": "{\n \"caoliu\":\"http://cl.bearhk.info/\",\n \"aicheng\":\"http://www.ac168.info/bt/\"\n} \n"
},
{
"path": "src/.ycm_extra_conf.py",
"chars": 5092,
"preview": "# This file is NOT licensed under the GPLv3, which is the license for the rest\n# of YouCompleteMe.\n#\n# Here's the licens"
},
{
"path": "src/lib/3rd/json11/LICENSE.txt",
"chars": 1057,
"preview": "Copyright (c) 2013 Dropbox, Inc.\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof this s"
},
{
"path": "src/lib/3rd/json11/README.md",
"chars": 1475,
"preview": "json11\n------\n\njson11 is a tiny JSON library for C++11, providing JSON parsing and serialization.\n\nThe core object provi"
},
{
"path": "src/lib/3rd/json11/json11.cpp",
"chars": 22345,
"preview": "/* Copyright (c) 2013 Dropbox, Inc.\n *\n * Permission is hereby granted, free of charge, to any person obtaining a copy\n "
},
{
"path": "src/lib/3rd/json11/json11.hpp",
"chars": 8360,
"preview": "/* json11\n *\n * json11 is a tiny JSON library for C++11, providing JSON parsing and serialization.\n *\n * The core object"
},
{
"path": "src/lib/3rd/json11/test.cpp",
"chars": 3320,
"preview": "#include <string>\n#include <cstdio>\n#include <iostream>\n#include <sstream>\n#include \"json11.hpp\"\n#include <cassert>\n#inc"
},
{
"path": "src/lib/helper/CmdlineOption.cpp",
"chars": 2063,
"preview": "// last modified \n\n#include \"CmdlineOption.h\"\n#include <unordered_map>\n#include <vector>\n#include <string>\n#include <ios"
},
{
"path": "src/lib/helper/CmdlineOption.h",
"chars": 516,
"preview": "// last modified \n\n#pragma once\n#include <string>\n#include <vector>\n#include <unordered_map>\n\nusing std::string;\nusing s"
},
{
"path": "src/lib/helper/Misc.cpp",
"chars": 11078,
"preview": "// last modified \n\n#include \"Misc.h\"\n#include <algorithm>\n#include <iostream>\n#include <iterator>\n#include <cstdlib>\n#in"
},
{
"path": "src/lib/helper/Misc.h",
"chars": 1431,
"preview": "// last modified \n\n#pragma once\n\n#include <sstream>\n#include <string>\n#include <vector>\n\nusing std::string;\nusing std::o"
},
{
"path": "src/lib/helper/RichTxt.h",
"chars": 1863,
"preview": "// last modified \n\n#pragma once\n#include <string>\n\nusing std::string;\n\nnamespace RichTxt\n{\n // bold\n static const "
},
{
"path": "src/lib/helper/Time.cpp",
"chars": 3710,
"preview": "// last modified \n\n#include \"Time.h\"\n#include <algorithm>\n#include <string>\n#include <sstream>\n#include <ctime>\n\nusing n"
},
{
"path": "src/lib/helper/Time.h",
"chars": 1165,
"preview": "// last modified \n\n#pragma once\n#include <string>\n\nusing std::string;\n\nclass Time \n{\n public:\n Time ();\n "
},
{
"path": "src/lib/helper/Webpage.cpp",
"chars": 30169,
"preview": "// last modified \n\n#include \"Webpage.h\"\n#include <iostream>\n#include <algorithm>\n#include <sstream>\n#include <iterator>\n"
},
{
"path": "src/lib/helper/Webpage.h",
"chars": 4280,
"preview": "// last modified \n\n#pragma once\n\n#include <string>\n#include <vector>\n#include <curl/curl.h>\n\nusing std::string;\nusing st"
},
{
"path": "src/lib/self/Aicheng.cpp",
"chars": 14001,
"preview": "// last modified \n\n#include \"Aicheng.h\"\n#include <iostream>\n#include <iomanip>\n#include <algorithm>\n#include <iterator>\n"
},
{
"path": "src/lib/self/Aicheng.h",
"chars": 821,
"preview": "// last modified \n\n#pragma once\n\n#include <string>\n#include <vector>\n\nusing std::string;\nusing std::vector;\n\n\nclass Aich"
},
{
"path": "src/lib/self/AichengTopicWebpage.cpp",
"chars": 4944,
"preview": "// last modified \n\n#include \"AichengTopicWebpage.h\"\n#include <iostream>\n#include <iterator>\n#include <algorithm>\n#includ"
},
{
"path": "src/lib/self/AichengTopicWebpage.h",
"chars": 318,
"preview": "// last modified \n\n#pragma once\n\n#include <string>\n#include <vector>\n#include \"TopicWebpage.h\"\n\nusing std::string;\nusing"
},
{
"path": "src/lib/self/AichengTopicsListWebpage.cpp",
"chars": 3540,
"preview": "// last modified \n\n#include \"AichengTopicsListWebpage.h\"\n#include <iostream>\n#include <cstdlib>\n#include \"../helper/Misc"
},
{
"path": "src/lib/self/AichengTopicsListWebpage.h",
"chars": 368,
"preview": "// last modified \n\n#pragma once\n\n#include <string>\n#include <vector>\n#include \"TopicsListWebpage.h\"\n\nusing std::string;\n"
},
{
"path": "src/lib/self/Caoliu.cpp",
"chars": 14993,
"preview": "// last modified \n\n#include \"Caoliu.h\"\n#include <iostream>\n#include <iomanip>\n#include <algorithm>\n#include <iterator>\n#"
},
{
"path": "src/lib/self/Caoliu.h",
"chars": 989,
"preview": "// last modified \n\n#pragma once\n\n#include <string>\n#include <vector>\n\nusing std::string;\nusing std::vector;\n\n\nclass Caol"
},
{
"path": "src/lib/self/CaoliuTopicWebpage.cpp",
"chars": 5039,
"preview": "// last modified \n\n#include \"CaoliuTopicWebpage.h\"\n#include <iostream>\n#include <iterator>\n#include <algorithm>\n#include"
},
{
"path": "src/lib/self/CaoliuTopicWebpage.h",
"chars": 315,
"preview": "// last modified \n\n#pragma once\n\n#include <string>\n#include <vector>\n#include \"TopicWebpage.h\"\n\nusing std::string;\nusing"
},
{
"path": "src/lib/self/CaoliuTopicsListWebpage.cpp",
"chars": 3907,
"preview": "// last modified \n\n#include \"CaoliuTopicsListWebpage.h\"\n#include <iostream>\n#include <cstdlib>\n#include \"../helper/Misc."
},
{
"path": "src/lib/self/CaoliuTopicsListWebpage.h",
"chars": 365,
"preview": "// last modified \n\n#pragma once\n\n#include <string>\n#include <vector>\n#include \"TopicsListWebpage.h\"\n\nusing std::string;\n"
},
{
"path": "src/lib/self/JandownSeedWebpage.cpp",
"chars": 1680,
"preview": "// last modified \n\n#include \"JandownSeedWebpage.h\"\n#include <iostream>\n#include <algorithm>\n#include <unistd.h>\n#include"
},
{
"path": "src/lib/self/JandownSeedWebpage.h",
"chars": 275,
"preview": "// last modified \n\n#pragma once\n\n#include <string>\n#include \"SeedWebpage.h\"\n\nusing std::string;\n\n\nclass JandownSeedWebpa"
},
{
"path": "src/lib/self/RmdownSeedWebpage.cpp",
"chars": 2650,
"preview": "// last modified \n\n#include \"RmdownSeedWebpage.h\"\n#include <iostream>\n#include <algorithm>\n#include <unistd.h>\n#include "
},
{
"path": "src/lib/self/RmdownSeedWebpage.h",
"chars": 272,
"preview": "// last modified \n\n#pragma once\n\n#include <string>\n#include \"SeedWebpage.h\"\n\nusing std::string;\n\n\nclass RmdownSeedWebpag"
},
{
"path": "src/lib/self/SeedWebpage.cpp",
"chars": 1139,
"preview": "// last modified \n\n#include \"SeedWebpage.h\"\n#include <iostream>\n#include <algorithm>\n#include <unistd.h>\n\nusing namespac"
},
{
"path": "src/lib/self/SeedWebpage.h",
"chars": 885,
"preview": "// last modified \n\n#pragma once\n\n#include <string>\n#include <vector>\n#include \"../helper/Webpage.h\"\n\nusing std::string;\n"
},
{
"path": "src/lib/self/TopicWebpage.cpp",
"chars": 3464,
"preview": "// last modified \n\n#include \"TopicWebpage.h\"\n#include <iostream>\n#include <sstream>\n#include \"../helper/Misc.h\"\n\n#includ"
},
{
"path": "src/lib/self/TopicWebpage.h",
"chars": 1384,
"preview": "// last modified \n\n#pragma once\n\n#include <string>\n#include <vector>\n#include \"../helper/Webpage.h\"\n\nusing std::string;\n"
},
{
"path": "src/lib/self/TopicsListWebpage.cpp",
"chars": 1774,
"preview": "// last modified \n\n#include \"TopicsListWebpage.h\"\n#include <iostream>\n\n\nusing namespace std;\n\n\nTopicsListWebpage::Topics"
},
{
"path": "src/lib/self/TopicsListWebpage.h",
"chars": 1582,
"preview": "// last modified \n\n#pragma once\n\n#include <string>\n#include <vector>\n#include \"../helper/Webpage.h\"\n\nusing std::string;\n"
},
{
"path": "src/main.cpp",
"chars": 22527,
"preview": "#include <iostream>\n#include <string>\n#include <algorithm>\n#include <iterator>\n#include <sstream>\n#include <cstring>\n#in"
}
]
About this extraction
This page contains the full source code of the yangyangwithgnu/hardseed GitHub repository, extracted and formatted as plain text for AI agents and large language models (LLMs). The extraction includes 42 files (217.2 KB), approximately 56.3k tokens, and a symbol index with 185 extracted functions, classes, methods, constants, and types. Use this with OpenClaw, Claude, ChatGPT, Cursor, Windsurf, or any other AI tool that accepts text input. You can copy the full output to your clipboard or download it as a .txt file.
Extracted by GitExtract — free GitHub repo to text converter for AI. Built by Nikandr Surkov.