## News
* [12/09/2023]: Hybrid-SORT is accepted by **AAAI2024**!
* [08/24/2023]: Hybrid-SORT is supported in [yolo_tracking](https://github.com/mikel-brostrom/yolo_tracking). Many thanks to [@mikel-brostrom](https://github.com/mikel-brostrom) for the contribution.
* [08/01/2023]: The [arxiv preprint](https://arxiv.org/abs/2308.00783) of Hybrid-SORT is released.
## Tracking performance
### Results on DanceTrack test set
| Tracker | HOTA | MOTA | IDF1 | FPS |
| :--------------- | :--: | :--: | :--: | :--: |
| OC-SORT | 54.6 | 89.6 | 54.6 | 30.3 |
| Hybrid-SORT | 62.2 | 91.6 | 63.0 | 27.8 |
| Hybrid-SORT-ReID | 65.7 | 91.8 | 67.4 | 15.5 |
### Results on MOT20 challenge test set
| Tracker | HOTA | MOTA | IDF1 |
| :--------------- | :--: | :--: | :--: |
| OC-SORT | 62.1 | 75.5 | 75.9 |
| Hybrid-SORT | 62.5 | 76.4 | 76.2 |
| Hybrid-SORT-ReID | 63.9 | 76.7 | 78.4 |
### Results on MOT17 challenge test set
| Tracker | HOTA | MOTA | IDF1 |
| :--------------- | :--: | :--: | :--: |
| OC-SORT | 63.2 | 78.0 | 77.5 |
| Hybrid-SORT | 63.6 | 79.3 | 78.4 |
| Hybrid-SORT-ReID | 64.0 | 79.9 | 78.7 |
## Installation
Hybrid-SORT code is based on [OC-SORT](https://github.com/noahcao/OC_SORT) and [FastReID](https://github.com/JDAI-CV/fast-reid). The ReID component is optional and based on [FastReID](https://github.com/JDAI-CV/fast-reid). Tested the code with Python 3.8 + Pytorch 1.10.0 + torchvision 0.11.0.
Step1. Install Hybrid_SORT
```shell
git clone https://github.com/ymzis69/HybridSORT.git
cd HybridSORT
pip3 install -r requirements.txt
python3 setup.py develop
```
Step2. Install [pycocotools](https://github.com/cocodataset/cocoapi).
```shell
pip3 install cython; pip3 install 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
```
Step3. Others
```shell
pip3 install cython_bbox pandas xmltodict
```
Step4. [optional] FastReID Installation
You can refer to [FastReID Installation](https://github.com/JDAI-CV/fast-reid/blob/master/INSTALL.md).
```shell
pip install -r fast_reid/docs/requirements.txt
```
## Data preparation
**Our data structure is the same as [OC-SORT](https://github.com/noahcao/OC_SORT).**
1. Download [MOT17](https://motchallenge.net/), [MOT20](https://motchallenge.net/), [CrowdHuman](https://www.crowdhuman.org/), [Cityperson](https://github.com/Zhongdao/Towards-Realtime-MOT/blob/master/DATASET_ZOO.md), [ETHZ](https://github.com/Zhongdao/Towards-Realtime-MOT/blob/master/DATASET_ZOO.md), [DanceTrack](https://github.com/DanceTrack/DanceTrack), [CUHKSYSU](http://www.ee.cuhk.edu.hk/~xgwang/PS/dataset.html) and put them under /datasets in the following structure (CrowdHuman, Cityperson and ETHZ are not needed if you download YOLOX weights from [ByteTrack](https://github.com/ifzhang/ByteTrack) or [OC-SORT](https://github.com/noahcao/OC_SORT)) :
```
datasets
|——————mot
| └——————train
| └——————test
└——————crowdhuman
| └——————Crowdhuman_train
| └——————Crowdhuman_val
| └——————annotation_train.odgt
| └——————annotation_val.odgt
└——————MOT20
| └——————train
| └——————test
└——————Cityscapes
| └——————images
| └——————labels_with_ids
└——————ETHZ
| └——————eth01
| └——————...
| └——————eth07
└——————CUHKSYSU
| └——————images
| └——————labels_with_ids
└——————dancetrack
└——————train
└——————train_seqmap.txt
└——————val
└——————val_seqmap.txt
└——————test
└——————test_seqmap.txt
```
2. Prepare DanceTrack dataset:
```python
# replace "dance" with ethz/mot17/mot20/crowdhuman/cityperson/cuhk for others
python3 tools/convert_dance_to_coco.py
```
3. Prepare MOT17/MOT20 dataset.
```python
# build mixed training sets for MOT17 and MOT20
python3 tools/mix_data_{ablation/mot17/mot20}.py
```
4. [optional] Prepare ReID datasets:
```
cd
# For MOT17
python3 fast_reid/datasets/generate_mot_patches.py --data_path --mot 17
# For MOT20
python3 fast_reid/datasets/generate_mot_patches.py --data_path --mot 20
# For DanceTrack
python3 fast_reid/datasets/generate_cuhksysu_dance_patches.py --data_path
```
## Model Zoo
Download and store the trained models in 'pretrained' folder as follow:
```
/pretrained
```
### Detection Model
We provide some pretrained YOLO-X weights for Hybrid-SORT, which are inherited from [ByteTrack](https://github.com/ifzhang/ByteTrack).
| Dataset | HOTA | IDF1 | MOTA | Model |
| --------------- | ---- | ---- | ---- | ------------------------------------------------------------ |
| DanceTrack-val | 59.3 | 60.6 | 89.5 | [Google Drive](https://drive.google.com/drive/folders/18IsZGeGiyKDshhYIzbpYXoNEcBhPY8lN?usp=sharing) |
| DanceTrack-test | 62.2 | 63.0 | 91.6 | [Google Drive](https://drive.google.com/drive/folders/18IsZGeGiyKDshhYIzbpYXoNEcBhPY8lN?usp=sharing) |
| MOT17-half-val | 67.1 | 78.0 | 75.8 | [Google Drive](https://drive.google.com/drive/folders/18IsZGeGiyKDshhYIzbpYXoNEcBhPY8lN?usp=sharing) |
| MOT17-test | 63.6 | 78.7 | 79.9 | [Google Drive](https://drive.google.com/drive/folders/18IsZGeGiyKDshhYIzbpYXoNEcBhPY8lN?usp=sharing) |
| MOT20-test | 62.5 | 78.4 | 76.7 | [Google Drive](https://drive.google.com/drive/folders/18IsZGeGiyKDshhYIzbpYXoNEcBhPY8lN?usp=sharing) |
* For more YOLO-X weights, please refer to the model zoo of [ByteTrack](https://github.com/ifzhang/ByteTrack).
### ReID Model
Ours ReID models for **MOT17/MOT20** is the same as [BoT-SORT](https://github.com/NirAharon/BOT-SORT) , you can download from [MOT17-SBS-S50](https://drive.google.com/drive/folders/18IsZGeGiyKDshhYIzbpYXoNEcBhPY8lN?usp=sharing), [MOT20-SBS-S50](https://drive.google.com/drive/folders/18IsZGeGiyKDshhYIzbpYXoNEcBhPY8lN?usp=sharing), ReID models for DanceTrack is trained by ourself, you can download from [DanceTrack](https://drive.google.com/drive/folders/18IsZGeGiyKDshhYIzbpYXoNEcBhPY8lN?usp=sharing).
**Notes**:
* [MOT20-SBS-S50](https://drive.google.com/drive/folders/18IsZGeGiyKDshhYIzbpYXoNEcBhPY8lN?usp=sharing) is trained by [Deep-OC-SORT](https://github.com/GerardMaggiolino/Deep-OC-SORT), because the weight from BOT-SORT is corrupted. Refer to [Issue](https://github.com/GerardMaggiolino/Deep-OC-SORT/issues/6).
* ReID models for DanceTrack is trained by ourself, with both DanceTrack and CUHKSYSU datasets.
## Training
### Train the Detection Model
You can use Hybrid-SORT without training by adopting existing detectors. But we borrow the training guidelines from ByteTrack in case you want work on your own detector.
Download the COCO-pretrained YOLOX weight [here](https://github.com/Megvii-BaseDetection/YOLOX/tree/0.1.0) and put it under *\/pretrained*.
* **Train ablation model (MOT17 half train and CrowdHuman)**
```shell
python3 tools/train.py -f exps/example/mot/yolox_x_ablation.py -d 8 -b 48 --fp16 -o -c pretrained/yolox_x.pth
```
* **Train MOT17 test model (MOT17 train, CrowdHuman, Cityperson and ETHZ)**
```shell
python3 tools/train.py -f exps/example/mot/yolox_x_mix_det.py -d 8 -b 48 --fp16 -o -c pretrained/yolox_x.pth
```
* **Train MOT20 test model (MOT20 train, CrowdHuman)**
For MOT20, you need to uncomment some code lines to add box clipping: [[1]](https://github.com/ifzhang/ByteTrack/blob/72cd6dd24083c337a9177e484b12bb2b5b3069a6/yolox/data/data_augment),[[2]](https://github.com/ifzhang/ByteTrack/blob/72cd6dd24083c337a9177e484b12bb2b5b3069a6/yolox/data/datasets/mosaicdetection.py#L122),[[3]](https://github.com/ifzhang/ByteTrack/blob/72cd6dd24083c337a9177e484b12bb2b5b3069a6/yolox/data/datasets/mosaicdetection.py#L217) and [[4]](https://github.com/ifzhang/ByteTrack/blob/72cd6dd24083c337a9177e484b12bb2b5b3069a6/yolox/utils/boxes.py#L115). Then run the command:
```shell
python3 tools/train.py -f exps/example/mot/yolox_x_mix_mot20_ch.py -d 8 -b 48 --fp16 -o -c pretrained/yolox_x.pth
```
* **Train on DanceTrack train set**
```shell
python3 tools/train.py -f exps/example/dancetrack/yolox_x.py -d 8 -b 48 --fp16 -o -c pretrained/yolox_x.pth
```
* **Train custom dataset**
First, you need to prepare your dataset in COCO format. You can refer to [MOT-to-COCO](https://github.com/ifzhang/ByteTrack/blob/main/tools/convert_mot17_to_coco.py) or [CrowdHuman-to-COCO](https://github.com/ifzhang/ByteTrack/blob/main/tools/convert_crowdhuman_to_coco.py). Then, you need to create a Exp file for your dataset. You can refer to the [CrowdHuman](https://github.com/ifzhang/ByteTrack/blob/main/exps/example/mot/yolox_x_ch.py) training Exp file. Don't forget to modify get_data_loader() and get_eval_loader in your Exp file. Finally, you can train bytetrack on your dataset by running:
```shell
python3 tools/train.py -f exps/example/mot/your_exp_file.py -d 8 -b 48 --fp16 -o -c pretrained/yolox_x.pth
```
### Train the ReID Model
After generating MOT ReID dataset as described in the 'Data Preparation' section.
```shell
cd
# For training MOT17
python3 fast_reid/tools/train_net.py --config-file ./fast_reid/configs/MOT17/sbs_S50.yml MODEL.DEVICE "cuda:0"
# For training MOT20
python3 fast_reid/tools/train_net.py --config-file ./fast_reid/configs/MOT20/sbs_S50.yml MODEL.DEVICE "cuda:0"
# For training DanceTrack, we joint the CHUKSUSY to train ReID Model for DanceTrack
python3 fast_reid/tools/train_net.py --config-file ./fast_reid/configs/CUHKSYSU_DanceTrack/sbs_S50.yml MODEL.DEVICE "cuda:0"
```
Refer to [FastReID](https://github.com/JDAI-CV/fast-reid) repository for addition explanations and options.
## Tracking
**Notes**:
* Some parameters are set in the cfg.py. For example, if you run Hybrid-SORT on the dancetrack-val dataset, you should pay attention to the line 35-45 in ```exps/example/mot/yolox_dancetrack_val_hybrid_sort.py``` .
* We set ```fp16==False``` on the MOT datasets becacuse fp16 will lead to significant result fluctuations.
### DanceTrack
**dancetrack-val dataset**
```
# Hybrid-SORT
python tools/run_hybrid_sort_dance.py -f exps/example/mot/yolox_dancetrack_val_hybrid_sort.py -b 1 -d 1 --fp16 --fuse --expn $exp_name
# Hybrid-SORT-ReID
python tools/run_hybrid_sort_dance.py -f exps/example/mot/yolox_dancetrack_val_hybrid_sort_reid.py -b 1 -d 1 --fp16 --fuse --expn $exp_name
```
**dancetrack-test dataset**
```
# Hybrid-SORT
python tools/run_hybrid_sort_dance.py --test -f exps/example/mot/yolox_dancetrack_test_hybrid_sort.py -b 1 -d 1 --fp16 --fuse --expn $exp_name
# Hybrid-SORT-ReID
python tools/run_hybrid_sort_dance.py --test -f exps/example/mot/yolox_dancetrack_test_hybrid_sort_reid.py -b 1 -d 1 --fp16 --fuse --expn $exp_name
```
### MOT20
**MOT20-test dataset**
```
#Hybrid-SORT
python tools/run_hybrid_sort_dance.py -f exps/example/mot/yolox_x_mix_mot20_ch_hybrid_sort.py -b 1 -d 1 --fuse --mot20 --expn $exp_name
#Hybrid-SORT-ReID
python tools/run_hybrid_sort_dance.py -f exps/example/mot/yolox_x_mix_mot20_ch_hybrid_sort_reid.py -b 1 -d 1 --fuse --mot20 --expn $exp_name
```
Hybrid-SORT is designed for online tracking, but offline interpolation has been demonstrated efficient for many cases and used by other online trackers. If you want to reproduct out result on **MOT20-test** dataset, please use the linear interpolation over existing tracking results:
```shell
# offline post-processing
python3 tools/interpolation.py $result_path $save_path
```
### MOT17
**MOT17-val dataset**
```
# Hybrid-SORT
python3 tools/run_hybrid_sort_dance.py -f exps/example/mot/yolox_x_ablation_hybrid_sort.py -b 1 -d 1 --fuse --expn $exp_name
# Hybrid-SORT-ReID
python3 tools/run_hybrid_sort_dance.py -f exps/example/mot/yolox_x_ablation_hybrid_sort_reid.py -b 1 -d 1 --fuse --expn $exp_name
```
**MOT17-test dataset**
```
# Hybrid-SORT
python3 tools/run_hybrid_sort_dance.py -f exps/example/mot/yolox_x_mix_det_hybrid_sort.py -b 1 -d 1 --fuse --expn $exp_name
# Hybrid-SORT-ReID
python3 tools/run_hybrid_sort_dance.py -f exps/example/mot/yolox_x_mix_det_hybrid_sort_reid.py -b 1 -d 1 --fuse --expn $exp_name
```
Hybrid-SORT is designed for online tracking, but offline interpolation has been demonstrated efficient for many cases and used by other online trackers. If you want to reproduct out result on **MOT17-test** dataset, please use the linear interpolation over existing tracking results:
```shell
# offline post-processing
python3 tools/interpolation.py $result_path $save_path
```
### Demo
Hybrid-SORT, with the parameter settings of the dancetrack-val dataset
```
python3 tools/demo_track.py --demo_type image -f exps/example/mot/yolox_dancetrack_val_hybrid_sort.py -c pretrained/ocsort_dance_model.pth.tar --path ./datasets/dancetrack/val/dancetrack0079/img1 --fp16 --fuse --save_result
```
Hybrid-SORT-ReID, with the parameter settings of the dancetrack-val dataset
```
python3 tools/demo_track.py --demo_type image -f exps/example/mot/yolox_dancetrack_val_hybrid_sort_reid.py -c pretrained/ocsort_dance_model.pth.tar --path ./datasets/dancetrack/val/dancetrack0079/img1 --fp16 --fuse --save_result
```
## TCM on other trackers
download ReID weight from [googlenet_part8_all_xavier_ckpt_56.h5](https://drive.google.com/drive/folders/18IsZGeGiyKDshhYIzbpYXoNEcBhPY8lN?usp=sharing) for MOTDT and DeepSORT.
**dancetrack-val dataset**
```
# SORT
python tools/run_sort_dance.py -f exps/example/mot/yolox_dancetrack_val.py -c pretrained/bytetrack_dance_model.pth.tar -b 1 -d 1 --fp16 --fuse --dataset dancetrack --expn sort_score_kalman_fir_step --TCM_first_step
# MOTDT
python3 tools/run_motdt_dance.py -f exps/example/mot/yolox_dancetrack_val.py -c pretrained/bytetrack_dance_model.pth.tar -b 1 -d 1 --fp16 --fuse --dataset dancetrack --expn motdt_score_kalman_fir_step --TCM_first_step
# ByteTrack
python3 tools/run_byte_dance.py -f exps/example/mot/yolox_dancetrack_val.py -c pretrained/bytetrack_dance_model.pth.tar -b 1 -d 1 --fp16 --fuse --dataset dancetrack --expn byte_score_kalman_fir_step --TCM_first_step
# DeepSORT
python3 tools/run_deepsort_dance.py -f exps/example/mot/yolox_dancetrack_val.py -c pretrained/bytetrack_dance_model.pth.tar -b 1 -d 1 --fp16 --fuse --dataset dancetrack --expn deepsort_score_kalman_fir_step --TCM_first_step
```
**mot17-val dataset**
```
# SORT
python3 tools/run_sort.py -f exps/example/mot/yolox_x_ablation.py -c pretrained/ocsort_mot17_ablation.pth.tar -b 1 -d 1 --fuse --expn mot17_sort_score_test_fp32 --TCM_first_step
# MOTDT
python3 tools/run_motdt.py -f exps/example/mot/yolox_x_ablation.py -c pretrained/ocsort_mot17_ablation.pth.tar -b 1 -d 1 --fuse --expn mot17_motdt_score_test_fp32 --TCM_first_step
# ByteTrack
python3 tools/run_byte.py -f exps/example/mot/yolox_x_ablation.py -c pretrained/ocsort_mot17_ablation.pth.tar -b 1 -d 1 --fuse --expn mot17_byte_score_test_fp32 --TCM_first_step --TCM_first_step_weight 0.6
# DeepSORT
python3 tools/run_deepsort.py -f exps/example/mot/yolox_x_ablation.py -c pretrained/ocsort_mot17_ablation.pth.tar -b 1 -d 1 --fuse --expn mot17_deepsort_score_test_fp32 --TCM_first_step
```
## Citation
If you find this work useful, please consider to cite our paper:
```
@inproceedings{yang2024hybrid,
title={Hybrid-sort: Weak cues matter for online multi-object tracking},
author={Yang, Mingzhan and Han, Guangxin and Yan, Bin and Zhang, Wenhua and Qi, Jinqing and Lu, Huchuan and Wang, Dong},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={38},
number={7},
pages={6504--6512},
year={2024}
}
```
## Acknowledgement
A large part of the code is borrowed from [YOLOX](https://github.com/Megvii-BaseDetection/YOLOX), [OC-SORT](https://github.com/noahcao/OC_SORT), [ByteTrack](https://github.com/ifzhang/ByteTrack), [BoT-SORT](https://github.com/NirAharon/BOT-SORT) and [FastReID](https://github.com/JDAI-CV/fast-reid). Many thanks for their wonderful works.
================================================
FILE: TrackEval/.gitignore
================================================
gt_data/*
!gt_data/Readme.md
tracker_output/*
!tracker_output/Readme.md
output/*
data/*
!goutput/Readme.md
**/__pycache__
.idea
error_log.txt
================================================
FILE: TrackEval/LICENSE
================================================
MIT License
Copyright (c) 2020 Jonathon Luiten
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: TrackEval/Readme.md
================================================
# TrackEval
*Code for evaluating object tracking.*
This codebase provides code for a number of different tracking evaluation metrics (including the [HOTA metrics](https://link.springer.com/article/10.1007/s11263-020-01375-2)), as well as supporting running all of these metrics on a number of different tracking benchmarks. Plus plotting of results and other things one may want to do for tracking evaluation.
## **NEW**: RobMOTS Challenge 2021
Call for submission to our [RobMOTS Challenge](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110) (Robust Multi-Object Tracking and Segmentation) held in conjunction with our [RVSU CVPR'21 Workshop](https://eval.vision.rwth-aachen.de/rvsu-workshop21/). Robust tracking evaluation against 8 tracking benchmarks. Challenge submission deadline June 15th. Also check out our workshop [call for papers](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=74).
## Official Evaluation Code
The following benchmarks use TrackEval as their official evaluation code, check out the links to see TrackEval in action:
- **[RobMOTS](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110)** ([Official Readme](docs/RobMOTS-Official/Readme.md))
- **[KITTI Tracking](http://www.cvlibs.net/datasets/kitti/eval_tracking.php)**
- **[KITTI MOTS](http://www.cvlibs.net/datasets/kitti/eval_mots.php)**
- **[MOTChallenge](https://motchallenge.net/)** ([Official Readme](docs/MOTChallenge-Official/Readme.md))
- **[Open World Tracking](https://openworldtracking.github.io)** ([Official Readme](docs/OpenWorldTracking-Official))
If you run a tracking benchmark and want to use TrackEval as your official evaluation code, please contact Jonathon (contact details below).
## Currently implemented metrics
The following metrics are currently implemented:
Metric Family | Sub metrics | Paper | Code | Notes |
|----- | ----------- |----- | ----------- | ----- |
| | | | | |
|**HOTA metrics**|HOTA, DetA, AssA, LocA, DetPr, DetRe, AssPr, AssRe|[paper](https://link.springer.com/article/10.1007/s11263-020-01375-2)|[code](trackeval/metrics/hota.py)|**Recommended tracking metric**|
|**CLEARMOT metrics**|MOTA, MOTP, MT, ML, Frag, etc.|[paper](https://link.springer.com/article/10.1155/2008/246309)|[code](trackeval/metrics/clear.py)| |
|**Identity metrics**|IDF1, IDP, IDR|[paper](https://arxiv.org/abs/1609.01775)|[code](trackeval/metrics/identity.py)| |
|**VACE metrics**|ATA, SFDA|[paper](https://link.springer.com/chapter/10.1007/11612704_16)|[code](trackeval/metrics/vace.py)| |
|**Track mAP metrics**|Track mAP|[paper](https://arxiv.org/abs/1905.04804)|[code](trackeval/metrics/track_map.py)|Requires confidence scores|
|**J & F metrics**|J&F, J, F|[paper](https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Perazzi_A_Benchmark_Dataset_CVPR_2016_paper.pdf)|[code](trackeval/metrics/j_and_f.py)|Only for Seg Masks|
|**ID Euclidean**|ID Euclidean|[paper](https://arxiv.org/pdf/2103.13516.pdf)|[code](trackeval/metrics/ideucl.py)| |
## Currently implemented benchmarks
The following benchmarks are currently implemented:
Benchmark | Sub-benchmarks | Type | Website | Code | Data Format |
|----- | ----------- |----- | ----------- | ----- | ----- |
| | | | | | |
|**RobMOTS**|Combination of 8 benchmarks|Seg Masks|[website](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110)|[code](trackeval/datasets/rob_mots.py)|[format](docs/RobMOTS-Official/Readme.md)|
|**Open World Tracking**|TAO-OW|OpenWorld / Seg Masks|[website](https://openworldtracking.github.io)|[code](trackeval/datasets/tao_ow.py)|[format](docs/OpenWorldTracking-Official/Readme.md)|
|**MOTChallenge**|MOT15/16/17/20|2D BBox|[website](https://motchallenge.net/)|[code](trackeval/datasets/mot_challenge_2d_box.py)|[format](docs/MOTChallenge-format.txt)|
|**KITTI Tracking**| |2D BBox|[website](http://www.cvlibs.net/datasets/kitti/eval_tracking.php)|[code](trackeval/datasets/kitti_2d_box.py)|[format](docs/KITTI-format.txt)|
|**BDD-100k**| |2D BBox|[website](https://bdd-data.berkeley.edu/)|[code](trackeval/datasets/bdd100k.py)|[format](docs/BDD100k-format.txt)|
|**TAO**| |2D BBox|[website](https://taodataset.org/)|[code](trackeval/datasets/tao.py)|[format](docs/TAO-format.txt)|
|**MOTS**|KITTI-MOTS, MOTS-Challenge|Seg Mask|[website](https://www.vision.rwth-aachen.de/page/mots)|[code](trackeval/datasets/mots_challenge.py) and [code](trackeval/datasets/kitti_mots.py)|[format](docs/MOTS-format.txt)|
|**DAVIS**|Unsupervised|Seg Mask|[website](https://davischallenge.org/)|[code](trackeval/datasets/davis.py)|[format](docs/DAVIS-format.txt)|
|**YouTube-VIS**| |Seg Mask|[website](https://youtube-vos.org/dataset/vis/)|[code](trackeval/datasets/youtube_vis.py)|[format](docs/YouTube-VIS-format.txt)|
|**Head Tracking Challenge**| |2D BBox|[website](https://arxiv.org/pdf/2103.13516.pdf)|[code](trackeval/datasets/head_tracking_challenge.py)|[format](docs/MOTChallenge-format.txt)|
## HOTA metrics
This code is also the official reference implementation for the HOTA metrics:
*[HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking](https://link.springer.com/article/10.1007/s11263-020-01375-2). IJCV 2020. Jonathon Luiten, Aljosa Osep, Patrick Dendorfer, Philip Torr, Andreas Geiger, Laura Leal-Taixe and Bastian Leibe.*
HOTA is a novel set of MOT evaluation metrics which enable better understanding of tracking behavior than previous metrics.
For more information check out the following links:
- [Short blog post on HOTA](https://jonathonluiten.medium.com/how-to-evaluate-tracking-with-the-hota-metrics-754036d183e1) - **HIGHLY RECOMMENDED READING**
- [IJCV version of paper](https://link.springer.com/article/10.1007/s11263-020-01375-2) (Open Access)
- [ArXiv version of paper](https://arxiv.org/abs/2009.07736)
- [Code](trackeval/metrics/hota.py)
## Properties of this codebase
The code is written 100% in python with only numpy and scipy as minimum requirements.
The code is designed to be easily understandable and easily extendable.
The code is also extremely fast, running at more than 10x the speed of the both [MOTChallengeEvalKit](https://github.com/dendorferpatrick/MOTChallengeEvalKit), and [py-motmetrics](https://github.com/cheind/py-motmetrics) (see detailed speed comparison below).
The implementation of CLEARMOT and ID metrics aligns perfectly with the [MOTChallengeEvalKit](https://github.com/dendorferpatrick/MOTChallengeEvalKit).
By default the code prints results to the screen, saves results out as both a summary txt file and a detailed results csv file, and outputs plots of the results. All outputs are by default saved to the 'tracker' folder for each tracker.
## Running the code
The code can be run in one of two ways:
- From the terminal via one of the scripts [here](scripts/). See each script for instructions and arguments, hopefully this is self-explanatory.
- Directly by importing this package into your code, see the same scripts above for how.
## Quickly evaluate on supported benchmarks
To enable you to use TrackEval for evaluation as quickly and easily as possible, we provide ground-truth data, meta-data and example trackers for all currently supported benchmarks.
You can download this here: [data.zip](https://omnomnom.vision.rwth-aachen.de/data/TrackEval/data.zip) (~150mb).
The data for RobMOTS is separate and can be found here: [rob_mots_train_data.zip](https://omnomnom.vision.rwth-aachen.de/data/RobMOTS/train_data.zip) (~750mb).
The easiest way to begin is to extract this zip into the repository root folder such that the file paths look like: TrackEval/data/gt/...
This then corresponds to the default paths in the code. You can now run each of the scripts [here](scripts/) without providing any arguments and they will by default evaluate all trackers present in the supplied file structure. To evaluate your own tracking results, simply copy your files as a new tracker folder into the file structure at the same level as the example trackers (MPNTrack, CIWT, track_rcnn, qdtrack, ags, Tracktor++, STEm_Seg), ensuring the same file structure for your trackers as in the example.
Of course, if your ground-truth and tracker files are located somewhere else you can simply use the script arguments to point the code toward your data.
To ensure your tracker outputs data in the correct format, check out our format guides for each of the supported benchmarks [here](docs), or check out the example trackers provided.
## Evaluate on your own custom benchmark
To evaluate on your own data, you have two options:
- Write custom dataset code (more effort, rarely worth it).
- Convert your current dataset and trackers to the same format of an already implemented benchmark.
To convert formats, check out the format specifications defined [here](docs).
By default, we would recommend the MOTChallenge format, although any implemented format should work. Note that for many cases you will want to use the argument ```--DO_PREPROC False``` unless you want to run preprocessing to remove distractor objects.
## Requirements
Code tested on Python 3.7.
- Minimum requirements: numpy, scipy
- For plotting: matplotlib
- For segmentation datasets (KITTI MOTS, MOTS-Challenge, DAVIS, YouTube-VIS): pycocotools
- For DAVIS dataset: Pillow
- For J & F metric: opencv_python, scikit_image
- For simples test-cases for metrics: pytest
use ```pip3 -r install requirements.txt``` to install all possible requirements.
use ```pip3 -r install minimum_requirments.txt``` to only install the minimum if you don't need the extra functionality as listed above.
## Timing analysis
Evaluating CLEAR + ID metrics on Lift_T tracker on MOT17-train (seconds) on a i7-9700K CPU with 8 physical cores (median of 3 runs):
Num Cores|TrackEval|MOTChallenge|Speedup vs MOTChallenge|py-motmetrics|Speedup vs py-motmetrics
:---|:---|:---|:---|:---|:---
1|9.64|66.23|6.87x|99.65|10.34x
4|3.01|29.42|9.77x| |33.11x*
8|1.62|29.51|18.22x| |61.51x*
*using a different number of cores as py-motmetrics doesn't allow multiprocessing.
```
python scripts/run_mot_challenge.py --BENCHMARK MOT17 --TRACKERS_TO_EVAL Lif_T --METRICS CLEAR Identity --USE_PARALLEL False --NUM_PARALLEL_CORES 1
```
Evaluating CLEAR + ID metrics on LPC_MOT tracker on MOT20-train (seconds) on a i7-9700K CPU with 8 physical cores (median of 3 runs):
Num Cores|TrackEval|MOTChallenge|Speedup vs MOTChallenge|py-motmetrics|Speedup vs py-motmetrics
:---|:---|:---|:---|:---|:---
1|18.63|105.3|5.65x|175.17|9.40x
```
python scripts/run_mot_challenge.py --BENCHMARK MOT20 --TRACKERS_TO_EVAL LPC_MOT --METRICS CLEAR Identity --USE_PARALLEL False --NUM_PARALLEL_CORES 1
```
## License
TrackEval is released under the [MIT License](LICENSE).
## Contact
If you encounter any problems with the code, please contact [Jonathon Luiten](https://www.vision.rwth-aachen.de/person/216/) ([luiten@vision.rwth-aachen.de](mailto:luiten@vision.rwth-aachen.de)).
If anything is unclear, or hard to use, please leave a comment either via email or as an issue and I would love to help.
## Dedication
This codebase was built for you, in order to make your life easier! For anyone doing research on tracking or using trackers, please don't hesitate to reach out with any comments or suggestions on how things could be improved.
## Contributing
We welcome contributions of new metrics and new supported benchmarks. Also any other new features or code improvements. Send a PR, an email, or open an issue detailing what you'd like to add/change to begin a conversation.
## Citing TrackEval
If you use this code in your research, please use the following BibTeX entry:
```BibTeX
@misc{luiten2020trackeval,
author = {Jonathon Luiten, Arne Hoffhues},
title = {TrackEval},
howpublished = {\url{https://github.com/JonathonLuiten/TrackEval}},
year = {2020}
}
```
Furthermore, if you use the HOTA metrics, please cite the following paper:
```
@article{luiten2020IJCV,
title={HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
author={Luiten, Jonathon and Osep, Aljosa and Dendorfer, Patrick and Torr, Philip and Geiger, Andreas and Leal-Taix{\'e}, Laura and Leibe, Bastian},
journal={International Journal of Computer Vision},
pages={1--31},
year={2020},
publisher={Springer}
}
```
If you use any other metrics please also cite the relevant papers, and don't forget to cite each of the benchmarks you evaluate on.
================================================
FILE: TrackEval/docs/BDD100k-format.txt
================================================
Taken from: https://bdd-data.berkeley.edu/wad-2020.html
BDD100K MOT Dataset
To advance the study on multiple object tracking, we introduce BDD100K MOT Dataset. We provide 1,400 video sequences for training, 200 video sequences for validation and 400 video sequences for testing. Each video sequence is about 40 seconds long with 5 FPS resulting in approximately 200 frames per video.
BDD100K MOT Dataset is not only diverse in visual scale among and within tracks, but in the temporal range of each track. Objects in the BDD100K MOT dataset also present complicated occlusion and reappearing patterns. An object may be fully occluded or move out of the frame, and then reappear later. BDD100K MOT Dataset shows real challenges of object re-identification for tracking in autonomous driving. Details about the MOT dataset can be found in the BDD100K paper (https://arxiv.org/abs/1805.04687). Access the BDD100K data website (https://bdd-data.berkeley.edu/) to download the data.
Folder Structure
bdd100k/
├── images/
| ├── track/
| | ├── train/
| | | ├── $VIDEO_NAME/
| | | | ├── $VIDEO_NAME-$FRAME_INDEX.jpg
| | ├── val/
| | ├── test/
├── labels-20/
| ├── box-track/
| | ├── train/
| | | ├── $VIDEO_NAME.json
| | | |
| | ├── val/
The frames for each video are stored in a folder in the images directory. The labels for each video are stored in a json file with the format detailed below.
Label Format
Each json file contains a list of frame objects, and each frame object has the format below. The format follows the schema of BDD100K data format (https://github.com/ucbdrive/bdd100k/blob/master/doc/format.md).
- name: string
- videoName: string
- index: int
- labels: [ ]
- id: string
- category: string
- attributes:
- Crowd: boolean
- Occluded: boolean
- Truncated: boolean
- box2d:
- x1: float
- y1: float
- x2: float
- y2: float
There are 11 object categories in this release:
pedestrian
rider
other person
car
bus
truck
train
trailer
other vehicle
motorcycle
bicycle
Notes:
The same instance shares "id" across frames.
The "pedestrian", "bicycle", and "motorcycle" correspond to the "person", "bike", and "motor" classes in the BDD100K Detection dataset.
We consider "other person", "trailer", and "other vehicle" as distractors, which are ignored during evaluation. We only evaluate the multi-object tracking of the other 8 categories.
We set three super-categories: "person" (with classes "pedestrian" and"rider"), "vehicle" ("car", "bus", "truck", and "train"), and "bike" ("motorcycle" and "bicycle") for the purpose of evaluation.
Submission Format
The submission file for each of the two phases is a json file compressed by zip. Each json file is a list of frame objects with the format detailed below. The format also follows the schema of BDD100K data format (https://github.com/ucbdrive/bdd100k/blob/master/doc/format.md).
- name: string
- labels [ ]:
- id: string
- category: string
- box2d:
- x1: float
- y1: float
- x2: float
- y2: float
Note that objects with the same identity share id across frames in a given video, and should be unique across different videos. Our evaluation will match the category string in evaluation, so you can assign your own integer ID for the categories in your model. But we recommend to encode the 8 relevant categories in the following order so that it is easier for the research community to share the models.
pedestrian
rider
car
truck
bus
train
motorcycle
bicycle
The evaluation server will perform evaluation for each category and aggregate the results to compute the overall metrics. Then the server will merge both the ground-truth and predicted labels into super-categories and evaluate for each super- category.
Evaluation
Evaluation platform: We host our evaluation server on CodaLab (https://competitions.codalab.org/competitions/24492). There are two phases for the challenge: val phase and test phase. The final ranking will be based on the test phase.
Pre-training: It is a fair game to pre-train your network with ImageNet or COCO, but if other datasets are used, please note in the submission description. We will rank the methods without using external datasets except ImageNet and COCO.
Ignoring distractors: As a preprocessing step, all predicted boxes are matched and the ones matched to distractor ground-truth boxes ("other person", "trailer", and "other vehicle") are ignored.
Crowd region: After bounding box matching, we ignore all detected false-positive boxes that has >50% overlap with the crowd region (ground-truth boxes with the "Crowd" attribute).
Super-category: In addition to the evaluation of all 8 classes, we merge ground truth and prediction categories into 3 super-categories specified above, and evaluate the results for each super-category. The super-category evaluation results will be provided only for the purpose of reference.
================================================
FILE: TrackEval/docs/DAVIS-format.txt
================================================
Annotation Format:
The annotations in each frame are stored in png format.
This png is stored indexed i.e. it has a single channel and each pixel has a value from 0 to 254 that corresponds to a color palette attached to the png file.
It is important to take this into account when decoding the png i.e. the output of decoding should be a single channel image and it should not be necessary to do any remap from RGB to indexes.
The latter is crucial to preseve the index of each object so it can match to the correct object in evaluation.
Each pixel that belongs to the same object has the same value in this png map through the whole video.
Start at 1 for the first object, then 2, 3, 4 etc.
The background (not an object) has value 0.
Also note that invalid/void pixels are stored with a 254 value.
These can be read like this:
import PIL.Image as Image
img = np.array(Image.open("000005.png"))
or like this:
ann_data = tf.read_file(ann_filename)
ann = tf.image.decode_image(ann_data, dtype=tf.uint8, channels=1)
See the code for loading the davis dataset for more details.
================================================
FILE: TrackEval/docs/How_To/Add_a_new_metric.md
================================================
# How to add a new or custom family of evaluation metrics to TrackEval
- Create your metrics code in ```trackeval/metrics/.py```.
- It's probably easiest to start by copying an existing metrics code and editing it, e.g. ```trackeval/metrics/identity.py``` is probably the simplest.
- Your metric should be class, and it should inherit from the ```trackeval.metrics._base_metric._BaseMetric``` class.
- Define an ```__init__``` function that defines the different ```fields``` (values) that your metric will calculate. See ```trackeval/metrics/_base_metric.py``` for a list of currently used field types. Feel free to add new types.
- Define your code to actually calculate your metric for a single sequence and single class in a function called ```eval_sequence```, which takes a data dictionary as input, and returns a results dictionary as output.
- Define functions for how to combine your metric field values over a) sequences ```combine_sequences```, b) over classes ```combine_classes_class_averaged```, and c) over classes weighted by the number of detections ```combine_classes_det_averaged```.
- We find using a function such as the ```_compute_final_fields``` function that we use in the current metrics is convienient because it is likely used for metrics calculation and for the different metric combination, however this is not required.
- Register your new metric by adding it to ```trackeval/metrics/init.py```
- Your new metric can be used by passing the metrics class to a list of metrics which is passed to the evaluator (see files in ```scripts/*```).
================================================
FILE: TrackEval/docs/KITTI-format.txt
================================================
Taken from download link found at: http://www.cvlibs.net/datasets/kitti/eval_tracking.php
###########################################################################
# THE KITTI VISION BENCHMARK SUITE: TRACKING BENCHMARK #
# Andreas Geiger Philip Lenz Raquel Urtasun #
# Karlsruhe Institute of Technology #
# Toyota Technological Institute at Chicago #
# www.cvlibs.net #
###########################################################################
For recent updates see http://www.cvlibs.net/datasets/kitti/eval_tracking.php.
This file describes the KITTI tracking benchmarks, consisting of 21
training sequences and 29 test sequences.
Despite the fact that we have labeled 8 different classes, only the classes
'Car' and 'Pedestrian' are evaluated in our benchmark, as only for those
classes enough instances for a comprehensive evaluation have been labeled.
The labeling process has been performed in two steps: First we hired a set
of annotators, to label 3D bounding boxes for tracklets in 3D Velodyne
point clouds. Since for a pedestrian tracklet, a single 3D bounding box
tracklet (dimensions have been fixed) often fits badly, we additionally
labeled the left/right boundaries of each object by making use of Mechanical
Turk. We also collected labels of the object's occlusion state, and computed
the object's truncation via backprojecting a car/pedestrian model into the
image plane.
NOTE: WHEN SUBMITTING RESULTS, PLEASE STORE THEM IN THE SAME DATA FORMAT IN
WHICH THE GROUND TRUTH DATA IS PROVIDED (SEE BELOW), USING THE FILE NAMES
0000.txt 0001.txt ... CREATE A ZIP ARCHIVE OF THEM AND STORE YOUR
RESULTS (ONLY THE RESULTS OF THE TEST SET) IN ITS ROOT FOLDER. FOR A
RE-SUBMISSION, _ONLY_ THE RE-SUBMITTED RESULTS WILL BE SHOWN IN THE TABLE.
Data Format Description
=======================
The data for training and testing can be found in the corresponding folders.
The sub-folders are structured as follows:
- image_02/%04d/ contains the left color camera sequence images (png)
- image_03/%04d/ contains the right color camera sequence images (png)
- label_02/ contains the left color camera label files (plain text files)
- calib/ contains the calibration for all four cameras (plain text files)
The label files contain the following information.
All values (numerical or strings) are separated via spaces, each row
corresponds to one object. The 17 columns represent:
#Values Name Description
----------------------------------------------------------------------------
1 frame Frame within the sequence where the object appearers
1 track id Unique tracking id of this object within this sequence
1 type Describes the type of object: 'Car', 'Van', 'Truck',
'Pedestrian', 'Person_sitting', 'Cyclist', 'Tram',
'Misc' or 'DontCare'
1 truncated Integer (0,1,2) indicating the level of truncation.
Note that this is in contrast to the object detection
benchmark where truncation is a float in [0,1].
1 occluded Integer (0,1,2,3) indicating occlusion state:
0 = fully visible, 1 = partly occluded
2 = largely occluded, 3 = unknown
1 alpha Observation angle of object, ranging [-pi..pi]
4 bbox 2D bounding box of object in the image (0-based index):
contains left, top, right, bottom pixel coordinates
3 dimensions 3D object dimensions: height, width, length (in meters)
3 location 3D object location x,y,z in camera coordinates (in meters)
1 rotation_y Rotation ry around Y-axis in camera coordinates [-pi..pi]
1 score Only for results: Float, indicating confidence in
detection, needed for p/r curves, higher is better.
Here, 'DontCare' labels denote regions in which objects have not been labeled,
for example because they have been too far away from the laser scanner. To
prevent such objects from being counted as false positives our evaluation
script will ignore objects tracked in don't care regions of the test set.
You can use the don't care labels in the training set to avoid that your object
detector/tracking algorithm is harvesting hard negatives from those areas,
in case you consider non-object regions from the training images as negative
examples.
The reference point for the 3D bounding box for each object is centered on the
bottom face of the box. The corners of bounding box are computed as follows with
respect to the reference point and in the object coordinate system:
x_corners = [l/2, l/2, -l/2, -l/2, l/2, l/2, -l/2, -l/2]^T
y_corners = [0, 0, 0, 0, -h, -h, -h, -h ]^T
z_corners = [w/2, -w/2, -w/2, w/2, w/2, -w/2, -w/2, w/2 ]^T
with l=length, h=height, and w=width.
The coordinates in the camera coordinate system can be projected in the image
by using the 3x4 projection matrix in the calib folder, where for the left
color camera for which the images are provided, P2 must be used. The
difference between rotation_y and alpha is, that rotation_y is directly
given in camera coordinates, while alpha also considers the vector from the
camera center to the object center, to compute the relative orientation of
the object with respect to the camera. For example, a car which is facing
along the X-axis of the camera coordinate system corresponds to rotation_y=0,
no matter where it is located in the X/Z plane (bird's eye view), while
alpha is zero only, when this object is located along the Z-axis of the
camera. When moving the car away from the Z-axis, the observation angle
(\alpha) will change.
An overview of the coordinate systems, reference point and geometrical
definitions is given in cs_overview.pdf.
To project a point from Velodyne coordinates into the left color image,
you can use this formula: x = P2 * R0_rect * Tr_velo_to_cam * y
For the right color image: x = P3 * R0_rect * Tr_velo_to_cam * y
Note: All matrices are stored row-major, i.e., the first values correspond
to the first row. R0_rect contains a 3x3 matrix which you need to extend to
a 4x4 matrix by adding a 1 as the bottom-right element and 0's elsewhere.
Tr_xxx is a 3x4 matrix (R|t), which you need to extend to a 4x4 matrix
in the same way!
The sensors were not moved between the different days while taking footage.
However, the full camera calibration was performed for every day separately.
Therefore, only 'Tr_imu_velo' is constant for all sequences.
Note that while all this information is available for the training data,
only the data which is actually needed for the particular benchmark must
be provided to the evaluation server. However, all 17 values must be provided
at all times, with the unused ones set to their default values (=invalid).
Additionally a 18'th value must be provided
with a floating value of the score for a particular tracked detection, where
higher indicates higher confidence in the detection. The range of your scores
will be automatically determined by our evaluation server, you don't have to
normalize it, but it should be roughly linear.
Tracking Benchmark
==================
The goal in the object tracking task is to estimate object tracklets for the
classes 'Car', 'Pedestrian', and (optional) 'Cyclist'. The tracking
algorithm must provide as output the 2D 0-based bounding boxes in each image in
the sequence using the format specified above, as well as a score, indicating
the confidence in the particular frame for this track. All other values must be
set to their default values (=invalid), see above. One text file per sequence
must be provided in a zip archive, where each file can contain many detections,
depending on the number of objects per sequence. In our evaluation we only
evaluate detections/objects larger than 25 pixel (height) in the image and do
not count Vans as false positives for cars or Sitting Persons as wrong positives
for Pedestrians due to their similarity in appearance. (All ignored objects
are considered as DontCare areas.) As evaluation criterion we follow the
HOTA, CLEARMOT and Mostly-Tracked/Partly-Tracked/Mostly-Lost metrics.
Raw Data
========
Raw data is mapped to the tracking benchmark sequences and available for
download.
The velodyne and positioning data for training and testing can be found in the
corresponding folders. The sub-folders are structured as follows:
- velodyne/%04d/ contains the raw velodyne point clouds (binary file)
- oxts/ contains the raw position (oxts) data (plain text files)
================================================
FILE: TrackEval/docs/MOTChallenge-Official/Readme.md
================================================

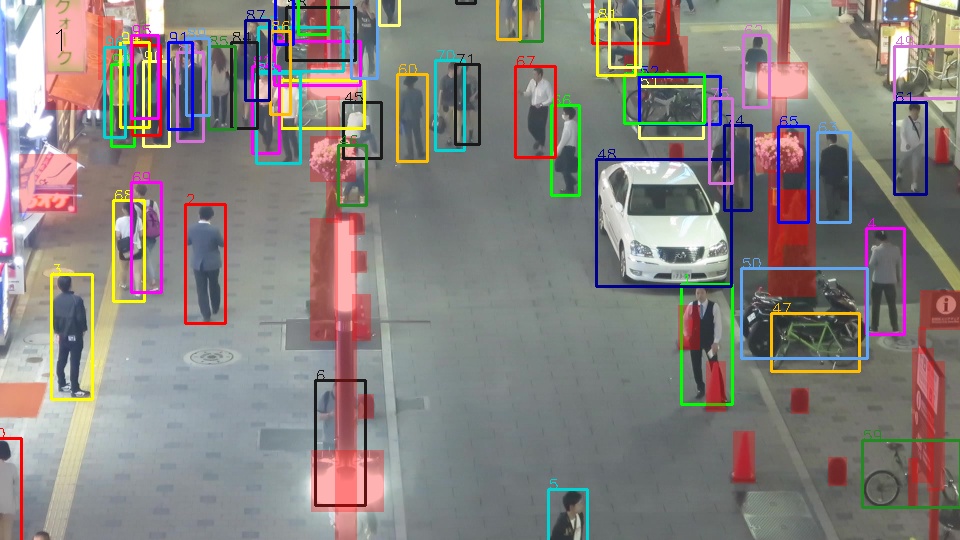
# MOTChallenge Official Evaluation Kit - Multi-Object Tracking - MOT15, MOT16, MOT17, MOT20
TrackEval is now the Official Evaluation Kit for MOTChallenge.
This repository contains the evaluation scripts for the MOT challenges available at www.MOTChallenge.net.
This codebase replaces the previous version that used to be accessible at https://github.com/dendorferpatrick/MOTChallengeEvalKit and is no longer maintained.
Challenge Name | Data url |
|----- | ----------- |
|2D MOT 15| https://motchallenge.net/data/MOT15/ |
|MOT 16| https://motchallenge.net/data/MOT16/ |
|MOT 17| https://motchallenge.net/data/MOT17/ |
|MOT 20| https://motchallenge.net/data/MOT20/ |
## Requirements
* Python (3.5 or newer)
* Numpy and Scipy
## Directories and Data
The easiest way to get started is to simply download the TrackEval example data from here: [data.zip](https://omnomnom.vision.rwth-aachen.de/data/TrackEval/data.zip) (~150mb).
This contains all the ground-truth, example trackers and meta-data that you will need.
Extract this zip into the repository root folder such that the file paths look like: TrackEval/data/gt/...
## Evaluation
To run the evaluation for your method please run the script at ```TrackEval/scripts/run_mot_challenge.py```.
Some of the basic arguments are described below. For more arguments, please see the script itself.
```BENCHMARK```: Name of the benchmark, e.g. MOT15, MO16, MOT17 or MOT20 (default : MOT17)
```SPLIT_TO_EVAL```: Data split on which to evalute e.g. train, test (default : train)
```TRACKERS_TO_EVAL```: List of tracker names for which you wish to run evaluation. e.g. MPNTrack (default: all trackers in tracker folder)
```METRICS```: List of metric families which you wish to compute. e.g. HOTA CLEAR Identity VACE (default: HOTA CLEAR Identity)
```USE_PARALLEL```: Whether to run evaluation in parallel on multiple cores. (default: False)
```NUM_PARALLEL_CORES```: Number of cores to use when running in parallel. (default: 8)
An example is below (this will work on the supplied example data above):
```
python scripts/run_mot_challenge.py --BENCHMARK MOT17 --SPLIT_TO_EVAL train --TRACKERS_TO_EVAL MPNTrack --METRICS HOTA CLEAR Identity VACE --USE_PARALLEL False --NUM_PARALLEL_CORES 1
```
## Data Format
The tracker file format should be the same as the ground truth file,
which is a CSV text-file containing one object instance per line.
Each line must contain 10 values:
<frame>,
<id>,
<bb_left>,
<bb_top>,
<bb_width>,
<bb_height>,
<conf>,
<x>,
<y>,
<z>
The world coordinates x,y,z
are ignored for the 2D challenge and can be filled with -1.
Similarly, the bounding boxes are ignored for the 3D challenge.
However, each line is still required to contain 10 values.
All frame numbers, target IDs and bounding boxes are 1-based. Here is an example:
## Evaluating on your own Data
The repository also allows you to include your own datasets and evaluate your method on your own challenge ``````. To do so, follow these two steps:
***1. Ground truth data preparation***
Prepare your sequences in directory ```TrackEval/data/gt/mot_challenge/``` following this structure:
```
.
|——
|—— gt
|—— gt.txt
|—— seqinfo.ini
|——
|—— ……
|——
|—— …...
```
***2. Sequence file***
Create text files containing the sequence names; ```-train.txt```, ```-test.txt```, ```-test.txt``` inside the ```seqmaps``` folder, e.g.:
```-all.txt```
```
name
```
```-train.txt```
```
name
```
```-test.txt```
```
name
```
To run the evaluation for your method adjust the file ```scripts/run_mot_challenge.py``` and set ```BENCHMARK = ```
## Citation
If you work with the code and the benchmark, please cite:
***TrackEval***
```
@misc{luiten2020trackeval,
author = {Jonathon Luiten, Arne Hoffhues},
title = {TrackEval},
howpublished = {\url{https://github.com/JonathonLuiten/TrackEval}},
year = {2020}
}
```
***MOTChallenge Journal***
```
@article{dendorfer2020motchallenge,
title={MOTChallenge: A Benchmark for Single-camera Multiple Target Tracking},
author={Dendorfer, Patrick and Osep, Aljosa and Milan, Anton and Schindler, Konrad and Cremers, Daniel and Reid, Ian and Roth, Stefan and Leal-Taix{\'e}, Laura},
journal={International Journal of Computer Vision},
pages={1--37},
year={2020},
publisher={Springer}
}
```
***MOT 15***
```
@article{MOTChallenge2015,
title = {{MOTC}hallenge 2015: {T}owards a Benchmark for Multi-Target Tracking},
shorttitle = {MOTChallenge 2015},
url = {http://arxiv.org/abs/1504.01942},
journal = {arXiv:1504.01942 [cs]},
author = {Leal-Taix\'{e}, L. and Milan, A. and Reid, I. and Roth, S. and Schindler, K.},
month = apr,
year = {2015},
note = {arXiv: 1504.01942},
keywords = {Computer Science - Computer Vision and Pattern Recognition}
}
```
***MOT 16, MOT 17***
```
@article{MOT16,
title = {{MOT}16: {A} Benchmark for Multi-Object Tracking},
shorttitle = {MOT16},
url = {http://arxiv.org/abs/1603.00831},
journal = {arXiv:1603.00831 [cs]},
author = {Milan, A. and Leal-Taix\'{e}, L. and Reid, I. and Roth, S. and Schindler, K.},
month = mar,
year = {2016},
note = {arXiv: 1603.00831},
keywords = {Computer Science - Computer Vision and Pattern Recognition}
}
```
***MOT 20***
```
@article{MOTChallenge20,
title={MOT20: A benchmark for multi object tracking in crowded scenes},
shorttitle = {MOT20},
url = {http://arxiv.org/abs/1906.04567},
journal = {arXiv:2003.09003[cs]},
author = {Dendorfer, P. and Rezatofighi, H. and Milan, A. and Shi, J. and Cremers, D. and Reid, I. and Roth, S. and Schindler, K. and Leal-Taix\'{e}, L. },
month = mar,
year = {2020},
note = {arXiv: 2003.09003},
keywords = {Computer Science - Computer Vision and Pattern Recognition}
}
```
***HOTA metrics***
```
@article{luiten2020IJCV,
title={HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
author={Luiten, Jonathon and Osep, Aljosa and Dendorfer, Patrick and Torr, Philip and Geiger, Andreas and Leal-Taix{\'e}, Laura and Leibe, Bastian},
journal={International Journal of Computer Vision},
pages={1--31},
year={2020},
publisher={Springer}
}
```
## Feedback and Contact
We are constantly working on improving our benchmark to provide the best performance to the community.
You can help us to make the benchmark better by open issues in the repo and reporting bugs.
For general questions, please contact one of the following:
```
Patrick Dendorfer - patrick.dendorfer@tum.de
Jonathon Luiten - luiten@vision.rwth-aachen.de
Aljosa Osep - aljosa.osep@tum.de
```
================================================
FILE: TrackEval/docs/MOTChallenge-format.txt
================================================
Taken from: https://motchallenge.net/instructions/
File Format
Please submit your results as a single .zip file. The results for each sequence must be stored in a separate .txt file in the archive's root folder. The file name must be exactly like the sequence name (case sensitive).
The file format should be the same as the ground truth file, which is a CSV text-file containing one object instance per line. Each line must contain 10 values:
, , , , , , , , ,
The conf value contains the detection confidence in the det.txt files. For the ground truth, it acts as a flag whether the entry is to be considered. A value of 0 means that this particular instance is ignored in the evaluation, while any other value can be used to mark it as active. For submitted results, all lines in the .txt file are considered. The world coordinates x,y,z are ignored for the 2D challenge and can be filled with -1. Similarly, the bounding boxes are ignored for the 3D challenge. However, each line is still required to contain 10 values.
All frame numbers, target IDs and bounding boxes are 1-based. Here is an example:
Tracking with bounding boxes
(MOT15, MOT16, MOT17, MOT20)
1, 3, 794.27, 247.59, 71.245, 174.88, -1, -1, -1, -1
1, 6, 1648.1, 119.61, 66.504, 163.24, -1, -1, -1, -1
1, 8, 875.49, 399.98, 95.303, 233.93, -1, -1, -1, -1
...
Multi Object Tracking & Segmentation
(MOTS Challenge)
Each line of an annotation txt file is structured like this (where rle means run-length encoding from COCO):
time_frame id class_id img_height img_width rle
An example line from a txt file:
52 1005 1 375 1242 WSV:2d;1O10000O10000O1O100O100O1O100O1000000000000000O100O102N5K00O1O1N2O110OO2O001O1NTga3
Meaning:
time frame 52
object id 1005 (meaning class id is 1, i.e. car and instance id is 5)
class id 1
image height 375
image width 1242
rle WSV:2d;1O10000O10000O1O100O100O1O100O1000000000000000O100O...1O1N
image height, image width, and rle can be used together to decode a mask using cocotools(https://github.com/cocodataset/cocoapi) .
================================================
FILE: TrackEval/docs/MOTS-format.txt
================================================
Taken from: https://www.vision.rwth-aachen.de/page/mots
Annotation Format
We provide two alternative and equivalent formats, one encoded as png images, and one encoded as txt files. The txt files are smaller, and faster to be read in, but the cocotools are needed to decode the masks. For code to read the annotations also see mots_tools/blob/master/mots_common/io.py
Note that in both formats an id value of 10,000 denotes an ignore region and 0 is background. The class id can be obtained by floor divison of the object id by 1000 (class_id = obj_id // 1000) and the instance id can be obtained by the object id modulo 1000 (instance_id = obj_id % 1000). The object ids are consistent over time.
The class ids are the following
car 1
pedestrian 2
png format
The png format has a single color channel with 16 bits and can for example be read like this:
import PIL.Image as Image
img = np.array(Image.open("000005.png"))
obj_ids = np.unique(img)
# to correctly interpret the id of a single object
obj_id = obj_ids[0]
class_id = obj_id // 1000
obj_instance_id = obj_id % 1000
When using a TensorFlow input pipeline for reading the annotations, you can use
ann_data = tf.read_file(ann_filename)
ann = tf.image.decode_image(ann_data, dtype=tf.uint16, channels=1)
txt format
Each line of an annotation txt file is structured like this (where rle means run-length encoding from COCO):
time_frame id class_id img_height img_width rle
An example line from a txt file:
52 1005 1 375 1242 WSV:2d;1O10000O10000O1O100O100O1O100O1000000000000000O100O102N5K00O1O1N2O110OO2O001O1NTga3
Which means
time frame 52
object id 1005 (meaning class id is 1, i.e. car and instance id is 5)
class id 1
image height 375
image width 1242
rle WSV:2d;1O10000O10000O1O100O100O1O100O1000000000000000O100O...1O1N
image height, image width, and rle can be used together to decode a mask using cocotools.
================================================
FILE: TrackEval/docs/OpenWorldTracking-Official/Readme.md
================================================

# Opening Up Open-World Tracking - Official Evaluation Code
TrackEval now contains the official evalution code for evaluating the task of **Open World Tracking**.
This is the official code from the following paper:
Opening up Open-World Tracking
Yang Liu*, Idil Esen Zulfikar*, Jonathon Luiten*, Achal Dave*, Deva Ramanan, Bastian Leibe, Aljoša Ošep, Laura Leal-Taixé
*Equal contribution
CVPR 2022
[Paper](https://arxiv.org/abs/2104.11221)
[Website](https://openworldtracking.github.io)
## Running and understanding the code
The code can be run by running the following script (see script for arguments and how to run):
[TAO-OW run script](https://github.com/JonathonLuiten/TrackEval/blob/master/scripts/run_tao_ow.py)
To understand the the data is being read and used, see the TAO-OW dataset class:
[TAO-OW dataset class](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/datasets/tao_ow.py)
The 'Open World Tracking Accuracy' (OWTA) metric proposed in the paper is call RHOTA (Recall-based HOTA) within this repository, and the implementation can be found here:
[OWTA/RHOTA metric](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/metrics/hota.py)
## Citation
If you work with the code and the benchmark, please cite:
***Opening Up Open-World Tracking***
```
@inproceedings{liu2022opening,
title={Opening up Open-World Tracking},
author={Liu, Yang and Zulfikar, Idil Esen and Luiten, Jonathon and Dave, Achal and Ramanan, Deva and Leibe, Bastian and O{\v{s}}ep, Aljo{\v{s}}a and Leal-Taix{\'e}, Laura},
journal={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2022}
}
```
***TrackEval***
```
@misc{luiten2020trackeval,
author = {Jonathon Luiten, Arne Hoffhues},
title = {TrackEval},
howpublished = {\url{https://github.com/JonathonLuiten/TrackEval}},
year = {2020}
}
```
================================================
FILE: TrackEval/docs/RobMOTS-Official/Readme.md
================================================
[](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110)
# RobMOTS Official Evaluation Code
### NEWS: [RobMOTS Challenge](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110) for the [RVSU CVPR'21 Workshop](https://eval.vision.rwth-aachen.de/rvsu-workshop21/) is now live!!!! Challenge deadline June 15.
### NEWS: [Call for short papers](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=74) (4 pages) on tracking and other video topics for [RVSU CVPR'21 Workshop](https://eval.vision.rwth-aachen.de/rvsu-workshop21/)!!!! Paper deadline June 4.
TrackEval is now the Official Evaluation Kit for the RobMOTS Challenge.
This repository contains the official evaluation code for the challenges available at the [RobMOTS Website](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110).
The RobMOTS Challenge tests trackers' ability to work robustly across 8 different benchmarks, while tracking the [80 categories of objects from COCO](https://cocodataset.org/#explore).
The following benchmarks are included:
Benchmark | Website |
|----- | ----------- |
|MOTS Challenge| https://motchallenge.net/results/MOTS/ |
|KITTI-MOTS| http://www.cvlibs.net/datasets/kitti/eval_mots.php |
|DAVIS Challenge Unsupervised| https://davischallenge.org/challenge2020/unsupervised.html |
|YouTube-VIS| https://youtube-vos.org/dataset/vis/ |
|BDD100k MOTS| https://bdd-data.berkeley.edu/ |
|TAO| https://taodataset.org/ |
|Waymo Open Dataset| https://waymo.com/open/ |
|OVIS| http://songbai.site/ovis/ |
## Installing, obtaining the data, and running
Simply follow the code snippet below to install the evaluation code, download the train groundtruth data and an example tracker, and run the evaluation code on the sample tracker.
Note the code requires python 3.5 or higher.
```
# Download the TrackEval repo
git clone https://github.com/JonathonLuiten/TrackEval.git
# Move to repo folder
cd TrackEval
# Create a virtual env in the repo for evaluation
python3 -m venv ./venv
# Activate the virtual env
source venv/bin/activate
# Update pip to have the latest version of packages
pip install --upgrade pip
# Install the required packages
pip install -r requirements.txt
# Download the train gt data
wget https://omnomnom.vision.rwth-aachen.de/data/RobMOTS/train_gt.zip
# Unzip the train gt data you just downloaded.
unzip train_gt.zip
# Download the example tracker
wget https://omnomnom.vision.rwth-aachen.de/data/RobMOTS/example_tracker.zip
# Unzip the example tracker you just downloaded.
unzip example_tracker.zip
# Run the evaluation on the provided example tracker on the train split (using 4 cores in parallel)
python scripts/run_rob_mots.py --ROBMOTS_SPLIT train --TRACKERS_TO_EVAL STP --USE_PARALLEL True --NUM_PARALLEL_CORES 4
```
You may further download the raw sequence images and supplied detections (as well as train GT data and example tracker) by following the ```Data Download``` link here:
[RobMOTS Challenge Info](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110)
## Accessing tracking evaluation results
You will find the results of the evaluation (for the supplied tracker STP) in the folder ```TrackEval/data/trackers/rob_mots/train/STP/```.
The overall summary of the results is in ```./final_results.csv```, and more detailed results per sequence and per class and results plots can be found under ```./results/*```.
The ```final_results.csv``` can be most easily read by opening it in Excel or similar. The ```c```, ```d``` and ```f``` prepending the metric names refer respectively to ```class averaged```, ```detection averaged (class agnostic)``` and ```final``` (the geometric mean of class and detection averaged).
## Supplied Detections
To make creating your own tracker particularly easy, we supply a set of strong supplied detection.
These detections are from the Detectron 2 Mask R-CNN X152 (very bottom model on this [page](https://github.com/facebookresearch/detectron2/blob/master/MODEL_ZOO.md) which achieves a COCO detection mAP score of 50.2).
We then obtain segmentation masks for these detections using the Box2Seg Network (also called Refinement Net), which results in far more accurate masks than the default Mask R-CNN masks. The code for this can be found [here](https://github.com/JonathonLuiten/PReMVOS/tree/master/code/refinement_net).
We supply two different supplied detections. The first is the ```raw_supplied``` detections, which is taking all 1000 detections output from the Mask R-CNN, and only removing those for which the maximum class score is less than 0.02 (here no non-maximum suppression, NMS, is run). These can be downloaded [here](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110).
The second is ```non_overlap_supplied``` detections. These are the same detections as above, but with further processing steps applied to them. First we perform Non-Maximum Suppression (NMS) with a threshold of 0.5 to remove any masks which have an IoU of 0.5 or more with any other mask that has a higher score. Second we run a Non-Overlap algorithm which forces all of the masks for a single image to be non-overlapping. It does this by putting all the masks 'on top of' each other, ordered by score, such that masks with a lower score will be partially removed if a mask with a higher score partially overlaps them. Note that these detections are still only thresholded at a score of 0.02, in general we recommend further thresholding with a higher value to get a good balance of precision and recall.
Code for this NMS and Non-Overlap algorithm can be found here:
[Non-Overlap Code](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/baselines/non_overlap.py).
Note that for RobMOTS evaluation the final tracking results need to be 'non-overlapping' so we recommend using the ```non_overlap_supplied``` detections, however you may use the ```raw_supplied```, or your own or any other detections as you like.
Supplied detections (both raw and non-overlapping) are available for the train, val and test sets.
Example code for reading in these detections and using them can be found here:
[Tracker Example](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/baselines/stp.py).
## Creating your own tracker
We provide sample code ([Tracker Example](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/baselines/stp.py)) for our STP tracker (Simplest Tracker Possible) which walks though how to create tracking results in the required RobMOTS format.
This includes code for reading in the supplied detections and writing out the tracking results in the desired format, plus many other useful functions (IoU calculation etc).
## Evaluating your own tracker
To evaluate your tracker, put the results in the folder ```TrackEval/data/trackers/rob_mots/train/```, in a folder alongside the supplied tracker STP with the folder labelled as your tracker name, e.g. YOUR_TRACKER.
You can then run the evaluation code on your tracker like this:
```
python scripts/run_rob_mots.py --ROBMOTS_SPLIT train --TRACKERS_TO_EVAL YOUR_TRACKER --USE_PARALLEL True --NUM_PARALLEL_CORES 4
```
## Data format
For RobMOTS, trackers must submit their results in the following folder format:
```
|——
|—— .txt
|—— .txt
|—— .txt
|——
|—— .txt
|—— .txt
|—— .txt
```
See the supplied STP tracker results (in the Train Data linked above) for an example.
Thus there is one .txt file for each sequence. This file has one row per detection (object mask in one frame). Each row must have 7 values and has the following format:
<Timestep>(int),
<Track ID>(int),
<Class Number>(int),
<Detection Confidence>(float),
<Image Height>(int),
<Image Width>(int),
<Compressed RLE Mask>(string),
Timesteps are the same as the frame names for the supplied images. These start at 0.
Track IDs must be unique across all classes within a frame. They can be non-unique across different sequences.
The mapping of class numbers to class names can be found is [this file](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/datasets/rob_mots_classmap.py). Note that this is the same as used in Detectron 2, and is the default COCO class ordering with the unused numbers removed.
Detection Confidence score should be between 0 and 1. This is not used for HOTA evaluation, but is used for other eval metrics like Track mAP.
Image height and width are needed to decode the compressed RLE mask representation.
The Compressed RLE Mask is the same format used by coco, pycocotools and mots.
An example of a tracker result file looks like this:
```
0 1 3 0.9917707443237305 1200 1920 VaTi0b0lT17F8K3M3N1O1N2O0O2M3N2N101O1O1O01O1O0100O100O01O1O100O10O1000O1000000000000000O1000001O0000000000000000O101O00000000000001O0000010O0110O0O100O1O2N1O2N0O2O2M3M2N2O1O2N5J;DgePZ1
0 2 3 0.989478349685669 1200 1920 Ql^c05ZU12O2N001O0O10OTkNIaT17^kNKaT15^kNLbT14^kNMaT13^kNOaT11_kN0`T10_kN1`T11_kN0`T11_kN0`T1a0O00001O1O1O3M;E5K3M2N000000000O100000000000000000001O00001O2N1O1O1O000001O001O0O2O0O2M3M3M3N2O1O1O1N2O002N1O2N10O02N10000O1O101M3N2N2M7H^_g_1
1 2 3 0.964085042476654 1200 1920 o_Uc03\U12O1O1N102N002N001O1O000O2O1O00002N6J1O001O2N1O3L3N2N4L5K2N1O000000000000001O1O2N01O01O010O01N2O0O2O1M4L3N2N101N2O001O1O100O0100000O1O1O1O2N6I4Mdm^`1
```
Note that for the evaluation to be valid, the masks must not overlap within one frame.
The supplied detections have the same format (but with all the Track IDs being set to 0).
The groundtruth data for most benchmarks is in the exact same format as above (usually Detection Confidence is set to 1.0). The exception is the few benchmarks for which the ground-truth is not segmentation masks but bounding boxes (Waymo and TAO). For these the last three columns are not there (height, width and mask) as these encode a mask, and instead there are 4 columns encoding the bounding box co-ordinates in the format ```x0 y0 x1 y1```, where x0 and y0 are the coordinates of the top left of the box and x1 and y0 are the coordinates for the bottom right.
The groundtruth can also contain ignore regions. The are marked by being having a class number of 100 or larger. Class number 100 encodes and ignore region for all class, which class numbers higher than 100 encode ignore regions specific to each class. E.g. class number 105 are ignore regions for class 5.
As well as the per sequence files described above, the groundtruth for each benchmark contains two more files ```clsmap.txt``` and ```seqmap.txt```.
```clsmap.txt``` is a single row, space-separated, containing all of the valid classes that should be evaluated for each benchmark (not all benchmarks evaluate all of the coco classes).
```seqmap.txt``` contains a list of the sequences to be evaluated for that benchmark. Each row has at least 4 values. These are:
```
```
More than 4 values can be present, the remaining values are 'ignore classes for this sequence'. E.g. classes which are evaluated for the particular benchmark as a whole, but should be ignored for this sequence.
## Visualizing GT and Tracker Masks
We provide code for converting our .txt format with compressed RLE masks into .png format where it is easy to visualize the GT and Predicted masks.
This code can be found here:
[Vizualize Tracking Results](https://github.com/JonathonLuiten/TrackEval/blob/master/trackeval/baselines/vizualize.py).
## Evaluate on the validation and test server
The val and test GT will NOT be provided. However we provide a live evaluation server to upload your tracking results and evaluate it on the val and test set.
The val server will allow infinite uploads, while the test will limit trackers to 4 uploads total.
These evaluation servers can be found here: https://eval.vision.rwth-aachen.de/vision/
Ensure that your files to upload are in the correct format. Examples of the correct way to upload files can be found here: [STP val upload](https://omnomnom.vision.rwth-aachen.de/data/RobMOTS/STP_val_upload.zip), [STP test upload](https://omnomnom.vision.rwth-aachen.de/data/RobMOTS/STP_test_upload.zip).
## Citation
If you work with the code and the benchmark, please cite:
***TrackEval***
```
@misc{luiten2020trackeval,
author = {Jonathon Luiten, Arne Hoffhues},
title = {TrackEval},
howpublished = {\url{https://github.com/JonathonLuiten/TrackEval}},
year = {2020}
}
```
***HOTA metrics***
```
@article{luiten2020IJCV,
title={HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
author={Luiten, Jonathon and Osep, Aljosa and Dendorfer, Patrick and Torr, Philip and Geiger, Andreas and Leal-Taix{\'e}, Laura and Leibe, Bastian},
journal={International Journal of Computer Vision},
pages={1--31},
year={2020},
publisher={Springer}
}
```
## Feedback and Contact
We are constantly working on improving RobMOTS, and wish to provide the most useful support to the community.
You can help us to make the benchmark better by open issues in the repo and reporting bugs.
For general questions, please contact the following:
```
Jonathon Luiten - luiten@vision.rwth-aachen.de
```
================================================
FILE: TrackEval/docs/TAO-format.txt
================================================
Taken from: https://github.com/TAO-Dataset/tao/blob/master/tao/toolkit/tao/tao.py
Annotation file format:
{
"info" : info,
"images" : [image],
"videos": [video],
"tracks": [track],
"annotations" : [annotation],
"categories": [category],
"licenses" : [license],
}
info: As in MS COCO
image: {
"id" : int,
"video_id": int,
"file_name" : str,
"license" : int,
# Redundant fields for COCO-compatibility
"width": int,
"height": int,
"frame_index": int
}
video: {
"id": int,
"name": str,
"width" : int,
"height" : int,
"neg_category_ids": [int],
"not_exhaustive_category_ids": [int],
"metadata": dict, # Metadata about the video
}
track: {
"id": int,
"category_id": int,
"video_id": int
}
category: {
"id": int,
"name": str,
"synset": str, # For non-LVIS objects, this is "unknown"
... [other fields copied from LVIS v0.5 and unused]
}
annotation: {
"image_id": int,
"track_id": int,
"bbox": [x,y,width,height],
"area": float,
# Redundant field for compatibility with COCO scripts
"category_id": int
}
license: {
"id" : int,
"name" : str,
"url" : str,
}
================================================
FILE: TrackEval/docs/YouTube-VIS-format.txt
================================================
Taken from: https://competitions.codalab.org/competitions/20128#participate-get-data
The label file follows MSCOCO's style in json format. We adapt the entry name and label format for video. The definition of json file is:
{
"info" : info,
"videos" : [video],
"annotations" : [annotation],
"categories" : [category],
}
video{
"id" : int,
"width" : int,
"height" : int,
"length" : int,
"file_names" : [file_name],
}
annotation{
"id" : int,
"video_id" : int,
"category_id" : int,
"segmentations" : [RLE or [polygon] or None],
"areas" : [float or None],
"bboxes" : [[x,y,width,height] or None],
"iscrowd" : 0 or 1,
}
category{
"id" : int,
"name" : str,
"supercategory" : str,
}
The submission file is also in json format. The file should contain a list of predictions:
prediction{
"video_id" : int,
"category_id" : int,
"segmentations" : [RLE or [polygon] or None],
"score" : float,
}
The submission file should be named as "results.json", and compressed without any subfolder. There is an example "valid_submission_sample.zip" in download links above. The example is generated by our proposed MaskTrack R-CNN algorithm.
================================================
FILE: TrackEval/minimum_requirements.txt
================================================
scipy==1.4.1
numpy==1.18.1
================================================
FILE: TrackEval/pyproject.toml
================================================
[build-system]
requires = [
"setuptools>=42",
"wheel"
]
build-backend = "setuptools.build_meta"
================================================
FILE: TrackEval/requirements.txt
================================================
numpy==1.18.1
scipy==1.4.1
pycocotools==2.0.2
matplotlib==3.2.1
opencv_python==4.4.0.46
scikit_image==0.16.2
pytest==6.0.1
Pillow==8.1.2
================================================
FILE: TrackEval/scripts/comparison_plots.py
================================================
import sys
import os
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
plots_folder = os.path.abspath(os.path.join(os.path.dirname(__file__), '..', 'data', 'plots'))
tracker_folder = os.path.abspath(os.path.join(os.path.dirname(__file__), '..', 'data', 'trackers'))
# dataset = os.path.join('kitti', 'kitti_2d_box_train')
# classes = ['cars', 'pedestrian']
dataset = os.path.join('mot_challenge', 'MOT17-train')
classes = ['pedestrian']
data_fol = os.path.join(tracker_folder, dataset)
trackers = os.listdir(data_fol)
out_loc = os.path.join(plots_folder, dataset)
for cls in classes:
trackeval.plotting.plot_compare_trackers(data_fol, trackers, cls, out_loc)
================================================
FILE: TrackEval/scripts/run_bdd.py
================================================
""" run_bdd.py
Run example:
run_bdd.py --USE_PARALLEL False --METRICS Hota --TRACKERS_TO_EVAL qdtrack
Command Line Arguments: Defaults, # Comments
Eval arguments:
'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
'BREAK_ON_ERROR': True,
'PRINT_RESULTS': True,
'PRINT_ONLY_COMBINED': False,
'PRINT_CONFIG': True,
'TIME_PROGRESS': True,
'OUTPUT_SUMMARY': True,
'OUTPUT_DETAILED': True,
'PLOT_CURVES': True,
Dataset arguments:
'GT_FOLDER': os.path.join(code_path, 'data/gt/bdd100k/bdd100k_val'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/bdd100k/bdd100k_val'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': ['pedestrian', 'rider', 'car', 'bus', 'truck', 'train', 'motorcycle', 'bicycle'],
# Valid: ['pedestrian', 'rider', 'car', 'bus', 'truck', 'train', 'motorcycle', 'bicycle']
'SPLIT_TO_EVAL': 'val', # Valid: 'training', 'val',
'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
Metric arguments:
'METRICS': ['Hota','Clear', 'ID', 'Count']
"""
import sys
import os
import argparse
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
if __name__ == '__main__':
freeze_support()
# Command line interface:
default_eval_config = trackeval.Evaluator.get_default_eval_config()
default_eval_config['PRINT_ONLY_COMBINED'] = True
default_dataset_config = trackeval.datasets.BDD100K.get_default_dataset_config()
default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity']}
config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
parser = argparse.ArgumentParser()
for setting in config.keys():
if type(config[setting]) == list or type(config[setting]) == type(None):
parser.add_argument("--" + setting, nargs='+')
else:
parser.add_argument("--" + setting)
args = parser.parse_args().__dict__
for setting in args.keys():
if args[setting] is not None:
if type(config[setting]) == type(True):
if args[setting] == 'True':
x = True
elif args[setting] == 'False':
x = False
else:
raise Exception('Command line parameter ' + setting + 'must be True or False')
elif type(config[setting]) == type(1):
x = int(args[setting])
elif type(args[setting]) == type(None):
x = None
else:
x = args[setting]
config[setting] = x
eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
# Run code
evaluator = trackeval.Evaluator(eval_config)
dataset_list = [trackeval.datasets.BDD100K(dataset_config)]
metrics_list = []
for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity]:
if metric.get_name() in metrics_config['METRICS']:
metrics_list.append(metric())
if len(metrics_list) == 0:
raise Exception('No metrics selected for evaluation')
evaluator.evaluate(dataset_list, metrics_list)
================================================
FILE: TrackEval/scripts/run_davis.py
================================================
""" run_davis.py
Run example:
run_davis.py --USE_PARALLEL False --METRICS HOTA --TRACKERS_TO_EVAL ags
Command Line Arguments: Defaults, # Comments
Eval arguments:
'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
'BREAK_ON_ERROR': True,
'PRINT_RESULTS': True,
'PRINT_ONLY_COMBINED': False,
'PRINT_CONFIG': True,
'TIME_PROGRESS': True,
'OUTPUT_SUMMARY': True,
'OUTPUT_DETAILED': True,
'PLOT_CURVES': True,
Dataset arguments:
' 'GT_FOLDER': os.path.join(code_path, 'data/gt/davis/'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/davis/davis_val'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'SPLIT_TO_EVAL': 'val', # Valid: 'val', 'train'
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/ImageSets/2017)
'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/split-to-eval.txt)
'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
'GT_LOC_FORMAT': '{gt_folder}/Annotations_unsupervised/480p/{seq}',
# '{gt_folder}/Annotations_unsupervised/480p/{seq}'
'MAX_DETECTIONS': 0 # Maximum number of allowed detections per sequence (0 for no threshold)
Metric arguments:
'METRICS': ['HOTA', 'CLEAR', 'Identity', 'JAndF']
"""
import sys
import os
import argparse
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
if __name__ == '__main__':
freeze_support()
# Command line interface:
default_eval_config = trackeval.Evaluator.get_default_eval_config()
default_dataset_config = trackeval.datasets.DAVIS.get_default_dataset_config()
default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity', 'JAndF']}
config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
parser = argparse.ArgumentParser()
for setting in config.keys():
if type(config[setting]) == list or type(config[setting]) == type(None):
parser.add_argument("--" + setting, nargs='+')
else:
parser.add_argument("--" + setting)
args = parser.parse_args().__dict__
for setting in args.keys():
if args[setting] is not None:
if type(config[setting]) == type(True):
if args[setting] == 'True':
x = True
elif args[setting] == 'False':
x = False
else:
raise Exception('Command line parameter ' + setting + 'must be True or False')
elif type(config[setting]) == type(1):
x = int(args[setting])
elif type(args[setting]) == type(None):
x = None
else:
x = args[setting]
config[setting] = x
eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
# Run code
evaluator = trackeval.Evaluator(eval_config)
dataset_list = [trackeval.datasets.DAVIS(dataset_config)]
metrics_list = []
for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity, trackeval.metrics.JAndF]:
if metric.get_name() in metrics_config['METRICS']:
metrics_list.append(metric())
if len(metrics_list) == 0:
raise Exception('No metrics selected for evaluation')
evaluator.evaluate(dataset_list, metrics_list)
================================================
FILE: TrackEval/scripts/run_headtracking_challenge.py
================================================
""" run_mot_challenge.py
Run example:
run_mot_challenge.py --USE_PARALLEL False --METRICS Hota --TRACKERS_TO_EVAL Lif_T
Command Line Arguments: Defaults, # Comments
Eval arguments:
'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
'BREAK_ON_ERROR': True,
'PRINT_RESULTS': True,
'PRINT_ONLY_COMBINED': False,
'PRINT_CONFIG': True,
'TIME_PROGRESS': True,
'OUTPUT_SUMMARY': True,
'OUTPUT_DETAILED': True,
'PLOT_CURVES': True,
Dataset arguments:
'GT_FOLDER': os.path.join(code_path, 'data/gt/mot_challenge/'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/mot_challenge/'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
'BENCHMARK': 'MOT17', # Valid: 'MOT17', 'MOT16', 'MOT20', 'MOT15'
'SPLIT_TO_EVAL': 'train', # Valid: 'train', 'test', 'all'
'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
'PRINT_CONFIG': True, # Whether to print current config
'DO_PREPROC': True, # Whether to perform preprocessing (never done for 2D_MOT_2015)
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
Metric arguments:
'METRICS': ['HOTA', 'CLEAR', 'Identity', 'IDEucl']
"""
import sys
import os
import argparse
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
if __name__ == '__main__':
freeze_support()
# Command line interface:
default_eval_config = trackeval.Evaluator.get_default_eval_config()
default_eval_config['DISPLAY_LESS_PROGRESS'] = False
default_dataset_config = trackeval.datasets.HeadTrackingChallenge.get_default_dataset_config()
default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity', 'IDEucl'], 'THRESHOLD': 0.4}
config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
parser = argparse.ArgumentParser()
for setting in config.keys():
if type(config[setting]) == list or type(config[setting]) == type(None):
parser.add_argument("--" + setting, nargs='+')
else:
parser.add_argument("--" + setting)
args = parser.parse_args().__dict__
for setting in args.keys():
if args[setting] is not None:
if type(config[setting]) == type(True):
if args[setting] == 'True':
x = True
elif args[setting] == 'False':
x = False
else:
raise Exception('Command line parameter ' + setting + 'must be True or False')
elif type(config[setting]) == type(1):
x = int(args[setting])
elif type(args[setting]) == type(None):
x = None
elif setting == 'SEQ_INFO':
x = dict(zip(args[setting], [None]*len(args[setting])))
else:
x = args[setting]
config[setting] = x
eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
# Run code
evaluator = trackeval.Evaluator(eval_config)
dataset_list = [trackeval.datasets.HeadTrackingChallenge(dataset_config)]
metrics_list = []
for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity, trackeval.metrics.IDEucl]:
if metric.get_name() in metrics_config['METRICS']:
metrics_list.append(metric(metrics_config))
if len(metrics_list) == 0:
raise Exception('No metrics selected for evaluation')
evaluator.evaluate(dataset_list, metrics_list)
================================================
FILE: TrackEval/scripts/run_kitti.py
================================================
""" run_kitti.py
Run example:
run_kitti.py --USE_PARALLEL False --METRICS Hota --TRACKERS_TO_EVAL CIWT
Command Line Arguments: Defaults, # Comments
Eval arguments:
'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
'BREAK_ON_ERROR': True,
'PRINT_RESULTS': True,
'PRINT_ONLY_COMBINED': False,
'PRINT_CONFIG': True,
'TIME_PROGRESS': True,
'OUTPUT_SUMMARY': True,
'OUTPUT_DETAILED': True,
'PLOT_CURVES': True,
Dataset arguments:
'GT_FOLDER': os.path.join(code_path, 'data/gt/kitti/kitti_2d_box_train'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/kitti/kitti_2d_box_train/'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': ['car', 'pedestrian'], # Valid: ['car', 'pedestrian']
'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val', 'training_minus_val', 'test'
'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '' # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
Metric arguments:
'METRICS': ['Hota','Clear', 'ID', 'Count']
"""
import sys
import os
import argparse
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
if __name__ == '__main__':
freeze_support()
# Command line interface:
default_eval_config = trackeval.Evaluator.get_default_eval_config()
default_eval_config['DISPLAY_LESS_PROGRESS'] = False
default_dataset_config = trackeval.datasets.Kitti2DBox.get_default_dataset_config()
default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity']}
config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
parser = argparse.ArgumentParser()
for setting in config.keys():
if type(config[setting]) == list or type(config[setting]) == type(None):
parser.add_argument("--" + setting, nargs='+')
else:
parser.add_argument("--" + setting)
args = parser.parse_args().__dict__
for setting in args.keys():
if args[setting] is not None:
if type(config[setting]) == type(True):
if args[setting] == 'True':
x = True
elif args[setting] == 'False':
x = False
else:
raise Exception('Command line parameter ' + setting + 'must be True or False')
elif type(config[setting]) == type(1):
x = int(args[setting])
elif type(args[setting]) == type(None):
x = None
else:
x = args[setting]
config[setting] = x
eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
# Run code
evaluator = trackeval.Evaluator(eval_config)
dataset_list = [trackeval.datasets.Kitti2DBox(dataset_config)]
metrics_list = []
for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity]:
if metric.get_name() in metrics_config['METRICS']:
metrics_list.append(metric())
if len(metrics_list) == 0:
raise Exception('No metrics selected for evaluation')
evaluator.evaluate(dataset_list, metrics_list)
================================================
FILE: TrackEval/scripts/run_kitti_mots.py
================================================
""" run_kitti_mots.py
Run example:
run_kitti_mots.py --USE_PARALLEL False --METRICS HOTA --TRACKERS_TO_EVAL trackrcnn
Command Line Arguments: Defaults, # Comments
Eval arguments:
'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
'BREAK_ON_ERROR': True,
'PRINT_RESULTS': True,
'PRINT_ONLY_COMBINED': False,
'PRINT_CONFIG': True,
'TIME_PROGRESS': True,
'OUTPUT_SUMMARY': True,
'OUTPUT_DETAILED': True,
'PLOT_CURVES': True,
Dataset arguments:
'GT_FOLDER': os.path.join(code_path, 'data/gt/kitti/kitti_mots'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/kitti/kitti_mots_val'), # Location of all
# trackers
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': ['car', 'pedestrian'], # Valid: ['car', 'pedestrian']
'SPLIT_TO_EVAL': 'val', # Valid: 'training', 'val'
'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER)
'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/split_to_eval.seqmap)
'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
'GT_LOC_FORMAT': '{gt_folder}/instances_txt/{seq}.txt', # format of gt localization
Metric arguments:
'METRICS': ['HOTA', 'CLEAR', 'Identity']
"""
import sys
import os
import argparse
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
if __name__ == '__main__':
freeze_support()
# Command line interface:
default_eval_config = trackeval.Evaluator.get_default_eval_config()
default_eval_config['DISPLAY_LESS_PROGRESS'] = False
default_dataset_config = trackeval.datasets.KittiMOTS.get_default_dataset_config()
default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity']}
config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
parser = argparse.ArgumentParser()
for setting in config.keys():
if type(config[setting]) == list or type(config[setting]) == type(None):
parser.add_argument("--" + setting, nargs='+')
else:
parser.add_argument("--" + setting)
args = parser.parse_args().__dict__
for setting in args.keys():
if args[setting] is not None:
if type(config[setting]) == type(True):
if args[setting] == 'True':
x = True
elif args[setting] == 'False':
x = False
else:
raise Exception('Command line parameter ' + setting + 'must be True or False')
elif type(config[setting]) == type(1):
x = int(args[setting])
elif type(args[setting]) == type(None):
x = None
else:
x = args[setting]
config[setting] = x
eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
# Run code
evaluator = trackeval.Evaluator(eval_config)
dataset_list = [trackeval.datasets.KittiMOTS(dataset_config)]
metrics_list = []
for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity, trackeval.metrics.JAndF]:
if metric.get_name() in metrics_config['METRICS']:
metrics_list.append(metric())
if len(metrics_list) == 0:
raise Exception('No metrics selected for evaluation')
evaluator.evaluate(dataset_list, metrics_list)
================================================
FILE: TrackEval/scripts/run_mot_challenge.py
================================================
""" run_mot_challenge.py
Run example:
run_mot_challenge.py --USE_PARALLEL False --METRICS Hota --TRACKERS_TO_EVAL Lif_T
Command Line Arguments: Defaults, # Comments
Eval arguments:
'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
'BREAK_ON_ERROR': True,
'PRINT_RESULTS': True,
'PRINT_ONLY_COMBINED': False,
'PRINT_CONFIG': True,
'TIME_PROGRESS': True,
'OUTPUT_SUMMARY': True,
'OUTPUT_DETAILED': True,
'PLOT_CURVES': True,
Dataset arguments:
'GT_FOLDER': os.path.join(code_path, 'data/gt/mot_challenge/'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/mot_challenge/'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
'BENCHMARK': 'MOT17', # Valid: 'MOT17', 'MOT16', 'MOT20', 'MOT15'
'SPLIT_TO_EVAL': 'train', # Valid: 'train', 'test', 'all'
'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
'PRINT_CONFIG': True, # Whether to print current config
'DO_PREPROC': True, # Whether to perform preprocessing (never done for 2D_MOT_2015)
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
Metric arguments:
'METRICS': ['HOTA', 'CLEAR', 'Identity', 'VACE']
"""
import sys
import os
import argparse
from multiprocessing import freeze_support
# python TrackEval/scripts/run_mot_challenge.py --BENCHMARK MOT17 --SPLIT_TO_EVAL train --TRACKERS_TO_EVAL ByteTrack --METRICS HOTA CLEAR Identity VACE --TIME_PROGRESS False --USE_PARALLEL False --NUM_PARALLEL_CORES 1 --GT_FOLDER datasets/mot/ --TRACKERS_FOLDER YOLOX_outputs/yolox_s_mot17_half_repro1/track_results_ByteTrack/track_results --GT_LOC_FORMAT {gt_folder}/{seq}/gt/gt_val_half.txt
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
if __name__ == '__main__':
freeze_support()
# Command line interface:
default_eval_config = trackeval.Evaluator.get_default_eval_config()
default_eval_config['DISPLAY_LESS_PROGRESS'] = False
default_dataset_config = trackeval.datasets.MotChallenge2DBox.get_default_dataset_config()
default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity'], 'THRESHOLD': 0.5}
config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
parser = argparse.ArgumentParser()
for setting in config.keys():
if type(config[setting]) == list or type(config[setting]) == type(None):
parser.add_argument("--" + setting, nargs='+')
else:
parser.add_argument("--" + setting)
args = parser.parse_args().__dict__
for setting in args.keys():
if args[setting] is not None:
if type(config[setting]) == type(True):
if args[setting] == 'True':
x = True
elif args[setting] == 'False':
x = False
else:
raise Exception('Command line parameter ' + setting + 'must be True or False')
elif type(config[setting]) == type(1):
x = int(args[setting])
elif type(args[setting]) == type(None):
x = None
elif setting == 'SEQ_INFO':
x = dict(zip(args[setting], [None]*len(args[setting])))
else:
x = args[setting]
config[setting] = x
eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
if type(dataset_config['SEQMAP_FILE']) is list: # TODO: [hgx 0409] for dancetrack dataset
dataset_config['SEQMAP_FILE'] = dataset_config['SEQMAP_FILE'][0]
# Run code
evaluator = trackeval.Evaluator(eval_config)
dataset_list = [trackeval.datasets.MotChallenge2DBox(dataset_config)]
metrics_list = []
for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity, trackeval.metrics.VACE]:
if metric.get_name() in metrics_config['METRICS']:
metrics_list.append(metric(metrics_config))
if len(metrics_list) == 0:
raise Exception('No metrics selected for evaluation')
evaluator.evaluate(dataset_list, metrics_list)
================================================
FILE: TrackEval/scripts/run_mots_challenge.py
================================================
""" run_mots.py
Run example:
run_mots.py --USE_PARALLEL False --METRICS Hota --TRACKERS_TO_EVAL TrackRCNN
Command Line Arguments: Defaults, # Comments
Eval arguments:
'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
'BREAK_ON_ERROR': True,
'PRINT_RESULTS': True,
'PRINT_ONLY_COMBINED': False,
'PRINT_CONFIG': True,
'TIME_PROGRESS': True,
'OUTPUT_SUMMARY': True,
'OUTPUT_DETAILED': True,
'PLOT_CURVES': True,
Dataset arguments:
'GT_FOLDER': os.path.join(code_path, 'data/gt/mot_challenge/'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/mot_challenge/'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
'SPLIT_TO_EVAL': 'train', # Valid: 'train', 'test'
'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/seqmaps)
'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/MOTS-split_to_eval)
'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
'GT_LOC_FORMAT': '{gt_folder}/{seq}/gt/gt.txt', # '{gt_folder}/{seq}/gt/gt.txt'
'SKIP_SPLIT_FOL': False, # If False, data is in GT_FOLDER/MOTS-SPLIT_TO_EVAL/ and in
# TRACKERS_FOLDER/MOTS-SPLIT_TO_EVAL/tracker/
# If True, then the middle 'MOTS-split' folder is skipped for both.
Metric arguments:
'METRICS': ['HOTA','CLEAR', 'Identity', 'VACE', 'JAndF']
"""
import sys
import os
import argparse
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
if __name__ == '__main__':
freeze_support()
# Command line interface:
default_eval_config = trackeval.Evaluator.get_default_eval_config()
default_eval_config['DISPLAY_LESS_PROGRESS'] = False
default_dataset_config = trackeval.datasets.MOTSChallenge.get_default_dataset_config()
default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity']}
config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
parser = argparse.ArgumentParser()
for setting in config.keys():
if type(config[setting]) == list or type(config[setting]) == type(None):
parser.add_argument("--" + setting, nargs='+')
else:
parser.add_argument("--" + setting)
args = parser.parse_args().__dict__
for setting in args.keys():
if args[setting] is not None:
if type(config[setting]) == type(True):
if args[setting] == 'True':
x = True
elif args[setting] == 'False':
x = False
else:
raise Exception('Command line parameter ' + setting + 'must be True or False')
elif type(config[setting]) == type(1):
x = int(args[setting])
elif type(args[setting]) == type(None):
x = None
elif setting == 'SEQ_INFO':
x = dict(zip(args[setting], [None]*len(args[setting])))
else:
x = args[setting]
config[setting] = x
eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
# Run code
evaluator = trackeval.Evaluator(eval_config)
dataset_list = [trackeval.datasets.MOTSChallenge(dataset_config)]
metrics_list = []
for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity, trackeval.metrics.VACE,
trackeval.metrics.JAndF]:
if metric.get_name() in metrics_config['METRICS']:
metrics_list.append(metric())
if len(metrics_list) == 0:
raise Exception('No metrics selected for evaluation')
evaluator.evaluate(dataset_list, metrics_list)
================================================
FILE: TrackEval/scripts/run_rob_mots.py
================================================
# python3 scripts/run_rob_mots.py --ROBMOTS_SPLIT train --TRACKERS_TO_EVAL STP --USE_PARALLEL True --NUM_PARALLEL_CORES 8
import sys
import os
import csv
import numpy as np
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
from trackeval import utils
code_path = utils.get_code_path()
if __name__ == '__main__':
freeze_support()
script_config = {
'ROBMOTS_SPLIT': 'train', # 'train', # valid: 'train', 'val', 'test', 'test_live', 'test_post', 'test_all'
'BENCHMARKS': None, # If None, use all for each split.
'GT_FOLDER': os.path.join(code_path, 'data/gt/rob_mots'),
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/rob_mots'),
}
default_eval_config = trackeval.Evaluator.get_default_eval_config()
default_eval_config['PRINT_ONLY_COMBINED'] = True
default_eval_config['DISPLAY_LESS_PROGRESS'] = True
default_dataset_config = trackeval.datasets.RobMOTS.get_default_dataset_config()
config = {**default_eval_config, **default_dataset_config, **script_config}
# Command line interface:
config = utils.update_config(config)
if not config['BENCHMARKS']:
if config['ROBMOTS_SPLIT'] == 'val':
config['BENCHMARKS'] = ['kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis',
'tao', 'mots_challenge', 'waymo']
config['SPLIT_TO_EVAL'] = 'val'
elif config['ROBMOTS_SPLIT'] == 'test' or config['SPLIT_TO_EVAL'] == 'test_live':
config['BENCHMARKS'] = ['kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'tao']
config['SPLIT_TO_EVAL'] = 'test'
elif config['ROBMOTS_SPLIT'] == 'test_post':
config['BENCHMARKS'] = ['mots_challenge', 'waymo', 'ovis']
config['SPLIT_TO_EVAL'] = 'test'
elif config['ROBMOTS_SPLIT'] == 'test_all':
config['BENCHMARKS'] = ['kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis',
'tao', 'mots_challenge', 'waymo']
config['SPLIT_TO_EVAL'] = 'test'
elif config['ROBMOTS_SPLIT'] == 'train':
config['BENCHMARKS'] = ['kitti_mots', 'davis_unsupervised', 'youtube_vis', 'ovis', 'tao', 'bdd_mots']
config['SPLIT_TO_EVAL'] = 'train'
else:
config['SPLIT_TO_EVAL'] = config['ROBMOTS_SPLIT']
metrics_config = {'METRICS': ['HOTA']}
eval_config = {k: v for k, v in config.items() if k in config.keys()}
dataset_config = {k: v for k, v in config.items() if k in config.keys()}
# Run code
try:
dataset_list = []
for bench in config['BENCHMARKS']:
dataset_config['SUB_BENCHMARK'] = bench
dataset_list.append(trackeval.datasets.RobMOTS(dataset_config))
evaluator = trackeval.Evaluator(eval_config)
metrics_list = []
for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity,
trackeval.metrics.VACE, trackeval.metrics.JAndF]:
if metric.get_name() in metrics_config['METRICS']:
metrics_list.append(metric())
if len(metrics_list) == 0:
raise Exception('No metrics selected for evaluation')
output_res, output_msg = evaluator.evaluate(dataset_list, metrics_list)
output = list(list(output_msg.values())[0].values())[0]
except Exception as err:
if type(err) == trackeval.utils.TrackEvalException:
output = str(err)
else:
output = 'Unknown error occurred.'
success = output == 'Success'
if not success:
output = 'ERROR, evaluation failed. \n\nError message: ' + output
print(output)
if config['TRACKERS_TO_EVAL']:
msg = "Thanks you for participating in the RobMOTS benchmark.\n\n"
msg += "The status of your evaluation is: \n" + output + '\n\n'
msg += "If your tracking results evaluated successfully on the evaluation server you can see your results here: \n"
msg += "https://eval.vision.rwth-aachen.de/vision/"
status_file = os.path.join(config['TRACKERS_FOLDER'], config['ROBMOTS_SPLIT'], config['TRACKERS_TO_EVAL'][0],
'status.txt')
with open(status_file, 'w', newline='') as f:
f.write(msg)
if success:
# For each benchmark, combine the 'all' score with the 'cls_averaged' using geometric mean.
metrics_to_calc = ['HOTA', 'DetA', 'AssA', 'DetRe', 'DetPr', 'AssRe', 'AssPr', 'LocA']
trackers = list(output_res['RobMOTS.' + config['BENCHMARKS'][0]].keys())
for tracker in trackers:
# final_results[benchmark][result_type][metric]
final_results = {}
res = {bench: output_res['RobMOTS.' + bench][tracker]['COMBINED_SEQ'] for bench in config['BENCHMARKS']}
for bench in config['BENCHMARKS']:
final_results[bench] = {'cls_av': {}, 'det_av': {}, 'final': {}}
for metric in metrics_to_calc:
final_results[bench]['cls_av'][metric] = np.mean(res[bench]['cls_comb_cls_av']['HOTA'][metric])
final_results[bench]['det_av'][metric] = np.mean(res[bench]['all']['HOTA'][metric])
final_results[bench]['final'][metric] = \
np.sqrt(final_results[bench]['cls_av'][metric] * final_results[bench]['det_av'][metric])
# Take the arithmetic mean over all the benchmarks
final_results['overall'] = {'cls_av': {}, 'det_av': {}, 'final': {}}
for metric in metrics_to_calc:
final_results['overall']['cls_av'][metric] = \
np.mean([final_results[bench]['cls_av'][metric] for bench in config['BENCHMARKS']])
final_results['overall']['det_av'][metric] = \
np.mean([final_results[bench]['det_av'][metric] for bench in config['BENCHMARKS']])
final_results['overall']['final'][metric] = \
np.mean([final_results[bench]['final'][metric] for bench in config['BENCHMARKS']])
# Save out result
headers = [config['SPLIT_TO_EVAL']] + [x + '___' + metric for x in ['f', 'c', 'd'] for metric in
metrics_to_calc]
def rowify(d):
return [d[x][metric] for x in ['final', 'cls_av', 'det_av'] for metric in metrics_to_calc]
out_file = os.path.join(config['TRACKERS_FOLDER'], config['ROBMOTS_SPLIT'], tracker,
'final_results.csv')
with open(out_file, 'w', newline='') as f:
writer = csv.writer(f, delimiter=',')
writer.writerow(headers)
writer.writerow(['overall'] + rowify(final_results['overall']))
for bench in config['BENCHMARKS']:
if bench == 'overall':
continue
writer.writerow([bench] + rowify(final_results[bench]))
================================================
FILE: TrackEval/scripts/run_tao.py
================================================
""" run_tao.py
Run example:
run_tao.py --USE_PARALLEL False --METRICS HOTA --TRACKERS_TO_EVAL Tracktor++
Command Line Arguments: Defaults, # Comments
Eval arguments:
'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
'BREAK_ON_ERROR': True,
'PRINT_RESULTS': True,
'PRINT_ONLY_COMBINED': False,
'PRINT_CONFIG': True,
'TIME_PROGRESS': True,
'OUTPUT_SUMMARY': True,
'OUTPUT_DETAILED': True,
'PLOT_CURVES': True,
Dataset arguments:
'GT_FOLDER': os.path.join(code_path, 'data/gt/tao/tao_training'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/tao/tao_training'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
'MAX_DETECTIONS': 300, # Number of maximal allowed detections per image (0 for unlimited)
Metric arguments:
'METRICS': ['HOTA', 'CLEAR', 'Identity', 'TrackMAP']
"""
import sys
import os
import argparse
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
if __name__ == '__main__':
freeze_support()
# Command line interface:
default_eval_config = trackeval.Evaluator.get_default_eval_config()
# print only combined since TrackMAP is undefined for per sequence breakdowns
default_eval_config['PRINT_ONLY_COMBINED'] = True
default_eval_config['DISPLAY_LESS_PROGRESS'] = True
default_dataset_config = trackeval.datasets.TAO.get_default_dataset_config()
default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity', 'TrackMAP']}
config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
parser = argparse.ArgumentParser()
for setting in config.keys():
if type(config[setting]) == list or type(config[setting]) == type(None):
parser.add_argument("--" + setting, nargs='+')
else:
parser.add_argument("--" + setting)
args = parser.parse_args().__dict__
for setting in args.keys():
if args[setting] is not None:
if type(config[setting]) == type(True):
if args[setting] == 'True':
x = True
elif args[setting] == 'False':
x = False
else:
raise Exception('Command line parameter ' + setting + 'must be True or False')
elif type(config[setting]) == type(1):
x = int(args[setting])
elif type(args[setting]) == type(None):
x = None
else:
x = args[setting]
config[setting] = x
eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
# Run code
evaluator = trackeval.Evaluator(eval_config)
dataset_list = [trackeval.datasets.TAO(dataset_config)]
metrics_list = []
for metric in [trackeval.metrics.TrackMAP, trackeval.metrics.CLEAR, trackeval.metrics.Identity,
trackeval.metrics.HOTA]:
if metric.get_name() in metrics_config['METRICS']:
metrics_list.append(metric())
if len(metrics_list) == 0:
raise Exception('No metrics selected for evaluation')
evaluator.evaluate(dataset_list, metrics_list)
================================================
FILE: TrackEval/scripts/run_tao_ow.py
================================================
""" run_tao.py
Run example:
run_tao.py --USE_PARALLEL False --METRICS HOTA --TRACKERS_TO_EVAL Tracktor++
Command Line Arguments: Defaults, # Comments
Eval arguments:
'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
'BREAK_ON_ERROR': True,
'PRINT_RESULTS': True,
'PRINT_ONLY_COMBINED': False,
'PRINT_CONFIG': True,
'TIME_PROGRESS': True,
'OUTPUT_SUMMARY': True,
'OUTPUT_DETAILED': True,
'PLOT_CURVES': True,
Dataset arguments:
'GT_FOLDER': os.path.join(code_path, 'data/gt/tao/tao_training'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/tao/tao_training'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
'MAX_DETECTIONS': 300, # Number of maximal allowed detections per image (0 for unlimited)
'SUBSET': 'unknown', # Evaluate on the following subsets ['all', 'known', 'unknown', 'distractor']
Metric arguments:
'METRICS': ['HOTA', 'CLEAR', 'Identity', 'TrackMAP']
"""
import sys
import os
import argparse
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
if __name__ == '__main__':
freeze_support()
# Command line interface:
default_eval_config = trackeval.Evaluator.get_default_eval_config()
# print only combined since TrackMAP is undefined for per sequence breakdowns
default_eval_config['PRINT_ONLY_COMBINED'] = True
default_eval_config['DISPLAY_LESS_PROGRESS'] = True
default_dataset_config = trackeval.datasets.TAO_OW.get_default_dataset_config()
default_metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity', 'TrackMAP']}
config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
parser = argparse.ArgumentParser()
for setting in config.keys():
if type(config[setting]) == list or type(config[setting]) == type(None):
parser.add_argument("--" + setting, nargs='+')
else:
parser.add_argument("--" + setting)
args = parser.parse_args().__dict__
for setting in args.keys():
if args[setting] is not None:
if type(config[setting]) == type(True):
if args[setting] == 'True':
x = True
elif args[setting] == 'False':
x = False
else:
raise Exception('Command line parameter ' + setting + 'must be True or False')
elif type(config[setting]) == type(1):
x = int(args[setting])
elif type(args[setting]) == type(None):
x = None
else:
x = args[setting]
config[setting] = x
eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
# Run code
evaluator = trackeval.Evaluator(eval_config)
dataset_list = [trackeval.datasets.TAO_OW(dataset_config)]
metrics_list = []
# for metric in [trackeval.metrics.TrackMAP, trackeval.metrics.CLEAR, trackeval.metrics.Identity,
# trackeval.metrics.HOTA]:
for metric in [trackeval.metrics.HOTA]:
if metric.get_name() in metrics_config['METRICS']:
metrics_list.append(metric())
if len(metrics_list) == 0:
raise Exception('No metrics selected for evaluation')
evaluator.evaluate(dataset_list, metrics_list)
================================================
FILE: TrackEval/scripts/run_youtube_vis.py
================================================
""" run_youtube_vis.py
Run example:
run_youtube_vis.py --USE_PARALLEL False --METRICS HOTA --TRACKERS_TO_EVAL STEm_Seg
Command Line Arguments: Defaults, # Comments
Eval arguments:
'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
'BREAK_ON_ERROR': True, # Raises exception and exits with error
'RETURN_ON_ERROR': False, # if not BREAK_ON_ERROR, then returns from function on error
'LOG_ON_ERROR': os.path.join(code_path, 'error_log.txt'), # if not None, save any errors into a log file.
'PRINT_RESULTS': True,
'PRINT_ONLY_COMBINED': False,
'PRINT_CONFIG': True,
'TIME_PROGRESS': True,
'DISPLAY_LESS_PROGRESS': True,
'OUTPUT_SUMMARY': True,
'OUTPUT_EMPTY_CLASSES': True, # If False, summary files are not output for classes with no detections
'OUTPUT_DETAILED': True,
'PLOT_CURVES': True,
Dataset arguments:
'GT_FOLDER': os.path.join(code_path, 'data/gt/youtube_vis/youtube_vis_training'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/youtube_vis/youtube_vis_training'),
# Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
'PRINT_CONFIG': True, # Whether to print current config
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
Metric arguments:
'METRICS': ['TrackMAP', 'HOTA', 'CLEAR', 'Identity']
"""
import sys
import os
import argparse
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
if __name__ == '__main__':
freeze_support()
# Command line interface:
default_eval_config = trackeval.Evaluator.get_default_eval_config()
# print only combined since TrackMAP is undefined for per sequence breakdowns
default_eval_config['PRINT_ONLY_COMBINED'] = True
default_dataset_config = trackeval.datasets.YouTubeVIS.get_default_dataset_config()
default_metrics_config = {'METRICS': ['TrackMAP', 'HOTA', 'CLEAR', 'Identity']}
config = {**default_eval_config, **default_dataset_config, **default_metrics_config} # Merge default configs
parser = argparse.ArgumentParser()
for setting in config.keys():
if type(config[setting]) == list or type(config[setting]) == type(None):
parser.add_argument("--" + setting, nargs='+')
else:
parser.add_argument("--" + setting)
args = parser.parse_args().__dict__
for setting in args.keys():
if args[setting] is not None:
if type(config[setting]) == type(True):
if args[setting] == 'True':
x = True
elif args[setting] == 'False':
x = False
else:
raise Exception('Command line parameter ' + setting + 'must be True or False')
elif type(config[setting]) == type(1):
x = int(args[setting])
elif type(args[setting]) == type(None):
x = None
else:
x = args[setting]
config[setting] = x
eval_config = {k: v for k, v in config.items() if k in default_eval_config.keys()}
dataset_config = {k: v for k, v in config.items() if k in default_dataset_config.keys()}
metrics_config = {k: v for k, v in config.items() if k in default_metrics_config.keys()}
# Run code
evaluator = trackeval.Evaluator(eval_config)
dataset_list = [trackeval.datasets.YouTubeVIS(dataset_config)]
metrics_list = []
for metric in [trackeval.metrics.TrackMAP, trackeval.metrics.HOTA, trackeval.metrics.CLEAR,
trackeval.metrics.Identity]:
if metric.get_name() in metrics_config['METRICS']:
# specify TrackMAP config for YouTubeVIS
if metric == trackeval.metrics.TrackMAP:
default_track_map_config = metric.get_default_metric_config()
default_track_map_config['USE_TIME_RANGES'] = False
default_track_map_config['AREA_RANGES'] = [[0 ** 2, 128 ** 2],
[ 128 ** 2, 256 ** 2],
[256 ** 2, 1e5 ** 2]]
metrics_list.append(metric(default_track_map_config))
else:
metrics_list.append(metric())
if len(metrics_list) == 0:
raise Exception('No metrics selected for evaluation')
evaluator.evaluate(dataset_list, metrics_list)
================================================
FILE: TrackEval/setup.cfg
================================================
[metadata]
name = trackeval
version = 1.0.dev1
author = Jonathon Luiten, Arne Hoffhues
author_email = jonoluiten@gmail.com
description = Code for evaluating object tracking
long_description = file: Readme.md
long_description_content_type = text/markdown
url = https://github.com/JonathonLuiten/TrackEval
project_urls =
Bug Tracker = https://github.com/JonathonLuiten/TrackEval/issues
classifiers =
Programming Language :: Python :: 3
Programming Language :: Python :: 3 :: Only
License :: OSI Approved :: MIT License
Operating System :: OS Independent
Topic :: Scientific/Engineering
license_files = LICENSE
[options]
install_requires =
numpy
scipy
packages = find:
[options.packages.find]
include = trackeval*
================================================
FILE: TrackEval/setup.py
================================================
from setuptools import setup
setup()
================================================
FILE: TrackEval/tests/test_all_quick.py
================================================
""" Test to ensure that the code is working correctly.
Should test ALL metrics across all datasets and splits currently supported.
Only tests one tracker per dataset/split to give a quick test result.
"""
import sys
import os
import numpy as np
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
# Fixes multiprocessing on windows, does nothing otherwise
if __name__ == '__main__':
freeze_support()
eval_config = {'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
}
evaluator = trackeval.Evaluator(eval_config)
metrics_list = [trackeval.metrics.HOTA(), trackeval.metrics.CLEAR(), trackeval.metrics.Identity()]
tests = [
{'DATASET': 'Kitti2DBox', 'SPLIT_TO_EVAL': 'training', 'TRACKERS_TO_EVAL': ['CIWT']},
{'DATASET': 'MotChallenge2DBox', 'BENCHMARK': 'MOT15', 'SPLIT_TO_EVAL': 'train', 'TRACKERS_TO_EVAL': ['MPNTrack']},
{'DATASET': 'MotChallenge2DBox', 'BENCHMARK': 'MOT16', 'SPLIT_TO_EVAL': 'train', 'TRACKERS_TO_EVAL': ['MPNTrack']},
{'DATASET': 'MotChallenge2DBox', 'BENCHMARK': 'MOT17', 'SPLIT_TO_EVAL': 'train', 'TRACKERS_TO_EVAL': ['MPNTrack']},
{'DATASET': 'MotChallenge2DBox', 'BENCHMARK': 'MOT20', 'SPLIT_TO_EVAL': 'train', 'TRACKERS_TO_EVAL': ['MPNTrack']},
]
for dataset_config in tests:
dataset_name = dataset_config.pop('DATASET')
if dataset_name == 'MotChallenge2DBox':
dataset_list = [trackeval.datasets.MotChallenge2DBox(dataset_config)]
file_loc = os.path.join('mot_challenge', dataset_config['BENCHMARK'] + '-' + dataset_config['SPLIT_TO_EVAL'])
elif dataset_name == 'Kitti2DBox':
dataset_list = [trackeval.datasets.Kitti2DBox(dataset_config)]
file_loc = os.path.join('kitti', 'kitti_2d_box_train')
else:
raise Exception('Dataset %s does not exist.' % dataset_name)
raw_results, messages = evaluator.evaluate(dataset_list, metrics_list)
classes = dataset_list[0].config['CLASSES_TO_EVAL']
tracker = dataset_config['TRACKERS_TO_EVAL'][0]
test_data_loc = os.path.join(os.path.dirname(__file__), '..', 'data', 'tests', file_loc)
for cls in classes:
results = {seq: raw_results[dataset_name][tracker][seq][cls] for seq in raw_results[dataset_name][tracker].keys()}
current_metrics_list = metrics_list + [trackeval.metrics.Count()]
metric_names = trackeval.utils.validate_metrics_list(current_metrics_list)
# Load expected results:
test_data = trackeval.utils.load_detail(os.path.join(test_data_loc, tracker, cls + '_detailed.csv'))
# Do checks
for seq in test_data.keys():
assert len(test_data[seq].keys()) > 250, len(test_data[seq].keys())
details = []
for metric, metric_name in zip(current_metrics_list, metric_names):
table_res = {seq_key: seq_value[metric_name] for seq_key, seq_value in results.items()}
details.append(metric.detailed_results(table_res))
res_fields = sum([list(s['COMBINED_SEQ'].keys()) for s in details], [])
res_values = sum([list(s[seq].values()) for s in details], [])
res_dict = dict(zip(res_fields, res_values))
for field in test_data[seq].keys():
assert np.isclose(res_dict[field], test_data[seq][field]), seq + ': ' + cls + ': ' + field
print('Tracker %s tests passed' % tracker)
print('All tests passed')
================================================
FILE: TrackEval/tests/test_davis.py
================================================
import sys
import os
import numpy as np
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
# Fixes multiprocessing on windows, does nothing otherwise
if __name__ == '__main__':
freeze_support()
eval_config = {'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
'PRINT_RESULTS': False,
'PRINT_CONFIG': True,
'TIME_PROGRESS': True,
'DISPLAY_LESS_PROGRESS': True,
'OUTPUT_SUMMARY': False,
'OUTPUT_EMPTY_CLASSES': False,
'OUTPUT_DETAILED': False,
'PLOT_CURVES': False,
}
evaluator = trackeval.Evaluator(eval_config)
metrics_list = [trackeval.metrics.HOTA(), trackeval.metrics.CLEAR(), trackeval.metrics.Identity(),
trackeval.metrics.JAndF()]
tests = [
{'SPLIT_TO_EVAL': 'val', 'TRACKERS_TO_EVAL': ['ags']},
]
for dataset_config in tests:
dataset_list = [trackeval.datasets.DAVIS(dataset_config)]
file_loc = os.path.join('davis', 'davis_unsupervised_' + dataset_config['SPLIT_TO_EVAL'])
raw_results, messages = evaluator.evaluate(dataset_list, metrics_list)
classes = dataset_list[0].config['CLASSES_TO_EVAL']
tracker = dataset_config['TRACKERS_TO_EVAL'][0]
test_data_loc = os.path.join(os.path.dirname(__file__), '..', 'data', 'tests', file_loc)
for cls in classes:
results = {seq: raw_results['DAVIS'][tracker][seq][cls] for seq in raw_results['DAVIS'][tracker].keys()}
current_metrics_list = metrics_list + [trackeval.metrics.Count()]
metric_names = trackeval.utils.validate_metrics_list(current_metrics_list)
# Load expected results:
test_data = trackeval.utils.load_detail(os.path.join(test_data_loc, tracker, cls + '_detailed.csv'))
# Do checks
for seq in test_data.keys():
assert len(test_data[seq].keys()) > 250, len(test_data[seq].keys())
details = []
for metric, metric_name in zip(current_metrics_list, metric_names):
table_res = {seq_key: seq_value[metric_name] for seq_key, seq_value in results.items()}
details.append(metric.detailed_results(table_res))
res_fields = sum([list(s['COMBINED_SEQ'].keys()) for s in details], [])
res_values = sum([list(s[seq].values()) for s in details], [])
res_dict = dict(zip(res_fields, res_values))
for field in test_data[seq].keys():
assert np.isclose(res_dict[field], test_data[seq][field]), seq + ': ' + cls + ': ' + field
print('Tracker %s tests passed' % tracker)
print('All tests passed')
================================================
FILE: TrackEval/tests/test_metrics.py
================================================
import numpy as np
import pytest
import trackeval
def no_confusion():
num_timesteps = 5
num_gt_ids = 2
num_tracker_ids = 2
# No overlap between pairs (0, 0) and (1, 1).
similarity = np.zeros([num_timesteps, num_gt_ids, num_tracker_ids])
similarity[:, 0, 1] = [0, 0, 0, 1, 1]
similarity[:, 1, 0] = [1, 1, 0, 0, 0]
gt_present = np.zeros([num_timesteps, num_gt_ids])
gt_present[:, 0] = [1, 1, 1, 1, 1]
gt_present[:, 1] = [1, 1, 1, 0, 0]
tracker_present = np.zeros([num_timesteps, num_tracker_ids])
tracker_present[:, 0] = [1, 1, 1, 1, 0]
tracker_present[:, 1] = [1, 1, 1, 1, 1]
expected = {
'clear': {
'CLR_TP': 4,
'CLR_FN': 4,
'CLR_FP': 5,
'IDSW': 0,
'MOTA': 1 - 9 / 8,
},
'identity': {
'IDTP': 4,
'IDFN': 4,
'IDFP': 5,
'IDR': 4 / 8,
'IDP': 4 / 9,
'IDF1': 2 * 4 / 17,
},
'vace': {
'STDA': 2 / 5 + 2 / 4,
'ATA': (2 / 5 + 2 / 4) / 2,
},
}
data = _from_dense(
num_timesteps=num_timesteps,
num_gt_ids=num_gt_ids,
num_tracker_ids=num_tracker_ids,
gt_present=gt_present,
tracker_present=tracker_present,
similarity=similarity,
)
return data, expected
def with_confusion():
num_timesteps = 5
num_gt_ids = 2
num_tracker_ids = 2
similarity = np.zeros([num_timesteps, num_gt_ids, num_tracker_ids])
similarity[:, 0, 1] = [0, 0, 0, 1, 1]
similarity[:, 1, 0] = [1, 1, 0, 0, 0]
# Add some overlap between (0, 0) and (1, 1).
similarity[:, 0, 0] = [0, 0, 1, 0, 0]
similarity[:, 1, 1] = [0, 1, 0, 0, 0]
gt_present = np.zeros([num_timesteps, num_gt_ids])
gt_present[:, 0] = [1, 1, 1, 1, 1]
gt_present[:, 1] = [1, 1, 1, 0, 0]
tracker_present = np.zeros([num_timesteps, num_tracker_ids])
tracker_present[:, 0] = [1, 1, 1, 1, 0]
tracker_present[:, 1] = [1, 1, 1, 1, 1]
expected = {
'clear': {
'CLR_TP': 5,
'CLR_FN': 3, # 8 - 5
'CLR_FP': 4, # 9 - 5
'IDSW': 1,
'MOTA': 1 - 8 / 8,
},
'identity': {
'IDTP': 4,
'IDFN': 4,
'IDFP': 5,
'IDR': 4 / 8,
'IDP': 4 / 9,
'IDF1': 2 * 4 / 17,
},
'vace': {
'STDA': 2 / 5 + 2 / 4,
'ATA': (2 / 5 + 2 / 4) / 2,
},
}
data = _from_dense(
num_timesteps=num_timesteps,
num_gt_ids=num_gt_ids,
num_tracker_ids=num_tracker_ids,
gt_present=gt_present,
tracker_present=tracker_present,
similarity=similarity,
)
return data, expected
def split_tracks():
num_timesteps = 5
num_gt_ids = 2
num_tracker_ids = 5
similarity = np.zeros([num_timesteps, num_gt_ids, num_tracker_ids])
# Split ground-truth 0 between tracks 0, 3.
similarity[:, 0, 0] = [1, 1, 0, 0, 0]
similarity[:, 0, 3] = [0, 0, 0, 1, 1]
# Split ground-truth 1 between tracks 1, 2, 4.
similarity[:, 1, 1] = [0, 0, 1, 1, 0]
similarity[:, 1, 2] = [0, 0, 0, 0, 1]
similarity[:, 1, 4] = [1, 1, 0, 0, 0]
gt_present = np.zeros([num_timesteps, num_gt_ids])
gt_present[:, 0] = [1, 1, 0, 1, 1]
gt_present[:, 1] = [1, 1, 1, 1, 1]
tracker_present = np.zeros([num_timesteps, num_tracker_ids])
tracker_present[:, 0] = [1, 1, 0, 0, 0]
tracker_present[:, 1] = [0, 0, 1, 1, 1]
tracker_present[:, 2] = [0, 0, 0, 0, 1]
tracker_present[:, 3] = [0, 0, 1, 1, 1]
tracker_present[:, 4] = [1, 1, 0, 0, 0]
expected = {
'clear': {
'CLR_TP': 9,
'CLR_FN': 0, # 9 - 9
'CLR_FP': 2, # 11 - 9
'IDSW': 3,
'MOTA': 1 - 5 / 9,
},
'identity': {
'IDTP': 4,
'IDFN': 5, # 9 - 4
'IDFP': 7, # 11 - 4
'IDR': 4 / 9,
'IDP': 4 / 11,
'IDF1': 2 * 4 / 20,
},
'vace': {
'STDA': 2 / 4 + 2 / 5,
'ATA': (2 / 4 + 2 / 5) / (0.5 * (2 + 5)),
},
}
data = _from_dense(
num_timesteps=num_timesteps,
num_gt_ids=num_gt_ids,
num_tracker_ids=num_tracker_ids,
gt_present=gt_present,
tracker_present=tracker_present,
similarity=similarity,
)
return data, expected
def _from_dense(num_timesteps, num_gt_ids, num_tracker_ids, gt_present, tracker_present, similarity):
gt_subset = [np.flatnonzero(gt_present[t, :]) for t in range(num_timesteps)]
tracker_subset = [np.flatnonzero(tracker_present[t, :]) for t in range(num_timesteps)]
similarity_subset = [
similarity[t][gt_subset[t], :][:, tracker_subset[t]]
for t in range(num_timesteps)
]
data = {
'num_timesteps': num_timesteps,
'num_gt_ids': num_gt_ids,
'num_tracker_ids': num_tracker_ids,
'num_gt_dets': np.sum(gt_present),
'num_tracker_dets': np.sum(tracker_present),
'gt_ids': gt_subset,
'tracker_ids': tracker_subset,
'similarity_scores': similarity_subset,
}
return data
METRICS_BY_NAME = {
'clear': trackeval.metrics.CLEAR(),
'identity': trackeval.metrics.Identity(),
'vace': trackeval.metrics.VACE(),
}
SEQUENCE_BY_NAME = {
'no_confusion': no_confusion(),
'with_confusion': with_confusion(),
'split_tracks': split_tracks(),
}
@pytest.mark.parametrize('sequence_name,metric_name', [
('no_confusion', 'clear'),
('no_confusion', 'identity'),
('no_confusion', 'vace'),
('with_confusion', 'clear'),
('with_confusion', 'identity'),
('with_confusion', 'vace'),
('split_tracks', 'clear'),
('split_tracks', 'identity'),
('split_tracks', 'vace'),
])
def test_metric(sequence_name, metric_name):
data, expected = SEQUENCE_BY_NAME[sequence_name]
metric = METRICS_BY_NAME[metric_name]
result = metric.eval_sequence(data)
for key, value in expected[metric_name].items():
assert result[key] == pytest.approx(value), key
================================================
FILE: TrackEval/tests/test_mot17.py
================================================
""" Test to ensure that the code is working correctly.
Runs all metrics on 14 trackers for the MOT Challenge MOT17 benchmark.
"""
import sys
import os
import numpy as np
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
# Fixes multiprocessing on windows, does nothing otherwise
if __name__ == '__main__':
freeze_support()
eval_config = {'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
}
evaluator = trackeval.Evaluator(eval_config)
metrics_list = [trackeval.metrics.HOTA(), trackeval.metrics.CLEAR(), trackeval.metrics.Identity()]
test_data_loc = os.path.join(os.path.dirname(__file__), '..', 'data', 'tests', 'mot_challenge', 'MOT17-train')
trackers = [
'DPMOT',
'GNNMatch',
'IA',
'ISE_MOT17R',
'Lif_T',
'Lif_TsimInt',
'LPC_MOT',
'MAT',
'MIFTv2',
'MPNTrack',
'SSAT',
'TracktorCorr',
'Tracktorv2',
'UnsupTrack',
]
for tracker in trackers:
# Run code on tracker
dataset_config = {'TRACKERS_TO_EVAL': [tracker],
'BENCHMARK': 'MOT17'}
dataset_list = [trackeval.datasets.MotChallenge2DBox(dataset_config)]
raw_results, messages = evaluator.evaluate(dataset_list, metrics_list)
results = {seq: raw_results['MotChallenge2DBox'][tracker][seq]['pedestrian'] for seq in
raw_results['MotChallenge2DBox'][tracker].keys()}
current_metrics_list = metrics_list + [trackeval.metrics.Count()]
metric_names = trackeval.utils.validate_metrics_list(current_metrics_list)
# Load expected results:
test_data = trackeval.utils.load_detail(os.path.join(test_data_loc, tracker, 'pedestrian_detailed.csv'))
assert len(test_data.keys()) == 22, len(test_data.keys())
# Do checks
for seq in test_data.keys():
assert len(test_data[seq].keys()) > 250, len(test_data[seq].keys())
details = []
for metric, metric_name in zip(current_metrics_list, metric_names):
table_res = {seq_key: seq_value[metric_name] for seq_key, seq_value in results.items()}
details.append(metric.detailed_results(table_res))
res_fields = sum([list(s['COMBINED_SEQ'].keys()) for s in details], [])
res_values = sum([list(s[seq].values()) for s in details], [])
res_dict = dict(zip(res_fields, res_values))
for field in test_data[seq].keys():
if not np.isclose(res_dict[field], test_data[seq][field]):
print(tracker, seq, res_dict[field], test_data[seq][field], field)
raise AssertionError
print('Tracker %s tests passed' % tracker)
print('All tests passed')
================================================
FILE: TrackEval/tests/test_mots.py
================================================
import sys
import os
import numpy as np
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
# Fixes multiprocessing on windows, does nothing otherwise
if __name__ == '__main__':
freeze_support()
eval_config = {'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
}
evaluator = trackeval.Evaluator(eval_config)
metrics_list = [trackeval.metrics.HOTA(), trackeval.metrics.CLEAR(), trackeval.metrics.Identity()]
tests = [
{'DATASET': 'KittiMOTS', 'SPLIT_TO_EVAL': 'val', 'TRACKERS_TO_EVAL': ['trackrcnn']},
{'DATASET': 'MOTSChallenge', 'SPLIT_TO_EVAL': 'train', 'TRACKERS_TO_EVAL': ['TrackRCNN']}
]
for dataset_config in tests:
dataset_name = dataset_config.pop('DATASET')
if dataset_name == 'MOTSChallenge':
dataset_list = [trackeval.datasets.MOTSChallenge(dataset_config)]
file_loc = os.path.join('mot_challenge', 'MOTS-' + dataset_config['SPLIT_TO_EVAL'])
elif dataset_name == 'KittiMOTS':
dataset_list = [trackeval.datasets.KittiMOTS(dataset_config)]
file_loc = os.path.join('kitti', 'kitti_mots_val')
else:
raise Exception('Dataset %s does not exist.' % dataset_name)
raw_results, messages = evaluator.evaluate(dataset_list, metrics_list)
classes = dataset_list[0].config['CLASSES_TO_EVAL']
tracker = dataset_config['TRACKERS_TO_EVAL'][0]
test_data_loc = os.path.join(os.path.dirname(__file__), '..', 'data', 'tests', file_loc)
for cls in classes:
results = {seq: raw_results[dataset_name][tracker][seq][cls] for seq in raw_results[dataset_name][tracker].keys()}
current_metrics_list = metrics_list + [trackeval.metrics.Count()]
metric_names = trackeval.utils.validate_metrics_list(current_metrics_list)
# Load expected results:
test_data = trackeval.utils.load_detail(os.path.join(test_data_loc, tracker, cls + '_detailed.csv'))
# Do checks
for seq in test_data.keys():
assert len(test_data[seq].keys()) > 250, len(test_data[seq].keys())
details = []
for metric, metric_name in zip(current_metrics_list, metric_names):
table_res = {seq_key: seq_value[metric_name] for seq_key, seq_value in results.items()}
details.append(metric.detailed_results(table_res))
res_fields = sum([list(s['COMBINED_SEQ'].keys()) for s in details], [])
res_values = sum([list(s[seq].values()) for s in details], [])
res_dict = dict(zip(res_fields, res_values))
for field in test_data[seq].keys():
assert np.isclose(res_dict[field], test_data[seq][field]), seq + ': ' + cls + ': ' + field
print('Tracker %s tests passed' % tracker)
print('All tests passed')
================================================
FILE: TrackEval/trackeval/__init__.py
================================================
from .eval import Evaluator
from . import datasets
from . import metrics
from . import plotting
from . import utils
================================================
FILE: TrackEval/trackeval/_timing.py
================================================
from functools import wraps
from time import perf_counter
import inspect
DO_TIMING = False
DISPLAY_LESS_PROGRESS = False
timer_dict = {}
counter = 0
def time(f):
@wraps(f)
def wrap(*args, **kw):
if DO_TIMING:
# Run function with timing
ts = perf_counter()
result = f(*args, **kw)
te = perf_counter()
tt = te-ts
# Get function name
arg_names = inspect.getfullargspec(f)[0]
if arg_names[0] == 'self' and DISPLAY_LESS_PROGRESS:
return result
elif arg_names[0] == 'self':
method_name = type(args[0]).__name__ + '.' + f.__name__
else:
method_name = f.__name__
# Record accumulative time in each function for analysis
if method_name in timer_dict.keys():
timer_dict[method_name] += tt
else:
timer_dict[method_name] = tt
# If code is finished, display timing summary
if method_name == "Evaluator.evaluate":
print("")
print("Timing analysis:")
for key, value in timer_dict.items():
print('%-70s %2.4f sec' % (key, value))
else:
# Get function argument values for printing special arguments of interest
arg_titles = ['tracker', 'seq', 'cls']
arg_vals = []
for i, a in enumerate(arg_names):
if a in arg_titles:
arg_vals.append(args[i])
arg_text = '(' + ', '.join(arg_vals) + ')'
# Display methods and functions with different indentation.
if arg_names[0] == 'self':
print('%-74s %2.4f sec' % (' '*4 + method_name + arg_text, tt))
elif arg_names[0] == 'test':
pass
else:
global counter
counter += 1
print('%i %-70s %2.4f sec' % (counter, method_name + arg_text, tt))
return result
else:
# If config["TIME_PROGRESS"] is false, or config["USE_PARALLEL"] is true, run functions normally without timing.
return f(*args, **kw)
return wrap
================================================
FILE: TrackEval/trackeval/baselines/__init__.py
================================================
import baseline_utils
import stp
import non_overlap
import pascal_colormap
import thresholder
import vizualize
================================================
FILE: TrackEval/trackeval/baselines/baseline_utils.py
================================================
import os
import csv
import numpy as np
from copy import deepcopy
from PIL import Image
from pycocotools import mask as mask_utils
from scipy.optimize import linear_sum_assignment
from trackeval.baselines.pascal_colormap import pascal_colormap
def load_seq(file_to_load):
""" Load input data from file in RobMOTS format (e.g. provided detections).
Returns: Data object with the following structure (see STP :
data['cls'][t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles'}
"""
fp = open(file_to_load)
dialect = csv.Sniffer().sniff(fp.readline(), delimiters=' ')
dialect.skipinitialspace = True
fp.seek(0)
reader = csv.reader(fp, dialect)
read_data = {}
num_timesteps = 0
for i, row in enumerate(reader):
if row[-1] in '':
row = row[:-1]
t = int(row[0])
cid = row[1]
c = int(row[2])
s = row[3]
h = row[4]
w = row[5]
rle = row[6]
if t >= num_timesteps:
num_timesteps = t + 1
if c in read_data.keys():
if t in read_data[c].keys():
read_data[c][t]['ids'].append(cid)
read_data[c][t]['scores'].append(s)
read_data[c][t]['im_hs'].append(h)
read_data[c][t]['im_ws'].append(w)
read_data[c][t]['mask_rles'].append(rle)
else:
read_data[c][t] = {}
read_data[c][t]['ids'] = [cid]
read_data[c][t]['scores'] = [s]
read_data[c][t]['im_hs'] = [h]
read_data[c][t]['im_ws'] = [w]
read_data[c][t]['mask_rles'] = [rle]
else:
read_data[c] = {t: {}}
read_data[c][t]['ids'] = [cid]
read_data[c][t]['scores'] = [s]
read_data[c][t]['im_hs'] = [h]
read_data[c][t]['im_ws'] = [w]
read_data[c][t]['mask_rles'] = [rle]
fp.close()
data = {}
for c in read_data.keys():
data[c] = [{} for _ in range(num_timesteps)]
for t in range(num_timesteps):
if t in read_data[c].keys():
data[c][t]['ids'] = np.atleast_1d(read_data[c][t]['ids']).astype(int)
data[c][t]['scores'] = np.atleast_1d(read_data[c][t]['scores']).astype(float)
data[c][t]['im_hs'] = np.atleast_1d(read_data[c][t]['im_hs']).astype(int)
data[c][t]['im_ws'] = np.atleast_1d(read_data[c][t]['im_ws']).astype(int)
data[c][t]['mask_rles'] = np.atleast_1d(read_data[c][t]['mask_rles']).astype(str)
else:
data[c][t]['ids'] = np.empty(0).astype(int)
data[c][t]['scores'] = np.empty(0).astype(float)
data[c][t]['im_hs'] = np.empty(0).astype(int)
data[c][t]['im_ws'] = np.empty(0).astype(int)
data[c][t]['mask_rles'] = np.empty(0).astype(str)
return data
def threshold(tdata, thresh):
""" Removes detections below a certian threshold ('thresh') score. """
new_data = {}
to_keep = tdata['scores'] > thresh
for field in ['ids', 'scores', 'im_hs', 'im_ws', 'mask_rles']:
new_data[field] = tdata[field][to_keep]
return new_data
def create_coco_mask(mask_rles, im_hs, im_ws):
""" Converts mask as rle text (+ height and width) to encoded version used by pycocotools. """
coco_masks = [{'size': [h, w], 'counts': m.encode(encoding='UTF-8')}
for h, w, m in zip(im_hs, im_ws, mask_rles)]
return coco_masks
def mask_iou(mask_rles1, mask_rles2, im_hs, im_ws, do_ioa=0):
""" Calculate mask IoU between two masks.
Further allows 'intersection over area' instead of IoU (over the area of mask_rle1).
Allows either to pass in 1 boolean for do_ioa for all mask_rles2 or also one for each mask_rles2.
It is recommended that mask_rles1 is a detection and mask_rles2 is a groundtruth.
"""
coco_masks1 = create_coco_mask(mask_rles1, im_hs, im_ws)
coco_masks2 = create_coco_mask(mask_rles2, im_hs, im_ws)
if not hasattr(do_ioa, "__len__"):
do_ioa = [do_ioa]*len(coco_masks2)
assert(len(coco_masks2) == len(do_ioa))
if len(coco_masks1) == 0 or len(coco_masks2) == 0:
iou = np.zeros(len(coco_masks1), len(coco_masks2))
else:
iou = mask_utils.iou(coco_masks1, coco_masks2, do_ioa)
return iou
def sort_by_score(t_data):
""" Sorts data by score """
sort_index = np.argsort(t_data['scores'])[::-1]
for k in t_data.keys():
t_data[k] = t_data[k][sort_index]
return t_data
def mask_NMS(t_data, nms_threshold=0.5, already_sorted=False):
""" Remove redundant masks by performing non-maximum suppression (NMS) """
# Sort by score
if not already_sorted:
t_data = sort_by_score(t_data)
# Calculate the mask IoU between all detections in the timestep.
mask_ious_all = mask_iou(t_data['mask_rles'], t_data['mask_rles'], t_data['im_hs'], t_data['im_ws'])
# Determine which masks NMS should remove
# (those overlapping greater than nms_threshold with another mask that has a higher score)
num_dets = len(t_data['mask_rles'])
to_remove = [False for _ in range(num_dets)]
for i in range(num_dets):
if not to_remove[i]:
for j in range(i + 1, num_dets):
if mask_ious_all[i, j] > nms_threshold:
to_remove[j] = True
# Remove detections which should be removed
to_keep = np.logical_not(to_remove)
for k in t_data.keys():
t_data[k] = t_data[k][to_keep]
return t_data
def non_overlap(t_data, already_sorted=False):
""" Enforces masks to be non-overlapping in an image, does this by putting masks 'on top of one another',
such that higher score masks 'occlude' and thus remove parts of lower scoring masks.
Help wanted: if anyone knows a way to do this WITHOUT converting the RLE to the np.array let me know, because that
would be MUCH more efficient. (I have tried, but haven't yet had success).
"""
# Sort by score
if not already_sorted:
t_data = sort_by_score(t_data)
# Get coco masks
coco_masks = create_coco_mask(t_data['mask_rles'], t_data['im_hs'], t_data['im_ws'])
# Create a single np.array to hold all of the non-overlapping mask
masks_array = np.zeros((t_data['im_hs'][0], t_data['im_ws'][0]), 'uint8')
# Decode each mask into a np.array, and place it into the overall array for the whole frame.
# Since masks with the lowest score are placed first, they are 'partially overridden' by masks with a higher score
# if they overlap.
for i, mask in enumerate(coco_masks[::-1]):
masks_array[mask_utils.decode(mask).astype('bool')] = i + 1
# Encode the resulting np.array back into a set of coco_masks which are now non-overlapping.
num_dets = len(coco_masks)
for i, j in enumerate(range(1, num_dets + 1)[::-1]):
coco_masks[i] = mask_utils.encode(np.asfortranarray(masks_array == j, dtype=np.uint8))
# Convert from coco_mask back into our mask_rle format.
t_data['mask_rles'] = [m['counts'].decode("utf-8") for m in coco_masks]
return t_data
def masks2boxes(mask_rles, im_hs, im_ws):
""" Extracts bounding boxes which surround a set of masks. """
coco_masks = create_coco_mask(mask_rles, im_hs, im_ws)
boxes = np.array([mask_utils.toBbox(x) for x in coco_masks])
if len(boxes) == 0:
boxes = np.empty((0, 4))
return boxes
def box_iou(bboxes1, bboxes2, box_format='xywh', do_ioa=False, do_giou=False):
""" Calculates the IOU (intersection over union) between two arrays of boxes.
Allows variable box formats ('xywh' and 'x0y0x1y1').
If do_ioa (intersection over area), then calculates the intersection over the area of boxes1 - this is commonly
used to determine if detections are within crowd ignore region.
If do_giou (generalized intersection over union, then calculates giou.
"""
if len(bboxes1) == 0 or len(bboxes2) == 0:
ious = np.zeros((len(bboxes1), len(bboxes2)))
return ious
if box_format in 'xywh':
# layout: (x0, y0, w, h)
bboxes1 = deepcopy(bboxes1)
bboxes2 = deepcopy(bboxes2)
bboxes1[:, 2] = bboxes1[:, 0] + bboxes1[:, 2]
bboxes1[:, 3] = bboxes1[:, 1] + bboxes1[:, 3]
bboxes2[:, 2] = bboxes2[:, 0] + bboxes2[:, 2]
bboxes2[:, 3] = bboxes2[:, 1] + bboxes2[:, 3]
elif box_format not in 'x0y0x1y1':
raise (Exception('box_format %s is not implemented' % box_format))
# layout: (x0, y0, x1, y1)
min_ = np.minimum(bboxes1[:, np.newaxis, :], bboxes2[np.newaxis, :, :])
max_ = np.maximum(bboxes1[:, np.newaxis, :], bboxes2[np.newaxis, :, :])
intersection = np.maximum(min_[..., 2] - max_[..., 0], 0) * np.maximum(min_[..., 3] - max_[..., 1], 0)
area1 = (bboxes1[..., 2] - bboxes1[..., 0]) * (bboxes1[..., 3] - bboxes1[..., 1])
if do_ioa:
ioas = np.zeros_like(intersection)
valid_mask = area1 > 0 + np.finfo('float').eps
ioas[valid_mask, :] = intersection[valid_mask, :] / area1[valid_mask][:, np.newaxis]
return ioas
else:
area2 = (bboxes2[..., 2] - bboxes2[..., 0]) * (bboxes2[..., 3] - bboxes2[..., 1])
union = area1[:, np.newaxis] + area2[np.newaxis, :] - intersection
intersection[area1 <= 0 + np.finfo('float').eps, :] = 0
intersection[:, area2 <= 0 + np.finfo('float').eps] = 0
intersection[union <= 0 + np.finfo('float').eps] = 0
union[union <= 0 + np.finfo('float').eps] = 1
ious = intersection / union
if do_giou:
enclosing_area = np.maximum(max_[..., 2] - min_[..., 0], 0) * np.maximum(max_[..., 3] - min_[..., 1], 0)
eps = 1e-7
# giou
ious = ious - ((enclosing_area - union) / (enclosing_area + eps))
return ious
def match(match_scores):
match_rows, match_cols = linear_sum_assignment(-match_scores)
return match_rows, match_cols
def write_seq(output_data, out_file):
out_loc = os.path.dirname(out_file)
if not os.path.exists(out_loc):
os.makedirs(out_loc, exist_ok=True)
fp = open(out_file, 'w', newline='')
writer = csv.writer(fp, delimiter=' ')
for row in output_data:
writer.writerow(row)
fp.close()
def combine_classes(data):
""" Converts data from a class-separated to a class-combined format.
Input format: data['cls'][t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles'}
Output format: data[t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles', 'cls'}
"""
output_data = [{} for _ in list(data.values())[0]]
for cls, cls_data in data.items():
for timestep, t_data in enumerate(cls_data):
for k in t_data.keys():
if k in output_data[timestep].keys():
output_data[timestep][k] += list(t_data[k])
else:
output_data[timestep][k] = list(t_data[k])
if 'cls' in output_data[timestep].keys():
output_data[timestep]['cls'] += [cls]*len(output_data[timestep]['ids'])
else:
output_data[timestep]['cls'] = [cls]*len(output_data[timestep]['ids'])
for timestep, t_data in enumerate(output_data):
for k in t_data.keys():
output_data[timestep][k] = np.array(output_data[timestep][k])
return output_data
def save_as_png(t_data, out_file, im_h, im_w):
""" Save a set of segmentation masks into a PNG format, the same as used for the DAVIS dataset."""
if len(t_data['mask_rles']) > 0:
coco_masks = create_coco_mask(t_data['mask_rles'], t_data['im_hs'], t_data['im_ws'])
list_of_np_masks = [mask_utils.decode(mask) for mask in coco_masks]
png = np.zeros((t_data['im_hs'][0], t_data['im_ws'][0]))
for mask, c_id in zip(list_of_np_masks, t_data['ids']):
png[mask.astype("bool")] = c_id + 1
else:
png = np.zeros((im_h, im_w))
if not os.path.exists(os.path.dirname(out_file)):
os.makedirs(os.path.dirname(out_file))
colmap = (np.array(pascal_colormap) * 255).round().astype("uint8")
palimage = Image.new('P', (16, 16))
palimage.putpalette(colmap)
im = Image.fromarray(np.squeeze(png.astype("uint8")))
im2 = im.quantize(palette=palimage)
im2.save(out_file)
def get_frame_size(data):
""" Gets frame height and width from data. """
for cls, cls_data in data.items():
for timestep, t_data in enumerate(cls_data):
if len(t_data['im_hs'] > 0):
im_h = t_data['im_hs'][0]
im_w = t_data['im_ws'][0]
return im_h, im_w
return None
================================================
FILE: TrackEval/trackeval/baselines/non_overlap.py
================================================
"""
Non-Overlap: Code to take in a set of raw detections and produce a set of non-overlapping detections from it.
Author: Jonathon Luiten
"""
import os
import sys
from multiprocessing.pool import Pool
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
from trackeval.baselines import baseline_utils as butils
from trackeval.utils import get_code_path
code_path = get_code_path()
config = {
'INPUT_FOL': os.path.join(code_path, 'data/detections/rob_mots/{split}/raw_supplied/data/'),
'OUTPUT_FOL': os.path.join(code_path, 'data/detections/rob_mots/{split}/non_overlap_supplied/data/'),
'SPLIT': 'train', # valid: 'train', 'val', 'test'.
'Benchmarks': None, # If None, all benchmarks in SPLIT.
'Num_Parallel_Cores': None, # If None, run without parallel.
'THRESHOLD_NMS_MASK_IOU': 0.5,
}
def do_sequence(seq_file):
# Load input data from file (e.g. provided detections)
# data format: data['cls'][t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles'}
data = butils.load_seq(seq_file)
# Converts data from a class-separated to a class-combined format.
# data[t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles', 'cls'}
data = butils.combine_classes(data)
# Where to accumulate output data for writing out
output_data = []
# Run for each timestep.
for timestep, t_data in enumerate(data):
# Remove redundant masks by performing non-maximum suppression (NMS)
t_data = butils.mask_NMS(t_data, nms_threshold=config['THRESHOLD_NMS_MASK_IOU'])
# Perform non-overlap, to get non_overlapping masks.
t_data = butils.non_overlap(t_data, already_sorted=True)
# Save result in output format to write to file later.
# Output Format = [timestep ID class score im_h im_w mask_RLE]
for i in range(len(t_data['ids'])):
row = [timestep, int(t_data['ids'][i]), t_data['cls'][i], t_data['scores'][i], t_data['im_hs'][i],
t_data['im_ws'][i], t_data['mask_rles'][i]]
output_data.append(row)
# Write results to file
out_file = seq_file.replace(config['INPUT_FOL'].format(split=config['SPLIT']),
config['OUTPUT_FOL'].format(split=config['SPLIT']))
butils.write_seq(output_data, out_file)
print('DONE:', seq_file)
if __name__ == '__main__':
# Required to fix bug in multiprocessing on windows.
freeze_support()
# Obtain list of sequences to run tracker for.
if config['Benchmarks']:
benchmarks = config['Benchmarks']
else:
benchmarks = ['davis_unsupervised', 'kitti_mots', 'youtube_vis', 'ovis', 'bdd_mots', 'tao']
if config['SPLIT'] != 'train':
benchmarks += ['waymo', 'mots_challenge']
seqs_todo = []
for bench in benchmarks:
bench_fol = os.path.join(config['INPUT_FOL'].format(split=config['SPLIT']), bench)
seqs_todo += [os.path.join(bench_fol, seq) for seq in os.listdir(bench_fol)]
# Run in parallel
if config['Num_Parallel_Cores']:
with Pool(config['Num_Parallel_Cores']) as pool:
results = pool.map(do_sequence, seqs_todo)
# Run in series
else:
for seq_todo in seqs_todo:
do_sequence(seq_todo)
================================================
FILE: TrackEval/trackeval/baselines/pascal_colormap.py
================================================
pascal_colormap = [
0 , 0, 0,
0.5020, 0, 0,
0, 0.5020, 0,
0.5020, 0.5020, 0,
0, 0, 0.5020,
0.5020, 0, 0.5020,
0, 0.5020, 0.5020,
0.5020, 0.5020, 0.5020,
0.2510, 0, 0,
0.7529, 0, 0,
0.2510, 0.5020, 0,
0.7529, 0.5020, 0,
0.2510, 0, 0.5020,
0.7529, 0, 0.5020,
0.2510, 0.5020, 0.5020,
0.7529, 0.5020, 0.5020,
0, 0.2510, 0,
0.5020, 0.2510, 0,
0, 0.7529, 0,
0.5020, 0.7529, 0,
0, 0.2510, 0.5020,
0.5020, 0.2510, 0.5020,
0, 0.7529, 0.5020,
0.5020, 0.7529, 0.5020,
0.2510, 0.2510, 0,
0.7529, 0.2510, 0,
0.2510, 0.7529, 0,
0.7529, 0.7529, 0,
0.2510, 0.2510, 0.5020,
0.7529, 0.2510, 0.5020,
0.2510, 0.7529, 0.5020,
0.7529, 0.7529, 0.5020,
0, 0, 0.2510,
0.5020, 0, 0.2510,
0, 0.5020, 0.2510,
0.5020, 0.5020, 0.2510,
0, 0, 0.7529,
0.5020, 0, 0.7529,
0, 0.5020, 0.7529,
0.5020, 0.5020, 0.7529,
0.2510, 0, 0.2510,
0.7529, 0, 0.2510,
0.2510, 0.5020, 0.2510,
0.7529, 0.5020, 0.2510,
0.2510, 0, 0.7529,
0.7529, 0, 0.7529,
0.2510, 0.5020, 0.7529,
0.7529, 0.5020, 0.7529,
0, 0.2510, 0.2510,
0.5020, 0.2510, 0.2510,
0, 0.7529, 0.2510,
0.5020, 0.7529, 0.2510,
0, 0.2510, 0.7529,
0.5020, 0.2510, 0.7529,
0, 0.7529, 0.7529,
0.5020, 0.7529, 0.7529,
0.2510, 0.2510, 0.2510,
0.7529, 0.2510, 0.2510,
0.2510, 0.7529, 0.2510,
0.7529, 0.7529, 0.2510,
0.2510, 0.2510, 0.7529,
0.7529, 0.2510, 0.7529,
0.2510, 0.7529, 0.7529,
0.7529, 0.7529, 0.7529,
0.1255, 0, 0,
0.6275, 0, 0,
0.1255, 0.5020, 0,
0.6275, 0.5020, 0,
0.1255, 0, 0.5020,
0.6275, 0, 0.5020,
0.1255, 0.5020, 0.5020,
0.6275, 0.5020, 0.5020,
0.3765, 0, 0,
0.8784, 0, 0,
0.3765, 0.5020, 0,
0.8784, 0.5020, 0,
0.3765, 0, 0.5020,
0.8784, 0, 0.5020,
0.3765, 0.5020, 0.5020,
0.8784, 0.5020, 0.5020,
0.1255, 0.2510, 0,
0.6275, 0.2510, 0,
0.1255, 0.7529, 0,
0.6275, 0.7529, 0,
0.1255, 0.2510, 0.5020,
0.6275, 0.2510, 0.5020,
0.1255, 0.7529, 0.5020,
0.6275, 0.7529, 0.5020,
0.3765, 0.2510, 0,
0.8784, 0.2510, 0,
0.3765, 0.7529, 0,
0.8784, 0.7529, 0,
0.3765, 0.2510, 0.5020,
0.8784, 0.2510, 0.5020,
0.3765, 0.7529, 0.5020,
0.8784, 0.7529, 0.5020,
0.1255, 0, 0.2510,
0.6275, 0, 0.2510,
0.1255, 0.5020, 0.2510,
0.6275, 0.5020, 0.2510,
0.1255, 0, 0.7529,
0.6275, 0, 0.7529,
0.1255, 0.5020, 0.7529,
0.6275, 0.5020, 0.7529,
0.3765, 0, 0.2510,
0.8784, 0, 0.2510,
0.3765, 0.5020, 0.2510,
0.8784, 0.5020, 0.2510,
0.3765, 0, 0.7529,
0.8784, 0, 0.7529,
0.3765, 0.5020, 0.7529,
0.8784, 0.5020, 0.7529,
0.1255, 0.2510, 0.2510,
0.6275, 0.2510, 0.2510,
0.1255, 0.7529, 0.2510,
0.6275, 0.7529, 0.2510,
0.1255, 0.2510, 0.7529,
0.6275, 0.2510, 0.7529,
0.1255, 0.7529, 0.7529,
0.6275, 0.7529, 0.7529,
0.3765, 0.2510, 0.2510,
0.8784, 0.2510, 0.2510,
0.3765, 0.7529, 0.2510,
0.8784, 0.7529, 0.2510,
0.3765, 0.2510, 0.7529,
0.8784, 0.2510, 0.7529,
0.3765, 0.7529, 0.7529,
0.8784, 0.7529, 0.7529,
0, 0.1255, 0,
0.5020, 0.1255, 0,
0, 0.6275, 0,
0.5020, 0.6275, 0,
0, 0.1255, 0.5020,
0.5020, 0.1255, 0.5020,
0, 0.6275, 0.5020,
0.5020, 0.6275, 0.5020,
0.2510, 0.1255, 0,
0.7529, 0.1255, 0,
0.2510, 0.6275, 0,
0.7529, 0.6275, 0,
0.2510, 0.1255, 0.5020,
0.7529, 0.1255, 0.5020,
0.2510, 0.6275, 0.5020,
0.7529, 0.6275, 0.5020,
0, 0.3765, 0,
0.5020, 0.3765, 0,
0, 0.8784, 0,
0.5020, 0.8784, 0,
0, 0.3765, 0.5020,
0.5020, 0.3765, 0.5020,
0, 0.8784, 0.5020,
0.5020, 0.8784, 0.5020,
0.2510, 0.3765, 0,
0.7529, 0.3765, 0,
0.2510, 0.8784, 0,
0.7529, 0.8784, 0,
0.2510, 0.3765, 0.5020,
0.7529, 0.3765, 0.5020,
0.2510, 0.8784, 0.5020,
0.7529, 0.8784, 0.5020,
0, 0.1255, 0.2510,
0.5020, 0.1255, 0.2510,
0, 0.6275, 0.2510,
0.5020, 0.6275, 0.2510,
0, 0.1255, 0.7529,
0.5020, 0.1255, 0.7529,
0, 0.6275, 0.7529,
0.5020, 0.6275, 0.7529,
0.2510, 0.1255, 0.2510,
0.7529, 0.1255, 0.2510,
0.2510, 0.6275, 0.2510,
0.7529, 0.6275, 0.2510,
0.2510, 0.1255, 0.7529,
0.7529, 0.1255, 0.7529,
0.2510, 0.6275, 0.7529,
0.7529, 0.6275, 0.7529,
0, 0.3765, 0.2510,
0.5020, 0.3765, 0.2510,
0, 0.8784, 0.2510,
0.5020, 0.8784, 0.2510,
0, 0.3765, 0.7529,
0.5020, 0.3765, 0.7529,
0, 0.8784, 0.7529,
0.5020, 0.8784, 0.7529,
0.2510, 0.3765, 0.2510,
0.7529, 0.3765, 0.2510,
0.2510, 0.8784, 0.2510,
0.7529, 0.8784, 0.2510,
0.2510, 0.3765, 0.7529,
0.7529, 0.3765, 0.7529,
0.2510, 0.8784, 0.7529,
0.7529, 0.8784, 0.7529,
0.1255, 0.1255, 0,
0.6275, 0.1255, 0,
0.1255, 0.6275, 0,
0.6275, 0.6275, 0,
0.1255, 0.1255, 0.5020,
0.6275, 0.1255, 0.5020,
0.1255, 0.6275, 0.5020,
0.6275, 0.6275, 0.5020,
0.3765, 0.1255, 0,
0.8784, 0.1255, 0,
0.3765, 0.6275, 0,
0.8784, 0.6275, 0,
0.3765, 0.1255, 0.5020,
0.8784, 0.1255, 0.5020,
0.3765, 0.6275, 0.5020,
0.8784, 0.6275, 0.5020,
0.1255, 0.3765, 0,
0.6275, 0.3765, 0,
0.1255, 0.8784, 0,
0.6275, 0.8784, 0,
0.1255, 0.3765, 0.5020,
0.6275, 0.3765, 0.5020,
0.1255, 0.8784, 0.5020,
0.6275, 0.8784, 0.5020,
0.3765, 0.3765, 0,
0.8784, 0.3765, 0,
0.3765, 0.8784, 0,
0.8784, 0.8784, 0,
0.3765, 0.3765, 0.5020,
0.8784, 0.3765, 0.5020,
0.3765, 0.8784, 0.5020,
0.8784, 0.8784, 0.5020,
0.1255, 0.1255, 0.2510,
0.6275, 0.1255, 0.2510,
0.1255, 0.6275, 0.2510,
0.6275, 0.6275, 0.2510,
0.1255, 0.1255, 0.7529,
0.6275, 0.1255, 0.7529,
0.1255, 0.6275, 0.7529,
0.6275, 0.6275, 0.7529,
0.3765, 0.1255, 0.2510,
0.8784, 0.1255, 0.2510,
0.3765, 0.6275, 0.2510,
0.8784, 0.6275, 0.2510,
0.3765, 0.1255, 0.7529,
0.8784, 0.1255, 0.7529,
0.3765, 0.6275, 0.7529,
0.8784, 0.6275, 0.7529,
0.1255, 0.3765, 0.2510,
0.6275, 0.3765, 0.2510,
0.1255, 0.8784, 0.2510,
0.6275, 0.8784, 0.2510,
0.1255, 0.3765, 0.7529,
0.6275, 0.3765, 0.7529,
0.1255, 0.8784, 0.7529,
0.6275, 0.8784, 0.7529,
0.3765, 0.3765, 0.2510,
0.8784, 0.3765, 0.2510,
0.3765, 0.8784, 0.2510,
0.8784, 0.8784, 0.2510,
0.3765, 0.3765, 0.7529,
0.8784, 0.3765, 0.7529,
0.3765, 0.8784, 0.7529,
0.8784, 0.8784, 0.7529]
================================================
FILE: TrackEval/trackeval/baselines/stp.py
================================================
"""
STP: Simplest Tracker Possible
Author: Jonathon Luiten
This simple tracker, simply assigns track IDs which maximise the 'bounding box IoU' between previous tracks and current
detections. It is also able to match detections to tracks at more than one timestep previously.
"""
import os
import sys
import numpy as np
from multiprocessing.pool import Pool
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
from trackeval.baselines import baseline_utils as butils
from trackeval.utils import get_code_path
code_path = get_code_path()
config = {
'INPUT_FOL': os.path.join(code_path, 'data/detections/rob_mots/{split}/non_overlap_supplied/data/'),
'OUTPUT_FOL': os.path.join(code_path, 'data/trackers/rob_mots/{split}/STP/data/'),
'SPLIT': 'train', # valid: 'train', 'val', 'test'.
'Benchmarks': None, # If None, all benchmarks in SPLIT.
'Num_Parallel_Cores': None, # If None, run without parallel.
'DETECTION_THRESHOLD': 0.5,
'ASSOCIATION_THRESHOLD': 1e-10,
'MAX_FRAMES_SKIP': 7
}
def track_sequence(seq_file):
# Load input data from file (e.g. provided detections)
# data format: data['cls'][t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles'}
data = butils.load_seq(seq_file)
# Where to accumulate output data for writing out
output_data = []
# To ensure IDs are unique per object across all classes.
curr_max_id = 0
# Run tracker for each class.
for cls, cls_data in data.items():
# Initialize container for holding previously tracked objects.
prev = {'boxes': np.empty((0, 4)),
'ids': np.array([], np.int),
'timesteps': np.array([])}
# Run tracker for each timestep.
for timestep, t_data in enumerate(cls_data):
# Threshold detections.
t_data = butils.threshold(t_data, config['DETECTION_THRESHOLD'])
# Convert mask dets to bounding boxes.
boxes = butils.masks2boxes(t_data['mask_rles'], t_data['im_hs'], t_data['im_ws'])
# Calculate IoU between previous and current frame dets.
ious = butils.box_iou(prev['boxes'], boxes)
# Score which decreases quickly for previous dets depending on how many timesteps before they come from.
prev_timestep_scores = np.power(10, -1 * prev['timesteps'])
# Matching score is such that it first tries to match 'most recent timesteps',
# and within each timestep maximised IoU.
match_scores = prev_timestep_scores[:, np.newaxis] * ious
# Find best matching between current dets and previous tracks.
match_rows, match_cols = butils.match(match_scores)
# Remove matches that have an IoU below a certain threshold.
actually_matched_mask = ious[match_rows, match_cols] > config['ASSOCIATION_THRESHOLD']
match_rows = match_rows[actually_matched_mask]
match_cols = match_cols[actually_matched_mask]
# Assign the prev track ID to the current dets if they were matched.
ids = np.nan * np.ones((len(boxes),), np.int)
ids[match_cols] = prev['ids'][match_rows]
# Create new track IDs for dets that were not matched to previous tracks.
num_not_matched = len(ids) - len(match_cols)
new_ids = np.arange(curr_max_id + 1, curr_max_id + num_not_matched + 1)
ids[np.isnan(ids)] = new_ids
# Update maximum ID to ensure future added tracks have a unique ID value.
curr_max_id += num_not_matched
# Drop tracks from 'previous tracks' if they have not been matched in the last MAX_FRAMES_SKIP frames.
unmatched_rows = [i for i in range(len(prev['ids'])) if
i not in match_rows and (prev['timesteps'][i] + 1 <= config['MAX_FRAMES_SKIP'])]
# Update the set of previous tracking results to include the newly tracked detections.
prev['ids'] = np.concatenate((ids, prev['ids'][unmatched_rows]), axis=0)
prev['boxes'] = np.concatenate((np.atleast_2d(boxes), np.atleast_2d(prev['boxes'][unmatched_rows])), axis=0)
prev['timesteps'] = np.concatenate((np.zeros((len(ids),)), prev['timesteps'][unmatched_rows] + 1), axis=0)
# Save result in output format to write to file later.
# Output Format = [timestep ID class score im_h im_w mask_RLE]
for i in range(len(t_data['ids'])):
row = [timestep, int(ids[i]), cls, t_data['scores'][i], t_data['im_hs'][i], t_data['im_ws'][i],
t_data['mask_rles'][i]]
output_data.append(row)
# Write results to file
out_file = seq_file.replace(config['INPUT_FOL'].format(split=config['SPLIT']),
config['OUTPUT_FOL'].format(split=config['SPLIT']))
butils.write_seq(output_data, out_file)
print('DONE:', seq_file)
if __name__ == '__main__':
# Required to fix bug in multiprocessing on windows.
freeze_support()
# Obtain list of sequences to run tracker for.
if config['Benchmarks']:
benchmarks = config['Benchmarks']
else:
benchmarks = ['davis_unsupervised', 'kitti_mots', 'youtube_vis', 'ovis', 'bdd_mots', 'tao']
if config['SPLIT'] != 'train':
benchmarks += ['waymo', 'mots_challenge']
seqs_todo = []
for bench in benchmarks:
bench_fol = os.path.join(config['INPUT_FOL'].format(split=config['SPLIT']), bench)
seqs_todo += [os.path.join(bench_fol, seq) for seq in os.listdir(bench_fol)]
# Run in parallel
if config['Num_Parallel_Cores']:
with Pool(config['Num_Parallel_Cores']) as pool:
results = pool.map(track_sequence, seqs_todo)
# Run in series
else:
for seq_todo in seqs_todo:
track_sequence(seq_todo)
================================================
FILE: TrackEval/trackeval/baselines/thresholder.py
================================================
"""
Thresholder
Author: Jonathon Luiten
Simply reads in a set of detection, thresholds them at a certain score threshold, and writes them out again.
"""
import os
import sys
from multiprocessing.pool import Pool
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
from trackeval.baselines import baseline_utils as butils
from trackeval.utils import get_code_path
THRESHOLD = 0.2
code_path = get_code_path()
config = {
'INPUT_FOL': os.path.join(code_path, 'data/detections/rob_mots/{split}/non_overlap_supplied/data/'),
'OUTPUT_FOL': os.path.join(code_path, 'data/detections/rob_mots/{split}/threshold_' + str(100*THRESHOLD) + '/data/'),
'SPLIT': 'train', # valid: 'train', 'val', 'test'.
'Benchmarks': None, # If None, all benchmarks in SPLIT.
'Num_Parallel_Cores': None, # If None, run without parallel.
'DETECTION_THRESHOLD': THRESHOLD,
}
def do_sequence(seq_file):
# Load input data from file (e.g. provided detections)
# data format: data['cls'][t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles'}
data = butils.load_seq(seq_file)
# Where to accumulate output data for writing out
output_data = []
# Run for each class.
for cls, cls_data in data.items():
# Run for each timestep.
for timestep, t_data in enumerate(cls_data):
# Threshold detections.
t_data = butils.threshold(t_data, config['DETECTION_THRESHOLD'])
# Save result in output format to write to file later.
# Output Format = [timestep ID class score im_h im_w mask_RLE]
for i in range(len(t_data['ids'])):
row = [timestep, int(t_data['ids'][i]), cls, t_data['scores'][i], t_data['im_hs'][i],
t_data['im_ws'][i], t_data['mask_rles'][i]]
output_data.append(row)
# Write results to file
out_file = seq_file.replace(config['INPUT_FOL'].format(split=config['SPLIT']),
config['OUTPUT_FOL'].format(split=config['SPLIT']))
butils.write_seq(output_data, out_file)
print('DONE:', seq_todo)
if __name__ == '__main__':
# Required to fix bug in multiprocessing on windows.
freeze_support()
# Obtain list of sequences to run tracker for.
if config['Benchmarks']:
benchmarks = config['Benchmarks']
else:
benchmarks = ['davis_unsupervised', 'kitti_mots', 'youtube_vis', 'ovis', 'bdd_mots', 'tao']
if config['SPLIT'] != 'train':
benchmarks += ['waymo', 'mots_challenge']
seqs_todo = []
for bench in benchmarks:
bench_fol = os.path.join(config['INPUT_FOL'].format(split=config['SPLIT']), bench)
seqs_todo += [os.path.join(bench_fol, seq) for seq in os.listdir(bench_fol)]
# Run in parallel
if config['Num_Parallel_Cores']:
with Pool(config['Num_Parallel_Cores']) as pool:
results = pool.map(do_sequence, seqs_todo)
# Run in series
else:
for seq_todo in seqs_todo:
do_sequence(seq_todo)
================================================
FILE: TrackEval/trackeval/baselines/vizualize.py
================================================
"""
Vizualize: Code which converts .txt rle tracking results into a visual .png format.
Author: Jonathon Luiten
"""
import os
import sys
from multiprocessing.pool import Pool
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..', '..')))
from trackeval.baselines import baseline_utils as butils
from trackeval.utils import get_code_path
from trackeval.datasets.rob_mots_classmap import cls_id_to_name
code_path = get_code_path()
config = {
# Tracker format:
'INPUT_FOL': os.path.join(code_path, 'data/trackers/rob_mots/{split}/STP/data/{bench}'),
'OUTPUT_FOL': os.path.join(code_path, 'data/viz/rob_mots/{split}/STP/data/{bench}'),
# GT format:
# 'INPUT_FOL': os.path.join(code_path, 'data/gt/rob_mots/{split}/{bench}/data/'),
# 'OUTPUT_FOL': os.path.join(code_path, 'data/gt_viz/rob_mots/{split}/{bench}/'),
'SPLIT': 'train', # valid: 'train', 'val', 'test'.
'Benchmarks': None, # If None, all benchmarks in SPLIT.
'Num_Parallel_Cores': None, # If None, run without parallel.
}
def do_sequence(seq_file):
# Folder to save resulting visualization in
out_fol = seq_file.replace(config['INPUT_FOL'].format(split=config['SPLIT'], bench=bench),
config['OUTPUT_FOL'].format(split=config['SPLIT'], bench=bench)).replace('.txt', '')
# Load input data from file (e.g. provided detections)
# data format: data['cls'][t] = {'ids', 'scores', 'im_hs', 'im_ws', 'mask_rles'}
data = butils.load_seq(seq_file)
# Get frame size for visualizing empty frames
im_h, im_w = butils.get_frame_size(data)
# First run for each class.
for cls, cls_data in data.items():
if cls >= 100:
continue
# Run for each timestep.
for timestep, t_data in enumerate(cls_data):
# Save out visualization
out_file = os.path.join(out_fol, cls_id_to_name[cls], str(timestep).zfill(5) + '.png')
butils.save_as_png(t_data, out_file, im_h, im_w)
# Then run for all classes combined
# Converts data from a class-separated to a class-combined format.
data = butils.combine_classes(data)
# Run for each timestep.
for timestep, t_data in enumerate(data):
# Save out visualization
out_file = os.path.join(out_fol, 'all_classes', str(timestep).zfill(5) + '.png')
butils.save_as_png(t_data, out_file, im_h, im_w)
print('DONE:', seq_file)
if __name__ == '__main__':
# Required to fix bug in multiprocessing on windows.
freeze_support()
# Obtain list of sequences to run tracker for.
if config['Benchmarks']:
benchmarks = config['Benchmarks']
else:
benchmarks = ['davis_unsupervised', 'kitti_mots', 'youtube_vis', 'ovis', 'bdd_mots', 'tao']
if config['SPLIT'] != 'train':
benchmarks += ['waymo', 'mots_challenge']
seqs_todo = []
for bench in benchmarks:
bench_fol = config['INPUT_FOL'].format(split=config['SPLIT'], bench=bench)
seqs_todo += [os.path.join(bench_fol, seq) for seq in os.listdir(bench_fol)]
# Run in parallel
if config['Num_Parallel_Cores']:
with Pool(config['Num_Parallel_Cores']) as pool:
results = pool.map(do_sequence, seqs_todo)
# Run in series
else:
for seq_todo in seqs_todo:
do_sequence(seq_todo)
================================================
FILE: TrackEval/trackeval/datasets/__init__.py
================================================
from .kitti_2d_box import Kitti2DBox
from .kitti_mots import KittiMOTS
from .mot_challenge_2d_box import MotChallenge2DBox
from .mots_challenge import MOTSChallenge
from .bdd100k import BDD100K
from .davis import DAVIS
from .tao import TAO
from .tao_ow import TAO_OW
from .youtube_vis import YouTubeVIS
from .head_tracking_challenge import HeadTrackingChallenge
from .rob_mots import RobMOTS
================================================
FILE: TrackEval/trackeval/datasets/_base_dataset.py
================================================
import csv
import io
import zipfile
import os
import traceback
import numpy as np
from copy import deepcopy
from abc import ABC, abstractmethod
from .. import _timing
from ..utils import TrackEvalException
class _BaseDataset(ABC):
@abstractmethod
def __init__(self):
self.tracker_list = None
self.seq_list = None
self.class_list = None
self.output_fol = None
self.output_sub_fol = None
self.should_classes_combine = True
self.use_super_categories = False
# Functions to implement:
@staticmethod
@abstractmethod
def get_default_dataset_config():
...
@abstractmethod
def _load_raw_file(self, tracker, seq, is_gt):
...
@_timing.time
@abstractmethod
def get_preprocessed_seq_data(self, raw_data, cls):
...
@abstractmethod
def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
...
# Helper functions for all datasets:
@classmethod
def get_class_name(cls):
return cls.__name__
def get_name(self):
return self.get_class_name()
def get_output_fol(self, tracker):
return os.path.join(self.output_fol, tracker, self.output_sub_fol)
def get_display_name(self, tracker):
""" Can be overwritten if the trackers name (in files) is different to how it should be displayed.
By default this method just returns the trackers name as is.
"""
return tracker
def get_eval_info(self):
"""Return info about the dataset needed for the Evaluator"""
return self.tracker_list, self.seq_list, self.class_list
@_timing.time
def get_raw_seq_data(self, tracker, seq):
""" Loads raw data (tracker and ground-truth) for a single tracker on a single sequence.
Raw data includes all of the information needed for both preprocessing and evaluation, for all classes.
A later function (get_processed_seq_data) will perform such preprocessing and extract relevant information for
the evaluation of each class.
This returns a dict which contains the fields:
[num_timesteps]: integer
[gt_ids, tracker_ids, gt_classes, tracker_classes, tracker_confidences]:
list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, tracker_dets, gt_crowd_ignore_regions]: list (for each timestep) of lists of detections.
[similarity_scores]: list (for each timestep) of 2D NDArrays.
[gt_extras]: dict (for each extra) of lists (for each timestep) of 1D NDArrays (for each det).
gt_extras contains dataset specific information used for preprocessing such as occlusion and truncation levels.
Note that similarities are extracted as part of the dataset and not the metric, because almost all metrics are
independent of the exact method of calculating the similarity. However datasets are not (e.g. segmentation
masks vs 2D boxes vs 3D boxes).
We calculate the similarity before preprocessing because often both preprocessing and evaluation require it and
we don't wish to calculate this twice.
We calculate similarity between all gt and tracker classes (not just each class individually) to allow for
calculation of metrics such as class confusion matrices. Typically the impact of this on performance is low.
"""
# Load raw data.
raw_gt_data = self._load_raw_file(tracker, seq, is_gt=True)
raw_tracker_data = self._load_raw_file(tracker, seq, is_gt=False)
raw_data = {**raw_tracker_data, **raw_gt_data} # Merges dictionaries
# Calculate similarities for each timestep.
similarity_scores = []
for t, (gt_dets_t, tracker_dets_t) in enumerate(zip(raw_data['gt_dets'], raw_data['tracker_dets'])):
ious = self._calculate_similarities(gt_dets_t, tracker_dets_t)
similarity_scores.append(ious)
raw_data['similarity_scores'] = similarity_scores
return raw_data
@staticmethod
def _load_simple_text_file(file, time_col=0, id_col=None, remove_negative_ids=False, valid_filter=None,
crowd_ignore_filter=None, convert_filter=None, is_zipped=False, zip_file=None,
force_delimiters=None):
""" Function that loads data which is in a commonly used text file format.
Assumes each det is given by one row of a text file.
There is no limit to the number or meaning of each column,
however one column needs to give the timestep of each det (time_col) which is default col 0.
The file dialect (deliminator, num cols, etc) is determined automatically.
This function automatically separates dets by timestep,
and is much faster than alternatives such as np.loadtext or pandas.
If remove_negative_ids is True and id_col is not None, dets with negative values in id_col are excluded.
These are not excluded from ignore data.
valid_filter can be used to only include certain classes.
It is a dict with ints as keys, and lists as values,
such that a row is included if "row[key].lower() is in value" for all key/value pairs in the dict.
If None, all classes are included.
crowd_ignore_filter can be used to read crowd_ignore regions separately. It has the same format as valid filter.
convert_filter can be used to convert value read to another format.
This is used most commonly to convert classes given as string to a class id.
This is a dict such that the key is the column to convert, and the value is another dict giving the mapping.
Optionally, input files could be a zip of multiple text files for storage efficiency.
Returns read_data and ignore_data.
Each is a dict (with keys as timesteps as strings) of lists (over dets) of lists (over column values).
Note that all data is returned as strings, and must be converted to float/int later if needed.
Note that timesteps will not be present in the returned dict keys if there are no dets for them
"""
if remove_negative_ids and id_col is None:
raise TrackEvalException('remove_negative_ids is True, but id_col is not given.')
if crowd_ignore_filter is None:
crowd_ignore_filter = {}
if convert_filter is None:
convert_filter = {}
try:
if is_zipped: # Either open file directly or within a zip.
if zip_file is None:
raise TrackEvalException('is_zipped set to True, but no zip_file is given.')
archive = zipfile.ZipFile(os.path.join(zip_file), 'r')
fp = io.TextIOWrapper(archive.open(file, 'r'))
else:
fp = open(file)
read_data = {}
crowd_ignore_data = {}
fp.seek(0, os.SEEK_END)
# check if file is empty
if fp.tell():
fp.seek(0)
dialect = csv.Sniffer().sniff(fp.readline(), delimiters=force_delimiters) # Auto determine structure.
dialect.skipinitialspace = True # Deal with extra spaces between columns
fp.seek(0)
reader = csv.reader(fp, dialect)
for row in reader:
try:
# Deal with extra trailing spaces at the end of rows
if row[-1] in '':
row = row[:-1]
timestep = str(int(float(row[time_col])))
# Read ignore regions separately.
is_ignored = False
for ignore_key, ignore_value in crowd_ignore_filter.items():
if row[ignore_key].lower() in ignore_value:
# Convert values in one column (e.g. string to id)
for convert_key, convert_value in convert_filter.items():
row[convert_key] = convert_value[row[convert_key].lower()]
# Save data separated by timestep.
if timestep in crowd_ignore_data.keys():
crowd_ignore_data[timestep].append(row)
else:
crowd_ignore_data[timestep] = [row]
is_ignored = True
if is_ignored: # if det is an ignore region, it cannot be a normal det.
continue
# Exclude some dets if not valid.
if valid_filter is not None:
for key, value in valid_filter.items():
if row[key].lower() not in value:
continue
if remove_negative_ids:
if int(float(row[id_col])) < 0:
continue
# Convert values in one column (e.g. string to id)
for convert_key, convert_value in convert_filter.items():
row[convert_key] = convert_value[row[convert_key].lower()]
# Save data separated by timestep.
if timestep in read_data.keys():
read_data[timestep].append(row)
else:
read_data[timestep] = [row]
except Exception:
exc_str_init = 'In file %s the following line cannot be read correctly: \n' % os.path.basename(
file)
exc_str = ' '.join([exc_str_init]+row)
raise TrackEvalException(exc_str)
fp.close()
except Exception:
print('Error loading file: %s, printing traceback.' % file)
traceback.print_exc()
raise TrackEvalException(
'File %s cannot be read because it is either not present or invalidly formatted' % os.path.basename(
file))
return read_data, crowd_ignore_data
@staticmethod
def _calculate_mask_ious(masks1, masks2, is_encoded=False, do_ioa=False):
""" Calculates the IOU (intersection over union) between two arrays of segmentation masks.
If is_encoded a run length encoding with pycocotools is assumed as input format, otherwise an input of numpy
arrays of the shape (num_masks, height, width) is assumed and the encoding is performed.
If do_ioa (intersection over area) , then calculates the intersection over the area of masks1 - this is commonly
used to determine if detections are within crowd ignore region.
:param masks1: first set of masks (numpy array of shape (num_masks, height, width) if not encoded,
else pycocotools rle encoded format)
:param masks2: second set of masks (numpy array of shape (num_masks, height, width) if not encoded,
else pycocotools rle encoded format)
:param is_encoded: whether the input is in pycocotools rle encoded format
:param do_ioa: whether to perform IoA computation
:return: the IoU/IoA scores
"""
# Only loaded when run to reduce minimum requirements
from pycocotools import mask as mask_utils
# use pycocotools for run length encoding of masks
if not is_encoded:
masks1 = mask_utils.encode(np.array(np.transpose(masks1, (1, 2, 0)), order='F'))
masks2 = mask_utils.encode(np.array(np.transpose(masks2, (1, 2, 0)), order='F'))
# use pycocotools for iou computation of rle encoded masks
ious = mask_utils.iou(masks1, masks2, [do_ioa]*len(masks2))
if len(masks1) == 0 or len(masks2) == 0:
ious = np.asarray(ious).reshape(len(masks1), len(masks2))
assert (ious >= 0 - np.finfo('float').eps).all()
assert (ious <= 1 + np.finfo('float').eps).all()
return ious
@staticmethod
def _calculate_box_ious(bboxes1, bboxes2, box_format='xywh', do_ioa=False):
""" Calculates the IOU (intersection over union) between two arrays of boxes.
Allows variable box formats ('xywh' and 'x0y0x1y1').
If do_ioa (intersection over area) , then calculates the intersection over the area of boxes1 - this is commonly
used to determine if detections are within crowd ignore region.
"""
if box_format in 'xywh':
# layout: (x0, y0, w, h)
bboxes1 = deepcopy(bboxes1)
bboxes2 = deepcopy(bboxes2)
bboxes1[:, 2] = bboxes1[:, 0] + bboxes1[:, 2]
bboxes1[:, 3] = bboxes1[:, 1] + bboxes1[:, 3]
bboxes2[:, 2] = bboxes2[:, 0] + bboxes2[:, 2]
bboxes2[:, 3] = bboxes2[:, 1] + bboxes2[:, 3]
elif box_format not in 'x0y0x1y1':
raise (TrackEvalException('box_format %s is not implemented' % box_format))
# layout: (x0, y0, x1, y1)
min_ = np.minimum(bboxes1[:, np.newaxis, :], bboxes2[np.newaxis, :, :])
max_ = np.maximum(bboxes1[:, np.newaxis, :], bboxes2[np.newaxis, :, :])
intersection = np.maximum(min_[..., 2] - max_[..., 0], 0) * np.maximum(min_[..., 3] - max_[..., 1], 0)
area1 = (bboxes1[..., 2] - bboxes1[..., 0]) * (bboxes1[..., 3] - bboxes1[..., 1])
if do_ioa:
ioas = np.zeros_like(intersection)
valid_mask = area1 > 0 + np.finfo('float').eps
ioas[valid_mask, :] = intersection[valid_mask, :] / area1[valid_mask][:, np.newaxis]
return ioas
else:
area2 = (bboxes2[..., 2] - bboxes2[..., 0]) * (bboxes2[..., 3] - bboxes2[..., 1])
union = area1[:, np.newaxis] + area2[np.newaxis, :] - intersection
intersection[area1 <= 0 + np.finfo('float').eps, :] = 0
intersection[:, area2 <= 0 + np.finfo('float').eps] = 0
intersection[union <= 0 + np.finfo('float').eps] = 0
union[union <= 0 + np.finfo('float').eps] = 1
ious = intersection / union
return ious
@staticmethod
def _calculate_euclidean_similarity(dets1, dets2, zero_distance=2.0):
""" Calculates the euclidean distance between two sets of detections, and then converts this into a similarity
measure with values between 0 and 1 using the following formula: sim = max(0, 1 - dist/zero_distance).
The default zero_distance of 2.0, corresponds to the default used in MOT15_3D, such that a 0.5 similarity
threshold corresponds to a 1m distance threshold for TPs.
"""
dist = np.linalg.norm(dets1[:, np.newaxis]-dets2[np.newaxis, :], axis=2)
sim = np.maximum(0, 1 - dist/zero_distance)
return sim
@staticmethod
def _check_unique_ids(data, after_preproc=False):
"""Check the requirement that the tracker_ids and gt_ids are unique per timestep"""
gt_ids = data['gt_ids']
tracker_ids = data['tracker_ids']
for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(gt_ids, tracker_ids)):
if len(tracker_ids_t) > 0:
unique_ids, counts = np.unique(tracker_ids_t, return_counts=True)
if np.max(counts) != 1:
duplicate_ids = unique_ids[counts > 1]
exc_str_init = 'Tracker predicts the same ID more than once in a single timestep ' \
'(seq: %s, frame: %i, ids:' % (data['seq'], t+1)
exc_str = ' '.join([exc_str_init] + [str(d) for d in duplicate_ids]) + ')'
if after_preproc:
exc_str_init += '\n Note that this error occurred after preprocessing (but not before), ' \
'so ids may not be as in file, and something seems wrong with preproc.'
raise TrackEvalException(exc_str)
if len(gt_ids_t) > 0:
unique_ids, counts = np.unique(gt_ids_t, return_counts=True)
if np.max(counts) != 1:
duplicate_ids = unique_ids[counts > 1]
exc_str_init = 'Ground-truth has the same ID more than once in a single timestep ' \
'(seq: %s, frame: %i, ids:' % (data['seq'], t+1)
exc_str = ' '.join([exc_str_init] + [str(d) for d in duplicate_ids]) + ')'
if after_preproc:
exc_str_init += '\n Note that this error occurred after preprocessing (but not before), ' \
'so ids may not be as in file, and something seems wrong with preproc.'
raise TrackEvalException(exc_str)
================================================
FILE: TrackEval/trackeval/datasets/bdd100k.py
================================================
import os
import json
import numpy as np
from scipy.optimize import linear_sum_assignment
from ..utils import TrackEvalException
from ._base_dataset import _BaseDataset
from .. import utils
from .. import _timing
class BDD100K(_BaseDataset):
"""Dataset class for BDD100K tracking"""
@staticmethod
def get_default_dataset_config():
"""Default class config values"""
code_path = utils.get_code_path()
default_config = {
'GT_FOLDER': os.path.join(code_path, 'data/gt/bdd100k/bdd100k_val'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/bdd100k/bdd100k_val'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': ['pedestrian', 'rider', 'car', 'bus', 'truck', 'train', 'motorcycle', 'bicycle'],
# Valid: ['pedestrian', 'rider', 'car', 'bus', 'truck', 'train', 'motorcycle', 'bicycle']
'SPLIT_TO_EVAL': 'val', # Valid: 'training', 'val',
'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
}
return default_config
def __init__(self, config=None):
"""Initialise dataset, checking that all required files are present"""
super().__init__()
# Fill non-given config values with defaults
self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
self.gt_fol = self.config['GT_FOLDER']
self.tracker_fol = self.config['TRACKERS_FOLDER']
self.should_classes_combine = True
self.use_super_categories = True
self.output_fol = self.config['OUTPUT_FOLDER']
if self.output_fol is None:
self.output_fol = self.tracker_fol
self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
# Get classes to eval
self.valid_classes = ['pedestrian', 'rider', 'car', 'bus', 'truck', 'train', 'motorcycle', 'bicycle']
self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
for cls in self.config['CLASSES_TO_EVAL']]
if not all(self.class_list):
raise TrackEvalException('Attempted to evaluate an invalid class. Only classes [pedestrian, rider, car, '
'bus, truck, train, motorcycle, bicycle] are valid.')
self.super_categories = {"HUMAN": [cls for cls in ["pedestrian", "rider"] if cls in self.class_list],
"VEHICLE": [cls for cls in ["car", "truck", "bus", "train"] if cls in self.class_list],
"BIKE": [cls for cls in ["motorcycle", "bicycle"] if cls in self.class_list]}
self.distractor_classes = ['other person', 'trailer', 'other vehicle']
self.class_name_to_class_id = {'pedestrian': 1, 'rider': 2, 'other person': 3, 'car': 4, 'bus': 5, 'truck': 6,
'train': 7, 'trailer': 8, 'other vehicle': 9, 'motorcycle': 10, 'bicycle': 11}
# Get sequences to eval
self.seq_list = []
self.seq_lengths = {}
self.seq_list = [seq_file.replace('.json', '') for seq_file in os.listdir(self.gt_fol)]
# Get trackers to eval
if self.config['TRACKERS_TO_EVAL'] is None:
self.tracker_list = os.listdir(self.tracker_fol)
else:
self.tracker_list = self.config['TRACKERS_TO_EVAL']
if self.config['TRACKER_DISPLAY_NAMES'] is None:
self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
else:
raise TrackEvalException('List of tracker files and tracker display names do not match.')
for tracker in self.tracker_list:
for seq in self.seq_list:
curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.json')
if not os.path.isfile(curr_file):
print('Tracker file not found: ' + curr_file)
raise TrackEvalException(
'Tracker file not found: ' + tracker + '/' + self.tracker_sub_fol + '/' + os.path.basename(
curr_file))
def get_display_name(self, tracker):
return self.tracker_to_disp[tracker]
def _load_raw_file(self, tracker, seq, is_gt):
"""Load a file (gt or tracker) in the BDD100K format
If is_gt, this returns a dict which contains the fields:
[gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, gt_crowd_ignore_regions]: list (for each timestep) of lists of detections.
if not is_gt, this returns a dict which contains the fields:
[tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
[tracker_dets]: list (for each timestep) of lists of detections.
"""
# File location
if is_gt:
file = os.path.join(self.gt_fol, seq + '.json')
else:
file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.json')
with open(file) as f:
data = json.load(f)
# sort data by frame index
data = sorted(data, key=lambda x: x['index'])
# check sequence length
if is_gt:
self.seq_lengths[seq] = len(data)
num_timesteps = len(data)
else:
num_timesteps = self.seq_lengths[seq]
if num_timesteps != len(data):
raise TrackEvalException('Number of ground truth and tracker timesteps do not match for sequence %s'
% seq)
# Convert data to required format
data_keys = ['ids', 'classes', 'dets']
if is_gt:
data_keys += ['gt_crowd_ignore_regions']
raw_data = {key: [None] * num_timesteps for key in data_keys}
for t in range(num_timesteps):
ig_ids = []
keep_ids = []
for i in range(len(data[t]['labels'])):
ann = data[t]['labels'][i]
if is_gt and (ann['category'] in self.distractor_classes or 'attributes' in ann.keys()
and ann['attributes']['Crowd']):
ig_ids.append(i)
else:
keep_ids.append(i)
if keep_ids:
raw_data['dets'][t] = np.atleast_2d([[data[t]['labels'][i]['box2d']['x1'],
data[t]['labels'][i]['box2d']['y1'],
data[t]['labels'][i]['box2d']['x2'],
data[t]['labels'][i]['box2d']['y2']
] for i in keep_ids]).astype(float)
raw_data['ids'][t] = np.atleast_1d([data[t]['labels'][i]['id'] for i in keep_ids]).astype(int)
raw_data['classes'][t] = np.atleast_1d([self.class_name_to_class_id[data[t]['labels'][i]['category']]
for i in keep_ids]).astype(int)
else:
raw_data['dets'][t] = np.empty((0, 4)).astype(float)
raw_data['ids'][t] = np.empty(0).astype(int)
raw_data['classes'][t] = np.empty(0).astype(int)
if is_gt:
if ig_ids:
raw_data['gt_crowd_ignore_regions'][t] = np.atleast_2d([[data[t]['labels'][i]['box2d']['x1'],
data[t]['labels'][i]['box2d']['y1'],
data[t]['labels'][i]['box2d']['x2'],
data[t]['labels'][i]['box2d']['y2']
] for i in ig_ids]).astype(float)
else:
raw_data['gt_crowd_ignore_regions'][t] = np.empty((0, 4)).astype(float)
if is_gt:
key_map = {'ids': 'gt_ids',
'classes': 'gt_classes',
'dets': 'gt_dets'}
else:
key_map = {'ids': 'tracker_ids',
'classes': 'tracker_classes',
'dets': 'tracker_dets'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
raw_data['num_timesteps'] = num_timesteps
return raw_data
@_timing.time
def get_preprocessed_seq_data(self, raw_data, cls):
""" Preprocess data for a single sequence for a single class ready for evaluation.
Inputs:
- raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
- cls is the class to be evaluated.
Outputs:
- data is a dict containing all of the information that metrics need to perform evaluation.
It contains the following fields:
[num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
[gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
[similarity_scores]: list (for each timestep) of 2D NDArrays.
Notes:
General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
1) Extract only detections relevant for the class to be evaluated (including distractor detections).
2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
distractor class, or otherwise marked as to be removed.
3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
other criteria (e.g. are too small).
4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
After the above preprocessing steps, this function also calculates the number of gt and tracker detections
and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
unique within each timestep.
BDD100K:
In BDD100K, the 4 preproc steps are as follow:
1) There are eight classes (pedestrian, rider, car, bus, truck, train, motorcycle, bicycle)
which are evaluated separately.
2) For BDD100K there is no removal of matched tracker dets.
3) Crowd ignore regions are used to remove unmatched detections.
4) No removal of gt dets.
"""
cls_id = self.class_name_to_class_id[cls]
data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'similarity_scores']
data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
unique_gt_ids = []
unique_tracker_ids = []
num_gt_dets = 0
num_tracker_dets = 0
for t in range(raw_data['num_timesteps']):
# Only extract relevant dets for this class for preproc and eval (cls)
gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
gt_class_mask = gt_class_mask.astype(np.bool)
gt_ids = raw_data['gt_ids'][t][gt_class_mask]
gt_dets = raw_data['gt_dets'][t][gt_class_mask]
tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
tracker_class_mask = tracker_class_mask.astype(np.bool)
tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
tracker_dets = raw_data['tracker_dets'][t][tracker_class_mask]
similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
# Match tracker and gt dets (with hungarian algorithm)
unmatched_indices = np.arange(tracker_ids.shape[0])
if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
matching_scores = similarity_scores.copy()
matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
match_rows, match_cols = linear_sum_assignment(-matching_scores)
actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
match_cols = match_cols[actually_matched_mask]
unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
# For unmatched tracker dets, remove those that are greater than 50% within a crowd ignore region.
unmatched_tracker_dets = tracker_dets[unmatched_indices, :]
crowd_ignore_regions = raw_data['gt_crowd_ignore_regions'][t]
intersection_with_ignore_region = self._calculate_box_ious(unmatched_tracker_dets, crowd_ignore_regions,
box_format='x0y0x1y1', do_ioa=True)
is_within_crowd_ignore_region = np.any(intersection_with_ignore_region > 0.5 + np.finfo('float').eps,
axis=1)
# Apply preprocessing to remove unwanted tracker dets.
to_remove_tracker = unmatched_indices[is_within_crowd_ignore_region]
data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
data['gt_ids'][t] = gt_ids
data['gt_dets'][t] = gt_dets
data['similarity_scores'][t] = similarity_scores
unique_gt_ids += list(np.unique(data['gt_ids'][t]))
unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
num_tracker_dets += len(data['tracker_ids'][t])
num_gt_dets += len(data['gt_ids'][t])
# Re-label IDs such that there are no empty IDs
if len(unique_gt_ids) > 0:
unique_gt_ids = np.unique(unique_gt_ids)
gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
for t in range(raw_data['num_timesteps']):
if len(data['gt_ids'][t]) > 0:
data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
if len(unique_tracker_ids) > 0:
unique_tracker_ids = np.unique(unique_tracker_ids)
tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
for t in range(raw_data['num_timesteps']):
if len(data['tracker_ids'][t]) > 0:
data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
# Record overview statistics.
data['num_tracker_dets'] = num_tracker_dets
data['num_gt_dets'] = num_gt_dets
data['num_tracker_ids'] = len(unique_tracker_ids)
data['num_gt_ids'] = len(unique_gt_ids)
data['num_timesteps'] = raw_data['num_timesteps']
# Ensure that ids are unique per timestep.
self._check_unique_ids(data)
return data
def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t, box_format='x0y0x1y1')
return similarity_scores
================================================
FILE: TrackEval/trackeval/datasets/davis.py
================================================
import os
import csv
import numpy as np
from ._base_dataset import _BaseDataset
from ..utils import TrackEvalException
from .. import utils
from .. import _timing
class DAVIS(_BaseDataset):
"""Dataset class for DAVIS tracking"""
@staticmethod
def get_default_dataset_config():
"""Default class config values"""
code_path = utils.get_code_path()
default_config = {
'GT_FOLDER': os.path.join(code_path, 'data/gt/davis/davis_unsupervised_val/'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/davis/davis_unsupervised_val/'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'SPLIT_TO_EVAL': 'val', # Valid: 'val', 'train'
'CLASSES_TO_EVAL': ['general'],
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
'SEQMAP_FILE': None, # Specify seqmap file
'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
# '{gt_folder}/Annotations_unsupervised/480p/{seq}'
'MAX_DETECTIONS': 0 # Maximum number of allowed detections per sequence (0 for no threshold)
}
return default_config
def __init__(self, config=None):
"""Initialise dataset, checking that all required files are present"""
super().__init__()
# Fill non-given config values with defaults
self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
# defining a default class since there are no classes in DAVIS
self.should_classes_combine = False
self.use_super_categories = False
self.gt_fol = self.config['GT_FOLDER']
self.tracker_fol = self.config['TRACKERS_FOLDER']
self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
self.output_fol = self.config['OUTPUT_FOLDER']
if self.output_fol is None:
self.output_fol = self.config['TRACKERS_FOLDER']
self.max_det = self.config['MAX_DETECTIONS']
# Get classes to eval
self.valid_classes = ['general']
self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
for cls in self.config['CLASSES_TO_EVAL']]
if not all(self.class_list):
raise TrackEvalException('Attempted to evaluate an invalid class. Only general class is valid.')
# Get sequences to eval
if self.config["SEQ_INFO"]:
self.seq_list = list(self.config["SEQ_INFO"].keys())
self.seq_lengths = self.config["SEQ_INFO"]
elif self.config["SEQMAP_FILE"]:
self.seq_list = []
seqmap_file = self.config["SEQMAP_FILE"]
if not os.path.isfile(seqmap_file):
raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
with open(seqmap_file) as fp:
reader = csv.reader(fp)
for i, row in enumerate(reader):
if row[0] == '':
continue
seq = row[0]
self.seq_list.append(seq)
else:
self.seq_list = os.listdir(self.gt_fol)
self.seq_lengths = {seq: len(os.listdir(os.path.join(self.gt_fol, seq))) for seq in self.seq_list}
# Get trackers to eval
if self.config['TRACKERS_TO_EVAL'] is None:
self.tracker_list = os.listdir(self.tracker_fol)
else:
self.tracker_list = self.config['TRACKERS_TO_EVAL']
for tracker in self.tracker_list:
for seq in self.seq_list:
curr_dir = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq)
if not os.path.isdir(curr_dir):
print('Tracker directory not found: ' + curr_dir)
raise TrackEvalException('Tracker directory not found: ' +
os.path.join(tracker, self.tracker_sub_fol, seq))
tr_timesteps = len(os.listdir(curr_dir))
if self.seq_lengths[seq] != tr_timesteps:
raise TrackEvalException('GT folder and tracker folder have a different number'
'timesteps for tracker %s and sequence %s' % (tracker, seq))
if self.config['TRACKER_DISPLAY_NAMES'] is None:
self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
else:
raise TrackEvalException('List of tracker files and tracker display names do not match.')
def _load_raw_file(self, tracker, seq, is_gt):
"""Load a file (gt or tracker) in the DAVIS format
If is_gt, this returns a dict which contains the fields:
[gt_ids] : list (for each timestep) of 1D NDArrays (for each det).
[gt_dets]: list (for each timestep) of lists of detections.
[masks_void]: list of masks with void pixels (pixels to be ignored during evaluation)
if not is_gt, this returns a dict which contains the fields:
[tracker_ids] : list (for each timestep) of 1D NDArrays (for each det).
[tracker_dets]: list (for each timestep) of lists of detections.
"""
# Only loaded when run to reduce minimum requirements
from pycocotools import mask as mask_utils
from PIL import Image
# File location
if is_gt:
seq_dir = os.path.join(self.gt_fol, seq)
else:
seq_dir = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq)
num_timesteps = self.seq_lengths[seq]
data_keys = ['ids', 'dets', 'masks_void']
raw_data = {key: [None] * num_timesteps for key in data_keys}
# read frames
frames = [os.path.join(seq_dir, im_name) for im_name in sorted(os.listdir(seq_dir))]
id_list = []
for t in range(num_timesteps):
frame = np.array(Image.open(frames[t]))
if is_gt:
void = frame == 255
frame[void] = 0
raw_data['masks_void'][t] = mask_utils.encode(np.asfortranarray(void.astype(np.uint8)))
id_values = np.unique(frame)
id_values = id_values[id_values != 0]
id_list += list(id_values)
tmp = np.ones((len(id_values), *frame.shape))
tmp = tmp * id_values[:, None, None]
masks = np.array(tmp == frame[None, ...]).astype(np.uint8)
raw_data['dets'][t] = mask_utils.encode(np.array(np.transpose(masks, (1, 2, 0)), order='F'))
raw_data['ids'][t] = id_values.astype(int)
num_objects = len(np.unique(id_list))
if not is_gt and num_objects > self.max_det > 0:
raise Exception('Number of proposals (%i) for sequence %s exceeds number of maximum allowed proposals (%i).'
% (num_objects, seq, self.max_det))
if is_gt:
key_map = {'ids': 'gt_ids',
'dets': 'gt_dets'}
else:
key_map = {'ids': 'tracker_ids',
'dets': 'tracker_dets'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
raw_data["num_timesteps"] = num_timesteps
raw_data['mask_shape'] = np.array(Image.open(frames[0])).shape
if is_gt:
raw_data['num_gt_ids'] = num_objects
else:
raw_data['num_tracker_ids'] = num_objects
return raw_data
@_timing.time
def get_preprocessed_seq_data(self, raw_data, cls):
""" Preprocess data for a single sequence for a single class ready for evaluation.
Inputs:
- raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
- cls is the class to be evaluated.
Outputs:
- data is a dict containing all of the information that metrics need to perform evaluation.
It contains the following fields:
[num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
[gt_ids, tracker_ids]: list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, tracker_dets]: list (for each timestep) of lists of detection masks.
[similarity_scores]: list (for each timestep) of 2D NDArrays.
Notes:
General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
1) Extract only detections relevant for the class to be evaluated (including distractor detections).
2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
distractor class, or otherwise marked as to be removed.
3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
other criteria (e.g. are too small).
4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
After the above preprocessing steps, this function also calculates the number of gt and tracker detections
and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
unique within each timestep.
DAVIS:
In DAVIS, the 4 preproc steps are as follow:
1) There are no classes, all detections are evaluated jointly
2) No matched tracker detections are removed.
3) No unmatched tracker detections are removed.
4) There are no ground truth detections (e.g. those of distractor classes) to be removed.
Preprocessing special to DAVIS: Pixels which are marked as void in the ground truth are set to zero in the
tracker detections since they are not considered during evaluation.
"""
# Only loaded when run to reduce minimum requirements
from pycocotools import mask as mask_utils
data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'similarity_scores']
data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
num_gt_dets = 0
num_tracker_dets = 0
unique_gt_ids = []
unique_tracker_ids = []
num_timesteps = raw_data['num_timesteps']
# count detections
for t in range(num_timesteps):
num_gt_dets += len(raw_data['gt_dets'][t])
num_tracker_dets += len(raw_data['tracker_dets'][t])
unique_gt_ids += list(np.unique(raw_data['gt_ids'][t]))
unique_tracker_ids += list(np.unique(raw_data['tracker_ids'][t]))
data['gt_ids'] = raw_data['gt_ids']
data['gt_dets'] = raw_data['gt_dets']
data['similarity_scores'] = raw_data['similarity_scores']
data['tracker_ids'] = raw_data['tracker_ids']
# set void pixels in tracker detections to zero
for t in range(num_timesteps):
void_mask = raw_data['masks_void'][t]
if mask_utils.area(void_mask) > 0:
void_mask_ious = np.atleast_1d(mask_utils.iou(raw_data['tracker_dets'][t], [void_mask], [False]))
if void_mask_ious.any():
rows, columns = np.where(void_mask_ious > 0)
for r in rows:
det = mask_utils.decode(raw_data['tracker_dets'][t][r])
void = mask_utils.decode(void_mask).astype(np.bool)
det[void] = 0
det = mask_utils.encode(np.array(det, order='F').astype(np.uint8))
raw_data['tracker_dets'][t][r] = det
data['tracker_dets'] = raw_data['tracker_dets']
# Re-label IDs such that there are no empty IDs
if len(unique_gt_ids) > 0:
unique_gt_ids = np.unique(unique_gt_ids)
gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
for t in range(raw_data['num_timesteps']):
if len(data['gt_ids'][t]) > 0:
data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
if len(unique_tracker_ids) > 0:
unique_tracker_ids = np.unique(unique_tracker_ids)
tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
for t in range(raw_data['num_timesteps']):
if len(data['tracker_ids'][t]) > 0:
data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
# Record overview statistics.
data['num_tracker_dets'] = num_tracker_dets
data['num_gt_dets'] = num_gt_dets
data['num_tracker_ids'] = raw_data['num_tracker_ids']
data['num_gt_ids'] = raw_data['num_gt_ids']
data['mask_shape'] = raw_data['mask_shape']
data['num_timesteps'] = num_timesteps
return data
def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
similarity_scores = self._calculate_mask_ious(gt_dets_t, tracker_dets_t, is_encoded=True, do_ioa=False)
return similarity_scores
================================================
FILE: TrackEval/trackeval/datasets/head_tracking_challenge.py
================================================
import os
import csv
import configparser
import numpy as np
from scipy.optimize import linear_sum_assignment
from ._base_dataset import _BaseDataset
from .. import utils
from .. import _timing
from ..utils import TrackEvalException
class HeadTrackingChallenge(_BaseDataset):
"""Dataset class for Head Tracking Challenge - 2D bounding box tracking"""
@staticmethod
def get_default_dataset_config():
"""Default class config values"""
code_path = utils.get_code_path()
default_config = {
'GT_FOLDER': os.path.join(code_path, 'data/gt/mot_challenge/'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/mot_challenge/'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
'BENCHMARK': 'HT', # Valid: 'HT'. Refers to "Head Tracking or the dataset CroHD"
'SPLIT_TO_EVAL': 'train', # Valid: 'train', 'test', 'all'
'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
'PRINT_CONFIG': True, # Whether to print current config
'DO_PREPROC': True, # Whether to perform preprocessing (never done for MOT15)
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/seqmaps)
'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/benchmark-split_to_eval)
'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
'GT_LOC_FORMAT': '{gt_folder}/{seq}/gt/gt.txt', # '{gt_folder}/{seq}/gt/gt.txt'
'SKIP_SPLIT_FOL': False, # If False, data is in GT_FOLDER/BENCHMARK-SPLIT_TO_EVAL/ and in
# TRACKERS_FOLDER/BENCHMARK-SPLIT_TO_EVAL/tracker/
# If True, then the middle 'benchmark-split' folder is skipped for both.
}
return default_config
def __init__(self, config=None):
"""Initialise dataset, checking that all required files are present"""
super().__init__()
# Fill non-given config values with defaults
self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
self.benchmark = self.config['BENCHMARK']
gt_set = self.config['BENCHMARK'] + '-' + self.config['SPLIT_TO_EVAL']
self.gt_set = gt_set
if not self.config['SKIP_SPLIT_FOL']:
split_fol = gt_set
else:
split_fol = ''
self.gt_fol = os.path.join(self.config['GT_FOLDER'], split_fol)
self.tracker_fol = os.path.join(self.config['TRACKERS_FOLDER'], split_fol)
self.should_classes_combine = False
self.use_super_categories = False
self.data_is_zipped = self.config['INPUT_AS_ZIP']
self.do_preproc = self.config['DO_PREPROC']
self.output_fol = self.config['OUTPUT_FOLDER']
if self.output_fol is None:
self.output_fol = self.tracker_fol
self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
# Get classes to eval
self.valid_classes = ['pedestrian']
self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
for cls in self.config['CLASSES_TO_EVAL']]
if not all(self.class_list):
raise TrackEvalException('Attempted to evaluate an invalid class. Only pedestrian class is valid.')
self.class_name_to_class_id = {'pedestrian': 1, 'static': 2, 'ignore': 3, 'person_on_vehicle': 4}
self.valid_class_numbers = list(self.class_name_to_class_id.values())
# Get sequences to eval and check gt files exist
self.seq_list, self.seq_lengths = self._get_seq_info()
if len(self.seq_list) < 1:
raise TrackEvalException('No sequences are selected to be evaluated.')
# Check gt files exist
for seq in self.seq_list:
if not self.data_is_zipped:
curr_file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
if not os.path.isfile(curr_file):
print('GT file not found ' + curr_file)
raise TrackEvalException('GT file not found for sequence: ' + seq)
if self.data_is_zipped:
curr_file = os.path.join(self.gt_fol, 'data.zip')
if not os.path.isfile(curr_file):
print('GT file not found ' + curr_file)
raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
# Get trackers to eval
if self.config['TRACKERS_TO_EVAL'] is None:
self.tracker_list = os.listdir(self.tracker_fol)
else:
self.tracker_list = self.config['TRACKERS_TO_EVAL']
if self.config['TRACKER_DISPLAY_NAMES'] is None:
self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
else:
raise TrackEvalException('List of tracker files and tracker display names do not match.')
for tracker in self.tracker_list:
if self.data_is_zipped:
curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
if not os.path.isfile(curr_file):
print('Tracker file not found: ' + curr_file)
raise TrackEvalException('Tracker file not found: ' + tracker + '/' + os.path.basename(curr_file))
else:
for seq in self.seq_list:
curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
if not os.path.isfile(curr_file):
print('Tracker file not found: ' + curr_file)
raise TrackEvalException(
'Tracker file not found: ' + tracker + '/' + self.tracker_sub_fol + '/' + os.path.basename(
curr_file))
def get_display_name(self, tracker):
return self.tracker_to_disp[tracker]
def _get_seq_info(self):
seq_list = []
seq_lengths = {}
if self.config["SEQ_INFO"]:
seq_list = list(self.config["SEQ_INFO"].keys())
seq_lengths = self.config["SEQ_INFO"]
# If sequence length is 'None' tries to read sequence length from .ini files.
for seq, seq_length in seq_lengths.items():
if seq_length is None:
ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
if not os.path.isfile(ini_file):
raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
ini_data = configparser.ConfigParser()
ini_data.read(ini_file)
seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
else:
if self.config["SEQMAP_FILE"]:
seqmap_file = self.config["SEQMAP_FILE"]
else:
if self.config["SEQMAP_FOLDER"] is None:
seqmap_file = os.path.join(self.config['GT_FOLDER'], 'seqmaps', self.gt_set + '.txt')
else:
seqmap_file = os.path.join(self.config["SEQMAP_FOLDER"], self.gt_set + '.txt')
if not os.path.isfile(seqmap_file):
print('no seqmap found: ' + seqmap_file)
raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
with open(seqmap_file) as fp:
reader = csv.reader(fp)
for i, row in enumerate(reader):
if i == 0 or row[0] == '':
continue
seq = row[0]
seq_list.append(seq)
ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
if not os.path.isfile(ini_file):
raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
ini_data = configparser.ConfigParser()
ini_data.read(ini_file)
seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
return seq_list, seq_lengths
def _load_raw_file(self, tracker, seq, is_gt):
"""Load a file (gt or tracker) in the MOT Challenge 2D box format
If is_gt, this returns a dict which contains the fields:
[gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, gt_crowd_ignore_regions]: list (for each timestep) of lists of detections.
[gt_extras] : list (for each timestep) of dicts (for each extra) of 1D NDArrays (for each det).
if not is_gt, this returns a dict which contains the fields:
[tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
[tracker_dets]: list (for each timestep) of lists of detections.
"""
# File location
if self.data_is_zipped:
if is_gt:
zip_file = os.path.join(self.gt_fol, 'data.zip')
else:
zip_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
file = seq + '.txt'
else:
zip_file = None
if is_gt:
file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
else:
file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
# Load raw data from text file
read_data, ignore_data = self._load_simple_text_file(file, is_zipped=self.data_is_zipped, zip_file=zip_file)
# Convert data to required format
num_timesteps = self.seq_lengths[seq]
data_keys = ['ids', 'classes', 'dets']
if is_gt:
data_keys += ['gt_crowd_ignore_regions', 'gt_extras']
else:
data_keys += ['tracker_confidences']
if self.benchmark == 'HT':
data_keys += ['visibility']
data_keys += ['gt_conf']
raw_data = {key: [None] * num_timesteps for key in data_keys}
# Check for any extra time keys
current_time_keys = [str( t+ 1) for t in range(num_timesteps)]
extra_time_keys = [x for x in read_data.keys() if x not in current_time_keys]
if len(extra_time_keys) > 0:
if is_gt:
text = 'Ground-truth'
else:
text = 'Tracking'
raise TrackEvalException(
text + ' data contains the following invalid timesteps in seq %s: ' % seq + ', '.join(
[str(x) + ', ' for x in extra_time_keys]))
for t in range(num_timesteps):
time_key = str(t+1)
if time_key in read_data.keys():
try:
time_data = np.asarray(read_data[time_key], dtype=np.float)
except ValueError:
if is_gt:
raise TrackEvalException(
'Cannot convert gt data for sequence %s to float. Is data corrupted?' % seq)
else:
raise TrackEvalException(
'Cannot convert tracking data from tracker %s, sequence %s to float. Is data corrupted?' % (
tracker, seq))
try:
raw_data['dets'][t] = np.atleast_2d(time_data[:, 2:6])
raw_data['ids'][t] = np.atleast_1d(time_data[:, 1]).astype(int)
except IndexError:
if is_gt:
err = 'Cannot load gt data from sequence %s, because there is not enough ' \
'columns in the data.' % seq
raise TrackEvalException(err)
else:
err = 'Cannot load tracker data from tracker %s, sequence %s, because there is not enough ' \
'columns in the data.' % (tracker, seq)
raise TrackEvalException(err)
if time_data.shape[1] >= 8:
raw_data['gt_conf'][t] = np.atleast_1d(time_data[:, 6]).astype(float)
raw_data['visibility'][t] = np.atleast_1d(time_data[:, 8]).astype(float)
raw_data['classes'][t] = np.atleast_1d(time_data[:, 7]).astype(int)
else:
if not is_gt:
raw_data['classes'][t] = np.ones_like(raw_data['ids'][t])
else:
raise TrackEvalException(
'GT data is not in a valid format, there is not enough rows in seq %s, timestep %i.' % (
seq, t))
if is_gt:
gt_extras_dict = {'zero_marked': np.atleast_1d(time_data[:, 6].astype(int))}
raw_data['gt_extras'][t] = gt_extras_dict
else:
raw_data['tracker_confidences'][t] = np.atleast_1d(time_data[:, 6])
else:
raw_data['dets'][t] = np.empty((0, 4))
raw_data['ids'][t] = np.empty(0).astype(int)
raw_data['classes'][t] = np.empty(0).astype(int)
if is_gt:
gt_extras_dict = {'zero_marked': np.empty(0)}
raw_data['gt_extras'][t] = gt_extras_dict
else:
raw_data['tracker_confidences'][t] = np.empty(0)
if is_gt:
raw_data['gt_crowd_ignore_regions'][t] = np.empty((0, 4))
if is_gt:
key_map = {'ids': 'gt_ids',
'classes': 'gt_classes',
'dets': 'gt_dets'}
else:
key_map = {'ids': 'tracker_ids',
'classes': 'tracker_classes',
'dets': 'tracker_dets'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
raw_data['num_timesteps'] = num_timesteps
raw_data['seq'] = seq
return raw_data
@_timing.time
def get_preprocessed_seq_data(self, raw_data, cls):
""" Preprocess data for a single sequence for a single class ready for evaluation.
Inputs:
- raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
- cls is the class to be evaluated.
Outputs:
- data is a dict containing all of the information that metrics need to perform evaluation.
It contains the following fields:
[num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
[gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
[similarity_scores]: list (for each timestep) of 2D NDArrays.
Notes:
General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
1) Extract only detections relevant for the class to be evaluated (including distractor detections).
2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
distractor class, or otherwise marked as to be removed.
3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
other criteria (e.g. are too small).
4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
After the above preprocessing steps, this function also calculates the number of gt and tracker detections
and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
unique within each timestep.
MOT Challenge:
In MOT Challenge, the 4 preproc steps are as follow:
1) There is only one class (pedestrian) to be evaluated, but all other classes are used for preproc.
2) Predictions are matched against all gt boxes (regardless of class), those matching with distractor
objects are removed.
3) There is no crowd ignore regions.
4) All gt dets except pedestrian are removed, also removes pedestrian gt dets marked with zero_marked.
"""
# Check that input data has unique ids
self._check_unique_ids(raw_data)
# 'static': 2, 'ignore': 3, 'person_on_vehicle':
distractor_class_names = ['static', 'ignore', 'person_on_vehicle']
distractor_classes = [self.class_name_to_class_id[x] for x in distractor_class_names]
cls_id = self.class_name_to_class_id[cls]
data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences',
'similarity_scores', 'gt_visibility']
data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
unique_gt_ids = []
unique_tracker_ids = []
num_gt_dets = 0
num_tracker_dets = 0
for t in range(raw_data['num_timesteps']):
# Get all data
gt_ids = raw_data['gt_ids'][t]
gt_dets = raw_data['gt_dets'][t]
gt_classes = raw_data['gt_classes'][t]
gt_visibility = raw_data['visibility'][t]
gt_conf = raw_data['gt_conf'][t]
gt_zero_marked = raw_data['gt_extras'][t]['zero_marked']
tracker_ids = raw_data['tracker_ids'][t]
tracker_dets = raw_data['tracker_dets'][t]
tracker_classes = raw_data['tracker_classes'][t]
tracker_confidences = raw_data['tracker_confidences'][t]
similarity_scores = raw_data['similarity_scores'][t]
# Evaluation is ONLY valid for pedestrian class
if len(tracker_classes) > 0 and np.max(tracker_classes) > 1:
raise TrackEvalException(
'Evaluation is only valid for pedestrian class. Non pedestrian class (%i) found in sequence %s at '
'timestep %i.' % (np.max(tracker_classes), raw_data['seq'], t))
# Match tracker and gt dets (with hungarian algorithm) and remove tracker dets which match with gt dets
# which are labeled as belonging to a distractor class.
to_remove_tracker = np.array([], np.int)
if self.do_preproc and self.benchmark != 'MOT15' and gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
# Check all classes are valid:
invalid_classes = np.setdiff1d(np.unique(gt_classes), self.valid_class_numbers)
if len(invalid_classes) > 0:
print(' '.join([str(x) for x in invalid_classes]))
raise(TrackEvalException('Attempting to evaluate using invalid gt classes. '
'This warning only triggers if preprocessing is performed, '
'e.g. not for MOT15 or where prepropressing is explicitly disabled. '
'Please either check your gt data, or disable preprocessing. '
'The following invalid classes were found in timestep ' + str(t) + ': ' +
' '.join([str(x) for x in invalid_classes])))
matching_scores = similarity_scores.copy()
matching_scores[matching_scores < 0.4 - np.finfo('float').eps] = 0
match_rows, match_cols = linear_sum_assignment(-matching_scores)
actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
match_rows = match_rows[actually_matched_mask]
match_cols = match_cols[actually_matched_mask]
is_distractor_class = np.logical_not(np.isin(gt_classes[match_rows], cls_id))
if self.benchmark == 'HT':
is_invisible_class = gt_visibility[match_rows] < np.finfo('float').eps
low_conf_class = gt_conf[match_rows] < np.finfo('float').eps
are_distractors = np.logical_or(is_invisible_class, is_distractor_class, low_conf_class)
to_remove_tracker = match_cols[are_distractors]
else:
to_remove_tracker = match_cols[is_distractor_class]
# Apply preprocessing to remove all unwanted tracker dets.
data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
# Remove gt detections marked as to remove (zero marked), and also remove gt detections not in pedestrian
if self.do_preproc and self.benchmark == 'HT':
gt_to_keep_mask = (np.not_equal(gt_zero_marked, 0)) & \
(np.equal(gt_classes, cls_id)) & \
(gt_visibility > 0.) & \
(gt_conf > 0.)
else:
# There are no classes for MOT15
gt_to_keep_mask = np.not_equal(gt_zero_marked, 0)
data['gt_ids'][t] = gt_ids[gt_to_keep_mask]
data['gt_dets'][t] = gt_dets[gt_to_keep_mask, :]
data['similarity_scores'][t] = similarity_scores[gt_to_keep_mask]
data['gt_visibility'][t] = gt_visibility # No mask!
unique_gt_ids += list(np.unique(data['gt_ids'][t]))
unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
num_tracker_dets += len(data['tracker_ids'][t])
num_gt_dets += len(data['gt_ids'][t])
# Re-label IDs such that there are no empty IDs
if len(unique_gt_ids) > 0:
unique_gt_ids = np.unique(unique_gt_ids)
gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
for t in range(raw_data['num_timesteps']):
if len(data['gt_ids'][t]) > 0:
data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
if len(unique_tracker_ids) > 0:
unique_tracker_ids = np.unique(unique_tracker_ids)
tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
for t in range(raw_data['num_timesteps']):
if len(data['tracker_ids'][t]) > 0:
data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
# Record overview statistics.
data['num_tracker_dets'] = num_tracker_dets
data['num_gt_dets'] = num_gt_dets
data['num_tracker_ids'] = len(unique_tracker_ids)
data['num_gt_ids'] = len(unique_gt_ids)
data['num_timesteps'] = raw_data['num_timesteps']
data['seq'] = raw_data['seq']
# Ensure again that ids are unique per timestep after preproc.
self._check_unique_ids(data, after_preproc=True)
return data
def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t, box_format='xywh')
return similarity_scores
================================================
FILE: TrackEval/trackeval/datasets/kitti_2d_box.py
================================================
import os
import csv
import numpy as np
from scipy.optimize import linear_sum_assignment
from ._base_dataset import _BaseDataset
from .. import utils
from ..utils import TrackEvalException
from .. import _timing
class Kitti2DBox(_BaseDataset):
"""Dataset class for KITTI 2D bounding box tracking"""
@staticmethod
def get_default_dataset_config():
"""Default class config values"""
code_path = utils.get_code_path()
default_config = {
'GT_FOLDER': os.path.join(code_path, 'data/gt/kitti/kitti_2d_box_train'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/kitti/kitti_2d_box_train/'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': ['car', 'pedestrian'], # Valid: ['car', 'pedestrian']
'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val', 'training_minus_val', 'test'
'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
}
return default_config
def __init__(self, config=None):
"""Initialise dataset, checking that all required files are present"""
super().__init__()
# Fill non-given config values with defaults
self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
self.gt_fol = self.config['GT_FOLDER']
self.tracker_fol = self.config['TRACKERS_FOLDER']
self.should_classes_combine = False
self.use_super_categories = False
self.data_is_zipped = self.config['INPUT_AS_ZIP']
self.output_fol = self.config['OUTPUT_FOLDER']
if self.output_fol is None:
self.output_fol = self.tracker_fol
self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
self.max_occlusion = 2
self.max_truncation = 0
self.min_height = 25
# Get classes to eval
self.valid_classes = ['car', 'pedestrian']
self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
for cls in self.config['CLASSES_TO_EVAL']]
if not all(self.class_list):
raise TrackEvalException('Attempted to evaluate an invalid class. Only classes [car, pedestrian] are valid.')
self.class_name_to_class_id = {'car': 1, 'van': 2, 'truck': 3, 'pedestrian': 4, 'person': 5, # person sitting
'cyclist': 6, 'tram': 7, 'misc': 8, 'dontcare': 9, 'car_2': 1}
# Get sequences to eval and check gt files exist
self.seq_list = []
self.seq_lengths = {}
seqmap_name = 'evaluate_tracking.seqmap.' + self.config['SPLIT_TO_EVAL']
seqmap_file = os.path.join(self.gt_fol, seqmap_name)
if not os.path.isfile(seqmap_file):
raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
with open(seqmap_file) as fp:
dialect = csv.Sniffer().sniff(fp.read(1024))
fp.seek(0)
reader = csv.reader(fp, dialect)
for row in reader:
if len(row) >= 4:
seq = row[0]
self.seq_list.append(seq)
self.seq_lengths[seq] = int(row[3])
if not self.data_is_zipped:
curr_file = os.path.join(self.gt_fol, 'label_02', seq + '.txt')
if not os.path.isfile(curr_file):
raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
if self.data_is_zipped:
curr_file = os.path.join(self.gt_fol, 'data.zip')
if not os.path.isfile(curr_file):
raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
# Get trackers to eval
if self.config['TRACKERS_TO_EVAL'] is None:
self.tracker_list = os.listdir(self.tracker_fol)
else:
self.tracker_list = self.config['TRACKERS_TO_EVAL']
if self.config['TRACKER_DISPLAY_NAMES'] is None:
self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
else:
raise TrackEvalException('List of tracker files and tracker display names do not match.')
for tracker in self.tracker_list:
if self.data_is_zipped:
curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
if not os.path.isfile(curr_file):
raise TrackEvalException('Tracker file not found: ' + tracker + '/' + os.path.basename(curr_file))
else:
for seq in self.seq_list:
curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
if not os.path.isfile(curr_file):
raise TrackEvalException(
'Tracker file not found: ' + tracker + '/' + self.tracker_sub_fol + '/' + os.path.basename(
curr_file))
def get_display_name(self, tracker):
return self.tracker_to_disp[tracker]
def _load_raw_file(self, tracker, seq, is_gt):
"""Load a file (gt or tracker) in the kitti 2D box format
If is_gt, this returns a dict which contains the fields:
[gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, gt_crowd_ignore_regions]: list (for each timestep) of lists of detections.
[gt_extras] : list (for each timestep) of dicts (for each extra) of 1D NDArrays (for each det).
if not is_gt, this returns a dict which contains the fields:
[tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
[tracker_dets]: list (for each timestep) of lists of detections.
"""
# File location
if self.data_is_zipped:
if is_gt:
zip_file = os.path.join(self.gt_fol, 'data.zip')
else:
zip_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
file = seq + '.txt'
else:
zip_file = None
if is_gt:
file = os.path.join(self.gt_fol, 'label_02', seq + '.txt')
else:
file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
# Ignore regions
if is_gt:
crowd_ignore_filter = {2: ['dontcare']}
else:
crowd_ignore_filter = None
# Valid classes
valid_filter = {2: [x for x in self.class_list]}
if is_gt:
if 'car' in self.class_list:
valid_filter[2].append('van')
if 'pedestrian' in self.class_list:
valid_filter[2] += ['person']
# Convert kitti class strings to class ids
convert_filter = {2: self.class_name_to_class_id}
# Load raw data from text file
read_data, ignore_data = self._load_simple_text_file(file, time_col=0, id_col=1, remove_negative_ids=True,
valid_filter=valid_filter,
crowd_ignore_filter=crowd_ignore_filter,
convert_filter=convert_filter,
is_zipped=self.data_is_zipped, zip_file=zip_file)
# Convert data to required format
num_timesteps = self.seq_lengths[seq]
data_keys = ['ids', 'classes', 'dets']
if is_gt:
data_keys += ['gt_crowd_ignore_regions', 'gt_extras']
else:
data_keys += ['tracker_confidences']
raw_data = {key: [None] * num_timesteps for key in data_keys}
# Check for any extra time keys
current_time_keys = [str(t) for t in range(num_timesteps)]
extra_time_keys = [x for x in read_data.keys() if x not in current_time_keys]
if len(extra_time_keys) > 0:
if is_gt:
text = 'Ground-truth'
else:
text = 'Tracking'
raise TrackEvalException(
text + ' data contains the following invalid timesteps in seq %s: ' % seq + ', '.join(
[str(x) + ', ' for x in extra_time_keys]))
for t in range(num_timesteps):
time_key = str(t)
if time_key in read_data.keys():
time_data = np.asarray(read_data[time_key], dtype=np.float)
raw_data['dets'][t] = np.atleast_2d(time_data[:, 6:10])
raw_data['ids'][t] = np.atleast_1d(time_data[:, 1]).astype(int)
raw_data['classes'][t] = np.atleast_1d(time_data[:, 2]).astype(int)
if is_gt:
gt_extras_dict = {'truncation': np.atleast_1d(time_data[:, 3].astype(int)),
'occlusion': np.atleast_1d(time_data[:, 4].astype(int))}
raw_data['gt_extras'][t] = gt_extras_dict
else:
if time_data.shape[1] > 17:
raw_data['tracker_confidences'][t] = np.atleast_1d(time_data[:, 17])
else:
raw_data['tracker_confidences'][t] = np.ones(time_data.shape[0])
else:
raw_data['dets'][t] = np.empty((0, 4))
raw_data['ids'][t] = np.empty(0).astype(int)
raw_data['classes'][t] = np.empty(0).astype(int)
if is_gt:
gt_extras_dict = {'truncation': np.empty(0),
'occlusion': np.empty(0)}
raw_data['gt_extras'][t] = gt_extras_dict
else:
raw_data['tracker_confidences'][t] = np.empty(0)
if is_gt:
if time_key in ignore_data.keys():
time_ignore = np.asarray(ignore_data[time_key], dtype=np.float)
raw_data['gt_crowd_ignore_regions'][t] = np.atleast_2d(time_ignore[:, 6:10])
else:
raw_data['gt_crowd_ignore_regions'][t] = np.empty((0, 4))
if is_gt:
key_map = {'ids': 'gt_ids',
'classes': 'gt_classes',
'dets': 'gt_dets'}
else:
key_map = {'ids': 'tracker_ids',
'classes': 'tracker_classes',
'dets': 'tracker_dets'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
raw_data['num_timesteps'] = num_timesteps
raw_data['seq'] = seq
return raw_data
@_timing.time
def get_preprocessed_seq_data(self, raw_data, cls):
""" Preprocess data for a single sequence for a single class ready for evaluation.
Inputs:
- raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
- cls is the class to be evaluated.
Outputs:
- data is a dict containing all of the information that metrics need to perform evaluation.
It contains the following fields:
[num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
[gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
[similarity_scores]: list (for each timestep) of 2D NDArrays.
Notes:
General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
1) Extract only detections relevant for the class to be evaluated (including distractor detections).
2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
distractor class, or otherwise marked as to be removed.
3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
other criteria (e.g. are too small).
4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
After the above preprocessing steps, this function also calculates the number of gt and tracker detections
and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
unique within each timestep.
KITTI:
In KITTI, the 4 preproc steps are as follow:
1) There are two classes (pedestrian and car) which are evaluated separately.
2) For the pedestrian class, the 'person' class is distractor objects (people sitting).
For the car class, the 'van' class are distractor objects.
GT boxes marked as having occlusion level > 2 or truncation level > 0 are also treated as
distractors.
3) Crowd ignore regions are used to remove unmatched detections. Also unmatched detections with
height <= 25 pixels are removed.
4) Distractor gt dets (including truncated and occluded) are removed.
"""
if cls == 'pedestrian':
distractor_classes = [self.class_name_to_class_id['person']]
elif cls == 'car':
distractor_classes = [self.class_name_to_class_id['van']]
else:
raise (TrackEvalException('Class %s is not evaluatable' % cls))
cls_id = self.class_name_to_class_id[cls]
data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences', 'similarity_scores']
data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
unique_gt_ids = []
unique_tracker_ids = []
num_gt_dets = 0
num_tracker_dets = 0
for t in range(raw_data['num_timesteps']):
# Only extract relevant dets for this class for preproc and eval (cls + distractor classes)
gt_class_mask = np.sum([raw_data['gt_classes'][t] == c for c in [cls_id] + distractor_classes], axis=0)
gt_class_mask = gt_class_mask.astype(np.bool)
gt_ids = raw_data['gt_ids'][t][gt_class_mask]
gt_dets = raw_data['gt_dets'][t][gt_class_mask]
gt_classes = raw_data['gt_classes'][t][gt_class_mask]
gt_occlusion = raw_data['gt_extras'][t]['occlusion'][gt_class_mask]
gt_truncation = raw_data['gt_extras'][t]['truncation'][gt_class_mask]
tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
tracker_class_mask = tracker_class_mask.astype(np.bool)
tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
tracker_dets = raw_data['tracker_dets'][t][tracker_class_mask]
tracker_confidences = raw_data['tracker_confidences'][t][tracker_class_mask]
similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
# Match tracker and gt dets (with hungarian algorithm) and remove tracker dets which match with gt dets
# which are labeled as truncated, occluded, or belonging to a distractor class.
to_remove_matched = np.array([], np.int)
unmatched_indices = np.arange(tracker_ids.shape[0])
if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
matching_scores = similarity_scores.copy()
matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
match_rows, match_cols = linear_sum_assignment(-matching_scores)
actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
match_rows = match_rows[actually_matched_mask]
match_cols = match_cols[actually_matched_mask]
is_distractor_class = np.isin(gt_classes[match_rows], distractor_classes)
is_occluded_or_truncated = np.logical_or(
gt_occlusion[match_rows] > self.max_occlusion + np.finfo('float').eps,
gt_truncation[match_rows] > self.max_truncation + np.finfo('float').eps)
to_remove_matched = np.logical_or(is_distractor_class, is_occluded_or_truncated)
to_remove_matched = match_cols[to_remove_matched]
unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
# For unmatched tracker dets, also remove those smaller than a minimum height.
unmatched_tracker_dets = tracker_dets[unmatched_indices, :]
unmatched_heights = unmatched_tracker_dets[:, 3] - unmatched_tracker_dets[:, 1]
is_too_small = unmatched_heights <= self.min_height + np.finfo('float').eps
# For unmatched tracker dets, also remove those that are greater than 50% within a crowd ignore region.
crowd_ignore_regions = raw_data['gt_crowd_ignore_regions'][t]
intersection_with_ignore_region = self._calculate_box_ious(unmatched_tracker_dets, crowd_ignore_regions,
box_format='x0y0x1y1', do_ioa=True)
is_within_crowd_ignore_region = np.any(intersection_with_ignore_region > 0.5 + np.finfo('float').eps, axis=1)
# Apply preprocessing to remove all unwanted tracker dets.
to_remove_unmatched = unmatched_indices[np.logical_or(is_too_small, is_within_crowd_ignore_region)]
to_remove_tracker = np.concatenate((to_remove_matched, to_remove_unmatched), axis=0)
data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
# Also remove gt dets that were only useful for preprocessing and are not needed for evaluation.
# These are those that are occluded, truncated and from distractor objects.
gt_to_keep_mask = (np.less_equal(gt_occlusion, self.max_occlusion)) & \
(np.less_equal(gt_truncation, self.max_truncation)) & \
(np.equal(gt_classes, cls_id))
data['gt_ids'][t] = gt_ids[gt_to_keep_mask]
data['gt_dets'][t] = gt_dets[gt_to_keep_mask, :]
data['similarity_scores'][t] = similarity_scores[gt_to_keep_mask]
unique_gt_ids += list(np.unique(data['gt_ids'][t]))
unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
num_tracker_dets += len(data['tracker_ids'][t])
num_gt_dets += len(data['gt_ids'][t])
# Re-label IDs such that there are no empty IDs
if len(unique_gt_ids) > 0:
unique_gt_ids = np.unique(unique_gt_ids)
gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
for t in range(raw_data['num_timesteps']):
if len(data['gt_ids'][t]) > 0:
data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
if len(unique_tracker_ids) > 0:
unique_tracker_ids = np.unique(unique_tracker_ids)
tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
for t in range(raw_data['num_timesteps']):
if len(data['tracker_ids'][t]) > 0:
data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
# Record overview statistics.
data['num_tracker_dets'] = num_tracker_dets
data['num_gt_dets'] = num_gt_dets
data['num_tracker_ids'] = len(unique_tracker_ids)
data['num_gt_ids'] = len(unique_gt_ids)
data['num_timesteps'] = raw_data['num_timesteps']
data['seq'] = raw_data['seq']
# Ensure that ids are unique per timestep.
self._check_unique_ids(data)
return data
def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t, box_format='x0y0x1y1')
return similarity_scores
================================================
FILE: TrackEval/trackeval/datasets/kitti_mots.py
================================================
import os
import csv
import numpy as np
from scipy.optimize import linear_sum_assignment
from ._base_dataset import _BaseDataset
from .. import utils
from .. import _timing
from ..utils import TrackEvalException
class KittiMOTS(_BaseDataset):
"""Dataset class for KITTI MOTS tracking"""
@staticmethod
def get_default_dataset_config():
"""Default class config values"""
code_path = utils.get_code_path()
default_config = {
'GT_FOLDER': os.path.join(code_path, 'data/gt/kitti/kitti_mots_val'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/kitti/kitti_mots_val'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': ['car', 'pedestrian'], # Valid: ['car', 'pedestrian']
'SPLIT_TO_EVAL': 'val', # Valid: 'training', 'val'
'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER)
'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/split_to_eval.seqmap)
'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
'GT_LOC_FORMAT': '{gt_folder}/label_02/{seq}.txt', # format of gt localization
}
return default_config
def __init__(self, config=None):
"""Initialise dataset, checking that all required files are present"""
super().__init__()
# Fill non-given config values with defaults
self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
self.gt_fol = self.config['GT_FOLDER']
self.tracker_fol = self.config['TRACKERS_FOLDER']
self.split_to_eval = self.config['SPLIT_TO_EVAL']
self.should_classes_combine = False
self.use_super_categories = False
self.data_is_zipped = self.config['INPUT_AS_ZIP']
self.output_fol = self.config['OUTPUT_FOLDER']
if self.output_fol is None:
self.output_fol = self.tracker_fol
self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
# Get classes to eval
self.valid_classes = ['car', 'pedestrian']
self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
for cls in self.config['CLASSES_TO_EVAL']]
if not all(self.class_list):
raise TrackEvalException('Attempted to evaluate an invalid class. '
'Only classes [car, pedestrian] are valid.')
self.class_name_to_class_id = {'car': '1', 'pedestrian': '2', 'ignore': '10'}
# Get sequences to eval and check gt files exist
self.seq_list, self.seq_lengths = self._get_seq_info()
if len(self.seq_list) < 1:
raise TrackEvalException('No sequences are selected to be evaluated.')
# Check gt files exist
for seq in self.seq_list:
if not self.data_is_zipped:
curr_file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
if not os.path.isfile(curr_file):
print('GT file not found ' + curr_file)
raise TrackEvalException('GT file not found for sequence: ' + seq)
if self.data_is_zipped:
curr_file = os.path.join(self.gt_fol, 'data.zip')
if not os.path.isfile(curr_file):
raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
# Get trackers to eval
if self.config['TRACKERS_TO_EVAL'] is None:
self.tracker_list = os.listdir(self.tracker_fol)
else:
self.tracker_list = self.config['TRACKERS_TO_EVAL']
if self.config['TRACKER_DISPLAY_NAMES'] is None:
self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
else:
raise TrackEvalException('List of tracker files and tracker display names do not match.')
for tracker in self.tracker_list:
if self.data_is_zipped:
curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
if not os.path.isfile(curr_file):
print('Tracker file not found: ' + curr_file)
raise TrackEvalException('Tracker file not found: ' + tracker + '/' + os.path.basename(curr_file))
else:
for seq in self.seq_list:
curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
if not os.path.isfile(curr_file):
print('Tracker file not found: ' + curr_file)
raise TrackEvalException(
'Tracker file not found: ' + tracker + '/' + self.tracker_sub_fol + '/' + os.path.basename(
curr_file))
def get_display_name(self, tracker):
return self.tracker_to_disp[tracker]
def _get_seq_info(self):
seq_list = []
seq_lengths = {}
seqmap_name = 'evaluate_mots.seqmap.' + self.config['SPLIT_TO_EVAL']
if self.config["SEQ_INFO"]:
seq_list = list(self.config["SEQ_INFO"].keys())
seq_lengths = self.config["SEQ_INFO"]
else:
if self.config["SEQMAP_FILE"]:
seqmap_file = self.config["SEQMAP_FILE"]
else:
if self.config["SEQMAP_FOLDER"] is None:
seqmap_file = os.path.join(self.config['GT_FOLDER'], seqmap_name)
else:
seqmap_file = os.path.join(self.config["SEQMAP_FOLDER"], seqmap_name)
if not os.path.isfile(seqmap_file):
print('no seqmap found: ' + seqmap_file)
raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
with open(seqmap_file) as fp:
reader = csv.reader(fp)
for i, _ in enumerate(reader):
dialect = csv.Sniffer().sniff(fp.read(1024))
fp.seek(0)
reader = csv.reader(fp, dialect)
for row in reader:
if len(row) >= 4:
seq = "%04d" % int(row[0])
seq_list.append(seq)
seq_lengths[seq] = int(row[3]) + 1
return seq_list, seq_lengths
def _load_raw_file(self, tracker, seq, is_gt):
"""Load a file (gt or tracker) in the KITTI MOTS format
If is_gt, this returns a dict which contains the fields:
[gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
[gt_dets]: list (for each timestep) of lists of detections.
[gt_ignore_region]: list (for each timestep) of masks for the ignore regions
if not is_gt, this returns a dict which contains the fields:
[tracker_ids, tracker_classes] : list (for each timestep) of 1D NDArrays (for each det).
[tracker_dets]: list (for each timestep) of lists of detections.
"""
# Only loaded when run to reduce minimum requirements
from pycocotools import mask as mask_utils
# File location
if self.data_is_zipped:
if is_gt:
zip_file = os.path.join(self.gt_fol, 'data.zip')
else:
zip_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
file = seq + '.txt'
else:
zip_file = None
if is_gt:
file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
else:
file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
# Ignore regions
if is_gt:
crowd_ignore_filter = {2: ['10']}
else:
crowd_ignore_filter = None
# Load raw data from text file
read_data, ignore_data = self._load_simple_text_file(file, crowd_ignore_filter=crowd_ignore_filter,
is_zipped=self.data_is_zipped, zip_file=zip_file,
force_delimiters=' ')
# Convert data to required format
num_timesteps = self.seq_lengths[seq]
data_keys = ['ids', 'classes', 'dets']
if is_gt:
data_keys += ['gt_ignore_region']
raw_data = {key: [None] * num_timesteps for key in data_keys}
# Check for any extra time keys
current_time_keys = [str(t) for t in range(num_timesteps)]
extra_time_keys = [x for x in read_data.keys() if x not in current_time_keys]
if len(extra_time_keys) > 0:
if is_gt:
text = 'Ground-truth'
else:
text = 'Tracking'
raise TrackEvalException(
text + ' data contains the following invalid timesteps in seq %s: ' % seq + ', '.join(
[str(x) + ', ' for x in extra_time_keys]))
for t in range(num_timesteps):
time_key = str(t)
# list to collect all masks of a timestep to check for overlapping areas
all_masks = []
if time_key in read_data.keys():
try:
raw_data['dets'][t] = [{'size': [int(region[3]), int(region[4])],
'counts': region[5].encode(encoding='UTF-8')}
for region in read_data[time_key]]
raw_data['ids'][t] = np.atleast_1d([region[1] for region in read_data[time_key]]).astype(int)
raw_data['classes'][t] = np.atleast_1d([region[2] for region in read_data[time_key]]).astype(int)
all_masks += raw_data['dets'][t]
except IndexError:
self._raise_index_error(is_gt, tracker, seq)
except ValueError:
self._raise_value_error(is_gt, tracker, seq)
else:
raw_data['dets'][t] = []
raw_data['ids'][t] = np.empty(0).astype(int)
raw_data['classes'][t] = np.empty(0).astype(int)
if is_gt:
if time_key in ignore_data.keys():
try:
time_ignore = [{'size': [int(region[3]), int(region[4])],
'counts': region[5].encode(encoding='UTF-8')}
for region in ignore_data[time_key]]
raw_data['gt_ignore_region'][t] = mask_utils.merge([mask for mask in time_ignore],
intersect=False)
all_masks += [raw_data['gt_ignore_region'][t]]
except IndexError:
self._raise_index_error(is_gt, tracker, seq)
except ValueError:
self._raise_value_error(is_gt, tracker, seq)
else:
raw_data['gt_ignore_region'][t] = mask_utils.merge([], intersect=False)
# check for overlapping masks
if all_masks:
masks_merged = all_masks[0]
for mask in all_masks[1:]:
if mask_utils.area(mask_utils.merge([masks_merged, mask], intersect=True)) != 0.0:
raise TrackEvalException(
'Tracker has overlapping masks. Tracker: ' + tracker + ' Seq: ' + seq + ' Timestep: ' + str(
t))
masks_merged = mask_utils.merge([masks_merged, mask], intersect=False)
if is_gt:
key_map = {'ids': 'gt_ids',
'classes': 'gt_classes',
'dets': 'gt_dets'}
else:
key_map = {'ids': 'tracker_ids',
'classes': 'tracker_classes',
'dets': 'tracker_dets'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
raw_data["num_timesteps"] = num_timesteps
raw_data['seq'] = seq
return raw_data
@_timing.time
def get_preprocessed_seq_data(self, raw_data, cls):
""" Preprocess data for a single sequence for a single class ready for evaluation.
Inputs:
- raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
- cls is the class to be evaluated.
Outputs:
- data is a dict containing all of the information that metrics need to perform evaluation.
It contains the following fields:
[num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
[gt_ids, tracker_ids]: list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, tracker_dets]: list (for each timestep) of lists of detection masks.
[similarity_scores]: list (for each timestep) of 2D NDArrays.
Notes:
General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
1) Extract only detections relevant for the class to be evaluated (including distractor detections).
2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
distractor class, or otherwise marked as to be removed.
3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
other criteria (e.g. are too small).
4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
After the above preprocessing steps, this function also calculates the number of gt and tracker detections
and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
unique within each timestep.
KITTI MOTS:
In KITTI MOTS, the 4 preproc steps are as follow:
1) There are two classes (car and pedestrian) which are evaluated separately.
2) There are no ground truth detections marked as to be removed/distractor classes.
Therefore also no matched tracker detections are removed.
3) Ignore regions are used to remove unmatched detections (at least 50% overlap with ignore region).
4) There are no ground truth detections (e.g. those of distractor classes) to be removed.
"""
# Check that input data has unique ids
self._check_unique_ids(raw_data)
cls_id = int(self.class_name_to_class_id[cls])
data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'similarity_scores']
data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
unique_gt_ids = []
unique_tracker_ids = []
num_gt_dets = 0
num_tracker_dets = 0
for t in range(raw_data['num_timesteps']):
# Only extract relevant dets for this class for preproc and eval (cls)
gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
gt_class_mask = gt_class_mask.astype(np.bool)
gt_ids = raw_data['gt_ids'][t][gt_class_mask]
gt_dets = [raw_data['gt_dets'][t][ind] for ind in range(len(gt_class_mask)) if gt_class_mask[ind]]
tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
tracker_class_mask = tracker_class_mask.astype(np.bool)
tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
tracker_dets = [raw_data['tracker_dets'][t][ind] for ind in range(len(tracker_class_mask)) if
tracker_class_mask[ind]]
similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
# Match tracker and gt dets (with hungarian algorithm)
unmatched_indices = np.arange(tracker_ids.shape[0])
if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
matching_scores = similarity_scores.copy()
matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = -10000
match_rows, match_cols = linear_sum_assignment(-matching_scores)
actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
match_cols = match_cols[actually_matched_mask]
unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
# For unmatched tracker dets, remove those that are greater than 50% within a crowd ignore region.
unmatched_tracker_dets = [tracker_dets[i] for i in range(len(tracker_dets)) if i in unmatched_indices]
ignore_region = raw_data['gt_ignore_region'][t]
intersection_with_ignore_region = self._calculate_mask_ious(unmatched_tracker_dets, [ignore_region],
is_encoded=True, do_ioa=True)
is_within_ignore_region = np.any(intersection_with_ignore_region > 0.5 + np.finfo('float').eps, axis=1)
# Apply preprocessing to remove unwanted tracker dets.
to_remove_tracker = unmatched_indices[is_within_ignore_region]
data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
# Keep all ground truth detections
data['gt_ids'][t] = gt_ids
data['gt_dets'][t] = gt_dets
data['similarity_scores'][t] = similarity_scores
unique_gt_ids += list(np.unique(data['gt_ids'][t]))
unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
num_tracker_dets += len(data['tracker_ids'][t])
num_gt_dets += len(data['gt_ids'][t])
# Re-label IDs such that there are no empty IDs
if len(unique_gt_ids) > 0:
unique_gt_ids = np.unique(unique_gt_ids)
gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
for t in range(raw_data['num_timesteps']):
if len(data['gt_ids'][t]) > 0:
data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
if len(unique_tracker_ids) > 0:
unique_tracker_ids = np.unique(unique_tracker_ids)
tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
for t in range(raw_data['num_timesteps']):
if len(data['tracker_ids'][t]) > 0:
data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
# Record overview statistics.
data['num_tracker_dets'] = num_tracker_dets
data['num_gt_dets'] = num_gt_dets
data['num_tracker_ids'] = len(unique_tracker_ids)
data['num_gt_ids'] = len(unique_gt_ids)
data['num_timesteps'] = raw_data['num_timesteps']
data['seq'] = raw_data['seq']
data['cls'] = cls
# Ensure again that ids are unique per timestep after preproc.
self._check_unique_ids(data, after_preproc=True)
return data
def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
similarity_scores = self._calculate_mask_ious(gt_dets_t, tracker_dets_t, is_encoded=True, do_ioa=False)
return similarity_scores
@staticmethod
def _raise_index_error(is_gt, tracker, seq):
"""
Auxiliary method to raise an evaluation error in case of an index error while reading files.
:param is_gt: whether gt or tracker data is read
:param tracker: the name of the tracker
:param seq: the name of the seq
:return: None
"""
if is_gt:
err = 'Cannot load gt data from sequence %s, because there are not enough ' \
'columns in the data.' % seq
raise TrackEvalException(err)
else:
err = 'Cannot load tracker data from tracker %s, sequence %s, because there are not enough ' \
'columns in the data.' % (tracker, seq)
raise TrackEvalException(err)
@staticmethod
def _raise_value_error(is_gt, tracker, seq):
"""
Auxiliary method to raise an evaluation error in case of an value error while reading files.
:param is_gt: whether gt or tracker data is read
:param tracker: the name of the tracker
:param seq: the name of the seq
:return: None
"""
if is_gt:
raise TrackEvalException(
'GT data for sequence %s cannot be converted to the right format. Is data corrupted?' % seq)
else:
raise TrackEvalException(
'Tracking data from tracker %s, sequence %s cannot be converted to the right format. '
'Is data corrupted?' % (tracker, seq))
================================================
FILE: TrackEval/trackeval/datasets/mot_challenge_2d_box.py
================================================
import os
import csv
import configparser
import numpy as np
from scipy.optimize import linear_sum_assignment
from ._base_dataset import _BaseDataset
from .. import utils
from .. import _timing
from ..utils import TrackEvalException
class MotChallenge2DBox(_BaseDataset):
"""Dataset class for MOT Challenge 2D bounding box tracking"""
@staticmethod
def get_default_dataset_config():
"""Default class config values"""
code_path = utils.get_code_path()
default_config = {
'GT_FOLDER': os.path.join(code_path, 'data/gt/mot_challenge/'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/mot_challenge/'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
'BENCHMARK': 'MOT17', # Valid: 'MOT17', 'MOT16', 'MOT20', 'MOT15'
'SPLIT_TO_EVAL': 'train', # Valid: 'train', 'test', 'all'
'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
'PRINT_CONFIG': True, # Whether to print current config
'DO_PREPROC': True, # Whether to perform preprocessing (never done for MOT15)
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/seqmaps)
'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/benchmark-split_to_eval)
'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
'GT_LOC_FORMAT': '{gt_folder}/{seq}/gt/gt.txt', # '{gt_folder}/{seq}/gt/gt.txt'
'SKIP_SPLIT_FOL': False, # If False, data is in GT_FOLDER/BENCHMARK-SPLIT_TO_EVAL/ and in
# TRACKERS_FOLDER/BENCHMARK-SPLIT_TO_EVAL/tracker/
# If True, then the middle 'benchmark-split' folder is skipped for both.
}
return default_config
def __init__(self, config=None):
"""Initialise dataset, checking that all required files are present"""
super().__init__()
# Fill non-given config values with defaults
self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
self.benchmark = self.config['BENCHMARK']
gt_set = self.config['SPLIT_TO_EVAL'] # TODO: [hgx 0401]: delete "self.config['BENCHMARK'] + '-' +"
self.gt_set = gt_set
if not self.config['SKIP_SPLIT_FOL']:
split_fol = gt_set
else:
split_fol = ''
self.gt_fol = os.path.join(self.config['GT_FOLDER'], split_fol)
self.tracker_fol = os.path.join(self.config['TRACKERS_FOLDER']) # TODO: [hgx 0401]: delete "split_fol"
self.should_classes_combine = False
self.use_super_categories = False
self.data_is_zipped = self.config['INPUT_AS_ZIP']
self.do_preproc = self.config['DO_PREPROC']
self.output_fol = self.config['OUTPUT_FOLDER']
if self.output_fol is None:
self.output_fol = self.tracker_fol
self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
# Get classes to eval
self.valid_classes = ['pedestrian']
self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
for cls in self.config['CLASSES_TO_EVAL']]
if not all(self.class_list):
raise TrackEvalException('Attempted to evaluate an invalid class. Only pedestrian class is valid.')
self.class_name_to_class_id = {'pedestrian': 1, 'person_on_vehicle': 2, 'car': 3, 'bicycle': 4, 'motorbike': 5,
'non_mot_vehicle': 6, 'static_person': 7, 'distractor': 8, 'occluder': 9,
'occluder_on_ground': 10, 'occluder_full': 11, 'reflection': 12, 'crowd': 13}
self.valid_class_numbers = list(self.class_name_to_class_id.values())
# Get sequences to eval and check gt files exist
self.seq_list, self.seq_lengths = self._get_seq_info()
if len(self.seq_list) < 1:
raise TrackEvalException('No sequences are selected to be evaluated.')
# Check gt files exist
for seq in self.seq_list:
if not self.data_is_zipped:
curr_file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
if not os.path.isfile(curr_file):
print('GT file not found ' + curr_file)
raise TrackEvalException('GT file not found for sequence: ' + seq)
if self.data_is_zipped:
curr_file = os.path.join(self.gt_fol, 'data.zip')
if not os.path.isfile(curr_file):
print('GT file not found ' + curr_file)
raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
# Get trackers to eval
if self.config['TRACKERS_TO_EVAL'] is None:
self.tracker_list = os.listdir(self.tracker_fol)
else:
self.tracker_list = self.config['TRACKERS_TO_EVAL']
if self.config['TRACKER_DISPLAY_NAMES'] is None:
self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
else:
raise TrackEvalException('List of tracker files and tracker display names do not match.')
for tracker in self.tracker_list:
if self.data_is_zipped:
curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
if not os.path.isfile(curr_file):
print('Tracker file not found: ' + curr_file)
raise TrackEvalException('Tracker file not found: ' + tracker + '/' + os.path.basename(curr_file))
else:
for seq in self.seq_list:
curr_file = os.path.join(self.tracker_fol, seq + '.txt') # TODO: [hgx 0401], delete "tracker, self.tracker_sub_fol"
if not os.path.isfile(curr_file):
print('Tracker file not found: ' + curr_file)
raise TrackEvalException(
'Tracker file not found: ' + tracker + '/' + self.tracker_sub_fol + '/' + os.path.basename(
curr_file))
def get_display_name(self, tracker):
return self.tracker_to_disp[tracker]
def _get_seq_info(self):
seq_list = []
seq_lengths = {}
if self.config["SEQ_INFO"]:
seq_list = list(self.config["SEQ_INFO"].keys())
seq_lengths = self.config["SEQ_INFO"]
# If sequence length is 'None' tries to read sequence length from .ini files.
for seq, seq_length in seq_lengths.items():
if seq_length is None:
ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
if not os.path.isfile(ini_file):
raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
ini_data = configparser.ConfigParser()
ini_data.read(ini_file)
seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
else:
if self.config["SEQMAP_FILE"]:
seqmap_file = self.config["SEQMAP_FILE"]
else:
if self.config["SEQMAP_FOLDER"] is None:
seqmap_file = os.path.join(self.config['GT_FOLDER'], 'seqmaps', self.gt_set + '.txt')
else:
seqmap_file = os.path.join(self.config["SEQMAP_FOLDER"], self.gt_set + '.txt')
if not os.path.isfile(seqmap_file):
print('no seqmap found: ' + seqmap_file)
raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
with open(seqmap_file) as fp:
reader = csv.reader(fp)
for i, row in enumerate(reader):
if i == 0 or row[0] == '':
continue
seq = row[0]
seq_list.append(seq)
ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
if not os.path.isfile(ini_file):
raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
ini_data = configparser.ConfigParser()
ini_data.read(ini_file)
seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
return seq_list, seq_lengths
def _load_raw_file(self, tracker, seq, is_gt):
"""Load a file (gt or tracker) in the MOT Challenge 2D box format
If is_gt, this returns a dict which contains the fields:
[gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, gt_crowd_ignore_regions]: list (for each timestep) of lists of detections.
[gt_extras] : list (for each timestep) of dicts (for each extra) of 1D NDArrays (for each det).
if not is_gt, this returns a dict which contains the fields:
[tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
[tracker_dets]: list (for each timestep) of lists of detections.
"""
# File location
if self.data_is_zipped:
if is_gt:
zip_file = os.path.join(self.gt_fol, 'data.zip')
else:
zip_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
file = seq + '.txt'
else:
zip_file = None
if is_gt:
file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
else:
file = os.path.join(self.tracker_fol, seq + '.txt') # TODO: [hgx 0401], delete "tracker, self.tracker_sub_fol"
# Load raw data from text file
read_data, ignore_data = self._load_simple_text_file(file, is_zipped=self.data_is_zipped, zip_file=zip_file)
# Convert data to required format
num_timesteps = self.seq_lengths[seq]
data_keys = ['ids', 'classes', 'dets']
if is_gt:
data_keys += ['gt_crowd_ignore_regions', 'gt_extras']
else:
data_keys += ['tracker_confidences']
raw_data = {key: [None] * num_timesteps for key in data_keys}
# Check for any extra time keys
current_time_keys = [str( t+ 1) for t in range(num_timesteps)]
extra_time_keys = [x for x in read_data.keys() if x not in current_time_keys]
if len(extra_time_keys) > 0:
if is_gt:
text = 'Ground-truth'
else:
text = 'Tracking'
raise TrackEvalException(
text + ' data contains the following invalid timesteps in seq %s: ' % seq + ', '.join(
[str(x) + ', ' for x in extra_time_keys]))
for t in range(num_timesteps):
time_key = str(t+1)
if time_key in read_data.keys():
try:
time_data = np.asarray(read_data[time_key], dtype=np.float)
except ValueError:
if is_gt:
raise TrackEvalException(
'Cannot convert gt data for sequence %s to float. Is data corrupted?' % seq)
else:
raise TrackEvalException(
'Cannot convert tracking data from tracker %s, sequence %s to float. Is data corrupted?' % (
tracker, seq))
try:
raw_data['dets'][t] = np.atleast_2d(time_data[:, 2:6])
raw_data['ids'][t] = np.atleast_1d(time_data[:, 1]).astype(int)
except IndexError:
if is_gt:
err = 'Cannot load gt data from sequence %s, because there is not enough ' \
'columns in the data.' % seq
raise TrackEvalException(err)
else:
err = 'Cannot load tracker data from tracker %s, sequence %s, because there is not enough ' \
'columns in the data.' % (tracker, seq)
raise TrackEvalException(err)
if time_data.shape[1] >= 8:
raw_data['classes'][t] = np.atleast_1d(time_data[:, 7]).astype(int)
else:
if not is_gt:
raw_data['classes'][t] = np.ones_like(raw_data['ids'][t])
else:
raise TrackEvalException(
'GT data is not in a valid format, there is not enough rows in seq %s, timestep %i.' % (
seq, t))
if is_gt:
gt_extras_dict = {'zero_marked': np.atleast_1d(time_data[:, 6].astype(int))}
raw_data['gt_extras'][t] = gt_extras_dict
else:
raw_data['tracker_confidences'][t] = np.atleast_1d(time_data[:, 6])
else:
raw_data['dets'][t] = np.empty((0, 4))
raw_data['ids'][t] = np.empty(0).astype(int)
raw_data['classes'][t] = np.empty(0).astype(int)
if is_gt:
gt_extras_dict = {'zero_marked': np.empty(0)}
raw_data['gt_extras'][t] = gt_extras_dict
else:
raw_data['tracker_confidences'][t] = np.empty(0)
if is_gt:
raw_data['gt_crowd_ignore_regions'][t] = np.empty((0, 4))
if is_gt:
key_map = {'ids': 'gt_ids',
'classes': 'gt_classes',
'dets': 'gt_dets'}
else:
key_map = {'ids': 'tracker_ids',
'classes': 'tracker_classes',
'dets': 'tracker_dets'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
raw_data['num_timesteps'] = num_timesteps
raw_data['seq'] = seq
return raw_data
@_timing.time
def get_preprocessed_seq_data(self, raw_data, cls):
""" Preprocess data for a single sequence for a single class ready for evaluation.
Inputs:
- raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
- cls is the class to be evaluated.
Outputs:
- data is a dict containing all of the information that metrics need to perform evaluation.
It contains the following fields:
[num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
[gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
[similarity_scores]: list (for each timestep) of 2D NDArrays.
Notes:
General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
1) Extract only detections relevant for the class to be evaluated (including distractor detections).
2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
distractor class, or otherwise marked as to be removed.
3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
other criteria (e.g. are too small).
4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
After the above preprocessing steps, this function also calculates the number of gt and tracker detections
and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
unique within each timestep.
MOT Challenge:
In MOT Challenge, the 4 preproc steps are as follow:
1) There is only one class (pedestrian) to be evaluated, but all other classes are used for preproc.
2) Predictions are matched against all gt boxes (regardless of class), those matching with distractor
objects are removed.
3) There is no crowd ignore regions.
4) All gt dets except pedestrian are removed, also removes pedestrian gt dets marked with zero_marked.
"""
# Check that input data has unique ids
self._check_unique_ids(raw_data)
distractor_class_names = ['person_on_vehicle', 'static_person', 'distractor', 'reflection']
if self.benchmark == 'MOT20':
distractor_class_names.append('non_mot_vehicle')
distractor_classes = [self.class_name_to_class_id[x] for x in distractor_class_names]
cls_id = self.class_name_to_class_id[cls]
data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences', 'similarity_scores']
data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
unique_gt_ids = []
unique_tracker_ids = []
num_gt_dets = 0
num_tracker_dets = 0
for t in range(raw_data['num_timesteps']):
# Get all data
gt_ids = raw_data['gt_ids'][t]
gt_dets = raw_data['gt_dets'][t]
gt_classes = raw_data['gt_classes'][t]
gt_zero_marked = raw_data['gt_extras'][t]['zero_marked']
tracker_ids = raw_data['tracker_ids'][t]
tracker_dets = raw_data['tracker_dets'][t]
tracker_classes = raw_data['tracker_classes'][t]
tracker_confidences = raw_data['tracker_confidences'][t]
similarity_scores = raw_data['similarity_scores'][t]
# Evaluation is ONLY valid for pedestrian class
if len(tracker_classes) > 0 and np.max(tracker_classes) > 1:
raise TrackEvalException(
'Evaluation is only valid for pedestrian class. Non pedestrian class (%i) found in sequence %s at '
'timestep %i.' % (np.max(tracker_classes), raw_data['seq'], t))
# Match tracker and gt dets (with hungarian algorithm) and remove tracker dets which match with gt dets
# which are labeled as belonging to a distractor class.
to_remove_tracker = np.array([], np.int)
if self.do_preproc and self.benchmark != 'MOT15' and gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
# Check all classes are valid:
invalid_classes = np.setdiff1d(np.unique(gt_classes), self.valid_class_numbers)
if len(invalid_classes) > 0:
print(' '.join([str(x) for x in invalid_classes]))
raise(TrackEvalException('Attempting to evaluate using invalid gt classes. '
'This warning only triggers if preprocessing is performed, '
'e.g. not for MOT15 or where prepropressing is explicitly disabled. '
'Please either check your gt data, or disable preprocessing. '
'The following invalid classes were found in timestep ' + str(t) + ': ' +
' '.join([str(x) for x in invalid_classes])))
matching_scores = similarity_scores.copy()
matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
match_rows, match_cols = linear_sum_assignment(-matching_scores)
actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
match_rows = match_rows[actually_matched_mask]
match_cols = match_cols[actually_matched_mask]
is_distractor_class = np.isin(gt_classes[match_rows], distractor_classes)
to_remove_tracker = match_cols[is_distractor_class]
# Apply preprocessing to remove all unwanted tracker dets.
data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
# Remove gt detections marked as to remove (zero marked), and also remove gt detections not in pedestrian
# class (not applicable for MOT15)
if self.do_preproc and self.benchmark != 'MOT15':
gt_to_keep_mask = (np.not_equal(gt_zero_marked, 0)) & \
(np.equal(gt_classes, cls_id))
else:
# There are no classes for MOT15
gt_to_keep_mask = np.not_equal(gt_zero_marked, 0)
data['gt_ids'][t] = gt_ids[gt_to_keep_mask]
data['gt_dets'][t] = gt_dets[gt_to_keep_mask, :]
data['similarity_scores'][t] = similarity_scores[gt_to_keep_mask]
unique_gt_ids += list(np.unique(data['gt_ids'][t]))
unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
num_tracker_dets += len(data['tracker_ids'][t])
num_gt_dets += len(data['gt_ids'][t])
# Re-label IDs such that there are no empty IDs
if len(unique_gt_ids) > 0:
unique_gt_ids = np.unique(unique_gt_ids)
gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
for t in range(raw_data['num_timesteps']):
if len(data['gt_ids'][t]) > 0:
data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
if len(unique_tracker_ids) > 0:
unique_tracker_ids = np.unique(unique_tracker_ids)
tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
for t in range(raw_data['num_timesteps']):
if len(data['tracker_ids'][t]) > 0:
data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
# Record overview statistics.
data['num_tracker_dets'] = num_tracker_dets
data['num_gt_dets'] = num_gt_dets
data['num_tracker_ids'] = len(unique_tracker_ids)
data['num_gt_ids'] = len(unique_gt_ids)
data['num_timesteps'] = raw_data['num_timesteps']
data['seq'] = raw_data['seq']
# Ensure again that ids are unique per timestep after preproc.
self._check_unique_ids(data, after_preproc=True)
return data
def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t, box_format='xywh')
return similarity_scores
================================================
FILE: TrackEval/trackeval/datasets/mots_challenge.py
================================================
import os
import csv
import configparser
import numpy as np
from scipy.optimize import linear_sum_assignment
from ._base_dataset import _BaseDataset
from .. import utils
from .. import _timing
from ..utils import TrackEvalException
class MOTSChallenge(_BaseDataset):
"""Dataset class for MOTS Challenge tracking"""
@staticmethod
def get_default_dataset_config():
"""Default class config values"""
code_path = utils.get_code_path()
default_config = {
'GT_FOLDER': os.path.join(code_path, 'data/gt/mot_challenge/'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/mot_challenge/'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': ['pedestrian'], # Valid: ['pedestrian']
'SPLIT_TO_EVAL': 'train', # Valid: 'train', 'test'
'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/seqmaps)
'SEQMAP_FILE': None, # Directly specify seqmap file (if none use seqmap_folder/MOTS-split_to_eval)
'SEQ_INFO': None, # If not None, directly specify sequences to eval and their number of timesteps
'GT_LOC_FORMAT': '{gt_folder}/{seq}/gt/gt.txt', # '{gt_folder}/{seq}/gt/gt.txt'
'SKIP_SPLIT_FOL': False, # If False, data is in GT_FOLDER/MOTS-SPLIT_TO_EVAL/ and in
# TRACKERS_FOLDER/MOTS-SPLIT_TO_EVAL/tracker/
# If True, then the middle 'MOTS-split' folder is skipped for both.
}
return default_config
def __init__(self, config=None):
"""Initialise dataset, checking that all required files are present"""
super().__init__()
# Fill non-given config values with defaults
self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
self.benchmark = 'MOTS'
self.gt_set = self.benchmark + '-' + self.config['SPLIT_TO_EVAL']
if not self.config['SKIP_SPLIT_FOL']:
split_fol = self.gt_set
else:
split_fol = ''
self.gt_fol = os.path.join(self.config['GT_FOLDER'], split_fol)
self.tracker_fol = os.path.join(self.config['TRACKERS_FOLDER'], split_fol)
self.should_classes_combine = False
self.use_super_categories = False
self.data_is_zipped = self.config['INPUT_AS_ZIP']
self.output_fol = self.config['OUTPUT_FOLDER']
if self.output_fol is None:
self.output_fol = self.tracker_fol
self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
# Get classes to eval
self.valid_classes = ['pedestrian']
self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
for cls in self.config['CLASSES_TO_EVAL']]
if not all(self.class_list):
raise TrackEvalException('Attempted to evaluate an invalid class. Only pedestrian class is valid.')
self.class_name_to_class_id = {'pedestrian': '2', 'ignore': '10'}
# Get sequences to eval and check gt files exist
self.seq_list, self.seq_lengths = self._get_seq_info()
if len(self.seq_list) < 1:
raise TrackEvalException('No sequences are selected to be evaluated.')
# Check gt files exist
for seq in self.seq_list:
if not self.data_is_zipped:
curr_file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
if not os.path.isfile(curr_file):
print('GT file not found ' + curr_file)
raise TrackEvalException('GT file not found for sequence: ' + seq)
if self.data_is_zipped:
curr_file = os.path.join(self.gt_fol, 'data.zip')
if not os.path.isfile(curr_file):
print('GT file not found ' + curr_file)
raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
# Get trackers to eval
if self.config['TRACKERS_TO_EVAL'] is None:
self.tracker_list = os.listdir(self.tracker_fol)
else:
self.tracker_list = self.config['TRACKERS_TO_EVAL']
if self.config['TRACKER_DISPLAY_NAMES'] is None:
self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
else:
raise TrackEvalException('List of tracker files and tracker display names do not match.')
for tracker in self.tracker_list:
if self.data_is_zipped:
curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
if not os.path.isfile(curr_file):
print('Tracker file not found: ' + curr_file)
raise TrackEvalException('Tracker file not found: ' + tracker + '/' + os.path.basename(curr_file))
else:
for seq in self.seq_list:
curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
if not os.path.isfile(curr_file):
print('Tracker file not found: ' + curr_file)
raise TrackEvalException(
'Tracker file not found: ' + tracker + '/' + self.tracker_sub_fol + '/' + os.path.basename(
curr_file))
def get_display_name(self, tracker):
return self.tracker_to_disp[tracker]
def _get_seq_info(self):
seq_list = []
seq_lengths = {}
if self.config["SEQ_INFO"]:
seq_list = list(self.config["SEQ_INFO"].keys())
seq_lengths = self.config["SEQ_INFO"]
# If sequence length is 'None' tries to read sequence length from .ini files.
for seq, seq_length in seq_lengths.items():
if seq_length is None:
ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
if not os.path.isfile(ini_file):
raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
ini_data = configparser.ConfigParser()
ini_data.read(ini_file)
seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
else:
if self.config["SEQMAP_FILE"]:
seqmap_file = self.config["SEQMAP_FILE"]
else:
if self.config["SEQMAP_FOLDER"] is None:
seqmap_file = os.path.join(self.config['GT_FOLDER'], 'seqmaps', self.gt_set + '.txt')
else:
seqmap_file = os.path.join(self.config["SEQMAP_FOLDER"], self.gt_set + '.txt')
if not os.path.isfile(seqmap_file):
print('no seqmap found: ' + seqmap_file)
raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
with open(seqmap_file) as fp:
reader = csv.reader(fp)
for i, row in enumerate(reader):
if i == 0 or row[0] == '':
continue
seq = row[0]
seq_list.append(seq)
ini_file = os.path.join(self.gt_fol, seq, 'seqinfo.ini')
if not os.path.isfile(ini_file):
raise TrackEvalException('ini file does not exist: ' + seq + '/' + os.path.basename(ini_file))
ini_data = configparser.ConfigParser()
ini_data.read(ini_file)
seq_lengths[seq] = int(ini_data['Sequence']['seqLength'])
return seq_list, seq_lengths
def _load_raw_file(self, tracker, seq, is_gt):
"""Load a file (gt or tracker) in the MOTS Challenge format
If is_gt, this returns a dict which contains the fields:
[gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
[gt_dets]: list (for each timestep) of lists of detections.
[gt_ignore_region]: list (for each timestep) of masks for the ignore regions
if not is_gt, this returns a dict which contains the fields:
[tracker_ids, tracker_classes] : list (for each timestep) of 1D NDArrays (for each det).
[tracker_dets]: list (for each timestep) of lists of detections.
"""
# Only loaded when run to reduce minimum requirements
from pycocotools import mask as mask_utils
# File location
if self.data_is_zipped:
if is_gt:
zip_file = os.path.join(self.gt_fol, 'data.zip')
else:
zip_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol + '.zip')
file = seq + '.txt'
else:
zip_file = None
if is_gt:
file = self.config["GT_LOC_FORMAT"].format(gt_folder=self.gt_fol, seq=seq)
else:
file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, seq + '.txt')
# Ignore regions
if is_gt:
crowd_ignore_filter = {2: ['10']}
else:
crowd_ignore_filter = None
# Load raw data from text file
read_data, ignore_data = self._load_simple_text_file(file, crowd_ignore_filter=crowd_ignore_filter,
is_zipped=self.data_is_zipped, zip_file=zip_file,
force_delimiters=' ')
# Convert data to required format
num_timesteps = self.seq_lengths[seq]
data_keys = ['ids', 'classes', 'dets']
if is_gt:
data_keys += ['gt_ignore_region']
raw_data = {key: [None] * num_timesteps for key in data_keys}
# Check for any extra time keys
current_time_keys = [str(t + 1) for t in range(num_timesteps)]
extra_time_keys = [x for x in read_data.keys() if x not in current_time_keys]
if len(extra_time_keys) > 0:
if is_gt:
text = 'Ground-truth'
else:
text = 'Tracking'
raise TrackEvalException(
text + ' data contains the following invalid timesteps in seq %s: ' % seq + ', '.join(
[str(x) + ', ' for x in extra_time_keys]))
for t in range(num_timesteps):
time_key = str(t+1)
# list to collect all masks of a timestep to check for overlapping areas
all_masks = []
if time_key in read_data.keys():
try:
raw_data['dets'][t] = [{'size': [int(region[3]), int(region[4])],
'counts': region[5].encode(encoding='UTF-8')}
for region in read_data[time_key]]
raw_data['ids'][t] = np.atleast_1d([region[1] for region in read_data[time_key]]).astype(int)
raw_data['classes'][t] = np.atleast_1d([region[2] for region in read_data[time_key]]).astype(int)
all_masks += raw_data['dets'][t]
except IndexError:
self._raise_index_error(is_gt, tracker, seq)
except ValueError:
self._raise_value_error(is_gt, tracker, seq)
else:
raw_data['dets'][t] = []
raw_data['ids'][t] = np.empty(0).astype(int)
raw_data['classes'][t] = np.empty(0).astype(int)
if is_gt:
if time_key in ignore_data.keys():
try:
time_ignore = [{'size': [int(region[3]), int(region[4])],
'counts': region[5].encode(encoding='UTF-8')}
for region in ignore_data[time_key]]
raw_data['gt_ignore_region'][t] = mask_utils.merge([mask for mask in time_ignore],
intersect=False)
all_masks += [raw_data['gt_ignore_region'][t]]
except IndexError:
self._raise_index_error(is_gt, tracker, seq)
except ValueError:
self._raise_value_error(is_gt, tracker, seq)
else:
raw_data['gt_ignore_region'][t] = mask_utils.merge([], intersect=False)
# check for overlapping masks
if all_masks:
masks_merged = all_masks[0]
for mask in all_masks[1:]:
if mask_utils.area(mask_utils.merge([masks_merged, mask], intersect=True)) != 0.0:
raise TrackEvalException(
'Tracker has overlapping masks. Tracker: ' + tracker + ' Seq: ' + seq + ' Timestep: ' + str(
t))
masks_merged = mask_utils.merge([masks_merged, mask], intersect=False)
if is_gt:
key_map = {'ids': 'gt_ids',
'classes': 'gt_classes',
'dets': 'gt_dets'}
else:
key_map = {'ids': 'tracker_ids',
'classes': 'tracker_classes',
'dets': 'tracker_dets'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
raw_data['num_timesteps'] = num_timesteps
raw_data['seq'] = seq
return raw_data
@_timing.time
def get_preprocessed_seq_data(self, raw_data, cls):
""" Preprocess data for a single sequence for a single class ready for evaluation.
Inputs:
- raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
- cls is the class to be evaluated.
Outputs:
- data is a dict containing all of the information that metrics need to perform evaluation.
It contains the following fields:
[num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
[gt_ids, tracker_ids]: list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, tracker_dets]: list (for each timestep) of lists of detection masks.
[similarity_scores]: list (for each timestep) of 2D NDArrays.
Notes:
General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
1) Extract only detections relevant for the class to be evaluated (including distractor detections).
2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
distractor class, or otherwise marked as to be removed.
3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
other criteria (e.g. are too small).
4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
After the above preprocessing steps, this function also calculates the number of gt and tracker detections
and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
unique within each timestep.
MOTS Challenge:
In MOTS Challenge, the 4 preproc steps are as follow:
1) There is only one class (pedestrians) to be evaluated.
2) There are no ground truth detections marked as to be removed/distractor classes.
Therefore also no matched tracker detections are removed.
3) Ignore regions are used to remove unmatched detections (at least 50% overlap with ignore region).
4) There are no ground truth detections (e.g. those of distractor classes) to be removed.
"""
# Check that input data has unique ids
self._check_unique_ids(raw_data)
cls_id = int(self.class_name_to_class_id[cls])
data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'similarity_scores']
data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
unique_gt_ids = []
unique_tracker_ids = []
num_gt_dets = 0
num_tracker_dets = 0
for t in range(raw_data['num_timesteps']):
# Only extract relevant dets for this class for preproc and eval (cls)
gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
gt_class_mask = gt_class_mask.astype(np.bool)
gt_ids = raw_data['gt_ids'][t][gt_class_mask]
gt_dets = [raw_data['gt_dets'][t][ind] for ind in range(len(gt_class_mask)) if gt_class_mask[ind]]
tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
tracker_class_mask = tracker_class_mask.astype(np.bool)
tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
tracker_dets = [raw_data['tracker_dets'][t][ind] for ind in range(len(tracker_class_mask)) if
tracker_class_mask[ind]]
similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
# Match tracker and gt dets (with hungarian algorithm)
unmatched_indices = np.arange(tracker_ids.shape[0])
if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
matching_scores = similarity_scores.copy()
matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = -10000
match_rows, match_cols = linear_sum_assignment(-matching_scores)
actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
match_cols = match_cols[actually_matched_mask]
unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
# For unmatched tracker dets, remove those that are greater than 50% within a crowd ignore region.
unmatched_tracker_dets = [tracker_dets[i] for i in range(len(tracker_dets)) if i in unmatched_indices]
ignore_region = raw_data['gt_ignore_region'][t]
intersection_with_ignore_region = self._calculate_mask_ious(unmatched_tracker_dets, [ignore_region],
is_encoded=True, do_ioa=True)
is_within_ignore_region = np.any(intersection_with_ignore_region > 0.5 + np.finfo('float').eps, axis=1)
# Apply preprocessing to remove unwanted tracker dets.
to_remove_tracker = unmatched_indices[is_within_ignore_region]
data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
# Keep all ground truth detections
data['gt_ids'][t] = gt_ids
data['gt_dets'][t] = gt_dets
data['similarity_scores'][t] = similarity_scores
unique_gt_ids += list(np.unique(data['gt_ids'][t]))
unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
num_tracker_dets += len(data['tracker_ids'][t])
num_gt_dets += len(data['gt_ids'][t])
# Re-label IDs such that there are no empty IDs
if len(unique_gt_ids) > 0:
unique_gt_ids = np.unique(unique_gt_ids)
gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
for t in range(raw_data['num_timesteps']):
if len(data['gt_ids'][t]) > 0:
data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
if len(unique_tracker_ids) > 0:
unique_tracker_ids = np.unique(unique_tracker_ids)
tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
for t in range(raw_data['num_timesteps']):
if len(data['tracker_ids'][t]) > 0:
data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
# Record overview statistics.
data['num_tracker_dets'] = num_tracker_dets
data['num_gt_dets'] = num_gt_dets
data['num_tracker_ids'] = len(unique_tracker_ids)
data['num_gt_ids'] = len(unique_gt_ids)
data['num_timesteps'] = raw_data['num_timesteps']
data['seq'] = raw_data['seq']
# Ensure again that ids are unique per timestep after preproc.
self._check_unique_ids(data, after_preproc=True)
return data
def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
similarity_scores = self._calculate_mask_ious(gt_dets_t, tracker_dets_t, is_encoded=True, do_ioa=False)
return similarity_scores
@staticmethod
def _raise_index_error(is_gt, tracker, seq):
"""
Auxiliary method to raise an evaluation error in case of an index error while reading files.
:param is_gt: whether gt or tracker data is read
:param tracker: the name of the tracker
:param seq: the name of the seq
:return: None
"""
if is_gt:
err = 'Cannot load gt data from sequence %s, because there are not enough ' \
'columns in the data.' % seq
raise TrackEvalException(err)
else:
err = 'Cannot load tracker data from tracker %s, sequence %s, because there are not enough ' \
'columns in the data.' % (tracker, seq)
raise TrackEvalException(err)
@staticmethod
def _raise_value_error(is_gt, tracker, seq):
"""
Auxiliary method to raise an evaluation error in case of an value error while reading files.
:param is_gt: whether gt or tracker data is read
:param tracker: the name of the tracker
:param seq: the name of the seq
:return: None
"""
if is_gt:
raise TrackEvalException(
'GT data for sequence %s cannot be converted to the right format. Is data corrupted?' % seq)
else:
raise TrackEvalException(
'Tracking data from tracker %s, sequence %s cannot be converted to the right format. '
'Is data corrupted?' % (tracker, seq))
================================================
FILE: TrackEval/trackeval/datasets/rob_mots.py
================================================
import os
import csv
import numpy as np
from scipy.optimize import linear_sum_assignment
from ._base_dataset import _BaseDataset
from .. import utils
from ..utils import TrackEvalException
from .. import _timing
from ..datasets.rob_mots_classmap import cls_id_to_name
class RobMOTS(_BaseDataset):
@staticmethod
def get_default_dataset_config():
"""Default class config values"""
code_path = utils.get_code_path()
default_config = {
'GT_FOLDER': os.path.join(code_path, 'data/gt/rob_mots'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/rob_mots'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'SUB_BENCHMARK': None, # REQUIRED. Sub-benchmark to eval. If None, then error.
# ['mots_challenge', 'kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis', 'waymo', 'tao']
'CLASSES_TO_EVAL': None, # List of classes to eval. If None, then it does all COCO classes.
'SPLIT_TO_EVAL': 'train', # valid: ['train', 'val', 'test']
'INPUT_AS_ZIP': False, # Whether tracker input files are zipped
'PRINT_CONFIG': True, # Whether to print current config
'OUTPUT_SUB_FOLDER': 'results', # Output files are saved in OUTPUT_FOLDER/DATA_LOC_FORMAT/OUTPUT_SUB_FOLDER
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/DATA_LOC_FORMAT/TRACKER_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
'SEQMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/dataset_subfolder/seqmaps)
'SEQMAP_FILE': None, # Directly specify seqmap file (if none use SEQMAP_FOLDER/BENCHMARK_SPLIT_TO_EVAL)
'CLSMAP_FOLDER': None, # Where seqmaps are found (if None, GT_FOLDER/dataset_subfolder/clsmaps)
'CLSMAP_FILE': None, # Directly specify seqmap file (if none use CLSMAP_FOLDER/BENCHMARK_SPLIT_TO_EVAL)
}
return default_config
def __init__(self, config=None):
super().__init__()
# Fill non-given config values with defaults
self.config = utils.init_config(config, self.get_default_dataset_config())
self.split = self.config['SPLIT_TO_EVAL']
valid_benchmarks = ['mots_challenge', 'kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis', 'waymo', 'tao']
self.box_gt_benchmarks = ['waymo', 'tao']
self.sub_benchmark = self.config['SUB_BENCHMARK']
if not self.sub_benchmark:
raise TrackEvalException('SUB_BENCHMARK config input is required (there is no default value)' +
', '.join(valid_benchmarks) + ' are valid.')
if self.sub_benchmark not in valid_benchmarks:
raise TrackEvalException('Attempted to evaluate an invalid benchmark: ' + self.sub_benchmark + '. Only benchmarks ' +
', '.join(valid_benchmarks) + ' are valid.')
self.gt_fol = self.config['GT_FOLDER']
self.tracker_fol = os.path.join(self.config['TRACKERS_FOLDER'], self.config['SPLIT_TO_EVAL'])
self.data_is_zipped = self.config['INPUT_AS_ZIP']
self.output_fol = self.config['OUTPUT_FOLDER']
if self.output_fol is None:
self.output_fol = self.tracker_fol
self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
self.output_sub_fol = os.path.join(self.config['OUTPUT_SUB_FOLDER'], self.sub_benchmark)
# Loops through all sub-benchmarks, and reads in seqmaps to info on all sequences to eval.
self._get_seq_info()
if len(self.seq_list) < 1:
raise TrackEvalException('No sequences are selected to be evaluated.')
valid_class_ids = np.atleast_1d(np.genfromtxt(os.path.join(self.gt_fol, self.split, self.sub_benchmark,
'clsmap.txt')))
valid_classes = [cls_id_to_name[int(x)] for x in valid_class_ids] + ['all']
self.valid_class_ids = valid_class_ids
self.class_name_to_class_id = {cls_name: cls_id for cls_id, cls_name in cls_id_to_name.items()}
self.class_name_to_class_id['all'] = -1
if not self.config['CLASSES_TO_EVAL']:
self.class_list = valid_classes
else:
self.class_list = [cls if cls in valid_classes else None
for cls in self.config['CLASSES_TO_EVAL']]
if not all(self.class_list):
raise TrackEvalException('Attempted to evaluate an invalid class. Only classes ' +
', '.join(valid_classes) + ' are valid.')
# Check gt files exist
for seq in self.seq_list:
if not self.data_is_zipped:
curr_file = os.path.join(self.gt_fol, self.split, self.sub_benchmark, 'data', seq + '.txt')
if not os.path.isfile(curr_file):
print('GT file not found ' + curr_file)
raise TrackEvalException('GT file not found for sequence: ' + seq)
if self.data_is_zipped:
curr_file = os.path.join(self.gt_fol, self.split, self.sub_benchmark, 'data.zip')
if not os.path.isfile(curr_file):
raise TrackEvalException('GT file not found: ' + os.path.basename(curr_file))
# Get trackers to eval
if self.config['TRACKERS_TO_EVAL'] is None:
self.tracker_list = os.listdir(self.tracker_fol)
else:
self.tracker_list = self.config['TRACKERS_TO_EVAL']
if self.config['TRACKER_DISPLAY_NAMES'] is None:
self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
else:
raise TrackEvalException('List of tracker files and tracker display names do not match.')
for tracker in self.tracker_list:
if self.data_is_zipped:
curr_file = os.path.join(self.tracker_fol, tracker, 'data.zip')
if not os.path.isfile(curr_file):
raise TrackEvalException('Tracker file not found: ' + os.path.basename(curr_file))
else:
for seq in self.seq_list:
curr_file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, self.sub_benchmark, seq
+ '.txt')
if not os.path.isfile(curr_file):
print('Tracker file not found: ' + curr_file)
raise TrackEvalException(
'Tracker file not found: ' + self.sub_benchmark + '/' + os.path.basename(curr_file))
def get_name(self):
return self.get_class_name() + '.' + self.sub_benchmark
def _get_seq_info(self):
self.seq_list = []
self.seq_lengths = {}
self.seq_sizes = {}
self.seq_ignore_class_ids = {}
if self.config["SEQMAP_FILE"]:
seqmap_file = self.config["SEQMAP_FILE"]
else:
if self.config["SEQMAP_FOLDER"] is None:
seqmap_file = os.path.join(self.gt_fol, self.split, self.sub_benchmark, 'seqmap.txt')
else:
seqmap_file = os.path.join(self.config["SEQMAP_FOLDER"], self.split + '.seqmap')
if not os.path.isfile(seqmap_file):
print('no seqmap found: ' + seqmap_file)
raise TrackEvalException('no seqmap found: ' + os.path.basename(seqmap_file))
with open(seqmap_file) as fp:
dialect = csv.Sniffer().sniff(fp.readline(), delimiters=' ')
fp.seek(0)
reader = csv.reader(fp, dialect)
for i, row in enumerate(reader):
if len(row) >= 4:
# first col: sequence, second col: sequence length, third and fourth col: sequence height/width
# The rest of the columns list the 'sequence ignore class ids' which are classes not penalized as
# FPs for this sequence.
seq = row[0]
self.seq_list.append(seq)
self.seq_lengths[seq] = int(row[1])
self.seq_sizes[seq] = (int(row[2]), int(row[3]))
self.seq_ignore_class_ids[seq] = [int(row[x]) for x in range(4, len(row))]
def get_display_name(self, tracker):
return self.tracker_to_disp[tracker]
def _load_raw_file(self, tracker, seq, is_gt):
"""Load a file (gt or tracker) in the unified RobMOTS format.
If is_gt, this returns a dict which contains the fields:
[gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, gt_crowd_ignore_regions]: list (for each timestep) of lists of detections.
if not is_gt, this returns a dict which contains the fields:
[tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
[tracker_dets]: list (for each timestep) of lists of detections.
"""
# import to reduce minimum requirements
from pycocotools import mask as mask_utils
# File location
if self.data_is_zipped:
if is_gt:
zip_file = os.path.join(self.gt_fol, self.split, self.sub_benchmark, 'data.zip')
else:
zip_file = os.path.join(self.tracker_fol, tracker, 'data.zip')
file = seq + '.txt'
else:
zip_file = None
if is_gt:
file = os.path.join(self.gt_fol, self.split, self.sub_benchmark, 'data', seq + '.txt')
else:
file = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, self.sub_benchmark, seq + '.txt')
# Load raw data from text file
read_data, ignore_data = self._load_simple_text_file(file, is_zipped=self.data_is_zipped, zip_file=zip_file,
force_delimiters=' ')
# Convert data to required format
num_timesteps = self.seq_lengths[seq]
data_keys = ['ids', 'classes', 'dets']
if not is_gt:
data_keys += ['tracker_confidences']
raw_data = {key: [None] * num_timesteps for key in data_keys}
for t in range(num_timesteps):
time_key = str(t)
# list to collect all masks of a timestep to check for overlapping areas (for segmentation datasets)
all_valid_masks = []
if time_key in read_data.keys():
try:
raw_data['ids'][t] = np.atleast_1d([det[1] for det in read_data[time_key]]).astype(int)
raw_data['classes'][t] = np.atleast_1d([det[2] for det in read_data[time_key]]).astype(int)
if (not is_gt) or (self.sub_benchmark not in self.box_gt_benchmarks):
raw_data['dets'][t] = [{'size': [int(region[4]), int(region[5])],
'counts': region[6].encode(encoding='UTF-8')}
for region in read_data[time_key]]
all_valid_masks += [mask for mask, cls in zip(raw_data['dets'][t], raw_data['classes'][t]) if
cls < 100]
else:
raw_data['dets'][t] = np.atleast_2d([det[4:8] for det in read_data[time_key]]).astype(float)
if not is_gt:
raw_data['tracker_confidences'][t] = np.atleast_1d([det[3] for det
in read_data[time_key]]).astype(float)
except IndexError:
self._raise_index_error(is_gt, self.sub_benchmark, seq)
except ValueError:
self._raise_value_error(is_gt, self.sub_benchmark, seq)
# no detection in this timestep
else:
if (not is_gt) or (self.sub_benchmark not in self.box_gt_benchmarks):
raw_data['dets'][t] = []
else:
raw_data['dets'][t] = np.empty((0, 4)).astype(float)
raw_data['ids'][t] = np.empty(0).astype(int)
raw_data['classes'][t] = np.empty(0).astype(int)
if not is_gt:
raw_data['tracker_confidences'][t] = np.empty(0).astype(float)
# check for overlapping masks
if all_valid_masks:
masks_merged = all_valid_masks[0]
for mask in all_valid_masks[1:]:
if mask_utils.area(mask_utils.merge([masks_merged, mask], intersect=True)) != 0.0:
err = 'Overlapping masks in frame %d' % t
raise TrackEvalException(err)
masks_merged = mask_utils.merge([masks_merged, mask], intersect=False)
if is_gt:
key_map = {'ids': 'gt_ids',
'classes': 'gt_classes',
'dets': 'gt_dets'}
else:
key_map = {'ids': 'tracker_ids',
'classes': 'tracker_classes',
'dets': 'tracker_dets'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
raw_data['num_timesteps'] = num_timesteps
raw_data['frame_size'] = self.seq_sizes[seq]
raw_data['seq'] = seq
return raw_data
@staticmethod
def _raise_index_error(is_gt, sub_benchmark, seq):
"""
Auxiliary method to raise an evaluation error in case of an index error while reading files.
:param is_gt: whether gt or tracker data is read
:param tracker: the name of the tracker
:param seq: the name of the seq
:return: None
"""
if is_gt:
err = 'Cannot load gt data from sequence %s, because there are not enough ' \
'columns in the data.' % seq
raise TrackEvalException(err)
else:
err = 'Cannot load tracker data from benchmark %s, sequence %s, because there are not enough ' \
'columns in the data.' % (sub_benchmark, seq)
raise TrackEvalException(err)
@staticmethod
def _raise_value_error(is_gt, sub_benchmark, seq):
"""
Auxiliary method to raise an evaluation error in case of an value error while reading files.
:param is_gt: whether gt or tracker data is read
:param tracker: the name of the tracker
:param seq: the name of the seq
:return: None
"""
if is_gt:
raise TrackEvalException(
'GT data for sequence %s cannot be converted to the right format. Is data corrupted?' % seq)
else:
raise TrackEvalException(
'Tracking data from benchmark %s, sequence %s cannot be converted to the right format. '
'Is data corrupted?' % (sub_benchmark, seq))
@_timing.time
def get_preprocessed_seq_data(self, raw_data, cls):
""" Preprocess data for a single sequence for a single class ready for evaluation.
Inputs:
- raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
- cls is the class to be evaluated.
Outputs:
- data is a dict containing all of the information that metrics need to perform evaluation.
It contains the following fields:
[num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
[gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
[similarity_scores]: list (for each timestep) of 2D NDArrays.
Notes:
Preprocessing (preproc) occurs in 3 steps.
1) Extract only detections relevant for the class to be evaluated.
2) Match gt dets and tracker dets. Tracker dets that are to a gt det (TPs) are marked as not to be
removed.
3) Remove unmatched tracker dets if they fall within an ignore region or are too small, or if that class
is marked as an ignore class for that sequence.
After the above preprocessing steps, this function also calculates the number of gt and tracker detections
and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
unique within each timestep.
Note that there is a special 'all' class, which evaluates all of the COCO classes together in a
'class agnostic' fashion.
"""
# import to reduce minimum requirements
from pycocotools import mask as mask_utils
# Check that input data has unique ids
self._check_unique_ids(raw_data)
cls_id = self.class_name_to_class_id[cls]
ignore_class_id = cls_id+100
seq = raw_data['seq']
data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences', 'similarity_scores']
data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
unique_gt_ids = []
unique_tracker_ids = []
num_gt_dets = 0
num_tracker_dets = 0
for t in range(raw_data['num_timesteps']):
# Only extract relevant dets for this class
if cls == 'all':
gt_class_mask = raw_data['gt_classes'][t] < 100
# For waymo, combine predictions for [car, truck, bus, motorcycle] into car, because they are all annotated
# together as one 'vehicle' class.
elif self.sub_benchmark == 'waymo' and cls == 'car':
waymo_vehicle_classes = np.array([3, 4, 6, 8])
gt_class_mask = np.isin(raw_data['gt_classes'][t], waymo_vehicle_classes)
else:
gt_class_mask = raw_data['gt_classes'][t] == cls_id
gt_class_mask = gt_class_mask.astype(np.bool)
gt_ids = raw_data['gt_ids'][t][gt_class_mask]
if cls == 'all':
ignore_regions_mask = raw_data['gt_classes'][t] >= 100
else:
ignore_regions_mask = raw_data['gt_classes'][t] == ignore_class_id
ignore_regions_mask = np.logical_or(ignore_regions_mask, raw_data['gt_classes'][t] == 100)
if self.sub_benchmark in self.box_gt_benchmarks:
gt_dets = raw_data['gt_dets'][t][gt_class_mask]
ignore_regions_box = raw_data['gt_dets'][t][ignore_regions_mask]
if len(ignore_regions_box) > 0:
ignore_regions_box[:, 2] = ignore_regions_box[:, 2] - ignore_regions_box[:, 0]
ignore_regions_box[:, 3] = ignore_regions_box[:, 3] - ignore_regions_box[:, 1]
ignore_regions = mask_utils.frPyObjects(ignore_regions_box, self.seq_sizes[seq][0], self.seq_sizes[seq][1])
else:
ignore_regions = []
else:
gt_dets = [raw_data['gt_dets'][t][ind] for ind in range(len(gt_class_mask)) if gt_class_mask[ind]]
ignore_regions = [raw_data['gt_dets'][t][ind] for ind in range(len(ignore_regions_mask)) if
ignore_regions_mask[ind]]
if cls == 'all':
tracker_class_mask = np.ones_like(raw_data['tracker_classes'][t])
else:
tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
tracker_class_mask = tracker_class_mask.astype(np.bool)
tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
tracker_dets = [raw_data['tracker_dets'][t][ind] for ind in range(len(tracker_class_mask)) if
tracker_class_mask[ind]]
tracker_confidences = raw_data['tracker_confidences'][t][tracker_class_mask]
similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
tracker_classes = raw_data['tracker_classes'][t][tracker_class_mask]
# Only do preproc if there are ignore regions defined to remove
if tracker_ids.shape[0] > 0:
# Match tracker and gt dets (with hungarian algorithm)
unmatched_indices = np.arange(tracker_ids.shape[0])
if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
matching_scores = similarity_scores.copy()
matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
match_rows, match_cols = linear_sum_assignment(-matching_scores)
actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
# match_rows = match_rows[actually_matched_mask]
match_cols = match_cols[actually_matched_mask]
unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
# For unmatched tracker dets remove those that are greater than 50% within an ignore region.
# unmatched_tracker_dets = tracker_dets[unmatched_indices, :]
# crowd_ignore_regions = raw_data['gt_ignore_regions'][t]
# intersection_with_ignore_region = self. \
# _calculate_box_ious(unmatched_tracker_dets, crowd_ignore_regions, box_format='x0y0x1y1',
# do_ioa=True)
if cls_id in self.seq_ignore_class_ids[seq]:
# Remove unmatched detections for classes that are marked as 'ignore' for the whole sequence.
to_remove_tracker = unmatched_indices
else:
unmatched_tracker_dets = [tracker_dets[i] for i in range(len(tracker_dets)) if
i in unmatched_indices]
# For unmatched tracker dets remove those that are too small.
tracker_boxes_t = mask_utils.toBbox(unmatched_tracker_dets)
unmatched_widths = tracker_boxes_t[:, 2]
unmatched_heights = tracker_boxes_t[:, 3]
unmatched_size = np.maximum(unmatched_heights, unmatched_widths)
min_size = np.min(self.seq_sizes[seq])/8
is_too_small = unmatched_size <= min_size + np.finfo('float').eps
# For unmatched tracker dets remove those that are greater than 50% within an ignore region.
if ignore_regions:
ignore_region_merged = ignore_regions[0]
for mask in ignore_regions[1:]:
ignore_region_merged = mask_utils.merge([ignore_region_merged, mask], intersect=False)
intersection_with_ignore_region = self. \
_calculate_mask_ious(unmatched_tracker_dets, [ignore_region_merged], is_encoded=True, do_ioa=True)
is_within_ignore_region = np.any(intersection_with_ignore_region > 0.5 + np.finfo('float').eps, axis=1)
to_remove_tracker = unmatched_indices[np.logical_or(is_too_small, is_within_ignore_region)]
else:
to_remove_tracker = unmatched_indices[is_too_small]
# For the special 'all' class, you need to remove unmatched detections from all ignore classes and
# non-evaluated classes.
if cls == 'all':
unmatched_tracker_classes = [tracker_classes[i] for i in range(len(tracker_classes)) if
i in unmatched_indices]
is_ignore_class = np.isin(unmatched_tracker_classes, self.seq_ignore_class_ids[seq])
is_not_evaled_class = np.logical_not(np.isin(unmatched_tracker_classes, self.valid_class_ids))
to_remove_all = unmatched_indices[np.logical_or(is_ignore_class, is_not_evaled_class)]
to_remove_tracker = np.concatenate([to_remove_tracker, to_remove_all], axis=0)
else:
to_remove_tracker = np.array([], dtype=np.int)
# remove all unwanted tracker detections
data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
# keep all ground truth detections
data['gt_ids'][t] = gt_ids
data['gt_dets'][t] = gt_dets
data['similarity_scores'][t] = similarity_scores
unique_gt_ids += list(np.unique(data['gt_ids'][t]))
unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
num_tracker_dets += len(data['tracker_ids'][t])
num_gt_dets += len(data['gt_ids'][t])
# Re-label IDs such that there are no empty IDs
if len(unique_gt_ids) > 0:
unique_gt_ids = np.unique(unique_gt_ids)
gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
for t in range(raw_data['num_timesteps']):
if len(data['gt_ids'][t]) > 0:
data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
if len(unique_tracker_ids) > 0:
unique_tracker_ids = np.unique(unique_tracker_ids)
tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
for t in range(raw_data['num_timesteps']):
if len(data['tracker_ids'][t]) > 0:
data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
# Record overview statistics.
data['num_tracker_dets'] = num_tracker_dets
data['num_gt_dets'] = num_gt_dets
data['num_tracker_ids'] = len(unique_tracker_ids)
data['num_gt_ids'] = len(unique_gt_ids)
data['num_timesteps'] = raw_data['num_timesteps']
data['seq'] = raw_data['seq']
data['frame_size'] = raw_data['frame_size']
# Ensure that ids are unique per timestep.
self._check_unique_ids(data, after_preproc=True)
return data
def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
# Only loaded when run to reduce minimum requirements
from pycocotools import mask as mask_utils
if self.sub_benchmark in self.box_gt_benchmarks:
# Convert tracker masks to bboxes (for benchmarks with only bbox ground-truth),
# and then convert to x0y0x1y1 format.
tracker_boxes_t = mask_utils.toBbox(tracker_dets_t)
tracker_boxes_t[:, 2] = tracker_boxes_t[:, 0] + tracker_boxes_t[:, 2]
tracker_boxes_t[:, 3] = tracker_boxes_t[:, 1] + tracker_boxes_t[:, 3]
similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_boxes_t, box_format='x0y0x1y1')
else:
similarity_scores = self._calculate_mask_ious(gt_dets_t, tracker_dets_t, is_encoded=True, do_ioa=False)
return similarity_scores
================================================
FILE: TrackEval/trackeval/datasets/rob_mots_classmap.py
================================================
cls_id_to_name = {
1: 'person',
2: 'bicycle',
3: 'car',
4: 'motorcycle',
5: 'airplane',
6: 'bus',
7: 'train',
8: 'truck',
9: 'boat',
10: 'traffic light',
11: 'fire hydrant',
12: 'stop sign',
13: 'parking meter',
14: 'bench',
15: 'bird',
16: 'cat',
17: 'dog',
18: 'horse',
19: 'sheep',
20: 'cow',
21: 'elephant',
22: 'bear',
23: 'zebra',
24: 'giraffe',
25: 'backpack',
26: 'umbrella',
27: 'handbag',
28: 'tie',
29: 'suitcase',
30: 'frisbee',
31: 'skis',
32: 'snowboard',
33: 'sports ball',
34: 'kite',
35: 'baseball bat',
36: 'baseball glove',
37: 'skateboard',
38: 'surfboard',
39: 'tennis racket',
40: 'bottle',
41: 'wine glass',
42: 'cup',
43: 'fork',
44: 'knife',
45: 'spoon',
46: 'bowl',
47: 'banana',
48: 'apple',
49: 'sandwich',
50: 'orange',
51: 'broccoli',
52: 'carrot',
53: 'hot dog',
54: 'pizza',
55: 'donut',
56: 'cake',
57: 'chair',
58: 'couch',
59: 'potted plant',
60: 'bed',
61: 'dining table',
62: 'toilet',
63: 'tv',
64: 'laptop',
65: 'mouse',
66: 'remote',
67: 'keyboard',
68: 'cell phone',
69: 'microwave',
70: 'oven',
71: 'toaster',
72: 'sink',
73: 'refrigerator',
74: 'book',
75: 'clock',
76: 'vase',
77: 'scissors',
78: 'teddy bear',
79: 'hair drier',
80: 'toothbrush'}
================================================
FILE: TrackEval/trackeval/datasets/run_rob_mots.py
================================================
# python3 scripts\run_rob_mots.py --ROBMOTS_SPLIT val --TRACKERS_TO_EVAL tracker_name (e.g. STP) --USE_PARALLEL True --NUM_PARALLEL_CORES 4
import sys
import os
import csv
import numpy as np
from multiprocessing import freeze_support
sys.path.insert(0, os.path.abspath(os.path.join(os.path.dirname(__file__), '..')))
import trackeval # noqa: E402
from trackeval import utils
code_path = utils.get_code_path()
if __name__ == '__main__':
freeze_support()
script_config = {
'ROBMOTS_SPLIT': 'train', # 'train', # valid: 'train', 'val', 'test', 'test_live', 'test_post', 'test_all'
'BENCHMARKS': ['kitti_mots', 'davis_unsupervised', 'youtube_vis', 'ovis', 'tao'], # 'bdd_mots' coming soon
'GT_FOLDER': os.path.join(code_path, 'data/gt/rob_mots'),
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/rob_mots'),
}
default_eval_config = trackeval.Evaluator.get_default_eval_config()
default_eval_config['PRINT_ONLY_COMBINED'] = True
default_eval_config['DISPLAY_LESS_PROGRESS'] = True
default_dataset_config = trackeval.datasets.RobMOTS.get_default_dataset_config()
config = {**default_eval_config, **default_dataset_config, **script_config}
# Command line interface:
config = utils.update_config(config)
if config['ROBMOTS_SPLIT'] == 'val':
config['BENCHMARKS'] = ['kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis',
'tao', 'mots_challenge']
config['SPLIT_TO_EVAL'] = 'val'
elif config['ROBMOTS_SPLIT'] == 'test' or config['SPLIT_TO_EVAL'] == 'test_live':
config['BENCHMARKS'] = ['kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis', 'tao']
config['SPLIT_TO_EVAL'] = 'test'
elif config['ROBMOTS_SPLIT'] == 'test_post':
config['BENCHMARKS'] = ['mots_challenge', 'waymo']
config['SPLIT_TO_EVAL'] = 'test'
elif config['ROBMOTS_SPLIT'] == 'test_all':
config['BENCHMARKS'] = ['kitti_mots', 'bdd_mots', 'davis_unsupervised', 'youtube_vis', 'ovis',
'tao', 'mots_challenge', 'waymo']
config['SPLIT_TO_EVAL'] = 'test'
elif config['ROBMOTS_SPLIT'] == 'train':
config['BENCHMARKS'] = ['kitti_mots', 'davis_unsupervised', 'youtube_vis', 'ovis', 'tao'] # 'bdd_mots' coming soon
config['SPLIT_TO_EVAL'] = 'train'
metrics_config = {'METRICS': ['HOTA']}
# metrics_config = {'METRICS': ['HOTA', 'CLEAR', 'Identity']}
eval_config = {k: v for k, v in config.items() if k in config.keys()}
dataset_config = {k: v for k, v in config.items() if k in config.keys()}
# Run code
dataset_list = []
for bench in config['BENCHMARKS']:
dataset_config['SUB_BENCHMARK'] = bench
dataset_list.append(trackeval.datasets.RobMOTS(dataset_config))
evaluator = trackeval.Evaluator(eval_config)
metrics_list = []
for metric in [trackeval.metrics.HOTA, trackeval.metrics.CLEAR, trackeval.metrics.Identity]:
if metric.get_name() in metrics_config['METRICS']:
metrics_list.append(metric())
if len(metrics_list) == 0:
raise Exception('No metrics selected for evaluation')
output_res, output_msg = evaluator.evaluate(dataset_list, metrics_list)
# For each benchmark, combine the 'all' score with the 'cls_averaged' using geometric mean.
metrics_to_calc = ['HOTA', 'DetA', 'AssA', 'DetRe', 'DetPr', 'AssRe', 'AssPr', 'LocA']
trackers = list(output_res['RobMOTS.' + config['BENCHMARKS'][0]].keys())
for tracker in trackers:
# final_results[benchmark][result_type][metric]
final_results = {}
res = {bench: output_res['RobMOTS.' + bench][tracker]['COMBINED_SEQ'] for bench in config['BENCHMARKS']}
for bench in config['BENCHMARKS']:
final_results[bench] = {'cls_av': {}, 'det_av': {}, 'final': {}}
for metric in metrics_to_calc:
final_results[bench]['cls_av'][metric] = np.mean(res[bench]['cls_comb_cls_av']['HOTA'][metric])
final_results[bench]['det_av'][metric] = np.mean(res[bench]['all']['HOTA'][metric])
final_results[bench]['final'][metric] = \
np.sqrt(final_results[bench]['cls_av'][metric] * final_results[bench]['det_av'][metric])
# Take the arithmetic mean over all the benchmarks
final_results['overall'] = {'cls_av': {}, 'det_av': {}, 'final': {}}
for metric in metrics_to_calc:
final_results['overall']['cls_av'][metric] = \
np.mean([final_results[bench]['cls_av'][metric] for bench in config['BENCHMARKS']])
final_results['overall']['det_av'][metric] = \
np.mean([final_results[bench]['det_av'][metric] for bench in config['BENCHMARKS']])
final_results['overall']['final'][metric] = \
np.mean([final_results[bench]['final'][metric] for bench in config['BENCHMARKS']])
# Save out result
headers = [config['SPLIT_TO_EVAL']] + [x + '___' + metric for x in ['f', 'c', 'd'] for metric in metrics_to_calc]
def rowify(d):
return [d[x][metric] for x in ['final', 'cls_av', 'det_av'] for metric in metrics_to_calc]
out_file = os.path.join(script_config['TRACKERS_FOLDER'], script_config['ROBMOTS_SPLIT'], tracker,
'final_results.csv')
with open(out_file, 'w', newline='') as f:
writer = csv.writer(f, delimiter=',')
writer.writerow(headers)
writer.writerow(['overall'] + rowify(final_results['overall']))
for bench in config['BENCHMARKS']:
if bench == 'overall':
continue
writer.writerow([bench] + rowify(final_results[bench]))
================================================
FILE: TrackEval/trackeval/datasets/tao.py
================================================
import os
import numpy as np
import json
import itertools
from collections import defaultdict
from scipy.optimize import linear_sum_assignment
from ..utils import TrackEvalException
from ._base_dataset import _BaseDataset
from .. import utils
from .. import _timing
class TAO(_BaseDataset):
"""Dataset class for TAO tracking"""
@staticmethod
def get_default_dataset_config():
"""Default class config values"""
code_path = utils.get_code_path()
default_config = {
'GT_FOLDER': os.path.join(code_path, 'data/gt/tao/tao_training'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/tao/tao_training'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
'MAX_DETECTIONS': 300, # Number of maximal allowed detections per image (0 for unlimited)
}
return default_config
def __init__(self, config=None):
"""Initialise dataset, checking that all required files are present"""
super().__init__()
# Fill non-given config values with defaults
self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
self.gt_fol = self.config['GT_FOLDER']
self.tracker_fol = self.config['TRACKERS_FOLDER']
self.should_classes_combine = True
self.use_super_categories = False
self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
self.output_fol = self.config['OUTPUT_FOLDER']
if self.output_fol is None:
self.output_fol = self.tracker_fol
self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
gt_dir_files = [file for file in os.listdir(self.gt_fol) if file.endswith('.json')]
if len(gt_dir_files) != 1:
raise TrackEvalException(self.gt_fol + ' does not contain exactly one json file.')
with open(os.path.join(self.gt_fol, gt_dir_files[0])) as f:
self.gt_data = json.load(f)
# merge categories marked with a merged tag in TAO dataset
self._merge_categories(self.gt_data['annotations'] + self.gt_data['tracks'])
# Get sequences to eval and sequence information
self.seq_list = [vid['name'].replace('/', '-') for vid in self.gt_data['videos']]
self.seq_name_to_seq_id = {vid['name'].replace('/', '-'): vid['id'] for vid in self.gt_data['videos']}
# compute mappings from videos to annotation data
self.videos_to_gt_tracks, self.videos_to_gt_images = self._compute_vid_mappings(self.gt_data['annotations'])
# compute sequence lengths
self.seq_lengths = {vid['id']: 0 for vid in self.gt_data['videos']}
for img in self.gt_data['images']:
self.seq_lengths[img['video_id']] += 1
self.seq_to_images_to_timestep = self._compute_image_to_timestep_mappings()
self.seq_to_classes = {vid['id']: {'pos_cat_ids': list({track['category_id'] for track
in self.videos_to_gt_tracks[vid['id']]}),
'neg_cat_ids': vid['neg_category_ids'],
'not_exhaustively_labeled_cat_ids': vid['not_exhaustive_category_ids']}
for vid in self.gt_data['videos']}
# Get classes to eval
considered_vid_ids = [self.seq_name_to_seq_id[vid] for vid in self.seq_list]
seen_cats = set([cat_id for vid_id in considered_vid_ids for cat_id
in self.seq_to_classes[vid_id]['pos_cat_ids']])
# only classes with ground truth are evaluated in TAO
self.valid_classes = [cls['name'] for cls in self.gt_data['categories'] if cls['id'] in seen_cats]
cls_name_to_cls_id_map = {cls['name']: cls['id'] for cls in self.gt_data['categories']}
if self.config['CLASSES_TO_EVAL']:
self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
for cls in self.config['CLASSES_TO_EVAL']]
if not all(self.class_list):
raise TrackEvalException('Attempted to evaluate an invalid class. Only classes ' +
', '.join(self.valid_classes) +
' are valid (classes present in ground truth data).')
else:
self.class_list = [cls for cls in self.valid_classes]
self.class_name_to_class_id = {k: v for k, v in cls_name_to_cls_id_map.items() if k in self.class_list}
# Get trackers to eval
if self.config['TRACKERS_TO_EVAL'] is None:
self.tracker_list = os.listdir(self.tracker_fol)
else:
self.tracker_list = self.config['TRACKERS_TO_EVAL']
if self.config['TRACKER_DISPLAY_NAMES'] is None:
self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
else:
raise TrackEvalException('List of tracker files and tracker display names do not match.')
self.tracker_data = {tracker: dict() for tracker in self.tracker_list}
for tracker in self.tracker_list:
tr_dir_files = [file for file in os.listdir(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol))
if file.endswith('.json')]
if len(tr_dir_files) != 1:
raise TrackEvalException(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol)
+ ' does not contain exactly one json file.')
with open(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, tr_dir_files[0])) as f:
curr_data = json.load(f)
# limit detections if MAX_DETECTIONS > 0
if self.config['MAX_DETECTIONS']:
curr_data = self._limit_dets_per_image(curr_data)
# fill missing video ids
self._fill_video_ids_inplace(curr_data)
# make track ids unique over whole evaluation set
self._make_track_ids_unique(curr_data)
# merge categories marked with a merged tag in TAO dataset
self._merge_categories(curr_data)
# get tracker sequence information
curr_videos_to_tracker_tracks, curr_videos_to_tracker_images = self._compute_vid_mappings(curr_data)
self.tracker_data[tracker]['vids_to_tracks'] = curr_videos_to_tracker_tracks
self.tracker_data[tracker]['vids_to_images'] = curr_videos_to_tracker_images
def get_display_name(self, tracker):
return self.tracker_to_disp[tracker]
def _load_raw_file(self, tracker, seq, is_gt):
"""Load a file (gt or tracker) in the TAO format
If is_gt, this returns a dict which contains the fields:
[gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
[gt_dets]: list (for each timestep) of lists of detections.
[classes_to_gt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
keys and corresponding segmentations as values) for each track
[classes_to_gt_track_ids, classes_to_gt_track_areas, classes_to_gt_track_lengths]: dictionary with class values
as keys and lists (for each track) as values
if not is_gt, this returns a dict which contains the fields:
[tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
[tracker_dets]: list (for each timestep) of lists of detections.
[classes_to_dt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
keys and corresponding segmentations as values) for each track
[classes_to_dt_track_ids, classes_to_dt_track_areas, classes_to_dt_track_lengths]: dictionary with class values
as keys and lists as values
[classes_to_dt_track_scores]: dictionary with class values as keys and 1D numpy arrays as values
"""
seq_id = self.seq_name_to_seq_id[seq]
# File location
if is_gt:
imgs = self.videos_to_gt_images[seq_id]
else:
imgs = self.tracker_data[tracker]['vids_to_images'][seq_id]
# Convert data to required format
num_timesteps = self.seq_lengths[seq_id]
img_to_timestep = self.seq_to_images_to_timestep[seq_id]
data_keys = ['ids', 'classes', 'dets']
if not is_gt:
data_keys += ['tracker_confidences']
raw_data = {key: [None] * num_timesteps for key in data_keys}
for img in imgs:
# some tracker data contains images without any ground truth information, these are ignored
try:
t = img_to_timestep[img['id']]
except KeyError:
continue
annotations = img['annotations']
raw_data['dets'][t] = np.atleast_2d([ann['bbox'] for ann in annotations]).astype(float)
raw_data['ids'][t] = np.atleast_1d([ann['track_id'] for ann in annotations]).astype(int)
raw_data['classes'][t] = np.atleast_1d([ann['category_id'] for ann in annotations]).astype(int)
if not is_gt:
raw_data['tracker_confidences'][t] = np.atleast_1d([ann['score'] for ann in annotations]).astype(float)
for t, d in enumerate(raw_data['dets']):
if d is None:
raw_data['dets'][t] = np.empty((0, 4)).astype(float)
raw_data['ids'][t] = np.empty(0).astype(int)
raw_data['classes'][t] = np.empty(0).astype(int)
if not is_gt:
raw_data['tracker_confidences'][t] = np.empty(0)
if is_gt:
key_map = {'ids': 'gt_ids',
'classes': 'gt_classes',
'dets': 'gt_dets'}
else:
key_map = {'ids': 'tracker_ids',
'classes': 'tracker_classes',
'dets': 'tracker_dets'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
all_classes = [self.class_name_to_class_id[cls] for cls in self.class_list]
if is_gt:
classes_to_consider = all_classes
all_tracks = self.videos_to_gt_tracks[seq_id]
else:
classes_to_consider = self.seq_to_classes[seq_id]['pos_cat_ids'] \
+ self.seq_to_classes[seq_id]['neg_cat_ids']
all_tracks = self.tracker_data[tracker]['vids_to_tracks'][seq_id]
classes_to_tracks = {cls: [track for track in all_tracks if track['category_id'] == cls]
if cls in classes_to_consider else [] for cls in all_classes}
# mapping from classes to track information
raw_data['classes_to_tracks'] = {cls: [{det['image_id']: np.atleast_1d(det['bbox'])
for det in track['annotations']} for track in tracks]
for cls, tracks in classes_to_tracks.items()}
raw_data['classes_to_track_ids'] = {cls: [track['id'] for track in tracks]
for cls, tracks in classes_to_tracks.items()}
raw_data['classes_to_track_areas'] = {cls: [track['area'] for track in tracks]
for cls, tracks in classes_to_tracks.items()}
raw_data['classes_to_track_lengths'] = {cls: [len(track['annotations']) for track in tracks]
for cls, tracks in classes_to_tracks.items()}
if not is_gt:
raw_data['classes_to_dt_track_scores'] = {cls: np.array([np.mean([float(x['score'])
for x in track['annotations']])
for track in tracks])
for cls, tracks in classes_to_tracks.items()}
if is_gt:
key_map = {'classes_to_tracks': 'classes_to_gt_tracks',
'classes_to_track_ids': 'classes_to_gt_track_ids',
'classes_to_track_lengths': 'classes_to_gt_track_lengths',
'classes_to_track_areas': 'classes_to_gt_track_areas'}
else:
key_map = {'classes_to_tracks': 'classes_to_dt_tracks',
'classes_to_track_ids': 'classes_to_dt_track_ids',
'classes_to_track_lengths': 'classes_to_dt_track_lengths',
'classes_to_track_areas': 'classes_to_dt_track_areas'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
raw_data['num_timesteps'] = num_timesteps
raw_data['neg_cat_ids'] = self.seq_to_classes[seq_id]['neg_cat_ids']
raw_data['not_exhaustively_labeled_cls'] = self.seq_to_classes[seq_id]['not_exhaustively_labeled_cat_ids']
raw_data['seq'] = seq
return raw_data
@_timing.time
def get_preprocessed_seq_data(self, raw_data, cls):
""" Preprocess data for a single sequence for a single class ready for evaluation.
Inputs:
- raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
- cls is the class to be evaluated.
Outputs:
- data is a dict containing all of the information that metrics need to perform evaluation.
It contains the following fields:
[num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
[gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
[similarity_scores]: list (for each timestep) of 2D NDArrays.
Notes:
General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
1) Extract only detections relevant for the class to be evaluated (including distractor detections).
2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
distractor class, or otherwise marked as to be removed.
3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
other criteria (e.g. are too small).
4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
After the above preprocessing steps, this function also calculates the number of gt and tracker detections
and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
unique within each timestep.
TAO:
In TAO, the 4 preproc steps are as follow:
1) All classes present in the ground truth data are evaluated separately.
2) No matched tracker detections are removed.
3) Unmatched tracker detections are removed if there is not ground truth data and the class does not
belong to the categories marked as negative for this sequence. Additionally, unmatched tracker
detections for classes which are marked as not exhaustively labeled are removed.
4) No gt detections are removed.
Further, for TrackMAP computation track representations for the given class are accessed from a dictionary
and the tracks from the tracker data are sorted according to the tracker confidence.
"""
cls_id = self.class_name_to_class_id[cls]
is_not_exhaustively_labeled = cls_id in raw_data['not_exhaustively_labeled_cls']
is_neg_category = cls_id in raw_data['neg_cat_ids']
data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences', 'similarity_scores']
data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
unique_gt_ids = []
unique_tracker_ids = []
num_gt_dets = 0
num_tracker_dets = 0
for t in range(raw_data['num_timesteps']):
# Only extract relevant dets for this class for preproc and eval (cls)
gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
gt_class_mask = gt_class_mask.astype(np.bool)
gt_ids = raw_data['gt_ids'][t][gt_class_mask]
gt_dets = raw_data['gt_dets'][t][gt_class_mask]
tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
tracker_class_mask = tracker_class_mask.astype(np.bool)
tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
tracker_dets = raw_data['tracker_dets'][t][tracker_class_mask]
tracker_confidences = raw_data['tracker_confidences'][t][tracker_class_mask]
similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
# Match tracker and gt dets (with hungarian algorithm).
unmatched_indices = np.arange(tracker_ids.shape[0])
if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
matching_scores = similarity_scores.copy()
matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
match_rows, match_cols = linear_sum_assignment(-matching_scores)
actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
match_cols = match_cols[actually_matched_mask]
unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
if gt_ids.shape[0] == 0 and not is_neg_category:
to_remove_tracker = unmatched_indices
elif is_not_exhaustively_labeled:
to_remove_tracker = unmatched_indices
else:
to_remove_tracker = np.array([], dtype=np.int)
# remove all unwanted unmatched tracker detections
data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
data['gt_ids'][t] = gt_ids
data['gt_dets'][t] = gt_dets
data['similarity_scores'][t] = similarity_scores
unique_gt_ids += list(np.unique(data['gt_ids'][t]))
unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
num_tracker_dets += len(data['tracker_ids'][t])
num_gt_dets += len(data['gt_ids'][t])
# Re-label IDs such that there are no empty IDs
if len(unique_gt_ids) > 0:
unique_gt_ids = np.unique(unique_gt_ids)
gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
for t in range(raw_data['num_timesteps']):
if len(data['gt_ids'][t]) > 0:
data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
if len(unique_tracker_ids) > 0:
unique_tracker_ids = np.unique(unique_tracker_ids)
tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
for t in range(raw_data['num_timesteps']):
if len(data['tracker_ids'][t]) > 0:
data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
# Record overview statistics.
data['num_tracker_dets'] = num_tracker_dets
data['num_gt_dets'] = num_gt_dets
data['num_tracker_ids'] = len(unique_tracker_ids)
data['num_gt_ids'] = len(unique_gt_ids)
data['num_timesteps'] = raw_data['num_timesteps']
data['seq'] = raw_data['seq']
# get track representations
data['gt_tracks'] = raw_data['classes_to_gt_tracks'][cls_id]
data['gt_track_ids'] = raw_data['classes_to_gt_track_ids'][cls_id]
data['gt_track_lengths'] = raw_data['classes_to_gt_track_lengths'][cls_id]
data['gt_track_areas'] = raw_data['classes_to_gt_track_areas'][cls_id]
data['dt_tracks'] = raw_data['classes_to_dt_tracks'][cls_id]
data['dt_track_ids'] = raw_data['classes_to_dt_track_ids'][cls_id]
data['dt_track_lengths'] = raw_data['classes_to_dt_track_lengths'][cls_id]
data['dt_track_areas'] = raw_data['classes_to_dt_track_areas'][cls_id]
data['dt_track_scores'] = raw_data['classes_to_dt_track_scores'][cls_id]
data['not_exhaustively_labeled'] = is_not_exhaustively_labeled
data['iou_type'] = 'bbox'
# sort tracker data tracks by tracker confidence scores
if data['dt_tracks']:
idx = np.argsort([-score for score in data['dt_track_scores']], kind="mergesort")
data['dt_track_scores'] = [data['dt_track_scores'][i] for i in idx]
data['dt_tracks'] = [data['dt_tracks'][i] for i in idx]
data['dt_track_ids'] = [data['dt_track_ids'][i] for i in idx]
data['dt_track_lengths'] = [data['dt_track_lengths'][i] for i in idx]
data['dt_track_areas'] = [data['dt_track_areas'][i] for i in idx]
# Ensure that ids are unique per timestep.
self._check_unique_ids(data)
return data
def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t)
return similarity_scores
def _merge_categories(self, annotations):
"""
Merges categories with a merged tag. Adapted from https://github.com/TAO-Dataset
:param annotations: the annotations in which the classes should be merged
:return: None
"""
merge_map = {}
for category in self.gt_data['categories']:
if 'merged' in category:
for to_merge in category['merged']:
merge_map[to_merge['id']] = category['id']
for ann in annotations:
ann['category_id'] = merge_map.get(ann['category_id'], ann['category_id'])
def _compute_vid_mappings(self, annotations):
"""
Computes mappings from Videos to corresponding tracks and images.
:param annotations: the annotations for which the mapping should be generated
:return: the video-to-track-mapping, the video-to-image-mapping
"""
vids_to_tracks = {}
vids_to_imgs = {}
vid_ids = [vid['id'] for vid in self.gt_data['videos']]
# compute an mapping from image IDs to images
images = {}
for image in self.gt_data['images']:
images[image['id']] = image
for ann in annotations:
ann["area"] = ann["bbox"][2] * ann["bbox"][3]
vid = ann["video_id"]
if ann["video_id"] not in vids_to_tracks.keys():
vids_to_tracks[ann["video_id"]] = list()
if ann["video_id"] not in vids_to_imgs.keys():
vids_to_imgs[ann["video_id"]] = list()
# Fill in vids_to_tracks
tid = ann["track_id"]
exist_tids = [track["id"] for track in vids_to_tracks[vid]]
try:
index1 = exist_tids.index(tid)
except ValueError:
index1 = -1
if tid not in exist_tids:
curr_track = {"id": tid, "category_id": ann['category_id'],
"video_id": vid, "annotations": [ann]}
vids_to_tracks[vid].append(curr_track)
else:
vids_to_tracks[vid][index1]["annotations"].append(ann)
# Fill in vids_to_imgs
img_id = ann['image_id']
exist_img_ids = [img["id"] for img in vids_to_imgs[vid]]
try:
index2 = exist_img_ids.index(img_id)
except ValueError:
index2 = -1
if index2 == -1:
curr_img = {"id": img_id, "annotations": [ann]}
vids_to_imgs[vid].append(curr_img)
else:
vids_to_imgs[vid][index2]["annotations"].append(ann)
# sort annotations by frame index and compute track area
for vid, tracks in vids_to_tracks.items():
for track in tracks:
track["annotations"] = sorted(
track['annotations'],
key=lambda x: images[x['image_id']]['frame_index'])
# Computer average area
track["area"] = (sum(x['area'] for x in track['annotations']) / len(track['annotations']))
# Ensure all videos are present
for vid_id in vid_ids:
if vid_id not in vids_to_tracks.keys():
vids_to_tracks[vid_id] = []
if vid_id not in vids_to_imgs.keys():
vids_to_imgs[vid_id] = []
return vids_to_tracks, vids_to_imgs
def _compute_image_to_timestep_mappings(self):
"""
Computes a mapping from images to the corresponding timestep in the sequence.
:return: the image-to-timestep-mapping
"""
images = {}
for image in self.gt_data['images']:
images[image['id']] = image
seq_to_imgs_to_timestep = {vid['id']: dict() for vid in self.gt_data['videos']}
for vid in seq_to_imgs_to_timestep:
curr_imgs = [img['id'] for img in self.videos_to_gt_images[vid]]
curr_imgs = sorted(curr_imgs, key=lambda x: images[x]['frame_index'])
seq_to_imgs_to_timestep[vid] = {curr_imgs[i]: i for i in range(len(curr_imgs))}
return seq_to_imgs_to_timestep
def _limit_dets_per_image(self, annotations):
"""
Limits the number of detections for each image to config['MAX_DETECTIONS']. Adapted from
https://github.com/TAO-Dataset/
:param annotations: the annotations in which the detections should be limited
:return: the annotations with limited detections
"""
max_dets = self.config['MAX_DETECTIONS']
img_ann = defaultdict(list)
for ann in annotations:
img_ann[ann["image_id"]].append(ann)
for img_id, _anns in img_ann.items():
if len(_anns) <= max_dets:
continue
_anns = sorted(_anns, key=lambda x: x["score"], reverse=True)
img_ann[img_id] = _anns[:max_dets]
return [ann for anns in img_ann.values() for ann in anns]
def _fill_video_ids_inplace(self, annotations):
"""
Fills in missing video IDs inplace. Adapted from https://github.com/TAO-Dataset/
:param annotations: the annotations for which the videos IDs should be filled inplace
:return: None
"""
missing_video_id = [x for x in annotations if 'video_id' not in x]
if missing_video_id:
image_id_to_video_id = {
x['id']: x['video_id'] for x in self.gt_data['images']
}
for x in missing_video_id:
x['video_id'] = image_id_to_video_id[x['image_id']]
@staticmethod
def _make_track_ids_unique(annotations):
"""
Makes the track IDs unqiue over the whole annotation set. Adapted from https://github.com/TAO-Dataset/
:param annotations: the annotation set
:return: the number of updated IDs
"""
track_id_videos = {}
track_ids_to_update = set()
max_track_id = 0
for ann in annotations:
t = ann['track_id']
if t not in track_id_videos:
track_id_videos[t] = ann['video_id']
if ann['video_id'] != track_id_videos[t]:
# Track id is assigned to multiple videos
track_ids_to_update.add(t)
max_track_id = max(max_track_id, t)
if track_ids_to_update:
print('true')
next_id = itertools.count(max_track_id + 1)
new_track_ids = defaultdict(lambda: next(next_id))
for ann in annotations:
t = ann['track_id']
v = ann['video_id']
if t in track_ids_to_update:
ann['track_id'] = new_track_ids[t, v]
return len(track_ids_to_update)
================================================
FILE: TrackEval/trackeval/datasets/tao_ow.py
================================================
import os
import numpy as np
import json
import itertools
from collections import defaultdict
from scipy.optimize import linear_sum_assignment
from ..utils import TrackEvalException
from ._base_dataset import _BaseDataset
from .. import utils
from .. import _timing
class TAO_OW(_BaseDataset):
"""Dataset class for TAO tracking"""
@staticmethod
def get_default_dataset_config():
"""Default class config values"""
code_path = utils.get_code_path()
default_config = {
'GT_FOLDER': os.path.join(code_path, 'data/gt/tao/tao_training'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/tao/tao_training'), # Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
'SPLIT_TO_EVAL': 'training', # Valid: 'training', 'val'
'PRINT_CONFIG': True, # Whether to print current config
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
'MAX_DETECTIONS': 300, # Number of maximal allowed detections per image (0 for unlimited)
'SUBSET': 'all'
}
return default_config
def __init__(self, config=None):
"""Initialise dataset, checking that all required files are present"""
super().__init__()
# Fill non-given config values with defaults
self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
self.gt_fol = self.config['GT_FOLDER']
self.tracker_fol = self.config['TRACKERS_FOLDER']
self.should_classes_combine = True
self.use_super_categories = False
self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
self.output_fol = self.config['OUTPUT_FOLDER']
if self.output_fol is None:
self.output_fol = self.tracker_fol
self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
gt_dir_files = [file for file in os.listdir(self.gt_fol) if file.endswith('.json')]
if len(gt_dir_files) != 1:
raise TrackEvalException(self.gt_fol + ' does not contain exactly one json file.')
with open(os.path.join(self.gt_fol, gt_dir_files[0])) as f:
self.gt_data = json.load(f)
self.subset = self.config['SUBSET']
if self.subset != 'all':
# Split GT data into `known`, `unknown` or `distractor`
self._split_known_unknown_distractor()
self.gt_data = self._filter_gt_data(self.gt_data)
# merge categories marked with a merged tag in TAO dataset
self._merge_categories(self.gt_data['annotations'] + self.gt_data['tracks'])
# Get sequences to eval and sequence information
self.seq_list = [vid['name'].replace('/', '-') for vid in self.gt_data['videos']]
self.seq_name_to_seq_id = {vid['name'].replace('/', '-'): vid['id'] for vid in self.gt_data['videos']}
# compute mappings from videos to annotation data
self.videos_to_gt_tracks, self.videos_to_gt_images = self._compute_vid_mappings(self.gt_data['annotations'])
# compute sequence lengths
self.seq_lengths = {vid['id']: 0 for vid in self.gt_data['videos']}
for img in self.gt_data['images']:
self.seq_lengths[img['video_id']] += 1
self.seq_to_images_to_timestep = self._compute_image_to_timestep_mappings()
self.seq_to_classes = {vid['id']: {'pos_cat_ids': list({track['category_id'] for track
in self.videos_to_gt_tracks[vid['id']]}),
'neg_cat_ids': vid['neg_category_ids'],
'not_exhaustively_labeled_cat_ids': vid['not_exhaustive_category_ids']}
for vid in self.gt_data['videos']}
# Get classes to eval
considered_vid_ids = [self.seq_name_to_seq_id[vid] for vid in self.seq_list]
seen_cats = set([cat_id for vid_id in considered_vid_ids for cat_id
in self.seq_to_classes[vid_id]['pos_cat_ids']])
# only classes with ground truth are evaluated in TAO
self.valid_classes = [cls['name'] for cls in self.gt_data['categories'] if cls['id'] in seen_cats]
# cls_name_to_cls_id_map = {cls['name']: cls['id'] for cls in self.gt_data['categories']}
if self.config['CLASSES_TO_EVAL']:
# self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
# for cls in self.config['CLASSES_TO_EVAL']]
self.class_list = ["object"] # class-agnostic
if not all(self.class_list):
raise TrackEvalException('Attempted to evaluate an invalid class. Only classes ' +
', '.join(self.valid_classes) +
' are valid (classes present in ground truth data).')
else:
# self.class_list = [cls for cls in self.valid_classes]
self.class_list = ["object"] # class-agnostic
# self.class_name_to_class_id = {k: v for k, v in cls_name_to_cls_id_map.items() if k in self.class_list}
self.class_name_to_class_id = {"object": 1} # class-agnostic
# Get trackers to eval
if self.config['TRACKERS_TO_EVAL'] is None:
self.tracker_list = os.listdir(self.tracker_fol)
else:
self.tracker_list = self.config['TRACKERS_TO_EVAL']
if self.config['TRACKER_DISPLAY_NAMES'] is None:
self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
else:
raise TrackEvalException('List of tracker files and tracker display names do not match.')
self.tracker_data = {tracker: dict() for tracker in self.tracker_list}
for tracker in self.tracker_list:
tr_dir_files = [file for file in os.listdir(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol))
if file.endswith('.json')]
if len(tr_dir_files) != 1:
raise TrackEvalException(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol)
+ ' does not contain exactly one json file.')
with open(os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol, tr_dir_files[0])) as f:
curr_data = json.load(f)
# limit detections if MAX_DETECTIONS > 0
if self.config['MAX_DETECTIONS']:
curr_data = self._limit_dets_per_image(curr_data)
# fill missing video ids
self._fill_video_ids_inplace(curr_data)
# make track ids unique over whole evaluation set
self._make_track_ids_unique(curr_data)
# merge categories marked with a merged tag in TAO dataset
self._merge_categories(curr_data)
# get tracker sequence information
curr_videos_to_tracker_tracks, curr_videos_to_tracker_images = self._compute_vid_mappings(curr_data)
self.tracker_data[tracker]['vids_to_tracks'] = curr_videos_to_tracker_tracks
self.tracker_data[tracker]['vids_to_images'] = curr_videos_to_tracker_images
def get_display_name(self, tracker):
return self.tracker_to_disp[tracker]
def _load_raw_file(self, tracker, seq, is_gt):
"""Load a file (gt or tracker) in the TAO format
If is_gt, this returns a dict which contains the fields:
[gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
[gt_dets]: list (for each timestep) of lists of detections.
[classes_to_gt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
keys and corresponding segmentations as values) for each track
[classes_to_gt_track_ids, classes_to_gt_track_areas, classes_to_gt_track_lengths]: dictionary with class values
as keys and lists (for each track) as values
if not is_gt, this returns a dict which contains the fields:
[tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
[tracker_dets]: list (for each timestep) of lists of detections.
[classes_to_dt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
keys and corresponding segmentations as values) for each track
[classes_to_dt_track_ids, classes_to_dt_track_areas, classes_to_dt_track_lengths]: dictionary with class values
as keys and lists as values
[classes_to_dt_track_scores]: dictionary with class values as keys and 1D numpy arrays as values
"""
seq_id = self.seq_name_to_seq_id[seq]
# File location
if is_gt:
imgs = self.videos_to_gt_images[seq_id]
else:
imgs = self.tracker_data[tracker]['vids_to_images'][seq_id]
# Convert data to required format
num_timesteps = self.seq_lengths[seq_id]
img_to_timestep = self.seq_to_images_to_timestep[seq_id]
data_keys = ['ids', 'classes', 'dets']
if not is_gt:
data_keys += ['tracker_confidences']
raw_data = {key: [None] * num_timesteps for key in data_keys}
for img in imgs:
# some tracker data contains images without any ground truth information, these are ignored
try:
t = img_to_timestep[img['id']]
except KeyError:
continue
annotations = img['annotations']
raw_data['dets'][t] = np.atleast_2d([ann['bbox'] for ann in annotations]).astype(float)
raw_data['ids'][t] = np.atleast_1d([ann['track_id'] for ann in annotations]).astype(int)
raw_data['classes'][t] = np.atleast_1d([1 for _ in annotations]).astype(int) # class-agnostic
if not is_gt:
raw_data['tracker_confidences'][t] = np.atleast_1d([ann['score'] for ann in annotations]).astype(float)
for t, d in enumerate(raw_data['dets']):
if d is None:
raw_data['dets'][t] = np.empty((0, 4)).astype(float)
raw_data['ids'][t] = np.empty(0).astype(int)
raw_data['classes'][t] = np.empty(0).astype(int)
if not is_gt:
raw_data['tracker_confidences'][t] = np.empty(0)
if is_gt:
key_map = {'ids': 'gt_ids',
'classes': 'gt_classes',
'dets': 'gt_dets'}
else:
key_map = {'ids': 'tracker_ids',
'classes': 'tracker_classes',
'dets': 'tracker_dets'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
# all_classes = [self.class_name_to_class_id[cls] for cls in self.class_list]
all_classes = [1] # class-agnostic
if is_gt:
classes_to_consider = all_classes
all_tracks = self.videos_to_gt_tracks[seq_id]
else:
# classes_to_consider = self.seq_to_classes[seq_id]['pos_cat_ids'] \
# + self.seq_to_classes[seq_id]['neg_cat_ids']
classes_to_consider = all_classes # class-agnostic
all_tracks = self.tracker_data[tracker]['vids_to_tracks'][seq_id]
# classes_to_tracks = {cls: [track for track in all_tracks if track['category_id'] == cls]
# if cls in classes_to_consider else [] for cls in all_classes}
classes_to_tracks = {cls: [track for track in all_tracks]
if cls in classes_to_consider else [] for cls in all_classes} # class-agnostic
# mapping from classes to track information
raw_data['classes_to_tracks'] = {cls: [{det['image_id']: np.atleast_1d(det['bbox'])
for det in track['annotations']} for track in tracks]
for cls, tracks in classes_to_tracks.items()}
raw_data['classes_to_track_ids'] = {cls: [track['id'] for track in tracks]
for cls, tracks in classes_to_tracks.items()}
raw_data['classes_to_track_areas'] = {cls: [track['area'] for track in tracks]
for cls, tracks in classes_to_tracks.items()}
raw_data['classes_to_track_lengths'] = {cls: [len(track['annotations']) for track in tracks]
for cls, tracks in classes_to_tracks.items()}
if not is_gt:
raw_data['classes_to_dt_track_scores'] = {cls: np.array([np.mean([float(x['score'])
for x in track['annotations']])
for track in tracks])
for cls, tracks in classes_to_tracks.items()}
if is_gt:
key_map = {'classes_to_tracks': 'classes_to_gt_tracks',
'classes_to_track_ids': 'classes_to_gt_track_ids',
'classes_to_track_lengths': 'classes_to_gt_track_lengths',
'classes_to_track_areas': 'classes_to_gt_track_areas'}
else:
key_map = {'classes_to_tracks': 'classes_to_dt_tracks',
'classes_to_track_ids': 'classes_to_dt_track_ids',
'classes_to_track_lengths': 'classes_to_dt_track_lengths',
'classes_to_track_areas': 'classes_to_dt_track_areas'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
raw_data['num_timesteps'] = num_timesteps
raw_data['neg_cat_ids'] = self.seq_to_classes[seq_id]['neg_cat_ids']
raw_data['not_exhaustively_labeled_cls'] = self.seq_to_classes[seq_id]['not_exhaustively_labeled_cat_ids']
raw_data['seq'] = seq
return raw_data
@_timing.time
def get_preprocessed_seq_data(self, raw_data, cls):
""" Preprocess data for a single sequence for a single class ready for evaluation.
Inputs:
- raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
- cls is the class to be evaluated.
Outputs:
- data is a dict containing all of the information that metrics need to perform evaluation.
It contains the following fields:
[num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
[gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
[similarity_scores]: list (for each timestep) of 2D NDArrays.
Notes:
General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
1) Extract only detections relevant for the class to be evaluated (including distractor detections).
2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
distractor class, or otherwise marked as to be removed.
3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
other criteria (e.g. are too small).
4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
After the above preprocessing steps, this function also calculates the number of gt and tracker detections
and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
unique within each timestep.
TAO:
In TAO, the 4 preproc steps are as follow:
1) All classes present in the ground truth data are evaluated separately.
2) No matched tracker detections are removed.
3) Unmatched tracker detections are removed if there is not ground truth data and the class does not
belong to the categories marked as negative for this sequence. Additionally, unmatched tracker
detections for classes which are marked as not exhaustively labeled are removed.
4) No gt detections are removed.
Further, for TrackMAP computation track representations for the given class are accessed from a dictionary
and the tracks from the tracker data are sorted according to the tracker confidence.
"""
cls_id = self.class_name_to_class_id[cls]
is_not_exhaustively_labeled = cls_id in raw_data['not_exhaustively_labeled_cls']
is_neg_category = cls_id in raw_data['neg_cat_ids']
data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'tracker_confidences', 'similarity_scores']
data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
unique_gt_ids = []
unique_tracker_ids = []
num_gt_dets = 0
num_tracker_dets = 0
for t in range(raw_data['num_timesteps']):
# Only extract relevant dets for this class for preproc and eval (cls)
gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
gt_class_mask = gt_class_mask.astype(np.bool)
gt_ids = raw_data['gt_ids'][t][gt_class_mask]
gt_dets = raw_data['gt_dets'][t][gt_class_mask]
tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
tracker_class_mask = tracker_class_mask.astype(np.bool)
tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
tracker_dets = raw_data['tracker_dets'][t][tracker_class_mask]
tracker_confidences = raw_data['tracker_confidences'][t][tracker_class_mask]
similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
# Match tracker and gt dets (with hungarian algorithm).
unmatched_indices = np.arange(tracker_ids.shape[0])
if gt_ids.shape[0] > 0 and tracker_ids.shape[0] > 0:
matching_scores = similarity_scores.copy()
matching_scores[matching_scores < 0.5 - np.finfo('float').eps] = 0
match_rows, match_cols = linear_sum_assignment(-matching_scores)
actually_matched_mask = matching_scores[match_rows, match_cols] > 0 + np.finfo('float').eps
match_cols = match_cols[actually_matched_mask]
unmatched_indices = np.delete(unmatched_indices, match_cols, axis=0)
if gt_ids.shape[0] == 0 and not is_neg_category:
to_remove_tracker = unmatched_indices
elif is_not_exhaustively_labeled:
to_remove_tracker = unmatched_indices
else:
to_remove_tracker = np.array([], dtype=np.int)
# remove all unwanted unmatched tracker detections
data['tracker_ids'][t] = np.delete(tracker_ids, to_remove_tracker, axis=0)
data['tracker_dets'][t] = np.delete(tracker_dets, to_remove_tracker, axis=0)
data['tracker_confidences'][t] = np.delete(tracker_confidences, to_remove_tracker, axis=0)
similarity_scores = np.delete(similarity_scores, to_remove_tracker, axis=1)
data['gt_ids'][t] = gt_ids
data['gt_dets'][t] = gt_dets
data['similarity_scores'][t] = similarity_scores
unique_gt_ids += list(np.unique(data['gt_ids'][t]))
unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
num_tracker_dets += len(data['tracker_ids'][t])
num_gt_dets += len(data['gt_ids'][t])
# Re-label IDs such that there are no empty IDs
if len(unique_gt_ids) > 0:
unique_gt_ids = np.unique(unique_gt_ids)
gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
for t in range(raw_data['num_timesteps']):
if len(data['gt_ids'][t]) > 0:
data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
if len(unique_tracker_ids) > 0:
unique_tracker_ids = np.unique(unique_tracker_ids)
tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
for t in range(raw_data['num_timesteps']):
if len(data['tracker_ids'][t]) > 0:
data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
# Record overview statistics.
data['num_tracker_dets'] = num_tracker_dets
data['num_gt_dets'] = num_gt_dets
data['num_tracker_ids'] = len(unique_tracker_ids)
data['num_gt_ids'] = len(unique_gt_ids)
data['num_timesteps'] = raw_data['num_timesteps']
data['seq'] = raw_data['seq']
# get track representations
data['gt_tracks'] = raw_data['classes_to_gt_tracks'][cls_id]
data['gt_track_ids'] = raw_data['classes_to_gt_track_ids'][cls_id]
data['gt_track_lengths'] = raw_data['classes_to_gt_track_lengths'][cls_id]
data['gt_track_areas'] = raw_data['classes_to_gt_track_areas'][cls_id]
data['dt_tracks'] = raw_data['classes_to_dt_tracks'][cls_id]
data['dt_track_ids'] = raw_data['classes_to_dt_track_ids'][cls_id]
data['dt_track_lengths'] = raw_data['classes_to_dt_track_lengths'][cls_id]
data['dt_track_areas'] = raw_data['classes_to_dt_track_areas'][cls_id]
data['dt_track_scores'] = raw_data['classes_to_dt_track_scores'][cls_id]
data['not_exhaustively_labeled'] = is_not_exhaustively_labeled
data['iou_type'] = 'bbox'
# sort tracker data tracks by tracker confidence scores
if data['dt_tracks']:
idx = np.argsort([-score for score in data['dt_track_scores']], kind="mergesort")
data['dt_track_scores'] = [data['dt_track_scores'][i] for i in idx]
data['dt_tracks'] = [data['dt_tracks'][i] for i in idx]
data['dt_track_ids'] = [data['dt_track_ids'][i] for i in idx]
data['dt_track_lengths'] = [data['dt_track_lengths'][i] for i in idx]
data['dt_track_areas'] = [data['dt_track_areas'][i] for i in idx]
# Ensure that ids are unique per timestep.
self._check_unique_ids(data)
return data
def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
similarity_scores = self._calculate_box_ious(gt_dets_t, tracker_dets_t)
return similarity_scores
def _merge_categories(self, annotations):
"""
Merges categories with a merged tag. Adapted from https://github.com/TAO-Dataset
:param annotations: the annotations in which the classes should be merged
:return: None
"""
merge_map = {}
for category in self.gt_data['categories']:
if 'merged' in category:
for to_merge in category['merged']:
merge_map[to_merge['id']] = category['id']
for ann in annotations:
ann['category_id'] = merge_map.get(ann['category_id'], ann['category_id'])
def _compute_vid_mappings(self, annotations):
"""
Computes mappings from Videos to corresponding tracks and images.
:param annotations: the annotations for which the mapping should be generated
:return: the video-to-track-mapping, the video-to-image-mapping
"""
vids_to_tracks = {}
vids_to_imgs = {}
vid_ids = [vid['id'] for vid in self.gt_data['videos']]
# compute an mapping from image IDs to images
images = {}
for image in self.gt_data['images']:
images[image['id']] = image
for ann in annotations:
ann["area"] = ann["bbox"][2] * ann["bbox"][3]
vid = ann["video_id"]
if ann["video_id"] not in vids_to_tracks.keys():
vids_to_tracks[ann["video_id"]] = list()
if ann["video_id"] not in vids_to_imgs.keys():
vids_to_imgs[ann["video_id"]] = list()
# Fill in vids_to_tracks
tid = ann["track_id"]
exist_tids = [track["id"] for track in vids_to_tracks[vid]]
try:
index1 = exist_tids.index(tid)
except ValueError:
index1 = -1
if tid not in exist_tids:
curr_track = {"id": tid, "category_id": ann['category_id'],
"video_id": vid, "annotations": [ann]}
vids_to_tracks[vid].append(curr_track)
else:
vids_to_tracks[vid][index1]["annotations"].append(ann)
# Fill in vids_to_imgs
img_id = ann['image_id']
exist_img_ids = [img["id"] for img in vids_to_imgs[vid]]
try:
index2 = exist_img_ids.index(img_id)
except ValueError:
index2 = -1
if index2 == -1:
curr_img = {"id": img_id, "annotations": [ann]}
vids_to_imgs[vid].append(curr_img)
else:
vids_to_imgs[vid][index2]["annotations"].append(ann)
# sort annotations by frame index and compute track area
for vid, tracks in vids_to_tracks.items():
for track in tracks:
track["annotations"] = sorted(
track['annotations'],
key=lambda x: images[x['image_id']]['frame_index'])
# Computer average area
track["area"] = (sum(x['area'] for x in track['annotations']) / len(track['annotations']))
# Ensure all videos are present
for vid_id in vid_ids:
if vid_id not in vids_to_tracks.keys():
vids_to_tracks[vid_id] = []
if vid_id not in vids_to_imgs.keys():
vids_to_imgs[vid_id] = []
return vids_to_tracks, vids_to_imgs
def _compute_image_to_timestep_mappings(self):
"""
Computes a mapping from images to the corresponding timestep in the sequence.
:return: the image-to-timestep-mapping
"""
images = {}
for image in self.gt_data['images']:
images[image['id']] = image
seq_to_imgs_to_timestep = {vid['id']: dict() for vid in self.gt_data['videos']}
for vid in seq_to_imgs_to_timestep:
curr_imgs = [img['id'] for img in self.videos_to_gt_images[vid]]
curr_imgs = sorted(curr_imgs, key=lambda x: images[x]['frame_index'])
seq_to_imgs_to_timestep[vid] = {curr_imgs[i]: i for i in range(len(curr_imgs))}
return seq_to_imgs_to_timestep
def _limit_dets_per_image(self, annotations):
"""
Limits the number of detections for each image to config['MAX_DETECTIONS']. Adapted from
https://github.com/TAO-Dataset/
:param annotations: the annotations in which the detections should be limited
:return: the annotations with limited detections
"""
max_dets = self.config['MAX_DETECTIONS']
img_ann = defaultdict(list)
for ann in annotations:
img_ann[ann["image_id"]].append(ann)
for img_id, _anns in img_ann.items():
if len(_anns) <= max_dets:
continue
_anns = sorted(_anns, key=lambda x: x["score"], reverse=True)
img_ann[img_id] = _anns[:max_dets]
return [ann for anns in img_ann.values() for ann in anns]
def _fill_video_ids_inplace(self, annotations):
"""
Fills in missing video IDs inplace. Adapted from https://github.com/TAO-Dataset/
:param annotations: the annotations for which the videos IDs should be filled inplace
:return: None
"""
missing_video_id = [x for x in annotations if 'video_id' not in x]
if missing_video_id:
image_id_to_video_id = {
x['id']: x['video_id'] for x in self.gt_data['images']
}
for x in missing_video_id:
x['video_id'] = image_id_to_video_id[x['image_id']]
@staticmethod
def _make_track_ids_unique(annotations):
"""
Makes the track IDs unqiue over the whole annotation set. Adapted from https://github.com/TAO-Dataset/
:param annotations: the annotation set
:return: the number of updated IDs
"""
track_id_videos = {}
track_ids_to_update = set()
max_track_id = 0
for ann in annotations:
t = ann['track_id']
if t not in track_id_videos:
track_id_videos[t] = ann['video_id']
if ann['video_id'] != track_id_videos[t]:
# Track id is assigned to multiple videos
track_ids_to_update.add(t)
max_track_id = max(max_track_id, t)
if track_ids_to_update:
print('true')
next_id = itertools.count(max_track_id + 1)
new_track_ids = defaultdict(lambda: next(next_id))
for ann in annotations:
t = ann['track_id']
v = ann['video_id']
if t in track_ids_to_update:
ann['track_id'] = new_track_ids[t, v]
return len(track_ids_to_update)
def _split_known_unknown_distractor(self):
all_ids = set([i for i in range(1, 2000)]) # 2000 is larger than the max category id in TAO-OW.
# `knowns` includes 78 TAO_category_ids that corresponds to 78 COCO classes.
# (The other 2 COCO classes do not have corresponding classes in TAO).
self.knowns = {4, 13, 1038, 544, 1057, 34, 35, 36, 41, 45, 58, 60, 579, 1091, 1097, 1099, 78, 79, 81, 91, 1115,
1117, 95, 1122, 99, 1132, 621, 1135, 625, 118, 1144, 126, 642, 1155, 133, 1162, 139, 154, 174, 185,
699, 1215, 714, 717, 1229, 211, 729, 221, 229, 747, 235, 237, 779, 276, 805, 299, 829, 852, 347,
371, 382, 896, 392, 926, 937, 428, 429, 961, 452, 979, 980, 982, 475, 480, 993, 1001, 502, 1018}
# `distractors` is defined as in the paper "Opening up Open-World Tracking"
self.distractors = {20, 63, 108, 180, 188, 204, 212, 247, 303, 403, 407, 415, 490, 504, 507, 513, 529, 567,
569, 588, 672, 691, 702, 708, 711, 720, 736, 737, 798, 813, 815, 827, 831, 851, 877, 883,
912, 971, 976, 1130, 1133, 1134, 1169, 1184, 1220}
self.unknowns = all_ids.difference(self.knowns.union(self.distractors))
def _filter_gt_data(self, raw_gt_data):
"""
Filter out irrelevant data in the raw_gt_data
Args:
raw_gt_data: directly loaded from json.
Returns:
filtered gt_data
"""
valid_cat_ids = list()
if self.subset == "known":
valid_cat_ids = self.knowns
elif self.subset == "distractor":
valid_cat_ids = self.distractors
elif self.subset == "unknown":
valid_cat_ids = self.unknowns
# elif self.subset == "test_only_unknowns":
# valid_cat_ids = test_only_unknowns
else:
raise Exception("The parameter `SUBSET` is incorrect")
filtered = dict()
filtered["videos"] = raw_gt_data["videos"]
# filtered["videos"] = list()
unwanted_vid = set()
# for video in raw_gt_data["videos"]:
# datasrc = video["name"].split('/')[1]
# if datasrc in data_srcs:
# filtered["videos"].append(video)
# else:
# unwanted_vid.add(video["id"])
filtered["annotations"] = list()
for ann in raw_gt_data["annotations"]:
if (ann["video_id"] not in unwanted_vid) and (ann["category_id"] in valid_cat_ids):
filtered["annotations"].append(ann)
filtered["tracks"] = list()
for track in raw_gt_data["tracks"]:
if (track["video_id"] not in unwanted_vid) and (track["category_id"] in valid_cat_ids):
filtered["tracks"].append(track)
filtered["images"] = list()
for image in raw_gt_data["images"]:
if image["video_id"] not in unwanted_vid:
filtered["images"].append(image)
filtered["categories"] = list()
for cat in raw_gt_data["categories"]:
if cat["id"] in valid_cat_ids:
filtered["categories"].append(cat)
filtered["info"] = raw_gt_data["info"]
filtered["licenses"] = raw_gt_data["licenses"]
return filtered
================================================
FILE: TrackEval/trackeval/datasets/youtube_vis.py
================================================
import os
import numpy as np
import json
from ._base_dataset import _BaseDataset
from ..utils import TrackEvalException
from .. import utils
from .. import _timing
class YouTubeVIS(_BaseDataset):
"""Dataset class for YouTubeVIS tracking"""
@staticmethod
def get_default_dataset_config():
"""Default class config values"""
code_path = utils.get_code_path()
default_config = {
'GT_FOLDER': os.path.join(code_path, 'data/gt/youtube_vis/'), # Location of GT data
'TRACKERS_FOLDER': os.path.join(code_path, 'data/trackers/youtube_vis/'),
# Trackers location
'OUTPUT_FOLDER': None, # Where to save eval results (if None, same as TRACKERS_FOLDER)
'TRACKERS_TO_EVAL': None, # Filenames of trackers to eval (if None, all in folder)
'CLASSES_TO_EVAL': None, # Classes to eval (if None, all classes)
'SPLIT_TO_EVAL': 'train_sub_split', # Valid: 'train', 'val', 'train_sub_split'
'PRINT_CONFIG': True, # Whether to print current config
'OUTPUT_SUB_FOLDER': '', # Output files are saved in OUTPUT_FOLDER/tracker_name/OUTPUT_SUB_FOLDER
'TRACKER_SUB_FOLDER': 'data', # Tracker files are in TRACKER_FOLDER/tracker_name/TRACKER_SUB_FOLDER
'TRACKER_DISPLAY_NAMES': None, # Names of trackers to display, if None: TRACKERS_TO_EVAL
}
return default_config
def __init__(self, config=None):
"""Initialise dataset, checking that all required files are present"""
super().__init__()
# Fill non-given config values with defaults
self.config = utils.init_config(config, self.get_default_dataset_config(), self.get_name())
self.gt_fol = self.config['GT_FOLDER'] + 'youtube_vis_' + self.config['SPLIT_TO_EVAL']
self.tracker_fol = self.config['TRACKERS_FOLDER'] + 'youtube_vis_' + self.config['SPLIT_TO_EVAL']
self.use_super_categories = False
self.should_classes_combine = True
self.output_fol = self.config['OUTPUT_FOLDER']
if self.output_fol is None:
self.output_fol = self.tracker_fol
self.output_sub_fol = self.config['OUTPUT_SUB_FOLDER']
self.tracker_sub_fol = self.config['TRACKER_SUB_FOLDER']
if not os.path.exists(self.gt_fol):
print("GT folder not found: " + self.gt_fol)
raise TrackEvalException("GT folder not found: " + os.path.basename(self.gt_fol))
gt_dir_files = [file for file in os.listdir(self.gt_fol) if file.endswith('.json')]
if len(gt_dir_files) != 1:
raise TrackEvalException(self.gt_fol + ' does not contain exactly one json file.')
with open(os.path.join(self.gt_fol, gt_dir_files[0])) as f:
self.gt_data = json.load(f)
# Get classes to eval
self.valid_classes = [cls['name'] for cls in self.gt_data['categories']]
cls_name_to_cls_id_map = {cls['name']: cls['id'] for cls in self.gt_data['categories']}
if self.config['CLASSES_TO_EVAL']:
self.class_list = [cls.lower() if cls.lower() in self.valid_classes else None
for cls in self.config['CLASSES_TO_EVAL']]
if not all(self.class_list):
raise TrackEvalException('Attempted to evaluate an invalid class. Only classes ' +
', '.join(self.valid_classes) + ' are valid.')
else:
self.class_list = [cls['name'] for cls in self.gt_data['categories']]
self.class_name_to_class_id = {k: v for k, v in cls_name_to_cls_id_map.items() if k in self.class_list}
# Get sequences to eval and check gt files exist
self.seq_list = [vid['file_names'][0].split('/')[0] for vid in self.gt_data['videos']]
self.seq_name_to_seq_id = {vid['file_names'][0].split('/')[0]: vid['id'] for vid in self.gt_data['videos']}
self.seq_lengths = {vid['id']: len(vid['file_names']) for vid in self.gt_data['videos']}
# encode masks and compute track areas
self._prepare_gt_annotations()
# Get trackers to eval
if self.config['TRACKERS_TO_EVAL'] is None:
self.tracker_list = os.listdir(self.tracker_fol)
else:
self.tracker_list = self.config['TRACKERS_TO_EVAL']
if self.config['TRACKER_DISPLAY_NAMES'] is None:
self.tracker_to_disp = dict(zip(self.tracker_list, self.tracker_list))
elif (self.config['TRACKERS_TO_EVAL'] is not None) and (
len(self.config['TRACKER_DISPLAY_NAMES']) == len(self.tracker_list)):
self.tracker_to_disp = dict(zip(self.tracker_list, self.config['TRACKER_DISPLAY_NAMES']))
else:
raise TrackEvalException('List of tracker files and tracker display names do not match.')
# counter for globally unique track IDs
self.global_tid_counter = 0
self.tracker_data = dict()
for tracker in self.tracker_list:
tracker_dir_path = os.path.join(self.tracker_fol, tracker, self.tracker_sub_fol)
tr_dir_files = [file for file in os.listdir(tracker_dir_path) if file.endswith('.json')]
if len(tr_dir_files) != 1:
raise TrackEvalException(tracker_dir_path + ' does not contain exactly one json file.')
with open(os.path.join(tracker_dir_path, tr_dir_files[0])) as f:
curr_data = json.load(f)
self.tracker_data[tracker] = curr_data
def get_display_name(self, tracker):
return self.tracker_to_disp[tracker]
def _load_raw_file(self, tracker, seq, is_gt):
"""Load a file (gt or tracker) in the YouTubeVIS format
If is_gt, this returns a dict which contains the fields:
[gt_ids, gt_classes] : list (for each timestep) of 1D NDArrays (for each det).
[gt_dets]: list (for each timestep) of lists of detections.
[classes_to_gt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
keys and corresponding segmentations as values) for each track
[classes_to_gt_track_ids, classes_to_gt_track_areas, classes_to_gt_track_iscrowd]: dictionary with class values
as keys and lists (for each track) as values
if not is_gt, this returns a dict which contains the fields:
[tracker_ids, tracker_classes, tracker_confidences] : list (for each timestep) of 1D NDArrays (for each det).
[tracker_dets]: list (for each timestep) of lists of detections.
[classes_to_dt_tracks]: dictionary with class values as keys and list of dictionaries (with frame indices as
keys and corresponding segmentations as values) for each track
[classes_to_dt_track_ids, classes_to_dt_track_areas]: dictionary with class values as keys and lists as values
[classes_to_dt_track_scores]: dictionary with class values as keys and 1D numpy arrays as values
"""
# select sequence tracks
seq_id = self.seq_name_to_seq_id[seq]
if is_gt:
tracks = [ann for ann in self.gt_data['annotations'] if ann['video_id'] == seq_id]
else:
tracks = self._get_tracker_seq_tracks(tracker, seq_id)
# Convert data to required format
num_timesteps = self.seq_lengths[seq_id]
data_keys = ['ids', 'classes', 'dets']
if not is_gt:
data_keys += ['tracker_confidences']
raw_data = {key: [None] * num_timesteps for key in data_keys}
for t in range(num_timesteps):
raw_data['dets'][t] = [track['segmentations'][t] for track in tracks if track['segmentations'][t]]
raw_data['ids'][t] = np.atleast_1d([track['id'] for track in tracks
if track['segmentations'][t]]).astype(int)
raw_data['classes'][t] = np.atleast_1d([track['category_id'] for track in tracks
if track['segmentations'][t]]).astype(int)
if not is_gt:
raw_data['tracker_confidences'][t] = np.atleast_1d([track['score'] for track in tracks
if track['segmentations'][t]]).astype(float)
if is_gt:
key_map = {'ids': 'gt_ids',
'classes': 'gt_classes',
'dets': 'gt_dets'}
else:
key_map = {'ids': 'tracker_ids',
'classes': 'tracker_classes',
'dets': 'tracker_dets'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
all_cls_ids = {self.class_name_to_class_id[cls] for cls in self.class_list}
classes_to_tracks = {cls: [track for track in tracks if track['category_id'] == cls] for cls in all_cls_ids}
# mapping from classes to track representations and track information
raw_data['classes_to_tracks'] = {cls: [{i: track['segmentations'][i]
for i in range(len(track['segmentations']))} for track in tracks]
for cls, tracks in classes_to_tracks.items()}
raw_data['classes_to_track_ids'] = {cls: [track['id'] for track in tracks]
for cls, tracks in classes_to_tracks.items()}
raw_data['classes_to_track_areas'] = {cls: [track['area'] for track in tracks]
for cls, tracks in classes_to_tracks.items()}
if is_gt:
raw_data['classes_to_gt_track_iscrowd'] = {cls: [track['iscrowd'] for track in tracks]
for cls, tracks in classes_to_tracks.items()}
else:
raw_data['classes_to_dt_track_scores'] = {cls: np.array([track['score'] for track in tracks])
for cls, tracks in classes_to_tracks.items()}
if is_gt:
key_map = {'classes_to_tracks': 'classes_to_gt_tracks',
'classes_to_track_ids': 'classes_to_gt_track_ids',
'classes_to_track_areas': 'classes_to_gt_track_areas'}
else:
key_map = {'classes_to_tracks': 'classes_to_dt_tracks',
'classes_to_track_ids': 'classes_to_dt_track_ids',
'classes_to_track_areas': 'classes_to_dt_track_areas'}
for k, v in key_map.items():
raw_data[v] = raw_data.pop(k)
raw_data['num_timesteps'] = num_timesteps
raw_data['seq'] = seq
return raw_data
@_timing.time
def get_preprocessed_seq_data(self, raw_data, cls):
""" Preprocess data for a single sequence for a single class ready for evaluation.
Inputs:
- raw_data is a dict containing the data for the sequence already read in by get_raw_seq_data().
- cls is the class to be evaluated.
Outputs:
- data is a dict containing all of the information that metrics need to perform evaluation.
It contains the following fields:
[num_timesteps, num_gt_ids, num_tracker_ids, num_gt_dets, num_tracker_dets] : integers.
[gt_ids, tracker_ids, tracker_confidences]: list (for each timestep) of 1D NDArrays (for each det).
[gt_dets, tracker_dets]: list (for each timestep) of lists of detections.
[similarity_scores]: list (for each timestep) of 2D NDArrays.
Notes:
General preprocessing (preproc) occurs in 4 steps. Some datasets may not use all of these steps.
1) Extract only detections relevant for the class to be evaluated (including distractor detections).
2) Match gt dets and tracker dets. Remove tracker dets that are matched to a gt det that is of a
distractor class, or otherwise marked as to be removed.
3) Remove unmatched tracker dets if they fall within a crowd ignore region or don't meet a certain
other criteria (e.g. are too small).
4) Remove gt dets that were only useful for preprocessing and not for actual evaluation.
After the above preprocessing steps, this function also calculates the number of gt and tracker detections
and unique track ids. It also relabels gt and tracker ids to be contiguous and checks that ids are
unique within each timestep.
YouTubeVIS:
In YouTubeVIS, the 4 preproc steps are as follow:
1) There are 40 classes which are evaluated separately.
2) No matched tracker dets are removed.
3) No unmatched tracker dets are removed.
4) No gt dets are removed.
Further, for TrackMAP computation track representations for the given class are accessed from a dictionary
and the tracks from the tracker data are sorted according to the tracker confidence.
"""
cls_id = self.class_name_to_class_id[cls]
data_keys = ['gt_ids', 'tracker_ids', 'gt_dets', 'tracker_dets', 'similarity_scores']
data = {key: [None] * raw_data['num_timesteps'] for key in data_keys}
unique_gt_ids = []
unique_tracker_ids = []
num_gt_dets = 0
num_tracker_dets = 0
for t in range(raw_data['num_timesteps']):
# Only extract relevant dets for this class for eval (cls)
gt_class_mask = np.atleast_1d(raw_data['gt_classes'][t] == cls_id)
gt_class_mask = gt_class_mask.astype(np.bool)
gt_ids = raw_data['gt_ids'][t][gt_class_mask]
gt_dets = [raw_data['gt_dets'][t][ind] for ind in range(len(gt_class_mask)) if gt_class_mask[ind]]
tracker_class_mask = np.atleast_1d(raw_data['tracker_classes'][t] == cls_id)
tracker_class_mask = tracker_class_mask.astype(np.bool)
tracker_ids = raw_data['tracker_ids'][t][tracker_class_mask]
tracker_dets = [raw_data['tracker_dets'][t][ind] for ind in range(len(tracker_class_mask)) if
tracker_class_mask[ind]]
similarity_scores = raw_data['similarity_scores'][t][gt_class_mask, :][:, tracker_class_mask]
data['tracker_ids'][t] = tracker_ids
data['tracker_dets'][t] = tracker_dets
data['gt_ids'][t] = gt_ids
data['gt_dets'][t] = gt_dets
data['similarity_scores'][t] = similarity_scores
unique_gt_ids += list(np.unique(data['gt_ids'][t]))
unique_tracker_ids += list(np.unique(data['tracker_ids'][t]))
num_tracker_dets += len(data['tracker_ids'][t])
num_gt_dets += len(data['gt_ids'][t])
# Re-label IDs such that there are no empty IDs
if len(unique_gt_ids) > 0:
unique_gt_ids = np.unique(unique_gt_ids)
gt_id_map = np.nan * np.ones((np.max(unique_gt_ids) + 1))
gt_id_map[unique_gt_ids] = np.arange(len(unique_gt_ids))
for t in range(raw_data['num_timesteps']):
if len(data['gt_ids'][t]) > 0:
data['gt_ids'][t] = gt_id_map[data['gt_ids'][t]].astype(np.int)
if len(unique_tracker_ids) > 0:
unique_tracker_ids = np.unique(unique_tracker_ids)
tracker_id_map = np.nan * np.ones((np.max(unique_tracker_ids) + 1))
tracker_id_map[unique_tracker_ids] = np.arange(len(unique_tracker_ids))
for t in range(raw_data['num_timesteps']):
if len(data['tracker_ids'][t]) > 0:
data['tracker_ids'][t] = tracker_id_map[data['tracker_ids'][t]].astype(np.int)
# Ensure that ids are unique per timestep.
self._check_unique_ids(data)
# Record overview statistics.
data['num_tracker_dets'] = num_tracker_dets
data['num_gt_dets'] = num_gt_dets
data['num_tracker_ids'] = len(unique_tracker_ids)
data['num_gt_ids'] = len(unique_gt_ids)
data['num_timesteps'] = raw_data['num_timesteps']
data['seq'] = raw_data['seq']
# get track representations
data['gt_tracks'] = raw_data['classes_to_gt_tracks'][cls_id]
data['gt_track_ids'] = raw_data['classes_to_gt_track_ids'][cls_id]
data['gt_track_areas'] = raw_data['classes_to_gt_track_areas'][cls_id]
data['gt_track_iscrowd'] = raw_data['classes_to_gt_track_iscrowd'][cls_id]
data['dt_tracks'] = raw_data['classes_to_dt_tracks'][cls_id]
data['dt_track_ids'] = raw_data['classes_to_dt_track_ids'][cls_id]
data['dt_track_areas'] = raw_data['classes_to_dt_track_areas'][cls_id]
data['dt_track_scores'] = raw_data['classes_to_dt_track_scores'][cls_id]
data['iou_type'] = 'mask'
# sort tracker data tracks by tracker confidence scores
if data['dt_tracks']:
idx = np.argsort([-score for score in data['dt_track_scores']], kind="mergesort")
data['dt_track_scores'] = [data['dt_track_scores'][i] for i in idx]
data['dt_tracks'] = [data['dt_tracks'][i] for i in idx]
data['dt_track_ids'] = [data['dt_track_ids'][i] for i in idx]
data['dt_track_areas'] = [data['dt_track_areas'][i] for i in idx]
return data
def _calculate_similarities(self, gt_dets_t, tracker_dets_t):
similarity_scores = self._calculate_mask_ious(gt_dets_t, tracker_dets_t, is_encoded=True, do_ioa=False)
return similarity_scores
def _prepare_gt_annotations(self):
"""
Prepares GT data by rle encoding segmentations and computing the average track area.
:return: None
"""
# only loaded when needed to reduce minimum requirements
from pycocotools import mask as mask_utils
for track in self.gt_data['annotations']:
h = track['height']
w = track['width']
for i, seg in enumerate(track['segmentations']):
if seg:
track['segmentations'][i] = mask_utils.frPyObjects(seg, h, w)
areas = [a for a in track['areas'] if a]
if len(areas) == 0:
track['area'] = 0
else:
track['area'] = np.array(areas).mean()
def _get_tracker_seq_tracks(self, tracker, seq_id):
"""
Prepares tracker data for a given sequence. Extracts all annotations for given sequence ID, computes
average track area and assigns a track ID.
:param tracker: the given tracker
:param seq_id: the sequence ID
:return: the extracted tracks
"""
# only loaded when needed to reduce minimum requirements
from pycocotools import mask as mask_utils
tracks = [ann for ann in self.tracker_data[tracker] if ann['video_id'] == seq_id]
for track in tracks:
track['areas'] = []
for seg in track['segmentations']:
if seg:
track['areas'].append(mask_utils.area(seg))
else:
track['areas'].append(None)
areas = [a for a in track['areas'] if a]
if len(areas) == 0:
track['area'] = 0
else:
track['area'] = np.array(areas).mean()
track['id'] = self.global_tid_counter
self.global_tid_counter += 1
return tracks
================================================
FILE: TrackEval/trackeval/eval.py
================================================
import time
import traceback
from multiprocessing.pool import Pool
from functools import partial
import os
from . import utils
from .utils import TrackEvalException
from . import _timing
from .metrics import Count
class Evaluator:
"""Evaluator class for evaluating different metrics for different datasets"""
@staticmethod
def get_default_eval_config():
"""Returns the default config values for evaluation"""
code_path = utils.get_code_path()
default_config = {
'USE_PARALLEL': False,
'NUM_PARALLEL_CORES': 8,
'BREAK_ON_ERROR': True, # Raises exception and exits with error
'RETURN_ON_ERROR': False, # if not BREAK_ON_ERROR, then returns from function on error
'LOG_ON_ERROR': os.path.join(code_path, 'error_log.txt'), # if not None, save any errors into a log file.
'PRINT_RESULTS': True,
'PRINT_ONLY_COMBINED': False,
'PRINT_CONFIG': True,
'TIME_PROGRESS': True,
'DISPLAY_LESS_PROGRESS': True,
'OUTPUT_SUMMARY': True,
'OUTPUT_EMPTY_CLASSES': True, # If False, summary files are not output for classes with no detections
'OUTPUT_DETAILED': True,
'PLOT_CURVES': True,
}
return default_config
def __init__(self, config=None):
"""Initialise the evaluator with a config file"""
self.config = utils.init_config(config, self.get_default_eval_config(), 'Eval')
# Only run timing analysis if not run in parallel.
if self.config['TIME_PROGRESS'] and not self.config['USE_PARALLEL']:
_timing.DO_TIMING = True
if self.config['DISPLAY_LESS_PROGRESS']:
_timing.DISPLAY_LESS_PROGRESS = True
@_timing.time
def evaluate(self, dataset_list, metrics_list):
"""Evaluate a set of metrics on a set of datasets"""
config = self.config
metrics_list = metrics_list + [Count()] # Count metrics are always run
metric_names = utils.validate_metrics_list(metrics_list)
dataset_names = [dataset.get_name() for dataset in dataset_list]
output_res = {}
output_msg = {}
for dataset, dataset_name in zip(dataset_list, dataset_names):
# Get dataset info about what to evaluate
output_res[dataset_name] = {}
output_msg[dataset_name] = {}
tracker_list, seq_list, class_list = dataset.get_eval_info()
print('\nEvaluating %i tracker(s) on %i sequence(s) for %i class(es) on %s dataset using the following '
'metrics: %s\n' % (len(tracker_list), len(seq_list), len(class_list), dataset_name,
', '.join(metric_names)))
# Evaluate each tracker
for tracker in tracker_list:
# if not config['BREAK_ON_ERROR'] then go to next tracker without breaking
try:
# Evaluate each sequence in parallel or in series.
# returns a nested dict (res), indexed like: res[seq][class][metric_name][sub_metric field]
# e.g. res[seq_0001][pedestrian][hota][DetA]
print('\nEvaluating %s\n' % tracker)
time_start = time.time()
if config['USE_PARALLEL']:
with Pool(config['NUM_PARALLEL_CORES']) as pool:
_eval_sequence = partial(eval_sequence, dataset=dataset, tracker=tracker,
class_list=class_list, metrics_list=metrics_list,
metric_names=metric_names)
results = pool.map(_eval_sequence, seq_list)
res = dict(zip(seq_list, results))
else:
res = {}
for curr_seq in sorted(seq_list):
res[curr_seq] = eval_sequence(curr_seq, dataset, tracker, class_list, metrics_list,
metric_names)
# Combine results over all sequences and then over all classes
# collecting combined cls keys (cls averaged, det averaged, super classes)
combined_cls_keys = []
res['COMBINED_SEQ'] = {}
# combine sequences for each class
for c_cls in class_list:
res['COMBINED_SEQ'][c_cls] = {}
for metric, metric_name in zip(metrics_list, metric_names):
curr_res = {seq_key: seq_value[c_cls][metric_name] for seq_key, seq_value in res.items() if
seq_key != 'COMBINED_SEQ'}
res['COMBINED_SEQ'][c_cls][metric_name] = metric.combine_sequences(curr_res)
# combine classes
if dataset.should_classes_combine:
combined_cls_keys += ['cls_comb_cls_av', 'cls_comb_det_av', 'all']
res['COMBINED_SEQ']['cls_comb_cls_av'] = {}
res['COMBINED_SEQ']['cls_comb_det_av'] = {}
for metric, metric_name in zip(metrics_list, metric_names):
cls_res = {cls_key: cls_value[metric_name] for cls_key, cls_value in
res['COMBINED_SEQ'].items() if cls_key not in combined_cls_keys}
res['COMBINED_SEQ']['cls_comb_cls_av'][metric_name] = \
metric.combine_classes_class_averaged(cls_res)
res['COMBINED_SEQ']['cls_comb_det_av'][metric_name] = \
metric.combine_classes_det_averaged(cls_res)
# combine classes to super classes
if dataset.use_super_categories:
for cat, sub_cats in dataset.super_categories.items():
combined_cls_keys.append(cat)
res['COMBINED_SEQ'][cat] = {}
for metric, metric_name in zip(metrics_list, metric_names):
cat_res = {cls_key: cls_value[metric_name] for cls_key, cls_value in
res['COMBINED_SEQ'].items() if cls_key in sub_cats}
res['COMBINED_SEQ'][cat][metric_name] = metric.combine_classes_det_averaged(cat_res)
# Print and output results in various formats
if config['TIME_PROGRESS']:
print('\nAll sequences for %s finished in %.2f seconds' % (tracker, time.time() - time_start))
output_fol = dataset.get_output_fol(tracker)
tracker_display_name = dataset.get_display_name(tracker)
for c_cls in res['COMBINED_SEQ'].keys(): # class_list + combined classes if calculated
summaries = []
details = []
num_dets = res['COMBINED_SEQ'][c_cls]['Count']['Dets']
if config['OUTPUT_EMPTY_CLASSES'] or num_dets > 0:
for metric, metric_name in zip(metrics_list, metric_names):
# for combined classes there is no per sequence evaluation
if c_cls in combined_cls_keys:
table_res = {'COMBINED_SEQ': res['COMBINED_SEQ'][c_cls][metric_name]}
else:
table_res = {seq_key: seq_value[c_cls][metric_name] for seq_key, seq_value
in res.items()}
if config['PRINT_RESULTS'] and config['PRINT_ONLY_COMBINED']:
dont_print = dataset.should_classes_combine and c_cls not in combined_cls_keys
if not dont_print:
metric.print_table({'COMBINED_SEQ': table_res['COMBINED_SEQ']},
tracker_display_name, c_cls, output_fol) # TODO: [hgx 0403], add 'output_fol'
elif config['PRINT_RESULTS']:
metric.print_table(table_res, tracker_display_name, c_cls, output_fol) # TODO: [hgx 0403], add 'output_fol'
if config['OUTPUT_SUMMARY']:
summaries.append(metric.summary_results(table_res))
if config['OUTPUT_DETAILED']:
details.append(metric.detailed_results(table_res))
if config['PLOT_CURVES']:
metric.plot_single_tracker_results(table_res, tracker_display_name, c_cls,
output_fol)
if config['OUTPUT_SUMMARY']:
utils.write_summary_results(summaries, c_cls, output_fol)
if config['OUTPUT_DETAILED']:
utils.write_detailed_results(details, c_cls, output_fol)
# Output for returning from function
output_res[dataset_name][tracker] = res
output_msg[dataset_name][tracker] = 'Success'
except Exception as err:
output_res[dataset_name][tracker] = None
if type(err) == TrackEvalException:
output_msg[dataset_name][tracker] = str(err)
else:
output_msg[dataset_name][tracker] = 'Unknown error occurred.'
print('Tracker %s was unable to be evaluated.' % tracker)
print(err)
traceback.print_exc()
if config['LOG_ON_ERROR'] is not None:
with open(config['LOG_ON_ERROR'], 'a') as f:
print(dataset_name, file=f)
print(tracker, file=f)
print(traceback.format_exc(), file=f)
print('\n\n\n', file=f)
if config['BREAK_ON_ERROR']:
raise err
elif config['RETURN_ON_ERROR']:
return output_res, output_msg
return output_res, output_msg
@_timing.time
def eval_sequence(seq, dataset, tracker, class_list, metrics_list, metric_names):
"""Function for evaluating a single sequence"""
raw_data = dataset.get_raw_seq_data(tracker, seq)
seq_res = {}
for cls in class_list:
seq_res[cls] = {}
data = dataset.get_preprocessed_seq_data(raw_data, cls)
for metric, met_name in zip(metrics_list, metric_names):
seq_res[cls][met_name] = metric.eval_sequence(data)
return seq_res
================================================
FILE: TrackEval/trackeval/metrics/__init__.py
================================================
from .hota import HOTA
from .clear import CLEAR
from .identity import Identity
from .count import Count
from .j_and_f import JAndF
from .track_map import TrackMAP
from .vace import VACE
from .ideucl import IDEucl
================================================
FILE: TrackEval/trackeval/metrics/_base_metric.py
================================================
import numpy as np
from abc import ABC, abstractmethod
from .. import _timing
from ..utils import TrackEvalException
import os
class _BaseMetric(ABC):
@abstractmethod
def __init__(self):
self.plottable = False
self.integer_fields = []
self.float_fields = []
self.array_labels = []
self.integer_array_fields = []
self.float_array_fields = []
self.fields = []
self.summary_fields = []
self.registered = False
#####################################################################
# Abstract functions for subclasses to implement
@_timing.time
@abstractmethod
def eval_sequence(self, data):
...
@abstractmethod
def combine_sequences(self, all_res):
...
@abstractmethod
def combine_classes_class_averaged(self, all_res, ignore_empty_classes=False):
...
@ abstractmethod
def combine_classes_det_averaged(self, all_res):
...
def plot_single_tracker_results(self, all_res, tracker, output_folder, cls):
"""Plot results of metrics, only valid for metrics with self.plottable"""
if self.plottable:
raise NotImplementedError('plot_results is not implemented for metric %s' % self.get_name())
else:
pass
#####################################################################
# Helper functions which are useful for all metrics:
@classmethod
def get_name(cls):
return cls.__name__
@staticmethod
def _combine_sum(all_res, field):
"""Combine sequence results via sum"""
return sum([all_res[k][field] for k in all_res.keys()])
@staticmethod
def _combine_weighted_av(all_res, field, comb_res, weight_field):
"""Combine sequence results via weighted average"""
return sum([all_res[k][field] * all_res[k][weight_field] for k in all_res.keys()]) / np.maximum(1.0, comb_res[
weight_field])
def print_table(self, table_res, tracker, cls, output_fol=None):
"""Prints table of results for all sequences"""
# TODO: [hgx 0403], make file folder for 'val_log.txt'
if output_fol is not None:
out_file = os.path.join(output_fol, 'val_log.txt')
os.makedirs(os.path.dirname(out_file), exist_ok=True)
else:
out_file = None
print('')
metric_name = self.get_name()
self._row_print(out_file, [metric_name + ': ' + tracker + '-' + cls] + self.summary_fields) # TODO: [hgx 0403], add 'output_fol'
for seq, results in sorted(table_res.items()):
if seq == 'COMBINED_SEQ':
continue
summary_res = self._summary_row(results)
self._row_print(out_file, [seq] + summary_res) # TODO: [hgx 0403], add 'output_fol'
summary_res = self._summary_row(table_res['COMBINED_SEQ'])
self._row_print(out_file, ['COMBINED'] + summary_res) # TODO: [hgx 0403], add 'output_fol'
def _summary_row(self, results_):
vals = []
for h in self.summary_fields:
if h in self.float_array_fields:
vals.append("{0:1.5g}".format(100 * np.mean(results_[h])))
elif h in self.float_fields:
vals.append("{0:1.5g}".format(100 * float(results_[h])))
elif h in self.integer_fields:
vals.append("{0:d}".format(int(results_[h])))
else:
raise NotImplementedError("Summary function not implemented for this field type.")
return vals
@staticmethod
def _row_print(out_file, *argv):
"""Prints results in an evenly spaced rows, with more space in first row"""
if len(argv) == 1:
argv = argv[0]
to_print = '%-35s' % argv[0]
for v in argv[1:]:
to_print += '%-10s' % str(v)
print(to_print)
if out_file is not None: # TODO: [hgx 0403], write terminal outputs to txt file
with open(out_file, 'a+', newline='') as f:
print(to_print, file=f)
def summary_results(self, table_res):
"""Returns a simple summary of final results for a tracker"""
return dict(zip(self.summary_fields, self._summary_row(table_res['COMBINED_SEQ'])))
def detailed_results(self, table_res):
"""Returns detailed final results for a tracker"""
# Get detailed field information
detailed_fields = self.float_fields + self.integer_fields
for h in self.float_array_fields + self.integer_array_fields:
for alpha in [int(100*x) for x in self.array_labels]:
detailed_fields.append(h + '___' + str(alpha))
detailed_fields.append(h + '___AUC')
# Get detailed results
detailed_results = {}
for seq, res in table_res.items():
detailed_row = self._detailed_row(res)
if len(detailed_row) != len(detailed_fields):
raise TrackEvalException(
'Field names and data have different sizes (%i and %i)' % (len(detailed_row), len(detailed_fields)))
detailed_results[seq] = dict(zip(detailed_fields, detailed_row))
return detailed_results
def _detailed_row(self, res):
detailed_row = []
for h in self.float_fields + self.integer_fields:
detailed_row.append(res[h])
for h in self.float_array_fields + self.integer_array_fields:
for i, alpha in enumerate([int(100 * x) for x in self.array_labels]):
detailed_row.append(res[h][i])
detailed_row.append(np.mean(res[h]))
return detailed_row
================================================
FILE: TrackEval/trackeval/metrics/clear.py
================================================
import numpy as np
from scipy.optimize import linear_sum_assignment
from ._base_metric import _BaseMetric
from .. import _timing
from .. import utils
class CLEAR(_BaseMetric):
"""Class which implements the CLEAR metrics"""
@staticmethod
def get_default_config():
"""Default class config values"""
default_config = {
'THRESHOLD': 0.5, # Similarity score threshold required for a TP match. Default 0.5.
'PRINT_CONFIG': True, # Whether to print the config information on init. Default: False.
}
return default_config
def __init__(self, config=None):
super().__init__()
main_integer_fields = ['CLR_TP', 'CLR_FN', 'CLR_FP', 'IDSW', 'MT', 'PT', 'ML', 'Frag']
extra_integer_fields = ['CLR_Frames']
self.integer_fields = main_integer_fields + extra_integer_fields
main_float_fields = ['MOTA', 'MOTP', 'MODA', 'CLR_Re', 'CLR_Pr', 'MTR', 'PTR', 'MLR', 'sMOTA']
extra_float_fields = ['CLR_F1', 'FP_per_frame', 'MOTAL', 'MOTP_sum']
self.float_fields = main_float_fields + extra_float_fields
self.fields = self.float_fields + self.integer_fields
self.summed_fields = self.integer_fields + ['MOTP_sum']
self.summary_fields = main_float_fields + main_integer_fields
# Configuration options:
self.config = utils.init_config(config, self.get_default_config(), self.get_name())
self.threshold = float(self.config['THRESHOLD'])
@_timing.time
def eval_sequence(self, data):
"""Calculates CLEAR metrics for one sequence"""
# Initialise results
res = {}
for field in self.fields:
res[field] = 0
# Return result quickly if tracker or gt sequence is empty
if data['num_tracker_dets'] == 0:
res['CLR_FN'] = data['num_gt_dets']
res['ML'] = data['num_gt_ids']
res['MLR'] = 1.0
return res
if data['num_gt_dets'] == 0:
res['CLR_FP'] = data['num_tracker_dets']
res['MLR'] = 1.0
return res
# Variables counting global association
num_gt_ids = data['num_gt_ids']
gt_id_count = np.zeros(num_gt_ids) # For MT/ML/PT
gt_matched_count = np.zeros(num_gt_ids) # For MT/ML/PT
gt_frag_count = np.zeros(num_gt_ids) # For Frag
# Note that IDSWs are counted based on the last time each gt_id was present (any number of frames previously),
# but are only used in matching to continue current tracks based on the gt_id in the single previous timestep.
prev_tracker_id = np.nan * np.zeros(num_gt_ids) # For scoring IDSW
prev_timestep_tracker_id = np.nan * np.zeros(num_gt_ids) # For matching IDSW
# Calculate scores for each timestep
for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
# Deal with the case that there are no gt_det/tracker_det in a timestep.
if len(gt_ids_t) == 0:
res['CLR_FP'] += len(tracker_ids_t)
continue
if len(tracker_ids_t) == 0:
res['CLR_FN'] += len(gt_ids_t)
gt_id_count[gt_ids_t] += 1
continue
# Calc score matrix to first minimise IDSWs from previous frame, and then maximise MOTP secondarily
similarity = data['similarity_scores'][t]
score_mat = (tracker_ids_t[np.newaxis, :] == prev_timestep_tracker_id[gt_ids_t[:, np.newaxis]])
score_mat = 1000 * score_mat + similarity
score_mat[similarity < self.threshold - np.finfo('float').eps] = 0
# Hungarian algorithm to find best matches
match_rows, match_cols = linear_sum_assignment(-score_mat)
actually_matched_mask = score_mat[match_rows, match_cols] > 0 + np.finfo('float').eps
match_rows = match_rows[actually_matched_mask]
match_cols = match_cols[actually_matched_mask]
matched_gt_ids = gt_ids_t[match_rows]
matched_tracker_ids = tracker_ids_t[match_cols]
# Calc IDSW for MOTA
prev_matched_tracker_ids = prev_tracker_id[matched_gt_ids]
is_idsw = (np.logical_not(np.isnan(prev_matched_tracker_ids))) & (
np.not_equal(matched_tracker_ids, prev_matched_tracker_ids))
res['IDSW'] += np.sum(is_idsw)
# Update counters for MT/ML/PT/Frag and record for IDSW/Frag for next timestep
gt_id_count[gt_ids_t] += 1
gt_matched_count[matched_gt_ids] += 1
not_previously_tracked = np.isnan(prev_timestep_tracker_id)
prev_tracker_id[matched_gt_ids] = matched_tracker_ids
prev_timestep_tracker_id[:] = np.nan
prev_timestep_tracker_id[matched_gt_ids] = matched_tracker_ids
currently_tracked = np.logical_not(np.isnan(prev_timestep_tracker_id))
gt_frag_count += np.logical_and(not_previously_tracked, currently_tracked)
# Calculate and accumulate basic statistics
num_matches = len(matched_gt_ids)
res['CLR_TP'] += num_matches
res['CLR_FN'] += len(gt_ids_t) - num_matches
res['CLR_FP'] += len(tracker_ids_t) - num_matches
if num_matches > 0:
res['MOTP_sum'] += sum(similarity[match_rows, match_cols])
# Calculate MT/ML/PT/Frag/MOTP
tracked_ratio = gt_matched_count[gt_id_count > 0] / gt_id_count[gt_id_count > 0]
res['MT'] = np.sum(np.greater(tracked_ratio, 0.8))
res['PT'] = np.sum(np.greater_equal(tracked_ratio, 0.2)) - res['MT']
res['ML'] = num_gt_ids - res['MT'] - res['PT']
res['Frag'] = np.sum(np.subtract(gt_frag_count[gt_frag_count > 0], 1))
res['MOTP'] = res['MOTP_sum'] / np.maximum(1.0, res['CLR_TP'])
res['CLR_Frames'] = data['num_timesteps']
# Calculate final CLEAR scores
res = self._compute_final_fields(res)
return res
def combine_sequences(self, all_res):
"""Combines metrics across all sequences"""
res = {}
for field in self.summed_fields:
res[field] = self._combine_sum(all_res, field)
res = self._compute_final_fields(res)
return res
def combine_classes_det_averaged(self, all_res):
"""Combines metrics across all classes by averaging over the detection values"""
res = {}
for field in self.summed_fields:
res[field] = self._combine_sum(all_res, field)
res = self._compute_final_fields(res)
return res
def combine_classes_class_averaged(self, all_res, ignore_empty_classes=False):
"""Combines metrics across all classes by averaging over the class values.
If 'ignore_empty_classes' is True, then it only sums over classes with at least one gt or predicted detection.
"""
res = {}
for field in self.integer_fields:
if ignore_empty_classes:
res[field] = self._combine_sum(
{k: v for k, v in all_res.items() if v['CLR_TP'] + v['CLR_FN'] + v['CLR_FP'] > 0}, field)
else:
res[field] = self._combine_sum({k: v for k, v in all_res.items()}, field)
for field in self.float_fields:
if ignore_empty_classes:
res[field] = np.mean(
[v[field] for v in all_res.values() if v['CLR_TP'] + v['CLR_FN'] + v['CLR_FP'] > 0], axis=0)
else:
res[field] = np.mean([v[field] for v in all_res.values()], axis=0)
return res
@staticmethod
def _compute_final_fields(res):
"""Calculate sub-metric ('field') values which only depend on other sub-metric values.
This function is used both for both per-sequence calculation, and in combining values across sequences.
"""
num_gt_ids = res['MT'] + res['ML'] + res['PT']
res['MTR'] = res['MT'] / np.maximum(1.0, num_gt_ids)
res['MLR'] = res['ML'] / np.maximum(1.0, num_gt_ids)
res['PTR'] = res['PT'] / np.maximum(1.0, num_gt_ids)
res['CLR_Re'] = res['CLR_TP'] / np.maximum(1.0, res['CLR_TP'] + res['CLR_FN'])
res['CLR_Pr'] = res['CLR_TP'] / np.maximum(1.0, res['CLR_TP'] + res['CLR_FP'])
res['MODA'] = (res['CLR_TP'] - res['CLR_FP']) / np.maximum(1.0, res['CLR_TP'] + res['CLR_FN'])
res['MOTA'] = (res['CLR_TP'] - res['CLR_FP'] - res['IDSW']) / np.maximum(1.0, res['CLR_TP'] + res['CLR_FN'])
res['MOTP'] = res['MOTP_sum'] / np.maximum(1.0, res['CLR_TP'])
res['sMOTA'] = (res['MOTP_sum'] - res['CLR_FP'] - res['IDSW']) / np.maximum(1.0, res['CLR_TP'] + res['CLR_FN'])
res['CLR_F1'] = res['CLR_TP'] / np.maximum(1.0, res['CLR_TP'] + 0.5*res['CLR_FN'] + 0.5*res['CLR_FP'])
res['FP_per_frame'] = res['CLR_FP'] / np.maximum(1.0, res['CLR_Frames'])
safe_log_idsw = np.log10(res['IDSW']) if res['IDSW'] > 0 else res['IDSW']
res['MOTAL'] = (res['CLR_TP'] - res['CLR_FP'] - safe_log_idsw) / np.maximum(1.0, res['CLR_TP'] + res['CLR_FN'])
return res
================================================
FILE: TrackEval/trackeval/metrics/count.py
================================================
from ._base_metric import _BaseMetric
from .. import _timing
class Count(_BaseMetric):
"""Class which simply counts the number of tracker and gt detections and ids."""
def __init__(self, config=None):
super().__init__()
self.integer_fields = ['Dets', 'GT_Dets', 'IDs', 'GT_IDs']
self.fields = self.integer_fields
self.summary_fields = self.fields
@_timing.time
def eval_sequence(self, data):
"""Returns counts for one sequence"""
# Get results
res = {'Dets': data['num_tracker_dets'],
'GT_Dets': data['num_gt_dets'],
'IDs': data['num_tracker_ids'],
'GT_IDs': data['num_gt_ids'],
'Frames': data['num_timesteps']}
return res
def combine_sequences(self, all_res):
"""Combines metrics across all sequences"""
res = {}
for field in self.integer_fields:
res[field] = self._combine_sum(all_res, field)
return res
def combine_classes_class_averaged(self, all_res, ignore_empty_classes=None):
"""Combines metrics across all classes by averaging over the class values"""
res = {}
for field in self.integer_fields:
res[field] = self._combine_sum(all_res, field)
return res
def combine_classes_det_averaged(self, all_res):
"""Combines metrics across all classes by averaging over the detection values"""
res = {}
for field in self.integer_fields:
res[field] = self._combine_sum(all_res, field)
return res
================================================
FILE: TrackEval/trackeval/metrics/hota.py
================================================
import os
import numpy as np
from scipy.optimize import linear_sum_assignment
from ._base_metric import _BaseMetric
from .. import _timing
class HOTA(_BaseMetric):
"""Class which implements the HOTA metrics.
See: https://link.springer.com/article/10.1007/s11263-020-01375-2
"""
def __init__(self, config=None):
super().__init__()
self.plottable = True
self.array_labels = np.arange(0.05, 0.99, 0.05)
self.integer_array_fields = ['HOTA_TP', 'HOTA_FN', 'HOTA_FP']
self.float_array_fields = ['HOTA', 'DetA', 'AssA', 'DetRe', 'DetPr', 'AssRe', 'AssPr', 'LocA', 'RHOTA']
self.float_fields = ['HOTA(0)', 'LocA(0)', 'HOTALocA(0)']
self.fields = self.float_array_fields + self.integer_array_fields + self.float_fields
self.summary_fields = self.float_array_fields + self.float_fields
@_timing.time
def eval_sequence(self, data):
"""Calculates the HOTA metrics for one sequence"""
# Initialise results
res = {}
for field in self.float_array_fields + self.integer_array_fields:
res[field] = np.zeros((len(self.array_labels)), dtype=np.float)
for field in self.float_fields:
res[field] = 0
# Return result quickly if tracker or gt sequence is empty
if data['num_tracker_dets'] == 0:
res['HOTA_FN'] = data['num_gt_dets'] * np.ones((len(self.array_labels)), dtype=np.float)
res['LocA'] = np.ones((len(self.array_labels)), dtype=np.float)
res['LocA(0)'] = 1.0
return res
if data['num_gt_dets'] == 0:
res['HOTA_FP'] = data['num_tracker_dets'] * np.ones((len(self.array_labels)), dtype=np.float)
res['LocA'] = np.ones((len(self.array_labels)), dtype=np.float)
res['LocA(0)'] = 1.0
return res
# Variables counting global association
potential_matches_count = np.zeros((data['num_gt_ids'], data['num_tracker_ids']))
gt_id_count = np.zeros((data['num_gt_ids'], 1))
tracker_id_count = np.zeros((1, data['num_tracker_ids']))
# First loop through each timestep and accumulate global track information.
for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
# Count the potential matches between ids in each timestep
# These are normalised, weighted by the match similarity.
similarity = data['similarity_scores'][t]
sim_iou_denom = similarity.sum(0)[np.newaxis, :] + similarity.sum(1)[:, np.newaxis] - similarity
sim_iou = np.zeros_like(similarity)
sim_iou_mask = sim_iou_denom > 0 + np.finfo('float').eps
sim_iou[sim_iou_mask] = similarity[sim_iou_mask] / sim_iou_denom[sim_iou_mask]
potential_matches_count[gt_ids_t[:, np.newaxis], tracker_ids_t[np.newaxis, :]] += sim_iou
# Calculate the total number of dets for each gt_id and tracker_id.
gt_id_count[gt_ids_t] += 1
tracker_id_count[0, tracker_ids_t] += 1
# Calculate overall jaccard alignment score (before unique matching) between IDs
global_alignment_score = potential_matches_count / (gt_id_count + tracker_id_count - potential_matches_count)
matches_counts = [np.zeros_like(potential_matches_count) for _ in self.array_labels]
# Calculate scores for each timestep
for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
# Deal with the case that there are no gt_det/tracker_det in a timestep.
if len(gt_ids_t) == 0:
for a, alpha in enumerate(self.array_labels):
res['HOTA_FP'][a] += len(tracker_ids_t)
continue
if len(tracker_ids_t) == 0:
for a, alpha in enumerate(self.array_labels):
res['HOTA_FN'][a] += len(gt_ids_t)
continue
# Get matching scores between pairs of dets for optimizing HOTA
similarity = data['similarity_scores'][t]
score_mat = global_alignment_score[gt_ids_t[:, np.newaxis], tracker_ids_t[np.newaxis, :]] * similarity
# Hungarian algorithm to find best matches
match_rows, match_cols = linear_sum_assignment(-score_mat)
# Calculate and accumulate basic statistics
for a, alpha in enumerate(self.array_labels):
actually_matched_mask = similarity[match_rows, match_cols] >= alpha - np.finfo('float').eps
alpha_match_rows = match_rows[actually_matched_mask]
alpha_match_cols = match_cols[actually_matched_mask]
num_matches = len(alpha_match_rows)
res['HOTA_TP'][a] += num_matches
res['HOTA_FN'][a] += len(gt_ids_t) - num_matches
res['HOTA_FP'][a] += len(tracker_ids_t) - num_matches
if num_matches > 0:
res['LocA'][a] += sum(similarity[alpha_match_rows, alpha_match_cols])
matches_counts[a][gt_ids_t[alpha_match_rows], tracker_ids_t[alpha_match_cols]] += 1
# Calculate association scores (AssA, AssRe, AssPr) for the alpha value.
# First calculate scores per gt_id/tracker_id combo and then average over the number of detections.
for a, alpha in enumerate(self.array_labels):
matches_count = matches_counts[a]
ass_a = matches_count / np.maximum(1, gt_id_count + tracker_id_count - matches_count)
res['AssA'][a] = np.sum(matches_count * ass_a) / np.maximum(1, res['HOTA_TP'][a])
ass_re = matches_count / np.maximum(1, gt_id_count)
res['AssRe'][a] = np.sum(matches_count * ass_re) / np.maximum(1, res['HOTA_TP'][a])
ass_pr = matches_count / np.maximum(1, tracker_id_count)
res['AssPr'][a] = np.sum(matches_count * ass_pr) / np.maximum(1, res['HOTA_TP'][a])
# Calculate final scores
res['LocA'] = np.maximum(1e-10, res['LocA']) / np.maximum(1e-10, res['HOTA_TP'])
res = self._compute_final_fields(res)
return res
def combine_sequences(self, all_res):
"""Combines metrics across all sequences"""
res = {}
for field in self.integer_array_fields:
res[field] = self._combine_sum(all_res, field)
for field in ['AssRe', 'AssPr', 'AssA']:
res[field] = self._combine_weighted_av(all_res, field, res, weight_field='HOTA_TP')
loca_weighted_sum = sum([all_res[k]['LocA'] * all_res[k]['HOTA_TP'] for k in all_res.keys()])
res['LocA'] = np.maximum(1e-10, loca_weighted_sum) / np.maximum(1e-10, res['HOTA_TP'])
res = self._compute_final_fields(res)
return res
def combine_classes_class_averaged(self, all_res, ignore_empty_classes=False):
"""Combines metrics across all classes by averaging over the class values.
If 'ignore_empty_classes' is True, then it only sums over classes with at least one gt or predicted detection.
"""
res = {}
for field in self.integer_array_fields:
if ignore_empty_classes:
res[field] = self._combine_sum(
{k: v for k, v in all_res.items()
if (v['HOTA_TP'] + v['HOTA_FN'] + v['HOTA_FP'] > 0 + np.finfo('float').eps).any()}, field)
else:
res[field] = self._combine_sum({k: v for k, v in all_res.items()}, field)
for field in self.float_fields + self.float_array_fields:
if ignore_empty_classes:
res[field] = np.mean([v[field] for v in all_res.values() if
(v['HOTA_TP'] + v['HOTA_FN'] + v['HOTA_FP'] > 0 + np.finfo('float').eps).any()],
axis=0)
else:
res[field] = np.mean([v[field] for v in all_res.values()], axis=0)
return res
def combine_classes_det_averaged(self, all_res):
"""Combines metrics across all classes by averaging over the detection values"""
res = {}
for field in self.integer_array_fields:
res[field] = self._combine_sum(all_res, field)
for field in ['AssRe', 'AssPr', 'AssA']:
res[field] = self._combine_weighted_av(all_res, field, res, weight_field='HOTA_TP')
loca_weighted_sum = sum([all_res[k]['LocA'] * all_res[k]['HOTA_TP'] for k in all_res.keys()])
res['LocA'] = np.maximum(1e-10, loca_weighted_sum) / np.maximum(1e-10, res['HOTA_TP'])
res = self._compute_final_fields(res)
return res
@staticmethod
def _compute_final_fields(res):
"""Calculate sub-metric ('field') values which only depend on other sub-metric values.
This function is used both for both per-sequence calculation, and in combining values across sequences.
"""
res['DetRe'] = res['HOTA_TP'] / np.maximum(1, res['HOTA_TP'] + res['HOTA_FN'])
res['DetPr'] = res['HOTA_TP'] / np.maximum(1, res['HOTA_TP'] + res['HOTA_FP'])
res['DetA'] = res['HOTA_TP'] / np.maximum(1, res['HOTA_TP'] + res['HOTA_FN'] + res['HOTA_FP'])
res['HOTA'] = np.sqrt(res['DetA'] * res['AssA'])
res['RHOTA'] = np.sqrt(res['DetRe'] * res['AssA'])
res['HOTA(0)'] = res['HOTA'][0]
res['LocA(0)'] = res['LocA'][0]
res['HOTALocA(0)'] = res['HOTA(0)']*res['LocA(0)']
return res
def plot_single_tracker_results(self, table_res, tracker, cls, output_folder):
"""Create plot of results"""
# Only loaded when run to reduce minimum requirements
from matplotlib import pyplot as plt
res = table_res['COMBINED_SEQ']
styles_to_plot = ['r', 'b', 'g', 'b--', 'b:', 'g--', 'g:', 'm']
for name, style in zip(self.float_array_fields, styles_to_plot):
plt.plot(self.array_labels, res[name], style)
plt.xlabel('alpha')
plt.ylabel('score')
plt.title(tracker + ' - ' + cls)
plt.axis([0, 1, 0, 1])
legend = []
for name in self.float_array_fields:
legend += [name + ' (' + str(np.round(np.mean(res[name]), 2)) + ')']
plt.legend(legend, loc='lower left')
out_file = os.path.join(output_folder, cls + '_plot.pdf')
os.makedirs(os.path.dirname(out_file), exist_ok=True)
plt.savefig(out_file)
plt.savefig(out_file.replace('.pdf', '.png'))
plt.clf()
================================================
FILE: TrackEval/trackeval/metrics/identity.py
================================================
import numpy as np
from scipy.optimize import linear_sum_assignment
from ._base_metric import _BaseMetric
from .. import _timing
from .. import utils
class Identity(_BaseMetric):
"""Class which implements the ID metrics"""
@staticmethod
def get_default_config():
"""Default class config values"""
default_config = {
'THRESHOLD': 0.5, # Similarity score threshold required for a IDTP match. Default 0.5.
'PRINT_CONFIG': True, # Whether to print the config information on init. Default: False.
}
return default_config
def __init__(self, config=None):
super().__init__()
self.integer_fields = ['IDTP', 'IDFN', 'IDFP']
self.float_fields = ['IDF1', 'IDR', 'IDP']
self.fields = self.float_fields + self.integer_fields
self.summary_fields = self.fields
# Configuration options:
self.config = utils.init_config(config, self.get_default_config(), self.get_name())
self.threshold = float(self.config['THRESHOLD'])
@_timing.time
def eval_sequence(self, data):
"""Calculates ID metrics for one sequence"""
# Initialise results
res = {}
for field in self.fields:
res[field] = 0
# Return result quickly if tracker or gt sequence is empty
if data['num_tracker_dets'] == 0:
res['IDFN'] = data['num_gt_dets']
return res
if data['num_gt_dets'] == 0:
res['IDFP'] = data['num_tracker_dets']
return res
# Variables counting global association
potential_matches_count = np.zeros((data['num_gt_ids'], data['num_tracker_ids']))
gt_id_count = np.zeros(data['num_gt_ids'])
tracker_id_count = np.zeros(data['num_tracker_ids'])
# First loop through each timestep and accumulate global track information.
for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
# Count the potential matches between ids in each timestep
matches_mask = np.greater_equal(data['similarity_scores'][t], self.threshold)
match_idx_gt, match_idx_tracker = np.nonzero(matches_mask)
potential_matches_count[gt_ids_t[match_idx_gt], tracker_ids_t[match_idx_tracker]] += 1
# Calculate the total number of dets for each gt_id and tracker_id.
gt_id_count[gt_ids_t] += 1
tracker_id_count[tracker_ids_t] += 1
# Calculate optimal assignment cost matrix for ID metrics
num_gt_ids = data['num_gt_ids']
num_tracker_ids = data['num_tracker_ids']
fp_mat = np.zeros((num_gt_ids + num_tracker_ids, num_gt_ids + num_tracker_ids))
fn_mat = np.zeros((num_gt_ids + num_tracker_ids, num_gt_ids + num_tracker_ids))
fp_mat[num_gt_ids:, :num_tracker_ids] = 1e10
fn_mat[:num_gt_ids, num_tracker_ids:] = 1e10
for gt_id in range(num_gt_ids):
fn_mat[gt_id, :num_tracker_ids] = gt_id_count[gt_id]
fn_mat[gt_id, num_tracker_ids + gt_id] = gt_id_count[gt_id]
for tracker_id in range(num_tracker_ids):
fp_mat[:num_gt_ids, tracker_id] = tracker_id_count[tracker_id]
fp_mat[tracker_id + num_gt_ids, tracker_id] = tracker_id_count[tracker_id]
fn_mat[:num_gt_ids, :num_tracker_ids] -= potential_matches_count
fp_mat[:num_gt_ids, :num_tracker_ids] -= potential_matches_count
# Hungarian algorithm
match_rows, match_cols = linear_sum_assignment(fn_mat + fp_mat)
# Accumulate basic statistics
res['IDFN'] = fn_mat[match_rows, match_cols].sum().astype(np.int)
res['IDFP'] = fp_mat[match_rows, match_cols].sum().astype(np.int)
res['IDTP'] = (gt_id_count.sum() - res['IDFN']).astype(np.int)
# Calculate final ID scores
res = self._compute_final_fields(res)
return res
def combine_classes_class_averaged(self, all_res, ignore_empty_classes=False):
"""Combines metrics across all classes by averaging over the class values.
If 'ignore_empty_classes' is True, then it only sums over classes with at least one gt or predicted detection.
"""
res = {}
for field in self.integer_fields:
if ignore_empty_classes:
res[field] = self._combine_sum({k: v for k, v in all_res.items()
if v['IDTP'] + v['IDFN'] + v['IDFP'] > 0 + np.finfo('float').eps},
field)
else:
res[field] = self._combine_sum({k: v for k, v in all_res.items()}, field)
for field in self.float_fields:
if ignore_empty_classes:
res[field] = np.mean([v[field] for v in all_res.values()
if v['IDTP'] + v['IDFN'] + v['IDFP'] > 0 + np.finfo('float').eps], axis=0)
else:
res[field] = np.mean([v[field] for v in all_res.values()], axis=0)
return res
def combine_classes_det_averaged(self, all_res):
"""Combines metrics across all classes by averaging over the detection values"""
res = {}
for field in self.integer_fields:
res[field] = self._combine_sum(all_res, field)
res = self._compute_final_fields(res)
return res
def combine_sequences(self, all_res):
"""Combines metrics across all sequences"""
res = {}
for field in self.integer_fields:
res[field] = self._combine_sum(all_res, field)
res = self._compute_final_fields(res)
return res
@staticmethod
def _compute_final_fields(res):
"""Calculate sub-metric ('field') values which only depend on other sub-metric values.
This function is used both for both per-sequence calculation, and in combining values across sequences.
"""
res['IDR'] = res['IDTP'] / np.maximum(1.0, res['IDTP'] + res['IDFN'])
res['IDP'] = res['IDTP'] / np.maximum(1.0, res['IDTP'] + res['IDFP'])
res['IDF1'] = res['IDTP'] / np.maximum(1.0, res['IDTP'] + 0.5 * res['IDFP'] + 0.5 * res['IDFN'])
return res
================================================
FILE: TrackEval/trackeval/metrics/ideucl.py
================================================
import numpy as np
from scipy.optimize import linear_sum_assignment
from ._base_metric import _BaseMetric
from .. import _timing
from collections import defaultdict
from .. import utils
class IDEucl(_BaseMetric):
"""Class which implements the ID metrics"""
@staticmethod
def get_default_config():
"""Default class config values"""
default_config = {
'THRESHOLD': 0.4, # Similarity score threshold required for a IDTP match. 0.4 for IDEucl.
'PRINT_CONFIG': True, # Whether to print the config information on init. Default: False.
}
return default_config
def __init__(self, config=None):
super().__init__()
self.fields = ['IDEucl']
self.float_fields = self.fields
self.summary_fields = self.fields
# Configuration options:
self.config = utils.init_config(config, self.get_default_config(), self.get_name())
self.threshold = float(self.config['THRESHOLD'])
@_timing.time
def eval_sequence(self, data):
"""Calculates IDEucl metrics for all frames"""
# Initialise results
res = {'IDEucl' : 0}
# Return result quickly if tracker or gt sequence is empty
if data['num_tracker_dets'] == 0 or data['num_gt_dets'] == 0.:
return res
data['centroid'] = []
for t, gt_det in enumerate(data['gt_dets']):
# import pdb;pdb.set_trace()
data['centroid'].append(self._compute_centroid(gt_det))
oid_hid_cent = defaultdict(list)
oid_cent = defaultdict(list)
for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
matches_mask = np.greater_equal(data['similarity_scores'][t], self.threshold)
# I hope the orders of ids and boxes are maintained in `data`
for ind, gid in enumerate(gt_ids_t):
oid_cent[gid].append(data['centroid'][t][ind])
match_idx_gt, match_idx_tracker = np.nonzero(matches_mask)
for m_gid, m_tid in zip(match_idx_gt, match_idx_tracker):
oid_hid_cent[gt_ids_t[m_gid], tracker_ids_t[m_tid]].append(data['centroid'][t][m_gid])
oid_hid_dist = {k : np.sum(np.linalg.norm(np.diff(np.array(v), axis=0), axis=1)) for k, v in oid_hid_cent.items()}
oid_dist = {int(k) : np.sum(np.linalg.norm(np.diff(np.array(v), axis=0), axis=1)) for k, v in oid_cent.items()}
unique_oid = np.unique([i[0] for i in oid_hid_dist.keys()]).tolist()
unique_hid = np.unique([i[1] for i in oid_hid_dist.keys()]).tolist()
o_len = len(unique_oid)
h_len = len(unique_hid)
dist_matrix = np.zeros((o_len, h_len))
for ((oid, hid), dist) in oid_hid_dist.items():
oid_ind = unique_oid.index(oid)
hid_ind = unique_hid.index(hid)
dist_matrix[oid_ind, hid_ind] = dist
# opt_hyp_dist contains GT ID : max dist covered by track
opt_hyp_dist = dict.fromkeys(oid_dist.keys(), 0.)
cost_matrix = np.max(dist_matrix) - dist_matrix
rows, cols = linear_sum_assignment(cost_matrix)
for (row, col) in zip(rows, cols):
value = dist_matrix[row, col]
opt_hyp_dist[int(unique_oid[row])] = value
assert len(opt_hyp_dist.keys()) == len(oid_dist.keys())
hyp_length = np.sum(list(opt_hyp_dist.values()))
gt_length = np.sum(list(oid_dist.values()))
id_eucl =np.mean([np.divide(a, b, out=np.zeros_like(a), where=b!=0) for a, b in zip(opt_hyp_dist.values(), oid_dist.values())])
res['IDEucl'] = np.divide(hyp_length, gt_length, out=np.zeros_like(hyp_length), where=gt_length!=0)
return res
def combine_classes_class_averaged(self, all_res, ignore_empty_classes=False):
"""Combines metrics across all classes by averaging over the class values.
If 'ignore_empty_classes' is True, then it only sums over classes with at least one gt or predicted detection.
"""
res = {}
for field in self.float_fields:
if ignore_empty_classes:
res[field] = np.mean([v[field] for v in all_res.values()
if v['IDEucl'] > 0 + np.finfo('float').eps], axis=0)
else:
res[field] = np.mean([v[field] for v in all_res.values()], axis=0)
return res
def combine_classes_det_averaged(self, all_res):
"""Combines metrics across all classes by averaging over the detection values"""
res = {}
for field in self.float_fields:
res[field] = self._combine_sum(all_res, field)
res = self._compute_final_fields(res, len(all_res))
return res
def combine_sequences(self, all_res):
"""Combines metrics across all sequences"""
res = {}
for field in self.float_fields:
res[field] = self._combine_sum(all_res, field)
res = self._compute_final_fields(res, len(all_res))
return res
@staticmethod
def _compute_centroid(box):
box = np.array(box)
if len(box.shape) == 1:
centroid = (box[0:2] + box[2:4])/2
else:
centroid = (box[:, 0:2] + box[:, 2:4])/2
return np.flip(centroid, axis=1)
@staticmethod
def _compute_final_fields(res, res_len):
"""
Exists only to match signature with the original Identiy class.
"""
return {k:v/res_len for k,v in res.items()}
================================================
FILE: TrackEval/trackeval/metrics/j_and_f.py
================================================
import numpy as np
import math
from scipy.optimize import linear_sum_assignment
from ..utils import TrackEvalException
from ._base_metric import _BaseMetric
from .. import _timing
class JAndF(_BaseMetric):
"""Class which implements the J&F metrics"""
def __init__(self, config=None):
super().__init__()
self.integer_fields = ['num_gt_tracks']
self.float_fields = ['J-Mean', 'J-Recall', 'J-Decay', 'F-Mean', 'F-Recall', 'F-Decay', 'J&F']
self.fields = self.float_fields + self.integer_fields
self.summary_fields = self.float_fields
self.optim_type = 'J' # possible values J, J&F
@_timing.time
def eval_sequence(self, data):
"""Returns J&F metrics for one sequence"""
# Only loaded when run to reduce minimum requirements
from pycocotools import mask as mask_utils
num_timesteps = data['num_timesteps']
num_tracker_ids = data['num_tracker_ids']
num_gt_ids = data['num_gt_ids']
gt_dets = data['gt_dets']
tracker_dets = data['tracker_dets']
gt_ids = data['gt_ids']
tracker_ids = data['tracker_ids']
# get shape of frames
frame_shape = None
if num_gt_ids > 0:
for t in range(num_timesteps):
if len(gt_ids[t]) > 0:
frame_shape = gt_dets[t][0]['size']
break
elif num_tracker_ids > 0:
for t in range(num_timesteps):
if len(tracker_ids[t]) > 0:
frame_shape = tracker_dets[t][0]['size']
break
if frame_shape:
# append all zero masks for timesteps in which tracks do not have a detection
zero_padding = np.zeros((frame_shape), order= 'F').astype(np.uint8)
padding_mask = mask_utils.encode(zero_padding)
for t in range(num_timesteps):
gt_id_det_mapping = {gt_ids[t][i]: gt_dets[t][i] for i in range(len(gt_ids[t]))}
gt_dets[t] = [gt_id_det_mapping[index] if index in gt_ids[t] else padding_mask for index
in range(num_gt_ids)]
tracker_id_det_mapping = {tracker_ids[t][i]: tracker_dets[t][i] for i in range(len(tracker_ids[t]))}
tracker_dets[t] = [tracker_id_det_mapping[index] if index in tracker_ids[t] else padding_mask for index
in range(num_tracker_ids)]
# also perform zero padding if number of tracker IDs < number of ground truth IDs
if num_tracker_ids < num_gt_ids:
diff = num_gt_ids - num_tracker_ids
for t in range(num_timesteps):
tracker_dets[t] = tracker_dets[t] + [padding_mask for _ in range(diff)]
num_tracker_ids += diff
j = self._compute_j(gt_dets, tracker_dets, num_gt_ids, num_tracker_ids, num_timesteps)
# boundary threshold for F computation
bound_th = 0.008
# perform matching
if self.optim_type == 'J&F':
f = np.zeros_like(j)
for k in range(num_tracker_ids):
for i in range(num_gt_ids):
f[k, i, :] = self._compute_f(gt_dets, tracker_dets, k, i, bound_th)
optim_metrics = (np.mean(j, axis=2) + np.mean(f, axis=2)) / 2
row_ind, col_ind = linear_sum_assignment(- optim_metrics)
j_m = j[row_ind, col_ind, :]
f_m = f[row_ind, col_ind, :]
elif self.optim_type == 'J':
optim_metrics = np.mean(j, axis=2)
row_ind, col_ind = linear_sum_assignment(- optim_metrics)
j_m = j[row_ind, col_ind, :]
f_m = np.zeros_like(j_m)
for i, (tr_ind, gt_ind) in enumerate(zip(row_ind, col_ind)):
f_m[i] = self._compute_f(gt_dets, tracker_dets, tr_ind, gt_ind, bound_th)
else:
raise TrackEvalException('Unsupported optimization type %s for J&F metric.' % self.optim_type)
# append zeros for false negatives
if j_m.shape[0] < data['num_gt_ids']:
diff = data['num_gt_ids'] - j_m.shape[0]
j_m = np.concatenate((j_m, np.zeros((diff, j_m.shape[1]))), axis=0)
f_m = np.concatenate((f_m, np.zeros((diff, f_m.shape[1]))), axis=0)
# compute the metrics for each ground truth track
res = {
'J-Mean': [np.nanmean(j_m[i, :]) for i in range(j_m.shape[0])],
'J-Recall': [np.nanmean(j_m[i, :] > 0.5 + np.finfo('float').eps) for i in range(j_m.shape[0])],
'F-Mean': [np.nanmean(f_m[i, :]) for i in range(f_m.shape[0])],
'F-Recall': [np.nanmean(f_m[i, :] > 0.5 + np.finfo('float').eps) for i in range(f_m.shape[0])],
'J-Decay': [],
'F-Decay': []
}
n_bins = 4
ids = np.round(np.linspace(1, data['num_timesteps'], n_bins + 1) + 1e-10) - 1
ids = ids.astype(np.uint8)
for k in range(j_m.shape[0]):
d_bins_j = [j_m[k][ids[i]:ids[i + 1] + 1] for i in range(0, n_bins)]
res['J-Decay'].append(np.nanmean(d_bins_j[0]) - np.nanmean(d_bins_j[3]))
for k in range(f_m.shape[0]):
d_bins_f = [f_m[k][ids[i]:ids[i + 1] + 1] for i in range(0, n_bins)]
res['F-Decay'].append(np.nanmean(d_bins_f[0]) - np.nanmean(d_bins_f[3]))
# count number of tracks for weighting of the result
res['num_gt_tracks'] = len(res['J-Mean'])
for field in ['J-Mean', 'J-Recall', 'J-Decay', 'F-Mean', 'F-Recall', 'F-Decay']:
res[field] = np.mean(res[field])
res['J&F'] = (res['J-Mean'] + res['F-Mean']) / 2
return res
def combine_sequences(self, all_res):
"""Combines metrics across all sequences"""
res = {'num_gt_tracks': self._combine_sum(all_res, 'num_gt_tracks')}
for field in self.summary_fields:
res[field] = self._combine_weighted_av(all_res, field, res, weight_field='num_gt_tracks')
return res
def combine_classes_class_averaged(self, all_res, ignore_empty_classes=False):
"""Combines metrics across all classes by averaging over the class values
'ignore empty classes' is not yet implemented here.
"""
res = {'num_gt_tracks': self._combine_sum(all_res, 'num_gt_tracks')}
for field in self.float_fields:
res[field] = np.mean([v[field] for v in all_res.values()])
return res
def combine_classes_det_averaged(self, all_res):
"""Combines metrics across all classes by averaging over the detection values"""
res = {'num_gt_tracks': self._combine_sum(all_res, 'num_gt_tracks')}
for field in self.float_fields:
res[field] = np.mean([v[field] for v in all_res.values()])
return res
@staticmethod
def _seg2bmap(seg, width=None, height=None):
"""
From a segmentation, compute a binary boundary map with 1 pixel wide
boundaries. The boundary pixels are offset by 1/2 pixel towards the
origin from the actual segment boundary.
Arguments:
seg : Segments labeled from 1..k.
width : Width of desired bmap <= seg.shape[1]
height : Height of desired bmap <= seg.shape[0]
Returns:
bmap (ndarray): Binary boundary map.
David Martin
January 2003
"""
seg = seg.astype(np.bool)
seg[seg > 0] = 1
assert np.atleast_3d(seg).shape[2] == 1
width = seg.shape[1] if width is None else width
height = seg.shape[0] if height is None else height
h, w = seg.shape[:2]
ar1 = float(width) / float(height)
ar2 = float(w) / float(h)
assert not (
width > w | height > h | abs(ar1 - ar2) > 0.01
), "Can" "t convert %dx%d seg to %dx%d bmap." % (w, h, width, height)
e = np.zeros_like(seg)
s = np.zeros_like(seg)
se = np.zeros_like(seg)
e[:, :-1] = seg[:, 1:]
s[:-1, :] = seg[1:, :]
se[:-1, :-1] = seg[1:, 1:]
b = seg ^ e | seg ^ s | seg ^ se
b[-1, :] = seg[-1, :] ^ e[-1, :]
b[:, -1] = seg[:, -1] ^ s[:, -1]
b[-1, -1] = 0
if w == width and h == height:
bmap = b
else:
bmap = np.zeros((height, width))
for x in range(w):
for y in range(h):
if b[y, x]:
j = 1 + math.floor((y - 1) + height / h)
i = 1 + math.floor((x - 1) + width / h)
bmap[j, i] = 1
return bmap
@staticmethod
def _compute_f(gt_data, tracker_data, tracker_data_id, gt_id, bound_th):
"""
Perform F computation for a given gt and a given tracker ID. Adapted from
https://github.com/davisvideochallenge/davis2017-evaluation
:param gt_data: the encoded gt masks
:param tracker_data: the encoded tracker masks
:param tracker_data_id: the tracker ID
:param gt_id: the ground truth ID
:param bound_th: boundary threshold parameter
:return: the F value for the given tracker and gt ID
"""
# Only loaded when run to reduce minimum requirements
from pycocotools import mask as mask_utils
from skimage.morphology import disk
import cv2
f = np.zeros(len(gt_data))
for t, (gt_masks, tracker_masks) in enumerate(zip(gt_data, tracker_data)):
curr_tracker_mask = mask_utils.decode(tracker_masks[tracker_data_id])
curr_gt_mask = mask_utils.decode(gt_masks[gt_id])
bound_pix = bound_th if bound_th >= 1 - np.finfo('float').eps else \
np.ceil(bound_th * np.linalg.norm(curr_tracker_mask.shape))
# Get the pixel boundaries of both masks
fg_boundary = JAndF._seg2bmap(curr_tracker_mask)
gt_boundary = JAndF._seg2bmap(curr_gt_mask)
# fg_dil = binary_dilation(fg_boundary, disk(bound_pix))
fg_dil = cv2.dilate(fg_boundary.astype(np.uint8), disk(bound_pix).astype(np.uint8))
# gt_dil = binary_dilation(gt_boundary, disk(bound_pix))
gt_dil = cv2.dilate(gt_boundary.astype(np.uint8), disk(bound_pix).astype(np.uint8))
# Get the intersection
gt_match = gt_boundary * fg_dil
fg_match = fg_boundary * gt_dil
# Area of the intersection
n_fg = np.sum(fg_boundary)
n_gt = np.sum(gt_boundary)
# % Compute precision and recall
if n_fg == 0 and n_gt > 0:
precision = 1
recall = 0
elif n_fg > 0 and n_gt == 0:
precision = 0
recall = 1
elif n_fg == 0 and n_gt == 0:
precision = 1
recall = 1
else:
precision = np.sum(fg_match) / float(n_fg)
recall = np.sum(gt_match) / float(n_gt)
# Compute F measure
if precision + recall == 0:
f_val = 0
else:
f_val = 2 * precision * recall / (precision + recall)
f[t] = f_val
return f
@staticmethod
def _compute_j(gt_data, tracker_data, num_gt_ids, num_tracker_ids, num_timesteps):
"""
Computation of J value for all ground truth IDs and all tracker IDs in the given sequence. Adapted from
https://github.com/davisvideochallenge/davis2017-evaluation
:param gt_data: the ground truth masks
:param tracker_data: the tracker masks
:param num_gt_ids: the number of ground truth IDs
:param num_tracker_ids: the number of tracker IDs
:param num_timesteps: the number of timesteps
:return: the J values
"""
# Only loaded when run to reduce minimum requirements
from pycocotools import mask as mask_utils
j = np.zeros((num_tracker_ids, num_gt_ids, num_timesteps))
for t, (time_gt, time_data) in enumerate(zip(gt_data, tracker_data)):
# run length encoded masks with pycocotools
area_gt = mask_utils.area(time_gt)
time_data = list(time_data)
area_tr = mask_utils.area(time_data)
area_tr = np.repeat(area_tr[:, np.newaxis], len(area_gt), axis=1)
area_gt = np.repeat(area_gt[np.newaxis, :], len(area_tr), axis=0)
# mask iou computation with pycocotools
ious = np.atleast_2d(mask_utils.iou(time_data, time_gt, [0]*len(time_gt)))
# set iou to 1 if both masks are close to 0 (no ground truth and no predicted mask in timestep)
ious[np.isclose(area_tr, 0) & np.isclose(area_gt, 0)] = 1
assert (ious >= 0 - np.finfo('float').eps).all()
assert (ious <= 1 + np.finfo('float').eps).all()
j[..., t] = ious
return j
================================================
FILE: TrackEval/trackeval/metrics/track_map.py
================================================
import numpy as np
from ._base_metric import _BaseMetric
from .. import _timing
from functools import partial
from .. import utils
from ..utils import TrackEvalException
class TrackMAP(_BaseMetric):
"""Class which implements the TrackMAP metrics"""
@staticmethod
def get_default_metric_config():
"""Default class config values"""
default_config = {
'USE_AREA_RANGES': True, # whether to evaluate for certain area ranges
'AREA_RANGES': [[0 ** 2, 32 ** 2], # additional area range sets for which TrackMAP is evaluated
[32 ** 2, 96 ** 2], # (all area range always included), default values for TAO
[96 ** 2, 1e5 ** 2]], # evaluation
'AREA_RANGE_LABELS': ["area_s", "area_m", "area_l"], # the labels for the area ranges
'USE_TIME_RANGES': True, # whether to evaluate for certain time ranges (length of tracks)
'TIME_RANGES': [[0, 3], [3, 10], [10, 1e5]], # additional time range sets for which TrackMAP is evaluated
# (all time range always included) , default values for TAO evaluation
'TIME_RANGE_LABELS': ["time_s", "time_m", "time_l"], # the labels for the time ranges
'IOU_THRESHOLDS': np.arange(0.5, 0.96, 0.05), # the IoU thresholds
'RECALL_THRESHOLDS': np.linspace(0.0, 1.00, int(np.round((1.00 - 0.0) / 0.01) + 1), endpoint=True),
# recall thresholds at which precision is evaluated
'MAX_DETECTIONS': 0, # limit the maximum number of considered tracks per sequence (0 for unlimited)
'PRINT_CONFIG': True
}
return default_config
def __init__(self, config=None):
super().__init__()
self.config = utils.init_config(config, self.get_default_metric_config(), self.get_name())
self.num_ig_masks = 1
self.lbls = ['all']
self.use_area_rngs = self.config['USE_AREA_RANGES']
if self.use_area_rngs:
self.area_rngs = self.config['AREA_RANGES']
self.area_rng_lbls = self.config['AREA_RANGE_LABELS']
self.num_ig_masks += len(self.area_rng_lbls)
self.lbls += self.area_rng_lbls
self.use_time_rngs = self.config['USE_TIME_RANGES']
if self.use_time_rngs:
self.time_rngs = self.config['TIME_RANGES']
self.time_rng_lbls = self.config['TIME_RANGE_LABELS']
self.num_ig_masks += len(self.time_rng_lbls)
self.lbls += self.time_rng_lbls
self.array_labels = self.config['IOU_THRESHOLDS']
self.rec_thrs = self.config['RECALL_THRESHOLDS']
self.maxDet = self.config['MAX_DETECTIONS']
self.float_array_fields = ['AP_' + lbl for lbl in self.lbls] + ['AR_' + lbl for lbl in self.lbls]
self.fields = self.float_array_fields
self.summary_fields = self.float_array_fields
@_timing.time
def eval_sequence(self, data):
"""Calculates GT and Tracker matches for one sequence for TrackMAP metrics. Adapted from
https://github.com/TAO-Dataset/"""
# Initialise results to zero for each sequence as the fields are only defined over the set of all sequences
res = {}
for field in self.fields:
res[field] = [0 for _ in self.array_labels]
gt_ids, dt_ids = data['gt_track_ids'], data['dt_track_ids']
if len(gt_ids) == 0 and len(dt_ids) == 0:
for idx in range(self.num_ig_masks):
res[idx] = None
return res
# get track data
gt_tr_areas = data.get('gt_track_areas', None) if self.use_area_rngs else None
gt_tr_lengths = data.get('gt_track_lengths', None) if self.use_time_rngs else None
gt_tr_iscrowd = data.get('gt_track_iscrowd', None)
dt_tr_areas = data.get('dt_track_areas', None) if self.use_area_rngs else None
dt_tr_lengths = data.get('dt_track_lengths', None) if self.use_time_rngs else None
is_nel = data.get('not_exhaustively_labeled', False)
# compute ignore masks for different track sets to eval
gt_ig_masks = self._compute_track_ig_masks(len(gt_ids), track_lengths=gt_tr_lengths, track_areas=gt_tr_areas,
iscrowd=gt_tr_iscrowd)
dt_ig_masks = self._compute_track_ig_masks(len(dt_ids), track_lengths=dt_tr_lengths, track_areas=dt_tr_areas,
is_not_exhaustively_labeled=is_nel, is_gt=False)
boxformat = data.get('boxformat', 'xywh')
ious = self._compute_track_ious(data['dt_tracks'], data['gt_tracks'], iou_function=data['iou_type'],
boxformat=boxformat)
for mask_idx in range(self.num_ig_masks):
gt_ig_mask = gt_ig_masks[mask_idx]
# Sort gt ignore last
gt_idx = np.argsort([g for g in gt_ig_mask], kind="mergesort")
gt_ids = [gt_ids[i] for i in gt_idx]
ious_sorted = ious[:, gt_idx] if len(ious) > 0 else ious
num_thrs = len(self.array_labels)
num_gt = len(gt_ids)
num_dt = len(dt_ids)
# Array to store the "id" of the matched dt/gt
gt_m = np.zeros((num_thrs, num_gt)) - 1
dt_m = np.zeros((num_thrs, num_dt)) - 1
gt_ig = np.array([gt_ig_mask[idx] for idx in gt_idx])
dt_ig = np.zeros((num_thrs, num_dt))
for iou_thr_idx, iou_thr in enumerate(self.array_labels):
if len(ious_sorted) == 0:
break
for dt_idx, _dt in enumerate(dt_ids):
iou = min([iou_thr, 1 - 1e-10])
# information about best match so far (m=-1 -> unmatched)
# store the gt_idx which matched for _dt
m = -1
for gt_idx, _ in enumerate(gt_ids):
# if this gt already matched continue
if gt_m[iou_thr_idx, gt_idx] > 0:
continue
# if _dt matched to reg gt, and on ignore gt, stop
if m > -1 and gt_ig[m] == 0 and gt_ig[gt_idx] == 1:
break
# continue to next gt unless better match made
if ious_sorted[dt_idx, gt_idx] < iou - np.finfo('float').eps:
continue
# if match successful and best so far, store appropriately
iou = ious_sorted[dt_idx, gt_idx]
m = gt_idx
# No match found for _dt, go to next _dt
if m == -1:
continue
# if gt to ignore for some reason update dt_ig.
# Should not be used in evaluation.
dt_ig[iou_thr_idx, dt_idx] = gt_ig[m]
# _dt match found, update gt_m, and dt_m with "id"
dt_m[iou_thr_idx, dt_idx] = gt_ids[m]
gt_m[iou_thr_idx, m] = _dt
dt_ig_mask = dt_ig_masks[mask_idx]
dt_ig_mask = np.array(dt_ig_mask).reshape((1, num_dt)) # 1 X num_dt
dt_ig_mask = np.repeat(dt_ig_mask, num_thrs, 0) # num_thrs X num_dt
# Based on dt_ig_mask ignore any unmatched detection by updating dt_ig
dt_ig = np.logical_or(dt_ig, np.logical_and(dt_m == -1, dt_ig_mask))
# store results for given video and category
res[mask_idx] = {
"dt_ids": dt_ids,
"gt_ids": gt_ids,
"dt_matches": dt_m,
"gt_matches": gt_m,
"dt_scores": data['dt_track_scores'],
"gt_ignore": gt_ig,
"dt_ignore": dt_ig,
}
return res
def combine_sequences(self, all_res):
"""Combines metrics across all sequences. Computes precision and recall values based on track matches.
Adapted from https://github.com/TAO-Dataset/
"""
num_thrs = len(self.array_labels)
num_recalls = len(self.rec_thrs)
# -1 for absent categories
precision = -np.ones(
(num_thrs, num_recalls, self.num_ig_masks)
)
recall = -np.ones((num_thrs, self.num_ig_masks))
for ig_idx in range(self.num_ig_masks):
ig_idx_results = [res[ig_idx] for res in all_res.values() if res[ig_idx] is not None]
# Remove elements which are None
if len(ig_idx_results) == 0:
continue
# Append all scores: shape (N,)
# limit considered tracks for each sequence if maxDet > 0
if self.maxDet == 0:
dt_scores = np.concatenate([res["dt_scores"] for res in ig_idx_results], axis=0)
dt_idx = np.argsort(-dt_scores, kind="mergesort")
dt_m = np.concatenate([e["dt_matches"] for e in ig_idx_results],
axis=1)[:, dt_idx]
dt_ig = np.concatenate([e["dt_ignore"] for e in ig_idx_results],
axis=1)[:, dt_idx]
elif self.maxDet > 0:
dt_scores = np.concatenate([res["dt_scores"][0:self.maxDet] for res in ig_idx_results], axis=0)
dt_idx = np.argsort(-dt_scores, kind="mergesort")
dt_m = np.concatenate([e["dt_matches"][:, 0:self.maxDet] for e in ig_idx_results],
axis=1)[:, dt_idx]
dt_ig = np.concatenate([e["dt_ignore"][:, 0:self.maxDet] for e in ig_idx_results],
axis=1)[:, dt_idx]
else:
raise Exception("Number of maximum detections must be >= 0, but is set to %i" % self.maxDet)
gt_ig = np.concatenate([res["gt_ignore"] for res in ig_idx_results])
# num gt anns to consider
num_gt = np.count_nonzero(gt_ig == 0)
if num_gt == 0:
continue
tps = np.logical_and(dt_m != -1, np.logical_not(dt_ig))
fps = np.logical_and(dt_m == -1, np.logical_not(dt_ig))
tp_sum = np.cumsum(tps, axis=1).astype(dtype=np.float)
fp_sum = np.cumsum(fps, axis=1).astype(dtype=np.float)
for iou_thr_idx, (tp, fp) in enumerate(zip(tp_sum, fp_sum)):
tp = np.array(tp)
fp = np.array(fp)
num_tp = len(tp)
rc = tp / num_gt
if num_tp:
recall[iou_thr_idx, ig_idx] = rc[-1]
else:
recall[iou_thr_idx, ig_idx] = 0
# np.spacing(1) ~= eps
pr = tp / (fp + tp + np.spacing(1))
pr = pr.tolist()
# Ensure precision values are monotonically decreasing
for i in range(num_tp - 1, 0, -1):
if pr[i] > pr[i - 1]:
pr[i - 1] = pr[i]
# find indices at the predefined recall values
rec_thrs_insert_idx = np.searchsorted(rc, self.rec_thrs, side="left")
pr_at_recall = [0.0] * num_recalls
try:
for _idx, pr_idx in enumerate(rec_thrs_insert_idx):
pr_at_recall[_idx] = pr[pr_idx]
except IndexError:
pass
precision[iou_thr_idx, :, ig_idx] = (np.array(pr_at_recall))
res = {'precision': precision, 'recall': recall}
# compute the precision and recall averages for the respective alpha thresholds and ignore masks
for lbl in self.lbls:
res['AP_' + lbl] = np.zeros((len(self.array_labels)), dtype=np.float)
res['AR_' + lbl] = np.zeros((len(self.array_labels)), dtype=np.float)
for a_id, alpha in enumerate(self.array_labels):
for lbl_idx, lbl in enumerate(self.lbls):
p = precision[a_id, :, lbl_idx]
if len(p[p > -1]) == 0:
mean_p = -1
else:
mean_p = np.mean(p[p > -1])
res['AP_' + lbl][a_id] = mean_p
res['AR_' + lbl][a_id] = recall[a_id, lbl_idx]
return res
def combine_classes_class_averaged(self, all_res, ignore_empty_classes=True):
"""Combines metrics across all classes by averaging over the class values
Note mAP is not well defined for 'empty classes' so 'ignore empty classes' is always true here.
"""
res = {}
for field in self.fields:
res[field] = np.zeros((len(self.array_labels)), dtype=np.float)
field_stacked = np.array([res[field] for res in all_res.values()])
for a_id, alpha in enumerate(self.array_labels):
values = field_stacked[:, a_id]
if len(values[values > -1]) == 0:
mean = -1
else:
mean = np.mean(values[values > -1])
res[field][a_id] = mean
return res
def combine_classes_det_averaged(self, all_res):
"""Combines metrics across all classes by averaging over the detection values"""
res = {}
for field in self.fields:
res[field] = np.zeros((len(self.array_labels)), dtype=np.float)
field_stacked = np.array([res[field] for res in all_res.values()])
for a_id, alpha in enumerate(self.array_labels):
values = field_stacked[:, a_id]
if len(values[values > -1]) == 0:
mean = -1
else:
mean = np.mean(values[values > -1])
res[field][a_id] = mean
return res
def _compute_track_ig_masks(self, num_ids, track_lengths=None, track_areas=None, iscrowd=None,
is_not_exhaustively_labeled=False, is_gt=True):
"""
Computes ignore masks for different track sets to evaluate
:param num_ids: the number of track IDs
:param track_lengths: the lengths of the tracks (number of timesteps)
:param track_areas: the average area of a track
:param iscrowd: whether a track is marked as crowd
:param is_not_exhaustively_labeled: whether the track category is not exhaustively labeled
:param is_gt: whether it is gt
:return: the track ignore masks
"""
# for TAO tracks for classes which are not exhaustively labeled are not evaluated
if not is_gt and is_not_exhaustively_labeled:
track_ig_masks = [[1 for _ in range(num_ids)] for i in range(self.num_ig_masks)]
else:
# consider all tracks
track_ig_masks = [[0 for _ in range(num_ids)]]
# consider tracks with certain area
if self.use_area_rngs:
for rng in self.area_rngs:
track_ig_masks.append([0 if rng[0] - np.finfo('float').eps <= area <= rng[1] + np.finfo('float').eps
else 1 for area in track_areas])
# consider tracks with certain duration
if self.use_time_rngs:
for rng in self.time_rngs:
track_ig_masks.append([0 if rng[0] - np.finfo('float').eps <= length
<= rng[1] + np.finfo('float').eps else 1 for length in track_lengths])
# for YouTubeVIS evaluation tracks with crowd tag are not evaluated
if is_gt and iscrowd:
track_ig_masks = [np.logical_or(mask, iscrowd) for mask in track_ig_masks]
return track_ig_masks
@staticmethod
def _compute_bb_track_iou(dt_track, gt_track, boxformat='xywh'):
"""
Calculates the track IoU for one detected track and one ground truth track for bounding boxes
:param dt_track: the detected track (format: dictionary with frame index as keys and
numpy arrays as values)
:param gt_track: the ground truth track (format: dictionary with frame index as keys and
numpy array as values)
:param boxformat: the format of the boxes
:return: the track IoU
"""
intersect = 0
union = 0
image_ids = set(gt_track.keys()) | set(dt_track.keys())
for image in image_ids:
g = gt_track.get(image, None)
d = dt_track.get(image, None)
if boxformat == 'xywh':
if d is not None and g is not None:
dx, dy, dw, dh = d
gx, gy, gw, gh = g
w = max(min(dx + dw, gx + gw) - max(dx, gx), 0)
h = max(min(dy + dh, gy + gh) - max(dy, gy), 0)
i = w * h
u = dw * dh + gw * gh - i
intersect += i
union += u
elif d is None and g is not None:
union += g[2] * g[3]
elif d is not None and g is None:
union += d[2] * d[3]
elif boxformat == 'x0y0x1y1':
if d is not None and g is not None:
dx0, dy0, dx1, dy1 = d
gx0, gy0, gx1, gy1 = g
w = max(min(dx1, gx1) - max(dx0, gx0), 0)
h = max(min(dy1, gy1) - max(dy0, gy0), 0)
i = w * h
u = (dx1 - dx0) * (dy1 - dy0) + (gx1 - gx0) * (gy1 - gy0) - i
intersect += i
union += u
elif d is None and g is not None:
union += (g[2] - g[0]) * (g[3] - g[1])
elif d is not None and g is None:
union += (d[2] - d[0]) * (d[3] - d[1])
else:
raise TrackEvalException('BoxFormat not implemented')
if intersect > union:
raise TrackEvalException("Intersection value > union value. Are the box values corrupted?")
return intersect / union if union > 0 else 0
@staticmethod
def _compute_mask_track_iou(dt_track, gt_track):
"""
Calculates the track IoU for one detected track and one ground truth track for segmentation masks
:param dt_track: the detected track (format: dictionary with frame index as keys and
pycocotools rle encoded masks as values)
:param gt_track: the ground truth track (format: dictionary with frame index as keys and
pycocotools rle encoded masks as values)
:return: the track IoU
"""
# only loaded when needed to reduce minimum requirements
from pycocotools import mask as mask_utils
intersect = .0
union = .0
image_ids = set(gt_track.keys()) | set(dt_track.keys())
for image in image_ids:
g = gt_track.get(image, None)
d = dt_track.get(image, None)
if d and g:
intersect += mask_utils.area(mask_utils.merge([d, g], True))
union += mask_utils.area(mask_utils.merge([d, g], False))
elif not d and g:
union += mask_utils.area(g)
elif d and not g:
union += mask_utils.area(d)
if union < 0.0 - np.finfo('float').eps:
raise TrackEvalException("Union value < 0. Are the segmentaions corrupted?")
if intersect > union:
raise TrackEvalException("Intersection value > union value. Are the segmentations corrupted?")
iou = intersect / union if union > 0.0 + np.finfo('float').eps else 0.0
return iou
@staticmethod
def _compute_track_ious(dt, gt, iou_function='bbox', boxformat='xywh'):
"""
Calculate track IoUs for a set of ground truth tracks and a set of detected tracks
"""
if len(gt) == 0 and len(dt) == 0:
return []
if iou_function == 'bbox':
track_iou_function = partial(TrackMAP._compute_bb_track_iou, boxformat=boxformat)
elif iou_function == 'mask':
track_iou_function = partial(TrackMAP._compute_mask_track_iou)
else:
raise Exception('IoU function not implemented')
ious = np.zeros([len(dt), len(gt)])
for i, j in np.ndindex(ious.shape):
ious[i, j] = track_iou_function(dt[i], gt[j])
return ious
@staticmethod
def _row_print(*argv):
"""Prints results in an evenly spaced rows, with more space in first row"""
if len(argv) == 1:
argv = argv[0]
to_print = '%-40s' % argv[0]
for v in argv[1:]:
to_print += '%-12s' % str(v)
print(to_print)
================================================
FILE: TrackEval/trackeval/metrics/vace.py
================================================
import numpy as np
from scipy.optimize import linear_sum_assignment
from ._base_metric import _BaseMetric
from .. import _timing
class VACE(_BaseMetric):
"""Class which implements the VACE metrics.
The metrics are described in:
Manohar et al. (2006) "Performance Evaluation of Object Detection and Tracking in Video"
https://link.springer.com/chapter/10.1007/11612704_16
This implementation uses the "relaxed" variant of the metrics,
where an overlap threshold is applied in each frame.
"""
def __init__(self, config=None):
super().__init__()
self.integer_fields = ['VACE_IDs', 'VACE_GT_IDs', 'num_non_empty_timesteps']
self.float_fields = ['STDA', 'ATA', 'FDA', 'SFDA']
self.fields = self.integer_fields + self.float_fields
self.summary_fields = ['SFDA', 'ATA']
# Fields that are accumulated over multiple videos.
self._additive_fields = self.integer_fields + ['STDA', 'FDA']
self.threshold = 0.5
@_timing.time
def eval_sequence(self, data):
"""Calculates VACE metrics for one sequence.
Depends on the fields:
data['num_gt_ids']
data['num_tracker_ids']
data['gt_ids']
data['tracker_ids']
data['similarity_scores']
"""
res = {}
# Obtain Average Tracking Accuracy (ATA) using track correspondence.
# Obtain counts necessary to compute temporal IOU.
# Assume that integer counts can be represented exactly as floats.
potential_matches_count = np.zeros((data['num_gt_ids'], data['num_tracker_ids']))
gt_id_count = np.zeros(data['num_gt_ids'])
tracker_id_count = np.zeros(data['num_tracker_ids'])
both_present_count = np.zeros((data['num_gt_ids'], data['num_tracker_ids']))
for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
# Count the number of frames in which two tracks satisfy the overlap criterion.
matches_mask = np.greater_equal(data['similarity_scores'][t], self.threshold)
match_idx_gt, match_idx_tracker = np.nonzero(matches_mask)
potential_matches_count[gt_ids_t[match_idx_gt], tracker_ids_t[match_idx_tracker]] += 1
# Count the number of frames in which the tracks are present.
gt_id_count[gt_ids_t] += 1
tracker_id_count[tracker_ids_t] += 1
both_present_count[gt_ids_t[:, np.newaxis], tracker_ids_t[np.newaxis, :]] += 1
# Number of frames in which either track is present (union of the two sets of frames).
union_count = (gt_id_count[:, np.newaxis]
+ tracker_id_count[np.newaxis, :]
- both_present_count)
# The denominator should always be non-zero if all tracks are non-empty.
with np.errstate(divide='raise', invalid='raise'):
temporal_iou = potential_matches_count / union_count
# Find assignment that maximizes temporal IOU.
match_rows, match_cols = linear_sum_assignment(-temporal_iou)
res['STDA'] = temporal_iou[match_rows, match_cols].sum()
res['VACE_IDs'] = data['num_tracker_ids']
res['VACE_GT_IDs'] = data['num_gt_ids']
# Obtain Frame Detection Accuracy (FDA) using per-frame correspondence.
non_empty_count = 0
fda = 0
for t, (gt_ids_t, tracker_ids_t) in enumerate(zip(data['gt_ids'], data['tracker_ids'])):
n_g = len(gt_ids_t)
n_d = len(tracker_ids_t)
if not (n_g or n_d):
continue
# n_g > 0 or n_d > 0
non_empty_count += 1
if not (n_g and n_d):
continue
# n_g > 0 and n_d > 0
spatial_overlap = data['similarity_scores'][t]
match_rows, match_cols = linear_sum_assignment(-spatial_overlap)
overlap_ratio = spatial_overlap[match_rows, match_cols].sum()
fda += overlap_ratio / (0.5 * (n_g + n_d))
res['FDA'] = fda
res['num_non_empty_timesteps'] = non_empty_count
res.update(self._compute_final_fields(res))
return res
def combine_classes_class_averaged(self, all_res, ignore_empty_classes=True):
"""Combines metrics across all classes by averaging over the class values.
If 'ignore_empty_classes' is True, then it only sums over classes with at least one gt or predicted detection.
"""
res = {}
for field in self.fields:
if ignore_empty_classes:
res[field] = np.mean([v[field] for v in all_res.values()
if v['VACE_GT_IDs'] > 0 or v['VACE_IDs'] > 0], axis=0)
else:
res[field] = np.mean([v[field] for v in all_res.values()], axis=0)
return res
def combine_classes_det_averaged(self, all_res):
"""Combines metrics across all classes by averaging over the detection values"""
res = {}
for field in self._additive_fields:
res[field] = _BaseMetric._combine_sum(all_res, field)
res = self._compute_final_fields(res)
return res
def combine_sequences(self, all_res):
"""Combines metrics across all sequences"""
res = {}
for header in self._additive_fields:
res[header] = _BaseMetric._combine_sum(all_res, header)
res.update(self._compute_final_fields(res))
return res
@staticmethod
def _compute_final_fields(additive):
final = {}
with np.errstate(invalid='ignore'): # Permit nan results.
final['ATA'] = (additive['STDA'] /
(0.5 * (additive['VACE_IDs'] + additive['VACE_GT_IDs'])))
final['SFDA'] = additive['FDA'] / additive['num_non_empty_timesteps']
return final
================================================
FILE: TrackEval/trackeval/plotting.py
================================================
import os
import numpy as np
from .utils import TrackEvalException
def plot_compare_trackers(tracker_folder, tracker_list, cls, output_folder, plots_list=None):
"""Create plots which compare metrics across different trackers."""
# Define what to plot
if plots_list is None:
plots_list = get_default_plots_list()
# Load data
data = load_multiple_tracker_summaries(tracker_folder, tracker_list, cls)
out_loc = os.path.join(output_folder, cls)
# Plot
for args in plots_list:
create_comparison_plot(data, out_loc, *args)
def get_default_plots_list():
# y_label, x_label, sort_label, bg_label, bg_function
plots_list = [
['AssA', 'DetA', 'HOTA', 'HOTA', 'geometric_mean'],
['AssPr', 'AssRe', 'HOTA', 'AssA', 'jaccard'],
['DetPr', 'DetRe', 'HOTA', 'DetA', 'jaccard'],
['HOTA(0)', 'LocA(0)', 'HOTA', 'HOTALocA(0)', 'multiplication'],
['HOTA', 'LocA', 'HOTA', None, None],
['HOTA', 'MOTA', 'HOTA', None, None],
['HOTA', 'IDF1', 'HOTA', None, None],
['IDF1', 'MOTA', 'HOTA', None, None],
]
return plots_list
def load_multiple_tracker_summaries(tracker_folder, tracker_list, cls):
"""Loads summary data for multiple trackers."""
data = {}
for tracker in tracker_list:
with open(os.path.join(tracker_folder, tracker, cls + '_summary.txt')) as f:
keys = next(f).split(' ')
done = False
while not done:
values = next(f).split(' ')
if len(values) == len(keys):
done = True
data[tracker] = dict(zip(keys, map(float, values)))
return data
def create_comparison_plot(data, out_loc, y_label, x_label, sort_label, bg_label=None, bg_function=None, settings=None):
""" Creates a scatter plot comparing multiple trackers between two metric fields, with one on the x-axis and the
other on the y axis. Adds pareto optical lines and (optionally) a background contour.
Inputs:
data: dict of dicts such that data[tracker_name][metric_field_name] = float
y_label: the metric_field_name to be plotted on the y-axis
x_label: the metric_field_name to be plotted on the x-axis
sort_label: the metric_field_name by which trackers are ordered and ranked
bg_label: the metric_field_name by which (optional) background contours are plotted
bg_function: the (optional) function bg_function(x,y) which converts the x_label / y_label values into bg_label.
settings: dict of plot settings with keys:
'gap_val': gap between axis ticks and bg curves.
'num_to_plot': maximum number of trackers to plot
"""
# Only loaded when run to reduce minimum requirements
from matplotlib import pyplot as plt
# Get plot settings
if settings is None:
gap_val = 2
num_to_plot = 20
else:
gap_val = settings['gap_val']
num_to_plot = settings['num_to_plot']
if (bg_label is None) != (bg_function is None):
raise TrackEvalException('bg_function and bg_label must either be both given or neither given.')
# Extract data
tracker_names = np.array(list(data.keys()))
sort_index = np.array([data[t][sort_label] for t in tracker_names]).argsort()[::-1]
x_values = np.array([data[t][x_label] for t in tracker_names])[sort_index][:num_to_plot]
y_values = np.array([data[t][y_label] for t in tracker_names])[sort_index][:num_to_plot]
# Print info on what is being plotted
tracker_names = tracker_names[sort_index][:num_to_plot]
print('\nPlotting %s vs %s, for the following (ordered) trackers:' % (y_label, x_label))
for i, name in enumerate(tracker_names):
print('%i: %s' % (i+1, name))
# Find best fitting boundaries for data
boundaries = _get_boundaries(x_values, y_values, round_val=gap_val/2)
fig = plt.figure()
# Plot background contour
if bg_function is not None:
_plot_bg_contour(bg_function, boundaries, gap_val)
# Plot pareto optimal lines
_plot_pareto_optimal_lines(x_values, y_values)
# Plot data points with number labels
labels = np.arange(len(y_values)) + 1
plt.plot(x_values, y_values, 'b.', markersize=15)
for xx, yy, l in zip(x_values, y_values, labels):
plt.text(xx, yy, str(l), color="red", fontsize=15)
# Add extra explanatory text to plots
plt.text(0, -0.11, 'label order:\nHOTA', horizontalalignment='left', verticalalignment='center',
transform=fig.axes[0].transAxes, color="red", fontsize=12)
if bg_label is not None:
plt.text(1, -0.11, 'curve values:\n' + bg_label, horizontalalignment='right', verticalalignment='center',
transform=fig.axes[0].transAxes, color="grey", fontsize=12)
plt.xlabel(x_label, fontsize=15)
plt.ylabel(y_label, fontsize=15)
title = y_label + ' vs ' + x_label
if bg_label is not None:
title += ' (' + bg_label + ')'
plt.title(title, fontsize=17)
plt.xticks(np.arange(0, 100, gap_val))
plt.yticks(np.arange(0, 100, gap_val))
min_x, max_x, min_y, max_y = boundaries
plt.xlim(min_x, max_x)
plt.ylim(min_y, max_y)
plt.gca().set_aspect('equal', adjustable='box')
plt.tight_layout()
os.makedirs(out_loc, exist_ok=True)
filename = os.path.join(out_loc, title.replace(' ', '_'))
plt.savefig(filename + '.pdf', bbox_inches='tight', pad_inches=0.05)
plt.savefig(filename + '.png', bbox_inches='tight', pad_inches=0.05)
def _get_boundaries(x_values, y_values, round_val):
x1 = np.min(np.floor((x_values - 0.5) / round_val) * round_val)
x2 = np.max(np.ceil((x_values + 0.5) / round_val) * round_val)
y1 = np.min(np.floor((y_values - 0.5) / round_val) * round_val)
y2 = np.max(np.ceil((y_values + 0.5) / round_val) * round_val)
x_range = x2 - x1
y_range = y2 - y1
max_range = max(x_range, y_range)
x_center = (x1 + x2) / 2
y_center = (y1 + y2) / 2
min_x = max(x_center - max_range / 2, 0)
max_x = min(x_center + max_range / 2, 100)
min_y = max(y_center - max_range / 2, 0)
max_y = min(y_center + max_range / 2, 100)
return min_x, max_x, min_y, max_y
def geometric_mean(x, y):
return np.sqrt(x * y)
def jaccard(x, y):
x = x / 100
y = y / 100
return 100 * (x * y) / (x + y - x * y)
def multiplication(x, y):
return x * y / 100
bg_function_dict = {
"geometric_mean": geometric_mean,
"jaccard": jaccard,
"multiplication": multiplication,
}
def _plot_bg_contour(bg_function, plot_boundaries, gap_val):
""" Plot background contour. """
# Only loaded when run to reduce minimum requirements
from matplotlib import pyplot as plt
# Plot background contour
min_x, max_x, min_y, max_y = plot_boundaries
x = np.arange(min_x, max_x, 0.1)
y = np.arange(min_y, max_y, 0.1)
x_grid, y_grid = np.meshgrid(x, y)
if bg_function in bg_function_dict.keys():
z_grid = bg_function_dict[bg_function](x_grid, y_grid)
else:
raise TrackEvalException("background plotting function '%s' is not defined." % bg_function)
levels = np.arange(0, 100, gap_val)
con = plt.contour(x_grid, y_grid, z_grid, levels, colors='grey')
def bg_format(val):
s = '{:1f}'.format(val)
return '{:.0f}'.format(val) if s[-1] == '0' else s
con.levels = [bg_format(val) for val in con.levels]
plt.clabel(con, con.levels, inline=True, fmt='%r', fontsize=8)
def _plot_pareto_optimal_lines(x_values, y_values):
""" Plot pareto optimal lines """
# Only loaded when run to reduce minimum requirements
from matplotlib import pyplot as plt
# Plot pareto optimal lines
cxs = x_values
cys = y_values
best_y = np.argmax(cys)
x_pareto = [0, cxs[best_y]]
y_pareto = [cys[best_y], cys[best_y]]
t = 2
remaining = cxs > x_pareto[t - 1]
cys = cys[remaining]
cxs = cxs[remaining]
while len(cxs) > 0 and len(cys) > 0:
best_y = np.argmax(cys)
x_pareto += [x_pareto[t - 1], cxs[best_y]]
y_pareto += [cys[best_y], cys[best_y]]
t += 2
remaining = cxs > x_pareto[t - 1]
cys = cys[remaining]
cxs = cxs[remaining]
x_pareto.append(x_pareto[t - 1])
y_pareto.append(0)
plt.plot(np.array(x_pareto), np.array(y_pareto), '--r')
================================================
FILE: TrackEval/trackeval/utils.py
================================================
import os
import csv
import argparse
from collections import OrderedDict
def init_config(config, default_config, name=None):
"""Initialise non-given config values with defaults"""
if config is None:
config = default_config
else:
for k in default_config.keys():
if k not in config.keys():
config[k] = default_config[k]
if name and config['PRINT_CONFIG']:
print('\n%s Config:' % name)
for c in config.keys():
print('%-20s : %-30s' % (c, config[c]))
return config
def update_config(config):
"""
Parse the arguments of a script and updates the config values for a given value if specified in the arguments.
:param config: the config to update
:return: the updated config
"""
parser = argparse.ArgumentParser()
for setting in config.keys():
if type(config[setting]) == list or type(config[setting]) == type(None):
parser.add_argument("--" + setting, nargs='+')
else:
parser.add_argument("--" + setting)
args = parser.parse_args().__dict__
for setting in args.keys():
if args[setting] is not None:
if type(config[setting]) == type(True):
if args[setting] == 'True':
x = True
elif args[setting] == 'False':
x = False
else:
raise Exception('Command line parameter ' + setting + 'must be True or False')
elif type(config[setting]) == type(1):
x = int(args[setting])
elif type(args[setting]) == type(None):
x = None
else:
x = args[setting]
config[setting] = x
return config
def get_code_path():
"""Get base path where code is"""
return os.path.abspath(os.path.join(os.path.dirname(__file__), '..'))
def validate_metrics_list(metrics_list):
"""Get names of metric class and ensures they are unique, further checks that the fields within each metric class
do not have overlapping names.
"""
metric_names = [metric.get_name() for metric in metrics_list]
# check metric names are unique
if len(metric_names) != len(set(metric_names)):
raise TrackEvalException('Code being run with multiple metrics of the same name')
fields = []
for m in metrics_list:
fields += m.fields
# check metric fields are unique
if len(fields) != len(set(fields)):
raise TrackEvalException('Code being run with multiple metrics with fields of the same name')
return metric_names
def write_summary_results(summaries, cls, output_folder):
"""Write summary results to file"""
fields = sum([list(s.keys()) for s in summaries], [])
values = sum([list(s.values()) for s in summaries], [])
# In order to remain consistent upon new fields being adding, for each of the following fields if they are present
# they will be output in the summary first in the order below. Any further fields will be output in the order each
# metric family is called, and within each family either in the order they were added to the dict (python >= 3.6) or
# randomly (python < 3.6).
default_order = ['HOTA', 'DetA', 'AssA', 'DetRe', 'DetPr', 'AssRe', 'AssPr', 'LocA', 'RHOTA', 'HOTA(0)', 'LocA(0)',
'HOTALocA(0)', 'MOTA', 'MOTP', 'MODA', 'CLR_Re', 'CLR_Pr', 'MTR', 'PTR', 'MLR', 'CLR_TP', 'CLR_FN',
'CLR_FP', 'IDSW', 'MT', 'PT', 'ML', 'Frag', 'sMOTA', 'IDF1', 'IDR', 'IDP', 'IDTP', 'IDFN', 'IDFP',
'Dets', 'GT_Dets', 'IDs', 'GT_IDs']
default_ordered_dict = OrderedDict(zip(default_order, [None for _ in default_order]))
for f, v in zip(fields, values):
default_ordered_dict[f] = v
for df in default_order:
if default_ordered_dict[df] is None:
del default_ordered_dict[df]
fields = list(default_ordered_dict.keys())
values = list(default_ordered_dict.values())
out_file = os.path.join(output_folder, cls + '_summary.txt')
os.makedirs(os.path.dirname(out_file), exist_ok=True)
with open(out_file, 'w', newline='') as f:
writer = csv.writer(f, delimiter=' ')
writer.writerow(fields)
writer.writerow(values)
def write_detailed_results(details, cls, output_folder):
"""Write detailed results to file"""
sequences = details[0].keys()
fields = ['seq'] + sum([list(s['COMBINED_SEQ'].keys()) for s in details], [])
out_file = os.path.join(output_folder, cls + '_detailed.csv')
os.makedirs(os.path.dirname(out_file), exist_ok=True)
with open(out_file, 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(fields)
for seq in sorted(sequences):
if seq == 'COMBINED_SEQ':
continue
writer.writerow([seq] + sum([list(s[seq].values()) for s in details], []))
writer.writerow(['COMBINED'] + sum([list(s['COMBINED_SEQ'].values()) for s in details], []))
def load_detail(file):
"""Loads detailed data for a tracker."""
data = {}
with open(file) as f:
for i, row_text in enumerate(f):
row = row_text.replace('\r', '').replace('\n', '').split(',')
if i == 0:
keys = row[1:]
continue
current_values = row[1:]
seq = row[0]
if seq == 'COMBINED':
seq = 'COMBINED_SEQ'
if (len(current_values) == len(keys)) and seq != '':
data[seq] = {}
for key, value in zip(keys, current_values):
data[seq][key] = float(value)
return data
class TrackEvalException(Exception):
"""Custom exception for catching expected errors."""
...
================================================
FILE: deploy/ONNXRuntime/README.md
================================================
## ByteTrack-ONNXRuntime in Python
This doc introduces how to convert your pytorch model into onnx, and how to run an onnxruntime demo to verify your convertion.
### Convert Your Model to ONNX
```shell
cd
python3 tools/export_onnx.py --output-name bytetrack_s.onnx -f exps/example/mot/yolox_s_mix_det.py -c pretrained/bytetrack_s_mot17.pth.tar
```
### ONNXRuntime Demo
You can run onnx demo with **16 FPS** (96-core Intel(R) Xeon(R) Platinum 8163 CPU @ 2.50GHz):
```shell
cd /deploy/ONNXRuntime
python3 onnx_inference.py
```
================================================
FILE: deploy/ONNXRuntime/onnx_inference.py
================================================
import argparse
import os
import cv2
import numpy as np
from loguru import logger
import onnxruntime
from yolox.data.data_augment import preproc as preprocess
from yolox.utils import mkdir, multiclass_nms, demo_postprocess, vis
from yolox.utils.visualize import plot_tracking
from trackers.ocsort_tracker.ocsort import OCSort
from trackers.tracking_utils.timer import Timer
def make_parser():
parser = argparse.ArgumentParser("onnxruntime inference sample")
parser.add_argument(
"-m",
"--model",
type=str,
default="../../ocsort.onnx",
help="Input your onnx model.",
)
parser.add_argument(
"-i",
"--video_path",
type=str,
default='../../videos/dance_demo.mp4',
help="Path to your input image.",
)
parser.add_argument(
"-o",
"--output_dir",
type=str,
default='demo_output',
help="Path to your output directory.",
)
parser.add_argument(
"-s",
"--score_thr",
type=float,
default=0.1,
help="Score threshould to filter the result.",
)
parser.add_argument(
"-n",
"--nms_thr",
type=float,
default=0.7,
help="NMS threshould.",
)
parser.add_argument(
"--input_shape",
type=str,
default="800,1440",
help="Specify an input shape for inference.",
)
parser.add_argument(
"--with_p6",
action="store_true",
help="Whether your model uses p6 in FPN/PAN.",
)
# tracking args
parser.add_argument("--track_thresh", type=float, default=0.6, help="tracking confidence threshold")
parser.add_argument("--iou_thresh", type=float, default=0.3, help="tracking confidence threshold")
parser.add_argument("--track_buffer", type=int, default=30, help="the frames for keep lost tracks")
parser.add_argument("--match_thresh", type=float, default=0.8, help="matching threshold for tracking")
parser.add_argument('--min-box-area', type=float, default=10, help='filter out tiny boxes')
parser.add_argument("--mot20", dest="mot20", default=False, action="store_true", help="test mot20.")
return parser
class Predictor(object):
def __init__(self, args):
self.rgb_means = (0.485, 0.456, 0.406)
self.std = (0.229, 0.224, 0.225)
self.args = args
self.session = onnxruntime.InferenceSession(args.model)
self.input_shape = tuple(map(int, args.input_shape.split(',')))
def inference(self, ori_img, timer):
img_info = {"id": 0}
height, width = ori_img.shape[:2]
img_info["height"] = height
img_info["width"] = width
img_info["raw_img"] = ori_img
img, ratio = preprocess(ori_img, self.input_shape, self.rgb_means, self.std)
img_info["ratio"] = ratio
ort_inputs = {self.session.get_inputs()[0].name: img[None, :, :, :]}
timer.tic()
output = self.session.run(None, ort_inputs)
predictions = demo_postprocess(output[0], self.input_shape, p6=self.args.with_p6)[0]
boxes = predictions[:, :4]
scores = predictions[:, 4:5] * predictions[:, 5:]
boxes_xyxy = np.ones_like(boxes)
boxes_xyxy[:, 0] = boxes[:, 0] - boxes[:, 2]/2.
boxes_xyxy[:, 1] = boxes[:, 1] - boxes[:, 3]/2.
boxes_xyxy[:, 2] = boxes[:, 0] + boxes[:, 2]/2.
boxes_xyxy[:, 3] = boxes[:, 1] + boxes[:, 3]/2.
boxes_xyxy /= ratio
dets = multiclass_nms(boxes_xyxy, scores, nms_thr=self.args.nms_thr, score_thr=self.args.score_thr)
return dets[:, :-1], img_info
def imageflow_demo(predictor, args):
cap = cv2.VideoCapture(args.video_path)
width = cap.get(cv2.CAP_PROP_FRAME_WIDTH) # float
height = cap.get(cv2.CAP_PROP_FRAME_HEIGHT) # float
fps = cap.get(cv2.CAP_PROP_FPS)
save_folder = args.output_dir
os.makedirs(save_folder, exist_ok=True)
save_path = os.path.join(save_folder, args.video_path.split("/")[-1])
logger.info(f"video save_path is {save_path}")
vid_writer = cv2.VideoWriter(
save_path, cv2.VideoWriter_fourcc(*"mp4v"), fps, (int(width), int(height))
)
tracker = OCSort(det_thresh=args.track_thresh, iou_threshold=args.iou_thresh)
timer = Timer()
frame_id = 0
results = []
while True:
if frame_id % 20 == 0:
logger.info('Processing frame {} ({:.2f} fps)'.format(frame_id, 1. / max(1e-5, timer.average_time)))
ret_val, frame = cap.read()
if ret_val:
outputs, img_info = predictor.inference(frame, timer)
online_targets = tracker.update(outputs, [img_info['height'], img_info['width']], [img_info['height'], img_info['width']])
online_tlwhs = []
online_ids = []
# online_scores = []
for t in online_targets:
tlwh = [t[0], t[1], t[2] - t[0], t[3] - t[1]]
tid = t[4]
vertical = tlwh[2] / tlwh[3] > 1.6
if tlwh[2] * tlwh[3] > args.min_box_area and not vertical:
online_tlwhs.append(tlwh)
online_ids.append(tid)
# online_scores.append(t.score)
timer.toc()
results.append((frame_id + 1, online_tlwhs, online_ids))
online_im = plot_tracking(img_info['raw_img'], online_tlwhs, online_ids, frame_id=frame_id + 1,
fps=1. / timer.average_time)
vid_writer.write(online_im)
ch = cv2.waitKey(1)
if ch == 27 or ch == ord("q") or ch == ord("Q"):
break
else:
break
frame_id += 1
if __name__ == '__main__':
args = make_parser().parse_args()
predictor = Predictor(args)
imageflow_demo(predictor, args)
================================================
FILE: deploy/TensorRT/cpp/CMakeLists.txt
================================================
cmake_minimum_required(VERSION 2.6)
project(bytetrack)
add_definitions(-std=c++11)
option(CUDA_USE_STATIC_CUDA_RUNTIME OFF)
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_BUILD_TYPE Debug)
find_package(CUDA REQUIRED)
include_directories(${PROJECT_SOURCE_DIR}/include)
include_directories(/usr/local/include/eigen3)
link_directories(${PROJECT_SOURCE_DIR}/include)
# include and link dirs of cuda and tensorrt, you need adapt them if yours are different
# cuda
include_directories(/usr/local/cuda/include)
link_directories(/usr/local/cuda/lib64)
# cudnn
include_directories(/data/cuda/cuda-10.2/cudnn/v8.0.4/include)
link_directories(/data/cuda/cuda-10.2/cudnn/v8.0.4/lib64)
# tensorrt
include_directories(/opt/tiger/demo/TensorRT-7.2.3.4/include)
link_directories(/opt/tiger/demo/TensorRT-7.2.3.4/lib)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wall -Ofast -Wfatal-errors -D_MWAITXINTRIN_H_INCLUDED")
find_package(OpenCV)
include_directories(${OpenCV_INCLUDE_DIRS})
file(GLOB My_Source_Files ${PROJECT_SOURCE_DIR}/src/*.cpp)
add_executable(bytetrack ${My_Source_Files})
target_link_libraries(bytetrack nvinfer)
target_link_libraries(bytetrack cudart)
target_link_libraries(bytetrack ${OpenCV_LIBS})
add_definitions(-O2 -pthread)
================================================
FILE: deploy/TensorRT/cpp/README.md
================================================
# ByteTrack-TensorRT in C++
## Installation
Install opencv with ```sudo apt-get install libopencv-dev``` (we don't need a higher version of opencv like v3.3+).
Install eigen-3.3.9 [[google]](https://drive.google.com/file/d/1rqO74CYCNrmRAg8Rra0JP3yZtJ-rfket/view?usp=sharing), [[baidu(code:ueq4)]](https://pan.baidu.com/s/15kEfCxpy-T7tz60msxxExg).
```shell
unzip eigen-3.3.9.zip
cd eigen-3.3.9
mkdir build
cd build
cmake ..
sudo make install
```
## Prepare serialized engine file
Follow the TensorRT Python demo to convert and save the serialized engine file.
Check the 'model_trt.engine' file, which will be automatically saved at the YOLOX_output dir.
## Build the demo
You should set the TensorRT path and CUDA path in CMakeLists.txt.
For bytetrack_s model, we set the input frame size 1088 x 608. For bytetrack_m, bytetrack_l, bytetrack_x models, we set the input frame size 1440 x 800. You can modify the INPUT_W and INPUT_H in src/bytetrack.cpp
```c++
static const int INPUT_W = 1088;
static const int INPUT_H = 608;
```
You can first build the demo:
```shell
cd /deploy/TensorRT/cpp
mkdir build
cd build
cmake ..
make
```
Then you can run the demo with **200 FPS**:
```shell
./bytetrack ../../../../YOLOX_outputs/yolox_s_mix_det/model_trt.engine -i ../../../../videos/palace.mp4
```
(If you find the output video lose some frames, you can convert the input video by running:
```shell
cd
python3 tools/convert_video.py
```
to generate an appropriate input video for TensorRT C++ demo. )
================================================
FILE: deploy/TensorRT/cpp/include/BYTETracker.h
================================================
#pragma once
#include "STrack.h"
struct Object
{
cv::Rect_ rect;
int label;
float prob;
};
class BYTETracker
{
public:
BYTETracker(int frame_rate = 30, int track_buffer = 30);
~BYTETracker();
vector update(const vector

 ## TCM on other trackers
download ReID weight from [googlenet_part8_all_xavier_ckpt_56.h5](https://drive.google.com/drive/folders/18IsZGeGiyKDshhYIzbpYXoNEcBhPY8lN?usp=sharing) for MOTDT and DeepSORT.
**dancetrack-val dataset**
```
# SORT
python tools/run_sort_dance.py -f exps/example/mot/yolox_dancetrack_val.py -c pretrained/bytetrack_dance_model.pth.tar -b 1 -d 1 --fp16 --fuse --dataset dancetrack --expn sort_score_kalman_fir_step --TCM_first_step
# MOTDT
python3 tools/run_motdt_dance.py -f exps/example/mot/yolox_dancetrack_val.py -c pretrained/bytetrack_dance_model.pth.tar -b 1 -d 1 --fp16 --fuse --dataset dancetrack --expn motdt_score_kalman_fir_step --TCM_first_step
# ByteTrack
python3 tools/run_byte_dance.py -f exps/example/mot/yolox_dancetrack_val.py -c pretrained/bytetrack_dance_model.pth.tar -b 1 -d 1 --fp16 --fuse --dataset dancetrack --expn byte_score_kalman_fir_step --TCM_first_step
# DeepSORT
python3 tools/run_deepsort_dance.py -f exps/example/mot/yolox_dancetrack_val.py -c pretrained/bytetrack_dance_model.pth.tar -b 1 -d 1 --fp16 --fuse --dataset dancetrack --expn deepsort_score_kalman_fir_step --TCM_first_step
```
**mot17-val dataset**
```
# SORT
python3 tools/run_sort.py -f exps/example/mot/yolox_x_ablation.py -c pretrained/ocsort_mot17_ablation.pth.tar -b 1 -d 1 --fuse --expn mot17_sort_score_test_fp32 --TCM_first_step
# MOTDT
python3 tools/run_motdt.py -f exps/example/mot/yolox_x_ablation.py -c pretrained/ocsort_mot17_ablation.pth.tar -b 1 -d 1 --fuse --expn mot17_motdt_score_test_fp32 --TCM_first_step
# ByteTrack
python3 tools/run_byte.py -f exps/example/mot/yolox_x_ablation.py -c pretrained/ocsort_mot17_ablation.pth.tar -b 1 -d 1 --fuse --expn mot17_byte_score_test_fp32 --TCM_first_step --TCM_first_step_weight 0.6
# DeepSORT
python3 tools/run_deepsort.py -f exps/example/mot/yolox_x_ablation.py -c pretrained/ocsort_mot17_ablation.pth.tar -b 1 -d 1 --fuse --expn mot17_deepsort_score_test_fp32 --TCM_first_step
```
## Citation
If you find this work useful, please consider to cite our paper:
```
@inproceedings{yang2024hybrid,
title={Hybrid-sort: Weak cues matter for online multi-object tracking},
author={Yang, Mingzhan and Han, Guangxin and Yan, Bin and Zhang, Wenhua and Qi, Jinqing and Lu, Huchuan and Wang, Dong},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={38},
number={7},
pages={6504--6512},
year={2024}
}
```
## Acknowledgement
A large part of the code is borrowed from [YOLOX](https://github.com/Megvii-BaseDetection/YOLOX), [OC-SORT](https://github.com/noahcao/OC_SORT), [ByteTrack](https://github.com/ifzhang/ByteTrack), [BoT-SORT](https://github.com/NirAharon/BOT-SORT) and [FastReID](https://github.com/JDAI-CV/fast-reid). Many thanks for their wonderful works.
================================================
FILE: TrackEval/.gitignore
================================================
gt_data/*
!gt_data/Readme.md
tracker_output/*
!tracker_output/Readme.md
output/*
data/*
!goutput/Readme.md
**/__pycache__
.idea
error_log.txt
================================================
FILE: TrackEval/LICENSE
================================================
MIT License
Copyright (c) 2020 Jonathon Luiten
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: TrackEval/Readme.md
================================================
# TrackEval
*Code for evaluating object tracking.*
This codebase provides code for a number of different tracking evaluation metrics (including the [HOTA metrics](https://link.springer.com/article/10.1007/s11263-020-01375-2)), as well as supporting running all of these metrics on a number of different tracking benchmarks. Plus plotting of results and other things one may want to do for tracking evaluation.
## **NEW**: RobMOTS Challenge 2021
Call for submission to our [RobMOTS Challenge](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110) (Robust Multi-Object Tracking and Segmentation) held in conjunction with our [RVSU CVPR'21 Workshop](https://eval.vision.rwth-aachen.de/rvsu-workshop21/). Robust tracking evaluation against 8 tracking benchmarks. Challenge submission deadline June 15th. Also check out our workshop [call for papers](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=74).
## Official Evaluation Code
The following benchmarks use TrackEval as their official evaluation code, check out the links to see TrackEval in action:
- **[RobMOTS](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110)** ([Official Readme](docs/RobMOTS-Official/Readme.md))
- **[KITTI Tracking](http://www.cvlibs.net/datasets/kitti/eval_tracking.php)**
- **[KITTI MOTS](http://www.cvlibs.net/datasets/kitti/eval_mots.php)**
- **[MOTChallenge](https://motchallenge.net/)** ([Official Readme](docs/MOTChallenge-Official/Readme.md))
- **[Open World Tracking](https://openworldtracking.github.io)** ([Official Readme](docs/OpenWorldTracking-Official))
If you run a tracking benchmark and want to use TrackEval as your official evaluation code, please contact Jonathon (contact details below).
## Currently implemented metrics
The following metrics are currently implemented:
Metric Family | Sub metrics | Paper | Code | Notes |
|----- | ----------- |----- | ----------- | ----- |
| | | | | |
|**HOTA metrics**|HOTA, DetA, AssA, LocA, DetPr, DetRe, AssPr, AssRe|[paper](https://link.springer.com/article/10.1007/s11263-020-01375-2)|[code](trackeval/metrics/hota.py)|**Recommended tracking metric**|
|**CLEARMOT metrics**|MOTA, MOTP, MT, ML, Frag, etc.|[paper](https://link.springer.com/article/10.1155/2008/246309)|[code](trackeval/metrics/clear.py)| |
|**Identity metrics**|IDF1, IDP, IDR|[paper](https://arxiv.org/abs/1609.01775)|[code](trackeval/metrics/identity.py)| |
|**VACE metrics**|ATA, SFDA|[paper](https://link.springer.com/chapter/10.1007/11612704_16)|[code](trackeval/metrics/vace.py)| |
|**Track mAP metrics**|Track mAP|[paper](https://arxiv.org/abs/1905.04804)|[code](trackeval/metrics/track_map.py)|Requires confidence scores|
|**J & F metrics**|J&F, J, F|[paper](https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Perazzi_A_Benchmark_Dataset_CVPR_2016_paper.pdf)|[code](trackeval/metrics/j_and_f.py)|Only for Seg Masks|
|**ID Euclidean**|ID Euclidean|[paper](https://arxiv.org/pdf/2103.13516.pdf)|[code](trackeval/metrics/ideucl.py)| |
## Currently implemented benchmarks
The following benchmarks are currently implemented:
Benchmark | Sub-benchmarks | Type | Website | Code | Data Format |
|----- | ----------- |----- | ----------- | ----- | ----- |
| | | | | | |
|**RobMOTS**|Combination of 8 benchmarks|Seg Masks|[website](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110)|[code](trackeval/datasets/rob_mots.py)|[format](docs/RobMOTS-Official/Readme.md)|
|**Open World Tracking**|TAO-OW|OpenWorld / Seg Masks|[website](https://openworldtracking.github.io)|[code](trackeval/datasets/tao_ow.py)|[format](docs/OpenWorldTracking-Official/Readme.md)|
|**MOTChallenge**|MOT15/16/17/20|2D BBox|[website](https://motchallenge.net/)|[code](trackeval/datasets/mot_challenge_2d_box.py)|[format](docs/MOTChallenge-format.txt)|
|**KITTI Tracking**| |2D BBox|[website](http://www.cvlibs.net/datasets/kitti/eval_tracking.php)|[code](trackeval/datasets/kitti_2d_box.py)|[format](docs/KITTI-format.txt)|
|**BDD-100k**| |2D BBox|[website](https://bdd-data.berkeley.edu/)|[code](trackeval/datasets/bdd100k.py)|[format](docs/BDD100k-format.txt)|
|**TAO**| |2D BBox|[website](https://taodataset.org/)|[code](trackeval/datasets/tao.py)|[format](docs/TAO-format.txt)|
|**MOTS**|KITTI-MOTS, MOTS-Challenge|Seg Mask|[website](https://www.vision.rwth-aachen.de/page/mots)|[code](trackeval/datasets/mots_challenge.py) and [code](trackeval/datasets/kitti_mots.py)|[format](docs/MOTS-format.txt)|
|**DAVIS**|Unsupervised|Seg Mask|[website](https://davischallenge.org/)|[code](trackeval/datasets/davis.py)|[format](docs/DAVIS-format.txt)|
|**YouTube-VIS**| |Seg Mask|[website](https://youtube-vos.org/dataset/vis/)|[code](trackeval/datasets/youtube_vis.py)|[format](docs/YouTube-VIS-format.txt)|
|**Head Tracking Challenge**| |2D BBox|[website](https://arxiv.org/pdf/2103.13516.pdf)|[code](trackeval/datasets/head_tracking_challenge.py)|[format](docs/MOTChallenge-format.txt)|
## HOTA metrics
This code is also the official reference implementation for the HOTA metrics:
*[HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking](https://link.springer.com/article/10.1007/s11263-020-01375-2). IJCV 2020. Jonathon Luiten, Aljosa Osep, Patrick Dendorfer, Philip Torr, Andreas Geiger, Laura Leal-Taixe and Bastian Leibe.*
HOTA is a novel set of MOT evaluation metrics which enable better understanding of tracking behavior than previous metrics.
For more information check out the following links:
- [Short blog post on HOTA](https://jonathonluiten.medium.com/how-to-evaluate-tracking-with-the-hota-metrics-754036d183e1) - **HIGHLY RECOMMENDED READING**
- [IJCV version of paper](https://link.springer.com/article/10.1007/s11263-020-01375-2) (Open Access)
- [ArXiv version of paper](https://arxiv.org/abs/2009.07736)
- [Code](trackeval/metrics/hota.py)
## Properties of this codebase
The code is written 100% in python with only numpy and scipy as minimum requirements.
The code is designed to be easily understandable and easily extendable.
The code is also extremely fast, running at more than 10x the speed of the both [MOTChallengeEvalKit](https://github.com/dendorferpatrick/MOTChallengeEvalKit), and [py-motmetrics](https://github.com/cheind/py-motmetrics) (see detailed speed comparison below).
The implementation of CLEARMOT and ID metrics aligns perfectly with the [MOTChallengeEvalKit](https://github.com/dendorferpatrick/MOTChallengeEvalKit).
By default the code prints results to the screen, saves results out as both a summary txt file and a detailed results csv file, and outputs plots of the results. All outputs are by default saved to the 'tracker' folder for each tracker.
## Running the code
The code can be run in one of two ways:
- From the terminal via one of the scripts [here](scripts/). See each script for instructions and arguments, hopefully this is self-explanatory.
- Directly by importing this package into your code, see the same scripts above for how.
## Quickly evaluate on supported benchmarks
To enable you to use TrackEval for evaluation as quickly and easily as possible, we provide ground-truth data, meta-data and example trackers for all currently supported benchmarks.
You can download this here: [data.zip](https://omnomnom.vision.rwth-aachen.de/data/TrackEval/data.zip) (~150mb).
The data for RobMOTS is separate and can be found here: [rob_mots_train_data.zip](https://omnomnom.vision.rwth-aachen.de/data/RobMOTS/train_data.zip) (~750mb).
The easiest way to begin is to extract this zip into the repository root folder such that the file paths look like: TrackEval/data/gt/...
This then corresponds to the default paths in the code. You can now run each of the scripts [here](scripts/) without providing any arguments and they will by default evaluate all trackers present in the supplied file structure. To evaluate your own tracking results, simply copy your files as a new tracker folder into the file structure at the same level as the example trackers (MPNTrack, CIWT, track_rcnn, qdtrack, ags, Tracktor++, STEm_Seg), ensuring the same file structure for your trackers as in the example.
Of course, if your ground-truth and tracker files are located somewhere else you can simply use the script arguments to point the code toward your data.
To ensure your tracker outputs data in the correct format, check out our format guides for each of the supported benchmarks [here](docs), or check out the example trackers provided.
## Evaluate on your own custom benchmark
To evaluate on your own data, you have two options:
- Write custom dataset code (more effort, rarely worth it).
- Convert your current dataset and trackers to the same format of an already implemented benchmark.
To convert formats, check out the format specifications defined [here](docs).
By default, we would recommend the MOTChallenge format, although any implemented format should work. Note that for many cases you will want to use the argument ```--DO_PREPROC False``` unless you want to run preprocessing to remove distractor objects.
## Requirements
Code tested on Python 3.7.
- Minimum requirements: numpy, scipy
- For plotting: matplotlib
- For segmentation datasets (KITTI MOTS, MOTS-Challenge, DAVIS, YouTube-VIS): pycocotools
- For DAVIS dataset: Pillow
- For J & F metric: opencv_python, scikit_image
- For simples test-cases for metrics: pytest
use ```pip3 -r install requirements.txt``` to install all possible requirements.
use ```pip3 -r install minimum_requirments.txt``` to only install the minimum if you don't need the extra functionality as listed above.
## Timing analysis
Evaluating CLEAR + ID metrics on Lift_T tracker on MOT17-train (seconds) on a i7-9700K CPU with 8 physical cores (median of 3 runs):
Num Cores|TrackEval|MOTChallenge|Speedup vs MOTChallenge|py-motmetrics|Speedup vs py-motmetrics
:---|:---|:---|:---|:---|:---
1|9.64|66.23|6.87x|99.65|10.34x
4|3.01|29.42|9.77x| |33.11x*
8|1.62|29.51|18.22x| |61.51x*
*using a different number of cores as py-motmetrics doesn't allow multiprocessing.
```
python scripts/run_mot_challenge.py --BENCHMARK MOT17 --TRACKERS_TO_EVAL Lif_T --METRICS CLEAR Identity --USE_PARALLEL False --NUM_PARALLEL_CORES 1
```
Evaluating CLEAR + ID metrics on LPC_MOT tracker on MOT20-train (seconds) on a i7-9700K CPU with 8 physical cores (median of 3 runs):
Num Cores|TrackEval|MOTChallenge|Speedup vs MOTChallenge|py-motmetrics|Speedup vs py-motmetrics
:---|:---|:---|:---|:---|:---
1|18.63|105.3|5.65x|175.17|9.40x
```
python scripts/run_mot_challenge.py --BENCHMARK MOT20 --TRACKERS_TO_EVAL LPC_MOT --METRICS CLEAR Identity --USE_PARALLEL False --NUM_PARALLEL_CORES 1
```
## License
TrackEval is released under the [MIT License](LICENSE).
## Contact
If you encounter any problems with the code, please contact [Jonathon Luiten](https://www.vision.rwth-aachen.de/person/216/) ([luiten@vision.rwth-aachen.de](mailto:luiten@vision.rwth-aachen.de)).
If anything is unclear, or hard to use, please leave a comment either via email or as an issue and I would love to help.
## Dedication
This codebase was built for you, in order to make your life easier! For anyone doing research on tracking or using trackers, please don't hesitate to reach out with any comments or suggestions on how things could be improved.
## Contributing
We welcome contributions of new metrics and new supported benchmarks. Also any other new features or code improvements. Send a PR, an email, or open an issue detailing what you'd like to add/change to begin a conversation.
## Citing TrackEval
If you use this code in your research, please use the following BibTeX entry:
```BibTeX
@misc{luiten2020trackeval,
author = {Jonathon Luiten, Arne Hoffhues},
title = {TrackEval},
howpublished = {\url{https://github.com/JonathonLuiten/TrackEval}},
year = {2020}
}
```
Furthermore, if you use the HOTA metrics, please cite the following paper:
```
@article{luiten2020IJCV,
title={HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
author={Luiten, Jonathon and Osep, Aljosa and Dendorfer, Patrick and Torr, Philip and Geiger, Andreas and Leal-Taix{\'e}, Laura and Leibe, Bastian},
journal={International Journal of Computer Vision},
pages={1--31},
year={2020},
publisher={Springer}
}
```
If you use any other metrics please also cite the relevant papers, and don't forget to cite each of the benchmarks you evaluate on.
================================================
FILE: TrackEval/docs/BDD100k-format.txt
================================================
Taken from: https://bdd-data.berkeley.edu/wad-2020.html
BDD100K MOT Dataset
To advance the study on multiple object tracking, we introduce BDD100K MOT Dataset. We provide 1,400 video sequences for training, 200 video sequences for validation and 400 video sequences for testing. Each video sequence is about 40 seconds long with 5 FPS resulting in approximately 200 frames per video.
BDD100K MOT Dataset is not only diverse in visual scale among and within tracks, but in the temporal range of each track. Objects in the BDD100K MOT dataset also present complicated occlusion and reappearing patterns. An object may be fully occluded or move out of the frame, and then reappear later. BDD100K MOT Dataset shows real challenges of object re-identification for tracking in autonomous driving. Details about the MOT dataset can be found in the BDD100K paper (https://arxiv.org/abs/1805.04687). Access the BDD100K data website (https://bdd-data.berkeley.edu/) to download the data.
Folder Structure
bdd100k/
├── images/
| ├── track/
| | ├── train/
| | | ├── $VIDEO_NAME/
| | | | ├── $VIDEO_NAME-$FRAME_INDEX.jpg
| | ├── val/
| | ├── test/
├── labels-20/
| ├── box-track/
| | ├── train/
| | | ├── $VIDEO_NAME.json
| | | |
| | ├── val/
The frames for each video are stored in a folder in the images directory. The labels for each video are stored in a json file with the format detailed below.
Label Format
Each json file contains a list of frame objects, and each frame object has the format below. The format follows the schema of BDD100K data format (https://github.com/ucbdrive/bdd100k/blob/master/doc/format.md).
- name: string
- videoName: string
- index: int
- labels: [ ]
- id: string
- category: string
- attributes:
- Crowd: boolean
- Occluded: boolean
- Truncated: boolean
- box2d:
- x1: float
- y1: float
- x2: float
- y2: float
There are 11 object categories in this release:
pedestrian
rider
other person
car
bus
truck
train
trailer
other vehicle
motorcycle
bicycle
Notes:
The same instance shares "id" across frames.
The "pedestrian", "bicycle", and "motorcycle" correspond to the "person", "bike", and "motor" classes in the BDD100K Detection dataset.
We consider "other person", "trailer", and "other vehicle" as distractors, which are ignored during evaluation. We only evaluate the multi-object tracking of the other 8 categories.
We set three super-categories: "person" (with classes "pedestrian" and"rider"), "vehicle" ("car", "bus", "truck", and "train"), and "bike" ("motorcycle" and "bicycle") for the purpose of evaluation.
Submission Format
The submission file for each of the two phases is a json file compressed by zip. Each json file is a list of frame objects with the format detailed below. The format also follows the schema of BDD100K data format (https://github.com/ucbdrive/bdd100k/blob/master/doc/format.md).
- name: string
- labels [ ]:
- id: string
- category: string
- box2d:
- x1: float
- y1: float
- x2: float
- y2: float
Note that objects with the same identity share id across frames in a given video, and should be unique across different videos. Our evaluation will match the category string in evaluation, so you can assign your own integer ID for the categories in your model. But we recommend to encode the 8 relevant categories in the following order so that it is easier for the research community to share the models.
pedestrian
rider
car
truck
bus
train
motorcycle
bicycle
The evaluation server will perform evaluation for each category and aggregate the results to compute the overall metrics. Then the server will merge both the ground-truth and predicted labels into super-categories and evaluate for each super- category.
Evaluation
Evaluation platform: We host our evaluation server on CodaLab (https://competitions.codalab.org/competitions/24492). There are two phases for the challenge: val phase and test phase. The final ranking will be based on the test phase.
Pre-training: It is a fair game to pre-train your network with ImageNet or COCO, but if other datasets are used, please note in the submission description. We will rank the methods without using external datasets except ImageNet and COCO.
Ignoring distractors: As a preprocessing step, all predicted boxes are matched and the ones matched to distractor ground-truth boxes ("other person", "trailer", and "other vehicle") are ignored.
Crowd region: After bounding box matching, we ignore all detected false-positive boxes that has >50% overlap with the crowd region (ground-truth boxes with the "Crowd" attribute).
Super-category: In addition to the evaluation of all 8 classes, we merge ground truth and prediction categories into 3 super-categories specified above, and evaluate the results for each super-category. The super-category evaluation results will be provided only for the purpose of reference.
================================================
FILE: TrackEval/docs/DAVIS-format.txt
================================================
Annotation Format:
The annotations in each frame are stored in png format.
This png is stored indexed i.e. it has a single channel and each pixel has a value from 0 to 254 that corresponds to a color palette attached to the png file.
It is important to take this into account when decoding the png i.e. the output of decoding should be a single channel image and it should not be necessary to do any remap from RGB to indexes.
The latter is crucial to preseve the index of each object so it can match to the correct object in evaluation.
Each pixel that belongs to the same object has the same value in this png map through the whole video.
Start at 1 for the first object, then 2, 3, 4 etc.
The background (not an object) has value 0.
Also note that invalid/void pixels are stored with a 254 value.
These can be read like this:
import PIL.Image as Image
img = np.array(Image.open("000005.png"))
or like this:
ann_data = tf.read_file(ann_filename)
ann = tf.image.decode_image(ann_data, dtype=tf.uint8, channels=1)
See the code for loading the davis dataset for more details.
================================================
FILE: TrackEval/docs/How_To/Add_a_new_metric.md
================================================
# How to add a new or custom family of evaluation metrics to TrackEval
- Create your metrics code in ```trackeval/metrics/
## TCM on other trackers
download ReID weight from [googlenet_part8_all_xavier_ckpt_56.h5](https://drive.google.com/drive/folders/18IsZGeGiyKDshhYIzbpYXoNEcBhPY8lN?usp=sharing) for MOTDT and DeepSORT.
**dancetrack-val dataset**
```
# SORT
python tools/run_sort_dance.py -f exps/example/mot/yolox_dancetrack_val.py -c pretrained/bytetrack_dance_model.pth.tar -b 1 -d 1 --fp16 --fuse --dataset dancetrack --expn sort_score_kalman_fir_step --TCM_first_step
# MOTDT
python3 tools/run_motdt_dance.py -f exps/example/mot/yolox_dancetrack_val.py -c pretrained/bytetrack_dance_model.pth.tar -b 1 -d 1 --fp16 --fuse --dataset dancetrack --expn motdt_score_kalman_fir_step --TCM_first_step
# ByteTrack
python3 tools/run_byte_dance.py -f exps/example/mot/yolox_dancetrack_val.py -c pretrained/bytetrack_dance_model.pth.tar -b 1 -d 1 --fp16 --fuse --dataset dancetrack --expn byte_score_kalman_fir_step --TCM_first_step
# DeepSORT
python3 tools/run_deepsort_dance.py -f exps/example/mot/yolox_dancetrack_val.py -c pretrained/bytetrack_dance_model.pth.tar -b 1 -d 1 --fp16 --fuse --dataset dancetrack --expn deepsort_score_kalman_fir_step --TCM_first_step
```
**mot17-val dataset**
```
# SORT
python3 tools/run_sort.py -f exps/example/mot/yolox_x_ablation.py -c pretrained/ocsort_mot17_ablation.pth.tar -b 1 -d 1 --fuse --expn mot17_sort_score_test_fp32 --TCM_first_step
# MOTDT
python3 tools/run_motdt.py -f exps/example/mot/yolox_x_ablation.py -c pretrained/ocsort_mot17_ablation.pth.tar -b 1 -d 1 --fuse --expn mot17_motdt_score_test_fp32 --TCM_first_step
# ByteTrack
python3 tools/run_byte.py -f exps/example/mot/yolox_x_ablation.py -c pretrained/ocsort_mot17_ablation.pth.tar -b 1 -d 1 --fuse --expn mot17_byte_score_test_fp32 --TCM_first_step --TCM_first_step_weight 0.6
# DeepSORT
python3 tools/run_deepsort.py -f exps/example/mot/yolox_x_ablation.py -c pretrained/ocsort_mot17_ablation.pth.tar -b 1 -d 1 --fuse --expn mot17_deepsort_score_test_fp32 --TCM_first_step
```
## Citation
If you find this work useful, please consider to cite our paper:
```
@inproceedings{yang2024hybrid,
title={Hybrid-sort: Weak cues matter for online multi-object tracking},
author={Yang, Mingzhan and Han, Guangxin and Yan, Bin and Zhang, Wenhua and Qi, Jinqing and Lu, Huchuan and Wang, Dong},
booktitle={Proceedings of the AAAI Conference on Artificial Intelligence},
volume={38},
number={7},
pages={6504--6512},
year={2024}
}
```
## Acknowledgement
A large part of the code is borrowed from [YOLOX](https://github.com/Megvii-BaseDetection/YOLOX), [OC-SORT](https://github.com/noahcao/OC_SORT), [ByteTrack](https://github.com/ifzhang/ByteTrack), [BoT-SORT](https://github.com/NirAharon/BOT-SORT) and [FastReID](https://github.com/JDAI-CV/fast-reid). Many thanks for their wonderful works.
================================================
FILE: TrackEval/.gitignore
================================================
gt_data/*
!gt_data/Readme.md
tracker_output/*
!tracker_output/Readme.md
output/*
data/*
!goutput/Readme.md
**/__pycache__
.idea
error_log.txt
================================================
FILE: TrackEval/LICENSE
================================================
MIT License
Copyright (c) 2020 Jonathon Luiten
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
in the Software without restriction, including without limitation the rights
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
copies of the Software, and to permit persons to whom the Software is
furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all
copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
================================================
FILE: TrackEval/Readme.md
================================================
# TrackEval
*Code for evaluating object tracking.*
This codebase provides code for a number of different tracking evaluation metrics (including the [HOTA metrics](https://link.springer.com/article/10.1007/s11263-020-01375-2)), as well as supporting running all of these metrics on a number of different tracking benchmarks. Plus plotting of results and other things one may want to do for tracking evaluation.
## **NEW**: RobMOTS Challenge 2021
Call for submission to our [RobMOTS Challenge](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110) (Robust Multi-Object Tracking and Segmentation) held in conjunction with our [RVSU CVPR'21 Workshop](https://eval.vision.rwth-aachen.de/rvsu-workshop21/). Robust tracking evaluation against 8 tracking benchmarks. Challenge submission deadline June 15th. Also check out our workshop [call for papers](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=74).
## Official Evaluation Code
The following benchmarks use TrackEval as their official evaluation code, check out the links to see TrackEval in action:
- **[RobMOTS](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110)** ([Official Readme](docs/RobMOTS-Official/Readme.md))
- **[KITTI Tracking](http://www.cvlibs.net/datasets/kitti/eval_tracking.php)**
- **[KITTI MOTS](http://www.cvlibs.net/datasets/kitti/eval_mots.php)**
- **[MOTChallenge](https://motchallenge.net/)** ([Official Readme](docs/MOTChallenge-Official/Readme.md))
- **[Open World Tracking](https://openworldtracking.github.io)** ([Official Readme](docs/OpenWorldTracking-Official))
If you run a tracking benchmark and want to use TrackEval as your official evaluation code, please contact Jonathon (contact details below).
## Currently implemented metrics
The following metrics are currently implemented:
Metric Family | Sub metrics | Paper | Code | Notes |
|----- | ----------- |----- | ----------- | ----- |
| | | | | |
|**HOTA metrics**|HOTA, DetA, AssA, LocA, DetPr, DetRe, AssPr, AssRe|[paper](https://link.springer.com/article/10.1007/s11263-020-01375-2)|[code](trackeval/metrics/hota.py)|**Recommended tracking metric**|
|**CLEARMOT metrics**|MOTA, MOTP, MT, ML, Frag, etc.|[paper](https://link.springer.com/article/10.1155/2008/246309)|[code](trackeval/metrics/clear.py)| |
|**Identity metrics**|IDF1, IDP, IDR|[paper](https://arxiv.org/abs/1609.01775)|[code](trackeval/metrics/identity.py)| |
|**VACE metrics**|ATA, SFDA|[paper](https://link.springer.com/chapter/10.1007/11612704_16)|[code](trackeval/metrics/vace.py)| |
|**Track mAP metrics**|Track mAP|[paper](https://arxiv.org/abs/1905.04804)|[code](trackeval/metrics/track_map.py)|Requires confidence scores|
|**J & F metrics**|J&F, J, F|[paper](https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/Perazzi_A_Benchmark_Dataset_CVPR_2016_paper.pdf)|[code](trackeval/metrics/j_and_f.py)|Only for Seg Masks|
|**ID Euclidean**|ID Euclidean|[paper](https://arxiv.org/pdf/2103.13516.pdf)|[code](trackeval/metrics/ideucl.py)| |
## Currently implemented benchmarks
The following benchmarks are currently implemented:
Benchmark | Sub-benchmarks | Type | Website | Code | Data Format |
|----- | ----------- |----- | ----------- | ----- | ----- |
| | | | | | |
|**RobMOTS**|Combination of 8 benchmarks|Seg Masks|[website](https://eval.vision.rwth-aachen.de/rvsu-workshop21/?page_id=110)|[code](trackeval/datasets/rob_mots.py)|[format](docs/RobMOTS-Official/Readme.md)|
|**Open World Tracking**|TAO-OW|OpenWorld / Seg Masks|[website](https://openworldtracking.github.io)|[code](trackeval/datasets/tao_ow.py)|[format](docs/OpenWorldTracking-Official/Readme.md)|
|**MOTChallenge**|MOT15/16/17/20|2D BBox|[website](https://motchallenge.net/)|[code](trackeval/datasets/mot_challenge_2d_box.py)|[format](docs/MOTChallenge-format.txt)|
|**KITTI Tracking**| |2D BBox|[website](http://www.cvlibs.net/datasets/kitti/eval_tracking.php)|[code](trackeval/datasets/kitti_2d_box.py)|[format](docs/KITTI-format.txt)|
|**BDD-100k**| |2D BBox|[website](https://bdd-data.berkeley.edu/)|[code](trackeval/datasets/bdd100k.py)|[format](docs/BDD100k-format.txt)|
|**TAO**| |2D BBox|[website](https://taodataset.org/)|[code](trackeval/datasets/tao.py)|[format](docs/TAO-format.txt)|
|**MOTS**|KITTI-MOTS, MOTS-Challenge|Seg Mask|[website](https://www.vision.rwth-aachen.de/page/mots)|[code](trackeval/datasets/mots_challenge.py) and [code](trackeval/datasets/kitti_mots.py)|[format](docs/MOTS-format.txt)|
|**DAVIS**|Unsupervised|Seg Mask|[website](https://davischallenge.org/)|[code](trackeval/datasets/davis.py)|[format](docs/DAVIS-format.txt)|
|**YouTube-VIS**| |Seg Mask|[website](https://youtube-vos.org/dataset/vis/)|[code](trackeval/datasets/youtube_vis.py)|[format](docs/YouTube-VIS-format.txt)|
|**Head Tracking Challenge**| |2D BBox|[website](https://arxiv.org/pdf/2103.13516.pdf)|[code](trackeval/datasets/head_tracking_challenge.py)|[format](docs/MOTChallenge-format.txt)|
## HOTA metrics
This code is also the official reference implementation for the HOTA metrics:
*[HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking](https://link.springer.com/article/10.1007/s11263-020-01375-2). IJCV 2020. Jonathon Luiten, Aljosa Osep, Patrick Dendorfer, Philip Torr, Andreas Geiger, Laura Leal-Taixe and Bastian Leibe.*
HOTA is a novel set of MOT evaluation metrics which enable better understanding of tracking behavior than previous metrics.
For more information check out the following links:
- [Short blog post on HOTA](https://jonathonluiten.medium.com/how-to-evaluate-tracking-with-the-hota-metrics-754036d183e1) - **HIGHLY RECOMMENDED READING**
- [IJCV version of paper](https://link.springer.com/article/10.1007/s11263-020-01375-2) (Open Access)
- [ArXiv version of paper](https://arxiv.org/abs/2009.07736)
- [Code](trackeval/metrics/hota.py)
## Properties of this codebase
The code is written 100% in python with only numpy and scipy as minimum requirements.
The code is designed to be easily understandable and easily extendable.
The code is also extremely fast, running at more than 10x the speed of the both [MOTChallengeEvalKit](https://github.com/dendorferpatrick/MOTChallengeEvalKit), and [py-motmetrics](https://github.com/cheind/py-motmetrics) (see detailed speed comparison below).
The implementation of CLEARMOT and ID metrics aligns perfectly with the [MOTChallengeEvalKit](https://github.com/dendorferpatrick/MOTChallengeEvalKit).
By default the code prints results to the screen, saves results out as both a summary txt file and a detailed results csv file, and outputs plots of the results. All outputs are by default saved to the 'tracker' folder for each tracker.
## Running the code
The code can be run in one of two ways:
- From the terminal via one of the scripts [here](scripts/). See each script for instructions and arguments, hopefully this is self-explanatory.
- Directly by importing this package into your code, see the same scripts above for how.
## Quickly evaluate on supported benchmarks
To enable you to use TrackEval for evaluation as quickly and easily as possible, we provide ground-truth data, meta-data and example trackers for all currently supported benchmarks.
You can download this here: [data.zip](https://omnomnom.vision.rwth-aachen.de/data/TrackEval/data.zip) (~150mb).
The data for RobMOTS is separate and can be found here: [rob_mots_train_data.zip](https://omnomnom.vision.rwth-aachen.de/data/RobMOTS/train_data.zip) (~750mb).
The easiest way to begin is to extract this zip into the repository root folder such that the file paths look like: TrackEval/data/gt/...
This then corresponds to the default paths in the code. You can now run each of the scripts [here](scripts/) without providing any arguments and they will by default evaluate all trackers present in the supplied file structure. To evaluate your own tracking results, simply copy your files as a new tracker folder into the file structure at the same level as the example trackers (MPNTrack, CIWT, track_rcnn, qdtrack, ags, Tracktor++, STEm_Seg), ensuring the same file structure for your trackers as in the example.
Of course, if your ground-truth and tracker files are located somewhere else you can simply use the script arguments to point the code toward your data.
To ensure your tracker outputs data in the correct format, check out our format guides for each of the supported benchmarks [here](docs), or check out the example trackers provided.
## Evaluate on your own custom benchmark
To evaluate on your own data, you have two options:
- Write custom dataset code (more effort, rarely worth it).
- Convert your current dataset and trackers to the same format of an already implemented benchmark.
To convert formats, check out the format specifications defined [here](docs).
By default, we would recommend the MOTChallenge format, although any implemented format should work. Note that for many cases you will want to use the argument ```--DO_PREPROC False``` unless you want to run preprocessing to remove distractor objects.
## Requirements
Code tested on Python 3.7.
- Minimum requirements: numpy, scipy
- For plotting: matplotlib
- For segmentation datasets (KITTI MOTS, MOTS-Challenge, DAVIS, YouTube-VIS): pycocotools
- For DAVIS dataset: Pillow
- For J & F metric: opencv_python, scikit_image
- For simples test-cases for metrics: pytest
use ```pip3 -r install requirements.txt``` to install all possible requirements.
use ```pip3 -r install minimum_requirments.txt``` to only install the minimum if you don't need the extra functionality as listed above.
## Timing analysis
Evaluating CLEAR + ID metrics on Lift_T tracker on MOT17-train (seconds) on a i7-9700K CPU with 8 physical cores (median of 3 runs):
Num Cores|TrackEval|MOTChallenge|Speedup vs MOTChallenge|py-motmetrics|Speedup vs py-motmetrics
:---|:---|:---|:---|:---|:---
1|9.64|66.23|6.87x|99.65|10.34x
4|3.01|29.42|9.77x| |33.11x*
8|1.62|29.51|18.22x| |61.51x*
*using a different number of cores as py-motmetrics doesn't allow multiprocessing.
```
python scripts/run_mot_challenge.py --BENCHMARK MOT17 --TRACKERS_TO_EVAL Lif_T --METRICS CLEAR Identity --USE_PARALLEL False --NUM_PARALLEL_CORES 1
```
Evaluating CLEAR + ID metrics on LPC_MOT tracker on MOT20-train (seconds) on a i7-9700K CPU with 8 physical cores (median of 3 runs):
Num Cores|TrackEval|MOTChallenge|Speedup vs MOTChallenge|py-motmetrics|Speedup vs py-motmetrics
:---|:---|:---|:---|:---|:---
1|18.63|105.3|5.65x|175.17|9.40x
```
python scripts/run_mot_challenge.py --BENCHMARK MOT20 --TRACKERS_TO_EVAL LPC_MOT --METRICS CLEAR Identity --USE_PARALLEL False --NUM_PARALLEL_CORES 1
```
## License
TrackEval is released under the [MIT License](LICENSE).
## Contact
If you encounter any problems with the code, please contact [Jonathon Luiten](https://www.vision.rwth-aachen.de/person/216/) ([luiten@vision.rwth-aachen.de](mailto:luiten@vision.rwth-aachen.de)).
If anything is unclear, or hard to use, please leave a comment either via email or as an issue and I would love to help.
## Dedication
This codebase was built for you, in order to make your life easier! For anyone doing research on tracking or using trackers, please don't hesitate to reach out with any comments or suggestions on how things could be improved.
## Contributing
We welcome contributions of new metrics and new supported benchmarks. Also any other new features or code improvements. Send a PR, an email, or open an issue detailing what you'd like to add/change to begin a conversation.
## Citing TrackEval
If you use this code in your research, please use the following BibTeX entry:
```BibTeX
@misc{luiten2020trackeval,
author = {Jonathon Luiten, Arne Hoffhues},
title = {TrackEval},
howpublished = {\url{https://github.com/JonathonLuiten/TrackEval}},
year = {2020}
}
```
Furthermore, if you use the HOTA metrics, please cite the following paper:
```
@article{luiten2020IJCV,
title={HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking},
author={Luiten, Jonathon and Osep, Aljosa and Dendorfer, Patrick and Torr, Philip and Geiger, Andreas and Leal-Taix{\'e}, Laura and Leibe, Bastian},
journal={International Journal of Computer Vision},
pages={1--31},
year={2020},
publisher={Springer}
}
```
If you use any other metrics please also cite the relevant papers, and don't forget to cite each of the benchmarks you evaluate on.
================================================
FILE: TrackEval/docs/BDD100k-format.txt
================================================
Taken from: https://bdd-data.berkeley.edu/wad-2020.html
BDD100K MOT Dataset
To advance the study on multiple object tracking, we introduce BDD100K MOT Dataset. We provide 1,400 video sequences for training, 200 video sequences for validation and 400 video sequences for testing. Each video sequence is about 40 seconds long with 5 FPS resulting in approximately 200 frames per video.
BDD100K MOT Dataset is not only diverse in visual scale among and within tracks, but in the temporal range of each track. Objects in the BDD100K MOT dataset also present complicated occlusion and reappearing patterns. An object may be fully occluded or move out of the frame, and then reappear later. BDD100K MOT Dataset shows real challenges of object re-identification for tracking in autonomous driving. Details about the MOT dataset can be found in the BDD100K paper (https://arxiv.org/abs/1805.04687). Access the BDD100K data website (https://bdd-data.berkeley.edu/) to download the data.
Folder Structure
bdd100k/
├── images/
| ├── track/
| | ├── train/
| | | ├── $VIDEO_NAME/
| | | | ├── $VIDEO_NAME-$FRAME_INDEX.jpg
| | ├── val/
| | ├── test/
├── labels-20/
| ├── box-track/
| | ├── train/
| | | ├── $VIDEO_NAME.json
| | | |
| | ├── val/
The frames for each video are stored in a folder in the images directory. The labels for each video are stored in a json file with the format detailed below.
Label Format
Each json file contains a list of frame objects, and each frame object has the format below. The format follows the schema of BDD100K data format (https://github.com/ucbdrive/bdd100k/blob/master/doc/format.md).
- name: string
- videoName: string
- index: int
- labels: [ ]
- id: string
- category: string
- attributes:
- Crowd: boolean
- Occluded: boolean
- Truncated: boolean
- box2d:
- x1: float
- y1: float
- x2: float
- y2: float
There are 11 object categories in this release:
pedestrian
rider
other person
car
bus
truck
train
trailer
other vehicle
motorcycle
bicycle
Notes:
The same instance shares "id" across frames.
The "pedestrian", "bicycle", and "motorcycle" correspond to the "person", "bike", and "motor" classes in the BDD100K Detection dataset.
We consider "other person", "trailer", and "other vehicle" as distractors, which are ignored during evaluation. We only evaluate the multi-object tracking of the other 8 categories.
We set three super-categories: "person" (with classes "pedestrian" and"rider"), "vehicle" ("car", "bus", "truck", and "train"), and "bike" ("motorcycle" and "bicycle") for the purpose of evaluation.
Submission Format
The submission file for each of the two phases is a json file compressed by zip. Each json file is a list of frame objects with the format detailed below. The format also follows the schema of BDD100K data format (https://github.com/ucbdrive/bdd100k/blob/master/doc/format.md).
- name: string
- labels [ ]:
- id: string
- category: string
- box2d:
- x1: float
- y1: float
- x2: float
- y2: float
Note that objects with the same identity share id across frames in a given video, and should be unique across different videos. Our evaluation will match the category string in evaluation, so you can assign your own integer ID for the categories in your model. But we recommend to encode the 8 relevant categories in the following order so that it is easier for the research community to share the models.
pedestrian
rider
car
truck
bus
train
motorcycle
bicycle
The evaluation server will perform evaluation for each category and aggregate the results to compute the overall metrics. Then the server will merge both the ground-truth and predicted labels into super-categories and evaluate for each super- category.
Evaluation
Evaluation platform: We host our evaluation server on CodaLab (https://competitions.codalab.org/competitions/24492). There are two phases for the challenge: val phase and test phase. The final ranking will be based on the test phase.
Pre-training: It is a fair game to pre-train your network with ImageNet or COCO, but if other datasets are used, please note in the submission description. We will rank the methods without using external datasets except ImageNet and COCO.
Ignoring distractors: As a preprocessing step, all predicted boxes are matched and the ones matched to distractor ground-truth boxes ("other person", "trailer", and "other vehicle") are ignored.
Crowd region: After bounding box matching, we ignore all detected false-positive boxes that has >50% overlap with the crowd region (ground-truth boxes with the "Crowd" attribute).
Super-category: In addition to the evaluation of all 8 classes, we merge ground truth and prediction categories into 3 super-categories specified above, and evaluate the results for each super-category. The super-category evaluation results will be provided only for the purpose of reference.
================================================
FILE: TrackEval/docs/DAVIS-format.txt
================================================
Annotation Format:
The annotations in each frame are stored in png format.
This png is stored indexed i.e. it has a single channel and each pixel has a value from 0 to 254 that corresponds to a color palette attached to the png file.
It is important to take this into account when decoding the png i.e. the output of decoding should be a single channel image and it should not be necessary to do any remap from RGB to indexes.
The latter is crucial to preseve the index of each object so it can match to the correct object in evaluation.
Each pixel that belongs to the same object has the same value in this png map through the whole video.
Start at 1 for the first object, then 2, 3, 4 etc.
The background (not an object) has value 0.
Also note that invalid/void pixels are stored with a 254 value.
These can be read like this:
import PIL.Image as Image
img = np.array(Image.open("000005.png"))
or like this:
ann_data = tf.read_file(ann_filename)
ann = tf.image.decode_image(ann_data, dtype=tf.uint8, channels=1)
See the code for loading the davis dataset for more details.
================================================
FILE: TrackEval/docs/How_To/Add_a_new_metric.md
================================================
# How to add a new or custom family of evaluation metrics to TrackEval
- Create your metrics code in ```trackeval/metrics/