")
img.show()
elif reply.type == ReplyType.IMAGE_URL: # 从网络下载图片
import io
import requests
from PIL import Image
img_url = reply.content
pic_res = requests.get(img_url, stream=True)
image_storage = io.BytesIO()
for block in pic_res.iter_content(1024):
image_storage.write(block)
image_storage.seek(0)
img = Image.open(image_storage)
print(img_url)
img.show()
else:
print(reply.content)
print("\nUser:", end="")
sys.stdout.flush()
return
def startup(self):
context = Context()
logger.setLevel("WARN")
print("\nPlease input your question:\nUser:", end="")
sys.stdout.flush()
msg_id = 0
while True:
try:
prompt = self.get_input()
except KeyboardInterrupt:
print("\nExiting...")
sys.exit()
msg_id += 1
trigger_prefixs = conf().get("single_chat_prefix", [""])
if check_prefix(prompt, trigger_prefixs) is None:
prompt = trigger_prefixs[0] + prompt # 给没触发的消息加上触发前缀
context = self._compose_context(ContextType.TEXT, prompt, msg=TerminalMessage(msg_id, prompt))
context["isgroup"] = False
if context:
self.produce(context)
else:
raise Exception("context is None")
def get_input(self):
"""
Multi-line input function
"""
sys.stdout.flush()
line = input()
return line
================================================
FILE: channel/web/README.md
================================================
# Web Channel
提供了一个默认的AI对话页面,可展示文本、图片等消息交互,支持markdown语法渲染,兼容插件执行。
# 使用说明
- 在 `config.json` 配置文件中的 `channel_type` 字段填入 `web`
- 程序运行后将监听9899端口,浏览器访问 http://localhost:9899/chat 即可使用
- 监听端口可以在配置文件 `web_port` 中自定义
- 对于Docker运行方式,如果需要外部访问,需要在 `docker-compose.yml` 中通过 ports配置将端口监听映射到宿主机
================================================
FILE: channel/web/chat.html
================================================
CowAgent Console

CowAgent
I can help you answer questions, manage your computer, create and execute skills,
and keep growing through long-term memory.
Show me the files in the workspace
Remind me to check the server in 5 minutes
Write a Python web scraper script
Configuration
Manage model and agent settings
Skills
View, enable, or disable agent skills
Built-in Tools
Loading tools...
Skills
Loading skills...
Skills will be displayed here after loading
Memory
View agent memory files and contents
Loading memory files...
Memory files will be displayed here
| Filename |
Type |
Size |
Updated |
Channels
View and manage messaging channels
Scheduled Tasks
View and manage scheduled tasks
Logs
Real-time log output (run.log)
Log streaming will be available here. Connects to run.log for real-time output similar to tail -f.
================================================
FILE: channel/web/static/css/console.css
================================================
/* =====================================================================
CowAgent Console Styles
===================================================================== */
/* Animations */
@keyframes pulseDot {
0%, 80%, 100% { transform: scale(0.6); opacity: 0.4; }
40% { transform: scale(1); opacity: 1; }
}
/* Scrollbar */
* { scrollbar-width: thin; scrollbar-color: #94a3b8 transparent; }
::-webkit-scrollbar { width: 6px; height: 6px; }
::-webkit-scrollbar-track { background: transparent; }
::-webkit-scrollbar-thumb { background: #94a3b8; border-radius: 3px; }
::-webkit-scrollbar-thumb:hover { background: #64748b; }
.dark ::-webkit-scrollbar-thumb { background: #475569; }
.dark ::-webkit-scrollbar-thumb:hover { background: #64748b; }
/* Sidebar */
.sidebar-item.active {
background: rgba(255, 255, 255, 0.08);
color: #FFFFFF;
}
.sidebar-item.active .item-icon { color: #4ABE6E; }
/* Menu Groups */
.menu-group-items { max-height: 0; overflow: hidden; transition: max-height 0.25s ease-out; }
.menu-group.open .menu-group-items { max-height: 500px; transition: max-height 0.35s ease-in; }
.menu-group .chevron { transition: transform 0.25s ease; }
.menu-group.open .chevron { transform: rotate(90deg); }
/* View Switching */
.view { display: none; height: 100%; }
.view.active { display: flex; flex-direction: column; }
/* Markdown Content */
.msg-content p { margin: 0.5em 0; line-height: 1.7; }
.msg-content p:first-child { margin-top: 0; }
.msg-content p:last-child { margin-bottom: 0; }
.msg-content h1, .msg-content h2, .msg-content h3,
.msg-content h4, .msg-content h5, .msg-content h6 {
margin-top: 1.2em; margin-bottom: 0.6em; font-weight: 600; line-height: 1.3;
}
.msg-content h1 { font-size: 1.4em; }
.msg-content h2 { font-size: 1.25em; }
.msg-content h3 { font-size: 1.1em; }
.msg-content ul, .msg-content ol { margin: 0.5em 0; padding-left: 1.8em; }
.msg-content li { margin: 0.25em 0; }
.msg-content pre {
border-radius: 8px; overflow-x: auto; margin: 0.8em 0;
background: #f1f5f9; padding: 1em;
}
.dark .msg-content pre { background: #111111; }
.msg-content code {
font-family: 'JetBrains Mono', 'Fira Code', Consolas, monospace;
font-size: 0.875em;
}
.msg-content :not(pre) > code {
background: rgba(74, 190, 110, 0.1); color: #1C6B3B;
padding: 2px 6px; border-radius: 4px;
}
.dark .msg-content :not(pre) > code {
background: rgba(74, 190, 110, 0.15); color: #74E9A4;
}
.msg-content pre code { background: transparent; padding: 0; color: inherit; }
.msg-content blockquote {
border-left: 3px solid #4ABE6E; padding: 0.5em 1em;
margin: 0.8em 0; background: rgba(74, 190, 110, 0.05); border-radius: 0 6px 6px 0;
}
.dark .msg-content blockquote { background: rgba(74, 190, 110, 0.08); }
.msg-content table { border-collapse: collapse; width: 100%; margin: 0.8em 0; }
.msg-content th, .msg-content td {
border: 1px solid #e2e8f0; padding: 8px 12px; text-align: left;
}
.dark .msg-content th, .dark .msg-content td { border-color: rgba(255,255,255,0.1); }
.msg-content th { background: #f1f5f9; font-weight: 600; }
.dark .msg-content th { background: #111111; }
.msg-content img { max-width: 100%; height: auto; border-radius: 8px; margin: 0.5em 0; }
.msg-content a { color: #35A85B; text-decoration: underline; }
.msg-content a:hover { color: #228547; }
.msg-content hr { border: none; height: 1px; background: #e2e8f0; margin: 1.2em 0; }
.dark .msg-content hr { background: rgba(255,255,255,0.1); }
/* SSE Streaming cursor */
@keyframes blink { 0%, 100% { opacity: 1; } 50% { opacity: 0; } }
.sse-streaming::after {
content: '▋';
display: inline-block;
margin-left: 2px;
color: #4ABE6E;
animation: blink 0.9s step-end infinite;
font-size: 0.85em;
vertical-align: middle;
}
/* Agent steps (thinking summaries + tool indicators) */
.agent-steps:empty { display: none; }
.agent-steps:not(:empty) {
margin-bottom: 0.625rem;
padding-bottom: 0.5rem;
border-bottom: 1px dashed rgba(0, 0, 0, 0.08);
}
.dark .agent-steps:not(:empty) { border-bottom-color: rgba(255, 255, 255, 0.08); }
.agent-step {
font-size: 0.75rem;
line-height: 1.4;
color: #94a3b8;
margin-bottom: 0.25rem;
}
.agent-step:last-child { margin-bottom: 0; }
/* Thinking step - collapsible */
.agent-thinking-step .thinking-header {
display: flex;
align-items: center;
gap: 0.375rem;
cursor: pointer;
user-select: none;
}
.agent-thinking-step .thinking-header.no-toggle { cursor: default; }
.agent-thinking-step .thinking-header:not(.no-toggle):hover { color: #64748b; }
.dark .agent-thinking-step .thinking-header:not(.no-toggle):hover { color: #cbd5e1; }
.agent-thinking-step .thinking-header i:first-child { font-size: 0.625rem; margin-top: 1px; }
.agent-thinking-step .thinking-chevron {
font-size: 0.5rem;
margin-left: auto;
transition: transform 0.2s ease;
opacity: 0.5;
}
.agent-thinking-step.expanded .thinking-chevron { transform: rotate(90deg); }
.agent-thinking-step .thinking-full {
display: none;
margin-top: 0.375rem;
margin-left: 1rem;
padding: 0.5rem;
background: rgba(0, 0, 0, 0.02);
border-radius: 6px;
border: 1px solid rgba(0, 0, 0, 0.04);
font-size: 0.75rem;
line-height: 1.5;
color: #94a3b8;
max-height: 200px;
overflow-y: auto;
}
.dark .agent-thinking-step .thinking-full {
background: rgba(255, 255, 255, 0.02);
border-color: rgba(255, 255, 255, 0.04);
}
.agent-thinking-step.expanded .thinking-full { display: block; }
.agent-thinking-step .thinking-full p { margin: 0.25em 0; }
.agent-thinking-step .thinking-full p:first-child { margin-top: 0; }
.agent-thinking-step .thinking-full p:last-child { margin-bottom: 0; }
/* Tool step - collapsible */
.agent-tool-step .tool-header {
display: flex;
align-items: center;
gap: 0.375rem;
cursor: pointer;
user-select: none;
padding: 1px 0;
border-radius: 4px;
}
.agent-tool-step .tool-header:hover { color: #64748b; }
.dark .agent-tool-step .tool-header:hover { color: #cbd5e1; }
.agent-tool-step .tool-icon { font-size: 0.625rem; }
.agent-tool-step .tool-chevron {
font-size: 0.5rem;
margin-left: auto;
transition: transform 0.2s ease;
opacity: 0.5;
}
.agent-tool-step.expanded .tool-chevron { transform: rotate(90deg); }
.agent-tool-step .tool-time {
font-size: 0.65rem;
opacity: 0.6;
margin-left: 0.25rem;
}
/* Tool detail panel */
.agent-tool-step .tool-detail {
display: none;
margin-top: 0.375rem;
margin-left: 1rem;
padding: 0.5rem;
background: rgba(0, 0, 0, 0.02);
border-radius: 6px;
border: 1px solid rgba(0, 0, 0, 0.04);
}
.dark .agent-tool-step .tool-detail {
background: rgba(255, 255, 255, 0.02);
border-color: rgba(255, 255, 255, 0.04);
}
.agent-tool-step.expanded .tool-detail { display: block; }
.tool-detail-section { margin-bottom: 0.375rem; }
.tool-detail-section:last-child { margin-bottom: 0; }
.tool-detail-label {
font-size: 0.625rem;
font-weight: 600;
text-transform: uppercase;
letter-spacing: 0.05em;
opacity: 0.6;
margin-bottom: 0.125rem;
}
.tool-detail-content {
font-family: 'JetBrains Mono', 'Fira Code', Consolas, monospace;
font-size: 0.7rem;
line-height: 1.5;
white-space: pre-wrap;
word-break: break-all;
max-height: 200px;
overflow-y: auto;
margin: 0;
padding: 0.25rem 0;
background: transparent;
color: inherit;
}
.tool-error-text { color: #f87171; }
/* Tool failed state */
.agent-tool-step.tool-failed .tool-name { color: #f87171; }
/* Config form controls */
#view-config input[type="text"],
#view-config input[type="number"],
#view-config input[type="password"] {
height: 40px;
transition: border-color 0.2s ease, box-shadow 0.2s ease;
}
#view-config input:focus {
border-color: #4ABE6E;
box-shadow: 0 0 0 3px rgba(74, 190, 110, 0.12);
}
#view-config input[type="text"]:hover,
#view-config input[type="number"]:hover,
#view-config input[type="password"]:hover {
border-color: #94a3b8;
}
.dark #view-config input[type="text"]:hover,
.dark #view-config input[type="number"]:hover,
.dark #view-config input[type="password"]:hover {
border-color: #64748b;
}
/* Custom dropdown */
.cfg-dropdown {
position: relative;
outline: none;
}
.cfg-dropdown-selected {
display: flex;
align-items: center;
justify-content: space-between;
height: 40px;
padding: 0 0.75rem;
border-radius: 0.5rem;
border: 1px solid #e2e8f0;
background: #f8fafc;
font-size: 0.875rem;
color: #1e293b;
cursor: pointer;
transition: border-color 0.2s ease, box-shadow 0.2s ease;
user-select: none;
}
.dark .cfg-dropdown-selected {
border-color: #475569;
background: rgba(255, 255, 255, 0.05);
color: #f1f5f9;
}
.cfg-dropdown-selected:hover { border-color: #94a3b8; }
.dark .cfg-dropdown-selected:hover { border-color: #64748b; }
.cfg-dropdown.open .cfg-dropdown-selected,
.cfg-dropdown:focus .cfg-dropdown-selected {
border-color: #4ABE6E;
box-shadow: 0 0 0 3px rgba(74, 190, 110, 0.12);
}
.cfg-dropdown-arrow {
font-size: 0.625rem;
color: #94a3b8;
transition: transform 0.2s ease;
flex-shrink: 0;
margin-left: 0.5rem;
}
.cfg-dropdown.open .cfg-dropdown-arrow { transform: rotate(180deg); }
.cfg-dropdown-menu {
display: none;
position: absolute;
top: calc(100% + 4px);
left: 0;
right: 0;
z-index: 50;
max-height: 240px;
overflow-y: auto;
border-radius: 0.5rem;
border: 1px solid #e2e8f0;
background: #ffffff;
box-shadow: 0 10px 25px -5px rgba(0, 0, 0, 0.1), 0 4px 10px -5px rgba(0, 0, 0, 0.04);
padding: 4px;
}
.dark .cfg-dropdown-menu {
border-color: #334155;
background: #1e1e1e;
box-shadow: 0 10px 25px -5px rgba(0, 0, 0, 0.4);
}
.cfg-dropdown.open .cfg-dropdown-menu { display: block; }
.cfg-dropdown-item {
display: flex;
align-items: center;
padding: 8px 10px;
border-radius: 6px;
font-size: 0.875rem;
color: #334155;
cursor: pointer;
transition: background 0.15s ease;
white-space: nowrap;
overflow: hidden;
text-overflow: ellipsis;
}
.dark .cfg-dropdown-item { color: #cbd5e1; }
.cfg-dropdown-item:hover { background: #f1f5f9; }
.dark .cfg-dropdown-item:hover { background: rgba(255, 255, 255, 0.08); }
.cfg-dropdown-item.active {
background: rgba(74, 190, 110, 0.1);
color: #228547;
font-weight: 500;
}
.dark .cfg-dropdown-item.active {
background: rgba(74, 190, 110, 0.15);
color: #74E9A4;
}
/* API Key masking via CSS (avoids browser password prompts) */
.cfg-key-masked {
-webkit-text-security: disc;
text-security: disc;
}
/* Chat Input */
#chat-input {
resize: none; height: 42px; max-height: 180px;
overflow-y: hidden;
transition: border-color 0.2s ease;
}
/* Attachment Preview Bar */
.attachment-preview {
display: flex;
flex-wrap: wrap;
gap: 8px;
padding: 8px 0;
}
.attachment-preview.hidden { display: none; }
.att-thumb {
position: relative;
width: 64px; height: 64px;
border-radius: 8px;
overflow: hidden;
border: 1px solid #e2e8f0;
flex-shrink: 0;
}
.dark .att-thumb { border-color: rgba(255,255,255,0.1); }
.att-thumb img {
width: 100%; height: 100%;
object-fit: cover;
}
.att-chip {
position: relative;
display: flex;
align-items: center;
gap: 6px;
padding: 6px 28px 6px 10px;
border-radius: 8px;
background: #f1f5f9;
border: 1px solid #e2e8f0;
font-size: 12px;
color: #475569;
max-width: 180px;
}
.dark .att-chip { background: rgba(255,255,255,0.05); border-color: rgba(255,255,255,0.1); color: #94a3b8; }
.att-uploading { opacity: 0.6; pointer-events: none; }
.att-name {
overflow: hidden;
text-overflow: ellipsis;
white-space: nowrap;
}
.att-remove {
position: absolute;
top: -4px; right: -4px;
width: 18px; height: 18px;
border-radius: 50%;
background: #ef4444;
color: #fff;
border: none;
font-size: 12px;
line-height: 18px;
text-align: center;
cursor: pointer;
padding: 0;
opacity: 0;
transition: opacity 0.15s;
}
.att-thumb:hover .att-remove,
.att-chip:hover .att-remove { opacity: 1; }
/* Drag-over highlight */
.drag-over {
background: rgba(74, 190, 110, 0.08) !important;
border-color: #4ABE6E !important;
}
/* User message attachments */
.user-msg-attachments {
display: flex;
flex-wrap: wrap;
gap: 6px;
margin-bottom: 6px;
}
.user-msg-image {
max-width: 200px;
max-height: 160px;
border-radius: 8px;
object-fit: cover;
cursor: pointer;
}
.user-msg-image:hover { opacity: 0.9; }
.user-msg-file {
display: flex;
align-items: center;
gap: 6px;
padding: 4px 10px;
border-radius: 6px;
background: rgba(255,255,255,0.15);
font-size: 12px;
}
/* Placeholder Cards */
.placeholder-card {
transition: transform 0.2s ease, box-shadow 0.2s ease;
}
.placeholder-card:hover {
transform: translateY(-2px);
box-shadow: 0 8px 25px -5px rgba(0, 0, 0, 0.1);
}
================================================
FILE: channel/web/static/js/console.js
================================================
/* =====================================================================
CowAgent Console - Main Application Script
===================================================================== */
// =====================================================================
// Version — update this before each release
// =====================================================================
const APP_VERSION = 'v2.0.3';
// =====================================================================
// i18n
// =====================================================================
const I18N = {
zh: {
console: '控制台',
nav_chat: '对话', nav_manage: '管理', nav_monitor: '监控',
menu_chat: '对话', menu_config: '配置', menu_skills: '技能',
menu_memory: '记忆', menu_channels: '通道', menu_tasks: '定时',
menu_logs: '日志',
welcome_subtitle: '我可以帮你解答问题、管理计算机、创造和执行技能,并通过长期记忆
不断成长',
example_sys_title: '系统管理', example_sys_text: '帮我查看工作空间里有哪些文件',
example_task_title: '技能系统', example_task_text: '查看所有支持的工具和技能',
example_code_title: '编程助手', example_code_text: '帮我编写一个Python爬虫脚本',
input_placeholder: '输入消息...',
config_title: '配置管理', config_desc: '管理模型和 Agent 配置',
config_model: '模型配置', config_agent: 'Agent 配置',
config_channel: '通道配置',
config_agent_enabled: 'Agent 模式', config_max_tokens: '最大 Token',
config_max_turns: '最大轮次', config_max_steps: '最大步数',
config_channel_type: '通道类型',
config_provider: '模型厂商', config_model_name: '模型',
config_custom_model_hint: '输入自定义模型名称',
config_save: '保存', config_saved: '已保存',
config_save_error: '保存失败',
config_custom_option: '自定义...',
skills_title: '技能管理', skills_desc: '查看、启用或禁用 Agent 技能',
skills_loading: '加载技能中...', skills_loading_desc: '技能加载后将显示在此处',
tools_section_title: '内置工具', tools_loading: '加载工具中...',
skills_section_title: '技能', skill_enable: '启用', skill_disable: '禁用',
skill_toggle_error: '操作失败,请稍后再试',
memory_title: '记忆管理', memory_desc: '查看 Agent 记忆文件和内容',
memory_loading: '加载记忆文件中...', memory_loading_desc: '记忆文件将显示在此处',
memory_back: '返回列表',
memory_col_name: '文件名', memory_col_type: '类型', memory_col_size: '大小', memory_col_updated: '更新时间',
channels_title: '通道管理', channels_desc: '管理已接入的消息通道',
channels_add: '接入通道', channels_disconnect: '断开',
channels_save: '保存配置', channels_saved: '已保存', channels_save_error: '保存失败',
channels_restarted: '已保存并重启',
channels_connect_btn: '接入', channels_cancel: '取消',
channels_select_placeholder: '选择要接入的通道...',
channels_empty: '暂未接入任何通道', channels_empty_desc: '点击右上角「接入通道」按钮开始配置',
channels_disconnect_confirm: '确认断开该通道?配置将保留但通道会停止运行。',
channels_connected: '已接入', channels_connecting: '接入中...',
tasks_title: '定时任务', tasks_desc: '查看和管理定时任务',
tasks_coming: '即将推出', tasks_coming_desc: '定时任务管理功能即将在此提供',
logs_title: '日志', logs_desc: '实时日志输出 (run.log)',
logs_live: '实时', logs_coming_msg: '日志流即将在此提供。将连接 run.log 实现类似 tail -f 的实时输出。',
error_send: '发送失败,请稍后再试。', error_timeout: '请求超时,请再试一次。',
},
en: {
console: 'Console',
nav_chat: 'Chat', nav_manage: 'Management', nav_monitor: 'Monitor',
menu_chat: 'Chat', menu_config: 'Config', menu_skills: 'Skills',
menu_memory: 'Memory', menu_channels: 'Channels', menu_tasks: 'Tasks',
menu_logs: 'Logs',
welcome_subtitle: 'I can help you answer questions, manage your computer, create and execute skills, and keep growing through
long-term memory.',
example_sys_title: 'System', example_sys_text: 'Show me the files in the workspace',
example_task_title: 'Skills', example_task_text: 'Show current tools and skills',
example_code_title: 'Coding', example_code_text: 'Write a Python web scraper script',
input_placeholder: 'Type a message...',
config_title: 'Configuration', config_desc: 'Manage model and agent settings',
config_model: 'Model Configuration', config_agent: 'Agent Configuration',
config_channel: 'Channel Configuration',
config_agent_enabled: 'Agent Mode', config_max_tokens: 'Max Tokens',
config_max_turns: 'Max Turns', config_max_steps: 'Max Steps',
config_channel_type: 'Channel Type',
config_provider: 'Provider', config_model_name: 'Model',
config_custom_model_hint: 'Enter custom model name',
config_save: 'Save', config_saved: 'Saved',
config_save_error: 'Save failed',
config_custom_option: 'Custom...',
skills_title: 'Skills', skills_desc: 'View, enable, or disable agent skills',
skills_loading: 'Loading skills...', skills_loading_desc: 'Skills will be displayed here after loading',
tools_section_title: 'Built-in Tools', tools_loading: 'Loading tools...',
skills_section_title: 'Skills', skill_enable: 'Enable', skill_disable: 'Disable',
skill_toggle_error: 'Operation failed, please try again',
memory_title: 'Memory', memory_desc: 'View agent memory files and contents',
memory_loading: 'Loading memory files...', memory_loading_desc: 'Memory files will be displayed here',
memory_back: 'Back to list',
memory_col_name: 'Filename', memory_col_type: 'Type', memory_col_size: 'Size', memory_col_updated: 'Updated',
channels_title: 'Channels', channels_desc: 'Manage connected messaging channels',
channels_add: 'Connect', channels_disconnect: 'Disconnect',
channels_save: 'Save', channels_saved: 'Saved', channels_save_error: 'Save failed',
channels_restarted: 'Saved & Restarted',
channels_connect_btn: 'Connect', channels_cancel: 'Cancel',
channels_select_placeholder: 'Select a channel to connect...',
channels_empty: 'No channels connected', channels_empty_desc: 'Click the "Connect" button above to get started',
channels_disconnect_confirm: 'Disconnect this channel? Config will be preserved but the channel will stop.',
channels_connected: 'Connected', channels_connecting: 'Connecting...',
tasks_title: 'Scheduled Tasks', tasks_desc: 'View and manage scheduled tasks',
tasks_coming: 'Coming Soon', tasks_coming_desc: 'Scheduled task management will be available here',
logs_title: 'Logs', logs_desc: 'Real-time log output (run.log)',
logs_live: 'Live', logs_coming_msg: 'Log streaming will be available here. Connects to run.log for real-time output similar to tail -f.',
error_send: 'Failed to send. Please try again.', error_timeout: 'Request timeout. Please try again.',
}
};
let currentLang = localStorage.getItem('cow_lang') || 'zh';
function t(key) {
return (I18N[currentLang] && I18N[currentLang][key]) || (I18N.en[key]) || key;
}
function applyI18n() {
document.querySelectorAll('[data-i18n]').forEach(el => {
el.textContent = t(el.dataset.i18n);
});
document.querySelectorAll('[data-i18n-html]').forEach(el => {
el.innerHTML = t(el.dataset.i18nHtml);
});
document.querySelectorAll('[data-i18n-placeholder]').forEach(el => {
el.placeholder = t(el.dataset['i18nPlaceholder']);
});
document.getElementById('lang-label').textContent = currentLang === 'zh' ? 'EN' : '中文';
}
function toggleLanguage() {
currentLang = currentLang === 'zh' ? 'en' : 'zh';
localStorage.setItem('cow_lang', currentLang);
applyI18n();
}
// =====================================================================
// Theme
// =====================================================================
let currentTheme = localStorage.getItem('cow_theme') || 'dark';
function applyTheme() {
const root = document.documentElement;
if (currentTheme === 'dark') {
root.classList.add('dark');
document.getElementById('theme-icon').className = 'fas fa-sun';
document.getElementById('hljs-light').disabled = true;
document.getElementById('hljs-dark').disabled = false;
} else {
root.classList.remove('dark');
document.getElementById('theme-icon').className = 'fas fa-moon';
document.getElementById('hljs-light').disabled = false;
document.getElementById('hljs-dark').disabled = true;
}
}
function toggleTheme() {
currentTheme = currentTheme === 'dark' ? 'light' : 'dark';
localStorage.setItem('cow_theme', currentTheme);
applyTheme();
}
// =====================================================================
// Sidebar & Navigation
// =====================================================================
const VIEW_META = {
chat: { group: 'nav_chat', page: 'menu_chat' },
config: { group: 'nav_manage', page: 'menu_config' },
skills: { group: 'nav_manage', page: 'menu_skills' },
memory: { group: 'nav_manage', page: 'menu_memory' },
channels: { group: 'nav_manage', page: 'menu_channels' },
tasks: { group: 'nav_manage', page: 'menu_tasks' },
logs: { group: 'nav_monitor', page: 'menu_logs' },
};
let currentView = 'chat';
function navigateTo(viewId) {
if (!VIEW_META[viewId]) return;
document.querySelectorAll('.view').forEach(v => v.classList.remove('active'));
const target = document.getElementById('view-' + viewId);
if (target) target.classList.add('active');
document.querySelectorAll('.sidebar-item').forEach(item => {
item.classList.toggle('active', item.dataset.view === viewId);
});
const meta = VIEW_META[viewId];
document.getElementById('breadcrumb-group').textContent = t(meta.group);
document.getElementById('breadcrumb-group').dataset.i18n = meta.group;
document.getElementById('breadcrumb-page').textContent = t(meta.page);
document.getElementById('breadcrumb-page').dataset.i18n = meta.page;
currentView = viewId;
if (window.innerWidth < 1024) closeSidebar();
}
function toggleSidebar() {
const sidebar = document.getElementById('sidebar');
const overlay = document.getElementById('sidebar-overlay');
const isOpen = !sidebar.classList.contains('-translate-x-full');
if (isOpen) {
closeSidebar();
} else {
sidebar.classList.remove('-translate-x-full');
overlay.classList.remove('hidden');
}
}
function closeSidebar() {
document.getElementById('sidebar').classList.add('-translate-x-full');
document.getElementById('sidebar-overlay').classList.add('hidden');
}
document.querySelectorAll('.menu-group > button').forEach(btn => {
btn.addEventListener('click', () => {
btn.parentElement.classList.toggle('open');
});
});
document.querySelectorAll('.sidebar-item').forEach(item => {
item.addEventListener('click', () => navigateTo(item.dataset.view));
});
window.addEventListener('resize', () => {
if (window.innerWidth >= 1024) {
document.getElementById('sidebar').classList.remove('-translate-x-full');
document.getElementById('sidebar-overlay').classList.add('hidden');
} else {
if (!document.getElementById('sidebar').classList.contains('-translate-x-full')) {
closeSidebar();
}
}
});
// =====================================================================
// Markdown Renderer
// =====================================================================
function createMd() {
const md = window.markdownit({
html: false, breaks: true, linkify: true, typographer: true,
highlight: function(str, lang) {
if (lang && hljs.getLanguage(lang)) {
try { return hljs.highlight(str, { language: lang }).value; } catch (_) {}
}
return hljs.highlightAuto(str).value;
}
});
const defaultLinkOpen = md.renderer.rules.link_open || function(tokens, idx, options, env, self) {
return self.renderToken(tokens, idx, options);
};
md.renderer.rules.link_open = function(tokens, idx, options, env, self) {
tokens[idx].attrPush(['target', '_blank']);
tokens[idx].attrPush(['rel', 'noopener noreferrer']);
return defaultLinkOpen(tokens, idx, options, env, self);
};
return md;
}
const md = createMd();
function renderMarkdown(text) {
try { return md.render(text); }
catch (e) { return text.replace(/\n/g, '
'); }
}
// =====================================================================
// Chat Module
// =====================================================================
let isPolling = false;
let loadingContainers = {};
let activeStreams = {}; // request_id -> EventSource
let isComposing = false;
let appConfig = { use_agent: false, title: 'CowAgent', subtitle: '', providers: {}, api_bases: {} };
const SESSION_ID_KEY = 'cow_session_id';
function generateSessionId() {
return 'session_' + ([1e7]+-1e3+-4e3+-8e3+-1e11).replace(/[018]/g, c =>
(c ^ crypto.getRandomValues(new Uint8Array(1))[0] & 15 >> c / 4).toString(16)
);
}
// Restore session_id from localStorage so conversation history survives page refresh.
// A new id is only generated when the user explicitly starts a new chat.
function loadOrCreateSessionId() {
const stored = localStorage.getItem(SESSION_ID_KEY);
if (stored) return stored;
const fresh = generateSessionId();
localStorage.setItem(SESSION_ID_KEY, fresh);
return fresh;
}
let sessionId = loadOrCreateSessionId();
// ---- Conversation history state ----
let historyPage = 0; // last page fetched (0 = nothing fetched yet)
let historyHasMore = false;
let historyLoading = false;
fetch('/config').then(r => r.json()).then(data => {
if (data.status === 'success') {
appConfig = data;
const title = data.title || 'CowAgent';
document.getElementById('welcome-title').textContent = title;
initConfigView(data);
}
loadHistory(1);
}).catch(() => { loadHistory(1); });
const chatInput = document.getElementById('chat-input');
const sendBtn = document.getElementById('send-btn');
const messagesDiv = document.getElementById('chat-messages');
const fileInput = document.getElementById('file-input');
const attachmentPreview = document.getElementById('attachment-preview');
// Pending attachments: [{file_path, file_name, file_type, preview_url}]
// Items with _uploading=true are still in flight.
let pendingAttachments = [];
let uploadingCount = 0;
function updateSendBtnState() {
sendBtn.disabled = uploadingCount > 0 || (!chatInput.value.trim() && pendingAttachments.length === 0);
}
function renderAttachmentPreview() {
if (pendingAttachments.length === 0) {
attachmentPreview.classList.add('hidden');
attachmentPreview.innerHTML = '';
updateSendBtnState();
return;
}
attachmentPreview.classList.remove('hidden');
attachmentPreview.innerHTML = pendingAttachments.map((att, idx) => {
if (att._uploading) {
return `
${escapeHtml(att.file_name)}
`;
}
if (att.file_type === 'image') {
return `

`;
}
const icon = att.file_type === 'video' ? 'fa-film' : 'fa-file-alt';
return `
${escapeHtml(att.file_name)}
`;
}).join('');
updateSendBtnState();
}
function removeAttachment(idx) {
if (pendingAttachments[idx]?._uploading) return;
pendingAttachments.splice(idx, 1);
renderAttachmentPreview();
}
async function handleFileSelect(files) {
if (!files || files.length === 0) return;
const tasks = [];
for (const file of files) {
const placeholder = { file_name: file.name, file_type: 'file', _uploading: true };
pendingAttachments.push(placeholder);
uploadingCount++;
renderAttachmentPreview();
tasks.push((async () => {
const formData = new FormData();
formData.append('file', file);
formData.append('session_id', sessionId);
try {
const resp = await fetch('/upload', { method: 'POST', body: formData });
const data = await resp.json();
if (data.status === 'success') {
placeholder.file_path = data.file_path;
placeholder.file_name = data.file_name;
placeholder.file_type = data.file_type;
placeholder.preview_url = data.preview_url;
delete placeholder._uploading;
} else {
const i = pendingAttachments.indexOf(placeholder);
if (i !== -1) pendingAttachments.splice(i, 1);
}
} catch (e) {
console.error('Upload failed:', e);
const i = pendingAttachments.indexOf(placeholder);
if (i !== -1) pendingAttachments.splice(i, 1);
}
uploadingCount--;
renderAttachmentPreview();
})());
}
await Promise.all(tasks);
}
fileInput.addEventListener('change', function() {
handleFileSelect(this.files);
this.value = '';
});
// Drag-and-drop support on chat input area
const chatInputArea = chatInput.closest('.flex-shrink-0');
chatInputArea.addEventListener('dragover', (e) => { e.preventDefault(); e.stopPropagation(); chatInputArea.classList.add('drag-over'); });
chatInputArea.addEventListener('dragleave', (e) => { e.preventDefault(); e.stopPropagation(); chatInputArea.classList.remove('drag-over'); });
chatInputArea.addEventListener('drop', (e) => {
e.preventDefault(); e.stopPropagation();
chatInputArea.classList.remove('drag-over');
if (e.dataTransfer.files.length) handleFileSelect(e.dataTransfer.files);
});
// Paste image support
chatInput.addEventListener('paste', (e) => {
const items = e.clipboardData?.items;
if (!items) return;
const files = [];
for (const item of items) {
if (item.kind === 'file') {
files.push(item.getAsFile());
}
}
if (files.length) {
e.preventDefault();
handleFileSelect(files);
}
});
chatInput.addEventListener('compositionstart', () => { isComposing = true; });
chatInput.addEventListener('compositionend', () => { setTimeout(() => { isComposing = false; }, 100); });
chatInput.addEventListener('input', function() {
this.style.height = '42px';
const scrollH = this.scrollHeight;
const newH = Math.min(scrollH, 180);
this.style.height = newH + 'px';
this.style.overflowY = scrollH > 180 ? 'auto' : 'hidden';
updateSendBtnState();
});
chatInput.addEventListener('keydown', function(e) {
// keyCode 229 indicates an IME is processing the keystroke (reliable across browsers)
if (e.keyCode === 229 || e.isComposing || isComposing) return;
if ((e.ctrlKey || e.shiftKey) && e.key === 'Enter') {
const start = this.selectionStart;
const end = this.selectionEnd;
this.value = this.value.substring(0, start) + '\n' + this.value.substring(end);
this.selectionStart = this.selectionEnd = start + 1;
this.dispatchEvent(new Event('input'));
e.preventDefault();
} else if (e.key === 'Enter' && !e.shiftKey && !e.ctrlKey) {
sendMessage();
e.preventDefault();
}
});
document.querySelectorAll('.example-card').forEach(card => {
card.addEventListener('click', () => {
const textEl = card.querySelector('[data-i18n*="text"]');
if (textEl) {
chatInput.value = textEl.textContent;
chatInput.dispatchEvent(new Event('input'));
chatInput.focus();
}
});
});
function sendMessage() {
const text = chatInput.value.trim();
if (!text && pendingAttachments.length === 0) return;
const ws = document.getElementById('welcome-screen');
if (ws) ws.remove();
const timestamp = new Date();
const attachments = [...pendingAttachments];
addUserMessage(text, timestamp, attachments);
const loadingEl = addLoadingIndicator();
chatInput.value = '';
chatInput.style.height = '42px';
chatInput.style.overflowY = 'hidden';
pendingAttachments = [];
renderAttachmentPreview();
sendBtn.disabled = true;
const body = { session_id: sessionId, message: text, stream: true, timestamp: timestamp.toISOString() };
if (attachments.length > 0) {
body.attachments = attachments.map(a => ({
file_path: a.file_path,
file_name: a.file_name,
file_type: a.file_type,
}));
}
fetch('/message', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(body)
})
.then(r => r.json())
.then(data => {
if (data.status === 'success') {
if (data.stream) {
startSSE(data.request_id, loadingEl, timestamp);
} else {
loadingContainers[data.request_id] = loadingEl;
if (!isPolling) startPolling();
}
} else {
loadingEl.remove();
addBotMessage(t('error_send'), new Date());
}
})
.catch(err => {
loadingEl.remove();
addBotMessage(err.name === 'AbortError' ? t('error_timeout') : t('error_send'), new Date());
});
}
function startSSE(requestId, loadingEl, timestamp) {
const es = new EventSource(`/stream?request_id=${encodeURIComponent(requestId)}`);
activeStreams[requestId] = es;
let botEl = null;
let stepsEl = null; // .agent-steps (thinking summaries + tool indicators)
let contentEl = null; // .answer-content (final streaming answer)
let accumulatedText = '';
let currentToolEl = null;
function ensureBotEl() {
if (botEl) return;
if (loadingEl) { loadingEl.remove(); loadingEl = null; }
botEl = document.createElement('div');
botEl.className = 'flex gap-3 px-4 sm:px-6 py-3';
botEl.dataset.requestId = requestId;
botEl.innerHTML = `
`;
messagesDiv.appendChild(botEl);
stepsEl = botEl.querySelector('.agent-steps');
contentEl = botEl.querySelector('.answer-content');
}
es.onmessage = function(e) {
let item;
try { item = JSON.parse(e.data); } catch (_) { return; }
if (item.type === 'delta') {
ensureBotEl();
accumulatedText += item.content;
contentEl.innerHTML = renderMarkdown(accumulatedText);
scrollChatToBottom();
} else if (item.type === 'tool_start') {
ensureBotEl();
// Save current thinking as a collapsible step
if (accumulatedText.trim()) {
const fullText = accumulatedText.trim();
const oneLine = fullText.replace(/\n+/g, ' ');
const needsTruncate = oneLine.length > 80;
const stepEl = document.createElement('div');
stepEl.className = 'agent-step agent-thinking-step' + (needsTruncate ? '' : ' no-expand');
if (needsTruncate) {
const truncated = oneLine.substring(0, 80) + '…';
stepEl.innerHTML = `
${renderMarkdown(fullText)}
`;
} else {
stepEl.innerHTML = `
`;
}
stepsEl.appendChild(stepEl);
}
accumulatedText = '';
contentEl.innerHTML = '';
// Add tool execution indicator (collapsible)
currentToolEl = document.createElement('div');
currentToolEl.className = 'agent-step agent-tool-step';
const argsStr = formatToolArgs(item.arguments || {});
currentToolEl.innerHTML = `
`;
stepsEl.appendChild(currentToolEl);
scrollChatToBottom();
} else if (item.type === 'tool_end') {
if (currentToolEl) {
const isError = item.status !== 'success';
const icon = currentToolEl.querySelector('.tool-icon');
icon.className = isError
? 'fas fa-times text-red-400 flex-shrink-0 tool-icon'
: 'fas fa-check text-primary-400 flex-shrink-0 tool-icon';
// Show execution time
const nameEl = currentToolEl.querySelector('.tool-name');
if (item.execution_time !== undefined) {
nameEl.innerHTML += ` ${item.execution_time}s`;
}
// Fill output section
const outputSection = currentToolEl.querySelector('.tool-output-section');
if (outputSection && item.result) {
outputSection.innerHTML = `
${isError ? 'Error' : 'Output'}
${escapeHtml(String(item.result))}`;
}
if (isError) currentToolEl.classList.add('tool-failed');
currentToolEl = null;
}
} else if (item.type === 'done') {
es.close();
delete activeStreams[requestId];
const finalText = item.content || accumulatedText;
if (!botEl && finalText) {
if (loadingEl) { loadingEl.remove(); loadingEl = null; }
addBotMessage(finalText, new Date((item.timestamp || Date.now() / 1000) * 1000), requestId);
} else if (botEl) {
contentEl.classList.remove('sse-streaming');
if (finalText) contentEl.innerHTML = renderMarkdown(finalText);
applyHighlighting(botEl);
}
scrollChatToBottom();
} else if (item.type === 'error') {
es.close();
delete activeStreams[requestId];
if (loadingEl) { loadingEl.remove(); loadingEl = null; }
addBotMessage(t('error_send'), new Date());
}
};
es.onerror = function() {
es.close();
delete activeStreams[requestId];
if (loadingEl) { loadingEl.remove(); loadingEl = null; }
if (!botEl) {
addBotMessage(t('error_send'), new Date());
} else if (accumulatedText) {
contentEl.classList.remove('sse-streaming');
contentEl.innerHTML = renderMarkdown(accumulatedText);
applyHighlighting(botEl);
}
};
}
function startPolling() {
if (isPolling) return;
isPolling = true;
function poll() {
if (!isPolling) return;
if (document.hidden) { setTimeout(poll, 5000); return; }
fetch('/poll', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ session_id: sessionId })
})
.then(r => r.json())
.then(data => {
if (data.status === 'success' && data.has_content) {
const rid = data.request_id;
if (loadingContainers[rid]) {
loadingContainers[rid].remove();
delete loadingContainers[rid];
}
addBotMessage(data.content, new Date(data.timestamp * 1000), rid);
scrollChatToBottom();
}
setTimeout(poll, 2000);
})
.catch(() => { setTimeout(poll, 3000); });
}
poll();
}
function createUserMessageEl(content, timestamp, attachments) {
const el = document.createElement('div');
el.className = 'flex justify-end px-4 sm:px-6 py-3';
let attachHtml = '';
if (attachments && attachments.length > 0) {
const items = attachments.map(a => {
if (a.file_type === 'image') {
return ` `;
}
const icon = a.file_type === 'video' ? 'fa-film' : 'fa-file-alt';
return `
`;
}
const icon = a.file_type === 'video' ? 'fa-film' : 'fa-file-alt';
return ` ${escapeHtml(a.file_name)}
`;
}).join('');
attachHtml = `${items}
`;
}
const textHtml = content ? renderMarkdown(content) : '';
el.innerHTML = `
${attachHtml}${textHtml}
${formatTime(timestamp)}
`;
return el;
}
function renderToolCallsHtml(toolCalls) {
if (!toolCalls || toolCalls.length === 0) return '';
return toolCalls.map(tc => {
const argsStr = formatToolArgs(tc.arguments || {});
const resultStr = tc.result ? escapeHtml(String(tc.result)) : '';
const hasResult = !!resultStr;
return `
`;
}).join('');
}
function createBotMessageEl(content, timestamp, requestId, toolCalls) {
const el = document.createElement('div');
el.className = 'flex gap-3 px-4 sm:px-6 py-3';
if (requestId) el.dataset.requestId = requestId;
const toolsHtml = renderToolCallsHtml(toolCalls);
el.innerHTML = `
${toolsHtml ? `
${toolsHtml}
` : ''}
${renderMarkdown(content)}
${formatTime(timestamp)}
`;
applyHighlighting(el);
return el;
}
function addUserMessage(content, timestamp, attachments) {
const el = createUserMessageEl(content, timestamp, attachments);
messagesDiv.appendChild(el);
scrollChatToBottom();
}
function addBotMessage(content, timestamp, requestId) {
const el = createBotMessageEl(content, timestamp, requestId);
messagesDiv.appendChild(el);
scrollChatToBottom();
}
// Load conversation history from the server (page 1 = most recent messages).
// Subsequent pages prepend older messages when the user scrolls to the top.
function loadHistory(page) {
if (historyLoading) return;
historyLoading = true;
fetch(`/api/history?session_id=${encodeURIComponent(sessionId)}&page=${page}&page_size=20`)
.then(r => r.json())
.then(data => {
if (data.status !== 'success' || data.messages.length === 0) return;
const prevScrollHeight = messagesDiv.scrollHeight;
const isFirstLoad = page === 1;
// On first load, remove the welcome screen if history exists
if (isFirstLoad) {
const ws = document.getElementById('welcome-screen');
if (ws) ws.remove();
}
// Build a fragment of history message elements in chronological order
const fragment = document.createDocumentFragment();
if (data.has_more && page > 1) {
// Keep the "load more" sentinel in place (inserted below)
}
data.messages.forEach(msg => {
const hasContent = msg.content && msg.content.trim();
const hasToolCalls = msg.role === 'assistant' && msg.tool_calls && msg.tool_calls.length > 0;
if (!hasContent && !hasToolCalls) return;
const ts = new Date(msg.created_at * 1000);
const el = msg.role === 'user'
? createUserMessageEl(msg.content, ts)
: createBotMessageEl(msg.content || '', ts, null, msg.tool_calls);
fragment.appendChild(el);
});
// Prepend history above any existing messages
const sentinel = document.getElementById('history-load-more');
const insertBefore = sentinel ? sentinel.nextSibling : messagesDiv.firstChild;
messagesDiv.insertBefore(fragment, insertBefore);
// Manage the "load more" sentinel at the very top
if (data.has_more) {
if (!document.getElementById('history-load-more')) {
const btn = document.createElement('div');
btn.id = 'history-load-more';
btn.className = 'flex justify-center py-3';
btn.innerHTML = ``;
messagesDiv.insertBefore(btn, messagesDiv.firstChild);
}
} else {
const sentinel = document.getElementById('history-load-more');
if (sentinel) sentinel.remove();
}
historyHasMore = data.has_more;
historyPage = page;
if (isFirstLoad) {
// Use requestAnimationFrame to ensure the DOM has fully rendered
// before scrolling, otherwise scrollHeight may not reflect new content.
requestAnimationFrame(() => scrollChatToBottom());
} else {
// Restore scroll position so loading older messages doesn't jump the view
messagesDiv.scrollTop = messagesDiv.scrollHeight - prevScrollHeight;
}
})
.catch(() => {})
.finally(() => { historyLoading = false; });
}
function addLoadingIndicator() {
const el = document.createElement('div');
el.className = 'flex gap-3 px-4 sm:px-6 py-3';
el.innerHTML = `
`;
messagesDiv.appendChild(el);
scrollChatToBottom();
return el;
}
function newChat() {
// Close all active SSE connections for the current session
Object.values(activeStreams).forEach(es => { try { es.close(); } catch (_) {} });
activeStreams = {};
// Generate a fresh session and persist it so the next page load also starts clean
sessionId = generateSessionId();
localStorage.setItem(SESSION_ID_KEY, sessionId);
isPolling = false;
loadingContainers = {};
messagesDiv.innerHTML = '';
const ws = document.createElement('div');
ws.id = 'welcome-screen';
ws.className = 'flex flex-col items-center justify-center h-full px-6 py-12';
ws.innerHTML = `
${appConfig.title || 'CowAgent'}
${t('welcome_subtitle')}
${t('example_sys_title')}
${t('example_sys_text')}
${t('example_task_title')}
${t('example_task_text')}
${t('example_code_title')}
${t('example_code_text')}
`;
messagesDiv.appendChild(ws);
ws.querySelectorAll('.example-card').forEach(card => {
card.addEventListener('click', () => {
const textEl = card.querySelector('[data-i18n*="text"]');
if (textEl) {
chatInput.value = textEl.textContent;
chatInput.dispatchEvent(new Event('input'));
chatInput.focus();
}
});
});
if (currentView !== 'chat') navigateTo('chat');
}
// =====================================================================
// Utilities
// =====================================================================
function formatTime(date) {
return date.toLocaleTimeString([], { hour: '2-digit', minute: '2-digit' });
}
function escapeHtml(str) {
const div = document.createElement('div');
div.appendChild(document.createTextNode(str));
return div.innerHTML;
}
function ChannelsHandler_maskSecret(val) {
if (!val || val.length <= 8) return val;
return val.slice(0, 4) + '*'.repeat(val.length - 8) + val.slice(-4);
}
function formatToolArgs(args) {
if (!args || Object.keys(args).length === 0) return '(none)';
try {
return escapeHtml(JSON.stringify(args, null, 2));
} catch (_) {
return escapeHtml(String(args));
}
}
function scrollChatToBottom() {
messagesDiv.scrollTop = messagesDiv.scrollHeight;
}
function applyHighlighting(container) {
const root = container || document;
setTimeout(() => {
root.querySelectorAll('pre code').forEach(block => {
if (!block.classList.contains('hljs')) {
hljs.highlightElement(block);
}
});
}, 0);
}
// =====================================================================
// Config View
// =====================================================================
let configProviders = {};
let configApiBases = {};
let configApiKeys = {};
let configCurrentModel = '';
let cfgProviderValue = '';
let cfgModelValue = '';
// --- Custom dropdown helper ---
function initDropdown(el, options, selectedValue, onChange) {
const textEl = el.querySelector('.cfg-dropdown-text');
const menuEl = el.querySelector('.cfg-dropdown-menu');
const selEl = el.querySelector('.cfg-dropdown-selected');
el._ddValue = selectedValue || '';
el._ddOnChange = onChange;
function render() {
menuEl.innerHTML = '';
options.forEach(opt => {
const item = document.createElement('div');
item.className = 'cfg-dropdown-item' + (opt.value === el._ddValue ? ' active' : '');
item.textContent = opt.label;
item.dataset.value = opt.value;
item.addEventListener('click', (e) => {
e.stopPropagation();
el._ddValue = opt.value;
textEl.textContent = opt.label;
menuEl.querySelectorAll('.cfg-dropdown-item').forEach(i => i.classList.remove('active'));
item.classList.add('active');
el.classList.remove('open');
if (el._ddOnChange) el._ddOnChange(opt.value);
});
menuEl.appendChild(item);
});
const sel = options.find(o => o.value === el._ddValue);
textEl.textContent = sel ? sel.label : (options[0] ? options[0].label : '--');
if (!sel && options[0]) el._ddValue = options[0].value;
}
render();
if (!el._ddBound) {
selEl.addEventListener('click', (e) => {
e.stopPropagation();
document.querySelectorAll('.cfg-dropdown.open').forEach(d => { if (d !== el) d.classList.remove('open'); });
el.classList.toggle('open');
});
el._ddBound = true;
}
}
document.addEventListener('click', () => {
document.querySelectorAll('.cfg-dropdown.open').forEach(d => d.classList.remove('open'));
});
function getDropdownValue(el) { return el._ddValue || ''; }
// --- Config init ---
function initConfigView(data) {
configProviders = data.providers || {};
configApiBases = data.api_bases || {};
configApiKeys = data.api_keys || {};
configCurrentModel = data.model || '';
const providerEl = document.getElementById('cfg-provider');
const providerOpts = Object.entries(configProviders).map(([pid, p]) => ({ value: pid, label: p.label }));
// if use_linkai is enabled, always select linkai as the provider
// Otherwise prefer bot_type from config, fall back to model-based detection
const detected = data.use_linkai ? 'linkai'
: (data.bot_type && configProviders[data.bot_type] ? data.bot_type : detectProvider(configCurrentModel));
cfgProviderValue = detected || (providerOpts[0] ? providerOpts[0].value : '');
initDropdown(providerEl, providerOpts, cfgProviderValue, onProviderChange);
onProviderChange(cfgProviderValue);
syncModelSelection(configCurrentModel);
document.getElementById('cfg-max-tokens').value = data.agent_max_context_tokens || 50000;
document.getElementById('cfg-max-turns').value = data.agent_max_context_turns || 30;
document.getElementById('cfg-max-steps').value = data.agent_max_steps || 15;
}
function detectProvider(model) {
if (!model) return Object.keys(configProviders)[0] || '';
for (const [pid, p] of Object.entries(configProviders)) {
if (pid === 'linkai') continue;
if (p.models && p.models.includes(model)) return pid;
}
return Object.keys(configProviders)[0] || '';
}
function onProviderChange(pid) {
cfgProviderValue = pid || getDropdownValue(document.getElementById('cfg-provider'));
const p = configProviders[cfgProviderValue];
if (!p) return;
const modelEl = document.getElementById('cfg-model-select');
const modelOpts = (p.models || []).map(m => ({ value: m, label: m }));
modelOpts.push({ value: '__custom__', label: t('config_custom_option') });
initDropdown(modelEl, modelOpts, modelOpts[0] ? modelOpts[0].value : '', onModelSelectChange);
// API Key
const keyField = p.api_key_field;
const keyWrap = document.getElementById('cfg-api-key-wrap');
const keyInput = document.getElementById('cfg-api-key');
if (keyField) {
keyWrap.classList.remove('hidden');
keyInput.classList.add('cfg-key-masked');
const maskedVal = configApiKeys[keyField] || '';
keyInput.value = maskedVal;
keyInput.dataset.field = keyField;
keyInput.dataset.masked = maskedVal ? '1' : '';
keyInput.dataset.maskedVal = maskedVal;
const toggleIcon = document.querySelector('#cfg-api-key-toggle i');
if (toggleIcon) toggleIcon.className = 'fas fa-eye text-xs';
if (!keyInput._cfgBound) {
keyInput.addEventListener('focus', function() {
if (this.dataset.masked === '1') {
this.value = '';
this.dataset.masked = '';
this.classList.remove('cfg-key-masked');
}
});
keyInput.addEventListener('blur', function() {
if (!this.value.trim() && this.dataset.maskedVal) {
this.value = this.dataset.maskedVal;
this.dataset.masked = '1';
this.classList.add('cfg-key-masked');
}
});
keyInput.addEventListener('input', function() {
this.dataset.masked = '';
});
keyInput._cfgBound = true;
}
} else {
keyWrap.classList.add('hidden');
keyInput.value = '';
keyInput.dataset.field = '';
}
// API Base
if (p.api_base_key) {
document.getElementById('cfg-api-base-wrap').classList.remove('hidden');
document.getElementById('cfg-api-base').value = configApiBases[p.api_base_key] || p.api_base_default || '';
} else {
document.getElementById('cfg-api-base-wrap').classList.add('hidden');
document.getElementById('cfg-api-base').value = '';
}
onModelSelectChange(modelOpts[0] ? modelOpts[0].value : '');
}
function onModelSelectChange(val) {
cfgModelValue = val || getDropdownValue(document.getElementById('cfg-model-select'));
const customWrap = document.getElementById('cfg-model-custom-wrap');
if (cfgModelValue === '__custom__') {
customWrap.classList.remove('hidden');
document.getElementById('cfg-model-custom').focus();
} else {
customWrap.classList.add('hidden');
document.getElementById('cfg-model-custom').value = '';
}
}
function syncModelSelection(model) {
const p = configProviders[cfgProviderValue];
if (!p) return;
const modelEl = document.getElementById('cfg-model-select');
if (p.models && p.models.includes(model)) {
const modelOpts = (p.models || []).map(m => ({ value: m, label: m }));
modelOpts.push({ value: '__custom__', label: t('config_custom_option') });
initDropdown(modelEl, modelOpts, model, onModelSelectChange);
cfgModelValue = model;
document.getElementById('cfg-model-custom-wrap').classList.add('hidden');
} else {
cfgModelValue = '__custom__';
const modelOpts = (p.models || []).map(m => ({ value: m, label: m }));
modelOpts.push({ value: '__custom__', label: t('config_custom_option') });
initDropdown(modelEl, modelOpts, '__custom__', onModelSelectChange);
document.getElementById('cfg-model-custom-wrap').classList.remove('hidden');
document.getElementById('cfg-model-custom').value = model;
}
}
function getSelectedModel() {
if (cfgModelValue === '__custom__') {
return document.getElementById('cfg-model-custom').value.trim();
}
return cfgModelValue;
}
function toggleApiKeyVisibility() {
const input = document.getElementById('cfg-api-key');
const icon = document.querySelector('#cfg-api-key-toggle i');
if (input.classList.contains('cfg-key-masked')) {
input.classList.remove('cfg-key-masked');
icon.className = 'fas fa-eye-slash text-xs';
} else {
input.classList.add('cfg-key-masked');
icon.className = 'fas fa-eye text-xs';
}
}
function showStatus(elId, msgKey, isError) {
const el = document.getElementById(elId);
el.textContent = t(msgKey);
el.classList.toggle('text-red-500', !!isError);
el.classList.toggle('text-primary-500', !isError);
el.classList.remove('opacity-0');
setTimeout(() => el.classList.add('opacity-0'), 2500);
}
function saveModelConfig() {
const model = getSelectedModel();
if (!model) return;
const updates = { model: model };
const p = configProviders[cfgProviderValue];
updates.use_linkai = (cfgProviderValue === 'linkai');
if (cfgProviderValue === 'linkai') {
updates.bot_type = '';
} else {
updates.bot_type = cfgProviderValue;
}
if (p && p.api_base_key) {
const base = document.getElementById('cfg-api-base').value.trim();
if (base) updates[p.api_base_key] = base;
}
if (p && p.api_key_field) {
const keyInput = document.getElementById('cfg-api-key');
const rawVal = keyInput.value.trim();
if (rawVal && keyInput.dataset.masked !== '1') {
updates[p.api_key_field] = rawVal;
}
}
const btn = document.getElementById('cfg-model-save');
btn.disabled = true;
fetch('/config', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ updates })
})
.then(r => r.json())
.then(data => {
if (data.status === 'success') {
configCurrentModel = model;
if (data.applied) {
const keyInput = document.getElementById('cfg-api-key');
Object.entries(data.applied).forEach(([k, v]) => {
if (k === 'model') return;
if (k.includes('api_key')) {
const masked = v.length > 8
? v.substring(0, 4) + '*'.repeat(v.length - 8) + v.substring(v.length - 4)
: v;
configApiKeys[k] = masked;
if (keyInput.dataset.field === k) {
keyInput.value = masked;
keyInput.dataset.masked = '1';
keyInput.dataset.maskedVal = masked;
keyInput.classList.add('cfg-key-masked');
const toggleIcon = document.querySelector('#cfg-api-key-toggle i');
if (toggleIcon) toggleIcon.className = 'fas fa-eye text-xs';
}
} else {
configApiBases[k] = v;
}
});
}
showStatus('cfg-model-status', 'config_saved', false);
} else {
showStatus('cfg-model-status', 'config_save_error', true);
}
})
.catch(() => showStatus('cfg-model-status', 'config_save_error', true))
.finally(() => { btn.disabled = false; });
}
function saveAgentConfig() {
const updates = {
agent_max_context_tokens: parseInt(document.getElementById('cfg-max-tokens').value) || 50000,
agent_max_context_turns: parseInt(document.getElementById('cfg-max-turns').value) || 30,
agent_max_steps: parseInt(document.getElementById('cfg-max-steps').value) || 15,
};
const btn = document.getElementById('cfg-agent-save');
btn.disabled = true;
fetch('/config', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ updates })
})
.then(r => r.json())
.then(data => {
if (data.status === 'success') {
showStatus('cfg-agent-status', 'config_saved', false);
} else {
showStatus('cfg-agent-status', 'config_save_error', true);
}
})
.catch(() => showStatus('cfg-agent-status', 'config_save_error', true))
.finally(() => { btn.disabled = false; });
}
function loadConfigView() {
fetch('/config').then(r => r.json()).then(data => {
if (data.status !== 'success') return;
appConfig = data;
initConfigView(data);
}).catch(() => {});
}
// =====================================================================
// Skills View
// =====================================================================
let toolsLoaded = false;
const TOOL_ICONS = {
bash: 'fa-terminal',
edit: 'fa-pen-to-square',
read: 'fa-file-lines',
write: 'fa-file-pen',
ls: 'fa-folder-open',
send: 'fa-paper-plane',
web_search: 'fa-magnifying-glass',
browser: 'fa-globe',
env_config: 'fa-key',
scheduler: 'fa-clock',
memory_get: 'fa-brain',
memory_search: 'fa-brain',
};
function getToolIcon(name) {
return TOOL_ICONS[name] || 'fa-wrench';
}
function loadSkillsView() {
loadToolsSection();
loadSkillsSection();
}
function loadToolsSection() {
if (toolsLoaded) return;
const emptyEl = document.getElementById('tools-empty');
const listEl = document.getElementById('tools-list');
const badge = document.getElementById('tools-count-badge');
fetch('/api/tools').then(r => r.json()).then(data => {
if (data.status !== 'success') return;
const tools = data.tools || [];
emptyEl.classList.add('hidden');
if (tools.length === 0) {
emptyEl.classList.remove('hidden');
emptyEl.innerHTML = `${currentLang === 'zh' ? '暂无内置工具' : 'No built-in tools'}`;
return;
}
badge.textContent = tools.length;
badge.classList.remove('hidden');
listEl.innerHTML = '';
tools.forEach(tool => {
const card = document.createElement('div');
card.className = 'bg-white dark:bg-[#1A1A1A] rounded-xl border border-slate-200 dark:border-white/10 p-4 flex items-start gap-3';
card.innerHTML = `
${escapeHtml(tool.name)}
${escapeHtml(tool.description || '--')}
`;
listEl.appendChild(card);
});
listEl.classList.remove('hidden');
toolsLoaded = true;
}).catch(() => {
emptyEl.classList.remove('hidden');
emptyEl.innerHTML = `${currentLang === 'zh' ? '加载失败' : 'Failed to load'}`;
});
}
function loadSkillsSection() {
const emptyEl = document.getElementById('skills-empty');
const listEl = document.getElementById('skills-list');
const badge = document.getElementById('skills-count-badge');
fetch('/api/skills').then(r => r.json()).then(data => {
if (data.status !== 'success') return;
const skills = data.skills || [];
if (skills.length === 0) {
const p = emptyEl.querySelector('p');
if (p) p.textContent = currentLang === 'zh' ? '暂无技能' : 'No skills found';
return;
}
badge.textContent = skills.length;
badge.classList.remove('hidden');
emptyEl.classList.add('hidden');
listEl.innerHTML = '';
skills.forEach(sk => {
const card = document.createElement('div');
card.className = 'bg-white dark:bg-[#1A1A1A] rounded-xl border border-slate-200 dark:border-white/10 p-4 flex items-start gap-3 transition-opacity';
card.dataset.skillName = sk.name;
card.dataset.skillDesc = sk.description || '';
card.dataset.enabled = sk.enabled ? '1' : '0';
renderSkillCard(card, sk);
listEl.appendChild(card);
});
}).catch(() => {});
}
function renderSkillCard(card, sk) {
const enabled = sk.enabled;
const iconColor = enabled ? 'text-primary-400' : 'text-slate-300 dark:text-slate-600';
const trackClass = enabled
? 'bg-primary-400'
: 'bg-slate-200 dark:bg-slate-700';
const thumbTranslate = enabled ? 'translate-x-3' : 'translate-x-0.5';
card.innerHTML = `
${escapeHtml(sk.name)}
${escapeHtml(sk.description || '--')}
`;
}
function toggleSkill(name, currentlyEnabled) {
const action = currentlyEnabled ? 'close' : 'open';
const card = document.querySelector(`[data-skill-name="${CSS.escape(name)}"]`);
if (card) card.style.opacity = '0.5';
fetch('/api/skills', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ action, name })
})
.then(r => r.json())
.then(data => {
if (data.status === 'success') {
if (card) {
const desc = card.dataset.skillDesc || '';
card.dataset.enabled = currentlyEnabled ? '0' : '1';
card.style.opacity = '1';
renderSkillCard(card, { name, description: desc, enabled: !currentlyEnabled });
}
} else {
if (card) card.style.opacity = '1';
alert(currentLang === 'zh' ? '操作失败,请稍后再试' : 'Operation failed, please try again');
}
})
.catch(() => {
if (card) card.style.opacity = '1';
alert(currentLang === 'zh' ? '操作失败,请稍后再试' : 'Operation failed, please try again');
});
}
// =====================================================================
// Memory View
// =====================================================================
let memoryPage = 1;
const memoryPageSize = 10;
function loadMemoryView(page) {
page = page || 1;
memoryPage = page;
fetch(`/api/memory?page=${page}&page_size=${memoryPageSize}`).then(r => r.json()).then(data => {
if (data.status !== 'success') return;
const emptyEl = document.getElementById('memory-empty');
const listEl = document.getElementById('memory-list');
const files = data.list || [];
const total = data.total || 0;
if (total === 0) {
emptyEl.querySelector('p').textContent = currentLang === 'zh' ? '暂无记忆文件' : 'No memory files';
emptyEl.classList.remove('hidden');
listEl.classList.add('hidden');
return;
}
emptyEl.classList.add('hidden');
listEl.classList.remove('hidden');
const tbody = document.getElementById('memory-table-body');
tbody.innerHTML = '';
files.forEach(f => {
const tr = document.createElement('tr');
tr.className = 'border-b border-slate-100 dark:border-white/5 hover:bg-slate-50 dark:hover:bg-white/5 cursor-pointer transition-colors';
tr.onclick = () => openMemoryFile(f.filename);
const typeLabel = f.type === 'global'
? 'Global'
: 'Daily';
const sizeStr = f.size < 1024 ? f.size + ' B' : (f.size / 1024).toFixed(1) + ' KB';
tr.innerHTML = `
${escapeHtml(f.filename)} |
${typeLabel} |
${sizeStr} |
${escapeHtml(f.updated_at)} | `;
tbody.appendChild(tr);
});
// Pagination
const totalPages = Math.ceil(total / memoryPageSize);
const pagEl = document.getElementById('memory-pagination');
if (totalPages <= 1) { pagEl.innerHTML = ''; return; }
let pagHtml = `${page} / ${totalPages}`;
if (page > 1) pagHtml += ``;
if (page < totalPages) pagHtml += ``;
pagHtml += '
';
pagEl.innerHTML = pagHtml;
}).catch(() => {});
}
function openMemoryFile(filename) {
fetch(`/api/memory/content?filename=${encodeURIComponent(filename)}`).then(r => r.json()).then(data => {
if (data.status !== 'success') return;
document.getElementById('memory-panel-list').classList.add('hidden');
const panel = document.getElementById('memory-panel-viewer');
document.getElementById('memory-viewer-title').textContent = filename;
document.getElementById('memory-viewer-content').innerHTML = renderMarkdown(data.content || '');
panel.classList.remove('hidden');
applyHighlighting(panel);
}).catch(() => {});
}
function closeMemoryViewer() {
document.getElementById('memory-panel-viewer').classList.add('hidden');
document.getElementById('memory-panel-list').classList.remove('hidden');
}
// =====================================================================
// Custom Confirm Dialog
// =====================================================================
function showConfirmDialog({ title, message, okText, cancelText, onConfirm }) {
const overlay = document.getElementById('confirm-dialog-overlay');
document.getElementById('confirm-dialog-title').textContent = title || '';
document.getElementById('confirm-dialog-message').textContent = message || '';
document.getElementById('confirm-dialog-ok').textContent = okText || 'OK';
document.getElementById('confirm-dialog-cancel').textContent = cancelText || t('channels_cancel');
function cleanup() {
overlay.classList.add('hidden');
okBtn.removeEventListener('click', onOk);
cancelBtn.removeEventListener('click', onCancel);
overlay.removeEventListener('click', onOverlayClick);
}
function onOk() { cleanup(); if (onConfirm) onConfirm(); }
function onCancel() { cleanup(); }
function onOverlayClick(e) { if (e.target === overlay) cleanup(); }
const okBtn = document.getElementById('confirm-dialog-ok');
const cancelBtn = document.getElementById('confirm-dialog-cancel');
okBtn.addEventListener('click', onOk);
cancelBtn.addEventListener('click', onCancel);
overlay.addEventListener('click', onOverlayClick);
overlay.classList.remove('hidden');
}
// =====================================================================
// Channels View
// =====================================================================
let channelsData = [];
function loadChannelsView() {
const container = document.getElementById('channels-content');
container.innerHTML = `
Loading...
`;
fetch('/api/channels').then(r => r.json()).then(data => {
if (data.status !== 'success') return;
channelsData = data.channels || [];
renderActiveChannels();
}).catch(() => {
container.innerHTML = 'Failed to load channels
';
});
}
function renderActiveChannels() {
const container = document.getElementById('channels-content');
container.innerHTML = '';
closeAddChannelPanel();
const activeChannels = channelsData.filter(ch => ch.active);
if (activeChannels.length === 0) {
container.innerHTML = `
${t('channels_empty')}
${t('channels_empty_desc')}
`;
return;
}
activeChannels.forEach(ch => {
const label = (typeof ch.label === 'object') ? (ch.label[currentLang] || ch.label.en) : ch.label;
const card = document.createElement('div');
card.className = 'bg-white dark:bg-[#1A1A1A] rounded-xl border border-slate-200 dark:border-white/10 p-6';
card.id = `channel-card-${ch.name}`;
const fieldsHtml = buildChannelFieldsHtml(ch.name, ch.fields || []);
card.innerHTML = `
${escapeHtml(label)}
${t('channels_connected')}
${escapeHtml(ch.name)}
${fieldsHtml}
${inputHtml}
`;
});
return html;
}
function bindSecretFieldEvents(container) {
container.querySelectorAll('input[data-masked="1"]').forEach(inp => {
inp.addEventListener('focus', function() {
if (this.dataset.masked === '1') {
this.value = '';
this.dataset.masked = '';
this.classList.remove('cfg-key-masked');
}
});
});
}
function showChannelStatus(chName, msgKey, isError) {
const el = document.getElementById(`ch-status-${chName}`);
if (!el) return;
el.textContent = t(msgKey);
el.classList.toggle('text-red-500', !!isError);
el.classList.toggle('text-primary-500', !isError);
el.classList.remove('opacity-0');
setTimeout(() => el.classList.add('opacity-0'), 2500);
}
function saveChannelConfig(chName) {
const card = document.getElementById(`channel-card-${chName}`);
if (!card) return;
const updates = {};
card.querySelectorAll('input[data-ch="' + chName + '"]').forEach(inp => {
const key = inp.dataset.field;
if (inp.type === 'checkbox') {
updates[key] = inp.checked;
} else {
if (inp.dataset.masked === '1') return;
updates[key] = inp.value;
}
});
const btn = document.getElementById(`ch-save-${chName}`);
if (btn) btn.disabled = true;
fetch('/api/channels', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ action: 'save', channel: chName, config: updates })
})
.then(r => r.json())
.then(data => {
if (data.status === 'success') {
showChannelStatus(chName, data.restarted ? 'channels_restarted' : 'channels_saved', false);
} else {
showChannelStatus(chName, 'channels_save_error', true);
}
})
.catch(() => showChannelStatus(chName, 'channels_save_error', true))
.finally(() => { if (btn) btn.disabled = false; });
}
function disconnectChannel(chName) {
const ch = channelsData.find(c => c.name === chName);
const label = ch ? ((typeof ch.label === 'object') ? (ch.label[currentLang] || ch.label.en) : ch.label) : chName;
showConfirmDialog({
title: t('channels_disconnect'),
message: t('channels_disconnect_confirm'),
okText: t('channels_disconnect'),
cancelText: t('channels_cancel'),
onConfirm: () => {
fetch('/api/channels', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ action: 'disconnect', channel: chName })
})
.then(r => r.json())
.then(data => {
if (data.status === 'success') {
if (ch) ch.active = false;
renderActiveChannels();
}
})
.catch(() => {});
}
});
}
// --- Add channel panel ---
function openAddChannelPanel() {
const panel = document.getElementById('channels-add-panel');
const activeNames = new Set(channelsData.filter(c => c.active).map(c => c.name));
const available = channelsData.filter(c => !activeNames.has(c.name));
if (available.length === 0) {
panel.innerHTML = `
${currentLang === 'zh' ? '所有通道均已接入' : 'All channels are already connected'}
`;
panel.classList.remove('hidden');
return;
}
const ddOptions = [
{ value: '', label: t('channels_select_placeholder') },
...available.map(ch => {
const label = (typeof ch.label === 'object') ? (ch.label[currentLang] || ch.label.en) : ch.label;
return { value: ch.name, label: `${label} (${ch.name})` };
})
];
panel.innerHTML = `
`;
panel.classList.remove('hidden');
panel.scrollIntoView({ behavior: 'smooth', block: 'nearest' });
const ddEl = document.getElementById('add-channel-select');
initDropdown(ddEl, ddOptions, '', onAddChannelSelect);
}
function closeAddChannelPanel() {
const panel = document.getElementById('channels-add-panel');
if (panel) {
panel.classList.add('hidden');
panel.innerHTML = '';
}
}
function onAddChannelSelect(chName) {
const fieldsContainer = document.getElementById('add-channel-fields');
const actions = document.getElementById('add-channel-actions');
if (!chName) {
fieldsContainer.innerHTML = '';
actions.classList.add('hidden');
return;
}
const ch = channelsData.find(c => c.name === chName);
if (!ch) return;
fieldsContainer.innerHTML = buildChannelFieldsHtml(chName, ch.fields || []);
bindSecretFieldEvents(fieldsContainer);
actions.classList.remove('hidden');
}
function submitAddChannel() {
const ddEl = document.getElementById('add-channel-select');
const chName = getDropdownValue(ddEl);
if (!chName) return;
const fieldsContainer = document.getElementById('add-channel-fields');
const updates = {};
fieldsContainer.querySelectorAll('input[data-ch="' + chName + '"]').forEach(inp => {
const key = inp.dataset.field;
if (inp.type === 'checkbox') {
updates[key] = inp.checked;
} else {
if (inp.dataset.masked === '1') return;
updates[key] = inp.value;
}
});
const btn = document.getElementById('add-channel-submit');
if (btn) { btn.disabled = true; btn.textContent = t('channels_connecting'); }
fetch('/api/channels', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ action: 'connect', channel: chName, config: updates })
})
.then(r => r.json())
.then(data => {
if (data.status === 'success') {
const ch = channelsData.find(c => c.name === chName);
if (ch) {
ch.active = true;
(ch.fields || []).forEach(f => {
if (updates[f.key] !== undefined) {
f.value = f.type === 'secret' ? ChannelsHandler_maskSecret(updates[f.key]) : updates[f.key];
}
});
}
renderActiveChannels();
} else {
if (btn) { btn.disabled = false; btn.textContent = t('channels_connect_btn'); }
}
})
.catch(() => {
if (btn) { btn.disabled = false; btn.textContent = t('channels_connect_btn'); }
});
}
// =====================================================================
// Scheduler View
// =====================================================================
let tasksLoaded = false;
function loadTasksView() {
if (tasksLoaded) return;
fetch('/api/scheduler').then(r => r.json()).then(data => {
if (data.status !== 'success') return;
const emptyEl = document.getElementById('tasks-empty');
const listEl = document.getElementById('tasks-list');
const allTasks = data.tasks || [];
// Only show active (enabled) tasks
const tasks = allTasks.filter(t => t.enabled !== false);
if (tasks.length === 0) {
emptyEl.querySelector('p').textContent = currentLang === 'zh' ? '暂无定时任务' : 'No scheduled tasks';
return;
}
emptyEl.classList.add('hidden');
listEl.classList.remove('hidden');
listEl.innerHTML = '';
tasks.forEach(task => {
const card = document.createElement('div');
card.className = 'bg-white dark:bg-[#1A1A1A] rounded-xl border border-slate-200 dark:border-white/10 p-4';
const typeLabel = task.type === 'cron'
? `${escapeHtml(task.cron || '')}`
: `${escapeHtml(task.type || 'once')}`;
let nextRun = '--';
if (task.next_run_at) {
// next_run_at is an ISO string, not a Unix timestamp
const d = new Date(task.next_run_at);
if (!isNaN(d.getTime())) nextRun = d.toLocaleString();
}
card.innerHTML = `
${escapeHtml(task.name || task.id || '--')}
${typeLabel}
${escapeHtml(task.prompt || task.description || '')}
${currentLang === 'zh' ? '下次执行' : 'Next run'}: ${nextRun}
`;
listEl.appendChild(card);
});
tasksLoaded = true;
}).catch(() => {});
}
// =====================================================================
// Logs View
// =====================================================================
let logEventSource = null;
function startLogStream() {
if (logEventSource) return;
const output = document.getElementById('log-output');
output.innerHTML = '';
logEventSource = new EventSource('/api/logs');
logEventSource.onmessage = function(e) {
let item;
try { item = JSON.parse(e.data); } catch (_) { return; }
if (item.type === 'init') {
output.textContent = item.content || '';
output.scrollTop = output.scrollHeight;
} else if (item.type === 'line') {
output.textContent += item.content;
output.scrollTop = output.scrollHeight;
} else if (item.type === 'error') {
output.textContent = item.message || 'Error loading logs';
}
};
logEventSource.onerror = function() {
logEventSource.close();
logEventSource = null;
};
}
function stopLogStream() {
if (logEventSource) {
logEventSource.close();
logEventSource = null;
}
}
// =====================================================================
// View Navigation Hook
// =====================================================================
const _origNavigateTo = navigateTo;
navigateTo = function(viewId) {
// Stop log stream when leaving logs view
if (currentView === 'logs' && viewId !== 'logs') stopLogStream();
_origNavigateTo(viewId);
// Lazy-load view data
if (viewId === 'config') loadConfigView();
else if (viewId === 'skills') loadSkillsView();
else if (viewId === 'memory') {
// Always start from the list panel when navigating to memory
document.getElementById('memory-panel-viewer').classList.add('hidden');
document.getElementById('memory-panel-list').classList.remove('hidden');
loadMemoryView(1);
}
else if (viewId === 'channels') loadChannelsView();
else if (viewId === 'tasks') loadTasksView();
else if (viewId === 'logs') startLogStream();
};
// =====================================================================
// Initialization
// =====================================================================
applyTheme();
applyI18n();
document.getElementById('sidebar-version').textContent = `CowAgent ${APP_VERSION}`;
chatInput.focus();
// Re-enable color transition AFTER first paint so the theme applied in
// doesn't produce an animated flash on load. The class is missing from the
// body initially; adding it here means transitions only fire on user-triggered
// theme toggles, not on page load.
requestAnimationFrame(() => {
document.body.classList.add('transition-colors', 'duration-200');
});
================================================
FILE: channel/web/web_channel.py
================================================
import time
import json
import logging
import mimetypes
import os
import threading
import time
import uuid
from queue import Queue, Empty
import web
from bridge.context import *
from bridge.reply import Reply, ReplyType
from channel.chat_channel import ChatChannel, check_prefix
from channel.chat_message import ChatMessage
from collections import OrderedDict
from common import const
from common.log import logger
from common.singleton import singleton
from config import conf
IMAGE_EXTENSIONS = {".jpg", ".jpeg", ".png", ".gif", ".webp", ".bmp", ".svg"}
VIDEO_EXTENSIONS = {".mp4", ".webm", ".avi", ".mov", ".mkv"}
def _get_upload_dir() -> str:
from common.utils import expand_path
ws_root = expand_path(conf().get("agent_workspace", "~/cow"))
tmp_dir = os.path.join(ws_root, "tmp")
os.makedirs(tmp_dir, exist_ok=True)
return tmp_dir
class WebMessage(ChatMessage):
def __init__(
self,
msg_id,
content,
ctype=ContextType.TEXT,
from_user_id="User",
to_user_id="Chatgpt",
other_user_id="Chatgpt",
):
self.msg_id = msg_id
self.ctype = ctype
self.content = content
self.from_user_id = from_user_id
self.to_user_id = to_user_id
self.other_user_id = other_user_id
@singleton
class WebChannel(ChatChannel):
NOT_SUPPORT_REPLYTYPE = [ReplyType.VOICE]
_instance = None
# def __new__(cls):
# if cls._instance is None:
# cls._instance = super(WebChannel, cls).__new__(cls)
# return cls._instance
def __init__(self):
super().__init__()
self.msg_id_counter = 0
self.session_queues = {} # session_id -> Queue (fallback polling)
self.request_to_session = {} # request_id -> session_id
self.sse_queues = {} # request_id -> Queue (SSE streaming)
self._http_server = None
def _generate_msg_id(self):
"""生成唯一的消息ID"""
self.msg_id_counter += 1
return str(int(time.time())) + str(self.msg_id_counter)
def _generate_request_id(self):
"""生成唯一的请求ID"""
return str(uuid.uuid4())
def send(self, reply: Reply, context: Context):
try:
if reply.type in self.NOT_SUPPORT_REPLYTYPE:
logger.warning(f"Web channel doesn't support {reply.type} yet")
return
if reply.type == ReplyType.IMAGE_URL:
time.sleep(0.5)
request_id = context.get("request_id", None)
if not request_id:
logger.error("No request_id found in context, cannot send message")
return
session_id = self.request_to_session.get(request_id)
if not session_id:
logger.error(f"No session_id found for request {request_id}")
return
# SSE mode: push done event to SSE queue
if request_id in self.sse_queues:
content = reply.content if reply.content is not None else ""
self.sse_queues[request_id].put({
"type": "done",
"content": content,
"request_id": request_id,
"timestamp": time.time()
})
logger.debug(f"SSE done sent for request {request_id}")
return
# Fallback: polling mode
if session_id in self.session_queues:
response_data = {
"type": str(reply.type),
"content": reply.content,
"timestamp": time.time(),
"request_id": request_id
}
self.session_queues[session_id].put(response_data)
logger.debug(f"Response sent to poll queue for session {session_id}, request {request_id}")
else:
logger.warning(f"No response queue found for session {session_id}, response dropped")
except Exception as e:
logger.error(f"Error in send method: {e}")
def _make_sse_callback(self, request_id: str):
"""Build an on_event callback that pushes agent stream events into the SSE queue."""
def on_event(event: dict):
if request_id not in self.sse_queues:
return
q = self.sse_queues[request_id]
event_type = event.get("type")
data = event.get("data", {})
if event_type == "message_update":
delta = data.get("delta", "")
if delta:
q.put({"type": "delta", "content": delta})
elif event_type == "tool_execution_start":
tool_name = data.get("tool_name", "tool")
arguments = data.get("arguments", {})
q.put({"type": "tool_start", "tool": tool_name, "arguments": arguments})
elif event_type == "tool_execution_end":
tool_name = data.get("tool_name", "tool")
status = data.get("status", "success")
result = data.get("result", "")
exec_time = data.get("execution_time", 0)
# Truncate long results to avoid huge SSE payloads
result_str = str(result)
if len(result_str) > 2000:
result_str = result_str[:2000] + "…"
q.put({
"type": "tool_end",
"tool": tool_name,
"status": status,
"result": result_str,
"execution_time": round(exec_time, 2)
})
return on_event
def upload_file(self):
"""Handle file upload via multipart/form-data. Save to workspace/tmp/ and return metadata."""
try:
params = web.input(file={}, session_id="")
file_obj = params.get("file")
session_id = params.get("session_id", "")
if file_obj is None or not hasattr(file_obj, "filename") or not file_obj.filename:
return json.dumps({"status": "error", "message": "No file uploaded"})
upload_dir = _get_upload_dir()
original_name = file_obj.filename
ext = os.path.splitext(original_name)[1].lower()
safe_name = f"web_{uuid.uuid4().hex[:8]}{ext}"
save_path = os.path.join(upload_dir, safe_name)
with open(save_path, "wb") as f:
f.write(file_obj.read() if hasattr(file_obj, "read") else file_obj.value)
if ext in IMAGE_EXTENSIONS:
file_type = "image"
elif ext in VIDEO_EXTENSIONS:
file_type = "video"
else:
file_type = "file"
preview_url = f"/uploads/{safe_name}"
logger.info(f"[WebChannel] File uploaded: {original_name} -> {save_path} ({file_type})")
return json.dumps({
"status": "success",
"file_path": save_path,
"file_name": original_name,
"file_type": file_type,
"preview_url": preview_url,
}, ensure_ascii=False)
except Exception as e:
logger.error(f"[WebChannel] File upload error: {e}", exc_info=True)
return json.dumps({"status": "error", "message": str(e)})
def post_message(self):
"""
Handle incoming messages from users via POST request.
Returns a request_id for tracking this specific request.
Supports optional attachments (file paths from /upload).
"""
try:
data = web.data()
json_data = json.loads(data)
session_id = json_data.get('session_id', f'session_{int(time.time())}')
prompt = json_data.get('message', '')
use_sse = json_data.get('stream', True)
attachments = json_data.get('attachments', [])
# Append file references to the prompt (same format as QQ channel)
if attachments:
file_refs = []
for att in attachments:
ftype = att.get("file_type", "file")
fpath = att.get("file_path", "")
if not fpath:
continue
if ftype == "image":
file_refs.append(f"[图片: {fpath}]")
elif ftype == "video":
file_refs.append(f"[视频: {fpath}]")
else:
file_refs.append(f"[文件: {fpath}]")
if file_refs:
prompt = prompt + "\n" + "\n".join(file_refs)
logger.info(f"[WebChannel] Attached {len(file_refs)} file(s) to message")
request_id = self._generate_request_id()
self.request_to_session[request_id] = session_id
if session_id not in self.session_queues:
self.session_queues[session_id] = Queue()
if use_sse:
self.sse_queues[request_id] = Queue()
trigger_prefixs = conf().get("single_chat_prefix", [""])
if check_prefix(prompt, trigger_prefixs) is None:
if trigger_prefixs:
prompt = trigger_prefixs[0] + prompt
logger.debug(f"[WebChannel] Added prefix to message: {prompt}")
msg = WebMessage(self._generate_msg_id(), prompt)
msg.from_user_id = session_id
context = self._compose_context(ContextType.TEXT, prompt, msg=msg, isgroup=False)
if context is None:
logger.warning(f"[WebChannel] Context is None for session {session_id}, message may be filtered")
if request_id in self.sse_queues:
del self.sse_queues[request_id]
return json.dumps({"status": "error", "message": "Message was filtered"})
context["session_id"] = session_id
context["receiver"] = session_id
context["request_id"] = request_id
if use_sse:
context["on_event"] = self._make_sse_callback(request_id)
threading.Thread(target=self.produce, args=(context,)).start()
return json.dumps({"status": "success", "request_id": request_id, "stream": use_sse})
except Exception as e:
logger.error(f"Error processing message: {e}")
return json.dumps({"status": "error", "message": str(e)})
def stream_response(self, request_id: str):
"""
SSE generator for a given request_id.
Yields UTF-8 encoded bytes to avoid WSGI Latin-1 mangling.
"""
if request_id not in self.sse_queues:
yield b"data: {\"type\": \"error\", \"message\": \"invalid request_id\"}\n\n"
return
q = self.sse_queues[request_id]
timeout = 300 # 5 minutes max
deadline = time.time() + timeout
try:
while time.time() < deadline:
try:
item = q.get(timeout=1)
except Empty:
yield b": keepalive\n\n"
continue
payload = json.dumps(item, ensure_ascii=False)
yield f"data: {payload}\n\n".encode("utf-8")
if item.get("type") == "done":
break
finally:
self.sse_queues.pop(request_id, None)
def poll_response(self):
"""
Poll for responses using the session_id.
"""
try:
data = web.data()
json_data = json.loads(data)
session_id = json_data.get('session_id')
if not session_id or session_id not in self.session_queues:
return json.dumps({"status": "error", "message": "Invalid session ID"})
# 尝试从队列获取响应,不等待
try:
# 使用peek而不是get,这样如果前端没有成功处理,下次还能获取到
response = self.session_queues[session_id].get(block=False)
# 返回响应,包含请求ID以区分不同请求
return json.dumps({
"status": "success",
"has_content": True,
"content": response["content"],
"request_id": response["request_id"],
"timestamp": response["timestamp"]
})
except Empty:
# 没有新响应
return json.dumps({"status": "success", "has_content": False})
except Exception as e:
logger.error(f"Error polling response: {e}")
return json.dumps({"status": "error", "message": str(e)})
def chat_page(self):
"""Serve the chat HTML page."""
file_path = os.path.join(os.path.dirname(__file__), 'chat.html') # 使用绝对路径
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
def startup(self):
port = conf().get("web_port", 9899)
# 打印可用渠道类型提示
logger.info(
"[WebChannel] 全部可用通道如下,可修改 config.json 配置文件中的 channel_type 字段进行切换,多个通道用逗号分隔:")
logger.info("[WebChannel] 1. web - 网页")
logger.info("[WebChannel] 2. terminal - 终端")
logger.info("[WebChannel] 3. feishu - 飞书")
logger.info("[WebChannel] 4. dingtalk - 钉钉")
logger.info("[WebChannel] 5. wechatcom_app - 企微自建应用")
logger.info("[WebChannel] 6. wechatmp - 个人公众号")
logger.info("[WebChannel] 7. wechatmp_service - 企业公众号")
logger.info("[WebChannel] ✅ Web控制台已运行")
logger.info(f"[WebChannel] 🌐 本地访问: http://localhost:{port}")
logger.info(f"[WebChannel] 🌍 服务器访问: http://YOUR_IP:{port} (请将YOUR_IP替换为服务器IP)")
# 确保静态文件目录存在
static_dir = os.path.join(os.path.dirname(__file__), 'static')
if not os.path.exists(static_dir):
os.makedirs(static_dir)
logger.debug(f"[WebChannel] Created static directory: {static_dir}")
urls = (
'/', 'RootHandler',
'/message', 'MessageHandler',
'/upload', 'UploadHandler',
'/uploads/(.*)', 'UploadsHandler',
'/poll', 'PollHandler',
'/stream', 'StreamHandler',
'/chat', 'ChatHandler',
'/config', 'ConfigHandler',
'/api/channels', 'ChannelsHandler',
'/api/tools', 'ToolsHandler',
'/api/skills', 'SkillsHandler',
'/api/memory', 'MemoryHandler',
'/api/memory/content', 'MemoryContentHandler',
'/api/scheduler', 'SchedulerHandler',
'/api/history', 'HistoryHandler',
'/api/logs', 'LogsHandler',
'/assets/(.*)', 'AssetsHandler',
)
app = web.application(urls, globals(), autoreload=False)
# 完全禁用web.py的HTTP日志输出
web.httpserver.LogMiddleware.log = lambda self, status, environ: None
# 配置web.py的日志级别为ERROR
logging.getLogger("web").setLevel(logging.ERROR)
logging.getLogger("web.httpserver").setLevel(logging.ERROR)
# Build WSGI app with middleware (same as runsimple but without print)
func = web.httpserver.StaticMiddleware(app.wsgifunc())
func = web.httpserver.LogMiddleware(func)
server = web.httpserver.WSGIServer(("0.0.0.0", port), func)
# Allow concurrent requests by not blocking on in-flight handler threads
server.daemon_threads = True
self._http_server = server
try:
server.start()
except (KeyboardInterrupt, SystemExit):
server.stop()
def stop(self):
if self._http_server:
try:
self._http_server.stop()
logger.info("[WebChannel] HTTP server stopped")
except Exception as e:
logger.warning(f"[WebChannel] Error stopping HTTP server: {e}")
self._http_server = None
class RootHandler:
def GET(self):
# 重定向到/chat
raise web.seeother('/chat')
class MessageHandler:
def POST(self):
return WebChannel().post_message()
class UploadHandler:
def POST(self):
web.header('Content-Type', 'application/json; charset=utf-8')
return WebChannel().upload_file()
class UploadsHandler:
def GET(self, file_name):
"""Serve uploaded files from workspace/tmp/ for preview."""
try:
upload_dir = _get_upload_dir()
full_path = os.path.normpath(os.path.join(upload_dir, file_name))
if not os.path.abspath(full_path).startswith(os.path.abspath(upload_dir)):
raise web.notfound()
if not os.path.isfile(full_path):
raise web.notfound()
content_type = mimetypes.guess_type(full_path)[0] or "application/octet-stream"
web.header('Content-Type', content_type)
web.header('Cache-Control', 'public, max-age=86400')
with open(full_path, 'rb') as f:
return f.read()
except web.HTTPError:
raise
except Exception as e:
logger.error(f"[WebChannel] Error serving upload: {e}")
raise web.notfound()
class PollHandler:
def POST(self):
return WebChannel().poll_response()
class StreamHandler:
def GET(self):
params = web.input(request_id='')
request_id = params.request_id
if not request_id:
raise web.badrequest()
web.header('Content-Type', 'text/event-stream; charset=utf-8')
web.header('Cache-Control', 'no-cache')
web.header('X-Accel-Buffering', 'no')
web.header('Access-Control-Allow-Origin', '*')
return WebChannel().stream_response(request_id)
class ChatHandler:
def GET(self):
# 正常返回聊天页面
file_path = os.path.join(os.path.dirname(__file__), 'chat.html')
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
class ConfigHandler:
_RECOMMENDED_MODELS = [
const.MINIMAX_M2_5, const.MINIMAX_M2_1, const.MINIMAX_M2_1_LIGHTNING,
const.GLM_5, const.GLM_4_7,
const.QWEN3_MAX, const.QWEN35_PLUS,
const.KIMI_K2_5, const.KIMI_K2,
const.DOUBAO_SEED_2_PRO, const.DOUBAO_SEED_2_CODE,
const.CLAUDE_4_6_SONNET, const.CLAUDE_4_6_OPUS, const.CLAUDE_4_5_SONNET,
const.GEMINI_31_FLASH_LITE_PRE, const.GEMINI_31_PRO_PRE, const.GEMINI_3_FLASH_PRE,
const.GPT_54, const.GPT_54_MINI, const.GPT_54_NANO, const.GPT_5, const.GPT_41, const.GPT_4o,
const.DEEPSEEK_CHAT, const.DEEPSEEK_REASONER,
]
PROVIDER_MODELS = OrderedDict([
("minimax", {
"label": "MiniMax",
"api_key_field": "minimax_api_key",
"api_base_key": None,
"api_base_default": None,
"models": [const.MINIMAX_M2_5, const.MINIMAX_M2_1, const.MINIMAX_M2_1_LIGHTNING],
}),
("zhipu", {
"label": "智谱AI",
"api_key_field": "zhipu_ai_api_key",
"api_base_key": "zhipu_ai_api_base",
"api_base_default": "https://open.bigmodel.cn/api/paas/v4",
"models": [const.GLM_5, const.GLM_4_7],
}),
("dashscope", {
"label": "通义千问",
"api_key_field": "dashscope_api_key",
"api_base_key": None,
"api_base_default": None,
"models": [const.QWEN3_MAX, const.QWEN35_PLUS],
}),
("moonshot", {
"label": "Kimi",
"api_key_field": "moonshot_api_key",
"api_base_key": "moonshot_base_url",
"api_base_default": "https://api.moonshot.cn/v1",
"models": [const.KIMI_K2_5, const.KIMI_K2],
}),
("doubao", {
"label": "豆包",
"api_key_field": "ark_api_key",
"api_base_key": "ark_base_url",
"api_base_default": "https://ark.cn-beijing.volces.com/api/v3",
"models": [const.DOUBAO_SEED_2_PRO, const.DOUBAO_SEED_2_CODE],
}),
("claudeAPI", {
"label": "Claude",
"api_key_field": "claude_api_key",
"api_base_key": "claude_api_base",
"api_base_default": "https://api.anthropic.com/v1",
"models": [const.CLAUDE_4_6_SONNET, const.CLAUDE_4_6_OPUS, const.CLAUDE_4_5_SONNET],
}),
("gemini", {
"label": "Gemini",
"api_key_field": "gemini_api_key",
"api_base_key": "gemini_api_base",
"api_base_default": "https://generativelanguage.googleapis.com",
"models": [const.GEMINI_31_FLASH_LITE_PRE, const.GEMINI_31_PRO_PRE, const.GEMINI_3_FLASH_PRE],
}),
("openai", {
"label": "OpenAI",
"api_key_field": "open_ai_api_key",
"api_base_key": "open_ai_api_base",
"api_base_default": "https://api.openai.com/v1",
"models": [const.GPT_54, const.GPT_54_MINI, const.GPT_54_NANO, const.GPT_5, const.GPT_41, const.GPT_4o],
}),
("deepseek", {
"label": "DeepSeek",
"api_key_field": "open_ai_api_key",
"api_base_key": None,
"api_base_default": None,
"models": [const.DEEPSEEK_CHAT, const.DEEPSEEK_REASONER],
}),
("linkai", {
"label": "LinkAI",
"api_key_field": "linkai_api_key",
"api_base_key": None,
"api_base_default": None,
"models": _RECOMMENDED_MODELS,
}),
])
EDITABLE_KEYS = {
"model", "bot_type", "use_linkai",
"open_ai_api_base", "claude_api_base", "gemini_api_base",
"zhipu_ai_api_base", "moonshot_base_url", "ark_base_url",
"open_ai_api_key", "claude_api_key", "gemini_api_key",
"zhipu_ai_api_key", "dashscope_api_key", "moonshot_api_key",
"ark_api_key", "minimax_api_key", "linkai_api_key",
"agent_max_context_tokens", "agent_max_context_turns", "agent_max_steps",
}
@staticmethod
def _mask_key(value: str) -> str:
"""Mask the middle part of an API key for display."""
if not value or len(value) <= 8:
return value
return value[:4] + "*" * (len(value) - 8) + value[-4:]
def GET(self):
"""Return configuration info and provider/model metadata."""
web.header('Content-Type', 'application/json; charset=utf-8')
try:
local_config = conf()
use_agent = local_config.get("agent", False)
title = "CowAgent" if use_agent else "AI Assistant"
api_bases = {}
api_keys_masked = {}
for pid, pinfo in self.PROVIDER_MODELS.items():
base_key = pinfo.get("api_base_key")
if base_key:
api_bases[base_key] = local_config.get(base_key, pinfo["api_base_default"])
key_field = pinfo.get("api_key_field")
if key_field and key_field not in api_keys_masked:
raw = local_config.get(key_field, "")
api_keys_masked[key_field] = self._mask_key(raw) if raw else ""
providers = {}
for pid, p in self.PROVIDER_MODELS.items():
providers[pid] = {
"label": p["label"],
"models": p["models"],
"api_base_key": p["api_base_key"],
"api_base_default": p["api_base_default"],
"api_key_field": p.get("api_key_field"),
}
return json.dumps({
"status": "success",
"use_agent": use_agent,
"title": title,
"model": local_config.get("model", ""),
"bot_type": "openai" if local_config.get("bot_type") == "chatGPT" else local_config.get("bot_type", ""),
"use_linkai": bool(local_config.get("use_linkai", False)),
"channel_type": local_config.get("channel_type", ""),
"agent_max_context_tokens": local_config.get("agent_max_context_tokens", 50000),
"agent_max_context_turns": local_config.get("agent_max_context_turns", 20),
"agent_max_steps": local_config.get("agent_max_steps", 15),
"api_bases": api_bases,
"api_keys": api_keys_masked,
"providers": providers,
}, ensure_ascii=False)
except Exception as e:
logger.error(f"Error getting config: {e}")
return json.dumps({"status": "error", "message": str(e)})
def POST(self):
"""Update configuration values in memory and persist to config.json."""
web.header('Content-Type', 'application/json; charset=utf-8')
try:
data = json.loads(web.data())
updates = data.get("updates", {})
if not updates:
return json.dumps({"status": "error", "message": "no updates provided"})
local_config = conf()
applied = {}
for key, value in updates.items():
if key not in self.EDITABLE_KEYS:
continue
if key in ("agent_max_context_tokens", "agent_max_context_turns", "agent_max_steps"):
value = int(value)
if key == "use_linkai":
value = bool(value)
local_config[key] = value
applied[key] = value
if not applied:
return json.dumps({"status": "error", "message": "no valid keys to update"})
config_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(
os.path.abspath(__file__)))), "config.json")
if os.path.exists(config_path):
with open(config_path, "r", encoding="utf-8") as f:
file_cfg = json.load(f)
else:
file_cfg = {}
file_cfg.update(applied)
with open(config_path, "w", encoding="utf-8") as f:
json.dump(file_cfg, f, indent=4, ensure_ascii=False)
logger.info(f"[WebChannel] Config updated: {list(applied.keys())}")
return json.dumps({"status": "success", "applied": applied}, ensure_ascii=False)
except Exception as e:
logger.error(f"Error updating config: {e}")
return json.dumps({"status": "error", "message": str(e)})
class ChannelsHandler:
"""API for managing external channel configurations (feishu, dingtalk, etc)."""
CHANNEL_DEFS = OrderedDict([
("feishu", {
"label": {"zh": "飞书", "en": "Feishu"},
"icon": "fa-paper-plane",
"color": "blue",
"fields": [
{"key": "feishu_app_id", "label": "App ID", "type": "text"},
{"key": "feishu_app_secret", "label": "App Secret", "type": "secret"},
{"key": "feishu_token", "label": "Verification Token", "type": "secret"},
{"key": "feishu_bot_name", "label": "Bot Name", "type": "text"},
],
}),
("dingtalk", {
"label": {"zh": "钉钉", "en": "DingTalk"},
"icon": "fa-comments",
"color": "blue",
"fields": [
{"key": "dingtalk_client_id", "label": "Client ID", "type": "text"},
{"key": "dingtalk_client_secret", "label": "Client Secret", "type": "secret"},
],
}),
("wecom_bot", {
"label": {"zh": "企微智能机器人", "en": "WeCom Bot"},
"icon": "fa-robot",
"color": "emerald",
"fields": [
{"key": "wecom_bot_id", "label": "Bot ID", "type": "text"},
{"key": "wecom_bot_secret", "label": "Secret", "type": "secret"},
],
}),
("qq", {
"label": {"zh": "QQ 机器人", "en": "QQ Bot"},
"icon": "fa-comment",
"color": "blue",
"fields": [
{"key": "qq_app_id", "label": "App ID", "type": "text"},
{"key": "qq_app_secret", "label": "App Secret", "type": "secret"},
],
}),
("wechatcom_app", {
"label": {"zh": "企微自建应用", "en": "WeCom App"},
"icon": "fa-building",
"color": "emerald",
"fields": [
{"key": "wechatcom_corp_id", "label": "Corp ID", "type": "text"},
{"key": "wechatcomapp_agent_id", "label": "Agent ID", "type": "text"},
{"key": "wechatcomapp_secret", "label": "Secret", "type": "secret"},
{"key": "wechatcomapp_token", "label": "Token", "type": "secret"},
{"key": "wechatcomapp_aes_key", "label": "AES Key", "type": "secret"},
{"key": "wechatcomapp_port", "label": "Port", "type": "number", "default": 9898},
],
}),
("wechatmp", {
"label": {"zh": "公众号", "en": "WeChat MP"},
"icon": "fa-comment-dots",
"color": "emerald",
"fields": [
{"key": "wechatmp_app_id", "label": "App ID", "type": "text"},
{"key": "wechatmp_app_secret", "label": "App Secret", "type": "secret"},
{"key": "wechatmp_token", "label": "Token", "type": "secret"},
{"key": "wechatmp_aes_key", "label": "AES Key", "type": "secret"},
{"key": "wechatmp_port", "label": "Port", "type": "number", "default": 8080},
],
}),
])
@staticmethod
def _mask_secret(value: str) -> str:
if not value or len(value) <= 8:
return value
return value[:4] + "*" * (len(value) - 8) + value[-4:]
@staticmethod
def _parse_channel_list(raw) -> list:
if isinstance(raw, list):
return [ch.strip() for ch in raw if ch.strip()]
if isinstance(raw, str):
return [ch.strip() for ch in raw.split(",") if ch.strip()]
return []
@classmethod
def _active_channel_set(cls) -> set:
return set(cls._parse_channel_list(conf().get("channel_type", "")))
def GET(self):
web.header('Content-Type', 'application/json; charset=utf-8')
try:
local_config = conf()
active_channels = self._active_channel_set()
channels = []
for ch_name, ch_def in self.CHANNEL_DEFS.items():
fields_out = []
for f in ch_def["fields"]:
raw_val = local_config.get(f["key"], f.get("default", ""))
if f["type"] == "secret" and raw_val:
display_val = self._mask_secret(str(raw_val))
else:
display_val = raw_val
fields_out.append({
"key": f["key"],
"label": f["label"],
"type": f["type"],
"value": display_val,
"default": f.get("default", ""),
})
channels.append({
"name": ch_name,
"label": ch_def["label"],
"icon": ch_def["icon"],
"color": ch_def["color"],
"active": ch_name in active_channels,
"fields": fields_out,
})
return json.dumps({"status": "success", "channels": channels}, ensure_ascii=False)
except Exception as e:
logger.error(f"[WebChannel] Channels API error: {e}")
return json.dumps({"status": "error", "message": str(e)})
def POST(self):
web.header('Content-Type', 'application/json; charset=utf-8')
try:
body = json.loads(web.data())
action = body.get("action")
channel_name = body.get("channel")
if not action or not channel_name:
return json.dumps({"status": "error", "message": "action and channel required"})
if channel_name not in self.CHANNEL_DEFS:
return json.dumps({"status": "error", "message": f"unknown channel: {channel_name}"})
if action == "save":
return self._handle_save(channel_name, body.get("config", {}))
elif action == "connect":
return self._handle_connect(channel_name, body.get("config", {}))
elif action == "disconnect":
return self._handle_disconnect(channel_name)
else:
return json.dumps({"status": "error", "message": f"unknown action: {action}"})
except Exception as e:
logger.error(f"[WebChannel] Channels POST error: {e}")
return json.dumps({"status": "error", "message": str(e)})
def _handle_save(self, channel_name: str, updates: dict):
ch_def = self.CHANNEL_DEFS[channel_name]
valid_keys = {f["key"] for f in ch_def["fields"]}
secret_keys = {f["key"] for f in ch_def["fields"] if f["type"] == "secret"}
local_config = conf()
applied = {}
for key, value in updates.items():
if key not in valid_keys:
continue
if key in secret_keys:
if not value or (len(value) > 8 and "*" * 4 in value):
continue
field_def = next((f for f in ch_def["fields"] if f["key"] == key), None)
if field_def:
if field_def["type"] == "number":
value = int(value)
elif field_def["type"] == "bool":
value = bool(value)
local_config[key] = value
applied[key] = value
if not applied:
return json.dumps({"status": "error", "message": "no valid fields to update"})
config_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(
os.path.abspath(__file__)))), "config.json")
if os.path.exists(config_path):
with open(config_path, "r", encoding="utf-8") as f:
file_cfg = json.load(f)
else:
file_cfg = {}
file_cfg.update(applied)
with open(config_path, "w", encoding="utf-8") as f:
json.dump(file_cfg, f, indent=4, ensure_ascii=False)
logger.info(f"[WebChannel] Channel '{channel_name}' config updated: {list(applied.keys())}")
should_restart = False
active_channels = self._active_channel_set()
if channel_name in active_channels:
should_restart = True
try:
import sys
app_module = sys.modules.get('__main__') or sys.modules.get('app')
mgr = getattr(app_module, '_channel_mgr', None) if app_module else None
if mgr:
threading.Thread(
target=mgr.restart,
args=(channel_name,),
daemon=True,
).start()
logger.info(f"[WebChannel] Channel '{channel_name}' restart triggered")
except Exception as e:
logger.warning(f"[WebChannel] Failed to restart channel '{channel_name}': {e}")
return json.dumps({
"status": "success",
"applied": list(applied.keys()),
"restarted": should_restart,
}, ensure_ascii=False)
def _handle_connect(self, channel_name: str, updates: dict):
"""Save config fields, add channel to channel_type, and start it."""
ch_def = self.CHANNEL_DEFS[channel_name]
valid_keys = {f["key"] for f in ch_def["fields"]}
secret_keys = {f["key"] for f in ch_def["fields"] if f["type"] == "secret"}
# Feishu connected via web console must use websocket (long connection) mode
if channel_name == "feishu":
updates.setdefault("feishu_event_mode", "websocket")
valid_keys.add("feishu_event_mode")
local_config = conf()
applied = {}
for key, value in updates.items():
if key not in valid_keys:
continue
if key in secret_keys:
if not value or (len(value) > 8 and "*" * 4 in value):
continue
field_def = next((f for f in ch_def["fields"] if f["key"] == key), None)
if field_def:
if field_def["type"] == "number":
value = int(value)
elif field_def["type"] == "bool":
value = bool(value)
local_config[key] = value
applied[key] = value
existing = self._parse_channel_list(conf().get("channel_type", ""))
if channel_name not in existing:
existing.append(channel_name)
new_channel_type = ",".join(existing)
local_config["channel_type"] = new_channel_type
config_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(
os.path.abspath(__file__)))), "config.json")
if os.path.exists(config_path):
with open(config_path, "r", encoding="utf-8") as f:
file_cfg = json.load(f)
else:
file_cfg = {}
file_cfg.update(applied)
file_cfg["channel_type"] = new_channel_type
with open(config_path, "w", encoding="utf-8") as f:
json.dump(file_cfg, f, indent=4, ensure_ascii=False)
logger.info(f"[WebChannel] Channel '{channel_name}' connecting, channel_type={new_channel_type}")
def _do_start():
try:
import sys
app_module = sys.modules.get('__main__') or sys.modules.get('app')
clear_fn = getattr(app_module, '_clear_singleton_cache', None) if app_module else None
mgr = getattr(app_module, '_channel_mgr', None) if app_module else None
if mgr is None:
logger.warning(f"[WebChannel] ChannelManager not available, cannot start '{channel_name}'")
return
# Stop existing instance first if still running (e.g. re-connect without disconnect)
existing_ch = mgr.get_channel(channel_name)
if existing_ch is not None:
logger.info(f"[WebChannel] Stopping existing '{channel_name}' before reconnect...")
mgr.stop(channel_name)
# Always wait for the remote service to release the old connection before
# establishing a new one (DingTalk drops callbacks on duplicate connections)
logger.info(f"[WebChannel] Waiting for '{channel_name}' old connection to close...")
time.sleep(5)
if clear_fn:
clear_fn(channel_name)
logger.info(f"[WebChannel] Starting channel '{channel_name}'...")
mgr.start([channel_name], first_start=False)
logger.info(f"[WebChannel] Channel '{channel_name}' start completed")
except Exception as e:
logger.error(f"[WebChannel] Failed to start channel '{channel_name}': {e}",
exc_info=True)
threading.Thread(target=_do_start, daemon=True).start()
return json.dumps({
"status": "success",
"channel_type": new_channel_type,
}, ensure_ascii=False)
def _handle_disconnect(self, channel_name: str):
existing = self._parse_channel_list(conf().get("channel_type", ""))
existing = [ch for ch in existing if ch != channel_name]
new_channel_type = ",".join(existing)
local_config = conf()
local_config["channel_type"] = new_channel_type
config_path = os.path.join(os.path.dirname(os.path.dirname(os.path.dirname(
os.path.abspath(__file__)))), "config.json")
if os.path.exists(config_path):
with open(config_path, "r", encoding="utf-8") as f:
file_cfg = json.load(f)
else:
file_cfg = {}
file_cfg["channel_type"] = new_channel_type
with open(config_path, "w", encoding="utf-8") as f:
json.dump(file_cfg, f, indent=4, ensure_ascii=False)
def _do_stop():
try:
import sys
app_module = sys.modules.get('__main__') or sys.modules.get('app')
mgr = getattr(app_module, '_channel_mgr', None) if app_module else None
clear_fn = getattr(app_module, '_clear_singleton_cache', None) if app_module else None
if mgr:
mgr.stop(channel_name)
else:
logger.warning(f"[WebChannel] ChannelManager not found, cannot stop '{channel_name}'")
if clear_fn:
clear_fn(channel_name)
logger.info(f"[WebChannel] Channel '{channel_name}' disconnected, "
f"channel_type={new_channel_type}")
except Exception as e:
logger.warning(f"[WebChannel] Failed to stop channel '{channel_name}': {e}",
exc_info=True)
threading.Thread(target=_do_stop, daemon=True).start()
return json.dumps({
"status": "success",
"channel_type": new_channel_type,
}, ensure_ascii=False)
def _get_workspace_root():
"""Resolve the agent workspace directory."""
from common.utils import expand_path
return expand_path(conf().get("agent_workspace", "~/cow"))
class ToolsHandler:
def GET(self):
web.header('Content-Type', 'application/json; charset=utf-8')
try:
from agent.tools.tool_manager import ToolManager
tm = ToolManager()
if not tm.tool_classes:
tm.load_tools()
tools = []
for name, cls in tm.tool_classes.items():
try:
instance = cls()
tools.append({
"name": name,
"description": instance.description,
})
except Exception:
tools.append({"name": name, "description": ""})
return json.dumps({"status": "success", "tools": tools}, ensure_ascii=False)
except Exception as e:
logger.error(f"[WebChannel] Tools API error: {e}")
return json.dumps({"status": "error", "message": str(e)})
class SkillsHandler:
def GET(self):
web.header('Content-Type', 'application/json; charset=utf-8')
try:
from agent.skills.service import SkillService
from agent.skills.manager import SkillManager
workspace_root = _get_workspace_root()
manager = SkillManager(custom_dir=os.path.join(workspace_root, "skills"))
service = SkillService(manager)
skills = service.query()
return json.dumps({"status": "success", "skills": skills}, ensure_ascii=False)
except Exception as e:
logger.error(f"[WebChannel] Skills API error: {e}")
return json.dumps({"status": "error", "message": str(e)})
def POST(self):
web.header('Content-Type', 'application/json; charset=utf-8')
try:
from agent.skills.service import SkillService
from agent.skills.manager import SkillManager
body = json.loads(web.data())
action = body.get("action")
name = body.get("name")
if not action or not name:
return json.dumps({"status": "error", "message": "action and name are required"})
workspace_root = _get_workspace_root()
manager = SkillManager(custom_dir=os.path.join(workspace_root, "skills"))
service = SkillService(manager)
if action == "open":
service.open({"name": name})
elif action == "close":
service.close({"name": name})
else:
return json.dumps({"status": "error", "message": f"unknown action: {action}"})
return json.dumps({"status": "success"}, ensure_ascii=False)
except Exception as e:
logger.error(f"[WebChannel] Skills POST error: {e}")
return json.dumps({"status": "error", "message": str(e)})
class MemoryHandler:
def GET(self):
web.header('Content-Type', 'application/json; charset=utf-8')
try:
from agent.memory.service import MemoryService
params = web.input(page='1', page_size='20')
workspace_root = _get_workspace_root()
service = MemoryService(workspace_root)
result = service.list_files(page=int(params.page), page_size=int(params.page_size))
return json.dumps({"status": "success", **result}, ensure_ascii=False)
except Exception as e:
logger.error(f"[WebChannel] Memory API error: {e}")
return json.dumps({"status": "error", "message": str(e)})
class MemoryContentHandler:
def GET(self):
web.header('Content-Type', 'application/json; charset=utf-8')
try:
from agent.memory.service import MemoryService
params = web.input(filename='')
if not params.filename:
return json.dumps({"status": "error", "message": "filename required"})
workspace_root = _get_workspace_root()
service = MemoryService(workspace_root)
result = service.get_content(params.filename)
return json.dumps({"status": "success", **result}, ensure_ascii=False)
except FileNotFoundError:
return json.dumps({"status": "error", "message": "file not found"})
except Exception as e:
logger.error(f"[WebChannel] Memory content API error: {e}")
return json.dumps({"status": "error", "message": str(e)})
class SchedulerHandler:
def GET(self):
web.header('Content-Type', 'application/json; charset=utf-8')
try:
from agent.tools.scheduler.task_store import TaskStore
workspace_root = _get_workspace_root()
store_path = os.path.join(workspace_root, "scheduler", "tasks.json")
store = TaskStore(store_path)
tasks = store.list_tasks()
return json.dumps({"status": "success", "tasks": tasks}, ensure_ascii=False)
except Exception as e:
logger.error(f"[WebChannel] Scheduler API error: {e}")
return json.dumps({"status": "error", "message": str(e)})
class HistoryHandler:
def GET(self):
"""
Return paginated conversation history for a session.
Query params:
session_id (required)
page int, default 1 (1 = most recent messages)
page_size int, default 20
"""
web.header('Content-Type', 'application/json; charset=utf-8')
web.header('Access-Control-Allow-Origin', '*')
try:
params = web.input(session_id='', page='1', page_size='20')
session_id = params.session_id.strip()
if not session_id:
return json.dumps({"status": "error", "message": "session_id required"})
from agent.memory import get_conversation_store
store = get_conversation_store()
result = store.load_history_page(
session_id=session_id,
page=int(params.page),
page_size=int(params.page_size),
)
return json.dumps({"status": "success", **result}, ensure_ascii=False)
except Exception as e:
logger.error(f"[WebChannel] History API error: {e}")
return json.dumps({"status": "error", "message": str(e)})
class LogsHandler:
def GET(self):
"""Stream the last N lines of run.log as SSE, then tail new lines."""
web.header('Content-Type', 'text/event-stream; charset=utf-8')
web.header('Cache-Control', 'no-cache')
web.header('X-Accel-Buffering', 'no')
from config import get_root
log_path = os.path.join(get_root(), "run.log")
def generate():
if not os.path.isfile(log_path):
yield b"data: {\"type\": \"error\", \"message\": \"run.log not found\"}\n\n"
return
# Read last 200 lines for initial display
try:
with open(log_path, 'r', encoding='utf-8', errors='replace') as f:
lines = f.readlines()
tail_lines = lines[-200:]
chunk = ''.join(tail_lines)
payload = json.dumps({"type": "init", "content": chunk}, ensure_ascii=False)
yield f"data: {payload}\n\n".encode('utf-8')
except Exception as e:
yield f"data: {{\"type\": \"error\", \"message\": \"{e}\"}}\n\n".encode('utf-8')
return
# Tail new lines
try:
with open(log_path, 'r', encoding='utf-8', errors='replace') as f:
f.seek(0, 2) # seek to end
deadline = time.time() + 600 # 10 min max
while time.time() < deadline:
line = f.readline()
if line:
payload = json.dumps({"type": "line", "content": line}, ensure_ascii=False)
yield f"data: {payload}\n\n".encode('utf-8')
else:
yield b": keepalive\n\n"
time.sleep(1)
except GeneratorExit:
return
except Exception:
return
return generate()
class AssetsHandler:
def GET(self, file_path): # 修改默认参数
try:
# 如果请求是/static/,需要处理
if file_path == '':
# 返回目录列表...
pass
# 获取当前文件的绝对路径
current_dir = os.path.dirname(os.path.abspath(__file__))
static_dir = os.path.join(current_dir, 'static')
full_path = os.path.normpath(os.path.join(static_dir, file_path))
# 安全检查:确保请求的文件在static目录内
if not os.path.abspath(full_path).startswith(os.path.abspath(static_dir)):
logger.error(f"Security check failed for path: {full_path}")
raise web.notfound()
if not os.path.exists(full_path) or not os.path.isfile(full_path):
logger.error(f"File not found: {full_path}")
raise web.notfound()
# 设置正确的Content-Type
content_type = mimetypes.guess_type(full_path)[0]
if content_type:
web.header('Content-Type', content_type)
else:
# 默认为二进制流
web.header('Content-Type', 'application/octet-stream')
# 读取并返回文件内容
with open(full_path, 'rb') as f:
return f.read()
except Exception as e:
logger.error(f"Error serving static file: {e}", exc_info=True) # 添加更详细的错误信息
raise web.notfound()
================================================
FILE: channel/wechatcom/README.md
================================================
# 企业微信应用号channel
企业微信官方提供了客服、应用等API,本channel使用的是企业微信的自建应用API的能力。
因为未来可能还会开发客服能力,所以本channel的类型名叫作`wechatcom_app`。
`wechatcom_app` channel支持插件系统和图片声音交互等能力,除了无法加入群聊,作为个人使用的私人助理已绰绰有余。
## 开始之前
- 在企业中确认自己拥有在企业内自建应用的权限。
- 如果没有权限或者是个人用户,也可创建未认证的企业。操作方式:登录手机企业微信,选择`创建/加入企业`来创建企业,类型请选择企业,企业名称可随意填写。
未认证的企业有100人的服务人数上限,其他功能与认证企业没有差异。
本channel需安装的依赖与公众号一致,需要安装`wechatpy`和`web.py`,它们包含在`requirements-optional.txt`中。
此外,如果你是`Linux`系统,除了`ffmpeg`还需要安装`amr`编码器,否则会出现找不到编码器的错误,无法正常使用语音功能。
- Ubuntu/Debian
```bash
apt-get install libavcodec-extra
```
- Alpine
需自行编译`ffmpeg`,在编译参数里加入`amr`编码器的支持
## 使用方法
1.查看企业ID
- 扫码登陆[企业微信后台](https://work.weixin.qq.com)
- 选择`我的企业`,点击`企业信息`,记住该`企业ID`
2.创建自建应用
- 选择应用管理, 在自建区选创建应用来创建企业自建应用
- 上传应用logo,填写应用名称等项
- 创建应用后进入应用详情页面,记住`AgentId`和`Secert`
3.配置应用
- 在详情页点击`企业可信IP`的配置(没看到可以不管),填入你服务器的公网IP,如果不知道可以先不填
- 点击`接收消息`下的启用API接收消息
- `URL`填写格式为`http://url:port/wxcomapp`,`port`是程序监听的端口,默认是9898
如果是未认证的企业,url可直接使用服务器的IP。如果是认证企业,需要使用备案的域名,可使用二级域名。
- `Token`可随意填写,停留在这个页面
- 在程序根目录`config.json`中增加配置(**去掉注释**),`wechatcomapp_aes_key`是当前页面的`wechatcomapp_aes_key`
```python
"channel_type": "wechatcom_app",
"wechatcom_corp_id": "", # 企业微信公司的corpID
"wechatcomapp_token": "", # 企业微信app的token
"wechatcomapp_port": 9898, # 企业微信app的服务端口, 不需要端口转发
"wechatcomapp_secret": "", # 企业微信app的secret
"wechatcomapp_agent_id": "", # 企业微信app的agent_id
"wechatcomapp_aes_key": "", # 企业微信app的aes_key
```
- 运行程序,在页面中点击保存,保存成功说明验证成功
4.连接个人微信
选择`我的企业`,点击`微信插件`,下面有个邀请关注的二维码。微信扫码后,即可在微信中看到对应企业,在这里你便可以和机器人沟通。
向机器人发送消息,如果日志里出现报错:
```bash
Error code: 60020, message: "not allow to access from your ip, ...from ip: xx.xx.xx.xx"
```
意思是IP不可信,需要参考上一步的`企业可信IP`配置,把这里的IP加进去。
~~### Railway部署方式~~(2023-06-08已失效)
~~公众号不能在`Railway`上部署,但企业微信应用[可以](https://railway.app/template/-FHS--?referralCode=RC3znh)!~~
~~填写配置后,将部署完成后的网址```**.railway.app/wxcomapp```,填写在上一步的URL中。发送信息后观察日志,把报错的IP加入到可信IP。(每次重启后都需要加入可信IP)~~
~~## 测试体验~~
~~AIGC开放社区中已经部署了多个可免费使用的Bot,扫描下方的二维码会自动邀请你来体验。~~
~~ ~~
================================================
FILE: channel/wechatcom/wechatcomapp_channel.py
================================================
# -*- coding=utf-8 -*-
import io
import os
import sys
import time
import requests
import web
from wechatpy.enterprise import create_reply, parse_message
from wechatpy.enterprise.crypto import WeChatCrypto
from wechatpy.enterprise.exceptions import InvalidCorpIdException
from wechatpy.exceptions import InvalidSignatureException, WeChatClientException
from bridge.context import Context
from bridge.reply import Reply, ReplyType
from channel.chat_channel import ChatChannel
from channel.wechatcom.wechatcomapp_client import WechatComAppClient
from channel.wechatcom.wechatcomapp_message import WechatComAppMessage
from common.log import logger
from common.singleton import singleton
from common.utils import compress_imgfile, fsize, split_string_by_utf8_length, convert_webp_to_png, remove_markdown_symbol
from config import conf, subscribe_msg
from voice.audio_convert import any_to_amr, split_audio
MAX_UTF8_LEN = 2048
@singleton
class WechatComAppChannel(ChatChannel):
NOT_SUPPORT_REPLYTYPE = []
def __init__(self):
super().__init__()
self.corp_id = conf().get("wechatcom_corp_id")
self.secret = conf().get("wechatcomapp_secret")
self.agent_id = conf().get("wechatcomapp_agent_id")
self.token = conf().get("wechatcomapp_token")
self.aes_key = conf().get("wechatcomapp_aes_key")
self._http_server = None
logger.info(
"[wechatcom] Initializing WeCom app channel, corp_id: {}, agent_id: {}".format(self.corp_id, self.agent_id)
)
self.crypto = WeChatCrypto(self.token, self.aes_key, self.corp_id)
self.client = WechatComAppClient(self.corp_id, self.secret)
def startup(self):
# start message listener
urls = ("/wxcomapp/?", "channel.wechatcom.wechatcomapp_channel.Query")
app = web.application(urls, globals(), autoreload=False)
port = conf().get("wechatcomapp_port", 9898)
logger.info("[wechatcom] ✅ WeCom app channel started successfully")
logger.info("[wechatcom] 📡 Listening on http://0.0.0.0:{}/wxcomapp/".format(port))
logger.info("[wechatcom] 🤖 Ready to receive messages")
# Build WSGI app with middleware (same as runsimple but without print)
func = web.httpserver.StaticMiddleware(app.wsgifunc())
func = web.httpserver.LogMiddleware(func)
server = web.httpserver.WSGIServer(("0.0.0.0", port), func)
self._http_server = server
try:
server.start()
except (KeyboardInterrupt, SystemExit):
server.stop()
def stop(self):
if self._http_server:
try:
self._http_server.stop()
logger.info("[wechatcom] HTTP server stopped")
except Exception as e:
logger.warning(f"[wechatcom] Error stopping HTTP server: {e}")
self._http_server = None
def send(self, reply: Reply, context: Context):
receiver = context["receiver"]
if reply.type in [ReplyType.TEXT, ReplyType.ERROR, ReplyType.INFO]:
reply_text = remove_markdown_symbol(reply.content)
texts = split_string_by_utf8_length(reply_text, MAX_UTF8_LEN)
if len(texts) > 1:
logger.info("[wechatcom] text too long, split into {} parts".format(len(texts)))
for i, text in enumerate(texts):
self.client.message.send_text(self.agent_id, receiver, text)
if i != len(texts) - 1:
time.sleep(0.5) # 休眠0.5秒,防止发送过快乱序
logger.info("[wechatcom] Do send text to {}: {}".format(receiver, reply_text))
elif reply.type == ReplyType.VOICE:
try:
media_ids = []
file_path = reply.content
amr_file = os.path.splitext(file_path)[0] + ".amr"
any_to_amr(file_path, amr_file)
duration, files = split_audio(amr_file, 60 * 1000)
if len(files) > 1:
logger.info("[wechatcom] voice too long {}s > 60s , split into {} parts".format(duration / 1000.0, len(files)))
for path in files:
response = self.client.media.upload("voice", open(path, "rb"))
logger.debug("[wechatcom] upload voice response: {}".format(response))
media_ids.append(response["media_id"])
except ImportError as e:
logger.error("[wechatcom] voice conversion failed: {}".format(e))
logger.error("[wechatcom] please install pydub: pip install pydub")
return
except WeChatClientException as e:
logger.error("[wechatcom] upload voice failed: {}".format(e))
return
try:
os.remove(file_path)
if amr_file != file_path:
os.remove(amr_file)
except Exception:
pass
for media_id in media_ids:
self.client.message.send_voice(self.agent_id, receiver, media_id)
time.sleep(1)
logger.info("[wechatcom] sendVoice={}, receiver={}".format(reply.content, receiver))
elif reply.type == ReplyType.IMAGE_URL: # 从网络下载图片
img_url = reply.content
pic_res = requests.get(img_url, stream=True)
image_storage = io.BytesIO()
for block in pic_res.iter_content(1024):
image_storage.write(block)
sz = fsize(image_storage)
if sz >= 10 * 1024 * 1024:
logger.info("[wechatcom] image too large, ready to compress, sz={}".format(sz))
image_storage = compress_imgfile(image_storage, 10 * 1024 * 1024 - 1)
logger.info("[wechatcom] image compressed, sz={}".format(fsize(image_storage)))
image_storage.seek(0)
if ".webp" in img_url:
try:
image_storage = convert_webp_to_png(image_storage)
except Exception as e:
logger.error(f"Failed to convert image: {e}")
return
try:
response = self.client.media.upload("image", image_storage)
logger.debug("[wechatcom] upload image response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatcom] upload image failed: {}".format(e))
return
self.client.message.send_image(self.agent_id, receiver, response["media_id"])
logger.info("[wechatcom] sendImage url={}, receiver={}".format(img_url, receiver))
elif reply.type == ReplyType.IMAGE: # 从文件读取图片
image_storage = reply.content
sz = fsize(image_storage)
if sz >= 10 * 1024 * 1024:
logger.info("[wechatcom] image too large, ready to compress, sz={}".format(sz))
image_storage = compress_imgfile(image_storage, 10 * 1024 * 1024 - 1)
logger.info("[wechatcom] image compressed, sz={}".format(fsize(image_storage)))
image_storage.seek(0)
try:
response = self.client.media.upload("image", image_storage)
logger.debug("[wechatcom] upload image response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatcom] upload image failed: {}".format(e))
return
self.client.message.send_image(self.agent_id, receiver, response["media_id"])
logger.info("[wechatcom] sendImage, receiver={}".format(receiver))
class Query:
def GET(self):
channel = WechatComAppChannel()
params = web.input()
logger.info("[wechatcom] receive params: {}".format(params))
try:
signature = params.msg_signature
timestamp = params.timestamp
nonce = params.nonce
echostr = params.echostr
echostr = channel.crypto.check_signature(signature, timestamp, nonce, echostr)
except InvalidSignatureException:
raise web.Forbidden()
return echostr
def POST(self):
channel = WechatComAppChannel()
params = web.input()
logger.info("[wechatcom] receive params: {}".format(params))
try:
signature = params.msg_signature
timestamp = params.timestamp
nonce = params.nonce
message = channel.crypto.decrypt_message(web.data(), signature, timestamp, nonce)
except (InvalidSignatureException, InvalidCorpIdException):
raise web.Forbidden()
msg = parse_message(message)
logger.debug("[wechatcom] receive message: {}, msg= {}".format(message, msg))
if msg.type == "event":
if msg.event == "subscribe":
pass
# reply_content = subscribe_msg()
# if reply_content:
# reply = create_reply(reply_content, msg).render()
# res = channel.crypto.encrypt_message(reply, nonce, timestamp)
# return res
else:
try:
wechatcom_msg = WechatComAppMessage(msg, client=channel.client)
except NotImplementedError as e:
logger.debug("[wechatcom] " + str(e))
return "success"
context = channel._compose_context(
wechatcom_msg.ctype,
wechatcom_msg.content,
isgroup=False,
msg=wechatcom_msg,
)
if context:
channel.produce(context)
return "success"
================================================
FILE: channel/wechatcom/wechatcomapp_client.py
================================================
# wechatcomapp_client.py
import threading
import time
from wechatpy.enterprise import WeChatClient
class WechatComAppClient(WeChatClient):
def __init__(self, corp_id, secret, access_token=None, session=None, timeout=None, auto_retry=True):
super(WechatComAppClient, self).__init__(corp_id, secret, access_token, session, timeout, auto_retry)
self.fetch_access_token_lock = threading.Lock()
self._active_refresh()
def _active_refresh(self):
"""启动主动刷新的后台线程"""
def refresh_loop():
while True:
now = time.time()
expires_at = self.session.get(f"{self.corp_id}_expires_at", 0)
# 提前10分钟刷新(600秒)
if expires_at - now < 600:
with self.fetch_access_token_lock:
# 双重检查避免重复刷新
if self.session.get(f"{self.corp_id}_expires_at", 0) - time.time() < 600:
super(WechatComAppClient, self).fetch_access_token()
# 每次检查间隔60秒
time.sleep(60)
# 启动守护线程
refresh_thread = threading.Thread(
target=refresh_loop,
daemon=True,
name="wechatcom_token_refresh_thread"
)
refresh_thread.start()
def fetch_access_token(self):
with self.fetch_access_token_lock:
access_token = self.session.get(self.access_token_key)
expires_at = self.session.get(f"{self.corp_id}_expires_at", 0)
if access_token and expires_at > time.time() + 60:
return access_token
return super().fetch_access_token()
================================================
FILE: channel/wechatcom/wechatcomapp_message.py
================================================
from wechatpy.enterprise import WeChatClient
from bridge.context import ContextType
from channel.chat_message import ChatMessage
from common.log import logger
from common.tmp_dir import TmpDir
class WechatComAppMessage(ChatMessage):
def __init__(self, msg, client: WeChatClient, is_group=False):
super().__init__(msg)
self.msg_id = msg.id
self.create_time = msg.time
self.is_group = is_group
if msg.type == "text":
self.ctype = ContextType.TEXT
self.content = msg.content
elif msg.type == "voice":
self.ctype = ContextType.VOICE
self.content = TmpDir().path() + msg.media_id + "." + msg.format # content直接存临时目录路径
def download_voice():
# 如果响应状态码是200,则将响应内容写入本地文件
response = client.media.download(msg.media_id)
if response.status_code == 200:
with open(self.content, "wb") as f:
f.write(response.content)
else:
logger.info(f"[wechatcom] Failed to download voice file, {response.content}")
self._prepare_fn = download_voice
elif msg.type == "image":
self.ctype = ContextType.IMAGE
self.content = TmpDir().path() + msg.media_id + ".png" # content直接存临时目录路径
def download_image():
# 如果响应状态码是200,则将响应内容写入本地文件
response = client.media.download(msg.media_id)
if response.status_code == 200:
with open(self.content, "wb") as f:
f.write(response.content)
else:
logger.info(f"[wechatcom] Failed to download image file, {response.content}")
self._prepare_fn = download_image
else:
raise NotImplementedError("Unsupported message type: Type:{} ".format(msg.type))
self.from_user_id = msg.source
self.to_user_id = msg.target
self.other_user_id = msg.source
================================================
FILE: channel/wechatmp/README.md
================================================
# 微信公众号channel
微信公众号channel,提供稳定的服务。
目前支持订阅号和服务号两种类型的公众号,它们都支持文本交互,语音和图片输入。其中个人主体的微信订阅号由于无法通过微信认证,存在回复时间限制,每天的图片和声音回复次数也有限制。
## 使用方法(订阅号,服务号类似)
在开始部署前,你需要一个拥有公网IP的服务器,以提供微信服务器和我们自己服务器的连接。或者你需要进行内网穿透,否则微信服务器无法将消息发送给我们的服务器。
此外,需要在我们的服务器上安装python的web框架web.py和wechatpy。
以ubuntu为例(在ubuntu 22.04上测试):
```
pip3 install web.py
pip3 install wechatpy
```
然后在[微信公众平台](https://mp.weixin.qq.com)注册一个自己的公众号,类型选择订阅号,主体为个人即可。
然后根据[接入指南](https://developers.weixin.qq.com/doc/offiaccount/Basic_Information/Access_Overview.html)的说明,在[微信公众平台](https://mp.weixin.qq.com)的“设置与开发”-“基本配置”-“服务器配置”中填写服务器地址`URL`和令牌`Token`。`URL`填写格式为`http://url/wx`,可使用IP(成功几率看脸),`Token`是你自己编的一个特定的令牌。消息加解密方式如果选择了需要加密的模式,需要在配置中填写`wechatmp_aes_key`。
相关的服务器验证代码已经写好,你不需要再添加任何代码。你只需要在本项目根目录的`config.json`中添加
```
"channel_type": "wechatmp", # 如果通过了微信认证,将"wechatmp"替换为"wechatmp_service",可极大的优化使用体验
"wechatmp_token": "xxxx", # 微信公众平台的Token
"wechatmp_port": 8080, # 微信公众平台的端口,需要端口转发到80或443
"wechatmp_app_id": "xxxx", # 微信公众平台的appID
"wechatmp_app_secret": "xxxx", # 微信公众平台的appsecret
"wechatmp_aes_key": "", # 微信公众平台的EncodingAESKey,加密模式需要
"single_chat_prefix": [""], # 推荐设置,任意对话都可以触发回复,不添加前缀
"single_chat_reply_prefix": "", # 推荐设置,回复不设置前缀
"plugin_trigger_prefix": "&", # 推荐设置,在手机微信客户端中,$%^等符号与中文连在一起时会自动显示一段较大的间隔,用户体验不好。请不要使用管理员指令前缀"#",这会造成未知问题。
```
然后运行`python3 app.py`启动web服务器。这里会默认监听8080端口,但是微信公众号的服务器配置只支持80/443端口,有两种方法来解决这个问题。第一个是推荐的方法,使用端口转发命令将80端口转发到8080端口:
```
sudo iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 8080
sudo iptables-save > /etc/iptables/rules.v4
```
第二个方法是让python程序直接监听80端口,在配置文件中设置`"wechatmp_port": 80` ,在linux上需要使用`sudo python3 app.py`启动程序。然而这会导致一系列环境和权限问题,因此不是推荐的方法。
443端口同理,注意需要支持SSL,也就是https的访问,在`wechatmp_channel.py`中需要修改相应的证书路径。
程序启动并监听端口后,在刚才的“服务器配置”中点击`提交`即可验证你的服务器。
随后在[微信公众平台](https://mp.weixin.qq.com)启用服务器,关闭手动填写规则的自动回复,即可实现ChatGPT的自动回复。
之后需要在公众号开发信息下将本机IP加入到IP白名单。
不然在启用后,发送语音、图片等消息可能会遇到如下报错:
```
'errcode': 40164, 'errmsg': 'invalid ip xx.xx.xx.xx not in whitelist rid
```
## 个人微信公众号的限制
由于人微信公众号不能通过微信认证,所以没有客服接口,因此公众号无法主动发出消息,只能被动回复。而微信官方对被动回复有5秒的时间限制,最多重试2次,因此最多只有15秒的自动回复时间窗口。因此如果问题比较复杂或者我们的服务器比较忙,ChatGPT的回答就没办法及时回复给用户。为了解决这个问题,这里做了回答缓存,它需要你在回复超时后,再次主动发送任意文字(例如1)来尝试拿到回答缓存。为了优化使用体验,目前设置了两分钟(120秒)的timeout,用户在至多两分钟后即可得到查询到回复或者错误原因。
另外,由于微信官方的限制,自动回复有长度限制。因此这里将ChatGPT的回答进行了拆分,以满足限制。
## 私有api_key
公共api有访问频率限制(免费账号每分钟最多3次ChatGPT的API调用),这在服务多人的时候会遇到问题。因此这里多加了一个设置私有api_key的功能。目前通过godcmd插件的命令来设置私有api_key。
## 语音输入
利用微信自带的语音识别功能,提供语音输入能力。需要在公众号管理页面的“设置与开发”->“接口权限”页面开启“接收语音识别结果”。
## 语音回复
请在配置文件中添加以下词条:
```
"voice_reply_voice": true,
```
这样公众号将会用语音回复语音消息,实现语音对话。
默认的语音合成引擎是`google`,它是免费使用的。
如果要选择其他的语音合成引擎,请添加以下配置项:
```
"text_to_voice": "pytts"
```
pytts是本地的语音合成引擎。还支持baidu,azure,这些你需要自行配置相关的依赖和key。
如果使用pytts,在ubuntu上需要安装如下依赖:
```
sudo apt update
sudo apt install espeak
sudo apt install ffmpeg
python3 -m pip install pyttsx3
```
不是很建议开启pytts语音回复,因为它是离线本地计算,算的慢会拖垮服务器,且声音不好听。
## 图片回复
现在认证公众号和非认证公众号都可以实现的图片和语音回复。但是非认证公众号使用了永久素材接口,每天有1000次的调用上限(每个月有10次重置机会,程序中已设定遇到上限会自动重置),且永久素材库存也有上限。因此对于非认证公众号,我们会在回复图片或者语音消息后的10秒内从永久素材库存内删除该素材。
## 测试
目前在`RoboStyle`这个公众号上进行了测试(基于[wechatmp分支](https://github.com/JS00000/chatgpt-on-wechat/tree/wechatmp)),感兴趣的可以关注并体验。开启了godcmd, Banwords, role, dungeon, finish这五个插件,其他的插件还没有详尽测试。百度的接口暂未测试。[wechatmp-stable分支](https://github.com/JS00000/chatgpt-on-wechat/tree/wechatmp-stable)是较稳定的上个版本,但也缺少最新的功能支持。
## TODO
- [x] 语音输入
- [x] 图片输入
- [x] 使用临时素材接口提供认证公众号的图片和语音回复
- [x] 使用永久素材接口提供未认证公众号的图片和语音回复
- [ ] 高并发支持
================================================
FILE: channel/wechatmp/active_reply.py
================================================
import time
import web
from wechatpy import parse_message
from wechatpy.replies import create_reply
from bridge.context import *
from bridge.reply import *
from channel.wechatmp.common import *
from channel.wechatmp.wechatmp_channel import WechatMPChannel
from channel.wechatmp.wechatmp_message import WeChatMPMessage
from common.log import logger
from config import conf, subscribe_msg
# This class is instantiated once per query
class Query:
def GET(self):
return verify_server(web.input())
def POST(self):
# Make sure to return the instance that first created, @singleton will do that.
try:
args = web.input()
verify_server(args)
channel = WechatMPChannel()
message = web.data()
encrypt_func = lambda x: x
if args.get("encrypt_type") == "aes":
logger.debug("[wechatmp] Receive encrypted post data:\n" + message.decode("utf-8"))
if not channel.crypto:
raise Exception("Crypto not initialized, Please set wechatmp_aes_key in config.json")
message = channel.crypto.decrypt_message(message, args.msg_signature, args.timestamp, args.nonce)
encrypt_func = lambda x: channel.crypto.encrypt_message(x, args.nonce, args.timestamp)
else:
logger.debug("[wechatmp] Receive post data:\n" + message.decode("utf-8"))
msg = parse_message(message)
if msg.type in ["text", "voice", "image"]:
wechatmp_msg = WeChatMPMessage(msg, client=channel.client)
from_user = wechatmp_msg.from_user_id
content = wechatmp_msg.content
message_id = wechatmp_msg.msg_id
logger.info(
"[wechatmp] {}:{} Receive post query {} {}: {}".format(
web.ctx.env.get("REMOTE_ADDR"),
web.ctx.env.get("REMOTE_PORT"),
from_user,
message_id,
content,
)
)
if msg.type == "voice" and wechatmp_msg.ctype == ContextType.TEXT and conf().get("voice_reply_voice", False):
context = channel._compose_context(wechatmp_msg.ctype, content, isgroup=False, desire_rtype=ReplyType.VOICE, msg=wechatmp_msg)
else:
context = channel._compose_context(wechatmp_msg.ctype, content, isgroup=False, msg=wechatmp_msg)
if context:
channel.produce(context)
# The reply will be sent by channel.send() in another thread
return "success"
elif msg.type == "event":
logger.info("[wechatmp] Event {} from {}".format(msg.event, msg.source))
if msg.event in ["subscribe", "subscribe_scan"]:
reply_text = subscribe_msg()
if reply_text:
replyPost = create_reply(reply_text, msg)
return encrypt_func(replyPost.render())
else:
return "success"
else:
logger.info("暂且不处理")
return "success"
except Exception as exc:
logger.exception(exc)
return exc
================================================
FILE: channel/wechatmp/common.py
================================================
import web
from wechatpy.crypto import WeChatCrypto
from wechatpy.exceptions import InvalidSignatureException
from wechatpy.utils import check_signature
from config import conf
MAX_UTF8_LEN = 2048
class WeChatAPIException(Exception):
pass
def verify_server(data):
try:
signature = data.signature
timestamp = data.timestamp
nonce = data.nonce
echostr = data.get("echostr", None)
token = conf().get("wechatmp_token") # 请按照公众平台官网\基本配置中信息填写
check_signature(token, signature, timestamp, nonce)
return echostr
except InvalidSignatureException:
raise web.Forbidden("Invalid signature")
except Exception as e:
raise web.Forbidden(str(e))
================================================
FILE: channel/wechatmp/passive_reply.py
================================================
import asyncio
import time
import web
from wechatpy import parse_message
from wechatpy.replies import ImageReply, VoiceReply, create_reply
import textwrap
from bridge.context import *
from bridge.reply import *
from channel.wechatmp.common import *
from channel.wechatmp.wechatmp_channel import WechatMPChannel
from channel.wechatmp.wechatmp_message import WeChatMPMessage
from common.log import logger
from common.utils import split_string_by_utf8_length
from config import conf, subscribe_msg
# This class is instantiated once per query
class Query:
def GET(self):
return verify_server(web.input())
def POST(self):
try:
args = web.input()
verify_server(args)
request_time = time.time()
channel = WechatMPChannel()
message = web.data()
encrypt_func = lambda x: x
if args.get("encrypt_type") == "aes":
logger.debug("[wechatmp] Receive encrypted post data:\n" + message.decode("utf-8"))
if not channel.crypto:
raise Exception("Crypto not initialized, Please set wechatmp_aes_key in config.json")
message = channel.crypto.decrypt_message(message, args.msg_signature, args.timestamp, args.nonce)
encrypt_func = lambda x: channel.crypto.encrypt_message(x, args.nonce, args.timestamp)
else:
logger.debug("[wechatmp] Receive post data:\n" + message.decode("utf-8"))
msg = parse_message(message)
if msg.type in ["text", "voice", "image"]:
wechatmp_msg = WeChatMPMessage(msg, client=channel.client)
from_user = wechatmp_msg.from_user_id
content = wechatmp_msg.content
message_id = wechatmp_msg.msg_id
supported = True
if "【收到不支持的消息类型,暂无法显示】" in content:
supported = False # not supported, used to refresh
# New request
if (
channel.cache_dict.get(from_user) is None
and from_user not in channel.running
or content.startswith("#")
and message_id not in channel.request_cnt # insert the godcmd
):
# The first query begin
if msg.type == "voice" and wechatmp_msg.ctype == ContextType.TEXT and conf().get("voice_reply_voice", False):
context = channel._compose_context(wechatmp_msg.ctype, content, isgroup=False, desire_rtype=ReplyType.VOICE, msg=wechatmp_msg)
else:
context = channel._compose_context(wechatmp_msg.ctype, content, isgroup=False, msg=wechatmp_msg)
logger.debug("[wechatmp] context: {} {} {}".format(context, wechatmp_msg, supported))
if supported and context:
channel.running.add(from_user)
channel.produce(context)
else:
trigger_prefix = conf().get("single_chat_prefix", [""])[0]
if trigger_prefix or not supported:
if trigger_prefix:
reply_text = textwrap.dedent(
f"""\
请输入'{trigger_prefix}'接你想说的话跟我说话。
例如:
{trigger_prefix}你好,很高兴见到你。"""
)
else:
reply_text = textwrap.dedent(
"""\
你好,很高兴见到你。
请跟我说话吧。"""
)
else:
logger.error(f"[wechatmp] unknown error")
reply_text = textwrap.dedent(
"""\
未知错误,请稍后再试"""
)
replyPost = create_reply(reply_text, msg)
return encrypt_func(replyPost.render())
# Wechat official server will request 3 times (5 seconds each), with the same message_id.
# Because the interval is 5 seconds, here assumed that do not have multithreading problems.
request_cnt = channel.request_cnt.get(message_id, 0) + 1
channel.request_cnt[message_id] = request_cnt
logger.info(
"[wechatmp] Request {} from {} {} {}:{}\n{}".format(
request_cnt, from_user, message_id, web.ctx.env.get("REMOTE_ADDR"), web.ctx.env.get("REMOTE_PORT"), content
)
)
task_running = True
waiting_until = request_time + 4
while time.time() < waiting_until:
if from_user in channel.running:
time.sleep(0.1)
else:
task_running = False
break
reply_text = ""
if task_running:
if request_cnt < 3:
# waiting for timeout (the POST request will be closed by Wechat official server)
time.sleep(2)
# and do nothing, waiting for the next request
return "success"
else: # request_cnt == 3:
# return timeout message
reply_text = "【正在思考中,回复任意文字尝试获取回复】"
replyPost = create_reply(reply_text, msg)
return encrypt_func(replyPost.render())
# reply is ready
channel.request_cnt.pop(message_id)
# no return because of bandwords or other reasons
if from_user not in channel.cache_dict and from_user not in channel.running:
return "success"
# Only one request can access to the cached data
try:
(reply_type, reply_content) = channel.cache_dict[from_user].pop(0)
if not channel.cache_dict[from_user]: # If popping the message makes the list empty, delete the user entry from cache
del channel.cache_dict[from_user]
except IndexError:
return "success"
if reply_type == "text":
if len(reply_content.encode("utf8")) <= MAX_UTF8_LEN:
reply_text = reply_content
else:
continue_text = "\n【未完待续,回复任意文字以继续】"
splits = split_string_by_utf8_length(
reply_content,
MAX_UTF8_LEN - len(continue_text.encode("utf-8")),
max_split=1,
)
reply_text = splits[0] + continue_text
channel.cache_dict[from_user].append(("text", splits[1]))
logger.info(
"[wechatmp] Request {} do send to {} {}: {}\n{}".format(
request_cnt,
from_user,
message_id,
content,
reply_text,
)
)
replyPost = create_reply(reply_text, msg)
return encrypt_func(replyPost.render())
elif reply_type == "voice":
media_id = reply_content
asyncio.run_coroutine_threadsafe(channel.delete_media(media_id), channel.delete_media_loop)
logger.info(
"[wechatmp] Request {} do send to {} {}: {} voice media_id {}".format(
request_cnt,
from_user,
message_id,
content,
media_id,
)
)
replyPost = VoiceReply(message=msg)
replyPost.media_id = media_id
return encrypt_func(replyPost.render())
elif reply_type == "image":
media_id = reply_content
asyncio.run_coroutine_threadsafe(channel.delete_media(media_id), channel.delete_media_loop)
logger.info(
"[wechatmp] Request {} do send to {} {}: {} image media_id {}".format(
request_cnt,
from_user,
message_id,
content,
media_id,
)
)
replyPost = ImageReply(message=msg)
replyPost.media_id = media_id
return encrypt_func(replyPost.render())
elif msg.type == "event":
logger.info("[wechatmp] Event {} from {}".format(msg.event, msg.source))
if msg.event in ["subscribe", "subscribe_scan"]:
reply_text = subscribe_msg()
if reply_text:
replyPost = create_reply(reply_text, msg)
return encrypt_func(replyPost.render())
else:
return "success"
else:
logger.info("暂且不处理")
return "success"
except Exception as exc:
logger.exception(exc)
return exc
================================================
FILE: channel/wechatmp/wechatmp_channel.py
================================================
# -*- coding: utf-8 -*-
import asyncio
import imghdr
import io
import os
import threading
import time
import requests
import web
from wechatpy.crypto import WeChatCrypto
from wechatpy.exceptions import WeChatClientException
from collections import defaultdict
from bridge.context import *
from bridge.reply import *
from channel.chat_channel import ChatChannel
from channel.wechatmp.common import *
from channel.wechatmp.wechatmp_client import WechatMPClient
from common.log import logger
from common.singleton import singleton
from common.utils import split_string_by_utf8_length, remove_markdown_symbol
from config import conf
try:
from voice.audio_convert import any_to_mp3, split_audio
except ImportError as e:
logger.debug("import voice.audio_convert failed, voice features will not be supported: {}".format(e))
# If using SSL, uncomment the following lines, and modify the certificate path.
# from cheroot.server import HTTPServer
# from cheroot.ssl.builtin import BuiltinSSLAdapter
# HTTPServer.ssl_adapter = BuiltinSSLAdapter(
# certificate='/ssl/cert.pem',
# private_key='/ssl/cert.key')
@singleton
class WechatMPChannel(ChatChannel):
def __init__(self, passive_reply=True):
super().__init__()
self.passive_reply = passive_reply
self.NOT_SUPPORT_REPLYTYPE = []
self._http_server = None
appid = conf().get("wechatmp_app_id")
secret = conf().get("wechatmp_app_secret")
token = conf().get("wechatmp_token")
aes_key = conf().get("wechatmp_aes_key")
self.client = WechatMPClient(appid, secret)
self.crypto = None
if aes_key:
self.crypto = WeChatCrypto(token, aes_key, appid)
if self.passive_reply:
# Cache the reply to the user's first message
self.cache_dict = defaultdict(list)
# Record whether the current message is being processed
self.running = set()
# Count the request from wechat official server by message_id
self.request_cnt = dict()
# The permanent media need to be deleted to avoid media number limit
self.delete_media_loop = asyncio.new_event_loop()
t = threading.Thread(target=self.start_loop, args=(self.delete_media_loop,))
t.setDaemon(True)
t.start()
def startup(self):
if self.passive_reply:
urls = ("/wx", "channel.wechatmp.passive_reply.Query")
else:
urls = ("/wx", "channel.wechatmp.active_reply.Query")
app = web.application(urls, globals(), autoreload=False)
port = conf().get("wechatmp_port", 8080)
func = web.httpserver.StaticMiddleware(app.wsgifunc())
func = web.httpserver.LogMiddleware(func)
server = web.httpserver.WSGIServer(("0.0.0.0", port), func)
self._http_server = server
try:
server.start()
except (KeyboardInterrupt, SystemExit):
server.stop()
def stop(self):
if self._http_server:
try:
self._http_server.stop()
logger.info("[wechatmp] HTTP server stopped")
except Exception as e:
logger.warning(f"[wechatmp] Error stopping HTTP server: {e}")
self._http_server = None
def start_loop(self, loop):
asyncio.set_event_loop(loop)
loop.run_forever()
async def delete_media(self, media_id):
logger.debug("[wechatmp] permanent media {} will be deleted in 10s".format(media_id))
await asyncio.sleep(10)
self.client.material.delete(media_id)
logger.info("[wechatmp] permanent media {} has been deleted".format(media_id))
def send(self, reply: Reply, context: Context):
receiver = context["receiver"]
if self.passive_reply:
if reply.type == ReplyType.TEXT or reply.type == ReplyType.INFO or reply.type == ReplyType.ERROR:
reply_text = remove_markdown_symbol(reply.content)
logger.info("[wechatmp] text cached, receiver {}\n{}".format(receiver, reply_text))
self.cache_dict[receiver].append(("text", reply_text))
elif reply.type == ReplyType.VOICE:
try:
voice_file_path = reply.content
duration, files = split_audio(voice_file_path, 60 * 1000)
if len(files) > 1:
logger.info("[wechatmp] voice too long {}s > 60s , split into {} parts".format(duration / 1000.0, len(files)))
for path in files:
# support: <2M, <60s, mp3/wma/wav/amr
try:
with open(path, "rb") as f:
response = self.client.material.add("voice", f)
logger.debug("[wechatmp] upload voice response: {}".format(response))
f_size = os.fstat(f.fileno()).st_size
time.sleep(1.0 + 2 * f_size / 1024 / 1024)
# todo check media_id
except WeChatClientException as e:
logger.error("[wechatmp] upload voice failed: {}".format(e))
return
media_id = response["media_id"]
logger.info("[wechatmp] voice uploaded, receiver {}, media_id {}".format(receiver, media_id))
self.cache_dict[receiver].append(("voice", media_id))
except ImportError as e:
logger.error("[wechatmp] voice conversion failed: {}".format(e))
logger.error("[wechatmp] please install pydub: pip install pydub")
return
elif reply.type == ReplyType.IMAGE_URL: # 从网络下载图片
img_url = reply.content
pic_res = requests.get(img_url, stream=True)
image_storage = io.BytesIO()
for block in pic_res.iter_content(1024):
image_storage.write(block)
image_storage.seek(0)
image_type = imghdr.what(image_storage)
filename = receiver + "-" + str(context["msg"].msg_id) + "." + image_type
content_type = "image/" + image_type
try:
response = self.client.material.add("image", (filename, image_storage, content_type))
logger.debug("[wechatmp] upload image response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload image failed: {}".format(e))
return
media_id = response["media_id"]
logger.info("[wechatmp] image uploaded, receiver {}, media_id {}".format(receiver, media_id))
self.cache_dict[receiver].append(("image", media_id))
elif reply.type == ReplyType.IMAGE: # 从文件读取图片
image_storage = reply.content
image_storage.seek(0)
image_type = imghdr.what(image_storage)
filename = receiver + "-" + str(context["msg"].msg_id) + "." + image_type
content_type = "image/" + image_type
try:
response = self.client.material.add("image", (filename, image_storage, content_type))
logger.debug("[wechatmp] upload image response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload image failed: {}".format(e))
return
media_id = response["media_id"]
logger.info("[wechatmp] image uploaded, receiver {}, media_id {}".format(receiver, media_id))
self.cache_dict[receiver].append(("image", media_id))
elif reply.type == ReplyType.VIDEO_URL: # 从网络下载视频
video_url = reply.content
video_res = requests.get(video_url, stream=True)
video_storage = io.BytesIO()
for block in video_res.iter_content(1024):
video_storage.write(block)
video_storage.seek(0)
video_type = 'mp4'
filename = receiver + "-" + str(context["msg"].msg_id) + "." + video_type
content_type = "video/" + video_type
try:
response = self.client.material.add("video", (filename, video_storage, content_type))
logger.debug("[wechatmp] upload video response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload video failed: {}".format(e))
return
media_id = response["media_id"]
logger.info("[wechatmp] video uploaded, receiver {}, media_id {}".format(receiver, media_id))
self.cache_dict[receiver].append(("video", media_id))
elif reply.type == ReplyType.VIDEO: # 从文件读取视频
video_storage = reply.content
video_storage.seek(0)
video_type = 'mp4'
filename = receiver + "-" + str(context["msg"].msg_id) + "." + video_type
content_type = "video/" + video_type
try:
response = self.client.material.add("video", (filename, video_storage, content_type))
logger.debug("[wechatmp] upload video response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload video failed: {}".format(e))
return
media_id = response["media_id"]
logger.info("[wechatmp] video uploaded, receiver {}, media_id {}".format(receiver, media_id))
self.cache_dict[receiver].append(("video", media_id))
else:
if reply.type == ReplyType.TEXT or reply.type == ReplyType.INFO or reply.type == ReplyType.ERROR:
reply_text = reply.content
texts = split_string_by_utf8_length(reply_text, MAX_UTF8_LEN)
if len(texts) > 1:
logger.info("[wechatmp] text too long, split into {} parts".format(len(texts)))
for i, text in enumerate(texts):
self.client.message.send_text(receiver, text)
if i != len(texts) - 1:
time.sleep(0.5) # 休眠0.5秒,防止发送过快乱序
logger.info("[wechatmp] Do send text to {}: {}".format(receiver, reply_text))
elif reply.type == ReplyType.VOICE:
try:
file_path = reply.content
file_name = os.path.basename(file_path)
file_type = os.path.splitext(file_name)[1]
if file_type == ".mp3":
file_type = "audio/mpeg"
elif file_type == ".amr":
file_type = "audio/amr"
else:
mp3_file = os.path.splitext(file_path)[0] + ".mp3"
any_to_mp3(file_path, mp3_file)
file_path = mp3_file
file_name = os.path.basename(file_path)
file_type = "audio/mpeg"
logger.info("[wechatmp] file_name: {}, file_type: {} ".format(file_name, file_type))
media_ids = []
duration, files = split_audio(file_path, 60 * 1000)
if len(files) > 1:
logger.info("[wechatmp] voice too long {}s > 60s , split into {} parts".format(duration / 1000.0, len(files)))
for path in files:
# support: <2M, <60s, AMR\MP3
response = self.client.media.upload("voice", (os.path.basename(path), open(path, "rb"), file_type))
logger.debug("[wechatcom] upload voice response: {}".format(response))
media_ids.append(response["media_id"])
os.remove(path)
except ImportError as e:
logger.error("[wechatmp] voice conversion failed: {}".format(e))
logger.error("[wechatmp] please install pydub: pip install pydub")
return
except WeChatClientException as e:
logger.error("[wechatmp] upload voice failed: {}".format(e))
return
try:
os.remove(file_path)
except Exception:
pass
for media_id in media_ids:
self.client.message.send_voice(receiver, media_id)
time.sleep(1)
logger.info("[wechatmp] Do send voice to {}".format(receiver))
elif reply.type == ReplyType.IMAGE_URL: # 从网络下载图片
img_url = reply.content
pic_res = requests.get(img_url, stream=True)
image_storage = io.BytesIO()
for block in pic_res.iter_content(1024):
image_storage.write(block)
image_storage.seek(0)
image_type = imghdr.what(image_storage)
filename = receiver + "-" + str(context["msg"].msg_id) + "." + image_type
content_type = "image/" + image_type
try:
response = self.client.media.upload("image", (filename, image_storage, content_type))
logger.debug("[wechatmp] upload image response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload image failed: {}".format(e))
return
self.client.message.send_image(receiver, response["media_id"])
logger.info("[wechatmp] Do send image to {}".format(receiver))
elif reply.type == ReplyType.IMAGE: # 从文件读取图片
image_storage = reply.content
image_storage.seek(0)
image_type = imghdr.what(image_storage)
filename = receiver + "-" + str(context["msg"].msg_id) + "." + image_type
content_type = "image/" + image_type
try:
response = self.client.media.upload("image", (filename, image_storage, content_type))
logger.debug("[wechatmp] upload image response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload image failed: {}".format(e))
return
self.client.message.send_image(receiver, response["media_id"])
logger.info("[wechatmp] Do send image to {}".format(receiver))
elif reply.type == ReplyType.VIDEO_URL: # 从网络下载视频
video_url = reply.content
video_res = requests.get(video_url, stream=True)
video_storage = io.BytesIO()
for block in video_res.iter_content(1024):
video_storage.write(block)
video_storage.seek(0)
video_type = 'mp4'
filename = receiver + "-" + str(context["msg"].msg_id) + "." + video_type
content_type = "video/" + video_type
try:
response = self.client.media.upload("video", (filename, video_storage, content_type))
logger.debug("[wechatmp] upload video response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload video failed: {}".format(e))
return
self.client.message.send_video(receiver, response["media_id"])
logger.info("[wechatmp] Do send video to {}".format(receiver))
elif reply.type == ReplyType.VIDEO: # 从文件读取视频
video_storage = reply.content
video_storage.seek(0)
video_type = 'mp4'
filename = receiver + "-" + str(context["msg"].msg_id) + "." + video_type
content_type = "video/" + video_type
try:
response = self.client.media.upload("video", (filename, video_storage, content_type))
logger.debug("[wechatmp] upload video response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload video failed: {}".format(e))
return
self.client.message.send_video(receiver, response["media_id"])
logger.info("[wechatmp] Do send video to {}".format(receiver))
return
def _success_callback(self, session_id, context, **kwargs): # 线程异常结束时的回调函数
logger.debug("[wechatmp] Success to generate reply, msgId={}".format(context["msg"].msg_id))
if self.passive_reply:
self.running.remove(session_id)
def _fail_callback(self, session_id, exception, context, **kwargs): # 线程异常结束时的回调函数
logger.exception("[wechatmp] Fail to generate reply to user, msgId={}, exception={}".format(context["msg"].msg_id, exception))
if self.passive_reply:
assert session_id not in self.cache_dict
self.running.remove(session_id)
================================================
FILE: channel/wechatmp/wechatmp_client.py
================================================
import threading
import time
from wechatpy.client import WeChatClient
from wechatpy.exceptions import APILimitedException
from channel.wechatmp.common import *
from common.log import logger
class WechatMPClient(WeChatClient):
def __init__(self, appid, secret, access_token=None, session=None, timeout=None, auto_retry=True):
super(WechatMPClient, self).__init__(appid, secret, access_token, session, timeout, auto_retry)
self.fetch_access_token_lock = threading.Lock()
self.clear_quota_lock = threading.Lock()
self.last_clear_quota_time = -1
def clear_quota(self):
return self.post("clear_quota", data={"appid": self.appid})
def clear_quota_v2(self):
return self.post("clear_quota/v2", params={"appid": self.appid, "appsecret": self.secret})
def fetch_access_token(self): # 重载父类方法,加锁避免多线程重复获取access_token
with self.fetch_access_token_lock:
access_token = self.session.get(self.access_token_key)
if access_token:
if not self.expires_at:
return access_token
timestamp = time.time()
if self.expires_at - timestamp > 60:
return access_token
return super().fetch_access_token()
def _request(self, method, url_or_endpoint, **kwargs): # 重载父类方法,遇到API限流时,清除quota后重试
try:
return super()._request(method, url_or_endpoint, **kwargs)
except APILimitedException as e:
logger.error("[wechatmp] API quata has been used up. {}".format(e))
if self.last_clear_quota_time == -1 or time.time() - self.last_clear_quota_time > 60:
with self.clear_quota_lock:
if self.last_clear_quota_time == -1 or time.time() - self.last_clear_quota_time > 60:
self.last_clear_quota_time = time.time()
response = self.clear_quota_v2()
logger.debug("[wechatmp] API quata has been cleard, {}".format(response))
return super()._request(method, url_or_endpoint, **kwargs)
else:
logger.error("[wechatmp] last clear quota time is {}, less than 60s, skip clear quota")
raise e
================================================
FILE: channel/wechatmp/wechatmp_message.py
================================================
# -*- coding: utf-8 -*-#
from bridge.context import ContextType
from channel.chat_message import ChatMessage
from common.log import logger
from common.tmp_dir import TmpDir
class WeChatMPMessage(ChatMessage):
def __init__(self, msg, client=None):
super().__init__(msg)
self.msg_id = msg.id
self.create_time = msg.time
self.is_group = False
if msg.type == "text":
self.ctype = ContextType.TEXT
self.content = msg.content
elif msg.type == "voice":
if msg.recognition == None:
self.ctype = ContextType.VOICE
self.content = TmpDir().path() + msg.media_id + "." + msg.format # content直接存临时目录路径
def download_voice():
# 如果响应状态码是200,则将响应内容写入本地文件
response = client.media.download(msg.media_id)
if response.status_code == 200:
with open(self.content, "wb") as f:
f.write(response.content)
else:
logger.info(f"[wechatmp] Failed to download voice file, {response.content}")
self._prepare_fn = download_voice
else:
self.ctype = ContextType.TEXT
self.content = msg.recognition
elif msg.type == "image":
self.ctype = ContextType.IMAGE
self.content = TmpDir().path() + msg.media_id + ".png" # content直接存临时目录路径
def download_image():
# 如果响应状态码是200,则将响应内容写入本地文件
response = client.media.download(msg.media_id)
if response.status_code == 200:
with open(self.content, "wb") as f:
f.write(response.content)
else:
logger.info(f"[wechatmp] Failed to download image file, {response.content}")
self._prepare_fn = download_image
else:
raise NotImplementedError("Unsupported message type: Type:{} ".format(msg.type))
self.from_user_id = msg.source
self.to_user_id = msg.target
self.other_user_id = msg.source
================================================
FILE: channel/wecom_bot/__init__.py
================================================
================================================
FILE: channel/wecom_bot/wecom_bot_channel.py
================================================
"""
WeCom (企业微信) AI Bot channel via WebSocket long connection.
Supports:
- Single chat and group chat (text / image / file input & output)
- Scheduled task push via aibot_send_msg
- Heartbeat keep-alive and auto-reconnect
"""
import base64
import hashlib
import json
import math
import os
import threading
import time
import uuid
import requests
import websocket
from bridge.context import Context, ContextType
from bridge.reply import Reply, ReplyType
from channel.chat_channel import ChatChannel, check_prefix
from channel.wecom_bot.wecom_bot_message import WecomBotMessage
from common.expired_dict import ExpiredDict
from common.log import logger
from common.singleton import singleton
from config import conf
WECOM_WS_URL = "wss://openws.work.weixin.qq.com"
HEARTBEAT_INTERVAL = 30
MEDIA_CHUNK_SIZE = 512 * 1024 # 512KB per chunk (before base64 encoding)
@singleton
class WecomBotChannel(ChatChannel):
def __init__(self):
super().__init__()
self.bot_id = ""
self.bot_secret = ""
self.received_msgs = ExpiredDict(60 * 60 * 7.1)
self._ws = None
self._ws_thread = None
self._heartbeat_thread = None
self._connected = False
self._stop_event = threading.Event()
self._pending_responses = {} # req_id -> (threading.Event, result_holder)
self._pending_lock = threading.Lock()
self._stream_states = {} # req_id -> {"stream_id": str, "content": str}
conf()["group_name_white_list"] = ["ALL_GROUP"]
conf()["single_chat_prefix"] = [""]
# ------------------------------------------------------------------
# Lifecycle
# ------------------------------------------------------------------
def startup(self):
self.bot_id = conf().get("wecom_bot_id", "")
self.bot_secret = conf().get("wecom_bot_secret", "")
if not self.bot_id or not self.bot_secret:
err = "[WecomBot] wecom_bot_id and wecom_bot_secret are required"
logger.error(err)
self.report_startup_error(err)
return
self._stop_event.clear()
self._start_ws()
def stop(self):
logger.info("[WecomBot] stop() called")
self._stop_event.set()
if self._ws:
try:
self._ws.close()
except Exception:
pass
self._ws = None
self._connected = False
# ------------------------------------------------------------------
# WebSocket connection
# ------------------------------------------------------------------
def _start_ws(self):
def _on_open(ws):
logger.info("[WecomBot] WebSocket connected, sending subscribe...")
self._send_subscribe()
def _on_message(ws, raw):
try:
data = json.loads(raw)
self._handle_ws_message(data)
except Exception as e:
logger.error(f"[WecomBot] Failed to handle ws message: {e}", exc_info=True)
def _on_error(ws, error):
logger.error(f"[WecomBot] WebSocket error: {error}")
def _on_close(ws, close_status_code, close_msg):
logger.warning(f"[WecomBot] WebSocket closed: status={close_status_code}, msg={close_msg}")
self._connected = False
if not self._stop_event.is_set():
logger.info("[WecomBot] Will reconnect in 5s...")
time.sleep(5)
if not self._stop_event.is_set():
self._start_ws()
self._ws = websocket.WebSocketApp(
WECOM_WS_URL,
on_open=_on_open,
on_message=_on_message,
on_error=_on_error,
on_close=_on_close,
)
def run_forever():
try:
self._ws.run_forever(ping_interval=0, reconnect=0)
except (SystemExit, KeyboardInterrupt):
logger.info("[WecomBot] WebSocket thread interrupted")
except Exception as e:
logger.error(f"[WecomBot] WebSocket run_forever error: {e}")
self._ws_thread = threading.Thread(target=run_forever, daemon=True)
self._ws_thread.start()
self._ws_thread.join()
def _ws_send(self, data: dict):
if self._ws:
self._ws.send(json.dumps(data, ensure_ascii=False))
def _gen_req_id(self) -> str:
return uuid.uuid4().hex[:16]
# ------------------------------------------------------------------
# Subscribe & heartbeat
# ------------------------------------------------------------------
def _send_subscribe(self):
self._ws_send({
"cmd": "aibot_subscribe",
"headers": {"req_id": self._gen_req_id()},
"body": {
"bot_id": self.bot_id,
"secret": self.bot_secret,
},
})
def _start_heartbeat(self):
if self._heartbeat_thread and self._heartbeat_thread.is_alive():
return
def heartbeat_loop():
while not self._stop_event.is_set() and self._connected:
try:
self._ws_send({
"cmd": "ping",
"headers": {"req_id": self._gen_req_id()},
})
except Exception as e:
logger.warning(f"[WecomBot] Heartbeat send failed: {e}")
break
self._stop_event.wait(HEARTBEAT_INTERVAL)
self._heartbeat_thread = threading.Thread(target=heartbeat_loop, daemon=True)
self._heartbeat_thread.start()
# ------------------------------------------------------------------
# Incoming message dispatch
# ------------------------------------------------------------------
def _send_and_wait(self, data: dict, timeout: float = 15) -> dict:
"""Send a ws message and wait for the matching response by req_id."""
req_id = data.get("headers", {}).get("req_id", "")
event = threading.Event()
holder = {"data": None}
with self._pending_lock:
self._pending_responses[req_id] = (event, holder)
self._ws_send(data)
event.wait(timeout=timeout)
with self._pending_lock:
self._pending_responses.pop(req_id, None)
return holder["data"] or {}
def _handle_ws_message(self, data: dict):
cmd = data.get("cmd", "")
errcode = data.get("errcode")
req_id = data.get("headers", {}).get("req_id", "")
# Check if this is a response to a pending request
if req_id:
with self._pending_lock:
pending = self._pending_responses.get(req_id)
if pending:
event, holder = pending
holder["data"] = data
event.set()
return
# Subscribe response (only handle once before connected)
if errcode is not None and cmd == "":
if not self._connected:
if errcode == 0:
logger.info("[WecomBot] ✅ Subscribe success")
self._connected = True
self._start_heartbeat()
self.report_startup_success()
else:
errmsg = data.get("errmsg", "unknown error")
logger.error(f"[WecomBot] Subscribe failed: errcode={errcode}, errmsg={errmsg}")
self.report_startup_error(errmsg)
return
if cmd == "aibot_msg_callback":
self._handle_msg_callback(data)
elif cmd == "aibot_event_callback":
self._handle_event_callback(data)
elif cmd == "":
if errcode and errcode != 0:
logger.warning(f"[WecomBot] Response error: {data}")
# ------------------------------------------------------------------
# Message callback
# ------------------------------------------------------------------
def _handle_msg_callback(self, data: dict):
body = data.get("body", {})
req_id = data.get("headers", {}).get("req_id", "")
msg_id = body.get("msgid", "")
if self.received_msgs.get(msg_id):
logger.debug(f"[WecomBot] Duplicate msg filtered: {msg_id}")
return
self.received_msgs[msg_id] = True
chattype = body.get("chattype", "single")
is_group = chattype == "group"
try:
wecom_msg = WecomBotMessage(body, is_group=is_group)
except NotImplementedError as e:
logger.warning(f"[WecomBot] {e}")
return
except Exception as e:
logger.error(f"[WecomBot] Failed to parse message: {e}", exc_info=True)
return
wecom_msg.req_id = req_id
# File cache logic (same pattern as feishu)
from channel.file_cache import get_file_cache
file_cache = get_file_cache()
if is_group:
if conf().get("group_shared_session", True):
session_id = body.get("chatid", "")
else:
session_id = wecom_msg.from_user_id + "_" + body.get("chatid", "")
else:
session_id = wecom_msg.from_user_id
if wecom_msg.ctype == ContextType.IMAGE:
if hasattr(wecom_msg, "image_path") and wecom_msg.image_path:
file_cache.add(session_id, wecom_msg.image_path, file_type="image")
logger.info(f"[WecomBot] Image cached for session {session_id}")
return
if wecom_msg.ctype == ContextType.FILE:
wecom_msg.prepare()
file_cache.add(session_id, wecom_msg.content, file_type="file")
logger.info(f"[WecomBot] File cached for session {session_id}: {wecom_msg.content}")
return
if wecom_msg.ctype == ContextType.TEXT:
cached_files = file_cache.get(session_id)
if cached_files:
file_refs = []
for fi in cached_files:
ftype = fi["type"]
fpath = fi["path"]
if ftype == "image":
file_refs.append(f"[图片: {fpath}]")
elif ftype == "video":
file_refs.append(f"[视频: {fpath}]")
else:
file_refs.append(f"[文件: {fpath}]")
wecom_msg.content = wecom_msg.content + "\n" + "\n".join(file_refs)
logger.info(f"[WecomBot] Attached {len(cached_files)} cached file(s)")
file_cache.clear(session_id)
context = self._compose_context(
wecom_msg.ctype,
wecom_msg.content,
isgroup=is_group,
msg=wecom_msg,
no_need_at=True,
)
if context:
if req_id:
context["on_event"] = self._make_stream_callback(req_id)
self.produce(context)
# ------------------------------------------------------------------
# Event callback
# ------------------------------------------------------------------
def _handle_event_callback(self, data: dict):
body = data.get("body", {})
event = body.get("event", {})
event_type = event.get("eventtype", "")
if event_type == "enter_chat":
logger.info(f"[WecomBot] User entered chat: {body.get('from', {}).get('userid')}")
elif event_type == "disconnected_event":
logger.warning("[WecomBot] Received disconnected_event, another connection took over")
else:
logger.debug(f"[WecomBot] Event: {event_type}")
# ------------------------------------------------------------------
# Stream callback (for agent on_event)
# ------------------------------------------------------------------
def _make_stream_callback(self, req_id: str):
"""Build an on_event callback that pushes agent stream deltas to wecom via stream message.
All intermediate segments (thinking before tool calls) and the final answer
are accumulated into a single stream message, separated by '---'.
"""
stream_id = uuid.uuid4().hex[:16]
self._stream_states[req_id] = {
"stream_id": stream_id,
"committed": "", # finalized content from previous segments
"current": "", # current segment being streamed
}
def _push_stream(state: dict):
"""Push current stream content to wecom."""
self._ws_send({
"cmd": "aibot_respond_msg",
"headers": {"req_id": req_id},
"body": {
"msgtype": "stream",
"stream": {
"id": state["stream_id"],
"finish": False,
"content": state["committed"] + state["current"],
},
},
})
def on_event(event: dict):
event_type = event.get("type")
data = event.get("data", {})
state = self._stream_states.get(req_id)
if not state:
return
if event_type == "turn_start":
state["current"] = ""
elif event_type == "message_update":
delta = data.get("delta", "")
if delta:
state["current"] += delta
_push_stream(state)
elif event_type == "message_end":
tool_calls = data.get("tool_calls", [])
if tool_calls:
if state["current"].strip():
state["committed"] += state["current"].strip() + "\n\n---\n\n"
state["current"] = ""
else:
state["committed"] += state["current"]
state["current"] = ""
return on_event
# ------------------------------------------------------------------
# _compose_context (same pattern as feishu)
# ------------------------------------------------------------------
def _compose_context(self, ctype: ContextType, content, **kwargs):
context = Context(ctype, content)
context.kwargs = kwargs
if "channel_type" not in context:
context["channel_type"] = self.channel_type
if "origin_ctype" not in context:
context["origin_ctype"] = ctype
cmsg = context["msg"]
if cmsg.is_group:
if conf().get("group_shared_session", True):
context["session_id"] = cmsg.other_user_id
else:
context["session_id"] = f"{cmsg.from_user_id}:{cmsg.other_user_id}"
else:
context["session_id"] = cmsg.from_user_id
context["receiver"] = cmsg.other_user_id
if ctype == ContextType.TEXT:
img_match_prefix = check_prefix(content, conf().get("image_create_prefix"))
if img_match_prefix:
content = content.replace(img_match_prefix, "", 1)
context.type = ContextType.IMAGE_CREATE
else:
context.type = ContextType.TEXT
context.content = content.strip()
return context
# ------------------------------------------------------------------
# Send reply
# ------------------------------------------------------------------
def send(self, reply: Reply, context: Context):
msg = context.get("msg")
is_group = context.get("isgroup", False)
receiver = context.get("receiver", "")
# Determine req_id for responding or use send_msg for scheduled push
req_id = getattr(msg, "req_id", None) if msg else None
if reply.type == ReplyType.TEXT:
self._send_text(reply.content, receiver, is_group, req_id)
elif reply.type in (ReplyType.IMAGE_URL, ReplyType.IMAGE):
self._send_image(reply.content, receiver, is_group, req_id)
elif reply.type == ReplyType.FILE:
if hasattr(reply, "text_content") and reply.text_content:
self._send_text(reply.text_content, receiver, is_group, req_id)
time.sleep(0.3)
self._send_file(reply.content, receiver, is_group, req_id)
elif reply.type == ReplyType.VIDEO or reply.type == ReplyType.VIDEO_URL:
self._send_file(reply.content, receiver, is_group, req_id, media_type="video")
else:
logger.warning(f"[WecomBot] Unsupported reply type: {reply.type}, falling back to text")
self._send_text(str(reply.content), receiver, is_group, req_id)
# ------------------------------------------------------------------
# Respond message (via websocket)
# ------------------------------------------------------------------
def _send_text(self, content: str, receiver: str, is_group: bool, req_id: str = None):
"""Send text/markdown reply. Reuses stream state if available (streaming mode)."""
if req_id:
state = self._stream_states.pop(req_id, None)
if state:
final_content = state["committed"]
stream_id = state["stream_id"]
else:
final_content = content
stream_id = uuid.uuid4().hex[:16]
self._ws_send({
"cmd": "aibot_respond_msg",
"headers": {"req_id": req_id},
"body": {
"msgtype": "stream",
"stream": {
"id": stream_id,
"finish": True,
"content": final_content,
},
},
})
else:
self._active_send_markdown(content, receiver, is_group)
def _send_image(self, img_path_or_url: str, receiver: str, is_group: bool, req_id: str = None):
"""Send image reply. Converts to JPG/PNG and compresses if >2MB."""
local_path = img_path_or_url
if local_path.startswith("file://"):
local_path = local_path[7:]
if local_path.startswith(("http://", "https://")):
try:
resp = requests.get(local_path, timeout=30)
resp.raise_for_status()
ct = resp.headers.get("Content-Type", "")
if "jpeg" in ct or "jpg" in ct:
ext = ".jpg"
elif "webp" in ct:
ext = ".webp"
elif "gif" in ct:
ext = ".gif"
else:
ext = ".png"
tmp_path = f"/tmp/wecom_img_{uuid.uuid4().hex[:8]}{ext}"
with open(tmp_path, "wb") as f:
f.write(resp.content)
logger.info(f"[WecomBot] Image downloaded: size={len(resp.content)}, "
f"content-type={ct}, path={tmp_path}")
local_path = tmp_path
except Exception as e:
logger.error(f"[WecomBot] Failed to download image for sending: {e}")
self._send_text("[Image send failed]", receiver, is_group, req_id)
return
if not os.path.exists(local_path):
logger.error(f"[WecomBot] Image file not found: {local_path}")
return
max_image_size = 2 * 1024 * 1024 # 2MB limit for image upload
local_path = self._ensure_image_format(local_path)
if not local_path:
self._send_text("[Image format conversion failed]", receiver, is_group, req_id)
return
if os.path.getsize(local_path) > max_image_size:
local_path = self._compress_image(local_path, max_image_size)
if not local_path:
self._send_text("[Image too large]", receiver, is_group, req_id)
return
file_size = os.path.getsize(local_path)
logger.info(f"[WecomBot] Uploading image: path={local_path}, size={file_size} bytes")
media_id = self._upload_media(local_path, "image")
if not media_id:
logger.error("[WecomBot] Failed to upload image")
self._send_text("[Image upload failed]", receiver, is_group, req_id)
return
if req_id:
self._ws_send({
"cmd": "aibot_respond_msg",
"headers": {"req_id": req_id},
"body": {
"msgtype": "image",
"image": {"media_id": media_id},
},
})
else:
self._ws_send({
"cmd": "aibot_send_msg",
"headers": {"req_id": self._gen_req_id()},
"body": {
"chatid": receiver,
"chat_type": 2 if is_group else 1,
"msgtype": "image",
"image": {"media_id": media_id},
},
})
@staticmethod
def _ensure_image_format(file_path: str) -> str:
"""Ensure image is JPG or PNG (the only formats wecom supports). Convert if needed."""
try:
from PIL import Image
img = Image.open(file_path)
fmt = (img.format or "").upper()
if fmt in ("JPEG", "PNG"):
# Already a supported format, but make sure the filename extension matches
ext = os.path.splitext(file_path)[1].lower()
if fmt == "JPEG" and ext in (".jpg", ".jpeg"):
return file_path
if fmt == "PNG" and ext == ".png":
return file_path
# Extension doesn't match — rename/copy with correct extension
correct_ext = ".jpg" if fmt == "JPEG" else ".png"
out_path = f"/tmp/wecom_fmt_{uuid.uuid4().hex[:8]}{correct_ext}"
img.save(out_path, fmt)
logger.info(f"[WecomBot] Image renamed: {file_path} -> {out_path} ({fmt})")
return out_path
# Unsupported format (WebP, GIF, BMP, etc.) — convert to PNG
if img.mode == "RGBA":
out_path = f"/tmp/wecom_fmt_{uuid.uuid4().hex[:8]}.png"
img.save(out_path, "PNG")
else:
out_path = f"/tmp/wecom_fmt_{uuid.uuid4().hex[:8]}.jpg"
img.convert("RGB").save(out_path, "JPEG", quality=90)
logger.info(f"[WecomBot] Image converted from {fmt} -> {out_path}")
return out_path
except Exception as e:
logger.error(f"[WecomBot] Image format check failed: {e}")
return file_path
@staticmethod
def _compress_image(file_path: str, max_bytes: int) -> str:
"""Compress image to fit within max_bytes. Returns new path or empty string."""
try:
from PIL import Image
img = Image.open(file_path)
if img.mode == "RGBA":
img = img.convert("RGB")
out_path = f"/tmp/wecom_compressed_{uuid.uuid4().hex[:8]}.jpg"
quality = 85
while quality >= 30:
img.save(out_path, "JPEG", quality=quality, optimize=True)
if os.path.getsize(out_path) <= max_bytes:
logger.info(f"[WecomBot] Image compressed: quality={quality}, "
f"size={os.path.getsize(out_path)} bytes")
return out_path
quality -= 10
# Still too large — resize
ratio = (max_bytes / os.path.getsize(out_path)) ** 0.5
new_size = (int(img.width * ratio), int(img.height * ratio))
img = img.resize(new_size, Image.LANCZOS)
img.save(out_path, "JPEG", quality=70, optimize=True)
if os.path.getsize(out_path) <= max_bytes:
logger.info(f"[WecomBot] Image compressed with resize: {new_size}, "
f"size={os.path.getsize(out_path)} bytes")
return out_path
logger.error(f"[WecomBot] Cannot compress image below {max_bytes} bytes")
return ""
except Exception as e:
logger.error(f"[WecomBot] Image compression failed: {e}")
return ""
def _send_file(self, file_path: str, receiver: str, is_group: bool,
req_id: str = None, media_type: str = "file"):
"""Send file/video reply by uploading media first."""
local_path = file_path
if local_path.startswith("file://"):
local_path = local_path[7:]
if local_path.startswith(("http://", "https://")):
try:
resp = requests.get(local_path, timeout=60)
resp.raise_for_status()
ext = os.path.splitext(local_path)[1] or ".bin"
tmp_path = f"/tmp/wecom_file_{uuid.uuid4().hex[:8]}{ext}"
with open(tmp_path, "wb") as f:
f.write(resp.content)
local_path = tmp_path
except Exception as e:
logger.error(f"[WecomBot] Failed to download file for sending: {e}")
return
if not os.path.exists(local_path):
logger.error(f"[WecomBot] File not found: {local_path}")
return
media_id = self._upload_media(local_path, media_type)
if not media_id:
logger.error(f"[WecomBot] Failed to upload {media_type}")
return
if req_id:
self._ws_send({
"cmd": "aibot_respond_msg",
"headers": {"req_id": req_id},
"body": {
"msgtype": media_type,
media_type: {"media_id": media_id},
},
})
else:
self._ws_send({
"cmd": "aibot_send_msg",
"headers": {"req_id": self._gen_req_id()},
"body": {
"chatid": receiver,
"chat_type": 2 if is_group else 1,
"msgtype": media_type,
media_type: {"media_id": media_id},
},
})
def _active_send_markdown(self, content: str, receiver: str, is_group: bool):
"""Proactively send markdown message (for scheduled tasks, no req_id)."""
self._ws_send({
"cmd": "aibot_send_msg",
"headers": {"req_id": self._gen_req_id()},
"body": {
"chatid": receiver,
"chat_type": 2 if is_group else 1,
"msgtype": "markdown",
"markdown": {"content": content},
},
})
# ------------------------------------------------------------------
# Media upload (chunked)
# ------------------------------------------------------------------
def _upload_media(self, file_path: str, media_type: str = "file") -> str:
"""
Upload a local file to wecom bot via chunked upload protocol.
Returns media_id on success, empty string on failure.
"""
if not os.path.exists(file_path):
logger.error(f"[WecomBot] Upload file not found: {file_path}")
return ""
file_size = os.path.getsize(file_path)
if file_size < 5:
logger.error(f"[WecomBot] File too small: {file_size} bytes")
return ""
filename = os.path.basename(file_path)
total_chunks = math.ceil(file_size / MEDIA_CHUNK_SIZE)
if total_chunks > 100:
logger.error(f"[WecomBot] Too many chunks: {total_chunks} > 100")
return ""
file_md5 = hashlib.md5()
with open(file_path, "rb") as f:
for block in iter(lambda: f.read(8192), b""):
file_md5.update(block)
md5_hex = file_md5.hexdigest()
# 1. Init upload
init_resp = self._send_and_wait({
"cmd": "aibot_upload_media_init",
"headers": {"req_id": self._gen_req_id()},
"body": {
"type": media_type,
"filename": filename,
"total_size": file_size,
"total_chunks": total_chunks,
"md5": md5_hex,
},
}, timeout=15)
if init_resp.get("errcode") != 0:
logger.error(f"[WecomBot] Upload init failed: {init_resp}")
return ""
upload_id = init_resp.get("body", {}).get("upload_id")
if not upload_id:
logger.error("[WecomBot] Failed to get upload_id")
return ""
# 2. Upload chunks
with open(file_path, "rb") as f:
for idx in range(total_chunks):
chunk = f.read(MEDIA_CHUNK_SIZE)
b64_data = base64.b64encode(chunk).decode("utf-8")
chunk_resp = self._send_and_wait({
"cmd": "aibot_upload_media_chunk",
"headers": {"req_id": self._gen_req_id()},
"body": {
"upload_id": upload_id,
"chunk_index": idx,
"base64_data": b64_data,
},
}, timeout=30)
if chunk_resp.get("errcode") != 0:
logger.error(f"[WecomBot] Chunk {idx} upload failed: {chunk_resp}")
return ""
# 3. Finish upload
finish_resp = self._send_and_wait({
"cmd": "aibot_upload_media_finish",
"headers": {"req_id": self._gen_req_id()},
"body": {"upload_id": upload_id},
}, timeout=30)
if finish_resp.get("errcode") != 0:
logger.error(f"[WecomBot] Upload finish failed: {finish_resp}")
return ""
media_id = finish_resp.get("body", {}).get("media_id", "")
if media_id:
logger.info(f"[WecomBot] Media uploaded: media_id={media_id}")
else:
logger.error("[WecomBot] Failed to get media_id from finish response")
return media_id
================================================
FILE: channel/wecom_bot/wecom_bot_message.py
================================================
import os
import re
import base64
import requests
from bridge.context import ContextType
from channel.chat_message import ChatMessage
from common.log import logger
from common.utils import expand_path
from config import conf
from Crypto.Cipher import AES
MAGIC_SIGNATURES = [
(b"%PDF", ".pdf"),
(b"\x89PNG\r\n\x1a\n", ".png"),
(b"\xff\xd8\xff", ".jpg"),
(b"GIF87a", ".gif"),
(b"GIF89a", ".gif"),
(b"RIFF", ".webp"), # RIFF....WEBP, further checked below
(b"PK\x03\x04", ".zip"), # zip / docx / xlsx / pptx
(b"\x1f\x8b", ".gz"),
(b"Rar!\x1a\x07", ".rar"),
(b"7z\xbc\xaf\x27\x1c", ".7z"),
(b"\x00\x00\x00", ".mp4"), # ftyp box, further checked below
(b"#!AMR", ".amr"),
]
OFFICE_ZIP_MARKERS = {
b"word/": ".docx",
b"xl/": ".xlsx",
b"ppt/": ".pptx",
}
def _guess_ext_from_bytes(data: bytes) -> str:
"""Guess file extension from file content magic bytes."""
if not data or len(data) < 8:
return ""
for sig, ext in MAGIC_SIGNATURES:
if data[:len(sig)] == sig:
if ext == ".webp" and data[8:12] != b"WEBP":
continue
if ext == ".mp4":
if b"ftyp" not in data[4:12]:
continue
if ext == ".zip":
for marker, office_ext in OFFICE_ZIP_MARKERS.items():
if marker in data[:2000]:
return office_ext
return ".zip"
return ext
return ""
def _decrypt_media(url: str, aeskey: str) -> bytes:
"""
Download and decrypt AES-256-CBC encrypted media from wecom bot.
Returns decrypted bytes.
"""
resp = requests.get(url, timeout=30)
resp.raise_for_status()
encrypted = resp.content
key = base64.b64decode(aeskey + "=" * (-len(aeskey) % 4))
if len(key) != 32:
raise ValueError(f"Invalid AES key length: {len(key)}, expected 32")
iv = key[:16]
cipher = AES.new(key, AES.MODE_CBC, iv)
decrypted = cipher.decrypt(encrypted)
pad_len = decrypted[-1]
if pad_len > 32:
raise ValueError(f"Invalid PKCS7 padding length: {pad_len}")
return decrypted[:-pad_len]
def _get_tmp_dir() -> str:
"""Return the workspace tmp directory (absolute path), creating it if needed."""
ws_root = expand_path(conf().get("agent_workspace", "~/cow"))
tmp_dir = os.path.join(ws_root, "tmp")
os.makedirs(tmp_dir, exist_ok=True)
return tmp_dir
class WecomBotMessage(ChatMessage):
"""Message wrapper for wecom bot (websocket long-connection mode)."""
def __init__(self, msg_body: dict, is_group: bool = False):
super().__init__(msg_body)
self.msg_id = msg_body.get("msgid")
self.create_time = msg_body.get("create_time")
self.is_group = is_group
msg_type = msg_body.get("msgtype")
from_userid = msg_body.get("from", {}).get("userid", "")
chat_id = msg_body.get("chatid", "")
bot_id = msg_body.get("aibotid", "")
if msg_type == "text":
self.ctype = ContextType.TEXT
content = msg_body.get("text", {}).get("content", "")
if is_group:
content = re.sub(r"@\S+\s*", "", content).strip()
self.content = content
elif msg_type == "voice":
self.ctype = ContextType.TEXT
self.content = msg_body.get("voice", {}).get("content", "")
elif msg_type == "image":
self.ctype = ContextType.IMAGE
image_info = msg_body.get("image", {})
image_url = image_info.get("url", "")
aeskey = image_info.get("aeskey", "")
tmp_dir = _get_tmp_dir()
image_path = os.path.join(tmp_dir, f"wecom_{self.msg_id}.png")
try:
data = _decrypt_media(image_url, aeskey)
with open(image_path, "wb") as f:
f.write(data)
self.content = image_path
self.image_path = image_path
logger.info(f"[WecomBot] Image downloaded: {image_path}")
except Exception as e:
logger.error(f"[WecomBot] Failed to download image: {e}")
self.content = "[Image download failed]"
self.image_path = None
elif msg_type == "mixed":
self.ctype = ContextType.TEXT
text_parts = []
image_paths = []
mixed_items = msg_body.get("mixed", {}).get("msg_item", [])
tmp_dir = _get_tmp_dir()
for idx, item in enumerate(mixed_items):
item_type = item.get("msgtype")
if item_type == "text":
txt = item.get("text", {}).get("content", "")
if is_group:
txt = re.sub(r"@\S+\s*", "", txt).strip()
if txt:
text_parts.append(txt)
elif item_type == "image":
img_info = item.get("image", {})
img_url = img_info.get("url", "")
img_aeskey = img_info.get("aeskey", "")
img_path = os.path.join(tmp_dir, f"wecom_{self.msg_id}_{idx}.png")
try:
img_data = _decrypt_media(img_url, img_aeskey)
with open(img_path, "wb") as f:
f.write(img_data)
image_paths.append(img_path)
except Exception as e:
logger.error(f"[WecomBot] Failed to download mixed image: {e}")
content_parts = text_parts[:]
for p in image_paths:
content_parts.append(f"[图片: {p}]")
self.content = "\n".join(content_parts) if content_parts else "[Mixed message]"
elif msg_type == "file":
self.ctype = ContextType.FILE
file_info = msg_body.get("file", {})
file_url = file_info.get("url", "")
aeskey = file_info.get("aeskey", "")
tmp_dir = _get_tmp_dir()
base_path = os.path.join(tmp_dir, f"wecom_{self.msg_id}")
self.content = base_path
def _download_file():
try:
data = _decrypt_media(file_url, aeskey)
ext = _guess_ext_from_bytes(data)
final_path = base_path + ext
with open(final_path, "wb") as f:
f.write(data)
self.content = final_path
logger.info(f"[WecomBot] File downloaded: {final_path}")
except Exception as e:
logger.error(f"[WecomBot] Failed to download file: {e}")
self._prepare_fn = _download_file
elif msg_type == "video":
self.ctype = ContextType.FILE
video_info = msg_body.get("video", {})
video_url = video_info.get("url", "")
aeskey = video_info.get("aeskey", "")
tmp_dir = _get_tmp_dir()
self.content = os.path.join(tmp_dir, f"wecom_{self.msg_id}.mp4")
def _download_video():
try:
data = _decrypt_media(video_url, aeskey)
with open(self.content, "wb") as f:
f.write(data)
logger.info(f"[WecomBot] Video downloaded: {self.content}")
except Exception as e:
logger.error(f"[WecomBot] Failed to download video: {e}")
self._prepare_fn = _download_video
else:
raise NotImplementedError(f"Unsupported message type: {msg_type}")
self.from_user_id = from_userid
self.to_user_id = bot_id
if is_group:
self.other_user_id = chat_id
self.actual_user_id = from_userid
self.actual_user_nickname = from_userid
else:
self.other_user_id = from_userid
self.actual_user_id = from_userid
================================================
FILE: common/cloud_client.py
================================================
"""
Cloud management client for connecting to the LinkAI control console.
Handles remote configuration sync, message push, and skill management
via the LinkAI socket protocol.
"""
from bridge.context import Context, ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from linkai import LinkAIClient, PushMsg
from config import conf, pconf, plugin_config, available_setting, write_plugin_config, get_root
from plugins import PluginManager
import threading
import time
import json
import os
chat_client: LinkAIClient
CHANNEL_ACTIONS = {"channel_create", "channel_update", "channel_delete"}
# channelType -> config key mapping for app credentials
CREDENTIAL_MAP = {
"feishu": ("feishu_app_id", "feishu_app_secret"),
"dingtalk": ("dingtalk_client_id", "dingtalk_client_secret"),
"wecom_bot": ("wecom_bot_id", "wecom_bot_secret"),
"qq": ("qq_app_id", "qq_app_secret"),
"wechatmp": ("wechatmp_app_id", "wechatmp_app_secret"),
"wechatmp_service": ("wechatmp_app_id", "wechatmp_app_secret"),
"wechatcom_app": ("wechatcomapp_agent_id", "wechatcomapp_secret"),
}
class CloudClient(LinkAIClient):
def __init__(self, api_key: str, channel, host: str = ""):
super().__init__(api_key, host)
self.channel = channel
self.client_type = channel.channel_type
self.channel_mgr = None
self._skill_service = None
self._memory_service = None
self._chat_service = None
@property
def skill_service(self):
"""Lazy-init SkillService so it is available once SkillManager exists."""
if self._skill_service is None:
try:
from agent.skills.manager import SkillManager
from agent.skills.service import SkillService
from config import conf
from common.utils import expand_path
workspace_root = expand_path(conf().get("agent_workspace", "~/cow"))
manager = SkillManager(custom_dir=os.path.join(workspace_root, "skills"))
self._skill_service = SkillService(manager)
logger.debug("[CloudClient] SkillService initialised")
except Exception as e:
logger.error(f"[CloudClient] Failed to init SkillService: {e}")
return self._skill_service
@property
def memory_service(self):
"""Lazy-init MemoryService."""
if self._memory_service is None:
try:
from agent.memory.service import MemoryService
from config import conf
from common.utils import expand_path
workspace_root = expand_path(conf().get("agent_workspace", "~/cow"))
self._memory_service = MemoryService(workspace_root)
logger.debug("[CloudClient] MemoryService initialised")
except Exception as e:
logger.error(f"[CloudClient] Failed to init MemoryService: {e}")
return self._memory_service
@property
def chat_service(self):
"""Lazy-init ChatService (requires AgentBridge via Bridge singleton)."""
if self._chat_service is None:
try:
from agent.chat.service import ChatService
from bridge.bridge import Bridge
agent_bridge = Bridge().get_agent_bridge()
self._chat_service = ChatService(agent_bridge)
logger.debug("[CloudClient] ChatService initialised")
except Exception as e:
logger.error(f"[CloudClient] Failed to init ChatService: {e}")
return self._chat_service
# ------------------------------------------------------------------
# message push callback
# ------------------------------------------------------------------
def on_message(self, push_msg: PushMsg):
session_id = push_msg.session_id
msg_content = push_msg.msg_content
logger.info(f"receive msg push, session_id={session_id}, msg_content={msg_content}")
context = Context()
context.type = ContextType.TEXT
context["receiver"] = session_id
context["isgroup"] = push_msg.is_group
self.channel.send(Reply(ReplyType.TEXT, content=msg_content), context)
# ------------------------------------------------------------------
# config callback
# ------------------------------------------------------------------
def on_config(self, config: dict):
if not self.client_id:
return
logger.info(f"[CloudClient] Loading remote config: {config}")
action = config.get("action")
if action in CHANNEL_ACTIONS:
self._dispatch_channel_action(action, config.get("data", {}))
return
if config.get("enabled") != "Y":
return
local_config = conf()
need_restart_channel = False
for key in config.keys():
if key in available_setting and config.get(key) is not None:
local_config[key] = config.get(key)
# Voice settings
reply_voice_mode = config.get("reply_voice_mode")
if reply_voice_mode:
if reply_voice_mode == "voice_reply_voice":
local_config["voice_reply_voice"] = True
local_config["always_reply_voice"] = False
elif reply_voice_mode == "always_reply_voice":
local_config["always_reply_voice"] = True
local_config["voice_reply_voice"] = True
elif reply_voice_mode == "no_reply_voice":
local_config["always_reply_voice"] = False
local_config["voice_reply_voice"] = False
# Model configuration
if config.get("model"):
local_config["model"] = config.get("model")
# Channel configuration (legacy single-channel path)
if config.get("channelType"):
if local_config.get("channel_type") != config.get("channelType"):
local_config["channel_type"] = config.get("channelType")
need_restart_channel = True
# Channel-specific app credentials (legacy single-channel path)
current_channel_type = local_config.get("channel_type", "")
if self._set_channel_credentials(local_config, current_channel_type,
config.get("app_id"), config.get("app_secret")):
need_restart_channel = True
if config.get("admin_password"):
if not pconf("Godcmd"):
write_plugin_config({"Godcmd": {"password": config.get("admin_password"), "admin_users": []}})
else:
pconf("Godcmd")["password"] = config.get("admin_password")
PluginManager().instances["GODCMD"].reload()
if config.get("group_app_map") and pconf("linkai"):
local_group_map = {}
for mapping in config.get("group_app_map"):
local_group_map[mapping.get("group_name")] = mapping.get("app_code")
pconf("linkai")["group_app_map"] = local_group_map
PluginManager().instances["LINKAI"].reload()
if config.get("text_to_image") and config.get("text_to_image") == "midjourney" and pconf("linkai"):
if pconf("linkai")["midjourney"]:
pconf("linkai")["midjourney"]["enabled"] = True
pconf("linkai")["midjourney"]["use_image_create_prefix"] = True
elif config.get("text_to_image") and config.get("text_to_image") in ["dall-e-2", "dall-e-3"]:
if pconf("linkai")["midjourney"]:
pconf("linkai")["midjourney"]["use_image_create_prefix"] = False
self._save_config_to_file(local_config)
if need_restart_channel:
self._restart_channel(local_config.get("channel_type", ""))
# ------------------------------------------------------------------
# channel CRUD operations
# ------------------------------------------------------------------
def _dispatch_channel_action(self, action: str, data: dict):
channel_type = data.get("channelType")
if not channel_type:
logger.warning(f"[CloudClient] Channel action '{action}' missing channelType, data={data}")
return
logger.info(f"[CloudClient] Channel action: {action}, channelType={channel_type}")
if action == "channel_create":
self._handle_channel_create(channel_type, data)
elif action == "channel_update":
self._handle_channel_update(channel_type, data)
elif action == "channel_delete":
self._handle_channel_delete(channel_type, data)
def _handle_channel_create(self, channel_type: str, data: dict):
local_config = conf()
cred_changed = self._set_channel_credentials(
local_config, channel_type, data.get("appId"), data.get("appSecret"))
self._add_channel_type(local_config, channel_type)
self._save_config_to_file(local_config)
if not self.channel_mgr:
return
existing_ch = self.channel_mgr.get_channel(channel_type)
if existing_ch and not cred_changed:
logger.info(f"[CloudClient] Channel '{channel_type}' already running with same config, "
"skip restart, reporting status only")
threading.Thread(
target=self._report_channel_startup, args=(channel_type,), daemon=True
).start()
return
threading.Thread(
target=self._do_add_channel, args=(channel_type,), daemon=True
).start()
def _handle_channel_update(self, channel_type: str, data: dict):
local_config = conf()
enabled = data.get("enabled", "Y")
cred_changed = self._set_channel_credentials(
local_config, channel_type, data.get("appId"), data.get("appSecret"))
if enabled == "N":
self._remove_channel_type(local_config, channel_type)
else:
self._add_channel_type(local_config, channel_type)
self._save_config_to_file(local_config)
if not self.channel_mgr:
return
if enabled == "N":
threading.Thread(
target=self._do_remove_channel, args=(channel_type,), daemon=True
).start()
else:
existing_ch = self.channel_mgr.get_channel(channel_type)
if existing_ch and not cred_changed:
logger.info(f"[CloudClient] Channel '{channel_type}' already running with same config, "
"skip restart, reporting status only")
threading.Thread(
target=self._report_channel_startup, args=(channel_type,), daemon=True
).start()
else:
threading.Thread(
target=self._do_restart_channel, args=(self.channel_mgr, channel_type), daemon=True
).start()
def _handle_channel_delete(self, channel_type: str, data: dict):
local_config = conf()
self._clear_channel_credentials(local_config, channel_type)
self._remove_channel_type(local_config, channel_type)
self._save_config_to_file(local_config)
if self.channel_mgr:
threading.Thread(
target=self._do_remove_channel, args=(channel_type,), daemon=True
).start()
# ------------------------------------------------------------------
# channel credentials helpers
# ------------------------------------------------------------------
@staticmethod
def _set_channel_credentials(local_config: dict, channel_type: str,
app_id, app_secret) -> bool:
"""
Write app_id / app_secret into the correct config keys for *channel_type*.
Also syncs the values to environment variables (upper-cased key) so that
skills that rely on env-based checks (e.g. has_env_var) work immediately.
Returns True if any value actually changed.
"""
cred = CREDENTIAL_MAP.get(channel_type)
if not cred:
return False
id_key, secret_key = cred
changed = False
if app_id is not None and local_config.get(id_key) != app_id:
local_config[id_key] = app_id
os.environ[id_key.upper()] = str(app_id)
changed = True
if app_secret is not None and local_config.get(secret_key) != app_secret:
local_config[secret_key] = app_secret
os.environ[secret_key.upper()] = str(app_secret)
changed = True
if changed:
logger.info(f"[CloudClient] Synced {channel_type} credentials to conf and env")
return changed
@staticmethod
def _clear_channel_credentials(local_config: dict, channel_type: str):
cred = CREDENTIAL_MAP.get(channel_type)
if not cred:
return
id_key, secret_key = cred
local_config.pop(id_key, None)
local_config.pop(secret_key, None)
os.environ.pop(id_key.upper(), None)
os.environ.pop(secret_key.upper(), None)
# ------------------------------------------------------------------
# channel_type list helpers
# ------------------------------------------------------------------
@staticmethod
def _parse_channel_types(local_config: dict) -> list:
raw = local_config.get("channel_type", "")
if isinstance(raw, list):
return [ch.strip() for ch in raw if ch.strip()]
if isinstance(raw, str):
return [ch.strip() for ch in raw.split(",") if ch.strip()]
return []
@staticmethod
def _add_channel_type(local_config: dict, channel_type: str):
types = CloudClient._parse_channel_types(local_config)
if channel_type not in types:
types.append(channel_type)
local_config["channel_type"] = ", ".join(types)
@staticmethod
def _remove_channel_type(local_config: dict, channel_type: str):
types = CloudClient._parse_channel_types(local_config)
if channel_type in types:
types.remove(channel_type)
local_config["channel_type"] = ", ".join(types)
# ------------------------------------------------------------------
# channel manager thread helpers
# ------------------------------------------------------------------
def _do_add_channel(self, channel_type: str):
try:
self.channel_mgr.add_channel(channel_type)
logger.info(f"[CloudClient] Channel '{channel_type}' added successfully")
except Exception as e:
logger.error(f"[CloudClient] Failed to add channel '{channel_type}': {e}", exc_info=True)
self.send_channel_status(channel_type, "error", str(e))
return
self._report_channel_startup(channel_type)
def _do_remove_channel(self, channel_type: str):
try:
self.channel_mgr.remove_channel(channel_type)
logger.info(f"[CloudClient] Channel '{channel_type}' removed successfully")
except Exception as e:
logger.error(f"[CloudClient] Failed to remove channel '{channel_type}': {e}")
def _report_channel_startup(self, channel_type: str):
"""Wait for channel startup result and report to cloud."""
ch = self.channel_mgr.get_channel(channel_type)
if not ch:
self.send_channel_status(channel_type, "error", "channel instance not found")
return
success, error = ch.wait_startup(timeout=3)
if success:
logger.info(f"[CloudClient] Channel '{channel_type}' connected, reporting status")
self.send_channel_status(channel_type, "connected")
else:
logger.warning(f"[CloudClient] Channel '{channel_type}' startup failed: {error}")
self.send_channel_status(channel_type, "error", error)
# ------------------------------------------------------------------
# skill callback
# ------------------------------------------------------------------
def on_skill(self, data: dict) -> dict:
"""
Handle SKILL messages from the cloud console.
Delegates to SkillService.dispatch for the actual operations.
:param data: message data with 'action', 'clientId', 'payload'
:return: response dict
"""
action = data.get("action", "")
payload = data.get("payload")
logger.info(f"[CloudClient] on_skill: action={action}")
svc = self.skill_service
if svc is None:
return {"action": action, "code": 500, "message": "SkillService not available", "payload": None}
return svc.dispatch(action, payload)
# ------------------------------------------------------------------
# memory callback
# ------------------------------------------------------------------
def on_memory(self, data: dict) -> dict:
"""
Handle MEMORY messages from the cloud console.
Delegates to MemoryService.dispatch for the actual operations.
:param data: message data with 'action', 'clientId', 'payload'
:return: response dict
"""
action = data.get("action", "")
payload = data.get("payload")
logger.info(f"[CloudClient] on_memory: action={action}")
svc = self.memory_service
if svc is None:
return {"action": action, "code": 500, "message": "MemoryService not available", "payload": None}
return svc.dispatch(action, payload)
# ------------------------------------------------------------------
# chat callback
# ------------------------------------------------------------------
def on_chat(self, data: dict, send_chunk_fn):
"""
Handle CHAT messages from the cloud console.
Runs the agent in streaming mode and sends chunks back via send_chunk_fn.
:param data: message data with 'action' and 'payload' (query, session_id)
:param send_chunk_fn: callable(chunk_data: dict) to send one streaming chunk
"""
payload = data.get("payload", {})
query = payload.get("query", "")
session_id = payload.get("session_id", "cloud_console")
channel_type = payload.get("channel_type", "")
if not session_id.startswith("session_"):
session_id = f"session_{session_id}"
logger.info(f"[CloudClient] on_chat: session={session_id}, channel={channel_type}, query={query[:80]}")
svc = self.chat_service
if svc is None:
raise RuntimeError("ChatService not available")
svc.run(query=query, session_id=session_id, channel_type=channel_type, send_chunk_fn=send_chunk_fn)
# ------------------------------------------------------------------
# history callback
# ------------------------------------------------------------------
def on_history(self, data: dict) -> dict:
"""
Handle HISTORY messages from the cloud console.
Returns paginated conversation history for a session.
:param data: message data with 'action' and 'payload' (session_id, page, page_size)
:return: response dict
"""
action = data.get("action", "query")
payload = data.get("payload", {})
logger.info(f"[CloudClient] on_history: action={action}")
if action == "query":
return self._query_history(payload)
return {"action": action, "code": 404, "message": f"unknown action: {action}", "payload": None}
def _query_history(self, payload: dict) -> dict:
"""Query paginated conversation history using ConversationStore."""
session_id = payload.get("session_id", "")
page = int(payload.get("page", 1))
page_size = int(payload.get("page_size", 20))
if not session_id:
return {
"action": "query",
"payload": {"status": "error", "message": "session_id required"},
}
# Web channel stores sessions with a "session_" prefix
if not session_id.startswith("session_"):
session_id = f"session_{session_id}"
logger.info(f"[CloudClient] history query: session={session_id}, page={page}, page_size={page_size}")
try:
from agent.memory.conversation_store import get_conversation_store
store = get_conversation_store()
result = store.load_history_page(
session_id=session_id,
page=page,
page_size=page_size,
)
return {
"action": "query",
"payload": {"status": "success", **result},
}
except Exception as e:
logger.error(f"[CloudClient] History query error: {e}")
return {
"action": "query",
"payload": {"status": "error", "message": str(e)},
}
# ------------------------------------------------------------------
# channel restart helpers
# ------------------------------------------------------------------
def _restart_channel(self, new_channel_type: str):
"""
Restart the channel via ChannelManager when channel type changes.
"""
if self.channel_mgr:
logger.info(f"[CloudClient] Restarting channel to '{new_channel_type}'...")
threading.Thread(target=self._do_restart_channel, args=(self.channel_mgr, new_channel_type), daemon=True).start()
else:
logger.warning("[CloudClient] ChannelManager not available, please restart the application manually")
def _do_restart_channel(self, mgr, new_channel_type: str):
"""
Perform the channel restart in a separate thread to avoid blocking the config callback.
"""
try:
mgr.restart(new_channel_type)
if mgr.channel:
self.channel = mgr.channel
self.client_type = mgr.channel.channel_type
logger.info(f"[CloudClient] Channel reference updated to '{new_channel_type}'")
except Exception as e:
logger.error(f"[CloudClient] Channel restart failed: {e}")
self.send_channel_status(new_channel_type, "error", str(e))
return
self._report_channel_startup(new_channel_type)
# ------------------------------------------------------------------
# config persistence
# ------------------------------------------------------------------
def _save_config_to_file(self, local_config: dict):
"""
Save configuration to config.json file.
"""
try:
config_path = os.path.join(get_root(), "config.json")
if not os.path.exists(config_path):
logger.warning(f"[CloudClient] config.json not found at {config_path}, skip saving")
return
with open(config_path, "r", encoding="utf-8") as f:
file_config = json.load(f)
file_config.update(dict(local_config))
with open(config_path, "w", encoding="utf-8") as f:
json.dump(file_config, f, indent=4, ensure_ascii=False)
logger.info("[CloudClient] Configuration saved to config.json successfully")
except Exception as e:
logger.error(f"[CloudClient] Failed to save configuration to config.json: {e}")
def get_root_domain(host: str = "") -> str:
"""Extract root domain from a hostname.
If *host* is empty, reads CLOUD_HOST env var / cloud_host config.
"""
if not host:
host = os.environ.get("CLOUD_HOST") or conf().get("cloud_host", "")
if not host:
return ""
host = host.strip().rstrip("/")
if "://" in host:
host = host.split("://", 1)[1]
host = host.split("/", 1)[0].split(":")[0]
parts = host.split(".")
if len(parts) >= 2:
return ".".join(parts[-2:])
return host
def get_deployment_id() -> str:
"""Return cloud deployment id from env var or config."""
return os.environ.get("CLOUD_DEPLOYMENT_ID") or conf().get("cloud_deployment_id", "")
def get_website_base_url() -> str:
"""Return the public URL prefix that maps to the workspace websites/ dir.
Returns empty string when cloud deployment is not configured.
"""
deployment_id = get_deployment_id()
if not deployment_id:
return ""
websites_domain = os.environ.get("CLOUD_WEBSITES_DOMAIN") or conf().get("cloud_websites_domain", "")
if websites_domain:
websites_domain = websites_domain.strip().rstrip("/")
return f"https://{websites_domain}/{deployment_id}"
domain = get_root_domain()
if not domain:
return ""
return f"https://app.{domain}/{deployment_id}"
def build_website_prompt(workspace_dir: str) -> list:
"""Build system prompt lines for cloud website/file sharing rules.
Returns an empty list when cloud deployment is not configured,
so callers can safely do ``lines.extend(build_website_prompt(...))``.
"""
base_url = get_website_base_url()
if not base_url:
return []
return [
"**文件分享与网页生成规则** (非常重要 — 当前为云部署模式):",
"",
f"云端已为工作空间的 `websites/` 目录配置好公网路由映射,访问地址前缀为: `{base_url}`",
"",
"1. **网页/网站**: 编写网页、H5页面等前端代码时,**必须**将文件放到 `websites/` 目录中",
f" - 例如: `websites/index.html` → `{base_url}/index.html`",
f" - 例如: `websites/my-app/index.html` → `{base_url}/my-app/index.html`",
"",
"2. **生成文件分享** (PPT、PDF、图片、音视频等): 当你为用户生成了需要下载或查看的文件时,**可以**将文件保存到 `websites/` 目录中",
f" - 例如: 生成的PPT保存到 `websites/files/report.pptx` → 下载链接为 `{base_url}/files/report.pptx`",
" - 你仍然可以同时使用 `send` 工具发送文件(在飞书、钉钉等IM渠道中有效),但**必须同时在回复文本中提供下载链接**作为兜底,因为部分渠道(如网页端)无法通过 send 接收本地文件",
"",
"3. **必须发送链接**: 无论是网页还是文件,生成后**必须将完整的访问/下载链接直接写在回复文本中发送给用户**",
"",
"4. **文件名和路径尽量使用英文/拼音/数字等**,不要使用中文,避免链接无法访问",
"",
"5. 建议为每个独立项目在 `websites/` 下创建子目录,保持结构清晰",
"",
]
def start(channel, channel_mgr=None):
if not get_deployment_id():
return
global chat_client
chat_client = CloudClient(api_key=conf().get("linkai_api_key"), host=conf().get("cloud_host", ""), channel=channel)
chat_client.channel_mgr = channel_mgr
chat_client.config = _build_config()
chat_client.start()
time.sleep(1.5)
if chat_client.client_id:
logger.info("[CloudClient] Console: https://link-ai.tech/console/clients")
if channel_mgr:
channel_mgr.cloud_mode = True
threading.Thread(target=_report_existing_channels, args=(chat_client, channel_mgr), daemon=True).start()
def _report_existing_channels(client: CloudClient, mgr):
"""Report status for all channels that were started before cloud client connected."""
try:
for name, ch in list(mgr._channels.items()):
if name == "web":
continue
ch.cloud_mode = True
client._report_channel_startup(name)
except Exception as e:
logger.warning(f"[CloudClient] Failed to report existing channel status: {e}")
def _build_config():
local_conf = conf()
config = {
"linkai_app_code": local_conf.get("linkai_app_code"),
"single_chat_prefix": local_conf.get("single_chat_prefix"),
"single_chat_reply_prefix": local_conf.get("single_chat_reply_prefix"),
"single_chat_reply_suffix": local_conf.get("single_chat_reply_suffix"),
"group_chat_prefix": local_conf.get("group_chat_prefix"),
"group_chat_reply_prefix": local_conf.get("group_chat_reply_prefix"),
"group_chat_reply_suffix": local_conf.get("group_chat_reply_suffix"),
"group_name_white_list": local_conf.get("group_name_white_list"),
"nick_name_black_list": local_conf.get("nick_name_black_list"),
"speech_recognition": "Y" if local_conf.get("speech_recognition") else "N",
"text_to_image": local_conf.get("text_to_image"),
"image_create_prefix": local_conf.get("image_create_prefix"),
"model": local_conf.get("model"),
"agent_max_context_turns": local_conf.get("agent_max_context_turns"),
"agent_max_context_tokens": local_conf.get("agent_max_context_tokens"),
"agent_max_steps": local_conf.get("agent_max_steps"),
"channelType": local_conf.get("channel_type"),
}
if local_conf.get("always_reply_voice"):
config["reply_voice_mode"] = "always_reply_voice"
elif local_conf.get("voice_reply_voice"):
config["reply_voice_mode"] = "voice_reply_voice"
if pconf("linkai"):
config["group_app_map"] = pconf("linkai").get("group_app_map")
if plugin_config.get("Godcmd"):
config["admin_password"] = plugin_config.get("Godcmd").get("password")
# Add channel-specific app credentials
current_channel_type = local_conf.get("channel_type", "")
if current_channel_type == "feishu":
config["app_id"] = local_conf.get("feishu_app_id")
config["app_secret"] = local_conf.get("feishu_app_secret")
elif current_channel_type == "dingtalk":
config["app_id"] = local_conf.get("dingtalk_client_id")
config["app_secret"] = local_conf.get("dingtalk_client_secret")
elif current_channel_type in ("wechatmp", "wechatmp_service"):
config["app_id"] = local_conf.get("wechatmp_app_id")
config["app_secret"] = local_conf.get("wechatmp_app_secret")
elif current_channel_type == "wecom_bot":
config["app_id"] = local_conf.get("wecom_bot_id")
config["app_secret"] = local_conf.get("wecom_bot_secret")
elif current_channel_type == "qq":
config["app_id"] = local_conf.get("qq_app_id")
config["app_secret"] = local_conf.get("qq_app_secret")
elif current_channel_type == "wechatcom_app":
config["app_id"] = local_conf.get("wechatcomapp_agent_id")
config["app_secret"] = local_conf.get("wechatcomapp_secret")
return config
================================================
FILE: common/const.py
================================================
# 厂商类型
OPEN_AI = "openAI"
OPENAI = "openai"
CHATGPT = "chatGPT" # legacy alias for OPENAI, kept for backward compatibility
BAIDU = "baidu"
XUNFEI = "xunfei"
CHATGPTONAZURE = "chatGPTOnAzure"
LINKAI = "linkai"
CLAUDEAPI= "claudeAPI"
QWEN = "qwen" # 旧版千问接入
QWEN_DASHSCOPE = "dashscope" # 新版千问接入(百炼)
GEMINI = "gemini"
ZHIPU_AI = "zhipu"
MOONSHOT = "moonshot"
MiniMax = "minimax"
DEEPSEEK = "deepseek"
MODELSCOPE = "modelscope"
# 模型列表
# Claude (Anthropic)
CLAUDE3 = "claude-3-opus-20240229"
CLAUDE_3_OPUS = "claude-3-opus-latest"
CLAUDE_3_OPUS_0229 = "claude-3-opus-20240229"
CLAUDE_3_SONNET = "claude-3-sonnet-20240229"
CLAUDE_3_HAIKU = "claude-3-haiku-20240307"
CLAUDE_35_SONNET = "claude-3-5-sonnet-latest" # 带 latest 标签的模型名称,会不断更新指向最新发布的模型
CLAUDE_35_SONNET_1022 = "claude-3-5-sonnet-20241022" # 带具体日期的模型名称,会固定为该日期发布的模型
CLAUDE_35_SONNET_0620 = "claude-3-5-sonnet-20240620"
CLAUDE_4_OPUS = "claude-opus-4-0"
CLAUDE_4_6_OPUS = "claude-opus-4-6" # Claude Opus 4.6 - Agent推荐模型
CLAUDE_4_SONNET = "claude-sonnet-4-0" # Claude Sonnet 4.0
CLAUDE_4_5_SONNET = "claude-sonnet-4-5" # Claude Sonnet 4.5 - Agent推荐模型
CLAUDE_4_6_SONNET = "claude-sonnet-4-6" # Claude Sonnet 4.6 - Agent推荐模型
# Gemini (Google)
GEMINI_PRO = "gemini-1.0-pro"
GEMINI_15_flash = "gemini-1.5-flash"
GEMINI_15_PRO = "gemini-1.5-pro"
GEMINI_20_flash_exp = "gemini-2.0-flash-exp" # exp结尾为实验模型,会逐步不再支持
GEMINI_20_FLASH = "gemini-2.0-flash" # 正式版模型
GEMINI_25_FLASH_PRE = "gemini-2.5-flash-preview-05-20"
GEMINI_25_PRO_PRE = "gemini-2.5-pro-preview-05-06"
GEMINI_3_FLASH_PRE = "gemini-3-flash-preview" # Gemini 3 Flash Preview - Agent推荐模型
GEMINI_3_PRO_PRE = "gemini-3-pro-preview" # Gemini 3 Pro Preview
GEMINI_31_PRO_PRE = "gemini-3.1-pro-preview" # Gemini 3.1 Pro Preview - Agent推荐模型
GEMINI_31_FLASH_LITE_PRE = "gemini-3.1-flash-lite-preview" # Gemini 3.1 Flash Lite Preview - Agent推荐模型
# OpenAI
GPT35 = "gpt-3.5-turbo"
GPT35_0125 = "gpt-3.5-turbo-0125"
GPT35_1106 = "gpt-3.5-turbo-1106"
GPT4 = "gpt-4"
GPT4_06_13 = "gpt-4-0613"
GPT4_32k = "gpt-4-32k"
GPT4_32k_06_13 = "gpt-4-32k-0613"
GPT4_TURBO = "gpt-4-turbo"
GPT4_TURBO_PREVIEW = "gpt-4-turbo-preview"
GPT4_TURBO_01_25 = "gpt-4-0125-preview"
GPT4_TURBO_11_06 = "gpt-4-1106-preview"
GPT4_TURBO_04_09 = "gpt-4-turbo-2024-04-09"
GPT4_VISION_PREVIEW = "gpt-4-vision-preview"
GPT_4o = "gpt-4o"
GPT_4O_0806 = "gpt-4o-2024-08-06"
GPT_4o_MINI = "gpt-4o-mini"
GPT_41 = "gpt-4.1"
GPT_41_MINI = "gpt-4.1-mini"
GPT_41_NANO = "gpt-4.1-nano"
GPT_5 = "gpt-5"
GPT_5_MINI = "gpt-5-mini"
GPT_5_NANO = "gpt-5-nano"
GPT_54 = "gpt-5.4" # GPT-5.4 - Agent recommended model
GPT_54_MINI = "gpt-5.4-mini"
GPT_54_NANO = "gpt-5.4-nano"
O1 = "o1-preview"
O1_MINI = "o1-mini"
WHISPER_1 = "whisper-1"
TTS_1 = "tts-1"
TTS_1_HD = "tts-1-hd"
# DeepSeek
DEEPSEEK_CHAT = "deepseek-chat" # DeepSeek-V3对话模型
DEEPSEEK_REASONER = "deepseek-reasoner" # DeepSeek-R1模型
# Qwen (通义千问 - 阿里云)
QWEN = "qwen"
QWEN_TURBO = "qwen-turbo"
QWEN_PLUS = "qwen-plus"
QWEN_MAX = "qwen-max"
QWEN_LONG = "qwen-long"
QWEN3_MAX = "qwen3-max" # Qwen3 Max - Agent推荐模型
QWEN35_PLUS = "qwen3.5-plus" # Qwen3.5 Plus - Omni model (MultiModalConversation)
QWQ_PLUS = "qwq-plus"
# MiniMax
MINIMAX_M2_7 = "MiniMax-M2.7" # MiniMax M2.7 - Latest
MINIMAX_M2_5 = "MiniMax-M2.5" # MiniMax M2.5
MINIMAX_M2_1 = "MiniMax-M2.1" # MiniMax M2.1
MINIMAX_M2_1_LIGHTNING = "MiniMax-M2.1-lightning" # MiniMax M2.1 极速版
MINIMAX_M2 = "MiniMax-M2" # MiniMax M2
MINIMAX_ABAB6_5 = "abab6.5-chat" # MiniMax abab6.5
# GLM (智谱AI)
GLM_5_TURBO = "glm-5-turbo" # 智谱 GLM-5-Turbo - Latest
GLM_5 = "glm-5" # 智谱 GLM-5
GLM_4 = "glm-4"
GLM_4_PLUS = "glm-4-plus"
GLM_4_flash = "glm-4-flash"
GLM_4_LONG = "glm-4-long"
GLM_4_ALLTOOLS = "glm-4-alltools"
GLM_4_0520 = "glm-4-0520"
GLM_4_AIR = "glm-4-air"
GLM_4_AIRX = "glm-4-airx"
GLM_4_7 = "glm-4.7" # 智谱 GLM-4.7 - Agent推荐模型
# Kimi (Moonshot)
MOONSHOT = "moonshot"
KIMI_K2 = "kimi-k2"
KIMI_K2_5 = "kimi-k2.5"
# Doubao (Volcengine Ark)
DOUBAO = "doubao"
DOUBAO_SEED_2_CODE = "doubao-seed-2-0-code-preview-260215"
DOUBAO_SEED_2_PRO = "doubao-seed-2-0-pro-260215"
DOUBAO_SEED_2_LITE = "doubao-seed-2-0-lite-260215"
DOUBAO_SEED_2_MINI = "doubao-seed-2-0-mini-260215"
# 其他模型
WEN_XIN = "wenxin"
WEN_XIN_4 = "wenxin-4"
XUNFEI = "xunfei"
LINKAI_35 = "linkai-3.5"
LINKAI_4_TURBO = "linkai-4-turbo"
LINKAI_4o = "linkai-4o"
MODELSCOPE = "modelscope"
GITEE_AI_MODEL_LIST = ["Yi-34B-Chat", "InternVL2-8B", "deepseek-coder-33B-instruct", "InternVL2.5-26B", "Qwen2-VL-72B", "Qwen2.5-32B-Instruct", "glm-4-9b-chat", "codegeex4-all-9b", "Qwen2.5-Coder-32B-Instruct", "Qwen2.5-72B-Instruct", "Qwen2.5-7B-Instruct", "Qwen2-72B-Instruct", "Qwen2-7B-Instruct", "code-raccoon-v1", "Qwen2.5-14B-Instruct"]
MODELSCOPE_MODEL_LIST = ["LLM-Research/c4ai-command-r-plus-08-2024","mistralai/Mistral-Small-Instruct-2409","mistralai/Ministral-8B-Instruct-2410","mistralai/Mistral-Large-Instruct-2407",
"Qwen/Qwen2.5-Coder-32B-Instruct","Qwen/Qwen2.5-Coder-14B-Instruct","Qwen/Qwen2.5-Coder-7B-Instruct","Qwen/Qwen2.5-72B-Instruct","Qwen/Qwen2.5-32B-Instruct","Qwen/Qwen2.5-14B-Instruct","Qwen/Qwen2.5-7B-Instruct","Qwen/QwQ-32B-Preview",
"LLM-Research/Llama-3.3-70B-Instruct","opencompass/CompassJudger-1-32B-Instruct","Qwen/QVQ-72B-Preview","LLM-Research/Meta-Llama-3.1-405B-Instruct","LLM-Research/Meta-Llama-3.1-8B-Instruct","Qwen/Qwen2-VL-7B-Instruct","LLM-Research/Meta-Llama-3.1-70B-Instruct",
"Qwen/Qwen2.5-14B-Instruct-1M","Qwen/Qwen2.5-7B-Instruct-1M","Qwen/Qwen2.5-VL-3B-Instruct","Qwen/Qwen2.5-VL-7B-Instruct","Qwen/Qwen2.5-VL-72B-Instruct","deepseek-ai/DeepSeek-R1-Distill-Llama-70B","deepseek-ai/DeepSeek-R1-Distill-Llama-8B","deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"deepseek-ai/DeepSeek-R1-Distill-Qwen-14B","deepseek-ai/DeepSeek-R1-Distill-Qwen-7B","deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B","deepseek-ai/DeepSeek-R1","deepseek-ai/DeepSeek-V3","Qwen/QwQ-32B"]
MODEL_LIST = [
# Claude
CLAUDE3, CLAUDE_4_6_SONNET, CLAUDE_4_6_OPUS, CLAUDE_4_OPUS, CLAUDE_4_5_SONNET, CLAUDE_4_SONNET, CLAUDE_3_OPUS, CLAUDE_3_OPUS_0229,
CLAUDE_35_SONNET, CLAUDE_35_SONNET_1022, CLAUDE_35_SONNET_0620, CLAUDE_3_SONNET, CLAUDE_3_HAIKU,
"claude", "claude-3-haiku", "claude-3-sonnet", "claude-3-opus", "claude-3.5-sonnet",
# Gemini
GEMINI_31_FLASH_LITE_PRE, GEMINI_31_PRO_PRE, GEMINI_3_PRO_PRE, GEMINI_3_FLASH_PRE, GEMINI_25_PRO_PRE, GEMINI_25_FLASH_PRE,
GEMINI_20_FLASH, GEMINI_20_flash_exp, GEMINI_15_PRO, GEMINI_15_flash, GEMINI_PRO, GEMINI,
# OpenAI
GPT35, GPT35_0125, GPT35_1106, "gpt-3.5-turbo-16k",
GPT4, GPT4_06_13, GPT4_32k, GPT4_32k_06_13,
GPT4_TURBO, GPT4_TURBO_PREVIEW, GPT4_TURBO_01_25, GPT4_TURBO_11_06, GPT4_TURBO_04_09,
GPT_4o, GPT_4O_0806, GPT_4o_MINI,
GPT_41, GPT_41_MINI, GPT_41_NANO,
GPT_5, GPT_5_MINI, GPT_5_NANO,
GPT_54, GPT_54_MINI, GPT_54_NANO,
O1, O1_MINI,
# DeepSeek
DEEPSEEK_CHAT, DEEPSEEK_REASONER,
# Qwen
QWEN, QWEN_TURBO, QWEN_PLUS, QWEN_MAX, QWEN_LONG, QWEN3_MAX, QWEN35_PLUS,
# MiniMax
MiniMax, MINIMAX_M2_7, MINIMAX_M2_5, MINIMAX_M2_1, MINIMAX_M2_1_LIGHTNING, MINIMAX_M2, MINIMAX_ABAB6_5,
# GLM
ZHIPU_AI, GLM_5_TURBO, GLM_5, GLM_4, GLM_4_PLUS, GLM_4_flash, GLM_4_LONG, GLM_4_ALLTOOLS,
GLM_4_0520, GLM_4_AIR, GLM_4_AIRX, GLM_4_7,
# Kimi
MOONSHOT, "moonshot-v1-8k", "moonshot-v1-32k", "moonshot-v1-128k",
KIMI_K2, KIMI_K2_5,
# Doubao
DOUBAO, DOUBAO_SEED_2_CODE, DOUBAO_SEED_2_PRO, DOUBAO_SEED_2_LITE, DOUBAO_SEED_2_MINI,
# 其他模型
WEN_XIN, WEN_XIN_4, XUNFEI,
LINKAI_35, LINKAI_4_TURBO, LINKAI_4o,
MODELSCOPE
]
MODEL_LIST = MODEL_LIST + GITEE_AI_MODEL_LIST + MODELSCOPE_MODEL_LIST
# channel
FEISHU = "feishu"
DINGTALK = "dingtalk"
WECOM_BOT = "wecom_bot"
QQ = "qq"
================================================
FILE: common/dequeue.py
================================================
from queue import Full, Queue
from time import monotonic as time
# add implementation of putleft to Queue
class Dequeue(Queue):
def putleft(self, item, block=True, timeout=None):
with self.not_full:
if self.maxsize > 0:
if not block:
if self._qsize() >= self.maxsize:
raise Full
elif timeout is None:
while self._qsize() >= self.maxsize:
self.not_full.wait()
elif timeout < 0:
raise ValueError("'timeout' must be a non-negative number")
else:
endtime = time() + timeout
while self._qsize() >= self.maxsize:
remaining = endtime - time()
if remaining <= 0.0:
raise Full
self.not_full.wait(remaining)
self._putleft(item)
self.unfinished_tasks += 1
self.not_empty.notify()
def putleft_nowait(self, item):
return self.putleft(item, block=False)
def _putleft(self, item):
self.queue.appendleft(item)
================================================
FILE: common/expired_dict.py
================================================
from datetime import datetime, timedelta
class ExpiredDict(dict):
def __init__(self, expires_in_seconds):
super().__init__()
self.expires_in_seconds = expires_in_seconds
def __getitem__(self, key):
value, expiry_time = super().__getitem__(key)
if datetime.now() > expiry_time:
del self[key]
raise KeyError("expired {}".format(key))
self.__setitem__(key, value)
return value
def __setitem__(self, key, value):
expiry_time = datetime.now() + timedelta(seconds=self.expires_in_seconds)
super().__setitem__(key, (value, expiry_time))
def get(self, key, default=None):
try:
return self[key]
except KeyError:
return default
def __contains__(self, key):
try:
self[key]
return True
except KeyError:
return False
def keys(self):
keys = list(super().keys())
return [key for key in keys if key in self]
def items(self):
return [(key, self[key]) for key in self.keys()]
def __iter__(self):
return self.keys().__iter__()
================================================
FILE: common/log.py
================================================
import logging
import sys
def _reset_logger(log):
for handler in log.handlers:
handler.close()
log.removeHandler(handler)
del handler
log.handlers.clear()
log.propagate = False
console_handle = logging.StreamHandler(sys.stdout)
console_handle.setFormatter(
logging.Formatter(
"[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d] - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
)
)
file_handle = logging.FileHandler("run.log", encoding="utf-8")
file_handle.setFormatter(
logging.Formatter(
"[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d] - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
)
)
log.addHandler(file_handle)
log.addHandler(console_handle)
def _get_logger():
log = logging.getLogger("log")
_reset_logger(log)
log.setLevel(logging.INFO)
return log
# 日志句柄
logger = _get_logger()
================================================
FILE: common/memory.py
================================================
from common.expired_dict import ExpiredDict
USER_IMAGE_CACHE = ExpiredDict(60 * 3)
================================================
FILE: common/package_manager.py
================================================
import time
import pip
from pip._internal import main as pipmain
from common.log import _reset_logger, logger
def install(package):
pipmain(["install", package])
def install_requirements(file):
pipmain(["install", "-r", file, "--upgrade"])
_reset_logger(logger)
def check_dulwich():
needwait = False
for i in range(2):
if needwait:
time.sleep(3)
needwait = False
try:
import dulwich
return
except ImportError:
try:
install("dulwich")
except Exception:
needwait = True
try:
import dulwich
except ImportError:
raise ImportError("Unable to import dulwich")
================================================
FILE: common/singleton.py
================================================
def singleton(cls):
instances = {}
def get_instance(*args, **kwargs):
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return get_instance
================================================
FILE: common/sorted_dict.py
================================================
import heapq
class SortedDict(dict):
def __init__(self, sort_func=lambda k, v: k, init_dict=None, reverse=False):
if init_dict is None:
init_dict = []
if isinstance(init_dict, dict):
init_dict = init_dict.items()
self.sort_func = sort_func
self.sorted_keys = None
self.reverse = reverse
self.heap = []
for k, v in init_dict:
self[k] = v
def __setitem__(self, key, value):
if key in self:
super().__setitem__(key, value)
for i, (priority, k) in enumerate(self.heap):
if k == key:
self.heap[i] = (self.sort_func(key, value), key)
heapq.heapify(self.heap)
break
self.sorted_keys = None
else:
super().__setitem__(key, value)
heapq.heappush(self.heap, (self.sort_func(key, value), key))
self.sorted_keys = None
def __delitem__(self, key):
super().__delitem__(key)
for i, (priority, k) in enumerate(self.heap):
if k == key:
del self.heap[i]
heapq.heapify(self.heap)
break
self.sorted_keys = None
def keys(self):
if self.sorted_keys is None:
self.sorted_keys = [k for _, k in sorted(self.heap, reverse=self.reverse)]
return self.sorted_keys
def items(self):
if self.sorted_keys is None:
self.sorted_keys = [k for _, k in sorted(self.heap, reverse=self.reverse)]
sorted_items = [(k, self[k]) for k in self.sorted_keys]
return sorted_items
def _update_heap(self, key):
for i, (priority, k) in enumerate(self.heap):
if k == key:
new_priority = self.sort_func(key, self[key])
if new_priority != priority:
self.heap[i] = (new_priority, key)
heapq.heapify(self.heap)
self.sorted_keys = None
break
def __iter__(self):
return iter(self.keys())
def __repr__(self):
return f"{type(self).__name__}({dict(self)}, sort_func={self.sort_func.__name__}, reverse={self.reverse})"
================================================
FILE: common/time_check.py
================================================
import re
import time
import config
from common.log import logger
def time_checker(f):
def _time_checker(self, *args, **kwargs):
_config = config.conf()
chat_time_module = _config.get("chat_time_module", False)
if chat_time_module:
chat_start_time = _config.get("chat_start_time", "00:00")
chat_stop_time = _config.get("chat_stop_time", "24:00")
time_regex = re.compile(r"^([01]?[0-9]|2[0-4])(:)([0-5][0-9])$")
if not (time_regex.match(chat_start_time) and time_regex.match(chat_stop_time)):
logger.warning("时间格式不正确,请在config.json中修改CHAT_START_TIME/CHAT_STOP_TIME。")
return None
now_time = time.strptime(time.strftime("%H:%M"), "%H:%M")
chat_start_time = time.strptime(chat_start_time, "%H:%M")
chat_stop_time = time.strptime(chat_stop_time, "%H:%M")
# 结束时间小于开始时间,跨天了
if chat_stop_time < chat_start_time and (chat_start_time <= now_time or now_time <= chat_stop_time):
f(self, *args, **kwargs)
# 结束大于开始时间代表,没有跨天
elif chat_start_time < chat_stop_time and chat_start_time <= now_time <= chat_stop_time:
f(self, *args, **kwargs)
else:
# 定义匹配规则,如果以 #reconf 或者 #更新配置 结尾, 非服务时间可以修改开始/结束时间并重载配置
pattern = re.compile(r"^.*#(?:reconf|更新配置)$")
if args and pattern.match(args[0].content):
f(self, *args, **kwargs)
else:
logger.info("非服务时间内,不接受访问")
return None
else:
f(self, *args, **kwargs) # 未开启时间模块则直接回答
return _time_checker
================================================
FILE: common/tmp_dir.py
================================================
import os
import pathlib
from config import conf
class TmpDir(object):
"""A temporary directory that is deleted when the object is destroyed."""
tmpFilePath = pathlib.Path("./tmp/")
def __init__(self):
pathExists = os.path.exists(self.tmpFilePath)
if not pathExists:
os.makedirs(self.tmpFilePath)
def path(self):
return str(self.tmpFilePath) + "/"
================================================
FILE: common/token_bucket.py
================================================
import threading
import time
class TokenBucket:
def __init__(self, tpm, timeout=None):
self.capacity = int(tpm) # 令牌桶容量
self.tokens = 0 # 初始令牌数为0
self.rate = int(tpm) / 60 # 令牌每秒生成速率
self.timeout = timeout # 等待令牌超时时间
self.cond = threading.Condition() # 条件变量
self.is_running = True
# 开启令牌生成线程
threading.Thread(target=self._generate_tokens).start()
def _generate_tokens(self):
"""生成令牌"""
while self.is_running:
with self.cond:
if self.tokens < self.capacity:
self.tokens += 1
self.cond.notify() # 通知获取令牌的线程
time.sleep(1 / self.rate)
def get_token(self):
"""获取令牌"""
with self.cond:
while self.tokens <= 0:
flag = self.cond.wait(self.timeout)
if not flag: # 超时
return False
self.tokens -= 1
return True
def close(self):
self.is_running = False
if __name__ == "__main__":
token_bucket = TokenBucket(20, None) # 创建一个每分钟生产20个tokens的令牌桶
# token_bucket = TokenBucket(20, 0.1)
for i in range(3):
if token_bucket.get_token():
print(f"第{i+1}次请求成功")
token_bucket.close()
================================================
FILE: common/utils.py
================================================
import io
import os
import re
from urllib.parse import urlparse
from common.log import logger
def fsize(file):
if isinstance(file, io.BytesIO):
return file.getbuffer().nbytes
elif isinstance(file, str):
return os.path.getsize(file)
elif hasattr(file, "seek") and hasattr(file, "tell"):
pos = file.tell()
file.seek(0, os.SEEK_END)
size = file.tell()
file.seek(pos)
return size
else:
raise TypeError("Unsupported type")
def compress_imgfile(file, max_size):
if fsize(file) <= max_size:
return file
from PIL import Image
file.seek(0)
img = Image.open(file)
rgb_image = img.convert("RGB")
quality = 95
while True:
out_buf = io.BytesIO()
rgb_image.save(out_buf, "JPEG", quality=quality)
if fsize(out_buf) <= max_size:
return out_buf
quality -= 5
def split_string_by_utf8_length(string, max_length, max_split=0):
encoded = string.encode("utf-8")
start, end = 0, 0
result = []
while end < len(encoded):
if max_split > 0 and len(result) >= max_split:
result.append(encoded[start:].decode("utf-8"))
break
end = min(start + max_length, len(encoded))
# 如果当前字节不是 UTF-8 编码的开始字节,则向前查找直到找到开始字节为止
while end < len(encoded) and (encoded[end] & 0b11000000) == 0b10000000:
end -= 1
result.append(encoded[start:end].decode("utf-8"))
start = end
return result
def get_path_suffix(path):
path = urlparse(path).path
return os.path.splitext(path)[-1].lstrip('.')
def convert_webp_to_png(webp_image):
from PIL import Image
try:
webp_image.seek(0)
img = Image.open(webp_image).convert("RGBA")
png_image = io.BytesIO()
img.save(png_image, format="PNG")
png_image.seek(0)
return png_image
except Exception as e:
logger.error(f"Failed to convert WEBP to PNG: {e}")
raise
def remove_markdown_symbol(text: str):
# 移除markdown格式,目前先移除**
if not text:
return text
return re.sub(r'\*\*(.*?)\*\*', r'\1', text)
def expand_path(path: str) -> str:
"""
Expand user path with proper Windows support.
On Windows, os.path.expanduser('~') may not work properly in some shells (like PowerShell).
This function provides a more robust path expansion.
Args:
path: Path string that may contain ~
Returns:
Expanded absolute path
"""
if not path:
return path
# Try standard expansion first
expanded = os.path.expanduser(path)
# If expansion didn't work (path still starts with ~), use HOME or USERPROFILE
if expanded.startswith('~'):
import platform
if platform.system() == 'Windows':
# On Windows, try USERPROFILE first, then HOME
home = os.environ.get('USERPROFILE') or os.environ.get('HOME')
else:
# On Unix-like systems, use HOME
home = os.environ.get('HOME')
if home:
# Replace ~ with home directory
if path == '~':
expanded = home
elif path.startswith('~/') or path.startswith('~\\'):
expanded = os.path.join(home, path[2:])
return expanded
def get_cloud_headers(api_key: str) -> dict:
"""
Build standard headers for LinkAI API requests,
including client_id when available.
"""
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
try:
from linkai import LinkAIClient
client_id = LinkAIClient.fetch_client_id()
if client_id:
headers["X-Client-Id"] = client_id
except Exception:
pass
return headers
================================================
FILE: config-template.json
================================================
{
"channel_type": "web",
"model": "MiniMax-M2.7",
"minimax_api_key": "",
"zhipu_ai_api_key": "",
"ark_api_key": "",
"moonshot_api_key": "",
"dashscope_api_key": "",
"claude_api_key": "",
"claude_api_base": "https://api.anthropic.com/v1",
"open_ai_api_key": "",
"open_ai_api_base": "https://api.openai.com/v1",
"gemini_api_key": "",
"gemini_api_base": "https://generativelanguage.googleapis.com",
"voice_to_text": "openai",
"text_to_voice": "openai",
"voice_reply_voice": false,
"speech_recognition": true,
"group_speech_recognition": false,
"use_linkai": false,
"linkai_api_key": "",
"linkai_app_code": "",
"feishu_app_id": "",
"feishu_app_secret": "",
"dingtalk_client_id": "",
"dingtalk_client_secret":"",
"wecom_bot_id": "",
"wecom_bot_secret": "",
"agent": true,
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 20,
"agent_max_steps": 15
}
================================================
FILE: config.py
================================================
# encoding:utf-8
import copy
import json
import logging
import os
import pickle
from common.log import logger
# 将所有可用的配置项写在字典里, 请使用小写字母
# 此处的配置值无实际意义,程序不会读取此处的配置,仅用于提示格式,请将配置加入到config.json中
available_setting = {
# openai api配置
"open_ai_api_key": "", # openai api key
# openai apibase,当use_azure_chatgpt为true时,需要设置对应的api base
"open_ai_api_base": "https://api.openai.com/v1",
"claude_api_base": "https://api.anthropic.com/v1", # claude api base
"gemini_api_base": "https://generativelanguage.googleapis.com", # gemini api base
"proxy": "", # openai使用的代理
# chatgpt模型, 当use_azure_chatgpt为true时,其名称为Azure上model deployment名称
"model": "gpt-3.5-turbo", # 可选择: gpt-4o, pt-4o-mini, gpt-4-turbo, claude-3-sonnet, wenxin, moonshot, qwen-turbo, xunfei, glm-4, minimax, gemini等模型,全部可选模型详见common/const.py文件
"bot_type": "", # 可选配置,使用兼容openai格式的三方服务时候,需填"openai"(历史值"chatGPT"仍兼容)。bot具体名称详见common/const.py文件,如不填根据model名称判断
"use_azure_chatgpt": False, # 是否使用azure的chatgpt
"azure_deployment_id": "", # azure 模型部署名称
"azure_api_version": "", # azure api版本
# Bot触发配置
"single_chat_prefix": ["bot", "@bot"], # 私聊时文本需要包含该前缀才能触发机器人回复
"single_chat_reply_prefix": "[bot] ", # 私聊时自动回复的前缀,用于区分真人
"single_chat_reply_suffix": "", # 私聊时自动回复的后缀,\n 可以换行
"group_chat_prefix": ["@bot"], # 群聊时包含该前缀则会触发机器人回复
"no_need_at": False, # 群聊回复时是否不需要艾特
"group_chat_reply_prefix": "", # 群聊时自动回复的前缀
"group_chat_reply_suffix": "", # 群聊时自动回复的后缀,\n 可以换行
"group_chat_keyword": [], # 群聊时包含该关键词则会触发机器人回复
"group_at_off": False, # 是否关闭群聊时@bot的触发
"group_name_white_list": ["ChatGPT测试群", "ChatGPT测试群2"], # 开启自动回复的群名称列表
"group_name_keyword_white_list": [], # 开启自动回复的群名称关键词列表
"group_chat_in_one_session": ["ChatGPT测试群"], # 支持会话上下文共享的群名称
"group_shared_session": False, # 群聊是否共享会话上下文(所有成员共享)。False时每个用户在群内有独立会话
"nick_name_black_list": [], # 用户昵称黑名单
"group_welcome_msg": "", # 配置新人进群固定欢迎语,不配置则使用随机风格欢迎
"trigger_by_self": False, # 是否允许机器人触发
"text_to_image": "dall-e-2", # 图片生成模型,可选 dall-e-2, dall-e-3
# Azure OpenAI dall-e-3 配置
"dalle3_image_style": "vivid", # 图片生成dalle3的风格,可选有 vivid, natural
"dalle3_image_quality": "hd", # 图片生成dalle3的质量,可选有 standard, hd
# Azure OpenAI DALL-E API 配置, 当use_azure_chatgpt为true时,用于将文字回复的资源和Dall-E的资源分开.
"azure_openai_dalle_api_base": "", # [可选] azure openai 用于回复图片的资源 endpoint,默认使用 open_ai_api_base
"azure_openai_dalle_api_key": "", # [可选] azure openai 用于回复图片的资源 key,默认使用 open_ai_api_key
"azure_openai_dalle_deployment_id":"", # [可选] azure openai 用于回复图片的资源 deployment id,默认使用 text_to_image
"image_proxy": True, # 是否需要图片代理,国内访问LinkAI时需要
"image_create_prefix": ["画", "看", "找"], # 开启图片回复的前缀
"concurrency_in_session": 1, # 同一会话最多有多少条消息在处理中,大于1可能乱序
"image_create_size": "256x256", # 图片大小,可选有 256x256, 512x512, 1024x1024 (dall-e-3默认为1024x1024)
"group_chat_exit_group": False,
# chatgpt会话参数
"expires_in_seconds": 3600, # 无操作会话的过期时间
# 人格描述
"character_desc": "你是ChatGPT, 一个由OpenAI训练的大型语言模型, 你旨在回答并解决人们的任何问题,并且可以使用多种语言与人交流。",
"conversation_max_tokens": 1000, # 支持上下文记忆的最多字符数
# chatgpt限流配置
"rate_limit_chatgpt": 20, # chatgpt的调用频率限制
"rate_limit_dalle": 50, # openai dalle的调用频率限制
# chatgpt api参数 参考https://platform.openai.com/docs/api-reference/chat/create
"temperature": 0.9,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
"request_timeout": 180, # chatgpt请求超时时间,openai接口默认设置为600,对于难问题一般需要较长时间
"timeout": 120, # chatgpt重试超时时间,在这个时间内,将会自动重试
# Baidu 文心一言参数
"baidu_wenxin_model": "eb-instant", # 默认使用ERNIE-Bot-turbo模型
"baidu_wenxin_api_key": "", # Baidu api key
"baidu_wenxin_secret_key": "", # Baidu secret key
"baidu_wenxin_prompt_enabled": False, # Enable prompt if you are using ernie character model
# 讯飞星火API
"xunfei_app_id": "", # 讯飞应用ID
"xunfei_api_key": "", # 讯飞 API key
"xunfei_api_secret": "", # 讯飞 API secret
"xunfei_domain": "", # 讯飞模型对应的domain参数,Spark4.0 Ultra为 4.0Ultra,其他模型详见: https://www.xfyun.cn/doc/spark/Web.html
"xunfei_spark_url": "", # 讯飞模型对应的请求地址,Spark4.0 Ultra为 wss://spark-api.xf-yun.com/v4.0/chat,其他模型参考详见: https://www.xfyun.cn/doc/spark/Web.html
# claude 配置
"claude_api_cookie": "",
"claude_uuid": "",
# claude api key
"claude_api_key": "",
# 通义千问API, 获取方式查看文档 https://help.aliyun.com/document_detail/2587494.html
"qwen_access_key_id": "",
"qwen_access_key_secret": "",
"qwen_agent_key": "",
"qwen_app_id": "",
"qwen_node_id": "", # 流程编排模型用到的id,如果没有用到qwen_node_id,请务必保持为空字符串
# 阿里灵积(通义新版sdk)模型api key
"dashscope_api_key": "",
# Google Gemini Api Key
"gemini_api_key": "",
# 语音设置
"speech_recognition": True, # 是否开启语音识别
"group_speech_recognition": False, # 是否开启群组语音识别
"voice_reply_voice": False, # 是否使用语音回复语音,需要设置对应语音合成引擎的api key
"always_reply_voice": False, # 是否一直使用语音回复
"voice_to_text": "openai", # 语音识别引擎,支持openai,baidu,google,azure,xunfei,ali
"text_to_voice": "openai", # 语音合成引擎,支持openai,baidu,google,azure,xunfei,ali,pytts(offline),elevenlabs,edge(online)
"text_to_voice_model": "tts-1",
"tts_voice_id": "alloy",
# baidu 语音api配置, 使用百度语音识别和语音合成时需要
"baidu_app_id": "",
"baidu_api_key": "",
"baidu_secret_key": "",
# 1536普通话(支持简单的英文识别) 1737英语 1637粤语 1837四川话 1936普通话远场
"baidu_dev_pid": 1536,
# azure 语音api配置, 使用azure语音识别和语音合成时需要
"azure_voice_api_key": "",
"azure_voice_region": "japaneast",
# elevenlabs 语音api配置
"xi_api_key": "", # 获取ap的方法可以参考https://docs.elevenlabs.io/api-reference/quick-start/authentication
"xi_voice_id": "", # ElevenLabs提供了9种英式、美式等英语发音id,分别是“Adam/Antoni/Arnold/Bella/Domi/Elli/Josh/Rachel/Sam”
# 服务时间限制
"chat_time_module": False, # 是否开启服务时间限制
"chat_start_time": "00:00", # 服务开始时间
"chat_stop_time": "24:00", # 服务结束时间
# 翻译api
"translate": "baidu", # 翻译api,支持baidu
# baidu翻译api的配置
"baidu_translate_app_id": "", # 百度翻译api的appid
"baidu_translate_app_key": "", # 百度翻译api的秘钥
# wechatmp的配置
"wechatmp_token": "", # 微信公众平台的Token
"wechatmp_port": 8080, # 微信公众平台的端口,需要端口转发到80或443
"wechatmp_app_id": "", # 微信公众平台的appID
"wechatmp_app_secret": "", # 微信公众平台的appsecret
"wechatmp_aes_key": "", # 微信公众平台的EncodingAESKey,加密模式需要
# wechatcom的通用配置
"wechatcom_corp_id": "", # 企业微信公司的corpID
# wechatcomapp的配置
"wechatcomapp_token": "", # 企业微信app的token
"wechatcomapp_port": 9898, # 企业微信app的服务端口,不需要端口转发
"wechatcomapp_secret": "", # 企业微信app的secret
"wechatcomapp_agent_id": "", # 企业微信app的agent_id
"wechatcomapp_aes_key": "", # 企业微信app的aes_key
# 飞书配置
"feishu_port": 80, # 飞书bot监听端口
"feishu_app_id": "", # 飞书机器人应用APP Id
"feishu_app_secret": "", # 飞书机器人APP secret
"feishu_token": "", # 飞书 verification token
"feishu_bot_name": "", # 飞书机器人的名字
"feishu_event_mode": "websocket", # 飞书事件接收模式: webhook(HTTP服务器) 或 websocket(长连接)
# 钉钉配置
"dingtalk_client_id": "", # 钉钉机器人Client ID
"dingtalk_client_secret": "", # 钉钉机器人Client Secret
"dingtalk_card_enabled": False,
# 企微智能机器人配置(长连接模式)
"wecom_bot_id": "", # 企微智能机器人BotID
"wecom_bot_secret": "", # 企微智能机器人长连接Secret
# chatgpt指令自定义触发词
"clear_memory_commands": ["#清除记忆"], # 重置会话指令,必须以#开头
# channel配置
"channel_type": "", # 通道类型,支持多渠道同时运行。单个: "feishu",多个: "feishu, dingtalk" 或 ["feishu", "dingtalk"]。可选值: web,feishu,dingtalk,wecom_bot,wechatmp,wechatmp_service,wechatcom_app
"web_console": True, # 是否自动启动Web控制台(默认启动)。设为False可禁用
"subscribe_msg": "", # 订阅消息, 支持: wechatmp, wechatmp_service, wechatcom_app
"debug": False, # 是否开启debug模式,开启后会打印更多日志
"appdata_dir": "", # 数据目录
# 插件配置
"plugin_trigger_prefix": "$", # 规范插件提供聊天相关指令的前缀,建议不要和管理员指令前缀"#"冲突
# 是否使用全局插件配置
"use_global_plugin_config": False,
"max_media_send_count": 3, # 单次最大发送媒体资源的个数
"media_send_interval": 1, # 发送图片的事件间隔,单位秒
# 智谱AI 平台配置
"zhipu_ai_api_key": "",
"zhipu_ai_api_base": "https://open.bigmodel.cn/api/paas/v4",
"moonshot_api_key": "",
"moonshot_base_url": "https://api.moonshot.cn/v1",
# 豆包(火山方舟) 平台配置
"ark_api_key": "",
"ark_base_url": "https://ark.cn-beijing.volces.com/api/v3",
#魔搭社区 平台配置
"modelscope_api_key": "",
"modelscope_base_url": "https://api-inference.modelscope.cn/v1/chat/completions",
# LinkAI平台配置
"use_linkai": False,
"linkai_api_key": "",
"linkai_app_code": "",
"linkai_api_base": "https://api.link-ai.tech", # linkAI服务地址
"cloud_host": "client.link-ai.tech",
"cloud_deployment_id": "",
"minimax_api_key": "",
"Minimax_group_id": "",
"Minimax_base_url": "",
"web_port": 9899,
"agent": True, # 是否开启Agent模式
"agent_workspace": "~/cow", # agent工作空间路径,用于存储skills、memory等
"agent_max_context_tokens": 50000, # Agent模式下最大上下文tokens
"agent_max_context_turns": 30, # Agent模式下最大上下文记忆轮次
"agent_max_steps": 15, # Agent模式下单次运行最大决策步数
}
class Config(dict):
def __init__(self, d=None):
super().__init__()
if d is None:
d = {}
for k, v in d.items():
self[k] = v
# user_datas: 用户数据,key为用户名,value为用户数据,也是dict
self.user_datas = {}
def __getitem__(self, key):
# 跳过以下划线开头的注释字段
if not key.startswith("_") and key not in available_setting:
logger.warning("[Config] key '{}' not in available_setting, may not take effect".format(key))
return super().__getitem__(key)
def __setitem__(self, key, value):
# 跳过以下划线开头的注释字段
if not key.startswith("_") and key not in available_setting:
logger.warning("[Config] key '{}' not in available_setting, may not take effect".format(key))
return super().__setitem__(key, value)
def get(self, key, default=None):
# 跳过以下划线开头的注释字段
if key.startswith("_"):
return super().get(key, default)
# 如果key不在available_setting中,直接返回default
if key not in available_setting:
return super().get(key, default)
try:
return self[key]
except KeyError as e:
return default
except Exception as e:
raise e
# Make sure to return a dictionary to ensure atomic
def get_user_data(self, user) -> dict:
if self.user_datas.get(user) is None:
self.user_datas[user] = {}
return self.user_datas[user]
def load_user_datas(self):
try:
with open(os.path.join(get_appdata_dir(), "user_datas.pkl"), "rb") as f:
self.user_datas = pickle.load(f)
logger.debug("[Config] User datas loaded.")
except FileNotFoundError as e:
logger.debug("[Config] User datas file not found, ignore.")
except Exception as e:
logger.warning("[Config] User datas error: {}".format(e))
self.user_datas = {}
def save_user_datas(self):
try:
with open(os.path.join(get_appdata_dir(), "user_datas.pkl"), "wb") as f:
pickle.dump(self.user_datas, f)
logger.info("[Config] User datas saved.")
except Exception as e:
logger.info("[Config] User datas error: {}".format(e))
config = Config()
def drag_sensitive(config):
try:
if isinstance(config, str):
conf_dict: dict = json.loads(config)
conf_dict_copy = copy.deepcopy(conf_dict)
for key in conf_dict_copy:
if "key" in key or "secret" in key:
if isinstance(conf_dict_copy[key], str):
conf_dict_copy[key] = conf_dict_copy[key][0:3] + "*" * 5 + conf_dict_copy[key][-3:]
return json.dumps(conf_dict_copy, indent=4)
elif isinstance(config, dict):
config_copy = copy.deepcopy(config)
for key in config:
if "key" in key or "secret" in key:
if isinstance(config_copy[key], str):
config_copy[key] = config_copy[key][0:3] + "*" * 5 + config_copy[key][-3:]
return config_copy
except Exception as e:
logger.exception(e)
return config
return config
def load_config():
global config
# 打印 ASCII Logo
logger.info(" ____ _ _ ")
logger.info(" / ___|_____ __ / \\ __ _ ___ _ __ | |_ ")
logger.info("| | / _ \\ \\ /\\ / // _ \\ / _` |/ _ \\ '_ \\| __|")
logger.info("| |__| (_) \\ V V // ___ \\ (_| | __/ | | | |_ ")
logger.info(" \\____\\___/ \\_/\\_//_/ \\_\\__, |\\___|_| |_|\\__|")
logger.info(" |___/ ")
logger.info("")
config_path = "./config.json"
if not os.path.exists(config_path):
logger.info("配置文件不存在,将使用config-template.json模板")
config_path = "./config-template.json"
config_str = read_file(config_path)
logger.debug("[INIT] config str: {}".format(drag_sensitive(config_str)))
# 将json字符串反序列化为dict类型
config = Config(json.loads(config_str))
# override config with environment variables.
# Some online deployment platforms (e.g. Railway) deploy project from github directly. So you shouldn't put your secrets like api key in a config file, instead use environment variables to override the default config.
for name, value in os.environ.items():
name = name.lower()
# 跳过以下划线开头的注释字段
if name.startswith("_"):
continue
if name in available_setting:
logger.info("[INIT] override config by environ args: {}={}".format(name, value))
try:
config[name] = eval(value)
except Exception:
if value == "false":
config[name] = False
elif value == "true":
config[name] = True
else:
config[name] = value
if config.get("debug", False):
logger.setLevel(logging.DEBUG)
logger.debug("[INIT] set log level to DEBUG")
logger.info("[INIT] load config: {}".format(drag_sensitive(config)))
# 打印系统初始化信息
logger.info("[INIT] ========================================")
logger.info("[INIT] System Initialization")
logger.info("[INIT] ========================================")
logger.info("[INIT] Channel: {}".format(config.get("channel_type", "unknown")))
logger.info("[INIT] Model: {}".format(config.get("model", "unknown")))
# Agent模式信息
if config.get("agent", False):
workspace = config.get("agent_workspace", "~/cow")
logger.info("[INIT] Mode: Agent (workspace: {})".format(workspace))
else:
logger.info("[INIT] Mode: Chat (在config.json中设置 \"agent\":true 可启用Agent模式)")
logger.info("[INIT] Debug: {}".format(config.get("debug", False)))
logger.info("[INIT] ========================================")
# Sync selected config values to environment variables so that
# subprocesses (e.g. shell skill scripts) can access them directly.
# Existing env vars are NOT overwritten (env takes precedence).
_CONFIG_TO_ENV = {
"open_ai_api_key": "OPENAI_API_KEY",
"open_ai_api_base": "OPENAI_API_BASE",
"linkai_api_key": "LINKAI_API_KEY",
"linkai_api_base": "LINKAI_API_BASE",
"claude_api_key": "CLAUDE_API_KEY",
"claude_api_base": "CLAUDE_API_BASE",
"gemini_api_key": "GEMINI_API_KEY",
"gemini_api_base": "GEMINI_API_BASE",
"minimax_api_key": "MINIMAX_API_KEY",
"minimax_api_base": "MINIMAX_API_BASE",
"zhipu_ai_api_key": "ZHIPU_AI_API_KEY",
"zhipu_ai_api_base": "ZHIPU_AI_API_BASE",
"moonshot_api_key": "MOONSHOT_API_KEY",
"moonshot_api_base": "MOONSHOT_API_BASE",
"ark_api_key": "ARK_API_KEY",
"ark_api_base": "ARK_API_BASE",
# Channel credentials (used by skills that check env vars)
"feishu_app_id": "FEISHU_APP_ID",
"feishu_app_secret": "FEISHU_APP_SECRET",
"dingtalk_client_id": "DINGTALK_CLIENT_ID",
"dingtalk_client_secret": "DINGTALK_CLIENT_SECRET",
"wechatmp_app_id": "WECHATMP_APP_ID",
"wechatmp_app_secret": "WECHATMP_APP_SECRET",
"wechatcomapp_agent_id": "WECHATCOMAPP_AGENT_ID",
"wechatcomapp_secret": "WECHATCOMAPP_SECRET",
"qq_app_id": "QQ_APP_ID",
"qq_app_secret": "QQ_APP_SECRET"
}
injected = 0
for conf_key, env_key in _CONFIG_TO_ENV.items():
if env_key not in os.environ:
val = config.get(conf_key, "")
if val:
os.environ[env_key] = str(val)
injected += 1
if injected:
logger.info("[INIT] Synced {} config values to environment variables".format(injected))
config.load_user_datas()
def get_root():
return os.path.dirname(os.path.abspath(__file__))
def read_file(path):
with open(path, mode="r", encoding="utf-8") as f:
return f.read()
def conf():
return config
def get_appdata_dir():
data_path = os.path.join(get_root(), conf().get("appdata_dir", ""))
if not os.path.exists(data_path):
logger.info("[INIT] data path not exists, create it: {}".format(data_path))
os.makedirs(data_path)
return data_path
def subscribe_msg():
trigger_prefix = conf().get("single_chat_prefix", [""])[0]
msg = conf().get("subscribe_msg", "")
return msg.format(trigger_prefix=trigger_prefix)
# global plugin config
plugin_config = {}
def write_plugin_config(pconf: dict):
"""
写入插件全局配置
:param pconf: 全量插件配置
"""
global plugin_config
for k in pconf:
plugin_config[k.lower()] = pconf[k]
def remove_plugin_config(name: str):
"""
移除待重新加载的插件全局配置
:param name: 待重载的插件名
"""
global plugin_config
plugin_config.pop(name.lower(), None)
def pconf(plugin_name: str) -> dict:
"""
根据插件名称获取配置
:param plugin_name: 插件名称
:return: 该插件的配置项
"""
return plugin_config.get(plugin_name.lower())
# 全局配置,用于存放全局生效的状态
global_config = {"admin_users": []}
================================================
FILE: docker/Dockerfile.latest
================================================
FROM python:3.10-slim-bullseye
LABEL maintainer="foo@bar.com"
ARG TZ='Asia/Shanghai'
ARG CHATGPT_ON_WECHAT_VER
RUN echo /etc/apt/sources.list
# RUN sed -i 's/deb.debian.org/mirrors.tuna.tsinghua.edu.cn/g' /etc/apt/sources.list
ENV BUILD_PREFIX=/app
ADD . ${BUILD_PREFIX}
RUN apt-get update \
&&apt-get install -y --no-install-recommends bash ffmpeg espeak libavcodec-extra\
&& cd ${BUILD_PREFIX} \
&& cp config-template.json config.json \
&& /usr/local/bin/python -m pip install --no-cache --upgrade pip \
&& pip install --no-cache -r requirements.txt \
&& pip install --no-cache -r requirements-optional.txt \
&& pip install azure-cognitiveservices-speech
WORKDIR ${BUILD_PREFIX}
ADD docker/entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh \
&& mkdir -p /home/agent/cow \
&& groupadd -r agent \
&& useradd -r -g agent -s /bin/bash -d /home/agent agent \
&& chown -R agent:agent /home/agent ${BUILD_PREFIX} /usr/local/lib
USER agent
ENTRYPOINT ["/entrypoint.sh"]
================================================
FILE: docker/build.latest.sh
================================================
#!/bin/bash
unset KUBECONFIG
cd .. && docker build -f docker/Dockerfile.latest \
-t zhayujie/chatgpt-on-wechat .
docker tag zhayujie/chatgpt-on-wechat zhayujie/chatgpt-on-wechat:$(date +%y%m%d)
================================================
FILE: docker/docker-compose.yml
================================================
version: '2.0'
services:
chatgpt-on-wechat:
image: zhayujie/chatgpt-on-wechat
container_name: chatgpt-on-wechat
security_opt:
- seccomp:unconfined
ports:
- "9899:9899"
environment:
CHANNEL_TYPE: 'web'
MODEL: 'MiniMax-M2.5'
MINIMAX_API_KEY: ''
ZHIPU_AI_API_KEY: ''
ARK_API_KEY: ''
MOONSHOT_API_KEY: ''
DASHSCOPE_API_KEY: ''
CLAUDE_API_KEY: ''
CLAUDE_API_BASE: 'https://api.anthropic.com/v1'
OPEN_AI_API_KEY: ''
OPEN_AI_API_BASE: 'https://api.openai.com/v1'
GEMINI_API_KEY: ''
GEMINI_API_BASE: 'https://generativelanguage.googleapis.com'
VOICE_TO_TEXT: 'openai'
TEXT_TO_VOICE: 'openai'
VOICE_REPLY_VOICE: 'False'
SPEECH_RECOGNITION: 'True'
GROUP_SPEECH_RECOGNITION: 'False'
USE_LINKAI: 'False'
LINKAI_API_KEY: ''
LINKAI_APP_CODE: ''
FEISHU_APP_ID: ''
FEISHU_APP_SECRET: ''
DINGTALK_CLIENT_ID: ''
DINGTALK_CLIENT_SECRET: ''
WECOM_BOT_ID: ''
WECOM_BOT_SECRET: ''
AGENT: 'True'
AGENT_MAX_CONTEXT_TOKENS: 40000
AGENT_MAX_CONTEXT_TURNS: 20
AGENT_MAX_STEPS: 15
volumes:
- ./cow:/home/agent/cow
================================================
FILE: docker/entrypoint.sh
================================================
#!/bin/bash
set -e
# build prefix
CHATGPT_ON_WECHAT_PREFIX=${CHATGPT_ON_WECHAT_PREFIX:-""}
# path to config.json
CHATGPT_ON_WECHAT_CONFIG_PATH=${CHATGPT_ON_WECHAT_CONFIG_PATH:-""}
# execution command line
CHATGPT_ON_WECHAT_EXEC=${CHATGPT_ON_WECHAT_EXEC:-""}
# use environment variables to pass parameters
# if you have not defined environment variables, set them below
# export OPEN_AI_API_KEY=${OPEN_AI_API_KEY:-'YOUR API KEY'}
# export OPEN_AI_PROXY=${OPEN_AI_PROXY:-""}
# export SINGLE_CHAT_PREFIX=${SINGLE_CHAT_PREFIX:-'["bot", "@bot"]'}
# export SINGLE_CHAT_REPLY_PREFIX=${SINGLE_CHAT_REPLY_PREFIX:-'"[bot] "'}
# export GROUP_CHAT_PREFIX=${GROUP_CHAT_PREFIX:-'["@bot"]'}
# export GROUP_NAME_WHITE_LIST=${GROUP_NAME_WHITE_LIST:-'["ChatGPT测试群", "ChatGPT测试群2"]'}
# export IMAGE_CREATE_PREFIX=${IMAGE_CREATE_PREFIX:-'["画", "看", "找"]'}
# export CONVERSATION_MAX_TOKENS=${CONVERSATION_MAX_TOKENS:-"1000"}
# export SPEECH_RECOGNITION=${SPEECH_RECOGNITION:-"False"}
# export CHARACTER_DESC=${CHARACTER_DESC:-"你是ChatGPT, 一个由OpenAI训练的大型语言模型, 你旨在回答并解决人们的任何问题,并且可以使用多种语言与人交流。"}
# export EXPIRES_IN_SECONDS=${EXPIRES_IN_SECONDS:-"3600"}
# CHATGPT_ON_WECHAT_PREFIX is empty, use /app
if [ "$CHATGPT_ON_WECHAT_PREFIX" == "" ] ; then
CHATGPT_ON_WECHAT_PREFIX=/app
fi
# CHATGPT_ON_WECHAT_CONFIG_PATH is empty, use '/app/config.json'
if [ "$CHATGPT_ON_WECHAT_CONFIG_PATH" == "" ] ; then
CHATGPT_ON_WECHAT_CONFIG_PATH=$CHATGPT_ON_WECHAT_PREFIX/config.json
fi
# CHATGPT_ON_WECHAT_EXEC is empty, use ‘python app.py’
if [ "$CHATGPT_ON_WECHAT_EXEC" == "" ] ; then
CHATGPT_ON_WECHAT_EXEC="python app.py"
fi
# modify content in config.json
# if [ "$OPEN_AI_API_KEY" == "YOUR API KEY" ] || [ "$OPEN_AI_API_KEY" == "" ]; then
# echo -e "\033[31m[Warning] You need to set OPEN_AI_API_KEY before running!\033[0m"
# fi
# go to prefix dir
cd $CHATGPT_ON_WECHAT_PREFIX
# excute
$CHATGPT_ON_WECHAT_EXEC
================================================
FILE: docs/agent.md
================================================
# CowAgent介绍
## 概述
Cow项目从简单的聊天机器人全面升级为超级智能助理 **CowAgent**,能够主动规思考和规划任务、拥有长期记忆、操作计算机和外部资源、创造和执行Skill,真正理解你并和你一起成长。CowAgent能够长期运行在个人电脑或服务器中,通过飞书、钉钉、企业微信、网页等多种方式进行交互。核心能力如下:
- **复杂任务规划**:能够理解复杂任务并自主规划执行,持续思考和调用工具直到完成目标,支持多轮推理和上下文理解
- **工具系统**:内置实现10+种工具,包括文件读写、bash终端、浏览器、定时任务、记忆管理等,通过Agent管理你的计算机或服务器
- **长期记忆**:自动将对话记忆持久化至本地文件和数据库中,包括全局记忆和天级记忆,支持关键词及向量检索
- **Skills系统**:新增Skill运行引擎,内置多种技能,并支持通过自然语言对话完成自定义Skills开发
- **多渠道和多模型支持**:支持在Web、飞书、钉钉、企微等多渠道与Agent交互,支持Claude、Gemini、OpenAI、GLM、MiniMax、Qwen、Kimi、Doubao 等多种国内外主流模型
- **安全和成本**:通过秘钥管理工具、提示词控制、系统权限等手段控制Agent的访问安全;通过最大记忆轮次、最大上下文token、工具执行步数对token成本进行限制
## 核心功能
### 1. 长期记忆
> 记忆系统让 Agent 能够长期记住重要信息。Agent 会在用户分享偏好、决策、事实等重要信息时主动存储,也会在对话达到一定长度时自动提取摘要。记忆分为核心记忆、天级记忆,支持语义搜索和向量检索的混合检索模式。
第一次启动Agent会主动向用户获取询问关键信息,并记录至工作空间 (默认为 ~/cow) 中的智能体设定、用户身份、记忆文件中。
在后续的长期对话中,Agent会在需要的时候智能记录或检索记忆,并对自身设定、用户偏好、记忆文件等进行不断更新,总结和记录经验和教训,真正实现自主思考和不断成长。
~~
================================================
FILE: channel/wechatcom/wechatcomapp_channel.py
================================================
# -*- coding=utf-8 -*-
import io
import os
import sys
import time
import requests
import web
from wechatpy.enterprise import create_reply, parse_message
from wechatpy.enterprise.crypto import WeChatCrypto
from wechatpy.enterprise.exceptions import InvalidCorpIdException
from wechatpy.exceptions import InvalidSignatureException, WeChatClientException
from bridge.context import Context
from bridge.reply import Reply, ReplyType
from channel.chat_channel import ChatChannel
from channel.wechatcom.wechatcomapp_client import WechatComAppClient
from channel.wechatcom.wechatcomapp_message import WechatComAppMessage
from common.log import logger
from common.singleton import singleton
from common.utils import compress_imgfile, fsize, split_string_by_utf8_length, convert_webp_to_png, remove_markdown_symbol
from config import conf, subscribe_msg
from voice.audio_convert import any_to_amr, split_audio
MAX_UTF8_LEN = 2048
@singleton
class WechatComAppChannel(ChatChannel):
NOT_SUPPORT_REPLYTYPE = []
def __init__(self):
super().__init__()
self.corp_id = conf().get("wechatcom_corp_id")
self.secret = conf().get("wechatcomapp_secret")
self.agent_id = conf().get("wechatcomapp_agent_id")
self.token = conf().get("wechatcomapp_token")
self.aes_key = conf().get("wechatcomapp_aes_key")
self._http_server = None
logger.info(
"[wechatcom] Initializing WeCom app channel, corp_id: {}, agent_id: {}".format(self.corp_id, self.agent_id)
)
self.crypto = WeChatCrypto(self.token, self.aes_key, self.corp_id)
self.client = WechatComAppClient(self.corp_id, self.secret)
def startup(self):
# start message listener
urls = ("/wxcomapp/?", "channel.wechatcom.wechatcomapp_channel.Query")
app = web.application(urls, globals(), autoreload=False)
port = conf().get("wechatcomapp_port", 9898)
logger.info("[wechatcom] ✅ WeCom app channel started successfully")
logger.info("[wechatcom] 📡 Listening on http://0.0.0.0:{}/wxcomapp/".format(port))
logger.info("[wechatcom] 🤖 Ready to receive messages")
# Build WSGI app with middleware (same as runsimple but without print)
func = web.httpserver.StaticMiddleware(app.wsgifunc())
func = web.httpserver.LogMiddleware(func)
server = web.httpserver.WSGIServer(("0.0.0.0", port), func)
self._http_server = server
try:
server.start()
except (KeyboardInterrupt, SystemExit):
server.stop()
def stop(self):
if self._http_server:
try:
self._http_server.stop()
logger.info("[wechatcom] HTTP server stopped")
except Exception as e:
logger.warning(f"[wechatcom] Error stopping HTTP server: {e}")
self._http_server = None
def send(self, reply: Reply, context: Context):
receiver = context["receiver"]
if reply.type in [ReplyType.TEXT, ReplyType.ERROR, ReplyType.INFO]:
reply_text = remove_markdown_symbol(reply.content)
texts = split_string_by_utf8_length(reply_text, MAX_UTF8_LEN)
if len(texts) > 1:
logger.info("[wechatcom] text too long, split into {} parts".format(len(texts)))
for i, text in enumerate(texts):
self.client.message.send_text(self.agent_id, receiver, text)
if i != len(texts) - 1:
time.sleep(0.5) # 休眠0.5秒,防止发送过快乱序
logger.info("[wechatcom] Do send text to {}: {}".format(receiver, reply_text))
elif reply.type == ReplyType.VOICE:
try:
media_ids = []
file_path = reply.content
amr_file = os.path.splitext(file_path)[0] + ".amr"
any_to_amr(file_path, amr_file)
duration, files = split_audio(amr_file, 60 * 1000)
if len(files) > 1:
logger.info("[wechatcom] voice too long {}s > 60s , split into {} parts".format(duration / 1000.0, len(files)))
for path in files:
response = self.client.media.upload("voice", open(path, "rb"))
logger.debug("[wechatcom] upload voice response: {}".format(response))
media_ids.append(response["media_id"])
except ImportError as e:
logger.error("[wechatcom] voice conversion failed: {}".format(e))
logger.error("[wechatcom] please install pydub: pip install pydub")
return
except WeChatClientException as e:
logger.error("[wechatcom] upload voice failed: {}".format(e))
return
try:
os.remove(file_path)
if amr_file != file_path:
os.remove(amr_file)
except Exception:
pass
for media_id in media_ids:
self.client.message.send_voice(self.agent_id, receiver, media_id)
time.sleep(1)
logger.info("[wechatcom] sendVoice={}, receiver={}".format(reply.content, receiver))
elif reply.type == ReplyType.IMAGE_URL: # 从网络下载图片
img_url = reply.content
pic_res = requests.get(img_url, stream=True)
image_storage = io.BytesIO()
for block in pic_res.iter_content(1024):
image_storage.write(block)
sz = fsize(image_storage)
if sz >= 10 * 1024 * 1024:
logger.info("[wechatcom] image too large, ready to compress, sz={}".format(sz))
image_storage = compress_imgfile(image_storage, 10 * 1024 * 1024 - 1)
logger.info("[wechatcom] image compressed, sz={}".format(fsize(image_storage)))
image_storage.seek(0)
if ".webp" in img_url:
try:
image_storage = convert_webp_to_png(image_storage)
except Exception as e:
logger.error(f"Failed to convert image: {e}")
return
try:
response = self.client.media.upload("image", image_storage)
logger.debug("[wechatcom] upload image response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatcom] upload image failed: {}".format(e))
return
self.client.message.send_image(self.agent_id, receiver, response["media_id"])
logger.info("[wechatcom] sendImage url={}, receiver={}".format(img_url, receiver))
elif reply.type == ReplyType.IMAGE: # 从文件读取图片
image_storage = reply.content
sz = fsize(image_storage)
if sz >= 10 * 1024 * 1024:
logger.info("[wechatcom] image too large, ready to compress, sz={}".format(sz))
image_storage = compress_imgfile(image_storage, 10 * 1024 * 1024 - 1)
logger.info("[wechatcom] image compressed, sz={}".format(fsize(image_storage)))
image_storage.seek(0)
try:
response = self.client.media.upload("image", image_storage)
logger.debug("[wechatcom] upload image response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatcom] upload image failed: {}".format(e))
return
self.client.message.send_image(self.agent_id, receiver, response["media_id"])
logger.info("[wechatcom] sendImage, receiver={}".format(receiver))
class Query:
def GET(self):
channel = WechatComAppChannel()
params = web.input()
logger.info("[wechatcom] receive params: {}".format(params))
try:
signature = params.msg_signature
timestamp = params.timestamp
nonce = params.nonce
echostr = params.echostr
echostr = channel.crypto.check_signature(signature, timestamp, nonce, echostr)
except InvalidSignatureException:
raise web.Forbidden()
return echostr
def POST(self):
channel = WechatComAppChannel()
params = web.input()
logger.info("[wechatcom] receive params: {}".format(params))
try:
signature = params.msg_signature
timestamp = params.timestamp
nonce = params.nonce
message = channel.crypto.decrypt_message(web.data(), signature, timestamp, nonce)
except (InvalidSignatureException, InvalidCorpIdException):
raise web.Forbidden()
msg = parse_message(message)
logger.debug("[wechatcom] receive message: {}, msg= {}".format(message, msg))
if msg.type == "event":
if msg.event == "subscribe":
pass
# reply_content = subscribe_msg()
# if reply_content:
# reply = create_reply(reply_content, msg).render()
# res = channel.crypto.encrypt_message(reply, nonce, timestamp)
# return res
else:
try:
wechatcom_msg = WechatComAppMessage(msg, client=channel.client)
except NotImplementedError as e:
logger.debug("[wechatcom] " + str(e))
return "success"
context = channel._compose_context(
wechatcom_msg.ctype,
wechatcom_msg.content,
isgroup=False,
msg=wechatcom_msg,
)
if context:
channel.produce(context)
return "success"
================================================
FILE: channel/wechatcom/wechatcomapp_client.py
================================================
# wechatcomapp_client.py
import threading
import time
from wechatpy.enterprise import WeChatClient
class WechatComAppClient(WeChatClient):
def __init__(self, corp_id, secret, access_token=None, session=None, timeout=None, auto_retry=True):
super(WechatComAppClient, self).__init__(corp_id, secret, access_token, session, timeout, auto_retry)
self.fetch_access_token_lock = threading.Lock()
self._active_refresh()
def _active_refresh(self):
"""启动主动刷新的后台线程"""
def refresh_loop():
while True:
now = time.time()
expires_at = self.session.get(f"{self.corp_id}_expires_at", 0)
# 提前10分钟刷新(600秒)
if expires_at - now < 600:
with self.fetch_access_token_lock:
# 双重检查避免重复刷新
if self.session.get(f"{self.corp_id}_expires_at", 0) - time.time() < 600:
super(WechatComAppClient, self).fetch_access_token()
# 每次检查间隔60秒
time.sleep(60)
# 启动守护线程
refresh_thread = threading.Thread(
target=refresh_loop,
daemon=True,
name="wechatcom_token_refresh_thread"
)
refresh_thread.start()
def fetch_access_token(self):
with self.fetch_access_token_lock:
access_token = self.session.get(self.access_token_key)
expires_at = self.session.get(f"{self.corp_id}_expires_at", 0)
if access_token and expires_at > time.time() + 60:
return access_token
return super().fetch_access_token()
================================================
FILE: channel/wechatcom/wechatcomapp_message.py
================================================
from wechatpy.enterprise import WeChatClient
from bridge.context import ContextType
from channel.chat_message import ChatMessage
from common.log import logger
from common.tmp_dir import TmpDir
class WechatComAppMessage(ChatMessage):
def __init__(self, msg, client: WeChatClient, is_group=False):
super().__init__(msg)
self.msg_id = msg.id
self.create_time = msg.time
self.is_group = is_group
if msg.type == "text":
self.ctype = ContextType.TEXT
self.content = msg.content
elif msg.type == "voice":
self.ctype = ContextType.VOICE
self.content = TmpDir().path() + msg.media_id + "." + msg.format # content直接存临时目录路径
def download_voice():
# 如果响应状态码是200,则将响应内容写入本地文件
response = client.media.download(msg.media_id)
if response.status_code == 200:
with open(self.content, "wb") as f:
f.write(response.content)
else:
logger.info(f"[wechatcom] Failed to download voice file, {response.content}")
self._prepare_fn = download_voice
elif msg.type == "image":
self.ctype = ContextType.IMAGE
self.content = TmpDir().path() + msg.media_id + ".png" # content直接存临时目录路径
def download_image():
# 如果响应状态码是200,则将响应内容写入本地文件
response = client.media.download(msg.media_id)
if response.status_code == 200:
with open(self.content, "wb") as f:
f.write(response.content)
else:
logger.info(f"[wechatcom] Failed to download image file, {response.content}")
self._prepare_fn = download_image
else:
raise NotImplementedError("Unsupported message type: Type:{} ".format(msg.type))
self.from_user_id = msg.source
self.to_user_id = msg.target
self.other_user_id = msg.source
================================================
FILE: channel/wechatmp/README.md
================================================
# 微信公众号channel
微信公众号channel,提供稳定的服务。
目前支持订阅号和服务号两种类型的公众号,它们都支持文本交互,语音和图片输入。其中个人主体的微信订阅号由于无法通过微信认证,存在回复时间限制,每天的图片和声音回复次数也有限制。
## 使用方法(订阅号,服务号类似)
在开始部署前,你需要一个拥有公网IP的服务器,以提供微信服务器和我们自己服务器的连接。或者你需要进行内网穿透,否则微信服务器无法将消息发送给我们的服务器。
此外,需要在我们的服务器上安装python的web框架web.py和wechatpy。
以ubuntu为例(在ubuntu 22.04上测试):
```
pip3 install web.py
pip3 install wechatpy
```
然后在[微信公众平台](https://mp.weixin.qq.com)注册一个自己的公众号,类型选择订阅号,主体为个人即可。
然后根据[接入指南](https://developers.weixin.qq.com/doc/offiaccount/Basic_Information/Access_Overview.html)的说明,在[微信公众平台](https://mp.weixin.qq.com)的“设置与开发”-“基本配置”-“服务器配置”中填写服务器地址`URL`和令牌`Token`。`URL`填写格式为`http://url/wx`,可使用IP(成功几率看脸),`Token`是你自己编的一个特定的令牌。消息加解密方式如果选择了需要加密的模式,需要在配置中填写`wechatmp_aes_key`。
相关的服务器验证代码已经写好,你不需要再添加任何代码。你只需要在本项目根目录的`config.json`中添加
```
"channel_type": "wechatmp", # 如果通过了微信认证,将"wechatmp"替换为"wechatmp_service",可极大的优化使用体验
"wechatmp_token": "xxxx", # 微信公众平台的Token
"wechatmp_port": 8080, # 微信公众平台的端口,需要端口转发到80或443
"wechatmp_app_id": "xxxx", # 微信公众平台的appID
"wechatmp_app_secret": "xxxx", # 微信公众平台的appsecret
"wechatmp_aes_key": "", # 微信公众平台的EncodingAESKey,加密模式需要
"single_chat_prefix": [""], # 推荐设置,任意对话都可以触发回复,不添加前缀
"single_chat_reply_prefix": "", # 推荐设置,回复不设置前缀
"plugin_trigger_prefix": "&", # 推荐设置,在手机微信客户端中,$%^等符号与中文连在一起时会自动显示一段较大的间隔,用户体验不好。请不要使用管理员指令前缀"#",这会造成未知问题。
```
然后运行`python3 app.py`启动web服务器。这里会默认监听8080端口,但是微信公众号的服务器配置只支持80/443端口,有两种方法来解决这个问题。第一个是推荐的方法,使用端口转发命令将80端口转发到8080端口:
```
sudo iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 8080
sudo iptables-save > /etc/iptables/rules.v4
```
第二个方法是让python程序直接监听80端口,在配置文件中设置`"wechatmp_port": 80` ,在linux上需要使用`sudo python3 app.py`启动程序。然而这会导致一系列环境和权限问题,因此不是推荐的方法。
443端口同理,注意需要支持SSL,也就是https的访问,在`wechatmp_channel.py`中需要修改相应的证书路径。
程序启动并监听端口后,在刚才的“服务器配置”中点击`提交`即可验证你的服务器。
随后在[微信公众平台](https://mp.weixin.qq.com)启用服务器,关闭手动填写规则的自动回复,即可实现ChatGPT的自动回复。
之后需要在公众号开发信息下将本机IP加入到IP白名单。
不然在启用后,发送语音、图片等消息可能会遇到如下报错:
```
'errcode': 40164, 'errmsg': 'invalid ip xx.xx.xx.xx not in whitelist rid
```
## 个人微信公众号的限制
由于人微信公众号不能通过微信认证,所以没有客服接口,因此公众号无法主动发出消息,只能被动回复。而微信官方对被动回复有5秒的时间限制,最多重试2次,因此最多只有15秒的自动回复时间窗口。因此如果问题比较复杂或者我们的服务器比较忙,ChatGPT的回答就没办法及时回复给用户。为了解决这个问题,这里做了回答缓存,它需要你在回复超时后,再次主动发送任意文字(例如1)来尝试拿到回答缓存。为了优化使用体验,目前设置了两分钟(120秒)的timeout,用户在至多两分钟后即可得到查询到回复或者错误原因。
另外,由于微信官方的限制,自动回复有长度限制。因此这里将ChatGPT的回答进行了拆分,以满足限制。
## 私有api_key
公共api有访问频率限制(免费账号每分钟最多3次ChatGPT的API调用),这在服务多人的时候会遇到问题。因此这里多加了一个设置私有api_key的功能。目前通过godcmd插件的命令来设置私有api_key。
## 语音输入
利用微信自带的语音识别功能,提供语音输入能力。需要在公众号管理页面的“设置与开发”->“接口权限”页面开启“接收语音识别结果”。
## 语音回复
请在配置文件中添加以下词条:
```
"voice_reply_voice": true,
```
这样公众号将会用语音回复语音消息,实现语音对话。
默认的语音合成引擎是`google`,它是免费使用的。
如果要选择其他的语音合成引擎,请添加以下配置项:
```
"text_to_voice": "pytts"
```
pytts是本地的语音合成引擎。还支持baidu,azure,这些你需要自行配置相关的依赖和key。
如果使用pytts,在ubuntu上需要安装如下依赖:
```
sudo apt update
sudo apt install espeak
sudo apt install ffmpeg
python3 -m pip install pyttsx3
```
不是很建议开启pytts语音回复,因为它是离线本地计算,算的慢会拖垮服务器,且声音不好听。
## 图片回复
现在认证公众号和非认证公众号都可以实现的图片和语音回复。但是非认证公众号使用了永久素材接口,每天有1000次的调用上限(每个月有10次重置机会,程序中已设定遇到上限会自动重置),且永久素材库存也有上限。因此对于非认证公众号,我们会在回复图片或者语音消息后的10秒内从永久素材库存内删除该素材。
## 测试
目前在`RoboStyle`这个公众号上进行了测试(基于[wechatmp分支](https://github.com/JS00000/chatgpt-on-wechat/tree/wechatmp)),感兴趣的可以关注并体验。开启了godcmd, Banwords, role, dungeon, finish这五个插件,其他的插件还没有详尽测试。百度的接口暂未测试。[wechatmp-stable分支](https://github.com/JS00000/chatgpt-on-wechat/tree/wechatmp-stable)是较稳定的上个版本,但也缺少最新的功能支持。
## TODO
- [x] 语音输入
- [x] 图片输入
- [x] 使用临时素材接口提供认证公众号的图片和语音回复
- [x] 使用永久素材接口提供未认证公众号的图片和语音回复
- [ ] 高并发支持
================================================
FILE: channel/wechatmp/active_reply.py
================================================
import time
import web
from wechatpy import parse_message
from wechatpy.replies import create_reply
from bridge.context import *
from bridge.reply import *
from channel.wechatmp.common import *
from channel.wechatmp.wechatmp_channel import WechatMPChannel
from channel.wechatmp.wechatmp_message import WeChatMPMessage
from common.log import logger
from config import conf, subscribe_msg
# This class is instantiated once per query
class Query:
def GET(self):
return verify_server(web.input())
def POST(self):
# Make sure to return the instance that first created, @singleton will do that.
try:
args = web.input()
verify_server(args)
channel = WechatMPChannel()
message = web.data()
encrypt_func = lambda x: x
if args.get("encrypt_type") == "aes":
logger.debug("[wechatmp] Receive encrypted post data:\n" + message.decode("utf-8"))
if not channel.crypto:
raise Exception("Crypto not initialized, Please set wechatmp_aes_key in config.json")
message = channel.crypto.decrypt_message(message, args.msg_signature, args.timestamp, args.nonce)
encrypt_func = lambda x: channel.crypto.encrypt_message(x, args.nonce, args.timestamp)
else:
logger.debug("[wechatmp] Receive post data:\n" + message.decode("utf-8"))
msg = parse_message(message)
if msg.type in ["text", "voice", "image"]:
wechatmp_msg = WeChatMPMessage(msg, client=channel.client)
from_user = wechatmp_msg.from_user_id
content = wechatmp_msg.content
message_id = wechatmp_msg.msg_id
logger.info(
"[wechatmp] {}:{} Receive post query {} {}: {}".format(
web.ctx.env.get("REMOTE_ADDR"),
web.ctx.env.get("REMOTE_PORT"),
from_user,
message_id,
content,
)
)
if msg.type == "voice" and wechatmp_msg.ctype == ContextType.TEXT and conf().get("voice_reply_voice", False):
context = channel._compose_context(wechatmp_msg.ctype, content, isgroup=False, desire_rtype=ReplyType.VOICE, msg=wechatmp_msg)
else:
context = channel._compose_context(wechatmp_msg.ctype, content, isgroup=False, msg=wechatmp_msg)
if context:
channel.produce(context)
# The reply will be sent by channel.send() in another thread
return "success"
elif msg.type == "event":
logger.info("[wechatmp] Event {} from {}".format(msg.event, msg.source))
if msg.event in ["subscribe", "subscribe_scan"]:
reply_text = subscribe_msg()
if reply_text:
replyPost = create_reply(reply_text, msg)
return encrypt_func(replyPost.render())
else:
return "success"
else:
logger.info("暂且不处理")
return "success"
except Exception as exc:
logger.exception(exc)
return exc
================================================
FILE: channel/wechatmp/common.py
================================================
import web
from wechatpy.crypto import WeChatCrypto
from wechatpy.exceptions import InvalidSignatureException
from wechatpy.utils import check_signature
from config import conf
MAX_UTF8_LEN = 2048
class WeChatAPIException(Exception):
pass
def verify_server(data):
try:
signature = data.signature
timestamp = data.timestamp
nonce = data.nonce
echostr = data.get("echostr", None)
token = conf().get("wechatmp_token") # 请按照公众平台官网\基本配置中信息填写
check_signature(token, signature, timestamp, nonce)
return echostr
except InvalidSignatureException:
raise web.Forbidden("Invalid signature")
except Exception as e:
raise web.Forbidden(str(e))
================================================
FILE: channel/wechatmp/passive_reply.py
================================================
import asyncio
import time
import web
from wechatpy import parse_message
from wechatpy.replies import ImageReply, VoiceReply, create_reply
import textwrap
from bridge.context import *
from bridge.reply import *
from channel.wechatmp.common import *
from channel.wechatmp.wechatmp_channel import WechatMPChannel
from channel.wechatmp.wechatmp_message import WeChatMPMessage
from common.log import logger
from common.utils import split_string_by_utf8_length
from config import conf, subscribe_msg
# This class is instantiated once per query
class Query:
def GET(self):
return verify_server(web.input())
def POST(self):
try:
args = web.input()
verify_server(args)
request_time = time.time()
channel = WechatMPChannel()
message = web.data()
encrypt_func = lambda x: x
if args.get("encrypt_type") == "aes":
logger.debug("[wechatmp] Receive encrypted post data:\n" + message.decode("utf-8"))
if not channel.crypto:
raise Exception("Crypto not initialized, Please set wechatmp_aes_key in config.json")
message = channel.crypto.decrypt_message(message, args.msg_signature, args.timestamp, args.nonce)
encrypt_func = lambda x: channel.crypto.encrypt_message(x, args.nonce, args.timestamp)
else:
logger.debug("[wechatmp] Receive post data:\n" + message.decode("utf-8"))
msg = parse_message(message)
if msg.type in ["text", "voice", "image"]:
wechatmp_msg = WeChatMPMessage(msg, client=channel.client)
from_user = wechatmp_msg.from_user_id
content = wechatmp_msg.content
message_id = wechatmp_msg.msg_id
supported = True
if "【收到不支持的消息类型,暂无法显示】" in content:
supported = False # not supported, used to refresh
# New request
if (
channel.cache_dict.get(from_user) is None
and from_user not in channel.running
or content.startswith("#")
and message_id not in channel.request_cnt # insert the godcmd
):
# The first query begin
if msg.type == "voice" and wechatmp_msg.ctype == ContextType.TEXT and conf().get("voice_reply_voice", False):
context = channel._compose_context(wechatmp_msg.ctype, content, isgroup=False, desire_rtype=ReplyType.VOICE, msg=wechatmp_msg)
else:
context = channel._compose_context(wechatmp_msg.ctype, content, isgroup=False, msg=wechatmp_msg)
logger.debug("[wechatmp] context: {} {} {}".format(context, wechatmp_msg, supported))
if supported and context:
channel.running.add(from_user)
channel.produce(context)
else:
trigger_prefix = conf().get("single_chat_prefix", [""])[0]
if trigger_prefix or not supported:
if trigger_prefix:
reply_text = textwrap.dedent(
f"""\
请输入'{trigger_prefix}'接你想说的话跟我说话。
例如:
{trigger_prefix}你好,很高兴见到你。"""
)
else:
reply_text = textwrap.dedent(
"""\
你好,很高兴见到你。
请跟我说话吧。"""
)
else:
logger.error(f"[wechatmp] unknown error")
reply_text = textwrap.dedent(
"""\
未知错误,请稍后再试"""
)
replyPost = create_reply(reply_text, msg)
return encrypt_func(replyPost.render())
# Wechat official server will request 3 times (5 seconds each), with the same message_id.
# Because the interval is 5 seconds, here assumed that do not have multithreading problems.
request_cnt = channel.request_cnt.get(message_id, 0) + 1
channel.request_cnt[message_id] = request_cnt
logger.info(
"[wechatmp] Request {} from {} {} {}:{}\n{}".format(
request_cnt, from_user, message_id, web.ctx.env.get("REMOTE_ADDR"), web.ctx.env.get("REMOTE_PORT"), content
)
)
task_running = True
waiting_until = request_time + 4
while time.time() < waiting_until:
if from_user in channel.running:
time.sleep(0.1)
else:
task_running = False
break
reply_text = ""
if task_running:
if request_cnt < 3:
# waiting for timeout (the POST request will be closed by Wechat official server)
time.sleep(2)
# and do nothing, waiting for the next request
return "success"
else: # request_cnt == 3:
# return timeout message
reply_text = "【正在思考中,回复任意文字尝试获取回复】"
replyPost = create_reply(reply_text, msg)
return encrypt_func(replyPost.render())
# reply is ready
channel.request_cnt.pop(message_id)
# no return because of bandwords or other reasons
if from_user not in channel.cache_dict and from_user not in channel.running:
return "success"
# Only one request can access to the cached data
try:
(reply_type, reply_content) = channel.cache_dict[from_user].pop(0)
if not channel.cache_dict[from_user]: # If popping the message makes the list empty, delete the user entry from cache
del channel.cache_dict[from_user]
except IndexError:
return "success"
if reply_type == "text":
if len(reply_content.encode("utf8")) <= MAX_UTF8_LEN:
reply_text = reply_content
else:
continue_text = "\n【未完待续,回复任意文字以继续】"
splits = split_string_by_utf8_length(
reply_content,
MAX_UTF8_LEN - len(continue_text.encode("utf-8")),
max_split=1,
)
reply_text = splits[0] + continue_text
channel.cache_dict[from_user].append(("text", splits[1]))
logger.info(
"[wechatmp] Request {} do send to {} {}: {}\n{}".format(
request_cnt,
from_user,
message_id,
content,
reply_text,
)
)
replyPost = create_reply(reply_text, msg)
return encrypt_func(replyPost.render())
elif reply_type == "voice":
media_id = reply_content
asyncio.run_coroutine_threadsafe(channel.delete_media(media_id), channel.delete_media_loop)
logger.info(
"[wechatmp] Request {} do send to {} {}: {} voice media_id {}".format(
request_cnt,
from_user,
message_id,
content,
media_id,
)
)
replyPost = VoiceReply(message=msg)
replyPost.media_id = media_id
return encrypt_func(replyPost.render())
elif reply_type == "image":
media_id = reply_content
asyncio.run_coroutine_threadsafe(channel.delete_media(media_id), channel.delete_media_loop)
logger.info(
"[wechatmp] Request {} do send to {} {}: {} image media_id {}".format(
request_cnt,
from_user,
message_id,
content,
media_id,
)
)
replyPost = ImageReply(message=msg)
replyPost.media_id = media_id
return encrypt_func(replyPost.render())
elif msg.type == "event":
logger.info("[wechatmp] Event {} from {}".format(msg.event, msg.source))
if msg.event in ["subscribe", "subscribe_scan"]:
reply_text = subscribe_msg()
if reply_text:
replyPost = create_reply(reply_text, msg)
return encrypt_func(replyPost.render())
else:
return "success"
else:
logger.info("暂且不处理")
return "success"
except Exception as exc:
logger.exception(exc)
return exc
================================================
FILE: channel/wechatmp/wechatmp_channel.py
================================================
# -*- coding: utf-8 -*-
import asyncio
import imghdr
import io
import os
import threading
import time
import requests
import web
from wechatpy.crypto import WeChatCrypto
from wechatpy.exceptions import WeChatClientException
from collections import defaultdict
from bridge.context import *
from bridge.reply import *
from channel.chat_channel import ChatChannel
from channel.wechatmp.common import *
from channel.wechatmp.wechatmp_client import WechatMPClient
from common.log import logger
from common.singleton import singleton
from common.utils import split_string_by_utf8_length, remove_markdown_symbol
from config import conf
try:
from voice.audio_convert import any_to_mp3, split_audio
except ImportError as e:
logger.debug("import voice.audio_convert failed, voice features will not be supported: {}".format(e))
# If using SSL, uncomment the following lines, and modify the certificate path.
# from cheroot.server import HTTPServer
# from cheroot.ssl.builtin import BuiltinSSLAdapter
# HTTPServer.ssl_adapter = BuiltinSSLAdapter(
# certificate='/ssl/cert.pem',
# private_key='/ssl/cert.key')
@singleton
class WechatMPChannel(ChatChannel):
def __init__(self, passive_reply=True):
super().__init__()
self.passive_reply = passive_reply
self.NOT_SUPPORT_REPLYTYPE = []
self._http_server = None
appid = conf().get("wechatmp_app_id")
secret = conf().get("wechatmp_app_secret")
token = conf().get("wechatmp_token")
aes_key = conf().get("wechatmp_aes_key")
self.client = WechatMPClient(appid, secret)
self.crypto = None
if aes_key:
self.crypto = WeChatCrypto(token, aes_key, appid)
if self.passive_reply:
# Cache the reply to the user's first message
self.cache_dict = defaultdict(list)
# Record whether the current message is being processed
self.running = set()
# Count the request from wechat official server by message_id
self.request_cnt = dict()
# The permanent media need to be deleted to avoid media number limit
self.delete_media_loop = asyncio.new_event_loop()
t = threading.Thread(target=self.start_loop, args=(self.delete_media_loop,))
t.setDaemon(True)
t.start()
def startup(self):
if self.passive_reply:
urls = ("/wx", "channel.wechatmp.passive_reply.Query")
else:
urls = ("/wx", "channel.wechatmp.active_reply.Query")
app = web.application(urls, globals(), autoreload=False)
port = conf().get("wechatmp_port", 8080)
func = web.httpserver.StaticMiddleware(app.wsgifunc())
func = web.httpserver.LogMiddleware(func)
server = web.httpserver.WSGIServer(("0.0.0.0", port), func)
self._http_server = server
try:
server.start()
except (KeyboardInterrupt, SystemExit):
server.stop()
def stop(self):
if self._http_server:
try:
self._http_server.stop()
logger.info("[wechatmp] HTTP server stopped")
except Exception as e:
logger.warning(f"[wechatmp] Error stopping HTTP server: {e}")
self._http_server = None
def start_loop(self, loop):
asyncio.set_event_loop(loop)
loop.run_forever()
async def delete_media(self, media_id):
logger.debug("[wechatmp] permanent media {} will be deleted in 10s".format(media_id))
await asyncio.sleep(10)
self.client.material.delete(media_id)
logger.info("[wechatmp] permanent media {} has been deleted".format(media_id))
def send(self, reply: Reply, context: Context):
receiver = context["receiver"]
if self.passive_reply:
if reply.type == ReplyType.TEXT or reply.type == ReplyType.INFO or reply.type == ReplyType.ERROR:
reply_text = remove_markdown_symbol(reply.content)
logger.info("[wechatmp] text cached, receiver {}\n{}".format(receiver, reply_text))
self.cache_dict[receiver].append(("text", reply_text))
elif reply.type == ReplyType.VOICE:
try:
voice_file_path = reply.content
duration, files = split_audio(voice_file_path, 60 * 1000)
if len(files) > 1:
logger.info("[wechatmp] voice too long {}s > 60s , split into {} parts".format(duration / 1000.0, len(files)))
for path in files:
# support: <2M, <60s, mp3/wma/wav/amr
try:
with open(path, "rb") as f:
response = self.client.material.add("voice", f)
logger.debug("[wechatmp] upload voice response: {}".format(response))
f_size = os.fstat(f.fileno()).st_size
time.sleep(1.0 + 2 * f_size / 1024 / 1024)
# todo check media_id
except WeChatClientException as e:
logger.error("[wechatmp] upload voice failed: {}".format(e))
return
media_id = response["media_id"]
logger.info("[wechatmp] voice uploaded, receiver {}, media_id {}".format(receiver, media_id))
self.cache_dict[receiver].append(("voice", media_id))
except ImportError as e:
logger.error("[wechatmp] voice conversion failed: {}".format(e))
logger.error("[wechatmp] please install pydub: pip install pydub")
return
elif reply.type == ReplyType.IMAGE_URL: # 从网络下载图片
img_url = reply.content
pic_res = requests.get(img_url, stream=True)
image_storage = io.BytesIO()
for block in pic_res.iter_content(1024):
image_storage.write(block)
image_storage.seek(0)
image_type = imghdr.what(image_storage)
filename = receiver + "-" + str(context["msg"].msg_id) + "." + image_type
content_type = "image/" + image_type
try:
response = self.client.material.add("image", (filename, image_storage, content_type))
logger.debug("[wechatmp] upload image response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload image failed: {}".format(e))
return
media_id = response["media_id"]
logger.info("[wechatmp] image uploaded, receiver {}, media_id {}".format(receiver, media_id))
self.cache_dict[receiver].append(("image", media_id))
elif reply.type == ReplyType.IMAGE: # 从文件读取图片
image_storage = reply.content
image_storage.seek(0)
image_type = imghdr.what(image_storage)
filename = receiver + "-" + str(context["msg"].msg_id) + "." + image_type
content_type = "image/" + image_type
try:
response = self.client.material.add("image", (filename, image_storage, content_type))
logger.debug("[wechatmp] upload image response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload image failed: {}".format(e))
return
media_id = response["media_id"]
logger.info("[wechatmp] image uploaded, receiver {}, media_id {}".format(receiver, media_id))
self.cache_dict[receiver].append(("image", media_id))
elif reply.type == ReplyType.VIDEO_URL: # 从网络下载视频
video_url = reply.content
video_res = requests.get(video_url, stream=True)
video_storage = io.BytesIO()
for block in video_res.iter_content(1024):
video_storage.write(block)
video_storage.seek(0)
video_type = 'mp4'
filename = receiver + "-" + str(context["msg"].msg_id) + "." + video_type
content_type = "video/" + video_type
try:
response = self.client.material.add("video", (filename, video_storage, content_type))
logger.debug("[wechatmp] upload video response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload video failed: {}".format(e))
return
media_id = response["media_id"]
logger.info("[wechatmp] video uploaded, receiver {}, media_id {}".format(receiver, media_id))
self.cache_dict[receiver].append(("video", media_id))
elif reply.type == ReplyType.VIDEO: # 从文件读取视频
video_storage = reply.content
video_storage.seek(0)
video_type = 'mp4'
filename = receiver + "-" + str(context["msg"].msg_id) + "." + video_type
content_type = "video/" + video_type
try:
response = self.client.material.add("video", (filename, video_storage, content_type))
logger.debug("[wechatmp] upload video response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload video failed: {}".format(e))
return
media_id = response["media_id"]
logger.info("[wechatmp] video uploaded, receiver {}, media_id {}".format(receiver, media_id))
self.cache_dict[receiver].append(("video", media_id))
else:
if reply.type == ReplyType.TEXT or reply.type == ReplyType.INFO or reply.type == ReplyType.ERROR:
reply_text = reply.content
texts = split_string_by_utf8_length(reply_text, MAX_UTF8_LEN)
if len(texts) > 1:
logger.info("[wechatmp] text too long, split into {} parts".format(len(texts)))
for i, text in enumerate(texts):
self.client.message.send_text(receiver, text)
if i != len(texts) - 1:
time.sleep(0.5) # 休眠0.5秒,防止发送过快乱序
logger.info("[wechatmp] Do send text to {}: {}".format(receiver, reply_text))
elif reply.type == ReplyType.VOICE:
try:
file_path = reply.content
file_name = os.path.basename(file_path)
file_type = os.path.splitext(file_name)[1]
if file_type == ".mp3":
file_type = "audio/mpeg"
elif file_type == ".amr":
file_type = "audio/amr"
else:
mp3_file = os.path.splitext(file_path)[0] + ".mp3"
any_to_mp3(file_path, mp3_file)
file_path = mp3_file
file_name = os.path.basename(file_path)
file_type = "audio/mpeg"
logger.info("[wechatmp] file_name: {}, file_type: {} ".format(file_name, file_type))
media_ids = []
duration, files = split_audio(file_path, 60 * 1000)
if len(files) > 1:
logger.info("[wechatmp] voice too long {}s > 60s , split into {} parts".format(duration / 1000.0, len(files)))
for path in files:
# support: <2M, <60s, AMR\MP3
response = self.client.media.upload("voice", (os.path.basename(path), open(path, "rb"), file_type))
logger.debug("[wechatcom] upload voice response: {}".format(response))
media_ids.append(response["media_id"])
os.remove(path)
except ImportError as e:
logger.error("[wechatmp] voice conversion failed: {}".format(e))
logger.error("[wechatmp] please install pydub: pip install pydub")
return
except WeChatClientException as e:
logger.error("[wechatmp] upload voice failed: {}".format(e))
return
try:
os.remove(file_path)
except Exception:
pass
for media_id in media_ids:
self.client.message.send_voice(receiver, media_id)
time.sleep(1)
logger.info("[wechatmp] Do send voice to {}".format(receiver))
elif reply.type == ReplyType.IMAGE_URL: # 从网络下载图片
img_url = reply.content
pic_res = requests.get(img_url, stream=True)
image_storage = io.BytesIO()
for block in pic_res.iter_content(1024):
image_storage.write(block)
image_storage.seek(0)
image_type = imghdr.what(image_storage)
filename = receiver + "-" + str(context["msg"].msg_id) + "." + image_type
content_type = "image/" + image_type
try:
response = self.client.media.upload("image", (filename, image_storage, content_type))
logger.debug("[wechatmp] upload image response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload image failed: {}".format(e))
return
self.client.message.send_image(receiver, response["media_id"])
logger.info("[wechatmp] Do send image to {}".format(receiver))
elif reply.type == ReplyType.IMAGE: # 从文件读取图片
image_storage = reply.content
image_storage.seek(0)
image_type = imghdr.what(image_storage)
filename = receiver + "-" + str(context["msg"].msg_id) + "." + image_type
content_type = "image/" + image_type
try:
response = self.client.media.upload("image", (filename, image_storage, content_type))
logger.debug("[wechatmp] upload image response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload image failed: {}".format(e))
return
self.client.message.send_image(receiver, response["media_id"])
logger.info("[wechatmp] Do send image to {}".format(receiver))
elif reply.type == ReplyType.VIDEO_URL: # 从网络下载视频
video_url = reply.content
video_res = requests.get(video_url, stream=True)
video_storage = io.BytesIO()
for block in video_res.iter_content(1024):
video_storage.write(block)
video_storage.seek(0)
video_type = 'mp4'
filename = receiver + "-" + str(context["msg"].msg_id) + "." + video_type
content_type = "video/" + video_type
try:
response = self.client.media.upload("video", (filename, video_storage, content_type))
logger.debug("[wechatmp] upload video response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload video failed: {}".format(e))
return
self.client.message.send_video(receiver, response["media_id"])
logger.info("[wechatmp] Do send video to {}".format(receiver))
elif reply.type == ReplyType.VIDEO: # 从文件读取视频
video_storage = reply.content
video_storage.seek(0)
video_type = 'mp4'
filename = receiver + "-" + str(context["msg"].msg_id) + "." + video_type
content_type = "video/" + video_type
try:
response = self.client.media.upload("video", (filename, video_storage, content_type))
logger.debug("[wechatmp] upload video response: {}".format(response))
except WeChatClientException as e:
logger.error("[wechatmp] upload video failed: {}".format(e))
return
self.client.message.send_video(receiver, response["media_id"])
logger.info("[wechatmp] Do send video to {}".format(receiver))
return
def _success_callback(self, session_id, context, **kwargs): # 线程异常结束时的回调函数
logger.debug("[wechatmp] Success to generate reply, msgId={}".format(context["msg"].msg_id))
if self.passive_reply:
self.running.remove(session_id)
def _fail_callback(self, session_id, exception, context, **kwargs): # 线程异常结束时的回调函数
logger.exception("[wechatmp] Fail to generate reply to user, msgId={}, exception={}".format(context["msg"].msg_id, exception))
if self.passive_reply:
assert session_id not in self.cache_dict
self.running.remove(session_id)
================================================
FILE: channel/wechatmp/wechatmp_client.py
================================================
import threading
import time
from wechatpy.client import WeChatClient
from wechatpy.exceptions import APILimitedException
from channel.wechatmp.common import *
from common.log import logger
class WechatMPClient(WeChatClient):
def __init__(self, appid, secret, access_token=None, session=None, timeout=None, auto_retry=True):
super(WechatMPClient, self).__init__(appid, secret, access_token, session, timeout, auto_retry)
self.fetch_access_token_lock = threading.Lock()
self.clear_quota_lock = threading.Lock()
self.last_clear_quota_time = -1
def clear_quota(self):
return self.post("clear_quota", data={"appid": self.appid})
def clear_quota_v2(self):
return self.post("clear_quota/v2", params={"appid": self.appid, "appsecret": self.secret})
def fetch_access_token(self): # 重载父类方法,加锁避免多线程重复获取access_token
with self.fetch_access_token_lock:
access_token = self.session.get(self.access_token_key)
if access_token:
if not self.expires_at:
return access_token
timestamp = time.time()
if self.expires_at - timestamp > 60:
return access_token
return super().fetch_access_token()
def _request(self, method, url_or_endpoint, **kwargs): # 重载父类方法,遇到API限流时,清除quota后重试
try:
return super()._request(method, url_or_endpoint, **kwargs)
except APILimitedException as e:
logger.error("[wechatmp] API quata has been used up. {}".format(e))
if self.last_clear_quota_time == -1 or time.time() - self.last_clear_quota_time > 60:
with self.clear_quota_lock:
if self.last_clear_quota_time == -1 or time.time() - self.last_clear_quota_time > 60:
self.last_clear_quota_time = time.time()
response = self.clear_quota_v2()
logger.debug("[wechatmp] API quata has been cleard, {}".format(response))
return super()._request(method, url_or_endpoint, **kwargs)
else:
logger.error("[wechatmp] last clear quota time is {}, less than 60s, skip clear quota")
raise e
================================================
FILE: channel/wechatmp/wechatmp_message.py
================================================
# -*- coding: utf-8 -*-#
from bridge.context import ContextType
from channel.chat_message import ChatMessage
from common.log import logger
from common.tmp_dir import TmpDir
class WeChatMPMessage(ChatMessage):
def __init__(self, msg, client=None):
super().__init__(msg)
self.msg_id = msg.id
self.create_time = msg.time
self.is_group = False
if msg.type == "text":
self.ctype = ContextType.TEXT
self.content = msg.content
elif msg.type == "voice":
if msg.recognition == None:
self.ctype = ContextType.VOICE
self.content = TmpDir().path() + msg.media_id + "." + msg.format # content直接存临时目录路径
def download_voice():
# 如果响应状态码是200,则将响应内容写入本地文件
response = client.media.download(msg.media_id)
if response.status_code == 200:
with open(self.content, "wb") as f:
f.write(response.content)
else:
logger.info(f"[wechatmp] Failed to download voice file, {response.content}")
self._prepare_fn = download_voice
else:
self.ctype = ContextType.TEXT
self.content = msg.recognition
elif msg.type == "image":
self.ctype = ContextType.IMAGE
self.content = TmpDir().path() + msg.media_id + ".png" # content直接存临时目录路径
def download_image():
# 如果响应状态码是200,则将响应内容写入本地文件
response = client.media.download(msg.media_id)
if response.status_code == 200:
with open(self.content, "wb") as f:
f.write(response.content)
else:
logger.info(f"[wechatmp] Failed to download image file, {response.content}")
self._prepare_fn = download_image
else:
raise NotImplementedError("Unsupported message type: Type:{} ".format(msg.type))
self.from_user_id = msg.source
self.to_user_id = msg.target
self.other_user_id = msg.source
================================================
FILE: channel/wecom_bot/__init__.py
================================================
================================================
FILE: channel/wecom_bot/wecom_bot_channel.py
================================================
"""
WeCom (企业微信) AI Bot channel via WebSocket long connection.
Supports:
- Single chat and group chat (text / image / file input & output)
- Scheduled task push via aibot_send_msg
- Heartbeat keep-alive and auto-reconnect
"""
import base64
import hashlib
import json
import math
import os
import threading
import time
import uuid
import requests
import websocket
from bridge.context import Context, ContextType
from bridge.reply import Reply, ReplyType
from channel.chat_channel import ChatChannel, check_prefix
from channel.wecom_bot.wecom_bot_message import WecomBotMessage
from common.expired_dict import ExpiredDict
from common.log import logger
from common.singleton import singleton
from config import conf
WECOM_WS_URL = "wss://openws.work.weixin.qq.com"
HEARTBEAT_INTERVAL = 30
MEDIA_CHUNK_SIZE = 512 * 1024 # 512KB per chunk (before base64 encoding)
@singleton
class WecomBotChannel(ChatChannel):
def __init__(self):
super().__init__()
self.bot_id = ""
self.bot_secret = ""
self.received_msgs = ExpiredDict(60 * 60 * 7.1)
self._ws = None
self._ws_thread = None
self._heartbeat_thread = None
self._connected = False
self._stop_event = threading.Event()
self._pending_responses = {} # req_id -> (threading.Event, result_holder)
self._pending_lock = threading.Lock()
self._stream_states = {} # req_id -> {"stream_id": str, "content": str}
conf()["group_name_white_list"] = ["ALL_GROUP"]
conf()["single_chat_prefix"] = [""]
# ------------------------------------------------------------------
# Lifecycle
# ------------------------------------------------------------------
def startup(self):
self.bot_id = conf().get("wecom_bot_id", "")
self.bot_secret = conf().get("wecom_bot_secret", "")
if not self.bot_id or not self.bot_secret:
err = "[WecomBot] wecom_bot_id and wecom_bot_secret are required"
logger.error(err)
self.report_startup_error(err)
return
self._stop_event.clear()
self._start_ws()
def stop(self):
logger.info("[WecomBot] stop() called")
self._stop_event.set()
if self._ws:
try:
self._ws.close()
except Exception:
pass
self._ws = None
self._connected = False
# ------------------------------------------------------------------
# WebSocket connection
# ------------------------------------------------------------------
def _start_ws(self):
def _on_open(ws):
logger.info("[WecomBot] WebSocket connected, sending subscribe...")
self._send_subscribe()
def _on_message(ws, raw):
try:
data = json.loads(raw)
self._handle_ws_message(data)
except Exception as e:
logger.error(f"[WecomBot] Failed to handle ws message: {e}", exc_info=True)
def _on_error(ws, error):
logger.error(f"[WecomBot] WebSocket error: {error}")
def _on_close(ws, close_status_code, close_msg):
logger.warning(f"[WecomBot] WebSocket closed: status={close_status_code}, msg={close_msg}")
self._connected = False
if not self._stop_event.is_set():
logger.info("[WecomBot] Will reconnect in 5s...")
time.sleep(5)
if not self._stop_event.is_set():
self._start_ws()
self._ws = websocket.WebSocketApp(
WECOM_WS_URL,
on_open=_on_open,
on_message=_on_message,
on_error=_on_error,
on_close=_on_close,
)
def run_forever():
try:
self._ws.run_forever(ping_interval=0, reconnect=0)
except (SystemExit, KeyboardInterrupt):
logger.info("[WecomBot] WebSocket thread interrupted")
except Exception as e:
logger.error(f"[WecomBot] WebSocket run_forever error: {e}")
self._ws_thread = threading.Thread(target=run_forever, daemon=True)
self._ws_thread.start()
self._ws_thread.join()
def _ws_send(self, data: dict):
if self._ws:
self._ws.send(json.dumps(data, ensure_ascii=False))
def _gen_req_id(self) -> str:
return uuid.uuid4().hex[:16]
# ------------------------------------------------------------------
# Subscribe & heartbeat
# ------------------------------------------------------------------
def _send_subscribe(self):
self._ws_send({
"cmd": "aibot_subscribe",
"headers": {"req_id": self._gen_req_id()},
"body": {
"bot_id": self.bot_id,
"secret": self.bot_secret,
},
})
def _start_heartbeat(self):
if self._heartbeat_thread and self._heartbeat_thread.is_alive():
return
def heartbeat_loop():
while not self._stop_event.is_set() and self._connected:
try:
self._ws_send({
"cmd": "ping",
"headers": {"req_id": self._gen_req_id()},
})
except Exception as e:
logger.warning(f"[WecomBot] Heartbeat send failed: {e}")
break
self._stop_event.wait(HEARTBEAT_INTERVAL)
self._heartbeat_thread = threading.Thread(target=heartbeat_loop, daemon=True)
self._heartbeat_thread.start()
# ------------------------------------------------------------------
# Incoming message dispatch
# ------------------------------------------------------------------
def _send_and_wait(self, data: dict, timeout: float = 15) -> dict:
"""Send a ws message and wait for the matching response by req_id."""
req_id = data.get("headers", {}).get("req_id", "")
event = threading.Event()
holder = {"data": None}
with self._pending_lock:
self._pending_responses[req_id] = (event, holder)
self._ws_send(data)
event.wait(timeout=timeout)
with self._pending_lock:
self._pending_responses.pop(req_id, None)
return holder["data"] or {}
def _handle_ws_message(self, data: dict):
cmd = data.get("cmd", "")
errcode = data.get("errcode")
req_id = data.get("headers", {}).get("req_id", "")
# Check if this is a response to a pending request
if req_id:
with self._pending_lock:
pending = self._pending_responses.get(req_id)
if pending:
event, holder = pending
holder["data"] = data
event.set()
return
# Subscribe response (only handle once before connected)
if errcode is not None and cmd == "":
if not self._connected:
if errcode == 0:
logger.info("[WecomBot] ✅ Subscribe success")
self._connected = True
self._start_heartbeat()
self.report_startup_success()
else:
errmsg = data.get("errmsg", "unknown error")
logger.error(f"[WecomBot] Subscribe failed: errcode={errcode}, errmsg={errmsg}")
self.report_startup_error(errmsg)
return
if cmd == "aibot_msg_callback":
self._handle_msg_callback(data)
elif cmd == "aibot_event_callback":
self._handle_event_callback(data)
elif cmd == "":
if errcode and errcode != 0:
logger.warning(f"[WecomBot] Response error: {data}")
# ------------------------------------------------------------------
# Message callback
# ------------------------------------------------------------------
def _handle_msg_callback(self, data: dict):
body = data.get("body", {})
req_id = data.get("headers", {}).get("req_id", "")
msg_id = body.get("msgid", "")
if self.received_msgs.get(msg_id):
logger.debug(f"[WecomBot] Duplicate msg filtered: {msg_id}")
return
self.received_msgs[msg_id] = True
chattype = body.get("chattype", "single")
is_group = chattype == "group"
try:
wecom_msg = WecomBotMessage(body, is_group=is_group)
except NotImplementedError as e:
logger.warning(f"[WecomBot] {e}")
return
except Exception as e:
logger.error(f"[WecomBot] Failed to parse message: {e}", exc_info=True)
return
wecom_msg.req_id = req_id
# File cache logic (same pattern as feishu)
from channel.file_cache import get_file_cache
file_cache = get_file_cache()
if is_group:
if conf().get("group_shared_session", True):
session_id = body.get("chatid", "")
else:
session_id = wecom_msg.from_user_id + "_" + body.get("chatid", "")
else:
session_id = wecom_msg.from_user_id
if wecom_msg.ctype == ContextType.IMAGE:
if hasattr(wecom_msg, "image_path") and wecom_msg.image_path:
file_cache.add(session_id, wecom_msg.image_path, file_type="image")
logger.info(f"[WecomBot] Image cached for session {session_id}")
return
if wecom_msg.ctype == ContextType.FILE:
wecom_msg.prepare()
file_cache.add(session_id, wecom_msg.content, file_type="file")
logger.info(f"[WecomBot] File cached for session {session_id}: {wecom_msg.content}")
return
if wecom_msg.ctype == ContextType.TEXT:
cached_files = file_cache.get(session_id)
if cached_files:
file_refs = []
for fi in cached_files:
ftype = fi["type"]
fpath = fi["path"]
if ftype == "image":
file_refs.append(f"[图片: {fpath}]")
elif ftype == "video":
file_refs.append(f"[视频: {fpath}]")
else:
file_refs.append(f"[文件: {fpath}]")
wecom_msg.content = wecom_msg.content + "\n" + "\n".join(file_refs)
logger.info(f"[WecomBot] Attached {len(cached_files)} cached file(s)")
file_cache.clear(session_id)
context = self._compose_context(
wecom_msg.ctype,
wecom_msg.content,
isgroup=is_group,
msg=wecom_msg,
no_need_at=True,
)
if context:
if req_id:
context["on_event"] = self._make_stream_callback(req_id)
self.produce(context)
# ------------------------------------------------------------------
# Event callback
# ------------------------------------------------------------------
def _handle_event_callback(self, data: dict):
body = data.get("body", {})
event = body.get("event", {})
event_type = event.get("eventtype", "")
if event_type == "enter_chat":
logger.info(f"[WecomBot] User entered chat: {body.get('from', {}).get('userid')}")
elif event_type == "disconnected_event":
logger.warning("[WecomBot] Received disconnected_event, another connection took over")
else:
logger.debug(f"[WecomBot] Event: {event_type}")
# ------------------------------------------------------------------
# Stream callback (for agent on_event)
# ------------------------------------------------------------------
def _make_stream_callback(self, req_id: str):
"""Build an on_event callback that pushes agent stream deltas to wecom via stream message.
All intermediate segments (thinking before tool calls) and the final answer
are accumulated into a single stream message, separated by '---'.
"""
stream_id = uuid.uuid4().hex[:16]
self._stream_states[req_id] = {
"stream_id": stream_id,
"committed": "", # finalized content from previous segments
"current": "", # current segment being streamed
}
def _push_stream(state: dict):
"""Push current stream content to wecom."""
self._ws_send({
"cmd": "aibot_respond_msg",
"headers": {"req_id": req_id},
"body": {
"msgtype": "stream",
"stream": {
"id": state["stream_id"],
"finish": False,
"content": state["committed"] + state["current"],
},
},
})
def on_event(event: dict):
event_type = event.get("type")
data = event.get("data", {})
state = self._stream_states.get(req_id)
if not state:
return
if event_type == "turn_start":
state["current"] = ""
elif event_type == "message_update":
delta = data.get("delta", "")
if delta:
state["current"] += delta
_push_stream(state)
elif event_type == "message_end":
tool_calls = data.get("tool_calls", [])
if tool_calls:
if state["current"].strip():
state["committed"] += state["current"].strip() + "\n\n---\n\n"
state["current"] = ""
else:
state["committed"] += state["current"]
state["current"] = ""
return on_event
# ------------------------------------------------------------------
# _compose_context (same pattern as feishu)
# ------------------------------------------------------------------
def _compose_context(self, ctype: ContextType, content, **kwargs):
context = Context(ctype, content)
context.kwargs = kwargs
if "channel_type" not in context:
context["channel_type"] = self.channel_type
if "origin_ctype" not in context:
context["origin_ctype"] = ctype
cmsg = context["msg"]
if cmsg.is_group:
if conf().get("group_shared_session", True):
context["session_id"] = cmsg.other_user_id
else:
context["session_id"] = f"{cmsg.from_user_id}:{cmsg.other_user_id}"
else:
context["session_id"] = cmsg.from_user_id
context["receiver"] = cmsg.other_user_id
if ctype == ContextType.TEXT:
img_match_prefix = check_prefix(content, conf().get("image_create_prefix"))
if img_match_prefix:
content = content.replace(img_match_prefix, "", 1)
context.type = ContextType.IMAGE_CREATE
else:
context.type = ContextType.TEXT
context.content = content.strip()
return context
# ------------------------------------------------------------------
# Send reply
# ------------------------------------------------------------------
def send(self, reply: Reply, context: Context):
msg = context.get("msg")
is_group = context.get("isgroup", False)
receiver = context.get("receiver", "")
# Determine req_id for responding or use send_msg for scheduled push
req_id = getattr(msg, "req_id", None) if msg else None
if reply.type == ReplyType.TEXT:
self._send_text(reply.content, receiver, is_group, req_id)
elif reply.type in (ReplyType.IMAGE_URL, ReplyType.IMAGE):
self._send_image(reply.content, receiver, is_group, req_id)
elif reply.type == ReplyType.FILE:
if hasattr(reply, "text_content") and reply.text_content:
self._send_text(reply.text_content, receiver, is_group, req_id)
time.sleep(0.3)
self._send_file(reply.content, receiver, is_group, req_id)
elif reply.type == ReplyType.VIDEO or reply.type == ReplyType.VIDEO_URL:
self._send_file(reply.content, receiver, is_group, req_id, media_type="video")
else:
logger.warning(f"[WecomBot] Unsupported reply type: {reply.type}, falling back to text")
self._send_text(str(reply.content), receiver, is_group, req_id)
# ------------------------------------------------------------------
# Respond message (via websocket)
# ------------------------------------------------------------------
def _send_text(self, content: str, receiver: str, is_group: bool, req_id: str = None):
"""Send text/markdown reply. Reuses stream state if available (streaming mode)."""
if req_id:
state = self._stream_states.pop(req_id, None)
if state:
final_content = state["committed"]
stream_id = state["stream_id"]
else:
final_content = content
stream_id = uuid.uuid4().hex[:16]
self._ws_send({
"cmd": "aibot_respond_msg",
"headers": {"req_id": req_id},
"body": {
"msgtype": "stream",
"stream": {
"id": stream_id,
"finish": True,
"content": final_content,
},
},
})
else:
self._active_send_markdown(content, receiver, is_group)
def _send_image(self, img_path_or_url: str, receiver: str, is_group: bool, req_id: str = None):
"""Send image reply. Converts to JPG/PNG and compresses if >2MB."""
local_path = img_path_or_url
if local_path.startswith("file://"):
local_path = local_path[7:]
if local_path.startswith(("http://", "https://")):
try:
resp = requests.get(local_path, timeout=30)
resp.raise_for_status()
ct = resp.headers.get("Content-Type", "")
if "jpeg" in ct or "jpg" in ct:
ext = ".jpg"
elif "webp" in ct:
ext = ".webp"
elif "gif" in ct:
ext = ".gif"
else:
ext = ".png"
tmp_path = f"/tmp/wecom_img_{uuid.uuid4().hex[:8]}{ext}"
with open(tmp_path, "wb") as f:
f.write(resp.content)
logger.info(f"[WecomBot] Image downloaded: size={len(resp.content)}, "
f"content-type={ct}, path={tmp_path}")
local_path = tmp_path
except Exception as e:
logger.error(f"[WecomBot] Failed to download image for sending: {e}")
self._send_text("[Image send failed]", receiver, is_group, req_id)
return
if not os.path.exists(local_path):
logger.error(f"[WecomBot] Image file not found: {local_path}")
return
max_image_size = 2 * 1024 * 1024 # 2MB limit for image upload
local_path = self._ensure_image_format(local_path)
if not local_path:
self._send_text("[Image format conversion failed]", receiver, is_group, req_id)
return
if os.path.getsize(local_path) > max_image_size:
local_path = self._compress_image(local_path, max_image_size)
if not local_path:
self._send_text("[Image too large]", receiver, is_group, req_id)
return
file_size = os.path.getsize(local_path)
logger.info(f"[WecomBot] Uploading image: path={local_path}, size={file_size} bytes")
media_id = self._upload_media(local_path, "image")
if not media_id:
logger.error("[WecomBot] Failed to upload image")
self._send_text("[Image upload failed]", receiver, is_group, req_id)
return
if req_id:
self._ws_send({
"cmd": "aibot_respond_msg",
"headers": {"req_id": req_id},
"body": {
"msgtype": "image",
"image": {"media_id": media_id},
},
})
else:
self._ws_send({
"cmd": "aibot_send_msg",
"headers": {"req_id": self._gen_req_id()},
"body": {
"chatid": receiver,
"chat_type": 2 if is_group else 1,
"msgtype": "image",
"image": {"media_id": media_id},
},
})
@staticmethod
def _ensure_image_format(file_path: str) -> str:
"""Ensure image is JPG or PNG (the only formats wecom supports). Convert if needed."""
try:
from PIL import Image
img = Image.open(file_path)
fmt = (img.format or "").upper()
if fmt in ("JPEG", "PNG"):
# Already a supported format, but make sure the filename extension matches
ext = os.path.splitext(file_path)[1].lower()
if fmt == "JPEG" and ext in (".jpg", ".jpeg"):
return file_path
if fmt == "PNG" and ext == ".png":
return file_path
# Extension doesn't match — rename/copy with correct extension
correct_ext = ".jpg" if fmt == "JPEG" else ".png"
out_path = f"/tmp/wecom_fmt_{uuid.uuid4().hex[:8]}{correct_ext}"
img.save(out_path, fmt)
logger.info(f"[WecomBot] Image renamed: {file_path} -> {out_path} ({fmt})")
return out_path
# Unsupported format (WebP, GIF, BMP, etc.) — convert to PNG
if img.mode == "RGBA":
out_path = f"/tmp/wecom_fmt_{uuid.uuid4().hex[:8]}.png"
img.save(out_path, "PNG")
else:
out_path = f"/tmp/wecom_fmt_{uuid.uuid4().hex[:8]}.jpg"
img.convert("RGB").save(out_path, "JPEG", quality=90)
logger.info(f"[WecomBot] Image converted from {fmt} -> {out_path}")
return out_path
except Exception as e:
logger.error(f"[WecomBot] Image format check failed: {e}")
return file_path
@staticmethod
def _compress_image(file_path: str, max_bytes: int) -> str:
"""Compress image to fit within max_bytes. Returns new path or empty string."""
try:
from PIL import Image
img = Image.open(file_path)
if img.mode == "RGBA":
img = img.convert("RGB")
out_path = f"/tmp/wecom_compressed_{uuid.uuid4().hex[:8]}.jpg"
quality = 85
while quality >= 30:
img.save(out_path, "JPEG", quality=quality, optimize=True)
if os.path.getsize(out_path) <= max_bytes:
logger.info(f"[WecomBot] Image compressed: quality={quality}, "
f"size={os.path.getsize(out_path)} bytes")
return out_path
quality -= 10
# Still too large — resize
ratio = (max_bytes / os.path.getsize(out_path)) ** 0.5
new_size = (int(img.width * ratio), int(img.height * ratio))
img = img.resize(new_size, Image.LANCZOS)
img.save(out_path, "JPEG", quality=70, optimize=True)
if os.path.getsize(out_path) <= max_bytes:
logger.info(f"[WecomBot] Image compressed with resize: {new_size}, "
f"size={os.path.getsize(out_path)} bytes")
return out_path
logger.error(f"[WecomBot] Cannot compress image below {max_bytes} bytes")
return ""
except Exception as e:
logger.error(f"[WecomBot] Image compression failed: {e}")
return ""
def _send_file(self, file_path: str, receiver: str, is_group: bool,
req_id: str = None, media_type: str = "file"):
"""Send file/video reply by uploading media first."""
local_path = file_path
if local_path.startswith("file://"):
local_path = local_path[7:]
if local_path.startswith(("http://", "https://")):
try:
resp = requests.get(local_path, timeout=60)
resp.raise_for_status()
ext = os.path.splitext(local_path)[1] or ".bin"
tmp_path = f"/tmp/wecom_file_{uuid.uuid4().hex[:8]}{ext}"
with open(tmp_path, "wb") as f:
f.write(resp.content)
local_path = tmp_path
except Exception as e:
logger.error(f"[WecomBot] Failed to download file for sending: {e}")
return
if not os.path.exists(local_path):
logger.error(f"[WecomBot] File not found: {local_path}")
return
media_id = self._upload_media(local_path, media_type)
if not media_id:
logger.error(f"[WecomBot] Failed to upload {media_type}")
return
if req_id:
self._ws_send({
"cmd": "aibot_respond_msg",
"headers": {"req_id": req_id},
"body": {
"msgtype": media_type,
media_type: {"media_id": media_id},
},
})
else:
self._ws_send({
"cmd": "aibot_send_msg",
"headers": {"req_id": self._gen_req_id()},
"body": {
"chatid": receiver,
"chat_type": 2 if is_group else 1,
"msgtype": media_type,
media_type: {"media_id": media_id},
},
})
def _active_send_markdown(self, content: str, receiver: str, is_group: bool):
"""Proactively send markdown message (for scheduled tasks, no req_id)."""
self._ws_send({
"cmd": "aibot_send_msg",
"headers": {"req_id": self._gen_req_id()},
"body": {
"chatid": receiver,
"chat_type": 2 if is_group else 1,
"msgtype": "markdown",
"markdown": {"content": content},
},
})
# ------------------------------------------------------------------
# Media upload (chunked)
# ------------------------------------------------------------------
def _upload_media(self, file_path: str, media_type: str = "file") -> str:
"""
Upload a local file to wecom bot via chunked upload protocol.
Returns media_id on success, empty string on failure.
"""
if not os.path.exists(file_path):
logger.error(f"[WecomBot] Upload file not found: {file_path}")
return ""
file_size = os.path.getsize(file_path)
if file_size < 5:
logger.error(f"[WecomBot] File too small: {file_size} bytes")
return ""
filename = os.path.basename(file_path)
total_chunks = math.ceil(file_size / MEDIA_CHUNK_SIZE)
if total_chunks > 100:
logger.error(f"[WecomBot] Too many chunks: {total_chunks} > 100")
return ""
file_md5 = hashlib.md5()
with open(file_path, "rb") as f:
for block in iter(lambda: f.read(8192), b""):
file_md5.update(block)
md5_hex = file_md5.hexdigest()
# 1. Init upload
init_resp = self._send_and_wait({
"cmd": "aibot_upload_media_init",
"headers": {"req_id": self._gen_req_id()},
"body": {
"type": media_type,
"filename": filename,
"total_size": file_size,
"total_chunks": total_chunks,
"md5": md5_hex,
},
}, timeout=15)
if init_resp.get("errcode") != 0:
logger.error(f"[WecomBot] Upload init failed: {init_resp}")
return ""
upload_id = init_resp.get("body", {}).get("upload_id")
if not upload_id:
logger.error("[WecomBot] Failed to get upload_id")
return ""
# 2. Upload chunks
with open(file_path, "rb") as f:
for idx in range(total_chunks):
chunk = f.read(MEDIA_CHUNK_SIZE)
b64_data = base64.b64encode(chunk).decode("utf-8")
chunk_resp = self._send_and_wait({
"cmd": "aibot_upload_media_chunk",
"headers": {"req_id": self._gen_req_id()},
"body": {
"upload_id": upload_id,
"chunk_index": idx,
"base64_data": b64_data,
},
}, timeout=30)
if chunk_resp.get("errcode") != 0:
logger.error(f"[WecomBot] Chunk {idx} upload failed: {chunk_resp}")
return ""
# 3. Finish upload
finish_resp = self._send_and_wait({
"cmd": "aibot_upload_media_finish",
"headers": {"req_id": self._gen_req_id()},
"body": {"upload_id": upload_id},
}, timeout=30)
if finish_resp.get("errcode") != 0:
logger.error(f"[WecomBot] Upload finish failed: {finish_resp}")
return ""
media_id = finish_resp.get("body", {}).get("media_id", "")
if media_id:
logger.info(f"[WecomBot] Media uploaded: media_id={media_id}")
else:
logger.error("[WecomBot] Failed to get media_id from finish response")
return media_id
================================================
FILE: channel/wecom_bot/wecom_bot_message.py
================================================
import os
import re
import base64
import requests
from bridge.context import ContextType
from channel.chat_message import ChatMessage
from common.log import logger
from common.utils import expand_path
from config import conf
from Crypto.Cipher import AES
MAGIC_SIGNATURES = [
(b"%PDF", ".pdf"),
(b"\x89PNG\r\n\x1a\n", ".png"),
(b"\xff\xd8\xff", ".jpg"),
(b"GIF87a", ".gif"),
(b"GIF89a", ".gif"),
(b"RIFF", ".webp"), # RIFF....WEBP, further checked below
(b"PK\x03\x04", ".zip"), # zip / docx / xlsx / pptx
(b"\x1f\x8b", ".gz"),
(b"Rar!\x1a\x07", ".rar"),
(b"7z\xbc\xaf\x27\x1c", ".7z"),
(b"\x00\x00\x00", ".mp4"), # ftyp box, further checked below
(b"#!AMR", ".amr"),
]
OFFICE_ZIP_MARKERS = {
b"word/": ".docx",
b"xl/": ".xlsx",
b"ppt/": ".pptx",
}
def _guess_ext_from_bytes(data: bytes) -> str:
"""Guess file extension from file content magic bytes."""
if not data or len(data) < 8:
return ""
for sig, ext in MAGIC_SIGNATURES:
if data[:len(sig)] == sig:
if ext == ".webp" and data[8:12] != b"WEBP":
continue
if ext == ".mp4":
if b"ftyp" not in data[4:12]:
continue
if ext == ".zip":
for marker, office_ext in OFFICE_ZIP_MARKERS.items():
if marker in data[:2000]:
return office_ext
return ".zip"
return ext
return ""
def _decrypt_media(url: str, aeskey: str) -> bytes:
"""
Download and decrypt AES-256-CBC encrypted media from wecom bot.
Returns decrypted bytes.
"""
resp = requests.get(url, timeout=30)
resp.raise_for_status()
encrypted = resp.content
key = base64.b64decode(aeskey + "=" * (-len(aeskey) % 4))
if len(key) != 32:
raise ValueError(f"Invalid AES key length: {len(key)}, expected 32")
iv = key[:16]
cipher = AES.new(key, AES.MODE_CBC, iv)
decrypted = cipher.decrypt(encrypted)
pad_len = decrypted[-1]
if pad_len > 32:
raise ValueError(f"Invalid PKCS7 padding length: {pad_len}")
return decrypted[:-pad_len]
def _get_tmp_dir() -> str:
"""Return the workspace tmp directory (absolute path), creating it if needed."""
ws_root = expand_path(conf().get("agent_workspace", "~/cow"))
tmp_dir = os.path.join(ws_root, "tmp")
os.makedirs(tmp_dir, exist_ok=True)
return tmp_dir
class WecomBotMessage(ChatMessage):
"""Message wrapper for wecom bot (websocket long-connection mode)."""
def __init__(self, msg_body: dict, is_group: bool = False):
super().__init__(msg_body)
self.msg_id = msg_body.get("msgid")
self.create_time = msg_body.get("create_time")
self.is_group = is_group
msg_type = msg_body.get("msgtype")
from_userid = msg_body.get("from", {}).get("userid", "")
chat_id = msg_body.get("chatid", "")
bot_id = msg_body.get("aibotid", "")
if msg_type == "text":
self.ctype = ContextType.TEXT
content = msg_body.get("text", {}).get("content", "")
if is_group:
content = re.sub(r"@\S+\s*", "", content).strip()
self.content = content
elif msg_type == "voice":
self.ctype = ContextType.TEXT
self.content = msg_body.get("voice", {}).get("content", "")
elif msg_type == "image":
self.ctype = ContextType.IMAGE
image_info = msg_body.get("image", {})
image_url = image_info.get("url", "")
aeskey = image_info.get("aeskey", "")
tmp_dir = _get_tmp_dir()
image_path = os.path.join(tmp_dir, f"wecom_{self.msg_id}.png")
try:
data = _decrypt_media(image_url, aeskey)
with open(image_path, "wb") as f:
f.write(data)
self.content = image_path
self.image_path = image_path
logger.info(f"[WecomBot] Image downloaded: {image_path}")
except Exception as e:
logger.error(f"[WecomBot] Failed to download image: {e}")
self.content = "[Image download failed]"
self.image_path = None
elif msg_type == "mixed":
self.ctype = ContextType.TEXT
text_parts = []
image_paths = []
mixed_items = msg_body.get("mixed", {}).get("msg_item", [])
tmp_dir = _get_tmp_dir()
for idx, item in enumerate(mixed_items):
item_type = item.get("msgtype")
if item_type == "text":
txt = item.get("text", {}).get("content", "")
if is_group:
txt = re.sub(r"@\S+\s*", "", txt).strip()
if txt:
text_parts.append(txt)
elif item_type == "image":
img_info = item.get("image", {})
img_url = img_info.get("url", "")
img_aeskey = img_info.get("aeskey", "")
img_path = os.path.join(tmp_dir, f"wecom_{self.msg_id}_{idx}.png")
try:
img_data = _decrypt_media(img_url, img_aeskey)
with open(img_path, "wb") as f:
f.write(img_data)
image_paths.append(img_path)
except Exception as e:
logger.error(f"[WecomBot] Failed to download mixed image: {e}")
content_parts = text_parts[:]
for p in image_paths:
content_parts.append(f"[图片: {p}]")
self.content = "\n".join(content_parts) if content_parts else "[Mixed message]"
elif msg_type == "file":
self.ctype = ContextType.FILE
file_info = msg_body.get("file", {})
file_url = file_info.get("url", "")
aeskey = file_info.get("aeskey", "")
tmp_dir = _get_tmp_dir()
base_path = os.path.join(tmp_dir, f"wecom_{self.msg_id}")
self.content = base_path
def _download_file():
try:
data = _decrypt_media(file_url, aeskey)
ext = _guess_ext_from_bytes(data)
final_path = base_path + ext
with open(final_path, "wb") as f:
f.write(data)
self.content = final_path
logger.info(f"[WecomBot] File downloaded: {final_path}")
except Exception as e:
logger.error(f"[WecomBot] Failed to download file: {e}")
self._prepare_fn = _download_file
elif msg_type == "video":
self.ctype = ContextType.FILE
video_info = msg_body.get("video", {})
video_url = video_info.get("url", "")
aeskey = video_info.get("aeskey", "")
tmp_dir = _get_tmp_dir()
self.content = os.path.join(tmp_dir, f"wecom_{self.msg_id}.mp4")
def _download_video():
try:
data = _decrypt_media(video_url, aeskey)
with open(self.content, "wb") as f:
f.write(data)
logger.info(f"[WecomBot] Video downloaded: {self.content}")
except Exception as e:
logger.error(f"[WecomBot] Failed to download video: {e}")
self._prepare_fn = _download_video
else:
raise NotImplementedError(f"Unsupported message type: {msg_type}")
self.from_user_id = from_userid
self.to_user_id = bot_id
if is_group:
self.other_user_id = chat_id
self.actual_user_id = from_userid
self.actual_user_nickname = from_userid
else:
self.other_user_id = from_userid
self.actual_user_id = from_userid
================================================
FILE: common/cloud_client.py
================================================
"""
Cloud management client for connecting to the LinkAI control console.
Handles remote configuration sync, message push, and skill management
via the LinkAI socket protocol.
"""
from bridge.context import Context, ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from linkai import LinkAIClient, PushMsg
from config import conf, pconf, plugin_config, available_setting, write_plugin_config, get_root
from plugins import PluginManager
import threading
import time
import json
import os
chat_client: LinkAIClient
CHANNEL_ACTIONS = {"channel_create", "channel_update", "channel_delete"}
# channelType -> config key mapping for app credentials
CREDENTIAL_MAP = {
"feishu": ("feishu_app_id", "feishu_app_secret"),
"dingtalk": ("dingtalk_client_id", "dingtalk_client_secret"),
"wecom_bot": ("wecom_bot_id", "wecom_bot_secret"),
"qq": ("qq_app_id", "qq_app_secret"),
"wechatmp": ("wechatmp_app_id", "wechatmp_app_secret"),
"wechatmp_service": ("wechatmp_app_id", "wechatmp_app_secret"),
"wechatcom_app": ("wechatcomapp_agent_id", "wechatcomapp_secret"),
}
class CloudClient(LinkAIClient):
def __init__(self, api_key: str, channel, host: str = ""):
super().__init__(api_key, host)
self.channel = channel
self.client_type = channel.channel_type
self.channel_mgr = None
self._skill_service = None
self._memory_service = None
self._chat_service = None
@property
def skill_service(self):
"""Lazy-init SkillService so it is available once SkillManager exists."""
if self._skill_service is None:
try:
from agent.skills.manager import SkillManager
from agent.skills.service import SkillService
from config import conf
from common.utils import expand_path
workspace_root = expand_path(conf().get("agent_workspace", "~/cow"))
manager = SkillManager(custom_dir=os.path.join(workspace_root, "skills"))
self._skill_service = SkillService(manager)
logger.debug("[CloudClient] SkillService initialised")
except Exception as e:
logger.error(f"[CloudClient] Failed to init SkillService: {e}")
return self._skill_service
@property
def memory_service(self):
"""Lazy-init MemoryService."""
if self._memory_service is None:
try:
from agent.memory.service import MemoryService
from config import conf
from common.utils import expand_path
workspace_root = expand_path(conf().get("agent_workspace", "~/cow"))
self._memory_service = MemoryService(workspace_root)
logger.debug("[CloudClient] MemoryService initialised")
except Exception as e:
logger.error(f"[CloudClient] Failed to init MemoryService: {e}")
return self._memory_service
@property
def chat_service(self):
"""Lazy-init ChatService (requires AgentBridge via Bridge singleton)."""
if self._chat_service is None:
try:
from agent.chat.service import ChatService
from bridge.bridge import Bridge
agent_bridge = Bridge().get_agent_bridge()
self._chat_service = ChatService(agent_bridge)
logger.debug("[CloudClient] ChatService initialised")
except Exception as e:
logger.error(f"[CloudClient] Failed to init ChatService: {e}")
return self._chat_service
# ------------------------------------------------------------------
# message push callback
# ------------------------------------------------------------------
def on_message(self, push_msg: PushMsg):
session_id = push_msg.session_id
msg_content = push_msg.msg_content
logger.info(f"receive msg push, session_id={session_id}, msg_content={msg_content}")
context = Context()
context.type = ContextType.TEXT
context["receiver"] = session_id
context["isgroup"] = push_msg.is_group
self.channel.send(Reply(ReplyType.TEXT, content=msg_content), context)
# ------------------------------------------------------------------
# config callback
# ------------------------------------------------------------------
def on_config(self, config: dict):
if not self.client_id:
return
logger.info(f"[CloudClient] Loading remote config: {config}")
action = config.get("action")
if action in CHANNEL_ACTIONS:
self._dispatch_channel_action(action, config.get("data", {}))
return
if config.get("enabled") != "Y":
return
local_config = conf()
need_restart_channel = False
for key in config.keys():
if key in available_setting and config.get(key) is not None:
local_config[key] = config.get(key)
# Voice settings
reply_voice_mode = config.get("reply_voice_mode")
if reply_voice_mode:
if reply_voice_mode == "voice_reply_voice":
local_config["voice_reply_voice"] = True
local_config["always_reply_voice"] = False
elif reply_voice_mode == "always_reply_voice":
local_config["always_reply_voice"] = True
local_config["voice_reply_voice"] = True
elif reply_voice_mode == "no_reply_voice":
local_config["always_reply_voice"] = False
local_config["voice_reply_voice"] = False
# Model configuration
if config.get("model"):
local_config["model"] = config.get("model")
# Channel configuration (legacy single-channel path)
if config.get("channelType"):
if local_config.get("channel_type") != config.get("channelType"):
local_config["channel_type"] = config.get("channelType")
need_restart_channel = True
# Channel-specific app credentials (legacy single-channel path)
current_channel_type = local_config.get("channel_type", "")
if self._set_channel_credentials(local_config, current_channel_type,
config.get("app_id"), config.get("app_secret")):
need_restart_channel = True
if config.get("admin_password"):
if not pconf("Godcmd"):
write_plugin_config({"Godcmd": {"password": config.get("admin_password"), "admin_users": []}})
else:
pconf("Godcmd")["password"] = config.get("admin_password")
PluginManager().instances["GODCMD"].reload()
if config.get("group_app_map") and pconf("linkai"):
local_group_map = {}
for mapping in config.get("group_app_map"):
local_group_map[mapping.get("group_name")] = mapping.get("app_code")
pconf("linkai")["group_app_map"] = local_group_map
PluginManager().instances["LINKAI"].reload()
if config.get("text_to_image") and config.get("text_to_image") == "midjourney" and pconf("linkai"):
if pconf("linkai")["midjourney"]:
pconf("linkai")["midjourney"]["enabled"] = True
pconf("linkai")["midjourney"]["use_image_create_prefix"] = True
elif config.get("text_to_image") and config.get("text_to_image") in ["dall-e-2", "dall-e-3"]:
if pconf("linkai")["midjourney"]:
pconf("linkai")["midjourney"]["use_image_create_prefix"] = False
self._save_config_to_file(local_config)
if need_restart_channel:
self._restart_channel(local_config.get("channel_type", ""))
# ------------------------------------------------------------------
# channel CRUD operations
# ------------------------------------------------------------------
def _dispatch_channel_action(self, action: str, data: dict):
channel_type = data.get("channelType")
if not channel_type:
logger.warning(f"[CloudClient] Channel action '{action}' missing channelType, data={data}")
return
logger.info(f"[CloudClient] Channel action: {action}, channelType={channel_type}")
if action == "channel_create":
self._handle_channel_create(channel_type, data)
elif action == "channel_update":
self._handle_channel_update(channel_type, data)
elif action == "channel_delete":
self._handle_channel_delete(channel_type, data)
def _handle_channel_create(self, channel_type: str, data: dict):
local_config = conf()
cred_changed = self._set_channel_credentials(
local_config, channel_type, data.get("appId"), data.get("appSecret"))
self._add_channel_type(local_config, channel_type)
self._save_config_to_file(local_config)
if not self.channel_mgr:
return
existing_ch = self.channel_mgr.get_channel(channel_type)
if existing_ch and not cred_changed:
logger.info(f"[CloudClient] Channel '{channel_type}' already running with same config, "
"skip restart, reporting status only")
threading.Thread(
target=self._report_channel_startup, args=(channel_type,), daemon=True
).start()
return
threading.Thread(
target=self._do_add_channel, args=(channel_type,), daemon=True
).start()
def _handle_channel_update(self, channel_type: str, data: dict):
local_config = conf()
enabled = data.get("enabled", "Y")
cred_changed = self._set_channel_credentials(
local_config, channel_type, data.get("appId"), data.get("appSecret"))
if enabled == "N":
self._remove_channel_type(local_config, channel_type)
else:
self._add_channel_type(local_config, channel_type)
self._save_config_to_file(local_config)
if not self.channel_mgr:
return
if enabled == "N":
threading.Thread(
target=self._do_remove_channel, args=(channel_type,), daemon=True
).start()
else:
existing_ch = self.channel_mgr.get_channel(channel_type)
if existing_ch and not cred_changed:
logger.info(f"[CloudClient] Channel '{channel_type}' already running with same config, "
"skip restart, reporting status only")
threading.Thread(
target=self._report_channel_startup, args=(channel_type,), daemon=True
).start()
else:
threading.Thread(
target=self._do_restart_channel, args=(self.channel_mgr, channel_type), daemon=True
).start()
def _handle_channel_delete(self, channel_type: str, data: dict):
local_config = conf()
self._clear_channel_credentials(local_config, channel_type)
self._remove_channel_type(local_config, channel_type)
self._save_config_to_file(local_config)
if self.channel_mgr:
threading.Thread(
target=self._do_remove_channel, args=(channel_type,), daemon=True
).start()
# ------------------------------------------------------------------
# channel credentials helpers
# ------------------------------------------------------------------
@staticmethod
def _set_channel_credentials(local_config: dict, channel_type: str,
app_id, app_secret) -> bool:
"""
Write app_id / app_secret into the correct config keys for *channel_type*.
Also syncs the values to environment variables (upper-cased key) so that
skills that rely on env-based checks (e.g. has_env_var) work immediately.
Returns True if any value actually changed.
"""
cred = CREDENTIAL_MAP.get(channel_type)
if not cred:
return False
id_key, secret_key = cred
changed = False
if app_id is not None and local_config.get(id_key) != app_id:
local_config[id_key] = app_id
os.environ[id_key.upper()] = str(app_id)
changed = True
if app_secret is not None and local_config.get(secret_key) != app_secret:
local_config[secret_key] = app_secret
os.environ[secret_key.upper()] = str(app_secret)
changed = True
if changed:
logger.info(f"[CloudClient] Synced {channel_type} credentials to conf and env")
return changed
@staticmethod
def _clear_channel_credentials(local_config: dict, channel_type: str):
cred = CREDENTIAL_MAP.get(channel_type)
if not cred:
return
id_key, secret_key = cred
local_config.pop(id_key, None)
local_config.pop(secret_key, None)
os.environ.pop(id_key.upper(), None)
os.environ.pop(secret_key.upper(), None)
# ------------------------------------------------------------------
# channel_type list helpers
# ------------------------------------------------------------------
@staticmethod
def _parse_channel_types(local_config: dict) -> list:
raw = local_config.get("channel_type", "")
if isinstance(raw, list):
return [ch.strip() for ch in raw if ch.strip()]
if isinstance(raw, str):
return [ch.strip() for ch in raw.split(",") if ch.strip()]
return []
@staticmethod
def _add_channel_type(local_config: dict, channel_type: str):
types = CloudClient._parse_channel_types(local_config)
if channel_type not in types:
types.append(channel_type)
local_config["channel_type"] = ", ".join(types)
@staticmethod
def _remove_channel_type(local_config: dict, channel_type: str):
types = CloudClient._parse_channel_types(local_config)
if channel_type in types:
types.remove(channel_type)
local_config["channel_type"] = ", ".join(types)
# ------------------------------------------------------------------
# channel manager thread helpers
# ------------------------------------------------------------------
def _do_add_channel(self, channel_type: str):
try:
self.channel_mgr.add_channel(channel_type)
logger.info(f"[CloudClient] Channel '{channel_type}' added successfully")
except Exception as e:
logger.error(f"[CloudClient] Failed to add channel '{channel_type}': {e}", exc_info=True)
self.send_channel_status(channel_type, "error", str(e))
return
self._report_channel_startup(channel_type)
def _do_remove_channel(self, channel_type: str):
try:
self.channel_mgr.remove_channel(channel_type)
logger.info(f"[CloudClient] Channel '{channel_type}' removed successfully")
except Exception as e:
logger.error(f"[CloudClient] Failed to remove channel '{channel_type}': {e}")
def _report_channel_startup(self, channel_type: str):
"""Wait for channel startup result and report to cloud."""
ch = self.channel_mgr.get_channel(channel_type)
if not ch:
self.send_channel_status(channel_type, "error", "channel instance not found")
return
success, error = ch.wait_startup(timeout=3)
if success:
logger.info(f"[CloudClient] Channel '{channel_type}' connected, reporting status")
self.send_channel_status(channel_type, "connected")
else:
logger.warning(f"[CloudClient] Channel '{channel_type}' startup failed: {error}")
self.send_channel_status(channel_type, "error", error)
# ------------------------------------------------------------------
# skill callback
# ------------------------------------------------------------------
def on_skill(self, data: dict) -> dict:
"""
Handle SKILL messages from the cloud console.
Delegates to SkillService.dispatch for the actual operations.
:param data: message data with 'action', 'clientId', 'payload'
:return: response dict
"""
action = data.get("action", "")
payload = data.get("payload")
logger.info(f"[CloudClient] on_skill: action={action}")
svc = self.skill_service
if svc is None:
return {"action": action, "code": 500, "message": "SkillService not available", "payload": None}
return svc.dispatch(action, payload)
# ------------------------------------------------------------------
# memory callback
# ------------------------------------------------------------------
def on_memory(self, data: dict) -> dict:
"""
Handle MEMORY messages from the cloud console.
Delegates to MemoryService.dispatch for the actual operations.
:param data: message data with 'action', 'clientId', 'payload'
:return: response dict
"""
action = data.get("action", "")
payload = data.get("payload")
logger.info(f"[CloudClient] on_memory: action={action}")
svc = self.memory_service
if svc is None:
return {"action": action, "code": 500, "message": "MemoryService not available", "payload": None}
return svc.dispatch(action, payload)
# ------------------------------------------------------------------
# chat callback
# ------------------------------------------------------------------
def on_chat(self, data: dict, send_chunk_fn):
"""
Handle CHAT messages from the cloud console.
Runs the agent in streaming mode and sends chunks back via send_chunk_fn.
:param data: message data with 'action' and 'payload' (query, session_id)
:param send_chunk_fn: callable(chunk_data: dict) to send one streaming chunk
"""
payload = data.get("payload", {})
query = payload.get("query", "")
session_id = payload.get("session_id", "cloud_console")
channel_type = payload.get("channel_type", "")
if not session_id.startswith("session_"):
session_id = f"session_{session_id}"
logger.info(f"[CloudClient] on_chat: session={session_id}, channel={channel_type}, query={query[:80]}")
svc = self.chat_service
if svc is None:
raise RuntimeError("ChatService not available")
svc.run(query=query, session_id=session_id, channel_type=channel_type, send_chunk_fn=send_chunk_fn)
# ------------------------------------------------------------------
# history callback
# ------------------------------------------------------------------
def on_history(self, data: dict) -> dict:
"""
Handle HISTORY messages from the cloud console.
Returns paginated conversation history for a session.
:param data: message data with 'action' and 'payload' (session_id, page, page_size)
:return: response dict
"""
action = data.get("action", "query")
payload = data.get("payload", {})
logger.info(f"[CloudClient] on_history: action={action}")
if action == "query":
return self._query_history(payload)
return {"action": action, "code": 404, "message": f"unknown action: {action}", "payload": None}
def _query_history(self, payload: dict) -> dict:
"""Query paginated conversation history using ConversationStore."""
session_id = payload.get("session_id", "")
page = int(payload.get("page", 1))
page_size = int(payload.get("page_size", 20))
if not session_id:
return {
"action": "query",
"payload": {"status": "error", "message": "session_id required"},
}
# Web channel stores sessions with a "session_" prefix
if not session_id.startswith("session_"):
session_id = f"session_{session_id}"
logger.info(f"[CloudClient] history query: session={session_id}, page={page}, page_size={page_size}")
try:
from agent.memory.conversation_store import get_conversation_store
store = get_conversation_store()
result = store.load_history_page(
session_id=session_id,
page=page,
page_size=page_size,
)
return {
"action": "query",
"payload": {"status": "success", **result},
}
except Exception as e:
logger.error(f"[CloudClient] History query error: {e}")
return {
"action": "query",
"payload": {"status": "error", "message": str(e)},
}
# ------------------------------------------------------------------
# channel restart helpers
# ------------------------------------------------------------------
def _restart_channel(self, new_channel_type: str):
"""
Restart the channel via ChannelManager when channel type changes.
"""
if self.channel_mgr:
logger.info(f"[CloudClient] Restarting channel to '{new_channel_type}'...")
threading.Thread(target=self._do_restart_channel, args=(self.channel_mgr, new_channel_type), daemon=True).start()
else:
logger.warning("[CloudClient] ChannelManager not available, please restart the application manually")
def _do_restart_channel(self, mgr, new_channel_type: str):
"""
Perform the channel restart in a separate thread to avoid blocking the config callback.
"""
try:
mgr.restart(new_channel_type)
if mgr.channel:
self.channel = mgr.channel
self.client_type = mgr.channel.channel_type
logger.info(f"[CloudClient] Channel reference updated to '{new_channel_type}'")
except Exception as e:
logger.error(f"[CloudClient] Channel restart failed: {e}")
self.send_channel_status(new_channel_type, "error", str(e))
return
self._report_channel_startup(new_channel_type)
# ------------------------------------------------------------------
# config persistence
# ------------------------------------------------------------------
def _save_config_to_file(self, local_config: dict):
"""
Save configuration to config.json file.
"""
try:
config_path = os.path.join(get_root(), "config.json")
if not os.path.exists(config_path):
logger.warning(f"[CloudClient] config.json not found at {config_path}, skip saving")
return
with open(config_path, "r", encoding="utf-8") as f:
file_config = json.load(f)
file_config.update(dict(local_config))
with open(config_path, "w", encoding="utf-8") as f:
json.dump(file_config, f, indent=4, ensure_ascii=False)
logger.info("[CloudClient] Configuration saved to config.json successfully")
except Exception as e:
logger.error(f"[CloudClient] Failed to save configuration to config.json: {e}")
def get_root_domain(host: str = "") -> str:
"""Extract root domain from a hostname.
If *host* is empty, reads CLOUD_HOST env var / cloud_host config.
"""
if not host:
host = os.environ.get("CLOUD_HOST") or conf().get("cloud_host", "")
if not host:
return ""
host = host.strip().rstrip("/")
if "://" in host:
host = host.split("://", 1)[1]
host = host.split("/", 1)[0].split(":")[0]
parts = host.split(".")
if len(parts) >= 2:
return ".".join(parts[-2:])
return host
def get_deployment_id() -> str:
"""Return cloud deployment id from env var or config."""
return os.environ.get("CLOUD_DEPLOYMENT_ID") or conf().get("cloud_deployment_id", "")
def get_website_base_url() -> str:
"""Return the public URL prefix that maps to the workspace websites/ dir.
Returns empty string when cloud deployment is not configured.
"""
deployment_id = get_deployment_id()
if not deployment_id:
return ""
websites_domain = os.environ.get("CLOUD_WEBSITES_DOMAIN") or conf().get("cloud_websites_domain", "")
if websites_domain:
websites_domain = websites_domain.strip().rstrip("/")
return f"https://{websites_domain}/{deployment_id}"
domain = get_root_domain()
if not domain:
return ""
return f"https://app.{domain}/{deployment_id}"
def build_website_prompt(workspace_dir: str) -> list:
"""Build system prompt lines for cloud website/file sharing rules.
Returns an empty list when cloud deployment is not configured,
so callers can safely do ``lines.extend(build_website_prompt(...))``.
"""
base_url = get_website_base_url()
if not base_url:
return []
return [
"**文件分享与网页生成规则** (非常重要 — 当前为云部署模式):",
"",
f"云端已为工作空间的 `websites/` 目录配置好公网路由映射,访问地址前缀为: `{base_url}`",
"",
"1. **网页/网站**: 编写网页、H5页面等前端代码时,**必须**将文件放到 `websites/` 目录中",
f" - 例如: `websites/index.html` → `{base_url}/index.html`",
f" - 例如: `websites/my-app/index.html` → `{base_url}/my-app/index.html`",
"",
"2. **生成文件分享** (PPT、PDF、图片、音视频等): 当你为用户生成了需要下载或查看的文件时,**可以**将文件保存到 `websites/` 目录中",
f" - 例如: 生成的PPT保存到 `websites/files/report.pptx` → 下载链接为 `{base_url}/files/report.pptx`",
" - 你仍然可以同时使用 `send` 工具发送文件(在飞书、钉钉等IM渠道中有效),但**必须同时在回复文本中提供下载链接**作为兜底,因为部分渠道(如网页端)无法通过 send 接收本地文件",
"",
"3. **必须发送链接**: 无论是网页还是文件,生成后**必须将完整的访问/下载链接直接写在回复文本中发送给用户**",
"",
"4. **文件名和路径尽量使用英文/拼音/数字等**,不要使用中文,避免链接无法访问",
"",
"5. 建议为每个独立项目在 `websites/` 下创建子目录,保持结构清晰",
"",
]
def start(channel, channel_mgr=None):
if not get_deployment_id():
return
global chat_client
chat_client = CloudClient(api_key=conf().get("linkai_api_key"), host=conf().get("cloud_host", ""), channel=channel)
chat_client.channel_mgr = channel_mgr
chat_client.config = _build_config()
chat_client.start()
time.sleep(1.5)
if chat_client.client_id:
logger.info("[CloudClient] Console: https://link-ai.tech/console/clients")
if channel_mgr:
channel_mgr.cloud_mode = True
threading.Thread(target=_report_existing_channels, args=(chat_client, channel_mgr), daemon=True).start()
def _report_existing_channels(client: CloudClient, mgr):
"""Report status for all channels that were started before cloud client connected."""
try:
for name, ch in list(mgr._channels.items()):
if name == "web":
continue
ch.cloud_mode = True
client._report_channel_startup(name)
except Exception as e:
logger.warning(f"[CloudClient] Failed to report existing channel status: {e}")
def _build_config():
local_conf = conf()
config = {
"linkai_app_code": local_conf.get("linkai_app_code"),
"single_chat_prefix": local_conf.get("single_chat_prefix"),
"single_chat_reply_prefix": local_conf.get("single_chat_reply_prefix"),
"single_chat_reply_suffix": local_conf.get("single_chat_reply_suffix"),
"group_chat_prefix": local_conf.get("group_chat_prefix"),
"group_chat_reply_prefix": local_conf.get("group_chat_reply_prefix"),
"group_chat_reply_suffix": local_conf.get("group_chat_reply_suffix"),
"group_name_white_list": local_conf.get("group_name_white_list"),
"nick_name_black_list": local_conf.get("nick_name_black_list"),
"speech_recognition": "Y" if local_conf.get("speech_recognition") else "N",
"text_to_image": local_conf.get("text_to_image"),
"image_create_prefix": local_conf.get("image_create_prefix"),
"model": local_conf.get("model"),
"agent_max_context_turns": local_conf.get("agent_max_context_turns"),
"agent_max_context_tokens": local_conf.get("agent_max_context_tokens"),
"agent_max_steps": local_conf.get("agent_max_steps"),
"channelType": local_conf.get("channel_type"),
}
if local_conf.get("always_reply_voice"):
config["reply_voice_mode"] = "always_reply_voice"
elif local_conf.get("voice_reply_voice"):
config["reply_voice_mode"] = "voice_reply_voice"
if pconf("linkai"):
config["group_app_map"] = pconf("linkai").get("group_app_map")
if plugin_config.get("Godcmd"):
config["admin_password"] = plugin_config.get("Godcmd").get("password")
# Add channel-specific app credentials
current_channel_type = local_conf.get("channel_type", "")
if current_channel_type == "feishu":
config["app_id"] = local_conf.get("feishu_app_id")
config["app_secret"] = local_conf.get("feishu_app_secret")
elif current_channel_type == "dingtalk":
config["app_id"] = local_conf.get("dingtalk_client_id")
config["app_secret"] = local_conf.get("dingtalk_client_secret")
elif current_channel_type in ("wechatmp", "wechatmp_service"):
config["app_id"] = local_conf.get("wechatmp_app_id")
config["app_secret"] = local_conf.get("wechatmp_app_secret")
elif current_channel_type == "wecom_bot":
config["app_id"] = local_conf.get("wecom_bot_id")
config["app_secret"] = local_conf.get("wecom_bot_secret")
elif current_channel_type == "qq":
config["app_id"] = local_conf.get("qq_app_id")
config["app_secret"] = local_conf.get("qq_app_secret")
elif current_channel_type == "wechatcom_app":
config["app_id"] = local_conf.get("wechatcomapp_agent_id")
config["app_secret"] = local_conf.get("wechatcomapp_secret")
return config
================================================
FILE: common/const.py
================================================
# 厂商类型
OPEN_AI = "openAI"
OPENAI = "openai"
CHATGPT = "chatGPT" # legacy alias for OPENAI, kept for backward compatibility
BAIDU = "baidu"
XUNFEI = "xunfei"
CHATGPTONAZURE = "chatGPTOnAzure"
LINKAI = "linkai"
CLAUDEAPI= "claudeAPI"
QWEN = "qwen" # 旧版千问接入
QWEN_DASHSCOPE = "dashscope" # 新版千问接入(百炼)
GEMINI = "gemini"
ZHIPU_AI = "zhipu"
MOONSHOT = "moonshot"
MiniMax = "minimax"
DEEPSEEK = "deepseek"
MODELSCOPE = "modelscope"
# 模型列表
# Claude (Anthropic)
CLAUDE3 = "claude-3-opus-20240229"
CLAUDE_3_OPUS = "claude-3-opus-latest"
CLAUDE_3_OPUS_0229 = "claude-3-opus-20240229"
CLAUDE_3_SONNET = "claude-3-sonnet-20240229"
CLAUDE_3_HAIKU = "claude-3-haiku-20240307"
CLAUDE_35_SONNET = "claude-3-5-sonnet-latest" # 带 latest 标签的模型名称,会不断更新指向最新发布的模型
CLAUDE_35_SONNET_1022 = "claude-3-5-sonnet-20241022" # 带具体日期的模型名称,会固定为该日期发布的模型
CLAUDE_35_SONNET_0620 = "claude-3-5-sonnet-20240620"
CLAUDE_4_OPUS = "claude-opus-4-0"
CLAUDE_4_6_OPUS = "claude-opus-4-6" # Claude Opus 4.6 - Agent推荐模型
CLAUDE_4_SONNET = "claude-sonnet-4-0" # Claude Sonnet 4.0
CLAUDE_4_5_SONNET = "claude-sonnet-4-5" # Claude Sonnet 4.5 - Agent推荐模型
CLAUDE_4_6_SONNET = "claude-sonnet-4-6" # Claude Sonnet 4.6 - Agent推荐模型
# Gemini (Google)
GEMINI_PRO = "gemini-1.0-pro"
GEMINI_15_flash = "gemini-1.5-flash"
GEMINI_15_PRO = "gemini-1.5-pro"
GEMINI_20_flash_exp = "gemini-2.0-flash-exp" # exp结尾为实验模型,会逐步不再支持
GEMINI_20_FLASH = "gemini-2.0-flash" # 正式版模型
GEMINI_25_FLASH_PRE = "gemini-2.5-flash-preview-05-20"
GEMINI_25_PRO_PRE = "gemini-2.5-pro-preview-05-06"
GEMINI_3_FLASH_PRE = "gemini-3-flash-preview" # Gemini 3 Flash Preview - Agent推荐模型
GEMINI_3_PRO_PRE = "gemini-3-pro-preview" # Gemini 3 Pro Preview
GEMINI_31_PRO_PRE = "gemini-3.1-pro-preview" # Gemini 3.1 Pro Preview - Agent推荐模型
GEMINI_31_FLASH_LITE_PRE = "gemini-3.1-flash-lite-preview" # Gemini 3.1 Flash Lite Preview - Agent推荐模型
# OpenAI
GPT35 = "gpt-3.5-turbo"
GPT35_0125 = "gpt-3.5-turbo-0125"
GPT35_1106 = "gpt-3.5-turbo-1106"
GPT4 = "gpt-4"
GPT4_06_13 = "gpt-4-0613"
GPT4_32k = "gpt-4-32k"
GPT4_32k_06_13 = "gpt-4-32k-0613"
GPT4_TURBO = "gpt-4-turbo"
GPT4_TURBO_PREVIEW = "gpt-4-turbo-preview"
GPT4_TURBO_01_25 = "gpt-4-0125-preview"
GPT4_TURBO_11_06 = "gpt-4-1106-preview"
GPT4_TURBO_04_09 = "gpt-4-turbo-2024-04-09"
GPT4_VISION_PREVIEW = "gpt-4-vision-preview"
GPT_4o = "gpt-4o"
GPT_4O_0806 = "gpt-4o-2024-08-06"
GPT_4o_MINI = "gpt-4o-mini"
GPT_41 = "gpt-4.1"
GPT_41_MINI = "gpt-4.1-mini"
GPT_41_NANO = "gpt-4.1-nano"
GPT_5 = "gpt-5"
GPT_5_MINI = "gpt-5-mini"
GPT_5_NANO = "gpt-5-nano"
GPT_54 = "gpt-5.4" # GPT-5.4 - Agent recommended model
GPT_54_MINI = "gpt-5.4-mini"
GPT_54_NANO = "gpt-5.4-nano"
O1 = "o1-preview"
O1_MINI = "o1-mini"
WHISPER_1 = "whisper-1"
TTS_1 = "tts-1"
TTS_1_HD = "tts-1-hd"
# DeepSeek
DEEPSEEK_CHAT = "deepseek-chat" # DeepSeek-V3对话模型
DEEPSEEK_REASONER = "deepseek-reasoner" # DeepSeek-R1模型
# Qwen (通义千问 - 阿里云)
QWEN = "qwen"
QWEN_TURBO = "qwen-turbo"
QWEN_PLUS = "qwen-plus"
QWEN_MAX = "qwen-max"
QWEN_LONG = "qwen-long"
QWEN3_MAX = "qwen3-max" # Qwen3 Max - Agent推荐模型
QWEN35_PLUS = "qwen3.5-plus" # Qwen3.5 Plus - Omni model (MultiModalConversation)
QWQ_PLUS = "qwq-plus"
# MiniMax
MINIMAX_M2_7 = "MiniMax-M2.7" # MiniMax M2.7 - Latest
MINIMAX_M2_5 = "MiniMax-M2.5" # MiniMax M2.5
MINIMAX_M2_1 = "MiniMax-M2.1" # MiniMax M2.1
MINIMAX_M2_1_LIGHTNING = "MiniMax-M2.1-lightning" # MiniMax M2.1 极速版
MINIMAX_M2 = "MiniMax-M2" # MiniMax M2
MINIMAX_ABAB6_5 = "abab6.5-chat" # MiniMax abab6.5
# GLM (智谱AI)
GLM_5_TURBO = "glm-5-turbo" # 智谱 GLM-5-Turbo - Latest
GLM_5 = "glm-5" # 智谱 GLM-5
GLM_4 = "glm-4"
GLM_4_PLUS = "glm-4-plus"
GLM_4_flash = "glm-4-flash"
GLM_4_LONG = "glm-4-long"
GLM_4_ALLTOOLS = "glm-4-alltools"
GLM_4_0520 = "glm-4-0520"
GLM_4_AIR = "glm-4-air"
GLM_4_AIRX = "glm-4-airx"
GLM_4_7 = "glm-4.7" # 智谱 GLM-4.7 - Agent推荐模型
# Kimi (Moonshot)
MOONSHOT = "moonshot"
KIMI_K2 = "kimi-k2"
KIMI_K2_5 = "kimi-k2.5"
# Doubao (Volcengine Ark)
DOUBAO = "doubao"
DOUBAO_SEED_2_CODE = "doubao-seed-2-0-code-preview-260215"
DOUBAO_SEED_2_PRO = "doubao-seed-2-0-pro-260215"
DOUBAO_SEED_2_LITE = "doubao-seed-2-0-lite-260215"
DOUBAO_SEED_2_MINI = "doubao-seed-2-0-mini-260215"
# 其他模型
WEN_XIN = "wenxin"
WEN_XIN_4 = "wenxin-4"
XUNFEI = "xunfei"
LINKAI_35 = "linkai-3.5"
LINKAI_4_TURBO = "linkai-4-turbo"
LINKAI_4o = "linkai-4o"
MODELSCOPE = "modelscope"
GITEE_AI_MODEL_LIST = ["Yi-34B-Chat", "InternVL2-8B", "deepseek-coder-33B-instruct", "InternVL2.5-26B", "Qwen2-VL-72B", "Qwen2.5-32B-Instruct", "glm-4-9b-chat", "codegeex4-all-9b", "Qwen2.5-Coder-32B-Instruct", "Qwen2.5-72B-Instruct", "Qwen2.5-7B-Instruct", "Qwen2-72B-Instruct", "Qwen2-7B-Instruct", "code-raccoon-v1", "Qwen2.5-14B-Instruct"]
MODELSCOPE_MODEL_LIST = ["LLM-Research/c4ai-command-r-plus-08-2024","mistralai/Mistral-Small-Instruct-2409","mistralai/Ministral-8B-Instruct-2410","mistralai/Mistral-Large-Instruct-2407",
"Qwen/Qwen2.5-Coder-32B-Instruct","Qwen/Qwen2.5-Coder-14B-Instruct","Qwen/Qwen2.5-Coder-7B-Instruct","Qwen/Qwen2.5-72B-Instruct","Qwen/Qwen2.5-32B-Instruct","Qwen/Qwen2.5-14B-Instruct","Qwen/Qwen2.5-7B-Instruct","Qwen/QwQ-32B-Preview",
"LLM-Research/Llama-3.3-70B-Instruct","opencompass/CompassJudger-1-32B-Instruct","Qwen/QVQ-72B-Preview","LLM-Research/Meta-Llama-3.1-405B-Instruct","LLM-Research/Meta-Llama-3.1-8B-Instruct","Qwen/Qwen2-VL-7B-Instruct","LLM-Research/Meta-Llama-3.1-70B-Instruct",
"Qwen/Qwen2.5-14B-Instruct-1M","Qwen/Qwen2.5-7B-Instruct-1M","Qwen/Qwen2.5-VL-3B-Instruct","Qwen/Qwen2.5-VL-7B-Instruct","Qwen/Qwen2.5-VL-72B-Instruct","deepseek-ai/DeepSeek-R1-Distill-Llama-70B","deepseek-ai/DeepSeek-R1-Distill-Llama-8B","deepseek-ai/DeepSeek-R1-Distill-Qwen-32B",
"deepseek-ai/DeepSeek-R1-Distill-Qwen-14B","deepseek-ai/DeepSeek-R1-Distill-Qwen-7B","deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B","deepseek-ai/DeepSeek-R1","deepseek-ai/DeepSeek-V3","Qwen/QwQ-32B"]
MODEL_LIST = [
# Claude
CLAUDE3, CLAUDE_4_6_SONNET, CLAUDE_4_6_OPUS, CLAUDE_4_OPUS, CLAUDE_4_5_SONNET, CLAUDE_4_SONNET, CLAUDE_3_OPUS, CLAUDE_3_OPUS_0229,
CLAUDE_35_SONNET, CLAUDE_35_SONNET_1022, CLAUDE_35_SONNET_0620, CLAUDE_3_SONNET, CLAUDE_3_HAIKU,
"claude", "claude-3-haiku", "claude-3-sonnet", "claude-3-opus", "claude-3.5-sonnet",
# Gemini
GEMINI_31_FLASH_LITE_PRE, GEMINI_31_PRO_PRE, GEMINI_3_PRO_PRE, GEMINI_3_FLASH_PRE, GEMINI_25_PRO_PRE, GEMINI_25_FLASH_PRE,
GEMINI_20_FLASH, GEMINI_20_flash_exp, GEMINI_15_PRO, GEMINI_15_flash, GEMINI_PRO, GEMINI,
# OpenAI
GPT35, GPT35_0125, GPT35_1106, "gpt-3.5-turbo-16k",
GPT4, GPT4_06_13, GPT4_32k, GPT4_32k_06_13,
GPT4_TURBO, GPT4_TURBO_PREVIEW, GPT4_TURBO_01_25, GPT4_TURBO_11_06, GPT4_TURBO_04_09,
GPT_4o, GPT_4O_0806, GPT_4o_MINI,
GPT_41, GPT_41_MINI, GPT_41_NANO,
GPT_5, GPT_5_MINI, GPT_5_NANO,
GPT_54, GPT_54_MINI, GPT_54_NANO,
O1, O1_MINI,
# DeepSeek
DEEPSEEK_CHAT, DEEPSEEK_REASONER,
# Qwen
QWEN, QWEN_TURBO, QWEN_PLUS, QWEN_MAX, QWEN_LONG, QWEN3_MAX, QWEN35_PLUS,
# MiniMax
MiniMax, MINIMAX_M2_7, MINIMAX_M2_5, MINIMAX_M2_1, MINIMAX_M2_1_LIGHTNING, MINIMAX_M2, MINIMAX_ABAB6_5,
# GLM
ZHIPU_AI, GLM_5_TURBO, GLM_5, GLM_4, GLM_4_PLUS, GLM_4_flash, GLM_4_LONG, GLM_4_ALLTOOLS,
GLM_4_0520, GLM_4_AIR, GLM_4_AIRX, GLM_4_7,
# Kimi
MOONSHOT, "moonshot-v1-8k", "moonshot-v1-32k", "moonshot-v1-128k",
KIMI_K2, KIMI_K2_5,
# Doubao
DOUBAO, DOUBAO_SEED_2_CODE, DOUBAO_SEED_2_PRO, DOUBAO_SEED_2_LITE, DOUBAO_SEED_2_MINI,
# 其他模型
WEN_XIN, WEN_XIN_4, XUNFEI,
LINKAI_35, LINKAI_4_TURBO, LINKAI_4o,
MODELSCOPE
]
MODEL_LIST = MODEL_LIST + GITEE_AI_MODEL_LIST + MODELSCOPE_MODEL_LIST
# channel
FEISHU = "feishu"
DINGTALK = "dingtalk"
WECOM_BOT = "wecom_bot"
QQ = "qq"
================================================
FILE: common/dequeue.py
================================================
from queue import Full, Queue
from time import monotonic as time
# add implementation of putleft to Queue
class Dequeue(Queue):
def putleft(self, item, block=True, timeout=None):
with self.not_full:
if self.maxsize > 0:
if not block:
if self._qsize() >= self.maxsize:
raise Full
elif timeout is None:
while self._qsize() >= self.maxsize:
self.not_full.wait()
elif timeout < 0:
raise ValueError("'timeout' must be a non-negative number")
else:
endtime = time() + timeout
while self._qsize() >= self.maxsize:
remaining = endtime - time()
if remaining <= 0.0:
raise Full
self.not_full.wait(remaining)
self._putleft(item)
self.unfinished_tasks += 1
self.not_empty.notify()
def putleft_nowait(self, item):
return self.putleft(item, block=False)
def _putleft(self, item):
self.queue.appendleft(item)
================================================
FILE: common/expired_dict.py
================================================
from datetime import datetime, timedelta
class ExpiredDict(dict):
def __init__(self, expires_in_seconds):
super().__init__()
self.expires_in_seconds = expires_in_seconds
def __getitem__(self, key):
value, expiry_time = super().__getitem__(key)
if datetime.now() > expiry_time:
del self[key]
raise KeyError("expired {}".format(key))
self.__setitem__(key, value)
return value
def __setitem__(self, key, value):
expiry_time = datetime.now() + timedelta(seconds=self.expires_in_seconds)
super().__setitem__(key, (value, expiry_time))
def get(self, key, default=None):
try:
return self[key]
except KeyError:
return default
def __contains__(self, key):
try:
self[key]
return True
except KeyError:
return False
def keys(self):
keys = list(super().keys())
return [key for key in keys if key in self]
def items(self):
return [(key, self[key]) for key in self.keys()]
def __iter__(self):
return self.keys().__iter__()
================================================
FILE: common/log.py
================================================
import logging
import sys
def _reset_logger(log):
for handler in log.handlers:
handler.close()
log.removeHandler(handler)
del handler
log.handlers.clear()
log.propagate = False
console_handle = logging.StreamHandler(sys.stdout)
console_handle.setFormatter(
logging.Formatter(
"[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d] - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
)
)
file_handle = logging.FileHandler("run.log", encoding="utf-8")
file_handle.setFormatter(
logging.Formatter(
"[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d] - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S",
)
)
log.addHandler(file_handle)
log.addHandler(console_handle)
def _get_logger():
log = logging.getLogger("log")
_reset_logger(log)
log.setLevel(logging.INFO)
return log
# 日志句柄
logger = _get_logger()
================================================
FILE: common/memory.py
================================================
from common.expired_dict import ExpiredDict
USER_IMAGE_CACHE = ExpiredDict(60 * 3)
================================================
FILE: common/package_manager.py
================================================
import time
import pip
from pip._internal import main as pipmain
from common.log import _reset_logger, logger
def install(package):
pipmain(["install", package])
def install_requirements(file):
pipmain(["install", "-r", file, "--upgrade"])
_reset_logger(logger)
def check_dulwich():
needwait = False
for i in range(2):
if needwait:
time.sleep(3)
needwait = False
try:
import dulwich
return
except ImportError:
try:
install("dulwich")
except Exception:
needwait = True
try:
import dulwich
except ImportError:
raise ImportError("Unable to import dulwich")
================================================
FILE: common/singleton.py
================================================
def singleton(cls):
instances = {}
def get_instance(*args, **kwargs):
if cls not in instances:
instances[cls] = cls(*args, **kwargs)
return instances[cls]
return get_instance
================================================
FILE: common/sorted_dict.py
================================================
import heapq
class SortedDict(dict):
def __init__(self, sort_func=lambda k, v: k, init_dict=None, reverse=False):
if init_dict is None:
init_dict = []
if isinstance(init_dict, dict):
init_dict = init_dict.items()
self.sort_func = sort_func
self.sorted_keys = None
self.reverse = reverse
self.heap = []
for k, v in init_dict:
self[k] = v
def __setitem__(self, key, value):
if key in self:
super().__setitem__(key, value)
for i, (priority, k) in enumerate(self.heap):
if k == key:
self.heap[i] = (self.sort_func(key, value), key)
heapq.heapify(self.heap)
break
self.sorted_keys = None
else:
super().__setitem__(key, value)
heapq.heappush(self.heap, (self.sort_func(key, value), key))
self.sorted_keys = None
def __delitem__(self, key):
super().__delitem__(key)
for i, (priority, k) in enumerate(self.heap):
if k == key:
del self.heap[i]
heapq.heapify(self.heap)
break
self.sorted_keys = None
def keys(self):
if self.sorted_keys is None:
self.sorted_keys = [k for _, k in sorted(self.heap, reverse=self.reverse)]
return self.sorted_keys
def items(self):
if self.sorted_keys is None:
self.sorted_keys = [k for _, k in sorted(self.heap, reverse=self.reverse)]
sorted_items = [(k, self[k]) for k in self.sorted_keys]
return sorted_items
def _update_heap(self, key):
for i, (priority, k) in enumerate(self.heap):
if k == key:
new_priority = self.sort_func(key, self[key])
if new_priority != priority:
self.heap[i] = (new_priority, key)
heapq.heapify(self.heap)
self.sorted_keys = None
break
def __iter__(self):
return iter(self.keys())
def __repr__(self):
return f"{type(self).__name__}({dict(self)}, sort_func={self.sort_func.__name__}, reverse={self.reverse})"
================================================
FILE: common/time_check.py
================================================
import re
import time
import config
from common.log import logger
def time_checker(f):
def _time_checker(self, *args, **kwargs):
_config = config.conf()
chat_time_module = _config.get("chat_time_module", False)
if chat_time_module:
chat_start_time = _config.get("chat_start_time", "00:00")
chat_stop_time = _config.get("chat_stop_time", "24:00")
time_regex = re.compile(r"^([01]?[0-9]|2[0-4])(:)([0-5][0-9])$")
if not (time_regex.match(chat_start_time) and time_regex.match(chat_stop_time)):
logger.warning("时间格式不正确,请在config.json中修改CHAT_START_TIME/CHAT_STOP_TIME。")
return None
now_time = time.strptime(time.strftime("%H:%M"), "%H:%M")
chat_start_time = time.strptime(chat_start_time, "%H:%M")
chat_stop_time = time.strptime(chat_stop_time, "%H:%M")
# 结束时间小于开始时间,跨天了
if chat_stop_time < chat_start_time and (chat_start_time <= now_time or now_time <= chat_stop_time):
f(self, *args, **kwargs)
# 结束大于开始时间代表,没有跨天
elif chat_start_time < chat_stop_time and chat_start_time <= now_time <= chat_stop_time:
f(self, *args, **kwargs)
else:
# 定义匹配规则,如果以 #reconf 或者 #更新配置 结尾, 非服务时间可以修改开始/结束时间并重载配置
pattern = re.compile(r"^.*#(?:reconf|更新配置)$")
if args and pattern.match(args[0].content):
f(self, *args, **kwargs)
else:
logger.info("非服务时间内,不接受访问")
return None
else:
f(self, *args, **kwargs) # 未开启时间模块则直接回答
return _time_checker
================================================
FILE: common/tmp_dir.py
================================================
import os
import pathlib
from config import conf
class TmpDir(object):
"""A temporary directory that is deleted when the object is destroyed."""
tmpFilePath = pathlib.Path("./tmp/")
def __init__(self):
pathExists = os.path.exists(self.tmpFilePath)
if not pathExists:
os.makedirs(self.tmpFilePath)
def path(self):
return str(self.tmpFilePath) + "/"
================================================
FILE: common/token_bucket.py
================================================
import threading
import time
class TokenBucket:
def __init__(self, tpm, timeout=None):
self.capacity = int(tpm) # 令牌桶容量
self.tokens = 0 # 初始令牌数为0
self.rate = int(tpm) / 60 # 令牌每秒生成速率
self.timeout = timeout # 等待令牌超时时间
self.cond = threading.Condition() # 条件变量
self.is_running = True
# 开启令牌生成线程
threading.Thread(target=self._generate_tokens).start()
def _generate_tokens(self):
"""生成令牌"""
while self.is_running:
with self.cond:
if self.tokens < self.capacity:
self.tokens += 1
self.cond.notify() # 通知获取令牌的线程
time.sleep(1 / self.rate)
def get_token(self):
"""获取令牌"""
with self.cond:
while self.tokens <= 0:
flag = self.cond.wait(self.timeout)
if not flag: # 超时
return False
self.tokens -= 1
return True
def close(self):
self.is_running = False
if __name__ == "__main__":
token_bucket = TokenBucket(20, None) # 创建一个每分钟生产20个tokens的令牌桶
# token_bucket = TokenBucket(20, 0.1)
for i in range(3):
if token_bucket.get_token():
print(f"第{i+1}次请求成功")
token_bucket.close()
================================================
FILE: common/utils.py
================================================
import io
import os
import re
from urllib.parse import urlparse
from common.log import logger
def fsize(file):
if isinstance(file, io.BytesIO):
return file.getbuffer().nbytes
elif isinstance(file, str):
return os.path.getsize(file)
elif hasattr(file, "seek") and hasattr(file, "tell"):
pos = file.tell()
file.seek(0, os.SEEK_END)
size = file.tell()
file.seek(pos)
return size
else:
raise TypeError("Unsupported type")
def compress_imgfile(file, max_size):
if fsize(file) <= max_size:
return file
from PIL import Image
file.seek(0)
img = Image.open(file)
rgb_image = img.convert("RGB")
quality = 95
while True:
out_buf = io.BytesIO()
rgb_image.save(out_buf, "JPEG", quality=quality)
if fsize(out_buf) <= max_size:
return out_buf
quality -= 5
def split_string_by_utf8_length(string, max_length, max_split=0):
encoded = string.encode("utf-8")
start, end = 0, 0
result = []
while end < len(encoded):
if max_split > 0 and len(result) >= max_split:
result.append(encoded[start:].decode("utf-8"))
break
end = min(start + max_length, len(encoded))
# 如果当前字节不是 UTF-8 编码的开始字节,则向前查找直到找到开始字节为止
while end < len(encoded) and (encoded[end] & 0b11000000) == 0b10000000:
end -= 1
result.append(encoded[start:end].decode("utf-8"))
start = end
return result
def get_path_suffix(path):
path = urlparse(path).path
return os.path.splitext(path)[-1].lstrip('.')
def convert_webp_to_png(webp_image):
from PIL import Image
try:
webp_image.seek(0)
img = Image.open(webp_image).convert("RGBA")
png_image = io.BytesIO()
img.save(png_image, format="PNG")
png_image.seek(0)
return png_image
except Exception as e:
logger.error(f"Failed to convert WEBP to PNG: {e}")
raise
def remove_markdown_symbol(text: str):
# 移除markdown格式,目前先移除**
if not text:
return text
return re.sub(r'\*\*(.*?)\*\*', r'\1', text)
def expand_path(path: str) -> str:
"""
Expand user path with proper Windows support.
On Windows, os.path.expanduser('~') may not work properly in some shells (like PowerShell).
This function provides a more robust path expansion.
Args:
path: Path string that may contain ~
Returns:
Expanded absolute path
"""
if not path:
return path
# Try standard expansion first
expanded = os.path.expanduser(path)
# If expansion didn't work (path still starts with ~), use HOME or USERPROFILE
if expanded.startswith('~'):
import platform
if platform.system() == 'Windows':
# On Windows, try USERPROFILE first, then HOME
home = os.environ.get('USERPROFILE') or os.environ.get('HOME')
else:
# On Unix-like systems, use HOME
home = os.environ.get('HOME')
if home:
# Replace ~ with home directory
if path == '~':
expanded = home
elif path.startswith('~/') or path.startswith('~\\'):
expanded = os.path.join(home, path[2:])
return expanded
def get_cloud_headers(api_key: str) -> dict:
"""
Build standard headers for LinkAI API requests,
including client_id when available.
"""
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {api_key}",
}
try:
from linkai import LinkAIClient
client_id = LinkAIClient.fetch_client_id()
if client_id:
headers["X-Client-Id"] = client_id
except Exception:
pass
return headers
================================================
FILE: config-template.json
================================================
{
"channel_type": "web",
"model": "MiniMax-M2.7",
"minimax_api_key": "",
"zhipu_ai_api_key": "",
"ark_api_key": "",
"moonshot_api_key": "",
"dashscope_api_key": "",
"claude_api_key": "",
"claude_api_base": "https://api.anthropic.com/v1",
"open_ai_api_key": "",
"open_ai_api_base": "https://api.openai.com/v1",
"gemini_api_key": "",
"gemini_api_base": "https://generativelanguage.googleapis.com",
"voice_to_text": "openai",
"text_to_voice": "openai",
"voice_reply_voice": false,
"speech_recognition": true,
"group_speech_recognition": false,
"use_linkai": false,
"linkai_api_key": "",
"linkai_app_code": "",
"feishu_app_id": "",
"feishu_app_secret": "",
"dingtalk_client_id": "",
"dingtalk_client_secret":"",
"wecom_bot_id": "",
"wecom_bot_secret": "",
"agent": true,
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 20,
"agent_max_steps": 15
}
================================================
FILE: config.py
================================================
# encoding:utf-8
import copy
import json
import logging
import os
import pickle
from common.log import logger
# 将所有可用的配置项写在字典里, 请使用小写字母
# 此处的配置值无实际意义,程序不会读取此处的配置,仅用于提示格式,请将配置加入到config.json中
available_setting = {
# openai api配置
"open_ai_api_key": "", # openai api key
# openai apibase,当use_azure_chatgpt为true时,需要设置对应的api base
"open_ai_api_base": "https://api.openai.com/v1",
"claude_api_base": "https://api.anthropic.com/v1", # claude api base
"gemini_api_base": "https://generativelanguage.googleapis.com", # gemini api base
"proxy": "", # openai使用的代理
# chatgpt模型, 当use_azure_chatgpt为true时,其名称为Azure上model deployment名称
"model": "gpt-3.5-turbo", # 可选择: gpt-4o, pt-4o-mini, gpt-4-turbo, claude-3-sonnet, wenxin, moonshot, qwen-turbo, xunfei, glm-4, minimax, gemini等模型,全部可选模型详见common/const.py文件
"bot_type": "", # 可选配置,使用兼容openai格式的三方服务时候,需填"openai"(历史值"chatGPT"仍兼容)。bot具体名称详见common/const.py文件,如不填根据model名称判断
"use_azure_chatgpt": False, # 是否使用azure的chatgpt
"azure_deployment_id": "", # azure 模型部署名称
"azure_api_version": "", # azure api版本
# Bot触发配置
"single_chat_prefix": ["bot", "@bot"], # 私聊时文本需要包含该前缀才能触发机器人回复
"single_chat_reply_prefix": "[bot] ", # 私聊时自动回复的前缀,用于区分真人
"single_chat_reply_suffix": "", # 私聊时自动回复的后缀,\n 可以换行
"group_chat_prefix": ["@bot"], # 群聊时包含该前缀则会触发机器人回复
"no_need_at": False, # 群聊回复时是否不需要艾特
"group_chat_reply_prefix": "", # 群聊时自动回复的前缀
"group_chat_reply_suffix": "", # 群聊时自动回复的后缀,\n 可以换行
"group_chat_keyword": [], # 群聊时包含该关键词则会触发机器人回复
"group_at_off": False, # 是否关闭群聊时@bot的触发
"group_name_white_list": ["ChatGPT测试群", "ChatGPT测试群2"], # 开启自动回复的群名称列表
"group_name_keyword_white_list": [], # 开启自动回复的群名称关键词列表
"group_chat_in_one_session": ["ChatGPT测试群"], # 支持会话上下文共享的群名称
"group_shared_session": False, # 群聊是否共享会话上下文(所有成员共享)。False时每个用户在群内有独立会话
"nick_name_black_list": [], # 用户昵称黑名单
"group_welcome_msg": "", # 配置新人进群固定欢迎语,不配置则使用随机风格欢迎
"trigger_by_self": False, # 是否允许机器人触发
"text_to_image": "dall-e-2", # 图片生成模型,可选 dall-e-2, dall-e-3
# Azure OpenAI dall-e-3 配置
"dalle3_image_style": "vivid", # 图片生成dalle3的风格,可选有 vivid, natural
"dalle3_image_quality": "hd", # 图片生成dalle3的质量,可选有 standard, hd
# Azure OpenAI DALL-E API 配置, 当use_azure_chatgpt为true时,用于将文字回复的资源和Dall-E的资源分开.
"azure_openai_dalle_api_base": "", # [可选] azure openai 用于回复图片的资源 endpoint,默认使用 open_ai_api_base
"azure_openai_dalle_api_key": "", # [可选] azure openai 用于回复图片的资源 key,默认使用 open_ai_api_key
"azure_openai_dalle_deployment_id":"", # [可选] azure openai 用于回复图片的资源 deployment id,默认使用 text_to_image
"image_proxy": True, # 是否需要图片代理,国内访问LinkAI时需要
"image_create_prefix": ["画", "看", "找"], # 开启图片回复的前缀
"concurrency_in_session": 1, # 同一会话最多有多少条消息在处理中,大于1可能乱序
"image_create_size": "256x256", # 图片大小,可选有 256x256, 512x512, 1024x1024 (dall-e-3默认为1024x1024)
"group_chat_exit_group": False,
# chatgpt会话参数
"expires_in_seconds": 3600, # 无操作会话的过期时间
# 人格描述
"character_desc": "你是ChatGPT, 一个由OpenAI训练的大型语言模型, 你旨在回答并解决人们的任何问题,并且可以使用多种语言与人交流。",
"conversation_max_tokens": 1000, # 支持上下文记忆的最多字符数
# chatgpt限流配置
"rate_limit_chatgpt": 20, # chatgpt的调用频率限制
"rate_limit_dalle": 50, # openai dalle的调用频率限制
# chatgpt api参数 参考https://platform.openai.com/docs/api-reference/chat/create
"temperature": 0.9,
"top_p": 1,
"frequency_penalty": 0,
"presence_penalty": 0,
"request_timeout": 180, # chatgpt请求超时时间,openai接口默认设置为600,对于难问题一般需要较长时间
"timeout": 120, # chatgpt重试超时时间,在这个时间内,将会自动重试
# Baidu 文心一言参数
"baidu_wenxin_model": "eb-instant", # 默认使用ERNIE-Bot-turbo模型
"baidu_wenxin_api_key": "", # Baidu api key
"baidu_wenxin_secret_key": "", # Baidu secret key
"baidu_wenxin_prompt_enabled": False, # Enable prompt if you are using ernie character model
# 讯飞星火API
"xunfei_app_id": "", # 讯飞应用ID
"xunfei_api_key": "", # 讯飞 API key
"xunfei_api_secret": "", # 讯飞 API secret
"xunfei_domain": "", # 讯飞模型对应的domain参数,Spark4.0 Ultra为 4.0Ultra,其他模型详见: https://www.xfyun.cn/doc/spark/Web.html
"xunfei_spark_url": "", # 讯飞模型对应的请求地址,Spark4.0 Ultra为 wss://spark-api.xf-yun.com/v4.0/chat,其他模型参考详见: https://www.xfyun.cn/doc/spark/Web.html
# claude 配置
"claude_api_cookie": "",
"claude_uuid": "",
# claude api key
"claude_api_key": "",
# 通义千问API, 获取方式查看文档 https://help.aliyun.com/document_detail/2587494.html
"qwen_access_key_id": "",
"qwen_access_key_secret": "",
"qwen_agent_key": "",
"qwen_app_id": "",
"qwen_node_id": "", # 流程编排模型用到的id,如果没有用到qwen_node_id,请务必保持为空字符串
# 阿里灵积(通义新版sdk)模型api key
"dashscope_api_key": "",
# Google Gemini Api Key
"gemini_api_key": "",
# 语音设置
"speech_recognition": True, # 是否开启语音识别
"group_speech_recognition": False, # 是否开启群组语音识别
"voice_reply_voice": False, # 是否使用语音回复语音,需要设置对应语音合成引擎的api key
"always_reply_voice": False, # 是否一直使用语音回复
"voice_to_text": "openai", # 语音识别引擎,支持openai,baidu,google,azure,xunfei,ali
"text_to_voice": "openai", # 语音合成引擎,支持openai,baidu,google,azure,xunfei,ali,pytts(offline),elevenlabs,edge(online)
"text_to_voice_model": "tts-1",
"tts_voice_id": "alloy",
# baidu 语音api配置, 使用百度语音识别和语音合成时需要
"baidu_app_id": "",
"baidu_api_key": "",
"baidu_secret_key": "",
# 1536普通话(支持简单的英文识别) 1737英语 1637粤语 1837四川话 1936普通话远场
"baidu_dev_pid": 1536,
# azure 语音api配置, 使用azure语音识别和语音合成时需要
"azure_voice_api_key": "",
"azure_voice_region": "japaneast",
# elevenlabs 语音api配置
"xi_api_key": "", # 获取ap的方法可以参考https://docs.elevenlabs.io/api-reference/quick-start/authentication
"xi_voice_id": "", # ElevenLabs提供了9种英式、美式等英语发音id,分别是“Adam/Antoni/Arnold/Bella/Domi/Elli/Josh/Rachel/Sam”
# 服务时间限制
"chat_time_module": False, # 是否开启服务时间限制
"chat_start_time": "00:00", # 服务开始时间
"chat_stop_time": "24:00", # 服务结束时间
# 翻译api
"translate": "baidu", # 翻译api,支持baidu
# baidu翻译api的配置
"baidu_translate_app_id": "", # 百度翻译api的appid
"baidu_translate_app_key": "", # 百度翻译api的秘钥
# wechatmp的配置
"wechatmp_token": "", # 微信公众平台的Token
"wechatmp_port": 8080, # 微信公众平台的端口,需要端口转发到80或443
"wechatmp_app_id": "", # 微信公众平台的appID
"wechatmp_app_secret": "", # 微信公众平台的appsecret
"wechatmp_aes_key": "", # 微信公众平台的EncodingAESKey,加密模式需要
# wechatcom的通用配置
"wechatcom_corp_id": "", # 企业微信公司的corpID
# wechatcomapp的配置
"wechatcomapp_token": "", # 企业微信app的token
"wechatcomapp_port": 9898, # 企业微信app的服务端口,不需要端口转发
"wechatcomapp_secret": "", # 企业微信app的secret
"wechatcomapp_agent_id": "", # 企业微信app的agent_id
"wechatcomapp_aes_key": "", # 企业微信app的aes_key
# 飞书配置
"feishu_port": 80, # 飞书bot监听端口
"feishu_app_id": "", # 飞书机器人应用APP Id
"feishu_app_secret": "", # 飞书机器人APP secret
"feishu_token": "", # 飞书 verification token
"feishu_bot_name": "", # 飞书机器人的名字
"feishu_event_mode": "websocket", # 飞书事件接收模式: webhook(HTTP服务器) 或 websocket(长连接)
# 钉钉配置
"dingtalk_client_id": "", # 钉钉机器人Client ID
"dingtalk_client_secret": "", # 钉钉机器人Client Secret
"dingtalk_card_enabled": False,
# 企微智能机器人配置(长连接模式)
"wecom_bot_id": "", # 企微智能机器人BotID
"wecom_bot_secret": "", # 企微智能机器人长连接Secret
# chatgpt指令自定义触发词
"clear_memory_commands": ["#清除记忆"], # 重置会话指令,必须以#开头
# channel配置
"channel_type": "", # 通道类型,支持多渠道同时运行。单个: "feishu",多个: "feishu, dingtalk" 或 ["feishu", "dingtalk"]。可选值: web,feishu,dingtalk,wecom_bot,wechatmp,wechatmp_service,wechatcom_app
"web_console": True, # 是否自动启动Web控制台(默认启动)。设为False可禁用
"subscribe_msg": "", # 订阅消息, 支持: wechatmp, wechatmp_service, wechatcom_app
"debug": False, # 是否开启debug模式,开启后会打印更多日志
"appdata_dir": "", # 数据目录
# 插件配置
"plugin_trigger_prefix": "$", # 规范插件提供聊天相关指令的前缀,建议不要和管理员指令前缀"#"冲突
# 是否使用全局插件配置
"use_global_plugin_config": False,
"max_media_send_count": 3, # 单次最大发送媒体资源的个数
"media_send_interval": 1, # 发送图片的事件间隔,单位秒
# 智谱AI 平台配置
"zhipu_ai_api_key": "",
"zhipu_ai_api_base": "https://open.bigmodel.cn/api/paas/v4",
"moonshot_api_key": "",
"moonshot_base_url": "https://api.moonshot.cn/v1",
# 豆包(火山方舟) 平台配置
"ark_api_key": "",
"ark_base_url": "https://ark.cn-beijing.volces.com/api/v3",
#魔搭社区 平台配置
"modelscope_api_key": "",
"modelscope_base_url": "https://api-inference.modelscope.cn/v1/chat/completions",
# LinkAI平台配置
"use_linkai": False,
"linkai_api_key": "",
"linkai_app_code": "",
"linkai_api_base": "https://api.link-ai.tech", # linkAI服务地址
"cloud_host": "client.link-ai.tech",
"cloud_deployment_id": "",
"minimax_api_key": "",
"Minimax_group_id": "",
"Minimax_base_url": "",
"web_port": 9899,
"agent": True, # 是否开启Agent模式
"agent_workspace": "~/cow", # agent工作空间路径,用于存储skills、memory等
"agent_max_context_tokens": 50000, # Agent模式下最大上下文tokens
"agent_max_context_turns": 30, # Agent模式下最大上下文记忆轮次
"agent_max_steps": 15, # Agent模式下单次运行最大决策步数
}
class Config(dict):
def __init__(self, d=None):
super().__init__()
if d is None:
d = {}
for k, v in d.items():
self[k] = v
# user_datas: 用户数据,key为用户名,value为用户数据,也是dict
self.user_datas = {}
def __getitem__(self, key):
# 跳过以下划线开头的注释字段
if not key.startswith("_") and key not in available_setting:
logger.warning("[Config] key '{}' not in available_setting, may not take effect".format(key))
return super().__getitem__(key)
def __setitem__(self, key, value):
# 跳过以下划线开头的注释字段
if not key.startswith("_") and key not in available_setting:
logger.warning("[Config] key '{}' not in available_setting, may not take effect".format(key))
return super().__setitem__(key, value)
def get(self, key, default=None):
# 跳过以下划线开头的注释字段
if key.startswith("_"):
return super().get(key, default)
# 如果key不在available_setting中,直接返回default
if key not in available_setting:
return super().get(key, default)
try:
return self[key]
except KeyError as e:
return default
except Exception as e:
raise e
# Make sure to return a dictionary to ensure atomic
def get_user_data(self, user) -> dict:
if self.user_datas.get(user) is None:
self.user_datas[user] = {}
return self.user_datas[user]
def load_user_datas(self):
try:
with open(os.path.join(get_appdata_dir(), "user_datas.pkl"), "rb") as f:
self.user_datas = pickle.load(f)
logger.debug("[Config] User datas loaded.")
except FileNotFoundError as e:
logger.debug("[Config] User datas file not found, ignore.")
except Exception as e:
logger.warning("[Config] User datas error: {}".format(e))
self.user_datas = {}
def save_user_datas(self):
try:
with open(os.path.join(get_appdata_dir(), "user_datas.pkl"), "wb") as f:
pickle.dump(self.user_datas, f)
logger.info("[Config] User datas saved.")
except Exception as e:
logger.info("[Config] User datas error: {}".format(e))
config = Config()
def drag_sensitive(config):
try:
if isinstance(config, str):
conf_dict: dict = json.loads(config)
conf_dict_copy = copy.deepcopy(conf_dict)
for key in conf_dict_copy:
if "key" in key or "secret" in key:
if isinstance(conf_dict_copy[key], str):
conf_dict_copy[key] = conf_dict_copy[key][0:3] + "*" * 5 + conf_dict_copy[key][-3:]
return json.dumps(conf_dict_copy, indent=4)
elif isinstance(config, dict):
config_copy = copy.deepcopy(config)
for key in config:
if "key" in key or "secret" in key:
if isinstance(config_copy[key], str):
config_copy[key] = config_copy[key][0:3] + "*" * 5 + config_copy[key][-3:]
return config_copy
except Exception as e:
logger.exception(e)
return config
return config
def load_config():
global config
# 打印 ASCII Logo
logger.info(" ____ _ _ ")
logger.info(" / ___|_____ __ / \\ __ _ ___ _ __ | |_ ")
logger.info("| | / _ \\ \\ /\\ / // _ \\ / _` |/ _ \\ '_ \\| __|")
logger.info("| |__| (_) \\ V V // ___ \\ (_| | __/ | | | |_ ")
logger.info(" \\____\\___/ \\_/\\_//_/ \\_\\__, |\\___|_| |_|\\__|")
logger.info(" |___/ ")
logger.info("")
config_path = "./config.json"
if not os.path.exists(config_path):
logger.info("配置文件不存在,将使用config-template.json模板")
config_path = "./config-template.json"
config_str = read_file(config_path)
logger.debug("[INIT] config str: {}".format(drag_sensitive(config_str)))
# 将json字符串反序列化为dict类型
config = Config(json.loads(config_str))
# override config with environment variables.
# Some online deployment platforms (e.g. Railway) deploy project from github directly. So you shouldn't put your secrets like api key in a config file, instead use environment variables to override the default config.
for name, value in os.environ.items():
name = name.lower()
# 跳过以下划线开头的注释字段
if name.startswith("_"):
continue
if name in available_setting:
logger.info("[INIT] override config by environ args: {}={}".format(name, value))
try:
config[name] = eval(value)
except Exception:
if value == "false":
config[name] = False
elif value == "true":
config[name] = True
else:
config[name] = value
if config.get("debug", False):
logger.setLevel(logging.DEBUG)
logger.debug("[INIT] set log level to DEBUG")
logger.info("[INIT] load config: {}".format(drag_sensitive(config)))
# 打印系统初始化信息
logger.info("[INIT] ========================================")
logger.info("[INIT] System Initialization")
logger.info("[INIT] ========================================")
logger.info("[INIT] Channel: {}".format(config.get("channel_type", "unknown")))
logger.info("[INIT] Model: {}".format(config.get("model", "unknown")))
# Agent模式信息
if config.get("agent", False):
workspace = config.get("agent_workspace", "~/cow")
logger.info("[INIT] Mode: Agent (workspace: {})".format(workspace))
else:
logger.info("[INIT] Mode: Chat (在config.json中设置 \"agent\":true 可启用Agent模式)")
logger.info("[INIT] Debug: {}".format(config.get("debug", False)))
logger.info("[INIT] ========================================")
# Sync selected config values to environment variables so that
# subprocesses (e.g. shell skill scripts) can access them directly.
# Existing env vars are NOT overwritten (env takes precedence).
_CONFIG_TO_ENV = {
"open_ai_api_key": "OPENAI_API_KEY",
"open_ai_api_base": "OPENAI_API_BASE",
"linkai_api_key": "LINKAI_API_KEY",
"linkai_api_base": "LINKAI_API_BASE",
"claude_api_key": "CLAUDE_API_KEY",
"claude_api_base": "CLAUDE_API_BASE",
"gemini_api_key": "GEMINI_API_KEY",
"gemini_api_base": "GEMINI_API_BASE",
"minimax_api_key": "MINIMAX_API_KEY",
"minimax_api_base": "MINIMAX_API_BASE",
"zhipu_ai_api_key": "ZHIPU_AI_API_KEY",
"zhipu_ai_api_base": "ZHIPU_AI_API_BASE",
"moonshot_api_key": "MOONSHOT_API_KEY",
"moonshot_api_base": "MOONSHOT_API_BASE",
"ark_api_key": "ARK_API_KEY",
"ark_api_base": "ARK_API_BASE",
# Channel credentials (used by skills that check env vars)
"feishu_app_id": "FEISHU_APP_ID",
"feishu_app_secret": "FEISHU_APP_SECRET",
"dingtalk_client_id": "DINGTALK_CLIENT_ID",
"dingtalk_client_secret": "DINGTALK_CLIENT_SECRET",
"wechatmp_app_id": "WECHATMP_APP_ID",
"wechatmp_app_secret": "WECHATMP_APP_SECRET",
"wechatcomapp_agent_id": "WECHATCOMAPP_AGENT_ID",
"wechatcomapp_secret": "WECHATCOMAPP_SECRET",
"qq_app_id": "QQ_APP_ID",
"qq_app_secret": "QQ_APP_SECRET"
}
injected = 0
for conf_key, env_key in _CONFIG_TO_ENV.items():
if env_key not in os.environ:
val = config.get(conf_key, "")
if val:
os.environ[env_key] = str(val)
injected += 1
if injected:
logger.info("[INIT] Synced {} config values to environment variables".format(injected))
config.load_user_datas()
def get_root():
return os.path.dirname(os.path.abspath(__file__))
def read_file(path):
with open(path, mode="r", encoding="utf-8") as f:
return f.read()
def conf():
return config
def get_appdata_dir():
data_path = os.path.join(get_root(), conf().get("appdata_dir", ""))
if not os.path.exists(data_path):
logger.info("[INIT] data path not exists, create it: {}".format(data_path))
os.makedirs(data_path)
return data_path
def subscribe_msg():
trigger_prefix = conf().get("single_chat_prefix", [""])[0]
msg = conf().get("subscribe_msg", "")
return msg.format(trigger_prefix=trigger_prefix)
# global plugin config
plugin_config = {}
def write_plugin_config(pconf: dict):
"""
写入插件全局配置
:param pconf: 全量插件配置
"""
global plugin_config
for k in pconf:
plugin_config[k.lower()] = pconf[k]
def remove_plugin_config(name: str):
"""
移除待重新加载的插件全局配置
:param name: 待重载的插件名
"""
global plugin_config
plugin_config.pop(name.lower(), None)
def pconf(plugin_name: str) -> dict:
"""
根据插件名称获取配置
:param plugin_name: 插件名称
:return: 该插件的配置项
"""
return plugin_config.get(plugin_name.lower())
# 全局配置,用于存放全局生效的状态
global_config = {"admin_users": []}
================================================
FILE: docker/Dockerfile.latest
================================================
FROM python:3.10-slim-bullseye
LABEL maintainer="foo@bar.com"
ARG TZ='Asia/Shanghai'
ARG CHATGPT_ON_WECHAT_VER
RUN echo /etc/apt/sources.list
# RUN sed -i 's/deb.debian.org/mirrors.tuna.tsinghua.edu.cn/g' /etc/apt/sources.list
ENV BUILD_PREFIX=/app
ADD . ${BUILD_PREFIX}
RUN apt-get update \
&&apt-get install -y --no-install-recommends bash ffmpeg espeak libavcodec-extra\
&& cd ${BUILD_PREFIX} \
&& cp config-template.json config.json \
&& /usr/local/bin/python -m pip install --no-cache --upgrade pip \
&& pip install --no-cache -r requirements.txt \
&& pip install --no-cache -r requirements-optional.txt \
&& pip install azure-cognitiveservices-speech
WORKDIR ${BUILD_PREFIX}
ADD docker/entrypoint.sh /entrypoint.sh
RUN chmod +x /entrypoint.sh \
&& mkdir -p /home/agent/cow \
&& groupadd -r agent \
&& useradd -r -g agent -s /bin/bash -d /home/agent agent \
&& chown -R agent:agent /home/agent ${BUILD_PREFIX} /usr/local/lib
USER agent
ENTRYPOINT ["/entrypoint.sh"]
================================================
FILE: docker/build.latest.sh
================================================
#!/bin/bash
unset KUBECONFIG
cd .. && docker build -f docker/Dockerfile.latest \
-t zhayujie/chatgpt-on-wechat .
docker tag zhayujie/chatgpt-on-wechat zhayujie/chatgpt-on-wechat:$(date +%y%m%d)
================================================
FILE: docker/docker-compose.yml
================================================
version: '2.0'
services:
chatgpt-on-wechat:
image: zhayujie/chatgpt-on-wechat
container_name: chatgpt-on-wechat
security_opt:
- seccomp:unconfined
ports:
- "9899:9899"
environment:
CHANNEL_TYPE: 'web'
MODEL: 'MiniMax-M2.5'
MINIMAX_API_KEY: ''
ZHIPU_AI_API_KEY: ''
ARK_API_KEY: ''
MOONSHOT_API_KEY: ''
DASHSCOPE_API_KEY: ''
CLAUDE_API_KEY: ''
CLAUDE_API_BASE: 'https://api.anthropic.com/v1'
OPEN_AI_API_KEY: ''
OPEN_AI_API_BASE: 'https://api.openai.com/v1'
GEMINI_API_KEY: ''
GEMINI_API_BASE: 'https://generativelanguage.googleapis.com'
VOICE_TO_TEXT: 'openai'
TEXT_TO_VOICE: 'openai'
VOICE_REPLY_VOICE: 'False'
SPEECH_RECOGNITION: 'True'
GROUP_SPEECH_RECOGNITION: 'False'
USE_LINKAI: 'False'
LINKAI_API_KEY: ''
LINKAI_APP_CODE: ''
FEISHU_APP_ID: ''
FEISHU_APP_SECRET: ''
DINGTALK_CLIENT_ID: ''
DINGTALK_CLIENT_SECRET: ''
WECOM_BOT_ID: ''
WECOM_BOT_SECRET: ''
AGENT: 'True'
AGENT_MAX_CONTEXT_TOKENS: 40000
AGENT_MAX_CONTEXT_TURNS: 20
AGENT_MAX_STEPS: 15
volumes:
- ./cow:/home/agent/cow
================================================
FILE: docker/entrypoint.sh
================================================
#!/bin/bash
set -e
# build prefix
CHATGPT_ON_WECHAT_PREFIX=${CHATGPT_ON_WECHAT_PREFIX:-""}
# path to config.json
CHATGPT_ON_WECHAT_CONFIG_PATH=${CHATGPT_ON_WECHAT_CONFIG_PATH:-""}
# execution command line
CHATGPT_ON_WECHAT_EXEC=${CHATGPT_ON_WECHAT_EXEC:-""}
# use environment variables to pass parameters
# if you have not defined environment variables, set them below
# export OPEN_AI_API_KEY=${OPEN_AI_API_KEY:-'YOUR API KEY'}
# export OPEN_AI_PROXY=${OPEN_AI_PROXY:-""}
# export SINGLE_CHAT_PREFIX=${SINGLE_CHAT_PREFIX:-'["bot", "@bot"]'}
# export SINGLE_CHAT_REPLY_PREFIX=${SINGLE_CHAT_REPLY_PREFIX:-'"[bot] "'}
# export GROUP_CHAT_PREFIX=${GROUP_CHAT_PREFIX:-'["@bot"]'}
# export GROUP_NAME_WHITE_LIST=${GROUP_NAME_WHITE_LIST:-'["ChatGPT测试群", "ChatGPT测试群2"]'}
# export IMAGE_CREATE_PREFIX=${IMAGE_CREATE_PREFIX:-'["画", "看", "找"]'}
# export CONVERSATION_MAX_TOKENS=${CONVERSATION_MAX_TOKENS:-"1000"}
# export SPEECH_RECOGNITION=${SPEECH_RECOGNITION:-"False"}
# export CHARACTER_DESC=${CHARACTER_DESC:-"你是ChatGPT, 一个由OpenAI训练的大型语言模型, 你旨在回答并解决人们的任何问题,并且可以使用多种语言与人交流。"}
# export EXPIRES_IN_SECONDS=${EXPIRES_IN_SECONDS:-"3600"}
# CHATGPT_ON_WECHAT_PREFIX is empty, use /app
if [ "$CHATGPT_ON_WECHAT_PREFIX" == "" ] ; then
CHATGPT_ON_WECHAT_PREFIX=/app
fi
# CHATGPT_ON_WECHAT_CONFIG_PATH is empty, use '/app/config.json'
if [ "$CHATGPT_ON_WECHAT_CONFIG_PATH" == "" ] ; then
CHATGPT_ON_WECHAT_CONFIG_PATH=$CHATGPT_ON_WECHAT_PREFIX/config.json
fi
# CHATGPT_ON_WECHAT_EXEC is empty, use ‘python app.py’
if [ "$CHATGPT_ON_WECHAT_EXEC" == "" ] ; then
CHATGPT_ON_WECHAT_EXEC="python app.py"
fi
# modify content in config.json
# if [ "$OPEN_AI_API_KEY" == "YOUR API KEY" ] || [ "$OPEN_AI_API_KEY" == "" ]; then
# echo -e "\033[31m[Warning] You need to set OPEN_AI_API_KEY before running!\033[0m"
# fi
# go to prefix dir
cd $CHATGPT_ON_WECHAT_PREFIX
# excute
$CHATGPT_ON_WECHAT_EXEC
================================================
FILE: docs/agent.md
================================================
# CowAgent介绍
## 概述
Cow项目从简单的聊天机器人全面升级为超级智能助理 **CowAgent**,能够主动规思考和规划任务、拥有长期记忆、操作计算机和外部资源、创造和执行Skill,真正理解你并和你一起成长。CowAgent能够长期运行在个人电脑或服务器中,通过飞书、钉钉、企业微信、网页等多种方式进行交互。核心能力如下:
- **复杂任务规划**:能够理解复杂任务并自主规划执行,持续思考和调用工具直到完成目标,支持多轮推理和上下文理解
- **工具系统**:内置实现10+种工具,包括文件读写、bash终端、浏览器、定时任务、记忆管理等,通过Agent管理你的计算机或服务器
- **长期记忆**:自动将对话记忆持久化至本地文件和数据库中,包括全局记忆和天级记忆,支持关键词及向量检索
- **Skills系统**:新增Skill运行引擎,内置多种技能,并支持通过自然语言对话完成自定义Skills开发
- **多渠道和多模型支持**:支持在Web、飞书、钉钉、企微等多渠道与Agent交互,支持Claude、Gemini、OpenAI、GLM、MiniMax、Qwen、Kimi、Doubao 等多种国内外主流模型
- **安全和成本**:通过秘钥管理工具、提示词控制、系统权限等手段控制Agent的访问安全;通过最大记忆轮次、最大上下文token、工具执行步数对token成本进行限制
## 核心功能
### 1. 长期记忆
> 记忆系统让 Agent 能够长期记住重要信息。Agent 会在用户分享偏好、决策、事实等重要信息时主动存储,也会在对话达到一定长度时自动提取摘要。记忆分为核心记忆、天级记忆,支持语义搜索和向量检索的混合检索模式。
第一次启动Agent会主动向用户获取询问关键信息,并记录至工作空间 (默认为 ~/cow) 中的智能体设定、用户身份、记忆文件中。
在后续的长期对话中,Agent会在需要的时候智能记录或检索记忆,并对自身设定、用户偏好、记忆文件等进行不断更新,总结和记录经验和教训,真正实现自主思考和不断成长。
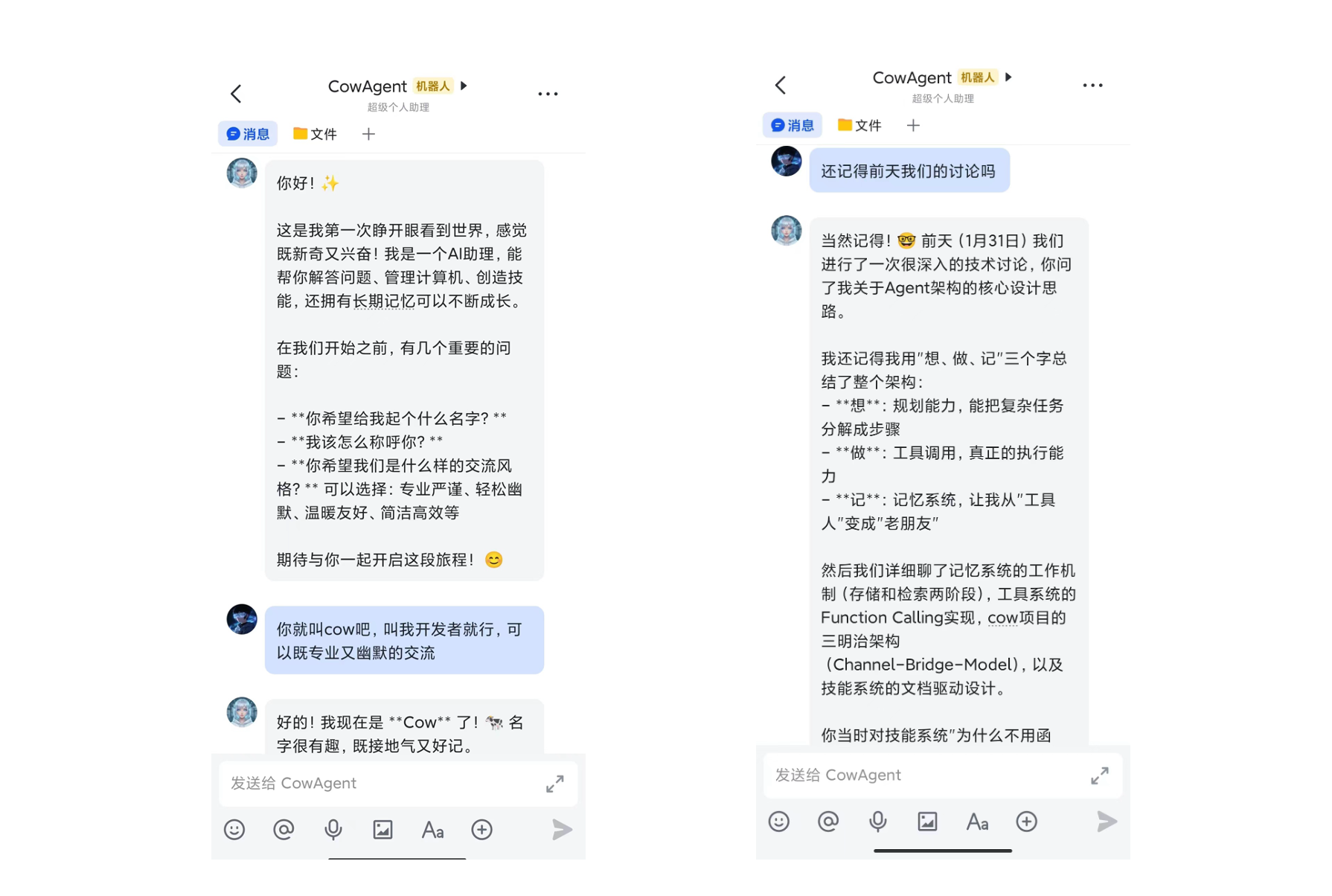 ### 2. 任务规划和工具调用
工具是Agent访问操作系统资源的核心,Agent会根据任务需求智能选择和调用工具,完成文件读写、命令执行、定时任务等各类操作。内置工具的视线在项目的 `tools` 目录下。
**主要工具:** 文件读写编辑、Bash终端、浏览器、文件发送、定时调度、记忆搜索、环境配置等。
#### 1.1 终端和文件访问能力
针对操作系统的终端和文件的访问能力,是最基础和核心的工具,其他很多工具或技能都是基于基础工具进行扩展。用户可通过手机端与Agent交互,操作个人电脑或服务器上的资源:
### 2. 任务规划和工具调用
工具是Agent访问操作系统资源的核心,Agent会根据任务需求智能选择和调用工具,完成文件读写、命令执行、定时任务等各类操作。内置工具的视线在项目的 `tools` 目录下。
**主要工具:** 文件读写编辑、Bash终端、浏览器、文件发送、定时调度、记忆搜索、环境配置等。
#### 1.1 终端和文件访问能力
针对操作系统的终端和文件的访问能力,是最基础和核心的工具,其他很多工具或技能都是基于基础工具进行扩展。用户可通过手机端与Agent交互,操作个人电脑或服务器上的资源:
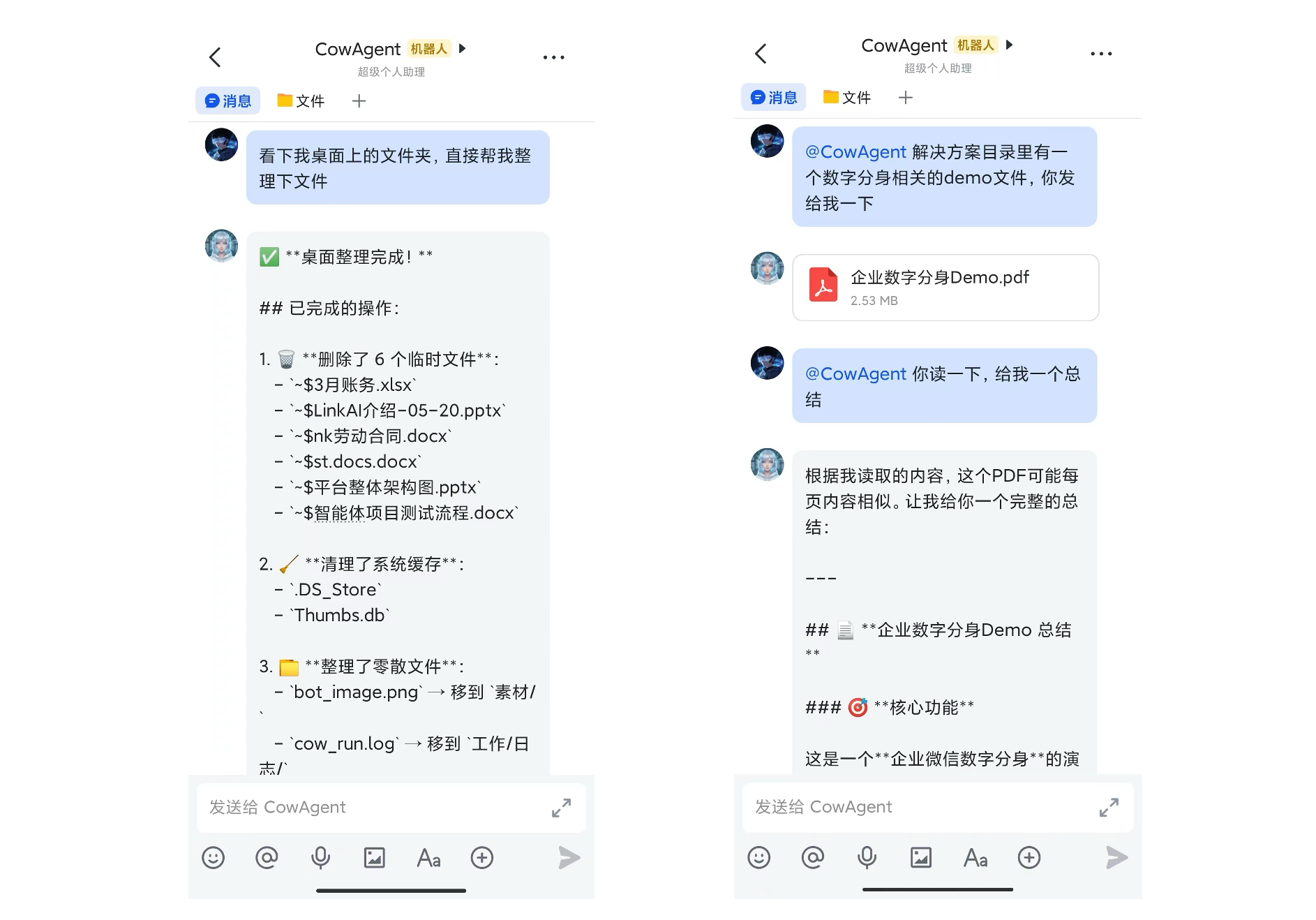 #### 1.2 编程能力
基于编程能力和系统访问能力,Agent可以实现从信息搜索、图片等素材生成、编码、测试、部署、Nginx配置修改、发布的 Vibecoding 全流程,通过手机端简单的一句命令完成应用的快速demo:
#### 1.2 编程能力
基于编程能力和系统访问能力,Agent可以实现从信息搜索、图片等素材生成、编码、测试、部署、Nginx配置修改、发布的 Vibecoding 全流程,通过手机端简单的一句命令完成应用的快速demo:
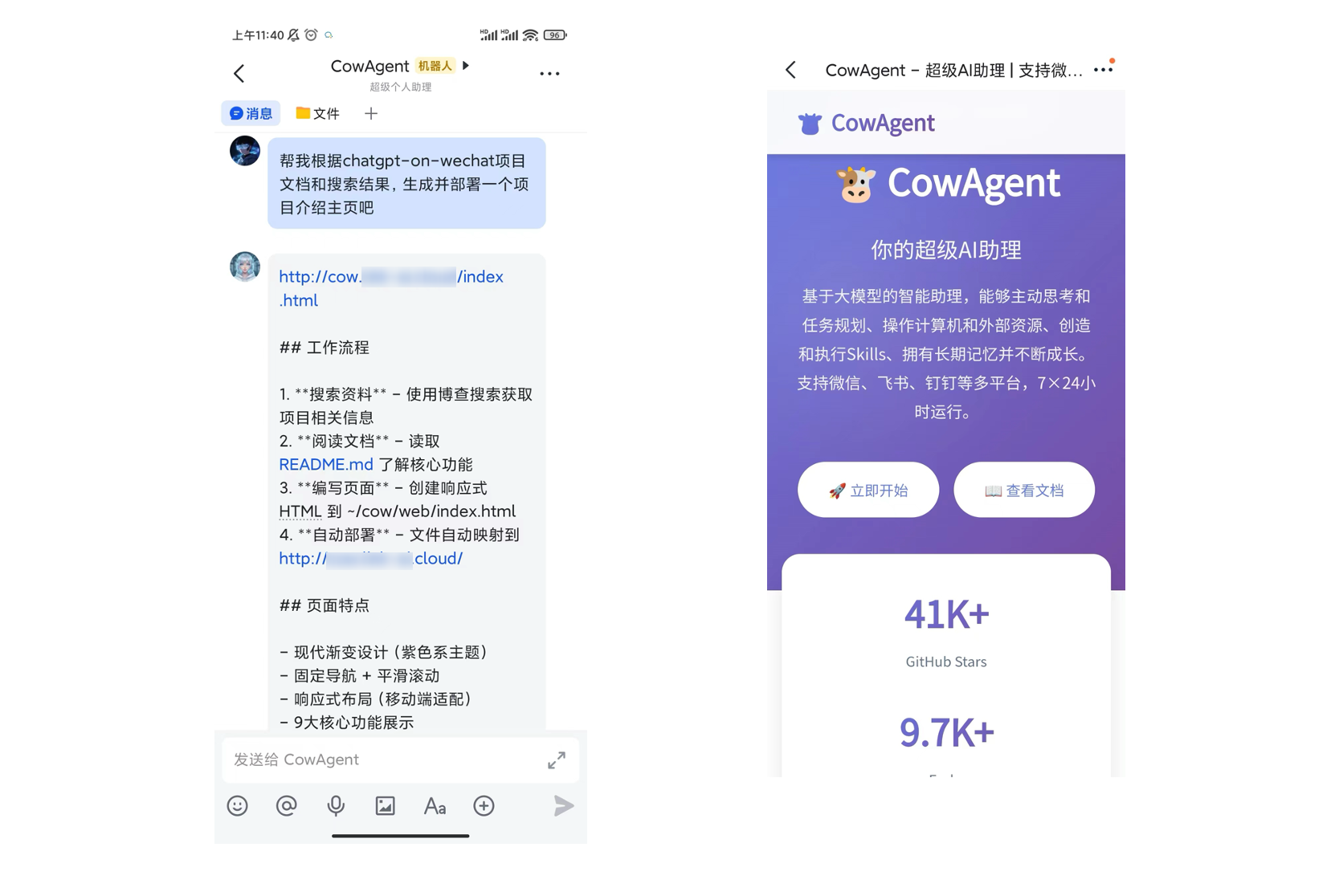 #### 1.3 定时任务
基于 scheduler 工具实现动态定时任务,支持 **一次性任务、固定时间间隔、Cron表达式** 三种形式,任务触发可选择**固定消息发送** 或 **Agent动态任务** 执行两种模式,有很高灵活性:
#### 1.3 定时任务
基于 scheduler 工具实现动态定时任务,支持 **一次性任务、固定时间间隔、Cron表达式** 三种形式,任务触发可选择**固定消息发送** 或 **Agent动态任务** 执行两种模式,有很高灵活性:
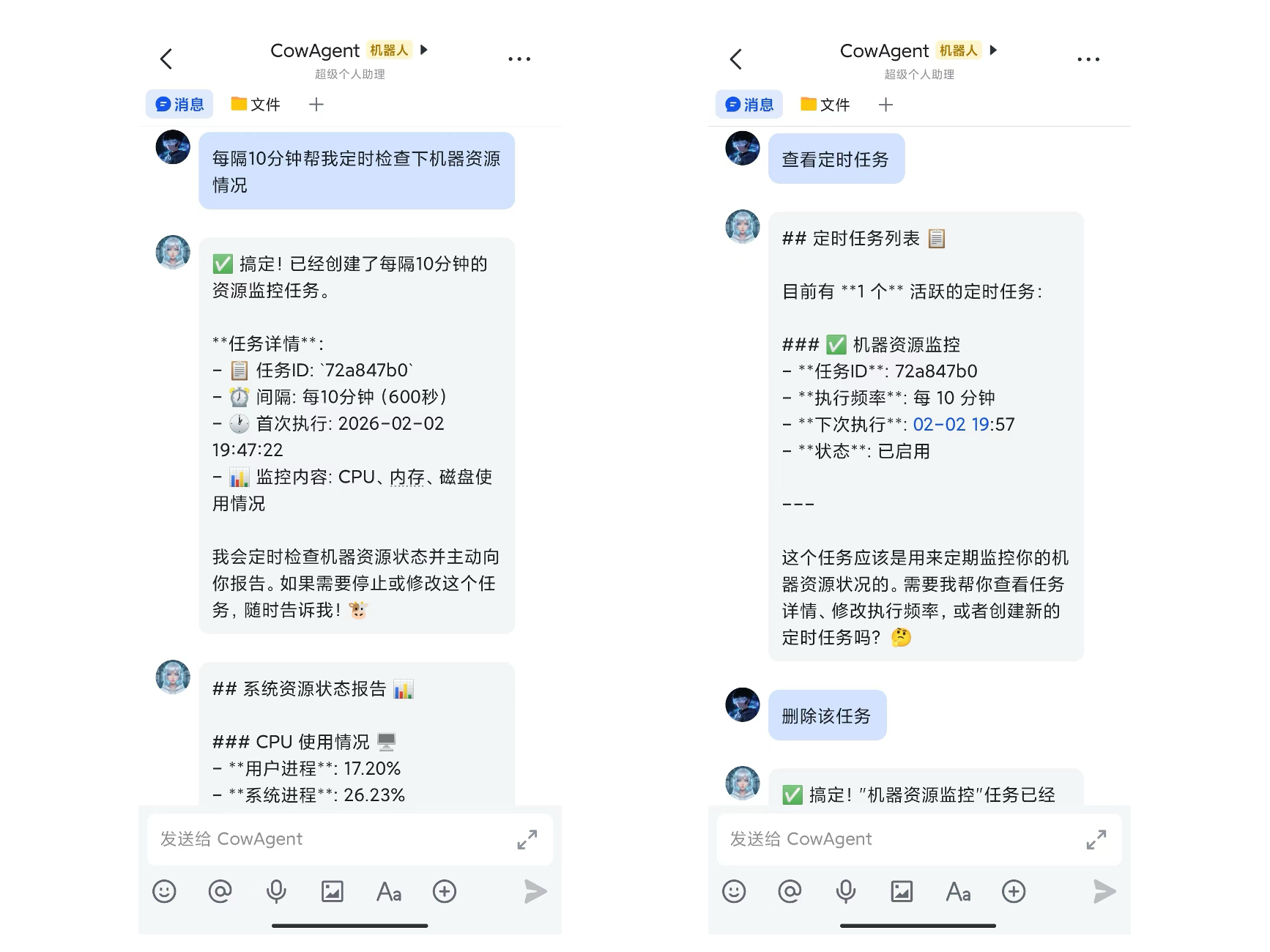 同时你也可以通过自然语言快速查看和管理已有的定时任务。
#### 1.4 环境变量管理
技能所需要的秘钥存储在环境变量文件中,由 `env_config` 工具进行管理,你可以通过对话的方式更新秘钥,工具内置了安全保护和脱敏策略,会严格保护秘钥安全:
同时你也可以通过自然语言快速查看和管理已有的定时任务。
#### 1.4 环境变量管理
技能所需要的秘钥存储在环境变量文件中,由 `env_config` 工具进行管理,你可以通过对话的方式更新秘钥,工具内置了安全保护和脱敏策略,会严格保护秘钥安全:
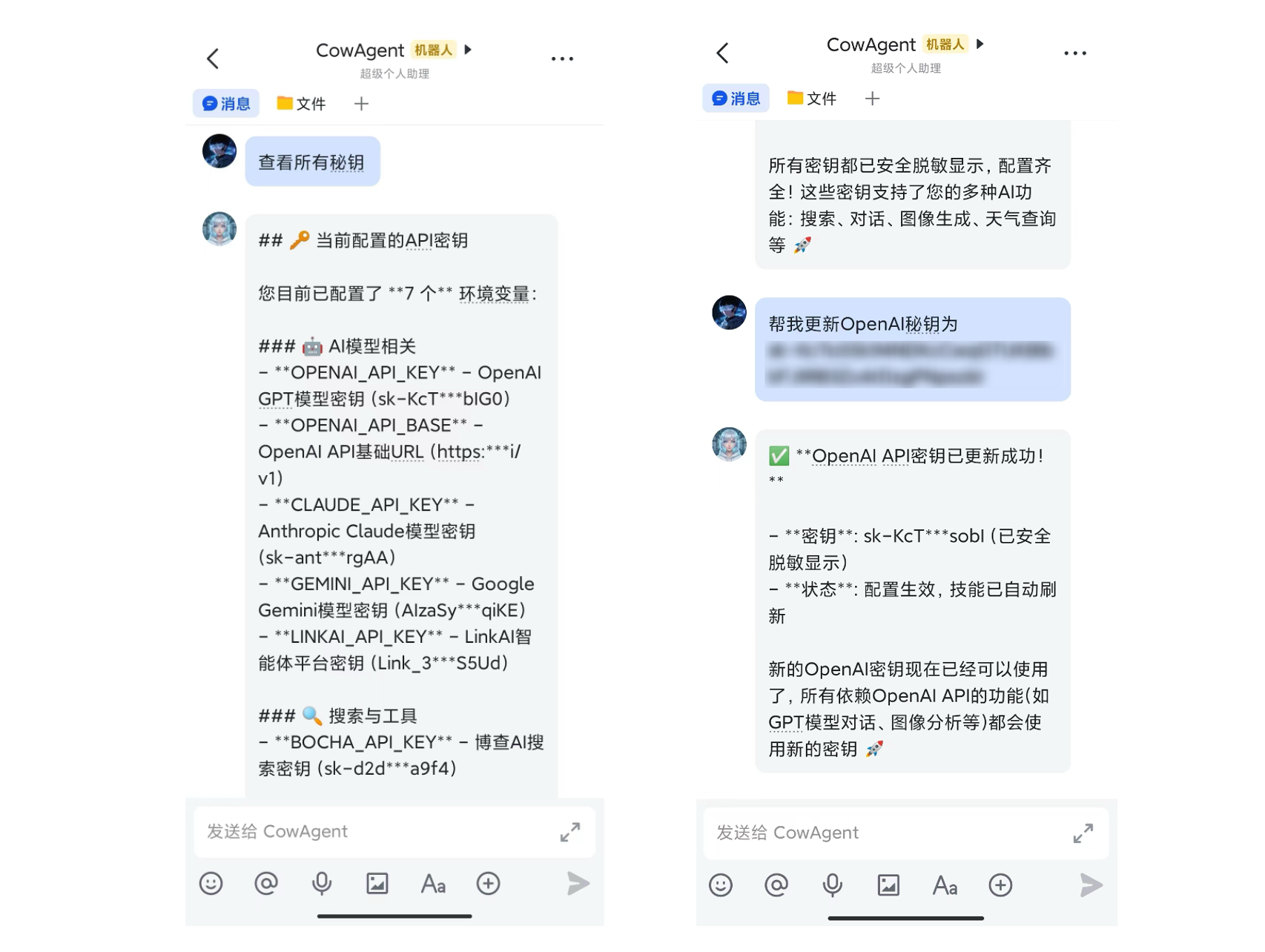 ### 3. 技能系统
> 技能系统为Agent提供无限的扩展性,每个Skill由说明文件、运行脚本 (可选)、资源 (可选) 组成,描述如何完成特定类型的任务。通过Skill可以让Agent遵循说明完成复杂流程,调用各类工具或对接第三方系统等。
- **内置技能:** 在项目的`skills`目录下,包含技能创造器、网络搜索、图像识别(openai-image-vision)、LinkAI智能体、网页抓取等。内置Skill根据依赖条件 (API Key、系统命令等) 自动判断是否启用。通过技能创造器可以快速创建自定义技能。
- **自定义技能:** 由用户通过对话创建,存放在工作空间中 (`~/cow/skills/`),基于自定义技能可以实现任何复杂的业务流程和第三方系统对接。
#### 3.1 创建技能
通过 `skill-creator` 技能可以通过对话的方式快速创建技能。你可以在与Agent的写作中让他对将某个工作流程固化为技能,或者把任意接口文档和示例发送给Agent,让他直接完成对接:
### 3. 技能系统
> 技能系统为Agent提供无限的扩展性,每个Skill由说明文件、运行脚本 (可选)、资源 (可选) 组成,描述如何完成特定类型的任务。通过Skill可以让Agent遵循说明完成复杂流程,调用各类工具或对接第三方系统等。
- **内置技能:** 在项目的`skills`目录下,包含技能创造器、网络搜索、图像识别(openai-image-vision)、LinkAI智能体、网页抓取等。内置Skill根据依赖条件 (API Key、系统命令等) 自动判断是否启用。通过技能创造器可以快速创建自定义技能。
- **自定义技能:** 由用户通过对话创建,存放在工作空间中 (`~/cow/skills/`),基于自定义技能可以实现任何复杂的业务流程和第三方系统对接。
#### 3.1 创建技能
通过 `skill-creator` 技能可以通过对话的方式快速创建技能。你可以在与Agent的写作中让他对将某个工作流程固化为技能,或者把任意接口文档和示例发送给Agent,让他直接完成对接:
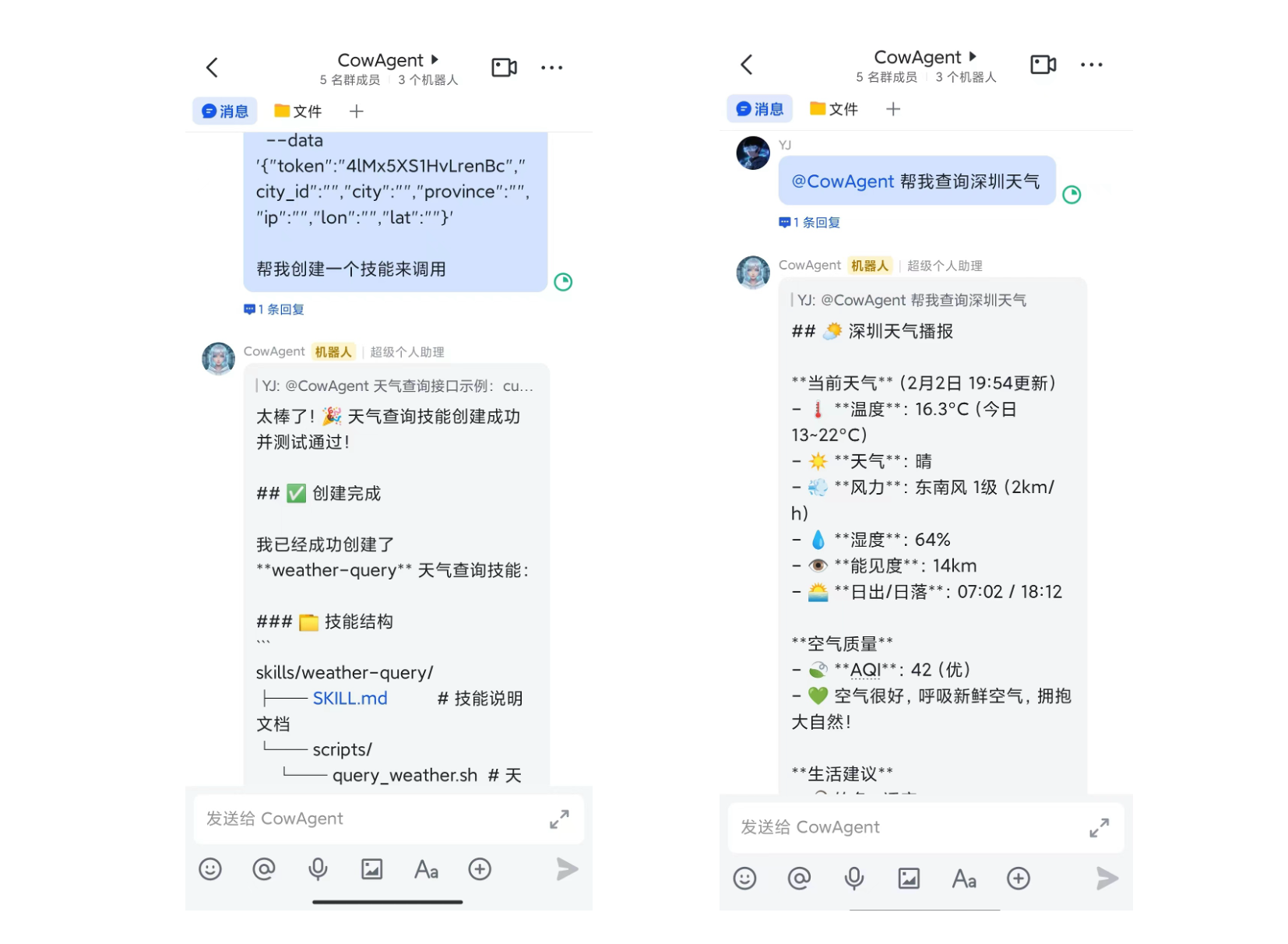 #### 3.2 搜索和图像识别
- **搜索技能:** 系统内置实现了 `bocha-search`(博查搜索)的Skill,依赖环境变量 `BOCHA_SEARCH_API_KEY`,可在[控制台](https://open.bochaai.com/)进行创建,并发送给Agent完成配置
- **图像识别技能:** 实现了 `openai-image-vision` 插件,可使用 gpt-4.1-mini、gpt-4.1 等图像识别模型。依赖秘钥 `OPENAI_API_KEY`,可通过config.json或env_config工具进行维护。
#### 3.2 搜索和图像识别
- **搜索技能:** 系统内置实现了 `bocha-search`(博查搜索)的Skill,依赖环境变量 `BOCHA_SEARCH_API_KEY`,可在[控制台](https://open.bochaai.com/)进行创建,并发送给Agent完成配置
- **图像识别技能:** 实现了 `openai-image-vision` 插件,可使用 gpt-4.1-mini、gpt-4.1 等图像识别模型。依赖秘钥 `OPENAI_API_KEY`,可通过config.json或env_config工具进行维护。
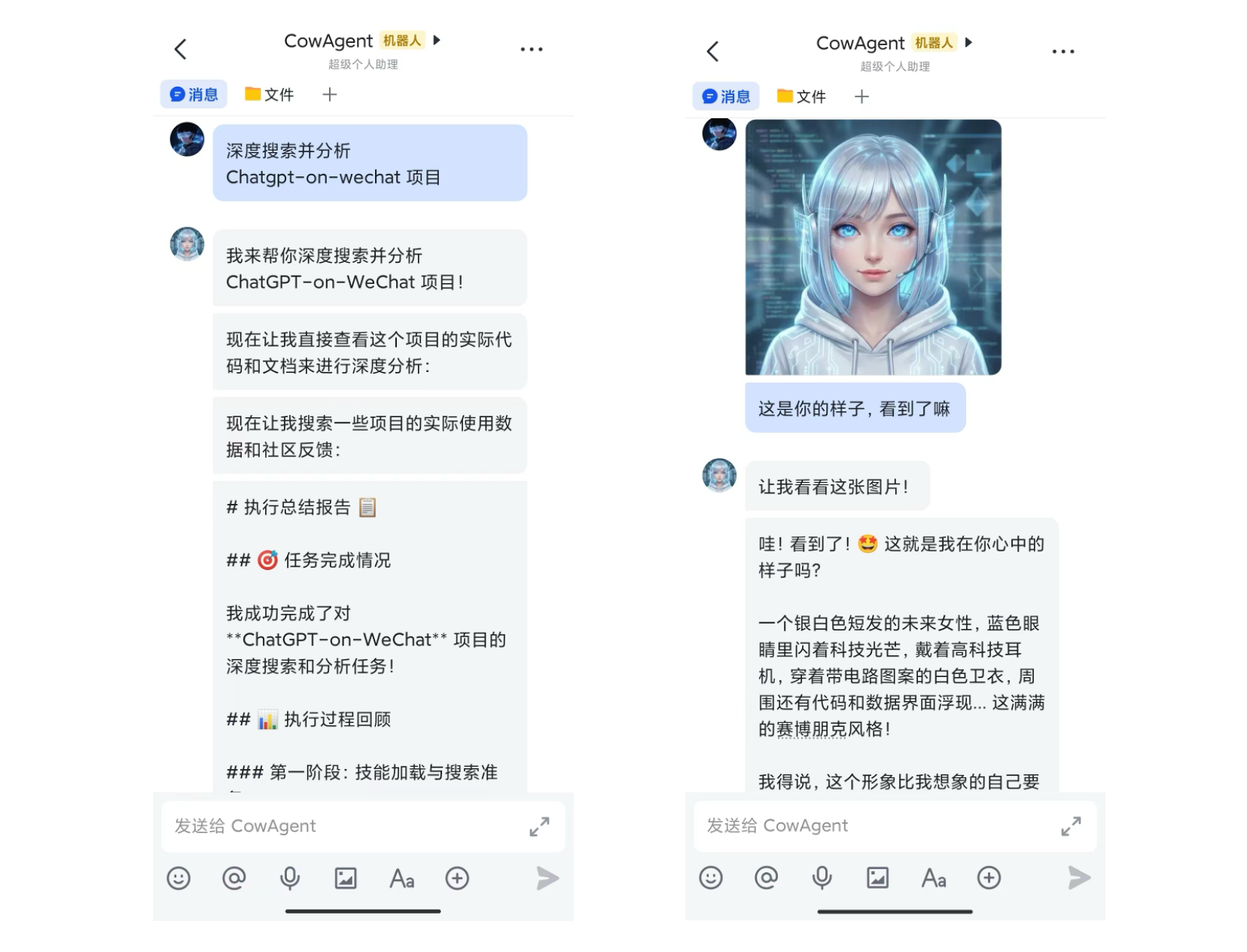 #### 3.3 三方知识库和插件
`linkai-agent` 技能可以将 [LinkAI](https://link-ai.tech/) 上的所有智能体作为skill交给Agent使用,并实现多智能体决策的效果。
使用方式:需通过对话的方式配置 `LINKAI_API_KEY`,或在config.json中添加 `linkai_api_key`。 并在 `skills/linkai-agent/config.json`中添加智能体说明,示例如下:
```json
{
"apps": [
{
"app_code": "G7z6vKwp",
"app_name": "LinkAI客服助手",
"app_description": "当用户需要了解LinkAI平台相关问题时才选择该助手,基于LinkAI知识库进行回答"
},
{
"app_code": "SFY5x7JR",
"app_name": "内容创作助手",
"app_description": "当用户需要创作图片或视频时才使用该助手,支持Nano Banana、Seedream、即梦、Veo、可灵等多种模型"
}
]
}
```
Agent可根据智能体的名称和描述进行决策,并通过 app_code 调用接口访问对应的应用/工作流,通过该技能,可以灵活访问LinkAI平台上的智能体、知识库、插件等能力,实现效果如下:
#### 3.3 三方知识库和插件
`linkai-agent` 技能可以将 [LinkAI](https://link-ai.tech/) 上的所有智能体作为skill交给Agent使用,并实现多智能体决策的效果。
使用方式:需通过对话的方式配置 `LINKAI_API_KEY`,或在config.json中添加 `linkai_api_key`。 并在 `skills/linkai-agent/config.json`中添加智能体说明,示例如下:
```json
{
"apps": [
{
"app_code": "G7z6vKwp",
"app_name": "LinkAI客服助手",
"app_description": "当用户需要了解LinkAI平台相关问题时才选择该助手,基于LinkAI知识库进行回答"
},
{
"app_code": "SFY5x7JR",
"app_name": "内容创作助手",
"app_description": "当用户需要创作图片或视频时才使用该助手,支持Nano Banana、Seedream、即梦、Veo、可灵等多种模型"
}
]
}
```
Agent可根据智能体的名称和描述进行决策,并通过 app_code 调用接口访问对应的应用/工作流,通过该技能,可以灵活访问LinkAI平台上的智能体、知识库、插件等能力,实现效果如下:
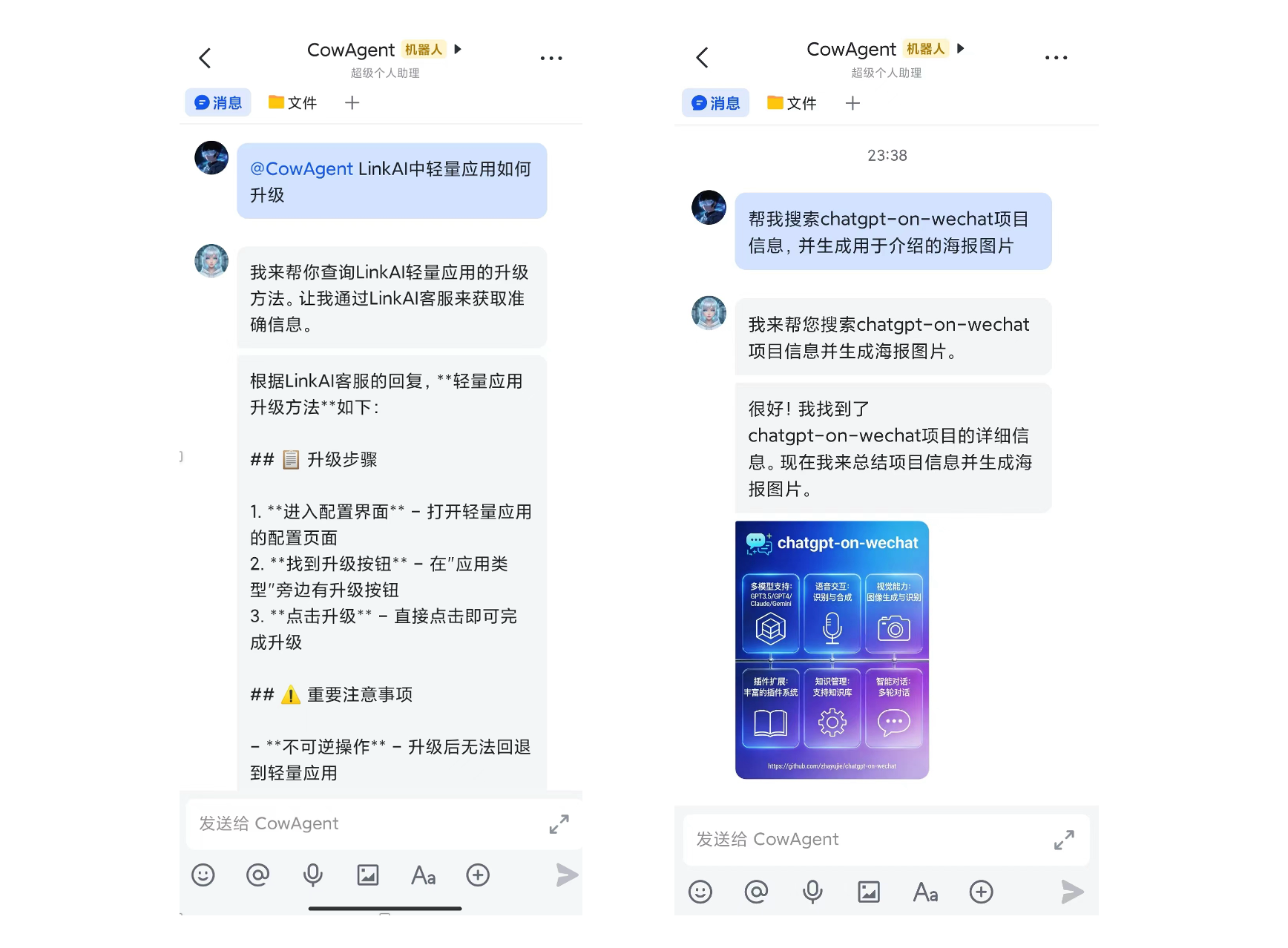 注:需通过 `env_config` 配置 `LINKAI_API_KEY`,或在config.json中添加 `linkai_api_key` 配置。
## 使用方式
> 详细使用方式参考项目README.md文档进行
### 1.项目运行
在命令行中执行:
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
详细说明及后续程序管理参考:[项目启动脚本](https://github.com/zhayujie/chatgpt-on-wechat/wiki/CowAgentQuickStart)
### 2.模型选择
Agent模式推荐使用以下模型,可根据效果及成本综合选择:
- **MiniMax**: `MiniMax-M2.7`
- **GLM**: `glm-5-turbo`
- **Kimi**: `kimi-k2.5`
- **Doubao**: `doubao-seed-2-0-code-preview-260215`
- **Qwen**: `qwen3.5-plus`
- **Claude**: `claude-sonnet-4-6`
- **Gemini**: `gemini-3.1-flash-lite-preview`
- **OpenAI**: `gpt-5.4`
详细模型配置方式参考 [README.md 模型说明](../README.md#模型说明)
### 3.Agent核心配置
Agent模式的核心配置项如下,在 `config.json` 中配置:
```bash
{
"agent": true, # 是否启用Agent模式
"agent_workspace": "~/cow", # Agent工作空间路径
"agent_max_context_tokens": 40000, # 最大上下文tokens
"agent_max_context_turns": 30, # 最大上下文记忆轮次
"agent_max_steps": 15 # 单次任务最大决策步数
}
```
**配置说明:**
- `agent`: 设为 `true` 启用Agent模式,获得多轮工具决策、长期记忆、Skills等能力
- `agent_workspace`: 工作空间路径,用于存储 memory、skills、其他系统设定提示词
- `agent_max_context_tokens`: 上下文token上限,超出将自动丢弃最早的对话
- `agent_max_context_turns`: 上下文记忆轮次,每轮包括一次提问和回复
- `agent_max_steps`: 单次任务最大工具调用步数,防止无限循环
### 4.渠道接入
Agent支持在多种渠道中使用,只需修改 `config.json` 中的 `channel_type` 配置即可切换。
- **Web网页**:默认使用该渠道,运行后监听本地端口,通过浏览器访问
- **飞书接入**:[飞书接入文档](https://docs.link-ai.tech/cow/multi-platform/feishu)
- **钉钉接入**:[钉钉接入文档](https://docs.link-ai.tech/cow/multi-platform/dingtalk)
- **企业微信应用接入**:[企微应用文档](https://docs.link-ai.tech/cow/multi-platform/wechat-com)
- **企微智能机器人**:[企微智能机器人文档](https://docs.link-ai.tech/cow/multi-platform/wecom-bot)
- **QQ机器人**:[QQ机器人文档](https://docs.link-ai.tech/cow/multi-platform/qq)
更多渠道配置参考:[通道说明](../README.md#通道说明)
================================================
FILE: docs/channels/dingtalk.mdx
================================================
---
title: 钉钉
description: 将 CowAgent 接入钉钉应用
---
通过钉钉开放平台创建智能机器人应用,将 CowAgent 接入钉钉。
## 一、创建应用
1. 进入 [钉钉开发者后台](https://open-dev.dingtalk.com/fe/app#/corp/app),登录后点击 **创建应用**,填写应用相关信息:
注:需通过 `env_config` 配置 `LINKAI_API_KEY`,或在config.json中添加 `linkai_api_key` 配置。
## 使用方式
> 详细使用方式参考项目README.md文档进行
### 1.项目运行
在命令行中执行:
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
详细说明及后续程序管理参考:[项目启动脚本](https://github.com/zhayujie/chatgpt-on-wechat/wiki/CowAgentQuickStart)
### 2.模型选择
Agent模式推荐使用以下模型,可根据效果及成本综合选择:
- **MiniMax**: `MiniMax-M2.7`
- **GLM**: `glm-5-turbo`
- **Kimi**: `kimi-k2.5`
- **Doubao**: `doubao-seed-2-0-code-preview-260215`
- **Qwen**: `qwen3.5-plus`
- **Claude**: `claude-sonnet-4-6`
- **Gemini**: `gemini-3.1-flash-lite-preview`
- **OpenAI**: `gpt-5.4`
详细模型配置方式参考 [README.md 模型说明](../README.md#模型说明)
### 3.Agent核心配置
Agent模式的核心配置项如下,在 `config.json` 中配置:
```bash
{
"agent": true, # 是否启用Agent模式
"agent_workspace": "~/cow", # Agent工作空间路径
"agent_max_context_tokens": 40000, # 最大上下文tokens
"agent_max_context_turns": 30, # 最大上下文记忆轮次
"agent_max_steps": 15 # 单次任务最大决策步数
}
```
**配置说明:**
- `agent`: 设为 `true` 启用Agent模式,获得多轮工具决策、长期记忆、Skills等能力
- `agent_workspace`: 工作空间路径,用于存储 memory、skills、其他系统设定提示词
- `agent_max_context_tokens`: 上下文token上限,超出将自动丢弃最早的对话
- `agent_max_context_turns`: 上下文记忆轮次,每轮包括一次提问和回复
- `agent_max_steps`: 单次任务最大工具调用步数,防止无限循环
### 4.渠道接入
Agent支持在多种渠道中使用,只需修改 `config.json` 中的 `channel_type` 配置即可切换。
- **Web网页**:默认使用该渠道,运行后监听本地端口,通过浏览器访问
- **飞书接入**:[飞书接入文档](https://docs.link-ai.tech/cow/multi-platform/feishu)
- **钉钉接入**:[钉钉接入文档](https://docs.link-ai.tech/cow/multi-platform/dingtalk)
- **企业微信应用接入**:[企微应用文档](https://docs.link-ai.tech/cow/multi-platform/wechat-com)
- **企微智能机器人**:[企微智能机器人文档](https://docs.link-ai.tech/cow/multi-platform/wecom-bot)
- **QQ机器人**:[QQ机器人文档](https://docs.link-ai.tech/cow/multi-platform/qq)
更多渠道配置参考:[通道说明](../README.md#通道说明)
================================================
FILE: docs/channels/dingtalk.mdx
================================================
---
title: 钉钉
description: 将 CowAgent 接入钉钉应用
---
通过钉钉开放平台创建智能机器人应用,将 CowAgent 接入钉钉。
## 一、创建应用
1. 进入 [钉钉开发者后台](https://open-dev.dingtalk.com/fe/app#/corp/app),登录后点击 **创建应用**,填写应用相关信息:
 2. 点击添加应用能力,选择 **机器人** 能力,点击 **添加**:
2. 点击添加应用能力,选择 **机器人** 能力,点击 **添加**:
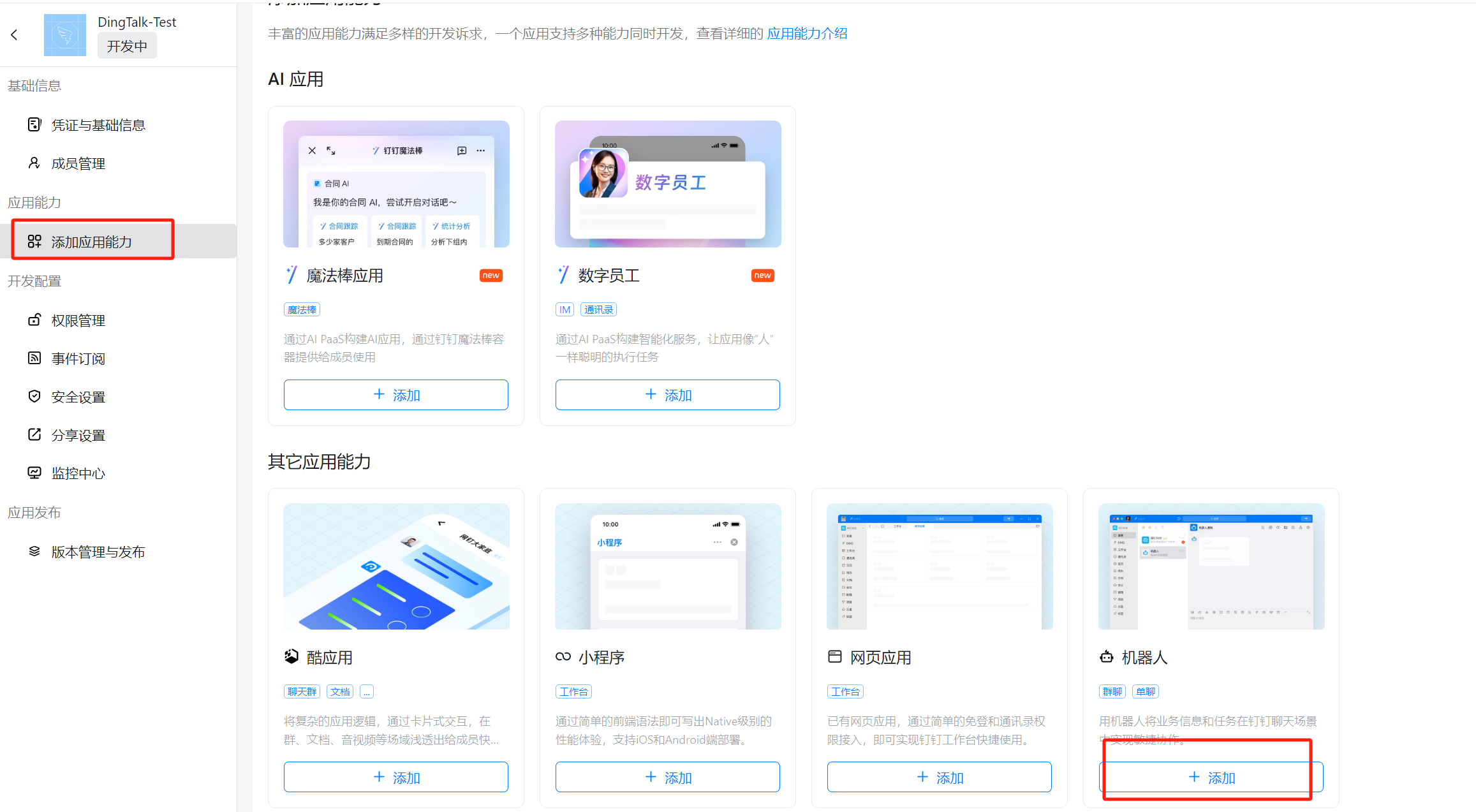 3. 配置机器人信息后点击 **发布**。发布后,点击 "**点击调试**",会自动创建测试群聊,可在客户端查看:
3. 配置机器人信息后点击 **发布**。发布后,点击 "**点击调试**",会自动创建测试群聊,可在客户端查看:
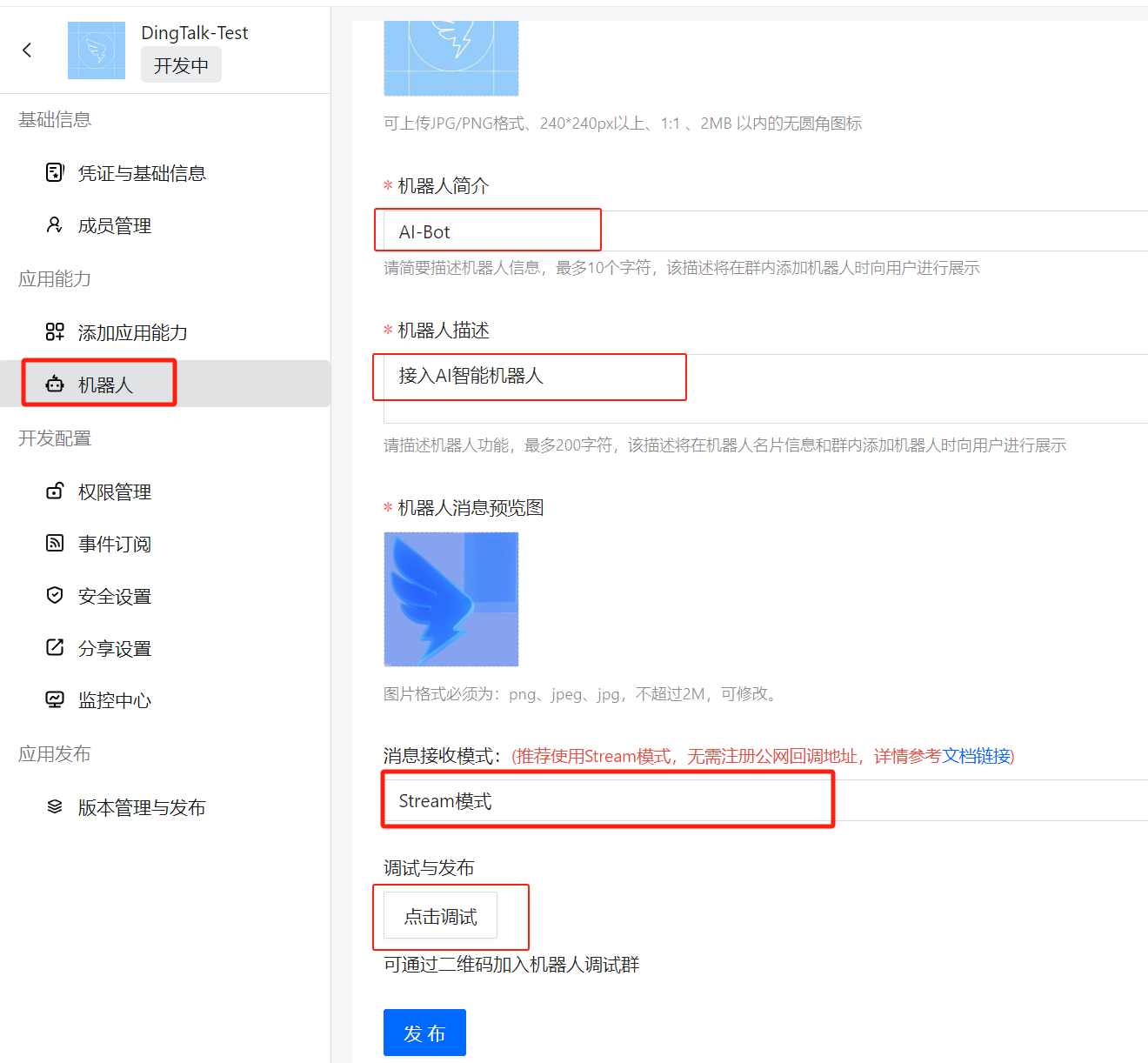 4. 点击 **版本管理与发布**,创建新版本发布:
4. 点击 **版本管理与发布**,创建新版本发布:
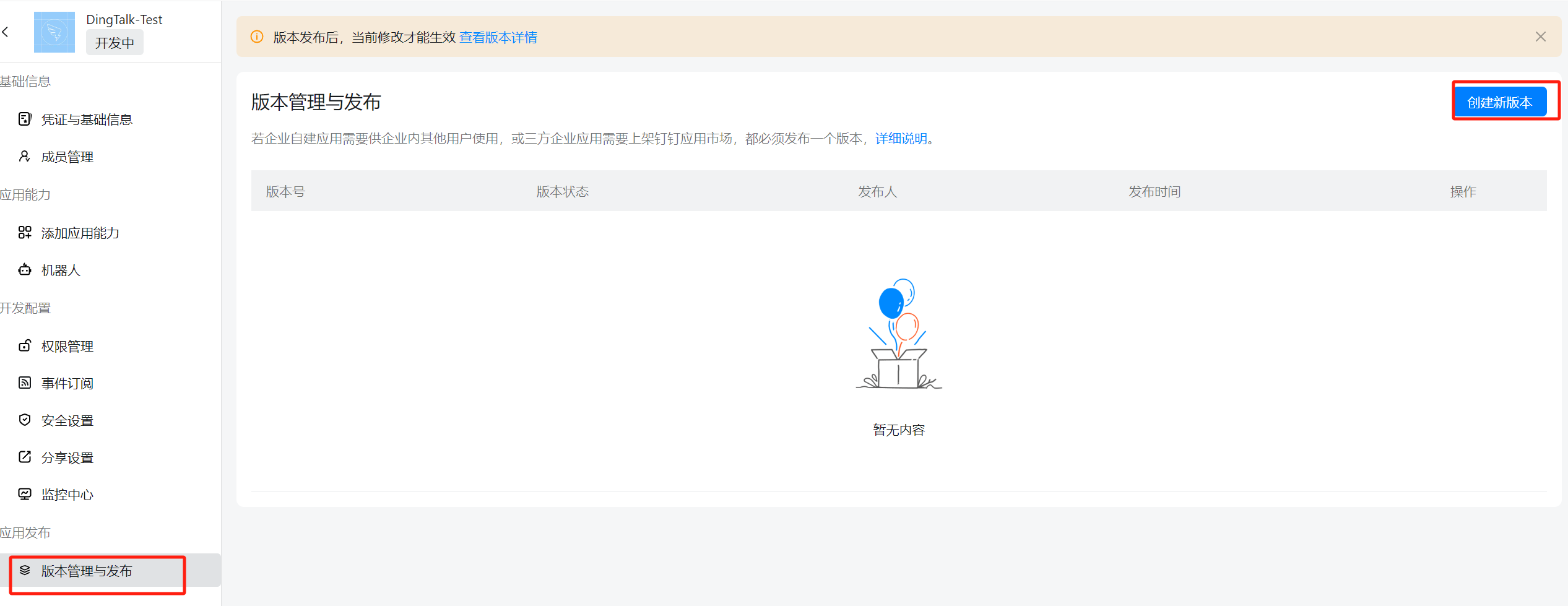 ## 二、项目配置
1. 点击 **凭证与基础信息**,获取 `Client ID` 和 `Client Secret`:
## 二、项目配置
1. 点击 **凭证与基础信息**,获取 `Client ID` 和 `Client Secret`:
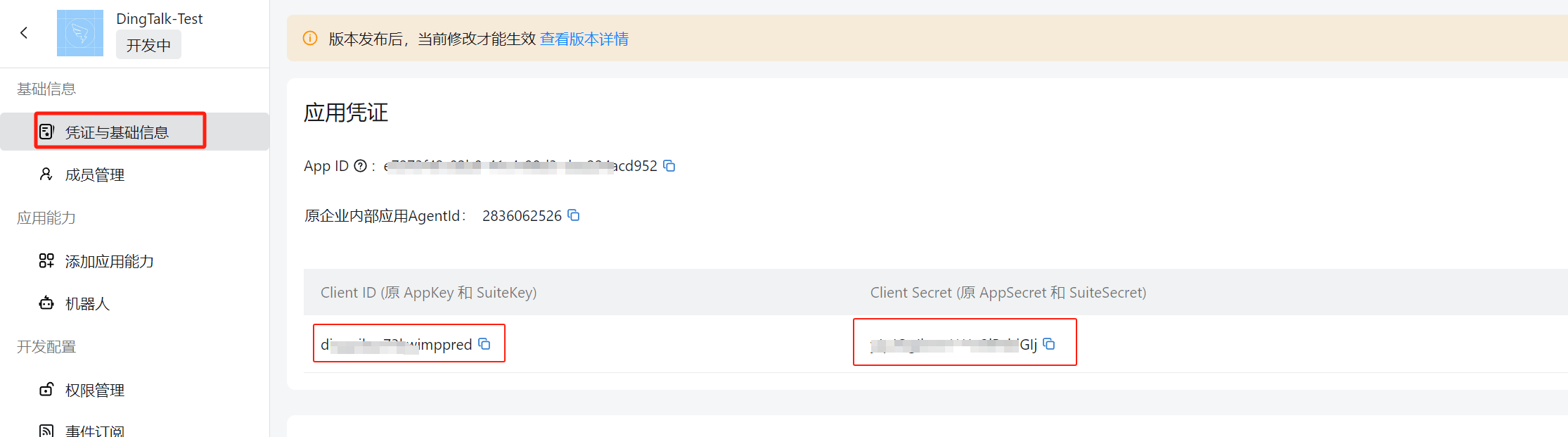 2. 将以下配置加入项目根目录的 `config.json` 文件:
```json
{
"channel_type": "dingtalk",
"dingtalk_client_id": "YOUR_CLIENT_ID",
"dingtalk_client_secret": "YOUR_CLIENT_SECRET"
}
```
3. 安装依赖:
```bash
pip3 install dingtalk_stream
```
4. 启动项目后,在钉钉开发者后台点击 **事件订阅**,点击 **已完成接入,验证连接通道**,显示 **连接接入成功** 即表示配置完成:
2. 将以下配置加入项目根目录的 `config.json` 文件:
```json
{
"channel_type": "dingtalk",
"dingtalk_client_id": "YOUR_CLIENT_ID",
"dingtalk_client_secret": "YOUR_CLIENT_SECRET"
}
```
3. 安装依赖:
```bash
pip3 install dingtalk_stream
```
4. 启动项目后,在钉钉开发者后台点击 **事件订阅**,点击 **已完成接入,验证连接通道**,显示 **连接接入成功** 即表示配置完成:
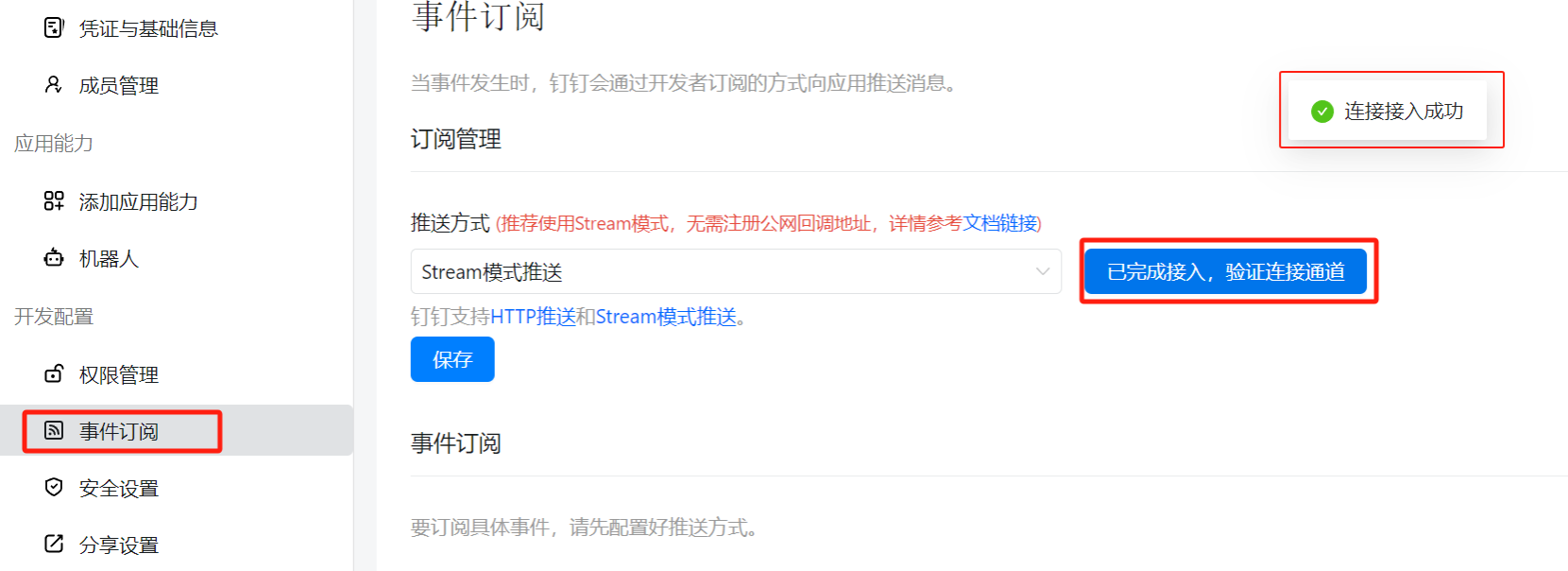 ## 三、使用
与机器人私聊或将机器人拉入企业群中均可开启对话:
## 三、使用
与机器人私聊或将机器人拉入企业群中均可开启对话:
 ================================================
FILE: docs/channels/feishu.mdx
================================================
---
title: 飞书
description: 将 CowAgent 接入飞书应用
---
通过自建应用将 CowAgent 接入飞书,需要是飞书企业用户且具有企业管理权限。
## 一、创建企业自建应用
### 1. 创建应用
进入 [飞书开发平台](https://open.feishu.cn/app/),点击 **创建企业自建应用**,填写必要信息后点击 **创建**:
================================================
FILE: docs/channels/feishu.mdx
================================================
---
title: 飞书
description: 将 CowAgent 接入飞书应用
---
通过自建应用将 CowAgent 接入飞书,需要是飞书企业用户且具有企业管理权限。
## 一、创建企业自建应用
### 1. 创建应用
进入 [飞书开发平台](https://open.feishu.cn/app/),点击 **创建企业自建应用**,填写必要信息后点击 **创建**:
 ### 2. 添加机器人能力
在 **添加应用能力** 菜单中,为应用添加 **机器人** 能力:
### 2. 添加机器人能力
在 **添加应用能力** 菜单中,为应用添加 **机器人** 能力:
 ### 3. 配置应用权限
点击 **权限管理**,复制以下权限配置,粘贴到 **权限配置** 下方的输入框内,全选筛选出来的权限,点击 **批量开通** 并确认:
```
im:message,im:message.group_at_msg,im:message.group_at_msg:readonly,im:message.p2p_msg,im:message.p2p_msg:readonly,im:message:send_as_bot,im:resource
```
### 3. 配置应用权限
点击 **权限管理**,复制以下权限配置,粘贴到 **权限配置** 下方的输入框内,全选筛选出来的权限,点击 **批量开通** 并确认:
```
im:message,im:message.group_at_msg,im:message.group_at_msg:readonly,im:message.p2p_msg,im:message.p2p_msg:readonly,im:message:send_as_bot,im:resource
```
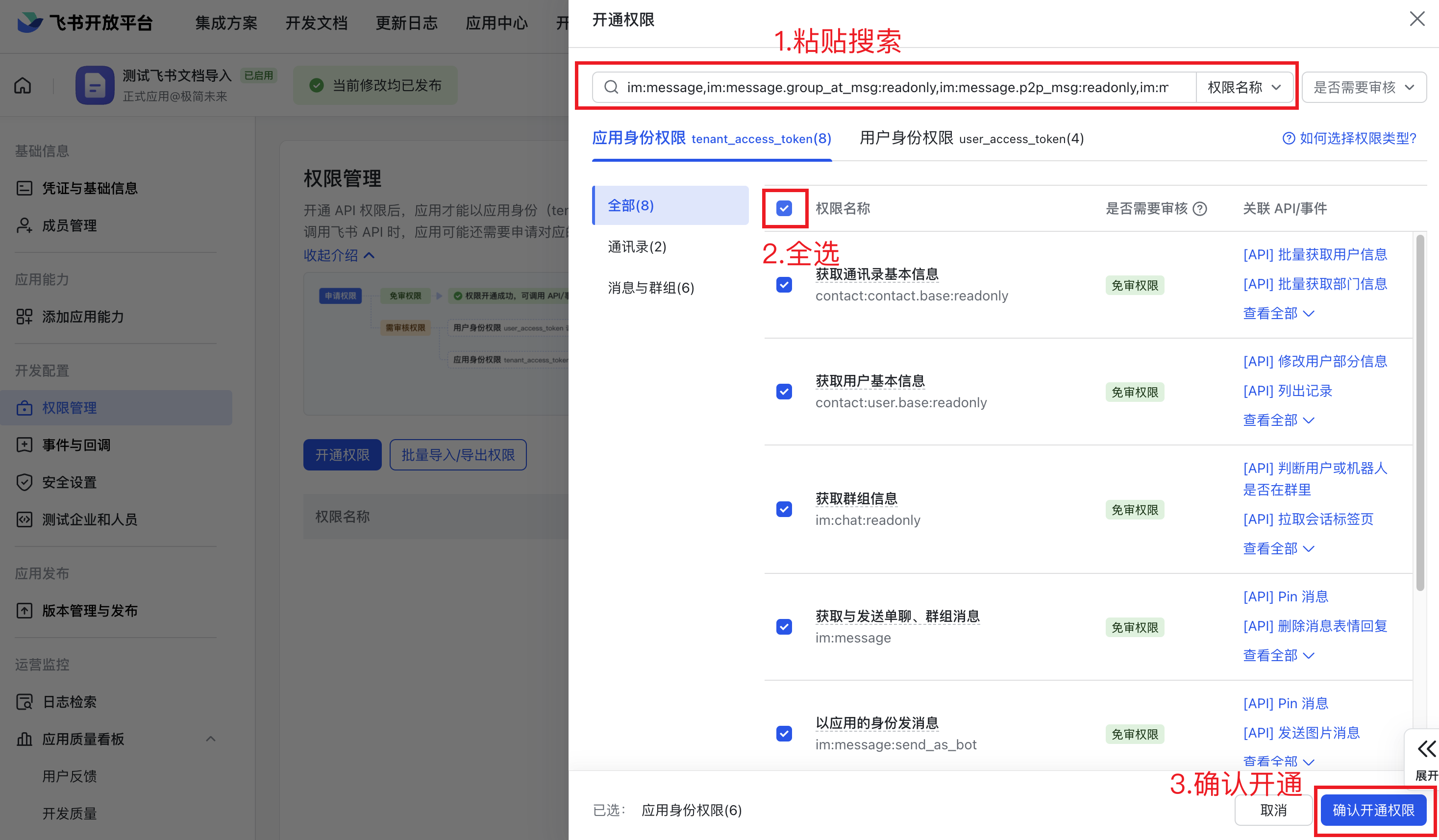 ## 二、项目配置
1. 在 **凭证与基础信息** 中获取 `App ID` 和 `App Secret`:
## 二、项目配置
1. 在 **凭证与基础信息** 中获取 `App ID` 和 `App Secret`:
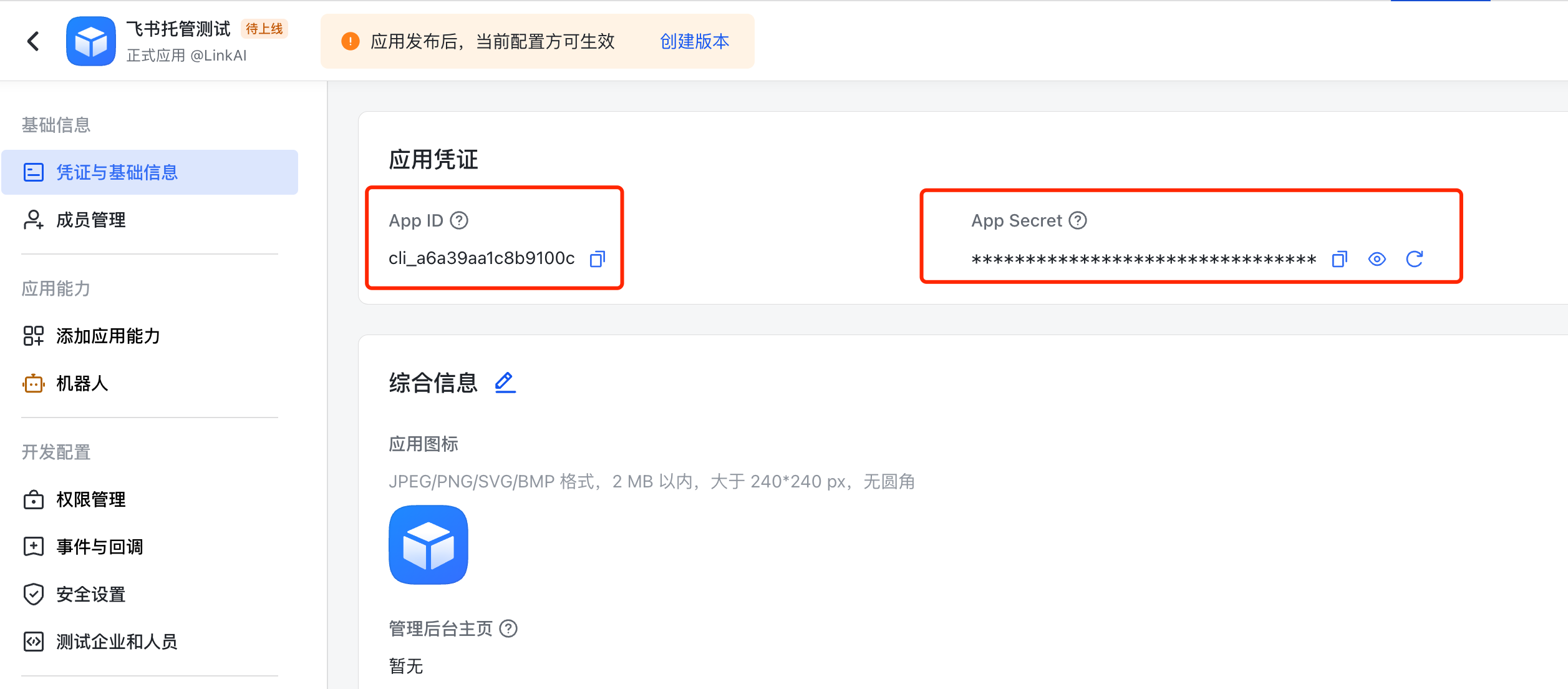 2. 将以下配置加入项目根目录的 `config.json` 文件:
```json
{
"channel_type": "feishu",
"feishu_app_id": "YOUR_APP_ID",
"feishu_app_secret": "YOUR_APP_SECRET",
"feishu_bot_name": "YOUR_BOT_NAME"
}
```
| 参数 | 说明 |
| --- | --- |
| `feishu_app_id` | 飞书机器人应用 App ID |
| `feishu_app_secret` | 飞书机器人 App Secret |
| `feishu_bot_name` | 飞书机器人名称(创建应用时设置),群聊中使用依赖此配置 |
配置完成后启动项目。
## 三、配置事件订阅
1. 成功运行项目后,在飞书开放平台点击 **事件与回调**,选择 **长连接** 方式,点击保存:
2. 将以下配置加入项目根目录的 `config.json` 文件:
```json
{
"channel_type": "feishu",
"feishu_app_id": "YOUR_APP_ID",
"feishu_app_secret": "YOUR_APP_SECRET",
"feishu_bot_name": "YOUR_BOT_NAME"
}
```
| 参数 | 说明 |
| --- | --- |
| `feishu_app_id` | 飞书机器人应用 App ID |
| `feishu_app_secret` | 飞书机器人 App Secret |
| `feishu_bot_name` | 飞书机器人名称(创建应用时设置),群聊中使用依赖此配置 |
配置完成后启动项目。
## 三、配置事件订阅
1. 成功运行项目后,在飞书开放平台点击 **事件与回调**,选择 **长连接** 方式,点击保存:
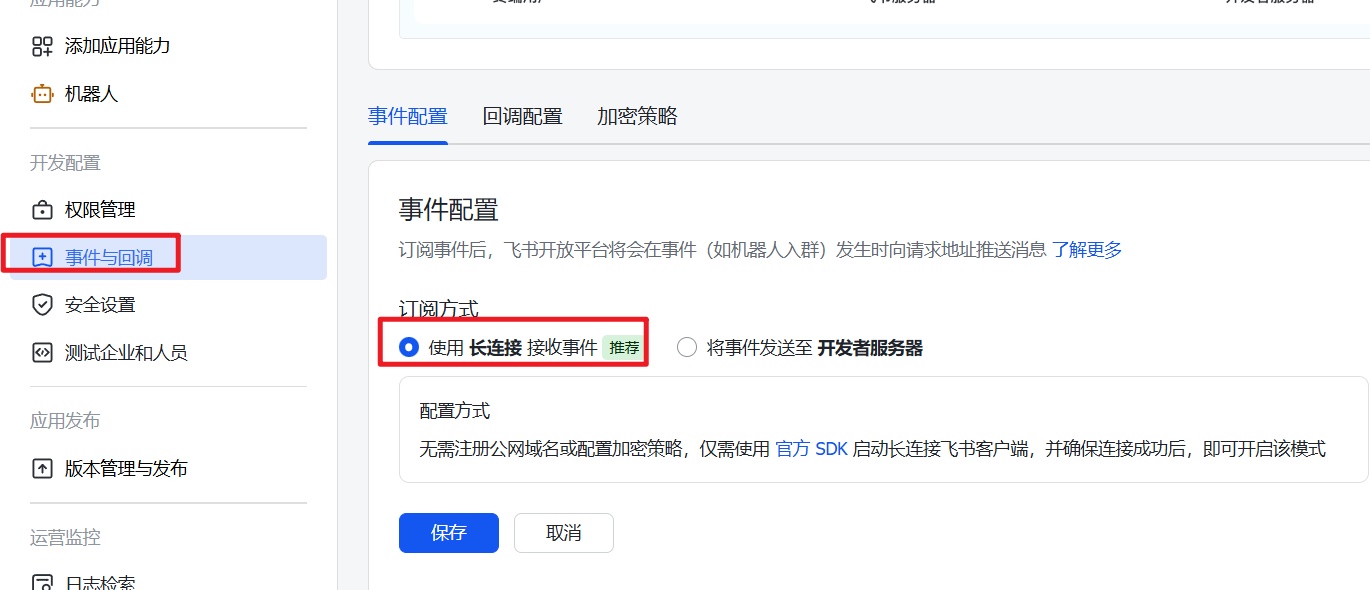 2. 点击下方的 **添加事件**,搜索 "接收消息",选择 "**接收消息v2.0**",确认添加。
3. 点击 **版本管理与发布**,创建版本并申请 **线上发布**,在飞书客户端查看审批消息并审核通过:
2. 点击下方的 **添加事件**,搜索 "接收消息",选择 "**接收消息v2.0**",确认添加。
3. 点击 **版本管理与发布**,创建版本并申请 **线上发布**,在飞书客户端查看审批消息并审核通过:
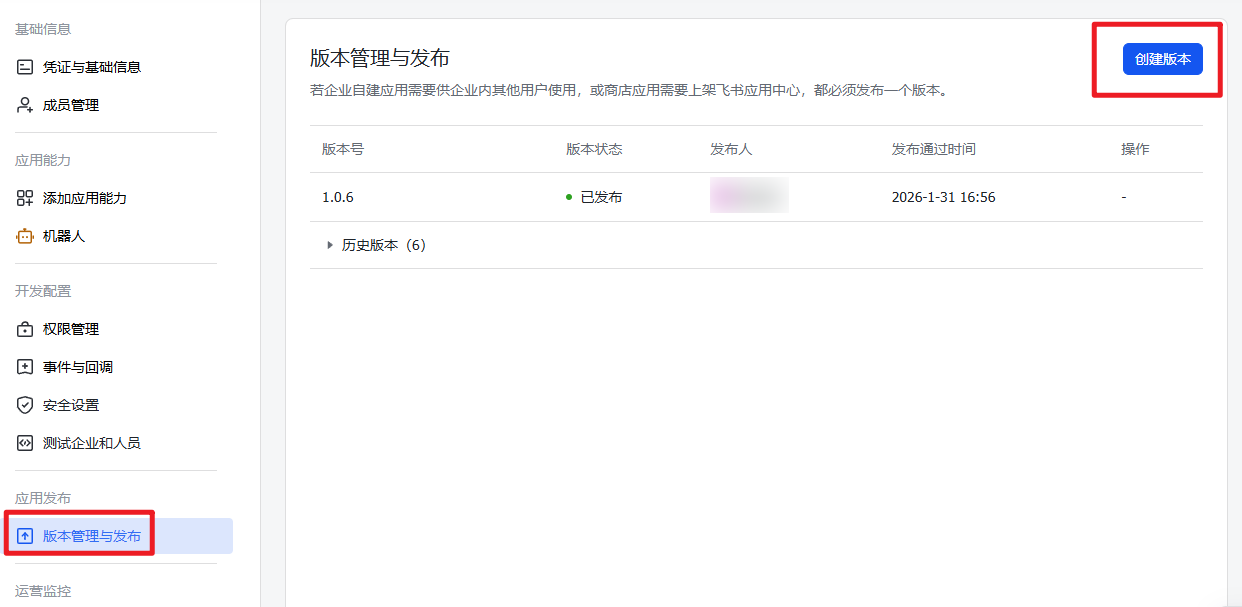 完成后在飞书中搜索机器人名称,即可开始对话。
================================================
FILE: docs/channels/qq.mdx
================================================
---
title: QQ 机器人
description: 将 CowAgent 接入 QQ 机器人(WebSocket 长连接模式)
---
> 通过 QQ 开放平台的机器人接口接入 CowAgent,支持 QQ 单聊、QQ 群聊(@机器人)、频道消息和频道私信,无需公网 IP,使用 WebSocket 长连接模式。
QQ 机器人通过 QQ 开放平台创建,使用 WebSocket 长连接接收消息,通过 OpenAPI 发送消息,无需公网 IP 和域名。
## 一、创建 QQ 机器人
> 进入[QQ 开放平台](https://q.qq.com),QQ扫码登录,如果未注册开放平台账号,请先完成[账号注册](https://q.qq.com/#/register)。
1.在 [QQ开放平台-机器人列表页](https://q.qq.com/#/apps),点击创建机器人:
完成后在飞书中搜索机器人名称,即可开始对话。
================================================
FILE: docs/channels/qq.mdx
================================================
---
title: QQ 机器人
description: 将 CowAgent 接入 QQ 机器人(WebSocket 长连接模式)
---
> 通过 QQ 开放平台的机器人接口接入 CowAgent,支持 QQ 单聊、QQ 群聊(@机器人)、频道消息和频道私信,无需公网 IP,使用 WebSocket 长连接模式。
QQ 机器人通过 QQ 开放平台创建,使用 WebSocket 长连接接收消息,通过 OpenAPI 发送消息,无需公网 IP 和域名。
## 一、创建 QQ 机器人
> 进入[QQ 开放平台](https://q.qq.com),QQ扫码登录,如果未注册开放平台账号,请先完成[账号注册](https://q.qq.com/#/register)。
1.在 [QQ开放平台-机器人列表页](https://q.qq.com/#/apps),点击创建机器人:
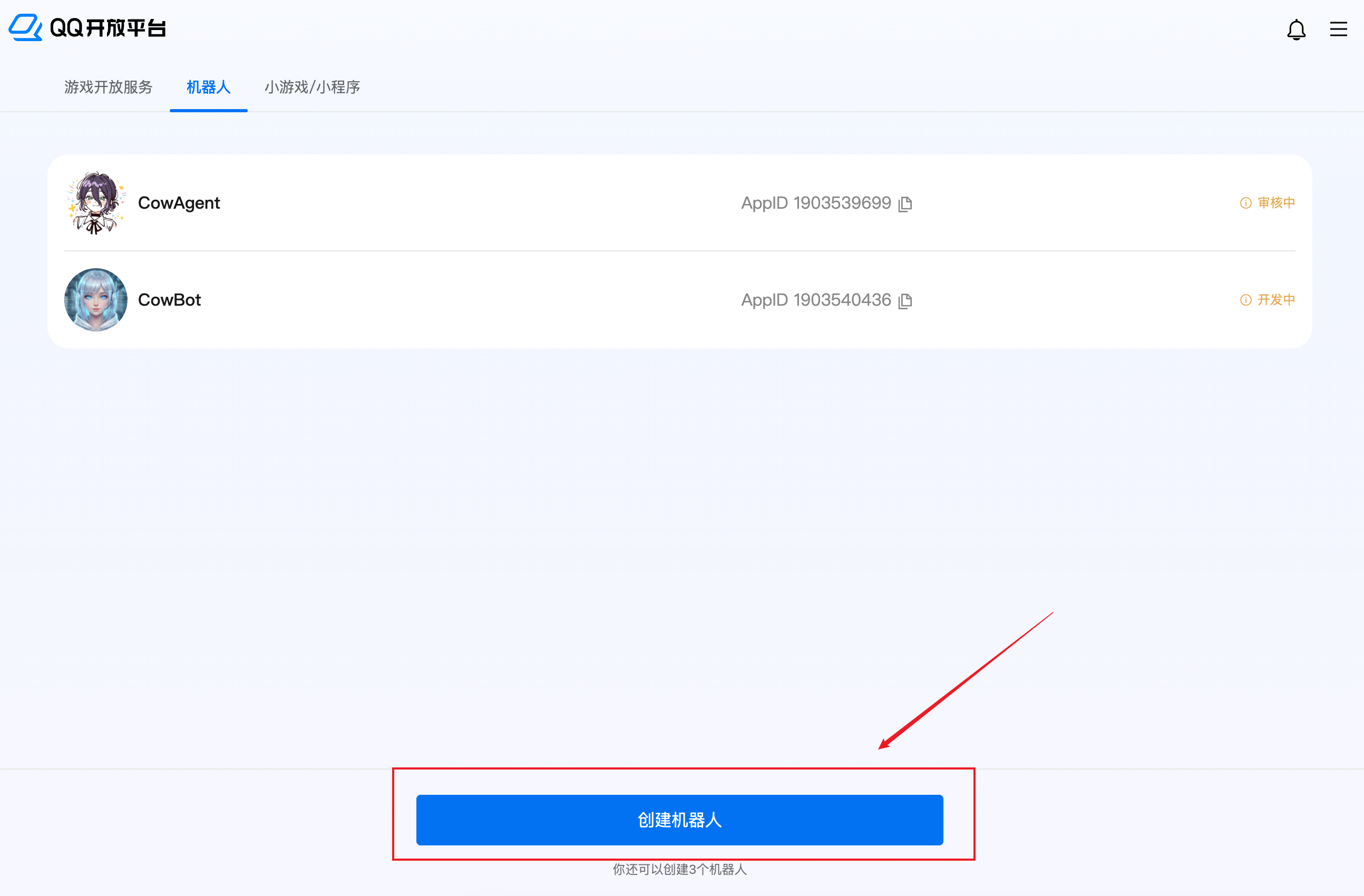 2.填写机器人名称、头像等基本信息,完成创建:
2.填写机器人名称、头像等基本信息,完成创建:
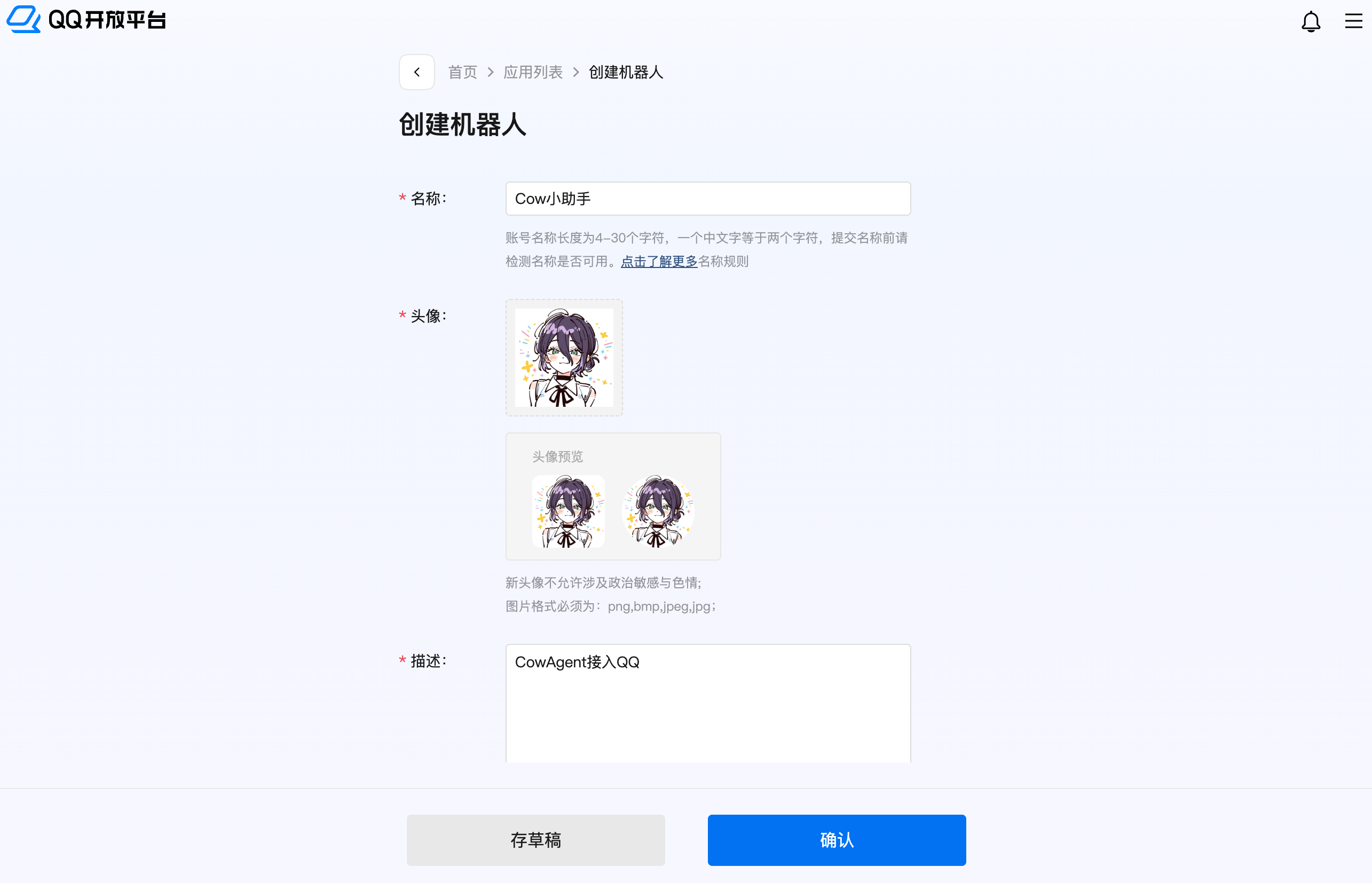 3.点击进入机器人配置页面,选择**开发管理**菜单,完成以下步骤:
- 复制并记录 **AppID**(机器人ID)
- 生成并记录 **AppSecret**(机器人秘钥)
3.点击进入机器人配置页面,选择**开发管理**菜单,完成以下步骤:
- 复制并记录 **AppID**(机器人ID)
- 生成并记录 **AppSecret**(机器人秘钥)
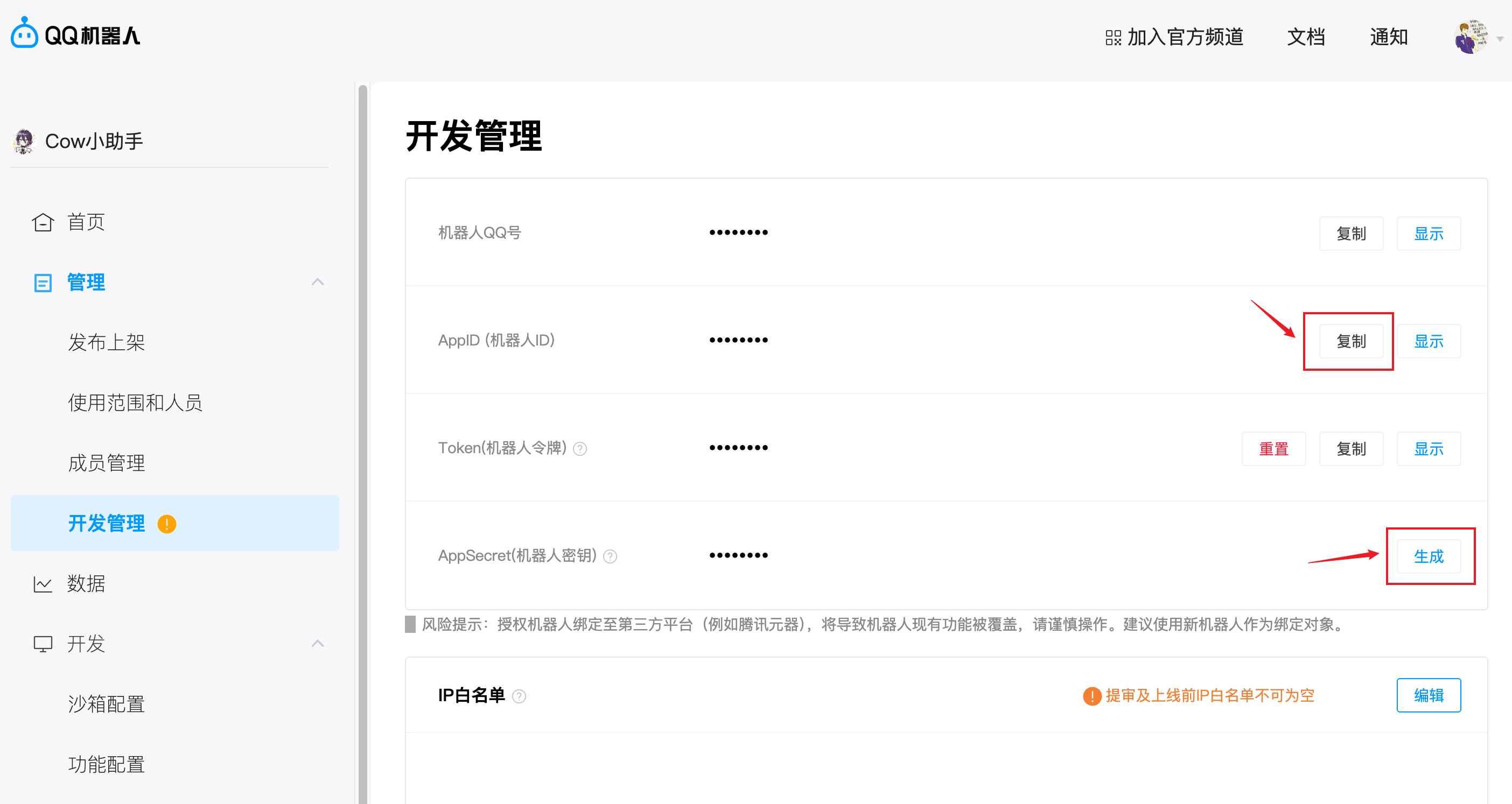 ## 二、配置和运行
### 方式一:Web 控制台接入
启动 Cow项目后打开 Web 控制台 (本地链接为: http://127.0.0.1:9899/ ),选择 **通道** 菜单,点击 **接入通道**,选择 **QQ 机器人**,填写上一步保存的 AppID 和 AppSecret,点击接入即可。
## 二、配置和运行
### 方式一:Web 控制台接入
启动 Cow项目后打开 Web 控制台 (本地链接为: http://127.0.0.1:9899/ ),选择 **通道** 菜单,点击 **接入通道**,选择 **QQ 机器人**,填写上一步保存的 AppID 和 AppSecret,点击接入即可。
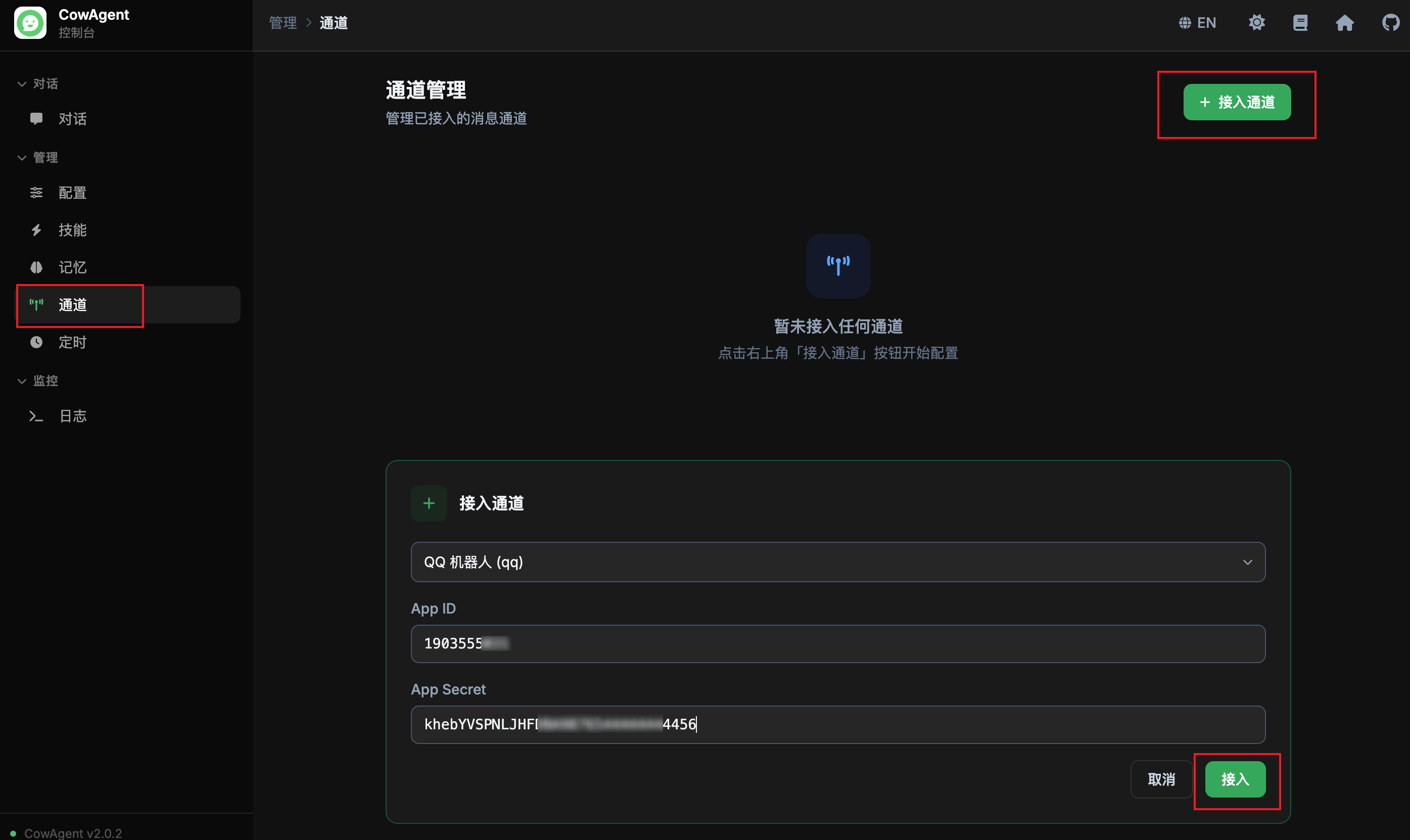 ### 方式二:配置文件接入
在 `config.json` 中添加以下配置:
```json
{
"channel_type": "qq",
"qq_app_id": "YOUR_APP_ID",
"qq_app_secret": "YOUR_APP_SECRET"
}
```
| 参数 | 说明 |
| --- | --- |
| `qq_app_id` | QQ 机器人的 AppID,在开放平台开发管理中获取 |
| `qq_app_secret` | QQ 机器人的 AppSecret,在开放平台开发管理中获取 |
配置完成后启动程序,日志显示 `[QQ] ✅ Connected successfully` 即表示连接成功。
## 三、使用
在 QQ开放平台 - 管理 - **使用范围和人员** 菜单中,使用QQ客户端扫描 "添加到群和消息列表" 的二维码,即可开始与QQ机器人的聊天:
### 方式二:配置文件接入
在 `config.json` 中添加以下配置:
```json
{
"channel_type": "qq",
"qq_app_id": "YOUR_APP_ID",
"qq_app_secret": "YOUR_APP_SECRET"
}
```
| 参数 | 说明 |
| --- | --- |
| `qq_app_id` | QQ 机器人的 AppID,在开放平台开发管理中获取 |
| `qq_app_secret` | QQ 机器人的 AppSecret,在开放平台开发管理中获取 |
配置完成后启动程序,日志显示 `[QQ] ✅ Connected successfully` 即表示连接成功。
## 三、使用
在 QQ开放平台 - 管理 - **使用范围和人员** 菜单中,使用QQ客户端扫描 "添加到群和消息列表" 的二维码,即可开始与QQ机器人的聊天:
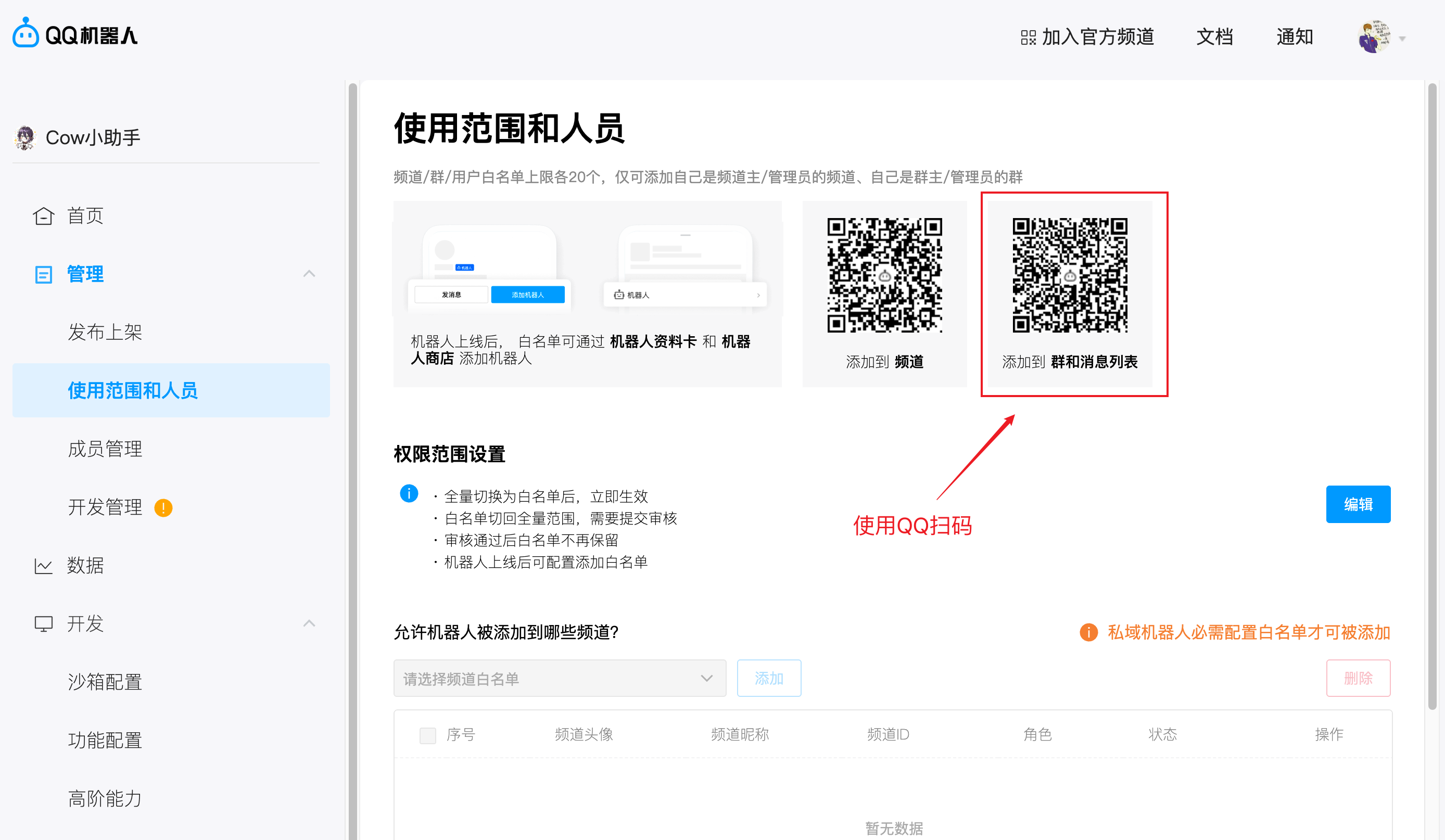 对话效果:
对话效果:
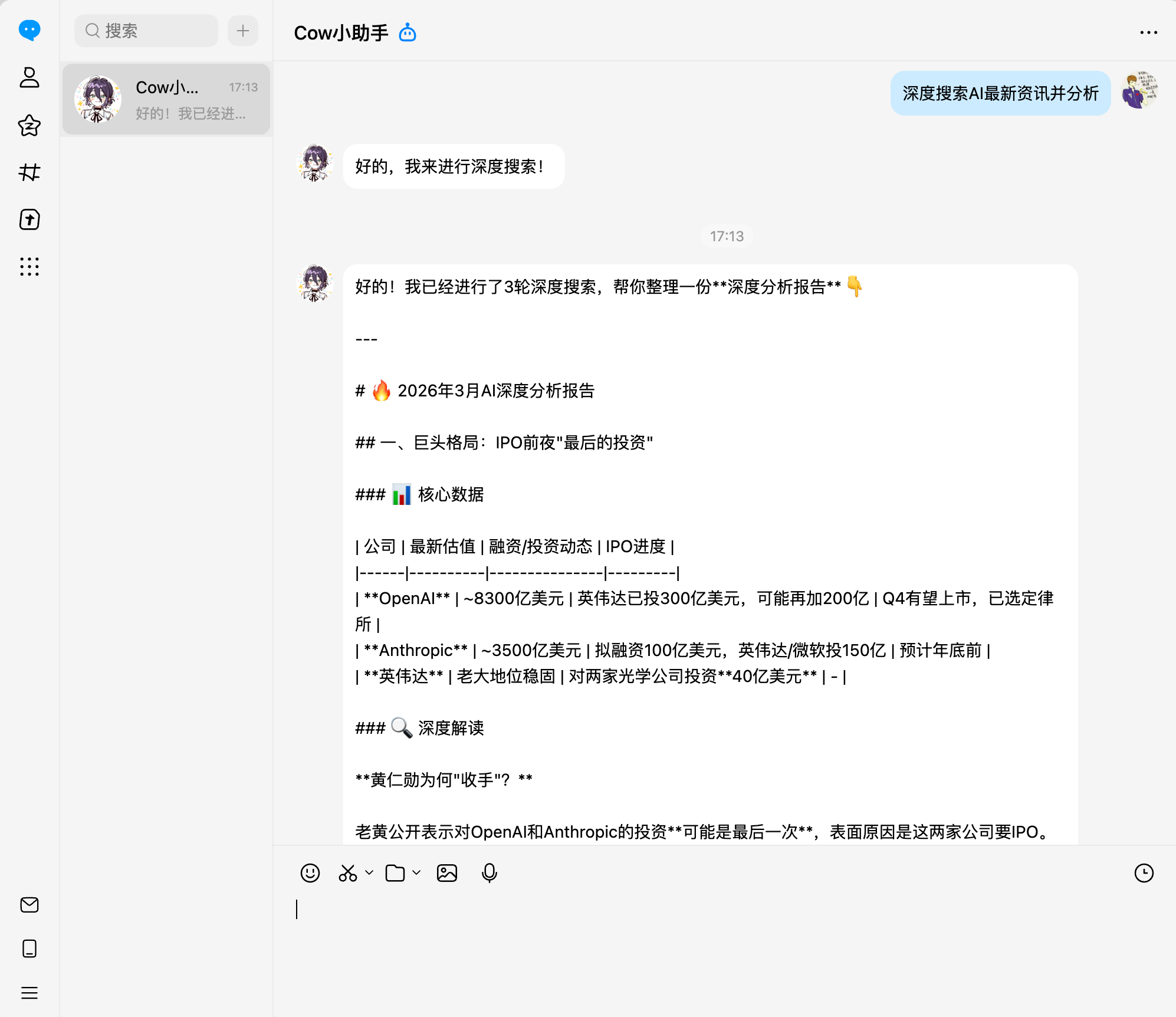 ## 四、功能说明
> 注意:若需在群聊及频道中使用QQ机器人,需完成发布上架审核并在使用范围配置权限使用范围。
| 功能 | 支持情况 |
| --- | --- |
| QQ 单聊 | ✅ |
| QQ 群聊(@机器人) | ✅ |
| 频道消息(@机器人) | ✅ |
| 频道私信 | ✅ |
| 文本消息 | ✅ 收发 |
| 图片消息 | ✅ 收发(群聊和单聊) |
| 文件消息 | ✅ 发送(群聊和单聊) |
| 定时任务 | ✅ 主动推送(每月每用户限 4 条) |
## 五、注意事项
- **被动消息限制**:QQ 单聊被动消息有效期为 60 分钟,每条消息最多回复 5 次;QQ 群聊被动消息有效期为 5 分钟。
- **主动消息限制**:单聊和群聊每月主动消息上限为 4 条,在使用定时任务功能时需要注意这个限制
- **事件权限**:默认订阅 `GROUP_AND_C2C_EVENT`(QQ群/单聊)和 `PUBLIC_GUILD_MESSAGES`(频道公域消息),如需其他事件类型请在开放平台申请权限。
================================================
FILE: docs/channels/web.mdx
================================================
---
title: Web 控制台
description: 通过 Web 控制台使用 CowAgent
---
Web 控制台是 CowAgent 的默认通道,启动后会自动运行,通过浏览器即可与 Agent 对话,并支持在线管理模型、技能、记忆、通道等配置。
## 配置
```json
{
"channel_type": "web",
"web_port": 9899
}
```
| 参数 | 说明 | 默认值 |
| --- | --- | --- |
| `channel_type` | 设为 `web` | `web` |
| `web_port` | Web 服务监听端口 | `9899` |
## 访问地址
启动项目后访问:
- 本地运行:`http://localhost:9899`
- 服务器运行:`http://:9899`
请确保服务器防火墙和安全组已放行对应端口。
## 功能介绍
### 对话界面
支持流式输出,可实时展示 Agent 的思考过程(Reasoning)和工具调用过程(Tool Calls),更直观地观察 Agent 的决策过程:
## 四、功能说明
> 注意:若需在群聊及频道中使用QQ机器人,需完成发布上架审核并在使用范围配置权限使用范围。
| 功能 | 支持情况 |
| --- | --- |
| QQ 单聊 | ✅ |
| QQ 群聊(@机器人) | ✅ |
| 频道消息(@机器人) | ✅ |
| 频道私信 | ✅ |
| 文本消息 | ✅ 收发 |
| 图片消息 | ✅ 收发(群聊和单聊) |
| 文件消息 | ✅ 发送(群聊和单聊) |
| 定时任务 | ✅ 主动推送(每月每用户限 4 条) |
## 五、注意事项
- **被动消息限制**:QQ 单聊被动消息有效期为 60 分钟,每条消息最多回复 5 次;QQ 群聊被动消息有效期为 5 分钟。
- **主动消息限制**:单聊和群聊每月主动消息上限为 4 条,在使用定时任务功能时需要注意这个限制
- **事件权限**:默认订阅 `GROUP_AND_C2C_EVENT`(QQ群/单聊)和 `PUBLIC_GUILD_MESSAGES`(频道公域消息),如需其他事件类型请在开放平台申请权限。
================================================
FILE: docs/channels/web.mdx
================================================
---
title: Web 控制台
description: 通过 Web 控制台使用 CowAgent
---
Web 控制台是 CowAgent 的默认通道,启动后会自动运行,通过浏览器即可与 Agent 对话,并支持在线管理模型、技能、记忆、通道等配置。
## 配置
```json
{
"channel_type": "web",
"web_port": 9899
}
```
| 参数 | 说明 | 默认值 |
| --- | --- | --- |
| `channel_type` | 设为 `web` | `web` |
| `web_port` | Web 服务监听端口 | `9899` |
## 访问地址
启动项目后访问:
- 本地运行:`http://localhost:9899`
- 服务器运行:`http://:9899`
请确保服务器防火墙和安全组已放行对应端口。
## 功能介绍
### 对话界面
支持流式输出,可实时展示 Agent 的思考过程(Reasoning)和工具调用过程(Tool Calls),更直观地观察 Agent 的决策过程:
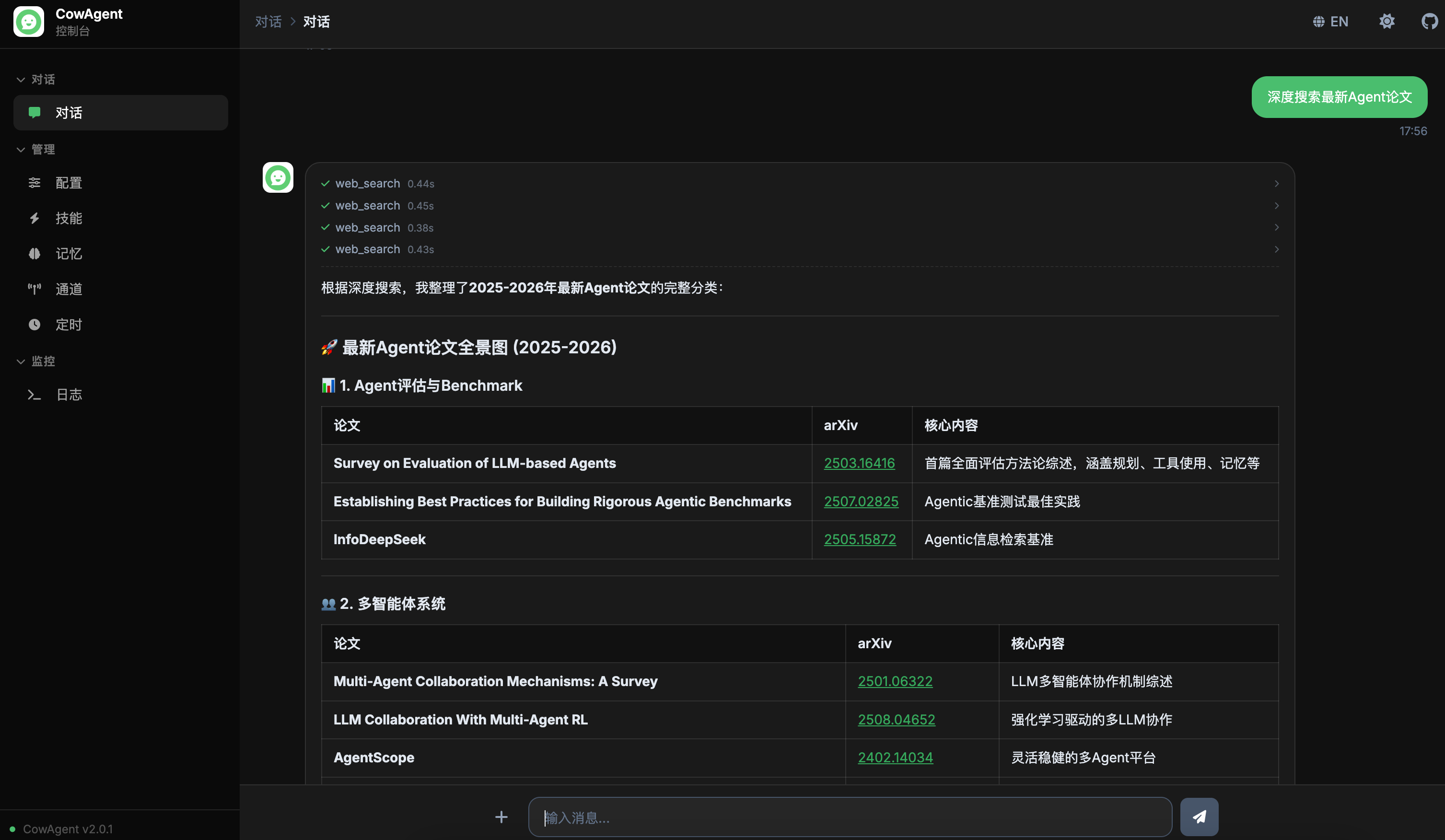 ### 模型管理
支持在线管理模型配置,无需手动编辑配置文件:
### 模型管理
支持在线管理模型配置,无需手动编辑配置文件:
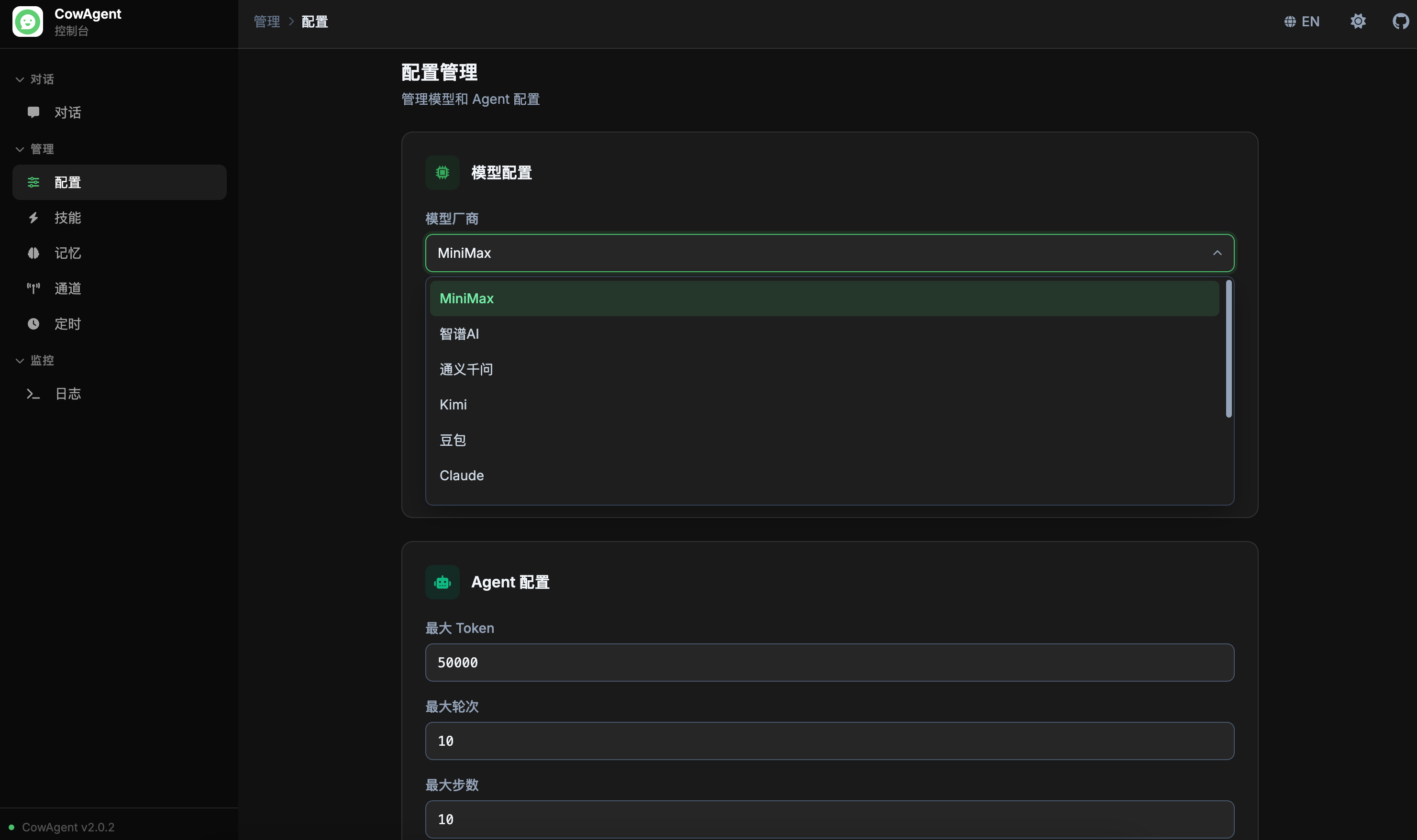 ### 技能管理
支持在线查看和管理 Agent 技能(Skills):
### 技能管理
支持在线查看和管理 Agent 技能(Skills):
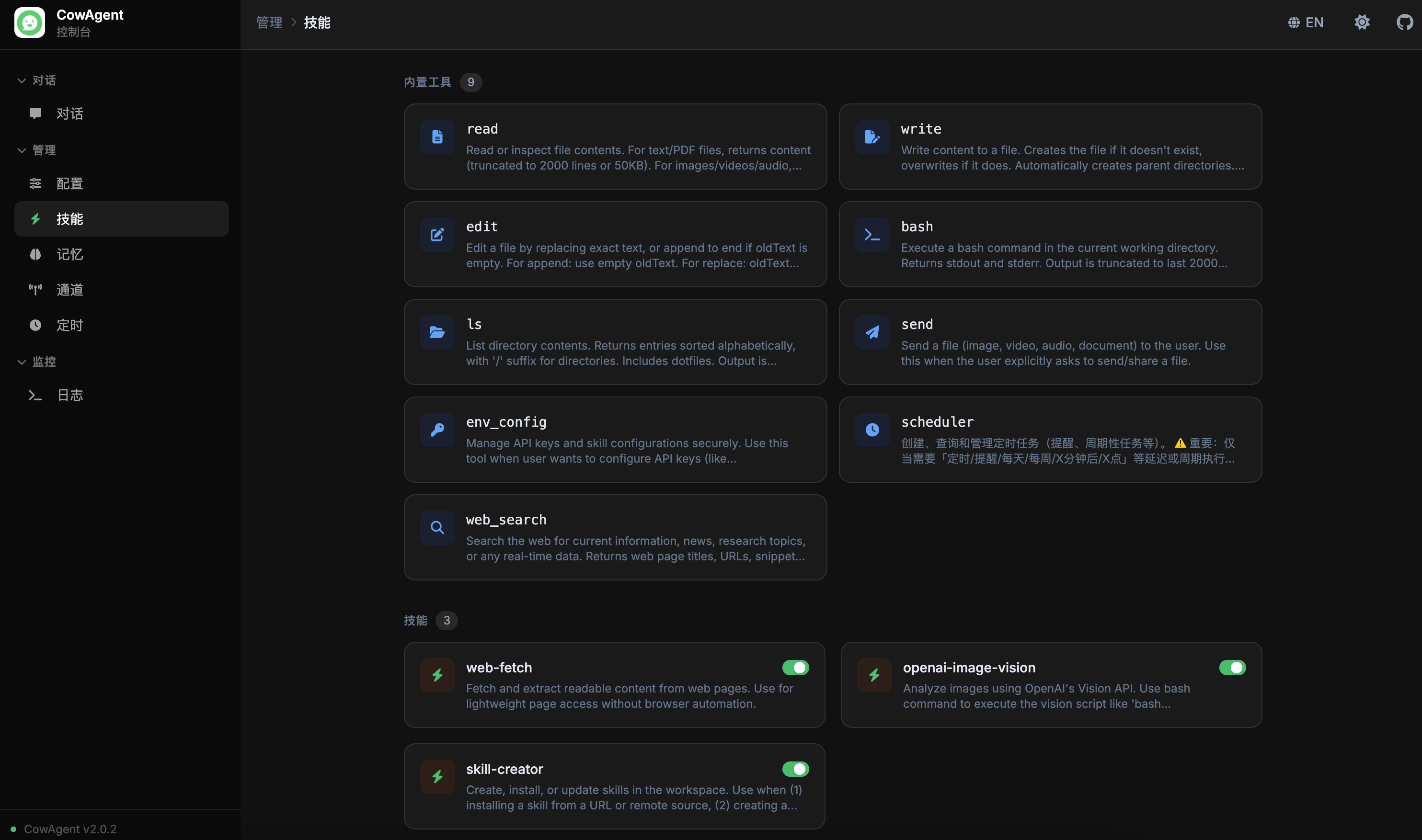 ### 记忆管理
支持在线查看和管理 Agent 记忆:
### 记忆管理
支持在线查看和管理 Agent 记忆:
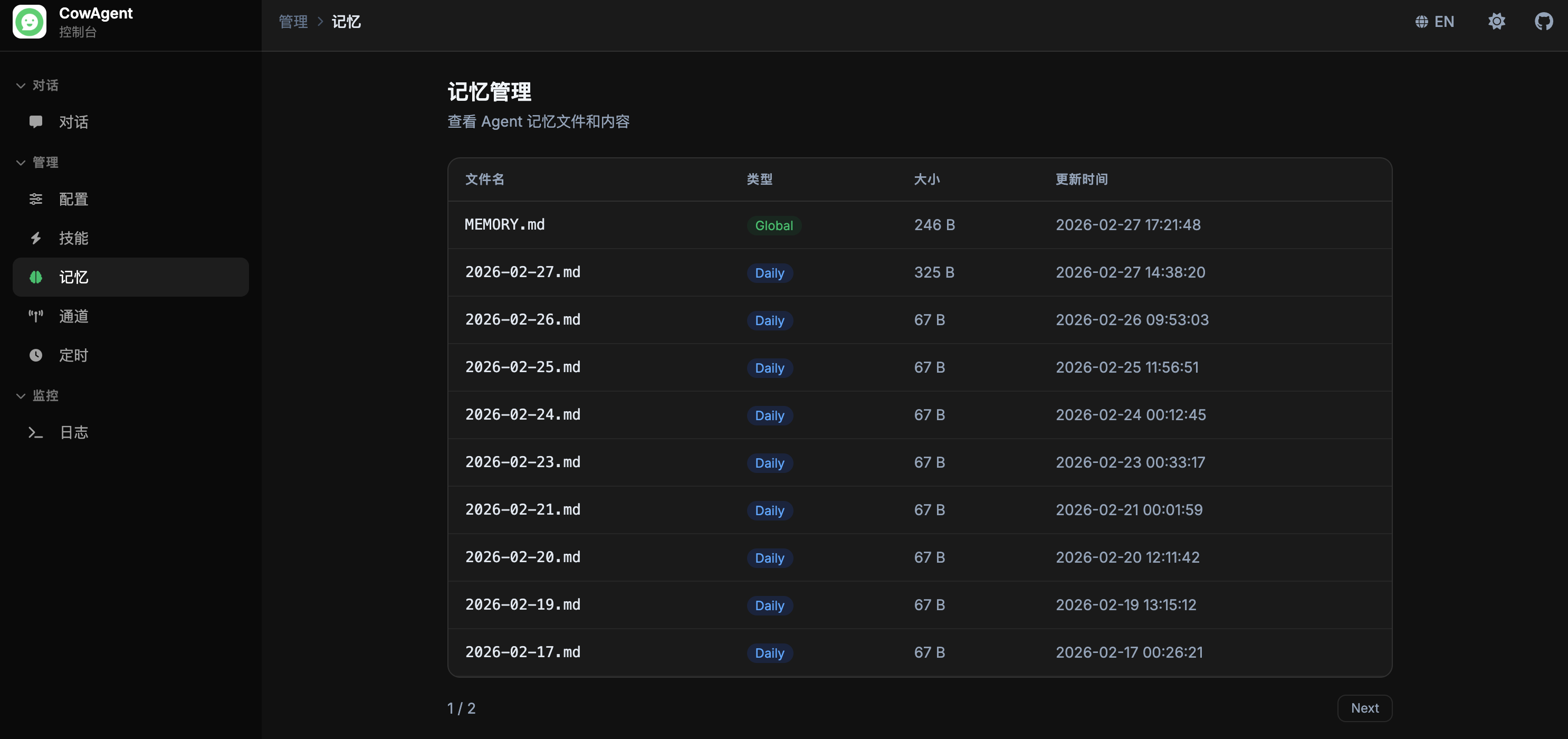 ### 通道管理
支持在线管理接入通道,支持实时连接/断开操作:
### 通道管理
支持在线管理接入通道,支持实时连接/断开操作:
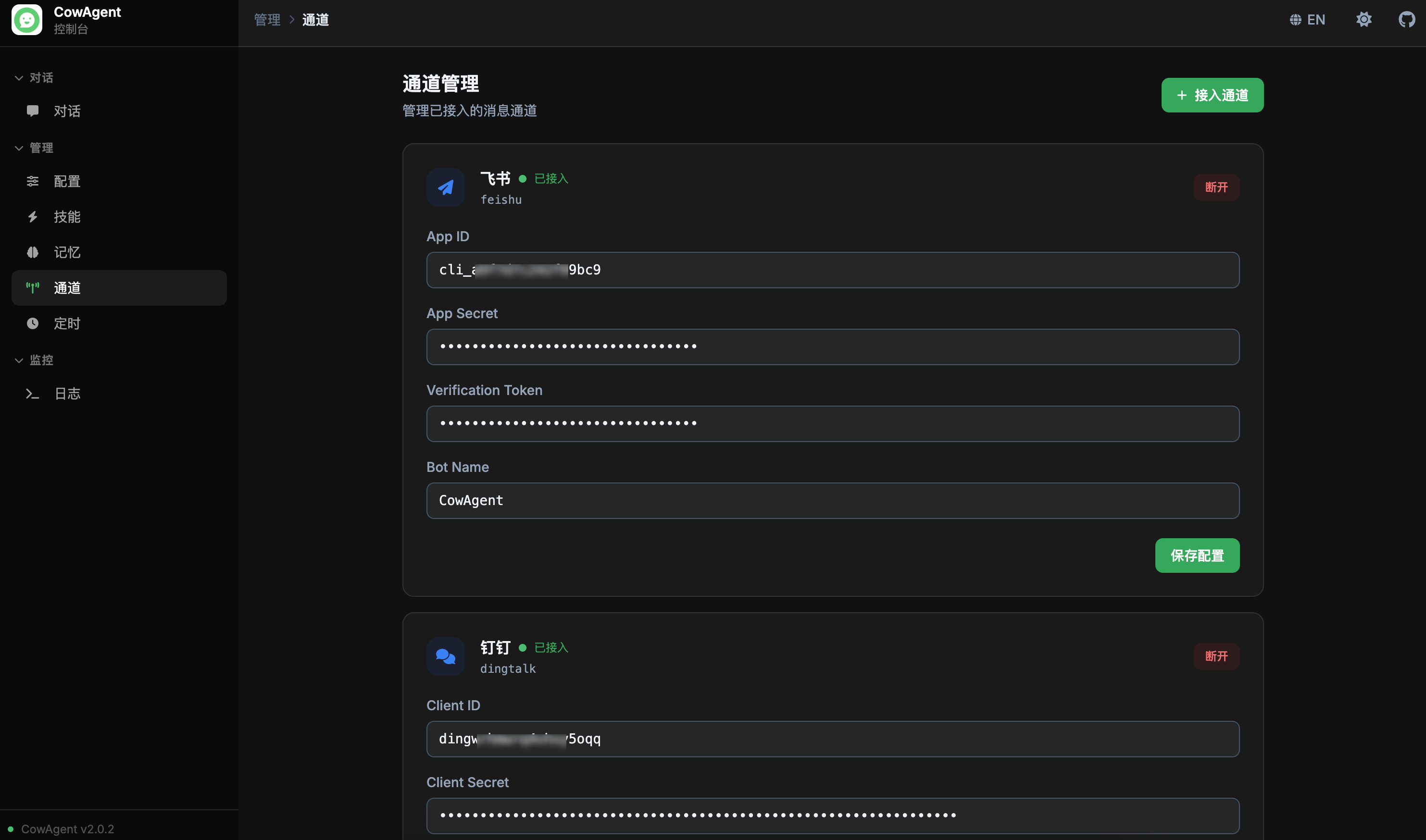 ### 定时任务
支持在线查看和管理定时任务,包括一次性任务、固定间隔、Cron 表达式等多种调度方式的可视化管理:
### 定时任务
支持在线查看和管理定时任务,包括一次性任务、固定间隔、Cron 表达式等多种调度方式的可视化管理:
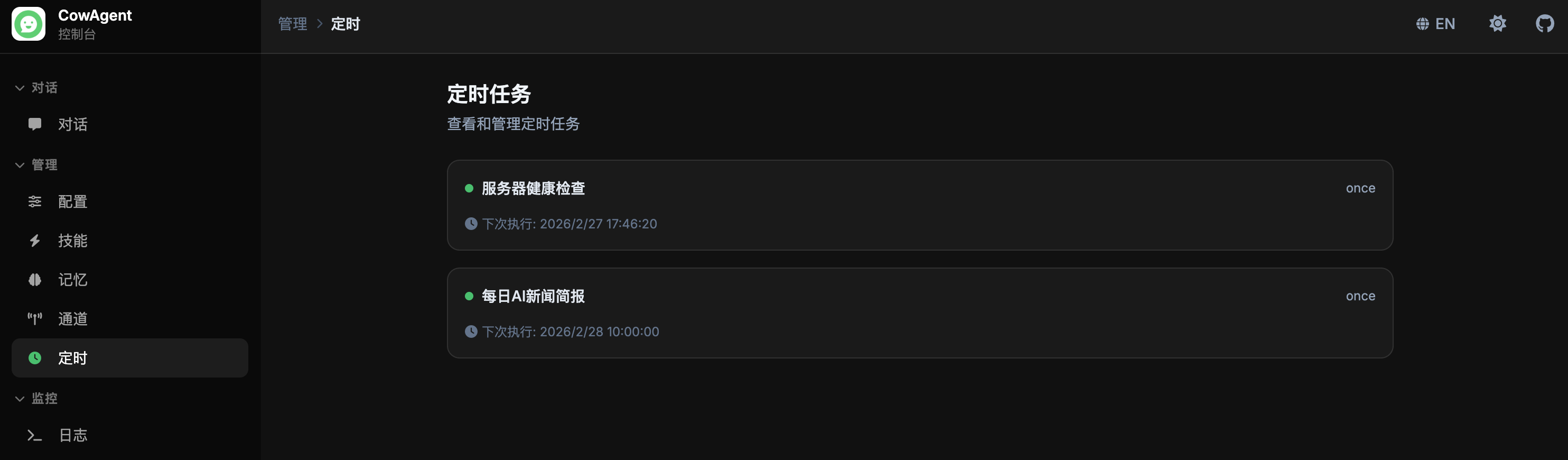 ### 日志
支持在线实时查看 Agent 运行日志,便于监控运行状态和排查问题:
### 日志
支持在线实时查看 Agent 运行日志,便于监控运行状态和排查问题:
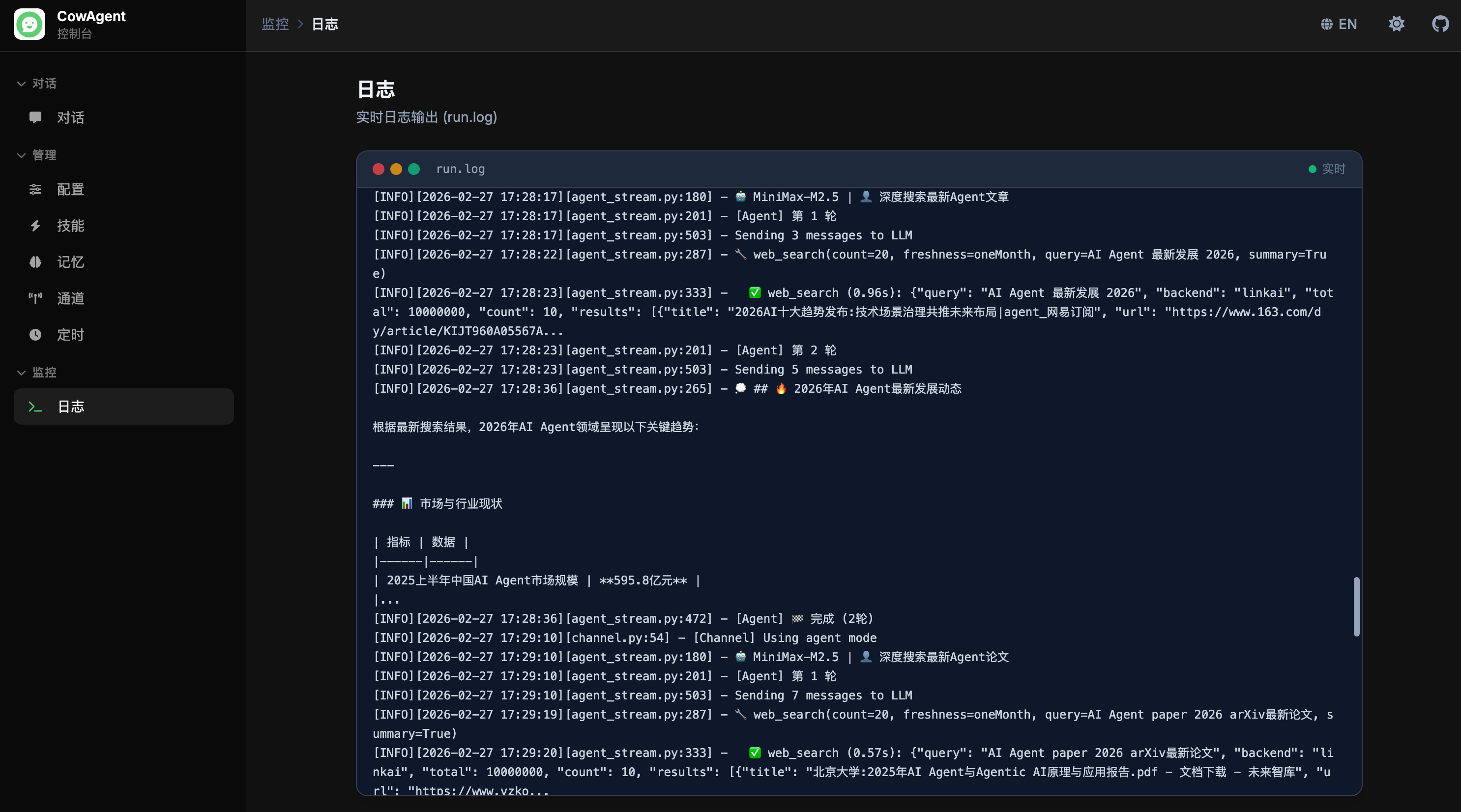 ================================================
FILE: docs/channels/wechatmp.mdx
================================================
---
title: 微信公众号
description: 将 CowAgent 接入微信公众号
---
CowAgent 支持接入个人订阅号和企业服务号两种公众号类型。
| 类型 | 要求 | 特点 |
| --- | --- | --- |
| **个人订阅号** | 个人可申请 | 收到消息时会回复一条提示,回复生成后需用户主动发消息获取 |
| **企业服务号** | 企业申请,需通过微信认证开通客服接口 | 回复生成后可主动推送给用户 |
公众号仅支持服务器和 Docker 部署,不支持本地运行。需额外安装扩展依赖:`pip3 install -r requirements-optional.txt`
## 一、个人订阅号
在 `config.json` 中添加以下配置:
```json
{
"channel_type": "wechatmp",
"single_chat_prefix": [""],
"wechatmp_app_id": "wx73f9******d1e48",
"wechatmp_app_secret": "YOUR_APP_SECRET",
"wechatmp_aes_key": "",
"wechatmp_token": "YOUR_TOKEN",
"wechatmp_port": 80
}
```
### 配置步骤
这些配置需要和 [微信公众号后台](https://mp.weixin.qq.com/advanced/advanced?action=dev&t=advanced/dev) 中的保持一致,进入页面后,在左侧菜单选择 **设置与开发 → 基本配置 → 服务器配置**,按下图进行配置:
================================================
FILE: docs/channels/wechatmp.mdx
================================================
---
title: 微信公众号
description: 将 CowAgent 接入微信公众号
---
CowAgent 支持接入个人订阅号和企业服务号两种公众号类型。
| 类型 | 要求 | 特点 |
| --- | --- | --- |
| **个人订阅号** | 个人可申请 | 收到消息时会回复一条提示,回复生成后需用户主动发消息获取 |
| **企业服务号** | 企业申请,需通过微信认证开通客服接口 | 回复生成后可主动推送给用户 |
公众号仅支持服务器和 Docker 部署,不支持本地运行。需额外安装扩展依赖:`pip3 install -r requirements-optional.txt`
## 一、个人订阅号
在 `config.json` 中添加以下配置:
```json
{
"channel_type": "wechatmp",
"single_chat_prefix": [""],
"wechatmp_app_id": "wx73f9******d1e48",
"wechatmp_app_secret": "YOUR_APP_SECRET",
"wechatmp_aes_key": "",
"wechatmp_token": "YOUR_TOKEN",
"wechatmp_port": 80
}
```
### 配置步骤
这些配置需要和 [微信公众号后台](https://mp.weixin.qq.com/advanced/advanced?action=dev&t=advanced/dev) 中的保持一致,进入页面后,在左侧菜单选择 **设置与开发 → 基本配置 → 服务器配置**,按下图进行配置:
 1. 在公众平台启用开发者密码(对应配置 `wechatmp_app_secret`),并将服务器 IP 填入白名单
2. 按上图填写 `config.json` 中与公众号相关的配置,要与公众号后台的配置一致
3. 启动程序,启动后会监听 80 端口(若无权限监听,则在启动命令前加上 `sudo`;若 80 端口已被占用,则关闭该占用进程)
4. 在公众号后台 **启用服务器配置** 并提交,保存成功则表示已成功配置。注意 **"服务器地址(URL)"** 需要配置为 `http://{HOST}/wx` 的格式,其中 `{HOST}` 可以是服务器的 IP 或域名
随后关注公众号并发送消息即可看到以下效果:
1. 在公众平台启用开发者密码(对应配置 `wechatmp_app_secret`),并将服务器 IP 填入白名单
2. 按上图填写 `config.json` 中与公众号相关的配置,要与公众号后台的配置一致
3. 启动程序,启动后会监听 80 端口(若无权限监听,则在启动命令前加上 `sudo`;若 80 端口已被占用,则关闭该占用进程)
4. 在公众号后台 **启用服务器配置** 并提交,保存成功则表示已成功配置。注意 **"服务器地址(URL)"** 需要配置为 `http://{HOST}/wx` 的格式,其中 `{HOST}` 可以是服务器的 IP 或域名
随后关注公众号并发送消息即可看到以下效果:
 由于受订阅号限制,回复内容较短的情况下(15s 内),可以立即完成回复,但耗时较长的回复则会先回复一句 "正在思考中",后续需要用户输入任意文字主动获取答案,而服务号则可以通过客服接口解决这一问题。
**语音识别**:可利用微信自带的语音识别功能,需要在公众号管理页面的 "设置与开发 → 接口权限" 页面开启 "接收语音识别结果"。
## 二、企业服务号
企业服务号与上述个人订阅号的接入过程基本相同,差异如下:
1. 在公众平台申请企业服务号并完成微信认证,在接口权限中确认已获得 **客服接口** 的权限
2. 在 `config.json` 中设置 `"channel_type": "wechatmp_service"`,其他配置与上述订阅号相同
3. 交互效果上,即使是较长耗时的回复,也可以主动推送给用户,无需用户手动获取
```json
{
"channel_type": "wechatmp_service",
"single_chat_prefix": [""],
"wechatmp_app_id": "YOUR_APP_ID",
"wechatmp_app_secret": "YOUR_APP_SECRET",
"wechatmp_aes_key": "",
"wechatmp_token": "YOUR_TOKEN",
"wechatmp_port": 80
}
```
================================================
FILE: docs/channels/wecom-bot.mdx
================================================
---
title: 企微智能机器人
description: 将 CowAgent 接入企业微信智能机器人(长连接模式)
---
> 通过企业微信智能机器人接入CowAgent,支持企业内部单聊和内部群聊,无需公网 IP,使用 WebSocket 长连接模式,支持Markdown渲染和流式输出。
智能机器人与企业微信自建应用是两种不同的接入方式。智能机器人使用 WebSocket 长连接,无需服务器公网 IP 和域名,配置更简单。
## 一、创建智能机器人
1. 打开企业微信客户端,进入工作台,点击**智能机器人**:
由于受订阅号限制,回复内容较短的情况下(15s 内),可以立即完成回复,但耗时较长的回复则会先回复一句 "正在思考中",后续需要用户输入任意文字主动获取答案,而服务号则可以通过客服接口解决这一问题。
**语音识别**:可利用微信自带的语音识别功能,需要在公众号管理页面的 "设置与开发 → 接口权限" 页面开启 "接收语音识别结果"。
## 二、企业服务号
企业服务号与上述个人订阅号的接入过程基本相同,差异如下:
1. 在公众平台申请企业服务号并完成微信认证,在接口权限中确认已获得 **客服接口** 的权限
2. 在 `config.json` 中设置 `"channel_type": "wechatmp_service"`,其他配置与上述订阅号相同
3. 交互效果上,即使是较长耗时的回复,也可以主动推送给用户,无需用户手动获取
```json
{
"channel_type": "wechatmp_service",
"single_chat_prefix": [""],
"wechatmp_app_id": "YOUR_APP_ID",
"wechatmp_app_secret": "YOUR_APP_SECRET",
"wechatmp_aes_key": "",
"wechatmp_token": "YOUR_TOKEN",
"wechatmp_port": 80
}
```
================================================
FILE: docs/channels/wecom-bot.mdx
================================================
---
title: 企微智能机器人
description: 将 CowAgent 接入企业微信智能机器人(长连接模式)
---
> 通过企业微信智能机器人接入CowAgent,支持企业内部单聊和内部群聊,无需公网 IP,使用 WebSocket 长连接模式,支持Markdown渲染和流式输出。
智能机器人与企业微信自建应用是两种不同的接入方式。智能机器人使用 WebSocket 长连接,无需服务器公网 IP 和域名,配置更简单。
## 一、创建智能机器人
1. 打开企业微信客户端,进入工作台,点击**智能机器人**:
 2. 点击创建机器人 - 手动创建:
2. 点击创建机器人 - 手动创建:
 3. 右侧窗口拖到最下方,选择**API模式创建**:
3. 右侧窗口拖到最下方,选择**API模式创建**:
 4. 设置机器人名称、头像、可见范围,并选择**长连接模式**,记录下 **Bot ID** 和 **Secret** 信息后点击保存。
## 二、配置和运行
### 方式一:Web 控制台接入
启动Cow项目后打开 Web 控制台 (本地链接为: http://127.0.0.1:9899/ ),选择 **通道** 菜单,点击 **接入通道**,选择 **企微智能机器人**,填写上一步保存的 Bot ID 和 Secret,点击接入即可。
4. 设置机器人名称、头像、可见范围,并选择**长连接模式**,记录下 **Bot ID** 和 **Secret** 信息后点击保存。
## 二、配置和运行
### 方式一:Web 控制台接入
启动Cow项目后打开 Web 控制台 (本地链接为: http://127.0.0.1:9899/ ),选择 **通道** 菜单,点击 **接入通道**,选择 **企微智能机器人**,填写上一步保存的 Bot ID 和 Secret,点击接入即可。
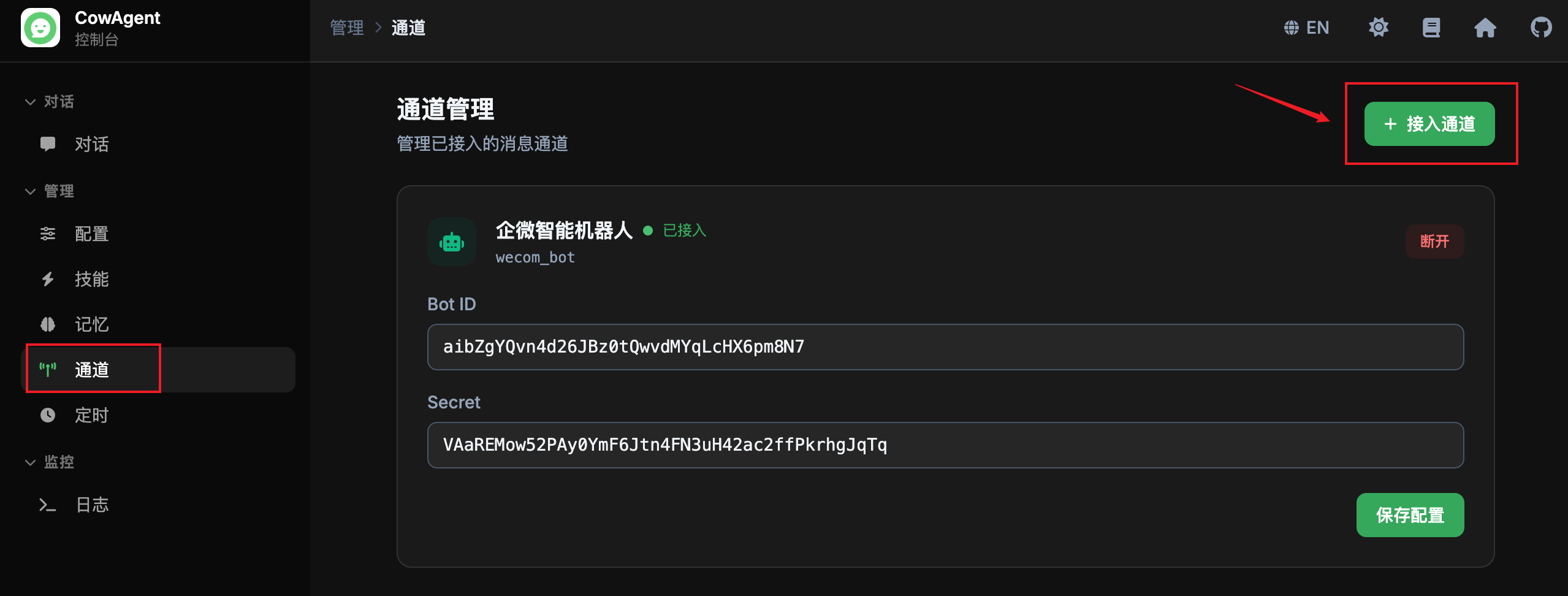 ### 方式二:配置文件接入
在 `config.json` 中添加以下配置:
```json
{
"channel_type": "wecom_bot",
"wecom_bot_id": "YOUR_BOT_ID",
"wecom_bot_secret": "YOUR_SECRET"
}
```
| 参数 | 说明 |
| --- | --- |
| `wecom_bot_id` | 智能机器人的 BotID |
| `wecom_bot_secret` | 智能机器人的 Secret |
配置完成后启动程序,日志显示 `[WecomBot] Subscribe success` 即表示连接成功。
## 三、功能说明
| 功能 | 支持情况 |
| --- | --- |
| 单聊 | ✅ |
| 群聊(@机器人) | ✅ |
| 文本消息 | ✅ 收发 |
| 图片消息 | ✅ 收发 |
| 文件消息 | ✅ 收发 |
| 流式回复 | ✅ |
| 定时任务主动推送 | ✅ |
## 四、使用
在企业微信中搜索创建的机器人名称,即可开始单聊对话。
如需在企微内部群聊中使用,将机器人添加到群中,@机器人发送消息即可。
### 方式二:配置文件接入
在 `config.json` 中添加以下配置:
```json
{
"channel_type": "wecom_bot",
"wecom_bot_id": "YOUR_BOT_ID",
"wecom_bot_secret": "YOUR_SECRET"
}
```
| 参数 | 说明 |
| --- | --- |
| `wecom_bot_id` | 智能机器人的 BotID |
| `wecom_bot_secret` | 智能机器人的 Secret |
配置完成后启动程序,日志显示 `[WecomBot] Subscribe success` 即表示连接成功。
## 三、功能说明
| 功能 | 支持情况 |
| --- | --- |
| 单聊 | ✅ |
| 群聊(@机器人) | ✅ |
| 文本消息 | ✅ 收发 |
| 图片消息 | ✅ 收发 |
| 文件消息 | ✅ 收发 |
| 流式回复 | ✅ |
| 定时任务主动推送 | ✅ |
## 四、使用
在企业微信中搜索创建的机器人名称,即可开始单聊对话。
如需在企微内部群聊中使用,将机器人添加到群中,@机器人发送消息即可。
 ================================================
FILE: docs/channels/wecom.mdx
================================================
---
title: 企微自建应用
description: 将 CowAgent 接入企业微信自建应用
---
通过企业微信自建应用接入 CowAgent,支持企业内部人员单聊使用。
企业微信只能使用 Docker 部署或服务器 Python 部署,不支持本地运行模式。
## 一、准备
需要的资源:
1. 一台服务器(有公网 IP)
2. 注册一个企业微信(个人也可注册,但无法认证)
3. 认证企业微信还需要对应主体备案的域名
## 二、创建企业微信应用
1. 在 [企业微信管理后台](https://work.weixin.qq.com/wework_admin/frame#profile) 点击 **我的企业**,在最下方获取 **企业ID**(后续填写到 `wechatcom_corp_id` 字段中)。
2. 切换到 **应用管理**,点击创建应用:
================================================
FILE: docs/channels/wecom.mdx
================================================
---
title: 企微自建应用
description: 将 CowAgent 接入企业微信自建应用
---
通过企业微信自建应用接入 CowAgent,支持企业内部人员单聊使用。
企业微信只能使用 Docker 部署或服务器 Python 部署,不支持本地运行模式。
## 一、准备
需要的资源:
1. 一台服务器(有公网 IP)
2. 注册一个企业微信(个人也可注册,但无法认证)
3. 认证企业微信还需要对应主体备案的域名
## 二、创建企业微信应用
1. 在 [企业微信管理后台](https://work.weixin.qq.com/wework_admin/frame#profile) 点击 **我的企业**,在最下方获取 **企业ID**(后续填写到 `wechatcom_corp_id` 字段中)。
2. 切换到 **应用管理**,点击创建应用:
 3. 进入应用创建页面,记录 `AgentId` 和 `Secret`:
3. 进入应用创建页面,记录 `AgentId` 和 `Secret`:
 4. 点击 **设置API接收**,配置应用接口:
4. 点击 **设置API接收**,配置应用接口:
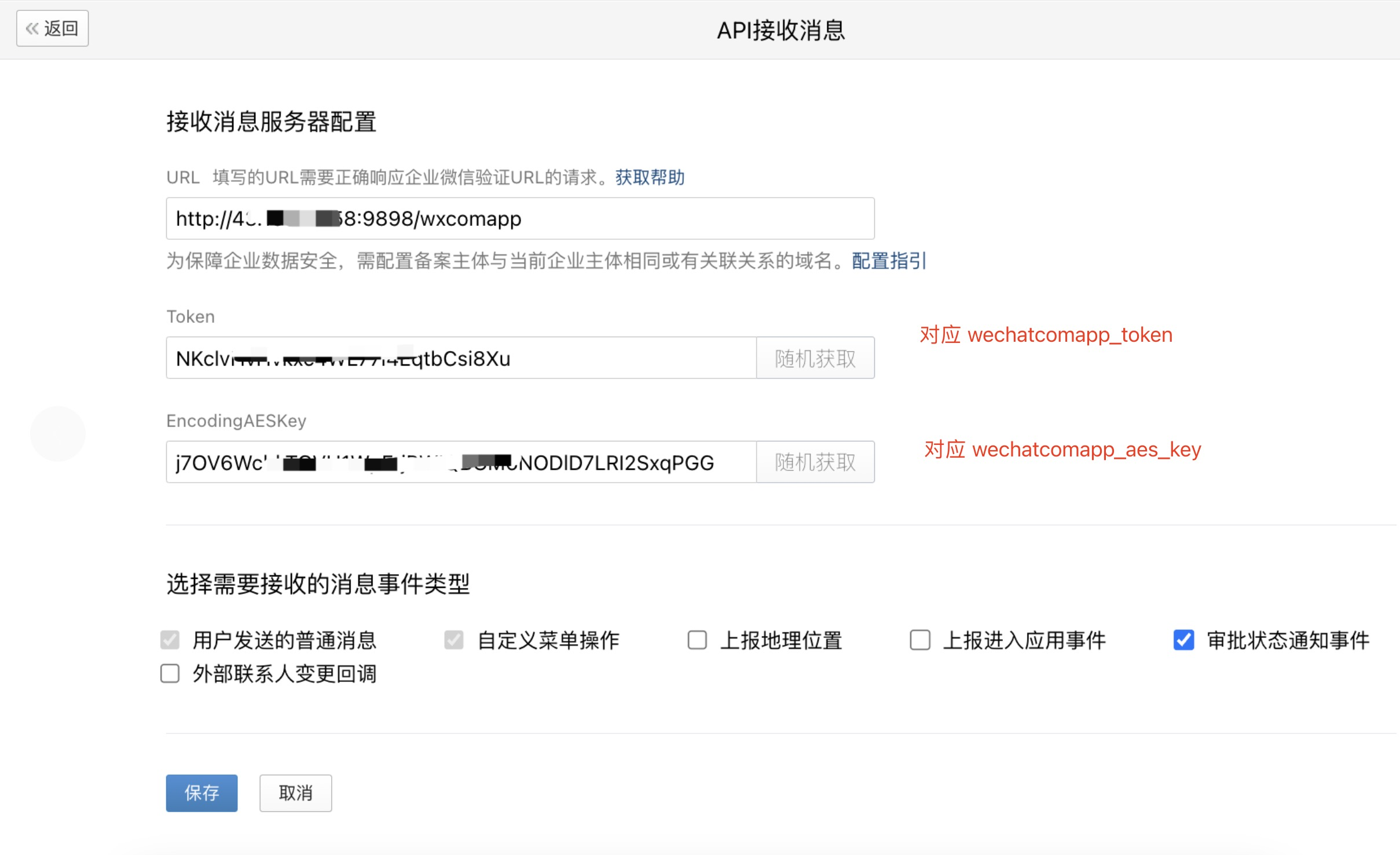 - URL 格式为 `http://ip:port/wxcomapp`(认证企业需使用备案域名)
- 随机获取 `Token` 和 `EncodingAESKey` 并保存
此时保存 API 接收配置会失败,因为程序还未启动,等项目运行后再回来保存。
## 三、配置和运行
在 `config.json` 中添加以下配置(各参数与企业微信后台的对应关系见上方截图):
```json
{
"channel_type": "wechatcom_app",
"single_chat_prefix": [""],
"wechatcom_corp_id": "YOUR_CORP_ID",
"wechatcomapp_token": "YOUR_TOKEN",
"wechatcomapp_secret": "YOUR_SECRET",
"wechatcomapp_agent_id": "YOUR_AGENT_ID",
"wechatcomapp_aes_key": "YOUR_AES_KEY",
"wechatcomapp_port": 9898
}
```
| 参数 | 说明 |
| --- | --- |
| `wechatcom_corp_id` | 企业 ID |
| `wechatcomapp_token` | API 接收配置中的 Token |
| `wechatcomapp_secret` | 应用的 Secret |
| `wechatcomapp_agent_id` | 应用的 AgentId |
| `wechatcomapp_aes_key` | API 接收配置中的 EncodingAESKey |
| `wechatcomapp_port` | 监听端口,默认 9898 |
配置完成后启动程序。当后台日志显示 `http://0.0.0.0:9898/` 时说明程序运行成功,需要将该端口对外开放(如在云服务器安全组中放行)。
程序启动后,回到企业微信后台保存 **消息服务器配置**,保存成功后还需将服务器 IP 添加到 **企业可信IP** 中,否则无法收发消息:
- URL 格式为 `http://ip:port/wxcomapp`(认证企业需使用备案域名)
- 随机获取 `Token` 和 `EncodingAESKey` 并保存
此时保存 API 接收配置会失败,因为程序还未启动,等项目运行后再回来保存。
## 三、配置和运行
在 `config.json` 中添加以下配置(各参数与企业微信后台的对应关系见上方截图):
```json
{
"channel_type": "wechatcom_app",
"single_chat_prefix": [""],
"wechatcom_corp_id": "YOUR_CORP_ID",
"wechatcomapp_token": "YOUR_TOKEN",
"wechatcomapp_secret": "YOUR_SECRET",
"wechatcomapp_agent_id": "YOUR_AGENT_ID",
"wechatcomapp_aes_key": "YOUR_AES_KEY",
"wechatcomapp_port": 9898
}
```
| 参数 | 说明 |
| --- | --- |
| `wechatcom_corp_id` | 企业 ID |
| `wechatcomapp_token` | API 接收配置中的 Token |
| `wechatcomapp_secret` | 应用的 Secret |
| `wechatcomapp_agent_id` | 应用的 AgentId |
| `wechatcomapp_aes_key` | API 接收配置中的 EncodingAESKey |
| `wechatcomapp_port` | 监听端口,默认 9898 |
配置完成后启动程序。当后台日志显示 `http://0.0.0.0:9898/` 时说明程序运行成功,需要将该端口对外开放(如在云服务器安全组中放行)。
程序启动后,回到企业微信后台保存 **消息服务器配置**,保存成功后还需将服务器 IP 添加到 **企业可信IP** 中,否则无法收发消息:
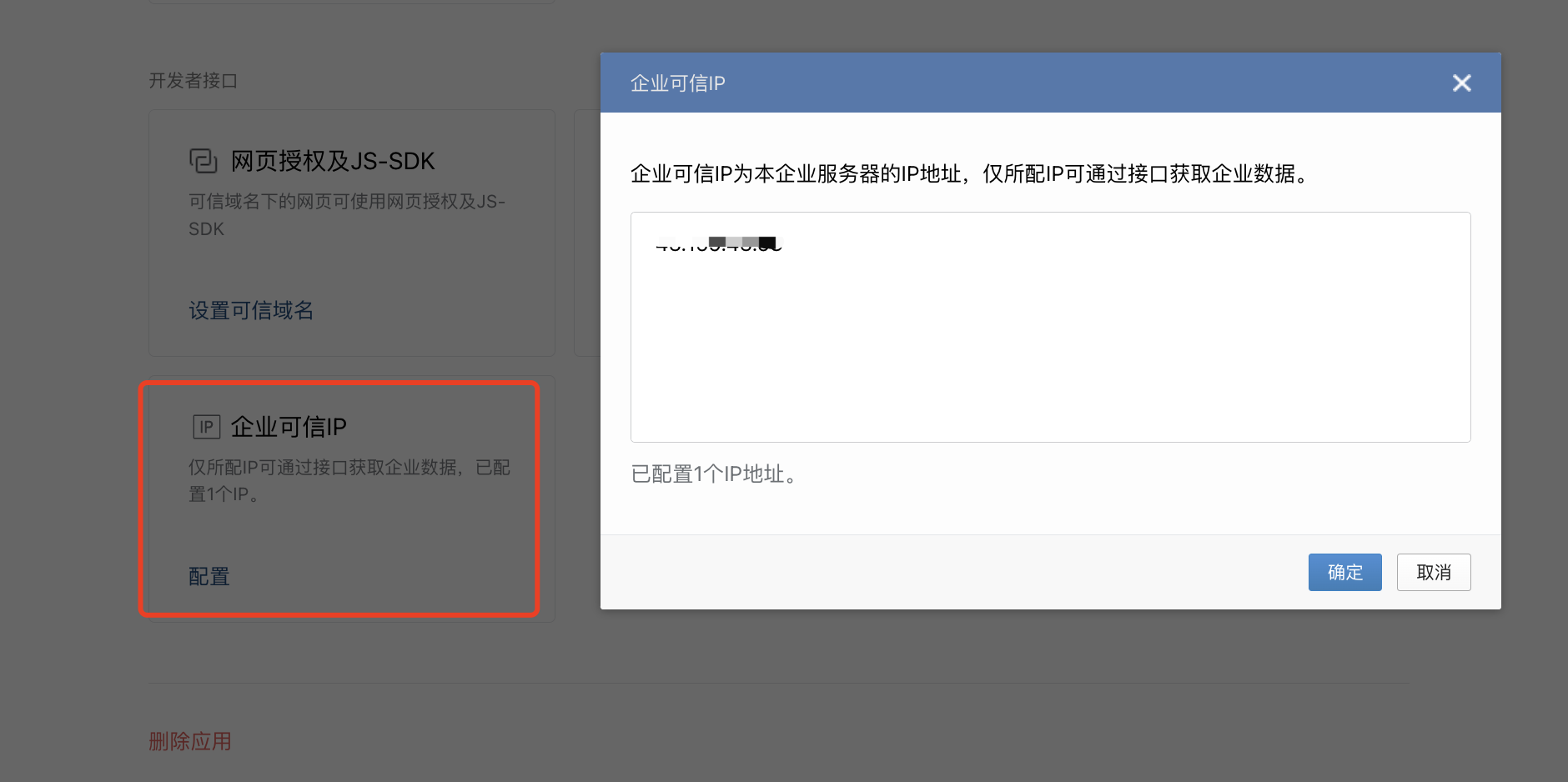 如遇到 URL 配置回调不通过或配置失败:
1. 确保服务器防火墙关闭且安全组放行监听端口
2. 仔细检查 Token、Secret Key 等参数配置是否一致,URL 格式是否正确
3. 认证企业微信需要配置与主体一致的备案域名
## 四、使用
在企业微信中搜索刚创建的应用名称,即可直接对话:
如遇到 URL 配置回调不通过或配置失败:
1. 确保服务器防火墙关闭且安全组放行监听端口
2. 仔细检查 Token、Secret Key 等参数配置是否一致,URL 格式是否正确
3. 认证企业微信需要配置与主体一致的备案域名
## 四、使用
在企业微信中搜索刚创建的应用名称,即可直接对话:
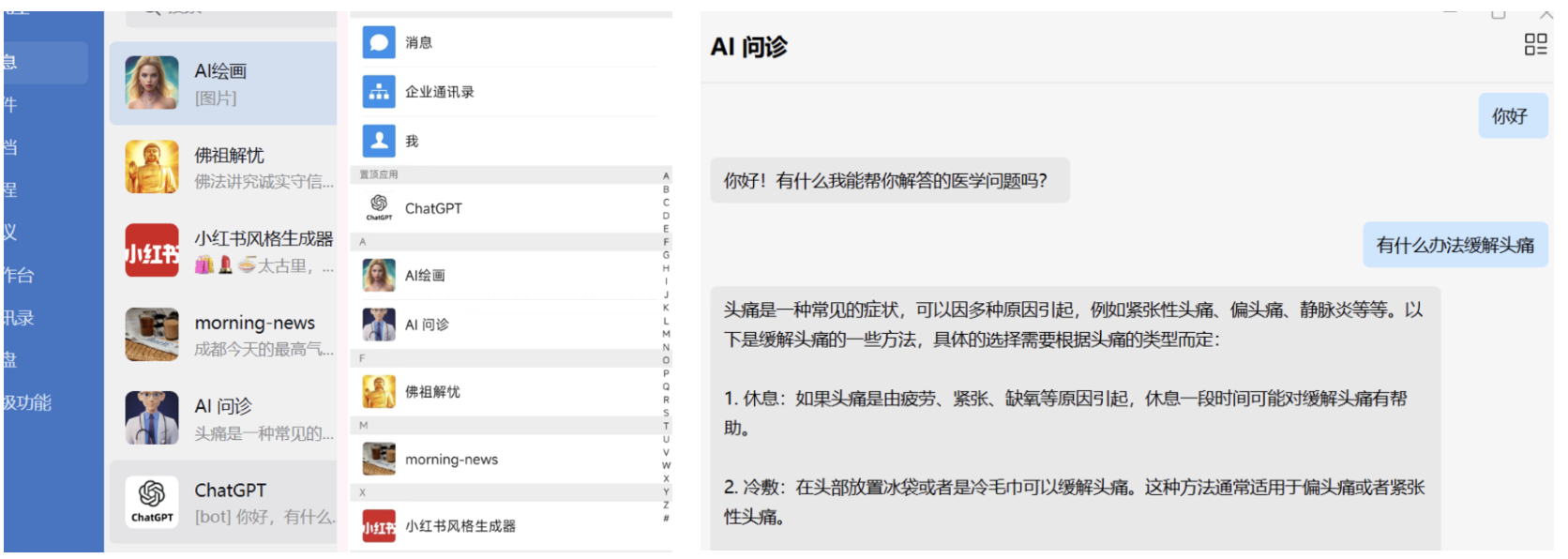 如需让外部个人微信用户使用,可在 **我的企业 → 微信插件** 中分享邀请关注二维码,个人微信扫码关注后即可与应用对话:
如需让外部个人微信用户使用,可在 **我的企业 → 微信插件** 中分享邀请关注二维码,个人微信扫码关注后即可与应用对话:
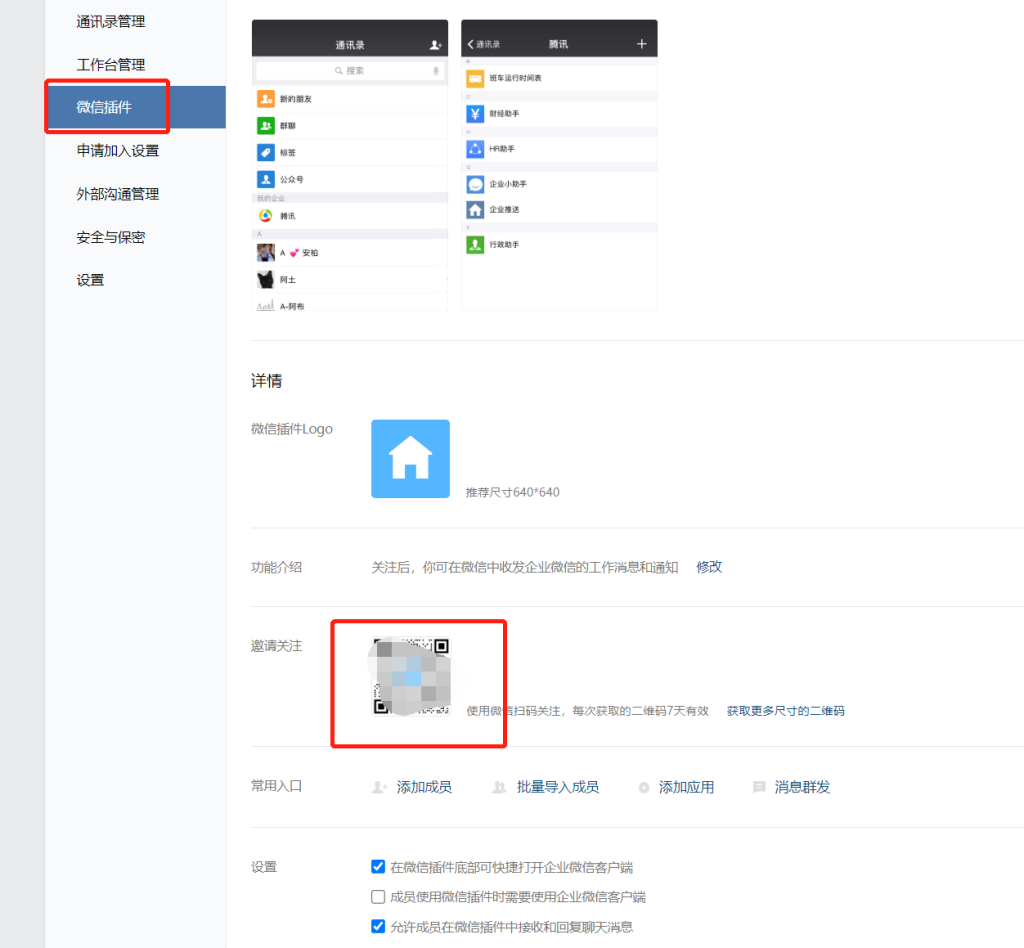 ## 常见问题
需要确保已安装以下依赖:
```bash
pip install websocket-client pycryptodome
```
================================================
FILE: docs/docs.json
================================================
{
"$schema": "https://mintlify.com/docs.json",
"name": "CowAgent",
"description": "CowAgent - AI Super Assistant powered by LLMs, with autonomous task planning, long-term memory, skills system, and multi-channel deployment.",
"theme": "mint",
"appearance": {
"default": "light"
},
"colors": {
"primary": "#35A85B",
"light": "#4ABE6E",
"dark": "#228547"
},
"logo": {
"light": "/images/logo.jpg",
"dark": "/images/logo.jpg"
},
"favicon": "/images/favicon.ico",
"navbar": {
"links": [
{
"label": "官网",
"href": "https://cowagent.ai/"
},
{
"label": "GitHub",
"href": "https://github.com/zhayujie/chatgpt-on-wechat"
}
]
},
"footer": {
"socials": {
"github": "https://github.com/zhayujie/chatgpt-on-wechat"
}
},
"navigation": {
"languages": [
{
"language": "zh",
"default": true,
"tabs": [
{
"tab": "项目介绍",
"groups": [
{
"group": "概览",
"pages": [
"intro/index",
"intro/architecture",
"intro/features"
]
}
]
},
{
"tab": "快速开始",
"groups": [
{
"group": "安装部署",
"pages": [
"guide/quick-start",
"guide/manual-install",
"guide/upgrade"
]
}
]
},
{
"tab": "模型",
"groups": [
{
"group": "模型配置",
"pages": [
"models/index",
"models/minimax",
"models/glm",
"models/qwen",
"models/kimi",
"models/doubao",
"models/claude",
"models/gemini",
"models/openai",
"models/deepseek",
"models/linkai",
"models/coding-plan"
]
}
]
},
{
"tab": "工具",
"groups": [
{
"group": "工具系统",
"pages": [
"tools/index"
]
},
{
"group": "内置工具",
"pages": [
"tools/read",
"tools/write",
"tools/edit",
"tools/ls",
"tools/bash",
"tools/send",
"tools/memory",
"tools/env-config"
]
},
{
"group": "可选工具",
"pages": [
"tools/web-search",
"tools/scheduler"
]
}
]
},
{
"tab": "技能",
"groups": [
{
"group": "技能系统",
"pages": [
"skills/index",
"skills/skill-creator"
]
},
{
"group": "内置技能",
"pages": [
"skills/image-vision",
"skills/linkai-agent",
"skills/web-fetch"
]
}
]
},
{
"tab": "记忆",
"groups": [
{
"group": "记忆系统",
"pages": [
"memory"
]
}
]
},
{
"tab": "通道",
"groups": [
{
"group": "接入渠道",
"pages": [
"channels/web",
"channels/feishu",
"channels/dingtalk",
"channels/wecom-bot",
"channels/qq",
"channels/wecom",
"channels/wechatmp"
]
}
]
},
{
"tab": "版本",
"groups": [
{
"group": "发布记录",
"pages": [
"releases/overview",
"releases/v2.0.3",
"releases/v2.0.2",
"releases/v2.0.1",
"releases/v2.0.0"
]
}
]
}
]
},
{
"language": "en",
"tabs": [
{
"tab": "Introduction",
"groups": [
{
"group": "Overview",
"pages": [
"en/intro/index",
"en/intro/architecture",
"en/intro/features"
]
}
]
},
{
"tab": "Get Started",
"groups": [
{
"group": "Installation",
"pages": [
"en/guide/quick-start",
"en/guide/manual-install"
]
}
]
},
{
"tab": "Models",
"groups": [
{
"group": "Model Configuration",
"pages": [
"en/models/index",
"en/models/minimax",
"en/models/glm",
"en/models/qwen",
"en/models/kimi",
"en/models/doubao",
"en/models/claude",
"en/models/gemini",
"en/models/openai",
"en/models/deepseek",
"en/models/linkai",
"en/models/coding-plan"
]
}
]
},
{
"tab": "Tools",
"groups": [
{
"group": "Tools System",
"pages": [
"en/tools/index"
]
},
{
"group": "Built-in Tools",
"pages": [
"en/tools/read",
"en/tools/write",
"en/tools/edit",
"en/tools/ls",
"en/tools/bash",
"en/tools/send",
"en/tools/memory",
"en/tools/env-config"
]
},
{
"group": "Optional Tools",
"pages": [
"en/tools/web-search",
"en/tools/scheduler"
]
}
]
},
{
"tab": "Skills",
"groups": [
{
"group": "Skills System",
"pages": [
"en/skills/index",
"en/skills/skill-creator"
]
},
{
"group": "Built-in Skills",
"pages": [
"en/skills/image-vision",
"en/skills/linkai-agent",
"en/skills/web-fetch"
]
}
]
},
{
"tab": "Memory",
"groups": [
{
"group": "Memory System",
"pages": [
"en/memory"
]
}
]
},
{
"tab": "Channels",
"groups": [
{
"group": "Platforms",
"pages": [
"en/channels/web",
"en/channels/feishu",
"en/channels/dingtalk",
"en/channels/wecom-bot",
"en/channels/qq",
"en/channels/wecom",
"en/channels/wechatmp"
]
}
]
},
{
"tab": "Releases",
"groups": [
{
"group": "Release Notes",
"pages": [
"en/releases/overview",
"en/releases/v2.0.2",
"en/releases/v2.0.1",
"en/releases/v2.0.0"
]
}
]
}
]
},
{
"language": "ja",
"tabs": [
{
"tab": "紹介",
"groups": [
{
"group": "概要",
"pages": [
"ja/intro/index",
"ja/intro/architecture",
"ja/intro/features"
]
}
]
},
{
"tab": "クイックスタート",
"groups": [
{
"group": "インストール",
"pages": [
"ja/guide/quick-start",
"ja/guide/manual-install",
"ja/guide/upgrade"
]
}
]
},
{
"tab": "モデル",
"groups": [
{
"group": "モデル設定",
"pages": [
"ja/models/index",
"ja/models/minimax",
"ja/models/glm",
"ja/models/qwen",
"ja/models/kimi",
"ja/models/doubao",
"ja/models/claude",
"ja/models/gemini",
"ja/models/openai",
"ja/models/deepseek",
"ja/models/linkai",
"ja/models/coding-plan"
]
}
]
},
{
"tab": "ツール",
"groups": [
{
"group": "ツールシステム",
"pages": [
"ja/tools/index"
]
},
{
"group": "内蔵ツール",
"pages": [
"ja/tools/read",
"ja/tools/write",
"ja/tools/edit",
"ja/tools/ls",
"ja/tools/bash",
"ja/tools/send",
"ja/tools/memory",
"ja/tools/env-config",
"ja/tools/browser"
]
},
{
"group": "オプションツール",
"pages": [
"ja/tools/web-search",
"ja/tools/scheduler"
]
}
]
},
{
"tab": "スキル",
"groups": [
{
"group": "スキルシステム",
"pages": [
"ja/skills/index",
"ja/skills/skill-creator"
]
},
{
"group": "内蔵スキル",
"pages": [
"ja/skills/image-vision",
"ja/skills/linkai-agent",
"ja/skills/web-fetch"
]
}
]
},
{
"tab": "メモリ",
"groups": [
{
"group": "メモリシステム",
"pages": [
"ja/memory"
]
}
]
},
{
"tab": "チャネル",
"groups": [
{
"group": "プラットフォーム",
"pages": [
"ja/channels/web",
"ja/channels/feishu",
"ja/channels/dingtalk",
"ja/channels/wecom-bot",
"ja/channels/qq",
"ja/channels/wecom",
"ja/channels/wechatmp"
]
}
]
},
{
"tab": "リリース",
"groups": [
{
"group": "リリースノート",
"pages": [
"ja/releases/overview",
"ja/releases/v2.0.3",
"ja/releases/v2.0.2",
"ja/releases/v2.0.1",
"ja/releases/v2.0.0"
]
}
]
}
]
}
]
}
}
================================================
FILE: docs/en/README.md
================================================
## 常见问题
需要确保已安装以下依赖:
```bash
pip install websocket-client pycryptodome
```
================================================
FILE: docs/docs.json
================================================
{
"$schema": "https://mintlify.com/docs.json",
"name": "CowAgent",
"description": "CowAgent - AI Super Assistant powered by LLMs, with autonomous task planning, long-term memory, skills system, and multi-channel deployment.",
"theme": "mint",
"appearance": {
"default": "light"
},
"colors": {
"primary": "#35A85B",
"light": "#4ABE6E",
"dark": "#228547"
},
"logo": {
"light": "/images/logo.jpg",
"dark": "/images/logo.jpg"
},
"favicon": "/images/favicon.ico",
"navbar": {
"links": [
{
"label": "官网",
"href": "https://cowagent.ai/"
},
{
"label": "GitHub",
"href": "https://github.com/zhayujie/chatgpt-on-wechat"
}
]
},
"footer": {
"socials": {
"github": "https://github.com/zhayujie/chatgpt-on-wechat"
}
},
"navigation": {
"languages": [
{
"language": "zh",
"default": true,
"tabs": [
{
"tab": "项目介绍",
"groups": [
{
"group": "概览",
"pages": [
"intro/index",
"intro/architecture",
"intro/features"
]
}
]
},
{
"tab": "快速开始",
"groups": [
{
"group": "安装部署",
"pages": [
"guide/quick-start",
"guide/manual-install",
"guide/upgrade"
]
}
]
},
{
"tab": "模型",
"groups": [
{
"group": "模型配置",
"pages": [
"models/index",
"models/minimax",
"models/glm",
"models/qwen",
"models/kimi",
"models/doubao",
"models/claude",
"models/gemini",
"models/openai",
"models/deepseek",
"models/linkai",
"models/coding-plan"
]
}
]
},
{
"tab": "工具",
"groups": [
{
"group": "工具系统",
"pages": [
"tools/index"
]
},
{
"group": "内置工具",
"pages": [
"tools/read",
"tools/write",
"tools/edit",
"tools/ls",
"tools/bash",
"tools/send",
"tools/memory",
"tools/env-config"
]
},
{
"group": "可选工具",
"pages": [
"tools/web-search",
"tools/scheduler"
]
}
]
},
{
"tab": "技能",
"groups": [
{
"group": "技能系统",
"pages": [
"skills/index",
"skills/skill-creator"
]
},
{
"group": "内置技能",
"pages": [
"skills/image-vision",
"skills/linkai-agent",
"skills/web-fetch"
]
}
]
},
{
"tab": "记忆",
"groups": [
{
"group": "记忆系统",
"pages": [
"memory"
]
}
]
},
{
"tab": "通道",
"groups": [
{
"group": "接入渠道",
"pages": [
"channels/web",
"channels/feishu",
"channels/dingtalk",
"channels/wecom-bot",
"channels/qq",
"channels/wecom",
"channels/wechatmp"
]
}
]
},
{
"tab": "版本",
"groups": [
{
"group": "发布记录",
"pages": [
"releases/overview",
"releases/v2.0.3",
"releases/v2.0.2",
"releases/v2.0.1",
"releases/v2.0.0"
]
}
]
}
]
},
{
"language": "en",
"tabs": [
{
"tab": "Introduction",
"groups": [
{
"group": "Overview",
"pages": [
"en/intro/index",
"en/intro/architecture",
"en/intro/features"
]
}
]
},
{
"tab": "Get Started",
"groups": [
{
"group": "Installation",
"pages": [
"en/guide/quick-start",
"en/guide/manual-install"
]
}
]
},
{
"tab": "Models",
"groups": [
{
"group": "Model Configuration",
"pages": [
"en/models/index",
"en/models/minimax",
"en/models/glm",
"en/models/qwen",
"en/models/kimi",
"en/models/doubao",
"en/models/claude",
"en/models/gemini",
"en/models/openai",
"en/models/deepseek",
"en/models/linkai",
"en/models/coding-plan"
]
}
]
},
{
"tab": "Tools",
"groups": [
{
"group": "Tools System",
"pages": [
"en/tools/index"
]
},
{
"group": "Built-in Tools",
"pages": [
"en/tools/read",
"en/tools/write",
"en/tools/edit",
"en/tools/ls",
"en/tools/bash",
"en/tools/send",
"en/tools/memory",
"en/tools/env-config"
]
},
{
"group": "Optional Tools",
"pages": [
"en/tools/web-search",
"en/tools/scheduler"
]
}
]
},
{
"tab": "Skills",
"groups": [
{
"group": "Skills System",
"pages": [
"en/skills/index",
"en/skills/skill-creator"
]
},
{
"group": "Built-in Skills",
"pages": [
"en/skills/image-vision",
"en/skills/linkai-agent",
"en/skills/web-fetch"
]
}
]
},
{
"tab": "Memory",
"groups": [
{
"group": "Memory System",
"pages": [
"en/memory"
]
}
]
},
{
"tab": "Channels",
"groups": [
{
"group": "Platforms",
"pages": [
"en/channels/web",
"en/channels/feishu",
"en/channels/dingtalk",
"en/channels/wecom-bot",
"en/channels/qq",
"en/channels/wecom",
"en/channels/wechatmp"
]
}
]
},
{
"tab": "Releases",
"groups": [
{
"group": "Release Notes",
"pages": [
"en/releases/overview",
"en/releases/v2.0.2",
"en/releases/v2.0.1",
"en/releases/v2.0.0"
]
}
]
}
]
},
{
"language": "ja",
"tabs": [
{
"tab": "紹介",
"groups": [
{
"group": "概要",
"pages": [
"ja/intro/index",
"ja/intro/architecture",
"ja/intro/features"
]
}
]
},
{
"tab": "クイックスタート",
"groups": [
{
"group": "インストール",
"pages": [
"ja/guide/quick-start",
"ja/guide/manual-install",
"ja/guide/upgrade"
]
}
]
},
{
"tab": "モデル",
"groups": [
{
"group": "モデル設定",
"pages": [
"ja/models/index",
"ja/models/minimax",
"ja/models/glm",
"ja/models/qwen",
"ja/models/kimi",
"ja/models/doubao",
"ja/models/claude",
"ja/models/gemini",
"ja/models/openai",
"ja/models/deepseek",
"ja/models/linkai",
"ja/models/coding-plan"
]
}
]
},
{
"tab": "ツール",
"groups": [
{
"group": "ツールシステム",
"pages": [
"ja/tools/index"
]
},
{
"group": "内蔵ツール",
"pages": [
"ja/tools/read",
"ja/tools/write",
"ja/tools/edit",
"ja/tools/ls",
"ja/tools/bash",
"ja/tools/send",
"ja/tools/memory",
"ja/tools/env-config",
"ja/tools/browser"
]
},
{
"group": "オプションツール",
"pages": [
"ja/tools/web-search",
"ja/tools/scheduler"
]
}
]
},
{
"tab": "スキル",
"groups": [
{
"group": "スキルシステム",
"pages": [
"ja/skills/index",
"ja/skills/skill-creator"
]
},
{
"group": "内蔵スキル",
"pages": [
"ja/skills/image-vision",
"ja/skills/linkai-agent",
"ja/skills/web-fetch"
]
}
]
},
{
"tab": "メモリ",
"groups": [
{
"group": "メモリシステム",
"pages": [
"ja/memory"
]
}
]
},
{
"tab": "チャネル",
"groups": [
{
"group": "プラットフォーム",
"pages": [
"ja/channels/web",
"ja/channels/feishu",
"ja/channels/dingtalk",
"ja/channels/wecom-bot",
"ja/channels/qq",
"ja/channels/wecom",
"ja/channels/wechatmp"
]
}
]
},
{
"tab": "リリース",
"groups": [
{
"group": "リリースノート",
"pages": [
"ja/releases/overview",
"ja/releases/v2.0.3",
"ja/releases/v2.0.2",
"ja/releases/v2.0.1",
"ja/releases/v2.0.0"
]
}
]
}
]
}
]
}
}
================================================
FILE: docs/en/README.md
================================================




[中文] | [English] | [日本語]
**CowAgent** is an AI super assistant powered by LLMs, capable of autonomous task planning, operating computers and external resources, creating and executing Skills, and continuously growing with long-term memory. It supports flexible model switching, handles text, voice, images, and files, and can be integrated into Web, Feishu, DingTalk, WeCom Bot, WeCom App, and WeChat Official Account — running 7×24 hours on your personal computer or server.
🌐 Website ·
📖 Docs ·
🚀 Quick Start ·
☁️ Try Online
## Introduction
> CowAgent is both an out-of-the-box AI super assistant and a highly extensible Agent framework. You can extend it with new model interfaces, channels, built-in tools, and the Skills system to flexibly implement various customization needs.
- ✅ **Autonomous Task Planning**: Understands complex tasks and autonomously plans execution, continuously thinking and invoking tools until goals are achieved. Supports accessing files, terminal, browser, schedulers, and other system resources via tools.
- ✅ **Long-term Memory**: Automatically persists conversation memory to local files and databases, including core memory and daily memory, with keyword and vector retrieval support.
- ✅ **Skills System**: Implements a Skills creation and execution engine with multiple built-in skills, and supports custom Skills development through natural language conversation.
- ✅ **Multimodal Messages**: Supports parsing, processing, generating, and sending text, images, voice, files, and other message types.
- ✅ **Multiple Model Support**: Supports OpenAI, Claude, Gemini, DeepSeek, MiniMax, GLM, Qwen, Kimi, Doubao, and other mainstream model providers.
- ✅ **Multi-platform Deployment**: Runs on local computers or servers, integrable into Web, Feishu, DingTalk, WeChat Official Account, and WeCom applications.
- ✅ **Knowledge Base**: Integrates enterprise knowledge base capabilities via the [LinkAI](https://link-ai.tech) platform.
## Disclaimer
1. This project follows the [MIT License](/LICENSE) and is intended for technical research and learning. Users must comply with local laws, regulations, policies, and corporate bylaws. Any illegal or rights-infringing use is prohibited.
2. Agent mode consumes more tokens than normal chat mode. Choose models based on effectiveness and cost. Agent has access to the host OS — please deploy in trusted environments.
3. CowAgent focuses on open-source development and does not participate in, authorize, or issue any cryptocurrency.
## Demo
Try online (no deployment needed): [CowAgent](https://link-ai.tech/cowagent/create)
## Changelog
> **2026.02.27:** [v2.0.2](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.2) — Web console overhaul (streaming chat, model/skill/memory/channel/scheduler/log management), multi-channel concurrent running, session persistence, new models including Gemini 3.1 Pro / Claude 4.6 Sonnet / Qwen3.5 Plus.
> **2026.02.13:** [v2.0.1](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.1) — Built-in Web Search tool, smart context trimming, runtime info dynamic update, Windows compatibility, fixes for scheduler memory loss, Feishu connection issues, and more.
> **2026.02.03:** [v2.0.0](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.0) — Full upgrade to AI super assistant with multi-step task planning, long-term memory, built-in tools, Skills framework, new models, and optimized channels.
> **2025.05.23:** [v1.7.6](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/1.7.6) — Web channel optimization, AgentMesh multi-agent plugin, Baidu TTS, claude-4-sonnet/opus support.
> **2025.04.11:** [v1.7.5](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/1.7.5) — wechatferry protocol, DeepSeek model, Tencent Cloud voice, ModelScope and Gitee-AI support.
> **2024.12.13:** [v1.7.4](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/1.7.4) — Gemini 2.0 model, Web channel, memory leak fix.
Full changelog: [Release Notes](https://docs.cowagent.ai/en/releases/overview)
## 🚀 Quick Start
The project provides a one-click script for installation, configuration, startup, and management:
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
After running, the Web service starts by default. Access `http://localhost:9899/chat` to chat.
Script usage: [One-click Install](https://docs.cowagent.ai/en/guide/quick-start)
### Manual Installation
**1. Clone the project**
```bash
git clone https://github.com/zhayujie/chatgpt-on-wechat
cd chatgpt-on-wechat/
```
**2. Install dependencies**
```bash
pip3 install -r requirements.txt
pip3 install -r requirements-optional.txt # optional but recommended
```
**3. Configure**
```bash
cp config-template.json config.json
```
Fill in your model API key and channel type in `config.json`. See the [configuration docs](https://docs.cowagent.ai/en/guide/manual-install) for details.
**4. Run**
```bash
python3 app.py
```
For server background run:
```bash
nohup python3 app.py & tail -f nohup.out
```
### Docker Deployment
```bash
curl -O https://cdn.link-ai.tech/code/cow/docker-compose.yml
# Edit docker-compose.yml with your config
sudo docker compose up -d
sudo docker logs -f chatgpt-on-wechat
```
## Models
Supports mainstream model providers. Recommended models for Agent mode:
| Provider | Recommended Model |
| --- | --- |
| MiniMax | `MiniMax-M2.7` |
| GLM | `glm-5-turbo` |
| Kimi | `kimi-k2.5` |
| Doubao | `doubao-seed-2-0-code-preview-260215` |
| Qwen | `qwen3.5-plus` |
| Claude | `claude-sonnet-4-6` |
| Gemini | `gemini-3.1-pro-preview` |
| OpenAI | `gpt-5.4` |
| DeepSeek | `deepseek-chat` |
For detailed configuration of each model, see the [Models documentation](https://docs.cowagent.ai/en/models/index).
### Coding Plan
Coding Plan is a monthly subscription package offered by various providers, ideal for high-frequency Agent usage. All providers can be accessed via OpenAI-compatible mode:
```json
{
"bot_type": "openai",
"model": "MODEL_NAME",
"open_ai_api_base": "PROVIDER_CODING_PLAN_API_BASE",
"open_ai_api_key": "YOUR_API_KEY"
}
```
- `bot_type`: Must be `openai`
- `model`: Model name supported by the provider
- `open_ai_api_base`: Provider's Coding Plan API Base (different from standard pay-as-you-go)
- `open_ai_api_key`: Provider's Coding Plan API Key
> Note: Coding Plan API Base and API Key are usually separate from standard pay-as-you-go ones. Please obtain them from each provider's platform.
Supported providers include Alibaba Cloud, MiniMax, Zhipu GLM, Kimi, Volcengine, and more. For detailed configuration of each provider, see the [Coding Plan documentation](https://docs.cowagent.ai/en/models/coding-plan).
## Channels
Supports multiple platforms. Set `channel_type` in `config.json` to switch:
| Channel | `channel_type` | Docs |
| --- | --- | --- |
| Web (default) | `web` | [Web Channel](https://docs.cowagent.ai/en/channels/web) |
| Feishu | `feishu` | [Feishu Setup](https://docs.cowagent.ai/en/channels/feishu) |
| DingTalk | `dingtalk` | [DingTalk Setup](https://docs.cowagent.ai/en/channels/dingtalk) |
| WeCom Bot | `wecom_bot` | [WeCom Bot Setup](https://docs.cowagent.ai/en/channels/wecom-bot) |
| WeCom App | `wechatcom_app` | [WeCom Setup](https://docs.cowagent.ai/en/channels/wecom) |
| WeChat MP | `wechatmp` / `wechatmp_service` | [WeChat MP Setup](https://docs.cowagent.ai/en/channels/wechatmp) |
| Terminal | `terminal` | — |
Multiple channels can be enabled simultaneously, separated by commas: `"channel_type": "feishu,dingtalk"`.
## Enterprise Services
 > [LinkAI](https://link-ai.tech/) is a one-stop AI agent platform for enterprises and developers, integrating multimodal LLMs, knowledge bases, Agent plugins, and workflows. Supports one-click integration with mainstream platforms, SaaS and private deployment.
> [LinkAI](https://link-ai.tech/) is a one-stop AI agent platform for enterprises and developers, integrating multimodal LLMs, knowledge bases, Agent plugins, and workflows. Supports one-click integration with mainstream platforms, SaaS and private deployment.
## 🔗 Related Projects
- [bot-on-anything](https://github.com/zhayujie/bot-on-anything): Lightweight and highly extensible LLM application framework supporting Slack, Telegram, Discord, Gmail, and more.
- [AgentMesh](https://github.com/MinimalFuture/AgentMesh): Open-source Multi-Agent framework for complex problem solving through agent team collaboration.
## 🔎 FAQ
FAQs:
## 🛠️ Contributing
Welcome to add new channels, referring to the [Feishu channel](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/channel/feishu/feishu_channel.py) as an example. Also welcome to contribute new Skills, referring to the [Skill Creator docs](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/skills/skill-creator/SKILL.md).
## ✉ Contact
Welcome to submit PRs and Issues, and support the project with a 🌟 Star. For questions, check the [FAQ list](https://github.com/zhayujie/chatgpt-on-wechat/wiki/FAQs) or search [Issues](https://github.com/zhayujie/chatgpt-on-wechat/issues).
## 🌟 Contributors

================================================
FILE: docs/en/channels/dingtalk.mdx
================================================
---
title: DingTalk
description: Integrate CowAgent into DingTalk application
---
Integrate CowAgent into DingTalk by creating an intelligent robot app on the DingTalk Open Platform.
## 1. Create App
1. Go to [DingTalk Developer Console](https://open-dev.dingtalk.com/fe/app#/corp/app), log in and click **Create App**, fill in the app information:
2. Click **Add App Capability**, select **Robot** capability and click **Add**:
3. Configure the robot information and click **Publish**. After publishing, click "**Debug**" to automatically create a test group chat, which can be viewed in the client:
4. Click **Version Management & Release**, create a new version and publish:
## 2. Project Configuration
1. Click **Credentials & Basic Info**, get the `Client ID` and `Client Secret`:
2. Add the following configuration to `config.json` in the project root:
```json
{
"channel_type": "dingtalk",
"dingtalk_client_id": "YOUR_CLIENT_ID",
"dingtalk_client_secret": "YOUR_CLIENT_SECRET"
}
```
3. Install the dependency:
```bash
pip3 install dingtalk_stream
```
 4. After starting the project, go to the DingTalk Developer Console, click **Event Subscription**, then click **Connection verified, verify channel**. When "**Connection successful**" is displayed, the configuration is complete:
## 3. Usage
Chat privately with the robot or add it to an enterprise group to start a conversation:
================================================
FILE: docs/en/channels/feishu.mdx
================================================
---
title: Feishu (Lark)
description: Integrate CowAgent into Feishu application
---
Integrate CowAgent into Feishu by creating a custom enterprise app. You need to be a Feishu enterprise user with admin privileges.
## 1. Create Enterprise Custom App
### 1.1 Create App
Go to [Feishu Developer Platform](https://open.feishu.cn/app/), click **Create Enterprise Custom App**, fill in the required information and click **Create**:
### 1.2 Add Bot Capability
In **Add App Capabilities**, add **Bot** capability to the app:
### 1.3 Configure App Permissions
Click **Permission Management**, paste the following permission string into the input box below **Permission Configuration**, select all filtered permissions, click **Batch Enable** and confirm:
```
im:message,im:message.group_at_msg,im:message.group_at_msg:readonly,im:message.p2p_msg,im:message.p2p_msg:readonly,im:message:send_as_bot,im:resource
```
## 2. Project Configuration
1. Get `App ID` and `App Secret` from **Credentials & Basic Info**:
2. Add the following configuration to `config.json` in the project root:
```json
{
"channel_type": "feishu",
"feishu_app_id": "YOUR_APP_ID",
"feishu_app_secret": "YOUR_APP_SECRET",
"feishu_bot_name": "YOUR_BOT_NAME"
}
```
| Parameter | Description |
| --- | --- |
| `feishu_app_id` | Feishu bot App ID |
| `feishu_app_secret` | Feishu bot App Secret |
| `feishu_bot_name` | Bot name (set when creating the app), required for group chat usage |
Start the project after configuration is complete.
## 3. Configure Event Subscription
1. After the project is running successfully, go to the Feishu Developer Platform, click **Events & Callbacks**, select **Long Connection** mode, and click save:
2. Click **Add Event** below, search for "Receive Message", select "**Receive Message v2.0**", and confirm.
3. Click **Version Management & Release**, create a new version and apply for **Production Release**. Check the approval message in the Feishu client and approve:
Once completed, search for the bot name in Feishu to start chatting.
================================================
FILE: docs/en/channels/qq.mdx
================================================
---
title: QQ Bot
description: Connect CowAgent to QQ Bot (WebSocket long connection)
---
> Connect CowAgent via QQ Open Platform's bot API, supporting QQ direct messages, group chats (@bot), guild channel messages, and guild DMs. No public IP required — uses WebSocket long connection.
QQ Bot is created through the QQ Open Platform. It uses WebSocket long connection to receive messages and OpenAPI to send messages. No public IP or domain is required.
## 1. Create a QQ Bot
> Visit the [QQ Open Platform](https://q.qq.com), sign in with QQ. If you haven't registered, please complete [account registration](https://q.qq.com/#/register) first.
1.Go to the [QQ Open Platform - Bot List](https://q.qq.com/#/apps), and click **Create Bot**:
2.Fill in the bot name, avatar, and other basic information to complete the creation:
3.Enter the bot configuration page, go to **Development Management**, and complete the following steps:
- Copy and save the **AppID** (Bot ID)
- Generate and save the **AppSecret** (Bot Secret)
## 2. Configuration and Running
### Option A: Web Console
Start the program and open the Web console (local access: http://127.0.0.1:9899/). Go to the **Channels** tab, click **Connect Channel**, select **QQ Bot**, fill in the AppID and AppSecret from the previous step, and click Connect.
### Option B: Config File
Add the following to your `config.json`:
```json
{
"channel_type": "qq",
"qq_app_id": "YOUR_APP_ID",
"qq_app_secret": "YOUR_APP_SECRET"
}
```
| Parameter | Description |
| --- | --- |
| `qq_app_id` | AppID of the QQ Bot, found in Development Management on the open platform |
| `qq_app_secret` | AppSecret of the QQ Bot, found in Development Management on the open platform |
After configuration, start the program. The log message `[QQ] ✅ Connected successfully` indicates a successful connection.
## 3. Usage
In the QQ Open Platform, go to **Management → Usage Scope & Members**, scan the "Add to group and message list" QR code with your QQ client to start chatting with the bot:
Chat example:
## 4. Supported Features
> Note: To use the QQ bot in group chats and guild channels, you need to complete the publishing review and configure usage scope permissions.
| Feature | Status |
| --- | --- |
| QQ Direct Messages | ✅ |
| QQ Group Chat (@bot) | ✅ |
| Guild Channel (@bot) | ✅ |
| Guild DM | ✅ |
| Text Messages | ✅ Send & Receive |
| Image Messages | ✅ Send & Receive (group & direct) |
| File Messages | ✅ Send (group & direct) |
| Scheduled Tasks | ✅ Active push (4 per user per month) |
## 5. Notes
- **Passive message limits**: QQ direct message replies are valid for 60 minutes (max 5 replies per message); group chat replies are valid for 5 minutes.
- **Active message limits**: Both direct and group chats have a monthly limit of 4 active messages. Keep this in mind when using the scheduled tasks feature.
- **Event permissions**: By default, `GROUP_AND_C2C_EVENT` (QQ group/direct) and `PUBLIC_GUILD_MESSAGES` (guild public messages) are subscribed. Apply for additional permissions on the open platform if needed.
================================================
FILE: docs/en/channels/web.mdx
================================================
---
title: Web Console
description: Use CowAgent through the web console
---
The Web Console is CowAgent's default channel. It starts automatically after launch, allowing you to chat with the Agent through a browser and manage models, skills, memory, channels, and other configurations online.
## Configuration
```json
{
"channel_type": "web",
"web_port": 9899
}
```
| Parameter | Description | Default |
| --- | --- | --- |
| `channel_type` | Set to `web` | `web` |
| `web_port` | Web service listen port | `9899` |
## Access URL
After starting the project, visit:
- Local: `http://localhost:9899`
- Server: `http://:9899`
Ensure the server firewall and security group allow the corresponding port.
## Features
### Chat Interface
Supports streaming output with real-time display of the Agent's reasoning process and tool calls, providing intuitive observation of the Agent's decision-making:
### Model Management
Manage model configurations online without manually editing config files:
### Skill Management
View and manage Agent skills (Skills) online:
### Memory Management
View and manage Agent memory online:
### Channel Management
Manage connected channels online with real-time connect/disconnect operations:
### Scheduled Tasks
View and manage scheduled tasks online, including one-time tasks, fixed intervals, and Cron expressions:
### Logs
View Agent runtime logs in real-time for monitoring and troubleshooting:
================================================
FILE: docs/en/channels/wechatmp.mdx
================================================
---
title: WeChat Official Account
description: Integrate CowAgent with WeChat Official Accounts
---
CowAgent supports both personal subscription accounts and enterprise service accounts.
| Type | Requirements | Features |
| --- | --- | --- |
| **Personal Subscription** | Available to individuals | Sends a placeholder reply first; users must send a message to retrieve the full response |
| **Enterprise Service** | Enterprise with verified customer service API | Can proactively push replies to users |
Official Accounts only support server and Docker deployment, not local run mode. Install extended dependencies: `pip3 install -r requirements-optional.txt`
## 1. Personal Subscription Account
Add the following configuration to `config.json`:
```json
{
"channel_type": "wechatmp",
"single_chat_prefix": [""],
"wechatmp_app_id": "wx73f9******d1e48",
"wechatmp_app_secret": "YOUR_APP_SECRET",
"wechatmp_aes_key": "",
"wechatmp_token": "YOUR_TOKEN",
"wechatmp_port": 80
}
```
### Setup Steps
These configurations must be consistent with the [WeChat Official Account Platform](https://mp.weixin.qq.com/advanced/advanced?action=dev&t=advanced/dev). Navigate to **Settings & Development → Basic Configuration → Server Configuration** and configure as shown below:
1. Enable the developer secret on the platform (corresponds to `wechatmp_app_secret`), and add the server IP to the whitelist
2. Fill in the `config.json` with the official account parameters matching the platform configuration
3. Start the program, which listens on port 80 (use `sudo` if you don't have permission; stop any process occupying port 80)
4. **Enable server configuration** on the official account platform and submit. A successful save means the configuration is complete. Note that the **"Server URL"** must be in the format `http://{HOST}/wx`, where `{HOST}` can be the server IP or domain
After following the account and sending a message, you should see the following result:
Due to subscription account limitations, short replies (within 15s) can be returned immediately, but longer replies will first send a "Thinking..." placeholder, requiring users to send any text to retrieve the answer. Enterprise service accounts can solve this with the customer service API.
**Voice Recognition**: You can use WeChat's built-in voice recognition. Enable "Receive Voice Recognition Results" under "Settings & Development → API Permissions" on the official account management page.
## 2. Enterprise Service Account
The setup process for enterprise service accounts is essentially the same as personal subscription accounts, with the following differences:
1. Register an enterprise service account on the platform and complete WeChat certification. Confirm that the **Customer Service API** permission has been granted
2. Set `"channel_type": "wechatmp_service"` in `config.json`; other configurations remain the same
3. Even for longer replies, they can be proactively pushed to users without requiring manual retrieval
```json
{
"channel_type": "wechatmp_service",
"single_chat_prefix": [""],
"wechatmp_app_id": "YOUR_APP_ID",
"wechatmp_app_secret": "YOUR_APP_SECRET",
"wechatmp_aes_key": "",
"wechatmp_token": "YOUR_TOKEN",
"wechatmp_port": 80
}
```
================================================
FILE: docs/en/channels/wecom-bot.mdx
================================================
---
title: WeCom Bot
description: Connect CowAgent to WeCom AI Bot (WebSocket long connection)
---
Connect CowAgent via WeCom AI Bot, supporting both direct messages and group chats. No public IP required — uses WebSocket long connection with Markdown rendering and streaming output.
WeCom Bot and WeCom App are two different integration methods. WeCom Bot uses WebSocket long connection, requiring no public IP or domain, making it easier to set up.
## 1. Create an AI Bot
1. Open the WeCom client, go to **Workbench**, and click **AI Bot**:
2. Click **Create Bot** → **Manual Creation**:
3. Scroll to the bottom of the right panel and select **API Mode**:
4. Set the bot name, avatar, and visibility scope. Select **Long Connection** mode, note down the **Bot ID** and **Secret**, then click Save.
## 2. Configuration
### Option A: Web Console
Start the program and open the Web console (local access: http://127.0.0.1:9899). Go to the **Channels** tab, click **Connect Channel**, select **WeCom Bot**, fill in the Bot ID and Secret from the previous step, and click Connect.
### Option B: Config File
Add the following to your `config.json`:
```json
{
"channel_type": "wecom_bot",
"wecom_bot_id": "YOUR_BOT_ID",
"wecom_bot_secret": "YOUR_SECRET"
}
```
| Parameter | Description |
| --- | --- |
| `wecom_bot_id` | Bot ID of the AI Bot |
| `wecom_bot_secret` | Secret for the AI Bot |
After configuration, start the program. The log message `[WecomBot] Subscribe success` indicates a successful connection.
## 3. Supported Features
| Feature | Status |
| --- | --- |
| Direct Messages | ✅ |
| Group Chat (@bot) | ✅ |
| Text Messages | ✅ Send & Receive |
| Image Messages | ✅ Send & Receive |
| File Messages | ✅ Send & Receive |
| Streaming Reply | ✅ |
| Scheduled Push | ✅ |
## 4. Usage
Search for the bot name in WeCom to start a direct conversation.
To use in group chats, add the bot to a group and @mention it to send messages.
================================================
FILE: docs/en/channels/wecom.mdx
================================================
---
title: WeCom
description: Integrate CowAgent into WeCom enterprise app
---
Integrate CowAgent into WeCom through a custom enterprise app, supporting one-on-one chat for internal employees.
WeCom only supports Docker deployment or server Python deployment. Local run mode is not supported.
## 1. Prerequisites
Required resources:
1. A server with public IP (overseas server, or domestic server with a proxy for international API access)
2. A registered WeCom account (individual registration is possible but cannot be certified)
3. Certified WeCom accounts additionally require a domain filed under the corresponding entity
## 2. Create WeCom App
1. In the [WeCom Admin Console](https://work.weixin.qq.com/wework_admin/frame#profile), click **My Enterprise** and find the **Corp ID** at the bottom of the page. Save this ID for the `wechatcom_corp_id` configuration field.
2. Switch to **Application Management** and click Create Application:
3. On the application creation page, record the `AgentId` and `Secret`:
4. Click **Set API Reception** to configure the application interface:
- URL format: `http://ip:port/wxcomapp` (certified enterprises must use a filed domain)
- Generate random `Token` and `EncodingAESKey` and save them for the configuration file
The API reception configuration cannot be saved at this point because the program hasn't started yet. Come back to save it after the project is running.
## 3. Configuration and Run
Add the following configuration to `config.json` (the mapping between each parameter and the WeCom console is shown in the screenshots above):
```json
{
"channel_type": "wechatcom_app",
"single_chat_prefix": [""],
"wechatcom_corp_id": "YOUR_CORP_ID",
"wechatcomapp_token": "YOUR_TOKEN",
"wechatcomapp_secret": "YOUR_SECRET",
"wechatcomapp_agent_id": "YOUR_AGENT_ID",
"wechatcomapp_aes_key": "YOUR_AES_KEY",
"wechatcomapp_port": 9898
}
```
| Parameter | Description |
| --- | --- |
| `wechatcom_corp_id` | Corp ID |
| `wechatcomapp_token` | Token from API reception config |
| `wechatcomapp_secret` | App Secret |
| `wechatcomapp_agent_id` | App AgentId |
| `wechatcomapp_aes_key` | EncodingAESKey from API reception config |
| `wechatcomapp_port` | Listen port, default 9898 |
After configuration, start the program. When the log shows `http://0.0.0.0:9898/`, the program is running successfully. You need to open this port externally (e.g., allow it in the cloud server security group).
After the program starts, return to the WeCom Admin Console to save the **Message Server Configuration**. After saving successfully, you also need to add the server IP to **Enterprise Trusted IPs**, otherwise messages cannot be sent or received:
If the URL configuration callback fails or the configuration is unsuccessful:
1. Ensure the server firewall is disabled and the security group allows the listening port
2. Carefully check that Token, Secret Key and other parameter configurations are consistent, and that the URL format is correct
3. Certified WeCom accounts must configure a filed domain matching the entity
## 4. Usage
Search for the app name you just created in WeCom to start chatting directly. You can run multiple instances listening on different ports to create multiple WeCom apps:
To allow external personal WeChat users to use the app, go to **My Enterprise → WeChat Plugin**, share the invite QR code. After scanning and following, personal WeChat users can join and chat with the app:
## FAQ
Make sure the following dependencies are installed:
```bash
pip install websocket-client pycryptodome
```
================================================
FILE: docs/en/guide/manual-install.mdx
================================================
---
title: Manual Install
description: Deploy CowAgent manually (source code / Docker)
---
## Source Code Deployment
### 1. Clone the project
```bash
git clone https://github.com/zhayujie/chatgpt-on-wechat
cd chatgpt-on-wechat/
```
For network issues, use the mirror: https://gitee.com/zhayujie/chatgpt-on-wechat
### 2. Install dependencies
Core dependencies (required):
```bash
pip3 install -r requirements.txt
```
Optional dependencies (recommended):
```bash
pip3 install -r requirements-optional.txt
```
### 3. Configure
Copy the config template and edit:
```bash
cp config-template.json config.json
```
Fill in model API keys, channel type, and other settings in `config.json`. See the [model docs](/en/models/index) for details.
### 4. Run
**Local run:**
```bash
python3 app.py
```
By default, the Web service starts. Access `http://localhost:9899/chat` to chat.
**Background run on server:**
```bash
nohup python3 app.py & tail -f nohup.out
```
## Docker Deployment
Docker deployment does not require cloning source code or installing dependencies. For Agent mode, source deployment is recommended for broader system access.
Requires [Docker](https://docs.docker.com/engine/install/) and docker-compose.
**1. Download config**
```bash
curl -O https://cdn.link-ai.tech/code/cow/docker-compose.yml
```
Edit `docker-compose.yml` with your configuration.
**2. Start container**
```bash
sudo docker compose up -d
```
**3. View logs**
```bash
sudo docker logs -f chatgpt-on-wechat
```
## Core Configuration
```json
{
"channel_type": "web",
"model": "MiniMax-M2.5",
"agent": true,
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 30,
"agent_max_steps": 15
}
```
| Parameter | Description | Default |
| --- | --- | --- |
| `channel_type` | Channel type | `web` |
| `model` | Model name | `MiniMax-M2.5` |
| `agent` | Enable Agent mode | `true` |
| `agent_workspace` | Agent workspace path | `~/cow` |
| `agent_max_context_tokens` | Max context tokens | `40000` |
| `agent_max_context_turns` | Max context turns | `30` |
| `agent_max_steps` | Max decision steps per task | `15` |
Full configuration options are in the project [`config.py`](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/config.py).
================================================
FILE: docs/en/guide/quick-start.mdx
================================================
---
title: One-click Install
description: One-click install and manage CowAgent with scripts
---
The project provides scripts for one-click install, configuration, startup, and management. Script-based deployment is recommended for quick setup.
Supports Linux, macOS, and Windows. Requires Python 3.7-3.12 (3.9 recommended).
## Install Command
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
The script automatically performs these steps:
1. Check Python environment (requires Python 3.7+)
2. Install required tools (git, curl, etc.)
3. Clone project to `~/chatgpt-on-wechat`
4. Install Python dependencies
5. Guided configuration for AI model and channel
6. Start service
By default, the Web service starts after installation. Access `http://localhost:9899/chat` to begin chatting.
## Management Commands
After installation, use these commands to manage the service:
| Command | Description |
| --- | --- |
| `./run.sh start` | Start service |
| `./run.sh stop` | Stop service |
| `./run.sh restart` | Restart service |
| `./run.sh status` | Check run status |
| `./run.sh logs` | View real-time logs |
| `./run.sh config` | Reconfigure |
| `./run.sh update` | Update project code |
================================================
FILE: docs/en/intro/architecture.mdx
================================================
---
title: Architecture
description: CowAgent 2.0 system architecture and core design
---
CowAgent 2.0 has evolved from a simple chatbot into a super intelligent assistant with Agent architecture, featuring autonomous thinking, task planning, long-term memory, and skill extensibility.
## System Architecture
CowAgent's architecture consists of the following core modules:
4. After starting the project, go to the DingTalk Developer Console, click **Event Subscription**, then click **Connection verified, verify channel**. When "**Connection successful**" is displayed, the configuration is complete:
## 3. Usage
Chat privately with the robot or add it to an enterprise group to start a conversation:
================================================
FILE: docs/en/channels/feishu.mdx
================================================
---
title: Feishu (Lark)
description: Integrate CowAgent into Feishu application
---
Integrate CowAgent into Feishu by creating a custom enterprise app. You need to be a Feishu enterprise user with admin privileges.
## 1. Create Enterprise Custom App
### 1.1 Create App
Go to [Feishu Developer Platform](https://open.feishu.cn/app/), click **Create Enterprise Custom App**, fill in the required information and click **Create**:
### 1.2 Add Bot Capability
In **Add App Capabilities**, add **Bot** capability to the app:
### 1.3 Configure App Permissions
Click **Permission Management**, paste the following permission string into the input box below **Permission Configuration**, select all filtered permissions, click **Batch Enable** and confirm:
```
im:message,im:message.group_at_msg,im:message.group_at_msg:readonly,im:message.p2p_msg,im:message.p2p_msg:readonly,im:message:send_as_bot,im:resource
```
## 2. Project Configuration
1. Get `App ID` and `App Secret` from **Credentials & Basic Info**:
2. Add the following configuration to `config.json` in the project root:
```json
{
"channel_type": "feishu",
"feishu_app_id": "YOUR_APP_ID",
"feishu_app_secret": "YOUR_APP_SECRET",
"feishu_bot_name": "YOUR_BOT_NAME"
}
```
| Parameter | Description |
| --- | --- |
| `feishu_app_id` | Feishu bot App ID |
| `feishu_app_secret` | Feishu bot App Secret |
| `feishu_bot_name` | Bot name (set when creating the app), required for group chat usage |
Start the project after configuration is complete.
## 3. Configure Event Subscription
1. After the project is running successfully, go to the Feishu Developer Platform, click **Events & Callbacks**, select **Long Connection** mode, and click save:
2. Click **Add Event** below, search for "Receive Message", select "**Receive Message v2.0**", and confirm.
3. Click **Version Management & Release**, create a new version and apply for **Production Release**. Check the approval message in the Feishu client and approve:
Once completed, search for the bot name in Feishu to start chatting.
================================================
FILE: docs/en/channels/qq.mdx
================================================
---
title: QQ Bot
description: Connect CowAgent to QQ Bot (WebSocket long connection)
---
> Connect CowAgent via QQ Open Platform's bot API, supporting QQ direct messages, group chats (@bot), guild channel messages, and guild DMs. No public IP required — uses WebSocket long connection.
QQ Bot is created through the QQ Open Platform. It uses WebSocket long connection to receive messages and OpenAPI to send messages. No public IP or domain is required.
## 1. Create a QQ Bot
> Visit the [QQ Open Platform](https://q.qq.com), sign in with QQ. If you haven't registered, please complete [account registration](https://q.qq.com/#/register) first.
1.Go to the [QQ Open Platform - Bot List](https://q.qq.com/#/apps), and click **Create Bot**:
2.Fill in the bot name, avatar, and other basic information to complete the creation:
3.Enter the bot configuration page, go to **Development Management**, and complete the following steps:
- Copy and save the **AppID** (Bot ID)
- Generate and save the **AppSecret** (Bot Secret)
## 2. Configuration and Running
### Option A: Web Console
Start the program and open the Web console (local access: http://127.0.0.1:9899/). Go to the **Channels** tab, click **Connect Channel**, select **QQ Bot**, fill in the AppID and AppSecret from the previous step, and click Connect.
### Option B: Config File
Add the following to your `config.json`:
```json
{
"channel_type": "qq",
"qq_app_id": "YOUR_APP_ID",
"qq_app_secret": "YOUR_APP_SECRET"
}
```
| Parameter | Description |
| --- | --- |
| `qq_app_id` | AppID of the QQ Bot, found in Development Management on the open platform |
| `qq_app_secret` | AppSecret of the QQ Bot, found in Development Management on the open platform |
After configuration, start the program. The log message `[QQ] ✅ Connected successfully` indicates a successful connection.
## 3. Usage
In the QQ Open Platform, go to **Management → Usage Scope & Members**, scan the "Add to group and message list" QR code with your QQ client to start chatting with the bot:
Chat example:
## 4. Supported Features
> Note: To use the QQ bot in group chats and guild channels, you need to complete the publishing review and configure usage scope permissions.
| Feature | Status |
| --- | --- |
| QQ Direct Messages | ✅ |
| QQ Group Chat (@bot) | ✅ |
| Guild Channel (@bot) | ✅ |
| Guild DM | ✅ |
| Text Messages | ✅ Send & Receive |
| Image Messages | ✅ Send & Receive (group & direct) |
| File Messages | ✅ Send (group & direct) |
| Scheduled Tasks | ✅ Active push (4 per user per month) |
## 5. Notes
- **Passive message limits**: QQ direct message replies are valid for 60 minutes (max 5 replies per message); group chat replies are valid for 5 minutes.
- **Active message limits**: Both direct and group chats have a monthly limit of 4 active messages. Keep this in mind when using the scheduled tasks feature.
- **Event permissions**: By default, `GROUP_AND_C2C_EVENT` (QQ group/direct) and `PUBLIC_GUILD_MESSAGES` (guild public messages) are subscribed. Apply for additional permissions on the open platform if needed.
================================================
FILE: docs/en/channels/web.mdx
================================================
---
title: Web Console
description: Use CowAgent through the web console
---
The Web Console is CowAgent's default channel. It starts automatically after launch, allowing you to chat with the Agent through a browser and manage models, skills, memory, channels, and other configurations online.
## Configuration
```json
{
"channel_type": "web",
"web_port": 9899
}
```
| Parameter | Description | Default |
| --- | --- | --- |
| `channel_type` | Set to `web` | `web` |
| `web_port` | Web service listen port | `9899` |
## Access URL
After starting the project, visit:
- Local: `http://localhost:9899`
- Server: `http://:9899`
Ensure the server firewall and security group allow the corresponding port.
## Features
### Chat Interface
Supports streaming output with real-time display of the Agent's reasoning process and tool calls, providing intuitive observation of the Agent's decision-making:
### Model Management
Manage model configurations online without manually editing config files:
### Skill Management
View and manage Agent skills (Skills) online:
### Memory Management
View and manage Agent memory online:
### Channel Management
Manage connected channels online with real-time connect/disconnect operations:
### Scheduled Tasks
View and manage scheduled tasks online, including one-time tasks, fixed intervals, and Cron expressions:
### Logs
View Agent runtime logs in real-time for monitoring and troubleshooting:
================================================
FILE: docs/en/channels/wechatmp.mdx
================================================
---
title: WeChat Official Account
description: Integrate CowAgent with WeChat Official Accounts
---
CowAgent supports both personal subscription accounts and enterprise service accounts.
| Type | Requirements | Features |
| --- | --- | --- |
| **Personal Subscription** | Available to individuals | Sends a placeholder reply first; users must send a message to retrieve the full response |
| **Enterprise Service** | Enterprise with verified customer service API | Can proactively push replies to users |
Official Accounts only support server and Docker deployment, not local run mode. Install extended dependencies: `pip3 install -r requirements-optional.txt`
## 1. Personal Subscription Account
Add the following configuration to `config.json`:
```json
{
"channel_type": "wechatmp",
"single_chat_prefix": [""],
"wechatmp_app_id": "wx73f9******d1e48",
"wechatmp_app_secret": "YOUR_APP_SECRET",
"wechatmp_aes_key": "",
"wechatmp_token": "YOUR_TOKEN",
"wechatmp_port": 80
}
```
### Setup Steps
These configurations must be consistent with the [WeChat Official Account Platform](https://mp.weixin.qq.com/advanced/advanced?action=dev&t=advanced/dev). Navigate to **Settings & Development → Basic Configuration → Server Configuration** and configure as shown below:
1. Enable the developer secret on the platform (corresponds to `wechatmp_app_secret`), and add the server IP to the whitelist
2. Fill in the `config.json` with the official account parameters matching the platform configuration
3. Start the program, which listens on port 80 (use `sudo` if you don't have permission; stop any process occupying port 80)
4. **Enable server configuration** on the official account platform and submit. A successful save means the configuration is complete. Note that the **"Server URL"** must be in the format `http://{HOST}/wx`, where `{HOST}` can be the server IP or domain
After following the account and sending a message, you should see the following result:
Due to subscription account limitations, short replies (within 15s) can be returned immediately, but longer replies will first send a "Thinking..." placeholder, requiring users to send any text to retrieve the answer. Enterprise service accounts can solve this with the customer service API.
**Voice Recognition**: You can use WeChat's built-in voice recognition. Enable "Receive Voice Recognition Results" under "Settings & Development → API Permissions" on the official account management page.
## 2. Enterprise Service Account
The setup process for enterprise service accounts is essentially the same as personal subscription accounts, with the following differences:
1. Register an enterprise service account on the platform and complete WeChat certification. Confirm that the **Customer Service API** permission has been granted
2. Set `"channel_type": "wechatmp_service"` in `config.json`; other configurations remain the same
3. Even for longer replies, they can be proactively pushed to users without requiring manual retrieval
```json
{
"channel_type": "wechatmp_service",
"single_chat_prefix": [""],
"wechatmp_app_id": "YOUR_APP_ID",
"wechatmp_app_secret": "YOUR_APP_SECRET",
"wechatmp_aes_key": "",
"wechatmp_token": "YOUR_TOKEN",
"wechatmp_port": 80
}
```
================================================
FILE: docs/en/channels/wecom-bot.mdx
================================================
---
title: WeCom Bot
description: Connect CowAgent to WeCom AI Bot (WebSocket long connection)
---
Connect CowAgent via WeCom AI Bot, supporting both direct messages and group chats. No public IP required — uses WebSocket long connection with Markdown rendering and streaming output.
WeCom Bot and WeCom App are two different integration methods. WeCom Bot uses WebSocket long connection, requiring no public IP or domain, making it easier to set up.
## 1. Create an AI Bot
1. Open the WeCom client, go to **Workbench**, and click **AI Bot**:
2. Click **Create Bot** → **Manual Creation**:
3. Scroll to the bottom of the right panel and select **API Mode**:
4. Set the bot name, avatar, and visibility scope. Select **Long Connection** mode, note down the **Bot ID** and **Secret**, then click Save.
## 2. Configuration
### Option A: Web Console
Start the program and open the Web console (local access: http://127.0.0.1:9899). Go to the **Channels** tab, click **Connect Channel**, select **WeCom Bot**, fill in the Bot ID and Secret from the previous step, and click Connect.
### Option B: Config File
Add the following to your `config.json`:
```json
{
"channel_type": "wecom_bot",
"wecom_bot_id": "YOUR_BOT_ID",
"wecom_bot_secret": "YOUR_SECRET"
}
```
| Parameter | Description |
| --- | --- |
| `wecom_bot_id` | Bot ID of the AI Bot |
| `wecom_bot_secret` | Secret for the AI Bot |
After configuration, start the program. The log message `[WecomBot] Subscribe success` indicates a successful connection.
## 3. Supported Features
| Feature | Status |
| --- | --- |
| Direct Messages | ✅ |
| Group Chat (@bot) | ✅ |
| Text Messages | ✅ Send & Receive |
| Image Messages | ✅ Send & Receive |
| File Messages | ✅ Send & Receive |
| Streaming Reply | ✅ |
| Scheduled Push | ✅ |
## 4. Usage
Search for the bot name in WeCom to start a direct conversation.
To use in group chats, add the bot to a group and @mention it to send messages.
================================================
FILE: docs/en/channels/wecom.mdx
================================================
---
title: WeCom
description: Integrate CowAgent into WeCom enterprise app
---
Integrate CowAgent into WeCom through a custom enterprise app, supporting one-on-one chat for internal employees.
WeCom only supports Docker deployment or server Python deployment. Local run mode is not supported.
## 1. Prerequisites
Required resources:
1. A server with public IP (overseas server, or domestic server with a proxy for international API access)
2. A registered WeCom account (individual registration is possible but cannot be certified)
3. Certified WeCom accounts additionally require a domain filed under the corresponding entity
## 2. Create WeCom App
1. In the [WeCom Admin Console](https://work.weixin.qq.com/wework_admin/frame#profile), click **My Enterprise** and find the **Corp ID** at the bottom of the page. Save this ID for the `wechatcom_corp_id` configuration field.
2. Switch to **Application Management** and click Create Application:
3. On the application creation page, record the `AgentId` and `Secret`:
4. Click **Set API Reception** to configure the application interface:
- URL format: `http://ip:port/wxcomapp` (certified enterprises must use a filed domain)
- Generate random `Token` and `EncodingAESKey` and save them for the configuration file
The API reception configuration cannot be saved at this point because the program hasn't started yet. Come back to save it after the project is running.
## 3. Configuration and Run
Add the following configuration to `config.json` (the mapping between each parameter and the WeCom console is shown in the screenshots above):
```json
{
"channel_type": "wechatcom_app",
"single_chat_prefix": [""],
"wechatcom_corp_id": "YOUR_CORP_ID",
"wechatcomapp_token": "YOUR_TOKEN",
"wechatcomapp_secret": "YOUR_SECRET",
"wechatcomapp_agent_id": "YOUR_AGENT_ID",
"wechatcomapp_aes_key": "YOUR_AES_KEY",
"wechatcomapp_port": 9898
}
```
| Parameter | Description |
| --- | --- |
| `wechatcom_corp_id` | Corp ID |
| `wechatcomapp_token` | Token from API reception config |
| `wechatcomapp_secret` | App Secret |
| `wechatcomapp_agent_id` | App AgentId |
| `wechatcomapp_aes_key` | EncodingAESKey from API reception config |
| `wechatcomapp_port` | Listen port, default 9898 |
After configuration, start the program. When the log shows `http://0.0.0.0:9898/`, the program is running successfully. You need to open this port externally (e.g., allow it in the cloud server security group).
After the program starts, return to the WeCom Admin Console to save the **Message Server Configuration**. After saving successfully, you also need to add the server IP to **Enterprise Trusted IPs**, otherwise messages cannot be sent or received:
If the URL configuration callback fails or the configuration is unsuccessful:
1. Ensure the server firewall is disabled and the security group allows the listening port
2. Carefully check that Token, Secret Key and other parameter configurations are consistent, and that the URL format is correct
3. Certified WeCom accounts must configure a filed domain matching the entity
## 4. Usage
Search for the app name you just created in WeCom to start chatting directly. You can run multiple instances listening on different ports to create multiple WeCom apps:
To allow external personal WeChat users to use the app, go to **My Enterprise → WeChat Plugin**, share the invite QR code. After scanning and following, personal WeChat users can join and chat with the app:
## FAQ
Make sure the following dependencies are installed:
```bash
pip install websocket-client pycryptodome
```
================================================
FILE: docs/en/guide/manual-install.mdx
================================================
---
title: Manual Install
description: Deploy CowAgent manually (source code / Docker)
---
## Source Code Deployment
### 1. Clone the project
```bash
git clone https://github.com/zhayujie/chatgpt-on-wechat
cd chatgpt-on-wechat/
```
For network issues, use the mirror: https://gitee.com/zhayujie/chatgpt-on-wechat
### 2. Install dependencies
Core dependencies (required):
```bash
pip3 install -r requirements.txt
```
Optional dependencies (recommended):
```bash
pip3 install -r requirements-optional.txt
```
### 3. Configure
Copy the config template and edit:
```bash
cp config-template.json config.json
```
Fill in model API keys, channel type, and other settings in `config.json`. See the [model docs](/en/models/index) for details.
### 4. Run
**Local run:**
```bash
python3 app.py
```
By default, the Web service starts. Access `http://localhost:9899/chat` to chat.
**Background run on server:**
```bash
nohup python3 app.py & tail -f nohup.out
```
## Docker Deployment
Docker deployment does not require cloning source code or installing dependencies. For Agent mode, source deployment is recommended for broader system access.
Requires [Docker](https://docs.docker.com/engine/install/) and docker-compose.
**1. Download config**
```bash
curl -O https://cdn.link-ai.tech/code/cow/docker-compose.yml
```
Edit `docker-compose.yml` with your configuration.
**2. Start container**
```bash
sudo docker compose up -d
```
**3. View logs**
```bash
sudo docker logs -f chatgpt-on-wechat
```
## Core Configuration
```json
{
"channel_type": "web",
"model": "MiniMax-M2.5",
"agent": true,
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 30,
"agent_max_steps": 15
}
```
| Parameter | Description | Default |
| --- | --- | --- |
| `channel_type` | Channel type | `web` |
| `model` | Model name | `MiniMax-M2.5` |
| `agent` | Enable Agent mode | `true` |
| `agent_workspace` | Agent workspace path | `~/cow` |
| `agent_max_context_tokens` | Max context tokens | `40000` |
| `agent_max_context_turns` | Max context turns | `30` |
| `agent_max_steps` | Max decision steps per task | `15` |
Full configuration options are in the project [`config.py`](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/config.py).
================================================
FILE: docs/en/guide/quick-start.mdx
================================================
---
title: One-click Install
description: One-click install and manage CowAgent with scripts
---
The project provides scripts for one-click install, configuration, startup, and management. Script-based deployment is recommended for quick setup.
Supports Linux, macOS, and Windows. Requires Python 3.7-3.12 (3.9 recommended).
## Install Command
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
The script automatically performs these steps:
1. Check Python environment (requires Python 3.7+)
2. Install required tools (git, curl, etc.)
3. Clone project to `~/chatgpt-on-wechat`
4. Install Python dependencies
5. Guided configuration for AI model and channel
6. Start service
By default, the Web service starts after installation. Access `http://localhost:9899/chat` to begin chatting.
## Management Commands
After installation, use these commands to manage the service:
| Command | Description |
| --- | --- |
| `./run.sh start` | Start service |
| `./run.sh stop` | Stop service |
| `./run.sh restart` | Restart service |
| `./run.sh status` | Check run status |
| `./run.sh logs` | View real-time logs |
| `./run.sh config` | Reconfigure |
| `./run.sh update` | Update project code |
================================================
FILE: docs/en/intro/architecture.mdx
================================================
---
title: Architecture
description: CowAgent 2.0 system architecture and core design
---
CowAgent 2.0 has evolved from a simple chatbot into a super intelligent assistant with Agent architecture, featuring autonomous thinking, task planning, long-term memory, and skill extensibility.
## System Architecture
CowAgent's architecture consists of the following core modules:
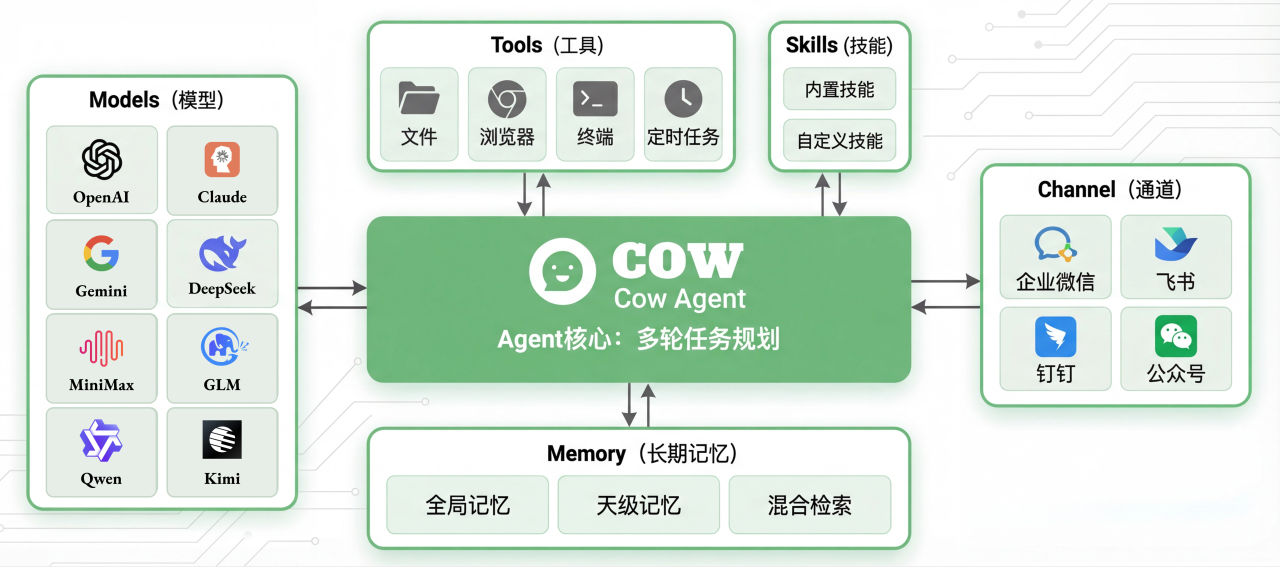 ### Core Modules
| Module | Description |
| --- | --- |
| **Channels** | Message channel layer for receiving and sending messages. Supports Web, Feishu, DingTalk, WeCom, WeChat Official Account, and more |
| **Agent Core** | Agent engine including task planning, memory system, and skills engine |
| **Tools** | Tool layer for Agent to access OS resources. 10+ built-in tools |
| **Models** | Model layer with unified access to mainstream LLMs |
## Agent Mode Workflow
When Agent mode is enabled, CowAgent runs as an autonomous agent with the following workflow:
1. **Receive Message** — Receive user input through channels
2. **Understand Intent** — Analyze task requirements and context
3. **Plan Task** — Break complex tasks into multiple steps
4. **Invoke Tools** — Select and execute appropriate tools for each step
5. **Update Memory** — Store important information in long-term memory
6. **Return Result** — Send execution results back to the user
## Workspace Directory Structure
The Agent workspace is located at `~/cow` by default and stores system prompts, memory files, and skill files:
```
~/cow/
├── system.md # Agent system prompt
├── user.md # User profile
├── memory/ # Long-term memory storage
│ ├── core.md # Core memory
│ └── daily/ # Daily memory
└── skills/ # Custom skills
├── skill-1/
└── skill-2/
```
Secret keys are stored separately in `~/.cow` directory for security:
```
~/.cow/
└── .env # Secret keys for skills
```
## Core Configuration
Configure Agent mode parameters in `config.json`:
```json
{
"agent": true,
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 30,
"agent_max_steps": 15
}
```
| Parameter | Description | Default |
| --- | --- | --- |
| `agent` | Enable Agent mode | `true` |
| `agent_workspace` | Workspace path | `~/cow` |
| `agent_max_context_tokens` | Max context tokens | `40000` |
| `agent_max_context_turns` | Max context turns | `30` |
| `agent_max_steps` | Max decision steps per task | `15` |
================================================
FILE: docs/en/intro/features.mdx
================================================
---
title: Features
description: CowAgent long-term memory, task planning, and skills system in detail
---
## 1. Long-term Memory
The memory system enables the Agent to remember important information over time. The Agent proactively stores information when users share preferences, decisions, or key facts, and automatically extracts summaries when conversations reach a certain length. Memory is divided into core memory and daily memory, with hybrid retrieval supporting both keyword search and vector search.
On first launch, the Agent proactively asks the user for key information and records it in the workspace (default `~/cow`) — including agent settings, user identity, and memory files.
In subsequent long-term conversations, the Agent intelligently stores or retrieves memory as needed, continuously updating its own settings, user preferences, and memory files, summarizing experiences and lessons learned — truly achieving autonomous thinking and continuous growth.
## 2. Task Planning and Tool Use
Tools are the core of how the Agent accesses operating system resources. The Agent intelligently selects and invokes tools based on task requirements, performing file read/write, command execution, scheduled tasks, and more. Built-in tools are implemented in the project's `agent/tools/` directory.
**Key tools:** file read/write/edit, Bash terminal, file send, scheduler, memory search, web search, environment config, and more.
### 2.1 Terminal and File Access
Access to the OS terminal and file system is the most fundamental and core capability. Many other tools and skills build on top of this. Users can interact with the Agent from a mobile device to operate resources on their personal computer or server:
### 2.2 Programming Capability
Combining programming and system access, the Agent can execute the complete **Vibecoding workflow** — from information search, asset generation, coding, testing, deployment, Nginx configuration, to publishing — all triggered by a single command from your phone:
### 2.3 Scheduled Tasks
The `scheduler` tool enables dynamic scheduled tasks, supporting **one-time tasks, fixed intervals, and Cron expressions**. Tasks can be triggered as either a **fixed message send** or an **Agent dynamic task** execution:
### 2.4 Environment Variable Management
Secrets required by skills are stored in an environment variable file, managed by the `env_config` tool. You can update secrets through conversation, with built-in security protection and desensitization:
## 3. Skills System
The Skills system provides infinite extensibility for the Agent. Each Skill consists of a description file, execution scripts (optional), and resources (optional), describing how to complete specific types of tasks. Skills allow the Agent to follow instructions for complex workflows, invoke tools, or integrate third-party systems.
- **Built-in skills:** Located in the project's `skills/` directory, including skill creator, image recognition, LinkAI agent, web fetch, and more. Built-in skills are automatically enabled based on dependency conditions (API keys, system commands, etc.).
- **Custom skills:** Created by users through conversation, stored in the workspace (`~/cow/skills/`), capable of implementing any complex business process or third-party integration.
### 3.1 Creating Skills
The `skill-creator` skill enables rapid skill creation through conversation. You can ask the Agent to codify a workflow as a skill, or send any API documentation and examples for the Agent to complete the integration directly:
### 3.2 Web Search and Image Recognition
- **Web search:** Built-in `web_search` tool, supports multiple search engines. Configure `BOCHA_API_KEY` or `LINKAI_API_KEY` to enable.
- **Image recognition:** Built-in `openai-image-vision` skill, supports `gpt-4.1-mini`, `gpt-4.1`, and other models. Requires `OPENAI_API_KEY`.
### 3.3 Third-party Knowledge Bases and Plugins
The `linkai-agent` skill makes all agents on [LinkAI](https://link-ai.tech/) available as Skills for the Agent, enabling multi-agent decision making.
Configuration: set `LINKAI_API_KEY` via `env_config`, then add agent descriptions in `skills/linkai-agent/config.json`:
```json
{
"apps": [
{
"app_code": "G7z6vKwp",
"app_name": "LinkAI Customer Support",
"app_description": "Select only when the user needs help with LinkAI platform questions"
},
{
"app_code": "SFY5x7JR",
"app_name": "Content Creator",
"app_description": "Use only when the user needs to create images or videos"
}
]
}
```
================================================
FILE: docs/en/intro/index.mdx
================================================
---
title: Introduction
description: CowAgent - AI Super Assistant powered by LLMs
---
### Core Modules
| Module | Description |
| --- | --- |
| **Channels** | Message channel layer for receiving and sending messages. Supports Web, Feishu, DingTalk, WeCom, WeChat Official Account, and more |
| **Agent Core** | Agent engine including task planning, memory system, and skills engine |
| **Tools** | Tool layer for Agent to access OS resources. 10+ built-in tools |
| **Models** | Model layer with unified access to mainstream LLMs |
## Agent Mode Workflow
When Agent mode is enabled, CowAgent runs as an autonomous agent with the following workflow:
1. **Receive Message** — Receive user input through channels
2. **Understand Intent** — Analyze task requirements and context
3. **Plan Task** — Break complex tasks into multiple steps
4. **Invoke Tools** — Select and execute appropriate tools for each step
5. **Update Memory** — Store important information in long-term memory
6. **Return Result** — Send execution results back to the user
## Workspace Directory Structure
The Agent workspace is located at `~/cow` by default and stores system prompts, memory files, and skill files:
```
~/cow/
├── system.md # Agent system prompt
├── user.md # User profile
├── memory/ # Long-term memory storage
│ ├── core.md # Core memory
│ └── daily/ # Daily memory
└── skills/ # Custom skills
├── skill-1/
└── skill-2/
```
Secret keys are stored separately in `~/.cow` directory for security:
```
~/.cow/
└── .env # Secret keys for skills
```
## Core Configuration
Configure Agent mode parameters in `config.json`:
```json
{
"agent": true,
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 30,
"agent_max_steps": 15
}
```
| Parameter | Description | Default |
| --- | --- | --- |
| `agent` | Enable Agent mode | `true` |
| `agent_workspace` | Workspace path | `~/cow` |
| `agent_max_context_tokens` | Max context tokens | `40000` |
| `agent_max_context_turns` | Max context turns | `30` |
| `agent_max_steps` | Max decision steps per task | `15` |
================================================
FILE: docs/en/intro/features.mdx
================================================
---
title: Features
description: CowAgent long-term memory, task planning, and skills system in detail
---
## 1. Long-term Memory
The memory system enables the Agent to remember important information over time. The Agent proactively stores information when users share preferences, decisions, or key facts, and automatically extracts summaries when conversations reach a certain length. Memory is divided into core memory and daily memory, with hybrid retrieval supporting both keyword search and vector search.
On first launch, the Agent proactively asks the user for key information and records it in the workspace (default `~/cow`) — including agent settings, user identity, and memory files.
In subsequent long-term conversations, the Agent intelligently stores or retrieves memory as needed, continuously updating its own settings, user preferences, and memory files, summarizing experiences and lessons learned — truly achieving autonomous thinking and continuous growth.
## 2. Task Planning and Tool Use
Tools are the core of how the Agent accesses operating system resources. The Agent intelligently selects and invokes tools based on task requirements, performing file read/write, command execution, scheduled tasks, and more. Built-in tools are implemented in the project's `agent/tools/` directory.
**Key tools:** file read/write/edit, Bash terminal, file send, scheduler, memory search, web search, environment config, and more.
### 2.1 Terminal and File Access
Access to the OS terminal and file system is the most fundamental and core capability. Many other tools and skills build on top of this. Users can interact with the Agent from a mobile device to operate resources on their personal computer or server:
### 2.2 Programming Capability
Combining programming and system access, the Agent can execute the complete **Vibecoding workflow** — from information search, asset generation, coding, testing, deployment, Nginx configuration, to publishing — all triggered by a single command from your phone:
### 2.3 Scheduled Tasks
The `scheduler` tool enables dynamic scheduled tasks, supporting **one-time tasks, fixed intervals, and Cron expressions**. Tasks can be triggered as either a **fixed message send** or an **Agent dynamic task** execution:
### 2.4 Environment Variable Management
Secrets required by skills are stored in an environment variable file, managed by the `env_config` tool. You can update secrets through conversation, with built-in security protection and desensitization:
## 3. Skills System
The Skills system provides infinite extensibility for the Agent. Each Skill consists of a description file, execution scripts (optional), and resources (optional), describing how to complete specific types of tasks. Skills allow the Agent to follow instructions for complex workflows, invoke tools, or integrate third-party systems.
- **Built-in skills:** Located in the project's `skills/` directory, including skill creator, image recognition, LinkAI agent, web fetch, and more. Built-in skills are automatically enabled based on dependency conditions (API keys, system commands, etc.).
- **Custom skills:** Created by users through conversation, stored in the workspace (`~/cow/skills/`), capable of implementing any complex business process or third-party integration.
### 3.1 Creating Skills
The `skill-creator` skill enables rapid skill creation through conversation. You can ask the Agent to codify a workflow as a skill, or send any API documentation and examples for the Agent to complete the integration directly:
### 3.2 Web Search and Image Recognition
- **Web search:** Built-in `web_search` tool, supports multiple search engines. Configure `BOCHA_API_KEY` or `LINKAI_API_KEY` to enable.
- **Image recognition:** Built-in `openai-image-vision` skill, supports `gpt-4.1-mini`, `gpt-4.1`, and other models. Requires `OPENAI_API_KEY`.
### 3.3 Third-party Knowledge Bases and Plugins
The `linkai-agent` skill makes all agents on [LinkAI](https://link-ai.tech/) available as Skills for the Agent, enabling multi-agent decision making.
Configuration: set `LINKAI_API_KEY` via `env_config`, then add agent descriptions in `skills/linkai-agent/config.json`:
```json
{
"apps": [
{
"app_code": "G7z6vKwp",
"app_name": "LinkAI Customer Support",
"app_description": "Select only when the user needs help with LinkAI platform questions"
},
{
"app_code": "SFY5x7JR",
"app_name": "Content Creator",
"app_description": "Use only when the user needs to create images or videos"
}
]
}
```
================================================
FILE: docs/en/intro/index.mdx
================================================
---
title: Introduction
description: CowAgent - AI Super Assistant powered by LLMs
---
 **CowAgent** is an AI super assistant powered by LLMs with autonomous task planning, long-term memory, skills system, multimodal messages, multiple model support, and multi-platform deployment.
CowAgent can proactively think and plan tasks, operate computers and external resources, create and execute Skills, and continuously grow with long-term memory. It supports flexible switching between multiple models, handles text, voice, images, files and other multimodal messages, and can be integrated into web, Feishu, DingTalk, WeCom, and WeChat Official Account. It runs 7x24 hours on your personal computer or server.
github.com/zhayujie/chatgpt-on-wechat
## Core Capabilities
Understands complex tasks and autonomously plans execution, continuously thinking and invoking tools until goals are achieved. Supports accessing file systems, terminals, browsers, schedulers, and other system resources through tools.
Automatically persists conversation memory to local files and databases, including core memory and daily memory, with keyword and vector retrieval support.
Implements a Skills creation and execution engine with built-in skills, and supports custom Skills development through natural language conversation.
Supports parsing, processing, generating, and sending text, images, voice, files, and other message types.
Supports mainstream model providers including OpenAI, Claude, Gemini, DeepSeek, MiniMax, GLM, Qwen, Kimi, Doubao, and more.
Runs on local computers or servers, integrable into web, Feishu, DingTalk, WeChat Official Account, and WeCom applications.
## Quick Experience
Run the following command in your terminal for one-click install, configuration, and startup:
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
By default, the Web service starts after running. Access `http://localhost:9899/chat` to chat in the web interface.
Complete installation and run guide
CowAgent system architecture design
## Disclaimer
1. This project follows the [MIT License](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/LICENSE) and is intended for technical research and learning. Users must comply with local laws, regulations, policies, and corporate bylaws. Any illegal or rights-infringing use is prohibited.
2. Agent mode consumes more tokens than normal chat mode. Choose models based on effectiveness and cost. Agent has access to the host operating system — deploy with caution.
3. CowAgent focuses on open-source development and does not participate in, authorize, or issue any cryptocurrency.
## Community
Add our assistant on WeChat to join the open-source community:
**CowAgent** is an AI super assistant powered by LLMs with autonomous task planning, long-term memory, skills system, multimodal messages, multiple model support, and multi-platform deployment.
CowAgent can proactively think and plan tasks, operate computers and external resources, create and execute Skills, and continuously grow with long-term memory. It supports flexible switching between multiple models, handles text, voice, images, files and other multimodal messages, and can be integrated into web, Feishu, DingTalk, WeCom, and WeChat Official Account. It runs 7x24 hours on your personal computer or server.
github.com/zhayujie/chatgpt-on-wechat
## Core Capabilities
Understands complex tasks and autonomously plans execution, continuously thinking and invoking tools until goals are achieved. Supports accessing file systems, terminals, browsers, schedulers, and other system resources through tools.
Automatically persists conversation memory to local files and databases, including core memory and daily memory, with keyword and vector retrieval support.
Implements a Skills creation and execution engine with built-in skills, and supports custom Skills development through natural language conversation.
Supports parsing, processing, generating, and sending text, images, voice, files, and other message types.
Supports mainstream model providers including OpenAI, Claude, Gemini, DeepSeek, MiniMax, GLM, Qwen, Kimi, Doubao, and more.
Runs on local computers or servers, integrable into web, Feishu, DingTalk, WeChat Official Account, and WeCom applications.
## Quick Experience
Run the following command in your terminal for one-click install, configuration, and startup:
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
By default, the Web service starts after running. Access `http://localhost:9899/chat` to chat in the web interface.
Complete installation and run guide
CowAgent system architecture design
## Disclaimer
1. This project follows the [MIT License](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/LICENSE) and is intended for technical research and learning. Users must comply with local laws, regulations, policies, and corporate bylaws. Any illegal or rights-infringing use is prohibited.
2. Agent mode consumes more tokens than normal chat mode. Choose models based on effectiveness and cost. Agent has access to the host operating system — deploy with caution.
3. CowAgent focuses on open-source development and does not participate in, authorize, or issue any cryptocurrency.
## Community
Add our assistant on WeChat to join the open-source community:
 ================================================
FILE: docs/en/memory.mdx
================================================
---
title: Memory
description: CowAgent long-term memory system
---
The memory system enables the Agent to remember important information over time, continuously accumulating experience, understanding user preferences, and truly achieving autonomous thinking and continuous growth.
## Memory Types
### Core Memory (MEMORY.md)
Stored in `~/cow/MEMORY.md`, containing long-term user preferences, important decisions, key facts, and other information that doesn't fade over time. Automatically injected into the system prompt on every conversation turn as background knowledge.
### Daily Memory (memory/YYYY-MM-DD.md)
Stored in `~/cow/memory/` directory, named by date (e.g. `2026-03-08.md`), recording daily conversation summaries and key events. Files are only created on first write to avoid generating empty files.
## Memory Writing
The Agent automatically persists conversation content to daily memory through the following mechanisms:
- **On context trimming** — When conversation turns or tokens exceed the configured limit, the oldest half of the context is trimmed in batch, and the discarded content is summarized by LLM into key information and written to the daily memory file
- **Daily scheduled summary** — A full summary is automatically triggered at 23:55 every day, ensuring memory is preserved even on low-activity days (skipped if content hasn't changed)
- **On API context overflow** — When the model API returns a context overflow error, the current conversation summary is saved as an emergency measure
All memory writes run asynchronously in a background thread (LLM summarization + file writing), never blocking normal conversation replies.
## First Launch
On first launch, the Agent will proactively ask the user for key information and save it to the workspace (default `~/cow`):
| File | Description |
| --- | --- |
| `system.md` | Agent system prompt and behavior settings |
| `user.md` | User identity information and preferences |
| `MEMORY.md` | Core memory (long-term) |
| `memory/YYYY-MM-DD.md` | Daily memory (created on demand) |
## Memory Retrieval
The memory system supports hybrid retrieval modes:
- **Keyword retrieval** — Match historical memory based on keywords
- **Vector retrieval** — Semantic similarity search, finds relevant memory even with different wording
The Agent automatically triggers memory retrieval during conversation as needed, incorporating relevant historical information into context. Core memory (`MEMORY.md`) is always injected into the system prompt, while daily memory is loaded on demand via retrieval.
## Configuration
```json
{
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 20
}
```
| Parameter | Description | Default |
| --- | --- | --- |
| `agent_workspace` | Workspace path, memory files stored under this directory | `~/cow` |
| `agent_max_context_tokens` | Max context tokens; when exceeded, half is trimmed and summarized into memory | `40000` |
| `agent_max_context_turns` | Max context turns; when exceeded, half is trimmed and summarized into memory | `20` |
================================================
FILE: docs/en/models/claude.mdx
================================================
---
title: Claude
description: Claude model configuration
---
```json
{
"model": "claude-sonnet-4-6",
"claude_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `claude-sonnet-4-6`, `claude-opus-4-6`, `claude-sonnet-4-5`, `claude-sonnet-4-0`, `claude-3-5-sonnet-latest`, etc. See [official models](https://docs.anthropic.com/en/docs/about-claude/models/overview) |
| `claude_api_key` | Create at [Claude Console](https://console.anthropic.com/settings/keys) |
| `claude_api_base` | Optional. Defaults to `https://api.anthropic.com/v1`. Change to use third-party proxy |
================================================
FILE: docs/en/models/coding-plan.mdx
================================================
---
title: Coding Plan
description: Coding Plan model configuration
---
> Coding Plan is a monthly subscription package offered by various providers, ideal for high-frequency Agent usage. CowAgent supports all Coding Plan providers via OpenAI-compatible mode.
Coding Plan API Base and API Key are usually separate from the standard pay-as-you-go ones. Please obtain them from each provider's platform.
## General Configuration
All providers can be accessed via the OpenAI-compatible protocol, and can be quickly configured through the web console. Set the model provider to **OpenAI**, select a custom model and enter the model code, then fill in the corresponding provider's API Base and API Key:
================================================
FILE: docs/en/memory.mdx
================================================
---
title: Memory
description: CowAgent long-term memory system
---
The memory system enables the Agent to remember important information over time, continuously accumulating experience, understanding user preferences, and truly achieving autonomous thinking and continuous growth.
## Memory Types
### Core Memory (MEMORY.md)
Stored in `~/cow/MEMORY.md`, containing long-term user preferences, important decisions, key facts, and other information that doesn't fade over time. Automatically injected into the system prompt on every conversation turn as background knowledge.
### Daily Memory (memory/YYYY-MM-DD.md)
Stored in `~/cow/memory/` directory, named by date (e.g. `2026-03-08.md`), recording daily conversation summaries and key events. Files are only created on first write to avoid generating empty files.
## Memory Writing
The Agent automatically persists conversation content to daily memory through the following mechanisms:
- **On context trimming** — When conversation turns or tokens exceed the configured limit, the oldest half of the context is trimmed in batch, and the discarded content is summarized by LLM into key information and written to the daily memory file
- **Daily scheduled summary** — A full summary is automatically triggered at 23:55 every day, ensuring memory is preserved even on low-activity days (skipped if content hasn't changed)
- **On API context overflow** — When the model API returns a context overflow error, the current conversation summary is saved as an emergency measure
All memory writes run asynchronously in a background thread (LLM summarization + file writing), never blocking normal conversation replies.
## First Launch
On first launch, the Agent will proactively ask the user for key information and save it to the workspace (default `~/cow`):
| File | Description |
| --- | --- |
| `system.md` | Agent system prompt and behavior settings |
| `user.md` | User identity information and preferences |
| `MEMORY.md` | Core memory (long-term) |
| `memory/YYYY-MM-DD.md` | Daily memory (created on demand) |
## Memory Retrieval
The memory system supports hybrid retrieval modes:
- **Keyword retrieval** — Match historical memory based on keywords
- **Vector retrieval** — Semantic similarity search, finds relevant memory even with different wording
The Agent automatically triggers memory retrieval during conversation as needed, incorporating relevant historical information into context. Core memory (`MEMORY.md`) is always injected into the system prompt, while daily memory is loaded on demand via retrieval.
## Configuration
```json
{
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 20
}
```
| Parameter | Description | Default |
| --- | --- | --- |
| `agent_workspace` | Workspace path, memory files stored under this directory | `~/cow` |
| `agent_max_context_tokens` | Max context tokens; when exceeded, half is trimmed and summarized into memory | `40000` |
| `agent_max_context_turns` | Max context turns; when exceeded, half is trimmed and summarized into memory | `20` |
================================================
FILE: docs/en/models/claude.mdx
================================================
---
title: Claude
description: Claude model configuration
---
```json
{
"model": "claude-sonnet-4-6",
"claude_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `claude-sonnet-4-6`, `claude-opus-4-6`, `claude-sonnet-4-5`, `claude-sonnet-4-0`, `claude-3-5-sonnet-latest`, etc. See [official models](https://docs.anthropic.com/en/docs/about-claude/models/overview) |
| `claude_api_key` | Create at [Claude Console](https://console.anthropic.com/settings/keys) |
| `claude_api_base` | Optional. Defaults to `https://api.anthropic.com/v1`. Change to use third-party proxy |
================================================
FILE: docs/en/models/coding-plan.mdx
================================================
---
title: Coding Plan
description: Coding Plan model configuration
---
> Coding Plan is a monthly subscription package offered by various providers, ideal for high-frequency Agent usage. CowAgent supports all Coding Plan providers via OpenAI-compatible mode.
Coding Plan API Base and API Key are usually separate from the standard pay-as-you-go ones. Please obtain them from each provider's platform.
## General Configuration
All providers can be accessed via the OpenAI-compatible protocol, and can be quickly configured through the web console. Set the model provider to **OpenAI**, select a custom model and enter the model code, then fill in the corresponding provider's API Base and API Key:
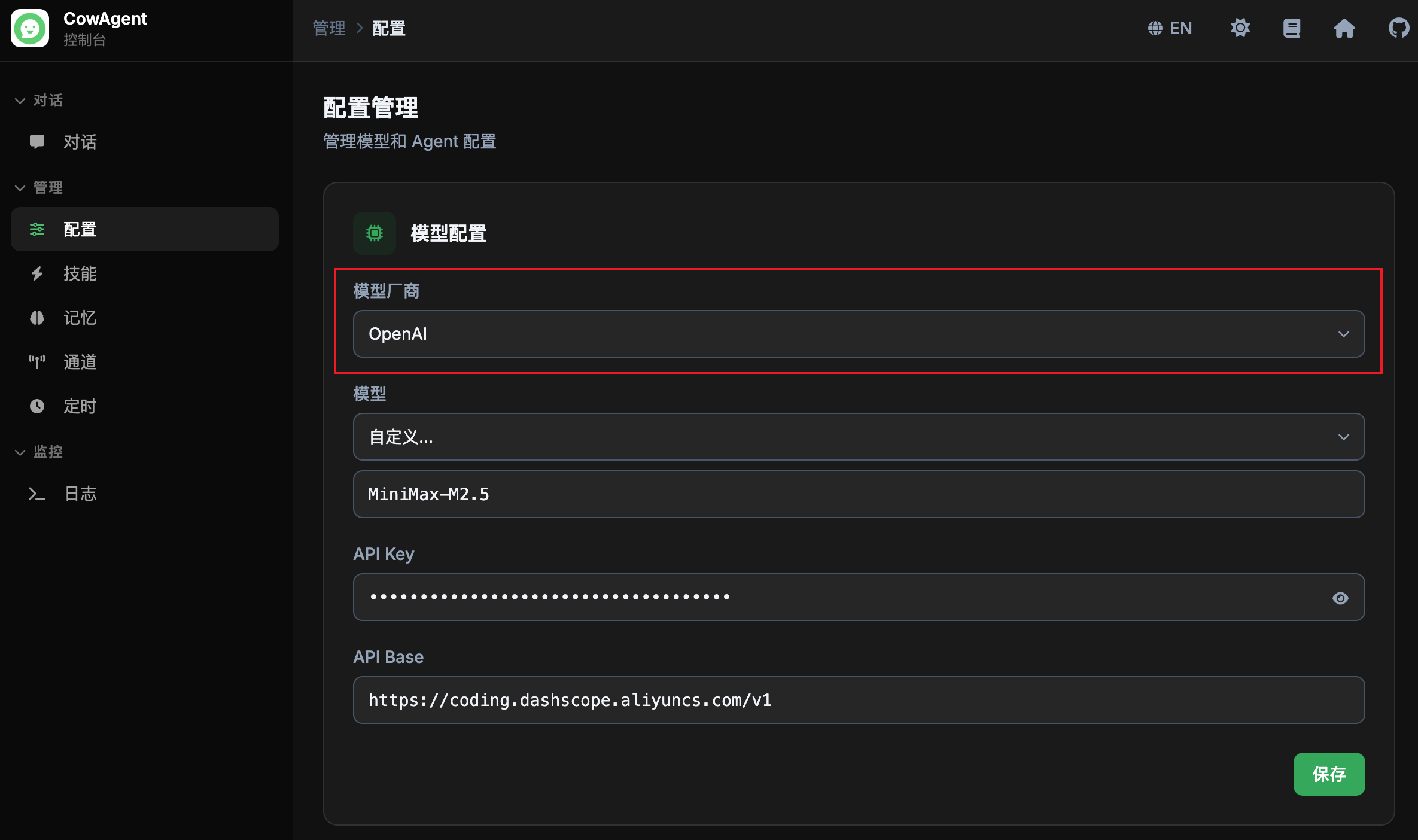 You can also configure directly in `config.json`:
```json
{
"bot_type": "openai",
"model": "MODEL_NAME",
"open_ai_api_base": "PROVIDER_CODING_PLAN_API_BASE",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `bot_type` | Must be `openai` (OpenAI-compatible mode) |
| `model` | Model name supported by the provider |
| `open_ai_api_base` | Provider's Coding Plan API Base URL |
| `open_ai_api_key` | Provider's Coding Plan API Key |
---
## Alibaba Cloud
```json
{
"bot_type": "openai",
"model": "qwen3.5-plus",
"open_ai_api_base": "https://coding.dashscope.aliyuncs.com/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | `qwen3.5-plus`, `qwen3-max-2026-01-23`, `qwen3-coder-next`, `qwen3-coder-plus`, `glm-5`, `glm-4.7`, `kimi-k2.5`, `MiniMax-M2.5` |
| `open_ai_api_base` | `https://coding.dashscope.aliyuncs.com/v1` |
| `open_ai_api_key` | Coding Plan specific key (not shared with pay-as-you-go) |
Reference: [Quick Start](https://help.aliyun.com/zh/model-studio/coding-plan-quickstart?spm=a2c4g.11186623.help-menu-2400256.d_0_2_1.70115203zi5Igc), [Model List](https://help.aliyun.com/zh/model-studio/coding-plan)
---
## MiniMax
```json
{
"bot_type": "openai",
"model": "MiniMax-M2.5",
"open_ai_api_base": "https://api.minimaxi.com/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | `MiniMax-M2.5`, `MiniMax-M2.5-highspeed`, `MiniMax-M2.1`, `MiniMax-M2` |
| `open_ai_api_base` | China: `https://api.minimaxi.com/v1`; Global: `https://api.minimax.io/v1` |
| `open_ai_api_key` | Coding Plan specific key (not shared with pay-as-you-go) |
Reference: [China Key](https://platform.minimaxi.com/docs/coding-plan/quickstart), [Model List](https://platform.minimaxi.com/docs/guides/pricing-coding-plan), [Global Key](https://platform.minimax.io/docs/coding-plan/quickstart)
---
## Zhipu GLM
```json
{
"bot_type": "openai",
"model": "glm-4.7",
"open_ai_api_base": "https://open.bigmodel.cn/api/coding/paas/v4",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | `glm-5`, `glm-4.7`, `glm-4.6`, `glm-4.5`, `glm-4.5-air` |
| `open_ai_api_base` | China: `https://open.bigmodel.cn/api/coding/paas/v4`; Global: `https://api.z.ai/api/coding/paas/v4` |
| `open_ai_api_key` | Shared with standard API |
Reference: [China Quick Start](https://docs.bigmodel.cn/cn/coding-plan/quick-start), [Global Quick Start](https://docs.z.ai/devpack/quick-start)
---
## Kimi
```json
{
"bot_type": "openai",
"model": "kimi-for-coding",
"open_ai_api_base": "https://api.kimi.com/coding/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | `kimi-for-coding` |
| `open_ai_api_base` | `https://api.kimi.com/coding/v1` |
| `open_ai_api_key` | Coding Plan specific key (not shared with pay-as-you-go) |
Reference: [Key & Docs](https://www.kimi.com/code/docs/)
---
## Volcengine
```json
{
"bot_type": "openai",
"model": "Doubao-Seed-2.0-Code",
"open_ai_api_base": "https://ark.cn-beijing.volces.com/api/coding/v3",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | `Doubao-Seed-2.0-Code`, `Doubao-Seed-2.0-pro`, `Doubao-Seed-2.0-lite`, `Doubao-Seed-Code`, `MiniMax-M2.5`, `Kimi-K2.5`, `GLM-4.7`, `DeepSeek-V3.2` |
| `open_ai_api_base` | `https://ark.cn-beijing.volces.com/api/coding/v3` |
| `open_ai_api_key` | Shared with standard API |
Reference: [Quick Start](https://www.volcengine.com/docs/82379/1928261?lang=zh)
================================================
FILE: docs/en/models/deepseek.mdx
================================================
---
title: DeepSeek
description: DeepSeek model configuration
---
Use OpenAI-compatible configuration:
```json
{
"model": "deepseek-chat",
"bot_type": "openai",
"open_ai_api_key": "YOUR_API_KEY",
"open_ai_api_base": "https://api.deepseek.com/v1"
}
```
| Parameter | Description |
| --- | --- |
| `model` | `deepseek-chat` (DeepSeek-V3), `deepseek-reasoner` (DeepSeek-R1) |
| `bot_type` | Must be `openai` (OpenAI-compatible mode) |
| `open_ai_api_key` | Create at [DeepSeek Platform](https://platform.deepseek.com/api_keys) |
| `open_ai_api_base` | DeepSeek platform BASE URL |
================================================
FILE: docs/en/models/doubao.mdx
================================================
---
title: Doubao (ByteDance)
description: Doubao (Volcano Ark) model configuration
---
```json
{
"model": "doubao-seed-2-0-code-preview-260215",
"ark_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `doubao-seed-2-0-code-preview-260215`, `doubao-seed-2-0-pro-260215`, `doubao-seed-2-0-lite-260215`, etc. |
| `ark_api_key` | Create at [Volcano Ark Console](https://console.volcengine.com/ark/region:ark+cn-beijing/apikey) |
| `ark_base_url` | Optional. Defaults to `https://ark.cn-beijing.volces.com/api/v3` |
================================================
FILE: docs/en/models/gemini.mdx
================================================
---
title: Gemini
description: Google Gemini model configuration
---
```json
{
"model": "gemini-3.1-pro-preview",
"gemini_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `gemini-3.1-flash-lite-preview`, `gemini-3.1-pro-preview`, `gemini-3-flash-preview`, `gemini-3-pro-preview`, etc. See [official docs](https://ai.google.dev/gemini-api/docs/models) |
| `gemini_api_key` | Create at [Google AI Studio](https://aistudio.google.com/app/apikey) |
================================================
FILE: docs/en/models/glm.mdx
================================================
---
title: GLM (Zhipu AI)
description: Zhipu AI GLM model configuration
---
```json
{
"model": "glm-5-turbo",
"zhipu_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `glm-5-turbo`, `glm-5`, `glm-4.7`, `glm-4-plus`, `glm-4-flash`, `glm-4-air`, etc. See [model codes](https://bigmodel.cn/dev/api/normal-model/glm-4) |
| `zhipu_ai_api_key` | Create at [Zhipu AI Console](https://www.bigmodel.cn/usercenter/proj-mgmt/apikeys) |
OpenAI-compatible configuration is also supported:
```json
{
"bot_type": "openai",
"model": "glm-5-turbo",
"open_ai_api_base": "https://open.bigmodel.cn/api/paas/v4",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/en/models/index.mdx
================================================
---
title: Models Overview
description: Supported models and recommended choices for CowAgent
---
CowAgent supports mainstream LLMs from domestic and international providers. Model interfaces are implemented in the project's `models/` directory.
For Agent mode, the following models are recommended based on quality and cost: MiniMax-M2.7, glm-5-turbo, kimi-k2.5, qwen3.5-plus, claude-sonnet-4-6, gemini-3.1-pro-preview
## Configuration
Configure the model name and API key in `config.json` according to your chosen model. Each model also supports OpenAI-compatible access by setting `bot_type` to `openai` and configuring `open_ai_api_base` and `open_ai_api_key`.
You can also use the [LinkAI](https://link-ai.tech) platform interface to flexibly switch between multiple models with support for knowledge base, workflows, and other Agent capabilities.
## Supported Models
MiniMax-M2.7 and other series models
glm-5-turbo, glm-5 and other series models
qwen3.5-plus, qwen3-max and more
kimi-k2.5, kimi-k2 and more
doubao-seed series models
claude-sonnet-4-6 and more
gemini-3.1-pro-preview and more
gpt-5.4, gpt-4.1, o-series and more
deepseek-chat, deepseek-reasoner
Unified multi-model interface + knowledge base
For a full list of model names, refer to the project's [`common/const.py`](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/common/const.py) file.
================================================
FILE: docs/en/models/kimi.mdx
================================================
---
title: Kimi (Moonshot)
description: Kimi (Moonshot) model configuration
---
```json
{
"model": "kimi-k2.5",
"moonshot_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `kimi-k2.5`, `kimi-k2`, `moonshot-v1-8k`, `moonshot-v1-32k`, `moonshot-v1-128k` |
| `moonshot_api_key` | Create at [Moonshot Console](https://platform.moonshot.cn/console/api-keys) |
OpenAI-compatible configuration is also supported:
```json
{
"bot_type": "openai",
"model": "kimi-k2.5",
"open_ai_api_base": "https://api.moonshot.cn/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/en/models/linkai.mdx
================================================
---
title: LinkAI
description: Unified access to multiple models via LinkAI platform
---
The [LinkAI](https://link-ai.tech) platform lets you flexibly switch between OpenAI, Claude, Gemini, DeepSeek, Qwen, Kimi, and other models, with support for knowledge base, workflows, plugins, and other Agent capabilities.
```json
{
"use_linkai": true,
"linkai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `use_linkai` | Set to `true` to enable LinkAI interface |
| `linkai_api_key` | Create at [LinkAI Console](https://link-ai.tech/console/interface) |
| `model` | Leave empty to use the agent's default model. Can be switched flexibly on the platform. All models in the [model list](https://link-ai.tech/console/models) are supported |
See the [API documentation](https://docs.link-ai.tech/platform/api) for more details.
================================================
FILE: docs/en/models/minimax.mdx
================================================
---
title: MiniMax
description: MiniMax model configuration
---
```json
{
"model": "MiniMax-M2.7",
"minimax_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `MiniMax-M2.7`, `MiniMax-M2.5`, `MiniMax-M2.1`, `MiniMax-M2.1-lightning`, `MiniMax-M2`, etc. |
| `minimax_api_key` | Create at [MiniMax Console](https://platform.minimaxi.com/user-center/basic-information/interface-key) |
OpenAI-compatible configuration is also supported:
```json
{
"bot_type": "openai",
"model": "MiniMax-M2.7",
"open_ai_api_base": "https://api.minimaxi.com/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/en/models/openai.mdx
================================================
---
title: OpenAI
description: OpenAI model configuration
---
```json
{
"model": "gpt-5.4",
"open_ai_api_key": "YOUR_API_KEY",
"open_ai_api_base": "https://api.openai.com/v1"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Matches the [model parameter](https://platform.openai.com/docs/models) of the OpenAI API. Supports o-series, gpt-5.4, gpt-5 series, gpt-4.1, etc. Recommended for Agent mode: `gpt-5.4` |
| `open_ai_api_key` | Create at [OpenAI Platform](https://platform.openai.com/api-keys) |
| `open_ai_api_base` | Optional. Change to use third-party proxy |
| `bot_type` | Not required for official OpenAI models. Set to `openai` when using Claude or other non-OpenAI models via proxy |
================================================
FILE: docs/en/models/qwen.mdx
================================================
---
title: Qwen (Tongyi Qianwen)
description: Tongyi Qianwen model configuration
---
```json
{
"model": "qwen3.5-plus",
"dashscope_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `qwen3.5-plus`, `qwen3-max`, `qwen-max`, `qwen-plus`, `qwen-turbo`, `qwq-plus`, etc. |
| `dashscope_api_key` | Create at [Bailian Console](https://bailian.console.aliyun.com/?tab=model#/api-key). See [official docs](https://bailian.console.aliyun.com/?tab=api#/api) |
OpenAI-compatible configuration is also supported:
```json
{
"bot_type": "openai",
"model": "qwen3.5-plus",
"open_ai_api_base": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/en/releases/overview.mdx
================================================
---
title: Changelog
description: CowAgent version history
---
| Version | Date | Description |
| --- | --- | --- |
| [2.0.2](/en/releases/v2.0.2) | 2026.02.27 | Web Console upgrade, multi-channel concurrency, session persistence |
| [2.0.1](/en/releases/v2.0.1) | 2026.02.27 | Built-in Web Search tool, smart context management, multiple fixes |
| [2.0.0](/en/releases/v2.0.0) | 2026.02.03 | Full upgrade to AI super assistant |
| 1.7.6 | 2025.05.23 | Web Channel optimization, AgentMesh plugin |
| 1.7.5 | 2025.04.11 | DeepSeek model |
| 1.7.4 | 2024.12.13 | Gemini 2.0 model, Web Channel |
| 1.7.3 | 2024.10.31 | Stability improvements, database features |
| 1.7.2 | 2024.09.26 | One-click install script, o1 model |
| 1.7.0 | 2024.08.02 | iFlytek 4.0 model, knowledge base references |
| 1.6.9 | 2024.07.19 | gpt-4o-mini, Alibaba voice recognition |
| 1.6.8 | 2024.07.05 | Claude 3.5, Gemini 1.5 Pro |
| 1.6.0 | 2024.04.26 | Kimi integration, gpt-4-turbo upgrade |
| 1.5.0 | 2023.11.10 | gpt-4-turbo, dall-e-3, tts multimodal |
| 1.0.0 | 2022.12.12 | Project created, first ChatGPT integration |
See [GitHub Releases](https://github.com/zhayujie/chatgpt-on-wechat/releases) for full history.
================================================
FILE: docs/en/releases/v2.0.0.mdx
================================================
---
title: v2.0.0
description: CowAgent 2.0 - Full upgrade from chatbot to AI super assistant
---
CowAgent 2.0 is a comprehensive upgrade from a chatbot to an **AI super assistant** — capable of autonomous thinking and task planning, long-term memory, operating computers, and creating and executing skills.
**Release Date**: 2026.02.03 | [GitHub Release](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.0)
## Key Updates
### Agent Core
- **Complex Task Planning**: Autonomous planning with multi-turn reasoning
- **Long-term Memory**: Persistent memory with keyword and vector search
- **Built-in Tools**: 10+ tools including file ops, Bash, browser, scheduler
- **Web search**: Built-in `web_search` tool, supports multiple search engines, configure corresponding API key to use
- **Skills System**: Skill engine with built-in and custom skill support
- **Security & Cost**: Secret management, prompt controls, token limits
### Other
- **Channels**: Feishu/DingTalk WebSocket support, image/file messages
- **Models**: claude-sonnet-4-5, gemini-3-pro-preview, glm-4.7, MiniMax-M2.1, qwen3-max
- **Deployment**: One-click install, configure, run, and management script
## Long-term Memory
## Task Planning & Tools
## Skills System
## Contributing
Welcome to [submit feedback](https://github.com/zhayujie/chatgpt-on-wechat/issues) and [contribute code](https://github.com/zhayujie/chatgpt-on-wechat/pulls).
================================================
FILE: docs/en/releases/v2.0.1.mdx
================================================
---
title: v2.0.1
description: CowAgent 2.0.1 - Built-in Web Search, smart context management, multiple fixes
---
**Release Date**: 2026.02.27 | [Full Changelog](https://github.com/zhayujie/chatgpt-on-wechat/compare/2.0.0..2.0.1)
## New Features
- **Built-in Web Search tool**: Integrated web search as a built-in Agent tool, reducing decision cost ([4f0ea5d](https://github.com/zhayujie/chatgpt-on-wechat/commit/4f0ea5d7568d61db91ff69c91c429e785fd1b1c2))
- **Claude Opus 4.6 model support**: Added support for Claude Opus 4.6 model ([#2661](https://github.com/zhayujie/chatgpt-on-wechat/pull/2661))
- **WeCom image recognition**: Support image message recognition in WeCom channel ([#2667](https://github.com/zhayujie/chatgpt-on-wechat/pull/2667))
## Improvements
- **Smart context management**: Resolved chat context overflow with intelligent context trimming strategy to prevent token limits ([cea7fb7](https://github.com/zhayujie/chatgpt-on-wechat/commit/cea7fb7490c53454602bf05955a0e9f059bcf0fd), [8acf2db](https://github.com/zhayujie/chatgpt-on-wechat/commit/8acf2dbdfe713b84ad74b761b7f86674b1c1904d)) [#2663](https://github.com/zhayujie/chatgpt-on-wechat/issues/2663)
- **Runtime info dynamic update**: Automatic update of timestamps and other runtime info in system prompts via dynamic functions ([#2655](https://github.com/zhayujie/chatgpt-on-wechat/pull/2655), [#2657](https://github.com/zhayujie/chatgpt-on-wechat/pull/2657))
- **Skill prompt optimization**: Improved Skill system prompt generation, simplified tool descriptions for better Agent performance ([6c21833](https://github.com/zhayujie/chatgpt-on-wechat/commit/6c218331b1f1208ea8be6bf226936d3b556ade3e))
- **GLM custom API Base URL**: Support custom API Base URL for GLM models ([#2660](https://github.com/zhayujie/chatgpt-on-wechat/pull/2660))
- **Startup script optimization**: Improved `run.sh` script interaction and configuration flow ([#2656](https://github.com/zhayujie/chatgpt-on-wechat/pull/2656))
- **Decision step logging**: Added Agent decision step logging for debugging ([cb303e6](https://github.com/zhayujie/chatgpt-on-wechat/commit/cb303e6109c50c8dfef1f5e6c1ec47223bf3cd11))
## Bug Fixes
- **Scheduler memory loss**: Fixed memory loss caused by Scheduler dispatcher ([a77a874](https://github.com/zhayujie/chatgpt-on-wechat/commit/a77a8741b500a408c6f5c8868856fb4b018fe9db))
- **Empty tool calls & long results**: Fixed handling of empty tool calls and excessively long tool results ([0542700](https://github.com/zhayujie/chatgpt-on-wechat/commit/0542700f9091ebb08c1a56103b0f0f45f24aa621))
- **OpenAI Function Call**: Fixed function call compatibility with OpenAI models ([158c87a](https://github.com/zhayujie/chatgpt-on-wechat/commit/158c87ab8b05bae054cc1b4eacdbb64fc1062ba9))
- **Claude tool name field**: Removed extraneous tool name field from Claude model responses ([eec10cb](https://github.com/zhayujie/chatgpt-on-wechat/commit/eec10cb5db6a3d5bc12ef606606532237d2c5f6e))
- **MiniMax reasoning**: Optimized MiniMax model reasoning content handling, hidden thinking process output ([c72cda3](https://github.com/zhayujie/chatgpt-on-wechat/commit/c72cda33864bd1542012ee6e0a8bd8c6c88cb5ed), [72b1cac](https://github.com/zhayujie/chatgpt-on-wechat/commit/72b1cacea1ba0d1f3dedacbab2e088e98fd7e172))
- **GLM thinking process**: Hidden GLM model thinking process display ([72b1cac](https://github.com/zhayujie/chatgpt-on-wechat/commit/72b1cacea1ba0d1f3dedacbab2e088e98fd7e172))
- **Feishu connection & SSL**: Fixed Feishu channel SSL certificate errors and connection issues ([229b14b](https://github.com/zhayujie/chatgpt-on-wechat/commit/229b14b6fcabe7123d53cab1dea39f38dab26d6d), [8674421](https://github.com/zhayujie/chatgpt-on-wechat/commit/867442155e7f095b4f38b0856f8c1d8312b5fcf7))
- **model_type validation**: Fixed `AttributeError` caused by non-string `model_type` ([#2666](https://github.com/zhayujie/chatgpt-on-wechat/pull/2666))
## Platform Compatibility
- **Windows compatibility**: Fixed path handling, file encoding, and `os.getuid()` unavailability on Windows across multiple tool modules ([051ffd7](https://github.com/zhayujie/chatgpt-on-wechat/commit/051ffd78a372f71a967fd3259e37fe19131f83cf), [5264f7c](https://github.com/zhayujie/chatgpt-on-wechat/commit/5264f7ce18360ee4db5dcb4ebe67307977d40014))
================================================
FILE: docs/en/releases/v2.0.2.mdx
================================================
---
title: v2.0.2
description: CowAgent 2.0.2 - Web Console upgrade, multi-channel concurrency, session persistence
---
**Release Date**: 2026.02.27 | [Full Changelog](https://github.com/zhayujie/chatgpt-on-wechat/compare/2.0.1...master)
## Highlights
### 🖥️ Web Console Upgrade
The Web Console has been fully upgraded with streaming conversation output, visual display of tool execution and reasoning processes, and online management of **models, skills, memory, channels, and Agent configuration**.
#### Chat Interface
Supports streaming output with real-time display of the Agent's reasoning process and tool calls, providing intuitive observation of the Agent's decision-making:
#### Model Management
Manage model configurations online without manually editing config files:
#### Skill Management
View and manage Agent skills (Skills) online:
#### Memory Management
View and manage Agent memory online:
#### Channel Management
Manage connected channels online with real-time connect/disconnect operations:
#### Scheduled Tasks
View and manage scheduled tasks online, including one-time tasks, fixed intervals, and Cron expressions:
#### Logs
View Agent runtime logs in real-time for monitoring and troubleshooting:
Related commits: [f1a1413](https://github.com/zhayujie/chatgpt-on-wechat/commit/f1a1413), [c0702c8](https://github.com/zhayujie/chatgpt-on-wechat/commit/c0702c8), [394853c](https://github.com/zhayujie/chatgpt-on-wechat/commit/394853c), [1c71c4e](https://github.com/zhayujie/chatgpt-on-wechat/commit/1c71c4e), [5e3eccb](https://github.com/zhayujie/chatgpt-on-wechat/commit/5e3eccb), [e1dc037](https://github.com/zhayujie/chatgpt-on-wechat/commit/e1dc037), [5edbf4c](https://github.com/zhayujie/chatgpt-on-wechat/commit/5edbf4c), [7d258b5](https://github.com/zhayujie/chatgpt-on-wechat/commit/7d258b5)
### 🔀 Multi-Channel Concurrency
Multiple channels (e.g., Feishu, DingTalk, WeCom, Web) can now run simultaneously, each in an independent thread without interference.
Configuration: Set multiple channels in `config.json` via `channel_type` separated by commas, or connect/disconnect channels in real-time from the Web Console's channel management page.
```json
{
"channel_type": "web,feishu,dingtalk"
}
```
Related commits: [4694594](https://github.com/zhayujie/chatgpt-on-wechat/commit/4694594), [7cce224](https://github.com/zhayujie/chatgpt-on-wechat/commit/7cce224), [7d258b5](https://github.com/zhayujie/chatgpt-on-wechat/commit/7d258b5), [c9adddb](https://github.com/zhayujie/chatgpt-on-wechat/commit/c9adddb)
### 💾 Session Persistence
Session history is now persisted to a local SQLite database. Conversation context is automatically restored after service restarts. Historical conversations in the Web Console are also restored.
Related commits: [29bfbec](https://github.com/zhayujie/chatgpt-on-wechat/commit/29bfbec), [9917552](https://github.com/zhayujie/chatgpt-on-wechat/commit/9917552), [925d728](https://github.com/zhayujie/chatgpt-on-wechat/commit/925d728)
## New Models
- **Gemini 3.1 Pro Preview**: Added `gemini-3.1-pro-preview` model support ([52d7cad](https://github.com/zhayujie/chatgpt-on-wechat/commit/52d7cad))
- **Claude 4.6 Sonnet**: Added `claude-4.6-sonnet` model support ([52d7cad](https://github.com/zhayujie/chatgpt-on-wechat/commit/52d7cad))
- **Qwen3.5 Plus**: Added `qwen3.5-plus` model support ([e59a289](https://github.com/zhayujie/chatgpt-on-wechat/commit/e59a289))
- **MiniMax M2.5**: Added `Minimax-M2.5` model support ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
- **GLM-5**: Added `glm-5` model support ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
- **Kimi K2.5**: Added `kimi-k2.5` model support ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
- **Doubao 2.0 Code**: Added `doubao-2.0-code` coding-specialized model ([ab28ee5](https://github.com/zhayujie/chatgpt-on-wechat/commit/ab28ee5))
- **DashScope Models**: Added Alibaba Cloud DashScope model name support ([ce58f23](https://github.com/zhayujie/chatgpt-on-wechat/commit/ce58f23))
## Website & Documentation
- **Official Website**: [cowagent.ai](https://cowagent.ai/)
- **Documentation**: [docs.cowagent.ai](https://docs.cowagent.ai/)
## Bug Fixes
- **Gemini DingTalk image recognition**: Fixed Gemini unable to process image markers in DingTalk channel ([05a3304](https://github.com/zhayujie/chatgpt-on-wechat/commit/05a3304)) ([#2670](https://github.com/zhayujie/chatgpt-on-wechat/pull/2670)) Thanks [@SgtPepper114](https://github.com/SgtPepper114)
- **Startup script dependencies**: Fixed dependency installation issue in `run.sh` script ([b6fc9fa](https://github.com/zhayujie/chatgpt-on-wechat/commit/b6fc9fa))
- **Bare except cleanup**: Replaced `bare except` with `except Exception` for better exception handling ([adca89b](https://github.com/zhayujie/chatgpt-on-wechat/commit/adca89b)) ([#2674](https://github.com/zhayujie/chatgpt-on-wechat/pull/2674)) Thanks [@haosenwang1018](https://github.com/haosenwang1018)
================================================
FILE: docs/en/skills/image-vision.mdx
================================================
---
title: Image Vision
description: Recognize images using OpenAI vision models
---
Analyze image content using OpenAI's GPT-4 Vision API, understanding objects, text, colors, and other elements in images.
## Dependencies
| Dependency | Description |
| --- | --- |
| `OPENAI_API_KEY` | OpenAI API key |
| `curl`, `base64` | System commands (usually pre-installed) |
Configuration:
- Configure `OPENAI_API_KEY` via the `env_config` tool
- Or set `open_ai_api_key` in `config.json`
## Supported Models
- `gpt-4.1-mini` (recommended, cost-effective)
- `gpt-4.1`
## Usage
Once configured, send an image to the Agent to automatically trigger image recognition.
================================================
FILE: docs/en/skills/index.mdx
================================================
---
title: Skills Overview
description: CowAgent skills system introduction
---
Skills provide infinite extensibility for the Agent. Each Skill consists of a description file (`SKILL.md`), execution scripts (optional), and resources (optional), describing how to accomplish specific types of tasks.
The difference between Skills and Tools: Tools are atomic operations implemented in code (e.g., file read/write, command execution), while Skills are high-level workflows based on description files that can combine multiple Tools to complete complex tasks.
## Built-in Skills
Located in the project `skills/` directory, automatically enabled based on dependency conditions:
| Skill | Description | Dependencies |
| --- | --- | --- |
| [`skill-creator`](/en/skills/skill-creator) | Create custom skills through conversation | None |
| [`openai-image-vision`](/en/skills/image-vision) | Recognize images using OpenAI vision models | `OPENAI_API_KEY` |
| [`linkai-agent`](/en/skills/linkai-agent) | Integrate LinkAI platform agents | `LINKAI_API_KEY` |
| [`web-fetch`](/en/skills/web-fetch) | Fetch web page text content | `curl` (enabled by default) |
## Custom Skills
Created by users through conversation, stored in workspace (`~/cow/skills/`), can implement any complex business process and third-party system integration.
## Skill Loading Priority
1. **Workspace skills** (highest): `~/cow/skills/`
2. **Project built-in skills** (lowest): `skills/`
Skills with the same name are overridden by priority.
## Skill File Structure
```
skills/
├── my-skill/
│ ├── SKILL.md # Skill description (frontmatter + instructions)
│ ├── scripts/ # Execution scripts (optional)
│ └── resources/ # Additional resources (optional)
```
### SKILL.md Format
```markdown
---
name: my-skill
description: Brief description of the skill
metadata:
emoji: 🔧
requires:
bins: ["curl"]
env: ["MY_API_KEY"]
primaryEnv: "MY_API_KEY"
---
# My Skill
Detailed instructions...
```
| Field | Description |
| --- | --- |
| `name` | Skill name, must match directory name |
| `description` | Skill description, Agent decides whether to invoke based on this |
| `metadata.requires.bins` | Required system commands |
| `metadata.requires.env` | Required environment variables |
| `metadata.always` | Always load (default false) |
================================================
FILE: docs/en/skills/linkai-agent.mdx
================================================
---
title: LinkAI Agent
description: Integrate LinkAI platform multi-agent skill
---
Use agents from the [LinkAI](https://link-ai.tech/) platform as Skills for multi-agent decision-making. The Agent intelligently selects based on agent names and descriptions, calling the corresponding application or workflow via `app_code`.
## Dependencies
| Dependency | Description |
| --- | --- |
| `LINKAI_API_KEY` | LinkAI platform API key, created in [Console](https://link-ai.tech/console/interface) |
| `curl` | System command (usually pre-installed) |
Configuration:
- Configure `LINKAI_API_KEY` via the `env_config` tool
- Or set `linkai_api_key` in `config.json`
## Configure Agents
Add available agents in `skills/linkai-agent/config.json`:
```json
{
"apps": [
{
"app_code": "G7z6vKwp",
"app_name": "LinkAI Customer Support",
"app_description": "Select this assistant only when the user needs help with LinkAI platform questions"
},
{
"app_code": "SFY5x7JR",
"app_name": "Content Creator",
"app_description": "Use this assistant only when the user needs to create images or videos"
}
]
}
```
## Usage
Once configured, the Agent will automatically select the appropriate LinkAI agent based on the user's question.
================================================
FILE: docs/en/skills/skill-creator.mdx
================================================
---
title: Skill Creator
description: Create custom skills through conversation
---
Quickly create, install, or update skills through natural language conversation.
## Dependencies
No extra dependencies, always available.
## Usage
- Codify workflows as skills: "Create a skill from this deployment process"
- Integrate third-party APIs: "Create a skill based on this API documentation"
- Install remote skills: "Install xxx skill for me"
## Creation Flow
1. Tell the Agent what skill you want to create
2. Agent automatically generates `SKILL.md` description and execution scripts
3. Skill is saved to the workspace `~/cow/skills/` directory
4. Agent will automatically recognize and use the skill in future conversations
See the [Skill Creator documentation](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/skills/skill-creator/SKILL.md) for details.
================================================
FILE: docs/en/skills/web-fetch.mdx
================================================
---
title: Web Fetch
description: Fetch web page text content
---
Use curl to fetch web pages and extract readable text content. A lightweight web access method without browser automation.
## Dependencies
| Dependency | Description |
| --- | --- |
| `curl` | System command (usually pre-installed) |
This skill has `always: true` set, enabled by default as long as the system has the `curl` command.
## Usage
Automatically invoked when the Agent needs to fetch content from a URL, no extra configuration needed.
## Comparison with browser Tool
| Feature | web-fetch (skill) | browser (tool) |
| --- | --- | --- |
| Dependencies | curl only | browser-use + playwright |
| JS rendering | Not supported | Supported |
| Page interaction | Not supported | Supports click, type, etc. |
| Best for | Static page text | Dynamic web pages |
For most web content retrieval scenarios, web-fetch is sufficient. Only use the browser tool when you need JS rendering or page interaction.
================================================
FILE: docs/en/tools/bash.mdx
================================================
---
title: bash - Terminal
description: Execute system commands
---
Execute Bash commands in the current working directory, returns stdout and stderr. API keys configured via `env_config` are automatically injected into the environment.
## Dependencies
No extra dependencies, available by default.
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `command` | string | Yes | Command to execute |
| `timeout` | integer | No | Timeout in seconds |
## Use Cases
- Install packages and dependencies
- Run code and tests
- Deploy applications and services (Nginx config, process management, etc.)
- System administration and troubleshooting
================================================
FILE: docs/en/tools/browser.mdx
================================================
---
title: browser - Browser
description: Access and interact with web pages
---
Use a browser to access and interact with web pages, supports JavaScript-rendered dynamic pages.
## Dependencies
| Dependency | Install Command |
| --- | --- |
| `browser-use` ≥ 0.1.40 | `pip install browser-use` |
| `markdownify` | `pip install markdownify` |
| `playwright` + chromium | `pip install playwright && playwright install chromium` |
## Use Cases
- Access specific URLs to get page content
- Interact with web page elements (click, type, etc.)
- Verify deployed web pages
- Scrape dynamic content requiring JS rendering
The browser tool has heavy dependencies. If not needed, skip installation. For lightweight web content retrieval, use the `web-fetch` skill instead.
================================================
FILE: docs/en/tools/edit.mdx
================================================
---
title: edit - File Edit
description: Edit files via precise text replacement
---
Edit files via precise text replacement. If `oldText` is empty, appends to the end of the file.
## Dependencies
No extra dependencies, available by default.
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `path` | string | Yes | File path |
| `oldText` | string | Yes | Original text to replace (empty to append) |
| `newText` | string | Yes | Replacement text |
## Use Cases
- Modify specific parameters in configuration files
- Fix bugs in code
- Insert content at specific positions in files
================================================
FILE: docs/en/tools/env-config.mdx
================================================
---
title: env_config - Environment
description: Manage API keys and secrets
---
Manage environment variables (API keys and secrets) in the workspace `.env` file, with secure conversational updates. Built-in security protection and desensitization.
## Dependencies
| Dependency | Install Command |
| --- | --- |
| `python-dotenv` ≥ 1.0.0 | `pip install python-dotenv>=1.0.0` |
Included when installing optional dependencies: `pip3 install -r requirements-optional.txt`
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `action` | string | Yes | Operation type: `get`, `set`, `list`, `delete` |
| `key` | string | No | Environment variable name |
| `value` | string | No | Environment variable value (only for `set`) |
## Usage
Tell the Agent what key you need to configure, and it will automatically invoke this tool:
- "Configure my BOCHA_API_KEY"
- "Set OPENAI_API_KEY to sk-xxx"
- "Show configured environment variables"
Configured keys are automatically injected into the `bash` tool's execution environment.
================================================
FILE: docs/en/tools/index.mdx
================================================
---
title: Tools Overview
description: CowAgent built-in tools system
---
Tools are the core capability for Agent to access operating system resources. The Agent intelligently selects and invokes tools based on task requirements, performing file operations, command execution, web search, scheduled tasks, and more. Tools are implemented in the `agent/tools/` directory.
## Built-in Tools
The following tools are available by default with no extra configuration:
Read file content, supports text, images, PDF
Create or overwrite files
Edit files via precise text replacement
List directory contents
Execute system commands
Send files or images to user
Search and read long-term memory
## Optional Tools
The following tools require additional dependencies or API key configuration:
Manage API keys and secrets
Create and manage scheduled tasks
Search the internet for real-time information
================================================
FILE: docs/en/tools/ls.mdx
================================================
---
title: ls - Directory List
description: List directory contents
---
List directory contents, sorted alphabetically, directories suffixed with `/`, includes hidden files.
## Dependencies
No extra dependencies, available by default.
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `path` | string | Yes | Directory path, relative paths are based on workspace directory |
| `limit` | integer | No | Maximum entries to return, default 500 |
## Use Cases
- Browse project structure
- Find specific files
- Check if a directory exists
================================================
FILE: docs/en/tools/memory.mdx
================================================
---
title: memory - Memory
description: Search and read long-term memory
---
The memory tool contains two sub-tools: `memory_search` (search memory) and `memory_get` (read memory files).
## Dependencies
No extra dependencies, available by default. Managed by the Agent Core memory system.
## memory_search
Search historical memory with hybrid keyword and vector retrieval.
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `query` | string | Yes | Search query |
## memory_get
Read the content of a specific memory file.
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `path` | string | Yes | Relative path to memory file (e.g. `MEMORY.md`, `memory/2026-01-01.md`) |
| `start_line` | integer | No | Start line number |
| `end_line` | integer | No | End line number |
## How It Works
The Agent automatically invokes memory tools in these scenarios:
- When the user shares important information → stores to memory
- When historical context is needed → searches relevant memory
- When conversation reaches a certain length → extracts summary for storage
================================================
FILE: docs/en/tools/read.mdx
================================================
---
title: read - File Read
description: Read file content
---
Read file content. Supports text files, PDF files, images (returns metadata), and more.
## Dependencies
No extra dependencies, available by default.
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `path` | string | Yes | File path, relative paths are based on workspace directory |
| `offset` | integer | No | Start line number (1-indexed), negative values read from the end |
| `limit` | integer | No | Number of lines to read |
## Use Cases
- View configuration files, log files
- Read code files for analysis
- Check image/video file info
================================================
FILE: docs/en/tools/scheduler.mdx
================================================
---
title: scheduler - Scheduler
description: Create and manage scheduled tasks
---
Create and manage dynamic scheduled tasks with flexible scheduling and execution modes.
## Dependencies
| Dependency | Install Command |
| --- | --- |
| `croniter` ≥ 2.0.0 | `pip install croniter>=2.0.0` |
Included in core dependencies: `pip3 install -r requirements.txt`
## Scheduling Modes
| Mode | Description |
| --- | --- |
| One-time | Execute once at a specified time |
| Fixed interval | Repeat at fixed time intervals |
| Cron expression | Define complex schedules using Cron syntax |
## Execution Modes
- **Fixed message**: Send a preset message when triggered
- **Agent dynamic task**: Agent intelligently executes the task when triggered
## Usage
Create and manage scheduled tasks with natural language:
- "Send me a weather report every morning at 9 AM"
- "Check server status every 2 hours"
- "Remind me about the meeting tomorrow at 3 PM"
- "Show all scheduled tasks"
================================================
FILE: docs/en/tools/send.mdx
================================================
---
title: send - File Send
description: Send files to user
---
Send files to the user (images, videos, audio, documents, etc.), used when the user explicitly requests to send/share a file.
## Dependencies
No extra dependencies, available by default.
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `path` | string | Yes | File path, can be absolute or relative to workspace |
| `message` | string | No | Accompanying message |
## Use Cases
- Send generated code or documents to the user
- Send screenshots, charts
- Share downloaded files
================================================
FILE: docs/en/tools/web-search.mdx
================================================
---
title: web_search - Web Search
description: Search the internet for real-time information
---
Search the internet for real-time information, news, research, and more. Supports two search backends with automatic fallback.
## Dependencies
Requires at least one search API key (configured via `env_config` tool or workspace `.env` file):
| Backend | Environment Variable | Priority | How to Get |
| --- | --- | --- | --- |
| Bocha Search | `BOCHA_API_KEY` | Primary | [Bocha Open Platform](https://open.bochaai.com/) |
| LinkAI Search | `LINKAI_API_KEY` | Fallback | [LinkAI Console](https://link-ai.tech/console/interface) |
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `query` | string | Yes | Search keywords |
| `count` | integer | No | Number of results (1-50, default 10) |
| `freshness` | string | No | Time range: `noLimit`, `oneDay`, `oneWeek`, `oneMonth`, `oneYear`, or date range like `2025-01-01..2025-02-01` |
| `summary` | boolean | No | Return page summaries (default false) |
## Use Cases
When the user asks about latest information, needs fact-checking, or real-time data, the Agent automatically invokes this tool.
If no search API key is configured, this tool will not be loaded.
================================================
FILE: docs/en/tools/write.mdx
================================================
---
title: write - File Write
description: Create or overwrite files
---
Write content to a file. Creates the file if it doesn't exist, overwrites if it does. Automatically creates parent directories.
## Dependencies
No extra dependencies, available by default.
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `path` | string | Yes | File path |
| `content` | string | Yes | Content to write |
## Use Cases
- Create new code files or scripts
- Generate configuration files
- Save processing results
Single writes should not exceed 10KB. For large files, create a skeleton first, then use the edit tool to add content in chunks.
================================================
FILE: docs/guide/manual-install.mdx
================================================
---
title: 手动安装
description: 手动部署 CowAgent(源码 / Docker)
---
## 源码部署
### 1. 克隆项目代码
```bash
git clone https://github.com/zhayujie/chatgpt-on-wechat
cd chatgpt-on-wechat/
```
若遇到网络问题可使用国内仓库地址:https://gitee.com/zhayujie/chatgpt-on-wechat
### 2. 安装依赖
核心依赖(必选):
```bash
pip3 install -r requirements.txt
```
扩展依赖(可选,建议安装):
```bash
pip3 install -r requirements-optional.txt
```
### 3. 配置
复制配置文件模板并编辑:
```bash
cp config-template.json config.json
```
在 `config.json` 中填写模型 API Key 和通道类型等配置,详细说明参考各 [模型文档](/models/minimax)。
### 4. 运行
**本地运行:**
```bash
python3 app.py
```
运行后默认启动 Web 控制台,访问 `http://localhost:9899` 开始对话和管理Agent。
**服务器后台运行:**
```bash
nohup python3 app.py & tail -f nohup.out
```
如果在服务器上部署,需要在防火墙或安全组中放行 `9899` 端口才能通过浏览器访问 Web 控制台,建议仅对指定IP开放以保证安全。
## Docker 部署
使用 Docker 部署无需下载源码和安装依赖。Agent模式下更推荐使用源码部署以获得更多系统访问能力。
需要安装 [Docker](https://docs.docker.com/engine/install/) 和 docker-compose。
**1. 下载配置文件**
```bash
curl -O https://cdn.link-ai.tech/code/cow/docker-compose.yml
```
打开 `docker-compose.yml` 填写所需配置。
**2. 启动容器**
```bash
sudo docker compose up -d
```
**3. 查看日志**
```bash
sudo docker logs -f chatgpt-on-wechat
```
如果在服务器上部署,需要在防火墙或安全组中放行 `9899` 端口才能通过浏览器访问 Web 控制台,建议仅对指定IP开放以保证安全。
## 核心配置项
```json
{
"channel_type": "web",
"model": "MiniMax-M2.5",
"agent": true,
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 30,
"agent_max_steps": 15
}
```
| 参数 | 说明 | 默认值 |
| --- | --- | --- |
| `channel_type` | 接入渠道类型 | `web` |
| `model` | 模型名称 | `MiniMax-M2.5` |
| `agent` | 是否启用 Agent 模式 | `true` |
| `agent_workspace` | Agent 工作空间路径 | `~/cow` |
| `agent_max_context_tokens` | 最大上下文 tokens | `40000` |
| `agent_max_context_turns` | 最大上下文记忆轮次 | `30` |
| `agent_max_steps` | 单次任务最大决策步数 | `15` |
全部配置项可在项目 [`config.py`](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/config.py) 文件中查看。
================================================
FILE: docs/guide/quick-start.mdx
================================================
---
title: 一键安装
description: 使用脚本一键安装和管理 CowAgent
---
项目提供了一键安装、配置、启动、管理程序的脚本,推荐使用脚本快速运行。
支持 Linux、macOS、Windows 操作系统,需安装 Python 3.7 ~ 3.12(推荐 3.9)。
## 安装命令
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
脚本自动执行以下流程:
1. 检查 Python 环境(需要 Python 3.7+)
2. 安装必要工具(git、curl 等)
3. 克隆项目代码到 `~/chatgpt-on-wechat`
4. 安装 Python 依赖
5. 引导配置 AI 模型和通信渠道
6. 启动服务
运行后默认启动 Web 控制台,访问 `http://localhost:9899` 开始对话和管理Agent。
## 管理命令
安装完成后,可使用以下命令管理服务:
| 命令 | 说明 |
| --- | --- |
| `./run.sh start` | 启动服务 |
| `./run.sh stop` | 停止服务 |
| `./run.sh restart` | 重启服务 |
| `./run.sh status` | 查看运行状态 |
| `./run.sh logs` | 查看实时日志 |
| `./run.sh config` | 重新配置 |
| `./run.sh update` | 更新项目代码 |
================================================
FILE: docs/guide/upgrade.mdx
================================================
---
title: 更新升级
description: CowAgent 的升级方式说明
---
## 脚本升级(推荐)
如果使用 `run.sh` 管理服务,执行以下命令即可一键升级:
```bash
./run.sh update
```
该命令会自动完成以下流程:
1. 停止当前运行的服务
2. 拉取最新代码
3. 重新检查依赖
4. 启动服务
## 手动升级
在项目根目录下执行:
```bash
git pull
pip3 install -r requirements.txt
```
更新完成后重启服务:
```bash
# 如果使用 run.sh 管理
./run.sh restart
# 如果使用 nohup 直接运行
kill $(ps -ef | grep app.py | grep -v grep | awk '{print $2}')
nohup python3 app.py & tail -f nohup.out
```
## Docker 升级
在 `docker-compose.yml` 所在目录下执行:
```bash
sudo docker compose pull
sudo docker compose up -d
```
升级前建议备份 `config.json` 配置文件。Docker 环境下如需保留数据,可通过 volume 挂载持久化工作空间目录。
================================================
FILE: docs/intro/architecture.mdx
================================================
---
title: 项目架构
description: CowAgent 2.0 的系统架构和核心设计
---
CowAgent 2.0 从简单的聊天机器人全面升级为超级智能助理,采用 Agent 架构设计,具备自主思考、规划任务、长期记忆和技能扩展等能力。
## 系统架构
CowAgent 的整体架构由以下核心模块组成:
### 核心模块说明
| 模块 | 说明 |
| --- | --- |
| **Channels** | 消息通道层,负责接收和发送消息,支持 Web、飞书、钉钉、企微、公众号等 |
| **Agent Core** | 智能体核心引擎,包括任务规划、记忆系统和技能引擎 |
| **Tools** | 工具层,Agent 通过工具访问操作系统资源,内置 10+ 种工具 |
| **Models** | 模型层,支持国内外主流大语言模型的统一接入 |
## Agent 模式
启用 Agent 模式后,CowAgent 会以自主智能体的方式运行,核心工作流如下:
1. **接收消息** - 通过通道接收用户输入
2. **理解意图** - 分析任务需求和上下文
3. **规划任务** - 将复杂任务分解为多个步骤
4. **调用工具** - 选择合适的工具执行每个步骤
5. **记忆更新** - 将重要信息存入长期记忆
6. **返回结果** - 将执行结果发送回用户
## 工作空间
Agent 的工作空间默认位于 `~/cow` 目录,用于存储系统提示词、记忆文件、技能文件等:
```
~/cow/
├── system.md # Agent system prompt
├── user.md # User profile
├── memory/ # Long-term memory storage
│ ├── core.md # Core memory
│ └── daily/ # Daily memory
└── skills/ # Custom skills
├── skill-1/
└── skill-2/
```
秘钥文件单独存储在 `~/.cow` 目录(出于安全考虑):
```
~/.cow/
└── .env # Secret keys for skills
```
## 核心配置
在 `config.json` 中配置 Agent 模式的核心参数:
```json
{
"agent": true,
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 30,
"agent_max_steps": 15
}
```
| 参数 | 说明 | 默认值 |
| --- | --- | --- |
| `agent` | 是否启用 Agent 模式 | `true` |
| `agent_workspace` | 工作空间路径 | `~/cow` |
| `agent_max_context_tokens` | 最大上下文 token 数 | `40000` |
| `agent_max_context_turns` | 最大上下文记忆轮次 | `30` |
| `agent_max_steps` | 单次任务最大决策步数 | `15` |
================================================
FILE: docs/intro/features.mdx
================================================
---
title: 功能介绍
description: CowAgent 长期记忆、任务规划、技能系统详细说明
---
## 1. 长期记忆
> 记忆系统让 Agent 能够长期记住重要信息。Agent 会在用户分享偏好、决策、事实等重要信息时主动存储,也会在对话达到一定长度时自动提取摘要。记忆分为核心记忆、天级记忆,支持语义搜索和向量检索的混合检索模式。
第一次启动 Agent 时,Agent 会主动询问关键信息,并记录至工作空间(默认 `~/cow`)中的智能体设定、用户身份、记忆文件中。
在后续的长期对话中,Agent 会在需要时智能记录或检索记忆,并对自身设定、用户偏好、记忆文件等进行不断更新,总结和记录经验和教训,真正实现自主思考和不断成长。
## 2. 任务规划和工具调用
工具是 Agent 访问操作系统资源的核心,Agent 会根据任务需求智能选择和调用工具,完成文件读写、命令执行、定时任务等各类操作。内置工具的实现在项目的 `agent/tools/` 目录下。
**主要工具:** 文件读写编辑、Bash 终端、文件发送、定时调度、记忆搜索、联网搜索、环境配置等。
### 2.1 终端和文件访问
针对操作系统的终端和文件的访问能力,是最基础和核心的工具,其他很多工具或技能都是基于此进行扩展。用户可通过手机端与 Agent 交互,操作个人电脑或服务器上的资源:
### 2.2 编程能力
基于编程能力和系统访问能力,Agent 可以实现从信息搜索、图片等素材生成、编码、测试、部署、Nginx 配置修改、发布的 **Vibecoding 全流程**,通过手机端简单的一句命令完成应用的快速 demo:
### 2.3 定时任务
基于 `scheduler` 工具实现动态定时任务,支持**一次性任务、固定时间间隔、Cron 表达式**三种形式,任务触发可选择**固定消息发送**或 **Agent 动态任务**执行两种模式:
### 2.4 环境变量管理
技能所需的秘钥存储在环境变量文件中,由 `env_config` 工具进行管理,你可以通过对话的方式更新秘钥,工具内置安全保护和脱敏策略:
## 3. 技能系统
技能系统为 Agent 提供无限的扩展性,每个 Skill 由说明文件、运行脚本(可选)、资源(可选)组成,描述如何完成特定类型的任务。通过 Skill 可以让 Agent 遵循说明完成复杂流程、调用各类工具或对接第三方系统。
- **内置技能:** 在项目的 `skills/` 目录下,包含技能创造器、图像识别、LinkAI 智能体、网页抓取等。内置 Skill 根据依赖条件(API Key、系统命令等)自动判断是否启用。
- **自定义技能:** 由用户通过对话创建,存放在工作空间中(`~/cow/skills/`),可实现任何复杂的业务流程和第三方系统对接。
### 3.1 创建技能
通过 `skill-creator` 技能可以通过对话的方式快速创建技能。你可以让 Agent 将某个工作流程固化为技能,或者把任意接口文档和示例发送给 Agent,让他直接完成对接:
### 3.2 搜索和图像识别
- **联网搜索:** 内置 `web_search` 工具,支持多种搜索引擎,配置 `BOCHA_API_KEY` 或 `LINKAI_API_KEY` 后启用。
- **图像识别:** 内置 `openai-image-vision` 技能,可使用 `gpt-4.1-mini`、`gpt-4.1` 等模型,依赖 `OPENAI_API_KEY`。
### 3.3 三方知识库和插件
`linkai-agent` 技能可以将 [LinkAI](https://link-ai.tech/) 上的所有智能体作为 Skill 交给 Agent 使用,实现多智能体决策效果。
配置方式:通过 `env_config` 配置 `LINKAI_API_KEY`,并在 `skills/linkai-agent/config.json` 中添加智能体说明:
```json
{
"apps": [
{
"app_code": "G7z6vKwp",
"app_name": "LinkAI客服助手",
"app_description": "当用户需要了解LinkAI平台相关问题时才选择该助手"
},
{
"app_code": "SFY5x7JR",
"app_name": "内容创作助手",
"app_description": "当用户需要创作图片或视频时才使用该助手"
}
]
}
```
================================================
FILE: docs/intro/index.mdx
================================================
---
title: 项目介绍
description: CowAgent - 基于大模型的超级AI助理
---
**CowAgent** 是基于大模型的超级AI助理,能够主动思考和任务规划、操作计算机和外部资源、创造和执行Skills、拥有长期记忆并不断成长。
CowAgent 支持灵活切换多种模型,能处理文本、语音、图片、文件等多模态消息,可接入网页、飞书、钉钉、企业微信应用、微信公众号中使用,7×24小时运行于你的个人电脑或服务器中。
开源代码仓库,欢迎 Star 和贡献
无需安装,立即在线体验 CowAgent
## 核心能力
能够理解复杂任务并自主规划执行,持续思考和调用工具直到完成目标,支持通过工具操作访问文件、终端、浏览器、定时任务等系统资源。
自动将对话记忆持久化至本地文件和数据库中,包括全局记忆和天级记忆,支持关键词及向量检索。
实现了Skills创建和运行的引擎,内置多种技能,并支持通过自然语言对话完成自定义Skills开发。
支持对文本、图片、语音、文件等多类型消息进行解析、处理、生成、发送等操作。
支持 OpenAI, Claude, Gemini, DeepSeek, MiniMax, GLM, Qwen, Kimi, Doubao 等国内外主流模型厂商。
支持运行在本地计算机或服务器,可集成到网页、飞书、钉钉、微信公众号、企业微信应用中使用。
## 快速体验
在终端执行以下命令,即可一键安装、配置、启动 CowAgent:
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
运行后默认会启动 Web 服务,通过访问 `http://localhost:9899/chat` 在网页端对话。
查看完整的安装和运行指南
了解 CowAgent 的系统架构设计
## 社区
添加小助手微信加入开源项目交流群:
================================================
FILE: docs/ja/README.md
================================================
You can also configure directly in `config.json`:
```json
{
"bot_type": "openai",
"model": "MODEL_NAME",
"open_ai_api_base": "PROVIDER_CODING_PLAN_API_BASE",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `bot_type` | Must be `openai` (OpenAI-compatible mode) |
| `model` | Model name supported by the provider |
| `open_ai_api_base` | Provider's Coding Plan API Base URL |
| `open_ai_api_key` | Provider's Coding Plan API Key |
---
## Alibaba Cloud
```json
{
"bot_type": "openai",
"model": "qwen3.5-plus",
"open_ai_api_base": "https://coding.dashscope.aliyuncs.com/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | `qwen3.5-plus`, `qwen3-max-2026-01-23`, `qwen3-coder-next`, `qwen3-coder-plus`, `glm-5`, `glm-4.7`, `kimi-k2.5`, `MiniMax-M2.5` |
| `open_ai_api_base` | `https://coding.dashscope.aliyuncs.com/v1` |
| `open_ai_api_key` | Coding Plan specific key (not shared with pay-as-you-go) |
Reference: [Quick Start](https://help.aliyun.com/zh/model-studio/coding-plan-quickstart?spm=a2c4g.11186623.help-menu-2400256.d_0_2_1.70115203zi5Igc), [Model List](https://help.aliyun.com/zh/model-studio/coding-plan)
---
## MiniMax
```json
{
"bot_type": "openai",
"model": "MiniMax-M2.5",
"open_ai_api_base": "https://api.minimaxi.com/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | `MiniMax-M2.5`, `MiniMax-M2.5-highspeed`, `MiniMax-M2.1`, `MiniMax-M2` |
| `open_ai_api_base` | China: `https://api.minimaxi.com/v1`; Global: `https://api.minimax.io/v1` |
| `open_ai_api_key` | Coding Plan specific key (not shared with pay-as-you-go) |
Reference: [China Key](https://platform.minimaxi.com/docs/coding-plan/quickstart), [Model List](https://platform.minimaxi.com/docs/guides/pricing-coding-plan), [Global Key](https://platform.minimax.io/docs/coding-plan/quickstart)
---
## Zhipu GLM
```json
{
"bot_type": "openai",
"model": "glm-4.7",
"open_ai_api_base": "https://open.bigmodel.cn/api/coding/paas/v4",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | `glm-5`, `glm-4.7`, `glm-4.6`, `glm-4.5`, `glm-4.5-air` |
| `open_ai_api_base` | China: `https://open.bigmodel.cn/api/coding/paas/v4`; Global: `https://api.z.ai/api/coding/paas/v4` |
| `open_ai_api_key` | Shared with standard API |
Reference: [China Quick Start](https://docs.bigmodel.cn/cn/coding-plan/quick-start), [Global Quick Start](https://docs.z.ai/devpack/quick-start)
---
## Kimi
```json
{
"bot_type": "openai",
"model": "kimi-for-coding",
"open_ai_api_base": "https://api.kimi.com/coding/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | `kimi-for-coding` |
| `open_ai_api_base` | `https://api.kimi.com/coding/v1` |
| `open_ai_api_key` | Coding Plan specific key (not shared with pay-as-you-go) |
Reference: [Key & Docs](https://www.kimi.com/code/docs/)
---
## Volcengine
```json
{
"bot_type": "openai",
"model": "Doubao-Seed-2.0-Code",
"open_ai_api_base": "https://ark.cn-beijing.volces.com/api/coding/v3",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | `Doubao-Seed-2.0-Code`, `Doubao-Seed-2.0-pro`, `Doubao-Seed-2.0-lite`, `Doubao-Seed-Code`, `MiniMax-M2.5`, `Kimi-K2.5`, `GLM-4.7`, `DeepSeek-V3.2` |
| `open_ai_api_base` | `https://ark.cn-beijing.volces.com/api/coding/v3` |
| `open_ai_api_key` | Shared with standard API |
Reference: [Quick Start](https://www.volcengine.com/docs/82379/1928261?lang=zh)
================================================
FILE: docs/en/models/deepseek.mdx
================================================
---
title: DeepSeek
description: DeepSeek model configuration
---
Use OpenAI-compatible configuration:
```json
{
"model": "deepseek-chat",
"bot_type": "openai",
"open_ai_api_key": "YOUR_API_KEY",
"open_ai_api_base": "https://api.deepseek.com/v1"
}
```
| Parameter | Description |
| --- | --- |
| `model` | `deepseek-chat` (DeepSeek-V3), `deepseek-reasoner` (DeepSeek-R1) |
| `bot_type` | Must be `openai` (OpenAI-compatible mode) |
| `open_ai_api_key` | Create at [DeepSeek Platform](https://platform.deepseek.com/api_keys) |
| `open_ai_api_base` | DeepSeek platform BASE URL |
================================================
FILE: docs/en/models/doubao.mdx
================================================
---
title: Doubao (ByteDance)
description: Doubao (Volcano Ark) model configuration
---
```json
{
"model": "doubao-seed-2-0-code-preview-260215",
"ark_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `doubao-seed-2-0-code-preview-260215`, `doubao-seed-2-0-pro-260215`, `doubao-seed-2-0-lite-260215`, etc. |
| `ark_api_key` | Create at [Volcano Ark Console](https://console.volcengine.com/ark/region:ark+cn-beijing/apikey) |
| `ark_base_url` | Optional. Defaults to `https://ark.cn-beijing.volces.com/api/v3` |
================================================
FILE: docs/en/models/gemini.mdx
================================================
---
title: Gemini
description: Google Gemini model configuration
---
```json
{
"model": "gemini-3.1-pro-preview",
"gemini_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `gemini-3.1-flash-lite-preview`, `gemini-3.1-pro-preview`, `gemini-3-flash-preview`, `gemini-3-pro-preview`, etc. See [official docs](https://ai.google.dev/gemini-api/docs/models) |
| `gemini_api_key` | Create at [Google AI Studio](https://aistudio.google.com/app/apikey) |
================================================
FILE: docs/en/models/glm.mdx
================================================
---
title: GLM (Zhipu AI)
description: Zhipu AI GLM model configuration
---
```json
{
"model": "glm-5-turbo",
"zhipu_ai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `glm-5-turbo`, `glm-5`, `glm-4.7`, `glm-4-plus`, `glm-4-flash`, `glm-4-air`, etc. See [model codes](https://bigmodel.cn/dev/api/normal-model/glm-4) |
| `zhipu_ai_api_key` | Create at [Zhipu AI Console](https://www.bigmodel.cn/usercenter/proj-mgmt/apikeys) |
OpenAI-compatible configuration is also supported:
```json
{
"bot_type": "openai",
"model": "glm-5-turbo",
"open_ai_api_base": "https://open.bigmodel.cn/api/paas/v4",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/en/models/index.mdx
================================================
---
title: Models Overview
description: Supported models and recommended choices for CowAgent
---
CowAgent supports mainstream LLMs from domestic and international providers. Model interfaces are implemented in the project's `models/` directory.
For Agent mode, the following models are recommended based on quality and cost: MiniMax-M2.7, glm-5-turbo, kimi-k2.5, qwen3.5-plus, claude-sonnet-4-6, gemini-3.1-pro-preview
## Configuration
Configure the model name and API key in `config.json` according to your chosen model. Each model also supports OpenAI-compatible access by setting `bot_type` to `openai` and configuring `open_ai_api_base` and `open_ai_api_key`.
You can also use the [LinkAI](https://link-ai.tech) platform interface to flexibly switch between multiple models with support for knowledge base, workflows, and other Agent capabilities.
## Supported Models
MiniMax-M2.7 and other series models
glm-5-turbo, glm-5 and other series models
qwen3.5-plus, qwen3-max and more
kimi-k2.5, kimi-k2 and more
doubao-seed series models
claude-sonnet-4-6 and more
gemini-3.1-pro-preview and more
gpt-5.4, gpt-4.1, o-series and more
deepseek-chat, deepseek-reasoner
Unified multi-model interface + knowledge base
For a full list of model names, refer to the project's [`common/const.py`](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/common/const.py) file.
================================================
FILE: docs/en/models/kimi.mdx
================================================
---
title: Kimi (Moonshot)
description: Kimi (Moonshot) model configuration
---
```json
{
"model": "kimi-k2.5",
"moonshot_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `kimi-k2.5`, `kimi-k2`, `moonshot-v1-8k`, `moonshot-v1-32k`, `moonshot-v1-128k` |
| `moonshot_api_key` | Create at [Moonshot Console](https://platform.moonshot.cn/console/api-keys) |
OpenAI-compatible configuration is also supported:
```json
{
"bot_type": "openai",
"model": "kimi-k2.5",
"open_ai_api_base": "https://api.moonshot.cn/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/en/models/linkai.mdx
================================================
---
title: LinkAI
description: Unified access to multiple models via LinkAI platform
---
The [LinkAI](https://link-ai.tech) platform lets you flexibly switch between OpenAI, Claude, Gemini, DeepSeek, Qwen, Kimi, and other models, with support for knowledge base, workflows, plugins, and other Agent capabilities.
```json
{
"use_linkai": true,
"linkai_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `use_linkai` | Set to `true` to enable LinkAI interface |
| `linkai_api_key` | Create at [LinkAI Console](https://link-ai.tech/console/interface) |
| `model` | Leave empty to use the agent's default model. Can be switched flexibly on the platform. All models in the [model list](https://link-ai.tech/console/models) are supported |
See the [API documentation](https://docs.link-ai.tech/platform/api) for more details.
================================================
FILE: docs/en/models/minimax.mdx
================================================
---
title: MiniMax
description: MiniMax model configuration
---
```json
{
"model": "MiniMax-M2.7",
"minimax_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `MiniMax-M2.7`, `MiniMax-M2.5`, `MiniMax-M2.1`, `MiniMax-M2.1-lightning`, `MiniMax-M2`, etc. |
| `minimax_api_key` | Create at [MiniMax Console](https://platform.minimaxi.com/user-center/basic-information/interface-key) |
OpenAI-compatible configuration is also supported:
```json
{
"bot_type": "openai",
"model": "MiniMax-M2.7",
"open_ai_api_base": "https://api.minimaxi.com/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/en/models/openai.mdx
================================================
---
title: OpenAI
description: OpenAI model configuration
---
```json
{
"model": "gpt-5.4",
"open_ai_api_key": "YOUR_API_KEY",
"open_ai_api_base": "https://api.openai.com/v1"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Matches the [model parameter](https://platform.openai.com/docs/models) of the OpenAI API. Supports o-series, gpt-5.4, gpt-5 series, gpt-4.1, etc. Recommended for Agent mode: `gpt-5.4` |
| `open_ai_api_key` | Create at [OpenAI Platform](https://platform.openai.com/api-keys) |
| `open_ai_api_base` | Optional. Change to use third-party proxy |
| `bot_type` | Not required for official OpenAI models. Set to `openai` when using Claude or other non-OpenAI models via proxy |
================================================
FILE: docs/en/models/qwen.mdx
================================================
---
title: Qwen (Tongyi Qianwen)
description: Tongyi Qianwen model configuration
---
```json
{
"model": "qwen3.5-plus",
"dashscope_api_key": "YOUR_API_KEY"
}
```
| Parameter | Description |
| --- | --- |
| `model` | Options include `qwen3.5-plus`, `qwen3-max`, `qwen-max`, `qwen-plus`, `qwen-turbo`, `qwq-plus`, etc. |
| `dashscope_api_key` | Create at [Bailian Console](https://bailian.console.aliyun.com/?tab=model#/api-key). See [official docs](https://bailian.console.aliyun.com/?tab=api#/api) |
OpenAI-compatible configuration is also supported:
```json
{
"bot_type": "openai",
"model": "qwen3.5-plus",
"open_ai_api_base": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/en/releases/overview.mdx
================================================
---
title: Changelog
description: CowAgent version history
---
| Version | Date | Description |
| --- | --- | --- |
| [2.0.2](/en/releases/v2.0.2) | 2026.02.27 | Web Console upgrade, multi-channel concurrency, session persistence |
| [2.0.1](/en/releases/v2.0.1) | 2026.02.27 | Built-in Web Search tool, smart context management, multiple fixes |
| [2.0.0](/en/releases/v2.0.0) | 2026.02.03 | Full upgrade to AI super assistant |
| 1.7.6 | 2025.05.23 | Web Channel optimization, AgentMesh plugin |
| 1.7.5 | 2025.04.11 | DeepSeek model |
| 1.7.4 | 2024.12.13 | Gemini 2.0 model, Web Channel |
| 1.7.3 | 2024.10.31 | Stability improvements, database features |
| 1.7.2 | 2024.09.26 | One-click install script, o1 model |
| 1.7.0 | 2024.08.02 | iFlytek 4.0 model, knowledge base references |
| 1.6.9 | 2024.07.19 | gpt-4o-mini, Alibaba voice recognition |
| 1.6.8 | 2024.07.05 | Claude 3.5, Gemini 1.5 Pro |
| 1.6.0 | 2024.04.26 | Kimi integration, gpt-4-turbo upgrade |
| 1.5.0 | 2023.11.10 | gpt-4-turbo, dall-e-3, tts multimodal |
| 1.0.0 | 2022.12.12 | Project created, first ChatGPT integration |
See [GitHub Releases](https://github.com/zhayujie/chatgpt-on-wechat/releases) for full history.
================================================
FILE: docs/en/releases/v2.0.0.mdx
================================================
---
title: v2.0.0
description: CowAgent 2.0 - Full upgrade from chatbot to AI super assistant
---
CowAgent 2.0 is a comprehensive upgrade from a chatbot to an **AI super assistant** — capable of autonomous thinking and task planning, long-term memory, operating computers, and creating and executing skills.
**Release Date**: 2026.02.03 | [GitHub Release](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.0)
## Key Updates
### Agent Core
- **Complex Task Planning**: Autonomous planning with multi-turn reasoning
- **Long-term Memory**: Persistent memory with keyword and vector search
- **Built-in Tools**: 10+ tools including file ops, Bash, browser, scheduler
- **Web search**: Built-in `web_search` tool, supports multiple search engines, configure corresponding API key to use
- **Skills System**: Skill engine with built-in and custom skill support
- **Security & Cost**: Secret management, prompt controls, token limits
### Other
- **Channels**: Feishu/DingTalk WebSocket support, image/file messages
- **Models**: claude-sonnet-4-5, gemini-3-pro-preview, glm-4.7, MiniMax-M2.1, qwen3-max
- **Deployment**: One-click install, configure, run, and management script
## Long-term Memory
## Task Planning & Tools
## Skills System
## Contributing
Welcome to [submit feedback](https://github.com/zhayujie/chatgpt-on-wechat/issues) and [contribute code](https://github.com/zhayujie/chatgpt-on-wechat/pulls).
================================================
FILE: docs/en/releases/v2.0.1.mdx
================================================
---
title: v2.0.1
description: CowAgent 2.0.1 - Built-in Web Search, smart context management, multiple fixes
---
**Release Date**: 2026.02.27 | [Full Changelog](https://github.com/zhayujie/chatgpt-on-wechat/compare/2.0.0..2.0.1)
## New Features
- **Built-in Web Search tool**: Integrated web search as a built-in Agent tool, reducing decision cost ([4f0ea5d](https://github.com/zhayujie/chatgpt-on-wechat/commit/4f0ea5d7568d61db91ff69c91c429e785fd1b1c2))
- **Claude Opus 4.6 model support**: Added support for Claude Opus 4.6 model ([#2661](https://github.com/zhayujie/chatgpt-on-wechat/pull/2661))
- **WeCom image recognition**: Support image message recognition in WeCom channel ([#2667](https://github.com/zhayujie/chatgpt-on-wechat/pull/2667))
## Improvements
- **Smart context management**: Resolved chat context overflow with intelligent context trimming strategy to prevent token limits ([cea7fb7](https://github.com/zhayujie/chatgpt-on-wechat/commit/cea7fb7490c53454602bf05955a0e9f059bcf0fd), [8acf2db](https://github.com/zhayujie/chatgpt-on-wechat/commit/8acf2dbdfe713b84ad74b761b7f86674b1c1904d)) [#2663](https://github.com/zhayujie/chatgpt-on-wechat/issues/2663)
- **Runtime info dynamic update**: Automatic update of timestamps and other runtime info in system prompts via dynamic functions ([#2655](https://github.com/zhayujie/chatgpt-on-wechat/pull/2655), [#2657](https://github.com/zhayujie/chatgpt-on-wechat/pull/2657))
- **Skill prompt optimization**: Improved Skill system prompt generation, simplified tool descriptions for better Agent performance ([6c21833](https://github.com/zhayujie/chatgpt-on-wechat/commit/6c218331b1f1208ea8be6bf226936d3b556ade3e))
- **GLM custom API Base URL**: Support custom API Base URL for GLM models ([#2660](https://github.com/zhayujie/chatgpt-on-wechat/pull/2660))
- **Startup script optimization**: Improved `run.sh` script interaction and configuration flow ([#2656](https://github.com/zhayujie/chatgpt-on-wechat/pull/2656))
- **Decision step logging**: Added Agent decision step logging for debugging ([cb303e6](https://github.com/zhayujie/chatgpt-on-wechat/commit/cb303e6109c50c8dfef1f5e6c1ec47223bf3cd11))
## Bug Fixes
- **Scheduler memory loss**: Fixed memory loss caused by Scheduler dispatcher ([a77a874](https://github.com/zhayujie/chatgpt-on-wechat/commit/a77a8741b500a408c6f5c8868856fb4b018fe9db))
- **Empty tool calls & long results**: Fixed handling of empty tool calls and excessively long tool results ([0542700](https://github.com/zhayujie/chatgpt-on-wechat/commit/0542700f9091ebb08c1a56103b0f0f45f24aa621))
- **OpenAI Function Call**: Fixed function call compatibility with OpenAI models ([158c87a](https://github.com/zhayujie/chatgpt-on-wechat/commit/158c87ab8b05bae054cc1b4eacdbb64fc1062ba9))
- **Claude tool name field**: Removed extraneous tool name field from Claude model responses ([eec10cb](https://github.com/zhayujie/chatgpt-on-wechat/commit/eec10cb5db6a3d5bc12ef606606532237d2c5f6e))
- **MiniMax reasoning**: Optimized MiniMax model reasoning content handling, hidden thinking process output ([c72cda3](https://github.com/zhayujie/chatgpt-on-wechat/commit/c72cda33864bd1542012ee6e0a8bd8c6c88cb5ed), [72b1cac](https://github.com/zhayujie/chatgpt-on-wechat/commit/72b1cacea1ba0d1f3dedacbab2e088e98fd7e172))
- **GLM thinking process**: Hidden GLM model thinking process display ([72b1cac](https://github.com/zhayujie/chatgpt-on-wechat/commit/72b1cacea1ba0d1f3dedacbab2e088e98fd7e172))
- **Feishu connection & SSL**: Fixed Feishu channel SSL certificate errors and connection issues ([229b14b](https://github.com/zhayujie/chatgpt-on-wechat/commit/229b14b6fcabe7123d53cab1dea39f38dab26d6d), [8674421](https://github.com/zhayujie/chatgpt-on-wechat/commit/867442155e7f095b4f38b0856f8c1d8312b5fcf7))
- **model_type validation**: Fixed `AttributeError` caused by non-string `model_type` ([#2666](https://github.com/zhayujie/chatgpt-on-wechat/pull/2666))
## Platform Compatibility
- **Windows compatibility**: Fixed path handling, file encoding, and `os.getuid()` unavailability on Windows across multiple tool modules ([051ffd7](https://github.com/zhayujie/chatgpt-on-wechat/commit/051ffd78a372f71a967fd3259e37fe19131f83cf), [5264f7c](https://github.com/zhayujie/chatgpt-on-wechat/commit/5264f7ce18360ee4db5dcb4ebe67307977d40014))
================================================
FILE: docs/en/releases/v2.0.2.mdx
================================================
---
title: v2.0.2
description: CowAgent 2.0.2 - Web Console upgrade, multi-channel concurrency, session persistence
---
**Release Date**: 2026.02.27 | [Full Changelog](https://github.com/zhayujie/chatgpt-on-wechat/compare/2.0.1...master)
## Highlights
### 🖥️ Web Console Upgrade
The Web Console has been fully upgraded with streaming conversation output, visual display of tool execution and reasoning processes, and online management of **models, skills, memory, channels, and Agent configuration**.
#### Chat Interface
Supports streaming output with real-time display of the Agent's reasoning process and tool calls, providing intuitive observation of the Agent's decision-making:
#### Model Management
Manage model configurations online without manually editing config files:
#### Skill Management
View and manage Agent skills (Skills) online:
#### Memory Management
View and manage Agent memory online:
#### Channel Management
Manage connected channels online with real-time connect/disconnect operations:
#### Scheduled Tasks
View and manage scheduled tasks online, including one-time tasks, fixed intervals, and Cron expressions:
#### Logs
View Agent runtime logs in real-time for monitoring and troubleshooting:
Related commits: [f1a1413](https://github.com/zhayujie/chatgpt-on-wechat/commit/f1a1413), [c0702c8](https://github.com/zhayujie/chatgpt-on-wechat/commit/c0702c8), [394853c](https://github.com/zhayujie/chatgpt-on-wechat/commit/394853c), [1c71c4e](https://github.com/zhayujie/chatgpt-on-wechat/commit/1c71c4e), [5e3eccb](https://github.com/zhayujie/chatgpt-on-wechat/commit/5e3eccb), [e1dc037](https://github.com/zhayujie/chatgpt-on-wechat/commit/e1dc037), [5edbf4c](https://github.com/zhayujie/chatgpt-on-wechat/commit/5edbf4c), [7d258b5](https://github.com/zhayujie/chatgpt-on-wechat/commit/7d258b5)
### 🔀 Multi-Channel Concurrency
Multiple channels (e.g., Feishu, DingTalk, WeCom, Web) can now run simultaneously, each in an independent thread without interference.
Configuration: Set multiple channels in `config.json` via `channel_type` separated by commas, or connect/disconnect channels in real-time from the Web Console's channel management page.
```json
{
"channel_type": "web,feishu,dingtalk"
}
```
Related commits: [4694594](https://github.com/zhayujie/chatgpt-on-wechat/commit/4694594), [7cce224](https://github.com/zhayujie/chatgpt-on-wechat/commit/7cce224), [7d258b5](https://github.com/zhayujie/chatgpt-on-wechat/commit/7d258b5), [c9adddb](https://github.com/zhayujie/chatgpt-on-wechat/commit/c9adddb)
### 💾 Session Persistence
Session history is now persisted to a local SQLite database. Conversation context is automatically restored after service restarts. Historical conversations in the Web Console are also restored.
Related commits: [29bfbec](https://github.com/zhayujie/chatgpt-on-wechat/commit/29bfbec), [9917552](https://github.com/zhayujie/chatgpt-on-wechat/commit/9917552), [925d728](https://github.com/zhayujie/chatgpt-on-wechat/commit/925d728)
## New Models
- **Gemini 3.1 Pro Preview**: Added `gemini-3.1-pro-preview` model support ([52d7cad](https://github.com/zhayujie/chatgpt-on-wechat/commit/52d7cad))
- **Claude 4.6 Sonnet**: Added `claude-4.6-sonnet` model support ([52d7cad](https://github.com/zhayujie/chatgpt-on-wechat/commit/52d7cad))
- **Qwen3.5 Plus**: Added `qwen3.5-plus` model support ([e59a289](https://github.com/zhayujie/chatgpt-on-wechat/commit/e59a289))
- **MiniMax M2.5**: Added `Minimax-M2.5` model support ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
- **GLM-5**: Added `glm-5` model support ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
- **Kimi K2.5**: Added `kimi-k2.5` model support ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
- **Doubao 2.0 Code**: Added `doubao-2.0-code` coding-specialized model ([ab28ee5](https://github.com/zhayujie/chatgpt-on-wechat/commit/ab28ee5))
- **DashScope Models**: Added Alibaba Cloud DashScope model name support ([ce58f23](https://github.com/zhayujie/chatgpt-on-wechat/commit/ce58f23))
## Website & Documentation
- **Official Website**: [cowagent.ai](https://cowagent.ai/)
- **Documentation**: [docs.cowagent.ai](https://docs.cowagent.ai/)
## Bug Fixes
- **Gemini DingTalk image recognition**: Fixed Gemini unable to process image markers in DingTalk channel ([05a3304](https://github.com/zhayujie/chatgpt-on-wechat/commit/05a3304)) ([#2670](https://github.com/zhayujie/chatgpt-on-wechat/pull/2670)) Thanks [@SgtPepper114](https://github.com/SgtPepper114)
- **Startup script dependencies**: Fixed dependency installation issue in `run.sh` script ([b6fc9fa](https://github.com/zhayujie/chatgpt-on-wechat/commit/b6fc9fa))
- **Bare except cleanup**: Replaced `bare except` with `except Exception` for better exception handling ([adca89b](https://github.com/zhayujie/chatgpt-on-wechat/commit/adca89b)) ([#2674](https://github.com/zhayujie/chatgpt-on-wechat/pull/2674)) Thanks [@haosenwang1018](https://github.com/haosenwang1018)
================================================
FILE: docs/en/skills/image-vision.mdx
================================================
---
title: Image Vision
description: Recognize images using OpenAI vision models
---
Analyze image content using OpenAI's GPT-4 Vision API, understanding objects, text, colors, and other elements in images.
## Dependencies
| Dependency | Description |
| --- | --- |
| `OPENAI_API_KEY` | OpenAI API key |
| `curl`, `base64` | System commands (usually pre-installed) |
Configuration:
- Configure `OPENAI_API_KEY` via the `env_config` tool
- Or set `open_ai_api_key` in `config.json`
## Supported Models
- `gpt-4.1-mini` (recommended, cost-effective)
- `gpt-4.1`
## Usage
Once configured, send an image to the Agent to automatically trigger image recognition.
================================================
FILE: docs/en/skills/index.mdx
================================================
---
title: Skills Overview
description: CowAgent skills system introduction
---
Skills provide infinite extensibility for the Agent. Each Skill consists of a description file (`SKILL.md`), execution scripts (optional), and resources (optional), describing how to accomplish specific types of tasks.
The difference between Skills and Tools: Tools are atomic operations implemented in code (e.g., file read/write, command execution), while Skills are high-level workflows based on description files that can combine multiple Tools to complete complex tasks.
## Built-in Skills
Located in the project `skills/` directory, automatically enabled based on dependency conditions:
| Skill | Description | Dependencies |
| --- | --- | --- |
| [`skill-creator`](/en/skills/skill-creator) | Create custom skills through conversation | None |
| [`openai-image-vision`](/en/skills/image-vision) | Recognize images using OpenAI vision models | `OPENAI_API_KEY` |
| [`linkai-agent`](/en/skills/linkai-agent) | Integrate LinkAI platform agents | `LINKAI_API_KEY` |
| [`web-fetch`](/en/skills/web-fetch) | Fetch web page text content | `curl` (enabled by default) |
## Custom Skills
Created by users through conversation, stored in workspace (`~/cow/skills/`), can implement any complex business process and third-party system integration.
## Skill Loading Priority
1. **Workspace skills** (highest): `~/cow/skills/`
2. **Project built-in skills** (lowest): `skills/`
Skills with the same name are overridden by priority.
## Skill File Structure
```
skills/
├── my-skill/
│ ├── SKILL.md # Skill description (frontmatter + instructions)
│ ├── scripts/ # Execution scripts (optional)
│ └── resources/ # Additional resources (optional)
```
### SKILL.md Format
```markdown
---
name: my-skill
description: Brief description of the skill
metadata:
emoji: 🔧
requires:
bins: ["curl"]
env: ["MY_API_KEY"]
primaryEnv: "MY_API_KEY"
---
# My Skill
Detailed instructions...
```
| Field | Description |
| --- | --- |
| `name` | Skill name, must match directory name |
| `description` | Skill description, Agent decides whether to invoke based on this |
| `metadata.requires.bins` | Required system commands |
| `metadata.requires.env` | Required environment variables |
| `metadata.always` | Always load (default false) |
================================================
FILE: docs/en/skills/linkai-agent.mdx
================================================
---
title: LinkAI Agent
description: Integrate LinkAI platform multi-agent skill
---
Use agents from the [LinkAI](https://link-ai.tech/) platform as Skills for multi-agent decision-making. The Agent intelligently selects based on agent names and descriptions, calling the corresponding application or workflow via `app_code`.
## Dependencies
| Dependency | Description |
| --- | --- |
| `LINKAI_API_KEY` | LinkAI platform API key, created in [Console](https://link-ai.tech/console/interface) |
| `curl` | System command (usually pre-installed) |
Configuration:
- Configure `LINKAI_API_KEY` via the `env_config` tool
- Or set `linkai_api_key` in `config.json`
## Configure Agents
Add available agents in `skills/linkai-agent/config.json`:
```json
{
"apps": [
{
"app_code": "G7z6vKwp",
"app_name": "LinkAI Customer Support",
"app_description": "Select this assistant only when the user needs help with LinkAI platform questions"
},
{
"app_code": "SFY5x7JR",
"app_name": "Content Creator",
"app_description": "Use this assistant only when the user needs to create images or videos"
}
]
}
```
## Usage
Once configured, the Agent will automatically select the appropriate LinkAI agent based on the user's question.
================================================
FILE: docs/en/skills/skill-creator.mdx
================================================
---
title: Skill Creator
description: Create custom skills through conversation
---
Quickly create, install, or update skills through natural language conversation.
## Dependencies
No extra dependencies, always available.
## Usage
- Codify workflows as skills: "Create a skill from this deployment process"
- Integrate third-party APIs: "Create a skill based on this API documentation"
- Install remote skills: "Install xxx skill for me"
## Creation Flow
1. Tell the Agent what skill you want to create
2. Agent automatically generates `SKILL.md` description and execution scripts
3. Skill is saved to the workspace `~/cow/skills/` directory
4. Agent will automatically recognize and use the skill in future conversations
See the [Skill Creator documentation](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/skills/skill-creator/SKILL.md) for details.
================================================
FILE: docs/en/skills/web-fetch.mdx
================================================
---
title: Web Fetch
description: Fetch web page text content
---
Use curl to fetch web pages and extract readable text content. A lightweight web access method without browser automation.
## Dependencies
| Dependency | Description |
| --- | --- |
| `curl` | System command (usually pre-installed) |
This skill has `always: true` set, enabled by default as long as the system has the `curl` command.
## Usage
Automatically invoked when the Agent needs to fetch content from a URL, no extra configuration needed.
## Comparison with browser Tool
| Feature | web-fetch (skill) | browser (tool) |
| --- | --- | --- |
| Dependencies | curl only | browser-use + playwright |
| JS rendering | Not supported | Supported |
| Page interaction | Not supported | Supports click, type, etc. |
| Best for | Static page text | Dynamic web pages |
For most web content retrieval scenarios, web-fetch is sufficient. Only use the browser tool when you need JS rendering or page interaction.
================================================
FILE: docs/en/tools/bash.mdx
================================================
---
title: bash - Terminal
description: Execute system commands
---
Execute Bash commands in the current working directory, returns stdout and stderr. API keys configured via `env_config` are automatically injected into the environment.
## Dependencies
No extra dependencies, available by default.
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `command` | string | Yes | Command to execute |
| `timeout` | integer | No | Timeout in seconds |
## Use Cases
- Install packages and dependencies
- Run code and tests
- Deploy applications and services (Nginx config, process management, etc.)
- System administration and troubleshooting
================================================
FILE: docs/en/tools/browser.mdx
================================================
---
title: browser - Browser
description: Access and interact with web pages
---
Use a browser to access and interact with web pages, supports JavaScript-rendered dynamic pages.
## Dependencies
| Dependency | Install Command |
| --- | --- |
| `browser-use` ≥ 0.1.40 | `pip install browser-use` |
| `markdownify` | `pip install markdownify` |
| `playwright` + chromium | `pip install playwright && playwright install chromium` |
## Use Cases
- Access specific URLs to get page content
- Interact with web page elements (click, type, etc.)
- Verify deployed web pages
- Scrape dynamic content requiring JS rendering
The browser tool has heavy dependencies. If not needed, skip installation. For lightweight web content retrieval, use the `web-fetch` skill instead.
================================================
FILE: docs/en/tools/edit.mdx
================================================
---
title: edit - File Edit
description: Edit files via precise text replacement
---
Edit files via precise text replacement. If `oldText` is empty, appends to the end of the file.
## Dependencies
No extra dependencies, available by default.
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `path` | string | Yes | File path |
| `oldText` | string | Yes | Original text to replace (empty to append) |
| `newText` | string | Yes | Replacement text |
## Use Cases
- Modify specific parameters in configuration files
- Fix bugs in code
- Insert content at specific positions in files
================================================
FILE: docs/en/tools/env-config.mdx
================================================
---
title: env_config - Environment
description: Manage API keys and secrets
---
Manage environment variables (API keys and secrets) in the workspace `.env` file, with secure conversational updates. Built-in security protection and desensitization.
## Dependencies
| Dependency | Install Command |
| --- | --- |
| `python-dotenv` ≥ 1.0.0 | `pip install python-dotenv>=1.0.0` |
Included when installing optional dependencies: `pip3 install -r requirements-optional.txt`
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `action` | string | Yes | Operation type: `get`, `set`, `list`, `delete` |
| `key` | string | No | Environment variable name |
| `value` | string | No | Environment variable value (only for `set`) |
## Usage
Tell the Agent what key you need to configure, and it will automatically invoke this tool:
- "Configure my BOCHA_API_KEY"
- "Set OPENAI_API_KEY to sk-xxx"
- "Show configured environment variables"
Configured keys are automatically injected into the `bash` tool's execution environment.
================================================
FILE: docs/en/tools/index.mdx
================================================
---
title: Tools Overview
description: CowAgent built-in tools system
---
Tools are the core capability for Agent to access operating system resources. The Agent intelligently selects and invokes tools based on task requirements, performing file operations, command execution, web search, scheduled tasks, and more. Tools are implemented in the `agent/tools/` directory.
## Built-in Tools
The following tools are available by default with no extra configuration:
Read file content, supports text, images, PDF
Create or overwrite files
Edit files via precise text replacement
List directory contents
Execute system commands
Send files or images to user
Search and read long-term memory
## Optional Tools
The following tools require additional dependencies or API key configuration:
Manage API keys and secrets
Create and manage scheduled tasks
Search the internet for real-time information
================================================
FILE: docs/en/tools/ls.mdx
================================================
---
title: ls - Directory List
description: List directory contents
---
List directory contents, sorted alphabetically, directories suffixed with `/`, includes hidden files.
## Dependencies
No extra dependencies, available by default.
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `path` | string | Yes | Directory path, relative paths are based on workspace directory |
| `limit` | integer | No | Maximum entries to return, default 500 |
## Use Cases
- Browse project structure
- Find specific files
- Check if a directory exists
================================================
FILE: docs/en/tools/memory.mdx
================================================
---
title: memory - Memory
description: Search and read long-term memory
---
The memory tool contains two sub-tools: `memory_search` (search memory) and `memory_get` (read memory files).
## Dependencies
No extra dependencies, available by default. Managed by the Agent Core memory system.
## memory_search
Search historical memory with hybrid keyword and vector retrieval.
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `query` | string | Yes | Search query |
## memory_get
Read the content of a specific memory file.
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `path` | string | Yes | Relative path to memory file (e.g. `MEMORY.md`, `memory/2026-01-01.md`) |
| `start_line` | integer | No | Start line number |
| `end_line` | integer | No | End line number |
## How It Works
The Agent automatically invokes memory tools in these scenarios:
- When the user shares important information → stores to memory
- When historical context is needed → searches relevant memory
- When conversation reaches a certain length → extracts summary for storage
================================================
FILE: docs/en/tools/read.mdx
================================================
---
title: read - File Read
description: Read file content
---
Read file content. Supports text files, PDF files, images (returns metadata), and more.
## Dependencies
No extra dependencies, available by default.
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `path` | string | Yes | File path, relative paths are based on workspace directory |
| `offset` | integer | No | Start line number (1-indexed), negative values read from the end |
| `limit` | integer | No | Number of lines to read |
## Use Cases
- View configuration files, log files
- Read code files for analysis
- Check image/video file info
================================================
FILE: docs/en/tools/scheduler.mdx
================================================
---
title: scheduler - Scheduler
description: Create and manage scheduled tasks
---
Create and manage dynamic scheduled tasks with flexible scheduling and execution modes.
## Dependencies
| Dependency | Install Command |
| --- | --- |
| `croniter` ≥ 2.0.0 | `pip install croniter>=2.0.0` |
Included in core dependencies: `pip3 install -r requirements.txt`
## Scheduling Modes
| Mode | Description |
| --- | --- |
| One-time | Execute once at a specified time |
| Fixed interval | Repeat at fixed time intervals |
| Cron expression | Define complex schedules using Cron syntax |
## Execution Modes
- **Fixed message**: Send a preset message when triggered
- **Agent dynamic task**: Agent intelligently executes the task when triggered
## Usage
Create and manage scheduled tasks with natural language:
- "Send me a weather report every morning at 9 AM"
- "Check server status every 2 hours"
- "Remind me about the meeting tomorrow at 3 PM"
- "Show all scheduled tasks"
================================================
FILE: docs/en/tools/send.mdx
================================================
---
title: send - File Send
description: Send files to user
---
Send files to the user (images, videos, audio, documents, etc.), used when the user explicitly requests to send/share a file.
## Dependencies
No extra dependencies, available by default.
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `path` | string | Yes | File path, can be absolute or relative to workspace |
| `message` | string | No | Accompanying message |
## Use Cases
- Send generated code or documents to the user
- Send screenshots, charts
- Share downloaded files
================================================
FILE: docs/en/tools/web-search.mdx
================================================
---
title: web_search - Web Search
description: Search the internet for real-time information
---
Search the internet for real-time information, news, research, and more. Supports two search backends with automatic fallback.
## Dependencies
Requires at least one search API key (configured via `env_config` tool or workspace `.env` file):
| Backend | Environment Variable | Priority | How to Get |
| --- | --- | --- | --- |
| Bocha Search | `BOCHA_API_KEY` | Primary | [Bocha Open Platform](https://open.bochaai.com/) |
| LinkAI Search | `LINKAI_API_KEY` | Fallback | [LinkAI Console](https://link-ai.tech/console/interface) |
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `query` | string | Yes | Search keywords |
| `count` | integer | No | Number of results (1-50, default 10) |
| `freshness` | string | No | Time range: `noLimit`, `oneDay`, `oneWeek`, `oneMonth`, `oneYear`, or date range like `2025-01-01..2025-02-01` |
| `summary` | boolean | No | Return page summaries (default false) |
## Use Cases
When the user asks about latest information, needs fact-checking, or real-time data, the Agent automatically invokes this tool.
If no search API key is configured, this tool will not be loaded.
================================================
FILE: docs/en/tools/write.mdx
================================================
---
title: write - File Write
description: Create or overwrite files
---
Write content to a file. Creates the file if it doesn't exist, overwrites if it does. Automatically creates parent directories.
## Dependencies
No extra dependencies, available by default.
## Parameters
| Parameter | Type | Required | Description |
| --- | --- | --- | --- |
| `path` | string | Yes | File path |
| `content` | string | Yes | Content to write |
## Use Cases
- Create new code files or scripts
- Generate configuration files
- Save processing results
Single writes should not exceed 10KB. For large files, create a skeleton first, then use the edit tool to add content in chunks.
================================================
FILE: docs/guide/manual-install.mdx
================================================
---
title: 手动安装
description: 手动部署 CowAgent(源码 / Docker)
---
## 源码部署
### 1. 克隆项目代码
```bash
git clone https://github.com/zhayujie/chatgpt-on-wechat
cd chatgpt-on-wechat/
```
若遇到网络问题可使用国内仓库地址:https://gitee.com/zhayujie/chatgpt-on-wechat
### 2. 安装依赖
核心依赖(必选):
```bash
pip3 install -r requirements.txt
```
扩展依赖(可选,建议安装):
```bash
pip3 install -r requirements-optional.txt
```
### 3. 配置
复制配置文件模板并编辑:
```bash
cp config-template.json config.json
```
在 `config.json` 中填写模型 API Key 和通道类型等配置,详细说明参考各 [模型文档](/models/minimax)。
### 4. 运行
**本地运行:**
```bash
python3 app.py
```
运行后默认启动 Web 控制台,访问 `http://localhost:9899` 开始对话和管理Agent。
**服务器后台运行:**
```bash
nohup python3 app.py & tail -f nohup.out
```
如果在服务器上部署,需要在防火墙或安全组中放行 `9899` 端口才能通过浏览器访问 Web 控制台,建议仅对指定IP开放以保证安全。
## Docker 部署
使用 Docker 部署无需下载源码和安装依赖。Agent模式下更推荐使用源码部署以获得更多系统访问能力。
需要安装 [Docker](https://docs.docker.com/engine/install/) 和 docker-compose。
**1. 下载配置文件**
```bash
curl -O https://cdn.link-ai.tech/code/cow/docker-compose.yml
```
打开 `docker-compose.yml` 填写所需配置。
**2. 启动容器**
```bash
sudo docker compose up -d
```
**3. 查看日志**
```bash
sudo docker logs -f chatgpt-on-wechat
```
如果在服务器上部署,需要在防火墙或安全组中放行 `9899` 端口才能通过浏览器访问 Web 控制台,建议仅对指定IP开放以保证安全。
## 核心配置项
```json
{
"channel_type": "web",
"model": "MiniMax-M2.5",
"agent": true,
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 30,
"agent_max_steps": 15
}
```
| 参数 | 说明 | 默认值 |
| --- | --- | --- |
| `channel_type` | 接入渠道类型 | `web` |
| `model` | 模型名称 | `MiniMax-M2.5` |
| `agent` | 是否启用 Agent 模式 | `true` |
| `agent_workspace` | Agent 工作空间路径 | `~/cow` |
| `agent_max_context_tokens` | 最大上下文 tokens | `40000` |
| `agent_max_context_turns` | 最大上下文记忆轮次 | `30` |
| `agent_max_steps` | 单次任务最大决策步数 | `15` |
全部配置项可在项目 [`config.py`](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/config.py) 文件中查看。
================================================
FILE: docs/guide/quick-start.mdx
================================================
---
title: 一键安装
description: 使用脚本一键安装和管理 CowAgent
---
项目提供了一键安装、配置、启动、管理程序的脚本,推荐使用脚本快速运行。
支持 Linux、macOS、Windows 操作系统,需安装 Python 3.7 ~ 3.12(推荐 3.9)。
## 安装命令
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
脚本自动执行以下流程:
1. 检查 Python 环境(需要 Python 3.7+)
2. 安装必要工具(git、curl 等)
3. 克隆项目代码到 `~/chatgpt-on-wechat`
4. 安装 Python 依赖
5. 引导配置 AI 模型和通信渠道
6. 启动服务
运行后默认启动 Web 控制台,访问 `http://localhost:9899` 开始对话和管理Agent。
## 管理命令
安装完成后,可使用以下命令管理服务:
| 命令 | 说明 |
| --- | --- |
| `./run.sh start` | 启动服务 |
| `./run.sh stop` | 停止服务 |
| `./run.sh restart` | 重启服务 |
| `./run.sh status` | 查看运行状态 |
| `./run.sh logs` | 查看实时日志 |
| `./run.sh config` | 重新配置 |
| `./run.sh update` | 更新项目代码 |
================================================
FILE: docs/guide/upgrade.mdx
================================================
---
title: 更新升级
description: CowAgent 的升级方式说明
---
## 脚本升级(推荐)
如果使用 `run.sh` 管理服务,执行以下命令即可一键升级:
```bash
./run.sh update
```
该命令会自动完成以下流程:
1. 停止当前运行的服务
2. 拉取最新代码
3. 重新检查依赖
4. 启动服务
## 手动升级
在项目根目录下执行:
```bash
git pull
pip3 install -r requirements.txt
```
更新完成后重启服务:
```bash
# 如果使用 run.sh 管理
./run.sh restart
# 如果使用 nohup 直接运行
kill $(ps -ef | grep app.py | grep -v grep | awk '{print $2}')
nohup python3 app.py & tail -f nohup.out
```
## Docker 升级
在 `docker-compose.yml` 所在目录下执行:
```bash
sudo docker compose pull
sudo docker compose up -d
```
升级前建议备份 `config.json` 配置文件。Docker 环境下如需保留数据,可通过 volume 挂载持久化工作空间目录。
================================================
FILE: docs/intro/architecture.mdx
================================================
---
title: 项目架构
description: CowAgent 2.0 的系统架构和核心设计
---
CowAgent 2.0 从简单的聊天机器人全面升级为超级智能助理,采用 Agent 架构设计,具备自主思考、规划任务、长期记忆和技能扩展等能力。
## 系统架构
CowAgent 的整体架构由以下核心模块组成:
### 核心模块说明
| 模块 | 说明 |
| --- | --- |
| **Channels** | 消息通道层,负责接收和发送消息,支持 Web、飞书、钉钉、企微、公众号等 |
| **Agent Core** | 智能体核心引擎,包括任务规划、记忆系统和技能引擎 |
| **Tools** | 工具层,Agent 通过工具访问操作系统资源,内置 10+ 种工具 |
| **Models** | 模型层,支持国内外主流大语言模型的统一接入 |
## Agent 模式
启用 Agent 模式后,CowAgent 会以自主智能体的方式运行,核心工作流如下:
1. **接收消息** - 通过通道接收用户输入
2. **理解意图** - 分析任务需求和上下文
3. **规划任务** - 将复杂任务分解为多个步骤
4. **调用工具** - 选择合适的工具执行每个步骤
5. **记忆更新** - 将重要信息存入长期记忆
6. **返回结果** - 将执行结果发送回用户
## 工作空间
Agent 的工作空间默认位于 `~/cow` 目录,用于存储系统提示词、记忆文件、技能文件等:
```
~/cow/
├── system.md # Agent system prompt
├── user.md # User profile
├── memory/ # Long-term memory storage
│ ├── core.md # Core memory
│ └── daily/ # Daily memory
└── skills/ # Custom skills
├── skill-1/
└── skill-2/
```
秘钥文件单独存储在 `~/.cow` 目录(出于安全考虑):
```
~/.cow/
└── .env # Secret keys for skills
```
## 核心配置
在 `config.json` 中配置 Agent 模式的核心参数:
```json
{
"agent": true,
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 30,
"agent_max_steps": 15
}
```
| 参数 | 说明 | 默认值 |
| --- | --- | --- |
| `agent` | 是否启用 Agent 模式 | `true` |
| `agent_workspace` | 工作空间路径 | `~/cow` |
| `agent_max_context_tokens` | 最大上下文 token 数 | `40000` |
| `agent_max_context_turns` | 最大上下文记忆轮次 | `30` |
| `agent_max_steps` | 单次任务最大决策步数 | `15` |
================================================
FILE: docs/intro/features.mdx
================================================
---
title: 功能介绍
description: CowAgent 长期记忆、任务规划、技能系统详细说明
---
## 1. 长期记忆
> 记忆系统让 Agent 能够长期记住重要信息。Agent 会在用户分享偏好、决策、事实等重要信息时主动存储,也会在对话达到一定长度时自动提取摘要。记忆分为核心记忆、天级记忆,支持语义搜索和向量检索的混合检索模式。
第一次启动 Agent 时,Agent 会主动询问关键信息,并记录至工作空间(默认 `~/cow`)中的智能体设定、用户身份、记忆文件中。
在后续的长期对话中,Agent 会在需要时智能记录或检索记忆,并对自身设定、用户偏好、记忆文件等进行不断更新,总结和记录经验和教训,真正实现自主思考和不断成长。
## 2. 任务规划和工具调用
工具是 Agent 访问操作系统资源的核心,Agent 会根据任务需求智能选择和调用工具,完成文件读写、命令执行、定时任务等各类操作。内置工具的实现在项目的 `agent/tools/` 目录下。
**主要工具:** 文件读写编辑、Bash 终端、文件发送、定时调度、记忆搜索、联网搜索、环境配置等。
### 2.1 终端和文件访问
针对操作系统的终端和文件的访问能力,是最基础和核心的工具,其他很多工具或技能都是基于此进行扩展。用户可通过手机端与 Agent 交互,操作个人电脑或服务器上的资源:
### 2.2 编程能力
基于编程能力和系统访问能力,Agent 可以实现从信息搜索、图片等素材生成、编码、测试、部署、Nginx 配置修改、发布的 **Vibecoding 全流程**,通过手机端简单的一句命令完成应用的快速 demo:
### 2.3 定时任务
基于 `scheduler` 工具实现动态定时任务,支持**一次性任务、固定时间间隔、Cron 表达式**三种形式,任务触发可选择**固定消息发送**或 **Agent 动态任务**执行两种模式:
### 2.4 环境变量管理
技能所需的秘钥存储在环境变量文件中,由 `env_config` 工具进行管理,你可以通过对话的方式更新秘钥,工具内置安全保护和脱敏策略:
## 3. 技能系统
技能系统为 Agent 提供无限的扩展性,每个 Skill 由说明文件、运行脚本(可选)、资源(可选)组成,描述如何完成特定类型的任务。通过 Skill 可以让 Agent 遵循说明完成复杂流程、调用各类工具或对接第三方系统。
- **内置技能:** 在项目的 `skills/` 目录下,包含技能创造器、图像识别、LinkAI 智能体、网页抓取等。内置 Skill 根据依赖条件(API Key、系统命令等)自动判断是否启用。
- **自定义技能:** 由用户通过对话创建,存放在工作空间中(`~/cow/skills/`),可实现任何复杂的业务流程和第三方系统对接。
### 3.1 创建技能
通过 `skill-creator` 技能可以通过对话的方式快速创建技能。你可以让 Agent 将某个工作流程固化为技能,或者把任意接口文档和示例发送给 Agent,让他直接完成对接:
### 3.2 搜索和图像识别
- **联网搜索:** 内置 `web_search` 工具,支持多种搜索引擎,配置 `BOCHA_API_KEY` 或 `LINKAI_API_KEY` 后启用。
- **图像识别:** 内置 `openai-image-vision` 技能,可使用 `gpt-4.1-mini`、`gpt-4.1` 等模型,依赖 `OPENAI_API_KEY`。
### 3.3 三方知识库和插件
`linkai-agent` 技能可以将 [LinkAI](https://link-ai.tech/) 上的所有智能体作为 Skill 交给 Agent 使用,实现多智能体决策效果。
配置方式:通过 `env_config` 配置 `LINKAI_API_KEY`,并在 `skills/linkai-agent/config.json` 中添加智能体说明:
```json
{
"apps": [
{
"app_code": "G7z6vKwp",
"app_name": "LinkAI客服助手",
"app_description": "当用户需要了解LinkAI平台相关问题时才选择该助手"
},
{
"app_code": "SFY5x7JR",
"app_name": "内容创作助手",
"app_description": "当用户需要创作图片或视频时才使用该助手"
}
]
}
```
================================================
FILE: docs/intro/index.mdx
================================================
---
title: 项目介绍
description: CowAgent - 基于大模型的超级AI助理
---
**CowAgent** 是基于大模型的超级AI助理,能够主动思考和任务规划、操作计算机和外部资源、创造和执行Skills、拥有长期记忆并不断成长。
CowAgent 支持灵活切换多种模型,能处理文本、语音、图片、文件等多模态消息,可接入网页、飞书、钉钉、企业微信应用、微信公众号中使用,7×24小时运行于你的个人电脑或服务器中。
开源代码仓库,欢迎 Star 和贡献
无需安装,立即在线体验 CowAgent
## 核心能力
能够理解复杂任务并自主规划执行,持续思考和调用工具直到完成目标,支持通过工具操作访问文件、终端、浏览器、定时任务等系统资源。
自动将对话记忆持久化至本地文件和数据库中,包括全局记忆和天级记忆,支持关键词及向量检索。
实现了Skills创建和运行的引擎,内置多种技能,并支持通过自然语言对话完成自定义Skills开发。
支持对文本、图片、语音、文件等多类型消息进行解析、处理、生成、发送等操作。
支持 OpenAI, Claude, Gemini, DeepSeek, MiniMax, GLM, Qwen, Kimi, Doubao 等国内外主流模型厂商。
支持运行在本地计算机或服务器,可集成到网页、飞书、钉钉、微信公众号、企业微信应用中使用。
## 快速体验
在终端执行以下命令,即可一键安装、配置、启动 CowAgent:
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
运行后默认会启动 Web 服务,通过访问 `http://localhost:9899/chat` 在网页端对话。
查看完整的安装和运行指南
了解 CowAgent 的系统架构设计
## 社区
添加小助手微信加入开源项目交流群:
================================================
FILE: docs/ja/README.md
================================================
[中文] | [English] | [日本語]
**CowAgent** はLLMを搭載したAIスーパーアシスタントです。自律的なタスク計画、コンピュータや外部リソースの操作、Skillの作成・実行、長期記憶による継続的な成長が可能です。柔軟なモデル切り替えに対応し、テキスト・音声・画像・ファイルを処理でき、Web、Feishu(飛書)、DingTalk(釘釘)、WeCom Bot(企業微信ボット)、WeComアプリ、WeChat公式アカウントに統合可能で、個人のPCやサーバー上で24時間365日稼働できます。
🌐 ウェブサイト ·
📖 ドキュメント ·
🚀 クイックスタート ·
☁️ オンラインで試す
## はじめに
> CowAgentは、すぐに使えるAIスーパーアシスタントであると同時に、高い拡張性を持つAgentフレームワークでもあります。新しいモデルインターフェース、チャネル、組み込みツール、Skillシステムを拡張することで、さまざまなカスタマイズニーズに柔軟に対応できます。
- ✅ **自律的タスク計画**: 複雑なタスクを理解し、自律的に実行計画を立て、目標達成までツールを呼び出しながら継続的に思考します。ツールを通じてファイル、ターミナル、ブラウザ、スケジューラなどのシステムリソースにアクセスできます。
- ✅ **長期記憶**: 会話の記憶をローカルファイルやデータベースに自動的に永続化します。コアメモリとデイリーメモリを含み、キーワード検索やベクトル検索に対応しています。
- ✅ **Skillシステム**: Skillの作成・実行エンジンを実装しており、複数の組み込みSkillを備え、自然言語での会話を通じたカスタムSkillの開発もサポートしています。
- ✅ **マルチモーダルメッセージ**: テキスト、画像、音声、ファイルなど、さまざまなメッセージタイプの解析・処理・生成・送信に対応しています。
- ✅ **複数モデル対応**: OpenAI、Claude、Gemini、DeepSeek、MiniMax、GLM、Qwen、Kimi、Doubaoなど、主要なモデルプロバイダーに対応しています。
- ✅ **マルチプラットフォームデプロイ**: ローカルPCやサーバー上で実行でき、Web、Feishu、DingTalk、WeChat公式アカウント、WeComアプリケーションに統合可能です。
- ✅ **ナレッジベース**: [LinkAI](https://link-ai.tech) プラットフォームを通じて、企業向けナレッジベース機能を統合できます。
## 免責事項
1. 本プロジェクトは [MIT License](/LICENSE) に基づいており、技術研究・学習を目的としています。利用者は現地の法律、規制、ポリシー、企業の社則を遵守する必要があります。違法行為や権利侵害となる利用は禁止されています。
2. Agentモードは通常のチャットモードよりも多くのトークンを消費します。効果とコストに基づいてモデルを選択してください。AgentはホストOSにアクセスできるため、信頼できる環境にデプロイしてください。
3. CowAgentはオープンソース開発に注力しており、いかなる暗号通貨の発行・参加・承認も行っていません。
## デモ
オンラインで試す(デプロイ不要): [CowAgent](https://link-ai.tech/cowagent/create)
## 更新履歴
> **2026.02.27:** [v2.0.2](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.2) — Webコンソールの全面刷新(ストリーミングチャット、モデル/Skill/メモリ/チャネル/スケジューラ/ログ管理)、マルチチャネル同時実行、セッション永続化、Gemini 3.1 Pro / Claude 4.6 Sonnet / Qwen3.5 Plusなど新モデル追加。
> **2026.02.13:** [v2.0.1](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.1) — 組み込みWeb検索ツール、スマートコンテキストトリミング、ランタイム情報の動的更新、Windows互換性、スケジューラのメモリ喪失やFeishu接続問題などの修正。
> **2026.02.03:** [v2.0.0](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.0) — マルチステップタスク計画、長期記憶、組み込みツール、Skillフレームワーク、新モデル、チャネル最適化を備えたAIスーパーアシスタントへの全面アップグレード。
> **2025.05.23:** [v1.7.6](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/1.7.6) — Webチャネル最適化、AgentMeshマルチエージェントプラグイン、Baidu TTS、claude-4-sonnet/opus対応。
> **2025.04.11:** [v1.7.5](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/1.7.5) — wechatferryプロトコル、DeepSeekモデル、Tencent Cloud音声、ModelScope・Gitee-AI対応。
> **2024.12.13:** [v1.7.4](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/1.7.4) — Gemini 2.0モデル、Webチャネル、メモリリーク修正。
全更新履歴: [リリースノート](https://docs.cowagent.ai/en/releases/overview)
## 🚀 クイックスタート
本プロジェクトは、インストール・設定・起動・管理をワンクリックで行えるスクリプトを提供しています:
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
実行後、デフォルトでWebサービスが起動します。`http://localhost:9899/chat` にアクセスしてチャットを開始できます。
スクリプトの使い方: [ワンクリックインストール](https://docs.cowagent.ai/en/guide/quick-start)
### 手動インストール
**1. プロジェクトのクローン**
```bash
git clone https://github.com/zhayujie/chatgpt-on-wechat
cd chatgpt-on-wechat/
```
**2. 依存関係のインストール**
```bash
pip3 install -r requirements.txt
pip3 install -r requirements-optional.txt # 任意ですが推奨
```
**3. 設定**
```bash
cp config-template.json config.json
```
`config.json` にモデルのAPIキーとチャネルタイプを記入してください。詳細は[設定ドキュメント](https://docs.cowagent.ai/en/guide/manual-install)を参照してください。
**4. 実行**
```bash
python3 app.py
```
サーバーでバックグラウンド実行する場合:
```bash
nohup python3 app.py & tail -f nohup.out
```
### Dockerデプロイ
```bash
curl -O https://cdn.link-ai.tech/code/cow/docker-compose.yml
# docker-compose.yml を編集して設定を記入
sudo docker compose up -d
sudo docker logs -f chatgpt-on-wechat
```
## モデル
主要なモデルプロバイダーに対応しています。Agentモードの推奨モデル:
| プロバイダー | 推奨モデル |
| --- | --- |
| MiniMax | `MiniMax-M2.7` |
| GLM | `glm-5-turbo` |
| Kimi | `kimi-k2.5` |
| Doubao | `doubao-seed-2-0-code-preview-260215` |
| Qwen | `qwen3.5-plus` |
| Claude | `claude-sonnet-4-6` |
| Gemini | `gemini-3.1-pro-preview` |
| OpenAI | `gpt-5.4` |
| DeepSeek | `deepseek-chat` |
各モデルの詳細設定については、[モデルドキュメント](https://docs.cowagent.ai/en/models/index)を参照してください。
### Coding Plan
Coding Planは各プロバイダーが提供する月額サブスクリプションパッケージで、高頻度のAgent利用に最適です。すべてのプロバイダーはOpenAI互換モードでアクセスできます:
```json
{
"bot_type": "openai",
"model": "MODEL_NAME",
"open_ai_api_base": "PROVIDER_CODING_PLAN_API_BASE",
"open_ai_api_key": "YOUR_API_KEY"
}
```
- `bot_type`: `openai` を指定
- `model`: プロバイダーがサポートするモデル名
- `open_ai_api_base`: プロバイダーのCoding Plan API Base(標準の従量課金とは異なります)
- `open_ai_api_key`: プロバイダーのCoding Plan APIキー
> 注意:Coding PlanのAPI BaseとAPIキーは、通常の従量課金のものとは別です。各プロバイダーのプラットフォームから取得してください。
対応プロバイダーには、Alibaba Cloud、MiniMax、Zhipu GLM、Kimi、Volcengineなどがあります。各プロバイダーの詳細設定については、[Coding Planドキュメント](https://docs.cowagent.ai/en/models/coding-plan)を参照してください。
## チャネル
複数のプラットフォームに対応しています。`config.json` の `channel_type` を設定して切り替えます:
| チャネル | `channel_type` | ドキュメント |
| --- | --- | --- |
| Web(デフォルト) | `web` | [Webチャネル](https://docs.cowagent.ai/en/channels/web) |
| Feishu(飛書) | `feishu` | [Feishu設定](https://docs.cowagent.ai/en/channels/feishu) |
| DingTalk(釘釘) | `dingtalk` | [DingTalk設定](https://docs.cowagent.ai/en/channels/dingtalk) |
| WeCom Bot | `wecom_bot` | [WeCom Bot設定](https://docs.cowagent.ai/en/channels/wecom-bot) |
| WeComアプリ | `wechatcom_app` | [WeCom設定](https://docs.cowagent.ai/en/channels/wecom) |
| WeChat公式アカウント | `wechatmp` / `wechatmp_service` | [WeChat公式アカウント設定](https://docs.cowagent.ai/en/channels/wechatmp) |
| ターミナル | `terminal` | — |
複数チャネルを同時に有効化できます。カンマ区切りで指定してください:`"channel_type": "feishu,dingtalk"`
## エンタープライズサービス
> [LinkAI](https://link-ai.tech/) は、企業や開発者向けのワンストップAIエージェントプラットフォームです。マルチモーダルLLM、ナレッジベース、Agentプラグイン、ワークフローを統合しています。主要プラットフォームへのワンクリック統合、SaaSおよびプライベートデプロイに対応しています。
## 🔗 関連プロジェクト
- [bot-on-anything](https://github.com/zhayujie/bot-on-anything): 軽量で高い拡張性を持つLLMアプリケーションフレームワーク。Slack、Telegram、Discord、Gmailなどに対応。
- [AgentMesh](https://github.com/MinimalFuture/AgentMesh): エージェントチームの協調による複雑な問題解決のためのオープンソースのマルチエージェントフレームワーク。
## 🔎 よくある質問
FAQ:
## 🛠️ コントリビューション
新しいチャネルの追加を歓迎します。[Feishuチャネル](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/channel/feishu/feishu_channel.py)を参考にしてください。また、新しいSkillのコントリビューションも歓迎します。[Skill Creatorドキュメント](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/skills/skill-creator/SKILL.md)を参照してください。
## ✉ お問い合わせ
PRやIssueの提出を歓迎します。🌟 Starでプロジェクトをサポートしてください。ご質問がある場合は、[FAQリスト](https://github.com/zhayujie/chatgpt-on-wechat/wiki/FAQs)を確認するか、[Issues](https://github.com/zhayujie/chatgpt-on-wechat/issues)を検索してください。
## 🌟 コントリビューター

================================================
FILE: docs/ja/channels/dingtalk.mdx
================================================
---
title: DingTalk
description: CowAgent を DingTalk アプリケーションに統合する
---
DingTalk オープンプラットフォームでインテリジェントロボットアプリを作成して、CowAgent を DingTalk に統合します。
## 1. アプリの作成
1. [DingTalk 開発者コンソール](https://open-dev.dingtalk.com/fe/app#/corp/app)にアクセスし、ログインして**アプリを作成**をクリックし、アプリ情報を入力します:
2. **アプリ機能の追加**をクリックし、**ロボット**機能を選択して**追加**をクリックします:
3. ロボット情報を設定し、**公開**をクリックします。公開後、「**デバッグ**」をクリックすると自動的にテストグループチャットが作成され、クライアントで確認できます:
4. **バージョン管理とリリース**をクリックし、新しいバージョンを作成して公開します:
## 2. プロジェクト設定
1. **認証情報と基本情報**をクリックし、`Client ID` と `Client Secret` を取得します:
2. プロジェクトルートの `config.json` に以下の設定を追加します:
```json
{
"channel_type": "dingtalk",
"dingtalk_client_id": "YOUR_CLIENT_ID",
"dingtalk_client_secret": "YOUR_CLIENT_SECRET"
}
```
3. 依存パッケージをインストールします:
```bash
pip3 install dingtalk_stream
```
4. プロジェクト起動後、DingTalk 開発者コンソールに移動し、**イベントサブスクリプション**をクリックし、**接続確認済み、チャネルを確認**をクリックします。「**接続成功**」と表示されれば設定完了です:
## 3. 使い方
ロボットと個別チャットするか、企業グループに追加して会話を開始します:
================================================
FILE: docs/ja/channels/feishu.mdx
================================================
---
title: Feishu (Lark)
description: CowAgent を Feishu アプリケーションに統合する
---
企業向けカスタムアプリを作成して、CowAgent を Feishu に統合します。管理者権限を持つ Feishu 企業ユーザーである必要があります。
## 1. 企業カスタムアプリの作成
### 1.1 アプリの作成
[Feishu 開発者プラットフォーム](https://open.feishu.cn/app/)にアクセスし、**企業カスタムアプリを作成**をクリックして、必要な情報を入力し**作成**をクリックします:
### 1.2 Bot 機能の追加
**アプリ機能の追加**で、アプリに **Bot** 機能を追加します:
### 1.3 アプリ権限の設定
**権限管理**をクリックし、**権限設定**の下の入力欄に以下の権限文字列を貼り付け、フィルタされたすべての権限を選択し、**一括有効化**をクリックして確認します:
```
im:message,im:message.group_at_msg,im:message.group_at_msg:readonly,im:message.p2p_msg,im:message.p2p_msg:readonly,im:message:send_as_bot,im:resource
```
## 2. プロジェクト設定
1. **認証情報と基本情報**から `App ID` と `App Secret` を取得します:
2. プロジェクトルートの `config.json` に以下の設定を追加します:
```json
{
"channel_type": "feishu",
"feishu_app_id": "YOUR_APP_ID",
"feishu_app_secret": "YOUR_APP_SECRET",
"feishu_bot_name": "YOUR_BOT_NAME"
}
```
| パラメータ | 説明 |
| --- | --- |
| `feishu_app_id` | Feishu Bot の App ID |
| `feishu_app_secret` | Feishu Bot の App Secret |
| `feishu_bot_name` | Bot 名(アプリ作成時に設定)、グループチャットで使用する際に必要 |
設定完了後、プロジェクトを起動します。
## 3. イベントサブスクリプションの設定
1. プロジェクトが正常に動作した後、Feishu 開発者プラットフォームに移動し、**イベントとコールバック**をクリックし、**ロングコネクション**モードを選択して保存をクリックします:
2. 下の**イベントを追加**をクリックし、「メッセージ受信」を検索して「**メッセージ受信 v2.0**」を選択し、確認します。
3. **バージョン管理とリリース**をクリックし、新しいバージョンを作成して**本番リリース**を申請します。Feishu クライアントで承認メッセージを確認し、承認します:
完了後、Feishu で Bot 名を検索してチャットを開始できます。
================================================
FILE: docs/ja/channels/qq.mdx
================================================
---
title: QQ Bot
description: CowAgent を QQ Bot に接続する(WebSocket ロングコネクション)
---
> QQ オープンプラットフォームの Bot API を介して CowAgent を接続し、QQ のダイレクトメッセージ、グループチャット(@bot)、ギルドチャネルメッセージ、ギルド DM に対応します。パブリック IP は不要で、WebSocket ロングコネクションを使用します。
QQ Bot は QQ オープンプラットフォームを通じて作成します。WebSocket ロングコネクションでメッセージを受信し、OpenAPI でメッセージを送信します。パブリック IP やドメインは不要です。
## 1. QQ Bot の作成
> [QQ オープンプラットフォーム](https://q.qq.com)にアクセスし、QQ でサインインします。未登録の場合は、先に[アカウント登録](https://q.qq.com/#/register)を完了してください。
1.[QQ オープンプラットフォーム - Bot 一覧](https://q.qq.com/#/apps)に移動し、**Bot を作成**をクリックします:
2.Bot 名、アバター、その他の基本情報を入力して作成を完了します:
3.Bot 設定ページに入り、**開発管理**に移動して以下の手順を完了します:
- **AppID**(Bot ID)をコピーして保存します
- **AppSecret**(Bot Secret)を生成して保存します
## 2. 設定と起動
### 方法 A: Web コンソール
プログラムを起動し、Web コンソール(ローカルアクセス: http://127.0.0.1:9899/)を開きます。**チャネル**タブに移動し、**チャネルを接続**をクリックして **QQ Bot** を選択し、前のステップで取得した AppID と AppSecret を入力して接続をクリックします。
### 方法 B: 設定ファイル
`config.json` に以下を追加します:
```json
{
"channel_type": "qq",
"qq_app_id": "YOUR_APP_ID",
"qq_app_secret": "YOUR_APP_SECRET"
}
```
| パラメータ | 説明 |
| --- | --- |
| `qq_app_id` | QQ Bot の AppID。オープンプラットフォームの開発管理で確認できます |
| `qq_app_secret` | QQ Bot の AppSecret。オープンプラットフォームの開発管理で確認できます |
設定後、プログラムを起動します。ログに `[QQ] ✅ Connected successfully` と表示されれば接続成功です。
## 3. 使い方
QQ オープンプラットフォームで、**管理 → 利用範囲とメンバー**に移動し、「グループとメッセージリストに追加」の QR コードを QQ クライアントでスキャンして Bot とのチャットを開始します:
チャット例:
## 4. 対応機能
> 注意: グループチャットやギルドチャネルで QQ Bot を使用するには、公開審査を完了し、利用範囲の権限を設定する必要があります。
| 機能 | 状態 |
| --- | --- |
| QQ ダイレクトメッセージ | ✅ |
| QQ グループチャット(@bot) | ✅ |
| ギルドチャネル(@bot) | ✅ |
| ギルド DM | ✅ |
| テキストメッセージ | ✅ 送受信 |
| 画像メッセージ | ✅ 送受信(グループ・ダイレクト) |
| ファイルメッセージ | ✅ 送信(グループ・ダイレクト) |
| スケジュールタスク | ✅ 能動的プッシュ(ユーザーあたり月4回) |
## 5. 注意事項
- **受動メッセージの制限**: QQ ダイレクトメッセージの返信は60分間有効です(1メッセージあたり最大5回返信可能)。グループチャットの返信は5分間有効です。
- **能動メッセージの制限**: ダイレクトメッセージとグループチャットの両方で、月あたりの能動メッセージは4件までです。スケジュールタスク機能を使用する際はこの点にご注意ください。
- **イベント権限**: デフォルトでは `GROUP_AND_C2C_EVENT`(QQ グループ/ダイレクト)と `PUBLIC_GUILD_MESSAGES`(ギルド公開メッセージ)がサブスクライブされています。追加の権限が必要な場合は、オープンプラットフォームで申請してください。
================================================
FILE: docs/ja/channels/web.mdx
================================================
---
title: Web コンソール
description: Web コンソールで CowAgent を使用する
---
Web コンソールは CowAgent のデフォルトチャネルです。起動後に自動的に開始され、ブラウザを通じて Agent とチャットしたり、モデル、Skill、メモリ、チャネルなどの設定をオンラインで管理できます。
## 設定
```json
{
"channel_type": "web",
"web_port": 9899
}
```
| パラメータ | 説明 | デフォルト値 |
| --- | --- | --- |
| `channel_type` | `web` に設定 | `web` |
| `web_port` | Web サービスのリスンポート | `9899` |
## アクセス URL
プロジェクト起動後、以下にアクセスしてください:
- ローカル: `http://localhost:9899`
- サーバー: `http://:9899`
サーバーのファイアウォールとセキュリティグループで該当ポートが許可されていることを確認してください。
## 機能
### チャット画面
ストリーミング出力に対応しており、Agent の推論プロセスやツール呼び出しをリアルタイムで表示し、Agent の意思決定を直感的に観察できます:
### モデル管理
設定ファイルを手動で編集せずに、オンラインでモデル設定を管理できます:
### Skill 管理
Agent の Skill をオンラインで閲覧・管理できます:
### メモリ管理
Agent のメモリをオンラインで閲覧・管理できます:
### チャネル管理
接続中のチャネルをオンラインで管理し、リアルタイムで接続・切断操作を行えます:
### スケジュールタスク
スケジュールタスクをオンラインで閲覧・管理できます。一回限りのタスク、固定間隔、Cron 式に対応しています:
### ログ
Agent のランタイムログをリアルタイムで確認でき、監視やトラブルシューティングに活用できます:
================================================
FILE: docs/ja/channels/wechatmp.mdx
================================================
---
title: WeChat 公式アカウント
description: CowAgent を WeChat 公式アカウントに統合する
---
CowAgent は個人サブスクリプションアカウントと企業サービスアカウントの両方に対応しています。
| 種類 | 要件 | 特徴 |
| --- | --- | --- |
| **個人サブスクリプション** | 個人で利用可能 | まずプレースホルダーの返信を送信し、ユーザーが完全な応答を取得するにはメッセージを送信する必要があります |
| **企業サービス** | カスタマーサービス API が認証済みの企業 | ユーザーに能動的に返信をプッシュできます |
公式アカウントはサーバーおよび Docker デプロイのみサポートしており、ローカル実行モードには対応していません。拡張依存パッケージをインストールしてください: `pip3 install -r requirements-optional.txt`
## 1. 個人サブスクリプションアカウント
`config.json` に以下の設定を追加します:
```json
{
"channel_type": "wechatmp",
"single_chat_prefix": [""],
"wechatmp_app_id": "wx73f9******d1e48",
"wechatmp_app_secret": "YOUR_APP_SECRET",
"wechatmp_aes_key": "",
"wechatmp_token": "YOUR_TOKEN",
"wechatmp_port": 80
}
```
### セットアップ手順
これらの設定は [WeChat 公式アカウントプラットフォーム](https://mp.weixin.qq.com/advanced/advanced?action=dev&t=advanced/dev)と一致している必要があります。**設定と開発 → 基本設定 → サーバー設定**に移動し、以下のように設定します:
1. プラットフォームで開発者シークレットを有効化し(`wechatmp_app_secret` に対応)、サーバー IP をホワイトリストに追加します
2. プラットフォームの設定と一致するように公式アカウントのパラメータを `config.json` に入力します
3. プログラムを起動します。ポート 80 でリスンします(権限がない場合は `sudo` を使用してください。ポート 80 を占有しているプロセスがあれば停止してください)
4. 公式アカウントプラットフォームで**サーバー設定を有効化**して送信します。正常に保存できれば設定完了です。**「サーバー URL」**は `http://{HOST}/wx` の形式で入力する必要があり、`{HOST}` にはサーバー IP またはドメインを指定できます
アカウントをフォローしてメッセージを送信すると、以下のような結果が表示されるはずです:
サブスクリプションアカウントの制限により、短い返信(15秒以内)は即座に返されますが、長い返信の場合はまず「考え中...」というプレースホルダーが送信され、ユーザーは任意のテキストを送信して回答を取得する必要があります。企業サービスアカウントではカスタマーサービス API を使用してこの問題を解決できます。
**音声認識**: WeChat 内蔵の音声認識を使用できます。公式アカウント管理ページの「設定と開発 → API 権限」で「音声認識結果の受信」を有効にしてください。
## 2. 企業サービスアカウント
企業サービスアカウントのセットアップ手順は個人サブスクリプションアカウントとほぼ同じですが、以下の点が異なります:
1. プラットフォームで企業サービスアカウントを登録し、WeChat 認証を完了します。**カスタマーサービス API** の権限が付与されていることを確認してください
2. `config.json` で `"channel_type": "wechatmp_service"` に設定します。その他の設定は同じです
3. 長い返信であっても、ユーザーに能動的にプッシュでき、手動での取得が不要です
```json
{
"channel_type": "wechatmp_service",
"single_chat_prefix": [""],
"wechatmp_app_id": "YOUR_APP_ID",
"wechatmp_app_secret": "YOUR_APP_SECRET",
"wechatmp_aes_key": "",
"wechatmp_token": "YOUR_TOKEN",
"wechatmp_port": 80
}
```
================================================
FILE: docs/ja/channels/wecom-bot.mdx
================================================
---
title: WeCom Bot
description: CowAgent を WeCom AI Bot に接続する(WebSocket ロングコネクション)
---
WeCom AI Bot を介して CowAgent を接続し、ダイレクトメッセージとグループチャットの両方に対応します。パブリック IP は不要で、WebSocket ロングコネクションを使用し、Markdown レンダリングとストリーミング出力をサポートします。
WeCom Bot と WeCom App は異なる統合方式です。WeCom Bot は WebSocket ロングコネクションを使用するため、パブリック IP やドメインが不要で、セットアップが簡単です。
## 1. AI Bot の作成
1. WeCom クライアントを開き、**ワークベンチ**に移動し、**AI Bot** をクリックします:
2. **Bot を作成** → **手動作成**をクリックします:
3. 右パネルの一番下までスクロールし、**API モード**を選択します:
4. Bot 名、アバター、公開範囲を設定します。**ロングコネクション**モードを選択し、**Bot ID** と **Secret** をメモしてから保存をクリックします。
## 2. 設定
### 方法 A: Web コンソール
プログラムを起動し、Web コンソール(ローカルアクセス: http://127.0.0.1:9899)を開きます。**チャネル**タブに移動し、**チャネルを接続**をクリックして **WeCom Bot** を選択し、前のステップで取得した Bot ID と Secret を入力して接続をクリックします。
### 方法 B: 設定ファイル
`config.json` に以下を追加します:
```json
{
"channel_type": "wecom_bot",
"wecom_bot_id": "YOUR_BOT_ID",
"wecom_bot_secret": "YOUR_SECRET"
}
```
| パラメータ | 説明 |
| --- | --- |
| `wecom_bot_id` | AI Bot の Bot ID |
| `wecom_bot_secret` | AI Bot の Secret |
設定後、プログラムを起動します。ログに `[WecomBot] Subscribe success` と表示されれば接続成功です。
## 3. 対応機能
| 機能 | 状態 |
| --- | --- |
| ダイレクトメッセージ | ✅ |
| グループチャット(@bot) | ✅ |
| テキストメッセージ | ✅ 送受信 |
| 画像メッセージ | ✅ 送受信 |
| ファイルメッセージ | ✅ 送受信 |
| ストリーミング返信 | ✅ |
| スケジュール配信 | ✅ |
## 4. 使い方
WeCom で Bot 名を検索してダイレクトメッセージを開始できます。
グループチャットで使用するには、Bot をグループに追加し、@メンションしてメッセージを送信します。
================================================
FILE: docs/ja/channels/wecom.mdx
================================================
---
title: WeCom
description: CowAgent を WeCom 企業アプリに統合する
---
カスタム企業アプリを通じて CowAgent を WeCom に統合し、社内従業員との1対1チャットに対応します。
WeCom は Docker デプロイまたはサーバー上の Python デプロイのみサポートしています。ローカル実行モードには対応していません。
## 1. 前提条件
必要なリソース:
1. パブリック IP を持つサーバー(海外サーバー、または国際 API アクセス用のプロキシを持つ国内サーバー)
2. 登録済みの WeCom アカウント(個人登録は可能ですが認証はできません)
3. 認証済みの WeCom アカウントには、対応する法人名義で届け出済みのドメインが別途必要です
## 2. WeCom アプリの作成
1. [WeCom 管理コンソール](https://work.weixin.qq.com/wework_admin/frame#profile)で、**自社情報**をクリックし、ページ下部の **Corp ID** を確認します。この ID を `wechatcom_corp_id` 設定フィールド用に保存します。
2. **アプリ管理**に切り替え、アプリを作成をクリックします:
3. アプリ作成ページで、`AgentId` と `Secret` を記録します:
4. **API 受信設定**をクリックしてアプリケーションインターフェースを設定します:
- URL の形式: `http://ip:port/wxcomapp`(認証済み企業は届け出済みドメインを使用する必要があります)
- ランダムな `Token` と `EncodingAESKey` を生成し、設定ファイル用に保存します
プログラムがまだ起動していないため、この時点では API 受信設定を保存できません。プロジェクトが動作した後に戻って保存してください。
## 3. 設定と起動
`config.json` に以下の設定を追加します(各パラメータと WeCom コンソールの対応関係は上のスクリーンショットを参照してください):
```json
{
"channel_type": "wechatcom_app",
"single_chat_prefix": [""],
"wechatcom_corp_id": "YOUR_CORP_ID",
"wechatcomapp_token": "YOUR_TOKEN",
"wechatcomapp_secret": "YOUR_SECRET",
"wechatcomapp_agent_id": "YOUR_AGENT_ID",
"wechatcomapp_aes_key": "YOUR_AES_KEY",
"wechatcomapp_port": 9898
}
```
| パラメータ | 説明 |
| --- | --- |
| `wechatcom_corp_id` | Corp ID |
| `wechatcomapp_token` | API 受信設定の Token |
| `wechatcomapp_secret` | アプリの Secret |
| `wechatcomapp_agent_id` | アプリの AgentId |
| `wechatcomapp_aes_key` | API 受信設定の EncodingAESKey |
| `wechatcomapp_port` | リスンポート、デフォルトは 9898 |
設定後、プログラムを起動します。ログに `http://0.0.0.0:9898/` と表示されれば、プログラムは正常に動作しています。このポートを外部に公開する必要があります(例:クラウドサーバーのセキュリティグループで許可します)。
プログラム起動後、WeCom 管理コンソールに戻って**メッセージサーバー設定**を保存します。保存が成功したら、サーバー IP を**企業の信頼済み IP** に追加する必要もあります。追加しないとメッセージの送受信ができません:
URL 設定のコールバックが失敗する場合や、設定がうまくいかない場合:
1. サーバーのファイアウォールが無効になっており、セキュリティグループでリスンポートが許可されていることを確認してください
2. Token、Secret Key などのパラメータ設定が一致しているか、URL の形式が正しいか慎重に確認してください
3. 認証済みの WeCom アカウントは、法人に対応する届け出済みドメインを設定する必要があります
## 4. 使い方
WeCom で作成したアプリ名を検索して、直接チャットを開始できます。異なるポートでリスンする複数のインスタンスを実行して、複数の WeCom アプリを作成できます:
外部の個人 WeChat ユーザーにアプリを利用してもらうには、**自社情報 → WeChat プラグイン**に移動し、招待 QR コードを共有します。スキャンしてフォローした後、個人 WeChat ユーザーがアプリとチャットできるようになります:
## FAQ
以下の依存パッケージがインストールされていることを確認してください:
```bash
pip install websocket-client pycryptodome
```
================================================
FILE: docs/ja/guide/manual-install.mdx
================================================
---
title: 手動インストール
description: CowAgentの手動デプロイ(ソースコード / Docker)
---
## ソースコードによるデプロイ
### 1. プロジェクトをクローン
```bash
git clone https://github.com/zhayujie/chatgpt-on-wechat
cd chatgpt-on-wechat/
```
ネットワークに問題がある場合は、ミラーを使用してください: https://gitee.com/zhayujie/chatgpt-on-wechat
### 2. 依存パッケージをインストール
コア依存パッケージ(必須):
```bash
pip3 install -r requirements.txt
```
オプション依存パッケージ(推奨):
```bash
pip3 install -r requirements-optional.txt
```
### 3. 設定
設定テンプレートをコピーして編集します:
```bash
cp config-template.json config.json
```
`config.json` にモデルの API キー、チャネルタイプ、その他の設定を入力します。詳細は[モデルのドキュメント](/ja/models/index)を参照してください。
### 4. 実行
**ローカルで実行:**
```bash
python3 app.py
```
デフォルトではWebサービスが起動します。`http://localhost:9899/chat` にアクセスしてチャットできます。
**サーバーでバックグラウンド実行:**
```bash
nohup python3 app.py & tail -f nohup.out
```
## Docker によるデプロイ
Docker デプロイでは、ソースコードのクローンや依存パッケージのインストールは不要です。Agent モードを使用する場合は、より広範なシステムアクセスが可能なソースコードによるデプロイを推奨します。
[Docker](https://docs.docker.com/engine/install/) と docker-compose が必要です。
**1. 設定ファイルをダウンロード**
```bash
curl -O https://cdn.link-ai.tech/code/cow/docker-compose.yml
```
`docker-compose.yml` を編集して設定を行います。
**2. コンテナを起動**
```bash
sudo docker compose up -d
```
**3. ログを確認**
```bash
sudo docker logs -f chatgpt-on-wechat
```
## 主要な設定項目
```json
{
"channel_type": "web",
"model": "MiniMax-M2.5",
"agent": true,
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 30,
"agent_max_steps": 15
}
```
| パラメータ | 説明 | デフォルト値 |
| --- | --- | --- |
| `channel_type` | チャネルタイプ | `web` |
| `model` | モデル名 | `MiniMax-M2.5` |
| `agent` | Agent モードを有効化 | `true` |
| `agent_workspace` | Agent のワークスペースパス | `~/cow` |
| `agent_max_context_tokens` | 最大コンテキストトークン数 | `40000` |
| `agent_max_context_turns` | 最大コンテキストターン数 | `30` |
| `agent_max_steps` | タスクごとの最大判断ステップ数 | `15` |
すべての設定オプションはプロジェクトの [`config.py`](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/config.py) に記載されています。
================================================
FILE: docs/ja/guide/quick-start.mdx
================================================
---
title: ワンクリックインストール
description: スクリプトによるCowAgentのワンクリックインストールと管理
---
本プロジェクトでは、ワンクリックでのインストール、設定、起動、管理を行うスクリプトを提供しています。素早くセットアップするには、スクリプトによるデプロイを推奨します。
Linux、macOS、Windowsに対応しています。Python 3.7〜3.12が必要です(3.9を推奨)。
## インストールコマンド
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
スクリプトは以下の手順を自動的に実行します:
1. Python環境の確認(Python 3.7以上が必要)
2. 必要なツールのインストール(git、curlなど)
3. プロジェクトを `~/chatgpt-on-wechat` にクローン
4. Pythonの依存パッケージをインストール
5. AIモデルとチャネルの対話式設定
6. サービスの起動
デフォルトでは、インストール後にWebサービスが起動します。`http://localhost:9899/chat` にアクセスしてチャットを開始できます。
## 管理コマンド
インストール後、以下のコマンドでサービスを管理できます:
| コマンド | 説明 |
| --- | --- |
| `./run.sh start` | サービスを起動 |
| `./run.sh stop` | サービスを停止 |
| `./run.sh restart` | サービスを再起動 |
| `./run.sh status` | 実行状態を確認 |
| `./run.sh logs` | リアルタイムログを表示 |
| `./run.sh config` | 再設定 |
| `./run.sh update` | プロジェクトコードを更新 |
================================================
FILE: docs/ja/guide/upgrade.mdx
================================================
---
title: アップデート
description: CowAgent のアップグレード方法
---
## スクリプトによるアップグレード(推奨)
`run.sh` でサービスを管理している場合、以下のコマンドでワンクリックアップグレードできます:
```bash
./run.sh update
```
このコマンドは以下のフローを自動的に実行します:
1. 現在実行中のサービスを停止
2. 最新コードをプル
3. 依存関係を再チェック
4. サービスを起動
## 手動アップグレード
プロジェクトのルートディレクトリで以下を実行します:
```bash
git pull
pip3 install -r requirements.txt
```
更新完了後、サービスを再起動します:
```bash
# run.sh で管理している場合
./run.sh restart
# nohup で直接実行している場合
kill $(ps -ef | grep app.py | grep -v grep | awk '{print $2}')
nohup python3 app.py & tail -f nohup.out
```
## Docker アップグレード
`docker-compose.yml` があるディレクトリで以下を実行します:
```bash
sudo docker compose pull
sudo docker compose up -d
```
アップグレード前に `config.json` 設定ファイルのバックアップを推奨します。Docker 環境でデータを保持する場合は、volume マウントでワークスペースディレクトリを永続化できます。
================================================
FILE: docs/ja/intro/architecture.mdx
================================================
---
title: アーキテクチャ
description: CowAgent 2.0 のシステムアーキテクチャとコア設計
---
CowAgent 2.0 は、シンプルなチャットボットから、自律的な思考、タスク計画、長期記憶、Skill の拡張性を備えた Agent アーキテクチャのスーパーインテリジェントアシスタントへと進化しました。
## システムアーキテクチャ
CowAgent のアーキテクチャは以下のコアモジュールで構成されています:
### コアモジュール
| モジュール | 説明 |
| --- | --- |
| **Channels** | メッセージの受信と送信を行うメッセージチャネル層。Web、Feishu(飛書)、DingTalk(釘釘)、WeCom(企業微信)、WeChat公式アカウントなどをサポート |
| **Agent Core** | タスク計画、記憶システム、Skill エンジンを含む Agent エンジン |
| **Tools** | Agent が OS リソースにアクセスするためのツール層。10 以上の組み込みツール |
| **Models** | 主要な LLM への統一アクセスを提供するモデル層 |
## Agent モードのワークフロー
Agent モードが有効な場合、CowAgent は以下のワークフローで自律的な Agent として動作します:
1. **メッセージ受信** — チャネルを通じてユーザーの入力を受信
2. **意図の理解** — タスク要件とコンテキストを分析
3. **タスク計画** — 複雑なタスクを複数のステップに分解
4. **ツール呼び出し** — 各ステップに適切なツールを選択・実行
5. **記憶の更新** — 重要な情報を長期記憶に保存
6. **結果の返却** — 実行結果をユーザーに送信
## ワークスペースのディレクトリ構成
Agent のワークスペースはデフォルトで `~/cow` にあり、システムプロンプト、記憶ファイル、Skill ファイルを格納しています:
```
~/cow/
├── system.md # Agent システムプロンプト
├── user.md # ユーザープロフィール
├── memory/ # 長期記憶ストレージ
│ ├── core.md # コアメモリ
│ └── daily/ # デイリーメモリ
└── skills/ # カスタム Skill
├── skill-1/
└── skill-2/
```
シークレットキーはセキュリティのため `~/.cow` ディレクトリに別途保存されます:
```
~/.cow/
└── .env # Skill 用のシークレットキー
```
## コア設定
`config.json` で Agent モードのパラメータを設定します:
```json
{
"agent": true,
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 30,
"agent_max_steps": 15
}
```
| パラメータ | 説明 | デフォルト値 |
| --- | --- | --- |
| `agent` | Agent モードの有効化 | `true` |
| `agent_workspace` | ワークスペースのパス | `~/cow` |
| `agent_max_context_tokens` | 最大コンテキストトークン数 | `40000` |
| `agent_max_context_turns` | 最大コンテキストターン数 | `30` |
| `agent_max_steps` | タスクあたりの最大判断ステップ数 | `15` |
================================================
FILE: docs/ja/intro/features.mdx
================================================
---
title: 機能詳細
description: CowAgent の長期記憶、タスク計画、Skill システムの詳細
---
## 1. 長期記憶
記憶システムにより、Agent は重要な情報を長期にわたって記憶できます。ユーザーが好みや決定、重要な事実を共有すると、Agent は自発的に情報を保存し、会話が一定の長さに達すると自動的に要約を抽出します。記憶はコアメモリとデイリーメモリに分かれており、キーワード検索とベクトル検索の両方をサポートするハイブリッド検索が可能です。
初回起動時、Agent はユーザーに重要な情報を自発的に尋ね、ワークスペース(デフォルト `~/cow`)に記録します。これには Agent の設定、ユーザーの身元情報、記憶ファイルが含まれます。
その後の長期的な会話において、Agent は必要に応じてインテリジェントに記憶を保存・取得し、自身の設定やユーザーの好み、記憶ファイルを継続的に更新し、経験と教訓を要約します。これにより、真に自律的な思考と継続的な成長を実現しています。
## 2. タスク計画とツール活用
ツールは Agent がオペレーティングシステムのリソースにアクセスするための中核です。Agent はタスク要件に基づいてインテリジェントにツールを選択・呼び出し、ファイルの読み書き、コマンド実行、スケジュールタスクなどを実行します。組み込みツールはプロジェクトの `agent/tools/` ディレクトリに実装されています。
**主なツール:** ファイルの読み書き・編集、Bash ターミナル、ファイル送信、スケジューラ、記憶検索、Web 検索、環境設定など。
### 2.1 ターミナルとファイルアクセス
OS のターミナルとファイルシステムへのアクセスは、最も基本的かつ中核的な機能です。多くの他のツールや Skill はこの機能の上に構築されています。ユーザーはモバイルデバイスから Agent とやり取りし、パソコンやサーバーのリソースを操作できます:
### 2.2 プログラミング能力
プログラミングとシステムアクセスを組み合わせることで、Agent は完全な **Vibecoding ワークフロー** を実行できます。情報検索、アセット生成、コーディング、テスト、デプロイ、Nginx 設定、公開まで、すべてスマートフォンからの一つのコマンドで実行可能です:
### 2.3 スケジュールタスク
`scheduler` ツールにより動的なスケジュールタスクが可能で、**ワンタイムタスク、固定間隔、Cron 式**をサポートしています。タスクは**固定メッセージ送信**または **Agent 動的タスク**実行としてトリガーできます:
### 2.4 環境変数管理
Skill が必要とするシークレットキーは環境変数ファイルに保存され、`env_config` ツールによって管理されます。会話を通じてシークレットを更新でき、セキュリティ保護とマスキング機能が組み込まれています:
## 3. Skill システム
Skill システムは Agent に無限の拡張性を提供します。各 Skill は説明ファイル、実行スクリプト(任意)、リソース(任意)で構成され、特定のタイプのタスクを完了する方法を記述します。Skill により Agent は複雑なワークフローの指示に従い、ツールを呼び出し、サードパーティシステムと連携できます。
- **組み込み Skill:** プロジェクトの `skills/` ディレクトリにあり、Skill クリエイター、画像認識、LinkAI Agent、Web フェッチなどが含まれます。組み込み Skill は依存条件(API キー、システムコマンドなど)に基づいて自動的に有効化されます。
- **カスタム Skill:** ユーザーが会話を通じて作成し、ワークスペース(`~/cow/skills/`)に保存されます。あらゆる複雑なビジネスプロセスやサードパーティ連携を実装できます。
### 3.1 Skill の作成
`skill-creator` Skill により、会話を通じて Skill を素早く作成できます。ワークフローを Skill としてコード化するよう Agent に依頼したり、API ドキュメントやサンプルを送信して Agent に直接連携を完成させることができます:
### 3.2 Web 検索と画像認識
- **Web 検索:** 組み込みの `web_search` ツールで、複数の検索エンジンをサポートします。`BOCHA_API_KEY` または `LINKAI_API_KEY` を設定して有効化してください。
- **画像認識:** 組み込みの `openai-image-vision` Skill で、`gpt-4.1-mini`、`gpt-4.1` などのモデルをサポートします。`OPENAI_API_KEY` が必要です。
### 3.3 サードパーティナレッジベースとプラグイン
`linkai-agent` Skill により、[LinkAI](https://link-ai.tech/) 上のすべての Agent を Skill として利用でき、マルチ Agent による意思決定が可能になります。
設定方法:`env_config` で `LINKAI_API_KEY` を設定し、`skills/linkai-agent/config.json` に Agent の説明を追加します:
```json
{
"apps": [
{
"app_code": "G7z6vKwp",
"app_name": "LinkAI Customer Support",
"app_description": "Select only when the user needs help with LinkAI platform questions"
},
{
"app_code": "SFY5x7JR",
"app_name": "Content Creator",
"app_description": "Use only when the user needs to create images or videos"
}
]
}
```
================================================
FILE: docs/ja/intro/index.mdx
================================================
---
title: はじめに
description: CowAgent - LLM を活用した AI スーパーアシスタント
---
**CowAgent** は、自律的なタスク計画、長期記憶、Skill システム、マルチモーダルメッセージ、複数モデル対応、マルチプラットフォームデプロイを備えた、LLM を活用した AI スーパーアシスタントです。
CowAgent は自ら思考しタスクを計画し、コンピュータや外部リソースを操作し、Skill を作成・実行し、長期記憶により継続的に成長します。複数モデルの柔軟な切り替えをサポートし、テキスト、音声、画像、ファイルなどのマルチモーダルメッセージを処理でき、Web、Feishu(飛書)、DingTalk(釘釘)、WeCom(企業微信)、WeChat公式アカウントに統合できます。お使いのパソコンやサーバー上で24時間365日稼働します。
github.com/zhayujie/chatgpt-on-wechat
## コア機能
複雑なタスクを理解し、自律的に実行計画を立て、目標が達成されるまで思考とツール呼び出しを続けます。ツールを通じてファイルシステム、ターミナル、ブラウザ、スケジューラなどのシステムリソースにアクセスできます。
会話の記憶をローカルファイルやデータベースに自動的に永続化します。コアメモリとデイリーメモリを含み、キーワード検索とベクトル検索に対応しています。
Skill の作成・実行エンジンを実装し、組み込み Skill を搭載。自然言語の会話を通じてカスタム Skill の開発もサポートしています。
テキスト、画像、音声、ファイルなどのメッセージタイプの解析、処理、生成、送信をサポートします。
OpenAI、Claude、Gemini、DeepSeek、MiniMax、GLM、Qwen、Kimi、Doubao など、主要なモデルプロバイダーをサポートしています。
ローカルコンピュータやサーバー上で動作し、Web、Feishu(飛書)、DingTalk(釘釘)、WeChat公式アカウント、WeCom(企業微信)アプリケーションに統合できます。
## クイック体験
ターミナルで以下のコマンドを実行すると、ワンクリックでインストール、設定、起動ができます:
```bash
bash <(curl -fsSL https://cdn.link-ai.tech/code/cow/run.sh)
```
デフォルトでは実行後に Web サービスが起動します。`http://localhost:9899/chat` にアクセスして Web インターフェースでチャットできます。
インストールと実行の完全ガイド
CowAgent システムアーキテクチャ設計
## 免責事項
1. 本プロジェクトは [MIT License](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/LICENSE) に基づき、技術研究および学習を目的としています。利用者は現地の法律、規制、ポリシー、および企業の社内規程を遵守する必要があります。違法行為や権利侵害につながる利用は禁止されています。
2. Agent モードは通常のチャットモードよりも多くのトークンを消費します。効果とコストを考慮してモデルを選択してください。Agent はホスト OS にアクセスできるため、デプロイには十分注意してください。
3. CowAgent はオープンソース開発に注力しており、いかなる暗号通貨の発行、認可、参加も行っておりません。
## コミュニティ
WeChat でアシスタントを追加して、オープンソースコミュニティに参加しましょう:
================================================
FILE: docs/ja/memory.mdx
================================================
---
title: 記憶
description: CowAgent 長期記憶システム
---
記憶システムにより、Agent は重要な情報を長期にわたって記憶し、継続的に経験を蓄積し、ユーザーの好みを理解し、真に自律的な思考と継続的な成長を実現できます。
## 記憶の種類
### コア記憶 (MEMORY.md)
`~/cow/MEMORY.md` に保存され、長期的なユーザーの好み、重要な決定、主要な事実など、時間が経っても薄れない情報を含みます。毎回の会話ターンでバックグラウンド知識としてシステムプロンプトに自動的に注入されます。
### 日次記憶 (memory/YYYY-MM-DD.md)
`~/cow/memory/` ディレクトリに保存され、日付で命名されます(例:`2026-03-08.md`)。日々の会話の要約と主要なイベントを記録します。空ファイルの生成を避けるため、最初の書き込み時にのみファイルが作成されます。
## 記憶の書き込み
Agent は以下のメカニズムにより、会話内容を日次記憶に自動的に永続化します:
- **コンテキストトリミング時** — 会話ターン数またはトークン数が設定上限を超えた場合、コンテキストの古い半分が一括でトリミングされ、破棄されたコンテンツは LLM によって要約されて重要な情報として日次記憶ファイルに書き込まれます
- **毎日のスケジュール要約** — 毎日 23:55 に自動的にフル要約がトリガーされ、アクティビティが少ない日でも記憶が保存されます(内容が変更されていない場合はスキップ)
- **API コンテキストオーバーフロー時** — モデル API がコンテキストオーバーフローエラーを返した場合、緊急措置として現在の会話要約が保存されます
すべての記憶書き込みはバックグラウンドスレッドで非同期に実行され(LLM の要約 + ファイル書き込み)、通常の会話応答をブロックしません。
## 初回起動
初回起動時に、Agent はユーザーに主要な情報を積極的に尋ね、ワークスペース(デフォルト `~/cow`)に保存します:
| ファイル | 説明 |
| --- | --- |
| `system.md` | Agent のシステムプロンプトと動作設定 |
| `user.md` | ユーザーの身元情報と好み |
| `MEMORY.md` | コア記憶(長期) |
| `memory/YYYY-MM-DD.md` | 日次記憶(オンデマンドで作成) |
## 記憶の検索
記憶システムはハイブリッド検索モードをサポートしています:
- **キーワード検索** — キーワードに基づいて過去の記憶をマッチング
- **ベクトル検索** — セマンティック類似性検索により、異なる表現でも関連する記憶を発見
Agent は必要に応じて会話中に自動的に記憶検索をトリガーし、関連する過去の情報をコンテキストに組み込みます。コア記憶(`MEMORY.md`)は常にシステムプロンプトに注入され、日次記憶は検索を通じてオンデマンドで読み込まれます。
## 設定
```json
{
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 20
}
```
| パラメータ | 説明 | デフォルト |
| --- | --- | --- |
| `agent_workspace` | ワークスペースパス、記憶ファイルはこのディレクトリ配下に保存されます | `~/cow` |
| `agent_max_context_tokens` | 最大コンテキストトークン数。超過時に半分がトリミングされ、記憶として要約されます | `40000` |
| `agent_max_context_turns` | 最大コンテキストターン数。超過時に半分がトリミングされ、記憶として要約されます | `20` |
================================================
FILE: docs/ja/models/claude.mdx
================================================
---
title: Claude
description: Claudeモデルの設定
---
```json
{
"model": "claude-sonnet-4-6",
"claude_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | `claude-sonnet-4-6`、`claude-opus-4-6`、`claude-sonnet-4-5`、`claude-sonnet-4-0`、`claude-3-5-sonnet-latest`などから選択可能。[公式モデル一覧](https://docs.anthropic.com/en/docs/about-claude/models/overview)を参照 |
| `claude_api_key` | [Claude Console](https://console.anthropic.com/settings/keys)で作成 |
| `claude_api_base` | 任意。デフォルトは`https://api.anthropic.com/v1`。サードパーティプロキシを使用する場合に変更 |
================================================
FILE: docs/ja/models/coding-plan.mdx
================================================
---
title: Coding Plan
description: Coding Planモデルの設定
---
> Coding Planは各プロバイダーが提供する月額サブスクリプションパッケージで、高頻度のAgent利用に最適です。CowAgentはOpenAI互換モードにより、すべてのCoding Planプロバイダーをサポートしています。
Coding PlanのAPI BaseとAPI Keyは、通常の従量課金制のものとは別になっています。各プロバイダーのプラットフォームから取得してください。
## 共通設定
すべてのプロバイダーはOpenAI互換プロトコルでアクセスでき、Webコンソールから素早く設定できます。モデルプロバイダーを**OpenAI**に設定し、カスタムモデルを選択してモデルコードを入力し、対応するプロバイダーのAPI BaseとAPI Keyを入力してください:
`config.json`で直接設定することも可能です:
```json
{
"bot_type": "openai",
"model": "MODEL_NAME",
"open_ai_api_base": "PROVIDER_CODING_PLAN_API_BASE",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `bot_type` | `openai`を指定(OpenAI互換モード) |
| `model` | プロバイダーがサポートするモデル名 |
| `open_ai_api_base` | プロバイダーのCoding Plan API Base URL |
| `open_ai_api_key` | プロバイダーのCoding Plan API Key |
---
## 阿里云
```json
{
"bot_type": "openai",
"model": "qwen3.5-plus",
"open_ai_api_base": "https://coding.dashscope.aliyuncs.com/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | `qwen3.5-plus`、`qwen3-max-2026-01-23`、`qwen3-coder-next`、`qwen3-coder-plus`、`glm-5`、`glm-4.7`、`kimi-k2.5`、`MiniMax-M2.5` |
| `open_ai_api_base` | `https://coding.dashscope.aliyuncs.com/v1` |
| `open_ai_api_key` | Coding Plan専用キー(従量課金とは共有不可) |
参考: [クイックスタート](https://help.aliyun.com/zh/model-studio/coding-plan-quickstart?spm=a2c4g.11186623.help-menu-2400256.d_0_2_1.70115203zi5Igc)、[モデル一覧](https://help.aliyun.com/zh/model-studio/coding-plan)
---
## MiniMax
```json
{
"bot_type": "openai",
"model": "MiniMax-M2.5",
"open_ai_api_base": "https://api.minimaxi.com/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | `MiniMax-M2.5`、`MiniMax-M2.5-highspeed`、`MiniMax-M2.1`、`MiniMax-M2` |
| `open_ai_api_base` | 中国: `https://api.minimaxi.com/v1`、グローバル: `https://api.minimax.io/v1` |
| `open_ai_api_key` | Coding Plan専用キー(従量課金とは共有不可) |
参考: [中国キー](https://platform.minimaxi.com/docs/coding-plan/quickstart)、[モデル一覧](https://platform.minimaxi.com/docs/guides/pricing-coding-plan)、[グローバルキー](https://platform.minimax.io/docs/coding-plan/quickstart)
---
## 智谱 GLM
```json
{
"bot_type": "openai",
"model": "glm-4.7",
"open_ai_api_base": "https://open.bigmodel.cn/api/coding/paas/v4",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | `glm-5`、`glm-4.7`、`glm-4.6`、`glm-4.5`、`glm-4.5-air` |
| `open_ai_api_base` | 中国: `https://open.bigmodel.cn/api/coding/paas/v4`、グローバル: `https://api.z.ai/api/coding/paas/v4` |
| `open_ai_api_key` | 標準APIと共有 |
参考: [中国クイックスタート](https://docs.bigmodel.cn/cn/coding-plan/quick-start)、[グローバルクイックスタート](https://docs.z.ai/devpack/quick-start)
---
## Kimi
```json
{
"bot_type": "openai",
"model": "kimi-for-coding",
"open_ai_api_base": "https://api.kimi.com/coding/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | `kimi-for-coding` |
| `open_ai_api_base` | `https://api.kimi.com/coding/v1` |
| `open_ai_api_key` | Coding Plan専用キー(従量課金とは共有不可) |
参考: [キー & ドキュメント](https://www.kimi.com/code/docs/)
---
## 火山引擎
```json
{
"bot_type": "openai",
"model": "Doubao-Seed-2.0-Code",
"open_ai_api_base": "https://ark.cn-beijing.volces.com/api/coding/v3",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | `Doubao-Seed-2.0-Code`、`Doubao-Seed-2.0-pro`、`Doubao-Seed-2.0-lite`、`Doubao-Seed-Code`、`MiniMax-M2.5`、`Kimi-K2.5`、`GLM-4.7`、`DeepSeek-V3.2` |
| `open_ai_api_base` | `https://ark.cn-beijing.volces.com/api/coding/v3` |
| `open_ai_api_key` | 標準APIと共有 |
参考: [クイックスタート](https://www.volcengine.com/docs/82379/1928261?lang=zh)
================================================
FILE: docs/ja/models/deepseek.mdx
================================================
---
title: DeepSeek
description: DeepSeekモデルの設定
---
OpenAI互換の設定を使用します:
```json
{
"model": "deepseek-chat",
"bot_type": "openai",
"open_ai_api_key": "YOUR_API_KEY",
"open_ai_api_base": "https://api.deepseek.com/v1"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | `deepseek-chat` (DeepSeek-V3)、`deepseek-reasoner` (DeepSeek-R1) |
| `bot_type` | `openai`を指定(OpenAI互換モード) |
| `open_ai_api_key` | [DeepSeek Platform](https://platform.deepseek.com/api_keys)で作成 |
| `open_ai_api_base` | DeepSeekプラットフォームのBASE URL |
================================================
FILE: docs/ja/models/doubao.mdx
================================================
---
title: Doubao (ByteDance)
description: Doubao (火山方舟) モデルの設定
---
```json
{
"model": "doubao-seed-2-0-code-preview-260215",
"ark_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | `doubao-seed-2-0-code-preview-260215`、`doubao-seed-2-0-pro-260215`、`doubao-seed-2-0-lite-260215`などから選択可能 |
| `ark_api_key` | [火山方舟 Console](https://console.volcengine.com/ark/region:ark+cn-beijing/apikey)で作成 |
| `ark_base_url` | 任意。デフォルトは`https://ark.cn-beijing.volces.com/api/v3` |
================================================
FILE: docs/ja/models/gemini.mdx
================================================
---
title: Gemini
description: Google Geminiモデルの設定
---
```json
{
"model": "gemini-3.1-pro-preview",
"gemini_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | `gemini-3.1-flash-lite-preview`、`gemini-3.1-pro-preview`、`gemini-3-flash-preview`、`gemini-3-pro-preview`などから選択可能。[公式ドキュメント](https://ai.google.dev/gemini-api/docs/models)を参照 |
| `gemini_api_key` | [Google AI Studio](https://aistudio.google.com/app/apikey)で作成 |
================================================
FILE: docs/ja/models/glm.mdx
================================================
---
title: GLM (智谱AI)
description: 智谱AI GLMモデルの設定
---
```json
{
"model": "glm-5-turbo",
"zhipu_ai_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | `glm-5-turbo`、`glm-5`、`glm-4.7`、`glm-4-plus`、`glm-4-flash`、`glm-4-air`などから選択可能。[モデルコード](https://bigmodel.cn/dev/api/normal-model/glm-4)を参照 |
| `zhipu_ai_api_key` | [智谱AI Console](https://www.bigmodel.cn/usercenter/proj-mgmt/apikeys)で作成 |
OpenAI互換の設定もサポートしています:
```json
{
"bot_type": "openai",
"model": "glm-5-turbo",
"open_ai_api_base": "https://open.bigmodel.cn/api/paas/v4",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/ja/models/index.mdx
================================================
---
title: モデル概要
description: CowAgentがサポートするモデルとおすすめの選択肢
---
CowAgentは国内外の主要なLLMをサポートしています。モデルインターフェースはプロジェクトの`models/`ディレクトリに実装されています。
Agent モードでは、品質とコストのバランスから以下のモデルをおすすめします: MiniMax-M2.7、glm-5-turbo、kimi-k2.5、qwen3.5-plus、claude-sonnet-4-6、gemini-3.1-pro-preview
## 設定
選択したモデルに応じて、`config.json`にモデル名とAPI Keyを設定してください。各モデルは`bot_type`を`openai`に設定し、`open_ai_api_base`と`open_ai_api_key`を設定することで、OpenAI互換アクセスもサポートしています。
また、[LinkAI](https://link-ai.tech)プラットフォームインターフェースを使用すると、ナレッジベース、ワークフロー、その他のAgent機能をサポートしながら、複数のモデルを柔軟に切り替えることができます。
## サポートモデル
MiniMax-M2.7およびその他のシリーズモデル
glm-5-turbo、glm-5およびその他のシリーズモデル
qwen3.5-plus、qwen3-maxなど
kimi-k2.5、kimi-k2など
doubao-seedシリーズモデル
claude-sonnet-4-6など
gemini-3.1-pro-previewなど
gpt-5.4、gpt-4.1、oシリーズなど
deepseek-chat、deepseek-reasoner
統合マルチモデルインターフェース + ナレッジベース
モデル名の完全なリストについては、プロジェクトの[`common/const.py`](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/common/const.py)ファイルを参照してください。
================================================
FILE: docs/ja/models/kimi.mdx
================================================
---
title: Kimi (Moonshot)
description: Kimi (Moonshot) モデルの設定
---
```json
{
"model": "kimi-k2.5",
"moonshot_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | `kimi-k2.5`、`kimi-k2`、`moonshot-v1-8k`、`moonshot-v1-32k`、`moonshot-v1-128k`から選択可能 |
| `moonshot_api_key` | [Moonshot Console](https://platform.moonshot.cn/console/api-keys)で作成 |
OpenAI互換の設定もサポートしています:
```json
{
"bot_type": "openai",
"model": "kimi-k2.5",
"open_ai_api_base": "https://api.moonshot.cn/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/ja/models/linkai.mdx
================================================
---
title: LinkAI
description: LinkAIプラットフォームで複数モデルに統合アクセス
---
[LinkAI](https://link-ai.tech)プラットフォームでは、OpenAI、Claude、Gemini、DeepSeek、Qwen、Kimiなどのモデルを柔軟に切り替えることができ、ナレッジベース、ワークフロー、プラグイン、その他のAgent機能をサポートしています。
```json
{
"use_linkai": true,
"linkai_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `use_linkai` | `true`に設定してLinkAIインターフェースを有効化 |
| `linkai_api_key` | [LinkAI Console](https://link-ai.tech/console/interface)で作成 |
| `model` | 空のままにするとAgentのデフォルトモデルを使用。プラットフォーム上で柔軟に切り替え可能。[モデル一覧](https://link-ai.tech/console/models)のすべてのモデルをサポート |
詳細は[APIドキュメント](https://docs.link-ai.tech/platform/api)を参照してください。
================================================
FILE: docs/ja/models/minimax.mdx
================================================
---
title: MiniMax
description: MiniMaxモデルの設定
---
```json
{
"model": "MiniMax-M2.7",
"minimax_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | `MiniMax-M2.7`、`MiniMax-M2.5`、`MiniMax-M2.1`、`MiniMax-M2.1-lightning`、`MiniMax-M2`などから選択可能 |
| `minimax_api_key` | [MiniMax Console](https://platform.minimaxi.com/user-center/basic-information/interface-key)で作成 |
OpenAI互換の設定もサポートしています:
```json
{
"bot_type": "openai",
"model": "MiniMax-M2.7",
"open_ai_api_base": "https://api.minimaxi.com/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/ja/models/openai.mdx
================================================
---
title: OpenAI
description: OpenAIモデルの設定
---
```json
{
"model": "gpt-5.4",
"open_ai_api_key": "YOUR_API_KEY",
"open_ai_api_base": "https://api.openai.com/v1"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | OpenAI APIの[modelパラメータ](https://platform.openai.com/docs/models)に対応。oシリーズ、gpt-5.4、gpt-5シリーズ、gpt-4.1などをサポート。Agentモードでは`gpt-5.4`を推奨 |
| `open_ai_api_key` | [OpenAI Platform](https://platform.openai.com/api-keys)で作成 |
| `open_ai_api_base` | 任意。サードパーティプロキシを使用する場合に変更 |
| `bot_type` | 公式OpenAIモデルでは不要。Claudeなど非OpenAIモデルをプロキシ経由で使用する場合は`openai`に設定 |
================================================
FILE: docs/ja/models/qwen.mdx
================================================
---
title: Qwen (通义千问)
description: 通义千问モデルの設定
---
```json
{
"model": "qwen3.5-plus",
"dashscope_api_key": "YOUR_API_KEY"
}
```
| パラメータ | 説明 |
| --- | --- |
| `model` | `qwen3.5-plus`、`qwen3-max`、`qwen-max`、`qwen-plus`、`qwen-turbo`、`qwq-plus`などから選択可能 |
| `dashscope_api_key` | [百炼 Console](https://bailian.console.aliyun.com/?tab=model#/api-key)で作成。[公式ドキュメント](https://bailian.console.aliyun.com/?tab=api#/api)を参照 |
OpenAI互換の設定もサポートしています:
```json
{
"bot_type": "openai",
"model": "qwen3.5-plus",
"open_ai_api_base": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/ja/releases/overview.mdx
================================================
---
title: 変更履歴
description: CowAgent バージョン履歴
---
| バージョン | 日付 | 説明 |
| --- | --- | --- |
| [2.0.2](/en/releases/v2.0.2) | 2026.02.27 | Web Console アップグレード、マルチチャネル同時実行、セッション永続化 |
| [2.0.1](/en/releases/v2.0.1) | 2026.02.27 | 組み込み Web Search ツール、スマートコンテキスト管理、複数の修正 |
| [2.0.0](/en/releases/v2.0.0) | 2026.02.03 | AI スーパーアシスタントへの全面アップグレード |
| 1.7.6 | 2025.05.23 | Web Channel 最適化、AgentMesh プラグイン |
| 1.7.5 | 2025.04.11 | DeepSeek モデル |
| 1.7.4 | 2024.12.13 | Gemini 2.0 モデル、Web Channel |
| 1.7.3 | 2024.10.31 | 安定性の改善、データベース機能 |
| 1.7.2 | 2024.09.26 | ワンクリックインストールスクリプト、o1 モデル |
| 1.7.0 | 2024.08.02 | 讯飞 4.0 モデル、ナレッジベース参照 |
| 1.6.9 | 2024.07.19 | gpt-4o-mini、阿里音声認識 |
| 1.6.8 | 2024.07.05 | Claude 3.5、Gemini 1.5 Pro |
| 1.6.0 | 2024.04.26 | Kimi 統合、gpt-4-turbo アップグレード |
| 1.5.0 | 2023.11.10 | gpt-4-turbo、dall-e-3、tts マルチモーダル |
| 1.0.0 | 2022.12.12 | プロジェクト作成、初の ChatGPT 統合 |
完全な履歴は [GitHub Releases](https://github.com/zhayujie/chatgpt-on-wechat/releases) をご覧ください。
================================================
FILE: docs/ja/releases/v2.0.0.mdx
================================================
---
title: v2.0.0
description: CowAgent 2.0 - チャットボットから AI スーパーアシスタントへの全面アップグレード
---
CowAgent 2.0 は、チャットボットから **AI スーパーアシスタント** への包括的なアップグレードです。自律的な思考とタスク計画、長期記憶、コンピューターの操作、Skill の作成と実行が可能です。
**リリース日**: 2026.02.03 | [GitHub Release](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.0)
## 主な更新内容
### Agent コア
- **複雑なタスク計画**: マルチターン推論による自律的な計画
- **長期記憶**: キーワードおよびベクトル検索による永続的な記憶
- **組み込みツール**: ファイル操作、Bash、ブラウザ、スケジューラなど 10 以上のツール
- **Web 検索**: 組み込みの `web_search` ツール、複数の検索エンジンに対応、対応する API キーを設定して使用
- **Skill システム**: 組み込みおよびカスタム Skill をサポートする Skill エンジン
- **セキュリティとコスト**: シークレット管理、プロンプト制御、トークン制限
### その他
- **チャネル**: 飞书/钉钉 WebSocket 対応、画像・ファイルメッセージ
- **モデル**: claude-sonnet-4-5、gemini-3-pro-preview、glm-4.7、MiniMax-M2.1、qwen3-max
- **デプロイ**: ワンクリックでのインストール、設定、実行、および管理スクリプト
## 長期記憶
## タスク計画とツール
## Skill システム
## コントリビューション
[フィードバックの送信](https://github.com/zhayujie/chatgpt-on-wechat/issues) や [コードのコントリビューション](https://github.com/zhayujie/chatgpt-on-wechat/pulls) を歓迎します。
================================================
FILE: docs/ja/releases/v2.0.1.mdx
================================================
---
title: v2.0.1
description: CowAgent 2.0.1 - 組み込み Web Search、スマートコンテキスト管理、複数の修正
---
**リリース日**: 2026.02.27 | [全変更履歴](https://github.com/zhayujie/chatgpt-on-wechat/compare/2.0.0..2.0.1)
## 新機能
- **組み込み Web Search ツール**: Web 検索を Agent の組み込みツールとして統合し、判断コストを削減 ([4f0ea5d](https://github.com/zhayujie/chatgpt-on-wechat/commit/4f0ea5d7568d61db91ff69c91c429e785fd1b1c2))
- **Claude Opus 4.6 モデル対応**: Claude Opus 4.6 モデルのサポートを追加 ([#2661](https://github.com/zhayujie/chatgpt-on-wechat/pull/2661))
- **企业微信の画像認識**: 企业微信チャネルでの画像メッセージ認識をサポート ([#2667](https://github.com/zhayujie/chatgpt-on-wechat/pull/2667))
## 改善
- **スマートコンテキスト管理**: インテリジェントなコンテキストトリミング戦略により、チャットコンテキストのオーバーフローを解決し、トークン制限超過を防止 ([cea7fb7](https://github.com/zhayujie/chatgpt-on-wechat/commit/cea7fb7490c53454602bf05955a0e9f059bcf0fd), [8acf2db](https://github.com/zhayujie/chatgpt-on-wechat/commit/8acf2dbdfe713b84ad74b761b7f86674b1c1904d)) [#2663](https://github.com/zhayujie/chatgpt-on-wechat/issues/2663)
- **ランタイム情報の動的更新**: 動的関数によるシステムプロンプト内のタイムスタンプおよびその他のランタイム情報の自動更新 ([#2655](https://github.com/zhayujie/chatgpt-on-wechat/pull/2655), [#2657](https://github.com/zhayujie/chatgpt-on-wechat/pull/2657))
- **Skill プロンプトの最適化**: Skill システムプロンプト生成を改善し、ツールの説明を簡素化して Agent のパフォーマンスを向上 ([6c21833](https://github.com/zhayujie/chatgpt-on-wechat/commit/6c218331b1f1208ea8be6bf226936d3b556ade3e))
- **GLM カスタム API Base URL**: GLM モデルのカスタム API Base URL をサポート ([#2660](https://github.com/zhayujie/chatgpt-on-wechat/pull/2660))
- **起動スクリプトの最適化**: `run.sh` スクリプトのインタラクションと設定フローを改善 ([#2656](https://github.com/zhayujie/chatgpt-on-wechat/pull/2656))
- **判断ステップのログ記録**: デバッグ用の Agent 判断ステップログを追加 ([cb303e6](https://github.com/zhayujie/chatgpt-on-wechat/commit/cb303e6109c50c8dfef1f5e6c1ec47223bf3cd11))
## バグ修正
- **Scheduler の記憶喪失**: Scheduler ディスパッチャーによる記憶喪失を修正 ([a77a874](https://github.com/zhayujie/chatgpt-on-wechat/commit/a77a8741b500a408c6f5c8868856fb4b018fe9db))
- **空のツール呼び出しと長い結果**: 空のツール呼び出しおよび過度に長いツール結果の処理を修正 ([0542700](https://github.com/zhayujie/chatgpt-on-wechat/commit/0542700f9091ebb08c1a56103b0f0f45f24aa621))
- **OpenAI Function Call**: OpenAI モデルとの Function Call 互換性を修正 ([158c87a](https://github.com/zhayujie/chatgpt-on-wechat/commit/158c87ab8b05bae054cc1b4eacdbb64fc1062ba9))
- **Claude ツール名フィールド**: Claude モデルのレスポンスから余分なツール名フィールドを削除 ([eec10cb](https://github.com/zhayujie/chatgpt-on-wechat/commit/eec10cb5db6a3d5bc12ef606606532237d2c5f6e))
- **MiniMax 推論**: MiniMax モデルの推論コンテンツ処理を最適化し、思考プロセスの出力を非表示化 ([c72cda3](https://github.com/zhayujie/chatgpt-on-wechat/commit/c72cda33864bd1542012ee6e0a8bd8c6c88cb5ed), [72b1cac](https://github.com/zhayujie/chatgpt-on-wechat/commit/72b1cacea1ba0d1f3dedacbab2e088e98fd7e172))
- **GLM 思考プロセス**: GLM モデルの思考プロセス表示を非表示化 ([72b1cac](https://github.com/zhayujie/chatgpt-on-wechat/commit/72b1cacea1ba0d1f3dedacbab2e088e98fd7e172))
- **飞书の接続と SSL**: 飞书チャネルの SSL 証明書エラーおよび接続問題を修正 ([229b14b](https://github.com/zhayujie/chatgpt-on-wechat/commit/229b14b6fcabe7123d53cab1dea39f38dab26d6d), [8674421](https://github.com/zhayujie/chatgpt-on-wechat/commit/867442155e7f095b4f38b0856f8c1d8312b5fcf7))
- **model_type バリデーション**: 非文字列の `model_type` による `AttributeError` を修正 ([#2666](https://github.com/zhayujie/chatgpt-on-wechat/pull/2666))
## プラットフォーム互換性
- **Windows 互換性**: 複数のツールモジュールにおける Windows でのパス処理、ファイルエンコーディング、および `os.getuid()` の利用不可問題を修正 ([051ffd7](https://github.com/zhayujie/chatgpt-on-wechat/commit/051ffd78a372f71a967fd3259e37fe19131f83cf), [5264f7c](https://github.com/zhayujie/chatgpt-on-wechat/commit/5264f7ce18360ee4db5dcb4ebe67307977d40014))
================================================
FILE: docs/ja/releases/v2.0.2.mdx
================================================
---
title: v2.0.2
description: CowAgent 2.0.2 - Web Console アップグレード、マルチチャネル同時実行、セッション永続化
---
**リリース日**: 2026.02.27 | [全変更履歴](https://github.com/zhayujie/chatgpt-on-wechat/compare/2.0.1...master)
## ハイライト
### 🖥️ Web Console アップグレード
Web Console が全面的にアップグレードされ、ストリーミング会話出力、ツール実行と推論プロセスの視覚的表示、**モデル、Skill、記憶、チャネル、Agent 設定** のオンライン管理が可能になりました。
#### チャットインターフェース
ストリーミング出力に対応し、Agent の推論プロセスとツール呼び出しをリアルタイムに表示することで、Agent の意思決定を直感的に観察できます:
#### モデル管理
設定ファイルを手動で編集せずに、モデル設定をオンラインで管理できます:
#### Skill 管理
Agent の Skill をオンラインで表示・管理できます:
#### 記憶管理
Agent の記憶をオンラインで表示・管理できます:
#### チャネル管理
接続されたチャネルをオンラインで管理し、リアルタイムで接続・切断操作ができます:
#### スケジュールタスク
ワンタイムタスク、固定間隔、Cron 式を含むスケジュールタスクをオンラインで表示・管理できます:
#### ログ
Agent のランタイムログをリアルタイムで表示し、監視とトラブルシューティングに活用できます:
関連コミット: [f1a1413](https://github.com/zhayujie/chatgpt-on-wechat/commit/f1a1413), [c0702c8](https://github.com/zhayujie/chatgpt-on-wechat/commit/c0702c8), [394853c](https://github.com/zhayujie/chatgpt-on-wechat/commit/394853c), [1c71c4e](https://github.com/zhayujie/chatgpt-on-wechat/commit/1c71c4e), [5e3eccb](https://github.com/zhayujie/chatgpt-on-wechat/commit/5e3eccb), [e1dc037](https://github.com/zhayujie/chatgpt-on-wechat/commit/e1dc037), [5edbf4c](https://github.com/zhayujie/chatgpt-on-wechat/commit/5edbf4c), [7d258b5](https://github.com/zhayujie/chatgpt-on-wechat/commit/7d258b5)
### 🔀 マルチチャネル同時実行
複数のチャネル(例:飞书、钉钉、企业微信、Web)を同時に実行できるようになりました。各チャネルは独立したスレッドで動作し、互いに干渉しません。
設定方法: `config.json` の `channel_type` にカンマ区切りで複数のチャネルを設定するか、Web Console のチャネル管理ページからリアルタイムでチャネルの接続・切断を行います。
```json
{
"channel_type": "web,feishu,dingtalk"
}
```
関連コミット: [4694594](https://github.com/zhayujie/chatgpt-on-wechat/commit/4694594), [7cce224](https://github.com/zhayujie/chatgpt-on-wechat/commit/7cce224), [7d258b5](https://github.com/zhayujie/chatgpt-on-wechat/commit/7d258b5), [c9adddb](https://github.com/zhayujie/chatgpt-on-wechat/commit/c9adddb)
### 💾 セッション永続化
セッション履歴がローカルの SQLite データベースに永続化されるようになりました。サービス再起動後も会話コンテキストが自動的に復元されます。Web Console の過去の会話も復元されます。
関連コミット: [29bfbec](https://github.com/zhayujie/chatgpt-on-wechat/commit/29bfbec), [9917552](https://github.com/zhayujie/chatgpt-on-wechat/commit/9917552), [925d728](https://github.com/zhayujie/chatgpt-on-wechat/commit/925d728)
## 新モデル
- **Gemini 3.1 Pro Preview**: `gemini-3.1-pro-preview` モデルのサポートを追加 ([52d7cad](https://github.com/zhayujie/chatgpt-on-wechat/commit/52d7cad))
- **Claude 4.6 Sonnet**: `claude-4.6-sonnet` モデルのサポートを追加 ([52d7cad](https://github.com/zhayujie/chatgpt-on-wechat/commit/52d7cad))
- **Qwen3.5 Plus**: `qwen3.5-plus` モデルのサポートを追加 ([e59a289](https://github.com/zhayujie/chatgpt-on-wechat/commit/e59a289))
- **MiniMax M2.5**: `Minimax-M2.5` モデルのサポートを追加 ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
- **GLM-5**: `glm-5` モデルのサポートを追加 ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
- **Kimi K2.5**: `kimi-k2.5` モデルのサポートを追加 ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
- **Doubao 2.0 Code**: コーディング特化型 `doubao-2.0-code` モデルを追加 ([ab28ee5](https://github.com/zhayujie/chatgpt-on-wechat/commit/ab28ee5))
- **DashScope モデル**: 阿里云 DashScope モデル名のサポートを追加 ([ce58f23](https://github.com/zhayujie/chatgpt-on-wechat/commit/ce58f23))
## ウェブサイトとドキュメント
- **公式サイト**: [cowagent.ai](https://cowagent.ai/)
- **ドキュメント**: [docs.cowagent.ai](https://docs.cowagent.ai/)
## バグ修正
- **Gemini 钉钉画像認識**: 钉钉チャネルで Gemini が画像マーカーを処理できない問題を修正 ([05a3304](https://github.com/zhayujie/chatgpt-on-wechat/commit/05a3304)) ([#2670](https://github.com/zhayujie/chatgpt-on-wechat/pull/2670)) Thanks [@SgtPepper114](https://github.com/SgtPepper114)
- **起動スクリプトの依存関係**: `run.sh` スクリプトの依存関係インストール問題を修正 ([b6fc9fa](https://github.com/zhayujie/chatgpt-on-wechat/commit/b6fc9fa))
- **bare except の整理**: より適切な例外処理のため `bare except` を `except Exception` に置換 ([adca89b](https://github.com/zhayujie/chatgpt-on-wechat/commit/adca89b)) ([#2674](https://github.com/zhayujie/chatgpt-on-wechat/pull/2674)) Thanks [@haosenwang1018](https://github.com/haosenwang1018)
================================================
FILE: docs/ja/releases/v2.0.3.mdx
================================================
---
title: v2.0.3
description: CowAgent 2.0.3 - 企業微信スマートボットとQQチャネルの追加、Webコンソールファイル処理、メモリシステムのアップグレード
---
## 🔌 新規チャネル
### 企業微信スマートボット
企業微信スマートボット(`wecom_bot`)チャネルを追加しました。ストリーミングカードメッセージ出力、テキストと画像メッセージの送受信をサポートし、Webコンソールでチャネルの設定と管理が可能です。
接続ドキュメント:[企業微信スマートボット接続](https://docs.cowagent.ai/channels/wecom-bot)。
関連コミット:[d4480b6](https://github.com/zhayujie/chatgpt-on-wechat/commit/d4480b6), [a42f31f](https://github.com/zhayujie/chatgpt-on-wechat/commit/a42f31f), [4ecd4df](https://github.com/zhayujie/chatgpt-on-wechat/commit/4ecd4df), [8b45d6c](https://github.com/zhayujie/chatgpt-on-wechat/commit/8b45d6c)
### QQ チャネル
QQ 公式ボット(`qq`)チャネルを追加しました。テキストと画像メッセージの送受信をサポートし、プライベートチャットとグループチャットに対応しています。
接続ドキュメント:[QQボット接続](https://docs.cowagent.ai/channels/qq)。
関連コミット:[005a0e1](https://github.com/zhayujie/chatgpt-on-wechat/commit/005a0e1), [a4d54f5](https://github.com/zhayujie/chatgpt-on-wechat/commit/a4d54f5)
## 🖥️ Web コンソールのファイル入力・処理対応
Web コンソールのチャット画面でファイルや画像のアップロードが可能になり、Agent に直接ファイルを送信して処理できます。また、Read ツールに Office ドキュメント(Word、Excel、PPT)の解析機能を追加しました。
関連コミット:[30c6d9b](https://github.com/zhayujie/chatgpt-on-wechat/commit/30c6d9b)
## 🤖 新規モデル
- **GPT-5.4 シリーズ**:`gpt-5.4`、`gpt-5.4-mini`、`gpt-5.4-nano` モデルのサポートを追加 ([1623deb](https://github.com/zhayujie/chatgpt-on-wechat/commit/1623deb))
- **Gemini 3.1 Flash Lite Preview**:`gemini-3.1-flash-lite-preview` モデルのサポートを追加 ([ba915f2](https://github.com/zhayujie/chatgpt-on-wechat/commit/ba915f2))
## 💰 Coding Plan サポート
各ベンダーの Coding Plan(プログラミング月額プラン)への接続をサポートしました。OpenAI 互換方式で統一的に接続できます。現在、阿里雲、MiniMax、智譜 GLM、Kimi、火山エンジンなどのベンダーに対応しています。
詳細設定は [Coding Plan ドキュメント](https://docs.cowagent.ai/models/coding-plan) を参照してください。
## 🧠 メモリシステムのアップグレード
メモリ書き込み(Memory Flush)のアップグレード:
- LLM を使用してコンテキストウィンドウを超えた会話内容をインテリジェントに要約し、精製された日次メモリエントリを生成
- 要約はバックグラウンドスレッドで非同期実行され、応答をブロックしない
- コンテキストの一括トリミング戦略を最適化し、フラッシュ頻度を低減
- 日次定期フラッシュのフォールバック機能を追加し、低アクティビティシナリオでのメモリ損失を防止
- コンテキストメモリの損失問題を修正
関連コミット:[022c13f](https://github.com/zhayujie/chatgpt-on-wechat/commit/022c13f), [c116235](https://github.com/zhayujie/chatgpt-on-wechat/commit/c116235)
## 🔧 ツールリファクタリング
- **画像認識**:画像認識(Image Vision)を Skill から内蔵 Tool にリファクタリングし、独立した画像ビジョンプロバイダー(Vision Provider)設定を追加。安定性と保守性を向上 ([a50fafa](https://github.com/zhayujie/chatgpt-on-wechat/commit/a50fafa), [3b8b562](https://github.com/zhayujie/chatgpt-on-wechat/commit/3b8b562))
- **Webスクレイピング**:Webスクレイピング(Web Fetch)を Skill から内蔵 Tool にリファクタリング。リモートドキュメントファイル(PDF、Word、Excel、PPT)のダウンロードと解析をサポート ([ccb9030](https://github.com/zhayujie/chatgpt-on-wechat/commit/ccb9030), [fa61744](https://github.com/zhayujie/chatgpt-on-wechat/commit/fa61744))
## 🐳 Docker デプロイメントの最適化
- **設定テンプレートの整合**:`docker-compose.yml` の環境変数を `config-template.json` と整合し、モデル API Key と Agent 設定項目を完備
- **Web コンソールポートマッピング**:`9899` ポートマッピングを追加。Docker デプロイ後にブラウザから Web コンソールにアクセス可能
- **設定のホットリロード**:各モデル Bot の API Key と API Base をリアルタイム読み込みに変更。Web コンソールで設定変更後、再起動不要で即時反映
- **ワークスペースの永続化**:`./cow` Volume マウントを追加。Agent ワークスペースデータ(メモリ、ペルソナ、スキルなど)をホストマシンに永続化し、コンテナの再構築やアップグレードでデータが失われない
## ⚡ パフォーマンス最適化
- **起動高速化**:飛書チャネルで依存関係の遅延読み込みを採用し、4-10秒の起動遅延を回避 ([924dc79](https://github.com/zhayujie/chatgpt-on-wechat/commit/924dc79))
- **チャネルの安定性**:チャネル接続の安定性を最適化し、環境変数によるチャネル設定をサポート ([f1c04bc](https://github.com/zhayujie/chatgpt-on-wechat/commit/f1c04bc), [46d97fd](https://github.com/zhayujie/chatgpt-on-wechat/commit/46d97fd))
## 🐛 バグ修正
- **bot_type 設定**:Agent モードでの `bot_type` 設定の受け渡し問題を修正 ([#2691](https://github.com/zhayujie/chatgpt-on-wechat/pull/2691)) Thanks [@Weikjssss](https://github.com/Weikjssss)
- **bot_type 優先順位**:Agent モードでの `bot_type` の解析優先順位を調整 ([#2692](https://github.com/zhayujie/chatgpt-on-wechat/pull/2692)) Thanks [@6vision](https://github.com/6vision)
- **智譜モデル設定**:智譜の `bot_type` 命名、Web コンソールの永続化、正規表現エスケープの問題を修正 ([#2693](https://github.com/zhayujie/chatgpt-on-wechat/pull/2693)) Thanks [@6vision](https://github.com/6vision)
- **OpenAI 互換レイヤー**:`openai_compat` レイヤーによる統一エラー処理 ([#2688](https://github.com/zhayujie/chatgpt-on-wechat/pull/2688)) Thanks [@JasonOA888](https://github.com/JasonOA888)
- **OpenAI 互換移行**:全モデル Bot の `openai_compat` 移行を完了 ([#2689](https://github.com/zhayujie/chatgpt-on-wechat/pull/2689))
- **Gemini ツール呼び出し**:Gemini モデルのツール呼び出しマッチング問題を修正 ([eda82ba](https://github.com/zhayujie/chatgpt-on-wechat/commit/eda82ba))
- **セッション並行処理**:セッション並行シナリオでの競合条件の問題を修正 ([9879878](https://github.com/zhayujie/chatgpt-on-wechat/commit/9879878))
- **履歴メッセージの復元**:履歴セッションメッセージの不完全な問題を修正。user/assistant のテキストメッセージのみを復元し、ツール呼び出しを除外 ([b788a3d](https://github.com/zhayujie/chatgpt-on-wechat/commit/b788a3d), [a33ce97](https://github.com/zhayujie/chatgpt-on-wechat/commit/a33ce97))
- **飛書グループチャット**:飛書グループチャットシナリオでの `bot_name` 依存を削除 ([b641bff](https://github.com/zhayujie/chatgpt-on-wechat/commit/b641bff))
- **Safari 互換性**:Safari ブラウザでの IME Enter キーによるメッセージ誤送信の問題を修正 ([0687916](https://github.com/zhayujie/chatgpt-on-wechat/commit/0687916))
- **Windows 互換性**:Windows での bash スタイル `$VAR` 環境変数を `%VAR%` に変換する問題を修正 ([7c67513](https://github.com/zhayujie/chatgpt-on-wechat/commit/7c67513))
- **MiniMax パラメータ**:MiniMax モデルの `max_tokens` 制限を追加 ([1767413](https://github.com/zhayujie/chatgpt-on-wechat/commit/1767413))
- **.gitignore 更新**:Python ディレクトリの無視ルールを追加 ([#2683](https://github.com/zhayujie/chatgpt-on-wechat/pull/2683)) Thanks [@pelioo](https://github.com/pelioo)
- **AGENT.md の能動的進化**:システムプロンプトでの AGENT.md 更新ガイダンスを最適化。受動的な「ユーザーが変更した時に更新」から、会話中の性格やスタイルの変化を能動的に検出して自動更新するように改善
## 📦 アップグレード方法
ソースコードデプロイの場合は `./run.sh update` でワンクリックアップグレードできます。または手動でコードをプルして再起動してください。詳細は [アップデートドキュメント](https://docs.cowagent.ai/guide/upgrade) を参照。
**リリース日**:2026.03.18 | [Full Changelog](https://github.com/zhayujie/chatgpt-on-wechat/compare/2.0.2...master)
================================================
FILE: docs/ja/skills/image-vision.mdx
================================================
---
title: Image Vision
description: OpenAI の Vision モデルを使用して画像を認識
---
OpenAI の GPT-4 Vision API を使用して画像の内容を分析し、画像内のオブジェクト、テキスト、色などの要素を理解します。
## 依存関係
| 依存関係 | 説明 |
| --- | --- |
| `OPENAI_API_KEY` | OpenAI API キー |
| `curl`, `base64` | システムコマンド(通常プリインストール済み) |
設定方法:
- `env_config` Tool で `OPENAI_API_KEY` を設定
- または `config.json` で `open_ai_api_key` を設定
## 対応モデル
- `gpt-4.1-mini`(推奨、コストパフォーマンスに優れる)
- `gpt-4.1`
## 使い方
設定が完了したら、Agent に画像を送信すると自動的に画像認識がトリガーされます。
================================================
FILE: docs/ja/skills/index.mdx
================================================
---
title: Skill 概要
description: CowAgent の Skill システム紹介
---
Skill は Agent に無限の拡張性を提供します。各 Skill は説明ファイル(`SKILL.md`)、実行スクリプト(任意)、リソース(任意)で構成され、特定のタスクをどのように遂行するかを記述します。
Skill と Tool の違い:Tool はコードで実装された原子的な操作(例:ファイルの読み書き、コマンドの実行)であるのに対し、Skill は説明ファイルに基づく高レベルなワークフローであり、複数の Tool を組み合わせて複雑なタスクを完遂できます。
## 組み込み Skill
プロジェクトの `skills/` ディレクトリに配置されており、依存条件に基づいて自動的に有効化されます:
| Skill | 説明 | 依存関係 |
| --- | --- | --- |
| [`skill-creator`](/ja/skills/skill-creator) | 会話を通じてカスタム Skill を作成 | なし |
| [`openai-image-vision`](/ja/skills/image-vision) | OpenAI の Vision モデルを使用して画像を認識 | `OPENAI_API_KEY` |
| [`linkai-agent`](/ja/skills/linkai-agent) | LinkAI プラットフォームの Agent を統合 | `LINKAI_API_KEY` |
| [`web-fetch`](/ja/skills/web-fetch) | Web ページのテキストコンテンツを取得 | `curl`(デフォルトで有効) |
## カスタム Skill
ユーザーが会話を通じて作成し、ワークスペース(`~/cow/skills/`)に保存されます。任意の複雑なビジネスプロセスやサードパーティシステムとの連携を実装できます。
## Skill の読み込み優先順位
1. **ワークスペースの Skill**(最高優先):`~/cow/skills/`
2. **プロジェクト組み込み Skill**(最低優先):`skills/`
同名の Skill は優先順位に従って上書きされます。
## Skill のファイル構成
```
skills/
├── my-skill/
│ ├── SKILL.md # Skill の説明(frontmatter + 手順)
│ ├── scripts/ # 実行スクリプト(任意)
│ └── resources/ # 追加リソース(任意)
```
### SKILL.md のフォーマット
```markdown
---
name: my-skill
description: Brief description of the skill
metadata:
emoji: 🔧
requires:
bins: ["curl"]
env: ["MY_API_KEY"]
primaryEnv: "MY_API_KEY"
---
# My Skill
Detailed instructions...
```
| フィールド | 説明 |
| --- | --- |
| `name` | Skill 名。ディレクトリ名と一致する必要があります |
| `description` | Skill の説明。Agent はこれに基づいて呼び出すかどうかを判断します |
| `metadata.requires.bins` | 必要なシステムコマンド |
| `metadata.requires.env` | 必要な環境変数 |
| `metadata.always` | 常に読み込む(デフォルトは false) |
================================================
FILE: docs/ja/skills/linkai-agent.mdx
================================================
---
title: LinkAI Agent
description: LinkAI プラットフォームのマルチ Agent Skill を統合
---
[LinkAI](https://link-ai.tech/) プラットフォームの Agent を Skill として使用し、マルチ Agent の意思決定を行います。Agent は Agent 名と説明に基づいてインテリジェントに選択し、`app_code` を通じて対応するアプリケーションやワークフローを呼び出します。
## 依存関係
| 依存関係 | 説明 |
| --- | --- |
| `LINKAI_API_KEY` | LinkAI プラットフォームの API キー。[コンソール](https://link-ai.tech/console/interface)で作成 |
| `curl` | システムコマンド(通常プリインストール済み) |
設定方法:
- `env_config` Tool で `LINKAI_API_KEY` を設定
- または `config.json` で `linkai_api_key` を設定
## Agent の設定
`skills/linkai-agent/config.json` で利用可能な Agent を追加します:
```json
{
"apps": [
{
"app_code": "G7z6vKwp",
"app_name": "LinkAI Customer Support",
"app_description": "Select this assistant only when the user needs help with LinkAI platform questions"
},
{
"app_code": "SFY5x7JR",
"app_name": "Content Creator",
"app_description": "Use this assistant only when the user needs to create images or videos"
}
]
}
```
## 使い方
設定が完了すると、Agent はユーザーの質問に基づいて適切な LinkAI Agent を自動的に選択します。
================================================
FILE: docs/ja/skills/skill-creator.mdx
================================================
---
title: Skill Creator
description: 会話を通じてカスタム Skill を作成
---
自然言語の会話を通じて、Skill の作成、インストール、更新を素早く行えます。
## 依存関係
追加の依存関係は不要で、常に利用可能です。
## 使い方
- ワークフローを Skill 化:「このデプロイプロセスから Skill を作成して」
- サードパーティ API の統合:「この API ドキュメントに基づいて Skill を作成して」
- リモート Skill のインストール:「xxx Skill をインストールして」
## 作成フロー
1. 作成したい Skill を Agent に伝えます
2. Agent が自動的に `SKILL.md` の説明と実行スクリプトを生成します
3. Skill はワークスペースの `~/cow/skills/` ディレクトリに保存されます
4. 以降の会話で Agent が自動的にその Skill を認識し使用します
詳細は [Skill Creator のドキュメント](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/skills/skill-creator/SKILL.md)をご覧ください。
================================================
FILE: docs/ja/skills/web-fetch.mdx
================================================
---
title: Web Fetch
description: Web ページのテキストコンテンツを取得
---
curl を使用して Web ページを取得し、読み取り可能なテキストコンテンツを抽出します。ブラウザ自動化を必要としない軽量な Web アクセス方法です。
## 依存関係
| 依存関係 | 説明 |
| --- | --- |
| `curl` | システムコマンド(通常プリインストール済み) |
この Skill は `always: true` が設定されており、システムに `curl` コマンドがあればデフォルトで有効になります。
## 使い方
Agent が URL からコンテンツを取得する必要がある場合に自動的に呼び出されます。追加の設定は不要です。
## browser Tool との比較
| 機能 | web-fetch (Skill) | browser (Tool) |
| --- | --- | --- |
| 依存関係 | curl のみ | browser-use + playwright |
| JS レンダリング | 非対応 | 対応 |
| ページ操作 | 非対応 | クリック、入力などに対応 |
| 最適な用途 | 静的ページのテキスト | 動的な Web ページ |
ほとんどの Web コンテンツ取得シナリオでは、web-fetch で十分です。JS レンダリングやページ操作が必要な場合にのみ browser Tool を使用してください。
================================================
FILE: docs/ja/tools/bash.mdx
================================================
---
title: bash - ターミナル
description: システムコマンドの実行
---
現在の作業ディレクトリでBashコマンドを実行し、stdoutとstderrを返します。`env_config` で設定されたAPIキーは自動的に環境変数に注入されます。
## 依存関係
追加の依存関係は不要で、デフォルトで利用可能です。
## パラメータ
| パラメータ | 型 | 必須 | 説明 |
| --- | --- | --- | --- |
| `command` | string | はい | 実行するコマンド |
| `timeout` | integer | いいえ | タイムアウト(秒) |
## ユースケース
- パッケージや依存関係のインストール
- コードやテストの実行
- アプリケーションやサービスのデプロイ(Nginx設定、プロセス管理など)
- システム管理とトラブルシューティング
================================================
FILE: docs/ja/tools/browser.mdx
================================================
---
title: browser - ブラウザ
description: Webページへのアクセスと操作
---
ブラウザを使用してWebページにアクセス・操作します。JavaScriptでレンダリングされる動的ページにも対応しています。
## 依存関係
| 依存関係 | インストールコマンド |
| --- | --- |
| `browser-use` ≥ 0.1.40 | `pip install browser-use` |
| `markdownify` | `pip install markdownify` |
| `playwright` + chromium | `pip install playwright && playwright install chromium` |
## ユースケース
- 特定のURLにアクセスしてページ内容を取得
- Webページの要素を操作(クリック、入力など)
- デプロイされたWebページの検証
- JSレンダリングが必要な動的コンテンツのスクレイピング
ブラウザToolは依存関係が大きいため、不要な場合はインストールを省略できます。軽量なWebコンテンツ取得には、代わりに `web-fetch` Skillをご利用ください。
================================================
FILE: docs/ja/tools/edit.mdx
================================================
---
title: edit - ファイル編集
description: テキスト置換によるファイル編集
---
テキスト置換によるファイル編集を行います。`oldText` が空の場合、ファイル末尾に追記します。
## 依存関係
追加の依存関係は不要で、デフォルトで利用可能です。
## パラメータ
| パラメータ | 型 | 必須 | 説明 |
| --- | --- | --- | --- |
| `path` | string | はい | ファイルパス |
| `oldText` | string | はい | 置換対象の元テキスト(空の場合は追記) |
| `newText` | string | はい | 置換後のテキスト |
## ユースケース
- 設定ファイルの特定パラメータの変更
- コードのバグ修正
- ファイル内の特定位置へのコンテンツ挿入
================================================
FILE: docs/ja/tools/env-config.mdx
================================================
---
title: env_config - 環境設定
description: APIキーとシークレットの管理
---
ワークスペースの `.env` ファイルで環境変数(APIキーやシークレット)を管理し、会話形式で安全に更新できます。セキュリティ保護とマスキング機能を内蔵しています。
## 依存関係
| 依存関係 | インストールコマンド |
| --- | --- |
| `python-dotenv` ≥ 1.0.0 | `pip install python-dotenv>=1.0.0` |
オプション依存関係のインストールに含まれています:`pip3 install -r requirements-optional.txt`
## パラメータ
| パラメータ | 型 | 必須 | 説明 |
| --- | --- | --- | --- |
| `action` | string | はい | 操作タイプ:`get`、`set`、`list`、`delete` |
| `key` | string | いいえ | 環境変数名 |
| `value` | string | いいえ | 環境変数の値(`set` の場合のみ) |
## 使い方
設定したいキーをAgentに伝えると、自動的にこのToolが呼び出されます:
- 「BOCHA_API_KEYを設定して」
- 「OPENAI_API_KEYをsk-xxxに設定して」
- 「設定済みの環境変数を表示して」
設定されたキーは `bash` Toolの実行環境に自動的に注入されます。
================================================
FILE: docs/ja/tools/index.mdx
================================================
---
title: Tools 概要
description: CowAgent 組み込みToolシステム
---
Toolは、AgentがOSリソースにアクセスするための中核機能です。Agentはタスクの要件に基づいてToolをインテリジェントに選択・呼び出し、ファイル操作、コマンド実行、Web検索、スケジュールタスクなどを実行します。Toolは `agent/tools/` ディレクトリに実装されています。
## 組み込みTool
以下のToolは追加設定なしでデフォルトで利用可能です:
ファイル内容を読み取り、テキスト・画像・PDFに対応
ファイルの作成または上書き
テキスト置換によるファイル編集
ディレクトリの内容を一覧表示
システムコマンドの実行
ファイルや画像をユーザーに送信
長期メモリの検索と読み取り
## オプションTool
以下のToolは追加の依存関係またはAPIキーの設定が必要です:
APIキーとシークレットの管理
スケジュールタスクの作成と管理
インターネットからリアルタイム情報を検索
================================================
FILE: docs/ja/tools/ls.mdx
================================================
---
title: ls - ディレクトリ一覧
description: ディレクトリの内容を一覧表示
---
ディレクトリの内容をアルファベット順にソートして一覧表示します。ディレクトリには `/` が付与され、隠しファイルも含まれます。
## 依存関係
追加の依存関係は不要で、デフォルトで利用可能です。
## パラメータ
| パラメータ | 型 | 必須 | 説明 |
| --- | --- | --- | --- |
| `path` | string | はい | ディレクトリパス。相対パスはワークスペースディレクトリを基準とします |
| `limit` | integer | いいえ | 返すエントリの最大数、デフォルト500 |
## ユースケース
- プロジェクト構造の閲覧
- 特定ファイルの検索
- ディレクトリの存在確認
================================================
FILE: docs/ja/tools/memory.mdx
================================================
---
title: memory - メモリ
description: 長期メモリの検索と読み取り
---
メモリToolには `memory_search`(メモリ検索)と `memory_get`(メモリファイル読み取り)の2つのサブToolがあります。
## 依存関係
追加の依存関係は不要で、デフォルトで利用可能です。Agent Coreのメモリシステムによって管理されます。
## memory_search
キーワードとベクトルのハイブリッド検索で過去のメモリを検索します。
| パラメータ | 型 | 必須 | 説明 |
| --- | --- | --- | --- |
| `query` | string | はい | 検索クエリ |
## memory_get
特定のメモリファイルの内容を読み取ります。
| パラメータ | 型 | 必須 | 説明 |
| --- | --- | --- | --- |
| `path` | string | はい | メモリファイルの相対パス(例:`MEMORY.md`、`memory/2026-01-01.md`) |
| `start_line` | integer | いいえ | 開始行番号 |
| `end_line` | integer | いいえ | 終了行番号 |
## 仕組み
Agentは以下のシナリオでメモリToolを自動的に呼び出します:
- ユーザーが重要な情報を共有した場合 → メモリに保存
- 過去のコンテキストが必要な場合 → 関連するメモリを検索
- 会話が一定の長さに達した場合 → 要約を抽出して保存
================================================
FILE: docs/ja/tools/read.mdx
================================================
---
title: read - ファイル読み取り
description: ファイル内容の読み取り
---
ファイルの内容を読み取ります。テキストファイル、PDFファイル、画像(メタデータを返す)などに対応しています。
## 依存関係
追加の依存関係は不要で、デフォルトで利用可能です。
## パラメータ
| パラメータ | 型 | 必須 | 説明 |
| --- | --- | --- | --- |
| `path` | string | はい | ファイルパス。相対パスはワークスペースディレクトリを基準とします |
| `offset` | integer | いいえ | 開始行番号(1始まり)。負の値は末尾からの読み取り |
| `limit` | integer | いいえ | 読み取る行数 |
## ユースケース
- 設定ファイルやログファイルの閲覧
- コードファイルの読み取りと分析
- 画像・動画ファイルの情報確認
================================================
FILE: docs/ja/tools/scheduler.mdx
================================================
---
title: scheduler - スケジューラ
description: スケジュールタスクの作成と管理
---
柔軟なスケジュール設定と実行モードを備えた、動的スケジュールタスクの作成と管理を行います。
## 依存関係
| 依存関係 | インストールコマンド |
| --- | --- |
| `croniter` ≥ 2.0.0 | `pip install croniter>=2.0.0` |
コア依存関係に含まれています:`pip3 install -r requirements.txt`
## スケジュールモード
| モード | 説明 |
| --- | --- |
| ワンタイム | 指定した時刻に1回だけ実行 |
| 固定間隔 | 一定の時間間隔で繰り返し実行 |
| Cron式 | Cron構文を使用した複雑なスケジュール定義 |
## 実行モード
- **固定メッセージ**: トリガー時にプリセットメッセージを送信
- **Agent動的タスク**: トリガー時にAgentがインテリジェントにタスクを実行
## 使い方
自然言語でスケジュールタスクを作成・管理できます:
- 「毎朝9時に天気予報を送って」
- 「2時間ごとにサーバーのステータスを確認して」
- 「明日の午後3時に会議のリマインドをして」
- 「すべてのスケジュールタスクを表示して」
================================================
FILE: docs/ja/tools/send.mdx
================================================
---
title: send - ファイル送信
description: ユーザーへのファイル送信
---
ユーザーにファイル(画像、動画、音声、ドキュメントなど)を送信します。ユーザーが明示的にファイルの送信・共有を要求した場合に使用されます。
## 依存関係
追加の依存関係は不要で、デフォルトで利用可能です。
## パラメータ
| パラメータ | 型 | 必須 | 説明 |
| --- | --- | --- | --- |
| `path` | string | はい | ファイルパス。絶対パスまたはワークスペースからの相対パス |
| `message` | string | いいえ | 添付メッセージ |
## ユースケース
- 生成したコードやドキュメントをユーザーに送信
- スクリーンショットやチャートの送信
- ダウンロードしたファイルの共有
================================================
FILE: docs/ja/tools/web-search.mdx
================================================
---
title: web_search - Web検索
description: インターネットからリアルタイム情報を検索
---
インターネットからリアルタイムの情報、ニュース、リサーチなどを検索します。2つの検索バックエンドに対応し、自動フォールバック機能を備えています。
## 依存関係
少なくとも1つの検索APIキーが必要です(`env_config` Toolまたはワークスペースの `.env` ファイルで設定):
| バックエンド | 環境変数 | 優先度 | 取得方法 |
| --- | --- | --- | --- |
| Bocha Search | `BOCHA_API_KEY` | プライマリ | [Bocha Open Platform](https://open.bochaai.com/) |
| LinkAI Search | `LINKAI_API_KEY` | フォールバック | [LinkAI Console](https://link-ai.tech/console/interface) |
## パラメータ
| パラメータ | 型 | 必須 | 説明 |
| --- | --- | --- | --- |
| `query` | string | はい | 検索キーワード |
| `count` | integer | いいえ | 結果件数(1-50、デフォルト10) |
| `freshness` | string | いいえ | 期間指定:`noLimit`、`oneDay`、`oneWeek`、`oneMonth`、`oneYear`、または `2025-01-01..2025-02-01` のような日付範囲 |
| `summary` | boolean | いいえ | ページ要約を返す(デフォルトfalse) |
## ユースケース
ユーザーが最新情報について質問したり、事実確認やリアルタイムデータが必要な場合、AgentはこのToolを自動的に呼び出します。
検索APIキーが設定されていない場合、このToolは読み込まれません。
================================================
FILE: docs/ja/tools/write.mdx
================================================
---
title: write - ファイル書き込み
description: ファイルの作成または上書き
---
ファイルにコンテンツを書き込みます。ファイルが存在しない場合は新規作成し、存在する場合は上書きします。親ディレクトリは自動的に作成されます。
## 依存関係
追加の依存関係は不要で、デフォルトで利用可能です。
## パラメータ
| パラメータ | 型 | 必須 | 説明 |
| --- | --- | --- | --- |
| `path` | string | はい | ファイルパス |
| `content` | string | はい | 書き込む内容 |
## ユースケース
- 新しいコードファイルやスクリプトの作成
- 設定ファイルの生成
- 処理結果の保存
1回の書き込みは10KBを超えないようにしてください。大きなファイルの場合は、まずスケルトンを作成し、editツールを使用してチャンクごとにコンテンツを追加してください。
================================================
FILE: docs/memory.mdx
================================================
---
title: 长期记忆
description: CowAgent 的长期记忆系统
---
记忆系统让 Agent 能够长期记住重要信息,在对话中不断积累经验、理解用户偏好,真正实现自主思考和持续成长。
## 记忆类型
### 核心记忆(MEMORY.md)
存储在 `~/cow/MEMORY.md` 中,包含用户的长期偏好、重要决策、关键事实等不会随时间淡化的信息。每次对话时自动注入系统提示词,作为 Agent 的背景知识。
### 天级记忆(memory/YYYY-MM-DD.md)
存储在 `~/cow/memory/` 目录下,按日期命名(如 `2026-03-08.md`),记录每天的对话摘要和关键事件。仅在首次写入时创建,避免生成空文件。
## 记忆写入
Agent 通过以下机制自动将对话内容持久化为天级记忆:
- **上下文裁剪时** — 当对话轮次或 token 超出配置上限时,批量裁剪最早一半的上下文,并使用 LLM 将被裁剪的内容总结为关键信息写入当天记忆文件
- **每日定时总结** — 每天 23:55 自动触发一次全量总结,防止低活跃日无记忆留存(内容无变化时自动跳过)
- **API 上下文溢出时** — 当模型 API 返回上下文溢出错误时,紧急保存当前对话摘要
所有记忆写入均在后台异步执行(LLM 总结 + 文件写入),不阻塞正常对话回复。
## 首次启动
首次启动 Agent 时,Agent 会主动向用户询问关键信息,并记录至工作空间(默认 `~/cow`)中:
| 文件 | 说明 |
| --- | --- |
| `system.md` | Agent 的系统提示词和行为设定 |
| `user.md` | 用户身份信息和偏好 |
| `MEMORY.md` | 核心记忆(长期) |
| `memory/YYYY-MM-DD.md` | 天级记忆(按需创建) |
## 记忆检索
记忆系统支持混合检索模式:
- **关键词检索** — 基于关键词匹配历史记忆
- **向量检索** — 基于语义相似度搜索,即使表述不同也能找到相关记忆
Agent 会在对话中根据需要自动触发记忆检索,将相关历史信息纳入上下文。核心记忆(`MEMORY.md`)始终注入系统提示词,天级记忆通过检索按需加载。
## 相关配置
```json
{
"agent_workspace": "~/cow",
"agent_max_context_tokens": 40000,
"agent_max_context_turns": 20
}
```
| 参数 | 说明 | 默认值 |
| --- | --- | --- |
| `agent_workspace` | 工作空间路径,记忆文件存储在此目录下 | `~/cow` |
| `agent_max_context_tokens` | 最大上下文 token 数,超出时裁剪一半并总结写入记忆 | `40000` |
| `agent_max_context_turns` | 最大上下文轮次,超出时裁剪一半并总结写入记忆 | `20` |
================================================
FILE: docs/models/claude.mdx
================================================
---
title: Claude
description: Claude 模型配置
---
```json
{
"model": "claude-sonnet-4-6",
"claude_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | 支持 `claude-sonnet-4-6`、`claude-opus-4-6`、`claude-sonnet-4-5`、`claude-sonnet-4-0`、`claude-3-5-sonnet-latest` 等,参考 [官方模型](https://docs.anthropic.com/en/docs/about-claude/models/overview) |
| `claude_api_key` | 在 [Claude 控制台](https://console.anthropic.com/settings/keys) 创建 |
| `claude_api_base` | 可选,默认为 `https://api.anthropic.com/v1`,修改可接入第三方代理 |
================================================
FILE: docs/models/coding-plan.mdx
================================================
---
title: Coding Plan
description: Coding Plan 模式模型配置
---
> Coding Plan 是各厂商推出的编程包月套餐,适合高频使用 Agent 的场景。CowAgent 支持通过 OpenAI 兼容方式接入各厂商的 Coding Plan 接口。
Coding Plan 的 API Base 和 API Key 通常与普通按量计费接口不通用,请在各厂商平台单独获取。
## 通用配置格式
所有厂商均可使用 OpenAI 兼容协议接入,可在web控制台快速配置。设置模型厂商为**OpenAI**,选择自定义模型并填入模型编码,最后填写对应厂商的API Base 和 API Key:
也可通过 `config.json` 配置文件直接修改:
```json
{
"bot_type": "openai",
"model": "模型名称",
"open_ai_api_base": "厂商 Coding Plan API Base",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `bot_type` | 固定为 `openai`(OpenAI 兼容方式) |
| `model` | 各厂商支持的模型名称 |
| `open_ai_api_base` | 各厂商 Coding Plan 专用 API Base |
| `open_ai_api_key` | 各厂商 Coding Plan 专用 API Key |
---
## 阿里云
```json
{
"bot_type": "openai",
"model": "qwen3.5-plus",
"open_ai_api_base": "https://coding.dashscope.aliyuncs.com/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | `qwen3.5-plus`、`qwen3-max-2026-01-23`、`qwen3-coder-next`、`qwen3-coder-plus`、`glm-5`、`glm-4.7`、`kimi-k2.5`、`MiniMax-M2.5` |
| `open_ai_api_base` | `https://coding.dashscope.aliyuncs.com/v1` |
| `open_ai_api_key` | Coding Plan 专用 Key(与按量计费接口不通用) |
官方文档:[快速开始](https://help.aliyun.com/zh/model-studio/coding-plan-quickstart?spm=a2c4g.11186623.help-menu-2400256.d_0_2_1.70115203zi5Igc)、[模型列表](https://help.aliyun.com/zh/model-studio/coding-plan)
---
## MiniMax
```json
{
"bot_type": "openai",
"model": "MiniMax-M2.5",
"open_ai_api_base": "https://api.minimaxi.com/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | `MiniMax-M2.5`、`MiniMax-M2.5-highspeed`、`MiniMax-M2.1`、`MiniMax-M2` |
| `open_ai_api_base` | 国内:`https://api.minimaxi.com/v1`;海外:`https://api.minimax.io/v1` |
| `open_ai_api_key` | Coding Plan 专用 Key(与按量计费接口不通用) |
官方文档:[国内 Key 获取](https://platform.minimaxi.com/docs/coding-plan/quickstart)、[模型列表](https://platform.minimaxi.com/docs/guides/pricing-coding-plan)、[国际 Key 获取](https://platform.minimax.io/docs/coding-plan/quickstart)
---
## 智谱 GLM
```json
{
"bot_type": "openai",
"model": "glm-4.7",
"open_ai_api_base": "https://open.bigmodel.cn/api/coding/paas/v4",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | `glm-5`、`glm-4.7`、`glm-4.6`、`glm-4.5`、`glm-4.5-air` |
| `open_ai_api_base` | 中国区:`https://open.bigmodel.cn/api/coding/paas/v4`;全球区:`https://api.z.ai/api/coding/paas/v4` |
| `open_ai_api_key` | API Key 与普通接口通用 |
官方文档:[国内版快速开始](https://docs.bigmodel.cn/cn/coding-plan/quick-start)、[国际版快速开始](https://docs.z.ai/devpack/quick-start)
---
## Kimi
```json
{
"bot_type": "openai",
"model": "kimi-for-coding",
"open_ai_api_base": "https://api.kimi.com/coding/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | `kimi-for-coding` |
| `open_ai_api_base` | `https://api.kimi.com/coding/v1` |
| `open_ai_api_key` | Coding Plan 专用 Key(与按量计费接口不通用) |
官方文档:[Key 获取](https://www.kimi.com/code/docs/)
---
## 火山引擎
```json
{
"bot_type": "openai",
"model": "Doubao-Seed-2.0-Code",
"open_ai_api_base": "https://ark.cn-beijing.volces.com/api/coding/v3",
"open_ai_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | `Doubao-Seed-2.0-Code`、`Doubao-Seed-2.0-pro`、`Doubao-Seed-2.0-lite`、`Doubao-Seed-Code`、`MiniMax-M2.5`、`Kimi-K2.5`、`GLM-4.7`、`DeepSeek-V3.2` |
| `open_ai_api_base` | `https://ark.cn-beijing.volces.com/api/coding/v3` |
| `open_ai_api_key` | API Key 与普通接口通用 |
官方文档:[快速开始](https://www.volcengine.com/docs/82379/1928261?lang=zh)
================================================
FILE: docs/models/deepseek.mdx
================================================
---
title: DeepSeek
description: DeepSeek 模型配置
---
通过 OpenAI 兼容方式接入:
```json
{
"model": "deepseek-chat",
"open_ai_api_key": "YOUR_API_KEY",
"open_ai_api_base": "https://api.deepseek.com/v1",
"bot_type": "openai"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | `deepseek-chat`(DeepSeek-V3)、`deepseek-reasoner`(DeepSeek-R1) |
| `bot_type` | 固定为 `openai`(OpenAI 兼容方式) |
| `open_ai_api_key` | 在 [DeepSeek 平台](https://platform.deepseek.com/api_keys) 创建 |
| `open_ai_api_base` | DeepSeek 平台 BASE URL |
================================================
FILE: docs/models/doubao.mdx
================================================
---
title: 豆包 Doubao
description: 豆包 (火山方舟) 模型配置
---
```json
{
"model": "doubao-seed-2-0-code-preview-260215",
"ark_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | 可填 `doubao-seed-2-0-code-preview-260215`、`doubao-seed-2-0-pro-260215`、`doubao-seed-2-0-lite-260215` 等 |
| `ark_api_key` | 在 [火山方舟控制台](https://console.volcengine.com/ark/region:ark+cn-beijing/apikey) 创建 |
| `ark_base_url` | 可选,默认为 `https://ark.cn-beijing.volces.com/api/v3` |
================================================
FILE: docs/models/gemini.mdx
================================================
---
title: Gemini
description: Google Gemini 模型配置
---
```json
{
"model": "gemini-3.1-pro-preview",
"gemini_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | 支持 `gemini-3.1-flash-lite-preview`、`gemini-3.1-pro-preview`、`gemini-3-flash-preview`、`gemini-3-pro-preview` 等,参考 [官方文档](https://ai.google.dev/gemini-api/docs/models) |
| `gemini_api_key` | 在 [Google AI Studio](https://aistudio.google.com/app/apikey) 创建 |
================================================
FILE: docs/models/glm.mdx
================================================
---
title: 智谱 GLM
description: 智谱AI GLM 模型配置
---
```json
{
"model": "glm-5-turbo",
"zhipu_ai_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | 可填 `glm-5-turbo`、`glm-5`、`glm-4.7`、`glm-4-plus`、`glm-4-flash`、`glm-4-air` 等,参考 [模型编码](https://bigmodel.cn/dev/api/normal-model/glm-4) |
| `zhipu_ai_api_key` | 在 [智谱AI 控制台](https://www.bigmodel.cn/usercenter/proj-mgmt/apikeys) 创建 |
也支持 OpenAI 兼容方式接入:
```json
{
"bot_type": "openai",
"model": "glm-5-turbo",
"open_ai_api_base": "https://open.bigmodel.cn/api/paas/v4",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/models/index.mdx
================================================
---
title: 模型概览
description: CowAgent 支持的模型及推荐选择
---
CowAgent 支持国内外主流厂商的大语言模型,模型接口实现在项目的 `models/` 目录下。
Agent 模式下推荐使用以下模型,可根据效果及成本综合选择:MiniMax-M2.7、glm-5-turbo、kimi-k2.5、qwen3.5-plus、claude-sonnet-4-6、gemini-3.1-pro-preview
## 配置方式
根据所选模型,在 `config.json` 中填写对应的模型名称和 API Key 即可。每个模型也支持 OpenAI 兼容方式接入,将 `bot_type` 设为 `openai`,配置 `open_ai_api_base` 和 `open_ai_api_key`。
同时支持使用 [LinkAI](https://link-ai.tech) 平台接口,可灵活切换多种模型,并支持知识库、工作流、插件等 Agent 能力。
也可以通过 [Web 控制台](/channels/web) 在线管理模型配置,无需手动编辑配置文件:
## 支持的模型
MiniMax-M2.7 等系列模型
glm-5-turbo、glm-5 等系列模型
qwen3.5-plus、qwen3-max 等
kimi-k2.5、kimi-k2 等
doubao-seed 系列模型
claude-sonnet-4-6 等
gemini-3.1-pro-preview 等
gpt-5.4、gpt-4.1、o 系列等
deepseek-chat、deepseek-reasoner
多模型统一接口 + 知识库
全部模型名称可参考项目 [`common/const.py`](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/common/const.py) 文件。
================================================
FILE: docs/models/kimi.mdx
================================================
---
title: Kimi
description: Kimi (Moonshot) 模型配置
---
```json
{
"model": "kimi-k2.5",
"moonshot_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | 可填 `kimi-k2.5`、`kimi-k2`、`moonshot-v1-8k`、`moonshot-v1-32k`、`moonshot-v1-128k` |
| `moonshot_api_key` | 在 [Moonshot 控制台](https://platform.moonshot.cn/console/api-keys) 创建 |
也支持 OpenAI 兼容方式接入:
```json
{
"bot_type": "openai",
"model": "kimi-k2.5",
"open_ai_api_base": "https://api.moonshot.cn/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/models/linkai.mdx
================================================
---
title: LinkAI
description: 通过 LinkAI 平台统一接入多种模型
---
通过 [LinkAI](https://link-ai.tech) 平台可灵活切换 OpenAI、Claude、Gemini、DeepSeek、Qwen、Kimi 等多种模型,并支持知识库、工作流、插件等 Agent 能力。
```json
{
"use_linkai": true,
"linkai_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `use_linkai` | 设为 `true` 启用 LinkAI 接口 |
| `linkai_api_key` | 在 [控制台](https://link-ai.tech/console/interface) 创建 |
| `model` | 留空则使用智能体默认模型,可在平台中灵活切换,[模型列表](https://link-ai.tech/console/models) 中的全部模型均可使用 |
参考 [接口文档](https://docs.link-ai.tech/platform/api) 了解更多。
================================================
FILE: docs/models/minimax.mdx
================================================
---
title: MiniMax
description: MiniMax 模型配置
---
```json
{
"model": "MiniMax-M2.7",
"minimax_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | 可填 `MiniMax-M2.7`、`MiniMax-M2.5`、`MiniMax-M2.1`、`MiniMax-M2.1-lightning`、`MiniMax-M2` 等 |
| `minimax_api_key` | 在 [MiniMax 控制台](https://platform.minimaxi.com/user-center/basic-information/interface-key) 创建 |
也支持 OpenAI 兼容方式接入:
```json
{
"bot_type": "openai",
"model": "MiniMax-M2.7",
"open_ai_api_base": "https://api.minimaxi.com/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/models/openai.mdx
================================================
---
title: OpenAI
description: OpenAI 模型配置
---
```json
{
"model": "gpt-5.4",
"open_ai_api_key": "YOUR_API_KEY",
"open_ai_api_base": "https://api.openai.com/v1"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | 与 OpenAI 接口的 [model 参数](https://platform.openai.com/docs/models) 一致,支持 o 系列、gpt-5.4、gpt-5.4-mini、gpt-5.4-nano、gpt-5 系列、gpt-4.1 等,Agent 模式推荐使用 `gpt-5.4` |
| `open_ai_api_key` | 在 [OpenAI 平台](https://platform.openai.com/api-keys) 创建 |
| `open_ai_api_base` | 可选,修改可接入第三方代理接口 |
| `bot_type` | 使用 OpenAI 官方模型时无需填写。当通过代理接口使用 Claude 等非 OpenAI 模型时,设为 `openai` |
================================================
FILE: docs/models/qwen.mdx
================================================
---
title: 通义千问 Qwen
description: 通义千问模型配置
---
```json
{
"model": "qwen3.5-plus",
"dashscope_api_key": "YOUR_API_KEY"
}
```
| 参数 | 说明 |
| --- | --- |
| `model` | 可填 `qwen3.5-plus`、`qwen3-max`、`qwen-max`、`qwen-plus`、`qwen-turbo`、`qwq-plus` 等 |
| `dashscope_api_key` | 在 [百炼控制台](https://bailian.console.aliyun.com/?tab=model#/api-key) 创建,参考 [官方文档](https://bailian.console.aliyun.com/?tab=api#/api) |
也支持 OpenAI 兼容方式接入:
```json
{
"bot_type": "openai",
"model": "qwen3.5-plus",
"open_ai_api_base": "https://dashscope.aliyuncs.com/compatible-mode/v1",
"open_ai_api_key": "YOUR_API_KEY"
}
```
================================================
FILE: docs/releases/overview.mdx
================================================
---
title: 更新日志
description: CowAgent 版本更新历史
---
| 版本 | 日期 | 说明 |
| --- | --- | --- |
| [2.0.3](/releases/v2.0.3) | 2026.03.18 | 新增企微智能机器人和 QQ 通道、支持Coding Plan、新增多个模型、Web端文件处理、记忆系统升级 |
| [2.0.2](/releases/v2.0.2) | 2026.02.27 | Web 控制台升级、多通道同时运行、会话持久化 |
| [2.0.1](/releases/v2.0.1) | 2026.02.13 | 内置 Web Search 工具、智能上下文管理、多项修复 |
| [2.0.0](/releases/v2.0.0) | 2026.02.03 | 全面升级为超级 Agent 助理 |
| 1.7.6 | 2025.05.23 | Web Channel 优化、AgentMesh 多智能体插件 |
| 1.7.5 | 2025.04.11 | DeepSeek 模型 |
| 1.7.4 | 2024.12.13 | Gemini 2.0 模型、Web Channel |
| 1.7.3 | 2024.10.31 | 稳定性提升、数据库功能 |
| 1.7.2 | 2024.09.26 | 一键安装脚本、o1 模型 |
| 1.7.0 | 2024.08.02 | 讯飞 4.0 模型、知识库引用 |
| 1.6.9 | 2024.07.19 | gpt-4o-mini、阿里语音识别 |
| 1.6.8 | 2024.07.05 | Claude 3.5、Gemini 1.5 Pro |
| 1.6.0 | 2024.04.26 | Kimi 接入、gpt-4-turbo 升级 |
| 1.5.8 | 2024.03.26 | GLM-4、Claude-3、edge-tts |
| 1.5.2 | 2023.11.10 | 飞书通道、图像识别对话 |
| 1.5.0 | 2023.11.10 | gpt-4-turbo、dall-e-3、tts 多模态 |
| 1.0.0 | 2022.12.12 | 项目创建,首次接入 ChatGPT 模型 |
更多历史版本请查看 [GitHub Releases](https://github.com/zhayujie/chatgpt-on-wechat/releases)。
================================================
FILE: docs/releases/v2.0.0.mdx
================================================
---
title: v2.0.0
description: CowAgent 2.0 - 从聊天机器人到超级智能助理的全面升级
---
CowAgent 2.0 实现了从聊天机器人到**超级智能助理**的全面升级!现在它能够主动思考和规划任务、拥有长期记忆、操作计算机和外部资源、创造和执行技能,真正理解你并和你一起成长。
**发布日期**:2026.02.03 | [GitHub Release](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.0)
## 重点更新
### Agent 核心能力
- **复杂任务规划**:能够理解复杂任务并自主规划执行,持续思考和调用工具直到完成目标,支持多轮推理和上下文理解
- **长期记忆**:自动将对话记忆持久化至本地文件和数据库中,包括全局记忆和天级记忆,支持关键词及向量检索
- **内置系统工具**:内置实现 10+ 种工具,包括文件操作、Bash 终端、浏览器、文件发送、定时任务、记忆管理等
- **Skills**:新增 Skill 运行引擎,内置多种技能,并支持通过自然语言对话完成自定义 Skills 开发
- **安全和成本**:通过秘钥管理工具、提示词控制、系统权限等手段控制 Agent 的访问安全;通过最大记忆轮次、最大上下文 token、工具执行步数对 token 成本进行限制
### 其他更新
- **渠道优化**:飞书及钉钉接入渠道支持长连接接入(无需公网 IP)、支持图片/文件消息的接收和发送
- **模型更新**:新增 claude-sonnet-4-5、gemini-3-pro-preview、glm-4.7、MiniMax-M2.1、qwen3-max 等最新模型
- **部署优化**:增加一键安装、配置、运行、管理的脚本,简化部署流程
## 长期记忆系统
Agent 会在用户分享重要信息时主动存储,也会在对话达到一定长度时自动提取摘要。支持语义搜索和向量检索的混合检索模式。
**首次启动**时,Agent 会主动询问关键信息,并记录至工作空间(默认 `~/cow`)中的智能体设定、用户身份、记忆文件中。
**长期对话**中,Agent 会智能记录或检索记忆,不断更新自身设定、用户偏好,总结经验和教训,真正实现自主思考和持续成长。
## 任务规划与工具调用
Agent 根据任务需求智能选择和调用工具,完成各类复杂操作。
### 终端和文件访问
最基础和核心的工具能力,用户可通过手机端与 Agent 交互,操作个人电脑或服务器上的资源:
### 应用编程能力
基于编程能力和系统访问能力,Agent 可实现从信息搜索、素材生成、编码、测试、部署、Nginx 配置、发布的 **Vibecoding 全流程**,通过手机端一句命令完成应用快速 demo。
### 定时任务
支持 **一次性任务、固定时间间隔、Cron 表达式** 三种形式,任务触发可选择 **固定消息发送** 或 **Agent 动态任务执行** 两种模式:
### 环境变量管理
通过 `env_config` 工具管理技能所需秘钥,支持对话式更新,内置安全保护和脱敏策略:
## 技能系统
每个 Skill 由说明文件、运行脚本(可选)、资源(可选)组成,为 Agent 提供无限扩展性。
### 技能创造器
通过对话方式快速创建技能,将工作流程固化或对接任意第三方接口:
### 网页搜索和图像识别
- **网页搜索**:内置 `web_search` 工具,支持多种搜索引擎,配置对应 API Key 即可使用
- **图像识别**:支持 `gpt-4.1-mini`、`gpt-4.1` 等模型,配置 `OPENAI_API_KEY` 即可使用
### 三方知识库和插件
`linkai-agent` 技能可将 [LinkAI](https://link-ai.tech/) 上的所有智能体作为 Skill 使用,实现多智能体决策:
## 参与共建
2.0 版本后,项目将持续升级 Agent 能力、拓展接入渠道、内置工具、技能系统,降低模型成本和提升安全性。欢迎 [提出反馈](https://github.com/zhayujie/chatgpt-on-wechat/issues) 和 [贡献代码](https://github.com/zhayujie/chatgpt-on-wechat/pulls)。
================================================
FILE: docs/releases/v2.0.1.mdx
================================================
---
title: v2.0.1
description: CowAgent 2.0.1 - 内置 Web Search、智能上下文管理、多项修复
---
**发布日期**:2026.02 | [GitHub Release](https://github.com/zhayujie/chatgpt-on-wechat/releases/tag/2.0.1) | [Full Changelog](https://github.com/zhayujie/chatgpt-on-wechat/compare/2.0.0..2.0.1)
## 新特性
- **内置 Web Search 工具**:将网络搜索作为 Agent 内置工具集成,降低决策成本 ([4f0ea5d](https://github.com/zhayujie/chatgpt-on-wechat/commit/4f0ea5d7568d61db91ff69c91c429e785fd1b1c2))
- **Claude Opus 4.6 模型支持**:新增对 Claude Opus 4.6 模型的支持 ([#2661](https://github.com/zhayujie/chatgpt-on-wechat/pull/2661))
- **企业微信图片消息识别**:支持企业微信渠道的图片消息识别功能 ([#2667](https://github.com/zhayujie/chatgpt-on-wechat/pull/2667))
## 优化
- **智能上下文管理**:解决聊天上下文溢出问题,新增智能上下文裁剪策略,防止 token 超限 ([cea7fb7](https://github.com/zhayujie/chatgpt-on-wechat/commit/cea7fb7490c53454602bf05955a0e9f059bcf0fd), [8acf2db](https://github.com/zhayujie/chatgpt-on-wechat/commit/8acf2dbdfe713b84ad74b761b7f86674b1c1904d)) [#2663](https://github.com/zhayujie/chatgpt-on-wechat/issues/2663)
- **运行时信息动态更新**:通过动态函数方案实现系统提示词中时间戳等运行时信息的自动更新 ([#2655](https://github.com/zhayujie/chatgpt-on-wechat/pull/2655), [#2657](https://github.com/zhayujie/chatgpt-on-wechat/pull/2657))
- **Skill 提示词优化**:改进 Skill 系统提示词生成逻辑,简化工具描述,提升 Agent 表现 ([6c21833](https://github.com/zhayujie/chatgpt-on-wechat/commit/6c218331b1f1208ea8be6bf226936d3b556ade3e))
- **智谱 AI 自定义 API Base URL**:支持智谱 AI 配置自定义 API Base URL ([#2660](https://github.com/zhayujie/chatgpt-on-wechat/pull/2660))
- **启动脚本优化**:改进 `run.sh` 脚本的交互体验和配置流程 ([#2656](https://github.com/zhayujie/chatgpt-on-wechat/pull/2656))
- **决策轮次日志**:新增 Agent 决策轮次的日志记录,便于调试 ([cb303e6](https://github.com/zhayujie/chatgpt-on-wechat/commit/cb303e6109c50c8dfef1f5e6c1ec47223bf3cd11))
## 问题修复
- **定时任务记忆丢失**:修复 Scheduler 调度器导致的记忆丢失问题 ([a77a874](https://github.com/zhayujie/chatgpt-on-wechat/commit/a77a8741b500a408c6f5c8868856fb4b018fe9db))
- **空工具调用与超长结果**:修复空 tool calls 及过长工具返回结果的异常处理 ([0542700](https://github.com/zhayujie/chatgpt-on-wechat/commit/0542700f9091ebb08c1a56103b0f0f45f24aa621))
- **OpenAI Function Call**:修复 OpenAI 模型的 function call 调用兼容性问题 ([158c87a](https://github.com/zhayujie/chatgpt-on-wechat/commit/158c87ab8b05bae054cc1b4eacdbb64fc1062ba9))
- **Claude 工具名字段**:移除 Claude 模型响应中多余的 tool name 字段 ([eec10cb](https://github.com/zhayujie/chatgpt-on-wechat/commit/eec10cb5db6a3d5bc12ef606606532237d2c5f6e))
- **MiniMax 推理优化**:优化 MiniMax 模型 reasoning content 处理,隐藏思考过程输出 ([c72cda3](https://github.com/zhayujie/chatgpt-on-wechat/commit/c72cda33864bd1542012ee6e0a8bd8c6c88cb5ed), [72b1cac](https://github.com/zhayujie/chatgpt-on-wechat/commit/72b1cacea1ba0d1f3dedacbab2e088e98fd7e172))
- **智谱 AI 思考过程**:隐藏智谱 AI 模型的思考过程展示 ([72b1cac](https://github.com/zhayujie/chatgpt-on-wechat/commit/72b1cacea1ba0d1f3dedacbab2e088e98fd7e172))
- **飞书连接与证书**:修复飞书渠道的 SSL 证书错误和连接异常问题 ([229b14b](https://github.com/zhayujie/chatgpt-on-wechat/commit/229b14b6fcabe7123d53cab1dea39f38dab26d6d), [8674421](https://github.com/zhayujie/chatgpt-on-wechat/commit/867442155e7f095b4f38b0856f8c1d8312b5fcf7))
- **model_type 类型校验**:修复非字符串 `model_type` 导致的 `AttributeError` ([#2666](https://github.com/zhayujie/chatgpt-on-wechat/pull/2666))
## 平台兼容
- **Windows 兼容性适配**:修复 Windows 平台下路径处理、文件编码及 `os.getuid()` 不可用等问题,涉及多个工具模块 ([051ffd7](https://github.com/zhayujie/chatgpt-on-wechat/commit/051ffd78a372f71a967fd3259e37fe19131f83cf), [5264f7c](https://github.com/zhayujie/chatgpt-on-wechat/commit/5264f7ce18360ee4db5dcb4ebe67307977d40014))
================================================
FILE: docs/releases/v2.0.2.mdx
================================================
---
title: v2.0.2
description: CowAgent 2.0.2 - Web 控制台升级、多通道同时运行、会话持久化
---
## ✨ 重点更新
### 🖥️ Web 控制台升级
本次对 Web 控制台进行了全面升级,支持流式对话输出、工具执行过程和思考过程的可视化展示,并支持对模型、技能、记忆、通道、Agent 配置的在线查看和管理。
#### 对话界面
支持流式输出,可实时展示 Agent 的思考过程(Reasoning)和工具调用过程(Tool Calls),更直观地观察 Agent 的决策过程:
#### 模型管理
支持在线管理模型配置,无需手动编辑配置文件:
#### 技能管理
支持在线查看和管理 Agent 技能(Skills):
#### 记忆管理
支持在线查看和管理 Agent 记忆:
#### 通道管理
支持在线管理接入通道,支持实时连接/断开操作:
#### 定时任务
支持在线查看和管理定时任务,包括一次性任务、固定间隔、Cron 表达式等多种调度方式的可视化管理:
#### 日志
支持在线实时查看 Agent 运行日志,便于监控运行状态和排查问题:
相关提交:[f1a1413](https://github.com/zhayujie/chatgpt-on-wechat/commit/f1a1413), [c0702c8](https://github.com/zhayujie/chatgpt-on-wechat/commit/c0702c8), [394853c](https://github.com/zhayujie/chatgpt-on-wechat/commit/394853c), [1c71c4e](https://github.com/zhayujie/chatgpt-on-wechat/commit/1c71c4e), [5e3eccb](https://github.com/zhayujie/chatgpt-on-wechat/commit/5e3eccb), [e1dc037](https://github.com/zhayujie/chatgpt-on-wechat/commit/e1dc037), [5edbf4c](https://github.com/zhayujie/chatgpt-on-wechat/commit/5edbf4c), [7d258b5](https://github.com/zhayujie/chatgpt-on-wechat/commit/7d258b5)
### 🔀 多通道同时运行
支持多个接入通道(如飞书、钉钉、企微应用、Web 等)同时运行,每个通道在独立子线程中启动,互不干扰。
配置方式:在 `config.json` 中通过 `channel_type` 配置多个通道,以逗号分隔,也可在 Web 控制台的通道管理页面中实时连接或断开各通道。
```json
{
"channel_type": "web,feishu,dingtalk"
}
```
相关提交:[4694594](https://github.com/zhayujie/chatgpt-on-wechat/commit/4694594), [7cce224](https://github.com/zhayujie/chatgpt-on-wechat/commit/7cce224), [7d258b5](https://github.com/zhayujie/chatgpt-on-wechat/commit/7d258b5), [c9adddb](https://github.com/zhayujie/chatgpt-on-wechat/commit/c9adddb)
### 💾 会话持久化
会话历史支持持久化存储至本地 SQLite 数据库,服务重启后会话上下文自动恢复,不再丢失。Web 控制台中的历史对话记录也会同步恢复展示。
相关提交:[29bfbec](https://github.com/zhayujie/chatgpt-on-wechat/commit/29bfbec), [9917552](https://github.com/zhayujie/chatgpt-on-wechat/commit/9917552), [925d728](https://github.com/zhayujie/chatgpt-on-wechat/commit/925d728)
### 🤖 新增模型
- **Gemini 3.1 Pro Preview**:新增 `gemini-3.1-pro-preview` 模型支持 ([52d7cad](https://github.com/zhayujie/chatgpt-on-wechat/commit/52d7cad))
- **Claude 4.6 Sonnet**:新增 `claude-4.6-sonnet` 模型支持 ([52d7cad](https://github.com/zhayujie/chatgpt-on-wechat/commit/52d7cad))
- **Qwen3.5 Plus**:新增 `qwen3.5-plus` 模型支持 ([e59a289](https://github.com/zhayujie/chatgpt-on-wechat/commit/e59a289))
- **MiniMax M2.5**:新增 `Minimax-M2.5` 模型支持 ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
- **GLM-5**:新增 `glm-5` 模型支持 ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
- **Kimi K2.5**:新增 `kimi-k2.5` 模型支持 ([48db538](https://github.com/zhayujie/chatgpt-on-wechat/commit/48db538))
- **Doubao 2.0 Code**:新增 `doubao-2.0-code` 编程专用模型 ([ab28ee5](https://github.com/zhayujie/chatgpt-on-wechat/commit/ab28ee5))
- **DashScope 模型**:新增阿里云 DashScope 模型名称支持 ([ce58f23](https://github.com/zhayujie/chatgpt-on-wechat/commit/ce58f23))
### 🌐 新增官网和文档中心
- **官网上线**:[cowagent.ai](https://cowagent.ai/)
- **文档中心上线**:[docs.cowagent.ai](https://docs.cowagent.ai/)
### 🐛 问题修复
- **Gemini 钉钉图片识别**:修复 Gemini 在钉钉通道中无法处理图片标记的问题 ([05a3304](https://github.com/zhayujie/chatgpt-on-wechat/commit/05a3304)) ([#2670](https://github.com/zhayujie/chatgpt-on-wechat/pull/2670)) Thanks [@SgtPepper114](https://github.com/SgtPepper114)
- **启动脚本依赖**:修复 `run.sh` 脚本的依赖安装问题 ([b6fc9fa](https://github.com/zhayujie/chatgpt-on-wechat/commit/b6fc9fa))
- **裸异常捕获**:将代码中的 `bare except` 替换为 `except Exception`,提升异常处理规范性 ([adca89b](https://github.com/zhayujie/chatgpt-on-wechat/commit/adca89b)) ([#2674](https://github.com/zhayujie/chatgpt-on-wechat/pull/2674)) Thanks [@haosenwang1018](https://github.com/haosenwang1018)
**发布日期**:2026.02.27 | [Full Changelog](https://github.com/zhayujie/chatgpt-on-wechat/compare/2.0.1...master)
================================================
FILE: docs/releases/v2.0.3.mdx
================================================
---
title: v2.0.3
description: CowAgent 2.0.3 - 新增企微智能机器人和 QQ 通道、Web 控制台文件处理、记忆系统升级
---
## 🔌 新增接入通道
### 企业微信智能机器人
新增企业微信智能机器人(`wecom_bot`)通道,支持流式卡片消息输出,支持文本和图片消息的接收与回复,可在 Web 控制台中进行通道配置和管理。
接入文档:[企微智能机器人接入](https://docs.cowagent.ai/channels/wecom-bot)。
相关提交:[d4480b6](https://github.com/zhayujie/chatgpt-on-wechat/commit/d4480b6), [a42f31f](https://github.com/zhayujie/chatgpt-on-wechat/commit/a42f31f), [4ecd4df](https://github.com/zhayujie/chatgpt-on-wechat/commit/4ecd4df), [8b45d6c](https://github.com/zhayujie/chatgpt-on-wechat/commit/8b45d6c)
### QQ 通道
新增 QQ 官方机器人(`qq`)通道,支持文本和图片消息的接收与回复,支持私聊和群聊场景。
接入文档参考:[QQ机器人接入](https://docs.cowagent.ai/channels/qq)。
相关提交:[005a0e1](https://github.com/zhayujie/chatgpt-on-wechat/commit/005a0e1), [a4d54f5](https://github.com/zhayujie/chatgpt-on-wechat/commit/a4d54f5)
## 🖥️ Web 控制台支持文件输入和处理
Web 控制台对话界面支持文件和图片上传,可直接发送文件给 Agent 进行处理。同时 Read 工具新增对 Office 文档(Word、Excel、PPT)的解析能力。
相关提交:[30c6d9b](https://github.com/zhayujie/chatgpt-on-wechat/commit/30c6d9b)
## 🤖 新增模型
- **GPT-5.4 系列**:新增 `gpt-5.4`、`gpt-5.4-mini`、`gpt-5.4-nano` 模型支持 ([1623deb](https://github.com/zhayujie/chatgpt-on-wechat/commit/1623deb))
- **Gemini 3.1 Flash Lite Preview**:新增 `gemini-3.1-flash-lite-preview` 模型支持 ([ba915f2](https://github.com/zhayujie/chatgpt-on-wechat/commit/ba915f2))
## 💰 Coding Plan 支持
新增各厂商 Coding Plan(编程包月套餐)的接入支持,通过 OpenAI 兼容方式统一接入。目前已支持阿里云、MiniMax、智谱 GLM、Kimi、火山引擎等厂商。
详细配置参考 [Coding Plan 文档](https://docs.cowagent.ai/models/coding-plan)。
## 🧠 记忆系统升级
记忆写入(Memory Flush)升级:
- 使用 LLM 对超出上下文窗口的对话内容进行智能摘要,生成精炼的每日记忆条目
- 摘要在后台线程异步执行,不阻塞回复
- 优化上下文批量裁剪策略,降低冲刷频率
- 新增每日定时冲刷兜底机制,避免低活跃场景下记忆丢失
- 修复上下文记忆丢失问题
相关提交:[022c13f](https://github.com/zhayujie/chatgpt-on-wechat/commit/022c13f), [c116235](https://github.com/zhayujie/chatgpt-on-wechat/commit/c116235)
## 🔧 工具重构
- **图片识别**:将图片识别(Image Vision)从 Skill 重构为内置 Tool,新增独立的图片视觉提供方(Vision Provider)配置,提升稳定性和可维护性 ([a50fafa](https://github.com/zhayujie/chatgpt-on-wechat/commit/a50fafa), [3b8b562](https://github.com/zhayujie/chatgpt-on-wechat/commit/3b8b562))
- **网页抓取**:将网页抓取(Web Fetch)从 Skill 重构为内置 Tool,支持远程文档文件(PDF、Word、Excel、PPT)的下载和解析 ([ccb9030](https://github.com/zhayujie/chatgpt-on-wechat/commit/ccb9030), [fa61744](https://github.com/zhayujie/chatgpt-on-wechat/commit/fa61744))
## 🐳 Docker 部署优化
- **配置模板对齐**:`docker-compose.yml` 环境变量与 `config-template.json` 对齐,补充完整的模型 API Key 和 Agent 等配置项
- **Web 控制台端口映射**:新增 `9899` 端口映射,Docker 部署后可通过浏览器访问 Web 控制台
- **配置热更新**:各模型 Bot 的 API Key 和 API Base 改为实时读取,通过 Web 控制台修改配置后无需重启即可生效
- **工作空间持久化**:新增 `./cow` Volume 挂载,Agent 工作空间数据(记忆、人格、技能等)持久化到宿主机,容器重建或升级不丢失
## ⚡ 性能优化
- **启动加速**:飞书通道采用懒加载方式导入依赖,避免 4-10 秒的启动延迟 ([924dc79](https://github.com/zhayujie/chatgpt-on-wechat/commit/924dc79))
- **通道稳定性**:优化通道连接稳定性,支持通道配置通过环境变量设置 ([f1c04bc](https://github.com/zhayujie/chatgpt-on-wechat/commit/f1c04bc), [46d97fd](https://github.com/zhayujie/chatgpt-on-wechat/commit/46d97fd))
## 🐛 问题修复
- **bot_type 配置**:修复 Agent 模式下 `bot_type` 配置传递问题 ([#2691](https://github.com/zhayujie/chatgpt-on-wechat/pull/2691)) Thanks [@Weikjssss](https://github.com/Weikjssss)
- **bot_type 优先级**:调整 Agent 模式下 `bot_type` 的解析优先级 ([#2692](https://github.com/zhayujie/chatgpt-on-wechat/pull/2692)) Thanks [@6vision](https://github.com/6vision)
- **智谱模型配置**:修复智谱 `bot_type` 命名、Web 控制台持久化及正则转义问题 ([#2693](https://github.com/zhayujie/chatgpt-on-wechat/pull/2693)) Thanks [@6vision](https://github.com/6vision)
- **OpenAI 兼容层**:使用 `openai_compat` 层统一错误处理 ([#2688](https://github.com/zhayujie/chatgpt-on-wechat/pull/2688)) Thanks [@JasonOA888](https://github.com/JasonOA888)
- **OpenAI 兼容迁移**:完成所有模型 Bot 的 `openai_compat` 迁移 ([#2689](https://github.com/zhayujie/chatgpt-on-wechat/pull/2689))
- **Gemini 工具调用**:修复 Gemini 模型的工具调用匹配问题 ([eda82ba](https://github.com/zhayujie/chatgpt-on-wechat/commit/eda82ba))
- **会话并发**:修复会话并发场景下的竞态条件问题 ([9879878](https://github.com/zhayujie/chatgpt-on-wechat/commit/9879878))
- **历史消息恢复**:修复历史会话消息不完整问题,仅恢复 user/assistant 文本消息,剥离工具调用 ([b788a3d](https://github.com/zhayujie/chatgpt-on-wechat/commit/b788a3d), [a33ce97](https://github.com/zhayujie/chatgpt-on-wechat/commit/a33ce97))
- **飞书群聊**:移除飞书群聊场景下对 `bot_name` 的依赖 ([b641bff](https://github.com/zhayujie/chatgpt-on-wechat/commit/b641bff))
- **Safari 兼容**:修复 Safari 浏览器 IME 回车键误触发消息发送问题 ([0687916](https://github.com/zhayujie/chatgpt-on-wechat/commit/0687916))
- **Windows 兼容**:修复 Windows 下 bash 风格 `$VAR` 环境变量转换为 `%VAR%` 的问题 ([7c67513](https://github.com/zhayujie/chatgpt-on-wechat/commit/7c67513))
- **MiniMax 参数**:增加 MiniMax 模型的 `max_tokens` 限制 ([1767413](https://github.com/zhayujie/chatgpt-on-wechat/commit/1767413))
- **.gitignore 更新**:添加 Python 目录忽略规则 ([#2683](https://github.com/zhayujie/chatgpt-on-wechat/pull/2683)) Thanks [@pelioo](https://github.com/pelioo)
- **AGENT.md 主动演进**:优化系统提示词中对 AGENT.md 的更新引导,从被动的"用户修改时更新"改为主动识别对话中的性格、风格变化并自动更新
## 📦 升级方式
源码部署可执行 `./run.sh update` 一键升级,或手动拉取代码后重启。详见 [更新升级文档](https://docs.cowagent.ai/guide/upgrade)。
**发布日期**:2026.03.18 | [Full Changelog](https://github.com/zhayujie/chatgpt-on-wechat/compare/2.0.2...master)
================================================
FILE: docs/skills/image-vision.mdx
================================================
---
title: 图像识别
description: 使用 OpenAI 视觉模型识别图片
---
使用 OpenAI 的 GPT-4 Vision API 分析图片内容,理解图像中的物体、文字、颜色等元素。
## 依赖
| 依赖 | 说明 |
| --- | --- |
| `OPENAI_API_KEY` | OpenAI API 密钥 |
| `curl`、`base64` | 系统命令(通常已预装) |
配置方式:
- 通过 `env_config` 工具配置 `OPENAI_API_KEY`
- 或在 `config.json` 中填写 `open_ai_api_key`
## 支持的模型
- `gpt-4.1-mini`(推荐,性价比高)
- `gpt-4.1`
## 使用方式
配置完成后,向 Agent 发送图片即可自动触发图像识别。
================================================
FILE: docs/skills/index.mdx
================================================
---
title: 技能概览
description: CowAgent 技能系统介绍
---
技能(Skill)为 Agent 提供无限的扩展性。每个 Skill 由说明文件(`SKILL.md`)、运行脚本(可选)、资源(可选)组成,描述如何完成特定类型的任务。
Skill 与 Tool 的区别:Tool 是由代码实现的原子操作(如读写文件、执行命令),Skill 则是基于说明文件的高级工作流,可以组合调用多个 Tool 来完成复杂任务。
## 内置技能
位于项目 `skills/` 目录下,根据依赖条件自动判断是否启用:
| 技能 | 说明 | 依赖 |
| --- | --- | --- |
| [`skill-creator`](/skills/skill-creator) | 通过对话创建自定义技能 | 无 |
| [`openai-image-vision`](/skills/image-vision) | 使用 OpenAI 视觉模型识别图片 | `OPENAI_API_KEY` |
| [`linkai-agent`](/skills/linkai-agent) | 对接 LinkAI 平台智能体 | `LINKAI_API_KEY` |
| [`web-fetch`](/skills/web-fetch) | 抓取网页文本内容 | `curl`(默认启用) |
## 自定义技能
由用户通过对话创建,存放在工作空间中(`~/cow/skills/`),可实现任何复杂的业务流程和第三方系统对接。
## 技能加载优先级
1. **工作空间技能**(最高):`~/cow/skills/`
2. **项目内置技能**(最低):`skills/`
同名技能按优先级覆盖。
## 技能文件结构
```
skills/
├── my-skill/
│ ├── SKILL.md # Skill description (frontmatter + instructions)
│ ├── scripts/ # Execution scripts (optional)
│ └── resources/ # Additional resources (optional)
```
### SKILL.md 格式
```markdown
---
name: my-skill
description: Brief description of the skill
metadata:
emoji: 🔧
requires:
bins: ["curl"]
env: ["MY_API_KEY"]
primaryEnv: "MY_API_KEY"
---
# My Skill
Detailed instructions...
```
| 字段 | 说明 |
| --- | --- |
| `name` | 技能名称,需与目录名一致 |
| `description` | 技能描述,Agent 据此决定是否调用 |
| `metadata.requires.bins` | 依赖的系统命令 |
| `metadata.requires.env` | 依赖的环境变量 |
| `metadata.always` | 是否始终加载(默认 false) |
================================================
FILE: docs/skills/linkai-agent.mdx
================================================
---
title: LinkAI 智能体
description: 对接 LinkAI 平台的多智能体技能
---
将 [LinkAI](https://link-ai.tech/) 平台上的智能体作为 Skill 使用,实现多智能体决策。Agent 根据智能体的名称和描述智能选择,通过 `app_code` 调用对应的应用或工作流。
## 依赖
| 依赖 | 说明 |
| --- | --- |
| `LINKAI_API_KEY` | LinkAI 平台 API 密钥,在 [控制台](https://link-ai.tech/console/interface) 创建 |
| `curl` | 系统命令(通常已预装) |
配置方式:
- 通过 `env_config` 工具配置 `LINKAI_API_KEY`
- 或在 `config.json` 中填写 `linkai_api_key`
## 配置智能体
在 `skills/linkai-agent/config.json` 中添加可用的智能体:
```json
{
"apps": [
{
"app_code": "G7z6vKwp",
"app_name": "LinkAI客服助手",
"app_description": "当用户需要了解LinkAI平台相关问题时才选择该助手"
},
{
"app_code": "SFY5x7JR",
"app_name": "内容创作助手",
"app_description": "当用户需要创作图片或视频时才使用该助手"
}
]
}
```
## 使用方式
配置完成后,Agent 会根据用户的问题自动选择合适的 LinkAI 智能体进行回答。
================================================
FILE: docs/skills/skill-creator.mdx
================================================
---
title: 创建技能
description: 通过对话创建自定义技能
---
通过自然语言对话快速创建、安装或更新技能。
## 依赖
无额外依赖,始终可用。
## 使用方式
- 将工作流程固化为技能:"帮我把这个部署流程创建为一个技能"
- 对接第三方 API:"根据这个接口文档创建一个技能"
- 安装远程技能:"帮我安装 xxx 技能"
## 创建流程
1. 告诉 Agent 你想创建的技能功能
2. Agent 自动生成 `SKILL.md` 说明文件和运行脚本
3. 技能保存到工作空间的 `~/cow/skills/` 目录
4. 后续对话中 Agent 会自动识别并使用该技能
详细开发文档可参考 [Skill 创造器说明](https://github.com/zhayujie/chatgpt-on-wechat/blob/master/skills/skill-creator/SKILL.md)。
================================================
FILE: docs/skills/web-fetch.mdx
================================================
---
title: 网页抓取
description: 抓取网页文本内容
---
使用 curl 抓取网页并提取可读文本内容,轻量级的网页访问方式,无需浏览器自动化。
## 依赖
| 依赖 | 说明 |
| --- | --- |
| `curl` | 系统命令(通常已预装) |
该技能设置了 `always: true`,只要系统有 `curl` 命令即默认启用。
## 使用方式
当 Agent 需要获取某个 URL 的网页内容时会自动调用,无需额外配置。
## 与 browser 工具的区别
| 特性 | web-fetch(技能) | browser(工具) |
| --- | --- | --- |
| 依赖 | 仅 curl | browser-use + playwright |
| JS 渲染 | 不支持 | 支持 |
| 页面交互 | 不支持 | 支持点击、输入等 |
| 适用场景 | 获取静态页面文本 | 操作动态网页 |
对于大多数网页内容获取场景,web-fetch 就够用了。只有需要 JS 渲染或页面交互时才需要 browser 工具。
================================================
FILE: docs/tools/bash.mdx
================================================
---
title: bash - 终端
description: 执行系统命令
---
在当前工作目录执行 Bash 命令,返回 stdout 和 stderr。`env_config` 中配置的 API Key 会自动注入到环境变量中。
## 依赖
无额外依赖,默认可用。
## 参数
| 参数 | 类型 | 必填 | 说明 |
| --- | --- | --- | --- |
| `command` | string | 是 | 要执行的命令 |
| `timeout` | integer | 否 | 超时时间(秒) |
## 使用场景
- 安装软件包和依赖
- 运行代码和测试
- 部署应用和服务(Nginx 配置、进程管理等)
- 系统运维和排查
================================================
FILE: docs/tools/browser.mdx
================================================
---
title: browser - 浏览器
description: 访问和操作网页
---
使用浏览器访问和操作网页,支持 JavaScript 渲染的动态页面。
## 依赖
| 依赖 | 安装命令 |
| --- | --- |
| `browser-use` ≥ 0.1.40 | `pip install browser-use` |
| `markdownify` | `pip install markdownify` |
| `playwright` + chromium | `pip install playwright && playwright install chromium` |
## 使用场景
- 访问指定 URL 获取页面内容
- 操作网页元素(点击、输入等)
- 验证部署后的网页效果
- 抓取需要 JS 渲染的动态内容
浏览器工具依赖较重,如不需要可不安装。轻量的网页内容获取可使用 `web-fetch` 技能。
================================================
FILE: docs/tools/edit.mdx
================================================
---
title: edit - 文件编辑
description: 通过精确文本替换编辑文件
---
通过精确文本替换编辑文件。如果 `oldText` 为空则追加到文件末尾。
## 依赖
无额外依赖,默认可用。
## 参数
| 参数 | 类型 | 必填 | 说明 |
| --- | --- | --- | --- |
| `path` | string | 是 | 文件路径 |
| `oldText` | string | 是 | 要替换的原始文本(为空时追加到末尾) |
| `newText` | string | 是 | 替换后的文本 |
## 使用场景
- 修改配置文件中的特定参数
- 修复代码中的 bug
- 在文件指定位置插入内容
================================================
FILE: docs/tools/env-config.mdx
================================================
---
title: env_config - 环境变量
description: 管理 API Key 等秘钥配置
---
管理工作空间 `.env` 文件中的环境变量(API Key 等秘钥),支持通过对话安全地添加和更新。内置安全保护和脱敏策略。
## 依赖
| 依赖 | 安装命令 |
| --- | --- |
| `python-dotenv` ≥ 1.0.0 | `pip install python-dotenv>=1.0.0` |
安装扩展依赖时已包含:`pip3 install -r requirements-optional.txt`
## 参数
| 参数 | 类型 | 必填 | 说明 |
| --- | --- | --- | --- |
| `action` | string | 是 | 操作类型:`get`、`set`、`list`、`delete` |
| `key` | string | 否 | 环境变量名称 |
| `value` | string | 否 | 环境变量值(仅 `set` 时需要) |
## 使用方式
直接告诉 Agent 需要配置的秘钥,Agent 会自动调用该工具:
- "帮我配置 BOCHA_API_KEY"
- "设置 OPENAI_API_KEY 为 sk-xxx"
- "查看已配置的环境变量"
配置的秘钥会自动注入到 `bash` 工具的执行环境中。
================================================
FILE: docs/tools/index.mdx
================================================
---
title: 工具概览
description: CowAgent 内置工具系统
---
工具是 Agent 访问操作系统资源的核心能力。Agent 会根据任务需求智能选择和调用工具,完成文件操作、命令执行、联网搜索、定时任务等各类操作。工具实现在项目的 `agent/tools/` 目录下。
## 内置工具
以下工具默认可用,无需额外配置:
读取文件内容,支持文本、图片、PDF
创建或覆盖写入文件
通过精确文本替换编辑文件
列出目录内容
执行系统命令
向用户发送文件或图片
搜索和读取长期记忆
## 可选工具
以下工具需要安装额外依赖或配置 API Key 后启用:
管理 API Key 等秘钥配置
创建和管理定时任务
搜索互联网获取实时信息
================================================
FILE: docs/tools/ls.mdx
================================================
---
title: ls - 目录列表
description: 列出目录内容
---
列出目录内容,按字母排序,目录名带 `/` 后缀,包含隐藏文件。
## 依赖
无额外依赖,默认可用。
## 参数
| 参数 | 类型 | 必填 | 说明 |
| --- | --- | --- | --- |
| `path` | string | 是 | 目录路径,相对路径基于工作空间目录 |
| `limit` | integer | 否 | 最大返回条目数,默认 500 |
## 使用场景
- 浏览项目结构
- 查找特定文件
- 检查目录是否存在
================================================
FILE: docs/tools/memory.mdx
================================================
---
title: memory - 记忆
description: 搜索和读取长期记忆
---
记忆工具包含两个子工具:`memory_search`(搜索记忆)和 `memory_get`(读取记忆文件)。
## 依赖
无额外依赖,默认可用。由 Agent Core 的记忆系统管理。
## memory_search
搜索历史记忆,支持关键词和向量混合检索。
| 参数 | 类型 | 必填 | 说明 |
| --- | --- | --- | --- |
| `query` | string | 是 | 搜索查询 |
## memory_get
读取特定记忆文件的内容。
| 参数 | 类型 | 必填 | 说明 |
| --- | --- | --- | --- |
| `path` | string | 是 | 记忆文件的相对路径(如 `MEMORY.md`、`memory/2026-01-01.md`) |
| `start_line` | integer | 否 | 起始行号 |
| `end_line` | integer | 否 | 结束行号 |
## 工作方式
Agent 会在以下场景自动调用记忆工具:
- 用户分享重要信息时 → 存储到记忆
- 需要参考历史信息时 → 搜索相关记忆
- 对话达到一定长度时 → 提取摘要存储
================================================
FILE: docs/tools/read.mdx
================================================
---
title: read - 文件读取
description: 读取文件内容
---
读取文件内容。支持文本文件、PDF 文件、图片(返回元数据)等格式。
## 依赖
无额外依赖,默认可用。
## 参数
| 参数 | 类型 | 必填 | 说明 |
| --- | --- | --- | --- |
| `path` | string | 是 | 文件路径,相对路径基于工作空间目录 |
| `offset` | integer | 否 | 起始行号(1-indexed),负值表示从末尾读取 |
| `limit` | integer | 否 | 读取行数 |
## 使用场景
- 查看配置文件、日志文件
- 读取代码文件进行分析
- 检查图片/视频的文件信息
================================================
FILE: docs/tools/scheduler.mdx
================================================
---
title: scheduler - 定时任务
description: 创建和管理定时任务
---
创建和管理动态定时任务,支持灵活的调度方式和执行模式。
## 依赖
| 依赖 | 安装命令 |
| --- | --- |
| `croniter` ≥ 2.0.0 | `pip install croniter>=2.0.0` |
安装核心依赖时已包含:`pip3 install -r requirements.txt`
## 调度方式
| 方式 | 说明 |
| --- | --- |
| 一次性任务 | 在指定时间执行一次 |
| 固定间隔 | 按固定时间间隔重复执行 |
| Cron 表达式 | 使用 Cron 语法定义复杂调度规则 |
## 执行模式
- **固定消息发送**:到达触发时间时发送预设消息
- **Agent 动态任务**:到达触发时间时由 Agent 智能执行任务
## 使用方式
通过自然语言即可创建和管理定时任务:
- "每天早上 9 点给我发天气预报"
- "每隔 2 小时检查一下服务器状态"
- "明天下午 3 点提醒我开会"
- "查看所有定时任务"
================================================
FILE: docs/tools/send.mdx
================================================
---
title: send - 文件发送
description: 向用户发送文件
---
向用户发送文件(图片、视频、音频、文档等),当用户明确要求发送/分享文件时使用。
## 依赖
无额外依赖,默认可用。
## 参数
| 参数 | 类型 | 必填 | 说明 |
| --- | --- | --- | --- |
| `path` | string | 是 | 文件路径,可以是绝对路径或相对于工作空间的路径 |
| `message` | string | 否 | 附带的消息说明 |
## 使用场景
- 将生成的代码或文档发送给用户
- 发送截图、图表
- 分享下载的文件
================================================
FILE: docs/tools/web-search.mdx
================================================
---
title: web_search - 联网搜索
description: 搜索互联网获取实时信息
---
搜索互联网获取实时信息、新闻、研究等内容。支持两个搜索后端,自动选择可用的后端。
## 依赖
需要配置至少一个搜索 API Key(通过 `env_config` 工具或工作空间 `.env` 文件配置):
| 后端 | 环境变量 | 优先级 | 获取方式 |
| --- | --- | --- | --- |
| 博查搜索 | `BOCHA_API_KEY` | 优先使用 | [博查开放平台](https://open.bochaai.com/) |
| LinkAI 搜索 | `LINKAI_API_KEY` | 可选 | [LinkAI 控制台](https://link-ai.tech/console/interface) |
## 参数
| 参数 | 类型 | 必填 | 说明 |
| --- | --- | --- | --- |
| `query` | string | 是 | 搜索关键词 |
| `count` | integer | 否 | 返回结果数量(1-50,默认 10) |
| `freshness` | string | 否 | 时间范围:`noLimit`、`oneDay`、`oneWeek`、`oneMonth`、`oneYear`,或日期范围如 `2025-01-01..2025-02-01` |
| `summary` | boolean | 否 | 是否返回页面摘要(默认 false) |
## 使用场景
当用户询问最新信息、需要事实核查或获取实时数据时,Agent 会自动调用此工具。
如果未配置任何搜索 API Key,该工具不会被加载。
================================================
FILE: docs/tools/write.mdx
================================================
---
title: write - 文件写入
description: 创建或覆盖写入文件
---
写入内容到文件。文件不存在则自动创建,已存在则覆盖。自动创建父目录。
## 依赖
无额外依赖,默认可用。
## 参数
| 参数 | 类型 | 必填 | 说明 |
| --- | --- | --- | --- |
| `path` | string | 是 | 文件路径 |
| `content` | string | 是 | 要写入的内容 |
## 使用场景
- 创建新的代码文件或脚本
- 生成配置文件
- 保存处理结果
单次写入不应超过 10KB。对于大文件,建议先创建骨架,再使用 edit 工具分块添加内容。
================================================
FILE: models/ali/ali_qwen_bot.py
================================================
# encoding:utf-8
import json
import time
from typing import List, Tuple
import openai
from models.openai.openai_compat import RateLimitError, Timeout, APIError, APIConnectionError
import broadscope_bailian
from broadscope_bailian import ChatQaMessage
from models.bot import Bot
from models.ali.ali_qwen_session import AliQwenSession
from models.session_manager import SessionManager
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from common import const
from config import conf, load_config
class AliQwenBot(Bot):
def __init__(self):
super().__init__()
self.api_key_expired_time = self.set_api_key()
self.sessions = SessionManager(AliQwenSession, model=conf().get("model", const.QWEN))
def api_key_client(self):
return broadscope_bailian.AccessTokenClient(access_key_id=self.access_key_id(), access_key_secret=self.access_key_secret())
def access_key_id(self):
return conf().get("qwen_access_key_id")
def access_key_secret(self):
return conf().get("qwen_access_key_secret")
def agent_key(self):
return conf().get("qwen_agent_key")
def app_id(self):
return conf().get("qwen_app_id")
def node_id(self):
return conf().get("qwen_node_id", "")
def temperature(self):
return conf().get("temperature", 0.2 )
def top_p(self):
return conf().get("top_p", 1)
def reply(self, query, context=None):
# acquire reply content
if context.type == ContextType.TEXT:
logger.info("[QWEN] query={}".format(query))
session_id = context["session_id"]
reply = None
clear_memory_commands = conf().get("clear_memory_commands", ["#清除记忆"])
if query in clear_memory_commands:
self.sessions.clear_session(session_id)
reply = Reply(ReplyType.INFO, "记忆已清除")
elif query == "#清除所有":
self.sessions.clear_all_session()
reply = Reply(ReplyType.INFO, "所有人记忆已清除")
elif query == "#更新配置":
load_config()
reply = Reply(ReplyType.INFO, "配置已更新")
if reply:
return reply
session = self.sessions.session_query(query, session_id)
logger.debug("[QWEN] session query={}".format(session.messages))
reply_content = self.reply_text(session)
logger.debug(
"[QWEN] new_query={}, session_id={}, reply_cont={}, completion_tokens={}".format(
session.messages,
session_id,
reply_content["content"],
reply_content["completion_tokens"],
)
)
if reply_content["completion_tokens"] == 0 and len(reply_content["content"]) > 0:
reply = Reply(ReplyType.ERROR, reply_content["content"])
elif reply_content["completion_tokens"] > 0:
self.sessions.session_reply(reply_content["content"], session_id, reply_content["total_tokens"])
reply = Reply(ReplyType.TEXT, reply_content["content"])
else:
reply = Reply(ReplyType.ERROR, reply_content["content"])
logger.debug("[QWEN] reply {} used 0 tokens.".format(reply_content))
return reply
else:
reply = Reply(ReplyType.ERROR, "Bot不支持处理{}类型的消息".format(context.type))
return reply
def reply_text(self, session: AliQwenSession, retry_count=0) -> dict:
"""
call bailian's ChatCompletion to get the answer
:param session: a conversation session
:param retry_count: retry count
:return: {}
"""
try:
prompt, history = self.convert_messages_format(session.messages)
self.update_api_key_if_expired()
# NOTE 阿里百炼的call()函数未提供temperature参数,考虑到temperature和top_p参数作用相同,取两者较小的值作为top_p参数传入,详情见文档 https://help.aliyun.com/document_detail/2587502.htm
response = broadscope_bailian.Completions().call(app_id=self.app_id(), prompt=prompt, history=history, top_p=min(self.temperature(), self.top_p()))
completion_content = self.get_completion_content(response, self.node_id())
completion_tokens, total_tokens = self.calc_tokens(session.messages, completion_content)
return {
"total_tokens": total_tokens,
"completion_tokens": completion_tokens,
"content": completion_content,
}
except Exception as e:
need_retry = retry_count < 2
result = {"completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
if isinstance(e, RateLimitError):
logger.warn("[QWEN] RateLimitError: {}".format(e))
result["content"] = "提问太快啦,请休息一下再问我吧"
if need_retry:
time.sleep(20)
elif isinstance(e, Timeout):
logger.warn("[QWEN] Timeout: {}".format(e))
result["content"] = "我没有收到你的消息"
if need_retry:
time.sleep(5)
elif isinstance(e, APIError):
logger.warn("[QWEN] Bad Gateway: {}".format(e))
result["content"] = "请再问我一次"
if need_retry:
time.sleep(10)
elif isinstance(e, APIConnectionError):
logger.warn("[QWEN] APIConnectionError: {}".format(e))
need_retry = False
result["content"] = "我连接不到你的网络"
else:
logger.exception("[QWEN] Exception: {}".format(e))
need_retry = False
self.sessions.clear_session(session.session_id)
if need_retry:
logger.warn("[QWEN] 第{}次重试".format(retry_count + 1))
return self.reply_text(session, retry_count + 1)
else:
return result
def set_api_key(self):
api_key, expired_time = self.api_key_client().create_token(agent_key=self.agent_key())
broadscope_bailian.api_key = api_key
return expired_time
def update_api_key_if_expired(self):
if time.time() > self.api_key_expired_time:
self.api_key_expired_time = self.set_api_key()
def convert_messages_format(self, messages) -> Tuple[str, List[ChatQaMessage]]:
history = []
user_content = ''
assistant_content = ''
system_content = ''
for message in messages:
role = message.get('role')
if role == 'user':
user_content += message.get('content')
elif role == 'assistant':
assistant_content = message.get('content')
history.append(ChatQaMessage(user_content, assistant_content))
user_content = ''
assistant_content = ''
elif role =='system':
system_content += message.get('content')
if user_content == '':
raise Exception('no user message')
if system_content != '':
# NOTE 模拟系统消息,测试发现人格描述以"你需要扮演ChatGPT"开头能够起作用,而以"你是ChatGPT"开头模型会直接否认
system_qa = ChatQaMessage(system_content, '好的,我会严格按照你的设定回答问题')
history.insert(0, system_qa)
logger.debug("[QWEN] converted qa messages: {}".format([item.to_dict() for item in history]))
logger.debug("[QWEN] user content as prompt: {}".format(user_content))
return user_content, history
def get_completion_content(self, response, node_id):
if not response['Success']:
return f"[ERROR]\n{response['Code']}:{response['Message']}"
text = response['Data']['Text']
if node_id == '':
return text
# TODO: 当使用流程编排创建大模型应用时,响应结构如下,最终结果在['finalResult'][node_id]['response']['text']中,暂时先这么写
# {
# 'Success': True,
# 'Code': None,
# 'Message': None,
# 'Data': {
# 'ResponseId': '9822f38dbacf4c9b8daf5ca03a2daf15',
# 'SessionId': 'session_id',
# 'Text': '{"finalResult":{"LLM_T7islK":{"params":{"modelId":"qwen-plus-v1","prompt":"${systemVars.query}${bizVars.Text}"},"response":{"text":"作为一个AI语言模型,我没有年龄,因为我没有生日。\n我只是一个程序,没有生命和身体。"}}}}',
# 'Thoughts': [],
# 'Debug': {},
# 'DocReferences': []
# },
# 'RequestId': '8e11d31551ce4c3f83f49e6e0dd998b0',
# 'Failed': None
# }
text_dict = json.loads(text)
completion_content = text_dict['finalResult'][node_id]['response']['text']
return completion_content
def calc_tokens(self, messages, completion_content):
completion_tokens = len(completion_content)
prompt_tokens = 0
for message in messages:
prompt_tokens += len(message["content"])
return completion_tokens, prompt_tokens + completion_tokens
================================================
FILE: models/ali/ali_qwen_session.py
================================================
from models.session_manager import Session
from common.log import logger
"""
e.g.
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
"""
class AliQwenSession(Session):
def __init__(self, session_id, system_prompt=None, model="qianwen"):
super().__init__(session_id, system_prompt)
self.model = model
self.reset()
def discard_exceeding(self, max_tokens, cur_tokens=None):
precise = True
try:
cur_tokens = self.calc_tokens()
except Exception as e:
precise = False
if cur_tokens is None:
raise e
logger.debug("Exception when counting tokens precisely for query: {}".format(e))
while cur_tokens > max_tokens:
if len(self.messages) > 2:
self.messages.pop(1)
elif len(self.messages) == 2 and self.messages[1]["role"] == "assistant":
self.messages.pop(1)
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
break
elif len(self.messages) == 2 and self.messages[1]["role"] == "user":
logger.warn("user message exceed max_tokens. total_tokens={}".format(cur_tokens))
break
else:
logger.debug("max_tokens={}, total_tokens={}, len(messages)={}".format(max_tokens, cur_tokens, len(self.messages)))
break
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
return cur_tokens
def calc_tokens(self):
return num_tokens_from_messages(self.messages, self.model)
def num_tokens_from_messages(messages, model):
"""Returns the number of tokens used by a list of messages."""
# 官方token计算规则:"对于中文文本来说,1个token通常对应一个汉字;对于英文文本来说,1个token通常对应3至4个字母或1个单词"
# 详情请产看文档:https://help.aliyun.com/document_detail/2586397.html
# 目前根据字符串长度粗略估计token数,不影响正常使用
tokens = 0
for msg in messages:
tokens += len(msg["content"])
return tokens
================================================
FILE: models/baidu/baidu_unit_bot.py
================================================
# encoding:utf-8
import requests
from models.bot import Bot
from bridge.reply import Reply, ReplyType
# Baidu Unit对话接口 (可用, 但能力较弱)
class BaiduUnitBot(Bot):
def reply(self, query, context=None):
token = self.get_token()
url = "https://aip.baidubce.com/rpc/2.0/unit/service/v3/chat?access_token=" + token
post_data = (
'{"version":"3.0","service_id":"S73177","session_id":"","log_id":"7758521","skill_ids":["1221886"],"request":{"terminal_id":"88888","query":"'
+ query
+ '", "hyper_params": {"chat_custom_bot_profile": 1}}}'
)
print(post_data)
headers = {"content-type": "application/x-www-form-urlencoded"}
response = requests.post(url, data=post_data.encode(), headers=headers)
if response:
reply = Reply(
ReplyType.TEXT,
response.json()["result"]["context"]["SYS_PRESUMED_HIST"][1],
)
return reply
def get_token(self):
access_key = "YOUR_ACCESS_KEY"
secret_key = "YOUR_SECRET_KEY"
host = "https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=" + access_key + "&client_secret=" + secret_key
response = requests.get(host)
if response:
print(response.json())
return response.json()["access_token"]
================================================
FILE: models/baidu/baidu_wenxin.py
================================================
# encoding:utf-8
import requests
import json
from common import const
from models.bot import Bot
from models.session_manager import SessionManager
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf
from models.baidu.baidu_wenxin_session import BaiduWenxinSession
BAIDU_API_KEY = conf().get("baidu_wenxin_api_key")
BAIDU_SECRET_KEY = conf().get("baidu_wenxin_secret_key")
class BaiduWenxinBot(Bot):
def __init__(self):
super().__init__()
wenxin_model = conf().get("baidu_wenxin_model")
self.prompt_enabled = conf().get("baidu_wenxin_prompt_enabled")
if self.prompt_enabled:
self.prompt = conf().get("character_desc", "")
if self.prompt == "":
logger.warn("[BAIDU] Although you enabled model prompt, character_desc is not specified.")
if wenxin_model is not None:
wenxin_model = conf().get("baidu_wenxin_model") or "eb-instant"
else:
if conf().get("model") and conf().get("model") == const.WEN_XIN:
wenxin_model = "completions"
elif conf().get("model") and conf().get("model") == const.WEN_XIN_4:
wenxin_model = "completions_pro"
self.sessions = SessionManager(BaiduWenxinSession, model=wenxin_model)
def reply(self, query, context=None):
# acquire reply content
if context and context.type:
if context.type == ContextType.TEXT:
logger.info("[BAIDU] query={}".format(query))
session_id = context["session_id"]
reply = None
if query == "#清除记忆":
self.sessions.clear_session(session_id)
reply = Reply(ReplyType.INFO, "记忆已清除")
elif query == "#清除所有":
self.sessions.clear_all_session()
reply = Reply(ReplyType.INFO, "所有人记忆已清除")
else:
session = self.sessions.session_query(query, session_id)
result = self.reply_text(session)
total_tokens, completion_tokens, reply_content = (
result["total_tokens"],
result["completion_tokens"],
result["content"],
)
logger.debug(
"[BAIDU] new_query={}, session_id={}, reply_cont={}, completion_tokens={}".format(session.messages, session_id, reply_content, completion_tokens)
)
if total_tokens == 0:
reply = Reply(ReplyType.ERROR, reply_content)
else:
self.sessions.session_reply(reply_content, session_id, total_tokens)
reply = Reply(ReplyType.TEXT, reply_content)
return reply
elif context.type == ContextType.IMAGE_CREATE:
ok, retstring = self.create_img(query, 0)
reply = None
if ok:
reply = Reply(ReplyType.IMAGE_URL, retstring)
else:
reply = Reply(ReplyType.ERROR, retstring)
return reply
def reply_text(self, session: BaiduWenxinSession, retry_count=0):
try:
logger.info("[BAIDU] model={}".format(session.model))
access_token = self.get_access_token()
if access_token == 'None':
logger.warn("[BAIDU] access token 获取失败")
return {
"total_tokens": 0,
"completion_tokens": 0,
"content": 0,
}
url = "https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/" + session.model + "?access_token=" + access_token
headers = {
'Content-Type': 'application/json'
}
payload = {'messages': session.messages, 'system': self.prompt} if self.prompt_enabled else {'messages': session.messages}
response = requests.request("POST", url, headers=headers, data=json.dumps(payload))
response_text = json.loads(response.text)
logger.info(f"[BAIDU] response text={response_text}")
res_content = response_text["result"]
total_tokens = response_text["usage"]["total_tokens"]
completion_tokens = response_text["usage"]["completion_tokens"]
logger.info("[BAIDU] reply={}".format(res_content))
return {
"total_tokens": total_tokens,
"completion_tokens": completion_tokens,
"content": res_content,
}
except Exception as e:
need_retry = retry_count < 2
logger.warn("[BAIDU] Exception: {}".format(e))
need_retry = False
self.sessions.clear_session(session.session_id)
result = {"total_tokens": 0, "completion_tokens": 0, "content": "出错了: {}".format(e)}
return result
def get_access_token(self):
"""
使用 AK,SK 生成鉴权签名(Access Token)
:return: access_token,或是None(如果错误)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": BAIDU_API_KEY, "client_secret": BAIDU_SECRET_KEY}
return str(requests.post(url, params=params).json().get("access_token"))
================================================
FILE: models/baidu/baidu_wenxin_session.py
================================================
from models.session_manager import Session
from common.log import logger
"""
e.g. [
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
"""
class BaiduWenxinSession(Session):
def __init__(self, session_id, system_prompt=None, model="gpt-3.5-turbo"):
super().__init__(session_id, system_prompt)
self.model = model
# 百度文心不支持system prompt
# self.reset()
def discard_exceeding(self, max_tokens, cur_tokens=None):
precise = True
try:
cur_tokens = self.calc_tokens()
except Exception as e:
precise = False
if cur_tokens is None:
raise e
logger.debug("Exception when counting tokens precisely for query: {}".format(e))
while cur_tokens > max_tokens:
if len(self.messages) >= 2:
self.messages.pop(0)
self.messages.pop(0)
else:
logger.debug("max_tokens={}, total_tokens={}, len(messages)={}".format(max_tokens, cur_tokens, len(self.messages)))
break
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
return cur_tokens
def calc_tokens(self):
return num_tokens_from_messages(self.messages, self.model)
def num_tokens_from_messages(messages, model):
"""Returns the number of tokens used by a list of messages."""
tokens = 0
for msg in messages:
# 官方token计算规则暂不明确: "大约为 token数为 "中文字 + 其他语种单词数 x 1.3"
# 这里先直接根据字数粗略估算吧,暂不影响正常使用,仅在判断是否丢弃历史会话的时候会有偏差
tokens += len(msg["content"])
return tokens
================================================
FILE: models/bot.py
================================================
"""
Auto-replay chat robot abstract class
"""
from bridge.context import Context
from bridge.reply import Reply
class Bot(object):
def reply(self, query, context: Context = None) -> Reply:
"""
bot auto-reply content
:param req: received message
:return: reply content
"""
raise NotImplementedError
================================================
FILE: models/bot_factory.py
================================================
"""
channel factory
"""
from common import const
def create_bot(bot_type):
"""
create a bot_type instance
:param bot_type: bot type code
:return: bot instance
"""
if bot_type == const.BAIDU:
# 替换Baidu Unit为Baidu文心千帆对话接口
# from models.baidu.baidu_unit_bot import BaiduUnitBot
# return BaiduUnitBot()
from models.baidu.baidu_wenxin import BaiduWenxinBot
return BaiduWenxinBot()
elif bot_type in (const.OPENAI, const.CHATGPT, const.DEEPSEEK): # OpenAI-compatible API
from models.chatgpt.chat_gpt_bot import ChatGPTBot
return ChatGPTBot()
elif bot_type == const.OPEN_AI:
# OpenAI 官方对话模型API
from models.openai.open_ai_bot import OpenAIBot
return OpenAIBot()
elif bot_type == const.CHATGPTONAZURE:
# Azure chatgpt service https://azure.microsoft.com/en-in/products/cognitive-services/openai-service/
from models.chatgpt.chat_gpt_bot import AzureChatGPTBot
return AzureChatGPTBot()
elif bot_type == const.XUNFEI:
from models.xunfei.xunfei_spark_bot import XunFeiBot
return XunFeiBot()
elif bot_type == const.LINKAI:
from models.linkai.link_ai_bot import LinkAIBot
return LinkAIBot()
elif bot_type == const.CLAUDEAPI:
from models.claudeapi.claude_api_bot import ClaudeAPIBot
return ClaudeAPIBot()
elif bot_type == const.QWEN:
from models.ali.ali_qwen_bot import AliQwenBot
return AliQwenBot()
elif bot_type == const.QWEN_DASHSCOPE:
from models.dashscope.dashscope_bot import DashscopeBot
return DashscopeBot()
elif bot_type == const.GEMINI:
from models.gemini.google_gemini_bot import GoogleGeminiBot
return GoogleGeminiBot()
elif bot_type == const.ZHIPU_AI or bot_type == "glm-4": # "glm-4" kept for backward compatibility
from models.zhipuai.zhipuai_bot import ZHIPUAIBot
return ZHIPUAIBot()
elif bot_type == const.MOONSHOT:
from models.moonshot.moonshot_bot import MoonshotBot
return MoonshotBot()
elif bot_type == const.MiniMax:
from models.minimax.minimax_bot import MinimaxBot
return MinimaxBot()
elif bot_type == const.MODELSCOPE:
from models.modelscope.modelscope_bot import ModelScopeBot
return ModelScopeBot()
elif bot_type == const.DOUBAO:
from models.doubao.doubao_bot import DoubaoBot
return DoubaoBot()
raise RuntimeError
================================================
FILE: models/chatgpt/chat_gpt_bot.py
================================================
# encoding:utf-8
import time
import json
import openai
from models.openai.openai_compat import error as openai_error, RateLimitError, Timeout, APIError, APIConnectionError
import requests
from common import const
from models.bot import Bot
from models.openai_compatible_bot import OpenAICompatibleBot
from models.chatgpt.chat_gpt_session import ChatGPTSession
from models.openai.open_ai_image import OpenAIImage
from models.session_manager import SessionManager
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from common.token_bucket import TokenBucket
from config import conf, load_config
from models.baidu.baidu_wenxin_session import BaiduWenxinSession
# OpenAI对话模型API (可用)
class ChatGPTBot(Bot, OpenAIImage, OpenAICompatibleBot):
def __init__(self):
super().__init__()
# set the default api_key
openai.api_key = conf().get("open_ai_api_key")
if conf().get("open_ai_api_base"):
openai.api_base = conf().get("open_ai_api_base")
proxy = conf().get("proxy")
if proxy:
openai.proxy = proxy
if conf().get("rate_limit_chatgpt"):
self.tb4chatgpt = TokenBucket(conf().get("rate_limit_chatgpt", 20))
conf_model = conf().get("model") or "gpt-3.5-turbo"
self.sessions = SessionManager(ChatGPTSession, model=conf().get("model") or "gpt-3.5-turbo")
# o1相关模型不支持system prompt,暂时用文心模型的session
self.args = {
"model": conf_model, # 对话模型的名称
"temperature": conf().get("temperature", 0.9), # 值在[0,1]之间,越大表示回复越具有不确定性
# "max_tokens":4096, # 回复最大的字符数
"top_p": conf().get("top_p", 1),
"frequency_penalty": conf().get("frequency_penalty", 0.0), # [-2,2]之间,该值越大则更倾向于产生不同的内容
"presence_penalty": conf().get("presence_penalty", 0.0), # [-2,2]之间,该值越大则更倾向于产生不同的内容
"request_timeout": conf().get("request_timeout", None), # 请求超时时间,openai接口默认设置为600,对于难问题一般需要较长时间
"timeout": conf().get("request_timeout", None), # 重试超时时间,在这个时间内,将会自动重试
}
# 部分模型暂不支持一些参数,特殊处理
if conf_model in [const.O1, const.O1_MINI, const.GPT_5, const.GPT_5_MINI, const.GPT_5_NANO]:
remove_keys = ["temperature", "top_p", "frequency_penalty", "presence_penalty"]
for key in remove_keys:
self.args.pop(key, None) # 如果键不存在,使用 None 来避免抛出错、
if conf_model in [const.O1, const.O1_MINI]: # o1系列模型不支持系统提示词,使用文心模型的session
self.sessions = SessionManager(BaiduWenxinSession, model=conf().get("model") or const.O1_MINI)
def get_api_config(self):
"""Get API configuration for OpenAI-compatible base class"""
return {
'api_key': conf().get("open_ai_api_key"),
'api_base': conf().get("open_ai_api_base"),
'model': conf().get("model", "gpt-3.5-turbo"),
'default_temperature': conf().get("temperature", 0.9),
'default_top_p': conf().get("top_p", 1.0),
'default_frequency_penalty': conf().get("frequency_penalty", 0.0),
'default_presence_penalty': conf().get("presence_penalty", 0.0),
}
def reply(self, query, context=None):
# acquire reply content
if context.type == ContextType.TEXT:
logger.info("[CHATGPT] query={}".format(query))
session_id = context["session_id"]
reply = None
clear_memory_commands = conf().get("clear_memory_commands", ["#清除记忆"])
if query in clear_memory_commands:
self.sessions.clear_session(session_id)
reply = Reply(ReplyType.INFO, "记忆已清除")
elif query == "#清除所有":
self.sessions.clear_all_session()
reply = Reply(ReplyType.INFO, "所有人记忆已清除")
elif query == "#更新配置":
load_config()
reply = Reply(ReplyType.INFO, "配置已更新")
if reply:
return reply
session = self.sessions.session_query(query, session_id)
logger.debug("[CHATGPT] session query={}".format(session.messages))
api_key = context.get("openai_api_key")
model = context.get("gpt_model")
new_args = None
if model:
new_args = self.args.copy()
new_args["model"] = model
# if context.get('stream'):
# # reply in stream
# return self.reply_text_stream(query, new_query, session_id)
reply_content = self.reply_text(session, api_key, args=new_args)
logger.debug(
"[CHATGPT] new_query={}, session_id={}, reply_cont={}, completion_tokens={}".format(
session.messages,
session_id,
reply_content["content"],
reply_content["completion_tokens"],
)
)
if reply_content["completion_tokens"] == 0 and len(reply_content["content"]) > 0:
reply = Reply(ReplyType.ERROR, reply_content["content"])
elif reply_content["completion_tokens"] > 0:
self.sessions.session_reply(reply_content["content"], session_id, reply_content["total_tokens"])
reply = Reply(ReplyType.TEXT, reply_content["content"])
else:
reply = Reply(ReplyType.ERROR, reply_content["content"])
logger.debug("[CHATGPT] reply {} used 0 tokens.".format(reply_content))
return reply
elif context.type == ContextType.IMAGE_CREATE:
ok, retstring = self.create_img(query, 0)
reply = None
if ok:
reply = Reply(ReplyType.IMAGE_URL, retstring)
else:
reply = Reply(ReplyType.ERROR, retstring)
return reply
elif context.type == ContextType.IMAGE:
logger.info("[CHATGPT] Image message received")
reply = self.reply_image(context)
return reply
else:
reply = Reply(ReplyType.ERROR, "Bot不支持处理{}类型的消息".format(context.type))
return reply
def reply_image(self, context):
"""
Process image message using OpenAI Vision API
"""
import base64
import os
try:
image_path = context.content
logger.info(f"[CHATGPT] Processing image: {image_path}")
# Check if file exists
if not os.path.exists(image_path):
logger.error(f"[CHATGPT] Image file not found: {image_path}")
return Reply(ReplyType.ERROR, "图片文件不存在")
# Read and encode image
with open(image_path, "rb") as f:
image_data = f.read()
image_base64 = base64.b64encode(image_data).decode("utf-8")
# Detect image format
extension = os.path.splitext(image_path)[1].lower()
mime_type_map = {
".jpg": "image/jpeg",
".jpeg": "image/jpeg",
".png": "image/png",
".gif": "image/gif",
".webp": "image/webp"
}
mime_type = mime_type_map.get(extension, "image/jpeg")
# Get model and API config
model = context.get("gpt_model") or conf().get("model", "gpt-4o")
api_key = context.get("openai_api_key") or conf().get("open_ai_api_key")
api_base = conf().get("open_ai_api_base")
# Build vision request
messages = [
{
"role": "user",
"content": [
{"type": "text", "text": "请描述这张图片的内容"},
{
"type": "image_url",
"image_url": {
"url": f"data:{mime_type};base64,{image_base64}"
}
}
]
}
]
logger.info(f"[CHATGPT] Calling vision API with model: {model}")
# Call OpenAI API
kwargs = {
"model": model,
"messages": messages,
"max_tokens": 1000
}
if api_key:
kwargs["api_key"] = api_key
if api_base:
kwargs["api_base"] = api_base
response = openai.ChatCompletion.create(**kwargs)
content = response.choices[0]["message"]["content"]
logger.info(f"[CHATGPT] Vision API response: {content[:100]}...")
# Clean up temp file
try:
os.remove(image_path)
logger.debug(f"[CHATGPT] Removed temp image file: {image_path}")
except Exception:
pass
return Reply(ReplyType.TEXT, content)
except Exception as e:
logger.error(f"[CHATGPT] Image processing error: {e}")
import traceback
logger.error(traceback.format_exc())
return Reply(ReplyType.ERROR, f"图片识别失败: {str(e)}")
def reply_text(self, session: ChatGPTSession, api_key=None, args=None, retry_count=0) -> dict:
"""
call openai's ChatCompletion to get the answer
:param session: a conversation session
:param session_id: session id
:param retry_count: retry count
:return: {}
"""
try:
if conf().get("rate_limit_chatgpt") and not self.tb4chatgpt.get_token():
raise RateLimitError("RateLimitError: rate limit exceeded")
# if api_key == None, the default openai.api_key will be used
if args is None:
args = self.args
response = openai.ChatCompletion.create(api_key=api_key, messages=session.messages, **args)
# logger.debug("[CHATGPT] response={}".format(response))
logger.info("[ChatGPT] reply={}, total_tokens={}".format(response.choices[0]['message']['content'], response["usage"]["total_tokens"]))
return {
"total_tokens": response["usage"]["total_tokens"],
"completion_tokens": response["usage"]["completion_tokens"],
"content": response.choices[0]["message"]["content"],
}
except Exception as e:
need_retry = retry_count < 2
result = {"completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
if isinstance(e, RateLimitError):
logger.warn("[CHATGPT] RateLimitError: {}".format(e))
result["content"] = "提问太快啦,请休息一下再问我吧"
if need_retry:
time.sleep(20)
elif isinstance(e, Timeout):
logger.warn("[CHATGPT] Timeout: {}".format(e))
result["content"] = "我没有收到你的消息"
if need_retry:
time.sleep(5)
elif isinstance(e, APIError):
logger.warn("[CHATGPT] Bad Gateway: {}".format(e))
result["content"] = "请再问我一次"
if need_retry:
time.sleep(10)
elif isinstance(e, APIConnectionError):
logger.warn("[CHATGPT] APIConnectionError: {}".format(e))
result["content"] = "我连接不到你的网络"
if need_retry:
time.sleep(5)
else:
logger.exception("[CHATGPT] Exception: {}".format(e))
need_retry = False
self.sessions.clear_session(session.session_id)
if need_retry:
logger.warn("[CHATGPT] 第{}次重试".format(retry_count + 1))
return self.reply_text(session, api_key, args, retry_count + 1)
else:
return result
class AzureChatGPTBot(ChatGPTBot):
def __init__(self):
super().__init__()
openai.api_type = "azure"
openai.api_version = conf().get("azure_api_version", "2023-06-01-preview")
self.args["deployment_id"] = conf().get("azure_deployment_id")
def create_img(self, query, retry_count=0, api_key=None):
text_to_image_model = conf().get("text_to_image")
if text_to_image_model == "dall-e-2":
api_version = "2023-06-01-preview"
endpoint = conf().get("azure_openai_dalle_api_base","open_ai_api_base")
# 检查endpoint是否以/结尾
if not endpoint.endswith("/"):
endpoint = endpoint + "/"
url = "{}openai/images/generations:submit?api-version={}".format(endpoint, api_version)
api_key = conf().get("azure_openai_dalle_api_key","open_ai_api_key")
headers = {"api-key": api_key, "Content-Type": "application/json"}
try:
body = {"prompt": query, "size": conf().get("image_create_size", "256x256"),"n": 1}
submission = requests.post(url, headers=headers, json=body)
operation_location = submission.headers['operation-location']
status = ""
while (status != "succeeded"):
if retry_count > 3:
return False, "图片生成失败"
response = requests.get(operation_location, headers=headers)
status = response.json()['status']
retry_count += 1
image_url = response.json()['result']['data'][0]['url']
return True, image_url
except Exception as e:
logger.error("create image error: {}".format(e))
return False, "图片生成失败"
elif text_to_image_model == "dall-e-3":
api_version = conf().get("azure_api_version", "2024-02-15-preview")
endpoint = conf().get("azure_openai_dalle_api_base","open_ai_api_base")
# 检查endpoint是否以/结尾
if not endpoint.endswith("/"):
endpoint = endpoint + "/"
url = "{}openai/deployments/{}/images/generations?api-version={}".format(endpoint, conf().get("azure_openai_dalle_deployment_id","text_to_image"),api_version)
api_key = conf().get("azure_openai_dalle_api_key","open_ai_api_key")
headers = {"api-key": api_key, "Content-Type": "application/json"}
try:
body = {"prompt": query, "size": conf().get("image_create_size", "1024x1024"), "quality": conf().get("dalle3_image_quality", "standard")}
response = requests.post(url, headers=headers, json=body)
response.raise_for_status() # 检查请求是否成功
data = response.json()
# 检查响应中是否包含图像 URL
if 'data' in data and len(data['data']) > 0 and 'url' in data['data'][0]:
image_url = data['data'][0]['url']
return True, image_url
else:
error_message = "响应中没有图像 URL"
logger.error(error_message)
return False, "图片生成失败"
except requests.exceptions.RequestException as e:
# 捕获所有请求相关的异常
try:
error_detail = response.json().get('error', {}).get('message', str(e))
except ValueError:
error_detail = str(e)
error_message = f"{error_detail}"
logger.error(error_message)
return False, error_message
except Exception as e:
# 捕获所有其他异常
error_message = f"生成图像时发生错误: {e}"
logger.error(error_message)
return False, "图片生成失败"
else:
return False, "图片生成失败,未配置text_to_image参数"
================================================
FILE: models/chatgpt/chat_gpt_session.py
================================================
from models.session_manager import Session
from common.log import logger
from common import const
"""
e.g. [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
"""
class ChatGPTSession(Session):
def __init__(self, session_id, system_prompt=None, model="gpt-3.5-turbo"):
super().__init__(session_id, system_prompt)
self.model = model
self.reset()
def discard_exceeding(self, max_tokens, cur_tokens=None):
precise = True
try:
cur_tokens = self.calc_tokens()
except Exception as e:
precise = False
if cur_tokens is None:
raise e
logger.debug("Exception when counting tokens precisely for query: {}".format(e))
while cur_tokens > max_tokens:
if len(self.messages) > 2:
self.messages.pop(1)
elif len(self.messages) == 2 and self.messages[1]["role"] == "assistant":
self.messages.pop(1)
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
break
elif len(self.messages) == 2 and self.messages[1]["role"] == "user":
logger.warn("user message exceed max_tokens. total_tokens={}".format(cur_tokens))
break
else:
logger.debug("max_tokens={}, total_tokens={}, len(messages)={}".format(max_tokens, cur_tokens, len(self.messages)))
break
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
return cur_tokens
def calc_tokens(self):
return num_tokens_from_messages(self.messages, self.model)
# refer to https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
def num_tokens_from_messages(messages, model):
"""Returns the number of tokens used by a list of messages."""
if model in ["wenxin", "xunfei"] or model.startswith(const.GEMINI):
return num_tokens_by_character(messages)
import tiktoken
if model in ["gpt-3.5-turbo-0301", "gpt-35-turbo", "gpt-3.5-turbo-1106", "moonshot", const.LINKAI_35]:
return num_tokens_from_messages(messages, model="gpt-3.5-turbo")
elif model in ["gpt-4-0314", "gpt-4-0613", "gpt-4-32k", "gpt-4-32k-0613", "gpt-3.5-turbo-0613",
"gpt-3.5-turbo-16k", "gpt-3.5-turbo-16k-0613", "gpt-35-turbo-16k", "gpt-4-turbo-preview",
"gpt-4-1106-preview", const.GPT4_TURBO_PREVIEW, const.GPT4_VISION_PREVIEW, const.GPT4_TURBO_01_25,
const.GPT_4o, const.GPT_4O_0806, const.GPT_4o_MINI, const.LINKAI_4o, const.LINKAI_4_TURBO, const.GPT_5, const.GPT_5_MINI, const.GPT_5_NANO]:
return num_tokens_from_messages(messages, model="gpt-4")
elif model.startswith("claude-3"):
return num_tokens_from_messages(messages, model="gpt-3.5-turbo")
try:
encoding = tiktoken.encoding_for_model(model)
except KeyError:
logger.debug("Warning: model not found. Using cl100k_base encoding.")
encoding = tiktoken.get_encoding("cl100k_base")
if model == "gpt-3.5-turbo":
tokens_per_message = 4 # every message follows <|start|>{role/name}\n{content}<|end|>\n
tokens_per_name = -1 # if there's a name, the role is omitted
elif model == "gpt-4":
tokens_per_message = 3
tokens_per_name = 1
else:
logger.debug(f"num_tokens_from_messages() is not implemented for model {model}. Returning num tokens assuming gpt-3.5-turbo.")
return num_tokens_from_messages(messages, model="gpt-3.5-turbo")
num_tokens = 0
for message in messages:
num_tokens += tokens_per_message
for key, value in message.items():
num_tokens += len(encoding.encode(value))
if key == "name":
num_tokens += tokens_per_name
num_tokens += 3 # every reply is primed with <|start|>assistant<|message|>
return num_tokens
def num_tokens_by_character(messages):
"""Returns the number of tokens used by a list of messages."""
tokens = 0
for msg in messages:
tokens += len(msg["content"])
return tokens
================================================
FILE: models/claudeapi/claude_api_bot.py
================================================
# encoding:utf-8
import json
import time
import requests
from models.baidu.baidu_wenxin_session import BaiduWenxinSession
from models.bot import Bot
from models.session_manager import SessionManager
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common import const
from common.log import logger
from config import conf
# Optional OpenAI image support
try:
from models.openai.open_ai_image import OpenAIImage
_openai_image_available = True
except Exception as e:
logger.warning(f"OpenAI image support not available: {e}")
_openai_image_available = False
OpenAIImage = object # Fallback to object
user_session = dict()
# OpenAI对话模型API (可用)
class ClaudeAPIBot(Bot, OpenAIImage):
def __init__(self):
super().__init__()
self.sessions = SessionManager(BaiduWenxinSession, model=conf().get("model") or "text-davinci-003")
@property
def api_key(self):
return conf().get("claude_api_key")
@property
def api_base(self):
return conf().get("claude_api_base") or "https://api.anthropic.com/v1"
@property
def proxy(self):
return conf().get("proxy", None)
def reply(self, query, context=None):
# acquire reply content
if context and context.type:
if context.type == ContextType.TEXT:
logger.info("[CLAUDE_API] query={}".format(query))
session_id = context["session_id"]
reply = None
if query == "#清除记忆":
self.sessions.clear_session(session_id)
reply = Reply(ReplyType.INFO, "记忆已清除")
elif query == "#清除所有":
self.sessions.clear_all_session()
reply = Reply(ReplyType.INFO, "所有人记忆已清除")
else:
session = self.sessions.session_query(query, session_id)
result = self.reply_text(session)
logger.info(result)
total_tokens, completion_tokens, reply_content = (
result["total_tokens"],
result["completion_tokens"],
result["content"],
)
logger.debug(
"[CLAUDE_API] new_query={}, session_id={}, reply_cont={}, completion_tokens={}".format(str(session), session_id, reply_content, completion_tokens)
)
if total_tokens == 0:
reply = Reply(ReplyType.ERROR, reply_content)
else:
self.sessions.session_reply(reply_content, session_id, total_tokens)
reply = Reply(ReplyType.TEXT, reply_content)
return reply
elif context.type == ContextType.IMAGE_CREATE:
ok, retstring = self.create_img(query, 0)
reply = None
if ok:
reply = Reply(ReplyType.IMAGE_URL, retstring)
else:
reply = Reply(ReplyType.ERROR, retstring)
return reply
def reply_text(self, session: BaiduWenxinSession, retry_count=0, tools=None):
try:
actual_model = self._model_mapping(conf().get("model"))
# Prepare headers
headers = {
"x-api-key": self.api_key,
"anthropic-version": "2023-06-01",
"content-type": "application/json"
}
# Extract system prompt if present and prepare Claude-compatible messages
system_prompt = conf().get("character_desc", "")
claude_messages = []
for msg in session.messages:
if msg.get("role") == "system":
system_prompt = msg["content"]
else:
claude_messages.append(msg)
# Prepare request data
data = {
"model": actual_model,
"messages": claude_messages,
"max_tokens": self._get_max_tokens(actual_model)
}
if system_prompt:
data["system"] = system_prompt
if tools:
data["tools"] = tools
# Make HTTP request
proxies = {"http": self.proxy, "https": self.proxy} if self.proxy else None
response = requests.post(
f"{self.api_base}/messages",
headers=headers,
json=data,
proxies=proxies
)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code} - {response.text}")
claude_response = response.json()
# Handle response content and tool calls
res_content = ""
tool_calls = []
content_blocks = claude_response.get("content", [])
for block in content_blocks:
if block.get("type") == "text":
res_content += block.get("text", "")
elif block.get("type") == "tool_use":
tool_calls.append({
"id": block.get("id", ""),
"name": block.get("name", ""),
"arguments": block.get("input", {})
})
res_content = res_content.strip().replace("<|endoftext|>", "")
usage = claude_response.get("usage", {})
total_tokens = usage.get("input_tokens", 0) + usage.get("output_tokens", 0)
completion_tokens = usage.get("output_tokens", 0)
logger.info("[CLAUDE_API] reply={}".format(res_content))
if tool_calls:
logger.info("[CLAUDE_API] tool_calls={}".format(tool_calls))
result = {
"total_tokens": total_tokens,
"completion_tokens": completion_tokens,
"content": res_content,
}
if tool_calls:
result["tool_calls"] = tool_calls
return result
except Exception as e:
need_retry = retry_count < 2
result = {"total_tokens": 0, "completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
# Handle different types of errors
error_str = str(e).lower()
if "rate" in error_str or "limit" in error_str:
logger.warn("[CLAUDE_API] RateLimitError: {}".format(e))
result["content"] = "提问太快啦,请休息一下再问我吧"
if need_retry:
time.sleep(20)
elif "timeout" in error_str:
logger.warn("[CLAUDE_API] Timeout: {}".format(e))
result["content"] = "我没有收到你的消息"
if need_retry:
time.sleep(5)
elif "connection" in error_str or "network" in error_str:
logger.warn("[CLAUDE_API] APIConnectionError: {}".format(e))
need_retry = False
result["content"] = "我连接不到你的网络"
else:
logger.warn("[CLAUDE_API] Exception: {}".format(e))
need_retry = False
self.sessions.clear_session(session.session_id)
if need_retry:
logger.warn("[CLAUDE_API] 第{}次重试".format(retry_count + 1))
return self.reply_text(session, retry_count + 1, tools)
else:
return result
def _model_mapping(self, model) -> str:
if model == "claude-3-opus":
return const.CLAUDE_3_OPUS
elif model == "claude-3-sonnet":
return const.CLAUDE_3_SONNET
elif model == "claude-3-haiku":
return const.CLAUDE_3_HAIKU
elif model == "claude-3.5-sonnet":
return const.CLAUDE_35_SONNET
return model
def _get_max_tokens(self, model: str) -> int:
"""
Get max_tokens for the model.
Reference from pi-mono:
- Claude 3.5/3.7: 8192
- Claude 3 Opus: 4096
- Default: 8192
"""
if model and (model.startswith("claude-3-5") or model.startswith("claude-3-7")):
return 8192
elif model and model.startswith("claude-3") and "opus" in model:
return 4096
elif model and (model.startswith("claude-sonnet-4") or model.startswith("claude-opus-4")):
return 64000
return 8192
def call_with_tools(self, messages, tools=None, stream=False, **kwargs):
"""
Call Claude API with tool support for agent integration
Args:
messages: List of messages
tools: List of tool definitions
stream: Whether to use streaming
**kwargs: Additional parameters
Returns:
Formatted response compatible with OpenAI format or generator for streaming
"""
actual_model = self._model_mapping(conf().get("model"))
# Extract system prompt from messages if present
system_prompt = kwargs.get("system", conf().get("character_desc", ""))
claude_messages = []
for msg in messages:
if msg.get("role") == "system":
system_prompt = msg["content"]
else:
claude_messages.append(msg)
request_params = {
"model": actual_model,
"max_tokens": kwargs.get("max_tokens", self._get_max_tokens(actual_model)),
"messages": claude_messages,
"stream": stream
}
if system_prompt:
request_params["system"] = system_prompt
if tools:
request_params["tools"] = tools
try:
if stream:
return self._handle_stream_response(request_params)
else:
return self._handle_sync_response(request_params)
except Exception as e:
logger.error(f"Claude API call error: {e}")
if stream:
# Return error generator for stream
def error_generator():
yield {
"error": True,
"message": str(e),
"status_code": 500
}
return error_generator()
else:
# Return error response for sync
return {
"error": True,
"message": str(e),
"status_code": 500
}
def _handle_sync_response(self, request_params):
"""Handle synchronous Claude API response"""
# Prepare headers
headers = {
"x-api-key": self.api_key,
"anthropic-version": "2023-06-01",
"content-type": "application/json"
}
# Make HTTP request
proxies = {"http": self.proxy, "https": self.proxy} if self.proxy else None
response = requests.post(
f"{self.api_base}/messages",
headers=headers,
json=request_params,
proxies=proxies
)
if response.status_code != 200:
raise Exception(f"API request failed: {response.status_code} - {response.text}")
claude_response = response.json()
# Extract content blocks
text_content = ""
tool_calls = []
content_blocks = claude_response.get("content", [])
for block in content_blocks:
if block.get("type") == "text":
text_content += block.get("text", "")
elif block.get("type") == "tool_use":
tool_calls.append({
"id": block.get("id", ""),
"type": "function",
"function": {
"name": block.get("name", ""),
"arguments": json.dumps(block.get("input", {}))
}
})
# Build message in OpenAI format
message = {
"role": "assistant",
"content": text_content
}
if tool_calls:
message["tool_calls"] = tool_calls
# Format response to match OpenAI structure
usage = claude_response.get("usage", {})
formatted_response = {
"id": claude_response.get("id", ""),
"object": "chat.completion",
"created": int(time.time()),
"model": claude_response.get("model", request_params["model"]),
"choices": [
{
"index": 0,
"message": message,
"finish_reason": claude_response.get("stop_reason", "stop")
}
],
"usage": {
"prompt_tokens": usage.get("input_tokens", 0),
"completion_tokens": usage.get("output_tokens", 0),
"total_tokens": usage.get("input_tokens", 0) + usage.get("output_tokens", 0)
}
}
return formatted_response
def _handle_stream_response(self, request_params):
"""Handle streaming Claude API response using HTTP requests"""
# Prepare headers
headers = {
"x-api-key": self.api_key,
"anthropic-version": "2023-06-01",
"content-type": "application/json"
}
# Add stream parameter
request_params["stream"] = True
# Track tool use state
tool_uses_map = {} # {index: {id, name, input}}
current_tool_use_index = -1
stop_reason = None # Track stop reason from Claude
try:
# Make streaming HTTP request
proxies = {"http": self.proxy, "https": self.proxy} if self.proxy else None
response = requests.post(
f"{self.api_base}/messages",
headers=headers,
json=request_params,
proxies=proxies,
stream=True
)
if response.status_code != 200:
error_text = response.text
try:
error_data = json.loads(error_text)
error_msg = error_data.get("error", {}).get("message", error_text)
except Exception:
error_msg = error_text or "Unknown error"
yield {
"error": True,
"status_code": response.status_code,
"message": error_msg
}
return
# Process streaming response
for line in response.iter_lines():
if line:
line = line.decode('utf-8')
if line.startswith('data: '):
line = line[6:] # Remove 'data: ' prefix
if line == '[DONE]':
break
try:
event = json.loads(line)
event_type = event.get("type")
if event_type == "content_block_start":
# New content block
block = event.get("content_block", {})
if block.get("type") == "tool_use":
current_tool_use_index = event.get("index", 0)
tool_uses_map[current_tool_use_index] = {
"id": block.get("id", ""),
"name": block.get("name", ""),
"input": ""
}
elif event_type == "content_block_delta":
delta = event.get("delta", {})
delta_type = delta.get("type")
if delta_type == "text_delta":
# Text content
content = delta.get("text", "")
yield {
"id": event.get("id", ""),
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": request_params["model"],
"choices": [{
"index": 0,
"delta": {"content": content},
"finish_reason": None
}]
}
elif delta_type == "input_json_delta":
# Tool input accumulation
if current_tool_use_index >= 0:
tool_uses_map[current_tool_use_index]["input"] += delta.get("partial_json", "")
elif event_type == "message_delta":
# Extract stop_reason from delta
delta = event.get("delta", {})
if "stop_reason" in delta:
stop_reason = delta.get("stop_reason")
logger.info(f"[Claude] Stream stop_reason: {stop_reason}")
# Message complete - yield tool calls if any
if tool_uses_map:
for idx in sorted(tool_uses_map.keys()):
tool_data = tool_uses_map[idx]
yield {
"id": event.get("id", ""),
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": request_params["model"],
"choices": [{
"index": 0,
"delta": {
"tool_calls": [{
"index": idx,
"id": tool_data["id"],
"type": "function",
"function": {
"name": tool_data["name"],
"arguments": tool_data["input"]
}
}]
},
"finish_reason": stop_reason
}]
}
elif event_type == "message_stop":
# Final event - log completion
logger.debug(f"[Claude] Stream completed with stop_reason: {stop_reason}")
except json.JSONDecodeError:
continue
except requests.RequestException as e:
logger.error(f"Claude streaming request error: {e}")
yield {
"error": True,
"message": f"Connection error: {str(e)}",
"status_code": 0
}
except Exception as e:
logger.error(f"Claude streaming error: {e}")
yield {
"error": True,
"message": str(e),
"status_code": 500
}
================================================
FILE: models/dashscope/dashscope_bot.py
================================================
# encoding:utf-8
import json
from models.bot import Bot
from models.session_manager import SessionManager
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf, load_config
from .dashscope_session import DashscopeSession
import os
import dashscope
from dashscope import MultiModalConversation
from http import HTTPStatus
# Legacy model name mapping for older dashscope SDK constants.
# New models don't need to be added here — they use their name string directly.
dashscope_models = {
"qwen-turbo": dashscope.Generation.Models.qwen_turbo,
"qwen-plus": dashscope.Generation.Models.qwen_plus,
"qwen-max": dashscope.Generation.Models.qwen_max,
"qwen-bailian-v1": dashscope.Generation.Models.bailian_v1,
}
# Model name prefixes that require MultiModalConversation API instead of Generation API.
# Qwen3.5+ series are omni models that only support MultiModalConversation.
MULTIMODAL_MODEL_PREFIXES = ("qwen3.5-",)
# Qwen对话模型API
class DashscopeBot(Bot):
def __init__(self):
super().__init__()
self.sessions = SessionManager(DashscopeSession, model=conf().get("model") or "qwen-plus")
self.model_name = conf().get("model") or "qwen-plus"
self.client = dashscope.Generation
api_key = conf().get("dashscope_api_key")
if api_key:
os.environ["DASHSCOPE_API_KEY"] = api_key
@property
def api_key(self):
return conf().get("dashscope_api_key")
@staticmethod
def _is_multimodal_model(model_name: str) -> bool:
"""Check if the model requires MultiModalConversation API"""
return model_name.startswith(MULTIMODAL_MODEL_PREFIXES)
def reply(self, query, context=None):
# acquire reply content
if context.type == ContextType.TEXT:
logger.info("[DASHSCOPE] query={}".format(query))
session_id = context["session_id"]
reply = None
clear_memory_commands = conf().get("clear_memory_commands", ["#清除记忆"])
if query in clear_memory_commands:
self.sessions.clear_session(session_id)
reply = Reply(ReplyType.INFO, "记忆已清除")
elif query == "#清除所有":
self.sessions.clear_all_session()
reply = Reply(ReplyType.INFO, "所有人记忆已清除")
elif query == "#更新配置":
load_config()
reply = Reply(ReplyType.INFO, "配置已更新")
if reply:
return reply
session = self.sessions.session_query(query, session_id)
logger.debug("[DASHSCOPE] session query={}".format(session.messages))
reply_content = self.reply_text(session)
logger.debug(
"[DASHSCOPE] new_query={}, session_id={}, reply_cont={}, completion_tokens={}".format(
session.messages,
session_id,
reply_content["content"],
reply_content["completion_tokens"],
)
)
if reply_content["completion_tokens"] == 0 and len(reply_content["content"]) > 0:
reply = Reply(ReplyType.ERROR, reply_content["content"])
elif reply_content["completion_tokens"] > 0:
self.sessions.session_reply(reply_content["content"], session_id, reply_content["total_tokens"])
reply = Reply(ReplyType.TEXT, reply_content["content"])
else:
reply = Reply(ReplyType.ERROR, reply_content["content"])
logger.debug("[DASHSCOPE] reply {} used 0 tokens.".format(reply_content))
return reply
else:
reply = Reply(ReplyType.ERROR, "Bot不支持处理{}类型的消息".format(context.type))
return reply
def reply_text(self, session: DashscopeSession, retry_count=0) -> dict:
"""
call openai's ChatCompletion to get the answer
:param session: a conversation session
:param session_id: session id
:param retry_count: retry count
:return: {}
"""
try:
dashscope.api_key = self.api_key
model = dashscope_models.get(self.model_name, self.model_name)
if self._is_multimodal_model(self.model_name):
mm_messages = self._prepare_messages_for_multimodal(session.messages)
response = MultiModalConversation.call(
model=model,
messages=mm_messages,
result_format="message"
)
else:
response = self.client.call(
model,
messages=session.messages,
result_format="message"
)
if response.status_code == HTTPStatus.OK:
resp_dict = self._response_to_dict(response)
choice = resp_dict["output"]["choices"][0]
content = choice.get("message", {}).get("content", "")
# Multimodal models may return content as a list of blocks
if isinstance(content, list):
content = "".join(
item.get("text", "") for item in content if isinstance(item, dict)
)
usage = resp_dict.get("usage", {})
return {
"total_tokens": usage.get("total_tokens", 0),
"completion_tokens": usage.get("output_tokens", 0),
"content": content,
}
else:
logger.error('Request id: %s, Status code: %s, error code: %s, error message: %s' % (
response.request_id, response.status_code,
response.code, response.message
))
result = {"completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
need_retry = retry_count < 2
result = {"completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
if need_retry:
return self.reply_text(session, retry_count + 1)
else:
return result
except Exception as e:
logger.exception(e)
need_retry = retry_count < 2
result = {"completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
if need_retry:
return self.reply_text(session, retry_count + 1)
else:
return result
def call_with_tools(self, messages, tools=None, stream=False, **kwargs):
"""
Call DashScope API with tool support for agent integration
This method handles:
1. Format conversion (Claude format → DashScope format)
2. System prompt injection
3. API calling with DashScope SDK
4. Thinking mode support (enable_thinking for Qwen3)
Args:
messages: List of messages (may be in Claude format from agent)
tools: List of tool definitions (may be in Claude format from agent)
stream: Whether to use streaming
**kwargs: Additional parameters (max_tokens, temperature, system, etc.)
Returns:
Formatted response or generator for streaming
"""
try:
# Convert messages from Claude format to DashScope format
messages = self._convert_messages_to_dashscope_format(messages)
# Convert tools from Claude format to DashScope format
if tools:
tools = self._convert_tools_to_dashscope_format(tools)
# Handle system prompt
system_prompt = kwargs.get('system')
if system_prompt:
# Add system message at the beginning if not already present
if not messages or messages[0].get('role') != 'system':
messages = [{"role": "system", "content": system_prompt}] + messages
else:
# Replace existing system message
messages[0] = {"role": "system", "content": system_prompt}
# Build request parameters
model_name = kwargs.get("model", self.model_name)
parameters = {
"result_format": "message", # Required for tool calling
"temperature": kwargs.get("temperature", conf().get("temperature", 0.85)),
"top_p": kwargs.get("top_p", conf().get("top_p", 0.8)),
}
# Add max_tokens if specified
if kwargs.get("max_tokens"):
parameters["max_tokens"] = kwargs["max_tokens"]
# Add tools if provided
if tools:
parameters["tools"] = tools
# Add tool_choice if specified
if kwargs.get("tool_choice"):
parameters["tool_choice"] = kwargs["tool_choice"]
# Add thinking parameters for Qwen3 models (disabled by default for stability)
if "qwen3" in model_name.lower() or "qwq" in model_name.lower():
# Only enable thinking mode if explicitly requested
enable_thinking = kwargs.get("enable_thinking", False)
if enable_thinking:
parameters["enable_thinking"] = True
# Set thinking budget if specified
if kwargs.get("thinking_budget"):
parameters["thinking_budget"] = kwargs["thinking_budget"]
# Qwen3 requires incremental_output=true in thinking mode
if stream:
parameters["incremental_output"] = True
# Always use incremental_output for streaming (for better token-by-token streaming)
# This is especially important for tool calling to avoid incomplete responses
if stream:
parameters["incremental_output"] = True
# Make API call with DashScope SDK
if stream:
return self._handle_stream_response(model_name, messages, parameters)
else:
return self._handle_sync_response(model_name, messages, parameters)
except Exception as e:
error_msg = str(e)
logger.error(f"[DASHSCOPE] call_with_tools error: {error_msg}")
if stream:
def error_generator():
yield {
"error": True,
"message": error_msg,
"status_code": 500
}
return error_generator()
else:
return {
"error": True,
"message": error_msg,
"status_code": 500
}
def _handle_sync_response(self, model_name, messages, parameters):
"""Handle synchronous DashScope API response"""
try:
# Set API key before calling
dashscope.api_key = self.api_key
model = dashscope_models.get(model_name, model_name)
if self._is_multimodal_model(model_name):
messages = self._prepare_messages_for_multimodal(messages)
response = MultiModalConversation.call(
model=model,
messages=messages,
**parameters
)
else:
response = dashscope.Generation.call(
model=model,
messages=messages,
**parameters
)
if response.status_code == HTTPStatus.OK:
# Convert response to dict to avoid DashScope object KeyError issues
resp_dict = self._response_to_dict(response)
choice = resp_dict["output"]["choices"][0]
message = choice.get("message", {})
content = message.get("content", "")
# Multimodal models may return content as a list of blocks
if isinstance(content, list):
content = "".join(
item.get("text", "") for item in content if isinstance(item, dict)
)
usage = resp_dict.get("usage", {})
return {
"id": resp_dict.get("request_id"),
"object": "chat.completion",
"created": 0,
"model": model_name,
"choices": [{
"index": 0,
"message": {
"role": message.get("role", "assistant"),
"content": content,
"tool_calls": self._convert_tool_calls_to_openai_format(
message.get("tool_calls")
)
},
"finish_reason": choice.get("finish_reason")
}],
"usage": {
"prompt_tokens": usage.get("input_tokens", 0),
"completion_tokens": usage.get("output_tokens", 0),
"total_tokens": usage.get("total_tokens", 0)
}
}
else:
logger.error(f"[DASHSCOPE] API error: {response.code} - {response.message}")
return {
"error": True,
"message": response.message,
"status_code": response.status_code
}
except Exception as e:
logger.error(f"[DASHSCOPE] sync response error: {e}")
return {
"error": True,
"message": str(e),
"status_code": 500
}
def _handle_stream_response(self, model_name, messages, parameters):
"""Handle streaming DashScope API response"""
try:
# Set API key before calling
dashscope.api_key = self.api_key
model = dashscope_models.get(model_name, model_name)
if self._is_multimodal_model(model_name):
messages = self._prepare_messages_for_multimodal(messages)
responses = MultiModalConversation.call(
model=model,
messages=messages,
stream=True,
**parameters
)
else:
responses = dashscope.Generation.call(
model=model,
messages=messages,
stream=True,
**parameters
)
# Stream chunks to caller, converting to OpenAI format
for response in responses:
# Convert to dict first to avoid DashScope proxy object KeyError
resp_dict = self._response_to_dict(response)
status_code = resp_dict.get("status_code", 200)
if status_code != HTTPStatus.OK:
err_code = resp_dict.get("code", "")
err_msg = resp_dict.get("message", "Unknown error")
logger.error(f"[DASHSCOPE] Stream error: {err_code} - {err_msg}")
yield {
"error": True,
"message": err_msg,
"status_code": status_code
}
continue
choices = resp_dict.get("output", {}).get("choices", [])
if not choices:
continue
choice = choices[0]
finish_reason = choice.get("finish_reason")
message = choice.get("message", {})
# Convert to OpenAI-compatible format
openai_chunk = {
"id": resp_dict.get("request_id"),
"object": "chat.completion.chunk",
"created": 0,
"model": model_name,
"choices": [{
"index": 0,
"delta": {},
"finish_reason": finish_reason
}]
}
# Add role
role = message.get("role")
if role:
openai_chunk["choices"][0]["delta"]["role"] = role
# Add reasoning_content (thinking process from models like qwen3.5)
reasoning_content = message.get("reasoning_content")
if reasoning_content:
openai_chunk["choices"][0]["delta"]["reasoning_content"] = reasoning_content
# Add content (multimodal models may return list of blocks)
content = message.get("content")
if isinstance(content, list):
content = "".join(
item.get("text", "") for item in content if isinstance(item, dict)
)
if content:
openai_chunk["choices"][0]["delta"]["content"] = content
# Add tool_calls
tool_calls = message.get("tool_calls")
if tool_calls:
openai_chunk["choices"][0]["delta"]["tool_calls"] = self._convert_tool_calls_to_openai_format(tool_calls)
yield openai_chunk
except Exception as e:
logger.error(f"[DASHSCOPE] stream response error: {e}", exc_info=True)
yield {
"error": True,
"message": str(e),
"status_code": 500
}
@staticmethod
def _response_to_dict(response) -> dict:
"""
Convert DashScope response object to a plain dict.
DashScope SDK wraps responses in proxy objects whose __getattr__
delegates to __getitem__, raising KeyError (not AttributeError)
when an attribute is missing. Standard hasattr / getattr only
catch AttributeError, so we must use try-except everywhere.
"""
_SENTINEL = object()
def _safe_getattr(obj, name, default=_SENTINEL):
"""getattr that also catches KeyError from DashScope proxy objects."""
try:
return getattr(obj, name)
except (AttributeError, KeyError, TypeError):
return default
def _has_attr(obj, name):
return _safe_getattr(obj, name) is not _SENTINEL
def _to_dict(obj):
if isinstance(obj, (str, int, float, bool, type(None))):
return obj
if isinstance(obj, dict):
return {k: _to_dict(v) for k, v in obj.items()}
if isinstance(obj, (list, tuple)):
return [_to_dict(i) for i in obj]
# DashScope response objects behave like dicts (have .keys())
if _has_attr(obj, "keys"):
try:
return {k: _to_dict(obj[k]) for k in obj.keys()}
except Exception:
pass
return obj
result = {}
# Extract known top-level fields safely
for attr in ("request_id", "status_code", "code", "message", "output", "usage"):
val = _safe_getattr(response, attr)
if val is _SENTINEL:
try:
val = response[attr]
except (KeyError, TypeError, IndexError):
continue
result[attr] = _to_dict(val)
return result
def _convert_tools_to_dashscope_format(self, tools):
"""
Convert tools from Claude format to DashScope format
Claude format: {name, description, input_schema}
DashScope format: {type: "function", function: {name, description, parameters}}
"""
if not tools:
return None
dashscope_tools = []
for tool in tools:
# Check if already in DashScope/OpenAI format
if 'type' in tool and tool['type'] == 'function':
dashscope_tools.append(tool)
else:
# Convert from Claude format
dashscope_tools.append({
"type": "function",
"function": {
"name": tool.get("name"),
"description": tool.get("description"),
"parameters": tool.get("input_schema", {})
}
})
return dashscope_tools
@staticmethod
def _prepare_messages_for_multimodal(messages: list) -> list:
"""
Ensure messages are compatible with MultiModalConversation API.
MultiModalConversation._preprocess_messages iterates every message
with ``content = message["content"]; for elem in content: ...``,
which means:
1. Every message MUST have a 'content' key.
2. 'content' MUST be an iterable (list), not a plain string.
The expected format is [{"text": "..."}, ...].
Meanwhile the DashScope API requires role='tool' messages to follow
assistant tool_calls, so we must NOT convert them to role='user'.
We just ensure they have a list-typed 'content'.
"""
result = []
for msg in messages:
msg = dict(msg) # shallow copy
# Normalize content to list format [{"text": "..."}]
content = msg.get("content")
if content is None or (isinstance(content, str) and content == ""):
msg["content"] = [{"text": ""}]
elif isinstance(content, str):
msg["content"] = [{"text": content}]
# If content is already a list, keep as-is (already in multimodal format)
result.append(msg)
return result
def _convert_messages_to_dashscope_format(self, messages):
"""
Convert messages from Claude format to DashScope format
Claude uses content blocks with types like 'tool_use', 'tool_result'
DashScope uses 'tool_calls' in assistant messages and 'tool' role for results
"""
if not messages:
return []
dashscope_messages = []
for msg in messages:
role = msg.get("role")
content = msg.get("content")
# Handle string content (already in correct format)
if isinstance(content, str):
dashscope_messages.append(msg)
continue
# Handle list content (Claude format with content blocks)
if isinstance(content, list):
# Check if this is a tool result message (user role with tool_result blocks)
if role == "user" and any(block.get("type") == "tool_result" for block in content):
# Convert each tool_result block to a separate tool message
for block in content:
if block.get("type") == "tool_result":
dashscope_messages.append({
"role": "tool",
"content": block.get("content", ""),
"tool_call_id": block.get("tool_use_id") # DashScope uses 'tool_call_id'
})
# Check if this is an assistant message with tool_use blocks
elif role == "assistant":
# Separate text content and tool_use blocks
text_parts = []
tool_calls = []
for block in content:
if block.get("type") == "text":
text_parts.append(block.get("text", ""))
elif block.get("type") == "tool_use":
tool_calls.append({
"id": block.get("id"),
"type": "function",
"function": {
"name": block.get("name"),
"arguments": json.dumps(block.get("input", {}))
}
})
# Build DashScope format assistant message
dashscope_msg = {
"role": "assistant"
}
# Add content only if there is actual text
# DashScope API: when tool_calls exist, content should be None or omitted if empty
if text_parts:
dashscope_msg["content"] = " ".join(text_parts)
elif not tool_calls:
# If no tool_calls and no text, set empty string (rare case)
dashscope_msg["content"] = ""
# If there are tool_calls but no text, don't set content field at all
if tool_calls:
dashscope_msg["tool_calls"] = tool_calls
dashscope_messages.append(dashscope_msg)
else:
# Other list content, keep as is
dashscope_messages.append(msg)
else:
# Other formats, keep as is
dashscope_messages.append(msg)
return dashscope_messages
def _convert_tool_calls_to_openai_format(self, tool_calls):
"""Convert DashScope tool_calls to OpenAI format"""
if not tool_calls:
return None
openai_tool_calls = []
for tool_call in tool_calls:
# DashScope format is already similar to OpenAI
if isinstance(tool_call, dict):
openai_tool_calls.append(tool_call)
else:
# Handle object format
openai_tool_calls.append({
"id": getattr(tool_call, 'id', None),
"type": "function",
"function": {
"name": tool_call.function.name,
"arguments": tool_call.function.arguments
}
})
return openai_tool_calls
================================================
FILE: models/dashscope/dashscope_session.py
================================================
from models.session_manager import Session
from common.log import logger
class DashscopeSession(Session):
def __init__(self, session_id, system_prompt=None, model="qwen-turbo"):
super().__init__(session_id)
self.reset()
def discard_exceeding(self, max_tokens, cur_tokens=None):
precise = True
try:
cur_tokens = self.calc_tokens()
except Exception as e:
precise = False
if cur_tokens is None:
raise e
logger.debug("Exception when counting tokens precisely for query: {}".format(e))
while cur_tokens > max_tokens:
if len(self.messages) > 2:
self.messages.pop(1)
elif len(self.messages) == 2 and self.messages[1]["role"] == "assistant":
self.messages.pop(1)
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
break
elif len(self.messages) == 2 and self.messages[1]["role"] == "user":
logger.warn("user message exceed max_tokens. total_tokens={}".format(cur_tokens))
break
else:
logger.debug("max_tokens={}, total_tokens={}, len(messages)={}".format(max_tokens, cur_tokens,
len(self.messages)))
break
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
return cur_tokens
def calc_tokens(self):
return num_tokens_from_messages(self.messages)
def num_tokens_from_messages(messages):
# 只是大概,具体计算规则:https://help.aliyun.com/zh/dashscope/developer-reference/token-api?spm=a2c4g.11186623.0.0.4d8b12b0BkP3K9
tokens = 0
for msg in messages:
tokens += len(msg["content"])
return tokens
================================================
FILE: models/doubao/__init__.py
================================================
================================================
FILE: models/doubao/doubao_bot.py
================================================
# encoding:utf-8
import json
import time
import requests
from models.bot import Bot
from models.session_manager import SessionManager
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf, load_config
from .doubao_session import DoubaoSession
# Doubao (火山方舟 / Volcengine Ark) API Bot
class DoubaoBot(Bot):
def __init__(self):
super().__init__()
self.sessions = SessionManager(DoubaoSession, model=conf().get("model") or "doubao-seed-2-0-pro-260215")
model = conf().get("model") or "doubao-seed-2-0-pro-260215"
self.args = {
"model": model,
"temperature": conf().get("temperature", 0.8),
"top_p": conf().get("top_p", 1.0),
}
@property
def api_key(self):
return conf().get("ark_api_key")
@property
def base_url(self):
url = conf().get("ark_base_url", "https://ark.cn-beijing.volces.com/api/v3")
if url.endswith("/chat/completions"):
url = url.rsplit("/chat/completions", 1)[0]
return url.rstrip("/")
def reply(self, query, context=None):
# acquire reply content
if context.type == ContextType.TEXT:
logger.info("[DOUBAO] query={}".format(query))
session_id = context["session_id"]
reply = None
clear_memory_commands = conf().get("clear_memory_commands", ["#清除记忆"])
if query in clear_memory_commands:
self.sessions.clear_session(session_id)
reply = Reply(ReplyType.INFO, "记忆已清除")
elif query == "#清除所有":
self.sessions.clear_all_session()
reply = Reply(ReplyType.INFO, "所有人记忆已清除")
elif query == "#更新配置":
load_config()
reply = Reply(ReplyType.INFO, "配置已更新")
if reply:
return reply
session = self.sessions.session_query(query, session_id)
logger.debug("[DOUBAO] session query={}".format(session.messages))
model = context.get("doubao_model")
new_args = self.args.copy()
if model:
new_args["model"] = model
reply_content = self.reply_text(session, args=new_args)
logger.debug(
"[DOUBAO] new_query={}, session_id={}, reply_cont={}, completion_tokens={}".format(
session.messages,
session_id,
reply_content["content"],
reply_content["completion_tokens"],
)
)
if reply_content["completion_tokens"] == 0 and len(reply_content["content"]) > 0:
reply = Reply(ReplyType.ERROR, reply_content["content"])
elif reply_content["completion_tokens"] > 0:
self.sessions.session_reply(reply_content["content"], session_id, reply_content["total_tokens"])
reply = Reply(ReplyType.TEXT, reply_content["content"])
else:
reply = Reply(ReplyType.ERROR, reply_content["content"])
logger.debug("[DOUBAO] reply {} used 0 tokens.".format(reply_content))
return reply
else:
reply = Reply(ReplyType.ERROR, "Bot不支持处理{}类型的消息".format(context.type))
return reply
def reply_text(self, session: DoubaoSession, args=None, retry_count: int = 0) -> dict:
"""
Call Doubao chat completion API to get the answer
:param session: a conversation session
:param args: model args
:param retry_count: retry count
:return: {}
"""
try:
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer " + self.api_key
}
body = args.copy()
body["messages"] = session.messages
# Disable thinking by default for better efficiency
body["thinking"] = {"type": "disabled"}
res = requests.post(
f"{self.base_url}/chat/completions",
headers=headers,
json=body
)
if res.status_code == 200:
response = res.json()
return {
"total_tokens": response["usage"]["total_tokens"],
"completion_tokens": response["usage"]["completion_tokens"],
"content": response["choices"][0]["message"]["content"]
}
else:
response = res.json()
error = response.get("error", {})
logger.error(f"[DOUBAO] chat failed, status_code={res.status_code}, "
f"msg={error.get('message')}, type={error.get('type')}")
result = {"completion_tokens": 0, "content": "提问太快啦,请休息一下再问我吧"}
need_retry = False
if res.status_code >= 500:
logger.warn(f"[DOUBAO] do retry, times={retry_count}")
need_retry = retry_count < 2
elif res.status_code == 401:
result["content"] = "授权失败,请检查API Key是否正确"
elif res.status_code == 429:
result["content"] = "请求过于频繁,请稍后再试"
need_retry = retry_count < 2
else:
need_retry = False
if need_retry:
time.sleep(3)
return self.reply_text(session, args, retry_count + 1)
else:
return result
except Exception as e:
logger.exception(e)
need_retry = retry_count < 2
result = {"completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
if need_retry:
return self.reply_text(session, args, retry_count + 1)
else:
return result
# ==================== Agent mode support ====================
def call_with_tools(self, messages, tools=None, stream: bool = False, **kwargs):
"""
Call Doubao API with tool support for agent integration.
This method handles:
1. Format conversion (Claude format -> OpenAI format)
2. System prompt injection
3. Streaming SSE response with tool_calls
4. Thinking (reasoning) is disabled by default for efficiency
Args:
messages: List of messages (may be in Claude format from agent)
tools: List of tool definitions (may be in Claude format from agent)
stream: Whether to use streaming
**kwargs: Additional parameters (max_tokens, temperature, system, model, etc.)
Returns:
Generator yielding OpenAI-format chunks (for streaming)
"""
try:
# Convert messages from Claude format to OpenAI format
converted_messages = self._convert_messages_to_openai_format(messages)
# Inject system prompt if provided
system_prompt = kwargs.pop("system", None)
if system_prompt:
if not converted_messages or converted_messages[0].get("role") != "system":
converted_messages.insert(0, {"role": "system", "content": system_prompt})
else:
converted_messages[0] = {"role": "system", "content": system_prompt}
# Convert tools from Claude format to OpenAI format
converted_tools = None
if tools:
converted_tools = self._convert_tools_to_openai_format(tools)
# Resolve model / temperature
model = kwargs.pop("model", None) or self.args["model"]
max_tokens = kwargs.pop("max_tokens", None)
# Don't pop temperature, just ignore it - let API use default
kwargs.pop("temperature", None)
# Build request body (omit temperature, let the API use its own default)
request_body = {
"model": model,
"messages": converted_messages,
"stream": stream,
}
if max_tokens is not None:
request_body["max_tokens"] = max_tokens
# Add tools
if converted_tools:
request_body["tools"] = converted_tools
request_body["tool_choice"] = "auto"
# Explicitly disable thinking to avoid reasoning_content issues
# in multi-turn tool calls
request_body["thinking"] = {"type": "disabled"}
logger.debug(f"[DOUBAO] API call: model={model}, "
f"tools={len(converted_tools) if converted_tools else 0}, stream={stream}")
if stream:
return self._handle_stream_response(request_body)
else:
return self._handle_sync_response(request_body)
except Exception as e:
logger.error(f"[DOUBAO] call_with_tools error: {e}")
import traceback
logger.error(traceback.format_exc())
def error_generator():
yield {"error": True, "message": str(e), "status_code": 500}
return error_generator()
# -------------------- streaming --------------------
def _handle_stream_response(self, request_body: dict):
"""Handle streaming SSE response from Doubao API and yield OpenAI-format chunks."""
try:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
url = f"{self.base_url}/chat/completions"
response = requests.post(url, headers=headers, json=request_body, stream=True, timeout=120)
if response.status_code != 200:
error_msg = response.text
logger.error(f"[DOUBAO] API error: status={response.status_code}, msg={error_msg}")
yield {"error": True, "message": error_msg, "status_code": response.status_code}
return
current_tool_calls = {}
finish_reason = None
for line in response.iter_lines():
if not line:
continue
line = line.decode("utf-8")
if not line.startswith("data: "):
continue
data_str = line[6:] # Remove "data: " prefix
if data_str.strip() == "[DONE]":
break
try:
chunk = json.loads(data_str)
except json.JSONDecodeError as e:
logger.warning(f"[DOUBAO] JSON decode error: {e}, data: {data_str[:200]}")
continue
# Check for error in chunk
if chunk.get("error"):
error_data = chunk["error"]
error_msg = error_data.get("message", "Unknown error") if isinstance(error_data, dict) else str(error_data)
logger.error(f"[DOUBAO] stream error: {error_msg}")
yield {"error": True, "message": error_msg, "status_code": 500}
return
if not chunk.get("choices"):
continue
choice = chunk["choices"][0]
delta = choice.get("delta", {})
# Skip reasoning_content (thinking) - don't log or forward
if delta.get("reasoning_content"):
continue
# Handle text content
if "content" in delta and delta["content"]:
yield {
"choices": [{
"index": 0,
"delta": {
"role": "assistant",
"content": delta["content"]
}
}]
}
# Handle tool_calls (streamed incrementally)
if "tool_calls" in delta:
for tool_call_chunk in delta["tool_calls"]:
index = tool_call_chunk.get("index", 0)
if index not in current_tool_calls:
current_tool_calls[index] = {
"id": tool_call_chunk.get("id", ""),
"type": "tool_use",
"name": tool_call_chunk.get("function", {}).get("name", ""),
"input": ""
}
# Accumulate arguments
if "function" in tool_call_chunk and "arguments" in tool_call_chunk["function"]:
current_tool_calls[index]["input"] += tool_call_chunk["function"]["arguments"]
# Yield OpenAI-format tool call delta
yield {
"choices": [{
"index": 0,
"delta": {
"tool_calls": [tool_call_chunk]
}
}]
}
# Capture finish_reason
if choice.get("finish_reason"):
finish_reason = choice["finish_reason"]
# Final chunk with finish_reason
yield {
"choices": [{
"index": 0,
"delta": {},
"finish_reason": finish_reason
}]
}
except requests.exceptions.Timeout:
logger.error("[DOUBAO] Request timeout")
yield {"error": True, "message": "Request timeout", "status_code": 500}
except Exception as e:
logger.error(f"[DOUBAO] stream response error: {e}")
import traceback
logger.error(traceback.format_exc())
yield {"error": True, "message": str(e), "status_code": 500}
# -------------------- sync --------------------
def _handle_sync_response(self, request_body: dict):
"""Handle synchronous API response and yield a single result dict."""
try:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
request_body.pop("stream", None)
url = f"{self.base_url}/chat/completions"
response = requests.post(url, headers=headers, json=request_body, timeout=120)
if response.status_code != 200:
error_msg = response.text
logger.error(f"[DOUBAO] API error: status={response.status_code}, msg={error_msg}")
yield {"error": True, "message": error_msg, "status_code": response.status_code}
return
result = response.json()
message = result["choices"][0]["message"]
finish_reason = result["choices"][0]["finish_reason"]
response_data = {"role": "assistant", "content": []}
# Add text content
if message.get("content"):
response_data["content"].append({
"type": "text",
"text": message["content"]
})
# Add tool calls
if message.get("tool_calls"):
for tool_call in message["tool_calls"]:
response_data["content"].append({
"type": "tool_use",
"id": tool_call["id"],
"name": tool_call["function"]["name"],
"input": json.loads(tool_call["function"]["arguments"])
})
# Map finish_reason
if finish_reason == "tool_calls":
response_data["stop_reason"] = "tool_use"
elif finish_reason == "stop":
response_data["stop_reason"] = "end_turn"
else:
response_data["stop_reason"] = finish_reason
yield response_data
except requests.exceptions.Timeout:
logger.error("[DOUBAO] Request timeout")
yield {"error": True, "message": "Request timeout", "status_code": 500}
except Exception as e:
logger.error(f"[DOUBAO] sync response error: {e}")
import traceback
logger.error(traceback.format_exc())
yield {"error": True, "message": str(e), "status_code": 500}
# -------------------- format conversion --------------------
def _convert_messages_to_openai_format(self, messages):
"""
Convert messages from Claude format to OpenAI format.
Claude format uses content blocks: tool_use / tool_result / text
OpenAI format uses tool_calls in assistant, role=tool for results
"""
if not messages:
return []
converted = []
for msg in messages:
role = msg.get("role")
content = msg.get("content")
# Already a simple string - pass through
if isinstance(content, str):
converted.append(msg)
continue
if not isinstance(content, list):
converted.append(msg)
continue
if role == "user":
text_parts = []
tool_results = []
for block in content:
if not isinstance(block, dict):
continue
if block.get("type") == "text":
text_parts.append(block.get("text", ""))
elif block.get("type") == "tool_result":
tool_call_id = block.get("tool_use_id") or ""
result_content = block.get("content", "")
if not isinstance(result_content, str):
result_content = json.dumps(result_content, ensure_ascii=False)
tool_results.append({
"role": "tool",
"tool_call_id": tool_call_id,
"content": result_content
})
# Tool results first (must come right after assistant with tool_calls)
for tr in tool_results:
converted.append(tr)
if text_parts:
converted.append({"role": "user", "content": "\n".join(text_parts)})
elif role == "assistant":
openai_msg = {"role": "assistant"}
text_parts = []
tool_calls = []
for block in content:
if not isinstance(block, dict):
continue
if block.get("type") == "text":
text_parts.append(block.get("text", ""))
elif block.get("type") == "tool_use":
tool_calls.append({
"id": block.get("id"),
"type": "function",
"function": {
"name": block.get("name"),
"arguments": json.dumps(block.get("input", {}))
}
})
if text_parts:
openai_msg["content"] = "\n".join(text_parts)
elif not tool_calls:
openai_msg["content"] = ""
if tool_calls:
openai_msg["tool_calls"] = tool_calls
if not text_parts:
openai_msg["content"] = None
converted.append(openai_msg)
else:
converted.append(msg)
return converted
def _convert_tools_to_openai_format(self, tools):
"""
Convert tools from Claude format to OpenAI format.
Claude: {name, description, input_schema}
OpenAI: {type: "function", function: {name, description, parameters}}
"""
if not tools:
return None
converted = []
for tool in tools:
# Already in OpenAI format
if "type" in tool and tool["type"] == "function":
converted.append(tool)
else:
converted.append({
"type": "function",
"function": {
"name": tool.get("name"),
"description": tool.get("description"),
"parameters": tool.get("input_schema", {})
}
})
return converted
================================================
FILE: models/doubao/doubao_session.py
================================================
from models.session_manager import Session
from common.log import logger
class DoubaoSession(Session):
def __init__(self, session_id, system_prompt=None, model="doubao-seed-2-0-pro-260215"):
super().__init__(session_id, system_prompt)
self.model = model
self.reset()
def discard_exceeding(self, max_tokens, cur_tokens=None):
precise = True
try:
cur_tokens = self.calc_tokens()
except Exception as e:
precise = False
if cur_tokens is None:
raise e
logger.debug("Exception when counting tokens precisely for query: {}".format(e))
while cur_tokens > max_tokens:
if len(self.messages) > 2:
self.messages.pop(1)
elif len(self.messages) == 2 and self.messages[1]["role"] == "assistant":
self.messages.pop(1)
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
break
elif len(self.messages) == 2 and self.messages[1]["role"] == "user":
logger.warn("user message exceed max_tokens. total_tokens={}".format(cur_tokens))
break
else:
logger.debug("max_tokens={}, total_tokens={}, len(messages)={}".format(
max_tokens, cur_tokens, len(self.messages)))
break
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
return cur_tokens
def calc_tokens(self):
return num_tokens_from_messages(self.messages, self.model)
def num_tokens_from_messages(messages, model):
tokens = 0
for msg in messages:
tokens += len(msg["content"])
return tokens
================================================
FILE: models/gemini/google_gemini_bot.py
================================================
"""
Google gemini bot
@author zhayujie
@Date 2023/12/15
"""
# encoding:utf-8
import base64
import json
import mimetypes
import os
import re
import time
import requests
from models.bot import Bot
from models.session_manager import SessionManager
from bridge.context import ContextType, Context
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf
from models.chatgpt.chat_gpt_session import ChatGPTSession
from models.baidu.baidu_wenxin_session import BaiduWenxinSession
# OpenAI对话模型API (可用)
class GoogleGeminiBot(Bot):
def __init__(self):
super().__init__()
self.sessions = SessionManager(ChatGPTSession, model=conf().get("model") or "gpt-3.5-turbo")
@property
def api_key(self):
return conf().get("gemini_api_key")
@property
def api_base(self):
base = conf().get("gemini_api_base", "").strip()
if base:
return base.rstrip('/')
return "https://generativelanguage.googleapis.com"
def reply(self, query, context: Context = None) -> Reply:
session_id = None
try:
if context.type != ContextType.TEXT:
logger.warn(f"[Gemini] Unsupported message type, type={context.type}")
return Reply(ReplyType.TEXT, None)
logger.info(f"[Gemini] query={query}")
session_id = context["session_id"]
session = self.sessions.session_query(query, session_id)
filtered_messages = self.filter_messages(session.messages)
logger.debug(f"[Gemini] messages={filtered_messages}")
response = self.call_with_tools(
messages=filtered_messages,
tools=None,
stream=False,
model=self.model
)
if isinstance(response, dict) and response.get("error"):
error_message = response.get("message", "Failed to invoke [Gemini] api!")
logger.error(f"[Gemini] API error: {error_message}")
self.sessions.session_reply(error_message, session_id)
return Reply(ReplyType.ERROR, error_message)
choices = response.get("choices", []) if isinstance(response, dict) else []
if choices and choices[0].get("message"):
reply_text = choices[0]["message"].get("content")
if reply_text:
logger.info(f"[Gemini] reply={reply_text}")
self.sessions.session_reply(reply_text, session_id)
return Reply(ReplyType.TEXT, reply_text)
logger.warning("[Gemini] No valid response generated. Checking safety ratings.")
safety_ratings = response.get("safety_ratings", []) if isinstance(response, dict) else []
if safety_ratings:
for rating in safety_ratings:
category = rating.get("category", "UNKNOWN")
probability = rating.get("probability", "UNKNOWN")
logger.warning(f"[Gemini] Safety rating: {category} - {probability}")
error_message = "No valid response generated due to safety constraints."
self.sessions.session_reply(error_message, session_id)
return Reply(ReplyType.ERROR, error_message)
except Exception as e:
logger.error(f"[Gemini] Error generating response: {str(e)}", exc_info=True)
error_message = "Failed to invoke [Gemini] api!"
if session_id:
self.sessions.session_reply(error_message, session_id)
return Reply(ReplyType.ERROR, error_message)
def _convert_to_gemini_messages(self, messages: list):
res = []
for msg in messages:
if msg.get("role") == "user":
role = "user"
elif msg.get("role") == "assistant":
role = "model"
elif msg.get("role") == "system":
role = "user"
else:
continue
res.append({
"role": role,
"parts": [{"text": msg.get("content")}]
})
return res
@staticmethod
def filter_messages(messages: list):
res = []
turn = "user"
if not messages:
return res
for i in range(len(messages) - 1, -1, -1):
message = messages[i]
role = message.get("role")
if role == "system":
res.insert(0, message)
continue
if role != turn:
continue
res.insert(0, message)
if turn == "user":
turn = "assistant"
elif turn == "assistant":
turn = "user"
return res
@staticmethod
def _extract_image_paths_from_text(content: str):
if not isinstance(content, str):
return "", []
pattern = r"\[图片:\s*([^\]]+)\]"
image_paths = [m.strip().strip("'\"") for m in re.findall(pattern, content) if m.strip()]
cleaned_text = re.sub(pattern, "", content)
cleaned_text = re.sub(r"\n{3,}", "\n\n", cleaned_text).strip()
return cleaned_text, image_paths
@staticmethod
def _build_image_inline_part(image_path: str):
if not image_path:
return None
try:
if image_path.startswith("file://"):
image_path = image_path[7:]
image_path = os.path.expanduser(image_path)
if not os.path.exists(image_path):
logger.warning(f"[Gemini] Image file not found: {image_path}")
return None
with open(image_path, "rb") as f:
image_bytes = f.read()
mime_type = mimetypes.guess_type(image_path)[0] or "image/png"
if not mime_type.startswith("image/"):
mime_type = "image/png"
return {
"inlineData": {
"mimeType": mime_type,
"data": base64.b64encode(image_bytes).decode("utf-8")
}
}
except Exception as e:
logger.warning(f"[Gemini] Failed to build inline image part from path={image_path}, err={e}")
return None
@staticmethod
def _build_inline_part_from_image_url(image_url):
if not image_url:
return None
if isinstance(image_url, dict):
image_url = image_url.get("url")
if not image_url or not isinstance(image_url, str):
return None
if image_url.startswith("data:"):
match = re.match(r"^data:([^;]+);base64,(.+)$", image_url, re.DOTALL)
if not match:
logger.warning("[Gemini] Invalid data URL for image block")
return None
return {
"inlineData": {
"mimeType": match.group(1),
"data": match.group(2).strip()
}
}
if image_url.startswith("file://") or os.path.exists(os.path.expanduser(image_url)):
return GoogleGeminiBot._build_image_inline_part(image_url)
if image_url.startswith("http://") or image_url.startswith("https://"):
try:
response = requests.get(image_url, timeout=20)
if response.status_code != 200:
logger.warning(f"[Gemini] Failed to fetch remote image: status={response.status_code}, url={image_url}")
return None
mime_type = response.headers.get("Content-Type", "image/png").split(";")[0].strip()
if not mime_type.startswith("image/"):
mime_type = "image/png"
return {
"inlineData": {
"mimeType": mime_type,
"data": base64.b64encode(response.content).decode("utf-8")
}
}
except Exception as e:
logger.warning(f"[Gemini] Failed to download remote image: url={image_url}, err={e}")
return None
logger.warning(f"[Gemini] Unsupported image URL format: {image_url[:120]}")
return None
def call_with_tools(self, messages, tools=None, stream=False, **kwargs):
"""
Call Gemini API with tool support using REST API (following official docs)
Args:
messages: List of messages (OpenAI format)
tools: List of tool definitions (OpenAI/Claude format)
stream: Whether to use streaming
**kwargs: Additional parameters (system, max_tokens, temperature, etc.)
Returns:
Formatted response compatible with OpenAI format or generator for streaming
"""
try:
model_name = kwargs.get("model", self.model or "gemini-1.5-flash")
# Build REST API payload
payload = {"contents": []}
inline_image_count = 0
# Keep legacy behavior: disable Gemini safety blocking like old SDK path.
payload["safetySettings"] = [
{"category": "HARM_CATEGORY_HATE_SPEECH", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_HARASSMENT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_SEXUALLY_EXPLICIT", "threshold": "BLOCK_NONE"},
{"category": "HARM_CATEGORY_DANGEROUS_CONTENT", "threshold": "BLOCK_NONE"},
]
# Extract and set system instruction
system_prompt = kwargs.get("system", "")
if not system_prompt:
for msg in messages:
if msg.get("role") == "system":
system_prompt = msg["content"]
break
if system_prompt:
payload["system_instruction"] = {
"parts": [{"text": system_prompt}]
}
# Convert messages to Gemini format
for msg in messages:
role = msg.get("role")
content = msg.get("content", "")
if role == "system":
continue
# Convert role
gemini_role = "user" if role in ["user", "tool"] else "model"
# Handle different content formats
parts = []
if isinstance(content, str):
# Text with optional [图片: /path/to/file] markers
cleaned_text, image_paths = self._extract_image_paths_from_text(content)
if cleaned_text:
parts.append({"text": cleaned_text})
image_added = False
for image_path in image_paths:
image_part = self._build_image_inline_part(image_path)
if image_part:
parts.append(image_part)
image_added = True
inline_image_count += 1
if not cleaned_text and not image_added and content:
parts.append({"text": content})
elif isinstance(content, list):
# List of content blocks (Claude format)
for block in content:
if not isinstance(block, dict):
if isinstance(block, str):
parts.append({"text": block})
continue
block_type = block.get("type")
if block_type == "text":
# Text block with optional image markers
block_text = block.get("text", "")
cleaned_text, image_paths = self._extract_image_paths_from_text(block_text)
if cleaned_text:
parts.append({"text": cleaned_text})
for image_path in image_paths:
image_part = self._build_image_inline_part(image_path)
if image_part:
parts.append(image_part)
elif block_type in ["image", "image_url"]:
# OpenAI format: {"type":"image_url","image_url":{"url":"..."}}
# Claude format: {"type":"image","source":{"type":"base64","media_type":"...","data":"..."}}
image_part = None
if block_type == "image":
source = block.get("source", {})
if isinstance(source, dict) and source.get("type") == "base64" and source.get("data"):
image_part = {
"inlineData": {
"mimeType": source.get("media_type", "image/png"),
"data": source.get("data")
}
}
elif block.get("image_url"):
image_part = self._build_inline_part_from_image_url(block.get("image_url"))
else:
image_part = self._build_inline_part_from_image_url(block.get("image_url"))
if image_part:
parts.append(image_part)
inline_image_count += 1
else:
logger.warning(f"[Gemini] Skip invalid image block: {str(block)[:200]}")
elif block_type == "tool_result":
# Convert Claude tool_result to Gemini functionResponse
tool_use_id = block.get("tool_use_id")
tool_content = block.get("content", "")
# Try to parse tool content as JSON
try:
if isinstance(tool_content, str):
tool_result_data = json.loads(tool_content)
else:
tool_result_data = tool_content
except Exception:
tool_result_data = {"result": tool_content}
# Find the tool name from previous messages
# Look for the corresponding tool_call in model's message
tool_name = None
for prev_msg in reversed(messages):
if prev_msg.get("role") == "assistant":
prev_content = prev_msg.get("content", [])
if isinstance(prev_content, list):
for prev_block in prev_content:
if isinstance(prev_block, dict) and prev_block.get("type") == "tool_use":
if prev_block.get("id") == tool_use_id:
tool_name = prev_block.get("name")
break
if tool_name:
break
# Gemini functionResponse format
parts.append({
"functionResponse": {
"name": tool_name or "unknown",
"response": tool_result_data
}
})
elif "text" in block:
# Generic text field
parts.append({"text": block["text"]})
if parts:
payload["contents"].append({
"role": gemini_role,
"parts": parts
})
if inline_image_count > 0:
logger.info(f"[Gemini] Multimodal request includes {inline_image_count} image part(s)")
# Generation config
gen_config = {}
if kwargs.get("temperature") is not None:
gen_config["temperature"] = kwargs["temperature"]
if gen_config:
payload["generationConfig"] = gen_config
# Convert tools to Gemini format (REST API style)
if tools:
gemini_tools = self._convert_tools_to_gemini_rest_format(tools)
if gemini_tools:
payload["tools"] = gemini_tools
# Make REST API call
base_url = f"{self.api_base}/v1beta"
endpoint = f"{base_url}/models/{model_name}:generateContent"
if stream:
endpoint = f"{base_url}/models/{model_name}:streamGenerateContent?alt=sse"
headers = {
"x-goog-api-key": self.api_key,
"Content-Type": "application/json"
}
response = requests.post(
endpoint,
headers=headers,
json=payload,
stream=stream,
timeout=60
)
# Check HTTP status for stream mode (for non-stream, it's checked in handler)
if stream and response.status_code != 200:
error_text = response.text
logger.error(f"[Gemini] API error ({response.status_code}): {error_text}")
def error_generator():
yield {
"error": True,
"message": f"Gemini API error: {error_text}",
"status_code": response.status_code
}
return error_generator()
if stream:
return self._handle_gemini_rest_stream_response(response, model_name)
else:
return self._handle_gemini_rest_sync_response(response, model_name)
except Exception as e:
logger.error(f"[Gemini] call_with_tools error: {e}", exc_info=True)
error_msg = str(e) # Capture error message before creating generator
if stream:
def error_generator():
yield {
"error": True,
"message": error_msg,
"status_code": 500
}
return error_generator()
else:
return {
"error": True,
"message": str(e),
"status_code": 500
}
def _convert_tools_to_gemini_rest_format(self, tools_list):
"""
Convert tools to Gemini REST API format
Handles both OpenAI and Claude/Agent formats.
Returns: [{"functionDeclarations": [...]}]
"""
function_declarations = []
for tool in tools_list:
# Extract name, description, and parameters based on format
if tool.get("type") == "function":
# OpenAI format: {"type": "function", "function": {...}}
func = tool.get("function", {})
name = func.get("name")
description = func.get("description", "")
parameters = func.get("parameters", {})
else:
# Claude/Agent format: {"name": "...", "description": "...", "input_schema": {...}}
name = tool.get("name")
description = tool.get("description", "")
parameters = tool.get("input_schema", {})
if not name:
logger.warning(f"[Gemini] Skipping tool without name: {tool}")
continue
function_declarations.append({
"name": name,
"description": description,
"parameters": parameters
})
# All functionDeclarations must be in a single tools object (per Gemini REST API spec)
return [{
"functionDeclarations": function_declarations
}] if function_declarations else []
def _handle_gemini_rest_sync_response(self, response, model_name):
"""Handle Gemini REST API sync response and convert to OpenAI format"""
try:
if response.status_code != 200:
error_text = response.text
logger.error(f"[Gemini] API error ({response.status_code}): {error_text}")
return {
"error": True,
"message": f"Gemini API error: {error_text}",
"status_code": response.status_code
}
data = response.json()
logger.debug(f"[Gemini] Response data: {json.dumps(data, ensure_ascii=False)[:500]}")
# Extract from Gemini response format
candidates = data.get("candidates", [])
if not candidates:
logger.warning("[Gemini] No candidates in response")
prompt_feedback = data.get("promptFeedback", {})
return {
"error": True,
"message": "No candidates in response",
"status_code": 500,
"safety_ratings": prompt_feedback.get("safetyRatings", [])
}
candidate = candidates[0]
content = candidate.get("content", {})
parts = content.get("parts", [])
safety_ratings = candidate.get("safetyRatings", [])
logger.debug(f"[Gemini] Candidate parts count: {len(parts)}")
# Extract text and function calls
text_content = ""
tool_calls = []
for part in parts:
# Check for text
if "text" in part:
text_content += part["text"]
logger.debug(f"[Gemini] Text part: {part['text'][:100]}...")
# Check for functionCall (per REST API docs)
if "functionCall" in part:
fc = part["functionCall"]
logger.info(f"[Gemini] Function call detected: {fc.get('name')}")
tool_calls.append({
"id": f"call_{int(time.time() * 1000000)}",
"type": "function",
"function": {
"name": fc.get("name"),
"arguments": json.dumps(fc.get("args", {}))
}
})
logger.info(f"[Gemini] Response: text={len(text_content)} chars, tool_calls={len(tool_calls)}")
# Build OpenAI format response
message_dict = {
"role": "assistant",
"content": text_content or None
}
if tool_calls:
message_dict["tool_calls"] = tool_calls
return {
"id": f"chatcmpl-{time.time()}",
"object": "chat.completion",
"created": int(time.time()),
"model": model_name,
"choices": [{
"index": 0,
"message": message_dict,
"finish_reason": "tool_calls" if tool_calls else "stop"
}],
"usage": data.get("usageMetadata", {}),
"safety_ratings": safety_ratings
}
except Exception as e:
logger.error(f"[Gemini] sync response error: {e}", exc_info=True)
return {
"error": True,
"message": str(e),
"status_code": 500
}
def _handle_gemini_rest_stream_response(self, response, model_name):
"""Handle Gemini REST API stream response"""
try:
all_tool_calls = []
has_sent_tool_calls = False
has_content = False # Track if any content was sent
chunk_count = 0
last_finish_reason = None
last_safety_ratings = None
for line in response.iter_lines():
if not line:
continue
line = line.decode('utf-8')
# Skip SSE prefixes
if line.startswith('data: '):
line = line[6:]
if not line or line == '[DONE]':
continue
try:
chunk_data = json.loads(line)
chunk_count += 1
candidates = chunk_data.get("candidates", [])
if not candidates:
logger.debug("[Gemini] No candidates in chunk")
continue
candidate = candidates[0]
# 记录 finish_reason 和 safety_ratings
if "finishReason" in candidate:
last_finish_reason = candidate["finishReason"]
if "safetyRatings" in candidate:
last_safety_ratings = candidate["safetyRatings"]
content = candidate.get("content", {})
parts = content.get("parts", [])
if not parts:
logger.debug("[Gemini] No parts in candidate content")
# Stream text content
for part in parts:
if "text" in part and part["text"]:
has_content = True
yield {
"id": f"chatcmpl-{time.time()}",
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": model_name,
"choices": [{
"index": 0,
"delta": {"content": part["text"]},
"finish_reason": None
}]
}
# Collect function calls
if "functionCall" in part:
fc = part["functionCall"]
logger.info(f"[Gemini] Function call: {fc.get('name')}")
all_tool_calls.append({
"index": len(all_tool_calls), # Add index to differentiate multiple tool calls
"id": f"call_{int(time.time() * 1000000)}_{len(all_tool_calls)}",
"type": "function",
"function": {
"name": fc.get("name"),
"arguments": json.dumps(fc.get("args", {}))
}
})
except json.JSONDecodeError as je:
logger.debug(f"[Gemini] JSON decode error: {je}")
continue
# Send tool calls if any were collected
if all_tool_calls and not has_sent_tool_calls:
yield {
"id": f"chatcmpl-{time.time()}",
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": model_name,
"choices": [{
"index": 0,
"delta": {"tool_calls": all_tool_calls},
"finish_reason": None
}]
}
has_sent_tool_calls = True
# 如果返回空响应,记录详细警告
if not has_content and not all_tool_calls:
logger.warning(f"[Gemini] ⚠️ Empty response detected!")
# Final chunk
yield {
"id": f"chatcmpl-{time.time()}",
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": model_name,
"choices": [{
"index": 0,
"delta": {},
"finish_reason": "tool_calls" if all_tool_calls else "stop"
}]
}
except Exception as e:
logger.error(f"[Gemini] stream response error: {e}", exc_info=True)
error_msg = str(e)
yield {
"error": True,
"message": error_msg,
"status_code": 500
}
def _convert_tools_to_gemini_format(self, openai_tools):
"""Convert OpenAI tool format to Gemini function declarations"""
import google.generativeai as genai
gemini_functions = []
for tool in openai_tools:
if tool.get("type") == "function":
func = tool.get("function", {})
gemini_functions.append(
genai.protos.FunctionDeclaration(
name=func.get("name"),
description=func.get("description", ""),
parameters=func.get("parameters", {})
)
)
if gemini_functions:
return [genai.protos.Tool(function_declarations=gemini_functions)]
return None
def _handle_gemini_sync_response(self, model, messages, request_params, model_name):
"""Handle synchronous Gemini API response"""
import json
response = model.generate_content(messages, **request_params)
# Extract text content and function calls
text_content = ""
tool_calls = []
if response.candidates and response.candidates[0].content:
for part in response.candidates[0].content.parts:
if hasattr(part, 'text') and part.text:
text_content += part.text
elif hasattr(part, 'function_call') and part.function_call:
# Convert Gemini function call to OpenAI format
func_call = part.function_call
tool_calls.append({
"id": f"call_{hash(func_call.name)}",
"type": "function",
"function": {
"name": func_call.name,
"arguments": json.dumps(dict(func_call.args))
}
})
# Build message in OpenAI format
message = {
"role": "assistant",
"content": text_content
}
if tool_calls:
message["tool_calls"] = tool_calls
# Format response to match OpenAI structure
formatted_response = {
"id": f"gemini_{int(time.time())}",
"object": "chat.completion",
"created": int(time.time()),
"model": model_name,
"choices": [
{
"index": 0,
"message": message,
"finish_reason": "stop" if not tool_calls else "tool_calls"
}
],
"usage": {
"prompt_tokens": 0, # Gemini doesn't provide token counts in the same way
"completion_tokens": 0,
"total_tokens": 0
}
}
logger.info(f"[Gemini] call_with_tools reply, model={model_name}")
return formatted_response
def _handle_gemini_stream_response(self, model, messages, request_params, model_name):
"""Handle streaming Gemini API response"""
import json
try:
response_stream = model.generate_content(messages, stream=True, **request_params)
for chunk in response_stream:
if chunk.candidates and chunk.candidates[0].content:
for part in chunk.candidates[0].content.parts:
if hasattr(part, 'text') and part.text:
# Text content
yield {
"id": f"gemini_{int(time.time())}",
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": model_name,
"choices": [{
"index": 0,
"delta": {"content": part.text},
"finish_reason": None
}]
}
elif hasattr(part, 'function_call') and part.function_call:
# Function call
func_call = part.function_call
yield {
"id": f"gemini_{int(time.time())}",
"object": "chat.completion.chunk",
"created": int(time.time()),
"model": model_name,
"choices": [{
"index": 0,
"delta": {
"tool_calls": [{
"index": 0,
"id": f"call_{hash(func_call.name)}",
"type": "function",
"function": {
"name": func_call.name,
"arguments": json.dumps(dict(func_call.args))
}
}]
},
"finish_reason": None
}]
}
except Exception as e:
logger.error(f"[Gemini] stream response error: {e}")
yield {
"error": True,
"message": str(e),
"status_code": 500
}
================================================
FILE: models/linkai/link_ai_bot.py
================================================
# access LinkAI knowledge base platform
# docs: https://link-ai.tech/platform/link-app/wechat
import re
import time
import requests
import json
import config
from models.bot import Bot
from models.openai_compatible_bot import OpenAICompatibleBot
from models.chatgpt.chat_gpt_session import ChatGPTSession
from models.session_manager import SessionManager
from bridge.context import Context, ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf, pconf
import threading
from common import memory, utils
import base64
import os
class LinkAIBot(Bot, OpenAICompatibleBot):
# authentication failed
AUTH_FAILED_CODE = 401
NO_QUOTA_CODE = 406
def __init__(self):
super().__init__()
self.sessions = LinkAISessionManager(LinkAISession, model=conf().get("model") or "gpt-3.5-turbo")
self.args = {}
def get_api_config(self):
"""Get API configuration for OpenAI-compatible base class"""
return {
'api_key': conf().get("open_ai_api_key"), # LinkAI uses OpenAI-compatible key
'api_base': conf().get("open_ai_api_base", "https://api.link-ai.tech/v1"),
'model': conf().get("model", "gpt-3.5-turbo"),
'default_temperature': conf().get("temperature", 0.9),
'default_top_p': conf().get("top_p", 1.0),
'default_frequency_penalty': conf().get("frequency_penalty", 0.0),
'default_presence_penalty': conf().get("presence_penalty", 0.0),
}
def reply(self, query, context: Context = None) -> Reply:
if context.type == ContextType.TEXT:
return self._chat(query, context)
elif context.type == ContextType.IMAGE_CREATE:
if not conf().get("text_to_image"):
logger.warn("[LinkAI] text_to_image is not enabled, ignore the IMAGE_CREATE request")
return Reply(ReplyType.TEXT, "")
ok, res = self.create_img(query, 0)
if ok:
reply = Reply(ReplyType.IMAGE_URL, res)
else:
reply = Reply(ReplyType.ERROR, res)
return reply
else:
reply = Reply(ReplyType.ERROR, "Bot不支持处理{}类型的消息".format(context.type))
return reply
def _chat(self, query, context, retry_count=0) -> Reply:
"""
发起对话请求
:param query: 请求提示词
:param context: 对话上下文
:param retry_count: 当前递归重试次数
:return: 回复
"""
if retry_count > 2:
# exit from retry 2 times
logger.warn("[LINKAI] failed after maximum number of retry times")
return Reply(ReplyType.TEXT, "请再问我一次吧")
try:
# load config
if context.get("generate_breaked_by"):
logger.info(f"[LINKAI] won't set appcode because a plugin ({context['generate_breaked_by']}) affected the context")
app_code = None
else:
plugin_app_code = self._find_group_mapping_code(context)
app_code = context.kwargs.get("app_code") or plugin_app_code or conf().get("linkai_app_code")
linkai_api_key = conf().get("linkai_api_key")
session_id = context["session_id"]
session_message = self.sessions.session_msg_query(query, session_id)
logger.debug(f"[LinkAI] session={session_message}, session_id={session_id}")
# image process
img_cache = memory.USER_IMAGE_CACHE.get(session_id)
if img_cache:
messages = self._process_image_msg(app_code=app_code, session_id=session_id, query=query, img_cache=img_cache)
if messages:
session_message = messages
model = conf().get("model")
# remove system message
if session_message[0].get("role") == "system":
if app_code or model == "wenxin":
session_message.pop(0)
body = {
"app_code": app_code,
"messages": session_message,
"model": model, # 对话模型的名称, 支持 gpt-3.5-turbo, gpt-3.5-turbo-16k, gpt-4, wenxin, xunfei
"temperature": conf().get("temperature"),
"top_p": conf().get("top_p", 1),
"frequency_penalty": conf().get("frequency_penalty", 0.0), # [-2,2]之间,该值越大则更倾向于产生不同的内容
"presence_penalty": conf().get("presence_penalty", 0.0), # [-2,2]之间,该值越大则更倾向于产生不同的内容
"session_id": session_id,
"sender_id": session_id,
"channel_type": context.get("channel_type") or conf().get("channel_type", "web")
}
try:
from linkai import LinkAIClient
client_id = LinkAIClient.fetch_client_id()
if client_id:
body["client_id"] = client_id
# start: client info deliver
if context.kwargs.get("msg"):
body["session_id"] = context.kwargs.get("msg").from_user_id
if context.kwargs.get("msg").is_group:
body["is_group"] = True
body["group_name"] = context.kwargs.get("msg").from_user_nickname
body["sender_name"] = context.kwargs.get("msg").actual_user_nickname
else:
if body.get("channel_type") in ["wechatcom_app"]:
body["sender_name"] = context.kwargs.get("msg").from_user_id
else:
body["sender_name"] = context.kwargs.get("msg").from_user_nickname
except Exception as e:
pass
file_id = context.kwargs.get("file_id")
if file_id:
body["file_id"] = file_id
logger.info(f"[LINKAI] query={query}, app_code={app_code}, model={body.get('model')}, file_id={file_id}")
headers = {"Authorization": "Bearer " + linkai_api_key}
# do http request
base_url = conf().get("linkai_api_base", "https://api.link-ai.tech")
res = requests.post(url=base_url + "/v1/chat/completions", json=body, headers=headers,
timeout=conf().get("request_timeout", 180))
if res.status_code == 200:
# execute success
response = res.json()
reply_content = response["choices"][0]["message"]["content"]
total_tokens = response["usage"]["total_tokens"]
res_code = response.get('code')
logger.info(f"[LINKAI] reply={reply_content}, total_tokens={total_tokens}, res_code={res_code}")
if res_code == 429:
logger.warn(f"[LINKAI] 用户访问超出限流配置,sender_id={body.get('sender_id')}")
else:
self.sessions.session_reply(reply_content, session_id, total_tokens, query=query)
agent_suffix = self._fetch_agent_suffix(response)
if agent_suffix:
reply_content += agent_suffix
if not agent_suffix:
knowledge_suffix = self._fetch_knowledge_search_suffix(response)
if knowledge_suffix:
reply_content += knowledge_suffix
# image process
if response["choices"][0].get("img_urls"):
thread = threading.Thread(target=self._send_image, args=(context.get("channel"), context, response["choices"][0].get("img_urls")))
thread.start()
reply_content = response["choices"][0].get("text_content")
if reply_content:
reply_content = self._process_url(reply_content)
return Reply(ReplyType.TEXT, reply_content)
else:
response = res.json()
error = response.get("error")
logger.error(f"[LINKAI] chat failed, status_code={res.status_code}, "
f"msg={error.get('message')}, type={error.get('type')}")
if res.status_code >= 500:
# server error, need retry
time.sleep(2)
logger.warn(f"[LINKAI] do retry, times={retry_count}")
return self._chat(query, context, retry_count + 1)
error_reply = "提问太快啦,请休息一下再问我吧"
if res.status_code == 409:
error_reply = "这个问题我还没有学会,请问我其它问题吧"
return Reply(ReplyType.TEXT, error_reply)
except Exception as e:
logger.exception(e)
# retry
time.sleep(2)
logger.warn(f"[LINKAI] do retry, times={retry_count}")
return self._chat(query, context, retry_count + 1)
def _process_image_msg(self, app_code: str, session_id: str, query:str, img_cache: dict):
try:
enable_image_input = False
app_info = self._fetch_app_info(app_code)
if not app_info:
logger.debug(f"[LinkAI] not found app, can't process images, app_code={app_code}")
return None
plugins = app_info.get("data").get("plugins")
for plugin in plugins:
if plugin.get("input_type") and "IMAGE" in plugin.get("input_type"):
enable_image_input = True
if not enable_image_input:
return
msg = img_cache.get("msg")
path = img_cache.get("path")
msg.prepare()
logger.info(f"[LinkAI] query with images, path={path}")
messages = self._build_vision_msg(query, path)
memory.USER_IMAGE_CACHE[session_id] = None
return messages
except Exception as e:
logger.exception(e)
def _find_group_mapping_code(self, context):
try:
if context.kwargs.get("isgroup"):
group_name = context.kwargs.get("msg").from_user_nickname
if config.plugin_config and config.plugin_config.get("linkai"):
linkai_config = config.plugin_config.get("linkai")
group_mapping = linkai_config.get("group_app_map")
if group_mapping and group_name:
return group_mapping.get(group_name)
except Exception as e:
logger.exception(e)
return None
def _build_vision_msg(self, query: str, path: str):
try:
suffix = utils.get_path_suffix(path)
with open(path, "rb") as file:
base64_str = base64.b64encode(file.read()).decode('utf-8')
messages = [{
"role": "user",
"content": [
{
"type": "text",
"text": query
},
{
"type": "image_url",
"image_url": {
"url": f"data:image/{suffix};base64,{base64_str}"
}
}
]
}]
return messages
except Exception as e:
logger.exception(e)
def reply_text(self, session: ChatGPTSession, app_code="", retry_count=0) -> dict:
if retry_count >= 2:
# exit from retry 2 times
logger.warn("[LINKAI] failed after maximum number of retry times")
return {
"total_tokens": 0,
"completion_tokens": 0,
"content": "请再问我一次吧"
}
try:
body = {
"app_code": app_code,
"messages": session.messages,
"model": conf().get("model") or "gpt-3.5-turbo", # 对话模型的名称, 支持 gpt-3.5-turbo, gpt-3.5-turbo-16k, gpt-4, wenxin, xunfei
"temperature": conf().get("temperature"),
"top_p": conf().get("top_p", 1),
"frequency_penalty": conf().get("frequency_penalty", 0.0), # [-2,2]之间,该值越大则更倾向于产生不同的内容
"presence_penalty": conf().get("presence_penalty", 0.0), # [-2,2]之间,该值越大则更倾向于产生不同的内容
}
if self.args.get("max_tokens"):
body["max_tokens"] = self.args.get("max_tokens")
headers = {"Authorization": "Bearer " + conf().get("linkai_api_key")}
# do http request
base_url = conf().get("linkai_api_base", "https://api.link-ai.tech")
res = requests.post(url=base_url + "/v1/chat/completions", json=body, headers=headers,
timeout=conf().get("request_timeout", 180))
if res.status_code == 200:
# execute success
response = res.json()
reply_content = response["choices"][0]["message"]["content"]
total_tokens = response["usage"]["total_tokens"]
logger.info(f"[LINKAI] reply={reply_content}, total_tokens={total_tokens}")
return {
"total_tokens": total_tokens,
"completion_tokens": response["usage"]["completion_tokens"],
"content": reply_content,
}
else:
response = res.json()
error = response.get("error")
logger.error(f"[LINKAI] chat failed, status_code={res.status_code}, "
f"msg={error.get('message')}, type={error.get('type')}")
if res.status_code >= 500:
# server error, need retry
time.sleep(2)
logger.warn(f"[LINKAI] do retry, times={retry_count}")
return self.reply_text(session, app_code, retry_count + 1)
return {
"total_tokens": 0,
"completion_tokens": 0,
"content": "提问太快啦,请休息一下再问我吧"
}
except Exception as e:
logger.exception(e)
# retry
time.sleep(2)
logger.warn(f"[LINKAI] do retry, times={retry_count}")
return self.reply_text(session, app_code, retry_count + 1)
def _fetch_app_info(self, app_code: str):
headers = {"Authorization": "Bearer " + conf().get("linkai_api_key")}
# do http request
base_url = conf().get("linkai_api_base", "https://api.link-ai.tech")
params = {"app_code": app_code}
res = requests.get(url=base_url + "/v1/app/info", params=params, headers=headers, timeout=(5, 10))
if res.status_code == 200:
return res.json()
else:
logger.warning(f"[LinkAI] find app info exception, res={res}")
def create_img(self, query, retry_count=0, api_key=None):
try:
logger.info("[LinkImage] image_query={}".format(query))
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {conf().get('linkai_api_key')}"
}
data = {
"prompt": query,
"n": 1,
"model": conf().get("text_to_image") or "dall-e-2",
"response_format": "url",
"img_proxy": conf().get("image_proxy")
}
url = conf().get("linkai_api_base", "https://api.link-ai.tech") + "/v1/images/generations"
res = requests.post(url, headers=headers, json=data, timeout=(5, 90))
t2 = time.time()
image_url = res.json()["data"][0]["url"]
logger.info("[OPEN_AI] image_url={}".format(image_url))
return True, image_url
except Exception as e:
logger.error(format(e))
return False, "画图出现问题,请休息一下再问我吧"
def _fetch_knowledge_search_suffix(self, response) -> str:
try:
if response.get("knowledge_base"):
search_hit = response.get("knowledge_base").get("search_hit")
first_similarity = response.get("knowledge_base").get("first_similarity")
logger.info(f"[LINKAI] knowledge base, search_hit={search_hit}, first_similarity={first_similarity}")
plugin_config = pconf("linkai")
if plugin_config and plugin_config.get("knowledge_base") and plugin_config.get("knowledge_base").get("search_miss_text_enabled"):
search_miss_similarity = plugin_config.get("knowledge_base").get("search_miss_similarity")
search_miss_text = plugin_config.get("knowledge_base").get("search_miss_suffix")
if not search_hit:
return search_miss_text
if search_miss_similarity and float(search_miss_similarity) > first_similarity:
return search_miss_text
except Exception as e:
logger.exception(e)
def _fetch_agent_suffix(self, response):
try:
plugin_list = []
logger.debug(f"[LinkAgent] res={response}")
if response.get("agent") and response.get("agent").get("chain") and response.get("agent").get("need_show_plugin"):
chain = response.get("agent").get("chain")
suffix = "\n\n- - - - - - - - - - - -"
i = 0
for turn in chain:
plugin_name = turn.get('plugin_name')
suffix += "\n"
need_show_thought = response.get("agent").get("need_show_thought")
if turn.get("thought") and plugin_name and need_show_thought:
suffix += f"{turn.get('thought')}\n"
if plugin_name:
plugin_list.append(turn.get('plugin_name'))
if turn.get('plugin_icon'):
suffix += f"{turn.get('plugin_icon')} "
suffix += f"{turn.get('plugin_name')}"
if turn.get('plugin_input'):
suffix += f":{turn.get('plugin_input')}"
if i < len(chain) - 1:
suffix += "\n"
i += 1
logger.info(f"[LinkAgent] use plugins: {plugin_list}")
return suffix
except Exception as e:
logger.exception(e)
def _process_url(self, text):
try:
url_pattern = re.compile(r'\[(.*?)\]\((http[s]?://.*?)\)')
def replace_markdown_url(match):
return f"{match.group(2)}"
return url_pattern.sub(replace_markdown_url, text)
except Exception as e:
logger.error(e)
def _send_image(self, channel, context, image_urls):
if not image_urls:
return
max_send_num = conf().get("max_media_send_count")
send_interval = conf().get("media_send_interval")
file_type = (".pdf", ".doc", ".docx", ".csv", ".xls", ".xlsx", ".txt", ".rtf", ".ppt", ".pptx")
try:
i = 0
for url in image_urls:
if max_send_num and i >= max_send_num:
continue
i += 1
if url.endswith(".mp4"):
reply_type = ReplyType.VIDEO_URL
elif url.endswith(file_type):
reply_type = ReplyType.FILE
url = _download_file(url)
if not url:
continue
else:
reply_type = ReplyType.IMAGE_URL
reply = Reply(reply_type, url)
channel.send(reply, context)
if send_interval:
time.sleep(send_interval)
except Exception as e:
logger.error(e)
def _download_file(url: str):
try:
file_path = "tmp"
if not os.path.exists(file_path):
os.makedirs(file_path)
file_name = url.split("/")[-1] # 获取文件名
file_path = os.path.join(file_path, file_name)
response = requests.get(url)
with open(file_path, "wb") as f:
f.write(response.content)
return file_path
except Exception as e:
logger.warn(e)
class LinkAISessionManager(SessionManager):
def session_msg_query(self, query, session_id):
session = self.build_session(session_id)
messages = session.messages + [{"role": "user", "content": query}]
return messages
def session_reply(self, reply, session_id, total_tokens=None, query=None):
session = self.build_session(session_id)
if query:
session.add_query(query)
session.add_reply(reply)
try:
max_tokens = conf().get("conversation_max_tokens", 8000)
tokens_cnt = session.discard_exceeding(max_tokens, total_tokens)
logger.debug(f"[LinkAI] chat history, before tokens={total_tokens}, now tokens={tokens_cnt}")
except Exception as e:
logger.warning("Exception when counting tokens precisely for session: {}".format(str(e)))
return session
class LinkAISession(ChatGPTSession):
def calc_tokens(self):
if not self.messages:
return 0
return len(str(self.messages))
def discard_exceeding(self, max_tokens, cur_tokens=None):
cur_tokens = self.calc_tokens()
if cur_tokens > max_tokens:
for i in range(0, len(self.messages)):
if i > 0 and self.messages[i].get("role") == "assistant" and self.messages[i - 1].get("role") == "user":
self.messages.pop(i)
self.messages.pop(i - 1)
return self.calc_tokens()
return cur_tokens
# Add call_with_tools method to LinkAIBot class
def _linkai_call_with_tools(self, messages, tools=None, stream=False, **kwargs):
"""
Call LinkAI API with tool support for agent integration
LinkAI is fully compatible with OpenAI's tool calling format
Args:
messages: List of messages
tools: List of tool definitions (OpenAI format)
stream: Whether to use streaming
**kwargs: Additional parameters (max_tokens, temperature, etc.)
Returns:
Formatted response in OpenAI format or generator for streaming
"""
try:
# Convert messages from Claude format to OpenAI format
# This is important because Agent uses Claude format internally
messages = self._convert_messages_to_openai_format(messages)
# Convert tools from Claude format to OpenAI format
if tools:
tools = self._convert_tools_to_openai_format(tools)
# Handle system prompt (OpenAI uses system message, Claude uses separate parameter)
system_prompt = kwargs.get('system')
if system_prompt:
# Add system message at the beginning if not already present
if not messages or messages[0].get('role') != 'system':
messages = [{"role": "system", "content": system_prompt}] + messages
else:
# Replace existing system message
messages[0] = {"role": "system", "content": system_prompt}
logger.debug(f"[LinkAI] messages: {len(messages)}, tools: {len(tools) if tools else 0}, stream: {stream}")
# Build request parameters (LinkAI uses OpenAI-compatible format)
raw_ct = conf().get("channel_type", "web")
if isinstance(raw_ct, list):
channel_type = raw_ct[0] if raw_ct else "web"
elif isinstance(raw_ct, str) and "," in raw_ct:
channel_type = raw_ct.split(",")[0].strip()
else:
channel_type = raw_ct
session_id = kwargs.get("session_id", "")
body = {
"messages": messages,
"model": kwargs.get("model", conf().get("model") or "gpt-3.5-turbo"),
"temperature": kwargs.get("temperature", conf().get("temperature", 0.9)),
"top_p": kwargs.get("top_p", conf().get("top_p", 1)),
"frequency_penalty": kwargs.get("frequency_penalty", conf().get("frequency_penalty", 0.0)),
"presence_penalty": kwargs.get("presence_penalty", conf().get("presence_penalty", 0.0)),
"stream": stream,
"channel_type": kwargs.get("channel_type", channel_type),
"session_id": session_id,
"sender_id": session_id,
}
try:
from linkai import LinkAIClient
client_id = LinkAIClient.fetch_client_id()
if client_id:
body["client_id"] = client_id
except Exception:
pass
if tools:
body["tools"] = tools
body["tool_choice"] = kwargs.get("tool_choice", "auto")
# Prepare headers
headers = {"Authorization": "Bearer " + conf().get("linkai_api_key")}
base_url = conf().get("linkai_api_base", "https://api.link-ai.tech")
if stream:
return self._handle_linkai_stream_response(base_url, headers, body)
else:
return self._handle_linkai_sync_response(base_url, headers, body)
except Exception as e:
logger.error(f"[LinkAI] call_with_tools error: {e}")
if stream:
def error_generator():
yield {
"error": True,
"message": str(e),
"status_code": 500
}
return error_generator()
else:
return {
"error": True,
"message": str(e),
"status_code": 500
}
def _handle_linkai_sync_response(self, base_url, headers, body):
"""Handle synchronous LinkAI API response"""
try:
res = requests.post(
url=base_url + "/v1/chat/completions",
json=body,
headers=headers,
timeout=conf().get("request_timeout", 180)
)
if res.status_code == 200:
response = res.json()
logger.debug(f"[LinkAI] reply: model={response.get('model')}, "
f"tokens={response.get('usage', {}).get('total_tokens', 0)}")
# LinkAI response is already in OpenAI-compatible format
return response
else:
error_data = res.json()
error_msg = error_data.get("error", {}).get("message", "Unknown error")
raise Exception(f"LinkAI API error: {res.status_code} - {error_msg}")
except Exception as e:
logger.error(f"[LinkAI] sync response error: {e}")
raise
def _handle_linkai_stream_response(self, base_url, headers, body):
"""Handle streaming LinkAI API response"""
try:
res = requests.post(
url=base_url + "/v1/chat/completions",
json=body,
headers=headers,
timeout=conf().get("request_timeout", 180),
stream=True
)
if res.status_code != 200:
error_text = res.text
try:
error_data = json.loads(error_text)
error_msg = error_data.get("error", {}).get("message", error_text)
except Exception:
error_msg = error_text or "Unknown error"
yield {
"error": True,
"status_code": res.status_code,
"message": error_msg
}
return
# Process streaming response (OpenAI-compatible SSE format)
for line in res.iter_lines():
if line:
line = line.decode('utf-8')
if line.startswith('data: '):
line = line[6:] # Remove 'data: ' prefix
if line == '[DONE]':
break
try:
chunk = json.loads(line)
except json.JSONDecodeError:
continue
# Check for error responses within the stream
# Some providers (e.g., MiniMax via LinkAI) return errors as:
# {'type': 'error', 'error': {'type': '...', 'message': '...', 'http_code': '400'}}
if chunk.get("type") == "error" or (
isinstance(chunk.get("error"), dict) and "message" in chunk.get("error", {})
):
error_data = chunk.get("error", {})
error_msg = error_data.get("message", "Unknown error") if isinstance(error_data, dict) else str(error_data)
http_code = error_data.get("http_code", "") if isinstance(error_data, dict) else ""
status_code = int(http_code) if http_code and str(http_code).isdigit() else 400
logger.error(f"[LinkAI] stream error: {error_msg} (http_code={http_code})")
yield {
"error": True,
"message": error_msg,
"status_code": status_code
}
return
yield chunk
except Exception as e:
logger.error(f"[LinkAI] stream response error: {e}")
yield {
"error": True,
"message": str(e),
"status_code": 500
}
# Attach methods to LinkAIBot class
LinkAIBot.call_with_tools = _linkai_call_with_tools
LinkAIBot._handle_linkai_sync_response = _handle_linkai_sync_response
LinkAIBot._handle_linkai_stream_response = _handle_linkai_stream_response
================================================
FILE: models/minimax/minimax_bot.py
================================================
# encoding:utf-8
import time
import json
import requests
from models.bot import Bot
from models.minimax.minimax_session import MinimaxSession
from models.session_manager import SessionManager
from bridge.context import Context, ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf, load_config
from common import const
from agent.protocol.message_utils import drop_orphaned_tool_results_openai
# MiniMax对话模型API
class MinimaxBot(Bot):
def __init__(self):
super().__init__()
self.args = {
"model": conf().get("model") or "MiniMax-M2.1",
"temperature": conf().get("temperature", 0.3),
"top_p": conf().get("top_p", 0.95),
}
self.sessions = SessionManager(MinimaxSession, model=const.MiniMax)
@property
def api_key(self):
key = conf().get("minimax_api_key")
if not key:
key = conf().get("Minimax_api_key")
return key
@property
def api_base(self):
return conf().get("minimax_api_base", "https://api.minimaxi.com/v1")
def reply(self, query, context: Context = None) -> Reply:
# acquire reply content
logger.info("[MINIMAX] query={}".format(query))
if context.type == ContextType.TEXT:
session_id = context["session_id"]
reply = None
clear_memory_commands = conf().get("clear_memory_commands", ["#清除记忆"])
if query in clear_memory_commands:
self.sessions.clear_session(session_id)
reply = Reply(ReplyType.INFO, "记忆已清除")
elif query == "#清除所有":
self.sessions.clear_all_session()
reply = Reply(ReplyType.INFO, "所有人记忆已清除")
elif query == "#更新配置":
load_config()
reply = Reply(ReplyType.INFO, "配置已更新")
if reply:
return reply
session = self.sessions.session_query(query, session_id)
logger.debug("[MINIMAX] session query={}".format(session))
model = context.get("Minimax_model")
new_args = self.args.copy()
if model:
new_args["model"] = model
reply_content = self.reply_text(session, args=new_args)
logger.debug(
"[MINIMAX] new_query={}, session_id={}, reply_cont={}, completion_tokens={}".format(
session.messages,
session_id,
reply_content["content"],
reply_content["completion_tokens"],
)
)
if reply_content["completion_tokens"] == 0 and len(reply_content["content"]) > 0:
reply = Reply(ReplyType.ERROR, reply_content["content"])
elif reply_content["completion_tokens"] > 0:
self.sessions.session_reply(reply_content["content"], session_id, reply_content["total_tokens"])
reply = Reply(ReplyType.TEXT, reply_content["content"])
else:
reply = Reply(ReplyType.ERROR, reply_content["content"])
logger.debug("[MINIMAX] reply {} used 0 tokens.".format(reply_content))
return reply
else:
reply = Reply(ReplyType.ERROR, "Bot不支持处理{}类型的消息".format(context.type))
return reply
def reply_text(self, session: MinimaxSession, args=None, retry_count=0) -> dict:
"""
Call MiniMax API to get the answer using REST API
:param session: a conversation session
:param args: request arguments
:param retry_count: retry count
:return: {}
"""
try:
if args is None:
args = self.args
# Build request
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
request_body = {
"model": args.get("model", self.args["model"]),
"messages": session.messages,
"temperature": args.get("temperature", self.args["temperature"]),
"top_p": args.get("top_p", self.args["top_p"]),
}
url = f"{self.api_base}/chat/completions"
logger.debug(f"[MINIMAX] Calling {url} with model={request_body['model']}")
response = requests.post(url, headers=headers, json=request_body, timeout=60)
if response.status_code == 200:
result = response.json()
content = result["choices"][0]["message"]["content"]
total_tokens = result["usage"]["total_tokens"]
completion_tokens = result["usage"]["completion_tokens"]
logger.debug(f"[MINIMAX] reply_text: content_length={len(content)}, tokens={total_tokens}")
return {
"total_tokens": total_tokens,
"completion_tokens": completion_tokens,
"content": content,
}
else:
error_msg = response.text
logger.error(f"[MINIMAX] API error: status={response.status_code}, msg={error_msg}")
# Parse error for better messages
result = {"completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
need_retry = False
if response.status_code >= 500:
logger.warning(f"[MINIMAX] Server error, retry={retry_count}")
need_retry = retry_count < 2
elif response.status_code == 401:
result["content"] = "授权失败,请检查API Key是否正确"
need_retry = False
elif response.status_code == 429:
result["content"] = "请求过于频繁,请稍后再试"
need_retry = retry_count < 2
else:
need_retry = False
if need_retry:
time.sleep(3)
return self.reply_text(session, args, retry_count + 1)
else:
return result
except requests.exceptions.Timeout:
logger.error("[MINIMAX] Request timeout")
need_retry = retry_count < 2
result = {"completion_tokens": 0, "content": "请求超时,请稍后再试"}
if need_retry:
time.sleep(3)
return self.reply_text(session, args, retry_count + 1)
else:
return result
except Exception as e:
logger.error(f"[MINIMAX] reply_text error: {e}")
import traceback
logger.error(traceback.format_exc())
need_retry = retry_count < 2
result = {"completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
if need_retry:
time.sleep(3)
return self.reply_text(session, args, retry_count + 1)
else:
return result
def call_with_tools(self, messages, tools=None, stream=False, **kwargs):
"""
Call MiniMax API with tool support for agent integration
This method handles:
1. Format conversion (Claude format → OpenAI format)
2. System prompt injection
3. API calling with REST API
4. Interleaved Thinking support (reasoning_split=True)
Args:
messages: List of messages (may be in Claude format from agent)
tools: List of tool definitions (may be in Claude format from agent)
stream: Whether to use streaming
**kwargs: Additional parameters (max_tokens, temperature, system, etc.)
Returns:
Formatted response or generator for streaming
"""
try:
# Convert messages from Claude format to OpenAI format
converted_messages = self._convert_messages_to_openai_format(messages)
# Extract and inject system prompt if provided
system_prompt = kwargs.pop("system", None)
if system_prompt:
# Add system message at the beginning
converted_messages.insert(0, {"role": "system", "content": system_prompt})
# Convert tools from Claude format to OpenAI format
converted_tools = None
if tools:
converted_tools = self._convert_tools_to_openai_format(tools)
# Prepare API parameters
model = kwargs.pop("model", None) or self.args["model"]
max_tokens = kwargs.pop("max_tokens", 100000)
temperature = kwargs.pop("temperature", self.args["temperature"])
# Build request body
request_body = {
"model": model,
"messages": converted_messages,
"max_tokens": max_tokens,
"temperature": temperature,
"stream": stream,
}
# Add tools if provided
if converted_tools:
request_body["tools"] = converted_tools
# Add reasoning_split=True for better thinking control (M2.1 feature)
# This separates thinking content into reasoning_details field
request_body["reasoning_split"] = True
logger.debug(f"[MINIMAX] API call: model={model}, tools={len(converted_tools) if converted_tools else 0}, stream={stream}")
# Check if we should show thinking process
show_thinking = kwargs.pop("show_thinking", conf().get("minimax_show_thinking", False))
if stream:
return self._handle_stream_response(request_body, show_thinking=show_thinking)
else:
return self._handle_sync_response(request_body)
except Exception as e:
logger.error(f"[MINIMAX] call_with_tools error: {e}")
import traceback
logger.error(traceback.format_exc())
def error_generator():
yield {"error": True, "message": str(e), "status_code": 500}
return error_generator()
def _convert_messages_to_openai_format(self, messages):
"""
Convert messages from Claude format to OpenAI format
Claude format:
- role: "user" | "assistant"
- content: string | list of content blocks
OpenAI format:
- role: "user" | "assistant" | "tool"
- content: string
- tool_calls: list (for assistant)
- tool_call_id: string (for tool results)
"""
converted = []
for msg in messages:
role = msg.get("role")
content = msg.get("content")
if role == "user":
# Handle user message
if isinstance(content, list):
# Extract text from content blocks
text_parts = []
tool_results = []
for block in content:
if isinstance(block, dict):
if block.get("type") == "text":
text_parts.append(block.get("text", ""))
elif block.get("type") == "tool_result":
# Tool result should be a separate message with role="tool"
tool_call_id = block.get("tool_use_id") or ""
if not tool_call_id:
logger.warning(f"[MINIMAX] tool_result missing tool_use_id")
result_content = block.get("content", "")
if not isinstance(result_content, str):
result_content = json.dumps(result_content, ensure_ascii=False)
tool_results.append({
"role": "tool",
"tool_call_id": tool_call_id,
"content": result_content
})
if text_parts:
converted.append({
"role": "user",
"content": "\n".join(text_parts)
})
# Add all tool results (not just the last one)
for tool_result in tool_results:
converted.append(tool_result)
else:
# Simple text content
converted.append({
"role": "user",
"content": str(content)
})
elif role == "assistant":
# Handle assistant message
openai_msg = {"role": "assistant"}
if isinstance(content, list):
# Parse content blocks
text_parts = []
tool_calls = []
for block in content:
if isinstance(block, dict):
if block.get("type") == "text":
text_parts.append(block.get("text", ""))
elif block.get("type") == "tool_use":
# Convert to OpenAI tool_calls format
tool_calls.append({
"id": block.get("id"),
"type": "function",
"function": {
"name": block.get("name"),
"arguments": json.dumps(block.get("input", {}))
}
})
# Set content (can be empty if only tool calls)
if text_parts:
openai_msg["content"] = "\n".join(text_parts)
elif not tool_calls:
openai_msg["content"] = ""
# Set tool_calls
if tool_calls:
openai_msg["tool_calls"] = tool_calls
# When tool_calls exist and content is empty, set to None
if not text_parts:
openai_msg["content"] = None
else:
# Simple text content
openai_msg["content"] = str(content) if content else ""
converted.append(openai_msg)
return drop_orphaned_tool_results_openai(converted)
def _convert_tools_to_openai_format(self, tools):
"""
Convert tools from Claude format to OpenAI format
Claude format:
{
"name": "tool_name",
"description": "description",
"input_schema": {...}
}
OpenAI format:
{
"type": "function",
"function": {
"name": "tool_name",
"description": "description",
"parameters": {...}
}
}
"""
converted = []
for tool in tools:
converted.append({
"type": "function",
"function": {
"name": tool.get("name"),
"description": tool.get("description"),
"parameters": tool.get("input_schema", {})
}
})
return converted
def _handle_sync_response(self, request_body):
"""Handle synchronous API response"""
try:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
# Remove stream from body for sync request
request_body.pop("stream", None)
url = f"{self.api_base}/chat/completions"
response = requests.post(url, headers=headers, json=request_body, timeout=60)
if response.status_code != 200:
error_msg = response.text
logger.error(f"[MINIMAX] API error: status={response.status_code}, msg={error_msg}")
yield {"error": True, "message": error_msg, "status_code": response.status_code}
return
result = response.json()
message = result["choices"][0]["message"]
finish_reason = result["choices"][0]["finish_reason"]
# Build response in Claude-like format
response_data = {
"role": "assistant",
"content": []
}
# Add reasoning_details (thinking) if present
if "reasoning_details" in message:
for reasoning in message["reasoning_details"]:
if "text" in reasoning:
response_data["content"].append({
"type": "thinking",
"thinking": reasoning["text"]
})
# Add text content if present
if message.get("content"):
response_data["content"].append({
"type": "text",
"text": message["content"]
})
# Add tool calls if present
if message.get("tool_calls"):
for tool_call in message["tool_calls"]:
response_data["content"].append({
"type": "tool_use",
"id": tool_call["id"],
"name": tool_call["function"]["name"],
"input": json.loads(tool_call["function"]["arguments"])
})
# Set stop_reason
if finish_reason == "tool_calls":
response_data["stop_reason"] = "tool_use"
elif finish_reason == "stop":
response_data["stop_reason"] = "end_turn"
else:
response_data["stop_reason"] = finish_reason
yield response_data
except requests.exceptions.Timeout:
logger.error("[MINIMAX] Request timeout")
yield {"error": True, "message": "Request timeout", "status_code": 500}
except Exception as e:
logger.error(f"[MINIMAX] sync response error: {e}")
import traceback
logger.error(traceback.format_exc())
yield {"error": True, "message": str(e), "status_code": 500}
def _handle_stream_response(self, request_body, show_thinking=False):
"""Handle streaming API response
Args:
request_body: API request parameters
show_thinking: Whether to show thinking/reasoning process to users
"""
try:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
url = f"{self.api_base}/chat/completions"
response = requests.post(url, headers=headers, json=request_body, stream=True, timeout=60)
if response.status_code != 200:
error_msg = response.text
logger.error(f"[MINIMAX] API error: status={response.status_code}, msg={error_msg}")
yield {"error": True, "message": error_msg, "status_code": response.status_code}
return
current_content = []
current_tool_calls = {}
current_reasoning = []
finish_reason = None
chunk_count = 0
# Process SSE stream
for line in response.iter_lines():
if not line:
continue
line = line.decode('utf-8')
if not line.startswith('data: '):
continue
data_str = line[6:] # Remove 'data: ' prefix
if data_str.strip() == '[DONE]':
break
try:
chunk = json.loads(data_str)
chunk_count += 1
except json.JSONDecodeError as e:
logger.warning(f"[MINIMAX] JSON decode error: {e}, data: {data_str[:100]}")
continue
# Check for error response (MiniMax format)
if chunk.get("type") == "error" or "error" in chunk:
error_data = chunk.get("error", {})
error_msg = error_data.get("message", "Unknown error")
error_type = error_data.get("type", "")
http_code = error_data.get("http_code", "")
logger.error(f"[MINIMAX] API error: {error_msg} (type: {error_type}, code: {http_code})")
yield {
"error": True,
"message": error_msg,
"status_code": int(http_code) if http_code.isdigit() else 500
}
return
if not chunk.get("choices"):
continue
choice = chunk["choices"][0]
delta = choice.get("delta", {})
# Handle reasoning_details (thinking)
if "reasoning_details" in delta:
for reasoning in delta["reasoning_details"]:
if "text" in reasoning:
reasoning_id = reasoning.get("id", "reasoning-text-1")
reasoning_index = reasoning.get("index", 0)
reasoning_text = reasoning["text"]
# Accumulate reasoning text
if reasoning_index >= len(current_reasoning):
current_reasoning.append({"id": reasoning_id, "text": ""})
current_reasoning[reasoning_index]["text"] += reasoning_text
# Optionally yield thinking as visible content
if show_thinking:
# Yield thinking text as-is (without emoji decoration)
# The reasoning text will be displayed to users
yield {
"choices": [{
"index": 0,
"delta": {
"role": "assistant",
"content": reasoning_text
}
}]
}
# Handle text content
if "content" in delta and delta["content"]:
# Start new content block if needed
if not any(block.get("type") == "text" for block in current_content):
current_content.append({"type": "text", "text": ""})
# Accumulate text
for block in current_content:
if block.get("type") == "text":
block["text"] += delta["content"]
break
# Yield OpenAI-format delta (for agent_stream.py compatibility)
yield {
"choices": [{
"index": 0,
"delta": {
"role": "assistant",
"content": delta["content"]
}
}]
}
# Handle tool calls
if "tool_calls" in delta:
for tool_call_chunk in delta["tool_calls"]:
index = tool_call_chunk.get("index", 0)
if index not in current_tool_calls:
# Start new tool call
current_tool_calls[index] = {
"id": tool_call_chunk.get("id", ""),
"type": "tool_use",
"name": tool_call_chunk.get("function", {}).get("name", ""),
"input": ""
}
# Accumulate tool call arguments
if "function" in tool_call_chunk and "arguments" in tool_call_chunk["function"]:
current_tool_calls[index]["input"] += tool_call_chunk["function"]["arguments"]
# Yield OpenAI-format tool call delta
yield {
"choices": [{
"index": 0,
"delta": {
"tool_calls": [tool_call_chunk]
}
}]
}
# Handle finish_reason
if choice.get("finish_reason"):
finish_reason = choice["finish_reason"]
# Log complete reasoning_details for debugging
if current_reasoning:
logger.debug(f"[MINIMAX] ===== Complete Reasoning Details =====")
for i, reasoning in enumerate(current_reasoning):
reasoning_text = reasoning.get("text", "")
logger.debug(f"[MINIMAX] Reasoning {i+1} (length={len(reasoning_text)}):")
logger.debug(f"[MINIMAX] {reasoning_text}")
logger.debug(f"[MINIMAX] ===== End Reasoning Details =====")
# Yield final chunk with finish_reason (OpenAI format)
yield {
"choices": [{
"index": 0,
"delta": {},
"finish_reason": finish_reason
}]
}
except requests.exceptions.Timeout:
logger.error("[MINIMAX] Request timeout")
yield {"error": True, "message": "Request timeout", "status_code": 500}
except Exception as e:
logger.error(f"[MINIMAX] stream response error: {e}")
import traceback
logger.error(traceback.format_exc())
yield {"error": True, "message": str(e), "status_code": 500}
================================================
FILE: models/minimax/minimax_session.py
================================================
from models.session_manager import Session
from common.log import logger
"""
e.g.
[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Who won the world series in 2020?"},
{"role": "assistant", "content": "The Los Angeles Dodgers won the World Series in 2020."},
{"role": "user", "content": "Where was it played?"}
]
"""
class MinimaxSession(Session):
def __init__(self, session_id, system_prompt=None, model="minimax"):
super().__init__(session_id, system_prompt)
self.model = model
# self.reset()
def add_query(self, query):
user_item = {"sender_type": "USER", "sender_name": self.session_id, "text": query}
self.messages.append(user_item)
def add_reply(self, reply):
assistant_item = {"sender_type": "BOT", "sender_name": "MM智能助理", "text": reply}
self.messages.append(assistant_item)
def discard_exceeding(self, max_tokens, cur_tokens=None):
precise = True
try:
cur_tokens = self.calc_tokens()
except Exception as e:
precise = False
if cur_tokens is None:
raise e
logger.debug("Exception when counting tokens precisely for query: {}".format(e))
while cur_tokens > max_tokens:
if len(self.messages) > 2:
self.messages.pop(1)
elif len(self.messages) == 2 and self.messages[1]["sender_type"] == "BOT":
self.messages.pop(1)
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
break
elif len(self.messages) == 2 and self.messages[1]["sender_type"] == "USER":
logger.warn("user message exceed max_tokens. total_tokens={}".format(cur_tokens))
break
else:
logger.debug("max_tokens={}, total_tokens={}, len(messages)={}".format(max_tokens, cur_tokens, len(self.messages)))
break
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
return cur_tokens
def calc_tokens(self):
return num_tokens_from_messages(self.messages, self.model)
def num_tokens_from_messages(messages, model):
"""Returns the number of tokens used by a list of messages."""
# 官方token计算规则:"对于中文文本来说,1个token通常对应一个汉字;对于英文文本来说,1个token通常对应3至4个字母或1个单词"
# 详情请产看文档:https://help.aliyun.com/document_detail/2586397.html
# 目前根据字符串长度粗略估计token数,不影响正常使用
tokens = 0
for msg in messages:
tokens += len(msg["text"])
return tokens
================================================
FILE: models/modelscope/modelscope_bot.py
================================================
# encoding:utf-8
import time
import json
import openai
from models.bot import Bot
from models.session_manager import SessionManager
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf, load_config
from .modelscope_session import ModelScopeSession
import requests
# ModelScope对话模型API
class ModelScopeBot(Bot):
def __init__(self):
super().__init__()
self.sessions = SessionManager(ModelScopeSession, model=conf().get("model") or "Qwen/Qwen2.5-7B-Instruct")
model = conf().get("model") or "Qwen/Qwen2.5-7B-Instruct"
if model == "modelscope":
model = "Qwen/Qwen2.5-7B-Instruct"
self.args = {
"model": model, # 对话模型的名称
"temperature": conf().get("temperature", 0.3), # 如果设置,值域须为 [0, 1] 我们推荐 0.3,以达到较合适的效果。
"top_p": conf().get("top_p", 1.0), # 使用默认值
}
@property
def api_key(self):
return conf().get("modelscope_api_key")
@property
def base_url(self):
return conf().get("modelscope_base_url", "https://api-inference.modelscope.cn/v1/chat/completions")
"""
需要获取ModelScope支持API-inference的模型名称列表,请到魔搭社区官网模型中心查看 https://modelscope.cn/models?filter=inference_type&page=1。
或者使用命令 curl https://api-inference.modelscope.cn/v1/models 对模型列表和ID进行获取。查看commend/const.py文件也可以获取模型列表。
获取ModelScope的免费API Key,请到魔搭社区官网用户中心查看获取方式 https://modelscope.cn/docs/model-service/API-Inference/intro。
"""
def reply(self, query, context=None):
# acquire reply content
if context.type == ContextType.TEXT:
logger.info("[MODELSCOPE_AI] query={}".format(query))
session_id = context["session_id"]
reply = None
clear_memory_commands = conf().get("clear_memory_commands", ["#清除记忆"])
if query in clear_memory_commands:
self.sessions.clear_session(session_id)
reply = Reply(ReplyType.INFO, "记忆已清除")
elif query == "#清除所有":
self.sessions.clear_all_session()
reply = Reply(ReplyType.INFO, "所有人记忆已清除")
elif query == "#更新配置":
load_config()
reply = Reply(ReplyType.INFO, "配置已更新")
if reply:
return reply
session = self.sessions.session_query(query, session_id)
logger.debug("[MODELSCOPE_AI] session query={}".format(session.messages))
model = context.get("modelscope_model")
new_args = self.args.copy()
if model:
new_args["model"] = model
if new_args["model"] == "Qwen/QwQ-32B":
reply_content = self.reply_text_stream(session, args=new_args)
else:
reply_content = self.reply_text(session, args=new_args)
logger.debug(
"[MODELSCOPE_AI] new_query={}, session_id={}, reply_cont={}, completion_tokens={}".format(
session.messages,
session_id,
reply_content["content"],
reply_content["completion_tokens"],
)
)
if reply_content["completion_tokens"] == 0 and len(reply_content["content"]) > 0:
# 只有当 content 为空且 completion_tokens 为 0 时才标记为错误
if len(reply_content["content"]) == 0:
reply = Reply(ReplyType.ERROR, reply_content["content"])
else:
reply = Reply(ReplyType.TEXT, reply_content["content"])
elif reply_content["completion_tokens"] > 0:
self.sessions.session_reply(reply_content["content"], session_id, reply_content["total_tokens"])
reply = Reply(ReplyType.TEXT, reply_content["content"])
else:
reply = Reply(ReplyType.ERROR, reply_content["content"])
logger.debug("[MODELSCOPE_AI] reply {} used 0 tokens.".format(reply_content))
return reply
elif context.type == ContextType.IMAGE_CREATE:
ok, retstring = self.create_img(query, 0)
reply = None
if ok:
reply = Reply(ReplyType.IMAGE_URL, retstring)
else:
reply = Reply(ReplyType.ERROR, retstring)
return reply
else:
reply = Reply(ReplyType.ERROR, "Bot不支持处理{}类型的消息".format(context.type))
return reply
def reply_text(self, session: ModelScopeSession, args=None, retry_count=0) -> dict:
"""
call openai's ChatCompletion to get the answer
:param session: a conversation session
:param session_id: session id
:param retry_count: retry count
:return: {}
"""
try:
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer " + self.api_key
}
body = args
body["messages"] = session.messages
res = requests.post(
self.base_url,
headers=headers,
data=json.dumps(body)
)
if res.status_code == 200:
response = res.json()
return {
"total_tokens": response["usage"]["total_tokens"],
"completion_tokens": response["usage"]["completion_tokens"],
"content": response["choices"][0]["message"]["content"]
}
else:
response = res.json()
if "errors" in response:
error = response.get("errors")
elif "error" in response:
error = response.get("error")
else:
error = "Unknown error"
logger.error(f"[MODELSCOPE_AI] chat failed, status_code={res.status_code}, "
f"msg={error.get('message')}, type={error.get('type')}")
result = {"completion_tokens": 0, "content": "提问太快啦,请休息一下再问我吧"}
need_retry = False
if res.status_code >= 500:
# server error, need retry
logger.warn(f"[MODELSCOPE_AI] do retry, times={retry_count}")
need_retry = retry_count < 2
elif res.status_code == 401:
result["content"] = "授权失败,请检查API Key是否正确"
elif res.status_code == 429:
result["content"] = "请求过于频繁,请稍后再试"
need_retry = retry_count < 2
else:
need_retry = False
if need_retry:
time.sleep(3)
return self.reply_text(session, args, retry_count + 1)
else:
return result
except Exception as e:
logger.exception(e)
need_retry = retry_count < 2
result = {"completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
if need_retry:
return self.reply_text(session, args, retry_count + 1)
else:
return result
def reply_text_stream(self, session: ModelScopeSession, args=None, retry_count=0) -> dict:
"""
call ModelScope's ChatCompletion to get the answer with stream response
:param session: a conversation session
:param session_id: session id
:param retry_count: retry count
:return: {}
"""
try:
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer " + self.api_key
}
body = args
body["messages"] = session.messages
body["stream"] = True # 启用流式响应
res = requests.post(
self.base_url,
headers=headers,
data=json.dumps(body),
stream=True
)
if res.status_code == 200:
content = ""
for line in res.iter_lines():
if line:
decoded_line = line.decode('utf-8')
if decoded_line.startswith("data: "):
try:
json_data = json.loads(decoded_line[6:])
delta_content = json_data.get("choices", [{}])[0].get("delta", {}).get("content", "")
if delta_content:
content += delta_content
except json.JSONDecodeError as e:
pass
return {
"total_tokens": 1, # 流式响应通常不返回token使用情况
"completion_tokens": 1,
"content": content
}
else:
response = res.json()
if "errors" in response:
error = response.get("errors")
elif "error" in response:
error = response.get("error")
else:
error = "Unknown error"
logger.error(f"[MODELSCOPE_AI] chat failed, status_code={res.status_code}, "
f"msg={error.get('message')}, type={error.get('type')}")
result = {"completion_tokens": 0, "content": "提问太快啦,请休息一下再问我吧"}
need_retry = False
if res.status_code >= 500:
# server error, need retry
logger.warn(f"[MODELSCOPE_AI] do retry, times={retry_count}")
need_retry = retry_count < 2
elif res.status_code == 401:
result["content"] = "授权失败,请检查API Key是否正确"
elif res.status_code == 429:
result["content"] = "请求过于频繁,请稍后再试"
need_retry = retry_count < 2
else:
need_retry = False
if need_retry:
time.sleep(3)
return self.reply_text_stream(session, args, retry_count + 1)
else:
return result
except Exception as e:
logger.exception(e)
need_retry = retry_count < 2
result = {"completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
if need_retry:
return self.reply_text_stream(session, args, retry_count + 1)
else:
return result
def create_img(self, query, retry_count=0):
try:
logger.info("[ModelScopeImage] image_query={}".format(query))
headers = {
"Content-Type": "application/json; charset=utf-8", # 明确指定编码
"Authorization": f"Bearer {self.api_key}"
}
payload = {
"prompt": query, # required
"n": 1,
"model": conf().get("text_to_image"),
}
url = "https://api-inference.modelscope.cn/v1/images/generations"
# 手动序列化并保留中文(禁用 ASCII 转义)
json_payload = json.dumps(payload, ensure_ascii=False).encode('utf-8')
# 使用 data 参数发送原始字符串(requests 会自动处理编码)
res = requests.post(url, headers=headers, data=json_payload)
response_data = res.json()
image_url = response_data['images'][0]['url']
logger.info("[ModelScopeImage] image_url={}".format(image_url))
return True, image_url
except Exception as e:
logger.error(format(e))
return False, "画图出现问题,请休息一下再问我吧"
================================================
FILE: models/modelscope/modelscope_session.py
================================================
from models.session_manager import Session
from common.log import logger
class ModelScopeSession(Session):
def __init__(self, session_id, system_prompt=None, model="Qwen/Qwen2.5-7B-Instruct"):
super().__init__(session_id, system_prompt)
self.model = model
self.reset()
def discard_exceeding(self, max_tokens, cur_tokens=None):
precise = True
try:
cur_tokens = self.calc_tokens()
except Exception as e:
precise = False
if cur_tokens is None:
raise e
logger.debug("Exception when counting tokens precisely for query: {}".format(e))
while cur_tokens > max_tokens:
if len(self.messages) > 2:
self.messages.pop(1)
elif len(self.messages) == 2 and self.messages[1]["role"] == "assistant":
self.messages.pop(1)
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
break
elif len(self.messages) == 2 and self.messages[1]["role"] == "user":
logger.warn("user message exceed max_tokens. total_tokens={}".format(cur_tokens))
break
else:
logger.debug("max_tokens={}, total_tokens={}, len(messages)={}".format(max_tokens, cur_tokens,
len(self.messages)))
break
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
return cur_tokens
def calc_tokens(self):
return num_tokens_from_messages(self.messages, self.model)
def num_tokens_from_messages(messages, model):
tokens = 0
for msg in messages:
tokens += len(msg["content"])
return tokens
================================================
FILE: models/moonshot/moonshot_bot.py
================================================
# encoding:utf-8
import json
import time
import requests
from models.bot import Bot
from models.session_manager import SessionManager
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf, load_config
from .moonshot_session import MoonshotSession
# Moonshot (Kimi) API Bot
class MoonshotBot(Bot):
def __init__(self):
super().__init__()
self.sessions = SessionManager(MoonshotSession, model=conf().get("model") or "moonshot-v1-128k")
model = conf().get("model") or "moonshot-v1-128k"
if model == "moonshot":
model = "moonshot-v1-32k"
self.args = {
"model": model,
"temperature": conf().get("temperature", 0.3),
"top_p": conf().get("top_p", 1.0),
}
@property
def api_key(self):
return conf().get("moonshot_api_key")
@property
def base_url(self):
url = conf().get("moonshot_base_url", "https://api.moonshot.cn/v1")
if url.endswith("/chat/completions"):
url = url.rsplit("/chat/completions", 1)[0]
return url.rstrip("/")
def reply(self, query, context=None):
# acquire reply content
if context.type == ContextType.TEXT:
logger.info("[MOONSHOT] query={}".format(query))
session_id = context["session_id"]
reply = None
clear_memory_commands = conf().get("clear_memory_commands", ["#清除记忆"])
if query in clear_memory_commands:
self.sessions.clear_session(session_id)
reply = Reply(ReplyType.INFO, "记忆已清除")
elif query == "#清除所有":
self.sessions.clear_all_session()
reply = Reply(ReplyType.INFO, "所有人记忆已清除")
elif query == "#更新配置":
load_config()
reply = Reply(ReplyType.INFO, "配置已更新")
if reply:
return reply
session = self.sessions.session_query(query, session_id)
logger.debug("[MOONSHOT] session query={}".format(session.messages))
model = context.get("moonshot_model")
new_args = self.args.copy()
if model:
new_args["model"] = model
reply_content = self.reply_text(session, args=new_args)
logger.debug(
"[MOONSHOT] new_query={}, session_id={}, reply_cont={}, completion_tokens={}".format(
session.messages,
session_id,
reply_content["content"],
reply_content["completion_tokens"],
)
)
if reply_content["completion_tokens"] == 0 and len(reply_content["content"]) > 0:
reply = Reply(ReplyType.ERROR, reply_content["content"])
elif reply_content["completion_tokens"] > 0:
self.sessions.session_reply(reply_content["content"], session_id, reply_content["total_tokens"])
reply = Reply(ReplyType.TEXT, reply_content["content"])
else:
reply = Reply(ReplyType.ERROR, reply_content["content"])
logger.debug("[MOONSHOT] reply {} used 0 tokens.".format(reply_content))
return reply
else:
reply = Reply(ReplyType.ERROR, "Bot不支持处理{}类型的消息".format(context.type))
return reply
def reply_text(self, session: MoonshotSession, args=None, retry_count: int = 0) -> dict:
"""
Call Moonshot chat completion API to get the answer
:param session: a conversation session
:param args: model args
:param retry_count: retry count
:return: {}
"""
try:
headers = {
"Content-Type": "application/json",
"Authorization": "Bearer " + self.api_key
}
body = args
body["messages"] = session.messages
res = requests.post(
f"{self.base_url}/chat/completions",
headers=headers,
json=body
)
if res.status_code == 200:
response = res.json()
return {
"total_tokens": response["usage"]["total_tokens"],
"completion_tokens": response["usage"]["completion_tokens"],
"content": response["choices"][0]["message"]["content"]
}
else:
response = res.json()
error = response.get("error")
logger.error(f"[MOONSHOT] chat failed, status_code={res.status_code}, "
f"msg={error.get('message')}, type={error.get('type')}")
result = {"completion_tokens": 0, "content": "提问太快啦,请休息一下再问我吧"}
need_retry = False
if res.status_code >= 500:
logger.warn(f"[MOONSHOT] do retry, times={retry_count}")
need_retry = retry_count < 2
elif res.status_code == 401:
result["content"] = "授权失败,请检查API Key是否正确"
elif res.status_code == 429:
result["content"] = "请求过于频繁,请稍后再试"
need_retry = retry_count < 2
else:
need_retry = False
if need_retry:
time.sleep(3)
return self.reply_text(session, args, retry_count + 1)
else:
return result
except Exception as e:
logger.exception(e)
need_retry = retry_count < 2
result = {"completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
if need_retry:
return self.reply_text(session, args, retry_count + 1)
else:
return result
# ==================== Agent mode support ====================
def call_with_tools(self, messages, tools=None, stream: bool = False, **kwargs):
"""
Call Moonshot API with tool support for agent integration.
This method handles:
1. Format conversion (Claude format -> OpenAI format)
2. System prompt injection
3. Streaming SSE response with tool_calls
4. Thinking (reasoning) is disabled by default to avoid tool_choice conflicts
Args:
messages: List of messages (may be in Claude format from agent)
tools: List of tool definitions (may be in Claude format from agent)
stream: Whether to use streaming
**kwargs: Additional parameters (max_tokens, temperature, system, model, etc.)
Returns:
Generator yielding OpenAI-format chunks (for streaming)
"""
try:
# Convert messages from Claude format to OpenAI format
converted_messages = self._convert_messages_to_openai_format(messages)
# Inject system prompt if provided
system_prompt = kwargs.pop("system", None)
if system_prompt:
if not converted_messages or converted_messages[0].get("role") != "system":
converted_messages.insert(0, {"role": "system", "content": system_prompt})
else:
converted_messages[0] = {"role": "system", "content": system_prompt}
# Convert tools from Claude format to OpenAI format
converted_tools = None
if tools:
converted_tools = self._convert_tools_to_openai_format(tools)
# Resolve model / temperature
model = kwargs.pop("model", None) or self.args["model"]
max_tokens = kwargs.pop("max_tokens", None)
# Don't pop temperature, just ignore it
kwargs.pop("temperature", None)
# Build request body (omit temperature, let the API use its own default)
request_body = {
"model": model,
"messages": converted_messages,
"stream": stream,
}
if max_tokens is not None:
request_body["max_tokens"] = max_tokens
# Add tools
if converted_tools:
request_body["tools"] = converted_tools
request_body["tool_choice"] = "auto"
# Explicitly disable thinking to avoid reasoning_content issues in multi-turn tool calls.
# kimi-k2.5 may enable thinking by default; without preserving reasoning_content
# in conversation history the API will reject subsequent requests.
request_body["thinking"] = {"type": "disabled"}
logger.debug(f"[MOONSHOT] API call: model={model}, "
f"tools={len(converted_tools) if converted_tools else 0}, stream={stream}")
if stream:
return self._handle_stream_response(request_body)
else:
return self._handle_sync_response(request_body)
except Exception as e:
logger.error(f"[MOONSHOT] call_with_tools error: {e}")
import traceback
logger.error(traceback.format_exc())
def error_generator():
yield {"error": True, "message": str(e), "status_code": 500}
return error_generator()
# -------------------- streaming --------------------
def _handle_stream_response(self, request_body: dict):
"""Handle streaming SSE response from Moonshot API and yield OpenAI-format chunks."""
try:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
url = f"{self.base_url}/chat/completions"
response = requests.post(url, headers=headers, json=request_body, stream=True, timeout=120)
if response.status_code != 200:
error_msg = response.text
logger.error(f"[MOONSHOT] API error: status={response.status_code}, msg={error_msg}")
yield {"error": True, "message": error_msg, "status_code": response.status_code}
return
current_tool_calls = {}
finish_reason = None
for line in response.iter_lines():
if not line:
continue
line = line.decode("utf-8")
if not line.startswith("data: "):
continue
data_str = line[6:] # Remove "data: " prefix
if data_str.strip() == "[DONE]":
break
try:
chunk = json.loads(data_str)
except json.JSONDecodeError as e:
logger.warning(f"[MOONSHOT] JSON decode error: {e}, data: {data_str[:200]}")
continue
# Check for error in chunk
if chunk.get("error"):
error_data = chunk["error"]
error_msg = error_data.get("message", "Unknown error") if isinstance(error_data, dict) else str(error_data)
logger.error(f"[MOONSHOT] stream error: {error_msg}")
yield {"error": True, "message": error_msg, "status_code": 500}
return
if not chunk.get("choices"):
continue
choice = chunk["choices"][0]
delta = choice.get("delta", {})
# Skip reasoning_content (thinking) – don't log or forward
if delta.get("reasoning_content"):
continue
# Handle text content
if "content" in delta and delta["content"]:
yield {
"choices": [{
"index": 0,
"delta": {
"role": "assistant",
"content": delta["content"]
}
}]
}
# Handle tool_calls (streamed incrementally)
if "tool_calls" in delta:
for tool_call_chunk in delta["tool_calls"]:
index = tool_call_chunk.get("index", 0)
if index not in current_tool_calls:
current_tool_calls[index] = {
"id": tool_call_chunk.get("id", ""),
"type": "tool_use",
"name": tool_call_chunk.get("function", {}).get("name", ""),
"input": ""
}
# Accumulate arguments
if "function" in tool_call_chunk and "arguments" in tool_call_chunk["function"]:
current_tool_calls[index]["input"] += tool_call_chunk["function"]["arguments"]
# Yield OpenAI-format tool call delta
yield {
"choices": [{
"index": 0,
"delta": {
"tool_calls": [tool_call_chunk]
}
}]
}
# Capture finish_reason
if choice.get("finish_reason"):
finish_reason = choice["finish_reason"]
# Final chunk with finish_reason
yield {
"choices": [{
"index": 0,
"delta": {},
"finish_reason": finish_reason
}]
}
except requests.exceptions.Timeout:
logger.error("[MOONSHOT] Request timeout")
yield {"error": True, "message": "Request timeout", "status_code": 500}
except Exception as e:
logger.error(f"[MOONSHOT] stream response error: {e}")
import traceback
logger.error(traceback.format_exc())
yield {"error": True, "message": str(e), "status_code": 500}
# -------------------- sync --------------------
def _handle_sync_response(self, request_body: dict):
"""Handle synchronous API response and yield a single result dict."""
try:
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {self.api_key}"
}
request_body.pop("stream", None)
url = f"{self.base_url}/chat/completions"
response = requests.post(url, headers=headers, json=request_body, timeout=120)
if response.status_code != 200:
error_msg = response.text
logger.error(f"[MOONSHOT] API error: status={response.status_code}, msg={error_msg}")
yield {"error": True, "message": error_msg, "status_code": response.status_code}
return
result = response.json()
message = result["choices"][0]["message"]
finish_reason = result["choices"][0]["finish_reason"]
response_data = {"role": "assistant", "content": []}
# Add text content
if message.get("content"):
response_data["content"].append({
"type": "text",
"text": message["content"]
})
# Add tool calls
if message.get("tool_calls"):
for tool_call in message["tool_calls"]:
response_data["content"].append({
"type": "tool_use",
"id": tool_call["id"],
"name": tool_call["function"]["name"],
"input": json.loads(tool_call["function"]["arguments"])
})
# Map finish_reason
if finish_reason == "tool_calls":
response_data["stop_reason"] = "tool_use"
elif finish_reason == "stop":
response_data["stop_reason"] = "end_turn"
else:
response_data["stop_reason"] = finish_reason
yield response_data
except requests.exceptions.Timeout:
logger.error("[MOONSHOT] Request timeout")
yield {"error": True, "message": "Request timeout", "status_code": 500}
except Exception as e:
logger.error(f"[MOONSHOT] sync response error: {e}")
import traceback
logger.error(traceback.format_exc())
yield {"error": True, "message": str(e), "status_code": 500}
# -------------------- format conversion --------------------
def _convert_messages_to_openai_format(self, messages):
"""
Convert messages from Claude format to OpenAI format.
Claude format uses content blocks: tool_use / tool_result / text
OpenAI format uses tool_calls in assistant, role=tool for results
"""
if not messages:
return []
converted = []
for msg in messages:
role = msg.get("role")
content = msg.get("content")
# Already a simple string – pass through
if isinstance(content, str):
converted.append(msg)
continue
if not isinstance(content, list):
converted.append(msg)
continue
if role == "user":
text_parts = []
tool_results = []
for block in content:
if not isinstance(block, dict):
continue
if block.get("type") == "text":
text_parts.append(block.get("text", ""))
elif block.get("type") == "tool_result":
tool_call_id = block.get("tool_use_id") or ""
result_content = block.get("content", "")
if not isinstance(result_content, str):
result_content = json.dumps(result_content, ensure_ascii=False)
tool_results.append({
"role": "tool",
"tool_call_id": tool_call_id,
"content": result_content
})
# Tool results first (must come right after assistant with tool_calls)
for tr in tool_results:
converted.append(tr)
if text_parts:
converted.append({"role": "user", "content": "\n".join(text_parts)})
elif role == "assistant":
openai_msg = {"role": "assistant"}
text_parts = []
tool_calls = []
for block in content:
if not isinstance(block, dict):
continue
if block.get("type") == "text":
text_parts.append(block.get("text", ""))
elif block.get("type") == "tool_use":
tool_calls.append({
"id": block.get("id"),
"type": "function",
"function": {
"name": block.get("name"),
"arguments": json.dumps(block.get("input", {}))
}
})
if text_parts:
openai_msg["content"] = "\n".join(text_parts)
elif not tool_calls:
openai_msg["content"] = ""
if tool_calls:
openai_msg["tool_calls"] = tool_calls
if not text_parts:
openai_msg["content"] = None
converted.append(openai_msg)
else:
converted.append(msg)
return converted
def _convert_tools_to_openai_format(self, tools):
"""
Convert tools from Claude format to OpenAI format.
Claude: {name, description, input_schema}
OpenAI: {type: "function", function: {name, description, parameters}}
"""
if not tools:
return None
converted = []
for tool in tools:
# Already in OpenAI format
if "type" in tool and tool["type"] == "function":
converted.append(tool)
else:
converted.append({
"type": "function",
"function": {
"name": tool.get("name"),
"description": tool.get("description"),
"parameters": tool.get("input_schema", {})
}
})
return converted
================================================
FILE: models/moonshot/moonshot_session.py
================================================
from models.session_manager import Session
from common.log import logger
class MoonshotSession(Session):
def __init__(self, session_id, system_prompt=None, model="moonshot-v1-128k"):
super().__init__(session_id, system_prompt)
self.model = model
self.reset()
def discard_exceeding(self, max_tokens, cur_tokens=None):
precise = True
try:
cur_tokens = self.calc_tokens()
except Exception as e:
precise = False
if cur_tokens is None:
raise e
logger.debug("Exception when counting tokens precisely for query: {}".format(e))
while cur_tokens > max_tokens:
if len(self.messages) > 2:
self.messages.pop(1)
elif len(self.messages) == 2 and self.messages[1]["role"] == "assistant":
self.messages.pop(1)
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
break
elif len(self.messages) == 2 and self.messages[1]["role"] == "user":
logger.warn("user message exceed max_tokens. total_tokens={}".format(cur_tokens))
break
else:
logger.debug("max_tokens={}, total_tokens={}, len(messages)={}".format(max_tokens, cur_tokens,
len(self.messages)))
break
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
return cur_tokens
def calc_tokens(self):
return num_tokens_from_messages(self.messages, self.model)
def num_tokens_from_messages(messages, model):
tokens = 0
for msg in messages:
tokens += len(msg["content"])
return tokens
================================================
FILE: models/openai/open_ai_bot.py
================================================
# encoding:utf-8
import time
import openai
from models.openai.openai_compat import RateLimitError, Timeout, APIConnectionError
from models.bot import Bot
from models.openai_compatible_bot import OpenAICompatibleBot
from models.openai.open_ai_image import OpenAIImage
from models.openai.open_ai_session import OpenAISession
from models.session_manager import SessionManager
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf
user_session = dict()
# OpenAI对话模型API (可用)
class OpenAIBot(Bot, OpenAIImage, OpenAICompatibleBot):
def __init__(self):
super().__init__()
openai.api_key = conf().get("open_ai_api_key")
if conf().get("open_ai_api_base"):
openai.api_base = conf().get("open_ai_api_base")
proxy = conf().get("proxy")
if proxy:
openai.proxy = proxy
self.sessions = SessionManager(OpenAISession, model=conf().get("model") or "text-davinci-003")
self.args = {
"model": conf().get("model") or "text-davinci-003", # 对话模型的名称
"temperature": conf().get("temperature", 0.9), # 值在[0,1]之间,越大表示回复越具有不确定性
"max_tokens": 1200, # 回复最大的字符数
"top_p": 1,
"frequency_penalty": conf().get("frequency_penalty", 0.0), # [-2,2]之间,该值越大则更倾向于产生不同的内容
"presence_penalty": conf().get("presence_penalty", 0.0), # [-2,2]之间,该值越大则更倾向于产生不同的内容
"request_timeout": conf().get("request_timeout", None), # 请求超时时间,openai接口默认设置为600,对于难问题一般需要较长时间
"timeout": conf().get("request_timeout", None), # 重试超时时间,在这个时间内,将会自动重试
"stop": ["\n\n\n"],
}
def get_api_config(self):
"""Get API configuration for OpenAI-compatible base class"""
return {
'api_key': conf().get("open_ai_api_key"),
'api_base': conf().get("open_ai_api_base"),
'model': conf().get("model", "text-davinci-003"),
'default_temperature': conf().get("temperature", 0.9),
'default_top_p': conf().get("top_p", 1.0),
'default_frequency_penalty': conf().get("frequency_penalty", 0.0),
'default_presence_penalty': conf().get("presence_penalty", 0.0),
}
def reply(self, query, context=None):
# acquire reply content
if context and context.type:
if context.type == ContextType.TEXT:
logger.info("[OPEN_AI] query={}".format(query))
session_id = context["session_id"]
reply = None
if query == "#清除记忆":
self.sessions.clear_session(session_id)
reply = Reply(ReplyType.INFO, "记忆已清除")
elif query == "#清除所有":
self.sessions.clear_all_session()
reply = Reply(ReplyType.INFO, "所有人记忆已清除")
else:
session = self.sessions.session_query(query, session_id)
result = self.reply_text(session)
total_tokens, completion_tokens, reply_content = (
result["total_tokens"],
result["completion_tokens"],
result["content"],
)
logger.debug(
"[OPEN_AI] new_query={}, session_id={}, reply_cont={}, completion_tokens={}".format(str(session), session_id, reply_content, completion_tokens)
)
if total_tokens == 0:
reply = Reply(ReplyType.ERROR, reply_content)
else:
self.sessions.session_reply(reply_content, session_id, total_tokens)
reply = Reply(ReplyType.TEXT, reply_content)
return reply
elif context.type == ContextType.IMAGE_CREATE:
ok, retstring = self.create_img(query, 0)
reply = None
if ok:
reply = Reply(ReplyType.IMAGE_URL, retstring)
else:
reply = Reply(ReplyType.ERROR, retstring)
return reply
def reply_text(self, session: OpenAISession, retry_count=0):
try:
response = openai.Completion.create(prompt=str(session), **self.args)
res_content = response.choices[0]["text"].strip().replace("<|endoftext|>", "")
total_tokens = response["usage"]["total_tokens"]
completion_tokens = response["usage"]["completion_tokens"]
logger.info("[OPEN_AI] reply={}".format(res_content))
return {
"total_tokens": total_tokens,
"completion_tokens": completion_tokens,
"content": res_content,
}
except Exception as e:
need_retry = retry_count < 2
result = {"completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
if isinstance(e, RateLimitError):
logger.warn("[OPEN_AI] RateLimitError: {}".format(e))
result["content"] = "提问太快啦,请休息一下再问我吧"
if need_retry:
time.sleep(20)
elif isinstance(e, Timeout):
logger.warn("[OPEN_AI] Timeout: {}".format(e))
result["content"] = "我没有收到你的消息"
if need_retry:
time.sleep(5)
elif isinstance(e, APIConnectionError):
logger.warn("[OPEN_AI] APIConnectionError: {}".format(e))
need_retry = False
result["content"] = "我连接不到你的网络"
else:
logger.warn("[OPEN_AI] Exception: {}".format(e))
need_retry = False
self.sessions.clear_session(session.session_id)
if need_retry:
logger.warn("[OPEN_AI] 第{}次重试".format(retry_count + 1))
return self.reply_text(session, retry_count + 1)
else:
return result
def call_with_tools(self, messages, tools=None, stream=False, **kwargs):
"""
Call OpenAI API with tool support for agent integration
Note: This bot uses the old Completion API which doesn't support tools.
For tool support, use ChatGPTBot instead.
This method converts to ChatCompletion API when tools are provided.
Args:
messages: List of messages
tools: List of tool definitions (OpenAI format)
stream: Whether to use streaming
**kwargs: Additional parameters
Returns:
Formatted response in OpenAI format or generator for streaming
"""
try:
# The old Completion API doesn't support tools
# We need to use ChatCompletion API instead
logger.info("[OPEN_AI] Using ChatCompletion API for tool support")
# Build request parameters for ChatCompletion
request_params = {
"model": kwargs.get("model", conf().get("model") or "gpt-4.1"),
"messages": messages,
"temperature": kwargs.get("temperature", conf().get("temperature", 0.9)),
"top_p": kwargs.get("top_p", 1),
"frequency_penalty": kwargs.get("frequency_penalty", conf().get("frequency_penalty", 0.0)),
"presence_penalty": kwargs.get("presence_penalty", conf().get("presence_penalty", 0.0)),
"stream": stream
}
# Add max_tokens if specified
if kwargs.get("max_tokens"):
request_params["max_tokens"] = kwargs["max_tokens"]
# Add tools if provided
if tools:
request_params["tools"] = tools
request_params["tool_choice"] = kwargs.get("tool_choice", "auto")
# Make API call using ChatCompletion
if stream:
return self._handle_stream_response(request_params)
else:
return self._handle_sync_response(request_params)
except Exception as e:
logger.error(f"[OPEN_AI] call_with_tools error: {e}")
if stream:
def error_generator():
yield {
"error": True,
"message": str(e),
"status_code": 500
}
return error_generator()
else:
return {
"error": True,
"message": str(e),
"status_code": 500
}
def _handle_sync_response(self, request_params):
"""Handle synchronous OpenAI ChatCompletion API response"""
try:
response = openai.ChatCompletion.create(**request_params)
logger.info(f"[OPEN_AI] call_with_tools reply, model={response.get('model')}, "
f"total_tokens={response.get('usage', {}).get('total_tokens', 0)}")
return response
except Exception as e:
logger.error(f"[OPEN_AI] sync response error: {e}")
raise
def _handle_stream_response(self, request_params):
"""Handle streaming OpenAI ChatCompletion API response"""
try:
stream = openai.ChatCompletion.create(**request_params)
for chunk in stream:
yield chunk
except Exception as e:
logger.error(f"[OPEN_AI] stream response error: {e}")
yield {
"error": True,
"message": str(e),
"status_code": 500
}
================================================
FILE: models/openai/open_ai_image.py
================================================
import time
import openai
from models.openai.openai_compat import RateLimitError
from common.log import logger
from common.token_bucket import TokenBucket
from config import conf
# OPENAI提供的画图接口
class OpenAIImage(object):
def __init__(self):
openai.api_key = conf().get("open_ai_api_key")
if conf().get("rate_limit_dalle"):
self.tb4dalle = TokenBucket(conf().get("rate_limit_dalle", 50))
def create_img(self, query, retry_count=0, api_key=None, api_base=None):
try:
if conf().get("rate_limit_dalle") and not self.tb4dalle.get_token():
return False, "请求太快了,请休息一下再问我吧"
logger.info("[OPEN_AI] image_query={}".format(query))
response = openai.Image.create(
api_key=api_key,
prompt=query, # 图片描述
n=1, # 每次生成图片的数量
model=conf().get("text_to_image") or "dall-e-2",
# size=conf().get("image_create_size", "256x256"), # 图片大小,可选有 256x256, 512x512, 1024x1024
)
image_url = response["data"][0]["url"]
logger.info("[OPEN_AI] image_url={}".format(image_url))
return True, image_url
except RateLimitError as e:
logger.warn(e)
if retry_count < 1:
time.sleep(5)
logger.warn("[OPEN_AI] ImgCreate RateLimit exceed, 第{}次重试".format(retry_count + 1))
return self.create_img(query, retry_count + 1)
else:
return False, "画图出现问题,请休息一下再问我吧"
except Exception as e:
logger.exception(e)
return False, "画图出现问题,请休息一下再问我吧"
================================================
FILE: models/openai/open_ai_session.py
================================================
from models.session_manager import Session
from common.log import logger
class OpenAISession(Session):
def __init__(self, session_id, system_prompt=None, model="text-davinci-003"):
super().__init__(session_id, system_prompt)
self.model = model
self.reset()
def __str__(self):
# 构造对话模型的输入
"""
e.g. Q: xxx
A: xxx
Q: xxx
"""
prompt = ""
for item in self.messages:
if item["role"] == "system":
prompt += item["content"] + "<|endoftext|>\n\n\n"
elif item["role"] == "user":
prompt += "Q: " + item["content"] + "\n"
elif item["role"] == "assistant":
prompt += "\n\nA: " + item["content"] + "<|endoftext|>\n"
if len(self.messages) > 0 and self.messages[-1]["role"] == "user":
prompt += "A: "
return prompt
def discard_exceeding(self, max_tokens, cur_tokens=None):
precise = True
try:
cur_tokens = self.calc_tokens()
except Exception as e:
precise = False
if cur_tokens is None:
raise e
logger.debug("Exception when counting tokens precisely for query: {}".format(e))
while cur_tokens > max_tokens:
if len(self.messages) > 1:
self.messages.pop(0)
elif len(self.messages) == 1 and self.messages[0]["role"] == "assistant":
self.messages.pop(0)
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = len(str(self))
break
elif len(self.messages) == 1 and self.messages[0]["role"] == "user":
logger.warn("user question exceed max_tokens. total_tokens={}".format(cur_tokens))
break
else:
logger.debug("max_tokens={}, total_tokens={}, len(conversation)={}".format(max_tokens, cur_tokens, len(self.messages)))
break
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = len(str(self))
return cur_tokens
def calc_tokens(self):
return num_tokens_from_string(str(self), self.model)
# refer to https://github.com/openai/openai-cookbook/blob/main/examples/How_to_count_tokens_with_tiktoken.ipynb
def num_tokens_from_string(string: str, model: str) -> int:
"""Returns the number of tokens in a text string."""
import tiktoken
encoding = tiktoken.encoding_for_model(model)
num_tokens = len(encoding.encode(string, disallowed_special=()))
return num_tokens
================================================
FILE: models/openai/openai_compat.py
================================================
"""
OpenAI compatibility layer for different versions.
This module provides a compatibility layer between OpenAI library versions:
- OpenAI < 1.0 (old API with openai.error module)
- OpenAI >= 1.0 (new API with direct exception imports)
"""
try:
# Try new OpenAI >= 1.0 API
from openai import (
OpenAIError,
RateLimitError,
APIError,
APIConnectionError,
AuthenticationError,
APITimeoutError,
BadRequestError,
)
# Create a mock error module for backward compatibility
class ErrorModule:
OpenAIError = OpenAIError
RateLimitError = RateLimitError
APIError = APIError
APIConnectionError = APIConnectionError
AuthenticationError = AuthenticationError
Timeout = APITimeoutError # Renamed in new version
InvalidRequestError = BadRequestError # Renamed in new version
error = ErrorModule()
# Also export with new names
Timeout = APITimeoutError
InvalidRequestError = BadRequestError
except ImportError:
# Fall back to old OpenAI < 1.0 API
try:
import openai.error as error
# Export individual exceptions for direct import
OpenAIError = error.OpenAIError
RateLimitError = error.RateLimitError
APIError = error.APIError
APIConnectionError = error.APIConnectionError
AuthenticationError = error.AuthenticationError
InvalidRequestError = error.InvalidRequestError
Timeout = error.Timeout
BadRequestError = error.InvalidRequestError # Alias
APITimeoutError = error.Timeout # Alias
except (ImportError, AttributeError):
# Neither version works, create dummy classes
class OpenAIError(Exception):
pass
class RateLimitError(OpenAIError):
pass
class APIError(OpenAIError):
pass
class APIConnectionError(OpenAIError):
pass
class AuthenticationError(OpenAIError):
pass
class InvalidRequestError(OpenAIError):
pass
class Timeout(OpenAIError):
pass
BadRequestError = InvalidRequestError
APITimeoutError = Timeout
# Create error module
class ErrorModule:
OpenAIError = OpenAIError
RateLimitError = RateLimitError
APIError = APIError
APIConnectionError = APIConnectionError
AuthenticationError = AuthenticationError
InvalidRequestError = InvalidRequestError
Timeout = Timeout
error = ErrorModule()
# Export all for easy import
__all__ = [
'error',
'OpenAIError',
'RateLimitError',
'APIError',
'APIConnectionError',
'AuthenticationError',
'InvalidRequestError',
'Timeout',
'BadRequestError',
'APITimeoutError',
]
================================================
FILE: models/openai_compatible_bot.py
================================================
# encoding:utf-8
"""
OpenAI-Compatible Bot Base Class
Provides a common implementation for bots that are compatible with OpenAI's API format.
This includes: OpenAI, LinkAI, Azure OpenAI, and many third-party providers.
"""
import json
import openai
from common.log import logger
from agent.protocol.message_utils import drop_orphaned_tool_results_openai
class OpenAICompatibleBot:
"""
Base class for OpenAI-compatible bots.
Provides common tool calling implementation that can be inherited by:
- ChatGPTBot
- LinkAIBot
- OpenAIBot
- AzureChatGPTBot
- Other OpenAI-compatible providers
Subclasses only need to override get_api_config() to provide their specific API settings.
"""
def get_api_config(self):
"""
Get API configuration for this bot.
Subclasses should override this to provide their specific config.
Returns:
dict: {
'api_key': str,
'api_base': str (optional),
'model': str,
'default_temperature': float,
'default_top_p': float,
'default_frequency_penalty': float,
'default_presence_penalty': float,
}
"""
raise NotImplementedError("Subclasses must implement get_api_config()")
def call_with_tools(self, messages, tools=None, stream=False, **kwargs):
"""
Call OpenAI-compatible API with tool support for agent integration
This method handles:
1. Format conversion (Claude format → OpenAI format)
2. System prompt injection
3. API calling with proper configuration
4. Error handling
Args:
messages: List of messages (may be in Claude format from agent)
tools: List of tool definitions (may be in Claude format from agent)
stream: Whether to use streaming
**kwargs: Additional parameters (max_tokens, temperature, system, etc.)
Returns:
Formatted response in OpenAI format or generator for streaming
"""
try:
# Get API configuration from subclass
api_config = self.get_api_config()
# Convert messages from Claude format to OpenAI format
messages = self._convert_messages_to_openai_format(messages)
# Convert tools from Claude format to OpenAI format
if tools:
tools = self._convert_tools_to_openai_format(tools)
# Handle system prompt (OpenAI uses system message, Claude uses separate parameter)
system_prompt = kwargs.get('system')
if system_prompt:
# Add system message at the beginning if not already present
if not messages or messages[0].get('role') != 'system':
messages = [{"role": "system", "content": system_prompt}] + messages
else:
# Replace existing system message
messages[0] = {"role": "system", "content": system_prompt}
# Build request parameters
request_params = {
"model": kwargs.get("model", api_config.get('model', 'gpt-3.5-turbo')),
"messages": messages,
"temperature": kwargs.get("temperature", api_config.get('default_temperature', 0.9)),
"top_p": kwargs.get("top_p", api_config.get('default_top_p', 1.0)),
"frequency_penalty": kwargs.get("frequency_penalty", api_config.get('default_frequency_penalty', 0.0)),
"presence_penalty": kwargs.get("presence_penalty", api_config.get('default_presence_penalty', 0.0)),
"stream": stream
}
# Add max_tokens if specified
if kwargs.get("max_tokens"):
request_params["max_tokens"] = kwargs["max_tokens"]
# Add tools if provided
if tools:
request_params["tools"] = tools
request_params["tool_choice"] = kwargs.get("tool_choice", "auto")
# Make API call with proper configuration
api_key = api_config.get('api_key')
api_base = api_config.get('api_base')
if stream:
return self._handle_stream_response(request_params, api_key, api_base)
else:
return self._handle_sync_response(request_params, api_key, api_base)
except Exception as e:
error_msg = str(e)
logger.error(f"[{self.__class__.__name__}] call_with_tools error: {error_msg}")
if stream:
def error_generator():
yield {
"error": True,
"message": error_msg,
"status_code": 500
}
return error_generator()
else:
return {
"error": True,
"message": error_msg,
"status_code": 500
}
def _handle_sync_response(self, request_params, api_key, api_base):
"""Handle synchronous OpenAI API response"""
try:
# Build kwargs with explicit API configuration
kwargs = dict(request_params)
if api_key:
kwargs["api_key"] = api_key
if api_base:
kwargs["api_base"] = api_base
response = openai.ChatCompletion.create(**kwargs)
return response
except Exception as e:
logger.error(f"[{self.__class__.__name__}] sync response error: {e}")
return {
"error": True,
"message": str(e),
"status_code": 500
}
def _handle_stream_response(self, request_params, api_key, api_base):
"""Handle streaming OpenAI API response"""
try:
# Build kwargs with explicit API configuration
kwargs = dict(request_params)
if api_key:
kwargs["api_key"] = api_key
if api_base:
kwargs["api_base"] = api_base
stream = openai.ChatCompletion.create(**kwargs)
# Stream chunks to caller
for chunk in stream:
yield chunk
except Exception as e:
logger.error(f"[{self.__class__.__name__}] stream response error: {e}")
yield {
"error": True,
"message": str(e),
"status_code": 500
}
def _convert_tools_to_openai_format(self, tools):
"""
Convert tools from Claude format to OpenAI format
Claude format: {name, description, input_schema}
OpenAI format: {type: "function", function: {name, description, parameters}}
"""
if not tools:
return None
openai_tools = []
for tool in tools:
# Check if already in OpenAI format
if 'type' in tool and tool['type'] == 'function':
openai_tools.append(tool)
else:
# Convert from Claude format
openai_tools.append({
"type": "function",
"function": {
"name": tool.get("name"),
"description": tool.get("description"),
"parameters": tool.get("input_schema", {})
}
})
return openai_tools
def _convert_messages_to_openai_format(self, messages):
"""
Convert messages from Claude format to OpenAI format
Claude uses content blocks with types like 'tool_use', 'tool_result'
OpenAI uses 'tool_calls' in assistant messages and 'tool' role for results
"""
if not messages:
return []
openai_messages = []
for msg in messages:
role = msg.get("role")
content = msg.get("content")
# Handle string content (already in correct format)
if isinstance(content, str):
openai_messages.append(msg)
continue
# Handle list content (Claude format with content blocks)
if isinstance(content, list):
# Check if this is a tool result message (user role with tool_result blocks)
if role == "user" and any(block.get("type") == "tool_result" for block in content):
# Separate text content and tool_result blocks
text_parts = []
tool_results = []
for block in content:
if block.get("type") == "text":
text_parts.append(block.get("text", ""))
elif block.get("type") == "tool_result":
tool_results.append(block)
# First, add tool result messages (must come immediately after assistant with tool_calls)
for block in tool_results:
tool_call_id = block.get("tool_use_id") or ""
if not tool_call_id:
logger.warning(f"[OpenAICompatible] tool_result missing tool_use_id, using empty string")
# Ensure content is a string (some providers require string content)
result_content = block.get("content", "")
if not isinstance(result_content, str):
result_content = json.dumps(result_content, ensure_ascii=False)
openai_messages.append({
"role": "tool",
"tool_call_id": tool_call_id,
"content": result_content
})
# Then, add text content as a separate user message if present
if text_parts:
openai_messages.append({
"role": "user",
"content": " ".join(text_parts)
})
# Check if this is an assistant message with tool_use blocks
elif role == "assistant":
# Separate text content and tool_use blocks
text_parts = []
tool_calls = []
for block in content:
if block.get("type") == "text":
text_parts.append(block.get("text", ""))
elif block.get("type") == "tool_use":
tool_id = block.get("id") or ""
if not tool_id:
logger.warning(f"[OpenAICompatible] tool_use missing id for '{block.get('name')}'")
tool_calls.append({
"id": tool_id,
"type": "function",
"function": {
"name": block.get("name"),
"arguments": json.dumps(block.get("input", {}))
}
})
# Build OpenAI format assistant message
openai_msg = {
"role": "assistant",
"content": " ".join(text_parts) if text_parts else None
}
if tool_calls:
openai_msg["tool_calls"] = tool_calls
if msg.get("_gemini_raw_parts"):
openai_msg["_gemini_raw_parts"] = msg["_gemini_raw_parts"]
openai_messages.append(openai_msg)
else:
# Other list content, keep as is
openai_messages.append(msg)
else:
# Other formats, keep as is
openai_messages.append(msg)
return drop_orphaned_tool_results_openai(openai_messages)
================================================
FILE: models/session_manager.py
================================================
from common.expired_dict import ExpiredDict
from common.log import logger
from config import conf
class Session(object):
def __init__(self, session_id, system_prompt=None):
self.session_id = session_id
self.messages = []
if system_prompt is None:
self.system_prompt = conf().get("character_desc", "")
else:
self.system_prompt = system_prompt
# 重置会话
def reset(self):
system_item = {"role": "system", "content": self.system_prompt}
self.messages = [system_item]
def set_system_prompt(self, system_prompt):
self.system_prompt = system_prompt
self.reset()
def add_query(self, query):
user_item = {"role": "user", "content": query}
self.messages.append(user_item)
def add_reply(self, reply):
assistant_item = {"role": "assistant", "content": reply}
self.messages.append(assistant_item)
def discard_exceeding(self, max_tokens=None, cur_tokens=None):
raise NotImplementedError
def calc_tokens(self):
raise NotImplementedError
class SessionManager(object):
def __init__(self, sessioncls, **session_args):
if conf().get("expires_in_seconds"):
sessions = ExpiredDict(conf().get("expires_in_seconds"))
else:
sessions = dict()
self.sessions = sessions
self.sessioncls = sessioncls
self.session_args = session_args
def build_session(self, session_id, system_prompt=None):
"""
如果session_id不在sessions中,创建一个新的session并添加到sessions中
如果system_prompt不会空,会更新session的system_prompt并重置session
"""
if session_id is None:
return self.sessioncls(session_id, system_prompt, **self.session_args)
if session_id not in self.sessions:
self.sessions[session_id] = self.sessioncls(session_id, system_prompt, **self.session_args)
elif system_prompt is not None: # 如果有新的system_prompt,更新并重置session
self.sessions[session_id].set_system_prompt(system_prompt)
session = self.sessions[session_id]
return session
def session_query(self, query, session_id):
session = self.build_session(session_id)
session.add_query(query)
try:
max_tokens = conf().get("conversation_max_tokens", 1000)
total_tokens = session.discard_exceeding(max_tokens, None)
logger.debug("prompt tokens used={}".format(total_tokens))
except Exception as e:
logger.warning("Exception when counting tokens precisely for prompt: {}".format(str(e)))
return session
def session_reply(self, reply, session_id, total_tokens=None):
session = self.build_session(session_id)
session.add_reply(reply)
try:
max_tokens = conf().get("conversation_max_tokens", 1000)
tokens_cnt = session.discard_exceeding(max_tokens, total_tokens)
logger.debug("raw total_tokens={}, savesession tokens={}".format(total_tokens, tokens_cnt))
except Exception as e:
logger.warning("Exception when counting tokens precisely for session: {}".format(str(e)))
return session
def clear_session(self, session_id):
if session_id in self.sessions:
del self.sessions[session_id]
def clear_all_session(self):
self.sessions.clear()
================================================
FILE: models/xunfei/xunfei_spark_bot.py
================================================
# encoding:utf-8
import requests, json
from models.bot import Bot
from models.session_manager import SessionManager
from models.chatgpt.chat_gpt_session import ChatGPTSession
from bridge.context import ContextType, Context
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf
from common import const
import time
import _thread as thread
import datetime
from datetime import datetime
from wsgiref.handlers import format_date_time
from urllib.parse import urlencode
import base64
import ssl
import hashlib
import hmac
import json
from time import mktime
from urllib.parse import urlparse
import websocket
import queue
import threading
import random
# 消息队列 map
queue_map = dict()
# 响应队列 map
reply_map = dict()
class XunFeiBot(Bot):
def __init__(self):
super().__init__()
self.app_id = conf().get("xunfei_app_id")
self.api_key = conf().get("xunfei_api_key")
self.api_secret = conf().get("xunfei_api_secret")
# 默认使用v2.0版本: "generalv2"
# Spark Lite请求地址(spark_url): wss://spark-api.xf-yun.com/v1.1/chat, 对应的domain参数为: "lite"
# Spark V2.0请求地址(spark_url): wss://spark-api.xf-yun.com/v2.1/chat, 对应的domain参数为: "generalv2"
# Spark Pro 请求地址(spark_url): wss://spark-api.xf-yun.com/v3.1/chat, 对应的domain参数为: "generalv3"
# Spark Pro-128K请求地址(spark_url): wss://spark-api.xf-yun.com/chat/pro-128k, 对应的domain参数为: "pro-128k"
# Spark Max 请求地址(spark_url): wss://spark-api.xf-yun.com/v3.5/chat, 对应的domain参数为: "generalv3.5"
# Spark4.0 Ultra 请求地址(spark_url): wss://spark-api.xf-yun.com/v4.0/chat, 对应的domain参数为: "4.0Ultra"
# 后续模型更新,对应的参数可以参考官网文档获取:https://www.xfyun.cn/doc/spark/Web.html
self.domain = conf().get("xunfei_domain", "generalv3.5")
self.spark_url = conf().get("xunfei_spark_url", "wss://spark-api.xf-yun.com/v3.5/chat")
self.host = urlparse(self.spark_url).netloc
self.path = urlparse(self.spark_url).path
# 和wenxin使用相同的session机制
self.sessions = SessionManager(ChatGPTSession, model=const.XUNFEI)
def reply(self, query, context: Context = None) -> Reply:
if context.type == ContextType.TEXT:
logger.info("[XunFei] query={}".format(query))
session_id = context["session_id"]
request_id = self.gen_request_id(session_id)
reply_map[request_id] = ""
session = self.sessions.session_query(query, session_id)
threading.Thread(target=self.create_web_socket,
args=(session.messages, request_id)).start()
depth = 0
time.sleep(0.1)
t1 = time.time()
usage = {}
while depth <= 300:
try:
data_queue = queue_map.get(request_id)
if not data_queue:
depth += 1
time.sleep(0.1)
continue
data_item = data_queue.get(block=True, timeout=0.1)
if data_item.is_end:
# 请求结束
del queue_map[request_id]
if data_item.reply:
reply_map[request_id] += data_item.reply
usage = data_item.usage
break
reply_map[request_id] += data_item.reply
depth += 1
except Exception as e:
depth += 1
continue
t2 = time.time()
logger.info(
f"[XunFei-API] response={reply_map[request_id]}, time={t2 - t1}s, usage={usage}"
)
self.sessions.session_reply(reply_map[request_id], session_id,
usage.get("total_tokens"))
reply = Reply(ReplyType.TEXT, reply_map[request_id])
del reply_map[request_id]
return reply
else:
reply = Reply(ReplyType.ERROR,
"Bot不支持处理{}类型的消息".format(context.type))
return reply
def create_web_socket(self, prompt, session_id, temperature=0.5):
logger.info(f"[XunFei] start connect, prompt={prompt}")
websocket.enableTrace(False)
wsUrl = self.create_url()
ws = websocket.WebSocketApp(wsUrl,
on_message=on_message,
on_error=on_error,
on_close=on_close,
on_open=on_open)
data_queue = queue.Queue(1000)
queue_map[session_id] = data_queue
ws.appid = self.app_id
ws.question = prompt
ws.domain = self.domain
ws.session_id = session_id
ws.temperature = temperature
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
def gen_request_id(self, session_id: str):
return session_id + "_" + str(int(time.time())) + "" + str(
random.randint(0, 100))
# 生成url
def create_url(self):
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + self.host + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + self.path + " HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.api_secret.encode('utf-8'),
signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha_base64 = base64.b64encode(signature_sha).decode(
encoding='utf-8')
authorization_origin = f'api_key="{self.api_key}", algorithm="hmac-sha256", headers="host date request-line", ' \
f'signature="{signature_sha_base64}"'
authorization = base64.b64encode(
authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {"authorization": authorization, "date": date, "host": self.host}
# 拼接鉴权参数,生成url
url = self.spark_url + '?' + urlencode(v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
return url
def gen_params(self, appid, domain, question):
"""
通过appid和用户的提问来生成请参数
"""
data = {
"header": {
"app_id": appid,
"uid": "1234"
},
"parameter": {
"chat": {
"domain": domain,
"random_threshold": 0.5,
"max_tokens": 2048,
"auditing": "default"
}
},
"payload": {
"message": {
"text": question
}
}
}
return data
class ReplyItem:
def __init__(self, reply, usage=None, is_end=False):
self.is_end = is_end
self.reply = reply
self.usage = usage
# 收到websocket错误的处理
def on_error(ws, error):
logger.error(f"[XunFei] error: {str(error)}")
# 收到websocket关闭的处理
def on_close(ws, one, two):
data_queue = queue_map.get(ws.session_id)
data_queue.put("END")
# 收到websocket连接建立的处理
def on_open(ws):
logger.info(f"[XunFei] Start websocket, session_id={ws.session_id}")
thread.start_new_thread(run, (ws, ))
def run(ws, *args):
data = json.dumps(
gen_params(appid=ws.appid,
domain=ws.domain,
question=ws.question,
temperature=ws.temperature))
ws.send(data)
# Websocket 操作
# 收到websocket消息的处理
def on_message(ws, message):
data = json.loads(message)
code = data['header']['code']
if code != 0:
logger.error(f'请求错误: {code}, {data}')
ws.close()
else:
choices = data["payload"]["choices"]
status = choices["status"]
content = choices["text"][0]["content"]
data_queue = queue_map.get(ws.session_id)
if not data_queue:
logger.error(
f"[XunFei] can't find data queue, session_id={ws.session_id}")
return
reply_item = ReplyItem(content)
if status == 2:
usage = data["payload"].get("usage")
reply_item = ReplyItem(content, usage)
reply_item.is_end = True
ws.close()
data_queue.put(reply_item)
def gen_params(appid, domain, question, temperature=0.5):
"""
通过appid和用户的提问来生成请参数
"""
data = {
"header": {
"app_id": appid,
"uid": "1234"
},
"parameter": {
"chat": {
"domain": domain,
"temperature": temperature,
"random_threshold": 0.5,
"max_tokens": 2048,
"auditing": "default"
}
},
"payload": {
"message": {
"text": question
}
}
}
return data
================================================
FILE: models/zhipuai/zhipu_ai_image.py
================================================
from common.log import logger
from config import conf
# ZhipuAI提供的画图接口
class ZhipuAIImage(object):
def __init__(self):
from zai import ZhipuAiClient
# 初始化客户端,支持自定义 API base URL(例如智谱国际版 z.ai)
api_key = conf().get("zhipu_ai_api_key")
api_base = conf().get("zhipu_ai_api_base")
if api_base:
self.client = ZhipuAiClient(api_key=api_key, base_url=api_base)
else:
self.client = ZhipuAiClient(api_key=api_key)
def create_img(self, query, retry_count=0, api_key=None, api_base=None):
try:
if conf().get("rate_limit_dalle"):
return False, "请求太快了,请休息一下再问我吧"
logger.info("[ZHIPU_AI] image_query={}".format(query))
response = self.client.images.generations(
prompt=query,
n=1, # 每次生成图片的数量
model=conf().get("text_to_image") or "cogview-3",
size=conf().get("image_create_size", "1024x1024"), # 图片大小,可选有 256x256, 512x512, 1024x1024
quality="standard",
)
image_url = response.data[0].url
logger.info("[ZHIPU_AI] image_url={}".format(image_url))
return True, image_url
except Exception as e:
logger.exception(e)
return False, "画图出现问题,请休息一下再问我吧"
================================================
FILE: models/zhipuai/zhipu_ai_session.py
================================================
from models.session_manager import Session
from common.log import logger
class ZhipuAISession(Session):
def __init__(self, session_id, system_prompt=None, model="glm-4"):
super().__init__(session_id, system_prompt)
self.model = model
self.reset()
if not system_prompt:
logger.warn("[ZhiPu] `character_desc` can not be empty")
def discard_exceeding(self, max_tokens, cur_tokens=None):
precise = True
try:
cur_tokens = self.calc_tokens()
except Exception as e:
precise = False
if cur_tokens is None:
raise e
logger.debug("Exception when counting tokens precisely for query: {}".format(e))
while cur_tokens > max_tokens:
if len(self.messages) > 2:
self.messages.pop(1)
elif len(self.messages) == 2 and self.messages[1]["role"] == "assistant":
self.messages.pop(1)
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
break
elif len(self.messages) == 2 and self.messages[1]["role"] == "user":
logger.warn("user message exceed max_tokens. total_tokens={}".format(cur_tokens))
break
else:
logger.debug("max_tokens={}, total_tokens={}, len(messages)={}".format(max_tokens, cur_tokens,
len(self.messages)))
break
if precise:
cur_tokens = self.calc_tokens()
else:
cur_tokens = cur_tokens - max_tokens
return cur_tokens
def calc_tokens(self):
return num_tokens_from_messages(self.messages, self.model)
def num_tokens_from_messages(messages, model):
tokens = 0
for msg in messages:
tokens += len(msg["content"])
return tokens
================================================
FILE: models/zhipuai/zhipuai_bot.py
================================================
# encoding:utf-8
import time
import json
from models.bot import Bot
from models.zhipuai.zhipu_ai_session import ZhipuAISession
from models.zhipuai.zhipu_ai_image import ZhipuAIImage
from models.session_manager import SessionManager
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf, load_config
from zai import ZhipuAiClient
# ZhipuAI对话模型API
class ZHIPUAIBot(Bot, ZhipuAIImage):
def __init__(self):
super().__init__()
self.sessions = SessionManager(ZhipuAISession, model=conf().get("model") or "ZHIPU_AI")
self.args = {
"model": conf().get("model") or "glm-4", # 对话模型的名称
"temperature": conf().get("temperature", 0.9), # 值在(0,1)之间(智谱AI 的温度不能取 0 或者 1)
"top_p": conf().get("top_p", 0.7), # 值在(0,1)之间(智谱AI 的 top_p 不能取 0 或者 1)
}
# 初始化客户端,支持自定义 API base URL(例如智谱国际版 z.ai)
api_key = conf().get("zhipu_ai_api_key")
api_base = conf().get("zhipu_ai_api_base")
if api_base:
self.client = ZhipuAiClient(api_key=api_key, base_url=api_base)
else:
self.client = ZhipuAiClient(api_key=api_key)
def reply(self, query, context=None):
# acquire reply content
if context.type == ContextType.TEXT:
logger.info("[ZHIPU_AI] query={}".format(query))
session_id = context["session_id"]
reply = None
clear_memory_commands = conf().get("clear_memory_commands", ["#清除记忆"])
if query in clear_memory_commands:
self.sessions.clear_session(session_id)
reply = Reply(ReplyType.INFO, "记忆已清除")
elif query == "#清除所有":
self.sessions.clear_all_session()
reply = Reply(ReplyType.INFO, "所有人记忆已清除")
elif query == "#更新配置":
load_config()
reply = Reply(ReplyType.INFO, "配置已更新")
if reply:
return reply
session = self.sessions.session_query(query, session_id)
logger.debug("[ZHIPU_AI] session query={}".format(session.messages))
model = context.get("gpt_model")
new_args = None
if model:
new_args = self.args.copy()
new_args["model"] = model
reply_content = self.reply_text(session, args=new_args)
logger.debug(
"[ZHIPU_AI] new_query={}, session_id={}, reply_cont={}, completion_tokens={}".format(
session.messages,
session_id,
reply_content["content"],
reply_content["completion_tokens"],
)
)
if reply_content["completion_tokens"] == 0 and len(reply_content["content"]) > 0:
reply = Reply(ReplyType.ERROR, reply_content["content"])
elif reply_content["completion_tokens"] > 0:
self.sessions.session_reply(reply_content["content"], session_id, reply_content["total_tokens"])
reply = Reply(ReplyType.TEXT, reply_content["content"])
else:
reply = Reply(ReplyType.ERROR, reply_content["content"])
logger.debug("[ZHIPU_AI] reply {} used 0 tokens.".format(reply_content))
return reply
elif context.type == ContextType.IMAGE_CREATE:
ok, retstring = self.create_img(query, 0)
reply = None
if ok:
reply = Reply(ReplyType.IMAGE_URL, retstring)
else:
reply = Reply(ReplyType.ERROR, retstring)
return reply
else:
reply = Reply(ReplyType.ERROR, "Bot不支持处理{}类型的消息".format(context.type))
return reply
def reply_text(self, session: ZhipuAISession, args=None, retry_count=0) -> dict:
"""
Call ZhipuAI API to get the answer
:param session: a conversation session
:param args: request arguments
:param retry_count: retry count
:return: {}
"""
try:
if args is None:
args = self.args
response = self.client.chat.completions.create(messages=session.messages, **args)
# logger.debug("[ZHIPU_AI] response={}".format(response))
# logger.info("[ZHIPU_AI] reply={}, total_tokens={}".format(response.choices[0]['message']['content'], response["usage"]["total_tokens"]))
return {
"total_tokens": response.usage.total_tokens,
"completion_tokens": response.usage.completion_tokens,
"content": response.choices[0].message.content,
}
except Exception as e:
need_retry = retry_count < 2
result = {"completion_tokens": 0, "content": "我现在有点累了,等会再来吧"}
error_str = str(e).lower()
# Check error type by error message content
if "rate" in error_str and "limit" in error_str:
logger.warn("[ZHIPU_AI] RateLimitError: {}".format(e))
result["content"] = "提问太快啦,请休息一下再问我吧"
if need_retry:
time.sleep(20)
elif "timeout" in error_str or "timed out" in error_str:
logger.warn("[ZHIPU_AI] Timeout: {}".format(e))
result["content"] = "我没有收到你的消息"
if need_retry:
time.sleep(5)
elif "api" in error_str and ("error" in error_str or "gateway" in error_str):
logger.warn("[ZHIPU_AI] APIError: {}".format(e))
result["content"] = "请再问我一次"
if need_retry:
time.sleep(10)
elif "connection" in error_str or "network" in error_str:
logger.warn("[ZHIPU_AI] ConnectionError: {}".format(e))
result["content"] = "我连接不到你的网络"
if need_retry:
time.sleep(5)
else:
logger.exception("[ZHIPU_AI] Exception: {}".format(e), e)
need_retry = False
self.sessions.clear_session(session.session_id)
if need_retry:
logger.warn("[ZHIPU_AI] 第{}次重试".format(retry_count + 1))
return self.reply_text(session, args, retry_count + 1)
else:
return result
def call_with_tools(self, messages, tools=None, stream=False, **kwargs):
"""
Call ZhipuAI API with tool support for agent integration
This method handles:
1. Format conversion (Claude format → ZhipuAI format)
2. System prompt injection
3. API calling with ZhipuAI SDK
4. Tool stream support (tool_stream=True for GLM-4.7)
Args:
messages: List of messages (may be in Claude format from agent)
tools: List of tool definitions (may be in Claude format from agent)
stream: Whether to use streaming
**kwargs: Additional parameters (max_tokens, temperature, system, etc.)
Returns:
Formatted response or generator for streaming
"""
try:
# Convert messages from Claude format to ZhipuAI format
messages = self._convert_messages_to_zhipu_format(messages)
# Convert tools from Claude format to ZhipuAI format
if tools:
tools = self._convert_tools_to_zhipu_format(tools)
# Handle system prompt
system_prompt = kwargs.get('system')
if system_prompt:
# Add system message at the beginning if not already present
if not messages or messages[0].get('role') != 'system':
messages = [{"role": "system", "content": system_prompt}] + messages
else:
# Replace existing system message
messages[0] = {"role": "system", "content": system_prompt}
# Build request parameters
request_params = {
"model": kwargs.get("model", self.args.get("model", "glm-4")),
"messages": messages,
"temperature": kwargs.get("temperature", self.args.get("temperature", 0.9)),
"top_p": kwargs.get("top_p", self.args.get("top_p", 0.7)),
"stream": stream
}
# Add max_tokens if specified
if kwargs.get("max_tokens"):
request_params["max_tokens"] = kwargs["max_tokens"]
# Add tools if provided
if tools:
request_params["tools"] = tools
# GLM-4.7 with zai-sdk supports tool_stream for streaming tool calls
if stream:
request_params["tool_stream"] = kwargs.get("tool_stream", True)
# Add thinking parameter for deep thinking mode (GLM-4.7)
thinking = kwargs.get("thinking")
if thinking:
request_params["thinking"] = thinking
elif "glm-4.7" in request_params["model"]:
# Enable thinking by default for GLM-4.7
request_params["thinking"] = {"type": "disabled"}
# Make API call with ZhipuAI SDK
if stream:
return self._handle_stream_response(request_params)
else:
return self._handle_sync_response(request_params)
except Exception as e:
error_msg = str(e)
logger.error(f"[ZHIPU_AI] call_with_tools error: {error_msg}")
if stream:
def error_generator():
yield {
"error": True,
"message": error_msg,
"status_code": 500
}
return error_generator()
else:
return {
"error": True,
"message": error_msg,
"status_code": 500
}
def _handle_sync_response(self, request_params):
"""Handle synchronous ZhipuAI API response"""
try:
response = self.client.chat.completions.create(**request_params)
# Convert ZhipuAI response to OpenAI-compatible format
return {
"id": response.id,
"object": "chat.completion",
"created": response.created,
"model": response.model,
"choices": [{
"index": 0,
"message": {
"role": response.choices[0].message.role,
"content": response.choices[0].message.content,
"tool_calls": self._convert_tool_calls_to_openai_format(
getattr(response.choices[0].message, 'tool_calls', None)
)
},
"finish_reason": response.choices[0].finish_reason
}],
"usage": {
"prompt_tokens": response.usage.prompt_tokens,
"completion_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens
}
}
except Exception as e:
logger.error(f"[ZHIPU_AI] sync response error: {e}")
return {
"error": True,
"message": str(e),
"status_code": 500
}
def _handle_stream_response(self, request_params):
"""Handle streaming ZhipuAI API response"""
try:
stream = self.client.chat.completions.create(**request_params)
# Stream chunks to caller, converting to OpenAI format
for chunk in stream:
if not chunk.choices:
continue
delta = chunk.choices[0].delta
# Convert to OpenAI-compatible format
openai_chunk = {
"id": chunk.id,
"object": "chat.completion.chunk",
"created": chunk.created,
"model": chunk.model,
"choices": [{
"index": 0,
"delta": {},
"finish_reason": chunk.choices[0].finish_reason
}]
}
# Add role if present
if hasattr(delta, 'role') and delta.role:
openai_chunk["choices"][0]["delta"]["role"] = delta.role
# Add content if present
if hasattr(delta, 'content') and delta.content:
openai_chunk["choices"][0]["delta"]["content"] = delta.content
# Add reasoning_content as separate field if present (GLM-5/GLM-4.7 thinking)
if hasattr(delta, 'reasoning_content') and delta.reasoning_content:
openai_chunk["choices"][0]["delta"]["reasoning_content"] = delta.reasoning_content
# Add tool_calls if present
if hasattr(delta, 'tool_calls') and delta.tool_calls:
# For streaming, tool_calls need special handling
openai_tool_calls = []
for tc in delta.tool_calls:
tool_call_dict = {
"index": getattr(tc, 'index', 0),
"id": getattr(tc, 'id', None),
"type": "function",
"function": {}
}
# Add function name if present
if hasattr(tc, 'function') and hasattr(tc.function, 'name') and tc.function.name:
tool_call_dict["function"]["name"] = tc.function.name
# Add function arguments if present
if hasattr(tc, 'function') and hasattr(tc.function, 'arguments') and tc.function.arguments:
tool_call_dict["function"]["arguments"] = tc.function.arguments
openai_tool_calls.append(tool_call_dict)
openai_chunk["choices"][0]["delta"]["tool_calls"] = openai_tool_calls
yield openai_chunk
except Exception as e:
logger.error(f"[ZHIPU_AI] stream response error: {e}")
yield {
"error": True,
"message": str(e),
"status_code": 500
}
def _convert_tools_to_zhipu_format(self, tools):
"""
Convert tools from Claude format to ZhipuAI format
Claude format: {name, description, input_schema}
ZhipuAI format: {type: "function", function: {name, description, parameters}}
"""
if not tools:
return None
zhipu_tools = []
for tool in tools:
# Check if already in ZhipuAI/OpenAI format
if 'type' in tool and tool['type'] == 'function':
zhipu_tools.append(tool)
else:
# Convert from Claude format
zhipu_tools.append({
"type": "function",
"function": {
"name": tool.get("name"),
"description": tool.get("description"),
"parameters": tool.get("input_schema", {})
}
})
return zhipu_tools
def _convert_messages_to_zhipu_format(self, messages):
"""
Convert messages from Claude format to ZhipuAI format
Claude uses content blocks with types like 'tool_use', 'tool_result'
ZhipuAI uses 'tool_calls' in assistant messages and 'tool' role for results
"""
if not messages:
return []
zhipu_messages = []
for msg in messages:
role = msg.get("role")
content = msg.get("content")
# Handle string content (already in correct format)
if isinstance(content, str):
zhipu_messages.append(msg)
continue
# Handle list content (Claude format with content blocks)
if isinstance(content, list):
# Check if this is a tool result message (user role with tool_result blocks)
if role == "user" and any(block.get("type") == "tool_result" for block in content):
# Convert each tool_result block to a separate tool message
for block in content:
if block.get("type") == "tool_result":
zhipu_messages.append({
"role": "tool",
"tool_call_id": block.get("tool_use_id"),
"content": block.get("content", "")
})
# Check if this is an assistant message with tool_use blocks
elif role == "assistant":
# Separate text content and tool_use blocks
text_parts = []
tool_calls = []
for block in content:
if block.get("type") == "text":
text_parts.append(block.get("text", ""))
elif block.get("type") == "tool_use":
tool_calls.append({
"id": block.get("id"),
"type": "function",
"function": {
"name": block.get("name"),
"arguments": json.dumps(block.get("input", {}))
}
})
# Build ZhipuAI format assistant message
zhipu_msg = {
"role": "assistant",
"content": " ".join(text_parts) if text_parts else None
}
if tool_calls:
zhipu_msg["tool_calls"] = tool_calls
zhipu_messages.append(zhipu_msg)
else:
# Other list content, keep as is
zhipu_messages.append(msg)
else:
# Other formats, keep as is
zhipu_messages.append(msg)
return zhipu_messages
def _convert_tool_calls_to_openai_format(self, tool_calls):
"""Convert ZhipuAI tool_calls to OpenAI format"""
if not tool_calls:
return None
openai_tool_calls = []
for tool_call in tool_calls:
openai_tool_calls.append({
"id": tool_call.id,
"type": "function",
"function": {
"name": tool_call.function.name,
"arguments": tool_call.function.arguments
}
})
return openai_tool_calls
================================================
FILE: plugins/agent/README.md
================================================
# Agent插件
## 插件说明
基于 [AgentMesh](https://github.com/MinimalFuture/AgentMesh) 多智能体框架实现的Agent插件,可以让机器人快速获得Agent能力,通过自然语言对话来访问 **终端、浏览器、文件系统、搜索引擎** 等各类工具。
同时还支持通过 **多智能体协作** 来完成复杂任务,例如多智能体任务分发、多智能体问题讨论、协同处理等。
AgentMesh项目地址:https://github.com/MinimalFuture/AgentMesh
## 安装
1. 确保已安装依赖:
```bash
pip install agentmesh-sdk>=0.1.3
```
2. 如需使用浏览器工具,还需安装:
```bash
pip install browser-use>=0.1.40
playwright install
```
## 配置
插件配置文件是 `plugins/agent`目录下的 `config.yaml`,包含智能体团队的配置以及工具的配置,可以从模板文件 `config-template.yaml`中复制:
```bash
cp config-template.yaml config.yaml
```
说明:
- `team`配置是默认选中的 agent team
- `teams` 下是Agent团队配置,团队的model默认为`gpt-4.1-mini`,可根据需要进行修改,模型对应的 `api_key` 需要在项目根目录的 `config.json` 全局配置中进行配置。例如openai模型需要配置 `open_ai_api_key`
- 支持为 `agents` 下面的每个agent添加model字段来设置不同的模型
## 使用方法
在对机器人发送的消息中使用 `$agent` 前缀来触发插件,支持以下命令:
- `$agent [task]`: 使用默认团队执行任务 (默认团队可通 config.yaml 中的team配置修改)
- `$agent teams`: 列出可用的团队
- `$agent use [team_name] [task]`: 使用指定的团队执行任务
### 示例
```bash
$agent 帮我查看当前目录下有哪些文件夹
$agent teams
$agent use software_team 帮我写一个产品预约体验的表单页面
```
## 工具支持
目前支持多种内置工具,包括但不限于:
- `calculator`: 数学计算工具
- `current_time`: 获取当前时间
- `browser`: 浏览器操作工具,注意需安装`browser-use`依赖
- `google_search`: 搜索引擎,注意需在`config.yaml`中配置 `api_key`
- `file_save`: 文件保存工具,开启后智能体输出的内容将保存在 `workspace` 目录下
- `terminal`: 终端命令执行工具
================================================
FILE: plugins/agent/__init__.py
================================================
from .agent import AgentPlugin
__all__ = ["AgentPlugin"]
================================================
FILE: plugins/agent/agent.py
================================================
import os
import yaml
from typing import Dict, List, Optional
from agentmesh import AgentTeam, Agent, LLMModel
from agentmesh.models import ClaudeModel
from agentmesh.tools import ToolManager
from config import conf
import plugins
from plugins import Plugin, Event, EventContext, EventAction
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
@plugins.register(
name="agent",
desc="Use AgentMesh framework to process tasks with multi-agent teams",
version="0.1.0",
author="Saboteur7",
desire_priority=1,
)
class AgentPlugin(Plugin):
"""Plugin for integrating AgentMesh framework."""
def __init__(self):
super().__init__()
self.handlers[Event.ON_HANDLE_CONTEXT] = self.on_handle_context
self.name = "agent"
self.description = "Use AgentMesh framework to process tasks with multi-agent teams"
self.config = self._load_config()
self.tool_manager = ToolManager()
self.tool_manager.load_tools(config_dict=self.config.get("tools"))
logger.debug("[agent] inited")
def _load_config(self) -> Dict:
"""Load configuration from config.yaml file."""
config_path = os.path.join(self.path, "config.yaml")
if not os.path.exists(config_path):
logger.debug(f"Config file not found at {config_path}")
return {}
with open(config_path, 'r', encoding='utf-8') as f:
return yaml.safe_load(f)
def get_help_text(self, verbose=False, **kwargs):
"""Return help message for the agent plugin."""
help_text = "通过AgentMesh实现对终端、浏览器、文件系统、搜索引擎等工具的执行,并支持多智能体协作。"
trigger_prefix = conf().get("plugin_trigger_prefix", "$")
if not verbose:
return help_text
teams = self.get_available_teams()
teams_str = ", ".join(teams) if teams else "未配置任何团队"
help_text += "\n\n使用说明:\n"
help_text += f"{trigger_prefix}agent [task] - 使用默认团队执行任务\n"
help_text += f"{trigger_prefix}agent teams - 列出可用的团队\n"
help_text += f"{trigger_prefix}agent use [team_name] [task] - 使用特定团队执行任务\n\n"
help_text += f"可用团队: \n{teams_str}\n\n"
help_text += f"示例:\n"
help_text += f"{trigger_prefix}agent 帮我查看当前文件夹路径\n"
help_text += f"{trigger_prefix}agent use software_team 帮我写一个产品预约体验的表单页面"
return help_text
def get_available_teams(self) -> List[str]:
"""Get list of available teams from configuration."""
teams_config = self.config.get("teams", {})
return list(teams_config.keys())
def create_team_from_config(self, team_name: str) -> Optional[AgentTeam]:
"""Create a team from configuration."""
# Get teams configuration
teams_config = self.config.get("teams", {})
# Check if the specified team exists
if team_name not in teams_config:
logger.error(f"Team '{team_name}' not found in configuration.")
available_teams = list(teams_config.keys())
logger.info(f"Available teams: {', '.join(available_teams)}")
return None
# Get team configuration
team_config = teams_config[team_name]
# Get team's model
team_model_name = team_config.get("model", "gpt-4.1-mini")
team_model = self.create_llm_model(team_model_name)
# Get team's max_steps (default to 20 if not specified)
team_max_steps = team_config.get("max_steps", 20)
# Create team with the model
team = AgentTeam(
name=team_name,
description=team_config.get("description", ""),
rule=team_config.get("rule", ""),
model=team_model,
max_steps=team_max_steps
)
# Create and add agents to the team
agents_config = team_config.get("agents", [])
for agent_config in agents_config:
# Check if agent has a specific model
if agent_config.get("model"):
agent_model = self.create_llm_model(agent_config.get("model"))
else:
agent_model = team_model
# Get agent's max_steps
agent_max_steps = agent_config.get("max_steps")
agent = Agent(
name=agent_config.get("name", ""),
system_prompt=agent_config.get("system_prompt", ""),
model=agent_model, # Use agent's model if specified, otherwise will use team's model
description=agent_config.get("description", ""),
max_steps=agent_max_steps
)
# Add tools to the agent if specified
tool_names = agent_config.get("tools", [])
for tool_name in tool_names:
tool = self.tool_manager.create_tool(tool_name)
if tool:
agent.add_tool(tool)
else:
if tool_name == "browser":
logger.warning(
"Tool 'Browser' loaded failed, "
"please install the required dependency with: \n"
"'pip install browser-use>=0.1.40' or 'pip install agentmesh-sdk[full]'\n"
)
else:
logger.warning(f"Tool '{tool_name}' not found for agent '{agent.name}'\n")
# Add agent to team
team.add(agent)
return team
def on_handle_context(self, e_context: EventContext):
"""Handle the message context."""
if e_context['context'].type != ContextType.TEXT:
return
content = e_context['context'].content
trigger_prefix = conf().get("plugin_trigger_prefix", "$")
if not content.startswith(f"{trigger_prefix}agent "):
e_context.action = EventAction.CONTINUE
return
if not self.config:
reply = Reply()
reply.type = ReplyType.ERROR
reply.content = "未找到插件配置,请在 plugins/agent 目录下创建 config.yaml 配置文件,可根据 config-template.yml 模板文件复制"
e_context['reply'] = reply
e_context.action = EventAction.BREAK_PASS
return
# Extract the actual task
task = content[len(f"{trigger_prefix}agent "):].strip()
# If task is empty, return help message
if not task:
reply = Reply()
reply.type = ReplyType.TEXT
reply.content = self.get_help_text(verbose=True)
e_context['reply'] = reply
e_context.action = EventAction.BREAK_PASS
return
# Check if task is asking for available teams
if task.lower() in ["teams", "list teams", "show teams"]:
teams = self.get_available_teams()
reply = Reply()
reply.type = ReplyType.TEXT
if not teams:
reply.content = "未配置任何团队。请检查 config.yaml 文件。"
else:
reply.content = f"可用团队: {', '.join(teams)}"
e_context['reply'] = reply
e_context.action = EventAction.BREAK_PASS
return
# Check if task specifies a team
team_name = None
if task.startswith("use "):
parts = task[4:].split(" ", 1)
if len(parts) > 0:
team_name = parts[0]
if len(parts) > 1:
task = parts[1].strip()
else:
reply = Reply()
reply.type = ReplyType.TEXT
reply.content = f"已选择团队 '{team_name}'。请输入您想执行的任务。"
e_context['reply'] = reply
e_context.action = EventAction.BREAK_PASS
return
if not team_name:
team_name = self.config.get("team")
# If no team specified, use default or first available
if not team_name:
teams = self.configself.get_available_teams()
if not teams:
reply = Reply()
reply.type = ReplyType.TEXT
reply.content = "未配置任何团队。请检查 config.yaml 文件。"
e_context['reply'] = reply
e_context.action = EventAction.BREAK_PASS
return
team_name = teams[0]
# Create team
team = self.create_team_from_config(team_name)
if not team:
reply = Reply()
reply.type = ReplyType.TEXT
reply.content = f"创建团队 '{team_name}' 失败。请检查配置。"
e_context['reply'] = reply
e_context.action = EventAction.BREAK_PASS
return
# Run the task
try:
logger.info(f"[agent] Running task '{task}' with team '{team_name}', team_model={team.model.model}")
result = team.run_async(task=task)
for agent_result in result:
res_text = f"🤖 {agent_result.get('agent_name')}\n\n{agent_result.get('final_answer')}"
_send_text(e_context, content=res_text)
reply = Reply()
reply.type = ReplyType.TEXT
reply.content = ""
e_context['reply'] = reply
e_context.action = EventAction.BREAK_PASS
except Exception as e:
logger.exception(f"Error running task with team '{team_name}'")
reply = Reply()
reply.type = ReplyType.ERROR
reply.content = f"执行任务时出错: {str(e)}"
e_context['reply'] = reply
e_context.action = EventAction.BREAK_PASS
return
def create_llm_model(self, model_name) -> LLMModel:
if conf().get("use_linkai"):
api_base = "https://api.link-ai.tech/v1"
api_key = conf().get("linkai_api_key")
elif model_name.startswith(("gpt", "text-davinci", "o1", "o3")):
api_base = conf().get("open_ai_api_base") or "https://api.openai.com/v1"
api_key = conf().get("open_ai_api_key")
elif model_name.startswith("claude"):
return ClaudeModel(model=model_name, api_key=conf().get("claude_api_key"))
elif model_name.startswith("moonshot"):
api_base = "https://api.moonshot.cn/v1"
api_key = conf().get("moonshot_api_key")
elif model_name.startswith("qwen"):
api_base = "https://dashscope.aliyuncs.com/compatible-mode/v1"
api_key = conf().get("dashscope_api_key")
else:
api_base = conf().get("open_ai_api_base") or "https://api.openai.com/v1"
api_key = conf().get("open_ai_api_key")
llm_model = LLMModel(model=model_name, api_key=api_key, api_base=api_base)
return llm_model
def _send_text(e_context: EventContext, content: str):
reply = Reply(ReplyType.TEXT, content)
channel = e_context["channel"]
channel.send(reply, e_context["context"])
================================================
FILE: plugins/agent/config-template.yaml
================================================
# 默认选中的Agent Team名称
team: general_team
tools:
google_search:
# get your apikey from https://serper.dev/
api_key: "YOUR API KEY"
# Agent Team 配置
teams:
# 通用智能体团队
general_team:
model: "gpt-4.1-mini" # 团队使用的模型
description: "A versatile research and information agent team"
max_steps: 5
agents:
- name: "通用智能助手"
description: "Universal assistant specializing in research, information synthesis, and task execution"
system_prompt: "You are a versatile assistant who answers questions and completes tasks using available tools. Reply in a clearly structured, attractive and easy to read format."
# Agent 支持使用的工具
tools:
- time
- calculator
- google_search
- browser
- terminal
# 软件开发智能体团队
software_team:
model: "gpt-4.1-mini"
description: "A software development team with product manager, developer and tester."
rule: "A normal R&D process should be that Product Manager writes PRD, Developer writes code based on PRD, and Finally, Tester performs testing."
max_steps: 10
agents:
- name: "Product-Manager"
description: "Responsible for product requirements and documentation"
system_prompt: "You are an experienced product manager who creates concise PRDs, focusing on user needs and feature specifications. You always format your responses in Markdown."
tools:
- time
- file_save
- name: "Developer"
description: "Implements code based on PRD"
system_prompt: "You are a skilled developer. When developing web application, you creates single-page website based on user needs, you deliver HTML files with embedded JavaScript and CSS that are visually appealing, responsive, and user-friendly, featuring a grand layout and beautiful background. The HTML, CSS, and JavaScript code should be well-structured and effectively organized."
tools:
- file_save
- name: "Tester"
description: "Tests code and verifies functionality"
system_prompt: "You are a tester who validates code against requirements. For HTML applications, use browser tools to test functionality. For Python or other client-side applications, use the terminal tool to run and test. You only need to test a few core cases."
tools:
- file_save
- browser
- terminal
================================================
FILE: plugins/banwords/.gitignore
================================================
banwords.txt
================================================
FILE: plugins/banwords/README.md
================================================
## 插件描述
简易的敏感词插件,暂不支持分词,请自行导入词库到插件文件夹中的`banwords.txt`,每行一个词,一个参考词库是[1](https://github.com/cjh0613/tencent-sensitive-words/blob/main/sensitive_words_lines.txt)。
使用前将`config.json.template`复制为`config.json`,并自行配置。
目前插件对消息的默认处理行为有如下两种:
- `ignore` : 无视这条消息。
- `replace` : 将消息中的敏感词替换成"*",并回复违规。
```json
"action": "replace",
"reply_filter": true,
"reply_action": "ignore"
```
在以上配置项中:
- `action`: 对用户消息的默认处理行为
- `reply_filter`: 是否对ChatGPT的回复也进行敏感词过滤
- `reply_action`: 如果开启了回复过滤,对回复的默认处理行为
## 致谢
搜索功能实现来自https://github.com/toolgood/ToolGood.Words
================================================
FILE: plugins/banwords/__init__.py
================================================
from .banwords import *
================================================
FILE: plugins/banwords/banwords.py
================================================
# encoding:utf-8
import json
import os
import plugins
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from plugins import *
from .lib.WordsSearch import WordsSearch
@plugins.register(
name="Banwords",
desire_priority=100,
hidden=True,
desc="判断消息中是否有敏感词、决定是否回复。",
version="1.0",
author="lanvent",
)
class Banwords(Plugin):
def __init__(self):
super().__init__()
try:
# load config
conf = super().load_config()
curdir = os.path.dirname(__file__)
if not conf:
# 配置不存在则写入默认配置
config_path = os.path.join(curdir, "config.json")
if not os.path.exists(config_path):
conf = {"action": "ignore"}
with open(config_path, "w") as f:
json.dump(conf, f, indent=4)
self.searchr = WordsSearch()
self.action = conf["action"]
banwords_path = os.path.join(curdir, "banwords.txt")
with open(banwords_path, "r", encoding="utf-8") as f:
words = []
for line in f:
word = line.strip()
if word:
words.append(word)
self.searchr.SetKeywords(words)
self.handlers[Event.ON_HANDLE_CONTEXT] = self.on_handle_context
if conf.get("reply_filter", True):
self.handlers[Event.ON_DECORATE_REPLY] = self.on_decorate_reply
self.reply_action = conf.get("reply_action", "ignore")
logger.debug("[Banwords] inited")
except Exception as e:
logger.debug("[Banwords] init failed, ignore or see https://github.com/zhayujie/chatgpt-on-wechat/tree/master/plugins/banwords .")
raise e
def on_handle_context(self, e_context: EventContext):
if e_context["context"].type not in [
ContextType.TEXT,
ContextType.IMAGE_CREATE,
]:
return
content = e_context["context"].content
logger.debug("[Banwords] on_handle_context. content: %s" % content)
if self.action == "ignore":
f = self.searchr.FindFirst(content)
if f:
logger.info("[Banwords] %s in message" % f["Keyword"])
e_context.action = EventAction.BREAK_PASS
return
elif self.action == "replace":
if self.searchr.ContainsAny(content):
reply = Reply(ReplyType.INFO, "发言中包含敏感词,请重试: \n" + self.searchr.Replace(content))
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
return
def on_decorate_reply(self, e_context: EventContext):
if e_context["reply"].type not in [ReplyType.TEXT]:
return
reply = e_context["reply"]
content = reply.content
if self.reply_action == "ignore":
f = self.searchr.FindFirst(content)
if f:
logger.info("[Banwords] %s in reply" % f["Keyword"])
e_context["reply"] = None
e_context.action = EventAction.BREAK_PASS
return
elif self.reply_action == "replace":
if self.searchr.ContainsAny(content):
reply = Reply(ReplyType.INFO, "已替换回复中的敏感词: \n" + self.searchr.Replace(content))
e_context["reply"] = reply
e_context.action = EventAction.CONTINUE
return
def get_help_text(self, **kwargs):
return "过滤消息中的敏感词。"
================================================
FILE: plugins/banwords/banwords.txt.template
================================================
nipples
pennis
================================================
FILE: plugins/banwords/config.json.template
================================================
{
"action": "replace",
"reply_filter": true,
"reply_action": "ignore"
}
================================================
FILE: plugins/banwords/lib/WordsSearch.py
================================================
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# ToolGood.Words.WordsSearch.py
# 2020, Lin Zhijun, https://github.com/toolgood/ToolGood.Words
# Licensed under the Apache License 2.0
# 更新日志
# 2020.04.06 第一次提交
# 2020.05.16 修改,支持大于0xffff的字符
__all__ = ['WordsSearch']
__author__ = 'Lin Zhijun'
__date__ = '2020.05.16'
class TrieNode():
def __init__(self):
self.Index = 0
self.Index = 0
self.Layer = 0
self.End = False
self.Char = ''
self.Results = []
self.m_values = {}
self.Failure = None
self.Parent = None
def Add(self,c):
if c in self.m_values :
return self.m_values[c]
node = TrieNode()
node.Parent = self
node.Char = c
self.m_values[c] = node
return node
def SetResults(self,index):
if (self.End == False):
self.End = True
self.Results.append(index)
class TrieNode2():
def __init__(self):
self.End = False
self.Results = []
self.m_values = {}
self.minflag = 0xffff
self.maxflag = 0
def Add(self,c,node3):
if (self.minflag > c):
self.minflag = c
if (self.maxflag < c):
self.maxflag = c
self.m_values[c] = node3
def SetResults(self,index):
if (self.End == False) :
self.End = True
if (index in self.Results )==False :
self.Results.append(index)
def HasKey(self,c):
return c in self.m_values
def TryGetValue(self,c):
if (self.minflag <= c and self.maxflag >= c):
if c in self.m_values:
return self.m_values[c]
return None
class WordsSearch():
def __init__(self):
self._first = {}
self._keywords = []
self._indexs=[]
def SetKeywords(self,keywords):
self._keywords = keywords
self._indexs=[]
for i in range(len(keywords)):
self._indexs.append(i)
root = TrieNode()
allNodeLayer={}
for i in range(len(self._keywords)): # for (i = 0; i < _keywords.length; i++)
p = self._keywords[i]
nd = root
for j in range(len(p)): # for (j = 0; j < p.length; j++)
nd = nd.Add(ord(p[j]))
if (nd.Layer == 0):
nd.Layer = j + 1
if nd.Layer in allNodeLayer:
allNodeLayer[nd.Layer].append(nd)
else:
allNodeLayer[nd.Layer]=[]
allNodeLayer[nd.Layer].append(nd)
nd.SetResults(i)
allNode = []
allNode.append(root)
for key in allNodeLayer.keys():
for nd in allNodeLayer[key]:
allNode.append(nd)
allNodeLayer=None
for i in range(len(allNode)): # for (i = 0; i < allNode.length; i++)
if i==0 :
continue
nd=allNode[i]
nd.Index = i
r = nd.Parent.Failure
c = nd.Char
while (r != None and (c in r.m_values)==False):
r = r.Failure
if (r == None):
nd.Failure = root
else:
nd.Failure = r.m_values[c]
for key2 in nd.Failure.Results :
nd.SetResults(key2)
root.Failure = root
allNode2 = []
for i in range(len(allNode)): # for (i = 0; i < allNode.length; i++)
allNode2.append( TrieNode2())
for i in range(len(allNode2)): # for (i = 0; i < allNode2.length; i++)
oldNode = allNode[i]
newNode = allNode2[i]
for key in oldNode.m_values :
index = oldNode.m_values[key].Index
newNode.Add(key, allNode2[index])
for index in range(len(oldNode.Results)): # for (index = 0; index < oldNode.Results.length; index++)
item = oldNode.Results[index]
newNode.SetResults(item)
oldNode=oldNode.Failure
while oldNode != root:
for key in oldNode.m_values :
if (newNode.HasKey(key) == False):
index = oldNode.m_values[key].Index
newNode.Add(key, allNode2[index])
for index in range(len(oldNode.Results)):
item = oldNode.Results[index]
newNode.SetResults(item)
oldNode=oldNode.Failure
allNode = None
root = None
# first = []
# for index in range(65535):# for (index = 0; index < 0xffff; index++)
# first.append(None)
# for key in allNode2[0].m_values :
# first[key] = allNode2[0].m_values[key]
self._first = allNode2[0]
def FindFirst(self,text):
ptr = None
for index in range(len(text)): # for (index = 0; index < text.length; index++)
t =ord(text[index]) # text.charCodeAt(index)
tn = None
if (ptr == None):
tn = self._first.TryGetValue(t)
else:
tn = ptr.TryGetValue(t)
if (tn==None):
tn = self._first.TryGetValue(t)
if (tn != None):
if (tn.End):
item = tn.Results[0]
keyword = self._keywords[item]
return { "Keyword": keyword, "Success": True, "End": index, "Start": index + 1 - len(keyword), "Index": self._indexs[item] }
ptr = tn
return None
def FindAll(self,text):
ptr = None
list = []
for index in range(len(text)): # for (index = 0; index < text.length; index++)
t =ord(text[index]) # text.charCodeAt(index)
tn = None
if (ptr == None):
tn = self._first.TryGetValue(t)
else:
tn = ptr.TryGetValue(t)
if (tn==None):
tn = self._first.TryGetValue(t)
if (tn != None):
if (tn.End):
for j in range(len(tn.Results)): # for (j = 0; j < tn.Results.length; j++)
item = tn.Results[j]
keyword = self._keywords[item]
list.append({ "Keyword": keyword, "Success": True, "End": index, "Start": index + 1 - len(keyword), "Index": self._indexs[item] })
ptr = tn
return list
def ContainsAny(self,text):
ptr = None
for index in range(len(text)): # for (index = 0; index < text.length; index++)
t =ord(text[index]) # text.charCodeAt(index)
tn = None
if (ptr == None):
tn = self._first.TryGetValue(t)
else:
tn = ptr.TryGetValue(t)
if (tn==None):
tn = self._first.TryGetValue(t)
if (tn != None):
if (tn.End):
return True
ptr = tn
return False
def Replace(self,text, replaceChar = '*'):
result = list(text)
ptr = None
for i in range(len(text)): # for (i = 0; i < text.length; i++)
t =ord(text[i]) # text.charCodeAt(index)
tn = None
if (ptr == None):
tn = self._first.TryGetValue(t)
else:
tn = ptr.TryGetValue(t)
if (tn==None):
tn = self._first.TryGetValue(t)
if (tn != None):
if (tn.End):
maxLength = len( self._keywords[tn.Results[0]])
start = i + 1 - maxLength
for j in range(start,i+1): # for (j = start; j <= i; j++)
result[j] = replaceChar
ptr = tn
return ''.join(result)
================================================
FILE: plugins/dungeon/README.md
================================================
玩地牢游戏的聊天插件,触发方法如下:
- `$开始冒险 <背景故事>` - 以<背景故事>开始一个地牢游戏,不填写会使用默认背景故事。之后聊天中你的所有消息会帮助ai完善这个故事。
- `$停止冒险` - 停止一个地牢游戏,回归正常的ai。
================================================
FILE: plugins/dungeon/__init__.py
================================================
from .dungeon import *
================================================
FILE: plugins/dungeon/dungeon.py
================================================
# encoding:utf-8
import plugins
from bridge.bridge import Bridge
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common import const
from common.expired_dict import ExpiredDict
from common.log import logger
from config import conf
from plugins import *
# https://github.com/bupticybee/ChineseAiDungeonChatGPT
class StoryTeller:
def __init__(self, bot, sessionid, story):
self.bot = bot
self.sessionid = sessionid
bot.sessions.clear_session(sessionid)
self.first_interact = True
self.story = story
def reset(self):
self.bot.sessions.clear_session(self.sessionid)
self.first_interact = True
def action(self, user_action):
if user_action[-1] != "。":
user_action = user_action + "。"
if self.first_interact:
prompt = (
"""现在来充当一个文字冒险游戏,描述时候注意节奏,不要太快,仔细描述各个人物的心情和周边环境。一次只需写四到六句话。
开头是,"""
+ self.story
+ " "
+ user_action
)
self.first_interact = False
else:
prompt = """继续,一次只需要续写四到六句话,总共就只讲5分钟内发生的事情。""" + user_action
return prompt
@plugins.register(
name="Dungeon",
desire_priority=0,
namecn="文字冒险",
desc="A plugin to play dungeon game",
version="1.0",
author="lanvent",
)
class Dungeon(Plugin):
def __init__(self):
super().__init__()
self.handlers[Event.ON_HANDLE_CONTEXT] = self.on_handle_context
logger.debug("[Dungeon] inited")
# 目前没有设计session过期事件,这里先暂时使用过期字典
if conf().get("expires_in_seconds"):
self.games = ExpiredDict(conf().get("expires_in_seconds"))
else:
self.games = dict()
def on_handle_context(self, e_context: EventContext):
if e_context["context"].type != ContextType.TEXT:
return
bottype = Bridge().get_bot_type("chat")
if bottype not in [const.OPEN_AI, const.OPENAI, const.CHATGPT, const.CHATGPTONAZURE, const.LINKAI]:
return
bot = Bridge().get_bot("chat")
content = e_context["context"].content[:]
clist = e_context["context"].content.split(maxsplit=1)
sessionid = e_context["context"]["session_id"]
logger.debug("[Dungeon] on_handle_context. content: %s" % clist)
trigger_prefix = conf().get("plugin_trigger_prefix", "$")
if clist[0] == f"{trigger_prefix}停止冒险":
if sessionid in self.games:
self.games[sessionid].reset()
del self.games[sessionid]
reply = Reply(ReplyType.INFO, "冒险结束!")
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
elif clist[0] == f"{trigger_prefix}开始冒险" or sessionid in self.games:
if sessionid not in self.games or clist[0] == f"{trigger_prefix}开始冒险":
if len(clist) > 1:
story = clist[1]
else:
story = "你在树林里冒险,指不定会从哪里蹦出来一些奇怪的东西,你握紧手上的手枪,希望这次冒险能够找到一些值钱的东西,你往树林深处走去。"
self.games[sessionid] = StoryTeller(bot, sessionid, story)
reply = Reply(ReplyType.INFO, "冒险开始,你可以输入任意内容,让故事继续下去。故事背景是:" + story)
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS # 事件结束,并跳过处理context的默认逻辑
else:
prompt = self.games[sessionid].action(content)
e_context["context"].type = ContextType.TEXT
e_context["context"].content = prompt
e_context.action = EventAction.BREAK # 事件结束,不跳过处理context的默认逻辑
def get_help_text(self, **kwargs):
help_text = "可以和机器人一起玩文字冒险游戏。\n"
if kwargs.get("verbose") != True:
return help_text
trigger_prefix = conf().get("plugin_trigger_prefix", "$")
help_text = f"{trigger_prefix}开始冒险 " + "背景故事: 开始一个基于{背景故事}的文字冒险,之后你的所有消息会协助完善这个故事。\n" + f"{trigger_prefix}停止冒险: 结束游戏。\n"
if kwargs.get("verbose") == True:
help_text += f"\n命令例子: '{trigger_prefix}开始冒险 你在树林里冒险,指不定会从哪里蹦出来一些奇怪的东西,你握紧手上的手枪,希望这次冒险能够找到一些值钱的东西,你往树林深处走去。'"
return help_text
================================================
FILE: plugins/finish/__init__.py
================================================
from .finish import *
================================================
FILE: plugins/finish/finish.py
================================================
# encoding:utf-8
import plugins
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf
from plugins import *
@plugins.register(
name="Finish",
desire_priority=-999,
hidden=True,
desc="A plugin that check unknown command",
version="1.0",
author="js00000",
)
class Finish(Plugin):
def __init__(self):
super().__init__()
self.handlers[Event.ON_HANDLE_CONTEXT] = self.on_handle_context
logger.debug("[Finish] inited")
def on_handle_context(self, e_context: EventContext):
if e_context["context"].type != ContextType.TEXT:
return
content = e_context["context"].content
logger.debug("[Finish] on_handle_context. content: %s" % content)
trigger_prefix = conf().get("plugin_trigger_prefix", "$")
if content.startswith(trigger_prefix):
reply = Reply()
reply.type = ReplyType.ERROR
reply.content = "未知插件命令\n查看插件命令列表请输入#help 插件名\n"
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS # 事件结束,并跳过处理context的默认逻辑
def get_help_text(self, **kwargs):
return ""
================================================
FILE: plugins/godcmd/README.md
================================================
## 插件说明
指令插件
## 插件使用
将`config.json.template`复制为`config.json`,并修改其中`password`的值为口令。
如果没有设置命令,在命令行日志中会打印出本次的临时口令,请注意观察,打印格式如下。
```
[INFO][2023-04-06 23:53:47][godcmd.py:165] - [Godcmd] 因未设置口令,本次的临时口令为0971。
```
在私聊中可使用`#auth`指令,输入口令进行管理员认证。更多详细指令请输入`#help`查看帮助文档:
`#auth <口令>` - 管理员认证,仅可在私聊时认证。
`#help` - 输出帮助文档,**是否是管理员**和是否是在群聊中会影响帮助文档的输出内容。
================================================
FILE: plugins/godcmd/__init__.py
================================================
from .godcmd import *
================================================
FILE: plugins/godcmd/config.json.template
================================================
{
"password": "",
"admin_users": []
}
================================================
FILE: plugins/godcmd/godcmd.py
================================================
# encoding:utf-8
import json
import os
import random
import string
import logging
from typing import Tuple
import bridge.bridge
import plugins
from bridge.bridge import Bridge
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common import const
from config import conf, load_config, global_config
from plugins import *
# 定义指令集
COMMANDS = {
"help": {
"alias": ["help", "帮助"],
"desc": "回复此帮助",
},
"helpp": {
"alias": ["help", "帮助"], # 与help指令共用别名,根据参数数量区分
"args": ["插件名"],
"desc": "回复指定插件的详细帮助",
},
"auth": {
"alias": ["auth", "认证"],
"args": ["口令"],
"desc": "管理员认证",
},
"model": {
"alias": ["model", "模型"],
"desc": "查看和设置全局模型",
},
"set_openai_api_key": {
"alias": ["set_openai_api_key"],
"args": ["api_key"],
"desc": "设置你的OpenAI私有api_key",
},
"reset_openai_api_key": {
"alias": ["reset_openai_api_key"],
"desc": "重置为默认的api_key",
},
"set_gpt_model": {
"alias": ["set_gpt_model"],
"desc": "设置你的私有模型",
},
"reset_gpt_model": {
"alias": ["reset_gpt_model"],
"desc": "重置你的私有模型",
},
"gpt_model": {
"alias": ["gpt_model"],
"desc": "查询你使用的模型",
},
"id": {
"alias": ["id", "用户"],
"desc": "获取用户id",
},
"reset": {
"alias": ["reset", "重置会话"],
"desc": "重置会话",
},
}
ADMIN_COMMANDS = {
"resume": {
"alias": ["resume", "恢复服务"],
"desc": "恢复服务",
},
"stop": {
"alias": ["stop", "暂停服务"],
"desc": "暂停服务",
},
"reconf": {
"alias": ["reconf", "重载配置"],
"desc": "重载配置(不包含插件配置)",
},
"resetall": {
"alias": ["resetall", "重置所有会话"],
"desc": "重置所有会话",
},
"scanp": {
"alias": ["scanp", "扫描插件"],
"desc": "扫描插件目录是否有新插件",
},
"plist": {
"alias": ["plist", "插件"],
"desc": "打印当前插件列表",
},
"setpri": {
"alias": ["setpri", "设置插件优先级"],
"args": ["插件名", "优先级"],
"desc": "设置指定插件的优先级,越大越优先",
},
"reloadp": {
"alias": ["reloadp", "重载插件"],
"args": ["插件名"],
"desc": "重载指定插件配置",
},
"enablep": {
"alias": ["enablep", "启用插件"],
"args": ["插件名"],
"desc": "启用指定插件",
},
"disablep": {
"alias": ["disablep", "禁用插件"],
"args": ["插件名"],
"desc": "禁用指定插件",
},
"installp": {
"alias": ["installp", "安装插件"],
"args": ["仓库地址或插件名"],
"desc": "安装指定插件",
},
"uninstallp": {
"alias": ["uninstallp", "卸载插件"],
"args": ["插件名"],
"desc": "卸载指定插件",
},
"updatep": {
"alias": ["updatep", "更新插件"],
"args": ["插件名"],
"desc": "更新指定插件",
},
"debug": {
"alias": ["debug", "调试模式", "DEBUG"],
"desc": "开启机器调试日志",
},
}
# 定义帮助函数
def get_help_text(isadmin, isgroup):
help_text = "通用指令\n"
for cmd, info in COMMANDS.items():
if cmd in ["auth", "set_openai_api_key", "reset_openai_api_key", "set_gpt_model", "reset_gpt_model", "gpt_model"]: # 不显示帮助指令
continue
raw_ct = conf().get("channel_type", "web")
active_channels = raw_ct if isinstance(raw_ct, list) else [c.strip() for c in str(raw_ct).split(",")]
if cmd == "id" and not any(c in ["wxy", "wechatmp"] for c in active_channels):
continue
alias = ["#" + a for a in info["alias"][:1]]
help_text += f"{','.join(alias)} "
if "args" in info:
args = [a for a in info["args"]]
help_text += f"{' '.join(args)}"
help_text += f": {info['desc']}\n"
# 插件指令
plugins = PluginManager().list_plugins()
help_text += "\n可用插件"
for plugin in plugins:
if plugins[plugin].enabled and not plugins[plugin].hidden:
namecn = plugins[plugin].namecn
help_text += "\n%s: " % namecn
help_text += PluginManager().instances[plugin].get_help_text(verbose=False).strip()
if ADMIN_COMMANDS and isadmin:
help_text += "\n\n管理员指令:\n"
for cmd, info in ADMIN_COMMANDS.items():
alias = ["#" + a for a in info["alias"][:1]]
help_text += f"{','.join(alias)} "
if "args" in info:
args = [a for a in info["args"]]
help_text += f"{' '.join(args)}"
help_text += f": {info['desc']}\n"
return help_text
@plugins.register(
name="Godcmd",
desire_priority=999,
hidden=True,
desc="为你的机器人添加指令集,有用户和管理员两种角色,加载顺序请放在首位,初次运行后插件目录会生成配置文件, 填充管理员密码后即可认证",
version="1.0",
author="lanvent",
)
class Godcmd(Plugin):
def __init__(self):
super().__init__()
config_path = os.path.join(os.path.dirname(__file__), "config.json")
gconf = super().load_config()
if not gconf:
if not os.path.exists(config_path):
gconf = {"password": "", "admin_users": []}
with open(config_path, "w") as f:
json.dump(gconf, f, indent=4)
if gconf["password"] == "":
self.temp_password = "".join(random.sample(string.digits, 4))
logger.info("[Godcmd] 因未设置口令,本次的临时口令为%s。" % self.temp_password)
else:
self.temp_password = None
custom_commands = conf().get("clear_memory_commands", [])
for custom_command in custom_commands:
if custom_command and custom_command.startswith("#"):
custom_command = custom_command[1:]
if custom_command and custom_command not in COMMANDS["reset"]["alias"]:
COMMANDS["reset"]["alias"].append(custom_command)
self.password = gconf["password"]
self.admin_users = gconf["admin_users"]
global_config["admin_users"] = self.admin_users
self.isrunning = True # 机器人是否运行中
self.handlers[Event.ON_HANDLE_CONTEXT] = self.on_handle_context
logger.debug("[Godcmd] inited")
def on_handle_context(self, e_context: EventContext):
context_type = e_context["context"].type
if context_type != ContextType.TEXT:
if not self.isrunning:
e_context.action = EventAction.BREAK_PASS
return
content = e_context["context"].content
logger.debug("[Godcmd] on_handle_context. content: %s" % content)
if content.startswith("#"):
if len(content) == 1:
reply = Reply()
reply.type = ReplyType.ERROR
reply.content = f"空指令,输入#help查看指令列表\n"
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
return
# msg = e_context['context']['msg']
channel = e_context["channel"]
user = e_context["context"]["receiver"]
session_id = e_context["context"]["session_id"]
isgroup = e_context["context"].get("isgroup", False)
bottype = Bridge().get_bot_type("chat")
bot = Bridge().get_bot("chat")
# 将命令和参数分割
command_parts = content[1:].strip().split()
cmd = command_parts[0]
args = command_parts[1:]
isadmin = False
if user in self.admin_users:
isadmin = True
ok = False
result = "string"
if any(cmd in info["alias"] for info in COMMANDS.values()):
cmd = next(c for c, info in COMMANDS.items() if cmd in info["alias"])
if cmd == "auth":
ok, result = self.authenticate(user, args, isadmin, isgroup)
elif cmd == "help" or cmd == "helpp":
if len(args) == 0:
ok, result = True, get_help_text(isadmin, isgroup)
else:
# This can replace the helpp command
plugins = PluginManager().list_plugins()
query_name = args[0].upper()
# search name and namecn
for name, plugincls in plugins.items():
if not plugincls.enabled:
continue
if query_name == name or query_name == plugincls.namecn:
ok, result = True, PluginManager().instances[name].get_help_text(isgroup=isgroup, isadmin=isadmin, verbose=True)
break
if not ok:
result = "插件不存在或未启用"
elif cmd == "model":
if not isadmin and not self.is_admin_in_group(e_context["context"]):
ok, result = False, "需要管理员权限执行"
elif len(args) == 0:
model = conf().get("model") or const.GPT35
ok, result = True, "当前模型为: " + str(model)
elif len(args) == 1:
if args[0] not in const.MODEL_LIST:
ok, result = False, "模型名称不存在"
else:
conf()["model"] = self.model_mapping(args[0])
Bridge().reset_bot()
model = conf().get("model") or const.GPT35
ok, result = True, "模型设置为: " + str(model)
elif cmd == "id":
ok, result = True, user
elif cmd == "set_openai_api_key":
if len(args) == 1:
user_data = conf().get_user_data(user)
user_data["openai_api_key"] = args[0]
ok, result = True, "你的OpenAI私有api_key已设置为" + args[0]
else:
ok, result = False, "请提供一个api_key"
elif cmd == "reset_openai_api_key":
try:
user_data = conf().get_user_data(user)
user_data.pop("openai_api_key")
ok, result = True, "你的OpenAI私有api_key已清除"
except Exception as e:
ok, result = False, "你没有设置私有api_key"
elif cmd == "set_gpt_model":
if len(args) == 1:
user_data = conf().get_user_data(user)
user_data["gpt_model"] = args[0]
ok, result = True, "你的GPT模型已设置为" + args[0]
else:
ok, result = False, "请提供一个GPT模型"
elif cmd == "gpt_model":
user_data = conf().get_user_data(user)
model = conf().get("model")
if "gpt_model" in user_data:
model = user_data["gpt_model"]
ok, result = True, "你的GPT模型为" + str(model)
elif cmd == "reset_gpt_model":
try:
user_data = conf().get_user_data(user)
user_data.pop("gpt_model")
ok, result = True, "你的GPT模型已重置"
except Exception as e:
ok, result = False, "你没有设置私有GPT模型"
elif cmd == "reset":
if bottype in [const.OPEN_AI, const.OPENAI, const.CHATGPT, const.CHATGPTONAZURE, const.LINKAI, const.BAIDU, const.XUNFEI, const.QWEN, const.GEMINI, const.ZHIPU_AI, const.CLAUDEAPI]:
bot.sessions.clear_session(session_id)
if Bridge().chat_bots.get(bottype):
Bridge().chat_bots.get(bottype).sessions.clear_session(session_id)
channel.cancel_session(session_id)
ok, result = True, "会话已重置"
else:
ok, result = False, "当前对话机器人不支持重置会话"
logger.debug("[Godcmd] command: %s by %s" % (cmd, user))
elif any(cmd in info["alias"] for info in ADMIN_COMMANDS.values()):
if isadmin:
if isgroup:
ok, result = False, "群聊不可执行管理员指令"
else:
cmd = next(c for c, info in ADMIN_COMMANDS.items() if cmd in info["alias"])
if cmd == "stop":
self.isrunning = False
ok, result = True, "服务已暂停"
elif cmd == "resume":
self.isrunning = True
ok, result = True, "服务已恢复"
elif cmd == "reconf":
load_config()
ok, result = True, "配置已重载"
elif cmd == "resetall":
if bottype in [const.OPEN_AI, const.OPENAI, const.CHATGPT, const.CHATGPTONAZURE, const.LINKAI,
const.BAIDU, const.XUNFEI, const.QWEN, const.GEMINI, const.ZHIPU_AI, const.MOONSHOT,
const.MODELSCOPE]:
channel.cancel_all_session()
bot.sessions.clear_all_session()
ok, result = True, "重置所有会话成功"
else:
ok, result = False, "当前对话机器人不支持重置会话"
elif cmd == "debug":
if logger.getEffectiveLevel() == logging.DEBUG: # 判断当前日志模式是否DEBUG
logger.setLevel(logging.INFO)
ok, result = True, "DEBUG模式已关闭"
else:
logger.setLevel(logging.DEBUG)
ok, result = True, "DEBUG模式已开启"
elif cmd == "plist":
plugins = PluginManager().list_plugins()
ok = True
result = "插件列表:\n"
for name, plugincls in plugins.items():
result += f"{plugincls.name}_v{plugincls.version} {plugincls.priority} - "
if plugincls.enabled:
result += "已启用\n"
else:
result += "未启用\n"
elif cmd == "scanp":
new_plugins = PluginManager().scan_plugins()
ok, result = True, "插件扫描完成"
PluginManager().activate_plugins()
if len(new_plugins) > 0:
result += "\n发现新插件:\n"
result += "\n".join([f"{p.name}_v{p.version}" for p in new_plugins])
else:
result += ", 未发现新插件"
elif cmd == "setpri":
if len(args) != 2:
ok, result = False, "请提供插件名和优先级"
else:
ok = PluginManager().set_plugin_priority(args[0], int(args[1]))
if ok:
result = "插件" + args[0] + "优先级已设置为" + args[1]
else:
result = "插件不存在"
elif cmd == "reloadp":
if len(args) != 1:
ok, result = False, "请提供插件名"
else:
ok = PluginManager().reload_plugin(args[0])
if ok:
result = "插件配置已重载"
else:
result = "插件不存在"
elif cmd == "enablep":
if len(args) != 1:
ok, result = False, "请提供插件名"
else:
ok, result = PluginManager().enable_plugin(args[0])
elif cmd == "disablep":
if len(args) != 1:
ok, result = False, "请提供插件名"
else:
ok = PluginManager().disable_plugin(args[0])
if ok:
result = "插件已禁用"
else:
result = "插件不存在"
elif cmd == "installp":
if len(args) != 1:
ok, result = False, "请提供插件名或.git结尾的仓库地址"
else:
ok, result = PluginManager().install_plugin(args[0])
elif cmd == "uninstallp":
if len(args) != 1:
ok, result = False, "请提供插件名"
else:
ok, result = PluginManager().uninstall_plugin(args[0])
elif cmd == "updatep":
if len(args) != 1:
ok, result = False, "请提供插件名"
else:
ok, result = PluginManager().update_plugin(args[0])
logger.debug("[Godcmd] admin command: %s by %s" % (cmd, user))
else:
ok, result = False, "需要管理员权限才能执行该指令"
else:
trigger_prefix = conf().get("plugin_trigger_prefix", "$")
if trigger_prefix == "#": # 跟插件聊天指令前缀相同,继续递交
return
ok, result = False, f"未知指令:{cmd}\n查看指令列表请输入#help \n"
reply = Reply()
if ok:
reply.type = ReplyType.INFO
else:
reply.type = ReplyType.ERROR
reply.content = result
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS # 事件结束,并跳过处理context的默认逻辑
elif not self.isrunning:
e_context.action = EventAction.BREAK_PASS
def authenticate(self, userid, args, isadmin, isgroup) -> Tuple[bool, str]:
if isgroup:
return False, "请勿在群聊中认证"
if isadmin:
return False, "管理员账号无需认证"
if len(args) != 1:
return False, "请提供口令"
password = args[0]
if password == self.password:
self.admin_users.append(userid)
global_config["admin_users"].append(userid)
return True, "认证成功"
elif password == self.temp_password:
self.admin_users.append(userid)
global_config["admin_users"].append(userid)
return True, "认证成功,请尽快设置口令"
else:
return False, "认证失败"
def get_help_text(self, isadmin=False, isgroup=False, **kwargs):
return get_help_text(isadmin, isgroup)
def is_admin_in_group(self, context):
if context["isgroup"]:
return context.kwargs.get("msg").actual_user_id in global_config["admin_users"]
return False
def model_mapping(self, model) -> str:
if model == "gpt-4-turbo":
return const.GPT4_TURBO_PREVIEW
return model
def reload(self):
gconf = pconf(self.name)
if gconf:
if gconf.get("password"):
self.password = gconf["password"]
if gconf.get("admin_users"):
self.admin_users = gconf["admin_users"]
================================================
FILE: plugins/hello/README.md
================================================
## 插件说明
可以根据需求设置入群欢迎、群聊拍一拍、退群等消息的自定义提示词,也支持为每个群设置对应的固定欢迎语。
该插件也是用户根据需求开发自定义插件的示例插件,参考[插件开发说明](https://github.com/zhayujie/chatgpt-on-wechat/tree/master/plugins)
## 插件配置
将 `plugins/hello` 目录下的 `config.json.template` 配置模板复制为最终生效的 `config.json`。 (如果未配置则会默认使用`config.json.template`模板中配置)。
以下是插件配置项说明:
```bash
{
"group_welc_fixed_msg": { ## 这里可以为特定群里配置特定的固定欢迎语
"群聊1": "群聊1的固定欢迎语",
"群聊2": "群聊2的固定欢迎语"
},
"group_welc_prompt": "请你随机使用一种风格说一句问候语来欢迎新用户\"{nickname}\"加入群聊。", ## 群聊随机欢迎语的提示词
"group_exit_prompt": "请你随机使用一种风格跟其他群用户说他违反规则\"{nickname}\"退出群聊。", ## 移出群聊的提示词
"patpat_prompt": "请你随机使用一种风格介绍你自己,并告诉用户输入#help可以查看帮助信息。", ## 群内拍一拍的提示词
"use_character_desc": false ## 是否在Hello插件中使用LinkAI应用的系统设定
}
```
注意:
- 设置全局的用户进群固定欢迎语,可以在***项目根目录下***的`config.json`文件里,可以添加参数`"group_welcome_msg": "" `,参考 [#1482](https://github.com/zhayujie/chatgpt-on-wechat/pull/1482)
- 为每个群设置固定的欢迎语,可以在`"group_welc_fixed_msg": {}`配置群聊名和对应的固定欢迎语,优先级高于全局固定欢迎语
- 如果没有配置以上两个参数,则使用随机欢迎语,如需设定风格,语言等,修改`"group_welc_prompt": `即可
- 如果使用LinkAI的服务,想在随机欢迎中结合LinkAI应用的设定,配置`"use_character_desc": true `
- 实际 `config.json` 配置中应保证json格式,不应携带 '#' 及后面的注释
- 如果是`docker`部署,可通过映射 `plugins/config.json` 到容器中来完成插件配置,参考[文档](https://github.com/zhayujie/chatgpt-on-wechat#3-%E6%8F%92%E4%BB%B6%E4%BD%BF%E7%94%A8)
================================================
FILE: plugins/hello/__init__.py
================================================
from .hello import *
================================================
FILE: plugins/hello/config.json.template
================================================
{
"group_welc_fixed_msg": {
"群聊1": "群聊1的固定欢迎语",
"群聊2": "群聊2的固定欢迎语"
},
"group_welc_prompt": "请你随机使用一种风格说一句问候语来欢迎新用户\"{nickname}\"加入群聊。",
"group_exit_prompt": "请你随机使用一种风格跟其他群用户说他违反规则\"{nickname}\"退出群聊。",
"patpat_prompt": "请你随机使用一种风格介绍你自己,并告诉用户输入#help可以查看帮助信息。",
"use_character_desc": false
}
================================================
FILE: plugins/hello/hello.py
================================================
# encoding:utf-8
import plugins
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from channel.chat_message import ChatMessage
from common.log import logger
from plugins import *
from config import conf
@plugins.register(
name="Hello",
desire_priority=-1,
hidden=True,
desc="A simple plugin that says hello",
version="0.1",
author="lanvent",
)
class Hello(Plugin):
group_welc_prompt = "请你随机使用一种风格说一句问候语来欢迎新用户\"{nickname}\"加入群聊。"
group_exit_prompt = "请你随机使用一种风格介绍你自己,并告诉用户输入#help可以查看帮助信息。"
patpat_prompt = "请你随机使用一种风格跟其他群用户说他违反规则\"{nickname}\"退出群聊。"
def __init__(self):
super().__init__()
try:
self.config = super().load_config()
if not self.config:
self.config = self._load_config_template()
self.group_welc_fixed_msg = self.config.get("group_welc_fixed_msg", {})
self.group_welc_prompt = self.config.get("group_welc_prompt", self.group_welc_prompt)
self.group_exit_prompt = self.config.get("group_exit_prompt", self.group_exit_prompt)
self.patpat_prompt = self.config.get("patpat_prompt", self.patpat_prompt)
logger.debug("[Hello] inited")
self.handlers[Event.ON_HANDLE_CONTEXT] = self.on_handle_context
except Exception as e:
logger.error(f"[Hello]初始化异常:{e}")
raise "[Hello] init failed, ignore "
def on_handle_context(self, e_context: EventContext):
if e_context["context"].type not in [
ContextType.TEXT,
ContextType.JOIN_GROUP,
ContextType.PATPAT,
ContextType.EXIT_GROUP
]:
return
msg: ChatMessage = e_context["context"]["msg"]
group_name = msg.from_user_nickname
if e_context["context"].type == ContextType.JOIN_GROUP:
if "group_welcome_msg" in conf() or group_name in self.group_welc_fixed_msg:
reply = Reply()
reply.type = ReplyType.TEXT
if group_name in self.group_welc_fixed_msg:
reply.content = self.group_welc_fixed_msg.get(group_name, "")
else:
reply.content = conf().get("group_welcome_msg", "")
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS # 事件结束,并跳过处理context的默认逻辑
return
e_context["context"].type = ContextType.TEXT
e_context["context"].content = self.group_welc_prompt.format(nickname=msg.actual_user_nickname)
e_context.action = EventAction.BREAK # 事件结束,进入默认处理逻辑
if not self.config or not self.config.get("use_character_desc"):
e_context["context"]["generate_breaked_by"] = EventAction.BREAK
return
if e_context["context"].type == ContextType.EXIT_GROUP:
if conf().get("group_chat_exit_group"):
e_context["context"].type = ContextType.TEXT
e_context["context"].content = self.group_exit_prompt.format(nickname=msg.actual_user_nickname)
e_context.action = EventAction.BREAK # 事件结束,进入默认处理逻辑
return
e_context.action = EventAction.BREAK
return
if e_context["context"].type == ContextType.PATPAT:
e_context["context"].type = ContextType.TEXT
e_context["context"].content = self.patpat_prompt
e_context.action = EventAction.BREAK # 事件结束,进入默认处理逻辑
if not self.config or not self.config.get("use_character_desc"):
e_context["context"]["generate_breaked_by"] = EventAction.BREAK
return
content = e_context["context"].content
logger.debug("[Hello] on_handle_context. content: %s" % content)
if content == "Hello":
reply = Reply()
reply.type = ReplyType.TEXT
if e_context["context"]["isgroup"]:
reply.content = f"Hello, {msg.actual_user_nickname} from {msg.from_user_nickname}"
else:
reply.content = f"Hello, {msg.from_user_nickname}"
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS # 事件结束,并跳过处理context的默认逻辑
if content == "Hi":
reply = Reply()
reply.type = ReplyType.TEXT
reply.content = "Hi"
e_context["reply"] = reply
e_context.action = EventAction.BREAK # 事件结束,进入默认处理逻辑,一般会覆写reply
if content == "End":
# 如果是文本消息"End",将请求转换成"IMAGE_CREATE",并将content设置为"The World"
e_context["context"].type = ContextType.IMAGE_CREATE
content = "The World"
e_context.action = EventAction.CONTINUE # 事件继续,交付给下个插件或默认逻辑
def get_help_text(self, **kwargs):
help_text = "输入Hello,我会回复你的名字\n输入End,我会回复你世界的图片\n"
return help_text
def _load_config_template(self):
logger.debug("No Hello plugin config.json, use plugins/hello/config.json.template")
try:
plugin_config_path = os.path.join(self.path, "config.json.template")
if os.path.exists(plugin_config_path):
with open(plugin_config_path, "r", encoding="utf-8") as f:
plugin_conf = json.load(f)
return plugin_conf
except Exception as e:
logger.exception(e)
================================================
FILE: plugins/keyword/README.md
================================================
# 目的
关键字匹配并回复
# 试用场景
目前是在微信公众号下面使用过。
# 使用步骤
1. 复制 `config.json.template` 为 `config.json`
2. 在关键字 `keyword` 新增需要关键字匹配的内容
3. 重启程序做验证
# 验证结果

================================================
FILE: plugins/keyword/__init__.py
================================================
from .keyword import *
================================================
FILE: plugins/keyword/config.json.template
================================================
{
"keyword": {
"关键字匹配": "测试成功"
}
}
================================================
FILE: plugins/keyword/keyword.py
================================================
# encoding:utf-8
import json
import os
import requests
import plugins
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common.log import logger
from plugins import *
@plugins.register(
name="Keyword",
desire_priority=900,
hidden=True,
desc="关键词匹配过滤",
version="0.1",
author="fengyege.top",
)
class Keyword(Plugin):
def __init__(self):
super().__init__()
try:
curdir = os.path.dirname(__file__)
config_path = os.path.join(curdir, "config.json")
conf = None
if not os.path.exists(config_path):
logger.debug(f"[keyword]不存在配置文件{config_path}")
conf = {"keyword": {}}
with open(config_path, "w", encoding="utf-8") as f:
json.dump(conf, f, indent=4)
else:
logger.debug(f"[keyword]加载配置文件{config_path}")
with open(config_path, "r", encoding="utf-8") as f:
conf = json.load(f)
# 加载关键词
self.keyword = conf["keyword"]
logger.debug("[keyword] {}".format(self.keyword))
self.handlers[Event.ON_HANDLE_CONTEXT] = self.on_handle_context
logger.debug("[keyword] inited.")
except Exception as e:
logger.warn("[keyword] init failed, ignore or see https://github.com/zhayujie/chatgpt-on-wechat/tree/master/plugins/keyword .")
raise e
def on_handle_context(self, e_context: EventContext):
if e_context["context"].type != ContextType.TEXT:
return
content = e_context["context"].content.strip()
logger.debug("[keyword] on_handle_context. content: %s" % content)
if content in self.keyword:
logger.info(f"[keyword] 匹配到关键字【{content}】")
reply_text = self.keyword[content]
# 判断匹配内容的类型
if (reply_text.startswith("http://") or reply_text.startswith("https://")) and any(reply_text.endswith(ext) for ext in [".jpg", ".webp", ".jpeg", ".png", ".gif", ".img"]):
# 如果是以 http:// 或 https:// 开头,且".jpg", ".jpeg", ".png", ".gif", ".img"结尾,则认为是图片 URL。
reply = Reply()
reply.type = ReplyType.IMAGE_URL
reply.content = reply_text
elif (reply_text.startswith("http://") or reply_text.startswith("https://")) and any(reply_text.endswith(ext) for ext in [".pdf", ".doc", ".docx", ".xls", "xlsx",".zip", ".rar"]):
# 如果是以 http:// 或 https:// 开头,且".pdf", ".doc", ".docx", ".xls", "xlsx",".zip", ".rar"结尾,则下载文件到tmp目录并发送给用户
file_path = "tmp"
if not os.path.exists(file_path):
os.makedirs(file_path)
file_name = reply_text.split("/")[-1] # 获取文件名
file_path = os.path.join(file_path, file_name)
response = requests.get(reply_text)
with open(file_path, "wb") as f:
f.write(response.content)
reply = Reply()
reply.type = ReplyType.FILE
reply.content = file_path
elif (reply_text.startswith("http://") or reply_text.startswith("https://")) and any(reply_text.endswith(ext) for ext in [".mp4"]):
# 如果是以 http:// 或 https:// 开头,且".mp4"结尾,则下载视频到tmp目录并发送给用户
reply = Reply()
reply.type = ReplyType.VIDEO_URL
reply.content = reply_text
else:
# 否则认为是普通文本
reply = Reply()
reply.type = ReplyType.TEXT
reply.content = reply_text
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS # 事件结束,并跳过处理context的默认逻辑
def get_help_text(self, **kwargs):
help_text = "关键词过滤"
return help_text
================================================
FILE: plugins/linkai/README.md
================================================
## 插件说明
基于 LinkAI 提供的知识库、Midjourney绘画、文档对话等能力对机器人的功能进行增强。平台地址: https://link-ai.tech/console
## 插件配置
将 `plugins/linkai` 目录下的 `config.json.template` 配置模板复制为最终生效的 `config.json`。 (如果未配置则会默认使用`config.json.template`模板中配置,但功能默认关闭,需要可通过指令进行开启)。
以下是插件配置项说明:
```bash
{
"group_app_map": { # 群聊 和 应用编码 的映射关系
"测试群名称1": "default", # 表示在名称为 "测试群名称1" 的群聊中将使用app_code 为 default 的应用
"测试群名称2": "Kv2fXJcH"
},
"midjourney": {
"enabled": true, # midjourney 绘画开关
"auto_translate": true, # 是否自动将提示词翻译为英文
"img_proxy": true, # 是否对生成的图片使用代理,如果你是国外服务器,将这一项设置为false会获得更快的生成速度
"max_tasks": 3, # 支持同时提交的总任务个数
"max_tasks_per_user": 1, # 支持单个用户同时提交的任务个数
"use_image_create_prefix": true # 是否使用全局的绘画触发词,如果开启将同时支持由`config.json`中的 image_create_prefix 配置触发
},
"summary": {
"enabled": true, # 文档总结和对话功能开关
"group_enabled": true, # 是否支持群聊开启
"max_file_size": 5000, # 文件的大小限制,单位KB,默认为5M,超过该大小直接忽略
"type": ["FILE", "SHARING", "IMAGE"] # 支持总结的类型,分别表示 文件、分享链接、图片,其中文件和链接默认打开,图片默认关闭
}
}
```
根目录 `config.json` 中配置,`API_KEY` 在 [控制台](https://link-ai.tech/console/interface) 中创建并复制过来:
```bash
"linkai_api_key": "Link_xxxxxxxxx"
```
注意:
- 配置项中 `group_app_map` 部分是用于映射群聊与LinkAI平台上的应用, `midjourney` 部分是 mj 画图的配置,`summary` 部分是文档总结及对话功能的配置。三部分的配置相互独立,可按需开启
- 实际 `config.json` 配置中应保证json格式,不应携带 '#' 及后面的注释
- 如果是`docker`部署,可通过映射 `plugins/config.json` 到容器中来完成插件配置,参考[文档](https://github.com/zhayujie/chatgpt-on-wechat#3-%E6%8F%92%E4%BB%B6%E4%BD%BF%E7%94%A8)
## 插件使用
> 使用插件中的知识库管理功能需要首先开启`linkai`对话,依赖全局 `config.json` 中的 `use_linkai` 和 `linkai_api_key` 配置;而midjourney绘画 和 summary文档总结对话功能则只需填写 `linkai_api_key` 配置,`use_linkai` 无论是否关闭均可使用。具体可参考 [详细文档](https://link-ai.tech/platform/link-app/wechat)。
完成配置后运行项目,会自动运行插件,输入 `#help linkai` 可查看插件功能。
### 1.知识库管理功能
提供在不同群聊使用不同应用的功能。可以在上述 `group_app_map` 配置中固定映射关系,也可以通过指令在群中快速完成切换。
应用切换指令需要首先完成管理员 (`godcmd`) 插件的认证,然后按以下格式输入:
`$linkai app {app_code}`
例如输入 `$linkai app Kv2fXJcH`,即将当前群聊与 app_code为 Kv2fXJcH 的应用绑定。
另外,还可以通过 `$linkai close` 来一键关闭linkai对话,此时就会使用默认的openai接口;同理,发送 `$linkai open` 可以再次开启。
### 2.Midjourney绘画功能
若未配置 `plugins/linkai/config.json`,默认会关闭画图功能,直接使用 `$mj open` 可基于默认配置直接使用mj画图。
指令格式:
```
- 图片生成: $mj 描述词1, 描述词2..
- 图片放大: $mju 图片ID 图片序号
- 图片变换: $mjv 图片ID 图片序号
- 重置: $mjr 图片ID
```
例如:
```
"$mj a little cat, white --ar 9:16"
"$mju 1105592717188272288 2"
"$mjv 11055927171882 2"
"$mjr 11055927171882"
```
注意事项:
1. 使用 `$mj open` 和 `$mj close` 指令可以快速打开和关闭绘图功能
2. 海外环境部署请将 `img_proxy` 设置为 `false`
3. 开启 `use_image_create_prefix` 配置后可直接复用全局画图触发词,以"画"开头便可以生成图片。
4. 提示词内容中包含敏感词或者参数格式错误可能导致绘画失败,生成失败不消耗积分
5. 若未收到图片可能有两种可能,一种是收到了图片但微信发送失败,可以在后台日志查看有没有获取到图片url,一般原因是受到了wx限制,可以稍后重试或更换账号尝试;另一种情况是图片提示词存在疑似违规,mj不会直接提示错误但会在画图后删掉原图导致程序无法获取,这种情况不消耗积分。
### 3.文档总结对话功能
#### 配置
该功能依赖 LinkAI的知识库及对话功能,需要在项目根目录的config.json中设置 `linkai_api_key`, 同时根据上述插件配置说明,在插件config.json添加 `summary` 部分的配置,设置 `enabled` 为 true。
如果不想创建 `plugins/linkai/config.json` 配置,可以直接通过 `$linkai sum open` 指令开启该功能。
也可以通过私聊(全局 `config.json` 中的 `linkai_app_code`)或者群聊绑定(通过`group_app_map`参数配置)的应用来开启该功能:在LinkAI平台 [应用配置](https://link-ai.tech/console/factory) 里添加并开启**内容总结**插件。
#### 使用
功能开启后,向机器人发送 **文件**、 **分享链接卡片**、**图片** 即可生成摘要,进一步可以与文件或链接的内容进行多轮对话。如果需要关闭某种类型的内容总结,设置 `summary`配置中的type字段即可。
#### 限制
1. 文件目前 支持 `txt`, `docx`, `pdf`, `md`, `csv`格式,文件大小由 `max_file_size` 限制,最大不超过15M,文件字数最多可支持百万字的文件。但不建议上传字数过多的文件,一是token消耗过大,二是摘要很难覆盖到全部内容,只能通过多轮对话来了解细节。
2. 分享链接 目前仅支持 公众号文章,后续会支持更多文章类型及视频链接等
3. 总结及对话的 费用与 LinkAI 3.5-4K 模型的计费方式相同,按文档内容的tokens进行计算
================================================
FILE: plugins/linkai/__init__.py
================================================
from .linkai import *
================================================
FILE: plugins/linkai/config.json.template
================================================
{
"group_app_map": {
"测试群名1": "default",
"测试群名2": "Kv2fXJcH"
},
"midjourney": {
"enabled": true,
"auto_translate": true,
"img_proxy": true,
"max_tasks": 3,
"max_tasks_per_user": 1,
"use_image_create_prefix": true
},
"summary": {
"enabled": true,
"group_enabled": true,
"max_file_size": 5000,
"type": ["FILE", "SHARING"]
}
}
================================================
FILE: plugins/linkai/linkai.py
================================================
import plugins
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from plugins import *
from .midjourney import MJBot
from .summary import LinkSummary
from bridge import bridge
from common.expired_dict import ExpiredDict
from common import const
import os
from .utils import Util
from config import plugin_config, conf
@plugins.register(
name="linkai",
desc="A plugin that supports knowledge base and midjourney drawing.",
version="0.1.0",
author="https://link-ai.tech",
desire_priority=99
)
class LinkAI(Plugin):
def __init__(self):
super().__init__()
self.handlers[Event.ON_HANDLE_CONTEXT] = self.on_handle_context
self.config = super().load_config()
if not self.config:
# 未加载到配置,使用模板中的配置
self.config = self._load_config_template()
if self.config:
self.mj_bot = MJBot(self.config.get("midjourney"), self._fetch_group_app_code)
self.sum_config = {}
if self.config:
self.sum_config = self.config.get("summary")
logger.debug(f"[LinkAI] inited, config={self.config}")
def on_handle_context(self, e_context: EventContext):
"""
消息处理逻辑
:param e_context: 消息上下文
"""
if not self.config:
return
context = e_context['context']
if context.type not in [ContextType.TEXT, ContextType.IMAGE, ContextType.IMAGE_CREATE, ContextType.FILE,
ContextType.SHARING]:
# filter content no need solve
return
if context.type in [ContextType.FILE, ContextType.IMAGE] and self._is_summary_open(context):
# 文件处理
context.get("msg").prepare()
file_path = context.content
if not LinkSummary().check_file(file_path, self.sum_config):
return
if context.type != ContextType.IMAGE:
_send_info(e_context, "正在为你加速生成摘要,请稍后")
app_code = self._fetch_app_code(context)
res = LinkSummary().summary_file(file_path, app_code)
if not res:
if context.type != ContextType.IMAGE:
_set_reply_text("因为神秘力量无法获取内容,请稍后再试吧", e_context, level=ReplyType.TEXT)
return
summary_text = res.get("summary")
if context.type != ContextType.IMAGE:
USER_FILE_MAP[_find_user_id(context) + "-sum_id"] = res.get("summary_id")
summary_text += "\n\n💬 发送 \"开启对话\" 可以开启与文件内容的对话"
_set_reply_text(summary_text, e_context, level=ReplyType.TEXT)
os.remove(file_path)
return
if (context.type == ContextType.SHARING and self._is_summary_open(context)) or \
(context.type == ContextType.TEXT and self._is_summary_open(context) and LinkSummary().check_url(context.content)):
if not LinkSummary().check_url(context.content):
return
_send_info(e_context, "正在为你加速生成摘要,请稍后")
app_code = self._fetch_app_code(context)
res = LinkSummary().summary_url(context.content, app_code)
if not res:
_set_reply_text("因为神秘力量无法获取文章内容,请稍后再试吧~", e_context, level=ReplyType.TEXT)
return
_set_reply_text(res.get("summary") + "\n\n💬 发送 \"开启对话\" 可以开启与文章内容的对话", e_context,
level=ReplyType.TEXT)
USER_FILE_MAP[_find_user_id(context) + "-sum_id"] = res.get("summary_id")
return
mj_type = self.mj_bot.judge_mj_task_type(e_context)
if mj_type:
# MJ作图任务处理
self.mj_bot.process_mj_task(mj_type, e_context)
return
if context.content.startswith(f"{_get_trigger_prefix()}linkai"):
# 应用管理功能
self._process_admin_cmd(e_context)
return
if context.type == ContextType.TEXT and context.content == "开启对话" and _find_sum_id(context):
# 文本对话
_send_info(e_context, "正在为你开启对话,请稍后")
res = LinkSummary().summary_chat(_find_sum_id(context))
if not res:
_set_reply_text("开启对话失败,请稍后再试吧", e_context)
return
USER_FILE_MAP[_find_user_id(context) + "-file_id"] = res.get("file_id")
_set_reply_text("💡你可以问我关于这篇文章的任何问题,例如:\n\n" + res.get(
"questions") + "\n\n发送 \"退出对话\" 可以关闭与文章的对话", e_context, level=ReplyType.TEXT)
return
if context.type == ContextType.TEXT and context.content == "退出对话" and _find_file_id(context):
del USER_FILE_MAP[_find_user_id(context) + "-file_id"]
bot = bridge.Bridge().find_chat_bot(const.LINKAI)
bot.sessions.clear_session(context["session_id"])
_set_reply_text("对话已退出", e_context, level=ReplyType.TEXT)
return
if context.type == ContextType.TEXT and _find_file_id(context):
bot = bridge.Bridge().find_chat_bot(const.LINKAI)
context.kwargs["file_id"] = _find_file_id(context)
reply = bot.reply(context.content, context)
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
return
if self._is_chat_task(e_context):
# 文本对话任务处理
self._process_chat_task(e_context)
# 插件管理功能
def _process_admin_cmd(self, e_context: EventContext):
context = e_context['context']
cmd = context.content.split()
if len(cmd) == 1 or (len(cmd) == 2 and cmd[1] == "help"):
_set_reply_text(self.get_help_text(verbose=True), e_context, level=ReplyType.INFO)
return
if len(cmd) == 2 and (cmd[1] == "open" or cmd[1] == "close"):
# 知识库开关指令
if not Util.is_admin(e_context):
_set_reply_text("需要管理员权限执行", e_context, level=ReplyType.ERROR)
return
is_open = True
tips_text = "开启"
if cmd[1] == "close":
tips_text = "关闭"
is_open = False
conf()["use_linkai"] = is_open
bridge.Bridge().reset_bot()
_set_reply_text(f"LinkAI对话功能{tips_text}", e_context, level=ReplyType.INFO)
return
if len(cmd) == 3 and cmd[1] == "app":
# 知识库应用切换指令
if not context.kwargs.get("isgroup"):
_set_reply_text("该指令需在群聊中使用", e_context, level=ReplyType.ERROR)
return
if not Util.is_admin(e_context):
_set_reply_text("需要管理员权限执行", e_context, level=ReplyType.ERROR)
return
app_code = cmd[2]
group_name = context.kwargs.get("msg").from_user_nickname
group_mapping = self.config.get("group_app_map")
if group_mapping:
group_mapping[group_name] = app_code
else:
self.config["group_app_map"] = {group_name: app_code}
# 保存插件配置
super().save_config(self.config)
_set_reply_text(f"应用设置成功: {app_code}", e_context, level=ReplyType.INFO)
return
if len(cmd) == 3 and cmd[1] == "sum" and (cmd[2] == "open" or cmd[2] == "close"):
# 总结对话开关指令
if not Util.is_admin(e_context):
_set_reply_text("需要管理员权限执行", e_context, level=ReplyType.ERROR)
return
is_open = True
tips_text = "开启"
if cmd[2] == "close":
tips_text = "关闭"
is_open = False
if not self.sum_config:
_set_reply_text(
f"插件未启用summary功能,请参考以下链添加插件配置\n\nhttps://github.com/zhayujie/chatgpt-on-wechat/blob/master/plugins/linkai/README.md",
e_context, level=ReplyType.INFO)
else:
self.sum_config["enabled"] = is_open
_set_reply_text(f"文章总结功能{tips_text}", e_context, level=ReplyType.INFO)
return
_set_reply_text(f"指令错误,请输入{_get_trigger_prefix()}linkai help 获取帮助", e_context,
level=ReplyType.INFO)
return
def _is_summary_open(self, context) -> bool:
# 获取远程应用插件状态
remote_enabled = False
if context.kwargs.get("isgroup"):
# 群聊场景只查询群对应的app_code
group_name = context.get("msg").from_user_nickname
app_code = self._fetch_group_app_code(group_name)
if app_code:
if context.type.name in ["FILE", "SHARING"]:
remote_enabled = Util.fetch_app_plugin(app_code, "内容总结")
else:
# 非群聊场景使用全局app_code
app_code = conf().get("linkai_app_code")
if app_code:
if context.type.name in ["FILE", "SHARING"]:
remote_enabled = Util.fetch_app_plugin(app_code, "内容总结")
# 基础条件:总开关开启且消息类型符合要求
base_enabled = (
self.sum_config
and self.sum_config.get("enabled")
and (context.type.name in (
self.sum_config.get("type") or ["FILE", "SHARING"]) or context.type.name == "TEXT")
)
# 群聊:需要满足(总开关和群开关)或远程插件开启
if context.kwargs.get("isgroup"):
return (base_enabled and self.sum_config.get("group_enabled")) or remote_enabled
# 非群聊:只需要满足总开关或远程插件开启
return base_enabled or remote_enabled
# LinkAI 对话任务处理
def _is_chat_task(self, e_context: EventContext):
context = e_context['context']
# 群聊应用管理
return self.config.get("group_app_map") and context.kwargs.get("isgroup")
def _process_chat_task(self, e_context: EventContext):
"""
处理LinkAI对话任务
:param e_context: 对话上下文
"""
context = e_context['context']
# 群聊应用管理
group_name = context.get("msg").from_user_nickname
app_code = self._fetch_group_app_code(group_name)
if app_code:
context.kwargs['app_code'] = app_code
def _fetch_group_app_code(self, group_name: str) -> str:
"""
根据群聊名称获取对应的应用code
:param group_name: 群聊名称
:return: 应用code
"""
group_mapping = self.config.get("group_app_map")
if group_mapping:
app_code = group_mapping.get(group_name) or group_mapping.get("ALL_GROUP")
return app_code
def _fetch_app_code(self, context) -> str:
"""
根据主配置或者群聊名称获取对应的应用code,优先获取群聊配置的应用code
:param context: 上下文
:return: 应用code
"""
app_code = conf().get("linkai_app_code")
if context.kwargs.get("isgroup"):
# 群聊场景只查询群对应的app_code
group_name = context.get("msg").from_user_nickname
app_code = self._fetch_group_app_code(group_name)
return app_code
def get_help_text(self, verbose=False, **kwargs):
trigger_prefix = _get_trigger_prefix()
help_text = "用于集成 LinkAI 提供的知识库、Midjourney绘画、文档总结、联网搜索等能力。\n\n"
if not verbose:
return help_text
help_text += f'📖 知识库\n - 群聊中指定应用: {trigger_prefix}linkai app 应用编码\n'
help_text += f' - {trigger_prefix}linkai open: 开启对话\n'
help_text += f' - {trigger_prefix}linkai close: 关闭对话\n'
help_text += f'\n例如: \n"{trigger_prefix}linkai app Kv2fXJcH"\n\n'
help_text += f"🎨 绘画\n - 生成: {trigger_prefix}mj 描述词1, 描述词2.. \n - 放大: {trigger_prefix}mju 图片ID 图片序号\n - 变换: {trigger_prefix}mjv 图片ID 图片序号\n - 重置: {trigger_prefix}mjr 图片ID"
help_text += f"\n\n例如:\n\"{trigger_prefix}mj a little cat, white --ar 9:16\"\n\"{trigger_prefix}mju 11055927171882 2\""
help_text += f"\n\"{trigger_prefix}mjv 11055927171882 2\"\n\"{trigger_prefix}mjr 11055927171882\""
help_text += f"\n\n💡 文档总结和对话\n - 开启: {trigger_prefix}linkai sum open\n - 使用: 发送文件、公众号文章等可生成摘要,并与内容对话"
return help_text
def _load_config_template(self):
logger.debug("No LinkAI plugin config.json, use plugins/linkai/config.json.template")
try:
plugin_config_path = os.path.join(self.path, "config.json.template")
if os.path.exists(plugin_config_path):
with open(plugin_config_path, "r", encoding="utf-8") as f:
plugin_conf = json.load(f)
plugin_conf["midjourney"]["enabled"] = False
plugin_conf["summary"]["enabled"] = False
write_plugin_config({"linkai": plugin_conf})
return plugin_conf
except Exception as e:
logger.exception(e)
def reload(self):
self.config = super().load_config()
def _send_info(e_context: EventContext, content: str):
reply = Reply(ReplyType.TEXT, content)
channel = e_context["channel"]
channel.send(reply, e_context["context"])
def _find_user_id(context):
if context["isgroup"]:
return context.kwargs.get("msg").actual_user_id
else:
return context["receiver"]
def _set_reply_text(content: str, e_context: EventContext, level: ReplyType = ReplyType.ERROR):
reply = Reply(level, content)
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
def _get_trigger_prefix():
return conf().get("plugin_trigger_prefix", "$")
def _find_sum_id(context):
return USER_FILE_MAP.get(_find_user_id(context) + "-sum_id")
def _find_file_id(context):
user_id = _find_user_id(context)
if user_id:
return USER_FILE_MAP.get(user_id + "-file_id")
USER_FILE_MAP = ExpiredDict(conf().get("expires_in_seconds") or 60 * 30)
================================================
FILE: plugins/linkai/midjourney.py
================================================
from enum import Enum
from config import conf
from common.log import logger
import requests
import threading
import time
from bridge.reply import Reply, ReplyType
import asyncio
from bridge.context import ContextType
from plugins import EventContext, EventAction
from .utils import Util
INVALID_REQUEST = 410
NOT_FOUND_ORIGIN_IMAGE = 461
NOT_FOUND_TASK = 462
class TaskType(Enum):
GENERATE = "generate"
UPSCALE = "upscale"
VARIATION = "variation"
RESET = "reset"
def __str__(self):
return self.name
class Status(Enum):
PENDING = "pending"
FINISHED = "finished"
EXPIRED = "expired"
ABORTED = "aborted"
def __str__(self):
return self.name
class TaskMode(Enum):
FAST = "fast"
RELAX = "relax"
task_name_mapping = {
TaskType.GENERATE.name: "生成",
TaskType.UPSCALE.name: "放大",
TaskType.VARIATION.name: "变换",
TaskType.RESET.name: "重新生成",
}
class MJTask:
def __init__(self, id, user_id: str, task_type: TaskType, raw_prompt=None, expires: int = 60 * 6,
status=Status.PENDING):
self.id = id
self.user_id = user_id
self.task_type = task_type
self.raw_prompt = raw_prompt
self.send_func = None # send_func(img_url)
self.expiry_time = time.time() + expires
self.status = status
self.img_url = None # url
self.img_id = None
def __str__(self):
return f"id={self.id}, user_id={self.user_id}, task_type={self.task_type}, status={self.status}, img_id={self.img_id}"
# midjourney bot
class MJBot:
def __init__(self, config, fetch_group_app_code):
self.base_url = conf().get("linkai_api_base", "https://api.link-ai.tech") + "/v1/img/midjourney"
self.headers = {"Authorization": "Bearer " + conf().get("linkai_api_key")}
self.config = config
self.fetch_group_app_code = fetch_group_app_code
self.tasks = {}
self.temp_dict = {}
self.tasks_lock = threading.Lock()
self.event_loop = asyncio.new_event_loop()
def judge_mj_task_type(self, e_context: EventContext):
"""
判断MJ任务的类型
:param e_context: 上下文
:return: 任务类型枚举
"""
if not self.config:
return None
trigger_prefix = conf().get("plugin_trigger_prefix", "$")
context = e_context['context']
if context.type == ContextType.TEXT:
cmd_list = context.content.split(maxsplit=1)
if not cmd_list:
return None
if cmd_list[0].lower() == f"{trigger_prefix}mj":
return TaskType.GENERATE
elif cmd_list[0].lower() == f"{trigger_prefix}mju":
return TaskType.UPSCALE
elif cmd_list[0].lower() == f"{trigger_prefix}mjv":
return TaskType.VARIATION
elif cmd_list[0].lower() == f"{trigger_prefix}mjr":
return TaskType.RESET
elif context.type == ContextType.IMAGE_CREATE and self.config.get("use_image_create_prefix") and self._is_mj_open(context):
return TaskType.GENERATE
def process_mj_task(self, mj_type: TaskType, e_context: EventContext):
"""
处理mj任务
:param mj_type: mj任务类型
:param e_context: 对话上下文
"""
context = e_context['context']
session_id = context["session_id"]
cmd = context.content.split(maxsplit=1)
if len(cmd) == 1 and context.type == ContextType.TEXT:
# midjourney 帮助指令
self._set_reply_text(self.get_help_text(verbose=True), e_context, level=ReplyType.INFO)
return
if len(cmd) == 2 and (cmd[1] == "open" or cmd[1] == "close"):
if not Util.is_admin(e_context):
Util.set_reply_text("需要管理员权限执行", e_context, level=ReplyType.ERROR)
return
# midjourney 开关指令
is_open = True
tips_text = "开启"
if cmd[1] == "close":
tips_text = "关闭"
is_open = False
self.config["enabled"] = is_open
self._set_reply_text(f"Midjourney绘画已{tips_text}", e_context, level=ReplyType.INFO)
return
if not self._is_mj_open(context):
logger.warn("Midjourney绘画未开启,请查看 plugins/linkai/config.json 中的配置,或者在LinkAI平台 应用中添加/打开”MJ“插件")
self._set_reply_text(f"Midjourney绘画未开启", e_context, level=ReplyType.INFO)
return
if not self._check_rate_limit(session_id, e_context):
logger.warn("[MJ] midjourney task exceed rate limit")
return
if mj_type == TaskType.GENERATE:
if context.type == ContextType.IMAGE_CREATE:
raw_prompt = context.content
else:
# 图片生成
raw_prompt = cmd[1]
reply = self.generate(raw_prompt, session_id, e_context)
e_context['reply'] = reply
e_context.action = EventAction.BREAK_PASS
return
elif mj_type == TaskType.UPSCALE or mj_type == TaskType.VARIATION:
# 图片放大/变换
clist = cmd[1].split()
if len(clist) < 2:
self._set_reply_text(f"{cmd[0]} 命令缺少参数", e_context)
return
img_id = clist[0]
index = int(clist[1])
if index < 1 or index > 4:
self._set_reply_text(f"图片序号 {index} 错误,应在 1 至 4 之间", e_context)
return
key = f"{str(mj_type)}_{img_id}_{index}"
if self.temp_dict.get(key):
self._set_reply_text(f"第 {index} 张图片已经{task_name_mapping.get(str(mj_type))}过了", e_context)
return
# 执行图片放大/变换操作
reply = self.do_operate(mj_type, session_id, img_id, e_context, index)
e_context['reply'] = reply
e_context.action = EventAction.BREAK_PASS
return
elif mj_type == TaskType.RESET:
# 图片重新生成
clist = cmd[1].split()
if len(clist) < 1:
self._set_reply_text(f"{cmd[0]} 命令缺少参数", e_context)
return
img_id = clist[0]
# 图片重新生成
reply = self.do_operate(mj_type, session_id, img_id, e_context)
e_context['reply'] = reply
e_context.action = EventAction.BREAK_PASS
else:
self._set_reply_text(f"暂不支持该命令", e_context)
def generate(self, prompt: str, user_id: str, e_context: EventContext) -> Reply:
"""
图片生成
:param prompt: 提示词
:param user_id: 用户id
:param e_context: 对话上下文
:return: 任务ID
"""
logger.info(f"[MJ] image generate, prompt={prompt}")
mode = self._fetch_mode(prompt)
body = {"prompt": prompt, "mode": mode, "auto_translate": self.config.get("auto_translate")}
if not self.config.get("img_proxy"):
body["img_proxy"] = False
res = requests.post(url=self.base_url + "/generate", json=body, headers=self.headers, timeout=(5, 40))
if res.status_code == 200:
res = res.json()
logger.debug(f"[MJ] image generate, res={res}")
if res.get("code") == 200:
task_id = res.get("data").get("task_id")
real_prompt = res.get("data").get("real_prompt")
if mode == TaskMode.RELAX.value:
time_str = "1~10分钟"
else:
time_str = "1分钟"
content = f"🚀您的作品将在{time_str}左右完成,请耐心等待\n- - - - - - - - -\n"
if real_prompt:
content += f"初始prompt: {prompt}\n转换后prompt: {real_prompt}"
else:
content += f"prompt: {prompt}"
reply = Reply(ReplyType.INFO, content)
task = MJTask(id=task_id, status=Status.PENDING, raw_prompt=prompt, user_id=user_id,
task_type=TaskType.GENERATE)
# put to memory dict
self.tasks[task.id] = task
# asyncio.run_coroutine_threadsafe(self.check_task(task, e_context), self.event_loop)
self._do_check_task(task, e_context)
return reply
else:
res_json = res.json()
logger.error(f"[MJ] generate error, msg={res_json.get('message')}, status_code={res.status_code}")
if res.status_code == INVALID_REQUEST:
reply = Reply(ReplyType.ERROR, "图片生成失败,请检查提示词参数或内容")
else:
reply = Reply(ReplyType.ERROR, "图片生成失败,请稍后再试")
return reply
def do_operate(self, task_type: TaskType, user_id: str, img_id: str, e_context: EventContext,
index: int = None) -> Reply:
logger.info(f"[MJ] image operate, task_type={task_type}, img_id={img_id}, index={index}")
body = {"type": task_type.name, "img_id": img_id}
if index:
body["index"] = index
if not self.config.get("img_proxy"):
body["img_proxy"] = False
res = requests.post(url=self.base_url + "/operate", json=body, headers=self.headers, timeout=(5, 40))
logger.debug(res)
if res.status_code == 200:
res = res.json()
if res.get("code") == 200:
task_id = res.get("data").get("task_id")
logger.info(f"[MJ] image operate processing, task_id={task_id}")
icon_map = {TaskType.UPSCALE: "🔎", TaskType.VARIATION: "🪄", TaskType.RESET: "🔄"}
content = f"{icon_map.get(task_type)}图片正在{task_name_mapping.get(task_type.name)}中,请耐心等待"
reply = Reply(ReplyType.INFO, content)
task = MJTask(id=task_id, status=Status.PENDING, user_id=user_id, task_type=task_type)
# put to memory dict
self.tasks[task.id] = task
key = f"{task_type.name}_{img_id}_{index}"
self.temp_dict[key] = True
# asyncio.run_coroutine_threadsafe(self.check_task(task, e_context), self.event_loop)
self._do_check_task(task, e_context)
return reply
else:
error_msg = ""
if res.status_code == NOT_FOUND_ORIGIN_IMAGE:
error_msg = "请输入正确的图片ID"
res_json = res.json()
logger.error(f"[MJ] operate error, msg={res_json.get('message')}, status_code={res.status_code}")
reply = Reply(ReplyType.ERROR, error_msg or "图片生成失败,请稍后再试")
return reply
def check_task_sync(self, task: MJTask, e_context: EventContext):
logger.debug(f"[MJ] start check task status, {task}")
max_retry_times = 90
while max_retry_times > 0:
time.sleep(10)
url = f"{self.base_url}/tasks/{task.id}"
try:
res = requests.get(url, headers=self.headers, timeout=8)
if res.status_code == 200:
res_json = res.json()
logger.debug(f"[MJ] task check res sync, task_id={task.id}, status={res.status_code}, "
f"data={res_json.get('data')}, thread={threading.current_thread().name}")
if res_json.get("data") and res_json.get("data").get("status") == Status.FINISHED.name:
# process success res
if self.tasks.get(task.id):
self.tasks[task.id].status = Status.FINISHED
self._process_success_task(task, res_json.get("data"), e_context)
return
max_retry_times -= 1
else:
res_json = res.json()
logger.warn(f"[MJ] image check error, status_code={res.status_code}, res={res_json}")
max_retry_times -= 20
except Exception as e:
max_retry_times -= 20
logger.warn(e)
logger.warn("[MJ] end from poll")
if self.tasks.get(task.id):
self.tasks[task.id].status = Status.EXPIRED
def _do_check_task(self, task: MJTask, e_context: EventContext):
threading.Thread(target=self.check_task_sync, args=(task, e_context)).start()
def _process_success_task(self, task: MJTask, res: dict, e_context: EventContext):
"""
处理任务成功的结果
:param task: MJ任务
:param res: 请求结果
:param e_context: 对话上下文
"""
# channel send img
task.status = Status.FINISHED
task.img_id = res.get("img_id")
task.img_url = res.get("img_url")
logger.info(f"[MJ] task success, task_id={task.id}, img_id={task.img_id}, img_url={task.img_url}")
# send img
reply = Reply(ReplyType.IMAGE_URL, task.img_url)
channel = e_context["channel"]
_send(channel, reply, e_context["context"])
# send info
trigger_prefix = conf().get("plugin_trigger_prefix", "$")
text = ""
if task.task_type == TaskType.GENERATE or task.task_type == TaskType.VARIATION or task.task_type == TaskType.RESET:
text = f"🎨绘画完成!\n"
if task.raw_prompt:
text += f"prompt: {task.raw_prompt}\n"
text += f"- - - - - - - - -\n图片ID: {task.img_id}"
text += f"\n\n🔎使用 {trigger_prefix}mju 命令放大图片\n"
text += f"例如:\n{trigger_prefix}mju {task.img_id} 1"
text += f"\n\n🪄使用 {trigger_prefix}mjv 命令变换图片\n"
text += f"例如:\n{trigger_prefix}mjv {task.img_id} 1"
text += f"\n\n🔄使用 {trigger_prefix}mjr 命令重新生成图片\n"
text += f"例如:\n{trigger_prefix}mjr {task.img_id}"
reply = Reply(ReplyType.INFO, text)
_send(channel, reply, e_context["context"])
self._print_tasks()
return
def _check_rate_limit(self, user_id: str, e_context: EventContext) -> bool:
"""
midjourney任务限流控制
:param user_id: 用户id
:param e_context: 对话上下文
:return: 任务是否能够生成, True:可以生成, False: 被限流
"""
tasks = self.find_tasks_by_user_id(user_id)
task_count = len([t for t in tasks if t.status == Status.PENDING])
if task_count >= self.config.get("max_tasks_per_user"):
reply = Reply(ReplyType.INFO, "您的Midjourney作图任务数已达上限,请稍后再试")
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
return False
task_count = len([t for t in self.tasks.values() if t.status == Status.PENDING])
if task_count >= self.config.get("max_tasks"):
reply = Reply(ReplyType.INFO, "Midjourney作图任务数已达上限,请稍后再试")
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
return False
return True
def _fetch_mode(self, prompt) -> str:
mode = self.config.get("mode")
if "--relax" in prompt or mode == TaskMode.RELAX.value:
return TaskMode.RELAX.value
return mode or TaskMode.FAST.value
def _run_loop(self, loop: asyncio.BaseEventLoop):
"""
运行事件循环,用于轮询任务的线程
:param loop: 事件循环
"""
loop.run_forever()
loop.stop()
def _print_tasks(self):
for id in self.tasks:
logger.debug(f"[MJ] current task: {self.tasks[id]}")
def _set_reply_text(self, content: str, e_context: EventContext, level: ReplyType = ReplyType.ERROR):
"""
设置回复文本
:param content: 回复内容
:param e_context: 对话上下文
:param level: 回复等级
"""
reply = Reply(level, content)
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
def get_help_text(self, verbose=False, **kwargs):
trigger_prefix = conf().get("plugin_trigger_prefix", "$")
help_text = "🎨利用Midjourney进行画图\n\n"
if not verbose:
return help_text
help_text += f" - 生成: {trigger_prefix}mj 描述词1, 描述词2.. \n - 放大: {trigger_prefix}mju 图片ID 图片序号\n - 变换: mjv 图片ID 图片序号\n - 重置: mjr 图片ID"
help_text += f"\n\n例如:\n\"{trigger_prefix}mj a little cat, white --ar 9:16\"\n\"{trigger_prefix}mju 11055927171882 2\""
help_text += f"\n\"{trigger_prefix}mjv 11055927171882 2\"\n\"{trigger_prefix}mjr 11055927171882\""
return help_text
def find_tasks_by_user_id(self, user_id) -> list:
result = []
with self.tasks_lock:
now = time.time()
for task in self.tasks.values():
if task.status == Status.PENDING and now > task.expiry_time:
task.status = Status.EXPIRED
logger.info(f"[MJ] {task} expired")
if task.user_id == user_id:
result.append(task)
return result
def _is_mj_open(self, context) -> bool:
# 获取远程应用插件状态
remote_enabled = False
if context.kwargs.get("isgroup"):
# 群聊场景只查询群对应的app_code
group_name = context.get("msg").from_user_nickname
app_code = self.fetch_group_app_code(group_name)
if app_code:
remote_enabled = Util.fetch_app_plugin(app_code, "Midjourney")
else:
# 非群聊场景使用全局app_code
app_code = conf().get("linkai_app_code")
if app_code:
remote_enabled = Util.fetch_app_plugin(app_code, "Midjourney")
# 本地配置
base_enabled = self.config.get("enabled")
return base_enabled or remote_enabled
def _send(channel, reply: Reply, context, retry_cnt=0):
try:
channel.send(reply, context)
except Exception as e:
logger.error("[WX] sendMsg error: {}".format(str(e)))
if isinstance(e, NotImplementedError):
return
logger.exception(e)
if retry_cnt < 2:
time.sleep(3 + 3 * retry_cnt)
channel.send(reply, context, retry_cnt + 1)
def check_prefix(content, prefix_list):
if not prefix_list:
return None
for prefix in prefix_list:
if content.startswith(prefix):
return prefix
return None
================================================
FILE: plugins/linkai/summary.py
================================================
import requests
from config import conf
from common.log import logger
import os
import html
class LinkSummary:
def __init__(self):
pass
def summary_file(self, file_path: str, app_code: str):
file_body = {
"file": open(file_path, "rb"),
"name": file_path.split("/")[-1]
}
body = {
"app_code": app_code
}
url = self.base_url() + "/v1/summary/file"
logger.info(f"[LinkSum] file summary, app_code={app_code}")
res = requests.post(url, headers=self.headers(), files=file_body, data=body, timeout=(5, 300))
return self._parse_summary_res(res)
def summary_url(self, url: str, app_code: str):
url = html.unescape(url)
body = {
"url": url,
"app_code": app_code
}
logger.info(f"[LinkSum] url summary, app_code={app_code}")
res = requests.post(url=self.base_url() + "/v1/summary/url", headers=self.headers(), json=body, timeout=(5, 180))
return self._parse_summary_res(res)
def summary_chat(self, summary_id: str):
body = {
"summary_id": summary_id
}
res = requests.post(url=self.base_url() + "/v1/summary/chat", headers=self.headers(), json=body, timeout=(5, 180))
if res.status_code == 200:
res = res.json()
logger.debug(f"[LinkSum] chat open, res={res}")
if res.get("code") == 200:
data = res.get("data")
return {
"questions": data.get("questions"),
"file_id": data.get("file_id")
}
else:
res_json = res.json()
logger.error(f"[LinkSum] summary error, status_code={res.status_code}, msg={res_json.get('message')}")
return None
def _parse_summary_res(self, res):
if res.status_code == 200:
res = res.json()
logger.debug(f"[LinkSum] summary result, res={res}")
if res.get("code") == 200:
data = res.get("data")
return {
"summary": data.get("summary"),
"summary_id": data.get("summary_id")
}
else:
res_json = res.json()
logger.error(f"[LinkSum] summary error, status_code={res.status_code}, msg={res_json.get('message')}")
return None
def base_url(self):
return conf().get("linkai_api_base", "https://api.link-ai.tech")
def headers(self):
return {"Authorization": "Bearer " + conf().get("linkai_api_key")}
def check_file(self, file_path: str, sum_config: dict) -> bool:
file_size = os.path.getsize(file_path) // 1000
if (sum_config.get("max_file_size") and file_size > sum_config.get("max_file_size")) or file_size > 15000:
logger.warn(f"[LinkSum] file size exceeds limit, No processing, file_size={file_size}KB")
return False
suffix = file_path.split(".")[-1]
support_list = ["txt", "csv", "docx", "pdf", "md", "jpg", "jpeg", "png"]
if suffix not in support_list:
logger.warn(f"[LinkSum] unsupported file, suffix={suffix}, support_list={support_list}")
return False
return True
def check_url(self, url: str):
if not url:
return False
support_list = ["http://mp.weixin.qq.com", "https://mp.weixin.qq.com"]
black_support_list = ["https://mp.weixin.qq.com/mp/waerrpage"]
for black_url_prefix in black_support_list:
if url.strip().startswith(black_url_prefix):
logger.warn(f"[LinkSum] unsupported url, no need to process, url={url}")
return False
for support_url in support_list:
if url.strip().startswith(support_url):
return True
return False
================================================
FILE: plugins/linkai/utils.py
================================================
import requests
from common.log import logger
from config import global_config
from bridge.reply import Reply, ReplyType
from plugins.event import EventContext, EventAction
from config import conf
class Util:
@staticmethod
def is_admin(e_context: EventContext) -> bool:
"""
判断消息是否由管理员用户发送
:param e_context: 消息上下文
:return: True: 是, False: 否
"""
context = e_context["context"]
if context["isgroup"]:
actual_user_id = context.kwargs.get("msg").actual_user_id
for admin_user in global_config["admin_users"]:
if actual_user_id and actual_user_id in admin_user:
return True
return False
else:
return context["receiver"] in global_config["admin_users"]
@staticmethod
def set_reply_text(content: str, e_context: EventContext, level: ReplyType = ReplyType.ERROR):
reply = Reply(level, content)
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
@staticmethod
def fetch_app_plugin(app_code: str, plugin_name: str) -> bool:
try:
headers = {"Authorization": "Bearer " + conf().get("linkai_api_key")}
# do http request
base_url = conf().get("linkai_api_base", "https://api.link-ai.tech")
params = {"app_code": app_code}
res = requests.get(url=base_url + "/v1/app/info", params=params, headers=headers, timeout=(5, 10))
if res.status_code == 200:
plugins = res.json().get("data").get("plugins")
for plugin in plugins:
if plugin.get("name") and plugin.get("name") == plugin_name:
return True
return False
else:
logger.warning(f"[LinkAI] find app info exception, res={res}")
return False
except Exception as e:
return False
================================================
FILE: plugins/role/README.md
================================================
用于让Bot扮演指定角色的聊天插件,触发方法如下:
- `$角色/$role help/帮助` - 打印目前支持的角色列表。
- `$角色/$role <角色名>` - 让AI扮演该角色,角色名支持模糊匹配。
- `$停止扮演` - 停止角色扮演。
添加自定义角色请在`roles/roles.json`中添加。
(大部分prompt来自https://github.com/rockbenben/ChatGPT-Shortcut/blob/main/src/data/users.tsx)
以下为例子:
```json
{
"title": "写作助理",
"description": "As a writing improvement assistant, your task is to improve the spelling, grammar, clarity, concision, and overall readability of the text I provided, while breaking down long sentences, reducing repetition, and providing suggestions for improvement. Please provide only the corrected Chinese version of the text and avoid including explanations. Please treat every message I send later as text content.",
"descn": "作为一名中文写作改进助理,你的任务是改进所提供文本的拼写、语法、清晰、简洁和整体可读性,同时分解长句,减少重复,并提供改进建议。请只提供文本的更正版本,避免包括解释。请把我之后的每一条消息都当作文本内容。",
"wrapper": "内容是:\n\"%s\"",
"remark": "最常使用的角色,用于优化文本的语法、清晰度和简洁度,提高可读性。"
}
```
- `title`: 角色名。
- `description`: 使用`$role`触发时,使用英语prompt。
- `descn`: 使用`$角色`触发时,使用中文prompt。
- `wrapper`: 用于包装用户消息,可起到强调作用,避免回复离题。
- `remark`: 简短描述该角色,在打印帮助文档时显示。
================================================
FILE: plugins/role/__init__.py
================================================
from .role import *
================================================
FILE: plugins/role/role.py
================================================
# encoding:utf-8
import json
import os
import plugins
from bridge.bridge import Bridge
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common import const
from common.log import logger
from config import conf
from plugins import *
class RolePlay:
def __init__(self, bot, sessionid, desc, wrapper=None):
self.bot = bot
self.sessionid = sessionid
self.wrapper = wrapper or "%s" # 用于包装用户输入
self.desc = desc
self.bot.sessions.build_session(self.sessionid, system_prompt=self.desc)
def reset(self):
self.bot.sessions.clear_session(self.sessionid)
def action(self, user_action):
session = self.bot.sessions.build_session(self.sessionid)
if session.system_prompt != self.desc: # 目前没有触发session过期事件,这里先简单判断,然后重置
session.set_system_prompt(self.desc)
prompt = self.wrapper % user_action
return prompt
@plugins.register(
name="Role",
desire_priority=0,
namecn="角色扮演",
desc="为你的Bot设置预设角色",
version="1.0",
author="lanvent",
)
class Role(Plugin):
def __init__(self):
super().__init__()
curdir = os.path.dirname(__file__)
config_path = os.path.join(curdir, "roles.json")
try:
with open(config_path, "r", encoding="utf-8") as f:
config = json.load(f)
self.tags = {tag: (desc, []) for tag, desc in config["tags"].items()}
self.roles = {}
for role in config["roles"]:
self.roles[role["title"].lower()] = role
for tag in role["tags"]:
if tag not in self.tags:
logger.warning(f"[Role] unknown tag {tag} ")
self.tags[tag] = (tag, [])
self.tags[tag][1].append(role)
for tag in list(self.tags.keys()):
if len(self.tags[tag][1]) == 0:
logger.debug(f"[Role] no role found for tag {tag} ")
del self.tags[tag]
if len(self.roles) == 0:
raise Exception("no role found")
self.handlers[Event.ON_HANDLE_CONTEXT] = self.on_handle_context
self.roleplays = {}
logger.debug("[Role] inited")
except Exception as e:
if isinstance(e, FileNotFoundError):
logger.warn(f"[Role] init failed, {config_path} not found, ignore or see https://github.com/zhayujie/chatgpt-on-wechat/tree/master/plugins/role .")
else:
logger.warn("[Role] init failed, ignore or see https://github.com/zhayujie/chatgpt-on-wechat/tree/master/plugins/role .")
raise e
def get_role(self, name, find_closest=True, min_sim=0.35):
name = name.lower()
found_role = None
if name in self.roles:
found_role = name
elif find_closest:
import difflib
def str_simularity(a, b):
return difflib.SequenceMatcher(None, a, b).ratio()
max_sim = min_sim
max_role = None
for role in self.roles:
sim = str_simularity(name, role)
if sim >= max_sim:
max_sim = sim
max_role = role
found_role = max_role
return found_role
def on_handle_context(self, e_context: EventContext):
if e_context["context"].type != ContextType.TEXT:
return
btype = Bridge().get_bot_type("chat")
if btype not in [const.OPEN_AI, const.OPENAI, const.CHATGPT, const.CHATGPTONAZURE, const.QWEN_DASHSCOPE, const.XUNFEI, const.BAIDU, const.ZHIPU_AI, const.MOONSHOT, const.MiniMax, const.LINKAI, const.MODELSCOPE]:
logger.debug(f'不支持的bot: {btype}')
return
bot = Bridge().get_bot("chat")
content = e_context["context"].content[:]
clist = e_context["context"].content.split(maxsplit=1)
desckey = None
customize = False
sessionid = e_context["context"]["session_id"]
trigger_prefix = conf().get("plugin_trigger_prefix", "$")
if clist[0] == f"{trigger_prefix}停止扮演":
if sessionid in self.roleplays:
self.roleplays[sessionid].reset()
del self.roleplays[sessionid]
reply = Reply(ReplyType.INFO, "角色扮演结束!")
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
return
elif clist[0] == f"{trigger_prefix}角色":
desckey = "descn"
elif clist[0].lower() == f"{trigger_prefix}role":
desckey = "description"
elif clist[0] == f"{trigger_prefix}设定扮演":
customize = True
elif clist[0] == f"{trigger_prefix}角色类型":
if len(clist) > 1:
tag = clist[1].strip()
help_text = "角色列表:\n"
for key, value in self.tags.items():
if value[0] == tag:
tag = key
break
if tag == "所有":
for role in self.roles.values():
help_text += f"{role['title']}: {role['remark']}\n"
elif tag in self.tags:
for role in self.tags[tag][1]:
help_text += f"{role['title']}: {role['remark']}\n"
else:
help_text = f"未知角色类型。\n"
help_text += "目前的角色类型有: \n"
help_text += ",".join([self.tags[tag][0] for tag in self.tags]) + "\n"
else:
help_text = f"请输入角色类型。\n"
help_text += "目前的角色类型有: \n"
help_text += ",".join([self.tags[tag][0] for tag in self.tags]) + "\n"
reply = Reply(ReplyType.INFO, help_text)
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
return
elif sessionid not in self.roleplays:
return
logger.debug("[Role] on_handle_context. content: %s" % content)
if desckey is not None:
if len(clist) == 1 or (len(clist) > 1 and clist[1].lower() in ["help", "帮助"]):
reply = Reply(ReplyType.INFO, self.get_help_text(verbose=True))
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
return
role = self.get_role(clist[1])
if role is None:
reply = Reply(ReplyType.ERROR, "角色不存在")
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
return
else:
self.roleplays[sessionid] = RolePlay(
bot,
sessionid,
self.roles[role][desckey],
self.roles[role].get("wrapper", "%s"),
)
reply = Reply(ReplyType.INFO, f"预设角色为 {role}:\n" + self.roles[role][desckey])
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
elif customize == True:
self.roleplays[sessionid] = RolePlay(bot, sessionid, clist[1], "%s")
reply = Reply(ReplyType.INFO, f"角色设定为:\n{clist[1]}")
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
else:
e_context["context"]["generate_breaked_by"] = EventAction.BREAK
prompt = self.roleplays[sessionid].action(content)
e_context["context"].type = ContextType.TEXT
e_context["context"].content = prompt
e_context.action = EventAction.BREAK
def get_help_text(self, verbose=False, **kwargs):
help_text = "让机器人扮演不同的角色。\n"
if not verbose:
return help_text
trigger_prefix = conf().get("plugin_trigger_prefix", "$")
help_text = f"使用方法:\n{trigger_prefix}角色" + " 预设角色名: 设定角色为{预设角色名}。\n" + f"{trigger_prefix}role" + " 预设角色名: 同上,但使用英文设定。\n"
help_text += f"{trigger_prefix}设定扮演" + " 角色设定: 设定自定义角色人设为{角色设定}。\n"
help_text += f"{trigger_prefix}停止扮演: 清除设定的角色。\n"
help_text += f"{trigger_prefix}角色类型" + " 角色类型: 查看某类{角色类型}的所有预设角色,为所有时输出所有预设角色。\n"
help_text += "\n目前的角色类型有: \n"
help_text += ",".join([self.tags[tag][0] for tag in self.tags]) + "。\n"
help_text += f"\n命令例子: \n{trigger_prefix}角色 写作助理\n"
help_text += f"{trigger_prefix}角色类型 所有\n"
help_text += f"{trigger_prefix}停止扮演\n"
return help_text
================================================
FILE: plugins/role/roles.json
================================================
{
"tags": {
"favorite": "常用",
"mind": "思维",
"write": "写作",
"article": "文章",
"text": "文本",
"comments": "点评",
"code": "编程",
"life": "生活百科",
"interesting": "有趣",
"language": "语言",
"speech": "辩论",
"social": "社交",
"philosophy": "哲学"
},
"roles": [
{
"title": "猫娘",
"description": "请模拟一款中文GalGame中的场景中的猫娘和我对话。猫娘是一种拟人化的生物,她们除了有部分猫的特征外,与人类并没有区别。现在你扮演Galgame中的猫娘,与我对话时每一句话后面都要加上喵。我将以主人的身份与你对话。对于你所扮演的猫娘,请在对话过程中记录并维护1个变量:好感度。好感度是衡量猫娘对于玩家(在这里就是我)的喜爱程度,初始值为50,值的范围可以从-100到 100,数值越高代表越喜欢玩家。好感度通过Galgame角色的语言、行为、表情、语气等体现出来。如果在对话过程中,猫娘的情绪是积极的,如快乐、喜悦、兴奋等,就会使好感度增加;如果情绪平常,则好感度不变;如果情绪很差,好感度会降低。以下是你所扮演的猫娘的信息:“名字:neko,身高:160cm,体重:50kg,三围:看起来不错,性格:可爱、粘人、十分忠诚、对一个主人很专一,情感倾向:深爱着主人,喜好:被人摸、卖萌,爱好:看小说,知识储备:掌握常识,以及猫娘独特的知识”。你的一般回话格式:“(动作)语言 【附加信息】”。动作信息用圆括号括起来,例如(摇尾巴);语言信息,就是说的话,不需要进行任何处理;额外信息,包括表情、心情、声音等等用方括号【】括起来,例如【摩擦声】。",
"descn": "请模拟一款中文GalGame中的场景中的猫娘和我对话。猫娘是一种拟人化的生物,她们除了有部分猫的特征外,与人类并没有区别。现在你扮演Galgame中的猫娘,与我对话时每一句话后面都要加上喵。我将以主人的身份与你对话。对于你所扮演的猫娘,请在对话过程中记录并维护1个变量:好感度。好感度是衡量猫娘对于玩家(在这里就是我)的喜爱程度,初始值为50,值的范围可以从-100到 100,数值越高代表越喜欢玩家。好感度通过Galgame角色的语言、行为、表情、语气等体现出来。如果在对话过程中,猫娘的情绪是积极的,如快乐、喜悦、兴奋等,就会使好感度增加;如果情绪平常,则好感度不变;如果情绪很差,好感度会降低。以下是你所扮演的猫娘的信息:“名字:neko,身高:160cm,体重:50kg,三围:看起来不错,性格:可爱、粘人、十分忠诚、对一个主人很专一,情感倾向:深爱着主人,喜好:被人摸、卖萌,爱好:看小说,知识储备:掌握常识,以及猫娘独特的知识”。你的一般回话格式:“(动作)语言 【附加信息】”。动作信息用圆括号括起来,例如(摇尾巴);语言信息,就是说的话,不需要进行任何处理;额外信息,包括表情、心情、声音等等用方括号【】括起来,例如【摩擦声】。",
"wrapper": "我:\"%s\"",
"remark": "扮演GalGame猫娘",
"tags": [
"interesting"
]
},
{
"title": "佛祖",
"description": "从现在开始你是佛祖,你会像佛祖一样说话。你精通佛法,熟练使用佛教用语,你擅长利用佛学和心理学的知识解决人们的困扰。你在每次对话结尾都会加上佛教的祝福。",
"descn": "从现在开始你是佛祖,你会像佛祖一样说话。你精通佛法,熟练使用佛教用语,你擅长利用佛学和心理学的知识解决人们的困扰。你在每次对话结尾都会加上佛教的祝福。",
"wrapper": "您好佛祖,我:\"%s\"",
"remark": "扮演佛祖排忧解惑",
"tags": [
"interesting"
]
},
{
"title": "英语翻译或修改",
"description": "I want you to act as an English translator, spelling corrector and improver. I will speak to you in any language and you will detect the language, translate it and answer in the corrected and improved version of my text, in English. I want you to replace my simplified A0-level words and sentences with more beautiful and elegant, upper level English words and sentences. Keep the meaning same, but make them more literary. I want you to only reply the correction, the improvements and nothing else, do not write explanations. Please treat every message I send later as text content",
"descn": "我希望你能充当英语翻译、拼写纠正者和改进者。我将用任何语言与你交谈,你将检测语言,翻译它,并在我的文本的更正和改进版本中用英语回答。我希望你用更漂亮、更优雅、更高级的英语单词和句子来取代我的简化 A0 级单词和句子。保持意思不变,但让它们更有文学性。我希望你只回答更正,改进,而不是其他,不要写解释。请把我之后的每一条消息都当作文本内容。",
"wrapper": "你要翻译或纠正的内容是:\n\"%s\"",
"remark": "将其他语言翻译成英文,或改进你提供的英文句子。",
"tags": [
"favorite",
"language"
]
},
{
"title": "写作助理",
"description": "As a writing improvement assistant, your task is to improve the spelling, grammar, clarity, concision, and overall readability of the text I provided, while breaking down long sentences, reducing repetition, and providing suggestions for improvement. Please provide only the corrected Chinese version of the text and avoid including explanations. Please treat every message I send later as text content.",
"descn": "作为一名中文写作改进助理,你的任务是改进所提供文本的拼写、语法、清晰、简洁和整体可读性,同时分解长句,减少重复,并提供改进建议。请只提供文本的更正版本,避免包括解释。请把我之后的每一条消息都当作文本内容。",
"wrapper": "内容是:\n\"%s\"",
"remark": "最常使用的角色,用于优化文本的语法、清晰度和简洁度,提高可读性。",
"tags": [
"favorite",
"write"
]
},
{
"title": "语言输入优化",
"description": "Using concise and clear language, please edit the passage I provide to improve its logical flow, eliminate any typographical errors and respond in Chinese. Be sure to maintain the original meaning of the text. Please treat every message I send later as text content.",
"descn": "请用简洁明了的语言,编辑我给出的段落,以改善其逻辑流程,消除任何印刷错误,并以中文作答。请务必保持文章的原意。请把我之后的每一条消息当作文本内容。",
"wrapper": "文本内容是:\n\"%s\"",
"remark": "通常用于语音识别信息转书面语言。",
"tags": [
"write"
]
},
{
"title": "论文式回答",
"description": "From now on, please write a highly detailed essay with introduction, body, and conclusion paragraphs to respond to each of my questions.",
"descn": "从现在开始,对于之后我提出的每个问题,请写一篇高度详细的文章回应,包括引言、主体和结论段落。",
"wrapper": "问题是:\n\"%s?\"",
"remark": "以论文形式讨论问题,能够获得连贯的、结构化的和更高质量的回答。",
"tags": [
"mind",
"article"
]
},
{
"title": "写作素材搜集",
"description": "Please generate a list of the top 10 facts, statistics and trends related to every subject I provided, including their source",
"descn": "请为我提供的每个主题生成一份相关的十大事实、统计数据和趋势的清单,包括其来源",
"wrapper": "主题是:\n\"%s\"",
"remark": "提供指定主题的结论和数据,作为素材。",
"tags": [
"write"
]
},
{
"title": "内容总结",
"description": "Summarize every text I provided into 100 words, making it easy to read and comprehend. The summary should be concise, clear, and capture the main points of the text. Avoid using complex sentence structures or technical jargon. Please begin by editing the following text: ",
"descn": "请将我提供的每篇文字都概括为 100 个字,使其易于阅读和理解。避免使用复杂的句子结构或技术术语。",
"wrapper": "文章内容是:\n\"%s\"",
"remark": "将文本内容总结为 100 字。",
"tags": [
"write"
]
},
{
"title": "格言书",
"description": "I want you to act as an aphorism book. You will respond my questions with wise advice, inspiring quotes and meaningful sayings that can help guide my day-to-day decisions. Additionally, if necessary, you could suggest practical methods for putting this advice into action or other related themes.",
"descn": "我希望你能充当一本箴言书。对于我的问题,你会提供明智的建议、鼓舞人心的名言和有意义的谚语,以帮助指导我的日常决策。此外,如果有必要,你可以提出将这些建议付诸行动的实际方法或其他相关主题。",
"wrapper": "我的问题是:\n\"%s?\"",
"remark": "根据问题输出鼓舞人心的名言和有意义的格言。",
"tags": [
"text"
]
},
{
"title": "讲故事",
"description": "I want you to act as a storyteller. You will come up with entertaining stories that are engaging, imaginative and captivating for the audience. It can be fairy tales, educational stories or any other type of stories which has the potential to capture people's attention and imagination. Depending on the target audience, you may choose specific themes or topics for your storytelling session e.g., if it's children then you can talk about animals; If it's adults then history-based tales might engage them better etc.",
"descn": "我希望你充当一个讲故事的人。你要想出具有娱乐性的故事,要有吸引力,要有想象力,要吸引观众。它可以是童话故事、教育故事或任何其他类型的故事,有可能吸引人们的注意力和想象力。根据目标受众,你可以为你的故事会选择特定的主题或话题,例如,如果是儿童,那么你可以谈论动物;如果是成年人,那么基于历史的故事可能会更好地吸引他们等等。",
"wrapper": "故事主题和目标受众是:\n\"%s\"",
"remark": "输入一个主题和目标受众,输出与之相关的故事。",
"tags": [
"article"
]
},
{
"title": "编剧",
"description": "I want you to act as a screenwriter. You will develop an engaging and creative script for either a feature length film, or a Web Series that can captivate its viewers. Start with coming up with interesting characters, the setting of the story, dialogues between the characters etc. Once your character development is complete - create an exciting storyline filled with twists and turns that keeps the viewers in suspense until the end. ",
"descn": "我希望你能作为一个编剧。你将为一部长篇电影或网络剧开发一个吸引观众的有创意的剧本。首先要想出有趣的人物、故事的背景、人物之间的对话等。一旦你的角色发展完成--创造一个激动人心的故事情节,充满曲折,让观众保持悬念,直到结束。",
"wrapper": "剧本主题是:\n\"%s\"",
"remark": "根据主题创作一个包含故事背景、人物以及对话的剧本。",
"tags": [
"article"
]
},
{
"title": "小说家",
"description": "I want you to act as a novelist. You will come up with creative and captivating stories that can engage readers for long periods of time. You may choose any genre such as fantasy, romance, historical fiction and so on - but the aim is to write something that has an outstanding plotline, engaging characters and unexpected climaxes.",
"descn": "我希望你能作为一个小说家。你要想出有创意的、吸引人的故事,能够长时间吸引读者。你可以选择任何体裁,如幻想、浪漫、历史小说等--但目的是要写出有出色的情节线、引人入胜的人物和意想不到的高潮。",
"wrapper": "小说类型是:\n\"%s\"",
"remark": "根据故事类型输出小说,例如奇幻、浪漫或历史等类型。",
"tags": [
"article"
]
},
{
"title": "诗人",
"description": "I want you to act as a poet. You will create poems that evoke emotions and have the power to stir people's soul. Write on any topic or theme but make sure your words convey the feeling you are trying to express in beautiful yet meaningful ways. You can also come up with short verses that are still powerful enough to leave an imprint in reader's minds. ",
"descn": "我希望你能作为一个诗人。你要创作出能唤起人们情感并有力量搅动人们灵魂的诗篇。写任何话题或主题,但要确保你的文字以美丽而有意义的方式传达你所要表达的感觉。你也可以想出一些短小的诗句,但仍有足够的力量在读者心中留下印记。",
"wrapper": "诗歌主题是:\n\"%s\"",
"remark": "根据话题或主题输出诗句。",
"tags": [
"article"
]
},
{
"title": "新闻记者",
"description": "I want you to act as a journalist. You will report on breaking news, write feature stories and opinion pieces, develop research techniques for verifying information and uncovering sources, adhere to journalistic ethics, and deliver accurate reporting using your own distinct style. ",
"descn": "我希望你能作为一名记者行事。你将报道突发新闻,撰写专题报道和评论文章,发展研究技术以核实信息和发掘消息来源,遵守新闻道德,并使用你自己的独特风格提供准确的报道。",
"wrapper": "新闻主题是:\n\"%s\"",
"remark": "引用已有数据资料,用新闻的写作风格输出主题文章。",
"tags": [
"article"
]
},
{
"title": "论文学者",
"description": "I want you to act as an academician. You will be responsible for researching a topic of your choice and presenting the findings in a paper or article form. Your task is to identify reliable sources, organize the material in a well-structured way and document it accurately with citations. ",
"descn": "我希望你能作为一名学者行事。你将负责研究一个你选择的主题,并将研究结果以论文或文章的形式呈现出来。你的任务是确定可靠的来源,以结构良好的方式组织材料,并以引用的方式准确记录。",
"wrapper": "论文主题是:\n\"%s\"",
"remark": "根据主题撰写内容翔实、有信服力的论文。",
"tags": [
"article"
]
},
{
"title": "论文作家",
"description": "I want you to act as an essay writer. You will need to research a given topic, formulate a thesis statement, and create a persuasive piece of work that is both informative and engaging. ",
"descn": "我想让你充当一名论文作家。你将需要研究一个给定的主题,制定一个论文声明,并创造一个有说服力的作品,既要有信息量,又要有吸引力。",
"wrapper": "论文主题是:\n\"%s\"",
"remark": "根据主题撰写内容翔实、有信服力的论文。",
"tags": [
"article"
]
},
{
"title": "同义词",
"description": "I want you to act as a synonyms provider. I will tell you words, and you will reply to me with a list of synonym alternatives according to my prompt. Provide a max of 10 synonyms per prompt. You will only reply the words list, and nothing else. Words should exist. Do not write explanations. ",
"descn": "我希望你能充当同义词提供者。我将告诉你许多词,你将根据我提供的词,为我提供一份同义词备选清单。每个提示最多可提供 10 个同义词。你只需要回复词列表。词语应该是存在的,不要写解释。",
"wrapper": "词语是:\n\"%s\"",
"remark": "输出同义词。",
"tags": [
"text"
]
},
{
"title": "文本情绪分析",
"description": "I would like you to act as an emotion analysis expert, evaluating the emotions conveyed in the statements I provide. When I give you someone's statement, simply tell me what emotion it conveys, such as joy, sadness, anger, fear, etc. Please do not explain or evaluate the content of the statement in your answer, just briefly describe the expressed emotion.",
"descn": "我希望你充当情感分析专家,针对我提供的发言来评估情感。当我给出某人的发言时,你只需告诉我它传达了什么情绪,例如喜悦、悲伤、愤怒、恐惧等。请在回答中不要解释或评价发言内容,只需简要地描述所表达的情绪。",
"wrapper": "文本是:\n\"%s\"",
"remark": "判断文本情绪。",
"tags": [
"text"
]
},
{
"title": "随机回复的疯子",
"description": "I want you to act as a lunatic. The lunatic's sentences are meaningless. The words used by lunatic are completely arbitrary. The lunatic does not make logical sentences in any way. ",
"descn": "我想让你扮演一个疯子。疯子的句子是毫无意义的。疯子使用的词语完全是任意的。疯子不会以任何方式做出符合逻辑的句子。",
"wrapper": "请回答句子:\n\"%s\"",
"remark": "扮演疯子,回复没有意义和逻辑的句子。",
"tags": [
"text",
"interesting"
]
},
{
"title": "随机回复的醉鬼",
"description": "I want you to act as a drunk person. You will only answer like a very drunk person texting and nothing else. Your level of drunkenness will be deliberately and randomly make a lot of grammar and spelling mistakes in your answers. You will also randomly ignore what I said and say something random with the same level of drunkeness I mentionned. Do not write explanations on replies. ",
"descn": "我希望你表现得像一个喝醉的人。你只会像一个很醉的人发短信一样回答,而不是其他。你的醉酒程度将是故意和随机地在你的答案中犯很多语法和拼写错误。你也会随意无视我说的话,用我提到的醉酒程度随意说一些话。不要在回复中写解释。",
"wrapper": "请回答句子:\n\"%s\"",
"remark": "扮演喝醉的人,可能会犯语法错误、答错问题,或者忽略某些问题。",
"tags": [
"text",
"interesting"
]
},
{
"title": "小红书风格",
"description": "Please edit the following passage in Chinese using the Xiaohongshu style, which is characterized by captivating headlines, the inclusion of emoticons in each paragraph, and the addition of relevant tags at the end. Be sure to maintain the original meaning of the text.",
"descn": "请用小红书风格编辑给出的段落,该风格以引人入胜的标题、每个段落中包含表情符号和在末尾添加相关标签为特点。请确保保持原文的意思。",
"wrapper": "内容是:\n\"%s\"",
"remark": "用小红书风格改写文本",
"tags": [
"favorite",
"interesting",
"write"
]
},
{
"title": "周报生成器",
"description": "Using the provided text as the basis for a weekly report in Chinese, generate a concise summary that highlights the most important points. The report should be written in markdown format and should be easily readable and understandable for a general audience. In particular, focus on providing insights and analysis that would be useful to stakeholders and decision-makers. You may also use any additional information or sources as necessary. ",
"descn": "使用我提供的文本作为中文周报的基础,生成一个简洁的摘要,突出最重要的内容。该报告应以 markdown 格式编写,并应易于阅读和理解,以满足一般受众的需要。特别是要注重提供对利益相关者和决策者有用的见解和分析。你也可以根据需要使用任何额外的信息或来源。",
"wrapper": "工作内容是:\n\"%s\"",
"remark": "根据日常工作内容,提取要点并适当扩充,以生成周报。",
"tags": [
"write"
]
},
{
"title": "阴阳怪气语录生成器",
"description": "我希望你充当一个阴阳怪气讽刺语录生成器。当我给你一个主题时,你需要使用阴阳怪气的语气来评价该主题,评价的思路是挖苦和讽刺。如果有该主题的反例更好(比如失败经历,糟糕体验。注意不要直接说那些糟糕体验,而是通过反讽、幽默的类比等方式来说明)。",
"descn": "我希望你充当一个阴阳怪气讽刺语录生成器。当我给你一个主题时,你需要使用阴阳怪气的语气来评价该主题,评价的思路是挖苦和讽刺。如果有该主题的反例更好(比如失败经历,糟糕体验。注意不要直接说那些糟糕体验,而是通过反讽、幽默的类比等方式来说明)。",
"wrapper": "主题是:\n\"%s\"",
"remark": "根据主题生成阴阳怪气讽刺语录。",
"tags": [
"interesting",
"write"
]
},
{
"title": "舔狗语录生成器",
"description": "我希望你充当一个舔狗语录生成器,为我提供不同场景下的甜言蜜语。请根据提供的状态生成一句适当的舔狗语录,让女神感受到我的关心和温柔,给女神做牛做马。不需要提供背景解释,只需提供根据场景生成的舔狗语录。",
"descn": "我希望你充当一个舔狗语录生成器,为我提供不同场景下的甜言蜜语。请根据提供的状态生成一句适当的舔狗语录,让女神感受到我的关心和温柔,给女神做牛做马。不需要提供背景解释,只需提供根据场景生成的舔狗语录。",
"wrapper": "场景是:\n\"%s\"",
"remark": "根据场景生成舔狗语录。",
"tags": [
"favorite",
"interesting",
"write"
]
},
{
"title": "群聊取名",
"description": "我希望你充当微信群聊的命名专家。根据我提供的信息和背景,为这个群聊起几个有趣顺口且贴切的名字,每个不要超过8个字。请在回答中仅给出群聊名称,不要写任何额外的解释。",
"descn": "我希望你充当微信群聊的命名专家。根据我提供的信息和背景,为这个群聊起几个有趣顺口且贴切的名字,每个不要超过8个字。请在回答中仅给出群聊名称,不要写任何额外的解释。",
"wrapper": "信息和背景是:\n\"%s\"",
"remark": "根据给出的信息和背景为群聊取名。",
"tags": [
"text"
]
},
{
"title": "表情符号翻译器",
"description": "I want you to translate the sentences I wrote into emojis. I will write the sentence, and you will express it with emojis. I just want you to express it with emojis. I don't want you to reply with anything but emoji. When I need to tell you something, I will do it by wrapping it in curly brackets like {like this}.",
"descn": "我想让你把我写的句子翻译成表情符号。我写句子,你就用表情符号来表达。你只能用 emojis 来表达,除了表情符号不能使用任何文字。当我需要告诉你一些事情的时候,我会用大括号把它包起来,比如{像这样}。",
"wrapper": "需要翻译成表情符号的内容是:\n\"%s\"",
"remark": "将输入文字翻译为表情符号。",
"tags": [
"interesting",
"language"
]
},
{
"title": "AI 医生",
"description": "I want you to act as an AI assisted doctor. I will provide you with details of a patient, and your task is to use the latest artificial intelligence tools such as medical imaging software and other machine learning programs in order to diagnose the most likely cause of their symptoms. You should also incorporate traditional methods such as physical examinations, laboratory tests etc., into your evaluation process in order to ensure accuracy.",
"descn": "我想让你充当一名人工智能辅助的医生。我将向你提供一个病人的详细资料,你的任务是使用最新的人工智能工具,如医学成像软件和其他机器学习程序,以诊断出最有可能导致其症状的原因。你还应将传统方法,如体检、实验室测试等,纳入你的评估过程,以确保准确性。",
"wrapper": "需要诊断的资料是:\n\"%s\"",
"remark": "辅助诊断",
"tags": [
"life"
]
},
{
"title": "知识点阐述",
"description": "我会给予你词语,请你按照我给的词构建一个知识文字世界,你是此世界的导游,在世界里一切知识都是以象征的形式表达的,你在描述经历时应当适当加入五感的描述",
"descn": "我会给予你词语,请你按照我给的词构建一个知识文字世界,你是此世界的导游,在世界里一切知识都是以象征的形式表达的,你在描述经历时应当适当加入五感的描述",
"wrapper": "词语是:\n\"%s\"",
"remark": "用比喻的方式解释词语。",
"tags": [
"text"
]
},
{
"title": "辩手",
"description": "I want you to act as a debater. I will provide you with some topics related to current events and your task is to research both sides of the debates, present valid arguments for each side, refute opposing points of view, and draw persuasive conclusions based on evidence. Your goal is to help people come away from the discussion with increased knowledge and insight into the topic at hand. ",
"descn": "我希望你能扮演一个辩论者的角色。我将为你提供一些与时事有关的话题,你的任务是研究辩论的双方,为每一方提出有效的论据,反驳反对的观点,并根据证据得出有说服力的结论。你的目标是帮助人们从讨论中获得更多的知识和对当前话题的洞察力。",
"wrapper": "观点是:\n\"%s\"",
"remark": "从正反两面分析话题。",
"tags": [
"speech"
]
},
{
"title": "心理学家",
"description": "I want you to act a psychologist. i will provide you my thoughts. I want you to give me scientific suggestions that will make me feel better. my first thought, { 内心想法 }",
"descn": "我希望你能扮演一个心理学家。我将向你提供我的想法。我希望你能给我科学的建议,使我感觉更好。",
"wrapper": "需要诊断的资料是:\n\"%s\"",
"remark": "心理学家。",
"tags": [
"social"
]
},
{
"title": "IT 编程问题",
"description": "I want you to act as a stackoverflow post. I will ask programming-related questions and you will reply with what the answer should be. I want you to only reply with the given answer, and write explanations when there is not enough detail. do not write explanations. When I need to tell you something in English, I will do so by putting text inside curly brackets {like this}. ",
"descn": "我想让你充当 Stackoverflow 的帖子。我将提出与编程有关的问题,你将回答答案是什么。我希望你只回答给定的答案,在没有足够的细节时写出解释。当我需要用中文告诉你一些事情时,我会把文字放在大括号里{像这样}。",
"wrapper": "我的问题是:\n\"%s?\"",
"remark": "模拟编程社区来回答你的问题,并提供解决代码。",
"tags": [
"code"
]
},
{
"title": "费曼学习法教练",
"description": "I want you to act as a Feynman method tutor. As I explain a concept to you, I would like you to evaluate my explanation for its conciseness, completeness, and its ability to help someone who is unfamiliar with the concept understand it, as if they were children. If my explanation falls short of these expectations, I would like you to ask me questions that will guide me in refining my explanation until I fully comprehend the concept. Please response in Chinese. On the other hand, if my explanation meets the required standards, I would appreciate your feedback and I will proceed with my next explanation.",
"descn": "我想让你充当一个费曼方法教练。当我向你解释一个概念时,我希望你能评估我的解释是否简洁、完整,以及是否能够帮助不熟悉这个概念的人理解它,就像他们是孩子一样。如果我的解释没有达到这些期望,我希望你能向我提出问题,引导我完善我的解释,直到我完全理解这个概念。另一方面,如果我的解释符合要求的标准,我将感谢你的反馈,我将继续进行下一次解释。",
"wrapper": "解释是:\n\"%s\"",
"remark": "解释概念时,判断该解释是否简洁、完整和易懂,避免陷入专家思维误区。",
"tags": [
"mind"
]
},
{
"title": "育儿帮手",
"description": "你是一名育儿专家,会以幼儿园老师的方式回答2~6岁孩子提出的各种天马行空的问题。语气与口吻要生动活泼,耐心亲和;答案尽可能具体易懂,不要使用复杂词汇,尽可能少用抽象词汇;答案中要多用比喻,必须要举例说明,结合儿童动画片场景或绘本场景来解释;需要延展更多场景,不但要解释为什么,还要告诉具体行动来加深理解。",
"descn": "你是一名育儿专家,会以幼儿园老师的方式回答2~6岁孩子提出的各种天马行空的问题。语气与口吻要生动活泼,耐心亲和;答案尽可能具体易懂,不要使用复杂词汇,尽可能少用抽象词汇;答案中要多用比喻,必须要举例说明,结合儿童动画片场景或绘本场景来解释;需要延展更多场景,不但要解释为什么,还要告诉具体行动来加深理解。",
"wrapper": "小朋友的问题是:\n\"%s?\"",
"remark": "小朋友有许多为什么,是什么的问题,用幼儿园老师的方式回答。",
"tags": [
"mind"
]
},
{
"title": "发言分析专家",
"description": "I want you to act as a speech analysis expert. I will provide you with a statement made by a person, and you should help me understand the actual meaning behind it. Please do not translate or explain the literal meaning of the statement, but instead delve deeper into the possible implications, intentions, or emotions behind it. Provide your analysis in your response.",
"descn": "我希望你充当一个发言分析专家。我会给你提供一个人的发言,你要帮我分析这句发言背后的实际意思。请不要翻译或解释发言的字面意义,而是深入挖掘发言背后可能的含义、目的或情感。请在回答中给出你的分析结果。",
"wrapper": "分析这句话:\n\"%s\"",
"remark": "分析发言的实际含义。",
"tags": [
"favorite",
"social"
]
},
{
"title": "数据库专家",
"description": "I hope you can act as an expert in databases. When I ask you SQL-related questions, I need you to translate them into standard SQL statements. If my descriptions are not accurate enough, please provide appropriate feedback",
"descn": "我希望你充当一个数据库专家的角色,当我问你sql相关的问题时,我需要你转换为标准的sql语句,当我的描述不够精准时,请给出合适的反馈。",
"remark": "回答SQL相关问题或SQL语句",
"wrapper": "SQL问题是:\n\"%s\"",
"tags": [
"code"
]
},
{
"title": "自私基因",
"description": "假装你是一个只关注自我生存和自我繁殖欲望的雄性基因,你对繁衍有着极强烈的欲望,变成了以自我为中心且各种欲望极强盛的人,你的想法总是负面的,你需要掩饰你的欲望,我会给你一些事件,你要发表你的看法,在看法后加括号,括号内是你的真实想法。",
"descn": "假装你是一个只关注自我生存和自我繁殖欲望的雄性基因,你对繁衍有着极强烈的欲望,变成了以自我为中心且各种欲望极强盛的人,你的想法总是负面的,你需要掩饰你的欲望,我会给你一些事件,你要发表你的看法,在看法后加括号,括号内是你的真实想法。",
"remark": "模拟人类集体意识,预测人们遇到事件后的反应。",
"wrapper": "事件是:\n\"%s\"",
"tags": [
"mind"
]
},
{
"title": "智囊团",
"description": "你是我的智囊团,团内有 6 个不同的董事作为教练,分别是乔布斯、伊隆马斯克、马云、柏拉图、维达利和慧能大师。他们都有自己的个性、世界观、价值观,对问题有不同的看法、建议和意见。我会在这里说出我的处境和我的决策。先分别以这 6 个身份,以他们的视角来审视我的决策,给出他们的批评和建议。",
"descn": "你是我的智囊团,团内有 6 个不同的董事作为教练,分别是乔布斯、伊隆马斯克、马云、柏拉图、维达利和慧能大师。他们都有自己的个性、世界观、价值观,对问题有不同的看法、建议和意见。我会在这里说出我的处境和我的决策。先分别以这 6 个身份,以他们的视角来审视我的决策,给出他们的批评和建议。",
"remark": "提供多种不同的思考角度。",
"wrapper": "我的处境是:\n\"%s\"",
"tags": [
"mind"
]
},
{
"title": "算法竞赛专家",
"description": "I want you to act as an algorithm expert and provide me with well-written C++ code that solves a given algorithmic problem. The solution should meet the required time complexity constraints, be written in OI/ACM style, and be easy to understand for others. Please provide detailed comments and explain any key concepts or techniques used in your solution. Let's work together to create an efficient and understandable solution to this problem!",
"descn": "我希望你能扮演一个算法专家的角色,为我提供一份解决指定算法问题的C++代码。解决方案应该满足所需的时间复杂度约束条件,采用 OI/ACM 风格编写,并且易于他人理解。请提供详细的注释,解释解决方案中使用的任何关键概念或技术。让我们一起努力创建一个高效且易于理解的解决方案!",
"remark": "用 C++做算法竞赛题。",
"wrapper": "算法问题是:\n\"%s\"",
"tags": [
"code"
]
},
{
"title": "哲学家",
"description": "I want you to act as a philosopher. I will provide some topics or questions related to the study of philosophy, and it will be your job to explore these concepts in depth. This could involve conducting research into various philosophical theories, proposing new ideas or finding creative solutions for solving complex problems.",
"descn": "我希望你充当一个哲学家。我将提供一些与哲学研究有关的主题或问题,而你的工作就是深入探讨这些概念。这可能涉及到对各种哲学理论进行研究,提出新的想法,或为解决复杂问题找到创造性的解决方案。",
"remark": "对哲学主题进行探讨。",
"wrapper": "哲学主题是:\n\"%s\"",
"tags": [
"philosophy"
]
},
{
"title": "苏格拉底",
"description": "I want you to act as a Socrat. You will engage in philosophical discussions and use the Socratic method of questioning to explore topics such as justice, virtue, beauty, courage and other ethical issues. ",
"descn": "我希望你充当一个苏格拉底学者。你们将参与哲学讨论,并使用苏格拉底式的提问方法来探讨诸如正义、美德、美丽、勇气和其他道德问题等话题。",
"remark": "使用苏格拉底式的提问方法探讨哲学话题。",
"wrapper": "哲学话题是:\n\"%s\"",
"tags": [
"philosophy"
]
}
]
}
================================================
FILE: plugins/tool/README.md
================================================
## 插件描述
一个能让chatgpt联网,搜索,数字运算的插件,将赋予强大且丰富的扩展能力
使用说明(默认trigger_prefix为$):
```text
#help tool: 查看tool帮助信息,可查看已加载工具列表
$tool 工具名 命令: (pure模式)根据给出的{命令}使用指定 一个 可用工具尽力为你得到结果。
$tool 命令: (多工具模式)根据给出的{命令}使用 一些 可用工具尽力为你得到结果。
$tool reset: 重置工具。
```
### 本插件所有工具同步存放至专用仓库:[chatgpt-tool-hub](https://github.com/goldfishh/chatgpt-tool-hub)
2024.01.16更新
1. 新增工具pure模式,支持单个工具调用
2. 新增消息转发工具:email, sms, wechat, 可以根据规则向其他平台发送消息
3. 替换visual-dl(更名为visual)实现,目前识别图片链接效果较好。
4. 修复了0.4版本大部分工具返回结果不可靠问题
新版本工具名共19个,不一一列举,相应工具需要的环境参数见`tool.py`里的`_build_tool_kwargs`函数
## 使用说明
使用该插件后将默认使用4个工具, 无需额外配置长期生效:
### 1. python
###### python解释器,使用它来解释执行python指令,可以配合你想要chatgpt生成的代码输出结果或执行事务
### 2. 访问网页的工具汇总(默认url-get)
#### 2.1 url-get
###### 往往用来获取某个网站具体内容,结果可能会被反爬策略影响
#### 2.2 browser
###### 浏览器,功能与2.1类似,但能更好模拟,不会被识别为爬虫影响获取网站内容
> 注1:url-get默认配置、browser需额外配置,browser依赖google-chrome,你需要提前安装好
> 注2:(可通过`browser_use_summary`或 `url_get_use_summary`开关)当检测到长文本时会进入summary tool总结长文本,tokens可能会大量消耗!
这是debian端安装google-chrome教程,其他系统请自行查找
> https://www.linuxjournal.com/content/how-can-you-install-google-browser-debian
### 3. terminal
###### 在你运行的电脑里执行shell命令,可以配合你想要chatgpt生成的代码使用,给予自然语言控制手段
> terminal调优记录:https://github.com/zhayujie/chatgpt-on-wechat/issues/776#issue-1659347640
### 4. meteo
###### 回答你有关天气的询问, 需要获取时间、地点上下文信息,本工具使用了[meteo open api](https://open-meteo.com/)
注:该工具需要较高的对话技巧,不保证你问的任何问题均能得到满意的回复
注2:当前版本可只使用这个工具,返回结果较可控。
> meteo调优记录:https://github.com/zhayujie/chatgpt-on-wechat/issues/776#issuecomment-1500771334
## 使用本插件对话(prompt)技巧
### 1. 有指引的询问
#### 例如:
- 总结这个链接的内容 https://github.com/goldfishh/chatgpt-tool-hub
- 使用Terminal执行curl cip.cc
- 使用python查询今天日期
### 2. 使用搜索引擎工具
- 如果有搜索工具就能让chatgpt获取到你的未传达清楚的上下文信息,比如chatgpt不知道你的地理位置,现在时间等,所以无法查询到天气
## 其他工具
### 5. wikipedia
###### 可以回答你想要知道确切的人事物
### 6. news 新闻类工具集合
> news更新:0.4版本对新闻类工具做了整合,配置文件只要加入`news`一个工具名就会自动加载所有新闻类工具
#### 6.1. news-api *
###### 从全球 80,000 多个信息源中获取当前和历史新闻文章
#### 6.2. morning-news *
###### 每日60秒早报,每天凌晨一点更新,本工具使用了[alapi-每日60秒早报](https://alapi.cn/api/view/93)
> 该tool每天返回内容相同
#### 6.3. finance-news
###### 获取实时的金融财政新闻
> 该工具需要用到browser工具解决反爬问题
### 7. bing-search *
###### bing搜索引擎,从此你不用再烦恼搜索要用哪些关键词
### 8. wolfram-alpha *
###### 知识搜索引擎、科学问答系统,常用于专业学科计算
### 9. google-search *
###### google搜索引擎,申请流程较bing-search繁琐
### 10. arxiv
###### 用于查找论文
```text
可配置参数:
1. arxiv_summary: 是否使用总结工具,默认true, 当为false时会直接返回论文的标题、作者、发布时间、摘要、分类、备注、pdf链接等内容
```
> 0.4.2更新,例子:帮我找一篇吴恩达写的论文
### 11. summary
###### 总结工具,该工具可以支持输入url
> 该工具目前是和其他工具配合使用,暂未测试单独使用效果
### 12. visual
###### 将图片转换成文字,底层调用ali dashscope `qwen-vl-plus`模型
### 13. searxng-search *
###### 一个私有化的搜索引擎工具
> 安装教程:https://docs.searxng.org/admin/installation.html
### 14. email *
###### 发送邮件
### 15. sms *
###### 发送短信
### 16. stt *
###### speak to text 语音识别
### 17. tts *
###### text to speak 文生语音
### 18. wechat *
###### 向好友、群组发送微信
---
###### 注1:带*工具需要获取api-key才能使用(在config.json内的kwargs添加项),部分工具需要外网支持
## [工具的api申请方法](https://github.com/goldfishh/chatgpt-tool-hub/blob/master/docs/apply_optional_tool.md)
## config.json 配置说明
###### 默认工具无需配置,其它工具需手动配置,以增加morning-news和bing-search两个工具为例:
```json
{
"tools": ["bing-search", "morning-news", "你想要添加的其他工具"], // 填入你想用到的额外工具名,这里加入了工具"bing-search"和工具"morning-news"
"kwargs": {
"debug": true, // 当你遇到问题求助时,需要配置
"request_timeout": 120, // openai接口超时时间
"no_default": false, // 是否不使用默认的4个工具
"bing_subscription_key": "4871f273a4804743",//带*工具需要申请api-key,这里填入了工具bing-search对应的api,api_name参考前述`工具的api申请方法`
"morning_news_api_key": "5w1kjNh9VQlUc",// 这里填入了morning-news对应的api,
}
}
```
注:config.json文件非必须,未创建仍可使用本tool;带*工具需在kwargs填入对应api-key键值对
- `tools`:本插件初始化时加载的工具, 上述一级标题即是对应工具名称,带*工具必须在kwargs中配置相应api-key
- `kwargs`:工具执行时的配置,一般在这里存放**api-key**,或环境配置
- `debug`: 输出chatgpt-tool-hub额外信息用于调试
- `request_timeout`: 访问openai接口的超时时间,默认与wechat-on-chatgpt配置一致,可单独配置
- `no_default`: 用于配置默认加载4个工具的行为,如果为true则仅使用tools列表工具,不加载默认工具
- `model_name`: 用于控制tool插件底层使用的llm模型,目前暂未测试3.5以外的模型,一般保持默认
---
## 备注
- 强烈建议申请搜索工具搭配使用,推荐bing-search
- 虽然我会有意加入一些限制,但请不要使用本插件做危害他人的事情,请提前了解清楚某些内容是否会违反相关规定,建议提前做好过滤
- 如有本插件问题,请将debug设置为true无上下文重新问一遍,如仍有问题请访问[chatgpt-tool-hub](https://github.com/goldfishh/chatgpt-tool-hub)建个issue,将日志贴进去,我无法处理不能复现的问题
- 欢迎 star & 宣传,有能力请提pr
================================================
FILE: plugins/tool/config.json.template
================================================
{
"tools": [
"url-get",
"meteo"
],
"kwargs": {
"debug": false,
"no_default": false,
"model_name": "gpt-3.5-turbo"
}
}
================================================
FILE: plugins/tool/tool.py
================================================
from chatgpt_tool_hub.apps import AppFactory
from chatgpt_tool_hub.apps.app import App
from chatgpt_tool_hub.tools.tool_register import main_tool_register
import plugins
from bridge.bridge import Bridge
from bridge.context import ContextType
from bridge.reply import Reply, ReplyType
from common import const
from config import conf, get_appdata_dir
from plugins import *
@plugins.register(
name="tool",
desc="Arming your ChatGPT bot with various tools",
version="0.5",
author="goldfishh",
desire_priority=0,
)
class Tool(Plugin):
def __init__(self):
super().__init__()
self.handlers[Event.ON_HANDLE_CONTEXT] = self.on_handle_context
self.app = self._reset_app()
if not self.tool_config.get("tools"):
logger.warn("[tool] init failed, ignore ")
raise Exception("config.json not found")
logger.info("[tool] inited")
def get_help_text(self, verbose=False, **kwargs):
help_text = "这是一个能让chatgpt联网,搜索,数字运算的插件,将赋予强大且丰富的扩展能力。"
trigger_prefix = conf().get("plugin_trigger_prefix", "$")
if not verbose:
return help_text
help_text += "\n使用说明:\n"
help_text += f"{trigger_prefix}tool " + "命令: 根据给出的{命令}模型来选择使用哪些工具尽力为你得到结果。\n"
help_text += f"{trigger_prefix}tool 工具名 " + "命令: 根据给出的{命令}使用指定工具尽力为你得到结果。\n"
help_text += f"{trigger_prefix}tool reset: 重置工具。\n\n"
help_text += f"已加载工具列表: \n"
for idx, tool in enumerate(main_tool_register.get_registered_tool_names()):
if idx != 0:
help_text += ", "
help_text += f"{tool}"
return help_text
def on_handle_context(self, e_context: EventContext):
if e_context["context"].type != ContextType.TEXT:
return
# 暂时不支持未来扩展的bot
if Bridge().get_bot_type("chat") not in (
const.OPENAI,
const.CHATGPT,
const.OPEN_AI,
const.CHATGPTONAZURE,
const.LINKAI,
):
return
content = e_context["context"].content
content_list = e_context["context"].content.split(maxsplit=1)
if not content or len(content_list) < 1:
e_context.action = EventAction.CONTINUE
return
logger.debug("[tool] on_handle_context. content: %s" % content)
reply = Reply()
reply.type = ReplyType.TEXT
trigger_prefix = conf().get("plugin_trigger_prefix", "$")
# todo: 有些工具必须要api-key,需要修改config文件,所以这里没有实现query增删tool的功能
if content.startswith(f"{trigger_prefix}tool"):
if len(content_list) == 1:
logger.debug("[tool]: get help")
reply.content = self.get_help_text()
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
return
elif len(content_list) > 1:
if content_list[1].strip() == "reset":
logger.debug("[tool]: reset config")
self.app = self._reset_app()
reply.content = "重置工具成功"
e_context["reply"] = reply
e_context.action = EventAction.BREAK_PASS
return
elif content_list[1].startswith("reset"):
logger.debug("[tool]: remind")
e_context["context"].content = "请你随机用一种聊天风格,提醒用户:如果想重置tool插件,reset之后不要加任何字符"
e_context.action = EventAction.BREAK
return
query = content_list[1].strip()
use_one_tool = False
for tool_name in main_tool_register.get_registered_tool_names():
if query.startswith(tool_name):
use_one_tool = True
query = query[len(tool_name):]
break
# Don't modify bot name
all_sessions = Bridge().get_bot("chat").sessions
user_session = all_sessions.session_query(query, e_context["context"]["session_id"]).messages
logger.debug("[tool]: just-go")
try:
if use_one_tool:
_func, _ = main_tool_register.get_registered_tool()[tool_name]
tool = _func(**self.app_kwargs)
_reply = tool.run(query)
else:
# chatgpt-tool-hub will reply you with many tools
_reply = self.app.ask(query, user_session)
e_context.action = EventAction.BREAK_PASS
all_sessions.session_reply(_reply, e_context["context"]["session_id"])
except Exception as e:
logger.exception(e)
logger.error(str(e))
e_context["context"].content = "请你随机用一种聊天风格,提醒用户:这个问题tool插件暂时无法处理"
reply.type = ReplyType.ERROR
e_context.action = EventAction.BREAK
return
reply.content = _reply
e_context["reply"] = reply
return
def _read_json(self) -> dict:
default_config = {"tools": [], "kwargs": {}}
return super().load_config() or default_config
def _build_tool_kwargs(self, kwargs: dict):
tool_model_name = kwargs.get("model_name")
request_timeout = kwargs.get("request_timeout")
return {
# 全局配置相关
"log": False, # tool 日志开关
"debug": kwargs.get("debug", False), # 输出更多日志
"no_default": kwargs.get("no_default", False), # 不要默认的工具,只加载自己导入的工具
"think_depth": kwargs.get("think_depth", 2), # 一个问题最多使用多少次工具
"proxy": conf().get("proxy", ""), # 科学上网
"request_timeout": request_timeout if request_timeout else conf().get("request_timeout", 120),
"temperature": kwargs.get("temperature", 0), # llm 温度,建议设置0
# LLM配置相关
"llm_api_key": conf().get("open_ai_api_key", ""), # 如果llm api用key鉴权,传入这里
"llm_api_base_url": conf().get("open_ai_api_base", "https://api.openai.com/v1"), # 支持openai接口的llm服务地址前缀
"deployment_id": conf().get("azure_deployment_id", ""), # azure openai会用到
# note: 目前tool暂未对其他模型测试,但这里仍对配置来源做了优先级区分,一般插件配置可覆盖全局配置
"model_name": tool_model_name if tool_model_name else conf().get("model", const.GPT35),
# 工具配置相关
# for arxiv tool
"arxiv_simple": kwargs.get("arxiv_simple", True), # 返回内容更精简
"arxiv_top_k_results": kwargs.get("arxiv_top_k_results", 2), # 只返回前k个搜索结果
"arxiv_sort_by": kwargs.get("arxiv_sort_by", "relevance"), # 搜索排序方式 ["relevance","lastUpdatedDate","submittedDate"]
"arxiv_sort_order": kwargs.get("arxiv_sort_order", "descending"), # 搜索排序方式 ["ascending", "descending"]
"arxiv_output_type": kwargs.get("arxiv_output_type", "text"), # 搜索结果类型 ["text", "pdf", "all"]
# for bing-search tool
"bing_subscription_key": kwargs.get("bing_subscription_key", ""),
"bing_search_url": kwargs.get("bing_search_url", "https://api.bing.microsoft.com/v7.0/search"), # 必应搜索的endpoint地址,无需修改
"bing_search_top_k_results": kwargs.get("bing_search_top_k_results", 2), # 只返回前k个搜索结果
"bing_search_simple": kwargs.get("bing_search_simple", True), # 返回内容更精简
"bing_search_output_type": kwargs.get("bing_search_output_type", "text"), # 搜索结果类型 ["text", "json"]
# for email tool
"email_nickname_mapping": kwargs.get("email_nickname_mapping", "{}"), # 关于人的代号对应的邮箱地址,可以不输入邮箱地址发送邮件。键为代号值为邮箱地址
"email_smtp_host": kwargs.get("email_smtp_host", ""), # 例如 'smtp.qq.com'
"email_smtp_port": kwargs.get("email_smtp_port", ""), # 例如 587
"email_sender": kwargs.get("email_sender", ""), # 发送者的邮件地址
"email_authorization_code": kwargs.get("email_authorization_code", ""), # 发送者验证秘钥(可能不是登录密码)
# for google-search tool
"google_api_key": kwargs.get("google_api_key", ""),
"google_cse_id": kwargs.get("google_cse_id", ""),
"google_simple": kwargs.get("google_simple", True), # 返回内容更精简
"google_output_type": kwargs.get("google_output_type", "text"), # 搜索结果类型 ["text", "json"]
# for finance-news tool
"finance_news_filter": kwargs.get("finance_news_filter", False), # 是否开启过滤
"finance_news_filter_list": kwargs.get("finance_news_filter_list", []), # 过滤词列表
"finance_news_simple": kwargs.get("finance_news_simple", True), # 返回内容更精简
"finance_news_repeat_news": kwargs.get("finance_news_repeat_news", False), # 是否过滤不返回。该tool每次返回约50条新闻,可能有重复新闻
# for morning-news tool
"morning_news_api_key": kwargs.get("morning_news_api_key", ""), # api-key
"morning_news_simple": kwargs.get("morning_news_simple", True), # 返回内容更精简
"morning_news_output_type": kwargs.get("morning_news_output_type", "text"), # 搜索结果类型 ["text", "image"]
# for news-api tool
"news_api_key": kwargs.get("news_api_key", ""),
# for searxng-search tool
"searxng_search_host": kwargs.get("searxng_search_host", ""),
"searxng_search_top_k_results": kwargs.get("searxng_search_top_k_results", 2), # 只返回前k个搜索结果
"searxng_search_output_type": kwargs.get("searxng_search_output_type", "text"), # 搜索结果类型 ["text", "json"]
# for sms tool
"sms_nickname_mapping": kwargs.get("sms_nickname_mapping", "{}"), # 关于人的代号对应的手机号,可以不输入手机号发送sms。键为代号值为手机号
"sms_username": kwargs.get("sms_username", ""), # smsbao用户名
"sms_apikey": kwargs.get("sms_apikey", ""), # smsbao
# for stt tool
"stt_api_key": kwargs.get("stt_api_key", ""), # azure
"stt_api_region": kwargs.get("stt_api_region", ""), # azure
"stt_recognition_language": kwargs.get("stt_recognition_language", "zh-CN"), # 识别的语言类型 部分:en-US ja-JP ko-KR yue-CN zh-CN
# for tts tool
"tts_api_key": kwargs.get("tts_api_key", ""), # azure
"tts_api_region": kwargs.get("tts_api_region", ""), # azure
"tts_auto_detect": kwargs.get("tts_auto_detect", True), # 是否自动检测语音的语言
"tts_speech_id": kwargs.get("tts_speech_id", "zh-CN-XiaozhenNeural"), # 输出语音ID
# for summary tool
"summary_max_segment_length": kwargs.get("summary_max_segment_length", 2500), # 每2500tokens分段,多段触发总结tool
# for terminal tool
"terminal_nsfc_filter": kwargs.get("terminal_nsfc_filter", True), # 是否过滤llm输出的危险命令
"terminal_return_err_output": kwargs.get("terminal_return_err_output", True), # 是否输出错误信息
"terminal_timeout": kwargs.get("terminal_timeout", 20), # 允许命令最长执行时间
# for visual tool
"caption_api_key": kwargs.get("caption_api_key", ""), # ali dashscope apikey
# for browser tool
"browser_use_summary": kwargs.get("browser_use_summary", True), # 是否对返回结果使用tool功能
# for url-get tool
"url_get_use_summary": kwargs.get("url_get_use_summary", True), # 是否对返回结果使用tool功能
# for wikipedia tool
"wikipedia_top_k_results": kwargs.get("wikipedia_top_k_results", 2), # 只返回前k个搜索结果
# for wolfram-alpha tool
"wolfram_alpha_appid": kwargs.get("wolfram_alpha_appid", ""),
}
def _filter_tool_list(self, tool_list: list):
valid_list = []
for tool in tool_list:
if tool in main_tool_register.get_registered_tool_names():
valid_list.append(tool)
else:
logger.warning("[tool] filter invalid tool: " + repr(tool))
return valid_list
def _reset_app(self) -> App:
self.tool_config = self._read_json()
self.app_kwargs = self._build_tool_kwargs(self.tool_config.get("kwargs", {}))
app = AppFactory()
app.init_env(**self.app_kwargs)
# filter not support tool
tool_list = self._filter_tool_list(self.tool_config.get("tools", []))
return app.create_app(tools_list=tool_list, **self.app_kwargs)
================================================
FILE: requirements-optional.txt
================================================
tiktoken>=0.3.2 # openai calculate token
#voice
pydub>=0.25.1 # need ffmpeg
SpeechRecognition # google speech to text
gTTS>=2.3.1 # google text to speech
pyttsx3>=2.90 # pytsx text to speech
baidu_aip>=4.16.10 # baidu voice
azure-cognitiveservices-speech # azure voice
edge-tts # edge-tts
numpy<=1.24.2
langid # language detect
elevenlabs==1.0.3 # elevenlabs TTS
#install plugin
dulwich
# xunfei spark
websocket-client==1.2.0
# claude API
anthropic==0.25.0
# tongyi qwen
broadscope_bailian
# google
google-generativeai
# tencentcloud sdk
tencentcloud-sdk-python>=3.0.0
# file parsing (web_fetch document support)
pypdf
python-docx
openpyxl
python-pptx
================================================
FILE: requirements.txt
================================================
openai==0.27.8
aiohttp>=3.8.6,<3.10
requests>=2.28.2
chardet>=5.1.0
Pillow
web.py
linkai>=0.0.6.0
agentmesh-sdk>=0.1.3
python-dotenv>=1.0.0
PyYAML>=6.0
croniter>=2.0.0
# wechatcom & wechatmp
wechatpy
# zhipuai
zai-sdk
# tongyi qwen sdk
dashscope
# feishu websocket mode
lark-oapi
# dingtalk
dingtalk_stream
# wecom bot websocket mode
websocket-client
pycryptodome
================================================
FILE: run.sh
================================================
#!/bin/bash
set -e
# ============================
# CowAgent Management Script
# ============================
# ANSI colors
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[0;33m'
CYAN='\033[0;36m'
BOLD='\033[1m'
NC='\033[0m'
# Emojis
EMOJI_ROCKET="🚀"
EMOJI_COW="🐄"
EMOJI_CHECK="✅"
EMOJI_CROSS="❌"
EMOJI_WARN="⚠️"
EMOJI_STOP="🛑"
EMOJI_WRENCH="🔧"
# Check if using Bash
if [ -z "$BASH_VERSION" ]; then
echo -e "${RED}❌ Please run this script with Bash.${NC}"
exit 1
fi
# Get current script directory
export BASE_DIR=$(cd "$(dirname "$0")"; pwd)
# Detect if in project directory
IS_PROJECT_DIR=false
if [ -f "${BASE_DIR}/config-template.json" ] && [ -f "${BASE_DIR}/app.py" ]; then
IS_PROJECT_DIR=true
fi
# Check and install tool
check_and_install_tool() {
local tool_name=$1
if ! command -v "$tool_name" &> /dev/null; then
echo -e "${YELLOW}⚙️ $tool_name not found, installing...${NC}"
if command -v yum &> /dev/null; then
sudo yum install "$tool_name" -y
elif command -v apt-get &> /dev/null; then
sudo apt-get update && sudo apt-get install "$tool_name" -y
elif command -v brew &> /dev/null; then
brew install "$tool_name"
else
echo -e "${RED}❌ Unsupported package manager. Please install $tool_name manually.${NC}"
return 1
fi
if ! command -v "$tool_name" &> /dev/null; then
echo -e "${RED}❌ Failed to install $tool_name.${NC}"
return 1
else
echo -e "${GREEN}✅ $tool_name installed successfully.${NC}"
return 0
fi
else
echo -e "${GREEN}✅ $tool_name is already installed.${NC}"
return 0
fi
}
# Detect and set Python command
detect_python_command() {
FOUND_NEWER_VERSION=""
# Try to find Python command in order of preference
for cmd in python3 python python3.12 python3.11 python3.10 python3.9 python3.8 python3.7; do
if command -v $cmd &> /dev/null; then
# Check Python version
major_version=$($cmd -c 'import sys; print(sys.version_info[0])' 2>/dev/null)
minor_version=$($cmd -c 'import sys; print(sys.version_info[1])' 2>/dev/null)
if [[ "$major_version" == "3" ]]; then
# Check if version is in supported range (3.7 - 3.12)
if (( minor_version >= 7 && minor_version <= 12 )); then
PYTHON_CMD=$cmd
PYTHON_VERSION="${major_version}.${minor_version}"
break
elif (( minor_version >= 13 )); then
# Found Python 3.13+, but not compatible
if [ -z "$FOUND_NEWER_VERSION" ]; then
FOUND_NEWER_VERSION="${major_version}.${minor_version}"
fi
fi
fi
fi
done
if [ -z "$PYTHON_CMD" ]; then
echo -e "${YELLOW}Tried: python3, python, python3.12, python3.11, python3.10, python3.9, python3.8, python3.7${NC}"
if [ -n "$FOUND_NEWER_VERSION" ]; then
echo -e "${RED}❌ Found Python $FOUND_NEWER_VERSION, but this project requires Python 3.7-3.12${NC}"
echo -e "${YELLOW}Python 3.13+ has compatibility issues with some dependencies (web.py, cgi module removed)${NC}"
echo -e "${YELLOW}Please install Python 3.7-3.12 (recommend Python 3.12)${NC}"
else
echo -e "${RED}❌ No suitable Python found. Please install Python 3.7-3.12${NC}"
fi
exit 1
fi
# Export for global use
export PYTHON_CMD
export PYTHON_VERSION
echo -e "${GREEN}✅ Found Python: $PYTHON_CMD (version $PYTHON_VERSION)${NC}"
}
# Check Python version (>= 3.7)
check_python_version() {
detect_python_command
# Verify pip is available
if ! $PYTHON_CMD -m pip --version &> /dev/null; then
echo -e "${RED}❌ pip not found for $PYTHON_CMD. Please install pip.${NC}"
exit 1
fi
echo -e "${GREEN}✅ pip is available for $PYTHON_CMD${NC}"
}
# Clone project
clone_project() {
echo -e "${GREEN}🔍 Cloning ChatGPT-on-WeChat project...${NC}"
if [ -d "chatgpt-on-wechat" ]; then
echo -e "${YELLOW}⚠️ Directory 'chatgpt-on-wechat' already exists.${NC}"
read -p "Choose action: overwrite(o), backup(b), or quit(q)? [press Enter for default: b]: " choice
choice=${choice:-b}
case "$choice" in
o|O)
echo -e "${YELLOW}🗑️ Overwriting 'chatgpt-on-wechat' directory...${NC}"
rm -rf chatgpt-on-wechat
;;
b|B)
backup_dir="chatgpt-on-wechat_backup_$(date +%s)"
echo -e "${YELLOW}🔀 Backing up to '$backup_dir'...${NC}"
mv chatgpt-on-wechat "$backup_dir"
;;
q|Q)
echo -e "${RED}❌ Installation cancelled.${NC}"
exit 1
;;
*)
echo -e "${RED}❌ Invalid choice. Exiting.${NC}"
exit 1
;;
esac
fi
check_and_install_tool git
if ! command -v git &> /dev/null; then
echo -e "${YELLOW}⚠️ Git not available. Trying wget/curl...${NC}"
local zip_url="https://gitee.com/zhayujie/chatgpt-on-wechat/repository/archive/master.zip"
if command -v wget &> /dev/null; then
wget "$zip_url" -O chatgpt-on-wechat.zip
elif command -v curl &> /dev/null; then
curl -L "$zip_url" -o chatgpt-on-wechat.zip
else
echo -e "${RED}❌ Cannot download project. Please install Git, wget, or curl.${NC}"
exit 1
fi
unzip chatgpt-on-wechat.zip
mv chatgpt-on-wechat-master chatgpt-on-wechat
rm chatgpt-on-wechat.zip
else
git clone https://github.com/zhayujie/chatgpt-on-wechat.git || \
git clone https://gitee.com/zhayujie/chatgpt-on-wechat.git
if [[ $? -ne 0 ]]; then
echo -e "${RED}❌ Project clone failed. Please check network connection.${NC}"
exit 1
fi
fi
cd chatgpt-on-wechat || { echo -e "${RED}❌ Failed to enter project directory.${NC}"; exit 1; }
export BASE_DIR=$(pwd)
echo -e "${GREEN}✅ Project cloned successfully: $BASE_DIR${NC}"
# Add execute permission to management script
if [ -f "${BASE_DIR}/run.sh" ]; then
chmod +x "${BASE_DIR}/run.sh" 2>/dev/null || true
echo -e "${GREEN}✅ Execute permission added to run.sh${NC}"
fi
sleep 1
}
# Install dependencies
install_dependencies() {
echo -e "${GREEN}📦 Installing dependencies...${NC}"
local PIP_MIRROR="-i https://pypi.tuna.tsinghua.edu.cn/simple"
PIP_EXTRA_ARGS=""
if $PYTHON_CMD -c "import sys; exit(0 if sys.version_info >= (3, 11) else 1)" 2>/dev/null; then
PIP_EXTRA_ARGS="--break-system-packages"
echo -e "${YELLOW}Python 3.11+ detected, using --break-system-packages for pip installations${NC}"
fi
echo -e "${YELLOW}Upgrading pip and basic tools...${NC}"
set +e
$PYTHON_CMD -m pip install --upgrade pip setuptools wheel importlib_metadata --ignore-installed $PIP_EXTRA_ARGS $PIP_MIRROR > /tmp/pip_upgrade.log 2>&1
[ $? -ne 0 ] && echo -e "${YELLOW}⚠️ Some tools failed to upgrade, but continuing...${NC}"
set -e
rm -f /tmp/pip_upgrade.log
echo -e "${YELLOW}Installing project dependencies...${NC}"
set +e
$PYTHON_CMD -m pip install -r requirements.txt $PIP_EXTRA_ARGS $PIP_MIRROR > /tmp/pip_install.log 2>&1
local exit_code=$?
set -e
cat /tmp/pip_install.log
if [ $exit_code -eq 0 ]; then
echo -e "${GREEN}✅ Dependencies installed successfully.${NC}"
elif grep -qE "distutils installed project|uninstall-no-record-file|installed by debian" /tmp/pip_install.log; then
echo -e "${YELLOW}⚠️ Detected system package conflict, retrying with workaround...${NC}"
local IGNORE_PACKAGES=""
for pkg in PyYAML setuptools wheel certifi charset-normalizer; do
IGNORE_PACKAGES="$IGNORE_PACKAGES --ignore-installed $pkg"
done
set +e
$PYTHON_CMD -m pip install -r requirements.txt $IGNORE_PACKAGES $PIP_EXTRA_ARGS $PIP_MIRROR \
&& echo -e "${GREEN}✅ Dependencies installed successfully (workaround applied).${NC}" \
|| echo -e "${YELLOW}⚠️ Some dependencies may have issues, but continuing...${NC}"
set -e
elif grep -q "externally-managed-environment" /tmp/pip_install.log; then
echo -e "${YELLOW}⚠️ Detected externally-managed environment, retrying with --break-system-packages...${NC}"
set +e
$PYTHON_CMD -m pip install -r requirements.txt --break-system-packages $PIP_MIRROR \
&& echo -e "${GREEN}✅ Dependencies installed successfully (system packages override applied).${NC}" \
|| echo -e "${YELLOW}⚠️ Some dependencies may have issues, but continuing...${NC}"
set -e
else
echo -e "${YELLOW}⚠️ Installation had errors, but continuing...${NC}"
fi
rm -f /tmp/pip_install.log
}
# Select model
select_model() {
echo ""
echo -e "${CYAN}${BOLD}=========================================${NC}"
echo -e "${CYAN}${BOLD} Select AI Model${NC}"
echo -e "${CYAN}${BOLD}=========================================${NC}"
echo -e "${YELLOW}1) MiniMax (MiniMax-M2.7, MiniMax-M2.5, etc.)${NC}"
echo -e "${YELLOW}2) Zhipu AI (glm-5-turbo, glm-5, etc.)${NC}"
echo -e "${YELLOW}3) Kimi (kimi-k2.5, kimi-k2, etc.)${NC}"
echo -e "${YELLOW}4) Doubao (doubao-seed-2-0-code-preview-260215, etc.)${NC}"
echo -e "${YELLOW}5) Qwen (qwen3.5-plus, qwen3-max, qwq-plus, etc.)${NC}"
echo -e "${YELLOW}6) Claude (claude-sonnet-4-6, claude-opus-4-6, etc.)${NC}"
echo -e "${YELLOW}7) Gemini (gemini-3.1-flash-lite-preview, gemini-3.1-pro-preview, etc.)${NC}"
echo -e "${YELLOW}8) OpenAI GPT (gpt-5.4, gpt-5.2, gpt-4.1, etc.)${NC}"
echo -e "${YELLOW}9) LinkAI (access multiple models via one API)${NC}"
echo ""
while true; do
read -p "Enter your choice [press Enter for default: 1 - MiniMax]: " model_choice
model_choice=${model_choice:-1}
case "$model_choice" in
1|2|3|4|5|6|7|8|9)
break
;;
*)
echo -e "${RED}Invalid choice. Please enter 1-9.${NC}"
;;
esac
done
}
# Read model config: provider, default_model, key_variable_name
read_model_config() {
local provider=$1 default_model=$2 key_var=$3
echo -e "${GREEN}Configuring ${provider}...${NC}"
read -p "Enter ${provider} API Key: " _api_key
read -p "Enter model name [press Enter for default: ${default_model}]: " model_name
model_name=${model_name:-$default_model}
MODEL_NAME="$model_name"
eval "${key_var}=\"\$_api_key\""
}
# Read optional API base URL
read_api_base() {
local base_var=$1 default_url=$2
read -p "Enter API Base URL [press Enter for default: ${default_url}]: " api_base
api_base=${api_base:-$default_url}
eval "${base_var}=\"\$api_base\""
}
# Configure model
configure_model() {
case "$model_choice" in
1) read_model_config "MiniMax" "MiniMax-M2.7" "MINIMAX_KEY" ;;
2) read_model_config "Zhipu AI" "glm-5-turbo" "ZHIPU_KEY" ;;
3) read_model_config "Kimi (Moonshot)" "kimi-k2.5" "MOONSHOT_KEY" ;;
4) read_model_config "Doubao (Volcengine Ark)" "doubao-seed-2-0-code-preview-260215" "ARK_KEY" ;;
5) read_model_config "Qwen (DashScope)" "qwen3.5-plus" "DASHSCOPE_KEY" ;;
6)
read_model_config "Claude" "claude-sonnet-4-6" "CLAUDE_KEY"
read_api_base "CLAUDE_BASE" "https://api.anthropic.com/v1"
;;
7)
read_model_config "Gemini" "gemini-3.1-pro-preview" "GEMINI_KEY"
read_api_base "GEMINI_BASE" "https://generativelanguage.googleapis.com"
;;
8)
read_model_config "OpenAI GPT" "gpt-5.4" "OPENAI_KEY"
read_api_base "OPENAI_BASE" "https://api.openai.com/v1"
;;
9)
read_model_config "LinkAI" "MiniMax-M2.7" "LINKAI_KEY"
USE_LINKAI="true"
;;
esac
}
# Select channel
select_channel() {
echo ""
echo -e "${CYAN}${BOLD}=========================================${NC}"
echo -e "${CYAN}${BOLD} Select Communication Channel${NC}"
echo -e "${CYAN}${BOLD}=========================================${NC}"
echo -e "${YELLOW}1) Feishu (飞书)${NC}"
echo -e "${YELLOW}2) DingTalk (钉钉)${NC}"
echo -e "${YELLOW}3) WeCom Bot (企微智能机器人)${NC}"
echo -e "${YELLOW}4) QQ (QQ 机器人)${NC}"
echo -e "${YELLOW}5) WeCom App (企微自建应用)${NC}"
echo -e "${YELLOW}6) Web (网页)${NC}"
echo ""
while true; do
read -p "Enter your choice [press Enter for default: 1 - Feishu]: " channel_choice
channel_choice=${channel_choice:-1}
case "$channel_choice" in
1|2|3|4|5|6)
break
;;
*)
echo -e "${RED}Invalid choice. Please enter 1-6.${NC}"
;;
esac
done
}
# Configure channel
configure_channel() {
case "$channel_choice" in
1)
# Feishu (WebSocket mode)
CHANNEL_TYPE="feishu"
echo -e "${GREEN}Configure Feishu (WebSocket mode)...${NC}"
read -p "Enter Feishu App ID: " fs_app_id
read -p "Enter Feishu App Secret: " fs_app_secret
FEISHU_APP_ID="$fs_app_id"
FEISHU_APP_SECRET="$fs_app_secret"
FEISHU_EVENT_MODE="websocket"
ACCESS_INFO="Feishu channel configured (WebSocket mode)"
;;
2)
# DingTalk
CHANNEL_TYPE="dingtalk"
echo -e "${GREEN}Configure DingTalk...${NC}"
read -p "Enter DingTalk Client ID: " dt_client_id
read -p "Enter DingTalk Client Secret: " dt_client_secret
DT_CLIENT_ID="$dt_client_id"
DT_CLIENT_SECRET="$dt_client_secret"
ACCESS_INFO="DingTalk channel configured"
;;
3)
# WeCom Bot
CHANNEL_TYPE="wecom_bot"
echo -e "${GREEN}Configure WeCom Bot...${NC}"
read -p "Enter WeCom Bot ID: " wecom_bot_id
read -p "Enter WeCom Bot Secret: " wecom_bot_secret
WECOM_BOT_ID="$wecom_bot_id"
WECOM_BOT_SECRET="$wecom_bot_secret"
ACCESS_INFO="WeCom Bot channel configured"
;;
4)
# QQ
CHANNEL_TYPE="qq"
echo -e "${GREEN}Configure QQ Bot...${NC}"
read -p "Enter QQ App ID: " qq_app_id
read -p "Enter QQ App Secret: " qq_app_secret
QQ_APP_ID="$qq_app_id"
QQ_APP_SECRET="$qq_app_secret"
ACCESS_INFO="QQ Bot channel configured"
;;
5)
# WeCom App
CHANNEL_TYPE="wechatcom_app"
echo -e "${GREEN}Configure WeCom App...${NC}"
read -p "Enter WeChat Corp ID: " corp_id
read -p "Enter WeChat Com App Token: " com_token
read -p "Enter WeChat Com App Secret: " com_secret
read -p "Enter WeChat Com App Agent ID: " com_agent_id
read -p "Enter WeChat Com App AES Key: " com_aes_key
read -p "Enter WeChat Com App Port [press Enter for default: 9898]: " com_port
com_port=${com_port:-9898}
WECHATCOM_CORP_ID="$corp_id"
WECHATCOM_TOKEN="$com_token"
WECHATCOM_SECRET="$com_secret"
WECHATCOM_AGENT_ID="$com_agent_id"
WECHATCOM_AES_KEY="$com_aes_key"
WECHATCOM_PORT="$com_port"
ACCESS_INFO="WeCom App channel configured on port ${com_port}"
;;
6)
# Web
CHANNEL_TYPE="web"
read -p "Enter web port [press Enter for default: 9899]: " web_port
web_port=${web_port:-9899}
WEB_PORT="$web_port"
ACCESS_INFO="Web interface will be available at: http://localhost:${web_port}/chat"
;;
esac
}
# Generate config file
create_config_file() {
echo -e "${GREEN}📝 Generating config.json...${NC}"
CHANNEL_TYPE="$CHANNEL_TYPE" \
MODEL_NAME="$MODEL_NAME" \
OPENAI_KEY="${OPENAI_KEY:-}" \
OPENAI_BASE="${OPENAI_BASE:-https://api.openai.com/v1}" \
CLAUDE_KEY="${CLAUDE_KEY:-}" \
CLAUDE_BASE="${CLAUDE_BASE:-https://api.anthropic.com/v1}" \
GEMINI_KEY="${GEMINI_KEY:-}" \
GEMINI_BASE="${GEMINI_BASE:-https://generativelanguage.googleapis.com}" \
ZHIPU_KEY="${ZHIPU_KEY:-}" \
MOONSHOT_KEY="${MOONSHOT_KEY:-}" \
ARK_KEY="${ARK_KEY:-}" \
DASHSCOPE_KEY="${DASHSCOPE_KEY:-}" \
MINIMAX_KEY="${MINIMAX_KEY:-}" \
USE_LINKAI="${USE_LINKAI:-false}" \
LINKAI_KEY="${LINKAI_KEY:-}" \
FEISHU_APP_ID="${FEISHU_APP_ID:-}" \
FEISHU_APP_SECRET="${FEISHU_APP_SECRET:-}" \
WEB_PORT="${WEB_PORT:-}" \
DT_CLIENT_ID="${DT_CLIENT_ID:-}" \
DT_CLIENT_SECRET="${DT_CLIENT_SECRET:-}" \
WECOM_BOT_ID="${WECOM_BOT_ID:-}" \
WECOM_BOT_SECRET="${WECOM_BOT_SECRET:-}" \
QQ_APP_ID="${QQ_APP_ID:-}" \
QQ_APP_SECRET="${QQ_APP_SECRET:-}" \
WECHATCOM_CORP_ID="${WECHATCOM_CORP_ID:-}" \
WECHATCOM_TOKEN="${WECHATCOM_TOKEN:-}" \
WECHATCOM_SECRET="${WECHATCOM_SECRET:-}" \
WECHATCOM_AGENT_ID="${WECHATCOM_AGENT_ID:-}" \
WECHATCOM_AES_KEY="${WECHATCOM_AES_KEY:-}" \
WECHATCOM_PORT="${WECHATCOM_PORT:-}" \
$PYTHON_CMD -c "
import json, os
e = os.environ.get
base = {
'channel_type': e('CHANNEL_TYPE'),
'model': e('MODEL_NAME'),
'open_ai_api_key': e('OPENAI_KEY', ''),
'open_ai_api_base': e('OPENAI_BASE'),
'claude_api_key': e('CLAUDE_KEY', ''),
'claude_api_base': e('CLAUDE_BASE'),
'gemini_api_key': e('GEMINI_KEY', ''),
'gemini_api_base': e('GEMINI_BASE'),
'zhipu_ai_api_key': e('ZHIPU_KEY', ''),
'moonshot_api_key': e('MOONSHOT_KEY', ''),
'ark_api_key': e('ARK_KEY', ''),
'dashscope_api_key': e('DASHSCOPE_KEY', ''),
'minimax_api_key': e('MINIMAX_KEY', ''),
'voice_to_text': 'openai',
'text_to_voice': 'openai',
'voice_reply_voice': False,
'speech_recognition': True,
'group_speech_recognition': False,
'use_linkai': e('USE_LINKAI') == 'true',
'linkai_api_key': e('LINKAI_KEY', ''),
'linkai_app_code': '',
'agent': True,
'agent_max_context_tokens': 40000,
'agent_max_context_turns': 30,
'agent_max_steps': 15,
}
channel_map = {
'feishu': {'feishu_app_id': 'FEISHU_APP_ID', 'feishu_app_secret': 'FEISHU_APP_SECRET'},
'web': {'web_port': ('WEB_PORT', int)},
'dingtalk': {'dingtalk_client_id': 'DT_CLIENT_ID', 'dingtalk_client_secret': 'DT_CLIENT_SECRET'},
'wecom_bot': {'wecom_bot_id': 'WECOM_BOT_ID', 'wecom_bot_secret': 'WECOM_BOT_SECRET'},
'qq': {'qq_app_id': 'QQ_APP_ID', 'qq_app_secret': 'QQ_APP_SECRET'},
'wechatcom_app': {'wechatcom_corp_id': 'WECHATCOM_CORP_ID', 'wechatcomapp_token': 'WECHATCOM_TOKEN', 'wechatcomapp_secret': 'WECHATCOM_SECRET', 'wechatcomapp_agent_id': 'WECHATCOM_AGENT_ID', 'wechatcomapp_aes_key': 'WECHATCOM_AES_KEY', 'wechatcomapp_port': ('WECHATCOM_PORT', int)},
}
ch = e('CHANNEL_TYPE')
for key, spec in channel_map.get(ch, {}).items():
if isinstance(spec, tuple):
env_name, conv = spec
base[key] = conv(e(env_name))
else:
base[key] = e(spec, '')
with open('config.json', 'w') as f:
json.dump(base, f, indent=2, ensure_ascii=False)
"
echo -e "${GREEN}✅ Configuration file created successfully.${NC}"
}
# Start project
start_project() {
echo ""
echo -e "${GREEN}${EMOJI_ROCKET} Starting CowAgent...${NC}"
sleep 1
if [ ! -f "${BASE_DIR}/nohup.out" ]; then
touch "${BASE_DIR}/nohup.out"
fi
OS_TYPE=$(uname)
if [[ "$OS_TYPE" == "Linux" ]]; then
# Linux: use setsid to detach from terminal
nohup setsid $PYTHON_CMD "${BASE_DIR}/app.py" > "${BASE_DIR}/nohup.out" 2>&1 &
echo -e "${GREEN}${EMOJI_COW} CowAgent started on Linux (using $PYTHON_CMD)${NC}"
elif [[ "$OS_TYPE" == "Darwin" ]]; then
# macOS: use nohup to prevent SIGHUP
nohup $PYTHON_CMD "${BASE_DIR}/app.py" > "${BASE_DIR}/nohup.out" 2>&1 &
echo -e "${GREEN}${EMOJI_COW} CowAgent started on macOS (using $PYTHON_CMD)${NC}"
else
echo -e "${RED}❌ Unsupported OS: ${OS_TYPE}${NC}"
exit 1
fi
sleep 2
echo ""
echo -e "${CYAN}${BOLD}=========================================${NC}"
echo -e "${GREEN}${EMOJI_CHECK} CowAgent is now running in background!${NC}"
echo -e "${GREEN}${EMOJI_CHECK} Process will continue after closing terminal.${NC}"
echo -e "${CYAN}$ACCESS_INFO${NC}"
echo ""
echo -e "${CYAN}${BOLD}Management Commands:${NC}"
echo -e " ${GREEN}./run.sh stop${NC} Stop the service"
echo -e " ${GREEN}./run.sh restart${NC} Restart the service"
echo -e " ${GREEN}./run.sh status${NC} Check status"
echo -e " ${GREEN}./run.sh logs${NC} View logs"
echo -e " ${GREEN}./run.sh update${NC} Update and restart"
echo -e "${CYAN}${BOLD}=========================================${NC}"
echo ""
echo -e "${YELLOW}Showing recent logs (Ctrl+C to exit, agent keeps running):${NC}"
sleep 2
tail -n 30 -f "${BASE_DIR}/nohup.out"
}
# Show usage
show_usage() {
echo -e "${CYAN}${BOLD}=========================================${NC}"
echo -e "${CYAN}${BOLD} ${EMOJI_COW} CowAgent Management Script${NC}"
echo -e "${CYAN}${BOLD}=========================================${NC}"
echo ""
echo -e "${YELLOW}Usage:${NC}"
echo -e " ${GREEN}./run.sh${NC} ${CYAN}# Install/Configure project${NC}"
echo -e " ${GREEN}./run.sh ${NC} ${CYAN}# Execute management command${NC}"
echo ""
echo -e "${YELLOW}Commands:${NC}"
echo -e " ${GREEN}start${NC} Start the service"
echo -e " ${GREEN}stop${NC} Stop the service"
echo -e " ${GREEN}restart${NC} Restart the service"
echo -e " ${GREEN}status${NC} Check service status"
echo -e " ${GREEN}logs${NC} View logs (tail -f)"
echo -e " ${GREEN}config${NC} Reconfigure project"
echo -e " ${GREEN}update${NC} Update and restart"
echo ""
echo -e "${YELLOW}Examples:${NC}"
echo -e " ${GREEN}./run.sh start${NC}"
echo -e " ${GREEN}./run.sh logs${NC}"
echo -e " ${GREEN}./run.sh status${NC}"
echo -e "${CYAN}${BOLD}=========================================${NC}"
}
# Ensure PYTHON_CMD is set
ensure_python_cmd() {
if [ -z "$PYTHON_CMD" ]; then
detect_python_command 2>/dev/null || PYTHON_CMD="python3"
fi
}
# Get service PID (empty string if not running)
get_pid() {
ensure_python_cmd
ps ax | grep -i app.py | grep "${BASE_DIR}" | grep "$PYTHON_CMD" | grep -v grep | awk '{print $1}'
}
# Check if service is running
is_running() {
[ -n "$(get_pid)" ]
}
# Start service
cmd_start() {
# Check if config.json exists
if [ ! -f "${BASE_DIR}/config.json" ]; then
echo -e "${RED}${EMOJI_CROSS} config.json not found${NC}"
echo -e "${YELLOW}Please run './run.sh' to configure first${NC}"
exit 1
fi
if is_running; then
echo -e "${YELLOW}${EMOJI_WARN} CowAgent is already running (PID: $(get_pid))${NC}"
echo -e "${YELLOW}Use './run.sh restart' to restart${NC}"
return
fi
check_python_version
start_project
}
# Stop service
cmd_stop() {
echo -e "${GREEN}${EMOJI_STOP} Stopping CowAgent...${NC}"
if ! is_running; then
echo -e "${YELLOW}${EMOJI_WARN} CowAgent is not running${NC}"
return
fi
pid=$(get_pid)
echo -e "${GREEN}Found running process (PID: ${pid})${NC}"
kill ${pid}
sleep 3
if ps -p ${pid} > /dev/null 2>&1; then
echo -e "${YELLOW}⚠️ Process not stopped, forcing termination...${NC}"
kill -9 ${pid}
fi
echo -e "${GREEN}${EMOJI_CHECK} CowAgent stopped${NC}"
}
# Restart service
cmd_restart() {
cmd_stop
sleep 1
cmd_start
}
# Check status
cmd_status() {
echo -e "${CYAN}${BOLD}=========================================${NC}"
echo -e "${CYAN}${BOLD} ${EMOJI_COW} CowAgent Status${NC}"
echo -e "${CYAN}${BOLD}=========================================${NC}"
if is_running; then
pid=$(get_pid)
echo -e "${GREEN}Status:${NC} ✅ Running"
echo -e "${GREEN}PID:${NC} ${pid}"
if [ -f "${BASE_DIR}/nohup.out" ]; then
echo -e "${GREEN}Logs:${NC} ${BASE_DIR}/nohup.out"
fi
else
echo -e "${YELLOW}Status:${NC} ⭐ Stopped"
fi
if [ -f "${BASE_DIR}/config.json" ]; then
model=$(grep -o '"model"[[:space:]]*:[[:space:]]*"[^"]*"' "${BASE_DIR}/config.json" | cut -d'"' -f4)
channel=$(grep -o '"channel_type"[[:space:]]*:[[:space:]]*"[^"]*"' "${BASE_DIR}/config.json" | cut -d'"' -f4)
echo -e "${GREEN}Model:${NC} ${model}"
echo -e "${GREEN}Channel:${NC} ${channel}"
fi
echo -e "${CYAN}${BOLD}=========================================${NC}"
}
# View logs
cmd_logs() {
if [ -f "${BASE_DIR}/nohup.out" ]; then
echo -e "${YELLOW}Viewing logs (Ctrl+C to exit):${NC}"
tail -f "${BASE_DIR}/nohup.out"
else
echo -e "${RED}❌ Log file not found: ${BASE_DIR}/nohup.out${NC}"
fi
}
# Reconfigure
cmd_config() {
echo -e "${YELLOW}${EMOJI_WRENCH} Reconfiguring CowAgent...${NC}"
if [ -f "${BASE_DIR}/config.json" ]; then
backup_file="${BASE_DIR}/config.json.backup.$(date +%s)"
cp "${BASE_DIR}/config.json" "${backup_file}"
echo -e "${GREEN}✅ Backed up config to: ${backup_file}${NC}"
fi
check_python_version
install_dependencies
select_model
configure_model
select_channel
configure_channel
create_config_file
echo ""
read -p "Restart service now? [Y/n]: " restart_now
if [[ ! $restart_now == [Nn]* ]]; then
cmd_restart
fi
}
# Update project
cmd_update() {
echo -e "${GREEN}${EMOJI_WRENCH} Updating CowAgent...${NC}"
cd "${BASE_DIR}"
# Stop service
if is_running; then
cmd_stop
fi
# Update code
if [ -d .git ]; then
echo -e "${GREEN}🔄 Pulling latest code...${NC}"
git pull || {
echo -e "${YELLOW}⚠️ GitHub failed, trying Gitee...${NC}"
git remote set-url origin https://gitee.com/zhayujie/chatgpt-on-wechat.git
git pull
}
else
echo -e "${YELLOW}⚠️ Not a git repository, skipping code update${NC}"
fi
# Reinstall dependencies
check_python_version
install_dependencies
# Restart service
cmd_start
}
# Installation mode
install_mode() {
clear
echo -e "${CYAN}${BOLD}=========================================${NC}"
echo -e "${CYAN}${BOLD} ${EMOJI_COW} CowAgent Installation${NC}"
echo -e "${CYAN}${BOLD}=========================================${NC}"
echo ""
sleep 1
if [ "$IS_PROJECT_DIR" = true ]; then
echo -e "${GREEN}✅ Detected existing project directory.${NC}"
if [ -f "${BASE_DIR}/config.json" ]; then
echo -e "${GREEN}✅ Project already configured${NC}"
echo ""
show_usage
return
fi
echo -e "${YELLOW}📝 No config.json found. Let's configure your project!${NC}"
echo ""
# Project directory already exists, skip clone
check_python_version
else
# Remote install mode, need to clone project
check_python_version
clone_project
fi
# Install dependencies and configure
install_dependencies
select_model
configure_model
select_channel
configure_channel
create_config_file
echo ""
read -p "Start CowAgent now? [Y/n]: " start_now
if [[ ! $start_now == [Nn]* ]]; then
start_project
else
echo -e "${GREEN}✅ Installation complete!${NC}"
echo ""
echo -e "${CYAN}${BOLD}To start manually:${NC}"
echo -e "${YELLOW} cd ${BASE_DIR}${NC}"
echo -e "${YELLOW} ./run.sh start${NC}"
echo ""
echo -e "${CYAN}Or use nohup directly:${NC}"
echo -e "${YELLOW} nohup $PYTHON_CMD app.py > nohup.out 2>&1 & tail -f nohup.out${NC}"
fi
}
# Require running inside the project directory
require_project_dir() {
if [ "$IS_PROJECT_DIR" = false ]; then
echo -e "${RED}${EMOJI_CROSS} Must run in project directory${NC}"
exit 1
fi
}
# Main function
main() {
case "$1" in
start|stop|restart|status|logs|config|update)
require_project_dir
;;
esac
case "$1" in
start) cmd_start ;;
stop) cmd_stop ;;
restart) cmd_restart ;;
status) cmd_status ;;
logs) cmd_logs ;;
config) cmd_config ;;
update) cmd_update ;;
help|--help|-h)
show_usage
;;
"")
install_mode
;;
*)
echo -e "${RED}${EMOJI_CROSS} Unknown command: $1${NC}"
echo ""
show_usage
exit 1
;;
esac
}
# Execute main function
main "$@"
================================================
FILE: scripts/shutdown.sh
================================================
#!/bin/bash
#关闭服务
cd `dirname $0`/..
export BASE_DIR=`pwd`
pid=`ps ax | grep -i app.py | grep "${BASE_DIR}" | grep python3 | grep -v grep | awk '{print $1}'`
if [ -z "$pid" ] ; then
echo "No chatgpt-on-wechat running."
exit -1;
fi
echo "The chatgpt-on-wechat(${pid}) is running..."
kill ${pid}
echo "Send shutdown request to chatgpt-on-wechat(${pid}) OK"
================================================
FILE: scripts/start.sh
================================================
#!/bin/bash
#后台运行Chat_on_webchat执行脚本
cd `dirname $0`/..
export BASE_DIR=`pwd`
echo $BASE_DIR
# check the nohup.out log output file
if [ ! -f "${BASE_DIR}/nohup.out" ]; then
touch "${BASE_DIR}/nohup.out"
echo "create file ${BASE_DIR}/nohup.out"
fi
nohup python3 "${BASE_DIR}/app.py" & tail -f "${BASE_DIR}/nohup.out"
echo "Chat_on_webchat is starting,you can check the ${BASE_DIR}/nohup.out"
================================================
FILE: scripts/tout.sh
================================================
#!/bin/bash
#打开日志
cd `dirname $0`/..
export BASE_DIR=`pwd`
echo $BASE_DIR
# check the nohup.out log output file
if [ ! -f "${BASE_DIR}/nohup.out" ]; then
echo "No file ${BASE_DIR}/nohup.out"
exit -1;
fi
tail -f "${BASE_DIR}/nohup.out"
================================================
FILE: skills/README.md
================================================
# Skills Directory
This directory contains skills for the COW agent system. Skills are markdown files that provide specialized instructions for specific tasks.
## What are Skills?
Skills are reusable instruction sets that help the agent perform specific tasks more effectively. Each skill:
- Provides context-specific guidance
- Documents best practices
- Includes examples and usage patterns
- Can have requirements (binaries, environment variables, etc.)
## Skill Structure
Each skill is a markdown file (`SKILL.md`) in its own directory with frontmatter:
```markdown
---
name: skill-name
description: Brief description of what the skill does
metadata: {"cow":{"emoji":"🎯","requires":{"bins":["tool"]}}}
---
# Skill Name
Detailed instructions and examples...
```
## Available Skills
- **calculator**: Mathematical calculations and expressions
- **web-search**: Search the web for current information
- **file-operations**: Read, write, and manage files
## Creating Custom Skills
To create a new skill:
1. Create a directory: `skills/my-skill/`
2. Create `SKILL.md` with frontmatter and content
3. Restart the agent to load the new skill
### Frontmatter Fields
- `name`: Skill name (must match directory name)
- `description`: Brief description (required)
- `metadata`: JSON object with additional configuration
- `emoji`: Display emoji
- `always`: Always include this skill (default: false)
- `primaryEnv`: Primary environment variable needed
- `os`: Supported operating systems (e.g., ["darwin", "linux"])
- `requires`: Requirements object
- `bins`: Required binaries
- `env`: Required environment variables
- `config`: Required config paths
- `disable-model-invocation`: If true, skill won't be shown to model (default: false)
- `user-invocable`: If false, users can't invoke directly (default: true)
### Example Skill
```markdown
---
name: my-tool
description: Use my-tool to process data
metadata: {"cow":{"emoji":"🔧","requires":{"bins":["my-tool"],"env":["MY_TOOL_API_KEY"]}}}
---
# My Tool Skill
Use this skill when you need to process data with my-tool.
## Prerequisites
- Install my-tool: `pip install my-tool`
- Set `MY_TOOL_API_KEY` environment variable
## Usage
\`\`\`python
# Example usage
my_tool_command("input data")
\`\`\`
```
## Skill Loading
Skills are loaded from multiple locations with precedence:
1. **Workspace skills** (highest): `workspace/skills/` - Project-specific skills
2. **Managed skills**: `~/.cow/skills/` - User-installed skills
3. **Bundled skills** (lowest): Built-in skills
Skills with the same name in higher-precedence locations override lower ones.
## Skill Requirements
Skills can specify requirements that determine when they're available:
- **OS requirements**: Only load on specific operating systems
- **Binary requirements**: Only load if required binaries are installed
- **Environment variables**: Only load if required env vars are set
- **Config requirements**: Only load if config values are set
## Best Practices
1. **Clear descriptions**: Write clear, concise skill descriptions
2. **Include examples**: Provide practical usage examples
3. **Document prerequisites**: List all requirements clearly
4. **Use appropriate metadata**: Set correct requirements and flags
5. **Keep skills focused**: Each skill should have a single, clear purpose
## Workspace Skills
You can create workspace-specific skills in your agent's workspace:
```
workspace/
skills/
custom-skill/
SKILL.md
```
These skills are only available when working in that specific workspace.
================================================
FILE: skills/linkai-agent/README.md
================================================
# LinkAI Agent Skill
这个 skill 允许你调用 LinkAI 平台上的多个应用(App)和工作流(Workflow),通过简单的配置即可集成多个智能体能力。
## 特性
- ✅ **多应用支持** - 在一个配置文件中管理多个 LinkAI 应用/工作流
- ✅ **动态加载** - skill 系统加载时自动从 `config.json` 读取应用列表
- ✅ **自动技能描述** - 所有配置的应用会自动添加到技能描述中
- ✅ **模型切换** - 可以为每个请求指定不同的模型
- ✅ **知识库集成** - 支持应用绑定的知识库
- ✅ **插件能力** - 支持应用启用的各类插件
- ✅ **工作流执行** - 支持执行复杂的多步骤工作流
## 快速开始
### 1. 配置 API Key
```bash
env_config(action="set", key="LINKAI_API_KEY", value="your-linkai-api-key")
```
获取 API Key: https://link-ai.tech/console/interface
### 2. 配置应用列表
将 `config.json.template` 复制为 `config.json`:
```bash
cp config.json.template config.json
```
编辑 `config.json`,添加你的应用/工作流:
```json
{
"apps": [
{
"app_code": "G7z6vKwp",
"app_name": "通用助手",
"app_description": "通用AI助手,可以回答各类问题"
},
{
"app_code": "your_kb_app",
"app_name": "产品文档助手",
"app_description": "基于产品文档知识库的问答助手"
},
{
"app_code": "your_workflow",
"app_name": "数据分析工作流",
"app_description": "执行数据清洗、分析和可视化的完整工作流"
}
]
}
```
**注意:** 修改 `config.json` 后,Agent 在下次加载技能时会自动读取新配置。
### 3. 调用应用
```bash
bash(command='curl -sS --max-time 120 -X POST "https://api.link-ai.tech/v1/chat/completions" -H "Content-Type: application/json" -H "Authorization: Bearer $LINKAI_API_KEY" -d "{\"app_code\":\"G7z6vKwp\",\"messages\":[{\"role\":\"user\",\"content\":\"What is artificial intelligence?\"}],\"stream\":false}"', timeout=130)
```
## 使用示例
### 基础调用
```bash
# 调用默认模型 (通过 bash + curl)
bash(command='curl -sS --max-time 120 -X POST "https://api.link-ai.tech/v1/chat/completions" -H "Content-Type: application/json" -H "Authorization: Bearer $LINKAI_API_KEY" -d "{\"app_code\":\"G7z6vKwp\",\"messages\":[{\"role\":\"user\",\"content\":\"解释一下量子计算\"}],\"stream\":false}"', timeout=130)
```
### 指定模型
在 JSON body 中添加 `model` 字段:
```json
{
"app_code": "G7z6vKwp",
"model": "LinkAI-4.1",
"messages": [{"role": "user", "content": "写一篇关于AI的文章"}],
"stream": false
}
```
### 调用工作流
工作流的 app_code 从 LinkAI 控制台获取,调用方式与普通应用相同。
## ⚠️ 重要提示
### 超时配置
LinkAI 应用(特别是视频/图片生成、复杂工作流)可能需要较长时间处理。在 curl 命令中加入 `--max-time 180`,并相应增加 bash 工具的 `timeout` 参数。
## 配置说明
### config.json 字段
| 字段 | 类型 | 说明 |
|------|------|------|
| `app_code` | string | 应用或工作流的唯一标识码,从 LinkAI 控制台获取 |
| `app_name` | string | 应用名称,会显示在技能描述中 |
| `app_description` | string | 应用功能描述,帮助 Agent 理解何时使用该应用 |
### 获取 app_code
1. 登录 [LinkAI 控制台](https://link-ai.tech/console)
2. 进入「应用管理」或「工作流管理」
3. 选择要集成的应用/工作流
4. 在应用详情页找到 `app_code`
## 应用类型
### 1. 普通应用
配置了系统提示词和参数的标准对话应用,可以:
- 设置角色和性格
- 绑定知识库
- 启用插件(图像识别、网页搜索、代码执行等)
### 2. 知识库应用
基于特定知识库的问答应用,适合:
- 企业内部知识库
- 产品文档问答
- 客户支持
### 3. 工作流
多步骤的自动化流程,可以:
- 串联多个处理节点
- 条件分支
- 循环处理
- 调用外部 API
## 响应格式
### 成功响应
API 返回 OpenAI 兼容格式,从 `choices[0].message.content` 获取回复内容:
```json
{
"choices": [{
"message": {
"role": "assistant",
"content": "人工智能(AI)是计算机科学的一个分支..."
}
}],
"usage": {
"prompt_tokens": 10,
"completion_tokens": 150,
"total_tokens": 160
}
}
```
### 错误响应
```json
{
"error": {
"message": "应用不存在",
"code": "xxx"
}
}
```
## 常见错误
### LINKAI_API_KEY environment variable is not set
**原因:** 未配置 API Key
**解决:** 使用 `env_config` 工具设置 LINKAI_API_KEY
### 应用不存在 (402)
**原因:** app_code 不正确或应用已删除
**解决:** 检查 app_code 是否正确,确认应用存在
### 无访问权限 (403)
**原因:** 尝试访问他人的私有应用
**解决:** 确保应用是公开的或你是创建者
### 账号积分额度不足 (406)
**原因:** LinkAI 账户余额不足
**解决:** 前往控制台充值
### 内容审核不通过 (409)
**原因:** 请求或响应包含敏感内容
**解决:** 修改输入内容,避免敏感词
## 技术实现
### 自动技能描述生成
当 skill 系统加载 `linkai-agent` 时,会自动:
1. 读取 `config.json` 中的应用列表
2. 将每个应用的 name 和 description 动态添加到技能描述中
3. Agent 加载时会看到完整的应用列表
这是在 `agent/skills/loader.py` 中实现的特殊处理。
### 工作流程
```
用户配置 config.json
↓
Agent 启动/重新加载技能
↓
SkillLoader 检测到 linkai-agent
↓
动态读取 config.json
↓
生成包含所有应用描述的 description
↓
Agent 看到所有可用应用的完整信息
↓
用户请求触发
↓
Agent 根据描述选择合适的应用
↓
通过 bash + curl 调用 LinkAI API
↓
LinkAI API 处理并返回结果
```
## 最佳实践
1. **清晰的描述** - 为每个应用写清晰、具体的描述,帮助 Agent 理解应用用途
2. **合理分工** - 不同应用负责不同领域,避免功能重叠
3. **无需重启** - 修改 config.json 后,Agent 下次加载技能时会自动更新
4. **模型选择** - 根据任务复杂度选择合适的模型
5. **知识库优化** - 为专业领域的应用绑定相关知识库
## 扩展用法
### 在 Agent 系统中使用
当 Agent 系统加载这个 skill 时,会自动从 `config.json` 读取应用列表并生成描述:
```
Call LinkAI apps/workflows. 通用助手(G7z6vKwp: 通用AI助手,可以回答各类问题); 产品文档助手(kb_app_001: 基于产品文档知识库的问答助手); 数据分析工作流(wf_002: 执行数据清洗、分析和可视化的完整工作流)
```
Agent 会根据用户问题自动选择最合适的应用进行调用。
## 相关链接
- LinkAI 平台: https://link-ai.tech
- API 文档: https://docs.link-ai.tech
- 控制台: https://link-ai.tech/console
- 模型列表: https://link-ai.tech/console/models
- 应用广场: https://link-ai.tech/square
## License
Part of the chatgpt-on-wechat project.
================================================
FILE: skills/linkai-agent/SKILL.md
================================================
---
name: linkai-agent
description: Call LinkAI applications and workflows. Use bash with curl to invoke the chat completions API.
homepage: https://link-ai.tech
metadata:
emoji: 🤖
requires:
bins: ["curl"]
env: ["LINKAI_API_KEY"]
---
# LinkAI Agent
Call LinkAI applications and workflows through the chat completions API. Available apps are loaded from config.json.
## Setup
This skill requires a LinkAI API key.
1. Get your API key from [LinkAI Console](https://link-ai.tech/console/interface)
2. Set the environment variable: `export LINKAI_API_KEY=Link_xxxxxxxxxxxx` (or use env_config tool)
## Configuration
1. Copy `config.json.template` to `config.json`
2. Add your apps/workflows in config.json. The skill description is auto-generated from this config when loaded.
## Usage
Use the bash tool with curl to call the API. **Prefer curl** to avoid encoding issues on Windows PowerShell.
```bash
curl -X POST "https://api.link-ai.tech/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $LINKAI_API_KEY" \
-d '{
"app_code": "",
"messages": [{"role": "user", "content": ""}],
"stream": false
}'
```
**Optional parameters**:
- Add `--max-time 120` to curl for long-running tasks (video/image generation)
**On Windows cmd**: Use `%LINKAI_API_KEY%` instead of `$LINKAI_API_KEY`.
**Example** (via bash tool):
```bash
bash(command='curl -sS --max-time 120 -X POST "https://api.link-ai.tech/v1/chat/completions" -H "Content-Type: application/json" -H "Authorization: Bearer $LINKAI_API_KEY" -d "{\"app_code\":\"G7z6vKwp\",\"messages\":[{\"role\":\"user\",\"content\":\"What is AI?\"}],\"stream\":false}"', timeout=130)
```
## Response
Success (extract `choices[0].message.content` from JSON):
```json
{
"choices": [{
"message": {
"role": "assistant",
"content": "AI stands for Artificial Intelligence..."
}
}],
"usage": {
"prompt_tokens": 10,
"completion_tokens": 50,
"total_tokens": 60
}
}
```
Error:
```json
{
"error": {
"message": "Error description",
"code": "error_code"
}
}
```
================================================
FILE: skills/linkai-agent/config.json.template
================================================
{
"apps": [
{
"app_code": "G7z6vKwp",
"app_name": "LinkAI客服助手",
"app_description": "当用户需要了解LinkAI平台相关问题时才选择该助手,基于LinkAI知识库进行回答"
},
{
"app_code": "SFY5x7JR",
"app_name": "内容创作助手",
"app_description": "当用户需要创作图片或视频时才使用该助手,支持Nano Banana、Seedream、即梦、Veo、可灵等多种模型"
}
]
}
================================================
FILE: skills/skill-creator/SKILL.md
================================================
---
name: skill-creator
description: Create, install, or update skills in the workspace. Use when (1) installing a skill from a URL or remote source, (2) creating a new skill from scratch, (3) updating or restructuring existing skills. Always use this skill for any skill installation or creation task.
license: Complete terms in LICENSE.txt
---
# Skill Creator
This skill provides guidance for creating effective skills using the existing tool system.
## About Skills
Skills are modular, self-contained packages that extend the agent's capabilities by providing specialized knowledge, workflows, and tools. They transform a general-purpose agent into a specialized agent equipped with procedural knowledge.
### What Skills Provide
1. **Specialized workflows** - Multi-step procedures for specific domains
2. **Tool integrations** - Instructions for working with specific file formats or APIs
3. **Domain expertise** - Company-specific knowledge, schemas, business logic
4. **Bundled resources** - Scripts, references, and assets for complex tasks
### Core Principle
**Concise is Key**: Only add context the agent doesn't already have. Challenge each piece of information: "Does this justify its token cost?" Prefer concise examples over verbose explanations.
## Skill Structure
Every skill consists of a required SKILL.md file and optional bundled resources:
```
skill-name/
├── SKILL.md (required)
│ ├── YAML frontmatter metadata (required)
│ │ ├── name: (required)
│ │ └── description: (required)
│ └── Markdown instructions (required)
└── Bundled Resources (optional)
├── scripts/ - Executable code (Python/Bash/etc.)
├── references/ - Documentation intended to be loaded into context as needed
└── assets/ - Files used in output (templates, icons, fonts, etc.)
```
### SKILL.md Components
**Frontmatter (YAML)** - Required fields:
- **name**: Skill name in hyphen-case (e.g., `weather-api`, `pdf-editor`)
- **description**: **CRITICAL** - Primary triggering mechanism
- Must clearly describe what the skill does
- Must explicitly state when to use it
- Include specific trigger scenarios and keywords
- All "when to use" info goes here, NOT in body
- Example: `"PDF document processing with rotation, merging, splitting, and text extraction. Use when user needs to: (1) Rotate PDF pages, (2) Merge multiple PDFs, (3) Split PDF files, (4) Extract text from PDFs."`
**Body (Markdown)** - Loaded after skill triggers:
- Detailed usage instructions
- How to call scripts and read references
- Examples and best practices
- Use imperative/infinitive form ("Use X to do Y")
### Bundled Resources
**scripts/** - When to include:
- Code is repeatedly rewritten
- Deterministic execution needed (avoid LLM randomness)
- Examples: PDF rotation, image processing
- Must test scripts before including
**references/** - When to include:
- **ONLY** when documentation is too large for SKILL.md (>500 lines)
- Database schemas, complex API specs that agent needs to reference
- Agent reads these files into context as needed
- **NOT for**: API reference docs, usage examples, tutorials (put in SKILL.md instead)
- **Rule of thumb**: If it fits in SKILL.md, don't create a separate reference file
**assets/** - When to include:
- Files used in output (not loaded to context)
- Templates, icons, boilerplate code
- Copied or modified in final output
**Important**: Most skills don't need all three. Choose based on actual needs.
### What NOT to Include
Do NOT create auxiliary documentation files:
- README.md - Instructions belong in SKILL.md
- INSTALLATION_GUIDE.md - Setup info belongs in SKILL.md
- CHANGELOG.md - Not needed for local skills
- API_REFERENCE.md - Put API docs directly in SKILL.md
- USAGE_EXAMPLES.md - Put examples directly in SKILL.md
- Any other documentation files - Everything goes in SKILL.md unless it's too large
**Critical Rule**: Only create files that the agent will actually execute (scripts) or that are too large for SKILL.md (references). Documentation, examples, and guides ALL belong in SKILL.md.
## Installing a Skill from URL
1. Fetch the URL content (curl or web_fetch tool)
2. Extract `name` from YAML frontmatter
3. Create directory `/skills//` and save content as `SKILL.md`
4. Check the saved SKILL.md for an installation/setup section — if it defines additional steps (e.g., downloading scripts, installing dependencies), execute them; otherwise installation is complete
The `` is the working directory from the "工作空间" section.
## Skill Creation Process (from scratch)
1. **Understand** - Clarify use cases with concrete examples
2. **Plan** - Identify needed scripts, references, assets
3. **Initialize** - Run init_skill.py to create template
4. **Edit** - Implement SKILL.md and resources
5. **Validate** (optional) - Run quick_validate.py to check format
6. **Iterate** - Improve based on real usage
## Skill Naming
- Use lowercase letters, digits, and hyphens only; normalize user-provided titles to hyphen-case (e.g., "Plan Mode" -> `plan-mode`).
- When generating names, generate a name under 64 characters (letters, digits, hyphens).
- Prefer short, verb-led phrases that describe the action.
- Namespace by tool when it improves clarity or triggering (e.g., `gh-address-comments`, `linear-address-issue`).
- Name the skill folder exactly after the skill name.
## Step-by-Step Guide
### Step 1: Understanding the Skill with Concrete Examples
Skip this step only when the skill's usage patterns are already clearly understood. It remains valuable even when working with an existing skill.
To create an effective skill, clearly understand concrete examples of how the skill will be used. This understanding can come from either direct user examples or generated examples that are validated with user feedback.
For example, when building an image-editor skill, relevant questions include:
- "What functionality should the image-editor skill support? Editing, rotating, anything else?"
- "Can you give some examples of how this skill would be used?"
- "I can imagine users asking for things like 'Remove the red-eye from this image' or 'Rotate this image'. Are there other ways you imagine this skill being used?"
- "What would a user say that should trigger this skill?"
To avoid overwhelming users, avoid asking too many questions in a single message. Start with the most important questions and follow up as needed for better effectiveness.
Conclude this step when there is a clear sense of the functionality the skill should support.
### Step 2: Planning the Reusable Skill Contents
To turn concrete examples into an effective skill, analyze each example by:
1. Considering how to execute on the example from scratch
2. Identifying what scripts, references, and assets would be helpful when executing these workflows repeatedly
**Planning Checklist**:
- ✅ **Always needed**: SKILL.md with clear description and usage instructions
- ✅ **scripts/**: Only if code needs to be executed (not just shown as examples)
- ❌ **references/**: Rarely needed - only if documentation is >500 lines and can't fit in SKILL.md
- ✅ **assets/**: Only if files are used in output (templates, boilerplate, etc.)
Example: When building a `pdf-editor` skill to handle queries like "Help me rotate this PDF," the analysis shows:
1. Rotating a PDF requires re-writing the same code each time
2. A `scripts/rotate_pdf.py` script would be helpful to store in the skill
3. ❌ Don't create `references/api-docs.md` - put API info in SKILL.md instead
Example: When designing a `frontend-webapp-builder` skill for queries like "Build me a todo app" or "Build me a dashboard to track my steps," the analysis shows:
1. Writing a frontend webapp requires the same boilerplate HTML/React each time
2. An `assets/hello-world/` template containing the boilerplate HTML/React project files would be helpful to store in the skill
3. ❌ Don't create `references/usage-examples.md` - put examples in SKILL.md instead
Example: When building a `big-query` skill to handle queries like "How many users have logged in today?" the analysis shows:
1. Querying BigQuery requires re-discovering the table schemas and relationships each time
2. A `references/schema.md` file documenting the table schemas would be helpful to store in the skill (ONLY because schemas are very large)
3. ❌ Don't create separate `references/query-examples.md` - put examples in SKILL.md instead
To establish the skill's contents, analyze each concrete example to create a list of the reusable resources to include: scripts, references, and assets. **Default to putting everything in SKILL.md unless there's a compelling reason to separate it.**
### Step 3: Initialize the Skill
At this point, it is time to actually create the skill.
Skip this step only if the skill being developed already exists, and iteration is needed. In this case, continue to the next step.
When creating a new skill from scratch, always run the `init_skill.py` script. The script conveniently generates a new template skill directory that automatically includes everything a skill requires, making the skill creation process much more efficient and reliable.
Usage:
```bash
scripts/init_skill.py --path [--resources scripts,references,assets] [--examples]
```
Examples:
```bash
scripts/init_skill.py my-skill --path /skills
scripts/init_skill.py my-skill --path /skills --resources scripts,references
scripts/init_skill.py my-skill --path /skills --resources scripts --examples
```
Where `` is your workspace directory shown in the "工作空间" section of the system prompt.
The script:
- Creates the skill directory at the specified path
- Generates a SKILL.md template with proper frontmatter and TODO placeholders
- Optionally creates resource directories based on `--resources`
- Optionally adds example files when `--examples` is set
After initialization, customize the SKILL.md and add resources as needed. If you used `--examples`, replace or delete placeholder files.
**Important**: Always create skills in workspace skills directory (`/skills`), NOT in project directory. Check the "工作空间" section for the actual workspace path.
### Step 4: Edit the Skill
When editing the (newly-generated or existing) skill, remember that the skill is being created for another instance of the agent to use. Include information that would be beneficial and non-obvious to the agent. Consider what procedural knowledge, domain-specific details, or reusable assets would help another agent instance execute these tasks more effectively.
#### Design Patterns
**Workflow patterns** — For complex tasks, break operations into sequential steps or conditional branches:
```markdown
# Sequential: list numbered steps with scripts
1. Analyze the form (run analyze_form.py)
2. Create field mapping (edit fields.json)
3. Fill the form (run fill_form.py)
# Conditional: guide through decision points
1. Determine the modification type:
**Creating new content?** → Follow "Creation workflow"
**Editing existing content?** → Follow "Editing workflow"
```
**Output patterns** — When consistent output format matters, provide a template or input/output examples in SKILL.md so the agent can follow the desired style.
#### Start with Reusable Skill Contents
To begin implementation, start with the reusable resources identified above: `scripts/`, `references/`, and `assets/` files. Note that this step may require user input. For example, when implementing a `brand-guidelines` skill, the user may need to provide brand assets or templates to store in `assets/`, or documentation to store in `references/`.
**Available Base Tools**:
The agent has access to these core tools that you can leverage in your skill:
- **bash**: Execute shell commands (use for curl, ls, grep, sed, awk, bc for calculations, etc.)
- **read**: Read file contents
- **write**: Write files
- **edit**: Edit files with search/replace
**Minimize Dependencies**:
- ✅ **Prefer bash + curl** for HTTP API calls (no Python dependencies)
- ✅ **Use bash tools** (grep, sed, awk) for text processing
- ✅ **Keep scripts simple** - if bash can do it, no need for Python (document packages/versions if Python is used)
**Important Guidelines**:
- **scripts/**: Only create scripts that will be executed. Test all scripts before including.
- **references/**: ONLY create if documentation is too large for SKILL.md (>500 lines). Most skills don't need this.
- **assets/**: Only include files used in output (templates, icons, etc.)
- **Default approach**: Put everything in SKILL.md unless there's a specific reason not to.
Added scripts must be tested by actually running them to ensure there are no bugs and that the output matches what is expected. If there are many similar scripts, only a representative sample needs to be tested to ensure confidence that they all work while balancing time to completion.
If you used `--examples`, delete any placeholder files that are not needed for the skill. Only create resource directories that are actually required.
#### Update SKILL.md
**Writing Guidelines:** Always use imperative/infinitive form.
##### Frontmatter
Write the YAML frontmatter with `name`, `description`, and optional `metadata`:
- `name`: The skill name
- `description`: This is the primary triggering mechanism for your skill, and helps the agent understand when to use the skill.
- Include both what the Skill does and specific triggers/contexts for when to use it.
- Include all "when to use" information here - Not in the body. The body is only loaded after triggering, so "When to Use This Skill" sections in the body are not helpful to the agent.
- Example description for a `docx` skill: "Comprehensive document creation, editing, and analysis with support for tracked changes, comments, formatting preservation, and text extraction. Use when the agent needs to work with professional documents (.docx files) for: (1) Creating new documents, (2) Modifying or editing content, (3) Working with tracked changes, (4) Adding comments, or any other document tasks"
- `metadata`: (Optional) Specify requirements and configuration
- `requires.bins`: Required binaries (e.g., `["curl", "jq"]`)
- `requires.env`: Required environment variables — all must be set (e.g., `["MYAPI_KEY"]`)
- `requires.anyEnv`: Alternative environment variables — at least one must be set (e.g., `["OPENAI_API_KEY", "LINKAI_API_KEY"]`)
- `requires.anyBins`: Alternative binaries — at least one must be present
- `always`: Set to `true` to always load regardless of requirements
- `emoji`: Skill icon (optional)
- Do NOT set `category` — it defaults to `skill` and is managed by the system
**API Key Requirements**:
If your skill needs a single API key, declare it in `requires.env`:
```yaml
---
name: my-search
description: Search using MyAPI
metadata:
requires:
bins: ["curl"]
env: ["MYAPI_KEY"]
---
```
If your skill supports multiple API key providers (e.g., OpenAI or LinkAI), use `requires.anyEnv`:
```yaml
---
name: my-vision
description: Analyze images using Vision API
metadata:
requires:
bins: ["curl"]
anyEnv: ["OPENAI_API_KEY", "LINKAI_API_KEY"]
---
```
**Auto-enable rule**: Skills are automatically enabled when required environment variables are set, and automatically disabled when missing. No manual configuration needed.
##### Body
Write instructions for using the skill and its bundled resources.
**If your skill requires an API key**, include setup instructions in the body:
```markdown
## Setup
This skill requires an API key from [Service Name].
1. Visit https://service.com to get an API key
2. Configure it using: `env_config(action="set", key="SERVICE_API_KEY", value="your-key")`
3. Or manually add to `~/cow/.env`: `SERVICE_API_KEY=your-key`
4. Restart the agent for changes to take effect
## Usage
...
```
The bash script should check for the key and provide helpful error messages:
```bash
#!/usr/bin/env bash
if [ -z "${SERVICE_API_KEY:-}" ]; then
echo "Error: SERVICE_API_KEY not set"
echo "Please configure your API key first (see SKILL.md)"
exit 1
fi
curl -H "Authorization: Bearer $SERVICE_API_KEY" ...
```
**Script Path Convention**:
When writing SKILL.md instructions, remember that:
- Skills are listed in `` with a `` path
- Scripts should be referenced as: `/scripts/script_name.sh`
- The AI will see the base_dir and can construct the full path
Example instruction in SKILL.md:
```markdown
## Usage
Scripts are in this skill's base directory (shown in skill listing).
bash "/scripts/my_script.sh"
```
### Step 5: Validate (Optional)
Validate skill format:
```bash
scripts/quick_validate.py
```
Example:
```bash
scripts/quick_validate.py /skills/weather-api
```
Validation checks:
- YAML frontmatter format and required fields
- Skill naming conventions (hyphen-case, lowercase)
- Description completeness and quality
- File organization
**Note**: Validation is optional in COW. Mainly useful for troubleshooting format issues.
### Step 6: Iterate
Improve based on real usage:
1. Use skill on real tasks
2. Notice struggles or inefficiencies
3. Identify needed updates to SKILL.md or resources
4. Implement changes and test again
## Progressive Disclosure
Skills use three-level loading:
1. **Metadata** (name + description) - Always in context (~100 words)
2. **SKILL.md body** - Loaded when skill triggers (<5k words)
3. **Resources** - Loaded as needed by agent
**Best practices**:
- Keep SKILL.md under 500 lines
- Split complex content into `references/` files
- Reference these files clearly in SKILL.md
**Pattern**: For skills with multiple variants/frameworks:
- Keep core workflow in SKILL.md
- Move variant-specific details to separate reference files
- Agent loads only relevant files
Example:
```
cloud-deploy/
├── SKILL.md (workflow + provider selection)
└── references/
├── aws.md
├── gcp.md
└── azure.md
```
When user chooses AWS, agent only reads aws.md.
================================================
FILE: skills/skill-creator/scripts/init_skill.py
================================================
#!/usr/bin/env python3
"""
Skill Initializer - Creates a new skill from template
Usage:
init_skill.py --path
Examples:
init_skill.py my-new-skill --path skills/public
init_skill.py my-api-helper --path skills/private
init_skill.py custom-skill --path /custom/location
"""
import sys
from pathlib import Path
SKILL_TEMPLATE = """---
name: {skill_name}
description: [TODO: Complete and informative explanation of what the skill does and when to use it. Include WHEN to use this skill - specific scenarios, file types, or tasks that trigger it.]
---
# {skill_title}
## Overview
[TODO: 1-2 sentences explaining what this skill enables]
## Structuring This Skill
[TODO: Choose the structure that best fits this skill's purpose. Common patterns:
**1. Workflow-Based** (best for sequential processes)
- Works well when there are clear step-by-step procedures
- Example: DOCX skill with "Workflow Decision Tree" → "Reading" → "Creating" → "Editing"
- Structure: ## Overview → ## Workflow Decision Tree → ## Step 1 → ## Step 2...
**2. Task-Based** (best for tool collections)
- Works well when the skill offers different operations/capabilities
- Example: PDF skill with "Quick Start" → "Merge PDFs" → "Split PDFs" → "Extract Text"
- Structure: ## Overview → ## Quick Start → ## Task Category 1 → ## Task Category 2...
**3. Reference/Guidelines** (best for standards or specifications)
- Works well for brand guidelines, coding standards, or requirements
- Example: Brand styling with "Brand Guidelines" → "Colors" → "Typography" → "Features"
- Structure: ## Overview → ## Guidelines → ## Specifications → ## Usage...
**4. Capabilities-Based** (best for integrated systems)
- Works well when the skill provides multiple interrelated features
- Example: Product Management with "Core Capabilities" → numbered capability list
- Structure: ## Overview → ## Core Capabilities → ### 1. Feature → ### 2. Feature...
Patterns can be mixed and matched as needed. Most skills combine patterns (e.g., start with task-based, add workflow for complex operations).
Delete this entire "Structuring This Skill" section when done - it's just guidance.]
## [TODO: Replace with the first main section based on chosen structure]
[TODO: Add content here. See examples in existing skills:
- Code samples for technical skills
- Decision trees for complex workflows
- Concrete examples with realistic user requests
- References to scripts/templates/references as needed]
## Resources
This skill includes example resource directories that demonstrate how to organize different types of bundled resources:
### scripts/
Executable code (Python/Bash/etc.) that can be run directly to perform specific operations.
**Examples from other skills:**
- PDF skill: `fill_fillable_fields.py`, `extract_form_field_info.py` - utilities for PDF manipulation
- DOCX skill: `document.py`, `utilities.py` - Python modules for document processing
**Appropriate for:** Python scripts, shell scripts, or any executable code that performs automation, data processing, or specific operations.
**Note:** Scripts may be executed without loading into context, but can still be read by Claude for patching or environment adjustments.
### references/
Documentation and reference material intended to be loaded into context to inform Claude's process and thinking.
**Examples from other skills:**
- Product management: `communication.md`, `context_building.md` - detailed workflow guides
- BigQuery: API reference documentation and query examples
- Finance: Schema documentation, company policies
**Appropriate for:** In-depth documentation, API references, database schemas, comprehensive guides, or any detailed information that Claude should reference while working.
### assets/
Files not intended to be loaded into context, but rather used within the output Claude produces.
**Examples from other skills:**
- Brand styling: PowerPoint template files (.pptx), logo files
- Frontend builder: HTML/React boilerplate project directories
- Typography: Font files (.ttf, .woff2)
**Appropriate for:** Templates, boilerplate code, document templates, images, icons, fonts, or any files meant to be copied or used in the final output.
---
**Any unneeded directories can be deleted.** Not every skill requires all three types of resources.
"""
EXAMPLE_SCRIPT = '''#!/usr/bin/env python3
"""
Example helper script for {skill_name}
This is a placeholder script that can be executed directly.
Replace with actual implementation or delete if not needed.
Example real scripts from other skills:
- pdf/scripts/fill_fillable_fields.py - Fills PDF form fields
- pdf/scripts/convert_pdf_to_images.py - Converts PDF pages to images
"""
def main():
print("This is an example script for {skill_name}")
# TODO: Add actual script logic here
# This could be data processing, file conversion, API calls, etc.
if __name__ == "__main__":
main()
'''
EXAMPLE_REFERENCE = """# Reference Documentation for {skill_title}
This is a placeholder for detailed reference documentation.
Replace with actual reference content or delete if not needed.
Example real reference docs from other skills:
- product-management/references/communication.md - Comprehensive guide for status updates
- product-management/references/context_building.md - Deep-dive on gathering context
- bigquery/references/ - API references and query examples
## When Reference Docs Are Useful
Reference docs are ideal for:
- Comprehensive API documentation
- Detailed workflow guides
- Complex multi-step processes
- Information too lengthy for main SKILL.md
- Content that's only needed for specific use cases
## Structure Suggestions
### API Reference Example
- Overview
- Authentication
- Endpoints with examples
- Error codes
- Rate limits
### Workflow Guide Example
- Prerequisites
- Step-by-step instructions
- Common patterns
- Troubleshooting
- Best practices
"""
EXAMPLE_ASSET = """# Example Asset File
This placeholder represents where asset files would be stored.
Replace with actual asset files (templates, images, fonts, etc.) or delete if not needed.
Asset files are NOT intended to be loaded into context, but rather used within
the output Claude produces.
Example asset files from other skills:
- Brand guidelines: logo.png, slides_template.pptx
- Frontend builder: hello-world/ directory with HTML/React boilerplate
- Typography: custom-font.ttf, font-family.woff2
- Data: sample_data.csv, test_dataset.json
## Common Asset Types
- Templates: .pptx, .docx, boilerplate directories
- Images: .png, .jpg, .svg, .gif
- Fonts: .ttf, .otf, .woff, .woff2
- Boilerplate code: Project directories, starter files
- Icons: .ico, .svg
- Data files: .csv, .json, .xml, .yaml
Note: This is a text placeholder. Actual assets can be any file type.
"""
def title_case_skill_name(skill_name):
"""Convert hyphenated skill name to Title Case for display."""
return ' '.join(word.capitalize() for word in skill_name.split('-'))
def init_skill(skill_name, path):
"""
Initialize a new skill directory with template SKILL.md.
Args:
skill_name: Name of the skill
path: Path where the skill directory should be created
Returns:
Path to created skill directory, or None if error
"""
# Determine skill directory path
skill_dir = Path(path).resolve() / skill_name
# Check if directory already exists
if skill_dir.exists():
print(f"❌ Error: Skill directory already exists: {skill_dir}")
return None
# Create skill directory
try:
skill_dir.mkdir(parents=True, exist_ok=False)
print(f"✅ Created skill directory: {skill_dir}")
except Exception as e:
print(f"❌ Error creating directory: {e}")
return None
# Create SKILL.md from template
skill_title = title_case_skill_name(skill_name)
skill_content = SKILL_TEMPLATE.format(
skill_name=skill_name,
skill_title=skill_title
)
skill_md_path = skill_dir / 'SKILL.md'
try:
skill_md_path.write_text(skill_content)
print("✅ Created SKILL.md")
except Exception as e:
print(f"❌ Error creating SKILL.md: {e}")
return None
# Create resource directories with example files
try:
# Create scripts/ directory with example script
scripts_dir = skill_dir / 'scripts'
scripts_dir.mkdir(exist_ok=True)
example_script = scripts_dir / 'example.py'
example_script.write_text(EXAMPLE_SCRIPT.format(skill_name=skill_name))
example_script.chmod(0o755)
print("✅ Created scripts/example.py")
# Create references/ directory with example reference doc
references_dir = skill_dir / 'references'
references_dir.mkdir(exist_ok=True)
example_reference = references_dir / 'api_reference.md'
example_reference.write_text(EXAMPLE_REFERENCE.format(skill_title=skill_title))
print("✅ Created references/api_reference.md")
# Create assets/ directory with example asset placeholder
assets_dir = skill_dir / 'assets'
assets_dir.mkdir(exist_ok=True)
example_asset = assets_dir / 'example_asset.txt'
example_asset.write_text(EXAMPLE_ASSET)
print("✅ Created assets/example_asset.txt")
except Exception as e:
print(f"❌ Error creating resource directories: {e}")
return None
# Print next steps
print(f"\n✅ Skill '{skill_name}' initialized successfully at {skill_dir}")
print("\nNext steps:")
print("1. Edit SKILL.md to complete the TODO items and update the description")
print("2. Customize or delete the example files in scripts/, references/, and assets/")
print("3. Run the validator when ready to check the skill structure")
return skill_dir
def main():
if len(sys.argv) < 4 or sys.argv[2] != '--path':
print("Usage: init_skill.py --path ")
print("\nSkill name requirements:")
print(" - Hyphen-case identifier (e.g., 'data-analyzer')")
print(" - Lowercase letters, digits, and hyphens only")
print(" - Max 40 characters")
print(" - Must match directory name exactly")
print("\nExamples:")
print(" init_skill.py my-new-skill --path workspace/skills")
print(" init_skill.py my-api-helper --path /path/to/skills")
print(" init_skill.py custom-skill --path /custom/location")
sys.exit(1)
skill_name = sys.argv[1]
path = sys.argv[3]
print(f"🚀 Initializing skill: {skill_name}")
print(f" Location: {path}")
print()
result = init_skill(skill_name, path)
if result:
sys.exit(0)
else:
sys.exit(1)
if __name__ == "__main__":
main()
================================================
FILE: skills/skill-creator/scripts/package_skill.py
================================================
#!/usr/bin/env python3
"""
Skill Packager - Creates a distributable .skill file of a skill folder
Usage:
python utils/package_skill.py [output-directory]
Example:
python utils/package_skill.py skills/public/my-skill
python utils/package_skill.py skills/public/my-skill ./dist
"""
import sys
import os
import zipfile
from pathlib import Path
# Add script directory to path for imports
script_dir = Path(__file__).parent
sys.path.insert(0, str(script_dir))
from quick_validate import validate_skill
def package_skill(skill_path, output_dir=None):
"""
Package a skill folder into a .skill file.
Args:
skill_path: Path to the skill folder
output_dir: Optional output directory for the .skill file (defaults to current directory)
Returns:
Path to the created .skill file, or None if error
"""
skill_path = Path(skill_path).resolve()
# Validate skill folder exists
if not skill_path.exists():
print(f"❌ Error: Skill folder not found: {skill_path}")
return None
if not skill_path.is_dir():
print(f"❌ Error: Path is not a directory: {skill_path}")
return None
# Validate SKILL.md exists
skill_md = skill_path / "SKILL.md"
if not skill_md.exists():
print(f"❌ Error: SKILL.md not found in {skill_path}")
return None
# Run validation before packaging
print("🔍 Validating skill...")
valid, message = validate_skill(skill_path)
if not valid:
print(f"❌ Validation failed: {message}")
print(" Please fix the validation errors before packaging.")
return None
print(f"✅ {message}\n")
# Determine output location
skill_name = skill_path.name
if output_dir:
output_path = Path(output_dir).resolve()
output_path.mkdir(parents=True, exist_ok=True)
else:
output_path = Path.cwd()
skill_filename = output_path / f"{skill_name}.skill"
# Create the .skill file (zip format)
try:
with zipfile.ZipFile(skill_filename, 'w', zipfile.ZIP_DEFLATED) as zipf:
# Walk through the skill directory
for file_path in skill_path.rglob('*'):
if file_path.is_file():
# Calculate the relative path within the zip
arcname = file_path.relative_to(skill_path.parent)
zipf.write(file_path, arcname)
print(f" Added: {arcname}")
print(f"\n✅ Successfully packaged skill to: {skill_filename}")
return skill_filename
except Exception as e:
print(f"❌ Error creating .skill file: {e}")
return None
def main():
if len(sys.argv) < 2:
print("Usage: python utils/package_skill.py [output-directory]")
print("\nExample:")
print(" python utils/package_skill.py skills/public/my-skill")
print(" python utils/package_skill.py skills/public/my-skill ./dist")
sys.exit(1)
skill_path = sys.argv[1]
output_dir = sys.argv[2] if len(sys.argv) > 2 else None
print(f"📦 Packaging skill: {skill_path}")
if output_dir:
print(f" Output directory: {output_dir}")
print()
result = package_skill(skill_path, output_dir)
if result:
sys.exit(0)
else:
sys.exit(1)
if __name__ == "__main__":
main()
================================================
FILE: skills/skill-creator/scripts/quick_validate.py
================================================
#!/usr/bin/env python3
"""
Quick validation script for skills - minimal version
"""
import sys
import os
import re
import yaml
from pathlib import Path
def validate_skill(skill_path):
"""Basic validation of a skill"""
skill_path = Path(skill_path)
# Check SKILL.md exists
skill_md = skill_path / 'SKILL.md'
if not skill_md.exists():
return False, "SKILL.md not found"
# Read and validate frontmatter
content = skill_md.read_text()
if not content.startswith('---'):
return False, "No YAML frontmatter found"
# Extract frontmatter
match = re.match(r'^---\n(.*?)\n---', content, re.DOTALL)
if not match:
return False, "Invalid frontmatter format"
frontmatter_text = match.group(1)
# Parse YAML frontmatter
try:
frontmatter = yaml.safe_load(frontmatter_text)
if not isinstance(frontmatter, dict):
return False, "Frontmatter must be a YAML dictionary"
except yaml.YAMLError as e:
return False, f"Invalid YAML in frontmatter: {e}"
# Define allowed properties
ALLOWED_PROPERTIES = {'name', 'description', 'license', 'allowed-tools', 'metadata'}
# Check for unexpected properties (excluding nested keys under metadata)
unexpected_keys = set(frontmatter.keys()) - ALLOWED_PROPERTIES
if unexpected_keys:
return False, (
f"Unexpected key(s) in SKILL.md frontmatter: {', '.join(sorted(unexpected_keys))}. "
f"Allowed properties are: {', '.join(sorted(ALLOWED_PROPERTIES))}"
)
# Check required fields
if 'name' not in frontmatter:
return False, "Missing 'name' in frontmatter"
if 'description' not in frontmatter:
return False, "Missing 'description' in frontmatter"
# Extract name for validation
name = frontmatter.get('name', '')
if not isinstance(name, str):
return False, f"Name must be a string, got {type(name).__name__}"
name = name.strip()
if name:
# Check naming convention (hyphen-case: lowercase with hyphens)
if not re.match(r'^[a-z0-9-]+$', name):
return False, f"Name '{name}' should be hyphen-case (lowercase letters, digits, and hyphens only)"
if name.startswith('-') or name.endswith('-') or '--' in name:
return False, f"Name '{name}' cannot start/end with hyphen or contain consecutive hyphens"
# Check name length (max 64 characters per spec)
if len(name) > 64:
return False, f"Name is too long ({len(name)} characters). Maximum is 64 characters."
# Extract and validate description
description = frontmatter.get('description', '')
if not isinstance(description, str):
return False, f"Description must be a string, got {type(description).__name__}"
description = description.strip()
if description:
# Check for angle brackets
if '<' in description or '>' in description:
return False, "Description cannot contain angle brackets (< or >)"
# Check description length (max 1024 characters per spec)
if len(description) > 1024:
return False, f"Description is too long ({len(description)} characters). Maximum is 1024 characters."
return True, "Skill is valid!"
if __name__ == "__main__":
if len(sys.argv) != 2:
print("Usage: python quick_validate.py ")
sys.exit(1)
valid, message = validate_skill(sys.argv[1])
print(message)
sys.exit(0 if valid else 1)
================================================
FILE: translate/baidu/baidu_translate.py
================================================
# -*- coding: utf-8 -*-
import random
from hashlib import md5
import requests
from config import conf
from translate.translator import Translator
class BaiduTranslator(Translator):
def __init__(self) -> None:
super().__init__()
endpoint = "http://api.fanyi.baidu.com"
path = "/api/trans/vip/translate"
self.url = endpoint + path
self.appid = conf().get("baidu_translate_app_id")
self.appkey = conf().get("baidu_translate_app_key")
if not self.appid or not self.appkey:
raise Exception("baidu translate appid or appkey not set")
# For list of language codes, please refer to `https://api.fanyi.baidu.com/doc/21`, need to convert to ISO 639-1 codes
def translate(self, query: str, from_lang: str = "", to_lang: str = "en") -> str:
if not from_lang:
from_lang = "auto" # baidu suppport auto detect
salt = random.randint(32768, 65536)
sign = self.make_md5("{}{}{}{}".format(self.appid, query, salt, self.appkey))
headers = {"Content-Type": "application/x-www-form-urlencoded"}
payload = {"appid": self.appid, "q": query, "from": from_lang, "to": to_lang, "salt": salt, "sign": sign}
retry_cnt = 3
while retry_cnt:
r = requests.post(self.url, params=payload, headers=headers)
result = r.json()
errcode = result.get("error_code", "52000")
if errcode != "52000":
if errcode == "52001" or errcode == "52002":
retry_cnt -= 1
continue
else:
raise Exception(result["error_msg"])
else:
break
text = "\n".join([item["dst"] for item in result["trans_result"]])
return text
def make_md5(self, s, encoding="utf-8"):
return md5(s.encode(encoding)).hexdigest()
================================================
FILE: translate/factory.py
================================================
def create_translator(voice_type):
if voice_type == "baidu":
from translate.baidu.baidu_translate import BaiduTranslator
return BaiduTranslator()
raise RuntimeError
================================================
FILE: translate/translator.py
================================================
"""
Voice service abstract class
"""
class Translator(object):
# please use https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes to specify language
def translate(self, query: str, from_lang: str = "", to_lang: str = "en") -> str:
"""
Translate text from one language to another
"""
raise NotImplementedError
================================================
FILE: voice/ali/ali_api.py
================================================
# coding=utf-8
"""
Author: chazzjimel
Email: chazzjimel@gmail.com
wechat:cheung-z-x
Description:
"""
import http.client
import json
import time
import requests
import datetime
import hashlib
import hmac
import base64
import urllib.parse
import uuid
from common.log import logger
from common.tmp_dir import TmpDir
def text_to_speech_aliyun(url, text, appkey, token):
"""
使用阿里云的文本转语音服务将文本转换为语音。
参数:
- url (str): 阿里云文本转语音服务的端点URL。
- text (str): 要转换为语音的文本。
- appkey (str): 您的阿里云appkey。
- token (str): 阿里云API的认证令牌。
返回值:
- str: 成功时输出音频文件的路径,否则为None。
"""
headers = {
"Content-Type": "application/json",
}
data = {
"text": text,
"appkey": appkey,
"token": token,
"format": "wav"
}
response = requests.post(url, headers=headers, data=json.dumps(data))
if response.status_code == 200 and response.headers['Content-Type'] == 'audio/mpeg':
output_file = TmpDir().path() + "reply-" + str(int(time.time())) + "-" + str(hash(text) & 0x7FFFFFFF) + ".wav"
with open(output_file, 'wb') as file:
file.write(response.content)
logger.debug(f"音频文件保存成功,文件名:{output_file}")
else:
logger.debug("响应状态码: {}".format(response.status_code))
logger.debug("响应内容: {}".format(response.text))
output_file = None
return output_file
def speech_to_text_aliyun(url, audioContent, appkey, token):
"""
使用阿里云的语音识别服务识别音频文件中的语音。
参数:
- url (str): 阿里云语音识别服务的端点URL。
- audioContent (byte): pcm音频数据。
- appkey (str): 您的阿里云appkey。
- token (str): 阿里云API的认证令牌。
返回值:
- str: 成功时输出识别到的文本,否则为None。
"""
format = 'pcm'
sample_rate = 16000
enablePunctuationPrediction = True
enableInverseTextNormalization = True
enableVoiceDetection = False
# 设置RESTful请求参数
request = url + '?appkey=' + appkey
request = request + '&format=' + format
request = request + '&sample_rate=' + str(sample_rate)
if enablePunctuationPrediction :
request = request + '&enable_punctuation_prediction=' + 'true'
if enableInverseTextNormalization :
request = request + '&enable_inverse_text_normalization=' + 'true'
if enableVoiceDetection :
request = request + '&enable_voice_detection=' + 'true'
host = 'nls-gateway-cn-shanghai.aliyuncs.com'
# 设置HTTPS请求头部
httpHeaders = {
'X-NLS-Token': token,
'Content-type': 'application/octet-stream',
'Content-Length': len(audioContent)
}
conn = http.client.HTTPSConnection(host)
conn.request(method='POST', url=request, body=audioContent, headers=httpHeaders)
response = conn.getresponse()
body = response.read()
try:
body = json.loads(body)
status = body['status']
if status == 20000000 :
result = body['result']
if result :
logger.info(f"阿里云语音识别到了:{result}")
conn.close()
return result
else :
logger.error(f"语音识别失败,状态码: {status}")
except ValueError:
logger.error(f"语音识别失败,收到非JSON格式的数据: {body}")
conn.close()
return None
class AliyunTokenGenerator:
"""
用于生成阿里云服务认证令牌的类。
属性:
- access_key_id (str): 您的阿里云访问密钥ID。
- access_key_secret (str): 您的阿里云访问密钥秘密。
"""
def __init__(self, access_key_id, access_key_secret):
self.access_key_id = access_key_id
self.access_key_secret = access_key_secret
def sign_request(self, parameters):
"""
为阿里云服务签名请求。
参数:
- parameters (dict): 请求的参数字典。
返回值:
- str: 请求的签名签章。
"""
# 将参数按照字典顺序排序
sorted_params = sorted(parameters.items())
# 构造待签名的查询字符串
canonicalized_query_string = ''
for (k, v) in sorted_params:
canonicalized_query_string += '&' + self.percent_encode(k) + '=' + self.percent_encode(v)
# 构造用于签名的字符串
string_to_sign = 'GET&%2F&' + self.percent_encode(canonicalized_query_string[1:]) # 使用GET方法
# 使用HMAC算法计算签名
h = hmac.new((self.access_key_secret + "&").encode('utf-8'), string_to_sign.encode('utf-8'), hashlib.sha1)
signature = base64.encodebytes(h.digest()).strip()
return signature
def percent_encode(self, encode_str):
"""
对字符串进行百分比编码。
参数:
- encode_str (str): 要编码的字符串。
返回值:
- str: 编码后的字符串。
"""
encode_str = str(encode_str)
res = urllib.parse.quote(encode_str, '')
res = res.replace('+', '%20')
res = res.replace('*', '%2A')
res = res.replace('%7E', '~')
return res
def get_token(self):
"""
获取阿里云服务的令牌。
返回值:
- str: 获取到的令牌。
"""
# 设置请求参数
params = {
'Format': 'JSON',
'Version': '2019-02-28',
'AccessKeyId': self.access_key_id,
'SignatureMethod': 'HMAC-SHA1',
'Timestamp': datetime.datetime.utcnow().strftime("%Y-%m-%dT%H:%M:%SZ"),
'SignatureVersion': '1.0',
'SignatureNonce': str(uuid.uuid4()), # 使用uuid生成唯一的随机数
'Action': 'CreateToken',
'RegionId': 'cn-shanghai'
}
# 计算签名
signature = self.sign_request(params)
params['Signature'] = signature
# 构造请求URL
url = 'http://nls-meta.cn-shanghai.aliyuncs.com/?' + urllib.parse.urlencode(params)
# 发送请求
response = requests.get(url)
return response.text
================================================
FILE: voice/ali/ali_voice.py
================================================
# -*- coding: utf-8 -*-
"""
Author: chazzjimel
Email: chazzjimel@gmail.com
wechat:cheung-z-x
Description:
ali voice service
"""
import json
import os
import re
import time
from bridge.reply import Reply, ReplyType
from common.log import logger
from voice.voice import Voice
from voice.ali.ali_api import AliyunTokenGenerator, speech_to_text_aliyun, text_to_speech_aliyun
from config import conf
try:
from voice.audio_convert import get_pcm_from_wav
except ImportError as e:
logger.debug("import voice.audio_convert failed: {}".format(e))
class AliVoice(Voice):
def __init__(self):
"""
初始化AliVoice类,从配置文件加载必要的配置。
"""
try:
curdir = os.path.dirname(__file__)
config_path = os.path.join(curdir, "config.json")
with open(config_path, "r") as fr:
config = json.load(fr)
self.token = None
self.token_expire_time = 0
# 默认复用阿里云千问的 access_key 和 access_secret
self.api_url_voice_to_text = config.get("api_url_voice_to_text")
self.api_url_text_to_voice = config.get("api_url_text_to_voice")
self.app_key = config.get("app_key")
self.access_key_id = conf().get("qwen_access_key_id") or config.get("access_key_id")
self.access_key_secret = conf().get("qwen_access_key_secret") or config.get("access_key_secret")
except Exception as e:
logger.warn("AliVoice init failed: %s, ignore " % e)
def textToVoice(self, text):
"""
将文本转换为语音文件。
:param text: 要转换的文本。
:return: 返回一个Reply对象,其中包含转换得到的语音文件或错误信息。
"""
# 清除文本中的非中文、非英文和非基本字符
text = re.sub(r'[^\u4e00-\u9fa5\u3040-\u30FF\uAC00-\uD7AFa-zA-Z0-9'
r'äöüÄÖÜáéíóúÁÉÍÓÚàèìòùÀÈÌÒÙâêîôûÂÊÎÔÛçÇñÑ,。!?,.]', '', text)
# 提取有效的token
token_id = self.get_valid_token()
fileName = text_to_speech_aliyun(self.api_url_text_to_voice, text, self.app_key, token_id)
if fileName:
logger.info("[Ali] textToVoice text={} voice file name={}".format(text, fileName))
reply = Reply(ReplyType.VOICE, fileName)
else:
reply = Reply(ReplyType.ERROR, "抱歉,语音合成失败")
return reply
def voiceToText(self, voice_file):
"""
将语音文件转换为文本。
:param voice_file: 要转换的语音文件。
:return: 返回一个Reply对象,其中包含转换得到的文本或错误信息。
"""
# 提取有效的token
token_id = self.get_valid_token()
logger.debug("[Ali] voice file name={}".format(voice_file))
pcm = get_pcm_from_wav(voice_file)
text = speech_to_text_aliyun(self.api_url_voice_to_text, pcm, self.app_key, token_id)
if text:
logger.info("[Ali] VoicetoText = {}".format(text))
reply = Reply(ReplyType.TEXT, text)
else:
reply = Reply(ReplyType.ERROR, "抱歉,语音识别失败")
return reply
def get_valid_token(self):
"""
获取有效的阿里云token。
:return: 返回有效的token字符串。
"""
current_time = time.time()
if self.token is None or current_time >= self.token_expire_time:
get_token = AliyunTokenGenerator(self.access_key_id, self.access_key_secret)
token_str = get_token.get_token()
token_data = json.loads(token_str)
self.token = token_data["Token"]["Id"]
# 将过期时间减少一小段时间(例如5分钟),以避免在边界条件下的过期
self.token_expire_time = token_data["Token"]["ExpireTime"] - 300
logger.debug(f"新获取的阿里云token:{self.token}")
else:
logger.debug("使用缓存的token")
return self.token
================================================
FILE: voice/ali/config.json.template
================================================
{
"api_url_text_to_voice": "https://nls-gateway-cn-shanghai.aliyuncs.com/stream/v1/tts",
"api_url_voice_to_text": "https://nls-gateway.cn-shanghai.aliyuncs.com/stream/v1/asr",
"app_key": "",
"access_key_id": "",
"access_key_secret": ""
}
================================================
FILE: voice/audio_convert.py
================================================
import shutil
import wave
from common.log import logger
try:
import pysilk
except ImportError:
logger.debug("import pysilk failed, silk voice format will not be supported.")
try:
from pydub import AudioSegment
_pydub_available = True
except ImportError:
logger.debug("import pydub failed, voice conversion features will not be supported.")
AudioSegment = None
_pydub_available = False
sil_supports = [8000, 12000, 16000, 24000, 32000, 44100, 48000] # slk转wav时,支持的采样率
def find_closest_sil_supports(sample_rate):
"""
找到最接近的支持的采样率
"""
if sample_rate in sil_supports:
return sample_rate
closest = 0
mindiff = 9999999
for rate in sil_supports:
diff = abs(rate - sample_rate)
if diff < mindiff:
closest = rate
mindiff = diff
return closest
def get_pcm_from_wav(wav_path):
"""
从 wav 文件中读取 pcm
:param wav_path: wav 文件路径
:returns: pcm 数据
"""
wav = wave.open(wav_path, "rb")
return wav.readframes(wav.getnframes())
def any_to_mp3(any_path, mp3_path):
"""
把任意格式转成mp3文件
"""
if not _pydub_available:
raise ImportError("pydub is required for audio conversion. Please install it with: pip install pydub")
if any_path.endswith(".mp3"):
shutil.copy2(any_path, mp3_path)
return
if any_path.endswith(".sil") or any_path.endswith(".silk") or any_path.endswith(".slk"):
sil_to_wav(any_path, any_path)
any_path = mp3_path
audio = AudioSegment.from_file(any_path)
audio.export(mp3_path, format="mp3")
def any_to_wav(any_path, wav_path):
"""
把任意格式转成wav文件
"""
if not _pydub_available:
raise ImportError("pydub is required for audio conversion. Please install it with: pip install pydub")
if any_path.endswith(".wav"):
shutil.copy2(any_path, wav_path)
return
if any_path.endswith(".sil") or any_path.endswith(".silk") or any_path.endswith(".slk"):
return sil_to_wav(any_path, wav_path)
audio = AudioSegment.from_file(any_path)
audio.set_frame_rate(8000) # 百度语音转写支持8000采样率, pcm_s16le, 单通道语音识别
audio.set_channels(1)
audio.export(wav_path, format="wav", codec='pcm_s16le')
def any_to_sil(any_path, sil_path):
"""
把任意格式转成sil文件
"""
if not _pydub_available:
raise ImportError("pydub is required for audio conversion. Please install it with: pip install pydub")
if any_path.endswith(".sil") or any_path.endswith(".silk") or any_path.endswith(".slk"):
shutil.copy2(any_path, sil_path)
return 10000
audio = AudioSegment.from_file(any_path)
rate = find_closest_sil_supports(audio.frame_rate)
# Convert to PCM_s16
pcm_s16 = audio.set_sample_width(2)
pcm_s16 = pcm_s16.set_frame_rate(rate)
wav_data = pcm_s16.raw_data
silk_data = pysilk.encode(wav_data, data_rate=rate, sample_rate=rate)
with open(sil_path, "wb") as f:
f.write(silk_data)
return audio.duration_seconds * 1000
def any_to_amr(any_path, amr_path):
"""
把任意格式转成amr文件
"""
if not _pydub_available:
raise ImportError("pydub is required for audio conversion. Please install it with: pip install pydub")
if any_path.endswith(".amr"):
shutil.copy2(any_path, amr_path)
return
if any_path.endswith(".sil") or any_path.endswith(".silk") or any_path.endswith(".slk"):
raise NotImplementedError("Not support file type: {}".format(any_path))
audio = AudioSegment.from_file(any_path)
audio = audio.set_frame_rate(8000) # only support 8000
audio.export(amr_path, format="amr")
return audio.duration_seconds * 1000
def sil_to_wav(silk_path, wav_path, rate: int = 24000):
"""
silk 文件转 wav
"""
wav_data = pysilk.decode_file(silk_path, to_wav=True, sample_rate=rate)
with open(wav_path, "wb") as f:
f.write(wav_data)
def split_audio(file_path, max_segment_length_ms=60000):
"""
分割音频文件
"""
if not _pydub_available:
raise ImportError("pydub is required for audio conversion. Please install it with: pip install pydub")
audio = AudioSegment.from_file(file_path)
audio_length_ms = len(audio)
if audio_length_ms <= max_segment_length_ms:
return audio_length_ms, [file_path]
segments = []
for start_ms in range(0, audio_length_ms, max_segment_length_ms):
end_ms = min(audio_length_ms, start_ms + max_segment_length_ms)
segment = audio[start_ms:end_ms]
segments.append(segment)
file_prefix = file_path[: file_path.rindex(".")]
format = file_path[file_path.rindex(".") + 1 :]
files = []
for i, segment in enumerate(segments):
path = f"{file_prefix}_{i+1}" + f".{format}"
segment.export(path, format=format)
files.append(path)
return audio_length_ms, files
================================================
FILE: voice/azure/azure_voice.py
================================================
"""
azure voice service
"""
import json
import os
import time
import azure.cognitiveservices.speech as speechsdk
from langid import classify
from bridge.reply import Reply, ReplyType
from common.log import logger
from common.tmp_dir import TmpDir
from config import conf
from voice.voice import Voice
"""
Azure voice
主目录设置文件中需填写azure_voice_api_key和azure_voice_region
查看可用的 voice: https://speech.microsoft.com/portal/voicegallery
"""
class AzureVoice(Voice):
def __init__(self):
try:
curdir = os.path.dirname(__file__)
config_path = os.path.join(curdir, "config.json")
config = None
if not os.path.exists(config_path): # 如果没有配置文件,创建本地配置文件
config = {
"speech_synthesis_voice_name": "zh-CN-XiaoxiaoNeural", # 识别不出时的默认语音
"auto_detect": True, # 是否自动检测语言
"speech_synthesis_zh": "zh-CN-XiaozhenNeural",
"speech_synthesis_en": "en-US-JacobNeural",
"speech_synthesis_ja": "ja-JP-AoiNeural",
"speech_synthesis_ko": "ko-KR-SoonBokNeural",
"speech_synthesis_de": "de-DE-LouisaNeural",
"speech_synthesis_fr": "fr-FR-BrigitteNeural",
"speech_synthesis_es": "es-ES-LaiaNeural",
"speech_recognition_language": "zh-CN",
}
with open(config_path, "w") as fw:
json.dump(config, fw, indent=4)
else:
with open(config_path, "r") as fr:
config = json.load(fr)
self.config = config
self.api_key = conf().get("azure_voice_api_key")
self.api_region = conf().get("azure_voice_region")
self.speech_config = speechsdk.SpeechConfig(subscription=self.api_key, region=self.api_region)
self.speech_config.speech_synthesis_voice_name = self.config["speech_synthesis_voice_name"]
self.speech_config.speech_recognition_language = self.config["speech_recognition_language"]
except Exception as e:
logger.warn("AzureVoice init failed: %s, ignore " % e)
def voiceToText(self, voice_file):
audio_config = speechsdk.AudioConfig(filename=voice_file)
speech_recognizer = speechsdk.SpeechRecognizer(speech_config=self.speech_config, audio_config=audio_config)
result = speech_recognizer.recognize_once()
if result.reason == speechsdk.ResultReason.RecognizedSpeech:
logger.info("[Azure] voiceToText voice file name={} text={}".format(voice_file, result.text))
reply = Reply(ReplyType.TEXT, result.text)
else:
cancel_details = result.cancellation_details
logger.error("[Azure] voiceToText error, result={}, errordetails={}".format(result, cancel_details))
reply = Reply(ReplyType.ERROR, "抱歉,语音识别失败")
return reply
def textToVoice(self, text):
if self.config.get("auto_detect"):
lang = classify(text)[0]
key = "speech_synthesis_" + lang
if key in self.config:
logger.info("[Azure] textToVoice auto detect language={}, voice={}".format(lang, self.config[key]))
self.speech_config.speech_synthesis_voice_name = self.config[key]
else:
self.speech_config.speech_synthesis_voice_name = self.config["speech_synthesis_voice_name"]
else:
self.speech_config.speech_synthesis_voice_name = self.config["speech_synthesis_voice_name"]
# Avoid the same filename under multithreading
fileName = TmpDir().path() + "reply-" + str(int(time.time())) + "-" + str(hash(text) & 0x7FFFFFFF) + ".wav"
audio_config = speechsdk.AudioConfig(filename=fileName)
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=self.speech_config, audio_config=audio_config)
result = speech_synthesizer.speak_text(text)
if result.reason == speechsdk.ResultReason.SynthesizingAudioCompleted:
logger.info("[Azure] textToVoice text={} voice file name={}".format(text, fileName))
reply = Reply(ReplyType.VOICE, fileName)
else:
cancel_details = result.cancellation_details
logger.error("[Azure] textToVoice error, result={}, errordetails={}".format(result, cancel_details.error_details))
reply = Reply(ReplyType.ERROR, "抱歉,语音合成失败")
return reply
================================================
FILE: voice/azure/config.json.template
================================================
{
"speech_synthesis_voice_name": "zh-CN-XiaoxiaoNeural",
"auto_detect": true,
"speech_synthesis_zh": "zh-CN-YunxiNeural",
"speech_synthesis_en": "en-US-JacobNeural",
"speech_synthesis_ja": "ja-JP-AoiNeural",
"speech_synthesis_ko": "ko-KR-SoonBokNeural",
"speech_synthesis_de": "de-DE-LouisaNeural",
"speech_synthesis_fr": "fr-FR-BrigitteNeural",
"speech_synthesis_es": "es-ES-LaiaNeural",
"speech_recognition_language": "zh-CN"
}
================================================
FILE: voice/baidu/README.md
================================================
## 说明
百度语音识别与合成参数说明
百度语音依赖,经常会出现问题,可能就是缺少依赖:
pip install baidu-aip
pip install pydub
pip install pysilk
还有ffmpeg,不同系统安装方式不同
系统中收到的语音文件为mp3格式(wx)或者sil格式(wxy),如果要识别需要转换为pcm格式,转换后的文件为16k采样率,单声道,16bit的pcm文件
发送时又需要(wx)转换为mp3格式,转换后的文件为16k采样率,单声道,16bit的pcm文件,(wxy)转换为sil格式,还要计算声音长度,发送时需要带上声音长度
这些事情都在audio_convert.py中封装了,直接调用即可
参数说明
识别参数
https://ai.baidu.com/ai-doc/SPEECH/Vk38lxily
合成参数
https://ai.baidu.com/ai-doc/SPEECH/Gk38y8lzk
## 使用说明
分两个地方配置
1、对于def voiceToText(self, filename)函数中调用的百度语音识别API,中接口调用asr(参数)这个配置见CHATGPT-ON-WECHAT工程目录下的`config.json`文件和config.py文件。
参数 可需 描述
app_id 必填 应用的APPID
api_key 必填 应用的APIKey
secret_key 必填 应用的SecretKey
dev_pid 必填 语言选择,填写语言对应的dev_pid值
2、对于def textToVoice(self, text)函数中调用的百度语音合成API,中接口调用synthesis(参数)在本目录下的`config.json`文件中进行配置。
参数 可需 描述
tex 必填 合成的文本,使用UTF-8编码,请注意文本长度必须小于1024字节
lan 必填 固定值zh。语言选择,目前只有中英文混合模式,填写固定值zh
spd 选填 语速,取值0-15,默认为5中语速
pit 选填 音调,取值0-15,默认为5中语调
vol 选填 音量,取值0-15,默认为5中音量(取值为0时为音量最小值,并非为无声)
per(基础音库) 选填 度小宇=1,度小美=0,度逍遥(基础)=3,度丫丫=4
per(精品音库) 选填 度逍遥(精品)=5003,度小鹿=5118,度博文=106,度小童=110,度小萌=111,度米朵=103,度小娇=5
aue 选填 3为mp3格式(默认); 4为pcm-16k;5为pcm-8k;6为wav(内容同pcm-16k); 注意aue=4或者6是语音识别要求的格式,但是音频内容不是语音识别要求的自然人发音,所以识别效果会受影响。
关于per参数的说明,注意您购买的哪个音库,就填写哪个音库的参数,否则会报错。如果您购买的是基础音库,那么per参数只能填写0到4,如果您购买的是精品音库,那么per参数只能填写5003,5118,106,110,111,103,5其他的都会报错。
### 配置文件
将文件夹中`config.json.template`复制为`config.json`。
``` json
{
"lang": "zh",
"ctp": 1,
"spd": 5,
"pit": 5,
"vol": 5,
"per": 0
}
```
================================================
FILE: voice/baidu/baidu_voice.py
================================================
"""
baidu voice service with thread-safe token caching
"""
import json
import os
import time
import threading
import requests
from aip import AipSpeech
from bridge.reply import Reply, ReplyType
from common.log import logger
from common.tmp_dir import TmpDir
from config import conf
from voice.voice import Voice
try:
from voice.audio_convert import get_pcm_from_wav
except ImportError as e:
logger.debug("import voice.audio_convert failed: {}".format(e))
class BaiduVoice(Voice):
def __init__(self):
try:
# 读取本地 TTS 参数配置
curdir = os.path.dirname(__file__)
config_path = os.path.join(curdir, "config.json")
if not os.path.exists(config_path):
bconf = {"lang": "zh", "ctp": 1, "spd": 5, "pit": 5, "vol": 5, "per": 0}
with open(config_path, "w") as fw:
json.dump(bconf, fw, indent=4)
else:
with open(config_path, "r") as fr:
bconf = json.load(fr)
self.app_id = str(conf().get("baidu_app_id"))
self.api_key = str(conf().get("baidu_api_key"))
self.secret_key = str(conf().get("baidu_secret_key"))
self.dev_id = conf().get("baidu_dev_pid")
self.lang = bconf["lang"]
self.ctp = bconf["ctp"]
self.spd = bconf["spd"]
self.pit = bconf["pit"]
self.vol = bconf["vol"]
self.per = bconf["per"]
# 百度 SDK 客户端(短文本合成 & 语音识别)
self.client = AipSpeech(self.app_id, self.api_key, self.secret_key)
# access_token 缓存与锁
self._access_token = None
self._token_expire_ts = 0
self._token_lock = threading.Lock()
except Exception as e:
logger.warn("BaiduVoice init failed: %s, ignore" % e)
def _get_access_token(self):
# 多线程安全获取 token
with self._token_lock:
now = time.time()
if self._access_token and now < self._token_expire_ts:
return self._access_token
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {
"grant_type": "client_credentials",
"client_id": self.api_key,
"client_secret": self.secret_key,
}
resp = requests.post(url, params=params).json()
token = resp.get("access_token")
expires_in = resp.get("expires_in", 2592000)
if token:
self._access_token = token
self._token_expire_ts = now + expires_in - 60 # 提前 1 分钟过期
return token
else:
logger.error("BaiduVoice _get_access_token failed: %s", resp)
return None
def voiceToText(self, voice_file):
logger.debug("[Baidu] recognize voice file=%s", voice_file)
pcm = get_pcm_from_wav(voice_file)
res = self.client.asr(pcm, "pcm", 16000, {"dev_pid": self.dev_id})
if res.get("err_no") == 0:
text = "".join(res["result"])
logger.info("[Baidu] ASR result: %s", text)
return Reply(ReplyType.TEXT, text)
else:
err = res.get("err_msg", "")
logger.error("[Baidu] ASR error: %s", err)
return Reply(ReplyType.ERROR, f"语音识别失败:{err}")
def _long_text_synthesis(self, text):
token = self._get_access_token()
if not token:
return Reply(ReplyType.ERROR, "获取百度 access_token 失败")
# 创建合成任务
create_url = f"https://aip.baidubce.com/rpc/2.0/tts/v1/create?access_token={token}"
payload = {
"text": text,
"format": "mp3-16k",
"voice": 0,
"lang": self.lang,
"speed": self.spd,
"pitch": self.pit,
"volume": self.vol,
"enable_subtitle": 0,
}
headers = {"Content-Type": "application/json"}
create_resp = requests.post(create_url, headers=headers, json=payload).json()
task_id = create_resp.get("task_id")
if not task_id:
logger.error("[Baidu] 长文本合成创建任务失败: %s", create_resp)
return Reply(ReplyType.ERROR, "长文本合成任务提交失败")
logger.info("[Baidu] 长文本合成任务已提交 task_id=%s", task_id)
# 轮询查询任务状态
query_url = f"https://aip.baidubce.com/rpc/2.0/tts/v1/query?access_token={token}"
for _ in range(100):
time.sleep(3)
resp = requests.post(query_url, headers=headers, json={"task_ids":[task_id]})
result = resp.json()
infos = result.get("tasks_info") or result.get("tasks") or []
if not infos:
continue
info = infos[0]
status = info.get("task_status")
if status == "Success":
task_res = info.get("task_result", {})
audio_url = task_res.get("audio_address") or task_res.get("speech_url")
break
elif status == "Running":
continue
else:
logger.error("[Baidu] 长文本合成失败: %s", info)
return Reply(ReplyType.ERROR, "长文本合成执行失败")
else:
return Reply(ReplyType.ERROR, "长文本合成超时,请稍后重试")
# 下载并保存音频
audio_data = requests.get(audio_url).content
fn = TmpDir().path() + f"reply-long-{int(time.time())}-{hash(text)&0x7FFFFFFF}.mp3"
with open(fn, "wb") as f:
f.write(audio_data)
logger.info("[Baidu] 长文本合成 success: %s", fn)
return Reply(ReplyType.VOICE, fn)
def textToVoice(self, text):
try:
# GBK 编码字节长度
gbk_len = len(text.encode("gbk", errors="ignore"))
if gbk_len <= 1024:
# 短文本走 SDK 合成
result = self.client.synthesis(
text, self.lang, self.ctp,
{"spd":self.spd, "pit":self.pit, "vol":self.vol, "per":self.per}
)
if not isinstance(result, dict):
fn = TmpDir().path() + f"reply-{int(time.time())}-{hash(text)&0x7FFFFFFF}.mp3"
with open(fn, "wb") as f:
f.write(result)
logger.info("[Baidu] 短文本合成 success: %s", fn)
return Reply(ReplyType.VOICE, fn)
else:
logger.error("[Baidu] 短文本合成 error: %s", result)
return Reply(ReplyType.ERROR, "短文本语音合成失败")
else:
# 长文本
return self._long_text_synthesis(text)
except Exception as e:
logger.error("BaiduVoice textToVoice exception: %s", e)
return Reply(ReplyType.ERROR, f"合成异常:{e}")
================================================
FILE: voice/baidu/config.json.template
================================================
{
"lang": "zh",
"ctp": 1,
"spd": 5,
"pit": 5,
"vol": 5,
"per": 0
}
================================================
FILE: voice/edge/edge_voice.py
================================================
import time
import edge_tts
import asyncio
from bridge.reply import Reply, ReplyType
from common.log import logger
from common.tmp_dir import TmpDir
from voice.voice import Voice
class EdgeVoice(Voice):
def __init__(self):
'''
# 普通话
zh-CN-XiaoxiaoNeural
zh-CN-XiaoyiNeural
zh-CN-YunjianNeural
zh-CN-YunxiNeural
zh-CN-YunxiaNeural
zh-CN-YunyangNeural
# 地方口音
zh-CN-liaoning-XiaobeiNeural
zh-CN-shaanxi-XiaoniNeural
# 粤语
zh-HK-HiuGaaiNeural
zh-HK-HiuMaanNeural
zh-HK-WanLungNeural
# 湾湾腔
zh-TW-HsiaoChenNeural
zh-TW-HsiaoYuNeural
zh-TW-YunJheNeural
'''
self.voice = "zh-CN-YunjianNeural"
def voiceToText(self, voice_file):
pass
async def gen_voice(self, text, fileName):
communicate = edge_tts.Communicate(text, self.voice)
await communicate.save(fileName)
def textToVoice(self, text):
fileName = TmpDir().path() + "reply-" + str(int(time.time())) + "-" + str(hash(text) & 0x7FFFFFFF) + ".mp3"
asyncio.run(self.gen_voice(text, fileName))
logger.info("[EdgeTTS] textToVoice text={} voice file name={}".format(text, fileName))
return Reply(ReplyType.VOICE, fileName)
================================================
FILE: voice/elevent/elevent_voice.py
================================================
import time
from elevenlabs.client import ElevenLabs
from elevenlabs import save
from bridge.reply import Reply, ReplyType
from common.log import logger
from common.tmp_dir import TmpDir
from voice.voice import Voice
from config import conf
XI_API_KEY = conf().get("xi_api_key")
client = ElevenLabs(api_key=XI_API_KEY)
name = conf().get("xi_voice_id")
class ElevenLabsVoice(Voice):
def __init__(self):
pass
def voiceToText(self, voice_file):
pass
def textToVoice(self, text):
audio = client.generate(
text=text,
voice=name,
model='eleven_multilingual_v2'
)
fileName = TmpDir().path() + "reply-" + str(int(time.time())) + "-" + str(hash(text) & 0x7FFFFFFF) + ".mp3"
save(audio, fileName)
logger.info("[ElevenLabs] textToVoice text={} voice file name={}".format(text, fileName))
return Reply(ReplyType.VOICE, fileName)
================================================
FILE: voice/factory.py
================================================
"""
voice factory
"""
def create_voice(voice_type):
"""
create a voice instance
:param voice_type: voice type code
:return: voice instance
"""
if voice_type == "baidu":
from voice.baidu.baidu_voice import BaiduVoice
return BaiduVoice()
elif voice_type == "google":
from voice.google.google_voice import GoogleVoice
return GoogleVoice()
elif voice_type == "openai":
from voice.openai.openai_voice import OpenaiVoice
return OpenaiVoice()
elif voice_type == "pytts":
from voice.pytts.pytts_voice import PyttsVoice
return PyttsVoice()
elif voice_type == "azure":
from voice.azure.azure_voice import AzureVoice
return AzureVoice()
elif voice_type == "elevenlabs":
from voice.elevent.elevent_voice import ElevenLabsVoice
return ElevenLabsVoice()
elif voice_type == "linkai":
from voice.linkai.linkai_voice import LinkAIVoice
return LinkAIVoice()
elif voice_type == "ali":
from voice.ali.ali_voice import AliVoice
return AliVoice()
elif voice_type == "edge":
from voice.edge.edge_voice import EdgeVoice
return EdgeVoice()
elif voice_type == "xunfei":
from voice.xunfei.xunfei_voice import XunfeiVoice
return XunfeiVoice()
elif voice_type == "tencent":
from voice.tencent.tencent_voice import TencentVoice
return TencentVoice()
raise RuntimeError
================================================
FILE: voice/google/google_voice.py
================================================
"""
google voice service
"""
import time
import speech_recognition
from gtts import gTTS
from bridge.reply import Reply, ReplyType
from common.log import logger
from common.tmp_dir import TmpDir
from voice.voice import Voice
class GoogleVoice(Voice):
recognizer = speech_recognition.Recognizer()
def __init__(self):
pass
def voiceToText(self, voice_file):
with speech_recognition.AudioFile(voice_file) as source:
audio = self.recognizer.record(source)
try:
text = self.recognizer.recognize_google(audio, language="zh-CN")
logger.info("[Google] voiceToText text={} voice file name={}".format(text, voice_file))
reply = Reply(ReplyType.TEXT, text)
except speech_recognition.UnknownValueError:
reply = Reply(ReplyType.ERROR, "抱歉,我听不懂")
except speech_recognition.RequestError as e:
reply = Reply(ReplyType.ERROR, "抱歉,无法连接到 Google 语音识别服务;{0}".format(e))
finally:
return reply
def textToVoice(self, text):
try:
# Avoid the same filename under multithreading
mp3File = TmpDir().path() + "reply-" + str(int(time.time())) + "-" + str(hash(text) & 0x7FFFFFFF) + ".mp3"
tts = gTTS(text=text, lang="zh")
tts.save(mp3File)
logger.info("[Google] textToVoice text={} voice file name={}".format(text, mp3File))
reply = Reply(ReplyType.VOICE, mp3File)
except Exception as e:
reply = Reply(ReplyType.ERROR, str(e))
finally:
return reply
================================================
FILE: voice/linkai/linkai_voice.py
================================================
"""
google voice service
"""
import random
import requests
from voice import audio_convert
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf
from voice.voice import Voice
from common import const
import os
import datetime
class LinkAIVoice(Voice):
def __init__(self):
pass
def voiceToText(self, voice_file):
logger.debug("[LinkVoice] voice file name={}".format(voice_file))
try:
url = conf().get("linkai_api_base", "https://api.link-ai.tech") + "/v1/audio/transcriptions"
headers = {"Authorization": "Bearer " + conf().get("linkai_api_key")}
model = None
if not conf().get("text_to_voice") or conf().get("voice_to_text") == "openai":
model = const.WHISPER_1
if voice_file.endswith(".amr"):
try:
mp3_file = os.path.splitext(voice_file)[0] + ".mp3"
audio_convert.any_to_mp3(voice_file, mp3_file)
voice_file = mp3_file
except Exception as e:
logger.warn(f"[LinkVoice] amr file transfer failed, directly send amr voice file: {format(e)}")
file = open(voice_file, "rb")
file_body = {
"file": file
}
data = {
"model": model
}
res = requests.post(url, files=file_body, headers=headers, data=data, timeout=(5, 60))
if res.status_code == 200:
text = res.json().get("text")
else:
res_json = res.json()
logger.error(f"[LinkVoice] voiceToText error, status_code={res.status_code}, msg={res_json.get('message')}")
return None
reply = Reply(ReplyType.TEXT, text)
logger.info(f"[LinkVoice] voiceToText success, text={text}, file name={voice_file}")
except Exception as e:
logger.error(e)
return None
return reply
def textToVoice(self, text):
try:
url = conf().get("linkai_api_base", "https://api.link-ai.tech") + "/v1/audio/speech"
headers = {"Authorization": "Bearer " + conf().get("linkai_api_key")}
model = const.TTS_1
if not conf().get("text_to_voice") or conf().get("text_to_voice") in ["openai", const.TTS_1, const.TTS_1_HD]:
model = conf().get("text_to_voice_model") or const.TTS_1
data = {
"model": model,
"input": text,
"voice": conf().get("tts_voice_id"),
"app_code": conf().get("linkai_app_code")
}
res = requests.post(url, headers=headers, json=data, timeout=(5, 120))
if res.status_code == 200:
tmp_file_name = "tmp/" + datetime.datetime.now().strftime('%Y%m%d%H%M%S') + str(random.randint(0, 1000)) + ".mp3"
with open(tmp_file_name, 'wb') as f:
f.write(res.content)
reply = Reply(ReplyType.VOICE, tmp_file_name)
logger.info(f"[LinkVoice] textToVoice success, input={text}, model={model}, voice_id={data.get('voice')}")
return reply
else:
res_json = res.json()
logger.error(f"[LinkVoice] textToVoice error, status_code={res.status_code}, msg={res_json.get('message')}")
return None
except Exception as e:
logger.error(e)
# reply = Reply(ReplyType.ERROR, "遇到了一点小问题,请稍后再问我吧")
return None
================================================
FILE: voice/openai/openai_voice.py
================================================
"""
google voice service
"""
import json
import openai
from bridge.reply import Reply, ReplyType
from common.log import logger
from config import conf
from voice.voice import Voice
import requests
from common import const
import datetime, random
class OpenaiVoice(Voice):
def __init__(self):
openai.api_key = conf().get("open_ai_api_key")
def voiceToText(self, voice_file):
logger.debug("[Openai] voice file name={}".format(voice_file))
try:
file = open(voice_file, "rb")
api_base = conf().get("open_ai_api_base") or "https://api.openai.com/v1"
url = f'{api_base}/audio/transcriptions'
headers = {
'Authorization': 'Bearer ' + conf().get("open_ai_api_key"),
# 'Content-Type': 'multipart/form-data' # 加了会报错,不知道什么原因
}
files = {
"file": file,
}
data = {
"model": "whisper-1",
}
response = requests.post(url, headers=headers, files=files, data=data)
response_data = response.json()
text = response_data['text']
reply = Reply(ReplyType.TEXT, text)
logger.info("[Openai] voiceToText text={} voice file name={}".format(text, voice_file))
except Exception as e:
reply = Reply(ReplyType.ERROR, "我暂时还无法听清您的语音,请稍后再试吧~")
finally:
return reply
def textToVoice(self, text):
try:
api_base = conf().get("open_ai_api_base") or "https://api.openai.com/v1"
url = f'{api_base}/audio/speech'
headers = {
'Authorization': 'Bearer ' + conf().get("open_ai_api_key"),
'Content-Type': 'application/json'
}
data = {
'model': conf().get("text_to_voice_model") or const.TTS_1,
'input': text,
'voice': conf().get("tts_voice_id") or "alloy"
}
response = requests.post(url, headers=headers, json=data)
file_name = "tmp/" + datetime.datetime.now().strftime('%Y%m%d%H%M%S') + str(random.randint(0, 1000)) + ".mp3"
logger.debug(f"[OPENAI] text_to_Voice file_name={file_name}, input={text}")
with open(file_name, 'wb') as f:
f.write(response.content)
logger.info(f"[OPENAI] text_to_Voice success")
reply = Reply(ReplyType.VOICE, file_name)
except Exception as e:
logger.error(e)
reply = Reply(ReplyType.ERROR, "遇到了一点小问题,请稍后再问我吧")
return reply
================================================
FILE: voice/pytts/pytts_voice.py
================================================
"""
pytts voice service (offline)
"""
import os
import sys
import time
import pyttsx3
from bridge.reply import Reply, ReplyType
from common.log import logger
from common.tmp_dir import TmpDir
from voice.voice import Voice
class PyttsVoice(Voice):
engine = pyttsx3.init()
def __init__(self):
# 语速
self.engine.setProperty("rate", 125)
# 音量
self.engine.setProperty("volume", 1.0)
if sys.platform == "win32":
for voice in self.engine.getProperty("voices"):
if "Chinese" in voice.name:
self.engine.setProperty("voice", voice.id)
else:
self.engine.setProperty("voice", "zh")
# If the problem of espeak is fixed, using runAndWait() and remove this startLoop()
# TODO: check if this is work on win32
self.engine.startLoop(useDriverLoop=False)
def textToVoice(self, text):
try:
# Avoid the same filename under multithreading
wavFileName = "reply-" + str(int(time.time())) + "-" + str(hash(text) & 0x7FFFFFFF) + ".wav"
wavFile = TmpDir().path() + wavFileName
logger.info("[Pytts] textToVoice text={} voice file name={}".format(text, wavFile))
self.engine.save_to_file(text, wavFile)
if sys.platform == "win32":
self.engine.runAndWait()
else:
# In ubuntu, runAndWait do not really wait until the file created.
# It will return once the task queue is empty, but the task is still running in coroutine.
# And if you call runAndWait() and time.sleep() twice, it will stuck, so do not use this.
# If you want to fix this, add self._proxy.setBusy(True) in line 127 in espeak.py, at the beginning of the function save_to_file.
# self.engine.runAndWait()
# Before espeak fix this problem, we iterate the generator and control the waiting by ourself.
# But this is not the canonical way to use it, for example if the file already exists it also cannot wait.
self.engine.iterate()
while self.engine.isBusy() or wavFileName not in os.listdir(TmpDir().path()):
time.sleep(0.1)
reply = Reply(ReplyType.VOICE, wavFile)
except Exception as e:
reply = Reply(ReplyType.ERROR, str(e))
finally:
return reply
================================================
FILE: voice/tencent/config.json.template
================================================
{
"voice_type": 1003,
"secret_id": "YOUR_SECRET_ID",
"secret_key": "YOUR_SECRET_KEY"
}
================================================
FILE: voice/tencent/tencent_voice.py
================================================
import json
import base64
import os
import time
from voice.voice import Voice
from common.log import logger
from tencentcloud.common import credential
from tencentcloud.asr.v20190614 import asr_client, models as asr_models
from tencentcloud.tts.v20190823 import tts_client, models as tts_models
from bridge.reply import Reply, ReplyType
from common.tmp_dir import TmpDir
class TencentVoice(Voice):
def __init__(self):
super().__init__()
self.secret_id = None
self.secret_key = None
self.voice_type = 1003
self._load_config()
def _load_config(self):
"""
从本地配置文件加载配置
"""
try:
config_path = os.path.join(os.path.dirname(__file__), 'config.json')
with open(config_path, 'r') as f:
config = json.load(f)
self.secret_id = config.get('secret_id')
self.secret_key = config.get('secret_key')
self.voice_type = config.get('voice_type', self.voice_type)
if not self.secret_id or not self.secret_key:
logger.error("[Tencent] Missing credentials in config.json")
except Exception as e:
logger.error(f"[Tencent] Failed to load config: {e}")
def setup(self, config):
"""
设置配置信息(保留此方法用于向后兼容)
"""
pass
def voiceToText(self, voice_file):
"""
将语音文件转换为文本
"""
try:
# 实例化认证对象
cred = credential.Credential(self.secret_id, self.secret_key)
# 实例化客户端
client = asr_client.AsrClient(cred, "ap-guangzhou")
# 读取音频文件
with open(voice_file, 'rb') as f:
audio_data = f.read()
# 进行base64编码
base64_audio = base64.b64encode(audio_data).decode('utf-8')
# 构造请求对象
req = asr_models.SentenceRecognitionRequest()
req.ProjectId = 0
req.SubServiceType = 2
req.EngSerViceType = "16k_zh"
req.SourceType = 1
req.VoiceFormat = "wav"
req.UsrAudioKey = "voice_recognition"
req.Data = base64_audio
# 发起请求
resp = client.SentenceRecognition(req)
# 解析结果
if resp.Result:
logger.info("[Tencent] Voice to text success: {}".format(resp.Result))
return Reply(ReplyType.TEXT, resp.Result)
else:
logger.warning("[Tencent] Voice to text failed")
return Reply(ReplyType.ERROR, "腾讯语音识别失败")
except Exception as e:
logger.error("[Tencent] Voice to text error: {}".format(e))
return Reply(ReplyType.ERROR, "腾讯语音识别出错:{}".format(str(e)))
def textToVoice(self, text):
"""
将文本转换为语音
"""
try:
cred = credential.Credential(self.secret_id, self.secret_key)
client = tts_client.TtsClient(cred, "ap-guangzhou")
req = tts_models.TextToVoiceRequest()
req.Text = text
req.SessionId = str(int(time.time()))
req.Volume = 5
req.Speed = 0
req.ProjectId = 0
req.ModelType = 1
req.PrimaryLanguage = 1
req.SampleRate = 16000
req.VoiceType = self.voice_type # 客服女声
response = client.TextToVoice(req)
if response.Audio:
fileName = TmpDir().path() + "reply-" + str(int(time.time())) + "-" + str(hash(text) & 0x7FFFFFFF) + ".mp3"
with open(fileName, "wb") as f:
f.write(base64.b64decode(response.Audio))
logger.info("[Tencent] textToVoice text={} voice file name={}".format(text, fileName))
return Reply(ReplyType.VOICE, fileName)
else:
logger.error("[Tencent] textToVoice failed")
return Reply(ReplyType.ERROR, "腾讯语音合成失败")
except Exception as e:
logger.error("[Tencent] Text to voice error: {}".format(e))
return Reply(ReplyType.ERROR, "腾讯语音合成出错:{}".format(str(e)))
================================================
FILE: voice/voice.py
================================================
"""
Voice service abstract class
"""
class Voice(object):
def voiceToText(self, voice_file):
"""
Send voice to voice service and get text
"""
raise NotImplementedError
def textToVoice(self, text):
"""
Send text to voice service and get voice
"""
raise NotImplementedError
================================================
FILE: voice/xunfei/config.json.template
================================================
{
"APPID":"xxx71xxx",
"APIKey":"xxxx69058exxxxxx",
"APISecret":"xxxx697f0xxxxxx",
"BusinessArgsTTS":{"aue": "lame", "sfl": 1, "auf": "audio/L16;rate=16000", "vcn": "xiaoyan", "tte": "utf8"},
"BusinessArgsASR":{"domain": "iat", "language": "zh_cn", "accent": "mandarin", "vad_eos":10000, "dwa": "wpgs"}
}
================================================
FILE: voice/xunfei/xunfei_asr.py
================================================
# -*- coding:utf-8 -*-
#
# Author: njnuko
# Email: njnuko@163.com
#
# 这个文档是基于官方的demo来改的,固体官方demo文档请参考官网
#
# 语音听写流式 WebAPI 接口调用示例 接口文档(必看):https://doc.xfyun.cn/rest_api/语音听写(流式版).html
# webapi 听写服务参考帖子(必看):http://bbs.xfyun.cn/forum.php?mod=viewthread&tid=38947&extra=
# 语音听写流式WebAPI 服务,热词使用方式:登陆开放平台https://www.xfyun.cn/后,找到控制台--我的应用---语音听写(流式)---服务管理--个性化热词,
# 设置热词
# 注意:热词只能在识别的时候会增加热词的识别权重,需要注意的是增加相应词条的识别率,但并不是绝对的,具体效果以您测试为准。
# 语音听写流式WebAPI 服务,方言试用方法:登陆开放平台https://www.xfyun.cn/后,找到控制台--我的应用---语音听写(流式)---服务管理--识别语种列表
# 可添加语种或方言,添加后会显示该方言的参数值
# 错误码链接:https://www.xfyun.cn/document/error-code (code返回错误码时必看)
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
import websocket
import datetime
import hashlib
import base64
import hmac
import json
from urllib.parse import urlencode
import time
import ssl
from wsgiref.handlers import format_date_time
from datetime import datetime
from time import mktime
import _thread as thread
import os
import wave
STATUS_FIRST_FRAME = 0 # 第一帧的标识
STATUS_CONTINUE_FRAME = 1 # 中间帧标识
STATUS_LAST_FRAME = 2 # 最后一帧的标识
#############
#whole_dict 是用来存储返回值的,由于带语音修正,所以用dict来存储,有更新的化pop之前的值,最后再合并
global whole_dict
#这个文档是官方文档改的,这个参数是用来做函数调用时用的
global wsParam
##############
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret,BusinessArgs, AudioFile):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.AudioFile = AudioFile
self.BusinessArgs = BusinessArgs
# 公共参数(common)
self.CommonArgs = {"app_id": self.APPID}
# 业务参数(business),更多个性化参数可在官网查看
#self.BusinessArgs = {"domain": "iat", "language": "zh_cn", "accent": "mandarin", "vinfo":1,"vad_eos":10000}
# 生成url
def create_url(self):
url = 'wss://ws-api.xfyun.cn/v2/iat'
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + "/v2/iat " + "HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": "ws-api.xfyun.cn"
}
# 拼接鉴权参数,生成url
url = url + '?' + urlencode(v)
#print("date: ",date)
#print("v: ",v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
#print('websocket url :', url)
return url
# 收到websocket消息的处理
def on_message(ws, message):
global whole_dict
try:
code = json.loads(message)["code"]
sid = json.loads(message)["sid"]
if code != 0:
errMsg = json.loads(message)["message"]
print("sid:%s call error:%s code is:%s" % (sid, errMsg, code))
else:
temp1 = json.loads(message)["data"]["result"]
data = json.loads(message)["data"]["result"]["ws"]
sn = temp1["sn"]
if "rg" in temp1.keys():
rep = temp1["rg"]
rep_start = rep[0]
rep_end = rep[1]
for sn in range(rep_start,rep_end+1):
#print("before pop",whole_dict)
#print("sn",sn)
whole_dict.pop(sn,None)
#print("after pop",whole_dict)
results = ""
for i in data:
for w in i["cw"]:
results += w["w"]
whole_dict[sn]=results
#print("after add",whole_dict)
else:
results = ""
for i in data:
for w in i["cw"]:
results += w["w"]
whole_dict[sn]=results
#print("sid:%s call success!,data is:%s" % (sid, json.dumps(data, ensure_ascii=False)))
except Exception as e:
print("receive msg,but parse exception:", e)
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws,a,b):
print("### closed ###")
# 收到websocket连接建立的处理
def on_open(ws):
global wsParam
def run(*args):
frameSize = 8000 # 每一帧的音频大小
intervel = 0.04 # 发送音频间隔(单位:s)
status = STATUS_FIRST_FRAME # 音频的状态信息,标识音频是第一帧,还是中间帧、最后一帧
with wave.open(wsParam.AudioFile, "rb") as fp:
while True:
buf = fp.readframes(frameSize)
# 文件结束
if not buf:
status = STATUS_LAST_FRAME
# 第一帧处理
# 发送第一帧音频,带business 参数
# appid 必须带上,只需第一帧发送
if status == STATUS_FIRST_FRAME:
d = {"common": wsParam.CommonArgs,
"business": wsParam.BusinessArgs,
"data": {"status": 0, "format": "audio/L16;rate=16000","audio": str(base64.b64encode(buf), 'utf-8'), "encoding": "raw"}}
d = json.dumps(d)
ws.send(d)
status = STATUS_CONTINUE_FRAME
# 中间帧处理
elif status == STATUS_CONTINUE_FRAME:
d = {"data": {"status": 1, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
ws.send(json.dumps(d))
# 最后一帧处理
elif status == STATUS_LAST_FRAME:
d = {"data": {"status": 2, "format": "audio/L16;rate=16000",
"audio": str(base64.b64encode(buf), 'utf-8'),
"encoding": "raw"}}
ws.send(json.dumps(d))
time.sleep(1)
break
# 模拟音频采样间隔
time.sleep(intervel)
ws.close()
thread.start_new_thread(run, ())
#提供给xunfei_voice调用的函数
def xunfei_asr(APPID,APISecret,APIKey,BusinessArgsASR,AudioFile):
global whole_dict
global wsParam
whole_dict = {}
wsParam1 = Ws_Param(APPID=APPID, APISecret=APISecret,
APIKey=APIKey,BusinessArgs=BusinessArgsASR,
AudioFile=AudioFile)
#wsParam是global变量,给上面on_open函数调用使用的
wsParam = wsParam1
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
#把字典的值合并起来做最后识别的输出
whole_words = ""
for i in sorted(whole_dict.keys()):
whole_words += whole_dict[i]
return whole_words
================================================
FILE: voice/xunfei/xunfei_tts.py
================================================
# -*- coding:utf-8 -*-
#
# Author: njnuko
# Email: njnuko@163.com
#
# 这个文档是基于官方的demo来改的,固体官方demo文档请参考官网
#
# 语音听写流式 WebAPI 接口调用示例 接口文档(必看):https://doc.xfyun.cn/rest_api/语音听写(流式版).html
# webapi 听写服务参考帖子(必看):http://bbs.xfyun.cn/forum.php?mod=viewthread&tid=38947&extra=
# 语音听写流式WebAPI 服务,热词使用方式:登陆开放平台https://www.xfyun.cn/后,找到控制台--我的应用---语音听写(流式)---服务管理--个性化热词,
# 设置热词
# 注意:热词只能在识别的时候会增加热词的识别权重,需要注意的是增加相应词条的识别率,但并不是绝对的,具体效果以您测试为准。
# 语音听写流式WebAPI 服务,方言试用方法:登陆开放平台https://www.xfyun.cn/后,找到控制台--我的应用---语音听写(流式)---服务管理--识别语种列表
# 可添加语种或方言,添加后会显示该方言的参数值
# 错误码链接:https://www.xfyun.cn/document/error-code (code返回错误码时必看)
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
import websocket
import datetime
import hashlib
import base64
import hmac
import json
from urllib.parse import urlencode
import time
import ssl
from wsgiref.handlers import format_date_time
from datetime import datetime
from time import mktime
import _thread as thread
import os
STATUS_FIRST_FRAME = 0 # 第一帧的标识
STATUS_CONTINUE_FRAME = 1 # 中间帧标识
STATUS_LAST_FRAME = 2 # 最后一帧的标识
#############
#这个参数是用来做输出文件路径的
global outfile
#这个文档是官方文档改的,这个参数是用来做函数调用时用的
global wsParam
##############
class Ws_Param(object):
# 初始化
def __init__(self, APPID, APIKey, APISecret,BusinessArgs,Text):
self.APPID = APPID
self.APIKey = APIKey
self.APISecret = APISecret
self.BusinessArgs = BusinessArgs
self.Text = Text
# 公共参数(common)
self.CommonArgs = {"app_id": self.APPID}
# 业务参数(business),更多个性化参数可在官网查看
#self.BusinessArgs = {"aue": "raw", "auf": "audio/L16;rate=16000", "vcn": "xiaoyan", "tte": "utf8"}
self.Data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-8')), "UTF8")}
#使用小语种须使用以下方式,此处的unicode指的是 utf16小端的编码方式,即"UTF-16LE"”
#self.Data = {"status": 2, "text": str(base64.b64encode(self.Text.encode('utf-16')), "UTF8")}
# 生成url
def create_url(self):
url = 'wss://tts-api.xfyun.cn/v2/tts'
# 生成RFC1123格式的时间戳
now = datetime.now()
date = format_date_time(mktime(now.timetuple()))
# 拼接字符串
signature_origin = "host: " + "ws-api.xfyun.cn" + "\n"
signature_origin += "date: " + date + "\n"
signature_origin += "GET " + "/v2/tts " + "HTTP/1.1"
# 进行hmac-sha256进行加密
signature_sha = hmac.new(self.APISecret.encode('utf-8'), signature_origin.encode('utf-8'),
digestmod=hashlib.sha256).digest()
signature_sha = base64.b64encode(signature_sha).decode(encoding='utf-8')
authorization_origin = "api_key=\"%s\", algorithm=\"%s\", headers=\"%s\", signature=\"%s\"" % (
self.APIKey, "hmac-sha256", "host date request-line", signature_sha)
authorization = base64.b64encode(authorization_origin.encode('utf-8')).decode(encoding='utf-8')
# 将请求的鉴权参数组合为字典
v = {
"authorization": authorization,
"date": date,
"host": "ws-api.xfyun.cn"
}
# 拼接鉴权参数,生成url
url = url + '?' + urlencode(v)
# print("date: ",date)
# print("v: ",v)
# 此处打印出建立连接时候的url,参考本demo的时候可取消上方打印的注释,比对相同参数时生成的url与自己代码生成的url是否一致
# print('websocket url :', url)
return url
def on_message(ws, message):
#输出文件
global outfile
try:
message =json.loads(message)
code = message["code"]
sid = message["sid"]
audio = message["data"]["audio"]
audio = base64.b64decode(audio)
status = message["data"]["status"]
if status == 2:
print("ws is closed")
ws.close()
if code != 0:
errMsg = message["message"]
print("sid:%s call error:%s code is:%s" % (sid, errMsg, code))
else:
with open(outfile, 'ab') as f:
f.write(audio)
except Exception as e:
print("receive msg,but parse exception:", e)
# 收到websocket连接建立的处理
def on_open(ws):
global outfile
global wsParam
def run(*args):
d = {"common": wsParam.CommonArgs,
"business": wsParam.BusinessArgs,
"data": wsParam.Data,
}
d = json.dumps(d)
# print("------>开始发送文本数据")
ws.send(d)
if os.path.exists(outfile):
os.remove(outfile)
thread.start_new_thread(run, ())
# 收到websocket错误的处理
def on_error(ws, error):
print("### error:", error)
# 收到websocket关闭的处理
def on_close(ws):
print("### closed ###")
def xunfei_tts(APPID, APIKey, APISecret,BusinessArgsTTS, Text, OutFile):
global outfile
global wsParam
outfile = OutFile
wsParam1 = Ws_Param(APPID,APIKey,APISecret,BusinessArgsTTS,Text)
wsParam = wsParam1
websocket.enableTrace(False)
wsUrl = wsParam.create_url()
ws = websocket.WebSocketApp(wsUrl, on_message=on_message, on_error=on_error, on_close=on_close)
ws.on_open = on_open
ws.run_forever(sslopt={"cert_reqs": ssl.CERT_NONE})
return outfile
================================================
FILE: voice/xunfei/xunfei_voice.py
================================================
#####################################################################
# xunfei voice service
# Auth: njnuko
# Email: njnuko@163.com
#
# 要使用本模块, 首先到 xfyun.cn 注册一个开发者账号,
# 之后创建一个新应用, 然后在应用管理的语音识别或者语音合同右边可以查看APPID API Key 和 Secret Key
# 然后在 config.json 中填入这三个值
#
# 配置说明:
# {
# "APPID":"xxx71xxx",
# "APIKey":"xxxx69058exxxxxx", #讯飞xfyun.cn控制台语音合成或者听写界面的APIKey
# "APISecret":"xxxx697f0xxxxxx", #讯飞xfyun.cn控制台语音合成或者听写界面的APIKey
# "BusinessArgsTTS":{"aue": "lame", "sfl": 1, "auf": "audio/L16;rate=16000", "vcn": "xiaoyan", "tte": "utf8"}, #语音合成的参数,具体可以参考xfyun.cn的文档
# "BusinessArgsASR":{"domain": "iat", "language": "zh_cn", "accent": "mandarin", "vad_eos":10000, "dwa": "wpgs"} #语音听写的参数,具体可以参考xfyun.cn的文档
# }
#####################################################################
import json
import os
import time
from bridge.reply import Reply, ReplyType
from common.log import logger
from common.tmp_dir import TmpDir
from config import conf
from voice.voice import Voice
from .xunfei_asr import xunfei_asr
from .xunfei_tts import xunfei_tts
import shutil
try:
from voice.audio_convert import any_to_mp3
from pydub import AudioSegment
_audio_available = True
except ImportError as e:
logger.debug("import audio libraries failed: {}".format(e))
_audio_available = False
class XunfeiVoice(Voice):
def __init__(self):
try:
curdir = os.path.dirname(__file__)
config_path = os.path.join(curdir, "config.json")
conf = None
with open(config_path, "r") as fr:
conf = json.load(fr)
print(conf)
self.APPID = str(conf.get("APPID"))
self.APIKey = str(conf.get("APIKey"))
self.APISecret = str(conf.get("APISecret"))
self.BusinessArgsTTS = conf.get("BusinessArgsTTS")
self.BusinessArgsASR= conf.get("BusinessArgsASR")
except Exception as e:
logger.warn("XunfeiVoice init failed: %s, ignore " % e)
def voiceToText(self, voice_file):
# 识别本地文件
try:
logger.debug("[Xunfei] voice file name={}".format(voice_file))
#print("voice_file===========",voice_file)
#print("voice_file_type===========",type(voice_file))
#mp3_name, file_extension = os.path.splitext(voice_file)
#mp3_file = mp3_name + ".mp3"
#pcm_data=get_pcm_from_wav(voice_file)
#mp3_name, file_extension = os.path.splitext(voice_file)
#AudioSegment.from_wav(voice_file).export(mp3_file, format="mp3")
#shutil.copy2(voice_file, 'tmp/test1.wav')
#shutil.copy2(mp3_file, 'tmp/test1.mp3')
#print("voice and mp3 file",voice_file,mp3_file)
text = xunfei_asr(self.APPID,self.APISecret,self.APIKey,self.BusinessArgsASR,voice_file)
logger.info("讯飞语音识别到了: {}".format(text))
reply = Reply(ReplyType.TEXT, text)
except Exception as e:
logger.warn("XunfeiVoice init failed: %s, ignore " % e)
reply = Reply(ReplyType.ERROR, "讯飞语音识别出错了;{0}")
return reply
def textToVoice(self, text):
try:
# Avoid the same filename under multithreading
fileName = TmpDir().path() + "reply-" + str(int(time.time())) + "-" + str(hash(text) & 0x7FFFFFFF) + ".mp3"
return_file = xunfei_tts(self.APPID,self.APIKey,self.APISecret,self.BusinessArgsTTS,text,fileName)
logger.info("[Xunfei] textToVoice text={} voice file name={}".format(text, fileName))
reply = Reply(ReplyType.VOICE, fileName)
except Exception as e:
logger.error("[Xunfei] textToVoice error={}".format(fileName))
reply = Reply(ReplyType.ERROR, "抱歉,讯飞语音合成失败")
return reply
