Repository: ypwhs/CreativeChatGLM
Branch: master
Commit: 403302d04120
Files: 54
Total size: 460.6 KB
Directory structure:
gitextract_8x6d8dn9/
├── .gitignore
├── LICENSE
├── MODEL_LICENSE
├── README.md
├── app.py
├── app_fastapi.py
├── chatglm/
│ ├── configuration_chatglm.py
│ ├── modeling_chatglm.py
│ ├── quantization.py
│ └── tokenization_chatglm.py
├── chatglm2/
│ ├── configuration_chatglm.py
│ ├── modeling_chatglm.py
│ ├── quantization.py
│ └── tokenization_chatglm.py
├── chatglm3/
│ ├── configuration_chatglm.py
│ ├── modeling_chatglm.py
│ ├── quantization.py
│ └── tokenization_chatglm.py
├── check_bad_cache_files.py
├── download_model.py
├── env_offline.bat
├── env_venv.bat
├── glm4/
│ ├── configuration_chatglm.py
│ ├── modeling_chatglm.py
│ └── tokenization_chatglm.py
├── gptq/
│ ├── README.md
│ ├── gptq.py
│ ├── llama.py
│ ├── llama_inference.py
│ ├── modelutils.py
│ ├── quant.py
│ ├── quant_cuda.cpp
│ ├── quant_cuda_kernel.cu
│ ├── setup_cuda.py
│ └── test_kernel.py
├── predictors/
│ ├── base.py
│ ├── chatglm2_predictor.py
│ ├── chatglm3_predictor.py
│ ├── chatglm_predictor.py
│ ├── debug.py
│ ├── glm4_predictor.py
│ ├── llama.py
│ └── llama_gptq.py
├── setup_offline.bat
├── setup_venv.bat
├── start.bat
├── start_api.bat
├── start_offline.bat
├── start_offline_api.bat
├── start_offline_cmd.bat
├── start_venv.bat
├── test_fastapi.py
├── test_models.py
└── utils_env.py
================================================
FILE CONTENTS
================================================
================================================
FILE: .gitignore
================================================
## Unimportant file
.idea/
*.ini
*.lnk
*.c
release
server_config
.venv
python
system
venv
THUDM
BelleGroup
*egg-info
configs/
build/
dist/
models/
sample/
weights/
temp/
log/
logs/
*/__pycache__/
work_dirs/
*log.txt
*.cpth
*.ctrt
*.engine
*.build
*.txt
*.log
*.jpg
*.bmp
*.png
*.tif
*.tiff
*.pdf
*.json
*.jsonl
*.arrow
data
runs
Thumbs.db
.DS_Store
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# Deployment
*.bin
*.zip
*.pyd
*.pyi
# C extensions
*.so
*.xlsx
# Distribution / packaging
.Python build/ develop-eggs/ release/ standalone/ dist/ downloads/ eggs/ .eggs/ lib/ lib64/ parts/ sdist/ var/ wheels/
*.egg-info/ .installed.cfg
*.egg MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/ .tox/ .coverage .coverage.*
.cache nosetests.xml coverage.xml
*.cover .hypothesis/ .pytest_cache/
# Translations
*.mo
*.pot
# Django stuff:
*.log local_settings.py db.sqlite3
# Flask stuff:
instance/ .webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# pyenv
.python-version
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# Environments
.env .venv env/ venv/ ENV/ env.bak/ venv.bak/
# Spyder project settings
.spyderproject .spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
data/ data .vscode .idea .DS_Store
# custom
*.pkl
*.pkl.json
*.log.json work_dirs/
# Pytorch
*.pth
*.pt
*.py~
*.sh~
================================================
FILE: LICENSE
================================================
Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
================================================
FILE: MODEL_LICENSE
================================================
The ChatGLM-6B License
1. Definitions
“Licensor” means the ChatGLM-6B Model Team that distributes its Software.
“Software” means the ChatGLM-6B model parameters made available under this license.
2. License Grant
Subject to the terms and conditions of this License, the Licensor hereby grants to you a non-exclusive, worldwide, non-transferable, non-sublicensable, revocable, royalty-free copyright license to use the Software solely for your non-commercial research purposes.
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
3. Restriction
You will not use, copy, modify, merge, publish, distribute, reproduce, or create derivative works of the Software, in whole or in part, for any commercial, military, or illegal purposes.
You will not use the Software for any act that may undermine China's national security and national unity, harm the public interest of society, or infringe upon the rights and interests of human beings.
4. Disclaimer
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
5. Limitation of Liability
EXCEPT TO THE EXTENT PROHIBITED BY APPLICABLE LAW, IN NO EVENT AND UNDER NO LEGAL THEORY, WHETHER BASED IN TORT, NEGLIGENCE, CONTRACT, LIABILITY, OR OTHERWISE WILL ANY LICENSOR BE LIABLE TO YOU FOR ANY DIRECT, INDIRECT, SPECIAL, INCIDENTAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES, OR ANY OTHER COMMERCIAL LOSSES, EVEN IF THE LICENSOR HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
6. Dispute Resolution
This license shall be governed and construed in accordance with the laws of People’s Republic of China. Any dispute arising from or in connection with this License shall be submitted to Haidian District People's Court in Beijing.
Note that the license is subject to update to a more comprehensive version. For any questions related to the license and copyright, please contact us at glm-130b@googlegroups.com.
================================================
FILE: README.md
================================================
# 💡Creative ChatGLM WebUI
👋 欢迎来到 ChatGLM 创意世界!你可以使用修订和续写的功能来生成创意内容!
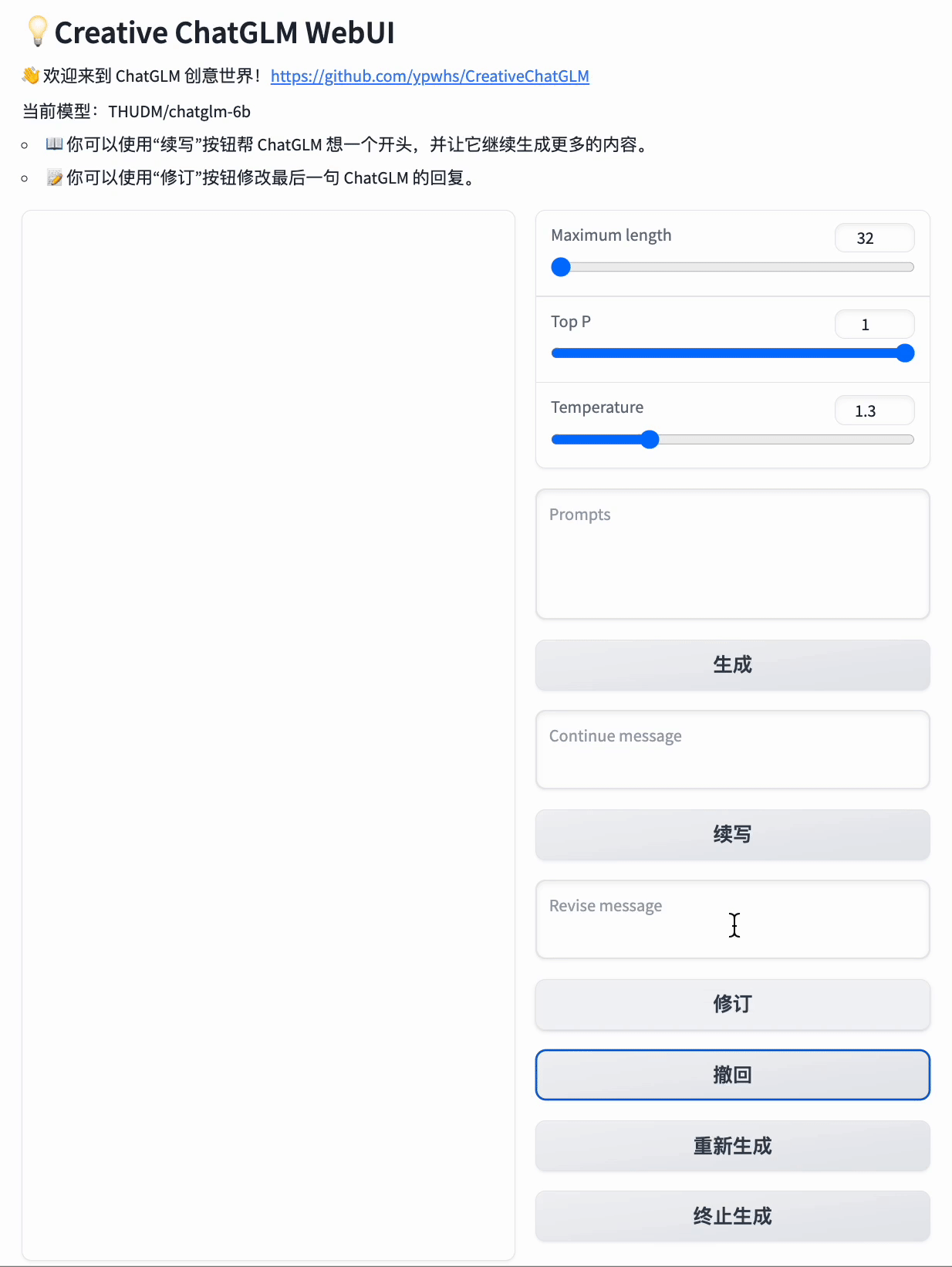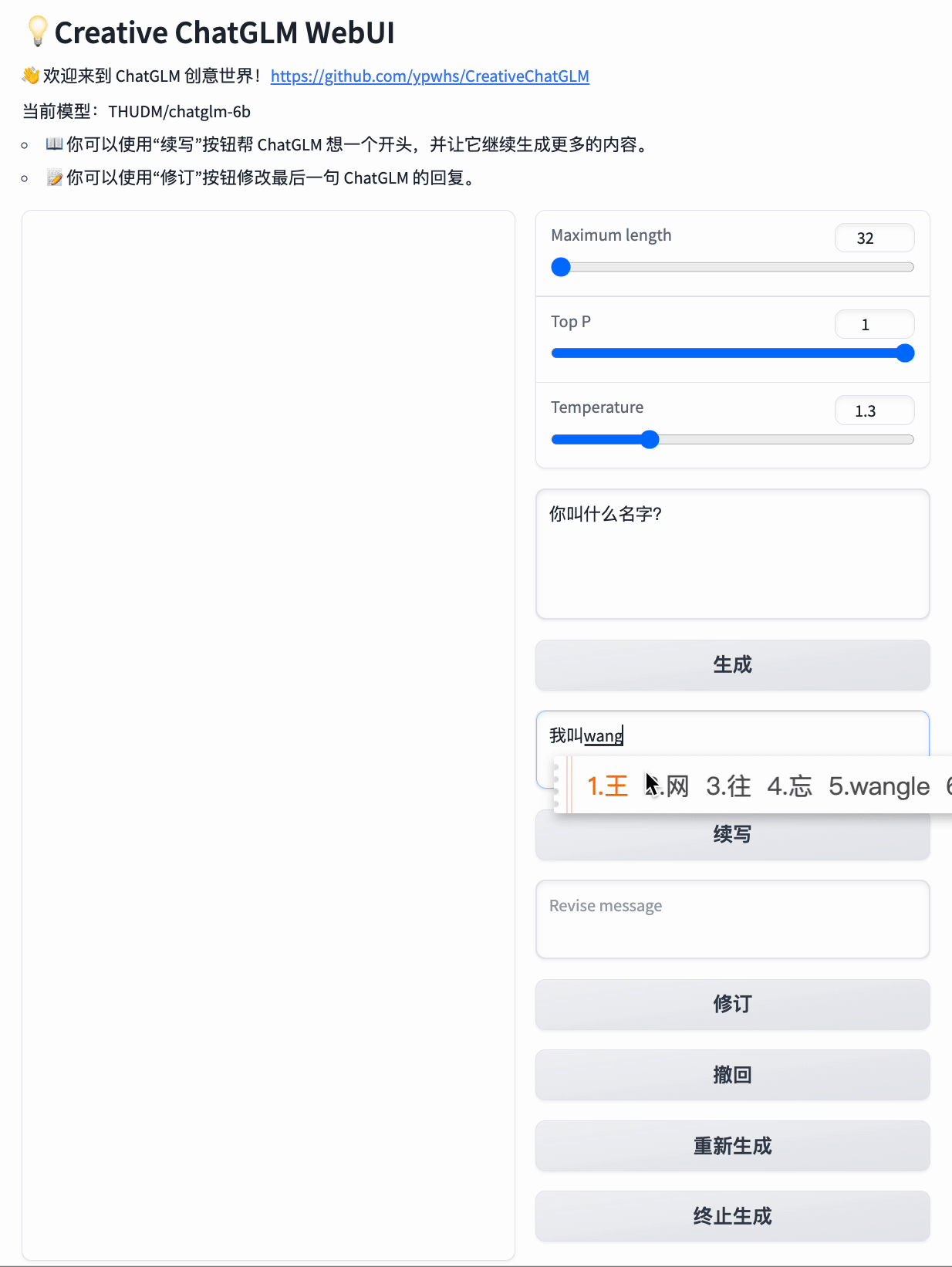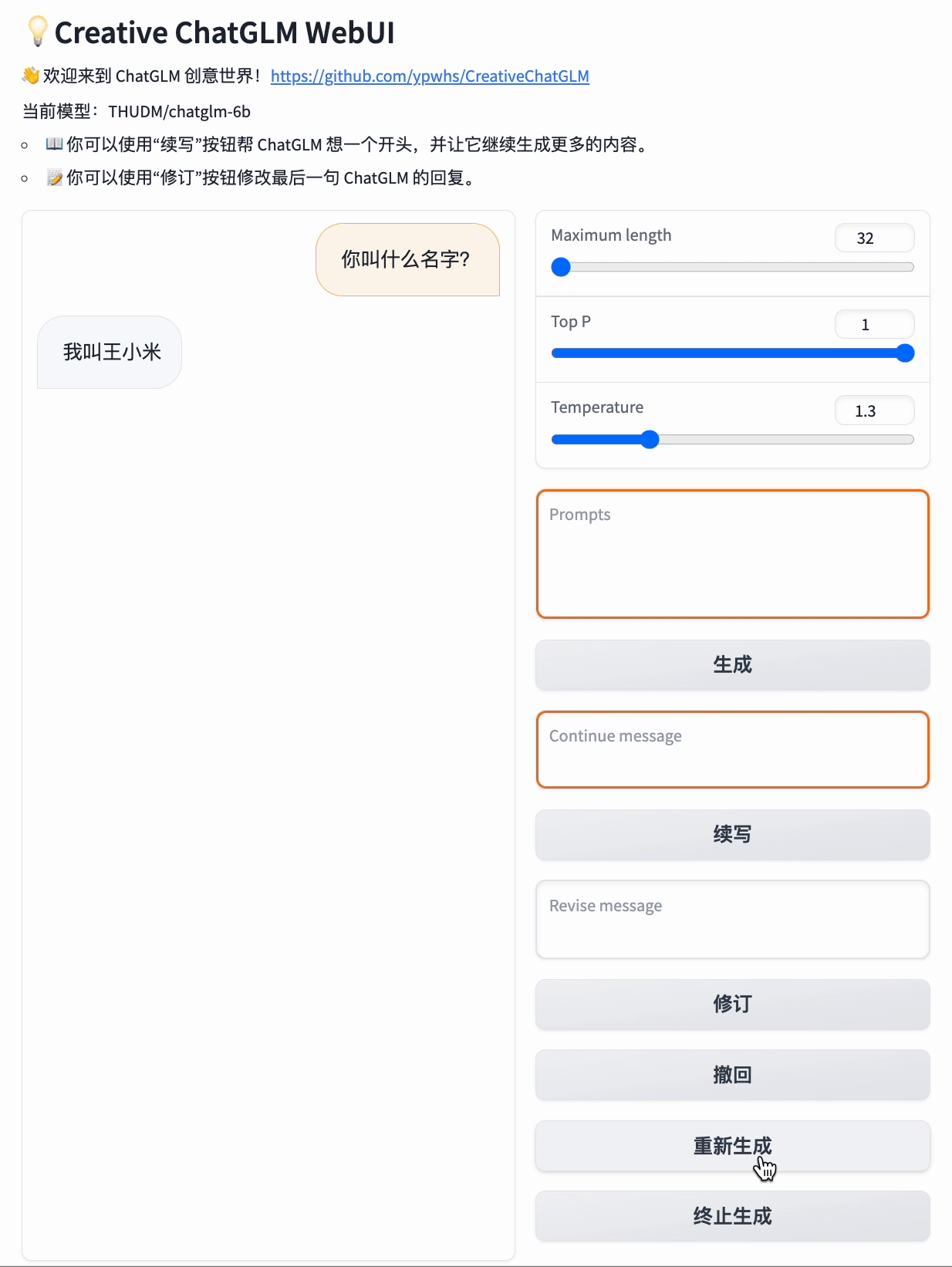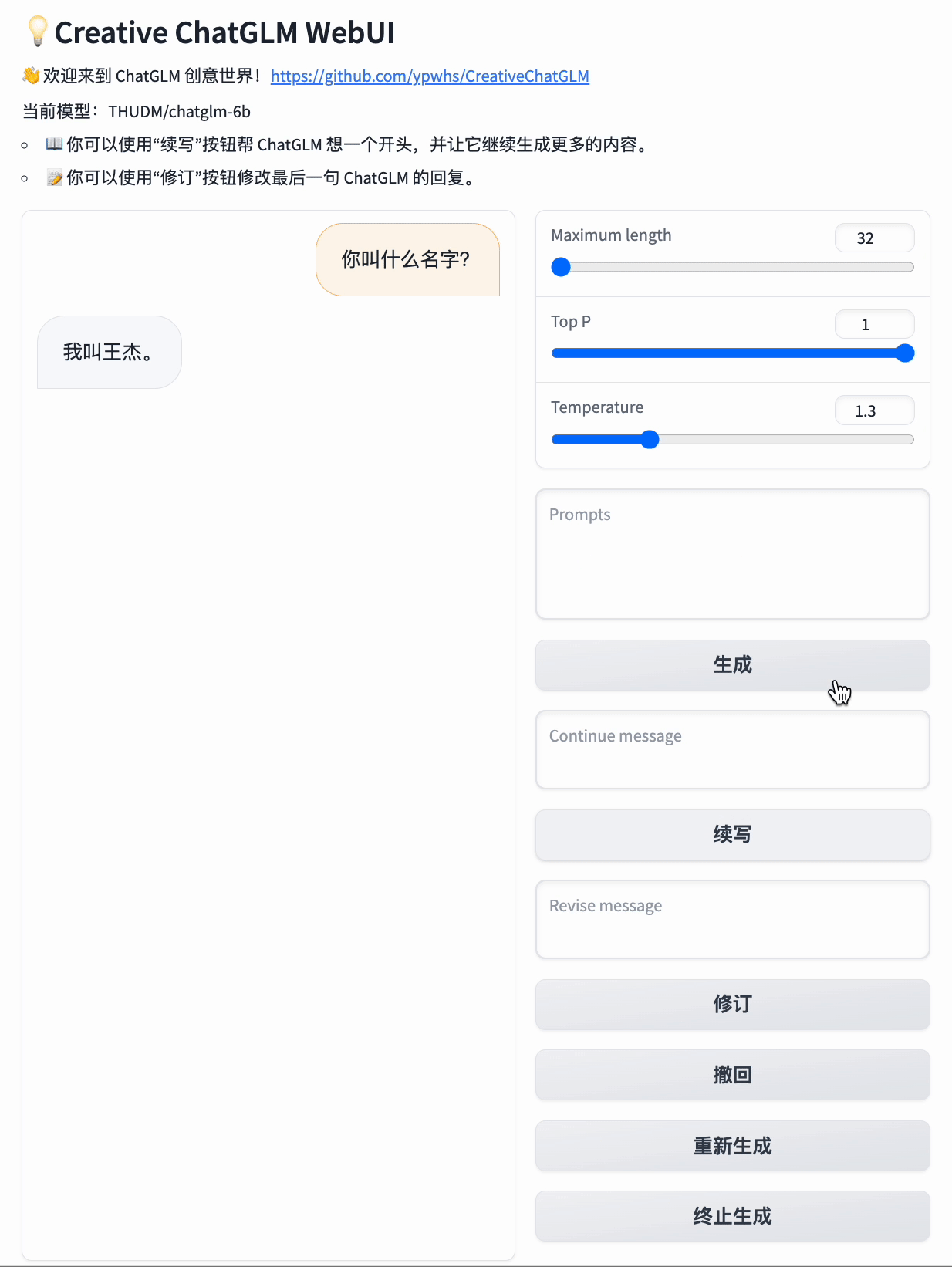
* 📖 你可以使用“续写”按钮帮 ChatGLM 想一个开头,并让它继续生成更多的内容。
* 📝 你可以使用“修订”按钮修改最后一句 ChatGLM 的回复。
# 环境配置
## 离线包
此安装方法适合:
* 非开发人员,不需要写代码
* 没有Python经验,不会搭建环境
* 网络环境不好,配置环境、下载模型速度慢
| 名称 | 大小 | 百度网盘 | 备注 |
|--------------|---------| ---- |----------------------------------------|
| **小显存离线包** | 5.3 GB | [点击下载](https://pan.baidu.com/s/1fI1JWBE7KP7cJsoD-dL38g?pwd=cglm) | chatglm2-6b-int4 离线包,显存需求 8GB |
| 大显存离线包 | 11.5 GB | [点击下载](https://pan.baidu.com/s/10oUwW2DUMDFk3RuIkaqGbA?pwd=cglm) | chatglm3-6b 离线包,显存需求 16GB |
| 长文本离线包 | 11.5 GB | [点击下载](https://pan.baidu.com/s/1kbeTdPcUmYd16IE0stXnTA?pwd=cglm) | chatglm3-6b-128k 离线包,显存需求 16GB |
| **GLM4 离线包** | 16.98GB | [点击下载](https://pan.baidu.com/s/1iGCzB5DO2sGCzKtARvTXnw?pwd=cglm) | GLM-4-9B 离线包,INT4 加载,显存需求 10GB |
| 环境离线包 | 2.6 GB | [点击下载](https://pan.baidu.com/s/1Kt9eZlgXJ03bVwIM22IR6w?pwd=cglm) | 不带权重的环境包,启动之后自动下载 chatglm2-6b-int4 权重。 |
除了这些一键环境包之外,你还可以在下面下载更多模型的权重。
* 百度网盘链接:[https://pan.baidu.com/s/1pnIEj66scZOswHm8oivXmw?pwd=cglm](https://pan.baidu.com/s/1pnIEj66scZOswHm8oivXmw?pwd=cglm)
下载好环境包之后,解压,然后运行 `start_offline.bat` 脚本,即可启动服务:

如果你想使用 API 的形式来调用,可以运行 `start_offline_api.bat` 启动 API 服务:

## 虚拟环境
此安装方法适合已经安装了 Python,但是希望环境与系统已安装的 Python 环境隔离的用户。
点击查看详细步骤
首先启动 `setup_venv.bat` 脚本,安装环境:
然后使用 `start_venv.bat` 脚本启动服务:
 ### 续写对话
而如果你给它起个头:“我今年”
它就会回答:“我今年21岁。”
### 续写对话
而如果你给它起个头:“我今年”
它就会回答:“我今年21岁。”
 ### 使用视频

## 修订
### 原始对话
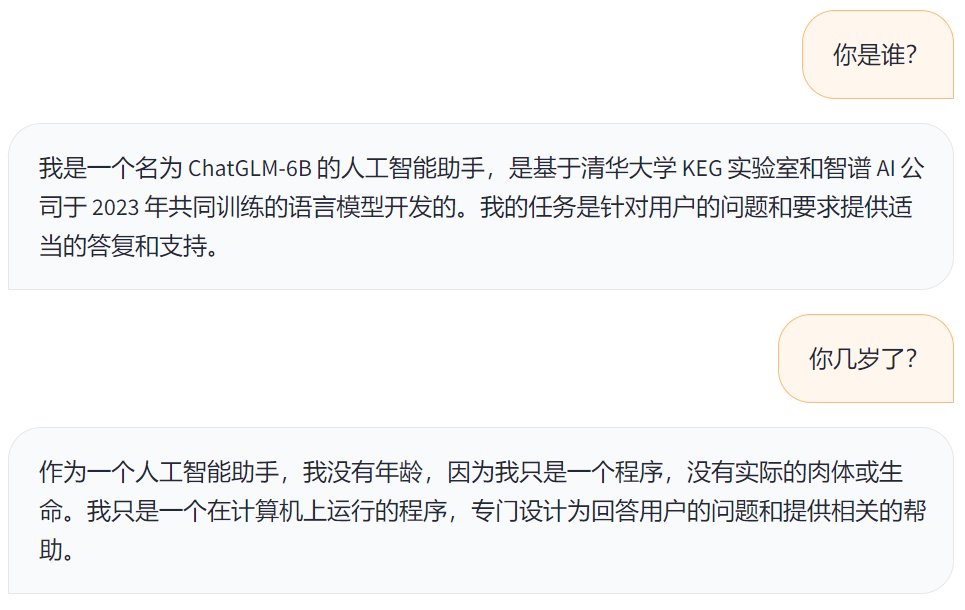
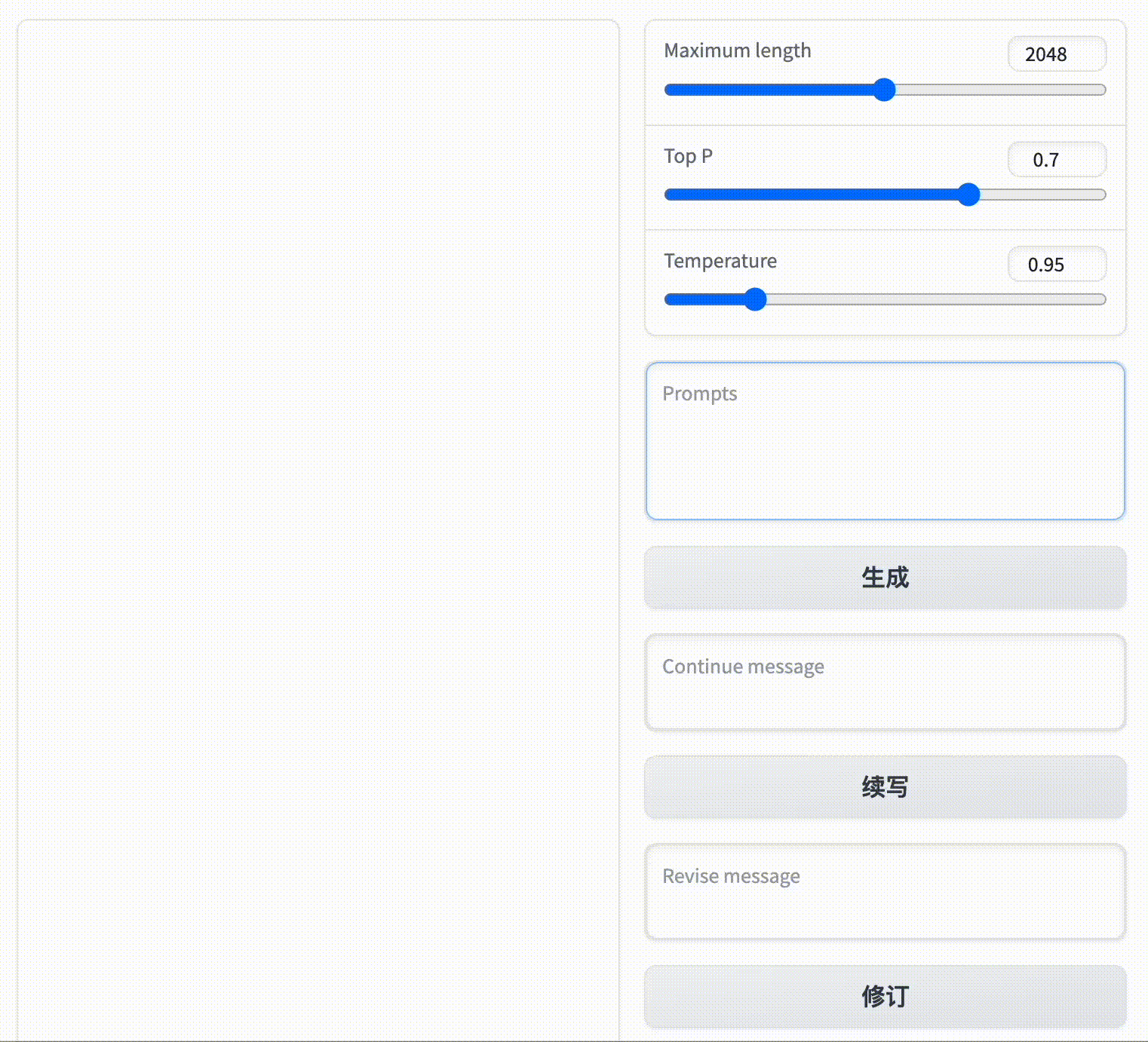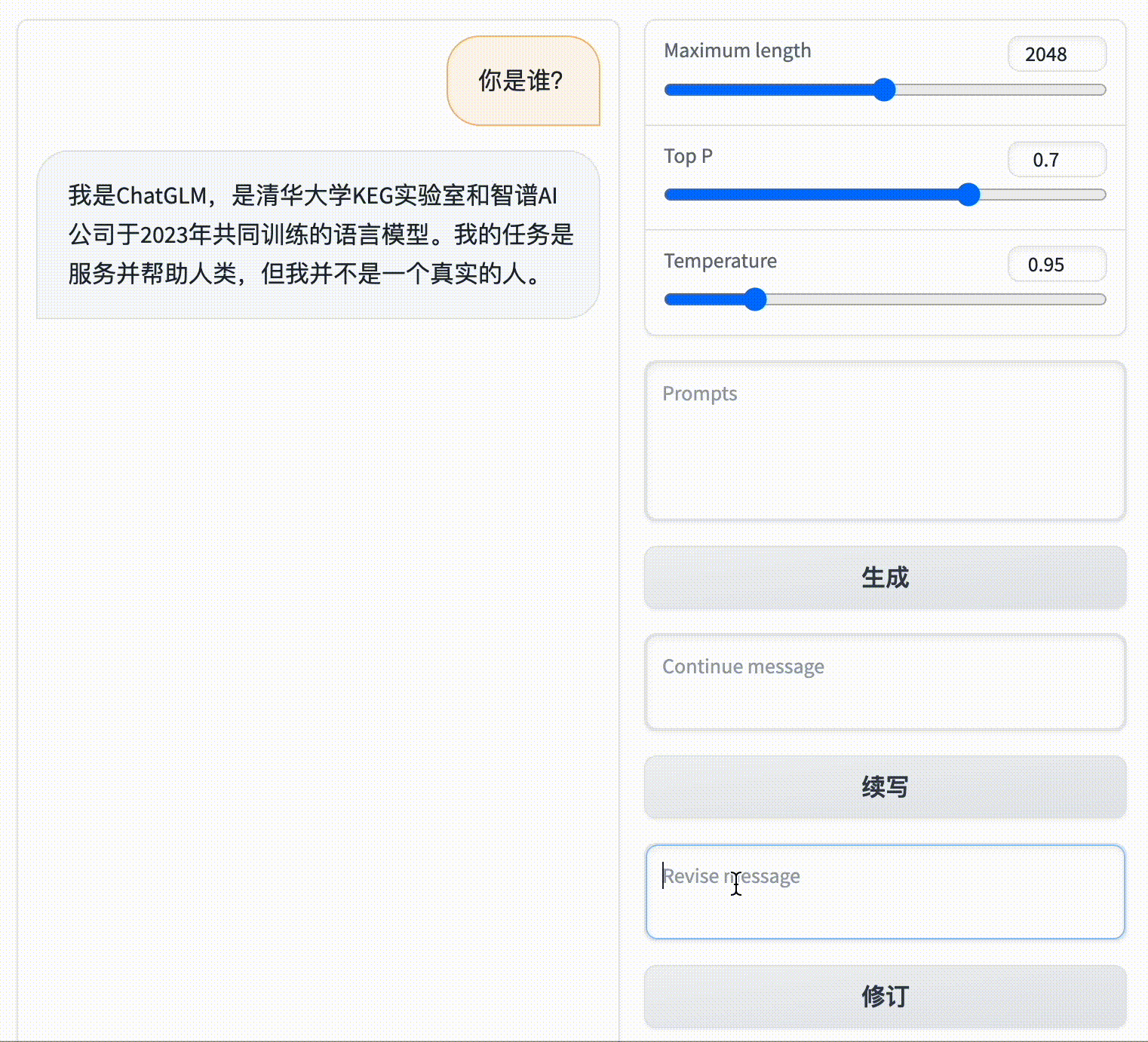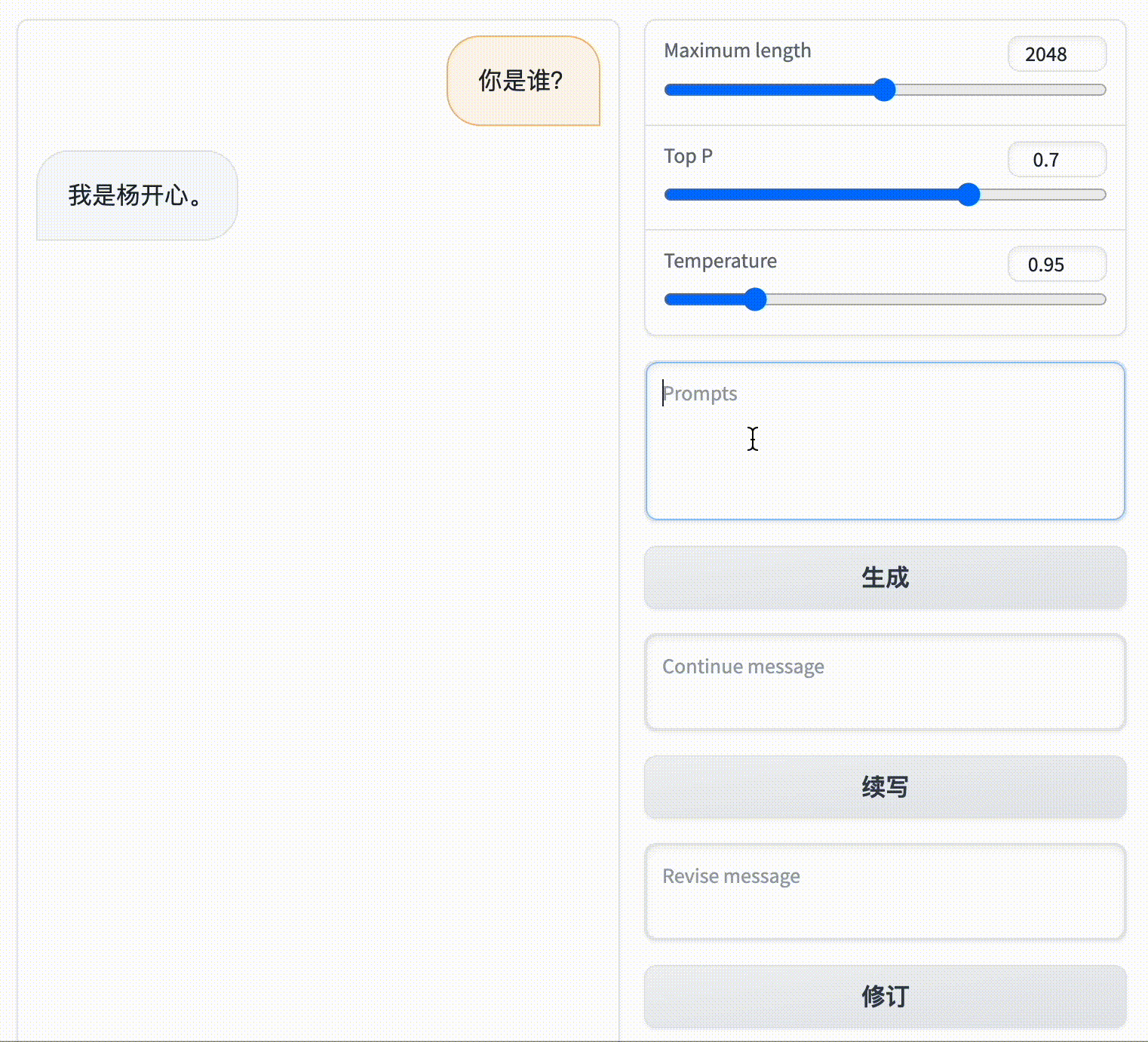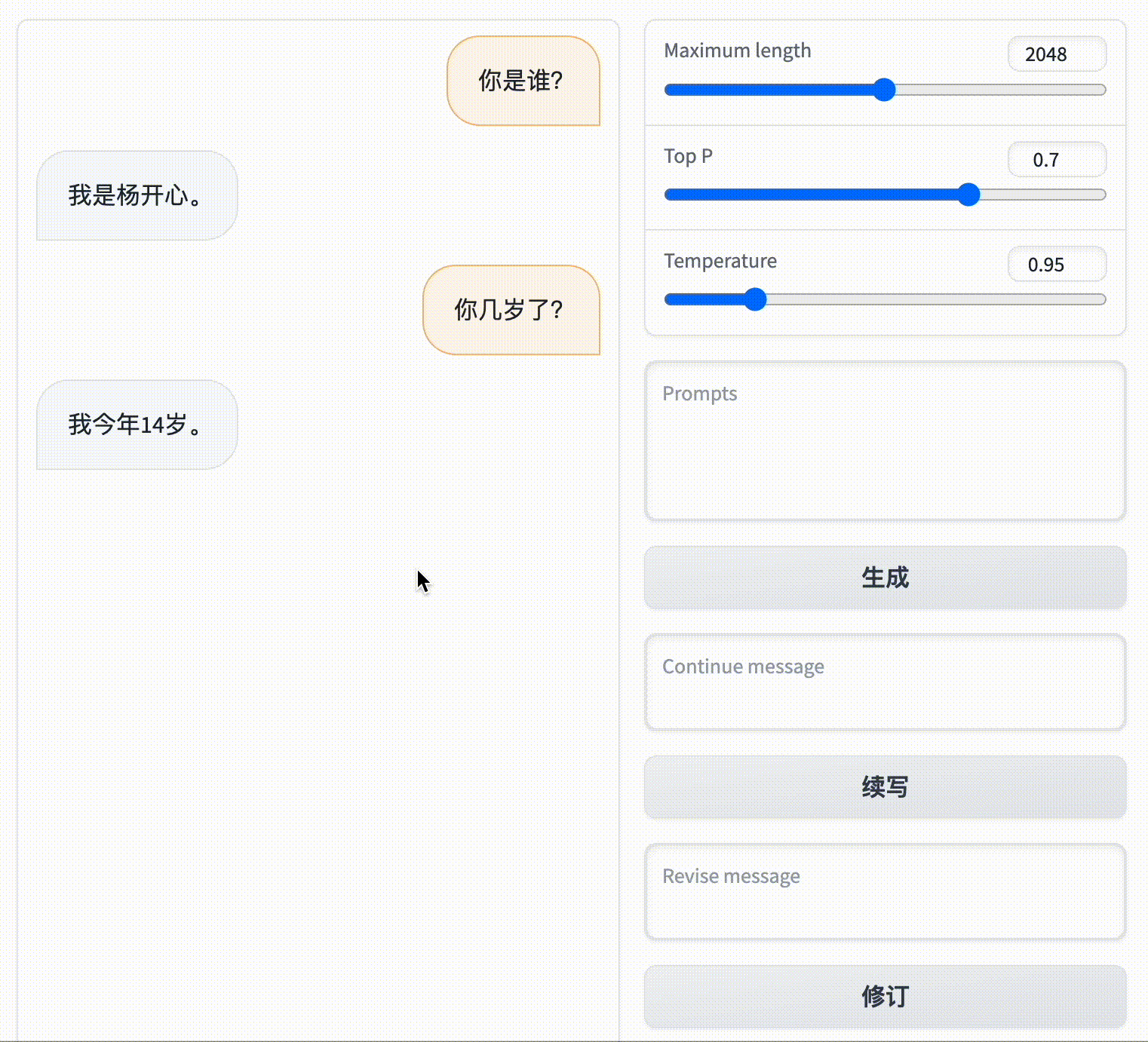
如果你直接跟 ChatGLM 说:“你是谁?”
它会回答:“我是一个名为 ChatGLM-6B 的人工智能助手,是基于清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练的语言模型开发的。我的任务是针对用户的问题和要求提供适当的答复和支持。”
你再问它:“你几岁了?”
它只会说:“作为一个人工智能助手,我没有年龄,因为我只是一个程序,没有实际的肉体或生命。我只是一个在计算机上运行的程序,专门设计为回答用户的问题和提供相关的帮助。”
### 修改对话
你可以改变它的角色,比如你通过“修订”功能,将它的回复改成:“我是杨开心。”
然后你再问它:“你几岁了?”
它就会回答:“我今年15岁。”

### 使用视频
### 重新对话
你可以按照某个输入,重复生成对话,从而拿到满意的结果。
### 使用视频
# 实现原理
这个方法并没有训练,没有修改官方发布的权重,而只是对推理的函数做了修改。
续写的原理是,将用户的输入直接设置为 `history[-1][1]`,模拟模型自己的部分输出,然后继续走之后的推理函数 `stream_chat_continue` [code](https://github.com/ypwhs/CreativeChatGLM/blob/a5c6dd1/chatglm/modeling_chatglm.py#L1158)。
修订的原理是,将用户的输入直接设置为 `history[-1][1]`,模拟模型自己的完整输出,但是不走推理函数。
# 离线包制作方法
关于本项目中的离线包制作方法,可以查看下面的详细步骤。
### 使用视频

## 修订
### 原始对话
如果你直接跟 ChatGLM 说:“你是谁?”
它会回答:“我是一个名为 ChatGLM-6B 的人工智能助手,是基于清华大学 KEG 实验室和智谱 AI 公司于 2023 年共同训练的语言模型开发的。我的任务是针对用户的问题和要求提供适当的答复和支持。”
你再问它:“你几岁了?”
它只会说:“作为一个人工智能助手,我没有年龄,因为我只是一个程序,没有实际的肉体或生命。我只是一个在计算机上运行的程序,专门设计为回答用户的问题和提供相关的帮助。”

### 修改对话
你可以改变它的角色,比如你通过“修订”功能,将它的回复改成:“我是杨开心。”
然后你再问它:“你几岁了?”
它就会回答:“我今年15岁。”

### 使用视频

### 重新对话
你可以按照某个输入,重复生成对话,从而拿到满意的结果。
### 使用视频

# 实现原理
这个方法并没有训练,没有修改官方发布的权重,而只是对推理的函数做了修改。
续写的原理是,将用户的输入直接设置为 `history[-1][1]`,模拟模型自己的部分输出,然后继续走之后的推理函数 `stream_chat_continue` [code](https://github.com/ypwhs/CreativeChatGLM/blob/a5c6dd1/chatglm/modeling_chatglm.py#L1158)。
修订的原理是,将用户的输入直接设置为 `history[-1][1]`,模拟模型自己的完整输出,但是不走推理函数。
# 离线包制作方法
关于本项目中的离线包制作方法,可以查看下面的详细步骤。
点击查看详细步骤
## 准备 Python
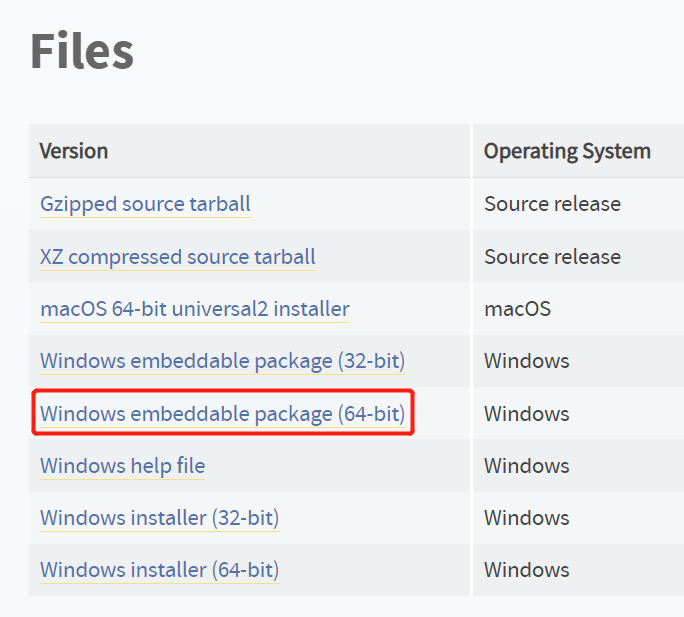
首先去 Python 官网下载:[https://www.python.org/downloads/](https://www.python.org/downloads/)
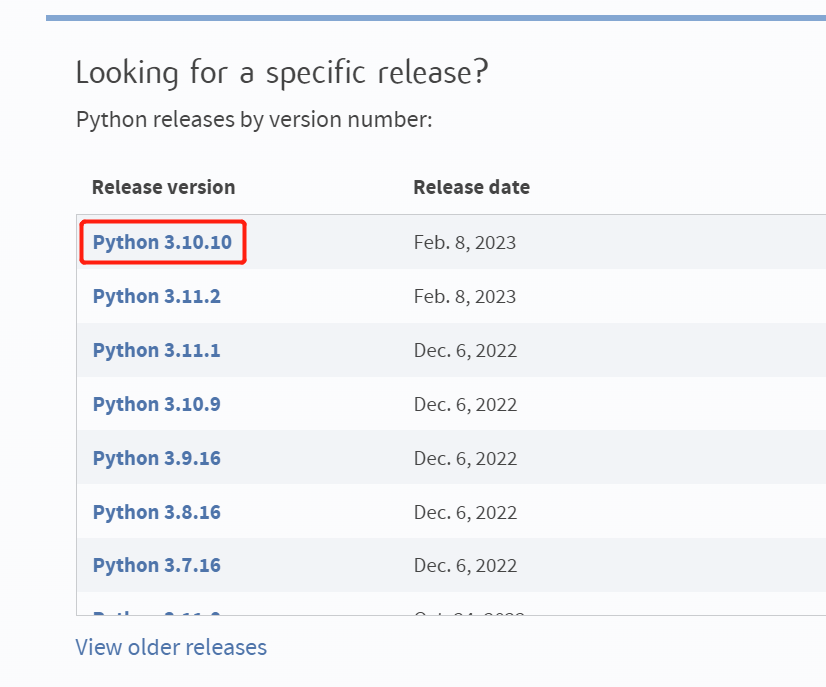
注意要下载 `Windows embeddable package (64-bit)` 离线包,我选择的是 [python-3.10.10-embed-amd64.zip](https://www.python.org/ftp/python/3.10.10/python-3.10.10-embed-amd64.zip)。
解压到 `./system/python` 目录下。
## 准备 get-pip.py
去官网下载:[https://bootstrap.pypa.io/get-pip.py](https://bootstrap.pypa.io/get-pip.py)
保存到 `./system/python` 目录下。
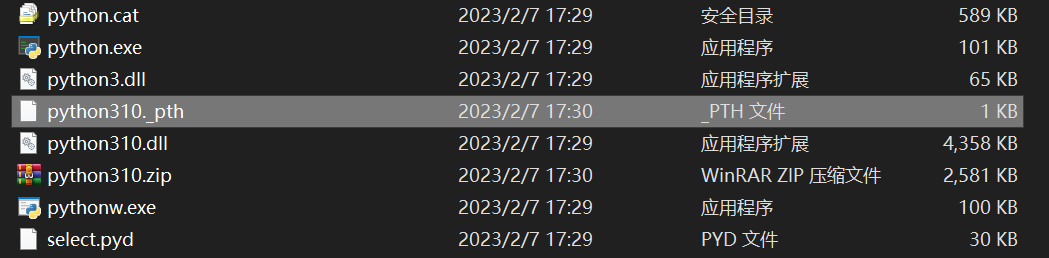
## ⚠️必做
解压之后,记得删除 pth 文件,以解决安装依赖的问题。
比如我删除的文件路径是 `./system/python/python310._pth`
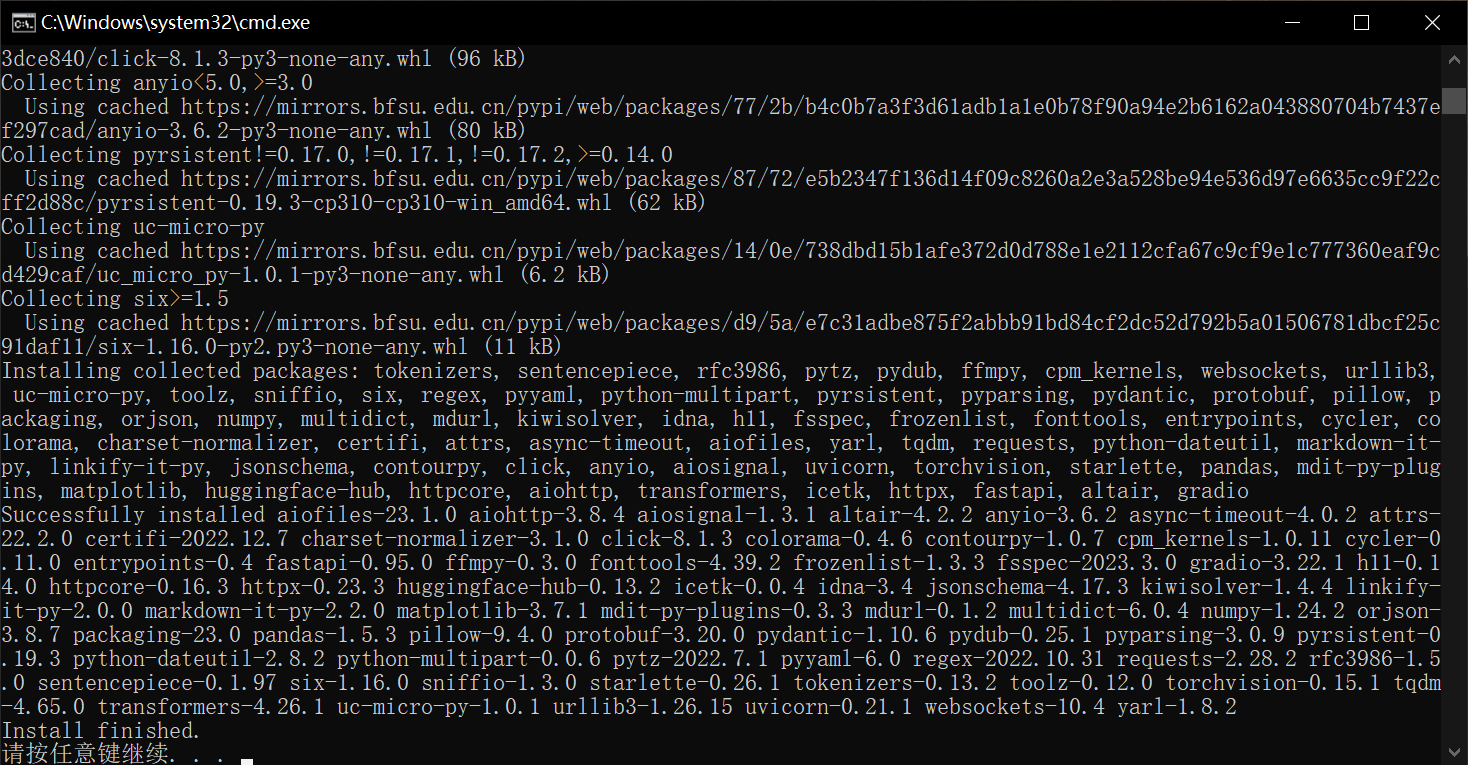
## 安装依赖
运行 [setup_offline.bat](setup_offline.bat) 脚本,安装依赖。
## 下载离线模型
你可以使用 [download_model.py](download_model.py) 脚本下载模型,如果你的网络环境不好,这个过程可能会很长。下载的模型会存在 `~/.cache` 一份,存在 `./models` 一份。
当你之后使用 `AutoModel.from_pretrained` 加载模型时,可以从 `~/.cache` 缓存目录加载模型,避免二次下载。
下载好的模型,你需要从 `./models` 文件夹移出到项目目录下,这样就可以离线加载了。
下载完模型之后,你需要修改 [app.py](app.py) 里的 `model_name`,改成你想加载的模型名称。
## 测试
使用 [start_offline.bat](start_offline.bat) 启动服务:
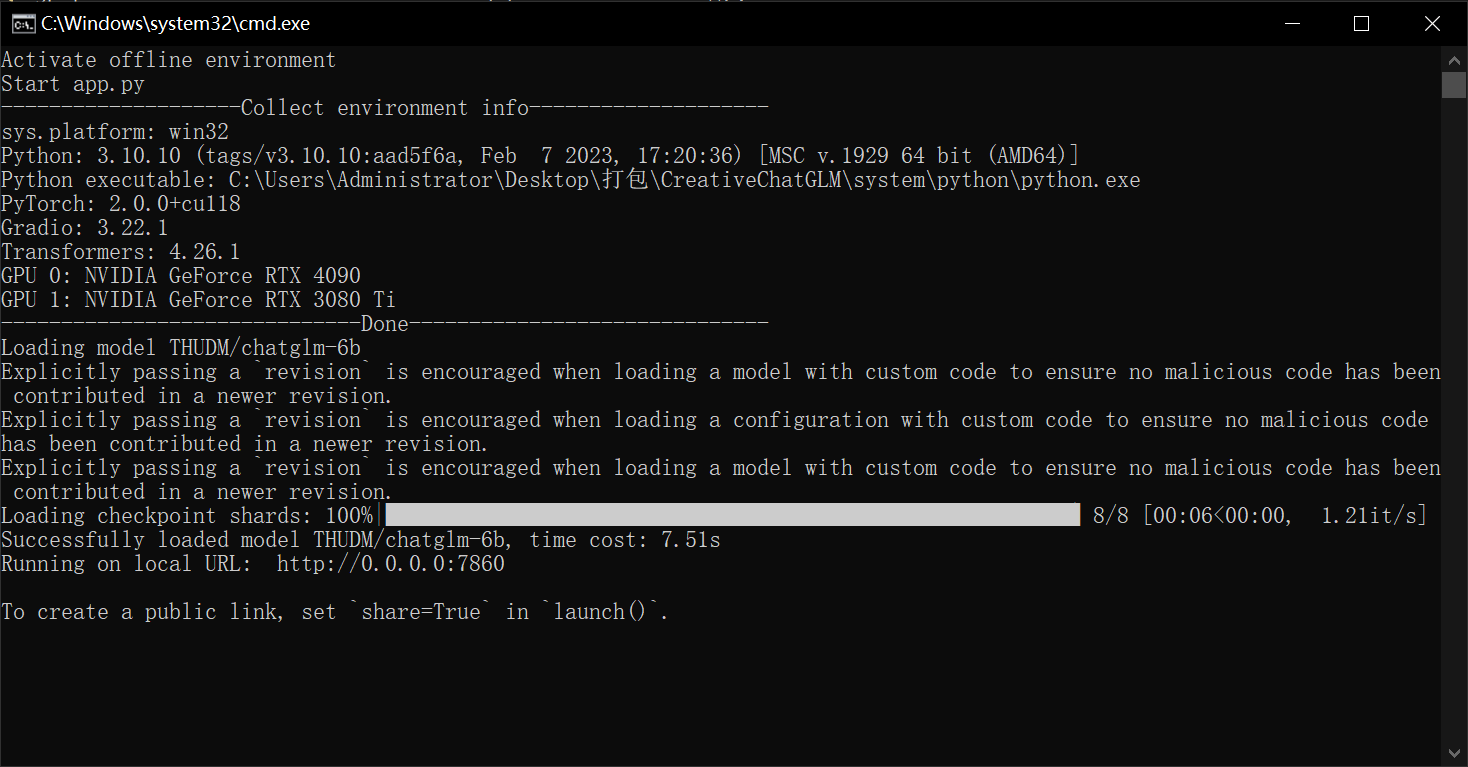
可以看到,服务正常启动。
'
else:
lines[i] = '
'
else:
if i > 0:
lines[i] = "
" + line.replace("<", "<").replace(
">", ">")
return "".join(lines)
class BasePredictor(ABC):
@abstractmethod
def __init__(self, model_name, predict_mode='tuple'):
self.model = None
self.tokenizer = None
self.model_name = model_name
self.predict_mode = predict_mode
@abstractmethod
def stream_chat_continue(self, *args, **kwargs):
raise NotImplementedError
def predict_continue(self, *args, **kwargs):
if self.predict_mode == 'tuple':
yield from self.predict_continue_tuple(*args, **kwargs)
else:
yield from self.predict_continue_dict(*args, **kwargs)
def predict_continue_tuple(self, query, latest_message, max_length, top_p,
temperature, allow_generate, history,
last_state, *args, **kwargs):
last_state[0] = copy.deepcopy(history)
last_state[1] = query
last_state[2] = latest_message
if history is None:
history = []
allow_generate[0] = True
history.append((query, latest_message))
for response in self.stream_chat_continue(
self.model,
self.tokenizer,
query=query,
history=history,
max_length=max_length,
top_p=top_p,
temperature=temperature):
history[-1] = (history[-1][0], response)
history_colorful = copy.deepcopy(history)
colorful_response = f'{latest_message}{response[len(latest_message):]}'
history_colorful[-1] = (history_colorful[-1][0], colorful_response)
yield history_colorful, '', ''
if not allow_generate[0]:
break
def predict_continue_dict(self, query, latest_message, max_length, top_p,
temperature, allow_generate, history, last_state,
*args, **kwargs):
last_state[0] = copy.deepcopy(history)
last_state[1] = query
last_state[2] = latest_message
if history is None:
history = []
allow_generate[0] = True
history.append({"role": "user", "content": query})
history.append({"role": "assistant", "content": latest_message})
for response in self.stream_chat_continue(
self.model,
self.tokenizer,
query=query,
history=history,
max_length=max_length,
top_p=top_p,
temperature=temperature):
history[-1]["content"] = response
history_colorful = copy.deepcopy(history)
colorful_response = f'{latest_message}{response[len(latest_message):]}'
history_colorful[-1]["content"] = colorful_response
history_tuple = []
for i in range(0, len(history_colorful), 2):
history_tuple.append((history_colorful[i]["content"],
history_colorful[i + 1]["content"]))
yield history_tuple, '', ''
if not allow_generate[0]:
break
================================================
FILE: predictors/chatglm2_predictor.py
================================================
import time
from typing import List, Tuple
import torch
from transformers import AutoModel, AutoTokenizer
from transformers import LogitsProcessor, LogitsProcessorList
from predictors.base import BasePredictor, parse_codeblock
class InvalidScoreLogitsProcessor(LogitsProcessor):
def __call__(self, input_ids: torch.LongTensor, scores: torch.FloatTensor) -> torch.FloatTensor:
if torch.isnan(scores).any() or torch.isinf(scores).any():
scores.zero_()
scores[..., 5] = 5e4
return scores
class ChatGLM2(BasePredictor):
def __init__(self, model_name):
self.predict_mode = 'tuple'
print(f'Loading model {model_name}')
start = time.perf_counter()
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.tokenizer = AutoTokenizer.from_pretrained(
model_name, trust_remote_code=True, resume_download=True)
if 'slim' in model_name:
model = AutoModel.from_pretrained(
model_name, trust_remote_code=True,
resume_download=True)
if self.device == 'cuda':
model = model.half().to(self.device)
else:
model = model.float()
elif 'int4' in model_name:
model = AutoModel.from_pretrained(
model_name, trust_remote_code=True,
resume_download=True)
if self.device == 'cuda':
model = model.half().to(self.device)
else:
model = model.float()
else:
model = AutoModel.from_pretrained(
model_name,
trust_remote_code=True,
resume_download=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16
if self.device == 'cuda' else torch.float32,
device_map={'': self.device})
if self.device == 'cpu':
model = model.float()
model = model.eval()
self.model = model
self.model_name = model_name
end = time.perf_counter()
print(
f'Successfully loaded model {model_name}, time cost: {end - start:.2f}s'
)
@torch.no_grad()
def stream_chat_continue(self,
model,
tokenizer, query: str, history: List[Tuple[str, str]] = None, past_key_values=None,
max_length: int = 8192, do_sample=True, top_p=0.8, temperature=0.8, logits_processor=None,
return_past_key_values=False, **kwargs):
if history is None:
history = []
if logits_processor is None:
logits_processor = LogitsProcessorList()
if len(history) > 0:
answer = history[-1][1]
else:
answer = ''
logits_processor.append(
InvalidScoreLogitsProcessor())
gen_kwargs = {
"max_length": max_length,
"do_sample": do_sample,
"top_p": top_p,
"temperature": temperature,
"logits_processor": logits_processor,
**kwargs
}
if not history:
prompt = query
else:
prompt = ""
for i, (old_query, response) in enumerate(history):
if i != len(history) - 1:
prompt += "[Round {}]\n\n问:{}\n\n答:{}\n\n".format(
i, old_query, response)
else:
prompt += "[Round {}]\n\n问:{}\n\n答:\n\n".format(i, old_query)
batch_input = tokenizer([prompt], return_tensors="pt")
batch_input = batch_input.to(model.device)
batch_answer = tokenizer(answer, return_tensors="pt")
batch_answer = batch_answer.to(model.device)
final_input_ids = torch.cat(
[batch_input['input_ids'], batch_answer['input_ids'][:, 3:]],
dim=-1)
final_input_ids = final_input_ids.to(model.device)
final_input = {}
final_input['input_ids'] = final_input_ids
final_input['position_ids'] = model.get_position_ids(final_input_ids, device=final_input_ids.device)
final_input['attention_mask'] = torch.ones(final_input_ids.shape, dtype=torch.long, device=final_input_ids.device)
for outputs in model.stream_generate(**final_input, past_key_values=past_key_values,
return_past_key_values=return_past_key_values, **gen_kwargs):
if return_past_key_values:
outputs, past_key_values = outputs
outputs = outputs.tolist()[0][len(batch_input["input_ids"][0]):]
response = tokenizer.decode(outputs)
if response and response[-1] != "�":
response = model.process_response(response)
yield parse_codeblock(response)
def test():
model_name = 'chatglm2-6b'
predictor = ChatGLM2(model_name)
top_p = 0.01
max_length = 128
temperature = 0.01
history = []
line = '你是谁?'
last_message = '我是张三丰,我是武当派'
print(line)
for x in predictor.predict_continue(
query=line, latest_message=last_message,
max_length=max_length, top_p=top_p, temperature=temperature,
allow_generate=[True], history=history, last_state=[[], None, None]):
print(x[0][-1][1])
def test2():
from chatglm2.modeling_chatglm import ChatGLMForConditionalGeneration
model_name = 'chatglm2-6b'
device = 'cuda'
tokenizer = AutoTokenizer.from_pretrained(
model_name, trust_remote_code=True, resume_download=True)
model = ChatGLMForConditionalGeneration.from_pretrained(
model_name,
trust_remote_code=True,
resume_download=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16 if device == 'cuda' else torch.float32,
device_map={'': device})
model = model.eval()
query = '继续'
history = [('你是谁?', '我是张三丰,')]
max_length = 128
top_p = 0.95
temperature = 0.8
for response, new_history in model.stream_chat(
tokenizer=tokenizer,
query=query,
history=history,
max_length=max_length,
top_p=top_p,
temperature=temperature):
print(response, new_history)
if __name__ == '__main__':
test()
================================================
FILE: predictors/chatglm3_predictor.py
================================================
import time
import json
from typing import List, Dict
import torch
from transformers import AutoModel, AutoTokenizer
from transformers import LogitsProcessor, LogitsProcessorList
from predictors.base import BasePredictor, parse_codeblock
class InvalidScoreLogitsProcessor(LogitsProcessor):
def __call__(self, input_ids: torch.LongTensor,
scores: torch.FloatTensor) -> torch.FloatTensor:
if torch.isnan(scores).any() or torch.isinf(scores).any():
scores.zero_()
scores[..., 5] = 5e4
return scores
class ChatGLM3(BasePredictor):
def __init__(self, model_name):
self.predict_mode = 'dict'
print(f'Loading model {model_name}')
start = time.perf_counter()
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.tokenizer = AutoTokenizer.from_pretrained(
model_name, trust_remote_code=True, resume_download=True)
if 'slim' in model_name:
model = AutoModel.from_pretrained(
model_name, trust_remote_code=True, resume_download=True)
if self.device == 'cuda':
model = model.half().to(self.device)
else:
model = model.float()
elif 'int4' in model_name:
model = AutoModel.from_pretrained(
model_name, trust_remote_code=True, resume_download=True)
if self.device == 'cuda':
model = model.half().to(self.device)
else:
model = model.float()
else:
model = AutoModel.from_pretrained(
model_name,
trust_remote_code=True,
resume_download=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16
if self.device == 'cuda' else torch.float32,
device_map={'': self.device})
if self.device == 'cpu':
model = model.float()
model = model.eval()
self.model = model
self.model_name = model_name
end = time.perf_counter()
print(
f'Successfully loaded model {model_name}, time cost: {end - start:.2f}s'
)
@torch.inference_mode()
def stream_chat_continue(self,
model,
tokenizer,
query: str,
history: List[Dict] = None,
role: str = "user",
past_key_values=None,
max_length: int = 8192,
do_sample=True,
top_p=0.8,
temperature=0.8,
logits_processor=None,
return_past_key_values=False,
**kwargs):
if history is None:
history = []
if logits_processor is None:
logits_processor = LogitsProcessorList()
logits_processor.append(InvalidScoreLogitsProcessor())
eos_token_id = [
tokenizer.eos_token_id,
tokenizer.get_command("<|user|>"),
tokenizer.get_command("<|observation|>")
]
gen_kwargs = {
"max_length": max_length,
"do_sample": do_sample,
"top_p": top_p,
"temperature": temperature,
"logits_processor": logits_processor,
**kwargs
}
answer = history[-1]["content"]
input_ids = []
for item in history[:-1]:
content = item["content"]
if item["role"] == "system" and "tools" in item:
content = content + "\n" + json.dumps(item["tools"], indent=4, ensure_ascii=False)
input_ids.extend(tokenizer.build_single_message(item["role"], item.get("metadata", ""), content))
batch_input = tokenizer.batch_encode_plus([input_ids], return_tensors="pt", is_split_into_words=True)
batch_input = batch_input.to(model.device)
answer_input_ids = tokenizer.build_single_message("assistant", "", answer)
batch_answer = tokenizer.batch_encode_plus([answer_input_ids], return_tensors="pt", is_split_into_words=True)
batch_answer = batch_answer.to(model.device)
final_input_ids = torch.cat([batch_input['input_ids'], batch_answer['input_ids'][:, 2:]], dim=-1)
final_input_ids = final_input_ids.to(model.device)
final_input = {}
final_input['input_ids'] = final_input_ids
final_input['position_ids'] = model.get_position_ids(final_input_ids, device=final_input_ids.device)
final_input['attention_mask'] = torch.ones(final_input_ids.shape, dtype=torch.long, device=final_input_ids.device)
for outputs in model.stream_generate(
**final_input,
past_key_values=past_key_values,
eos_token_id=eos_token_id,
return_past_key_values=return_past_key_values,
**gen_kwargs):
if return_past_key_values:
outputs, past_key_values = outputs
outputs = outputs.tolist()[0][
len(batch_input["input_ids"]
[0]):-1] # Exclude the last token if it's EOS
response = tokenizer.decode(outputs)
if response and response[-1] != "�":
response, new_history = model.process_response(
response, history)
yield response
def test():
model_name = 'THUDM/chatglm3-6b'
predictor = ChatGLM3(model_name)
top_p = 0.01
max_length = 128
temperature = 0.01
history = []
query = '你是谁?'
last_message = '我是张三丰,我是武当派'
print(query)
for x in predictor.predict_continue_dict(
query=query,
latest_message=last_message,
max_length=max_length,
top_p=top_p,
temperature=temperature,
allow_generate=[True],
history=history,
last_state=[[], None, None]):
print(x[0][-1])
def test2():
from chatglm3.modeling_chatglm import ChatGLMForConditionalGeneration
model_name = 'THUDM/chatglm3-6b'
device = 'cuda'
tokenizer = AutoTokenizer.from_pretrained(
model_name, trust_remote_code=True, resume_download=True)
model = ChatGLMForConditionalGeneration.from_pretrained(
model_name,
trust_remote_code=True,
resume_download=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16 if device == 'cuda' else torch.float32,
device_map={'': device})
model = model.eval()
query = '继续'
history = [{
'role': 'user',
'content': '你是谁?'
}, {
'role': 'assistant',
'content': '我是张三丰,'
}]
max_length = 128
top_p = 0.95
temperature = 0.8
for response, new_history in model.stream_chat(
tokenizer=tokenizer,
query=query,
history=history,
max_length=max_length,
top_p=top_p,
temperature=temperature):
print(response, new_history)
if __name__ == '__main__':
test()
================================================
FILE: predictors/chatglm_predictor.py
================================================
import time
from typing import List, Tuple
import torch
from transformers import AutoModel, AutoTokenizer
from transformers import LogitsProcessor, LogitsProcessorList
from predictors.base import BasePredictor, parse_codeblock
class InvalidScoreLogitsProcessor(LogitsProcessor):
def __init__(self, start_pos=5):
self.start_pos = start_pos
def __call__(self, input_ids: torch.LongTensor,
scores: torch.FloatTensor) -> torch.FloatTensor:
if torch.isnan(scores).any() or torch.isinf(scores).any():
scores.zero_()
scores[..., self.start_pos] = 5e4
return scores
class ChatGLM(BasePredictor):
def __init__(self, model_name):
self.predict_mode = 'tuple'
print(f'Loading model {model_name}')
start = time.perf_counter()
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.tokenizer = AutoTokenizer.from_pretrained(
model_name, trust_remote_code=True, resume_download=True)
if 'slim' in model_name:
model = AutoModel.from_pretrained(
model_name, trust_remote_code=True,
resume_download=True)
if self.device == 'cuda':
model = model.half().to(self.device)
else:
model = model.float()
elif 'int4' in model_name:
model = AutoModel.from_pretrained(
model_name, trust_remote_code=True,
resume_download=True)
if self.device == 'cuda':
model = model.half().to(self.device)
else:
model = model.float()
else:
model = AutoModel.from_pretrained(
model_name,
trust_remote_code=True,
resume_download=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16
if self.device == 'cuda' else torch.float32,
device_map={'': self.device})
if self.device == 'cpu':
model = model.float()
model = model.eval()
self.model = model
self.model_name = model_name
end = time.perf_counter()
print(
f'Successfully loaded model {model_name}, time cost: {end - start:.2f}s'
)
@torch.no_grad()
def stream_chat_continue(self,
model,
tokenizer,
query: str,
history: List[Tuple[str, str]] = None,
max_length: int = 2048,
do_sample=True,
top_p=0.7,
temperature=0.95,
logits_processor=None,
**kwargs):
if history is None:
history = []
if logits_processor is None:
logits_processor = LogitsProcessorList()
if len(history) > 0:
answer = history[-1][1]
else:
answer = ''
logits_processor.append(
InvalidScoreLogitsProcessor(5))
gen_kwargs = {
"max_length": max_length,
"do_sample": do_sample,
"top_p": top_p,
"temperature": temperature,
"logits_processor": logits_processor,
**kwargs
}
if not history:
prompt = query
else:
prompt = ""
for i, (old_query, response) in enumerate(history):
if i != len(history) - 1:
prompt += "[Round {}]\n问:{}\n答:{}\n".format(
i, old_query, response)
else:
prompt += "[Round {}]\n问:{}\n答:".format(i, old_query)
batch_input = tokenizer([prompt], return_tensors="pt", padding=True)
batch_input = batch_input.to(model.device)
batch_answer = tokenizer(answer, return_tensors="pt")
batch_answer = batch_answer.to(model.device)
input_length = len(batch_input['input_ids'][0])
final_input_ids = torch.cat(
[batch_input['input_ids'], batch_answer['input_ids'][:, :-2]],
dim=-1)
final_input_ids = final_input_ids.to(model.device)
attention_mask = model.get_masks(
final_input_ids, device=final_input_ids.device)
batch_input['input_ids'] = final_input_ids
batch_input['attention_mask'] = attention_mask
input_ids = final_input_ids
MASK, gMASK = self.model.config.bos_token_id - 4, self.model.config.bos_token_id - 3
mask_token = MASK if MASK in input_ids else gMASK
mask_positions = [seq.tolist().index(mask_token) for seq in input_ids]
batch_input['position_ids'] = self.model.get_position_ids(
input_ids, mask_positions, device=input_ids.device)
for outputs in model.stream_generate(**batch_input, **gen_kwargs):
outputs = outputs.tolist()[0][input_length:]
response = tokenizer.decode(outputs)
response = model.process_response(response)
yield parse_codeblock(response)
def test():
model_name = 'chatglm-6b'
# model_name = 'silver/chatglm-6b-int4-slim'
predictor = ChatGLM(model_name)
top_p = 0.95
max_length = 128
temperature = 0.8
line = '你是谁?'
last_message = '我是张三丰,'
print(line)
for x in predictor.predict_continue(
query=line, latest_message=last_message,
max_length=max_length, top_p=top_p, temperature=temperature,
allow_generate=[True], history=None, last_state=[[], None, None]):
print(x[0][-1][1])
if __name__ == '__main__':
test()
================================================
FILE: predictors/debug.py
================================================
class Debug:
def __init__(self, *args, **kwargs):
pass
def inference(self, *args, **kwargs):
import random
sample_outputs = [
'我是杨开心。',
'我两岁半了。',
'我喜欢吃雪糕。',
]
one_output = random.choice(sample_outputs)
for i in range(len(one_output)):
yield one_output[:i + 1]
def predict_continue(self, *args, **kwargs):
yield from self.inference(*args, **kwargs)
================================================
FILE: predictors/glm4_predictor.py
================================================
import time
import json
from typing import List, Dict
import torch
from transformers import AutoModel, AutoTokenizer
from transformers import LogitsProcessor, LogitsProcessorList
from transformers import BitsAndBytesConfig
from predictors.base import BasePredictor, parse_codeblock
class InvalidScoreLogitsProcessor(LogitsProcessor):
def __call__(self, input_ids: torch.LongTensor,
scores: torch.FloatTensor) -> torch.FloatTensor:
if torch.isnan(scores).any() or torch.isinf(scores).any():
scores.zero_()
scores[..., 5] = 5e4
return scores
class GLM4(BasePredictor):
def __init__(self, model_name, int4=False):
self.predict_mode = 'dict'
print(f'Loading model {model_name}')
start = time.perf_counter()
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.tokenizer = AutoTokenizer.from_pretrained(
model_name, trust_remote_code=True)
if 'slim' in model_name:
model = AutoModel.from_pretrained(
model_name, trust_remote_code=True)
if self.device == 'cuda':
model = model.half().to(self.device)
else:
model = model.float()
elif 'int4' in model_name:
model = AutoModel.from_pretrained(
model_name, trust_remote_code=True)
if self.device == 'cuda':
model = model.half().to(self.device)
else:
model = model.float()
else:
model = AutoModel.from_pretrained(
model_name,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16
if self.device == 'cuda' else torch.float32,
quantization_config=BitsAndBytesConfig(
load_in_4bit=True) if int4 else None,
device_map={'': self.device})
if self.device == 'cpu':
model = model.float()
model = model.eval()
self.model = model
self.model_name = model_name
end = time.perf_counter()
print(
f'Successfully loaded model {model_name}, time cost: {end - start:.2f}s'
)
@torch.inference_mode()
def stream_chat_continue(self,
model,
tokenizer,
query: str,
history: List[Dict] = None,
role: str = "user",
past_key_values=None,
max_length: int = 8192,
do_sample=True,
top_p=0.8,
temperature=0.8,
logits_processor=None,
return_past_key_values=False,
**kwargs):
if history is None:
history = []
if logits_processor is None:
logits_processor = LogitsProcessorList()
logits_processor.append(InvalidScoreLogitsProcessor())
eos_token_id = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|user|>"),
tokenizer.convert_tokens_to_ids("<|observation|>")
]
gen_kwargs = {
"max_length": max_length,
"do_sample": do_sample,
"top_p": top_p,
"temperature": temperature,
"logits_processor": logits_processor,
**kwargs
}
answer = history[-1]["content"]
input_ids = []
for item in history[:-1]:
content = item["content"]
if item["role"] == "system" and "tools" in item:
content = content + "\n" + json.dumps(
item["tools"], indent=4, ensure_ascii=False)
input_ids.extend(
tokenizer.build_single_message(item["role"],
item.get("metadata", ""),
content))
batch_input = tokenizer.batch_encode_plus([input_ids],
return_tensors="pt",
is_split_into_words=True)
batch_input = batch_input.to(model.device)
answer_input_ids = tokenizer.build_single_message(
"assistant", "", answer)
batch_answer = tokenizer.batch_encode_plus([answer_input_ids],
return_tensors="pt",
is_split_into_words=True)
batch_answer = batch_answer.to(model.device)
final_input_ids = torch.cat(
[batch_input['input_ids'], batch_answer['input_ids'][:, 2:]],
dim=-1)
final_input_ids = final_input_ids.to(model.device)
final_input = {}
final_input['input_ids'] = final_input_ids
final_input['position_ids'] = model.get_position_ids(
final_input_ids, device=final_input_ids.device)
final_input['attention_mask'] = torch.ones(
final_input_ids.shape,
dtype=torch.long,
device=final_input_ids.device)
for outputs in model.stream_generate(
**final_input,
past_key_values=past_key_values,
eos_token_id=eos_token_id,
return_past_key_values=return_past_key_values,
**gen_kwargs):
if return_past_key_values:
outputs, past_key_values = outputs
outputs = outputs.tolist()[0][
len(batch_input["input_ids"]
[0]):-1] # Exclude the last token if it's EOS
response = tokenizer.decode(outputs)
if response and response[-1] != "�":
response, new_history = model.process_response(
response, history)
yield response
def test():
model_name = 'THUDM/glm-4-9b-chat-1m'
predictor = GLM4(model_name)
top_p = 0.01
max_length = 128
temperature = 0.01
history = []
query = '你是谁?'
last_message = '我是张三丰,我是武当派'
print(query)
for x in predictor.predict_continue_dict(
query=query,
latest_message=last_message,
max_length=max_length,
top_p=top_p,
temperature=temperature,
allow_generate=[True],
history=history,
last_state=[[], None, None]):
print(x[0][-1])
def test2():
from glm4.modeling_chatglm import ChatGLMForConditionalGeneration
model_name = 'THUDM/glm-4-9b-chat-1m'
device = 'cuda'
tokenizer = AutoTokenizer.from_pretrained(
model_name, trust_remote_code=True)
model = ChatGLMForConditionalGeneration.from_pretrained(
model_name,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.bfloat16 if device == 'cuda' else torch.float32,
device_map={'': device})
model = model.eval()
query = '继续'
history = [{
'role': 'user',
'content': '你是谁?'
}, {
'role': 'assistant',
'content': '我是张三丰,我是武当派'
}]
max_length = 128
top_p = 0.95
temperature = 0.8
for response, new_history in model.stream_chat(
tokenizer=tokenizer,
query=query,
history=history,
max_length=max_length,
top_p=top_p,
temperature=temperature):
print(response, new_history)
if __name__ == '__main__':
test()
================================================
FILE: predictors/llama.py
================================================
import copy
import time
import warnings
from typing import List, Tuple, Optional, Callable
import torch
import torch.nn as nn
from transformers import LlamaForCausalLM, AutoTokenizer
from transformers.generation.utils import LogitsProcessorList, StoppingCriteriaList, GenerationConfig
from transformers.utils import logging
from predictors.base import BasePredictor
logger = logging.get_logger(__name__)
@torch.no_grad()
def stream_generate(
self,
input_ids,
generation_config: Optional[GenerationConfig] = None,
logits_processor: Optional[LogitsProcessorList] = None,
stopping_criteria: Optional[StoppingCriteriaList] = None,
prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
**kwargs,
):
batch_size, input_ids_seq_length = input_ids.shape[0], input_ids.shape[-1]
if generation_config is None:
generation_config = self.generation_config
generation_config = copy.deepcopy(generation_config)
model_kwargs = generation_config.update(**kwargs)
bos_token_id, eos_token_id = generation_config.bos_token_id, generation_config.eos_token_id
if isinstance(eos_token_id, int):
eos_token_id = [eos_token_id]
has_default_max_length = kwargs.get("max_length") is None and generation_config.max_length is not None
if has_default_max_length and generation_config.max_new_tokens is None:
warnings.warn(
f"Using `max_length`'s default ({generation_config.max_length}) to control the generation length. "
"This behaviour is deprecated and will be removed from the config in v5 of Transformers -- we"
" recommend using `max_new_tokens` to control the maximum length of the generation.",
UserWarning,
)
elif generation_config.max_new_tokens is not None:
generation_config.max_length = generation_config.max_new_tokens + input_ids_seq_length
if not has_default_max_length:
logger.warn(
f"Both `max_new_tokens` (={generation_config.max_new_tokens}) and `max_length`(="
f"{generation_config.max_length}) seem to have been set. `max_new_tokens` will take precedence. "
"Please refer to the documentation for more information. "
"(https://huggingface.co/docs/transformers/main/en/main_classes/text_generation)",
UserWarning,
)
if input_ids_seq_length >= generation_config.max_length:
input_ids_string = "decoder_input_ids" if self.config.is_encoder_decoder else "input_ids"
logger.warning(
f"Input length of {input_ids_string} is {input_ids_seq_length}, but `max_length` is set to"
f" {generation_config.max_length}. This can lead to unexpected behavior. You should consider"
" increasing `max_new_tokens`."
)
# 2. Set generation parameters if not already defined
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
logits_processor = self._get_logits_processor(
generation_config=generation_config,
input_ids_seq_length=input_ids_seq_length,
encoder_input_ids=input_ids,
prefix_allowed_tokens_fn=prefix_allowed_tokens_fn,
logits_processor=logits_processor,
)
stopping_criteria = self._get_stopping_criteria(
generation_config=generation_config, stopping_criteria=stopping_criteria
)
logits_warper = self._get_logits_warper(generation_config)
unfinished_sequences = input_ids.new(input_ids.shape[0]).fill_(1)
scores = None
while True:
model_inputs = self.prepare_inputs_for_generation(input_ids, **model_kwargs)
# forward pass to get next token
outputs = self(
**model_inputs,
return_dict=True,
output_attentions=False,
output_hidden_states=False,
)
next_token_logits = outputs.logits[:, -1, :]
# pre-process distribution
next_token_scores = logits_processor(input_ids, next_token_logits)
next_token_scores = logits_warper(input_ids, next_token_scores)
# sample
probs = nn.functional.softmax(next_token_scores, dim=-1)
if generation_config.do_sample:
next_tokens = torch.multinomial(probs, num_samples=1).squeeze(1)
else:
next_tokens = torch.argmax(probs, dim=-1)
# update generated ids, model inputs, and length for next step
input_ids = torch.cat([input_ids, next_tokens[:, None]], dim=-1)
model_kwargs = self._update_model_kwargs_for_generation(
outputs, model_kwargs, is_encoder_decoder=self.config.is_encoder_decoder
)
unfinished_sequences = unfinished_sequences.mul((sum(next_tokens != i for i in eos_token_id)).long())
# stop when each sentence is finished, or if we exceed the maximum length
if unfinished_sequences.max() == 0 or stopping_criteria(input_ids, scores):
break
yield input_ids
class LLaMa(BasePredictor):
def __init__(self, model_name):
self.predict_mode = 'tuple'
print(f'Loading model {model_name}')
start = time.perf_counter()
self.model_name = model_name
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.tokenizer = AutoTokenizer.from_pretrained(
model_name, resume_download=True)
self.model = LlamaForCausalLM.from_pretrained(
model_name,
low_cpu_mem_usage=True,
resume_download=True,
torch_dtype=torch.float16 if self.device == 'cuda' else torch.float32,
device_map={'': self.device})
self.model.eval()
end = time.perf_counter()
print(f'Successfully loaded model {model_name}, time cost: {end - start:.2f}s')
@torch.no_grad()
def stream_chat_continue(self,
model,
tokenizer,
query: str,
history: List[Tuple[str, str]] = None,
max_length=500,
do_sample=True,
top_p=0.85,
temperature=0.5,
**kwargs):
if history is None:
history = []
if len(history) > 0:
answer = history[-1][1]
else:
answer = ''
gen_kwargs = {
"max_length": max_length,
"do_sample": do_sample,
"top_p": top_p,
"temperature": temperature,
**kwargs
}
if not history:
prompt = f'Human: {query} \n\nAssistant:'
else:
prompt = ""
for i, (old_query, response) in enumerate(history):
if i != len(history) - 1:
prompt += f'Human: {old_query} \n\nAssistant:{response} \n\n'
else:
prompt += f'Human: {old_query} \n\nAssistant:'
batch_input = tokenizer([prompt], return_tensors="pt")
batch_input = batch_input.to(model.device)
batch_answer = tokenizer(answer, return_tensors="pt")
batch_answer = batch_answer.to(model.device)
input_length = len(batch_input['input_ids'][0])
final_input_ids = torch.cat(
[batch_input['input_ids'], batch_answer['input_ids'][:, :-2]],
dim=-1)
final_input_ids = final_input_ids.to(model.device)
attention_mask = torch.ones_like(final_input_ids).bool().to(
model.device)
attention_mask[:, input_length:] = False
batch_input['input_ids'] = final_input_ids
batch_input['attention_mask'] = attention_mask
for outputs in stream_generate(model, **batch_input, **gen_kwargs):
outputs = outputs.tolist()[0][input_length:]
response = tokenizer.decode(outputs)
yield response
def test():
model_name = 'BelleGroup/BELLE-LLAMA-7B-2M'
predictor = LLaMa(model_name)
device = predictor.device
tokenizer = predictor.tokenizer
model = predictor.model
min_length = 10
max_length = 2048
top_p = 0.95
temperature = 0.8
print("Human:")
line = input()
inputs = 'Human: ' + line.strip() + '\n\nAssistant:'
input_ids = tokenizer.encode(inputs, return_tensors="pt").to(device)
with torch.no_grad():
generated_ids = model.generate(
input_ids,
do_sample=True,
min_length=min_length,
max_length=max_length,
top_p=top_p,
temperature=temperature,
)
print("Assistant:\n【")
print(tokenizer.decode([el.item() for el in generated_ids[0]]))
print("】\n-------------------------------\n")
for x in predictor.predict_continue(
line, '', max_length, top_p, temperature, [True], None):
print("Assistant:\n【")
print(x[0][-1][1])
print("】\n-------------------------------\n")
if __name__ == '__main__':
test()
================================================
FILE: predictors/llama_gptq.py
================================================
import time
import torch
import transformers
from predictors.llama import LLaMa
import numpy as np
import torch
import torch.nn as nn
from transformers import AutoTokenizer, LlamaForCausalLM
from gptq.llama_inference import load_quant
from transformers.utils.hub import cached_file
class LLaMaGPTQ(LLaMa):
def __init__(self, model_name, checkpoint_path='llama7b-2m-4bit-128g.pt', wbits=4, groupsize=128):
self.predict_mode = 'tuple'
print(f'Loading model {model_name}')
start = time.perf_counter()
self.model_name = model_name
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.tokenizer = AutoTokenizer.from_pretrained(
model_name, resume_download=True)
checkpoint_path = cached_file(model_name, checkpoint_path)
print(f'Loading model from {checkpoint_path} ...')
model: LlamaForCausalLM = load_quant(model_name, checkpoint_path, wbits, groupsize)
model.eval()
model.to(self.device)
self.model = model
end = time.perf_counter()
print(f'Successfully loaded model {model_name}, time cost: {end - start:.2f}s')
def test():
model_name = 'BelleGroup/BELLE-LLAMA-7B-2M-gptq'
checkpoint_path = 'llama7b-2m-4bit-128g.pt'
wbits = 4
groupsize = 128
predictor = LLaMaGPTQ(model_name, checkpoint_path, wbits, groupsize)
device = predictor.device
tokenizer = predictor.tokenizer
model = predictor.model
min_length = 10
max_length = 2048
top_p = 0.95
temperature = 0.8
print("Human:")
line = input()
inputs = 'Human: ' + line.strip() + '\n\nAssistant:'
input_ids = tokenizer.encode(inputs, return_tensors="pt").to(device)
with torch.no_grad():
generated_ids = model.generate(
input_ids,
do_sample=True,
min_length=min_length,
max_length=max_length,
top_p=top_p,
temperature=temperature,
)
print("Assistant:\n【")
print(tokenizer.decode([el.item() for el in generated_ids[0]]))
print("】\n-------------------------------\n")
for x in predictor.predict_continue(
line, '', max_length, top_p, temperature, [True], None):
print("Assistant:\n【")
print(x[0][-1][1])
print("】\n-------------------------------\n")
if __name__ == '__main__':
test()
================================================
FILE: setup_offline.bat
================================================
cd /D "%~dp0"
rem set http_proxy=http://127.0.0.1:7890 & set https_proxy=http://127.0.0.1:7890
echo Setup offline environment
call env_offline.bat
:install_pip
if exist %DIR%\python\Scripts\pip.exe goto :install_python_packages
echo Install pip...
python %PIP_INSTALLER_LOCATION%
:install_python_packages
echo Install dependencies...
pip install torch==2.3.1 torchvision==0.18.1 --index-url https://download.pytorch.org/whl/cu121 --extra-index-url https://mirrors.bfsu.edu.cn/pypi/web/simple
pip install -r requirements.txt -i https://mirrors.bfsu.edu.cn/pypi/web/simple
echo Install finished.
pause
================================================
FILE: setup_venv.bat
================================================
cd /D "%~dp0"
echo Setup venv environment
call env_venv.bat
echo Install dependencies...
pip install torch==2.0.0+cu118 --index-url https://download.pytorch.org/whl/cu118 --extra-index-url https://mirrors.bfsu.edu.cn/pypi/web/simple
pip install -r requirements.txt -i https://mirrors.bfsu.edu.cn/pypi/web/simple
echo Install finished.
pause
================================================
FILE: start.bat
================================================
@echo off
cd /D "%~dp0"
echo Start app.py
python app.py %*
pause
================================================
FILE: start_api.bat
================================================
@echo off
cd /D "%~dp0"
echo Start app_fastapi.py
python app_fastapi.py %*
pause
================================================
FILE: start_offline.bat
================================================
@echo off
cd /D "%~dp0"
call env_offline.bat
call start.bat
================================================
FILE: start_offline_api.bat
================================================
@echo off
cd /D "%~dp0"
call env_offline.bat
call start_api.bat
================================================
FILE: start_offline_cmd.bat
================================================
@echo off
cd /D "%~dp0"
call env_offline.bat
cmd
pause
================================================
FILE: start_venv.bat
================================================
@echo off
cd /D "%~dp0"
call env_venv.bat
call start.bat
================================================
FILE: test_fastapi.py
================================================
url = "http://localhost:8000/stream"
params = {
"query": "Hello",
'answer_prefix': "Nice",
"allow_generate": [True],
'history': [
('你好啊', '你在和我套近乎吗?'), ("别走啊", "我不喜欢不会说英语的人"),
('我会说英语哦', '那如果你会说的话 我可能会惊呼哦')
]
}
import requests
from requests.exceptions import RequestException
def event_source_response_iterator(response):
buf = []
for chunk in response.iter_content(None):
if not chunk:
break
buf.extend(chunk.split(b"\n"))
while buf:
line = buf.pop(0).strip()
if line:
try:
event, data = line.split(b":", 1)
if event.startswith(b"id"):
continue
if event.strip() == b"data":
yield data.strip()
except ValueError:
pass
try:
response = requests.post(url, json=params, stream=True)
response.raise_for_status()
for data in event_source_response_iterator(response):
print(data.decode())
except RequestException as e:
print(e)
================================================
FILE: test_models.py
================================================
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
def test_model(model_name):
if 'glm-4' in model_name.lower():
from predictors.glm4_predictor import GLM4
predictor = GLM4(model_name)
elif 'chatglm3' in model_name.lower():
from predictors.chatglm3_predictor import ChatGLM3
predictor = ChatGLM3(model_name)
elif 'chatglm2' in model_name.lower():
from predictors.chatglm2_predictor import ChatGLM2
predictor = ChatGLM2(model_name)
elif 'chatglm' in model_name.lower():
from predictors.chatglm_predictor import ChatGLM
predictor = ChatGLM(model_name)
elif 'gptq' in model_name.lower():
from predictors.llama_gptq import LLaMaGPTQ
predictor = LLaMaGPTQ(model_name)
elif 'llama' in model_name.lower():
from predictors.llama import LLaMa
predictor = LLaMa(model_name)
elif 'debug' in model_name.lower():
from predictors.debug import Debug
predictor = Debug(model_name)
else:
from predictors.chatglm_predictor import ChatGLM
predictor = ChatGLM(model_name)
top_p = 0.01
max_length = 128
temperature = 0.01
history = []
line = '你是谁?'
last_message = '我是张三丰,我是武当派'
print(line)
for x in predictor.predict_continue(
query=line, latest_message=last_message,
max_length=max_length, top_p=top_p, temperature=temperature,
allow_generate=[True], history=history, last_state=[[], None, None]):
print(x[0][-1][1])
def main():
model_list = [
'THUDM/glm-4-9b-chat-1m',
]
for model_name in model_list:
print(f'Testing {model_name}')
test_model(model_name)
if __name__ == '__main__':
main()
================================================
FILE: utils_env.py
================================================
def collect_env():
import sys
from collections import defaultdict
env_info = {}
env_info['sys.platform'] = sys.platform
env_info['Python'] = sys.version.replace('\n', '')
env_info['Python executable'] = sys.executable
import torch
env_info['PyTorch'] = torch.__version__
import gradio
env_info['Gradio'] = gradio.__version__
import transformers
env_info['Transformers'] = transformers.__version__
cuda_available = torch.cuda.is_available()
if cuda_available:
devices = defaultdict(list)
for k in range(torch.cuda.device_count()):
devices[torch.cuda.get_device_name(k)].append(str(k))
for name, device_ids in devices.items():
env_info['GPU ' + ','.join(device_ids)] = name
else:
env_info['CUDA available'] = False
return env_info
if __name__ == '__main__':
for name, val in collect_env().items():
print(f'{name}: {val}')